コンテナーガイド
コンテナーへの Red Hat Ceph Storage のデプロイと管理
概要
第1章 コンテナーへの Red Hat Ceph Storage のデプロイ
この章では、Ansible アプリケーションと ceph-ansible Playbook を使用して Red Hat Ceph Storage 3 をコンテナーにデプロイする方法について説明します。
- Red Hat Ceph Storage をインストールするには、「コンテナーへの Red Hat Ceph Storage Cluster のインストール」 を参照してください。
- Ceph Object Gatewayをインストールするには、「コンテナーへの Ceph Object Gateway のインストール」 を参照してください。
- メタデータサーバをインストールするには、「メタデータサーバーのインストール」 を参照してください。
-
Ansibleの
--limitオプションについては、「limitオプションについて」 を参照してください。
1.1. 前提条件
- 有効なカスタマーサブスクリプションを取得します。
クラスタノードの準備各ノードで以下を行います。
1.1.1. Red Hat Ceph Storage ノードの CDN への登録とサブスクリプションのアタッチ
各 Red Hat Ceph Storage (RHCS) ノードをコンテンツ配信ネットワーク (CDN) に登録し、ノードがソフトウェアリポジトリーにアクセスできるように適切なサブスクリプションを割り当てます。各 RHCS ノードは、Red Hat Enterprise Linux 7 のベースコンテンツとエクストラリポジトリのコンテンツに完全にアクセスできる必要があります。
前提条件
- 有効な Red Hat サブスクリプション
- RHCS のノードは、インターネットに接続できる必要があります。
インストール中にインターネットにアクセスできない RHCS ノードの場合、最初にインターネットにアクセスできるシステムで次の手順を実行する必要があります。
ローカル Docker レジストリーを起動します。
docker run -d -p 5000:5000 --restart=always --name registry registry:2
# docker run -d -p 5000:5000 --restart=always --name registry registry:2Copy to Clipboard Copied! Toggle word wrap Toggle overflow Red Hat Customer Portal から Red Hat Ceph Storage 3.x イメージをプルします。
docker pull registry.access.redhat.com/rhceph/rhceph-3-rhel7
# docker pull registry.access.redhat.com/rhceph/rhceph-3-rhel7Copy to Clipboard Copied! Toggle word wrap Toggle overflow イメージにタグを付けます。
docker tag registry.access.redhat.com/rhceph/rhceph-3-rhel7 <local-host-fqdn>:5000/cephimageinlocalreg
# docker tag registry.access.redhat.com/rhceph/rhceph-3-rhel7 <local-host-fqdn>:5000/cephimageinlocalregCopy to Clipboard Copied! Toggle word wrap Toggle overflow <local-host-fqdn>をローカルホストの FQDN に置き換えます。イメージを、起動したローカルの Docker レジストリーにプッシュします。
docker push <local-host-fqdn>:5000/cephimageinlocalreg
# docker push <local-host-fqdn>:5000/cephimageinlocalregCopy to Clipboard Copied! Toggle word wrap Toggle overflow <local-host-fqdn>をローカルホストの FQDN に置き換えます。
手順
ストレージクラスター内のすべてのノードで root ユーザーとして以下の手順を実行します。
ノードを登録する。プロンプトが表示されたら、Red Hat カスタマーポータルの認証情報を入力します。
subscription-manager register
# subscription-manager registerCopy to Clipboard Copied! Toggle word wrap Toggle overflow CDN から最新のサブスクリプションデータをプルします。
subscription-manager refresh
# subscription-manager refreshCopy to Clipboard Copied! Toggle word wrap Toggle overflow Red Hat Ceph Storage で利用可能なサブスクリプションの一覧を表示します。
subscription-manager list --available --all --matches="*Ceph*"
# subscription-manager list --available --all --matches="*Ceph*"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 適切なサブスクリプションを特定し、プール ID を取得します。
サブスクリプションを割り当てます。
subscription-manager attach --pool=$POOL_ID
# subscription-manager attach --pool=$POOL_IDCopy to Clipboard Copied! Toggle word wrap Toggle overflow - 置き換え
-
$POOL_IDを、直前の手順で特定されたプール ID に置き換えます。
-
デフォルトのソフトウェアリポジトリーを無効にします。次に、Red Hat Enterprise Linux 7 Server、Red Hat Enterprise Linux 7 Server Extras、および RHCS リポジトリーを有効にします。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow システムを更新して、最新のパッケージを受け取ります。
yum update
# yum updateCopy to Clipboard Copied! Toggle word wrap Toggle overflow
関連情報
- Red Hat Enterprise Linux 7 のシステム管理者ガイドのシステムの登録とサブスクリプションの管理の章を参照してください。
1.1.2. sudo アクセスのある Ansible ユーザーの作成
Ansible は、ソフトウェアをインストールし、パスワードを要求せずに設定ファイルを作成するための root 権限を持つユーザーとして、すべての Red Hat Ceph Storage (RHCS) ノードにログインできる必要があります。Ansible を使用して Red Hat Ceph Storage クラスターをデプロイおよび設定する際に、ストレージクラスター内のすべてのノードにパスワードなしの root アクセスで Ansible ユーザーを作成する必要があります。
前提条件
-
ストレージクラスター内のすべてのノードへの
rootまたはsudoアクセスがある。
手順
Ceph ノードに
rootユーザーとしてログインします。ssh root@$HOST_NAME
ssh root@$HOST_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow - 置き換え
-
$HOST_NAMEは、Ceph ノードのホスト名に置き換えます。
-
例
ssh root@mon01
# ssh root@mon01Copy to Clipboard Copied! Toggle word wrap Toggle overflow プロンプトに従い
rootパスワードを入力します。新しい Ansible ユーザーを作成します。
adduser $USER_NAME
adduser $USER_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow - 置き換え
-
$USER_NAMEは、Ansible ユーザーの新規ユーザー名に置き換えます。
-
例
adduser admin
# adduser adminCopy to Clipboard Copied! Toggle word wrap Toggle overflow 重要cephをユーザー名として使用しないでください。cephユーザー名は、Ceph デーモン用に予約されます。クラスター全体で統一されたユーザー名を使用すると、使いやすさが向上しますが、侵入者は通常、そのユーザー名をブルートフォース攻撃に使用するため、明白なユーザー名の使用は避けてください。このユーザーに新しいパスワードを設定します。
passwd $USER_NAME
# passwd $USER_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow - 置き換え
-
$USER_NAMEは、Ansible ユーザーの新規ユーザー名に置き換えます。
-
例
passwd admin
# passwd adminCopy to Clipboard Copied! Toggle word wrap Toggle overflow プロンプトが表示されたら、新しいパスワードを 2 回入力します。
新規に作成されたユーザーの
sudoアクセスを設定します。cat << EOF >/etc/sudoers.d/$USER_NAME $USER_NAME ALL = (root) NOPASSWD:ALL EOF
cat << EOF >/etc/sudoers.d/$USER_NAME $USER_NAME ALL = (root) NOPASSWD:ALL EOFCopy to Clipboard Copied! Toggle word wrap Toggle overflow - 置き換え
-
$USER_NAMEは、Ansible ユーザーの新規ユーザー名に置き換えます。
-
例
cat << EOF >/etc/sudoers.d/admin admin ALL = (root) NOPASSWD:ALL EOF
# cat << EOF >/etc/sudoers.d/admin admin ALL = (root) NOPASSWD:ALL EOFCopy to Clipboard Copied! Toggle word wrap Toggle overflow 正しいファイル権限を新しいファイルに割り当てます。
chmod 0440 /etc/sudoers.d/$USER_NAME
chmod 0440 /etc/sudoers.d/$USER_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow - 置き換え
-
$USER_NAMEは、Ansible ユーザーの新規ユーザー名に置き換えます。
-
例
chmod 0440 /etc/sudoers.d/admin
# chmod 0440 /etc/sudoers.d/adminCopy to Clipboard Copied! Toggle word wrap Toggle overflow
関連情報
- Red Hat Enterprise Linux 7 の『システム管理者のガイド』 の「 新しいユーザーの追加 」セクションを参照してください。
1.1.3. Ansible のパスワードなしの SSH の有効化
Ansible 管理ノードで SSH キーペアを生成し、ストレージクラスター内の各ノードに公開キーを配布して、Ansible がパスワードの入力を求められることなくノードにアクセスできるようにします。
前提条件
手順
Ansible 管理ノードから、Ansible ユーザーとして次の手順を実行します。
SSH キーペアを生成し、デフォルトのファイル名を受け入れ、パスフレーズを空のままにします。
ssh-keygen
[user@admin ~]$ ssh-keygenCopy to Clipboard Copied! Toggle word wrap Toggle overflow 公開鍵をストレージクラスター内のすべてのノードにコピーします。
ssh-copy-id $USER_NAME@$HOST_NAME
ssh-copy-id $USER_NAME@$HOST_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow - 置き換え
-
$USER_NAMEは、Ansible ユーザーの新規ユーザー名に置き換えます。 -
$HOST_NAMEは、Ceph ノードのホスト名に置き換えます。
-
例
ssh-copy-id admin@ceph-mon01
[user@admin ~]$ ssh-copy-id admin@ceph-mon01Copy to Clipboard Copied! Toggle word wrap Toggle overflow ~/.ssh/configファイルを作成および編集します。重要~/.ssh/configファイルを作成および編集することで、ansible-playbookコマンドを実行するたびに-u $USER_NAMEオプションを指定する必要はありません。SSH
configファイルを作成します。touch ~/.ssh/config
[user@admin ~]$ touch ~/.ssh/configCopy to Clipboard Copied! Toggle word wrap Toggle overflow 編集のために
configファイルを開きます。ストレージクラスターの各ノードのHostnameとUserオプションを設定します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 置き換え
-
$HOST_NAMEは、Ceph ノードのホスト名に置き換えます。 -
$USER_NAMEは、Ansible ユーザーの新規ユーザー名に置き換えます。
-
例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
~/.ssh/configファイルに正しいファイルパーミッションを設定します。chmod 600 ~/.ssh/config
[admin@admin ~]$ chmod 600 ~/.ssh/configCopy to Clipboard Copied! Toggle word wrap Toggle overflow
関連情報
-
ssh_config(5)の man ページ - Red Hat Enterprise Linux7 の システム管理者ガイド の Open SSH の章
1.1.4. Red Hat Ceph Storage のファイアウォールの設定
Red Hat Ceph Storage (RHCS) は firewalld サービスを使用します。
Monitor デーモンは、Ceph Storage クラスター内の通信にポート 6789 を使用します。
各 Ceph OSD ノードで、OSD デーモンは範囲 6800-7300 内の複数のポートを使用します。
- パブリックネットワークを介してクライアントおよびモニターと通信するための 1 つ
- クラスターネットワーク上で他の OSD にデータを送信する 1 つ (利用可能な場合)。それ以外の場合は、パブリックネットワーク経由でデータを送信します。
- 可能な場合は、クラスターネットワークを介してハートビートパケットを交換するための 1 つ。それ以外の場合は、パブリックネットワーク経由
Ceph Manager (ceph-mgr) デーモンは、6800-7300 範囲内のポートを使用します。同じノード上で Ceph Monitor と ceph-mgr デーモンを共存させることを検討してください。
Ceph Metadata Server ノード(ceph-mds) は、6800~7300 の範囲のポートを使用します。
Ceph Object Gateway ノードは、デフォルトで 8080 を使用するように Ansible によって設定されます。ただし、デフォルトのポート (例: ポート 80) を変更できます。
SSL/TLS サービスを使用するには、ポート 443 を開きます。
前提条件
- ネットワークハードウェアが接続されている。
手順
以下のコマンドを root ユーザーで実行します。
すべての RHCS ノードで、
firewalldサービスを起動します。これを有効にして、システムの起動時に実行し、実行していることを確認します。systemctl enable firewalld systemctl start firewalld systemctl status firewalld
# systemctl enable firewalld # systemctl start firewalld # systemctl status firewalldCopy to Clipboard Copied! Toggle word wrap Toggle overflow すべての Monitor ノードで、パブリックネットワークの
6789ポートを開く。firewall-cmd --zone=public --add-port=6789/tcp firewall-cmd --zone=public --add-port=6789/tcp --permanent
[root@monitor ~]# firewall-cmd --zone=public --add-port=6789/tcp [root@monitor ~]# firewall-cmd --zone=public --add-port=6789/tcp --permanentCopy to Clipboard Copied! Toggle word wrap Toggle overflow ソースアドレスに基づいてアクセスを制限するには、以下を実行します。
firewall-cmd --zone=public --add-rich-rule="rule family="ipv4" \ source address="IP_address/netmask_prefix" port protocol="tcp" \ port="6789" accept"
firewall-cmd --zone=public --add-rich-rule="rule family="ipv4" \ source address="IP_address/netmask_prefix" port protocol="tcp" \ port="6789" accept"Copy to Clipboard Copied! Toggle word wrap Toggle overflow firewall-cmd --zone=public --add-rich-rule="rule family="ipv4" \ source address="IP_address/netmask_prefix" port protocol="tcp" \ port="6789" accept" --permanent
firewall-cmd --zone=public --add-rich-rule="rule family="ipv4" \ source address="IP_address/netmask_prefix" port protocol="tcp" \ port="6789" accept" --permanentCopy to Clipboard Copied! Toggle word wrap Toggle overflow - 置き換え
-
IP_addressには、Monitor ノードのネットワークアドレスを指定します。 -
netmask_prefixには、CIDR 表記のネットマスクを指定します。
-
例
firewall-cmd --zone=public --add-rich-rule="rule family="ipv4" \ source address="192.168.0.11/24" port protocol="tcp" \ port="6789" accept"
[root@monitor ~]# firewall-cmd --zone=public --add-rich-rule="rule family="ipv4" \ source address="192.168.0.11/24" port protocol="tcp" \ port="6789" accept"Copy to Clipboard Copied! Toggle word wrap Toggle overflow firewall-cmd --zone=public --add-rich-rule="rule family="ipv4" \ source address="192.168.0.11/24" port protocol="tcp" \ port="6789" accept" --permanent
[root@monitor ~]# firewall-cmd --zone=public --add-rich-rule="rule family="ipv4" \ source address="192.168.0.11/24" port protocol="tcp" \ port="6789" accept" --permanentCopy to Clipboard Copied! Toggle word wrap Toggle overflow すべての OSD ノードで、パブリックネットワークでポート
6800-7300を開きます。firewall-cmd --zone=public --add-port=6800-7300/tcp firewall-cmd --zone=public --add-port=6800-7300/tcp --permanent
[root@osd ~]# firewall-cmd --zone=public --add-port=6800-7300/tcp [root@osd ~]# firewall-cmd --zone=public --add-port=6800-7300/tcp --permanentCopy to Clipboard Copied! Toggle word wrap Toggle overflow 別のクラスターネットワークがある場合には、適切なゾーンでコマンドを繰り返します。
すべての Ceph Manager (
ceph-mgr) ノード (通常はMonitorのノードと同じ) で、パブリックネットワークの6800~7300番ポートを開きます。firewall-cmd --zone=public --add-port=6800-7300/tcp firewall-cmd --zone=public --add-port=6800-7300/tcp --permanent
[root@monitor ~]# firewall-cmd --zone=public --add-port=6800-7300/tcp [root@monitor ~]# firewall-cmd --zone=public --add-port=6800-7300/tcp --permanentCopy to Clipboard Copied! Toggle word wrap Toggle overflow 別のクラスターネットワークがある場合には、適切なゾーンでコマンドを繰り返します。
すべての Ceph Metadata Server (
ceph-mds) ノードにおいて、パブリックネットワークでポート6800を開きます。firewall-cmd --zone=public --add-port=6800/tcp firewall-cmd --zone=public --add-port=6800/tcp --permanent
[root@monitor ~]# firewall-cmd --zone=public --add-port=6800/tcp [root@monitor ~]# firewall-cmd --zone=public --add-port=6800/tcp --permanentCopy to Clipboard Copied! Toggle word wrap Toggle overflow 別のクラスターネットワークがある場合には、適切なゾーンでコマンドを繰り返します。
すべての Ceph Object Gateway ノードで、パブリックネットワーク上の関連するポートを開きます。
デフォルトの Ansible が設定されたポート
8080を開くには、以下のコマンドを実行します。firewall-cmd --zone=public --add-port=8080/tcp firewall-cmd --zone=public --add-port=8080/tcp --permanent
[root@gateway ~]# firewall-cmd --zone=public --add-port=8080/tcp [root@gateway ~]# firewall-cmd --zone=public --add-port=8080/tcp --permanentCopy to Clipboard Copied! Toggle word wrap Toggle overflow ソースアドレスに基づいてアクセスを制限するには、以下を実行します。
firewall-cmd --zone=public --add-rich-rule="rule family="ipv4" \ source address="IP_address/netmask_prefix" port protocol="tcp" \ port="8080" accept"
firewall-cmd --zone=public --add-rich-rule="rule family="ipv4" \ source address="IP_address/netmask_prefix" port protocol="tcp" \ port="8080" accept"Copy to Clipboard Copied! Toggle word wrap Toggle overflow firewall-cmd --zone=public --add-rich-rule="rule family="ipv4" \ source address="IP_address/netmask_prefix" port protocol="tcp" \ port="8080" accept" --permanent
firewall-cmd --zone=public --add-rich-rule="rule family="ipv4" \ source address="IP_address/netmask_prefix" port protocol="tcp" \ port="8080" accept" --permanentCopy to Clipboard Copied! Toggle word wrap Toggle overflow - 置き換え
-
オブジェクトゲートウェイノードのネットワークアドレスを含む
IP_address。 -
netmask_prefixには、CIDR 表記のネットマスクを指定します。
-
オブジェクトゲートウェイノードのネットワークアドレスを含む
例
firewall-cmd --zone=public --add-rich-rule="rule family="ipv4" \ source address="192.168.0.31/24" port protocol="tcp" \ port="8080" accept"
[root@gateway ~]# firewall-cmd --zone=public --add-rich-rule="rule family="ipv4" \ source address="192.168.0.31/24" port protocol="tcp" \ port="8080" accept"Copy to Clipboard Copied! Toggle word wrap Toggle overflow firewall-cmd --zone=public --add-rich-rule="rule family="ipv4" \ source address="192.168.0.31/24" port protocol="tcp" \ port="8080" accept" --permanent
[root@gateway ~]# firewall-cmd --zone=public --add-rich-rule="rule family="ipv4" \ source address="192.168.0.31/24" port protocol="tcp" \ port="8080" accept" --permanentCopy to Clipboard Copied! Toggle word wrap Toggle overflow オプション:Ansible を使用して Ceph Object Gateway をインストールし、使用する Ceph Object Gateway を Ansible が構成するデフォルトのポートを
8080からポート80に変更した場合は、次のポートを開きます。firewall-cmd --zone=public --add-port=80/tcp firewall-cmd --zone=public --add-port=80/tcp --permanent
[root@gateway ~]# firewall-cmd --zone=public --add-port=80/tcp [root@gateway ~]# firewall-cmd --zone=public --add-port=80/tcp --permanentCopy to Clipboard Copied! Toggle word wrap Toggle overflow ソースアドレスに基づいてアクセスを制限するには、以下のコマンドを実行します。
firewall-cmd --zone=public --add-rich-rule="rule family="ipv4" \ source address="IP_address/netmask_prefix" port protocol="tcp" \ port="80" accept"
firewall-cmd --zone=public --add-rich-rule="rule family="ipv4" \ source address="IP_address/netmask_prefix" port protocol="tcp" \ port="80" accept"Copy to Clipboard Copied! Toggle word wrap Toggle overflow firewall-cmd --zone=public --add-rich-rule="rule family="ipv4" \ source address="IP_address/netmask_prefix" port protocol="tcp" \ port="80" accept" --permanent
firewall-cmd --zone=public --add-rich-rule="rule family="ipv4" \ source address="IP_address/netmask_prefix" port protocol="tcp" \ port="80" accept" --permanentCopy to Clipboard Copied! Toggle word wrap Toggle overflow - 置き換え
-
オブジェクトゲートウェイノードのネットワークアドレスを含む
IP_address。 -
netmask_prefixには、CIDR 表記のネットマスクを指定します。
-
オブジェクトゲートウェイノードのネットワークアドレスを含む
例
firewall-cmd --zone=public --add-rich-rule="rule family="ipv4" \ source address="192.168.0.31/24" port protocol="tcp" \ port="80" accept"
[root@gateway ~]# firewall-cmd --zone=public --add-rich-rule="rule family="ipv4" \ source address="192.168.0.31/24" port protocol="tcp" \ port="80" accept"Copy to Clipboard Copied! Toggle word wrap Toggle overflow firewall-cmd --zone=public --add-rich-rule="rule family="ipv4" \ source address="192.168.0.31/24" port protocol="tcp" \ port="80" accept" --permanent
[root@gateway ~]# firewall-cmd --zone=public --add-rich-rule="rule family="ipv4" \ source address="192.168.0.31/24" port protocol="tcp" \ port="80" accept" --permanentCopy to Clipboard Copied! Toggle word wrap Toggle overflow オプション:SSL/TLS を使用するには、
443ポートを開きます。firewall-cmd --zone=public --add-port=443/tcp firewall-cmd --zone=public --add-port=443/tcp --permanent
[root@gateway ~]# firewall-cmd --zone=public --add-port=443/tcp [root@gateway ~]# firewall-cmd --zone=public --add-port=443/tcp --permanentCopy to Clipboard Copied! Toggle word wrap Toggle overflow ソースアドレスに基づいてアクセスを制限するには、以下のコマンドを実行します。
firewall-cmd --zone=public --add-rich-rule="rule family="ipv4" \ source address="IP_address/netmask_prefix" port protocol="tcp" \ port="443" accept"
firewall-cmd --zone=public --add-rich-rule="rule family="ipv4" \ source address="IP_address/netmask_prefix" port protocol="tcp" \ port="443" accept"Copy to Clipboard Copied! Toggle word wrap Toggle overflow firewall-cmd --zone=public --add-rich-rule="rule family="ipv4" \ source address="IP_address/netmask_prefix" port protocol="tcp" \ port="443" accept" --permanent
firewall-cmd --zone=public --add-rich-rule="rule family="ipv4" \ source address="IP_address/netmask_prefix" port protocol="tcp" \ port="443" accept" --permanentCopy to Clipboard Copied! Toggle word wrap Toggle overflow - 置き換え
-
オブジェクトゲートウェイノードのネットワークアドレスを含む
IP_address。 -
netmask_prefixには、CIDR 表記のネットマスクを指定します。
-
オブジェクトゲートウェイノードのネットワークアドレスを含む
例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
関連情報
- パブリックネットワークおよびクラスターネットワークの詳細は、「Red Hat Ceph Storage のネットワーク設定の確認」を参照してください。
-
Firewalldの詳細は、 Red Hat Enterprise Linux 7 のセキュリティーガイドのファイアウォールの使用の章を参照してください。
1.1.5. HTTP プロキシーの使用
Ceph ノードが HTTP/HTTPS プロキシーの背後にある場合は、レジストリー内のイメージにアクセスするように docker を設定する必要があります。以下の手順に従って、HTTP/HTTPS プロキシーを使用して docker のアクセスを設定します。
前提条件
- 実行中の HTTP/HTTPS プロキシー
手順
rootとして、docker サービスの systemd ディレクトリーを作成します。mkdir /etc/systemd/system/docker.service.d/
# mkdir /etc/systemd/system/docker.service.d/Copy to Clipboard Copied! Toggle word wrap Toggle overflow rootとして、HTTP/HTTPS 設定ファイルを作成します。HTTP の場合は、
/etc/systemd/system/docker.service.d/http-proxy.confファイルを作成し、以下の行をファイルに追加します。[Service] Environment="HTTP_PROXY=http://proxy.example.com:80/"
[Service] Environment="HTTP_PROXY=http://proxy.example.com:80/"Copy to Clipboard Copied! Toggle word wrap Toggle overflow HTTPS の場合は、
/etc/systemd/system/docker.service.d/https-proxy.confファイルを作成し、以下の行をファイルに追加します。[Service] Environment="HTTPS_PROXY=https://proxy.example.com:443/"
[Service] Environment="HTTPS_PROXY=https://proxy.example.com:443/"Copy to Clipboard Copied! Toggle word wrap Toggle overflow
-
rootとして、ceph-ansible Playbookを実行する前に、ストレージクラスター内のすべての Ceph ノードに HTTP/HTTPS 設定ファイルをコピーします。
1.2. コンテナーへの Red Hat Ceph Storage Cluster のインストール
ceph-ansible playbook で Ansible アプリケーションを使用して、Red Hat Ceph Storage 3 をコンテナーにインストールします。
実稼動環境で使用される Ceph クラスターは、通常、10 個以上のノードで設定されます。Red Hat Ceph Storage をコンテナーイメージとしてデプロイするには、Red Hat では、少なくとも 3 つの OSD と 3 つの Monitor ノードで設定される Ceph クラスターを使用することを推奨しています。
Ceph は 1 つのモニターで実行できますが、実稼働クラスターで高可用性を確保するためには、Red Hat は少なくとも 3 つのモニターノードを持つデプロイメントのみをサポートします。
前提条件
Ansible 管理ノードで root ユーザーアカウントを使用して、Red Hat Ceph Storage 3 Tools リポジトリーと Ansible リポジトリーを有効にします。
subscription-manager repos --enable=rhel-7-server-rhceph-3-tools-els-rpms --enable=rhel-7-server-ansible-2.6-rpms
[root@admin ~]# subscription-manager repos --enable=rhel-7-server-rhceph-3-tools-els-rpms --enable=rhel-7-server-ansible-2.6-rpmsCopy to Clipboard Copied! Toggle word wrap Toggle overflow ceph-ansibleパッケージをインストールします。yum install ceph-ansible
[root@admin ~]# yum install ceph-ansibleCopy to Clipboard Copied! Toggle word wrap Toggle overflow
手順
指示がない限り、Ansible の管理ノードから以下のコマンドを実行します。
Ansibleのユーザーとして、
ceph-ansiblePlaybook で生成された一時的な値をAnsibleが保存するceph-ansible-keysディレクトリーを作成します。mkdir ~/ceph-ansible-keys
[user@admin ~]$ mkdir ~/ceph-ansible-keysCopy to Clipboard Copied! Toggle word wrap Toggle overflow root として、
/etc/ansible/ディレクトリーに/usr/share/ceph-ansible/group_varsディレクトリーへのシンボリックリンクを作成します。ln -s /usr/share/ceph-ansible/group_vars /etc/ansible/group_vars
[root@admin ~]# ln -s /usr/share/ceph-ansible/group_vars /etc/ansible/group_varsCopy to Clipboard Copied! Toggle word wrap Toggle overflow /usr/share/ceph-ansibleディレクトリーに移動します。cd /usr/share/ceph-ansible
[root@admin ~]$ cd /usr/share/ceph-ansibleCopy to Clipboard Copied! Toggle word wrap Toggle overflow yml.sampleファイルのコピーを新たに作成します。cp group_vars/all.yml.sample group_vars/all.yml cp group_vars/osds.yml.sample group_vars/osds.yml cp site-docker.yml.sample site-docker.yml
[root@admin ceph-ansible]# cp group_vars/all.yml.sample group_vars/all.yml [root@admin ceph-ansible]# cp group_vars/osds.yml.sample group_vars/osds.yml [root@admin ceph-ansible]# cp site-docker.yml.sample site-docker.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow コピーしたファイルを編集します。
group_vars/all.ymlファイルを編集します。アンコメントする最も一般的な必須およびオプションのパラメータについては、以下の表を参照してください。なお、この表にはすべてのパラメータが含まれているわけではありません。重要カスタムクラスター名の使用はサポートされていないため、
cluster: cephパラメータにceph以外の値を設定しないでください。Expand 表1.1 Ansible の一般的な設定 オプション 値 必要性 備考 monitor_interfaceMonitor ノードがリッスンするインターフェイス
MONITOR_INTERFACE、MONITOR_ADDRESS、またはMONITOR_ADDRESS_BLOCKが必要です。monitor_addressMonitor ノードがリッスンするアドレス
monitor_address_blockCeph のパブリックネットワークのサブネット
ノードの IP アドレスは不明だが、サブネットはわかっている場合に使用します
ip_versionipv6IPv6 アドレスを使用している場合は Yes
journal_size必要なジャーナルのサイズ (MB)
不要
public_networkCeph パブリックネットワークの IP アドレスとネットマスク
必要
Red Hat Enterprise Linux のインストールガイドのRed Hat Ceph Storage のネットワーク設定の検証 セクション
cluster_networkCeph クラスターネットワークの IP アドレスとネットマスク
不要
ceph_docker_imagerhceph/rhceph-3-rhel7、またはローカル Docker レジストリーを使用する場合はcephimageinlocalreg必要
containerized_deploymenttrue必要
ceph_docker_registryregistry.access.redhat.com、またはローカル Docker レジストリーを使用する場合は<local-host-fqdn>必要
all.ymlファイルの例は次のようになります。Copy to Clipboard Copied! Toggle word wrap Toggle overflow 詳細は、
all.ymlファイルを参照してください。group_vars/osds.ymlファイルを編集します。アンコメントする最も一般的な必須およびオプションのパラメータについては、以下の表を参照してください。なお、この表にはすべてのパラメータが含まれているわけではありません。重要OSD のインストールには、OSD がインストールされている機器とは異なる物理的な機器を使用してください。オペレーティングシステムと OSD 間で同じデバイスを共有すると、パフォーマンスの問題が発生することになります。
Expand 表1.2 OSD Ansible 設定 オプション 値 必要性 備考 osd_scenariocollocated。ログ先行書き込みとキー/値データ (Blue Store) またはジャーナル (File Store) と OSD データに同じデバイスを使用non-collocated。SSD や NVMe メディアなどの専用デバイスを使用して先行書き込みログとキー/値データ (Blue Store) またはジャーナルデータ(File Store)を保存するためlvm: OSDデータの保存に論理ボリュームマネージャを使用する場合必要
osd_scenario:non-collocated、ceph-ansibleを使用する場合、devicesとdedicated_devicesの変数の数が一致することを期待します。たとえば、devicesで 10 個のディスクを指定する場合は、dedicated_devicesで 10 個のエントリーを指定する必要があります。osd_auto_discoveryOSD を自動的に検出する場合は
trueosd_scenario: collocatedを使用している場合は Yesdevices設定を使用している場合は使用できません。devicesceph dataが保存されているデバイスのリストデバイスのリストを指定する場合は Yes
osd_auto_discovery設定を使用する場合は使用できません。osd_scenarioとしてlvmを使用し、devicesオプションを設定する場合、ceph-volume lvm batchモードは最適化された OSD 構成を作成します。dedicated_devicesceph journalが保存されている非コロケーション OSD 専用デバイスのリストosd_scenario: non-collocated場合は Yes非分割型のデバイスであること
dmcryptOSD を暗号化する場合は
true不要
デフォルトは
falselvm_volumesFile Store または Blue Store 辞書のリスト
osd_scenario: lvm使用している場合、ストレージ デバイスがdevicesを使用して定義されている場合は Yes各ディクショナリーには、
dataキー、journalキー、およびdata_vgキーが含まれている必要があります。論理ボリュームまたはボリュームグループはすべて、完全パスではなく、名前にする必要があります。dataキーおよびjournalキーは論理ボリューム (LV) またはパーティションにすることができますが、複数のdata論理ボリュームに 1 つのジャーナルを使用しないでください。data_vgキーは、data論理ボリューム含むボリュームグループである必要があります。必要に応じて、journal_vgキーを使用して、ジャーナル LV を含むボリュームグループを指定できます (該当する場合)。サポートされているさまざまな構成については、以下の例を参照してください。osds_per_deviceデバイスごとに作成する OSD 数。
不要
デフォルトは
1ですosd_objectstoreOSD の Ceph オブジェクトストアタイプ。
不要
デフォルトは
bluestoreです。もう一つの選択肢は、filestoreです。アップグレードに必要です。以下は、
collocated、non-collocated、lvmの 3つの OSD シナリオを使用した場合のosds.ymlファイルの例です。指定されていない場合、デフォルトの OSD オブジェクトストアフォーマットは BlueStore です。コロケート済み
osd_objectstore: filestore osd_scenario: collocated devices: - /dev/sda - /dev/sdb
osd_objectstore: filestore osd_scenario: collocated devices: - /dev/sda - /dev/sdbCopy to Clipboard Copied! Toggle word wrap Toggle overflow コロケートされていない - BlueStore
Copy to Clipboard Copied! Toggle word wrap Toggle overflow コロケートされていない例では、デバイスごとに 1 つずつ、4 つの Blue Store OSD が作成されます。この例では、従来のハードドライブ (
sda、sdb、sdc、sdd) がオブジェクトデータに使用され、ソリッドステートドライブ (SSD) (/ dev/nvme0n1、/ dev/nvme1n1) が Blue Store データベースに使用されて書き込みます-先行書き込みログ。この構成では、/dev/sdaおよび/dev/sdbデバイスを/dev/nvme0n1デバイスとペアにし、/dev/sdcおよび/dev/sddデバイスを/dev/nvme1n1デバイスとペアにします。非コロケーション - Filestore
Copy to Clipboard Copied! Toggle word wrap Toggle overflow LVM simple
osd_objectstore: bluestore osd_scenario: lvm devices: - /dev/sda - /dev/sdb
osd_objectstore: bluestore osd_scenario: lvm devices: - /dev/sda - /dev/sdbCopy to Clipboard Copied! Toggle word wrap Toggle overflow または
Copy to Clipboard Copied! Toggle word wrap Toggle overflow これらの単純な構成では
ceph-ansibleはバッチモード (ceph-volume lvm batch) を使用して OSD を作成します。最初のシナリオでは、
devicesを従来のハードドライブまたは SSD の場合には、デバイスごとに OSD が 1 つ作成されます。2 つ目のシナリオでは、従来のハードドライブと SSD が混在している場合、データは従来のハードドライブ (
sda、sdb) に配置され、BlueStore データベース (block.db) は SSD (nvme0n1) にできる限り大きく作成されます。LVM advance
Copy to Clipboard Copied! Toggle word wrap Toggle overflow または
Copy to Clipboard Copied! Toggle word wrap Toggle overflow これらの事前シナリオ例では、事前にボリュームグループと論理ボリュームを作成しておく必要があります。それらは
ceph-ansibleによって作成されません。注記すべての NVMe SSD を使用する場合は、
osd_scenario: lvmとosds_per_device:4オプション。詳細については、Red Hat Ceph Storage Container Guide の Configuring OSD Ansible settings for all NVMe Storage セクションを参照してください。詳細は、
osds.ymlファイルのコメントをご覧ください。
デフォルトでは
/etc/ansible/hostsにある Ansible のインベントリファイルを編集します。サンプルホストをコメントアウトすることを忘れないでください。[mons]セクションの下に Monitor のノードを追加します。[mons] <monitor-host-name> <monitor-host-name> <monitor-host-name>
[mons] <monitor-host-name> <monitor-host-name> <monitor-host-name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow [osds]セクションの下に OSD ノードを追加します。ノードがシーケンシャルなネーミングの場合は、レンジの使用を検討してください。[osds] <osd-host-name[1:10]>
[osds] <osd-host-name[1:10]>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 注記新規インストールの OSD の場合、デフォルトのオブジェクトストア形式は BlueStore です。
または、
monsセクションとosdsセクションの下に同じノードを追加することで、1 つのノードに OSD デーモンと一緒にモニターを配置することもできます。詳細は、2章コンテナー化された Ceph デーモンのコロケーション を参照してください。
オプションで、ベアメタルまたはコンテナー内のすべてのデプロイメントで、
ansible-playbookを使用してカスタム CRUSH 階層を作成できます。Ansible のインベントリーファイルを設定します。
osd_crush_locationパラメーターを使用して、OSD ホストを CRUSH マップの階層内のどこに配置するかを指定します。OSD の場所を指定するために、2 つ以上の CRUSH バケットタイプを指定し、1 つのバケットのtypeをホストに指定する必要があります。デフォルトでは、これには、root、datacenter、room、row、pod、pdu、rack、chassisおよびhostが含まれます。構文
[osds] CEPH_OSD_NAME osd_crush_location="{ 'root': ROOT_BUCKET_', 'rack': 'RACK_BUCKET', 'pod': 'POD_BUCKET', 'host': 'CEPH_HOST_NAME' }"[osds] CEPH_OSD_NAME osd_crush_location="{ 'root': ROOT_BUCKET_', 'rack': 'RACK_BUCKET', 'pod': 'POD_BUCKET', 'host': 'CEPH_HOST_NAME' }"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[osds] ceph-osd-01 osd_crush_location="{ 'root': 'default', 'rack': 'rack1', 'pod': 'monpod', 'host': 'ceph-osd-01' }"[osds] ceph-osd-01 osd_crush_location="{ 'root': 'default', 'rack': 'rack1', 'pod': 'monpod', 'host': 'ceph-osd-01' }"Copy to Clipboard Copied! Toggle word wrap Toggle overflow crush_rule_configパラメーターとcreate_crush_treeパラメーターをTrueに設定し、デフォルトの CRUSH ルールを使用しない場合は、少なくとも 1 つの CRUSH ルールを作成します。たとえば、HDD デバイスを使用している場合は、次のようにパラメーターを編集します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow SSD デバイスを使用している場合は、以下のようにパラメーターを編集してください。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 注記ssd と hdd の両方の OSD がデプロイされていない場合、デフォルトの CRUSH ルールは失敗します。これは、デフォルトのルールに、定義する必要のあるクラスパラメーターが含まれているためです。
注記この構成を機能させるには、以下の手順で説明するように、host_vars ディレクトリーの OSD ファイルにもカスタム CRUSH 階層を追加します。
group_vars/clients.ymlファイルで作成したcrush_rulesを使用してpoolsを作成します。例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow ツリーを表示します。
ceph osd tree
[root@mon ~]# ceph osd treeCopy to Clipboard Copied! Toggle word wrap Toggle overflow プールを検証します。
for i in $(rados lspools);do echo "pool: $i"; ceph osd pool get $i crush_rule;done pool: pool1 crush_rule: HDD
# for i in $(rados lspools);do echo "pool: $i"; ceph osd pool get $i crush_rule;done pool: pool1 crush_rule: HDDCopy to Clipboard Copied! Toggle word wrap Toggle overflow
ベアメタル またはコンテナー内 のすべてのデプロイメントで、Ansible インベントリーファイル (デフォルトでは
/etc/ansible/hostsファイル) を編集するために開きます。例のホストをコメントアウトします。[mgrs]セクションに Ceph Manager (ceph-mgr) ノードを追加します。Ceph Manager デーモンを Monitor ノードにコロケーションします。[mgrs] <monitor-host-name> <monitor-host-name> <monitor-host-name>
[mgrs] <monitor-host-name> <monitor-host-name> <monitor-host-name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
Ansible ユーザーとして、Ansible が Ceph ホストに到達できることを確認します。
ansible all -m ping
[user@admin ~]$ ansible all -m pingCopy to Clipboard Copied! Toggle word wrap Toggle overflow rootとして、/var/log/ansible/ディレクトリーを作成し、ansibleユーザーに適切な権限を割り当てます。mkdir /var/log/ansible chown ansible:ansible /var/log/ansible chmod 755 /var/log/ansible
[root@admin ~]# mkdir /var/log/ansible [root@admin ~]# chown ansible:ansible /var/log/ansible [root@admin ~]# chmod 755 /var/log/ansibleCopy to Clipboard Copied! Toggle word wrap Toggle overflow 次のように
log_path値を更新して、/usr/share/ceph-ansible/ansible.cfgファイルを編集します。log_path = /var/log/ansible/ansible.log
log_path = /var/log/ansible/ansible.logCopy to Clipboard Copied! Toggle word wrap Toggle overflow
Ansible ユーザーとして、
/usr/share/ceph-ansible/ディレクトリーに移動します。cd /usr/share/ceph-ansible/
[user@admin ~]$ cd /usr/share/ceph-ansible/Copy to Clipboard Copied! Toggle word wrap Toggle overflow ceph-ansiblePlaybook を実行します。ansible-playbook site-docker.yml
[user@admin ceph-ansible]$ ansible-playbook site-docker.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 注記Red Hat Ceph Storage を Red Hat Enterprise Linux Atomic Host ホストにデプロイする場合は、
--skip-tags=with_pkgオプションを使用します。ansible-playbook site-docker.yml --skip-tags=with_pkg
[user@admin ceph-ansible]$ ansible-playbook site-docker.yml --skip-tags=with_pkgCopy to Clipboard Copied! Toggle word wrap Toggle overflow 注記デプロイメントの速度を増やすには、
--forksオプションをansible-playbookに指定します。デフォルトでは、ceph-ansibleはフォークを20に設定します。この設定では、ノードを同時にインストールします。一度に最大 30 個のノードをインストールするには、ansible-playbook --forks 30 PLAYBOOKFILEを実行します。管理ノードのリソースが過剰に使用されていないことを確認するために、監視する必要があります。そうである場合は、--forksに渡される数を減らします。モニターノードの root アカウントを使用して、Ceph クラスターのステータスを確認します。
docker exec ceph-<mon|mgr>-<id> ceph health
docker exec ceph-<mon|mgr>-<id> ceph healthCopy to Clipboard Copied! Toggle word wrap Toggle overflow 以下を置き換えます。
-
<id>を Monitor ノードのホスト名に置き換えます。
以下は例になります。
docker exec ceph-mon-mon0 ceph health HEALTH_OK
[root@monitor ~]# docker exec ceph-mon-mon0 ceph health HEALTH_OKCopy to Clipboard Copied! Toggle word wrap Toggle overflow -
1.3. すべての NVMe ストレージに OSD Ansible 設定の構成
ストレージに NVMe (Non-volatile Memory Express) デバイスのみを使用する場合のパフォーマンスを最適化するには、各 NVMe デバイスに 4 つの OSD を構成します。通常、OSD はデバイスごとに1つしか設定されないため、NVMe デバイスのスループットを十分に活用できません。
SSD と HDD を混在させる場合、SSD は OSD ではなくジャーナルまたは block.db のいずれかに使用されます。
テストでは、各 NVMe デバイスに 4 つの OSD を設定すると、最適なパフォーマンスが得られます。osds_per_device:4 を設定することをお勧めしますが、必須ではありません。他の値を設定すると、お客様の環境でより良いパフォーマンスが得られる場合があります。
前提条件
- Ceph クラスターのソフトウェアおよびハードウェアの要件をすべて満たすこと。
手順
osd_scenario:lvmおよびosds_per_device:4をgroup_vars/osds.ymlに設定します。osd_scenario: lvm osds_per_device: 4
osd_scenario: lvm osds_per_device: 4Copy to Clipboard Copied! Toggle word wrap Toggle overflow devicesの下に NVMe デバイスを一覧表示します。devices: - /dev/nvme0n1 - /dev/nvme1n1 - /dev/nvme2n1 - /dev/nvme3n1
devices: - /dev/nvme0n1 - /dev/nvme1n1 - /dev/nvme2n1 - /dev/nvme3n1Copy to Clipboard Copied! Toggle word wrap Toggle overflow group_vars/osds.ymlの設定は以下のようになります。Copy to Clipboard Copied! Toggle word wrap Toggle overflow
lvm_volumes ではなく、この設定で devices を使用する必要があります。これは、lvm_volumes が、通常、作成済みの論理ボリュームで使用され、osds_per_device は Ceph による論理ボリュームの自動作成を意味するためです。
1.4. コンテナーへの Ceph Object Gateway のインストール
ceph-ansible playbook で Ansible アプリケーションを使用して、Ceph Object Gateway をコンテナーにインストールします。
前提条件
- 稼働中の Red Hat Ceph Storage クラスター
手順
特に指定がない限り、Ansible 管理ノードから次のコマンドを実行します。
rootユーザーとして、/usr/share/ceph-ansible/ディレクトリーにナビゲートします。cd /usr/share/ceph-ansible/
[root@admin ~]# cd /usr/share/ceph-ansible/Copy to Clipboard Copied! Toggle word wrap Toggle overflow group_vars/all.ymlファイルのradosgw_interfaceパラメーターのコメントを外します。radosgw_interface: interface
radosgw_interface: interfaceCopy to Clipboard Copied! Toggle word wrap Toggle overflow interface を、Ceph Object Gateway ノードがリッスンするインターフェイスに置き換えます。
オプション:デフォルトの変数を変更します。
group_varsディレクトリーにあるrgws.yml.sampleファイルの新しいコピーを作成します。cp group_vars/rgws.yml.sample group_vars/rgws.yml
[root@admin ceph-ansible]# cp group_vars/rgws.yml.sample group_vars/rgws.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow -
group_vars/rgws.ymlファイルを編集します。詳細については、rgws.ymlファイルを参照してください。
Ceph Object Gateway ノードのホスト名を、デフォルトで
/etc/ansible/hostsにある Ansible インベントリーファイルの[rgws]セクションに追加します。[rgws] gateway01
[rgws] gateway01Copy to Clipboard Copied! Toggle word wrap Toggle overflow または、
[osds]セクションと[rgws]セクションの下に同じノードを追加することで、Ceph Object Gateway を OSD デーモンと同じノードに配置することもできます。詳細は、「コンテナー化された Ceph デーモンのコロケーション」を参照してください。Ansible ユーザーとして、
ceph-ansible Playbookを実行します。ansible-playbook site-docker.yml --limit rgws
[user@admin ceph-ansible]$ ansible-playbook site-docker.yml --limit rgwsCopy to Clipboard Copied! Toggle word wrap Toggle overflow 注記Red Hat Ceph Storage を Red Hat Enterprise Linux Atomic Host ホストにデプロイする場合は、
--skip-tags=with_pkgオプションを使用します。ansible-playbook site-docker.yml --skip-tags=with_pkg
[user@admin ceph-ansible]$ ansible-playbook site-docker.yml --skip-tags=with_pkgCopy to Clipboard Copied! Toggle word wrap Toggle overflow Ceph Object Gateway ノードが正常にデプロイされたことを確認します。
rootユーザーとして Monitor ノードに接続します。ssh hostname
ssh hostnameCopy to Clipboard Copied! Toggle word wrap Toggle overflow hostname を Monitor ノードのホスト名に置き換えます。次に例を示します。
ssh root@monitor
[user@admin ~]$ ssh root@monitorCopy to Clipboard Copied! Toggle word wrap Toggle overflow Ceph Object Gateway プールが正しく作成されたことを確認します。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow Ceph クラスターと同じネットワーク上の任意のクライアント (モニターノードなど) から、
curlコマンドを使用して、Ceph Object Gateway ホストの IP アドレスを使用してポート 8080 で HTTP 要求を送信します。curl http://IP-address:8080
curl http://IP-address:8080Copy to Clipboard Copied! Toggle word wrap Toggle overflow IP-address を Ceph Object Gateway ノードの IP アドレスに置き換えます。Ceph Object Gateway ホストの IP アドレスを確認するには、
ifconfigまたはipコマンドを使用します。curl http://192.168.122.199:8080 <?xml version="1.0" encoding="UTF-8"?><ListAllMyBucketsResult xmlns="http://s3.amazonaws.com/doc/2006-03-01/"><Owner><ID>anonymous</ID><DisplayName></DisplayName></Owner><Buckets></Buckets></ListAllMyBucketsResult>
[root@client ~]# curl http://192.168.122.199:8080 <?xml version="1.0" encoding="UTF-8"?><ListAllMyBucketsResult xmlns="http://s3.amazonaws.com/doc/2006-03-01/"><Owner><ID>anonymous</ID><DisplayName></DisplayName></Owner><Buckets></Buckets></ListAllMyBucketsResult>Copy to Clipboard Copied! Toggle word wrap Toggle overflow バケットを一覧表示します。
docker exec ceph-mon-mon1 radosgw-admin bucket list
[root@monitor ~]# docker exec ceph-mon-mon1 radosgw-admin bucket listCopy to Clipboard Copied! Toggle word wrap Toggle overflow
関連情報
- Red Hat Enterprise Linux 用の Red Hat Ceph Storage 3 Ceph Object Gateway ガイド
-
limitオプションについて
1.5. メタデータサーバーのインストール
Ansible 自動化アプリケーションを使用して Ceph Metadata Server (MDS) をインストールします。Ceph File System をデプロイするには、メタデータサーバーデーモンが必要です。
前提条件
- 稼働中の Red Hat Ceph Storage クラスター
手順
Ansible 管理ノードで以下の手順を実行します。
新しいセクション
[mdss]を/etc/ansible/hostsファイルに追加します。[mdss] hostname hostname hostname
[mdss] hostname hostname hostnameCopy to Clipboard Copied! Toggle word wrap Toggle overflow hostname を、Ceph Metadata Server をインストールするノードのホスト名に置き換えます。
[osds]セクションおよび[mdss]セクションに同じノードを追加して、1 つのノードにメタデータサーバーと OSD デーモンを同じ場所に置く事ができます。詳細は、「コンテナー化された Ceph デーモンのコロケーション」を参照してください。/usr/share/ceph-ansibleディレクトリーに移動します。cd /usr/share/ceph-ansible
[root@admin ~]# cd /usr/share/ceph-ansibleCopy to Clipboard Copied! Toggle word wrap Toggle overflow オプション:デフォルトの変数を変更します。
mdss.ymlという名前のgroup_vars/mdss.yml.sampleファイルのコピーを作成します。cp group_vars/mdss.yml.sample group_vars/mdss.yml
[root@admin ceph-ansible]# cp group_vars/mdss.yml.sample group_vars/mdss.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow -
オプションで、
mdss.ymlのパラメーターを編集します。詳細は、mdss.ymlを参照してください。
Ansible のユーザーとして、Ansible のプレイブックを実行します。
ansible-playbook site-docker.yml --limit mdss
[user@admin ceph-ansible]$ ansible-playbook site-docker.yml --limit mdssCopy to Clipboard Copied! Toggle word wrap Toggle overflow - メタデータサーバーをインストールしたら、設定を行います。詳細は、Red Hat Ceph Storage3 の Ceph ファイルシステムガイドの メタデータサーバーデーモンの設定 の章を参照してください。
関連情報
- Red Hat Ceph Storage 3 のCeph ファイルシステムガイド
-
limitオプションについて
1.6. NFS-Ganesha ゲートウェイのインストール
Ceph NFS Ganesha ゲートウェイは、Ceph Object Gateway 上に構築される NFS インターフェースで、ファイルシステム内のファイルを Ceph Object Storage に移行するために POSIX ファイルシステムインターフェースを使用するアプリケーションを Ceph Object Gateway に提供します。
前提条件
-
稼働中の Ceph ストレージクラスター (
active + cleanの状態が望ましい)。 - Ceph Object Gateway を実行するノードを少なくとも 1 つ。
- 開始前の手順を 実行します。
手順
Ansible 管理ノードで以下のタスクを実行します。
サンプルファイルから
nfssファイルを作成します。cd /usr/share/ceph-ansible/group_vars cp nfss.yml.sample nfss.yml
[root@ansible ~]# cd /usr/share/ceph-ansible/group_vars [root@ansible ~]# cp nfss.yml.sample nfss.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow [nfss]グループの下にゲートウェイホストを/etc/ansible/hostsファイルに追加して、Ansible へのグループメンバーシップを特定します。ホストがシーケンシャルに命名されている場合は、範囲を指定します。以下は例になります。[nfss] <nfs_host_name_1> <nfs_host_name_2> <nfs_host_name[3..10]>
[nfss] <nfs_host_name_1> <nfs_host_name_2> <nfs_host_name[3..10]>Copy to Clipboard Copied! Toggle word wrap Toggle overflow Ansible の設定ディレクトリである
/etc/ansible/に移動します。cd /usr/share/ceph-ansible
[root@ansible ~]# cd /usr/share/ceph-ansibleCopy to Clipboard Copied! Toggle word wrap Toggle overflow 管理者キーを Ceph Object Gateway ノードにコピーするには、
/usr/share/ceph-ansible/group_vars/nfss.ymlファイルのcopy_admin_key設定をコメント解除します。copy_admin_key: true
copy_admin_key: trueCopy to Clipboard Copied! Toggle word wrap Toggle overflow /usr/share/ceph-ansible/group_vars/nfss.ymlファイルの FSAL (File System Abstraction Layer) セクションを設定します。ID、S3 ユーザー ID、S3 アクセスキーおよびシークレットを指定します。NFSv4 の場合は、以下のようになります。Copy to Clipboard Copied! Toggle word wrap Toggle overflow 警告アクセスおよびシークレットキーは任意で、生成できます。
Ansible Playbook の実行:
ansible-playbook site-docker.yml --limit nfss
[user@admin ceph-ansible]$ ansible-playbook site-docker.yml --limit nfssCopy to Clipboard Copied! Toggle word wrap Toggle overflow
関連情報
1.7. コンテナーへの Ceph iSCSI ゲートウェイのインストール
Ansible デプロイメントアプリケーションは、コンテナーに Ceph iSCSI ゲートウェイを設定するために必要なデーモンとツールをインストールします。
前提条件
- 稼働中の Red Hat Ceph Storage クラスター
手順
root ユーザーとして、
/etc/ansible/hostsファイルを開いて編集します。iSCSI ゲートウェイグループにノード名エントリーを追加します。例
[iscsigws] ceph-igw-1 ceph-igw-2
[iscsigws] ceph-igw-1 ceph-igw-2Copy to Clipboard Copied! Toggle word wrap Toggle overflow /usr/share/ceph-ansibleディレクトリーに移動します。cd /usr/share/ceph-ansible/
[root@admin ~]# cd /usr/share/ceph-ansible/Copy to Clipboard Copied! Toggle word wrap Toggle overflow iscsigws.yml.sampleファイルのコピーを作成し、iscsigws.ymlという名前を付けます。cp group_vars/iscsigws.yml.sample group_vars/iscsigws.yml
[root@admin ceph-ansible]# cp group_vars/iscsigws.yml.sample group_vars/iscsigws.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 重要新しいファイル名 (
iscsigws.yml) と新しいセクション見出し (iscsigws) は、Red Hat Ceph Storage 3.1 以降にのみ適用されます。以前のバージョンの Red Hat Ceph Storage から 3.1 にアップグレードすると、古いファイル名 (iscsi-gws.yml) と古いセクション見出し (iscsi-gws) が引き続き使用されます。重要現在、Red Hat は、コンテナーベースのデプロイメントで ceph-ansible を使用してインストールする以下のオプションをサポートしていません。
-
gateway_iqn -
rbd_devices -
client_connections
これらのオプションを手動で設定する手順について は、コンテナーでの Ceph iSCSI ゲートウェイの設定 セクションを参照してください。
-
-
iscsigws.ymlファイルを開いて編集します。 IPv4 アドレスまたは IPv6 アドレスを使用して、iSCSI ゲートウェイ IP アドレスを追加して、
gateway_ip_listオプションを設定します。例
gateway_ip_list: 192.168.1.1,192.168.1.2
gateway_ip_list: 192.168.1.1,192.168.1.2Copy to Clipboard Copied! Toggle word wrap Toggle overflow 重要IPv4 アドレスと IPv6 アドレスを混在させることはできません。
必要に応じて、
trusted_ip_listオプションのコメントを解除し、SSL を使用する場合は IPv4 または IPv6 アドレスを適宜追加します。SSL を設定するには、iSCSI ゲートウェイコンテナーへのrootアクセスが必要です。SSL を設定するには、以下の手順を実行します。-
必要に応じて、すべての iSCSI ゲートウェイコンテナー内に
opensslパッケージをインストールします。 プライマリー iSCSI ゲートウェイコンテナーで、SSL キーを保持するディレクトリーを作成します。
mkdir ~/ssl-keys cd ~/ssl-keys
# mkdir ~/ssl-keys # cd ~/ssl-keysCopy to Clipboard Copied! Toggle word wrap Toggle overflow プライマリー iSCSI ゲートウェイコンテナーで、証明書とキーファイルを作成します。
openssl req -newkey rsa:2048 -nodes -keyout iscsi-gateway.key -x509 -days 365 -out iscsi-gateway.crt
# openssl req -newkey rsa:2048 -nodes -keyout iscsi-gateway.key -x509 -days 365 -out iscsi-gateway.crtCopy to Clipboard Copied! Toggle word wrap Toggle overflow 注記環境情報を入力するよう求められます。
プライマリー iSCSI ゲートウェイコンテナーで、PEM ファイルを作成します。
cat iscsi-gateway.crt iscsi-gateway.key > iscsi-gateway.pem
# cat iscsi-gateway.crt iscsi-gateway.key > iscsi-gateway.pemCopy to Clipboard Copied! Toggle word wrap Toggle overflow プライマリー iSCSI ゲートウェイコンテナーで、公開鍵を作成します。
openssl x509 -inform pem -in iscsi-gateway.pem -pubkey -noout > iscsi-gateway-pub.key
# openssl x509 -inform pem -in iscsi-gateway.pem -pubkey -noout > iscsi-gateway-pub.keyCopy to Clipboard Copied! Toggle word wrap Toggle overflow -
プライマリー iSCSI ゲートウェイコンテナーから、
iscsi-gateway.crt、iscsi-gateway.pem、iscsi-gateway-pub.key、およびiscsi-gateway.keyファイルを他の iSCSI ゲートウェイコンテナーの/etc/ceph/ディレクトリーにコピーします。
-
必要に応じて、すべての iSCSI ゲートウェイコンテナー内に
必要に応じて、次の iSCSI ターゲット API サービスオプションのいずれかを確認し、コメントを解除します。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 必要に応じて、次のリソースオプションのいずれかを確認してコメントを外し、ワークロードのニーズに応じて更新します。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow Ansible のユーザーとして、Ansible のプレイブックを実行します。
ansible-playbook site-docker.yml --limit iscsigws
[user@admin ceph-ansible]$ ansible-playbook site-docker.yml --limit iscsigwsCopy to Clipboard Copied! Toggle word wrap Toggle overflow Red Hat Enterprise Linux Atomic の場合、
--skip-tags=with_pkgオプションを追加します。ansible-playbook site-docker.yml --limit iscsigws --skip-tags=with_pkg
[user@admin ceph-ansible]$ ansible-playbook site-docker.yml --limit iscsigws --skip-tags=with_pkgCopy to Clipboard Copied! Toggle word wrap Toggle overflow Ansible Playbook が完了したら、
trusted_ip_listオプションにリストされている各ノードで、TCP ポート3260とiscsigws.ymlファイルで指定されたapi_portを開きます。注記api_portオプションが指定されていない場合、デフォルトのポートは5000です。
関連情報
- コンテナーへの Red Hat Ceph Storage の インストールに関する詳細は、コンテナーへの Red Hat Ceph Storage クラスター のインストールセクションを参照してください。
- Ceph の iSCSI ゲートウェイオプションの詳細については、Red Hat Ceph Storage Block Device Guide の 表 8.1 を参照してください。
- iSCSI ターゲット API オプションの詳細については、Red Hat Ceph Storage Block Device Guide の 表 8.2 を参照してください。
-
iscsigws.ymlファイルの例については、Red Hat Ceph Storage Block Device Guide の 付録 A を参照してください。
1.7.1. コンテナーでの Ceph iSCSI ゲートウェイの設定
Ceph iSCSI ゲートウェイの設定は、iSCSI ターゲット、論理ユニット番号 (LUN)、およびアクセス制御リスト (ACL) を作成および管理するための gwcli コマンドラインユーティリティーを使用して行います。
前提条件
- 稼働中の Red Hat Ceph Storage クラスター
- iSCSI ゲートウェイソフトウェアのインストール。
手順
rootユーザーとして、iSCSI ゲートウェイのコマンドラインインターフェイスを開始します。docker exec -it rbd-target-api gwcli
# docker exec -it rbd-target-api gwcliCopy to Clipboard Copied! Toggle word wrap Toggle overflow IPv4 アドレスまたは IPv6 アドレスのいずれかを使用して iSCSI ゲートウェイを作成します。
構文
>/iscsi-target create iqn.2003-01.com.redhat.iscsi-gw:$TARGET_NAME > goto gateways > create $ISCSI_GW_NAME $ISCSI_GW_IP_ADDR > create $ISCSI_GW_NAME $ISCSI_GW_IP_ADDR
>/iscsi-target create iqn.2003-01.com.redhat.iscsi-gw:$TARGET_NAME > goto gateways > create $ISCSI_GW_NAME $ISCSI_GW_IP_ADDR > create $ISCSI_GW_NAME $ISCSI_GW_IP_ADDRCopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
>/iscsi-target create iqn.2003-01.com.redhat.iscsi-gw:ceph-igw > goto gateways > create ceph-gw-1 10.172.19.21 > create ceph-gw-2 10.172.19.22
>/iscsi-target create iqn.2003-01.com.redhat.iscsi-gw:ceph-igw > goto gateways > create ceph-gw-1 10.172.19.21 > create ceph-gw-2 10.172.19.22Copy to Clipboard Copied! Toggle word wrap Toggle overflow 重要IPv4 アドレスと IPv6 アドレスを混在させることはできません。
RADOS ブロックデバイス (RBD) を追加します。
構文
> cd /disks >/disks/ create $POOL_NAME image=$IMAGE_NAME size=$IMAGE_SIZE[m|g|t] max_data_area_mb=$BUFFER_SIZE
> cd /disks >/disks/ create $POOL_NAME image=$IMAGE_NAME size=$IMAGE_SIZE[m|g|t] max_data_area_mb=$BUFFER_SIZECopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
> cd /disks >/disks/ create rbd image=disk_1 size=50g max_data_area_mb=32
> cd /disks >/disks/ create rbd image=disk_1 size=50g max_data_area_mb=32Copy to Clipboard Copied! Toggle word wrap Toggle overflow 重要プール名またはイメージ名にピリオド (.) を含めることはできません。
警告Red Hat サポートからの指示がない限り、
max_data_area_mbオプションを調整しないでください。max_data_area_mbオプションは、iSCSI ターゲットと Ceph クラスターの間で SCSI コマンドデータを渡す時に各イメージが使用できるメモリー量をメガバイト単位で制御します。この値が小さすぎると、パフォーマンスに影響を与える過剰なキューのフル再試行が発生する可能性があります。値が大きすぎると、1 つのディスクがシステムのメモリーを過剰に使用する結果になり、他のサブシステムの割り当てエラーを引き起こす可能性があります。デフォルト値は 8 です。この値は、
reconfigureコマンドを使用して変更できます。このコマンドを有効にするには、イメージが iSCSI イニシエーターによって使用されていてはなりません。構文
>/disks/ reconfigure max_data_area_mb $NEW_BUFFER_SIZE
>/disks/ reconfigure max_data_area_mb $NEW_BUFFER_SIZECopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
>/disks/ reconfigure max_data_area_mb 64
>/disks/ reconfigure max_data_area_mb 64Copy to Clipboard Copied! Toggle word wrap Toggle overflow クライアントを作成します。
構文
> goto hosts > create iqn.1994-05.com.redhat:$CLIENT_NAME > auth chap=$USER_NAME/$PASSWORD
> goto hosts > create iqn.1994-05.com.redhat:$CLIENT_NAME > auth chap=$USER_NAME/$PASSWORDCopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
> goto hosts > create iqn.1994-05.com.redhat:rh7-client > auth chap=iscsiuser1/temp12345678
> goto hosts > create iqn.1994-05.com.redhat:rh7-client > auth chap=iscsiuser1/temp12345678Copy to Clipboard Copied! Toggle word wrap Toggle overflow 重要CHAP の無効化は、Red Hat Ceph Storage 3.1 以降でのみサポートされています。Red Hat は、CHAP が有効になっているクライアントと CHAP が無効になっているクライアントの混在をサポートしていません。すべてのクライアントの CHAP を有効にするか、無効にする必要があります。デフォルトの動作としては、イニシエーター名でイニシエーターを認証するだけです。
イニシエーターがターゲットへのログインに失敗している場合、一部のイニシエーターで CHAP 認証が正しく設定されていない可能性があります。
例
o- hosts ................................ [Hosts: 2: Auth: MISCONFIG]
o- hosts ................................ [Hosts: 2: Auth: MISCONFIG]Copy to Clipboard Copied! Toggle word wrap Toggle overflow hostsレベルで次のコマンドを実行して、すべての CHAP 認証をリセットします。Copy to Clipboard Copied! Toggle word wrap Toggle overflow ディスクをクライアントに追加します。
構文
>/iscsi-target..eph-igw/hosts> cd iqn.1994-05.com.redhat:$CLIENT_NAME > disk add $POOL_NAME.$IMAGE_NAME
>/iscsi-target..eph-igw/hosts> cd iqn.1994-05.com.redhat:$CLIENT_NAME > disk add $POOL_NAME.$IMAGE_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
>/iscsi-target..eph-igw/hosts> cd iqn.1994-05.com.redhat:rh7-client > disk add rbd.disk_1
>/iscsi-target..eph-igw/hosts> cd iqn.1994-05.com.redhat:rh7-client > disk add rbd.disk_1Copy to Clipboard Copied! Toggle word wrap Toggle overflow 次のコマンドを実行して、iSCSI ゲートウェイの設定を確認します。
> ls
> lsCopy to Clipboard Copied! Toggle word wrap Toggle overflow 必要に応じて、API が SSL を正しく使用していることを確認し、
/var/log/rbd-target-api.logファイルでhttpsを調べます。次に例を示します。Aug 01 17:27:42 test-node.example.com python[1879]: * Running on https://0.0.0.0:5000/
Aug 01 17:27:42 test-node.example.com python[1879]: * Running on https://0.0.0.0:5000/Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 次のステップは、iSCSI イニシエーターを設定することです。
関連情報
- コンテナーへの Red Hat Ceph Storage の インストールに関する詳細は、コンテナーへの Red Hat Ceph Storage クラスター のインストールセクションを参照してください。
- コンテナーへの iSCSI ゲートウェイソフトウェアのインストールの詳細については、コンテナー への Ceph iSCSI ゲートウェイのインストール セクションを参照してください。
- iSCSI イニシエーターの接続に関する詳細は、Red Hat Ceph Storage Block Device Guide の Configuring the iSCSI Initiator セクションを参照してください。
1.7.2. コンテナー内の Ceph iSCSI ゲートウェイの削除
Ceph iSCSI ゲートウェイ設定は、Ansible を使用して削除できます。
前提条件
- 稼働中の Red Hat Ceph Storage クラスター
- iSCSI ゲートウェイソフトウェアのインストール。
- エクスポートされた RBD イメージ。
- Red Hat Ceph Storage クラスターへのルートレベルのアクセス。
- iSCSI イニシエーターへのルートレベルのアクセス。
- Ansible 管理ノードへのアクセス
手順
iSCSI ゲートウェイ設定をパージする前に、すべての iSCSI イニシエーターを切断します。適切なオペレーティングシステムについては、次の手順に従ってください。
Red Hat Enterprise Linux イニシエーター:
rootで次のコマンドを実行します。構文
iscsiadm -m node -T TARGET_NAME --logout
iscsiadm -m node -T TARGET_NAME --logoutCopy to Clipboard Copied! Toggle word wrap Toggle overflow TARGET_NAME は、設定した iSCSI ターゲット名に置き換えます。
例
iscsiadm -m node -T iqn.2003-01.com.redhat.iscsi-gw:ceph-igw --logout Logging out of session [sid: 1, target: iqn.2003-01.com.redhat.iscsi-gw:iscsi-igw, portal: 10.172.19.21,3260] Logging out of session [sid: 2, target: iqn.2003-01.com.redhat.iscsi-gw:iscsi-igw, portal: 10.172.19.22,3260] Logout of [sid: 1, target: iqn.2003-01.com.redhat.iscsi-gw:iscsi-igw, portal: 10.172.19.21,3260] successful. Logout of [sid: 2, target: iqn.2003-01.com.redhat.iscsi-gw:iscsi-igw, portal: 10.172.19.22,3260] successful.
# iscsiadm -m node -T iqn.2003-01.com.redhat.iscsi-gw:ceph-igw --logout Logging out of session [sid: 1, target: iqn.2003-01.com.redhat.iscsi-gw:iscsi-igw, portal: 10.172.19.21,3260] Logging out of session [sid: 2, target: iqn.2003-01.com.redhat.iscsi-gw:iscsi-igw, portal: 10.172.19.22,3260] Logout of [sid: 1, target: iqn.2003-01.com.redhat.iscsi-gw:iscsi-igw, portal: 10.172.19.21,3260] successful. Logout of [sid: 2, target: iqn.2003-01.com.redhat.iscsi-gw:iscsi-igw, portal: 10.172.19.22,3260] successful.Copy to Clipboard Copied! Toggle word wrap Toggle overflow Windows イニシエーター:
詳細は、Microsoft のドキュメント を参照してください。
VMware ESXi イニシエーター:
詳細は、VMware のドキュメント を参照してください。
rootユーザーとして、iSCSI ゲートウェイコマンドラインユーティリティーを実行します。gwcli
# gwcliCopy to Clipboard Copied! Toggle word wrap Toggle overflow ホストを削除します。
構文
/> cd /iscsi-target/iqn.2003-01.com.redhat.iscsi-gw:_TARGET_NAME_/hosts /> /iscsi-target...TARGET_NAME/hosts> delete CLIENT_NAME
/> cd /iscsi-target/iqn.2003-01.com.redhat.iscsi-gw:_TARGET_NAME_/hosts /> /iscsi-target...TARGET_NAME/hosts> delete CLIENT_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow TARGET_NAME を設定済みの iSCSI ターゲット名に置き換え、CLIENT_NAME を iSCSI イニシエーター名に置き換えます。
例
/> cd /iscsi-target/iqn.2003-01.com.redhat.iscsi-gw:ceph-igw/hosts /> /iscsi-target...eph-igw/hosts> delete iqn.1994-05.com.redhat:rh7-client
/> cd /iscsi-target/iqn.2003-01.com.redhat.iscsi-gw:ceph-igw/hosts /> /iscsi-target...eph-igw/hosts> delete iqn.1994-05.com.redhat:rh7-clientCopy to Clipboard Copied! Toggle word wrap Toggle overflow ディスクを削除します。
構文
/> cd /disks/ /disks> delete POOL_NAME.IMAGE_NAME
/> cd /disks/ /disks> delete POOL_NAME.IMAGE_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow POOL_NAME をプールの名前に置き換え、IMAGE_NAME をイメージの名前に置き換えます。
例
/> cd /disks/ /disks> delete rbd.disk_1
/> cd /disks/ /disks> delete rbd.disk_1Copy to Clipboard Copied! Toggle word wrap Toggle overflow iSCSI ターゲットおよびゲートウェイ設定を削除します。
/> cd /iscsi-target/ /iscsi-target> clearconfig confirm=true
/> cd /iscsi-target/ /iscsi-target> clearconfig confirm=trueCopy to Clipboard Copied! Toggle word wrap Toggle overflow Ceph Monitor または Client ノードで、
rootユーザーとして、iSCSI ゲートウェイ設定オブジェクト (gateway.conf) を削除します。rados rm -p pool gateway.conf
[root@mon ~]# rados rm -p pool gateway.confCopy to Clipboard Copied! Toggle word wrap Toggle overflow オプションで、エクスポートされた Ceph RADOS Block Device (RBD) が不要になった場合は、RBD イメージを削除します。
rootユーザーとして、Ceph Monitor またはクライアントノードで以下のコマンドを実行します。構文
rbd rm IMAGE_NAME
rbd rm IMAGE_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
rbd rm rbd01
[root@mon ~]# rbd rm rbd01Copy to Clipboard Copied! Toggle word wrap Toggle overflow
関連情報
- コンテナーへの Red Hat Ceph Storage の インストールに関する詳細は、コンテナーへの Red Hat Ceph Storage クラスター のインストールセクションを参照してください。
- コンテナーへの iSCSI ゲートウェイソフトウェアのインストールの詳細については、コンテナー への Ceph iSCSI ゲートウェイのインストール セクションを参照してください。
1.7.3. iSCSI ターゲットのパフォーマンスの最適化
ネットワーク上で iSCSI ターゲット転送データを送信する方法を制御する設定は多数あります。これらの設定を使用して、iSCSI ゲートウェイのパフォーマンスを最適化できます。
Red Hat サポートの指示または本書の記載がない限り、この設定は変更しないでください。
gwcli reconfigure サブコマンド
gwcli reconfigure サブコマンドは、iSCSI ゲートウェイのパフォーマンスの最適化に使用される設定を制御します。
iSCSI ターゲットのパフォーマンスに影響する設定
- max_data_area_mb
- cmdsn_depth
- immediate_data
- initial_r2t
- max_outstanding_r2t
- first_burst_length
- max_burst_length
- max_recv_data_segment_length
- max_xmit_data_segment_length
関連情報
-
max_data_area_mbに関する情報 (gwcli reconfigureを使用して調整する方法を示す例を含む) は、ブロックデバイスガイドのコマンドラインインターフェイスを使用した iSCSI ターゲットの設定 セクションと、コンテナーガイド のコンテナー での Ceph iSCSI ゲートウェイの設定セクションに あります。
1.8. limit オプションについて
本セクションでは、Ansible の --limit オプションを説明します。
Ansible は --limit オプションをサポートしており、インベントリーファイルの特定のセクションに対して site および site-docker Ansible Playbook を使用できます。
ansible-playbook site.yml|site-docker.yml --limit osds|rgws|clients|mdss|nfss|iscsigws
$ ansible-playbook site.yml|site-docker.yml --limit osds|rgws|clients|mdss|nfss|iscsigwsたとえば、コンテナーに OSD のみを再デプロイするには、Ansible ユーザーとして以下のコマンドを実行します。
ansible-playbook /usr/share/ceph-ansible/site-docker.yml --limit osds
$ ansible-playbook /usr/share/ceph-ansible/site-docker.yml --limit osds1.9. 関連情報
- Red Hat Enterprise Linux Atomic Host の コンテナー入門 ガイド
第2章 コンテナー化された Ceph デーモンのコロケーション
このセクションでは、以下について説明します。
2.1. コロケーションの仕組みとその利点
コンテナー化された Ceph デーモンを同じノードの同じ場所に配置できます。Ceph のサービスの一部を共存する利点を以下に示します。
- 小規模での総所有コスト (TCO) の大幅な改善
- 最小設定の場合は、6 ノードから 3 ノードまで削減します。
- より簡単なアップグレード
- リソース分離の改善
コロケーションの仕組み
Ansible インベントリーファイルの適切なセクションに同じノードを追加することで、次のリストから 1 つのデーモンを OSD デーモンと同じ場所に配置できます。
-
Ceph Object Gateway (
radosgw) - メタデータサーバー (MDS)
-
RBD mirror (
rbd-mirror) -
監視および Ceph Manager デーモン (
ceph-mgr) - NFS Ganesha
以下の例は、コロケートデーモンを持つインベントリーファイルがどのようになるかを示しています。
例2.1 同じ場所に配置されたデーモンを含む Ansible インベントリーファイル
図2.1「同じ場所に配置されたデーモン」 イメージおよび 図2.2「同じ場所に配置されていないデーモン」 イメージは、同じ場所に置かれたデーモンと、同じ場所に置かれていないデーモンの相違点を示しています。
図2.1 同じ場所に配置されたデーモン
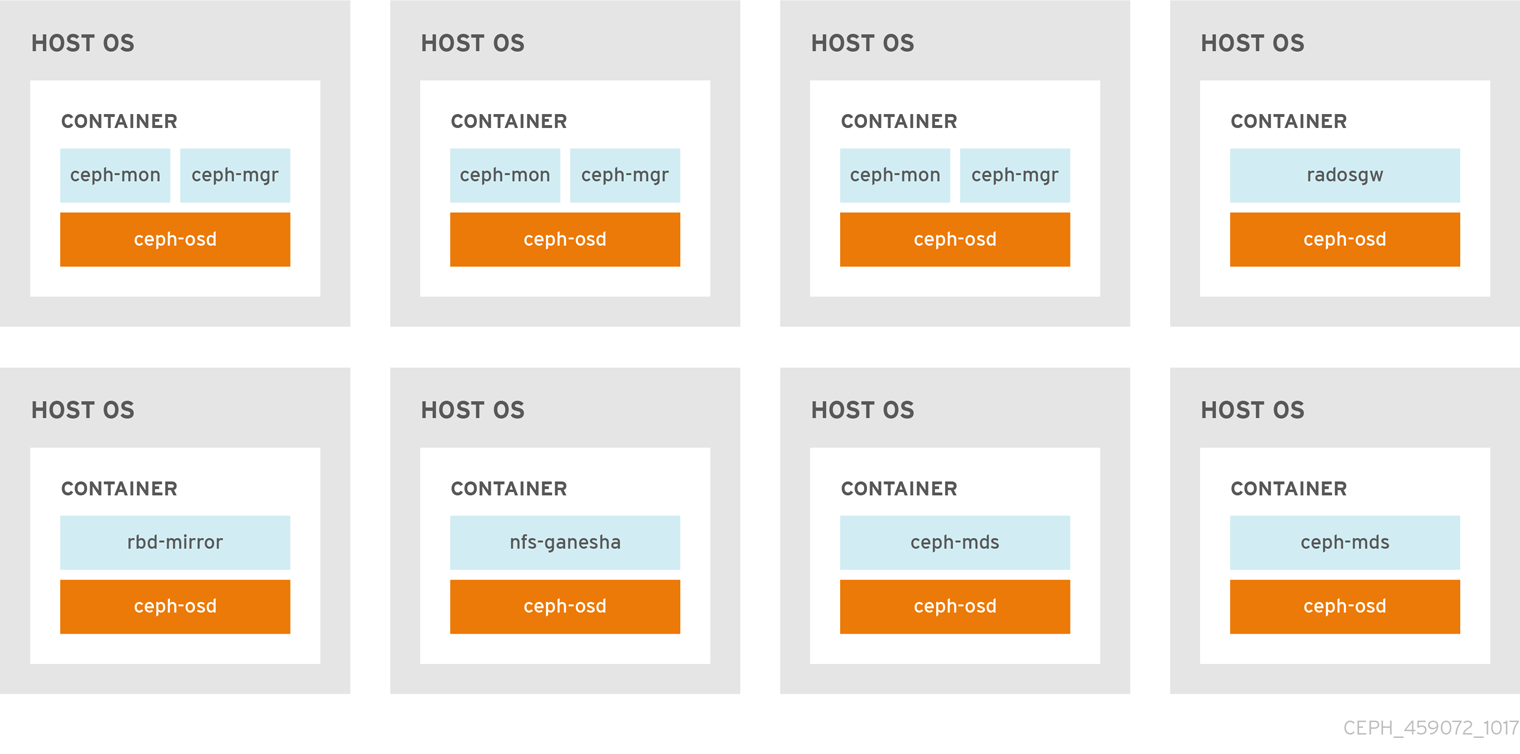
図2.2 同じ場所に配置されていないデーモン

複数のコンテナー化された Ceph デーモンを同じノードにコロケートする場合、Playbook ceph-ansible は専用の CPU および RAM リソースをそれぞれに予約します。デフォルトでは、ceph-ansible は Red Hat Ceph Storage Hardware Selection Guide 3 の 推奨最小ハードウェア の章に記載されている値を使用します。デフォルト値の変更方法は、「同じ場所に配置されたデーモンの専用リソースの設定」セクションを参照してください。
2.2. 同じ場所に配置されたデーモンの専用リソースの設定
同じノードで 2 つの Ceph デーモンを共存させる場合には、Playbook ceph-ansible は各デーモンに CPU および RAM リソースを予約します。ceph-ansible が使用するデフォルト値は、『Red Hat Ceph Storage ハードウェア選択ガイド』の「推奨される最小ハードウェア」の章に記載されています。デフォルト値を変更するには、Ceph デーモンのデプロイ時に必要なパラメーターを設定します。
手順
デーモンのデフォルト CPU 制限を変更するには、デーモンのデプロイ時に、適切な
.yml設定ファイルにceph_daemon-type_docker_cpu_limitパラメーターを設定します。詳細は以下の表を参照してください。Expand デーモン パラメーター 設定ファイル OSD
ceph_osd_docker_cpu_limitosds.ymlMDS
ceph_mds_docker_cpu_limitmdss.ymlRGW
ceph_rgw_docker_cpu_limitrgws.ymlたとえば、Ceph Object Gateway のデフォルトの CPU 制限を 2 に変更するには、以下のように
/usr/share/ceph-ansible/group_vars/rgws.ymlファイルを編集します。ceph_rgw_docker_cpu_limit: 2
ceph_rgw_docker_cpu_limit: 2Copy to Clipboard Copied! Toggle word wrap Toggle overflow OSD デーモンのデフォルト RAM を変更するには、デーモンのデプロイ時に
/usr/share/ceph-ansible/group_vars/all.ymlファイルにosd_memory_targetを設定します。たとえば、OSD RAM を 6 GB に制限するには、以下を実行します。ceph_conf_overrides: osd: osd_memory_target=6000000000ceph_conf_overrides: osd: osd_memory_target=6000000000Copy to Clipboard Copied! Toggle word wrap Toggle overflow 重要ハイパーコンバージドインフラストラクチャー (HCI) 設定では、
osd_memory_targetパラメーターを使用して OSD のメモリーを制限することをお勧めします。ceph_osd_docker_memory_limitパラメーターは必要ありませんが、使用する場合は、ceph_osd_docker_memory_limitをosd_memory_targetよりも 50% 高く設定して、CGroup 制限が HCI 設定のデフォルトよりも制約されるようにします。たとえば、osd_memory_targetが 6 GB に設定されている場合は、ceph_osd_docker_memory_limitを 9 GB に設定します。ceph_osd_docker_memory_limit: 9g
ceph_osd_docker_memory_limit: 9gCopy to Clipboard Copied! Toggle word wrap Toggle overflow
ceph_osd_docker_memory_limit パラメーターは使用しないでください。値を超えると、OSD が使用されていれば実行を停止することができます。osd_memory_target パラメーターはソフト制限を設定して、値を超えるとコンテナーが実行を停止し、割り込みサービスを停止するようにします。
関連情報
-
/usr/share/ceph-ansible/group_vars/ディレクトリーにある設定ファイルのサンプル
2.3. 関連情報
第3章 コンテナーで実行される Ceph クラスターの管理
この章では、コンテナーで実行される Ceph クラスターで実行する基本的な管理タスクについて説明します。
3.1. コンテナー内で実行される Ceph デーモンの開始、停止、および再起動
systemctl コマンドを使用して、コンテナーで実行するCeph デーモンの起動、停止、再起動を行います。
手順
コンテナーで実行している Ceph デーモンを起動、停止、または再起動するには、以下の形式で構成されるように、
rootでsystemctlコマンドを実行します。systemctl action ceph-daemon@ID
systemctl action ceph-daemon@IDCopy to Clipboard Copied! Toggle word wrap Toggle overflow ここで、
-
action は、実行するアクション (
start、stop、またはrestart) です。 -
daemon で、
osd、mon、mds、またはrgwです。 ID は以下のいずれかになります。
-
ceph-monデーモン、ceph-mdsデーモン、またはceph-rgwデーモンが実行している短いホスト名。 -
lvmに設定されているosd_scenarioパラメーターが展開された場合のceph-osdデーモンの ID -
osd_scenarioパラメーターをcollocatedまたはnon-collocatedに設定してデプロイされた場合にceph-osdデーモンが使用するデバイス名
-
たとえば、
osd01でceph-osdデーモンを再起動するには、以下のコマンドを実行します。systemctl restart ceph-osd@osd01
# systemctl restart ceph-osd@osd01Copy to Clipboard Copied! Toggle word wrap Toggle overflow ceph-monitor01ホストで実行するceph-monデーモンを起動するには、以下のコマンドを実行します。systemctl start ceph-mon@ceph-monitor01
# systemctl start ceph-mon@ceph-monitor01Copy to Clipboard Copied! Toggle word wrap Toggle overflow ceph-rgw01ホストで実行するceph-rgwデーモンを停止するには、以下のコマンドを実行します。systemctl stop ceph-radosgw@ceph-rgw01
# systemctl stop ceph-radosgw@ceph-rgw01Copy to Clipboard Copied! Toggle word wrap Toggle overflow -
action は、実行するアクション (
アクションが正常に完了したことを確認します。
systemctl status ceph-daemon@_ID
systemctl status ceph-daemon@_IDCopy to Clipboard Copied! Toggle word wrap Toggle overflow 以下は例になります。
systemctl status ceph-mon@ceph-monitor01
# systemctl status ceph-mon@ceph-monitor01Copy to Clipboard Copied! Toggle word wrap Toggle overflow
関連情報
- Red Hat Ceph Storage 3 の 管理ガイド の systemd サービスとしての Ceph の実行 セクション。
3.2. コンテナー内で実行される Ceph デーモンのログファイルの表示
コンテナーホストからの journald デーモンを使用して、コンテナーから Ceph デーモンのログファイルを表示します。
手順
Ceph ログファイル全体を表示するには、以下の形式で構成される
rootでjournalctlコマンドを実行します。journalctl -u ceph-daemon@ID
journalctl -u ceph-daemon@IDCopy to Clipboard Copied! Toggle word wrap Toggle overflow ここで、
-
daemon は Ceph デーモン (
osd、mon、またはrgw) です。 ID は以下のいずれかになります。
-
ceph-monデーモン、ceph-mdsデーモン、またはceph-rgwデーモンが実行している短いホスト名。 -
lvmに設定されているosd_scenarioパラメーターが展開された場合のceph-osdデーモンの ID -
osd_scenarioパラメーターをcollocatedまたはnon-collocatedに設定してデプロイされた場合にceph-osdデーモンが使用するデバイス名
-
たとえば、ID
osd01のceph-osdデーモンのログ全体を表示するには、以下のコマンドを実行します。journalctl -u ceph-osd@osd01
# journalctl -u ceph-osd@osd01Copy to Clipboard Copied! Toggle word wrap Toggle overflow -
daemon は Ceph デーモン (
最近のジャーナルエントリーのみを表示するには、
-fオプションを使用します。journalctl -fu ceph-daemon@ID
journalctl -fu ceph-daemon@IDCopy to Clipboard Copied! Toggle word wrap Toggle overflow たとえば、
ceph-monitor01ホストで実行するceph-monデーモンの最近のジャーナルエントリーのみを表示するには、以下のコマンドを実行します。journalctl -fu ceph-mon@ceph-monitor01
# journalctl -fu ceph-mon@ceph-monitor01Copy to Clipboard Copied! Toggle word wrap Toggle overflow
sosreport ユーティリティーを使用して journald ログを表示することもできます。SOS レポートの詳細については、Red Hat カスタマーポータルのソリューションの What is a sosreport and how to create one in Red Hat Enterprise Linux 4.6 and later? を参照してください。
関連情報
-
journalctl(1)の man ページ
3.3. コマンドラインインターフェースを使用した Ceph OSD の追加
OSD を Red Hat Ceph Storage に手動で追加するハイレベルのワークフローを以下に示します。
-
ceph-osdパッケージをインストールして、新規 OSD インスタンスを作成します。 - OSD データおよびジャーナルドライブを準備してマウントします。
- 新規 OSD ノードを CRUSH マップに追加します。
- 所有者およびグループパーミッションを更新します。
-
ceph-osdデーモンを有効にして起動します。
ceph-disk コマンドは非推奨となりました。ceph-volume コマンドは、コマンドラインインターフェースから OSD をデプロイするのに推奨される方法です。現在、ceph-volume コマンドは lvm プラグインのみをサポートしています。Red Hat は、本ガイドで両方のコマンドを参照として使用している例を提供します。これにより、ストレージ管理者は ceph-disk に依存するカスタムスクリプトを ceph-volume に変換できます。
ceph-volume コマンドの使用方法は、Red Hat Ceph Storage Administration Guideを参照してください。
カスタムストレージクラスター名の場合は、ceph コマンドおよび ceph-osd コマンドで --cluster $CLUSTER_NAME オプションを使用します。
前提条件
- Red Hat Ceph Storage クラスターが実行中である。
- Installation Guide for Red Hat Enterprise Linux または Ubuntu の Requirements for Installing Red Hat Ceph Storage の章を参照してください。
-
新規ノードへの
rootアクセスがあること。
手順
Red Hat Ceph Storage 3 OSD ソフトウェアリポジトリーを有効にします。
Red Hat Enterprise Linux
subscription-manager repos --enable=rhel-7-server-rhceph-3-osd- els-rpms
[root@osd ~]# subscription-manager repos --enable=rhel-7-server-rhceph-3-osd- els-rpmsCopy to Clipboard Copied! Toggle word wrap Toggle overflow -
/etc/ceph/ディレクトリーを作成します。 - 新しい OSD ノードで、Ceph 管理キーリングと設定ファイルを Ceph Monitor ノードの 1 つからコピーします。
ceph-osdパッケージを新しい Ceph OSD ノードにインストールします。Red Hat Enterprise Linux
yum install ceph-osd
[root@osd ~]# yum install ceph-osdCopy to Clipboard Copied! Toggle word wrap Toggle overflow 新規 OSD について、ジャーナルを共存させるか、または専用のジャーナルを使用するかどうかを決定します。
注記--filestoreオプションが必要です。ジャーナルを共存させる OSD の場合:
構文
docker exec $CONTAINER_ID ceph-disk --setuser ceph --setgroup ceph prepare --filestore /dev/$DEVICE_NAME
[root@osd ~]# docker exec $CONTAINER_ID ceph-disk --setuser ceph --setgroup ceph prepare --filestore /dev/$DEVICE_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow 例:
docker exec ceph-osd-osd1 ceph-disk --setuser ceph --setgroup ceph prepare --filestore /dev/sda
[root@osd ~]# docker exec ceph-osd-osd1 ceph-disk --setuser ceph --setgroup ceph prepare --filestore /dev/sdaCopy to Clipboard Copied! Toggle word wrap Toggle overflow 専用のジャーナルを持つ OSD の場合:
構文
docker exec $CONTAINER_ID ceph-disk --setuser ceph --setgroup ceph prepare --filestore /dev/$DEVICE_NAME /dev/$JOURNAL_DEVICE_NAME
[root@osd ~]# docker exec $CONTAINER_ID ceph-disk --setuser ceph --setgroup ceph prepare --filestore /dev/$DEVICE_NAME /dev/$JOURNAL_DEVICE_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow または
docker exec $CONTAINER_ID ceph-volume lvm prepare --filestore --data /dev/$DEVICE_NAME --journal /dev/$JOURNAL_DEVICE_NAME
[root@osd ~]# docker exec $CONTAINER_ID ceph-volume lvm prepare --filestore --data /dev/$DEVICE_NAME --journal /dev/$JOURNAL_DEVICE_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
docker exec ceph-osd-osd1 ceph-disk --setuser ceph --setgroup ceph prepare --filestore /dev/sda /dev/sdb
[root@osd ~]# docker exec ceph-osd-osd1 ceph-disk --setuser ceph --setgroup ceph prepare --filestore /dev/sda /dev/sdbCopy to Clipboard Copied! Toggle word wrap Toggle overflow docker exec ceph-osd-osd1 ceph-volume lvm prepare --filestore --data /dev/vg00/lvol1 --journal /dev/sdb
[root@osd ~]# docker exec ceph-osd-osd1 ceph-volume lvm prepare --filestore --data /dev/vg00/lvol1 --journal /dev/sdbCopy to Clipboard Copied! Toggle word wrap Toggle overflow
noupオプションを設定します。ceph osd set noup
[root@osd ~]# ceph osd set noupCopy to Clipboard Copied! Toggle word wrap Toggle overflow 新しい OSD をアクティベートします。
構文
docker exec $CONTAINER_ID ceph-disk activate /dev/$DEVICE_NAME
[root@osd ~]# docker exec $CONTAINER_ID ceph-disk activate /dev/$DEVICE_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow または
docker exec $CONTAINER_ID ceph-volume lvm activate --filestore $OSD_ID $OSD_FSID
[root@osd ~]# docker exec $CONTAINER_ID ceph-volume lvm activate --filestore $OSD_ID $OSD_FSIDCopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
docker exec ceph-osd-osd1 ceph-disk activate /dev/sda
[root@osd ~]# docker exec ceph-osd-osd1 ceph-disk activate /dev/sdaCopy to Clipboard Copied! Toggle word wrap Toggle overflow docker exec ceph-osd-osd1 ceph-volume lvm activate --filestore 0 6cc43680-4f6e-4feb-92ff-9c7ba204120e
[root@osd ~]# docker exec ceph-osd-osd1 ceph-volume lvm activate --filestore 0 6cc43680-4f6e-4feb-92ff-9c7ba204120eCopy to Clipboard Copied! Toggle word wrap Toggle overflow OSD を CRUSH マップに追加します。
構文
ceph osd crush add $OSD_ID $WEIGHT [$BUCKET_TYPE=$BUCKET_NAME ...]
ceph osd crush add $OSD_ID $WEIGHT [$BUCKET_TYPE=$BUCKET_NAME ...]Copy to Clipboard Copied! Toggle word wrap Toggle overflow 例
ceph osd crush add 4 1 host=node4
[root@osd ~]# ceph osd crush add 4 1 host=node4Copy to Clipboard Copied! Toggle word wrap Toggle overflow 注記複数のバケットを指定する場合、コマンドは OSD を指定したバケットから最も具体的なバケットに配置、および 指定した他のバケットに従ってバケットを移動します。
注記CRUSH マップを手動で編集することもできます。Red Hat Ceph Storage 3 の Storage Strategies ガイドの Editing a CRUSH map セクションを参照してください。
重要ルートバケットのみを指定する場合、OSD はルートに直接アタッチしますが、CRUSH ルールは OSD がホストバケット内に置かれることを想定します。
noupオプションの設定を解除します。ceph osd unset noup
[root@osd ~]# ceph osd unset noupCopy to Clipboard Copied! Toggle word wrap Toggle overflow 新規作成されたディレクトリーの所有者とグループのパーミッションを更新します。
構文
chown -R $OWNER:$GROUP $PATH_TO_DIRECTORY
chown -R $OWNER:$GROUP $PATH_TO_DIRECTORYCopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
chown -R ceph:ceph /var/lib/ceph/osd chown -R ceph:ceph /var/log/ceph chown -R ceph:ceph /var/run/ceph chown -R ceph:ceph /etc/ceph
[root@osd ~]# chown -R ceph:ceph /var/lib/ceph/osd [root@osd ~]# chown -R ceph:ceph /var/log/ceph [root@osd ~]# chown -R ceph:ceph /var/run/ceph [root@osd ~]# chown -R ceph:ceph /etc/cephCopy to Clipboard Copied! Toggle word wrap Toggle overflow カスタム名のクラスターを使用する場合は、以下の行を適切なファイルに追加します。
Red Hat Enterprise Linux
echo "CLUSTER=$CLUSTER_NAME" >> /etc/sysconfig/ceph
[root@osd ~]# echo "CLUSTER=$CLUSTER_NAME" >> /etc/sysconfig/cephCopy to Clipboard Copied! Toggle word wrap Toggle overflow $CLUSTER_NAMEは、カスタムクラスター名に置き換えます。新規 OSD が
起動し、データを受信する準備ができていることを確認するには、OSD サービスを有効にして起動します。構文
systemctl enable ceph-osd@$OSD_ID systemctl start ceph-osd@$OSD_ID
systemctl enable ceph-osd@$OSD_ID systemctl start ceph-osd@$OSD_IDCopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
systemctl enable ceph-osd@4 systemctl start ceph-osd@4
[root@osd ~]# systemctl enable ceph-osd@4 [root@osd ~]# systemctl start ceph-osd@4Copy to Clipboard Copied! Toggle word wrap Toggle overflow
3.4. コマンドラインインターフェースを使用した Ceph OSD の削除
ストレージクラスターから OSD を削除するには、クラスターマップの更新、その認証キーの削除、OSD マップからの OSD の削除、および ceph.conf ファイルからの OSD の削除を行う必要があります。ノードに複数のドライブがある場合は、この手順を繰り返して、それぞれのドライブについて OSD を削除する必要がある場合があります。
前提条件
- 実行中の Red Hat Ceph Storage クラスター
-
利用可能な OSD が十分になるようにして、ストレージクラスターが
ほぼ完全な比率にならないようにしてください。 -
OSDノードへの
rootアクセス権限があること。
手順
OSD サービスを無効にし、停止します。
構文
systemctl disable ceph-osd@$DEVICE_NAME systemctl stop ceph-osd@$DEVICE_NAME
systemctl disable ceph-osd@$DEVICE_NAME systemctl stop ceph-osd@$DEVICE_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
systemctl disable ceph-osd@sdb systemctl stop ceph-osd@sdb
[root@osd ~]# systemctl disable ceph-osd@sdb [root@osd ~]# systemctl stop ceph-osd@sdbCopy to Clipboard Copied! Toggle word wrap Toggle overflow OSD が停止したら、
停止します。ストレージクラスターから OSD を削除します。
構文
ceph osd out $DEVICE_NAME
ceph osd out $DEVICE_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
ceph osd out sdb
[root@osd ~]# ceph osd out sdbCopy to Clipboard Copied! Toggle word wrap Toggle overflow 重要OSD が削除されると、Ceph は再バランス調整を開始し、データをストレージクラスター内の他の OSD にコピーします。Red Hat は、次の手順に進む前に、ストレージクラスターが
active+cleanになるまで待つことを推奨します。データの移行を確認するには、以下のコマンドを実行します。ceph -w
[root@monitor ~]# ceph -wCopy to Clipboard Copied! Toggle word wrap Toggle overflow CRUSH マップから OSD を削除して、データを受信しないようにします。
構文
ceph osd crush remove $OSD_NAME
ceph osd crush remove $OSD_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
ceph osd crush remove osd.4
[root@osd ~]# ceph osd crush remove osd.4Copy to Clipboard Copied! Toggle word wrap Toggle overflow 注記CRUSH マップをコンパイルし、デバイス一覧から OSD を削除して、ホストバケットの項目としてデバイスを削除するか、またはホストバケットを削除することもできます。CRUSH マップにあり、ホストを削除するには、マップを再コンパイルしてからこれを設定します。詳細は、Storage Strategies Guide を参照してください。
OSD 認証キーを削除します。
構文
ceph auth del osd.$DEVICE_NAME
ceph auth del osd.$DEVICE_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
ceph auth del osd.sdb
[root@osd ~]# ceph auth del osd.sdbCopy to Clipboard Copied! Toggle word wrap Toggle overflow OSD を削除します。
構文
ceph osd rm $DEVICE_NAME
ceph osd rm $DEVICE_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
ceph osd rm sdb
[root@osd ~]# ceph osd rm sdbCopy to Clipboard Copied! Toggle word wrap Toggle overflow ストレージクラスターの設定ファイル (デフォルトでは
/etc/ceph.conf) を編集して、OSD エントリーが存在する場合は削除します。例
[osd.4] host = $HOST_NAME
[osd.4] host = $HOST_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow -
OSD を手動で追加している場合は、
/etc/fstabファイルで OSD への参照を削除します。 更新された設定ファイルを、ストレージクラスター内の他のすべてのノードの
/etc/ceph/ディレクトリーにコピーします。構文
scp /etc/ceph/$CLUSTER_NAME.conf $USER_NAME@$HOST_NAME:/etc/ceph/
scp /etc/ceph/$CLUSTER_NAME.conf $USER_NAME@$HOST_NAME:/etc/ceph/Copy to Clipboard Copied! Toggle word wrap Toggle overflow 例
scp /etc/ceph/ceph.conf root@node4:/etc/ceph/
[root@osd ~]# scp /etc/ceph/ceph.conf root@node4:/etc/ceph/Copy to Clipboard Copied! Toggle word wrap Toggle overflow
3.5. OSD ID の保持中に OSD ドライブの置き換え
障害のある OSD ドライブを置き換える場合は、元の OSD ID および CRUSH マップエントリーを保持できます。
ceph-volume lvm コマンドのデフォルトは、OSD 用の BlueStore です。FileStore OSD を使用するには、--filestore、--data、および --journal オプションを使用します。
詳細は、OSD データおよびジャーナルドライブの準備 セクションを参照してください。
前提条件
- 実行中の Red Hat Ceph Storage クラスター
- 障害の発生したディスク。
手順
OSD を破棄します。
ceph osd destroy $OSD_ID --yes-i-really-mean-it
ceph osd destroy $OSD_ID --yes-i-really-mean-itCopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
ceph osd destroy 1 --yes-i-really-mean-it
$ ceph osd destroy 1 --yes-i-really-mean-itCopy to Clipboard Copied! Toggle word wrap Toggle overflow 必要に応じて、交換ディスクを以前使用していた場合は、ディスクを
ザッピングする必要があります。docker exec $CONTAINER_ID ceph-volume lvm zap $DEVICE
docker exec $CONTAINER_ID ceph-volume lvm zap $DEVICECopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
docker exec ceph-osd-osd1 ceph-volume lvm zap /dev/sdb
$ docker exec ceph-osd-osd1 ceph-volume lvm zap /dev/sdbCopy to Clipboard Copied! Toggle word wrap Toggle overflow 既存の OSD ID で新規 OSD を作成します。
docker exec $CONTAINER_ID ceph-volume lvm create --osd-id $OSD_ID --data $DEVICE
docker exec $CONTAINER_ID ceph-volume lvm create --osd-id $OSD_ID --data $DEVICECopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
docker exec ceph-osd-osd1 ceph-volume lvm create --osd-id 1 --data /dev/sdb
$ docker exec ceph-osd-osd1 ceph-volume lvm create --osd-id 1 --data /dev/sdbCopy to Clipboard Copied! Toggle word wrap Toggle overflow
3.6. Ansible によってデプロイされたクラスターのパージ
Ceph クラスターを使用する必要がなくなった場合は、purge-docker-cluster.yml Playbook を使用してクラスターをパージします。クラスターのパージは、インストールプロセスが失敗し、最初からやり直したい場合にも役立ちます。
Ceph クラスターをパージすると、OSD 上のすべてのデータが失われます。
前提条件
-
/var/log/ansible.logファイルが書き込み可能であることを確認します。
手順
Ansible の管理ノードから以下のコマンドを使用します。
rootユーザーとして、/usr/share/ceph-ansible/ディレクトリーにナビゲートします。cd /usr/share/ceph-ansible
[root@admin ~]# cd /usr/share/ceph-ansibleCopy to Clipboard Copied! Toggle word wrap Toggle overflow /usr/share/infrastructure-playbooks/ディレクトリーから現在のディレクトリーにpurge-docker-cluster.ymlPlaybook をコピーします。cp infrastructure-playbooks/purge-docker-cluster.yml .
[root@admin ceph-ansible]# cp infrastructure-playbooks/purge-docker-cluster.yml .Copy to Clipboard Copied! Toggle word wrap Toggle overflow Ansible ユーザーとして、
purge-docker-cluster.ymlPlaybook を使用して Ceph クラスターを消去します。すべてのパッケージ、コンテナー、設定ファイル、および
ceph-ansible Playbookによって作成されたすべてのデータを削除するには:ansible-playbook purge-docker-cluster.yml
[user@admin ceph-ansible]$ ansible-playbook purge-docker-cluster.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow デフォルトのもの (
/etc/ansible/hosts) とは異なるインベントリーファイルを指定するには、-iパラメーターを使用します。ansible-playbook purge-docker-cluster.yml -i inventory-file
ansible-playbook purge-docker-cluster.yml -i inventory-fileCopy to Clipboard Copied! Toggle word wrap Toggle overflow inventory-file をインベントリーファイルへのパスに置き換えます。
以下は例になります。
ansible-playbook purge-docker-cluster.yml -i ~/ansible/hosts
[user@admin ceph-ansible]$ ansible-playbook purge-docker-cluster.yml -i ~/ansible/hostsCopy to Clipboard Copied! Toggle word wrap Toggle overflow Ceph コンテナーイメージの削除を省略するには、
--skip-tags=”remove_img”オプションを使用します。ansible-playbook --skip-tags="remove_img" purge-docker-cluster.yml
[user@admin ceph-ansible]$ ansible-playbook --skip-tags="remove_img" purge-docker-cluster.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow インストール時にインストールしたパッケージの削除を省略するには、
--skip-tags=”with_pkg”オプションを使用します。ansible-playbook --skip-tags="with_pkg" purge-docker-cluster.yml
[user@admin ceph-ansible]$ ansible-playbook --skip-tags="with_pkg" purge-docker-cluster.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
第4章 コンテナー内の Red Hat Ceph Storage のアップグレード
Ansible アプリケーションは、コンテナー内で実行されている Red Hat Ceph Storage のアップグレードを実行します。
4.1. 前提条件
- Red Hat Ceph Storage クラスターが実行中である。
4.2. コンテナーで実行される Red Hat Ceph Storage クラスターのアップグレード
このセクションでは、Red Hat Ceph Storage コンテナーイメージの新しいマイナーまたはメジャーバージョンにアップグレードする方法について説明します。
- ストレージクラスターをアップグレードするには、「ストレージクラスターのアップグレード」 を参照してください。
- Red Hat Ceph Storage Dashboard をアップグレードするには、「Red Hat Ceph Storage Dashboard のアップグレード」 を参照してください。
管理ノードの /usr/share/ceph-ansible/infrastructure-playbooks/ ディレクトリーにある Ansiblerolling_update.yml Playbook を使用して、Red Hat Ceph Storage の 2 つのメジャーバージョンまたはマイナーバージョン間でアップグレードするか、非同期更新を適用します。
Ansible は Ceph ノードを以下の順序でアップグレードします。
- ノードの監視
- MGR ノード
- OSD ノード
- MDS ノード
- Ceph Object Gateway ノード
- その他すべての Ceph クライアントノード
Red Hat Ceph Storage 3 では、/usr/share/ceph-ansible/group_vars/ ディレクトリーにある Ansible 設定ファイルにいくつかの変更が導入されており、特定のパラメーターの名前が変更されたり削除されたりしています。したがって、バージョン 3 にアップグレードした後、all.yml.sample ファイルと osds.yml.sample ファイルから新しいコピーを作成する前に、all.yml ファイルと osds.yml ファイルのバックアップコピーを作成してください。変更点の詳細は、付録A バージョン 2 と 3 の間の Ansible 変数の変更 をご覧ください。
Red Hat Ceph Storage 3.1 以降では、Object Gateway および高速 NVMe ベースの SSD (および SATA SSD) を使用する場合のパフォーマンスのためにストレージを最適化するために、新しい Ansible プレイブックが導入されています。Playbook は、ジャーナルとバケットインデックスを SSD に一緒に配置することでこれを行います。これにより、すべてのジャーナルを 1 つのデバイスに配置する場合に比べてパフォーマンスを向上させることができます。これらの Playbook は、Ceph のインストール時に使用されます。既存の OSD は動作し続け、アップグレード中に追加のステップは必要ありません。このようにストレージを最適化するために OSD を同時に再設定する際に、Ceph クラスターをアップグレードする方法はありません。ジャーナルまたはバケットインデックスに異なるデバイスを使用するには、OSD を再プロビジョニングする必要があります。詳細は、Ceph Object Gateway for Production での LVM での NVMe の最適な使用を参照してください。
Playbook rolling_update.yml には、同時に更新するノード数を調整する シリアル 変数が含まれます。Red Hat では、デフォルト値 (1) を使用することを強く推奨します。これにより、Ansible がクラスターノードを 1 つずつアップグレードします。
rolling_update.yml Playbook を使用して Red Hat Ceph Storage 3.x バージョンにアップグレードする場合、Ceph ファイルシステム (Ceph FS)を使用するユーザーは、Metadata Server (MDS) クラ スターを手動で更新する必要があります。これは、既知の問題によるものです。
ceph-ansible rolling_update.yml を使用してクラスター全体をアップグレードする前に /etc/ansible/hosts の MDS ホストをコメントアウトしてから、MDS を手動でアップグレードします。/etc/ansible/hosts ファイルでは
#[mdss] #host-abc
#[mdss]
#host-abcMDS クラスターの更新方法など、この既知の問題の詳細については、Red Hat Ceph Storage 3.0 リリースノート を参照してください。
Red Hat Ceph Storage クラスターを以前のバージョンからバージョン 3.2 にアップグレードする場合、Ceph Ansible 設定ではデフォルトのオブジェクトストアタイプが BlueStore に設定されます。OSD オブジェクトストアに FileStore を使用する場合は、Ceph Ansible 設定を明示的に FileStore に設定します。これにより、新たにデプロイされ、置き換えられた OSD は FileStore を使用します。
Playbook rolling_update.yml を使用して Red Hat Ceph Storage 3.x バージョンにアップグレードし、マルチサイト Ceph Object Gateway 設定を使用している場合には、マルチサイト設定を指定するために all.yml ファイルを手動で更新する必要はありません。
前提条件
-
ストレージクラスター内のすべてのノードで
rootユーザーとしてログインします。 ストレージクラスターのすべてのノードで、
rhel-7-server-extras-rpmsリポジトリーを有効にします。subscription-manager repos --enable=rhel-7-server-extras-rpms
# subscription-manager repos --enable=rhel-7-server-extras-rpmsCopy to Clipboard Copied! Toggle word wrap Toggle overflow Red Hat Ceph Storage 2.x から 3.x にアップグレードする場合は、Ansible 管理ノードと RBD ミラーリングノードで、Red Hat Ceph Storage 3 Tools リポジトリーを有効にします。
subscription-manager repos --enable=rhel-7-server-rhceph-3-tools-els-rpms
# subscription-manager repos --enable=rhel-7-server-rhceph-3-tools-els-rpmsCopy to Clipboard Copied! Toggle word wrap Toggle overflow Ansible 管理ノードで、Ansible リポジトリーを有効にします。
subscription-manager repos --enable=rhel-7-server-ansible-2.6-rpms
[root@admin ~]# subscription-manager repos --enable=rhel-7-server-ansible-2.6-rpmsCopy to Clipboard Copied! Toggle word wrap Toggle overflow Ansible 管理ノードで、
ansibleパッケージおよびceph-ansibleパッケージの最新バージョンがインストールされていることを確認します。yum update ansible ceph-ansible
[root@admin ~]# yum update ansible ceph-ansibleCopy to Clipboard Copied! Toggle word wrap Toggle overflow
4.3. ストレージクラスターのアップグレード
手順
Ansible の管理ノードから以下のコマンドを使用します。
rootユーザーとして、/usr/share/ceph-ansible/ディレクトリーにナビゲートします。cd /usr/share/ceph-ansible/
[root@admin ~]# cd /usr/share/ceph-ansible/Copy to Clipboard Copied! Toggle word wrap Toggle overflow Red Hat Ceph Storage バージョン 3.x から最新バージョンにアップグレードする場合は、この手順をスキップします。
group_vars/all.ymlファイルおよびgroup_vars/osds.ymlファイルをバックアップします。cp group_vars/all.yml group_vars/all_old.yml cp group_vars/osds.yml group_vars/osds_old.yml cp group_vars/clients.yml group_vars/clients_old.yml
[root@admin ceph-ansible]# cp group_vars/all.yml group_vars/all_old.yml [root@admin ceph-ansible]# cp group_vars/osds.yml group_vars/osds_old.yml [root@admin ceph-ansible]# cp group_vars/clients.yml group_vars/clients_old.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow Red Hat Ceph Storage バージョン 3.x から最新バージョンにアップグレードする場合は、この手順をスキップします。Red Hat Ceph Storage 2.x から 3.x にアップグレードする場合は、
group_vars/all.yml.sample、group_vars/osds.yml.sample、group_vars/clients.yml.sampleファイルの新しいコピーを作成して、それぞれgroup_vars/all.yml、group_vars/osds.yml、group_vars/clients.ymlに名前を変更します。それらを開いて編集します。詳しくは、付録A バージョン 2 と 3 の間の Ansible 変数の変更 と 「コンテナーへの Red Hat Ceph Storage Cluster のインストール」 をご覧ください。cp group_vars/all.yml.sample group_vars/all.yml cp group_vars/osds.yml.sample group_vars/osds.yml cp group_vars/clients.yml.sample group_vars/clients.yml
[root@admin ceph-ansible]# cp group_vars/all.yml.sample group_vars/all.yml [root@admin ceph-ansible]# cp group_vars/osds.yml.sample group_vars/osds.yml [root@admin ceph-ansible]# cp group_vars/clients.yml.sample group_vars/clients.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow Red Hat Ceph Storage バージョン 3.x から最新バージョンにアップグレードする場合は、この手順をスキップします。Red Hat Ceph Storage 2.x から 3.x にアップグレードする場合は、
group_vars/clients.ymlファイルを開き、以下の行をアンコメントします。keys: - { name: client.test, caps: { mon: "allow r", osd: "allow class-read object_prefix rbd_children, allow rwx pool=test" }, mode: "{{ ceph_keyring_permissions }}" }keys: - { name: client.test, caps: { mon: "allow r", osd: "allow class-read object_prefix rbd_children, allow rwx pool=test" }, mode: "{{ ceph_keyring_permissions }}" }Copy to Clipboard Copied! Toggle word wrap Toggle overflow client.testを実際のクライアント名に置き換え、クライアントキーをクライアント定義の行に追加します。以下に例を示します。key: "ADD-KEYRING-HERE=="
key: "ADD-KEYRING-HERE=="Copy to Clipboard Copied! Toggle word wrap Toggle overflow これで、行全体の例は次のようになります。
- { name: client.test, key: "AQAin8tUMICVFBAALRHNrV0Z4MXupRw4v9JQ6Q==", caps: { mon: "allow r", osd: "allow class-read object_prefix rbd_children, allow rwx pool=test" }, mode: "{{ ceph_keyring_permissions }}" }- { name: client.test, key: "AQAin8tUMICVFBAALRHNrV0Z4MXupRw4v9JQ6Q==", caps: { mon: "allow r", osd: "allow class-read object_prefix rbd_children, allow rwx pool=test" }, mode: "{{ ceph_keyring_permissions }}" }Copy to Clipboard Copied! Toggle word wrap Toggle overflow 注記クライアントキーを取得するには、
ceph auth get-or-createコマンドを実行して、指定されたクライアントのキーを表示します。
2.x から 3.x にアップグレードする場合、
group_vars/all.ymlファイルでceph_docker_imageパラメーターを変更して、Ceph 3 コンテナーのバージョンを指すようにします。ceph_docker_image: rhceph/rhceph-3-rhel7
ceph_docker_image: rhceph/rhceph-3-rhel7Copy to Clipboard Copied! Toggle word wrap Toggle overflow group_vars/all.ymlファイルにfetch_directoryパラメーターを追加してください。fetch_directory: <full_directory_path>
fetch_directory: <full_directory_path>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 以下を置き換えます。
-
<full_directory_path>を、書き込み可能な場所 (Ansible ユーザーのホームディレクトリーなど) に置き換えます。ストレージクラスターの初期インストール時に使用した既存のパスを入力してください。
既存のパスが失われていたり、なくなっていたりする場合は、まず次のことを行ってください。
既存の
group_vars/all.ymlファイルに以下のオプションを追加します。fsid: <add_the_fsid> generate_fsid: false
fsid: <add_the_fsid> generate_fsid: falseCopy to Clipboard Copied! Toggle word wrap Toggle overflow take-over-existing-cluster.ymlAnsible playbook を実行します。cp infrastructure-playbooks/take-over-existing-cluster.yml . ansible-playbook take-over-existing-cluster.yml
[user@admin ceph-ansible]$ cp infrastructure-playbooks/take-over-existing-cluster.yml . [user@admin ceph-ansible]$ ansible-playbook take-over-existing-cluster.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
-
アップグレードするクラスターに Ceph Object Gateway ノードが含まれている場合は、
radosgw_interfaceパラメーターをgroup_vars/all.ymlファイルに追加します。radosgw_interface: <interface>
radosgw_interface: <interface>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 以下を置き換えます。
-
Ceph Object Gateway がリッスンするインターフェースを使用する
<interface>
-
Ceph Object Gateway がリッスンするインターフェースを使用する
Red Hat Ceph Storage 3.2 から、デフォルトの OSD オブジェクトストアは BlueStore です。従来の OSD オブジェクトストアを維持するには、
osd_objectstoreオプションをgroup_vars/all.ymlファイルのfilestoreに明示的に設定する必要があります。osd_objectstore: filestore
osd_objectstore: filestoreCopy to Clipboard Copied! Toggle word wrap Toggle overflow 注記osd_objectstoreオプションをfilestoreに設定し、OSD を置き換えると BlueStore ではなく FileStore が使用されます。/etc/ansible/hostsにある Ansible インベントリーファイルで、[mgrs]セクションの下に Ceph Manager (ceph-mgr) ノードを追加します。Ceph Manager デーモンを Monitor ノードにコロケーションします。バージョン 3.x から最新のバージョンにアップグレードする場合は、この手順をスキップします。[mgrs] <monitor-host-name> <monitor-host-name> <monitor-host-name>
[mgrs] <monitor-host-name> <monitor-host-name> <monitor-host-name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow infrastructure-playbooksディレクトリーから現在のディレクトリーに、rolling_update.ymlをコピーします。cp infrastructure-playbooks/rolling_update.yml .
[root@admin ceph-ansible]# cp infrastructure-playbooks/rolling_update.yml .Copy to Clipboard Copied! Toggle word wrap Toggle overflow /var/log/ansible/ディレクトリーを作成し、ansibleユーザーに適切な権限を割り当てます。mkdir /var/log/ansible chown ansible:ansible /var/log/ansible chmod 755 /var/log/ansible
[root@admin ceph-ansible]# mkdir /var/log/ansible [root@admin ceph-ansible]# chown ansible:ansible /var/log/ansible [root@admin ceph-ansible]# chmod 755 /var/log/ansibleCopy to Clipboard Copied! Toggle word wrap Toggle overflow 次のように
log_path値を更新して、/usr/share/ceph-ansible/ansible.cfgファイルを編集します。log_path = /var/log/ansible/ansible.log
log_path = /var/log/ansible/ansible.logCopy to Clipboard Copied! Toggle word wrap Toggle overflow
Ansible ユーザーとして、Playbook を実行します。
ansible-playbook rolling_update.yml
[user@admin ceph-ansible]$ ansible-playbook rolling_update.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow Ansible インベントリーファイルの特定のノードグループにのみ Playbook を使用するには、
--limitオプションを使用します。詳細は、「limitオプションについて」 を参照してください。RBD ミラーリングデーモンノードに
rootユーザーとしてログインしているときに、rbd-mirrorを手動でアップグレードします。yum upgrade rbd-mirror
# yum upgrade rbd-mirrorCopy to Clipboard Copied! Toggle word wrap Toggle overflow デーモンを再起動します。
systemctl restart ceph-rbd-mirror@<client-id>
# systemctl restart ceph-rbd-mirror@<client-id>Copy to Clipboard Copied! Toggle word wrap Toggle overflow クラスターの健全性に問題がないことを確認します。
rootユーザーとしてモニターノードにログインし、実行中のすべてのコンテナーをリストします。docker ps
[root@monitor ~]# docker psCopy to Clipboard Copied! Toggle word wrap Toggle overflow クラスターの正常性が正常であることを確認します。
docker exec ceph-mon-<mon-id> ceph -s
[root@monitor ~]# docker exec ceph-mon-<mon-id> ceph -sCopy to Clipboard Copied! Toggle word wrap Toggle overflow 以下を置き換えます。
-
<mon-id>は、最初の手順で見つかった Monitor コンテナーの名前に置き換えます。
以下は例になります。
docker exec ceph-mon-monitor ceph -s
[root@monitor ~]# docker exec ceph-mon-monitor ceph -sCopy to Clipboard Copied! Toggle word wrap Toggle overflow -
OpenStack 環境で動作する場合には、すべての
cephxユーザーがプールに RBD プロファイルを使用するように更新します。以下のコマンドはrootユーザーとして実行する必要があります。Glance ユーザー
ceph auth caps client.glance mon 'profile rbd' osd 'profile rbd pool=<glance-pool-name>'
ceph auth caps client.glance mon 'profile rbd' osd 'profile rbd pool=<glance-pool-name>'Copy to Clipboard Copied! Toggle word wrap Toggle overflow 例
ceph auth caps client.glance mon 'profile rbd' osd 'profile rbd pool=images'
[root@monitor ~]# ceph auth caps client.glance mon 'profile rbd' osd 'profile rbd pool=images'Copy to Clipboard Copied! Toggle word wrap Toggle overflow Cinder ユーザー
ceph auth caps client.cinder mon 'profile rbd' osd 'profile rbd pool=<cinder-volume-pool-name>, profile rbd pool=<nova-pool-name>, profile rbd-read-only pool=<glance-pool-name>'
ceph auth caps client.cinder mon 'profile rbd' osd 'profile rbd pool=<cinder-volume-pool-name>, profile rbd pool=<nova-pool-name>, profile rbd-read-only pool=<glance-pool-name>'Copy to Clipboard Copied! Toggle word wrap Toggle overflow 例
ceph auth caps client.cinder mon 'profile rbd' osd 'profile rbd pool=volumes, profile rbd pool=vms, profile rbd-read-only pool=images'
[root@monitor ~]# ceph auth caps client.cinder mon 'profile rbd' osd 'profile rbd pool=volumes, profile rbd pool=vms, profile rbd-read-only pool=images'Copy to Clipboard Copied! Toggle word wrap Toggle overflow OpenStack の一般ユーザー
ceph auth caps client.openstack mon 'profile rbd' osd 'profile rbd-read-only pool=<cinder-volume-pool-name>, profile rbd pool=<nova-pool-name>, profile rbd-read-only pool=<glance-pool-name>'
ceph auth caps client.openstack mon 'profile rbd' osd 'profile rbd-read-only pool=<cinder-volume-pool-name>, profile rbd pool=<nova-pool-name>, profile rbd-read-only pool=<glance-pool-name>'Copy to Clipboard Copied! Toggle word wrap Toggle overflow 例
ceph auth caps client.openstack mon 'profile rbd' osd 'profile rbd-read-only pool=volumes, profile rbd pool=vms, profile rbd-read-only pool=images'
[root@monitor ~]# ceph auth caps client.openstack mon 'profile rbd' osd 'profile rbd-read-only pool=volumes, profile rbd pool=vms, profile rbd-read-only pool=images'Copy to Clipboard Copied! Toggle word wrap Toggle overflow 重要ライブクライアントの移行を実行する前に、これらの CAPS 更新を行います。これにより、クライアントがメモリーで実行している新しいライブラリーを使用でき、古い CAPS 設定がキャッシュから破棄され、新しい RBD プロファイル設定が適用されるようになります。
4.4. Red Hat Ceph Storage Dashboard のアップグレード
以下の手順では、Red Hat Ceph Storage Dashboard をバージョン 3.1 から 3.2 にアップグレードする手順の概要を説明しています。
アップグレードする前に、Red Hat Ceph Storage がバージョン 3.1 から 3.2 にアップグレードされていることを確認してください。手順は、4.1.ストレージクラスターのアップグレードを参照してください。
アップグレード手順により、ストレージダッシュボードの履歴データが削除されます。
手順
rootユーザーとして、Ansible 管理ノードからcephmetrics-ansibleパッケージを更新します。yum update cephmetrics-ansible
[root@admin ~]# yum update cephmetrics-ansibleCopy to Clipboard Copied! Toggle word wrap Toggle overflow /usr/share/cephmetrics-ansibleディレクトリーに移動します。cd /usr/share/cephmetrics-ansible
[root@admin ~]# cd /usr/share/cephmetrics-ansibleCopy to Clipboard Copied! Toggle word wrap Toggle overflow 更新された Red Hat Ceph ストレージダッシュボードをインストールします。
ansible-playbook -v playbook.yml
[root@admin cephmetrics-ansible]# ansible-playbook -v playbook.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
第5章 Red Hat Ceph Storage Dashboard を使用したコンテナーで実行されている Ceph クラスターのモニタリング
Red Hat Ceph Storage Dashboard は、Ceph Storage Cluster の状態を視覚化するためのモニタリングダッシュボードを提供します。また、Red Hat Ceph Storage Dashboard アーキテクチャーは、ストレージクラスターに機能を追加する追加のモジュール用のフレームワークを提供します。
- Dashboard の詳細は、「Red Hat Ceph Storage Dashboard」 を参照してください。
- Dashboard をインストールするには、「Red Hat Ceph Storage Dashboard のインストール」 を参照してください。
- Dashboard にアクセスするには、「Red Hat Ceph Storage Dashboard へのアクセス」 を参照してください。
- Dashboard のインストール後にデフォルトのパスワードを変更するには、「デフォルトの Red Hat Ceph Storage ダッシュボードパスワードの変更」 を参照してください。
- Prometheus プラグインの詳細は、「Red Hat Ceph Storage の Prometheus プラグイン」 を参照してください。
- Red Hat Ceph Storage Dashboard のアラートおよび設定方法について詳しく知るには、「Red Hat Ceph Storage Dashboard アラート」 を参照してください。
前提条件
- コンテナーで実行されている Red Hat Ceph Storage クラスター
5.1. Red Hat Ceph Storage Dashboard
Red Hat Ceph Storage Dashboard は、Ceph クラスターのモニタリングダッシュボードを提供し、ストレージクラスターの状態を可視化します。ダッシュボードは Web ブラウザーからアクセスでき、クラスター、モニター、OSD、プール、またはネットワークの状態に関するメトリックおよびグラフを多数提供します。
Red Hat Ceph Storage のこれまでのリリースでは、監視データは collectd プラグインを介して提供され、これにより、データを Graphite 監視ユーティリティーのインスタンスに送信されました。Red Hat Ceph Storage 3.3 以降、監視データは ceph-mgr Prometheus プラグインを使用して ceph-mgr デーモンから直接取得されます。
監視データソースとして Prometheus が導入されたことで、Red Hat Ceph Storage Dashboard ソリューションのデプロイメントと操作管理が簡素化され、全体的なハードウェア要件も軽減されました。Ceph モニタリングデータを直接適用することで、Red Hat Ceph Storage Dashboard ソリューションはコンテナーにデプロイされる Ceph クラスターをよりよくサポートできるようになりました。
アーキテクチャーにおけるこの変更により、監視データの Red Hat Ceph Storage 2.x および 3.0 から Red Hat Ceph Storage 3.3 への移行パスはありません。
Red Hat Ceph Storage Dashboard は、以下のユーティリティーを使用します。
- デプロイメント用の Ansible 自動化アプリケーション。
-
埋め込み Prometheus
ceph-mgrプラグイン。 -
ストレージクラスターの各ノードで実行される Prometheus
node-exporterデーモン。 - ユーザーインターフェースおよびアラートを提供する Grafana プラットフォーム。
Red Hat Ceph Storage Dashboard は以下の機能をサポートします。
- 一般機能
- Red Hat Ceph Storage 3.1 以降のサポート
- SELinux サポート
- FileStore および BlueStore OSD バックエンドのサポート
- 暗号化された OSD および暗号化されていない OSD のサポート
- Monitor、OSD、Ceph Object Gateway、および iSCSI ロールのサポート
- Metadata Servers (MDS) の初期サポート
- ドリルダウンおよびダッシュボードのリンク
- 15 秒の粒度
- ハードディスクドライブ (HDD)、ソリッドステートドライブ (SSD)、Non-volatile Memory Express (NVMe) インターフェース、Intel® Cache Acceleration Software (Intel® CAS) のサポート
- ノードメトリクス
- CPU および RAM の使用状況
- ネットワーク負荷
- 設定可能なアラート
- OOB (Out-of-Band) アラートおよびトリガー
- インストール時に通知チャネルが自動的に定義される
デフォルトで作成された Ceph Health Summary ダッシュボード
詳細は、「Red Hat Ceph Storage Dashboard Alerts」セクションを参照してください。
- クラスターの概要
- OSD 設定概要
- OSD FileStore および BlueStore の概要
- ロール別のクラスターバージョンの内訳
- ディスクサイズの概要
- 容量およびディスク数によるホストサイズ
- 配置グループ (PG) の状況内訳
- プール数
- HDD vs などのデバイスクラスの概要SSD
- クラスターの詳細
-
クラスターフラグの状況 (
noout、nodownなど) -
OSD または Ceph Object Gateway ホストの
upおよびdownステータス - プールごとの容量使用度
- Raw 容量の使用状況
- アクティブなスクラブおよびリカバリープロセスのインジケーター
- 増加の追跡および予想 (raw 容量)
-
OSD ホストおよびディスクを含む、
downまたはnear fullの OSD に関する情報 - OSD ごとの PG の分散
- 使用過剰または使用不足の OSD を強調するための PG 数別の OSD
-
クラスターフラグの状況 (
- OSD のパフォーマンス
- 1 秒あたりの I/O 操作に関する情報 (IOPS) およびプール別のスループット
- OSD パフォーマンスインジケーター
- OSD ごとのディスク統計
- クラスター全体のディスクスループット
- 読み取り/書き込み比率 (クライアント IOPS)
- ディスク使用率ヒートマップ
- Ceph ロールによるネットワーク負荷
- Ceph Object Gateway の詳細
- 集約された負荷ビュー
- ホストごとのレイテンシーとスループット
- HTTP 操作によるワークロードの内訳
- Ceph iSCSI Gateway の詳細
- 集約ビュー
- 設定
- パフォーマンス
- Gateway ごとのリソース使用度
- クライアントごとの負荷および設定
- Ceph Block Device 別のイメージパフォーマンス
5.2. Red Hat Ceph Storage Dashboard のインストール
Red Hat Ceph Storage Dashboard は、実行中の Ceph Storage Cluster のさまざまなメトリックを監視するビジュアルダッシュボードを提供します。
Red Hat Ceph Storage Dashboard のアップグレードに関する情報は、『Installation Guide for Red Hat Enterprise Linux』の「Upgrading Red Hat Ceph Storage Dashboard」を参照してください。
前提条件
- Ansible Automation アプリケーションでデプロイされたコンテナーで実行される Ceph Storage クラスター。
ストレージクラスターノードは Red Hat Enterprise Linux 7 を使用します。
詳細は、「Red Hat Ceph Storage ノードの CDN への登録とサブスクリプションのアタッチ」 を参照してください。
- クラスターノードからデータを受信し、Red Hat Ceph Storage Dashboard を提供する別のノードである Red Hat Ceph Storage Dashboard ノード。
Red Hat Ceph Storage Dashboard ノードを準備します。
- システムを Red Hat コンテンツ配信ネットワーク (CDN) に登録し、サブスクリプションをアタッチして、Red Hat Enterprise Linux リポジトリーを有効にします。詳細は、「Red Hat Ceph Storage ノードの CDN への登録とサブスクリプションのアタッチ」 を参照してください。
すべてのノードで Tools リポジトリーを有効にします。
詳細は、Red Hat Ceph Storage 3『Installation Guide for Red Hat Enterprise Linux』の「Enabling the Red Hat Ceph Storage Repositories」セクションを参照してください。
ファイアウォールを使用している場合は、以下の TCP ポートが開いていることを確認します。
Expand 表5.1 TCP ポート要件 ポート 使用方法 場所 3000Grafana
Red Hat Ceph Storage Dashboard ノード。
9090基本的な Prometheus グラフ
Red Hat Ceph Storage Dashboard ノード。
9100Prometheus の
node-exporterデーモンすべてのストレージクラスターノード。
9283Ceph データの収集
すべての
ceph-mgrノード。9287Ceph iSCSI ゲートウェイデータ
すべての Ceph iSCSI ゲートウェイノード。
詳細は、Red Hat Enterprise Linux 7『Security Guide』の「Using Firewalls」の章 を参照してください。
手順
Ansible 管理ノードで root ユーザーとして以下のコマンドを実行します。
cephmetrics-ansibleパッケージをインストールします。yum install cephmetrics-ansible
[root@admin ~]# yum install cephmetrics-ansibleCopy to Clipboard Copied! Toggle word wrap Toggle overflow Ceph Ansible インベントリーをベースとして使用し、デフォルトでは
/etc/ansible/hostsにある Ansible インベントリーファイルの[ceph-grafana]セクションに Red Hat Ceph Storage Dashboard ノードを追加します。[ceph-grafana] $HOST_NAME
[ceph-grafana] $HOST_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow 以下を置き換えます。
-
$HOST_NAMEは、Red Hat Ceph Storage Dashboard ノードの名前に置き換えます。
以下は例になります。
[ceph-grafana] node0
[ceph-grafana] node0Copy to Clipboard Copied! Toggle word wrap Toggle overflow -
/usr/share/cephmetrics-ansible/ディレクトリーに移動します。cd /usr/share/cephmetrics-ansible
[root@admin ~]# cd /usr/share/cephmetrics-ansibleCopy to Clipboard Copied! Toggle word wrap Toggle overflow Ansible Playbook を実行します。
ansible-playbook -v playbook.yml
[root@admin cephmetrics-ansible]# ansible-playbook -v playbook.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 重要MON または OSD ノードを追加するなど、クラスター設定を更新するたびに、
cephmetricsAnsible Playbook を再実行する必要があります。注記cephmetricsAnsible Playbook は以下のアクションを実行します。-
ceph-mgrインスタンスを更新して、prometheus プラグインを有効にし、TCP ポート 9283 を開きます。 Prometheus
node-exporterデーモンをストレージクラスターの各ノードにデプロイします。- TCP ポート 9100 を開きます。
-
node-exporterデーモンを起動します。
Grafana および Prometheus コンテナーを、Red Hat Ceph Storage Dashboard ノードの Docker/systemd 下にデプロイします。
- Prometheus は、ceph-mgr ノードおよび各 ceph ホストで稼働している node-exporters からデータを収集するように設定されます。
- TCP ポート 3000 を開きます。
- ダッシュボード、テーマ、およびユーザーアカウントはすべて Grafana に作成されます。
- 管理者の Grafana の URL を出力します。
-
5.3. Red Hat Ceph Storage Dashboard へのアクセス
Red Hat Ceph Storage Dashboard にアクセスすると、Red Hat Ceph Storage クラスターを管理する Web ベースの管理ツールにアクセスできます。
前提条件
- Red Hat Ceph Storage Dashboard のインストール。
- ノードが適切に同期されない場合に Ceph Storage Dashboard ノード、クラスターノード、およびブラウザーとの間でタイムラグが発生する可能性があるため、NTP がクロックを正しく同期していることを確認してください。Red Hat Ceph Storage 3『Installation Guide for Red Hat Enterprise Linux』の「Configuring the Network Time Protocol for Red Hat Ceph Storage」または「Ubuntu」を参照してください。
手順
Web ブラウザーに以下の URL を入力します。
http://$HOST_NAME:3000
http://$HOST_NAME:3000Copy to Clipboard Copied! Toggle word wrap Toggle overflow 以下を置き換えます。
-
$HOST_NAMEは、Red Hat Ceph Storage Dashboard ノードの名前に置き換えます。
以下は例になります。
http://cephmetrics:3000
http://cephmetrics:3000Copy to Clipboard Copied! Toggle word wrap Toggle overflow -
adminユーザーのパスワードを入力します。インストール時にパスワードを設定しなかった場合は、デフォルトのパスワードであるadminを使用します。ログインすると、Ceph At a Glance ダッシュボードに自動的に配置されます。Ceph At a Glance ダッシュボードは、ハイレベルの容量の概要、パフォーマンス、およびノードレベルのパフォーマンス情報を提供します。
例

関連情報
- 『Red Hat Ceph Storage Administration Guide』の「Changing the Default Red Hat Ceph Storage Dashboard Password」セクションを参照してください。
5.4. デフォルトの Red Hat Ceph Storage ダッシュボードパスワードの変更
Red Hat Ceph Storage Dashboard にアクセスするためのデフォルトのユーザー名およびパスワードは admin および admin に設定されます。セキュリティー上の理由から、インストール後にパスワードを変更する必要がある場合があります。
パスワードをデフォルト値にリセットしないようにするには、/usr/share/cephmetrics-ansible/group_vars/all.yml ファイルでカスタムパスワードを更新します。
手順
- 左上隅の Grafana アイコンをクリックします。
-
パスワードを変更するユーザー名の上にカーソルを合わせます。この場合、
adminになります。 -
Profileをクリックします。 -
Change Passwordをクリックします。 -
新しいパスワードを 2 回入力し、
Change Passwordをクリックします。
その他のリソース
- パスワードを忘れた場合は、Grafana Web ページの「Reset admin password」の手順に従います。
5.5. Red Hat Ceph Storage の Prometheus プラグイン
ストレージ管理者は、パフォーマンスデータを収集し、Red Hat Ceph Storage Dashboard の Prometheus プラグインモジュールを使用してそのデータをエクスポートしてから、このデータでクエリーを実行できます。Prometheus モジュールにより、ceph-mgr は Ceph 関連の状態およびパフォーマンスデータを Prometheus サーバーに公開することができます。
5.5.1. 前提条件
- Red Hat Ceph Storage 3.1 以降を稼働している。
- Red Hat Ceph Storage Dashboard のインストール。
5.5.2. Prometheus プラグイン
Prometheus プラグインは、ceph-mgr のコレクションポイントから Ceph パフォーマンスカウンターに渡すためのエクスポーターを提供します。Red Hat Ceph Storage Dashboard は、Ceph Monitors や OSD などのすべての MgrClient プロセスから MMgrReport メッセージを受信します。歳簿のサンプル数の循環バッファーには、パフォーマンスカウンタースキーマデータと実際のカウンターデータが含まれます。このプラグインは HTTP エンドポイントを作成し、ポーリング時にすべてのカウンターの最新サンプルを取得します。HTTP パスおよびクエリーパラメーターは無視され、すべてのレポートエンティティーのすべての現存カウンターはテキスト表示形式で返されます。
関連情報
- テキスト表示形式についての詳細は、Prometheus ドキュメントを参照してください。
5.5.3. Prometheus 環境の管理
Prometheus を使用して Ceph ストレージクラスターを監視するには、Prometheus エクスポーターを設定および有効にし、Ceph ストレージクラスターに関するメタデータ情報を収集できるようにします。
前提条件
- 稼働中の Red Hat Ceph Storage 3.1 クラスター
- Red Hat Ceph Storage Dashboard のインストール
手順
rootユーザーとして、/etc/prometheus/prometheus.ymlファイルを開いて編集します。globalセクションで、scrape_intervalおよびevaluation_intervalオプションを 15 秒に設定します。例
global: scrape_interval: 15s evaluation_interval: 15s
global: scrape_interval: 15s evaluation_interval: 15sCopy to Clipboard Copied! Toggle word wrap Toggle overflow scrape_configsセクションの下にhonor_labels: trueオプションを追加し、ceph-mgrノードごとにtargetsオプションおよびinstanceオプションを編集します。例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 注記honor_labelsオプションを使用すると、Ceph は Ceph Storage クラスターの任意のノードに関連する適切にラベル付けされたデータを出力できます。これにより、Prometheus が上書きせずに Ceph は適切なinstanceラベルをエクスポートできます。新規ノードを追加するには、以下の形式で
targetsオプションおよびinstanceオプションを追加します。例
- targets: [ 'new-node.example.com:9100' ] labels: instance: "new-node"- targets: [ 'new-node.example.com:9100' ] labels: instance: "new-node"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 注記instanceラベルは、Ceph の OSD メタデータのinstanceフィールドに表示されるノードの短いホスト名と一致する必要があります。これにより、Ceph 統計をノードの統計と関連付けるのに役立ちます。
以下の形式で、Ceph ターゲットを
/etc/prometheus/ceph_targets.ymlファイルに追加します。例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow Prometheus モジュールを有効にします。
ceph mgr module enable prometheus
# ceph mgr module enable prometheusCopy to Clipboard Copied! Toggle word wrap Toggle overflow
5.5.4. Prometheus データおよびクエリーの使用
統計名は Ceph の名前と同じで、無効な文字がアンダースコアに変換され、すべての名前の先頭に ceph_ が付きます。すべての Ceph デーモン統計には、ceph_daemon ラベルがあります。そのラベルからデーモンのタイプと ID を識別します (例:osd.123)。統計情報の中には、異なる種類のデーモンから得られるものもあるため、クエリを実行するときには、Ceph Monitorと RocksDB の統計情報が混ざらないように、osd で始まる Ceph デーモンに絞り込む必要があります。グローバル Ceph ストレージクラスター統計には、レポート対象に応じたラベルが付けられています。たとえば、プールに関連するメトリクスには pool_id ラベルが付けられます。コア Ceph のヒストグラムを表す長期的な平均値は、sum と count のパフォーマンスメトリクスのペアで表されます。
以下のクエリーの例は、Prometheus expression browser で使用できます。
OSD の物理ディスク使用状況を表示
(irate(node_disk_io_time_ms[1m]) /10) and on(device,instance) ceph_disk_occupation{ceph_daemon="osd.1"}
(irate(node_disk_io_time_ms[1m]) /10) and on(device,instance) ceph_disk_occupation{ceph_daemon="osd.1"}オペレーティングシステムから見た OSD の物理的な IOPS を表示
irate(node_disk_reads_completed[1m]) + irate(node_disk_writes_completed[1m]) and on (device, instance) ceph_disk_occupation{ceph_daemon="osd.1"}
irate(node_disk_reads_completed[1m]) + irate(node_disk_writes_completed[1m]) and on (device, instance) ceph_disk_occupation{ceph_daemon="osd.1"}プールおよび OSD メタデータシリーズ
特定のメタデータフィールドの表示とクエリーを可能にするために、特別なデータシリーズが出力されます。プールには、以下の例のような ceph_pool_metadataフィールドがあります。
ceph_pool_metadata{pool_id="2",name="cephfs_metadata_a"} 1.0
ceph_pool_metadata{pool_id="2",name="cephfs_metadata_a"} 1.0
OSD には、以下の例のような ceph_osd_metadataフィールドがあります。
ceph_osd_metadata{cluster_addr="172.21.9.34:6802/19096",device_class="ssd",ceph_daemon="osd.0",public_addr="172.21.9.34:6801/19096",weight="1.0"} 1.0
ceph_osd_metadata{cluster_addr="172.21.9.34:6802/19096",device_class="ssd",ceph_daemon="osd.0",public_addr="172.21.9.34:6801/19096",weight="1.0"} 1.0node_exporter でのドライブ統計の相関
Ceph からの Prometheus 出力は、Prometheus ノードエクスポーターからの汎用ノードモニタリングと併せて使用するように設計されています。Ceph OSD 統計値と汎用ノード監視ドライブ統計値を相関させると、以下の例のような特別なデータシリーズが出力されます。
ceph_disk_occupation{ceph_daemon="osd.0",device="sdd", exported_instance="node1"}
ceph_disk_occupation{ceph_daemon="osd.0",device="sdd", exported_instance="node1"}
OSD ID でディスクの統計を取得するには、Prometheus クエリーの and 演算子またはアスタリスク (*) 演算子を使用します。すべてのメタデータメトリクスの値は 1 であるため、アスタリスク演算子で中立になります。アスタリスク演算子を使用すると、group_left および group_right グループ化修飾子を使用することができ、結果として得られるメトリックに、クエリの一方から追加ラベルが付けられます。以下は例になります。
rate(node_disk_bytes_written[30s]) and on (device,instance) ceph_disk_occupation{ceph_daemon="osd.0"}
rate(node_disk_bytes_written[30s]) and on (device,instance) ceph_disk_occupation{ceph_daemon="osd.0"}label_replace の使用
label_replace 関数は、クエリのメトリックにラベルを追加したり、ラベルを変更したりすることができます。OSDとそのディスクの書き込み率を相関させるには、次のようなクエリーを使用できます。
label_replace(rate(node_disk_bytes_written[30s]), "exported_instance", "$1", "instance", "(.*):.*") and on (device,exported_instance) ceph_disk_occupation{ceph_daemon="osd.0"}
label_replace(rate(node_disk_bytes_written[30s]), "exported_instance", "$1", "instance", "(.*):.*") and on (device,exported_instance) ceph_disk_occupation{ceph_daemon="osd.0"}関連情報
- クエリー作成についての詳細は、Prometheus「querying basics」を参照してください。
-
詳細は、Prometheus の
label_replaceドキュメントを参照してください。
5.5.5. Prometheus expression browser の使用
組み込みの Prometheus expression browser を使用して、収集したデータに対してクエリーを実行します。
前提条件
- 稼働中の Red Hat Ceph Storage 3.1 クラスター
- Red Hat Ceph Storage Dashboard のインストール
手順
Web ブラウザーで Prometheus の URL を入力します。
http://$DASHBOARD_SEVER_NAME:9090/graph
http://$DASHBOARD_SEVER_NAME:9090/graphCopy to Clipboard Copied! Toggle word wrap Toggle overflow 以下を置き換えます。
-
$DASHBOARD_SEVER_NAMEは、Red Hat Ceph Storage Dashboard サーバーの名前に置き換えます。
-
Graph をクリックして、クエリーウィンドウにクエリーを入力または貼り付けし、Execute ボタンを押します。
- コンソールウィンドウの結果を確認します。
- Graph をクリックしてレンダリングされたデータを表示します。
関連情報
- 詳細は、Prometheus Web サイトの Prometheus expression browser ドキュメントを参照してください。
5.5.6. 関連情報
5.6. Red Hat Ceph Storage Dashboard アラート
本項では、Red Hat Ceph Storage Dashboard でのアラートについて説明します。
- Red Hat Ceph Storage Dashboard のアラートの詳細は、「アラートについて」 を参照してください。
- アラートを表示するには、「Alert Status ダッシュボードへのアクセス」 を参照してください。
- 通知ターゲットを設定するには、「通知ターゲットの設定」 を参照してください。
- デフォルトのアラートを変更したり、新規のアラートを追加するには、「デフォルトアラートの変更および新規アラートの追加」 を参照してください。
5.6.1. 前提条件
5.6.2. アラートについて
Red Hat Ceph Storage Dashboard は、Grafana プラットフォームで提供されるアラートメカニズムをサポートします。メトリクスが特定の値に到達する際に、ダッシュボードが通知を送信するように設定できます。このようなメトリクスは Alert Status ダッシュボードにあります。
デフォルトでは、Alert Status には、Overall Ceph Health、OSDs Down、または Pool Capacity などの特定のメトリクスがすでに含まれています。このダッシュボードに関心のあるメトリクスを追加したり、トリガーの値を変更したりすることができます。
以下は、Red Hat Ceph Storage Dashboard に含まれる事前に定義されたアラートの一覧です。
- Overall Ceph Health
- Disks Near Full (>85%)
- OSD Down
- OSD Host Down
- PG’s Stuck Inactive
- OSD Host Less - Free Capacity Check
- OSD’s With High Response Times
- Network Errors
- Pool Capacity High
- Monitors Down
- Overall Cluster Capacity Low
- OSDs With High PG Count
5.6.3. Alert Status ダッシュボードへのアクセス
Red Hat Ceph Storage Dashboard の特定のアラートは、Alert Status ダッシュボードでデフォルトで設定されます。ここでは、そのアクセス方法を 2 つ紹介します。
手順
ダッシュボードにアクセスするには、以下を行います。
- メインの At the Glance Dashboard で、右上隅の Active Alerts パネルをクリックします。
または以下を行います。
- Grafana アイコンの横にある左上隅のダッシュボードメニューをクリックします。Alert Status を選択します。
5.6.4. 通知ターゲットの設定
cephmetrics と呼ばれる通知チャンネルはインストール時に自動的に作成されます。事前設定されているアラートはすべて cephmetrics チャネルを参照しますが、アラートを受け取る前に、必要な通知タイプを選択して通知チャネル定義を完了します。Grafana プラットフォームは、メール、Slack、PagerDuty などのさまざまな通知タイプをサポートします。
手順
- 通知チャネルを設定するには、Grafana Web ページの Alert Notifications セクションの手順に従います。
5.6.5. デフォルトアラートの変更および新規アラートの追加
ここでは、すでに設定されているアラートのトリガー値を変更する方法と、Alert Status ダッシュボードに新しいアラートを追加する方法について説明します。
手順
アラートのトリガー値を変更したり、新しいアラートを追加したりするには、Grafana Webページの「Alerting Engine & Rules Guide」に従います。
重要カスタムアラートを上書きしないようにするため、トリガーの値を変更したり、新しいアラートを追加したりするときに、Red Hat Ceph Storage Dashboard パッケージをアップグレードしても、Alert Status ダッシュボードは更新されません。
関連情報
付録A バージョン 2 と 3 の間の Ansible 変数の変更
Red Hat Ceph Storage 3 では、/usr/share/ceph-ansible/group_vars/ ディレクトリーにある構成ファイルの特定の変数が変更されたか、削除されました。以下の表は、すべての変更点を示しています。バージョン3へのアップグレード後は、all.yml.sample と osds.yml.sample を再度コピーし、これらの変更を反映させてください。詳細については、コンテナーで実行される Red Hat Ceph Storage クラスターのアップグレード を参照してください。
| 旧オプション | 新規オプション | File |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|