このコンテンツは選択した言語では利用できません。
Infinispan Query Guide
Using the Infinispan Query Module in Red Hat JBoss Data Grid 6.4.1
Abstract
Chapter 1. Getting Started with Infinispan Query
1.1. Introduction
- Keyword, Range, Fuzzy, Wildcard, and Phrase queries
- Combining queries
- Sorting, filtering, and pagination of query results
1.2. Installing Querying for Red Hat JBoss Data Grid
Warning
infinispan-embedded-query.jar file. Do not include other versions of Hibernate Search and Lucene in the same deployment as infinispan-embedded-query. This action will cause classpath conflicts and result in unexpected behavior.
1.3. About Querying in Red Hat JBoss Data Grid
1.3.1. Hibernate Search and the Query Module
- Retrieve all red cars (an exact metadata match).
- Search for all books about a specific topic (full text search and relevance scoring).
1.3.2. Apache Lucene and the Query Module
- Apache Lucene is a document indexing tool and search engine. JBoss Data Grid uses Apache Lucene 3.6.
- JBoss Data Grid's Query Module is a toolkit based on Hibernate Search that reduces Java objects into a format similar to a document, which is able to be indexed and queried by Apache Lucene.
1.4. Indexing
1.4.1. Indexing with Transactional and Non-transactional Caches
- If the cache is transactional, index updates are applied using a listener after the commit process (after-commit listener). Index update failure does not cause the write to fail.
- If the cache is not transactional, index updates are applied using a listener that works after the event completes (post-event listener). Index update failure does not cause the write to fail.
1.5. Searching
org.infinispan.query.CacheQuery to get the required functionality from the Lucene-based API. The following code prepares a query against the indexed fields. Executing the code returns a list of Books.
Example 1.1. Using Infinispan Query to Create and Execute a Search
Chapter 2. Set Up and Configure Infinispan Query
2.1. Set Up Infinispan Query
2.1.1. Infinispan Query Dependencies in Library Mode
<dependency>
<groupId>org.infinispan</groupId>
<artifactId>infinispan-embedded-query</artifactId>
<version>${infinispan.version}</version>
</dependency>
<dependency>
<groupId>org.infinispan</groupId>
<artifactId>infinispan-embedded-query</artifactId>
<version>${infinispan.version}</version>
</dependency>infinispan-embedded-query.jar, infinispan-embedded.jar, jboss-transaction-api_1.1_spec-1.0.1.Final-redhat-2.jar files from the JBoss Data Grid distribution.
Warning
infinispan-embedded-query.jar file. Do not include other versions of Hibernate Search and Lucene in the same deployment as infinispan-embedded-query. This action will cause classpath conflicts and result in unexpected behavior.
2.2. Indexing Modes
2.2.1. Managing Indexes
- Each node can maintain an individual copy of the global index.
- The index can be shared across all nodes.
directory provider, which is used to store the index. The index can be stored, for example, as in-memory, on filesystem, or in distributed cache.
2.2.2. Managing the Index in Local Mode
indexLocalOnly option is meaningless in local mode.
2.2.3. Managing the Index in Replicated Mode
indexLocalOnly to false, so that each node will apply the required updates it receives from other nodes in addition to the updates started locally.
indexLocalOnly must be set to true so that each node will only apply the changes originated locally. While there is no risk of having an out of sync index, this causes contention on the node used for updating the index.
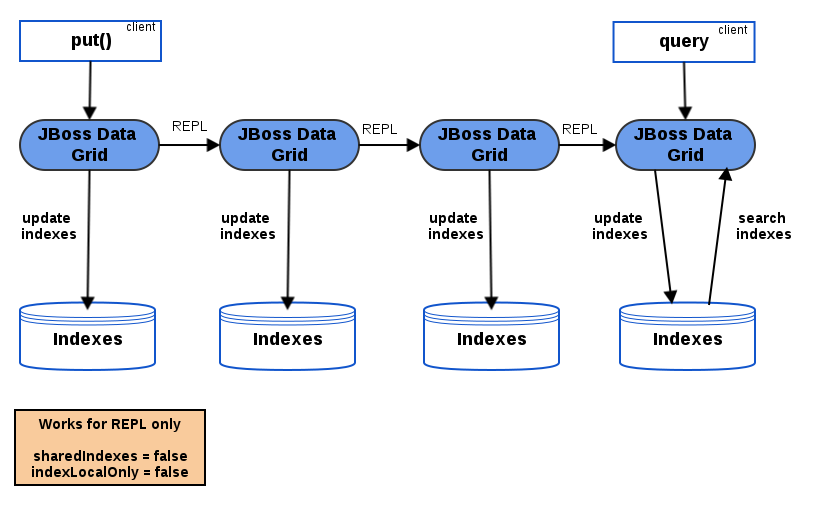
Figure 2.1. Replicated Cache Querying
2.2.4. Managing the Index in Distribution Mode
indexLocalOnly set to true.
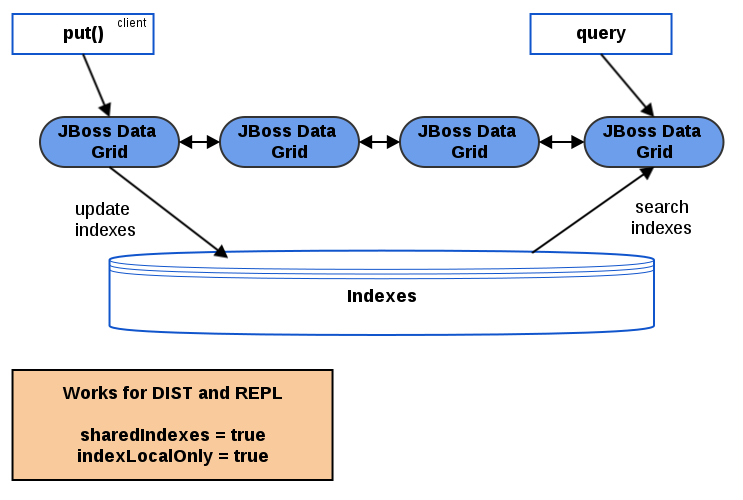
Figure 2.2. Querying with a Shared Index
2.2.5. Managing the Index in Invalidation Mode
2.3. Directory Providers
- RAM Directory Provider
- Filesystem Directory Provider
- Infinispan Directory Provider
2.3.1. RAM Directory Provider
- maintain its own index.
- use Lucene's in-memory or filesystem-based index directory.
2.3.2. Filesystem Directory Provider
Example 2.1. Disk-based Index Store
2.3.3. Infinispan Directory Provider
infinispan-directory module.
Note
infinispan-directory in the context of the Querying feature, not as a standalone feature.
infinispan-directory allows Lucene to store indexes within the distributed data grid. This allows the indexes to be distributed, stored in-memory, and optionally written to disk using the cache store for durability.
InfinispanIndexManager provides a default back end that sends all updates to master node which later applies the updates to the index. In case of master node failure, the update can be lost, therefore keeping the cache and index non-synchronized. Non-default back ends are not supported.
Example 2.2. Enable Shared Indexes
2.4. Configure Indexing
2.4.1. Configure Indexing in Library Mode Using XML
<indexing ... /> element to the cache configuration in the Infinispan core configuration file, and optionally pass additional properties in the embedded Lucene-based Query API engine. For example:
Example 2.3. Configuring Indexing Using XML
2.4.2. Configure Indexing Programmatically
Author, which is stored in the grid and made searchable via two properties, without annotating the class.
Example 2.4. Configure Indexing Programmatically
2.4.3. Configure the Index in Remote Client-Server Mode
- NONE
- LOCAL = indexLocalOnly="true"
- ALL = indexLocalOnly="false"
Example 2.5. Configuration in Remote-Client Server Mode
<indexing index="LOCAL">
<property name="default.directory_provider" value="ram" />
<!-- Additional configuration information here -->
</indexing>
<indexing index="LOCAL">
<property name="default.directory_provider" value="ram" />
<!-- Additional configuration information here -->
</indexing>2.4.4. Rebuilding the Index
- The definition of what is indexed in the types has changed.
- A parameter affecting how the index is defined, such as the
Analyserchanges. - The index is destroyed or corrupted, possibly due to a system administration error.
MassIndexer and start it as follows:
SearchManager searchManager = Search.getSearchManager(cache); searchManager.getMassIndexer().start();
SearchManager searchManager = Search.getSearchManager(cache);
searchManager.getMassIndexer().start();2.5. Tuning the Index
2.5.1. Near-Realtime Index Manager
<property name="default.indexmanager" value="near-real-time" />
<property name="default.indexmanager" value="near-real-time" />2.5.2. Tuning Infinispan Directory
- Data cache
- Metadata cache
- Locking cache
Example 2.6. Tuning the Infinispan Directory
2.5.3. Per-Index Configuration
default. prefix for each property. To specify different configuration for each index, replace default with the index name. By default, this is the full class name of the indexed object, however you can override the index name in the @Indexed annotation.
Chapter 3. Annotating Objects and Querying
@Indexed
@Field.
Example 3.1. Annotating Objects with @Field
Important
module.xml file. The custom annotations are not picked by the queries without the org.infinispan.query dependency and results in an error.
3.1. Registering a Transformer via Annotations
org.infinispan.query.Transformer.
org.infinispan.query.Transformer:
Example 3.2. Annotating the Key Type
Example 3.3. Biunique Correspondence
A.equals( transformer.fromString( transformer.toString( A ) )
A.equals( transformer.fromString( transformer.toString( A ) )3.2. Querying Example
Person object has been annotated using the following:
Example 3.4. Annotating the Person Object
Person objects have been stored in JBoss DataGrid, they can be searched using querying. The following code creates a SearchManager and QueryBuilder instance:
Example 3.5. Creating the SearchManager and QueryBuilder
SearchManager and QueryBuilder are used to construct a Lucene query. The Lucene query is then passed to the SearchManager to obtain a CacheQuery instance:
Example 3.6. Running the Query
CacheQuery query = manager.getQuery(luceneQuery);
List<Object> results = cacheQuery.list();
for (Object result : results) {
System.out.println("Found " + result);
}
CacheQuery query = manager.getQuery(luceneQuery);
List<Object> results = cacheQuery.list();
for (Object result : results) {
System.out.println("Found " + result);
}CacheQuery instance contains the results of the query, and can be used to produce a list or it can be used for repeat queries.
Chapter 4. Mapping Domain Objects to the Index Structure
4.1. Basic Mapping
@Indexed objects is the key used to store the value. How the key is indexed can still be customized by using a combination of @Transformable, @ProvidedId, custom types and custom FieldBridge implementations.
@DocumentId identifier does not apply to JBoss Data Grid values.
- @Indexed
- @Field
- @NumericField
4.1.1. @Indexed
@Indexed annotation declares a cached entry indexable. All entries not annotated with @Indexed are ignored.
Example 4.1. Making a class indexable with @Indexed
@Indexed
public class Essay {
}
@Indexed
public class Essay {
}index attribute of the @Indexed annotation to change the default name of the index.
4.1.2. @Field
@Field annotation declares a property as indexed and allows the configuration of several aspects of the indexing process by setting one or more of the following attributes:
name- The name under which the property will be stored in the Lucene Document. By default, this attribute is the same as the property name, following the JavaBeans convention.
store- Specifies if the property is stored in the Lucene index. When a property is stored it can be retrieved in its original value from the Lucene Document. This is regardless of whether or not the element is indexed. Valid options are:
Store.YES: Consumes more index space but allows projection. See Section 5.1.3.4, “Projection”Store.COMPRESS: Stores the property as compressed. This attribute consumes more CPU.Store.NO: No storage. This is the default setting for the store attribute.
index- Describes if property is indexed or not. The following values are applicable:
Index.NO: No indexing is applied; cannot be found by querying. This setting is used for properties that are not required to be searchable, but are able to be projected.Index.YES: The element is indexed and is searchable. This is the default setting for the index attribute.
analyze- Determines if the property is analyzed. The analyze attribute allows a property to be searched by its contents. For example, it may be worthwhile to analyze a text field, whereas a date field does not need to be analyzed. Enable or disable the Analyze attribute using the following:The analyze attribute is enabled by default. The
Analyze.YESAnalyze.NO
Analyze.YESsetting requires the property to be indexed via theIndex.YESattribute.
norms- Determines whether or not to store index time boosting information. Valid settings are:The default for this attribute is
Norms.YESNorms.NO
Norms.YES. Disabling norms conserves memory, however no index time boosting information will be available. termVector- Describes collections of term-frequency pairs. This attribute enables the storing of the term vectors within the documents during indexing. The default value is
TermVector.NO. Available settings for this attribute are:TermVector.YES: Stores the term vectors of each document. This produces two synchronized arrays, one contains document terms and the other contains the term's frequency.TermVector.NO: Does not store term vectors.TermVector.WITH_OFFSETS: Stores the term vector and token offset information. This is the same asTermVector.YESplus it contains the starting and ending offset position information for the terms.TermVector.WITH_POSITIONS: Stores the term vector and token position information. This is the same asTermVector.YESplus it contains the ordinal positions of each occurrence of a term in a document.TermVector.WITH_POSITION_OFFSETS: Stores the term vector, token position and offset information. This is a combination of theYES,WITH_OFFSETS, andWITH_POSITIONS.
indexNullAs- By default, null values are ignored and not indexed. However, using
indexNullAspermits specification of a string to be inserted as token for the null value. When using theindexNullAsparameter, use the same token in the search query to search for null value. Use this feature only withAnalyze.NO. Valid settings for this attribute are:Field.DO_NOT_INDEX_NULL: This is the default value for this attribute. This setting indicates that null values will not be indexed.Field.DEFAULT_NULL_TOKEN: Indicates that a default null token is used. This default null token can be specified in the configuration using the default_null_token property. If this property is not set andField.DEFAULT_NULL_TOKENis specified, the string "_null_" will be used as default.
Warning
FieldBridge or TwoWayFieldBridge it is up to the developer to handle the indexing of null values (see JavaDocs of LuceneOptions.indexNullAs()).
4.1.3. @NumericField
@NumericField annotation can be specified in the same scope as @Field.
@NumericField annotation can be specified for Integer, Long, Float, and Double properties. At index time the value will be indexed using a Trie structure. When a property is indexed as numeric field, it enables efficient range query and sorting, orders of magnitude faster than doing the same query on standard @Field properties. The @NumericField annotation accept the following optional parameters:
forField: Specifies the name of the related@Fieldthat will be indexed as numeric. It is mandatory when a property contains more than a@Fielddeclaration.precisionStep: Changes the way that the Trie structure is stored in the index. SmallerprecisionStepslead to more disk space usage, and faster range and sort queries. Larger values lead to less space used, and range query performance closer to the range query in normal@Fields. The default value forprecisionStepis 4.
@NumericField supports only Double, Long, Integer, and Float. It is not possible to take any advantage from a similar functionality in Lucene for the other numeric types, therefore remaining types must use the string encoding via the default or custom TwoWayFieldBridge.
NumericFieldBridge can also be used. Custom configurations require approximation during type transformation. The following is an example defines a custom NumericFieldBridge.
Example 4.2. Defining a custom NumericFieldBridge
4.2. Mapping Properties Multiple Times
@Fields can be used to perform this search. For example:
Example 4.3. Using @Fields to map a property multiple times
summary is indexed twice - once as summary in a tokenized way, and once as summary_forSort in an untokenized way. @Field supports 2 attributes useful when @Fields is used:
- analyzer: defines a @Analyzer annotation per field rather than per property
- bridge: defines a @FieldBridge annotation per field rather than per property
4.3. Embedded and Associated Objects
4.3.1. Indexing Associated Objects
address.city:Atlanta. The place fields are indexed in the Place index. The Place index documents also contain the following fields:
address.idaddress.streetaddress.city
Example 4.4. Indexing associations
4.3.2. @IndexedEmbedded
@IndexedEmbedded technique, data is denormalized in the Lucene index. As a result, the Lucene-based Query API must be updated with any changes in the Place and Address objects to keep the index up to date. Ensure the Place Lucene document is updated when its Address changes by marking the other side of the bidirectional relationship with @ContainedIn. @ContainedIn can be used for both associations pointing to entities and on embedded objects.
@IndexedEmbedded annotation can be nested. Attributes can be annotated with @IndexedEmbedded. The attributes of the associated class are then added to the main entity index. In the following example, the index will contain the following fields:
- name
- address.street
- address.city
- address.ownedBy_name
Example 4.5. Nested usage of @IndexedEmbedded and @ContainedIn
propertyName, following the traditional object navigation convention. This can be overridden using the prefix attribute as it is shown on the ownedBy property.
Note
depth property is used when the object graph contains a cyclic dependency of classes. For example, if Owner points to Place. the Query Module stops including attributes after reaching the expected depth, or object graph boundaries. A self-referential class is an example of cyclic dependency. In the provided example, because depth is set to 1, any @IndexedEmbedded attribute in Owner is ignored.
@IndexedEmbedded for object associations allows queries to be expressed using Lucene's query syntax. For example:
- Return places where name contains JBoss and where address city is Atlanta. In Lucene query this is:
+name:jboss +address.city:atlanta
+name:jboss +address.city:atlantaCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Return places where name contains JBoss and where owner's name contain Joe. In Lucene query this is:
+name:jboss +address.ownedBy_name:joe
+name:jboss +address.ownedBy_name:joeCopy to Clipboard Copied! Toggle word wrap Toggle overflow
@Indexed. When @IndexedEmbedded points to an entity, the association must be directional and the other side must be annotated using @ContainedIn. If not, the Lucene-based Query API cannot update the root index when the associated entity is updated. In the provided example, a Place index document is updated when the associated Address instance updates.
4.3.3. The targetElement Property
targetElement parameter. This method can be used when the object type annotated by @IndexedEmbedded is not the object type targeted by the data grid and the Lucene-based Query API. This occurs when interfaces are used instead of their implementation.
Example 4.6. Using the targetElement property of @IndexedEmbedded
4.4. Boosting
4.4.1. Static Index Time Boosting
@Boost annotation is used to define a static boost value for an indexed class or property. This annotation can be used within @Field, or can be specified directly on the method or class level.
- the probability of Essay reaching the top of the search list will be multiplied by 1.7.
@Field.boostand@Booston a property are cumulative, therefore the summary field will be 3.0 (2 x 1.5), and more important than the ISBN field.- The text field is 1.2 times more important than the ISBN field.
Example 4.7. Different ways of using @Boost
4.4.2. Dynamic Index Time Boosting
@Boost annotation defines a static boost factor that is independent of the state of the indexed entity at runtime. However, in some cases the boost factor may depend on the actual state of the entity. In this case, use the @DynamicBoost annotation together with an accompanying custom BoostStrategy.
@Boost and @DynamicBoost annotations can both be used in relation to an entity, and all defined boost factors are cumulative. The @DynamicBoost can be placed at either class or field level.
VIPBoostStrategy as implementation of the BoostStrategy interface used at indexing time. Depending on the annotation placement, either the whole entity is passed to the defineBoost method or only the annotated field/property value. The passed object must be cast to the correct type.
Example 4.8. Dynamic boost example
Note
BoostStrategy implementation must define a public no argument constructor.
4.5. Analysis
Analyzers to control this process.
4.5.1. Default Analyzer and Analyzer by Class
default.analyzer property. The default value for this property is org.apache.lucene.analysis.standard.StandardAnalyzer.
@Field, which is useful when multiple fields are indexed from a single property.
EntityAnalyzer is used to index all tokenized properties, such as name except, summary and body, which are indexed with PropertyAnalyzer and FieldAnalyzer respectively.
Example 4.9. Different ways of using @Analyzer
Note
QueryParser. Use the same analyzer for indexing and querying on any field.
4.5.2. Named Analyzers
@Analyzer declarations and includes the following:
- a name: the unique string used to refer to the definition.
- a list of
CharFilters: eachCharFilteris responsible to pre-process input characters before the tokenization.CharFilterscan add, change, or remove characters. One common usage is for character normalization. - a
Tokenizer: responsible for tokenizing the input stream into individual words. - a list of filters: each filter is responsible to remove, modify, or sometimes add words into the stream provided by the
Tokenizer.
Analyzer separates these components into multiple tasks, allowing individual components to be reused and components to be built with flexibility using the following procedure:
Procedure 4.1. The Analyzer Process
- The
CharFiltersprocess the character input. Tokenizerconverts the character input into tokens.- The tokens are the processed by the
TokenFilters.
4.5.3. Analyzer Definitions
@Analyzer annotation.
Example 4.10. Referencing an analyzer by name
@AnalyzerDef are also available by their name in the SearchFactory, which is useful when building queries.
Analyzer analyzer = Search.getSearchManager(cache).getSearchFactory().getAnalyzer("customanalyzer")
Analyzer analyzer = Search.getSearchManager(cache).getSearchFactory().getAnalyzer("customanalyzer")4.5.4. @AnalyzerDef for Solr
org.hibernate:hibernate-search-analyzers. Add the following dependency:
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-search-analyzers</artifactId>
<version>${version.hibernate.search}</version>
<dependency>
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-search-analyzers</artifactId>
<version>${version.hibernate.search}</version>
<dependency>CharFilter is defined by its factory. In this example, a mapping char filter is used, which will replace characters in the input based on the rules specified in the mapping file. Finally, a list of filters is defined by their factories. In this example, the StopFilter filter is built reading the dedicated words property file. The filter will ignore case.
Procedure 4.2. @AnalyzerDef and the Solr framework
Configure the CharFilter
Define aCharFilterby factory. In this example, a mappingCharFilteris used, which will replace characters in the input based on the rules specified in the mapping file.Copy to Clipboard Copied! Toggle word wrap Toggle overflow Define the Tokenizer
ATokenizeris then defined using theStandardTokenizerFactory.class.Copy to Clipboard Copied! Toggle word wrap Toggle overflow List of Filters
Define a list of filters by their factories. In this example, theStopFilterfilter is built reading the dedicated words property file. The filter will ignore case.Copy to Clipboard Copied! Toggle word wrap Toggle overflow
Note
CharFilters are applied in the order they are defined in the @AnalyzerDef annotation.
4.5.5. Loading Analyzer Resources
Tokenizers, TokenFilters, and CharFilters can load resources such as configuration or metadata files using the StopFilterFactory.class or the synonym filter. The virtual machine default can be explicitly specified by adding a resource_charset parameter.
Example 4.11. Use a specific charset to load the property file
4.5.6. Dynamic Analyzer Selection
@AnalyzerDiscriminator annotation to enable the dynamic analyzer selection.
BlogEntry class, the analyzer can depend on the language property of the entry. Depending on this property, the correct language-specific stemmer can then be chosen to index the text.
Discriminator interface must return the name of an existing Analyzer definition, or null if the default analyzer is not overridden.
de' or 'en', which is specified in the @AnalyzerDefs.
Procedure 4.3. Configure the @AnalyzerDiscriminator
Predefine Dynamic Analyzers
The@AnalyzerDiscriminatorrequires that all analyzers that are to be used dynamically are predefined via@AnalyzerDef. The@AnalyzerDiscriminatorannotation can then be placed either on the class, or on a specific property of the entity, in order to dynamically select an analyzer. An implementation of theDiscriminatorinterface can be specified using the@AnalyzerDiscriminatorimplparameter.Copy to Clipboard Copied! Toggle word wrap Toggle overflow Implement the Discriminator Interface
Implement thegetAnalyzerDefinitionName()method, which is called for each field added to the Lucene document. The entity being indexed is also passed to the interface method.Thevalueparameter is set if the@AnalyzerDiscriminatoris placed on the property level instead of the class level. In this example, the value represents the current value of this property.Copy to Clipboard Copied! Toggle word wrap Toggle overflow
4.5.7. Retrieving an Analyzer
- Standard analyzer: used in the
titlefield. - Stemming analyzer: used in the
title_stemmedfield.
Example 4.12. Using the scoped analyzer when building a full-text query
Note
@AnalyzerDef can also be retrieved by their definition name using searchFactory.getAnalyzer(String).
4.5.8. Available Analyzers
CharFilters, tokenizers, and filters. A complete list of CharFilter, tokenizer, and filter factories is available at http://wiki.apache.org/solr/AnalyzersTokenizersTokenFilters. The following tables provide some example CharFilters, tokenizers, and filters.
| Factory | Description | Parameters | Additional dependencies |
|---|---|---|---|
MappingCharFilterFactory | Replaces one or more characters with one or more characters, based on mappings specified in the resource file | mapping: points to a resource file containing the mappings using the format:
| none |
HTMLStripCharFilterFactory | Remove HTML standard tags, keeping the text | none | none |
| Factory | Description | Parameters | Additional dependencies |
|---|---|---|---|
StandardTokenizerFactory | Use the Lucene StandardTokenizer | none | none |
HTMLStripCharFilterFactory | Remove HTML tags, keep the text and pass it to a StandardTokenizer. | none | solr-core |
PatternTokenizerFactory | Breaks text at the specified regular expression pattern. | pattern: the regular expression to use for tokenizing
group: says which pattern group to extract into tokens
| solr-core |
| Factory | Description | Parameters | Additional dependencies |
|---|---|---|---|
StandardFilterFactory | Remove dots from acronyms and 's from words | none | solr-core |
LowerCaseFilterFactory | Lowercases all words | none | solr-core |
StopFilterFactory | Remove words (tokens) matching a list of stop words | words: points to a resource file containing the stop words
ignoreCase: true if
case should be ignored when comparing stop words, false otherwise
| solr-core |
SnowballPorterFilterFactory | Reduces a word to it's root in a given language. (example: protect, protects, protection share the same root). Using such a filter allows searches matching related words. | language: Danish, Dutch, English, Finnish, French, German, Italian, Norwegian, Portuguese, Russian, Spanish, Swedish and a few more | solr-core |
ISOLatin1AccentFilterFactory | Remove accents for languages like French | none | solr-core |
PhoneticFilterFactory | Inserts phonetically similar tokens into the token stream | encoder: One of DoubleMetaphone, Metaphone, Soundex or RefinedSoundex
inject:
true will add tokens to the stream, false will replace the existing token
maxCodeLength: sets the maximum length of the code to be generated. Supported only for Metaphone and DoubleMetaphone encodings
| solr-core and commons-codec |
CollationKeyFilterFactory | Converts each token into its java.text.CollationKey, and then encodes the CollationKey with IndexableBinaryStringTools, to allow it to be stored as an index term. | custom, language, country, variant, strength, decompositionsee Lucene's CollationKeyFilter javadocs for more info | solr-core and commons-io |
org.apache.solr.analysis.TokenizerFactory and org.apache.solr.analysis.TokenFilterFactory are checked in your IDE to see available implementations.
4.6. Bridges
@Field are converted to strings to be indexed. Built-in bridges automatically translates properties for the Lucene-based Query API. The bridges can be customized to gain control over the translation process.
4.6.1. Built-in Bridges
- null
- Per default
nullelements are not indexed. Lucene does not support null elements. However, in some situation it can be useful to insert a custom token representing thenullvalue. See Section 4.1.2, “@Field” for more information. - java.lang.String
- Strings are indexed, as are:
short,Shortinteger,Integerlong,Longfloat,Floatdouble,DoubleBigIntegerBigDecimal
Numbers are converted into their string representation. Note that numbers cannot be compared by Lucene, or used in ranged queries out of the box, and must be paddedNote
Using a Range query has disadvantages. An alternative approach is to use a Filter query which will filter the result query to the appropriate range.The Query Module supports using a customStringBridge. See Section 4.6.2, “Custom Bridges”. - java.util.Date
- Dates are stored as yyyyMMddHHmmssSSS in GMT time (200611072203012 for Nov 7th of 2006 4:03PM and 12ms EST). When using a
TermRangeQuery, dates are expressed in GMT.@DateBridgedefines the appropriate resolution to store in the index, for example:@DateBridge(resolution=Resolution.DAY). The date pattern will then be truncated accordingly.@Indexed public class Meeting { @Field(analyze=Analyze.NO) @DateBridge(resolution=Resolution.MINUTE) private Date date;@Indexed public class Meeting { @Field(analyze=Analyze.NO) @DateBridge(resolution=Resolution.MINUTE) private Date date;Copy to Clipboard Copied! Toggle word wrap Toggle overflow The defaultDatebridge uses Lucene'sDateToolsto convert from and toString. All dates are expressed in GMT time. Implement a custom date bridge in order to store dates in a fixed time zone. - java.net.URI, java.net.URL
- URI and URL are converted to their string representation
- java.lang.Class
- Class are converted to their fully qualified class name. The thread context classloader is used when the class is rehydrated
4.6.2. Custom Bridges
4.6.2.1. FieldBridge
FieldBridge. The FieldBridge interface provides a property value, which can then be mapped in the Lucene Document. For example, a property can be stored in two different document fields.
Example 4.13. Implementing the FieldBridge Interface
Lucene Document. Instead the addition is delegated to the LuceneOptions helper. The helper will apply the options selected on @Field, such as Store or TermVector, or apply the chosen @Boost value.
LuceneOptions is delegated to add fields to the Document, however the Document can also be edited directly, ignoring the LuceneOptions.
Note
LuceneOptions shields the application from changes in Lucene API and simplifies the code.
4.6.2.2. StringBridge
org.infinispan.query.bridge.StringBridge interface to provide the Lucene-based Query API with an implementation of the expected Object to String bridge, or StringBridge. All implementations are used concurrently, and therefore must be thread-safe.
Example 4.14. Custom StringBridge implementation
@FieldBridge annotation allows any property or field in the provided example to use the bridge:
@FieldBridge(impl = PaddedIntegerBridge.class) private Integer length;
@FieldBridge(impl = PaddedIntegerBridge.class)
private Integer length;4.6.2.3. Two-Way Bridge
TwoWayStringBridge is an extended version of a StringBridge, which can be used when the bridge implementation is used on an ID property. The Lucene-based Query API reads the string representation of the identifier and uses it to generate an object. The @FieldBridge annotation is used in the same way.
Example 4.15. Implementing a TwoWayStringBridge for ID Properties
Important
4.6.2.4. Parameterized Bridge
ParameterizedBridge interface passes parameters to the bridge implementation, making it more flexible. The ParameterizedBridge interface can be implemented by StringBridge, TwoWayStringBridge, FieldBridge implementations. All implementations must be thread-safe.
ParameterizedBridge interface, with parameters passed through the @FieldBridge annotation.
Example 4.16. Configure the ParameterizedBridge Interface
4.6.2.5. Type Aware Bridge
AppliedOnTypeAwareBridge will get the type the bridge is applied on injected. For example:
- the return type of the property for field/getter-level bridges.
- the class type for class-level bridges.
4.6.2.6. ClassBridge
@ClassBridge annotation. @ClassBridge can be defined at class level, and supports the termVector attribute.
FieldBridge implementation receives the entity instance as the value parameter, rather than a particular property. The particular CatFieldsClassBridge is applied to the department instance.The FieldBridge then concatenates both branch and network, and indexes the concatenation.
Example 4.17. Implementing a ClassBridge
Chapter 5. Querying
Procedure 5.1. Prepare and Execute a Query
- Get
SearchManagerof an indexing enabled cache as follows:SearchManager manager = Search.getSearchManager(cache);
SearchManager manager = Search.getSearchManager(cache);Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Create a
QueryBuilderto build queries forMyth.classas follows:final org.hibernate.search.query.dsl.QueryBuilder queryBuilder = manager.buildQueryBuilderForClass(Myth.class).get();
final org.hibernate.search.query.dsl.QueryBuilder queryBuilder = manager.buildQueryBuilderForClass(Myth.class).get();Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Create an Apache Lucene query that queries the
Myth.classclass' atributes as follows:Copy to Clipboard Copied! Toggle word wrap Toggle overflow
5.1. Building Queries
5.1.1. Building a Lucene Query Using the Lucene-based Query API
5.1.2. Building a Lucene Query
QueryBuilder for this task.
- Method names are in English. As a result, API operations can be read and understood as a series of English phrases and instructions.
- It uses IDE autocompletion which helps possible completions for the current input prefix and allows the user to choose the right option.
- It often uses the chaining method pattern.
- It is easy to use and read the API operations.
QueryBuilder knows what analyzer to use and what field bridge to apply. Several QueryBuilders (one for each type involved in the root of your query) can be created. The QueryBuilder is derived from the SearchFactory.
Search.getSearchManager(cache).buildQueryBuilderForClass(Myth.class).get();
Search.getSearchManager(cache).buildQueryBuilderForClass(Myth.class).get();QueryBuilder mythQB = searchFactory.buildQueryBuilder()
.forEntity( Myth.class )
.overridesForField("history","stem_analyzer_definition")
.get();
QueryBuilder mythQB = searchFactory.buildQueryBuilder()
.forEntity( Myth.class )
.overridesForField("history","stem_analyzer_definition")
.get();5.1.2.1. Keyword Queries
Example 5.1. Keyword Search
Query luceneQuery = mythQB.keyword().onField("history").matching("storm").createQuery();
Query luceneQuery = mythQB.keyword().onField("history").matching("storm").createQuery();| Parameter | Description |
|---|---|
| keyword() | Use this parameter to find a specific word |
| onField() | Use this parameter to specify in which lucene field to search the word |
| matching() | use this parameter to specify the match for search string |
| createQuery() | creates the Lucene query object |
- The value "storm" is passed through the
historyFieldBridge. This is useful when numbers or dates are involved. - The field bridge value is then passed to the analyzer used to index the field
history. This ensures that the query uses the same term transformation than the indexing (lower case, ngram, stemming and so on). If the analyzing process generates several terms for a given word, a boolean query is used with theSHOULDlogic (roughly anORlogic).
Note
Date object had to be converted to its string representation (in this case the year)
FieldBridge has an objectToString method (and all built-in FieldBridge implementations do).
Example 5.2. Searching Using Ngram Analyzers
y). All that is transparently done for the user.
Note
ignoreAnalyzer() or ignoreFieldBridge() functions can be called.
Example 5.3. Searching for Multiple Words
//search document with storm or lightning in their history
Query luceneQuery =
mythQB.keyword().onField("history").matching("storm lightning").createQuery();
//search document with storm or lightning in their history
Query luceneQuery =
mythQB.keyword().onField("history").matching("storm lightning").createQuery();onFields method.
Example 5.4. Searching Multiple Fields
Query luceneQuery = mythQB
.keyword()
.onFields("history","description","name")
.matching("storm")
.createQuery();
Query luceneQuery = mythQB
.keyword()
.onFields("history","description","name")
.matching("storm")
.createQuery();andField() method.
Example 5.5. Using the andField Method
5.1.2.2. Fuzzy Queries
keyword query and add the fuzzy flag.
Example 5.6. Fuzzy Query
threshold is the limit above which two terms are considering matching. It is a decimal between 0 and 1 and the default value is 0.5. The prefixLength is the length of the prefix ignored by the "fuzzyness". While the default value is 0, a non zero value is recommended for indexes containing a huge amount of distinct terms.
5.1.2.3. Wildcard Queries
? represents a single character and * represents any character sequence. Note that for performance purposes, it is recommended that the query does not start with either ? or *.
Example 5.7. Wildcard Query
Note
* or ? being mangled is too high.
5.1.2.4. Phrase Queries
phrase() to do so.
Example 5.8. Phrase Query
Query luceneQuery = mythQB
.phrase()
.onField("history")
.sentence("Thou shalt not kill")
.createQuery();
Query luceneQuery = mythQB
.phrase()
.onField("history")
.sentence("Thou shalt not kill")
.createQuery();Example 5.9. Adding Slop Factor
5.1.2.5. Range Queries
Example 5.10. Range Query
5.1.2.6. Combining Queries
SHOULD: the query should contain the matching elements of the subquery.MUST: the query must contain the matching elements of the subquery.MUST NOT: the query must not contain the matching elements of the subquery.
Example 5.11. Combining Subqueries
5.1.2.7. Query Options
boostedTo(on query type and on field) boosts the query or field to a provided factor.withConstantScore(on query) returns all results that match the query and have a constant score equal to the boost.filteredBy(Filter)(on query) filters query results using theFilterinstance.ignoreAnalyzer(on field) ignores the analyzer when processing this field.ignoreFieldBridge(on field) ignores the field bridge when processing this field.
Example 5.12. Querying Options
5.1.3. Build a Query with Infinispan Query
5.1.3.1. Generality
Example 5.13. Wrapping a Lucene Query in an Infinispan CacheQuery
CacheQuery cacheQuery = Search.getSearchManager(cache).getQuery(luceneQuery);
CacheQuery cacheQuery = Search.getSearchManager(cache).getQuery(luceneQuery);Example 5.14. Filtering the Search Result by Entity Type
CacheQuery cacheQuery = Search.getSearchManager(cache).getQuery(luceneQuery, Customer.class); // or CacheQuery cacheQuery = Search.getSearchManager(cache).getQuery(luceneQuery, Item.class, Actor.class);
CacheQuery cacheQuery = Search.getSearchManager(cache).getQuery(luceneQuery,
Customer.class);
// or
CacheQuery cacheQuery = Search.getSearchManager(cache).getQuery(luceneQuery,
Item.class, Actor.class);Customers. The second part of the same example returns matching Actors and Items. The type restriction is polymorphic. As a result, if the two subclasses Salesman and Customer of the base class Person return, specify Person.class to filter based on result types.
5.1.3.2. Pagination
Example 5.15. Defining pagination for a search query
CacheQuery cacheQuery = Search.getSearchManager(cache).getQuery(luceneQuery, Customer.class); cacheQuery.firstResult(15); //start from the 15th element cacheQuery.maxResults(10); //return 10 elements
CacheQuery cacheQuery = Search.getSearchManager(cache).getQuery(luceneQuery, Customer.class);
cacheQuery.firstResult(15); //start from the 15th element
cacheQuery.maxResults(10); //return 10 elementsNote
cacheQuery.getResultSize().
5.1.3.3. Sorting
Example 5.16. Specifying a Lucene Sort
org.infinispan.query.CacheQuery cacheQuery = Search.getSearchManager(cache).getQuery(luceneQuery, Book.class);
org.apache.lucene.search.Sort sort = new Sort(
new SortField("title", SortField.STRING));
cacheQuery.setSort(sort);
List results = cacheQuery.list();
org.infinispan.query.CacheQuery cacheQuery = Search.getSearchManager(cache).getQuery(luceneQuery, Book.class);
org.apache.lucene.search.Sort sort = new Sort(
new SortField("title", SortField.STRING));
cacheQuery.setSort(sort);
List results = cacheQuery.list();Note
5.1.3.4. Projection
Example 5.17. Using Projection Instead of Returning the Full Domain Object
Object[]. Projections prevent a time consuming database round-trip. However, they have following constraints:
- The properties projected must be stored in the index (
@Field(store=Store.YES)), which increases the index size. - The properties projected must use a
FieldBridgeimplementingorg.infinispan.query.bridge.TwoWayFieldBridgeororg.infinispan.query.bridge.TwoWayStringBridge, the latter being the simpler version.Note
All Lucene-based Query API built-in types are two-way. - Only the simple properties of the indexed entity or its embedded associations can be projected. Therefore a whole embedded entity cannot be projected.
- Projection does not work on collections or maps which are indexed via
@IndexedEmbedded
Example 5.18. Using Projection to Retrieve Metadata
FullTextQuery.THISreturns the initialized and managed entity as a non-projected query does.FullTextQuery.DOCUMENTreturns the Lucene Document related to the projected object.FullTextQuery.OBJECT_CLASSreturns the indexed entity's class.FullTextQuery.SCOREreturns the document score in the query. Use scores to compare one result against another for a given query. However, scores are not relevant to compare the results of two different queries.FullTextQuery.IDis the ID property value of the projected object.FullTextQuery.DOCUMENT_IDis the Lucene document ID. The Lucene document ID changes between two IndexReader openings.FullTextQuery.EXPLANATIONreturns the Lucene Explanation object for the matching object/document in the query. This is not suitable for retrieving large amounts of data. RunningFullTextQuery.EXPLANATIONis as expensive as running a Lucene query for each matching element. As a result, projection is recommended.
5.1.3.5. Limiting the Time of a Query
- Raise an exception when arriving at the limit.
- Limit to the number of results retrieved when the time limit is raised.
5.1.3.6. Raise an Exception on Time Limit
Example 5.19. Defining a Timeout in Query Execution
getResultSize(), iterate() and scroll() honor the timeout until the end of the method call. As a result, Iterable or the ScrollableResults ignore the timeout. Additionally, explain() does not honor this timeout period. This method is used for debugging and to check the reasons for slow performance of a query.
Important
5.2. Retrieving the Results
list().
5.2.1. Performance Considerations
list() can be used to receive a reasonable number of results (for example when using pagination) and to work on them all. list() works best if the batch-size entity is correctly set up. If list() is used, the Query Module processes all Lucene Hits elements within the pagination.
5.2.2. Result Size
Example 5.20. Determining the Result Size of a Query
5.2.3. Understanding Results
Explanation object for a given result (in a given query). This is an advanced class. Access the Explanation object as follows:
cacheQuery.explain(int) method
This method requires a document ID as a parameter and returns the Explanation object.
Note
5.3. Filters
- security
- temporal data (example, view only last month's data)
- population filter (example, search limited to a given category)
- and many more
5.3.1. Defining and Implementing a Filter
Example 5.21. Enabling Fulltext Filters for a Query
cacheQuery = Search.getSearchManager(cache).getQuery(query, Driver.class);
cacheQuery.enableFullTextFilter("bestDriver");
cacheQuery.enableFullTextFilter("security").setParameter( "login", "andre" );
cacheQuery.list(); //returns only best drivers where andre has credentials
cacheQuery = Search.getSearchManager(cache).getQuery(query, Driver.class);
cacheQuery.enableFullTextFilter("bestDriver");
cacheQuery.enableFullTextFilter("security").setParameter( "login", "andre" );
cacheQuery.list(); //returns only best drivers where andre has credentials@FullTextFilterDef annotation. This annotation applies to @Indexed entities irrespective of the filter's query. Filter definitions are global therefore each filter must have a unique name. If two @FullTextFilterDef annotations with the same name are defined, a SearchException is thrown. Each named filter must specify its filter implementation.
Example 5.22. Defining and Implementing a Filter
@FullTextFilterDefs( {
@FullTextFilterDef(name = "bestDriver", impl = BestDriversFilter.class),
@FullTextFilterDef(name = "security", impl = SecurityFilterFactory.class)
})
public class Driver { ... }
@FullTextFilterDefs( {
@FullTextFilterDef(name = "bestDriver", impl = BestDriversFilter.class),
@FullTextFilterDef(name = "security", impl = SecurityFilterFactory.class)
})
public class Driver { ... }BestDriversFilter is a Lucene filter that reduces the result set to drivers where the score is 5. In the example, the filter implements the org.apache.lucene.search.Filter directly and contains a no-arg constructor.
5.3.2. The @Factory Filter
Example 5.23. Creating a filter using the factory pattern
@Factory annotated method to build the filter instance. The factory must have a no argument constructor.
Example 5.24. Passing parameters to a defined filter
cacheQuery = Search.getSearchManager(cache).getQuery(query, Driver.class);
cacheQuery.enableFullTextFilter("security").setParameter( "level", 5 );
cacheQuery = Search.getSearchManager(cache).getQuery(query, Driver.class);
cacheQuery.enableFullTextFilter("security").setParameter( "level", 5 );Example 5.25. Using parameters in the actual filter implementation
@Key returns a FilterKey object. The returned object has a special contract: the key object must implement equals() / hashCode() so that two keys are equal if and only if the given Filter types are the same and the set of parameters are the same. In other words, two filter keys are equal if and only if the filters from which the keys are generated can be interchanged. The key object is used as a key in the cache mechanism.
5.3.3. Key Objects
@Key methods are needed only if:
- the filter caching system is enabled (enabled by default)
- the filter has parameters
StandardFilterKey delegates the equals() / hashCode() implementation to each of the parameters equals and hashcode methods.
SoftReferences when needed. Once the limit of the hard reference cache is reached additional filters are cached as SoftReferences. To adjust the size of the hard reference cache, use default.filter.cache_strategy.size (defaults to 128). For advanced use of filter caching, you can implement your own FilterCachingStrategy. The classname is defined by default.filter.cache_strategy.
IndexReader around a CachingWrapperFilter. The wrapper will cache the DocIdSet returned from the getDocIdSet(IndexReader reader) method to avoid expensive recomputation. It is important to mention that the computed DocIdSet is only cachable for the same IndexReader instance, because the reader effectively represents the state of the index at the moment it was opened. The document list cannot change within an opened IndexReader. A different/newIndexReader instance, however, works potentially on a different set of Documents (either from a different index or simply because the index has changed), hence the cached DocIdSet has to be recomputed.
5.3.4. Full Text Filter
cache flag of @FullTextFilterDef, set to FilterCacheModeType.INSTANCE_AND_DOCIDSETRESULTS which automatically caches the filter instance and wraps the filter around a Hibernate specific implementation of CachingWrapperFilter. Unlike Lucene's version of this class, SoftReferences are used with a hard reference count (see discussion about filter cache). The hard reference count is adjusted using default.filter.cache_docidresults.size (defaults to 5). Wrapping is controlled using the @FullTextFilterDef.cache parameter. There are three different values for this parameter:
| Value | Definition |
|---|---|
| FilterCacheModeType.NONE | No filter instance and no result is cached by the Query Module. For every filter call, a new filter instance is created. This setting addresses rapidly changing data sets or heavily memory constrained environments. |
| FilterCacheModeType.INSTANCE_ONLY | The filter instance is cached and reused across concurrent Filter.getDocIdSet() calls. DocIdSet results are not cached. This setting is useful when a filter uses its own specific caching mechanism or the filter results change dynamically due to application specific events making DocIdSet caching in both cases unnecessary. |
| FilterCacheModeType.INSTANCE_AND_DOCIDSETRESULTS | Both the filter instance and the DocIdSet results are cached. This is the default value. |
- The system does not update the targeted entity index often (in other words, the IndexReader is reused a lot).
- The Filter's DocIdSet is expensive to compute (compared to the time spent to execute the query).
5.3.5. Using Filters in a Sharded Environment
- Create a sharding strategy to select a subset of
IndexManagers depending on filter configurations. - Activate the filter when running the query.
Example 5.26. Querying a Specific Shard
customer filter is present in the example, the query only uses the shard dedicated to the customer. The query returns all shards if the customer filter is not found. The sharding strategy reacts to each filter depending on the provided parameters.
ShardSensitiveOnlyFilter class to declare the filter.
Example 5.27. Using the ShardSensitiveOnlyFilter Class
ShardSensitiveOnlyFilter filter is used, Lucene filters do not need to be implemented. Use filters and sharding strategies reacting to these filters for faster query execution in a sharded environment.
5.4. Optimizing the Query Process
- The Lucene query.
- The number of objects loaded: use pagination or index projection where required.
- The way the Query Module interacts with the Lucene readers defines the appropriate reader strategy.
- Caching frequently extracted values from the index.
5.4.1. Caching Index Values: FieldCache
@CacheFromIndex annotation is used to perform caching on the main metadata fields required by the Lucene-based Query API.
Example 5.28. The @CacheFromIndex Annotation
CLASS: The Query Module uses a Lucene FieldCache to improve performance of the Class type extraction from the index.This value is enabled by default. The Lucene-based Query API applies this value when the@CacheFromIndexannotation is not specified.ID: Extracting the primary identifier uses a cache. This method produces the best querying results, however it may reduce performance.
Note
- Memory usage: Typically the CLASS cache has lower requirements than the ID cache.
- Index warmup: When using field caches, the first query on a new index or segment is slower than when caching is disabled.
CLASS field cache even when enabled. For example, when targeting a single class, all returned values are of that type.
TwoWayFieldBridge. All types being loaded in a specific query must use the fieldname for the id and have ids of the same type. This is evaluated at query execution.
Chapter 6. The Infinispan Query DSL
6.1. Creating Queries with Infinispan Query DSL
QueryFactory instance, which is obtained using Search.getQueryFactory(). Each QueryFactory instance is bound to the one cache instance, and is a stateless and thread-safe object that can be used for creating multiple parallel queries.
- A query is created by invocating the
from(Class entityType)method, which returns aQueryBuilderobject that is responsible for creating queries for the specified entity class from the given cache. - The
QueryBuilderaccumulates search criteria and configuration specified through invoking its DSL methods, and is used to build aQueryobject by invoking theQueryBuilder.build()method, which completes the construction. TheQueryBuilderobject cannot be used for constructing multiple queries at the same time except for nested queries, however it can be reused afterwards. - Invoke the
list()method of theQueryobject to execute the query and fetch the results. Once executed, theQueryobject is not reusable. If new results must be fetched, a new instance must be obtained by callingQueryBuilder.build().
Important
6.2. Enabling Infinispan Query DSL-based Queries
- All libraries required for Infinispan Query (see Section 2.1.1, “Infinispan Query Dependencies in Library Mode” for details) on the classpath.
- Indexing enabled and configured for caches (optional). See Section 2.4, “Configure Indexing” for details.
- Annotated POJO cache values (optional). If indexing is not enabled, POJO annotations are also not required and are ignored if set. If indexing is not enabled, all fields that follow JavaBeans conventions are searchable instead of only the fields with Hibernate Search annotations.
Note
6.3. Running Infinispan Query DSL-based Queries
QueryFactory from the Search in order to run a DSL-based query.
In Library mode, obtain a QueryFactory as follows:
QueryFactory qf = org.infinispan.query.Search.getQueryFactory(Cache<?, ?> cache)
QueryFactory qf = org.infinispan.query.Search.getQueryFactory(Cache<?, ?> cache)Example 6.1. Constructing a DSL-based Query
Search object resides in package org.infinispan.client.hotrod. See the example in Section 7.2, “Performing Remote Queries via the Hot Rod Java Client” for details.
Example 6.2. Combining Multiple Conditions
Book entity.
Example 6.3. Querying the Book Entity
Chapter 7. Remote Querying
JBoss Data Grid uses its own query language based on an internal DSL. The Infinispan Query DSL provides a simplified way of writing queries, and is agnostic of the underlying query mechanisms. Querying via the Hot Rod client allows remote, language-neutral querying, and is implementable in all languages currently available for the Hot Rod client.
Google's Protocol Buffers is used as an encoding format for both storing and querying data. The Infinispan Query DSL can be used remotely via the Hot Rod client that is configured to use the Protobuf marshaller. Protocol Buffers are used to adopt a common format for storing cache entries and marshalling them.
7.1. Querying Comparison
| Feature | Embedded Querying and Lucene Query | Embedded DSL | Remote Querying |
|---|---|---|---|
| Indexing |
Mandatory
|
Optional but highly recommended
|
Optional but highly recommended
|
|
Index contents
|
Selected fields
|
Selected fields
|
Selected fields
|
| Data Storage Format |
Java objects
|
Java objects
|
Protocol buffers
|
| Keyword Queries |
Yes
|
Yes
|
Yes
|
| Range Queries |
Yes
|
Yes
|
Yes
|
| Fuzzy Queries |
Yes
|
No
|
No
|
| Wildcard |
Yes
|
Limited to like queries (Matches a wildcard pattern that follows JPA rules).
|
Limited to like queries (Matches a wildcard pattern that follows JPA rules).
|
| Phrase Queries |
Yes
|
No
|
No
|
| Combining Queries |
AND, OR, NOT, SHOULD
|
AND, OR, NOT
|
AND, OR, NOT
|
| Sorting Results |
Yes
|
Yes
|
Yes
|
| Filtering Results |
Yes, both within the query and as appended operator
|
Within the query
|
Within the query
|
| Pagination of Results |
Yes
|
Yes
|
Yes
|
7.2. Performing Remote Queries via the Hot Rod Java Client
RemoteCacheManager has been configured with the Protobuf marshaller.
RemoteCacheManager must be configured to use the Protobuf Marshaller.
Procedure 7.1. Enabling Remote Querying via Hot Rod
Add the
infinispan-remote.jarTheinfinispan-remote.jaris an uberjar, and therefore no other dependencies are required for this feature.Enable indexing on the cache configuration.
Indexing is not mandatory for Remote Queries, but it is highly recommended because it makes searches on caches that contain large amounts of data significantly faster. Indexing can be configured at any time. Enabling and configuring indexing is the same as for Library mode.Add the following configuration within thecache-containerelement loated inside the Infinispan subsystem element.Copy to Clipboard Copied! Toggle word wrap Toggle overflow Register the Protobuf schema definition files
Register the Protobuf schema definition files by adding them in the___protobuf_metadatasystem cache. The cache key is a string that denotes the file name and the value is.protofile, as a string. Alternatively, protobuf schemas can also be registered by invoking theregisterProtofilemethods of the server'sProtobufMetadataManagerMBean. There is one instance of this MBean per cache container and is backed by the___protobuf_metadata, so that the two approaches are equivalent.For an example of providing the protobuf schema via___protobuf_metadatasystem cache, see Example 7.6, “Registering a Protocol Buffers schema file”.The following example demonstrates how to invoke theregisterProtofilemethods of theProtobufMetadataManagerMBean.Example 7.1. Registering Protobuf schema definition files via JMX
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
All data placed in the cache is immediately searchable, whether or not indexing is in use. Entries do not need to be annotated, unlike embedded queries. The entity classes are only meaningful to the Java client and do not exist on the server.
QueryFactory can be obtained using the following:
Example 7.2. Obtaining the QueryFactory
7.3. Protobuf Encoding
7.3.1. Storing Protobuf Encoded Entities
.proto files
Example 7.3. .library.proto
- An entity named
Bookis placed in a package namedbook_sample.package book_sample; message Book {package book_sample; message Book {Copy to Clipboard Copied! Toggle word wrap Toggle overflow - The entity declares several fields of primitive types and a repeatable field named
authors.Copy to Clipboard Copied! Toggle word wrap Toggle overflow - The
Authormessage instances are embedded in theBookmessage instance.message Author { required string name = 1; required string surname = 2; }message Author { required string name = 1; required string surname = 2; }Copy to Clipboard Copied! Toggle word wrap Toggle overflow
7.3.2. About Protobuf Messages
- Nesting of messages is possible, however the resulting structure is strictly a tree, and never a graph.
- There is no type inheritance.
- Collections are not supported, however arrays can be easily emulated using repeated fields.
7.3.3. Using Protobuf with Hot Rod
- Configure the client to use a dedicated marshaller, in this case, the
ProtoStreamMarshaller. This marshaller uses theProtoStreamlibrary to assist in encoding objects.Important
In order to use theProtoStreamMarshaller, the infinispan-remote-query-client Maven dependency must be added. - Instruct
ProtoStreamlibrary on how to marshall message types by registering per entity marshallers.
Example 7.4. Use the ProtoStreamMarshaller to Encode and Marshall Messages
- The
SerializationContextis provided by theProtoStreamlibrary. - The
SerializationContext.registerProtofilemethod receives the name of a.protoclasspath resource file that contains the message type definitions. - The
SerializationContextassociated with theRemoteCacheManageris obtained, thenProtoStreamis instructed to marshall the protobuf types.
Note
RemoteCacheManager has no SerializationContext associated with it unless it was configured to use ProtoStreamMarshaller.
7.3.4. Registering Per Entity Marshallers
ProtoStreamMarshaller for remote querying purposes, registration of per entity marshallers for domain model types must be provided by the user for each type or marshalling will fail. When writing marshallers, it is essential that they are stateless and threadsafe, as a single instance of them is being used.
Example 7.5. BookMarshaller.java
Book and Author.
7.3.5. Indexing Protobuf Encoded Entities
.proto extension. The schema is supplied to the server either by placing it in the ___protobuf_metadata cache by a put, putAll, putIfAbsent, or replace operation, or alternatively by invoking ProtobufMetadataManager MBean via JMX. Both keys and values of ___protobuf_metadata cache are Strings, the key being the file name, while the value is the schema file contents.
Example 7.6. Registering a Protocol Buffers schema file
ProtobufMetadataManager is a cluster-wide replicated repository of Protobuf schema definitions or.proto files. For each running cache manager, a separate ProtobufMetadataManager MBean instance exists, and is backed by the ___protobuf_metadata cache. The ProtobufMetadataManager ObjectName uses the following pattern:
<jmx domain>:type=RemoteQuery,name=<cache manager<methodname>putAll name>,component=ProtobufMetadataManager
<jmx domain>:type=RemoteQuery,name=<cache manager<methodname>putAll
name>,component=ProtobufMetadataManagervoid registerProtofile(String name, String contents)
void registerProtofile(String name, String contents)Note
7.3.6. Custom Fields Indexing with Protobuf
@Indexed and @IndexedField annotations directly to the Protobuf schema in the documentation comments of message type definitions and field definitions.
Example 7.7. Specifying Which Fields are Indexed
@Indexed annotation only applies to message types, has a boolean value (the default is true). As a result, using @Indexed is equivalent to @Indexed(true). This annotation is used to selectively specify the fields of the message type which must be indexed. Using @Indexed(false), however, indicates that no fields are to be indexed and so the eventual @IndexedField annotation at the field level is ignored.
@IndexedField annotation only applies to fields, has two attributes (index and store), both of which default to true (using @IndexedField is equivalent to @IndexedField(index=true, store=true)). The index attribute indicates whether the field is indexed, and is therefore used for indexed queries. The store attributes indicates whether the field value must be stored in the index, so that the value is available for projections.
Note
@IndexedField annotation is only effective if the message type that contains it is annotated with @Indexed.
7.3.7. Defining Protocol Buffers Schemas With Java Annotations
MessageMarshaller implementation and a .proto schema file, you can add minimal annotations to a Java class and its fields.
ProtoStream library. The ProtoStream library internally generates the marshallar and does not require a manually implemented one. The Java annotations require minimal information such as the Protobuf tag number. The rest is inferred based on common sense defaults ( Protobuf type, Java collection type, and collection element type) and is possible to override.
SerializationContext and is also available to the users to be used as a reference to implement domain model classes and marshallers for other languages.
Example 7.8. User.Java
Example 7.9. Note.Java
Example 7.10. ProtoSchemaBuilderDemo.Java
.proto file that is generated by the ProtoSchemaBuilderDemo.java example.
Example 7.11. Sample_Schema.Proto
| Annotation | Applies To | Purpose | Requirement | Parameters |
|---|---|---|---|---|
@ProtoDoc | Class/Field/Enum/Enum member | Specifies the documentation comment that will be attached to the generated Protobuf schema element (message type, field definition, enum type, enum value definition) | Optional | A single String parameter, the documentation text |
@ProtoMessage | Class | Specifies the name of the generated message type. If missing, the class name if used instead | Optional | name (String), the name of the generated message type; if missing the Java class name is used by default |
@ProtoField | Field, Getter or Setter |
Specifies the Protobuf field number and its Protobuf type. Also indicates if the field is repeated, optional or required and its (optional) default value. If the Java field type is an interface or an abstract class, its actual type must be indicated. If the field is repeatable and the declared collection type is abstract then the actual collection implementation type must be specified. If this annotation is missing, the field is ignored for marshalling (it is transient). A class must have at least one
@ProtoField annotated field to be considered Protobuf marshallable.
| Required | number (int, mandatory), the Protobuf number type (org.infinispan.protostream.descriptors.Type, optional), the Protobuf type, it can usually be inferred required (boolean, optional)name (String, optional), the Protobuf namejavaType (Class, optional), the actual type, only needed if declared type is abstract collectionImplementation (Class, optional), the actual collection type, only needed if declared type is abstract defaultValue (String, optional), the string must have the proper format according to the Java field type |
@ProtoEnum | Enum | Specifies the name of the generated enum type. If missing, the Java enum name if used instead | Optional | name (String), the name of the generated enum type; if missing the Java enum name is used by default |
@ProtoEnumValue | Enum member | Specifies the numeric value of the corresponding Protobuf enum value | Required | number (int, mandatory), the Protobuf number name (String), the Protobuf name; if missing the name of the Java member is used |
Note
@ProtoDoc annotation can be used to provide documentation comments in the generated schema and also allows to inject the @Indexed and @IndexedField annotations where needed (see Section 7.3.6, “Custom Fields Indexing with Protobuf”).
Chapter 8. Monitoring
generate_statistics property in the configuration.
8.1. About Java Management Extensions (JMX)
MBeans.
8.1.1. Using JMX with Red Hat JBoss Data Grid
8.2. StatisticsInfoMBean
StatisticsInfoMBean MBean accesses the Statistics object as described in the previous section.
Appendix A. Revision History
| Revision History | ||||||
|---|---|---|---|---|---|---|
| Revision 6.4.0-9 | Wed Apr 1 2015 | |||||
| ||||||
| Revision 6.4.0-8 | Tue Jan 27 2015 | |||||
| ||||||
| Revision 6.4.0-7 | Mon Jan 19 2015 | |||||
| ||||||
| Revision 6.4.0-6 | Tue Jan 06 2015 | |||||
| ||||||
| Revision 6.4.0-5 | Wed Dec 24 2014 | |||||
| ||||||
| Revision 6.4.0-4 | Tue Nov 18 2014 | |||||
| ||||||
| Revision 6.4.0-3 | Thu Nov 13 2014 | |||||
| ||||||
| Revision 6.4.0-2 | Mon Oct 27 2014 | |||||
| ||||||
| Revision 6.4.0-1 | Thu Oct 16 2014 | |||||
| ||||||
| Revision 6.4.0-0 | Wed Sep 24 2014 | |||||
| ||||||