オペレーションガイド
Red Hat Ceph Storage の操作タスク
概要
第1章 Ceph Orchestrator の紹介
ストレージ管理者として、Red Hat Ceph Storage クラスターでデバイスを検出し、サービスを作成する機能を提供する Ceph Orchestrator with Cephadm ユーティリティーを使用できます。
1.1. Ceph Orchestrator の使用
Red Hat Ceph Storage Orchestrators は、主に Red Hat Ceph Storage クラスターと、Rook や Cephadm などのデプロイメントツール間のブリッジとして機能するマネージャーモジュールです。また、Ceph コマンドラインインターフェイスおよび Ceph Dashboard と統合します。
以下は、Ceph Orchestrator のワークフローの図です。
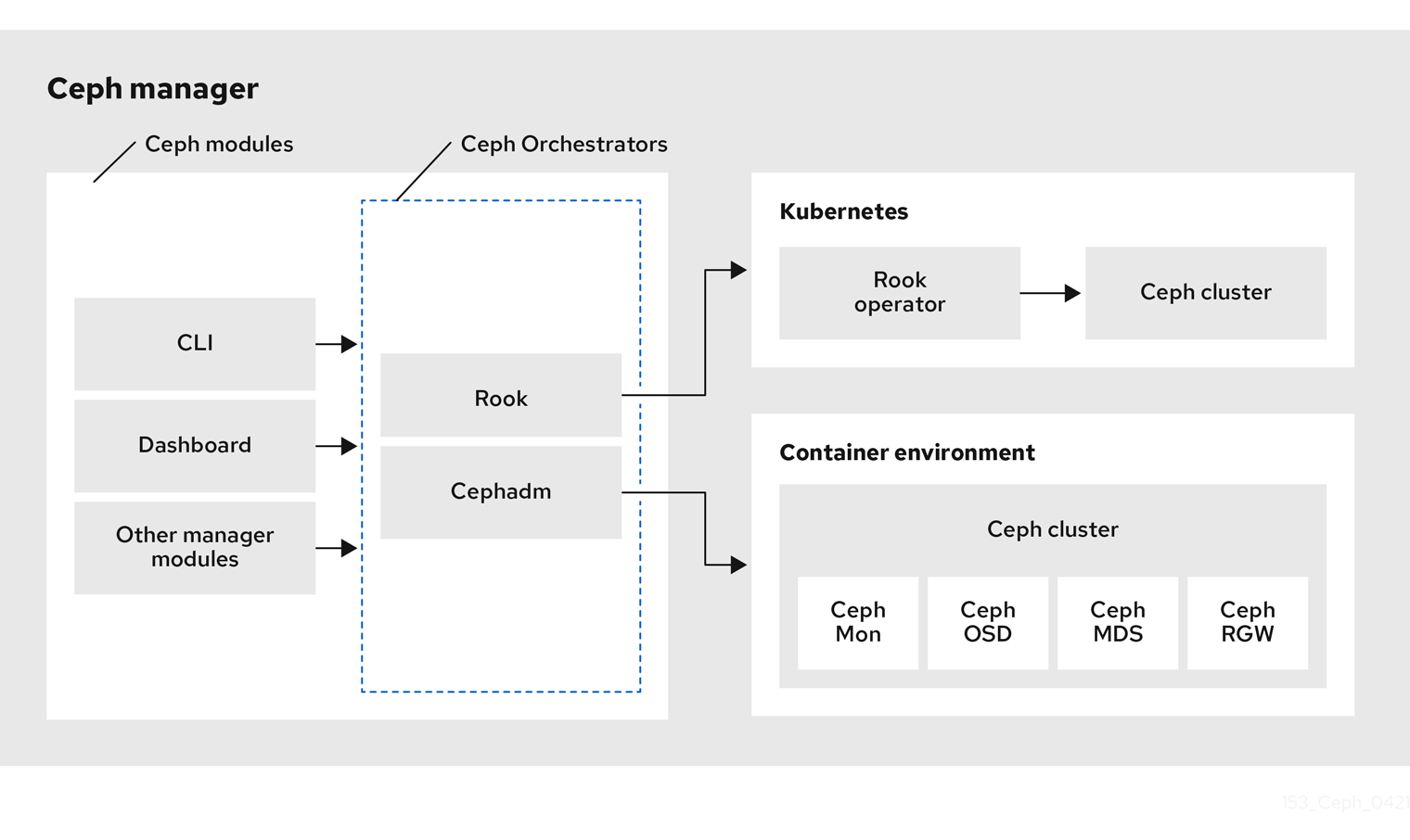
Red Hat Ceph Storage Orchestrators の種類
Red Hat Ceph Storage Orchestrators には、主に 3 つのタイプがあります。
Orchestrator CLI : これらは Orchestrators で使用される一般的な API で、実装できるコマンドセットが含まれます。これらの API は、
ceph-mgrモジュールを外部オーケストレーションサービスとオーケストレートする一般的なコマンドラインインターフェイス (CLI) も提供しています。以下は、Ceph Orchestrator で使用される用語です。- ホスト: これは、物理ホストのホスト名で、コンテナー内の Pod 名、DNS 名、コンテナー名、またはホスト名ではありません。
- サービスタイプ: これは、nfs、mds、osd、mon、ragw、mgr、iscsi などのサービスのタイプです。
- サービス: モニターサービス、マネージャーサービス、OSD サービス、Ceph Object Gateway サービス、NFS サービスなど、Ceph Storage クラスターが提供する機能サービス。
- デーモン: Ceph Object Gateway サービスなどの 1 つ以上のホストによってデプロイされるサービスの特定のインスタンスでは、3 つの異なるホストで異なる Ceph Object Gateway デーモンを実行することができます。
Cephadm Orchestrator: これは、Rook または Ansible などの外部ツールに依存しない Ceph Orchestrator モジュールであり、SSH 接続を確立し、明示的な管理コマンドを実行することでクラスターのノードを管理します。このモジュールは Day One および Day Two 操作を対象としています。
Cephadm Orchestrator の使用は、Ansible などのデプロイメントフレームワークを使用せずに Ceph Storage クラスターをインストールする推奨方法です。これは、ストレージデバイスのインベントリーの作成、OSD のデプロイメントと交換、Ceph デーモンの起動と停止など、あらゆる管理操作を実行するために、クラスター内のすべてのノードに接続できる SSH 設定および鍵にアクセスできるマネージャーデーモンを提供するものです。さらに、Cephadm Orchestrator は、同一の場所に配置されたサービスの独立したアップグレードを可能にするために、
systemdによって管理されるコンテナーイメージをデプロイします。また、このオーケストレーターでは、Ceph Monitor および Ceph Manager を実行する最低限のクラスターをブートストラップするコマンドなど、現在のホストでコンテナーイメージベースのサービスのデプロイメントを管理するために、必要なすべての操作をカプセル化するツールが重要なポイントとなるでしょう。
Rook Orchestrator: Rook は、Kubernetes Rook operator を使用して Kubernetes クラスター内で実行される Ceph ストレージクラスターを管理するオーケストレーションツールです。rook モジュールは、Ceph の Orchestrator フレームワークと Rook との間の統合を提供します。Rook は、Kubernetes のオープンソースクラウドネイティブストレージ operator です。
Rook は operator モデルに従い、ここでは Ceph ストレージクラスターおよびその望ましい状態を記述するためにカスタムリソース定義 (CRD) オブジェクトが Kubernetes で定義されます。rook operator デーモンは、現在のクラスター状態と望ましい状態を比較する制御ループで実行され、それらを収束させるための手順を実行します。Ceph の望ましい状態を記述する主なオブジェクトは Ceph ストレージクラスター CRD で、どのデバイスが OSD によって消費されるか、実行すべきモニターの数、使用すべき Ceph バージョンなどの情報が含まれます。Rook は、RBD プール、CephFS ファイルシステムなどを記述するために他の複数の CRD を定義します。
Rook Orchestrator モジュールは、
ceph-mgrデーモンで実行されるグルーで、必要なクラスターの状態を記述する Kubernetes で Ceph ストレージクラスターに変更を加えて Ceph オーケストレーション API を実装します。Rook クラスターのceph-mgrデーモンは Kubernetes Pod として実行されているため、rook モジュールは明示的な設定がなくても Kubernetes API に接続できます。
第2章 Ceph Orchestrator を使用したサービスの管理
ストレージ管理者は、Red Hat Ceph Storage クラスターのインストール後に、Ceph Orchestrator を使用してストレージクラスターのサービスを監視および管理できます。サービスは、一緒に設定されるデーモンのグループです。
本セクションでは、以下の管理情報について説明します。
2.1. サービスステータスの確認
ceph orch ls コマンドを使用して、Red Hat Ceph Storage クラスターのサービスの以下のステータスを確認できます。
- サービスの一覧を出力します。
- ステータスを確認するサービスを見つけます。
- サービスのステータスを出力します。
ブートストラップ中にサービスが ceph orch apply コマンドで適用されると、サービス仕様ファイルの変更が複雑になります。代わりに、ceph orch ls コマンドで --export オプションを使用して実行中の仕様をエクスポートし、yaml ファイルを更新してサービスを再適用できます。
前提条件
- 稼働中の Red Hat Ceph Storage クラスターがある。
-
Cephadmシェルにログインします。
手順
サービスの一覧を出力します。
構文
ceph orch ls [--service_type SERVICE_TYPE] [--service_name SERVICE_NAME] [--export] [--format FORMAT] [--refresh]
ceph orch ls [--service_type SERVICE_TYPE] [--service_name SERVICE_NAME] [--export] [--format FORMAT] [--refresh]Copy to Clipboard Copied! Toggle word wrap Toggle overflow 形式は plain、
json、json-pretty、yaml、xml-pretty、またはxmlです。例
[ceph: root@host01 /]# ceph orch ls
[ceph: root@host01 /]# ceph orch lsCopy to Clipboard Copied! Toggle word wrap Toggle overflow 特定のサービスまたはデーモンのステータスを確認します。
構文
ceph orch ls [--service_type SERVICE_TYPE] [--service_name SERVICE_NAME] [--refresh]
ceph orch ls [--service_type SERVICE_TYPE] [--service_name SERVICE_NAME] [--refresh]Copy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph orch ls --service-type mds [ceph: root@host01 /]# ceph orch ls --service-name rgw.realm.myzone
[ceph: root@host01 /]# ceph orch ls --service-type mds [ceph: root@host01 /]# ceph orch ls --service-name rgw.realm.myzoneCopy to Clipboard Copied! Toggle word wrap Toggle overflow サービス仕様をエクスポートします。
例
[ceph: root@host01 /]# ceph orch ls --service-type mgr --export > mgr.yaml [ceph: root@host01 /]# ceph orch ls --export > cluster.yaml
[ceph: root@host01 /]# ceph orch ls --service-type mgr --export > mgr.yaml [ceph: root@host01 /]# ceph orch ls --export > cluster.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow これにより、ファイルが
.yamlファイル形式でエクスポートされます。このファイルは、単一のサービスのサービス仕様を取得するためにceph orch apply -iコマンドと併用できます。
2.2. デーモンステータスの確認
デーモンは、実行中の systemd ユニットで、サービスの一部です。
ceph orch ps コマンドを使用して、Red Hat Ceph Storage クラスターのデーモンの以下のステータスを確認できます。
- すべてのデーモンの一覧を出力します。
- ターゲットデーモンのステータスをクエリーします。
前提条件
- 稼働中の Red Hat Ceph Storage クラスターがある。
-
Cephadmシェルにログインします。
手順
デーモンの一覧を出力します。
構文
ceph orch ps [--daemon-type DAEMON_TYPE] [--service_name SERVICE_NAME] [--daemon_id DAEMON_ID] [--format FORMAT] [--refresh]
ceph orch ps [--daemon-type DAEMON_TYPE] [--service_name SERVICE_NAME] [--daemon_id DAEMON_ID] [--format FORMAT] [--refresh]Copy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph orch ps
[ceph: root@host01 /]# ceph orch psCopy to Clipboard Copied! Toggle word wrap Toggle overflow 特定のサービスインスタンスのステータスを確認します。
構文
ceph orch ls [--daemon-type DAEMON_TYPE] [--daemon_id DAEMON_ID] [--refresh]
ceph orch ls [--daemon-type DAEMON_TYPE] [--daemon_id DAEMON_ID] [--refresh]Copy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph orch ps --daemon_type osd --daemon_id 0
[ceph: root@host01 /]# ceph orch ps --daemon_type osd --daemon_id 0Copy to Clipboard Copied! Toggle word wrap Toggle overflow
2.3. Ceph Orchestrator の配置仕様
Ceph Orchestrator を使用して、osds、mons、mgrs、mds、rgw、および iSCSI サービスをデプロイできます。Red Hat は、配置仕様を使用してサービスをデプロイすることを推奨します。Ceph Orchestrator を使用して、サービスをデプロイするためにデプロイする必要があるデーモンの場所と数を把握する必要があります。配置仕様は、コマンドライン引数または yaml ファイルのサービス仕様として渡すことができます。
配置仕様を使用してサービスをデプロイする方法は 2 つあります。
コマンドラインインターフェイスで配置仕様を直接使用します。たとえば、ホストに 3 つのモニターをデプロイする場合は、以下のコマンドを実行して
host01、host02、およびhost03に 3 つのモニターをデプロイします。例
[ceph: root@host01 /]# ceph orch apply mon --placement="3 host01 host02 host03"
[ceph: root@host01 /]# ceph orch apply mon --placement="3 host01 host02 host03"Copy to Clipboard Copied! Toggle word wrap Toggle overflow YAML ファイルでの配置仕様の使用。たとえば、すべてのホストに
node-exporterをデプロイする場合には、yamlファイルで以下を指定できます。例
service_type: node-exporter placement: host_pattern: '*'
service_type: node-exporter placement: host_pattern: '*'Copy to Clipboard Copied! Toggle word wrap Toggle overflow
2.4. コマンドラインインターフェイスを使用した Ceph デーモンのデプロイ
Ceph Orchestrator を使用すると、ceph orch コマンドを使用して Ceph Manager、Ceph Monitors、Ceph OSD、モニタリングスタックなどのデーモンをデプロイできます。配置仕様は、Orchestrator コマンドの --placement 引数として渡されます。
前提条件
- 稼働中の Red Hat Ceph Storage クラスターがある。
- ホストがストレージクラスターに追加されている。
手順
Cephadm シェルにログインします。
例
cephadm shell
[root@host01 ~]# cephadm shellCopy to Clipboard Copied! Toggle word wrap Toggle overflow 以下のいずれかの方法を使用して、ホストにデーモンをデプロイします。
方法 1: デーモンの数とホスト名を指定します。
構文
ceph orch apply SERVICE_NAME --placement="NUMBER_OF_DAEMONS HOST_NAME_1 HOST_NAME_2 HOST_NAME_3"
ceph orch apply SERVICE_NAME --placement="NUMBER_OF_DAEMONS HOST_NAME_1 HOST_NAME_2 HOST_NAME_3"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph orch apply mon --placement="3 host01 host02 host03"
[ceph: root@host01 /]# ceph orch apply mon --placement="3 host01 host02 host03"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 方法 2: ラベルをホストに追加してから、ラベルを使用してデーモンをデプロイします。
ホストにラベルを追加します。
構文
ceph orch host label add HOSTNAME_1 LABEL
ceph orch host label add HOSTNAME_1 LABELCopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph orch host label add host01 mon
[ceph: root@host01 /]# ceph orch host label add host01 monCopy to Clipboard Copied! Toggle word wrap Toggle overflow ラベルでデーモンをデプロイします。
構文
ceph orch apply DAEMON_NAME label:LABEL
ceph orch apply DAEMON_NAME label:LABELCopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
ceph orch apply mon label:mon
ceph orch apply mon label:monCopy to Clipboard Copied! Toggle word wrap Toggle overflow
方法 3: ラベルをホストに追加し、
--placement引数を使用してデプロイします。ホストにラベルを追加します。
構文
ceph orch host label add HOSTNAME_1 LABEL
ceph orch host label add HOSTNAME_1 LABELCopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph orch host label add host01 mon
[ceph: root@host01 /]# ceph orch host label add host01 monCopy to Clipboard Copied! Toggle word wrap Toggle overflow ラベルの配置仕様を使用してデーモンをデプロイします。
構文
ceph orch apply DAEMON_NAME --placement="label:LABEL"
ceph orch apply DAEMON_NAME --placement="label:LABEL"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 例
ceph orch apply mon --placement="label:mon"
ceph orch apply mon --placement="label:mon"Copy to Clipboard Copied! Toggle word wrap Toggle overflow
検証
サービスをリスト表示します。
例
[ceph: root@host01 /]# ceph orch ls
[ceph: root@host01 /]# ceph orch lsCopy to Clipboard Copied! Toggle word wrap Toggle overflow ホスト、デーモン、およびプロセスをリスト表示します。
構文
ceph orch ps --daemon_type=DAEMON_NAME ceph orch ps --service_name=SERVICE_NAME
ceph orch ps --daemon_type=DAEMON_NAME ceph orch ps --service_name=SERVICE_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph orch ps --daemon_type=mon [ceph: root@host01 /]# ceph orch ps --service_name=mon
[ceph: root@host01 /]# ceph orch ps --daemon_type=mon [ceph: root@host01 /]# ceph orch ps --service_name=monCopy to Clipboard Copied! Toggle word wrap Toggle overflow
2.5. コマンドラインインターフェイスを使用したホストのサブセットへの Ceph デーモンのデプロイ
--placement オプションを使用して、ホストのサブセットにデーモンをデプロイできます。デーモンをデプロイするホストの名前で、配置仕様のデーモン数を指定できます。
前提条件
- 稼働中の Red Hat Ceph Storage クラスターがある。
- ホストがクラスターに追加されている。
手順
Cephadm シェルにログインします。
例
cephadm shell
[root@host01 ~]# cephadm shellCopy to Clipboard Copied! Toggle word wrap Toggle overflow Ceph デーモンをデプロイするホストをリスト表示します。
例
[ceph: root@host01 /]# ceph orch host ls
[ceph: root@host01 /]# ceph orch host lsCopy to Clipboard Copied! Toggle word wrap Toggle overflow デーモンをデプロイします。
構文
ceph orch apply SERVICE_NAME --placement="NUMBER_OF_DAEMONS HOST_NAME_1 _HOST_NAME_2 HOST_NAME_3"
ceph orch apply SERVICE_NAME --placement="NUMBER_OF_DAEMONS HOST_NAME_1 _HOST_NAME_2 HOST_NAME_3"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 例
ceph orch apply mgr --placement="2 host01 host02 host03"
ceph orch apply mgr --placement="2 host01 host02 host03"Copy to Clipboard Copied! Toggle word wrap Toggle overflow この例では、
mgrデーモンは、2 つのホストにのみデプロイされます。
検証
ホストをリスト表示します。
例
[ceph: root@host01 /]# ceph orch host ls
[ceph: root@host01 /]# ceph orch host lsCopy to Clipboard Copied! Toggle word wrap Toggle overflow
2.6. Ceph Orchestrator のサービス仕様
サービス仕様は、Ceph サービスのデプロイに使用されるサービス属性および設定を指定するデータ構造です。以下は、サービス仕様を指定するためのマルチドキュメント YAML ファイル cluster.yml の例になります。
例
以下は、サービス仕様のプロパティーが以下のように定義されるパラメーターのリストです。
service_type: サービスのタイプ- mon、crash、mds、mgr、osd、rbd、rbd-mirror などの Ceph サービス。
- nfs や rgw などの Ceph ゲートウェイ。
- Alertmanager、Prometheus、Grafana、または Node-exporter などのモニタリングスタック。
- カスタムコンテナーのコンテナー。
-
service_id: サービスの一意名 -
placement: これは、デーモンの場所とデプロイ方法を定義するために使用されます。 -
unmanaged:trueに設定すると、Orchestrator は、このサービスに関連付けられたデーモンをデプロイまたは削除しません。
Orchestrator のステートレスサービス
ステートレスサービスは、状態の情報を利用可能にする必要がないサービスです。たとえば、rgw サービスを起動するには、サービスの起動または実行に追加情報は必要ありません。rgw サービスは、機能を提供するためにこの状態に関する情報を作成しません。rgw サービスを開始されるタイミングに関係なく、状態は同じになります。
2.7. サービス仕様を使用した Ceph デーモンのデプロイ
Ceph Orchestrator を使用すると、YAML ファイルのサービス仕様を使用して Ceph Manager、Ceph Monitors、Ceph OSD、モニタリングスタックなどのデーモンをデプロイできます。
前提条件
- 稼働中の Red Hat Ceph Storage クラスターがある。
- すべてのノードへの root レベルのアクセス。
手順
yamlファイルを作成します。例
touch mon.yaml
[root@host01 ~]# touch mon.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow このファイルは 2 つの方法で設定できます。
ファイルを編集して、配置仕様にホストの詳細を含めます。
構文
service_type: SERVICE_NAME placement: hosts: - HOST_NAME_1 - HOST_NAME_2service_type: SERVICE_NAME placement: hosts: - HOST_NAME_1 - HOST_NAME_2Copy to Clipboard Copied! Toggle word wrap Toggle overflow 例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow ファイルを編集し、ラベルの詳細を配置仕様に含めます。
構文
service_type: SERVICE_NAME placement: label: "LABEL_1"
service_type: SERVICE_NAME placement: label: "LABEL_1"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 例
service_type: mon placement: label: "mon"
service_type: mon placement: label: "mon"Copy to Clipboard Copied! Toggle word wrap Toggle overflow
オプション: サービスのデプロイ中に、CPU、CA 証明書、その他のファイルなどのサービス仕様ファイルで追加のコンテナー引数を使用することもできます。
例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow YAML ファイルをコンテナー内のディレクトリーにマウントします。
例
cephadm shell --mount mon.yaml:/var/lib/ceph/mon/mon.yaml
[root@host01 ~]# cephadm shell --mount mon.yaml:/var/lib/ceph/mon/mon.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow そのディレクトリーに移動します。
例
[ceph: root@host01 /]# cd /var/lib/ceph/mon/
[ceph: root@host01 /]# cd /var/lib/ceph/mon/Copy to Clipboard Copied! Toggle word wrap Toggle overflow サービス仕様を使用して Ceph デーモンをデプロイします。
構文
ceph orch apply -i FILE_NAME.yaml
ceph orch apply -i FILE_NAME.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 mon]# ceph orch apply -i mon.yaml
[ceph: root@host01 mon]# ceph orch apply -i mon.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
検証
サービスをリスト表示します。
例
[ceph: root@host01 /]# ceph orch ls
[ceph: root@host01 /]# ceph orch lsCopy to Clipboard Copied! Toggle word wrap Toggle overflow ホスト、デーモン、およびプロセスをリスト表示します。
構文
ceph orch ps --daemon_type=DAEMON_NAME
ceph orch ps --daemon_type=DAEMON_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph orch ps --daemon_type=mon
[ceph: root@host01 /]# ceph orch ps --daemon_type=monCopy to Clipboard Copied! Toggle word wrap Toggle overflow
第3章 Ceph Orchestrator を使用したホストの管理
ストレージ管理者は、バックエンドで Cephadm で Ceph Orchestrator を使用し、既存の Red Hat Ceph Storage クラスターでホストを追加、リスト表示、および削除できます。
ホストにラベルを追加することもできます。ラベルは自由形式であり、特別な意味はありません。各ホストに複数のラベルを指定できます。たとえば、Monitor デーモンがデプロイされたすべてのホストに mon ラベルを適用し、Manager デーモンがデプロイされたすべてのホストに mgr を適用し、Ceph オブジェクトゲートウェイに rgw を適用します。
ストレージクラスター内のすべてのホストにラベルを付けると、各ホストで実行されているデーモンをすばやく識別できるため、システム管理タスクが簡素化されます。さらに、Ceph Orchestrator または YAML ファイルを使用して、特定のホストラベルを持つホストにデーモンをデプロイまたは削除できます。
本セクションでは、以下の管理タスクを説明します。
- Ceph Orchestrator を使用したホストの追加
- Ceph Orchestrator を使用した複数ホストの追加
- Ceph Orchestrator を使用したホストのリスト表示
- Ceph Orchestrator を使用したホストへのラベルの追加
- ホストからのラベルの削除。
- Ceph Orchestrator を使用したホストの削除
- Ceph Orchestrator を使用したホストのメンテナンスモード。
3.1. 前提条件
- 稼働中の Red Hat Ceph Storage クラスターがある。
- すべてのノードへの root レベルのアクセス。
-
新しいホストの IP アドレスは
/etc/hostsファイルで更新する必要があります。
3.2. Ceph Orchestrator を使用したホストの追加
バックエンドで Cephadm で Ceph Orchestrator を使用して、ホストを既存の Red Hat Ceph Storage クラスターに追加できます。
前提条件
- 稼働中の Red Hat Ceph Storage クラスターがある。
- ストレージクラスター内のすべてのノードへの root レベルのアクセス。
- ノードを CDN に登録して、サブスクリプションを割り当てます。
-
ストレージクラスター内のすべてのノードへの sudo アクセスおよびパスワードなしの
sshアクセスのある Ansible ユーザー。
手順
Ceph 管理ノードから、Cephadm シェルにログインします。
例
cephadm shell
[root@host01 ~]# cephadm shellCopy to Clipboard Copied! Toggle word wrap Toggle overflow クラスターの SSH 公開鍵をフォルダーにデプロイメントします。
構文
ceph cephadm get-pub-key > ~/PATH
ceph cephadm get-pub-key > ~/PATHCopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph cephadm get-pub-key > ~/ceph.pub
[ceph: root@host01 /]# ceph cephadm get-pub-key > ~/ceph.pubCopy to Clipboard Copied! Toggle word wrap Toggle overflow Ceph クラスターの SSH 公開鍵を、新たなホストの root ユーザーの
authorized_keysファイルにコピーします。構文
ssh-copy-id -f -i ~/PATH root@HOST_NAME_2
ssh-copy-id -f -i ~/PATH root@HOST_NAME_2Copy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ssh-copy-id -f -i ~/ceph.pub root@host02
[ceph: root@host01 /]# ssh-copy-id -f -i ~/ceph.pub root@host02Copy to Clipboard Copied! Toggle word wrap Toggle overflow Ansible 管理ノードから、新しいホストを Ansible インベントリーファイルに追加します。ファイルのデフォルトの場所は
/usr/share/cephadm-ansible/hosts/です。以下の例は、一般的なインベントリーファイルの構造を示しています。例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 注記以前に新しいホストを Ansible インベントリーファイルに追加し、ホストでプリフライト Playbook を実行している場合は、ステップ 6 に進みます。
--limitオプションを指定して、プリフライト Playbook を実行します。構文
ansible-playbook -i INVENTORY_FILE cephadm-preflight.yml --extra-vars "ceph_origin=rhcs" --limit NEWHOST
ansible-playbook -i INVENTORY_FILE cephadm-preflight.yml --extra-vars "ceph_origin=rhcs" --limit NEWHOSTCopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
ansible-playbook -i hosts cephadm-preflight.yml --extra-vars "ceph_origin=rhcs" --limit host02
[ceph-admin@admin cephadm-ansible]$ ansible-playbook -i hosts cephadm-preflight.yml --extra-vars "ceph_origin=rhcs" --limit host02Copy to Clipboard Copied! Toggle word wrap Toggle overflow プリフライト Playbook は、新しいホストに
podman、lvm2、chronyd、およびcephadmをインストールします。インストールが完了すると、cephadmは/usr/sbin/ディレクトリーに配置されます。Ceph 管理ノードから、Cephadm シェルにログインします。
例
cephadm shell
[root@host01 ~]# cephadm shellCopy to Clipboard Copied! Toggle word wrap Toggle overflow cephadmオーケストレーターを使用して、ストレージクラスターにホストを追加します。構文
ceph orch host add HOST_NAME IP_ADDRESS_OF_HOST [--label=LABEL_NAME_1,LABEL_NAME_2]
ceph orch host add HOST_NAME IP_ADDRESS_OF_HOST [--label=LABEL_NAME_1,LABEL_NAME_2]Copy to Clipboard Copied! Toggle word wrap Toggle overflow --labelオプションは任意です。これを使用すると、ホストの追加時にラベルが追加されます。ホストには複数のラベルを追加できます。例
[ceph: root@host01 /]# ceph orch host add host02 10.10.128.70 --labels=mon,mgr
[ceph: root@host01 /]# ceph orch host add host02 10.10.128.70 --labels=mon,mgrCopy to Clipboard Copied! Toggle word wrap Toggle overflow
検証
ホストをリスト表示します。
例
[ceph: root@host01 /]# ceph orch host ls
[ceph: root@host01 /]# ceph orch host lsCopy to Clipboard Copied! Toggle word wrap Toggle overflow
3.3. ホストの初期 CRUSH ロケーションの設定
指定した階層にある新しい CRUSH ホストを作成するように cephadm tp に指示するホストに、location 識別子を追加できます。
location 属性は、最初の CRUSH の場所にのみ影響します。その後の location プロパティーの変更は無視されます。また、ホストを削除しても、CRUSH バケットは削除されません。
前提条件
- 稼働中の Red Hat Ceph Storage クラスターがある。
手順
hosts.yamlファイルを編集し、以下の詳細を含めます。例
service_type: host hostname: host01 addr: 192.168.0.11 location: rack: rack1
service_type: host hostname: host01 addr: 192.168.0.11 location: rack: rack1Copy to Clipboard Copied! Toggle word wrap Toggle overflow YAML ファイルをコンテナー内のディレクトリーにマウントします。
例
cephadm shell --mount hosts.yaml:/var/lib/ceph/hosts.yaml
[root@host01 ~]# cephadm shell --mount hosts.yaml:/var/lib/ceph/hosts.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow そのディレクトリーに移動します。
例
[ceph: root@host01 /]# cd /var/lib/ceph/
[ceph: root@host01 /]# cd /var/lib/ceph/Copy to Clipboard Copied! Toggle word wrap Toggle overflow サービス仕様を使用してホストをデプロイします。
構文
ceph orch apply -i FILE_NAME.yaml
ceph orch apply -i FILE_NAME.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 ceph]# ceph orch apply -i hosts.yaml
[ceph: root@host01 ceph]# ceph orch apply -i hosts.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
3.4. Ceph Orchestrator を使用した複数ホストの追加
YAML ファイル形式のサービス仕様の使用と同時に、Ceph Orchestrator を使用して複数のホストを Red Hat Ceph Storage クラスターに追加することができます。
前提条件
- 稼働中の Red Hat Ceph Storage クラスターがある。
手順
hosts.yamlファイルを作成します。例
touch hosts.yaml
[root@host01 ~]# touch hosts.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow hosts.yamlファイルを編集し、以下の詳細を含めます。例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow YAML ファイルをコンテナー内のディレクトリーにマウントします。
例
cephadm shell --mount hosts.yaml:/var/lib/ceph/hosts.yaml
[root@host01 ~]# cephadm shell --mount hosts.yaml:/var/lib/ceph/hosts.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow そのディレクトリーに移動します。
例
[ceph: root@host01 /]# cd /var/lib/ceph/
[ceph: root@host01 /]# cd /var/lib/ceph/Copy to Clipboard Copied! Toggle word wrap Toggle overflow サービス仕様を使用してホストをデプロイします。
構文
ceph orch apply -i FILE_NAME.yaml
ceph orch apply -i FILE_NAME.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 hosts]# ceph orch apply -i hosts.yaml
[ceph: root@host01 hosts]# ceph orch apply -i hosts.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
検証
ホストをリスト表示します。
例
[ceph: root@host01 /]# ceph orch host ls
[ceph: root@host01 /]# ceph orch host lsCopy to Clipboard Copied! Toggle word wrap Toggle overflow
3.5. Ceph Orchestrator を使用したホストのリスト表示
Ceph クラスターのホストを Ceph Orchestrator で リスト表示できます。
ホストの STATUS は、ceph orch host ls コマンドの出力では空白になります。
前提条件
- 稼働中の Red Hat Ceph Storage クラスターがある。
- ホストがストレージクラスターに追加されている。
手順
Cephadm シェルにログインします。
例
cephadm shell
[root@host01 ~]# cephadm shellCopy to Clipboard Copied! Toggle word wrap Toggle overflow クラスターのホストをリスト表示します。
例
[ceph: root@host01 /]# ceph orch host ls
[ceph: root@host01 /]# ceph orch host lsCopy to Clipboard Copied! Toggle word wrap Toggle overflow ホストの STATUS が空白であることを確認できます。これは想定内です。
3.6. Ceph Orchestrator を使用したホストへのラベルの追加
Ceph Orchestrator を使用して、既存の Red Hat Ceph Storage クラスター内のホストにラベルを追加できます。ラベルの例の一部は、ホストにデプロイされるサービスに基づいて、mgr、mon、および osd になります。
cephadm に特別な意味を持ち、_ で始まる以下のホストラベルを追加することもできます。
-
_no_schedule: このラベルは、cephadmがホスト上でデーモンをスケジュールまたはデプロイすることを阻止します。すでに Ceph デーモンが含まれている既存のホストに追加されると、これにより、cephadmは、自動的に削除されない OSD を除いて、それらのデーモンを別の場所に移動します。ホストに_no_scheduleラベルが追加されると、デーモンはそのホストにデプロイされません。ホストが削除される前にデーモンがドレインされると、そのホストに_no_scheduleラベルが設定されます。 -
_no_autotune_memory: このラベルは、ホスト上のメモリーを自動調整しません。そのホスト上の 1 つ以上のデーモンに対して、osd_memory_target_autotuneオプションまたは他の同様のオプションが有効になっている場合でも、デーモンメモリーが調整されることを阻止します。 -
_admin: デフォルトでは、_adminラベルはストレージクラスター内のブートストラップされたホストに適用され、client.adminキーは、ceph orch client-keyring {ls|set|rm}関数でそのホストに配布されるように設定されます。このラベルを追加のホストに追加すると、通常、cephadmは設定ファイルとキーリングファイルを/etc/cephにデプロイします。
前提条件
- 稼働中の Red Hat Ceph Storage クラスターがある。
- ホストがストレージクラスターに追加される。
手順
Cephadm シェルにログインします。
例
cephadm shell
[root@host01 ~]# cephadm shellCopy to Clipboard Copied! Toggle word wrap Toggle overflow ホストにラベルを追加します。
構文
ceph orch host label add HOST_NAME LABEL_NAME
ceph orch host label add HOST_NAME LABEL_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph orch host label add host02 mon
[ceph: root@host01 /]# ceph orch host label add host02 monCopy to Clipboard Copied! Toggle word wrap Toggle overflow
検証
ホストをリスト表示します。
例
[ceph: root@host01 /]# ceph orch host ls
[ceph: root@host01 /]# ceph orch host lsCopy to Clipboard Copied! Toggle word wrap Toggle overflow
3.7. ホストからのラベルの削除
Ceph オーケストレーターを使用して、ホストからラベルを削除します。
前提条件
- インストールされ、ブートストラップされたストレージクラスター。
- ストレージクラスター内のすべてのノードへの root レベルのアクセス。
手順
cephadmシェルを起動します。cephadm shell [ceph: root@host01 /]#
[root@host01 ~]# cephadm shell [ceph: root@host01 /]#Copy to Clipboard Copied! Toggle word wrap Toggle overflow ラベルを削除します。
構文
ceph orch host label rm HOSTNAME LABEL
ceph orch host label rm HOSTNAME LABELCopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph orch host label rm host02 mon
[ceph: root@host01 /]# ceph orch host label rm host02 monCopy to Clipboard Copied! Toggle word wrap Toggle overflow
検証
ホストをリスト表示します。
例
[ceph: root@host01 /]# ceph orch host ls
[ceph: root@host01 /]# ceph orch host lsCopy to Clipboard Copied! Toggle word wrap Toggle overflow
3.8. Ceph Orchestrator を使用したホストの削除
Ceph Orchestrator で、Ceph クラスターのホストを削除できます。すべてのデーモンは、_no_schedule ラベルを追加する drain オプションで削除され、操作が完了するまでデーモンまたはクラスターをデプロイメントできないようにします。
ブートストラップホストを削除する場合は、ホストを削除する前に、必ず管理キーリングと設定ファイルをストレージクラスター内の別のホストにコピーしてください。
前提条件
- 稼働中の Red Hat Ceph Storage クラスターがある。
- すべてのノードへの root レベルのアクセス。
- ホストがストレージクラスターに追加されている。
- すべてのサービスがデプロイされている。
- Cephadm が、サービスを削除する必要があるノードにデプロイされている。
手順
Cephadm シェルにログインします。
例
cephadm shell
[root@host01 ~]# cephadm shellCopy to Clipboard Copied! Toggle word wrap Toggle overflow ホストの詳細を取得します。
例
[ceph: root@host01 /]# ceph orch host ls
[ceph: root@host01 /]# ceph orch host lsCopy to Clipboard Copied! Toggle word wrap Toggle overflow ホストからすべてのデーモンをドレインします。
構文
ceph orch host drain HOSTNAME
ceph orch host drain HOSTNAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph orch host drain host02
[ceph: root@host01 /]# ceph orch host drain host02Copy to Clipboard Copied! Toggle word wrap Toggle overflow _no_scheduleラベルは、デプロイメントをブロックするホストに自動的に適用されます。OSD の削除のステータスを確認します。
例
[ceph: root@host01 /]# ceph orch osd rm status
[ceph: root@host01 /]# ceph orch osd rm statusCopy to Clipboard Copied! Toggle word wrap Toggle overflow OSD に配置グループ (PG) が残っていない場合、OSD は廃止され、ストレージクラスターから削除されます。
ストレージクラスターからすべてのデーモンが削除されているかどうかを確認します。
構文
ceph orch ps HOSTNAME
ceph orch ps HOSTNAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph orch ps host02
[ceph: root@host01 /]# ceph orch ps host02Copy to Clipboard Copied! Toggle word wrap Toggle overflow ホストを削除。
構文
ceph orch host rm HOSTNAME
ceph orch host rm HOSTNAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph orch host rm host02
[ceph: root@host01 /]# ceph orch host rm host02Copy to Clipboard Copied! Toggle word wrap Toggle overflow
3.9. Ceph Orchestrator を使用したホストのメンテナンスモード
Ceph Orchestrator を使用して、ホストのメンテナンスモードを切り替えできます。ceph orch host maintenance enter コマンドは、systemd target を停止します。これにより、ホスト上のすべての Ceph デーモンが停止します。同様に、ceph orch host maintenance exit コマンドは systemd target を再起動し、Ceph デーモンは自動的に再起動します。
ホストがメンテナンス状態になると、オーケストレータは次のワークフローを採用します。
-
orch host ok-to stopコマンドを実行して、ホストの削除がデータの可用性に影響しないことを確認します。 -
ホストに Ceph OSD デーモンがある場合、ホストサブツリーに
nooutを適用して、計画されたメンテナンススロット中にデータ移行がトリガーされないようにします。 - Ceph ターゲットを停止して、すべてのデーモンを停止します。
-
ホストで
ceph targetを無効にして、再起動によって Ceph サービスが自動的に開始されないようにします。
メンテナンスを終了すると、上記の順序が逆になります。
前提条件
- 稼働中の Red Hat Ceph Storage クラスターがある。
- すべてのノードへの root レベルのアクセス。
- クラスターに追加されたホスト。
手順
Cephadm シェルにログインします。
例
cephadm shell
[root@host01 ~]# cephadm shellCopy to Clipboard Copied! Toggle word wrap Toggle overflow ホストをメンテナンスモードにしたり、メンテナンスモードから解除したりできます。
ホストをメンテナンスモードにします。
構文
ceph orch host maintenance enter HOST_NAME [--force]
ceph orch host maintenance enter HOST_NAME [--force]Copy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph orch host maintenance enter host02 --force
[ceph: root@host01 /]# ceph orch host maintenance enter host02 --forceCopy to Clipboard Copied! Toggle word wrap Toggle overflow --forceフラグを使用すると、ユーザーは警告を回避できますが、アラートは回避できません。ホストをメンテナンスモードから解除します。
構文
ceph orch host maintenance exit HOST_NAME
ceph orch host maintenance exit HOST_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph orch host maintenance exit host02
[ceph: root@host01 /]# ceph orch host maintenance exit host02Copy to Clipboard Copied! Toggle word wrap Toggle overflow
検証
ホストをリスト表示します。
例
[ceph: root@host01 /]# ceph orch host ls
[ceph: root@host01 /]# ceph orch host lsCopy to Clipboard Copied! Toggle word wrap Toggle overflow
第4章 Ceph Orchestrator を使用したモニターの管理
ストレージ管理者は、配置仕様を使用して追加のモニターをデプロイし、サービス仕様を使用してモニターを追加し、サブネット設定にモニターを追加し、特定のホストにモニターを追加できます。さらに、Ceph Orchestrator を使用してモニターを削除できます。
デフォルトでは、一般的な Red Hat Ceph Storage クラスターには、3 つまたは 5 つのモニターデーモンが異なるホストにデプロイされます。
Red Hat は、クラスターに 5 つ以上のノードがある場合に、5 つのモニターをデプロイすることを推奨します。
Red Hat では、Ceph を OSP director とともにデプロイする場合、3 つのモニターをデプロイすることを推奨します。
Ceph は、クラスターの拡大とともにモニターデーモンを自動的にデプロイし、クラスターの縮小とともにモニターデーモンを自動的にスケールバックします。このような自動拡大および縮小のスムーズな実行は、適切なサブネット設定によります。
モニターノードまたはクラスター全体が単一のサブネットにある場合、Cephadm は新規ホストをクラスターに追加する際に最大 5 つのモニターデーモンを自動的を追加します。Cephadm は、新しいホストでモニターデーモンを自動的に設定します。新しいホストは、ストレージクラスターのブートストラップされたホストと同じサブネットにあります。
Cephadm はストレージクラスターのサイズの変更に対応するようモニターをデプロイし、スケーリングすることもできます。
4.1. Ceph Monitor
Ceph Monitor は、ストレージクラスターマップのマスターコピーを維持する軽量プロセスです。すべての Ceph クライアントは Ceph モニターに問い合わせ、ストレージクラスターマップの現在のコピーを取得し、クライアントがプールにバインドし、読み取りと書き込みを可能にします。
Ceph Monitor は Paxos プロトコルのバリエーションを使用して、ストレージクラスター全体でマップやその他の重要な情報について合意を確立します。Paxos の性質上、Ceph は、クォーラムを確立するためにモニターの大部分を実行する必要があり、合意を確立します。
Red Hat では、実稼働クラスターのサポートを受け取るために、別のホストで少なくとも 3 つのモニターが必要になります。
Red Hat は、奇数のモニターをデプロイすることを推奨します。奇数の Ceph モニターは、偶数のモニターよりも障害に対する回復性が高くなっています。たとえば、2 つのモニターデプロイメントでクォーラムを維持するには、Ceph は障害を許容できません。3 つのモニターでは障害を 1 つ、4 つのモニターでは障害を 1 つ、5 つのモニターでは障害を 2 つ許容します。このため、奇数も推奨されています。要約すると、Ceph は、モニターの大部分 (3 つのうち 2 つ、 4 つのうち 3 つなど) が実行され、相互に通信できるようにする必要があります。
マルチノードの Ceph ストレージクラスターの初回のデプロイには、Red Hat では 3 つのモニターが必要です。3 つ以上のモニターが有効な場合には、一度に数を 2 つ増やします。
Ceph Monitor は軽量であるため、OpenStack ノードと同じホストで実行できます。ただし、Red Hat は、別のホストでモニターを実行することを推奨します。
Red Hat は、コンテナー化された環境における Ceph サービスを共存させることのみをサポートしています。
ストレージクラスターからモニターを削除する場合、Ceph Monitor は Paxos プロトコルを使用して、マスターストレージクラスターマップに関する合意を確立することを検討してください。クォーラムを確立するには、十分な数の Ceph モニターが必要です。
4.2. モニタリング選択ストラテジーの設定
モニター選択ストラテジーは、ネット分割を識別し、障害を処理します。選択モニターストラテジーは、3 つの異なるモードで設定できます。
-
classic- これは、2 つのサイト間のエレクターモジュールに基づいて、最も低いランクのモニターが投票されるデフォルトのモードです。 -
disallow- このモードでは、モニターを不許可とマークできます。この場合、モニターはクォーラムに参加してクライアントにサービスを提供しますが、選出されたリーダーになることはできません。これにより、許可されていないリーダーのリストにモニターを追加できます。モニターが許可されていないリストにある場合、そのモニターは常に別のモニターに先送りされます。 -
connectivity- このモードは、主にネットワークの不一致を解決するために使用されます。各モニターがピアに対して提供する、liveness をチェックする ping に基づいて接続スコアを評価し、最も接続性が高く信頼性の高いモニターをリーダーに選択します。このモードは、クラスターが複数のデータセンターにまたがっている場合や影響を受けやすい場合に発生する可能性のあるネット分割を処理するように設計されています。このモードでは接続スコア評価が組み込まれ、最良スコアのモニターが選択されます。特定のモニターをリーダーにする必要がある場合は、特定のモニターがリスト内でランクが0の最初のモニターになるように選択ストラテジーを設定します。
他のモードで機能が必要でない限り、Red Hat は、classic モードに留まります。
クラスターを構築する前に、以下のコマンドで election_strategy を classic、disallow、または connectivity に変更します。
構文
ceph mon set election_strategy {classic|disallow|connectivity}
ceph mon set election_strategy {classic|disallow|connectivity}4.3. コマンドラインインターフェイスを使用した Ceph モニターデーモンのデプロイ
Ceph Orchestrator はデフォルトで 1 つのモニターデーモンをデプロイします。コマンドラインインターフェイスで placement 仕様を使用して、追加のモニターデーモンをデプロイできます。異なる数のモニターデーモンをデプロイするには、別の数を指定します。モニターデーモンがデプロイされるホストを指定しないと、Ceph Orchestrator はホストをランダムに選択し、モニターデーモンをそれらにデプロイします。
ストレッチモードでクラスターを使用している場合は、Ceph Monitor を追加する前に、crush_location を手動でモニターに追加します。
構文
ceph mon add HOST IP_ADDRESS datacenter=DATACENTER
ceph mon add HOST IP_ADDRESS datacenter=DATACENTER例
[ceph: root@host01 /]# ceph mon add host01 213.222.226.50 datacenter=DC1 adding mon.host01 at [v2:213.222.226.50:3300/0,v1:213.222.226.50:6789/0]
[ceph: root@host01 /]# ceph mon add host01 213.222.226.50 datacenter=DC1
adding mon.host01 at [v2:213.222.226.50:3300/0,v1:213.222.226.50:6789/0]
この例では、datacenter=DC1 は crush_location です。
前提条件
- 稼働中の Red Hat Ceph Storage クラスターがある。
- ホストがクラスターに追加されている。
手順
Cephadm シェルにログインします。
例
cephadm shell
[root@host01 ~]# cephadm shellCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Ceph モニターデーモンをデプロイするには、以下の 4 つの方法があります。
方法 1
配置仕様を使用して、ホストにモニターをデプロイします。
注記Red Hat は
--placementオプションを使用して特定のホストにデプロイすることを推奨します。構文
ceph orch apply mon --placement="HOST_NAME_1 HOST_NAME_2 HOST_NAME_3"
ceph orch apply mon --placement="HOST_NAME_1 HOST_NAME_2 HOST_NAME_3"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph orch apply mon --placement="host01 host02 host03"
[ceph: root@host01 /]# ceph orch apply mon --placement="host01 host02 host03"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 注記コマンドの最初のノードとしてブートストラップノードが含まれるようにしてください。
重要モニターを個別に追加しないでください。
ceph orch apply monは置き換えを行うため、モニターはすべてのホストに追加されません。たとえば、以下のコマンドを実行すると、最初のコマンドがhost01にモニターを作成します。2 番目のコマンドは host1 のモニターの代わりにhost02にモニターを作成します。3 番目のコマンドはhost02のモニターの代わりにhost03にモニターを作成します。最終的には、3 番目のホストにのみモニターが存在することになります。ceph orch apply mon host01 ceph orch apply mon host02 ceph orch apply mon host03
# ceph orch apply mon host01 # ceph orch apply mon host02 # ceph orch apply mon host03Copy to Clipboard Copied! Toggle word wrap Toggle overflow
方法 2
配置仕様を使用して、ラベルの付いた特定ホストに特定数のモニターをデプロイします。
ホストにラベルを追加します。
構文
ceph orch host label add HOSTNAME_1 LABEL
ceph orch host label add HOSTNAME_1 LABELCopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph orch host label add host01 mon
[ceph: root@host01 /]# ceph orch host label add host01 monCopy to Clipboard Copied! Toggle word wrap Toggle overflow デーモンをデプロイします。
構文
ceph orch apply mon --placement="HOST_NAME_1:mon HOST_NAME_2:mon HOST_NAME_3:mon"
ceph orch apply mon --placement="HOST_NAME_1:mon HOST_NAME_2:mon HOST_NAME_3:mon"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph orch apply mon --placement="host01:mon host02:mon host03:mon"
[ceph: root@host01 /]# ceph orch apply mon --placement="host01:mon host02:mon host03:mon"Copy to Clipboard Copied! Toggle word wrap Toggle overflow
方法 3
配置仕様を使用して、特定ホストに特定数のモニターをデプロイします。
構文
ceph orch apply mon --placement="NUMBER_OF_DAEMONS HOST_NAME_1 HOST_NAME_2 HOST_NAME_3"
ceph orch apply mon --placement="NUMBER_OF_DAEMONS HOST_NAME_1 HOST_NAME_2 HOST_NAME_3"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph orch apply mon --placement="3 host01 host02 host03"
[ceph: root@host01 /]# ceph orch apply mon --placement="3 host01 host02 host03"Copy to Clipboard Copied! Toggle word wrap Toggle overflow
方法 4
ストレージクラスターのホストにモニターデーモンを無作為にデプロイします。
構文
ceph orch apply mon NUMBER_OF_DAEMONS
ceph orch apply mon NUMBER_OF_DAEMONSCopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph orch apply mon 3
[ceph: root@host01 /]# ceph orch apply mon 3Copy to Clipboard Copied! Toggle word wrap Toggle overflow
検証
サービスをリスト表示します。
例
[ceph: root@host01 /]# ceph orch ls
[ceph: root@host01 /]# ceph orch lsCopy to Clipboard Copied! Toggle word wrap Toggle overflow ホスト、デーモン、およびプロセスをリスト表示します。
構文
ceph orch ps --daemon_type=DAEMON_NAME
ceph orch ps --daemon_type=DAEMON_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph orch ps --daemon_type=mon
[ceph: root@host01 /]# ceph orch ps --daemon_type=monCopy to Clipboard Copied! Toggle word wrap Toggle overflow
4.4. サービス仕様を使用した Ceph モニターデーモンのデプロイ
Ceph Orchestrator はデフォルトで 1 つのモニターデーモンをデプロイします。YAML 形式のファイルなどのサービス仕様を使用して、追加のモニターデーモンをデプロイできます。
前提条件
- 稼働中の Red Hat Ceph Storage クラスターがある。
- ホストがクラスターに追加されている。
手順
mon.yamlファイルを作成します。例
touch mon.yaml
[root@host01 ~]# touch mon.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow mon.ymlファイルを編集し、以下の詳細を含めます。構文
service_type: mon placement: hosts: - HOST_NAME_1 - HOST_NAME_2service_type: mon placement: hosts: - HOST_NAME_1 - HOST_NAME_2Copy to Clipboard Copied! Toggle word wrap Toggle overflow 例
service_type: mon placement: hosts: - host01 - host02service_type: mon placement: hosts: - host01 - host02Copy to Clipboard Copied! Toggle word wrap Toggle overflow YAML ファイルをコンテナー内のディレクトリーにマウントします。
例
cephadm shell --mount mon.yaml:/var/lib/ceph/mon/mon.yaml
[root@host01 ~]# cephadm shell --mount mon.yaml:/var/lib/ceph/mon/mon.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow そのディレクトリーに移動します。
例
[ceph: root@host01 /]# cd /var/lib/ceph/mon/
[ceph: root@host01 /]# cd /var/lib/ceph/mon/Copy to Clipboard Copied! Toggle word wrap Toggle overflow モニターデーモンをデプロイします。
構文
ceph orch apply -i FILE_NAME.yaml
ceph orch apply -i FILE_NAME.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 mon]# ceph orch apply -i mon.yaml
[ceph: root@host01 mon]# ceph orch apply -i mon.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
検証
サービスをリスト表示します。
例
[ceph: root@host01 /]# ceph orch ls
[ceph: root@host01 /]# ceph orch lsCopy to Clipboard Copied! Toggle word wrap Toggle overflow ホスト、デーモン、およびプロセスをリスト表示します。
構文
ceph orch ps --daemon_type=DAEMON_NAME
ceph orch ps --daemon_type=DAEMON_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph orch ps --daemon_type=mon
[ceph: root@host01 /]# ceph orch ps --daemon_type=monCopy to Clipboard Copied! Toggle word wrap Toggle overflow
4.5. Ceph Orchestrator を使用した特定ネットワークでのモニターデーモンのデプロイ
Ceph Orchestrator はデフォルトで 1 つのモニターデーモンをデプロイします。各モニターに IP アドレスまたは CIDR ネットワークを明示的に指定し、各モニターが配置される場所を制御できます。
前提条件
- 稼働中の Red Hat Ceph Storage クラスターがある。
- ホストがクラスターに追加されている。
手順
Cephadm シェルにログインします。
例
cephadm shell
[root@host01 ~]# cephadm shellCopy to Clipboard Copied! Toggle word wrap Toggle overflow 自動化されたモニターのデプロイメントを無効にします。
例
[ceph: root@host01 /]# ceph orch apply mon --unmanaged
[ceph: root@host01 /]# ceph orch apply mon --unmanagedCopy to Clipboard Copied! Toggle word wrap Toggle overflow 特定ネットワーク上のホストにモニターをデプロイします。
構文
ceph orch daemon add mon HOST_NAME_1:IP_OR_NETWORK
ceph orch daemon add mon HOST_NAME_1:IP_OR_NETWORKCopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph orch daemon add mon host03:10.1.2.123
[ceph: root@host01 /]# ceph orch daemon add mon host03:10.1.2.123Copy to Clipboard Copied! Toggle word wrap Toggle overflow
検証
サービスをリスト表示します。
例
[ceph: root@host01 /]# ceph orch ls
[ceph: root@host01 /]# ceph orch lsCopy to Clipboard Copied! Toggle word wrap Toggle overflow ホスト、デーモン、およびプロセスをリスト表示します。
構文
ceph orch ps --daemon_type=DAEMON_NAME
ceph orch ps --daemon_type=DAEMON_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph orch ps --daemon_type=mon
[ceph: root@host01 /]# ceph orch ps --daemon_type=monCopy to Clipboard Copied! Toggle word wrap Toggle overflow
4.6. Ceph Orchestrator を使用したモニターデーモンの削除
ホストからモニターデーモンを削除するには、他のホストにモニターデーモンを再デプロイします。
前提条件
- 稼働中の Red Hat Ceph Storage クラスターがある。
- ホストがクラスターに追加されている。
- ホストにデプロイされたモニターデーモン 1 つ以上。
手順
Cephadm シェルにログインします。
例
cephadm shell
[root@host01 ~]# cephadm shellCopy to Clipboard Copied! Toggle word wrap Toggle overflow ceph orch applyコマンドを実行して、必要なモニターデーモンをデプロイします。構文
ceph orch apply mon “NUMBER_OF_DAEMONS HOST_NAME_1 HOST_NAME_3”
ceph orch apply mon “NUMBER_OF_DAEMONS HOST_NAME_1 HOST_NAME_3”Copy to Clipboard Copied! Toggle word wrap Toggle overflow host02から monitor デーモンを削除する場合は、他のホストにモニターを再デプロイします。例
[ceph: root@host01 /]# ceph orch apply mon “2 host01 host03”
[ceph: root@host01 /]# ceph orch apply mon “2 host01 host03”Copy to Clipboard Copied! Toggle word wrap Toggle overflow
検証
ホスト、デーモン、およびプロセスをリスト表示します。
構文
ceph orch ps --daemon_type=DAEMON_NAME
ceph orch ps --daemon_type=DAEMON_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph orch ps --daemon_type=mon
[ceph: root@host01 /]# ceph orch ps --daemon_type=monCopy to Clipboard Copied! Toggle word wrap Toggle overflow
4.7. 異常なストレージクラスターからの Ceph Monitor の削除
正常でないストレージクラスターから、ceph-mon デーモンを削除できます。正常でないストレージクラスターとは、配置グループが永続的に active + clean 状態ではないストレージクラスターのことです。
前提条件
- 稼働中の Red Hat Ceph Storage クラスターがある。
- Ceph Monitor ノードへの root レベルのアクセス。
- Ceph Monitor ノードが少なくとも 1 台実行している。
手順
存続しているモニターを特定し、ホストにログインします。
構文
ssh root@MONITOR_ID
ssh root@MONITOR_IDCopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
ssh root@host00
[root@admin ~]# ssh root@host00Copy to Clipboard Copied! Toggle word wrap Toggle overflow 各 Ceph Monitor ホストにログインし、すべての Ceph Monitor を停止します。
構文
cephadm unit --name DAEMON_NAME.HOSTNAME stop
cephadm unit --name DAEMON_NAME.HOSTNAME stopCopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
cephadm unit --name mon.host00 stop
[root@host00 ~]# cephadm unit --name mon.host00 stopCopy to Clipboard Copied! Toggle word wrap Toggle overflow 拡張デーモンのメンテナンスに適した環境と、デーモンを対話的に実行するための環境を設定します。
構文
cephadm shell --name DAEMON_NAME.HOSTNAME
cephadm shell --name DAEMON_NAME.HOSTNAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
cephadm shell --name mon.host00
[root@host00 ~]# cephadm shell --name mon.host00Copy to Clipboard Copied! Toggle word wrap Toggle overflow monmapファイルのコピーを抽出します。構文
ceph-mon -i HOSTNAME --extract-monmap TEMP_PATH
ceph-mon -i HOSTNAME --extract-monmap TEMP_PATHCopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host00 /]# ceph-mon -i host01 --extract-monmap /tmp/monmap 2022-01-05T11:13:24.440+0000 7f7603bd1700 -1 wrote monmap to /tmp/monmap
[ceph: root@host00 /]# ceph-mon -i host01 --extract-monmap /tmp/monmap 2022-01-05T11:13:24.440+0000 7f7603bd1700 -1 wrote monmap to /tmp/monmapCopy to Clipboard Copied! Toggle word wrap Toggle overflow Ceph Monitor 以外を削除します。
構文
monmaptool TEMPORARY_PATH --rm HOSTNAME
monmaptool TEMPORARY_PATH --rm HOSTNAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host00 /]# monmaptool /tmp/monmap --rm host01
[ceph: root@host00 /]# monmaptool /tmp/monmap --rm host01Copy to Clipboard Copied! Toggle word wrap Toggle overflow 削除されたモニターを含む存続しているモニターマップを、存続している Ceph モニターに挿入します。
構文
ceph-mon -i HOSTNAME --inject-monmap TEMP_PATH
ceph-mon -i HOSTNAME --inject-monmap TEMP_PATHCopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host00 /]# ceph-mon -i host00 --inject-monmap /tmp/monmap
[ceph: root@host00 /]# ceph-mon -i host00 --inject-monmap /tmp/monmapCopy to Clipboard Copied! Toggle word wrap Toggle overflow 存続しているモニターのみを起動します。
構文
cephadm unit --name DAEMON_NAME.HOSTNAME start
cephadm unit --name DAEMON_NAME.HOSTNAME startCopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
cephadm unit --name mon.host00 start
[root@host00 ~]# cephadm unit --name mon.host00 startCopy to Clipboard Copied! Toggle word wrap Toggle overflow モニターがクォーラムを形成していることを確認します。
例
[ceph: root@host00 /]# ceph -s
[ceph: root@host00 /]# ceph -sCopy to Clipboard Copied! Toggle word wrap Toggle overflow -
オプション: 削除された Ceph Monitor のデータディレクトリーを
/var/lib/ceph/CLUSTER_FSID/mon.HOSTNAMEディレクトリーにアーカイブします。
第5章 Ceph Orchestrator を使用したマネージャーの管理
ストレージ管理者は、Ceph Orchestrator を使用して追加のマネージャーデーモンをデプロイできます。Cephadm は、ブートストラッププロセス中にブートストラップノードにマネージャーデーモンを自動的にインストールします。
一般的に、同じレベルの可用性を実現するには、Ceph Monitor デーモンを実行している各ホストに Ceph Manager を設定する必要があります。
デフォルトでは、最初に起動した ceph-mgr インスタンスが Ceph Monitors によって有効になり、それ以外はスタンバイマネージャーになります。ceph-mgr デーモン間にクォーラムが存在する必要はありません。
アクティブデーモンが mon mgr beacon grace を超えてモニターに beacon を送信できない場合、スタンバイデーモンに置き換えられます。
フェイルオーバーを事前に回避する場合は、ceph mgr fail MANAGER_NAME コマンドを使用して、ceph-mgr デーモンを明示的に失敗としてマークできます。
5.1. 前提条件
- 稼働中の Red Hat Ceph Storage クラスターがある。
- すべてのノードへの root レベルのアクセス。
- ホストがクラスターに追加されている。
5.2. Ceph Orchestrator を使用したマネージャーデーモンのデプロイ
Ceph Orchestrator はデフォルトで 2 つの Manager デーモンをデプロイします。コマンドラインインターフェイスで placement 仕様を使用して、追加のマネージャーデーモンをデプロイできます。異なる数の Manager デーモンをデプロイするには、別の数を指定します。Manager デーモンがデプロイされるホストを指定しないと、Ceph Orchestrator はホストをランダムに選択し、Manager デーモンをそれらにデプロイします。
デプロイメントごとに少なくとも 3 つの Ceph Manager がデプロイメントに含まれるようにします。
前提条件
- 稼働中の Red Hat Ceph Storage クラスターがある。
- ホストがクラスターに追加されている。
手順
Cephadm シェルにログインします。
例
cephadm shell
[root@host01 ~]# cephadm shellCopy to Clipboard Copied! Toggle word wrap Toggle overflow - マネージャーデーモンをデプロイする方法は 2 つあります。
方法 1
特定のホストセットに配置仕様を使用してマネージャーデーモンをデプロイします。
注記Red Hat は
--placementオプションを使用して特定のホストにデプロイすることを推奨します。構文
ceph orch apply mgr --placement=" HOST_NAME_1 HOST_NAME_2 HOST_NAME_3"
ceph orch apply mgr --placement=" HOST_NAME_1 HOST_NAME_2 HOST_NAME_3"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph orch apply mgr --placement="host01 host02 host03"
[ceph: root@host01 /]# ceph orch apply mgr --placement="host01 host02 host03"Copy to Clipboard Copied! Toggle word wrap Toggle overflow
方法 2
ストレージクラスターのホストにマネージャーデーモンを無作為にデプロイします。
構文
ceph orch apply mgr NUMBER_OF_DAEMONS
ceph orch apply mgr NUMBER_OF_DAEMONSCopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph orch apply mgr 3
[ceph: root@host01 /]# ceph orch apply mgr 3Copy to Clipboard Copied! Toggle word wrap Toggle overflow
検証
サービスをリスト表示します。
例
[ceph: root@host01 /]# ceph orch ls
[ceph: root@host01 /]# ceph orch lsCopy to Clipboard Copied! Toggle word wrap Toggle overflow ホスト、デーモン、およびプロセスをリスト表示します。
構文
ceph orch ps --daemon_type=DAEMON_NAME
ceph orch ps --daemon_type=DAEMON_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph orch ps --daemon_type=mgr
[ceph: root@host01 /]# ceph orch ps --daemon_type=mgrCopy to Clipboard Copied! Toggle word wrap Toggle overflow
5.3. Ceph Orchestrator を使用したマネージャーデーモンの削除
ホストからマネージャーデーモンを削除するには、他のホストにデーモンを再デプロイします。
前提条件
- 稼働中の Red Hat Ceph Storage クラスターがある。
- すべてのノードへの root レベルのアクセス。
- ホストがクラスターに追加されている。
- ホストにデプロイされたマネージャーデーモン 1 つ以上。
手順
Cephadm シェルにログインします。
例
cephadm shell
[root@host01 ~]# cephadm shellCopy to Clipboard Copied! Toggle word wrap Toggle overflow ceph orch applyコマンドを実行して、必要なマネージャーデーモンを再デプロイします。構文
ceph orch apply mgr "NUMBER_OF_DAEMONS HOST_NAME_1 HOST_NAME_3"
ceph orch apply mgr "NUMBER_OF_DAEMONS HOST_NAME_1 HOST_NAME_3"Copy to Clipboard Copied! Toggle word wrap Toggle overflow host02からマネージャーデーモンを削除する場合は、他のホストにマネージャーデーモンを再デプロイします。例
[ceph: root@host01 /]# ceph orch apply mgr "2 host01 host03"
[ceph: root@host01 /]# ceph orch apply mgr "2 host01 host03"Copy to Clipboard Copied! Toggle word wrap Toggle overflow
検証
ホスト、デーモン、およびプロセスをリスト表示します。
構文
ceph orch ps --daemon_type=DAEMON_NAME
ceph orch ps --daemon_type=DAEMON_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph orch ps --daemon_type=mgr
[ceph: root@host01 /]# ceph orch ps --daemon_type=mgrCopy to Clipboard Copied! Toggle word wrap Toggle overflow
5.4. Ceph Manager モジュールの使用
ceph mgr module ls コマンドを使用して、使用可能なモジュールと現在有効になっているモジュールを確認します。
ceph mgr module enable MODULE コマンドまたは ceph mgr module enable MODULE コマンドを使用して、モジュールを有効または無効にします。
モジュールが有効になっている場合、アクティブな ceph-mgr デーモンがそれをロードして実行します。HTTP サーバーなどのサービスを提供するモジュールの場合、モジュールはロード時にアドレスを公開することがあります。このようなモジュールのアドレスを確認するには、ceph mgr services コマンドを実行します。
一部のモジュールでは、アクティブデーモンだけでなくスタンバイ ceph-mgr デーモンでも実行される特別なスタンバイモードを実装する場合もあります。これにより、クライアントがスタンバイに接続しようとした場合に、サービスを提供するモジュールがクライアントをアクティブデーモンにリダイレクトできるようになります。
以下はダッシュボードモジュールを有効にする例です。
クラスターの初回起動時に、mgr_initial_modules 設定を使用して、有効にするモジュールが上書きされます。ただし、この設定はクラスターの残りの有効期間中は無視されます。ブートストラップにのみ使用してください。たとえば、モニターデーモンを初めて起動する前に、ceph.conf ファイルに次のようなセクションを追加します。
[mon]
mgr initial modules = dashboard balancer
[mon]
mgr initial modules = dashboard balancerモジュールがコメント行フックを実装している場合、コマンドは通常の Ceph コマンドとしてアクセス可能であり、Ceph はモジュールコマンドを標準 CLI インターフェイスに自動的に組み込み、それらをモジュールに適切にルーティングします。
[ceph: root@host01 /]# ceph <command | help>
[ceph: root@host01 /]# ceph <command | help>上記のコマンドでは、次の設定パラメーターを使用できます。
| 設定 | 説明 | 型 | デフォルト |
|---|---|---|---|
|
| モジュールをロードするパス。 | String |
|
|
| デーモンデータをロードするパス (キーリングなど) | String |
|
|
| マネージャーの becon からモニターまでの間隔、およびその他の定期的なチェックの間隔 (秒数)。 | Integer |
|
|
| 最後の beacon からどれくらいの時間が経過すると、マネージャーは障害が発生したとみなさるか。 | Integer |
|
5.5. Ceph Manager バランサーモジュールの使用
バランサーは、Ceph Manager (ceph-mgr) のモジュールで、OSD 全体の配置グループ (PG) の配置を最適化することで、自動または監視された方法でバランスの取れた分散を実現します。
現在、バランサーモジュールを無効にできません。これをオフにして設定をカスタマイズすることしかできません。
モード
現在、サポートされるバランサーモードが 2 つあります。
crush-compat: CRUSH compat モードは、Ceph Luminous で導入された compat の
weight-set機能を使用して、CRUSH 階層のデバイスの別の重みセットを管理します。通常の重みは、デバイスに保存する目的のデータ量を反映するために、デバイスのサイズに設定したままにする必要があります。その後バランサーは、可能な限り目的のディストリビューションに一致するディストリビューションを達成するために、weight-setの値を少しずつ増減させ、値を最適化します。PG の配置は擬似ランダムプロセスであるため、配置には自然なばらつきが伴います。重みを最適化することで、バランサーはこの自然なばらつきに対応します。このモードは、古いクライアントと完全に後方互換性があります。OSDMap および CRUSH マップが古いクライアントと共有されると、バランサーは最適化された重みを実際の重みとして提示します。
このモードの主な制限は、階層のサブツリーが OSD を共有する場合に、バランサーが配置ルールの異なる複数の CRUSH 階層を処理できないことです。この設定では、共有 OSD での領域の使用を管理するのが困難になるため、一般的には推奨されません。そのため、通常、この制限は問題にはなりません。
upmap: Luminous 以降、OSDMap は、通常の CRUSH 配置計算への例外として、個々の OSD の明示的なマッピングを保存できます。これらの
upmapエントリーにより、PG マッピングを細かく制御できます。この CRUSH モードは、バランスの取れた分散を実現するために、個々の PG の配置を最適化します。多くの場合、この分散は各 OSD の PG 数 +/-1 PG で完璧です。これは割り切れない場合があるためです。重要この機能の使用を許可するには、次のコマンドを使用して、luminous 以降のクライアントのみをサポートする必要があることをクラスターに伝える必要があります。
[ceph: root@host01 /]# ceph osd set-require-min-compat-client luminous
[ceph: root@host01 /]# ceph osd set-require-min-compat-client luminousCopy to Clipboard Copied! Toggle word wrap Toggle overflow このコマンドは、luminous 以前のクライアントまたはデーモンがモニターに接続されていると失敗します。
既知の問題により、カーネル CephFS クライアントは自身を jewel クライアントとして報告します。この問題を回避するには、
--yes-i-really-mean-itフラグを使用します。[ceph: root@host01 /]# ceph osd set-require-min-compat-client luminous --yes-i-really-mean-it
[ceph: root@host01 /]# ceph osd set-require-min-compat-client luminous --yes-i-really-mean-itCopy to Clipboard Copied! Toggle word wrap Toggle overflow 使用しているクライアントのバージョンは、以下で確認できます。
[ceph: root@host01 /]# ceph features
[ceph: root@host01 /]# ceph featuresCopy to Clipboard Copied! Toggle word wrap Toggle overflow
前提条件
- 稼働中の Red Hat Ceph Storage クラスターがある。
手順
balancer モジュールが有効になっていることを確認します。
例
[ceph: root@host01 /]# ceph mgr module enable balancer
[ceph: root@host01 /]# ceph mgr module enable balancerCopy to Clipboard Copied! Toggle word wrap Toggle overflow balancer モジュールをオンにします。
例
[ceph: root@host01 /]# ceph balancer on
[ceph: root@host01 /]# ceph balancer onCopy to Clipboard Copied! Toggle word wrap Toggle overflow デフォルトのモードは
upmapです。モードは以下のように変更できます。例
[ceph: root@host01 /]# ceph balancer mode crush-compact
[ceph: root@host01 /]# ceph balancer mode crush-compactCopy to Clipboard Copied! Toggle word wrap Toggle overflow または
例
[ceph: root@host01 /]# ceph balancer mode upmap
[ceph: root@host01 /]# ceph balancer mode upmapCopy to Clipboard Copied! Toggle word wrap Toggle overflow
ステータス
バランサーの現在のステータスは、以下を実行していつでも確認できます。
例
[ceph: root@host01 /]# ceph balancer status
[ceph: root@host01 /]# ceph balancer status自動バランシング
デフォルトでは、バランサーモジュールをオンにする場合、自動分散が使用されます。
例
[ceph: root@host01 /]# ceph balancer on
[ceph: root@host01 /]# ceph balancer on以下を使用して、バランサーを再度オフにできます。
例
[ceph: root@host01 /]# ceph balancer off
[ceph: root@host01 /]# ceph balancer off
これには、古いクライアントと後方互換性があり、時間の経過とともにデータディストリビューションに小さな変更を加えて、OSD を同等に利用されるようにする crush-compat モードを使用します。
スロットリング
たとえば、OSD が失敗し、システムがまだ修復していない場合などに、クラスターのパフォーマンスが低下する場合は、PG ディストリビューションには調整は行われません。
クラスターが正常な場合、バランサーは変更を調整して、置き間違えた、または移動する必要のある PG の割合がデフォルトで 5% のしきい値を下回るようにします。この割合は、target_max_misplaced_ratio の設定を使用して調整できます。たとえば、しきい値を 7% に増やすには、次のコマンドを実行します。
例
[ceph: root@host01 /]# ceph config-key set mgr target_max_misplaced_ratio .07
[ceph: root@host01 /]# ceph config-key set mgr target_max_misplaced_ratio .07自動バランシングの場合:
- 自動バランサーの実行間におけるスリープ時間を秒単位で設定します。
例
[ceph: root@host01 /]# ceph config set mgr mgr/balancer/sleep_interval 60
[ceph: root@host01 /]# ceph config set mgr mgr/balancer/sleep_interval 60- 自動バランシングを開始する時刻を HHMM 形式で設定します。
例
[ceph: root@host01 /]# ceph config set mgr mgr/balancer/begin_time 0000
[ceph: root@host01 /]# ceph config set mgr mgr/balancer/begin_time 0000- 自動バランシングを終了する時刻を HHMM 形式で設定します。
例
[ceph: root@host01 /]# ceph config set mgr mgr/balancer/end_time 2359
[ceph: root@host01 /]# ceph config set mgr mgr/balancer/end_time 2359-
自動バランシングをこの曜日以降に制限します。
0は日曜日、1は月曜日というように、crontab と同じ規則を使用します。
例
[ceph: root@host01 /]# ceph config set mgr mgr/balancer/begin_weekday 0
[ceph: root@host01 /]# ceph config set mgr mgr/balancer/begin_weekday 0-
自動バランシングをこの曜日以前に制限します。
0は日曜日、1は月曜日というように、crontab と同じ規則を使用します。
例
[ceph: root@host01 /]# ceph config set mgr mgr/balancer/end_weekday 6
[ceph: root@host01 /]# ceph config set mgr mgr/balancer/end_weekday 6-
自動バランシングを制限するプール ID を定義します。これのデフォルトは空の文字列で、すべてのプールが均衡していることを意味します。数値のプール ID は、
ceph osd pool ls detailコマンドで取得できます。
例
[ceph: root@host01 /]# ceph config set mgr mgr/balancer/pool_ids 1,2,3
[ceph: root@host01 /]# ceph config set mgr mgr/balancer/pool_ids 1,2,3監視付き最適化
balancer 操作はいくつかの異なるフェーズに分類されます。
-
プランの構築。 -
現在の PG ディストリビューションまたは
プラン実行後に得られる PG ディストリビューションに対するデータ分散の品質の評価。 プランの実行。現在のディストリビューションを評価し、スコアを付けます。
例
[ceph: root@host01 /]# ceph balancer eval
[ceph: root@host01 /]# ceph balancer evalCopy to Clipboard Copied! Toggle word wrap Toggle overflow 単一プールのディストリビューションを評価するには、以下を実行します。
構文
ceph balancer eval POOL_NAME
ceph balancer eval POOL_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph balancer eval rbd
[ceph: root@host01 /]# ceph balancer eval rbdCopy to Clipboard Copied! Toggle word wrap Toggle overflow 評価の詳細を表示するには、以下を実行します。
例
[ceph: root@host01 /]# ceph balancer eval-verbose ...
[ceph: root@host01 /]# ceph balancer eval-verbose ...Copy to Clipboard Copied! Toggle word wrap Toggle overflow 現在設定されているモードを使用してプランを生成するには、以下を実行します。
構文
ceph balancer optimize PLAN_NAME
ceph balancer optimize PLAN_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow PLAN_NAME は、カスタムプラン名に置き換えます。
例
[ceph: root@host01 /]# ceph balancer optimize rbd_123
[ceph: root@host01 /]# ceph balancer optimize rbd_123Copy to Clipboard Copied! Toggle word wrap Toggle overflow プランの内容を表示するには、以下を実行します。
構文
ceph balancer show PLAN_NAME
ceph balancer show PLAN_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph balancer show rbd_123
[ceph: root@host01 /]# ceph balancer show rbd_123Copy to Clipboard Copied! Toggle word wrap Toggle overflow 古いプランを破棄するには、以下を実行します。
構文
ceph balancer rm PLAN_NAME
ceph balancer rm PLAN_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph balancer rm rbd_123
[ceph: root@host01 /]# ceph balancer rm rbd_123Copy to Clipboard Copied! Toggle word wrap Toggle overflow 現在記録されているプランを表示するには、status コマンドを使用します。
[ceph: root@host01 /]# ceph balancer status
[ceph: root@host01 /]# ceph balancer statusCopy to Clipboard Copied! Toggle word wrap Toggle overflow プラン実行後に生じるディストリビューションの品質を計算するには、以下を実行します。
構文
ceph balancer eval PLAN_NAME
ceph balancer eval PLAN_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph balancer eval rbd_123
[ceph: root@host01 /]# ceph balancer eval rbd_123Copy to Clipboard Copied! Toggle word wrap Toggle overflow プランを実行するには、以下を実行します。
構文
ceph balancer execute PLAN_NAME
ceph balancer execute PLAN_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph balancer execute rbd_123
[ceph: root@host01 /]# ceph balancer execute rbd_123Copy to Clipboard Copied! Toggle word wrap Toggle overflow 注記ディストリビューションの改善が想定される場合にのみ、プランを実行します。実行後、プランは破棄されます。
5.6. CephManager アラートモジュールの使用
Ceph Manager アラートモジュールを使用して、Red Hat Ceph Storage クラスターの健全性に関する簡単なアラートメッセージを電子メールで送信できます。
このモジュールは、堅牢な監視ソリューションを目的としたものではありません。Ceph クラスター自体の一部として実行されるため、ceph-mgr デーモンに障害が発生するとアラートが送信されないという根本的な制約があります。ただし、このモジュールは、既存の監視インフラストラクチャーが存在しない環境に存在するスタンドアロンクラスターには役立ちます。
前提条件
- 稼働中の Red Hat Ceph Storage クラスターがある。
- Ceph Monitor ノードへの root レベルのアクセス。
手順
Cephadm シェルにログインします。
例
cephadm shell
[root@host01 ~]# cephadm shellCopy to Clipboard Copied! Toggle word wrap Toggle overflow アラートモジュールを有効にします。
例
[ceph: root@host01 /]# ceph mgr module enable alerts
[ceph: root@host01 /]# ceph mgr module enable alertsCopy to Clipboard Copied! Toggle word wrap Toggle overflow アラートモジュールが有効になっていることを確認します。
例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow Simple Mail Transfer Protocol (SMTP) を設定します。
構文
ceph config set mgr mgr/alerts/smtp_host SMTP_SERVER ceph config set mgr mgr/alerts/smtp_destination RECEIVER_EMAIL_ADDRESS ceph config set mgr mgr/alerts/smtp_sender SENDER_EMAIL_ADDRESS
ceph config set mgr mgr/alerts/smtp_host SMTP_SERVER ceph config set mgr mgr/alerts/smtp_destination RECEIVER_EMAIL_ADDRESS ceph config set mgr mgr/alerts/smtp_sender SENDER_EMAIL_ADDRESSCopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph config set mgr mgr/alerts/smtp_host smtp.example.com [ceph: root@host01 /]# ceph config set mgr mgr/alerts/smtp_destination example@example.com [ceph: root@host01 /]# ceph config set mgr mgr/alerts/smtp_sender example2@example.com
[ceph: root@host01 /]# ceph config set mgr mgr/alerts/smtp_host smtp.example.com [ceph: root@host01 /]# ceph config set mgr mgr/alerts/smtp_destination example@example.com [ceph: root@host01 /]# ceph config set mgr mgr/alerts/smtp_sender example2@example.comCopy to Clipboard Copied! Toggle word wrap Toggle overflow オプション: ポートを 465 に変更します。
構文
ceph config set mgr mgr/alerts/smtp_port PORT_NUMBER
ceph config set mgr mgr/alerts/smtp_port PORT_NUMBERCopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph config set mgr mgr/alerts/smtp_port 587
[ceph: root@host01 /]# ceph config set mgr mgr/alerts/smtp_port 587Copy to Clipboard Copied! Toggle word wrap Toggle overflow 重要SSL は、Red Hat Ceph Storage 5 クラスターではサポートされていません。アラートの設定中に
smtp_sslパラメーターを設定しないでください。SMTP サーバーへの認証:
構文
ceph config set mgr mgr/alerts/smtp_user USERNAME ceph config set mgr mgr/alerts/smtp_password PASSWORD
ceph config set mgr mgr/alerts/smtp_user USERNAME ceph config set mgr mgr/alerts/smtp_password PASSWORDCopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph config set mgr mgr/alerts/smtp_user admin1234 [ceph: root@host01 /]# ceph config set mgr mgr/alerts/smtp_password admin1234
[ceph: root@host01 /]# ceph config set mgr mgr/alerts/smtp_user admin1234 [ceph: root@host01 /]# ceph config set mgr mgr/alerts/smtp_password admin1234Copy to Clipboard Copied! Toggle word wrap Toggle overflow オプション: デフォルトでは、SMTP
From名はCephです。これを変更するには、smtp_from_nameパラメーターを設定します。構文
ceph config set mgr mgr/alerts/smtp_from_name CLUSTER_NAME
ceph config set mgr mgr/alerts/smtp_from_name CLUSTER_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph config set mgr mgr/alerts/smtp_from_name 'Ceph Cluster Test'
[ceph: root@host01 /]# ceph config set mgr mgr/alerts/smtp_from_name 'Ceph Cluster Test'Copy to Clipboard Copied! Toggle word wrap Toggle overflow オプション: デフォルトでは、アラートモジュールはストレージクラスターの健全性を毎分チェックし、クラスターの健全ステータスに変更があった場合にメッセージを送信します。頻度を変更するには、
intervalパラメーターを設定します。構文
ceph config set mgr mgr/alerts/interval INTERVAL
ceph config set mgr mgr/alerts/interval INTERVALCopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph config set mgr mgr/alerts/interval "5m"
[ceph: root@host01 /]# ceph config set mgr mgr/alerts/interval "5m"Copy to Clipboard Copied! Toggle word wrap Toggle overflow この例では、間隔は 5 分に設定されています。
オプション: アラートをすぐに送信します。
例
[ceph: root@host01 /]# ceph alerts send
[ceph: root@host01 /]# ceph alerts sendCopy to Clipboard Copied! Toggle word wrap Toggle overflow
5.7. Ceph Manager クラッシュモジュールの使用
Ceph Manager クラッシュモジュールを使用すると、デーモンの crashdump に関する情報を収集し、これを Red Hat Ceph Storage クラスターに保存して詳細な分析を行うことができます。
デフォルトでは、デーモンの crashdump は /var/lib/ceph/crash にダンプされます。crash dir オプションを使用して設定できます。クラッシュディレクトリーの名前は、時間、日付、およびランダムに生成される UUID で名前が付けられ、同じ crash_id を持つメタデータファイルの meta と最近のログファイルが含まれます。
ceph-crash.service を使用して、これらのクラッシュを自動的に送信し、Ceph Monitor で永続化することができます。ceph-crash.service は crashdump ディレクトリーを監視し、それらを ceph crash post でアップロードします。
RECENT_CRASH ヘルスメッセージは、Ceph クラスター内の最も一般的なヘルスメッセージのいずれかとなります。このヘルスメッセージは、1 つ以上の Ceph デーモンが最近クラッシュし、そのクラッシュが管理者によってアーカイブまたは確認されていないことを意味します。これは、ソフトウェアのバグや、障害のあるディスクなどのハードウェアの問題があることを示している可能性があります。オプション mgr/crash/warn_recent_interval は、最新の方法の期間 (デフォルトでは 2 週間) を制御します。以下のコマンドを実行して警告を無効にすることができます。
例
[ceph: root@host01 /]# ceph config set mgr/crash/warn_recent_interval 0
[ceph: root@host01 /]# ceph config set mgr/crash/warn_recent_interval 0
mgr/crash/retain_interval オプションは、自動的にパージされるまでクラッシュレポートを保持する期間を制御します。このオプションのデフォルトは 1 年です。
前提条件
- 稼働中の Red Hat Ceph Storage クラスターがある。
手順
crash モジュールが有効になっていることを確認します。
例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow クラッシュダンプの保存:
metaファイルは、メタとして crash ディレクトリーに保存されている JSON blob です。ceph コマンド-i -オプションを呼び出すことができます。これは、stdin から読み取ります。例
[ceph: root@host01 /]# ceph crash post -i meta
[ceph: root@host01 /]# ceph crash post -i metaCopy to Clipboard Copied! Toggle word wrap Toggle overflow 新しいクラッシュ情報およびアーカイブされたすべてのクラッシュ情報のタイムスタンプまたは UUID クラッシュ ID を表示します。
例
[ceph: root@host01 /]# ceph crash ls
[ceph: root@host01 /]# ceph crash lsCopy to Clipboard Copied! Toggle word wrap Toggle overflow すべての新規クラッシュ情報のタイムスタンプまたは UUID クラッシュ ID をリスト表示します。
例
[ceph: root@host01 /]# ceph crash ls-new
[ceph: root@host01 /]# ceph crash ls-newCopy to Clipboard Copied! Toggle word wrap Toggle overflow すべての新規クラッシュ情報のタイムスタンプまたは UUID クラッシュ ID をリスト表示します。
例
[ceph: root@host01 /]# ceph crash ls-new
[ceph: root@host01 /]# ceph crash ls-newCopy to Clipboard Copied! Toggle word wrap Toggle overflow 保存されたクラッシュ情報の概要を経過時間別にグループ化してリスト表示します。
例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 保存したクラッシュの詳細を表示します。
構文
ceph crash info CRASH_ID
ceph crash info CRASH_IDCopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow KEEP の日数より古い保存済みクラッシュを削除します。ここで、KEEP は整数である必要があります。
構文
ceph crash prune KEEP
ceph crash prune KEEPCopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph crash prune 60
[ceph: root@host01 /]# ceph crash prune 60Copy to Clipboard Copied! Toggle word wrap Toggle overflow RECENT_CRASHヘルスチェックで考慮されなくなり、crash ls-newの出力に表示されないようにクラッシュレポートをアーカイブします。crash lsに表示されます。構文
ceph crash archive CRASH_ID
ceph crash archive CRASH_IDCopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph crash archive 2022-05-24T19:58:42.549073Z_b2382865-ea89-4be2-b46f-9a59af7b7a2d
[ceph: root@host01 /]# ceph crash archive 2022-05-24T19:58:42.549073Z_b2382865-ea89-4be2-b46f-9a59af7b7a2dCopy to Clipboard Copied! Toggle word wrap Toggle overflow すべてのクラッシュレポートをアーカイブします。
例
[ceph: root@host01 /]# ceph crash archive-all
[ceph: root@host01 /]# ceph crash archive-allCopy to Clipboard Copied! Toggle word wrap Toggle overflow クラッシュダンプを削除します。
構文
ceph crash rm CRASH_ID
ceph crash rm CRASH_IDCopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph crash rm 2022-05-24T19:58:42.549073Z_b2382865-ea89-4be2-b46f-9a59af7b7a2d
[ceph: root@host01 /]# ceph crash rm 2022-05-24T19:58:42.549073Z_b2382865-ea89-4be2-b46f-9a59af7b7a2dCopy to Clipboard Copied! Toggle word wrap Toggle overflow
第6章 Ceph Orchestrator を使用した OSD の管理
ストレージ管理者は、Ceph Orchestrators を使用して Red Hat Ceph Storage クラスターの OSD を管理できます。
6.1. Ceph OSD
Red Hat Ceph Storage クラスターが稼働している場合は、ランタイム時に OSD をストレージクラスターに追加できます。
Ceph OSD は、通常 1 つのストレージドライブおよびノード内の関連付けられたジャーナル用に 1 つの ceph-osd デーモンで設定されます。ノードに複数のストレージドライブがある場合は、ドライブごとに 1 つの ceph-osd デーモンをマッピングします。
Red Hat は、クラスターの容量を定期的に確認して、ストレージ容量の最後に到達するかどうかを確認することを推奨します。ストレージクラスターが ほぼ完全 の比率に達すると、1 つ以上の OSD を追加してストレージクラスターの容量を拡張します。
Red Hat Ceph Storage クラスターのサイズを縮小したり、ハードウェアを置き換える場合は、ランタイム時に OSD を削除することも可能です。ノードに複数のストレージドライブがある場合には、そのドライブ用に ceph-osd デーモンのいずれかを削除する必要もあります。通常、ストレージクラスターの容量を確認して、容量の上限に達したかどうかを確認することが推奨されます。ストレージクラスターが ほぼ完全 の比率ではないことを OSD を削除する場合。
OSD を追加する前に、ストレージクラスターが 完全な 比率を超えないようにします。ストレージクラスターが ほぼ完全な 比率に達した後に OSD の障害が発生すると、ストレージクラスターが 完全な 比率を超過する可能性があります。Ceph は、ストレージ容量の問題を解決するまでデータを保護するための書き込みアクセスをブロックします。完全な 比率の影響を考慮せずに OSD を削除しないでください。
6.2. Ceph OSD ノードの設定
OSD を使用するプールのストレージストラテジーとして同様に Ceph OSD とサポートするハードウェアを設定します。Ceph は、一貫性のあるパフォーマンスプロファイルを確保するために、プール全体でハードウェアを統一します。最適なパフォーマンスを得るには、同じタイプまたはサイズのドライブのある CRUSH 階層を検討してください。
異なるサイズのドライブを追加する場合は、それに応じて重量を調整してください。OSD を CRUSH マップに追加する場合は、新規 OSD の重みを考慮してください。ハードドライブの容量は、1 年あたり約 40% 増加するため、新しい OSD ノードはストレージクラスターの古いノードよりも大きなハードドライブを持つ可能性があります。つまり、重みが大きくなる可能性があります。
新たにインストールを行う前に、Installation Guide のRequirements for Installing Red Hat Ceph Storageの章を確認します。
6.3. OSD メモリーの自動チューニング
OSD デーモンは、osd_memory_target 設定オプションに基づいてメモリー消費を調整します。osd_memory_target オプションは、システムで利用可能な RAM に基づいて OSD メモリーを設定します。
Red Hat Ceph Storage が他のサービスとメモリーを共有しない専用ノードにデプロイされている場合、cephadm は RAM の合計量とデプロイされた OSD の数に基づいて OSD ごとの消費を自動的に調整します。
デフォルトでは、Red Hat Ceph Storage 5.1 で osd_memory_target_autotune パラメーターは true に設定されます。
構文
ceph config set osd osd_memory_target_autotune true
ceph config set osd osd_memory_target_autotune true
OSD の追加や OSD の置き換えなど、クラスターのメンテナンスのためにストレージクラスターを Red Hat Ceph Storage 5.0 にアップグレードした後、Red Hat は osd_memory_target_autotune パラメーターを true に設定し、システムメモリーごとに osd メモリーを自動調整することを推奨します。
Cephadm は、mgr/cephadm/autotune_memory_target_ratio の割合で始まります。これはデフォルトでは、システムの合計 RAM 容量の 0.7 になります。これから、非 OSDS や osd_memory_target_autotune が false の OSD などの自動調整されないデーモンによって消費されるメモリー分を引き、残りの OSD で割ります。
デフォルトでは、autotune_memory_target_ratio は、ハイパーコンバージドインフラストラクチャーでは 0.2、その他の環境では 0.7 です。
osd_memory_target パラメーターは、以下のように計算されます。
構文
osd_memory_target = TOTAL_RAM_OF_THE_OSD_NODE (in Bytes) * (autotune_memory_target_ratio) / NUMBER_OF_OSDS_IN_THE_OSD_NODE - (SPACE_ALLOCATED_FOR_OTHER_DAEMONS (in Bytes))
osd_memory_target = TOTAL_RAM_OF_THE_OSD_NODE (in Bytes) * (autotune_memory_target_ratio) / NUMBER_OF_OSDS_IN_THE_OSD_NODE - (SPACE_ALLOCATED_FOR_OTHER_DAEMONS (in Bytes))SPACE_ALLOCATED_FOR_OTHER_DAEMONS には、任意で以下のデーモン領域の割り当てを含めることができます。
- Alertmanager: 1 GB
- Grafana: 1 GB
- Ceph Manager: 4 GB
- Ceph Monitor: 2 GB
- Node-exporter: 1 GB
- Prometheus: 1 GB
たとえば、ノードに OSD が 24 個あり、251 GB の RAM 容量がある場合、 osd_memory_target は 7860684936 になります。
最後のターゲットは、オプションとともに設定データベースに反映されます。MEM LIMIT 列の ceph orch ps の出力で、制限と各デーモンによって消費される現在のメモリーを確認できます。
Red Hat Ceph Storage 5.1 では、osd_memory_target_autotune のデフォルト設定 true は、コンピュートサービスと Ceph ストレージサービスが共存するハイパーコンバージドインフラストラクチャーでは適切ではありません。ハイパーコンバージドインフラストラクチャーでは、autotune_memory_target_ratio を 0.2 に設定して、Ceph のメモリー消費を減らすことができます。
例
[ceph: root@host01 /]# ceph config set mgr mgr/cephadm/autotune_memory_target_ratio 0.2
[ceph: root@host01 /]# ceph config set mgr mgr/cephadm/autotune_memory_target_ratio 0.2ストレージクラスターで OSD の特定のメモリーターゲットを手動で設定できます。
例
[ceph: root@host01 /]# ceph config set osd.123 osd_memory_target 7860684936
[ceph: root@host01 /]# ceph config set osd.123 osd_memory_target 7860684936ストレージクラスターで OSD ホストの特定のメモリーターゲットを手動で設定できます。
構文
ceph config set osd/host:HOSTNAME osd_memory_target TARGET_BYTES
ceph config set osd/host:HOSTNAME osd_memory_target TARGET_BYTES例
[ceph: root@host01 /]# ceph config set osd/host:host01 osd_memory_target 1000000000
[ceph: root@host01 /]# ceph config set osd/host:host01 osd_memory_target 1000000000
osd_memory_target_autotune を有効にすると、既存の手動の OSD メモリーターゲット設定が上書きされます。osd_memory_target_autotune オプションまたはその他の同様のオプションが有効になっている場合でもデーモンメモリーがチューニングされないようにするには、ホストに _no_autotune_memory ラベルを設定します。
構文
ceph orch host label add HOSTNAME _no_autotune_memory
ceph orch host label add HOSTNAME _no_autotune_memory自動チューニングオプションを無効にし、特定のメモリーターゲットを設定して、OSD をメモリー自動チューニングから除外できます。
例
[ceph: root@host01 /]# ceph config set osd.123 osd_memory_target_autotune false [ceph: root@host01 /]# ceph config set osd.123 osd_memory_target 16G
[ceph: root@host01 /]# ceph config set osd.123 osd_memory_target_autotune false
[ceph: root@host01 /]# ceph config set osd.123 osd_memory_target 16G6.4. Ceph OSD デプロイメント用のデバイスのリスト表示
Ceph Orchestrator を使用して OSD をデプロイする前に、利用可能なデバイスのリストを確認することができます。コマンドは、Cephadm によって検出可能なデバイスのリストを出力するために使用されます。以下の条件がすべて満たされると、ストレージデバイスが利用可能であるとみなされます。
- デバイスにはパーティションがない。
- デバイスは LVM 状態でない。
- デバイスをマウントしてはいけない。
- デバイスにはファイルシステムを含めることはできない。
- デバイスには Ceph BlueStore OSD を含めることはできない。
- デバイスは 5 GB を超える必要がある。
Ceph は、利用できないデバイスに OSD をプロビジョニングしません。
前提条件
- 稼働中の Red Hat Ceph Storage クラスターがある。
- ホストがクラスターに追加されている。
- すべてのマネージャーおよびモニターデーモンがデプロイされている。
手順
Cephadm シェルにログインします。
例
cephadm shell
[root@host01 ~]# cephadm shellCopy to Clipboard Copied! Toggle word wrap Toggle overflow OSD をデプロイするために利用可能なデバイスをリスト表示します。
構文
ceph orch device ls [--hostname=HOSTNAME_1 HOSTNAME_2] [--wide] [--refresh]
ceph orch device ls [--hostname=HOSTNAME_1 HOSTNAME_2] [--wide] [--refresh]Copy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph orch device ls --wide --refresh
[ceph: root@host01 /]# ceph orch device ls --wide --refreshCopy to Clipboard Copied! Toggle word wrap Toggle overflow --wideオプションを使用すると、デバイスが OSD として使用できない可能性がある理由など、デバイスに関連するすべての詳細が提供されます。このオプションは、NVMe デバイスをサポートしません。任意手順:
ceph orch device lsの出力で Health、Ident および Fault フィールドを有効にするには、以下のコマンドを実行します。注記これらのフィールドは
libstoragemgmtライブラリーによってサポートされ、現時点では SCSI、SAS、SATA デバイスをサポートします。Cephadm シェルの外部で root ユーザーとして、ハードウェアと
libstoragemgmtライブラリーとの互換性を確認して、サービスの予期しない中断を回避します。例
cephadm shell lsmcli ldl
[root@host01 ~]# cephadm shell lsmcli ldlCopy to Clipboard Copied! Toggle word wrap Toggle overflow この出力で、それぞれの SCSI VPD 0x83 ID で Health Status が Good と表示されます。
注記この情報を取得しないと、フィールドを有効にした場合にデバイスで異常な挙動が発生する可能性があります。
Cephadm シェルに再度ログインし、
libstoragemgmtサポートを有効にします。例
cephadm shell [ceph: root@host01 /]# ceph config set mgr mgr/cephadm/device_enhanced_scan true
[root@host01 ~]# cephadm shell [ceph: root@host01 /]# ceph config set mgr mgr/cephadm/device_enhanced_scan trueCopy to Clipboard Copied! Toggle word wrap Toggle overflow これが有効化されると、
ceph orch device lsを実行した場合、Health フィールドの出力は Good になります。
検証
デバイスをリスト表示します。
例
[ceph: root@host01 /]# ceph orch device ls
[ceph: root@host01 /]# ceph orch device lsCopy to Clipboard Copied! Toggle word wrap Toggle overflow
6.5. Ceph OSD デプロイメントのデバイスの消去
OSD をデプロイする前に、利用可能なデバイスのリストを確認する必要があります。デバイスに空き容量がない場合は、そのデバイスを消去してデバイス上のデータを消去します。
前提条件
- 稼働中の Red Hat Ceph Storage クラスターがある。
- ホストがクラスターに追加されている。
- すべてのマネージャーおよびモニターデーモンがデプロイされている。
手順
Cephadm シェルにログインします。
例
cephadm shell
[root@host01 ~]# cephadm shellCopy to Clipboard Copied! Toggle word wrap Toggle overflow OSD をデプロイするために利用可能なデバイスをリスト表示します。
構文
ceph orch device ls [--hostname=HOSTNAME_1 HOSTNAME_2] [--wide] [--refresh]
ceph orch device ls [--hostname=HOSTNAME_1 HOSTNAME_2] [--wide] [--refresh]Copy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph orch device ls --wide --refresh
[ceph: root@host01 /]# ceph orch device ls --wide --refreshCopy to Clipboard Copied! Toggle word wrap Toggle overflow デバイスのデータをクリアします。
構文
ceph orch device zap HOSTNAME FILE_PATH --force
ceph orch device zap HOSTNAME FILE_PATH --forceCopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph orch device zap host02 /dev/sdb --force
[ceph: root@host01 /]# ceph orch device zap host02 /dev/sdb --forceCopy to Clipboard Copied! Toggle word wrap Toggle overflow
検証
デバイスに容量があることを確認します。
例
[ceph: root@host01 /]# ceph orch device ls
[ceph: root@host01 /]# ceph orch device lsCopy to Clipboard Copied! Toggle word wrap Toggle overflow Available の下のフィールドが Yes であることを確認できます。
6.6. すべての利用可能なデバイスへの Ceph OSD のデプロイ
すべての OSDS を利用可能なすべてのデバイスにデプロイできます。Cephadm により、Ceph Orchestrator は利用可能な未使用のストレージデバイスで OSD を検出およびデプロイできます。使用可能なすべてのデバイスに OSD をデプロイメントするには、unmanaged パラメーターを指定せずにコマンドを実行し、その後 OSD が作成されないようにパラメーターを指定してコマンドを再実行します。
--all-available-devices を使用した OSD のデプロイメントは、通常、小規模なクラスターに使用されます。大規模なクラスターの場合は、OSD 仕様ファイルを使用します。
前提条件
- 稼働中の Red Hat Ceph Storage クラスターがある。
- ホストがクラスターに追加されている。
- すべてのマネージャーおよびモニターデーモンがデプロイされている。
手順
Cephadm シェルにログインします。
例
cephadm shell
[root@host01 ~]# cephadm shellCopy to Clipboard Copied! Toggle word wrap Toggle overflow OSD をデプロイするために利用可能なデバイスをリスト表示します。
構文
ceph orch device ls [--hostname=HOSTNAME_1 HOSTNAME_2] [--wide] [--refresh]
ceph orch device ls [--hostname=HOSTNAME_1 HOSTNAME_2] [--wide] [--refresh]Copy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph orch device ls --wide --refresh
[ceph: root@host01 /]# ceph orch device ls --wide --refreshCopy to Clipboard Copied! Toggle word wrap Toggle overflow すべての利用可能なデバイスに OSD をデプロイします。
例
[ceph: root@host01 /]# ceph orch apply osd --all-available-devices
[ceph: root@host01 /]# ceph orch apply osd --all-available-devicesCopy to Clipboard Copied! Toggle word wrap Toggle overflow ceph orch applyの影響は永続的であり、Orchestrator は自動的にデバイスを見つけ、それをクラスターに追加し、新しい OSD を作成します。これは、以下の条件下で実行されます。- 新しいディスクまたはドライブがシステムに追加される。
- 既存のディスクまたはドライブは消去される。
OSD は削除され、デバイスは消去される。
--unmanagedパラメーターを使用して、利用可能なすべてのデバイスで OSD の自動作成を無効にできます。例
[ceph: root@host01 /]# ceph orch apply osd --all-available-devices --unmanaged=true
[ceph: root@host01 /]# ceph orch apply osd --all-available-devices --unmanaged=trueCopy to Clipboard Copied! Toggle word wrap Toggle overflow パラメーター
--unmanagedをtrueに設定すると、OSD の作成が無効になり、新しい OSD サービスを適用しても変更はありません。注記コマンド
ceph orch daemon addは、新しい OSD を作成しますが、OSD サービスを追加しません。
検証
サービスをリスト表示します。
例
[ceph: root@host01 /]# ceph orch ls
[ceph: root@host01 /]# ceph orch lsCopy to Clipboard Copied! Toggle word wrap Toggle overflow ノードとデバイスの詳細を表示します。
例
[ceph: root@host01 /]# ceph osd tree
[ceph: root@host01 /]# ceph osd treeCopy to Clipboard Copied! Toggle word wrap Toggle overflow
6.7. 特定のデバイスおよびホストへの Ceph OSD のデプロイ
Ceph Orchestrator を使用して、特定のデバイスおよびホストにすべての Ceph OSD をデプロイできます。
前提条件
- 稼働中の Red Hat Ceph Storage クラスターがある。
- ホストがクラスターに追加されている。
- すべてのマネージャーおよびモニターデーモンがデプロイされている。
手順
Cephadm シェルにログインします。
例
cephadm shell
[root@host01 ~]# cephadm shellCopy to Clipboard Copied! Toggle word wrap Toggle overflow OSD をデプロイするために利用可能なデバイスをリスト表示します。
構文
ceph orch device ls [--hostname=HOSTNAME_1 HOSTNAME_2] [--wide] [--refresh]
ceph orch device ls [--hostname=HOSTNAME_1 HOSTNAME_2] [--wide] [--refresh]Copy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph orch device ls --wide --refresh
[ceph: root@host01 /]# ceph orch device ls --wide --refreshCopy to Clipboard Copied! Toggle word wrap Toggle overflow 特定のデバイスおよびホストに OSD をデプロイします。
構文
ceph orch daemon add osd HOSTNAME:DEVICE_PATH
ceph orch daemon add osd HOSTNAME:DEVICE_PATHCopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph orch daemon add osd host02:/dev/sdb
[ceph: root@host01 /]# ceph orch daemon add osd host02:/dev/sdbCopy to Clipboard Copied! Toggle word wrap Toggle overflow LVM レイヤーを使用せずに raw 物理デバイスに ODS をデプロイするには、
--method rawオプションを使用します。構文
ceph orch daemon add osd --method raw HOSTNAME:DEVICE_PATH
ceph orch daemon add osd --method raw HOSTNAME:DEVICE_PATHCopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph orch daemon add osd --method raw host02:/dev/sdb
[ceph: root@host01 /]# ceph orch daemon add osd --method raw host02:/dev/sdbCopy to Clipboard Copied! Toggle word wrap Toggle overflow 注記別の DB または WAL デバイスがある場合、ブロックと DB デバイスまたは WAL デバイスの比率は 1:1 でなければなりません。
検証
サービスをリスト表示します。
例
[ceph: root@host01 /]# ceph orch ls osd
[ceph: root@host01 /]# ceph orch ls osdCopy to Clipboard Copied! Toggle word wrap Toggle overflow ノードとデバイスの詳細を表示します。
例
[ceph: root@host01 /]# ceph osd tree
[ceph: root@host01 /]# ceph osd treeCopy to Clipboard Copied! Toggle word wrap Toggle overflow ホスト、デーモン、およびプロセスをリスト表示します。
構文
ceph orch ps --service_name=SERVICE_NAME
ceph orch ps --service_name=SERVICE_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph orch ps --service_name=osd
[ceph: root@host01 /]# ceph orch ps --service_name=osdCopy to Clipboard Copied! Toggle word wrap Toggle overflow
6.8. OSD をデプロイするための高度なサービス仕様およびフィルター
タイプ OSD のサービス仕様は、ディスクのプロパティーを使用してクラスターレイアウトを記述する 1 つの方法です。これは、デバイスの名前やパスの指定を把握せずに、必要な設定でどのディスクを OSD にするか Ceph に知らせる抽象的な方法をユーザーに提供します。各デバイスおよび各ホストに対して、yaml ファイルまたは json ファイルを定義します。
OSD 仕様の一般設定
- service_type: 'osd': これは、OSDS の作成には必須です。
- service_id: 希望するサービス名または ID を使用します。OSD のセットは、仕様ファイルを使用して作成されます。この名前は、すべての OSD を管理し、Orchestrator サービスを表すために使用されます。
placement: これは、OSD をデプロイする必要のあるホストを定義するために使用されます。
以下のオプションで使用できます。
- host_pattern: '*' - ホストの選択に使用するホスト名パターン。
- Label: 'osd_host' - OSD をデプロイする必要のあるホストで使用されるラベル。
- hosts: 'host01', 'host02': OSD をデプロイする必要があるホスト名の明示的なリスト。
selection of devices: OSD が作成されるデバイス。これにより、OSD が異なるデバイスから分離されます。3 つのコンポーネントを持つ BlueStore OSD のみを作成できます。
- OSD データ: すべての OSD データが含まれます。
- WAL: BlueStore 内部ジャーナルまたはログ先行書き込み
- DB: BlueStore 内部メタデータ
- data_devices: OSD をデプロイするデバイスを定義します。この場合、OSD は同じ場所に配置されるスキーマに作成されます。フィルターを使用して、デバイスおよびフォルダーを選択できます。
- wal_devices: WAL OSD に使用されるデバイスを定義します。フィルターを使用して、デバイスおよびフォルダーを選択できます。
- db_devices: DB OSD のデバイスを定義します。フィルターを使用して、デバイスおよびフォルダーを選択できます。
-
encrypted:
TrueまたはFalseのいずれかに設定される OSD の情報を暗号化するオプションのパラメーター - unmanaged: オプションのパラメーターで、デフォルトでは False に設定されます。Orchestrator で OSD サービスを管理しない場合は、これを True に設定します。
- block_wal_size: ユーザー定義の値 (バイト単位) 。
- block_db_size: ユーザー定義の値 (バイト単位) 。
- osds_per_device: デバイスごとに複数の OSD をデプロイするためのユーザー定義値。
-
method: OSD が LVM レイヤーで作成されるかどうかを指定するオプションのパラメーター。LVM レイヤーを含まない raw 物理デバイス上に OSD を作成する場合は
rawに設定します。別の DB または WAL デバイスがある場合、ブロックと DB デバイスまたは WAL デバイスの比率は 1:1 でなければなりません。
デバイスを指定するためのフィルター
フィルターは、data_devices、wal_devices、および db_devices パラメーターとともに使用されます。
| フィルターの名前 | 説明 | 構文 | 例 |
| Model |
ターゲット固有のディスク。 | Model: DISK_MODEL_NAME | Model: MC-55-44-XZ |
| Vendor | ターゲット固有のディスク | Vendor: DISK_VENDOR_NAME | Vendor: Vendor Cs |
| Size Specification | 正確なサイズのディスク | size: EXACT | size: '10G' |
| Size Specification | 範囲内にあるディスクサイズ | size: LOW:HIGH | size: '10G:40G' |
| Size Specification | サイズがこれ以下のディスク | size: :HIGH | size: ':10G' |
| Size Specification | サイズがこれ以上のディスク | size: LOW: | size: '40G:' |
| Rotational | ディスクの回転属性。1 はローテーションされるすべてのディスクと一致し、0 はローテーションされないすべてのディスクと一致します。rotational =0 の場合、OSD は SSD または NVME で設定されます。rotational=1 の場合、OSD は HDD で設定されます。 | rotational: 0 or 1 | rotational: 0 |
| All | 利用可能なディスクをすべて考慮します。 | all: true | all: true |
| Limiter | 有効なフィルターが指定されていても、一致するディスクの量を制限する場合は、'limit' ディレクティブを使用できます。これは、最後の手段としてのみ使用してください。 | limit: NUMBER | limit: 2 |
同じホストに同じ場所にないコンポーネントを持つ OSD を作成するには、使用される異なるタイプのデバイスを指定し、デバイスが同じホスト上になければなりません。
OSD のデプロイに使用されるデバイスは、libstoragemgmt によってサポートされる必要があります。
6.9. 高度なサービス仕様を使用した Ceph OSD のデプロイ
タイプ OSD のサービス仕様は、ディスクのプロパティーを使用してクラスターレイアウトを記述する 1 つの方法です。これは、デバイスの名前やパスの指定を把握せずに、必要な設定でどのディスクを OSD にするか Ceph に知らせる抽象的な方法をユーザーに提供します。
各デバイスおよび各ホストに OSD をデプロイするには、yaml ファイルまたは json ファイルを定義します。
前提条件
- 稼働中の Red Hat Ceph Storage クラスターがある。
- ホストがクラスターに追加されている。
- すべてのマネージャーおよびモニターデーモンがデプロイされている。
手順
モニターノードで、
osd_spec.yamlファイルを作成します。例
touch osd_spec.yaml
[root@host01 ~]# touch osd_spec.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow osd_spec.ymlファイルを編集し、以下の詳細を含めます。構文
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 単純なシナリオ: これらのケースでは、すべてのノードが同じ設定になっています。
例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 単純なシナリオ: この場合、すべてのノードが、LVM レイヤーを使用せず、raw モードで作成された OSD デバイスと同じ設定になっています。
例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 高度なシナリオ: これにより、すべての HDD を専用の DB または WAL デバイスとして割り当てられた 2 つの SSD のある
data_devicesとして使用し、目的のレイアウトを作成します。残りの SSD は、NVME ベンダーが専用の DB または WAL デバイスとして割り当てられているdata_devicesです。例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 不均一のノードを使用する高度なシナリオ: これは、host_pattern キーに応じて、異なる OSD 仕様を異なるホストに適用します。
例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 専用の WAL および DB デバイスを使用した高度なシナリオ:
例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow デバイスごとに複数の OSD がある高度なシナリオ:
例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 事前に作成されたボリュームの場合、
osd_spec.yamlファイルを編集して、次の詳細を含めます。構文
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow ID による OSD の場合は、
osd_spec.yamlファイルを編集して次の詳細を含めます。注記この設定は、Red Hat Ceph Storage 5.3z1 以降のリリースに適用されます。以前のリリースの場合は、事前に作成された LVM を使用してください。
構文
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow パス別の OSD の場合は、
osd_spec.yamlファイルを編集して次の詳細を含めます。注記この設定は、Red Hat Ceph Storage 5.3z1 以降のリリースに適用されます。以前のリリースの場合は、事前に作成された LVM を使用してください。
構文
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
YAML ファイルをコンテナー内のディレクトリーにマウントします。
例
cephadm shell --mount osd_spec.yaml:/var/lib/ceph/osd/osd_spec.yaml
[root@host01 ~]# cephadm shell --mount osd_spec.yaml:/var/lib/ceph/osd/osd_spec.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow そのディレクトリーに移動します。
例
[ceph: root@host01 /]# cd /var/lib/ceph/osd/
[ceph: root@host01 /]# cd /var/lib/ceph/osd/Copy to Clipboard Copied! Toggle word wrap Toggle overflow OSD をデプロイする前にドライランを実行します。
注記この手順は、デーモンをデプロイしなくても、デプロイメントのプレビューを提供します。
例
[ceph: root@host01 osd]# ceph orch apply -i osd_spec.yaml --dry-run
[ceph: root@host01 osd]# ceph orch apply -i osd_spec.yaml --dry-runCopy to Clipboard Copied! Toggle word wrap Toggle overflow サービス仕様を使用して OSD をデプロイします。
構文
ceph orch apply -i FILE_NAME.yml
ceph orch apply -i FILE_NAME.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 osd]# ceph orch apply -i osd_spec.yaml
[ceph: root@host01 osd]# ceph orch apply -i osd_spec.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
検証
サービスをリスト表示します。
例
[ceph: root@host01 /]# ceph orch ls osd
[ceph: root@host01 /]# ceph orch ls osdCopy to Clipboard Copied! Toggle word wrap Toggle overflow ノードとデバイスの詳細を表示します。
例
[ceph: root@host01 /]# ceph osd tree
[ceph: root@host01 /]# ceph osd treeCopy to Clipboard Copied! Toggle word wrap Toggle overflow
6.10. Ceph Orchestrator を使用した OSD デーモンの削除
Cephadm を使用して、OSD をクラスターから削除できます。
クラスターから OSD を削除するには、2 つの手順を実行します。
- クラスターからすべての配置グループ (PG) を退避します。
- PG のない OSD をクラスターから削除します。
--zap オプションにより、ボリュームグループ、論理ボリューム、LVM メタデータが削除されました。
OSD を削除した後、OSD がデプロイメントされたドライブが再び使用可能になった場合、既存のドライブグループの仕様と一致する場合、cephadm` はこれらのドライブにさらに OSD をデプロイメントしようとする可能性があります。削除する OSD を仕様とともにデプロイメントし、削除後に新しい OSD をドライブにデプロイメントしたくない場合は、削除する前にドライブグループの仕様を変更します。OSD のデプロイメント中に --all-available-devices オプションを使用した場合は、unmanaged: true を設定して、新しいドライブをまったく取得しないようにします。他のデプロイメントの場合は、仕様を変更してください。詳細は、高度なサービス仕様を使用した Ceph OSD のデプロイ を参照してください。
前提条件
- 稼働中の Red Hat Ceph Storage クラスターがある。
- ホストがクラスターに追加されている。
- Ceph Monitor、Ceph Manager、および Ceph OSD デーモンがストレージクラスターにデプロイされます。
手順
Cephadm シェルにログインします。
例
cephadm shell
[root@host01 ~]# cephadm shellCopy to Clipboard Copied! Toggle word wrap Toggle overflow OSD を削除する必要があるデバイスとノードを確認します。
例
[ceph: root@host01 /]# ceph osd tree
[ceph: root@host01 /]# ceph osd treeCopy to Clipboard Copied! Toggle word wrap Toggle overflow OSD を削除します。
構文
ceph orch osd rm OSD_ID [--replace] [--force] --zap
ceph orch osd rm OSD_ID [--replace] [--force] --zapCopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph orch osd rm 0 --zap
[ceph: root@host01 /]# ceph orch osd rm 0 --zapCopy to Clipboard Copied! Toggle word wrap Toggle overflow 注記--replaceなどのオプションを指定せずにストレージクラスターから OSD を削除すると、デバイスはストレージクラスターから完全に削除されます。OSD のデプロイに同じデバイスを使用する必要がある場合は、ストレージクラスターにデバイスを追加する前に、最初にデバイスをザッピングする必要があります。オプション: 特定のノードから複数の OSD を削除するには、次のコマンドを実行します。
構文
ceph orch osd rm OSD_ID OSD_ID --zap
ceph orch osd rm OSD_ID OSD_ID --zapCopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph orch osd rm 2 5 --zap
[ceph: root@host01 /]# ceph orch osd rm 2 5 --zapCopy to Clipboard Copied! Toggle word wrap Toggle overflow OSD の削除のステータスを確認します。
例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow OSD に PG が残っていない場合は廃止され、クラスターから削除されます。
検証
Ceph OSD が削除されたデバイスおよびノードの詳細を確認します。
例
[ceph: root@host01 /]# ceph osd tree
[ceph: root@host01 /]# ceph osd treeCopy to Clipboard Copied! Toggle word wrap Toggle overflow
6.11. Ceph Orchestrator を使用した OSD の置き換え
ディスクに障害が発生した場合は、物理ストレージデバイスを交換し、同じ OSD ID を再利用することで、CRUSH マップを再設定する必要がなくなります。
--replace オプションを使用して、クラスターから OSD を置き換えることができます。
単一の OSD を置き換える場合は、特定のデバイスおよびホストへの Ceph OSD のデプロイ を参照してください。利用可能なすべてのデバイスに OSD をデプロイする場合は、すべての利用可能なデバイスへの Ceph OSD のデプロイ を参照してください。
このオプションは、ceph orch rm コマンドを使用して OSD ID を保存します。OSD は CRUSH 階層から永続的に削除されませんが、destroyed フラグが割り当てられます。このフラグは、次の OSD デプロイメントで再利用できる OSD ID を判断するために使用されます。destroyed フラグは、次の OSD デプロイメントで再利用される OSD ID を判断するために使用されます。
rm コマンドと同様に、クラスターから OSD を置き換えるには、次の 2 つの手順が必要です。
- クラスターからすべての配置グループ (PG) を退避します。
- クラスターから PG のない OSD を削除します。
導入に OSD 仕様を使用する場合、交換されるディスクの OSD ID は、新しく追加されたディスクが挿入されるとすぐに自動的に割り当てられます。
OSD を削除した後、OSD がデプロイメントされたドライブが再び使用可能になった場合、既存のドライブグループの仕様と一致する場合、cephadm` はこれらのドライブにさらに OSD をデプロイメントしようとする可能性があります。削除する OSD を仕様とともにデプロイメントし、削除後に新しい OSD をドライブにデプロイメントしたくない場合は、削除する前にドライブグループの仕様を変更します。OSD のデプロイメント中に --all-available-devices オプションを使用した場合は、unmanaged: true を設定して、新しいドライブをまったく取得しないようにします。他のデプロイメントの場合は、仕様を変更してください。詳細は、高度なサービス仕様を使用した Ceph OSD のデプロイ を参照してください。
前提条件
- 稼働中の Red Hat Ceph Storage クラスターがある。
- ホストがクラスターに追加されている。
- Monitor、Manager、および OSD デーモンはストレージクラスターにデプロイされます。
- 削除された OSD を置き換える新しい OSD は、OSD が削除されたのと同じホストで作成する必要があります。
手順
Cephadm シェルにログインします。
例
cephadm shell
[root@host01 ~]# cephadm shellCopy to Clipboard Copied! Toggle word wrap Toggle overflow 今後の参照のために、OSD 設定のマッピングを必ずダンプして保存してください。
例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow OSD を置き換える必要のあるデバイスとノードを確認します。
例
[ceph: root@host01 /]# ceph osd tree
[ceph: root@host01 /]# ceph osd treeCopy to Clipboard Copied! Toggle word wrap Toggle overflow cephadmマネージドクラスターから OSD を削除します。重要ストレージクラスターに
health_warnまたはそれに関連するその他のエラーがある場合は、データの損失を回避するために、OSD を交換する前にエラーを確認して修正してください。構文
ceph orch osd rm OSD_ID --replace [--force]
ceph orch osd rm OSD_ID --replace [--force]Copy to Clipboard Copied! Toggle word wrap Toggle overflow --forceオプションは、ストレージクラスターで進行中の操作がある場合に使用できます。例
[ceph: root@host01 /]# ceph orch osd rm 0 --replace
[ceph: root@host01 /]# ceph orch osd rm 0 --replaceCopy to Clipboard Copied! Toggle word wrap Toggle overflow 次の OSD 仕様を適用して、新しい OSD を再作成します。
例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow OSD 置き換えのステータスを確認します。
例
[ceph: root@host01 /]# ceph orch osd rm status
[ceph: root@host01 /]# ceph orch osd rm statusCopy to Clipboard Copied! Toggle word wrap Toggle overflow オーケストレーターを停止して、既存の OSD 仕様を適用します。
例
[ceph: root@node /]# ceph orch pause [ceph: root@node /]# ceph orch status Backend: cephadm Available: Yes Paused: Yes
[ceph: root@node /]# ceph orch pause [ceph: root@node /]# ceph orch status Backend: cephadm Available: Yes Paused: YesCopy to Clipboard Copied! Toggle word wrap Toggle overflow 削除された OSD デバイスをザップします。
例
[ceph: root@node /]# ceph orch device zap node.example.com /dev/sdi --force zap successful for /dev/sdi on node.example.com [ceph: root@node /]# ceph orch device zap node.example.com /dev/sdf --force zap successful for /dev/sdf on node.example.com
[ceph: root@node /]# ceph orch device zap node.example.com /dev/sdi --force zap successful for /dev/sdi on node.example.com [ceph: root@node /]# ceph orch device zap node.example.com /dev/sdf --force zap successful for /dev/sdf on node.example.comCopy to Clipboard Copied! Toggle word wrap Toggle overflow Orcestrator を一時停止モードから再開する
例
[ceph: root@node /]# ceph orch resume
[ceph: root@node /]# ceph orch resumeCopy to Clipboard Copied! Toggle word wrap Toggle overflow OSD 置き換えのステータスを確認します。
例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
検証
Ceph OSD が置き換えられるデバイスとノードの詳細を確認します。
例
[ceph: root@host01 /]# ceph osd tree
[ceph: root@host01 /]# ceph osd treeCopy to Clipboard Copied! Toggle word wrap Toggle overflow 置き換えたものと同じ ID を持つ OSD が同じホスト上で実行されていることがわかります。
新しくデプロイされた OSD の db_device が置き換えられた db_device であることを確認します。
例
[ceph: root@host01 /]# ceph osd metadata 0 | grep bluefs_db_devices "bluefs_db_devices": "nvme0n1", [ceph: root@host01 /]# ceph osd metadata 1 | grep bluefs_db_devices "bluefs_db_devices": "nvme0n1",
[ceph: root@host01 /]# ceph osd metadata 0 | grep bluefs_db_devices "bluefs_db_devices": "nvme0n1", [ceph: root@host01 /]# ceph osd metadata 1 | grep bluefs_db_devices "bluefs_db_devices": "nvme0n1",Copy to Clipboard Copied! Toggle word wrap Toggle overflow
6.12. OSD を事前に作成された LVM に置き換える
ceph-volume lvm zap コマンドを使用して OSD をパージした後、ディレクトリーが存在しない場合は、事前に作成された LVM を使用して OSD を OSd サービス仕様ファイルに置き換えることができます。
前提条件
- 稼働中の Red Hat Ceph Storage クラスターがある。
- 失敗した OSD
手順
Cephadm シェルにログインします。
例
cephadm shell
[root@host01 ~]# cephadm shellCopy to Clipboard Copied! Toggle word wrap Toggle overflow OSD を削除します。
構文
ceph orch osd rm OSD_ID [--replace]
ceph orch osd rm OSD_ID [--replace]Copy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph orch osd rm 8 --replace Scheduled OSD(s) for removal
[ceph: root@host01 /]# ceph orch osd rm 8 --replace Scheduled OSD(s) for removalCopy to Clipboard Copied! Toggle word wrap Toggle overflow OSD が破壊されていることを確認します。
例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow ceph-volumeコマンドを使用して、OSD をザップして削除します。構文
ceph-volume lvm zap --osd-id OSD_ID
ceph-volume lvm zap --osd-id OSD_IDCopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow OSD トポロジーを確認します。
例
[ceph: root@host01 /]# ceph-volume lvm list
[ceph: root@host01 /]# ceph-volume lvm listCopy to Clipboard Copied! Toggle word wrap Toggle overflow 特定の OSD トポロジーに対応する仕様ファイルを使用して OSD を再作成します。
例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 更新された仕様ファイルを適用します。
例
[ceph: root@host01 /]# ceph orch apply -i osd.yml Scheduled osd.osd_service update...
[ceph: root@host01 /]# ceph orch apply -i osd.yml Scheduled osd.osd_service update...Copy to Clipboard Copied! Toggle word wrap Toggle overflow OSD が戻っていることを確認します。
例
[ceph: root@host01 /]# ceph -s [ceph: root@host01 /]# ceph osd tree
[ceph: root@host01 /]# ceph -s [ceph: root@host01 /]# ceph osd treeCopy to Clipboard Copied! Toggle word wrap Toggle overflow
6.13. 非共存シナリオでの OSD の交換
非コロケーションシナリオで OSD に障害が発生した場合は、WAL/DB デバイスを交換できます。DB デバイスと WAL デバイスの手順は同じです。DB デバイスの場合は db_devices の下の paths を編集し、WAL デバイスの場合は wal_devices の下の paths を編集する必要があります。
前提条件
- 稼働中の Red Hat Ceph Storage クラスターがある。
- デーモンは同じ場所に配置されません。
- 失敗した OSD
手順
クラスター内のデバイスを特定します。
例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow Cephadm シェルにログインします。
例
cephadm shell
[root@host01 ~]# cephadm shellCopy to Clipboard Copied! Toggle word wrap Toggle overflow OSD とその DB デバイスを特定します。
例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow osds.yamlファイルで、unmagedパラメーターをtrueに設定します。それ以外の場合、cephadmは OSD を再デプロイします。例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 更新された仕様ファイルを適用します。
例
[ceph: root@host01 /]# ceph orch apply -i osds.yml Scheduled osd.non-colocated update...
[ceph: root@host01 /]# ceph orch apply -i osds.yml Scheduled osd.non-colocated update...Copy to Clipboard Copied! Toggle word wrap Toggle overflow ステータスを確認します。
例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow OSD を削除します。バックエンドサービスを削除するには
--zapオプションを使用し、OSD ID を保持するには--replaceオプションを使用してください。例
[ceph: root@host01 /]# ceph orch osd rm 2 5 --zap --replace Scheduled OSD(s) for removal
[ceph: root@host01 /]# ceph orch osd rm 2 5 --zap --replace Scheduled OSD(s) for removalCopy to Clipboard Copied! Toggle word wrap Toggle overflow ステータスを確認します。
例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow osds.yaml仕様ファイルを編集してアンマネージドパラメーターをfalseに変更し、デバイスが物理的に交換された後にパスが変更された場合は DB デバイスへのパスを置き換えます。例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 上記の例では、
/dev/sdhは/dev/sdeに置き換えられます。重要同じホスト仕様ファイルを使用して単一の OSD ノード上の障害のある DB デバイスを交換する場合は、OSD ノードのみを指定するように
host_patternオプションを変更します。そうしなければ、デプロイメントが失敗し、他のホストで新しい DB デバイスが見つかりません。--dry-runオプションを指定して仕様ファイルを再適用し、OSD が新しい DB デバイスでデプロイされることを確認します。例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 仕様ファイルを適用します。
例
[ceph: root@host01 /]# ceph orch apply -i osds.yml Scheduled osd.non-colocated update...
[ceph: root@host01 /]# ceph orch apply -i osds.yml Scheduled osd.non-colocated update...Copy to Clipboard Copied! Toggle word wrap Toggle overflow OSD が再デプロイメントされていることを確認します。
例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
検証
OSDS が再デプロイされている OSD ホストから、OSDS が新しい DB デバイス上にあるかどうかを確認します。
例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
6.14. Ceph Orchestrator を使用した OSD の削除停止
削除用にキューに置かれた OSD のみの削除を停止することができます。これにより、OSD の初期状態がリセットされ、削除キューから削除されます。
OSD の削除処理中である場合は、プロセスを停止することはできません。
前提条件
- 稼働中の Red Hat Ceph Storage クラスターがある。
- ホストがクラスターに追加されている。
- Monitor、Manager デーモン、および OSD デーモンがクラスターにデプロイされている。
- 開始した OSD プロセスを削除する。
手順
Cephadm シェルにログインします。
例
cephadm shell
[root@host01 ~]# cephadm shellCopy to Clipboard Copied! Toggle word wrap Toggle overflow 削除するために開始された OSD のデバイスとノードを確認します。
例
[ceph: root@host01 /]# ceph osd tree
[ceph: root@host01 /]# ceph osd treeCopy to Clipboard Copied! Toggle word wrap Toggle overflow キューに置かれた OSD の削除を停止します。
構文
ceph orch osd rm stop OSD_ID
ceph orch osd rm stop OSD_IDCopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph orch osd rm stop 0
[ceph: root@host01 /]# ceph orch osd rm stop 0Copy to Clipboard Copied! Toggle word wrap Toggle overflow OSD の削除のステータスを確認します。
例
[ceph: root@host01 /]# ceph orch osd rm status
[ceph: root@host01 /]# ceph orch osd rm statusCopy to Clipboard Copied! Toggle word wrap Toggle overflow
検証
Ceph OSD を削除するためにキューに入れられたデバイスおよびノードの詳細を確認します。
例
[ceph: root@host01 /]# ceph osd tree
[ceph: root@host01 /]# ceph osd treeCopy to Clipboard Copied! Toggle word wrap Toggle overflow
6.15. Ceph Orchestrator を使用した OSD のアクティブ化
ホストのオペレーティングシステムが再インストールされた場合に、クラスターで OSD をアクティブにすることができます。
前提条件
- 稼働中の Red Hat Ceph Storage クラスターがある。
- ホストがクラスターに追加されている。
- Monitor、Manager、および OSD デーモンがストレージクラスターにデプロイされている。
手順
Cephadm シェルにログインします。
例
cephadm shell
[root@host01 ~]# cephadm shellCopy to Clipboard Copied! Toggle word wrap Toggle overflow ホストのオペレーティングシステムを再インストールしたら、OSD をアクティベートします。
構文
ceph cephadm osd activate HOSTNAME
ceph cephadm osd activate HOSTNAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph cephadm osd activate host03
[ceph: root@host01 /]# ceph cephadm osd activate host03Copy to Clipboard Copied! Toggle word wrap Toggle overflow
検証
サービスをリスト表示します。
例
[ceph: root@host01 /]# ceph orch ls
[ceph: root@host01 /]# ceph orch lsCopy to Clipboard Copied! Toggle word wrap Toggle overflow ホスト、デーモン、およびプロセスをリスト表示します。
構文
ceph orch ps --service_name=SERVICE_NAME
ceph orch ps --service_name=SERVICE_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph orch ps --service_name=osd
[ceph: root@host01 /]# ceph orch ps --service_name=osdCopy to Clipboard Copied! Toggle word wrap Toggle overflow
6.15.1. データ移行の監視
OSD を CRUSH マップに追加または削除すると、Ceph は配置グループを新規または既存の OSD に移行してデータのリバランスを開始します。ceph-w コマンドを使用して、データの移行を確認できます。
前提条件
- 稼働中の Red Hat Ceph Storage クラスターがある。
- 最近 OSD を追加または削除した。
手順
データの移行を確認するには、以下を実行します。
例
[ceph: root@host01 /]# ceph -w
[ceph: root@host01 /]# ceph -wCopy to Clipboard Copied! Toggle word wrap Toggle overflow -
配置グループのステータスが
active+cleanからactive, some degraded objectsし、最後に移行の完了時にactive+cleanに変わるのを確認します。 -
ユーティリティーを終了するには、
Ctrl + Cを押します。
6.16. 配置グループの再計算
配置グループ (PG) は、利用可能な OSD にまたがるプールデータの分散を定義します。配置グループは、使用する冗長性アルゴリズムに基づいて構築されます。3 方向のレプリケーションでは、冗長性は 3 つの異なる OSD を使用するように設定されます。イレイジャーコーディングされたプールの場合、使用する OSD の数はチャンクの数で定義されます。
プールを定義する場合、配置グループの数によって、使用可能なすべての OSD にデータが分散される粒度のグレードが定義されます。数値が大きいほど、容量負荷の均等化が向上します。ただし、データを再構築する場合は配置グループの処理も重要であるため、事前に慎重に選択する必要があります。計算をサポートするには、アジャイル環境の生成に利用できるツールを使用できます。
ストレージクラスターの有効期間中、プールが最初に予想される制限を上回る可能性があります。ドライブの数が増えると、再計算が推奨されます。OSD ごとの配置グループの数は約 100 である必要があります。ストレージクラスターに OSD を追加すると、OSD あたりの PG の数は時間の経過とともに減少します。ストレージクラスターで最初に 120 ドライブを使用し、プールの pg_num を 4000 に設定すると、レプリケーション係数が 3 の場合に、OSD ごとに 100 PG に設定されます。時間の経過とともに、OSD の数が 10 倍になると、OSD あたりの PG の数は 10 になります。OSD ごとの PG の数が少ないと、容量が不均一に分散される傾向があるため、プールごとの PG を調整することを検討してください。
配置グループ数の調整は、オンラインで実行できます。再計算は PG 番号の再計算だけでなく、データの再配置が関係し、長いプロセスになります。ただし、データの可用性はいつでも維持されます。
OSD ごとの非常に高い PG は、失敗した OSD 上でのすべての PG を再構築すると同時に起動されるため、回避する必要があります。時間内に再構築を実行するには、多くの IOPS が必要ですが、これは利用できない可能性があります。これにより、I/O キューが深くなり、待ち時間が長くなり、ストレージクラスターが使用できなくなったり、修復時間が長くなったりします。
第7章 Ceph Orchestrator を使用したモニタリングスタックの管理
ストレージ管理者は、バックエンドにて Cephadm と Ceph Orchestrator を使用して、モニタリングおよびアラートスタックをデプロイできます。モニタリングスタックは、Prometheus、Prometheus エクスポーター、Prometheus Alertmanager、および Grafana で設定されます。ユーザーは、YAML 設定ファイルの Cephadm でこれらのサービスを定義するか、コマンドラインインターフェイスを使用してそれらをデプロイする必要があります。同じタイプの複数のサービスがデプロイされると、可用性の高い設定がデプロイされます。ノードエクスポーターはこのルールの例外です。
Red Hat Ceph Storage 5.0 は、Prometheus、Grafana、Alertmanager、および node-exporter などのモニタリングサービスをデプロイするためのカスタムイメージをサポートしません。
以下のモニタリングサービスは、Cephadm でデプロイすることができます。
Prometheus はモニタリングおよびアラートツールキットです。これは、Prometheus エクスポーターによって提供されるデータを収集し、事前に定義されたしきい値に達した場合に事前設定されたアラートを実行します。Prometheus マネージャーモジュールは、
ceph-mgrのコレクションポイントから Ceph パフォーマンスカウンターに渡す Prometheus エクスポーターを提供します。デーモンを提供するメトリックなど、スクレープターゲットなどの Prometheus 設定は、Cephadm によって自動的に設定されます。Cephadm は、デフォルトのアラートのリスト (例: health error、10% OSDs down、pgs inactive) もデプロイします。
- Alertmanager は、Prometheus サーバーによって送信されるアラートを処理します。これは、正しい受信側にアラートを複製解除、グループ化、およびルーティングします。デフォルトでは、Ceph Dashboard は受信側として自動的に設定されます。Alertmanager は、Prometheus サーバーによって送信されるアラートを処理します。アラートは Alertmanager を使用して無音にすることができますが、無音は Ceph Dashboard を使用して管理することもできます。
Grafana は可視化およびアラートソフトウェアです。Grafana のアラート機能は、このモニタリングスタックによって使用されません。アラートについては、Alertmanager が使用されます。
デフォルトでは、Grafana へのトラフィックは TLS で暗号化されます。独自の TLS 証明書を指定するか、自己署名の証明書を使用できます。Grafana をデプロイする前にカスタム証明書が設定されていない場合、自己署名証明書が自動的に作成され、Grafana に設定されます。Grafana のカスタム証明書は、以下のコマンドを使用して設定できます。
構文
ceph config-key set mgr/cephadm/grafana_key -i PRESENT_WORKING_DIRECTORY/key.pem ceph config-key set mgr/cephadm/grafana_crt -i PRESENT_WORKING_DIRECTORY/certificate.pem
ceph config-key set mgr/cephadm/grafana_key -i PRESENT_WORKING_DIRECTORY/key.pem ceph config-key set mgr/cephadm/grafana_crt -i PRESENT_WORKING_DIRECTORY/certificate.pemCopy to Clipboard Copied! Toggle word wrap Toggle overflow
ノードエクスポーターは Prometheus のエクスポーターで、インストールされているノードに関するデータを提供します。ノードエクスポーターをすべてのノードにインストールすることが推奨されます。これは、node-exporter サービスタイプの monitoring.yml ファイルを使用して実行できます。
7.1. Ceph Orchestrator を使用したモニタリングスタックのデプロイ
モニタリングスタックは、Prometheus、Prometheus エクスポーター、Prometheus Alertmanager、Grafana、および Ceph エクスポーターから設定されます。Ceph Dashboard はこれらのコンポーネントを使用して、クラスターの使用状況およびパフォーマンスの詳細なメトリックを保存し、可視化します。
YAML ファイル形式のサービス仕様を使用して、モニタリングスタックをデプロイできます。すべてのモニタリングサービスのバインド先のネットワークおよびポートは yml ファイルで設定できます。
前提条件
- 稼働中の Red Hat Ceph Storage クラスターがある。
- ノードへの root レベルのアクセス。
手順
Ceph Manager デーモンで prometheus モジュールを有効にします。これにより、内部 Ceph メトリックが公開され、Prometheus がそれらを読み取りできます。
例
[ceph: root@host01 /]# ceph mgr module enable prometheus
[ceph: root@host01 /]# ceph mgr module enable prometheusCopy to Clipboard Copied! Toggle word wrap Toggle overflow 重要このコマンドは、Prometheus のデプロイ前に実行されるようにします。デプロイメントの前にコマンドが実行されなかった場合は、Prometheus を再デプロイして設定を更新する必要があります。
ceph orch redeploy prometheus
ceph orch redeploy prometheusCopy to Clipboard Copied! Toggle word wrap Toggle overflow 以下のディレクトリーに移動します。
構文
cd /var/lib/ceph/DAEMON_PATH/
cd /var/lib/ceph/DAEMON_PATH/Copy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 mds/]# cd /var/lib/ceph/monitoring/
[ceph: root@host01 mds/]# cd /var/lib/ceph/monitoring/Copy to Clipboard Copied! Toggle word wrap Toggle overflow 注記ディレクトリー
monitoringが存在しない場合は、作成します。monitoring.ymlファイルを作成します。例
[ceph: root@host01 monitoring]# touch monitoring.yml
[ceph: root@host01 monitoring]# touch monitoring.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 以下の例のような内容で仕様ファイルを編集します。
例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 注記監視スタックコンポーネントの
alertmanager、prometheus、およびgrafanaが同じホストにデプロイされていることを確認します。node-exporterおよびceph-exporterコンポーネントは、すべてのホストにデプロイする必要があります。モニタリングサービスを適用します。
例
[ceph: root@host01 monitoring]# ceph orch apply -i monitoring.yml
[ceph: root@host01 monitoring]# ceph orch apply -i monitoring.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
検証
サービスをリスト表示します。
例
[ceph: root@host01 /]# ceph orch ls
[ceph: root@host01 /]# ceph orch lsCopy to Clipboard Copied! Toggle word wrap Toggle overflow ホスト、デーモン、およびプロセスをリスト表示します。
構文
ceph orch ps --service_name=SERVICE_NAME
ceph orch ps --service_name=SERVICE_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph orch ps --service_name=prometheus
[ceph: root@host01 /]# ceph orch ps --service_name=prometheusCopy to Clipboard Copied! Toggle word wrap Toggle overflow
Prometheus、Grafana、および Ceph Dashboard はすべて相互に対話するように自動設定されるため、Ceph Dashboard で Grafana 統合が完全に機能します。
7.2. Ceph Orchestrator を使用したモニタリングスタックの削除
ceph orch rm コマンドを使用してモニタリングスタックを削除できます。
前提条件
- 稼働中の Red Hat Ceph Storage クラスターがある。
手順
Cephadm シェルにログインします。
例
cephadm shell
[root@host01 ~]# cephadm shellCopy to Clipboard Copied! Toggle word wrap Toggle overflow ceph orch rmコマンドを使用してモニタリングスタックを削除します。構文
ceph orch rm SERVICE_NAME --force
ceph orch rm SERVICE_NAME --forceCopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow プロセスのステータスを確認します。
例
[ceph: root@host01 /]# ceph orch status
[ceph: root@host01 /]# ceph orch statusCopy to Clipboard Copied! Toggle word wrap Toggle overflow
検証
サービスをリスト表示します。
例
[ceph: root@host01 /]# ceph orch ls
[ceph: root@host01 /]# ceph orch lsCopy to Clipboard Copied! Toggle word wrap Toggle overflow ホスト、デーモン、およびプロセスをリスト表示します。
構文
ceph orch ps
ceph orch psCopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph orch ps
[ceph: root@host01 /]# ceph orch psCopy to Clipboard Copied! Toggle word wrap Toggle overflow
第8章 基本的な Red Hat Ceph Storage のクライアント設定
ストレージ管理者は、ストレージクラスターと対話するために基本設定でクライアントマシンを設定する必要があります。ほとんどのクライアントマシンには ceph-common package とその依存関係のみがインストールされている必要があります。これは、基本的な ceph コマンドおよび rados コマンドと、mount.ceph や rbd などのその他のコマンドを提供します。
8.1. クライアントマシンでのファイルの設定
通常、クライアントマシンには完全なストレージクラスターメンバーよりも小さな設定ファイルが必要になります。Ceph モニターに到達するためにクライアントに情報を提供する最小限の設定ファイルを生成できます。
前提条件
- 稼働中の Red Hat Ceph Storage クラスターがある。
- ノードへの root アクセス。
手順
ファイルを設定するノードで、
/etcフォルダーにディレクトリーcephを作成します。例
mkdir /etc/ceph/
[root@host01 ~]# mkdir /etc/ceph/Copy to Clipboard Copied! Toggle word wrap Toggle overflow /etc/cephディレクトリーに移動します。例
cd /etc/ceph/
[root@host01 ~]# cd /etc/ceph/Copy to Clipboard Copied! Toggle word wrap Toggle overflow cephディレクトリーで設定ファイルを生成します。例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow このファイルのコンテンツは、
/etc/ceph/ceph.confパスにインストールする必要があります。この設定ファイルを使用して、Ceph モニターに到達できます。
8.2. クライアントマシンでのキーリングの設定
ほとんどの Ceph クラスターは認証が有効な状態で実行され、クライアントはクラスターマシンと通信するために鍵が必要です。Ceph モニターに到達するためにクライアントに詳細を提供できるキーリングを生成できます。
前提条件
- 稼働中の Red Hat Ceph Storage クラスターがある。
- ノードへの root アクセス。
手順
キーリングを設定するノードで、
/etcフォルダーにディレクトリーcephを作成します。例
mkdir /etc/ceph/
[root@host01 ~]# mkdir /etc/ceph/Copy to Clipboard Copied! Toggle word wrap Toggle overflow cephディレクトリーの/etc/cephディレクトリーに移動します。例
cd /etc/ceph/
[root@host01 ~]# cd /etc/ceph/Copy to Clipboard Copied! Toggle word wrap Toggle overflow クライアントのキーリングを生成します。
構文
ceph auth get-or-create client.CLIENT_NAME -o /etc/ceph/NAME_OF_THE_FILE
ceph auth get-or-create client.CLIENT_NAME -o /etc/ceph/NAME_OF_THE_FILECopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
ceph auth get-or-create client.fs -o /etc/ceph/ceph.keyring
[root@host01 ceph]# ceph auth get-or-create client.fs -o /etc/ceph/ceph.keyringCopy to Clipboard Copied! Toggle word wrap Toggle overflow ceph.keyringファイルの出力を確認します。例
[root@host01 ceph]# cat ceph.keyring [client.fs] key = AQAvoH5gkUCsExAATz3xCBLd4n6B6jRv+Z7CVQ==
[root@host01 ceph]# cat ceph.keyring [client.fs] key = AQAvoH5gkUCsExAATz3xCBLd4n6B6jRv+Z7CVQ==Copy to Clipboard Copied! Toggle word wrap Toggle overflow 出力は
/etc/ceph/ceph.keyringなどのキーリングファイルに配置する必要があります。
第9章 Ceph Orchestrator を使用した MDS サービスの管理
ストレージ管理者は、バックエンドにて Cephadm と Ceph Orchestrator を使用して MDS サービスをデプロイできます。デフォルトでは、Ceph File System (CephFS) はアクティブな MDS デーモンを 1 つだけ使用します。ただし、多くのクライアントがあるシステムでは複数のアクティブな MDS デーモンを使用する利点があります。
本セクションでは、以下の管理タスクを説明します。
9.1. 前提条件
- 稼働中の Red Hat Ceph Storage クラスターがある。
- すべてのノードへの root レベルのアクセス。
- ホストがクラスターに追加されている。
- すべてのマネージャー、モニター、および OSD デーモンがデプロイされている。
9.2. コマンドラインインターフェイスを使用した MDS サービスのデプロイ
Ceph Orchestrator を使用すると、コマンドラインインターフェイスで placement 仕様を使用して、Metadata Server (MDS) サービスをデプロイできます。Ceph ファイルシステム (CephFS) には、1 つ以上の MDS が必要です。
最低でも、Ceph ファイルシステム (CephFS) データ用のプール 1 つと CephFS メタデータ用のプール 1 つの 2 つのプールがあるようにしてください。
前提条件
- 稼働中の Red Hat Ceph Storage クラスターがある。
- ホストがクラスターに追加されている。
- すべてのマネージャー、モニター、および OSD デーモンがデプロイされます。
手順
Cephadm シェルにログインします。
例
cephadm shell
[root@host01 ~]# cephadm shellCopy to Clipboard Copied! Toggle word wrap Toggle overflow - 配置仕様を使用して MDS デーモンをデプロイする方法は 2 つあります。
方法 1
ceph fs volumeを使用して MDS デーモンを作成します。これにより、CephFS に関連付けられた CephFS ボリュームとプールが作成され、ホストで MDS サービスも開始されます。構文
ceph fs volume create FILESYSTEM_NAME --placement="NUMBER_OF_DAEMONS HOST_NAME_1 HOST_NAME_2 HOST_NAME_3"
ceph fs volume create FILESYSTEM_NAME --placement="NUMBER_OF_DAEMONS HOST_NAME_1 HOST_NAME_2 HOST_NAME_3"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 注記デフォルトでは、このコマンドに対してレプリケートされたプールが作成されます。
例
[ceph: root@host01 /]# ceph fs volume create test --placement="2 host01 host02"
[ceph: root@host01 /]# ceph fs volume create test --placement="2 host01 host02"Copy to Clipboard Copied! Toggle word wrap Toggle overflow
方法 2
プール、CephFS を作成してから、配置仕様を使用して MDS サービスをデプロイします。
CephFS のプールを作成します。
構文
ceph osd pool create DATA_POOL [PG_NUM] ceph osd pool create METADATA_POOL [PG_NUM]
ceph osd pool create DATA_POOL [PG_NUM] ceph osd pool create METADATA_POOL [PG_NUM]Copy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph osd pool create cephfs_data 64 [ceph: root@host01 /]# ceph osd pool create cephfs_metadata 64
[ceph: root@host01 /]# ceph osd pool create cephfs_data 64 [ceph: root@host01 /]# ceph osd pool create cephfs_metadata 64Copy to Clipboard Copied! Toggle word wrap Toggle overflow 通常、メタデータプールは、データプールよりもオブジェクトがはるかに少ないため、控えめな数の配置グループ (PG) で開始できます。必要に応じて PG の数を増やすことができます。プールサイズの範囲は 64 PG ~ 512 PG です。データプールのサイズは、ファイルシステム内で予想されるファイルの数とサイズに比例します。
重要メタデータプールでは、以下を使用することを検討してください。
- このプールへのデータ損失によりファイルシステム全体にアクセスできなくなる可能性があるため、レプリケーションレベルが高くなります。
- Solid-State Drive (SSD) ディスクなどのレイテンシーが低くなるストレージ。これは、クライアントで観察されるファイルシステム操作のレイテンシーに直接影響するためです。
データプールおよびメタデータプールのファイルシステムを作成します。
構文
ceph fs new FILESYSTEM_NAME METADATA_POOL DATA_POOL
ceph fs new FILESYSTEM_NAME METADATA_POOL DATA_POOLCopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph fs new test cephfs_metadata cephfs_data
[ceph: root@host01 /]# ceph fs new test cephfs_metadata cephfs_dataCopy to Clipboard Copied! Toggle word wrap Toggle overflow ceph orch applyコマンドを使用して MDS サービスをデプロイします。構文
ceph orch apply mds FILESYSTEM_NAME --placement="NUMBER_OF_DAEMONS HOST_NAME_1 HOST_NAME_2 HOST_NAME_3"
ceph orch apply mds FILESYSTEM_NAME --placement="NUMBER_OF_DAEMONS HOST_NAME_1 HOST_NAME_2 HOST_NAME_3"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph orch apply mds test --placement="2 host01 host02"
[ceph: root@host01 /]# ceph orch apply mds test --placement="2 host01 host02"Copy to Clipboard Copied! Toggle word wrap Toggle overflow
検証
サービスをリスト表示します。
例
[ceph: root@host01 /]# ceph orch ls
[ceph: root@host01 /]# ceph orch lsCopy to Clipboard Copied! Toggle word wrap Toggle overflow CephFS のステータスを確認します。
例
[ceph: root@host01 /]# ceph fs ls [ceph: root@host01 /]# ceph fs status
[ceph: root@host01 /]# ceph fs ls [ceph: root@host01 /]# ceph fs statusCopy to Clipboard Copied! Toggle word wrap Toggle overflow ホスト、デーモン、およびプロセスをリスト表示します。
構文
ceph orch ps --daemon_type=DAEMON_NAME
ceph orch ps --daemon_type=DAEMON_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph orch ps --daemon_type=mds
[ceph: root@host01 /]# ceph orch ps --daemon_type=mdsCopy to Clipboard Copied! Toggle word wrap Toggle overflow
9.3. サービス仕様を使用した MDS サービスのデプロイ
Ceph Orchestrator を使用すると、サービス仕様を使用して MDS サービスをデプロイできます。
少なくとも 2 つのプールがあることを確認してください。1 つは Ceph ファイルシステム (CephFS) データ用で、もう 1 つは CephFS メタデータ用です。
前提条件
- 稼働中の Red Hat Ceph Storage クラスターがある。
- ホストがクラスターに追加されている。
- すべてのマネージャー、モニター、および OSD デーモンがデプロイされます。
手順
mds.yamlファイルを作成します。例
touch mds.yaml
[root@host01 ~]# touch mds.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow mds.yamlファイルを編集し、以下の詳細を含めます。構文
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow YAML ファイルをコンテナー内のディレクトリーにマウントします。
例
cephadm shell --mount mds.yaml:/var/lib/ceph/mds/mds.yaml
[root@host01 ~]# cephadm shell --mount mds.yaml:/var/lib/ceph/mds/mds.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow そのディレクトリーに移動します。
例
[ceph: root@host01 /]# cd /var/lib/ceph/mds/
[ceph: root@host01 /]# cd /var/lib/ceph/mds/Copy to Clipboard Copied! Toggle word wrap Toggle overflow Cephadm シェルにログインします。
例
cephadm shell
[root@host01 ~]# cephadm shellCopy to Clipboard Copied! Toggle word wrap Toggle overflow 以下のディレクトリーに移動します。
例
[ceph: root@host01 /]# cd /var/lib/ceph/mds/
[ceph: root@host01 /]# cd /var/lib/ceph/mds/Copy to Clipboard Copied! Toggle word wrap Toggle overflow サービス仕様を使用して MDS サービスをデプロイします。
構文
ceph orch apply -i FILE_NAME.yaml
ceph orch apply -i FILE_NAME.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 mds]# ceph orch apply -i mds.yaml
[ceph: root@host01 mds]# ceph orch apply -i mds.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow MDS サービスがデプロイされ、機能したら、CephFS を作成します。
構文
ceph fs new CEPHFS_NAME METADATA_POOL DATA_POOL
ceph fs new CEPHFS_NAME METADATA_POOL DATA_POOLCopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph fs new test metadata_pool data_pool
[ceph: root@host01 /]# ceph fs new test metadata_pool data_poolCopy to Clipboard Copied! Toggle word wrap Toggle overflow
検証
サービスをリスト表示します。
例
[ceph: root@host01 /]# ceph orch ls
[ceph: root@host01 /]# ceph orch lsCopy to Clipboard Copied! Toggle word wrap Toggle overflow ホスト、デーモン、およびプロセスをリスト表示します。
構文
ceph orch ps --daemon_type=DAEMON_NAME
ceph orch ps --daemon_type=DAEMON_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph orch ps --daemon_type=mds
[ceph: root@host01 /]# ceph orch ps --daemon_type=mdsCopy to Clipboard Copied! Toggle word wrap Toggle overflow
9.4. Ceph Orchestrator を使用した MDS サービスの削除
ceph orch rm コマンドを使用してサービスを削除できます。または、ファイルシステムおよび関連するプールを削除できます。
前提条件
- 稼働中の Red Hat Ceph Storage クラスターがある。
- すべてのノードへの root レベルのアクセス。
- ホストがクラスターに追加されている。
- ホストにデプロイされた MDS デーモン 1 つ以上。
手順
- MDS デーモンをクラスターから削除する方法は 2 つあります。
方法 1
CephFS ボリューム、関連するプール、およびサービスを削除します。
Cephadm シェルにログインします。
例
cephadm shell
[root@host01 ~]# cephadm shellCopy to Clipboard Copied! Toggle word wrap Toggle overflow 設定パラメーター
mon_allow_pool_deleteをtrueに設定します。例
[ceph: root@host01 /]# ceph config set mon mon_allow_pool_delete true
[ceph: root@host01 /]# ceph config set mon mon_allow_pool_delete trueCopy to Clipboard Copied! Toggle word wrap Toggle overflow ファイルシステムを削除します。
構文
ceph fs volume rm FILESYSTEM_NAME --yes-i-really-mean-it
ceph fs volume rm FILESYSTEM_NAME --yes-i-really-mean-itCopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph fs volume rm cephfs-new --yes-i-really-mean-it
[ceph: root@host01 /]# ceph fs volume rm cephfs-new --yes-i-really-mean-itCopy to Clipboard Copied! Toggle word wrap Toggle overflow このコマンドは、ファイルシステム、そのデータ、メタデータプールを削除します。また、有効な
ceph-mgrOrchestrator モジュールを使用して MDS を削除しようとします。
方法 2
ceph orch rmコマンドを使用して、クラスター全体から MDS サービスを削除します。サービスをリスト表示します。
例
[ceph: root@host01 /]# ceph orch ls
[ceph: root@host01 /]# ceph orch lsCopy to Clipboard Copied! Toggle word wrap Toggle overflow サービスの削除
構文
ceph orch rm SERVICE_NAME
ceph orch rm SERVICE_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph orch rm mds.test
[ceph: root@host01 /]# ceph orch rm mds.testCopy to Clipboard Copied! Toggle word wrap Toggle overflow
検証
ホスト、デーモン、およびプロセスをリスト表示します。
構文
ceph orch ps
ceph orch psCopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph orch ps
[ceph: root@host01 /]# ceph orch psCopy to Clipboard Copied! Toggle word wrap Toggle overflow
第10章 Ceph Orchestrator を使用した Ceph オブジェクトゲートウェイの管理
ストレージ管理者は、コマンドラインインターフェイスまたはサービス仕様を使用して、Ceph オブジェクトゲートウェイをデプロイできます。
また、マルチサイトオブジェクトゲートウェイを設定し、Ceph Orchestrator を使用して Ceph オブジェクトゲートウェイを削除することもできます。
Cephadm は、Ceph オブジェクトゲートウェイを、単一クラスターデプロイメントを管理するデーモンのコレクションまたはマルチサイトデプロイメントの特定のレルムおよびゾーンを管理するデーモンのコレクションとしてデプロイします。
Cephadm では、オブジェクトゲートウェイデーモンは、ceph.conf やコマンドラインではなく、モニター設定データベースを使用して設定されます。この設定が client.rgw セクションにない場合は、オブジェクトゲートウェイデーモンがデフォルト設定で起動し、ポート 80 にバインドします。
.default.rgw.buckets.index プールは、Ceph Object Gateway でバケットが作成された後にのみ作成されます。一方、データはバケットにアップロードされた後に .default.rgw.buckets.data プールが作成されます。
本セクションでは、以下の管理タスクを説明します。
10.1. 前提条件
- 稼働中の Red Hat Ceph Storage クラスターがある。
- すべてのノードへの root レベルのアクセス。
- ホストがクラスターに追加されている。
- すべてのマネージャー、モニター、および OSD がストレージクラスターにデプロイされます。
10.2. コマンドラインインターフェイスを使用した Ceph オブジェクトゲートウェイのデプロイ
Ceph Orchestrator を使用すると、コマンドラインインターフェイスで ceph orch コマンドを使用して Ceph オブジェクトゲートウェイをデプロイできます。
前提条件
- 稼働中の Red Hat Ceph Storage クラスターがある。
- すべてのノードへの root レベルのアクセス。
- ホストがクラスターに追加されている。
- すべてのマネージャー、モニター、および OSD デーモンがデプロイされている。
手順
Cephadm シェルにログインします。
例
cephadm shell
[root@host01 ~]# cephadm shellCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Ceph オブジェクトゲートウェイデーモンは、以下の 3 つの方法でデプロイできます。
方法 1
レルム、ゾーングループ、ゾーンを作成し、ホスト名で配置仕様を使用します。
レルムを作成します。
構文
radosgw-admin realm create --rgw-realm=REALM_NAME --default
radosgw-admin realm create --rgw-realm=REALM_NAME --defaultCopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# radosgw-admin realm create --rgw-realm=test_realm --default
[ceph: root@host01 /]# radosgw-admin realm create --rgw-realm=test_realm --defaultCopy to Clipboard Copied! Toggle word wrap Toggle overflow ゾーングループを作成します。
構文
radosgw-admin zonegroup create --rgw-zonegroup=ZONE_GROUP_NAME --master --default
radosgw-admin zonegroup create --rgw-zonegroup=ZONE_GROUP_NAME --master --defaultCopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# radosgw-admin zonegroup create --rgw-zonegroup=default --master --default
[ceph: root@host01 /]# radosgw-admin zonegroup create --rgw-zonegroup=default --master --defaultCopy to Clipboard Copied! Toggle word wrap Toggle overflow ゾーンを作成します。
構文
radosgw-admin zone create --rgw-zonegroup=ZONE_GROUP_NAME --rgw-zone=ZONE_NAME --master --default
radosgw-admin zone create --rgw-zonegroup=ZONE_GROUP_NAME --rgw-zone=ZONE_NAME --master --defaultCopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# radosgw-admin zone create --rgw-zonegroup=default --rgw-zone=test_zone --master --default
[ceph: root@host01 /]# radosgw-admin zone create --rgw-zonegroup=default --rgw-zone=test_zone --master --defaultCopy to Clipboard Copied! Toggle word wrap Toggle overflow 変更をコミットします。
構文
radosgw-admin period update --rgw-realm=REALM_NAME --commit
radosgw-admin period update --rgw-realm=REALM_NAME --commitCopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# radosgw-admin period update --rgw-realm=test_realm --commit
[ceph: root@host01 /]# radosgw-admin period update --rgw-realm=test_realm --commitCopy to Clipboard Copied! Toggle word wrap Toggle overflow ceph orch applyコマンドを実行します。構文
ceph orch apply rgw NAME [--realm=REALM_NAME] [--zone=ZONE_NAME] --placement="NUMBER_OF_DAEMONS [HOST_NAME_1 HOST_NAME_2]"
ceph orch apply rgw NAME [--realm=REALM_NAME] [--zone=ZONE_NAME] --placement="NUMBER_OF_DAEMONS [HOST_NAME_1 HOST_NAME_2]"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph orch apply rgw test --realm=test_realm --zone=test_zone --placement="2 host01 host02"
[ceph: root@host01 /]# ceph orch apply rgw test --realm=test_realm --zone=test_zone --placement="2 host01 host02"Copy to Clipboard Copied! Toggle word wrap Toggle overflow
方法 2
任意のサービス名を使用して、単一のクラスターデプロイメント用に 2 つの Ceph オブジェクトゲートウェイデーモンをデプロイします。
構文
ceph orch apply rgw SERVICE_NAME
ceph orch apply rgw SERVICE_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph orch apply rgw foo
[ceph: root@host01 /]# ceph orch apply rgw fooCopy to Clipboard Copied! Toggle word wrap Toggle overflow
方法 3
ホストのラベル付きセットで任意のサービス名を使用します。
構文
ceph orch host label add HOST_NAME_1 LABEL_NAME ceph orch host label add HOSTNAME_2 LABEL_NAME ceph orch apply rgw SERVICE_NAME --placement="label:LABEL_NAME count-per-host:NUMBER_OF_DAEMONS" --port=8000
ceph orch host label add HOST_NAME_1 LABEL_NAME ceph orch host label add HOSTNAME_2 LABEL_NAME ceph orch apply rgw SERVICE_NAME --placement="label:LABEL_NAME count-per-host:NUMBER_OF_DAEMONS" --port=8000Copy to Clipboard Copied! Toggle word wrap Toggle overflow 注記NUMBER_OF_DAEMONS は、各ホストにデプロイされる Ceph オブジェクトゲートウェイの数を制御します。追加のコストを発生させずに最高のパフォーマンスを実現するには、この値を 2 に設定します。
例
[ceph: root@host01 /]# ceph orch host label add host01 rgw # the 'rgw' label can be anything [ceph: root@host01 /]# ceph orch host label add host02 rgw [ceph: root@host01 /]# ceph orch apply rgw foo --placement="2 label:rgw" --port=8000
[ceph: root@host01 /]# ceph orch host label add host01 rgw # the 'rgw' label can be anything [ceph: root@host01 /]# ceph orch host label add host02 rgw [ceph: root@host01 /]# ceph orch apply rgw foo --placement="2 label:rgw" --port=8000Copy to Clipboard Copied! Toggle word wrap Toggle overflow
検証
サービスをリスト表示します。
例
[ceph: root@host01 /]# ceph orch ls
[ceph: root@host01 /]# ceph orch lsCopy to Clipboard Copied! Toggle word wrap Toggle overflow ホスト、デーモン、およびプロセスをリスト表示します。
構文
ceph orch ps --daemon_type=DAEMON_NAME
ceph orch ps --daemon_type=DAEMON_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph orch ps --daemon_type=rgw
[ceph: root@host01 /]# ceph orch ps --daemon_type=rgwCopy to Clipboard Copied! Toggle word wrap Toggle overflow
10.3. サービス仕様を使用した Ceph Object Gateway のデプロイ
Ceph Object Gateway は、デフォルトまたはカスタムのレルム、ゾーン、およびゾーングループいずれかのサービス仕様を使用してデプロイできます。
前提条件
- 稼働中の Red Hat Ceph Storage クラスターがある。
- ブートストラップされたホストへの root レベルのアクセス。
- ホストがクラスターに追加されている。
- すべてのマネージャー、モニター、および OSD デーモンがデプロイされます。
手順
root ユーザーとして、仕様ファイルを作成します。
例
touch radosgw.yml
[root@host01 ~]# touch radosgw.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow radosgw.ymlファイルを編集し、デフォルトレルム、ゾーン、およびゾーングループの以下の詳細を追加します。構文
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 注記NUMBER_OF_DAEMONS は、各ホストにデプロイされる Ceph Object Gateway の数を制御します。追加のコストを発生させずに最高のパフォーマンスを実現するには、この値を 2 に設定します。
例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow オプション: カスタムレルム、ゾーン、およびゾーングループの場合は、リソースを作成し、
radosgw.ymlファイルを作成します。カスタムレルム、ゾーン、およびゾーングループを作成します。
例
radosgw-admin realm create --rgw-realm=test_realm --default radosgw-admin zonegroup create --rgw-zonegroup=test_zonegroup --default radosgw-admin zone create --rgw-zonegroup=test_zonegroup --rgw-zone=test_zone --default radosgw-admin period update --rgw-realm=test_realm --commit
[root@host01 ~]# radosgw-admin realm create --rgw-realm=test_realm --default [root@host01 ~]# radosgw-admin zonegroup create --rgw-zonegroup=test_zonegroup --default [root@host01 ~]# radosgw-admin zone create --rgw-zonegroup=test_zonegroup --rgw-zone=test_zone --default [root@host01 ~]# radosgw-admin period update --rgw-realm=test_realm --commitCopy to Clipboard Copied! Toggle word wrap Toggle overflow 以下の内容で
radosgw.ymlファイルを作成します。例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
radosgw.ymlファイルをコンテナーのディレクトリーにマウントします。例
cephadm shell --mount radosgw.yml:/var/lib/ceph/radosgw/radosgw.yml
[root@host01 ~]# cephadm shell --mount radosgw.yml:/var/lib/ceph/radosgw/radosgw.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 注記シェルを終了するたびに、デーモンをデプロイする前にファイルをコンテナーにマウントする必要があります。
サービス仕様を使用して Ceph Object Gateway をデプロイします。
構文
ceph orch apply -i FILE_NAME.yml
ceph orch apply -i FILE_NAME.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph orch apply -i radosgw.yml
[ceph: root@host01 /]# ceph orch apply -i radosgw.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
検証
サービスをリスト表示します。
例
[ceph: root@host01 /]# ceph orch ls
[ceph: root@host01 /]# ceph orch lsCopy to Clipboard Copied! Toggle word wrap Toggle overflow ホスト、デーモン、およびプロセスをリスト表示します。
構文
ceph orch ps --daemon_type=DAEMON_NAME
ceph orch ps --daemon_type=DAEMON_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph orch ps --daemon_type=rgw
[ceph: root@host01 /]# ceph orch ps --daemon_type=rgwCopy to Clipboard Copied! Toggle word wrap Toggle overflow
10.4. Ceph Orchestrator を使用したマルチサイト Ceph Object Gateway のデプロイ
Ceph Orchestrator は、Ceph Object Gateway のマルチサイト設定オプションをサポートしています。
各オブジェクトゲートウェイを active-active ゾーン設定で機能するように設定すると、非プライマリーゾーンへの書き込みが可能になります。マルチサイト設定は、レルムと呼ばれるコンテナー内に保存されます。
レルムは、ゾーングループ、ゾーン、および期間を保存します。rgw デーモンは同期を処理し、個別の同期エージェントが不要になるため、アクティブ-アクティブ設定で動作します。
コマンドラインインターフェイス (CLI) を使用してマルチサイトゾーンをデプロイすることもできます。
以下の設定では、少なくとも 2 つの Red Hat Ceph Storage クラスターが地理的に別々の場所であることを前提としています。ただし、この設定は同じサイトでも機能します。
前提条件
- 少なくとも 2 つの実行中の Red Hat Ceph Storage クラスター
- 少なくとも 2 つの Ceph Object Gateway インスタンス (各 Red Hat Ceph Storage クラスターに 1 つ)。
- すべてのノードへの root レベルのアクセス。
- ノードまたはコンテナーがストレージクラスターに追加されます。
- すべての Ceph Manager、Monitor、および OSD デーモンがデプロイされます。
手順
cephadmシェルで、プライマリーゾーンを設定します。レルムを作成します。
構文
radosgw-admin realm create --rgw-realm=REALM_NAME --default
radosgw-admin realm create --rgw-realm=REALM_NAME --defaultCopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# radosgw-admin realm create --rgw-realm=test_realm --default
[ceph: root@host01 /]# radosgw-admin realm create --rgw-realm=test_realm --defaultCopy to Clipboard Copied! Toggle word wrap Toggle overflow ストレージクラスターに単一のレルムがある場合は、
--defaultフラグを指定します。プライマリーゾーングループを作成します。
構文
radosgw-admin zonegroup create --rgw-zonegroup=ZONE_GROUP_NAME --endpoints=http://RGW_PRIMARY_HOSTNAME:RGW_PRIMARY_PORT_NUMBER_1 --master --default
radosgw-admin zonegroup create --rgw-zonegroup=ZONE_GROUP_NAME --endpoints=http://RGW_PRIMARY_HOSTNAME:RGW_PRIMARY_PORT_NUMBER_1 --master --defaultCopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# radosgw-admin zonegroup create --rgw-zonegroup=us --endpoints=http://rgw1:80 --master --default
[ceph: root@host01 /]# radosgw-admin zonegroup create --rgw-zonegroup=us --endpoints=http://rgw1:80 --master --defaultCopy to Clipboard Copied! Toggle word wrap Toggle overflow プライマリーゾーンを作成します。
構文
radosgw-admin zone create --rgw-zonegroup=PRIMARY_ZONE_GROUP_NAME --rgw-zone=PRIMARY_ZONE_NAME --endpoints=http://RGW_PRIMARY_HOSTNAME:RGW_PRIMARY_PORT_NUMBER_1 --access-key=SYSTEM_ACCESS_KEY --secret=SYSTEM_SECRET_KEY
radosgw-admin zone create --rgw-zonegroup=PRIMARY_ZONE_GROUP_NAME --rgw-zone=PRIMARY_ZONE_NAME --endpoints=http://RGW_PRIMARY_HOSTNAME:RGW_PRIMARY_PORT_NUMBER_1 --access-key=SYSTEM_ACCESS_KEY --secret=SYSTEM_SECRET_KEYCopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# radosgw-admin zone create --rgw-zonegroup=us --rgw-zone=us-east-1 --endpoints=http://rgw1:80 --access-key=LIPEYZJLTWXRKXS9LPJC --secret-key=IsAje0AVDNXNw48LjMAimpCpI7VaxJYSnfD0FFKQ
[ceph: root@host01 /]# radosgw-admin zone create --rgw-zonegroup=us --rgw-zone=us-east-1 --endpoints=http://rgw1:80 --access-key=LIPEYZJLTWXRKXS9LPJC --secret-key=IsAje0AVDNXNw48LjMAimpCpI7VaxJYSnfD0FFKQCopy to Clipboard Copied! Toggle word wrap Toggle overflow 必要に応じて、デフォルトゾーン、ゾーングループ、および関連するプールを削除します。
重要デフォルトゾーンおよびゾーングループを使用してデータを保存する場合は、デフォルトゾーンとそのプールは削除しないでください。また、デフォルトのゾーングループを削除して、システムユーザーを削除します。
defaultゾーンおよびゾーングループの古いデータにアクセスするには、radosgw-adminコマンドで--rgw-zone defaultおよび--rgw-zonegroup defaultを使用します。例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow システムユーザーを作成します。
構文
radosgw-admin user create --uid=USER_NAME --display-name="USER_NAME" --access-key=SYSTEM_ACCESS_KEY --secret=SYSTEM_SECRET_KEY --system
radosgw-admin user create --uid=USER_NAME --display-name="USER_NAME" --access-key=SYSTEM_ACCESS_KEY --secret=SYSTEM_SECRET_KEY --systemCopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# radosgw-admin user create --uid=zone.user --display-name="Zone user" --system
[ceph: root@host01 /]# radosgw-admin user create --uid=zone.user --display-name="Zone user" --systemCopy to Clipboard Copied! Toggle word wrap Toggle overflow access_keyおよびsecret_keyを書き留めておきます。アクセスキーとシステムキーをプライマリーゾーンに追加します。
構文
radosgw-admin zone modify --rgw-zone=PRIMARY_ZONE_NAME --access-key=ACCESS_KEY --secret=SECRET_KEY
radosgw-admin zone modify --rgw-zone=PRIMARY_ZONE_NAME --access-key=ACCESS_KEY --secret=SECRET_KEYCopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# radosgw-admin zone modify --rgw-zone=us-east-1 --access-key=NE48APYCAODEPLKBCZVQ --secret=u24GHQWRE3yxxNBnFBzjM4jn14mFIckQ4EKL6LoW
[ceph: root@host01 /]# radosgw-admin zone modify --rgw-zone=us-east-1 --access-key=NE48APYCAODEPLKBCZVQ --secret=u24GHQWRE3yxxNBnFBzjM4jn14mFIckQ4EKL6LoWCopy to Clipboard Copied! Toggle word wrap Toggle overflow 変更をコミットします。
構文
radosgw-admin period update --commit
radosgw-admin period update --commitCopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# radosgw-admin period update --commit
[ceph: root@host01 /]# radosgw-admin period update --commitCopy to Clipboard Copied! Toggle word wrap Toggle overflow cephadmシェルの外部で、ストレージクラスターおよびプロセスのFSIDを取得します。例
systemctl list-units | grep ceph
[root@host01 ~]# systemctl list-units | grep cephCopy to Clipboard Copied! Toggle word wrap Toggle overflow Ceph Object Gateway デーモンを起動します。
構文
systemctl start ceph-FSID@DAEMON_NAME systemctl enable ceph-FSID@DAEMON_NAME
systemctl start ceph-FSID@DAEMON_NAME systemctl enable ceph-FSID@DAEMON_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
systemctl start ceph-62a081a6-88aa-11eb-a367-001a4a000672@rgw.test_realm.us-east-1.host01.ahdtsw.service systemctl enable ceph-62a081a6-88aa-11eb-a367-001a4a000672@rgw.test_realm.us-east-1.host01.ahdtsw.service
[root@host01 ~]# systemctl start ceph-62a081a6-88aa-11eb-a367-001a4a000672@rgw.test_realm.us-east-1.host01.ahdtsw.service [root@host01 ~]# systemctl enable ceph-62a081a6-88aa-11eb-a367-001a4a000672@rgw.test_realm.us-east-1.host01.ahdtsw.serviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow
Cephadm シェルで、セカンダリーゾーンを設定します。
ホストからプライマリーレルム設定をプルします。
構文
radosgw-admin realm pull --rgw-realm=PRIMARY_REALM --url=URL_TO_PRIMARY_ZONE_GATEWAY --access-key=ACCESS_KEY --secret-key=SECRET_KEY --default
radosgw-admin realm pull --rgw-realm=PRIMARY_REALM --url=URL_TO_PRIMARY_ZONE_GATEWAY --access-key=ACCESS_KEY --secret-key=SECRET_KEY --defaultCopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host04 /]# radosgw-admin realm pull --rgw-realm=test_realm --url=http://10.74.249.26:80 --access-key=LIPEYZJLTWXRKXS9LPJC --secret-key=IsAje0AVDNXNw48LjMAimpCpI7VaxJYSnfD0FFKQ --default
[ceph: root@host04 /]# radosgw-admin realm pull --rgw-realm=test_realm --url=http://10.74.249.26:80 --access-key=LIPEYZJLTWXRKXS9LPJC --secret-key=IsAje0AVDNXNw48LjMAimpCpI7VaxJYSnfD0FFKQ --defaultCopy to Clipboard Copied! Toggle word wrap Toggle overflow ホストからプライマリー期間設定をプルします。
構文
radosgw-admin period pull --url=URL_TO_PRIMARY_ZONE_GATEWAY --access-key=ACCESS_KEY --secret-key=SECRET_KEY
radosgw-admin period pull --url=URL_TO_PRIMARY_ZONE_GATEWAY --access-key=ACCESS_KEY --secret-key=SECRET_KEYCopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host04 /]# radosgw-admin period pull --url=http://10.74.249.26:80 --access-key=LIPEYZJLTWXRKXS9LPJC --secret-key=IsAje0AVDNXNw48LjMAimpCpI7VaxJYSnfD0FFKQ
[ceph: root@host04 /]# radosgw-admin period pull --url=http://10.74.249.26:80 --access-key=LIPEYZJLTWXRKXS9LPJC --secret-key=IsAje0AVDNXNw48LjMAimpCpI7VaxJYSnfD0FFKQCopy to Clipboard Copied! Toggle word wrap Toggle overflow セカンダリーゾーンを設定します。
構文
radosgw-admin zone create --rgw-zonegroup=ZONE_GROUP_NAME \ --rgw-zone=SECONDARY_ZONE_NAME --endpoints=http://RGW_SECONDARY_HOSTNAME:RGW_PRIMARY_PORT_NUMBER_1 \ --access-key=SYSTEM_ACCESS_KEY --secret=SYSTEM_SECRET_KEY \ --endpoints=http://FQDN:80 \ [--read-only]radosgw-admin zone create --rgw-zonegroup=ZONE_GROUP_NAME \ --rgw-zone=SECONDARY_ZONE_NAME --endpoints=http://RGW_SECONDARY_HOSTNAME:RGW_PRIMARY_PORT_NUMBER_1 \ --access-key=SYSTEM_ACCESS_KEY --secret=SYSTEM_SECRET_KEY \ --endpoints=http://FQDN:80 \ [--read-only]Copy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host04 /]# radosgw-admin zone create --rgw-zonegroup=us --rgw-zone=us-east-2 --endpoints=http://rgw2:80 --access-key=LIPEYZJLTWXRKXS9LPJC --secret-key=IsAje0AVDNXNw48LjMAimpCpI7VaxJYSnfD0FFKQ
[ceph: root@host04 /]# radosgw-admin zone create --rgw-zonegroup=us --rgw-zone=us-east-2 --endpoints=http://rgw2:80 --access-key=LIPEYZJLTWXRKXS9LPJC --secret-key=IsAje0AVDNXNw48LjMAimpCpI7VaxJYSnfD0FFKQCopy to Clipboard Copied! Toggle word wrap Toggle overflow 必要に応じて、デフォルトゾーンを削除します。
重要デフォルトゾーンおよびゾーングループを使用してデータを保存する場合は、デフォルトゾーンとそのプールは削除しないでください。
defaultゾーンおよびゾーングループの古いデータにアクセスするには、radosgw-adminコマンドで--rgw-zone defaultおよび--rgw-zonegroup defaultを使用します。例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow Ceph 設定データベースを更新します。
構文
ceph config set SERVICE_NAME rgw_zone SECONDARY_ZONE_NAME
ceph config set SERVICE_NAME rgw_zone SECONDARY_ZONE_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host04 /]# ceph config set rgw rgw_zone us-east-2
[ceph: root@host04 /]# ceph config set rgw rgw_zone us-east-2Copy to Clipboard Copied! Toggle word wrap Toggle overflow 変更をコミットします。
構文
radosgw-admin period update --commit
radosgw-admin period update --commitCopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host04 /]# radosgw-admin period update --commit
[ceph: root@host04 /]# radosgw-admin period update --commitCopy to Clipboard Copied! Toggle word wrap Toggle overflow Cephadm シェルの外部で、ストレージクラスターおよびプロセスの FSID を取得します。
例
systemctl list-units | grep ceph
[root@host04 ~]# systemctl list-units | grep cephCopy to Clipboard Copied! Toggle word wrap Toggle overflow Ceph Object Gateway デーモンを起動します。
構文
systemctl start ceph-FSID@DAEMON_NAME systemctl enable ceph-FSID@DAEMON_NAME
systemctl start ceph-FSID@DAEMON_NAME systemctl enable ceph-FSID@DAEMON_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
systemctl start ceph-62a081a6-88aa-11eb-a367-001a4a000672@rgw.test_realm.us-east-2.host04.ahdtsw.service systemctl enable ceph-62a081a6-88aa-11eb-a367-001a4a000672@rgw.test_realm.us-east-2.host04.ahdtsw.service
[root@host04 ~]# systemctl start ceph-62a081a6-88aa-11eb-a367-001a4a000672@rgw.test_realm.us-east-2.host04.ahdtsw.service [root@host04 ~]# systemctl enable ceph-62a081a6-88aa-11eb-a367-001a4a000672@rgw.test_realm.us-east-2.host04.ahdtsw.serviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow
必要に応じて、配置仕様を使用して、マルチサイトの Ceph Object Gateway をデプロイします。
構文
ceph orch apply rgw NAME --realm=REALM_NAME --zone=PRIMARY_ZONE_NAME --placement="NUMBER_OF_DAEMONS HOST_NAME_1 HOST_NAME_2"
ceph orch apply rgw NAME --realm=REALM_NAME --zone=PRIMARY_ZONE_NAME --placement="NUMBER_OF_DAEMONS HOST_NAME_1 HOST_NAME_2"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host04 /]# ceph orch apply rgw east --realm=test_realm --zone=us-east-1 --placement="2 host01 host02"
[ceph: root@host04 /]# ceph orch apply rgw east --realm=test_realm --zone=us-east-1 --placement="2 host01 host02"Copy to Clipboard Copied! Toggle word wrap Toggle overflow
検証
同期のステータスを確認してデプロイメントを確認します。
例
[ceph: root@host04 /]# radosgw-admin sync status
[ceph: root@host04 /]# radosgw-admin sync statusCopy to Clipboard Copied! Toggle word wrap Toggle overflow
10.5. Ceph Orchestrator を使用した Ceph Object Gateway の削除
ceph orch rm コマンドを使用して、Ceph オブジェクトゲートウェイデーモンを削除できます。
前提条件
- 稼働中の Red Hat Ceph Storage クラスターがある。
- すべてのノードへの root レベルのアクセス。
- ホストがクラスターに追加されている。
- ホストにデプロイされた Ceph オブジェクトゲートウェイデーモンが少なくとも 1 つ含まれます。
手順
Cephadm シェルにログインします。
例
cephadm shell
[root@host01 ~]# cephadm shellCopy to Clipboard Copied! Toggle word wrap Toggle overflow サービスをリスト表示します。
例
[ceph: root@host01 /]# ceph orch ls
[ceph: root@host01 /]# ceph orch lsCopy to Clipboard Copied! Toggle word wrap Toggle overflow サービスを削除します。
構文
ceph orch rm SERVICE_NAME
ceph orch rm SERVICE_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph orch rm rgw.test_realm.test_zone_bb
[ceph: root@host01 /]# ceph orch rm rgw.test_realm.test_zone_bbCopy to Clipboard Copied! Toggle word wrap Toggle overflow
検証
ホスト、デーモン、およびプロセスをリスト表示します。
構文
ceph orch ps
ceph orch psCopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph orch ps
[ceph: root@host01 /]# ceph orch psCopy to Clipboard Copied! Toggle word wrap Toggle overflow
第11章 Ceph Orchestrator を使用した NFS-Ganesha ゲートウェイの管理 (利用制限あり)
ストレージ管理者は、バックエンドにて Cephadm と Orchestrator を使用して、NFS-Ganesha ゲートウェイをデプロイできます。Cephadm は、事前定義された RADOS プールおよびオプションの namespace を使用して NFS Ganesha をデプロイします。
この技術には、利用制限があります。詳細は、Deprecated functionality の章を参照してください。
Red Hat は、NFS v4.0+ プロトコルでのみ CephFS エクスポートをサポートします。
本セクションでは、以下の管理タスクを説明します。
- Ceph Orchestrator を使用した NFS-Ganesha クラスターの作成
- コマンドラインインターフェイスを使用した NFS-Ganesha ゲートウェイのデプロイ
- サービス仕様を使用した NFS-Ganesha ゲートウェイのデプロイ
- HA for CephFS/NFS サービスの実装
- Ceph Orchestrator を使用した NFS-Ganesha クラスターの更新
- Ceph Orchestrator を使用した NFS-Ganesha クラスター情報の表示
- Ceph Orchestrator を使用した NFS-Ganesha クラスターログの取得
- Ceph Orchestrator を使用したカスタム NFS-Ganesha の設定
- Ceph Orchestrator を使用したカスタム NFS-Ganesha 設定のリセット
- Ceph Orchestrator を使用した NFS-Ganesha クラスターの削除
- Ceph Orchestrator を使用した NFS Ganesha ゲートウェイの削除
11.1. 前提条件
- 稼働中の Red Hat Ceph Storage クラスターがある。
- すべてのノードへの root レベルのアクセス。
- ホストがクラスターに追加されている。
- すべてのマネージャー、モニター、および OSD デーモンがデプロイされている。
11.2. Ceph Orchestrator を使用した NFS-Ganesha クラスターの作成
Ceph Orchestrator の mgr/nfs モジュールを使用して、NFS-Ganesha クラスターを作成できます。このモジュールは、バックエンドで Cephadm を使用して NFS クラスターをデプロイします。
これにより、すべての NFS-Ganesha デーモンの共通のリカバリープール、clusterid に基づく新規ユーザー、および共通の NFS-Ganesha 設定 RADOS オブジェクトが作成されます。
デーモンごとに、新しいユーザーおよび共通の設定がプールに作成されます。すべてのクラスターにはクラスター名に関して異なる namespace がありますが、それらは同じリカバリープールを使用します。
前提条件
- 稼働中の Red Hat Ceph Storage クラスターがある。
- ホストがクラスターに追加されている。
- すべてのマネージャー、モニター、および OSD デーモンがデプロイされている。
手順
Cephadm シェルにログインします。
例
cephadm shell
[root@host01 ~]# cephadm shellCopy to Clipboard Copied! Toggle word wrap Toggle overflow mgr/nfsモジュールを有効にします。例
[ceph: root@host01 /]# ceph mgr module enable nfs
[ceph: root@host01 /]# ceph mgr module enable nfsCopy to Clipboard Copied! Toggle word wrap Toggle overflow クラスターを作成します。
構文
ceph nfs cluster create CLUSTER_NAME ["HOST_NAME_1 HOST_NAME_2 HOST_NAME_3"]
ceph nfs cluster create CLUSTER_NAME ["HOST_NAME_1 HOST_NAME_2 HOST_NAME_3"]Copy to Clipboard Copied! Toggle word wrap Toggle overflow CLUSTER_NAME は任意の文字列です。HOST _NAME_1 は、NFS-Ganesha デーモンをデプロイするためにホストを表す任意の文字列です。
例
[ceph: root@host01 /]# ceph nfs cluster create nfsganesha "host01 host02" NFS Cluster Created Successful
[ceph: root@host01 /]# ceph nfs cluster create nfsganesha "host01 host02" NFS Cluster Created SuccessfulCopy to Clipboard Copied! Toggle word wrap Toggle overflow これにより、
host01およびhost02の 1 つのデーモンと、NFS_Ganesha クラスターnfsganeshaが作成されます。
検証
クラスターの詳細をリスト表示します。
例
[ceph: root@host01 /]# ceph nfs cluster ls
[ceph: root@host01 /]# ceph nfs cluster lsCopy to Clipboard Copied! Toggle word wrap Toggle overflow NFS-Ganesha クラスター情報を表示します。
構文
ceph nfs cluster info CLUSTER_NAME
ceph nfs cluster info CLUSTER_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph nfs cluster info nfsganesha
[ceph: root@host01 /]# ceph nfs cluster info nfsganeshaCopy to Clipboard Copied! Toggle word wrap Toggle overflow
11.3. コマンドラインインターフェイスを使用した NFS-Ganesha ゲートウェイのデプロイ
バックエンドで Cephadm と Ceph Orchestrator を使用し、配置仕様を使用して NFS-Ganesha ゲートウェイをデプロイできます。この場合、RADOS プールを作成し、namespace を作成してから、ゲートウェイをデプロイする必要があります。
Red Hat は、NFS v4.0+ プロトコルでのみ CephFS エクスポートをサポートします。
前提条件
- 稼働中の Red Hat Ceph Storage クラスターがある。
- ホストがクラスターに追加されている。
- すべてのマネージャー、モニター、および OSD デーモンがデプロイされている。
手順
Cephadm シェルにログインします。
例
cephadm shell
[root@host01 ~]# cephadm shellCopy to Clipboard Copied! Toggle word wrap Toggle overflow RADOS プール namespace を作成し、アプリケーションを有効化します。RBD プールの場合、RBD を有効化します。
構文
ceph osd pool create POOL_NAME ceph osd pool application enable POOL_NAME freeform/rgw/rbd/cephfs/nfs rbd pool init -p POOL_NAME
ceph osd pool create POOL_NAME ceph osd pool application enable POOL_NAME freeform/rgw/rbd/cephfs/nfs rbd pool init -p POOL_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph osd pool create nfs-ganesha [ceph: root@host01 /]# ceph osd pool application enable nfs-ganesha nfs [ceph: root@host01 /]# rbd pool init -p nfs-ganesha
[ceph: root@host01 /]# ceph osd pool create nfs-ganesha [ceph: root@host01 /]# ceph osd pool application enable nfs-ganesha nfs [ceph: root@host01 /]# rbd pool init -p nfs-ganeshaCopy to Clipboard Copied! Toggle word wrap Toggle overflow コマンドラインインターフェイスで配置仕様を使用して NFS-Ganesha ゲートウェイをデプロイします。
構文
ceph orch apply nfs SERVICE_ID --placement="NUMBER_OF_DAEMONS HOST_NAME_1 HOST_NAME_2 HOST_NAME_3"
ceph orch apply nfs SERVICE_ID --placement="NUMBER_OF_DAEMONS HOST_NAME_1 HOST_NAME_2 HOST_NAME_3"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph orch apply nfs foo --placement="2 host01 host02"
[ceph: root@host01 /]# ceph orch apply nfs foo --placement="2 host01 host02"Copy to Clipboard Copied! Toggle word wrap Toggle overflow これにより、
host01およびhost02の 1 つのデーモンと、NFS-Ganesha クラスターnfsganeshaがデプロイされます。
検証
サービスをリスト表示します。
例
[ceph: root@host01 /]# ceph orch ls
[ceph: root@host01 /]# ceph orch lsCopy to Clipboard Copied! Toggle word wrap Toggle overflow ホスト、デーモン、およびプロセスをリスト表示します。
構文
ceph orch ps --daemon_type=DAEMON_NAME
ceph orch ps --daemon_type=DAEMON_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph orch ps --daemon_type=nfs
[ceph: root@host01 /]# ceph orch ps --daemon_type=nfsCopy to Clipboard Copied! Toggle word wrap Toggle overflow
11.4. サービス仕様を使用した NFS-Ganesha ゲートウェイのデプロイ
バックエンドで Cephadm と Ceph Orchestrator を使用し、サービス仕様を使用して NFS-Ganesha ゲートウェイをデプロイできます。この場合、RADOS プールを作成し、namespace を作成してから、ゲートウェイをデプロイする必要があります。
前提条件
- 稼働中の Red Hat Ceph Storage クラスターがある。
- ホストがクラスターに追加されている。
手順
nfs.yamlファイルを作成します。例
touch nfs.yaml
[root@host01 ~]# touch nfs.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow nfs.yamlファイルを編集し、以下の詳細を含めます。構文
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow YAML ファイルをコンテナー内のディレクトリーにマウントします。
例
cephadm shell --mount nfs.yaml:/var/lib/ceph/nfs.yaml
[root@host01 ~]# cephadm shell --mount nfs.yaml:/var/lib/ceph/nfs.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow RADOS プールと namespace を作成し、RBD を有効にします。
構文
ceph osd pool create POOL_NAME ceph osd pool application enable POOL_NAME rbd rbd pool init -p POOL_NAME
ceph osd pool create POOL_NAME ceph osd pool application enable POOL_NAME rbd rbd pool init -p POOL_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph osd pool create nfs-ganesha [ceph: root@host01 /]# ceph osd pool application enable nfs-ganesha rbd [ceph: root@host01 /]# rbd pool init -p nfs-ganesha
[ceph: root@host01 /]# ceph osd pool create nfs-ganesha [ceph: root@host01 /]# ceph osd pool application enable nfs-ganesha rbd [ceph: root@host01 /]# rbd pool init -p nfs-ganeshaCopy to Clipboard Copied! Toggle word wrap Toggle overflow そのディレクトリーに移動します。
例
[ceph: root@host01 /]# cd /var/lib/ceph/
[ceph: root@host01 /]# cd /var/lib/ceph/Copy to Clipboard Copied! Toggle word wrap Toggle overflow サービス仕様を使用して NFS-Ganesha ゲートウェイをデプロイします。
構文
ceph orch apply -i FILE_NAME.yaml
ceph orch apply -i FILE_NAME.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 ceph]# ceph orch apply -i nfs.yaml
[ceph: root@host01 ceph]# ceph orch apply -i nfs.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
検証
サービスをリスト表示します。
例
[ceph: root@host01 /]# ceph orch ls
[ceph: root@host01 /]# ceph orch lsCopy to Clipboard Copied! Toggle word wrap Toggle overflow ホスト、デーモン、およびプロセスをリスト表示します。
構文
ceph orch ps --daemon_type=DAEMON_NAME
ceph orch ps --daemon_type=DAEMON_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph orch ps --daemon_type=nfs
[ceph: root@host01 /]# ceph orch ps --daemon_type=nfsCopy to Clipboard Copied! Toggle word wrap Toggle overflow
11.5. HA for CephFS/NFS サービスの実装 (テクノロジープレビュー)
--ingress フラグを使用し、仮想 IP アドレスを指定することで、高可用性 (HA) フロントエンド、仮想 IP、およびロードバランサーを備えた NFS をデプロイできます。これにより、keepalived と haproxy の組み合わせがデプロイされ、NFS サービスに高可用性の NFS フロントエンドが提供されます。
--ingress フラグを指定してクラスターを作成すると、NFS サーバーの負荷分散と高可用性を提供するために、Ingress サービスが追加でデプロイされます。仮想 IP は、すべての NFS クライアントがマウントに使用できる既知の安定した NFS エンドポイントを提供するために使用されます。Ceph は、仮想 IP 上の NFS トラフィックを適切なバックエンド NFS サーバーにリダイレクトする詳細を処理し、失敗した場合に NFS サーバーを再デプロイします。
既存のサービスに Ingress サービスをデプロイすると、以下が提供されます。
- NFS サーバーへのアクセスに使用できる安定した仮想 IP。
- 複数の NFS ゲートウェイに負荷を分散します。
- ホストに障害が発生した場合のホスト間のフェイルオーバー。
HA for CephFS/NFS はテクノロジープレビュー機能のみになります。テクノロジープレビュー機能は、実稼働環境での Red Hat サービスレベルアグリーメント (SLA) ではサポートされておらず、機能的に完全ではない可能性があるため、Red Hat では実稼働環境での使用を推奨していません。テクノロジープレビュー機能は、最新の製品機能をいち早く提供して、開発段階で機能のテストを行いフィードバックを提供していただくことを目的としています。詳細は、Red Hat テクノロジープレビュー機能のサポート範囲 を参照してください。
ingress サービスが NFS クラスターの前にデプロイされると、バックエンドの NFS-ganesha サーバーは、クライアントの IP アドレスではなく、haproxy の IP アドレスを認識します。その結果、IP アドレスに基づいてクライアントアクセスを制限している場合、NFS エクスポートのアクセス制限は想定どおりに機能しません。
クライアントにサービスを提供しているアクティブな NFS サーバーがダウンした場合、クライアントの I/O は、アクティブな NFS サーバーの代替サーバーがオンラインになり、NFS クラスターが再びアクティブになるまで中断されます。
前提条件
- 稼働中の Red Hat Ceph Storage クラスターがある。
- ホストがクラスターに追加されている。
- すべてのマネージャー、モニター、および OSD デーモンがデプロイされている。
- NFS モジュールが有効になっていることを確認している。
手順
Cephadm シェルにログインします。
例
cephadm shell
[root@host01 ~]# cephadm shellCopy to Clipboard Copied! Toggle word wrap Toggle overflow --ingressフラグを使用して NFS クラスターを作成します。構文
ceph nfs cluster create CLUSTER_ID [PLACEMENT] [--port PORT_NUMBER] [--ingress --virtual-ip IP_ADDRESS/CIDR_PREFIX]
ceph nfs cluster create CLUSTER_ID [PLACEMENT] [--port PORT_NUMBER] [--ingress --virtual-ip IP_ADDRESS/CIDR_PREFIX]Copy to Clipboard Copied! Toggle word wrap Toggle overflow - CLUSTER_ID を一意の文字列に置き換えて、NFS Ganesha クラスターに名前を付けます。
- PLACEMENT を、デプロイする NFS サーバーの数と、NFS Ganesha デーモンコンテナーをデプロイするホスト (1 つまたは複数) に置き換えます。
-
--portPORT_NUMBER フラグを使用して、デフォルトのポート 2049 以外のポートに NFS をデプロイします。 -
--ingressフラグを--virtual-ipフラグと組み合わせると、高可用性フロントエンド (仮想 IP およびロードバランサー) を使用して NFS がデプロイされます。 --virtual-ipIP_ADDRESS を IP アドレスに置き換えて、すべてのクライアントが NFS エクスポートをマウントするために使用できる既知の安定した NFS エンドポイントを提供します。--virtual-ipには、CIDR 接頭辞長を含める必要があります。仮想 IP は通常、同じサブネット内に既存の IP を持つ最初に識別されたネットワークインターフェイスで設定されます。注記NFS サービスに割り当てるホストの数は、デプロイを要求するアクティブな NFS サーバーの数 (
placement: countパラメーターで指定) よりも大きくする必要があります。以下の例では、1 つのアクティブな NFS サーバーが要求され、2 つのホストが割り当てられます。例
[ceph: root@host01 /]# ceph nfs cluster create mycephnfs "1 host02 host03" --ingress --virtual-ip 10.10.128.75/22
[ceph: root@host01 /]# ceph nfs cluster create mycephnfs "1 host02 host03" --ingress --virtual-ip 10.10.128.75/22Copy to Clipboard Copied! Toggle word wrap Toggle overflow 注記NFS デーモンと Ingress サービスのデプロイメントは非同期であり、サービスが完全に開始される前にコマンドが返される場合があります。
サービスが正常に開始されたことを確認します。
構文
ceph orch ls --service_name=nfs.CLUSTER_ID ceph orch ls --service_name=ingress.nfs.CLUSTER_ID
ceph orch ls --service_name=nfs.CLUSTER_ID ceph orch ls --service_name=ingress.nfs.CLUSTER_IDCopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
検証
IP エンドポイント、個々の NFS デーモンの IP、および
ingressサービスの仮想 IP を表示します。構文
ceph nfs cluster info CLUSTER_ID
ceph nfs cluster info CLUSTER_IDCopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow ホストおよびプロセスをリスト表示します。
例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
11.6. スタンドアロン CephFS/NFS cluster for HA のアップグレード
ストレージ管理者は、既存の NFS サービスに ingress サービスをデプロイすることで、スタンドアロンストレージクラスターを高可用性 (HA) クラスターにアップグレードできます。
前提条件
- 既存の NFS サービスを備えた実行中の Red Hat Ceph Storage クラスター。
- ホストがクラスターに追加されている。
- すべてのマネージャー、モニター、および OSD デーモンがデプロイされている。
- NFS モジュールが有効になっていることを確認している。
手順
Cephadm シェルにログインします。
例
cephadm shell
[root@host01 ~]# cephadm shellCopy to Clipboard Copied! Toggle word wrap Toggle overflow 既存の NFS クラスターをリスト表示します。
例
[ceph: root@host01 /]# ceph nfs cluster ls mynfs
[ceph: root@host01 /]# ceph nfs cluster ls mynfsCopy to Clipboard Copied! Toggle word wrap Toggle overflow 注記スタンドアロン NFS クラスターが 1 つのノードに作成されている場合、HA 用に 2 つ以上のノードに増やす必要があります。NFS サービスを増やすには、
nfs.yamlファイルを編集し、同じポート番号で配置を増やします。NFS サービスに割り当てるホストの数は、デプロイを要求するアクティブな NFS サーバーの数 (
placement: countパラメーターで指定) よりも大きくする必要があります。構文
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow この例では、既存の NFS サービスがポート
12345で実行されており、同じポートを使用して追加のノードが NFS クラスターに追加されます。nfs.yamlサービス仕様の変更を適用して、2 ノード NFS サービスにアップグレードします。例
[ceph: root@host01 ceph]# ceph orch apply -i nfs.yaml
[ceph: root@host01 ceph]# ceph orch apply -i nfs.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 既存の NFS クラスター ID を使用して
ingress.yaml仕様ファイルを編集します。構文
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow Ingress サービスをデプロイします。
例
[ceph: root@host01 /]# ceph orch apply -i ingress.yaml
[ceph: root@host01 /]# ceph orch apply -i ingress.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 注記NFS デーモンと Ingress サービスのデプロイメントは非同期であり、サービスが完全に開始される前にコマンドが返される場合があります。
Ingress サービスが正常に開始されたことを確認します。
構文
ceph orch ls --service_name=ingress.nfs.CLUSTER_ID
ceph orch ls --service_name=ingress.nfs.CLUSTER_IDCopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph orch ls --service_name=ingress.nfs.mynfs NAME PORTS RUNNING REFRESHED AGE PLACEMENT ingress.nfs.mynfs 10.10.128.75:2049,9000 4/4 4m ago 22m count:2
[ceph: root@host01 /]# ceph orch ls --service_name=ingress.nfs.mynfs NAME PORTS RUNNING REFRESHED AGE PLACEMENT ingress.nfs.mynfs 10.10.128.75:2049,9000 4/4 4m ago 22m count:2Copy to Clipboard Copied! Toggle word wrap Toggle overflow
検証
IP エンドポイント、個々の NFS デーモンの IP、および
ingressサービスの仮想 IP を表示します。構文
ceph nfs cluster info CLUSTER_ID
ceph nfs cluster info CLUSTER_IDCopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow ホストおよびプロセスをリスト表示します。
例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
11.7. 仕様ファイルを使用した HA for CephFS/NFS のデプロイ
仕様ファイルを使用して HA for CephFS/NFS をデプロイするには、最初に NFS サービスをデプロイしてから、同じ NFS サービスに ingress をデプロイします。
前提条件
- 稼働中の Red Hat Ceph Storage クラスターがある。
- ホストがクラスターに追加されている。
- すべてのマネージャー、モニター、および OSD デーモンがデプロイされている。
- NFS モジュールが有効になっていることを確認している。
手順
Cephadm シェルにログインします。
例
cephadm shell
[root@host01 ~]# cephadm shellCopy to Clipboard Copied! Toggle word wrap Toggle overflow NFS モジュールが有効になっていることを確認します。
例
[ceph: root@host01 /]# ceph mgr module ls | more
[ceph: root@host01 /]# ceph mgr module ls | moreCopy to Clipboard Copied! Toggle word wrap Toggle overflow Cephadm シェルを終了し、
nfs.yamlファイルを作成します。例
touch nfs.yaml
[root@host01 ~]# touch nfs.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow nfs.yamlファイルを編集し、以下の詳細を含めます。構文
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 注記NFS サービスに割り当てるホストの数は、デプロイを要求するアクティブな NFS サーバーの数 (
placement: countパラメーターで指定) よりも大きくする必要があります。例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow この例では、サーバーは、host02 と host03 のデフォルトポート
2049ではなく、デフォルト以外のポート12345で実行されます。YAML ファイルをコンテナー内のディレクトリーにマウントします。
例
cephadm shell --mount nfs.yaml:/var/lib/ceph/nfs.yaml
[root@host01 ~]# cephadm shell --mount nfs.yaml:/var/lib/ceph/nfs.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow Cephadm シェルにログインし、ディレクトリーに移動します。
例
[ceph: root@host01 /]# cd /var/lib/ceph/
[ceph: root@host01 /]# cd /var/lib/ceph/Copy to Clipboard Copied! Toggle word wrap Toggle overflow サービス仕様を使用して NFS サービスをデプロイします。
構文
ceph orch apply -i FILE_NAME.yaml
ceph orch apply -i FILE_NAME.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 ceph]# ceph orch apply -i nfs.yaml
[ceph: root@host01 ceph]# ceph orch apply -i nfs.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 注記NFS サービスのデプロイメントは非同期で行われるため、サービスが完全に開始される前にコマンドが返ってくる可能性があります。
NFS サービスが正常に開始されたことを確認します。
構文
ceph orch ls --service_name=nfs.CLUSTER_ID
ceph orch ls --service_name=nfs.CLUSTER_IDCopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph orch ls --service_name=nfs.cephfsnfs NAME PORTS RUNNING REFRESHED AGE PLACEMENT nfs.cephfsnfs ?:12345 2/2 3m ago 13m host02;host03
[ceph: root@host01 /]# ceph orch ls --service_name=nfs.cephfsnfs NAME PORTS RUNNING REFRESHED AGE PLACEMENT nfs.cephfsnfs ?:12345 2/2 3m ago 13m host02;host03Copy to Clipboard Copied! Toggle word wrap Toggle overflow Cephadm シェルを終了し、
ingress.yamlファイルを作成します。例
touch ingress.yaml
[root@host01 ~]# touch ingress.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow ingress.yamlファイルを編集して、以下の詳細を含めます。構文
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 注記この例では、
placement: count: 2はkeepalivedおよびhaproxyサービスをランダムなノードにデプロイします。keepalivedとhaproxyをデプロイするノードを指定するには、placement: hostsオプションを使用します。例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow YAML ファイルをコンテナー内のディレクトリーにマウントします。
例
cephadm shell --mount ingress.yaml:/var/lib/ceph/ingress.yaml
[root@host01 ~]# cephadm shell --mount ingress.yaml:/var/lib/ceph/ingress.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow Cephadm シェルにログインし、ディレクトリーに移動します。
例
[ceph: root@host01 /]# cd /var/lib/ceph/
[ceph: root@host01 /]# cd /var/lib/ceph/Copy to Clipboard Copied! Toggle word wrap Toggle overflow サービス仕様を使用して
ingressサービスをデプロイします。構文
ceph orch apply -i FILE_NAME.yaml
ceph orch apply -i FILE_NAME.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 ceph]# ceph orch apply -i ingress.yaml
[ceph: root@host01 ceph]# ceph orch apply -i ingress.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow Ingress サービスが正常に開始されたことを確認します。
構文
ceph orch ls --service_name=ingress.nfs.CLUSTER_ID
ceph orch ls --service_name=ingress.nfs.CLUSTER_IDCopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph orch ls --service_name=ingress.nfs.cephfsnfs NAME PORTS RUNNING REFRESHED AGE PLACEMENT ingress.nfs.cephfsnfs 10.10.128.75:2049,9000 4/4 4m ago 22m count:2
[ceph: root@host01 /]# ceph orch ls --service_name=ingress.nfs.cephfsnfs NAME PORTS RUNNING REFRESHED AGE PLACEMENT ingress.nfs.cephfsnfs 10.10.128.75:2049,9000 4/4 4m ago 22m count:2Copy to Clipboard Copied! Toggle word wrap Toggle overflow
検証
IP エンドポイント、個々の NFS デーモンの IP、および
ingressサービスの仮想 IP を表示します。構文
ceph nfs cluster info CLUSTER_ID
ceph nfs cluster info CLUSTER_IDCopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow ホストおよびプロセスをリスト表示します。
例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
11.8. Ceph Orchestrator を使用した NFS-Ganesha クラスターの更新
バックエンドで Ceph Orchestrator と Cephadm を使用して、ホスト上のデーモンの配置を変更して、NFS-Ganesha クラスターを更新できます。
前提条件
- 稼働中の Red Hat Ceph Storage クラスターがある。
- ホストがクラスターに追加されている。
- すべてのマネージャー、モニター、および OSD デーモンがデプロイされている。
-
mgr/nfsモジュールを使用して作成された NFS-Ganesha クラスター。
手順
Cephadm シェルにログインします。
例
cephadm shell
[root@host01 ~]# cephadm shellCopy to Clipboard Copied! Toggle word wrap Toggle overflow クラスターを更新します。
構文
ceph orch apply nfs CLUSTER_NAME ["HOST_NAME_1,HOST_NAME_2,HOST_NAME_3"]
ceph orch apply nfs CLUSTER_NAME ["HOST_NAME_1,HOST_NAME_2,HOST_NAME_3"]Copy to Clipboard Copied! Toggle word wrap Toggle overflow CLUSTER_NAME は任意の文字列です。HOST _NAME_1 は、デプロイされた NFS-Ganesha デーモンをするためにホストを表す任意の文字列です。
例
[ceph: root@host01 /]# ceph orch apply nfs nfsganesha "host02"
[ceph: root@host01 /]# ceph orch apply nfs nfsganesha "host02"Copy to Clipboard Copied! Toggle word wrap Toggle overflow これにより、
host02上のnfsganeshaクラスターが更新されます。
検証
クラスターの詳細をリスト表示します。
例
[ceph: root@host01 /]# ceph nfs cluster ls
[ceph: root@host01 /]# ceph nfs cluster lsCopy to Clipboard Copied! Toggle word wrap Toggle overflow NFS-Ganesha クラスター情報を表示します。
構文
ceph nfs cluster info CLUSTER_NAME
ceph nfs cluster info CLUSTER_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph nfs cluster info nfsganesha
[ceph: root@host01 /]# ceph nfs cluster info nfsganeshaCopy to Clipboard Copied! Toggle word wrap Toggle overflow ホスト、デーモン、およびプロセスをリスト表示します。
構文
ceph orch ps --daemon_type=DAEMON_NAME
ceph orch ps --daemon_type=DAEMON_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph orch ps --daemon_type=nfs
[ceph: root@host01 /]# ceph orch ps --daemon_type=nfsCopy to Clipboard Copied! Toggle word wrap Toggle overflow
11.9. Ceph Orchestrator を使用した NFS-Ganesha クラスター情報の確認
Ceph Orchestrator を使用して、NFS-Ganesha クラスターの情報を確認できます。すべての NFS Ganesha クラスターや、ポート、IP アドレス、およびクラスターが作成されたホストの名前のある特定のクラスターに関する情報を取得できます。
前提条件
- 稼働中の Red Hat Ceph Storage クラスターがある。
- ホストがクラスターに追加されている。
- すべてのマネージャー、モニター、および OSD デーモンがデプロイされている。
-
mgr/nfsモジュールを使用して作成された NFS-Ganesha クラスター。
手順
Cephadm シェルにログインします。
例
cephadm shell
[root@host01 ~]# cephadm shellCopy to Clipboard Copied! Toggle word wrap Toggle overflow NFS-Ganesha クラスター情報を表示します。
構文
ceph nfs cluster info CLUSTER_NAME
ceph nfs cluster info CLUSTER_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
11.10. Ceph Orchestrator を使用した NFS-Ganesha clutser ログの取得
Ceph Orchestrator を使用すると、NFS-Ganesha クラスターログを取得できます。サービスがデプロイされているノードにいる必要があります。
前提条件
- 稼働中の Red Hat Ceph Storage クラスターがある。
- NFS がデプロイされたノードに Cephadm がインストールされている。
- すべてのノードへの root レベルのアクセス。
- ホストがクラスターに追加されている。
-
mgr/nfsモジュールを使用して作成された NFS-Ganesha クラスター。
手順
root ユーザーとして、ストレージクラスターの FSID を取得します。
例
cephadm ls
[root@host03 ~]# cephadm lsCopy to Clipboard Copied! Toggle word wrap Toggle overflow FSID とサービスの名前をコピーします。
ログを取得します。
構文
cephadm logs --fsid FSID --name SERVICE_NAME
cephadm logs --fsid FSID --name SERVICE_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
cephadm logs --fsid 499829b4-832f-11eb-8d6d-001a4a000635 --name nfs.foo.host03
[root@host03 ~]# cephadm logs --fsid 499829b4-832f-11eb-8d6d-001a4a000635 --name nfs.foo.host03Copy to Clipboard Copied! Toggle word wrap Toggle overflow
11.11. Ceph Orchestrator を使用したカスタム NFS-Ganesha 設定の設定
NFS-Ganesha クラスターはデフォルトの設定ブロックで定義されます。Ceph Orchestrator を使用すると、設定をカスタマイズでき、デフォルトの設定ブロックよりも優先されます。
前提条件
- 稼働中の Red Hat Ceph Storage クラスターがある。
- ホストがクラスターに追加されている。
- すべてのマネージャー、モニター、および OSD デーモンがデプロイされている。
-
mgr/nfsモジュールを使用して作成された NFS-Ganesha クラスター。
手順
Cephadm シェルにログインします。
例
cephadm shell
[root@host01 ~]# cephadm shellCopy to Clipboard Copied! Toggle word wrap Toggle overflow 以下は、NFS-Ganesha クラスターのデフォルト設定の例です。
例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow NFS-Ganesha クラスター設定をカスタマイズします。以下は、設定をカスタマイズする 2 つの例です。
ログレベルを変更します。
例
LOG { COMPONENTS { ALL = FULL_DEBUG; } }LOG { COMPONENTS { ALL = FULL_DEBUG; } }Copy to Clipboard Copied! Toggle word wrap Toggle overflow カスタムエクスポートブロックを追加します。
ユーザーを作成します。
注記FSAL ブロックで指定されたユーザーは、NFS-Ganesha デーモンが Ceph ク ラスターにアクセスするための適切な上限を設定する必要があります。
構文
ceph auth get-or-create client.USER_ID mon 'allow r' osd 'allow rw pool=.nfs namespace=NFS_CLUSTER_NAME, allow rw tag cephfs data=FS_NAME' mds 'allow rw path=EXPORT_PATH'
ceph auth get-or-create client.USER_ID mon 'allow r' osd 'allow rw pool=.nfs namespace=NFS_CLUSTER_NAME, allow rw tag cephfs data=FS_NAME' mds 'allow rw path=EXPORT_PATH'Copy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph auth get-or-create client.f64f341c-655d-11eb-8778-fa163e914bcc mon 'allow r' osd 'allow rw pool=.nfs namespace=nfs_cluster_name, allow rw tag cephfs data=fs_name' mds 'allow rw path=export_path'
[ceph: root@host01 /]# ceph auth get-or-create client.f64f341c-655d-11eb-8778-fa163e914bcc mon 'allow r' osd 'allow rw pool=.nfs namespace=nfs_cluster_name, allow rw tag cephfs data=fs_name' mds 'allow rw path=export_path'Copy to Clipboard Copied! Toggle word wrap Toggle overflow 以下のディレクトリーに移動します。
構文
cd /var/lib/ceph/DAEMON_PATH/
cd /var/lib/ceph/DAEMON_PATH/Copy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# cd /var/lib/ceph/nfs/
[ceph: root@host01 /]# cd /var/lib/ceph/nfs/Copy to Clipboard Copied! Toggle word wrap Toggle overflow nfsディレクトリーが存在しない場合は、パス上に作成します。新しい設定ファイルを作成します。
構文
touch PATH_TO_CONFIG_FILE
touch PATH_TO_CONFIG_FILECopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 nfs]# touch nfs-ganesha.conf
[ceph: root@host01 nfs]# touch nfs-ganesha.confCopy to Clipboard Copied! Toggle word wrap Toggle overflow カスタムエクスポートブロックを追加して設定ファイルを編集します。1 つのエクスポートを作成し、これは Ceph NFS エクスポートインターフェイスによって管理されます。
構文
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
新しい設定をクラスターに適用します。
構文
ceph nfs cluster config set CLUSTER_NAME -i PATH_TO_CONFIG_FILE
ceph nfs cluster config set CLUSTER_NAME -i PATH_TO_CONFIG_FILECopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 nfs]# ceph nfs cluster config set nfs-ganesha -i /var/lib/ceph/nfs/nfs-ganesha.conf
[ceph: root@host01 nfs]# ceph nfs cluster config set nfs-ganesha -i /var/lib/ceph/nfs/nfs-ganesha.confCopy to Clipboard Copied! Toggle word wrap Toggle overflow これにより、カスタム設定のサービスも再起動されます。
検証
サービスをリスト表示します。
例
[ceph: root@host01 /]# ceph orch ls
[ceph: root@host01 /]# ceph orch lsCopy to Clipboard Copied! Toggle word wrap Toggle overflow ホスト、デーモン、およびプロセスをリスト表示します。
構文
ceph orch ps --daemon_type=DAEMON_NAME
ceph orch ps --daemon_type=DAEMON_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph orch ps --daemon_type=nfs
[ceph: root@host01 /]# ceph orch ps --daemon_type=nfsCopy to Clipboard Copied! Toggle word wrap Toggle overflow カスタム設定を確認します。
構文
/bin/rados -p POOL_NAME -N CLUSTER_NAME get userconf-nfs.CLUSTER_NAME -
/bin/rados -p POOL_NAME -N CLUSTER_NAME get userconf-nfs.CLUSTER_NAME -Copy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# /bin/rados -p nfs-ganesha -N nfsganesha get userconf-nfs.nfsganesha -
[ceph: root@host01 /]# /bin/rados -p nfs-ganesha -N nfsganesha get userconf-nfs.nfsganesha -Copy to Clipboard Copied! Toggle word wrap Toggle overflow
11.12. Ceph Orchestrator を使用したカスタム NFS-Ganesha 設定のリセット
Ceph Orchestrator を使用すると、ユーザー定義の設定をデフォルト設定にリセットできます。
前提条件
- 稼働中の Red Hat Ceph Storage クラスターがある。
- ホストがクラスターに追加されている。
- すべてのマネージャー、モニター、および OSD デーモンがデプロイされている。
-
mgr/nfsモジュールを使用してデプロイされた NFS-Ganesha - カスタム NFS クラスターの設定がセットアップされている。
手順
Cephadm シェルにログインします。
例
cephadm shell
[root@host01 ~]# cephadm shellCopy to Clipboard Copied! Toggle word wrap Toggle overflow NFS_Ganesha 設定をリセットします。
構文
ceph nfs cluster config reset CLUSTER_NAME
ceph nfs cluster config reset CLUSTER_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph nfs cluster config reset nfs-cephfs
[ceph: root@host01 /]# ceph nfs cluster config reset nfs-cephfsCopy to Clipboard Copied! Toggle word wrap Toggle overflow
検証
サービスをリスト表示します。
例
[ceph: root@host01 /]# ceph orch ls
[ceph: root@host01 /]# ceph orch lsCopy to Clipboard Copied! Toggle word wrap Toggle overflow ホスト、デーモン、およびプロセスをリスト表示します。
構文
ceph orch ps --daemon_type=DAEMON_NAME
ceph orch ps --daemon_type=DAEMON_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph orch ps --daemon_type=nfs
[ceph: root@host01 /]# ceph orch ps --daemon_type=nfsCopy to Clipboard Copied! Toggle word wrap Toggle overflow カスタム設定が削除されていることを確認します。
構文
/bin/rados -p POOL_NAME -N CLUSTER_NAME get userconf-nfs.CLUSTER_NAME -
/bin/rados -p POOL_NAME -N CLUSTER_NAME get userconf-nfs.CLUSTER_NAME -Copy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# /bin/rados -p nfs-ganesha -N nfsganesha get userconf-nfs.nfsganesha -
[ceph: root@host01 /]# /bin/rados -p nfs-ganesha -N nfsganesha get userconf-nfs.nfsganesha -Copy to Clipboard Copied! Toggle word wrap Toggle overflow
11.13. Ceph Orchestrator を使用した NFS-Ganesha クラスターの削除
バックエンドで Cephadm と Ceph Orchestrator を使用すると、NFS-Ganesha クラスターを削除できます。
前提条件
- 稼働中の Red Hat Ceph Storage クラスターがある。
- ホストがクラスターに追加されている。
- すべてのマネージャー、モニター、および OSD デーモンがデプロイされている。
-
mgr/nfsモジュールを使用して作成された NFS-Ganesha クラスター。
手順
Cephadm シェルにログインします。
例
cephadm shell
[root@host01 ~]# cephadm shellCopy to Clipboard Copied! Toggle word wrap Toggle overflow クラスターを削除します。
構文
ceph nfs cluster rm CLUSTER_NAME
ceph nfs cluster rm CLUSTER_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow CLUSTER_NAME は任意の文字列です。
例
[ceph: root@host01 /]# ceph nfs cluster rm nfsganesha NFS Cluster Deleted Successfully
[ceph: root@host01 /]# ceph nfs cluster rm nfsganesha NFS Cluster Deleted SuccessfullyCopy to Clipboard Copied! Toggle word wrap Toggle overflow
検証
クラスターの詳細をリスト表示します。
例
[ceph: root@host01 /]# ceph nfs cluster ls
[ceph: root@host01 /]# ceph nfs cluster lsCopy to Clipboard Copied! Toggle word wrap Toggle overflow
11.14. Ceph Orchestrator を使用した NFS-Ganesha ゲートウェイの削除
ceph orch rm コマンドを使用して、NFS-Ganesha ゲートウェイを削除できます。
前提条件
- 稼働中の Red Hat Ceph Storage クラスターがある。
- すべてのノードへの root レベルのアクセス。
- ホストがクラスターに追加されている。
- ホストにデプロイされた 1 つ以上の NFS-Ganesha ゲートウェイ。
手順
Cephadm シェルにログインします。
例
cephadm shell
[root@host01 ~]# cephadm shellCopy to Clipboard Copied! Toggle word wrap Toggle overflow サービスをリスト表示します。
例
[ceph: root@host01 /]# ceph orch ls
[ceph: root@host01 /]# ceph orch lsCopy to Clipboard Copied! Toggle word wrap Toggle overflow サービスを削除します。
構文
ceph orch rm SERVICE_NAME
ceph orch rm SERVICE_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph orch rm nfs.foo
[ceph: root@host01 /]# ceph orch rm nfs.fooCopy to Clipboard Copied! Toggle word wrap Toggle overflow
検証
ホスト、デーモン、およびプロセスをリスト表示します。
構文
ceph orch ps
ceph orch psCopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph orch ps
[ceph: root@host01 /]# ceph orch psCopy to Clipboard Copied! Toggle word wrap Toggle overflow
第12章 Ceph Orchestrator を使用した iSCSI ゲートウェイの管理 (利用制限あり)
ストレージ管理者は、Ceph Orchestrator を使用して iSCSI ゲートウェイをデプロイできます。iSCSI ゲートウェイは、RADOS Block Device (RBD) イ メージを SCSI ディスクとしてエクスポートする高可用性 (HA) iSCSI ターゲットを提供します。
YAML ファイルのように、配置仕様またはサービス仕様のいずれかを使用して iSCSI ゲートウェイをデプロイできます。
この技術には、利用制限があります。詳細は、Deprecated functionality の章を参照してください。
本セクションでは、以下の管理タスクを説明します。
12.1. 前提条件
- 稼働中の Red Hat Ceph Storage クラスターがある。
- すべてのノードへの root レベルのアクセス。
- ホストがクラスターに追加されている。
- すべてのマネージャー、モニター、および OSD デーモンがデプロイされている。
12.2. コマンドラインインターフェイスを使用した iSCSI ゲートウェイのデプロイ
Ceph Orchestrator を使用すると、コマンドラインインターフェイスで ceph orch コマンドを使用して iSCSI ゲートウェイをデプロイできます。
前提条件
- 稼働中の Red Hat Ceph Storage クラスターがある。
- ホストがクラスターに追加されている。
- すべてのマネージャー、モニター、および OSD デーモンがデプロイされている。
手順
Cephadm シェルにログインします。
例
cephadm shell
[root@host01 ~]# cephadm shellCopy to Clipboard Copied! Toggle word wrap Toggle overflow プールを作成します。
構文
ceph osd pool create POOL_NAME
ceph osd pool create POOL_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph osd pool create mypool
[ceph: root@host01 /]# ceph osd pool create mypoolCopy to Clipboard Copied! Toggle word wrap Toggle overflow コマンドラインインターフェイスを使用して iSCSI ゲートウェイをデプロイします。
構文
ceph orch apply iscsi POOLNAME admin admin --placement="NUMBER_OF_DAEMONS HOST_NAME_1 HOST_NAME_2"
ceph orch apply iscsi POOLNAME admin admin --placement="NUMBER_OF_DAEMONS HOST_NAME_1 HOST_NAME_2"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph orch apply iscsi mypool admin admin --placement="1 host01"
[ceph: root@host01 /]# ceph orch apply iscsi mypool admin admin --placement="1 host01"Copy to Clipboard Copied! Toggle word wrap Toggle overflow
検証
サービスをリスト表示します。
例
[ceph: root@host01 /]# ceph orch ls
[ceph: root@host01 /]# ceph orch lsCopy to Clipboard Copied! Toggle word wrap Toggle overflow ホストおよびプロセスをリスト表示します。
構文
ceph orch ps --daemon_type=DAEMON_NAME
ceph orch ps --daemon_type=DAEMON_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph orch ps --daemon_type=iscsi
[ceph: root@host01 /]# ceph orch ps --daemon_type=iscsiCopy to Clipboard Copied! Toggle word wrap Toggle overflow
12.3. サービス仕様を使用した iSCSI ゲートウェイのデプロイ
Ceph Orchestrator を使用すると、サービス仕様を使用して iSCSI ゲートウェイをデプロイできます。
前提条件
- 稼働中の Red Hat Ceph Storage クラスターがある。
- ホストがクラスターに追加されている。
- すべてのマネージャー、モニター、および OSD デーモンがデプロイされている。
手順
iscsi.ymlファイルを作成します。例
touch iscsi.yml
[root@host01 ~]# touch iscsi.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow iscsi.ymlファイルを編集して、以下の詳細を含めます。構文
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow YAML ファイルをコンテナー内のディレクトリーにマウントします。
例
cephadm shell --mount iscsi.yaml:/var/lib/ceph/iscsi.yaml
[root@host01 ~]# cephadm shell --mount iscsi.yaml:/var/lib/ceph/iscsi.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 以下のディレクトリーに移動します。
構文
cd /var/lib/ceph/DAEMON_PATH/
cd /var/lib/ceph/DAEMON_PATH/Copy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# cd /var/lib/ceph/
[ceph: root@host01 /]# cd /var/lib/ceph/Copy to Clipboard Copied! Toggle word wrap Toggle overflow サービス仕様を使用して iSCSI ゲートウェイをデプロイします。
構文
ceph orch apply -i FILE_NAME.yml
ceph orch apply -i FILE_NAME.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 iscsi]# ceph orch apply -i iscsi.yml
[ceph: root@host01 iscsi]# ceph orch apply -i iscsi.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
検証
サービスをリスト表示します。
例
[ceph: root@host01 /]# ceph orch ls
[ceph: root@host01 /]# ceph orch lsCopy to Clipboard Copied! Toggle word wrap Toggle overflow ホスト、デーモン、およびプロセスをリスト表示します。
構文
ceph orch ps --daemon_type=DAEMON_NAME
ceph orch ps --daemon_type=DAEMON_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph orch ps --daemon_type=iscsi
[ceph: root@host01 /]# ceph orch ps --daemon_type=iscsiCopy to Clipboard Copied! Toggle word wrap Toggle overflow
12.4. Ceph Orchestrator を使用した iSCSI ゲートウェイの削除
ceph orch rm コマンドを使用して、iSCSI ゲートウェイデーモンを削除できます。
前提条件
- 稼働中の Red Hat Ceph Storage クラスターがある。
- すべてのノードへの root レベルのアクセス。
- ホストがクラスターに追加されている。
- ホストにデプロイされた 1 つ以上の iSCSI ゲートウェイデーモン。
手順
Cephadm シェルにログインします。
例
cephadm shell
[root@host01 ~]# cephadm shellCopy to Clipboard Copied! Toggle word wrap Toggle overflow サービスをリスト表示します。
例
[ceph: root@host01 /]# ceph orch ls
[ceph: root@host01 /]# ceph orch lsCopy to Clipboard Copied! Toggle word wrap Toggle overflow サービスの削除
構文
ceph orch rm SERVICE_NAME
ceph orch rm SERVICE_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph orch rm iscsi.iscsi
[ceph: root@host01 /]# ceph orch rm iscsi.iscsiCopy to Clipboard Copied! Toggle word wrap Toggle overflow
検証
ホスト、デーモン、およびプロセスをリスト表示します。
構文
ceph orch ps
ceph orch psCopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph orch ps
[ceph: root@host01 /]# ceph orch psCopy to Clipboard Copied! Toggle word wrap Toggle overflow
第13章 SNMP トラップの設定
ストレージ管理者は、Red Hat Ceph Storage クラスターに簡易ネットワーク管理プロトコル (SNMP) ゲートウェイをデプロイおよび設定して、Prometheus Alertmanager からアラートを受信し、SNMP トラップとしてそれらをクラスターにルーティングできます。
13.1. 簡易ネットワーク管理プロトコル
簡易ネットワーク管理プロトコル (SNMP) は、さまざまなハードウェアおよびソフトウェアプラットフォームにまたがる分散システムおよびデバイスを監視するためのもので、最も広く使用されているオープンプロトコルの 1 つです。Ceph の SNMP 統合は、Prometheus Alertmanager クラスターからゲートウェイデーモンへのアラートの転送に重点を置いています。ゲートウェイデーモンはアラートを SNMP 通知に変換し、これを指定された SNMP 管理プラットフォームに送信します。ゲートウェイデーモンは snmp_notifier_project からのものであり、認証と暗号化による SNMP V2c および V3 サポートを提供します。
Red Hat Ceph Storage SNMP ゲートウェイサービスは、デフォルトでゲートウェイの 1 つのインスタンスをデプロイします。配置情報を提供することで、これを増やすことができます。ただし、複数の SNMP ゲートウェイデーモンを有効にすると、SNMP 管理プラットフォームは同じイベントに対して複数の通知を受け取ります。
SNMP トラップはアラートメッセージであり、Prometheus Alertmanager はこれらのアラートを SNMP 通知機能に送信し、SNMP 通知機能は指定されたアラートのラベルでオブジェクト識別子 (OID) を探します。各 SNMP トラップには一意の ID があり、ステータスが更新された追加のトラップを特定の SNMP ポーラーに送信できます。SNMP は Ceph の健全性チェックにフックして、すべての健全性警告が特定の SNMP トラップを生成するようにします。
正しく動作し、デバイスステータスに関する情報をユーザーに転送して監視するために、SNMP はいくつかのコンポーネントに依存しています。SNMP を設定する 4 つの主要なコンポーネントがあります。
- SNMP マネージャー - SNMP マネージャーは、管理ステーションとも呼ばれ、ネットワーク監視プラットフォームを実行するコンピューターです。SNMP 対応デバイスをポーリングし、それらからデータを取得するロールを持つプラットフォーム。SNMP マネージャーは、エージェントにクエリーを実行し、エージェントからの応答を受信し、エージェントからの非同期イベントを確認します。
- SNMP エージェント - SNMP エージェントは、マネージドのシステムで実行されるプログラムであり、システムの MIB データベースが含まれています。これらは、帯域幅やディスク容量などのデータを収集して集約し、Management Information Base (MIB) に送信します。
- Management information base (MIB) - これらは SNMP エージェントに含まれるコンポーネントです。SNMP マネージャーはこれをデータベースとして使用し、エージェントに特定の情報へのアクセスを要求します。この情報は、ネットワーク管理システム (NMS) に必要です。NMS は、エージェントをポーリングしてこれらのファイルから情報を取得してから、それらをユーザーが見ることができるグラフやディスプレイに変換する処理を行います。MIB には、ネットワークデバイスによって決定される統計値と制御値が含まれています。
- SNMP デバイス
以下のバージョンの SNMP は互換性があり、ゲートウェイの実装でサポートされています。
- V2c - 認証なしでコミュニティー文字列を使用し、外部からの攻撃に対して脆弱です。
- V3 authNoPriv - 暗号化せずにユーザー名とパスワードの認証を使用します。
- V3 authPriv - SNMP 管理プラットフォームへの暗号化を伴うユーザー名とパスワードの認証を使用します。
SNMP トラップを使用する場合は、バージョン番号のセキュリティー設定が正しいことを確認して、SNMP に固有の脆弱性を最小限に抑え、許可されていないユーザーからネットワークを保護してください。
13.2. snmptrapd の設定
snmptrapd デーモンには、snmp-gateway サービスの作成時に指定する必要のある認証設定が含まれているため、snmp-gateway をデプロイする前に Simple Network Management Protocol (SNMP) ターゲットを設定することが重要です。
SNMP ゲートウェイ機能は、Prometheus スタックで生成されたアラートを SNMP 管理プラットフォームに公開する手段を提供します。snmptrapd ツールに基づいて、宛先への SNMP トラップを設定できます。このツールを使用すると、1 つ以上の SNMP トラップリスナーを確立できます。
設定には以下のパラメーターが重要となります。
-
engine-idは、デバイスの一意の識別子 (16 進数) であり、SNMPV3 ゲートウェイで必要とされています。Red Hat では、このパラメーターに `8000C53F_CLUSTER_FSID_WITHOUT_DASHES_` を使用することを推奨しています。 -
SNMP_COMMUNITY_FOR_SNMPV2 パラメーターである
snmp-communityは、SNMPV2c ゲートウェイに対してpublicです。 -
AUTH_PROTOCOL である
auth-protocolは、SNMPV3 ゲートウェイでは必須であり、デフォルトではSHAになります。 -
SNMPV3 ゲートウェイでは、PRIVACY_PROTOCOL である
privacy-protocolは必須となります。 - PRIVACY_PASSWORD は、暗号化された SNMPV3 ゲートウェイでは必須となります。
- SNMP_V3_AUTH_USER_NAME はユーザー名であり、SNMPV3 ゲートウェイでは必須となります。
- SNMP_V3_AUTH_PASSWORD はパスワードであり、SNMPV3 ゲートウェイでは必須となります。
前提条件
- 稼働中の Red Hat Ceph Storage クラスターがある。
- ノードへの root レベルのアクセス。
-
Red Hat Enterprise Linux システムに
firewalldをインストールします。
手順
SNMP 管理ホストで、SNMP パッケージをインストールします。
例
dnf install -y net-snmp-utils net-snmp
[root@host01 ~]# dnf install -y net-snmp-utils net-snmpCopy to Clipboard Copied! Toggle word wrap Toggle overflow SNMP のポート 162 を開いて、アラートを受信します。
例
firewall-cmd --zone=public --add-port=162/udp firewall-cmd --zone=public --add-port=162/udp --permanent
[root@host01 ~]# firewall-cmd --zone=public --add-port=162/udp [root@host01 ~]# firewall-cmd --zone=public --add-port=162/udp --permanentCopy to Clipboard Copied! Toggle word wrap Toggle overflow 管理情報ベース (MIB) を実装して、SNMP 通知を理解し、宛先ホストでの SNMP サポートを強化します。メインリポジトリーから raw ファイルをコピーします: https://github.com/ceph/ceph/blob/master/monitoring/snmp/CEPH-MIB.txt
例
curl -o CEPH_MIB.txt -L https://raw.githubusercontent.com/ceph/ceph/master/monitoring/snmp/CEPH-MIB.txt scp CEPH_MIB.txt root@host02:/usr/share/snmp/mibs
[root@host01 ~]# curl -o CEPH_MIB.txt -L https://raw.githubusercontent.com/ceph/ceph/master/monitoring/snmp/CEPH-MIB.txt [root@host01 ~]# scp CEPH_MIB.txt root@host02:/usr/share/snmp/mibsCopy to Clipboard Copied! Toggle word wrap Toggle overflow snmptrapdディレクトリーを作成します。例
mkdir /root/snmptrapd/
[root@host01 ~]# mkdir /root/snmptrapd/Copy to Clipboard Copied! Toggle word wrap Toggle overflow SNMP バージョンに基づいて、各プロトコルの
snmptrapdディレクトリーに設定ファイルを作成します。構文
format2 %V\n% Agent Address: %A \n Agent Hostname: %B \n Date: %H - %J - %K - %L - %M - %Y \n Enterprise OID: %N \n Trap Type: %W \n Trap Sub-Type: %q \n Community/Infosec Context: %P \n Uptime: %T \n Description: %W \n PDU Attribute/Value Pair Array:\n%v \n -------------- \n createuser -e 0x_ENGINE_ID_ SNMPV3_AUTH_USER_NAME AUTH_PROTOCOL SNMP_V3_AUTH_PASSWORD PRIVACY_PROTOCOL PRIVACY_PASSWORD authuser log,execute SNMP_V3_AUTH_USER_NAME authCommunity log,execute,net SNMP_COMMUNITY_FOR_SNMPV2
format2 %V\n% Agent Address: %A \n Agent Hostname: %B \n Date: %H - %J - %K - %L - %M - %Y \n Enterprise OID: %N \n Trap Type: %W \n Trap Sub-Type: %q \n Community/Infosec Context: %P \n Uptime: %T \n Description: %W \n PDU Attribute/Value Pair Array:\n%v \n -------------- \n createuser -e 0x_ENGINE_ID_ SNMPV3_AUTH_USER_NAME AUTH_PROTOCOL SNMP_V3_AUTH_PASSWORD PRIVACY_PROTOCOL PRIVACY_PASSWORD authuser log,execute SNMP_V3_AUTH_USER_NAME authCommunity log,execute,net SNMP_COMMUNITY_FOR_SNMPV2Copy to Clipboard Copied! Toggle word wrap Toggle overflow SNMPV2c の場合、以下のように
snmptrapd_public.confファイルを作成します。例
format2 %V\n% Agent Address: %A \n Agent Hostname: %B \n Date: %H - %J - %K - %L - %M - %Y \n Enterprise OID: %N \n Trap Type: %W \n Trap Sub-Type: %q \n Community/Infosec Context: %P \n Uptime: %T \n Description: %W \n PDU Attribute/Value Pair Array:\n%v \n -------------- \n authCommunity log,execute,net public
format2 %V\n% Agent Address: %A \n Agent Hostname: %B \n Date: %H - %J - %K - %L - %M - %Y \n Enterprise OID: %N \n Trap Type: %W \n Trap Sub-Type: %q \n Community/Infosec Context: %P \n Uptime: %T \n Description: %W \n PDU Attribute/Value Pair Array:\n%v \n -------------- \n authCommunity log,execute,net publicCopy to Clipboard Copied! Toggle word wrap Toggle overflow ここでの
public設定は、snmp-gatewayサービスをデプロイするときに使用されるsnmp_community設定と一致する必要があります。認証のみの SNMPV3 の場合は、以下のように
snmptrapd_auth.confファイルを作成します。例
format2 %V\n% Agent Address: %A \n Agent Hostname: %B \n Date: %H - %J - %K - %L - %M - %Y \n Enterprise OID: %N \n Trap Type: %W \n Trap Sub-Type: %q \n Community/Infosec Context: %P \n Uptime: %T \n Description: %W \n PDU Attribute/Value Pair Array:\n%v \n -------------- \n createuser -e 0x8000C53Ff64f341c655d11eb8778fa163e914bcc myuser SHA mypassword authuser log,execute myuser
format2 %V\n% Agent Address: %A \n Agent Hostname: %B \n Date: %H - %J - %K - %L - %M - %Y \n Enterprise OID: %N \n Trap Type: %W \n Trap Sub-Type: %q \n Community/Infosec Context: %P \n Uptime: %T \n Description: %W \n PDU Attribute/Value Pair Array:\n%v \n -------------- \n createuser -e 0x8000C53Ff64f341c655d11eb8778fa163e914bcc myuser SHA mypassword authuser log,execute myuserCopy to Clipboard Copied! Toggle word wrap Toggle overflow 0x8000C53Ff64f341c655d11eb8778fa163e914bcc文字列はengine_idで、myuserとmypasswordは認証情報です。パスワードのセキュリティーは、SHAアルゴリズムによって定義されます。これは、
snmp-gatewayデーモンをデプロイするための設定に対応します。例
snmp_v3_auth_username: myuser snmp_v3_auth_password: mypassword
snmp_v3_auth_username: myuser snmp_v3_auth_password: mypasswordCopy to Clipboard Copied! Toggle word wrap Toggle overflow 認証と暗号化を使用する SNMPV3 の場合、以下のように
snmptrapd_authpriv.confファイルを作成します。例
format2 %V\n% Agent Address: %A \n Agent Hostname: %B \n Date: %H - %J - %K - %L - %M - %Y \n Enterprise OID: %N \n Trap Type: %W \n Trap Sub-Type: %q \n Community/Infosec Context: %P \n Uptime: %T \n Description: %W \n PDU Attribute/Value Pair Array:\n%v \n -------------- \n createuser -e 0x8000C53Ff64f341c655d11eb8778fa163e914bcc myuser SHA mypassword DES mysecret authuser log,execute myuser
format2 %V\n% Agent Address: %A \n Agent Hostname: %B \n Date: %H - %J - %K - %L - %M - %Y \n Enterprise OID: %N \n Trap Type: %W \n Trap Sub-Type: %q \n Community/Infosec Context: %P \n Uptime: %T \n Description: %W \n PDU Attribute/Value Pair Array:\n%v \n -------------- \n createuser -e 0x8000C53Ff64f341c655d11eb8778fa163e914bcc myuser SHA mypassword DES mysecret authuser log,execute myuserCopy to Clipboard Copied! Toggle word wrap Toggle overflow 0x8000C53Ff64f341c655d11eb8778fa163e914bcc文字列はengine_idで、myuserとmypasswordは認証情報です。パスワードセキュリティーはSHAアルゴリズムで定義され、DESはプライバシー暗号化のタイプになります。これは、
snmp-gatewayデーモンをデプロイするための設定に対応します。例
snmp_v3_auth_username: myuser snmp_v3_auth_password: mypassword snmp_v3_priv_password: mysecret
snmp_v3_auth_username: myuser snmp_v3_auth_password: mypassword snmp_v3_priv_password: mysecretCopy to Clipboard Copied! Toggle word wrap Toggle overflow
SNMP 管理ホストでデーモンを実行します。
構文
/usr/sbin/snmptrapd -M /usr/share/snmp/mibs -m CEPH-MIB.txt -f -C -c /root/snmptrapd/CONFIGURATION_FILE -Of -Lo :162
/usr/sbin/snmptrapd -M /usr/share/snmp/mibs -m CEPH-MIB.txt -f -C -c /root/snmptrapd/CONFIGURATION_FILE -Of -Lo :162Copy to Clipboard Copied! Toggle word wrap Toggle overflow 例
/usr/sbin/snmptrapd -M /usr/share/snmp/mibs -m CEPH-MIB.txt -f -C -c /root/snmptrapd/snmptrapd_auth.conf -Of -Lo :162
[root@host01 ~]# /usr/sbin/snmptrapd -M /usr/share/snmp/mibs -m CEPH-MIB.txt -f -C -c /root/snmptrapd/snmptrapd_auth.conf -Of -Lo :162Copy to Clipboard Copied! Toggle word wrap Toggle overflow ストレージクラスターでアラートがトリガーされた場合は、SNMP 管理ホストで出力を監視できます。SNMP トラップと、MIB によってデコードされたトラップを確認します。
例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 上記の例では、Prometheus モジュールが無効になった後にアラートが生成されます。
13.3. SNMP ゲートウェイのデプロイ
SNMPV2c または SNMPV3 のいずれかを使用して、Simple Network Management Protocol (SNMP) ゲートウェイをデプロイできます。SNMP ゲートウェイをデプロイするには、次の 2 つの方法があります。
- 認証情報ファイルを作成する方法
- すべての詳細を含む 1 つのサービス設定 yaml ファイルを作成する方法。
以下のパラメーターを使用して、バージョンに基づいて SNMP ゲートウェイをデプロイできます。
-
service_typeはsnmp-gatewayです。 -
service_nameは、任意のユーザー定義の文字列です。 -
countは、ストレージクラスターにデプロイされる SNMP ゲートウェイの数です。 -
snmp_destinationパラメーターは、hostname:port の形式である必要があります。 -
engine-idは、デバイスの一意の識別子 (16 進数) であり、SNMPV3 ゲートウェイで必要とされています。Red Hat では、このパラメーターに `8000C53F_CLUSTER_FSID_WITHOUT_DASHES_` を使用することを推奨しています。 -
snmp_communityパラメーターは、SNMPV2c ゲートウェイに対してpublicです。 -
auth-protocolは SNMPV3 ゲートウェイでは必須であり、デフォルトではSHAになります。 -
privacy-protocolでは、認証と暗号化を備えた SNMPV3 ゲートウェイが必須となります。 -
デフォルトでは、ポートは
9464です。 -
シークレットとパスワードをオーケストレーターに渡すには、
-i FILENAMEを指定する必要があります。
SNMP ゲートウェイサービスがデプロイまたは更新されると、Prometheus Alertmanager 設定が自動的に更新され、objectidentifier を持つアラートが SNMP ゲートウェイデーモンに転送されてさらに処理されます。
前提条件
- 稼働中の Red Hat Ceph Storage クラスターがある。
- ノードへの root レベルのアクセス。
-
SNMP 管理ホストである宛先ホストで
snmptrapdを設定します。
手順
Cephadm シェルにログインします。
例
cephadm shell
[root@host01 ~]# cephadm shellCopy to Clipboard Copied! Toggle word wrap Toggle overflow SNMP ゲートウェイをデプロイする必要があるホストのラベルを作成します。
構文
ceph orch host label add HOSTNAME snmp-gateway
ceph orch host label add HOSTNAME snmp-gatewayCopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph orch host label add host02 snmp-gateway
[ceph: root@host01 /]# ceph orch host label add host02 snmp-gatewayCopy to Clipboard Copied! Toggle word wrap Toggle overflow SNMP のバージョンに応じて、認証情報ファイルまたはサービス設定ファイルを作成します。
SNMPV2c の場合、以下のようにファイルを作成します。
例
[ceph: root@host01 /]# cat snmp_creds.yml snmp_community: public
[ceph: root@host01 /]# cat snmp_creds.yml snmp_community: publicCopy to Clipboard Copied! Toggle word wrap Toggle overflow OR
例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 認証のみの SNMPV3 の場合は、以下のようにファイルを作成します。
例
[ceph: root@host01 /]# cat snmp_creds.yml snmp_v3_auth_username: myuser snmp_v3_auth_password: mypassword
[ceph: root@host01 /]# cat snmp_creds.yml snmp_v3_auth_username: myuser snmp_v3_auth_password: mypasswordCopy to Clipboard Copied! Toggle word wrap Toggle overflow OR
例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 認証と暗号化を使用する SNMPV3 の場合、以下のようにファイルを作成します。
例
[ceph: root@host01 /]# cat snmp_creds.yml snmp_v3_auth_username: myuser snmp_v3_auth_password: mypassword snmp_v3_priv_password: mysecret
[ceph: root@host01 /]# cat snmp_creds.yml snmp_v3_auth_username: myuser snmp_v3_auth_password: mypassword snmp_v3_priv_password: mysecretCopy to Clipboard Copied! Toggle word wrap Toggle overflow OR
例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
ceph orchコマンドを実行します。構文
ceph orch apply snmp-gateway --snmp_version=V2c_OR_V3 --destination=SNMP_DESTINATION [--port=PORT_NUMBER]\ [--engine-id=8000C53F_CLUSTER_FSID_WITHOUT_DASHES_] [--auth-protocol=MDS_OR_SHA] [--privacy_protocol=DES_OR_AES] -i FILENAME
ceph orch apply snmp-gateway --snmp_version=V2c_OR_V3 --destination=SNMP_DESTINATION [--port=PORT_NUMBER]\ [--engine-id=8000C53F_CLUSTER_FSID_WITHOUT_DASHES_] [--auth-protocol=MDS_OR_SHA] [--privacy_protocol=DES_OR_AES] -i FILENAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow OR
構文
ceph orch apply -i FILENAME.yml
ceph orch apply -i FILENAME.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow SNMPV2c の場合、
snmp_credsファイルを使用して、snmp-versionをV2cとして指定して、ceph orchコマンドを実行します。例
[ceph: root@host01 /]# ceph orch apply snmp-gateway --snmp-version=V2c --destination=192.168.122.73:162 --port=9464 -i snmp_creds.yml
[ceph: root@host01 /]# ceph orch apply snmp-gateway --snmp-version=V2c --destination=192.168.122.73:162 --port=9464 -i snmp_creds.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow SNMPV3 で認証のみの場合、
snmp_credsファイルを用いて、snmp-versionをV3およびengine-idとして指定して、ceph orchコマンドを実行します。例
[ceph: root@host01 /]# ceph orch apply snmp-gateway --snmp-version=V3 --engine-id=8000C53Ff64f341c655d11eb8778fa163e914bcc--destination=192.168.122.73:162 -i snmp_creds.yml
[ceph: root@host01 /]# ceph orch apply snmp-gateway --snmp-version=V3 --engine-id=8000C53Ff64f341c655d11eb8778fa163e914bcc--destination=192.168.122.73:162 -i snmp_creds.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 認証と暗号化を使用する SNMPV3 の場合、
snmp_credsファイルを使用して、snmp-versionをV3、privacy-protocol、およびengine-idとして指定して、ceph orchコマンドを実行します。例
[ceph: root@host01 /]# ceph orch apply snmp-gateway --snmp-version=V3 --engine-id=8000C53Ff64f341c655d11eb8778fa163e914bcc--destination=192.168.122.73:162 --privacy-protocol=AES -i snmp_creds.yml
[ceph: root@host01 /]# ceph orch apply snmp-gateway --snmp-version=V3 --engine-id=8000C53Ff64f341c655d11eb8778fa163e914bcc--destination=192.168.122.73:162 --privacy-protocol=AES -i snmp_creds.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow OR
すべての SNMP バージョンの場合、
snmp-gatewayファイルを使用して、以下のコマンドを実行します。例
[ceph: root@host01 /]# ceph orch apply -i snmp-gateway.yml
[ceph: root@host01 /]# ceph orch apply -i snmp-gateway.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
第14章 ノードの障害の処理
ストレージクラスター内でノード全体に障害が発生する可能性があります。ストレージ管理者が行うノード障害の処理は、ディスク障害の処理と同様です。ノードの障害として Ceph が 1 つのディスクに対してのみ配置グループ (PG) を復元する代わりに、そのノード内のディスクのすべての PG を復元する必要があります。Ceph は OSD がすべてダウンしていることを検出し、自己修復として知られる復元プロセスを自動的に開始します。
ノードの障害シナリオは 3 つあります。ノードを置き換える際の各シナリオにおけるハイレベルのワークフローを以下に示します。
ノードの置き換えには、失敗したノードから root ディスクおよび Ceph OSD ディスクを使用します。
- バックフィルを無効にします。
- ノードを置き換え、古いノードからディスクを取得し、それらを新規ノードに追加します。
- バックフィルを有効にします。
ノードを置き換え、オペレーティングシステムを再インストールし、障害が発生したノードから Ceph OSD ディスクを使用します。
- バックフィルを無効にします。
- Ceph 設定のバックアップを作成します。
- ノードを置き換え、障害が発生したノードから Ceph OSD ディスクを追加します。
- ディスクを JBOD として設定
- オペレーティングシステムをインストールします。
- Ceph の設定を復元します。
- Ceph Orchestrator コマンドを使用して新規ノードをストレージクラスターに追加します。Ceph デーモンが自動的に対応するノードに配置されます。
- バックフィルを有効にします。
ノードを置き換え、オペレーティングシステムを再インストールし、すべての新規 Ceph OSD ディスクを使用します。
- バックフィルを無効にします。
- 障害のあるノードのすべての OSD をストレージクラスターから削除します。
- Ceph 設定のバックアップを作成します。
ノードを置き換え、障害が発生したノードから Ceph OSD ディスクを追加します。
- ディスクを JBOD として設定
- オペレーティングシステムをインストールします。
- Ceph Orchestrator コマンドを使用して新規ノードをストレージクラスターに追加します。Ceph デーモンが自動的に対応するノードに配置されます。
- バックフィルを有効にします。
14.1. 前提条件
- 稼働中の Red Hat Ceph Storage クラスターがある。
- 障害のあるノード。
14.2. ノードの追加または削除前の考慮事項
Ceph の未処理の機能の 1 つは、ランタイム時に Ceph OSD ノードを追加または削除できる機能です。つまり、ストレージクラスターの容量のサイズを変更したり、ストレージクラスターを縮小せずにハードウェアを置き換えることができることを意味します。
ストレージクラスターの状態が劣化 (degraded) している間に Ceph クライアントを提供する機能にも運用上の利点があります。たとえば、残業や週末ではなく、通常の営業時間内にハードウェアを追加、削除、または交換できます。ただし、Ceph OSD ノードの追加および削除により、パフォーマンスに大きな影響を与える可能性があります。
Ceph OSD ノードを追加または削除する前に、ストレージクラスターのパフォーマンスへの影響を考慮してください。
- ストレージクラスターの容量を拡張または縮小するか、Ceph OSD ノードを追加または削除することで、ストレージクラスターのリバランスとしてバックフィルを予測します。このリバランス期間中に、Ceph は追加のリソースを使用します。これにより、ストレージクラスターのパフォーマンスに影響する可能性があります。
- 実稼働用 Ceph Storage クラスターでは、Ceph OSD ノードに特定のタイプのストレージストラテジーを容易にする特定のハードウェア設定があります。
- Ceph OSD ノードは CRUSH 階層の一部であるため、ノードの追加または削除のパフォーマンスへの影響は通常 CRUSH ルールセットを使用するプールのパフォーマンスに影響します。
14.3. パフォーマンスに関する考慮事項
以下の要素は通常、Ceph OSD ノードの追加時または削除時のストレージクラスターのパフォーマンスに影響します。
- Ceph クライアントは、Ceph への I/O インターフェイスの負荷を配置します。つまり、クライアントはプールに負荷を置きます。プールは CRUSH ルールセットにマップします。基礎となる CRUSH 階層により、Ceph は障害ドメインにデータを配置できます。基礎となる Ceph OSD ノードにクライアント負荷が高いプールが必要な場合、クライアントの負荷は復元時間に大きな影響を及ぼし、パフォーマンスが低下する可能性があります。書き込み操作には持続性のためにデータのレプリケーションが必要になるため、特に書き込み集約型クライアント負荷は、ストレージクラスターを回復するのに要する時間が長くなる可能性があります。
- 通常、追加または削除している容量は、クラスターの復元に影響を及ぼします。さらに、追加または削除するノードのストレージの密度も復元時間に影響を及ぼす可能性があります。たとえば、36 OSD を持つノードは、通常、12 OSD を持つノードよりも復元にかかる時間が長くなります。
-
ノードを削除する際には、十分な容量を確保して、
完全な比率またはほぼ完全比率に到達しないようにします。ストレージクラスターがフル比率になると、Ceph は書き込み動作を一時停止してデータの損失を防ぎます。 - Ceph OSD ノードは、少なくとも 1 つの Ceph CRUSH 階層にマッピングし、階層は少なくとも 1 つのプールにマップされます。CRUSH ルールセットを使用する各プールは、Ceph OSD ノードが追加または削除される際にパフォーマンスに影響が出ます。
-
レプリケーションプールは、データのディープコピーを複製するネットワーク帯域幅を使用する傾向がありますが、イレイジャーコーディングプールはより多くの CPU を使用して
k+mコーディングのチャンクを計算する傾向があります。データに存在するより多くのコピーで、ストレージクラスターを回復するのにかかる時間が長くなります。たとえば、大きなプールまたはk+mチャンクの数が大きい場合は、同じデータのコピー数が少ないレプリケーションプールよりも復元にかかる時間が長くなります。 - ドライブ、コントローラー、およびネットワークインターフェイスカードはすべて、復元時間に影響を与える可能性があるスループットの特性を持ちます。一般に、10 Gbps や SSD などのスループット特性が高いノードは、1Gbps や SATA ドライブなどのスループット特性が低いノードよりも迅速に回復します。
14.4. ノードの追加または削除に関する推奨事項
Red Hat は、ノード内の一度に 1 つの OSD を追加または削除して、次の OSD に進む前にストレージクラスターを回復させることを推奨します。これは、ストレージクラスターのパフォーマンスへの影響を最小限に抑えるのに役立ちます。ノードに障害が発生した場合は、一度に 1 つの OSD ではなく、ノード全体を一度に変更する必要がある場合があります。
OSD を削除するには、以下を実行します。
OSD を追加するには、以下を実行します。
Ceph OSD ノードを追加または削除する場合は、他の継続中のプロセスがストレージクラスターのパフォーマンスにも影響することを検討してください。クライアント I/O への影響を減らすために、Red Hat では以下を推奨します。
容量の計算
Ceph OSD ノードを削除する前に、ストレージクラスターがそのすべての OSD の内容を 完全な比率 に到達せずにバックフィルするようにしてください。フル比率 に達すると、ストレージクラスターは書き込み操作を拒否するようになります。
スクラビングを一時的に無効にする
スクラビングはストレージクラスターのデータの持続性を確保するために不可欠ですが、リソース集約型です。Ceph OSD ノードを追加または削除する前に、スクラビングおよびディープスクラビングを無効にして、現在のスクラビング操作を完了してから続行します。
ceph osd set noscrub ceph osd set nodeep-scrub
ceph osd set noscrub
ceph osd set nodeep-scrub
Ceph OSD ノードを追加または削除すると、ストレージクラスターが active+clean 状態に戻り、noscrub および nodeep-scrub の設定を解除します。
ceph osd unset noscrub ceph osd unset nodeep-scrub
ceph osd unset noscrub
ceph osd unset nodeep-scrubバックフィルと復元の制限
妥当なデータの永続性がある場合は、パフォーマンスが劣化 (degraded) した状態での動作に問題はありません。たとえば、osd_pool_default_size = 3 および osd_pool_default_min_size = 2 を使用してストレージクラスターを操作できます。可能な限り早い復元時間用にストレージクラスターを調整することができますが、これにより Ceph クライアントの I/O パフォーマンスが大幅に影響を受ける可能性があります。最大の Ceph クライアント I/O パフォーマンスを維持するには、バックフィルと復元の操作を制限し、その操作に長い時間がかかる可能性があります。
osd_max_backfills = 1 osd_recovery_max_active = 1 osd_recovery_op_priority = 1
osd_max_backfills = 1
osd_recovery_max_active = 1
osd_recovery_op_priority = 1
osd_recovery_sleep などの sleep パラメーターおよび delay パラメーターを設定することもできます。
配置グループの数を増やす
最後に、ストレージクラスターのサイズを拡張する場合は、配置グループの数を増やすことが必要となる場合があります。配置グループの数を拡張する必要がある場合、Red Hat はプレースメントグループの数を段階的に増やすことを推奨します。配置グループの数を大幅に増やすと、パフォーマンスが大幅に低下します。
14.5. Ceph OSD ノードの追加
Red Hat Ceph Storage クラスターの容量を拡張するには、OSD ノードを追加します。
前提条件
- 稼働中の Red Hat Ceph Storage クラスターがある。
- ネットワーク接続が割り当てられたプロビジョニングされたノード
手順
- ストレージクラスターの他のノードが、短縮ホスト名で新規ノードに到達できることを確認します。
スクラビングを一時的に無効にします。
例
[ceph: root@host01 /]# ceph osd set noscrub [ceph: root@host01 /]# ceph osd set nodeep-scrub
[ceph: root@host01 /]# ceph osd set noscrub [ceph: root@host01 /]# ceph osd set nodeep-scrubCopy to Clipboard Copied! Toggle word wrap Toggle overflow バックフィルおよび復元機能を制限します。
構文
ceph tell DAEMON_TYPE.* injectargs --OPTION_NAME VALUE [--OPTION_NAME VALUE]
ceph tell DAEMON_TYPE.* injectargs --OPTION_NAME VALUE [--OPTION_NAME VALUE]Copy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph tell osd.* injectargs --osd-max-backfills 1 --osd-recovery-max-active 1 --osd-recovery-op-priority 1
[ceph: root@host01 /]# ceph tell osd.* injectargs --osd-max-backfills 1 --osd-recovery-max-active 1 --osd-recovery-op-priority 1Copy to Clipboard Copied! Toggle word wrap Toggle overflow クラスターの SSH 公開鍵をフォルダーにデプロイメントします。
構文
ceph cephadm get-pub-key > ~/PATH
ceph cephadm get-pub-key > ~/PATHCopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph cephadm get-pub-key > ~/ceph.pub
[ceph: root@host01 /]# ceph cephadm get-pub-key > ~/ceph.pubCopy to Clipboard Copied! Toggle word wrap Toggle overflow ceph クラスターの SSH 公開鍵を、新たなホストの root ユーザーの
authorized_keysファイルにコピーします。構文
ssh-copy-id -f -i ~/PATH root@HOST_NAME_2
ssh-copy-id -f -i ~/PATH root@HOST_NAME_2Copy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ssh-copy-id -f -i ~/ceph.pub root@host02
[ceph: root@host01 /]# ssh-copy-id -f -i ~/ceph.pub root@host02Copy to Clipboard Copied! Toggle word wrap Toggle overflow 新規ノードを CRUSH マップに追加します。
構文
ceph orch host add NODE_NAME IP_ADDRESS
ceph orch host add NODE_NAME IP_ADDRESSCopy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph orch host add host02 10.10.128.70
[ceph: root@host01 /]# ceph orch host add host02 10.10.128.70Copy to Clipboard Copied! Toggle word wrap Toggle overflow ノードの各ディスクの OSD をストレージクラスターに追加します。
OSD ノードを Red Hat Ceph Storage クラスターに追加する場合、Red Hat は、1 度に 1 つの OSD デーモンを追加し、次の OSD に進む前にクラスターを active+clean 状態に復元できるようにすることを推奨します。
14.6. Ceph OSD ノードの削除
ストレージクラスターの容量を減らすには、OSD ノードを削除します。
Ceph OSD ノードを削除する前に、ストレージクラスターが 完全な比率 に到達せずにすべての OSD の内容をバックフィルするようにしてください。フル比率 に達すると、ストレージクラスターは書き込み操作を拒否するようになります。
前提条件
- 稼働中の Red Hat Ceph Storage クラスターがある。
- ストレージクラスター内のすべてのノードへの root レベルのアクセス。
手順
ストレージクラスターの容量を確認します。
構文
ceph df rados df ceph osd df
ceph df rados df ceph osd dfCopy to Clipboard Copied! Toggle word wrap Toggle overflow スクラビングを一時的に無効にします。
構文
ceph osd set noscrub ceph osd set nodeep-scrub
ceph osd set noscrub ceph osd set nodeep-scrubCopy to Clipboard Copied! Toggle word wrap Toggle overflow バックフィルおよび復元機能を制限します。
構文
ceph tell DAEMON_TYPE.* injectargs --OPTION_NAME VALUE [--OPTION_NAME VALUE]
ceph tell DAEMON_TYPE.* injectargs --OPTION_NAME VALUE [--OPTION_NAME VALUE]Copy to Clipboard Copied! Toggle word wrap Toggle overflow 例
[ceph: root@host01 /]# ceph tell osd.* injectargs --osd-max-backfills 1 --osd-recovery-max-active 1 --osd-recovery-op-priority 1
[ceph: root@host01 /]# ceph tell osd.* injectargs --osd-max-backfills 1 --osd-recovery-max-active 1 --osd-recovery-op-priority 1Copy to Clipboard Copied! Toggle word wrap Toggle overflow ノード上の各 OSD をストレージクラスターから削除します。
Ceph Orchestrator を使用した OSD デーモンの削除
重要ストレージクラスターから OSD ノードを削除する場合、Red Hat は、ノード内の一度に 1 つの OSD を削除してから、次の OSD を削除する前にクラスターが
active+clean状態に回復できるようにすることを推奨します。OSD を削除したら、ストレージクラスターが
ほぼ完全比率に達していないことを確認します。構文
ceph -s ceph df
ceph -s ceph dfCopy to Clipboard Copied! Toggle word wrap Toggle overflow - ノードのすべての OSD がストレージクラスターから削除されるまでこの手順を繰り返します。
すべての OSD が削除されたら、ホストを削除します。
14.7. ノードの障害のシミュレーション
ハードノードの障害をシミュレーションするには、ノードの電源をオフにし、オペレーティングシステムを再インストールします。
前提条件
- 正常かつ実行中の Red Hat Ceph Storage クラスター
- ストレージクラスター内のすべてのノードへの root レベルのアクセス。
手順
ストレージクラスターの容量を確認し、ノードの削除への影響を確認します。
例
[ceph: root@host01 /]# ceph df [ceph: root@host01 /]# rados df [ceph: root@host01 /]# ceph osd df
[ceph: root@host01 /]# ceph df [ceph: root@host01 /]# rados df [ceph: root@host01 /]# ceph osd dfCopy to Clipboard Copied! Toggle word wrap Toggle overflow 必要に応じて、復元およびバックフィルを無効にします。
例
[ceph: root@host01 /]# ceph osd set noout [ceph: root@host01 /]# ceph osd set noscrub [ceph: root@host01 /]# ceph osd set nodeep-scrub
[ceph: root@host01 /]# ceph osd set noout [ceph: root@host01 /]# ceph osd set noscrub [ceph: root@host01 /]# ceph osd set nodeep-scrubCopy to Clipboard Copied! Toggle word wrap Toggle overflow - ノードをシャットダウンします。
ホスト名を変更する場合は、CRUSH マップからノードを削除します。
例
[ceph: root@host01 /]# ceph osd crush rm host03
[ceph: root@host01 /]# ceph osd crush rm host03Copy to Clipboard Copied! Toggle word wrap Toggle overflow ストレージクラスターのステータスを確認します。
例
[ceph: root@host01 /]# ceph -s
[ceph: root@host01 /]# ceph -sCopy to Clipboard Copied! Toggle word wrap Toggle overflow - ノードにオペレーティングシステムを再インストールします。
新しいノードを追加します。
必要に応じて、復元およびバックフィルを有効にします。
例
[ceph: root@host01 /]# ceph osd unset noout [ceph: root@host01 /]# ceph osd unset noscrub [ceph: root@host01 /]# ceph osd unset nodeep-scrub
[ceph: root@host01 /]# ceph osd unset noout [ceph: root@host01 /]# ceph osd unset noscrub [ceph: root@host01 /]# ceph osd unset nodeep-scrubCopy to Clipboard Copied! Toggle word wrap Toggle overflow Ceph のヘルスを確認します。
例
[ceph: root@host01 /]# ceph -s
[ceph: root@host01 /]# ceph -sCopy to Clipboard Copied! Toggle word wrap Toggle overflow
第15章 データセンター障害の処理
ストレージ管理者は、データセンター障害を回避するために予防措置を取ることができます。これには、以下の予防措置があります。
- データセンターインフラストラクチャーの設定
- CRUSH マップ階層内に障害ドメインの設定
- ドメイン内での障害ノードの指定
15.1. 前提条件
- 正常かつ実行中の Red Hat Ceph Storage クラスター
- ストレージクラスター内のすべてのノードへの root レベルのアクセス。
15.2. データセンター障害の回避
データセンターインフラストラクチャーの設定
ストレッチクラスター内の各データセンターには、ローカル機能および依存関係を反映するために異なるストレージクラスターの設定を指定できます。データの保存に役立つデータセンター間でレプリケーションを設定します。1 つのデータセンターに障害が発生しても、ストレージクラスターの他のデータセンターにデータのコピーが含まれます。
CRUSH マップ階層内での障害ドメインの設定
障害またはフェイルオーバーのドメインは、ストレージクラスター内のドメインの冗長コピーです。アクティブなドメインが失敗すると、障害ドメインはアクティブドメインになります。
デフォルトで、CRUSH マップはフラット階層内のストレージクラスターのすべてのノードをリスト表示します。ただし、最善の結果を得るには、CRUSH マップ内に論理階層構造を作成します。階層は、各ノードが属するドメインと、障害のあるドメインを含む、ストレージクラスター内のそれらのドメイン間の関係を指定します。階層内の各ドメインの障害ドメインを定義すると、ストレージクラスターの信頼性が向上します。
複数のデータセンターを含むストレージクラスターを計画する際には、CRUSH マップ階層内にノードを配置するため、1 つのデータセンターが停止した場合には、残りのストレージクラスターは稼働し続けます。
ドメイン内での障害ノードの設計
ストレージクラスター内のデータに 3 方向のレプリケーションを使用する予定の場合には、障害ドメイン内のノードの場所を考慮してください。データセンター内で停止が発生した場合は、一部のデータが 1 つのコピーにのみ存在する可能性があります。このシナリオでは、2 つのオプションがあります。
- 標準設定で、データは読み取り専用ステータスのままにします。
- ライブは、停止期間に 1 つのコピーのみを行います。
標準設定では、ノード間でのデータ配置のランダム性のため、すべてのデータが影響を受けるわけではありませんが、一部のデータは 1 つのコピーしか持つことができず、ストレージクラスターは読み取り専用モードに戻ります。ただし、一部のデータが 1 つのコピーにのみ存在する場合、ストレージクラスターは読み取り専用モードに戻ります。
15.3. データセンター障害の処理
Red Hat Ceph Storage は、ストレッチクラスターでデータセンターのいずれかを失うなど、インフラストラクチャーに非常に致命的な障害がある場合があります。標準のオブジェクトストアのユースケースでは、3 つのデータセンターすべての設定は、それらの間にレプリケーションを設定して個別に実行できます。このシナリオでは、各データセンターのストレージクラスター設定は異なり、ローカルの機能と依存関係を反映する可能性があります。
配置階層の論理構造を考慮する必要があります。適切な CRUSH マップは使用でき、インフラストラクチャー内の障害ドメインの階層構造が反映されます。論理階層定義を使用すると、標準の階層定義を使用することではなく、ストレージクラスターの信頼性が向上します。障害ドメインは CRUSH マップで定義されます。デフォルトの CRUSH マップには、フラットな階層のすべてのノードが含まれます。ストレッチクラスターなどの 3 つのデータセンター環境では、ノードの配置は、1 つのデータセンターが停止できるように管理する必要がありますが、ストレージクラスターは稼働したままです。データに対して 3 方向レプリケーションを使用する場合に、ノードがある障害について検討してください。
以下の例では、作成されるマップは 6 つの OSD ノードを持つストレージクラスターの初期設定から派生しています。この例では、すべてのノードが 1 つのディスクを持つため、1 つの OSD しかありません。すべてのノードは、階層ツリーの標準 root であるデフォルトの root 下に分類されます。2 つの OSD に重みが割り当てられているため、これらの OSD は他の OSD よりも少ないデータチャンクを受け取ります。これらのノードは、最初の OSD ディスクよりも大きなディスクを持つ後から導入されました。これは、ノードのグループが失敗しているデータ配置には影響しません。
例
論理階層定義を使用してノードを同じデータセンターにグループ化すると、データの配置の成熟度を実行できます。root、datacenter、rack、row、および host の定義タイプにより、3 つのデータセンターのストッククラスターで障害ドメインを反映させることができます。
- ノード host01 および host02 はデータセンター 1 (DC1) にあります。
- ノード host03 および host05 はデータセンター 2 (DC2) にあります。
- ノード host04 および host06 はデータセンター 3 (DC3) にあります。
- すべてのデータセンターが同じ構造に属する (全 DC)
ホストのすべての OSD はホスト定義に属しているため、変更は必要ありません。その他のすべての割り当ては、ストレージクラスターの実行時に以下によって調整できます。
以下のコマンドで バケット 構造を定義します。
ceph osd crush add-bucket allDC root ceph osd crush add-bucket DC1 datacenter ceph osd crush add-bucket DC2 datacenter ceph osd crush add-bucket DC3 datacenter
ceph osd crush add-bucket allDC root ceph osd crush add-bucket DC1 datacenter ceph osd crush add-bucket DC2 datacenter ceph osd crush add-bucket DC3 datacenterCopy to Clipboard Copied! Toggle word wrap Toggle overflow CRUSH マップを変更して、ノードをこの構造内の適切な場所に移動します。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
この構造内で、新しいホストや新しいディスクを追加することもできます。OSD を階層の右側に配置することにより、CRUSH アルゴリズムが冗長な部分を構造内の異なる障害ドメインに配置するように変更されます。
上記の例は、以下のようになります。
例
上記のリストには、osd ツリーを表示することで、生成される CRUSH マップが表示されます。ホストがデータセンターにどのように属し、すべてのデータセンターが同じトップレベル構造に属しているかがわかりやすくなりましたが、場所が明確に区別されています。
マップに応じてデータを適切な場所に配置すると、正常なクラスター内でのみ適切に機能します。一部の OSD が利用できない状況では、置き違えが発生する可能性があります。この誤差は、可能な場合は自動的に修正されます。
関連情報
- 詳細は、Red Hat Ceph Storage の Storage Strategies Guide の CRUSH administration の章を参照してください。