ストレージデバイスの管理
ローカルおよびリモートのストレージデバイスの設定と管理
概要
- RAID (Redundant Array of Independent Disks) を作成して、複数のドライブにデータを保存し、データ損失を回避します。
- iSCSI および NVMe over Fabrics を使用して、ネットワーク経由でストレージにアクセスします。
- 物理ストレージデバイスのプールを管理するように Stratis をセットアップします。
Red Hat ドキュメントへのフィードバック (英語のみ)
Red Hat は質の高いドキュメントを提供することに尽力しており、皆様からのフィードバックを大切にしています。改善にご協力いただくため、Red Hat Jira トラッキングシステムを通じてご提案やエラー報告をお寄せください。
手順
Jira の Web サイトにログインします。
アカウントがない場合、アカウント作成オプションを選択します。
- 上部のナビゲーションバーで Create をクリックします。
- Summary フィールドにわかりやすいタイトルを入力します。
- Description フィールドに、ドキュメントの改善に関するご意見を記入してください。ドキュメントの該当部分へのリンクも追加してください。
- ウィンドウ下部の Create をクリックします。
第1章 利用可能なストレージオプションの概要
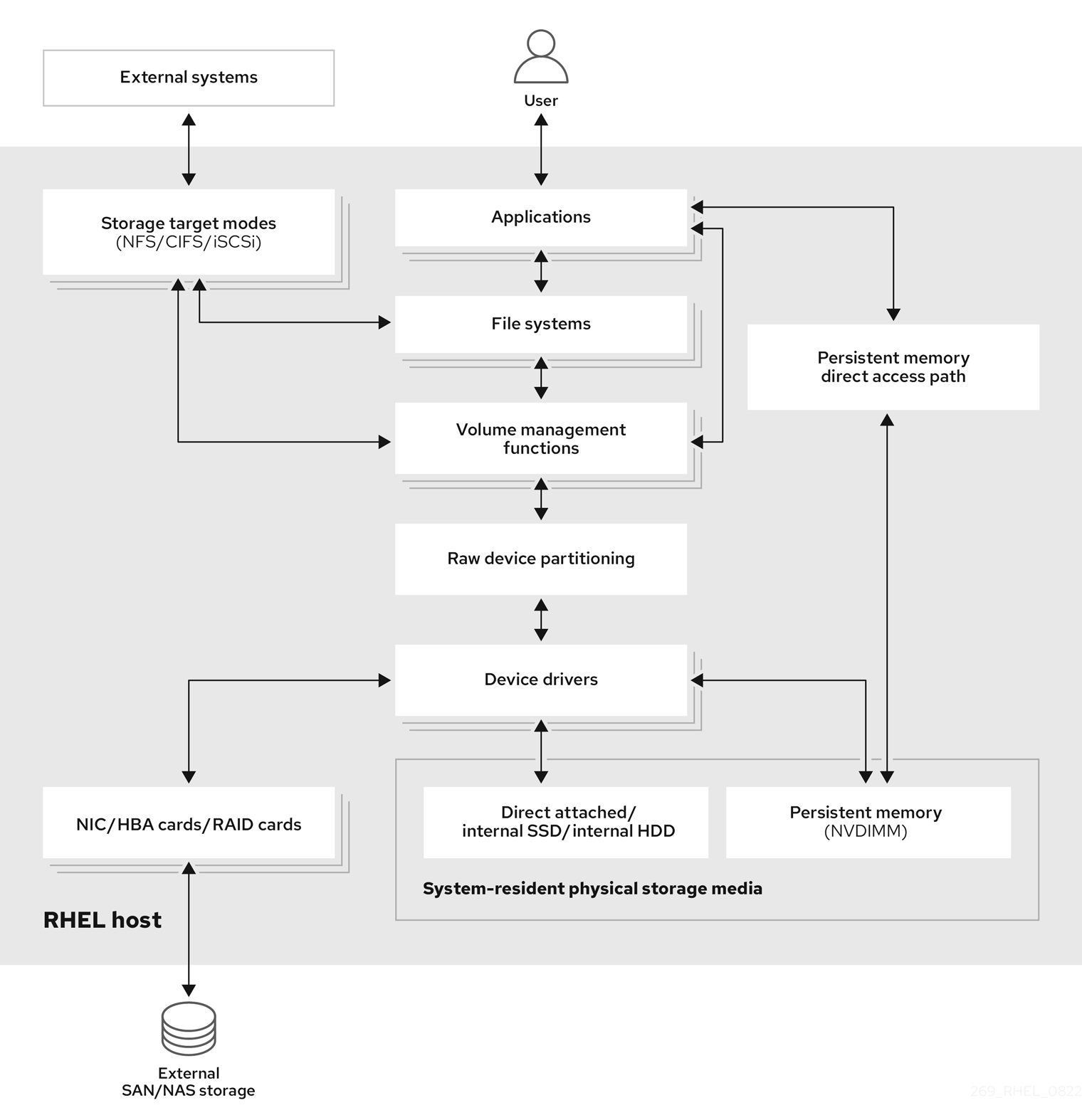
Red Hat Enterprise Linux で利用可能なローカル、リモート、およびクラスターベースのストレージオプションを紹介します。ストレージのアーキテクチャーを理解できるように、直接接続されたストレージデバイスと、LAN、インターネット、またはファイバーチャネルネットワーク経由でアクセスされるリモートストレージについて説明します。
ローカルストレージは、ストレージデバイスがシステムにインストールされているか、システムに直接接続されていることを意味します。
リモートストレージでは、LAN、インターネット、またはファイバーチャネルネットワークを介してデバイスにアクセスします。以下の Red Hat Enterprise Linux ストレージダイアグラムの概要では、さまざまなストレージオプションを説明します。
図1.1 Red Hat Enterprise Linux ストレージダイアグラム (概要)
1.1. ローカルストレージの概要
ローカルストレージとは、システムにインストールされているか、直接接続されているストレージデバイスを指します。これには、ネットワーク接続なしで管理できるディスクパーティション、論理ボリューム、およびファイルシステムが含まれます。
Red Hat Enterprise Linux 10 は、ローカルストレージオプションを複数提供します。
- 基本的なディスク管理:
partedとfdiskを使用して、ディスクパーティションを作成、変更、削除、および表示できます。パーティショニングレイアウトの標準は以下のようになります。- GUID パーティションテーブル (GPT)
- Globally Unique Identifier (GUID) を使用し、一意のディスクおよびパーティション GUID を提供します。
- マスターブートレコード (MBR)
- BIOS ベースのコンピューターで使用されます。プライマリーパーティション、拡張パーティション、および論理パーティションを作成できます。
- ストレージ使用オプション
- Non-Volatile Dual In-line Memory Modules (NVDIMM) の管理
- メモリーとストレージの組み合わせです。システムに接続した NVDIMM デバイスで、さまざまな種類のストレージを有効にして管理できます。
- ブロックストレージ管理
- 各ブロックに固有の識別子を持つブロックの形式でデータを保存します。
- ファイルストレージ
- データは、ローカルシステムのファイルレベルに保存されます。これらのデータには、XFS (デフォルト) または ext4 を使用してローカルでアクセスすることも、NFS および SMB を使用してネットワーク経由でアクセスすることもできます。
- 論理ボリューム
- 論理ボリュームマネージャー (LVM)
- 物理デバイスから論理デバイスを作成します。論理ボリューム (LV) は、物理ボリューム (PV) とボリュームグループ (VG) の組み合わせです。
- VDO (Virtual Data Optimizer)
重複排除、圧縮、およびシンプロビジョニングを使用して、データの削減に使用されます。VDO の下で論理ボリュームを使用すると、次のことができます。
- VDO ボリュームの拡張
- 複数のデバイスにまたがる VDO ボリューム
- ローカルファイルシステム
- XFS
- デフォルトの RHEL ファイルシステム。
- Ext4
- レガシーファイルシステム。
- Stratis
- Stratis は、高度なストレージ機能に対応する、ユーザーとカーネルのハイブリッドローカルストレージ管理システムです。
1.2. リモートストレージの概要
リモートストレージは、LAN、インターネット、ファイバーチャネルなどのネットワーク接続を介して、ストレージデバイスへのアクセスを提供します。これを使用すると、ストレージリソースを一元管理し、複数のシステム間で共有できます。
RHEL 10 で利用可能なリモートストレージオプションは次のとおりです。
- ストレージの接続オプション
- iSCSI
- RHEL 10 は targetcli ツールを使用して、iSCSI ストレージの相互接続を追加、削除、表示、および監視します。
- ファイバーチャネル (FC)
RHEL 10 は、以下のネイティブファイバーチャネルドライバーを提供します。
-
lpfc -
qla2xxx -
zfcp
-
- NVMe (Non-volatile Memory Express)
ホストソフトウェアユーティリティーがソリッドステートドライブと通信できるようにするインターフェイス。NVMe over Fabrics を設定するには、次のタイプの fabric トランスポートを使用します。
- Remote Direct Memory Access (NVMe/RDMA) を使用する NVMe over Fabrics
- ファイバーチャネルを使用した NVMe over Fabrics (NVMe/FC)
- TCP を使用した NVMe over Fabrics (NVMe/TCP)
- Device Mapper Multipath (DM Multipath)
- サーバーノードとストレージアレイ間の複数の I/O パスを 1 つのデバイスに設定できます。これらの I/O パスは、個別のケーブル、スイッチ、コントローラーを含むことができる物理的な SAN 接続です。
- ネットワークファイルシステム
- NFS
- SMB
第2章 永続的な命名属性
永続的な命名属性 (PNA) は、ハードウェア固有の特性に基づき、安定した予測可能なデバイス識別を提供します。これにより、システムの再起動やハードウェアの変更を経ても、命名が一貫したものになります。
ストレージデバイスを識別および管理する方法により、システムの安定性と予測可能性が確保されます。
RHEL 10 では、この目的のために、従来のデバイス名と永続的な命名属性という 2 つの主要な命名スキームを使用します。
従来のデバイス名
Linux カーネルは、システム内でのデバイスの表示順序または列挙に基づいて、従来のデバイス名を割り当てます。たとえば、通常、最初の SATA ドライブには /dev/sda というラベルが付けられ、2 番目の SATA ドライブには /dev/sdb というラベルが付けられます。これらの名前はわかりやすいですが、デバイスが追加または削除されたり、ハードウェア設定が変更されたり、システムが再起動されたりすると、変更される可能性があります。これにより、スクリプトと設定ファイルに問題が生じる可能性があります。さらに、従来の名前には、デバイスの目的や特性の説明的な情報が欠けています。
永続的な命名属性
永続的な命名属性 (PNA) は、ストレージデバイスの固有の特性に基づいているため、システムに対して提示された際に、システムの再起動後もより安定して予測可能な名前付けが可能になります。PNA の主な利点の 1 つは、ハードウェア設定の変更に対する回復力であり、一貫した命名規則を維持するのに最適であることです。PNA を使用すると、予期しない名前の変更を心配することなく、スクリプト、設定ファイル、管理ツール内でストレージデバイスを参照できます。さらに、PNA には、ベンダー、モデル名、シリアル番号の組み合わせなどのデバイスタイプや製造元情報などの貴重なメタデータが含まれることが多く、効果的なデバイス識別と管理のための記述性が向上します。PNA は最終的に、個々のデバイスにアクセスするために /dev/disk ディレクトリーにデバイスリンクを作成するために使用されます。デバイスリンク名の構築および管理方法は、udev ルールによって決まります。
以下は /dev/disk/ にあるディレクトリーのリストです。
システムの再起動後もコンテンツが一意のままであるディレクトリー:
-
by-id:vendor/model/serial_string組み合わせを使用したハードウェア属性に基づきます。 -
by-path*: 物理的なハードウェアの配置に基づきます。マシンに物理的に接続されているデバイスまたはディスクの場合、これはマザーボード上のホストバスに物理的に接続されているスロットまたはポートです。ただし、ネットワーク経由で接続されたデバイスまたはディスクの場合、これにはネットワークアドレスの指定が含まれます。 -
by-partlabel: デバイスパーティションに割り当てられたラベルに基づきます。これらのラベルはユーザーによって割り当てられます。 -
by-partuuid: 自動生成されるUUID形式の一意の番号に基づきます。 -
by-uuid: 自動生成される UUID 形式の一意の番号に基づきます。
-
現在のシステム実行中は一意のままであるが、システムの再起動後は一意ではなくなるコンテンツを含むディレクトリー:
-
by-diskseq:diskseqは 'ディスクシーケンス番号' のことで、システム起動時に 1 から順に割り当てが開始されます。この番号は新しく接続されたディスクに割り当てられ、その後の各ディスクには順番に次の番号が割り当てられます。システムを再起動すると、カウンターは 1 から再開されます。
-
ループデバイス専用に使用されるコンテンツを含むディレクトリー:
-
by-loop-ref -
by-loop-inode
-
2.1. ファイルシステムとブロックデバイスを識別するための永続属性
RHEL 10 のストレージでは、永続的な命名属性 (PNA) は、システムの再起動、ハードウェアの変更、またはその他のイベント全体にわたってストレージデバイスに一貫した信頼性の高い命名を提供するメカニズムです。
これらの属性は、ストレージデバイスが追加、削除、または再設定された場合でも、一貫してストレージデバイスを識別するために使用されます。PNA はファイルシステムとブロックデバイスの両方を識別するために使用されますが、目的は異なります。
- ファイルシステムを識別するための永続属性
ユニバーサル一意識別子 (UUID)
UUID は主に、ストレージデバイス上のファイルシステムを一意に識別するために使用されます。各ファイルシステムインスタンスには独自の UUID が自動的に割り当てられ、ファイルシステムがアンマウントや再マウントされたり、デバイスが切断されて再接続されたりしても、この識別子は一定のままです。
ラベル
ラベルは、ユーザーがファイルシステムに割り当てた名前です。これらはファイルシステムの識別と参照に使用できますが、UUID ほど標準化されていません。ファイルシステムラベルはユーザーが割り当てるため、その一意性はユーザーの選択によって決まります。ラベルは、設定ファイルでファイルシステムを指定するための UUID の代替としてよく使用されます。
ファイルシステムにラベルを割り当てると、そのラベルはファイルシステムのメタデータの一部になります。このラベルは、ファイルシステムがアンマウントや再マウントされたり、デバイスが切断されて再接続されたりしても、ファイルシステムに関連付けられたままになります。
- ブロックデバイスを識別するための永続属性
ユニバーサル一意識別子 (UUID)
UUID を使用してストレージブロックデバイスを識別できます。ストレージデバイスがフォーマットされると、多くの場合、デバイス自体に UUID が割り当てられます。このような UUID は通常、実際のデバイスが最下位レベルにある他のブロックデバイスの上に階層化された仮想ブロックデバイスに生成され、割り当てられます。たとえば、device-mapper (DM) ベースのデバイスと、論理ボリュームマネージャー (LVM) や暗号化などの関連サブシステムは、論理ボリューム UUID (LVUUID) や暗号化 UUID などの UUID を使用してデバイスを識別します。
また、multiple-device (MD) ベースのデバイスには UUID が割り当てられています。仮想デバイスは通常、基盤となるデバイスをコンポーネント UUID でマークします。たとえば、LVM は基盤となるデバイスを物理ボリューム UUID (PVUUID) でマークし、MD は基盤となるデバイスを MD コンポーネント UUID でマークします。
これらの UUID は仮想ブロックデバイスのメタデータ内に埋め込まれ、永続的な命名属性として使用されます。これにより、ブロックデバイス上に存在するファイルシステムを変更した場合でも、ブロックデバイスを一意に識別できるようになります。UUID はデバイスパーティションにも割り当てられます。
このような UUID は他のデバイス ID と共存できます。たとえば、デバイススタックの下部にある sda デバイスは、
vendor/model/serial_numberの組み合わせまたは WWID によって識別されますが、LVM によって割り当てられた PVUUID を持つこともできます。これは LVM 自体によって認識され、その上の層にボリュームグループ (VG) または論理ボリューム (LV) が構築されます。- ラベル、名前ラベル、または名前は、特定のブロックデバイスにも割り当てることができます。これは、ユーザーがラベルを割り当てることができるパーティションに適用されます。device-mapper (DM) ベースのデバイスや multiple-device (MD) ベースのデバイスなど、一部の仮想ブロックデバイスも、デバイスを識別するために名前を使用します。
World Wide Identifier (WWID)
WWID は、グローバルに一意であり、一般的にストレージブロックデバイスまたはストレージコンポーネントに関連付けられている識別子のファミリーを包含します。これらは、ファイバーチャネル (FC) などのエンタープライズレベルの Storage Area Network (SAN) で、ストレージノード (World Wide Node Name (WWNN)) またはノード上のストレージデバイスへの実際のポート/接続 (World Wide Port Name (WWPN)) を識別するためによく使用されます。WWID は、サーバーと SAN ストレージデバイス間の一貫した通信を実現し、ストレージデバイスへの冗長パスの管理に役立ちます。
NVME デバイスなど、他の種類のデバイスでも WWID の形式が使用される場合があります。これらのデバイスは、必ずしもネットワークまたは SAN 経由でアクセスする必要はなく、エンタープライズレベルのデバイスである必要もありません。
WWID 形式は単一の標準に従っていません。たとえば、SCSI では NAA、T10、EUI などの形式が使用されます。NVME は、EUI-64、NGUUID、UUID などの形式を使用します。
シリアル文字列
シリアル文字列は、製造元によって各ストレージブロックデバイスに割り当てられた一意の文字列識別子です。これはストレージデバイスを区別するために使用できます。また、デバイス管理のために UUID や WWID などの他の属性と組み合わせて使用することもできます。
udev rules内において、またその結果として生成される/dev/disk/by-idの内容においても、'短縮シリアル文字列' は、通常デバイス自体によって報告される実際のシリアル文字列を表します。一方、'シリアル文字列' は複数の要素で構成され、通常は<bus_type>-<vendor_name>_<model_name>_<short_serial_string>という形式です。実デバイスに対しては、WWID およびシリアル文字列の使用が推奨されます。仮想デバイスの場合、UUID または名前が推奨されます。
2.2. udev デバイスの命名規則
ユーザー空間デバイスマネージャー (udev) サブシステムを使用すると、デバイスに永続的な名前を割り当てるためのルールを定義できます。これらのルールは、.rules 拡張子を持つファイルに保存されます。
udev ルールを保存する主な場所は 2 つあります。
-
/usr/lib/udev/rules.d/ディレクトリーには、インストールされたパッケージに付属するデフォルトのルールが含まれています。 -
/etc/udev/rules.dディレクトリーはカスタムudevルール用です。
/usr/lib/udev/rules.d/ のルールが変更された場合、更新中にパッケージのルールファイルによって上書きされます。したがって、手動またはカスタムのルールは /etc/udev/rules.d に追加する必要があります。これらのルールは、明示的に削除されるまで保持されます。使用する前に、両方のディレクトリーの udev ルールがマージされます。/etc/udev/rules.d 内のルールが /usr/lib/udev/rules.d/ 内のルールと同じ名前である場合、前者のルールが優先されます。
これらのルールの目的は、システムの再起動後や設定の変更後も、ストレージデバイスが一貫して予測どおりに識別されるようにすることです。
udev ルールは、デバイスの追加、変更、または削除を通知する受信イベントに基づいて実行するアクションを定義します。これは、永続ストレージ属性の値を収集し、収集された情報に基づいて udev に /dev コンテンツを作成するように指示するのにも役立ちます。udev ルールは、キーと値のペアを使用して人間が読める形式で記述されます。
ストレージデバイスの場合、udev ルールは /dev/disk/ ディレクトリー内のシンボリックリンクの作成を制御します。これらのシンボリックリンクはストレージデバイスに使いやすいエイリアスを提供するため、これらのデバイスの参照と管理がより便利になります。
カスタムの udev ルールを作成して、シリアル番号、World Wide Name (WWN) 識別子、その他のデバイス固有の特性などのさまざまな属性に基づいてデバイスに名前を付ける方法を指定できます。特定の命名規則を定義することにより、システム内でデバイスを識別する方法を正確に制御できます。デバイスの特定のカスタムシンボリックリンクを/dev に作成するには、システムの udev(7) man ページを参照してください。
udev ルールは非常に柔軟ですが、udev の制限事項に注意することが重要です。
-
アクセス可能なタイミング: 一部のストレージデバイスは、
udevクエリー時にアクセスできない場合があります。 -
イベントベースの処理: カーネルはいつでも
udevイベントを送信できます。そのため、デバイスがアクセスできない場合は、ルール処理とリンクの削除をトリガーする可能性があります。 - 処理の遅延: 特に多数のデバイスがある場合、イベントの生成と処理の間に遅延が発生する可能性があります。これにより、カーネルがデバイスを検出してからリンクが利用可能になるまでに遅れが生じます。
-
デバイスのアクセシビリティー:
udevルールによって呼び出される外部プログラム (blkidなど) がデバイスを一時的に開き、他のタスクからデバイスに一時的にアクセスできなくなる可能性があります。 -
リンクの更新:
/dev/disk/でudevによって管理されるデバイス名は、メジャーリリース間で変更される可能性があります。その場合、リンクの更新が必要になります。
次の表は、/dev/disk で使用可能なシンボリックリンクを示しています。
| デバイスの種別 | 非永続名 (カーネル名) | 永続的なシンボリックリンク名 |
|---|---|---|
| 実際のデバイス | ||
| nvme (Non-Volatile Memory Express) | /dev/nvme* | /dev/disk/by-id/nvme-<wwid> /dev/disk/by-id/nvme-<model>_<serial>_<nsid> |
| scsi (Small Computer System Interface) | /dev/sd*、/dev/sr* | /dev/disk/by-id/scsi-<model>_<serial> /dev/disk/by-id/wwn-<wwn> /dev/disk/by-id/usb-<vendor>_<model>_<serial>-<instance> /dev/disk/by-id/ieee1394-<ieee1394_id> /dev/disk/by-path/ip-<ip_address>:<ip_port>-iscsi-<iqn_name>-lun-<lun_number> /dev/disk/by-id/scsi-0<vendor>_<model>_<id> /dev/disk/by-id/scsi-1<t10_vendor_id> /dev/disk/by-id/scsi-2<eui64_id> /dev/disk/by-id/scsi-3<naa_regext_id> /dev/disk/by-id/scsi-3<naa_reg_id> /dev/disk/by-id/scsi-3<naa_ext_id> /dev/disk/by-id/scsi-3<naa_local_id> /dev/disk/by-id/scsi-8<name> /dev/disk/by-id/scsi-S<vendor>_<model>_<serial> |
| ata (Advanced Technology Attachment)/atapi (ATA Packet Interface) | /dev/sd*、/dev/sr* | /dev/disk/by-id/ata-<model>_<serial> /dev/disk/by-id/wwn-<wwn> |
| cciss (Compaq Command Interface for SCSI-3 Support) | /dev/cciss* | /dev/disk/by-id/cciss-<model>_<serial> /dev/cciss/<ccissid> |
| virtio (Virtual Input Output) | /dev/vd* | /dev/disk/by-id/virtio-<serial> |
| pmem (Persistent Memory) | /dev/pmem* | /dev/disk/by-id/pmem-<uuid> |
| mmc (MultiMedia Card) | /dev/mmcblk* | /dev/disk/by-id/mmc-<name>_<serial> |
| memstick (Memory Stick) | /dev/msblk* | /dev/disk/by-id/memstick-<name>_<serial> |
| 仮想デバイス | ||
| loop | /dev/loop* | /dev/disk/by-loop-inode/<id_loop_backing_device>-<id_loop_backing_inode> /dev/disk/by-loop-ref/<id_loop_backing_filename> |
| dm (device-mapper) | /dev/dm-* | /dev/mapper/<name> /dev/disk/by-id/dm-name-<name> /dev/disk/by-id/dm-uuid-<uuid> /dev/disk/by-id/wwn-<wwn> |
| md (multiple device) | /dev/md* | /dev/md/<devname> /dev/disk/by-id/md-name-<name> /dev/disk/by-id/md-uuid-<uuid> |
| パーティション (実デバイス上または仮想デバイス上) | ||
| (any) | (any) | /dev/disk/by-partuuid/<uuid> /dev/disk/by-partlabel/<label> /dev/…/<persistent_symlink_name>-part<number> |
| LVM PV (論理ボリュームマネージャー物理ボリューム。実デバイスまたは仮想デバイス上) | ||
| (any) | (any) | /dev/disk/by-id/lvm-pv-uuid-<pvuuid> |
2.2.1. 既存デバイスのデバイスリンク値を取得する
現在の udev データベースから、既存のデバイスのデバイスリンクの値を取得できます。
前提条件
- デバイスが存在し、システムに接続されています。
手順
既存のデバイスの
/dev配下のベースカーネルデバイスノード (DEVNAME) に割り当てられたすべてのデバイスシンボリックリンク (DEVLINKS) をリスト表示します。# udevadm info --name /dev/nvme0n1 --query property --property DEVLINKS --value/dev/disk/by-path/pci-0000:00:02.0-nvme-1 /dev/disk/by-diskseq/6 /dev/disk/by-id/nvme-QEMU_NVMe_Ctrl_nvme-1_1 /dev/disk/by-id/nvme-QEMU_NVMe_Ctrl_nvme-1 /dev/disk/by-id/nvme-QEMU_NVMe_Ctrl_nvme-1-ns-1 /dev/disk/by-id/nvme-nvme.8086-6e766d652d31-51454d55204e564d65204374726c-00000001nvme0n1 をデバイス名に置き換えます。
次のコマンドを使用して、すべての devlink が指すベースカーネル名を取得することもできます。
# udevadm info --name /dev/nvme0n1 --query property --property DEVNAME --value /dev/nvme0n1カーネル名とその devlink は互換的に使用できます。
次のコマンドを使用し、devlink の 1 つを使用して devlink の完全なリストを取得できます。
# udevadm info --name /dev/disk/by-id/nvme-nvme.8086-6e766d652d31-51454d55204e564d65204374726c-00000001 --query property --property DEVLINKS --value/dev/disk/by-id/nvme-QEMU_NVMe_Ctrl_nvme-1 /dev/disk/by-diskseq/6 /dev/disk/by-id/nvme-nvme.8086-6e766d652d31-51454d55204e564d65204374726c-00000001 /dev/disk/by-id/nvme-QEMU_NVMe_Ctrl_nvme-1-ns-1 /dev/disk/by-id/nvme-QEMU_NVMe_Ctrl_nvme-1_1 /dev/disk/by-path/pci-0000:00:02.0-nvme-1
第3章 ディスクパーティション
パーティションテーブル、MBR と GPT の比較、パーティションタイプ、命名スキーム、マウントポイントなど、ディスクパーティション設定の基礎を説明します。ディスクを論理領域に分割して個別に管理する方法も説明します。
ディスクを 1 つ以上の論理領域に分割するには、ディスクのパーティション設定ユーティリティーを使用します。これにより、各パーティションを個別に管理できます。
3.1. パーティションの概要
ディスクパーティションは、物理ストレージデバイスを個別のセクションに分割します。各セクションは、オペレーティングシステムによって独立したディスクとして扱われます。これにより、データとシステムファイルの整理、セキュリティー確保、および管理をより適切に行えるようになります。
ハードディスクは、パーティションテーブルの各ディスクパーティションの場所とサイズに関する情報を保存します。オペレーティングシステムは、パーティションテーブルの情報を使用して、各パーティションを論理ディスクとして扱います。ディスクパーティション設定には、次のような利点があります。
- 物理ボリュームの管理上の見落としの可能性を減らす。
- 十分なバックアップを確保する。
- 効率的なディスク管理を提供する。
3.2. パーティションテーブルの種類の比較
パーティションテーブルの種類には、最大パーティション数やサイズなど、さまざまなプロパティーがあります。GUID パーティションテーブルおよびマスターブートレコードフォーマットでは、さまざまな設定がサポートされています。
次の表では、ブロックデバイスで作成できるさまざまな種類のパーティションテーブルのプロパティーを比較しています。
このセクションでは、IBM Z アーキテクチャーに固有の DASD パーティションテーブルを説明しません。
| パーティションテーブル | パーティションの最大数 | パーティションの最大サイズ |
|---|---|---|
| GUID パーティションテーブル (GPT) | 128 | 512 b セクターのドライブを使用する場合は 8 ZiB、4 k セクターのドライブを使用する場合は 64 ZiB |
| マスターブートレコード (MBR) | 4 つのプライマリーパーティション、または 3 つのプライマリーパーティションと 56 の論理パーティションを持つ 1 つの拡張パーティション | 512 b セクターのドライブを使用する場合は 2 TiB、4k セクターのドライブを使用する場合は 16 TiB |
3.3. GUID パーティションテーブル
GUID パーティションテーブル (GPT) は、Globally Unique Identifier (GUID) に基づくパーティション設定スキームです。
GPT は、マスターブートレコード (MBR) パーティションテーブルの制限に対処するものです。MBR パーティションテーブルは、約 2.2 TB に相当する 2 TiB を超えるストレージに対応できません。代わりに、GPT は大容量のハードディスクをサポートします。アドレス指定可能な最大ディスクサイズは、512 b セクタードライブを使用する場合は 8 ZiB、4096 b セクタードライブを使用する場合は 64 ZiB です。さらに、デフォルトで、GPT は最大 128 のプライマリーパーティションの作成をサポートします。パーティションテーブルにより多くの領域を割り当てて、プライマリーパーティションの最大量を拡張します。
GPT には GUID に基づくパーティションタイプがあります。特定のパーティションには特定の GUID が必要です。たとえば、Extensible Firmware Interface (EFI) ブートローダーのシステムパーティションには、GUID C12A7328-F81F-11D2-BA4B-00A0C93EC93B が必要です。
GPT ディスクは、論理ブロックアドレス指定 (LBA) とパーティションレイアウトを以下のように使用します。
- MBR ディスクとの下位互換性のために、システムは MBR データ用に GPT の最初のセクター (LBA 0) を予約し、"protective MBR" という名前を適用します。
プライマリー GPT
- ヘッダーは、デバイスの 2 番目の論理ブロック (LBA 1) から始まります。ヘッダーには、ディスク GUID、プライマリーパーティションテーブルの場所、セカンダリー GPT ヘッダーの場所、および CRC32 チェックサム、およびプライマリーパーティションテーブルが含まれます。また、テーブルにあるパーティションエントリーの数も指定します。
- デフォルトでは、プライマリー GPT には 128 のパーティションエントリーが含まれます。各パーティションには、128 バイトのエントリーサイズ、パーティションタイプ GUID、一意のパーティション GUID があります。
セカンダリー GPT
- リカバリーの場合は、プライマリーパーティションテーブルが破損した場合にバックアップテーブルとして役立ちます。
- ディスクの最後の論理セクターにはセカンダリー GPT ヘッダーが含まれており、プライマリーヘッダーが破損した場合に備えて GPT 情報を回復します。
以下が含まれます。
- ディスク GUID
- セカンダリーパーティションテーブルとプライマリー GPT ヘッダーの場所
- それ自体の CRC32 チェックサム
- セカンダリーパーティションテーブル
- 可能なパーティションエントリーの数
図3.1 GUID パーティションテーブルを含むディスク
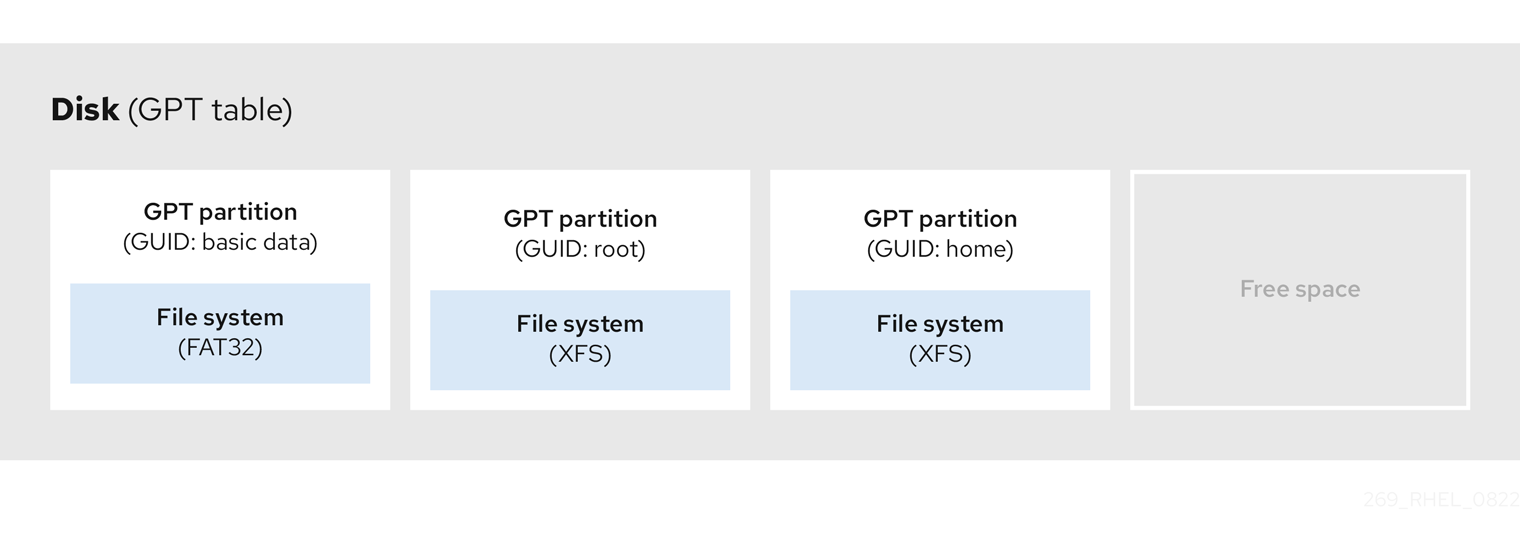
BIOS システムまたは BIOS 互換モードで実行されている UEFI システムの GPT ディスクにブートローダーを正常にインストールするには、BIOS ブートパーティションが存在している必要があります。
3.4. MBR ディスクパーティション
パーティションテーブルはそのディスクの先頭部分となる、他のファイルシステムまたはユーザーデータの前に格納されています。
わかりやすくするために、次の図ではパーティションテーブルを区切って示しています。
図3.2 MBR パーティションテーブルがあるディスク

上記の図で示したとおり、パーティションテーブルは使用していない 4 つのプライマリーパーティションの 4 つのセクションに分けられます。プライマリーパーティションは、論理ディスクドライブ (またはセクション) を 1 つだけ含むハードドライブのパーティションです。各論理ドライブは、1 つのパーティションの定義に必要な情報を保持できます。つまり、パーティションテーブルで定義できるプライマリーパーティションは 4 つまでです。
各パーティションテーブルエントリーには、パーティションの重要な特徴が含まれています。
- ディスク上のパーティションの開始点と終了点
-
パーティションの状態 (
activeとしてフラグを付けることができるのは 1 つのパーティションのみ) - パーティションのタイプ
開始点と終了点は、ディスク上のパーティションのサイズと場所を定義します。一部のオペレーティングシステムブートローダーは、active フラグを使用します。つまり、"active" とマークされているパーティションのオペレーティングシステムが起動します。
タイプとは、パーティションの用途を識別する番号です。一部のオペレーティングシステムでは、パーティションの種類を使用して以下を行います。
- 特定のファイルシステムタイプを示します。
- 特定のオペレーティングシステムに関連付けられているパーティションにフラグを付けます。
- パーティションに起動可能なオペレーティングシステムが含まれていることを示します。
以下の図は、パーティションが 1 つあるドライブの例を示しています。この例では、最初のパーティションには DOS パーティションタイプのラベルが付けられています。
図3.3 1 つのパーティションを持つディスク

3.5. 拡張 MBR パーティション
必要があれば、タイプを extended に設定して追加のパーティションを作成します。拡張パーティションは、ディスクドライブに似ています。拡張パーティション内に完全に含まれる 1 つ以上の論理パーティションを指す独自のパーティションテーブルがあります。
次の図は、2 つのプライマリーパーティションと、2 つの論理パーティションを含む 1 つの拡張パーティション、およびパーティション設定されていない空き領域を備えたディスクドライブを示しています。
図3.4 2 つのプライマリーパーティションと拡張 MBR パーティションの両方を備えたディスク

最大 4 つのプライマリーパーティション、または 3 つのプライマリーパーティションと 1 つの拡張パーティションのみを持つことができます。論理パーティションの数に固定の制限はありません。Linux ではパーティションへのアクセスに制限があり、1 つのディスクドライブでは最大 60 個のパーティションが許可されます。
3.6. MBR パーティションタイプ
マスターブートレコードパーティションタイプは、特定の 16 進数の識別子を使用して、ブロックデバイス上のさまざまなファイルシステムとパーティションの目的を指定します。
次の表は、最も一般的に使用される MBR パーティションタイプとそれらを表す 16 進数のリストです。
| MBR パーティションタイプ | 値 |
|---|---|
| 空白 | 00 |
| Extended | 05 |
| Linux swap | 82 |
| Linux ネイティブ | 83 |
| Linux 拡張 | 85 |
| Win95 FAT32 | 0b |
| Win95 FAT32 (LBA) | 0c |
| Win95 FAT16 (LBA) | 0e |
| Win95 Extended (LBA) | 0f |
3.7. パーティションタイプ
主要なパーティションタイプと支援ユーティリティー (fdisk や parted など) は、ストレージのレイアウトを定義、識別、管理します。パーティションフラグと GUID は、Linux 環境でのファイルシステムの使用、ブートオプション、およびデバイスの互換性を制御します。
パーティションタイプを管理する方法は複数あります。
-
fdiskユーティリティーは、16 進数コードを指定することで、あらゆる種類のパーティションタイプに対応します。 -
systemd-gpt-auto-generatorはユニットジェネレーターユーティリティーで、パーティションタイプを使用してデバイスを自動的に識別し、マウントします。 partedユーティリティーは、フラグ を使用してパーティションタイプをマップします。partedユーティリティーは、LVM、swap、RAID など、特定のパーティションタイプのみを処理します。partedユーティリティーは、次のフラグの設定をサポートしています。-
boot -
root -
swap -
hidden -
raid -
lvm -
lba -
legacy_boot -
irst -
esp -
palo
-
parted 3.5 を使用する Red Hat Enterprise Linux 10 では、追加のフラグ chromeos_kernel および bls_boot を使用できます。
parted ユーティリティーは、パーティションを作成するときにオプションでファイルシステムタイプ引数を受け付けます。値を使用して以下を行います。
- MBR にパーティションフラグを設定します。
-
GPT にパーティションの UUID タイプを設定します。たとえば、ファイルシステムタイプの
swap、fat、またはhfsには、異なる GUID が設定されます。デフォルト値は Linux Data GUID です。
この引数では、パーティションのファイルシステムは変更されません。サポート対象フラグと GUID のみ区別します。
次のファイルシステムのタイプがサポートされています。
-
xfs -
ext2 -
ext3 -
ext4 -
fat16 -
fat32 -
hfs -
hfs+ -
linux-swap -
ntfs -
reiserfs
3.8. パーティション命名スキーム
Red Hat Enterprise Linux は、/dev/xxyN 形式のファイル名を持つファイルベースの命名スキームを使用します。
デバイスおよびパーティション名は、以下の構造で構成されています。
/dev/-
すべてのデバイスファイルが含まれるディレクトリーの名前。ハードディスクにはパーティションが含まれるため、すべてのパーティションを表すファイルは
/devにあります。 xx- パーティション名の最初の 2 文字は、パーティションを含むデバイスのタイプを示します。
y-
この文字は、パーティションを含む特定のデバイスを示します。たとえば、
/dev/sdaは最初のハードディスク、/dev/sdbは 2 番目のハードディスクです。ドライブの数が 26 を超えるシステムでは、さらに多くの文字を使用できます (例:/dev/sdaa1)。 N最後の文字は、パーティションを表す数字を示します。最初の 4 つのパーティション (プライマリーまたは拡張) のパーティションには、
1から4までの番号が付けられます。論理パーティションは5から始まります。たとえば、/dev/sda3は 1 番目のハードディスクの 3 番目のプライマリーパーティションまたは拡張パーティションで、2 番目のハードディスク上の 2 番目の論理パーティション/dev/sdb6です。ドライブのパーティション番号は、MBR パーティションテーブルにのみ適用されます。N は常にパーティションを意味するものではないことに注意してください。数字で終わるディスクの場合、パーティションに
pが追加されます。たとえば、NVMe ドライブnvme0n1の最初のパーティションはnvme0n1p1です。
Red Hat Enterprise Linux は、すべて の種類のディスクパーティションを識別して参照できる場合でも、ファイルシステムを読み取って、すべてのパーティションタイプに保存されているデータにアクセスできるとは限りません。ただし、多くの場合、別のオペレーティングシステム専用のパーティション上にあるデータには問題なくアクセスすることができます。
3.9. マウントポイントとディスクパーティション
Red Hat Enterprise Linux では、各パーティションは、ファイルおよびディレクトリーの単一セットをサポートするのに必要なストレージの一部を形成します。パーティションをマウントすると、指定されたディレクトリー (マウントポイント と呼ばれる) を開始点としてそのパーティションのストレージが利用可能になります。
たとえば、パーティション /dev/sda5 が /usr/ にマウントされている場合、/usr/ 下にあるすべてのファイルとディレクトリーは物理的に /dev/sda5 上に存在することになります。ファイル /usr/share/doc/FAQ/txt/Linux-FAQ は /dev/sda5 にありますが、ファイル /etc/gdm/custom.conf はありません。
また、この例では、/usr/ 以下の 1 つ以上のディレクトリーが他のパーティションのマウントポイントになる可能性もあります。たとえば、/usr/local にマウントされた /dev/sda7 パーティションが含まれる場合、/usr/local/man/whatis は /dev/sda5 ではなく /dev/sda7 にあります。
第4章 パーティションの使用
ディスクのパーティション設定を行うことで、ディスクが複数の論理領域に分割され、それぞれを独立して処理できるようになります。ハードディスクは、場所とサイズのデータをパーティションテーブルに保存します。OS は各パーティションを個別の論理ディスクとして認識し、読み取りおよび書き込み操作を個別に許可します。
4.1. parted でディスクにパーティションテーブルを作成
ディスク上にパーティションテーブルを作成し、ストレージ領域を個別の管理可能なセクションに整理するためのレイアウトを定義します。この重要なセットアップ手順により、さまざまな目的やオペレーティングシステム用に複数のパーティションを作成できます。
パーティションテーブルを使用してブロックデバイスをフォーマットすると、そのデバイスに保存されているすべてのデータが削除されます。
手順
インタラクティブな
partedシェルを起動します。# parted block-deviceデバイスにパーティションテーブルがあるかどうかを確認します。
(parted) printデバイスにパーティションが含まれている場合は、次の手順でパーティションを削除します。
新しいパーティションテーブルを作成します。
(parted) mklabel table-typetable-type を、使用するパーティションテーブルのタイプに置き換えます。
-
msdos(MBR の場合) gpt(GPT の場合)たとえば、ディスクに GPT テーブルを作成するには、次のコマンドを使用します。
(parted) mklabel gptこのコマンドを入力すると、変更の適用が開始されます。
-
パーティションテーブルを表示して、作成されたことを確認します。
(parted) printpartedシェルを終了します。(parted) quit
4.2. parted でパーティションテーブルの表示
ブロックデバイスのパーティションテーブルを表示して、パーティションレイアウトと個々のパーティションの詳細を確認します。parted ユーティリティーを使用して、ブロックデバイスのパーティションテーブルを表示できます。詳細は、システム上の parted(8) man ページを参照してください。
手順
partedユーティリティーを起動します。たとえば、次の出力は、デバイス/dev/sdaをリストします。# parted /dev/sdaパーティションテーブルを表示します。
(parted) printModel: ATA SAMSUNG MZNLN256 (scsi) Disk /dev/sda: 256GB Sector size (logical/physical): 512B/512B Partition Table: msdos Disk Flags: Number Start End Size Type File system Flags 1 1049kB 269MB 268MB primary xfs boot 2 269MB 34.6GB 34.4GB primary 3 34.6GB 45.4GB 10.7GB primary 4 45.4GB 256GB 211GB extended 5 45.4GB 256GB 211GB logicalオプション: 次に調べるデバイスに切り替えます。
(parted) select block-deviceprint コマンドの出力の詳細は、以下を参照してください。
Model: ATA SAMSUNG MZNLN256 (scsi)- ディスクタイプ、製造元、モデル番号、およびインターフェイス。
Disk /dev/sda: 256GB- ブロックデバイスへのファイルパスとストレージ容量。
Partition Table: msdos- ディスクラベルの種類。
Number-
パーティション番号。たとえば、マイナー番号 1 のパーティションは、
/dev/sda1に対応します。 StartおよびEnd- デバイスにおけるパーティションの開始場所と終了場所。
Type- 有効なタイプは、メタデータ、フリー、プライマリー、拡張、または論理です。
File system-
ファイルシステムの種類。ファイルシステムの種類が不明な場合は、デバイスの
File systemフィールドに値が表示されません。partedユーティリティーは、暗号化されたデバイスのファイルシステムを認識できません。 Flags-
パーティションのフラグ設定リスト。最もよく使用されるフラグは、
boot、root、swap、hidden、raid、lvm、lbaです。フラグの完全なリストは、システムのparted(8)man ページを参照してください。
4.3. parted を使用したパーティションの作成
新しいディスクパーティションを作成して、ストレージスペースを効率的に整理し、異なる種類のデータを分離します。この基本的なストレージ管理タスクにより、システムファイル、ユーザーデータ、およびスワップスペース専用の領域をセットアップできます。
前提条件
- ディスクのパーティションテーブルがある。
- 2 TiB を超えるパーティションを作成する場合は、GUID Partition Table (GPT) でディスクをフォーマットしている。
必要なパーティションは、swap、/boot/、および / (root) です。
手順
partedユーティリティーを起動します。# parted block-device現在のパーティションテーブルを表示し、十分な空き領域があるかどうかを確認します。
(parted) print- 十分な空き容量がない場合は、パーティションのサイズを変更してください。
パーティションテーブルから、以下を確認します。
- 新しいパーティションの開始点と終了点
- MBR で、どのパーティションタイプにすべきか
新しいパーティションを作成します。
MS-DOS の場合:
(parted) mkpart part-type fs-type start endGPT の場合:
(parted) mkpart part-name fs-type start end-
part-type を
primary、logical、またはextendedに置き換えます。これは MBR パーティションテーブルにのみ適用されます。 - name を任意のパーティション名に置き換えます。これは GPT パーティションテーブルに必要です。
-
fs-type を、
xfs、ext2、ext3、ext4、fat16、fat32、hfs、hfs+、linux-swap、ntfs、またはreiserfsに置き換えます。fs-type パラメーターは任意です。partedユーティリティーは、パーティションにファイルシステムを作成しないことに注意してください。 start と end を、パーティションの開始点と終了点を決定するサイズに置き換えます (ディスクの開始からカウントします)。
512MiB、20GiB、1.5TiBなどのサイズ接尾辞を使用できます。デフォルトサイズの単位はメガバイトです。たとえば、MBR テーブルに 1024 MiB から 2048 MiB までのプライマリーパーティションを作成するには、次のコマンドを使用します。
(parted) mkpart primary 1024MiB 2048MiBコマンドを入力すると、変更の適用が開始されます。
-
part-type を
パーティションテーブルを表示して、作成されたパーティションのパーティションタイプ、ファイルシステムタイプ、サイズが、パーティションテーブルに正しく表示されていることを確認します。
(parted) printpartedシェルを終了します。(parted) quitカーネルが新しいパーティションを認識していることを確認します。
# cat /proc/partitions
4.4. fdisk でパーティションタイプの設定
fdisk ユーティリティーを使用して、パーティションタイプまたはフラグを設定できます。
前提条件
- ディスク上のパーティション。
手順
インタラクティブな
fdiskシェルを起動します。# fdisk block-device現在のパーティションテーブルを表示して、パーティションのマイナー番号を確認します。
Command (m for help): print現在のパーティションタイプは
Type列で、それに対応するタイプ ID はId列で確認できます。パーティションタイプコマンドを入力し、マイナー番号を使用してパーティションを選択します。
Command (m for help): type Partition number (1-3, default 3): 2オプション: パーティションの種類を表示します。
MBR パーティションテーブルを持つディスクの場合:
Hex code or alias (type L to list all codes): LGPT パーティションテーブルを持つディスクの場合:
Partition type or alias (type L to list all): L
パーティションタイプを設定します。
MBR パーティションテーブルを持つディスクの場合:
Hex code or alias (type L to list all codes): 8eGPT パーティションテーブルを持つディスクの場合:
Partition type or alias (type L to list all): 44
変更を書き込み、
fdiskシェルを終了します。Command (m for help): write The partition table has been altered. Syncing disks.
検証
変更を確認します。
# fdisk --list block-device
4.5. parted でパーティションのサイズ変更
parted ユーティリティーを使用して、パーティションを拡張して未使用のディスク領域を利用したり、パーティションを縮小してその容量をさまざまな目的に使用したりできます。詳細は、システム上の parted(8) man ページを参照してください。
前提条件
- パーティションを縮小する前にデータをバックアップする。
- 2 TiB を超えるパーティションを作成する場合は、GUID Partition Table (GPT) でディスクをフォーマットしている。
- パーティションを縮小する場合は、サイズを変更したパーティションより大きくならないように、最初にファイルシステムを縮小しておく。
XFS は縮小に対応していません。
手順
partedユーティリティーを起動します。# parted block-device現在のパーティションテーブルを表示します。
(parted) printパーティションテーブルから、以下を確認します。
- パーティションのマイナー番号。
既存のパーティションの位置とサイズ変更後の新しい終了点。
重要パーティションのサイズを変更する場合は、サイズ変更するパーティションの末尾と次のパーティションの先頭 (最後のパーティションの場合はディスクの末尾) との間に、十分な未割り当て領域があることを確認してください。十分な領域がない場合、
partedはエラーを返します。ただし、パーティションの重複を避けるために、サイズを変更する前に使用可能な領域を確認することが推奨されます。
パーティションのサイズを変更します。
(parted) resizepart 1 2GiB- 1 を、サイズを変更するパーティションのマイナー番号に置き換えます。
-
2 を、サイズを変更するパーティションの新しい終了点を決定するサイズに置き換えます (ディスクの開始からカウントします)。
512MiB、20GiB、1.5TiBなどのサイズ接尾辞を使用できます。デフォルトサイズの単位はメガバイトです。
パーティションテーブルを表示して、サイズ変更したパーティションのサイズが、パーティションテーブルで正しく表示されていることを確認します。
(parted) printpartedシェルを終了します。(parted) quitカーネルが新しいパーティションを登録していることを確認します。
# cat /proc/partitions- オプション: パーティションを拡張した場合は、そこにあるファイルシステムも拡張します。
4.6. parted でパーティションの削除
不要なディスクパーティションを削除して、ストレージ領域を他の目的に再利用します。この操作は、ディスクレイアウトの再編成、未使用のパーティションの削除、システム上のストレージ使用率の最適化に役立ちます。
手順
インタラクティブな
partedシェルを起動します。# parted block-device-
block-device を、パーティションを削除するデバイスへのパス (例:
/dev/sda) に置き換えます。
-
block-device を、パーティションを削除するデバイスへのパス (例:
現在のパーティションテーブルを表示して、削除するパーティションのマイナー番号を確認します。
(parted) printパーティションを削除します。
(parted) rm partition-number- partition-number は、削除するパーティション番号に置き換えます。
このコマンドを実行すると、すぐに変更の適用が開始されます。
パーティションテーブルからパーティションが削除されたことを確認します。
(parted) printpartedシェルを終了します。(parted) quitパーティションが削除されたことをカーネルが登録していることを確認します。
# cat /proc/partitions-
パーティションが存在する場合は、
/etc/fstabファイルからパーティションを削除します。削除したパーティションを宣言している行を見つけ、ファイルから削除します。 システムが新しい
/etc/fstab設定を登録するように、マウントユニットを再生成します。# systemctl daemon-reload重要/proc/cmdlineに記載されているパーティション、または LVM の一部であるパーティションを削除するには、論理ボリュームの設定と管理 と、システム上のdracut(8)およびgrubby (8)の man ページを参照してください。
第5章 ディスクを再設定するストラテジー
ほとんどの RHEL システムは、LVM を使用してストレージスペースを管理します。しかし、パーティションテーブルの操作は、デバイスレベルで発生するストレージ領域を管理するための基本的かつ低レベルの方法であることには変わりありません。ディスクのパーティション設定操作には、parted、fdisk、もしくは他のグラフィカルツールを使用できます。
ディスクのパーティションを再設定する方法は複数あります。これには、以下が含まれます。
- パーティションが分割されていない空き領域が利用できる。
- 未使用のパーティションが利用可能である。
- アクティブに使用されているパーティションの空き領域が利用可能である。
次の例は、パーティション設定手法の一般的な概要を示しています。わかりやすいように簡略化されており、一般的な Red Hat Enterprise Linux インストール時の正確なパーティションレイアウトを反映しているわけではありません。
5.1. パーティションが分割されていない空き領域の使用
すでに定義されているパーティションはハードディスク全体にまたがらないため、定義されたパーティションには含まれない未割り当ての領域が残されます。
未使用のハードディスクもこのカテゴリーに分類されます。唯一の違いは、すべて の領域が定義されたパーティションの一部ではないことです。
新しいディスクでは、未使用の領域から必要なパーティションを作成できます。ほとんどのオペレーティングシステムは、ディスクドライブ上の利用可能な領域をすべて取得するように設定されています。
5.2. 未使用パーティションの領域の使用
未使用のパーティションに割り当てられた領域を使用するには、パーティションを削除してから、代わりに適切な Linux パーティションを作成します。または、インストールプロセス時に未使用のパーティションを削除し、新しいパーティションを手動で作成します。
5.3. アクティブなパーティションの空き領域の使用
必要な空き領域がすでに使用されているアクティブパーティション上にある場合、このプロセスの管理は困難になる可能性があります。ソフトウェアがプリインストールされたほとんどのコンピューターには、オペレーティングシステムとユーザーデータの両方を保持する 1 つの大きなパーティションがあります。
オペレーティングシステム (OS) が含まれるアクティブなパーティションのサイズや設定を変更しようとすると、OS が失われたり、OS が起動できなくなったりするリスクがあります。その結果、場合によっては OS を再インストールする必要があるかもしれません。続行する前に、システムにリカバリーメディアまたはインストールメディアが含まれているかどうかを確認してください。
使用可能な空き領域の使用を最適化するには、破壊的または非破壊的なパーティション再設定の方法を使用できます。
5.3.1. 破壊的な再設定
破壊的なパーティション再設定を行うと、ハードドライブ上のパーティションが破壊され、その場所に新しいパーティションが作成されます。この方法はコンテンツ全体を削除するため、元のパーティションから必要なデータをバックアップします。
既存のオペレーティングシステムから新しいパーティションを作成した後、次の操作を実行できます。
- ソフトウェアの再インストール。
- データの復元。
このメソッドは、元のパーティションに保存されたデータをすべて削除します。
5.3.2. 非破壊的な再パーティション
非破壊的なパーティション再設定では、データの損失なしにパーティションのサイズを変更します。この方法は信頼性が高いものの、大容量のドライブでは処理時間が長くなります。
以下に、非破壊的なパーティション再設定を開始するのに役立つ方法をいくつかを示します。
- 既存データの再編成
一部のデータの保存場所は変更できないため、パーティションを必要なサイズに変更できない可能性があり、最終的には破壊的なパーティション再設定プロセスが必要になります。既存のパーティション内のデータを再編成すると、必要に応じてパーティションのサイズを変更し、パーティションを追加するための領域を追加したり、使用可能な空き領域を最大化したりすることができます。
データ損失の可能性を回避するには、データ移行プロセスを続行する前にバックアップを作成します。
- 既存パーティションのサイズ変更
既存のパーティションのサイズを変更すると、未使用の領域を解放できます。結果は、サイズ変更ソフトウェアにより異なります。多くの場合、元のパーティションと同じタイプのフォーマットされていない新しいパーティションを作成できます。
サイズ変更後の手順は、使用するソフトウェアにより異なります。以下の例では、新しい DOS (Disk Operating System) パーティションを削除し、代わりに Linux パーティションを作成することを推奨します。サイズ変更プロセスを開始する前に、何がディスクに最適か確認してください。
パーティションのサイズ変更と作成は、parted や GParted などの使用ツールにより異なる場合があります。具体的な手順は、ツールのドキュメントを参照してください。
- オプション: 新規パーティションの作成
一部のサイズ変更ソフトウェアは、Linux ベースのシステムをサポートしています。この場合、サイズ変更後に新たに作成されたパーティションを削除する必要はありません。新しいパーティションの作成方法は、使用するソフトウェアによって異なります。
第6章 iSCSI ターゲットの設定
targetcli を使用して iSCSI ターゲットを設定し、ファイル、ボリューム、SCSI デバイス、RAM ディスクなどのローカルストレージリソースをエクスポートします。バックストアの作成、ポータルのセットアップ、LUN 設定、および認証について説明します。
Red Hat Enterprise Linux では、コマンドラインインターフェイスとして targetcli シェルを使用し、以下の操作を行います。
- iSCSI ハードウェアを使用できるように iSCSI ストレージ相互接続を追加、削除、表示、監視します。
- ファイル、ボリューム、ローカル SCSI デバイス、またはリモートシステムへの RAM ディスクで対応しているローカルストレージリソースをエクスポートします。
targetcli ツールには、組み込みタブ補完、自動補完サポート、インラインドキュメントなどのツリーベースのレイアウトがあります。
6.1. targetcli のインストール
iSCSI ストレージの相互接続を追加、監視、削除するには、targetcli ツールをインストールします。
targetcliツールをインストールします。# dnf install targetcliターゲットサービスを起動します。
# systemctl start targetシステムの起動時にターゲットサービスが起動するように設定するには、次のコマンドを実行します。
# systemctl enable targetファイアウォールの
3260ポートを開き、ファイアウォール設定を再読み込みします。# firewall-cmd --permanent --add-port=3260/tcp success# firewall-cmd --reload success
検証
targetcliレイアウトを表示します。# targetcli/> ls o- /........................................[...] o- backstores.............................[...] | o- block.................[Storage Objects: 0] | o- fileio................[Storage Objects: 0] | o- pscsi.................[Storage Objects: 0] | o- ramdisk...............[Storage Objects: 0] o- iscsi...........................[Targets: 0] o- loopback........................[Targets: 0] o- srpt ...........................[Targets: 0]
6.2. iSCSI ターゲットの作成
クライアントがリモートで接続できるネットワークアクセス可能なストレージを提供するには、iSCSI ターゲットを設定します。この設定により、ネットワーク全体でストレージリソースを共有し、複数のシステムのストレージ管理を一元化できます。
前提条件
-
targetcliをインストールして、実行している。詳細は、targetcli のインストール を参照してください。
手順
iSCSI ディレクトリーに移動します。
cdコマンドを使用して iSCSI ディレクトリーに移動することもできます。/> iscsi/iSCSI ターゲットを作成するには、以下のいずれかのオプションを使用します。
デフォルトのターゲット名を使用した iSCSI ターゲットの作成:
/iscsi> createCreated target iqn.2003-01.org.linux-iscsi.hostname.x8664:sn.78b473f296ff Created TPG1特定の名前を使用した iSCSI ターゲットの作成:
/iscsi> create iqn.2006-04.com.example:444Created target iqn.2006-04.com.example:444 Created TPG1iqn.2006-04.com.example:444 を、特定のターゲット名に置き換えます。
新たに作成されたターゲットを確認します。
/iscsi> lso- iscsi.......................................[1 Target] o- iqn.2006-04.com.example:444................[1 TPG] o- tpg1...........................[enabled, auth] o- acls...............................[0 ACL] o- luns...............................[0 LUN] o- portals.........................[0 Portal]
6.3. iSCSI バックストア
iSCSI バックストアは、エクスポートした LUN のデータをローカルマシンに保存するさまざまな方法に対応します。ストレージオブジェクトを作成して、バックストアが使用するリソースを定義します。
管理者は、LIO (Linux-IO) が対応する以下のバックストアデバイスのいずれかを選択できます。
fileioバックストア-
ローカルファイルシステム上の通常のファイルをディスクイメージとして使用する場合は、
fileioストレージオブジェクトを作成します。 blockバックストア-
ローカルのブロックデバイスおよび論理デバイスを使用している場合には、
blockストレージオブジェクトを作成します。 pscsiバックストア-
ストレージオブジェクトが SCSI コマンドの直接パススルーに対応している場合は、
pscsiストレージオブジェクトを作成します。 ramdiskバックストア-
一時的な RAM 対応デバイスを作成する場合は、
ramdiskストレージオブジェクトを作成します。
6.4. fileio ストレージオブジェクトの作成
fileio ストレージオブジェクトは、write_back または write_thru 操作のいずれかをサポートできます。write_back 操作では、ローカルファイルシステムキャッシュが有効になります。これにより、パフォーマンスが向上しますが、データの損失のリスクが高まります。
write_thru 操作を優先させるために、write_back=false を使用して write_back 操作を無効にすることが推奨されます。
前提条件
-
targetcliをインストールして、実行している。詳細は、targetcli のインストール を参照してください。
手順
backstores/ディレクトリーからfileio/に移動します。/> backstores/fileiofileioストレージオブジェクトを作成します。/backstores/fileio> create file1 /tmp/disk1.img 200M write_back=falseCreated fileio file1 with size 209715200
検証
作成された
fileioストレージオブジェクトを確認します。/backstores/fileio> ls
6.5. ブロックストレージオブジェクトの作成
ブロックドライバーを使用すると、/sys/block/ ディレクトリーにあるブロックデバイスを LIO (Linux-IO) で使用できます。これには、HDD、SSD、CD、DVD などの物理デバイス、およびソフトウェアやハードウェアの RAID ボリューム、LVM ボリュームなどの論理デバイスが含まれます。
前提条件
-
targetcliをインストールして、実行している。
手順
backstores/ディレクトリーからblock/に移動します。/> backstores/block/blockバックストアを作成します。/backstores/block> create name=block_backend dev=/dev/sdbCreated block storage object block_backend using /dev/sdb.
検証
作成された
blockストレージオブジェクトを確認します。/backstores/block> ls
6.6. pscsi ストレージオブジェクトの作成
SCSI エミュレーションがない場合、かつ /proc/scsi/scsi に lsscsi で表示される基盤の SCSI デバイスが存在する場合には、SCSI コマンドの直接パススルーをサポートするストレージオブジェクトであれば、どれでもバックストアとして設定できます。たとえば、SAS ハードドライブなどが該当します。このサブシステムでは、SCSI-3 以降に対応しています。
pscsi は、上級ユーザーのみが使用してください。非対称論理ユニット割り当て (ALUA) や永続予約 (VMware ESX や vSphere で使用される永続予約など) は、通常はデバイスのファームウェアに実装されず、誤作動やクラッシュが発生する原因となることがあります。確信が持てない場合は、実稼働の設定に block バックストアを使用してください。
前提条件
-
targetcliをインストールして、実行している。
手順
backstores/ディレクトリーからpscsi/に移動します。/> backstores/pscsi/この例では、
/dev/sr0を使用して物理 SCSI デバイスである TYPE_ROM デバイスのpscsiバックストアを作成します。/backstores/pscsi> create name=pscsi_backend dev=/dev/sr0 Created pscsi storage object pscsi_backend using /dev/sr0
検証
作成した
pscsiストレージオブジェクトを確認します。/backstores/pscsi> ls
6.7. メモリーコピーの RAM ディスクストレージオブジェクトの作成
メモリーコピー RAM ディスク (ramdisk) は、完全な SCSI エミュレーションと、イニシエーターのメモリーコピーを使用した個別のメモリーマッピングが含まれる RAM ディスクを提供します。これにより、マルチセッションの機能を利用できます。これは、特に実稼働環境での高速で不揮発性の大容量ストレージで有用です。
前提条件
-
targetcliをインストールして、実行している。
手順
backstores/ディレクトリーからramdisk/に移動します。/> backstores/ramdisk/1GB RAM ディスクバックストアを作成します。
/backstores/ramdisk> create name=rd_backend size=1GBCreated ramdisk rd_backend with size 1GB.
検証
作成した
ramdiskストレージオブジェクトを確認します。/backstores/ramdisk> ls
6.8. iSCSI ポータルの作成
iSCSI ポータルを作成できます。これにより、IP アドレスとポートがターゲットに追加され、ターゲットが有効な状態に維持されます。詳細は、システム上の targetcli(8) man ページを参照してください。
前提条件
-
targetcliをインストールして、実行している。詳細は、targetcli のインストール を参照してください。 - ターゲットポータルグループ (TPG) に関連付けられた iSCSI ターゲット。詳細は、iSCSI ターゲットの作成 を参照してください。
手順
TPG ディレクトリーに移動します。
/iscsi> iqn.2006-04.com.example:444/tpg1/iSCSI ポータルを作成するには、以下のいずれかのオプションを使用します。
デフォルトポータルを作成するには、デフォルトの iSCSI ポート
3260を使用し、ターゲットがそのポートのすべての IP アドレスをリッスンできるようにします。/iscsi/iqn.20...mple:444/tpg1> portals/ createUsing default IP port 3260 Binding to INADDR_Any (0.0.0.0) Created network portal 0.0.0.0:3260特定の IP アドレスを使用したポータルの作成:
/iscsi/iqn.20...mple:444/tpg1> portals/ create 192.168.122.137Using default IP port 3260 Created network portal 192.168.122.137:3260
検証
新たに作成されたポータルを確認します。
/iscsi/iqn.20...mple:444/tpg1> lso- tpg.................................. [enabled, auth] o- acls ......................................[0 ACL] o- luns ......................................[0 LUN] o- portals ................................[1 Portal] o- 192.168.122.137:3260......................[OK]
6.9. iSCSI LUN の作成
論理ユニット番号 (LUN) は、iSCSI バックストアで対応している物理デバイスです。各 LUN には固有の番号があります。詳細は、システム上の targetcli(8) man ページを参照してください。
前提条件
-
targetcliをインストールして、実行している。詳細は、targetcli のインストール を参照してください。 - ターゲットポータルグループ (TPG) に関連付けられた iSCSI ターゲット。詳細は、iSCSI ターゲットの作成 を参照してください。
- 作成したストレージオブジェクト。詳細は、iSCSI バックストア を参照してください。
手順
作成したストレージオブジェクトの LUN を作成します。
/iscsi/iqn.20...mple:444/tpg1> luns/ create /backstores/ramdisk/rd_backendCreated LUN 0./iscsi/iqn.20...mple:444/tpg1> luns/ create /backstores/block/block_backendCreated LUN 1./iscsi/iqn.20...mple:444/tpg1> luns/ create /backstores/fileio/file1 Created LUN 2.作成した LUN を確認します。
/iscsi/iqn.20...mple:444/tpg1> lso- tpg.................................. [enabled, auth] o- acls ......................................[0 ACL] o- luns .....................................[3 LUNs] | o- lun0.........................[ramdisk/ramdisk1] | o- lun1.................[block/block1 (/dev/vdb1)] | o- lun2...................[fileio/file1 (/foo.img)] o- portals ................................[1 Portal] o- 192.168.122.137:3260......................[OK]デフォルトの LUN 名は
0から始まります。重要デフォルトでは、読み書きパーミッションを持つ LUN が作成されます。ACL の作成後に新しい LUN が追加されると、LUN は自動的に利用可能なすべての ACL にマッピングされ、セキュリティー上のリスクが発生します。読み取り専用権限を持つ LUN の作成については、Creating a read-only iSCSI LUN を参照してください。
- ACL を設定します。詳細は、iSCSI ACL の作成 を参照してください。
6.10. 読み取り専用の iSCSI LUN の作成
デフォルトでは、読み書きパーミッションを持つ LUN が作成されます。読み取り専用の LUN を作成できます。詳細は、システム上の targetcli(8) man ページを参照してください。
前提条件
-
targetcliをインストールして、実行している。詳細は、targetcli のインストール を参照してください。 - ターゲットポータルグループ (TPG) に関連付けられた iSCSI ターゲット。詳細は、iSCSI ターゲットの作成 を参照してください。
- 作成したストレージオブジェクト。詳細は、iSCSI バックストア を参照してください。
手順
読み取り専用パーミッションを設定します。
/> set global auto_add_mapped_luns=falseParameter auto_add_mapped_luns is now 'false'.これにより、LUN が既存の ACL へ自動的にマッピングされないようになり、LUN を手動でマッピングできるようになります。
initiator_iqn_name ディレクトリーに移動します。
/> iscsi/target_iqn_name/tpg1/acls/initiator_iqn_name/LUN を作成します。
/iscsi/target_iqn_name/tpg1/acls/initiator_iqn_name> create mapped_lun=next_sequential_LUN_number tpg_lun_or_backstore=backstore write_protect=1たとえば、以下のようになります。
/iscsi/target_iqn_name/tpg1/acls/2006-04.com.example:888> create mapped_lun=1 tpg_lun_or_backstore=/backstores/block/block2 write_protect=1Created LUN 1. Created Mapped LUN 1.作成した LUN を確認します。
/iscsi/target_iqn_name/tpg1/acls/2006-04.com.example:888> lso- 2006-04.com.example:888 .. [Mapped LUNs: 2] | o- mapped_lun0 .............. [lun0 block/disk1 (rw)] | o- mapped_lun1 .............. [lun1 block/disk2 (ro)](mapped_lun0 の (
rw) とは異なり) mapped_lun1 行の最後に (ro) が表示されますが、これは、読み取り専用であることを表しています。- ACL を設定します。詳細は、iSCSI ACL の作成 を参照してください。
6.11. iSCSI ACL の作成
アクセス制御リスト (ACL) を作成して、特定のストレージターゲットにアクセスできるイニシエーターを定義し、セキュアな iSCSI 接続のための権限を制御します。この重要なセキュリティー対策により、許可されたクライアントだけが共有ストレージリソースにアクセスできるようになります。
詳細は、システム上の targetcli(8) man ページを参照してください。
前提条件
-
targetcliをインストールして、実行している。詳細は、targetcli のインストール を参照してください。 - ターゲットポータルグループ (TPG) に関連付けられた iSCSI ターゲット。詳細は、iSCSI ターゲットの作成 を参照してください。
ターゲットとイニシエーターにはどちらも一意の識別名があります。ACL を設定するには、イニシエーターの一意の名前を知っている必要があります。iscsi-initiator-utils パッケージによって提供される /etc/iscsi/initiatorname.iscsi ファイルには、iSCSI イニシエーター名が含まれています。
手順
- オプション: ACL への LUN の自動マッピングを無効にするには、読み取り専用の iSCSI LUN の作成 を参照してください。
aclsディレクトリーへ移動します。/> iscsi/target_iqn_name/tpg_name/acls/ACL を作成するには、以下のいずれかのオプションを使用します。
イニシエーターの
/etc/iscsi/initiatorname.iscsiファイルの initiator_iqn_name を使用します。iscsi/target_iqn_name/tpg_name/acls> create initiator_iqn_nameCreated Node ACL for initiator_iqn_name Created mapped LUN 2. Created mapped LUN 1. Created mapped LUN 0.custom_name を使用し、それに一致するようにイニシエーターを更新します。
iscsi/target_iqn_name/tpg_name/acls> create custom_nameCreated Node ACL for custom_name Created mapped LUN 2. Created mapped LUN 1. Created mapped LUN 0.イニシエーター名の更新方法の詳細は、iSCSI イニシエーターの作成 を参照してください。
検証
作成した ACL を確認します。
iscsi/target_iqn_name/tpg_name/acls> lso- acls .................................................[1 ACL] o- target_iqn_name ....[3 Mapped LUNs, auth] o- mapped_lun0 .............[lun0 ramdisk/ramdisk1 (rw)] o- mapped_lun1 .................[lun1 block/block1 (rw)] o- mapped_lun2 .................[lun2 fileio/file1 (rw)]
6.12. ターゲットのチャレンジハンドシェイク認証プロトコルの設定
Challenge-Handshake Authentication Protocol (CHAP) を使用すると、パスワードでターゲットを保護できます。イニシエーターは、このパスワードでターゲットに接続できることを認識している必要があります。詳細は、システム上の targetcli(8) man ページを参照してください。
前提条件
- iSCSI ACL を作成している。詳細は、iSCSI ACL の作成 を参照してください。
手順
属性認証を設定します。
/iscsi/iqn.20...mple:444/tpg1> set attribute authentication=1Parameter authentication is now '1'.useridとpasswordを設定します。/tpg1> set auth userid=redhat Parameter userid is now 'redhat'./iscsi/iqn.20...689dcbb3/tpg1> set auth password=redhat_passwd Parameter password is now 'redhat_passwd'.aclsディレクトリーへ移動します。/> iscsi/target_iqn_name/tpg1/acls/initiator_iqn_name/属性認証を設定します。
/iscsi/iqn.20...:605fcc6a48be> set attribute authentication=1Parameter authentication is now '1'.useridとpasswordを設定します。/iscsi/iqn.20...:605fcc6a48be> set auth userid=redhatParameter userid is now 'redhat'./iscsi/iqn.20...:605fcc6a48be> set auth password=redhat_passwdParameter password is now 'redhat_passwd'.
6.13. targetcli ツールを使用した iSCSI オブジェクトの削除
targetcli ツールを使用して iSCSI オブジェクトを削除できます。詳細は、システム上の targetcli(8) man ページを参照してください。
手順
ターゲットからログオフします。
# iscsiadm -m node -T iqn.2006-04.com.example:444 -uターゲットへのログイン方法の詳細は、iSCSI イニシエーターの作成 を参照してください。
ACL、LUN、およびポータルのすべてを含め、ターゲット全体を削除します。
/> iscsi/ delete iqn.2006-04.com.example:444iqn.2006-04.com.example:444 を target_iqn_name に置き換えます。
iSCSI バックストアを削除するには、次のコマンドを実行します。
/> backstores/backstore-type/ delete block_backendbackstore-type を
fileio、block、pscsi、またはramdiskに置き換えます。block_backend を、削除する バックストア名 に置き換えます。
ACL などの iSCSI ターゲットの一部を削除するには、次のコマンドを実行します。
/> /iscsi/iqn-name/tpg/acls/ delete iqn.2006-04.com.example:444
検証
変更を表示します。
/> iscsi/ ls
第7章 iSCSI イニシエーターの設定
iSCSI イニシエーターは、iSCSI ターゲットに接続するためにセッションを開始します。iscsiadm の実行後、iSCSI サービスがデフォルトでオンデマンドで起動します。ルートファイルシステムが iSCSI デバイス上にない場合、または node.startup = automatic を持つノードがない場合、iscsiadm が iscsid またはカーネルモジュールをトリガーするまで、サービスは起動しません。
iscsid サービスを強制的に実行し、iSCSI カーネルモジュールをロードするには、root として systemctl start iscsid コマンドを実行します。
7.1. iSCSI イニシエーターの作成
サーバー上のストレージデバイスにアクセスするために、iSCSI ターゲットに接続するための iSCSI イニシエーターを作成します。詳細は、システム上の targetcli(8) および iscsiadm(8) man ページを参照してください。
前提条件
iSCSI ターゲットのホスト名と IP アドレスがあります。
- 外部ソフトウェアが作成したストレージターゲットに接続している場合は、ストレージ管理者からターゲットのホスト名と IP アドレスを取得します。
- iSCSI ターゲットを作成する場合は、iSCSI ターゲットの作成 を参照してください。
手順
クライアントマシンに
iscsi-initiator-utilsをインストールします。# dnf install iscsi-initiator-utilsiscsidサービスを起動します。# systemctl start iscsidイニシエーター名を確認します。
# cat /etc/iscsi/initiatorname.iscsiInitiatorName=iqn.2006-04.com.example:888iSCSI ACL の作成 で ACL にカスタム名を指定した場合は、ACL と一致するようにイニシエーター名を更新します。
/etc/iscsi/initiatorname.iscsiファイルを開き、イニシエーター名を変更します。# vi /etc/iscsi/initiatorname.iscsiInitiatorName=custom-nameiscsidサービスを再起動します。# systemctl restart iscsid
ターゲットを検出し、表示されたターゲット IQN でターゲットにログインします。
# iscsiadm -m discovery -t st -p 10.64.24.17910.64.24.179:3260,1 iqn.2006-04.com.example:444# iscsiadm -m node -T iqn.2006-04.com.example:444 -lLogging in to [iface: default, target: iqn.2006-04.com.example:444, portal: 10.64.24.179,3260] (multiple) Login to [iface: default, target: iqn.2006-04.com.example:444, portal: 10.64.24.179,3260] successful.10.64.24.179 を、target-ip-address に置き換えます。
この手順では、iSCSI ACL の作成 で説明されているように、それぞれのイニシエーター名が ACL に追加されている場合は、同じターゲットに接続されている任意の数のイニシエーターに対してこの手順を使用できます。
iSCSI ディスク名を確認して、この iSCSI ディスクにファイルシステムを作成します。
# grep "Attached SCSI" /var/log/messages # mkfs.ext4 /dev/disk_namedisk_name を、
/var/log/messagesファイルに記載されている iSCSI ディスク名に置き換えます。ファイルシステムをマウントします。
# mkdir /mount/point# mount /dev/disk_name /mount/point/mount/point を、パーティションのマウントポイントに置き換えます。
システムの起動時にファイルシステムを自動的にマウントするように
/etc/fstabを編集します。# vi /etc/fstab/dev/disk_name /mount/point ext4 _netdev 0 0disk_name を iSCSI ディスク名に置き換え、/mount/point を、パーティションのマウントポイントに置き換えます。
7.2. イニシエーター用のチャレンジハンドシェイク認証プロトコルの設定
Challenge-Handshake Authentication Protocol (CHAP) を使用すると、パスワードでターゲットを保護できます。イニシエーターは、このパスワードでターゲットに接続できることを認識している必要があります。詳細は、システム上の iscsiadm(8) man ページを参照してください。
前提条件
- iSCSI イニシエーターを作成しました。詳細は、iSCSI イニシエーターの作成 を参照してください。
-
ターゲットの
CHAPを設定します。詳細は、ターゲットのチャレンジハンドシェイク認証プロトコルの設定 を参照してください。
手順
iscsid.confファイルで CHAP 認証を有効にします。# vi /etc/iscsi/iscsid.confnode.session.auth.authmethod = CHAPデフォルトでは、
node.session.auth.authmethodはNoneに設定されています。ターゲットの
usernameとpasswordをiscsid.confファイルに追加します。node.session.auth.username = redhat node.session.auth.password = redhat_passwdiscsidサービスを再起動します。# systemctl restart iscsid
7.3. iscsiadm ユーティリティーを使用して iSCSI セッションを監視する
iscsiadm ユーティリティーを使用して iscsi セッションを監視できます。
デフォルトでは、iSCSI サービスは起動に時間がかかり、iscsiadm コマンドの実行後にサービスが起動します。root が iSCSI デバイスにない場合や、node.startup = automatic でマークされたノードがない場合は、iscsiadm コマンドが実行するまで iSCSI サービスが起動しなくなります。これには、カーネルモジュール iscsid または iscsi の起動が必要になります。
iscsid サービスを強制的に実行し、iSCSI カーネルモジュールをロードするには、root として systemctl start iscsid コマンドを使用します。
詳細は以下を参照してください。
-
/usr/share/doc/iscsi-initiator-utils/READMEファイル -
システム上の
iscsiadm(8)man ページ
手順
クライアントマシンに
iscsi-initiator-utilsをインストールします。# dnf install iscsi-initiator-utils実行中のセッションに関する情報を検索します。
# iscsiadm -m session -P 3このコマンドは、セッションまたはデバイスの状態、セッション ID (sid)、いくつかのネゴシエートしたパラメーター、およびセッション経由でアクセス可能な SCSI デバイスを表示します。
より短い出力 (たとえば
sid-to-node間のマッピングのみの表示) には、次のコマンドを実行します。# iscsiadm -m session -P 0or# iscsiadm -m sessiontcp [2] 10.15.84.19:3260,2 iqn.1992-08.com.netapp:sn.33615311 tcp [3] 10.15.85.19:3260,3 iqn.1992-08.com.netapp:sn.33615311このコマンドは、
driver [sid] target_ip:port,target_portal_group_tag proper_target_nameの形式で実行中のセッションのリストを表示します。
7.4. DM Multipath によるデバイスのタイムアウトのオーバーライド
sysfs オプションの recovery_tmo は、特定の Internet Small Computer Systems Interface (iSCSI) デバイスのタイムアウトを制御します。
次のオプションは、recovery_tmo 値をグローバルにオーバーライドします。
-
replacement_timeout設定オプションは、すべての iSCSI デバイスのrecovery_tmo値をグローバルにオーバーライドします。 DM Multipath の
fast_io_fail_tmoオプションは、DM Multipath によって管理されるすべての iSCSI デバイスのrecovery_tmo値をグローバルにオーバーライドします。DM Multipath の
fast_io_fail_tmoオプションは、ファイバーチャネルデバイスのfast_io_fail_tmoオプションもオーバーライドします。
DM Multipath の fast_io_fail_tmo オプションは、replacement_timeout よりも優先されます。multipathd サービスがリロードされるたびに、recovery_tmo が fast_io_fail_tmo 設定オプションの値にリセットされます。DM Multipath によって管理されるデバイスの recovery_tmo をオーバーライドするには、DM Multipath の fast_io_fail_tmo 設定オプションを使用してください。
第8章 ファイバーチャネルデバイスの使用
lpfc、qla2xxx、zfcp などのネイティブの RHEL ドライバーを使用してファイバーチャネルデバイスを設定します。LUN の再スキャン、リンク損失動作の設定、およびファイバーチャネル設定ファイルの管理について説明します。
8.1. LUN のサイズ変更後にファイバーチャネル論理ユニットを再スキャンする
外部ストレージの論理ユニット番号 (LUN) のサイズを変更した場合は、echo コマンドを使用してカーネルのサイズのビューを更新します。
手順
multipath論理ユニットのパスとなるデバイスを特定します。# multipath -llマルチパスを使用するシステムで、ファイバーチャネル論理ユニットを再スキャンします。
$ echo 1 > /sys/block/<device_ID>/device/rescan<device_ID>は、デバイスの ID (例:sda) に置き換えます。
8.2. ファイバーチャネルを使用したデバイスのリンク切れ動作の特定
ドライバーがトランスポートの dev_loss_tmo コールバックを実装している場合、トランスポートの問題が検出されるとリンクを経由したデバイスへのアクセス試行がブロックされます。
手順
リモートポートの状態を判断します。
$ cat /sys/class/fc_remote_ports/rport-host:bus:remote-port/port_stateこのコマンドは、次のいずれかの出力を返します。
-
リモートポートからアクセスしたデバイスとともにリモートポートがブロックされると
Blockedとなります。 リモートポートが正常に動作しているときには
Onlineとなりますdev_loss_tmo秒以内に問題が解決されない場合は、rportおよびデバイスのブロックが解除されます。そのデバイスで実行しているすべての I/O は、そのデバイスに送信された新しい I/O とともにすべて失敗します。リンクロスが
dev_loss_tmoを超えると、scsi_deviceデバイスおよびsd_N_デバイスが削除されます。通常、ファイバーチャネルクラスがデバイスを変更することはありません。たとえば、/dev/sdaは/dev/sdaのままです。これは、ターゲットバインディングがファイバーチャネルドライバーによって保存されており、ターゲットポートが復帰した際に SCSI アドレスが忠実に再作成されるためです。ただし、これは保証されません。ストレージボックス内の LUN 設定に追加の変更が加えられていない場合にのみ、デバイスが復元されます。
-
リモートポートからアクセスしたデバイスとともにリモートポートがブロックされると
8.3. ファイバーチャネル設定ファイル
ファイバーチャネル設定ファイル、/sys/class/ ディレクトリー内のその構造、主要な変数、およびマルチパスソフトウェアを使用する環境でデバイスパラメーターを安全に調整するための推奨事項を説明します。
以下は、ユーザー空間の API をファイバーチャネルに提供する /sys/class/ ディレクトリーの設定ファイルのリストです。
項目は以下の変数を使用します。
H- ホスト番号
B- バス番号
T- ターゲット
L- 論理ユニット (LUN)
R- リモートポート番号
システムでマルチパスソフトウェアを使用している場合は、このセクションで説明されている値を変更する前にハードウェアベンダーにお問い合わせください。
/sys/class/fc_transport/targetH:B:T/ のトランスポート設定
port_id- 24 ビットのポート ID/アドレス
node_name- 64 ビットのノード名
port_name- 64 ビットのポート名
/sys/class/fc_remote_ports/rport-H:B-R/ のリモートポート設定
-
port_id -
node_name -
port_name dev_loss_tmoscsi デバイスがシステムから削除されるタイミングを制御します。
dev_loss_tmoがトリガーされると、scsi デバイスが削除されます。multipath.confファイルでは、dev_loss_tmoをinfinityに設定できます。Red Hat Enterprise Linux 10 では、
fast_io_fail_tmoオプションを設定しないと、dev_loss_tmoの上限が600秒になります。デフォルトでは、Red Hat Enterprise Linux 10 では、multipathdサービスが実行中の場合、fast_io_fail_tmoは5秒に設定され、それ以外の場合はoffに設定されます。fast_io_fail_tmoリンクに "bad" のマークが付くまでの待機秒数を指定します。リンクに bad のマークが付けられると、対応するパス上の既存の実行中の I/O または新しい I/O が失敗します。
I/O がブロックされたキューに存在する場合は、
dev_loss_tmoの期限が切れ、キューのブロックが解除されるまでエラーを起こしません。fast_io_fail_tmoを off 以外の値に設定すると、dev_loss_tmoは取得されません。fast_io_fail_tmoを off に設定すると、システムからデバイスが削除されるまで I/O は失敗します。fast_io_fail_tmoに数値を設定すると、fast_io_fail_tmoタイムアウトが発生するとすぐに I/O が失敗します。
/sys/class/fc_host/hostH/ のホスト設定
-
port_id -
node_name -
port_name issue_lipリモートポートを再検出するようにドライバーに指示します。
第9章 NVMe over fabric デバイスの概要
Non-Volatile Memory Express™ (NVMe™) は、ホストソフトウェアユーティリティーがソリッドステートドライブと通信できるようにするインターフェイスです。
次の種類のファブリックトランスポートを使用して、NVMe over fabric デバイスを設定します。
- NVMe over Remote Direct Memory Access (NVMe/RDMA)
- NVMe over Fibre Channel (NVMe/FC)
- NVMe over TCP (NVMe/TCP)
NVMe over Fabrics を使用する場合、ソリッドステートドライブはシステムにローカルである必要はありません。NVMe over Fabrics デバイスを介してリモートで設定できます。
第10章 NVMe/RDMA を使用した NVMe over Fabrics の設定
NVMe コントローラーとイニシエーターの設定を含む NVMe over RDMA セットアップを設定します。configfs と nvmetcli を使用して RDMA コントローラーを設定し、高速なストレージアクセスのために RDMA ホストを設定できます。
10.1. configfs を使用した NVMe/RDMA コントローラーの設定
configfs を使用して、Non-volatile Memory Express™ (NVMe™) over RDMA (NVMe™/RDMA) コントローラーを設定できます。詳細は、システム上の nvme(1) man ページを参照してください。
前提条件
-
nvmetサブシステムに割り当てるブロックデバイスがあることを確認する。
手順
nvmet-rdmaサブシステムを作成します。# modprobe nvmet-rdma# mkdir /sys/kernel/config/nvmet/subsystems/testnqn# cd /sys/kernel/config/nvmet/subsystems/testnqntestnqn を、サブシステム名に置き換えます。
すべてのホストがこのコントローラーに接続できるようにします。
# echo 1 > attr_allow_any_host名前空間を設定します。
# mkdir namespaces/10# cd namespaces/1010 は、名前空間の番号に置き換えます。
NVMe デバイスへのパスを設定します。
# echo -n /dev/nvme0n1 > device_path名前空間を有効にします。
# echo 1 > enableNVMe ポートでディレクトリーを作成します。
# mkdir /sys/kernel/config/nvmet/ports/1# cd /sys/kernel/config/nvmet/ports/1mlx5_ib0 の IP アドレスを表示します。
# ip addr show mlx5_ib08: mlx5_ib0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 4092 qdisc mq state UP group default qlen 256 link/infiniband 00:00:06:2f:fe:80:00:00:00:00:00:00:e4:1d:2d:03:00:e7:0f:f6 brd 00:ff:ff:ff:ff:12:40:1b:ff:ff:00:00:00:00:00:00:ff:ff:ff:ff inet 172.31.0.202/24 brd 172.31.0.255 scope global noprefixroute mlx5_ib0 valid_lft forever preferred_lft forever inet6 fe80::e61d:2d03:e7:ff6/64 scope link noprefixroute valid_lft forever preferred_lft foreverコントローラーのトランスポートアドレスを設定します。
# echo -n 172.31.0.202 > addr_traddrRDMA をトランスポートタイプとして設定します。
# echo rdma > addr_trtype# echo 4420 > addr_trsvcidポートのアドレスファミリーを設定します。
# echo ipv4 > addr_adrfamソフトリンクを作成します。
# ln -s /sys/kernel/config/nvmet/subsystems/testnqn /sys/kernel/config/nvmet/ports/1/subsystems/testnqn
検証
NVMe コントローラーが指定されたポートでリッスンしていて、接続要求の準備ができていることを確認します。
# dmesg | grep "enabling port"[ 1091.413648] nvmet_rdma: enabling port 1 (172.31.0.202:4420)
10.2. nvmetcli を使用して NVMe™/RDMA コントローラーの設定
nvmetcli ユーティリティーを使用して、Non-volatile Memory Express™ (NVMe™) over RDMA (NVMe™/RDMA) コントローラーを設定できます。nvmetcli ユーティリティーには、コマンドラインと対話式のシェルオプションが用意されています。詳細は、システム上の nvmetcli および nvme(1) man ページを参照してください。
前提条件
-
nvmetサブシステムに割り当てるブロックデバイスがあることを確認する。 -
root ユーザーとして、以下の
nvmetcli操作を実行する。
手順
nvmetcliパッケージをインストールします。# dnf install nvmetclirdma.jsonファイルをダウンロードします。# wget http://git.infradead.org/users/hch/nvmetcli.git/blob_plain/0a6b088db2dc2e5de11e6f23f1e890e4b54fee64:/rdma.json-
rdma.jsonファイルを編集して、traddrの値を172.31.0.202に変更します。 NVMe コントローラー設定ファイルをロードして、コントローラーをセットアップします。
# nvmetcli restore rdma.json注記NVMe コントローラー設定ファイル名を指定しない場合は、
nvmetcliが/etc/nvmet/config.jsonファイルを使用します。
検証
NVMe コントローラーが指定されたポートでリッスンしていて、接続要求の準備ができていることを確認します。
# dmesg | tail -1[ 4797.132647] nvmet_rdma: enabling port 2 (172.31.0.202:4420)オプション: 現在の NVMe コントローラーをクリアします。
# nvmetcli clear
10.3. NVMe/RDMA ホストの設定
NVMe 管理コマンドラインインターフェイス (nvme-cli) ツールを使用して、Non-volatile Memory Express™ (NVMe™) over RDMA (NVMe™/RDMA) ホストを設定できます。詳細は、システム上の nvme(1) man ページを参照してください。
手順
nvme-cliツールをインストールします。# dnf install nvme-clinvme-rdmaモジュールが読み込まれていない場合は、読み込みます。# modprobe nvme-rdmaNVMe コントローラーで使用可能なサブシステムを検出します。
# nvme discover -t rdma -a 172.31.0.202 -s 4420Discovery Log Number of Records 2, Generation counter 2 =====Discovery Log Entry 0====== trtype: rdma adrfam: ipv4 subtype: current discovery subsystem treq: not specified, sq flow control disable supported portid: 2 trsvcid: 4420 subnqn: nqn.2014-08.org.nvmexpress.discovery traddr: 172.31.0.202 eflags: none rdma_prtype: not specified rdma_qptype: connected rdma_cms: rdma-cm rdma_pkey: 0000 =====Discovery Log Entry 1====== trtype: rdma adrfam: ipv4 subtype: nvme subsystem treq: not specified, sq flow control disable supported portid: 2 trsvcid: 4420 subnqn: testnqn traddr: 172.31.0.202 eflags: none rdma_prtype: not specified rdma_qptype: connected rdma_cms: rdma-cm rdma_pkey: 0000検出されたサブシステムに接続します。
# nvme connect -t rdma -a 172.31.0.202 -s 4420 -n testnqnconnecting to device: nvme0# lsblkNAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sda 8:0 0 465.8G 0 disk ├─sda1 8:1 0 1G 0 part /boot └─sda2 8:2 0 464.8G 0 part ├─rhel_rdma--virt--03-root 253:0 0 50G 0 lvm / ├─rhel_rdma--virt--03-swap 253:1 0 4G 0 lvm [SWAP] └─rhel_rdma--virt--03-home 253:2 0 410.8G 0 lvm /home nvme0n1# cat /sys/class/nvme/nvme0/transportrdmatestnqn を NVMe サブシステム名に置き換えます。
172.31.0.202 をコントローラーの IP アドレスに置き換えます。
4420 を、ポート番号に置き換えます。
検証
現在接続されている NVMe デバイスのリストを表示します。
# nvme listオプション: コントローラーから切断します。
# nvme disconnect -n testnqnNQN:testnqn disconnected 1 controller(s) # lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sda 8:0 0 465.8G 0 disk ├─sda1 8:1 0 1G 0 part /boot └─sda2 8:2 0 464.8G 0 part ├─rhel_rdma--virt--03-root 253:0 0 50G 0 lvm / ├─rhel_rdma--virt--03-swap 253:1 0 4G 0 lvm [SWAP] └─rhel_rdma--virt--03-home 253:2 0 410.8G 0 lvm /home
第11章 NVMe/FC を使用した NVMe over Fabrics の設定
Non-volatile Memory Express™ (NVMe™) over Fibre Channel (NVMe™/FC) トランスポートは、特定の Broadcom Emulex および Marvell Qlogic ファイバーチャネルアダプターと共に使用する場合、ホストモードで完全にサポートされます。
11.1. Broadcom アダプターの NVMe ホストの設定
NVMe 管理コマンドラインインターフェイス (nvme-cli) ユーティリティーを使用して、Broadcom アダプターで Non-volatile Memory Express™ (NVMe™) ホストを設定できます。詳細は、システム上の nvme(1) man ページを参照してください。
手順
nvme-cliユーティリティーをインストールします。# dnf install nvme-cliこれにより、
/etc/nvme/ディレクトリーにhostnqnファイルが作成されます。hostnqnファイルは、NVMe ホストを識別します。ローカルポートとリモートポートのワールドワイドノード名 (WWNN) とワールドワイドポート名 (WWPN) 識別子を見つけます。
# cat /sys/class/scsi_host/host*/nvme_infoNVME Host Enabled XRI Dist lpfc0 Total 6144 IO 5894 ELS 250 NVME LPORT lpfc0 WWPN x10000090fae0b5f5 WWNN x20000090fae0b5f5 DID x010f00 ONLINE NVME RPORT WWPN x204700a098cbcac6 WWNN x204600a098cbcac6 DID x01050e TARGET DISCSRVC ONLINE NVME Statistics LS: Xmt 000000000e Cmpl 000000000e Abort 00000000 LS XMIT: Err 00000000 CMPL: xb 00000000 Err 00000000 Total FCP Cmpl 00000000000008ea Issue 00000000000008ec OutIO 0000000000000002 abort 00000000 noxri 00000000 nondlp 00000000 qdepth 00000000 wqerr 00000000 err 00000000 FCP CMPL: xb 00000000 Err 00000000これらの
host-traddrとtraddrの値を使用して、Subsystem NVMe Qualified Name (NQN) を検索します。# nvme discover --transport fc \ --traddr nn-0x204600a098cbcac6:pn-0x204700a098cbcac6 \ --host-traddr nn-0x20000090fae0b5f5:pn-0x10000090fae0b5f5Discovery Log Number of Records 2, Generation counter 49530 =====Discovery Log Entry 0====== trtype: fc adrfam: fibre-channel subtype: nvme subsystem treq: not specified portid: 0 trsvcid: none subnqn: nqn.1992-08.com.netapp:sn.e18bfca87d5e11e98c0800a098cbcac6:subsystem.st14_nvme_ss_1_1 traddr: nn-0x204600a098cbcac6:pn-0x204700a098cbcac6nn-0x204600a098cbcac6:pn-0x204700a098cbcac6 を、
traddrに置き換えます。nn-0x20000090fae0b5f5:pn-0x10000090fae0b5f5 を、
host-traddrに置き換えます。nvme-cliを使用して NVMe コントローラーに接続します。# nvme connect --transport fc \ --traddr nn-0x204600a098cbcac6:pn-0x204700a098cbcac6 \ --host-traddr nn-0x20000090fae0b5f5:pn-0x10000090fae0b5f5 \ -n nqn.1992-08.com.netapp:sn.e18bfca87d5e11e98c0800a098cbcac6:subsystem.st14_nvme_ss_1_1 \ -k 5注記接続時間がデフォルトの keep-alive タイムアウト値を超えると
keep-alive timer (5 seconds) expired!と表示される場合は、-kオプションを使用して値を増やします。たとえば、-k 7を使用できます。ここでは、以下のようになります。
nn-0x204600a098cbcac6:pn-0x204700a098cbcac6 を、
traddrに置き換えます。nn-0x20000090fae0b5f5:pn-0x10000090fae0b5f5 を、
host-traddrに置き換えます。nqn.1992-08.com.netapp:sn.e18bfca87d5e11e98c0800a098cbcac6:subsystem.st14_nvme_ss_1_1 を、
subnqnに置き換えます。5 を keep-alive タイムアウト値 (秒単位) に置き換えます。
検証
現在接続されている NVMe デバイスのリストを表示します。
# nvme listNode SN Model Namespace Usage Format FW Rev ---------------- -------------------- ---------------------------------------- --------- -------------------------- ---------------- -------- /dev/nvme0n1 80BgLFM7xMJbAAAAAAAC NetApp ONTAP Controller 1 107.37 GB / 107.37 GB 4 KiB + 0 B FFFFFFFF# lsblk |grep nvme nvme0n1 259:0 0 100G 0 disk
11.2. QLogic アダプターの NVMe ホストの設定
NVMe 管理コマンドラインインターフェイス (nvme-cli) ユーティリティーを使用して、Qlogic アダプターで Non-volatile Memory Express™ (NVMe™) ホストを設定できます。詳細は、システム上の nvme(1) man ページを参照してください。
手順
nvme-cliユーティリティーをインストールします。# dnf install nvme-cliこれにより、
/etc/nvme/ディレクトリーにhostnqnファイルが作成されます。hostnqnファイルは、NVMe ホストを識別します。qla2xxxを再読み込みします。# modprobe -r qla2xxx# modprobe qla2xxxローカルポートとリモートポートのワールドワイドノード名 (WWNN) とワールドワイドポート名 (WWPN) 識別子を見つけます。
# dmesg |grep traddr[ 6.139862] qla2xxx [0000:04:00.0]-ffff:0: register_localport: host-traddr=nn-0x20000024ff19bb62:pn-0x21000024ff19bb62 on portID:10700 [ 6.241762] qla2xxx [0000:04:00.0]-2102:0: qla_nvme_register_remote: traddr=nn-0x203b00a098cbcac6:pn-0x203d00a098cbcac6 PortID:01050dこれらの
host-traddrとtraddrの値を使用して、Subsystem NVMe Qualified Name (NQN) を検索します。# nvme discover --transport fc \ --traddr nn-0x203b00a098cbcac6:pn-0x203d00a098cbcac6 \ --host-traddr nn-0x20000024ff19bb62:pn-0x21000024ff19bb62Discovery Log Number of Records 2, Generation counter 49530 =====Discovery Log Entry 0====== trtype: fc adrfam: fibre-channel subtype: nvme subsystem treq: not specified portid: 0 trsvcid: none subnqn: nqn.1992-08.com.netapp:sn.c9ecc9187b1111e98c0800a098cbcac6:subsystem.vs_nvme_multipath_1_subsystem_468 traddr: nn-0x203b00a098cbcac6:pn-0x203d00a098cbcac6nn-0x203b00a098cbcac6:pn-0x203d00a098cbcac6 を、
traddrに置き換えます。nn-0x20000024ff19bb62:pn-0x21000024ff19bb62 を、
host-traddrに置き換えます。nvme-cliツールを使用して NVMe コントローラーに接続します。# nvme connect --transport fc \ --traddr nn-0x203b00a098cbcac6:pn-0x203d00a098cbcac6 \ --host-traddr nn-0x20000024ff19bb62:pn-0x21000024ff19bb62 \ -n nqn.1992-08.com.netapp:sn.c9ecc9187b1111e98c0800a098cbcac6:subsystem.vs_nvme_multipath_1_subsystem_468\ -k 5注記接続時間がデフォルトの keep-alive タイムアウト値を超えると
keep-alive timer (5 seconds) expired!と表示される場合は、-kオプションを使用して値を増やします。たとえば、-k 7を使用できます。ここでは、以下のようになります。
nn-0x203b00a098cbcac6:pn-0x203d00a098cbcac6 を、
traddrに置き換えます。nn-0x20000024ff19bb62:pn-0x21000024ff19bb62 を、
host-traddrに置き換えます。nqn.1992-08.com.netapp:sn.c9ecc9187b1111e98c0800a098cbcac6:subsystem.vs_nvme_multipath_1_subsystem_468 を、
subnqnに置き換えます。5 を keep-live タイムアウト値 (秒単位) に置き換えます。
検証
現在接続されている NVMe デバイスのリストを表示します。
# nvme listNode SN Model Namespace Usage Format FW Rev ---------------- -------------------- ---------------------------------------- --------- -------------------------- ---------------- -------- /dev/nvme0n1 80BgLFM7xMJbAAAAAAAC NetApp ONTAP Controller 1 107.37 GB / 107.37 GB 4 KiB + 0 B FFFFFFFF# lsblk |grep nvmenvme0n1 259:0 0 100G 0 disk
第12章 NVMe/TCP を使用した NVMe over Fabrics の設定
Non-volatile Memory Express™ (NVMe™) over TCP (NVMe/TCP) セットアップでは、ホストモードは完全にサポートされており、コントローラーセットアップはサポートされていません。
Red Hat は NVMe ターゲット (nvmet) 機能をサポートしていません。NVMe over Fabrics ブロックストレージターゲットデバイスを設定する方法については、ストレージ製造元のドキュメントを参照してください。
Red Hat Enterprise Linux 10 では、ネイティブ NVMe マルチパスがデフォルトで有効になっています。DM マルチパスの有効化は、NVMe/TCP ではサポートされていません。
12.1. NVMe/TCP ホストの設定
NVMe 管理コマンドラインインターフェイス (nvme-cli) ツールを使用して、Non-volatile Memory Express™ (NVMe™) over TCP (NVMe/TCP) ホストを設定できます。詳細は、システム上の nvme(1) man ページを参照してください。
手順
nvme-cliツールをインストールします。# dnf install nvme-cliコントローラーのステータスを確認します。
# nmcli device show ens6GENERAL.DEVICE: ens6 GENERAL.TYPE: ethernet GENERAL.HWADDR: 52:57:02:12:02:02 GENERAL.MTU: 1500 GENERAL.STATE: 30 (disconnected) GENERAL.CONNECTION: -- GENERAL.CON-PATH: -- WIRED-PROPERTIES.CARRIER: on静的 IP アドレスを使用して、新しくインストールされたイーサネットコントローラーのホストネットワークを設定します。
# nmcli connection add con-name ens6 ifname ens6 type ethernet ip4 192.168.101.154/24 gw4 192.168.101.1ここで、192.168.101.154 をホスト IP アドレスに置き換えます。
# nmcli connection mod ens6 ipv4.method manual# nmcli connection up ens6NVMe/TCP ホストを NVMe/TCP コントローラーに接続するための新しいネットワークが作成されるため、コントローラーでもこの手順を繰り返します。
検証
新しく作成されたホストネットワークが正しく機能するかどうかを確認します。
# nmcli device show ens6GENERAL.DEVICE: ens6 GENERAL.TYPE: ethernet GENERAL.HWADDR: 52:57:02:12:02:02 GENERAL.MTU: 1500 GENERAL.STATE: 100 (connected) GENERAL.CONNECTION: ens6 GENERAL.CON-PATH: /org/freedesktop/NetworkManager/ActiveConnection/5 WIRED-PROPERTIES.CARRIER: on IP4.ADDRESS[1]: 192.168.101.154/24 IP4.GATEWAY: 192.168.101.1 IP4.ROUTE[1]: dst = 192.168.101.0/24, nh = 0.0.0.0, mt = 101 IP4.ROUTE[2]: dst = 192.168.1.1/32, nh = 0.0.0.0, mt = 101 IP4.ROUTE[3]: dst = 0.0.0.0/0, nh = 192.168.1.1, mt = 101 IP6.ADDRESS[1]: fe80::27ce:dde1:620:996c/64 IP6.GATEWAY: -- IP6.ROUTE[1]: dst = fe80::/64, nh = ::, mt = 101
12.2. NVMe/TCP ホストを NVMe/TCP コントローラーに接続する
NVMe™ over TCP (NVMe/TCP) ホストを NVMe/TCP コントローラーシステムに接続して、NVMe/TCP ホストが名前空間にアクセスできるようになったことを確認します。詳細は、システム上の nvme(1) man ページを参照してください。
NVMe/TCP コントローラー (nvmet-tcp) モジュールはサポートされていません。
前提条件
- NVMe/TCP ホストを設定している。詳細は NVMe/TCP ホストの設定 を参照してください。
- 外部ストレージソフトウェアを使用して NVMe/TCP コントローラーを設定し、コントローラー上でネットワークを設定している。この手順では、192.168.101.55 が NVMe/TCP コントローラーの IP アドレスです。
手順
nvme-tcpモジュールをロードしていない場合はロードします。# modprobe nvme-tcpNVMe コントローラーで使用可能なサブシステムを検出します。
# nvme discover --transport=tcp --traddr=192.168.101.55 --trsvcid=8009Discovery Log Number of Records 2, Generation counter 7 =====Discovery Log Entry 0====== trtype: tcp adrfam: ipv4 subtype: current discovery subsystem treq: not specified, sq flow control disable supported portid: 2 trsvcid: 8009 subnqn: nqn.2014-08.org.nvmexpress.discovery traddr: 192.168.101.55 eflags: not specified sectype: none =====Discovery Log Entry 1====== trtype: tcp adrfam: ipv4 subtype: nvme subsystem treq: not specified, sq flow control disable supported portid: 2 trsvcid: 8009 subnqn: nqn.2014-08.org.nvmexpress:uuid:0c468c4d-a385-47e0-8299-6e95051277db traddr: 192.168.101.55 eflags: not specified sectype: none192.168.101.55 は、NVMe/TCP コントローラーの IP アドレスです。
/etc/nvme/discovery.confファイルを設定して、nvme discoverコマンドで使用するパラメーターを追加します。# echo "--transport=tcp --traddr=192.168.101.55 --trsvcid=8009" >> /etc/nvme/discovery.confNVMe/TCP ホストをコントローラーシステムに接続します。
# nvme connect-allNVMe/TCP 接続を永続化します。
# systemctl enable nvmf-autoconnect.service
検証
NVMe/TCP ホストが名前空間にアクセスできることを確認します。
# nvme list-subsysnvme-subsys3 - NQN=nqn.2014-08.org.nvmexpress:uuid:0c468c4d-a385-47e0-8299-6e95051277db \ +- nvme3 tcp traddr=192.168.101.55,trsvcid=8009,host_traddr=192.168.101.154 live optimized # nvme list Node Generic SN Model Namespace Usage Format FW Rev --------------------- --------------------- -------------------- ---------------------------------------- --------- -------------------------- ---------------- -------- /dev/nvme3n1 /dev/ng3n1 d93a63d394d043ab4b74 Linux 1 21.47 GB / 21.47 GB 512 B + 0 B 5.18.5-2
12.3. NVMe ホスト認証の設定
NVMe over Fabrics (NVMe-oF) コントローラーとの認証された接続を確立するには、Non-volatile Memory Express (NVMe) ホストで認証を設定できます。NVMe 認証では、共有シークレットまたはシークレットのペアと、チャレンジレスポンスプロトコル (NVMe DH-HMAC-CHAP など) が使用されます。
NVMe 認証は、NVMe/TCP トランスポートタイプでのみサポートされます。この機能は、NVMe over Remote Direct Memory Access (NVMe/RDMA) や NVMe over Fibre Channel (NVMe/FC) などの他のトランスポートでは使用できません。
前提条件
-
nvme-cliパッケージがインストールされている。 -
双方向認証を使用する場合は、Host NVMe Qualified Name (Host NQN) と Subsystem NVMe Qualified Name (Subsystem NQN) を把握している。システムのデフォルトの Host NQN を確認するには、
nvme show-hostnqnqを実行します。
手順
認証シークレットを生成します。
ホストの場合:
# hostkey=$(nvme gen-dhchap-key -n ${HOSTNQN})サブシステムの場合:
# ctrlkey=$(nvme gen-dhchap-key -n ${SUBSYSTEM})
認証用にホストを設定します。
# nvme connect -t tcp -n ${SUBSYSTEM} -a ${TRADDR} -s 4420 --dhchap-secret=${hostkey} --dhchap-ctrl-secret=${ctrlkey}これにより、
nvme-connectユーティリティーに認証シークレットが提供され、認証が行われ、ターゲットへの接続が確立されます。-
オプション: 自動ログインを有効にするには、永続的な NVMe fabrics 設定をセットアップします。これを行うには、
--dhchap-secretおよび--dhchap-ctrl-secretパラメーターを/etc/nvme/discovery.confまたは/etc/nvme/config.jsonに追加します。
-
オプション: 自動ログインを有効にするには、永続的な NVMe fabrics 設定をセットアップします。これを行うには、
検証
NVMe ストレージが接続されていることを確認します。
# nvme list現在ホストに接続されている NVMe デバイスのリストが表示されます。予期したストレージがリストされ、ストレージサーバーへの接続が成功したことを確認します。
第13章 スワップの使用
スワップ領域は、物理メモリーがいっぱいになったときに、非アクティブなプロセスとデータ用の一時的なストレージを提供します。これはメモリー不足エラーを防ぐのに役立ちます。スワップ領域は臨時のメモリーとして機能し、システムを継続的な実行を可能にします。ただし、スワップによってパフォーマンスが低下する可能性があります。そのため、まず物理メモリーの使用を最適化してください。
13.1. スワップ領域の概要
Linux の スワップ領域 は、物理メモリー (RAM) が使い果たされたときに使用されます。より多くのメモリーが必要になり、RAM がいっぱいになると、非アクティブなメモリーページがスワップに移動されます。スワップは RAM が限られているシステムに役立ちますが、実際のメモリーを追加することの代わりにはなりません。
スワップ領域はハードドライブにあり、そのアクセス速度は物理メモリーに比べると遅くなります。スワップ領域の設定は、専用のスワップパーティション (推奨)、スワップファイル、またはスワップパーティションとスワップファイルの組み合せが考えられます。
過去数年、推奨されるスワップ領域のサイズは、システムの RAM サイズに比例して増加していました。しかし、最近のシステムには通常、数百ギガバイトの RAM が含まれます。結果として、推奨されるスワップ領域は、システムのメモリーではなく、システムメモリーのワークロードの機能とみなされます。
13.2. システムの推奨スワップ領域
スワップパーティションの適切なサイズは、最終的にはシステムメモリーの負荷量によって決まります。システムメモリー自体によって決まるわけではありません。次の表は、システムに搭載されている RAM の容量に基づくスワップパーティションの推奨最小サイズのガイドラインを示しています。通常、このサイズはインストール時に自動的に設定されます。
スワップパーティションのサイズは、インストール時に自動的に設定されます。ハイバネートを可能にするには、カスタムのパーティション分割段階でスワップ領域を編集する必要があります。
以下のガイドラインは、1 GB 以下など、メモリー容量の少ないシステムでは特に重要です。このようなシステムで十分なスワップ領域を割り当てられないと、システムが不安定になったり、インストールしたシステムが起動できなくなったりする可能性があります。
| システム内の RAM の容量 | 推奨されるスワップ領域 | ハイバネートを許可する場合に推奨されるスワップ領域 |
|---|---|---|
| 2 GiB 未満 | RAM 容量の 2 倍 | RAM 容量の 3 倍 |
| 2 GiB - 8 GiB | RAM 容量と同じ | RAM 容量の 2 倍 |
| 8 GiB - 64 GiB | 4 GiB 以上 | RAM 容量の 1.5 倍 |
| 64 GiB を超える場合 | ワークロードによる (最小 4 GiB) | ハイバネートは推奨されない |
スワップ領域を複数のストレージデバイスに分散させると、特に高速ドライブ、コントローラー、およびインターフェイスを備えたシステムで、スワップ領域のパフォーマンスが向上します。
スワップ領域として割り当てたファイルシステムおよび LVM2 ボリュームは、変更時に 使用しない でください。システムプロセスまたはカーネルがスワップ領域を使用していると、スワップの修正に失敗します。free コマンドおよび cat /proc/swaps コマンドを使用して、スワップの使用量と、使用中の場所を確認します。
スワップ領域のサイズを変更するには、一時的にシステムからスワップ領域を削除する必要があります。これは、swapoff コマンドを使用してファイルのスワップボリュームを無効にすることで行います。これは、実行中のアプリケーションが追加のスワップ領域に依存し、メモリーが不足する可能性がある場合に問題になる可能性があります。
大きなメモリー負荷やページのロックが原因でスワップを無効にする際に問題が発生する場合は、代わりにレスキューモードからスワップのサイズ変更を実行してください。ファイルシステムのマウントを求められたら、 を選択してください。
13.3. スワップ用の LVM2 論理ボリュームの作成
スワップ用の LVM2 論理ボリュームを作成できます。ここでは、追加するスワップボリュームを /dev/VolGroup00/LogVol02 とします。
前提条件
- 十分なディスク領域がある。
手順
サイズが 4 GB の LVM2 論理ボリュームを作成します。
# lvcreate -n LogVol02 -L 4G VolGroup00新しいスワップ領域をフォーマットします。
# mkswap /dev/VolGroup00/LogVol02次のエントリーを
/etc/fstabファイルに追加します。/dev/VolGroup00/LogVol02 none swap defaults 0 0システムが新しい設定を登録するように、マウントユニットを再生成します。
# systemctl daemon-reload論理ボリュームでスワップをアクティブにします。
# swapon -v /dev/VolGroup00/LogVol02
検証
スワップ論理ボリュームが正常に作成され、アクティブになったかをテストするには、次のコマンドを使用して、アクティブなスワップ領域を調べます。
# cat /proc/swapsFilename Type Size Used Priority /dev/dm-6 partition 4194300 0 -2# free -h total used free shared buff/cache available Mem: 30Gi 1.2Gi 28Gi 12Mi 995Mi 28Gi Swap: 4.0Gi 0B 4.0Gi
13.4. 標準スワップパーティションの作成と管理
スワップ領域には標準のスワップパーティションを使用してください。fdisk や parted などの標準的なパーティション設定ツールを使用して、専用パーティションを作成できます。
前提条件
- ドライブに十分な未割り当てディスク領域がある。
-
ディスクデバイスの名前 (例:
/dev/sda) が分かっている。
手順
ディスクのパーティション設定ツールを起動します。たとえば、
/dev/sdaの場合は以下を実行します。$ fdisk /dev/sda希望するサイズの新しいパーティションを作成し、そのタイプを
Linux swapに設定します。注記fdiskを使用する場合は、't' コマンドでパーティションの種類を変更し、Linux swap 用の 16 進数コードである82を入力します。- 変更内容を書き込み、ユーティリティーを終了します。
新しいスワップパーティションをフォーマットします (新しいパーティションが
/dev/sda4であると仮定します)。# mkswap /dev/sda4起動時にスワップパーティションを有効にするために、
/etc/fstabファイルにエントリーを追加します。# /dev/sda4 none swap defaults 0 0マウントユニットを再生成して新しい設定を登録します。
# systemctl daemon-reloadスワップパーティションを直ちにアクティブ化します。
# swapon -v /dev/sda4
検証
スワップパーティションが作成され、アクティブ化されていることを確認するには、アクティブなスワップ領域を調べます。
# cat /proc/swaps# free -h
13.5. スワップファイルの作成
物理 RAM がいっぱいになったときにシステムクラッシュを防ぐ仮想メモリーを提供するスワップファイルを設定します。この方法は、ディスクのパーティションを再設定したり、既存のストレージ設定を変更したりせずに、追加のスワップ領域を確保する必要がある場合に特に便利です。
前提条件
- 十分なディスク領域がある。
手順
- 新しいスワップファイルのサイズをメガバイト単位で指定してから、そのサイズに 1024 をかけてブロック数を指定します。たとえば、64 MB のファイルに必要な 1024 バイトサイズのブロックの数は 65536 です。
空のファイルの作成:
# dd if=/dev/zero of=/swapfile bs=1024 count=6553665536 を、必要なブロックサイズと同じ値に置き換えます。
注記ext4 や XFS などの最新のファイルシステムでは、
ddの代わりにfallocateを使用することを推奨します。この方法のほうが高速であり、不要なディスク I/O を回避できます。次のコマンドでスワップファイルをセットアップします。
# mkswap /swapfileスワップファイルのセキュリティーを変更して、全ユーザーで読み込みができないようにします。
# chmod 0600 /swapfileシステムの起動時にスワップファイルを有効にするには、次のエントリーを使用して
/etc/fstabファイルを編集します。/swapfile none swap defaults 0 0次にシステムが起動すると新しいスワップファイルが有効になります。
システムが新しい
/etc/fstab設定を登録するように、マウントユニットを再生成します。# systemctl daemon-reloadすぐにスワップファイルをアクティブにします。
# swapon /swapfile
検証
新しいスワップファイルが正常に作成され、有効になったかをテストするには、次のコマンドを使用して、アクティブなスワップ領域を調べます。
$ cat /proc/swaps$ free -h
13.6. storage RHEL システムロールを使用したスワップボリュームの作成
storage RHEL システムロールを使用して、ブロックデバイス上にスワップボリュームを作成または変更できます。
前提条件
- コントロールノードと管理対象ノードの準備が完了している。
- 管理対象ノードで Playbook を実行できるユーザーとしてコントロールノードにログインしている。
-
管理対象ノードへの接続に使用するアカウントに、そのノードに対する
sudo権限がある。
手順
次の内容を含む Playbook ファイル (例:
~/playbook.yml) を作成します。--- - name: Create a disk device with swap hosts: managed-node-01.example.com roles: - rhel-system-roles.storage vars: storage_volumes: - name: swap_fs type: disk disks: - /dev/sdb size: 15 GiB fs_type: swap現在、ボリューム名 (この例では
swap_fs) は任意です。storageロールは、disks:属性にリスト表示されているディスクデバイスでボリュームを特定します。Playbook で使用されるすべての変数の詳細は、コントロールノードの
/usr/share/ansible/roles/rhel-system-roles.storage/README.mdファイルを参照してください。Playbook の構文を検証します。
$ ansible-playbook --syntax-check ~/playbook.ymlこのコマンドは構文を検証するだけであり、有効だが不適切な設定から保護するものではないことに注意してください。
Playbook を実行します。
$ ansible-playbook ~/playbook.yml
13.7. LVM2 論理ボリュームでのスワップ領域の拡張
既存の LVM2 論理ボリューム上のスワップ領域を拡張できます。ここでは、2 GB 拡張したいボリュームを /dev/VolGroup00/LogVol02 とします。
前提条件
- 十分なディスク領域がある。
手順
関連付けられている論理ボリュームのスワップ機能を無効にします。
# swapoff -v /dev/VolGroup00/LogVol02LVM2 論理ボリュームのサイズを 2 GB 増やします。
# lvresize -L +2G /dev/VolGroup00/LogVol02新しいスワップ領域をフォーマットします。
# mkswap /dev/VolGroup00/LogVol02拡張論理ボリュームを有効にします。
# swapon -v /dev/VolGroup00/LogVol02
検証
スワップの論理ボリュームの拡張に成功したかどうかをテストするには、アクティブなスワップ容量を調べます。
# cat /proc/swapsFilename Type Size Used Priority /dev/dm-6 partition 6291452 0 -2# free -htotal used free shared buff/cache available Mem: 30Gi 1.2Gi 28Gi 12Mi 994Mi 28Gi Swap: 6.0Gi 0B 6.0Gi
13.8. LVM2 論理ボリュームでのスワップ領域の縮小
LVM2 論理ボリュームのスワップ領域を縮小できます。ここでは、縮小するボリュームを /dev/VolGroup00/LogVol02 とします。
手順
関連付けられている論理ボリュームのスワップ機能を無効にします。
# swapoff -v /dev/VolGroup00/LogVol02スワップ署名を削除します。
# wipefs -a /dev/VolGroup00/LogVol02LVM2 論理ボリュームのサイズを変更して 512 MB 削減します。
# lvreduce -L -512M /dev/VolGroup00/LogVol02新しいスワップ領域をフォーマットします。
# mkswap /dev/VolGroup00/LogVol02論理ボリュームでスワップをアクティブにします。
# swapon -v /dev/VolGroup00/LogVol02
検証
スワップ論理ボリュームが正常に削減されたかをテストするには、次のコマンドを使用して、アクティブなスワップ領域を調べます。
$ cat /proc/swaps$ free -h
13.9. スワップ用の LVM2 論理ボリュームの削除
スワップ用の LVM2 論理ボリュームを削除できます。削除するスワップボリュームを /dev/VolGroup00/LogVol02 とします。
手順
関連付けられている論理ボリュームのスワップ機能を無効にします。
# swapoff -v /dev/VolGroup00/LogVol02LVM2 論理ボリュームを削除します。
# lvremove /dev/VolGroup00/LogVol02次の関連エントリーを
/etc/fstabファイルから削除します。/dev/VolGroup00/LogVol02 none swap defaults 0 0マウントユニットを再生成して新しい設定を登録します。
# systemctl daemon-reload
検証
論理ボリュームが正常に削除されたかどうかをテストし、次のコマンドを使用してアクティブなスワップ領域を調べます。
$ cat /proc/swaps$ free -h
13.10. スワップファイルの削除
スワップファイルを削除できます。
手順
/swapfileスワップファイルを無効にします。# swapoff -v /swapfile-
/etc/fstabファイルからエントリーを削除します。 システムが新しい設定を登録するように、マウントユニットを再生成します。
# systemctl daemon-reload実際のファイルを削除します。
# rm /swapfile
13.11. 仮想メモリー (VM) 調整可能パラメーターの調整
仮想メモリー (VM) の調整可能パラメーターは、スワップ領域をどれだけ積極的に使用するかなどを含め、システムによるメモリーの管理方法を制御するカーネルパラメーターです。これらの設定を調整すると、ワークロードによってはシステムのパフォーマンスに大きな影響が及ぶことがあります。
vm.swappiness パラメーターは、カーネルがプロセスを物理メモリーからスワップ領域に移動させる傾向を制御するものです。値は 0 から 100 までのパーセンテージで指定します。
- 大きな値 (例: 60 や 100): カーネルはより積極的にプロセスをディスクにスワップします。これにより、物理メモリーを他の用途 (ファイルシステムキャッシュなど) のために解放できます。ただし、スワップされたプロセスが頻繁に必要となる場合は、I/O 操作とレイテンシーが増加する可能性があります。
- 小さな値 (例:0 や 10): カーネルはスワッピングを回避し、プロセスを可能な限り長く物理メモリーに保持しようとします。これは一般的に、高速な I/O と大容量の RAM を備えたデスクトップシステムやサーバーに適しています。
以下に示すその他の仮想メモリー調整可能パラメーターでも、スワップの動作に影響を与えることができます。
- vm.dirty_ratio: カーネルが "ダーティー" ページ (変更済みだが、まだディスクに書き込まれていないメモリーページ) を積極的に書き出し始める前に、ダーティーページで埋めることができるシステムメモリーの割合。
-
vm.dirty_background_ratio: バックグラウンドのカーネルプロセスがダーティーページを書き出し始める前に、ダーティーページで埋めることができるシステムメモリーの割合。これは、
vm.dirty_ratioよりも積極性の低い操作です。
手順
現在の値を表示します。
$ cat /proc/sys/vm/swappinessデフォルト値は 60 です。
値を一時的に 10 などに設定します。
# sysctl vm.swappiness=10/etc/sysctl.d/99-sysctl.confまたは同様の設定ファイルを編集し、再起動後も設定が保持されるように永続的に設定します。vm.swappiness = 10変更を適用します。
# sysctl -p
第14章 Fibre Channel over Ethernet の設定
IEEE T11 FC-BB-5 で定義されている Fibre Channel over Ethernet (FCoE) は、ファイバーチャネルのフレームをイーサネット上でカプセル化します。これにより、LAN と SAN を 1 つの統合ネットワークに集約して、ハードウェアとエネルギーのコストを削減し、複雑さを軽減できます。ただし、これはイーサネットがロスレスストレージトラフィック用に設定されていることが前提です。
14.1. RHEL でのハードウェア FCoE HBA の使用
RHEL では、ハードウェアの Fibre Channel over Ethernet (FCoE) Host Bus Adapter (HBA) を使用できます。これは、qedf および fnic ドライバーでサポートされています。このような HBA を使用する場合は、HBA の設定で FCoE を設定します。詳細は、アダプターのドキュメントを参照してください。
HBA を設定すると、Storage Area Network (SAN) からエクスポートした論理ユニット番号 (LUN) が、/dev/sd* デバイスとして RHEL で自動的に利用可能になります。ローカルストレージデバイスと同様に、これらのデバイスを使用できます。
第15章 テープデバイスの管理
テープデバイスは磁気テープ上にデータを保存します。データはテープドライブを介してシーケンシャルにアクセスされます。テープデバイスに書き込むためにファイルシステムは必要ありません。テープドライブは SCSI、FC、USB、SATA、またはその他のインターフェイスを介して接続できます。これにより、データのバックアップとアーカイブが容易になります。
15.1. テープデバイスの種類
テープデバイスは、データをシーケンシャルに読み書きする磁気ストレージメディアであり、バックアップやアーカイブの目的に最適です。コスト効率が高く安定したストレージを提供し、データ破損に対する耐性を備えているため、長期にわたるデータ保持に適しています。
以下は、さまざまなタイプのテープデバイスのリストです。
-
/dev/st0は、巻き戻しありのテープデバイスです。 -
/dev/nst0は、巻き戻しなしのテープデバイスです。日次バックアップには、巻き戻しなしのデバイスを使用します。
テープデバイスを使用するメリットは複数あります。コスト効率が高く、安定しています。テープデバイスは、データの破損に対しても回復力があり、データの保持に適しています。
15.2. テープドライブ管理ツールのインストール
テープドライブ操作用の mt-st パッケージをインストールします。磁気テープドライブの操作を制御するには mt ユーティリティーを使用します。SCSI テープドライバーを制御するには st ユーティリティーを使用します。
手順
mt-stパッケージをインストールします。# dnf install mt-st詳細は、システム上の
mt(1)およびst(4)man ページを参照してください。
15.3. テープコマンド
mt ユーティリティーは、ステータスのチェック、巻き戻し、ヘッドの位置決めなど、テープデバイスの操作を管理するための磁気テープ制御コマンドを提供します。
以下は、一般的な mt コマンドです。
| コマンド | 説明 |
|---|---|
|
| テープデバイスの状態を表示します。 |
|
| テープ全体を消去します。 |
|
| テープデバイスを巻き戻します。 |
|
| テープヘッドを次のレコードに切り替えます。ここでは、n はオプションのファイル数です。ファイル数を指定すると、テープヘッドは n 件のレコードをスキップします。 |
|
| テープヘッドを前のレコードに切り替えます。 |
|
| テープヘッドをデータの最後に切り替えます。 |
15.4. 巻き戻しテープデバイスへの書き込み
巻き戻しテープデバイスは、操作のたびにテープを巻き戻します。データをバックアップするには、tar コマンドを使用できます。デフォルトでは、テープデバイスの block size は 10 KB (bs=10k) です。
export TAPE=/dev/st0 属性を使用して TAPE 環境変数を設定できます。代わりに -f デバイスオプションを使用してテープデバイスファイルを指定します。このオプションは、複数のテープデバイスを使用する場合に役立ちます。
前提条件
-
mt-stパッケージがインストールされている。詳細は、テープドライブ管理ツールのインストール を参照。 テープドライブが読み込まれている。
# mt -f /dev/st0 load
手順
テープヘッドを確認します。
# mt -f /dev/st0 statusSCSI 2 tape drive: File number=-1, block number=-1, partition=0. Tape block size 0 bytes. Density code 0x0 (default). Soft error count since last status=0 General status bits on (50000): DR_OPEN IM_REP_ENここでは、以下のようになります。
-
現在の
file numberは -1 です。 -
block numberはテープヘッドを定義します。デフォルトでは、-1 に設定されます。 -
block size0 は、テープデバイスのブロックサイズが固定されていないことを示します。 -
Soft error countは、mt status コマンドの実行後に発生したエラーの数を示します。 -
General status bitsは、テープデバイスの統計を表示します。 -
DR_OPENは、ドアが開き、テープデバイスが空であることを示します。IM_REP_ENは即時レポートモードです。
-
現在の
テープデバイスが空でない場合は、それを上書きします。
# tar -czf /dev/st0 _/source/directoryこのコマンドは、テープデバイスのデータを
/source/directoryの内容で上書きします。/source/directoryをテープデバイスにバックアップします。# tar -czf /dev/st0 _/source/directorytar: Removing leading `/' from member names /source/directory /source/directory/man_db.conf /source/directory/DIR_COLORS /source/directory/rsyslog.conf [...]テープデバイスのステータスを表示します。
# mt -f /dev/st0 status
検証
テープデバイスにあるすべてのファイルのリストを表示します。
# tar -tzf /dev/st0/source/directory/ /source/directory/man_db.conf /source/directory/DIR_COLORS /source/directory/rsyslog.conf [...]
15.5. 巻き戻しなしのテープデバイスへの書き込み
特定のコマンドの実行を完了した後、巻き戻しなしのテープデバイスはテープをその状態のままにします。たとえば、巻き戻しなしのテープデバイスでは、バックアップの後にさらにデータを追加できます。また、これを使用して予期しない巻き戻しを回避することもできます。
前提条件
-
mt-stパッケージがインストールされている。詳細は、テープドライブ管理ツールのインストール を参照。 テープドライブが読み込まれている。
# mt -f /dev/nst0 load
手順
巻き戻しなしのテープデバイス
/dev/nst0のテープヘッドを確認します。# mt -f /dev/nst0 statusテープのヘッドまたはテープの最後にポインターを指定します。
# mt -f /dev/nst0 rewindテープデバイスにデータを追加するには、次のコマンドを実行します。
# mt -f /dev/nst0 eod# tar -czf /dev/nst0 /source/directory//source/directory/をテープデバイスにバックアップします。# tar -czf /dev/nst0 /source/directory/tar: Removing leading `/' from member names /source/directory/ /source/directory/man_db.conf /source/directory/DIR_COLORS /source/directory/rsyslog.conf [...]テープデバイスのステータスを表示します。
# mt -f /dev/nst0 status
検証
テープデバイスにあるすべてのファイルのリストを表示します。
# tar -tzf /dev/nst0/source/directory/ /source/directory/man_db.conf /source/directory/DIR_COLORS /source/directory/rsyslog.conf [...]
15.6. テープデバイスでのテープヘッドの切り替え
eod オプションを使用して、テープデバイス内のテープヘッドを切り替えることができます。
前提条件
-
mt-stパッケージがインストールされている。詳細は、テープドライブ管理ツールのインストール を参照。 - データはテープデバイスに書き込まれる。詳細は、Writing to rewinding tape devices または Writing to non-rewinding tape devices を参照してください。
手順
テープポインターの現在の位置を表示するには、次のコマンドを実行します。
# mt -f /dev/nst0 tellデータをテープデバイスに追加する際にテープヘッドを切り替えるには、次のコマンドを実行します。
# mt -f /dev/nst0 eod前のレコードに移動するには、以下を実行します。
# mt -f /dev/nst0 bsfm 1次のレコードに移動するには、以下を行います。
# mt -f /dev/nst0 fsf 1
15.7. テープデバイスからのデータの復元
tar コマンドを使用して、テープデバイスからデータを復元できます。詳細は、システム上の mt(1) および tar(1) man ページを参照してください。
前提条件
-
mt-stパッケージがインストールされている。詳細は、テープドライブ管理ツールのインストール を参照。 - データはテープデバイスに書き込まれる。詳細は、Writing to rewinding tape devices または Writing to non-rewinding tape devices を参照してください。
手順
巻き戻しありのテープデバイス
/dev/st0の場合、以下を実行します。/source/directory/を復元します。# tar -xzf /dev/st0 /source/directory/
巻き戻しなしのテープデバイス
/dev/nst0の場合、以下を実行します。テープデバイスを巻き戻します。
# mt -f /dev/nst0 rewindetcディレクトリーを復元します。# tar -xzf /dev/nst0 /source/directory/
15.8. テープデバイスのデータの消去
erase オプションを使用して、テープデバイスからデータを消去できます。
前提条件
-
mt-stパッケージがインストールされている。詳細は、テープドライブ管理ツールのインストール を参照。 - データはテープデバイスに書き込まれる。詳細は、Writing to rewinding tape devices または Writing to non-rewinding tape devices を参照してください。
手順
テープデバイスからデータを削除します。
# mt -f /dev/st0 eraseテープデバイスをアンロードします。
# mt -f /dev/st0 offline
第16章 RAID の管理
Redundant Array of Independent Disks (RAID) を使用して、複数のドライブにデータを保存できます。ドライブに障害が発生した場合に、データの損失を回避することができます。
16.1. RAID の概要
RAID では、複数のドライブ (HDD、SSD、または NVMe) を 1 つのアレイに結合します。これにより、1 台の高価なドライブが提供できる以上のパフォーマンスや冗長性を実現します。このアレイは、システムでは 1 つの論理ストレージユニットとして認識されます。
RAID は、レベル 0、1、4、5、6、10、リニアなど、さまざまな構成をサポートしています。RAID は、ディスクストライピング (RAID レベル 0)、ディスクミラーリング (RAID レベル 1)、およびパリティーによるディスクストライピング (RAID レベル 4、5、および 6) などの技術を使用して、冗長性、低遅延、帯域の増加、ハードディスクのクラッシュからの回復能力の最大化を達成します。
RAID は、データを一貫して使用するチャンク (通常は 256KB または 512KB、他の値は受け入れ可能) に分割することで、アレイ内の各デバイスにデータを分散します。採用されている RAID レベルに従って、これらのチャンクを RAID アレイ内のハードドライブに書き込みます。データの読み取り中はプロセスが逆になり、アレイ内の複数のデバイスが実際には 1 つの大きなドライブであるかのように見えます。
RAID テクノロジーは、大量のデータを管理するユーザーにとって有益です。RAID を導入する主な理由は次のとおりです。
- 速度を高める
- 1 台の仮想ディスクを使用してストレージ容量を増やす
- ディスク障害によるデータ損失を最小限に抑える
- RAID レイアウトおよびレベルのオンライン変換
16.2. RAID のタイプ
RAID は、ファームウェア、専用のハードウェアコントローラー、またはソフトウェアを通じて実装できます。タイプによって、コスト、パフォーマンス、機能の面で利点がそれぞれ異なります。そのため、ストレージ要件に合わせて最適な方法を選択できます。
RAID のタイプとして考えられるのは以下の通りです。
- ファームウェア RAID
- ファームウェア RAID (ATARAID とも呼ばれる) とは、ソフトウェア RAID の種類で、ファームウェアベースのメニューを使用して RAID セットを設定できます。このタイプの RAID で使用されるファームウェアは BIOS にもフックされるため、その RAID セットから起動できます。異なるベンダーは、異なるオンディスクメタデータ形式を使用して、RAID セットのメンバーをマークします。Intel Matrix RAID は、ファームウェア RAID システムの一例を示しています。
- ハードウェア RAID
ハードウェアベースのアレイは、RAID サブシステムをホストとは別に管理します。ホストに対して RAID アレイごとに複数のデバイスが表示される場合があります。
ハードウェア RAID デバイスは、システムの内部または外部になる場合があります。内部デバイスは通常、RAID タスクをオペレーティングシステムに対して透過的に処理する専用のコントローラーカードで構成されます。外部デバイスは、一般的には SCSI、ファイバーチャネル、iSCSI、InfiniBand などの高速ネットワーク相互接続を介してシステムに接続し、システムへの論理ユニットなどのボリュームを提示します。
RAID コントローラーカードは、オペレーティングシステムへの SCSI コントローラーのように動作し、実際のドライブ通信をすべて処理します。ドライブを通常の SCSI コントローラーと同様に RAID コントローラーに接続し、RAID コントローラーの設定に追加できます。オペレーティングシステムはこの違いを認識できません。
- ソフトウェア RAID
ソフトウェア RAID は、カーネルブロックデバイスコード内にさまざまな RAID レベルを実装します。高価なディスクコントローラーカードやホットスワップシャーシが不要なため、可能な限り安価なソリューションを提供します。ホットスワップシャーシを使用すると、システムの電源を切らずにハードドライブを取り外すことができます。ソフトウェア RAID は、SATA、SCSI、NVMe などの Linux カーネルが対応しているブロックストレージでも機能します。今日の高速な CPU では、ハイエンドのストレージデバイスを使用しない限り、ソフトウェア RAID は一般的にハードウェア RAID よりも優れたパフォーマンスを発揮します。
Linux カーネルにはマルチデバイス (MD) ドライバーが含まれているため、RAID ソリューションは完全にハードウェアに依存しません。ソフトウェアベースのアレイのパフォーマンスは、サーバーの CPU パフォーマンスと負荷によって異なります。
Linux ソフトウェア RAID スタックの主な機能は次のとおりです。
- マルチスレッド設計
- 再構築なしで Linux マシン間でのアレイの移植性
- アイドルシステムリソースを使用したバックグラウンドのアレイ再構築
- ホットスワップドライブのサポート
- CPU の自動検出は、ストリーミング SIMD (Single Instruction Multiple Data) サポートなどの特定の CPU 機能を利用するための自動 CPU 検出
- アレイ内のディスク上にある不良セクターの自動修正
- RAID データの整合性を定期的にチェックしアレイの健全性を確保
- 重要なイベントが発生すると、指定された電子メールアドレスに送信される電子メールアラートによるアレイのプロアクティブな監視
ライトインテントビットマップ。これは、システムクラッシュ後にアレイ全体を再同期するのではなく、ディスクのどの部分を再同期する必要があるかをカーネルが正確に認識できるようにすることで、再同期イベントの速度を大幅に向上させる機能です。
注記再同期は、既存の RAID 内のデバイス間でデータを同期して冗長性を実現するプロセスです。
- チェックポイントを再同期して、再同期中にコンピューターを再起動すると、起動時に再同期が中断したところから再開され、最初からやり直すことはありません。
- インストール後にアレイのパラメーターを変更する機能は、再形成と呼ばれます。たとえば、新しいデバイスを追加しても、4 つのディスクの RAID5 アレイを 5 つのディスク RAID5 アレイに増大させることができます。この拡張操作はライブで行うため、新しいアレイで再インストールする必要はありません。
- 再成形は、RAID アルゴリズム、RAID アレイタイプのサイズ (RAID4、RAID5、RAID6、RAID10 など) の変更に対応しています。
- テイクオーバーは、RAID0 から RAID6 などの RAID レベルの変換をサポートしています。
- クラスターのストレージソリューションである Cluster MD は、RAID1 ミラーリングの冗長性をクラスターに提供します。現在、RAID1 のみがサポートされています。
16.3. RAID レベルとリニアサポート
RAID およびリニアストレージレベルは、データ保護、パフォーマンス、容量に関して、さまざまな選択肢を提供します。信頼性の高い Linux ストレージを実現するために、RAID レベル 0、1、4、5、6、10、およびリニアアレイを比較して、最適な構成を決定してください。
レベル 0、1、4、5、6、10、およびリニアを含む、RAID でサポートされている構成を以下に示します。
- レベル 0
ストライピングとも呼ばれる RAID レベル 0 は、パフォーマンス指向のストライピングデータマッピング技術です。これは、アレイに書き込まれるデータがストライプに分割され、メンバーディスク全体に分散して書き込まれることを意味します。これにより、低い固有コストで高い I/O 性能を実現できますが、冗長性は提供されません。
RAID レベル 0 実装は、アレイ内の最小デバイスのサイズまで、メンバーデバイス全体にだけデータをストライピングします。つまり、サイズがわずかに異なる複数のデバイスがある場合でも、それぞれのデバイスは同じサイズとして扱われます。各デバイスは、最小サイズのドライブと同等のサイズであるとみなされます。したがって、レベル 0 アレイの共通ストレージ容量は、すべてのディスクの合計容量です。メンバーディスクのサイズが異なる場合、RAID0 は使用可能なゾーンを使用して、それらのディスクのすべての領域を使用します。
- レベル 1
RAID レベル 1 (ミラーリング) は、アレイの各メンバーディスクに同一のデータを書き込むことで冗長性を提供します。各ディスクにはミラーリングされたコピーが残ります。ミラーリングは、その簡便さとデータ可用性の高さから、依然として人気です。レベル 1 は 2 台以上のディスクで動作し、比較的高いコストと引き換えに、非常に優れたデータの信頼性と、読み取り集約型ワークロードにおけるパフォーマンスの向上を実現します。
RAID レベル 1 は、アレイ内のすべてのディスクに同じ情報を書き込むため、コストが高くなります。データの信頼性は確保されますが、レベル 5 などのパリティーベースの RAID レベルに比べると領域の効率性がはるかに低くなります。しかし、この領域効率の悪さは、パフォーマンス上の利点をもたらします。パリティーベースの RAID レベルは、パリティーを生成するために相当量の CPU パワーを消費します。RAID レベル 1 は、最小限の CPU 負荷で複数のメンバーに同一のデータを書き込みます。そのため、ソフトウェア RAID を使用するシステムにおいて、RAID レベル 1 のパフォーマンスはパリティーベースの RAID レベルよりも高くなる可能性があります。これは特に、CPU リソースが RAID 以外の操作によって大量に使用される場合に当てはまります。
レベル 1 アレイのストレージ容量は、ハードウェア RAID における最小のミラーリングされたハードディスクの容量に相当します。または、ソフトウェア RAID における最小のミラーリングされたパーティションと等しくなります。レベル 1 の冗長性は、すべての RAID タイプの中で最高レベルです。アレイは、ディスクが 1 つだけでも動作を継続できます。
- レベル 4
レベル 4 は、データを保護するために、1 つのディスクドライブに集約されたパリティーを使用します。パリティー情報は、アレイ内の残りのメンバーディスクのコンテンツに基づいて計算されます。この情報は、アレイ内のいずれかのディスクに障害が発生した場合にデータの再構築に使用できます。再構築されたデータは、障害が発生したディスクの交換前はそのディスクへの I/O 要求に対応するために使用し、交換後はそのディスクにデータを再書き込みするために使用できます。
専用パリティーディスクは、RAID アレイへのすべての書き込みトランザクションにおいて固有のボトルネックとなります。したがって、レベル 4 は、ライトバックキャッシングなどの付随テクノロジーなしで使用されることはほとんどありません。レベル 4 が使用されるのは、システム管理者がこのボトルネックを承知のうえで意図的にソフトウェア RAID デバイスを設計する場合です。これは、データが一度格納されると書き込みトランザクションがほとんど、あるいはまったく発生しないアレイに当てはまります。RAID レベル 4 にはほとんど使用されないため、Anaconda ではこのオプションとしては使用できません。ただし、実際には必要な場合は、ユーザーが手動で作成できます。
ハードウェア RAID レベル 4 の容量は、最小のメンバーパーティション容量にパーティションの総数から 1 を引いた数を掛けた値と等しくなります。RAID レベル 4 アレイのパフォーマンスは常に非対称です。つまり、読み込みは書き込みを上回ります。これは、書き込み操作がパリティー生成時に余分な CPU リソースとメインメモリー帯域幅を消費するためです。また、書き込み操作は、実際のデータをディスクに書き込む際に、データとパリティーの両方を書き込むため、余分なバス帯域幅を消費します。読み取り操作は、アレイが縮退状態にない限り、データだけを読み取り、パリティーは読み取りません。その結果、通常の動作条件下では、同じデータ転送量であっても、ドライブやコンピューターバスへのトラフィックの生成量は少なくなります。
- レベル 5
これは RAID の最も一般的なタイプです。RAID レベル 5 は、アレイのすべてのメンバーディスクドライブにパリティーを分散することにより、レベル 4 に固有の書き込みボトルネックを排除します。パリティー計算プロセス自体のみがパフォーマンスのボトルネックです。最近の CPU はパリティーを非常に高速に計算できます。しかし、RAID 5 アレイに多数のディスクが含まれる場合、データ転送速度が速いとパリティー計算がボトルネックになる可能性があります。
レベル 5 のパフォーマンスは非対称であり、読み取りは書き込みよりも大幅に優れています。RAID レベル 5 のストレージ容量は、レベル 4 と同じです。
- レベル 6
この RAID レベルがよく使用されるのは、パフォーマンスよりもデータの冗長性と保全が最優先されるが、レベル 1 の領域効率の悪さは許容できないという場合です。レベル 6 は、アレイ内の任意の 2 台のドライブが失われても復旧できるように、複雑なパリティスキームを採用しています。この複雑なパリティースキームにより、ソフトウェア RAID デバイスの CPU 負荷が大幅に増加し、書き込みトランザクション中の負荷も増加します。したがって、レベル 6 はレベル 4 や 5 よりもパフォーマンスにおいて、非常に非対称です。
RAID レベル 6 アレイの総容量は、RAID レベル 5 および 4 と同様の方法で計算されます。ただし、パリティーストレージ領域を増やすためには、デバイス数から 1 ではなく 2 を差し引く必要があります。
- レベル 10
この RAID レベルでは、レベル 0 のパフォーマンスとレベル 1 の冗長性を組み合わせます。また、2 台以上のデバイスを使用するレベル 1 アレイの無駄なスペースをある程度削減することができます。レベル 10 では、3 つのドライブで構成されるアレイを作成し、各データのコピーを 2 つだけ保存できます。この場合、アレイの合計サイズは最小デバイスサイズの 1.5 倍になり、3 デバイス構成のレベル 1 アレイのように同じにはなりません。これにより、RAID レベル 6 と同様のパリティー計算に CPU プロセスを使用することが回避されますが、領域効率は低下します。
RAID レベル 10 の作成は、インストール時には対応していません。インストール後に手動で作成できます。
- リニア RAID
リニア RAID は、より大きな仮想ドライブを作成するドライブのグループ化です。
リニア RAID では、チャンクは 1 つのメンバードライブから順次割り当てられ、最初のドライブがいっぱいになってから次のドライブに移動します。これにより、メンバードライブ間の I/O 操作が分割される可能性はないため、パフォーマンスの向上は見られません。リニア RAID は冗長性がなく、信頼性は低下します。メンバードライブが 1 台でも故障すると、アレイ全体が使用できなくなり、データが失われる可能性があります。容量はすべてのメンバーディスクの合計になります。
16.4. サポートされている RAID 変換
特定の mdadm コマンドを使用することで、異なる構成間で RAID レベルを変換できます。ただし、変換先の RAID タイプにより、ディスクの要件が異なります。
ある RAID レベルから別の RAID レベルに変換できます。たとえば、RAID10 から RAID5 に変換できますが、その間に RAID10 から RAID0、さらに RAID5 への中間ステップがあります。サポートされている RAID 変換の詳細は、次の表を参照してください。
| RAID 変換レベル | 変換手順 | 注記 |
|---|---|---|
| RAID レベル 0 から RAID レベル 4 |
| MD アレイには、少なくとも 3 つのディスクが必要なため、ディスクを追加する必要があります。 |
| RAID レベル 0 から RAID レベル 5 |
| MD アレイには、少なくとも 3 つのディスクが必要なため、ディスクを追加する必要があります。 |
| RAID レベル 0 から RAID レベル 10 |
| MD アレイに 2 つのディスクを追加する必要があります。 |
| RAID レベル 1 から RAID レベル 0 |
| |
| RAID レベル 1 から RAID レベル 5 |
| MD アレイに 3 つのディスクを追加する必要があります。 |
| RAID レベル 4 から RAID レベル 0 |
| |
| RAID レベル 4 から RAID レベル 5 |
| |
| RAID レベル 5 から RAID レベル 0 |
| |
| RAID レベル 5 から RAID レベル 1 |
|
|
| RAID レベル 5 から RAID レベル 4 |
| |
| RAID レベル 5 から RAID レベル 6 |
| |
| RAID レベル 5 から RAID レベル 10 |
| RAID レベル 5 から RAID レベル 10 への変換は、次の 2 つのステップで行います。
RAID0 への変換後、RAID5 ディスクの 1 つが削除されます。 |
| RAID レベル 6 から RAID レベル 5 |
| 新しい RAID5 アレイでは、RAID6 ディスクの 1 つがスペア状態 (ホットバックアップ用) になっています。 |
| RAID レベル 10 から RAID レベル 0 |
| 新しい RAID0 アレイから RAID10 ディスクのうち 2 つが削除されます。 |
RAID5 から RAID0 および RAID4 への変換は、ALGORITHM_PARITY_N レイアウトでのみ可能です。
RAID レベルを変換した後、mdadm --detail /dev/md0 または cat /proc/mdstat コマンドを使用して変換を確認します。
16.5. RAID サブシステム
RAID サブシステムは、システム上の RAID アレイを管理するソフトウェアコンポーネントです。各サブシステムは異なるメタデータ形式と管理ツールを使用します。Red Hat Enterprise Linux では、mdraid が推奨されるソフトウェア RAID ソリューションです。
RAID は次のサブシステムで構成されます。
- ハードウェア RAID コントローラードライバー
- ハードウェア RAID コントローラーに固有の RAID サブシステムはありません。特別な RAID チップセットを使用するため、ハードウェア RAID コントローラーには専用のドライバーが付属しています。これらのドライバーを使用すると、システムは RAID セットを通常のディスクとして検出します。
mdraidmdraidサブシステムはソフトウェア RAID ソリューションとして設計されました。これは、Red Hat Enterprise Linux のソフトウェア RAID の推奨ソリューションでもあります。このサブシステムでは独自のメタデータ形式が使用され、通常はネイティブの MD メタデータと呼ばれます。mdraid は、外部メタデータとして知られる他のメタデータ形式にも対応しています。Red Hat Enterprise Linux 10 は
mdraidと外部メタデータを使用して、Intel Rapid Storage (ISW) または Intel Matrix Storage Manager (IMSM) セットと Storage Networking Industry Association (SNIA) Disk Drive Format (DDF) にアクセスします。mdraidサブシステムセットは、mdadmユーティリティーによって設定および制御されます。
16.6. インストール中のソフトウェア RAID の作成
Redundant Arrays of Independent Disks (RAID) デバイスは、複数のストレージデバイスから構成されます。これらのデバイスは、パフォーマンスを向上させるように、また構成によっては、フォールトトレランスを向上させるように配置されます。RAID デバイスはワンステップで作成され、必要に応じてディスクが追加または削除されます。
システム内の物理ディスクごとに 1 つの RAID パーティションを設定できます。インストールプログラムで使用できるディスクの数によって、使用できる RAID デバイスのレベルが決まります。たとえば、システムにディスクが 2 つある場合は、RAID 10 デバイスを作成することはできません。少なくともディスクが 3 つ必要になるためです。RHEL は、システムのストレージパフォーマンスと信頼性を最適化するために、インストールされたシステムにストレージを設定するための LVM および LVM シンプロビジョニングを使用したソフトウェア RAID 0、RAID 1、RAID 4、RAID 5、RAID 6、および RAID 10 タイプをサポートしています。
64 ビットの IBM Z では、ストレージサブシステムが RAID を透過的に使用します。ソフトウェア RAID を手動で設定する必要はありません。
前提条件
- RAID 設定オプションは、インストール用に複数のディスクを選択している場合にのみ表示される。作成する RAID タイプに応じて、少なくとも 2 つのディスクが必要です。
- Installation Destination ウィンドウで ラジオボタンを選択し、Done ボタンをクリックして Manual Partitioning ウィンドウに入りました。
- マウントポイントを作成している。マウントポイントを設定して、RAID デバイスを設定します。
手順
- 手動パーティション設定 画面の左側のペインで、必要なパーティションを選択します。
- デバイスタイプ ドロップダウンメニューをクリックして、RAID を選択します。
- デバイス セクションの下にある をクリックします。マウントポイントの設定 ダイアログボックスが開きます。
- RAID デバイスに含めるディスクを選択し、 をクリックしてダイアログボックスを閉じます。
- ファイルシステム のドロップダウンメニューをクリックして、目的のファイルシステムタイプを選択します。
- RAID レベル ドロップダウンメニューをクリックして、目的の RAID レベルを選択します。
- をクリックして、変更を保存します。
- をクリックして設定を適用し、インストールの概要 ウィンドウに戻ります。
16.7. インストール済みシステムでのソフトウェア RAID の作成
mdadm ユーティリティーを使用して、既存のシステムにソフトウェア Redundant Array of Independent Disks (RAID) を作成できます。
前提条件
-
mdadmパッケージがインストールされている。 - システム上に 2 つ以上のパーティションを作成している。詳細な手順は、parted を使用したパーティションの作成 を参照してください。
手順
/dev/sda1 と /dev/sdc1 などの 2 つのブロックデバイスの RAID を作成します。
# mdadm --create /dev/md0 --level=0 --raid-devices=2 /dev/sda1 /dev/sdc1mdadm: Defaulting to version 1.2 metadata mdadm: array /dev/md0 started.level_value オプションは、RAID レベルを定義します。
オプション: RAID のステータスを確認します。
# mdadm --detail /dev/md0/dev/md0: Version : 1.2 Creation Time : Thu Oct 13 15:17:39 2022 Raid Level : raid0 Array Size : 18649600 (17.79 GiB 19.10 GB) Raid Devices : 2 Total Devices : 2 Persistence : Superblock is persistent Update Time : Thu Oct 13 15:17:39 2022 State : clean Active Devices : 2 Working Devices : 2 Failed Devices : 0 Spare Devices : 0 [...]オプション: RAID 内の各デバイスに関する詳細情報を確認します。
# mdadm --examine /dev/sda1 /dev/sdc1/dev/sda1: Magic : a92b4efc Version : 1.2 Feature Map : 0x1000 Array UUID : 77ddfb0a:41529b0e:f2c5cde1:1d72ce2c Name : 0 Creation Time : Thu Oct 13 15:17:39 2022 Raid Level : raid0 Raid Devices : 2 [...]RAID ドライブにファイルシステムを作成します。
# mkfs -t xfs /dev/md0xfs を、ドライブをフォーマットするために選択したファイルシステムに置き換えます。
RAID ドライブのマウントポイントを作成してマウントします。
# mkdir /mnt/raid1# mount /dev/md0 /mnt/raid1/mnt/raid1 をマウントポイントに置き換えます。
システムの起動時に RHEL が
md0RAID デバイスを自動的にマウントするようにするには、デバイスのエントリーを/etc/fstabファイルに追加します。/dev/md0 /mnt/raid1 xfs defaults 0 0
16.8. Web コンソールで RAID の作成
RHEL 10 Web コンソールで RAID を設定します。
前提条件
RHEL 10 Web コンソールがインストールされている。
手順は、Web コンソールのインストールおよび有効化 を参照してください。
-
cockpit-storagedパッケージがシステムにインストールされている。 - 物理ディスクが接続されており、システムに認識されている。
手順
- RHEL 10 Web コンソールにログインします。
- パネルで、Storage をクリックします。
- Storage テーブルで、メニューボタンをクリックし、Create MDRAID device を選択します。
- Create RAID Device フィールドに、新しい RAID の名前を入力します。
- RAID レベル ドロップダウンリストで、使用する RAID レベルを選択します。
- Chunk Size ドロップダウンリストから、使用可能なオプションのリストからサイズを選択します。Chunk Size の値は、データ書き込み用の各ブロックの大きさを指定します。たとえば、チャンクサイズが 512 KiB の場合、システムは最初の 512 KiB を最初のディスクに書き込み、次の 512 KiB を次のディスクに書き込み、その次の 512 KiB をその次のディスクに書き込みます。RAID に 3 つのディスクがある場合は、4 つ目の 512 KiB が最初のディスクに再度書き込まれます。
- RAID に使用するディスクを選択します。
- Create をクリックします。
検証
- ストレージ セクションに移動し、RAID デバイス ボックスに新しい RAID が表示されることを確認します。
16.9. Web コンソールで RAID のフォーマット
RHEL 10 Web コンソールでソフトウェア RAID デバイスをフォーマットおよびマウントできます。
ボリュームのサイズや、選択するオプションによって、フォーマットに数分かかることがあります。
前提条件
RHEL 10 Web コンソールがインストールされている。
手順は、Web コンソールのインストールおよび有効化 を参照してください。
-
cockpit-storagedパッケージがインストールされている。 - 物理ディスクが接続されており、システムに認識されている。
- RAID が作成されている。
手順
- RHEL 10 Web コンソールにログインします。
- パネルで、Storage をクリックします。
- Storage テーブルで、フォーマットする RAID デバイスのメニューボタン をクリックします。
- ドロップダウンメニューから を選択します。
- Format フィールドに名前を入力します。
- Mount Point フィールドにマウントパスを追加します。
- Type ドロップダウンリストから、ファイルシステムのタイプを選択します。
- オプション: ディスクに機密データが含まれており、それを上書きする場合は、Overwrite existing data with zeros オプションをオンにします。オンにしない場合、ディスクヘッダーだけが書き換えられます。
- Encryption ドロップダウンメニューで、暗号化の種類を選択します。ボリュームを暗号化しない場合は、No encryption を選択します。
- At boot ドロップダウンメニューで、ボリュームをマウントするタイミングを選択します。
Mount options セクションで以下を実行します。
- ボリュームを読み取り専用論理ボリュームとしてマウントする場合は、Mount read only チェックボックスをオンにします。
- デフォルトのマウントオプションを変更する場合は、Custom mount options チェックボックスをオンにして、マウントオプションを追加します。
RAID パーティションをフォーマットします。
- パーティションをフォーマットしてマウントする場合は、 ボタンをクリックします。
- パーティションのみをフォーマットする場合は、 ボタンをクリックします。
検証
- フォーマットが正常に完了すると、Storage ページの Storage テーブルでフォーマットされた論理ボリュームの詳細を確認できます。
16.10. RAID サービス
systemd と mdadm を使用すると、RAID の整合性チェックを自動化できます。Linux システム上のストレージの信頼性を維持するために、定期的なスキャンをスケジュールし、不良ブロックを検出して修復し、不整合をログに記録してください。
次のコンポーネントは連携して動作し、systemd で mdadm を使用してシステム上で自動 RAID 整合性チェックを実行します。
config.file-
/etc/sysconfig/raid-checkファイルには、RAID チェック動作の設定手順が含まれています。 raid-check.timer-
これは、
raid-checkサービスがいつ実行されるかを決定する systemd タイマーです。必要に応じてスケジュールを設定できます。 raid-check.service-
これは、
raid-check timerによってトリガーされたときに実行される systemdraid-checkサービスです。/usr/sbin/raid-checkスクリプトを実行します。 raid-check script-
raid-check.serviceは、raid-checkスクリプトを実行します。データの不整合数をチェックし、発見された不良ブロックの修復を試みます。不整合が検出されると、不整合カウントが機能しない RAID1 および RAID10 を除き、警告が記録されます。ただし、不良ブロックを識別して修正するために、RAID および RAID10 でもチェック操作は実行されます。
16.11. Web コンソールを使用した RAID 上のパーティションテーブルの作成
RHEL 10 インターフェイスで作成した新しいソフトウェア RAID デバイスで、パーティションテーブルを有する RAID をフォーマットします。
前提条件
RHEL 10 Web コンソールがインストールされている。
手順は、Web コンソールのインストールおよび有効化 を参照してください。
-
cockpit-storagedパッケージがインストールされている。 - 物理ディスクが接続されており、システムに認識されている。
- RAID が作成されている。
手順
- RHEL 10 Web コンソールにログインします。
- パネルで、Storage をクリックします。
- Storage テーブルで、パーティションテーブルを作成する RAID デバイスをクリックします。
- MDRAID device セクションのメニューボタン をクリックします。
- ドロップダウンメニューから、 を選択します。
Initialize disk ダイアログボックスで、以下を選択します。
パーティション設定:
- すべてのシステムおよびデバイスとの互換性をパーティションに持たせる必要がある場合は、MBR を選択します。
- 最新のシステムとの互換性をパーティションに持たせる必要があり、2 TB を超えるハードディスクが必要な場合は、GPT を選択します。
- パーティション設定が必要ない場合は、No partitioning を選択します。
オーバーライト:
- ディスクに機密データが含まれており、それを上書きする場合は、Overwrite existing data with zeros オプションをオンにします。オンにしない場合、ディスクヘッダーだけが書き換えられます。
- をクリックします。
16.12. Web コンソールを使用した RAID 上のパーティションの作成
既存のパーティションテーブルにパーティションを作成します。パーティションを作成した後、さらにパーティションを作成できます。
前提条件
RHEL 10 Web コンソールがインストールされている。
手順は、Web コンソールのインストールおよび有効化 を参照してください。
-
cockpit-storagedパッケージがシステムにインストールされている。 - RAID 上にパーティションテーブルが作成されている。
手順
- RHEL 10 Web コンソールにログインします。
- パネルで、Storage をクリックします。
- パーティションを作成する RAID デバイスをクリックします。
- RAID デバイスページで、GPT partitions セクションまでスクロールし、メニューボタン [⋮] をクリックします。
- をクリックし、Create partition フィールドにファイルシステムの名前を入力します。名前にスペースは使用しないでください。
- Mount Point フィールドにマウントパスを入力します。
- Type ドロップダウンリストで、ファイルシステムのタイプを選択します。
- Size スライダーで、パーティションのサイズを設定します。
- オプション: ディスクに機密データが含まれており、それを上書きする場合は、Overwrite existing data with zeros を選択します。オンにしない場合、ディスクヘッダーだけが書き換えられます。
- Encryption ドロップダウンメニューで、暗号化の種類を選択します。ボリュームを暗号化しない場合は、No encryption を選択します。
- At boot ドロップダウンメニューで、ボリュームをマウントするタイミングを選択します。
Mount options セクションで以下を実行します。
- ボリュームを読み取り専用論理ボリュームとしてマウントする場合は、Mount read only チェックボックスをオンにします。
- デフォルトのマウントオプションを変更する場合は、Custom mount options チェックボックスをオンにして、マウントオプションを追加します。
パーティションを作成します。
- パーティションを作成してマウントする場合は、 ボタンをクリックします。
パーティションのみを作成する場合は、 ボタンをクリックします。
ボリュームのサイズや、選択するオプションによって、フォーマットに数分かかることがあります。
検証
- フォーマットされた論理ボリュームの詳細は、メインストレージページの Storage テーブルで確認できます。
16.13. Web コンソールを使用した RAID 上のボリュームグループの作成
ソフトウェア RAID からボリュームグループを構築
前提条件
RHEL 10 Web コンソールがインストールされている。
手順は、Web コンソールのインストールおよび有効化 を参照してください。
-
cockpit-storagedパッケージがインストールされている。 - フォーマットされておらず、マウントされていない RAID デバイスがある。
手順
- RHEL 10 Web コンソールにログインします。
- パネルで、Storage をクリックします。
- Storage テーブルで、メニューボタン [⋮] をクリックし、Create LVM2 volume group を選択します。
- Create LVM2 volume group フィールドに、新しいボリュームグループの名前を入力します。
Disks リストで、RAID デバイスを選択します。
リストに RAID が表示されない場合は、システムから RAID のマウントを解除します。RAID デバイスは、RHEL 10 システムでは使用できません。
- をクリックします。
16.14. storage RHEL システムロールを使用した RAID ボリュームの設定
storage システムロールを使用すると、Red Hat Ansible Automation Platform と Ansible-Core を使用して RHEL に RAID ボリュームを設定できます。要件に合わせて RAID ボリュームを設定するためのパラメーターを使用して、Ansible Playbook を作成します。
特定の状況でデバイス名が変更する場合があります。たとえば、新しいディスクをシステムに追加するときなどです。したがって、データの損失を防ぐために、Playbook では永続的な命名属性を使用してください。永続的な命名属性の詳細は、永続的な命名属性 を参照してください。
前提条件
- コントロールノードと管理対象ノードの準備が完了している。
- 管理対象ノードで Playbook を実行できるユーザーとしてコントロールノードにログインしている。
-
管理対象ノードへの接続に使用するアカウントに、そのノードに対する
sudo権限がある。
手順
次の内容を含む Playbook ファイル (例:
~/playbook.yml) を作成します。--- - name: Manage local storage hosts: managed-node-01.example.com tasks: - name: Create a RAID on sdd, sde, sdf, and sdg ansible.builtin.include_role: name: redhat.rhel_system_roles.storage vars: storage_safe_mode: false storage_volumes: - name: data type: raid disks: [sdd, sde, sdf, sdg] raid_level: raid0 raid_chunk_size: 32 KiB mount_point: /mnt/data state: presentPlaybook で使用されるすべての変数の詳細は、コントロールノードの
/usr/share/ansible/roles/rhel-system-roles.storage/README.mdファイルを参照してください。Playbook の構文を検証します。
$ ansible-playbook --syntax-check ~/playbook.ymlこのコマンドは構文を検証するだけであり、有効だが不適切な設定から保護するものではないことに注意してください。
Playbook を実行します。
$ ansible-playbook ~/playbook.yml
検証
アレイが正しく作成されたことを確認します。
# ansible managed-node-01.example.com -m command -a 'mdadm --detail /dev/md/data'
16.15. RAID の拡張
mdadm ユーティリティーの --grow オプションを使用して RAID を拡張できます。詳細は、システム上の mdadm(8) man ページを参照してください。
前提条件
- 十分なディスク領域
-
partedパッケージがインストールされている
手順
- RAID パーティションを拡張します。詳細は、parted を使用したパーティションのサイズ変更 を参照してください。
RAID をパーティション容量の最大値まで拡張します。
# mdadm --grow --size=max /dev/md0特定のサイズを設定するには、
--sizeパラメーターの値を kB 単位で記述します (例:--size=524228)。ファイルシステムのサイズを拡大します。たとえば、ボリュームが XFS を使用し、/mnt/ にマウントされている場合は、次のように入力します。
# xfs_growfs /mnt/
16.16. RAID を縮小
mdadm ユーティリティーの --grow オプションを使用して RAID を縮小できます。詳細は、システム上の mdadm(8) man ページを参照してください。
XFS ファイルシステムは縮小に対応していません。
前提条件
-
partedパッケージがインストールされている
手順
- ファイルシステムを縮小します。詳細は、ファイルシステムの管理 を参照してください。
RAID のサイズを 512 MB などに減らします。
# mdadm --grow --size=524228 /dev/md0--sizeパラメーターを kB 単位で記述します。- パーティションのサイズを、必要なサイズまで縮小します。
16.17. インストール後にルートディスクを RAID1 に変換する
Red Hat Enterprise Linux 10 をインストールした後、非 RAID ルートディスクを RAID1 ミラーに変換できます。
手順
- x86 アーキテクチャーの場合は、Red Hat ナレッジベースソリューション How to convert single disk EFI boot to software RAID after installation of Red Hat Enterprise Linux 10 の手順を完了します。
- PowerPC (PPC) アーキテクチャーの場合は、Red Hat ナレッジベースソリューション How do I convert my root disk to RAID1 after installation of Red Hat Enterprise Linux 10 の手順を完了します。
16.18. 高度な RAID デバイスの作成
場合によっては、インストールが完了する前に作成されたアレイにオペレーティングシステムをインストールすることを推奨します。通常、これは複雑な RAID デバイスに /boot または root ファイルシステムアレイを設定することを意味します。このような場合、Anaconda インストーラーでサポートされていないアレイオプションを使用する必要がある場合があります。これを回避するには、以下の手順を行います。
インストーラーの制限されたレスキューモードには man ページは含まれません。mdadm(8) と md(4) の両方の man ページには、カスタム RAID アレイを作成するための有用な情報が含まれており、回避策全体で必要になる場合があります。
手順
- インストールディスクを挿入します。
-
初回起動時に、Install または Upgrade ではなく、Rescue Mode を選択します。システムが
Rescue modeで完全に起動すると、コマンドラインターミナルが表示されます。 このターミナルから、次のコマンドを実行します。
-
partedコマンドを使用して、ターゲットハードドライブに RAID パーティションを作成します。 -
使用可能なすべての設定とオプションを使用して、これらのパーティションから
mdadmコマンドを使用して手動で RAID アレイを作成します。
-
- オプション: アレイを作成したら、アレイ上にもファイルシステムを作成します。
- コンピューターを再起動して、インストール または 更新 を選択して通常通りにインストールします。Anaconda インストーラーはシステム内のディスクを検索するため、既存の RAID デバイスが見つかります。
- システムのディスクの使い方を求められたら、カスタムレイアウト を選択して をクリックします。デバイス一覧に、既存の MD RAID デバイスが表示されます。
- RAID デバイスを選択し、 をクリックします。
- マウントポイントを設定し、必要に応じて、以前に作成していない場合は使用するファイルシステムのタイプを設定し、 をクリックします。Anaconda は、この既存の RAID デバイスにインストールし、Rescue モードで作成したときに選択したカスタムオプションを保持します。
16.19. RAID を監視するための電子メール通知の設定
mdadm ツールを使用して RAID を監視するように電子メールアラートを設定できます。MAILADDR 変数が必要な電子メールアドレスに設定されると、監視システムは追加された電子メールアドレスにアラートを送信します。詳細は、システム上の mdadm.conf(5) man ページを参照してください。
前提条件
-
mdadmパッケージがインストールされている。 - メールサービスが設定されている。
手順
RAID の詳細をスキャンして、アレイを監視するための
/etc/mdadm.conf設定ファイルを作成します。# mdadm --detail --scan >> /etc/mdadm.confARRAYおよびMAILADDRは必須の変数であることに注意してください。任意のテキストエディターで
/etc/mdadm.conf設定ファイルを開き、MAILADDR変数に通知用のメールアドレスを追加します。たとえば、次の行を追加します。MAILADDR example@example.comexample@example.com は、アレイの監視からアラートを受信するためのメールアドレスです。
-
/etc/mdadm.confファイルに変更を保存して、閉じます。
16.20. RAID での障害のあるディスクの置き換え
残りのディスクを使用して、故障したディスクからデータを再構築できます。データを正常に再構築するために最低限必要な残りのディスクの量は、RAID レベルとディスクの総数によって決まります。
この手順では、/dev/md0 RAID に 4 つのディスクが含まれています。/dev/sdd ディスクに障害が発生したため、/dev/sdf ディスクと交換する必要があります。
前提条件
- 交換用スペアディスク。
-
mdadmパッケージがインストールされている。
手順
障害が発生したディスクを確認します。
カーネルログを表示します。
# journalctl -k -f次のようなメッセージを検索します。
md/raid:md0: Disk failure on sdd, disabling device. md/raid:md0: Operation continuing on 3 devices.-
キーボードの Ctrl+C を押して、
journalctlプログラムを終了します。
障害の発生したディスクに faulty のマークを付けます。
# mdadm --manage /dev/md0 --fail /dev/sddオプション: 障害が発生したディスクが正しくマークされているかどうかを確認します。
# mdadm --detail /dev/md0出力の最後には、ディスク /dev/sdd のステータスが faulty の /dev/md0 RAID 内にあるディスクのリストが表示されます。
Number Major Minor RaidDevice State 0 8 16 0 active sync /dev/sdb 1 8 32 1 active sync /dev/sdc - 0 0 2 removed 3 8 64 3 active sync /dev/sde 2 8 48 - faulty /dev/sdd障害が発生したディスクを RAID から取り外します。
# mdadm --manage /dev/md0 --remove /dev/sdd警告RAID が別のディスク障害に耐えられない場合は、新しいディスクのステータスが active sync になるまでディスクを取り外さないでください。
watch cat /proc/mdstatコマンドを使用すると、進捗を監視できます。新しいディスクを RAID に追加します。
# mdadm --manage /dev/md0 --add /dev/sdf/dev/md0 RAID には新しいディスク /dev/sdf が含まれるようになり、
mdadmサービスは他のディスクからデータのコピーを自動的に開始します。
検証
アレイの詳細を確認します。
# mdadm --detail /dev/md0このコマンドの出力の最後に表示される /dev/md0 RAID 内のディスクのリストで、新しいディスクのステータスが spare rebuilding である場合、データはまだ他のディスクからコピーされています。
Number Major Minor RaidDevice State 0 8 16 0 active sync /dev/sdb 1 8 32 1 active sync /dev/sdc 4 8 80 2 spare rebuilding /dev/sdf 3 8 64 3 active sync /dev/sdeデータのコピーが完了すると、新しいディスクは active sync 状態になります。
同期の進行状況を確認します。
# cat /proc/mdstatPersonalities : [raid4] [raid5] [raid6] md0 : active raid5 sdf[5] sde[4] sdc[1] sdb[0] 6282240 blocks super 1.2 level 5, 512k chunk, algorithm 2 [4/3] [UU_U] [==============>......] recovery = 72.0% (1509820/2094080) finish=0.0min speed=215688K/sec unused devices: <none>
16.21. RAID ディスクの修復
repair オプションを使用して、RAID アレイ内のディスクを修復できます。
前提条件
-
mdadmパッケージがインストールされている。
手順
障害が発生したディスクの動作についてアレイを確認します。
# echo check > /sys/block/md0/md/sync_actionこれによりアレイがチェックされ、
/sys/block/md0/md/sync_actionファイルに同期アクションが表示されます。-
/sys/block/md0/md/sync_actionファイルを任意のテキストエディターで開き、ディスク同期の失敗に関するメッセージがあるかどうかを確認します。 -
/sys/block/md0/md/mismatch_cntファイルを表示します。mismatch_cntパラメーターが0でない場合は、RAID ディスクを修復する必要があることを意味します。 アレイ内のディスクを修復します。
# echo repair > /sys/block/md0/md/sync_actionこれにより、アレイ内のディスクが修復され、結果が
/sys/block/md0/md/sync_actionファイルに書き込まれます。同期の進行状況を表示します。
# cat /sys/block/md0/md/sync_actionrepair# cat /proc/mdstatPersonalities : [raid0] [raid6] [raid5] [raid4] [raid1] md0 : active raid1 sdg[1] dm-3[0] 511040 blocks super 1.2 [2/2] [UU] unused devices: <none>
第17章 LUKS を使用したブロックデバイスの暗号化
ディスク暗号化を使用して、ブロックデバイス上のデータを保護できます。復号されたコンテンツにアクセスするには、パスフレーズまたは鍵を入力します。これはラップトップやリムーバブルメディアにとって特に重要です。コンテンツはデバイスが物理的に取り外された場合でも保護されます。Red Hat Enterprise Linux のデフォルトのブロックデバイス暗号化形式は LUKS です。
17.1. LUKS ディスクの暗号化
Linux Unified Key Setup-on-disk-format (LUKS) は、暗号化されたデバイスの管理を簡素化するツールセットを提供します。LUKS を使用すると、ブロックデバイスを暗号化し、複数のユーザーキーでマスターキーを復号化できるようになります。
Red Hat Enterprise Linux は、LUKS を使用してブロックデバイスの暗号化を実行します。デフォルトではインストール時に、ブロックデバイスを暗号化するオプションが指定されていません。ディスクを暗号化するオプションを選択すると、コンピューターを起動するたびにパスフレーズの入力が求められます。このパスフレーズは、パーティションを復号化するバルク暗号鍵のロックを解除します。デフォルトのパーティションテーブルを変更する場合は、暗号化するパーティションを選択できます。この設定は、パーティションテーブル設定で行われます。
Ciphers
LUKS に使用されるデフォルトの暗号は aes-xts-plain64 です。LUKS のデフォルトの鍵サイズは 512 ビットです。Anaconda XTS モードを使用した LUKS のデフォルトの鍵サイズは 512 ビットです。使用可能な暗号は次のとおりです。
- 高度暗号化標準 (Advanced Encryption Standard, AES)
- Twofish
- Serpent
LUKS によって実行される操作
- LUKS は、ブロックデバイス全体を暗号化するため、脱着可能なストレージメディアやラップトップのディスクドライブといった、モバイルデバイスのコンテンツを保護するのに適しています。
- 暗号化されたブロックデバイスの基本的な内容は任意であり、スワップデバイスの暗号化に役立ちます。また、とりわけデータストレージ用にフォーマットしたブロックデバイスを使用する特定のデータベースに関しても有用です。
- LUKS は、既存のデバイスマッパーのカーネルサブシステムを使用します。
- LUKS はパスフレーズのセキュリティーを強化し、辞書攻撃から保護します。
- LUKS デバイスには複数のキースロットが含まれているため、バックアップキーやパスフレーズを追加できます。
LUKS は次のシナリオには推奨されません。
- LUKS などのディスク暗号化ソリューションは、システムの停止時にしかデータを保護しません。システムの電源がオンになり、LUKS がディスクを復号化すると、そのディスクのファイルは、そのファイルにアクセスできるすべてのユーザーが使用できます。
- 同じデバイスに対する個別のアクセスキーを複数のユーザーが持つ必要があるシナリオ。LUKS1 形式はキースロットを 8 個提供し、LUKS2 形式はキースロットを最大 32 個提供します。
- ファイルレベルの暗号化を必要とするアプリケーション。
17.2. RHEL の LUKS バージョン
Red Hat Enterprise Linux では、LUKS 暗号化のデフォルト形式は LUKS2 です。古い LUKS1 形式は引き続き完全にサポートされており、以前の Red Hat Enterprise Linux リリースと互換性のある形式で提供されます。LUKS2 再暗号化は、LUKS1 再暗号化と比較して、より堅牢で安全に使用できる形式と考えられています。
LUKS2 形式を使用すると、バイナリー構造を変更することなく、さまざまな部分を後に更新できます。LUKS2 は、内部的にメタデータに JSON テキスト形式を使用し、メタデータの冗長性を提供し、メタデータの破損を検出し、メタデータのコピーから自動的に修復します。
LUKS1 のみをサポートするシステムでは LUKS2 を使用しないでください。
Red Hat Enterprise Linux 9.2 以降では、両方の LUKS バージョンで cryptsetup reencrypt コマンドを使用してディスクを暗号化できます。
オンラインの再暗号化
LUKS2 形式は、デバイスが使用中の間に、暗号化したデバイスの再暗号化に対応します。たとえば、以下のタスクを実行するにあたり、デバイスでファイルシステムをアンマウントする必要はありません。
- ボリュームキーの変更
暗号化アルゴリズムの変更
暗号化されていないデバイスを暗号化する場合は、ファイルシステムのマウントを解除する必要があります。暗号化の短い初期化後にファイルシステムを再マウントできます。
LUKS1 形式は、オンライン再暗号化に対応していません。
変換
特定の状況では、LUKS1 を LUKS2 に変換できます。具体的には、以下のシナリオでは変換ができません。
-
LUKS1 デバイスが、Policy-Based Decryption (PBD) Clevis ソリューションにより使用されているとマークされている。
cryptsetupツールは、luksmetaメタデータが検出されると、そのデバイスを変換することを拒否します。 - デバイスがアクティブになっている。デバイスが非アクティブ状態でなければ、変換することはできません。
17.3. LUKS2 再暗号化中のデータ保護のオプション
LUKS2 では、再暗号化プロセスで、パフォーマンスやデータ保護の優先度を設定する複数のオプションを選択できます。
resilience オプションには次のモードが用意されています。cryptsetup reencrypt --resilience resilience-mode /dev/<device_ID> コマンドを使用すると、これらのモードのいずれかを選択できます。<device_ID> は、デバイスの ID に置き換えてください。
checksumデフォルトのモード。データ保護とパフォーマンスのバランスを取ります。
このモードでは、再暗号化領域内のセクターのチェックサムが個別に保存されます。チェックサムは、LUKS2 によって再暗号化されたセクターについて、復旧プロセスで検出できます。このモードでは、ブロックデバイスセクターの書き込みがアトミックである必要があります。
journal- 最も安全なモードですが、最も遅いモードでもあります。このモードでは、再暗号化領域をバイナリー領域にジャーナル化するため、LUKS2 はデータを 2 回書き込みます。
none-
noneモードではパフォーマンスが優先され、データ保護は提供されません。SIGTERMシグナルやユーザーによる Ctrl+C キーの押下など、安全なプロセス終了からのみデータを保護します。予期しないシステム障害やアプリケーション障害が発生すると、データが破損する可能性があります。
LUKS2 の再暗号化プロセスが強制的に突然終了した場合、LUKS2 は以下のいずれかの方法で復旧を実行できます。
- 自動
次のいずれかのアクションを実行すると、次回の LUKS2 デバイスを開くアクション中に自動復旧アクションがトリガーされます。
-
cryptsetup openコマンドを実行する。 -
systemd-cryptsetupコマンドを使用してデバイスを接続する。
-
- 手動
-
LUKS2 デバイスで
cryptsetup repair /dev/<device_ID>コマンドを使用します。
17.4. LUKS2 を使用したブロックデバイスの既存データの暗号化
LUKS2 形式を使用して、まだ暗号化されていないデバイスの既存のデータを暗号化できます。新しい LUKS ヘッダーは、デバイスのヘッドに保存されます。
前提条件
- ブロックデバイスにファイルシステムがある。
データのバックアップを作成している。
警告ハードウェア、カーネル、または人的ミスにより、暗号化プロセス時にデータが失われる場合があります。データの暗号化を開始する前に、信頼性の高いバックアップを作成してください。
手順
暗号化するデバイスにあるファイルシステムのマウントをすべて解除します。次に例を示します。
# umount /dev/mapper/vg00-lv00LUKS ヘッダーを保存するための空き容量を確認します。シナリオに合わせて、次のいずれかのオプションを使用します。
論理ボリュームを暗号化する場合は、以下のように、ファイルシステムのサイズを変更せずに、論理ボリュームを拡張できます。以下に例を示します。
# lvextend -L+32M /dev/mapper/vg00-lv00-
partedなどのパーティション管理ツールを使用してパーティションを拡張します。 -
このデバイスのファイルシステムを縮小します。ext2、ext3、または ext4 のファイルシステムには
resize2fsユーティリティーを使用できます。XFS ファイルシステムは縮小できないことに注意してください。
暗号化を初期化します。
# cryptsetup reencrypt --encrypt --init-only --reduce-device-size 32M /dev/mapper/vg00-lv00 lv00_encrypted/dev/mapper/lv00_encrypted is now active and ready for online encryption.デバイスをマウントします。
# mount /dev/mapper/lv00_encrypted /mnt/lv00_encrypted永続的なマッピングのエントリーを
/etc/crypttabファイルに追加します。luksUUIDを見つけます。# cryptsetup luksUUID /dev/mapper/vg00-lv00a52e2cc9-a5be-47b8-a95d-6bdf4f2d9325任意のテキストエディターで
/etc/crypttabを開き、このファイルにデバイスを追加します。$ vi /etc/crypttablv00_encrypted UUID=a52e2cc9-a5be-47b8-a95d-6bdf4f2d9325 nonea52e2cc9-a5be-47b8-a95d-6bdf4f2d9325 は、デバイスの
luksUUIDに置き換えます。dracutで initramfs を更新します。$ dracut -f --regenerate-all
-
/etc/fstabファイルにこのデバイスのエントリーが存在する場合は、デバイス名ではなくファイルシステムの UUID が使用されていることを確認します。 オンライン暗号化を再開します。
# cryptsetup reencrypt --resume-only /dev/mapper/vg00-lv00Enter passphrase for /dev/mapper/vg00-lv00: Auto-detected active dm device 'lv00_encrypted' for data device /dev/mapper/vg00-lv00. Finished, time 00:31.130, 10272 MiB written, speed 330.0 MiB/s
検証
既存のデータが暗号化されているかどうかを確認します。
# cryptsetup luksDump /dev/mapper/vg00-lv00LUKS header information Version: 2 Epoch: 4 Metadata area: 16384 [bytes] Keyslots area: 16744448 [bytes] UUID: a52e2cc9-a5be-47b8-a95d-6bdf4f2d9325 Label: (no label) Subsystem: (no subsystem) Flags: (no flags) Data segments: 0: crypt offset: 33554432 [bytes] length: (whole device) cipher: aes-xts-plain64 [...]暗号化された空のブロックデバイスのステータスを表示します。
# cryptsetup status lv00_encrypted/dev/mapper/lv00_encrypted is active and is in use. type: LUKS2 cipher: aes-xts-plain64 keysize: 512 bits key location: keyring device: /dev/mapper/vg00-lv00
17.5. 独立したヘッダーがある LUKS2 を使用してブロックデバイスの既存データの暗号化
LUKS ヘッダーを保存するための空き領域を作成せずに、ブロックデバイスの既存のデータを暗号化できます。ヘッダーは、追加のセキュリティー層としても使用できる、独立した場所に保存されます。この手順では、LUKS2 暗号化形式を使用します。
前提条件
- ブロックデバイスにファイルシステムがある。
データがバックアップ済みである。
警告ハードウェア、カーネル、または人的ミスにより、暗号化プロセス時にデータが失われる場合があります。データの暗号化を開始する前に、信頼性の高いバックアップを作成してください。
手順
以下のように、そのデバイスのファイルシステムをすべてアンマウントします。
# umount /dev/<nvme0n1p1><nvme0n1p1>は、アンマウントするパーティションに対応するデバイス識別子に置き換えます。暗号化を初期化します。
# cryptsetup reencrypt --encrypt --init-only --header </home/header> /dev/<nvme0n1p1> <nvme_encrypted>WARNING! ======== Header file does not exist, do you want to create it? Are you sure? (Type 'yes' in capital letters): YES Enter passphrase for </home/header>: Verify passphrase: /dev/mapper/<nvme_encrypted> is now active and ready for online encryption.以下のように置き換えます。
-
</home/header>には、独立した LUKS ヘッダーを含むファイルへのパスを指定します。後で暗号化したデバイスのロックを解除するために、独立した LUKS ヘッダーにアクセスできる必要があります。 -
<nvme_encrypted>は、暗号化後に作成されるデバイスマッパーの名前に置き換えます。
-
デバイスをマウントします。
# mount /dev/mapper/<nvme_encrypted> /mnt/<nvme_encrypted>永続的なマッピングのエントリーを
/etc/crypttabファイルに追加します。# <nvme_encrypted> /dev/disk/by-id/<nvme-partition-id> none header=</home/header><nvme-partition-id>は、NVMe パーティションの識別子に置き換えます。dracutを使用して initramfs を再生成します。# dracut -f --regenerate-all -v/etc/fstabファイルに永続的なマウントのエントリーを追加します。アクティブな LUKS ブロックデバイスのファイルシステムの UUID を見つけます。
$ blkid -p /dev/mapper/<nvme_encrypted>/dev/mapper/<nvme_encrypted>: UUID="37bc2492-d8fa-4969-9d9b-bb64d3685aa9" BLOCK_SIZE="4096" TYPE="xfs" USAGE="filesystem"テキストエディターで
/etc/fstabを開き、このファイルにデバイスを追加します。次に例を示します。$ vi /etc/fstabUUID=<file_system_UUID> /home auto rw,user,auto 0<file_system_UUID>は、ファイルシステムの UUID に置き換えます。
オンライン暗号化を再開します。
# cryptsetup reencrypt --resume-only --header </home/header> /dev/<nvme0n1p1>Enter passphrase for /dev/<nvme0n1p1>: Auto-detected active dm device '<nvme_encrypted>' for data device /dev/<nvme0n1p1>. Finished, time 00m51s, 10 GiB written, speed 198.2 MiB/s
検証
独立したヘッダーがある LUKS2 を使用するブロックデバイスの既存のデータが暗号化されているかどうかを確認します。
# cryptsetup luksDump </home/header>LUKS header information Version: 2 Epoch: 88 Metadata area: 16384 [bytes] Keyslots area: 16744448 [bytes] UUID: c4f5d274-f4c0-41e3-ac36-22a917ab0386 Label: (no label) Subsystem: (no subsystem) Flags: (no flags) Data segments: 0: crypt offset: 0 [bytes] length: (whole device) cipher: aes-xts-plain64 sector: 512 [bytes] [...]暗号化された空のブロックデバイスのステータスを表示します。
# cryptsetup status <nvme_encrypted> --header </home/header>/dev/mapper/<nvme_encrypted> is active and is in use. type: LUKS2 cipher: aes-xts-plain64 keysize: 512 bits key location: keyring device: /dev/<nvme0n1p1> sector size: 512 offset: 0 sectors size: 10485760 sectors mode: read/write
17.6. LUKS2 を使用した空のブロックデバイスの暗号化
空のブロックデバイスを暗号化して、強力な暗号化でデータを保護するセキュアなストレージを作成します。このプロセスは、最初からデータの機密性を確保する必要のある新しいストレージデバイスに最適です。
前提条件
-
空のブロックデバイス。
lsblkなどのコマンドを使用して、そのデバイス上に実際のデータ (ファイルシステムなど) がないかどうかを確認できます。
手順
暗号化した LUKS パーティションとしてパーティションを設定します。
# cryptsetup luksFormat /dev/nvme0n1p1WARNING! ======== This will overwrite data on /dev/nvme0n1p1 irrevocably. Are you sure? (Type 'yes' in capital letters): YES Enter passphrase for /dev/nvme0n1p1: Verify passphrase:暗号化した LUKS パーティションを開きます。
# cryptsetup open /dev/nvme0n1p1 nvme0n1p1_encryptedEnter passphrase for /dev/nvme0n1p1:これにより、パーティションのロックが解除され、デバイスマッパーを使用してパーティションが新しいデバイスにマッピングされます。暗号化されたデータを上書きしないように、このコマンドは、デバイスが暗号化されたデバイスであり、
/dev/mapper/device_mapped_nameパスを使用して LUKS を通じてアドレス指定されることをカーネルに警告します。暗号化されたデータをパーティションに書き込むためのファイルシステムを作成します。このパーティションには、デバイスマップ名を介してアクセスする必要があります。
# mkfs -t ext4 /dev/mapper/nvme0n1p1_encryptedデバイスをマウントします。
# mount /dev/mapper/nvme0n1p1_encrypted mount-point
検証
空のブロックデバイスが暗号化されているかどうかを確認します。
# cryptsetup luksDump /dev/nvme0n1p1LUKS header information Version: 2 Epoch: 3 Metadata area: 16384 [bytes] Keyslots area: 16744448 [bytes] UUID: 34ce4870-ffdf-467c-9a9e-345a53ed8a25 Label: (no label) Subsystem: (no subsystem) Flags: (no flags) Data segments: 0: crypt offset: 16777216 [bytes] length: (whole device) cipher: aes-xts-plain64 sector: 512 [bytes] [...]暗号化された空のブロックデバイスのステータスを表示します。
# cryptsetup status nvme0n1p1_encrypted/dev/mapper/nvme0n1p1_encrypted is active and is in use. type: LUKS2 cipher: aes-xts-plain64 keysize: 512 bits key location: keyring device: /dev/nvme0n1p1 sector size: 512 offset: 32768 sectors size: 20938752 sectors mode: read/write
17.7. Web コンソールでの LUKS パスフレーズの設定
システムの既存の論理ボリュームに暗号化を追加する場合は、ボリュームをフォーマットすることでしか実行できません。
前提条件
RHEL 10 Web コンソールがインストールされている。
手順は、Web コンソールのインストールおよび有効化 を参照してください。
-
cockpit-storagedパッケージがシステムにインストールされている。 - 暗号化なしで、既存の論理ボリュームを利用できます。
手順
- RHEL 10 Web コンソールにログインします。
- パネルで、Storage をクリックします。
- Storage テーブルで、暗号化するストレージデバイスのメニューボタン をクリックし、 をクリックします。
- Encryption field で、暗号化仕様 LUKS1 または LUKS2 を選択します。
- 新しいパスフレーズを設定し、確認します。
- オプション: さらなる暗号化オプションを変更します。
- フォーマット設定の最終処理
- Format をクリックします。
17.8. コマンドラインを使用した LUKS パスフレーズの変更
コマンドラインを使用して、暗号化されたディスクまたはパーティションの LUKS パスフレーズを変更します。cryptsetup ユーティリティーを使用すると、さまざまな設定オプションと機能を使用して暗号化プロセスを制御し、既存の自動化ワークフローにプロセスを統合できます。
前提条件
-
root特権、またはsudoを使用して管理コマンドを入力する権限がある。
手順
LUKS 暗号化デバイスの既存のパスフレーズを変更します。
# cryptsetup luksChangeKey /dev/<device_ID><device_ID>は、デバイス指定子 (例:sda) に置き換えます。複数のキースロットが設定されている場合は、使用するスロットを指定できます。
# cryptsetup luksChangeKey /dev/<device_ID> --key-slot <slot_number><slot_number>は、変更するキースロットの番号に置き換えます。現在のパスフレーズと新しいパスフレーズを入力します。
Enter passphrase to be changed: Enter new passphrase: Verify passphrase:新しいパスフレーズを検証します。
# cryptsetup --verbose open --test-passphrase /dev/<device_ID>
検証
新しいパスフレーズでデバイスのロックを解除できることを確認します。
Enter passphrase for /dev/<device_ID>: Key slot <slot_number> unlocked. Command successful.
17.9. Web コンソールでの LUKS パスフレーズの変更
Web コンソールで、暗号化されたディスクまたはパーティションで LUKS パスフレーズを変更します。
前提条件
RHEL 10 Web コンソールがインストールされている。
手順は、Web コンソールのインストールおよび有効化 を参照してください。
-
cockpit-storagedパッケージがシステムにインストールされている。
手順
- RHEL 10 Web コンソールにログインします。
- パネルで、Storage をクリックします。
- Storage テーブルで、暗号化されたデータを含むディスクを選択します。
- ディスクページで、Keys セクションまでスクロールし、編集ボタンをクリックします。
パスフレーズの変更 ダイアログウィンドウで、以下を行います。
- 現在のパスフレーズを入力します。
- 新しいパスフレーズを入力します。
- 新しいパスフレーズを確認します。
- Save をクリックします。
17.10. storage RHEL システムロールを使用して LUKS2 暗号化ボリュームを作成する
storage ロールを使用し、Ansible Playbook を実行して、LUKS で暗号化されたボリュームを作成および設定できます。
前提条件
- コントロールノードと管理対象ノードの準備が完了している。
- 管理対象ノードで Playbook を実行できるユーザーとしてコントロールノードにログインしている。
-
管理対象ノードへの接続に使用するアカウントに、そのノードに対する
sudo権限がある。
手順
機密性の高い変数を暗号化されたファイルに保存します。
vault を作成します。
$ ansible-vault create ~/vault.ymlNew Vault password: <vault_password> Confirm New Vault password: <vault_password>ansible-vault createコマンドでエディターが開いたら、機密データを<key>: <value>形式で入力します。luks_password: <password>- 変更を保存して、エディターを閉じます。Ansible は vault 内のデータを暗号化します。
次の内容を含む Playbook ファイル (例:
~/playbook.yml) を作成します。--- - name: Manage local storage hosts: managed-node-01.example.com vars_files: - ~/vault.yml tasks: - name: Create and configure a volume encrypted with LUKS ansible.builtin.include_role: name: redhat.rhel_system_roles.storage vars: storage_volumes: - name: barefs type: disk disks: - sdb fs_type: xfs fs_label: <label> mount_point: /mnt/data encryption: true encryption_password: "{{ luks_password }}" encryption_cipher: <cipher> encryption_key_size: <key_size> encryption_luks_version: luks2サンプル Playbook で指定されている設定は次のとおりです。
encryption_cipher: <cipher>-
LUKS 暗号を指定します。可能な値は、
twofish-xts-plain64、serpent-xts-plain64、およびaes-xts-plain64(デフォルト) です。 encryption_key_size: <key_size>-
LUKS キーのサイズを指定します。デフォルトは
512ビットです。 encryption_luks_version: luks2-
LUKS バージョンを指定します。デフォルトは
luks2です。
Playbook で使用されるすべての変数の詳細は、コントロールノードの
/usr/share/ansible/roles/rhel-system-roles.storage/README.mdファイルを参照してください。Playbook の構文を検証します。
$ ansible-playbook --ask-vault-pass --syntax-check ~/playbook.ymlこのコマンドは構文を検証するだけであり、有効だが不適切な設定から保護するものではないことに注意してください。
Playbook を実行します。
$ ansible-playbook --ask-vault-pass ~/playbook.yml
検証
作成された LUKS 暗号化ボリュームを確認します。
# ansible managed-node-01.example.com -m command -a 'cryptsetup luksDump /dev/sdb'LUKS header information Version: 2 Epoch: 3 Metadata area: 16384 [bytes] Keyslots area: 16744448 [bytes] UUID: bdf6463f-6b3f-4e55-a0a6-1a66f0152a46 Label: (no label) Subsystem: (no subsystem) Flags: (no flags) Data segments: 0: crypt offset: 16777216 [bytes] length: (whole device) cipher: aes-cbc-essiv:sha256 sector: 512 [bytes] Keyslots: 0: luks2 Key: 256 bits Priority: normal Cipher: aes-cbc-essiv:sha256 Cipher key: 256 bits
第18章 NVDIMM 永続メモリーストレージの使用
システムに接続された Non-Volatile Dual In-line Memory Modules (NVDIMM) デバイス上で、さまざまなタイプのストレージを有効にして管理できます。
18.1. NVDIMM 永続メモリーテクノロジー
Non-Volatile Dual In-line Memory Modules (NVDIMM) 永続メモリーは、ストレージの耐久性と RAM (DRAM) の速度および低遅延性を兼ね備えています。このバイト単位でアドレス指定可能なテクノロジーは、電源が失われてもデータを保持し、同時にアプリケーションにメモリー並みのパフォーマンスを提供します。
NVDIMM を使用するその他の利点は次のとおりです。
- NVDIMM ストレージはバイトアドレス指定可能です。つまり、CPU ロードおよびストア命令を使用してアクセスできます。従来のブロックベースのストレージへのアクセスに必要なシステムコール read() および write() の他に、NVDIMM はダイレクトロードとストアプログラミングモデルにも対応しています。
- NVDIMM のパフォーマンス特性は、アクセスレイテンシーが非常に低い DRAM と似ています。通常、数万から数十万ナノ秒です。
- NVDIMM に保存されたデータは、永続メモリーと同様に、電源がオフになっても保持されます。
- ダイレクトアクセス (DAX) テクノロジーを使用すると、システムページキャッシュを経由せずにメモリーマップストレージへのアプリケーションを直接実行できます。これにより、別の目的で DRAM を解放します。
NVDIMM は、次のようなユースケースでメリットがあります。
- データベース
- NVDIMM でのストレージアクセスレイテンシーの短縮により、データベースのパフォーマンスが向上します。
- 高速な再起動
高速な再起動は、ウォームキャッシュ効果とも呼ばれます。たとえば、ファイルサーバーは起動後、メモリー内にファイルコンテンツを持ちません。クライアントがデータを接続して読み書きすると、そのデータはページキャッシュにキャッシュされます。最終的に、キャッシュには、ほとんどのホットデータが含まれます。再起動後、システムは従来のストレージで再度プロセスを開始する必要があります。
NVDIMM を使用すると、アプリケーションが適切に設計されていれば、再起動後もウォームキャッシュを維持できます。この例には、ページキャッシュは含まれません。アプリケーションは、永続メモリーに直接データをキャッシュします。
- 高速書き込みキャッシュ
- 多くの場合、ファイルサーバーは、データが耐久性のあるメディアに保存されるまで、クライアントの書き込み要求を認識しません。NVDIMM を高速な書き込みキャッシュとして使用すると、ファイルサーバーが書き込み要求をすばやく認識できるようになり、遅延が少なくなります。
18.2. NVDIMM のインターリービングおよび地域
Non-Volatile Dual In-line Memory Modules (NVDIMM) デバイスは、インターリーブされた領域へのグループ化をサポートしています。NVDIMM デバイスは、通常のダイナミック RAM (DRAM) と同じ方法でインターリーブセットにグループ化できます。
インターリーブセットは、複数の DIMM にまたがる RAID 0 レベル (ストライプ) 設定と似ています。インターリーブセットは、リージョンとも呼ばれます。
インターリービングには、以下の利点があります。
- NVDIMM は、インターリーブセットに設定するとパフォーマンスが向上します。
- インターリービングは、複数の小さな NVDIMM デバイスを大きな論理デバイスに組み合わせます。
NVDIMM インターリーブセットは、システムの BIOS または UEFI ファームウェアで設定されます。Red Hat Enterprise Linux は、各インターリーブセットにリージョンデバイスを作成します。
18.3. NVDIMM 名前空間
Non-Volatile Dual In-line Memory Modules (NVDIMM) の領域は、ラベル領域のサイズに応じて 1 つ以上の名前空間に分割できます。名前空間を使用すると、fsdax、devdax、raw などのアクセスモードに基づいて、さまざまな方法でデバイスにアクセスできます。
一部の NVDIMM デバイスは、任意のリージョンでの複数の名前空間に対応していません。
- お使いの NVDIMM デバイスがラベルに対応している場合は、リージョンを名前空間に分割できます。
- NVDIMM デバイスがラベルに対応していない場合は、リージョンに名前空間を 1 つだけ追加できます。この場合、Red Hat Enterprise Linux は、リージョン全体に対応するデフォルトの名前空間を作成します。
18.4. NVDIMM アクセスモード
Non-Volatile Dual In-line Memory Module の名前空間は、devdax、fsdax、raw モードなどのさまざまなアクセスモードをサポートしています。アクセスモードにはそれぞれ固有の機能と制限があります。
Non-Volatile Dual In-line Memory Modules (NVDIMM) 名前空間を設定して、次のいずれかのモードを使用できます。
devdaxまたはデバイスダイレクトアクセス (DAX)devdaxを使用すると、NVDIMM デバイスは、Storage Networking Industry Association (SNIA) Non-Volatile Memory (NVM) Programming Model 仕様で説明されているように、直接アクセスプログラミングをサポートします。このモードでは、I/O はカーネルのストレージスタックを回避します。したがって、デバイスマッパードライバーは使用できません。デバイス DAX は、DAX キャラクターデバイスノードを使用して NVDIMM ストレージへの raw アクセスを提供します。CPU キャッシュのフラッシュ命令とフェンシング命令を使用して、
devdaxデバイスのデータを作成できます。特定のデータベースおよび仮想マシンのハイパーバイザーは、このモードの利点を得られます。devdaxデバイスにファイルシステムを作成することはできません。このモードのデバイスは
/dev/daxN.Mとして利用できます。名前空間を作成したら、リストされたchardev値を確認します。fsdaxまたはファイルシステムダイレクトアクセス (DAX)fsdaxを使用すると、NVDIMM デバイスは、Storage Networking Industry Association (SNIA) Non-Volatile Memory (NVM) Programming Model 仕様で説明されているように、直接アクセスプログラミングをサポートします。このモードでは、I/O はカーネルのストレージスタックを回避するため、多くのデバイスマッパードライバーが使用できなくなります。ファイルシステム DAX デバイスにファイルシステムを作成できます。
このモードのデバイスは、
/dev/pmemNとして利用できます。名前空間を作成したら、リストされているblockdev値を確認します。rawDAX に対応していないメモリーディスクを示します。このモードでは、名前空間にいくつかの制限があるため、使用すべきではありません。
このモードのデバイスは、
/dev/pmemNとして利用できます。名前空間を作成したら、リストされているblockdev値を確認します。
18.5. ndctl のインストール
ndctl ユーティリティーをインストールして、Non-Volatile Dual In-line Memory Modules (NVDIMM) デバイスを設定および監視できます。
手順
ndctlユーティリティーをインストールします。# dnf install ndctl
18.6. NVDIMM でのデバイス DAX 名前空間の作成
システムに接続されている NVDIMM デバイスをデバイス DAX モードで設定して、ダイレクトアクセス機能を備えたキャラクターストレージをサポートします。
これを行うには、次の選択肢を検討してください。
- 既存の名前空間をデバイス DAX モードに再設定する。
- 利用可能な領域がある場合は、新しいデバイスの DAX 名前空間を作成する。
18.6.1. デバイスのダイレクトアクセスモードの NVDIMM
デバイスダイレクトアクセス (デバイス DAX である devdax) は、ファイルシステムの関与なしで、アプリケーションがストレージに直接アクセスできる手段を提供します。デバイス DAX の利点は、ndctl ユーティリティーの --align オプションを使用して設定できる、保証されたフォールトの粒度を提供することです。
Intel 64 アーキテクチャーおよび AMD64 アーキテクチャーでは、以下のフォールト粒度に対応しています。
- 4 KiB
- 2 MiB
- 1 GiB
デバイス DAX ノードは、以下のシステム呼び出しにのみ対応しています。
-
open() -
close() -
mmap()
ndctl list --human --capabilities コマンドを使用して、NVDIMM デバイスのサポートされているアライメントを表示できます。たとえば、region0 デバイスについて表示するには、ndctl list --human --capabilities -r region0 コマンドを使用します。
デバイス DAX のユースケースは SNIA Non-Volatile Memory Programming Model に準拠しているため、read() および write() システムコールはサポートされていません。
18.6.2. 既存の NVDIMM 名前空間をデバイス DAX モードに再設定
既存の Non-Volatile Dual In-line Memory Modules (NVDIMM) 名前空間をデバイス DAX モードに再設定できます。
名前空間を再設定すると、名前空間に以前に保存されたデータが削除されます。
前提条件
-
ndctlユーティリティーがインストールされている。詳細は、ndctl のインストール を参照してください。
手順
システムにある名前空間のリストを表示します。
# ndctl list --namespaces --idle[ { "dev":"namespace1.0", "mode":"raw", "size":34359738368, "uuid":"ac951312-b312-4e76-9f15-6e00c8f2e6f4" "state":"disabled", "numa_node":1 }, { "dev":"namespace0.0", "mode":"raw", "size":38615912448, "uuid":"ff5a0a16-3495-4ce8-b86b-f0e3bd9d1817", "state":"disabled", "numa_node":0 } ]名前空間を再設定します。
# ndctl create-namespace --force --mode=devdax --reconfig=namespace-IDたとえば、次のコマンドは、DAX をサポートしているデータストレージ用に
namespace0.1を再設定します。オペレーティングシステムが一度に 2 MiB ページでフォールトされるように、2 MiB フォールトの粒度に合わせて調整されます。# ndctl create-namespace --force --mode=devdax --align=2M --reconfig=namespace0.1{ "dev":"namespace0.1", "mode":"devdax", "map":"dev", "size":"35.44 GiB (38.05 GB)", "uuid":"426d6a52-df92-43d2-8cc7-046241d6d761", "daxregion":{ "id":0, "size":"35.44 GiB (38.05 GB)", "align":2097152, "devices":[ { "chardev":"dax0.1", "size":"35.44 GiB (38.05 GB)", "target_node":4, "mode":"devdax" } ] }, "align":2097152 }名前空間は、
/dev/dax0.1パスで利用できます。
検証
システム上の既存の名前空間が再設定されているかどうかを確認します。
# ndctl list --namespace namespace0.1[ { "dev":"namespace0.1", "mode":"devdax", "map":"dev", "size":38048628736, "uuid":"426d6a52-df92-43d2-8cc7-046241d6d761", "chardev":"dax0.1", "align":2097152 } ]
18.6.3. デバイス DAX モードでの新しい NVDIMM 名前空間の作成
領域内に使用可能な空き容量がある場合は、Non-Volatile Dual In-line Memory Modules (NVDIMM) デバイス上に、新しいデバイス DAX 名前空間を作成できます。
前提条件
-
ndctlユーティリティーがインストールされている。詳細は、ndctl のインストール を参照してください。 NVDIMM デバイスは、リージョン内に複数の名前空間を作成するためのラベルをサポートしています。これは、次のコマンドを使用して確認できます。
# ndctl read-labels nmem0 >/dev/nullread 1 nmemこれは、1 つの NVDIMM デバイスのラベルを読み取ったことを示しています。値が
0の場合、デバイスがラベルをサポートしていないことを意味します。
手順
利用可能な領域があるシステムの
pmemリージョンのリストを表示します。以下の例では、region1 リージョンと region0 リージョンの領域が利用できます。# ndctl list --regions[ { "dev":"region1", "size":2156073582592, "align":16777216, "available_size":2117418876928, "max_available_extent":2117418876928, "type":"pmem", "iset_id":-9102197055295954944, "badblock_count":1, "persistence_domain":"memory_controller" }, { "dev":"region0", "size":2156073582592, "align":16777216, "available_size":2143188680704, "max_available_extent":2143188680704, "type":"pmem", "iset_id":736272362787276936, "badblock_count":3, "persistence_domain":"memory_controller" } ]利用可能な領域のいずれかに、1 つ以上の名前空間を割り当てます。
# ndctl create-namespace --mode=devdax --region=regionN --size=namespace-sizeたとえば、次のコマンドは、
region0に 36 GiB のデバイス DAX 名前空間を作成します。オペレーティングシステムが一度に 2 MiB ページでフォールトされるように、2 MiB フォールトの粒度に合わせて調整されます。# ndctl create-namespace --mode=devdax --region=region0 --align=2M --size=36G{ "dev":"namespace0.2", "mode":"devdax", "map":"dev", "size":"35.44 GiB (38.05 GB)", "uuid":"89d13f41-be6c-425b-9ec7-1e2a239b5303", "daxregion":{ "id":0, "size":"35.44 GiB (38.05 GB)", "align":2097152, "devices":[ { "chardev":"dax0.2", "size":"35.44 GiB (38.05 GB)", "target_node":4, "mode":"devdax" } ] }, "align":2097152 }名前空間は
/dev/dax0.2として利用できるようになりました。
検証
新しい名前空間がデバイス DAX モードで作成されたかどうかを確認します。
# ndctl list -RN -n namespace0.2{ "regions":[ { "dev":"region0", "size":2156073582592, "align":16777216, "available_size":2065879269376, "max_available_extent":2065879269376, "type":"pmem", "iset_id":736272362787276936, "badblock_count":3, "persistence_domain":"memory_controller", "namespaces":[ { "dev":"namespace0.2", "mode":"devdax", "map":"dev", "size":38048628736, "uuid":"89d13f41-be6c-425b-9ec7-1e2a239b5303", "chardev":"dax0.2", "align":2097152 } ] } ] }
18.7. NVDIMM でのファイルシステム DAX 名前空間の作成
システムに接続されている NVDIMM デバイスをファイルシステム DAX モードで設定して、ダイレクトアクセス機能を備えたファイルシステムをサポートします。
これを行うには、次の選択肢を検討してください。
- ファイルシステムの DAX モードに既存の名前空間を再設定する。
- 新しいファイルシステムの DAX 名前空間を作成する (利用可能な領域がある場合)。
18.7.1. ファイルシステムの直接アクセスモードの NVDIMM
NVDIMM デバイスがファイルシステムダイレクトアクセス (ファイルシステム DAX、fsdax) モードで設定されている場合、その上にファイルシステムを作成できます。このファイルシステムのファイルで mmap() 操作を実行するアプリケーションは、ストレージに直接アクセスします。これにより、NVDIMM 上のプログラミングモデルに直接アクセスできます。
次の新しい -o dax オプションが利用できるようになりました。必要に応じて、ファイル属性を介して直接アクセスの動作を制御できます。
-o dax=inodeこれは、ファイルシステムのマウント時に dax オプションを指定しない場合のデフォルトオプションです。このオプションを使用すると、ファイルに属性フラグを設定して、dax モードをアクティブにできるかどうかを制御できます。必要に応じて、個々のファイルにこのフラグを設定できます。
このフラグをディレクトリーに設定することもでき、そのディレクトリー内のすべてのファイルが同じフラグで作成されます。この属性フラグは、
xfs_io -c 'chattr +x'directory-name コマンドを使用して設定できます。-o dax=never-
このオプションを使用すると、dax フラグが
inodeモードに設定されていても、dax モードは有効になりません。これは、inode ごとの dax 属性フラグが無視され、このフラグが設定されたファイルは直接アクセスが有効にならないことを意味します。 -o dax=alwaysこのオプションは、古い
-o daxの動作と同等です。このオプションを使用すると、dax 属性フラグに関係なく、ファイルシステム上の任意のファイルに対して直接アクセスモードを有効にできます。警告今後のリリースでは、
-o daxがサポートされなくなる可能性があります。必要に応じて、代わりに-o dax=alwaysを使用できます。このモードでは、すべてのファイルが直接アクセスモードになる可能性があります。- ページごとのメタデータ割り当て
このモードでは、システム DRAM または NVDIMM デバイス自体でページごとのメタデータを割り当てる必要があります。このデータ構造のオーバーヘッドは、4 KiB ページごとに 64 バイトです。
- 小さいデバイスでは、問題なく DRAM に収まるのに十分なオーバーヘッド量があります。たとえば、16 GiB の名前空間では、ページ構造に必要なのは 256 MiB だけです。NVDIMM デバイスは通常小さくて高価であるため、ページトラッキングデータ構造を DRAM に格納することが推奨されます。
テラバイト以上のサイズの NVDIMM デバイスの場合は、ページトラッキングデータ構造の格納に必要なメモリーの量がシステム内の DRAM の量を超える可能性があります。NVDIMM の 1 TiB に対して、ページ構造だけで 16 GiB が必要です。したがって、このような場合には、NVDIMM 自体にデータ構造を保存することが推奨されます。
名前空間の設定時に
--mapオプションを使用して、ページごとのメタデータを保存する場所を設定できます。-
システム RAM に割り当てるには、
--map=memを使用します。 -
NVDIMM に割り当てるには、
--map=devを使用します。
18.7.2. ファイルシステム DAX モードへの既存の NVDIMM 名前空間の再設定
ndctl を使用すると、既存の Non-Volatile Dual In-line Memory Modules (NVDIMM) 名前空間を、ファイルシステム DAX モードに再設定できます。DAX を有効にしてストレージパフォーマンスを向上させることもできます。また、名前空間を安全に変換するために、再設定を行うと以前に保存されたデータがすべて削除されることを理解しておいてください。
名前空間を再設定すると、名前空間に以前に保存されたデータが削除されます。
前提条件
-
ndctlユーティリティーがインストールされている。詳細は、ndctl のインストール を参照してください。
手順
システムにある名前空間のリストを表示します。
# ndctl list --namespaces --idle[ { "dev":"namespace1.0", "mode":"raw", "size":34359738368, "uuid":"ac951312-b312-4e76-9f15-6e00c8f2e6f4" "state":"disabled", "numa_node":1 }, { "dev":"namespace0.0", "mode":"raw", "size":38615912448, "uuid":"ff5a0a16-3495-4ce8-b86b-f0e3bd9d1817", "state":"disabled", "numa_node":0 } ]名前空間を再設定します。
# ndctl create-namespace --force --mode=fsdax --reconfig=namespace-IDたとえば、DAX をサポートしているファイルシステムに
namespace0.0を使用するには、次のコマンドを使用します。# ndctl create-namespace --force --mode=fsdax --reconfig=namespace0.0{ "dev":"namespace0.0", "mode":"fsdax", "map":"dev", "size":"11.81 GiB (12.68 GB)", "uuid":"f8153ee3-c52d-4c6e-bc1d-197f5be38483", "sector_size":512, "align":2097152, "blockdev":"pmem0" }名前空間は
/dev/pmem0パスで利用できるようになりました。
検証
システム上の既存の名前空間が再設定されているかどうかを確認します。
# ndctl list --namespace namespace0.0[ { "dev":"namespace0.0", "mode":"fsdax", "map":"dev", "size":12681478144, "uuid":"f8153ee3-c52d-4c6e-bc1d-197f5be38483", "sector_size":512, "align":2097152, "blockdev":"pmem0" } ]
18.7.3. ファイルシステム DAX モードで新しい NVDIMM 名前空間の作成
領域内に使用可能な空き容量がある場合は、Non-Volatile Dual In-line Memory Modules (NVDIMM) デバイス上に、新しいファイルシステム DAX 名前空間を作成できます。
前提条件
-
ndctlユーティリティーがインストールされている。詳細は、ndctl のインストール を参照してください。 NVDIMM デバイスは、リージョン内に複数の名前空間を作成するためのラベルをサポートしています。これは、次のコマンドを使用して確認できます。
# ndctl read-labels nmem0 >/dev/nullread 1 nmemこれは、1 つの NVDIMM デバイスのラベルを読み取ったことを示しています。値が
0の場合、デバイスがラベルをサポートしていないことを意味します。
手順
利用可能な領域があるシステムの
pmemリージョンのリストを表示します。以下の例では、region1 リージョンと region0 リージョンの領域が利用できます。# ndctl list --regions[ { "dev":"region1", "size":2156073582592, "align":16777216, "available_size":2117418876928, "max_available_extent":2117418876928, "type":"pmem", "iset_id":-9102197055295954944, "badblock_count":1, "persistence_domain":"memory_controller" }, { "dev":"region0", "size":2156073582592, "align":16777216, "available_size":2143188680704, "max_available_extent":2143188680704, "type":"pmem", "iset_id":736272362787276936, "badblock_count":3, "persistence_domain":"memory_controller" } ]利用可能な領域のいずれかに、1 つ以上の名前空間を割り当てます。
# ndctl create-namespace --mode=fsdax --region=regionN --size=namespace-sizeたとえば、次のコマンドは、region0 に 36 GiB のファイルシステム DAX 名前空間を作成します。
# ndctl create-namespace --mode=fsdax --region=region0 --size=36G{ "dev":"namespace0.3", "mode":"fsdax", "map":"dev", "size":"35.44 GiB (38.05 GB)", "uuid":"99e77865-42eb-4b82-9db6-c6bc9b3959c2", "sector_size":512, "align":2097152, "blockdev":"pmem0.3" }名前空間は
/dev/pmem0.3として利用できるようになりました。
検証
新しい名前空間がファイルシステム DAX モードで作成されたかどうかを確認します。
# ndctl list -RN -n namespace0.3{ "regions":[ { "dev":"region0", "size":2156073582592, "align":16777216, "available_size":2027224563712, "max_available_extent":2027224563712, "type":"pmem", "iset_id":736272362787276936, "badblock_count":3, "persistence_domain":"memory_controller", "namespaces":[ { "dev":"namespace0.3", "mode":"fsdax", "map":"dev", "size":38048628736, "uuid":"99e77865-42eb-4b82-9db6-c6bc9b3959c2", "sector_size":512, "align":2097152, "blockdev":"pmem0.3" } ] } ] }
18.7.4. ファイルシステム DAX デバイスでのファイルシステムの作成
ファイルシステム DAX デバイス上にファイルシステムを作成し、ファイルシステムをマウントできます。ファイルシステムを作成した後、アプリケーションは永続メモリーを使用して mount-point ディレクトリーにファイルを作成し、ファイルを開き、mmap 操作を使用して直接アクセスできるようにファイルをマップできます。
手順
オプション: ファイルシステム DAX デバイス上にパーティションを作成します。詳細は、parted を使用したパーティションの作成 を参照してください。
注記fsdaxデバイスにパーティションを作成する場合、パーティションはページの境界に調整する必要があります。Intel 64 アーキテクチャーおよび AMD64 アーキテクチャーでは、パーティションの開始と終了に最低 4 KiB のアライメントが必要です。2 MiB が優先されるアライメントです。partedツールは、デフォルトでは 1 MiB の境界にパーティションをそろえます。最初のパーティションには、パーティションの開始部分として 2 MiB を指定します。パーティションのサイズが 2 MiB の倍数である場合は、他のすべてのパーティションもそろえられます。パーティションまたは NVDIMM デバイスに XFS または ext4 ファイルシステムを作成します。
# mkfs.xfs -d su=2m,sw=1 fsdax-partition-or-device注記dax 対応ファイルと reflinked ファイルは、ファイルシステム上で共存できるようになりました。ただし、個々のファイルの場合、dax と reflink は相互に排他的です。
また、大規模ページのマッピングの可能性を高めるために、ストライプユニットとストライプ幅を設定してください。
ファイルシステムをマウントします。
# mount f_sdax-partition-or-device mount-point_直接アクセスモードを有効にするために dax オプションを使用してファイルシステムをマウントする必要はありません。マウント時に dax オプションを指定しない場合、ファイルシステムは
dax=inodeモードになります。直接アクセスモードをアクティブにする前に、ファイルに dax オプションを設定します。
18.8. S.M.A.R.T. を使用した NVDIMM の健全性の監視
Non-Volatile Dual In-line Memory Modules (NVDIMM) デバイスによっては、健全性情報を取得するための Self-Monitoring, Analysis and Reporting Technology (SMART) インターフェイスをサポートしているものもあります。詳細は、システム上の ndctl-list(1) man ページを参照してください。
データの損失を防ぐために、NVDIMM の健全性状態を定期的に監視してください。SMART が NVDIMM デバイスのヘルスステータスに関する問題を報告した場合は、Detecting and replacing a broken NVDIMM device の説明に従って交換します。
前提条件
オプション: 一部のシステムでは、次のコマンドを使用して
acpi_ipmiドライバーをアップロードし、ヘルス情報を取得します。# modprobe acpi_ipmi
手順
ヘルス情報にアクセスします。
# ndctl list --dimms --health[ { "dev":"nmem1", "id":"8089-a2-1834-00001f13", "handle":17, "phys_id":32, "security":"disabled", "health":{ "health_state":"ok", "temperature_celsius":36.0, "controller_temperature_celsius":37.0, "spares_percentage":100, "alarm_temperature":false, "alarm_controller_temperature":false, "alarm_spares":false, "alarm_enabled_media_temperature":true, "temperature_threshold":82.0, "alarm_enabled_ctrl_temperature":true, "controller_temperature_threshold":98.0, "alarm_enabled_spares":true, "spares_threshold":50, "shutdown_state":"clean", "shutdown_count":4 } }, [...] ]
18.9. 破損した NVDIMM デバイスの検出と交換
Non-Volatile Dual In-line Memory Modules (NVDIMM) に関連するエラーメッセージが、システムログまたは S.M.A.R.T. によって報告されている場合は、NVDIMM デバイスに障害が発生している可能性があります。
この場合は、以下を行う必要があります。
- どの NVDIMM デバイスに障害が発生しているかを検出する
- そこにに保存されているデータをバックアップする
- デバイスを物理的に交換する
手順
壊れたデバイスを検出します。
# ndctl list --dimms --regions --health{ "dimms":[ { "dev":"nmem1", "id":"8089-a2-1834-00001f13", "handle":17, "phys_id":32, "security":"disabled", "health":{ "health_state":"ok", "temperature_celsius":35.0, [...] } [...] }破損した NVDIMM の
phys_id属性を見つけます。# ndctl list --dimms --human前述の例では、
nmem0が破損した NVDIMM になります。したがって、nmem0のphys_id属性を確認します。以下の例では、
phys_idは0x10です。# ndctl list --dimms --human[ { "dev":"nmem1", "id":"XXXX-XX-XXXX-XXXXXXXX", "handle":"0x120", "phys_id":"0x1c" }, { "dev":"nmem0", "id":"XXXX-XX-XXXX-XXXXXXXX", "handle":"0x20", "phys_id":"0x10", "flag_failed_flush":true, "flag_smart_event":true } ]壊れた NVDIMM のメモリースロットを見つけます。
# dmidecode出力において、Handle 識別子が、破損した NVDIMM の
phys_id属性と一致するエントリーを確認します。Locator フィールドは、破損した NVDIMM が使用するメモリースロットの一覧を表示します。以下の例では、
nmem0デバイスが0x0010の識別子に一致し、DIMM-XXX-YYYYメモリースロットを使用します。# dmidecode... Handle 0x0010, DMI type 17, 40 bytes Memory Device Array Handle: 0x0004 Error Information Handle: Not Provided Total Width: 72 bits Data Width: 64 bits Size: 125 GB Form Factor: DIMM Set: 1 Locator: DIMM-XXX-YYYY Bank Locator: Bank0 Type: Other Type Detail: Non-Volatile Registered (Buffered) ...NVDIMM 上の名前空間にある全データのバックアップを作成します。NVDIMM を交換する前にデータのバックアップを作成しないと、システムから NVDIMM を削除したときにデータが失われます。
警告時折、NVDIMM が完全に破損すると、バックアップが失敗することがあります。
これを防ぐには、S.M.A.R.T. を使用した NVDIMM の健全性の監視 で説明されているように、S.M.A.R.T. を使用して NVDIMM デバイスを定期的に監視し、障害の兆候のある NVDIMM を故障する前に交換してください。
NVDIMM の名前空間を一覧表示します。
# ndctl list --namespaces --dimm=DIMM-ID-number以下の例では、
nmem0デバイスには、バックアップが必要な名前空間のnamespace0.0とnamespace0.2が含まれます。# ndctl list --namespaces --dimm=0[ { "dev":"namespace0.2", "mode":"sector", "size":67042312192, "uuid":"XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX", "raw_uuid":"XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX", "sector_size":4096, "blockdev":"pmem0.2s", "numa_node":0 }, { "dev":"namespace0.0", "mode":"sector", "size":67042312192, "uuid":"XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX", "raw_uuid":"XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX", "sector_size":4096, "blockdev":"pmem0s", "numa_node":0 } ]- 破損した NVDIMM を物理的に交換します。
第19章 未使用ブロックの破棄
破棄操作は、どのブロックが使用されなくなったかをストレージデバイスに通知することで、ストレージのパフォーマンスと寿命を向上させます。これは、SSD がウェアレベリングを最適化し、シンプロビジョニングされたストレージが領域を再利用できるようにします。
要件
ファイルシステムの基礎となるブロックデバイスは、物理的な破棄操作に対応している必要があります。
/sys/block/<device>/queue/discard_max_bytesファイルの値がゼロではない場合は、物理的な破棄操作はサポートされます。
19.1. ブロック破棄操作のタイプ
ブロック破棄操作は、バッチ、オンライン、または定期的な方法を使用して実行できます。それぞれに特定のユースケースとパフォーマンス推奨事項があります。
次のリストは、さまざまな破棄操作について説明しています。
- バッチ破棄
-
fstrimコマンドに、このタイプの破棄が含まれています。ファイルシステム内にある未使用のブロックで、管理者が指定した基準に一致するものをすべて破棄します。Red Hat Enterprise Linux 10 は、XFS および ext4 でフォーマットされおり、物理的な破棄操作に対応するデバイスでのバッチ破棄をサポートします。 - オンライン破棄
このタイプの破棄操作は、discard オプションを指定してマウント時に設定します。この操作は、ユーザーの介入なしにリアルタイムで実行されます。ただし、未使用から空き状態に移行しているブロックのみを破棄します。Red Hat Enterprise Linux 10 では XFS および ext4 フォーマットのデバイスでオンライン破棄をサポートしています。
パフォーマンスを維持するためにオンライン破棄が必要な場合、またはシステムのワークロードに対してバッチ破棄が実行不可能な場合を除き、バッチ破棄を使用します。
- 定期的な破棄
-
systemdサービスが定期的に実行するバッチ操作です。
すべてのタイプは、XFS ファイルシステムおよび ext4 ファイルシステムでサポートされます。
推奨事項
バッチまたは定期的な破棄を使用します。
以下の場合にのみ、オンライン破棄を使用してください。
- システムのワークロードでバッチ破棄が実行できない場合
- パフォーマンス維持にオンライン破棄操作が必要な場合
19.2. バッチブロック破棄の実行
バッチブロック破棄操作を実行して、マウントされたファイルシステムの未使用ブロックを破棄することができます。
前提条件
- ファイルシステムがマウントされている。
- ファイルシステムの基礎となるブロックデバイスが物理的な破棄操作に対応している。
手順
fstrimユーティリティーを使用します。選択したファイルシステムでのみ破棄を実行するには、次のコマンドを使用します。
# fstrim mount-pointマウントされているすべてのファイルシステムで破棄を実行するには、次のコマンドを使用します。
# fstrim --all
fstrimコマンドを実行する場合:- 破棄操作をサポートしていないデバイス、または
複数のデバイスで構成された論理デバイス (LVM または MD) で、いずれかのデバイスが破棄操作をサポートしていない場合、次のメッセージが表示されます。
# fstrim /mnt/non_discardfstrim: /mnt/non_discard: the discard operation is not supported
19.3. オンラインブロック破棄の有効化
オンラインブロック破棄操作を実行して、サポートしているすべてのファイルシステムで未使用のブロックを自動的に破棄できます。詳細は、システム上の mount(8) および fstab(5) man ページを参照してください。
手順
マウント時のオンライン破棄を有効にします。
ファイルシステムを手動でマウントするには、
-o discardマウントオプションを追加します。# mount -o discard device mount-point-
ファイルシステムを永続的にマウントするには、
/etc/fstabファイルのマウントエントリーにdiscardオプションを追加します。
19.4. storage RHEL システムロールを使用してオンラインブロック破棄を有効にする
オンラインブロック破棄オプションを使用すると、XFS ファイルシステムをマウントし、未使用のブロックを自動的に破棄できます。
前提条件
- コントロールノードと管理対象ノードの準備が完了している。
- 管理対象ノードで Playbook を実行できるユーザーとしてコントロールノードにログインしている。
-
管理対象ノードへの接続に使用するアカウントに、そのノードに対する
sudo権限がある。
手順
次の内容を含む Playbook ファイル (例:
~/playbook.yml) を作成します。--- - name: Manage local storage hosts: managed-node-01.example.com tasks: - name: Enable online block discard ansible.builtin.include_role: name: redhat.rhel_system_roles.storage vars: storage_volumes: - name: barefs type: disk disks: - /dev/sdb fs_type: xfs mount_point: /mnt/data mount_options: discardPlaybook で使用されるすべての変数の詳細は、コントロールノードの
/usr/share/ansible/roles/rhel-system-roles.storage/README.mdファイルを参照してください。Playbook の構文を検証します。
$ ansible-playbook --syntax-check ~/playbook.ymlこのコマンドは構文を検証するだけであり、有効だが不適切な設定から保護するものではないことに注意してください。
Playbook を実行します。
$ ansible-playbook ~/playbook.yml
検証
オンラインブロック破棄オプションが有効になっていることを確認します。
# ansible managed-node-01.example.com -m command -a 'findmnt /mnt/data'
19.5. 定期的なブロック破棄の有効化
systemd タイマーを有効にして、サポートしているすべてのファイルシステムで未使用ブロックを定期的に破棄できます。
手順
systemdタイマーを有効にして起動します。# systemctl enable --now fstrim.timerCreated symlink /etc/systemd/system/timers.target.wants/fstrim.timer → /usr/lib/systemd/system/fstrim.timer.
検証
タイマーのステータスを確認します。
# systemctl status fstrim.timerfstrim.timer - Discard unused blocks once a week Loaded: loaded (/usr/lib/systemd/system/fstrim.timer; enabled; vendor preset: disabled) Active: active (waiting) since Wed 2023-05-17 13:24:41 CEST; 3min 15s ago Trigger: Mon 2023-05-22 01:20:46 CEST; 4 days left Docs: man:fstrim May 17 13:24:41 localhost.localdomain systemd[1]: Started Discard unused blocks once a week.
第20章 ストレージデバイスの削除
実行中のシステムからストレージデバイスを安全に削除することで、システムメモリーのオーバーロードやデータ損失を防ぐことができます。
次のシステムではストレージデバイスを削除しないでください。
- 空きメモリーが合計メモリーの 5 % 未満 (サンプル 100 件の内 10 件以上)。
-
スワップが有効になっている (
vmstatコマンドの出力でsiとsoのコラムが 0 以外の値)。
I/O フラッシュ中にシステムメモリーの負荷が増加するため、ストレージデバイスを削除する前に、システムメモリーが十分にあることを確認する。システムの現在のメモリー負荷と空きメモリーを表示するには、次のコマンドを使用します。
+
# vmstat 1 100+
# free20.1. ストレージデバイスの安全な削除
稼働中のシステムからストレージデバイスを安全に取り外すには、上から下へのアプローチが必要です。アプリケーションやファイルシステムなどの最上位層から始め、物理デバイスなどの最下位層に向かって作業を進めます。
ストレージデバイスは複数の方法で使用でき、物理デバイスの上層に別の仮想設定を指定できます。たとえば、1 つのデバイスの複数のインスタンスをグループ化してマルチパスデバイスにしたり、そのデバイスを Redundant Array of Independent Disks (RAID) に組み込んだりすることができます。デバイスを論理ボリュームマネージャー (LVM) グループの一部にすることもできます。また、デバイスにはファイルシステム経由でアクセスすることも、"raw" デバイスのように直接アクセスすることもできます。
上から下へのアプローチを用いながら、次のことを確認する必要があります。
- 削除したいデバイスが使用中でないこと
- デバイスへの保留中の I/O がすべてフラッシュされる
- オペレーティングシステムがストレージデバイスを参照していない
20.2. ブロックデバイスと関連メタデータの削除
実行中のシステムからブロックデバイスを安全に削除し、メモリーの過負荷やデータの損失を回避するには、まずそのメタデータを削除します。システムの安定性と整合性を維持するために、ファイルシステムからディスクまで、各レイヤーを 1 つずつ処理してください。
前提条件
- ファイルシステム、論理ボリューム、およびボリュームグループを含む既存のブロックデバイススタックがある。
- 削除するデバイスを他のアプリケーションやサービスが使用していないことを確認した。
- 削除するデバイスからデータをバックアップした。
オプション: マルチパスデバイスを削除する必要があり、そのパスデバイスにアクセスできない場合は、次のコマンドを実行してマルチパスデバイスのキューイングを無効にしておく。
# multipathd disablequeueing map multipath-device無効にすることで、デバイスの I/O が失敗し、デバイスを使用しているアプリケーションがシャットダウンできるようになります。
メタデータを含むデバイスを一度に 1 レイヤーずつ削除することで、ディスクに古い署名が残らないようにします。
削除するデバイスの種類に応じて、特定のコマンドを使用します。
-
LVM の場合は、
lvremove、vgremove、pvremoveを実行します。 -
ソフトウェア Redundant Array of Independent Disks (RAID) の場合は、
mdadmを実行してアレイを削除します。詳細は、RAID の管理 を参照してください。 - Linux Unified Key Setup (LUKS) を使用して暗号化されたブロックデバイスの場合、特定の手順が追加で必要です。次の手順は、LUKS を使用して暗号化されたブロックデバイスでは機能しません。詳細は、LUKS を使用したブロックデバイスの暗号化 を参照してください。
この手順に従わずに Small Computer System Interface (SCSI) バスを再スキャンしたり、オペレーティングシステムの状態を変更するその他の操作を実行したりすると、遅延が発生する可能性があります。そのような遅延は、I/O タイムアウト、予期せぬデバイスの取り外し、またはデータ損失によって発生する可能性があります。
手順
ファイルシステムをアンマウントします。
# umount /mnt/mount-pointファイルシステムを削除します。
# wipefs -a /dev/vg0/myvol/etc/fstabファイルにエントリーを追加して、ファイルシステムとマウントポイントの間の永続的な関連付けを作成した場合は、この時点で/etc/fstabを編集してそのエントリーを削除します。削除するデバイスのタイプに応じて、次の手順に進みます。
ファイルシステムを含む論理ボリューム (LV) を削除します。
# lvremove vg0/myvolボリュームグループ (VG) に他の論理ボリュームが残っていない場合は、デバイスを含む VG を安全に削除できます。
# vgremove vg0物理ボリューム (PV) メタデータを PV デバイスから削除します。
# pvremove /dev/sdc1# wipefs -a /dev/sdc1PV が含まれていたパーティションを削除します。
# parted /dev/sdc rm 1デバイスを完全に消去する場合は、パーティションテーブルを削除します。
# wipefs -a /dev/sdcデバイスを物理的に取り外す場合にのみ、次の手順を実行します。
マルチパスデバイスを削除する場合は,次のコマンドを実行します。
デバイスへの全パスを表示します。
# multipath -lこのコマンドの出力は、後のステップで必要になります。
I/O をフラッシュして、マルチパスデバイスを削除します。
# multipath -f multipath-device
デバイスがマルチパスデバイスとして設定されていない場合や、デバイスがマルチパスデバイスとして設定されていて、過去に I/O を個別のパスに渡している場合は、未処理の I/O を、使用されている全デバイスパスにフラッシュします。
# blockdev --flushbufs deviceこの操作は、
umountコマンドまたはvgreduceコマンドで I/O がフラッシュされないデバイスに直接アクセスする場合に重要になります。SCSI デバイスを取り外す場合は、以下のコマンドを実行します。
-
システム上のアプリケーション、スクリプト、またはユーティリティーで、
/dev/sd、/dev/disk/by-path、またはmajor:minor番号など、デバイスのパスベースの名前への参照をすべて削除します。参照を削除することで、今後追加される別のデバイスが現在のデバイスと混同されないようにします。 SCSI サブシステムからデバイスへの各パスを削除します。
# echo 1 > /sys/block/device-name/device/deleteデバイスが以前にマルチパスデバイスとして使用されていた場合、
device-nameは、multipath -lコマンドの出力からの内容に置き換えます。
-
システム上のアプリケーション、スクリプト、またはユーティリティーで、
- 稼働中のシステムから物理デバイスを削除します。このデバイスを削除しても、他のデバイスへの I/O は停止しないことに注意してください。
検証
削除したデバイスが
lsblkコマンドの出力に表示されないことを確認します。出力例を以下に示します。# lsblkNAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sda 8:0 0 5G 0 disk sr0 11:0 1 1024M 0 rom vda 252:0 0 10G 0 disk |-vda1 252:1 0 1M 0 part |-vda2 252:2 0 100M 0 part /boot/efi `-vda3 252:3 0 9.9G 0 part /
第21章 Stratis ファイルシステムの設定
Stratis は、Red Hat Enterprise Linux 用のローカルストレージ管理ソリューションです。これは、シンプルさと使いやすさを重視し、高度なストレージ機能にアクセスできます。
Stratis は、物理ストレージデバイスのプールを管理するためにサービスとして実行され、複雑なストレージ設定のセットアップと管理を支援しながら、ローカルストレージ管理を使いやすく簡素化します。
Stratis は、以下のために使用できます。
- ストレージの初期設定
- その後の変更
- 高度なストレージ機能の使用
Stratis の中心的な概念はストレージプールです。このプールは 1 つ以上のローカルディスクまたはパーティションから作成され、ファイルシステムはプールから作成されます。プールでは次のような機能が有効になります。
- ファイルシステムのスナップショット
- シンプロビジョニング
- キャッシュ
- 暗号化
21.1. Stratis ファイルシステムのコンポーネント
Stratis は、ブロックデバイス、ストレージプール、ファイルシステムという、連携して高度なストレージ管理を提供する 3 つの主要コンポーネントで構成されています。これらのコンポーネントにより、シンプロビジョニング、スナップショット、自動スペース管理が可能になります。
外部的には、Stratis はコマンドラインと API を通じて次のファイルシステムコンポーネントを提供します。
blockdev- ディスクやディスクパーティションなどのブロックデバイス。
pool1 つ以上のブロックデバイスで構成されます。
プールの合計サイズは固定で、ブロックデバイスのサイズと同じです。
プールには、
dm-cacheターゲットを使用した不揮発性データキャッシュなど、ほとんどの Stratis レイヤーが含まれています。Stratis は、各プールの
/dev/stratis/my-pool/ディレクトリーを作成します。このディレクトリーには、プール内の Stratis ファイルシステムを表すデバイスへのリンクが含まれています。filesystem各プールには 0 個以上のファイルシステムを含めることができます。ファイルシステムを含むプールには、任意の数のファイルを保存できます。
ファイルシステムはシンプロビジョニングされており、合計サイズは固定されていません。ファイルシステムの実際のサイズは、そこに格納されているデータとともに大きくなります。データのサイズがファイルシステムの仮想サイズに近づくと、Stratis はシンボリュームとファイルシステムを自動的に拡張します。
ファイルシステムは XFS ファイルシステムでフォーマットされます。Stratis はストレージに XFS ファイルシステムを使用し、Stratis ボリュームをプロビジョニングします。
コマンドラインインターフェイスとの整合性を保つため、これ以降、このドキュメントでは Stratis ボリュームを "Stratis ファイルシステム" と呼びます。
Stratis は、XFS が認識しない、作成されたファイルシステムに関する情報を追跡します。また、XFS を使用して行われた変更によって、Stratis が自動的に更新されることはありません。ユーザーは、Stratis が管理する XFS ファイルシステムを再フォーマットまたは再設定しないでください。
Stratis は、/dev/stratis/my-pool/my-fs パスにファイルシステムへのリンクを作成します。
Stratis は、dmsetup リストと /proc/partitions ファイルに表示される多くの Device Mapper デバイスを使用します。同様に、lsblk コマンドの出力は、Stratis の内部の仕組みとレイヤーを反映します。
21.2. Stratis と互換性のあるブロックデバイス
Stratis は、物理ドライブ、論理ボリューム、ネットワークストレージなど、さまざまなブロックデバイスをサポートしています。シンプロビジョニングやスナップショットなどの高度な機能を維持しながら、さまざまなストレージタイプから Stratis プールを構築できます。
Stratis で使用可能なストレージデバイス。
対応デバイス
Stratis プールは、次の種類のブロックデバイスで動作するかどうかをテスト済みです。
- LUKS
- LVM 論理ボリューム
- MD RAID
- DM Multipath
- iSCSI
- HDD および SSD
- NVMe デバイス
21.3. Stratis のインストール
Stratis ストレージ管理システムをインストールすると、RHEL システムでシンプロビジョニング、ファイルシステムスナップショット、柔軟なプールベースのストレージ管理などの高度なストレージ機能が有効になります。
手順
Stratis サービスとコマンドラインユーティリティーを提供するパッケージをインストールします。
# dnf install stratisd stratis-clistratisdサービスを開始し、ブート時に起動できるようにするには、以下を実行します。# systemctl enable --now stratisd
検証
stratisdサービスが有効になっていて実行されていることを確認します。# systemctl status stratisdstratisd.service - Stratis daemon Loaded: loaded (/usr/lib/systemd/system/stratisd.service; enabled; preset:> Active: active (running) since Tue 2025-03-25 14:04:42 CET; 30min ago Docs: man:stratisd(8) Main PID: 24141 (stratisd) Tasks: 22 (limit: 99365) Memory: 10.4M CPU: 1.436s CGroup: /system.slice/stratisd.service └─24141 /usr/libexec/stratisd --log-level debug
21.4. 暗号化されていない Stratis プールの作成
1 つ以上のブロックデバイスから暗号化されていない Stratis プールを作成できます。
前提条件
-
Stratis がインストールされ、
stratisdサービスが実行されている。詳細は、Stratis のインストール を参照してください。 - Stratis プールを作成するブロックデバイスは、使用もマウントもされておらず、1 GB 以上の領域がある。
IBM Z アーキテクチャーで、
/dev/dasd*ブロックデバイスがパーティション設定されている。Stratis プールの作成には、パーティションデバイスを使用します。DASD デバイスのパーティション設定の詳細は、64-bit IBM Z での Linux インスタンスの設定 を参照してください。
Stratis プールは作成時にのみ暗号化でき、後から暗号化することはできません。
手順
Stratis プールで使用する各ブロックデバイスに存在するファイルシステム、パーティションテーブル、または RAID 署名をすべて削除します。
# wipefs --all block-deviceblock-deviceの値は、ブロックデバイスへのパスです (例:/dev/sdb)。選択したブロックデバイスに新しい暗号化されていない Stratis プールを作成します。
# stratis pool create my-pool block-deviceblock-deviceの値は、空または消去されたブロックデバイスへのパスです。次のコマンドを使用して、1 行に複数のブロックデバイスを指定することもできます。
# stratis pool create my-pool block-device-1 block-device-2
検証
新しい Stratis プールが作成されていることを確認します。
# stratis pool list
21.5. Web コンソールを使用した暗号化されていない Stratis プールの作成
Web コンソールを使用して、1 つ以上のブロックデバイスから暗号化されていない Stratis プールを作成できます。
前提条件
RHEL 10 Web コンソールがインストールされている。
手順は、Web コンソールのインストールおよび有効化 を参照してください。
-
Stratis がインストールされ、
stratisdサービスが実行されている。詳細は、Stratis のインストール を参照してください。 - Stratis プールを作成するブロックデバイスは、使用もマウントもされておらず、1 GB 以上の領域がある。
暗号化されていない Stratis プールの作成後に、当該 Stratis プールを暗号化することはできません。
手順
- RHEL 10 Web コンソールにログインします。
- をクリックします。
- Storage テーブルで、メニューボタンをクリックし、Create Stratis pool を選択します。
- Name フィールドに、Stratis プールの名前を入力します。
- Stratis プールの作成元となる Block devices を選択します。
- オプション: プールに作成する各ファイルシステムの最大サイズを指定する場合は、Manage filesystem sizes を選択します。
- をクリックします。
検証
- Storage セクションに移動し、Devices テーブルに新しい Stratis プールが表示されていることを確認します。
21.6. カーネルキーリング内のキーを使用して暗号化された Stratis プールを作成する
データを保護するために、カーネルキーリングを使用して、1 つ以上のブロックデバイスから暗号化された Stratis プールを作成できます。
この方法で暗号化された Stratis プールを作成すると、カーネルキーリングはプライマリー暗号化メカニズムとして使用されます。その後のシステムを再起動すると、このカーネルキーリングは、暗号化された Stratis プールのロックを解除します。
1 つ以上のブロックデバイスから暗号化された Stratis プールを作成する場合は、次の点に注意してください。
-
各ブロックデバイスは
cryptsetupライブラリーを使用して暗号化され、LUKS2形式を実装します。 - 各 Stratis プールは、一意の鍵を持つか、他のプールと同じ鍵を共有できます。これらのキーはカーネルキーリングに保存されます。
- Stratis プールを構成するブロックデバイスは、すべて暗号化または暗号化されていないデバイスである必要があります。同じ Stratis プールに、暗号化したブロックデバイスと暗号化されていないブロックデバイスの両方を含めることはできません。
- 暗号化 Stratis プールのデータキャッシュに追加されるブロックデバイスは、自動的に暗号化されます。
前提条件
-
Stratis v2.1.0 以降がインストールされ、
stratisdサービスが実行されている。詳細は、Stratis のインストール を参照してください。 - Stratis プールを作成するブロックデバイスは、使用もマウントもされておらず、1 GB 以上の領域がある。
IBM Z アーキテクチャーで、
/dev/dasd*ブロックデバイスがパーティション設定されている。Stratis プールでパーティションを使用します。DASD デバイスのパーティション設定の詳細は、64-bit IBM Z での Linux インスタンスの設定 を参照してください。
手順
Stratis プールで使用する各ブロックデバイスに存在するファイルシステム、パーティションテーブル、または RAID 署名をすべて削除します。
# wipefs --all block-deviceblock-deviceの値は、ブロックデバイスへのパスです (例:/dev/sdb)。キーをまだ作成していない場合は、次のコマンドを実行し、プロンプトに従って暗号化に使用するキーセットを作成します。
# stratis key set --capture-key key-descriptionkey-descriptionは、カーネルキーリングで作成されるキーへの参照になります。コマンドラインで、キー値の入力を求められます。キー値をファイルに配置し、--capture-keyオプションの代わりに--keyfile-pathオプションを使用することもできます。暗号化した Stratis プールを作成し、暗号化に使用すキーの説明を指定します。
# stratis pool create --key-desc key-description my-pool block-devicekey-description- 直前の手順で作成したカーネルキーリングに存在するキーを参照します。
my-pool- 新しい Stratis プールの名前を指定します。
block-device空のブロックデバイスまたは消去したブロックデバイスへのパスを指定します。
次のコマンドを使用して、1 行に複数のブロックデバイスを指定することもできます。
# stratis pool create --key-desc key-description my-pool block-device-1 block-device-2
検証
新しい Stratis プールが作成されていることを確認します。
# stratis pool list
21.7. Clevis を使用して暗号化された Stratis プールを作成する
Stratis 2.4.0 以降では、コマンドラインで Clevis オプションを指定することにより、Clevis メカニズムを使用して暗号化されたプールを作成できます。
前提条件
-
Stratis v2.3.0 以降がインストールされ、
stratisdサービスが実行されている。詳細は、Stratis のインストール を参照してください。 - 暗号化された Stratis プールが作成されている。詳細は、カーネルキーリング内のキーを使用して暗号化された Stratis プールを作成する を参照してください。
- 使用しているシステムは TPM 2.0 をサポートしている。
手順
Stratis プールで使用する各ブロックデバイスに存在するファイルシステム、パーティションテーブル、または RAID 署名をすべて削除します。
# wipefs --all block-deviceblock-deviceの値は、ブロックデバイスへのパスです (例:/dev/sdb)。暗号化された Stratis プールを作成し、暗号化に使用する Clevis メカニズムを指定します。
# stratis pool create --clevis tpm2 my-pool block-devicetpm2- 使用する Clevis 機構を指定します。
my-pool- 新しい Stratis プールの名前を指定します。
block-device空のブロックデバイスまたは消去したブロックデバイスへのパスを指定します。
または、次のコマンドを使用して Clevis tang サーバーメカニズムを使用します。
# stratis pool create --clevis tang --tang-url my-url --thumbprint thumbprint my-pool block-devicetang- 使用する Clevis 機構を指定します。
my-url- tang サーバーの URL を指定します。
thumbprinttang サーバーの thumbprint を参照します。
次のコマンドを使用して、1 行に複数のブロックデバイスを指定することもできます。
# stratis pool create --clevis tpm2 my-pool block-device-1 block-device-2
検証
新しい Stratis プールが作成されていることを確認します。
# stratis pool list注記プール作成時に Clevis と keyring の両方のオプションを同時に指定することで、Clevis と keyring の両方のメカニズムを使用して暗号化されたプールを作成することもできます。
21.8. storage RHEL システムロールを使用して暗号化された Stratis プールを作成する
データを保護するために、storage RHEL システムロールを使用して暗号化された Stratis プールを作成できます。パスフレーズに加えて、暗号化方法として Clevis と Tang または TPM 保護を使用できます。
Stratis 暗号化はプール全体でのみ設定できます。
前提条件
- コントロールノードと管理対象ノードの準備が完了している。
- 管理対象ノードで Playbook を実行できるユーザーとしてコントロールノードにログインしている。
-
管理対象ノードへの接続に使用するアカウントに、そのノードに対する
sudo権限がある。 - Tang サーバーに接続できる。詳細は、SELinux を Enforcing モードで有効にした Tang サーバーのデプロイメント を参照してください。
手順
機密性の高い変数を暗号化されたファイルに保存します。
vault を作成します。
$ ansible-vault create ~/vault.ymlNew Vault password: <vault_password> Confirm New Vault password: <vault_password>ansible-vault createコマンドでエディターが開いたら、機密データを<key>: <value>形式で入力します。luks_password: <password>- 変更を保存して、エディターを閉じます。Ansible は vault 内のデータを暗号化します。
次の内容を含む Playbook ファイル (例:
~/playbook.yml) を作成します。--- - name: Manage local storage hosts: managed-node-01.example.com vars_files: - ~/vault.yml tasks: - name: Create a new encrypted Stratis pool with Clevis and Tang ansible.builtin.include_role: name: redhat.rhel_system_roles.storage vars: storage_pools: - name: mypool disks: - sdd - sde type: stratis encryption: true encryption_password: "{{ luks_password }}" encryption_clevis_pin: tang encryption_tang_url: tang-server.example.com:7500サンプル Playbook で指定されている設定は次のとおりです。
encryption_password- LUKS ボリュームのロックを解除するために使用するパスワードまたはパスフレーズ。
encryption_clevis_pin-
作成されたプールを暗号化するために使用できる Clevis の方式。
tangとtpm2を使用できます。 encryption_tang_url- Tang サーバーの URL。
Playbook で使用されるすべての変数の詳細は、コントロールノードの
/usr/share/ansible/roles/rhel-system-roles.storage/README.mdファイルを参照してください。Playbook の構文を検証します。
$ ansible-playbook --ask-vault-pass --syntax-check ~/playbook.ymlこのコマンドは構文を検証するだけであり、有効だが不適切な設定から保護するものではないことに注意してください。
Playbook を実行します。
$ ansible-playbook --ask-vault-pass ~/playbook.yml
検証
Clevis と Tang が設定された状態でプールが作成されたことを確認します。
$ ansible managed-node-01.example.com -m command -a 'sudo stratis report'... "clevis_config": { "thp": "j-G4ddvdbVfxpnUbgxlpbe3KutSKmcHttILAtAkMTNA", "url": "tang-server.example.com:7500" }, "clevis_pin": "tang", "in_use": true, "key_description": "blivet-mypool",
21.9. Web コンソールを使用した暗号化された Stratis プールの作成
データを保護するために、Web コンソールを使用して、1 つ以上のブロックデバイスから暗号化された Stratis プールを作成できます。
1 つ以上のブロックデバイスから暗号化された Stratis プールを作成する場合は、次の点に注意してください。
- 各ブロックデバイスは cryptsetup ライブラリーを使用して暗号化され、LUKS2 形式を実装します。
- 各 Stratis プールは、一意の鍵を持つか、他のプールと同じ鍵を共有できます。これらのキーはカーネルキーリングに保存されます。
- Stratis プールを構成するブロックデバイスは、すべて暗号化または暗号化されていないデバイスである必要があります。同じ Stratis プールに、暗号化したブロックデバイスと暗号化されていないブロックデバイスの両方を含めることはできません。
- 暗号化 Stratis プールのデータ層に追加されるブロックデバイスは、自動的に暗号化されます。
前提条件
RHEL 10 Web コンソールがインストールされている。
手順は、Web コンソールのインストールおよび有効化 を参照してください。
-
Stratis v2.1.0 以降がインストールされ、
stratisdサービスが実行されている。 - Stratis プールを作成するブロックデバイスは、使用もマウントもされておらず、1 GB 以上の領域がある。
手順
- RHEL 10 Web コンソールにログインします。
- をクリックします。
- Storage テーブルで、メニューボタンをクリックし、Create Stratis pool を選択します。
- Name フィールドに、Stratis プールの名前を入力します。
- Stratis プールの作成元となる Block devices を選択します。
暗号化のタイプを選択します。パスフレーズ、Tang キーサーバー、またはその両方を使用できます。
パスフレーズ:
- パスフレーズを入力します。
- パスフレーズを確定します。
Tang キーサーバー:
- キーサーバーのアドレスを入力します。詳細は、SELinux を Enforcing モードで有効にした Tang サーバーのデプロイメント を参照してください。
- オプション: プールに作成する各ファイルシステムの最大サイズを指定する場合は、Manage filesystem sizes を選択します。
- をクリックします。
検証
- Storage セクションに移動し、Devices テーブルに新しい Stratis プールが表示されていることを確認します。
21.10. Web コンソールを使用した Stratis プールの名前変更
Web コンソールを使用して、既存の Stratis プールの名前を変更できます。
前提条件
RHEL 10 Web コンソールがインストールされている。
手順は、Web コンソールのインストールおよび有効化 を参照してください。
Stratis がインストールされ、
stratisdサービスが実行されている。Web コンソールがデフォルトで Stratis を検出してインストールしている。ただし、Stratis を手動でインストールする場合は、Stratis のインストール を参照してください。
- Stratis プールが作成されている。
手順
- RHEL 10 Web コンソールにログインします。
- をクリックします。
- Storage テーブルで、名前を変更する Stratis プールをクリックします。
- Stratis pool ページで、Name フィールドの横にある をクリックします。
- Rename Stratis pool ダイアログボックスで、新しい名前を入力します。
- をクリックします。
21.11. Stratis ファイルシステムでのオーバープロビジョニングモードの設定
デフォルトでは、すべての Stratis プールはオーバープロビジョニングされており、論理ファイルシステムのサイズが物理的に割り当てられた領域を超える可能性があります。Stratis はファイルシステムの使用状況を監視し、必要に応じて使用可能な領域を使用して割り当てを自動的に増やします。ただし、すでに使用可能な領域がすべて割り当てられており、プールがいっぱいの場合は、ファイルシステムに追加領域を割り当てることはできません。
ファイルシステムの容量が不足すると、ユーザーはデータを失う可能性があります。データ損失のリスクがオーバープロビジョニングの利点を上回るアプリケーションの場合、この機能を無効にできます。
Stratis はプールの使用状況を継続的に監視し、D-Bus API を使用して値を報告します。ストレージ管理者はこれらの値を監視し、容量に達しないように必要に応じてデバイスをプールに追加する必要があります。
前提条件
- Stratis がインストールされている。詳細は、Stratis のインストール を参照してください。
手順
プールを正しく設定するには、次の 2 つの方法があります。
1 つ以上のブロックデバイスからプールを作成して、作成時にプールが完全にプロビジョニングされるようにします。
# stratis pool create --no-overprovision pool-name /dev/sdb--no-overprovisionオプションを使用すると、プールは実際に利用可能な物理領域よりも多くの論理領域を割り当てることができません。既存のプールにオーバープロビジョニングモードを設定します。
# stratis pool overprovision pool-name <yes|no>"yes" に設定すると、プールへのオーバープロビジョニングが有効になります。これは、プールによってサポートされる Stratis ファイルシステムの論理サイズの合計が、利用可能なデータ領域の量を超える可能性があることを意味します。プールがオーバープロビジョニングされ、すべてのファイルシステムの論理サイズの合計がプールで使用可能な領域を超える場合、システムはオーバープロビジョニングをオフにできず、エラーを返します。
検証
Stratis プールの完全なリストを表示します。
# stratis pool listName Total Physical Properties UUID Alerts pool-name 1.42 TiB / 23.96 MiB / 1.42 TiB ~Ca,~Cr,~Op cb7cb4d8-9322-4ac4-a6fd-eb7ae9e1e540-
stratis pool listの出力に、プールのオーバープロビジョニングモードフラグが表示されているかどうかを確認します。" ~ " は "NOT" を表す数学記号であるため、~Opはオーバープロビジョニングなしという意味です。 オプション: 特定のプールのオーバープロビジョニングを確認します。
# stratis pool overprovision pool-name yes# stratis pool listName Total Physical Properties UUID Alerts pool-name 1.42 TiB / 23.96 MiB / 1.42 TiB ~Ca,~Cr,~Op cb7cb4d8-9322-4ac4-a6fd-eb7ae9e1e540
21.12. Stratis プールの NBDE へのバインド
暗号化された Stratis プールを Network Bound Disk Encryption (NBDE) にバインドするには、Tang サーバーが必要です。Stratis プールを含むシステムが再起動すると、Tang サーバーに接続して、カーネルキーリングの説明を指定しなくても、暗号化したプールのロックを自動的に解除します。
Stratis プールを補助 Clevis 暗号化メカニズムにバインドすると、プライマリーカーネルキーリング暗号化は削除されません。
前提条件
-
Stratis v2.3.0 以降がインストールされ、
stratisdサービスが実行されている。詳細は、Stratis のインストール を参照してください。 - 暗号化した Stratis プールを作成し、暗号化に使用したキーの説明がある。詳細は、カーネルキーリング内のキーを使用して暗号化された Stratis プールを作成する を参照してください。
- Tang サーバーに接続できる。詳細は、SELinux を Enforcing モードで有効にした Tang サーバーのデプロイメント を参照してください。
手順
暗号化された Stratis プールを NBDE にバインドする。
# stratis pool bind nbde --trust-url my-pool tang-servermy-pool- 暗号化された Stratis プールの名前を指定します。
tang-server- Tang サーバーの IP アドレスまたは URL を指定します。
21.13. Stratis プールの TPM へのバインド
暗号化された Stratis プールを Trusted Platform Module (TPM) 2.0 にバインドすると、プールを含むシステムが再起動され、カーネルキーリングの説明を指定しなくても、プールは自動的にロック解除されます。
前提条件
-
Stratis v2.3.0 以降がインストールされ、
stratisdサービスが実行されている。詳細は、Stratis のインストール を参照してください。 - 暗号化した Stratis プールを作成し、暗号化に使用したキーの説明がある。詳細は、カーネルキーリング内のキーを使用して暗号化された Stratis プールを作成する を参照してください。
- 使用しているシステムは TPM 2.0 をサポートしている。
手順
暗号化された Stratis プールを TPM にバインドします。
# stratis pool bind tpm my-poolmy-pool- 暗号化された Stratis プールの名前を指定します。
key-description- 暗号化された Stratis プールの作成時に生成されたカーネルキーリングに存在するキーを参照します。
21.14. カーネルキーリングを使用した暗号化 Stratis プールのロック解除
システムの再起動後、暗号化した Stratis プール、またはこれを構成するブロックデバイスが表示されない場合があります。プールの暗号化に使用したカーネルキーリングを使用して、プールのロックを解除できます。
前提条件
-
Stratis v2.1.0 がインストールされ、
stratisdサービスが実行されている。詳細は、Stratis のインストール を参照してください。 - 暗号化された Stratis プールが作成されている。詳細は、カーネルキーリング内のキーを使用して暗号化された Stratis プールを作成する を参照してください。
手順
以前使用したものと同じキー記述を使用して、キーセットを再作成します。
# stratis key set --capture-key key-descriptionkey-descriptionは、暗号化された Stratis プールの作成時に生成されたカーネルキーリングに存在するキーを参照します。Stratis プールが表示されることを確認します。
# stratis pool list
21.15. 補助暗号化からの Stratis プールのバインド解除
暗号化した Stratis プールを、サポート対象の補助暗号化メカニズムからバインドを解除すると、プライマリーカーネルキーリングの暗号化はそのまま残ります。これは、最初から Clevis 暗号化を使用して作成されたプールには当てはまりません。
前提条件
- Stratis v2.3.0 以降がシステムにインストールされている。詳細は、Stratis のインストール を参照してください。
- 暗号化された Stratis プールが作成されている。詳細は、カーネルキーリング内のキーを使用して暗号化された Stratis プールを作成する を参照してください。
- 暗号化した Stratis プールは、サポート対象の補助暗号化メカニズムにバインドされます。
手順
補助暗号化メカニズムから暗号化された Stratis プールのバインドを解除します。
# stratis pool unbind clevis my-poolmy-poolは、バインドを解除する Stratis プールの名前を指定します。
21.16. Stratis プールの開始および停止
Stratis プールを開始および停止できます。この操作により、ファイルシステム、キャッシュデバイス、シンプール、暗号化されたデバイスなど、プールの構築に使用されたすべてのオブジェクトを解体または停止できます。プールがデバイスまたはファイルシステムをアクティブに使用している場合は、警告が表示され、停止できない可能性があることに注意してください。
停止状態は、プールのメタデータに記録されます。これらのプールは、プールが開始コマンドを受信するまで、次のブートでは開始されません。
前提条件
-
Stratis がインストールされ、
stratisdサービスが実行されている。詳細は、Stratis のインストール を参照してください。 - 暗号化されていない、または暗号化された Stratis プールを作成した。詳細は、暗号化されていない Stratis プールの作成 または カーネルキーリング内のキーを使用して暗号化された Stratis プールを作成する を参照してください。
手順
次のコマンドを使用して、Stratis プールを停止します。これにより、ストレージスタックが切断されますが、メタデータはすべて保持されます。
# stratis pool stop --name pool-name以下のコマンドを使用して Stratis プールを起動します。
--unlock-methodオプションは、プールが暗号化されている場合にプールのロックを解除する方法を指定します。# stratis pool start --unlock-method <keyring|clevis> --name pool-name注記プール名またはプール UUID のいずれかを使用してプールを開始できます。
検証
次のコマンドを使用して、システム上のすべてのアクティブなプールをリスト表示します。
# stratis pool list次のコマンドを使用して、停止されたプールをすべてリスト表示します。
# stratis pool list --stopped次のコマンドを使用して、停止したプールの詳細情報を表示します。UUID を指定すると、このコマンドは UUID に対応するプールに関する詳細情報を出力します。
# stratis pool list --stopped --uuid UUID
21.17. Stratis ファイルシステムの作成
Stratis ファイルシステムを作成して、シンプロビジョニング、自動ファイルシステム拡張、ストレージプール内の統合スナップショットサポートなどの高度なストレージ機能を活用します。
前提条件
-
Stratis がインストールされ、
stratisdサービスが実行されている。詳細は、Stratis のインストール を参照してください。 - Stratis プールが作成されている。詳細は、暗号化されていない Stratis プールの作成 または カーネルキーリング内のキーの使用 を参照してください。
手順
プールに Stratis ファイルシステムを作成します。
# stratis filesystem create --size number-and-unit my-pool my-fsnumber-and-unit- ファイルシステムのサイズを指定します。仕様形式は、入力の標準サイズ指定形式 (B、KiB、MiB、GiB、TiB、または PiB) に準拠する必要があります。
my-pool- Stratis プールの名前を指定します。
my-fsファイルシステムの任意名を指定します。
たとえば、Stratis ファイルシステムを作成します。
# stratis filesystem create --size 10GiB pool1 filesystem1
ファイルシステムのサイズ制限を設定します。
# stratis filesystem create --size number-and-unit --size-limit number-and-unit my-pool my-fs注記このオプションは、Stratis 3.6.0 以降で利用できます。
必要に応じて、後でサイズ制限を削除することもできます。
# stratis filesystem unset-size-limit my-pool my-fs
検証
プール内のファイルシステムをリスト表示して、Stratis ファイルシステムが作成されているかどうかを確認します。
# stratis fs list my-pool
21.18. Stratis ファイルシステムのマウント
既存の Stratis ファイルシステムをマウントして、コンテンツにアクセスします。
前提条件
-
Stratis がインストールされ、
stratisdサービスが実行されている。詳細は、Stratis のインストール を参照してください。 - Stratis ファイルシステムが作成されます。詳細は、Stratis ファイルシステムの作成 を参照してください。
手順
ファイルシステムをマウントするには、
/dev/stratis/ディレクトリーに Stratis が維持するエントリーを使用します。# mount /dev/stratis/my-pool/my-fs mount-pointこれでファイルシステムは mount-point ディレクトリーにマウントされ、使用できるようになりました。
注記プールを停止する前に、プールに属するすべてのファイルシステムをアンマウントします。ファイルシステムがまだマウントされている場合、プールは停止しません。
21.19. ブート時に Stratis ファイルシステムをマウントする設定
ファイルシステムのプールを正しく起動するメカニズムを設定することで、Stratis ファイルシステムをブート時にマウントするように設定できます。これを行わないと、マウント操作が失敗します。Stratis はこのプロセスをサポートするために 2 つの systemd サービスを提供します。
Stratis は現在、ルートファイルシステムの管理をサポートしていません。次の手順は、ルート以外のファイルシステムにのみ適用されます。
前提条件
- Stratis ファイルシステム (例: <my-fs>) が、Stratis プール (例: <my-pool>) 上に作成されている。詳細は、Stratis ファイルシステムの作成 を参照してください。
- マウントポイントディレクトリー (例: <mount-point>) が作成されている。
- ファイルシステムのプールの UUID が特定されている (例: <pool-uuid>)。
手順
root として、
/etc/fstabファイルを編集します。ファイルシステムの
/etc/fstabエントリーのマウントオプションにx-systemd.requires=stratis-fstab-setup@<pool-uuid>.serviceを追加します。/dev/stratis/<my-pool>/<my-fs> <mount-point> xfs defaults,x-systemd.requires=stratis-fstab-setup@<pool-uuid>.serviceプールが Clevis により NBDE (Network Bound Disk Encryption) を使用して暗号化されている場合は、
x-systemd.requires=stratis-fstab-setup-with-network@<pool-uuid>.serviceと_netdevを追加します。/dev/stratis/<my-pool>/<my-fs> <mount-point> xfs defaults,x-systemd.requires=stratis-fstab-setup-with-network@<pool-uuid>.service,_netdev以下のように置き換えます。
- <my-pool> は、ファイルシステムが含まれる Stratis プールの名前です。
- <my-fs> は、プール内に作成した Stratis ファイルシステムの名前です。
- <mount-point> は、ファイルシステムをマウントするディレクトリーの名前です。
<pool-uuid> は、ファイルシステムのプールの UUID です。
重要暗号化された Stratis プールから Stratis ファイルシステムをブート時にマウントすると、パスワードが入力されるまでブートプロセスが停止する可能性があります。プールが NBDE や TPM2 などの無人メカニズムを使用して暗号化されている場合、Stratis プールは自動的にロック解除されます。そうでない場合は、ユーザーがコンソールにパスワードを入力して、ファイルシステムのプールのロックを解除する必要がある可能性があります。
21.20. Web コンソールを使用した Stratis ファイルシステムの作成および設定
Web コンソールを使用して、既存の Stratis プール上にファイルシステムを作成できます。
前提条件
RHEL 10 Web コンソールがインストールされている。
手順は、Web コンソールのインストールおよび有効化 を参照してください。
-
stratisdサービスを実行している。 - Stratis プールが作成されている。
手順
- RHEL 10 Web コンソールにログインします。
- をクリックします。
- ファイルシステムを作成する Stratis プールをクリックします。
- Stratis pool ページで、Stratis filesystems セクションまでスクロールし、 をクリックします。
- ファイルシステムの名前を入力します。
- ファイルシステムのマウントポイントを入力します。
- マウントオプションを選択します。
- At boot ドロップダウンメニューで、ファイルシステムをマウントするタイミングを選択します。
ファイルシステムを作成します。
- ファイルシステムを作成してマウントする場合は、 をクリックします。
- ファイルシステムの作成のみを行う場合は、 をクリックします。
検証
- 新しいファイルシステムは、Stratis pool ページの Stratis filesystems タブに表示されます。
第22章 追加のブロックデバイスで Stratis プールを拡張する
Stratis ファイルシステムのストレージ容量を増やすために、追加のブロックデバイスを Stratis プールに追加できます。手動で行うことも、Web コンソールを使用して行うこともできます。
22.1. Stratis プールへのブロックデバイスの追加
Stratis プールに 1 つ以上のブロックデバイスを追加できます。
前提条件
-
Stratis がインストールされ、
stratisdサービスが実行されている。詳細は、Stratis のインストール を参照してください。 - Stratis プールを作成するブロックデバイスは、使用もマウントもされておらず、1 GB 以上の領域がある。
手順
1 つ以上のブロックデバイスをプールに追加するには、以下を使用します。
# stratis pool add-data my-pool device-1 device-2 device-n
22.2. Web コンソールを使用した Stratis プールへのブロックデバイスの追加
Web コンソールを使用して、既存の Stratis プールにブロックデバイスを追加できます。キャッシュをブロックデバイスとして追加することもできます。
前提条件
RHEL 10 Web コンソールがインストールされている。
手順は、Web コンソールのインストールおよび有効化 を参照してください。
-
stratisdサービスを実行している。 - Stratis プールが作成されている。
- Stratis プールを作成するブロックデバイスは、使用もマウントもされておらず、1 GB 以上の領域がある。
手順
- RHEL 10 Web コンソールにログインします。
- をクリックします。
- Storage テーブルで、ブロックデバイスを追加する Stratis プールをクリックします。
- Stratis pool ページで、 をクリックし、ブロックデバイスをデータまたはキャッシュとして追加する Tier を選択します。
- パスフレーズで暗号化された Stratis プールにブロックデバイスを追加する場合は、パスフレーズを入力します。
- Block devices で、プールに追加するデバイスを選択します。
- をクリックします。
第23章 Stratis ファイルシステムの監視
Stratis ユーザーは、システムにある Stratis ファイルシステムに関する情報を表示して、その状態と空き容量を監視できます。
23.1. Stratis ファイルシステムに関する情報の表示
stratis ユーティリティーを使用すると、Stratis ファイルシステムの合計サイズ、使用サイズ、空きサイズ、プールに属するファイルシステムとブロックデバイスなどに関する統計情報をリスト表示できます。
XFS ファイルシステムのサイズは、管理できるユーザーデータの合計量です。シンプロビジョニングされた Stratis プールでは、Stratis ファイルシステムのサイズが、割り当てられた領域よりも大きいように見える場合があります。XFS ファイルシステムのサイズは、この見かけのサイズに合わせて設定されます。つまり、通常は割り当てられた領域よりも大きくなります。df などの標準 Linux ユーティリティーは、XFS ファイルシステムのサイズを報告します。この値は通常、XFS ファイルシステムに必要な領域、つまり Stratis によって割り当てられた領域を過大評価します。
オーバープロビジョニングされた Stratis プールの使用状況を定期的に監視してください。ファイルシステムの使用量が割り当てられた領域に近づくと、Stratis はプール内の使用可能な領域を使用して割り当てを自動的に増加します。ただし、すでに使用可能な領域がすべて割り当てられていて、プールがいっぱいの場合は、追加の領域を割り当てることができず、ファイルシステムの領域が不足することになります。これにより、Stratis ファイルシステムを使用するアプリケーションでデータが失われるリスクが生じる可能性があります。
前提条件
-
Stratis がインストールされ、
stratisdサービスが実行されている。詳細は、Stratis のインストール を参照してください。
手順
システムで Stratis に使用されているすべての ブロックデバイス に関する情報を表示する場合は、次のコマンドを実行します。
# stratis blockdevPool Name Device Node Physical Size Tier UUID my-pool /dev/sdb 9.10 TiB Data ec9fb718-f83c-11ef-861e-7446a09dccfbシステムにあるすべての Stratis プール に関する情報を表示するには、次のコマンドを実行します。
# stratis poolName Total/Used/Free Properties UUID Alerts my-pool 8.00 GiB / 800.99 MiB / 7.22 GiB -Ca,-Cr,Op e22772c2-afe9-446c-9be5-2f78f682284e WS001システムにあるすべての Stratis ファイルシステム に関する情報を表示するには、次のコマンドを実行します。
# stratis filesystemPool Filesystem Total/Used/Free/Limit Device UUID Spool1 sfs1 1 TiB / 546 MiB / 1023.47 GiB / None /dev/stratis/spool1/sfs1 223265f5-8f17-4cc2-bf12-c3e9e71ff7bfファイルシステム名または UUID を指定して、システム上の Stratis ファイルシステムに関する詳細情報を表示することもできます。
# stratis filesystem list my-pool --name my-fsUUID: 47255008-9bc7-4bd2-8294-e9d25cd9e7ba Name: my-fs Pool: my-pool Device: /dev/stratis/my-pool/my-fs Created: Nov 08 2018 08:03 Snapshot origin: None Sizes: Logical size of thin device: 1 TiB Total used (including XFS metadata): 546 MiB Free: 1023.47 GiB Size Limit: None
23.2. Web コンソールを使用した Stratis プールの表示
Web コンソールを使用して、既存の Stratis プールとそれに含まれるファイルシステムを表示できます。
前提条件
RHEL 10 Web コンソールがインストールされている。
手順は、Web コンソールのインストールおよび有効化 を参照してください。
-
stratisdサービスを実行している。 - 既存の Stratis プールがある。
手順
- RHEL 10 Web コンソールにログインします。
- をクリックします。
Storage テーブルで、表示する Stratis プールをクリックします。
Stratis プールページには、プールおよびプール内に作成したファイルシステムに関するすべての情報が表示されます。
第24章 Stratis ファイルシステムでのスナップショットの使用
Stratis ファイルシステムのスナップショットを使用して、ファイルシステムの状態を任意の時点でキャプチャーし、後でそれを復元できます。
24.1. Stratis スナップショットの特徴
Stratis スナップショットは、他の Stratis ファイルシステムの特定時点のコピーとして作成される通常のファイルシステムです。これらはソースファイルシステムとは独立して動作し、バックアップ、テスト、またはデータ回復の目的で使用できます。
Stratis の現在のスナップショット実装は、次のような特徴があります。
- ファイルシステムのスナップショットは別のファイルシステムです。
- スナップショットと元のファイルシステムのリンクは、有効期間中は行われません。スナップショットされたファイルシステムは、元のファイルシステムよりも長く存続します。
- スナップショットを作成するためにファイルシステムをマウントする必要はありません。
- 各スナップショットは、XFS ログに必要となる実際のバッキングストレージの約半分のギガバイトを使用します。
24.2. Stratis スナップショットの作成
既存の Stratis ファイルシステムのスナップショットとして Stratis ファイルシステムを作成できます。
前提条件
-
Stratis がインストールされ、
stratisdサービスが実行されている。詳細は、Stratis のインストール を参照してください。 - Stratis ファイルシステムを作成している。詳細は、Stratis ファイルシステムの作成 を参照してください。
手順
Stratis スナップショットを作成します。
# stratis fs snapshot my-pool my-fs my-fs-snapshotスナップショットは、中心的な Stratis ファイルシステムです。Stratis スナップショットは複数作成できます。単一のオリジンファイルシステム、または別のスナップショットファイルシステムのスナップショットがあります。ファイルシステムがスナップショットの場合、origin フィールドには、詳細なファイルシステムリストの元のファイルシステムの UUID が表示されます。
24.3. Stratis スナップショットのコンテンツへのアクセス
Stratis ファイルシステムのスナップショットを、読み取りおよび書き込み操作でアクセスできるようにマウントすることができます。
前提条件
-
Stratis がインストールされ、
stratisdサービスが実行されている。詳細は、Stratis のインストール を参照してください。 - Stratis スナップショットを作成している。詳細は、Stratis スナップショットの作成 を参照してください。
手順
スナップショットにアクセスするには、
/dev/stratis/my-pool/ディレクトリーから通常のファイルシステムとしてマウントします。# mount /dev/stratis/my-pool/my-fs-snapshot mount-point
24.4. Stratis ファイルシステムを以前のスナップショットに戻す
Stratis ファイルシステムの内容を、Stratis スナップショットでキャプチャーされた状態に戻すことができます。
前提条件
-
Stratis がインストールされ、
stratisdサービスが実行されている。詳細は、Stratis のインストール を参照してください。 - Stratis スナップショットを作成している。詳細は、Stratis スナップショットの作成 を参照してください。
手順
オプション: 後でアクセスできるように、ファイルシステムの現在の状態をバックアップします。
# stratis filesystem snapshot my-pool my-fs my-fs-backupファイルシステムを以前に取得したスナップショットに戻すスケジュールを設定します。
# stratis filesystem schedule-revert my-pool my-fs-snapshotオプション: 次のコマンドを実行して、元に戻す操作が正常にスケジュールされているかどうかを確認します。
# stratis filesystem list my-pool --name my-fs-snapshotUUID: b14987eb-b735-4c68-8962-f53f6b644cbc Name: my-fs-snapshot Pool: my-pool Device: /dev/stratis/p1/my-fs-snapshot Created: Mar 18 2025 12:29 Snapshot origin: f5a881b1-299d-4147-8ead-b4a56c623692 Revert scheduled: Yes Sizes: Logical size of thin device: 1 TiB Total used (including XFS metadata): 5.42 GiB Free: 1018.58 GiB注記同じ元のファイルシステムに対して、元に戻す操作を複数スケジュールすることはできません。また、元のファイルシステムまたは復元がスケジュールされているスナップショットのいずれかを破棄しようとすると、破棄操作は失敗します。
プールを再起動する前に、いつでも元に戻す操作をキャンセルできます。
# stratis filesystem cancel-revert my-pool my-fs-snapshot次のコマンドを実行して、キャンセルが正常にスケジュールされているかどうかを確認できます。
# stratis filesystem list my-pool --name my-fs-snapshotUUID: b14987eb-b735-4c68-8962-f53f6b644cbc Name: my-fs-snapshot Pool: my-pool Device: /dev/stratis/p1/my-fs-snapshot Created: Mar 18 2025 12:29 Snapshot origin: f5a881b1-299d-4147-8ead-b4a56c623692 Revert scheduled: No Sizes: Logical size of thin device: 1 TiB Total used (including XFS metadata): 5.42 GiB Free: 1018.58 GiB Size Limit: Noneキャンセルされていない場合は、プールの再起動時にスケジュールされた元に戻す操作が続行されます。
# stratis pool stop --name my-pool# stratis pool start --name my-pool
検証
プールに属するファイルシステムをリスト表示します。
# stratis filesystem list my-pool
my-fs-snapshot は、以前にコピーされた my-fs-snapshot 状態に戻されたため、プール内のファイルシステムのリストに表示されなくなりました。my-fs という名前のファイルシステムの内容は、スナップショット my-fs-snapshot と同じになりました。
24.5. Stratis スナップショットの削除
プールから Stratis スナップショットを削除できます。スナップショットのデータは失われます。
前提条件
-
Stratis がインストールされ、
stratisdサービスが実行されている。詳細は、Stratis のインストール を参照してください。 - Stratis スナップショットを作成している。詳細は、Stratis スナップショットの作成 を参照してください。
手順
スナップショットをアンマウントします。
# umount /dev/stratis/my-pool/my-fs-snapshotスナップショットを破棄します。
# stratis filesystem destroy my-pool my-fs-snapshot
第25章 Stratis ファイルシステムの削除
既存の Stratis ファイルシステムまたはプールを削除できます。削除した Stratis ファイルシステムやプールは復元できません。
25.1. Stratis ファイルシステムの削除
既存の Stratis ファイルシステムを削除できます。そこに保存されているデータは失われます。
前提条件
-
Stratis がインストールされ、
stratisdサービスが実行されている。詳細は、Stratis のインストール を参照してください。 - Stratis ファイルシステムを作成している。詳細は、Stratis ファイルシステムの作成 を参照してください。
手順
ファイルシステムをアンマウントします。
# umount /dev/stratis/my-pool/my-fsファイルシステムを破棄します。
# stratis filesystem destroy my-pool my-fs
検証
ファイルシステムがもう存在しないことを確認します。
# stratis filesystem list my-pool
25.2. Web コンソールを使用した Stratis プールからのファイルシステムの削除
Web コンソールを使用して、既存の Stratis プールからファイルシステムを削除できます。
Stratis プールのファイルシステムを削除すると、そこに含まれるすべてのデータが消去されます。
前提条件
RHEL 10 Web コンソールがインストールされている。
手順は、Web コンソールのインストールおよび有効化 を参照してください。
Stratis がインストールされ、
stratisdサービスが実行されている。Web コンソールがデフォルトで Stratis を検出してインストールしている。ただし、Stratis を手動でインストールする場合は、Stratis のインストール を参照してください。
- 既存の Stratis プールがあり、その Stratis プール上にファイルシステムが作成されている。
手順
- RHEL 10 Web コンソールにログインします。
- をクリックします。
- Storage テーブルで、ファイルシステムを削除する Stratis プールをクリックします。
- Stratis pool ページで、Stratis filesystems セクションまでスクロールし、削除するファイルシステムのメニューボタン をクリックします。
- ドロップダウンメニューから を選択します。
- Confirm deletion ダイアログボックスで、 をクリックします。
25.3. Stratis プールの削除
既存の Stratis プールを削除できます。そこに保存されているデータは失われます。
前提条件
-
Stratis がインストールされ、
stratisdサービスが実行されている。詳細は、Stratis のインストール を参照してください。 Stratis プールを作成している。
- 暗号化されていないプールを作成するには、暗号化されていない Stratis プールの作成 を参照してください。
- 暗号化されたプールを作成するには、カーネルキーリング内のキーを使用して暗号化された Stratis プールを作成する を参照してください。
手順
プールにあるファイルシステムのリストを表示します。
# stratis filesystem list my-poolプール上のすべてのファイルシステムをアンマウントします。
# umount /dev/stratis/my-pool/my-fs-1 \ /dev/stratis/my-pool/my-fs-2 \ /dev/stratis/my-pool/my-fs-nファイルシステムを破棄します。
# stratis filesystem destroy my-pool my-fs-1 my-fs-2プールを破棄します。
# stratis pool destroy my-pool
検証
プールがなくなったことを確認します。
# stratis pool list
25.4. Web コンソールを使用した Stratis プールの削除
Web コンソールを使用して、既存の Stratis プールを削除できます。
Stratis プールを削除すると、そこに含まれるすべてのデータが消去されます。
前提条件
RHEL 10 Web コンソールがインストールされている。
手順は、Web コンソールのインストールおよび有効化 を参照してください。
-
stratisdサービスを実行している。 - 既存の Stratis プールがある。
手順
- RHEL 10 Web コンソールにログインします。
- をクリックします。
- Storage テーブルで、削除する Stratis プールのメニューボタン をクリックします。
- ドロップダウンメニューから を選択します。
- Permanently delete pool ダイアログボックスで、 をクリックします。