Data Grid キャッシュの設定
Data Grid キャッシュを設定してデプロイメントをカスタマイズする
概要
Red Hat Data Grid
Data Grid は、高性能の分散型インメモリーデータストアです。
- スキーマレスデータ構造
- さまざまなオブジェクトをキーと値のペアとして格納する柔軟性があります。
- グリッドベースのデータストレージ
- クラスター間でデータを分散および複製するように設計されています。
- エラスティックスケーリング
- サービスを中断することなく、ノードの数を動的に調整して要件を満たします。
- データの相互運用性
- さまざまなエンドポイントからグリッド内のデータを保存、取得、およびクエリーします。
Data Grid のドキュメント
Data Grid のドキュメントは、Red Hat カスタマーポータルで入手できます。
Data Grid のダウンロード
Red Hat カスタマーポータルで Data Grid Software Downloads にアクセスします。
Data Grid ソフトウェアにアクセスしてダウンロードするには、Red Hat アカウントが必要です。
多様性を受け入れるオープンソースの強化
Red Hat では、コード、ドキュメント、Web プロパティーにおける配慮に欠ける用語の置き換えに取り組んでいます。まずは、マスター (master)、スレーブ (slave)、ブラックリスト (blacklist)、ホワイトリスト (whitelist) の 4 つの用語の置き換えから始めます。この取り組みは膨大な作業を要するため、今後の複数のリリースで段階的に用語の置き換えを実施して参ります。詳細は、Red Hat CTO である Chris Wright のメッセージ を参照してください。
第1章 Data Grid キャッシュ
Data Grid キャッシュは、以下のようなユースケースに合わせて、柔軟なインメモリーデータストアを提供します。
- 高速のローカルキャッシュでアプリケーションのパフォーマンスを向上させる。
- 書き込み操作のボリュームを減らすことでデータベースを最適化します。
- クラスター全体で一貫したデータに対する回復性および持続性を提供します。
1.1. キャッシュ API
Cache<K,V> は、Data Grid の中央インターフェイスであり、java.util.concurrent.ConcurrentMap を拡張します。
キャッシュエントリーは、単純な文字列からより複雑なオブジェクトまで、幅広いデータ型をサポートする key:value 形式の同時データ構造です。
1.2. キャッシュマネージャー
CacheManager API は、Data Grid キャッシュと対話するための開始点です。キャッシュマネージャーはキャッシュのライフサイクルを制御し、キャッシュインスタンスの作成、変更、および削除を行います。
Data Grid は、2 つの CacheManager 実装を提供します。
EmbeddedCacheManager- クライアントアプリケーションと同じ Java 仮想マシン (JVM) 内で Data Grid を実行する場合のキャッシュのエントリーポイント。
RemoteCacheManager-
独自の JVM で Data Grid Server を実行する場合のキャッシュのエントリーポイント。
RemoteCacheManagerをインスタンス化すると、Hot Rod エンドポイントを使用して Data Grid Server への永続的な TCP 接続を確立します。
埋め込みおよびリモートの CacheManager 実装は、一部のメソッドとプロパティーを共有します。ただし、セマンティックの違いは EmbeddedCacheManager と RemoteCacheManager の間に存在します。
1.3. キャッシュモード
Data Grid キャッシュマネージャーは、異なるモードを使用する複数のキャッシュを作成および制御できます。たとえば、ローカルキャッシュ、分散キャッシュ、およびインバリデーションモードでのキャッシュに、同じキャッシュマネージャーを使用することができます。
- Local
- Data Grid は単一ノードとして実行され、キャッシュエントリーに対して読み取り操作または書き込み操作を複製しません。
- Replicated (レプリケート)
- Data Grid は、クラスター内のすべてのノードのすべてのキャッシュエントリーを複製し、ローカル読み取り操作のみを実行します。
- Distributed (分散)
-
Data Grid は、クラスター内のノードのサブセットでキャッシュエントリーを複製し、エントリーを固定所有者ノードに割り当てます。
Data Grid は所有者ノードから読み取り操作を要求し、正しい値を返すようにします。 - Invalidation (無効化)
- Data Grid は、操作のキャッシュ内のエントリーが変更されるたびに、すべてのノードから古いデータをエビクトします。Data Grid は、ローカルの読み取り操作のみを実行します。
- Scattered(散在)
-
Data Grid は、ノードのサブセット全体でキャッシュエントリーを保存します。
デフォルトでは、Data Grid はプライマリーの所有者とバックアップ所有者を scattered キャッシュの各キャッシュエントリーに割り当てます。
Data Grid は分散キャッシュと同じ方法でプライマリー所有者を割り当てますが、バックアップ所有者は常に書き込み操作を開始するノードになります。
Data Grid は、少なくとも 1 つの所有者ノードから読み取り操作を要求し、正しい値を返すようにします。
1.3.1. キャッシュモードの比較
選択するキャッシュモードは、データに必要な数量と保証によって異なります。
以下の表は、キャッシュモードの主な相違点をまとめています。
| キャッシュモード | クラスター化 ? | 読み取りパフォーマンス | 書き込みパフォーマンス | 容量 | 可用性 | 機能 |
|---|---|---|---|---|---|---|
| Local | いいえ | 高(ローカル) | 高(ローカル) | 単一ノード | 単一ノード | 完了 |
| Simple (単純) | いいえ | 最高(ローカル) | 最高(ローカル) | 単一ノード | 単一ノード | Partial: トランザクション、永続性、またはインデックスなし。 |
| Invalidation (無効化) | Yes | 高(ローカル) | 低い(すべてのノード、データなし) | 単一ノード | 単一ノード | 部分的: インデックス化なし |
| Replicated (レプリケート) | Yes | 高(ローカル) | 最低(すべてのノード) | 最小のノード | 全ノード | 完了 |
| Distributed (分散) | Yes | メディア(所有者) | メディア(所有者ノード) | 所有者数で区分されたすべてのノード容量の合計。 | 所有者ノード | 完了 |
| Scattered(散在) | Yes | 中(プライマリー) | さらに高 (単一 RPC) | 2 で除算されたすべてのノード容量の合計。 | 所有者ノード | 部分的: トランザクションがありません。 |
1.4. ローカルキャッシュ
Data Grid は、ConcurrentHashMap に似たローカルキャッシュモードを提供します。
キャッシュは、永続ストレージやエビクションや有効期限などの管理機能など、単純なマップよりも多くの機能を提供します。
Data Grid Cache API は Java の ConcurrentMap API を拡張し、マップから Data Grid キャッシュへの移行を容易にします。
ローカルキャッシュの設定
XML
<local-cache name="mycache"
statistics="true">
<encoding media-type="application/x-protostream"/>
</local-cache>
<local-cache name="mycache"
statistics="true">
<encoding media-type="application/x-protostream"/>
</local-cache>JSON
YAML
localCache:
name: "mycache"
statistics: "true"
encoding:
mediaType: "application/x-protostream"
localCache:
name: "mycache"
statistics: "true"
encoding:
mediaType: "application/x-protostream"1.4.1. 単純なキャッシュ
単純なキャッシュは、以下の機能のサポートを無効にするローカルキャッシュのタイプです。
- トランザクションと呼び出しのバッチ処理
- 永続ストレージ
- カスタムインターセプター
- インデックス化
- トランダング
ただし、有効期限、エビクション、統計、およびセキュリティー機能などの単純なキャッシュで他の Data Grid 機能を使用できます。単純なキャッシュと互換性がない機能を設定すると、Data Grid は例外を出力します。
単純なキャッシュ設定
XML
<local-cache simple-cache="true" />
<local-cache simple-cache="true" />JSON
{
"local-cache" : {
"simple-cache" : "true"
}
}
{
"local-cache" : {
"simple-cache" : "true"
}
}YAML
localCache: simpleCache: "true"
localCache:
simpleCache: "true"第2章 クラスター化されたキャッシュ
ノード間でデータをレプリケートする Data Grid クラスターで組み込みキャッシュおよびリモートキャッシュを作成できます。
2.1. レプリケートされたキャッシュ
Data Grid は、キャッシュ内のすべてのエントリーをクラスター内のすべてのノードに複製します。各ノードはローカルに読み取り操作を実行できます。
レプリケートされたキャッシュは、クラスター全体で状態をすばやく簡単に共有する方法を提供しますが、10 未満のノードのクラスターに適しています。レプリケーション要求の数はクラスター内のノード数を線形にスケールするため、大規模なクラスターでレプリケートされたキャッシュを使用するとパフォーマンスが低下します。ただし、レプリケーション要求に UDP マルチキャストを使用すると、パフォーマンスを向上させることができます。
各キーにはプライマリー所有者があり、一貫性を提供するためにデータコンテナーの更新をシリアル化します。
図2.1 レプリケートされたキャッシュ
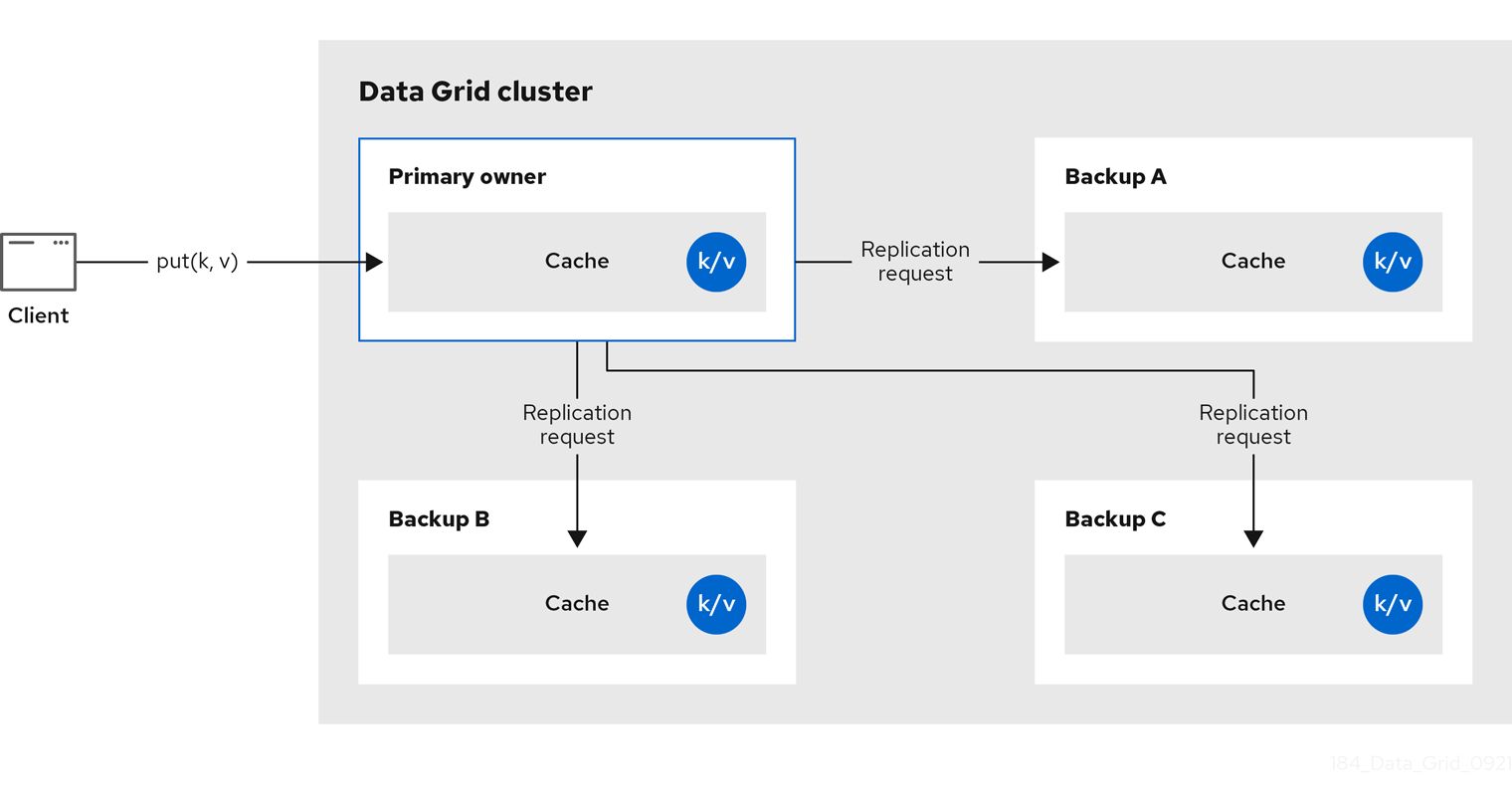
同期または非同期のレプリケーション
-
同期レプリケーションは、変更がクラスターのすべてのノードに正常に複製されるまで、呼び出し元 (
cache.put(key, value)など) をブロックします。 - 非同期レプリケーションはバックグラウンドでレプリケーションを実行し、書き込み操作が即座に返されます。非同期レプリケーションは推奨されません。これは、通信エラーやリモートノードで発生したエラーは呼び出し元に報告されないためです。
トランザクション
トランザクションが有効になっていると、書き込み操作はプライマリー所有者によって複製されません。
悲観的ロックでは、各書き込みは、すべてのノードにブロードキャストされるロックメッセージをトリガーします。トランザクションのコミット時に、送信元は 1 フェーズの準備メッセージとロック解除メッセージ (任意) をブロードキャストします。1 フェーズの準備またはロック解除メッセージのいずれかが fire-and-forget になります。
楽観的ロックを使用すると、発信者は準備メッセージ、コミットメッセージ、およびロック解除メッセージ (任意) をブロードキャストします。ここで、1 フェーズの準備またはロック解除メッセージが fire-and-forget になります。
2.2. 分散キャッシュ
Data Grid は、numOwners として設定された、キャッシュ内のエントリーの固定数のコピーを維持しようとします。これにより、分散キャッシュを線形にスケールでき、ノードをクラスターに追加する際により多くのデータを保存できます。
ノードがクラスターに参加およびクラスターから離脱すると、キーのコピー数が numOwners より多い場合と少ない場合があります。特に、numOwners ノードがすぐに連続して離れると、一部のエントリーが失われるため、分散キャッシュは、numOwners - 1 ノードの障害を許容すると言われます。
コピー数は、パフォーマンスとデータの持続性を示すトレードオフを表します。維持するコピーが増えると、パフォーマンスは低くなりますが、サーバーやネットワークの障害によるデータ喪失のリスクも低くなります。
Data Grid は、キーの所有者を 1 つの プライマリー所有者 に分割します。これにより、キーへの書き込みが行われ、ゼロ以上の バックアップ所有者 が調整されます。
以下の図は、クライアントがバックアップ所有者に送信する書き込み操作を示しています。この場合、バックアップノードはプライマリー所有者に書き込みを転送し、書き込みをバックアップに複製します。
図2.2 クラスターのレプリケーション
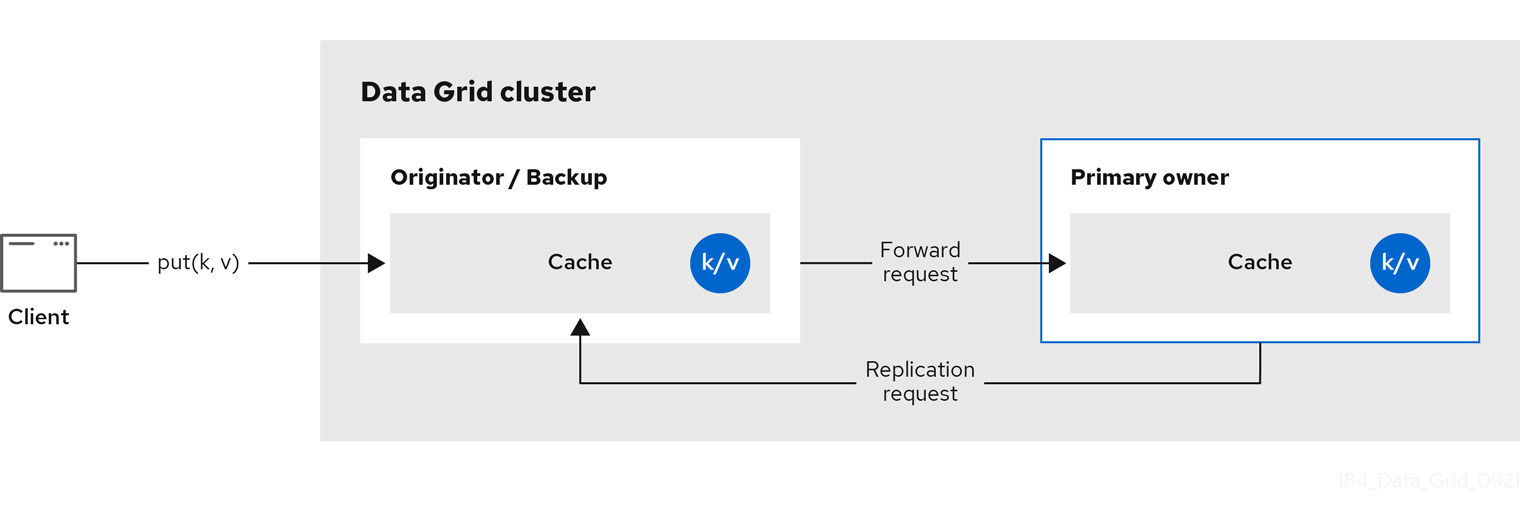
図2.3 分散キャッシュ
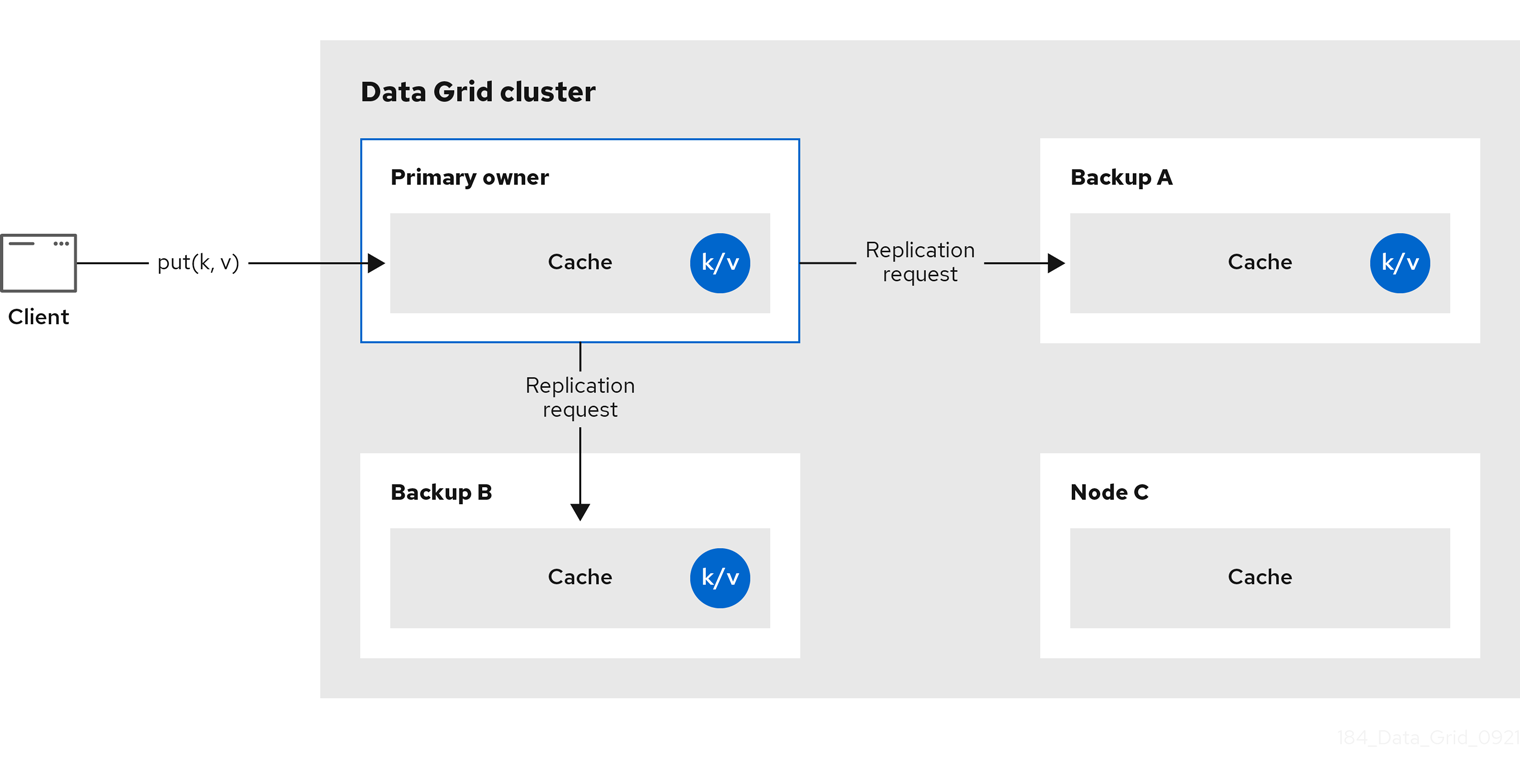
読み取り操作
読み取り操作は、プライマリー所有者から値を要求します。プライマリー所有者が妥当な時間内に応答しない場合は、Data Grid はバックアップの所有者から値も要求します。
キーがローカルキャッシュに存在する場合、読み取り操作には 0 メッセージが必要になる場合があり、すべての所有者が遅い場合は最大 2 * numOwners メッセージが必要になる場合があります。
書き込み操作
書き込み操作により、最大 2 * numOwners メッセージが生成されます。発信者からプライマリー所有者への 1 つのメッセージ。プライマリー所有者からバックアップノードへの numOwners - 1 メッセージと、対応する確認応答メッセージ。
キャッシュトポロジーの変更により、読み取り操作と書き込み操作の両方に対して再試行が行われる可能性があります。
同期または非同期のレプリケーション
更新を失う可能性があるため、非同期のレプリケーションは推奨されません。更新の喪失に加えて、非同期の分散キャッシュは、スレッドがキーに書き込むときに古い値を確認し、その後に同じキーをすぐに読み取ることもできます。
トランザクション
トランザクション分散キャッシュは、影響を受けるノードにのみロック/prepare/commit/unlock メッセージを送信します。つまり、トランザクションの影響を受ける 1 つの鍵を所有するすべてのノードを意味します。最適化として、トランザクションが単一のキーに書き込み、送信元がキーの主な所有者である場合、ロックメッセージは複製されません。
2.2.1. 読み取りの一貫性
同期レプリケーションを使用しても、分散キャッシュは線形化できません。トランザクションキャッシュでは、シリアル化/スナップショットの分離はサポートしません。
たとえば、スレッドは 1 つの配置リクエストを行います。
cache.get(k) -> v1 cache.put(k, v2) cache.get(k) -> v2
cache.get(k) -> v1
cache.put(k, v2)
cache.get(k) -> v2ただし、別のスレッドでは、異なる順序で値が表示される場合があります。
cache.get(k) -> v2 cache.get(k) -> v1
cache.get(k) -> v2
cache.get(k) -> v1理由は、プライマリー所有者の返信速度が速いかによって、読み取りはどの所有者からでも値を返すことができるからです。書き込みは、すべての所有者全体でアトミックではありません。実際、プライマリーは、バックアップから確認を受け取った後にのみ更新をコミットします。プライマリーがバックアップからの確認メッセージを待機している間、バックアップからの読み取りには新しい値が表示されますが、プライマリーからの読み取りには古い値が表示されます。
2.2.2. キーの所有権
分散キャッシュは、エントリーを固定数のセグメントに分割し、各セグメントを所有者ノードのリストに割り当てます。レプリケートされたキャッシュは同じで、すべてのノードが所有者である場合を除きます。
所有者リストの最初のノードはプライマリー所有者です。リストのその他のノードはバックアップの所有者です。キャッシュトポロジーが変更するると、ノードがクラスターに参加またはクラスターから離脱するため、セグメント所有権テーブルがすべてのノードにブロードキャストされます。これにより、ノードはマルチキャスト要求を行ったり、各キーのメタデータを維持したりすることなく、キーを見つけることができます。
numSegments プロパティーでは、利用可能なセグメントの数を設定します。ただし、クラスターが再起動しない限り、セグメントの数は変更できません。
同様に、キーからセグメントのマッピングは変更できません。鍵は、クラスタートポロジーの変更に関係なく、常に同じセグメントにマップする必要があります。キーからセグメントのマッピングは、クラスタートポロジーの変更時に移動する必要のあるセグメント数を最小限に抑える一方で、各ノードに割り当てられたセグメント数を均等に分散することが重要になります。
| 一貫性のあるハッシュファクトリーの実装 | 説明 |
|---|---|
|
| 一貫性のあるハッシュ に基づくアルゴリズムを使用します。サーバーヒントを無効にした場合は、デフォルトで選択されています。 この実装では、クラスターが対称である限り、すべてのキャッシュの同じノードに常にキーが割り当てられます。つまり、すべてのキャッシュがすべてのノードで実行します。この実装には、負荷の分散が若干不均等であるため、負のポイントが若干異なります。また、参加または脱退時に厳密に必要な数よりも多くのセグメントを移動します。 |
|
|
|
|
|
|
|
|
|
|
| レプリケートされたキャッシュの実装に内部で使用されます。このアルゴリズムは分散キャッシュで明示的に選択しないでください。 |
ハッシュ設定
組み込みキャッシュのみを使用して、カスタムを含む ConsistentHashFactory 実装を設定できます。
XML
<distributed-cache name="distributedCache"
owners="2"
segments="100"
capacity-factor="2" />
<distributed-cache name="distributedCache"
owners="2"
segments="100"
capacity-factor="2" />ConfigurationBuilder
2.2.3. 容量要素
容量係数は、クラスター内の各ノードで利用可能なリソースに基づいてセグメント数を割り当てます。
ノードの容量係数は、ノードがプライマリー所有者とバックアップ所有者の両方であるセグメントに適用されます。つまり、容量係数は、ノードがクラスター内の他のノードと比較した合計容量です。
デフォルト値は 1 です。つまり、クラスターのすべてのノードに同じ容量があり、Data Grid はクラスターのすべてのノードに同じ数のセグメントを割り当てます。
ただし、ノードにさまざまなメモリー量がある場合は、Data Grid ハッシュアルゴリズムが各ノードの容量で重み付けする多数のセグメントを割り当てるように、キャパシティー係数を設定することができます。
容量係数の設定の値は正の値で、1.5 などの分数になります。容量係数 0 を設定することもできますが、クラスターを一時的に参加するノードのみに推奨されます。代わりに、容量設定を使用することが推奨されます。
2.2.3.1. ゼロ容量ノード
すべてのキャッシュ、ユーザー定義のキャッシュ、および内部キャッシュに対して容量係数が 0 であるノードを設定できます。ゼロ容量ノードを定義する場合、ノードにはデータを保持しません。
ゼロ容量ノードの設定
XML
<infinispan> <cache-container zero-capacity-node="true" /> </infinispan>
<infinispan>
<cache-container zero-capacity-node="true" />
</infinispan>JSON
YAML
infinispan:
cacheContainer:
zeroCapacityNode: "true"
infinispan:
cacheContainer:
zeroCapacityNode: "true"ConfigurationBuilder
new GlobalConfigurationBuilder().zeroCapacityNode(true);
new GlobalConfigurationBuilder().zeroCapacityNode(true);2.2.4. レベル 1(L1) キャッシュ
Data Grid ノードは、clsuter の別のノードからエントリーを取得すると、ローカルレプリカを作成します。L1 キャッシュは、プライマリー所有者ノードでエントリーを繰り返し検索せずに、パフォーマンスを追加します。
以下の図は、L1 キャッシュの動作を示しています。
図2.4 L1 cache
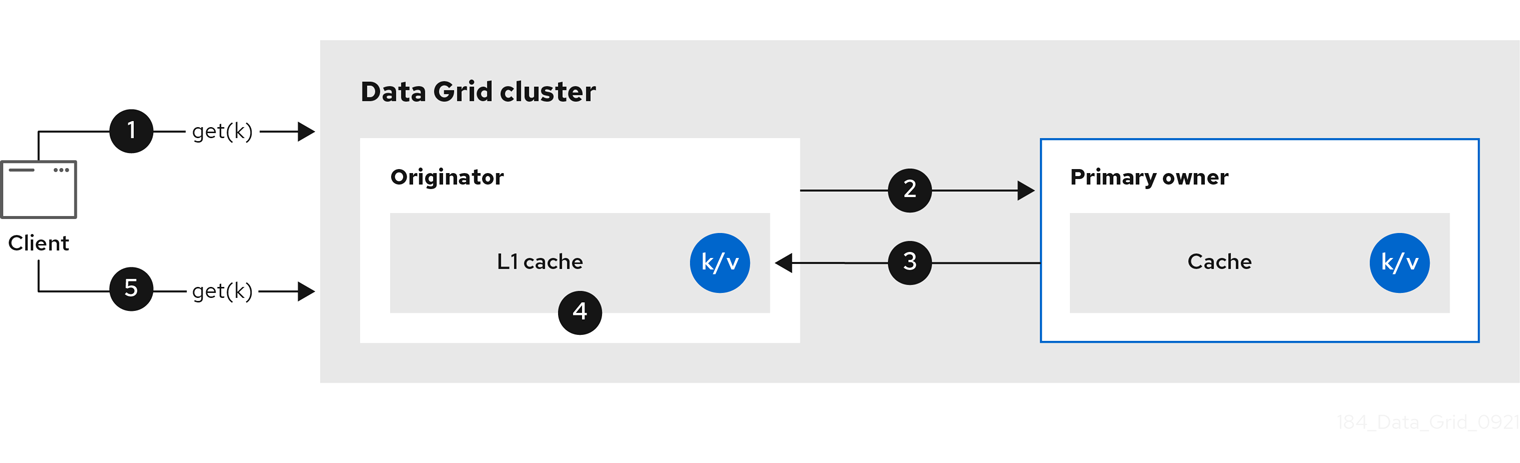
L1 cache の図では、以下のようになります。
-
クライアントは
cache.get()を呼び出して、クラスター内の別のノードがプライマリー所有者であるエントリーを読み取ります。 - 元のノードは読み取り操作をプライマリー所有者に転送します。
- プライマリー所有者はキー/値エントリーを返します。
- 元のノードはローカルコピーを作成します。
-
後続の
cache.get()呼び出しは、プライマリー所有者に転送するのではなく、ローカルエントリーを返します。
L1 キャッシュパフォーマンス
L1 を有効にすると読み取り操作のパフォーマンスが改善されますが、エントリーが変更されたときにプライマリー所有者ノードがメッセージをブロードキャストする必要があります。これにより、Data Grid はクラスター全体で古くなったレプリカをすべて削除します。ただし、これにより書き込み操作のパフォーマンスが低下し、メモリー使用量が増大し、キャッシュの全体的な容量が削減されます。
Data Grid は、他のキャッシュエントリーと同様に、ローカルレプリカまたは L1 エントリーをエビクトして期限切れにします。
L1 キャッシュ設定
XML
<distributed-cache l1-lifespan="5000"
l1-cleanup-interval="60000">
</distributed-cache>
<distributed-cache l1-lifespan="5000"
l1-cleanup-interval="60000">
</distributed-cache>JSON
YAML
distributedCache: l1Lifespan: "5000" l1-cleanup-interval: "60000"
distributedCache:
l1Lifespan: "5000"
l1-cleanup-interval: "60000"ConfigurationBuilder
ConfigurationBuilder builder = new ConfigurationBuilder();
builder.clustering().cacheMode(CacheMode.DIST_SYNC)
.l1()
.lifespan(5000, TimeUnit.MILLISECONDS)
.cleanupTaskFrequency(60000, TimeUnit.MILLISECONDS);
ConfigurationBuilder builder = new ConfigurationBuilder();
builder.clustering().cacheMode(CacheMode.DIST_SYNC)
.l1()
.lifespan(5000, TimeUnit.MILLISECONDS)
.cleanupTaskFrequency(60000, TimeUnit.MILLISECONDS);2.2.5. サーバーヒント
サーバーヒントは、できるだけ多くのサーバー、ラック、およびデータセンター間でエントリーをレプリケートすることで、分散キャッシュのデータ可用性を高めます。
サーバーのヒントは、分散キャッシュにのみ適用されます。
Data Grid がデータのコピーを配布する場合は、サイト、ラック、マシン、およびノードの優先順位に従います。すべての設定属性はオプションです。たとえば、ラック ID のみを指定する場合、Data Grid はコピーを別のラックおよびノードに分散します。
サーバーのヒントは、キャッシュのセグメント数が少なすぎる場合に必要以上のセグメントを移動し、クラスターのリバランス操作に影響を与える可能性があります。
複数のデータセンターにおけるクラスターの代替は、クロスサイトレプリケーションです。
サーバーヒントの設定
XML
JSON
YAML
GlobalConfigurationBuilder
2.2.6. キーアフィニティーサービス
分散キャッシュでは、不透明なアルゴリズムを使用してノードのリストにキーが割り当てられます。計算を逆にし、特定のノードにマップする鍵を生成する簡単な方法はありません。ただし、Data Grid は一連の (疑似) ランダムキーを生成し、それらのプライマリー所有者が何であるかを確認し、特定のノードへのキーマッピングが必要なときにアプリケーションに渡すことができます。
以下のコードスニペットは、このサービスへの参照を取得し、使用する方法を示しています。
サービスはステップ 2 で開始します。この時点以降、サービスは提供されたエグゼキューターを使用してキーを生成してキューに入れます。ステップ 3 では、サービスから鍵を取得し、手順 4 ではそれを使用します。
ライフサイクル
KeyAffinityService は ライフサイクル を拡張し、停止と (再) 起動を可能にします。
public interface Lifecycle {
void start();
void stop();
}
public interface Lifecycle {
void start();
void stop();
}
サービスは KeyAffinityServiceFactory でインスタンス化されます。ファクトリーメソッドはすべて Executor パラメーターを持ち、これは非同期キー生成に使用されます (呼び出し元のスレッドでは処理されません)。ユーザーは、この Executor のシャットダウンを処理します。
KeyAffinityService が起動したら、明示的に停止する必要があります。これにより、バックグラウンドキーの生成が停止し、保持されている他のリソースが解放されます。
KeyAffinityService がそれ自体で停止する唯一の状況は、登録済みのキャッシュマネージャーがシャットダウンした時です。
トポロジーの変更
キャッシュトポロジーが変更すると、KeyAffinityService によって生成されたキーの所有権が変更される可能性があります。主なアフィニティーサービスはこれらのトポロジーの変更を追跡し、現在別のノードにマップされるキーを返しませんが、先に生成したキーに関しては何も実行しません。
そのため、アプリケーションは KeyAffinityService を純粋に最適化として処理し、正確性のために生成されたキーの場所に依存しないようにしてください。
特に、アプリケーションは、同じアドレスが常に一緒に配置されるように、KeyAffinityService によって生成されたキーに依存するべきではありません。キーのコロケーションは、Grouping API によってのみ提供されます。
2.2.7. グループ化 API
キーアフィニティーサービスを補完する Grouping API を使用すると、実際のノードを選択することなく、同じノードにエントリーのグループを同じ場所にコロケートできます。
デフォルトでは、キーのセグメントはキーの hashCode() を使用して計算されます。Grouping API を使用する場合、Data Grid はグループのセグメントを計算し、それをキーのセグメントとして使用します。
Grouping API が使用されている場合、すべてのノードが他のノードと通信せずにすべてのキーの所有者を計算できることが重要です。このため、グループは手動で指定できません。グループは、エントリーに固有 (キークラスによって生成される) または外部 (外部関数によって生成される) のいずれかです。
Grouping API を使用するには、グループを有効にする必要があります。
Configuration c = new ConfigurationBuilder() .clustering().hash().groups().enabled() .build();
Configuration c = new ConfigurationBuilder()
.clustering().hash().groups().enabled()
.build();<distributed-cache> <groups enabled="true"/> </distributed-cache>
<distributed-cache>
<groups enabled="true"/>
</distributed-cache>
キークラスを制御できる場合 (クラス定義を変更できるが、変更不可能なライブラリーの一部ではない)、組み込みグループを使用することを推奨します。侵入グループは、@Group アノテーションをメソッドに追加して指定します。以下に例を示します。
group メソッドは String を返す必要があります。
キークラスを制御できない場合、またはグループの決定がキークラスと直交する懸念事項である場合は、外部グループを使用することを推奨します。外部グループは、Grouper インターフェイスを実装することによって指定されます。
public interface Grouper<T> {
String computeGroup(T key, String group);
Class<T> getKeyType();
}
public interface Grouper<T> {
String computeGroup(T key, String group);
Class<T> getKeyType();
}
同じキータイプに対して複数の Grouper クラスが設定されている場合は、それらすべてが呼び出され、前のクラスで計算された値を受け取ります。キークラスにも @Group アノテーションがある場合、最初の Grouper はアノテーション付きのメソッドによって計算されたグループを受信します。これにより、組み込みグループを使用するときに、グループをさらに細かく制御できます。
Grouper 実装の例
Grouper 実装は、キャッシュ設定で明示的に登録する必要があります。プログラムを用いて Data Grid を設定している場合は、以下を行います。
Configuration c = new ConfigurationBuilder() .clustering().hash().groups().enabled().addGrouper(new KXGrouper()) .build();
Configuration c = new ConfigurationBuilder()
.clustering().hash().groups().enabled().addGrouper(new KXGrouper())
.build();または、XML を使用している場合は、以下を行います。
<distributed-cache>
<groups enabled="true">
<grouper class="com.example.KXGrouper" />
</groups>
</distributed-cache>
<distributed-cache>
<groups enabled="true">
<grouper class="com.example.KXGrouper" />
</groups>
</distributed-cache>高度な API
AdvancedCache には、グループ固有のメソッドが 2 つあります。
-
getGroup(groupName)は、グループに属するキャッシュ内のすべてのキーを取得します。 -
removeGroup(groupName)は、グループに属するキャッシュにあるすべてのキーを削除します。
どちらのメソッドもデータコンテナー全体とストア (存在する場合) を繰り返し処理するため、キャッシュに多くの小規模なグループが含まれる場合に処理が遅くなる可能性があります。
2.3. Invalidation(インバリデーション) キャッシュ
Data Grid をインバリデーションモードで使用して、大量の読み取り操作を実行するシステムを最適化できます。良い例は、インバリデーションを使用して、状態の変化が発生したときに大量のデータベース書き込みを防ぐことです。
このキャッシュモードは、データベースなどのデータ用に別の永続的なストアがあり、読み取りが多いシステムで最適化として Data Grid を使用している場合にのみ意味があり、読み取りごとにデータベースにアクセスするのを防ぎます。キャッシュがインバリデーション用に設定されている場合は、データをキャッシュに変更するたびに、クラスター内の他のキャッシュは、データが古いため、メモリーおよびローカルストアから削除される必要があることを通知するメッセージを受信します。
図2.5 Invalidation cache
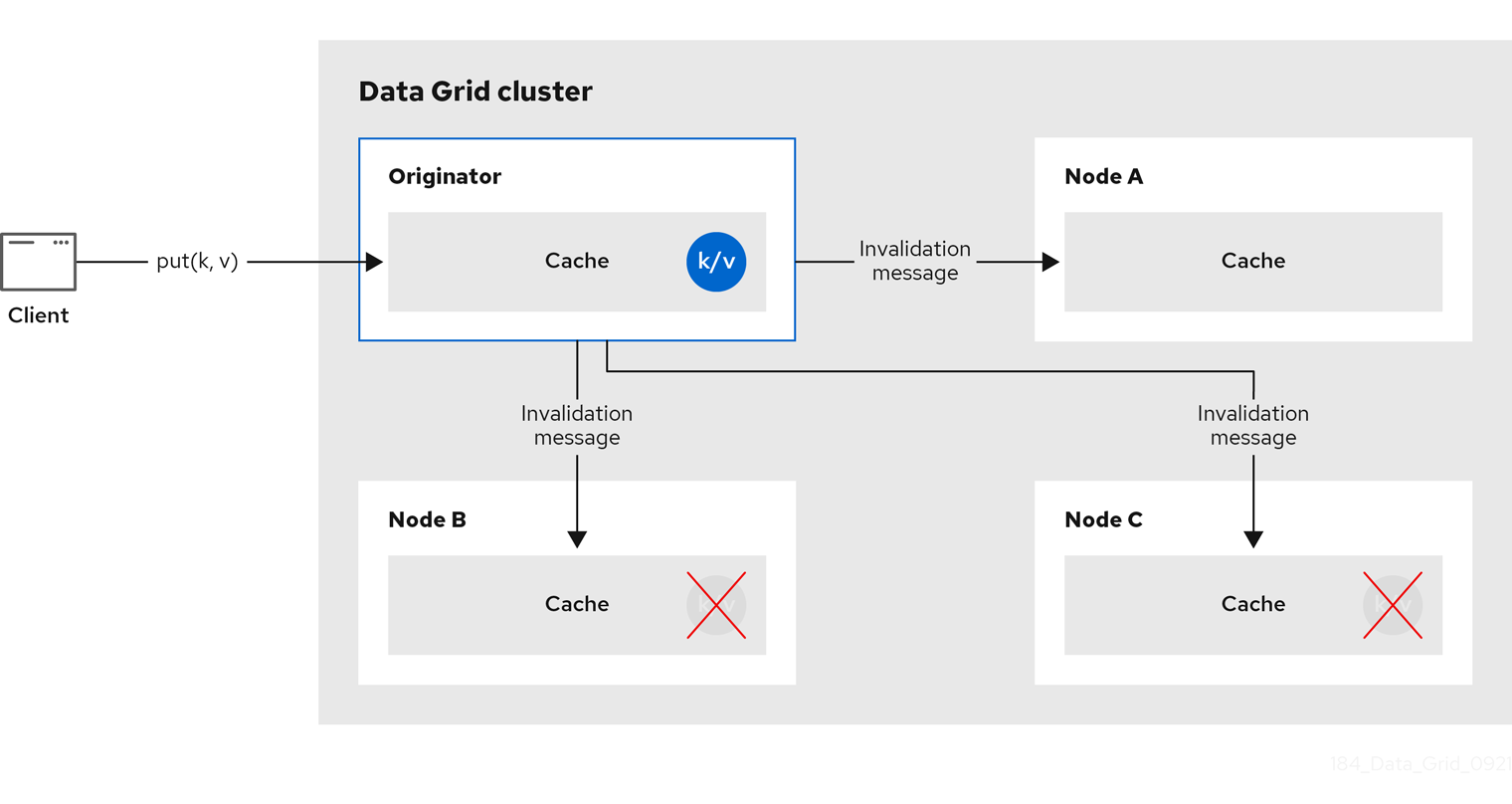
アプリケーションは外部ストアから値を読み取り、他のノードから削除せずにローカルキャッシュに書き込む場合があります。これを実行するには、Cache.put(key, value) の代わりに Cache.putForExternalRead(key, value) を呼び出す必要があります。
インバリデーションモードは、共有キャッシュストアと使用できます。書き込み操作は、共有ストアを更新し、他のノードメモリーから古い値を削除します。これには 2 つの利点があります。値全体を複製する場合に比べてインバリデーションメッセージが非常に小さいため、ネットワークトラフィックが最小限に抑えられます。また、クラスター内の他のキャッシュは、必要な場合にのみ、変更されたデータを遅延的に検索します。
ローカル、共有されていないキャッシュストアでは invalidation モードを使用しないでください。インバリデーションメッセージはローカルストアのエントリーを削除せず、一部のノードが古い値を認識します。
インバリデーションキャッシュは、特別なキャッシュローダー (ClusterLoader) で設定することもできます。ClusterLoader が有効になっている場合、ローカルノードでキーが見つからない読み取り操作は、最初に他のすべてのノードからキーを要求し、ローカルのメモリーに保存します。特定の状況では古い値を保存するため、古くなった値の耐性がある場合にのみ使用します。
同期または非同期のレプリケーション
同期すると、クラスター内のすべてのノードが古い値をエビクトするまで、書き込みがブロックされます。非同期の場合、元のブロードキャストは無効化メッセージを無効にしますが、応答を待ちません。つまり、発信者で書き込みが完了した後も、他のノードはしばらくの間古い値を確認します。
トランザクション
トランザクションはインバリデーションメッセージをバッチするために使用できます。トランザクションはプライマリー所有者でキーロックを取得します。
悲観的ロックでは、各書き込みは、すべてのノードにブロードキャストされるロックメッセージをトリガーします。トランザクションのコミット中に、発信者は、影響を受けるすべてのキーを無効にし、ロックを解放する 1 フェーズの準備メッセージ (任意で fire-and-forget) をブロードキャストします。
楽観的ロックを使用すると、発信者は準備メッセージ、コミットメッセージ、およびロック解除メッセージ (任意) をブロードキャストします。1 フェーズの準備またはロック解除メッセージのいずれかが fire-and-forget であり、最後のメッセージは常にロックを解放します。
2.4. 散在 (scattered) キャッシュ
散在 (scattered) キャッシュは、クラスターの線形のスケーリングが可能であるため、分散キャッシュと非常に似ています。散在 (scattered) キャッシュにより、データ (numOwners=2) の 2 つのコピーを維持することで、単一ノードの障害が可能になります。分散キャッシュとは異なり、データの場所は固定されていません。同じ Consistent Hash アルゴリズムを使用してプライマリー所有者を特定しますが、バックアップコピーは前回データを書き込んだノードに保存されます。書き込みがプライマリー所有者で行われる場合、バックアップコピーは他のノードに保存されます (このコピーの正確な場所は重要ではありません)。
これには、すべての書き込み (分散キャッシュ) に単一の Remote Procedure Call(RPC) を活用しますが、読み取りは常にプライマリー所有者を対象にする必要があります。これにより書き込みが高速になりますが、読み取り速度が遅い可能性があるため、このモードは書き込み集約型アプリケーションに適しています。
複数のバックアップコピーを保存すると、メモリー消費が若干高くなります。古いバックアップコピーを削除するために、インバリデーションメッセージがクラスターでブロードキャストされ、オーバーヘッドが発生します。これにより、多数のノードを持つクラスターでの散在キャッシュのパフォーマンスが低下します。
ノードがクラッシュすると、プライマリーコピーが失われる可能性があります。そのため、クラスターはバックアップを調整し、最後に書き込まれたバックアップコピーを見つける必要があります。このプロセスにより、状態遷移時によりネットワークトラフィックが上がります。
データの書き込みもバックアップであるため、トランスポートレベルでマシン/ラック/サイト ID を指定していても、同じマシン/ラック/サイトの障害に対して、クラスターが回復性を持つことができません。
トランザクションまたは非同期レプリケーションでは、散財キャッシュを使用することはできません。
キャッシュは、他のキャッシュモードと同様に設定されます。以下は宣言型設定の例です。
<scattered-cache name="scatteredCache" />
<scattered-cache name="scatteredCache" />Configuration c = new ConfigurationBuilder() .clustering().cacheMode(CacheMode.SCATTERED_SYNC) .build();
Configuration c = new ConfigurationBuilder()
.clustering().cacheMode(CacheMode.SCATTERED_SYNC)
.build();サーバーは通常 Hot Rod プロトコルを介してアクセスされるため、分散モードはサーバー設定では公開されません。このプロトコルは、書き込み用のプライマリー所有者を自動的に選択し (2 所有者を持つ分散モード)、クラスター内で単一の RPC が必要になります。したがって、分散キャッシュはパフォーマンス上の利点をもたらしません。
2.5. 非同期のレプリケーション
すべてのクラスター化キャッシュモードは、<replicated-cache/>、<distributed-cache>、または <invalidation-cache/> 要素上で mode="ASYNC" 属性と非同期通信を使用するように設定できます。
非同期通信では、送信元ノードは操作のステータスについて他のノードから確認応答を受け取ることはありません。そのため、他のノードで成功したかどうかを確認する方法はありません。
非同期通信はデータに不整合を引き起こす可能性があり、結果を推論するのが難しいため、一般的に非同期通信は推奨しません。ただし、速度が一貫性よりも重要であり、このようなケースでオプションが利用できる場合があります。
Asynchronous API
非同期 API を使用すると、ユーザースレッドをブロックしなくても同期通信を使用できます。
注意点が 1 つあります。非同期操作はプログラムの順序を保持しません。スレッドが cache.putAsync(k, v1); cache.putAsync(k, v2) を呼び出す場合の k の最終的な値は v1 または v2 のいずれかになります。非同期通信を使用する場合の利点は、最終的な値をあるノードで v1 にして別のノードで v2 にすることができないことです。
2.5.1. 非同期レプリケーションのある戻り値
Cache インターフェイスは java.util.Map を拡張するため、put(key, value) や remove(key) などの書き込みメソッドはデフォルトで以前の値を返します。
戻り値が正しくないことがあります。
-
Flag.IGNORE_RETURN_VALUE、Flag.SKIP_REMOTE_LOOKUP、またはFlag.SKIP_CACHE_LOADでAdvancedCache.withFlags()を使用する場合。 -
キャッシュに
unreliable-return-values="true"が設定されている場合。 - 非同期通信を使用する場合。
- 同じキーへの同時書き込みが複数あり、キャッシュトポロジーが変更された場合。トポロジーの変更により、Data Grid は書き込み操作を再試行します。また、再試行操作の戻り値は信頼性がありません。
トランザクションキャッシュは、3 と 4 の場合、正しい以前の値を返します。しかし、トランザクションキャッシュには gotcha: in distributed モードもあり、read-committed 分離レベルは、繰り返し可能な読み取りとして実装されます。つまり、この"double-checked locking"例は機能しません。
これを実装する適切な方法として、cache.getAdvancedCache().withFlags(Flag.FORCE_WRITE_LOCK).get(k) を使用します。
最適化されたロックを持つキャッシュでは、書き込みは古い以前の値を返すことができます。書き込み skew チェックでは、古い値を回避できます。
2.6. 初期クラスターサイズの設定
Data Grid は、クラスタートポロジーの変更を動的に処理します。これは、Data Grid がキャッシュを初期化する前に、他のノードがクラスターに参加する必要がないことを意味します。
キャッシュの開始前にアプリケーションがクラスター内の特定のノードを必要とする場合は、初期クラスターサイズをトランスポートの一部として設定できます。
手順
- Data Grid 設定を開いて編集します。
-
キャッシュの開始前に必要なノードの最小数を
initial-cluster-size属性またはinitialClusterSize()メソッドで設定します。 -
キャッシュマネージャーが
initial-cluster-timeout属性またはinitialClusterTimeout()メソッドで開始しないまでの時間をミリ秒単位で設定します。 - Data Grid 設定を保存して閉じます。
初期クラスターサイズの設定
XML
JSON
YAML
infinispan:
cacheContainer:
transport:
initialClusterSize: "4"
initialClusterTimeout: "30000"
infinispan:
cacheContainer:
transport:
initialClusterSize: "4"
initialClusterTimeout: "30000"ConfigurationBuilder
GlobalConfiguration global = GlobalConfigurationBuilder.defaultClusteredBuilder() .transport() .initialClusterSize(4) .initialClusterTimeout(30000, TimeUnit.MILLISECONDS);
GlobalConfiguration global = GlobalConfigurationBuilder.defaultClusteredBuilder()
.transport()
.initialClusterSize(4)
.initialClusterTimeout(30000, TimeUnit.MILLISECONDS);第3章 Data Grid キャッシュの設定
キャッシュ設定は、Data Grid がデータを保存する方法を制御します。
キャッシュ設定の一部として、使用するキャッシュモードを宣言します。たとえば、Data Grid クラスターがレプリケートされたキャッシュまたは分散キャッシュを使用するように設定できます。
設定は、キャッシュの特性も定義し、データの処理時に使用する Data Grid 機能を有効にします。たとえば、エントリーがモビリティーまたは immortal である場合は、Data Grid がキャッシュ内のエントリーをエンコードする方法、レプリケーション要求がノード間で同期または非同期に行われるかを設定できます。
3.1. 宣言型キャッシュの設定
Data Grid スキーマに従って、XML または JSON 形式でキャッシュを宣言型で設定できます。
宣言型キャッシュ設定には、プログラムによる設定と比較して、以下のような利点があります。
- 移植性
-
埋め込みキャッシュおよびリモートキャッシュを作成するために使用できるスタンドアロンファイルに各設定を定義します。
宣言型設定を使用して、OpenShift で実行しているクラスターの Data Grid Operator でキャッシュを作成することもできます。 - 簡素化
-
マークアップ言語をプログラミング言語とは別に維持します。
たとえば、リモートキャッシュを作成するには、通常、複雑な XML を Java コードに直接追加しないことが推奨されます。
Data Grid Server 設定は infinispan.xml を拡張し、クラスタートランスポートメカニズム、セキュリティーレルム、およびエンドポイント設定が含まれます。Data Grid Server 設定の一部としてキャッシュを宣言する場合、Ansible または Chef などの管理ツールを使用して、クラスター全体で同期する必要があります。
Data Grid クラスター全体でリモートキャッシュを動的に同期するには、実行時に作成します。
3.1.1. キャッシュ設定
XML、JSON、および YAML 形式で宣言型キャッシュ設定を作成できます。
すべての宣言型キャッシュは Data Grid スキーマに準拠する必要があります。JSON 形式の設定は XML 設定の構造に従う必要があります。要素がオブジェクトに対応し、属性はフィールドに対応します。
Data Grid では、キャッシュ名またはキャッシュテンプレート名の文字数を最大 255 文字に制限しています。この文字制限を超えると、Data Grid サーバーは例外メッセージを発行せずに突然停止する場合があります。簡潔なキャッシュ名とキャッシュテンプレート名を記述します。
ファイルシステムによってファイル名の長さに制限が設定される場合があるため、キャッシュの名前がこの制限を超えないようにしてください。キャッシュ名がファイルシステムの命名制限を超えると、そのキャッシュに対する一般的な操作または初期化操作が失敗する可能性があります。簡潔なキャッシュ名とキャッシュテンプレート名を記述します。
分散キャッシュ
XML
JSON
YAML
レプリケートされたキャッシュ
XML
JSON
YAML
複数のキャッシュ
XML
YAML
JSON
3.2. キャッシュテンプレートの追加
Data Grid スキーマには、テンプレートの作成に使用できる *-cache-configuration 要素が含まれます。その後、同じ設定を複数回使用して、オンデマンドでキャッシュを作成することができます。
手順
- Data Grid 設定を開いて編集します。
-
適切な
*-cache-configuration要素またはオブジェクトをキャッシュマネージャーに追加します。 - Data Grid 設定を保存して閉じます。
キャッシュテンプレートの例
XML
JSON
YAML
3.2.1. テンプレートからのキャッシュの作成
設定テンプレートからキャッシュを作成します。
リモートキャッシュのテンプレートは、Data Grid コンソールの Cache templates メニューから利用できます。
前提条件
- キャッシュマネージャーに少なくとも 1 つのキャッシュテンプレートを追加します。
手順
- Data Grid 設定を開いて編集します。
-
キャッシュが
configuration属性またはフィールドを継承するテンプレートを指定します。 - Data Grid 設定を保存して閉じます。
テンプレートから継承されたキャッシュ設定
XML
<distributed-cache configuration="my-dist-template" />
<distributed-cache configuration="my-dist-template" />JSON
{
"distributed-cache": {
"configuration": "my-dist-template"
}
}
{
"distributed-cache": {
"configuration": "my-dist-template"
}
}YAML
distributedCache: configuration: "my-dist-template"
distributedCache:
configuration: "my-dist-template"3.2.2. キャッシュテンプレートの継承
キャッシュ設定テンプレートは、他のテンプレートから継承して、設定を拡張し、上書きすることができます。
キャッシュテンプレートの継承は階層的です。親から継承する子設定テンプレートの場合は、親テンプレートの後に追加する必要があります。
さらに、複数の値を持つ要素にはテンプレート継承が追加されます。別のテンプレートから継承するキャッシュは、そのテンプレートから値をマージし、プロパティーを上書きできます。
テンプレート継承の例
XML
JSON
YAML
3.2.3. キャッシュテンプレートのワイルドカード
ワイルドカードをキャッシュ設定テンプレート名に追加できます。名前がワイルドカードに一致するキャッシュを作成すると、Data Grid は設定テンプレートを適用します。
キャッシュ名が複数のワイルドカードと一致する場合は、Data Grid は例外を出力します。
テンプレートワイルドカードの例
XML
JSON
YAML
上記の例では、async-dist-cache-prod という名前のキャッシュを作成する場合、Data Grid は async-dist-cache-* テンプレートの設定を使用します。
3.2.4. 複数の XML ファイルからのキャッシュテンプレート
キャッシュ設定テンプレートを複数の XML ファイルに分割して、粒度を柔軟に参照し、XML 包含 (XInclude) で参照します。
Data Grid は、XInclude 仕様の最小限のサポートを提供します。つまり、xpointer 属性、xi:fallback 要素、テキスト処理、またはコンテンツネゴシエーションを使用できません。
また、XInclude を使用するには xmlns:xi="http://www.w3.org/2001/XInclude" namespace を infinispan.xml に追加する必要もあります。
Xinclude キャッシュテンプレート
Data Grid は、設定フラグメントで使用できる infinispan-config-fragment-13.0.xsd スキーマも提供します。
設定フラグメントスキーマ
<local-cache xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="urn:infinispan:config:13.0 https://infinispan.org/schemas/infinispan-config-fragment-13.0.xsd"
xmlns="urn:infinispan:config:13.0"
name="mycache"/>
<local-cache xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="urn:infinispan:config:13.0 https://infinispan.org/schemas/infinispan-config-fragment-13.0.xsd"
xmlns="urn:infinispan:config:13.0"
name="mycache"/>3.3. リモートキャッシュの作成
ランタイム時にリモートキャッシュを作成すると、Data Grid Server はクラスター全体で設定を同期し、全ノードがコピーを持つようにします。このため、常に以下のメカニズムを使用してリモートキャッシュを動的に作成する必要があります。
- Data Grid コンソール
- Data Grid コマンドラインインターフェイス (CLI)
- Hot Rod または HTTP クライアント
3.3.1. デフォルトの Cache Manager
Data Grid Server は、リモートキャッシュのライフサイクルを制御するデフォルトの Cache Manager を提供します。Data Grid Server を起動すると、Cache Manager が自動的にインスタンス化されるため、リモートキャッシュや Protobuf スキーマなどの他のリソースを作成および削除できます。
Data Grid Server を起動してユーザー認証情報を追加したら、Cache Manager の詳細を表示し、Data Grid コンソールからクラスター情報を取得できます。
-
任意のブラウザーで
127.0.0.1:11222を開きます。
コマンドラインインターフェイス (CLI) または REST API を使用して Cache Manager に関する情報を取得することもできます。
- CLI
デフォルトのコンテナーで
describeコマンドを使用します。[//containers/default]> describe
[//containers/default]> describeCopy to Clipboard Copied! Toggle word wrap Toggle overflow - REST
-
任意のブラウザーで
127.0.0.1:11222/rest/v2/cache-managers/default/を開きます。
デフォルトの Cache Manager の設定
XML
JSON
YAML
3.3.2. Data Grid コンソールを使用したキャッシュの作成
Data Grid コンソールを使用して、任意の Web ブラウザーから直感的なビジュアルインターフェイスでリモートキャッシュを作成します。
前提条件
-
adminパーミッションを持つ Data Grid ユーザーを作成します。 - 1 つ以上の Data Grid Server インスタンスを起動します。
- Data Grid キャッシュ設定があります。
手順
-
任意のブラウザーで
127.0.0.1:11222/console/を開きます。 - Create Cache を選択し、プロセスを Data Grid コンソールガイドの手順に従ってください。
3.3.3. Data Grid CLI を使用したリモートキャッシュの作成
Data Grid コマンドラインインターフェイス (CLI) を使用して、Data Grid Server にリモートキャッシュを追加します。
前提条件
-
adminパーミッションを持つ Data Grid ユーザーを作成します。 - 1 つ以上の Data Grid Server インスタンスを起動します。
- Data Grid キャッシュ設定があります。
手順
CLI を起動し、プロンプトが表示されたら認証情報を入力します。
bin/cli.sh
bin/cli.shCopy to Clipboard Copied! Toggle word wrap Toggle overflow create cacheコマンドを使用してリモートキャッシュを作成します。たとえば、以下のように
mycache.xmlという名前のファイルから"mycache"という名前のキャッシュを作成します。create cache --file=mycache.xml mycache
create cache --file=mycache.xml mycacheCopy to Clipboard Copied! Toggle word wrap Toggle overflow
検証
lsコマンドを使用して、すべてのリモートキャッシュをリスト表示します。ls caches mycache
ls caches mycacheCopy to Clipboard Copied! Toggle word wrap Toggle overflow describeコマンドでキャッシュ設定を表示します。describe caches/mycache
describe caches/mycacheCopy to Clipboard Copied! Toggle word wrap Toggle overflow
3.3.4. Hot Rod クライアントからのリモートキャッシュの作成
Data Grid Hot Rod API を使用して、Java、C++、.NET/C#、JS クライアントなどから Data Grid Server にリモートキャッシュを作成します。
この手順では、最初のアクセスでリモートキャッシュを作成する Hot Rod Java クライアントを使用する方法を示します。他の Hot Rod クライアントのコード例は、Data Grid Tutorials を参照してください。
前提条件
-
adminパーミッションを持つ Data Grid ユーザーを作成します。 - 1 つ以上の Data Grid Server インスタンスを起動します。
- Data Grid キャッシュ設定があります。
手順
-
ConfigurationBuilderの一部としてremoteCache()メソッドを呼び出します。 -
クラスパスの
hotrod-client.propertiesファイルでconfigurationまたはconfiguration_uriプロパティーを設定します。
ConfigurationBuilder
hotrod-client.properties
infinispan.client.hotrod.cache.another-cache.configuration=<distributed-cache name=\"another-cache\"/> infinispan.client.hotrod.cache.[my.other.cache].configuration_uri=file:///path/to/infinispan.xml
infinispan.client.hotrod.cache.another-cache.configuration=<distributed-cache name=\"another-cache\"/>
infinispan.client.hotrod.cache.[my.other.cache].configuration_uri=file:///path/to/infinispan.xml
リモートキャッシュの名前に . が含まれる場合は、hotrod-client.properties ファイルを使用する場合は角括弧で囲む必要があります。
3.3.5. REST API を使用したリモートキャッシュの作成
Data Grid REST API を使用して、適切な HTTP クライアントから Data Grid Server でリモートキャッシュを作成します。
前提条件
-
adminパーミッションを持つ Data Grid ユーザーを作成します。 - 1 つ以上の Data Grid Server インスタンスを起動します。
- Data Grid キャッシュ設定があります。
手順
-
ペイロードにキャッシュ設定を指定して
/rest/v2/caches/<cache_name>にPOST要求を呼び出します。
3.4. 組み込みキャッシュの作成
Data Grid は、プログラムを使用して Cache Manager と組み込みキャッシュライフサイクルの両方を制御できる EmbeddedCacheManager API を提供します。
3.4.1. Data Grid のプロジェクトへの追加
Data Grid をプロジェクトに追加して、アプリケーションで組み込みキャッシュを作成します。
前提条件
- Maven リポジトリーから Data Grid アーティファクトを取得するようにプロジェクトを設定します。
手順
-
以下のように、
infinispan-coreアーティファクトをpom.xmlの依存関係として追加します。
3.4.2. 組み込みキャッシュの設定
Data Grid は、キャッシュマネージャーと、埋め込みキャッシュを設定する ConfigurationBuilder API を制御する GlobalConfigurationBuilder API を提供します。
前提条件
-
infinispan-coreアーティファクトをpom.xmlの依存関係として追加します。
手順
- デフォルトのキャッシュマネージャーを初期化し、埋め込みキャッシュを追加できます。
-
ConfigurationBuilderAPI を使用して、埋め込みキャッシュを 1 つ以上追加します。 -
クラスターのすべてのノードで組み込みキャッシュを作成するか、すでに存在するキャッシュを返す
getOrCreateCache()メソッドを呼び出します。
第4章 Data Grid 統計および JMX 監視の有効化および設定
Data Grid は、JMX MBean をエクスポートしたり、Cache Manager およびキャッシュ統計を提供できます。
4.1. Data Grid メトリックの設定
Data Grid は、MicroProfile Metrics API と互換性のあるメトリックを生成します。
- ゲージは、書き込み操作または JVM アップタイムの平均数 (ナノ秒) などの値を指定します。
- ヒストグラムは、読み取り、書き込み、削除の時間などの操作実行時間の詳細を提供します。
デフォルトでは、Data Grid は統計を有効にするとゲージを生成しますが、ヒストグラムを生成するように設定することもできます。
手順
- Data Grid 設定を開いて編集します。
-
metrics要素またはオブジェクトをキャッシュコンテナーに追加します。 -
gauges属性またはフィールドを使用してゲージを有効または無効にします。 -
histograms属性またはフィールドでヒストグラムを有効または無効にします。 - クライアント設定を保存して閉じます。
メトリックの設定
XML
JSON
YAML
4.2. JMX MBean の登録
Data Grid は、統計の収集と管理操作の実行に使用できる JMX MBean を登録できます。統計を有効にする必要もあります。そうしないと、Data Grid は JMX MBean のすべての統計属性に 0 値を提供します。
手順
- Data Grid 設定を開いて編集します。
-
jmx要素またはオブジェクトをキャッシュコンテナーに追加し、enabled属性またはフィールドの値としてtrueを指定します。 -
domain属性またはフィールドを追加し、必要に応じて JMX MBean が公開されるドメインを指定します。 - クライアント設定を保存して閉じます。
JMX の設定
XML
JSON
YAML
4.2.1. JMX リモートポートの有効化
一意のリモート JMX ポートを提供し、JMXServiceURL 形式の接続を介して Data Grid MBean を公開します。
次のいずれかの方法を使用して、リモート JMX ポートを有効にできます。
- Data Grid サーバーセキュリティーレルムの 1 つに対する認証を必要とするリモート JMX ポートを有効にします。
- 標準の Java 管理設定オプションを使用して、手動でリモート JMX ポートを有効にします。
前提条件
-
認証付きのリモート JMX の場合、デフォルトのセキュリティーレルムを使用してユーザーロールを定義します。ユーザーが JMX リソースにアクセスするには、読み取り/書き込みアクセス権を持つ
controlRoleまたは読み取り専用アクセス権を持つmonitorRoleが必要です。
手順
次のいずれかの方法を使用して、リモート JMX ポートを有効にして Data Grid サーバーを起動します。
ポート
9999を介してリモート JMX を有効にします。bin/server.sh --jmx 9999
bin/server.sh --jmx 9999Copy to Clipboard Copied! Toggle word wrap Toggle overflow 警告SSL を無効にしてリモート JMX を使用することは、本番環境向けではありません。
起動時に以下のシステムプロパティーを Data Grid サーバーに渡します。
bin/server.sh -Dcom.sun.management.jmxremote.port=9999 -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false
bin/server.sh -Dcom.sun.management.jmxremote.port=9999 -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=falseCopy to Clipboard Copied! Toggle word wrap Toggle overflow 警告認証または SSL なしでリモート JMX を有効にすることは安全ではなく、どのような環境でも推奨されません。認証と SSL を無効にすると、権限のないユーザーがサーバーに接続し、そこでホストされているデータにアクセスできるようになります。
4.2.2. Data Grid MBean
Data Grid は、管理可能なリソースを表す JMX MBean を公開します。
org.infinispan:type=Cache- キャッシュインスタンスに使用できる属性および操作。
org.infinispan:type=CacheManager- Data Grid キャッシュやクラスターのヘルス統計など、Cache Manager で使用できる属性および操作。
使用できる JMX MBean の詳細なリストおよび説明、ならびに使用可能な操作および属性については、Data Grid JMX Components のドキュメントを参照してください。
4.2.3. カスタム MBean サーバーでの MBean の登録
Data Grid には、カスタム MBeanServer インスタンスに MBean を登録するのに使用できる MBeanServerLookup インターフェイスが含まれています。
前提条件
-
getMBeanServer()メソッドがカスタム MBeanServer インスタンスを返すようにMBeanServerLookupの実装を作成します。 - JMX MBean を登録するように Data Grid を設定します。
手順
- Data Grid 設定を開いて編集します。
-
mbean-server-lookup属性またはフィールドをキャッシュマネージャーの JMX 設定に追加します。 -
MBeanServerLookup実装の完全修飾名 (FQN) を指定します。 - クライアント設定を保存して閉じます。
JMX MBean サーバールックアップの設定
XML
JSON
YAML
第5章 JVM メモリー使用量の設定
以下を行って、Data Grid がデータを JVM メモリーに保存する方法を制御します。
- キャッシュからデータを自動的に削除するエビクションを使用した JVM メモリー使用量の管理
- ライフスパンを追加し、エントリー失効させるために最大アイドル時間を追加し、古くなったデータを防ぎます。
- データをオフヒープのネイティブメモリーに保存するための Data Grid の設定
5.1. デフォルトのメモリー設定
デフォルトでは、Data Grid はキャッシュエントリーを JVM ヒープにオブジェクトとして保存します。時間の経過とともに、アプリケーションによってエントリーが追加されると、キャッシュのサイズが JVM で利用可能なメモリー量を超える可能性があります。同様に、Data Grid がプライマリーデータストアではない場合、エントリーに古いデータが含まれることを意味します。
XML
<distributed-cache> <memory storage="HEAP"/> </distributed-cache>
<distributed-cache>
<memory storage="HEAP"/>
</distributed-cache>JSON
YAML
distributedCache:
memory:
storage: "HEAP"
distributedCache:
memory:
storage: "HEAP"5.2. エビクションと有効期限
エビクションと有効期限は、古い未使用のエントリーを削除してデータコンテナーをクリーンアップするための 2 つの戦略です。エビクションと有効期限は同じですが、重要な違いがいくつかあります。
- ✓ エビクションを使用すると、コンテナーが設定されたしきい値より大きくなったときにエントリーを削除することで、Data Grid がデータコンテナーのサイズを制御できます。
-
✓ 有効期限により、エントリーの存在が制限されます。Data Grid はスケジューラーを使用して、期限切れのエントリーを定期的に削除します。有効期限が切れていても削除されていないエントリーは、アクセスするとすぐに削除されます。この場合、期限切れのエントリーに対する
get()呼び出しは、"null" 値を返します。 - ✓ エビクションは Data Grid ノードのローカルです。
- ✓有効期限は Data Grid クラスター全体で実行されます。
- ✓ エビクションと有効期限を一緒に使用することも、個別に使用できます。
-
✓
infinispan.xmlでエビクションおよび有効期限を宣言型で設定し、エントリーのキャッシュ全体のデフォルトを適用できます。 - ✓ 特定のエントリーの有効期限設定を明示的に定義できますが、エントリーごとにエビクションを定義することはできません。
- ✓ エントリーを手動でエビクトし、有効期限を手動でトリガーできます。
5.3. Data Grid キャッシュを使用したエビクション
エビクションを使用すると、以下の 2 つの方法のいずれかでメモリーからエントリーを削除して、データコンテナーのサイズを制御できます。
-
エントリーの合計数 (
max-count)。 -
メモリーの最大量 (
max-size)。
エビクションは、一度に 1 つのエントリーをデータコンテナーから破棄し、そのエントリーが実行するノードに対してローカルにあります。
エビクションはメモリーからエントリーを削除しますが、永続的なキャッシュストアからは削除しません。Data Grid がエビクトした後もエントリーが利用可能な状態を維持し、データの一貫性を防ぐためには、永続ストレージを設定する必要があります。
memory を設定する場合、Data Grid はデータコンテナーの現在のメモリー使用量を概算します。エントリーが追加または変更されると、Data Grid はデータコンテナーの現在のメモリー使用量を最大サイズと比較します。サイズが最大値を超えると、Data Grid はエビクションを実行します。
エビクションは、最大サイズを超えるエントリーを追加するスレッドですぐに行われます。
5.3.1. エビクションストラテジー
Data Grid エビクションを設定する場合は、以下を指定します。
- データコンテナーの最大サイズ。
- キャッシュがしきい値に達するとエントリーを削除するストラテジー。
エビクションは手動で実行することも、Data Grid を以下のいずれかを実行するように設定したりできます。
- 古いエントリーを削除して、新しいエントリー用の領域を作成します。
ContainerFullExceptionを出力し、新規エントリーが作成されないようにします。例外エビクションストラテジーは、2 フェーズコミットを使用するトランザクションキャッシュでのみ動作しますが、1 フェーズコミットまたは同期の最適化とは関係しません。
エビクションストラテジーについての詳細は、スキーマ参照を参照してください。
Data Grid には、TinyLFU と呼ばれる Least Frequently Used (LFU) キャッシュ置換アルゴリズムのバリエーションを実装する Caffeine キャッシングライブラリーが含まれています。オフヒープストレージの場合、Data Grid は LeastRecent Used (LRU) アルゴリズムのカスタム実装を使用します。
5.3.2. 最大カウントエビクションの設定
Data Grid キャッシュのサイズをエントリーの合計数に制限します。
手順
- Data Grid 設定を開いて編集します。
-
Data Grid が
max-count属性またはmaxCount()メソッドのいずれかでエビクションを実行する前のキャッシュに含まれるエントリーの合計数を指定します。 以下のいずれかをエビクションストラテジーとして設定し、Data Grid が
when-full属性またはwhenFull()メソッドを持つエントリーを削除する方法を制御します。-
REMOVEData Grid はエビクションを実行します。これはデフォルトのストラテジーです。 -
MANUAL組み込みキャッシュのエビクションを手動で実行します。 -
EXCEPTIONData Grid は、エントリーをエビクトするのではなく、例外を出力します。
-
- Data Grid 設定を保存して閉じます。
最大数エビクション
以下の例では、キャッシュに合計 500 エントリーが含まれ、新しいエントリーが作成されると、Data Grid はエントリーを削除します。
XML
<distributed-cache> <memory max-count="500" when-full="REMOVE"/> </distributed-cache>
<distributed-cache>
<memory max-count="500" when-full="REMOVE"/>
</distributed-cache>JSON
YAML
distributedCache:
memory:
maxCount: "500"
whenFull: "REMOVE"
distributedCache:
memory:
maxCount: "500"
whenFull: "REMOVE"ConfigurationBuilder
ConfigurationBuilder builder = new ConfigurationBuilder(); builder.memory().maxCount(500).whenFull(EvictionStrategy.REMOVE);
ConfigurationBuilder builder = new ConfigurationBuilder();
builder.memory().maxCount(500).whenFull(EvictionStrategy.REMOVE);5.3.3. 最大サイズのエビクションの設定
Data Grid キャッシュのサイズを最大メモリー容量に制限します。
手順
- Data Grid 設定を開いて編集します。
application/x-protostreamをキャッシュエンコーディングのメディアタイプとして指定します。最大サイズのエビクションを使用するには、バイナリーメディアタイプを指定する必要があります。
-
Data Grid が
max-size属性またはmaxSize()メソッドでエビクションを実行する前にキャッシュが使用できるメモリーの最大量 (バイト単位) を設定します。 任意で、測定のバイト単位を指定します。
デフォルトは B(バイト単位) です。サポートされるユニットの設定スキーマを参照してください。
以下のいずれかをエビクションストラテジーとして設定し、Data Grid が
when-full属性またはwhenFull()メソッドを持つエントリーのいずれかを削除する方法を制御します。-
REMOVEData Grid はエビクションを実行します。これはデフォルトのストラテジーです。 -
MANUAL組み込みキャッシュのエビクションを手動で実行します。 -
EXCEPTIONData Grid は、エントリーをエビクトするのではなく、例外を出力します。
-
- Data Grid 設定を保存して閉じます。
最大サイズのエビクション
以下の例では、キャッシュのサイズが 1.5 GB(ギガバイト) に達すると、Data Grid はエントリーを削除します。
XML
<distributed-cache> <encoding media-type="application/x-protostream"/> <memory max-size="1.5GB" when-full="REMOVE"/> </distributed-cache>
<distributed-cache>
<encoding media-type="application/x-protostream"/>
<memory max-size="1.5GB" when-full="REMOVE"/>
</distributed-cache>JSON
YAML
ConfigurationBuilder
ConfigurationBuilder builder = new ConfigurationBuilder();
builder.encoding().mediaType("application/x-protostream")
.memory()
.maxSize("1.5GB")
.whenFull(EvictionStrategy.REMOVE);
ConfigurationBuilder builder = new ConfigurationBuilder();
builder.encoding().mediaType("application/x-protostream")
.memory()
.maxSize("1.5GB")
.whenFull(EvictionStrategy.REMOVE);5.3.4. 手動エビクション
手動エビクションストラテジーを選択する場合、Data Grid はエビクションを実行しません。これは、evict() メソッドで手動で行う必要があります。
組み込みキャッシュでのみ手動のエビクションを使用する必要があります。リモートキャッシュの場合は、REMOVE または EXCEPTION エビクションストラテジーで Data Grid を常に設定する必要があります。
この設定は、パッシベーションを有効にし、エビクションを設定しない場合に警告メッセージを防ぎます。
XML
<distributed-cache> <memory max-count="500" when-full="MANUAL"/> </distributed-cache>
<distributed-cache>
<memory max-count="500" when-full="MANUAL"/>
</distributed-cache>JSON
YAML
distributedCache:
memory:
maxCount: "500"
whenFull: "MANUAL"
distributedCache:
memory:
maxCount: "500"
whenFull: "MANUAL"ConfigurationBuilder
ConfigurationBuilder builder = new ConfigurationBuilder();
builder.encoding().mediaType("application/x-protostream")
.memory()
.maxSize("1.5GB")
.whenFull(EvictionStrategy.REMOVE);
ConfigurationBuilder builder = new ConfigurationBuilder();
builder.encoding().mediaType("application/x-protostream")
.memory()
.maxSize("1.5GB")
.whenFull(EvictionStrategy.REMOVE);5.3.5. エビクションによるパッシベーション
パッシベーションは、Data Grid がエントリーをエビクトする際にキャッシュストアにデータを永続化します。以下の例のように、エビクションをパッシベーションを有効にする場合は、常にエビクションを有効にする必要があります。
XML
JSON
YAML
distributedCache:
memory:
maxCount: "100"
persistence:
passivation: "true"
distributedCache:
memory:
maxCount: "100"
persistence:
passivation: "true"ConfigurationBuilder
ConfigurationBuilder builder = new ConfigurationBuilder(); builder.memory().maxCount(100); builder.persistence().passivation(true); //Persistent storage configuration
ConfigurationBuilder builder = new ConfigurationBuilder();
builder.memory().maxCount(100);
builder.persistence().passivation(true); //Persistent storage configuration5.4. ライフスパンと最大アイドル期間の有効期限
有効期限は、以下の時間制限のいずれかに到達すると、キャッシュからエントリーを削除するように Data Grid を設定します。
- 有効期間
- エントリーが存在することができる最大時間を設定します。
- 最大アイドル
- エントリーがアイドル状態のままになる期間を指定します。エントリーに対して操作が行われない場合は、アイドル状態になります。
現在、アイドルの最大有効期限は永続ストレージのキャッシュをサポートしていません。
EXCEPTION エビクションストラテジーで expiration および eviction を使用する場合に、有効期限が切れているが、キャッシュから削除されないエントリーは、データコンテナーのサイズに対してカウントされます。
5.4.1. 有効期限の仕組み
有効期限を設定する場合、Data Grid はエントリーが期限切れになるタイミングを決定するメタデータを持つキーを保存します。
-
有効期限は、
creationタイムスタンプとlifespan設定プロパティーの値を使用します。 -
最大アイドルは、
last usedタイムスタンプとmax-idle設定プロパティーの値を使用します。
Data Grid は、有効期限または最大アイドルメタデータが設定されているかどうかを確認し、値と現在の時間を比較します。
(creation + lifespan < currentTime) または (lastUsed + maxIdle < currentTime) の場合、Data Grid はエントリーが期限切れであると検出します。
有効期限は、有効期限リーパーによってエントリーがアクセスまたは検出されるたびに発生します。
たとえば、k1 は最大アイドル時間に到達し、クライアントは Cache.get(k1) 要求を作成します。この場合、Data Grid はエントリーが期限切れであることを検出し、データコンテナーから削除します。Cache.get(k1) リクエストは null を返します。
Data Grid はキャッシュストアのエントリーも期限切れになりますが、ライフサイクルの有効期限のみになります。最大アイドル有効期限はキャッシュストアでは機能しません。キャッシュローダーの場合、ローダーは外部ストレージからしか読み取ることができないため、Data Grid はエントリーを期限切れにすることはできません。
Data Grid は、期限切れのメタデータを、long プリミティブデータタイプとしてキャッシュエントリーに追加します。これにより、32 バイトだけにキーのサイズが増える可能性があります。
5.4.2. 有効期限のリーパー
Data Grid は、定期的に実行されるリーパースレッドを使用して、期限切れのエントリーを検出して削除します。有効期限により、アクセスされなくなった期限切れのエントリーが確実に削除されるようにします。
Data Grid の ExpirationManager インターフェイスは、有効期限リーパーを処理し、processExpiration() メソッドを公開します。
場合によっては、processExpiration() を呼び出すことで、有効期限リーパーを無効にし、エントリーを手動で期限切れにすることができます。たとえば、メンテナンススレッドが定期的に実行するカスタムアプリケーションでローカルキャッシュモードを使用している場合です。
クラスター化されたキャッシュモードを使用する場合は、有効期限リーパーを無効にしないでください。
キャッシュストアを使用する場合は、Data Grid は常に有効期限のリーパーを使用します。この場合、無効にすることはできません。
5.4.3. アイドルおよびクラスター化されたキャッシュの最大数
最大アイドル有効期限はキャッシュエントリーの最後のアクセス時間に依存するため、クラスター化されたキャッシュモードにはいくつかの制限があります。
有効期限が切れると、キャッシュエントリーの作成時間は、クラスター化されたキャッシュ全体で一貫した値を提供します。たとえば、k1 の作成時間は、常にすべてのノードで同じです。
クラスター化されたキャッシュを使用した最大アイドル有効期限のため、エントリーに対する最終アクセス時間は、常にすべてのノードで同じではありません。クラスター全体で相対アクセス時間が同じになるように、Data Grid はキーへのアクセス時に、すべての所有者に touch コマンドを送信します。
Data Grid が送信する touch コマンドには、以下の考慮事項があります。
-
Cache.get()リクエストは、すべての touch コマンドが完了するまで返されません。この同期動作により、クライアント要求のレイテンシーが長くなります。 - touch コマンドは、すべての所有者のキャッシュエントリーの recently accessed メタデータも更新します。
- scattered キャッシュモードの場合、Data Grid はプライマリーおよびバックアップ所有者のみではなく、touch コマンドをすべてのノードに送信します。
関連情報
- 最大アイドル有効期限はインバリデーションモードでは機能しません。
- クラスター化されたキャッシュでの反復は、最大アイドル時間制限を超過した期限切れのエントリーを返すことができます。この動作は、反復中にリモート呼び出しが実行されないため、パフォーマンスが向上します。また、繰り返しは期限切れのエントリーを更新しないことに注意してください。
5.4.4. キャッシュのライフサイクルと最大アイドル時間の設定
キャッシュ内のすべてのエントリーの有効期間と最大アイドル時間を設定します。
手順
- Data Grid 設定を開いて編集します。
-
lifespan属性またはlifespan()メソッドでエントリーがキャッシュ内に留まることができる期間をミリ秒単位で指定します。 -
max-idle属性またはmaxIdle()メソッドを使用した最後のアクセス後にエントリーがアイドル状態でいられる期間をミリ秒単位で指定します。 - Data Grid 設定を保存して閉じます。
Data Grid キャッシュの有効期限
以下の例では、Data Grid は、最後のアクセス時間が過ぎてから 5 秒または 1 秒後にすべてのキャッシュエントリーの有効期限が切れるようにします。
XML
<replicated-cache> <expiration lifespan="5000" max-idle="1000" /> </replicated-cache>
<replicated-cache>
<expiration lifespan="5000" max-idle="1000" />
</replicated-cache>JSON
YAML
replicatedCache:
expiration:
lifespan: "5000"
maxIdle: "1000"
replicatedCache:
expiration:
lifespan: "5000"
maxIdle: "1000"ConfigurationBuilder
ConfigurationBuilder builder = new ConfigurationBuilder();
builder.expiration().lifespan(5000, TimeUnit.MILLISECONDS)
.maxIdle(1000, TimeUnit.MILLISECONDS);
ConfigurationBuilder builder = new ConfigurationBuilder();
builder.expiration().lifespan(5000, TimeUnit.MILLISECONDS)
.maxIdle(1000, TimeUnit.MILLISECONDS);5.4.5. エントリーごとのライフスパンおよび最大アイドル時間の設定
各エントリーの lifespan と maximum idle times を指定します。ライフスパンとアイドル時間をエントリーに追加する場合、これらの値はキャッシュの有効期限の設定よりも優先されます。
キャッシュエントリーの lifespan と最大アイドル時間の値を明示的に定義すると、Data Grid はキャッシュエントリーとともにクラスター全体でこれらの値を複製します。同様に、Data Grid は有効期限の値とエントリーを永続ストレージに書き込みます。
手順
リモートキャッシュでは、Data Grid コンソールを使用して、有効期限とアイドル時間を対話的にエントリーに追加できます。
Data Grid コマンドラインインターフェイス (CLI) で、
putコマンドで--max-idle=および--ttl=引数を使用します。リモートキャッシュと組み込みキャッシュの両方に対して、
cache.put()呼び出しでライフスパンと最大アイドル時間を追加できます。Copy to Clipboard Copied! Toggle word wrap Toggle overflow
5.5. JVM ヒープおよびオフヒープメモリー
Data Grid は、キャッシュエントリーを、デフォルトで JVM ヒープメモリーに保存します。Data Grid は、オフヒープストレージを使用するように設定できます。つまり、管理された JVM メモリー領域外のネイティブメモリーが、データで占有されます。
以下の図は、Data Grid が実行している JVM プロセスのメモリー領域を簡略して示しています。
図5.1 JVM メモリー領域

JVM ヒープメモリー
ヒープは、参照される Java オブジェクトや他のアプリケーションデータをメモリーに維持するのに役立つ新しい世代と古い世代に分けられます。GC プロセスは、到達不能オブジェクトから領域を回収し、新しい生成メモリープールでより頻繁に実行します。
Data Grid がキャッシュエントリーを JVM ヒープメモリーに保存すると、キャッシュへのデータ追加を開始するため、GC の実行が完了するまで時間がかかる場合があります。GC は集中的なプロセスであるため、実行が長く頻繁になると、アプリケーションのパフォーマンスが低下する可能性があります。
オフヒープメモリー
オフヒープメモリーは、JVM メモリー管理以外のネイティブで利用可能なシステムメモリーです。JVM メモリーの領域 の図には、クラスメタデータを保持し、ネイティブメモリーから割り当てられる メタスペース メモリープールが表示されます。この図は、Data Grid キャッシュエントリーを保持するネイティブメモリーのセクションも含まれています。
オフヒープメモリー
- エントリーごとに少ないメモリーを使用します。
- Garbage Collector (GC) の実行を回避するために、JVM 全体のパフォーマンスを改善します。
ただし、JVM ヒープダンプはオフヒープメモリーに保存されているエントリーを表示しない点が短所です。
5.5.1. オフヒープデータストレージ
オフヒープキャッシュにエントリーを追加すると、Data Grid はネイティブメモリーをデータに動的に割り当てます。
Data Grid は、各キーのシリアル化された byte [] を、標準の Java HashMap と同様のバケットにハッシュ値を持ちます。バケットには、Data Grid がオフヒープメモリーに保存するエントリーの検索に使用するアドレスポインターが含まれます。
Data Grid はキャッシュエントリーをネイティブメモリーに保存する場合でも、ランタイム操作にはこれらのオブジェクトの JVM ヒープ表現が必要です。たとえば、cache.get() 操作は、返される前にオブジェクトをヒープメモリーに読み取ります。同様に、状態転送操作は、オブジェクトのサブセットが実行している間は、それらをヒープメモリーに保持します。
オブジェクトの等価性
Data Grid は、オブジェクトインスタンスではなく、各オブジェクトのシリアライズされた byte[] 表現を使用して、オフヒープストレージで Java オブジェクトの等価性を決定します。
データの整合性
Data Grid は、ロックの配列を使用して、オフヒープアドレス空間を保護します。ロックの数は、コア数に 2 倍になり、その後に最も近い 2 の累乗に丸められます。これにより、書き込み操作が読み取り操作をブロックしないように、ReadWriteLock インスタンスの配分も存在します。
5.5.2. オフヒープメモリーの設定
JVM ヒープ領域以外のネイティブメモリーにキャッシュエントリーを保存するように Data Grid を設定します。
手順
- Data Grid 設定を開いて編集します。
-
OFF_HEAPをstorage属性またはstorage()メソッドの値として設定します。 - エビクションを設定して、キャッシュのサイズに境界を設定します。
- Data Grid 設定を保存して閉じます。
オフヒープストレージ
Data Grid は、キャッシュエントリーをバイトとしてネイティブメモリーに保存します。エビクションは、データコンテナーに 100 エントリーがあり、Data Grid が新規エントリーを作成する要求を取得すると発生します。
XML
<replicated-cache> <memory storage="OFF_HEAP" max-count="500"/> </replicated-cache>
<replicated-cache>
<memory storage="OFF_HEAP" max-count="500"/>
</replicated-cache>JSON
YAML
replicatedCache:
memory:
storage: "OFF_HEAP"
maxCount: "500"
replicatedCache:
memory:
storage: "OFF_HEAP"
maxCount: "500"ConfigurationBuilder
ConfigurationBuilder builder = new ConfigurationBuilder(); builder.memory().storage(StorageType.OFF_HEAP).maxCount(500);
ConfigurationBuilder builder = new ConfigurationBuilder();
builder.memory().storage(StorageType.OFF_HEAP).maxCount(500);第6章 Configuring persistent storage
Data Grid は、キャッシュストアとローダーを使用して永続ストレージと対話します。
- 持続性
- キャッシュストアを追加すると、不揮発性ストレージにデータを永続化できるため、再起動後も存続することができます。
- ライトスルーキャッシュ
- Data Grid を永続ストレージの前のキャッシュレイヤーとして設定すると、Data Grid が外部ストレージとのすべての対話を処理するため、アプリケーションのデータアクセスが簡素化されます。
- データオーバーフロー
- エビクションとパッシベーションの手法を使用すると、Data Grid は頻繁に使用されるデータのみをメモリー内に保持し、古いエントリーを永続ストレージに書き込みます。
6.1. パッシベーション
パッシベーションは、これらのエントリーをメモリーからエビクトする際に、ストアにエントリーを書き込むように Data Grid を設定します。この方法により、パッシベーションは、インメモリーまたはキャッシュストアのいずれかによって単一のエントリーのコピーのみが維持されるようになります。これにより、不要な書き込みや永続ストレージへのコストがかかる可能性があります。
アクティベーションとは、パッシベートされたエントリーにアクセスしようとすると、キャッシュストアからメモリーにエントリーを復元するプロセスのことです。このため、パッシベーションを有効にすると、CacheWriter インターフェイスと CacheLoader インターフェイスの両方を実装するキャッシュストアを設定して、永続ストレージからエントリーを書き込み、読み込めるようにします。
Data Grid がキャッシュからエントリーをエビクトすると、エントリーがパッシベートされてからキャッシュストアにエントリーを保存するようキャッシュリスナーに通知します。Data Grid がエビクトされたエントリーへのアクセス要求を取得すると、キャッシュストアからエントリーをメモリーにロードし、エントリーがアクティブになるキャッシュリスナーに通知します。
- パッシベーションは、Data Grid 設定の最初のキャッシュローダーを使用し、その他はすべて無視します。
パッシベーションは以下ではサポートされません。
- トランザクションストア。パッシベーションは、実際の Data Grid コミット境界の範囲外のストアからエントリーを作成し、削除します。
- 共有ストア。共有キャッシュストアでは、他の所有者に対して常にストアにエントリーが存在する必要があります。そのため、エントリーを削除できないため、パッシベーションはサポートされません。
トランザクションストアまたは共有ストアでパッシベーションを有効にすると、Data Grid は例外を出力します。
6.1.1. パッシベーションの仕組み
無効のパッシベーション
メモリーのデータへの書き込みにより、永続ストレージが書き込まれます。
Data Grid がデータをメモリーからエビクトする場合、永続ストレージのデータにはメモリーからエビクトされるエントリーが含まれます。このようにして、永続ストレージはインメモリーキャッシュのスーパーセットになります。
エビクションを設定しない場合、永続ストレージのデータはメモリーにデータのコピーを提供します。
有効のパッシベーション
Data Grid は、メモリーからデータをエビクトする場合にのみ、データを永続ストレージに追加します。
Data Grid がエントリーをアクティベートすると、メモリーのデータが復元され、永続ストレージからデータが削除されます。これにより、永続ストレージのメモリーおよびデータ内のデータは、データセット全体のサブセットを切り離し、2 つの間の交差はありません。
共有ストレージのエントリーは、共有キャッシュストアの使用時に古くなる可能性があります。これは、Data Grid はアクティブ時に共有キャッシュストアからパッシベートされたエントリーを削除しないため発生します。
値はメモリーで更新されますが、以前にパッシベートされたエントリーは、古い値で永続ストレージに残ります。
以下の表は、一連の操作後のメモリーおよび永続ストレージのデータを示しています。
| 操作 | 無効のパッシベーション | 有効のパッシベーション | 共有キャッシュストアでパッシベーションが有効になっている |
|---|---|---|---|
| k1 を挿入します。 |
Memory: k1 |
Memory: k1 |
Memory: k1 |
| k2 を挿入します。 |
Memory: k1, k2 |
Memory: k1, k2 |
Memory: k1, k2 |
| エビクションスレッドが実行され、k1 をエビクトします。 |
Memory: k2 |
Memory: k2 |
Memory: k2 |
| k1 の読み取り |
Memory: k1, k2 |
Memory: k1, k2 |
Memory: k1, k2 |
| エビクションスレッドが実行され、k2 をエビクトします。 |
Memory: k1 |
Memory: k1 |
Memory: k1 |
| k2 を削除します。 |
Memory: k1 |
Memory: k1 |
Memory: k1 |
6.2. ライトスルーキャッシュストア
ライトスルーは、メモリーへの書き込みとキャッシュストアへの書き込みが同期されるキャッシュ書き込みモードです。クライアントアプリケーションがキャッシュエントリーを更新すると、Cache.put() を呼び出すと、Data Grid はキャッシュストアを更新するまで呼び出しを返しません。このキャッシュ書き込みモードを使用すると、クライアントスレッドの境界内にあるキャッシュストアに更新されます。
write-through モードの主な利点は、キャッシュおよびキャッシュストアが同時に更新され、キャッシュストアが常にキャッシュと一致していることです。
ただし、ライトスルーモードは、キャッシュ操作にレイテンシーを直接追加する必要があるため、パフォーマンスが低下する可能性があります。
ライトスルー設定
Data Grid は、キャッシュに write-behind 設定を明示的に追加しない限り、ライトスルーモードを使用します。write-through モードを設定する別の要素またはメソッドはありません。
たとえば、以下の設定は、ライトスルーモードを暗黙的に使用するキャッシュにファイルベースのストアを追加します。
6.3. write-behind キャッシュストア
write-behind は、メモリーへの書き込みが同期され、キャッシュストアへの書き込みが非同期であるキャッシュ書き込みモードです。
クライアントが書き込み要求を送信すると、Data Grid はこれらの操作を変更キューに追加します。Data Grid は、呼び出しスレッドがブロックされず、操作がすぐに完了しないように、キューに参加する際に操作を処理します。
変更キューの書き込み操作の数がキューのサイズを超えた場合、Data Grid はこれらの追加操作をキューに追加します。ただし、これらの操作は、すでにキューにある Data Grid が処理するまで完了しません。
たとえば、Cache.putAsync を呼び出すとすぐに戻り、変更キューが満杯でない場合はすぐに Stage も完了します。変更キューが満杯であったり、Data Grid が書き込み操作のバッチを処理している場合、Cache.putAsync は即座に戻り、Stage は後で完了します。
write-behind モードは、キャッシュ操作で基礎となるキャッシュストアへの更新が完了するまで待つ必要がないため、ライトスルーモードよりもパフォーマンス上の利点があります。ただし、キャッシュストアのデータは、変更キューが処理されるまでキャッシュ内のデータと一貫性がありません。このため、Write-Behind モードは、非共有およびローカルのファイルベースのキャッシュストアなど、低レイテンシーでキャッシュストアに適しています。ここでは、キャッシュへの書き込みとキャッシュストアの書き込みの間隔が可能な限り小さくなります。
ライトビハインドの設定
XML
JSON
YAML
ConfigurationBuilder
ConfigurationBuilder builder = new ConfigurationBuilder();
builder.persistence()
.async()
.modificationQueueSize(2048)
.failSilently(true);
ConfigurationBuilder builder = new ConfigurationBuilder();
builder.persistence()
.async()
.modificationQueueSize(2048)
.failSilently(true);サイレント失敗
write-behind 設定には、キャッシュストアが利用できない場合や、変更キューが満杯になったときに何が発生するかを制御する fail-silently のパラメーターが含まれます。
-
fail-silently="true"の場合、Data Grid は WARN メッセージをログに記録し、書き込み操作を拒否します。 fail-silently="false"の場合、書き込み操作中にキャッシュストアが利用できないことを検知すると、Data Grid は例外を出力します。同様に、変更キューがいっぱいになると、Data Grid は例外を出力します。Data Grid の再起動および書き込み操作が変更キューに存在すると、データ喪失が発生する可能性があります。たとえば、キャッシュストアはオフラインになりますが、キャッシュストアが利用できないことを検知するのにかかると、フルではないため、変更キューへの書き込み操作が追加されます。Data Grid が再起動するか、キャッシュストアがオンラインに戻る前に利用できなくなると、永続化していないため、変更キューへの書き込み操作が失われます。
6.4. セグメント化されたキャッシュストア
キャッシュストアは、キーがマップされるハッシュ空間セグメントにデータを編成できます。
セグメント化ストアは、一括操作の読み取りパフォーマンスを向上させます。たとえば、データ (Cache.size、Cache.entrySet.stream) をストリーミングし、キャッシュを事前読み込み、状態遷移操作を行います。
ただし、セグメントストアを使用すると、書き込み操作のパフォーマンスが低下する可能性があります。このパフォーマンス損失は、トランザクションまたはライトビハイストアで実行可能なバッチ書き込み操作に対して特に該当します。このため、セグメント化されたストアを有効にする前に、書き込み操作のオーバーヘッドを評価する必要があります。書き込み操作のパフォーマンスが大幅に低下した場合、一括読み取り操作のパフォーマンスは許容できない場合があります。
キャッシュストア用に設定するセグメント数は、clustering.hash.numSegments パラメーターと Data Grid 設定で定義するセグメントの数と一致している必要があります。
セグメント化されたキャッシュストアを追加した後に設定の numSegments パラメーターを変更すると、Data Grid はそのキャッシュストアからデータを読み取ることができません。
6.6. 永続キャッシュストアを使用するトランザクション
Data Grid は、JDBC ベースのキャッシュストアでのみトランザクション操作をサポートします。キャッシュをトランザクションとして設定するには、transactional=true を設定して、永続ストレージのデータをメモリー内のデータと同期させる必要があります。
他のすべてのキャッシュストアでは、Data Grid はトランザクション操作でリストキャッシュローダーをエンリスト化しません。これにより、メモリー内のデータの変更中にトランザクションが正常に実行されたものの、キャッシュストアのデータへの変更が完全に適用されない場合は、データの不整合が生じる可能性があります。このような場合、キャッシュストアでは手動リカバリーができません。
6.7. グローバルの永続的な場所
Data Grid は、再起動後にクラスタートポロジーおよびキャッシュされたデータを復元できるようにグローバル状態を保持します。
リモートキャッシュ
Data Grid Server は、クラスターの状態を $RHDG_HOME/server/data ディレクトリーに保存します。
server/data ディレクトリーまたはその内容を削除または変更しないでください。Data Grid は、サーバーインスタンスを再起動すると、このディレクトリーからクラスターの状態を復元します。
デフォルト設定を変更したり、server/data ディレクトリーを直接変更すると、予期しない動作が発生し、データが失われる可能性があります。
組み込みキャッシュ
Data Grid は、グローバルな永続的な場所として user.dir システムプロパティーにデフォルト設定されます。ほとんどの場合、これはアプリケーションが開始するディレクトリーです。
クラスター化された組み込みキャッシュ (レプリケートまたは分散など) の場合は、クラスタートポロジーを復元するためにグローバルの永続的な場所を常に有効にし、設定する必要があります。
グローバルの永続的な場所外にあるファイルベースのキャッシュストアの絶対パスを設定しないでください。この場合、Data Grid は以下の例外をログに書き込みます。
ISPN000558: "The store location 'foo' is not a child of the global persistent location 'bar'"
ISPN000558: "The store location 'foo' is not a child of the global persistent location 'bar'"6.7.1. グローバルの永続的な場所の設定
Data Grid がクラスター化された組み込みキャッシュのグローバル状態を保存する場所を有効にして設定します。
Data Grid Server は、グローバル永続性を有効にし、デフォルトの場所を設定します。グローバル永続性を無効にしたり、リモートキャッシュのデフォルト設定を変更したりしないでください。
前提条件
- Data Grid をプロジェクトに追加します。
手順
以下のいずれかの方法でグローバル状態を有効にします。
-
global-state要素を Data Grid 設定に追加します。 -
GlobalConfigurationBuilderAPI でglobalState().enable()メソッドを呼び出します。
-
グローバルの永続的な場所は各ノードに一意であるか、クラスター間で共有されるかどうかを定義します。
Expand ロケーションのタイプ 設定 各ノードに一意
persistent-location要素またはpersistentLocation()メソッドクラスター間で共有される
shared-persistent-location要素またはsharedPersistentLocation(String)メソッドData Grid がクラスターの状態を保存するパスを設定します。
たとえば、ファイルベースのキャッシュストアは、パスはホストファイルシステムのディレクトリーです。
値は以下のとおりです。
- ルートを含む完全な場所を含む絶対的な場所が含まれます。
- ルートの場所と相対的です。
パスに相対値を指定する場合は、ルートロケーションに解決するシステムプロパティーも指定する必要があります。
たとえば、
global/stateをパスとして設定する Linux ホストシステムでは、以下のようになります。また、/opt/dataルートロケーションに解決するmy.dataプロパティーも設定します。この場合、Data Grid はグローバルの永続的な場所として/opt/data/global/stateを使用します。
グローバルの永続的な場所設定
XML
JSON
YAML
cacheContainer:
globalState:
persistentLocation:
path: "global/state"
relativeTo : "my.data"
cacheContainer:
globalState:
persistentLocation:
path: "global/state"
relativeTo : "my.data"GlobalConfigurationBuilder
new GlobalConfigurationBuilder().globalState()
.enable()
.persistentLocation("global/state", "my.data");
new GlobalConfigurationBuilder().globalState()
.enable()
.persistentLocation("global/state", "my.data");6.8. ファイルベースのキャッシュストア
ファイルベースのキャッシュストアは、Data Grid が実行されているローカルホストのファイルシステムで永続ストレージを提供します。クラスター化されたキャッシュでは、ファイルベースのキャッシュストアは各 Data Grid ノードに固有のものです。
NFS や Samba 共有などの共有ファイルシステムには、ファイルシステムベースのキャッシュストアを使用しないでください。これは、ファイルのロック機能やデータの破損が発生する可能性があるためです。
また、共有ファイルシステムでトランザクションキャッシュを使用しようとすると、コミットフェーズでファイルに書き込む際に修復不能な障害が発生する可能性があります。
Soft-Index ファイルストア
SoftIndexFileStore は、ファイルベースのキャッシュストアのデフォルト実装で、追加のみのファイルのセットにデータを保存します。
追加のみのファイルの場合:
- 最大サイズに達すると、Data Grid は新しいファイルを作成し、書き込みを開始します。
- 使用率が 50% 未満の圧縮しきい値に達すると、Data Grid はエントリーを新しいファイルに上書きしてから、古いファイルを削除します。
B+ ツリー
パフォーマンスを改善するために、SoftIndexFileStore の追記のみのファイルは、ディスクおよびメモリーの両方に格納できる B+ ツリー を使用してインデックス化されます。インメモリーインデックスは Java ソフト参照を使用して、ガベージコレクション (GC) によって削除された場合に再構築してから再度要求できるようにします。
SoftIndexFileStore は Java ソフト参照を使用してインデックスをメモリーに維持するため、メモリー不足の例外を防ぐのに役立ちます。GC は、ディスクにフォールバックしながら、メモリーを過剰に消費する前にインデックスを削除します。
index 要素の segments 属性で宣言型で、あるいは indexSegments() メソッドでプログラム的に、任意の数の B+ ツリーを設定できます。デフォルトでは、Data Grid は最大 16 の B+ ツリーを作成します。つまり、最大 16 個のインデックスを持つことができます。複数のインデックスがあると、インデックスへの同時書き込みからのボトルネックを防ぎ、Data Grid がメモリーに保持する必要のあるエントリーの数を減らします。ソフトインデックスファイルストアを繰り返し処理するため、Data Grid はインデックスのすべてのエントリーを同時に読み取ります。
B+ ツリーの各エントリーはノードです。デフォルトでは、各ノードのサイズは 4096 バイトに制限されます。SoftIndexFileStore は、シリアル化後にキーが長い場合に例外を出力します。
セグメンテーション
soft-index ファイルの場所は常にセグメント化されます。
AdvancedStore.purgeExpired() メソッドは SoftIndexFileStore に実装されていません。
単一ファイルキャッシュストア
単一ファイルキャッシュストアは非推奨となり、削除される予定です。
Single File キャッシュストアである SingleFileStore は、ファイルにデータを永続化します。また、データ Grid は、キーと値がファイルに保存される間に、キーのインメモリーインデックスも維持されます。
SingleFileStore はキーのインメモリーインデックス、および値の場所を保持するため、キーのサイズと数に応じて追加のメモリーが必要です。このため、SingleFileStore は、キーが大きく、または多数の値がある可能性のあるユースケースには推奨しません。
SingleFileStore が断片化される場合もあります。値のサイズが継続的に増加している場合は、単一ファイルで利用可能な領域は使用されませんが、エントリーはファイルの最後に追加されます。このファイルで使用可能な領域は、エントリーに収まることができる場合に限り使用されます。同様に、メモリーからすべてのエントリーを削除すると、単一のファイルストアのサイズが減少したり、デフラグしたりしません。
セグメンテーション
単一ファイルキャッシュストアは、デフォルトではセグメントごとに個別のインスタンスを持つセグメント化され、これにより複数のディレクトリーが作成されます。各ディレクトリーは、データマップ先のセグメントを表す数字です。
6.8.1. ファイルベースのキャッシュストアの設定
ファイルベースのキャッシュストアを Data Grid に追加し、ホストファイルシステムでデータを永続化します。
前提条件
- 組み込みキャッシュを設定する場合は、グローバルの状態を有効にし、グローバルの永続的な場所を設定します。
手順
-
persistence要素をキャッシュ設定に追加します。 -
オプションで、データがメモリーからエビクトされる場合にのみ、ファイルベースのキャッシュストアに書き込む
passivation属性の値としてtrueを指定します。 -
file-store要素を含め、属性を適宜設定します。 Falseをshared属性の値として指定します。ファイルベースのキャッシュストアは、常に各 Data Grid インスタンスに固有のものである必要があります。クラスター全体で同じ永続を使用する場合は、JDBC 文字列ベースのキャッシュストアなどの共有ストレージを設定します。
-
indexとdata要素を設定し、Data Grid がインデックスを作成し、データを格納する場所を指定します。 -
write-behindモードでキャッシュストアを設定する場合は、write-behind 要素を含めます。
ファイルベースのキャッシュストアの設定
XML
JSON
YAML
ConfigurationBuilder
6.8.2. 単一ファイルキャッシュストアの設定
必要な場合は、Data Grid を設定して単一のファイルストアを作成することができます。
単一ファイルストアは非推奨になりました。単一のファイルストアと比べ、ソフトインデックスファイルストアを使用すると、パフォーマンスとデータの整合性が向上します。
前提条件
- 組み込みキャッシュを設定する場合は、グローバルの状態を有効にし、グローバルの永続的な場所を設定します。
手順
-
persistence要素をキャッシュ設定に追加します。 -
オプションで、データがメモリーからエビクトされる場合にのみ、ファイルベースのキャッシュストアに書き込む
passivation属性の値としてtrueを指定します。 -
single-file-store要素を含めます。 -
Falseをshared属性の値として指定します。 - その他の属性を必要に応じて設定します。
-
write-behind要素を追加して、書き込み ではなく、書き込みの背後でキャッシュストアを設定します。
単一ファイルキャッシュストアの設定
XML
JSON
YAML
ConfigurationBuilder
6.9. JDBC 接続ファクトリー
Data Grid は、データベースへの接続を可能にするさまざまな ConnectionFactory 実装を提供します。SQL キャッシュストアと JDBC 文字列ベースのキャッシュストアで JDBC 接続を使用します。
接続プール
接続プールは、スタンドアロンの Data Grid デプロイメントに適していますが、Agroal をベースにしています。
XML
JSON
YAML
ConfigurationBuilder
管理データソース
データソース接続は、アプリケーションサーバーなどの管理環境に適しています。
XML
<distributed-cache>
<persistence>
<data-source jndi-url="java:/StringStoreWithManagedConnectionTest/DS" />
</persistence>
</distributed-cache>
<distributed-cache>
<persistence>
<data-source jndi-url="java:/StringStoreWithManagedConnectionTest/DS" />
</persistence>
</distributed-cache>JSON
YAML
distributedCache:
persistence:
dataSource:
jndiUrl: "java:/StringStoreWithManagedConnectionTest/DS"
distributedCache:
persistence:
dataSource:
jndiUrl: "java:/StringStoreWithManagedConnectionTest/DS"ConfigurationBuilder
ConfigurationBuilder builder = new ConfigurationBuilder();
builder.persistence()
.dataSource()
.jndiUrl("java:/StringStoreWithManagedConnectionTest/DS");
ConfigurationBuilder builder = new ConfigurationBuilder();
builder.persistence()
.dataSource()
.jndiUrl("java:/StringStoreWithManagedConnectionTest/DS");セキュアな接続
単純な接続ファクトリーは呼び出しごとにデータベース接続を作成し、テスト環境または開発環境での使用を目的としています。
XML
JSON
YAML
ConfigurationBuilder
6.9.1. マネージドデータソースの設定
Data Grid Server 設定の一部としてマネージドデータソースを作成し、JDBC データベース接続の接続プールとパフォーマンスを最適化します。その後、キャッシュ内のマネージドデータソースの JDNI 名を指定して、デプロイメントの JDBC 接続設定を一元化できます。
前提条件
-
データベースドライバーを、Data Grid Server インストールの
server/libディレクトリーにコピーします。
手順
- Data Grid Server 設定を開いて編集します。
-
data-sourcesセクションに新しいdata-sourceを追加します。 -
name属性またはフィールドでデータソースを一意に識別します。 jndi-name属性またはフィールドを使用してデータソースの JNDI 名を指定します。ヒントJNDI 名を使用して、JDBC キャッシュストア設定でデータソースを指定します。
-
trueをstatistics属性またはフィールドの値に設定し、/metricsエンドポイント経由でデータソースの統計を有効にします。 connection-factoryセクションのデータソースへの接続方法を定義する JDBC ドライバーの詳細を提供します。-
driver属性またはフィールドを使用して、データベースドライバーの名前を指定します。 -
url属性またはフィールドを使用して、JDBC 接続 URL を指定します。 -
usernameおよびpassword属性またはフィールドを使用して、認証情報を指定します。 - 必要に応じて他の設定を指定します。
-
-
Data Grid Server ノードが接続をプールして再利用する方法を、
connection-poolセクションの接続プール調整プロパティーで定義します。 - 変更を設定に保存します。
検証
以下のように、Data Grid コマンドラインインターフェイス (CLI) を使用して、データソース接続をテストします。
CLI セッションを開始します。
bin/cli.sh
bin/cli.shCopy to Clipboard Copied! Toggle word wrap Toggle overflow すべてのデータソースをリスト表示し、作成したデータソースが利用できることを確認します。
server datasource ls
server datasource lsCopy to Clipboard Copied! Toggle word wrap Toggle overflow データソース接続をテストします。
server datasource test my-datasource
server datasource test my-datasourceCopy to Clipboard Copied! Toggle word wrap Toggle overflow
マネージドデータソースの設定
XML
JSON
YAML
6.9.1.1. JNDI 名を使用したキャッシュの設定
マネージドデータソースを Data Grid Server に追加するとき、JNDI 名を JDBC ベースのキャッシュストア設定に追加できます。
前提条件
- マネージドデータソースを使用した Data Grid Server の設定
手順
- キャッシュ設定を開いて編集します。
-
data-source要素またはフィールドを JDBC ベースのキャッシュストア設定に追加します。 -
マネージドデータソースの JNDI 名を
jndi-url属性の値として指定します。 - JDBC ベースのキャッシュストアを適宜設定します。
- 変更を設定に保存します。
キャッシュ設定の JNDI 名
XML
JSON
YAML
6.9.1.2. 接続プールのチューニングプロパティー
Data Grid Server 設定で、マネージドデータソースの JDBC 接続プールを調整できます。
| プロパティー | 説明 |
|---|---|
|
| プールが保持する最初の接続数。 |
|
| プールの最大接続数。 |
|
| プールが保持する必要のある接続の最小数。 |
|
|
例外が発生する前に、接続を待機している間にブロックする最大時間 (ミリ秒単位)。新しい接続の作成に非常に長い時間がかかる場合は、これによって例外が出力されることはありません。デフォルトは |
|
|
バックグラウンド検証の実行の間隔 (ミリ秒単位)。期間 |
|
|
ミリ秒単位で指定された、この時間より長いアイドル状態の接続は、取得される前に検証されます (フォアグラウンド検証)。期間 |
|
| 削除される前の接続がアイドル状態でなくてはならない時間 (分単位)。 |
|
| リーク警告の前に接続を保持しなければならない時間 (ミリ秒単位)。 |
6.9.2. Agroal プロパティーを使用した JDBC 接続プールの設定
プロパティーファイルを使用して、JDBC 文字列ベースのキャッシュストアにプールされた接続ファクトリーを設定できます。
手順
以下の例のように、
org.infinispan.agroal.*プロパティーで JDBC 接続プール設定を指定します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow properties-file属性またはPooledConnectionFactoryConfiguration.propertyFile()メソッドでプロパティーファイルを使用するように Data Grid を設定します。XML
<connection-pool properties-file="path/to/agroal.properties"/>
<connection-pool properties-file="path/to/agroal.properties"/>Copy to Clipboard Copied! Toggle word wrap Toggle overflow JSON
"persistence": { "connection-pool": { "properties-file": "path/to/agroal.properties" } }"persistence": { "connection-pool": { "properties-file": "path/to/agroal.properties" } }Copy to Clipboard Copied! Toggle word wrap Toggle overflow YAML
persistence: connectionPool: propertiesFile: path/to/agroal.propertiespersistence: connectionPool: propertiesFile: path/to/agroal.propertiesCopy to Clipboard Copied! Toggle word wrap Toggle overflow ConfigurationBuilder
.connectionPool().propertyFile("path/to/agroal.properties").connectionPool().propertyFile("path/to/agroal.properties")Copy to Clipboard Copied! Toggle word wrap Toggle overflow
6.10. SQL キャッシュストア
SQL キャッシュストアを使用すると、既存のデータベーステーブルから Data Grid キャッシュを読み込むことができます。Data Grid は、2 種類の SQL キャッシュストアを提供します。
- テーブル
- Data Grid は、1 つのデータベーステーブルからエントリーを読み込みます。
- Query
- Data Grid は SQL クエリーを使用して、単一または複数のデータベーステーブルからエントリーを読み込み (これらのテーブルのサブ列からの読み込みを含む)、挿入、更新、および削除操作を実行します。
コードチュートリアルにアクセスして、SQL キャッシュストアの動作を試します。Persistence code tutorial with remote caches を参照してください。
SQL テーブルとクエリーストアの両方は以下のようになります。
- 永続ストレージに対する読み取りおよび書き込み操作を許可します。
- 読み取り専用で、キャッシュローダーとして機能します。
単一のデータベース列または複数のデータベース列の複合に対応するキーと値をサポートします。
複合キーと値の場合は、キーと値を記述する Protobuf スキーマ (
.protoファイル) で Data Grid を指定する必要があります。Data Grid Server を使用すると、schema コマンドを使用して、Data Grid Console または Command Line Interface(CLI) からschemaを追加できます。
SQL キャッシュストアは有効期限またはセグメンテーションをサポートしません。
6.10.1. キーおよび値のデータ型
Data Grid は、適切なデータ型を使用して、SQL キャッシュストアを介してデータベーステーブルの列からキーと値を読み込みます。以下の CREATE ステートメントは、isbn と title の 2 つの列が含まれる books という名前のテーブルを追加します。
2 列のデータベーステーブル
CREATE TABLE books (
isbn NUMBER(13),
title varchar(120)
PRIMARY KEY(isbn)
);
CREATE TABLE books (
isbn NUMBER(13),
title varchar(120)
PRIMARY KEY(isbn)
);
SQL キャッシュストアでこのテーブルを使用すると、Data Grid は isbn 列をキーとして、title 列を値として使用してキャッシュに追加します。
6.10.1.1. 複合キーと値
複合プライマリーキーまたは複合値を含むデータベーステーブルで SQL ストアを使用できます。
複合キーまたは値を使用するには、データ型を記述する Protobuf スキーマで Data Grid を指定する必要があります。また、SQL ストアに schema 設定を追加し、キーと値のメッセージ名を指定する必要があります。
Data Grid は、ProtoStream プロセッサーで Protobuf スキーマを生成することを推奨します。次に、Data Grid コンソール、CLI、または REST API を使用してリモートキャッシュの Protobuf スキーマをアップロードできます。
複合値
以下のデータベーステーブルは、title および author 列の複合値を保持します。
Data Grid は、isbn 列をキーとして使用してキャッシュにエントリーを追加します。値の場合、Data Grid には title 列と author 列をマッピングする Protobuf スキーマが必要です。
複合キーと値
以下のデータベーステーブルは複合プライマリーキーと複合値を保持し、それぞれに 2 列があります。
キーと値の両方で、Data Grid には列をキーと値にマッピングする Protobuf スキーマが必要です。
6.10.1.2. 埋め込みキー
以下の例のように、Protobuf スキーマは値の中にキーを含めることができます。
組み込みキーを使用した Protobuf スキーマ
埋め込みキーを使用するには、SQL ストア設定に embedded-key="true" 属性または embeddedKey(true) メソッドを含める必要があります。
6.10.1.3. SQL から Protobuf タイプへ
以下の表に、SQL データ型のデフォルトを Protobuf データ型にマッピングしています。
| SQL 型 | Protobuf タイプ |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
6.10.2. データベーステーブルからの Data Grid キャッシュの読み込み
Data Grid にデータベーステーブルからデータを読み込ませる場合は、SQL テーブルキャッシュストアを設定に追加します。データベースに接続すると、Data Grid はテーブルからメタデータを使用して列名とデータタイプを検出します。また、Data Grid は、データベースのどの列がプライマリーキーの一部であるかを自動的に決定します。
前提条件
-
JDBC 接続の詳細を把握している。
JDBC 接続ファクトリーを直接キャッシュ設定に追加できます。
実稼働環境でのリモートキャッシュでは、マネージドデータソースを Data Grid Server 設定に追加し、キャッシュ設定で JNDI 名を指定する必要があります。 複合キーまたは複合値の Protobuf スキーマを生成し、スキーマを Data Grid に登録します。
ヒントData Grid は、ProtoStream プロセッサーで Protobuf スキーマを生成することを推奨します。リモートキャッシュでは、Data Grid コンソール、CLI、または REST API を使用してスキーマを追加して、スキーマを登録できます。
手順
データベースドライバーを Data Grid デプロイメントに追加します。
-
リモートキャッシュ: データベースドライバーを、Data Grid Server インストールの
server/libディレクトリーにコピーします。 組み込みキャッシュ:
infinispan-cachestore-sql依存関係をpomファイルに追加します。<dependency> <groupId>org.infinispan</groupId> <artifactId>infinispan-cachestore-sql</artifactId> </dependency>
<dependency> <groupId>org.infinispan</groupId> <artifactId>infinispan-cachestore-sql</artifactId> </dependency>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
-
リモートキャッシュ: データベースドライバーを、Data Grid Server インストールの
- Data Grid 設定を開いて編集します。
SQL テーブルキャッシュストアを追加します。
宣言的
table-jdbc-store xmlns="urn:infinispan:config:store:sql:13.0"
table-jdbc-store xmlns="urn:infinispan:config:store:sql:13.0"Copy to Clipboard Copied! Toggle word wrap Toggle overflow プログラマティック
persistence().addStore(TableJdbcStoreConfigurationBuilder.class)
persistence().addStore(TableJdbcStoreConfigurationBuilder.class)Copy to Clipboard Copied! Toggle word wrap Toggle overflow -
データベースダイアレクトを
dialect=""またはdialect()のいずれかで指定します (例:dialect="H2"またはdialect="postgres")。 以下のように、必要なプロパティーで SQL キャッシュストアを設定します。
-
クラスター全体で同じキャッシュストアを使用するには、
shared="true"またはshared(true)を設定します。 -
読み取り専用のキャッシュストアを作成するには、
read-only="true"または.ignoreModifications(true)を設定します。
-
クラスター全体で同じキャッシュストアを使用するには、
-
table-name="<database_table_name>"またはtable.name("<database_table_name>")を使用して、キャッシュを読み込むデータベーステーブルに名前を付けます。 schema要素または.schemaJdbcConfigurationBuilder()メソッドを追加し、複合キーまたは値の Protobuf スキーマ設定を追加します。-
package属性またはpackage()メソッドを使用してパッケージ名を指定します。 -
message-name属性またはmessageName()メソッドを使用して複合値を指定します。 -
key-message-name属性またはkeyMessageName()メソッドを使用して複合キーを指定します。 -
スキーマで値内にキーが含まれている場合は、
embedded-key属性またはembeddedKey()メソッドにtrueの値を設定します。
-
- 変更を設定に保存します。
SQL テーブルストアの設定
以下の例では、Protobuf スキーマで定義された複合値を使用して、books という名前のデータベーステーブルから分散キャッシュを読み込みます。
XML
JSON
YAML
ConfigurationBuilder
6.10.3. SQL クエリーを使用したデータのロードおよび操作の実行
SQL クエリーキャッシュストアを使用すると、データベーステーブルのサブ列からなど、複数のデータベーステーブルからキャッシュを読み込み、挿入、更新、および削除操作を実行することができます。
前提条件
-
JDBC 接続の詳細を把握している。
JDBC 接続ファクトリーを直接キャッシュ設定に追加できます。
実稼働環境でのリモートキャッシュでは、マネージドデータソースを Data Grid Server 設定に追加し、キャッシュ設定で JNDI 名を指定する必要があります。 複合キーまたは複合値の Protobuf スキーマを生成し、スキーマを Data Grid に登録します。
ヒントData Grid は、ProtoStream プロセッサーで Protobuf スキーマを生成することを推奨します。リモートキャッシュでは、Data Grid コンソール、CLI、または REST API を使用してスキーマを追加して、スキーマを登録できます。
手順
データベースドライバーを Data Grid デプロイメントに追加します。
-
リモートキャッシュ: データベースドライバーを、Data Grid Server インストールの
server/libディレクトリーにコピーします。 組み込みキャッシュ:
infinispan-cachestore-sql依存関係をpomファイルに追加し、データベースドライバーがアプリケーションクラスパス上にあることを確認します。<dependency> <groupId>org.infinispan</groupId> <artifactId>infinispan-cachestore-sql</artifactId> </dependency>
<dependency> <groupId>org.infinispan</groupId> <artifactId>infinispan-cachestore-sql</artifactId> </dependency>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
-
リモートキャッシュ: データベースドライバーを、Data Grid Server インストールの
- Data Grid 設定を開いて編集します。
SQL クエリーキャッシュストアを追加します。
宣言的
query-jdbc-store xmlns="urn:infinispan:config:store:jdbc:13.0"
query-jdbc-store xmlns="urn:infinispan:config:store:jdbc:13.0"Copy to Clipboard Copied! Toggle word wrap Toggle overflow プログラマティック
persistence().addStore(QueriesJdbcStoreConfigurationBuilder.class)
persistence().addStore(QueriesJdbcStoreConfigurationBuilder.class)Copy to Clipboard Copied! Toggle word wrap Toggle overflow -
データベースダイアレクトを
dialect=""またはdialect()のいずれかで指定します (例:dialect="H2"またはdialect="postgres")。 以下のように、必要なプロパティーで SQL キャッシュストアを設定します。
-
クラスター全体で同じキャッシュストアを使用するには、
shared="true"またはshared(true)を設定します。 -
読み取り専用のキャッシュストアを作成するには、
read-only="true"または.ignoreModifications(true)を設定します。
-
クラスター全体で同じキャッシュストアを使用するには、
データでキャッシュを読み込み、
queries要素またはqueries()メソッドでデータベーステーブルを変更する SQL クエリーステートメントを定義します。Expand クエリーステートメント 説明 SELECT単一のエントリーをキャッシュに読み込みます。ワイルドカードを使用できますが、キーのパラメーターを指定する必要があります。ラベル付きの式を使用できます。
SELECT ALL複数のエントリーをキャッシュに読み込みます。返された列の数がキーと値の列数と一致する場合は、
*ワイルドカードを使用できます。ラベル付きの式を使用できます。SIZEキャッシュ内のエントリー数をカウントします。
DELETEキャッシュからエントリーを 1 つ削除します。
DELETE ALLキャッシュからすべてのエントリーを削除します。
UPSERTキャッシュのエントリーを修正します。
注記DELETE、DELETE ALL、およびUPSERTステートメントは読み取り専用キャッシュストアには適用されませんが、キャッシュストアが変更を許可する場合は必要です。DELETEステートメントのパラメーターは、SELECTステートメントのパラメーターに完全に一致する必要があります。UPSERTステートメントの変数には、SELECTおよびSELECT ALLステートメントが返すものと同じ数の一意に名前が付けられた変数が必要です。たとえば、SELECTがfooとbarを返す場合、このステートメントは変数として:fooおよび:barのみを取る必要があります。ただし、ステートメントに同じ名前の変数を複数回適用することができます。SQL クエリーには、
JOIN、ONおよびデータベースがサポートするその他の句を含めることができます。schema要素または.schemaJdbcConfigurationBuilder()メソッドを追加し、複合キーまたは値の Protobuf スキーマ設定を追加します。-
package属性またはpackage()メソッドを使用してパッケージ名を指定します。 -
message-name属性またはmessageName()メソッドを使用して複合値を指定します。 -
key-message-name属性またはkeyMessageName()メソッドを使用して複合キーを指定します。 -
スキーマで値内にキーが含まれている場合は、
embedded-key属性またはembeddedKey()メソッドにtrueの値を設定します。
-
- 変更を設定に保存します。
6.10.3.1. SQL クエリーストアの設定
このセクションでは、person と address の 2 つのデータベーステーブルのデータを含む分散キャッシュを読み込む SQL クエリーキャッシュストアの設定例を説明します。
SQL ステートメント
person および address テーブルの SQL データ定義言語 (DDL) ステートメントは以下のとおりです。
person テーブルの SQL ステートメント
address テーブルの SQL ステートメント
Protobuf スキーマ
person および address テーブルの Protobuf スキーマは以下のとおりです。
person テーブルの Protobuf スキーマ
address テーブルの Protobuf スキーマ
キャッシュ設定
以下の例では、JOIN 句を含む SQL クエリーを使用して、person テーブルおよび address テーブルから分散キャッシュを読み込みます。
XML
JSON
YAML
ConfigurationBuilder
6.10.4. SQL キャッシュストアに関するトラブルシューティング
SQL キャッシュストアに関する一般的な問題およびエラーと、そのトラブルシューティング方法を確認してください。
ISPN008064: No primary keys found for table <table_name>, check case sensitivity
ISPN008064: No primary keys found for table <table_name>, check case sensitivityData Grid は、以下の場合にこのメッセージをログに記録します。
- データベーステーブルが存在しない。
- データベーステーブル名は大文字と小文字が区別され、データベースプロバイダーに応じて、すべての小文字またはすべての大文字のいずれかである必要があります。
- データベーステーブルにプライマリーキーが定義されていない。
この問題を解決するには、以下を行う必要があります。
- SQL キャッシュストア設定を確認し、既存のテーブルの名前を指定するようにしてください。
- データベーステーブル名が大文字/小文字の要件に準拠することを確認します。
- データベーステーブルに、適切な行を一意に識別するプライマリーキーがあることを確認します。
6.11. JDBC 文字列ベースのキャッシュストア
JDBC 文字列ベースのキャッシュストアである JdbcStringBasedStore は JDBC ドライバーを使用して、基礎となるデータベースに値を読み込みおよび保存します。
JDBC 文字列ベースのキャッシュストア:
- 各エントリーをテーブルに独自の行に保存し、同時ロードのスループットを向上させます。
-
key-to-string-mapperインターフェイスを使用して各キーをStringオブジェクトにマップする単純な 1 対 1 のマッピングを使用します。
Data Grid は、プリミティブタイプを処理するDefaultTwoWayKey2StringMapperのデフォルト実装を提供します。
キャッシュエントリーを保存するために使用されるデータテーブルの他に、ストアはメタデータを保存するための _META テーブルも作成します。この表は、既存のデータベースコンテンツが現在の Data Grid バージョンおよび設定と互換性があることを確認するために使用されます。
デフォルトでは、Data Grid 共有は保存されません。つまり、クラスター内のすべてのノードが更新ごとに基盤のストアに書き込まれます。基盤のデータベースに一度書き込みを行う場合、JDBC ストアを共有として設定する必要があります。
セグメンテーション
JdbcStringBasedStore はデフォルトでセグメンテーションを使用し、エントリーが属するセグメントを表すためにデータベーステーブルの列を必要とします。
6.11.1. JDBC 文字列ベースのキャッシュストアの設定
データベースに接続できる JDBC 文字列ベースのキャッシュストアで Data Grid キャッシュを設定します。
前提条件
-
リモートキャッシュ: データベースドライバーを、Data Grid Server インストールの
server/libディレクトリーにコピーします。 組み込みキャッシュ:
infinispan-cachestore-jdbc依存関係をpomファイルに追加します。<dependency> <groupId>org.infinispan</groupId> <artifactId>infinispan-cachestore-jdbc</artifactId> </dependency>
<dependency> <groupId>org.infinispan</groupId> <artifactId>infinispan-cachestore-jdbc</artifactId> </dependency>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
手順
以下のいずれかの方法で JDBC 文字列ベースのキャッシュストア設定を作成します。
宣言的に、
persistence要素またはフィールドを追加してから、以下のスキーマ名前空間でstring-keyed-jdbc-storeを追加します。xmlns="urn:infinispan:config:store:jdbc:13.0"
xmlns="urn:infinispan:config:store:jdbc:13.0"Copy to Clipboard Copied! Toggle word wrap Toggle overflow プログラムで以下のメソッドを
ConfigurationBuilderに追加します。persistence().addStore(JdbcStringBasedStoreConfigurationBuilder.class)
persistence().addStore(JdbcStringBasedStoreConfigurationBuilder.class)Copy to Clipboard Copied! Toggle word wrap Toggle overflow
-
dialect属性またはdialect()メソッドのいずれかを使用して データベースの ダイアレクトを指定します。 JDBC 文字列ベースのキャッシュストアのプロパティーを随時設定します。
たとえば、キャッシュストアが共有属性または
sharedメソッドまたはshared()メソッドのいずれかで複数のキャッシュインスタンスと共有されるかどうかを指定します。- Data Grid がデータベースに接続できるように、JDBC 接続ファクトリーを追加します。
- キャッシュエントリーを保存するデータベーステーブルを追加します。
JDBC 文字列ベースのキャッシュストアの設定
XML
JSON
YAML
ConfigurationBuilder
6.12. RocksDB のキャッシュストア
RocksDB は、同時環境のパフォーマンスと信頼性が高いキー/ファイルシステムベースのストレージを提供します。
RocksDB キャッシュストア RocksDBStore は、2 つのデータベースを使用します。1 つのデータベースは、データをメモリーに主要なキャッシュストアを提供します。他のデータベースには、Data Grid がメモリーから失効するエントリーを保持します。
| パラメーター | 説明 |
|---|---|
|
| プライマリーキャッシュストアを提供する RocksDB データベースへのパスを指定します。ロケーションを設定しない場合には、自動的に作成されます。パスはグローバル永続の場所と相対的である必要があります。 |
|
| 期限切れのデータのキャッシュストアを提供する RocksDB データベースへのパスを指定します。ロケーションを設定しない場合には、自動的に作成されます。パスはグローバル永続の場所と相対的である必要があります。 |
|
| 期限切れのエントリーのためにインメモリーキューのサイズを設定します。キューがサイズに達すると、Data Grid は期限切れの RocksDB キャッシュストアにフラッシュします。 |
|
| RocksDB データベースを削除し、再初期化する (re-init) 前にエントリーの最大数を設定します。サイズが小さいキャッシュストアの場合、すべてのエントリーを繰り返し処理し、各エントリーを個別に削除すると、より高速な方法が得られます。 |
チューニングパラメーター
以下の RocksDB チューニングパラメーターを指定することもできます。
-
compressionType -
blockSize -
cacheSize
設定プロパティー
任意で、以下のように設定でプロパティーを設定します。
-
RocksDB データベースを調整およびチューニングするために、プロパティーの前に
database接頭辞を追加します。 -
プロパティーの前に
data接頭辞を追加して、RocksDB がデータを格納する列ファミリーを設定します。
<property name="database.max_background_compactions">2</property> <property name="data.write_buffer_size">64MB</property> <property name="data.compression_per_level">kNoCompression:kNoCompression:kNoCompression:kSnappyCompression:kZSTD:kZSTD</property>
<property name="database.max_background_compactions">2</property>
<property name="data.write_buffer_size">64MB</property>
<property name="data.compression_per_level">kNoCompression:kNoCompression:kNoCompression:kSnappyCompression:kZSTD:kZSTD</property>セグメンテーション
RocksDBStore はセグメンテーションをサポートし、セグメントごとに個別の列ファミリーを作成します。セグメント化された RocksDB キャッシュストアは、ルックアップのパフォーマンスと反復が改善されますが、書き込み操作のパフォーマンスに若干低下します。
数百のセグメントを複数設定しないでください。RocksDB は、列ファミリーの数を無制限に指定するように設計されていません。セグメントが多すぎると、キャッシュストアの起動時間が大幅に増加します。
RocksDB キャッシュストアの設定
XML
JSON
YAML
ConfigurationBuilder
プロパティーを持つ ConfigurationBuilder
6.13. リモートキャッシュストア
リモートキャッシュストア RemoteStore は Hot Rod プロトコルを使用して Data Grid クラスターにデータを保存します。
リモートキャッシュストアを共有として設定している場合は、事前にデータを読み込めません。つまり、設定の shared="true" の場合は、preload="false" を設定する必要があります。
セグメンテーション
RemoteStore はセグメンテーションをサポートし、セグメントごとにキーとエントリーを公開できるため、一括操作がより効率的になります。ただし、セグメンテーションは Data Grid Hot Rod プロトコルバージョン 2.3 以降でのみ利用できます。
RemoteStore のセグメンテーションを有効にすると、Data Grid サーバー設定で定義したセグメントの数が使用されます。
ソースキャッシュがセグメント化され、RemoteStore 以外のセグメントを使用する場合は、一括操作のために誤った値が返されます。この場合は、RemoteStore のセグメンテーションを無効にする必要があります。
リモートキャッシュストアの設定
XML
JSON
YAML
ConfigurationBuilder
6.14. JPA キャッシュストア
JPA (Java Persistence API) キャッシュストア、JpaStore は正式なスキーマを使用してデータを永続化します。
その後、他のアプリケーションは永続ストレージから読み取れ、Data Grid からデータを読み込むことができます。ただし、他のアプリケーションは、Data Grid と同時に永続ストレージを使用しないでください。
JPA キャッシュストアを使用する際には、以下の点を考慮する必要があります。
- キーはエンティティーの ID である必要があります。値はエンティティーオブジェクトにする必要があります。
-
1 つの
@Idまたは@EmbeddedIdアノテーションのみが許可されます。 -
@GeneratedValueアノテーションを使用した自動生成 ID はサポートされません。 - すべてのエントリーは immortal として保存されます。
- JPA のキャッシュストアは、セグメント化をサポートしていません。
Data Grid キャッシュを組み込んだ JPA キャッシュストアのみを使用する必要があります。
JPA キャッシュストアの設定
XML
ConfigurationBuilder
Configuration cacheConfig = new ConfigurationBuilder().persistence()
.addStore(JpaStoreConfigurationBuilder.class)
.persistenceUnitName("org.infinispan.loaders.jpa.configurationTest")
.entityClass(User.class)
.build();
Configuration cacheConfig = new ConfigurationBuilder().persistence()
.addStore(JpaStoreConfigurationBuilder.class)
.persistenceUnitName("org.infinispan.loaders.jpa.configurationTest")
.entityClass(User.class)
.build();設定パラメーター
| 宣言型 | プログラマティック | 詳細 |
|---|---|---|
|
|
|
JPA エンティティークラスを含む JPA 設定ファイル |
|
|
| このキャッシュに保存されることが想定される完全修飾 JPA エンティティークラス名を指定します。1 つのクラスのみが許可されます。 |
6.14.1. JPA キャッシュストアの例
このセクションでは、JPA キャッシュストアを使用する例を紹介します。
前提条件
- JPA エンティティーをマーシャリングするように Data Grid を設定します。
手順
永続性ユニット "myPersistenceUnit" を
persistence.xmlで定義します。<persistence-unit name="myPersistenceUnit"> <!-- Persistence configuration goes here. --> </persistence-unit>
<persistence-unit name="myPersistenceUnit"> <!-- Persistence configuration goes here. --> </persistence-unit>Copy to Clipboard Copied! Toggle word wrap Toggle overflow ユーザーエンティティークラスを作成します。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow JPA キャッシュストアで"usersCache"という名前のキャッシュを設定します。
キャッシュ usersCache を設定して JPA キャッシュストアを使用するように設定できます。これにより、データをキャッシュに配置すると、JPA 設定を基にデータがデータベースに永続化されます。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow JPA キャッシュストアを使用するキャッシュは、以下の例のように、1 種類のデータのみを保存できます。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow @EmbeddedIdアノテーションでは、以下の例のように複合キーを使用できます。Copy to Clipboard Copied! Toggle word wrap Toggle overflow
6.15. クラスターキャッシュローダー
ClusterCacheLoader は、他の Data Grid クラスターメンバーからデータを取得しますが、データは永続化されません。つまり、ClusterCacheLoader はキャッシュストアではありません。
ClusterLoader は非推奨であり、将来のバージョンで削除される予定です。
ClusterCacheLoader は、状態遷移へのブロック以外の部分を提供します。ClusterCacheLoader は、それらの鍵がローカルノードで利用できない場合に、他のノードからキーを取得します。これは、キャッシュコンテンツを後で読み込むのと似ています。
以下のポイントは ClusterCacheLoader にも適用されます。
-
事前読み込みは有効になりません (
preload=true)。 -
永続状態の取得はサポートされていません (
fetch-state=true)。 - セグメンテーションはサポートされていません。
クラスターキャッシュブートローダーの設定を変更します。
XML
<distributed-cache>
<persistence>
<cluster-loader preload="true" remote-timeout="500"/>
</persistence>
</distributed-cache>
<distributed-cache>
<persistence>
<cluster-loader preload="true" remote-timeout="500"/>
</persistence>
</distributed-cache>JSON
YAML
distributedCache:
persistence:
clusterLoader:
preload: "true"
remoteTimeout: "500"
distributedCache:
persistence:
clusterLoader:
preload: "true"
remoteTimeout: "500"ConfigurationBuilder
ConfigurationBuilder b = new ConfigurationBuilder();
b.persistence()
.addClusterLoader()
.remoteCallTimeout(500);
ConfigurationBuilder b = new ConfigurationBuilder();
b.persistence()
.addClusterLoader()
.remoteCallTimeout(500);6.16. カスタムキャッシュストア実装の作成
Data Grid の永続 SPI を使用してカスタムキャッシュストアを作成できます。
6.16.1. Data Grid 永続性 SPI
Data Grid Service Provider Interface (SPI) は、NonBlockingStore インターフェイスを介して外部ストレージへの読み書き操作を有効にし、以下の機能を持ちます。
- JCache 準拠のベンダー間での移植性
-
Data Grid は、ブロッキングコードを処理するアダプターを使用して、
NonBlockingStoreインターフェイスとJSR-107JCache 仕様間の互換性を維持します。 - 簡素化されたトランザクション統合
- Data Grid はロックを自動的に処理するため、実装は永続ストアへの同時アクセスを調整する必要はありません。使用するロックモードによっては、通常、同じキーへの同時書き込みは発生しません。ただし、永続ストレージ上の操作は複数のスレッドから発信され、この動作を許容する実装を作成することを想定する必要があります。
- 並列反復
- Data Grid を使用すると、複数のスレッドを持つ永続ストアのエントリーを繰り返すことができます。
- シリアル化の減少による CPU 使用率の削減
- Data Grid は、リモートで送信できるシリアル化された形式で保存されたエントリーを公開します。このため、Data Grid は永続ストレージから取得されたエントリーをデシリアライズし、ネットワークに書き込む際に再びシリアライズする必要はありません。
6.16.2. キャッシュストアの作成
NonBlockingStore API の実装により、カスタムキャッシュストアを作成することができます。
手順
- 適切な Data Grid の永続 SPI を実装します。
-
カスタム設定がある場合は、ストアクラスに
@ConfiguredByアノテーションを付けます。 必要に応じてカスタムキャッシュストア設定およびビルダーを作成します。
-
AbstractStoreConfigurationおよびAbstractStoreConfigurationBuilderを拡張します。 オプションで以下のアノテーションをストア設定クラスに追加し、カスタム設定ビルダーが XML からキャッシュストア設定を解析できるようにします。
-
@ConfigurationFor @BuiltByこれらのアノテーションを追加しないと、
CustomStoreConfigurationBuilderはAbstractStoreConfigurationで定義された共通のストア属性を解析し、追加の要素は無視されます。注記設定が
@ConfigurationForアノテーションを宣言しない場合は、Data Grid がキャッシュを初期化する際に警告メッセージがログに記録されます。
-
-
6.16.3. カスタムキャッシュストアの設定例
以下の例では、カスタムキャッシュストアの実装で Data Grid を設定する方法を示しています。
XML
<distributed-cache>
<persistence>
<store class="org.infinispan.persistence.example.MyInMemoryStore" />
</persistence>
</distributed-cache>
<distributed-cache>
<persistence>
<store class="org.infinispan.persistence.example.MyInMemoryStore" />
</persistence>
</distributed-cache>JSON
YAML
distributedCache:
persistence:
store:
class: "org.infinispan.persistence.example.MyInMemoryStore"
distributedCache:
persistence:
store:
class: "org.infinispan.persistence.example.MyInMemoryStore"ConfigurationBuilder
Configuration config = new ConfigurationBuilder()
.persistence()
.addStore(CustomStoreConfigurationBuilder.class)
.build();
Configuration config = new ConfigurationBuilder()
.persistence()
.addStore(CustomStoreConfigurationBuilder.class)
.build();6.16.4. カスタムキャッシュストアの導入
作成したキャッシュストア実装を Data Grid Server で使用するには、JAR ファイルで提供する必要があります。
前提条件
Data Grid Server が実行している場合は停止します。
Data Grid は起動時にのみ JAR ファイルを読み込みます。
手順
- カスタムキャッシュストア実装を JAR ファイルにパッケージ化します。
-
JAR ファイルを Data Grid Server インストールの
server/libディレクトリーに追加します。
6.17. キャッシュストア間のデータの移行
Data Grid は、あるキャッシュストアから別のキャッシュストアにデータを移行するユーティリティーを提供します。
6.17.1. キャッシュストアマイグレーター
Data Grid は、最新の Data Grid キャッシュストア実装のデータを再作成する StoreMigrator.java ユーティリティーを提供します。
StoreMigrator は以前のバージョンの Data Grid のキャッシュストアを取得し、キャッシュストア実装をターゲットとして使用します。
StoreMigrator を実行すると、EmbeddedCacheManager インターフェイスを使用して定義したキャッシュストアタイプでターゲットキャッシュが作成されます。StoreMigrator は、ソースストアからメモリーにエントリーを読み込み、それらをターゲットキャッシュに配置します。
StoreMigrator を使用すると、あるタイプのキャッシュストアから別のストアにデータを移行することもできます。たとえば、JDBC String ベースのキャッシュストアから RocksDB キャッシュストアに移行することができます。
StoreMigrator は、セグメント化されたキャッシュストアから以下にデータを移行できません。
- 非セグメント化されたキャッシュストア。
- セグメント数が異なるセグメント化されたキャッシュストア。
6.17.2. キャッシュストアマイグレーターの取得
StoreMigrator は、Data Grid ツールライブラリー infinispan-tools の一部として利用でき、Maven リポジトリーに含まれます。
手順
StoreMigratorのpom.xmlを以下のように設定します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow
6.17.3. キャッシュストアマイグレーターの設定
ソースおよびターゲットのキャッシュストアのプロパティーを migrator.properties ファイルに設定します。
手順
-
migrator.propertiesファイルを作成します。 ソースキャッシュストアを
migrator.propertiesに設定します。以下の例にあるように、すべての設定プロパティーの先頭に
source.を追加します。source.type=SOFT_INDEX_FILE_STORE source.cache_name=myCache source.location=/path/to/source/sifs source.version=<version>
source.type=SOFT_INDEX_FILE_STORE source.cache_name=myCache source.location=/path/to/source/sifs source.version=<version>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
migrator.propertiesでターゲットキャッシュストアを設定します。以下の例のように、すべての設定プロパティーの先頭に
target.を付けます。target.type=SINGLE_FILE_STORE target.cache_name=myCache target.location=/path/to/target/sfs.dat
target.type=SINGLE_FILE_STORE target.cache_name=myCache target.location=/path/to/target/sfs.datCopy to Clipboard Copied! Toggle word wrap Toggle overflow
6.17.3.1. キャッシュストアマイグレーターの設定プロパティー
ソースおよびターゲットのキャッシュストアを StoreMigrator プロパティーで設定します。
| プロパティー | 説明 | 必須/オプション |
|---|---|---|
|
| ソースまたはターゲットのキャッシュストアタイプのタイプを指定します。
| 必須 |
| プロパティー | 説明 | 値の例 | 必須/オプション |
|---|---|---|---|
|
| ストアがバックアップするキャッシュに名前を付けます。 |
| 必須 |
|
| セグメンテーションを使用できるターゲットキャッシュストアのセグメント数を指定します。
セグメント数は、Data Grid 設定の つまり、キャッシュストアのセグメント数は、対応するキャッシュのセグメント数と一致する必要があります。セグメントの数が同一でない場合、Data Grid はキャッシュストアからデータを読み込めません。 |
| 任意 |
| プロパティー | 説明 | 必須/オプション |
|---|---|---|
|
| 基礎となるデータベースのダイアレクトを指定します。 | 必須 |
|
|
ソースキャッシュストアのマーシャラーバージョンを指定します。
* Data Grid 7.2.x の場合は
* Data Grid 7.3.x の場合は
* Data Grid 8.0.x の場合は
* Data Grid 8.1.x の場合は
* Data Grid 8.2.x の場合は
* Data Grid 8.3.x の場合は | ソースストアにのみ必要です。 |
|
| カスタムマーシャラークラスを指定します。 | カスタムマーシャラーを使用する場合に必要です。 |
|
|
| 任意 |
|
| JDBC 接続 URL を指定します。 | 必須 |
|
| JDBC ドライバーのクラスを指定します。 | 必須 |
|
| データベースユーザー名を指定します。 | 必須 |
|
| データベースユーザー名のパスワードを指定します。 | 必須 |
|
| データベースのメジャーバージョンを設定します。 | 任意 |
|
| データベースのマイナーバージョンを設定します。 | 任意 |
|
| データベース upsert を無効にします。 | Optional |
|
| テーブルインデックスが作成されるかどうかを指定します。 | Optional |
|
| テーブル名の追加接頭辞を指定します。 | Optional |
|
| 列名を指定します。 | 必須 |
|
| 列タイプを指定します。 | 必須 |
|
|
| 任意 |
Binary キャッシュストアから古い Data Grid バージョンの移行には、以下のプロパティーで table.string.* を table.binary.\* に変更します。
-
source.table.binary.table_name_prefix -
source.table.binary.<id\|data\|timestamp>.name -
source.table.binary.<id\|data\|timestamp>.type
| プロパティー | 説明 | 必須/オプション |
|---|---|---|
|
| データベースディレクトリーを設定します。 | 必須 |
|
| 使用する圧縮タイプを指定します。 | 任意 |
# Example configuration for migrating from a RocksDB cache store. source.type=ROCKSDB source.cache_name=myCache source.location=/path/to/rocksdb/database source.compression=SNAPPY
# Example configuration for migrating from a RocksDB cache store.
source.type=ROCKSDB
source.cache_name=myCache
source.location=/path/to/rocksdb/database
source.compression=SNAPPY| プロパティー | 説明 | 必須/オプション |
|---|---|---|
|
|
キャッシュストア | 必須 |
# Example configuration for migrating to a Single File cache store. target.type=SINGLE_FILE_STORE target.cache_name=myCache target.location=/path/to/sfs.dat
# Example configuration for migrating to a Single File cache store.
target.type=SINGLE_FILE_STORE
target.cache_name=myCache
target.location=/path/to/sfs.dat| プロパティー | 説明 | 値 |
|---|---|---|
| 必須/オプション |
| データベースディレクトリーを設定します。 |
| 必須 |
| データベースインデックスディレクトリーを設定します。 |
# Example configuration for migrating to a Soft-Index File cache store. target.type=SOFT_INDEX_FILE_STORE target.cache_name=myCache target.location=path/to/sifs/database target.location=path/to/sifs/index
# Example configuration for migrating to a Soft-Index File cache store.
target.type=SOFT_INDEX_FILE_STORE
target.cache_name=myCache
target.location=path/to/sifs/database
target.location=path/to/sifs/index6.17.4. Data Grid キャッシュストアの移行
StoreMigrator を実行して、あるキャッシュストアから別のキャッシュストアにデータを移行します。
前提条件
-
infinispan-tools.jarを取得します。 -
ソースおよびターゲットのキャッシュストアを設定する
migrator.propertiesファイルを作成します。
手順
ソースから
infinispan-tools.jarをビルドする場合は、以下を実行します。-
JDBC ドライバーなどのソースおよびターゲットのデータベースの
infinispan-tools.jarおよび依存関係をクラスパスに追加します。 -
migrator.propertiesファイルをStoreMigratorの引数として指定します。
-
JDBC ドライバーなどのソースおよびターゲットのデータベースの
Maven リポジトリーから
infinispan-tools.jarをプルする場合は、以下のコマンドを実行します。mvn exec:java
第7章 ネットワークパーティションを処理するための Data Grid 設定
Data Grid クラスターは、ノードのサブセットが相互に分離されるネットワークパーティションに分割できます。この状態により、クラスターキャッシュの可用性や一貫性が失われます。Data Grid はクラッシュしたノードを自動的に検出し、競合を解決してキャッシュを 1 つにマージします。
7.1. クラスターおよびネットワークパーティションの分割
ネットワークパーティションは、ネットワークルーターがクラッシュした場合など、稼働中の環境でのエラー状態の結果です。クラスターがパーティションに分割されると、ノードはそのパーティションのノードのみが含まれる JGroups クラスタービューを作成します。この状態は、1 つのパーティションのノードが、他のパーティションのノードとは独立して動作できることを意味します。
分割の検出
ネットワークパーティションを自動的に検出するために、Data Grid はデフォルトの JGroups スタックで FD_ALL プロトコルを使用して、ノードが突然クラスターから離れるタイミングを判断します。
Data Grid は、ノードが突然離れる原因を検知できません。これは、ネットワーク障害の発生時だけでなく、ガベージコレクション (GC) が JVM を一時停止した場合など、その他の理由で発生する可能性があります。
Data Grid は、以下の時間が経過すると (ミリ秒単位)、ノードがクラッシュしたことを疑います。
FD_ALL.timeout + FD_ALL.interval + VERIFY_SUSPECT.timeout + GMS.view_ack_collection_timeout
FD_ALL.timeout + FD_ALL.interval + VERIFY_SUSPECT.timeout + GMS.view_ack_collection_timeoutクラスターがネットワークパーティションに分割されていることを検出すると、Data Grid はキャッシュ操作処理のストラテジーを使用します。アプリケーションの要件に応じて Data Grid は以下を行うことができます。
- 可用性のために読み取りおよび書き込み操作を許可する
- 一貫性を保つために読み取りおよび書き込み操作を拒否する
パーティションのマージ
分割クラスターを修正するため、Data Grid はパーティションを 1 つにマージします。マージ時に、Data Grid はキャッシュエントリーの値に .equals() メソッドを使用して、競合が存在するかどうかを判断します。パーティションで見つかったレプリカ間の競合を解決するために、Data Grid は設定可能なマージポリシーを使用します。
7.1.1. 分割されたクラスター内のデータの一貫性
Data Grid クラスターをパーティションに分割させるネットワークの停止またはエラーにより、処理ストラテジーやマージポリシーに関係なく、データ喪失や一貫性の問題が発生する可能性があります。
分割と検出の間
分割が発生し、Data Grid が分割を検出する前にマイナーパーティションにあるノードで書き込み操作が行われた場合、マージ中に Data Grid がそのマイナーパーティションに状態を転送すると、その値が失われます。
すべてのパーティションが DEGRADED モードになっている場合、状態の転送は発生しないためその値は失われませんが、エントリーに一貫性のない値が含まれる可能性があります。分割が発生したときに進行中のトランザクションキャッシュの書き込み操作は、一部のノードでコミットされ他のノードでロールバックされる場合があるので、このケースでも一貫性のない値が生じます。
分割が発生し、Data Grid がそれを検出する間、まだ DEGRADED モードになっていないマイナーパーティションのキャッシュからの古い読み取りが生じる可能性があります。
マージ中
Data Grid がパーティションの削除を開始すると、ノードは一連のマージイベントでクラスターに再接続されます。このマージプロセスを完了する前に、一部のノードではトランザクションキャッシュでの書き込み操作が成功し、他のノードでは成功しない可能性があります。この場合、エントリーが更新されるまで、古い読み取りが発生する可能性があります。
7.2. キャッシュの可用性およびデグレードモード
DENY_READ_WRITES または ALLOW_READS パーティション処理ストラテジーのいずれかを使用するように設定すると、データの整合性を維持するために、Data Grid は キャッシュを DEGRADED モードに設定できます。
Data Grid は、以下の条件が満たされる場合に、パーティション内のキャッシュを DEGRADED モードに設定します。
-
1 つ以上のセグメントですべての所有者が失われている。
これは、分散キャッシュの所有者の数と同じか、それ以上の数のノードがクラスターを離れている場合に生じます。 -
パーティションに大多数のノードがない。
大多数のノードとは、最新の安定したトポロジー (クラスターのリバランス操作が最後に正常に完了した時) からのクラスター内のノード合計数の過半数です。
キャッシュが DEGRADED モードの場合、Data Grid は以下を行います。
- エントリーのすべてのレプリカが同じパーティションにある場合にのみ、読み取りおよび書き込み操作を許可する。
パーティションにエントリーのすべてのレプリカが含まれていない場合は、読み取り操作および書き込み操作を拒否し、
AvailabilityExceptionを出力する。注記ALLOW_READSストラテジーを使用すると、Data Grid はDEGRADEDモードのキャッシュで読み取り操作を許可します。
DEGRADED モードは、異なるパーティションの同じキーに対して書き込み操作が行われないようにすることで一貫性を保証します。さらに、DEGRADED モードは、キーが 1 つのパーティションで更新され、別のパーティションで読み取られる場合に発生する古い読み取り操作を防ぎます。
すべてのパーティションが DEGRADED モードにある場合は、クラスターに最新の安定したトポロジーからの過半数のノードが含まれ、各エントリーに少なくとも 1 つのレプリカがある場合にのみ、マージ後にキャッシュが再び利用可能になります。クラスターに各エントリーのレプリカが少なくとも 1 つある場合、キーが失われることはなく、Data Grid はクラスターのリバランス中に所有者の数に基づいて新しいレプリカを作成できます。
あるパーティションで DEGRADED モードに設定されている間、場合によっては、別のパーティションのキャッシュを引き続き利用できます。これが生じると、利用可能なパーティションは通常通りにキャッシュ操作を続行し、Data Grid はそれらのノード間でデータのリバランスを試行します。キャッシュを 1 つにマージするために、Data Grid は必ず利用可能なパーティションから DEGRADED モードのパーティションに状態を転送します。
7.2.1. 低下したキャッシュのリカバリー例
このトピックでは、Data Grid が DENY_READ_WRITES パーティション処理ストラテジーを使用するキャッシュを持つ分割されたクラスターからリカバリーする方法を示しています。
たとえば、Data Grid クラスターには 4 つのノードがあり、各エントリーに対してレプリカが 2 つある分散キャッシュが含まれています (owners=2)。キャッシュには、k1、k2、k3、および k4 の 4 つのエントリーがあります。
DENY_READ_WRITES ストラテジーでは、クラスターがパーティションに分割されると、Data Grid はエントリーのすべてのレプリカが同じパーティションにある場合にのみキャッシュ操作を許可します。
以下の図では、キャッシュがパーティションに分割されている間、Data Grid はパーティション 1 上の k1 およびパーティション 2 の k4 の読み取りおよび書き込み操作を許可します。パーティション 1 またはパーティション 2 の k2 と k3 のにはレプリカが 1 つしかないため、Data Grid はこれらのエントリーの読み取りおよび書き込み操作を拒否します。
ネットワーク条件により、ノードが同じクラスタービューに再ジョインするのが許可されると、Data Grid は状態の送信なしにパーティションをマージし、通常のキャッシュ操作を回復します。
7.2.2. ネットワークパーティション時のキャッシュ可用性の確認
ネットワークパーティション時に、Data Grid クラスターのキャッシュが AVAILABLE モードまたは DEGRADED モードにあるかどうかを判別します。
Data Grid クラスターがパーティションに分割されると、それらのパーティションのノードは DEGRADED モードに入り、データの一貫性を確保できます。DEGRADED モードでは、クラスターは可用性の喪失につながるキャッシュ操作を許可しません
手順
以下のいずれかの方法で、ネットワークパーティションでクラスター化されたキャッシュの可用性を確認します。
-
Data Grid ログで、クラスターが利用可能か、少なくとも 1 つのキャッシュが
DEGRADEDモードにあるかどうかを示すISPN100011メッセージを探します。 Data Grid Console または REST API を使用して、リモートキャッシュの可用性を取得します。
- ブラウザーで Data Grid Console を開き、Data Container タブを選択し、Health 列で可用性のステータスを特定します。
REST API からキャッシュの健全性を取得します。
GET /rest/v2/cache-managers/<cacheManagerName>/health
GET /rest/v2/cache-managers/<cacheManagerName>/healthCopy to Clipboard Copied! Toggle word wrap Toggle overflow
-
AdvancedCacheAPI のgetAvailability()メソッドを使用して、組み込みキャッシュの可用性をプログラム的に取得します。
7.2.3. キャッシュを使用できるようにする
キャッシュを強制的に DEGRADED モードから解除することで、キャッシュを読み取りおよび書き込み操作に利用できるようにします。
デプロイメントでデータ喪失や不整合を許容できる場合にのみ、クラスターを強制的に DEGRADED モードから解除する必要があります。
手順
以下のいずれかの方法で、キャッシュを利用できるようにします。
REST API でリモートキャッシュの可用性を変更します。
POST /v2/caches/<cacheName>?action=set-availability&availability=AVAILABLE
POST /v2/caches/<cacheName>?action=set-availability&availability=AVAILABLECopy to Clipboard Copied! Toggle word wrap Toggle overflow AdvancedCacheAPI で、組み込みキャッシュの可用性をプログラム的に変更します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow
7.3. パーティション処理の設定
パーティション処理ストラテジーとマージポリシーを使用するように Data Grid を設定し、ネットワークの問題が発生したときに分離されたクラスターを解決できるようにします。デフォルトでは、Data Grid はデータの一貫性を犠牲にして可用性を提供するストラテジーを使用します。ネットワークのパーティションによってクラスターが分割されると、クライアントは引き続きキャッシュで読み取りおよび書き込み操作を実行できます。
可用性よりも整合性が要求される場合は、クラスターがパーティションに分割されている間に、読み取りおよび書き込み操作を拒否するように Data Grid を設定することができます。または、読み取り操作を許可し、書き込み操作を拒否できます。また、カスタムのマージポリシー実装を指定して、Data Grid を設定し、要件に合わせたカスタムロジックで分割を解決することもできます。
前提条件
レプリケートされたキャッシュまたは分散キャッシュのいずれかを作成できる Data Grid クラスターが必要です。
注記パーティション処理の設定は、レプリケートされたキャッシュと分散キャッシュにのみ適用されます。
手順
- Data Grid 設定を開いて編集します。
-
partition-handling要素またはpartitionHandling()メソッドのいずれかを使用して、キャッシュにパーティション処理設定を追加します。 when-split属性またはwhenSplit()メソッドを使用して、クラスターがパーティションに分割される際に Data Grid が使用するストラテジーを指定します。デフォルトのパーティション処理ストラテジーは
ALLOW_READ_WRITESであるため、キャッシュは利用可能のままです。ユースケースでキャッシュの可用性よりデータの整合性が要求される場合は、DENY_READ_WRITESストラテジーを指定します。merge-policy属性またはmergePolicy()メソッドで、パーティションをマージする際に Data Grid が競合するエントリーを解決するために使用するポリシーを指定します。デフォルトでは、Data Grid はマージ時の競合を解決しません。
- 変更を Data Grid の設定に保存します。
パーティション処理の設定
XML
<distributed-cache>
<partition-handling when-split="DENY_READ_WRITES"
merge-policy="PREFERRED_ALWAYS"/>
</distributed-cache>
<distributed-cache>
<partition-handling when-split="DENY_READ_WRITES"
merge-policy="PREFERRED_ALWAYS"/>
</distributed-cache>JSON
YAML
distributedCache:
partitionHandling:
whenSplit: DENY_READ_WRITES
mergePolicy: PREFERRED_ALWAYS
distributedCache:
partitionHandling:
whenSplit: DENY_READ_WRITES
mergePolicy: PREFERRED_ALWAYSConfigurationBuilder
ConfigurationBuilder builder = new ConfigurationBuilder();
builder.clustering().cacheMode(CacheMode.DIST_SYNC)
.partitionHandling()
.whenSplit(PartitionHandling.DENY_READ_WRITES)
.mergePolicy(MergePolicy.PREFERRED_NON_NULL);
ConfigurationBuilder builder = new ConfigurationBuilder();
builder.clustering().cacheMode(CacheMode.DIST_SYNC)
.partitionHandling()
.whenSplit(PartitionHandling.DENY_READ_WRITES)
.mergePolicy(MergePolicy.PREFERRED_NON_NULL);7.4. パーティション処理ストラテジー
パーティション処理ストラテジーは、クラスターの分割時に Data Grid が読み取りおよび書き込み操作を許可するかどうかを制御します。設定するストラテジーにより、キャッシュの可用性またはデータの整合性を優先するかどうかが決定されます。
| ストラテジー | 説明 | 可用性または一貫性 |
|---|---|---|
|
| クラスターがネットワークパーティションに分割されている間、Data Grid はキャッシュに対する読み取りおよび書き込み操作を許可します。各パーティションのノードは可用性を維持し、相互に独立して機能します。これは、デフォルトのパーティション処理ストラテジーです。 | 可用性 |
|
| エントリーのすべてのレプリカがパーティションにある場合にのみ、Data Grid は読み取りおよび書き込み操作を許可します。パーティションにエントリーのすべてのレプリカが含まれていない場合、Data Grid はそのエントリーのキャッシュ操作を防ぎます。 | 一貫性 |
|
| パーティションにエントリーのすべてのレプリカが含まれない限り、Data Grid はエントリーに対する読み取り操作を許可し、書き込み操作を防ぎます。 | 読み取りが可能な一貫性 |
7.5. マージポリシー
マージポリシーは、クラスターパーティションを 1 つにまとめる際に Data Grid がレプリカ間の競合を解決する方法を制御します。Data Grid が提供するマージポリシーのいずれかを使用するか、EntryMergePolicy API のカスタム実装を作成できます。
| マージポリシー | 説明 | 留意事項 |
|---|---|---|
|
| Data Grid は、分割されたクラスターをマージする際に競合を解決しません。これは、デフォルトのマージポリシーです。 | ノードはプライマリーの所有者ではないセグメントをドロップするため、データが失われる可能性があります。 |
|
| Data Grid は、クラスター内の過半数のノードに存在する値を検出し、競合を解決するのに使用します。 | Data Grid は、古い値を使用して競合を解決する可能性があります。エントリーが過半数のノードで利用可能な場合でも、少数派側のパーティションで最後の更新が行われる可能性があります。 |
|
| Data Grid は、クラスター上で見つかった最初の null 以外の値を使用して競合を解決します。 | Data Grid は削除されたエントリーを復元する場合があります。 |
|
| Data Grid は、競合するすべてのエントリーをキャッシュから削除します。 | 分割されたクラスターをマージする際に、異なる値を持つエントリーが失われます。 |
7.6. カスタムマージポリシーの設定
ネットワークパーティションの処理時に EntryMergePolicy API のカスタム実装を使用するように Data Grid を設定します。
前提条件
EntryMergePolicyAPI を実装している。Copy to Clipboard Copied! Toggle word wrap Toggle overflow
手順
リモートキャッシュを使用する場合は、マージポリシーの実装を Data Grid Server にデプロイします。
マージポリシーの完全修飾クラス名が含まれる
META-INF/services/org.infinispan.conflict.EntryMergePolicyファイルが含まれる JAR ファイルとしてクラスをパッケージ化します。# List implementations of EntryMergePolicy with the full qualified class name org.example.CustomMergePolicy
# List implementations of EntryMergePolicy with the full qualified class name org.example.CustomMergePolicyCopy to Clipboard Copied! Toggle word wrap Toggle overflow -
JAR ファイルを
server/libディレクトリーに追加します。
- Data Grid 設定を開いて編集します。
必要に応じて
encoding要素またはencoding()メソッドを使用して、適宜キャッシュエンコーディングを設定します。リモートキャッシュでは、エントリーのマージ時に比較にオブジェクトメタデータのみを使用する場合は、メディアタイプとして
application/x-protostreamを使用できます。この場合、Data Grid はエントリーをEntryMergePolicyにbyte[]として返します。競合のマージ時にオブジェクト自体が必要な場合、キャッシュを
application/x-java-objectメディアタイプで設定する必要があります。この場合、関連する ProtoStream マーシャラーを Data Grid Server にデプロイし、クライアントが Protobuf エンコーディングを使用する場合に、オブジェクト変換にbyte[]を実行できるようにする必要があります。-
パーティション処理設定の一部として
merge-policy属性またはmergePolicy()メソッドを使用して、カスタムのマージポリシーを指定します。 - 変更を保存します。
カスタムマージポリシーの設定
XML
<distributed-cache name="mycache">
<partition-handling when-split="DENY_READ_WRITES"
merge-policy="org.example.CustomMergePolicy"/>
</distributed-cache>
<distributed-cache name="mycache">
<partition-handling when-split="DENY_READ_WRITES"
merge-policy="org.example.CustomMergePolicy"/>
</distributed-cache>JSON
YAML
distributedCache:
partitionHandling:
whenSplit: DENY_READ_WRITES
mergePolicy: org.example.CustomMergePolicy
distributedCache:
partitionHandling:
whenSplit: DENY_READ_WRITES
mergePolicy: org.example.CustomMergePolicyConfigurationBuilder
ConfigurationBuilder builder = new ConfigurationBuilder();
builder.clustering().cacheMode(CacheMode.DIST_SYNC)
.partitionHandling()
.whenSplit(PartitionHandling.DENY_READ_WRITES)
.mergePolicy(new CustomMergePolicy());
ConfigurationBuilder builder = new ConfigurationBuilder();
builder.clustering().cacheMode(CacheMode.DIST_SYNC)
.partitionHandling()
.whenSplit(PartitionHandling.DENY_READ_WRITES)
.mergePolicy(new CustomMergePolicy());7.7. 組み込みキャッシュでのパーティションの手動マージ
ネットワークパーティションの発生後に、組み込みキャッシュを手動でマージするために競合するエントリーを検出し、解決します。
手順
以下の例のように、
EmbeddedCacheManagerからConflictManagerを取得し、キャッシュ内の競合するエントリーを検出して解決します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow
ConflictManager::getConflicts ストリームはエントリーごとに処理されますが、基礎となるスプリタレイターは、セグメントごとにキャッシュエントリーを遅延読み込みします。
第8章 ユーザーロールとパーミッションの設定
承認は、ユーザーがキャッシュにアクセスしたり、Data Grid リソースとやり取りしたりする前に、特定の権限を持つ必要があるセキュリティー機能です。読み取り専用アクセスから完全なスーパーユーザー特権まで、さまざまなレベルのパーミッションを提供するロールをユーザーに割り当てます。
8.1. セキュリティー−認証
Data Grid の認証は、ユーザーアクセスを制限することでデプロイメントを保護します。
ユーザーアプリケーションまたはクライアントは、Cache Manager またはキャッシュで操作を実行する前に、十分なパーミッションが割り当てられたロールに属している必要があります。
たとえば、特定のキャッシュインスタンスで承認を設定して、Cache.get() を呼び出すには、読み取り権限を持つロールを ID に割り当てる必要があり、Cache.put() を呼び出すには書き込み権限を持つロールが必要になるようにします。
このシナリオでは、io ロールが割り当てられたユーザーアプリケーションまたはクライアントがエントリーの書き込みを試みると、Data Grid はリクエストを拒否し、セキュリティー例外を出力します。writer ロールのあるユーザーアプリケーションまたはクライアントが書き込みリクエストを送信する場合、Data Grid は承認を検証し、後続の操作のためにトークンを発行します。
アイデンティティー
アイデンティティーは java.security.Principal タイプのセキュリティープリンシパルです。javax.security.auth.Subject クラスで実装されたサブジェクトは、セキュリティープリンシパルのグループを表します。つまり、サブジェクトはユーザーとそれが属するすべてのグループを表します。
ロールのアイデンティティー
Data Grid はロールマッパーを使用するため、セキュリティープリンシパルが 1 つ以上のパーミッションを割り当てるロールに対応します。
以下の図は、セキュリティープリンシパルがロールにどのように対応するかを示しています。
8.1.1. ユーザーロールとパーミッション
Data Grid には、データにアクセスして Data Grid リソースと対話するためのパーミッションをユーザーに付与するデフォルトのロールのセットが含まれています。
ClusterRoleMapper は、Data Grid がセキュリティープリンシパルを承認ロールに関連付けるために使用するデフォルトのメカニズムです。
ClusterRoleMapper は、プリンシパル名をロール名に一致させます。admin という名前のユーザーは admin パーミッションを自動的に取得し、deployer という名前のユーザーは deployer パーミッションを取得する、というようになります。
| ロール | パーミッション | 説明 |
|---|---|---|
|
| ALL | Cache Manager ライフサイクルの制御など、すべてのパーミッションを持つスーパーユーザー。 |
|
| ALL_READ、ALL_WRITE、LISTEN、EXEC、MONITOR、CREATE |
|
|
| ALL_READ、ALL_WRITE、LISTEN、EXEC、MONITOR |
|
|
| ALL_READ、MONITOR |
|
|
| MONITOR |
JMX および |
8.1.2. パーミッション
承認ロールには、Data Grid へのアクセスレベルが異なるさまざまなパーミッションがあります。パーミッションを使用すると、Cache Manager とキャッシュの両方へのユーザーアクセスを制限できます。
8.1.2.1. Cache Manager のパーミッション
| パーミッション | 機能 | 説明 |
|---|---|---|
| 設定 |
| 新しいキャッシュ設定を定義します。 |
| LISTEN |
| キャッシュマネージャーに対してリスナーを登録します。 |
| ライフサイクル |
| キャッシュマネージャーを停止します。 |
| CREATE |
| キャッシュ、カウンター、スキーマ、スクリプトなどのコンテナーリソースを作成および削除することができます。 |
| MONITOR |
|
JMX 統計および |
| ALL | - | すべてのキャッシュマネージャーのアクセス許可が含まれます。 |
8.1.2.2. キャッシュ権限
| パーミッション | 機能 | 説明 |
|---|---|---|
| READ |
| キャッシュからエントリーを取得します。 |
| WRITE |
| キャッシュ内のデータの書き込み、置換、削除、エビクト。 |
| EXEC |
| キャッシュに対するコードの実行を許可します。 |
| LISTEN |
| キャッシュに対してリスナーを登録します。 |
| BULK_READ |
| 一括取得操作を実行します。 |
| BULK_WRITE |
| 一括書き込み操作を実行します。 |
| ライフサイクル |
| キャッシュを開始および停止します。 |
| ADMIN |
| 基盤となるコンポーネントと内部構造へのアクセスを許可します。 |
| MONITOR |
|
JMX 統計および |
| ALL | - | すべてのキャッシュパーミッションが含まれます。 |
| ALL_READ | - | READ パーミッションと BULK_READ パーミッションを組み合わせます。 |
| ALL_WRITE | - | WRITE パーミッションと BULK_WRITE パーミッションを組み合わせます。 |
8.1.3. ロールマッパー
Data Grid には、サブジェクトのセキュリティープリンシパルをユーザーに割り当てる承認ロールにマップする PrincipalRoleMapper API が含まれています。
8.1.3.1. クラスターのロールマッパー
ClusterRoleMapper は永続的にレプリケートされたキャッシュを使用して、デフォルトのロールおよびパーミッションのプリンシパルからロールへのマッピングを動的に保存します。
デフォルトでは、プリンシパル名をロール名として使用し、実行時にロールマッピングを変更するメソッドを公開する org.infinispan.security.MutableRoleMapper を実装します。
-
Java クラス:
org.infinispan.security.mappers.ClusterRoleMapper -
宣言型設定:
<cluster-role-mapper />
8.1.3.2. ID ロールマッパー
IdentityRoleMapper は、プリンシパル名をロール名として使用します。
-
Java クラス:
org.infinispan.security.mappers.IdentityRoleMapper -
宣言型設定:
<identity-role-mapper />
8.1.3.3. CommonName ロールマッパー
CommonNameRoleMapper は、プリンシパル名が識別名 (DN) の場合は Common Name (CN) をロール名として使用します。
たとえば、この DN (cn=managers,ou=people,dc=example,dc=com) は managers ロールにマッピングします。
-
Java クラス:
org.infinispan.security.mappers.CommonRoleMapper -
宣言型設定:
<common-name-role-mapper />
8.1.3.4. カスタムロールマッパー
カスタムロールマッパーは org.infinispan.security.PrincipalRoleMapper の実装です。
-
宣言型設定:
<custom-role-mapper class="my.custom.RoleMapper" />
8.2. アクセス制御リスト (ACL) キャッシュ
Data Grid は、パフォーマンスの最適化のために内部でユーザーに付与するロールをキャッシュします。ロールをユーザーに付与または拒否するたびに、Data Grid は ACL キャッシュをフラッシュして、ユーザーのパーミッションが正しく適用されていることを確認します。
必要に応じて、ACL キャッシュを無効にするか、cache-size および cache-timeout 属性を使用してこれを設定することができます。
XML
JSON
YAML
8.3. ロールおよびパーミッションのカスタマイズ
Data Grid 設定の認証設定をカスタマイズして、異なるロールとパーミッションの組み合わせでロールマッパーを使用できます。
手順
- Cache Manager 設定でロールマッパーとカスタムロールとパーミッションのセットを宣言します。
- ユーザーロールに基づいてアクセスを制限するようにキャッシュの承認を設定します。
カスタムロールおよびパーミッションの設定
XML
JSON
YAML
8.4. セキュリティー承認によるキャッシュの設定
キャッシュ設定で承認を使用して、ユーザーアクセスを制限します。キャッシュエントリーの読み取りや書き込み、キャッシュの作成または削除を行う前に、ユーザーは十分なレベルのパーミッションを持つロールを持っている必要があります。
前提条件
authorization要素がcache-container設定のsecurityセクションに含まれていることを確認します。Data Grid はデフォルトで Cache Manager でセキュリティー承認を有効にし、キャッシュのグローバルロールおよびパーミッションを提供します。
- 必要な場合は、Cache Manager 設定でカスタムロールとパーミッションを宣言します。
手順
- キャッシュ設定を開いて編集します。
-
authorization要素をキャッシュに追加し、ロールおよびパーミッションに基づいてユーザーアクセスを制限します。 - 変更を設定に保存します。
認証設定
以下の設定は、デフォルトのロールおよびパーミッションで暗黙的な認証設定を使用する方法を示しています。
XML
<distributed-cache>
<security>
<!-- Inherit authorization settings from the cache-container. --> <authorization/>
</security>
</distributed-cache>
<distributed-cache>
<security>
<!-- Inherit authorization settings from the cache-container. --> <authorization/>
</security>
</distributed-cache>JSON
YAML
distributedCache:
security:
authorization:
enabled: true
distributedCache:
security:
authorization:
enabled: trueカスタムロールおよびパーミッション
XML
<distributed-cache>
<security>
<authorization roles="admin supervisor"/>
</security>
</distributed-cache>
<distributed-cache>
<security>
<authorization roles="admin supervisor"/>
</security>
</distributed-cache>JSON
YAML
distributedCache:
security:
authorization:
enabled: true
roles: ["admin","supervisor"]
distributedCache:
security:
authorization:
enabled: true
roles: ["admin","supervisor"]8.5. セキュリティー承認の無効化
ローカル開発環境では、ユーザーがロールおよびパーミッションを必要としないように、承認を無効にできます。セキュリティー承認を無効にすると、すべてのユーザーがデータにアクセスでき、Data Grid リソースと対話できます。
手順
- Data Grid 設定を開いて編集します。
-
Cache Manager
security設定からauthorization要素を削除します。 -
キャッシュから
authorization設定を削除します。 - 変更を設定に保存します。