パフォーマンスチューニングガイド
Red Hat Enterprise Linux 6 におけるサブシステムのスループットを最適化
エディッション 4.0
概要
第1章 概要
1.1. 本書を読むにあたって
- 機能
- 各サブシステムの章では、Red Hat Enterprise Linux 6 特有の (または別の方法で実装されている) パフォーマンス機能を説明します。また、Red Hat Enterprise Linux 5 と比べて特定のサブシステムのパフォーマンスを大幅に改善した Red Hat Enterprise Linux 6 の更新も説明します。
- 分析
- 本書では、各サブシステム特有のパフォーマンス指標も紹介します。これら指標の通常の値は特定サービスのコンテキスト内で説明されるので、実際の本番システムでの重要度の理解が容易になります。また『パフォーマンスチューニングガイド』 は、サブシステムのパフォーマンスデータ (プロファイリング) の別の取得方法も紹介します。ここで示されているプロファイリングツールには、本書以外でより詳しく説明されているものもあります。
- 設定
- 本書で最も重要な情報は、おそらく Red Hat Enterprise Linux 6 の固有のサブシステムのパフォーマンスを調整する方法に関する指示になります。『パフォーマンスチューニングガイド』 では、特定のサービスについて Red Hat Enterprise Linux 6 のサブシステムを微調整する方法を説明しています。
1.1.1. 対象読者
- システム / ビジネスアナリスト
- 本書では、Red Hat Enterprise Linux 6 の高いレベルのパフォーマンス機能を説明しており、(デフォルトと最適化された時の両方での) 特定の作業負荷においてサブシステムがどのように作動するかについての十分な情報を提供しています。Red Hat Enterprise Linux 6 のパフォーマンス機能は詳細なレベルで説明されているので、受け入れ可能なレベルでリソース集約型のサービスを提供する際のこのプラットフォームの適合性を潜在的な顧客やセールスエンジニアが理解できるようになっています。『パフォーマンスチューニングガイド』 は、可能な限り各機能のより詳細なドキュメンテーションへのリンクも提供しています。この詳細なレベルでは、ユーザーはパフォーマンス機能を十分に理解して Red Hat Enterprise Linux 6 の導入および最適化における高レベルな戦略を形成することができます。これによりユーザーは、インフラストラクチャー提案を開発しかつ 評価することができます。本書は機能にフォーカスしたドキュメンテーションなので、Linux サブシステムおよび企業レベルのネットワークを高度に理解できるユーザーが対象となります。
- システム管理者
- 本書の手順は、RHCE [1] スキルレベル (もしくはそれと同等。つまり、Linux の導入および管理の経験が 3-5 年) のシステム管理者向けとなっています。『パフォーマンスチューニングガイド』 では、各設定の影響に関してできるだけの詳細を提供しており、パフォーマンスの代償の可能性もすべて説明されています。パフォーマンスチューニングで基礎となるスキルは、サブシステムの分析やチューニング方法の知識ではありません。むしろ、パフォーマンスチューニングに精通しているシステム管理者は、特定の目的で Red Hat Enterprise Linux 6 システムのバランスを取り最適化する方法を理解しています。これは、特定のサブシステムのパフォーマンスを改善するための設定を実装する際に、代償やパフォーマンス低下についても理解していることを意味します。
1.2. リリースの概要
1.2.1. Red Hat Enterprise Linux 6 における新機能
1.2.1.1. 6.6 リリースでの新機能
- perf がバージョン 3.12 に更新され、以下の新機能が含まれています。
perf recordの-jおよび-bの各オプションで、連続するブランチの統計サンプルを行います。詳細は、man perf-recordを参照してください。--groupおよび--percent-limitを含む新たなperf reportパラメーターと、perf record-jおよび-bのオプションを有効にして収集されたデータを分類する追加オプション。詳細は、man perf-reportを参照してください。- ロードおよび保存メモリーアクセスをプロファイリングする新たな
perf memコマンド。 --percent-limitおよび--obj-dumpを含むperf topの新オプション。--forceおよび--appendのオプションがperf recordから削除されました。perf statの新オプション--initial-delay。perf traceの新オプション--output-filename。perf evlistの新オプション--group。perf top-Gおよびperf record-gの各オプションが変更されました。これらはもう、--call-graphオプションの代わりにはなりません。今後の Red Hat Enterprise Linux バージョンにlibunwindサポートが追加されると、これらのオプションは設定済みアンワインドメソッドを有効にします。
1.2.1.2. 6.5 リリースでの新機能
- カーネルへの更新で、IRQ テーブルのサイズが 1 GB 以上の場合、I/O ロードが複数のメモリープールに拡散することが可能になることで、メモリー管理のボトルネックが取り除かれ、パフォーマンスが改善します。
- cpupowerutils パッケージが更新され、turbostat および x86_energy_perf_policy ツールが含まれるようになりました。これらのツールは、「turbostat」 および 「ハードウェアパフォーマンスポリシー (x86_energy_perf_policy)」 で説明されています。
- CIFS がより大型の rsize オプションと非同期の readpage をサポートすることで、スループットの大幅な増加が可能になりました。
- GFS2 が Orlov ブロックアロケータ―を提供するようになり、ブロック割り当てが速く行われるようになりました。
- tuned の
virtual-hostsプロファイルが調整されました。kernel.sched_migration_costの値は、カーネルのデフォルトの500000ナノ秒 (0.5 ミリ秒) ではなく、5000000ナノ秒 (5 ミリ秒) となっています。これにより、大規模な仮想化ホスト用の実行キューロックにおける競合が減ることになります。 - tuned の
latency-performanceプロファイルが調整されました。サービスの電力管理の質であるcpu_dma_latency要件の値が、0ではなく1になっています。 - カーネル
copy_from_user()およびcopy_to_user()の関数にいくつかの最適化が含まれ、この両方のパフォーマンスを改善しています。 - perf ツールに、以下のものを含む多くの更新および機能強化がなされています。
- Perf が、System z CPU 測定カウンター機能が提供するハードウェアカウンターを使用できるようになりました。利用可能なハードウェアカウンターの 4 つのセットは、基本カウンターセット、問題状態カウンターセット、暗号化アクティビティーカウンターセット、および拡張カウンターセットです。
- 新たに
perf traceコマンドが利用可能になりました。これにより、perf インフラストラクチャーを使用した strace のような動作で追加ターゲットの追跡が可能になります。詳細は、「Perf」 を参照してください。 - スクリプトブラウザーが追加され、ユーザーは現行の perf データファイルに利用可能なすべてのスクリプトを閲覧できるようになりました。
- いくつかの追加のサンプルスクリプトが利用可能になっています。
- Ext3 が更新され、ロックの競合を減らしています。これにより、マルチスレッド書き込み操作のパフォーマンスが改善しています。
- KSM が、NUMA トポロジーを認識するように更新されました。これにより、ページ結合の際に NUMA の場所を考慮することが可能になっています。これで、ページがリモートのノードに移動することに関するパフォーマンス低下が避けられます。Red Hat では、KSM の使用時にクロスノードのメモリーマージを避けることを推奨しています。この更新では、新たに調整可能な
/sys/kernel/mm/ksm/merge_nodesを導入してこの動作を制御しています。デフォルト値 (1) は、異なる NUMA ノードにまたがるページをマージします。merge_nodesを0に設定すると、同一ノード上のページのみがマージされます。 - hdparm が
--fallocate、--offset、および-R(読み-書き-検証 の有効化) を含む新たなフラグで更新されました。また、--trim-sectorsオプションが--trim-sector-rangesおよび--trim-sector-ranges-stdinのオプションに置換されています。これで、複数セクターの範囲が指定できます。これらのオプションの詳細情報は、man ページを参照してください。
1.2.2. 水平方向のスケーラビリティ
1.2.2.1. パラレルコンピューティング
1.2.3. 分散システム
- 通信
- 水平的スケーラビリティでは、多くのタスクが (パラレルで) 同時実行される必要があります。このため、これらのタスクは、プロセス間通信 で作業を調整する必要があります。さらに、水平的スケーラビリティのプラットホームは、複数システムにわたってタスク共有が可能である必要があります。
- ストレージ
- ローカルディスクによるストレージは、水平的スケーラビリティの要件に対応するには不十分です。なんらかの分散もしくは共有ストレージが必要です。単一ストレージボリュームの容量が新たなストレージハードウェアを追加することで、シームレスに拡大できるような抽象化レイヤーを備えたものが必要になります。
- 管理
- 分散コンピューティングにおける最も重要な任務は、管理 層になります。この管理層は、すべてのソフトウェアおよびハードウェアのコンポーネントを連携させ、通信とストレージ、共有リソースの使用を効率的に管理するものです。
1.2.3.1. 通信
- ハードウェア
- ソフトウェア
コンピューター間の最も一般的な通信方法は、イーサネットを使ったものです。現在ではシステム上で Gigabit イーサネット (GbE) がデフォルトで提供されており、ほとんどのサーバーには Gigabit イーサネットのポートが 2-4 個あります。GbE はすぐれた帯域幅と待ち時間を提供します。これは、現在使用されているほとんどの分散システムの基礎となっています。システムに高速ネットワークハードウェアがある場合でも、専用の管理インターフェースには GbE を使うのが一般的です。
10 Gigabit イーサネット (10GbE) の使用は、ハイエンドおよびミッドレンジサーバーで急速に拡大しています。10GbE は、GbE の 10 倍の帯域幅を提供します。その主な長所の一つは、最新のマルチコアプロセッサーと使用すると、通信とコンピューティングのバランスを回復する点です。シングルコアシステムで GbE を使う場合と 8 コアシステムで 10GbE を使う場合を比較すると違いがよく分かります。この方法で使うと、総合的なシステムパフォーマンスを維持し、通信ボトルネックを回避するという点で 10GbE は特に有用です。
Infiniband は 10GbE よりもさらに高いパフォーマンスを提供します。イーサネットで使用する TCP/IP および UDP ネットワーク接続に加えて、Infiniband は共有メモリ通信もサポートします。これにより Infiniband は、remote direct memory access (RDMA) によるシステム間での作業が可能になります。
RDMA over Converged Ethernet (RoCE) は、Infiniband スタイルの通信 (RDMA を含む) を 10GbE インフラストラクチャー上で実装します。増大している 10GbE 製品の価格改善傾向を考えると、RDMA と RoCE が幅広いシステムやアプリケーションでより多く使われることが見込まれます。
1.2.3.2. ストレージ
- 単一のロケーションで複数のシステムがデータを保存している。
- 複数のストレージアプライアンスで構成されるストレージユニット (例: ボリューム)
Network File System (NFS) は、複数のサーバーやユーザーが TCP もしくは UDP 経由でリモートストレージの同一インスタンスをマウントもしくは使用することを可能にします。NFS は一般的に、複数のアプリケーションが共有するデータを保持します。また大量データの一括保存にも便利です。
ストレージエリアネットワーク (SAN) は、Fibre Channel もしくは iSCSI プロトコルを使ってストレージへのリモートアクセスを提供します。(Fibre Channel ホストバスアダプターやスイッチ、ストレージアレイといった) Fibre Channel インフラストラクチャーは、高パフォーマンスと高い帯域幅、大量ストレージを組み合わせます。SAN はプロセッシングからストレージを分離することで、システムデザインの柔軟性を大幅に高めます。
- ストレージへのアクセス制御
- 大量データの管理
- システムのプロビジョニング
- データのバックアップと複製
- スナップショットの作成
- システムフェイルオーバーのサポート
- データ整合性の確保
- データの移行
Red Hat Global File System 2 (GFS2) ファイルシステムは、特別機能をいくつか提供します。GFS2 の基本機能は単一ファイルシステムの提供で、これには同時読み取り/書き込みアクセスが含まれ、クラスターの複数メンバー間で共有されます。つまり、このクラスターの各メンバーは、GFS2 ファイルシステム内の「ディスク上」で全くの同一データを見ることになります。
1.2.3.3. 集中型ネットワーク
FCoE では、標準のファイバーチャンネルコマンドとデータパケットは、単一の 集中型ネットワークアダプター (CNA) 経由で 10GbE の物理ネットワークを使って移動します。標準 TCP/IP イーサネットトラフィックとファイバーチャンネルストレージ操作も同一リンク経由で移動できます。FCoE は 1 つの物理ネットワークインターフェース (および 1 本のケーブル) を使って複数の論理ネットワーク/ストレージ接続を行います。
- 接続数が減少
- FCoE を使うと、サーバーへのネットワーク接続数が半分になります。パフォーマンスやアベイラビリティ目的で複数接続を選ぶことは依然として可能ですが、単一接続でストレージとネットワーク接続の両方が提供されます。これは特にピザボックスサーバーとブレードサーバーの場合、コンポーネントのスペースが限られているため、便利なものになります。
- 低コスト
- 接続数が減ると、直ちにケーブルやスイッチ、その他のネットワーク機器の数が減ることになります。また、イーサネットの例では規模の経済が機能します。市場におけるデバイス数が数百万から数十億に増えると、100Mb イーサネットとギガバイトのイーサネットデバイスの価格下落で見られたように、ネットワーク費用は劇的に低下します。同様に、10GbE を採用する企業が増えるにつれて、その価格はより安価になります。また、CNA ハードウェアがシングルチップに統合されることで、その仕様拡大が市場でのボリュームを増大させ、長期的には価格が大幅に下落することになります。
インターネット SCSI (iSCSI) は別のタイプの集中型ネットワークプロトコルで、FCoE の代わりとなるものです。ファイバーチャンネルのように、iSCSI はネットワークを使ったブロックレベルのストレージを提供します。しかし iSCSI は完全な管理環境は提供しません。FCoE に対する iSCSI の利点は、iSCSI はファイバーチャンネルのほとんどの機能と柔軟性をより低コストで提供できるという点です。
第2章 Red Hat Enterprise Linux 6 のパフォーマンス機能
2.1. 64 ビットのサポート
- Huge pages および transparent huge pages
- Non-Uniform Memory Access (NUMA) の改善
Red Hat Enterprise Linux 6 に huge pages が実装されたことで、システムは異なるメモリーワークロードにまたがってメモリー使用を効率的に管理できるようになりました。Huge pages は標準の 4 KB ページと比較すると、動的に 2 MB ページを利用するので、アプリケーションはギガバイトやさらにはテラバイトのメモリー処理中にうまく拡張ができます。
新しいシステムの多くは Non-Uniform Memory Access (NUMA) をサポートしています。NUMA は、大規模システム用のハードウェアの設計および作成を簡素化します。しかし、アプリケーション開発に新たな複雑性を加えることにもなります。例えば、NUMA はローカルとリモートの両方でメモリーを実装し、リモートの方はローカルよりもアクセスに数倍の時間がかかります。この機能は、オペレーティングシステムやアプリケーションのパフォーマンスに影響を及ぼすので、慎重に設定してください。
2.2. Ticket Spinlocks
2.3. 動的リスト構造
2.4. Tickless カーネル
2.5. コントロールグループ
- Cgroup に割り当てられたタスクのリスト
- これらのタスクに割り当てられたリソース
- CPUsets
- メモリ
- I/O
- ネットワーク (帯域幅)
2.6. ストレージおよびファイルシステムの改善
Ext4 は Red Hat Enterprise Linux 6 のデフォルトのファイルシステムです。EXT ファイルシステムファミリーの第 4 世代になり、理論上では最大 1 エクサバイトのファイルシステムと 16 TB のシングルファイルをサポートします。Red Hat Enterprise Linux 6 は、最大 16 TB のファイルシステムと 16 TB のシングルファイルをサポートします。より大規模なストレージ能力に加えて ext4 の新機能には以下のものが含まれます。
- 範囲ベースのメタデータ
- 遅延割り当て
- ジャーナルチェック加算
XFS は堅牢かつ成熟した 64 ビットのジャーナリングファイルシステムで、単一ホスト上の非常に大規模なファイルおよびファイルシステムをサポートします。このファイルシステムは当初、SGI が開発したもので、非常に大型のサーバーおよびストレージアレイにおける長期間の稼働実績があります。XFS の機能には以下のものがあります。
- 遅延割り当て
- 動的配分のアイノード
- 未使用領域管理のスケーラビリティ用の B ツリーインデックス化
- オンラインデフラグおよびファイルシステム拡張
- 高度なメタデータ先読みアルゴリズム
従来の BIOS は、最大 2.2TB のディスクサイズをサポートしてきました。BIOS を使用する Red Hat Enterprise Linux 6 は、Global Partition Table (GPT) と呼ばれる新たなディスク構造を使うことで 2.2TB 以上のディスクをサポートします。GPT は、データディスクにのみ使用可能です。GPT は BIOS を使うブートドライブには使用できないので、ブートドライブの最大サイズは 2.2TB になります。BIOS は当初、IBM PC 用に作成されました。BIOS が最新のハードウェアに適応するように大幅に進化した一方で、Unified Extensible Firmware Interface (UEFI) は新たな最新ハードウェアをサポートするように設計されています。
重要
重要
第3章 システムパフォーマンスのモニタリングと分析
3.1. proc ファイルシステム
proc 「ファイルシステム」は、Linux カーネルの現在の状況を示すファイルの階層が含まれているディレクトリーです。これにより、アプリケーションとユーザーはシステムのカーネルビューを確認することができます。
proc ディレクトリーには、システムのハードウェアおよび実行中のプロセスに関する情報が格納されています。これらファイルのほとんどは読み取り専用ですが、(主に /proc/sys 内の) ファイルのなかには、ユーザーやアプリケーションが操作することで、設定変更をカーネルに伝達できるものもあります。
proc ディレクトリー内のファイルの表示および編集に関する詳細情報は、『導入ガイド』 を参照してください。これは http://access.redhat.com/site/documentation/Red_Hat_Enterprise_Linux/ から入手できます。
3.2. GNOME および KDE システムモニタ
GNOME システムモニタ は基本的なシステム情報を表示し、システムプロセスやリソース、ファイルシステムの使用量を監視することができます。GNOME システムモニタを開くには、端末で gnome-system-monitor コマンドを実行するか、 メニューをクリックして > を選択します。
- コンピューターのハードウェアおよびソフトウェアの基本情報を表示します。
- 実行中のプロセス、それらのプロセスの関係、各プロセスの詳細情報を表示します。表示されたプロセスにフィルターをかけたり、それらのプロセスに特定のアクションを実行することもできます (スタート、ストップ、強制終了、優先順位の変更、など)。
- 現在の CPU 使用時間、メモリおよびスワップ領域の使用量、ネットワークの使用量を表示します。
- マウントされているファイルシステムの全一覧と、ファイルシステムのタイプやマウントポイント、メモリ使用量などの各ファイルシステムの基本情報が表示されます。
KDE System Guard では、現在のシステム負荷と実行中のプロセスが確認できます。また、プロセスに対するアクションも実行できます。KDE System Guardを開くには、端末 で ksysguard コマンドを実行するか、 をクリックし > > を選択します。
- 実行中のプロセス一覧をデフォルトではアルファベット順に表示します。また、CPU 使用量や物理もしくは共有メモリ使用量、所有者、優先順位などのプロパティーでプロセスを分類することもできます。表示された結果をフィルターにかけたり、特定のプロセスを検索したり、プロセスに対して特定のアクションを実行したりすることもできます。
- CPU 使用量、メモリおよびスワップ領域使用量、ネットワーク使用量の履歴を表示します。グラフ上にマウスを持って行くと、詳細な分析とグラフのキーが表示されます。
3.3. Performance Co-Pilot (PCP)
yum install pcp
# yum install pcp/usr/share/doc/pcp-doc ディレクトリーにインストールする pcp-doc パッケージも推奨しています。
3.3.1. PCP アーキテクチャー
- コレクター
- コレクターシステムは 1 つ以上のドメインからパフォーマンスデータを収集し、分析するために保存します。コレクターには Performance Metrics Collector Daemon (
pmcd) があり、これはパフォーマンスデータのリクエストを適切な Performance Metrics Domain Agent および 1 つ以上の Performance Metrics Domain Agents (PMDA) と受け渡します。これらのエージェントは、該当ドメイン (データベース、サーバー、アプリケーションなど) についてのリクエストに関する反応を担います。PMDA は、同一コレクター上で実行しているpmcdで制御されます。 - モニター
- モニターシステムは、
pmieやpmreportなどのモニタリングツールを使って、ローカルもしくはリモートコレクターからのデータを表示、分析します。
3.3.2. PCP の設定
pmcd) と 1 つ以上の Performance Metrics Domain Agents (PMDA) を必要とします。
手順3.1 コレクターの設定
PCP のインストール
以下のコマンドを実行して、システムに PCP をインストールします。yum install pcp
# yum install pcpCopy to Clipboard Copied! Toggle word wrap Toggle overflow pmcdの起動service pmcd start
# service pmcd startCopy to Clipboard Copied! Toggle word wrap Toggle overflow 追加 PMDA の設定 (オプション)
カーネル、pmcd、per-process、memory-mapped の値、XFS、および JBD2 PMDA はデフォルトで、/etc/pcp/pmcd/pmcd.confにインストールされ、ここで設定します。追加の PMDA を設定するには、そのディレクトリーに移動し (たとえば、/var/lib/pcp/pmdas/pmdaname)、Installスクリプトを実行します。たとえば、proc用の PMDA をインストールするには、以下を実行します。cd /var/lib/pcp/pmdas/proc ./Install
# cd /var/lib/pcp/pmdas/proc # ./InstallCopy to Clipboard Copied! Toggle word wrap Toggle overflow そしてプロンプトにしたがい、コレクターシステムまたはモニターおよびコレクターシステム用に PMDA を設定します。リモートモニターをリッスン (オプション)
リモートモニターに反応するには、pmcd はポート 44321 経由でリモートモニターをリッスンできる必要があります。以下を実行して、適切なポートを開きます。iptables -I INPUT -p tcp -dport 44321 -j ACCEPT iptables save
# iptables -I INPUT -p tcp -dport 44321 -j ACCEPT # iptables saveCopy to Clipboard Copied! Toggle word wrap Toggle overflow 他のファイアウォールルールがこのポートへのアクセスをブロックしていないことを確認する必要があります。
手順3.2 リモートモニターの設定
PCP のインストール
以下のコマンドを実行して、リモートモニターシステムに PCP をインストールします。yum install pcp
# yum install pcpCopy to Clipboard Copied! Toggle word wrap Toggle overflow リモートコレクターへの接続
リモートコレクターシステムに接続するには、PCP はポート 44321 経由でリモートコレクターに連絡できる必要があります。以下を実行して、適切なポートを開きます。iptables -I INPUT -p tcp -dport 44321 -j ACCEPT iptables save
# iptables -I INPUT -p tcp -dport 44321 -j ACCEPT # iptables saveCopy to Clipboard Copied! Toggle word wrap Toggle overflow 他のファイアウォールルールがこのポートへのアクセスをブロックしていないことを確認する必要もあります。
-h オプションを付けてパフォーマンスモニタリングツールを実行することで、リモートコレクターに接続できるかどうかをテストできます。このオプションは、接続先のコレクターの IP アドレスを指定します。例を示します。
pminfo -h 192.168.122.30
# pminfo -h 192.168.122.303.4. irqbalance
--oneshot オプションで 1 回きりの実行も可能です。
- --powerthresh
- CPU が省電力モードになる前にアイドル状態になることが可能な CPU 数を設定します。しきい値を超える CPU 数が平均 softirq ワークロードを 1 標準偏差以上下回り、平均値から 1 標準偏差を超える CPU がなく、複数の irq がこれらに割り当てられている場合、CPU は省電力モードに入ります。このモードでは、CPU は irq バランシングの一部ではないので、不必要に再開されることがありません。
- --hintpolicy
- irq カーネルアフィニティーヒンティングの処理方法を決定します。有効な値は、
exact(irq アフィニティーヒンティングを常に適用)、subset(irq はバランシングされるものの、割り当てオブジェクトはアフィニティーヒンティングのサブセット)、またはignore(irq アフィニティーヒンティングを完全に無視) になります。 - --policyscript
- 各割り込みリクエストを実行するスクリプトの場所を定義します。デバイスパスおよび irq 番号が引数として渡され、irqbalance はゼロ終了コードを予想します。定義されたスクリプトでは、渡された irq の管理で irqbalance をガイドするために、ゼロもしくはそれ以上の鍵の値のペアを指定することができます。有効な鍵の値のペアとして認識されるのは、以下のものです。
- ban
- 有効な値は、
true(バランシングから渡された irq を除外) もしくはfalse(この irq でバランシングを実施) です。 - balance_level
- 渡された irq のバランシングレベルをユーザーが上書きできるようにします。デフォルトでは、バランスレベルは、irq を所有するデバイスの PCI デバイスクラスに基づきます。有効な値は、
none,package、cache、またはcoreになります。 - numa_node
- 渡された irq にはローカルとみなされる NUMA ノードを、ユーザーが上書きできるようにします。ローカルノードについての情報が ACPI で指定されていない場合は、デバイスはすべてのノードから等距離とみなされます。有効な値は、特定の NUMA ノードを識別する整数 (0 から)、および irq が全ノードから等距離であるとみなすことを指定する
-1になります。
- --banirq
- 指定された割り込みリクエスト番号のある割り込みが禁止された割り込みリストに追加されます。
IRQBALANCE_BANNED_CPUS 環境変数を使って、irqbalance によって無視される CPU のマスクを指定することもできます。
man irqbalance
$ man irqbalance3.5. ビルトインのコマンドラインモニタリングツール
toptop ツールは、実行中のシステムのプロセスを動的かつリアルタイムで表示します。システムサマリーや Linux カーネルが現在管理しているタスクなどの様々な情報の表示が可能です。また、プロセスを操作する一定の機能もあります。表示される操作と情報はどちらとも高度な設定が可能で、設定詳細は再起動後も維持するようにできます。
man top を参照してください。
psps ツールは、選択したアクティブなプロセスグループのスナップショットを撮ります。デフォルトでは、このグループは現行ユーザーが所有しているもので同一端末に関連するプロセスに限られています。
man ps を参照してください。
vmstatvmstat (Virtual Memory Statistics) は、システムのプロセス、メモリ、ページング、ブロック I/O、割り込み、CPU アクティビティについてのある時点でのレポートを出力します。
man vmstat を参照してください。
sarsar (System Activity Reporter) は、当日のその時点までのシステムアクティビティを収集し、レポートします。デフォルトでは、その日の最初から 10 分間隔で CPU 使用量を出力します。
12:00:01 AM CPU %user %nice %system %iowait %steal %idle 12:10:01 AM all 0.10 0.00 0.15 2.96 0.00 96.79 12:20:01 AM all 0.09 0.00 0.13 3.16 0.00 96.61 12:30:01 AM all 0.09 0.00 0.14 2.11 0.00 97.66 ...
12:00:01 AM CPU %user %nice %system %iowait %steal %idle
12:10:01 AM all 0.10 0.00 0.15 2.96 0.00 96.79
12:20:01 AM all 0.09 0.00 0.13 3.16 0.00 96.61
12:30:01 AM all 0.09 0.00 0.14 2.11 0.00 97.66
...man sar を参照してください。
3.6. Tuned および ktune
default- デフォルトの省電力プロファイルで、最も基本的な省電力プロファイルです。ディスクと CPU プラグインのみを使用可能にします。これは、tuned-adm をオフにすることとは違います。tuned-adm をオフにすると、tuned と ktune の両方が使用できません。
latency-performance- 標準的な遅延パフォーマンスチューニング用のサーバープロファイルです。このプロファイルは、動的チューニングメカニズムと transparent hugepages を無効にします。これは、
cpuspeedで p 状態用にperformanceガバナーを使用し、I/O スケジューラーをdeadlineに設定します。また Red Hat Enterprise Linux 6.5 およびそれ以降では、プロファイルはcpu_dma_latencyの値1を要求します。Red Hat Enterprise Linux 6.4 およびそれ以前では、cpu_dma_latencyは0の値を要求していました。 throughput-performance- 標準的なスループットのパフォーマンスチューニング用のサーバープロファイルです。システムにエンタープライズクラスのストレージがない場合に、このプロファイルが推奨されます。throughput-performance は省電力メカニズムを無効にし、
deadlineI/O スケジューラーを有効にします。CPU ガバナーは、performanceに設定されます。kernel.sched_min_granularity_ns(スケジューラーの最小の先取り粒度) は10ミリ秒に、kernel.sched_wakeup_granularity_ns(スケジューラーの再開粒度) は15ミリ秒に、vm.dirty_ratio(仮想メモリー汚染比率) は 40% に設定され、transparent huge pages が有効になります。 enterprise-storage- このプロファイルは、バッテリー駆動のコントローラーキャッシュ保護とオンディスクのキャッシュ管理などを含むエンタープライズクラスのストレージがあるエンタープライズサイズのサーバー設定に推奨されます。
throughput-performanceプロファイルと同一ですが、ファイルシステムがbarrier=0で再マウントされています。 virtual-guest- このプロファイルは、仮想マシン用に最適化されています。
enterprise-storageプロファイルをベースとしていますが、virtual-guestも仮想メモリーの swap を低減します。このプロファイルは Red Hat Enterprise Linux 6.3 以降で利用可能です。 virtual-hostenterprise-storageプロファイルに基づき、virtual-hostも仮想メモリーの swap を減らし、ダーティーページのより積極的な書き戻しを可能にします。barrier=0で root ファイルシステムおよび起動ファイルシステム以外のファイルシステムがマウントされます。さらに Red Hat Enterprise Linux 6.5 では、kernel.sched_migration_costパラメーターが5ミリ秒に設定されます。Red Hat Enterprise Linux 6.5 より前では、kernel.sched_migration_costはデフォルト値の0.5ミリ秒を使用していました。このプロファイルは Red Hat Enterprise Linux 6.3 およびそれ以降で利用可能になっています。
3.7. アプリケーションプロファイラー
3.7.1. SystemTap
/usr/share/doc/systemtap-client-version/examples ディレクトリーにインストールされます。
ネットワークモニタリングスクリプト (examples/network 内)
nettop.stp- 5 秒ごとにプロセス (プロセス ID およびコマンド) のリストをプリントします。これには、この間隔で送受信されたパケット数やプロセスが送受信したデータ量が含まれます。
socket-trace.stp- Linux カーネルの
net/socket.cファイル内の各関数をインストルメント化して、追跡データをプリントします。 tcp_connections.stp- システムが受け入れた新たな受信 TCP 接続についての情報をプリントします。この情報には UID、接続を受け入れているコマンド、コマンドのプロセス ID、接続しているポート、リクエストの発信元の IP アドレスが含まれます。
dropwatch.stp- カーネル内の場所で解放されたソケットバッファー数を 5 秒ごとにプリントします。シンボリック名を見るには、
--all-modulesオプションを使用します。
ストレージモニタリングスクリプト (examples/io 内)
disktop.stp- 読み込み/書き込みディスクの状態を 5 秒ごとに確認し、この期間の上位 10 位のエントリーを出力します。
iotime.stp- 読み取り/書き込み操作に費やされた時間と読み取り/書き込みのバイト数をプリントします。
traceio.stp- 観測された累積 I/O トラフィックに基づいて上位 10 位の実行可能ファイルを毎秒プリントします。
traceio2.stp- 指定されたデバイスへの読み取りおよび書き込みが発生する際に実行可能ファイル名およびプロセス ID をプリントします。
inodewatch.stp- 指定されたメジャー/マイナーデバイス上の指定された inode で読み取りおよび書き込みが発生するたびに、実行可能ファイル名とプロセス ID をプリントします。
inodewatch2.stp- 指定されたメジャー/マイナーデバイス上の指定された inode で属性が変更されるたびに、実行可能ファイル名、プロセス ID、属性をプリントします。
latencytap.stp スクリプトは、異なるタイプの遅延が 1 つ以上のプロセスに及ぼす影響を記録します。30 秒ごとに遅延タイプのリストをプロセスの時間またはプロセスが待機した時間の合計の多い順で分類してプリントします。これは、ストレージとネットワークの両方の遅延の原因特定で便利なものです。Red Hat では、このスクリプトで --all-modules オプションを使用して遅延イベントのマッピングを有効にすることを推奨しています。デフォルトでは、このスクリプトは /usr/share/doc/systemtap-client-version/examples/profiling ディレクトリーにインストールされます。
3.7.2. OProfile
- パフォーマンスのモニタリングサンプルが正確でない場合があります。プロセッサーは順番通りに指示を実行しない場合があるので、サンプルは割り込みを発生させた指示ではなく、近くの指示から記録される場合があります。
- OProfile はシステム全体にわたり、プロセスが複数回にわたって開始・停止することを想定しているので、複数の実行からのサンプルが集積されます。つまり、以前の実行からのサンプルを削除する必要がある場合があります。
- これは CPU 限定のプロセスでの問題の識別にフォーカスするので、他のイベント発生をロック状態で待つ間、スリープとなっているプロセスは識別しません。
/usr/share/doc/oprofile-<version> にあります。
3.7.3. Valgrind
man valgrind コマンドを使用してください。付随資料は以下の場所にもあります。
/usr/share/doc/valgrind-<version>/valgrind_manual.pdf/usr/share/doc/valgrind-<version>/html/index.html
3.7.4. Perf
perf stat- このコマンドは、実行された指示や消費されたクロックサイクルなどを含む一般的なパフォーマンスイベントの全体的な統計を提供します。オプションフラグを使ってデフォルト測定イベント以外のイベントの統計を収集することができます。Red Hat Enterprise Linux 6.4 では、
perf statを使って 1 つ以上の指定コントロールグループ (cgroups) を基にモニタリングにフィルターをかけることができます。詳細は、man ページ:man perf-statを参照してください。 perf record- このコマンドは、パフォーマンスデータを記録します。これは後で
perf reportを使って分析することができます。詳細については、man ページ:man perf-recordを参照してください。Red Hat Enterprise Linux 6.6 では、-bおよび-jのオプションが提供され、ブランチのサンプリングが可能になっています。-bオプションは選択されたブランチのサンプリングを行い、-jオプションはユーザーレベルやカーネルレベルのブランチなどの異なるタイプのブランチのサンプルを行うように調整できます。 perf report- このコマンドは、ファイルからパフォーマンスデータを読み取り、記録されたデータを分析します。詳細については、man ページ:
man perf-reportを参照してください。 perf list- このコマンドは、特定のマシン上で利用可能なイベントを一覧表示します。これらのイベントは、パフォーマンスモニタリングハードウェアとシステムのソフトウェア設定によって異なります。詳細については man ページ:
man perf-listを参照してください。 perf mem- Red Hat Enterprise Linux 6.6 から利用可能となっているこのコマンドは、指定されたアプリケーションまたはコマンドが実行するメモリーアクセス操作の各タイプの頻度をプロファイリングします。これによりユーザーは、プロファイルされたアプリケーションが実行する読み込みおよび保存操作の頻度を見ることができます。詳細は、man ページ:
man perf-memを参照してください。 perf top- このコマンドは、top ツールとよく似た機能を実行します。リアルタイムでパフォーマンスカウンタープロファイルを生成し、表示します。詳細については man ページ:
man perf-topを参照してください。 perf trace- このコマンドは、strace ツールと同様の機能を実行します。指定されたスレッドまたはプロセスが使用するシステムコールとそのアプリケーションが受信するすべてのシグナルを監視します。追加の追跡ターゲットも使用可能です。完全なリストは、man ページを参照してください。
3.8. Red Hat Enterprise MRG
- 電力管理、エラー検出、システム管理割り込みに関連する BIOS パラメーター
- 割り込みコアレッシングなどのネットワーク設定および TCP の使用
- ジャーナリングファイルシステム内でのジャーナリングアクティビティ
- システムロギング
- 割り込みおよびユーザープロセスが特定の CPU もしくはいくつかの CPU で処理されたかどうか
- Swap 領域が使われたかどうか
- out-of-memory 例外の対処方法
第4章 CPU
トポロジー
スレッド
割り込み
4.1. CPUトポロジー
4.1.1. CPU と NUMA トポロジー
- シリアルバス
- NUMA トポロジー
- システムのトポロジーは何か?
- アプリケーションは現在、どこで実行中か?
- 一番近いメモリバンクはどこか?
4.1.2. CPU パフォーマンスのチューニング
- CPU (0-3 のいずれか) がメモリアドレスをローカルのメモリコントローラーに提示します。
- メモリコントローラーがメモリアドレスへのアクセスを設定します。
- そのメモリアドレス上で、CPU が読み取り/書き込み操作を実行します。
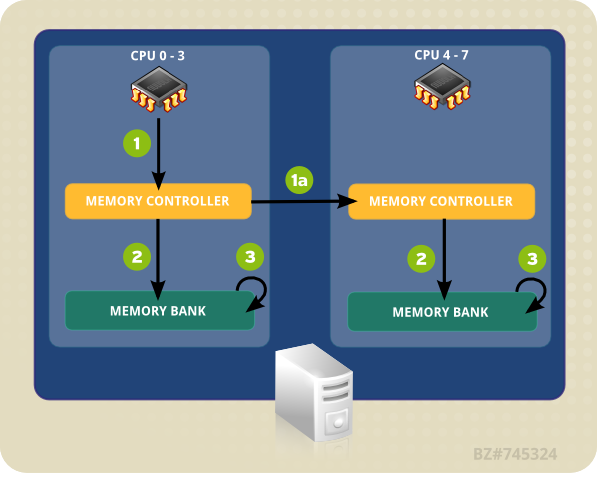
図4.1 NUMA トポロジーにおけるローカルおよびリモートのメモリアクセス
- CPU (0-3 のいずれか) がリモートのメモリアドレスをローカルのメモリコントローラーに提示します。
- このリモートのメモリアドレスに対する CPU の要請は、そのメモリアドレスがあるノードがローカルである、リモートのメモリコントローラーに渡されます。
- リモートのメモリコントローラーがリモートのメモリアドレスへのアクセスを設定します。
- そのリモートメモリアドレス上で、CPU が読み取り/書き込み操作を実行します。
- システムのトポロジー (コンポーネントの接続方法)
- アプリケーションを実行するコア
- 一番近いメモリバンクの位置
4.1.2.1. taskset を使った CPU アフィニティの設定
0x00000001 はプロセッサー 0 を、0x00000003 はプロセッサー 0 および 1 を表します。
taskset -p mask pid
# taskset -p mask pidtaskset mask -- program
# taskset mask -- program-c オプションを使って別個のプロセッサーのコンマ区切りの一覧表やプロセッサーの範囲を提供することもできます。
taskset -c 0,5,7-9 -- myprogram
# taskset -c 0,5,7-9 -- myprogramman taskset を参照してください。
4.1.2.2. numactl を使った NUMA ポリシーのコントロール
numactl は、指定されたスケジュールまたはメモリプレースメントポリシーでプロセスを実行します。選択されたポリシーは、そのプロセスとその子プロセスすべてに設定されます。numactl は共有メモリセグメントもしくはファイル向けに維持するポリシーも設定でき、プロセスの CPU アフィニティおよびメモリアフィニティも設定できます。 /sys ファイルシステムを使ってシステムトポロジーを決定します。
/sys ファイルシステムには、CPU とメモリ、周辺機器が NUMA 相互接続経由でどのように接続されているかについての情報が含まれています。特に、/sys/devices/system/cpu ディレクトリーには、システムの CPU がそれぞれどのように接続されているかについての情報が含まれています。/sys/devices/system/node ディレクトリーには、システム内の NUMA ノードとノード間の相対距離についての情報が含まれています。
--show- 現行プロセスの NUMA ポリシー設定を表示します。このパラメーターにはさらなるパラメーターは必要なく、以下のように使用できます。
numactl --show --hardware- システム上で利用可能なノードのインベントリーを表示します。
--membind- 指定のノードからのメモリのみを割り当てます。これを使用中は、このノード上のメモリが不足すると割り当ては失敗します。このパラメーターの使用方法は、
numactl --membind=nodes programです。ここでは、nodes はメモリの割り当て元となるノードのリストで、program はそのノードからメモリを割り当てられる必要のあるプログラムのことです。ノード番号は、コンマ区切りの一覧表か範囲、もしくはこの 2 つの組み合わせになります。詳細は、numactl の man ページ:man numactlを参照してください。 --cpunodebind- 指定ノードに属する CPU上のコマンド (およびその子プロセス) のみを実行します。このパラメーターの使用方法は、
numactl --cpunodebind=nodes programです。ここでは、nodes は指定プログラム (program) をバインドする CPU のあるノード一覧のことです。ノード番号は、コンマ区切りの一覧表か範囲、もしくはこの 2 つの組み合わせになります。詳細は、numactl の man ページ:man numactlを参照してください。 --physcpubind- 指定ノード上のコマンド (およびその子プロセス) のみを実行します。このパラメーターの使用方法は、
numactl --physcpubind=cpu programです。ここでは、cpu は/proc/cpuinfoのプロセッサーフィード内で表示されている物理 CPU番号のコンマ区切り一覧で、program はこれらの CPU 上でのみ実行するプログラムです。CPU は、現行cpusetに相対的にも指定できます。詳細は、numactl の man ページ:man numactlを参照してください。 --localalloc- 現行ノード上に常に割り当てられるメモリを指定します。
--preferred- 可能な場合、メモリは指定のノードに割り当てられます。指定ノードへのメモリ割り当てができない場合、別のノードにフォールバックします。このオプションでは以下のように 1 つのノード番号のみを使います。
numactl --preferred=node。詳細は numactl の man ページ:man numactlを参照してください。
man numa(7) を参照してください。
4.1.3. ハードウェアパフォーマンスポリシー (x86_energy_perf_policy)
CPUID.06H.ECX.bit3 で示されます。
x86_energy_perf_policy は root 権限を必要とし、デフォルトですべての CPU で実行できます。
x86_energy_perf_policy -r
# x86_energy_perf_policy -rx86_energy_perf_policy profile_name
# x86_energy_perf_policy profile_nameperformance- プロセッサーは省エネルギーのためにパフォーマンスを犠牲にすることを嫌がります。これがデフォルト値です。
normal- 大幅な省エネルギーの可能性がある場合、プロセッサーはマイナーなパフォーマンス低下を許可します。これは、ほとんどのデスクトップおよびサーバーで妥当な設定です。
powersave- プロセッサーは、エネルギー効率を最大化するために大幅なパフォーマンス低下の可能性を受け入れます。
man x86_energy_perf_policy を参照してください。
4.1.4. turbostat
root 権限が必要になります。また、不変タイムスタンプカウンターをサポートしているプロセッサーと、APERF および MPERF のモデル固有レジスタが必要になります。
- pkg
- プロセッサーのパッケージ番号。
- core
- プロセッサーのコア番号。
- CPU
- Linux CPU (論理プロセッサー) 番号。
- %c0
- CPU リタイヤ状態の指示の間隔のパーセント。
- GHz
- CPU が c0 状態にあった間の平均クロック速度。この数値が TSC の値よりも高い場合は、CPU はターボモードになります。
- TSC
- 間隔全体にわたる平均クロック速度。この数値が TSC の値よりも低い場合は、CPU はターボモードになります。
- %c1、%c3、および %c6
- プロセッサーが c1、c3、または c6 の各状態だった間隔のパーセント。
- %pc3 または %pc6
- プロセッサーが pc3 または pc6 の各状態だった間隔のパーセント。
-i オプションを使ってカウンター結果の間の異なる期間を指定します。たとえば、turbostat -i 10 を実行すると、10 秒ごとに結果がプリントされます。
注記
man turbostat を参照してください。
4.1.5. numastat
重要
numastat でオプションやパラメーターなし) はツールのこれまでのバージョンと厳密な互換性を維持していますが、オプションやパラメーターが加えられるとこのコマンドの出力コンテンツとフォーマットが大幅に変わることに注意してください。
numastat を実行すると、各ノードの以下のイベントカテゴリーごとに占有されているメモリのページ数を表示します。
numa_miss および numa_foreign の値が低いと、CPU パフォーマンスが優れていることを示します。
デフォルトの追跡カテゴリー
- numa_hit
- 当該ノードに割り当てを試みたもので成功した数。
- numa_miss
- 別のノードに割り当てを試みたもので、当初の意図されたノードがメモリ不足だったために当該ノードに割り当てられた数。各
numa_missイベントには、対応するnuma_foreignイベントが別のノード上にあります。 - numa_foreign
- 当初は当該ノードへの割り当てを意図したもので、別のノードに割り当てられた数。
numa_foreignイベントには対応するnuma_missイベントが別のノード上にあります。 - interleave_hit
- 当該ノードに試みたインターリーブポリシーの割り当てで成功した数。
- local_node
- 当該ノード上のプロセスが当該ノード上へのメモリ割り当てに成功した回数。
- other_node
- 別のノード上のプロセスが当該ノード上にメモリを割り当てた回数。
-c- 表示情報の表を横方向に縮小します。これは、NUMA ノード数が多いシステムでは有用ですが、コラムの幅とコラム間の間隔はあまり予測可能ではありません。このオプションが使用されると、メモリ量は一番近いメガバイトに切り上げ/下げられます。
-m- ノードあたりでのシステム全体のメモリ使用量を表示します。
/proc/meminfoにある情報に類似したものです。 -n- オリジナルの
numastatコマンド (numa_hit、numa_miss、numa_foreign、interleave_hit、local_node、other_node) と同一情報を表示しますが、測定単位にメガバイトを使用した更新フォーマットが使われます。 -p pattern- 指定されたパターンのノードごとのメモリー情報を表示します。pattern の値が数字の場合は、numastat は数値プロセス識別子とみなされます。それ以外の場合は、numastat は指定されたパターンのプロセスコマンドラインを検索します。
-pオプションの値の後に入力されるコマンドライン引数は、フィルターにかける追加のパターンとみなされます。追加のパターンは、フィルターを絞り込むのではなく拡張します。 -s- 表示データを降順に並び替えるので、(
totalコラムの) メモリ消費量の多いものが最初に来ます。オプションで node を指定すると、表は node コラムにしたがって並び替えられます。このオプションの使用時には、以下のように node 値は-sオプションのすぐあとに来る必要があります。numastat -s2
numastat -s2Copy to Clipboard Copied! Toggle word wrap Toggle overflow このオプションと値の間に空白スペースを入れないでください。 -v- 詳細情報を表示します。つまり、複数プロセスのプロセス情報が各プロセスの詳細情報を表示します。
-V- numastat のバージョン情報を表示します。
-z- 情報情報から値が 0 の行と列のみを省略します。表示目的で 0 に切り下げられている 0 に近い値は、表示出力から省略されません。
4.1.6. NUMA アフィニティ管理デーモン (numad)
/proc ファイルシステムからの情報にアクセスし、ノードごとに利用可能なシステムリソースを監視します。その後はデーモンが、十分な配置メモリと最適な NUMA パフォーマンスのための CPU リソースがある NUMA ノード上に重要なプロセスを配置します。プロセス管理の最新のしきい値は 1 つの CPU の少なくとも 50%と 300 MB のメモリです。numad はリソース使用量のレベルの維持を図り、割り当ての再バランス化が必要な場合は NUMA ノード間でプロセスを移動します。
-w オプションで配置前アドバイスを使用する方法については、man ページ: man numad を参照してください。
4.1.6.1. numad の利点
4.1.6.2. オペレーションモード
注記
/sys/kernel/mm/ksm/merge_nodes の調整可能な値を 0 に変更して NUMA にまたがるページのマージを回避します。カーネルメモリーが計算した統計は、大量のクロスノードのマージ後にはそれぞれの間で相反する場合があります。そのため、KSM デーモンが大量のメモリーをマージすると、numad は混乱する可能性があります。システムに未使用のメモリーが大量にあると、KSM デーモンをオフにして無効にすることでパフォーマンスが高まる場合があります。
- サービスとして使用
- 実行可能ファイルとして使用
4.1.6.2.1. numad をサービスとして使用
service numad start
# service numad startchkconfig numad on
# chkconfig numad on4.1.6.2.2. numad を実行可能ファイルとして使用
numad
# numad/var/log/numad.log にログ記録されます。
numad -S 0 -p pid
# numad -S 0 -p pid-p pid- 指定の pid を明示的な対象一覧に加えます。指定されたプロセスは、 numad プロセスの重要度しきい値に達するまで管理されません。
-S mode-Sパラメーターはプロセススキャニングのタイプを指定します。例のように0に設定すると numad 管理を明示的に付加プロセスに限定します。
numad -i 0
# numad -i 0man numad を参照してください。
4.2. CPU のスケジューリング
- リアルタイムポリシー
- SCHED_FIFO
- SCHED_RR
- 通常のポリシー
- SCHED_OTHER
- SCHED_BATCH
- SCHED_IDLE
4.2.1. リアルタイムのスケジューリングポリシー
SCHED_FIFO- このポリシーは static priority scheduling (静的優先順位スケジューリング) とも呼ばれます。これは、各スレッドの固定優先順位 (1 から 99 の間で) を定義するためです。このスケジューラーは、SCHED_FIFO スレッド一覧を優先順位でスキャンして、実行準備ができているもので最も優先順位が高いスレッドをスケジュールします。このスレッドは、ブロックまたは終了するか、実行準備ができたより優先順位の高いスレッドに取って代わられるまで実行します。優先順位が一番低いリアルタイムスレッドでも、非リアルタイムポリシーのスレッドよりも先にスケジュールされます。リアルタイムスレッドが 1 つだけの場合は、
SCHED_FIFOの優先順位の値は無関係になります。 SCHED_RRSCHED_FIFOポリシーのラウンドロビン版です。SCHED_RRスレッドも固定優先順位 (1 から 99 の間で) が与えられます。しかし、優先順位が同じスレッドは、特定のクォンタム、または時間枠内でラウンドロビンでスケジュールされます。sched_rr_get_interval(2)システムコールはこの時間枠の値を返しますが、時間枠の長さをユーザーが設定することはできません。このポリシーは、同じ優先順位で複数のスレッドを実行する必要がある場合に有用です。
SCHED_FIFO スレッドは、ブロックまたは終了するか、より優先順位の高いスレッドに取って代わられるまで実行します。このため、優先順位を 99 に設定することは推奨されません。これだと、プロセスをマイグレーションやウォッチドッグスレッドと同じ優先順位とすることになってしまいます。スレッドが演算ループに入ってしまったためにこれらのスレッドがブロックされると、実行不可能となってしまいます。この状況では、ユニプロセッサーシステムは最終的にはロックアップしてしまいます。
SCHED_FIFO ポリシーには帯域幅制限メカニズムが含まれます。これによりリアルタイムのアプリケーションプログラマーを、CPU を独占する可能性のあるリアルタイムタスクから保護します。このメカニズムは、以下の /proc ファイルシステムパラメーターで調整できます。
/proc/sys/kernel/sched_rt_period_us- CPU 帯域幅の 100% と考えられる時間をマイクロ秒で定義します (「us」はプレーンテキストで「µs」に一番近いもの)。デフォルト値は 1000000µs もしくは 1 秒です。
/proc/sys/kernel/sched_rt_runtime_us- リアルタイムスレッドの実行に当てられる時間をマイクロ秒で定義します (「us」はプレーンテキストで「µs」に一番近いもの)。デフォルト値は 950000µs もしくは 0.95 秒です。
4.2.2. 通常のスケジューリングポリシー
SCHED_OTHER、SCHED_BATCH、SCHED_IDLE の 3 つがあります。しかし、SCHED_BATCH および SCHED_IDLE ポリシーは優先順位が非常に低いものを対象としており、このためパフォーマンスチューニングガイドにおける関心度は低くなっています。
SCHED_OTHERまたはSCHED_NORMAL- デフォルトのスケジューリングポリシーです。このポリシーは、Completely Fair Scheduler (CFS) を使ってこのポリシーを使用するすべてのスレッドに対して公平なアクセス期間を提供します。CFS は、部分的に各プロセススレッドの
niceness値に基づいて動的にな優先順位リストを確立します。(このパラメーターと/procファイルシステムの詳細に関しては、『導入ガイド』 を参照してください。) これによりユーザーは、プロセスの優先順位に関して間接的なレベルのコントロールを手にしますが、動的な優先順位リストを直接変更できるのは CFS を使った場合のみです。
4.2.3. ポリシーの選択
SCHED_OTHER を使ってシステムが CPU 使用率を管理するようにします。
SCHED_FIFO を使います。スレッド数が少ない場合は、CPU ソケットを孤立させ、スレッドをソケットのコアに移動することでそのコア上で他のスレッドと時間を競合することがないようにする方法を考慮してください。
4.3. 割り込みおよび IRQ チューニング
/proc/interrupts ファイルは、I/O デバイスあたりの CPU あたりの割り込み数を一覧表示します。表示されるのは、IRQ 番号、各 CPU コアが処理するその割り込みの番号、割り込みのタイプ、その割り込みを受信するために登録されているドライバーのコンマ区切り一覧、です。(詳細に関しては、proc(5) の man ページ: man 5 proc を参照してください。)
smp_affinity、があり、これはその IRQ の ISR の実行を許可する CPU コアを定義します。このプロパティーは、割り込みアフィニティとアプリケーションのスレッドアフィニティの両方を 1 つ以上の特定の CPU コアに割り当てることでアプリケーションのパフォーマンスを改善します。これにより、指定割り込みとアプリケーションスレッド間のキャッシュライン共有が可能になります。
/proc/irq/IRQ_NUMBER/smp_affinity ファイルに保存され、root ユーザーはこれを閲覧、修正できます。このファイルに保存された値は 16 進法のビットマスクで、システムの全 CPU コアを表します。
grep eth0 /proc/interrupts
# grep eth0 /proc/interrupts
32: 0 140 45 850264 PCI-MSI-edge eth0smp_affinity ファイルの位置を特定します。
cat /proc/irq/32/smp_affinity f
# cat /proc/irq/32/smp_affinity
ff で、これはシステム内のどの CPU でも IRQ が実行できることを意味します。以下のようにこの値を 1 に設定すると、CPU 0 のみがこの割り込みを実行できることになります。
echo 1 >/proc/irq/32/smp_affinity cat /proc/irq/32/smp_affinity
# echo 1 >/proc/irq/32/smp_affinity
# cat /proc/irq/32/smp_affinity
1smp_affinity 値を別々の 32 ビットグループに設定することができます。32 コアを超えるシステムでは、これが必要になります。例えば、以下の例では IRQ 40 が 64 コアシステムの全コア上で実行されることを示しています。
cat /proc/irq/40/smp_affinity ffffffff,ffffffff
# cat /proc/irq/40/smp_affinity
ffffffff,ffffffffecho 0xffffffff,00000000 > /proc/irq/40/smp_affinity cat /proc/irq/40/smp_affinity
# echo 0xffffffff,00000000 > /proc/irq/40/smp_affinity
# cat /proc/irq/40/smp_affinity
ffffffff,00000000注記
smp_affinity を修正することでハードウェアを設定し、割り込みを特定の CPU で実行する決定がカーネルからの干渉なしにハードウェアレベルでできるようになります。
4.4. CPU 周波数ガバナー
cpufreq ガバナーは常に、より高いまたは低い周波数への変更を促す動作についてのルールセットに基づいて、CPU の周波数を決定します。
cpufreq_ondemand ガバナーがシステムに負荷がある時に高い CPU 周波数でより高いパフォーマンスを、またシステムの負荷が高くないときには低い CPU 周波数で省電力を提供することから、ほとんどの状況でこのガバナーを推奨しています。
cpufreq_performance ガバナーを使用します。このガバナーは、できるだけ高い CPU 周波数を使用してタスクができるだけ迅速に実行されるようにします。このガバナーは、スリープやアイドルなどの省電力メカニズムを使用しないので、データセンターや類似の大型導入には推奨されません。
手順4.1 ガバナーの有効化および設定
- cpupowerutils がインストールされていることを確認します。
yum install cpupowerutils
# yum install cpupowerutilsCopy to Clipboard Copied! Toggle word wrap Toggle overflow - 使用したいドライバーが利用可能であることを確認します。
cpupower frequency-info --governors
# cpupower frequency-info --governorsCopy to Clipboard Copied! Toggle word wrap Toggle overflow - ドライバーが利用可能でない場合は、
modprobeコマンドを使用してそのドライバーをシステムに追加します。たとえば、ondemandガバナーを追加するには、以下を実行します。modprobe cpufreq_ondemand
# modprobe cpufreq_ondemandCopy to Clipboard Copied! Toggle word wrap Toggle overflow - cpupower コマンドラインツールを使ってガバナーを一時的に設定します。たとえば、
ondemandガバナーを設定するには、以下を実行します。cpupower frequency-set --governor ondemand
# cpupower frequency-set --governor ondemandCopy to Clipboard Copied! Toggle word wrap Toggle overflow
4.5. Red Hat Enterprise Linux 6 での NUMA 機能強化
4.5.1. ベアメタルおよびスケーラビリティの最適化
4.5.1.1. トポロジー認識における機能強化
- トポロジー検出の強化
- この機能により、オペレーティングシステムは低レベルのハードウェア詳細 (論理 CPU やハイパースレッド、コア、ソケット、NUMA ノード、ノード間のアクセス時間など) を起動時に検出でき、システム上の処理を最適化できます。
- Completely Fair Scheduler (CFS)
- この新たなスケジューリングモードは、ランタイムが有効なプロセス間で同等に共有されるようにします。これをトポロジー検出と組み合わせることで、プロセスが同一ソケット内の CPU にスケジュールされ、不経済なリモートメモリアクセスを避けることができます。また、キャンセルコンテンツが可能な場所に確実に保存されるようにします。
mallocmallocは、プロセスに割り当てられるメモリのリージョンがプロセスが実行されるコアに物理的にできるだけ近くなるように最適化されました。これにより、メモリのアクセス速度が高まっています。- skbuff I/O バッファ割り当て
mallocと同様に、デバイス割り込みなどの I/O 操作を処理する CPU に物理的に一番近いメモリを使用するように最適化されています。- デバイス割り込みアフィニティ
- デバイスドライバーが記録した、どの CPU がどの割り込みを処理するかという情報を使って、同一の物理ソケット内の CPU に割り込み処理を限定できます。これにより、キャンセルアフィニティが保存され、ソケット間の高ボリュームな通信が制限されます。
4.5.1.2. マルチプロセッサー同期における機能強化
- Read-Copy-Update (RCU) ロック
- 通常、ロックの 90% は読み取り専用目的で取得されます。RCU ロックは、アクセスされているデータが修正されていない場合、排他アクセスロックを取得する必要性を取り除きます。このロッキングモードは、ページキャッシュメモリの割り当てに使用されます。ロッキングが使用されるのは、割り当てもしくは解放操作のみです。
- CPU 別およびソケット別のアルゴリズム
- 多くのアルゴリズムは、同一ソケット上の 協同 CPU のロック調整を行うために更新され、より粒度の細かいロッキングを可能にしています。多くのグローバル spinlock はソケットごとのロッキング方法に置換されています。また、アップデートされたメモリアロケーターゾーンと関連メモリのページ一覧により、操作の割り当てもしくは解放の実行時に、メモリ割り当て論理がより効率的にメモリマッピングデータ構造のサブセットを行き来できます。
4.5.2. 仮想化の最適化
- CPU ピン設定
- 仮想ゲストを特定のソケットで実行するよう固定します。これは、ローカルキャッシュの使用を最適化し、不経済なソケット間の通信とリモートメモリのアクセスの必要性を排除するためです。
- transparent hugepages (THP)
- THP を有効にすると、システムは連続する大量メモリに対して自動的に NUMA 認識メモリの割り当てを実行します。これにより、ロック競合と必要なトランスレーションルックアサイドバッファ (TLB) のメモリ管理操作回数が減少するとともに、仮想化ゲストのパフォーマンスが最大 20% 向上します。
- カーネルベースの I/O 実装
- 仮想ゲストの I/O サブシステムがカーネルに実装されており、大量のコンテキストスイッチングと同期、通信オーバーヘッドが回避されることで、ノード間の通信およびメモリアクセスの時間が大幅に削減されます。
第5章 メモリ
5.1. Huge トランスレーションルックアサイドバッファ (HugeTLB)
/usr/share/doc/kernel-doc-version/Documentation/vm/hugetlbpage.txt を参照してください。
5.2. Huge pages および transparent huge pages
- ハードウェアのメモリ管理ユニットでページテーブルエントリの数を増やす。
- ページサイズを拡大する。
5.3. Valgrind を使ったメモリ使用量のプロファイリング
valgrind --tool=toolname program
valgrind --tool=toolname programmemcheck、massif、cachegrind のいずれか)、program を Valgrind でプロファイリングするプログラム名に置き換えます。Valgrind のインストルメンテーションを使うと、プログラムの実行が通常よりも遅くなることに留意してください。
man valgrind コマンドで表示するか、以下の場所で見つけられます。
/usr/share/doc/valgrind-version/valgrind_manual.pdf/usr/share/doc/valgrind-version/html/index.html
5.3.1. Memcheck を使ったメモリ使用量のプロファイリング
valgrind program で --tool=memcheck 指定せずに実行できます。本来発生すべきでないメモリアクセスや未定義もしくは初期化されていない値の使用、誤って解放されたヒープメモリ、重複するポインター、メモリリークなどの検出や診断が難しい多くのメモリエラーを検出し、それらについてレポートします。Memcheck を使うと、プログラムは通常の実行時に比べて、10-30 倍の時間がかかります。
/usr/share/doc/valgrind-version/valgrind_manual.pdf に含まれている Valgrind の資料に詳細が説明されています。
--leak-check- これを有効にすると、Memcheck はクライアントプログラムの完了時にメモリリークを検索します。デフォルト値は
summaryで、これは発見されたリーク数を出力します。使用可能な他の値はyesとfullで、両方とも個別リークの詳細を提供します。また、noを使用すると、メモリリークチェックが無効になります。 --undef-value-errors- これを有効にすると (
yesに設定)、Memcheck は未定義の値が使用された際にレポートします。無効にすると (noに設定)、未定義の値エラーはレポートされません。デフォルトでは有効になっており、無効にすると Memcheck スピードが若干高まります。 --ignore-ranges- Memcheck がアドレス指定能力をチェックする際に無視する 1 つ以上の範囲をユーザーが指定できるようになります。複数の範囲は以下のようにコンマで区切ります。
--ignore-ranges=0xPP-0xQQ,0xRR-0xSS
/usr/share/doc/valgrind-version/valgrind_manual.pdf にある資料を参照してください。
5.3.2. Cachegrind を使ったキャッシュ使用量のプロファイリング
valgrind --tool=cachegrind program
# valgrind --tool=cachegrind program- 第 1 レベルの指示キャッシュ読み取り (または実行された指示) と読み取りミス、および最終レベルのキャッシュ指示読み取りミス
- データキャッシュ読み取り (またはメモリ読み取り)、読み取りミス、最終レベルのキャッシュデータ読み取りミス
- データキャッシュ書き込み (またはメモリ書き込み)、書き込みミス、最終レベルのキャッシュ書き込みミス
- 実行済みおよび間違って予測された条件分岐
- 実行済みおよび間違って予測された間接分岐
cachegrind.out.pid。ここでの pid は Cachegrind を実行するプログラムのプロセス IDになります) により詳細なプロファイリング情報を書き込みます。このファイルは以下のように、付随する cg_annotate ツールでさらに処理可能です。
cg_annotate cachegrind.out.pid
# cg_annotate cachegrind.out.pid注記
cg_diff first second
# cg_diff first second--I1- コンマ区切りで最初のレベルの指示キャッシュのサイズ、結合性、行のサイズを指定します:
--I1=size,associativity,line size. --D1- コンマ区切りで最初のレベルのデータキャッシュのサイズ、結合性、行のサイズを指定します:
--D1=size,associativity,line size. --LL- コンマ区切りで最終レベルのキャッシュのサイズ、結合性、行のサイズを指定します:
--LL=size,associativity,line size. --cache-sim- キャッシュアクセスおよびミスの数の収集を有効化/無効化します。デフォルト値は
yes(有効) です。このオプションと--branch-simの両方を無効にすると、Cachegrind には収集する情報がなくなります。 --branch-sim- 分岐指示および予想を誤った数の収集を有効化/無効化します。これは Cachegrind を約 25% 遅くするので、デフォルトは
no(無効) に設定されています。このオプションと-cache-simの両方を無効にすると、Cachegrind には収集する情報がなくなります。
/usr/share/doc/valgrind-version/valgrind_manual.pdf にある資料を参照してください。
5.3.3. Massif を使ったヒープおよびスタック領域のプロファイリング
massifを使用する Valgrind ツールとして指定します。
valgrind --tool=massif program
# valgrind --tool=massif programmassif.out.pid と呼ばれるファイルに書き込まれます。ここでは、pid は指定されたprogram のプロセス ID になります。
ms_print コマンドでグラフ化することも可能です。
ms_print massif.out.pid
# ms_print massif.out.pid--heap- ヒーププロファイリングを実行するかどうかを指定します。デフォルト値は
yesです。このオプションをnoに設定すると、ヒーププロファイリングを無効にできます。 --heap-admin- ヒーププロファイリングの有効時に管理用に使用するブロックあたりのバイト数を指定します。デフォルト値はブロックあたり
8バイトです。 --stacks- スタックプロファイリングを実行するかどうかを指定します。デフォルト値は
no(無効) です。スタックプロファイリングを有効にするには、このオプションをyesに設定します。ただし、この設定では Massif が大幅に遅くなることに留意してください。また、プロファイリングされているプログラムがコントロールするスタック部分のサイズをより分かりやすく示すために、メインスタックはスタート時にサイズがゼロであると Massif が仮定していることにも注意してください。 --time-unit- プロファイリングに使用される時間の単位を指定します。このオプションには 3 つの有効な値があります。実行済みの指示 (
i) - これはデフォルト値で、ほとんどのケースに使えます。リアルタイム (ms、ミリ秒) - 特定のインスタンスでは有用です。ヒープ上に割り当て/解放されたバイトおよび/もしくはスタック (B) - これは異なるマシンで最も再現可能なので、非常に短期稼働のプログラムやテスト目的で有用です。このオプションは、ms_printで Massif 出力をグラフ化する際に有用です。
/usr/share/doc/valgrind-version/valgrind_manual.pdf にある資料を参照してください。
5.4. 容量のチューニング
overcommit_memory を一時的に 1 に設定するには、以下のように実行します。
echo 1 > /proc/sys/vm/overcommit_memory
# echo 1 > /proc/sys/vm/overcommit_memorysysctl コマンドを使用する必要があります。詳細については、『導入ガイド』 を参照してください。http://access.redhat.com/site/documentation/Red_Hat_Enterprise_Linux/ から入手できます。
容量関連のメモリのチューニング可能なパラメーター
/proc/sys/vm/ にあります。
overcommit_memory- 大量メモリの要求を受け入れるか拒否するかを決定する条件を定義します。このパラメーターには 3 つの値があります。
0— デフォルト設定。カーネルがメモリの空き容量を概算し、明らかに無効な要求を失敗させることで、ヒューリスティックなメモリオーバーコミット処理を実行します。残念ながら、メモリは厳密なアルゴリズムではなくヒューリスティックなアルゴリズムを使用して割り当てられるため、この設定でシステム上のメモリの空き容量がオーバーロードとなる場合があります。1— カーネルはメモリオーバーコミット処理を行いません。この設定では、メモリのオーバーロードの可能性が高くなりますが、メモリ集約型のタスクのパフォーマンスも向上します。2— カーネルは、利用可能なスワップとovercommit_ratioで指定されている物理 RAM の割合の合計とメモリが同等もしくはそれよりも大きい場合の要求を拒否します。メモリのオーバーコミットのリスクを減らしたい場合は、この設定が最適です。注記
この設定は、スワップ領域が物理メモリよりも大きいシステムにのみ推奨されます。
overcommit_ratioovercommit_memoryが2に設定されている場合に考慮される物理 RAM の割合を指定します。デフォルト値は50です。max_map_count- プロセスが使用可能なメモリマップ領域の最大数を定義します。ほとんどのケースでは、適切なデフォルト値は
65530です。アプリケーションがこのファイル数よりも多くマッピングする必要がある場合は、この値を増やします。 nr_hugepages- カーネルで設定される hugepages の数を定義します。デフォルト値は 0 です。システム内に物理的に連続する空白ページが十分にある場合のみ、hugepages を割り当てる (もしくは解放する) ことが可能です。このパラメーターで保持するページは、他の目的には使えません。詳細はインストール済み資料
/usr/share/doc/kernel-doc-kernel_version/Documentation/vm/hugetlbpage.txtを参照してください。Oracle のデータベースワークロードには、システム上で実行されているデータベースすべてのシステムグローバルエリアの合計よりもわずかに大きいサイズと同等の hugepage 数を Red Hat では推奨しています。データベースのインスタンスあたり 5 つの追加 hugepage で十分です。
容量関連のカーネルの設定可能なパラメーター
/proc/sys/kernel/ にあります。
msgmax- メッセージキューでの単一メッセージの最大許容サイズをバイト単位で定義します。この値は、キューのサイズ (
msgmnb) を超えることはできません。デフォルト値は65536です。 msgmnb- 単一メッセージキューの最大サイズをバイト単位で定義します。デフォルト値は
65536バイトです。 msgmni- メッセージキュー識別子の最大数を定義します (つまり、キューの最大数)。デフォルト値は低メモリーページの数で増大します。計算式は、全ページ数から高メモリーページ数を引き、その結果を 32 で割り、バイト数単位のページサイズでそれを掛け、最後に MSGMNB の値で割ります。
- sem
- プロセスとスレッドの同期を促進するセマフォは通常、データベースのワークロードを助けるように設定されます。推奨値はデータベースによって異なります。セマフォの値の詳細については、ご使用のデータベースの資料を参照してください。このパラメーターは空白で区切られた 4 つの値を取り、それらは SEMMSL、SEMMNS、SEMOPM、および SEMMNI を表します。
shmall- 一度にシステム上で使用可能な共有メモリーページの合計数を定義します。Red Hat ではデータベースのワークロードの場合、この値を
shmmaxを hugepage サイズで割った結果に設定することを推奨しています。ただし、Red Hat では推奨値をベンダー資料で確認することを推奨しています。 shmmax- カーネルが許可する共有メモリーセグメントの最大数をバイト数単位で定義します。Red Hat ではデータベースのワークロードの場合、この値をシステムの総メモリーサイズの 75% 以下にすることを推奨しています。ただし、Red Hat では推奨値をベンダー資料で確認することを推奨しています。
shmmni- システム全体の共有メモリセグメントの最大数を定義します。デフォルト値は、64 ビットと 32 ビット の両方のアーキテクチャーで
4096です。 threads-max- システム全体でカーネルが一度に使用するスレッド (タスク) の最大数を定義します。デフォルト値は、カーネルの
max_threads値と同等です。使用されている式は以下のとおりです。max_threads = mempages / (8 * THREAD_SIZE / PAGE_SIZE )
max_threads = mempages / (8 * THREAD_SIZE / PAGE_SIZE )Copy to Clipboard Copied! Toggle word wrap Toggle overflow threads-maxの最低値は20です。
容量関連のファイルシステムのチューニング可能なパラメーター
/proc/sys/fs/ にあります。
aio-max-nr- すべてのアクティブな非同期 I/O コンテキスト内で許可されるイベントの最大数を定義します。デフォルト値は
65536です。この値を変更しても、カーネルデータ構造を事前に割り当てたり、サイズの変更がされないことに留意してください。 file-max- カーネルが割り当てるファイルハンドルの最大数を一覧表示します。デフォルト値は、カーネル内の
files_stat.max_filesの値と一致し、これは(mempages * (PAGE_SIZE / 1024)) / 10もしくはNR_FILE(Red Hat Enterprise Linux では 8192) のどちらか大きい方に設定されます。このファイルで設定値を高くすると、使用可能なファイルハンドルの欠如で発生したエラーを解決できます。
Out of Memory (メモリ不足) 強制終了のチューニング可能な パラメーター
/proc/sys/vm/panic_on_oom パラメーターを 0 に設定すると、OOM 発生時にカーネルが oom_killer 機能を呼び出します。通常は、oom_killer は非承認のプロセスを強制終了し、システムは維持されます。
oom_killer 機能で強制終了するプロセスの制御能力が高まります。これは、proc ファイルシステムの /proc/pid/ にあり、ここでの pid はプロセス ID 番号になります。
oom_adj- 値を
-16から15の間で定義して、プロセスのoom_scoreの決定に役立ちます。oom_scoreの値が高いと、oom_killerでプロセスが強制終了される可能性が高まります。oom_adjの値を-17に設定すると、そのプロセスのoom_killerは無効になります。重要
調整されたプロセスによって生成されたプロセスは、いずれもそのプロセスのoom_scoreを継承します。例えば、sshdプロセスがoom_killer機能から保護されているとすると、その SSH セッションが開始したプロセスもすべて保護されることになります。これは、OOM 発生時にシステムを救助するoom_killer機能の能力に影響します。
5.5. 仮想メモリのチューニング
swappiness- 0 から 100 の値でシステムがスワップを行う程度を制御します。値が高い場合はシステムのパフォーマンスを優先し、物理メモリがアクティブでない場合にメモリからプロセスを積極的にスワップします。値が低いと対話機能を優先し、できるだけ長く物理メモリからのプロセスのスワップを回避することから、反応の待ち時間が低下します。デフォルト値は
60です。データベースワークロードでは、swappinessの値を高く設定することは推奨されません。たとえば、Oracle データベースでは、swappinessの値を10にすることを Red Hat では推奨しています。vm.swappiness=10
vm.swappiness=10Copy to Clipboard Copied! Toggle word wrap Toggle overflow min_free_kbytes- システム全体で空白としておく最低限のキロバイト数です。この値は各低メモリゾーンで警告を発生させる値の計算に使われます。計算後、そのサイズに比例する保存済みの空白ページ数が割り当てられます。
警告
このパラメーターを設定する際には注意してください。値が高すぎたり低すぎたりすると、損害を与える可能性があります。min_free_kbytesの設定が低すぎると、システムによるメモリの回収が妨げられます。これによりシステムがハングし、メモリ不足によって複数のプロセスが強制終了される可能性があります。しかしこの値を高く設定しすぎると (システムメモリ全体の 5-10%)、システムが即座にメモリ不足に陥ります。Linux は、利用可能な RAM すべてを使ってファイルシステムデータをキャッシュするように設計されています。min_free_kbytesの値を高く設定すると、システムがメモリ回収に時間を費やしすぎることになります。 dirty_ratio- パーセントの値を定義します。ダーティーデータの writeout は (pdflush 経由で) ダーティーデータがシステムメモリ合計のこのパーセントを占める際に開始されます。デフォルト値は
20です。Red Hat はデータベースのワークロードに、少し低めの15を推奨しています。 dirty_background_ratio- パーセントの値を定義します。ダーティーデータの writeout は (pdflush 経由で) ダーティーデータがメモリ合計のこのパーセントを占める際にバックグラウンドで開始されます。デフォルト値は
10です。Red Hat はデータベースのワークロードに、少し低めの3を推奨しています。 dirty_expire_centisecs- ダーティーデータがディスクに書き戻されるまでにページキャッシュにとどまる時間を 100 分の 1 秒単位で指定します。Red Hat では、このパラメーターの調整は推奨していません。
dirty_writeback_centisecs- カーネルフラッシャースレッドが再開して適格なデータをディスクに書き込む間隔の長さを 100 分の 1 秒単位で指定します。これを
0に設定すると、定期書き込み動作は無効になります。Red Hat ではこのパラメーターの調整は推奨していません。 drop_caches- この値を
1、2、3のいずれかに設定すると、カーネルはページキャッシュとスラブキャッシュの様々な組み合わせをもたらします。- 1
- システムはすべてのページキャッシュメモリを無効にして、解放します。
- 2
- システムはすべての未使用スラブキャッシュメモリを解放します。
- 3
- システムはすべてのページキャッシュとスラブキャッシュメモリを解放します。
これは非破壊的な操作です。ダーティーオブジェクトは解放できないので、このパラメーターの値を設定する前にsyncを実行することが推奨されます。重要
実稼働環境では、drop_cachesを使ったメモリの解放は推奨されません。
swappiness を一時的に 50 に設定するには、以下を実行します。
echo 50 > /proc/sys/vm/swappiness
# echo 50 > /proc/sys/vm/swappinesssysctl コマンドを使う必要があります。詳細は 『導入ガイド』 を参照してください。これは http://access.redhat.com/site/documentation/Red_Hat_Enterprise_Linux/ から入手できます。
第6章 入出力
6.1. 特徴
- SSD (ソリッドステートドライブ) が自動で認識され、このデバイスが実行可能な 1 秒あたりの高い I/O を活用するために I/O スケジューラーのパフォーマンスがチューニングされます。
- Discard support (破棄サポート) がカーネルに追加され、基礎となるストレージに未使用ブロックの範囲がレポートされます。これは、SSD のウェアレベリングに役立ちます。また、実際に使用中のストレージ量に関するクローズしたタブを保持することで、論理ブロックプロビジョニング (ストレージ用の仮想アドレス領域のようなもの) をサポートするストレージに役立ちます。
- Red Hat Enterprise Linux 6.1 では、ファイルシステムバリア実装が整備され、より高性能になっています。
pdflushが per-backing-device flusher スレッドに置き換えられました。これは、大規模な LUN カウントの設定でシステムの拡張性を大幅に改善するものです。
6.2. 分析
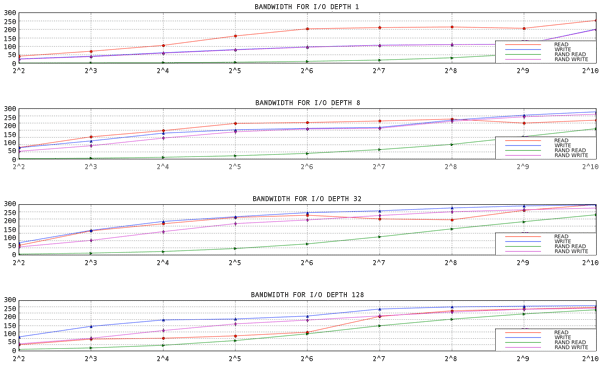
図6.1 1 スレッド、1 ファイルでの aio-stress 出力
- aio-stress
- iozone
- fio
6.3. ツール
si (swap in)、so (swap out)、bi (block in)、 bo (block out)、wa (I/O wait time)。si と so は、スワップ領域がデータパーティションと同じデバイス上にある時、および全体のメモリプレッシャーの指標として便利です。si と bi は読み取り操作で、so と bo は書き込み操作です。各カテゴリーはキロバイトでレポートされます。wa はアイドル時間で、実行キューのどの部分がブロックされて I/O の完了を待っているかを示します。
free、buff、cache のコラムも注目に値します。cache の値が bo の値とともに増えて、その後に cache が減少し free が増えていれば、システムはページキャッシュのライトバックと無効化を実行していることを示します。
avgqu-sz) を使うと、ストレージのパフォーマンスを特徴付ける際に生成したグラフを使って、ストレージのパフォーマンスを予想することができます。ここでは一般化が適用されます。例えば、要求の平均サイズが 4KB でキューの平均サイズが 1 の場合、スループットが非常に高性能である可能性は低くなります。
- Q — ブロック I/O がキュー待ち
- G — 要求を取得新たにキュー待ちとなったブロック I/O は既存要求とマージする候補ではないので、新たなブロック層要求が割り当てられます。
- M — ブロック I/O 既存の要求とマージされます。
- I — 要求がデバイスのキューに挿入されます。
- D — 要求がデバイスに発行されます。
- C — 要求がドライバーによって完了されます。
- P — ブロックデバイスキューが接続され、要求の集合を許可します。
- U — デバイスキューが除外され、要求の集合のデバイスへの発行を許可します。
- Q2Q — ブロック層に送信された要求間の時間
- Q2G — ブロック I/O がキュー待ちになってから要求が割り当てられるまでの時間
- G2I — 要求が割り当てられてからデバイスのキューに挿入されるまでの時間
- Q2M — ブロック I/O がキュー待ちになってから既存の要求とマージされるまでの時間
- I2D — 要求がデバイスのキューに挿入されてから実際にデバイスに発行されるまでの時間
- M2D — ブロック I/O が既存の要求とマージしてから要求がデバイスに発行されるまでの時間
- D2C — デバイスによる要求のサービス時間
- Q2C — 要求がブロック層で費やした合計時間
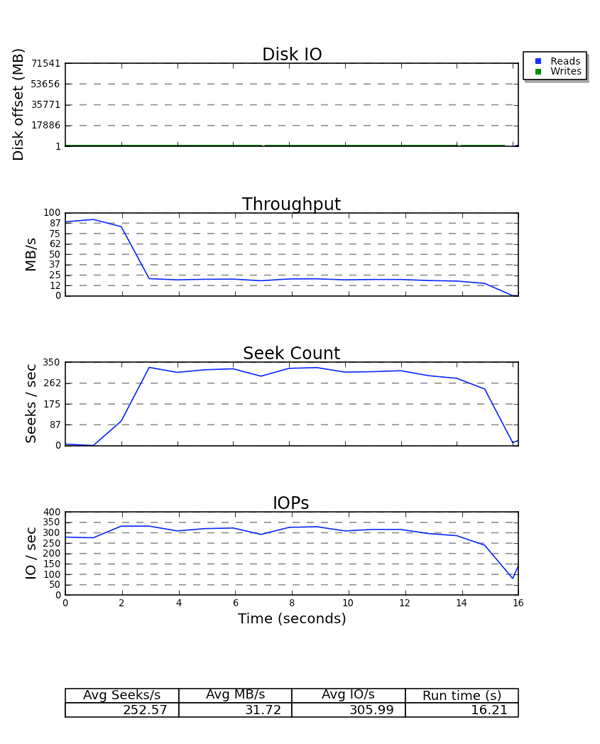
図6.2 seekwatcher の出力例
6.4. 設定
6.4.1. Completely Fair Queuing (CFQ)
ionice コマンドを使って手動で割り当てるか、ioprio_set システムコール経由でプログラムで割り当てることができます。デフォルトでは、プロセスはベストエフォート型のスケジューリングクラスに置かれます。リアルタイムとベストエフォートのスケジューリングクラスはさらに各クラス内で 8 つの I/O 優先順位に分けられます。このうち、0 の優先順位が一番高く、7 が一番低くなります。リアルタイムのスケジューリングクラスのプロセスは、ベストエフォートやアイドルにあるプロセスよりも積極的なスケジュールになるので、スケジュールされたリアルタイムの I/O は常にベストエフォートやアイドルの I/O よりも先に実行されます。つまり、リアルタイムの優先順位が付けられている I/O は、ベストエフォートとアイドルクラスの両方に悪影響を与える可能性があることになります。ベストエフォートスケジューリングはデフォルトのスケジューリングクラスで、このクラス内のデフォルトの優先順位は 4 になります。アイドルのスケジューリングクラス内のプロセスは、システム内に実行されていない他の I/O がない場合にのみ、実行されます。つまり、プロセスの I/O スケジューリングクラスをアイドルに設定するのは、そのプロセスからの I/O が進行に全く必要ない場合だけにします。
/sys/block/device/queue/iosched/ にある同一名のファイルで以下のパラメーターを設定します。
slice_idle = 0 quantum = 64 group_idle = 1
slice_idle = 0
quantum = 64
group_idle = 1group_idle が 1 に設定されても、I/O ストールの可能性は残ります (これにより、バックエンドのストレージはアイドリングのためにビジーではありません)。しかし、これらのストールの頻度は、システムの各キューでのアイドリングよりも少なくなります。
チューニング可能なパラメーター
back_seek_max- 後方シークは、ヘッドの位置変更で前方シークよりも大幅な遅延を発生させる可能性があるので、パフォーマンスには通常マイナスとなります。しかし、大きくない場合は、CFQ はそれらを実行します。このパラメーターは、I/O が後方シークに許可する最大の距離を KB で制御します。デフォルト値は、
16KB です。 back_seek_penalty- 後方シークはその非効率性のために、それぞれにペナルティーが関連付けられます。ペナルティーは乗数で、例えば 1024KB のディスクヘッド位置を考えてみましょう。キューに 2 つの要求があるとします。ひとつは 1008KB にあり、もうひとつは 1040KB にあります。これら 2 つの要求は、現在のヘッド位置から等距離にあります。しかし、後方シークペナルティー (デフォルトでは 2) を適用すると、ディスク上で後ろの位置にある要求の位置は、前の位置にあるものよりも 2 倍の距離になってしまいます。このため、ヘッドは前に移動します。
fifo_expire_async- このパラメーターは、async (バッファリングされた書き込み) 要求が実行されない時間を制御します。有効時間 (ミリ秒) の後に、単一のリソース不足となっている非同期要求は、ディスパッチリストに移動されます。デフォルト値は、
250ミリ秒です。 fifo_expire_sync- 同期 (読み取りおよび O_DIRECT 書き込み) 要求では、これは fifo_expire_async と同じです。デフォルト値は、
125ミリ秒です。 group_idle- これが設定されると、CFQ は cgroup で I/O を発行している最後のプロセスでアイドルになります。比例加重 I/O cgroup の使用時にはこれを
1に設定し、slice_idleを0に設定 (通常は高速ストレージで実行) することが推奨されます。 group_isolation- グループ分離 (
1に設定) が有効な場合、これはスループットを代償にして、グループ間の分離を強化します。通常は、グループ分離が無効になっていると、公平性が提供されるのは連続するワークロードのみです。グループ分離を有効にすると、連続するワークロードランダムなワークロードの両方の公平性が提供されます。デフォルト値は0(無効) です。詳細はDocumentation/cgroups/blkio-controller.txtを参照してください。 low_latency- low latency を有効にすると (
1に設定)、CFQ はデバイス上で I/O を発行している各プロセスに最大 300 ミリ秒の待ち時間を与えようとします。これにより、スループットよりも公平性が優先されます。low latency を無効にすると (0に設定)、ターゲットの待ち時間が無視され、システムの各プロセスが完全なタイムスライスを取得します。low latency はデフォルトでは有効になっています。 quantum- quantum は、CFQ が一度にストレージに送信する I/O 数を制御し、実質上はデバイスキューの深さを制限します。デフォルトでは、
8に設定されています。ストレージはより深いキューをサポートする可能性がありますが、quantumを高めると待ち時間にマイナスの影響を与え、特に大量の連続する書き込みワークロードがある場合はマイナスの影響があります。 slice_async- このパラメーターは、非同期 (バッファリングされた書き込み) I/O を発行する各プロセスに割り当てられるタイムスライスを制御します。デフォルト値は
40ミリ秒に設定されています。 slice_idle- これは、CFQ が新たな要求を待っている間にアイドルになる時間を指定します。Red Hat Enterprise Linux 6.1 およびそれ以前でのデフォルト値は、
8ミリ秒です。Red Hat Enterprise Linux 6.2 およびそれ以降のデフォルト値は、0です。値が 0 だとキューおよびサービスツリーレベルのアイドリングをすべて削除するので、外部 RAID ストレージのスループットが改善されます。ただし、これは全体のシーク回数を増やすので、内部の非 RAID ストレージのスループットを低下させる場合があります。非 RAID ストレージでのslice_idleの値は、0 よりも大きくすることが推奨されます。 slice_sync- このパラメーターは、同期 (読み取りおよび直接書き込み) I/O を発行するプロセスに割り当てられるタイムスライスを規定します。デフォルト値は
100ミリ秒です。
6.4.2. デッドライン I/O スケジューラー
チューニング可能なパラメーター
fifo_batch- これは、単一バッチで発行される読み取りまたは書き込み数を決定します。デフォルト値は
16です。これを高く設定するとスループットは改善しますが、待ち時間も長くなる可能性があります。 front_merges- ワークロードが前方マージを生成しないと分かっている場合、これを
0に設定できます。このチェックのオーバーヘッドを測定していない場合は、デフォルト設定のまま (1) にしておくことが推奨されます。 read_expire- このパラメーターで、読み取り要求が実行される時間をミリ秒で設定できます。デフォルト値は
500ミリ秒 (0.5 秒) です。 write_expire- このパラメーターで、書き込み要求が実行される時間をミリ秒で設定できます。デフォルト値は
5000ミリ秒 (5 秒) です。 writes_starved- このパラメーターは書き込みバッチの処理前に処理可能な読み取りバッチ数を制御します。この値を高く設定すればするほど、読み取りが優先されます。
6.4.3. Noop
/sys/block/sdX/queue のチューニング可能なパラメーター
- add_random
- いくつかのケースでは、
/dev/randomのエントロピープールに貢献している I/O イベントのオーバーヘッドは計測可能です。このような場合、この値を 0 に設定することが推奨されます。 max_sectors_kb- デフォルトでは、ディスクに送信される要求の最大サイズは
512KB です。このパラメーターは、この値を上げたり下げたりできます。最小値は論理ブロックサイズに制限されます。最大値はmax_hw_sectors_kbで制限されます。I/O サイズが内部の消去ブロックサイズを超えるとパフォーマンスが悪化する SSD もあります。そのような場合には、max_hw_sectors_kbを消去ブロックのサイズに下げることが推奨されます。これは、iozone や aio-stress などの I/O ジェネレーターでレコードサイズを512バイトから1MB に変えるなどしてテストすることができます。 nomerges- このパラメーターは、基本的にデバッグの助けとなるものです。ほとんどのワークロードでは、要求のマージが役に立ちます (SSD などの高速ストレージでも)。しかし、マージを無効にすることがよい場合もあります。例えば、先読みを無効にしたりランダム I/O を実行することなく、ストレージバックエンドが処理できる IOPS の数を知りたい場合などです。
nr_requests- 各要求キューには、読み取りもしくは書き込み I/O ごとに割り当て可能な要求記述子の合計数に制限があります。デフォルトではこれが
128になっていて、プロセスをスリープにする前に 128 の読み取りと 128 の書き込みを一度にキュー待ちにすることができます。スリープ状態にされるプロセスは、要求の割り当てを試みる次のもので、必ずしも利用可能な要求のすべてを割り当てたプロセスではありません。待ち時間に影響を受けやすいアプリケーションがある場合は、要求キューのnr_requestsの値を引き下げ、ストレージ上のコマンドキューを (1にまで) 低い数値に制限することが推奨されます。こうすると、ライトバック I/O は利用可能なすべての要求記述子を割り当てることができず、書き込み I/O でデバイスキューを満たすことができません。nr_requestsが割り当てられると、I/O の実行を試みている他のすべての プロセスがスリープになり、要求が利用可能になるまで待機します。これだと (1 つのプロセスが連続してすべてを消費するのではなく) 要求がラウンドロビン方式で分配されるので、公平性が維持されます。デッドラインもしくは Noop スケジューラーの使用時にのみ、これが問題となることに留意してください。これは、デフォルトの CFQ 設定がこの状況に対して保護するためです。 optimal_io_size- 状況によっては、基礎的なストレージが最適な I/O サイズをレポートします。これは、最適な I/O サイズがストライプサイズであるハードウェアおよびソフトウェア RAID で最も一般的です。この値がレポートされると、アプリケーションは可能な限り、最適な I/O サイズに調整され、その倍数の I/O を発行します。
read_ahead_kb- オペレーティングシステムは、アプリケーションがファイルやディスクから連続してデータを読み取っている際に、これを検出します。そのような場合、インテリジェントな先読みアルゴリズムを実行し、ユーザーが要求したデータよりも多くのデータをディスクから読み取ります。つまり、ユーザーが次のデータブロックを読み取ろうとする際には、そのデータはオペレーティングシステムのページキャッシュに既にあることになります。この動作の考えられるマイナス面は、オペレーティングシステムが必要以上のデータをディスクから読み取る可能性があるということです。この場合、メモリのプレッシャーが大きいという理由でデータが削除されるまで、このデータはページキャッシュのスペースをふさぐことになります。この状況では、複数のプロセスが間違って先読みを行うと、メモリのプレッシャーを高めることになります。デバイスマッパーのデバイスでは、
read_ahead_kbの値を8192などの大きいものにすることが推奨されます。これは、デバイスマッパーのデバイスが複数の基礎的デバイスで構成されていることが多いためです。チューニングの手始めとしては、デフォルト値 (128KB) をマッピングするデバイス数で掛けたものにするとよいでしょう。 rotational- 従来のハードディスクは回転式 (回転する円盤で構成) でしたが、SSD は違います。ほとんどの SSD は、これを適切にアドバタイズしますが、このフラグを適切にアドバタイズしないデバイスの場合は、rotational を手動で
0に設定する必要がある場合があります。rotational が無効の場合は、非回転式メディアでのシーク操作にほとんどペナルティーがないことから、I/O エレベーターはシークを減らすための論理を使用しません。 rq_affinity- I/O の完了は、その I/O を発行した CPU とは別の CPUで処理できます。
rq_affinityを1に設定すると、I/O が発行された CPU にカーネルが完了を配信します。これにより、CPU データのキャッシング効果が高まります。
第7章 ファイルシステム
7.1. ファイルシステムのチューニングで考慮すべき点
7.1.1. フォーマットのオプション
ブロックサイズは、mkfs 実行時に選択することができます。有効なサイズの範囲はシステムによって異なります。上限はホストシステムの最大ページサイズで、下限は使用しているファイルシステムに依存します。デフォルトのブロックサイズは、ほとんどのユースケースに適しています。
システムで RAID5 などのストライプストレージを使用している場合、mkfs 実行時に基礎的ストレージジオメトリを使ってデータやメタデータを整えて、パフォーマンスを改善することができます。ソフトウェア RAID (LVM または MD) とエンタープライズハードウェアストレージのいくつかでは、この情報はクエリされ自動的に設定されますが、多くの場合、管理者がコマンドラインで mkfs を使って手動でこのジオメトリを指定する必要があります。
メタデータ集約型のワークロードは、(ext4 や XFS などの) ジャーナリングファイルシステムのログセクションが非常に頻繁に更新されることを意味します。ファイルシステムからジャーナルへのシーク回数を最小限にするには、ジャーナルを専用のストレージに配置します。しかし、主たるファイルシステムよりも遅い外部ストレージにジャーナルを配置すると、外部ストレージを使用することで得られる利点が帳消しになる場合もあることに注意してください。
警告
mkfs 実行時に作成されます。詳細は mke2fs(8)、mkfs.xfs(8)、mount(8) の man ページを参照してください。
7.1.2. マウントオプション
書き込みバリアは、揮発性の書き込みキャッシュが電源を喪失しても、ファイルシステムのメタデータが正しく書かれ、一貫性のあるストレージに整理されていることを確認するためのカーネルメカニズムです。書き込みバリアが有効なファイルシステムは、fsync() 経由で発信されたデータが停電中も確実に持続されるようにします。Red Hat Enterprise Linux はデフォルトでサポート対象の全ハードウェアに対してバリアを有効にします。
fsync() を大量に使うアプリケーションや小さいファイルを多く作成したり削除したりするアプリケーションは特にそうです。揮発性の書き込みキャッシュがないストレージや、電源喪失後のファイルシステムの不整合やデータ損失が許される場合などの稀なケースでは、nobarrier マウントオプションを使用してバリアを無効にできます。詳細は 『ストレージ管理ガイド』 を参照してください。
従来はファイルが読み取られると、そのファイルのアクセスタイム (atime) は inode メタデータで更新される必要があり、このために新たな 書き込み I/O が行われました。正確な atime メタデータが不要な場合は、noatime オプションでファイルシステムをマウントしてこのメタデータ更新を削除します。しかしほとんどの場合、Red Hat Enterprise Linux 6 カーネルにおけるデフォルトの相対的 atime (または relatime) 動作のために、atime のオーバーヘッドは大きなものではありません。relatime 動作は、以前の atime が修正時間 (mtime) やステータス変更時間 (ctime) よりも古い場合にのみ、atime を更新します。
注記
noatime オプションを有効にすると、nodiratime 動作も有効になります。noatime と nodiratime の両方を設定する必要はありません。
先読みは、データを先に取得してページキャッシュにロードすることでディスクからではなくメモリで先に使用可能となり、ファイルアクセスを速くします。大量の連続 I/O のストリーミングを行うワークロードなどでは、先読みの値が高いと効果が高まります。
blockdev コマンドを使います。特定のブロックデバイスに対する現在の先読みの値を表示するには、以下のコマンドを実行します。
blockdev -getra device
# blockdev -getra deviceblockdev -setra N device
# blockdev -setra N deviceblockdev コマンドで選択された値は、リブート後には維持されないことに注意してください。ブート中にこの値を設定するには、ランレベル init.d スクリプトを作成することが推奨されます。
7.1.3. ファイルシステムのメンテナンス
バッチ破棄やオンライン破棄のオペレーションは、マウント済みファイルシステムの機能で、ファイルシステムが使用していないブロックを破棄します。ソリッドステートドライブとシンプロビジョニングのストレージの両方で役に立ちます。
fstrim コマンドで明示的に実行されます。このコマンドは、ユーザーの条件と一致するファイルシステム内の未使用ブロックをすべて破棄します。両方のオペレーションタイプは、ファイルシステムの基盤となっているブロックデバイスが物理的な破棄オペレーションに対応している限り、Red Hat Enterprise Linux 6.2 以降の XFS および ext4 ファイルシステムでの使用が可能です。物理的な破棄オペレーションは、/sys/block/device/queue/discard_max_bytes の値がゼロでない場合にサポートされます。
-o discard オプション (/etc/fstab 内、または mount コマンドで指定) で指定して、ユーザーの介入なしでリアルタイムで実行されます。オンライン破棄オペレーションは、使用済から空きに移行するブロックのみを破棄します。オンライン破棄オペレーションは、Red Hat Enterprise Linux 6.2 以降の ext4 ファイルシステムか、Red Hat Enterprise Linux 6.4 以降の XFS ファイルシステムで対応しています。
7.1.4. アプリケーションの留意事項
ext4、XFS、GFS2 の各ファイルシステムは、fallocate(2) glibc コール経由で効率的なスペースの事前割り当てをサポートします。書き込みパターンが理由でファイルが非常に断片化され、読み取りパフォーマンスが悪化する場合、スペースの事前割り当ては便利なテクニックになります。事前割り当てでは、データをスペースに書き込まずにそのディスクスペースがまるでファイルに割り当てられたかのようにマークします。事前割り当てのブロックに実際のデータが書き込まれるまで、読み取りオペレーションはゼロを返します。
7.2. ファイルシステムパフォーマンスのプロファイル
latency-performance- 標準的な遅延パフォーマンスチューニング用のサーバープロファイルです。これは、tuned と ktune の省電力メカニズムを無効にし、
cpuspeedモードがperformanceに変更されます。各デバイスで I/O エレベーターがdeadlineに変更されます。cpu_dma_latencyパラメーターは0の値 (最低の待ち時間) で登録され、可能な範囲で Power Management Quality-of-Service が電源管理の待ち時間を制限します。 throughput-performance- 標準的なスループットのパフォーマンスチューニング用のサーバープロファイルです。システムにエンタープライズクラスのストレージがない場合に、このプロファイルが推奨されます。
latency-performanceと同じですが、以下の点が異なります。kernel.sched_min_granularity_ns(スケジューラーの最小先取り粒度) が10ミリ秒に設定されます。kernel.sched_wakeup_granularity_ns(スケジューラーのウェイクアップ粒度) が15ミリ秒に設定されます。vm.dirty_ratio(仮想メモリーダーティー率) が 40% に設定されます。- Transparent huge pages が使用可能になります。
enterprise-storage- このプロファイルは、バッテリー駆動のコントローラーキャッシュ保護とオンディスクのキャッシュ管理などを含むエンタープライズクラスのストレージがあるエンタープライズサイズのサーバー設定に推奨されます。
throughput-performanceプロファイルと同じですが、以下の点が異なります。readahead値が4xに設定されます。- root/boot ファイルシステム以外のファイルシステムが、
barrier=0で再マウントされます。
man tuned-adm) または 『電力管理ガイド』 を参照してください。これは http://access.redhat.com/site/documentation/Red_Hat_Enterprise_Linux/ から入手できます。
7.3. ファイルシステム
7.3.1. Ext4 ファイルシステム
注記
- Inode table の初期化
- 大規模なファイルシステムでは、
mkfs.ext4プロセスがファイルシステム内のすべての inode table を初期化するのに長時間かかる場合があります。このプロセスは、-E lazy_itable_init=1オプションで先送りすることが可能です。これを使用すると、カーネルプロセスはファイルシステムのマウント後に初期化を継続します。この初期化の発生率は、mountコマンドの-o init_itable=nオプションでコントロールできます。このバックグラウンド初期化に費やされる時間はおよそ 1/n で、nのデフォルト値は10です。 - Auto-fsync 動作
- アプリケーションの中には既存ファイルの名前変更や切り取りおよび書き換え後に
fsync()が常に適切に機能するとは限らないものがあるので、rename 経由の replace 操作および truncate 経由の replace 操作の後には、ext4 はファイルの自動同期をデフォルト設定します。この動作は、ほぼ以前の ext3 ファイルシステムの動作と一致しています。しかし、fsync()操作は時間がかかるので、この自動動作が必要ない場合は、mountコマンドの-o noauto_da_allocオプションを使って無効にします。つまり、アプリケーションは明示的にfsync()を使ってデータの一貫性を確保する必要があります。 - ジャーナル I/O の優先順位
- デフォルトでは、ジャーナルコミット I/O は通常の I/O よりもわずかに高い優先順位を与えられています。この優先順位は、
mountコマンドのjournal_ioprio=nオプションで制御可能で、デフォルト値は3です。有効な値の範囲は 0 から 7 で、0 が一番高い優先順位となります。
mkfs およびチューニングオプションについては、mkfs.ext4(8) および mount(8) の man ページと、kernel-doc パッケージの Documentation/filesystems/ext4.txt ファイルを参照してください。
7.3.2. XFS ファイルシステム
mkfs 実行時に XFS が提供するチューニングオプションのいくつかは b-tree の幅が異なり、これが異なるサブシステムのスケーラビリティの特徴を変更します。
7.3.2.1. XFS の基本的なチューニング
mkfs.xfs コマンドが自動的に正しいストライプ単位と幅で設定を行ってハードウェアと調整します。ハードウェア RAID が使用されている場合は、この作業は手動で設定する必要がある場合があります。
inode64 マウントオプションが強く推奨されます。
logbsize マウントオプションが推奨されます。デフォルト値は MAX (32 KB、ログストライプユニット)で、最大サイズは 256 KB です。大幅な修正が行われるファイルシステムには、256 KB の値が推奨されます。
7.3.2.2. XFS の高度なチューニング
7.3.2.2.1. 多数のファイルの最適化
mkfs.xfs コマンドで inodes に許可されるファイルシステムのスペースの割合を増やすことができます。ファイルシステムの作成後にファイルの制限に遭遇した場合 (空白スペースが利用可能でもファイルやディレクトリーを作成しようとする際に ENOSPC エラーで示されることが多い) は、xfs_growfs コマンドで制限を調整できます。
7.3.2.2.2. 単一ディレクトリー内の多数のファイルの最適化
mkfs による初期フォーマット時以外は変更できません。最小のディレクトリーブロックはファイルシステムのブロックサイズで、このデフォルト値は MAX (4 KB、ファイルシステムのブロックサイズ) です。通常、このディレクトリーブロックサイズを縮小する必要はありません。
- 100–200 万までのディレクトリーエントリー (エントリー名の長さは 20–40 バイト) を必要とするファイルシステムは、4 KB のファイルシステムブロックサイズおよび 4 KB のディレクトリーブロックサイズのデフォルト設定でパフォーマンスがベストになります。
- 100-1000 万のディレクトリーエントリーを必要とするファイルシステムは、より大きい 16 KB のブロックサイズでパフォーマンスが向上します。
- 1000 万以上のディレクトリーエントリーを必要とするファイルシステムは、より大きい 64 KB のブロックサイズでパフォーマンスが向上します。
7.3.2.2.3. 同時実行の最適化
7.3.2.2.4. 拡張属性を使用するアプリケーションの最適化
7.3.2.2.5. 維持されたメタデータ修正の最適化
mkfs はデフォルトでこれをMD および DM のデバイスで行いますが、ハードウェア RAID の場合は指定する必要があります。これを正確に設定することで、ディスクに修正を書き込む際にログ I/O が I/Oの不整列を引き起こし、読み取り・修正・書き込みの操作がその後に続く可能性を回避します。
logbsize) を増やすと、ログに変更を書き込むスピードが高まります。デフォルトのログバッファーサイズは MAX (32 KB、ログストライプユニット) で、最大サイズは 256 KB です。一般的に値が大きいとパフォーマンス速度が高まります。しかし、fsync の多いワークロードでは、大型のストライプユニットの調整を使うと小さいログバッファーの方が明らかに大型バッファーよりも速くなります。
delaylog マウントオプションも、ログへの変更数を減らして維持されるメタデータの修正パフォーマンスを向上させます。これは、ログに変更を書き込む前にメモリ内の個別の変更を統合することで達成されます。頻繁に修正されるメタデータは、修正ごとにではなく、定期的にログに書き込まれます。このオプションはダーティーメタデータによるメモリ使用量を増やし、クラッシュ発生時のオペレーション損失の可能性を高めますが、メタデータ修正速度とスケーラビリティを 1 桁以上改善できます。fsync、fdatasync、sync のいずれかを使ってデータおよびメタデータのディスクへの書き込みを確認している場合は、このオプションの使用でデータまたはメタデータの整合性が低下することはありません。
7.4. クラスタリング
7.4.1. Global File System 2
T 属性のマークを付けます。以下のようになります。
chattr +T directory
chattr +T directory- 可能な場合に
fallocateでファイルおよびディレクトリーを事前に割り当て、割り当てプロセスを最適化するとともにソースページをロックする必要性を回避します。 - 複数ノード間で共有されるファイルシステムのエリアを最小化し、ノード間キャッシュの無効化を最小限にするとともにパフォーマンスを改善します。例えば、複数のノードが同一ファイルシステムをマウントしても、異なるサブディレクトリーにアクセスすると、あるサブディレクトリーを別のファイルシステムに移動することでパフォーマンスが向上する可能性が高まります。
- 最適なリソースグループのサイズと数を選択します。これは、典型的なファイルサイズとシステム上で利用可能なツリースペースによって異なります。また、複数ノードがあるリソースグループを同時に使用しようと試みる可能性に影響を与えます。リソースグループが多すぎると、割り当てスペースを探す間にブロックの割り当てが遅くなります。一方で、リソースグループが少なすぎると、解放中にロック競合を引き起こす可能性があります。通常は、複数の設定を試して、ワークロードに最適なものを決定するのがよい方法です。
- クラスターノードから予測される I/O パターンおよびファイルシステムのパフォーマンス要件にしたがってストレージハードウェアを選択します。
- 可能な場合はソリッドステートストレージを使用してシーク時間を短縮します。
- ワークロードに適したサイズのファイルシステムを作成し、ファイルシステムが容量の 80% を超えないようにします。より小さいファイルシステムではバックアップ時間は大きさに比例して短くなり、ファイルシステムのチェックに要する時間とメモリが少なくなりますが、ワークロードに対して小さすぎると断片化が進む傾向があります。
- メタデータ集約型のワークロードの場合、もしくはジャーナル化されたデータを使用する場合に、ジャーナルサイズを大きく設定します。これはより多くのメモリを使用しますが、書き込みが必要となる前により多くのジャーナリングスペースがデータ保存に使えることから、パフォーマンスが改善します
- GFS2 ノード上のクロックが確実に同期して、ネットワーク化されたアプリケーションとの問題を回避するようにします。NTP (Network Time Protocol) の使用が推奨されます。
- アプリケーションの操作でファイルまたはディレクトリーのアクセス時間がクリティカルでないならば、ファイルシステムに
noatimeとnodiratimeのマウントオプションをマウントします。注記
Red Hat は GFS2 でnoatimeオプションを使用することを強く推奨します。 - クォータを使用する必要がある場合は、クォータ同期処理の頻度を下げるか、fuzzy クォータ同期を使用して継続的なクォータファイル更新から発生するパフォーマンス問題を防止します。
注記
Fuzzy quota accounting を使うと、ユーザーやグループはクォータの制限値を若干超えることが許されます。この問題を最小化するために、ユーザーもしくはグループがクォータ制限値に近づくと、GFS2 は動的に同期期間を引き下げます。
第8章 ネットワーキング
8.1. ネットワークパフォーマンスの機能強化
Receive Packet Steering (RPS)
rx キューが受信 softirq ワークロードを複数の CPU に分散することを可能にします。これを行うと、ネットワークトラフィックが単一 NIC ハードウェアキューでボトルネックとなることを防ぐのに役立ちます。
/sys/class/net/ethX/queues/rx-N/rps_cpus で特定し、ethX を NIC の対応するデバイス名 (例えば eth1、eth2 など) で、rx-N を指定された NIC 受信キューで置き換えます。こうすることで、ファイル内で指定された CPU が ethX 上のキュー rx-N からのデータを処理できるようになります。CPU を指定する際には、キューの キャッシュ アフィニティ [4] を考慮します。
Receive Flow Steering (RFS)
/proc/sys/net/core/rps_sock_flow_entries- これは、カーネルが指定された CPU に誘導可能なソケット/フローの最大数を制御します。これはシステム全体での共有制限値です。
/sys/class/net/ethX/queues/rx-N/rps_flow_cnt- これは、NIC (
ethX) 上の特定受信キュー (rx-N) に誘導するソケット/フローの最大数を制御します。全 NIC 上のこのファイル用のキューごとの値の合計は、/proc/sys/net/core/rps_sock_flow_entriesと同じかそれ以下にすることに留意してください。
TCP thin-stream の getsockopt サポート
getsockopt コールが強化されて以下の 2 つのオプションをサポートするようになりました。
- TCP_THIN_DUPACK
- このブール値は、1 回の dupACK の後に thin stream の再送信の動的タグ付を有効にします。
- TCP_THIN_LINEAR_TIMEOUTS
- このブール値は、thin stream の linear timeout の動的タグ付を有効にします。
file:///usr/share/doc/kernel-doc-version/Documentation/networking/ip-sysctl.txt を参照してください。thin-stream についての詳細は、file:///usr/share/doc/kernel-doc-version/Documentation/networking/tcp-thin.txt を参照してください。
透過プロキシ (TProxy) のサポート
file:///usr/share/doc/kernel-doc-version/Documentation/networking/tproxy.txt を参照してください。
8.2. ネットワーク設定の最適化
- netstat
- ネットワーク接続やルーティング表、インターフェース統計、マスカレード接続、マルチキャストメンバーシップを印刷するコマンドラインユーティリティです。
/proc/net/ファイルシステムからネットワーキングサブシステムについての情報を取得します。ファイルは以下のものです。/proc/net/dev(デバイス情報)/proc/net/tcp(TCP ソケット情報)/proc/net/unix(Unix ドメインソケット情報)
netstatおよび/proc/net/の関連ファイルについての詳細は、netstatの man ページ:man netstatを参照してください。 - dropwatch
- カーネルがドロップするパケットを監視する監視ユーティリティです。詳細は
dropwatchの man ページ:man dropwatchを参照してください。 - ip
- ルートやデバイス、ポリシールーティング、トンネルを管理、監視するユーティリティです。詳細は
ipの man ページ:man ipを参照してください。 - ethtool
- NIC 設定を表示、変更するユーティリティです。詳細は
ethtoolの man ページ:man ethtoolを参照してください。 - /proc/net/snmp
snmpエージェントで IP、ICMP、TCP、UDP 管理情報ベースに必要な ASCII データを表示するファイルです。リアルタイムの UDP-lite 統計も表示します。
/proc/net/snmp で UDP 入力エラーが増えていれば、ネットワークスタックが新たなフレームをアプリケーションのソケットに加えようとする際に、1 つ以上のソケット受信キューが満杯であることを示しています。
ソケット受信バッファーサイズ
sk_stream_wait_memory.stp で提示される分析のようなさらなる分析でソケットキューの排出率が遅すぎると示されている場合は、アプリケーションのソケットキューの深さを高めます。これを行うには、以下のどちらかの値を設定してソケットが使用する受信バッファーのサイズを大きくします。
- rmem_default
- ソケットが使用する受信バッファーの デフォルトの サイズを制御するカーネルパラメーターです。これを設定するには、以下のコマンドを実行します。
sysctl -w net.core.rmem_default=N
sysctl -w net.core.rmem_default=NCopy to Clipboard Copied! Toggle word wrap Toggle overflow Nを希望する バッファーサイズのバイト数で置き換えます。このカーネルパラメーターの値を決定するには、/proc/sys/net/core/rmem_defaultを表示させます。rmem_defaultの値はrmem_max(/proc/sys/net/core/rmem_max) を超えないように注意してください。必要な場合はrmem_maxの値を上げてください。 - SO_RCVBUF
- ソケットの受信バッファーの 最大 サイズをバイト数で制限するソケットオプションです。
SO_RCVBUFの詳細については man ページ:man 7 socketを参照してください。SO_RCVBUFを制限するには、setsockoptユーティリティを使います。現行のSO_RCVBUFの値はgetsockoptで取得できます。これらのユーティリティの詳細情報は、setsockoptの man ページ:man setsockoptを参照してください。
8.3. パケット受信の概要

図8.1 ネットワーク受信パスの図
- ハードウェア受信: ネットワークインターフェースカード (NIC) が接続線上でフレームを受信します。そのドライバー設定により、NIC はフレームを内部のハードウェアバッファーメモリか指定されたリングバッファーに移動します。
- ハード IRQ: NIC が CPU に割り込むことでネットフレームの存在をアサートします。これにより NIC ドライバーは割り込みを承認し、ソフト IRQ オペレーション をスケジュールします。
- ソフト IRQ: このステージでは、実際のフレーム受信プロセスを実装し、
softirqコンテキストで実行します。つまり、このステージは指定された CPU上で実行されている全アプリケーションよりも先に行われますが、ハード IRQ のアサートは許可します。(ハード IRQ と同じ CPU 上で実行することでロッキングオーバーヘッドを最小化している) このコンテキストでは、カーネルは実際に NIC ハードウェアバッファーからフレームを削除し、ネットワークスタックで処理します。ここからは、フレームはターゲットのリスニングソケットへの転送、破棄、パスのいずれかが行われます。フレームはソケットにパスされると、ソケットを所有するアプリケーションに追加されます。このプロセスは、NIC ハードウェアバッファーのフレームがなくなるまで、または device weight (dev_weight) まで繰り返されます。device weight についての詳細は 「NIC ハードウェアバッファー」 を参照してください。 - アプリケーション受信: アプリケーションがフレームを受信し、標準 POSIX コール (
read、recv、recvfrom) で所有されているソケットからキューを外します。この時点で、ネットワークで受信されたデータはネットワークソケット上には存在しなくなります。
CPU/キャッシュアフィニティ
8.4. 一般的なキュー/フレーム損失問題の解決
8.4.1. NIC ハードウェアバッファー
softirq で排出を行います。これは NIC が割り込みでアサートするものです。このキューのステータスを調べるには、以下のコマンドを使います。
ethtool -S ethX
ethtool -S ethXethX を NIC の対応するデバイス名で置き換えます。こうすることで、ethX 内でいくつのフレームがドロップされたかが表示されます。ドロップが発生する理由の多くは、キューがフレームを保存するバッファースペースを使い切ってしまうためです。
- 入力トラフィック
- queue overrun は、入力トラフィックを遅らせることで防ぐことができます。これは、フィルタリングで統合マルチキャストグループの数を減らし、ブロードキャストトラフィックを抑えることで実現できます。
- キューの長さ
- 別の方法では、キューの長さを伸ばすこともできます。これは、ドライバーが許可する最高値まで指定のキューでバッファー数を増やすというものです。これを行うには、以下のように
ethXコマンドのrx/txリングパラメーターを編集します。ethtool --set-ring ethX
ethtool --set-ring ethXCopy to Clipboard Copied! Toggle word wrap Toggle overflow 上記のコマンドにrxもしくはtxの値を追加します。詳細に関してはman ethtoolを参照してください。 - Device weight
- また、キューからの排出率を高めることもできます。これを行うには、NIC の device weight をそれに応じて調整します。この属性は、
softirqコンテキストが CPU を放棄して再スケジュールを行う前に NIC が受信可能なフレームの最大数を指します。これは、/proc/sys/net/core/dev_weight変数で制御されます。
8.4.2. ソケットキュー
softirq コンテキストからのネットワークスタックで満たされます。するとアプリケーションは read や recvfrom などのコールで対応するソケットのキューを排出します。
netstat ユーティリティを使います。Recv-Q コラムはキューのサイズを表示します。一般的に、ソケットキューのオーバーランは NIC ハードウェアバッファーのオーバーランと同じ方法で管理されます (「NIC ハードウェアバッファー」 を参照)。
- 入力トラフィック
- 最初のオプションは、キューを満たす割合を設定することで入力トラフィックを遅らせます。これを行うには、フレームにフィルターをかけるか、前もってドロップさせます。NIC の device weight を下げることでも入力トラフィックを遅らせることができます [6]。
- キューの深さ
- キューの深さを高めることでも、ソケットキューのオーバーランを防ぐことができます。これを行うには、
rmem_defaultカーネルパラメーターかSO_RCVBUFソケットオプションのどちらかの値を増やします。これら両方に関する詳細は 「ネットワーク設定の最適化」 を参照してください。 - アプリケーション呼び出しの頻度
- 可能な場合はいつでも、アプリケーションを最適化して呼び出し頻度を高めます。これは、ネットワークアプリケーションを修正または再構成して、POSIX 呼び出し (
recvやreadなど) の実行頻度を高くすることで行います。こうすることで、アプリケーションによるキューの排出が速くなります。
8.5. マルチキャストにおける留意点
softirq コンテキストで発生します。
softirq コンテキストの実行時間に直接影響します。マルチキャストグループにリスナーを加えると、カーネルがそのグループ向けに受信された各フレームに新たなコピーを作成する必要性が生まれます。
softirq コンテキストの実行時間が長くなり、ネットワークカードとソケットキューの両方でフレームドロップが発生します。softirq ランタイムが長くなると、アプリケーションが高負荷のシステムで稼働する機会が少なくなるので、高ボリュームのマルチキャストグループをリッスンするアプリケーションの数が増えればマルチキャストフレームが失われる割合が高くなります。
8.6. Receive-Side Scaling (RSS)
/proc/interrupts にあるインターフェイスに関連付けられているかどうかを確認します。たとえば、p1p1 インターフェイスを確認するには、以下を実行します。
p1p1 インターフェイスに作成したことを示しています (p1p1-0 から p1p1-5)。 また、各キューでいくつの割り込みが処理されたか、どの CPU が割り込みを処理したかも示しています。このケースでは、デフォルトでこの NIC ドライバーが CPU ごとに 1 つのキューを作成し、システムに 6 つの CPU があるので、キューが 6 つ作成されています。これは、NIC ドライバーの中ではかなり一般的なパターンです。
ls -1 /sys/devices/*/*/device_pci_address/msi_irqs の出力をチェックします。たとえば、PCI アドレスが 0000:01:00.0 のデバイスをチェックするには、以下のコマンドを実行するとそのデバイスの割り込みリクエストキューを一覧表示できます。
bnx2x ドライバーの場合は、num_queues で設定されます。sfc ドライバーは、rss_cpus パラメーターで設定されます。いずれにしても、通常は /sys/class/net/device/queues/rx-queue/ で設定されます。ここでの device は (eth1 のような) ネットワークデバイス名で、rx-queue は適切な受信キューの名前になります。
ethtool --show-rxfh-indir および --set-rxfh-indir パラメーターを使ってネットワークアクティビティーの配布方法を修正したり、特定のタイプのネットワークアクティビティーを他のものよりも重要なもにに加重配分することもできます。
irqbalance デーモンを RSS と併用してクロスノードのメモリー転送やキャッシュラインバウンスの可能性を減らすことができます。これは、処理ネットワークパケットの遅延を低減します。irqbalance と RSS の両方が使われている場合、irqbalance がネットワークデバイスに関連付けられている割り込みを適切な RSS キューに向けることで、遅延が最小限になります。
8.7. Receive Packet Steering (RPS)
- RPS はいかなるネットワークインターフェイスカードとも使用できます。
- 新たなプロトコルに対応するために RPS にソフトウェアフィルターを追加することが容易です。
- RPS はネットワークデバイスのハードウェア割り込み率を高めません。ただし、プロセッサー間の割り込みは取り込みます。
/sys/class/net/device/queues/rx-queue/rps_cpus ファイル内でネットワークデバイスおよび受信キューごとに設定されます。ここでの device は (eth0 などの) ネットワークデバイス名で、rx-queue は (rx-0 などの) 適切な受信キューの名前です。
rps_cpus ファイルのデフォルト値はゼロです。この場合 RPS は無効になるので、ネットワーク割り込みを処理する CPU がパケットも処理します。
rps_cpus ファイルを設定します。
rps_cpus ファイルは、コンマ区切りの CPU ビットマップを使用します。つまり、CPU がインターフェイス上の受信キューの割り込みを処理できるようにするには、ビットマップ上の位置の値を 1 に設定します。たとえば、CPU 0、1、2、および 3 で割り込みを処理するには、rps_cpus の値を 00001111 (1+2+4+8)、もしくは f (15 の 16進法での値) に設定します。
8.8. Receive Flow Steering (RFS)
/proc/sys/net/core/rps_sock_flow_entries- このファイルの値を同時にアクティブとなる接続数で予測される最大値に設定します。適度なサーバー負荷の場合は、
32768に設定することが推奨されます。実際には、入力された値はすべて、直近の 2 の累乗に切り上げ/下げられます。 /sys/class/net/device/queues/rx-queue/rps_flow_cnt- device を (
eth0など) 設定するネットワークデバイス名に、rx-queue を (rx-0など) 設定する受信キューに置き換えます。このファイルの値をrps_sock_flow_entriesをNで割った値に設定します。ここでのNは、デバイス上の受信キューの数です。たとえば、rps_flow_entriesが32768に設定され、設定済みの受信キューが 16 ある場合、rps_flow_cntを2048に設定します。単一キューデバイスでは、rps_flow_cntはrps_sock_flow_entriesの値と等しくなります。
numactl または taskset を使用してアプリケーションを特定のコア、ソケット、または NUMA ノードに固定することを検討してみてください。これにより、パケットが間違った順番で処理されることを防ぐことができます。
8.9. アクセラレート RFS
- アクセラレート RFS がネットワークインターフェイスカードでサポートされていること。アクセラレート RFS は、
ndo_rx_flow_steer()netdevice 機能をエクスポートするカードでサポートされています。 ntupleフィルタリングが有効になっていること。
/proc/sys/net/core/dev_weight で制御されます。device weight についての詳細情報とその調節による影響は、「NIC ハードウェアバッファー」 を参照してください。
付録A 改訂履歴
| 改訂履歴 | |||||||
|---|---|---|---|---|---|---|---|
| 改訂 4.2-17.2 | Thu Jan 8 2015 | ||||||
| |||||||
| 改訂 4.2-17.1 | Thu Jan 8 2015 | ||||||
| |||||||
| 改訂 4.2-17 | Wed Oct 08 2014 | ||||||
| |||||||
| 改訂 4.2-16 | Thu Sep 11 2014 | ||||||
| |||||||
| 改訂 4.2-14 | Wed Sep 10 2014 | ||||||
| |||||||
| 改訂 4.2-12 | Mon Aug 18 2014 | ||||||
| |||||||
| 改訂 4.2-10 | Mon Aug 11 2014 | ||||||
| |||||||
| 改訂 4.2-9 | Mon Aug 11 2014 | ||||||
| |||||||
| 改訂 4.2-7 | Fri Aug 01 2014 | ||||||
| |||||||
| 改訂 4.2-6 | Tue Jul 22 2014 | ||||||
| |||||||
| 改訂 4.2-4 | Fri Jun 13 2014 | ||||||
| |||||||
| 改訂 4.2-2 | Fri Jun 06 2014 | ||||||
| |||||||
| 改訂 4.2-0 | Thu Jun 05 2014 | ||||||
| |||||||
| 改訂 4.1-5 | Wed Jun 04 2014 | ||||||
| |||||||
| 改訂 4.1-2 | Wed May 21 2014 | ||||||
| |||||||
| 改訂 4.1-1 | Thu May 08 2014 | ||||||
| |||||||
| 改訂 4.1-0 | Tue May 06 2014 | ||||||
| |||||||
| 改訂 4.0-43 | Wed Nov 13 2013 | ||||||
| |||||||
| 改訂 4.0-42 | Tue Oct 15 2013 | ||||||
| |||||||
| 改訂 4.0-41 | Thu Sep 12 2013 | ||||||
| |||||||
| 改訂 4.0-38 | Tue Aug 13 2013 | ||||||
| |||||||
| 改訂 4.0-35 | Fri Aug 09 2013 | ||||||
| |||||||
| 改訂 4.0-32 | Tue Aug 06 2013 | ||||||
| |||||||
| 改訂 4.0-30 | Tue Aug 06 2013 | ||||||
| |||||||
| 改訂 4.0-28 | Mon Aug 05 2013 | ||||||
| |||||||
| 改訂 4.0-26 | Wed Jul 31 2013 | ||||||
| |||||||
| 改訂 4.0-25 | Fri Jul 26 2013 | ||||||
| |||||||
| 改訂 4.0-24 | Thu Jul 25 2013 | ||||||
| |||||||
| 改訂 4.0-23 | Mon Jul 01 2013 | ||||||
| |||||||
| 改訂 4.0-22 | Tue Jun 25 2013 | ||||||
| |||||||
| 改訂 4.0-21 | Tue May 28 2013 | ||||||
| |||||||
| 改訂 4.0-20 | Wed Jan 16 2013 | ||||||
| |||||||
| 改訂 4.0-18 | Tue Nov 27 2012 | ||||||
| |||||||
| 改訂 4.0-17 | Mon Nov 19 2012 | ||||||
| |||||||
| 改訂 4.0-16 | Thu Nov 08 2012 | ||||||
| |||||||
| 改訂 4.0-15 | Wed Oct 17 2012 | ||||||
| |||||||
| 改訂 4.0-13 | Wed Oct 17 2012 | ||||||
| |||||||
| 改訂 4.0-12 | Tue Oct 16 2012 | ||||||
| |||||||
| 改訂 4.0-9 | Tue Oct 9 2012 | ||||||
| |||||||
| 改訂 4.0-6 | Thu Oct 4 2012 | ||||||
| |||||||
| 改訂 4.0-3 | Tue Sep 18 2012 | ||||||
| |||||||
| 改訂 4.0-2 | Mon Sep 10 2012 | ||||||
| |||||||
| 改訂 3.0-15 | Thursday March 22 2012 | ||||||
| |||||||
| 改訂 3.0-10 | Friday March 02 2012 | ||||||
| |||||||
| 改訂 3.0-8 | Thursday February 02 2012 | ||||||
| |||||||
| 改訂 3.0-5 | Tuesday January 17 2012 | ||||||
| |||||||
| 改訂 3.0-3 | Wednesday January 11 2012 | ||||||
| |||||||
| 改訂 1.0-0 | Friday December 02 2011 | ||||||
| |||||||