ストレージ管理ガイド
RHEL 7 での単一ノードストレージのデプロイおよび設定
概要
第1章 概要
1.1. Red Hat Enterprise Linux 7 の新機能および改良された機能
eCryptfs は含まれていません。
System Storage Manager
XFS はデフォルトのファイルシステムです。
ファイルシステムの再構築
/bin、/sbin、/lib、および /lib 64/usr の下にネストされるようになりました。
Snapper
Btrfs (テクノロジープレビュー)
NFSv2 はサポートされなくなりました
パート I. ファイルシステム
第2章 ファイルシステム構造とメンテナンス
- 共有可能および共有不可能なファイル
- 共有可能 ファイルは、ローカルおよびリモートホストからアクセスできます。Unsharable ファイルはローカルでのみ利用可能です。
- 変数および静的ファイル
- ドキュメントなどの 変数 ファイルはいつでも変更できます。バイナリー などの 静的 ファイルは、システム管理者のアクションなしでは変更されません。
2.1. ファイルシステム階層標準 (FHS) の概要
- 他の FHS 準拠システムとの互換性
/usr/パーティションを読み取り専用としてマウントする機能。/usr/には一般的な実行ファイルが含まれており、ユーザーが変更すべきではないため、これは重要です。さらに、/usr/は読み取り専用としてマウントされているため、CD-ROM ドライブまたは他のマシンから、読み取り専用 NFS マウントを介してマウントできる必要があります。
2.1.1. FHS 組織
2.1.1.1. ファイルシステム情報の収集
df コマンド
例2.1 df コマンドの出力
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/mapper/VolGroup00-LogVol00
11675568 6272120 4810348 57% / /dev/sda1
100691 9281 86211 10% /boot
none 322856 0 322856 0% /dev/shm
例2.2 df -h コマンドの出力
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/VolGroup00-LogVol00
12G 6.0G 4.6G 57% / /dev/sda1
99M 9.1M 85M 10% /boot
none 316M 0 316M 0% /dev/shm
/dev/shm はシステムの仮想メモリーファイルシステムを表します。
du コマンド
GNOME システムモニター
図2.1 GNOME システムモニターのファイルシステムタブ

[D]
2.1.1.2. /boot/ ディレクトリー
/boot/ ディレクトリーには、Linux カーネルなど、システムを起動するために必要な静的ファイルが含まれます。これらのファイルは、システムが正しく起動するためには不可欠です。
/boot/ ディレクトリーを削除しないでください。削除すると、システムが起動できなくなります。
2.1.1.3. /dev/ ディレクトリー
/dev/ ディレクトリーには、以下のデバイス種別を表すデバイスノードが含まれます。
- システムに接続されているデバイス
- カーネルが提供する仮想デバイス
/dev/ 内のデバイスノードを作成および削除します。
/dev/ ディレクトリーおよびサブディレクトリー内のデバイスは、文字 (マウスやキーボードなどの入出力のシリアルストリームのみを提供)または ブロック (ハードドライブやフロッピードライブなどのランダムにアクセス可能)のいずれかで定義されます。GNOME または KDE がインストールされている場合は、一部のストレージデバイスは (USB などで) 接続または (CD または DVD ドライブなどの) 挿入時に自動的に検出され、内容を表示するポップアップウィンドウが表示されます。
| ファイル | 説明 |
|---|---|
/dev/hda | プライマリー IDE チャネル上のマスターデバイス。 |
/dev/hdb | プライマリー IDE チャンネル上のスレーブデバイス。 |
/dev/tty0 | 最初の仮想コンソール。 |
/dev/tty1 | 2 番目の仮想コンソール |
/dev/sda | プライマリー SCSI または SATA チャネル上の最初のデバイス。 |
/dev/lp0 | 最初の並列ポート。 |
- マップされたデバイス
- ボリュームグループの論理ボリューム(例:
/dev/mapper/VolGroup00-LogVol02)。 - 静的デバイス
- たとえば、/dev/sdbX などの従来のストレージボリューム。sdb はストレージデバイス名で、X はパーティション番号になります。
/dev/sdbXは、/dev/disk/by-id/WWIDまたは/dev/disk/by-uuid/UUIDにすることもできます。詳細は、「永続的な命名」 を参照してください。
2.1.1.4. /etc/ ディレクトリー
/etc/ ディレクトリーは、マシンのローカルとなる設定ファイル用に予約されています。バイナリーを含めることはできません。バイナリーがある場合は、それらを /usr/bin/ または /usr/sbin/ に移動します。
/etc/skel/ ディレクトリーにはスケルトンユーザーファイルが格納されます。このファイルは、ユーザーの初回作成時にホームディレクトリーを設定するために使用されます。また、アプリケーションはこのディレクトリーに設定ファイルを保存し、実行時にそれらを参照する可能性があります。/etc/exports ファイルは、リモートホストにどのファイルシステムをエクスポートするかを制御します。
2.1.1.5. /mnt/ ディレクトリー
/mnt/ ディレクトリーは、NFS ファイルシステムのマウントなど、一時的にマウントされたファイルシステム用に予約されています。すべてのリムーバブルストレージメディアには、/media/ ディレクトリーを使用します。自動的に検出されたリムーバブルメディアは、/media ディレクトリーにマウントされます。
/mnt ディレクトリーは、インストールプログラムでは使用しないでください。
2.1.1.6. /opt/ ディレクトリー
/opt/ ディレクトリーは通常、デフォルトのインストールの一部ではないソフトウェアおよびアドオンパッケージ用に予約されています。/opt/ にインストールするパッケージは、その名前を持つディレクトリーを作成します(例: /opt/packagename/ )。多くの場合、このようなパッケージは予測可能なサブディレクトリー構造に従います。ほとんどの場合、バイナリーを /opt/packagename/bin/ に保存し、man ページを /opt/packagename/man/ に保存します。
2.1.1.7. /proc/ ディレクトリー
/proc/ ディレクトリーには、カーネルから情報を抽出するか、カーネルに情報を送信する特別なファイルが含まれています。このような情報の例には、システムメモリー、CPU 情報、およびハードウェア設定が含まれます。/proc/ の詳細は、「/proc 仮想ファイルシステム」 を参照してください。
2.1.1.8. /srv/ ディレクトリー
/srv/ ディレクトリーには、Red Hat Enterprise Linux システムが提供するサイト固有のデータが含まれます。このディレクトリーは、FTP、WWW、または CVS などの特定サービスのデータファイルの場所をユーザーに提供します。特定のユーザーのみに関連するデータは、/home/ ディレクトリーに置く必要があります。
2.1.1.9. /sys/ ディレクトリー
/sys/ ディレクトリーは、カーネルに固有の新しい sysfs 仮想ファイルシステムを使用します。カーネルのホットプラグハードウェアデバイスのサポートが増えると、/sys/ ディレクトリーには、/proc/ が保持する情報と同様の情報が含まれますが、ホットプラグデバイスに固有のデバイス情報の階層ビューが表示されます。
2.1.1.10. /usr/ ディレクトリー
/usr/ ディレクトリーは、複数のマシンにまたがって共有できるファイル用です。/usr/ ディレクトリーは、多くの場合、独自のパーティションにあり、読み取り専用でマウントされます。少なくとも、/usr/ には以下のサブディレクトリーが含まれている必要があります。
/usr/bin- このディレクトリーはバイナリーに使用されます。
/usr/etc- このディレクトリーは、システム全体の設定ファイルに使用されます。
/usr/games- このディレクトリーにはゲームが保存されています。
/usr/include- このディレクトリーは C ヘッダーファイルに使用されます。
/usr/kerberos- このディレクトリーは、Kerberos 関連のバイナリーおよびファイルに使用されます。
/usr/lib- このディレクトリーは、シェルスクリプトまたはユーザーが直接使用するように設計されていないオブジェクトファイルやライブラリーに使用されます。Red Hat Enterprise Linux 7.0 以降、
/lib/ディレクトリーは/usr/libに統合されました。/usr/bin/および/usr/sbin/でバイナリーを実行するために必要なライブラリーも含まれるようになりました。これらの共有ライブラリーイメージは、システムを起動したり、root ファイルシステム内でコマンドを実行したりするために使用されます。 /usr/libexec- このディレクトリーには、他のプログラムによって呼び出される小さなヘルパープログラムが含まれます。
/usr/sbin- Red Hat Enterprise Linux 7.0 以降、
/sbinは/usr/sbinに移動しました。これは、システムの起動、復元、復旧、または修復に不可欠なものを含む、すべてのシステム管理バイナリーが含まれていることを意味します。/usr/sbin/のバイナリーを使用するには、root 権限が必要です。 /usr/share- このディレクトリーには、アーキテクチャー固有ではないファイルを保存します。
/usr/src- このディレクトリーには、ソースコードが保存されます。
/var/tmpにリンクされている/usr/tmp- このディレクトリーには、一時ファイルが保存されます。
/usr/ ディレクトリーには、/local/ サブディレクトリーも含まれている必要があります。FHS によると、このサブディレクトリーは、ソフトウェアをローカルでインストールする際にシステム管理者によって使用されるので、システムの更新中に上書きされないようにする必要があります。 /usr/ local ディレクトリーには /usr/ と似ており、以下のサブディレクトリーが含まれます。
/usr/local/bin/usr/local/etc/usr/local/games/usr/local/include/usr/local/lib/usr/local/libexec/usr/local/sbin/usr/local/share/usr/local/src
/usr/local/ の使用は FHS とは若干異なります。FHS は、/usr/local/ を使用して、システムソフトウェアのアップグレードから安全に保つ必要があるソフトウェアを保存する必要があることを示しています。RPM Package Manager はソフトウェアのアップグレードを安全に実行できるため、ファイルを /usr/local/ に保存してファイルを保護する必要はありません。
/usr/local/ を使用します。たとえば、/usr/ ディレクトリーがリモートホストから読み取り専用 NFS 共有としてマウントされている場合でも、/usr/local/ ディレクトリーにパッケージまたはプログラムをインストールすることができます。
2.1.1.11. /var/ ディレクトリー
/usr/ を読み取り専用としてマウントする必要があるため、ログファイルを書き込むプログラムや、spool/ または lock/ ディレクトリーが必要なプログラムは、それらを /var/ ディレクトリーに書き込む必要があります。FHS は、/var/ は、スプールディレクトリーとファイル、ロギングデータ、一時的ファイルなどの変数データ用です。
/var/ ディレクトリーにあるディレクトリーの一部です。
/var/account//var/arpwatch//var/cache//var/crash//var/db//var/empty//var/ftp//var/gdm//var/kerberos//var/lib//var/local//var/lock//var/log//var/spool/mail/にリンクされた/var/mail/var/mailman//var/named//var/nis//var/opt//var/preserve//var/run//var/spool//var/tmp//var/tux//var/www//var/yp/
/var/run/media/ユーザー ディレクトリーには、USB ストレージメディア、DVD、CD-ROM、Zip ディスクなどのリムーバブルメディアのマウントポイントとして使用されるサブディレクトリーが含まれます。以前は、/media/ ディレクトリーがこの目的で使用されていたことに注意してください。
メッセージ や lastlog などのシステムログファイルは、/var/log/ ディレクトリーに移動します。/var/lib/rpm/ ディレクトリーには RPM システムデータベースが含まれます。ロックファイルは、通常は ファイルを使用するプログラムのディレクトリーにある /var/lock/ ディレクトリーに移動します。/var/spool/ ディレクトリーには、一部のプログラムのデータファイルを保存するサブディレクトリーがあります。これらのサブディレクトリーには以下が含まれます。
/var/spool/at//var/spool/clientmqueue//var/spool/cron//var/spool/cups//var/spool/exim//var/spool/lpd//var/spool/mail//var/spool/mailman//var/spool/mqueue//var/spool/news//var/spool/postfix//var/spool/repackage//var/spool/rwho//var/spool/samba//var/spool/squid//var/spool/squirrelmail//var/spool/up2date//var/spool/uucp//var/spool/uucppublic//var/spool/vbox/
2.2. 特別な Red Hat Enterprise Linux ファイルの場所
/var/lib/rpm/ ディレクトリーに保持されます。RPM の詳細は、man rpm を参照してください。
/var/cache/yum/ ディレクトリーには、システムの RPM ヘッダー情報など 、パッケージアップデータ が使用するファイルが含まれます。この場所は、システムの更新中にダウンロードされた RPM を一時的に保存するためにも使用できます。Red Hat Network の詳細は https://rhn.redhat.com/ を参照してください。
/etc/sysconfig/ ディレクトリーです。このディレクトリーには、さまざまな設定情報が格納されています。システムの起動時に実行されるスクリプトの多くは、このディレクトリー内のファイルを使用します。
2.3. /proc 仮想ファイルシステム
/proc にはテキストファイルもバイナリーファイルも含まれていません。仮想ファイル を格納するため、/proc は仮想ファイルシステムと呼ばれます。これらの仮想ファイルは、大量の情報が含まれている場合でも、サイズは通常 0 バイトになります。
/proc ファイルシステムはストレージには使用されません。この主な目的は、ハードウェア、メモリー、実行中のプロセス、および他のシステムコンポーネントにファイルベースのインターフェイスを提供することです。リアルタイム情報は、対応する /proc ファイルを表示することで、多くのシステムコンポーネントで取得できます。/proc 内の一部のファイルは、カーネルを設定するために(ユーザーとアプリケーションの両方で)操作することもできます。
/proc ファイルは、システムストレージの管理および監視に関連しています。
- /proc/devices
- 現在設定されているさまざまな文字およびブロックデバイスを表示します。
- /proc/filesystems
- カーネルで現在対応しているすべてのファイルシステムタイプをリスト表示します。
- /proc/mdstat
- システム上の複数ディスクまたは RAID 設定に関する現在の情報が含まれます (存在する場合)。
- /proc/mounts
- システムで現在使用しているマウントをすべてリスト表示します。
- /proc/partitions
- パーティションブロック割り当て情報が含まれます。
/proc ファイルシステムの詳細は、Red Hat Enterprise Linux 7 『デプロイメントガイド』 を参照してください。
2.4. 未使用ブロックの破棄
- バッチ破棄操作 は、ユーザーが fstrim コマンドを使用して明示的に実行します。このコマンドは、ファイルシステム内にある未使用のブロックで、管理者が指定した基準に一致するものをすべて破棄します。
- オンライン破棄操作 は、マウント時に、mount コマンドの一部として
-o discardオプションを使用するか、/etc/fstabファイルのdiscardオプションで指定します。ユーザーによる介入なしでリアルタイムで実行されます。オンライン破棄操作は、使用中から空きに移行しているブロックのみを破棄します。
/sys/block/デバイス/queue/discard_max_bytes ファイルに保存されている値がゼロでない場合、物理的な破棄 操作がサポートされます。
- 破棄操作をサポートしていないデバイス、または
- 複数のデバイスで設定され、そのデバイスのいずれかが破棄操作をサポートしていない論理デバイス (LVM または MD)
fstrim -v /mnt/non_discard
fstrim: /mnt/non_discard: the discard operation is not supported
第3章 XFS ファイルシステム
- XFS の主な機能
- XFS は、メタデータジャーナリング をサポートしているため、クラッシュリカバリーを迅速に行うことができます。
- XFS ファイルシステムは、マウントされ、アクティブな状態でデフラグし、拡張できます。
- また、Red Hat Enterprise Linux 7 は XFS 固有のバックアップおよび復元ユーティリティーをサポートしています。
- 割り当て機能
- XFS は、次の割り当てスキームを特長としています。
- エクステント (領域) ベースの割り当て
- ストライプを認識できる割り当てポリシー
- 遅延割り当て
- 領域の事前割り当て
遅延割り当てや他のパフォーマンスの最適化は、ext4 と同じように XFS に影響を与えます。つまり、XFS ファイルシステムへのプログラムの書き込みは、プログラムが後で fsync () 呼び出しを発行しない限り、ディスク上のオンディスクである保証はありません。ファイルシステム (ext4 および XFS) での遅延割り当ての影響の詳細は、5章ext4 ファイルシステム の 割り当て機能 を参照してください。注記ディスク容量が十分であるように見えても、ファイルの作成またはデプロイメントが予期しない ENOSPC 書き込みエラーで失敗することがあります。これは、XFS のパフォーマンス指向の設計が原因となります。実際には、残りの容量が数ブロックしかない場合にのみ発生するため、問題にはなりません。 - その他の XFS 機能
- XFS ファイルシステムは、以下もサポートしています。
- 拡張属性 (
xattr) - これにより、システムが、ファイルごとに、名前と値の組み合わせを追加で関連付けられるようになります。これは、デフォルトで有効になっています。
- クォータジャーナリング
- クラッシュ後に行なわれる、時間がかかるクォータの整合性チェックが不要になります。
- プロジェクト/ディレクトリークォータ
- ディレクトリーツリー全体にクォータ制限を適用できます。
- サブセカンド (一秒未満) のタイムスタンプ
- これにより、タイムスタンプはサブセカンド (一秒未満) になることができます。
- 拡張属性 (
- デフォルトの atime 動作は relatimeです。
- XFS では、デフォルトで relatime が オンになっています。正しい atime 値を維持しながら、noatime と比較してオーバーヘッドはほとんどありません。
3.1. XFS ファイルシステムの作成
- XFS ファイルシステムを作成するには、以下のコマンドを使用します。
#mkfs.xfs block_device- block_device をブロックデバイスへのパスに置き換えます。たとえば、
/dev/sdb1、/dev/disk/by-uuid/05e99ec8-def1-4a5e-8a9d-5945339ceb2a、または/dev/my-volgroup/my-lvです。 - 通常、デフォルトのオプションは、一般的な使用に最適なものです。
- 既存のファイルシステムを含むブロックデバイスで mkfs.xfs を使用する場合は、
-fオプションを追加してそのファイルシステムを上書きします。
例3.1 mkfs.xfs コマンドの出力
meta-data=/dev/device isize=256 agcount=4, agsize=3277258 blks
= sectsz=512 attr=2
data = bsize=4096 blocks=13109032, imaxpct=25
= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0
log =internal log bsize=4096 blocks=6400, version=2
= sectsz=512 sunit=0 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
ストライプ化ブロックデバイス
mkfs ユーティリティー(ext3、ext4、xfs の場合)は自動的にこのジオメトリーを使用します。ストレージに実際にストライプジオメトリーがある場合でも mkfs ユーティリティーによってストライプジオメトリーが検出されない場合は、次のオプションを使用してファイルシステムを作成するときに手動で指定できます。
- su=value
- ストライプユニットまたは RAID チャンクサイズを指定します。値 はバイト単位で指定する必要があります。オプションで
k、m、またはgの接尾辞を指定します。 - sw=value
- RAID デバイス内のデータディスク数、または 1 ストライプ内のストライプユニット数を指定します。
# mkfs.xfs -d su=64k,sw=4 /dev/block_device関連情報
- mkfs.xfs(8) の man ページ
3.2. XFS ファイルシステムのマウント
# mount /dev/device /mount/pointmke2fs とは異なり、mkfs.xfs は設定ファイルを使用しません。これらはすべてコマンドラインで指定されます。
書き込みバリア
# mount -o nobarrier /dev/device /mount/pointDirect Access テクノロジープレビュー
Direct Access (DAX)がテクノロジープレビューとして利用できます。これは、アプリケーションが永続メモリーをそのアドレス空間に直接マッピングするための手段です。DAX を使用するには、システムで利用可能な永続メモリーの形式が必要です。通常は、NVDIMM (Non-Volatile Dual In-line Memory Module) の形式で、DAX に対応するファイルシステムを NVDIMM に作成する必要があります。また、ファイルシステムは dax マウントオプション でマウントする必要があります。これにより、dax をマウントしたファイルシステムのファイルの mmap が、アプリケーションのアドレス空間にストレージを直接マッピングされます。
3.3. XFS クォータ管理
- uquota/uqnoenforce: ユーザークォータ
- gquota/gqnoenforce: グループクォータ
- pquota/pqnoenforce: プロジェクトクォータ
- quota username/userID
- 指定の username または numeric userIDの使用状況および制限を表示します
- df
- ブロックおよび inode の空きおよび使用済みの数を表示します。
# xfs_quota -x- report /path
- 特定のファイルシステムのクォータ情報を報告します。
- limit
- クォータの制限を変更します。
例3.2 サンプルクォータレポートの表示
/dev/blockdeviceの) /home のクォータレポートのサンプルを表示するには、xfs_quota -x -c 'report -h' /home コマンドを使用します。これにより、以下のような出力が表示されます。
User quota on /home (/dev/blockdevice) Blocks User ID Used Soft Hard Warn/Grace ---------- --------------------------------- root 0 0 0 00 [------] testuser 103.4G 0 0 00 [------] ...
/home/john のユーザー john に対して、inode 数のソフト制限およびハード制限をそれぞれ 500 と 700 に設定するには、以下のコマンドを使用します。
# xfs_quota -x -c 'limit isoft=500 ihard=700 john' /home/例3.3 ソフトブロックおよびハードブロック制限の設定
/target/path ファイルシステムで アカウンティング をグループ化するために、ソフトブロック制限とハードブロック制限をそれぞれ 1000m と 1200m に設定するには、次のコマンドを使用します。
# xfs_quota -x -c 'limit -g bsoft=1000m bhard=1200m accounting' /target/pathプロジェクト制限の設定
- プロジェクトが制御するディレクトリーを
/etc/projectsに追加します。たとえば、以下は一意の ID が 11 の/var/logパスを/etc/projectsに追加します。プロジェクト ID には、プロジェクトにマッピングされる任意の数値を指定できます。#echo 11:/var/log >> /etc/projects - プロジェクト名を
/etc/projidに追加して、プロジェクト ID をプロジェクト名にマッピングします。たとえば、以下は、前のステップで定義されたように logfiles というプロジェクトをプロジェクト ID 11 に関連付けます。#echo logfiles:11 >> /etc/projid - プロジェクトのディレクトリーを初期化します。たとえば、以下はプロジェクトディレクトリー
/varを初期化します。#xfs_quota -x -c 'project -s logfiles' /var - 初期化したディレクトリーでプロジェクトのクォータを設定します。
#xfs_quota -x -c 'limit -p bhard=lg logfiles' /var
3.4. XFS ファイルシステムのサイズの拡大
# xfs_growfs /mount/point -D size3.5. XFS ファイルシステムの修復
# xfs_repair /dev/device3.6. XFS ファイルシステムの一時停止
# xfs_freeze mount-pointxfsprogs パッケージで提供されます。これは x86_64 でのみ利用できます。
# xfs_freeze -f /mount/point
# xfs_freeze -u /mount/point3.7. XFS ファイルシステムのバックアップおよび復元
- バックアップを作成するための xfsdump
- バックアップから復元するための xfsrestore
3.7.1. XFS バックアップおよび復元の機能
バックアップ
xfsdump ユーティリティーを使用して以下を行うことができます。
- 通常のファイルイメージへのバックアップ通常のファイルに書き込むことができるバックアップは 1 つだけです。
- テープドライブへのバックアップ
xfsdumpユーティリティーを使用すると、同じテープに複数のバックアップを書き込むこともできます。バックアップは、複数のテープを分割して書き込むことができます。複数のファイルシステムのバックアップを 1 つのテープデバイスに作成するには、XFS バックアップがすでに含まれているテープにバックアップを書き込みます。これにより、古いバックアップに、新しいバックアップが追加されます。xfsdumpは、デフォルトでは既存のバックアップを上書きしません。 - 増分バックアップの作成
xfsdumpユーティリティーは dump レベル を使用して、他のバックアップの相対的なベースバックアップを決定します。0から9までの数字は、ダンプレベルの増加を指します。増分バックアップは、下位レベルの最後のダンプ以降に変更したファイルのみが対象となります。- フルバックアップを実行する場合は、ファイルシステムで レベル 0 のダンプを実行します。
- レベル 1 のダンプは、フルバックアップ後の最初の増分バックアップです。次の増分バックアップはレベル 2 になります。これは、前回のレベル 1 などのダンプ以降に変更したファイルのみが対象となります。最大でレベル 9 までが対象となります。
- ファイルを絞り込むサイズ、サブツリー、または inode のフラグを使用して、バックアップからファイルを除外
復元
xfsrestore インタラクティブモードを起動します。インタラクティブモードでは、バックアップファイルを操作する一連のコマンドが提供されます。
3.7.2. XFS ファイルシステムのバックアップ
手順3.1 XFS ファイルシステムのバックアップ
- 次のコマンドを使用して、XFS ファイルシステムのバックアップを作成します。
#xfsdump -l level [-L label] -f backup-destination path-to-xfs-filesystem- level をバックアップのダンプレベルに置き換えます。完全バックアップを実行するには
0を、結果として生じる増分バックアップを実行するには、1から9を使用します。 - backup-destination を、バックアップを保存する場所のパスに置き換えます。保存場所は、通常のファイル、テープドライブ、またはリモートテープデバイスです。たとえば、ファイルの場合は
/backup-files/Data.xfsdump、テープドライブの場合は/dev/st0です。 - path-to-xfs-filesystem をバックアップを作成する XFS ファイルシステムのマウントポイントに置き換えます。たとえば、
/mnt/data/です。ファイルシステムをマウントする必要があります。 - 複数のファイルシステムのバックアップを作成して 1 つのテープデバイスに保存する場合は、復元時にそれらを簡単に識別できるように
-L labelオプションを使用して、各バックアップにセッションラベルを追加します。label をバックアップの名前(例:backup_data)に置き換えます。
例3.4 複数の XFS ファイルシステムのバックアップ
/boot/ディレクトリーおよび/data/ディレクトリーにマウントされた XFS ファイルシステムのコンテンツのバックアップを作成し、それらをファイルとして/backup-files/ディレクトリーに保存するには、次のコマンドを実行します。#xfsdump -l 0 -f /backup-files/boot.xfsdump /boot#xfsdump -l 0 -f /backup-files/data.xfsdump /data- 1 つのテープデバイスにある複数のファイルシステムのバックアップを作成する場合は、
-L labelオプションを使用して、各バックアップにセッションラベルを追加します。#xfsdump -l 0 -L "backup_boot" -f /dev/st0 /boot#xfsdump -l 0 -L "backup_data" -f /dev/st0 /data
関連情報
- XFS ファイルシステムのバックアップの詳細は、xfsdump(8) の man ページを参照してください。
3.7.3. バックアップからの XFS ファイルシステムの復元
前提条件
- 「XFS ファイルシステムのバックアップ」 の説明に従って、XFS ファイルシステムのファイルまたはテープのバックアップを作成する必要があります。
手順3.2 バックアップからの XFS ファイルシステムの復元
- バックアップを復元するコマンドは、フルバックアップから復元するか、増分バックアップから復元するか、1 つのテープデバイスから複数のバックアップを復元するかによって異なります。
#xfsrestore [-r] [-S session-id] [-L session-label] [-i]-f backup-locationrestoration-path- backup-location を、バックアップの場所に置き換えます。これは、通常のファイル、テープドライブ、またはリモートテープデバイスになります。たとえば、ファイルの場合は
/backup-files/Data.xfsdump、テープドライブの場合は/dev/st0です。 - restoration-path を、ファイルシステムを復元するディレクトリーへのパスに置き換えます。たとえば、
/mnt/data/です。 - ファイルシステムを増分 (レベル 1 からレベル 9) バックアップから復元するには、
-rオプションを追加します。 - 複数のバックアップを含むテープデバイスからバックアップを復元するには、
-Sオプションまたは-Lオプションを使用してバックアップを指定します。-Sではセッション ID でバックアップを選択できます。-Lではセッションラベルでバックアップを選択できます。セッション ID とセッションラベルを取得するには、xfsrestore -I コマンドを使用します。session-id を、バックアップのセッション ID に置き換えます。たとえば、b74a3586-e52e-4a4a-8775-c3334fa8ea2cです。session-label を、バックアップのセッションラベルに置き換えます。たとえば、my_backup_session_labelです。 xfsrestoreを対話的に使用するには、-iオプションを使用します。対話式ダイアログは、xfsrestoreが指定のデバイスの読み取りを終了すると開始します。インタラクティブなxfsrestoreシェルの使用可能なコマンドには、cd、ls、add、delete、および extract があります。コマンドの完全なリストについては、help コマンドを使用します。
例3.5 複数の XFS ファイルシステムの復元
/mnt/ の下のディレクトリーに保存するには、以下を実行します。
#xfsrestore -f /backup-files/boot.xfsdump /mnt/boot/#xfsrestore -f /backup-files/data.xfsdump /mnt/data/
#xfsrestore -f /dev/st0 -L "backup_boot" /mnt/boot/#xfsrestore -f /dev/st0 -S "45e9af35-efd2-4244-87bc-4762e476cbab" /mnt/data/
テープからバックアップを復元する際の情報メッセージ
xfsrestore ユーティリティーがメッセージを発行する場合があります。このメッセージは、xfsrestore がテープ上の各バックアップを順番に検査する際に、要求されたバックアップと一致するものが見つかったかどうかを通知します。以下に例を示します。
xfsrestore: preparing drive xfsrestore: examining media file 0 xfsrestore: inventory session uuid (8590224e-3c93-469c-a311-fc8f23029b2a) does not match the media header's session uuid (7eda9f86-f1e9-4dfd-b1d4-c50467912408) xfsrestore: examining media file 1 xfsrestore: inventory session uuid (8590224e-3c93-469c-a311-fc8f23029b2a) does not match the media header's session uuid (7eda9f86-f1e9-4dfd-b1d4-c50467912408) [...]
関連情報
- XFS ファイルシステムの復元の詳細は、xfsrestore(8) の man ページを参照してください。
3.8. エラー動作の設定
- 以下のいずれかになるまで再試行を続行します。
- I/O 操作が成功するか、または
- I/O 操作の再試行回数または時間制限を超えた場合
- エラーが永続化し、システムが停止することを考慮してください。
EIO: デバイスへの書き込み試行時のエラーENOSPC: No space left on the deviceENODEV: デバイスが見つかりません
3.8.1. 特定の条件および定義されていない条件の設定ファイル
/sys/fs/xfs/device/error/ ディレクトリーにあります。
/sys/fs/xfs/デバイス/error/metadata/ ディレクトリーには、特定のエラー 状態ごとにサブディレクトリーが含まれます。
EIO エラー状態の /sys/fs/xfs/デバイス/error/metadata/EIO/ENODEV エラー条件の /sys/fs/xfs/デバイス/error/metadata/ENODEV/ENOSPC エラー条件の /sys/fs/xfs/デバイス/error/metadata/ENOSPC/
/sys/fs/xfs/device/error/metadata/condition/max_retries: XFS が操作を再試行する最大回数を制御します。/sys/fs/xfs/device/error/metadata/condition/retry_timeout_seconds: XFS が操作の再試行を停止するまでの時間制限(秒単位)
/sys/fs/xfs/device/error/metadata/default/max_retries: 再試行の最大数を制御します。/sys/fs/xfs/device/error/metadata/default/retry_timeout_seconds: 再試行する時間制限を制御します。
3.8.2. 特定かつ未定義の条件に対するファイルシステムの動作の設定
max_retries ファイルに書き込みます。
- 特定の条件の場合:
#echo value > /sys/fs/xfs/device/error/metadata/condition/max_retries - 未定義の条件の場合:
#echo value > /sys/fs/xfs/device/error/metadata/default/max_retries
- 1 から可能な最大値 int (C 符号付き整数型)の間の数値です。これは、64 ビット Linux では 2147483647 です。
retry_timeout_seconds ファイルに書き込みます。
- 特定の条件の場合:
#echo value > /sys/fs/xfs/device/error/metadata/condition/retry_timeout_seconds - 未定義の条件の場合:
#echo value > /sys/fs/xfs/device/error/metadata/default/retry_timeout_seconds
86400 の間の数字で、これは 1 日の秒数です。
max_retries オプションと retry_timeout_seconds オプションの両方で、- 1 は永久に再試行し、0 は即座に停止することを意味します。
/dev/ ディレクトリーにあるデバイス名です。たとえば、sda などです。
ENODEV などの一部のエラーは、再試行数に関係なく致命的で回復不能であると見なされるため、デフォルト値は 0 です。
3.8.3. アンマウント動作の設定
fail_at_unmount オプションが設定されている場合、ファイルシステムはアンマウント時に他のすべてのエラー設定を上書きし、I/O 操作を再試行せずにすぐにファイルシステムを非表示にします。これにより、永続的なエラーが発生した場合でも、マウント解除操作を成功できます。
# echo value > /sys/fs/xfs/device/error/fail_at_unmount1 または 0 です。
1は、エラーが見つかったらすぐに再試行を取り消すことを意味します。0は、max_retriesオプションおよびretry_timeout_secondsオプションを尊重することを意味します。
/dev/ ディレクトリーにあるデバイス名です。たとえば、sda などです。
fail_at_unmount オプションは、ファイルシステムのアンマウントを試行する前に必要に応じて設定する必要があります。マウント解除操作が開始されると、設定ファイルおよびディレクトリーが利用できなくなる可能性があります。
3.9. XFS ファイルシステムのその他のユーティリティー
- xfs_fsr
- マウントしている XFS ファイルシステムのデフラグを行う際に使用します。引数を指定せずに呼び出すと、xfs_fsr は、マウントされているすべての XFS ファイルシステム内のすべての通常ファイルをデフラグします。このユーティリティーでは、ユーザーは指定された時間にデフラグを一時停止し、後で中断したところから再開することもできます。さらに、xfs_fsr /path/to/fileのように、xfs_fsr は 1 つのファイルのみをデフラグする こともできます。XFS はデフォルトで断片化を回避するため、Red Hat では、ファイルシステム全体を定期的にデフラグしないことを推奨しています。システム全体のデフラグは、空き領域での断片化という副作用を引き起こす可能性があります。
- xfs_bmap
- XFS ファイルシステム内のファイル群で使用されているディスクブロックのマップを表示します。指定したファイルによって使用されているエクステントや、該当するブロックがないファイルの領域 (ホール) をリスト表示します。
- xfs_info
- XFS ファイルシステムの情報を表示します。
- xfs_admin
- XFS ファイルシステムのパラメーターを変更します。xfs_admin ユーティリティーは、マウントされていないデバイスまたはファイルシステムのパラメーターのみを変更できます。
- xfs_copy
- XFS ファイルシステム全体のコンテンツを 1 つまたは複数のターゲットに同時にコピーします。
- xfs_metadump
- XFS ファイルシステムのメタデータをファイルにコピーします。Red Hat は、xfs_metadump ユーティリティーを使用して、マウントされていないファイルシステムまたは読み取り専用でマウントされたファイルシステムをコピーすることのみをサポートします。そうしないと、生成されたダンプが破損したり、一貫性のないりする可能性があります。
- xfs_mdrestore
- XFS メタダンプイメージ( xfs_metadumpを使用して生成された)をファイルシステムイメージに復元します。
- xfs_db
- XFS ファイルシステムをデバッグします。
3.10. ext4 から XFS への移行
3.10.1. Ext3/4 と XFS の相違点
- ファイルシステムの修復
- Ext3/4 は、システムの起動時にユーザースペースで e2fsck を実行して、必要に応じてジャーナルを復元します。比較すると、XFS はマウント時にカーネル空間でジャーナルリカバリーを実行します。
fsck.xfsシェルスクリプトが提供されますが、initscript 要件を満たすためだけに存在するため、便利なアクションは実行しません。XFS ファイルシステムの修復またはチェックが要求されたら、xfs_repair コマンドを使用します。読み取り専用チェックには -n オプションを使用します。xfs_repair コマンドは、ダーティーログのあるファイルシステムで動作しません。このようなファイルシステムを修復するには、最初に アン マウント を実行してログを再生する必要があります。ログが破損していて再生できない場合は、-L オプションを使用してログのゼロアウトできます。XFS ファイルシステムのファイルシステム修復の詳細は、「XFS」 を参照してください。 - メタデータエラーの動作
- ext3/4 ファイルシステムでは、メタデータエラーが発生した場合の動作を設定できますが、デフォルトは単に継続します。XFS がリカバリーできないメタデータエラーに遭遇すると、ファイルシステムがシャットダウンされ、
EFSCORRUPTEDエラーが返されます。システムログには発生したエラーの詳細が含まれ、必要に応じて xfs_repair の実行が推奨されます。 - Quotas
- XFS クォータは再マウントできるオプションではありません。クォータを有効にするには、初期マウントで -o quota オプションを指定する必要があります。quota パッケージの標準ツールは、基本的なクォータ管理タスク( setquota や repquotaなどのツール)を実行できますが、xfs_quota ツールは、プロジェクトクォータ管理などの XFS 固有の機能に使用できます。quotacheck コマンドは、XFS ファイルシステムには影響しません。クォータアカウンティングが初めてオンになると、内部で自動的に quotacheck を実行します。XFS クォータメタデータは、ファーストクラスのジャーナル化されたメタデータオブジェクトであるため、クォータシステムは、クォータが手動でオフになるまで常に一貫しています。
- ファイルシステムのサイズ変更
- XFS ファイルシステムには、ファイルシステムを縮小するユーティリティーはありません。XFS ファイルシステムは、xfs_growfs コマンドを使用してオンラインで拡張できます。
- Inode 番号
- 256 バイトの inode を持つ 1TB を超えるファイルシステム、または 512 バイトの inode を持つ 2TB を超えるファイルシステムでは、XFS の inode 番号が 2^32 を超える可能性があります。このような大きな inode 番号により、32 ビットの stat 呼び出しが EOVERFLOW の戻り値で失敗します。上記の問題は、デフォルトの Red Hat Enterprise Linux 7 設定 (4 つの割り当てグループでストライプ化されていない) を使用する場合に発生する可能性があります。ファイルシステムの拡張子や XFS ファイルシステムのパラメーターの変更など、カスタム設定では異なる動作が発生する場合があります。通常、アプリケーションは、このように大きな inode 番号を正しく処理します。必要に応じて、-o inode32 パラメーターを指定して XFS ファイルシステムをマウントし、2^32 未満の inode 番号を強制します。
inode32を使用しても、すでに 64 ビットの数値が割り当てられている inode には影響しないことに注意してください。重要特定の環境に必要な場合を除き、inode32オプション は 使用しない でください。inode32オプションは、割り当て動作を変更します。これにより、下層のディスクブロックに inode を割り当てるための領域がない場合に、ENOSPC エラーが発生する可能性があります。 - 投機的事前割り当て
- XFS は、投機的事前割り当て を使用して、ファイルの書き込み時に EOF を超えてブロックを割り当てます。これにより、NFS サーバーでの同時ストリーミング書き込みワークロードによるファイルの断片化を回避します。デフォルトでは、この事前割り当てはファイルのサイズとともに増加し、"du" の出力で確認できます。投機的事前割り当てのあるファイルで 5 分間ダーティーが発生しない場合、事前割り当ては破棄されます。その時間より前に、inode がキャッシュからサイクルアウトされると、inode が回収される際に、事前割り当てが破棄されます。投機的事前割り当てにより premature ENOSPC の問題が発生する場合は、固定事前割り当て量を -o allocsize=amount マウントオプションで指定できます。
- フラグメンテーション関連のツール
- フラグメント化は、割り当ての遅延や投機的な事前割り当てなどのヒューリスティックおよび動作のために、XFS ファイルシステムで重大な問題になることはめったにありません。ただし、ファイルシステムの断片化を測定したり、ファイルシステムのデフラグを行うツールは存在します。それらの使用は推奨されていません。xfs_db frag コマンドは、すべてのファイルシステムの割り当てを 1 つの断片化番号に分割しようとします。これはパーセンテージで表されます。コマンドの出力には、その意味を理解するための十分な専門知識が必要です。たとえば、75% のフラグメント化ファクターの場合は、ファイルあたり平均 4 つのエクステントのみを意味します。このため、xfs_db のフラグメントの出力は有用とは見なされず、フラグメント化の問題を注意深く分析することが推奨されます。警告xfs_fsr コマンドを使用して、個々のファイルまたはファイルシステム上のすべてのファイルをデフラグできます。後者は、ファイルの局所性を破壊し、空き領域をフラグメント化する可能性があるため、特に推奨しません。
XFS と比較した ext3 および ext4 で使用されるコマンド
| タスク | ext3/4 | XFS |
|---|---|---|
| ファイルシステムを作成する | mkfs.ext4 または mkfs.ext3 | mkfs.xfs |
| ファイルシステム検査 | e2fsck | xfs_repair |
| ファイルシステムのサイズ変更 | resize2fs | xfs_growfs |
| ファイルシステムのイメージを保存する | e2image | xfs_metadump および xfs_mdrestore |
| ファイルシステムのラベル付けまたはチューニングを行う | tune2fs | xfs_admin |
| ファイルシステムのバックアップ | dump および restore | xfsdump および xfsrestore |
| タスク | ext4 | XFS |
|---|---|---|
| クォータ | quota | xfs_quota |
| ファイルマッピング | filefrag | xfs_bmap |
第4章 Ext3 ファイルシステム。
- 可用性
- 予期しない停電やシステムクラッシュ (クリーンでないシステムシャットダウン とも言われる) が発生すると、マシンにマウントしている各 ext2 ファイルシステムは、e2fsck プログラムで整合性をチェックする必要があります。これは時間を浪費するプロセスであり、大量のファイルを含む大型ボリュームでは、システムの起動時間を著しく遅らせます。このプロセスの間、そのボリュームにあるデータは使用できません。ライブファイルシステムで fsck -n を実行できます。ただし、変更は行われず、部分的に書き込まれたメタデータが検出された場合、誤解を招く結果が生じる可能性があります。スタックで LVM が使用されている場合は、ファイルシステムの LVM スナップショットを作成し、そのファイルシステムで fsck を実行する方法があります。もしくは、ファイルシステムを読み込み専用で再マウントするオプションがあります。保留中のメタデータ更新 (および書き込み) は、すべて再マウントの前にディスクへ強制的に入れられます。これにより、以前に破損がない限り、ファイルシステムが一貫した状態になります。fsck -n を実行できるようになりました。ext3 ファイルシステムで提供されるジャーナリングは、クリーンでないシステムシャットダウンが発生してもこの種のファイルシステムの検査が不要であることを意味します。ext3 の使用していても整合性チェックが必要になる唯一の場面は、ハードドライブの障害が発生した場合など、ごく稀なハードウェア障害のケースのみです。クリーンでないシャットダウンの発生後に ext3 ファイルシステムを復元する時間は、ファイルシステムのサイズやファイルの数量ではなく、一貫性を維持するために使用される ジャーナル のサイズに依存します。デフォルトのジャーナルサイズは、ハードウェアの速度に応じて、復旧するのに約 1 秒かかります注記Red Hat がサポートする ext3 の唯一のジャーナリングモードは data=ordered (デフォルト)です。
- データの整合性
- ext3 ファイルシステムは、クリーンでないシステムシャットダウンが発生した際にデータの整合性が失われることを防止します。ext3 ファイルシステムにより、データが受けることのできる保護のタイプとレベルを選択できるようになります。ファイルシステムの状態に関しては、ext3 のボリュームはデフォルトで高度なレベルのデータ整合性を維持するように設定されています。
- 速度
- 一部のデータを複数回書き込みますが、ext3 のジャーナリングにより、ハードドライブのヘッドモーションが最適化されるため、ほとんどの場合、ext3 のスループットは ext2 よりも高くなります。速度を最適化するために 3 つのジャーナリングモードから選択できますが、システムに障害が発生する可能性のある状況では、モードの選択はデータの整合性がトレードオフの関係になることがあります。注記Red Hat がサポートする ext3 の唯一のジャーナリングモードは data=ordered (デフォルト)です。
- 簡単なトランジション
- ext2 から ext3 に簡単に移行でき、再フォーマットをせずに、堅牢なジャーナリングファイルシステムの恩恵を受けることができます。このタスクの実行方法は、「ext3 ファイルシステムへの変換」 を参照してください。
ext4.ko を使用します。つまり、カーネルメッセージは、使用されている ext ファイルシステムに関係なく、常に ext4 を参照します。
4.1. Ext3 ファイルシステムの作成
mkfs.ext3ユーティリティーを使用して、パーティションまたは LVM ボリュームを ext3 ファイルシステムでフォーマットします。#mkfs.ext3 block_device- block_device をブロックデバイスへのパスに置き換えます。たとえば、
/dev/sdb1、/dev/disk/by-uuid/05e99ec8-def1-4a5e-8a9d-5945339ceb2a、または/dev/my-volgroup/my-lvです。
e2labelユーティリティーを使用してファイルシステムにラベルを付けます。#e2label block_device volume_label
UUID の設定
-U オプションを使用します。
# mkfs.ext3 -U UUID device- UUID は、設定する UUID に置き換えます(例:
7cd65de3-e0be-41d9-b66d-96d749c02da7)。 - device を、ext3 ファイルシステムへのパスに置き換え、UUID を追加します(例:
/dev/sda8)。
関連情報
- mkfs.ext3(8) の man ページ
- e2label(8) の man ページ
4.2. ext3 ファイルシステムへの変換
ext2 ファイルシステムを ext3 に変換します。
ext2 ファイルシステムを ext3 に変換するには、root としてログインし、端末に以下のコマンドを入力します。
# tune2fs -j block_device4.3. Ext2 ファイルシステムへの復元
/dev/mapper/VolGroup00-LogVol02
手順4.1 ext3 から ext2 に戻す
- root としてログインし、パーティションをアンマウントして以下を入力します。
# umount /dev/mapper/VolGroup00-LogVol02 - 以下のコマンドを入力して、ファイルシステムの種類を ext2 に変更します。
# tune2fs -O ^has_journal /dev/mapper/VolGroup00-LogVol02 - 以下のコマンドを入力して、パーティションでエラーの有無を確認します。
# e2fsck -y /dev/mapper/VolGroup00-LogVol02 - 次に、以下を入力して ext2 ファイルシステムとしてパーティションを再度マウントします。
# mount -t ext2 /dev/mapper/VolGroup00-LogVol02 /mount/point/mount/point をパーティションのマウントポイントに置き換えます。注記.journalファイルがパーティションのルートレベルに存在する場合は、これを削除します。
/etc/fstab ファイルを更新することを忘れないでください。そうしないと、起動後に元に戻されます。
第5章 ext4 ファイルシステム
- 主な特長
- ext4 ファイルシステムはエクステントを使用します (ext2 および ext3 で使用される従来のブロックマッピングスキームとは異なります)。これにより、大きなファイルを使用する際のパフォーマンスが向上し、大きなファイルのメタデータオーバーヘッドが低減します。また、ext4 では、未使用のブロックグループと inode テーブルのセクションにそれぞれラベル付けが行なわれます。これにより、ファイルシステムの検査時にこれらを省略することができます。また、ファイルシステムの検査速度が上がるため、ファイルシステムが大きくなるほどその便宜性は顕著になります。
- 割り当て機能
- Ext4 ファイルシステムには、以下のような割り当てスキームが備わっています。
- 永続的な事前割り当て
- 遅延割り当て
- マルチブロック割り当て
- ストライプ認識割り当て
遅延割り当てや他のパフォーマンスが最適化されるため、ext4 のディスクへのファイル書き込み動作は ext3 の場合とは異なります。ext4 では、プログラムがファイルシステムに書き込むと、プログラムが後で fsync () 呼び出しを発行しない限り、ディスク上のディスク上の保証はありません。デフォルトでは、ext3 は、fsync ()を使用せずに、新規作成されたファイルをほぼ即時にディスクに強制し ます。この動作により、書き込まれたデータがオンディスクにあることを確認するために fsync () を使用しないプログラムのバグが妨げられました。一方、ext4 ファイルシステムは、ディスクへの変更書き込みの前に数秒間待機することが多く、書き込みを結合して再度順序付けを行うことにより、ext3 を上回るディスクパフォーマンスを実現しています。警告ext3 とは異なり、ext4 ファイルシステムでは、トランザクションコミット時にディスクへのデータの書き込みを強制しません。このため、バッファーされた書き込みがディスクにフラッシュされるまでに時間がかかります。ファイルシステムと同様に、fsync () などのデータの整合性呼び出しを使用して、データが永続ストレージに書き込まれるようにします。 - Ext4 のその他の機能
- ext4 ファイルシステムでは次の機能にも対応しています。
- 拡張属性 (
xattr): これにより、システムはファイルごとに追加の名前と値のペアを関連付けることができます。 - Quota journaling: クラッシュ後に行なわれる時間がかかるクォータの整合性チェックが不要になります。注記ext4 で対応しているジャーナリングモードは data=ordered (デフォルト)のみです。
- サブセカンド (一秒未満) のタイムスタンプ - サブセカンドのタイムスタンプを指定します。
5.1. Ext4 ファイルシステムの作成
- ext4 ファイルシステムを作成するには、以下のコマンドを使用します。
#mkfs.ext4 block_device- block_device をブロックデバイスへのパスに置き換えます。たとえば、
/dev/sdb1、/dev/disk/by-uuid/05e99ec8-def1-4a5e-8a9d-5945339ceb2a、または/dev/my-volgroup/my-lvです。 - 一般的な用途では、デフォルトのオプションが最適です。
例5.1 mkfs.ext4 コマンドの出力
~]# mkfs.ext4 /dev/sdb1
mke2fs 1.41.12 (17-May-2010)
Filesystem label=
OS type: Linux
Block size=4096 (log=2)
Fragment size=4096 (log=2)
Stride=0 blocks, Stripe width=0 blocks
245280 inodes, 979456 blocks
48972 blocks (5.00%) reserved for the super user
First data block=0
Maximum filesystem blocks=1006632960
30 block groups
32768 blocks per group, 32768 fragments per group
8176 inodes per group
Superblock backups stored on blocks:
32768, 98304, 163840, 229376, 294912, 819200, 884736
Writing inode tables: done
Creating journal (16384 blocks): done
Writing superblocks and filesystem accounting information: done
ストライプ化ブロックデバイス
- stride=value
- RAID チャンクサイズを指定します。
- stripe-width=value
- RAID デバイス内のデータディスク数、または 1 ストライプ内のストライプユニット数を指定します。
# mkfs.ext4 -E stride=16,stripe-width=64 /dev/block_deviceUUID の設定
-U オプションを使用します。
# mkfs.ext4 -U UUID device- UUID は、設定する UUID に置き換えます(例:
7cd65de3-e0be-41d9-b66d-96d749c02da7)。 - device を、ext4 ファイルシステムへのパスに置き換え、UUID を追加します(例:
/dev/sda8)。
関連情報
- mkfs.ext4(8) の man ページ
5.2. ext4 ファイルシステムのマウント
# mount /dev/device /mount/point
# mount -o acl,user_xattr /dev/device /mount/point
# mount -o data_err=abort /dev/device /mount/point書き込みバリア
# mount -o nobarrier /dev/device /mount/pointDirect Access テクノロジープレビュー
Direct Access (DAX)は、ext4 および XFS ファイルシステムのテクノロジープレビューとして、アプリケーションが永続メモリーをそのアドレス空間に直接マッピングする手段を提供します。DAX を使用するには、システムで利用可能な永続メモリーの形式が必要になります。通常は、NVDIMM (Non-Volatile Dual In-line Memory Module) の形式で、DAX に対応するファイルシステムを NVDIMM に作成する必要があります。また、ファイルシステムは dax マウントオプション でマウントする必要があります。これにより、dax をマウントしたファイルシステムのファイルの mmap が、アプリケーションのアドレス空間にストレージを直接マッピングされます。
5.3. ext4 ファイルシステムのサイズ変更
# resize2fs /mount/device size
# resize2fs /dev/device size- S - 512 バイトのセクター
- K - キロバイト
- M - メガバイト
- G - ギガバイト
5.4. ext2、ext3、または ext4 のファイルシステムのバックアップ
前提条件
- システムが長時間実行されている場合は、バックアップの前にパーティションで
e2fsckユーティリティーを実行します。#e2fsck /dev/device
手順5.1 ext2、ext3、または ext4 のファイルシステムのバックアップ
/etc/fstabファイルの内容や fdisk -l コマンドの出力など、設定情報をバックアップします。これは、パーティションを復元する場合に役立ちます。この情報を取得するには、sosreportユーティリティーまたはsysreportユーティリティーを実行します。sosreport の詳細は、What is asosreportand how to create one in Red Hat Enterprise Linux 4.6 and later?を参照してください。ナレッジベースの記事- パーティションのロールに応じて、以下を行います。
- バックアップを作成しているパーティションがオペレーティングシステムのパーティションの場合は、システムをレスキューモードで起動します。『System Administrator's Guide』 の Booting to Rescue Mode セクションを参照してください。
- 通常のデータパーティションのバックアップを作成する場合は、パーティションのマウントを解除します。マウント中にデータパーティションのバックアップを作成することは可能ですが、マウントしたデータパーティションのバックアップを作成する結果は予測できない場合があります。
dumpユーティリティーを使用して、マウントしたファイルシステムのバックアップを作成する必要がある場合は、ファイルシステムの負荷が高くないときにバックアップを作成してください。バックアップ作成時にファイルシステムで発生しているアクティビティーが多いほど、バックアップの破損のリスクが高くなります。
dumpユーティリティーを使用して、パーティションの内容をバックアップします。#dump -0uf backup-file /dev/devicebackup-file を、バックアップを保存するファイルへのパスに置き換えます。device を、バックアップを作成する ext4 パーティションの名前に置き換えます。バックアップを、バックアップを作成しているパーティションとは別のパーティションにマウントされているディレクトリーに保存していることを確認してください。例5.2 複数の ext4 パーティションのバックアップの作成
/dev/sda1、/dev/sda2、および/dev/sda3パーティションのコンテンツを/backup-files/ディレクトリーに保存されているバックアップファイルにバックアップするには、次のコマンドを使用します。#dump -0uf /backup-files/sda1.dump /dev/sda1#dump -0uf /backup-files/sda2.dump /dev/sda2#dump -0uf /backup-files/sda3.dump /dev/sda3リモートバックアップを作成するには、sshユーティリティーを使用するか、パスワードなしのsshログインを設定します。sshおよびパスワードなしのログインの詳細は、『システム管理者のガイド』 の Using the ssh Utility および Using Key-based Authentication セクションを参照してください。たとえば、sshを使用する場合は、以下のようになります。例5.3
sshを使用したリモートバックアップの実行#dump -0u -f - /dev/device | ssh root@remoteserver.example.com dd of=backup-file標準のリダイレクトを使用する場合は、-fオプションを個別に渡す必要があることに注意してください。
関連情報
- 詳細は、dump(8) の man ページを参照してください。
5.5. ext2、ext3、または ext4 のファイルシステムの復元
前提条件
- 「ext2、ext3、または ext4 のファイルシステムのバックアップ」 の説明に従って、パーティションとそのメタデータのバックアップを作成する必要があります。
手順5.2 ext2、ext3、または ext4 のファイルシステムの復元
- オペレーティングシステムパーティションを復元する場合は、システムをレスキューモードで起動します。『System Administrator's Guide』 の Booting to Rescue Mode セクションを参照してください。この手順は、通常のデータパーティションには不要です。
fdiskユーティリティーまたはpartedユーティリティーを使用して、復元するパーティションを再構築します。パーティションが存在しなくなった場合は、再作成します。新しいパーティションは、復元したデータを含めるのに十分な大きさである必要があります。開始番号と終了番号を正しく取得することが重要です。これらは、バックアップ時にfdiskユーティリティーから取得したパーティションの開始セクター番号と終了セクター番号です。パーティションの変更に関する詳細は、13章Partitions を参照してください。mkfsユーティリティーを使用して、宛先パーティションをフォーマットします。#mkfs.ext4 /dev/device重要バックアップファイルを保存するパーティションをフォーマットしないでください。- 新しいパーティションを作成した場合は、
/etc/fstabファイルのエントリーと一致するように、すべてのパーティションにラベルを付け直します。#e2label /dev/device label - 一時的なマウントポイントを作成し、そこにパーティションをマウントします。
#mkdir /mnt/device#mount -t ext4 /dev/device /mnt/device - マウントしたパーティションのバックアップからデータを復元します。
#cd /mnt/device#restore -rf device-backup-fileリモートマシンに復元するか、リモートホストに保存されているバックアップファイルから復元する場合は、sshユーティリティーを使用できます。sshの詳細は、『システム管理者のガイドの Using the ssh Utility セクションを参照して』 ください。以下のコマンドには、パスワードを使用しないログインを設定する必要があることに注意してください。パスワードなしのsshログインの設定に関する詳細は、『システム管理者のガイド』 の キーベース認証の使用 セクションを参照してください。- 同じマシンに保存されているバックアップファイルから、リモートマシンのパーティションを復元する場合は、次のコマンドを実行します。
#ssh remote-address "cd /mnt/device && cat backup-file | /usr/sbin/restore -r -f -" - 別のリモートマシンに保存されているバックアップファイルから、リモートマシンのパーティションを復元するには、次のコマンドを実行します。
#ssh remote-machine-1 "cd /mnt/device && RSH=/usr/bin/ssh /usr/sbin/restore -rf remote-machine-2:backup-file"
- 再起動します。
#systemctl reboot
例5.4 複数の ext4 パーティションの復元
/dev/sda1 パーティション、/dev/sda2 パーティション、および /dev/sda3 パーティションを 例5.2「複数の ext4 パーティションのバックアップの作成」 から復元するには、以下のコマンドを実行します。
- fdisk コマンドを使用して、復元するパーティションを再構築します。
- 宛先パーティションをフォーマットします。
#mkfs.ext4 /dev/sda1#mkfs.ext4 /dev/sda2#mkfs.ext4 /dev/sda3 /etc/fstabファイルと一致するように、すべてのパーティションにラベルを付け直します。#e2label /dev/sda1 Boot1#e2label /dev/sda2 Root#e2label /dev/sda3 Data- 作業ディレクトリーを準備します。新しいパーティションをマウントします。
#mkdir /mnt/sda1#mount -t ext4 /dev/sda1 /mnt/sda1#mkdir /mnt/sda2#mount -t ext4 /dev/sda2 /mnt/sda2#mkdir /mnt/sda3#mount -t ext4 /dev/sda3 /mnt/sda3バックアップファイルを含むパーティションをマウントします。#mkdir /backup-files#mount -t ext4 /dev/sda6 /backup-files - バックアップから、マウントしたパーティションにデータを復元します。
#cd /mnt/sda1#restore -rf /backup-files/sda1.dump#cd /mnt/sda2#restore -rf /backup-files/sda2.dump#cd /mnt/sda3#restore -rf /backup-files/sda3.dump - 再起動します。
#systemctl reboot
関連情報
- 詳細は、restore(8) の man ページを参照してください。
5.6. ext4 ファイルシステムのその他のユーティリティー
- e2fsck
- ext4 ファイルシステムの修復時に使用します。このツールは、ext4 ディスク構造の更新により、ext3 よりも効率的に ext4 ファイルシステムを検査および修復します。
- e2label
- ext4 ファイルシステムのラベル変更を行います。このツールは ext2 および ext3 のファイルシステムでも動作します。
- quota
- ext4 ファイルシステムで、ユーザーおよびグループごとのディスク領域 (ブロック) やファイル (inode) の使用量を制御し、それを報告します。クォータの使用についての詳細は、man quota および 「ディスククォータの設定」 を参照してください。
- fsfreeze
- ファイルシステムへのアクセスを一時停止するには、# fsfreeze -f mount-point コマンドを使用してフリーズし、# fsfreeze -u mount-point を実行してフリーズを解除します。これにより、ファイルシステムへのアクセスが停止し、ディスクに安定したイメージが作成されます。注記デバイスマッパードライブに fsfreeze を使用する必要はありません。詳細は、fsfreeze (8) の man ページを参照してください。
- debugfs
- ext2、ext3、ext4 の各ファイルシステムのデバッグを行います。
- e2image
- ext2、ext3、または ext4 の重要なファイルシステムメタデータをファイルに保存します。
第6章 Btrfs (テクノロジープレビュー)
6.1. btrfs ファイルシステムの作成
# mkfs.btrfs /dev/device6.2. btrfs ファイルシステムのマウント
# mount /dev/device /mount-point
- device=/dev/name
- このオプションを mount コマンドに追加すると、btrfs は、指定されたデバイスで btrfs ボリュームをスキャンするように指示されます。これは、btrfs 以外のデバイスをマウントしようとするとマウントが失敗するため、マウントが成功することを確認するために使用されます。注記これは、すべてのデバイスがファイルシステムに追加されることを意味するのではなく、それらをスキャンするだけです。
- max_inline=number
- このオプションを使用して、メタデータ B-tree リーフ内のデータのインライン化に使用できる領域の最大量 (バイト単位) を設定します。デフォルトは 8192 バイトです。4k ページの場合は、リーフに収める必要があるヘッダーが追加されているため、サイズは 3900 バイトに制限されています。
- alloc_start=number
- このオプションを使用して、ディスク割り当ての開始位置を設定します。
- thread_pool=number
- このオプションを使用して、割り当てられたワーカースレッドの数を割り当てます。
- discard
- このオプションは、空きブロックで discard/TRIM を有効にする場合に使用します。
- noacl
- このオプションを使用して、ACL の使用を無効にします。
- space_cache
- このオプションを使用して空き領域データをディスクに保存し、ブロックグループのキャッシュを高速化します。これは永続的な変更であり、古いカーネルで安全に起動できます。
- nospace_cache
- 上記の space_cache を無効にするには、このオプションを使用します。
- clear_cache
- このオプションを使用して、マウント中にすべての空き領域キャッシュをクリアします。これは安全なオプションですが、スペースキャッシュの再構築がトリガーされます。そのため、再構築プロセスを終了させるために、ファイルシステムをマウントしたままにしておきます。このマウントオプションは、空き領域に問題が明らかになった後でのみ、一度使用することを目的としています。
- enospc_debug
- このオプションは、"no space left" 問題をデバッグするために使用します。
- recovery
- マウント時に自動リカバリーを有効にするには、このオプションを使用します。
6.3. btrfs ファイルシステムのサイズの変更
btrfs ファイルシステムの拡張
# btrfs filesystem resize amount /mount-point
# btrfs filesystem resize +200M /btrfssingle Resize '/btrfssingle' of '+200M'
# btrfs filesystem show /mount-point
# btrfs filesystem show /btrfstest Label: none uuid: 755b41b7-7a20-4a24-abb3-45fdbed1ab39 Total devices 4 FS bytes used 192.00KiB devid 1 size 1.00GiB used 224.75MiB path /dev/vdc devid 2 size 524.00MiB used 204.75MiB path /dev/vdd devid 3 size 1.00GiB used 8.00MiB path /dev/vde devid 4 size 1.00GiB used 8.00MiB path /dev/vdf Btrfs v3.16.2
devid を特定したら、次のコマンドを使用します。
# btrfs filesystem resize devid:amount /mount-point
# btrfs filesystem resize 2:+200M /btrfstest Resize '/btrfstest/' of '2:+200M'
btrfs ファイルシステムの縮小
# btrfs filesystem resize amount /mount-point
# btrfs filesystem resize -200M /btrfssingle Resize '/btrfssingle' of '-200M'
# btrfs filesystem show /mount-point
# btrfs filesystem show /btrfstest Label: none uuid: 755b41b7-7a20-4a24-abb3-45fdbed1ab39 Total devices 4 FS bytes used 192.00KiB devid 1 size 1.00GiB used 224.75MiB path /dev/vdc devid 2 size 524.00MiB used 204.75MiB path /dev/vdd devid 3 size 1.00GiB used 8.00MiB path /dev/vde devid 4 size 1.00GiB used 8.00MiB path /dev/vdf Btrfs v3.16.2
devid を特定したら、次のコマンドを使用します。
# btrfs filesystem resize devid:amount /mount-point
# btrfs filesystem resize 2:-200M /btrfstest Resize '/btrfstest' of '2:-200M'
ファイルシステムのサイズの設定
# btrfs filesystem resize amount /mount-point
# btrfs filesystem resize 700M /btrfssingle Resize '/btrfssingle' of '700M'
# btrfs filesystem show /mount-point
# btrfs filesystem show /btrfstest Label: none uuid: 755b41b7-7a20-4a24-abb3-45fdbed1ab39 Total devices 4 FS bytes used 192.00KiB devid 1 size 1.00GiB used 224.75MiB path /dev/vdc devid 2 size 724.00MiB used 204.75MiB path /dev/vdd devid 3 size 1.00GiB used 8.00MiB path /dev/vde devid 4 size 1.00GiB used 8.00MiB path /dev/vdf Btrfs v3.16.2
devid を特定したら、次のコマンドを使用します。
# btrfs filesystem resize devid:amount /mount-point
# btrfs filesystem resize 2:300M /btrfstest Resize '/btrfstest' of '2:300M'
6.4. 複数のデバイスの統合ボリューム管理
6.4.1. 複数のデバイスを使用したファイルシステムの作成
- raid0
- raid1
- raid10
- dup
- single
例6.1 RAID 10 btrfs ファイルシステムの作成
# mkfs.btrfs /dev/device1 /dev/device2 /dev/device3 /dev/device4
# mkfs.btrfs -m raid0 /dev/device1 /dev/device2
# mkfs.btrfs -m raid10 -d raid10 /dev/device1 /dev/device2 /dev/device3 /dev/device4
# mkfs.btrfs -m single /dev/device
# mkfs.btrfs -d single /dev/device1 /dev/device2 /dev/device3
# btrfs device add /dev/device1 /mount-point
6.4.2. btrfs デバイスのスキャン
/dev の下にあるすべてのブロックデバイスをスキャンし、btrfs ボリュームをプローブします。ファイルシステムで複数のデバイスを実行している場合は、btrfs モジュールを読み込んだ後に実行する必要があります。
# btrfs device scan
# btrfs device scan /dev/device
6.4.3. btrfs ファイルシステムへの新しいデバイスの追加
例6.2 btrfs ファイルシステムへの新しいデバイスの追加
# mkfs.btrfs /dev/device1 # mount /dev/device1
# btrfs device add /dev/device2 /mount-point
/dev/device1 にのみ保存されます。すべてのデバイスに分散するには、バランスを調整する必要があります。
# btrfs filesystem balance /mount-point
6.4.4. btrfs ファイルシステムの変換
例6.3 btrfs ファイルシステムの変換
/dev/sdb1 )を 2 つのデバイス(raid1 システム)に変換して、単一のディスク障害から保護するには、次のコマンドを使用します。
# mount /dev/sdb1 /mnt # btrfs device add /dev/sdc1 /mnt # btrfs balance start -dconvert=raid1 -mconvert=raid1 /mnt
6.4.5. btrfs デバイスの削除
例6.4 btrfs ファイルシステム上のデバイスの削除
# mkfs.btrfs /dev/sdb /dev/sdc /dev/sdd /dev/sde # mount /dev/sdb /mnt
# btrfs device delete /dev/sdc /mnt
6.4.6. btrfs ファイルシステムでの障害が発生したデバイスの置き換え
# mkfs.btrfs -m raid1 /dev/sdb /dev/sdc /dev/sdd /dev/sde ssd is destroyed or removed, use -o degraded to force the mount to ignore missing devices # mount -o degraded /dev/sdb /mnt 'missing' is a special device name # btrfs device delete missing /mnt
- 動作が低下したモードでのマウント
- 新しいデバイスの追加
- 不足しているデバイスの削除
6.4.7. /etc/fstabでの btrfs ファイルシステムの登録
initrd がない場合や、btrfs デバイススキャンを実行していない場合は、ファイルシステムのすべてのデバイスを明示的に mount コマンドに渡すことで、マルチボリューム btrfs ファイルシステムを マウント できます。
例6.5 /etc/fstab エントリーの例
/etc/fstab エントリーの例を以下に示します。
/dev/sdb /mnt btrfs device=/dev/sdb,device=/dev/sdc,device=/dev/sdd,device=/dev/sde 0
6.5. SSD の最適化
/sys/block/ デバイスの /queue/rotational がゼロである場合に、mkfs.btrfs が単一のデバイス でメタデータの重複をオフにすることです。これは、コマンドラインで -m single を指定するのと同じです。これは、-m dup オプションを指定することで上書きし、メタデータを複製できます。SSD ファームウェアは両方のコピーを失う可能性があるため、複製は必要ありません。これはスペースを浪費し、パフォーマンスが犠牲になります。
- より大きなメタデータのクラスターの割り当てを許可します。
- 可能な場合は、より順序立ててデータを割り当てます。
- 鍵とブロック順序に一致するように btree リーフの書き換えを無効にします。
- 複数のプロセスをバッチ処理せずにログフラグメントをコミットします。
6.6. Btrfs リファレンス
- スナップショットを管理するためのすべてのサブボリュームコマンド。
デバイスを管理するデバイスコマンド。- scrub コマンド、balance コマンド、および defragment コマンド。
第7章 Global File System 2
gfs2.ko カーネルモジュールは GFS2 ファイルシステムを実装し、GFS2 クラスターノードにロードされます。
第8章 Network File System (NFS)
8.1. NFS の概要
- NFS バージョン 3 (NFSv3) は、安全な非同期書き込みをサポートし、以前の NFSv2 よりもエラー処理で堅牢です。また、64 ビットのファイルサイズとオフセットにも対応しているため、クライアントは 2GB 以上のファイルデータにアクセスできます。
- NFS バージョン 4 (NFSv4)はファイアウォールやインターネットを介して動作し、rpcbind サービスが不要になり、ACL に対応し、ステートフルな操作を利用します。
- スパースファイル: ファイルの領域の効率を検証し、プレースホルダーがストレージの効率を向上できるようにします。これは、1 つ以上のホールがあるファイルです。ホールは、ゼロのみで設定される、割り当てられていないデータブロックまたは初期化されていないデータブロックです。
lseek()NFSv4.2 での 操作は、seek_hole()およびseek_data()に対応しています。これにより、アプリケーションはスパースファイルのホールの場所をマッピングできます。 - 領域の予約: ストレージサーバーが空き領域を予約することを許可します。これにより、サーバーで領域が不足することがなくなります。NFSv4.2 は、領域を予約するための
allocate()操作、領域の予約を解除するdeallocate()操作、およびファイル内の領域の事前割り当てまたは割り当て解除を行うfallocate()操作に対応します。 - ラベル付き NFS: データアクセス権を強制し、NFS ファイルシステム上の個々のファイルに対して、クライアントとサーバーとの間の SELinux ラベルを有効にします。
- レイアウトの機能拡張:NFSv4.2 は、クライアントがレイアウトとの通信についてメタデータサーバーに通知するために使用できる新しい操作
layoutstats()を提供します。
- ネットワークのパフォーマンスとセキュリティーを向上させ、Parallel NFS (pNFS) に対するクライアント側のサポートも追加されました。
- コールバックに個別の TCP 接続が必要なくなり、クライアントと通信できない場合でも、NFS サーバーは委任を許可できるようになりました。たとえば、NAT やファイアウォールが干渉する場合です。
- 応答が失われ、操作が 2 回送信された場合に特定の操作が不正確な結果を返すことがあるという以前の問題を防ぐために、1 回限りのセマンティクスを提供します (再起動操作を除く)。
/etc/exports 設定ファイルを参照して、クライアントがエクスポートされたファイルシステムにアクセスできるかどうかを判断します。アクセスが可能なことが確認されると、そのユーザーは、ファイルおよびディレクトリーへの全操作を行えるようになります。
8.1.1. 必要なサービス
- nfs
- systemctl start nfs は、NFS サーバーと適切な RPC プロセスを開始し、共有 NFS ファイルシステムの要求を処理します。
- nfslock
- systemctl start nfs-lock は、適切な RPC プロセスを開始する必須サービスをアクティブにし、NFS クライアントがサーバー上のファイルをロックできるようにします。
- rpcbind
- rpcbind は、ローカルの RPC サービスからのポート予約を受け入れます。その後、これらのポートは、対応するリモートの RPC サービスによりアクセス可能であることが公開されます。rpcbind は RPC サービスの要求に応答し、要求された RPC サービスへの接続を設定します。このプロセスは NFSv4 では使用されません。
- rpc.mountd
- このプロセスは、NFS サーバーが NFSv3 クライアントからの MOUNT 要求を処理するために使用されます。要求されている NFS 共有が現在 NFS サーバーによりエクスポートされているか、またその共有へのクライアントのアクセスが許可されているかを確認します。マウント要求が許可されると、rpc.mountd サーバーは
Successステータスで応答し、この NFS 共有のFile-Handleを NFS クライアントに戻します。 - rpc.nfsd
- rpc.nfsd を使用すると、サーバーがアドバタイズする明示的な NFS バージョンとプロトコルを定義できます。NFS クライアントが接続するたびにサーバースレッドを提供するなど、NFS クライアントの動的な要求に対応するため、Linux カーネルと連携して動作します。このプロセスは、nfs サービスに対応します。
- lockd
- lockd は、クライアントとサーバーの両方で実行するカーネルスレッドです。Network Lock Manager (NLM) プロトコルを実装し、これにより、NFSv3 クライアントがサーバー上のファイルをロックできるようになります。NFS サーバーが実行中で、NFS ファイルシステムがマウントされていれば、このプロセスは常に自動的に起動します。
- rpc.statd
- このプロセスは、Network Status Monitor (NSM) RPC プロトコルを実装します。NFS サーバーが正常にシャットダウンされずに再起動すると、NFS クライアントに通知します。rpc.statd は、nfslock サービスにより自動的に開始されるため、ユーザー設定は必要ありません。このプロセスは NFSv4 では使用されません。
- rpc.rquotad
- このプロセスは、リモートユーザーのユーザークォーター情報を提供します。rpc.rquotad は、nfs サービスにより自動的に開始されるため、ユーザー設定は必要ありません。
- rpc.idmapd
- rpc.idmapd は、ネットワーク上の NFSv4 名(
ユーザー@ドメインの形式の文字列)とローカル UID と GID の間でマッピングされる NFSv4 クライアントおよびサーバーのアップコールを提供します。idmapd を NFSv4 で機能させるには、/etc/idmapd.confファイルを設定する必要があります。少なくとも、NFSv4 マッピングドメインを定義する Domain パラメーターを指定する必要があります。NFSv4 マッピングドメインが DNS ドメイン名と同じ場合は、このパラメーターは必要ありません。クライアントとサーバーが ID マッピングの NFSv4 マッピングドメインに合意しないと、適切に動作しません。注記Red Hat Enterprise Linux 7 では、NFSv4 サーバーのみが rpc.idmapd を使用します。NFSv4 クライアントは、キーリングベースの idmapper nfsidmap を使用します。nfsidmap は、ID マッピングを実行するためにカーネルがオンデマンドで呼び出されるスタンドアロンプログラムです。これはデーモンではありません。nfsidmap に問題が発生した場合、クライアントは rpc.idmapd の使用にフォールバックします。nfsidmap の詳細は、man ページの nfsidmap を参照してください。
8.2. NFS クライアントの設定
# mount -t nfs -o options server:/remote/export /local/directory- options
- マウントオプションのコンマ区切りリスト。有効な NFS マウントオプションの詳細は、「一般的な NFS マウントオプション」 を参照してください。
- server
- マウントするファイルシステムをエクスポートするサーバーのホスト名、IP アドレス、または完全修飾ドメイン名
- /remote/export
- サーバー からエクスポートされるファイルシステムまたはディレクトリー、つまり、マウントするディレクトリー
- /local/directory
- /remote/export がマウントされているクライアントの場所
/etc/fstab ファイルと autofs サービス)を提供します。詳細は、「/etc/fstabを使用した NFS ファイルシステムのマウント」 および 「autofs」 を参照してください。
8.2.1. /etc/fstabを使用した NFS ファイルシステムのマウント
/etc/fstab ファイルに行を追加することです。その行には、NFS サーバーのホスト名、エクスポートされるサーバーディレクトリー、および NFS 共有がマウントされるローカルマシンディレクトリーを記述する必要があります。/etc/fstab ファイルを変更するには、root である必要があります。
例8.1 構文の例
/etc/fstab の行の一般的な構文は以下のとおりです。
server:/usr/local/pub /pub nfs defaults 0 0
/pub がクライアントマシンに存在している必要があります。この行をクライアントシステムの /etc/fstab に追加した後、コマンド mount /pub を使用すると、マウントポイント /pub がサーバーからマウントされます。
/etc/fstab エントリーには、以下の情報が含まれている必要があります。
server:/remote/export /local/directory nfs options 0 0
/etc/fstab を読み取る前に、マウントポイント /local/directory がクライアントに存在している必要があります。それ以外の場合は、マウントに失敗します。
/etc/fstab を編集した後、システムが新しい設定を登録するようにマウントユニットを再生成します。
# systemctl daemon-reload関連情報
/etc/fstabの詳細は、man fstab を参照してください。
8.3. autofs
/etc/fstab を使用する欠点の 1 つは、NFS がマウントされたファイルシステムにユーザーがアクセスする頻度に関わらず、マウントされたファイルシステムを所定の場所で維持するために、システムがリソースを割り当てる必要があることです。これは 1 つまたは 2 つのマウントでは問題になりませんが、システムが一度に多くのシステムへのマウントを維持している場合、システム全体のパフォーマンスに影響を与える可能性があります。/etc/fstab の代わりに、カーネルベースの automount ユーティリティーを使用します。自動マウント機能は以下の 2 つのコンポーネントで設定されます。
- ファイルシステムを実装するカーネルモジュール
- 他のすべての機能を実行するユーザー空間デーモン
/etc/auto.master (マスターマップ)を使用します。これは、Name Service Switch (NSS)メカニズムとともに autofs 設定( /etc/sysconfig/autofs内)を使用して、サポートされている別のネットワークソースと名前を使用するように変更できます。autofs バージョン 4 デーモンのインスタンスは、マスターマップで設定された各マウントポイントに対して実行されるため、任意のマウントポイントに対してコマンドラインから手動で実行できます。autofs バージョン 5 では、設定されたすべてのマウントポイントを管理するために単一のデーモンが使用されるため、これは不可能です。そのため、すべての自動マウントをマスターマップで設定する必要があります。これは、他の業界標準の自動マウント機能の通常の要件と一致しています。マウントポイント、ホスト名、エクスポートしたディレクトリー、および各種オプションは各ホストに対して手動で設定するのではなく、すべて 1 つのファイルセット (またはサポートされている別のネットワークソース) 内に指定することができます。
8.3.1. バージョン 4 と比較した autofs バージョン 5 の改善点
- ダイレクトマップのサポート
- autofs のダイレクトマップは、ファイルシステム階層の任意の時点でファイルシステムを自動的にマウントするメカニズムを提供します。ダイレクトマップは、マスターマップの
/-のマウントポイントで示されます。ダイレクトマップのエントリーには、(間接マップで使用される相対パス名の代わりに) 絶対パス名がキーとして含まれています。 - レイジーマウントとアンマウントのサポート
- マルチマウントマップエントリーは、単一のキーの下にあるマウントポイントの階層を記述します。この良い例として、
-hostsマップがあります。これは通常、マルチマウントマップエントリーとして/net/hostの下のホストからのすべてのエクスポートを自動マウントするために使用されます。-hostsマップを使用する場合、/net/ホストの ls は、ホスト から各エクスポートの autofs トリガーマウントをマウントします。次に、これらはマウントされ、アクセスされると期限切れとなります。これにより、エクスポートが多数あるサーバーにアクセスする際に必要なアクティブなマウントの数を大幅に減らすことができます。 - 強化された LDAP サポート
- autofs 設定ファイル(
/etc/sysconfig/autofs)は、サイトが実装する autofs スキーマを指定するメカニズムを提供するため、アプリケーション自体で試行とエラーによってこれを判断する必要がなくなります。さらに、共通の LDAP サーバー実装でサポートされるほとんどのメカニズムを使用して、LDAP サーバーへの認証済みバインドがサポートされるようになりました。このサポート用の新しい設定ファイル(/etc/autofs_ldap_auth.conf)が追加されました。デフォルトの設定ファイルは自己文書化されており、XML 形式を使用します。 - Name Service Switch (nsswitch)設定の適切な使用。
- Name Service Switch 設定ファイルは、特定の設定データがどこから来るのかを判別する手段を提供するために存在します。この設定の理由は、データにアクセスするための統一されたソフトウェアインターフェイスを維持しながら、管理者が最適なバックエンドデータベースを柔軟に使用できるようにするためです。バージョン 4 の自動マウント機能は、今まで以上に NSS 設定を処理できるようになっていますが、まだ完全ではありません。一方、autofs バージョン 5 は完全な実装です。このファイルで対応している構文の詳細は、man nsswitch.conf を参照してください。すべての NSS データベースが有効なマップソースである訳ではなく、パーサーは無効なデータベースを拒否します。有効なソースは、ファイル、yp、nis、nisplus、ldap、および hesiod です。
- autofs マウントポイントごとの複数のマスターマップエントリー
- 頻繁に使用されますが、まだ記述されていないのは、直接マウントポイント
/-の複数のマスターマップエントリーを処理することです。各エントリーのマップキーはマージされ、1 つのマップとして機能します。例8.2 autofs マウントポイントごとの複数のマスターマップエントリー
以下は、ダイレクトマウントの connectathon テストマップの例です。/- /tmp/auto_dcthon /- /tmp/auto_test3_direct /- /tmp/auto_test4_direct
8.3.2. autofs の設定
/etc/auto.master です。これは、マスターマップ とも呼ばれます。これは、「バージョン 4 と比較した autofs バージョン 5 の改善点」 で説明されているように変更できます。マスターマップには、システム上の autofsで制御されたマウントポイントと、それに対応する設定ファイルまたはネットワークソースが自動マウントマップとして知られています。マスターマップの形式は次のとおりです。
mount-point map-name options
- mount-point
- autofs マウントポイント(例:
/home) - map-name
- マウントポイントのリストとマウントポイントがマウントされるファイルシステムの場所が記載されているマップソース名です。
- options
- 指定されている場合は、それ自体にオプションが指定されていない場合に限り、指定されたマップのすべてのエントリーに適用されます。この動作は、オプションが累積されていた autofs バージョン 4 とは異なります。混合環境の互換性を実装させるため変更が加えられています。
例8.3 /etc/auto.master ファイル
/etc/auto.master ファイルのサンプル行です( cat /etc/auto.masterで表示)。
/home /etc/auto.misc
mount-point [options] location
- mount-point
- これは autofs マウントポイントを参照します。これは 1 つのインダイレクトマウント用の 1 つのディレクトリー名にすることも、複数のダイレクトマウント用のマウントポイントの完全パスにすることもできます。各ダイレクトマップエントリーキー(マウントポイント)の後に、スペースで区切られたオフセットディレクトリー(
/で始まるサブディレクトリー名)のリストが続き、マルチマウントエントリーと呼ばれるものになります。 - options
- 指定した場合は、これらは、独自のオプションを指定しないマップエントリーのマウントオプションになります。
- location
- これは、ローカルファイルシステムパス(Sun マップ形式のエスケープ文字 ":" が先頭に付き、マップ名が
/で始まる場合)、NFS ファイルシステム、またはその他の有効なファイルシステムの場所などのファイルシステムの場所を参照します。
/etc/auto.misc)。
payroll -fstype=nfs personnel:/dev/hda3 sales -fstype=ext3 :/dev/hda4
sales および payroll )を示してい ます。2 列目は autofs マウントのオプションを示し、3 番目のコラムはマウントのソースを示しています。指定された設定に従うと、autofs マウントポイントは /home/payroll および /home/sales になります。-fstype= オプションは省略されることが多く、通常は正しい操作には必要ありません。
# systemctl start autofs# systemctl restart autofs/home/payroll/2006/July.sxc などのアンマウントされた autofs ディレクトリーへのアクセスを必要とする場合、自動マウントデーモンはディレクトリーを自動的にマウントします。タイムアウトを指定した場合は、タイムアウト期間中ディレクトリーにアクセスしないと、ディレクトリーが自動的にアンマウントされます。
# systemctl status autofs8.3.3. サイト設定ファイルの上書きまたは拡張
- 自動マウント機能マップは NIS に保存され、
/etc/nsswitch.confファイルには以下のディレクティブがあります。automount: files nis
auto.masterファイルには以下が含まれます。+auto.master
- NIS の
auto.masterマップファイルには以下が含まれます。/home auto.home
- NIS の
auto.homeマップには以下が含まれます。beth fileserver.example.com:/export/home/beth joe fileserver.example.com:/export/home/joe * fileserver.example.com:/export/home/&
- ファイルマップ
/etc/auto.homeは存在しません。
auto.home を上書きし、別のサーバーからホームディレクトリーをマウントする必要があると仮定します。この場合、クライアントは以下の /etc/auto.master マップを使用する必要があります。
/home /etc/auto.home +auto.master
/etc/auto.home マップにはエントリーが含まれます。
* labserver.example.com:/export/home/&
/home には NIS auto.home マップではなく、/etc/auto.home の内容が含まれます。
auto.home マップをいくつかのエントリーで拡張するには、/etc/auto.home ファイルマップを作成し、新しいエントリーを追加します。最後に、NIS auto.home マップを含めます。次に、/etc/auto.home ファイルマップは以下のようになります。
mydir someserver:/export/mydir +auto.home
auto.home マップ条件により、ls /home コマンドは以下を出力します。
beth joe mydir
8.3.4. LDAP を使用した自動マウント機能マップの格納
openldap パッケージは自動マウント機能 の依存関係として自動的にインストールされ ます。LDAP アクセスを設定するには、/etc/openldap/ldap.conf を変更します。BASE、URI、スキーマなどが使用するサイトに適した設定になっていることを確認してください。
rfc2307bis に記載されています。このスキーマを使用するには、スキーマ定義からコメント文字を削除して、autofs 設定(/etc/sysconfig/autofs)に設定する必要があります。以下に例を示します。
例8.4 autofs の設定
DEFAULT_MAP_OBJECT_CLASS="automountMap" DEFAULT_ENTRY_OBJECT_CLASS="automount" DEFAULT_MAP_ATTRIBUTE="automountMapName" DEFAULT_ENTRY_ATTRIBUTE="automountKey" DEFAULT_VALUE_ATTRIBUTE="automountInformation"
rfc2307bis スキーマの cn 属性を置き換えます。以下は、LDAP データ交換形式(LDIF)の設定例です。
例8.5 LDF の設定
# extended LDIF # # LDAPv3 # base <> with scope subtree # filter: (&(objectclass=automountMap)(automountMapName=auto.master)) # requesting: ALL # # auto.master, example.com dn: automountMapName=auto.master,dc=example,dc=com objectClass: top objectClass: automountMap automountMapName: auto.master # extended LDIF # # LDAPv3 # base <automountMapName=auto.master,dc=example,dc=com> with scope subtree # filter: (objectclass=automount) # requesting: ALL # # /home, auto.master, example.com dn: automountMapName=auto.master,dc=example,dc=com objectClass: automount cn: /home automountKey: /home automountInformation: auto.home # extended LDIF # # LDAPv3 # base <> with scope subtree # filter: (&(objectclass=automountMap)(automountMapName=auto.home)) # requesting: ALL # # auto.home, example.com dn: automountMapName=auto.home,dc=example,dc=com objectClass: automountMap automountMapName: auto.home # extended LDIF # # LDAPv3 # base <automountMapName=auto.home,dc=example,dc=com> with scope subtree # filter: (objectclass=automount) # requesting: ALL # # foo, auto.home, example.com dn: automountKey=foo,automountMapName=auto.home,dc=example,dc=com objectClass: automount automountKey: foo automountInformation: filer.example.com:/export/foo # /, auto.home, example.com dn: automountKey=/,automountMapName=auto.home,dc=example,dc=com objectClass: automount automountKey: / automountInformation: filer.example.com:/export/&
8.4. 一般的な NFS マウントオプション
/etc/fstab 設定、および autofs で使用できます。
- lookupcache=mode
- 任意のマウントポイントに対して、カーネルがディレクトリーエントリーのキャッシュを管理する方法を指定します。mode の有効な引数は、
すべて、none、またはpos/positiveです。 - nfsvers=version
- 使用する NFS プロトコルのバージョンを指定します。version は、3 または 4 になります。これは、複数の NFS サーバーを実行するホストに役立ちます。バージョンを指定しないと、NFS はカーネルおよび mount コマンドで対応している最新バージョンを使用します。vers オプションは nfsvers と同じですが、互換性のためにこのリリースに含まれています。
- noacl
- ACL の処理をすべてオフにします。古いバージョンの Red Hat Enterprise Linux、Red Hat Linux、Solaris と連動させる場合に必要となることがあります。こうした古いシステムには、最新の ACL テクノロジーに対する互換性がないためです。
- nolock
- ファイルのロック機能を無効にします。この設定は、非常に古いバージョンの NFS サーバーに接続する場合に必要となる場合があります。
- noexec
- マウントしたファイルシステムでバイナリーが実行されないようにします。互換性のないバイナリーを含む、Linux 以外のファイルシステムをマウントしている場合に便利です。
- nosuid
set-user-identifierビットまたはset-group-identifierビットを無効にします。これにより、リモートユーザーが setuid プログラムを実行してより高い権限を取得するのを防ぎます。- port=num
- NFS サーバーポートの数値を指定します。num が 0 (デフォルト値)の場合、mount は、使用するポート番号についてリモートホストの rpcbind サービスのクエリーを実行します。リモートホストの NFS デーモンがその rpcbind サービスに登録されていない場合は、代わりに TCP 2049 の標準 NFS ポート番号が使用されます。
- rsize=num および wsize=num
- このオプションは、1 回の NFS 読み取り操作または書き込み操作で転送される最大バイト数を設定します。
rsizeとwsizeには、固定のデフォルト値がありません。デフォルトでは、NFS はサーバーとクライアントの両方がサポートしている最大の値を使用します。Red Hat Enterprise Linux 7 では、クライアントとサーバーの最大値は 1,048,576 バイトです。詳細は、What are the default and maximum values for rsize and wsize with NFS mounts? 参照してください。KBase の記事。 - sec=flavors
- マウントされたエクスポート上のファイルにアクセスするために使用するセキュリティーフレーバーです。flavors の値は、複数のセキュリティーフレーバーのコロンで区切られたリストです。デフォルトでは、クライアントは、クライアントとサーバーの両方をサポートするセキュリティーフレーバーの検索を試みます。サーバーが選択したフレーバーのいずれかに対応していない場合、マウント操作は失敗します。
sec=sysは、ローカルの UNIX UID および GID を使用します。AUTH_SYSを使用して NFS 操作を認証します。sec=krb5は、ユーザー認証に、ローカルの UNIX の UID と GID ではなく、Kerberos V5 を使用します。sec=krb5iは、ユーザー認証に Kerberos V5 を使用し、データの改ざんを防ぐ安全なチェックサムを使用して、NFS 操作の整合性チェックを行います。sec=krb5pは、ユーザー認証に Kerberos V5 を使用し、整合性チェックを実行し、トラフィックの傍受を防ぐため NFS トラフィックの暗号化を行います。これが最も安全な設定になりますが、パフォーマンスのオーバーヘッドも最も高くなります。 - tcp
- NFS マウントが TCP プロトコルを使用するよう指示します。
- udp
- NFS マウントが UDP プロトコルを使用するよう指示します。
8.5. NFS サーバーの起動と停止
前提条件
- NFSv2 または NFSv3 の接続に対応するサーバーでは、
rpcbind[1] サービスを実行している必要があります。rpcbindがアクティブであることを確認するには、次のコマンドを使用します。$systemctl status rpcbindrpcbindを必要としない NFSv4 専用サーバーを設定するには、「NFSv4 専用サーバーの設定」 を参照してください。 - Red Hat Enterprise Linux 7.0 では、NFS サーバーが NFSv3 をエクスポートし、起動時に起動できるようにするには、
nfs-lockサービスを手動で起動して有効にする必要があります。#systemctl start nfs-lock#systemctl enable nfs-lockRed Hat Enterprise Linux 7.1 以降では、必要に応じてnfs-lockが自動的に起動し、手動で有効にしようとすると失敗します。
手順
- NFS サーバーを起動するには、次のコマンドを使用します。
# systemctl start nfs - システムの起動時に NFS が起動するようにするには、次のコマンドを使用します。
# systemctl enable nfs - サーバーを停止させるには、以下を使用します。
# systemctl stop nfs restartオプションは、NFS を停止して起動する簡単な方法です。これは、NFS の設定ファイルを編集した後に設定変更を有効にする最も効率的な方法です。サーバーを再起動するには、次のコマンドを実行します。# systemctl restart nfs/etc/sysconfig/nfsファイルを編集したら、以下のコマンドを実行して nfs-config サービスを再起動して新しい値を有効にします。# systemctl restart nfs-configtry-restartコマンドは、現在実行されている場合にのみ nfs を起動します。このコマンドは、Red Hat init スクリプトの condrestart (条件付き再起動)と同等で、NFS が実行されていない場合にデーモンを起動しないため便利です。条件付きでサーバーを再起動するには、以下を入力します。# systemctl try-restart nfs- サービスを再起動せずに NFS サーバー設定ファイルの再読み込みを実行するには、以下のように入力します。
# systemctl reload nfs
8.6. NFS サーバーの設定
- NFS 設定ファイル(
/etc/exports)を手動で編集する。 - コマンドラインで、コマンド exportfsを使用する方法。
8.6.1. /etc/exports 設定ファイル
/etc/exports ファイルは、リモートホストにどのファイルシステムをエクスポートするかを制御し、オプションを指定します。以下の構文ルールに従います。
- 空白行は無視する。
- コメントを追加するには、ハッシュマーク(#)で行を開始します。
- 長い行はバックスラッシュ(\)で囲むことができます。
- エクスポートするファイルシステムは、それぞれ 1 行で指定する。
- 許可するホストのリストは、エクスポートするファイルシステムの後に空白文字を追加し、その後に追加する。
- 各ホストのオプションは、ホストの識別子の直後に括弧を追加し、その中に指定する。ホストと最初の括弧の間には空白を使用しない。
export host(options)
- export
- エクスポートするディレクトリー
- host
- エクスポートを共有するホストまたはネットワーク
- オプション
- host に使用されるオプション
export host1(options1) host2(options2) host3(options3)
/etc/exports ファイルに、エクスポートされるディレクトリーと、そのディレクトリーへのアクセスを許可するホストを指定するだけです。以下に例を示します。
例8.6 /etc/exports ファイル
/exported/directory bob.example.com
bob.example.com は、NFS サーバーから /exported/directory/ をマウントできます。この例ではオプションが指定されていないため、デフォルト 設定が使用されます。
- ro
- エクスポートするファイルシステムは読み取り専用です。リモートホストは、このファイルシステムで共有されているデータを変更できません。このファイルシステムで変更 (読み取り/書き込み) を可能にするには、
rwオプションを指定します。 - sync
- NFS サーバーは、以前の要求で発生した変更がディスクに書き込まれるまで、要求に応答しません。代わりに非同期書き込みを有効にするには、
asyncオプションを指定します。 - wdelay
- NFS サーバーは、別の書き込み要求が差し迫っていると判断すると、ディスクへの書き込みを遅らせます。これにより、複数の書き込みコマンドが同じディスクにアクセスする回数を減らすことができるため、書き込みのオーバーヘッドが低下し、パフォーマンスが向上します。これを無効にするには、
no_wdelayを指定します。no_wdelayは、デフォルトのsyncオプションも指定されている場合にのみ使用できます。 - root_squash
- (ローカルからではなく) リモート から接続している root ユーザーが root 権限を持つことを阻止します。代わりに、NFS サーバーはユーザー ID
nfsnobodyを割り当てます。これにより、リモートの root ユーザーの権限を、最も低いローカルユーザーレベルにまで下げて (squash)、高い確率でリモートサーバーへの書き込む権限を与えないようにすることができます。root squashing を無効にするには、no_root_squashを指定します。
all_squash を使用します。特定ホストのリモートユーザーに対して、NFS サーバーが割り当てるユーザー ID とグループ ID を指定するには、anonuid オプションと anongid オプションを以下のように使用します。
export host(anonuid=uid,anongid=gid)
anonuid オプションと anongid オプションにより、共有するリモート NFS ユーザー用に、特別なユーザーアカウントおよびグループアカウントを作成できます。
rw オプションを指定しないと、エクスポートするファイルシステムが読み取り専用として共有されます。以下は、/etc/exports のサンプル行で、2 つのデフォルトオプションを上書きします。
/another/exported/directory/ の読み取りおよび書き込みをマウントでき、ディスクへの書き込みはすべて非同期です。エクスポートオプションの詳細は、man exportfs を参照してください。
/etc/exports ファイルのフォーマットは、特に空白文字の使用に関して非常に正確です。ホストからエクスポートするファイルシステムの間、そしてホスト同士の間には、必ず空白文字を挿入してください。また、それ以外の場所 (コメント行を除く) には、空白文字を追加しないでください。
/home bob.example.com(rw) /home bob.example.com (rw)
bob.example.com からのユーザーのみが /home ディレクトリーへの読み取りおよび書き込みアクセスを許可します。2 行目では、bob.example.com からのユーザーがディレクトリーを読み取り専用(デフォルト)としてマウントすることを許可し、残りのユーザーは読み取り/書き込みでマウントできます。
8.6.2. exportfs コマンド
/etc/exports ファイルにリストされています。nfs サービスが起動すると、/usr/sbin/exportfs コマンドが起動し、このファイルを読み込み、制御を実際のマウントプロセスの rpc.mountd (NFSv3 の場合は)に渡してから、リモートユーザーがファイルシステムを利用できる rpc.nfsd に渡します。
/var/lib/nfs/xtab に書き込みます。ファイルシステムへのアクセス権限を決定する際には、rpc.mountd が xtab ファイルを参照するため、エクスポートしたファイルシステムのリストへの変更がすぐに反映されます。
- -r
/var/lib/nfs/etabに新しいエクスポート一覧を作成して、/etc/exportsに一覧表示されているすべてのディレクトリーをエクスポートします。このオプションにより、/etc/exportsに加えられた変更でエクスポート一覧が効果的に更新されます。- -a
- /usr/sbin/exportfs に渡される他のオプションに応じて、すべてのディレクトリーがエクスポートまたはアンエクスポートされます。その他のオプションが指定されていない場合、/usr/sbin/exportfs は、
/etc/exportsで指定されたすべてのファイルシステムをエクスポートします。 - -o file-systems
/etc/exportsに記載されていないエクスポートするディレクトリーを指定します。file-systems の部分を、エクスポートされる追加のファイルシステムに置き換えます。これらのファイルシステムは、/etc/exportsで指定したのと同じ方法でフォーマットする必要があります。このオプションは、エクスポートするファイルシステムのリストに永続的に追加する前に、エクスポートするファイルシステムをテストするためによく使用されます。/etc/exports構文の詳細は、「/etc/exports設定ファイル」 を参照してください。- -i
/etc/exportsを無視します。コマンドラインから指定したオプションのみが、エクスポートされるファイルシステムの定義に使用されます。- -u
- すべての共有ディレクトリーをエクスポートしなくなります。コマンド /usr/sbin/exportfs -ua は、すべての NFS デーモンを起動したままにして NFS ファイル共有を一時停止します。NFS 共有を再度有効にするには、exportfs -r を使用します。
- -v
- exportfs コマンドの実行時にエクスポートまたはエクスポートされていないファイルシステムの詳細を表示する詳細な操作です。
8.6.2.1. NFSv4 での exportfs の使用
/etc/sysconfig/nfs で RPCNFSDARGS= -N 4 を設定して無効にします。
8.6.3. ファイアウォール背後での NFS の実行
/etc/sysconfig/nfs ファイルを編集して、RPC サービスを実行するポートを設定します。クライアントがファイアウォールを介して RPC クォータにアクセスできるようにする方法は、「ファイアウォールを介した RPC クォータのアクセス」 を参照してください。
/etc/sysconfig/nfs ファイルは、デフォルトではすべてのシステムに存在しません。/etc/sysconfig/nfs が存在しない場合は作成し、以下を指定します。
- RPCMOUNTDOPTS="-p port"
- これにより、"-p port" が rpc.mount コマンドラインに追加されます( rpc.mount -p port )。
nlockmgr サービスが使用するポートを指定するには、/etc/modprobe.d/lockd.conf ファイルの nlm_tcpport オプションおよび nlm_udpport オプションのポート番号を設定します。
/var/log/messages を確認してください。通常、すでに使用されているポート番号を指定すると、NFS が起動しません。/etc/sysconfig/nfs を編集したら、以下のコマンドを実行して、Red Hat Enterprise Linux 7.2 以前で nfs-config サービスを再起動する必要があります。
# systemctl restart nfs-config
次に、NFS サーバーを再起動します。
# systemctl restart nfs-server
rpcinfo -p を実行して、変更が有効になったことを確認します。
/proc/sys/fs/nfs/nfs_callback_tcpport を設定し、サーバーがクライアント上のそのポートに接続できるようにします。
mountd、statd、および lockd 用の他のポートは必要ありません。
8.6.3.1. NFS エクスポートの検出
- NFSv3 に対応するサーバーでは、showmount コマンドを使用します。
$showmount -e myserver Export list for mysever /exports/foo /exports/bar - NFSv4 に対応するサーバーで、root ディレクトリーを マウント し、確認します。
#mount myserver:/ /mnt/#cd /mnt/ exports#ls exports foo bar
8.6.4. ファイアウォールを介した RPC クォータのアクセス
手順8.1 ファイアウォールの内側で RPC クォータにアクセスできるようにする
rpc-rquotadサービスを有効にするには、以下のコマンドを使用します。#systemctl enable rpc-rquotadrpc-rquotadサービスを起動するには、以下のコマンドを使用します。#systemctl start rpc-rquotadrpc-rquotadが有効になっている場合は、nfs-serverサービスの起動後に自動的に起動することに注意してください。- ファイアウォールの内側でクォータ RPC サービスにアクセスできるようにするには、UDP または TCP ポート
875を開く必要があります。デフォルトのポート番号は/etc/servicesファイルで定義されています。/etc/sysconfig/rpcを追加して、デフォルトのポート番号をオーバーライドできます。-rquotadファイルのRPCRQUOTADOPTS変数に -p port-number rpc-rquotadを再起動して、/etc/sysconfig/rpc-rquotadファイルの変更を有効にします。#systemctl restart rpc-rquotad
リモートホストからのクォータの設定
/etc/sysconfig/rpc-rquotad ファイルの RPCRQUOTADOPTS 変数に -S オプションを追加します。
rpc-rquotad を再起動して、/etc/sysconfig/rpc-rquotad ファイルの変更を有効にします。
# systemctl restart rpc-rquotad
8.6.5. ホスト名の形式
- 単独のマシン
- 完全修飾型ドメイン名 (サーバーで解決可能な形式)、ホスト名 (サーバーで解決可能な形式)、あるいは IP アドレス
- ワイルドカードで指定された一連のマシン
- 文字列の一致を指定するには、
*文字または?文字を使用します。ワイルドカードは IP アドレスでは使用しないことになっていますが、逆引き DNS ルックアップが失敗した場合には誤って動作する可能性があります。完全修飾ドメイン名でワイルドカードを指定する場合、ドット(.)はワイルドカードに含まれません。たとえば、*.example.comにはone.example.comが含まれていますが、1.two.example.com は含まれません。 - IP ネットワーク
- a.b.c.d/z を使用します。ここで、a.b.c.d はネットワーク、z はネットマスクのビット数です (たとえば、192.168.0.0/24)。別の使用可能形式は a.b.c.d/netmask となり、ここで a.b.c.d がネットワークで、netmask がネットマスクです (たとえば、192.168.100.8/255.255.255.0)。
- Netgroups
- 形式 @group-name を使用します。ここで、group-name は NIS netgroup の名前です。
8.6.6. NFS over RDMA の有効化 (NFSoRDMA)
- rdma パッケージと rdma-core パッケージをインストールします。
/etc/rdma/rdma.confファイルには、デフォルトでXPRTRDMA_LOAD=yesを設定する行が含まれています。これは、rdmaサービスに NFSoRDMA クライアント モジュールを読み込むように要求します。 - NFSoRDMA サーバー モジュールの自動読み込みを有効にするには、
/etc/rdma/rdma.confの新しい行にSVCRDMA_LOAD=yesを追加します。/etc/sysconfig/nfsファイルのRPCNFSDARGS="--rdma=20049"は、NFSoRDMA サービスがクライアントをリッスンするポート番号を指定します。『RFC 5667』 は、RDMA で NFSv4 サービスを提供する際に、サーバーがポート20049をリッスンする必要があることを指定します。 /etc/rdma/rdma.confファイルの編集後に、nfsサービスを再起動します。#systemctl restart nfs以前のカーネルバージョンでは、変更を有効にするために/etc/rdma/rdma.confの編集後にシステムを再起動する必要があることに注意してください。
8.6.7. NFSv4 専用サーバーの設定
rpcbind サービスがネットワークをリッスンする必要がないため、これにより、システムで開いているポートと実行中のサービスの数が最小限に抑えられます。
Requested NFS version or transport protocol is not supported.
手順8.2 NFSv4 専用サーバーの設定
/etc/sysconfig/nfs設定ファイルに以下の行を追加して、NFSv2、NFSv3、および UDP を無効にします。RPCNFSDARGS="-N 2 -N 3 -U"
- 必要に応じて、
RPCBIND、MOUNT、およびNSMプロトコル呼び出しのリッスンを無効にします。これは、NFSv4 専用の場合は不要です。このオプションを無効にすると、以下のような影響があります。- NFSv2 または NFSv3 を使用してサーバーから共有をマウントしようとするクライアントが応答しなくなります。
- NFS サーバー自体が、NFSv2 および NFSv3 のファイルシステムをマウントできなくなります。
このオプションを無効にするには、以下を実行します。- 以下を
/etc/sysconfig/nfsファイルに追加します。RPCMOUNTDOPTS="-N 2 -N 3"
- 関連するサービスを無効にします。
#systemctl mask --now rpc-statd.service rpcbind.service rpcbind.socket
- NFS サーバーを再起動します。
#systemctl restart nfs変更は、NFS サーバーを起動または再起動するとすぐに反映されます。
NFSv4 専用の設定の確認
netstat ユーティリティーを使用して、NFSv4 専用モードで NFS サーバーが設定されていることを確認できます。
- 以下は、NFSv4 専用サーバーでの
netstat出力例です。RPCBIND、MOUNT、およびNSMをリッスンして無効になります。nfsは、唯一のリスニング NFS サービスです。#netstat -ltu Active Internet connections (only servers) Proto Recv-Q Send-Q Local Address Foreign Address State tcp 0 0 0.0.0.0:nfs 0.0.0.0:* LISTEN tcp 0 0 0.0.0.0:ssh 0.0.0.0:* LISTEN tcp 0 0 localhost:smtp 0.0.0.0:* LISTEN tcp6 0 0 [::]:nfs [::]:* LISTEN tcp6 0 0 [::]:12432 [::]:* LISTEN tcp6 0 0 [::]:12434 [::]:* LISTEN tcp6 0 0 localhost:7092 [::]:* LISTEN tcp6 0 0 [::]:ssh [::]:* LISTEN udp 0 0 localhost:323 0.0.0.0:* udp 0 0 0.0.0.0:bootpc 0.0.0.0:* udp6 0 0 localhost:323 [::]:* - 一方、NFSv4 専用サーバーを設定する前の
netstat出力には、sunrpcおよびmountdサービスが含まれます。#netstat -ltu Active Internet connections (only servers) Proto Recv-Q Send-Q Local Address Foreign Address State tcp 0 0 0.0.0.0:nfs 0.0.0.0:* LISTEN tcp 0 0 0.0.0.0:36069 0.0.0.0:* LISTEN tcp 0 0 0.0.0.0:52364 0.0.0.0:* LISTEN tcp 0 0 0.0.0.0:sunrpc 0.0.0.0:* LISTEN tcp 0 0 0.0.0.0:mountd 0.0.0.0:* LISTEN tcp 0 0 0.0.0.0:ssh 0.0.0.0:* LISTEN tcp 0 0 localhost:smtp 0.0.0.0:* LISTEN tcp6 0 0 [::]:34941 [::]:* LISTEN tcp6 0 0 [::]:nfs [::]:* LISTEN tcp6 0 0 [::]:sunrpc [::]:* LISTEN tcp6 0 0 [::]:mountd [::]:* LISTEN tcp6 0 0 [::]:12432 [::]:* LISTEN tcp6 0 0 [::]:56881 [::]:* LISTEN tcp6 0 0 [::]:12434 [::]:* LISTEN tcp6 0 0 localhost:7092 [::]:* LISTEN tcp6 0 0 [::]:ssh [::]:* LISTEN udp 0 0 localhost:323 0.0.0.0:* udp 0 0 0.0.0.0:37190 0.0.0.0:* udp 0 0 0.0.0.0:876 0.0.0.0:* udp 0 0 localhost:877 0.0.0.0:* udp 0 0 0.0.0.0:mountd 0.0.0.0:* udp 0 0 0.0.0.0:38588 0.0.0.0:* udp 0 0 0.0.0.0:nfs 0.0.0.0:* udp 0 0 0.0.0.0:bootpc 0.0.0.0:* udp 0 0 0.0.0.0:sunrpc 0.0.0.0:* udp6 0 0 localhost:323 [::]:* udp6 0 0 [::]:57683 [::]:* udp6 0 0 [::]:876 [::]:* udp6 0 0 [::]:mountd [::]:* udp6 0 0 [::]:40874 [::]:* udp6 0 0 [::]:nfs [::]:* udp6 0 0 [::]:sunrpc [::]:*
8.7. NFS のセキュア化
8.7.1. AUTH_SYS とエクスポート制御による NFS セキュリティー保護
AUTH_SYS ( AUTH_UNIXとも呼ばれます)を使用してこれを行い、クライアントに依存し、ユーザーの UID と GID を示していました。つまり、悪意のあるクライアントや誤って設定されたクライアントがこれを誤用し、ファイルへのアクセスを許可すべきではないユーザーに対して、ファイルへのアクセスを簡単に与えてしまうことができるため注意が必要です。
8.7.2. AUTH_GSSを使用した NFS 保護
Kerberos の設定
手順8.3 RPCSEC_GSS を使用するための IdM 用の NFS サーバーとクライアントの設定
- NFS サーバー側で
nfs/hostname.domain@REALMプリンシパルを作成します。 - サーバーとクライアント側の両方に、
host/hostname.domain@REALMを作成します。注記ホスト名 は、NFS サーバーのホスト名 と同じでなければなりません。 - クライアントとサーバーのキータブに、対応する鍵を追加します。
手順は、Red Hat Enterprise Linux 7 Linux Domain Identity, Authentication, and Policy Guide の Adding and Editing Service Entries and Keytabs and Setting up a Kerberos-aware NFS Server のセクションを参照してください。- サーバーで、
sec=オプションを使用して、希望するセキュリティーフレーバーを有効にします。すべてのセキュリティーフレーバーと非暗号化マウントを有効にするには、以下のコマンドを実行します。/export *(sec=sys:krb5:krb5i:krb5p)
sec=オプションで使用する有効なセキュリティーフレーバーは次のとおりです。sys: 暗号化の保護なし(デフォルト)krb5: 認証のみkrb5i: 整合性保護krb5p: プライバシー保護
- クライアント側で、
sec=krb5(または設定に応じてsec=krb5i、またはsec=krb5p)をマウントオプションに追加します。# mount -o sec=krb5 server:/export /mnt
NFS クライアントの設定方法の詳細は、Red Hat Enterprise Linux 7 Linux Domain Identity, Authentication, and Policy Guide の Setting up a Kerberos-aware NFS Client セクションを参照してください。
関連情報
- Red Hat は IdM の使用を推奨しますが、Active Directory (AD) Kerberos サーバーにも対応しています。詳細は、Red Hat ナレッジベースの記事 How to set up NFS using Kerberos authentication on RHEL 7 using SSSD and Active Directory を参照してください。
- Kerberos で保護された NFS 共有に root としてファイルを書き込み、そのファイルで root 所有権を保持する必要がある場合は、https://access.redhat.com/articles/4040141 を参照してください。この設定は推奨されません。
8.7.2.1. NFSv4 による NFS のセキュリティー保護
MOUNT プロトコルを使用することを削除することです。MOUNT プロトコルは、プロトコルがファイルを処理する方法が原因でセキュリティーリスクを示しました。
8.7.3. ファイル権限
nobody に設定されます。root squashing は、デフォルトのオプション root_squash で制御されます。このオプションの詳細については、「/etc/exports 設定ファイル」 を参照してください。できる限りこの root squash 機能は無効にしないでください。
all_squash オプションの使用を検討してください。このオプションでは、エクスポートしたファイルシステムにアクセスするすべてのユーザーが、nfsnobody ユーザーのユーザー ID を取得します。
8.8. NFS および rpcbind
rpcbind サービスを必要とする NFSv3 実装にのみ適用されます。
rpcbind を必要としない NFSv4 専用サーバーを設定する方法は、「NFSv4 専用サーバーの設定」 を参照してください。
8.8.1. NFS と rpcbindのトラブルシューティング
# rpcinfo -p例8.7 rpcinfo -p コマンドの出力
program vers proto port service
100021 1 udp 32774 nlockmgr
100021 3 udp 32774 nlockmgr
100021 4 udp 32774 nlockmgr
100021 1 tcp 34437 nlockmgr
100021 3 tcp 34437 nlockmgr
100021 4 tcp 34437 nlockmgr
100011 1 udp 819 rquotad
100011 2 udp 819 rquotad
100011 1 tcp 822 rquotad
100011 2 tcp 822 rquotad
100003 2 udp 2049 nfs
100003 3 udp 2049 nfs
100003 2 tcp 2049 nfs
100003 3 tcp 2049 nfs
100005 1 udp 836 mountd
100005 1 tcp 839 mountd
100005 2 udp 836 mountd
100005 2 tcp 839 mountd
100005 3 udp 836 mountd
100005 3 tcp 839 mountd8.9. pNFS
pNFS の Flex ファイル
pNFS 共有のマウント
- pNFS 機能を有効にするには、NFS バージョン 4.1 以降を使用して、pNFS が有効になっているサーバーから共有をマウントします。
#mount -t nfs -o v4.1 server:/remote-export /local-directoryサーバーが pNFS が有効な後に、nfs_layout_nfsv41_filesカーネルが自動的に最初のマウントに読み込まれます。出力のマウントエントリーには、minorversion=1 が含まれている必要があります。次のコマンドを使用して、モジュールが読み込まれたことを確認します。$ lsmod | grep nfs_layout_nfsv41_files - Flex ファイルに対応するサーバーから、Flex ファイル機能で NFS 共有をマウントするには、NFS バージョン 4.2 以降を使用します。
#mount -t nfs -o v4.2 server:/remote-export /local-directorynfs_layout_flexfilesモジュールが読み込まれていることを確認します。$lsmod | grep nfs_layout_flexfiles
関連情報
8.10. NFS での pNFS SCSI レイアウトの有効化
前提条件
- クライアントとサーバーの両方で、SCSI コマンドを同じブロックデバイスに送信する必要があります。つまり、ブロックデバイスは共有 SCSI バス上になければなりません。
- ブロックデバイスに XFS ファイルシステムが含まれている必要があります。
- SCSI デバイスは、 SCSI-3 Primary Commands 仕様で説明されているように、SCSI Persistent Reservation に対応している必要があります。
8.10.1. pNFS SCSI レイアウト
クライアントとサーバーとの間の操作
LAYOUTGET 操作を実行します。サーバーは、SCSI デバイスのファイルの場所に反応します。クライアントは、使用する SCSI デバイスを判別するために GETDEVICEINFO の追加操作が必要になる場合があります。これらの操作が正しく機能すると、クライアントは、READ 操作および WRITE 操作をサーバーに送信する代わりに、SCSI デバイスに直接 I/O 要求を発行することができます。
READ 操作および WRITE 操作を発行するようにフォールバックします。
デバイスの予約
8.10.2. pNFS と互換性がある SCSI デバイスの確認
前提条件
- 以下のコマンドで、sg3-utils パッケージがインストールされている。
# yum install sg3_utils
手順8.4 pNFS と互換性がある SCSI デバイスの確認
- サーバーおよびクライアントの両方で、適切な SCSI デバイスサポートを確認します。
# sg_persist --in --report-capabilities --verbose path-to-scsi-device
Persist Through Power Loss Active (PTPL_A)ビットが設定されていることを確認します。例8.8 pNFS SCSI をサポートする SCSI デバイス
以下は、pNFS SCSI をサポートする SCSI デバイスに対するsg_persist出力の例です。PTPL_Aビットは1を報告します。inquiry cdb: 12 00 00 00 24 00 Persistent Reservation In cmd: 5e 02 00 00 00 00 00 20 00 00 LIO-ORG block11 4.0 Peripheral device type: disk Report capabilities response: Compatible Reservation Handling(CRH): 1 Specify Initiator Ports Capable(SIP_C): 1 All Target Ports Capable(ATP_C): 1 Persist Through Power Loss Capable(PTPL_C): 1 Type Mask Valid(TMV): 1 Allow Commands: 1 Persist Through Power Loss Active(PTPL_A): 1 Support indicated in Type mask: Write Exclusive, all registrants: 1 Exclusive Access, registrants only: 1 Write Exclusive, registrants only: 1 Exclusive Access: 1 Write Exclusive: 1 Exclusive Access, all registrants: 1
関連情報
- sg_persist(8) の man ページ
8.10.3. サーバーでの pNFS SCSI の設定
手順8.5 サーバーでの pNFS SCSI の設定
- サーバーで、SCSI デバイスで作成した XFS ファイルシステムをマウントします。
- NFS バージョン 4.1 以降をエクスポートするように NFS サーバーを設定します。
/etc/nfs.confファイルの[nfsd]セクションに以下のオプションを設定します。[nfsd] vers4.1=y
pnfsオプションを使用して、NFS で XFS ファイルシステムをエクスポートするように NFS サーバーを設定します。例8.9 pNFS SCSI をエクスポートする /etc/exports のエントリー
/etc/exports設定ファイルの以下のエントリーは、/exported/directory/にマウントされているファイルシステムを、pNFS SCSI レイアウトとしてallowed.example.comクライアントにエクスポートします。/exported/directory allowed.example.com(pnfs)
関連情報
- NFS サーバーの設定に関する詳細は、「NFS サーバーの設定」 を参照してください。
8.10.4. クライアントでの pNFS SCSI の設定
前提条件
- NFS サーバーは、pNFS SCSI で XFS ファイルシステムをエクスポートするように設定されています。「サーバーでの pNFS SCSI の設定」 を参照してください。
手順8.6 クライアントでの pNFS SCSI の設定
- クライアントで、NFS バージョン 4.1 以降を使用して、エクスポートした XFS ファイルシステムをマウントします。
# mount -t nfs -o nfsvers=4.1 host:/remote/export /local/directory
NFS なしで XFS ファイルシステムを直接マウントしないでください。
関連情報
- NFS 共有のマウントの詳細は、「NFS クライアントの設定」 を参照してください。
8.10.5. サーバーでの pNFS SCSI 予約の解放
前提条件
- 以下のコマンドで、sg3-utils パッケージがインストールされている。
# yum install sg3_utils
手順8.7 サーバーでの pNFS SCSI 予約の解放
- サーバーで、既存の予約をクエリーします。
# sg_persist --read-reservation path-to-scsi-device
例8.10 /dev/sda での予約のクエリー
# sg_persist --read-reservation /dev/sda LIO-ORG block_1 4.0 Peripheral device type: disk PR generation=0x8, Reservation follows: Key=0x100000000000000 scope: LU_SCOPE, type: Exclusive Access, registrants only - サーバーにある既存の登録を削除します。
# sg_persist --out \ --release \ --param-rk=reservation-key \ --prout-type=6 \ path-to-scsi-device例8.11 /dev/sda にある予約の削除
# sg_persist --out \ --release \ --param-rk=0x100000000000000 \ --prout-type=6 \ /dev/sda LIO-ORG block_1 4.0 Peripheral device type: disk
関連情報
- sg_persist(8) の man ページ
8.10.6. pNFS SCSI レイアウト機能の監視
前提条件
- pNFS SCSI クライアントとサーバーが設定されている。
8.10.6.1. nfsstat を使用したサーバーからの pNFS SCSI 操作のチェック
nfsstat ユーティリティーを使用して、サーバーからの pNFS SCSI 操作を監視します。
手順8.8 nfsstat を使用したサーバーからの pNFS SCSI 操作のチェック
- サーバーから操作サービスを監視します。
# watch --differences \ "nfsstat --server | egrep --after-context=1 read\|write\|layout" Every 2.0s: nfsstat --server | egrep --after-context=1 read\|write\|layout putrootfh read readdir readlink remove rename 2 0% 0 0% 1 0% 0 0% 0 0% 0 0% -- setcltidconf verify write rellockowner bc_ctl bind_conn 0 0% 0 0% 0 0% 0 0% 0 0% 0 0% -- getdevlist layoutcommit layoutget layoutreturn secinfononam sequence 0 0% 29 1% 49 1% 5 0% 0 0% 2435 86% - クライアントとサーバーは、以下の場合に pNFS SCSI 操作を使用します。
layoutgetカウンター、layoutreturnカウンター、およびlayoutcommitカウンターの増分値。これは、サーバーがレイアウトを提供することを意味します。- サーバーの
読み取りおよび書き込みカウンターはインクリメントしません。これは、クライアントが SCSI デバイスに直接 I/O 要求を実行していることを意味します。
8.10.6.2. mountstats を使用したクライアントからの pNFS SCSI 操作のチェック
/proc/self/mountstats ファイルを使用して、クライアントからの pNFS SCSI 操作を監視します。
手順8.9 mountstats を使用したクライアントからの pNFS SCSI 操作のチェック
- マウントごとの操作カウンターをリスト表示します。
# cat /proc/self/mountstats \ | awk /scsi_lun_0/,/^$/ \ | egrep device\|READ\|WRITE\|LAYOUT device 192.168.122.73:/exports/scsi_lun_0 mounted on /mnt/rhel7/scsi_lun_0 with fstype nfs4 statvers=1.1 nfsv4: bm0=0xfdffbfff,bm1=0x40f9be3e,bm2=0x803,acl=0x3,sessions,pnfs=LAYOUT_SCSI READ: 0 0 0 0 0 0 0 0 WRITE: 0 0 0 0 0 0 0 0 READLINK: 0 0 0 0 0 0 0 0 READDIR: 0 0 0 0 0 0 0 0 LAYOUTGET: 49 49 0 11172 9604 2 19448 19454 LAYOUTCOMMIT: 28 28 0 7776 4808 0 24719 24722 LAYOUTRETURN: 0 0 0 0 0 0 0 0 LAYOUTSTATS: 0 0 0 0 0 0 0 0 - 結果は以下のようになります。
LAYOUT統計は、クライアントとサーバーが pNFS SCSI 操作を使用する要求を示します。READおよびWRITE統計は、クライアントとサーバーが NFS 操作にフォールバックする要求を示します。
8.11. NFS のリファレンス
インストールされているドキュメント
- man mount - NFS サーバーとクライアント両方のマウントオプションに関する包括的な説明が含まれています。
- man fstab: システムの起動時にファイルシステムをマウントするために使用される
/etc/fstabファイルの形式の詳細を提供します。 - man nfs - NFS 固有のファイルシステムのエクスポートとマウントオプションの詳細を提供します。
- man exports - NFS ファイルシステムのエクスポート時に
/etc/exportsファイルで使用される一般的なオプションを表示します。
便利な Web サイト
- http://linux-nfs.org — プロジェクトの更新状況を確認できる開発者向けの最新サイトです。
- http://nfs.sourceforge.net/ — 開発者向けのホームページで、少し古いですが、役に立つ情報が多数掲載されています。
- http://www.citi.umich.edu/projects/nfsv4/linux/ — Linux 2.6 カーネル用 NFSv4 のリソースです。
- http://citeseer.ist.psu.edu/viewdoc/summary?doi=10.1.1.111.4086 — NFS バージョン 4 プロトコルの機能および拡張機能について記載しているホワイトペーパーです。
第9章 サーバーメッセージブロック (SMB)
cifs-utils ユーティリティーを使用してリモートサーバーから SMB 共有をマウントします。
cifs という名前を使用します。
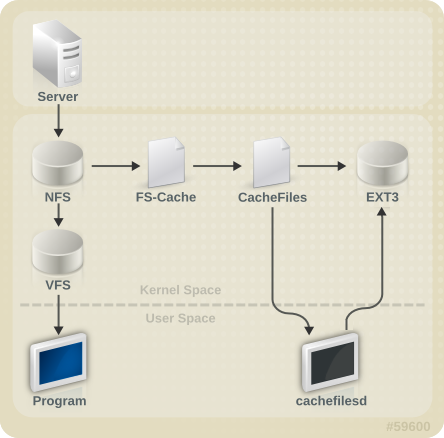
第10章 FS-Cache
図10.1 FS-Cache の概要
[D]
10.1. パフォーマンスに関する保証
10.2. キャッシュの設定
/etc/cachefilesd.conf ファイルは、cachefiles がキャッシュサービスを提供する方法を制御します。
$ dir /path/to/cache/etc/cachefilesd.conf に /var/cache/fscache として設定されます。
$ dir /var/cache/fscache
/var/cache/fscache と同じである必要があります。
#semanage fcontext -a -e /var/cache/fscache /path/to/cache#restorecon -Rv /path/to/cache
#semanage permissive -a cachefilesd_t#semanage permissive -a cachefiles_kernel_t
/)をホストファイルシステムとして使用することが推奨されますが、デスクトップマシンでは、キャッシュ専用のディスクパーティションをマウントする方が安全です。
- ext3 (拡張属性が有効)
- ext4
- Btrfs
- XFS
# tune2fs -o user_xattr /dev/device
# mount /dev/device /path/to/cache -o user_xattrcachefilesd サービスを起動します。
# systemctl start cachefilesd
# systemctl enable cachefilesd10.3. NFS でのキャッシュの使用
# mount nfs-share:/ /mount/point -o fsc10.3.1. キャッシュの共有
- レベル 1: サーバーの詳細
- レベル 2: 一部のマウントオプション、セキュリティータイプ、FSID、識別子
- レベル 3: ファイルハンドル
- レベル 4: ファイル内のページ番号
例10.1 キャッシュの共有
/home/fred と /home/jim は同じオプションがあるため、スーパーブロックを共有する可能性が高くなります。特に NFS サーバー上の同じボリューム/パーティションからのものである場合(home0)。ここで、2 つの後続のマウントコマンドを示します。
/home/fred および /home/jim はレベル 2 キーの一部であるネットワークアクセスパラメーターが異なるため、スーパーブロックを共有しません。次のマウントシーケンスについても同じことが言えます。
/home/fred1 および /home/fred2)の内容が 2 回 キャッシュされます。
:/disk0/fred および home0:/disk 0/jim を区別するものがないため、スーパーブロックの 1 つだけがキャッシュを使用できます。これに対処するには、少なくとも 1 つのマウントに 一意の識別子 を追加します。つまり、fsc=unique-identifier です。以下に例を示します。
/home/jim のキャッシュで使用されるレベル 2 キーに追加されます。
10.3.2. NFS でのキャッシュの制限
- ダイレクト I/O で共有ファイルシステムからファイルを開くと、自動的にキャッシュが回避されます。これは、この種のアクセスがサーバーに直接行なわれる必要があるためです。
- 書き込みで共有ファイルシステムからファイルを開いても NFS のバージョン 2 およびバージョン 3 では動作しません。これらのバージョンのプロトコルは、クライアントが、別のクライアントからの同じファイルへの同時書き込みを検出するのに必要な整合性の管理に関する十分な情報を提供しません。
- ダイレクト I/O または書き込みのいずれかで共有ファイルシステムからファイルを開くと、キャッシュされたファイルのコピーがフラッシュされます。ダイレクト I/O や書き込みのためにファイルが開かれなくなるまで、FS-Cache はファイルを再キャッシュしません。
- さらに、FS-Cache の今回のリリースでは、通常の NFS ファイルのみをキャッシュします。FS-Cache はディレクトリー、シンボリックリンク、デバイスファイル、FIFO、ソケットを キャッシュしません。
10.4. キャッシュカリング制限の設定
/etc/cachefilesd.conf の設定で制御される制限は 6 つあります。
- brun N% (ブロックのパーセンテージ) , frun N% (ファイルのパーセンテージ)
- キャッシュの空き領域と利用可能なファイルの数がこれらの制限を上回ると、カリングはオフになります。
- bcull N% (ブロックのパーセンテージ), fcull N% (ファイルのパーセンテージ)
- キャッシュの空き領域と利用可能なファイルの数がこれらの制限のいずれかを下回ると、カリング動作が開始します。
- bstop N% (ブロックのパーセンテージ), fstop N% (ファイルのパーセンテージ)
- キャッシュ内の使用可能な領域または使用可能なファイルの数がこの制限のいずれかを下回ると、カリングによってこれらの制限を超える状態になるまで、ディスク領域またはファイルのそれ以上の割り当ては許可されません。
N のデフォルト値は以下の通りです。
- brun/frun - 10%
- bcull/fcull - 7%
- bstop/fstop - 3%
- 0 DHE bstop < bcull < brun < 100
- 0 DHE fstop < fcull < frun < 100
10.5. 統計情報
# cat /proc/fs/fscache/stats/usr/share/doc/kernel-doc-version/Documentation/filesystems/caching/fscache.txt
10.6. FS-Cache の参考資料
/usr/share/doc/cachefilesd-version-number/README/usr/share/man/man5/cachefilesd.conf.5.gz/usr/share/man/man8/cachefilesd.8.gz
/usr/share/doc/kernel-doc-version/Documentation/filesystems/caching/fscache.txtを参照してください。
パート II. ストレージ管理
第11章 ストレージをインストールする際の注意点
11.1. 特に注意を要する事項について
/home、/opt、/usr/local には別々のパーティションを用意する
/home、/opt、および /usr/local を別のデバイスに配置します。これにより、ユーザーデータやアプリケーションデータを保持しながら、オペレーティングシステムが含まれるデバイスやファイルシステムを再フォーマットできます。
IBM System Z における DASD デバイスと zFCP デバイス
DASD= パラメーターとしてデバイス番号(またはデバイス番号の範囲)を一覧表示することを意味します。
FCP_x= 行を使用すると、インストーラーにこの情報を指定できます。
LUKS を使用したブロックデバイスの暗号化
古い BIOS RAID メタデータ
# dmraid -r -E /device/iSCSI の検出および設定
FCoE の検出および設定
DASD
DIF/DIX を有効にしているブロックデバイス
第12章 ファイルシステム検査
/etc/fstab に一覧表示されている各ファイルシステムで実行されます。ジャーナリングファイルシステムの場合、ファイルシステムのメタデータジャーナリングはクラッシュ後も一貫性を保証するため、これは通常非常に短い操作になります。
/etc/fstab の 6 番目のフィールドを 0 に設定すると、システムの起動時にファイルシステムの検査を無効にできます。
12.1. fsck のベストプラクティス
- Dry run
- ほとんどのファイルシステムチェッカーには、ファイルシステムを検査しますが修復しない操作モードがあります。このモードでは、チェッカーは、ファイルシステムを実際に変更することなく、検出したエラーと実行したアクションを出力します。注記整合性チェック後のフェーズでは、修復モードで実行していた場合に前のフェーズで修正されていた不整合が検出される可能性があるため、追加のエラーが出力される場合があります。
- 最初にファイルシステムイメージを操作する
- ほとんどのファイルシステムは、メタデータのみを含むファイルシステムのスパースコピーである メタデータイメージ の作成に対応しています。ファイルシステムチェッカーはメタデータのみを操作するため、このようなイメージを使用して、実際のファイルシステム修復のドライランを実行し、実際にどのような変更が行われるかを評価できます。変更が受け入れられる場合は、ファイルシステム自体で修復を実行できます。注記ファイルシステムが大幅に損傷している場合は、メタデータイメージの作成に関連して問題が発生する可能性があります。
- サポート調査のためにファイルシステムイメージを保存します。
- 破損がソフトウェアのバグによるものである可能性がある場合、修復前のファイルシステムメタデータイメージは、サポート調査に役立つことがよくあります。修復前のイメージに見つかる破損のパターンは、根本原因の分析に役立つことがあります。
- マウントされていないファイルシステムでのみ動作します。
- ファイルシステムの修復は、マウントされていないファイルシステムでのみ実行する必要があります。ツールには、ファイルシステムへの単独アクセスが必要であり、それがないと追加の損傷が発生する可能性があります。ほとんどのファイルシステムツールは、修復モードでこの要件を適用しますが、一部のツールは、マウントされたファイルシステムでチェックのみモードだけをサポートします。チェックのみモードが、マウントされたファイルシステムで実行されていると、マウントされていないファイルシステムで実行しても見つからない疑わしいエラーが検出されることがあります。
- ディスクエラー
- ファイルシステムの検査ツールは、ハードウェアの問題を修復できません。修復を正常に動作させるには、ファイルシステムが完全に読み取り可能かつ書き込み可能である必要があります。ハードウェアエラーが原因でファイルシステムが破損した場合は、まず dd (8) ユーティリティーなどを使用して、ファイルシステムを適切なディスクに移動する必要があります。
12.2. fsck のファイルシステム固有の情報
12.2.1. ext2、ext3、および ext4
e2fsck バイナリーを使用して、ファイルシステムの検査と修復を実行します。ファイル名の fsck.ext2、fsck.ext3、および fsck.ext4 はこの同じバイナリーへのハードリンクです。これらのバイナリーは、システムの起動時に自動的に実行し、その動作は確認されるファイルシステムと、そのファイルシステムの状態によって異なります。
- -n
- 非変更モード。チェックのみの操作。
- -b スーパーブロック
- プライマリーシステムが破損している場合は、別のスーパーブロックのブロック番号を指定します。
- -f
- スーパーブロックに記録されたエラーがなくても、フルチェックを強制実行します。
- -j journal-dev
- 外部のジャーナルデバイス (ある場合) を指定します。
- -p
- ユーザー入力のないファイルシステムを自動的に修復または preen (修復) する
- -y
- すべての質問に yes の回答を想定する
- Inode、ブロック、およびサイズのチェック。
- ディレクトリー構造のチェック。
- ディレクトリー接続のチェック。
- 参照数のチェック。
- グループサマリー情報のチェック。
12.2.2. XFS
fsck.xfs バイナリーがありますが、これは、システムの起動時に fsck.ファイルシステム バイナリーを検索する initscripts を満たすためにのみ存在します。fsck.xfs は、即座に終了コード 0 で終了します。
- -n
- 非変更モードです。チェックのみの操作。
- -L
- ゼロメタデータログ。マウントによってログを再生できない場合にのみ使用します。
- -m maxmem
- 最大 MB の実行時に使用されるメモリーを制限します。必要な最小メモリーの概算を出すために 0 を指定できます。
- -l logdev
- 外部ログデバイス (ある場合) を指定します。
- Inode および inode ブロックマップ (アドレス指定) のチェック。
- Inode 割り当てマップのチェック。
- Inode サイズのチェック。
- ディレクトリーのチェック。
- パス名のチェック。
- リンク数のチェック。
- フリーマップのチェック。
- スーパーブロックチェック。
12.2.3. Btrfs
- エクステントのチェック。
- ファイルシステムの root チェック。
- ルートの参照数のチェック。
第13章 Partitions
- 既存パーティションテーブルの表示
- 既存パーティションのサイズ変更
- 空き領域または他のハードドライブからのパーティションの追加
# parted /dev/sda使用中のデバイスでのパーティションの操作
パーティションテーブルの変更
# partx --update --nr partition-number disk
- システムディスクの場合など、ディスクのパーティションのマウントを解除できない場合は、レスキューモードでシステムを起動します。
- ファイルシステムをマウントするように求められたら、 を選択します。
| コマンド | 説明 |
|---|---|
| help | 利用可能なコマンドのリストを表示します。 |
| mklabel label | パーティションテーブル用のディスクラベルを作成します。 |
| mkpart part-type [fs-type] start-mb end-mb | 新しいファイルシステムを作成せずに、パーティションを作成します。 |
| name minor-num name | Mac と PC98 のディスクラベル用のみのパーティションに名前を付けます。 |
| パーティションテーブルを表示します。 | |
| quit | partedを終了します。 |
| rescue start-mb end-mb | start-mb から end-mb へ、消失したパーティションを復旧します。 |
| rm minor-num | パーティションを削除します。 |
| select device | 設定する別のデバイスを選択します。 |
| set minor-num flag state | パーティションにフラグを設定します。state はオンまたはオフのいずれかになります。 |
| toggle [NUMBER [FLAG] | パーティション NUMBER 上の FLAG の状態を切り替えます。 |
| unit UNIT | デフォルトのユニットを UNIT に設定します。 |
13.1. パーティションテーブルの表示
- parted を起動します。
- パーティションテーブルを表示するには、次のコマンドを使用します。
(parted)print
例13.1 パーティションテーブル
Model: ATA ST3160812AS (scsi) Disk /dev/sda: 160GB Sector size (logical/physical): 512B/512B Partition Table: msdos Number Start End Size Type File system Flags 1 32.3kB 107MB 107MB primary ext3 boot 2 107MB 105GB 105GB primary ext3 3 105GB 107GB 2147MB primary linux-swap 4 107GB 160GB 52.9GB extended root 5 107GB 133GB 26.2GB logical ext3 6 133GB 133GB 107MB logical ext3 7 133GB 160GB 26.6GB logical lvm
- Model: ATA ST3160812AS (scsi): ディスクの種類、製造元、モデル番号、およびインターフェイスについて説明しています。
- Disk /dev/sda: 160GB: ブロックデバイスへのファイルパスと、ストレージキャパシティーを表示しています。
- Partition Table: msdos: ディスクラベルのタイプを表示しています。
- パーティションテーブルでは、
Numberはパーティション番号です。たとえば、マイナー番号 1 のパーティションは/dev/sda1に対応します。StartおよびEndの値はメガバイト単位です。有効なタイプは、metadata、free、primary、extended、または logical です。File systemはファイルシステムのタイプです。Flags 列には、パーティションに設定されたフラグが一覧表示されます。利用可能なフラグは、boot、root、swap、hidden、raid、lvm、または lba です。
File system は、以下のいずれかになります。
- ext2
- ext3
- fat16
- fat32
- hfs
- jfs
- linux-swap
- ntfs
- reiserfs
- hp-ufs
- sun-ufs
- xfs
システム に値が表示されない場合は、ファイルシステムのタイプが不明であることを意味します。
13.2. パーティションの作成
手順13.1 パーティションの作成
- パーティションを作成する前に、レスキューモードで起動します (または、デバイス上のパーティションをアンマウントして、デバイス上のスワップ領域をすべてオフにします)。
- parted を起動します。
# parted /dev/sda/dev/sda をパーティションを作成するデバイス名に置き換えます。 - 現在のパーティションテーブルを表示し、十分な空き領域があるかどうかを確認します。
(parted)print十分な空き容量がない場合は、既存のパーティションのサイズを変更できます。詳細は、「fdisk でのパーティションのサイズ変更」 を参照してください。パーティションテーブルから、新しいパーティションの開始点と終了点、およびパーティションのタイプを決定します。プライマリーパーティションは、1 つのデバイス上に 4 つまで保有できます (この場合は拡張パーティションは含みません)。パーティションが 5 つ以上必要な場合は、プライマリーパーティションを 3 つ、拡張パーティションを 1 つにし、その拡張パーティションの中に複数の論理パーティションを追加します。ディスクパーティションの概要は、Red Hat Enterprise Linux 7 Installation Guide の付録 An Introduction to Disk Partitions を参照してください。 - パーティションを作成するには、以下を実行します。
(parted)mkpart part-type name fs-type start endpart-type を必要に応じて、primary、logical、または extended に置き換えます。name を partition-name に置き換えます。GPT パーティションテーブルには name が必要です。fs-type を、btrfs、ext2、ext3、ext4、fat16、fat32、hfs、hfs+、linux-swap、ntfs、reiserfs、または xfs のいずれかに置き換えます。fs-type はオプションです。必要に応じて、start end をメガバイト単位で置き換えます。たとえば、ハードドライブの 1024 メガバイトから 2048 メガバイトに ext3 ファイルシステムのプライマリーパーティションを作成するには、以下のコマンドを入力します。(parted)mkpart primary 1024 2048注記代わりに mkpartfs コマンドを使用すると、パーティションの作成後にファイルシステムが作成されます。ただし、parted は ext3 ファイルシステムの作成をサポートしていません。したがって、ext3 ファイルシステムを作成する場合は、mkpart を使用して、後述するように mkfs コマンドでファイルシステムを作成します。変更は Enter を押すとすぐに行われます。したがって、コマンドを確認してから確認してください。 - パーティションテーブルを表示し、次のコマンドを使用して、作成されたパーティションのパーティションタイプ、ファイルシステムタイプ、サイズが、パーティションテーブルに正しく表示されていることを確認します。
(parted)print新しいパーティションのマイナー番号も覚えておいてください。そのパーティション上のファイルシステムにラベルを付けることができます。 - parted シェルを終了します。
(parted)quit - parted を閉じた後、以下のコマンドを実行して、カーネルが新しいパーティションを認識していることを確認します。
#cat /proc/partitions
13.2.1. パーティションのフォーマットとラベル付け
手順13.2 パーティションのフォーマットとラベル付け
- パーティションにファイルシステムがない。
ext4ファイルシステムを作成するには、次のコマンドを実行します。#mkfs.ext4 /dev/sda6Warningパーティションをフォーマットすると、そのパーティションに現存するすべてのデータが永久に抹消されます。 - パーティションにファイルシステムのラベルを付けます。たとえば、新しいパーティションのファイルシステムが
/dev/sda6で、Workのラベルを付ける場合は、以下を使用します。#e2label /dev/sda6 "Work"デフォルトでは、インストールプログラムはパーティションのマウントポイントをラベルとして使用して、ラベルが固有なものとなるようにします。ユーザーは使用するラベルを選択できます。 - root でマウントポイント(例:
/work)を作成します。
13.2.2. /etc/fstabへのパーティションの追加
- root として、
/etc/fstabファイルを編集し、パーティションの UUID を使用して新しいパーティションを追加します。パーティションの UUID の完全なリストには blkid -o list コマンドを使用し、個々のデバイスの詳細には blkid device コマンドを使用します。/etc/fstabの場合:- 最初の列には、
UUID=の後にファイルシステムの UUID が含まれている必要があります。 - 2 番目の列には、新しいパーティションのマウントポイントが含まれている必要があります。
- 3 番目の列は、ファイルシステムのタイプ(
ext4またはswapなど)である必要があります。 - 4 番目の列は、ファイルシステムのマウントオプションのリストになります。ここでの
defaultsという用語は、システムの起動時に、パーティションがデフォルトのオプションでマウントされることを意味します。 - 5 番目と 6 番目のフィールドは、バックアップとチェックのオプションを指定します。root 以外のパーティションの値の例は
0 2です。
- システムが新しい設定を登録するように、マウントユニットを再生成します。
#systemctl daemon-reload - ファイルシステムをマウントして、設定が機能することを確認します。
# mount /work
追加情報
/etc/fstabの形式に関する詳細は、fstab(5) の man ページを参照してください。
13.3. パーティションの削除
手順13.3 パーティションの削除
- パーティションを削除する前に、以下のいずれかを行います。
- レスキューモードで起動します。
- デバイスのパーティションをアンマウントし、デバイスのスワップスペースをオフにします。
partedユーティリティーを起動します。# parted devicedevice を、パーティションを削除するデバイス(例:/dev/sda)に置き換えます。- 現在のパーティションテーブルを表示して、削除するパーティションのマイナー番号を確認します。
(parted) print - rm コマンドでパーティションを削除します。例えば、マイナー番号 3 のパーティションを削除するのは以下のコマンドです。
(parted) rm 3変更は Enter を押すとすぐに行われるため、コマンドを確認してからコミットします。 - パーティションを削除したら、print コマンドを使用して、パーティションテーブルから削除されていることを確認します。
(parted) print partedシェルを終了します。(parted) quit/proc/partitionsファイルの内容を調べて、パーティションが削除されたことをカーネルが認識していることを確認します。# cat /proc/partitions/etc/fstabファイルからパーティションを削除します。削除したパーティションを宣言している行を見つけ、ファイルから削除します。- システムが新しい
/etc/fstab設定を登録するように、マウントユニットを再生成します。#systemctl daemon-reload
13.4. パーティションタイプの設定
systemd-gpt-auto-generator などのオンザフライジェネレーターにとって重要です。
fdisk ユーティリティーを起動し、t コマンドを使用してパーティションタイプを設定できます。以下の例は、最初のパーティションのパーティションタイプを 0x83 (Linux のデフォルト) に変更する方法を示しています。
#fdisk /dev/sdc Command (m for help): t Selected partition1Partition type (type L to list all types):83Changed type of partition 'Linux LVM' to 'Linux'.
parted ユーティリティーは、パーティションタイプをflags にマッピングすることでパーティションタイプを制御します。これは、エンドユーザーにとっては役に立ちません。parted ユーティリティーは、LVM や RAID などの特定のパーティションタイプのみを処理できます。たとえば、parted を使用した最初のパーティションから lvm フラグを削除するには、次のコマンドを実行します。
# parted /dev/sdc 'set 1 lvm off'
13.5. fdisk でのパーティションのサイズ変更
fdisk ユーティリティーを使用すると、GPT、MBR、Sun、SGI、および BSD パーティションテーブルを作成および操作できます。GUID パーティションテーブル(GPT)のディスクでは、fdisk GPT サポートは実験的なフェーズであるため、parted ユーティリティーを使用することが推奨されます。
fdisk を使用してパーティションサイズを変更する唯一の方法は、パーティションを削除して再作成するため、パーティションのサイズを変更する前に、ファイルシステムに保存されているデータを バックアップ して手順をテストします。
手順13.4 パーティションのサイズ変更
fdisk を使用してパーティションのサイズを変更するには、以下を実行します。
- デバイスをアンマウントします。
#umount /dev/vda - fdisk disk_name を実行します。以下に例を示します。
#fdisk /dev/vda Welcome to fdisk (util-linux 2.23.2). Changes will remain in memory only, until you decide to write them. Be careful before using the write command. Command (m for help): pオプションを使用して、削除するパーティションの行番号を決定します。Command (m for help): p Disk /dev/vda: 16.1 GB, 16106127360 bytes, 31457280 sectors Units = sectors of 1 * 512 = 512 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disk label type: dos Disk identifier: 0x0006d09a Device Boot Start End Blocks Id System /dev/vda1 * 2048 1026047 512000 83 Linux /dev/vda2 1026048 31457279 15215616 8e Linux LVM
- d オプションを使用してパーティションを削除します。複数のパーティションが利用可能な場合は、fdisk により、削除するパーティションの数を指定するようにプロンプトが表示されます。
Command (m for help): d Partition number (1,2, default 2): 2 Partition 2 is deleted
nオプションを使用してパーティションを作成し、プロンプトに従います。今後サイズを変更する場合は、十分な領域を確保してください。fdisk のデフォルト動作(Enterを押す)は、デバイス上のすべての領域を使用することです。パーティションの終わりをセクターで指定するか、+ <size> <suffix> を使用して人間が判読できるサイズ を指定できます(例:+500M、または +10G)。fdisk はパーティションの終わりを物理セクターに合わせるため、すべての空き領域を使用しない場合は、人間が判読可能なサイズの指定を使用することを Red Hat は推奨しています。正確な数(セクター内)を指定してサイズを指定すると、fdisk はパーティションの終わりをあわせません。Command (m for help): n Partition type: p primary (1 primary, 0 extended, 3 free) e extended Select (default p): *Enter* Using default response p Partition number (2-4, default 2): *Enter* First sector (1026048-31457279, default 1026048): *Enter* Using default value 1026048 Last sector, +sectors or +size{K,M,G} (1026048-31457279, default 31457279): +500M Partition 2 of type Linux and of size 500 MiB is set- パーティションのタイプを LVM に設定します。
Command (m for help): t Partition number (1,2, default 2): *Enter* Hex code (type L to list all codes): 8e Changed type of partition 'Linux' to 'Linux LVM'
- エラーが選択したパーティションで不安定になる可能性があるため、変更が正しい場合は、w オプションで変更を書き込みます。
- デバイスで e2fsck を実行して、整合性をチェックします。
#e2fsck /dev/vda e2fsck 1.41.12 (17-May-2010) Pass 1:Checking inodes, blocks, and sizes Pass 2:Checking directory structure Pass 3:Checking directory connectivity Pass 4:Checking reference counts Pass 5:Checking group summary information ext4-1:11/131072 files (0.0% non-contiguous),27050/524128 blocks - デバイスをマウントします。
#mount /dev/vda
第14章 Snapper でのスナップショットの作成と管理
14.1. Snapper の初期設定の作成
手順14.1 Snapper 設定ファイルの作成
- 以下のいずれかを作成または選択します。
- シンプロビジョニングされた論理ボリューム (Red Hat がサポートするファイルシステムがその上にある)、または
- Btrfs サブボリューム。
- ファイルシステムをマウントします。
- このボリュームを定義する設定ファイルを作成します。LVM2 の場合:
#snapper -c config_name create-config -f "lvm(fs_type)" /mount-pointたとえば、/lvm_mount にマウントした ext4 ファイルシステムを持つ LVM2 サブボリュームに、lvm_config という設定ファイルを作成する場合は、次のコマンドを実行します。#snapper -c lvm_config create-config -f "lvm(ext4)" /lvm_mountBtrfs の場合:#snapper -c config_name create-config -f btrfs /mount-point- -c config_name オプションは、設定ファイルの名前を指定します。
- create-config は snapper に設定ファイルを作成するように指示します。
- -f file_system は snapper に、使用するファイルシステムを指示します。これを省略すると、snapper がファイルシステムの検出を試みます。
- /mount-point は、サブボリュームまたはシンプロビジョニングされた LVM2 ファイルシステムがマウントされる場所です。
または、/btrfs_mountにマウントされている Btrfs サブボリュームにbtrfs_configという設定ファイルを作成するには、次のコマンドを実行します。#snapper -c btrfs_config create-config -f btrfs /btrfs_mount
/etc/snapper/configs/ ディレクトリーに保存されます。
14.2. Snapper スナップショットの作成
- プレスナップショット
- プレスナップショットは、ポストスナップショットの作成元として機能します。この 2 つは密接に関連しており、2 つのポイント間でファイルシステムの修正を追跡するように設計されています。ポストスナップショットを作成する前に、プレスナップショットを作成する必要があります。
- ポストスナップショット
- ポストスナップショットは、プレスナップショットのエンドポイントとして機能します。結合されたプレスナップショットとポストスナップショットは、比較の範囲を定義します。デフォルトでは、すべての新しい snapper ボリュームは、関連するポストスナップショットが正常に作成された後にバックグラウンド比較を作成するように設定されています。
- シングルスナップショット
- 1 つのスナップショットとは、特定の時点で作成されたスタンドアロンのスナップショットのことです。これらを使用すると、修正のタイムラインを追跡し、後で戻るための一般的なポイントを持つために使用することができます
14.2.1. プレスナップショットとポストスナップショットのペアの作成
14.2.1.1. Snapper を使用したプレスナップショットの作成
# snapper -c config_name create -t prepre、post または single です。
lvm_config 設定ファイルを使用してプレスナップショットを作成するには、以下のコマンドを実行します。
# snapper -c SnapperExample create -t pre -p
1
-p オプションは、作成されたスナップショットの番号を出力しますが、使用するかどうかは任意です。
14.2.1.2. Snapper を使用しポストスナップショットの作成
手順14.2 ポストスナップショットの作成
- プレスナップショットの数を指定します。
#snapper -c config_name listたとえば、設定ファイルlvm_configを使用して作成されたスナップショットの一覧を表示するには、次のコマンドを実行します。#snapper -c lvm_config list Type | # | Pre # | Date | User | Cleanup | Description | Userdata -------+---+-------+-------------------+------+----------+-------------+--------- single | 0 | | | root | | current | pre | 1 | | Mon 06<...> | root | | |この出力は、プレスナップショットが番号 1 であることを示しています。 - 事前に作成したプレスナップショットにリンクされる、ポストスナップショットを作成します。
#snapper -c config_file create -t post --pre-num pre_snapshot_number- -t post オプションは、ポストスナップショットの作成を指定します。
- --pre-num オプションは、対応するプレスナップショットを指定します。
たとえば、lvm_config設定ファイルを使用してポストスナップショットを作成し、プレスナップショット番号 1 にリンクするには、次のコマンドを実行します。#snapper -c lvm_config create -t post --pre-num 1 -p 2-pオプションは、作成されたスナップショットの番号を出力しますが、使用するかどうかは任意です。 - プレスナップショット 1 とポストスナップショット 2 が作成され、ペアになりました。list コマンドを使用してこれを確認します。
#snapper -c lvm_config list Type | # | Pre # | Date | User | Cleanup | Description | Userdata -------+---+-------+-------------------+------+----------+-------------+--------- single | 0 | | | root | | current | pre | 1 | | Mon 06<...> | root | | | post | 2 | 1 | Mon 06<...> | root | | |
14.2.1.3. スナップショット前およびスナップショット後のコマンドのラップ
- snapper create pre snapshot コマンドを実行している。
- コマンドの実行、またはファイルシステムのコンテンツに影響を与える可能性があるアクションを実行するコマンドのリスト。
- snapper create post snapshot コマンドを実行している。
手順14.3 スナップショット前およびスナップショット後のコマンドのラップ
- プレスナップショットとポストスナップショットでコマンドをラップするには、以下のコマンドを実行します。
#snapper -c lvm_config create --command "command_to_be_tracked"たとえば、/lvm_mount/hello_fileファイルの作成を追跡するには、次のコマンドを実行します。#snapper -c lvm_config create --command "echo Hello > /lvm_mount/hello_file" - これを確認するには、status コマンドを使用します。
#snapper -c config_file status first_snapshot_number..second_snapshot_numberたとえば、最初の手順で行った変更を追跡するには、以下のコマンドを実行します。#snapper -c lvm_config status 3..4 +..... /lvm_mount/hello_file必要に応じて、list コマンドを使用してスナップショットの番号を確認します。status コマンドの詳細は、「スナップショット間での変更の追跡」 を参照してください。
14.2.2. 1 つのスナップショットの作成
-t オプションのみが単一を指定します。1 つのスナップショットを使用すれば、他のスナップショットとは無関係に、1 つのスナップショットを作成できます。ただし、比較を自動的に生成したり、追加情報をリスト表示したりせずに、LVM2 シンボリュームのスナップショットを簡単に作成したい場合は、「スナップショット」 で説明しているように、Red Hat では、この目的で Snapper の代わりに System Storage Manager を使用することを推奨しています。
# snapper -c config_name create -t singlelvm_config 設定ファイルを使用して単一のスナップショットを作成します。
# snapper -c lvm_config create -t single14.2.3. 自動スナップショットを作成するための Snapper の設定
- 10 時間ごとのスナップショットと、最後の 1 時間ごとのスナップショットは、1 日単位のスナップショットとして保存されます。
- 1 日単位 10 のスナップショットと、1 カ月の最後の 1 日単位のスナップショットは、月単位のスナップショットとして保存されます。
- 月単位 10 のスナップショット、および最後の月単位のスナップショットは年単位のスナップショットとして保存されます。
- 年単位 10 のスナップショット
/etc/snapper/config-templates/default ファイルで指定されます。snapper create-config コマンドを使用して設定を作成すると、指定されていない値はデフォルト設定に基づいて設定されます。/etc/snapper/configs/config_name ファイルで定義されているボリュームの設定を編集できます。
14.3. スナップショット間での変更の追跡
- status
- status コマンドは、2 つのスナップショット間で作成、変更、または削除されたファイルおよびディレクトリーの一覧を表示します。これは、2 つのスナップショット間の変更の包括的なリストです。このコマンドを使用すると、詳細を必要以上に表示することなく、変更の概要を取得できます。詳細は、「status コマンドでの変更の比較」 を参照してください。
- diff
- diff コマンドは、少なくとも 1 つの変更が検出された場合に、status コマンドから受信した 2 つのスナップショット間で変更されたファイルおよびディレクトリーの差分を表示します。詳細は、「diff コマンドでの変更の比較」 を参照してください。
- xadiff
- xadiff コマンドは、ファイルまたはディレクトリーの拡張属性が 2 つのスナップショット間でどのように変更されたかを比較します。詳細は、「xadiff コマンドでの変更の比較」 を参照してください。
14.3.1. status コマンドでの変更の比較
# snapper -c config_file status first_snapshot_number..second_snapshot_numberlvm_config を使用して、スナップショット 1 から 2 の間に加えられた変更を表示します。
#snapper -c lvm_config status 1..2
tp.... /lvm_mount/dir1
-..... /lvm_mount/dir1/file_a
c.ug.. /lvm_mount/file2
+..... /lvm_mount/file3
....x. /lvm_mount/file4
cp..xa /lvm_mount/file5
+..... /lvm_mount/file3 |||||| 123456
| 出力 | 意味 |
|---|---|
| . | 何も変更されていません。 |
| + | ファイルが作成されました。 |
| - | ファイルが削除されました。 |
| c | コンテンツが変更されました。 |
| t | ディレクトリーエントリーのタイプが変更されました。(例: 以前のシンボリックリンクが同じファイル名の通常のファイルに変更されるなど。) |
| 出力 | 意味 |
|---|---|
| . | パーミッションは変更されませんでした。 |
| p | パーミッションが変更されました。 |
| 出力 | 意味 |
|---|---|
| . | ユーザーの所有権は変更されていません。 |
| u | ユーザーの所有権が変更されました。 |
| 出力 | 意味 |
|---|---|
| . | グループの所有権は変更されていません。 |
| g | グループの所有権が変更されました。 |
| 出力 | 意味 |
|---|---|
| . | 拡張属性は変更されていません。 |
| x | 拡張属性が変更されました。 |
| 出力 | 意味 |
|---|---|
| . | ACL は変更されていません。 |
| a | ACL が変更されました。 |
14.3.2. diff コマンドでの変更の比較
# snapper -c config_name diff first_snapshot_number..second_snapshot_numberlvm_config 設定ファイルを使用して作成されたスナップショット 1 とスナップショット 2 の間にファイルに加えられた変更を比較するには、次のコマンドを実行します。
# snapper -c lvm_config diff 1..2
--- /lvm_mount/.snapshots/13/snapshot/file4 19<...>
+++ /lvm_mount/.snapshots/14/snapshot/file4 20<...>
@@ -0,0 +1 @@
+words
file4 が「単語」を追加するように変更されたことを示しています。
14.3.3. xadiff コマンドでの変更の比較
# snapper -c config_name xadiff first_snapshot_number..second_snapshot_numberlvm_config 設定ファイルを使用して作成されたスナップショット番号 1 とスナップショット番号 2 の間の xadiff 出力を表示するには、次のコマンドを実行します。
# snapper -c lvm_config xadiff 1..214.4. スナップショット間の変更を元に戻す
1 は最初のスナップショットで、2 は 2 番目のスナップショットです。
snapper -c config_name undochange 1..2
図14.1 時間の経過に伴う Snapper のステータス

[D]
snapshot_1 が作成された時点、file_a が作成され、file_b が削除されることを示しています。次に Snapshot_2 が作成され、その後に file_a が編集され、file_c が作成されます。これが、システムの現在の状態になります。現在のシステムには、編集バージョンの file_a があり、file_b はなく、新しく作成された file_c があります。
file_a が作成され、file_b が削除されます)を作成し、それらを現在のシステムに適用します。そのため、以下に留意してください。
- 現在のシステムには
file_aがありません。これは、snapshot_1の作成時にまだ作成されていないためです。 file_bは存在します。snapshot_1から現在のシステムにコピーされます。file_cは、作成が指定の時間外であったため、存在します。
file_b と file_c が競合すると、システムが破損する可能性があることに注意してください。
file_a を snapshot_1 からコピーされたものに置き換えます。これにより、snapshot_2 の作成後に行われたファイルの編集が取り消されます。
mount および unmount コマンドを使用して変更を元に戻す
/etc/snapper/configs/config_name ファイルには、ユーザーおよびグループを追加できる ALLOW_USERS= 変数および ALLOW_GROUPS= 変数が含まれています。次に、snapperd を使用すると、追加したユーザーおよびグループのマウント操作を実行できます。
14.5. Snapper スナップショットの削除
# snapper -c config_name delete snapshot_number第15章 swap 領域
| システム内の RAM の容量 | 推奨されるスワップ領域 | ハイバネートを許可する場合に推奨されるスワップ領域 |
|---|---|---|
| ⩽ 2 GB | RAM 容量の 2 倍 | RAM 容量の 3 倍 |
| > 2 GB ~ 8 GB | RAM 容量と同じ | RAM 容量の 2 倍 |
| > 8 GB ~ 64 GB | 最低 4GB | RAM 容量の 1.5 倍 |
| > 64 GB | 最低 4GB | ハイバネートは推奨されない |
レスキュー モードで起動している間にスワップ領域を変更する必要があります。『Red Hat Enterprise Linux 7 Installation Guide』 の Booting Your Computer in Rescue Mode を参照してください。ファイルシステムをマウントするように求められたら、 を選択します。
15.1. スワップ領域の追加
15.1.1. LVM2 論理ボリュームでのスワップ領域の拡張
/dev/VolGroup00/LogVol01 が 2 GB 拡張するボリュームであると想定)。
手順15.1 LVM2 論理ボリュームでのスワップ領域の拡張
- 関連付けられている論理ボリュームのスワップ機能を無効にします。
# swapoff -v /dev/VolGroup00/LogVol01 - LVM2 論理ボリュームのサイズを 2 GB 増やします。
# lvresize /dev/VolGroup00/LogVol01 -L +2G - 新しいスワップ領域をフォーマットします。
# mkswap /dev/VolGroup00/LogVol01 - 拡張論理ボリュームを有効にします。
# swapon -v /dev/VolGroup00/LogVol01 - スワップの論理ボリュームの拡張に成功したかどうかをテストするには、アクティブなスワップ容量を調べます。
$ cat /proc/swaps $ free -h
15.1.2. スワップの LVM2 論理ボリュームの作成
/dev/VolGroup00/LogVol02 が追加するスワップボリュームであると想定します。
- サイズが 2 GB の LVM2 論理ボリュームを作成します。
# lvcreate VolGroup00 -n LogVol02 -L 2G - 新しいスワップ領域をフォーマットします。
# mkswap /dev/VolGroup00/LogVol02 - 以下のエントリーを
/etc/fstabファイルに追加します。/dev/VolGroup00/LogVol02 swap swap defaults 0 0
- システムが新しい設定を登録するように、マウントユニットを再生成します。
#systemctl daemon-reload - 論理ボリュームでスワップをアクティブにします。
# swapon -v /dev/VolGroup00/LogVol02 - スワップ論理ボリュームの作成に成功したかどうかをテストするには、アクティブなスワップ容量を調べます。
$ cat /proc/swaps $ free -h
15.1.3. スワップファイルの作成
手順15.2 スワップファイルの追加
- 新しいスワップファイルのサイズをメガバイト単位で指定してから、そのサイズに 1024 をかけてブロック数を指定します。たとえばスワップファイルのサイズが 64 MB の場合は、ブロック数が 65536 になります。
- 空のファイルの作成:
# dd if=/dev/zero of=/swapfile bs=1024 count=65536希望のブロックサイズと同等の値に count を置き換えます。 - 次のコマンドでスワップファイルをセットアップします。
# mkswap /swapfile - スワップファイルのセキュリティーを変更して、全ユーザーで読み込みができないようにします。
# chmod 0600 /swapfile - システムの起動時にスワップファイルを有効にするには、root で
/etc/fstabを編集して、以下のエントリーを追加します。/swapfile swap swap defaults 0 0
次にシステムが起動すると新しいスワップファイルが有効になります。 - システムが新しい
/etc/fstab設定を登録するように、マウントユニットを再生成します。#systemctl daemon-reload - スワップファイルをすぐに有効にするには、次のコマンドを実行します。
# swapon /swapfile - 新しいスワップファイルを作成して有効にできたことをテストするには、アクティブなスワップ容量を調べます。
$ cat /proc/swaps $ free -h
15.2. スワップ領域の削除
15.2.1. LVM2 論理ボリュームでのスワップ領域の縮小
/dev/VolGroup00/LogVol01 が縮小するボリュームであると想定):
手順15.3 LVM2 の swap 論理ボリュームの削減
- 関連付けられている論理ボリュームのスワップ機能を無効にします。
# swapoff -v /dev/VolGroup00/LogVol01 - LVM2 論理ボリュームのサイズを変更して 512 MB 削減します。
# lvreduce /dev/VolGroup00/LogVol01 -L -512M - 新しいスワップ領域をフォーマットします。
# mkswap /dev/VolGroup00/LogVol01 - 論理ボリュームでスワップをアクティブにします。
# swapon -v /dev/VolGroup00/LogVol01 - スワップ論理ボリュームの縮小に成功したかどうかをテストするには、アクティブなスワップ容量を調べます。
$ cat /proc/swaps $ free -h
15.2.2. スワップの LVM2 論理ボリュームの削除
/dev/VolGroup00/LogVol02 が削除するスワップボリュームであると想定)、以下を実行します。
手順15.4 swap ボリュームグループの削除
- 関連付けられている論理ボリュームのスワップ機能を無効にします。
#swapoff -v /dev/VolGroup00/LogVol02 - LVM2 論理ボリュームを削除します。
#lvremove /dev/VolGroup00/LogVol02 /etc/fstabファイルから、以下の関連エントリーを削除します。/dev/VolGroup00/LogVol02 swap swap defaults 0 0
- システムが新しい設定を登録するように、マウントユニットを再生成します。
#systemctl daemon-reload - 削除されたスワップストレージへの参照をすべて
/etc/default/grubファイルから削除します。#vi /etc/default/grub - grub 設定を再構築します。
- BIOS ベースのマシンでは、次を実行します。
#grub2-mkconfig -o /boot/grub2/grub.cfg - UEFI ベースのマシンでは、次を実行します。
#grub2-mkconfig -o /boot/efi/EFI/redhat/grub.cfg
- 論理ボリュームの削除に成功したかどうかをテストするには、アクティブなスワップ容量を調べます。
$ cat /proc/swaps $ free -h
15.2.3. スワップファイルの削除
手順15.5 swap ファイルの削除
- シェルプロンプトで次のコマンドを実行してスワップファイルを無効にします(
/swapfileはスワップファイルです)。# swapoff -v /swapfile /etc/fstabファイルからエントリーを削除します。- システムが新しい設定を登録するように、マウントユニットを再生成します。
#systemctl daemon-reload - 実際のファイルを削除します。
# rm /swapfile
15.3. Swap 領域の移動
- スワップ領域の削除 「スワップ領域の削除」。
- スワップ領域の追加 「スワップ領域の追加」。
第16章 System Storage Manager (SSM)
16.1. SSM のバックエンド
ssmlib/main.py のコア抽象化レイヤーを使用します。これは、基礎となるテクノロジーの詳細を無視して、デバイス、プール、およびボリュームの抽象化に準拠します。バックエンドを ssmlib/main.py に登録して、作成、スナップショット、ボリュームやプールの 削除 など、特定のストレージテクノロジーメソッドを処理します。
16.1.1. Btrfs バックエンド
16.1.1.1. Btrfs プール
btrfs_pool です。
btrfs_device_base_nameの形式で内部使用の名前 を生成します。
16.1.1.2. Btrfs ボリューム
/dev/lvm_pool/lvol001 と表示されます。ボリュームを作成するには、このパスにあるすべてのオブジェクトが存在している必要があります。ボリュームは、マウントポイントで参照することもできます。
16.1.1.3. Btrfs スナップショット
16.1.1.4. Btrfs デバイス
16.1.2. LVM バックエンド
16.1.2.1. LVM プール
lvm_pool です。
16.1.2.2. LVM ボリューム
16.1.2.3. LVM スナップショット
スナップショット ボリュームが作成されます。Btrfs とは異なり、LVM ではスナップショットと通常のボリュームを区別できるため、スナップショット名を特定のパターンに一致させる必要はありません。
16.1.2.4. LVM デバイス
16.1.3. 暗号化バックエンド
16.1.3.1. 暗号化ボリューム
16.1.3.2. 暗号化スナップショット
16.1.4. 複数のデバイス (MD) のバックエンド
16.2. 一般的な SSM タスク
16.2.1. SSM のインストール
# yum install system-storage-manager
- LVM バックエンドには
lvm2パッケージが必要です。 - Btrfs バックエンドには
btrfs-progsパッケージが必要です。 - Crypt バックエンドには、
device-mapperパッケージおよびcryptsetupパッケージが必要です。
16.2.2. 検出されたすべてのデバイスに関する情報の表示
# ssm list
----------------------------------------------------------
Device Free Used Total Pool Mount point
----------------------------------------------------------
/dev/sda 2.00 GB PARTITIONED
/dev/sda1 47.83 MB /test
/dev/vda 15.00 GB PARTITIONED
/dev/vda1 500.00 MB /boot
/dev/vda2 0.00 KB 14.51 GB 14.51 GB rhel
----------------------------------------------------------
------------------------------------------------
Pool Type Devices Free Used Total
------------------------------------------------
rhel lvm 1 0.00 KB 14.51 GB 14.51 GB
------------------------------------------------
---------------------------------------------------------------------------------
Volume Pool Volume size FS FS size Free Type Mount point
---------------------------------------------------------------------------------
/dev/rhel/root rhel 13.53 GB xfs 13.52 GB 9.64 GB linear /
/dev/rhel/swap rhel 1000.00 MB linear
/dev/sda1 47.83 MB xfs 44.50 MB 44.41 MB part /test
/dev/vda1 500.00 MB xfs 496.67 MB 403.56 MB part /boot
---------------------------------------------------------------------------------
- devices 引数または dev 引数を実行すると、デバイスの一部が省略されます。たとえば、CDRoms デバイスや DM/MD デバイスは、ボリュームとして記載されているときに意図的に非表示になります。
- バックエンドの中にはスナップショットに対応していないものや、通常のボリュームとスナップショットを区別できないものがあります。これらのバックエンドのいずれかで snapshot 引数を実行すると、SSM はスナップショットを識別するためにボリューム名を認識しようとします。SSM の正規表現がスナップショットパターンと一致しない場合、スナップショットは認識されません。
- メインの Btrfs ボリューム (ファイルシステム自体) を除き、マウントされていない Btrfs ボリュームは表示されません。
16.2.3. 新しいプール、論理ボリューム、およびファイルシステムの作成
/dev/vdb および /dev/vdc、1G の論理ボリューム、および XFS ファイルシステムを持つデフォルト名で新しいプールが作成されます。
- --fs オプションは、必要なファイルシステムのタイプを指定します。現在対応しているファイルシステムの種類は次のとおりです。
- ext3
- ext4
- xfs
- btrfs
- -s は、論理ボリュームのサイズを指定します。単位を定義するために、次の接尾辞がサポートされています。
- キロバイトの場合は
kまたは k Mまたはm(メガバイト)- ギガバイトの場合は
Gまたはg - テラバイトの場合は
Tまたはt pまたは p (ペタバイト)eまたはe(エクサバイト)
- また、-s オプションを使用すると、新しいサイズをパーセンテージで指定できます。例を参照してください。
- プールサイズの合計 10 パーセントで 10
% - 10
%FREE: 空きプール領域の 10 パーセントの場合 - 使用されているプール領域の 10
%USED
/dev/vdb と /dev/vdc )は、作成する 2 つのデバイスです。
# ssm create --fs xfs -s 1G /dev/vdb /dev/vdc
Physical volume "/dev/vdb" successfully created
Physical volume "/dev/vdc" successfully created
Volume group "lvm_pool" successfully created
Logical volume "lvol001" created
lvm_pool を使用していました。ただし、特定の名前を使用して、既存の命名規則に適合させるには、-p オプションを使用する必要があります。
# ssm create --fs xfs -p new_pool -n XFS_Volume /dev/vdd
Volume group "new_pool" successfully created
Logical volume "XFS_Volume" created
16.2.4. ファイルシステムの整合性の確認
lvol001 内のすべてのデバイスをチェックするには、ssm check /dev/lvm_pool/lvol001 コマンドを実行します。
# ssm check /dev/lvm_pool/lvol001
Checking xfs file system on '/dev/mapper/lvm_pool-lvol001'.
Phase 1 - find and verify superblock...
Phase 2 - using internal log
- scan filesystem freespace and inode maps...
- found root inode chunk
Phase 3 - for each AG...
- scan (but don't clear) agi unlinked lists...
- process known inodes and perform inode discovery...
- agno = 0
- agno = 1
- agno = 2
- agno = 3
- agno = 4
- agno = 5
- agno = 6
- process newly discovered inodes...
Phase 4 - check for duplicate blocks...
- setting up duplicate extent list...
- check for inodes claiming duplicate blocks...
- agno = 0
- agno = 1
- agno = 2
- agno = 3
- agno = 4
- agno = 5
- agno = 6
No modify flag set, skipping phase 5
Phase 6 - check inode connectivity...
- traversing filesystem ...
- traversal finished ...
- moving disconnected inodes to lost+found ...
Phase 7 - verify link counts...
No modify flag set, skipping filesystem flush and exiting.
16.2.5. ボリュームのサイズを大きくする
/dev/vdb に論理ボリュームが 1 つあり、これは 900MB の lvol001 です。
# ssm list
-----------------------------------------------------------------
Device Free Used Total Pool Mount point
-----------------------------------------------------------------
/dev/vda 15.00 GB PARTITIONED
/dev/vda1 500.00 MB /boot
/dev/vda2 0.00 KB 14.51 GB 14.51 GB rhel
/dev/vdb 120.00 MB 900.00 MB 1.00 GB lvm_pool
/dev/vdc 1.00 GB
-----------------------------------------------------------------
---------------------------------------------------------
Pool Type Devices Free Used Total
---------------------------------------------------------
lvm_pool lvm 1 120.00 MB 900.00 MB 1020.00 MB
rhel lvm 1 0.00 KB 14.51 GB 14.51 GB
---------------------------------------------------------
--------------------------------------------------------------------------------------------
Volume Pool Volume size FS FS size Free Type Mount point
--------------------------------------------------------------------------------------------
/dev/rhel/root rhel 13.53 GB xfs 13.52 GB 9.64 GB linear /
/dev/rhel/swap rhel 1000.00 MB linear
/dev/lvm_pool/lvol001 lvm_pool 900.00 MB xfs 896.67 MB 896.54 MB linear
/dev/vda1 500.00 MB xfs 496.67 MB 403.56 MB part /boot
--------------------------------------------------------------------------------------------
~]# ssm resize -s +500M /dev/lvm_pool/lvol001 /dev/vdc
Physical volume "/dev/vdc" successfully created
Volume group "lvm_pool" successfully extended
Phase 1 - find and verify superblock...
Phase 2 - using internal log
- scan filesystem freespace and inode maps...
- found root inode chunk
Phase 3 - for each AG...
- scan (but don't clear) agi unlinked lists...
- process known inodes and perform inode discovery...
- agno = 0
- agno = 1
- agno = 2
- agno = 3
- process newly discovered inodes...
Phase 4 - check for duplicate blocks...
- setting up duplicate extent list...
- check for inodes claiming duplicate blocks...
- agno = 0
- agno = 1
- agno = 2
- agno = 3
No modify flag set, skipping phase 5
Phase 6 - check inode connectivity...
- traversing filesystem ...
- traversal finished ...
- moving disconnected inodes to lost+found ...
Phase 7 - verify link counts...
No modify flag set, skipping filesystem flush and exiting.
Extending logical volume lvol001 to 1.37 GiB
Logical volume lvol001 successfully resized
meta-data=/dev/mapper/lvm_pool-lvol001 isize=256 agcount=4, agsize=57600 blks
= sectsz=512 attr=2, projid32bit=1
= crc=0
data = bsize=4096 blocks=230400, imaxpct=25
= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0 ftype=0
log =internal bsize=4096 blocks=853, version=2
= sectsz=512 sunit=0 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
data blocks changed from 230400 to 358400
# ssm list
------------------------------------------------------------------
Device Free Used Total Pool Mount point
------------------------------------------------------------------
/dev/vda 15.00 GB PARTITIONED
/dev/vda1 500.00 MB /boot
/dev/vda2 0.00 KB 14.51 GB 14.51 GB rhel
/dev/vdb 0.00 KB 1020.00 MB 1.00 GB lvm_pool
/dev/vdc 640.00 MB 380.00 MB 1.00 GB lvm_pool
------------------------------------------------------------------
------------------------------------------------------
Pool Type Devices Free Used Total
------------------------------------------------------
lvm_pool lvm 2 640.00 MB 1.37 GB 1.99 GB
rhel lvm 1 0.00 KB 14.51 GB 14.51 GB
------------------------------------------------------
----------------------------------------------------------------------------------------------
Volume Pool Volume size FS FS size Free Type Mount point
----------------------------------------------------------------------------------------------
/dev/rhel/root rhel 13.53 GB xfs 13.52 GB 9.64 GB linear /
/dev/rhel/swap rhel 1000.00 MB linear
/dev/lvm_pool/lvol001 lvm_pool 1.37 GB xfs 1.36 GB 1.36 GB linear
/dev/vda1 500.00 MB xfs 496.67 MB 403.56 MB part /boot
----------------------------------------------------------------------------------------------
# ssm resize -s-50M /dev/lvm_pool/lvol002
Rounding size to boundary between physical extents: 972.00 MiB
WARNING: Reducing active logical volume to 972.00 MiB
THIS MAY DESTROY YOUR DATA (filesystem etc.)
Do you really want to reduce lvol002? [y/n]: y
Reducing logical volume lvol002 to 972.00 MiB
Logical volume lvol002 successfully resized
16.2.6. スナップショット
lvol001 のスナップショットを作成するには、次のコマンドを使用します。
# ssm snapshot /dev/lvm_pool/lvol001
Logical volume "snap20150519T130900" created
# ssm list
----------------------------------------------------------------
Device Free Used Total Pool Mount point
----------------------------------------------------------------
/dev/vda 15.00 GB PARTITIONED
/dev/vda1 500.00 MB /boot
/dev/vda2 0.00 KB 14.51 GB 14.51 GB rhel
/dev/vdb 0.00 KB 1020.00 MB 1.00 GB lvm_pool
/dev/vdc 1.00 GB
----------------------------------------------------------------
--------------------------------------------------------
Pool Type Devices Free Used Total
--------------------------------------------------------
lvm_pool lvm 1 0.00 KB 1020.00 MB 1020.00 MB
rhel lvm 1 0.00 KB 14.51 GB 14.51 GB
--------------------------------------------------------
----------------------------------------------------------------------------------------------
Volume Pool Volume size FS FS size Free Type Mount point
----------------------------------------------------------------------------------------------
/dev/rhel/root rhel 13.53 GB xfs 13.52 GB 9.64 GB linear /
/dev/rhel/swap rhel 1000.00 MB linear
/dev/lvm_pool/lvol001 lvm_pool 900.00 MB xfs 896.67 MB 896.54 MB linear
/dev/vda1 500.00 MB xfs 496.67 MB 403.56 MB part /boot
----------------------------------------------------------------------------------------------
----------------------------------------------------------------------------------
Snapshot Origin Pool Volume size Size Type
----------------------------------------------------------------------------------
/dev/lvm_pool/snap20150519T130900 lvol001 lvm_pool 120.00 MB 0.00 KB linear
----------------------------------------------------------------------------------
16.2.7. 項目の削除
# ssm remove lvm_pool
Do you really want to remove volume group "lvm_pool" containing 2 logical volumes? [y/n]: y
Do you really want to remove active logical volume snap20150519T130900? [y/n]: y
Logical volume "snap20150519T130900" successfully removed
Do you really want to remove active logical volume lvol001? [y/n]: y
Logical volume "lvol001" successfully removed
Volume group "lvm_pool" successfully removed
16.3. SSM リソース
- man ssm ページには、適切な説明と例が記載されています。また、記載するコマンドやオプションの詳細については、こちらを参照してください。
- SSM のローカルドキュメントは、
doc/ディレクトリーに保存されます。 - SSM Wiki は、http://storagemanager.sourceforge.net/index.html からアクセスできます。
- https://lists.sourceforge.net/lists/listinfo/storagemanager-devel からメーリングリストのサブスクライブ、http://sourceforge.net/mailarchive/forum.php?forum_name=storagemanager-devel からメーリングリストのアーカイブが可能です。メーリングリストは、開発者がコミュニケーションをとる場所です。現在、ユーザーのメーリングリストはありませんので、そこにも質問を投稿してください。
第17章 ディスククォータ
17.1. ディスククォータの設定
/etc/fstabファイルを変更して、ファイルシステムごとのクォータを有効にします。- ファイルシステムを再マウントします。
- クォータデータベースファイルを作成して、ディスク使用状況テーブルを生成します。
- クォータポリシーを割り当てます。
17.1.1. クォータの有効化
手順17.1 クォータの有効化
- root でログインします。
/etc/fstabファイルを編集します。- クォータを必要とするファイルシステムに usrquota オプションまたは grpquota オプションのいずれか、または両方のオプションを追加します。
例17.1 /etc/fstabを編集します。
vim を使用するには、以下を入力します。
# vim /etc/fstab例17.2 クォータの追加
/dev/VolGroup00/LogVol00 / ext3 defaults 1 1 LABEL=/boot /boot ext3 defaults 1 2 none /dev/pts devpts gid=5,mode=620 0 0 none /dev/shm tmpfs defaults 0 0 none /proc proc defaults 0 0 none /sys sysfs defaults 0 0 /dev/VolGroup00/LogVol02 /home ext3 defaults,usrquota,grpquota 1 2 /dev/VolGroup00/LogVol01 swap swap defaults 0 0 . . .
/home ファイルシステムで、ユーザーおよびグループの両方のクォータが有効になっています。
/etc/fstab ファイルでクォータポリシーを設定するために使用できます。
17.1.2. ファイルシステムの再マウント
fstab エントリーが変更された各ファイルシステムを再マウントします。ファイルシステムがどのプロセスでも使用されていない場合は、以下のいずれかの方法を使用します。
- umount コマンドの後に mount コマンドを実行してファイルシステムを再 マウント します。さまざまなファイルシステムタイプのマウントとアンマウントを行う具体的な構文は、umount と mount の man ページを参照してください。
- mount -o remount file-systemコマンド( file-system はファイルシステムの名前)を実行して、ファイルシステムを再マウントします。たとえば、
/homeファイルシステムを再マウントするには、mount -o remount /home コマンドを実行します。
17.1.3. クォータデータベースファイルの作成
手順17.2 クォータデータベースファイルの作成
- 次のコマンドを使用して、ファイルシステムにクォータファイルを作成します。
#quotacheck -cug /file system - 次のコマンドを使用して、ファイルシステムごとの現在のディスク使用量の表を生成します。
#quotacheck -avug
- c
- クォータファイルを、クォータを有効にしたファイルシステムごとに作成するように指定します。
- u
- ユーザークォータを確認します。
- g
- グループクォータを確認します。
-gのみを指定すると、グループクォータファイルのみが作成されます。
-u オプションまたは -g オプションのいずれも指定しない場合は、ユーザークォータファイルのみが作成されます。
- a
- クォータが有効にされた、ローカルマウントのファイルシステムをすべてチェック
- v
- クォータチェックの進行状態について詳細情報を表示
- u
- ユーザーディスククォータの情報をチェック
- g
- グループディスククォータの情報をチェック
/home などの、クォータが有効になっているローカルにマウントされた各ファイルシステムのデータが取り込まれます。
17.1.4. ユーザーごとのクォータ割り当て
- ユーザーは、ユーザークォータを設定する前に存在する必要があります。
手順17.3 ユーザーごとのクォータ割り当て
- ユーザーにクォータを割り当てるには、次のコマンドを使用します。
#edquota usernameusername を、クォータを割り当てるユーザーに置き換えます。 - ユーザーのクォータが設定されていることを確認するには、次のコマンドを使用します。
#quota username
例17.3 ユーザーへのクォータの割り当て
/home パーティションの /etc/fstab でクォータが有効になっている場合(以下の例では/dev/VolGroup00/LogVol02 )、コマンド edquota testuser を実行すると、システムのデフォルトとして設定されているエディターに次のように表示されます。
Disk quotas for user testuser (uid 501): Filesystem blocks soft hard inodes soft hard /dev/VolGroup00/LogVol02 440436 0 0 37418 0 0
EDITOR 環境変数で定義されるテキストエディターは、edquota により使用されます。エディターを変更するには、~/.bash_profile ファイルの EDITOR 環境変数を、選択したエディターのフルパスに設定します。
inodes 列には、ユーザーが現在使用している inode の数が表示されます。最後の 2 列は、ファイルシステムのユーザーに対するソフトおよびハードの inode 制限を設定するのに使用されます。
例17.4 必要な制限の変更
Disk quotas for user testuser (uid 501): Filesystem blocks soft hard inodes soft hard /dev/VolGroup00/LogVol02 440436 500000 550000 37418 0 0
# quota testuser
Disk quotas for user username (uid 501):
Filesystem blocks quota limit grace files quota limit grace
/dev/sdb 1000* 1000 1000 0 0 0
17.1.5. グループごとのクォータ割り当て
- グループは、グループクォータを設定する前に存在している必要があります。
手順17.4 グループごとのクォータ割り当て
- グループクォータを設定するには、次のコマンドを使用します。
#edquota -g groupname - グループクォータが設定されていることを確認するには、次のコマンドを使用します。
#quota -g groupname
例17.5 クォータのグループへの割り当て
devel グループのグループクォータを設定するには、コマンドを使用します。
# edquota -g develDisk quotas for group devel (gid 505): Filesystem blocks soft hard inodes soft hard /dev/VolGroup00/LogVol02 440400 0 0 37418 0 0
# quota -g devel17.1.6. ソフト制限の猶予期間の設定
# edquota -t17.2. ディスククォータの管理
17.2.1. 有効化と無効化
# quotaoff -vaug-u オプションまたは -g オプションのいずれも指定しない場合は、ユーザークォータのみが無効になります。-g のみを指定すると、グループクォータのみが無効になります。-v スイッチにより、コマンドの実行時に詳細なステータス情報が表示されます。
# quotaon# quotaon -vaug-u オプションまたは -g オプションのいずれも指定しない場合は、ユーザークォータのみが有効になります。-g のみが指定されている場合は、グループのクォータのみが有効になります。
/home などの特定のファイルシステムのクォータを有効にするには、次のコマンドを使用します。
# quotaon -vug /home17.2.2. ディスククォータに関するレポート
例17.6 repquota コマンドの出力
*** Report for user quotas on device /dev/mapper/VolGroup00-LogVol02 Block grace time: 7days; Inode grace time: 7days Block limits File limits User used soft hard grace used soft hard grace ---------------------------------------------------------------------- root -- 36 0 0 4 0 0 kristin -- 540 0 0 125 0 0 testuser -- 440400 500000 550000 37418 0 0
-a) のディスク使用状況レポートを表示するには、次のコマンドを使用します。
# repquota -a-- は、ブロックまたは inode の制限を超えるかを簡単に判断できます。いずれかのソフト制限を超えると、対応する - の代わりに + が表示されます。最初の - はブロックの制限を表し、2 つ目は inode の制限を表します。
grace 列は空白です。ソフト制限が超過した場合、その列には猶予期間に残り時間量に相当する時間指定が含まれます。猶予期間が過ぎると、代わりに 何も 表示されません。
17.2.3. クォータの精度維持
# quotacheck- 次回の再起動時に quotacheck を確実に実行する
- ほとんどのシステムに最適な方法この方法は、定期的に再起動する (ビジーな) 複数ユーザーシステムに最も適しています。シェルスクリプトを
/etc/cron.daily/ディレクトリーまたは/etc/cron.weekly/ディレクトリーに保存するか、次のコマンドを使用してシェルスクリプトをスケジュールします。#crontab -ecrontab -e コマンドには、touch /forcequotacheck コマンドが含まれます。このスクリプトは root ディレクトリーに空のforcequotacheckファイルを作成するため、起動時にシステムの init スクリプトがこれを検索します。このディレクトリーが検出されると、init スクリプトは quotacheck を実行します。その後、init スクリプトは/forcequotacheckファイルを削除します。このように、cronでこのファイルが定期的に作成されるようにスケジュールすることにより、次回の再起動時に quotacheck を確実に実行することができます。cron の詳細は、man cron を参照してください。 - シングルユーザーモードで quotacheck を実行
- quotacheck を安全に実行する別の方法として、クオータファイルのデータ破損の可能性を回避するためにシングルユーザーモードでシステムを起動して、以下のコマンドを実行する方法があります。
#quotaoff -vug /file_system#quotacheck -vug /file_system#quotaon -vug /file_system - 実行中のシステムで quotacheck を実行
- 必要な場合には、いずれのユーザーもログインしておらず、チェックされているファイルシステムに開いているファイルがない状態のマシン上で quotacheck を実行することができます。quotacheck -vug file_system コマンドを実行します。このコマンドは、quotacheck が指定された file_system を読み取り専用に再マウントできない場合に失敗します。チェックの後には、ファイルシステムは読み込み/書き込みとして再マウントされることに注意してください。警告読み込み/書き込みでマウントされているライブのファイルシステム上での quotacheck の実行は、quota ファイルが破損する可能性があるため、推奨されません。
17.3. ディスククオータのリファレンス
- quotacheck
- edquota
- repquota
- quota
- quotaon
- quotaoff
第18章 RAID (Redundant Array of Independent Disks)
- 速度を高める
- 1 台の仮想ディスクを使用してストレージ容量を増加する
- ディスク障害によるデータ損失を最小限に抑える
18.1. RAID のタイプ
ファームウェア RAID
ハードウェア RAID
ソフトウェア RAID
- マルチスレッド設計
- 再構築なしで Linux マシン間でのアレイの移植性
- アイドルシステムリソースを使用したバックグラウンドのアレイ再構築
- ホットスワップ可能なドライブのサポート
- CPU の自動検出でストリーミング SIMD サポートなどの特定 CPU の機能を活用
- アレイ内のディスク上にある不良セクターの自動修正
- RAID データの整合性を定期的にチェックしアレイの健全性を確保
- 重要なイベントで指定された電子メールアドレスに送信された電子メールアラートによるアレイのプロアクティブな監視
- 書き込みを集中としたビットマップ、アレイ全体を再同期させるのではなく再同期を必要とするディスク部分を正確にカーネルに認識させることで再同期イベントの速度を大幅に高速化
- チェックポイントを再同期して、再同期中にコンピューターを再起動すると、起動時に再同期が中断したところから再開し、最初からやり直さないようにします。
- インストール後のアレイのパラメーター変更が可能です。たとえば、新しいデバイスを追加しても、4 つのディスクの RAID5 アレイを 5 つのディスク RAID5 アレイに増大させることができます。この拡張操作はライブで行うため、新しいアレイで再インストールする必要はありません。
18.2. RAID レベルとリニアサポート
- レベル 0
- RAID レベル 0 は、多くの場合ストライプ化と呼ばれていますが、パフォーマンス指向のストライプ化データマッピング技術です。これは、アレイに書き込まれるデータがストライプに分割され、アレイのメンバーディスク全体に書き込まれることを意味します。これにより低い固有コストで高い I/O パフォーマンスを実現できますが、冗長性は提供されません。多くの RAID レベル 0 実装は、アレイ内の最小デバイスのサイズまで、メンバーデバイス全体にデータをストライプ化します。つまり、複数のデバイスのサイズが少し異なる場合、それぞれのデバイスは最小ドライブと同じサイズであるかのように処理されます。そのため、レベル 0 アレイの一般的なストレージ容量は、ハードウェア RAID 内の最小メンバーディスクの容量と同じか、アレイ内のディスク数またはパーティション数で乗算したソフトウェア RAID 内の最小メンバーパーティションの容量と同じになります。
- レベル 1
- RAID レベル 1 またはミラーリングは、他の RAID 形式よりも長く使用されています。レベル 1 は、アレイ内の各メンバーディスクに同一データを書き込むことで冗長性を提供し、各ディスクに対してミラーリングコピーをそのまま残します。ミラーリングは、データの可用性の単純化と高レベルにより、いまでも人気があります。レベル 1 は 2 つ以上のディスクと連携して、非常に優れたデータ信頼性を提供し、読み取り集中型のアプリケーションに対してパフォーマンスが向上しますが、比較的コストが高くなります。[3]レベル 1 アレイのストレージ容量は、ハードウェア RAID 内でミラーリングされている最小サイズのハードディスクの容量と同じか、ソフトウェア RAID 内でミラーリングされている最小のパーティションと同じ容量になります。レベル 1 の冗長性は、すべての RAID タイプの中で最も高いレベルであり、アレイは 1 つのディスクのみで動作できます。
- レベル 4
- レベル 4 でパリティーを使用 [4] データを保護するため、1 つのディスクドライブで連結します。専用パリティーディスクは RAID アレイへのすべての書き込みトランザクションに固有のボトルネックを表すため、レベル 4 は、ライトバックキャッシュなどの付随技術なしで、またはシステム管理者がこれを使用してソフトウェア RAID デバイスを意図的に設計する特定の状況で使用されることはほとんどありません。ボトルネック (配列にデータが入力されると、書き込みトランザクションがほとんどまたはまったくない配列など) を念頭に置いてください。RAID レベル 4 にはほとんど使用されないため、Anaconda ではこのオプションとしては使用できません。ただし、実際には必要な場合は、ユーザーが手動で作成できます。ハードウェア RAID レベル 4 のストレージ容量は、最小メンバーパーティションの容量にパーティションの数を掛けて、-1 を引いたものになります。RAID レベル 4 アレイのパフォーマンスは常に非対称になります。つまり、読み込みは書き込みを上回ります。これは、パリティーを生成するときに書き込みが余分な CPU 帯域幅とメインメモリーの帯域幅を消費し、データだけでなくパリティーも書き込むため、実際のデータをディスクに書き込むときに余分なバス帯域幅も消費するためです。読み取りが必要なのは、アレイが劣化状態にない限り、パリティーではなくデータでを読み取るだけです。その結果、通常の動作条件下で同じ量のデータ転送を行う場合は、読み取りによってドライブへのトラフィック、またはコンピューターのバスを経由するトラフィックが少なくなります。
- レベル 5
- これは RAID の最も一般的なタイプです。RAID レベル 5 は、アレイのすべてのメンバーディスクドライブにパリティーを分散することにより、レベル 4 に固有の書き込みボトルネックを排除します。パリティー計算プロセス自体のみがパフォーマンスのボトルネックです。最新の CPU とソフトウェア RAID では、最近の CPU がパリティーが非常に高速になるため、通常はボトルネックではありません。ただし、ソフトウェア RAID5 アレイに多数のメンバーデバイスがあり、組み合わせたすべてのデバイス間のデータ転送速度が十分であれば、このボトルネックは再生できます。レベル 4 と同様に、レベル 5 のパフォーマンスは非対称であり、読み取りは書き込みを大幅に上回ります。RAID レベル 5 のストレージ容量は、レベル 4 と同じです。
- レベル 6
- パフォーマンスではなくデータの冗長性と保存が最重要事項であるが、レベル 1 の領域の非効率性が許容できない場合は、これが RAID の一般的なレベルです。レベル 6 では、複雑なパリティースキームを使用して、アレイ内の 2 つのドライブから失われたドライブから復旧できます。複雑なパリティースキームにより、ソフトウェア RAID デバイスで CPU 幅が大幅に高くなり、書き込みトランザクションの際に増大度が高まります。したがって、レベル 6 はレベル 4 や 5 よりもパフォーマンスにおいて、非常に非対称です。RAID レベル 6 アレイの合計容量は、RAID レベル 5 および 4 と同様に計算されますが、デバイス数から追加パリティーストレージ領域用に 2 つのデバイス (1 ではなく) を引きます。
- レベル 10
- この RAID レベルでは、レベル 0 のパフォーマンスとレベル 1 の冗長性を組み合わせます。また、2 を超えるデバイスを持つレベル 1 アレイで領域の一部を軽減するのに役立ちます。レベル 10 では、データごとに 2 つのコピーのみを格納するように設定された 3 ドライブアレイを作成することができます。これにより、全体用のアレイサイズを最小デバイスのみと同じサイズ (3 つのデバイス、レベル 1 アレイなど) ではなく、最小サイズのデバイスが 1.5 倍になります。レベル 10 アレイを作成する際の使用可能なオプションの数が多く、特定のユースケースに適切なオプションを選択することが簡単ではないため、インストール時に作成するのは実用的とは言えません。コマンドラインの mdadm ツールを使用して手動で作成できます。オプションと、それぞれのパフォーマンスのトレードオフに関する詳細は、man md を参照してください。
- リニア RAID
- リニア RAID は、より大きな仮想ドライブを作成するドライブのグループ化です。リニア RAID では、あるメンバードライブからチャンクが順次割り当てられます。最初のドライブが完全に満杯になったときにのみ次のドライブに移動します。これにより、メンバードライブ間の I/O 操作が分割される可能性はないため、パフォーマンスの向上は見られません。リニア RAID には冗長性がなく、信頼性は低下します。メンバードライブに障害が発生した場合は、アレイ全体を使用することはできません。容量はすべてのメンバーディスクの合計になります。
18.3. Linux RAID サブシステム
Linux ハードウェア RAID のコントローラードライバー
mdraid
dmraid
18.4. Anaconda インストーラーでの RAID のサポート
18.5. インストール後のルートディスクの RAID1 への変換
- PowerPC Reference Platform (PReP)ブートパーティションのコンテンツを
/dev/sda1から/dev/sdb1にコピーします。#dd if=/dev/sda1 of=/dev/sdb1 - 両方のディスクの最初のパーティションで Prep フラグおよび boot フラグを更新します。
$parted /dev/sda set 1 prep on$parted /dev/sda set 1 boot on$parted /dev/sdb set 1 prep on$parted /dev/sdb set 1 boot on
18.6. RAID セットの設定
mdadm
dmraid
18.7. 高度な RAID デバイスの作成
/boot または root ファイルシステムアレイを設定することを意味します。このような場合には、Anaconda で対応していないアレイオプションの使用が必要になる場合があります。これを回避するには、以下の手順を行います。
手順18.1 高度な RAID デバイスの作成
- インストールディスクを挿入します。
- 初回起動時に、 または の代わりに を選択します。システムが レスキューモード で完全に起動すると、コマンドラインターミナルが表示されます。
- このターミナルから parted を使用して、ターゲットハードドライブに RAID パーティションを作成します。次に、mdadm を使用して、利用可能なすべての設定およびオプションを使用して、これらのパーティションから RAID アレイを手動で作成します。これらの方法の詳細については、13章Partitions、man parted、および man mdadm を参照してください。
- アレイを作成したら、必要に応じてアレイにファイルシステムを作成することもできます。
- コンピューターを再起動します。今回は または を選択して通常どおりインストールします。Anaconda はシステム内のディスクを検索すると、既存の RAID デバイスを見つけます。
- システムのディスクの使用方法を尋ねたら、 を選択して 次へ をクリックし 。デバイスリストに、既存の MD RAID デバイスが表示されます。
- RAID デバイスを選択し、 をクリックしてそのマウントポイントと(必要に応じて)使用するファイルシステムのタイプを設定し、完了 をクリックし 。Anaconda は、この既存の RAID デバイスにインストールを実行し、レスキューモード で作成したときに選択したカスタムオプションを保持 します。
第19章 mount コマンドの使用
19.1. 現在マウントされているファイルシステムのリスト表示
$ mountdevice on directory type type (options)
$ findmnt19.1.1. ファイルシステムタイプの指定
sysfs や tmpfs などのさまざまな仮想ファイルシステムが含まれます。特定のファイルシステムタイプを持つデバイスのみを表示するには、-t オプションを指定します。
$ mount -t type$ findmnt -t typeext4 ファイルシステムの一覧表示」 を参照してください。
例19.1 現在マウントされている ext4 ファイルシステムの一覧表示
/ boot パーティションの両方が ext4 を使用するようにフォーマットされます。このファイルシステムを使用するマウントポイントのみを表示するには、以下のコマンドを使用します。
$ mount -t ext4
/dev/sda2 on / type ext4 (rw)
/dev/sda1 on /boot type ext4 (rw)
$ findmnt -t ext4
TARGET SOURCE FSTYPE OPTIONS
/ /dev/sda2 ext4 rw,realtime,seclabel,barrier=1,data=ordered
/boot /dev/sda1 ext4 rw,realtime,seclabel,barrier=1,data=ordered
19.2. ファイルシステムのマウント
$ mount [option…] device directory- ブロックデバイス へのフルパス:
/dev/sda3など - ユニバーサル一意識別子 (UUID):
UUID=34795a28-ca6d-4fd8-a347-73671d0c19cb - ボリュームラベル: たとえば、
LABEL=homeです。
findmnt directory; echo $?1 を返します。
/etc/fstab ファイルの内容を読み取り、指定したファイルシステムがリストにあるかどうかをチェックします。/etc/fstab ファイルには、選択したファイルシステムがマウントされるデバイス名およびディレクトリーの一覧と、ファイルシステムタイプおよびマウントオプションが含まれます。したがって、/etc/fstab で指定されたファイルシステムをマウントする場合は、以下のいずれかのオプションを選択できます。
mount [option…] directory mount [option…] device
root でコマンドを実行しない限り、ファイルシステムのマウントにはパーミッションが必要であることに注意してください( 「マウントオプションの指定」を参照してください)。
blkid device/dev/sda3 に関する情報を表示するには、次のコマンドを実行します。
# blkid /dev/sda3
/dev/sda3: LABEL="home" UUID="34795a28-ca6d-4fd8-a347-73671d0c19cb" TYPE="ext3"
19.2.1. ファイルシステムタイプの指定
NFS (Network File System)や CIFS (Common Internet File System)など、認識されない特定のファイルシステムがあり、手動で指定する必要があります。ファイルシステムのタイプを指定するには、以下の形式で mount コマンドを使用します。
$ mount -t type device directory| 型 | 説明 |
|---|---|
ext2 | ext2 ファイルシステム。 |
ext3 | ext3 ファイルシステム。 |
ext4 | ext4 ファイルシステム。 |
btrfs | btrfs ファイルシステム。 |
xfs | xfs ファイルシステム。 |
iso9660 | ISO 9660 ファイルシステム。通常、これは光学メディア (通常は CD) で使用されます。 |
nfs | NFS ファイルシステム。通常、これはネットワーク経由でファイルにアクセスするために使用されます。 |
nfs4 | NFSv4 ファイルシステム。通常、これはネットワーク経由でファイルにアクセスするために使用されます。 |
udf | UDF ファイルシステム。通常、これは光学メディア (通常は DVD) で使用されます。 |
vfat | FAT ファイルシステム。通常、これは Windows オペレーティングシステムを実行しているマシンや、USB フラッシュドライブやフロッピーディスクなどの特定のデジタルメディアで使用されます。 |
例19.2 USB フラッシドライブのマウント
/dev/sdc1 デバイスを使用し、/media/flashdisk/ ディレクトリーが存在すると仮定して、root で次のコマンドを実行します。
~]# mount -t vfat /dev/sdc1 /media/flashdisk19.2.2. マウントオプションの指定
mount -o options device directory| オプション | 説明 |
|---|---|
async | ファイルシステム上での非同期の入/出力を許可します。 |
auto | mount -a コマンドを使用して、ファイルシステムを自動的にマウントできるようにします。 |
defaults | async,auto,dev,exec,nouser,rw,suid のエイリアスを指定します。 |
exec | 特定のファイルシステムでのバイナリーファイルの実行を許可します。 |
loop | イメージをループデバイスとしてマウントします。 |
noauto | デフォルトの動作では、mount -a コマンドを使用したファイルシステムの自動マウントが禁止されます。 |
noexec | 特定のファイルシステムでのバイナリーファイルの実行は許可しません。 |
nouser | 通常のユーザー( root以外のユーザー)によるファイルシステムのマウントとアンマウントを禁止します。 |
remount | ファイルシステムがすでにマウントされている場合は再度マウントを行います。 |
ro | 読み取り専用でファイルシステムをマウントします。 |
rw | ファイルシステムを読み取りと書き込み両方でマウントします。 |
user | 通常のユーザー(つまり root以外のユーザー)がファイルシステムをマウントおよびアンマウントすることを許可します。 |
例19.3 ISO イメージのマウント
/media/cdrom/ ディレクトリーが存在すると仮定して、次のコマンドを実行してイメージをこのディレクトリーにマウントします。
# mount -o ro,loop Fedora-14-x86_64-Live-Desktop.iso /media/cdrom19.2.3. マウントの共有
--bind オプションを実装します。以下のような使用法になります。
$ mount --bind old_directory new_directory$ mount --rbind old_directory new_directory- 共有マウント
- 共有マウントにより、任意のマウントポイントと同一の複製マウントポイントを作成することができます。マウントポイントが共有マウントとしてマークされている場合は、元のマウントポイント内のすべてのマウントが複製マウントポイントに反映されます (その逆も同様です)。マウントポイントのタイプを共有マウントに変更するには、シェルプロンプトで以下を入力します。
$mount --make-shared mount_pointまたは、選択したマウントポイントとその下のすべてのマウントポイントのマウントタイプを変更する場合は、次のコマンドを実行します。$mount --make-rshared mount_point使用例は、例19.4「共有マウントポイントの作成」 を参照してください。 - スレーブマウント
- スレーブマウントにより、所定のマウントポイントの複製を作成する際に制限を課すことができます。マウントポイントがスレーブマウントとしてマークされている場合は、元のマウントポイント内のすべてのマウントが複製マウントポイントに反映されますが、スレーブマウント内のマウントは元のポイントに反映されません。マウントポイントのタイプをスレーブマウントに変更するには、シェルプロンプトで次を入力します。
mount
--make-slavemount_point選択したマウントポイントとその下にあるすべてのマウントポイントのマウントタイプを変更することも可能です。次のように入力します。mount
--make-rslavemount_point使用例は、例19.5「スレーブマウントポイントの作成」 を参照してください。例19.5 スレーブマウントポイントの作成
この例は、/media/ディレクトリーのコンテンツが/mnt/にも表示される方法を示していますが、/mnt/ディレクトリーのマウントが/media/に反映されません。rootで、最初に/media/ディレクトリーを共有としてマークします。~]# mount --bind /media /media ~]# mount --make-shared /media
次に、その複製を/mnt/で作成します。ただし、"slave" とマークします。~]# mount --bind /media /mnt ~]# mount --make-slave /mnt
/media/内のマウントが/mnt/にも表示されていることを確認します。たとえば、CD-ROM ドライブに空でないメディアが含まれ、/media/cdrom/ディレクトリーが存在する場合は、以下のコマンドを実行します。~]# mount /dev/cdrom /media/cdrom ~]# ls /media/cdrom EFI GPL isolinux LiveOS ~]# ls /mnt/cdrom EFI GPL isolinux LiveOS
また、/mnt/ディレクトリーにマウントされているファイルシステムが/media/に反映されていないことを確認します。たとえば、/dev/sdc1デバイスを使用する空でない USB フラッシュドライブが接続されており、/mnt/flashdisk/ディレクトリーが存在する場合は、以下を入力します。~]# mount /dev/sdc1 /mnt/flashdisk ~]# ls /media/flashdisk ~]# ls /mnt/flashdisk en-US publican.cfg
- プライベートマウント
- プライベートマウントはマウントのデフォルトタイプであり、共有マウントやスレーブマウントと異なり、伝播イベントの受信や転送は一切行いません。マウントポイントを明示的にプライベートマウントにするには、シェルプロンプトで以下を入力します。
mount
--make-privatemount_pointまたは、選択したマウントポイントとその下にあるすべてのマウントポイントを変更することもできます。mount
--make-rprivatemount_point使用例は、例19.6「プライベートマウントポイントの作成」 を参照してください。例19.6 プライベートマウントポイントの作成
例19.4「共有マウントポイントの作成」 のシナリオを考慮に入れて、rootで以下のコマンドを使用して、共有マウントポイントが事前に作成されていると仮定します。~]# mount --bind /media /media ~]# mount --make-shared /media ~]# mount --bind /media /mnt
/mnt/ディレクトリーをプライベートとしてマークするには、以下を入力します。~]# mount --make-private /mnt/media/内のマウントが/mnt/に表示されないことを確認することができるようになりました。たとえば、CD-ROM ドライブに空でないメディアが含まれ、/media/cdrom/ディレクトリーが存在する場合は、以下のコマンドを実行します。~]# mount /dev/cdrom /media/cdrom ~]# ls /media/cdrom EFI GPL isolinux LiveOS ~]# ls /mnt/cdrom ~]#
/mnt/ディレクトリーにマウントされているファイルシステムが/media/に反映されていないことを確認することもできます。たとえば、/dev/sdc1デバイスを使用する空でない USB フラッシュドライブが接続されており、/mnt/flashdisk/ディレクトリーが存在する場合は、以下を入力します。~]# mount /dev/sdc1 /mnt/flashdisk ~]# ls /media/flashdisk ~]# ls /mnt/flashdisk en-US publican.cfg
- バインド不可能なマウント
- 任意のマウントポイントに対して一切複製が行われないようにするには、バインド不能のマウントを使用します。マウントポイントのタイプをバインド不能のマウントに変更するには、次のようにシェルプロンプトに入力します。
mount
--make-unbindablemount_pointまたは、選択したマウントポイントとその下にあるすべてのマウントポイントを変更することもできます。mount
--make-runbindablemount_point使用例は、例19.7「バインド不可能なマウントポイントの作成」 を参照してください。例19.7 バインド不可能なマウントポイントの作成
/media/ディレクトリーが共有されないようにするには、rootとして以下を実行します。#mount --bind /media /media#mount --make-unbindable /mediaこの方法だと、これ以降、このマウントの複製を作成しようとすると、以下のエラーが出て失敗します。#mount --bind /media /mnt mount: wrong fs type, bad option, bad superblock on /media, missing codepage or helper program, or other error In some cases useful info is found in syslog - try dmesg | tail or so
19.2.4. マウントポイントの移動
# mount --move old_directory new_directory例19.8 既存の NFS マウントポイントの移動
/mnt/userdirs/ にマウントされています。root で以下のコマンドを使用して、このマウントポイントを /home に移動します。
# mount --move /mnt/userdirs /home#ls /mnt/userdirs#ls /home jill joe
19.2.5. rootの読み取り専用パーミッションの設定
19.2.5.1. 起動時に読み取り専用パーミッションでマウントする ルート の設定
/etc/sysconfig/readonly-rootファイルで、READONLYをyesに変更します。# Set to 'yes' to mount the file systems as read-only. READONLY=yes [output truncated]/etc/fstabファイルで、ルートエントリー(/)でデフォルトをroに変更します。/dev/mapper/luks-c376919e... / ext4 ro,x-systemd.device-timeout=0 1 1/etc/default/grubファイルのGRUB_CMDLINE_LINUXディレクティブにroを追加し、rwが含まれていないことを確認します。GRUB_CMDLINE_LINUX="crashkernel=auto rd.lvm.lv=rhel/root rd.lvm.lv=rhel/swap rhgb quiet ro"- GRUB2 設定ファイルを再作成します。
#grub2-mkconfig -o /boot/grub2/grub.cfg tmpfsファイルシステムに書き込みパーミッションでマウントするファイルおよびディレクトリーを追加する必要がある場合は、/etc/rwtab.d/ディレクトリーにテキストファイルを作成し、そこに設定を配置します。たとえば、/etc/example/fileを書き込みパーミッションでマウントするには、以下の行を/etc/rwtab.d/ のサンプルファイルに追加します。files /etc/example/file
重要tmpfsのファイルおよびディレクトリーへの変更は、再起動後は維持されません。この手順の詳細は、「書き込みパーミッションを保持するファイルおよびディレクトリー」 を参照してください。- システムを再起動します。
19.2.5.2. root を即座に再マウントする
/)がシステム起動時に読み取り専用権限でマウントされている場合は、書き込み権限で再マウントできます。
# mount -o remount,rw // が読み取り専用パーミッションで誤ってマウントされている場合に特に便利です。
/ を再マウントするには、次のコマンドを実行します。
# mount -o remount,ro // 全体 をマウントします。より良い方法は、「起動時に読み取り専用パーミッションでマウントする ルート の設定」 で説明されているように、特定のファイルとディレクトリーを RAM にコピーして、それらの書き込み権限を保持することです。
19.2.5.3. 書き込みパーミッションを保持するファイルおよびディレクトリー
tmpfs 一時ファイルシステムの RAM にマウントされます。このようなファイルおよびディレクトリーのデフォルトセットは、以下を含む /etc/rwtab ファイルから読み込まれます。
dirs /var/cache/man dirs /var/gdm [output truncated] empty /tmp empty /var/cache/foomatic [output truncated] files /etc/adjtime files /etc/ntp.conf [output truncated]
/etc/rwtab ファイルのエントリーは、以下の形式に従います。
how the file or directory is copied to tmpfs path to the file or directory
tmpfs にコピーすることができます。
空の パス: 空のパスがtmpfsにコピーされます。例:empty /tmpdirs path: ディレクトリーツリーが空の状態でtmpfsにコピーされます。例:dirs /var/runファイル パス: ファイルまたはディレクトリーツリーはそのままtmpfsにコピーされます。例:files /etc/resolv.conf
/etc/rwtab.d/ に追加する場合も同じ形式が適用されます。
19.3. ファイルシステムのアンマウント
$umount directory$umount device
root でログインしているときにこれを実行しない限り、ファイルシステムのマウントを解除するには、正しいパーミッションが利用可能である必要があることに注意してください。詳細は、「マウントオプションの指定」 を参照してください。使用例は、例19.9「CD のアンマウント」 を参照してください。
$fuser-mdirectory
/media/cdrom/ ディレクトリーにマウントされているファイルシステムにアクセスしているプロセスの一覧を表示するには、次のコマンドを実行します。
$ fuser -m /media/cdrom
/media/cdrom: 1793 2013 2022 2435 10532c 10672c
例19.9 CD のアンマウント
/media/cdrom/ ディレクトリーにマウントされていた CD をアンマウントするには、次のコマンドを使用します。
$ umount /media/cdrom19.4. マウント コマンドリファレンス
man ページドキュメント
- man 8 mount: mount コマンドの man ページです。使い方などに関する詳細が記載されています。
- man 8 umount: umount コマンドの man ページです。使い方などに関する詳細が記載されています。
- man 8 findmnt: findmnt コマンドの man ページです。使い方などに関する詳細が記載されています。
- man 5 fstab:
/etc/fstabファイル形式の詳細な説明を示す man ページです。
便利な Web サイト
- 『Shared subtrees』 — 共有サブツリーの概念について解説されている LWN の記事です。
第20章 volume_key 機能
20.1. volume_key コマンド
volume_key [OPTION]... OPERAND- --save
- このコマンドは、オペランドのボリューム [パケット] を想定しています。パケット が提供されている場合、volume_key はそこからキーとパスフレーズを抽出します。packet が指定されていない場合は、volume_key は ボリューム から鍵とパスフレーズを抽出し、必要に応じてユーザーに要求します。この鍵およびパスフレーズは、1 つ以上の出力パケットに格納されます。
- --restore
- このコマンドは、オペランドのボリュームパケットを想定します。次に volume を開き、packet のキーとパスフレーズを使用して volume を再度アクセス可能にし、必要に応じてユーザー (たとえば、ユーザーが新しいパスフレーズの入力を許可するなど) を求めるプロンプトを出します。
- --setup-volume
- このコマンドは、オペランドのボリュームパケット名 を想定しています。次に volume を開き、packet のキーとパスフレーズを使用して、復号されたデータを name として使用するための volume を設定します。Name は、dm-crypt ボリュームの名前です。この操作により、復号化されたボリュームは
/dev/mapper/名として利用可能になります。この動作は、たとえば、新しいパスフレーズを追加しても、ボリューム を永続的に変更することはありません。ユーザーは復号された volume にアクセスし、変更できます。 - --reencrypt、--secrets、および --dump
- この 3 つのコマンドは、出力方法が異なりますが、同様の機能を実行します。それらは、それぞれがオペランド パケット を必要とし、それぞれが パケット を開き、必要に応じて復号化します。--reencrypt は、情報を 1 つ以上の新しい出力パケットに保存します。--secrets は、パケット に含まれるキーとパスフレーズを出力します。--dump は パケット の内容を出力しますが、鍵とパスフレーズはデフォルトでは出力されません。これは、--with-secrets をコマンドに追加することで変更できます。--unencrypted コマンドを使用して、暗号化されていない部分(存在する場合)のみをダンプすることもできます。パスフレーズや秘密鍵のアクセスは必要ありません。
- -o、--output packet
- このコマンドは、デフォルトの鍵またはパスフレーズをパケットに書き込みます。デフォルトの鍵またはパスフレーズは、ボリューム形式によって異なります。有効期限が切れる可能性が低いものであることを確認し、--restore がボリュームへのアクセスを復元できるようにします。
- --output-format format
- このコマンドは、すべての出力パケットに指定された format 形式を使用します。現在、format は以下のいずれかになります。
- 非対称: CMS を使用してパケット全体を暗号化し、証明書を必要とします。
- asymmetric_wrap_secret_only: シークレットまたは鍵とパスフレーズのみをラップし、証明書を必要とします。
- passphrase: GPG を使用してパケット全体を暗号化し、パスフレーズを必要とします。
- --create-random-passphrase packet
- このコマンドは、ランダムな英数字のパスフレーズを生成し、それを ボリューム に追加して (他のパスフレーズに影響を与えることなく)、このランダムなパスフレーズを パケット に格納します。
20.2. volume_key を個別のユーザーとして使用する
/path/to/volume は LUKS デバイスであり、そこに含まれるプレーンテキストデバイスではありません。blkid -s type /path/to/volume should report type="crypto_LUKS".
手順20.1 volume_key スタンドアロンの使用
- 以下を実行します。
volume_key --save次に、キーを保護するために escrow パケットパスフレーズを要求するプロンプトが表示されます。/path/to/volume-o escrow-packet - 生成された
escrow-packetファイルを保存し、パスフレーズを忘れないようにします。
手順20.2 escrow パケットを使用したデータへのアクセスの復元
- volume_key を実行し、escrow パケットが利用できる環境でシステムを起動します(レスキューモードなど)。
- 以下を実行します。
volume_key --restoreescrow パケットの作成時に使用した escrow パケットパスフレーズと、ボリュームの新しいパスフレーズを尋ねるプロンプトが表示されます。/path/to/volumeescrow-packet - 選択したパスフレーズを使用してボリュームをマウントします。
20.3. 大規模な組織での volume_key の使用
20.3.1. 暗号化キーを保存するための準備
手順20.3 準備
- X509 証明書/プライベートペアを作成します。
- 信頼できるユーザーを指定します。このユーザーは、秘密鍵を危険にさらさないという点で信頼されています。このようなユーザーは、escrow パケットを復号化できます。
- escrow パケットの復号に使用するシステムを選択します。このようなシステムでは、秘密鍵を含む NSS データベースを設定します。秘密鍵が NSS データベースで作成されていない場合は、以下の手順を行います。
- 証明書と秘密鍵を
PKCS#12ファイルに保存します。 - 以下を実行します。
certutil -d/the/nss/directory-Nこの時点で、NSS データベースのパスワードを選択できます。各 NSS データベースには異なるパスワードを設定できるため、各ユーザーが個別の NSS データベースを使用する場合に、指定したユーザーは単一のパスワードを共有する必要はありません。 - 以下を実行します。
pk12util -d/the/nss/directory-ithe-pkcs12-file
- システムをインストールしている人、または既存システムに鍵を保存している人に証明書を配布します。
- 保存した秘密鍵については、マシンおよびボリュームから検索できるように、ストレージを準備します。たとえば、マシンごとに 1 つのサブディレクトリーを持つ単純なディレクトリーや、その他のシステム管理タスクに使用されるデータベースなどです。
20.3.2. 暗号化キーの保存
/path/to/volume は LUKS デバイスであり、含まれるプレーンテキストデバイスではありません。blkid -s type /path/to/volume は、タイプ="crypto_LUKS" を報告する必要があります。
手順20.4 暗号化キーの保存
- 以下を実行します。
volume_key --save/path/to/volume-c/path/to/certescrow-packet - 準備したストレージに、生成された
escrow-packetファイルを保存し、システムおよびボリュームと関連付けます。
20.3.3. ボリュームへのアクセスの復元
手順20.5 ボリュームへのアクセスの復元
- パケットストレージからボリュームの escrow パケットを取得し、指定したユーザーのいずれかに送信して復号化します。
- 指定されたユーザーは、以下を実行します。
volume_key --reencrypt -d/the/nss/directoryescrow-packet-in -o escrow-packet-outNSS データベースのパスワードを提供した後、指定されたユーザーは escrow-packet-out を暗号化するパスフレーズを選択します。このパスフレーズは毎回異なるものにでき、指定されたユーザーからターゲットシステムに暗号化キーが移動されている間のみ暗号化キーを保護します。 - 指定されたユーザーから
escrow-packet-outファイルとパスフレーズを取得します。 - レスキューモードなどで volume_key を実行し、
escrow-packet-outファイルを使用できる環境でターゲットシステムを起動します。 - 以下を実行します。
volume_key --restore/path/to/volumeescrow-packet-out指定ユーザーが選択したパケットパスフレーズとボリュームの新しいパスフレーズを求めるプロンプトが表示されます。 - 選択したボリュームパスフレーズを使用してボリュームをマウントします。
20.3.4. 緊急パスフレーズの設定
volume_key --save /path/to/volume -c /path/to/ert --create-random-passphrase passphrase-packetpassphrase-packet に格納します。--create-random-passphrase オプションと -o オプションを組み合わせて両方のパケットを同時に生成することもできます。
volume_key --secrets -d /your/nss/directory passphrase-packet20.4. volume_key リファレンス
/usr/share/doc/volume_key-*/READMEにある readme ファイルで- man volume_key を使用した volume_key の man ページ
第21章 ソリッドステートディスクのデプロイメントガイドライン
- ファイルシステムにはまだ空き領域がある。
- 基盤となるストレージデバイスの論理ブロックのほとんどは、すでに書き込まれている。
/sys/block/sda/queue/discard_granularity を確認します。
デプロイメントに関する考慮事項
- 非決定論的 TRIM
- 確定的 TRIM (DRAT)
- TRIM 後の確定的読み取りゼロ(RZAT)
# hdparm -I /dev/sda | grep TRIM
Data Set Management TRIM supported (limit 8 block)
Deterministic read data after TRIM
discard を正しく処理しない場合、パフォーマンスが低下します。raid456.conf ファイルまたは GRUB2 設定で破棄を設定できます。手順は、以下の手順を参照してください。
手順21.1 raid456.conf で破棄を設定する
devices_handle_discard_safely モジュールパラメーターは raid456 モジュールに設定されます。raid456.conf ファイルで破棄を有効にするには、次のコマンドを実行します。
- ハードウェアが破棄に対応していることを確認します。
#cat /sys/block/disk-name/queue/discard_zeroes_data戻り値が1の場合は、破棄がサポートされます。コマンドが0を返すと、RAID コードはディスクをゼロにする必要があり、これには時間がかかります。 /etc/modprobe.d/raid456.confファイルを作成し、以下の行を追加します。options raid456 devices_handle_discard_safely=Y
- dracut -f コマンドを使用して、初期 ramdisk (
initrd)を再構築します。 - システムを再起動して、変更を有効にします。
手順21.2 GRUB2 設定での破棄の設定
devices_handle_discard_safely モジュールパラメーターは raid456 モジュールに設定されます。GRUB2 設定で破棄を有効にするには、次のコマンドを実行します。
- ハードウェアが破棄に対応していることを確認します。
#cat /sys/block/disk-name/queue/discard_zeroes_data戻り値が1の場合は、破棄がサポートされます。コマンドが0を返すと、RAID コードはディスクをゼロにする必要があり、これには時間がかかります。 /etc/default/grubファイルに以下の行を追加します。raid456.devices_handle_discard_safely=Y
- GRUB2 設定ファイルの場所は、BIOS ファームウェアがインストールされているシステムと、UEFI がインストールされているシステムで異なります。次のいずれかのコマンドを使用して、GRUB2 設定ファイルを再作成します。
- BIOS ファームウェアを使用している場合は、以下のコマンドを使用します。
#grub2-mkconfig -o /boot/grub2/grub.cfg - UEFI ファームウェアを使用している場合は、以下のコマンドを使用します。
#grub2-mkconfig -o /boot/efi/EFI/redhat/grub.cfg
- システムを再起動して、変更を有効にします。
/dev/sda2 を /mnt にマウントするには、次のコマンドを実行します。
# mount -t ext4 -o discard /dev/sda2 /mntパフォーマンスチューニングの考慮事項
第22章 書き込みバリア
22.1. 書き込みバリアの重要性
- ファイルシステムは、トランザクションの本文をストレージデバイスに送信します。
- ファイルシステムは、コミットブロックを送信します。
- トランザクションとそれに対応するコミットブロックがディスクに書き込まれる場合、ファイルシステムは、トランザクションが電源障害に耐えられると想定します。
書き込みバリアのしくみ
- ディスクに、すべてのデータが含まれている。
- 順序の並べ替えは発生していません。
22.2. 書き込みバリアの有効化と無効化
/var/log/messages にエラーメッセージを記録します。詳細は、表22.1「ファイルシステムごとにバリアエラーメッセージを書き込む」 を参照してください。
| ファイルシステム | エラーメッセージ |
|---|---|
| ext3/ext4 | JBD: barrier-based sync failed on device - disabling barriers |
| XFS | Filesystem device - Disabling barriers, trial barrier write failed |
| btrfs | btrfs: disabling barriers on dev device |
22.3. 書き込みバリアに関する考慮事項
書き込みキャッシュの無効化
# hdparm -W0 /device/バッテリーでバックアップされる書き込みキャッシュ
# MegaCli64 -LDGetProp -DskCache -LAll -aALL# MegaCli64 -LDSetProp -DisDskCache -Lall -aALLハイエンドアレイ
NFS
第23章 ストレージ I/O アライメントとサイズ
23.1. ストレージアクセスパラメーター
- physical_block_size
- デバイスが動作できる最小の内部ユニット
- logical_block_size
- デバイス上の場所指定に外部で使用される
- alignment_offset
- 基礎となる物理的なアライメントのオフセットとなる Linux ブロックデバイス (パーティション/MD/LVM デバイス) の先頭部分のバイト数
- minimum_io_size
- ランダムな I/O に対して推奨のデバイス最小ユニット
- optimal_io_size
- I/O ストリーミングで推奨されるデバイスのユニット
23.2. ユーザー空間アクセス
libblkid-devel パッケージで提供されます。
sysfs インターフェイス
- /sys/block/
disk/alignment_offsetまたは/sys/block/disk/partition/alignment_offset注記ファイルの場所は、ディスクが物理ディスク (ローカルディスク、ローカル RAID、またはマルチパス LUN) か、仮想ディスクかによって異なります。最初のファイルの場所は物理ディスクに適用され、2 番目のファイルの場所は仮想ディスクに適用されます。これは、virtio-blk がパーティションのアラインメント値を常に報告するためです。物理ディスクは、アライメント値を報告する場合と報告しない場合があります。 - /sys/block/
disk/queue/physical_block_size - /sys/block/
disk/queue/logical_block_size - /sys/block/
disk/queue/minimum_io_size - /sys/block/
disk/queue/optimal_io_size
例23.1 sysfs インターフェイス
alignment_offset: 0 physical_block_size: 512 logical_block_size: 512 minimum_io_size: 512 optimal_io_size: 0
ブロックデバイス ioctls
- BLKALIGNOFF:
alignment_offset - BLKPBSZGET:
physical_block_size - BLKSSZGET:
logical_block_size - BLKIOMIN:
minimum_io_size - BLKIOOPT:
optimal_io_size
23.3. I/O 規格
ATA
SCSI
BLOCK LIMITS VPD ページへのアクセスを取得)と READ CAPACITY (16) コマンドのみを送信します。
LOGICAL BLOCK LENGTH IN BYTESは、/sys/block/ディスク/queue/physical_block_sizeの導出に使用されます。LOGICAL BLOCKS PER PHYSICAL BLOCK EXPONENTは、/sys/block/ディスク/queue/logical_block_sizeの導出に使用されます。LOWEST ALIGNED LOGICAL BLOCK ADDRESS は、以下を取得するために使用されます。/sys/block/disk/alignment_offset/sys/block/disk/partition/alignment_offset
BLOCK LIMITS VPD ページ(0xb0)は、I/O ヒントを提供します。また、OPTIMAL TRANSFER LENGTH GRANULARITY および OPTIMAL TRANSFER LENGTH を使用して以下を取得します。
/sys/block/disk/queue/minimum_io_size/sys/block/disk/queue/optimal_io_size
sg3_utils パッケージは、BLOCK LIMITS VPD ページにアクセスするために使用できる sg_inq ユーティリティーを提供します。そのためには、以下のコマンドを実行します。
# sg_inq -p 0xb0 disk23.4. I/O パラメーターのスタッキング
- I/O スタックの 1 つのレイヤーのみがゼロ以外の alignment_offset について調整する必要があります。レイヤーがそれに応じて調整されると、alignment_offset がゼロのデバイスがエクスポートされます。
- LVM で作成されたストライプ化デバイスマッパー(DM)デバイスは、ストライプ数(ディスク数)とユーザー提供のチャンクサイズを基準にして minimum_io_size と optimal_io_size をエクスポートする必要があります。
23.5. 論理ボリュームマネージャー
/etc/lvm/lvm.conf で data_alignment_offset_detection を 0 に設定すると、この動作を無効にできます。これを無効にすることは推奨されません。
/etc/lvm/lvm.conf で data_alignment_detection を 0 に設定すると、この動作を無効にできます。これを無効にすることは推奨されません。
23.6. パーティションおよびファイルシステムツール
util-linux-ng の libblkid と fdisk
util-linux-ng パッケージで提供される libblkid ライブラリーには、デバイスの I/O パラメーターにアクセスするためのプログラム API が含まれています。libblkid を使用すると、アプリケーション、特に Direct I/O を使用するアプリケーションが、I/O 要求のサイズを適切に調整できます。util-linux-ng の fdisk ユーティリティーは、libblkid を使用して、すべてのパーティションの配置を最適化するためにデバイスの I/O パラメーターを決定します。fdisk ユーティリティーは、すべてのパーティションを 1MB の境界に合わせます。
parted と libparted
libparted ライブラリーは、libblkid の I/O パラメーター API も使用します。Red Hat Enterprise Linux 7 インストーラーである Anaconda は libparted を使用します。つまり、インストーラーまたは parted のいずれかで作成されたすべてのパーティションが適切に調整されます。I/O パラメーターを提供していないように見えるデバイスで作成されたすべてのパーティションの場合、デフォルトの調整は 1MB になります。
- 報告された alignment_offset は、常に最初のプライマリーパーティションの開始オフセットとして使用します。
- optimal_io_size が定義されている場合( 0ではない)は、すべてのパーティションを optimal_io_size 境界に合わせます。
- optimal_io_size が定義されていない場合( 0など)、alignment_offset は 0 で、minimum_io_size は 2 の累乗で、1MB のデフォルトアライメントを使用します。これは、I/O ヒントを提供していないように見えるレガシーデバイスのキャッチオールです。このため、デフォルトでは、すべてのパーティションは 1MB の境界にアライメントされます。注記Red Hat Enterprise Linux 7 は、I/O ヒントを提供しないデバイスと、alignment_offset=0 および optimal_io_ size=0 でこれを行うデバイスを区別できません。このようなデバイスは、SAS 4K デバイスが 1 つだけの場合があります。そのため、最悪の場合はディスクの起動時に 1MB の領域が失われます。
ファイルシステムツール
第24章 リモートディスクレスシステムの設定
tftp-serverxinetddhcpsyslinuxdracut-network注記dracut-networkパッケージをインストールしたら、以下の行を/etc/dracut.confに追加します。add_dracutmodules+="nfs"
tftp-serverにより提供)と DHCP サービス( dhcpにより提供)の両方が必要です。tftp サービスは、PXE ローダーを介してネットワーク経由でカーネルイメージと initrd を取得するために使用されます。
/etc/sysconfig/nfs で NFS を明示的に有効にする必要があります。
/var/lib/tftpboot/pxelinux.cfg/default で、root=nfs:server-ip:/exported/root/directory を root=nfs:server-ip:/exported/root/directory,vers=4.2 に変更します。
24.1. ディスクレスクライアントの tftp サービスの設定
前提条件
- 必要なパッケージをインストールしている。24章リモートディスクレスシステムの設定 を参照してください。
手順
手順24.1 tftpを設定するには、以下を実行します。
- ネットワーク上での PXE ブートを有効にします。
#systemctl enable --now tftp - tftp root ディレクトリー(chroot)は、
/var/lib/tftpbootにあります。/usr/share/syslinux/pxelinux.0を/var/lib/tftpboot/にコピーします。#cp /usr/share/syslinux/pxelinux.0 /var/lib/tftpboot/ - tftp の root ディレクトリーに
pxelinux.cfgディレクトリーを作成します。#mkdir -p /var/lib/tftpboot/pxelinux.cfg/ - tftp トラフィックを許可するようにファイアウォールルールを設定します。tftp は TCP ラッパーに対応しているため、
/etc/hosts.allow設定ファイルで tftp へのホストアクセスを設定できます。TCP ラッパーおよび/etc/hosts.allow設定ファイルの設定に関する詳細は、Red Hat Enterprise Linux 7 セキュリティーガイド を参照してください。hosts_access(5) は、/etc/hosts.allowに関する情報も提供します。
次のステップ
24.2. ディスクレスクライアント用の DHCP の設定
前提条件
- 必要なパッケージをインストールしている。24章リモートディスクレスシステムの設定 を参照してください。
tftpサービスを設定します。「ディスクレスクライアントの tftp サービスの設定」 を参照してください。
手順
- tftp サーバーの設定後に、同じホストマシンに DHCP サービスを設定する必要があります。DHCP サーバーの設定手順は、Configuring a DHCP Server を参照してください。
/etc/dhcp/dhcpd.confに以下の設定を追加して、DHCP サーバーで PXE ブートを有効にします。allow booting; allow bootp; class "pxeclients" { match if substring(option vendor-class-identifier, 0, 9) = "PXEClient"; next-server server-ip; filename "pxelinux.0"; }server-ipを、tftp サービスと DHCP サービスが置かれているホストマシンの IP アドレスに置き換えます。
注記libvirt 仮想マシンをディスクレスクライアントとして使用する場合、libvirt は DHCP サービスを提供し、スタンドアロン DHCP サーバーは使用されません。このような場合、libvirt ネットワーク設定の bootp file='filename' オプションを使用して、ネットワークブートを有効にする必要があります( virsh net-edit )。
次のステップ
24.3. ディスクレスクライアントのエクスポートしたファイルシステムの設定
前提条件
- 必要なパッケージをインストールしている。24章リモートディスクレスシステムの設定 を参照してください。
tftpサービスを設定します。「ディスクレスクライアントの tftp サービスの設定」 を参照してください。- DHCP を設定している。「ディスクレスクライアント用の DHCP の設定」 を参照してください。
手順
- エクスポートしたファイルシステムのルートディレクトリー (ネットワーク上のディスクレスクライアントが使用) は、NFS 経由で共有されます。root ディレクトリーを
/etc/exportsに追加して、root ディレクトリーをエクスポートするように NFS サービスを設定します。手順は、「/etc/exports設定ファイル」を参照してください。 - ディスクレスクライアントに完全に対応できるようにするには、root ディレクトリーには Red Hat Enterprise Linux の完全なインストールが含まれている必要があります。既存のインストールのクローンを作成するか、新しいベースシステムをインストールできます。
- 実行中のシステムと同期するには、
rsyncユーティリティーを使用します。#rsync -a -e ssh --exclude='/proc/*' --exclude='/sys/*' \ hostname.com:/exported-root-directory- hostname.com を、
rsyncを介して同期する実行中のシステムのホスト名に置き換えます。 - exported-root-directory を、エクスポートしたファイルシステムへのパスに置き換えます。
- Red Hat Enterprise Linux をエクスポートした場所にインストールするには、
--installrootオプションを指定してyumユーティリティーを使用します。#yum install @Base kernel dracut-network nfs-utils \ --installroot=exported-root-directory --releasever=/
手順24.2 ファイルシステムの設定
- ディスクレスクライアントが使用するカーネル(
vmlinuz-kernel-version)を選択し、tftp ブートディレクトリーにコピーします。#cp /boot/vmlinuz-kernel-version /var/lib/tftpboot/ - NFS サポートで
initrd(initramfs-kernel-version.img)を作成します。#dracut --add nfs initramfs-kernel-version.img kernel-version - 次のコマンドを使用して、initrd のファイル権限を 644 に変更します。
#chmod 644 initramfs-kernel-version.img警告initrd のファイルパーミッションが変更されないと、pxelinux.0 ブートローダーが file not found エラーで失敗します。 - 作成された
initramfs-kernel-version.imgを tftp ブートディレクトリーにもコピーします。 /var/lib/tftpboot/ディレクトリーでinitrdおよびカーネルを使用するようにデフォルトのブート設定を編集します。この設定は、エクスポートしたファイルシステム(/exported/root/directory)を読み書きとしてマウントするようにディスクレスクライアントの root に指示する必要があります。/var/lib/tftpboot/pxelinux.cfg/defaultファイルに以下の設定を追加します。default rhel7 label rhel7 kernel vmlinuz-kernel-version append initrd=initramfs-kernel-version.img root=nfs:server-ip:/exported/root/directory rw
server-ipを、tftp サービスと DHCP サービスが置かれているホストマシンの IP アドレスに置き換えます。
第25章 オンラインストレージ管理
/usr/share/doc/kernel-doc-version/Documentation/sysfs-rules.txt を参照してください。
25.1. ターゲットの設定
#systemctl start target#systemctl enable target
25.1.1. targetcli のインストールおよび実行
# yum install targetcliターゲット サービスを起動します。
# systemctl start targetターゲット が開始するように設定します。
# systemctl enable target3260 を開き、ファイアウォール設定を再読み込みします。
#firewall-cmd --permanent --add-port=3260/tcp Success#firewall-cmd --reload Success
# targetcli
:
/> ls
o- /........................................[...]
o- backstores.............................[...]
| o- block.................[Storage Objects: 0]
| o- fileio................[Storage Objects: 0]
| o- pscsi.................[Storage Objects: 0]
| o- ramdisk...............[Storage Ojbects: 0]
o- iscsi...........................[Targets: 0]
o- loopback........................[Targets: 0]
25.1.2. バックストアの作成
- FILEIO (Linux ファイルバッキングストレージ)
- FILEIO ストレージオブジェクトは、write_back 操作または write_thru 操作のいずれかをサポートできます。write_back は、ローカルファイルシステムキャッシュを有効にします。これにより、パフォーマンスが向上しますが、データの損失のリスクが高まります。write_thru を優先して write_back を無効にするには、write_back=false を使用することが推奨されます。fileio ストレージオブジェクトを作成するには、/backstores/fileio create file_name file_location file_size write_back=false コマンドを実行します。以下に例を示します。
/> /backstores/fileio create file1 /tmp/disk1.img 200M write_back=false Created fileio file1 with size 209715200
- BLOCK (Linux BLOCK デバイス)
- ブロックドライバーを使用すると、
/sys/blockに表示されるブロックデバイスを LIO で使用できます。これには物理デバイス (HDD、SSD、CD、DVD など) および論理デバイス (ソフトウェアまたはハードウェアの RAID ボリューム、LVM ボリュームなど) が含まれます。注記BLOCK バックストアは通常、最高のパフォーマンスを提供します。任意のブロックデバイスを使用して BLOCK バックストアを作成する場合は、以下のコマンドを使用します。#fdisk/dev/vdbWelcome to fdisk (util-linux 2.23.2). Changes will remain in memory only, until you decide to write them. Be careful before using the write command. Device does not contain a recognized partition table Building a new DOS disklabel with disk identifier 0x39dc48fb. Command (m for help): n Partition type: p primary (0 primary, 0 extended, 4 free) e extended Select (default p): *Enter* Using default response p Partition number (1-4, default 1): *Enter* First sector (2048-2097151, default 2048): *Enter* Using default value 2048 Last sector, +sectors or +size{K,M,G} (2048-2097151, default 2097151): +250M Partition 1 of type Linux and of size 250 MiB is set Command (m for help): w The partition table has been altered! Calling ioctl() to re-read partition table. Syncing disks./> /backstores/block create name=block_backend dev=/dev/vdb Generating a wwn serial. Created block storage object block_backend using /dev/vdb.
注記論理ボリューム上に BLOCK バックストアを作成することもできます。 - PSCSI (Linux パススルー SCSI デバイス)
- SCSI エミュレーションなしで SCSI コマンドの直接パススルーをサポートするストレージオブジェクト、および
/proc/scsi/scsi(SAS ハードドライブなど)の lsscsi とともに表示される基礎となる SCSI デバイスを持つストレージオブジェクトは、バックストアとして設定できます。このサブシステムでは、SCSI-3 以降に対応しています。警告PSCSI は、上級ユーザーのみが使用してください。非対称論理ユニット割り当て (ALUA) や永続予約 (VMware ESX や vSphere で使用される永続予約など) は、通常はデバイスのファームウェアに実装されず、誤作動やクラッシュが発生する原因となることがあります。疑わしい場合は、代わりに BLOCK を使用して実稼働環境のセットアップを行います。物理 SCSI デバイス(この例では/dev/sr0を使用する TYPE_ROM デバイス)用の PSCSI バックストアを作成するには、次のコマンドを実行します。/> backstores/pscsi/ create name=pscsi_backend dev=/dev/sr0 Generating a wwn serial. Created pscsi storage object pscsi_backend using /dev/sr0
- メモリーコピー RAM ディスク (Linux RAMDISK_MCP)
- メモリーコピー RAM ディスク(ramdisk)は、完全な SCSI エミュレーションと、イニシエーターのメモリーコピーを使用した個別のメモリーマッピングを持つ RAM ディスクを提供します。これにより、マルチセッションの機能を利用できます。これは、特に実稼働環境での高速で不揮発性の大容量ストレージで有用です。1GB の RAM ディスクバックストアを作成するには、次のコマンドを使用します。
/> backstores/ramdisk/ create name=rd_backend size=1GB Generating a wwn serial. Created rd_mcp ramdisk rd_backend with size 1GB.
25.1.3. iSCSI ターゲットの作成
手順25.1 iSCSI ターゲットの作成
- targetcli を実行します。
- iSCSI 設定パスに移動します。
/> iscsi/
注記cd コマンドは、ディレクトリーの変更も許可され、移動先のパスを一覧表示するだけです。 - デフォルトのターゲット名を使用して iSCSI ターゲットを作成します。
/iscsi> create Created target iqn.2003-01.org.linux-iscsi.hostname.x8664:sn.78b473f296ff Created TPG1
または、指定した名前を使用して iSCSI ターゲットを作成します。/iscsi > create iqn.2006-04.com.example:444 Created target iqn.2006-04.com.example:444 Created TPG1
- ls を使用してターゲットが一覧表示されるときに、新しく作成されたターゲットが表示されていることを確認します。
/iscsi > ls o- iscsi.......................................[1 Target] o- iqn.2006-04.com.example:444................[1 TPG] o- tpg1...........................[enabled, auth] o- acls...............................[0 ACL] o- luns...............................[0 LUN] o- portals.........................[0 Portal]
25.1.4. iSCSI ポータルの設定
手順25.2 iSCSI ポータルの作成
- TPG に移動します。
/iscsi> iqn.2006-04.example:444/tpg1/
- ポータルを作成する方法は、デフォルトのポータルを作成する方法と、リッスンする IP アドレスを指定するポータルを作成する方法の 2 つがあります。デフォルトのポータルを作成すると、デフォルトの iSCSI ポート 3260 が使用され、ターゲットがそのポートのすべての IP アドレスをリッスンできるようになります。
/iscsi/iqn.20...mple:444/tpg1> portals/ create Using default IP port 3260 Binding to INADDR_Any (0.0.0.0) Created network portal 0.0.0.0:3260
リッスンする IP アドレスを指定するポータルを作成するには、次のコマンドを使用します。/iscsi/iqn.20...mple:444/tpg1> portals/ create 192.168.122.137 Using default IP port 3260 Created network portal 192.168.122.137:3260
- 新しく作成したポータルが ls コマンドで表示されていることを確認します。
/iscsi/iqn.20...mple:444/tpg1> ls o- tpg.................................. [enambled, auth] o- acls ......................................[0 ACL] o- luns ......................................[0 LUN] o- portals ................................[1 Portal] o- 192.168.122.137:3260......................[OK]
25.1.5. LUN の設定
手順25.3 LUN の設定
- 作成したストレージオブジェクトの LUN を作成します。
/iscsi/iqn.20...mple:444/tpg1> luns/ create /backstores/ramdisk/rd_backend Created LUN 0. /iscsi/iqn.20...mple:444/tpg1> luns/ create /backstores/block/block_backend Created LUN 1. /iscsi/iqn.20...mple:444/tpg1> luns/ create /backstores/fileio/file1 Created LUN 2.
- 変更を表示します。
/iscsi/iqn.20...mple:444/tpg1> ls o- tpg.................................. [enambled, auth] o- acls ......................................[0 ACL] o- luns .....................................[3 LUNs] | o- lun0.........................[ramdisk/ramdisk1] | o- lun1.................[block/block1 (/dev/vdb1)] | o- lun2...................[fileio/file1 (/foo.img)] o- portals ................................[1 Portal] o- 192.168.122.137:3260......................[OK]
注記デフォルトの LUN 名は 0 で始まります。これは、Red Hat Enterprise Linux 6 で tgtd を使用する場合にあった 1 とは対照的です。 - ACL を設定します。詳細は、「ACL の設定」 を参照してください。
手順25.4 読み取り専用 LUN の作成
- 読み取り専用権限で LUN を作成するには、最初に次のコマンドを使用します。
/> set global auto_add_mapped_luns=false Parameter auto_add_mapped_luns is now 'false'.
これにより、LUN が既存の ACL へ自動的にマッピングされないようになり、LUN を手動でマッピングできるようになります。 - 次に、iscsi/target_iqn_name/tpg1/acls/initiator_iqn_name/ create mapped_lun=next_sequential_LUN_number tpg_lun_or_backstore=backstore write_protect=1 コマンドを使用して、LUN を手動で作成します。
/> iscsi/iqn.2015-06.com.redhat:target/tpg1/acls/iqn.2015-06.com.redhat:initiator/ create mapped_lun=1 tpg_lun_or_backstore=/backstores/block/block2 write_protect=1 Created LUN 1. Created Mapped LUN 1. /> ls o- / ...................................................... [...] o- backstores ........................................... [...] <snip> o- iscsi ......................................... [Targets: 1] | o- iqn.2015-06.com.redhat:target .................. [TPGs: 1] | o- tpg1 ............................ [no-gen-acls, no-auth] | o- acls ....................................... [ACLs: 2] | | o- iqn.2015-06.com.redhat:initiator .. [Mapped LUNs: 2] | | | o- mapped_lun0 .............. [lun0 block/disk1 (rw)] | | | o- mapped_lun1 .............. [lun1 block/disk2 (ro)] | o- luns ....................................... [LUNs: 2] | | o- lun0 ...................... [block/disk1 (/dev/vdb)] | | o- lun1 ...................... [block/disk2 (/dev/vdc)] <snip>
(mapped_lun0 の (rw) とは異なり) mapped_lun1 行の最後に (ro) が表示されますが、これは、読み取り専用であることを表しています。 - ACL を設定します。詳細は、「ACL の設定」 を参照してください。
25.1.6. ACL の設定
/etc/iscsi/initiatorname.iscsi にあります。
手順25.5 ACL の設定
- acls ディレクトリーに移動します。
/iscsi/iqn.20...mple:444/tpg1> acls/
- ACL を作成します。イニシエーターの
/etc/iscsi/initiatorname.iscsiにあるイニシエーター名を使用するか、覚えやすい名前を使用する場合は、「iSCSI イニシエーターの作成」 を参照して、ACL がイニシエーターと一致するようにします。以下に例を示します。/iscsi/iqn.20...444/tpg1/acls> create iqn.2006-04.com.example.foo:888 Created Node ACL for iqn.2006-04.com.example.foo:888 Created mapped LUN 2. Created mapped LUN 1. Created mapped LUN 0.
注記指定した例の動作は、使用される設定によって異なります。この場合、グローバル設定 auto_add_mapped_luns が使用されます。これにより、作成された ACL に LUN が自動的にマッピングされます。ターゲットサーバーの TPG ノードに、ユーザーが作成した ACL を設定します。/iscsi/iqn.20...scsi:444/tpg1>set attribute generate_node_acls=1 - 変更を表示します。
/iscsi/iqn.20...444/tpg1/acls> ls o- acls .................................................[1 ACL] o- iqn.2006-04.com.example.foo:888 ....[3 Mapped LUNs, auth] o- mapped_lun0 .............[lun0 ramdisk/ramdisk1 (rw)] o- mapped_lun1 .................[lun1 block/block1 (rw)] o- mapped_lun2 .................[lun2 fileio/file1 (rw)]
25.1.7. ファイバーチャネルオーバーイーサネット (FCoE) ターゲットの設定
手順25.6 FCoE ターゲットの設定
- FCoE ターゲットを設定するには、
targetcliパッケージとその依存関係をインストールする必要があります。targetcli の基本および設定に関する詳細は、「ターゲットの設定」 を参照してください。 - FCoE インターフェイスに FCoE ターゲットインスタンスを作成します。
/> tcm_fc/ create 00:11:22:33:44:55:66:77FCoE インターフェイスがシステムに存在する場合は、create の後にタブ補完を実行すると、利用可能なインターフェイスが一覧表示されます。そうでない場合は、fcoeadm -iが有効なインターフェイスを表示していることを確認します。 - バックストアをターゲットインスタンスにマッピングします。
例25.1 ターゲットインスタンスへのバックストアのマッピングの例
/> tcm_fc/00:11:22:33:44:55:66:77/> luns/ create /backstores/fileio/example2 - FCoE イニシエーターから LUN へのアクセスを許可します。
/> acls/ create 00:99:88:77:66:55:44:33これにより、そのイニシエーターが LUN にアクセスできるようになります。 - 再起動後も変更を永続化するには、saveconfig コマンドを使用し、プロンプトが表示されたら yes と入力します。これを行わないと、システムの再起動後に設定が失われます。
- exit を入力するか、または ctrl+D を入力して targetcli を終了します。
25.1.8. targetcliを使用したオブジェクトの削除
/> /backstores/backstore-type/backstore-name
/> /iscsi/iqn-name/tpg/acls/ delete iqn-name
/> /iscsi delete iqn-name
25.1.9. targetcli リファレンス
- man targetcli
- man ページの targetcliこれには、サンプルウォークスルーが含まれます。
- Linux SCSI ターゲット Wiki
- Andy Grover によるスクリーンキャスト
- 注記これは、2012 年 2 月 28 日にアップロードされました。そのため、サービス名が targetcli から ターゲット に変更されました。
25.2. iSCSI イニシエーターの作成
手順25.7 iSCSI イニシエーターの作成
- iscsi-initiator-utils をインストールします。
#yum install iscsi-initiator-utils -y - 「ACL の設定」 で ACL にカスタム名が指定されている場合は、それに応じて
/etc/iscsi/initiatorname.iscsiファイルを変更します。以下に例を示します。#cat /etc/iscsi/initiatorname.iscsi InitiatorName=iqn.2006-04.com.example.node1#vi /etc/iscsi/initiatorname.iscsi - ターゲットを検出します。
#iscsiadm -m discovery -t st -p target-ip-address 10.64.24.179:3260,1 iqn.2006-04.com.example:3260 - 手順 3 で検出したターゲット IQN でターゲットにログインします。
#iscsiadm -m node -T iqn.2006-04.com.example:3260 -l Logging in to [iface: default, target: iqn.2006-04.com.example:3260, portal: 10.64.24.179,3260] (multiple) Login to [iface: default, target: iqn.2006-04.com.example:3260, portal: 10.64.24.179,3260] successful.この手順は、「ACL の設定」 で説明するように。特定のイニシエーター名が ACL に追加されている限り、同じ LUN に接続されている任意の数のイニシエーターが使用することができます。 - iSCSI ディスク名を確認して、この iSCSI ディスクにファイルシステムを作成します。
#grep "Attached SCSI" /var/log/messages#mkfs.ext4/dev/disk_namedisk_name を、/var/log/messagesに表示される iSCSI ディスク名に置き換えます。 - ファイルシステムをマウントします。
#mkdir /mount/point#mount/dev/disk_name/mount/point/mount/point をパーティションのマウントポイントに置き換えます。 - システムの起動時にファイルシステムを自動的にマウントするように
/etc/fstabを編集します。#vim /etc/fstab/dev/disk_name/mount/point ext4 _netdev 0 0disk_name を iSCSI ディスク名に置き換えます。 - ターゲットからログオフします。
#iscsiadm -m node -T iqn.2006-04.com.example:3260 -u
25.3. チャレンジハンドシェイク認証プロトコルの設定
手順25.8 ターゲットの CHAP の設定
- 属性認証を設定します。
/iscsi/iqn.20...mple:444/tpg1>set attribute authentication=1 Parameter authentication is now '1'. - ユーザー ID とパスワードを設定します。
/iscsi/iqn.20...mple:444/tpg1>set auth userid=redhat Parameter userid is now 'redhat'./iscsi/iqn.20...mple:444/tpg1>set auth password=redhat_passwd Parameter password is now 'redhat_passwd'.
手順25.9 イニシエーターの CHAP の設定
iscsid.confファイルを編集します。iscsid.confファイルで CHAP 認証を有効にします。#vi /etc/iscsi/iscsid.conf node.session.auth.authmethod = CHAPデフォルトでは、node.session.auth.authmethod オプションは None に設定されています。- ターゲットのユーザー名とパスワードを
iscsid.confファイルに追加します。node.session.auth.username = redhat node.session.auth.password = redhat_passwd
- iscsid サービスを再起動します。
#systemctl restart iscsid.service
25.4. ファイバーチャネル
25.4.1. ファイバーチャネル API
/sys/class/ ディレクトリーの一覧です。各項目では、ホスト番号は H、バス番号は B、ターゲットは T、論理ユニット番号(LUN)は L、リモートポート番号は R です。
- トランスポート:
/sys/class/fc_transport/targetH:B:T/ port_id- 24 ビットポート ID/アドレスnode_name- 64 ビットノード名port_name- 64 ビットポート名
- リモートポート:
/sys/class/fc_remote_ports/rport-H:B-R/ port_idnode_nameport_namedev_loss_tmo: scsi デバイスがシステムから削除されるタイミングを制御します。dev_loss_tmoがトリガーされると、scsi デバイスが削除されます。multipath.confでは、dev_loss_tmoをinfinityに設定できます。この値は 2,147,483,647 秒、または 68 年に設定し、dev_loss_tmoの最大値です。Red Hat Enterprise Linux 7 では、fast_io_fail_tmoオプションを設定しないと、dev_loss_tmoは 600 秒に制限されます。デフォルトでは、multipathdサービスが実行している場合は、Red Hat Enterprise Linux 7 でfast_io_fail_tmoが 5 秒に設定されています。それ以外の場合は、offに設定されます。fast_io_fail_tmo: リンクに bad のマークを付けるまで待機する秒数を指定します。リンクに bad のマークが付けられると、対応するパス上の既存の実行中の I/O または新しい I/O が失敗します。I/O がブロックされたキューにある場合、dev_loss_tmoの期限が切れ、キューがブロックが解除されるまで失敗しません。fast_io_fail_tmoをoff以外の値に設定すると、dev_loss_tmoはカプセル化されません。fast_io_fail_tmoをoffに設定すると、システムからデバイスが削除されるまで I/O は失敗します。fast_io_fail_tmoを数値に設定すると、fast_io_fail_tmoタイムアウトがトリガーされると、I/O はすぐに失敗します。
- Host:
/sys/class/fc_host/hostH/ port_idissue_lip: リモートポートを再検出するようにドライバーに指示します。
25.4.2. ネイティブファイバーチャネルのドライバーおよび機能
lpfcqla2xxxzfcpbfa
qlini_mode モジュールパラメーターでファイバーチャネルターゲットモードを有効にします。
/usr/lib/modprobe.d/qla2xxx.conf qla2xxx モジュール設定ファイルに追加します。
options qla2xxx qlini_mode=disabled
initrd)を再構築し、システムを再起動して変更を有効にします。
| lpfc | qla2xxx | zfcp | bfa | |
|---|---|---|---|---|
Transport port_id | X | X | X | X |
Transport node_name | X | X | X | X |
Transport port_name | X | X | X | X |
リモートポートの dev_loss_tmo | X | X | X | X |
リモートポート fast_io_fail_tmo | X | X [a] | X [b] | X |
host port_id | X | X | X | X |
Host issue_lip | X | X | X | |
[a]
Red Hat Enterprise Linux 5.4 以降でサポート
[b]
Red Hat Enterprise Linux 6.0 以降でサポート
| ||||
25.5. ファイバーチャネルオーバーイーサネットインターフェイスの設定
fcoe-utilslldpad
手順25.10 FCoE を使用するためにイーサネットインターフェイスの設定
- 新しい VLAN を設定するには、既存のネットワークスクリプト(例:
/etc/fcoe/cfg-eth0)のコピーを作成し、名前を FCoE をサポートするイーサネットデバイスに変更します。これにより、設定するデフォルトファイルが提供されます。FCoE デバイスが ethX の場合は、次のコマンドを実行します。# cp /etc/fcoe/cfg-ethx /etc/fcoe/cfg-ethX
必要に応じてcfg-ethXの内容を変更します。特に、ハードウェアデータセンターブリッジ交換 Exchange (DCBX)プロトコルクライアントを実装するネットワークインターフェイスの場合は、DCB_REQUIREDをnoに設定します。 - システムの起動時にデバイスを自動的にロードする場合は、対応する
/etc/sysconfig/network-scripts/ifcfg-ethXファイルでONBOOT=yesを設定します。たとえば、FCoE デバイスが eth2 の場合は、それに応じて/etc/sysconfig/network-scripts/ifcfg-eth2を編集します。 - 以下を実行して、データセンターのブリッジングデーモン(dcbd)を起動します。
# systemctl start lldpad
- ハードウェア DCBX クライアントを実装するネットワークインターフェイスの場合は、この手順を省略してください。ソフトウェア DCBX クライアントを必要とするインターフェイスの場合は、以下のコマンドを実行して、イーサネットインターフェイスでデータセンターブリッジングを有効にします。
# dcbtool sc ethX dcb on
次に、以下を実行して、イーサネットインターフェイスで FCoE を有効にします。# dcbtool sc ethX app:fcoe e:1
このコマンドは、イーサネットインターフェイスの dcbd 設定が変更されていない場合にのみ機能することに注意してください。 - 現在使用している FCoE デバイスを読み込みます。
# ip link set dev ethX up
- 以下を使用して FCoE を起動します。
# systemctl start fcoe
ファブリック上のその他の設定がすべて正しくなると、FCoE デバイスがすぐに表示されます。設定した FCoE デバイスを表示するには、次のコマンドを実行します。# fcoeadm -i
lldpad サービスを設定することを推奨します。これを行うには、systemctl ユーティリティーを使用します。
# systemctl enable lldpad
# systemctl enable fcoe25.6. システムの起動時に FCoE インターフェイスを自動マウントする設定
/usr/share/doc/fcoe-utils-バージョン/README で入手できます。マイナーリリース全体で考えられる変更については、そのドキュメントを参照してください。
/lib/systemd/system/fcoe.service です。
例25.2 FCoE マウントコード
/etc/fstab のワイルドカードで指定されたファイルシステムをマウントするための FCoE マウントコードの例です。
mount_fcoe_disks_from_fstab()
{
local timeout=20
local done=1
local fcoe_disks=($(egrep 'by-path\/fc-.*_netdev' /etc/fstab | cut -d ' ' -f1))
test -z $fcoe_disks && return 0
echo -n "Waiting for fcoe disks . "
while [ $timeout -gt 0 ]; do
for disk in ${fcoe_disks[*]}; do
if ! test -b $disk; then
done=0
break
fi
done
test $done -eq 1 && break;
sleep 1
echo -n ". "
done=1
let timeout--
done
if test $timeout -eq 0; then
echo "timeout!"
else
echo "done!"
fi
# mount any newly discovered disk
mount -a 2>/dev/null
}/etc/fstab で以下のパスで指定された FCoE ディスクがマウントされます。
/dev/disk/by-path/fc-0xXX:0xXX /mnt/fcoe-disk1 ext3 defaults,_netdev 0 0 /dev/disk/by-path/fc-0xYY:0xYY /mnt/fcoe-disk2 ext3 defaults,_netdev 0 0
fc- および _netdev サブ文字列を持つエントリーにより、mount_fcoe_disks_from_fstab 関数が FCoE ディスクマウントエントリーを識別できます。/etc/fstab エントリーの詳細は、man 5 fstab を参照してください。
25.7. iSCSI
iscsi-initiator-utils を実行して iscsi-initiator-utils パッケージを最初にインストールします。
node.startup = automatic でマークされたノードがない場合、iSCSI サービスは iscsiadm コマンドが実行されるまで起動しません。これには iscsid または iscsi カーネルモジュールの開始が必要になります。たとえば、検出コマンド iscsiadm -m discovery -t st -p ip:port を実行すると、iscsiadm が iSCSI サービスを開始します。
25.7.1. iSCSI API
# iscsiadm -m session -P 3
# iscsiadm -m session -P 0
# iscsiadm -m session
driver [sid] target_ip:port,target_portal_group_tag proper_target_name
例25.3 iscsisadm -m session コマンドの出力
# iscsiadm -m session tcp [2] 10.15.84.19:3260,2 iqn.1992-08.com.netapp:sn.33615311 tcp [3] 10.15.85.19:3260,3 iqn.1992-08.com.netapp:sn.33615311
/usr/share/doc/iscsi-initiator-utils-version/README を参照してください。
25.8. 永続的な命名
25.8.1. ストレージデバイスのメジャー番号およびマイナー番号
sd ドライバーによって管理されるストレージデバイスは、メジャーデバイス番号とそれに関連するマイナー番号の集合によって内部的に識別されます。この目的で使用される主要なデバイス番号は、連続した範囲ではありません。各ストレージデバイスは、メジャー番号とマイナー番号の範囲で表され、デバイス全体またはデバイス内のパーティションを識別するために使用されます。デバイスに割り当てられたメジャー番号とマイナー番号は、sd <letter (s)>[number (s)] の形で直接関連付けられます。sd ドライバーが新しいデバイスを検出するたびに、利用可能なメジャー番号とマイナー番号の範囲が割り当てられます。オペレーティングシステムからデバイスを削除すると、メジャー番号およびマイナー番号の範囲が解放され、後で再利用できます。
sd 名は、検出時に各デバイスに割り当てられます。つまり、デバイス検出の順序が変更されると、メジャー番号とマイナー番号の範囲と関連する sd 名間の関連付けが変更される可能性があります。これは、一部のハードウェア設定 (たとえば、内部 SCSI コントローラーとシャーシ内の物理的な場所によって割り当てられた SCSI ターゲット ID を持つディスク) ではまれですが、それでも発生する可能性があります。これが発生する可能性がある状況の例を以下に示します。
- ディスクの電源がオンにならなかったり、SCSI コントローラーへの応答に失敗したりする場合があります。この場合は、通常のデバイスプローブにより検出されません。ディスクはシステムからアクセスできず、後続のデバイスには、シフトダウンした関連する
sd名など、メジャー番号とマイナー番号の範囲があります。たとえば、通常sdbと呼ばれるディスクが検出されない場合、通常はsdcと呼ばれるディスクはsdbとして表示されます。 - SCSI コントローラー (ホストバスアダプター、または HBA) の初期化に失敗し、その HBA に接続したすべてのディスクが検出されない場合があります。その後プローブされた HBA に接続されているディスクには、異なるメジャー番号とマイナー番号の範囲、および関連する
sd名が割り当てられます。 - システムに異なるタイプの HBA が存在すると、ドライバーの初期化の順序が変更される可能性があります。これにより、これらの HBA に接続されたディスクが別の順序で検出されます。これは、HBA がシステム上の別の PCI スロットに移動した場合にも発生することがあります。
- ストレージアレイや干渉するスイッチの電源が切れた場合など、ストレージデバイスがプローブされたときに、ファイバーチャネル、iSCSI、または FCoE アダプターを持つシステムに接続されたディスクがアクセスできなくなる可能性があります。これは、電源障害の後にシステムが再起動したときに、ストレージアレイのオンラインにかかる時間が、システムの起動にかかる時間よりも長くなる場合に発生します。一部のファイバーチャネルドライバーは、永続的な SCSI ターゲット ID を WWPN マッピングに指定するメカニズムをサポートしていますが、メジャー番号およびマイナー番号の範囲や関連する
sd名は予約されず、一貫性のある SCSI ターゲット ID 番号のみが提供されます。
/etc/fstab ファイルなど、デバイスを参照する際にメジャー番号およびマイナー番号の範囲または関連する sd 名を使用することは望ましくありません。間違ったデバイスがマウントされ、データが破損する可能性があります。
sd 名を参照する必要がある場合があります(デバイスによってエラーが報告される場合など)。これは、Linux カーネルがデバイスに関するカーネルメッセージで sd 名(および SCSI ホスト/チャネル/ターゲット/LUN タプル)を使用するためです。
25.8.2. World Wide Identifier (WWID)
0x83ページ)または Unit Serial Number ( 0x80ページ)を取得することで取得できます。これらの WWID から現在の /dev/sd 名へのマッピングは、/dev/disk/by-id/ ディレクトリーに保持されているシンボリックリンクで確認できます。
例25.4 WWID
0x83 識別子を持つデバイスには、以下のものがあります。
scsi-3600508b400105e210000900000490000 -> ../../sda
0x80 識別子を持つデバイスには、以下が含まれます。
scsi-SSEAGATE_ST373453LW_3HW1RHM6 -> ../../sda
/dev/sd 名への適切なマッピングを自動的に維持します。デバイスへのパスが変更したり、別のシステムからデバイスにアクセスする場合でも、アプリケーションはディスク上のデータを参照するために /dev/disk/by-id/ 名を使用できます。
/dev/mapper/wwid ディレクトリーに単一の疑似デバイスを表示します(例: /dev/mapper/3600508b400105df70000e00000ac0000 )。
Host:Channel:Target: Target :LUN、/dev/sd 名、および major:minor 番号。
3600508b400105df70000e00000ac0000 dm-2 vendor,product [size=20G][features=1 queue_if_no_path][hwhandler=0][rw] \_ round-robin 0 [prio=0][active] \_ 5:0:1:1 sdc 8:32 [active][undef] \_ 6:0:1:1 sdg 8:96 [active][undef] \_ round-robin 0 [prio=0][enabled] \_ 5:0:0:1 sdb 8:16 [active][undef] \_ 6:0:0:1 sdf 8:80 [active][undef]
/dev/sd 名への適切なマッピングを自動的に維持します。これらの名前は、パスが変更しても持続し、他のシステムからデバイスにアクセスする際に一貫性を保持します。
user_friendly_names 機能を使用すると、WWID は /dev/mapper/mpathn 形式の名前にマップされます。デフォルトでは、このマッピングは /etc/multipath/bindings ファイルで維持されます。これらの mpathn 名は、そのファイルが維持されている限り永続的です。
user_friendly_names を使用する場合は、クラスター内で一貫した名前を取得するために追加の手順が必要です。DM Multipathブックの Consistent Multipath Device Names in a Cluster を参照してください。
udev ルールを使用して独自の永続的な名前を実装し、ストレージの WWID にマップすることもできます。
25.8.3. /dev/disk/by-*の udev メカニズムによって管理されるデバイス名
udev メカニズムは、以下の 3 つの主要コンポーネントで設定されています。
- カーネル
- デバイスの追加、削除、または変更時にユーザー空間に送信されるイベントを生成します。
udevdサービス- イベントを受信します。
udevルールudevサービスがカーネルイベントを受信するときに実行するアクションを指定します。
/dev/disk/ ディレクトリーにシンボリックリンクを作成する udev ルールが含まれます。これにより、ストレージデバイスは、そのコンテンツ、一意の識別子、シリアル番号、またはデバイスへのアクセスに使用されるハードウェアパスによって参照されます。
/dev/disk/by-label/- このディレクトリーのエントリーは、デバイスに格納されているコンテンツ (つまりデータ) 内のラベルにより、ストレージデバイスを参照するシンボリック名を提供します。blkid ユーティリティーは、デバイスからデータを読み込み、デバイスの名前(ラベル)を決定するために使用されます。以下に例を示します。
/dev/disk/by-label/Boot
注記情報はデバイスのコンテンツ (つまりデータ) から取得されるため、コンテンツが別のデバイスにコピーされても、ラベルは同じままになります。このラベルは、以下の構文を使用して/etc/fstabでデバイスを参照することもできます。LABEL=Boot
/dev/disk/by-uuid/- このディレクトリーのエントリーは、デバイスに格納されているコンテンツ (つまりデータ) 内の 一意の ID により、ストレージデバイスを参照するシンボリック名を提供します。blkid ユーティリティーは、デバイスからデータを読み取って、デバイスの一意の識別子(UUID)を取得するために使用されます。以下に例を示します。
UUID=3e6be9de-8139-11d1-9106-a43f08d823a6
/dev/disk/by-id/- このディレクトリーのエントリーは、(その他のすべてのストレージデバイスとは異なる) 固有の ID により、ストレージデバイスを参照するシンボリック名を提供します。この識別子はデバイスのプロパティーですが、デバイスのコンテンツ (つまりデータ) には保存されません。以下に例を示します。
/dev/disk/by-id/scsi-3600508e000000000ce506dc50ab0ad05
/dev/disk/by-id/wwn-0x600508e000000000ce506dc50ab0ad05
この id は、デバイスの World-Wide ID またはデバイスのシリアル番号から取得されます。/dev/disk/by-id/エントリーには、パーティション番号を含めることもできます。以下に例を示します。/dev/disk/by-id/scsi-3600508e000000000ce506dc50ab0ad05-part1
/dev/disk/by-id/wwn-0x600508e000000000ce506dc50ab0ad05-part1
/dev/disk/by-path/- このディレクトリーのエントリーは、シンボリック名を提供します。このシンボリック名は、PCI 階層内のストレージコントローラーへの参照から始まり、デバイスのアクセスに使用されるハードウェアパスによりストレージデバイスを参照し、SCSI ホスト、チャネル、ターゲット、LUN 番号、パーティション番号 (オプション) を含みます。これらの名前は、メジャー番号およびマイナー番号または
sd名の使用が推奨されますが、ファイバーチャネル SAN 環境ではターゲット番号が変更されないように注意する必要があります(たとえば、永続的なバインディングを使用)。また、ホストアダプターを別の PCI スロットに移動すると、名前が更新されます。また、HBA がプローブに失敗した場合、ドライバーが別の順序で読み込まれている場合、またはシステムに新しい HBA がインストールされている場合に、SCSI ホスト番号が変更する可能性があります。パス別のリスト表示の例を以下に示します。/dev/disk/by-path/pci-0000:03:00.0-scsi-0:1:0:0
/dev/disk/by-path/エントリーには、以下のようなパーティション番号を含めることもできます。/dev/disk/by-path/pci-0000:03:00.0-scsi-0:1:0:0-part1
25.8.3.1. udev デバイス命名規則の制約
udev 命名規則の制約の一部は次のとおりです。
udevメカニズムは、udevイベントに対してudevルールが処理される際にストレージデバイスをクエリーする機能に依存する可能性があるため、クエリーの実行時にデバイスにアクセスできない可能性があります。これは、ファイバーチャネル、iSCSI、または FCoE ストレージデバイスといった、デバイスがサーバーシャーシにない場合に発生する可能性が高くなります。- また、カーネルはいつでも
udevイベントを送信する可能性があり、デバイスにアクセスできない場合に/dev/disk/by-*/リンクが削除される可能性があります。 udevイベントが生成され、それが処理されるまでに遅延が生じる可能性があります。たとえば、多数のデバイスが検出され、ユーザー空間のudevdサービスが各デバイスのルールを処理するのにある程度の時間がかかる場合などです。これにより、カーネルがデバイスを検出したときと、/dev/disk/by-*/名が利用可能になるまでの間に遅延が発生する可能性がありました。- ルールによって呼び出される blkid などの外部プログラムはデバイスを短期間開き、他の目的でデバイスにアクセスできなくなる可能性があります。
25.8.3.2. 永続的な命名属性の変更
udev の命名属性は永続的ですが、システムの再起動後も独自に変更されないため、設定可能なものもあります。以下の永続的な命名属性には、カスタム値を設定できます。
UUID: ファイルシステムの UUIDLABEL: ファイルシステムラベル
UUID 属性と LABEL 属性はファイルシステムに関連するため、使用するツールはそのパーティションのファイルシステムによって異なります。
- XFS ファイルシステムの
UUID属性またはLABEL属性を変更するには、ファイルシステムをアンマウントしてから、xfs_admin ユーティリティーを使用して属性を変更します。#umount /dev/device#xfs_admin [-U new_uuid] [-L new_label] /dev/device#udevadm settle - ext4、ext3、または ext2 ファイルシステムの
UUID属性またはLABEL属性を変更するには、tune2fs ユーティリティーを使用します。#tune2fs [-U new_uuid] [-L new_label] /dev/device#udevadm settle
1cdfbc07-1c90-4984-b5ec-f61943f5ea50 )に置き換えます。new_label を、ラベル(例: backup_data )に置き換えます。
udev 属性の変更はバックグラウンドで行われ、時間がかかる場合があります。udevadm settle コマンドは、変更が完全に登録されるまで待機します。これにより、次のコマンドが新しい属性を正しく利用できるようになります。
PARTUUID 属性または PARTLABEL 属性でパーティションを作成した後、または新規ファイルシステムを作成した後などです。
25.9. ストレージデバイスの削除
- 空きメモリーは、100 あたり 10 を超えるサンプルで、合計メモリーの 5% 未満です(コマンド free を使用して合計メモリーを表示することもできます)。
- スワッピングが有効である( vmstat 出力の
si列およびso列がゼロ以外の)。
手順25.11 デバイスの完全削除
- 必要に応じて、デバイスのすべてのユーザーとデバイスデータのバックアップを閉じます。
- umount を使用して、デバイスをマウントしたファイルシステムをアンマウントします。
- デバイスを使用して、md ボリュームおよび LVM ボリュームからデバイスを削除します。デバイスが LVM ボリュームグループのメンバーである場合は、pvmove コマンドを使用してデバイスからデータを移動し、vgreduce コマンドを使用して物理ボリュームを削除し、(必要に応じて) pvremove を使用してディスクから LVM メタデータを削除する必要がある場合があります。
- multipath -l コマンドを実行して、マルチパス デバイスとして設定されているデバイスの一覧を表示します。デバイスがマルチパスデバイスとして設定されている場合は、multipath -f device コマンドを実行して未処理の I/O をフラッシュし、マルチパスデバイスを削除します。
- 使用されているパスに、未処理の I/O をフラッシュします。これは、I/O フラッシュを引き起こす umount または vgreduce 操作がない raw デバイスにとって重要です。この手順は、次の場合にのみ行う必要があります。
- デバイスがマルチパスデバイスとして設定されていない場合。または、
- デバイスはマルチパスデバイスとして設定され、I/O は過去のある時点で個々のパスに直接発行されている場合。
未処理の I/O をフラッシュするには、次のコマンドを使用します。#blockdev --flushbufs device - システム上のアプリケーション、スクリプト、またはユーティリティーで、
/dev/sd、/dev/disk/by-path、または major:minor 番号など、デバイスのパスベースの名前への参照をすべて削除します。これは、将来追加される別のデバイスが、現在のデバイスと誤認されないようにするために重要です。 - 最後に、SCSI サブシステムからデバイスへの各パスを削除します。これを行うには、echo 1 > /sys/block/device-name/device/delete コマンドを使用します。device-name は
sdeなどになります。この操作の別のバリエーションは echo 1 > /sys/class/scsi_device/h:c:t:l/device/delete です。ここで、h は HBA 番号、c は HBA のチャンネル、t は SCSI ターゲット ID、l は LUN です。注記このコマンドの古い形式である echo "scsi remove-single-device 0 0 0 0" > /proc/scsi/scsi が非推奨になりました。
25.10. ストレージデバイスへのパスの削除
手順25.12 ストレージデバイスへのパスの削除
- システム上のアプリケーション、スクリプト、またはユーティリティーで、
/dev/sd、/dev/disk/by-path、または major:minor 番号など、デバイスのパスベースの名前への参照をすべて削除します。これは、将来追加される別のデバイスが、現在のデバイスと誤認されないようにするために重要です。 - echo offline > /sys/block/sda/device/state を使用してパスをオフラインにします。これにより、このパスのデバイスに送信される後続の I/O がすぐに失敗します。device-mapper-multipath は、デバイスへの残りのパスを引き続き使用します。
- SCSI サブシステムからパスを削除します。これを行うには、echo 1 > /sys/block/device-name/device/delete コマンドを使用します。device-name は、たとえば 手順25.11「デバイスの完全削除」で説明されているように、
sdeにすることができます。
25.11. ストレージデバイスまたはパスの追加
/dev/disk/by-path 名など)が、以前は削除されているデバイスによって使用されている可能性があることに注意してください。そのため、パスベースのデバイス名への古い参照がすべて削除されていることを確認してください。新しいデバイスを古いデバイスと間違える可能性があります。
手順25.13 ストレージデバイスまたはパスの追加
- ストレージデバイスまたはパスを追加する最初の手順は、新規ストレージデバイス、または既存デバイスへの新規パスへのアクセスを物理的に有効にすることです。これは、ファイバーチャネルまたは iSCSI ストレージサーバーで、ベンダー固有のコマンドを使用して実行します。その際、ホストに提示される新しいストレージの LUN 値をメモしてください。ストレージサーバーがファイバーチャネルの場合は、ストレージサーバーの WWNN (World Wide Node Name) も確認し、ストレージサーバーのすべてのポートに 1 つの WWNN があるかどうかを判断します。そうでない場合は、新しい LUN へのアクセスに使用される各ポートの World Wide Port Name (WWPN) をメモします。
- 次に、オペレーティングシステムが新しいストレージデバイス、または既存のデバイスへのパスを認識するようにします。推奨されるコマンドは以下のとおりです。
$ echo "c t l" > /sys/class/scsi_host/hosth/scan
上記のコマンドでは、h は HBA 番号、c は HBA のチャンネル、t は SCSI ターゲット ID、l は LUN です。注記このコマンドの古い形式である echo "scsi add-single-device 0 0 0 0" > /proc/scsi/scsi が非推奨になりました。- ファイバーチャネルハードウェアによっては、ループ初期化プロトコル (LIP) 操作が実行されるまで、RAID アレイで新しく作成された LUN がオペレーティングシステムに表示されない場合があります。実行手順については、「ストレージの相互接続のスキャン」 を参照してください。重要LIP が必要な場合は、この操作の実行中に I/O を停止する必要があります。
- 新しい LUN が RAID アレイに追加されましたが、オペレーティングシステムでまだ設定されていない場合は、sg 3_utils パッケージに含まれる sg_luns コマンドを使用して、アレイでエクスポートされている LUN の一覧を確認します。これにより、SCSI REPORT LUNS コマンドを RAID アレイに発行し、存在する LUN の一覧を返します。
すべてのポートに単一の WWNN を実装するファイバーチャネルストレージサーバーの場合は、sysfs で WWNN を検索して、正しい h、c、および t 値(HBA 番号、HBA チャネル、および SCSI ターゲット ID)を決定できます。例25.5 正しい h、c、および t の値を決定する
たとえば、ストレージサーバーの WWNN が0x5006016090203181の場合は、以下を使用します。$ grep 5006016090203181 /sys/class/fc_transport/*/node_name
これにより、以下のような出力が表示されます。/sys/class/fc_transport/target5:0:2/node_name:0x5006016090203181 /sys/class/fc_transport/target5:0:3/node_name:0x5006016090203181 /sys/class/fc_transport/target6:0:2/node_name:0x5006016090203181 /sys/class/fc_transport/target6:0:3/node_name:0x5006016090203181
これは、このターゲットへのファイバーチャネルルートが 4 つあることを示しています (それぞれ 2 つのストレージポートにつながるシングルチャネル HBA が 2 つ)。LUN の値が56であるとすると、次のコマンドは最初のパスを設定します。$ echo "0 2 56" > /sys/class/scsi_host/host5/scan
これは、新規デバイスへのパスごとに行う必要があります。すべてのポートに 1 つの WWNN を実装しないファイバーチャネルストレージサーバーの場合は、sysfs で各 WWPN を検索して、正しい HBA 番号、HBA チャネル、および SCSI ターゲット ID を決定できます。HBA 番号、HBA チャネル、および SCSI ターゲット ID を決定する別の方法として、新しいデバイスと同じパスにすでに設定されているデバイスを参照する方法があります。これは、lsscsi、scsi_id、multipath -l、ls -l /dev/disk/by-* などのさまざまなコマンドで実行できます。この情報と新しいデバイスの LUN 番号を上記のように使用して、新しいデバイスへのパスをプローブおよび設定できます。 - デバイスにすべての SCSI パスを追加したら、multipath コマンドを実行して、デバイスが適切に設定されていることを確認します。この時点で、デバイスを md、LVM、mkfs、または mount に追加できます。
25.12. ストレージの相互接続のスキャン
- 影響を受ける相互接続のすべての I/O は、手順を実行する前に一時停止してフラッシュする必要があります。また、I/O を再開する前にスキャンの結果を確認する必要があります。
- デバイスの取り外しと同様に、システムのメモリーが逼迫している場合は、相互接続スキャンを行わないことが推奨されます。メモリー不足のレベルを確認するには、vmstat 1 100 コマンドを実行します。(サンプル 100 件の内 11 件以上で) 空きメモリーが合計メモリーの 5 % 未満の場合、相互接続スキャンは推奨されません。また、スワッピングがアクティブな場合( vmstat 出力のゼロ以外の
si列およびso列)は、相互接続スキャンは推奨されません。free コマンドは、合計メモリーを表示することもできます。
- echo "1" > /sys/class/fc_host/hostN/issue_lip
- (N をホスト番号に置き換えます。)この操作は、ループ初期化プロトコル( LIP) を実行し、相互接続をスキャンして、現在バス上にあるデバイスを反映するように SCSI レイヤーを更新します。基本的に、LIP はバスのリセットであり、デバイスの追加と削除を引き起こします。この手順は、ファイバーチャネル相互接続に新しい SCSI ターゲットを設定する場合に必要です。issue_lip は非同期操作であることに注意してください。コマンドは、スキャン全体が完了する前に完了する可能性があります。issue_lip の終了タイミングを決定するには、
/var/log/messagesを監視する必要があります。lpfcドライバー、qla2xxxドライバー、およびbnx2fcドライバーは、issue_lip をサポートします。Red Hat Enterprise Linux の各ドライバーがサポートする API 機能に関する詳細は、表25.1「ファイバーチャネル API の機能」 を参照してください。 /usr/bin/rescan-scsi-bus.sh/usr/bin/rescan-scsi-bus.shスクリプトは、Red Hat Enterprise Linux 5.4 で導入されました。デフォルトでは、このスクリプトは、システムの SCSI バスをすべてスキャンし、SCSI レイヤーを更新して、バスの新しいデバイスを反映します。このスクリプトでは、デバイスの削除や LIP の実行を許可する追加オプションが提供されます。既知の問題など、このスクリプトの詳細は、「rescan-scsi-bus.sh を使用した論理ユニットの追加/削除」 を参照してください。- echo "- - -" > /sys/class/scsi_host/hosth/scan
- これは、「ストレージデバイスまたはパスの追加」 で説明されているように、ストレージデバイスまたはパスを追加するコマンドと同じです。ただし、この場合は、チャネル番号、SCSI ターゲット ID、および LUN の値がワイルドカードに置き換わります。識別子とワイルドカードの組み合わせは自由なので、必要なだけ具体的に、あるいは幅広くコマンドを作成することができます。この手順では、LUN を追加しますが、削除することはありません。
- modprobe --remove driver-name, modprobe driver-name
- modprobe --remove driver-name コマンドの後に modprobe driver-nameコマンドを実行すると、ドライバー によって制御されるすべての相互接続の状態が完全に再初期化されます。かなり極端ですが、説明されているコマンドを使用することは、特定の状況で適切な場合があります。コマンドを使用して、たとえば、異なるモジュールパラメーター値でドライバーを再起動できます。
25.13. iSCSI 検出設定
/etc/iscsi/iscsid.conf です。このファイルには、iscsid および iscsiadm で使用される iSCSI 設定が含まれます。
/etc/iscsi/iscsid.conf の設定を使用して、2 種類のレコードを作成します。
/var/lib/iscsi/nodes内のノードレコード- ターゲットにログインすると、iscsiadm はこのファイル内の設定を使用します。
/var/lib/iscsi/discovery_typeにおける検出レコード- 同じ宛先に対して検出を実行すると、iscsiadm はこのファイル内の設定を使用します。
/var/lib/iscsi/discovery_type)を最初に削除します。これを行うには、以下のコマンドを使用します。[5]
# iscsiadm -m discovery -t discovery_type -p target_IP:port -o deletesendtargets、isns、または fw のいずれかになります。
- 検出を実行する前に、
/etc/iscsi/iscsid.confファイルを直接編集します。検出設定では、接頭辞discoveryを使用します。表示するには、以下を実行します。#iscsiadm -m discovery -t discovery_type -p target_IP:port - または、iscsiadm を使用して、以下のように検出レコード設定を直接変更することもできます。
#iscsiadm -m discovery -t discovery_type -p target_IP:port -o update -n setting -v %value利用可能なsettingオプションと、それぞれに有効なvalueオプションの詳細は、man ページの iscsiadm(8) を参照してください。
/etc/iscsi/iscsid.conf ファイルには、適切な設定構文の例も含まれています。
25.14. iSCSI オフロードおよびインターフェイスバインディングの設定
$ ping -I ethX target_IP
25.14.1. 利用可能な iface 設定の表示
- ソフトウェア iSCSI
- このスタックは、セッションごとに iSCSI ホストインスタンス( scsi_host)を割り当て、セッションごとに単一の接続を使用します。その結果、
/sys/class_scsi_hostおよび/proc/scsiは、ログインしている各接続/セッションの scsi_host を報告します。 - iSCSI のオフロード
- このスタックは、PCI デバイスごとに scsi_host を割り当てます。そのため、ホストバスアダプター上の各ポートは異なる PCI デバイスとして表示され、HBA ポートごとに異なる scsi_host が表示されます。
/var/lib/iscsi/ iface s に iface 設定を入力する必要があります。
iface_name transport_name,hardware_address,ip_address,net_ifacename,initiator_name
| 設定 | 説明 |
|---|---|
| iface_name | iface 設定名。 |
| transport_name | ドライバーの名前 |
| hardware_address | MAC アドレス |
| ip_address | このポートに使用する IP アドレス |
| net_iface_name | ソフトウェア iSCSI セッションの vlan または alias バインディングに使用される名前。iSCSI オフロードの場合、この値は再起動後も持続しないため、net_iface_name は < empty > になります。 |
| initiator_name | この設定は、イニシエーターのデフォルト名を上書きするために使用されます。これは、/etc/iscsi/initiatorname.iscsiで定義されます。 |
例25.6 iscsiadm -m iface コマンドの出力例
iface0 qla4xxx,00:c0:dd:08:63:e8,20.15.0.7,default,iqn.2005-06.com.redhat:madmax iface1 qla4xxx,00:c0:dd:08:63:ea,20.15.0.9,default,iqn.2005-06.com.redhat:madmax
例25.7 Chelsio ネットワークカードを使用した iscsiadm -m iface 出力
default tcp,<empty>,<empty>,<empty>,<empty> iser iser,<empty>,<empty>,<empty>,<empty> cxgb3i.00:07:43:05:97:07 cxgb3i,00:07:43:05:97:07,<empty>,<empty>,<empty>
iface.setting = value
例25.8 Chelsio コンバージドネットワークアダプターでの iface 設定の使用
# BEGIN RECORD 2.0-871 iface.iscsi_ifacename = cxgb3i.00:07:43:05:97:07 iface.net_ifacename = <empty> iface.ipaddress = <empty> iface.hwaddress = 00:07:43:05:97:07 iface.transport_name = cxgb3i iface.initiatorname = <empty> # END RECORD
25.14.2. ソフトウェア iSCSI 用の iface の設定
# iscsiadm -m iface -I iface_name --op=new
# iscsiadm -m iface -I iface_name --op=update -n iface.setting -v hw_address
例25.9 iface0の MAC アドレスの設定
iface0 の MAC アドレス(hardware_address)を 00:0F: 1F:92:6B:BF に設定するには、次のコマンドを実行します。
# iscsiadm -m iface -I iface0 --op=update -n iface.hwaddress -v 00:0F:1F:92:6B:BF
デフォルト または iser を iface 名として使用しないでください。どちらの文字列も、後方互換性のために iscsiadm で使用される特別な値です。手動で作成された default または iser という名前の iface 設定は、後方互換性を無効にします。
25.14.3. iSCSI オフロード用の iface の設定
iscsiadm は、ポートごとに iface 設定を作成します。利用可能な iface 設定を表示するには、ソフトウェア iSCSI の場合と同じコマンドである iscsiadm -m iface を使用します。
iface.ipaddress 値を、インターフェイスが使用するイニシエーター IP アドレスに設定します。
be2iscsiドライバーを使用するデバイスの場合、IP アドレスは BIOS 設定画面で設定されます。- 他のすべてのデバイスで、
ifaceの IP アドレスを設定するには、次のコマンドを実行します。# iscsiadm -m iface -I iface_name -o update -n iface.ipaddress -v initiator_ip_address
例25.10 Chelsio カードの iface IP アドレスの設定
iface 名が cxgb3i .00:07:43:05:97:07 のカードを使用する場合は、iface IP アドレスを 20.15.0.66 に設定するには、次のコマンドを実行します。
# iscsiadm -m iface -I cxgb3i.00:07:43:05:97:07 -o update -n iface.ipaddress -v 20.15.0.66
25.14.4. iface のポータルへのバインド/バインド解除
/var/lib/iscsi/ifaces の各 iface 設定の iface.transport 設定を確認します。その後、iscsiadm ユーティリティーは、検出されたポータルを、 iface.transport が tcp である任意の iface にバインドします。
# iscsiadm -m discovery -t st -p target_IP:port -I iface_name -P 1 [5]
tcp に設定されないためです。そのため、iface 設定は、検出されたポータルに手動でバインドする必要があります。
default を iface_name として使用します。
# iscsiadm -m discovery -t st -p IP:port -I default -P 1
# iscsiadm -m node -targetname proper_target_name -I iface0 --op=delete[6]
# iscsiadm -m node -I iface_name --op=delete
# iscsiadm -m node -p IP:port -I iface_name --op=delete
/var/lib/iscsi/ iface に iface 設定が定義されておらず、-I オプションが使用されていない場合、iscsiadm はネットワークサブシステムが特定のポータルが使用するデバイスを決定できるようにします。
25.15. iSCSI 相互接続のスキャン
# iscsiadm -m discovery -t sendtargets -p target_IP:port [5]
target_IP:port,target_portal_group_tag proper_target_name
例25.11 iscsiadm を使用した sendtargets コマンドの発行
iqn.1992-08.com.netapp:sn.33615311 で、target_IP:port が 10.15.85.19:3260 のターゲットでは、出力は以下のようになります。
10.15.84.19:3260,2 iqn.1992-08.com.netapp:sn.33615311 10.15.85.19:3260,3 iqn.1992-08.com.netapp:sn.33615311
10.15.84.19:3260 および 10.15 .85.19:3260 を使用します。
Target: proper_target_name
Portal: target_IP:port,target_portal_group_tag
Iface Name: iface_name例25.12 iface 設定の表示
Target: iqn.1992-08.com.netapp:sn.33615311
Portal: 10.15.84.19:3260,2
Iface Name: iface2
Portal: 10.15.85.19:3260,3
Iface Name: iface2
iqn.1992-08.com.netapp:sn.33615311 は、iface 設定として iface2 を使用します。
# iscsiadm -m session --rescan
# iscsiadm -m session -r SID --rescan[7]
/var/lib/iscsi/nodes データベースの内容を上書きします。このデータベースは、/etc/iscsi/iscsid.conf の設定を使用して再入力されます。ただし、セッションが現在ログインしており、使用中の場合は発生しません。
/var/lib/iscsi/nodes を上書きせずに新しいターゲット/ポータルを追加するには、以下のコマンドを使用します。
iscsiadm -m discovery -t st -p target_IP -o new
/var/lib/iscsi/nodes エントリーを削除するには、次のコマンドを実行します。
iscsiadm -m discovery -t st -p target_IP -o delete
iscsiadm -m discovery -t st -p target_IP -o delete -o new
ip:port,target_portal_group_tag proper_target_name
例25.13 sendtargets コマンドの出力
10.16.41.155:3260,0 iqn.2001-05.com.equallogic:6-8a0900-ac3fe0101-63aff113e344a4a2-dl585-03-1
# iscsiadm --mode node --targetname proper_target_name --portal ip:port,target_portal_group_tag \ --login [8]
例25.14 完全な iscsiadm コマンド
# iscsiadm --mode node --targetname \ iqn.2001-05.com.equallogic:6-8a0900-ac3fe0101-63aff113e344a4a2-dl585-03-1 \ --portal 10.16.41.155:3260,0 --login[8]
25.16. iSCSI ターゲットへのログイン
# systemctl start iscsiinit スクリプトは、node.startup 設定が自動として設定されているターゲットに 自動 的にログインします。これは、すべてのターゲットの node.startup のデフォルト値です。
node.startup を manual に設定します。これを実行するには、以下のコマンドを実行します。
# iscsiadm -m node --targetname proper_target_name -p target_IP:port -o update -n node.startup -v manual
# iscsiadm -m node --targetname proper_target_name -p target_IP:port -o delete
/etc/fstab にマウント用のパーティションエントリーを追加します。たとえば、起動時に iSCSI デバイス sdb を /mount/iscsi に自動的にマウントするには、以下の行を /etc/fstab に追加します。
/dev/sdb /mnt/iscsi ext3 _netdev 0 0
# iscsiadm -m node --targetname proper_target_name -p target_IP:port -l
25.17. オンライン論理ユニットのサイズの変更
25.17.1. ファイバーチャネル論理ユニットのサイズ変更
$ echo 1 > /sys/block/sdX/device/rescan
25.17.2. iSCSI 論理ユニットのサイズを変更
# iscsiadm -m node --targetname target_name -R [5]
# iscsiadm -m node -R -I interface
- echo "- - -" > /sys/class/scsi_host/ host / scan コマンドと同じ方法で新しいデバイスをスキャンします( 「iSCSI 相互接続のスキャン」を参照)。
- echo 1 > /sys/block/sdX/device/rescan コマンドと同じ方法で、新規/ 変更された論理ユニットを再スキャンします。このコマンドは、ファイバーチャネルの論理ユニットを再スキャンする際に使用するコマンドと同じであることに注意してください。
25.17.3. マルチパスデバイスのサイズの更新
# multipathd -k"resize map multipath_device"
/dev/mapper 内のデバイスの対応するマルチパスエントリーです。システムでマルチパスの設定方法に応じて、multipath_device は 2 つの形式のいずれかになります。
- X: X はデバイスの対応するエントリーです(例: mpath0)。
- a WWID; for example, 3600508b400105e210000900000490000
/etc/multipath.confで) no_path_retry パラメーターが "queue" に設定され、デバイスへのアクティブなパスがない場合は、このコマンドを使用しないでください。
25.17.4. オンライン論理ユニットの読み取り/書き込み状態の変更
# blockdev --getro /dev/sdXYZ
# cat /sys/block/sdXYZ/ro 1 = read-only 0 = read-write36001438005deb4710000500000640000 dm-8 GZ,GZ500 [size=20G][features=0][hwhandler=0][ro] \_ round-robin 0 [prio=200][active] \_ 6:0:4:1 sdax 67:16 [active][ready] \_ 6:0:5:1 sday 67:32 [active][ready] \_ round-robin 0 [prio=40][enabled] \_ 6:0:6:1 sdaz 67:48 [active][ready] \_ 6:0:7:1 sdba 67:64 [active][ready]
手順25.14 R/W の状態の変更
- デバイスを RO から R/W に移動するには、手順 2 を参照してください。デバイスを R/W から RO に移動するには、それ以上の書き込みが発行されないようにします。これを行うには、アプリケーションを停止するか、適切なアプリケーション固有のアクションを実行します。次のコマンドを使用して、すべての未処理の書き込み I/O が完了していることを確認します。
# blockdev --flushbufs /dev/devicedevice を目的のデザイン者に置き換えます。デバイスマッパーマルチパスの場合、これはdev/mapperのデバイスのエントリーになります。たとえば、/dev/mapper/mpath3です。 - ストレージデバイスの管理インターフェイスを使用して、論理ユニットの状態を R/W から RO に、または RO から R/W に変更します。この手順は、アレイごとに異なります。詳細は、該当するストレージアレイベンダーのドキュメントを参照してください。
- デバイスの R/W 状態に関するオペレーティングシステムのビューを更新するには、デバイスの再スキャンを実行します。デバイスマッパーマルチパスを使用している場合は、デバイスへのパスごとにこの再スキャンを実行してから、マルチパスにデバイスマップをリロードするように指示するコマンドを発行します。この手順は、「論理ユニットの再スキャン」 で詳細に説明されています。
25.17.4.1. 論理ユニットの再スキャン
# echo 1 > /sys/block/sdX/device/rescan例25.15 multipath -11 コマンドの使用
# echo 1 > /sys/block/sdax/device/rescan # echo 1 > /sys/block/sday/device/rescan # echo 1 > /sys/block/sdaz/device/rescan # echo 1 > /sys/block/sdba/device/rescan
25.17.4.2. マルチパスデバイスの R/W 状態の更新
# multipath -r25.17.4.3. Documentation
25.18. rescan-scsi-bus.sh を使用した論理ユニットの追加/削除
sg3_utils パッケージは、rescan-scsi-bus.sh スクリプトを提供します。このスクリプトは、(デバイスをシステムに追加した後に)必要に応じてホストの論理ユニット設定を自動的に更新できます。rescan-scsi-bus.sh スクリプトは、サポートされているデバイスで issue_lip を実行することもできます。このスクリプトの使用方法は、rescan-scsi-bus.sh --help を参照してください。
sg3_utils パッケージをインストールするには、yum install sg3_utils を実行します。
rescan-scsi-bus.sh の既知の問題
rescan-scsi-bus.sh スクリプトを使用する場合は、以下の既知の問題を書き留めておきます。
rescan-scsi-bus.shが正しく機能するには、LUN0 が最初にマッピングされた論理ユニットである必要があります。rescan-scsi-bus.shは、最初にマップされた論理ユニットが LUN0 の場合にのみ検出できます。--nooptscan オプションを使用していても、最初にマップされた論理ユニットを検出しない限り、rescan-scsi-bus.shは、他の論理ユニットをスキャンできません。- 競合状態では、論理ユニットが最初にマッピングされている場合に
rescan-scsi-bus.shを 2 回実行する必要があります。最初のスキャン中に、rescan-scsi-bus.shは LUN0 のみを追加します。その他の論理ユニットはすべて 2 番目のスキャンに追加されます。 rescan-scsi-bus.shスクリプトのバグにより、--remove オプションが使用されると、論理ユニットサイズの変更を認識するための機能が誤って実行されます。rescan-scsi-bus.shスクリプトは、ISCSI 論理ユニットの削除を認識しません。
25.19. リンクロス動作の変更
25.19.1. ファイバーチャネル
dev_loss_tmo コールバックを実装している場合、トランスポートの問題が検出されるとリンクを介したデバイスへのアクセス試行がブロックされます。デバイスがブロックされているかどうかを確認するには、次のコマンドを実行します。
$ cat /sys/block/device/device/state
ブロック されている場合に blocked を返します。デバイスが正常に動作している場合、このコマンドは の 実行 を返します。
手順25.15 リモートポートの状態の判断
- リモートポートの状態を判断するには、次のコマンドを実行します。
$ cat /sys/class/fc_remote_port/rport-H:B:R/port_state
- このコマンドは、リモートポート(およびそのポートからアクセスされるデバイス)がブロックされると、
Blockedを返します。リモートポートが正常に動作している場合、コマンドはOnlineを返します。 dev_loss_tmo秒以内に問題が解決されない場合、rport およびデバイスはブロックされず、そのデバイスで実行しているすべての I/O (およびそのデバイスに送信される新しい I/O)は失敗します。
手順25.16 dev_loss_tmoの変更
dev_loss_tmo値を変更するには、目的の値を ファイルに echo します。たとえば、dev_loss_tmoを 30 秒に設定するには、以下のコマンドを実行します。$ echo 30 > /sys/class/fc_remote_port/rport-H:B:R/dev_loss_tmo
dev_loss_tmo の詳細は、「ファイバーチャネル API」 を参照してください。
dev_loss_tmo を超えると、scsi_device デバイスおよび sdN デバイスが削除されます。通常、ファイバーチャネルクラスはデバイスをそのまま残します。つまり、/dev/sd x は /dev/sdx のままになります。これは、ターゲットのバインディングがファイバーチャネルドライバーにより保存されるため、ターゲットポートが戻ると、SCSI アドレスが忠実に再作成されます。ただし、これは保証されません。LUN のストレージ内ボックス設定に追加の変更がない場合に限り、sdx が復元されます。
25.19.2. dm-multipathでの iSCSI 設定
/etc/multipath.conf の device { の下に以下の行をネストします。
features "1 queue_if_no_path"
25.19.2.1. NOP-Out 間隔/タイムアウト
5 秒です。これを調整するには、/etc/iscsi/iscsid.conf を開き、以下の行を編集します。
node.conn[0].timeo.noop_out_interval = [interval value]
node.conn[0].timeo.noop_out_timeout = [timeout value]
SCSI エラーハンドラー
# iscsiadm -m session -P 3
25.19.2.2. replacement_timeout
/etc/iscsi/iscsid.conf を開き、以下の行を編集します。
node.session.timeo.replacement_timeout = [replacement_timeout]
/etc/multipath.conf の 1 queue_if_no_path オプションは、iSCSI タイマーを設定して、マルチパス層に直ちにコマンドを推測します( 「dm-multipathでの iSCSI 設定」を参照)。この設定により、I/O エラーがアプリケーションに伝搬されなくなります。このため、replacement_timeout を 15-20 秒に設定することができます。
/etc/iscsi/iscsid.conf ではなく、/etc/multipath.conf の設定に基づいて I/O を内部でキューに入れます。
iSCSI および DM Multipath のオーバーライド
recovery_tmo sysfs オプションは、特定の iSCSI デバイスのタイムアウトを制御します。以下のオプションは、システム全体の recovery_tmo 値を上書きします。
replacement_timeout設定オプションは、すべての iSCSI デバイスのrecovery_tmo値をグローバルに上書きします。- DM Multipath が管理するすべての iSCSI デバイスについては、DM Multipath の
fast_io_fail_tmoオプションがグローバルにrecovery_tmo値を上書きします。DM Multipath のfast_io_fail_tmoオプションは、ファイバーチャネルデバイスのfast_io_fail_tmoオプションを上書きします。DM Multipathfast_io_fail_tmoオプションはreplacement_timeoutよりも優先されます。Red Hat では、replacement_timeoutを使用して、DM Multipath が管理するデバイスでrecovery_tmoを上書きすることは推奨していません。これは、multipathdサービスが再読み込みされると、DM Multipath が常にrecovery_tmoをリセットするためです。
25.19.3. iSCSI ルート
/etc/iscsi/iscsid.conf を開き、以下のように編集します。
node.conn[0].timeo.noop_out_interval = 0 node.conn[0].timeo.noop_out_timeout = 0
/etc/iscsi/iscsid.conf を開き、以下の行を編集します。
node.session.timeo.replacement_timeout = replacement_timeout
/etc/iscsi/iscsid.conf を設定したら、影響を受けるストレージのリ検出を実行する必要があります。これにより、システムが /etc/iscsi/iscsid.conf の新しい値を読み込み、使用できるようになります。iSCSI デバイスの検出方法に関する詳細は、「iSCSI 相互接続のスキャン」 を参照してください。
特定セッションのタイムアウトの設定
/etc/iscsi/iscsid.confを使用する代わりに)永続化しないようにすることもできます。これを行うには、次のコマンドを実行します (必要に応じて変数を置き換えます)。
# iscsiadm -m node -T target_name -p target_IP:port -o update -n node.session.timeo.replacement_timeout -v $timeout_value
25.20. SCSI コマンドタイマーおよびデバイスステータスの制御
- コマンドの中止
- デバイスのリセット
- バスのリセット
- ホストをリセットします。
デバイスの状態
$ cat /sys/block/device-name/device/state
# echo running > /sys/block/device-name/device/state
コマンドタイマー
/sys/block/device-name/device/timeout ファイルを変更します。
# echo value > /sys/block/device-name/device/timeout
25.21. オンラインストレージ設定のトラブルシューティング
- 論理ユニットの削除ステータスは、ホストには反映されません。
- 設定されているファイラーで論理ユニットを削除しても、その変更はホストには反映されません。このような場合、論理ユニットが 古くなっ たため、dm-multipath を使用すると、lvm コマンドは無期限にハングします。これを回避するには、以下の手順を行います。
手順25.17 古い論理ユニットの操作
/etc/lvm/cache/.cache内のどの mpath リンクエントリーが古い論理ユニットに固有であるかを判別します。これを実行するには、以下のコマンドを実行します。$ ls -l /dev/mpath | grep stale-logical-unit
例25.16 特定の mpath リンクエントリーの決定
たとえば、stale-logical-unit が 3600d0230003414f30000203a7bc41a00 の場合、以下の結果が表示される場合があります。lrwxrwxrwx 1 root root 7 Aug 2 10:33 /3600d0230003414f30000203a7bc41a00 -> ../dm-4 lrwxrwxrwx 1 root root 7 Aug 2 10:33 /3600d0230003414f30000203a7bc41a00p1 -> ../dm-5
つまり、3600d0230003414f30000203a7bc41a00 は、dm- 4 と dm -5 の 2 つの mpath リンクにマップされ ます。- 次に、
/etc/lvm/cache/.cacheを開きます。stale-logical-unit と、stale-logical-unit がマップする mpath リンクを含むすべての行を削除します。例25.17 関連行の削除
前の手順と同じ例を使用する場合、削除する必要のある行は次のとおりです。/dev/dm-4 /dev/dm-5 /dev/mapper/3600d0230003414f30000203a7bc41a00 /dev/mapper/3600d0230003414f30000203a7bc41a00p1 /dev/mpath/3600d0230003414f30000203a7bc41a00 /dev/mpath/3600d0230003414f30000203a7bc41a00p1
25.22. eh_deadline を使用したエラー復旧の最大時間の設定
eh_deadline パラメーターを有効にする必要はありません。eh_deadline パラメーターは、ファイバーチャネルスイッチとターゲットポート間でリンクの損失が発生した場合や、Host Bus Adapter (HBA)が Registered State Change Notifications (RSCN)を受信しない場合など、特定のシナリオで役立ちます。このような場合、I/O 要求やエラーからの復旧コマンドは、エラーに遭遇することなく、すべてタイムアウトになります。この環境で eh_deadline を設定すると、復旧時間に上限が設定されます。これにより、マルチパスによって、失敗した I/O を別のパスで再試行できます。
eh_deadline 機能は追加の利点を提供しません。これにより、マルチパスを再試行できます。
eh_deadline パラメーターを使用すると、HBA 全体を停止およびリセットする前に、SCSI エラー処理メカニズムがエラーリカバリーを実行しようとする最大時間を設定できます。
eh_deadline の値は秒単位で指定されます。デフォルト設定は off で、時間制限を無効にし、すべてのエラー回復を可能にします。sysfs の使用に加えて、scsi_mod.eh_deadline カーネルパラメーターを使用すると、すべての SCSI HBA にデフォルト値を設定できます。
eh_deadline の期限が切れると HBA がリセットされることに注意してください。これは、障害が発生したものだけでなく、HBA 上のすべてのターゲットパスに影響します。結果として、他の理由で冗長パスの一部が使用できない場合、I/O エラーが発生する可能性があります。eh_deadline は、すべてのターゲットに完全な冗長マルチパス設定がある場合にのみ有効にします。
第26章 Device Mapper Multipathing (DM Multipath) と仮想マシン用のストレージ
26.1. 仮想マシン用のストレージ
- ファイバーチャンネル
- iSCSI
- NFS
- GFS2
- ローカルストレージのプール
- ローカルストレージには、ホスト、ローカルディレクトリー、直接接続のディスク、および LVM ボリュームグループに直接接続されているストレージデバイス、ファイル、またはディレクトリーが含まれます。
- ネットワーク (共有) ストレージプール
- ネットワークストレージは、標準プロトコルを使用して、ネットワーク上で共有されるストレージデバイスをカバーします。これには、ファイバーチャネル、iSCSI、NFS、GFS2、および SCSI RDMA プロトコルを使用する共有ストレージデバイスが含まれ、ホスト間で仮想化ゲストを移行するための要件になります。
26.2. DM Multipath
- 冗長性
- DM Multipath は、アクティブ/パッシブ設定でフェイルオーバーを提供できます。アクティブ/パッシブ設定では、パスは、I/O には常に半分しか使用されません。I/O パスのいずれかの要素に障害が発生した場合、DM マルチパスは代替パスに切り替わります。
- パフォーマンスの向上
- DM Multipath を active/active モードに設定すると、I/O はラウンドロビン式でパス全体に分散されます。一部の設定では、DM Multipath は I/O パスの負荷を検出し、負荷を動的に再調整できます。
第27章 外部アレイ管理 (libStorageMgmt)
libStorageMgmt と呼ばれる新しい外部アレイ管理ライブラリーが同梱されます。
27.1. libStorageMgmt の概要
libStorageMgmt ライブラリーは、ストレージアレイに依存しないアプリケーションプログラミングインターフェイス(API)です。開発者は、この API を使用してさまざまなストレージアレイを管理し、ハードウェアアクセラレーション機能を活用できます。
libStorageMgmt ライブラリーを使用すると、以下の操作を実行できます。
- ストレージプール、ボリューム、アクセスグループ、またはファイルシステムのリストを表示します。
- ボリューム、アクセスグループ、ファイルシステム、または NFS のエクスポートを作成して削除します。
- ボリューム、アクセスグループ、またはイニシエーターへのアクセスを許可および削除します。
- スナップショット、クローン、およびコピーを使用してボリュームを複製します。
- アクセスグループの作成と削除、およびグループのメンバーの編集
- クライアントアプリケーションおよびプラグイン開発者向けの安定した C および Python の API。
- ライブラリーを使用するコマンドラインインターフェイス(
lsmcli) - プラグインを実行するデーモン(
lsmd)。 - クライアントアプリケーション(
sim)のテストを可能にするシミュレータープラグイン。 - アレイとインターフェイスするためのプラグインアーキテクチャー。
libStorageMgmt ライブラリーは、REPORTED LUNS DATA HAS CHANGED ユニット注意を処理するデフォルトの udev ルールを追加します。
sysfs で自動的に再スキャンされます。
/lib/udev/rules.d/90-scsi-ua.rules には、カーネルが生成できる他のイベントを列挙できる例が含まれています。
libStorageMgmt ライブラリーは、プラグインアーキテクチャーを使用して、ストレージアレイの相違点に対応します。libStorageMgmt プラグインとその作成方法の詳細は、Red Hat Developer Guide を参照してください。
27.2. libStorageMgmt の用語
- ストレージアレイ
- ブロックアクセス (FC、FCoE、iSCSI)、またはネットワークアタッチストレージ (NAS) を介したファイルアクセスを提供するストレージシステム。
- ボリューム
- ストレージエリアネットワーク (SAN) ストレージアレイは、FC、iSCSI、または FCoE などのさまざまなトランスポートを介して、Host Bus Adapter (HBA) にボリュームを公開できます。ホスト OS は、これをブロックデバイスとして扱います。
multipath[2]が有効になっている場合、1 つのボリュームを多くのディスクに公開できます。これは、論理ユニット番号 (LUN)、SNIA 用語を使用した StorageVolume、または仮想ディスクとしても知られています。 - プール
- ストレージ領域のグループ。ファイルシステムまたはボリュームは、プールから作成できます。プールは、ディスク、ボリューム、およびその他のプールから作成できます。プールには RAID 設定やシンプロビジョニング設定が含まれる場合もあります。これは、SNIA 用語を使用した StoragePool としても知られています。
- スナップショット
- 特定の時点で、読み取り専用で、領域を効率的に使用するデータのコピー。これは、読み取り専用スナップショットとも呼ばれます。
- Clone
- 特定の時点で、読み取りおよび書き込み可能で、領域を効率的に使用するデータのコピー。これは、読み取りおよび書き込み可能なスナップショットとも呼ばれます。
- コピー
- データの完全なビット単位のコピー。領域全体を占めます。
- ミラーリング
- 継続的に更新されるコピー (同期および非同期)。
- アクセスグループ
- 1 つ以上のストレージボリュームへのアクセスを許可されている iSCSI、FC、および FCoE のイニシエーターのコレクション。これにより、指定のイニシエーターがアクセスできるのはストレージボリュームのみとなります。これはイニシエーターグループとしても知られています。
- アクセス許可
- 指定したアクセスグループまたはイニシエーターへのボリュームの公開。
libStorageMgmtライブラリーは、現在、特定の論理ユニット番号を選択する機能を備えた LUN マッピングをサポートしていません。libStorageMgmtライブラリーを使用すると、ストレージアレイは次に割り当てに使用できる LUN を選択できます。SAN からの起動や、256 を超えるボリュームのマスクを設定する場合は、OS、ストレージアレイ、または HBA のドキュメントを必ずお読みください。アクセス許可は LUN マスキングとも呼ばれます。 - システム
- ストレージアレイまたは直接接続ストレージ RAID を表します。
- ファイルシステム
- ネットワークアタッチストレージ (NAS) ストレージアレイは、NFS プロトコルまたは CIFS プロトコルのいずれかを使用して、IP ネットワークを介して、OS をホストするファイルシステムを公開できます。ホスト OS は、クライアントのオペレーティングシステムに応じて、マウントポイントまたはファイルを含むフォルダーとして扱います。
- ディスク
- データを保持する物理ディスク。通常、これは RAID 設定を含むプールを作成する場合に使用されます。これは、SNIA 用語を使用した DiskDrive としても知られています。
- イニシエーター
- ファイバーチャネル (FC) またはファイバーチャネルオーバーイーサネット (FCoE) では、イニシエーターは World Wide Port Name (WWPN) または World Wide Node Name (WWNN) です。iSCSI では、イニシエーターは iSCSI 修飾名 (IQN) です。NFS または CIFS では、イニシエーターはホストのホスト名または IP アドレスです。
- 子の依存関係
- 一部のアレイには、作成元 (親ボリュームまたはファイルシステム) と、子 (スナップショットやクローンなど) の間に暗黙の関係があります。たとえば、依存している子が 1 つ以上ある場合は、親を削除できません。API は、このような関係が存在するかどうかを判断するメソッドと、必要なブロックを複製して依存関係を削除するメソッドを提供します。
27.3. libStorageMgmt のインストール
libStorageMgmt をインストールするには、以下のコマンドを使用します。
# yum install libstoragemgmt libstoragemgmt-python
# yum install libstoragemgmt-devellibStorageMgmt をインストールするには、以下のコマンドで適切なプラグインパッケージを 1 つ以上選択します。
# yum install libstoragemgmt-name-plugin- libstoragemgmt-smis-plugin
- 一般的な SMI-S アレイのサポート。
- libstoragemgmt-netapp-plugin
- NetApp ファイルの特定のサポート。
- libstoragemgmt-nstor-plugin
- NexentaStor の特定のサポート。
- libstoragemgmt-targetd-plugin
- targetd の特定のサポート。
lsmd)は、システムの標準サービスのように動作します。
# systemctl status libstoragemgmt# systemctl stop libstoragemgmt# systemctl start libstoragemgmt27.4. libStorageMgmt の使用
libStorageMgmt を対話的に使用するには、lsmcli ツールを使用します。
- アレイに接続するプラグインと、アレイに必要な設定可能なオプションを識別するために使用される URI (Uniform Resource Identifier) です。
- アレイの有効なユーザー名およびパスワード。
plugin+optional-transport://user-name@host:port/?query-string-parameters
例27.1 さまざまなプラグイン要件の例
ユーザー名やパスワードを必要としないシミュレータープラグイン
sim://
ユーザー名に root を使用した SSL 経由の NetApp プラグイン
ONTAP+ssl://root@filer.company.com/
EMC アレイ用 SSL 経由の SMI-S プラグイン
smis+ssl://admin@provider.com:5989/?namespace=root/emc
- コマンドの一部として URI を渡します。
$lsmcli -u sim:// - URI を環境変数に保存します。
$export LSMCLI_URI=sim:// - URI をファイル
~/.lsmcliに配置します。このファイルには、"=" で区切られた名前と値のペアが含まれます。現在対応している設定は 'uri' のみです。
-P オプションを指定するか、環境変数 LSMCLI_PASSWORD に配置してパスワードを指定します。
例27.2 lsmcli の例
$ lsmcli list --type SYSTEMS
ID | Name | Status
-------+-------------------------------+--------
sim-01 | LSM simulated storage plug-in | OK
$ lsmcli list --type POOLS -H
ID | Name | Total space | Free space | System ID
-----+---------------+----------------------+----------------------+-----------
POO2 | Pool 2 | 18446744073709551616 | 18446744073709551616 | sim-01
POO3 | Pool 3 | 18446744073709551616 | 18446744073709551616 | sim-01
POO1 | Pool 1 | 18446744073709551616 | 18446744073709551616 | sim-01
POO4 | lsm_test_aggr | 18446744073709551616 | 18446744073709551616 | sim-01
$ lsmcli volume-create --name volume_name --size 20G --pool POO1 -H
ID | Name | vpd83 | bs | #blocks | status | ...
-----+-------------+----------------------------------+-----+----------+--------+----
Vol1 | volume_name | F7DDF7CA945C66238F593BC38137BD2F | 512 | 41943040 | OK | ...
$ lsmcli --create-access-group example_ag --id iqn.1994-05.com.domain:01.89bd01 --type ISCSI --system sim-01
ID | Name | Initiator ID |SystemID
---------------------------------+------------+----------------------------------+--------
782d00c8ac63819d6cca7069282e03a0 | example_ag | iqn.1994-05.com.domain:01.89bd01 |sim-01
$ lsmcli access-group-create --name example_ag --init iqn.1994-05.com.domain:01.89bd01 --init-type ISCSI --sys sim-01
ID | Name | Initiator IDs | System ID
---------------------------------+------------+----------------------------------+-----------
782d00c8ac63819d6cca7069282e03a0 | example_ag | iqn.1994-05.com.domain:01.89bd01 | sim-01$ lsmcli access-group-grant --ag 782d00c8ac63819d6cca7069282e03a0 --vol Vol1 --access RW-bオプションを使用することができます。終了コードが 0 の場合、コマンドは完了します。終了コードが 7 の場合、コマンドは進行中で、ジョブ識別子が標準出力に書き込まれます。次に、ユーザーまたはスクリプトはジョブ ID を取得し、lsmcli --jobstatus JobID を使用して必要に応じてコマンドのステータスをクエリーできます。ジョブが完了すると、終了値が 0 になり、結果が標準出力に出力されます。コマンドがまだ進行中の場合、戻り値は 7 になり、完了率が標準出力に出力されます。
例27.3 非同期の例
-bオプションを渡してボリュームを作成します。
$ lsmcli volume-create --name async_created --size 20G --pool POO1 -b JOB_3$ echo $?
7$ lsmcli job-status --job JOB_3
33$ echo $?
7$ lsmcli job-status --job JOB_3
ID | Name | vpd83 | Block Size | ...
-----+---------------+----------------------------------+-------------+-----
Vol2 | async_created | 855C9BA51991B0CC122A3791996F6B15 | 512 | ...
-t SeparatorCharacters オプションを渡します。これにより、出力の解析が容易になります。
例27.4 スクリプトの例
$ lsmcli list --type volumes -t#
Vol1#volume_name#049167B5D09EC0A173E92A63F6C3EA2A#512#41943040#21474836480#OK#sim-01#POO1
Vol2#async_created#3E771A2E807F68A32FA5E15C235B60CC#512#41943040#21474836480#OK#sim-01#POO1
$ lsmcli list --type volumes -t " | "
Vol1 | volume_name | 049167B5D09EC0A173E92A63F6C3EA2A | 512 | 41943040 | 21474836480 | OK | 21474836480 | sim-01 | POO1
Vol2 | async_created | 3E771A2E807F68A32FA5E15C235B60CC | 512 | 41943040 | 21474836480 | OK | sim-01 | POO1
$ lsmcli list --type volumes -s
---------------------------------------------
ID | Vol1
Name | volume_name
VPD83 | 049167B5D09EC0A173E92A63F6C3EA2A
Block Size | 512
#blocks | 41943040
Size | 21474836480
Status | OK
System ID | sim-01
Pool ID | POO1
---------------------------------------------
ID | Vol2
Name | async_created
VPD83 | 3E771A2E807F68A32FA5E15C235B60CC
Block Size | 512
#blocks | 41943040
Size | 21474836480
Status | OK
System ID | sim-01
Pool ID | POO1
---------------------------------------------
第28章 永続メモリー : NVDIMMs
pmem)は、ストレージクラスメモリーとしても呼び出され、メモリーとストレージの組み合わせです。PMEM は、ストレージの耐久性と低アクセスレイテンシー、動的 RAM (DRAM)の高帯域幅を組み合わせたものです。
- 永続メモリーはバイト単位でアドレスを指定できるため、CPU 読み込みおよびストア命令でアクセスできます。従来のブロックベースのストレージへのアクセスに必要な
read()またはwrite()システムコールに加えて、pmemはダイレクトロードおよびストアプログラミングモデルもサポートします。 - 永続メモリーのパフォーマンス特性は、アクセスレイテンシーが非常に低い (通常、数十から数百ナノ秒) DRAM と似ています。
- 永続メモリーの内容は、ストレージと同様に、電源が切れても保持されます。
永続メモリーの使用は、以下のようなユースケースで利点があります。
- 高速な起動: データセットはすでにメモリーにあります。
- 高速な起動は、ウォームキャッシュ効果とも呼ばれます。起動後、ファイルサーバーのメモリーにファイルの内容はありません。クライアントがデータを接続して読み書きすると、そのデータはページキャッシュにキャッシュされます。最終的に、キャッシュには、ほとんどのホットデータが含まれます。システムを再起動したら、プロセスを再起動する必要があります。永続メモリーを使用すると、アプリケーションが適切に設計されていれば、システムの再起動後もアプリケーションのウォームキャッシュを維持できます。この例には、ページキャッシュは含まれません。アプリケーションは、永続メモリーに直接データをキャッシュします。
- 高速書き込みキャッシュ
- ファイルサーバーは多くの場合、耐久性のあるメディアにデータが存在するまで、クライアントの書き込み要求を承認しません。永続メモリーを高速書き込みキャッシュとして使用すると、
pmemのレイテンシーが低くなるため、ファイルサーバーは書き込み要求をすばやく確認できます。
NVDIMMs のインターリーブ
- DRAM と同様に、NVDIMMs もインターリーブセットに設定するとパフォーマンスが向上します。
- これを使用すると、複数の小規模な NVDIMMs を、1 つのより大きな論理デバイスに統合できます。
- NVDIMMs がラベルに対応している場合は、リージョンデバイスを名前空間にさらに細かく分けることができます。
- NVDIMMs がラベルに対応していない場合、リージョンデバイスは、単一の名前空間しか含むことができません。この場合、カーネルは、リージョン全体に対応するデフォルトの namespace を作成します。
永続メモリーアクセスモード
セクター、fsdax、devdax (デバイスダイレクトアクセス)または raw モードで使用できます。
sectorモード- ストレージは高速ブロックデバイスとして提示されます。セクターモードの使用は、永続メモリーを使用するように変更されていない従来のアプリケーションや、デバイスマッパーを含む完全な I/O スタックを利用するアプリケーションに役立ちます。
fsdaxモード- これにより、Storage Networking Industry Association (SNIA) 非揮発性メモリー (NVM) プログラミングモデル仕様 で説明されているように、永続メモリーデバイスは、ダイレクトアクセスプログラミングをサポートできます。このモードでは、I/O はカーネルのストレージスタックを回避するため、多くのデバイスマッパードライバーが使用できなくなります。
devdaxモードdevdax(デバイス DAX)モードは、DAX キャラクターデバイスノードを使用して永続メモリーへの raw アクセスを提供します。devdaxデバイスのデータは、CPU キャッシュのフラッシュとフェンシング命令を使用して永続化できます。特定のデータベースおよび仮想マシンのハイパーバイザーは、devdaxモードの利点を活用できます。ファイルシステムは、デバイスdevdaxインスタンスで作成することはできません。rawモード- raw モードの名前空間にいくつかの制限があるため、使用すべきではありません。
28.1. ndctl を使用した永続メモリーの設定
# yum install ndctl手順28.1 ラベルをサポートしないデバイスの永続メモリーの設定
- システムで利用可能な
pmemリージョンを一覧表示します。以下の例では、コマンドは、ラベルをサポートしない NVDIMM-N デバイスをリスト表示します。#ndctl list --regions [ { "dev":"region1", "size":34359738368, "available_size":0, "type":"pmem" }, { "dev":"region0", "size":34359738368, "available_size":0, "type":"pmem" } ]Red Hat Enterprise Linux では、各リージョンにデフォルトの名前空間が作成されます。これは、ここにある NVDIMM-N デバイスがラベルに対応していないためです。そのため、使用可能なサイズは 0 バイトです。 - システムでアクティブでない名前空間のリストを表示します。
#ndctl list --namespaces --idle [ { "dev":"namespace1.0", "mode":"raw", "size":34359738368, "state":"disabled", "numa_node":1 }, { "dev":"namespace0.0", "mode":"raw", "size":34359738368, "state":"disabled", "numa_node":0 } ] - この領域を使用できるように、非アクティブの名前空間を再設定します。たとえば、DAX に対応するファイルシステムに namespace0.0 を使用する場合は、次のコマンドを使用します。
#ndctl create-namespace --force --reconfig=namespace0.0 --mode=fsdax --map=mem { "dev":"namespace0.0", "mode":"fsdax", "size":"32.00 GiB (34.36 GB)", "uuid":"ab91cc8f-4c3e-482e-a86f-78d177ac655d", "blockdev":"pmem0", "numa_node":0 }
手順28.2 ラベルをサポートするデバイスの永続メモリーの設定
- システムで利用可能な
pmemリージョンを一覧表示します。以下の例では、コマンドは、ラベルをサポートする NVDIMM-N デバイスをリスト表示します。#ndctl list --regions [ { "dev":"region5", "size":270582939648, "available_size":270582939648, "type":"pmem", "iset_id":-7337419320239190016 }, { "dev":"region4", "size":270582939648, "available_size":270582939648, "type":"pmem", "iset_id":-137289417188962304 } ] - NVDIMM デバイスがラベルをサポートしている場合、デフォルトの名前空間は作成されず、--force フラグまたは --reconfigure フラグを使用せずに、リージョンから 1 つ以上の名前空間を割り当てることができます。
#ndctl create-namespace --region=region4 --mode=fsdax --map=dev --size=36G { "dev":"namespace4.0", "mode":"fsdax", "size":"35.44 GiB (38.05 GB)", "uuid":"9c5330b5-dc90-4f7a-bccd-5b558fa881fe", "blockdev":"pmem4", "numa_node":0 }これで、同じリージョンから別の名前空間を作成できるようになります。#ndctl create-namespace --region=region4 --mode=fsdax --map=dev --size=36G { "dev":"namespace4.1", "mode":"fsdax", "size":"35.44 GiB (38.05 GB)", "uuid":"91868e21-830c-4b8f-a472-353bf482a26d", "blockdev":"pmem4.1", "numa_node":0 }以下のコマンドを使用して、同じリージョンから異なるタイプの名前空間を作成することもできます。#ndctl create-namespace --region=region4 --mode=devdax --align=2M --size=36G { "dev":"namespace4.2", "mode":"devdax", "size":"35.44 GiB (38.05 GB)", "uuid":"a188c847-4153-4477-81bb-7143e32ffc5c", "daxregion": { "id":4, "size":"35.44 GiB (38.05 GB)", "align":2097152, "devices":[ { "chardev":"dax4.2", "size":"35.44 GiB (38.05 GB)" }] }, "numa_node":0 }
28.2. ブロックデバイスとして使用する永続メモリーの設定 (レガシーモード)
# ndctl create-namespace --force --reconfig=namespace1.0 --mode=sector
{
"dev":"namespace1.0",
"mode":"sector",
"size":17162027008,
"uuid":"029caa76-7be3-4439-8890-9c2e374bcc76",
"sector_size":4096,
"blockdev":"pmem1s"
}
namespace1.0 はセクターモードに再設定されます。ブロックデバイス名が pmem1 から pmem1 s に変更されました。このデバイスは、システム上の他のブロックデバイスと同じように使用できます。たとえば、デバイスをパーティション化して、デバイスにファイルシステムを作成したり、デバイスをソフトウェア RAID セットの一部として設定したり、デバイスを dm-cache のキャッシュデバイスにしたりできます。
28.3. ファイルシステムのダイレクトアクセス向け永続メモリーの設定
fsdax モードに設定する必要があります。このモードでは、ダイレクトアクセスプログラミングモデルが可能になります。デバイスが fsdax モードで設定されている場合、その上にファイルシステムを作成し、-o fsdax マウントオプションでマウントできます。次に、このファイルシステムのファイルで mmap() 操作を実行するアプリケーションは、そのストレージに直接アクセスします。以下の例を参照してください。
# ndctl create-namespace --force --reconfig=namespace0.0 --mode=fsdax --map=mem
{
"dev":"namespace0.0",
"mode":"fsdax",
"size":17177772032,
"uuid":"e6944638-46aa-4e06-a722-0b3f16a5acbf",
"blockdev":"pmem0"
}
namespace0.0 は名前空間 fsdax モードに変換されます。--map=mem 引数を使用すると、ndctl はダイレクトメモリーアクセス(DMA)に使用されるオペレーティングシステムのデータ構造をシステム DRAM に配置します。
fsdax モードで名前空間を設定すると、名前空間がファイルシステムの準備が整います。Red Hat Enterprise Linux 7.3 以降、Ext4 と XFS の両方のファイルシステムで、テクノロジープレビューとして永続メモリーを使用できるようになりました。ファイルシステムの作成に特別な引数は必要ありません。DAX 機能を取得するには、dax マウントオプションを使用してファイルシステムをマウントします。以下に例を示します。
#mkfs -t xfs /dev/pmem0#mount -o dax /dev/pmem0 /mnt/pmem/
/mnt/pmem/ ディレクトリーにファイルを作成し、ファイルを開き、mmap 操作を使用して直接アクセス用のファイルをマップできます。
pmem デバイスにパーティションを作成する場合は、パーティションはページ境界に合わせる必要があります。Intel 64 および AMD64 アーキテクチャーでは、パーティションの開始および終了に 4KiB 以上のアライメントを使用しますが、推奨されるアライメントは 2MiB です。parted ツールは、デフォルトでは 1MiB の境界にパーティションを合わせます。最初のパーティションには、パーティションの開始部分として 2MiB を指定します。パーティションのサイズが 2MiB の倍数の場合は、その他のパーティションも合わせてアライメントされます。
28.4. デバイス DAX モードで使用する永続メモリーの設定
devdax)は、ファイルシステムの関与なしに、アプリケーションがストレージに直接アクセスできる手段を提供します。デバイス DAX の利点は、ndctl ユーティリティーの --align オプションを使用して設定できる、保証されたフォールトの粒度を提供することです。
# ndctl create-namespace --force --reconfig=namespace0.0 --mode=devdax --align=2M- 4KiB
- 2MiB
- 1GiB
/dev/daxN.M)は、以下のシステムコールのみをサポートします。
open()close()mmap()fallocate()
read() ユースケースは永続メモリープログラミングに関連付けられるため、write() バリアントおよび バリアントはサポートされません。
28.5. NVDIMM のトラブルシューティング
28.5.1. S.M.A.R.T を使用した NVDIMM の正常性の監視
前提条件
- 一部のシステムでは、以下のコマンドを使用して正常性情報を取得するために、acpi_ipmi ドライバーを読み込む必要があります。
#modprobe acpi_ipmi
手順
- 正常性情報にアクセスするには、次のコマンドを使用します。
#ndctl list --dimms --health ... { "dev":"nmem0", "id":"802c-01-1513-b3009166", "handle":1, "phys_id":22, "health": { "health_state":"ok", "temperature_celsius":25.000000, "spares_percentage":99, "alarm_temperature":false, "alarm_spares":false, "temperature_threshold":50.000000, "spares_threshold":20, "life_used_percentage":1, "shutdown_state":"clean" } } ...
28.5.2. 破損した NVDIMM の検出と置き換え
- どの NVDIMM デバイスに障害が発生しているかを検出する
- 保存されているデータのバックアップを作成する
- デバイスを物理的に交換する
手順28.3 破損した NVDIMM の検出と置き換え
- 破損した DIMM を検出するには、次のコマンドを使用します。
# ndctl list --dimms --regions --health --media-errors --human
badblocksフィールドは、NVDIMM が破損していることを示しています。devフィールドに名前を書き留めます。以下の例では、nmem0という名前の NVDIMM が破損しています。例28.1 NVDIMM デバイスの正常性ステータス
# ndctl list --dimms --regions --health --media-errors --human ... "regions":[ { "dev":"region0", "size":"250.00 GiB (268.44 GB)", "available_size":0, "type":"pmem", "numa_node":0, "iset_id":"0xXXXXXXXXXXXXXXXX", "mappings":[ { "dimm":"nmem1", "offset":"0x10000000", "length":"0x1f40000000", "position":1 }, { "dimm":"nmem0", "offset":"0x10000000", "length":"0x1f40000000", "position":0 } ], "badblock_count":1, "badblocks":[ { "offset":65536, "length":1, "dimms":[ "nmem0" ] } ], "persistence_domain":"memory_controller" } ] } - 次のコマンドを使用して、破損した NVDIMM の
phys_id属性を検索します。# ndctl list --dimms --human
前の例では、nmem0が破損した NVDIMM であることがわかります。したがって、nmem0のphys_id属性を確認します。以下の例では、phys_idは0x10です。例28.2 NVDIMMs の phys_id 属性
# ndctl list --dimms --human [ { "dev":"nmem1", "id":"XXXX-XX-XXXX-XXXXXXXX", "handle":"0x120", "phys_id":"0x1c" }, { "dev":"nmem0", "id":"XXXX-XX-XXXX-XXXXXXXX", "handle":"0x20", "phys_id":"0x10", "flag_failed_flush":true, "flag_smart_event":true } ] - 次のコマンドを使用して、破損した NVDIMM のメモリースロットを確認します。
# dmidecode
出力で、Handle識別子が破損した NVDIMM のphys_id属性と一致するエントリーを見つけます。Locatorフィールドには、破損した NVDIMM が使用するメモリースロットが一覧表示されます。以下の例では、nmem0デバイスは0x0010識別子と一致し、DIMM-XXX-YYYYメモリースロットを使用します。例28.3 NVDIMM メモリースロットリスティング
# dmidecode ... Handle 0x0010, DMI type 17, 40 bytes Memory Device Array Handle: 0x0004 Error Information Handle: Not Provided Total Width: 72 bits Data Width: 64 bits Size: 125 GB Form Factor: DIMM Set: 1 Locator: DIMM-XXX-YYYY Bank Locator: Bank0 Type: Other Type Detail: Non-Volatile Registered (Buffered) ... - NVDIMM 上の名前空間にある全データのバックアップを作成します。NVDIMM を交換する前にデータのバックアップを作成しないと、システムから NVDIMM を削除したときにデータが失われます。警告時折、NVDIMM が完全に破損すると、バックアップが失敗することがあります。これを防ぐため、「S.M.A.R.T を使用した NVDIMM の正常性の監視」 の説明に従って、S.M.A.R.T. を使用して NVDIMMs デバイスを定期的に監視し、破損する前にエラーを起こしている NVDIMMs を交換してください。次のコマンドを使用して、NVDIMM の名前空間をリスト表示します。
# ndctl list --namespaces --dimm=DIMM-ID-number
以下の例では、nmem0デバイスには、バックアップする必要があるnamespace0.0および namespace0.2 の名前空間が含まれます。例28.4 NVDIMM 名前空間のリスト表示
# ndctl list --namespaces --dimm=0 [ { "dev":"namespace0.2", "mode":"sector", "size":67042312192, "uuid":"XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX", "raw_uuid":"XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX", "sector_size":4096, "blockdev":"pmem0.2s", "numa_node":0 }, { "dev":"namespace0.0", "mode":"sector", "size":67042312192, "uuid":"XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX", "raw_uuid":"XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX", "sector_size":4096, "blockdev":"pmem0s", "numa_node":0 } ] - 破損した NVDIMM を物理的に交換します。
第29章 NVMe over fabric デバイスの概要
NVMe over fabric デバイスを設定します。
- RDMA (Remote Direct Memory Access) を使用する NVMe over fabricsNVMe/RDMA の設定方法の詳細は、「RDMA を使用した NVMe over fabrics」 を参照してください。
- ファイバーチャネル (FC) を使用する NVMe over fabricsFC-NVMe の設定方法の詳細は、「FC を使用した NVMe over fabrics」 を参照してください。
29.1. RDMA を使用した NVMe over fabrics
29.1.1. RDMA クライアントでの NVMe の設定
nvme-cli)を使用して NVMe/RDMA クライアントを設定します。
nvme-cliパッケージをインストールします。#yum install nvme-clinvme-rdmaモジュールが読み込まれていない場合は読み込みます。#modprobe nvme-rdma- NVMe ターゲットで利用可能なサブシステムを検出します。
#nvme discover -t rdma -a 172.31.0.202 -s 4420 Discovery Log Number of Records 1, Generation counter 2 =====Discovery Log Entry 0====== trtype: rdma adrfam: ipv4 subtype: nvme subsystem treq: not specified, sq flow control disable supported portid: 1 trsvcid: 4420 subnqn: testnqn traddr: 172.31.0.202 rdma_prtype: not specified rdma_qptype: connected rdma_cms: rdma-cm rdma_pkey: 0x0000 - 検出されたサブシステムに接続します。
#nvme connect -t rdma -n testnqn -a 172.31.0.202 -s 4420#lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sda 8:0 0 465.8G 0 disk ├─sda1 8:1 0 1G 0 part /boot └─sda2 8:2 0 464.8G 0 part ├─rhel_rdma--virt--03-root 253:0 0 50G 0 lvm / ├─rhel_rdma--virt--03-swap 253:1 0 4G 0 lvm [SWAP] └─rhel_rdma--virt--03-home 253:2 0 410.8G 0 lvm /home nvme0n1#cat /sys/class/nvme/nvme0/transport rdmatestnqn を、NVMe サブシステムの名前に置き換えます。172.31.0.202 を、目的の IP アドレスに置き換えます。4420 を、ポート番号に置き換えます。 - 現在接続されている NVMe デバイスのリストを表示します。
#nvme list - (必要に応じて) ターゲットから切断します。
#nvme disconnect -n testnqn NQN:testnqn disconnected 1 controller(s)#lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sda 8:0 0 465.8G 0 disk ├─sda1 8:1 0 1G 0 part /boot └─sda2 8:2 0 464.8G 0 part ├─rhel_rdma--virt--03-root 253:0 0 50G 0 lvm / ├─rhel_rdma--virt--03-swap 253:1 0 4G 0 lvm [SWAP] └─rhel_rdma--virt--03-home 253:2 0 410.8G 0 lvm /home
関連情報
- 詳細は、
nvmeの man ページおよび NVMe-cli Github リポジトリー を参照してください。
29.2. FC を使用した NVMe over fabrics
29.2.1. Broadcom アダプターの NVMe イニシエーターの設定
nvme-cli)ツールを使用して、Broadcom アダプタークライアントの NVMe イニシエーターを設定します。
nvme-cliツールをインストールします。#yum install nvme-cliこれにより、/etc/nvme/ディレクトリーにhostnqnファイルが作成されます。hostnqnファイルは NVMe ホストを識別します。新しいhostnqnを生成するには、以下を実行します。#nvme gen-hostnqn- 以下の内容で
/etc/modprobe.d/lpfc.confファイルを作成します。options lpfc lpfc_enable_fc4_type=3
initramfsイメージを再構築します。# dracut --force
- ホストシステムを再起動して、
lpfcドライバーを再設定します。# systemctl reboot
- ローカルポートおよびリモートポートの WWNN および WWPN を見つけ、この出力を使用してサブシステム NQN を見つけます。
#cat /sys/class/scsi_host/host*/nvme_info NVME Initiator Enabled XRI Dist lpfc0 Total 6144 IO 5894 ELS 250 NVME LPORT lpfc0 WWPN x10000090fae0b5f5 WWNN x20000090fae0b5f5 DID x010f00 ONLINE NVME RPORT WWPN x204700a098cbcac6 WWNN x204600a098cbcac6 DID x01050e TARGET DISCSRVC ONLINE NVME Statistics LS: Xmt 000000000e Cmpl 000000000e Abort 00000000 LS XMIT: Err 00000000 CMPL: xb 00000000 Err 00000000 Total FCP Cmpl 00000000000008ea Issue 00000000000008ec OutIO 0000000000000002 abort 00000000 noxri 00000000 nondlp 00000000 qdepth 00000000 wqerr 00000000 err 00000000 FCP CMPL: xb 00000000 Err 00000000#nvme discover --transport fc \ --traddr nn-0x204600a098cbcac6:pn-0x204700a098cbcac6 \ --host-traddr nn-0x20000090fae0b5f5:pn-0x10000090fae0b5f5 Discovery Log Number of Records 2, Generation counter 49530 =====Discovery Log Entry 0====== trtype: fc adrfam: fibre-channel subtype: nvme subsystem treq: not specified portid: 0 trsvcid: none subnqn: nqn.1992-08.com.netapp:sn.e18bfca87d5e11e98c0800a098cbcac6:subsystem.st14_nvme_ss_1_1 traddr: nn-0x204600a098cbcac6:pn-0x204700a098cbcac6nn-0x204600a098cbcac6:pn-0x204700a098cbcac6 を、traddrに置き換えます。nn-0x20000090fae0b5f5:pn-0x10000090fae0b5f5 を、host_traddrに置き換えます。 nvme-cliを使用して NVMe ターゲットに接続します。#nvme connect --transport fc --traddr nn-0x204600a098cbcac6:pn-0x204700a098cbcac6 --host-traddr nn-0x20000090fae0b5f5:pn-0x10000090fae0b5f5 -n nqn.1992-08.com.netapp:sn.e18bfca87d5e11e98c0800a098cbcac6:subsystem.st14_nvme_ss_1_1nn-0x204600a098cbcac6:pn-0x204700a098cbcac6 をtraddr に置き換えます。nn-0x20000090fae0b5f5:pn-0x10000090fae0b5f5 をhost_traddr に置き換えます。nqn.1992-08.com.netapp:sn.e18bfca87d5e11e98c0800a098cbcac6:subsystem.st14_nvme_ss_1_ 1 を、subnqn に置き換えます。- NVMe デバイスが現在接続されていることを確認します。
#nvme list Node SN Model Namespace Usage Format FW Rev ---------------- -------------------- ---------------------------------------- --------- -------------------------- ---------------- -------- /dev/nvme0n1 80BgLFM7xMJbAAAAAAAC NetApp ONTAP Controller 1 107.37 GB / 107.37 GB 4 KiB + 0 B FFFFFFFF#lsblk |grep nvme nvme0n1 259:0 0 100G 0 disk
関連情報
- 詳細は、
nvmeの man ページおよび NVMe-cli Github リポジトリー を参照してください。
29.2.2. QLogic アダプターの NVMe イニシエーターの設定
(nvme-cli) ツールを使用して、Qlogic アダプタークライアントの NVMe イニシエーターを設定します。
nvme-cliツールをインストールします。#yum install nvme-cliこれにより、/etc/nvme/ディレクトリーにhostnqnファイルが作成されます。hostnqnファイルは NVMe ホストを識別します。新しいhostnqnを生成するには、以下を実行します。#nvme gen-hostnqnqla2xxxモジュールを削除して再読み込みします。#rmmod qla2xxx#modprobe qla2xxx- ローカルポートおよびリモートポートの WWNN および WWPN を検索します。
#dmesg |grep traddr [ 6.139862] qla2xxx [0000:04:00.0]-ffff:0: register_localport: host-traddr=nn-0x20000024ff19bb62:pn-0x21000024ff19bb62 on portID:10700 [ 6.241762] qla2xxx [0000:04:00.0]-2102:0: qla_nvme_register_remote: traddr=nn-0x203b00a098cbcac6:pn-0x203d00a098cbcac6 PortID:01050dこのhost-traddrおよびtraddrを使用して、サブシステム NQN を見つけます。#nvme discover --transport fc --traddr nn-0x203b00a098cbcac6:pn-0x203d00a098cbcac6 --host-traddr nn-0x20000024ff19bb62:pn-0x21000024ff19bb62 Discovery Log Number of Records 2, Generation counter 49530 =====Discovery Log Entry 0====== trtype: fc adrfam: fibre-channel subtype: nvme subsystem treq: not specified portid: 0 trsvcid: none subnqn: nqn.1992-08.com.netapp:sn.c9ecc9187b1111e98c0800a098cbcac6:subsystem.vs_nvme_multipath_1_subsystem_468 traddr: nn-0x203b00a098cbcac6:pn-0x203d00a098cbcac6nn-0x203b00a098cbcac6:pn-0x203d00a098cbcac6 をtraddr に置き換えます。nn-0x20000024ff19bb62:pn-0x21000024ff19bb62 を、host_traddr に置き換えます。 nvme-cliツールを使用して NVMe ターゲットに接続します。#nvme connect --transport fc --traddr nn-0x203b00a098cbcac6:pn-0x203d00a098cbcac6 --host_traddr nn-0x20000024ff19bb62:pn-0x21000024ff19bb62 -n nqn.1992-08.com.netapp:sn.c9ecc9187b1111e98c0800a098cbcac6:subsystem.vs_nvme_multipath_1_subsystem_468nn-0x203b00a098cbcac6:pn-0x203d00a098cbcac6 をtraddr に置き換えます。nn-0x20000024ff19bb62:pn-0x21000024ff19bb62 を、host_traddr に置き換えます。nqn.1992-08.com.netapp:sn.c9ecc9187b1111e98c0800a098cbcac6:subsystem.vs_nvme_multipath_1_subsystem_468 をsubnqn に置き換えます。- NVMe デバイスが現在接続されていることを確認します。
#nvme list Node SN Model Namespace Usage Format FW Rev ---------------- -------------------- ---------------------------------------- --------- -------------------------- ---------------- -------- /dev/nvme0n1 80BgLFM7xMJbAAAAAAAC NetApp ONTAP Controller 1 107.37 GB / 107.37 GB 4 KiB + 0 B FFFFFFFF#lsblk |grep nvme nvme0n1 259:0 0 100G 0 disk
関連情報
- 詳細は、
nvmeの man ページおよび NVMe-cli Github リポジトリー を参照してください。
パート III. VDO を使用したデータの重複排除と圧縮
第30章 VDO 統合
30.1. VDO の理論的概要
- 重複排除 とは、重複ブロックの複数のコピーを削除することで、ストレージリソースの消費を低減させるための技術です。同じデータを複数回書き込むのではなく、VDO は各重複ブロックを検出し、元のブロックへの参照として記録します。VDO は、VDO の上にあるストレージ層により使用されている論理ブロックアドレスから、VDO の下にあるストレージ層で使用される物理ブロックアドレスへのマッピングを維持します。重複排除後、複数の論理ブロックアドレスは、同じ物理ブロックアドレスにマッピングできます。これらは、共有ブロック と呼ばれます。ブロックストレージの共有は、VDO が存在しない場合に、読み込みブロックと書き込みブロックが行われるストレージのユーザーには表示されません。共有ブロックを上書きすると、新しい物理ブロックが割り当てられて新しいブロックデータが保存され、共有物理ブロックにマッピングされているその他の論理ブロックアドレスが変更されないようにします。
- 圧縮 は、ログファイルやデータベースなど、必ずしもブロックレベルの冗長性を示さないファイル形式で適切に機能するデータ削減技術です。詳細は、「圧縮の使用」 を参照してください。
kvdo- Linux Device Mapper 層に読み込まれるカーネルモジュールは、重複排除され、圧縮され、シンプロビジョニングされたブロックストレージボリュームを提供します。
uds- ボリューム上の Universal Deduplication Service (UDS) インデックスと通信し、データの重複を分析するカーネルモジュール。
- コマンドラインツール
- 最適化されたストレージの設定および管理
30.1.1. UDS カーネルモジュール(uds)
uds カーネルモジュールとして実行されます。
30.1.2. VDO カーネルモジュール(kvdo)
kvdo Linux カーネルモジュールは、Linux Device Mapper レイヤー内でブロック層の重複排除サービスを提供します。Linux カーネルでは、Device Mapper はブロックストレージのプールを管理する一般的なフレームワークとして機能し、カーネルのブロックインターフェイスと実際のストレージデバイスドライバーとの間でストレージスタックにブロック処理モジュールを挿入できるようにします。
kvdo モジュールは、ブロックストレージ用に直接アクセスできるブロックデバイスとして公開され、XFS や ext4 など、利用可能な多くの Linux ファイルシステムのいずれかを介して提示されます。kvdo が VDO ボリュームからデータの(論理)ブロックを読み取る要求を受信すると、要求された論理ブロックを基礎となる物理ブロックにマッピングし、要求されたデータを読み取り、返します。
kvdo は、データのブロックを VDO ボリュームに書き込む要求を受信すると、最初にそれが DISCARD または TRIM 要求であるかどうか、データが均一にゼロであるかどうかを確認します。これらの条件のいずれかが保持されている場合、kvdo はブロックマップを更新し、要求を承認します。それ以外の場合は、リクエストで使用する物理ブロックが割り当てられます。
VDO 書き込みポリシーの概要
kvdo モジュールが同期モードで動作している場合は、以下を行います。
- リクエストのデータを一時的に、割り当てられたブロックに書き込み、リクエストを承認します。
- 承認が完了すると、ブロックデータの MurmurHash-3 署名を計算してブロックの重複排除が試行されます。これは、VDO インデックスに送信されます。
- VDO インデックスに同じ署名を持つブロックのエントリーが含まれている場合、
kvdoは示されたブロックを読み取り、2 つのブロックのバイトバイバイト比較を行い、同一であることを確認します。 - 同一であると、
kvdoはブロックマップを更新し、論理ブロックが対応する物理ブロックをポイントするようにし、割り当てられた物理ブロックを解放します。 - VDO インデックスに、書き込まれているブロックの署名のエントリーが含まれていないか、示されたブロックに実際に同じデータが含まれていない場合、
kvdoはブロックマップを更新して、一時的な物理ブロックを永続的にします。
kvdo が非同期モードで動作している場合は、以下を行います。
- データを書き込む代わりに、リクエストをすぐに承認します。
- 上記の説明と同じように、ブロックの重複排除試行が行われます。
- ブロックが重複していると、
kvdoはブロックマップを更新し、割り当てられたブロックを解放します。それ以外の場合は、要求のデータが割り当てられたブロックに書き込まれ、ブロックマップが更新されて物理ブロックが永続的になります。
30.1.3. VDO ボリューム
図30.1 VDO ディスクの設定

スラブ
| 物理ボリュームのサイズ | 推奨されるスラブサイズ |
|---|---|
| 10 - 99 GB | 1 GB |
| 100 GB - 1 TB | 2 GB |
| 2 - 256 TB | 32 GB |
vdo create コマンドに
--vdoSlabSize=megabytes
オプションを指定することで制御できます。
物理サイズと利用可能な物理サイズ
- 物理サイズ は、基盤となるブロックデバイスと同じサイズになります。VDO は、以下の目的でこのストレージを使用します。
- 重複排除および圧縮される可能性があるユーザーデータ
- UDS インデックスなどの VDO メタデータ
- 利用可能な物理サイズ は、VDO がユーザーデータに使用できる物理サイズの一部です。これは、メタデータのサイズを引いた物理サイズと同等で、指定のスラブサイズでボリュームをスラブに分割した後の残りを引いたものと同じです。
論理サイズ
--vdoLogicalSize オプションを指定しない場合は、使用可能な物理ボリュームのサイズが、論理ボリュームのデフォルトサイズとなります。図30.1「VDO ディスクの設定」 では、VDO で重複排除したストレージターゲットがブロックデバイス上に完全に配置されています。つまり、VDO ボリュームの物理サイズは、基礎となるブロックデバイスと同じサイズになります。
30.1.4. コマンドラインツール
30.2. システム要件
プロセッサーアーキテクチャー
RAM
- VDO モジュールには、マネージドの物理ストレージ 1TB ごとに 370MB と、追加の 268MB が必要です。
- Universal Deduplication Service (UDS) インデックスには、最低 250MB の DRAM が必要です。これは、重複排除が使用するデフォルトの容量でもあります。UDS のメモリー使用量は、「UDS インデックスのメモリー要件」 を参照してください。
ストレージ
追加のシステムソフトウェア
- LVM
- Python 2.7
yum パッケージマネージャーは、必要なすべてのソフトウェア依存関係を自動的にインストールします。
ストレージスタックでの VDO の配置
- VDO の下:DM-Multipath、DM-Crypt、およびソフトウェア RAID (LVM または
mdraid)。 - VDO の上: LVM キャッシュ、LVM スナップショット、および LVM シンプロビジョニング。
- VDO ボリュームの上に VDO - ストレージ → LVM → VDO
- LVM スナップショット上の VDO
- LVM キャッシュ上の VDO
- ループバックデバイス上の VDO
- LVM シンプロビジョニング上の VDO
- VDO の上に 暗号化されたボリューム - ストレージ → VDO → DM-Crypt
- VDO ボリューム上のパーティション:
fdisk、parted、および同様のパーティション - VDO ボリューム上の RAID (LVM、MD、またはその他のタイプ)
sync と async の 2 つの書き込みモードに対応します。VDO が sync モードの場合、基礎となるストレージがデータを永続的に書き込みすると、VDO デバイスへの書き込みが確認されます。VDO が async モードの場合、永続ストレージに書き込まれる前に書き込みが確認されます。
auto オプションに設定されており、適切なポリシーが自動的に選択されます。
30.2.1. UDS インデックスのメモリー要件
- 一意のブロックごとに最大 1 つのエントリーを含むメモリーでは、コンパクトな表が用いられています。
- 発生する際に、インデックスに対して示される関連のブロック名を順に記録するオンディスクコンポーネント。
- デンスインデックスの場合、UDS は、RAM 1GB あたり 1TB の重複排除ウィンドウを提供します。通常、最大 4TB のストレージシステムには 1GB のインデックスで十分です。
- スパースインデックスの場合、UDS は、RAM 1GB あたり 10TB の重複排除ウィンドウを提供します。通常、最大 40 TB の物理ストレージには、1 GB の sparse インデックスで十分です。
30.2.2. VDO ストレージ領域の要件
- VDO は、2 種類のメタデータを基盤となる物理ストレージに書き込みます。
- 最初のタイプは、VDO ボリュームの物理サイズでスケーリングし、物理ストレージの 4GB ごとに約 1MB を使用し、スラブごとにさらに 1MB を使用します。
- 2 番目のタイプは、VDO ボリュームの論理サイズでスケーリングされ、論理ストレージが 1GB ごとに約 1.25MB を消費し、最も近いスラブに切り上げられます。
スラブの詳細は、「VDO ボリューム」 を参照してください。 - UDS インデックスは VDO ボリュームグループ内に保存され、関連付けられた VDO インスタンスによって管理されます。必要なストレージの量は、インデックスのタイプと、インデックスに割り当てられている RAM の量により異なります。RAM 1GB ごとに、デンス UDS インデックスはストレージを 17GB 使用し、スパース UDS インデックスはストレージを 170GB 使用します。
30.2.3. 物理ボリュームのサイズ別の VDO システム要件の例
プライマリーストレージのデプロイメント
| 物理ボリュームのサイズ | 10 GB - 1-TB | 2–10 TB | 11–50 TB | 51–100 TB | 101–256 TB |
|---|---|---|---|---|---|
| RAM の使用 | 250 MB |
デンス: 1 GB
スパース: 250 MB
| 2 GB | 3 GB | 12 GB |
| ディスクの使用率 | 2.5 GB |
デンス: 10 GB
スパース: 22 GB
| 170 GB | 255 GB | 1020 GB |
| インデックスタイプ | デンス | デンスまたはスパース | スパース | スパース | スパース |
バックアップストレージのデプロイメント
| 物理ボリュームのサイズ | 10 GB – 1 TB | 2–10 TB | 11–50 TB | 51–100 TB | 101–256 TB |
|---|---|---|---|---|---|
| RAM の使用 | 250 MB | 2 GB | 10 GB | 20 GB | 26 GB |
| ディスクの使用率 | 2.5 GB | 170 GB | 850 GB | 1700 GB | 3400 GB |
| インデックスタイプ | デンス | スパース | スパース | スパース | スパース |
30.3. VDO の使用
30.3.1. 導入部分
- アクティブな仮想マシンまたはコンテナーをホストする場合、Red Hat は、論理と物理の割合が 10 対 1 のストレージをプロビジョニングすることを推奨します。つまり、物理ストレージを 1 TB 使用している場合は、論理ストレージを 10 TB にします。
- Ceph が提供するタイプなどのオブジェクトストレージの場合、Red Hat では、論理対物理の比率を 3:1 にすることを推奨しています。つまり、物理ストレージが 1TB の場合は、論理ストレージを 3TB にします。
- Red Hat Virtualization を使用して構築したサーバーなどの仮想サーバー用の直接接続のユースケース
- Ceph Storage を使用して構築したものなど、オブジェクトベースの分散ストレージクラスターのクラウドストレージのユースケース。注記Ceph を使用した VDO デプロイメントは現在サポートされていません。
30.3.2. VDO のインストール
- vdo
- kmod-kvdo
# yum install vdo kmod-kvdo30.3.3. VDO ボリュームの作成
vdo1 など)に置き換えます。
- VDO Manager を使用して VDO ボリュームを作成します。
#vdo create \--name=vdo_name\--device=block_device\--vdoLogicalSize=logical_size \[--vdoSlabSize=slab_size]- block_device を、VDO ボリュームを作成するブロックデバイスの永続名に置き換えます。たとえば、
/dev/disk/by-id/scsi-3600508b1001c264ad2af21e903ad031fなどです。重要永続的なデバイス名を使用します。永続的なデバイス名を使用しないと、今後デバイスの名前が変わった場合に、VDO が正しく起動しなくなることがあります。永続的な名前の詳細は、「永続的な命名」 を参照してください。 - logical_size を、VDO ボリュームが存在する論理ストレージの容量に置き換えます。
- アクティブな仮想マシンまたはコンテナーストレージには、ブロックデバイスの物理サイズの 10 倍の論理サイズを使用します。たとえば、ブロックデバイスのサイズが 1 TB の場合は、
10Tを使用します。 - オブジェクトのストレージには、ブロックデバイスの物理サイズの 3 倍の論理サイズを使用します。たとえば、ブロックデバイスのサイズが 1 TB の場合は、
3Tを使用します。
- ブロックデバイスが 16 TiB を超える場合は、
--vdoSlabSize=32Gを追加して、ボリューム上のスラブサイズを 32 GiB に増やします。16 TiB を超えるブロックデバイスでデフォルトのスラブサイズ 2 GiB を使用すると、vdo create コマンドが失敗し、以下のエラーが発生します。vdo: ERROR - vdoformat: formatVDO failed on '/dev/device': VDO Status: Exceeds maximum number of slabs supported
詳細は、「VDO ボリューム」 を参照してください。
例30.1 コンテナーストレージ用の VDO の作成
たとえば、1TB のブロックデバイスにコンテナーストレージ用の VDO ボリュームを作成する場合は、次のコマンドを使用します。#vdo create \--name=vdo1\--device=/dev/disk/by-id/scsi-3600508b1001c264ad2af21e903ad031f\--vdoLogicalSize=10TVDO ボリュームが作成されると、VDO はエントリーを/etc/vdoconf.yml設定ファイルに追加します。次に、vdo.servicesystemd ユニットは、エントリーを使用して、デフォルトでボリュームを起動します。重要VDO ボリュームの作成中に問題が発生した場合は、ボリュームを削除してください。詳細は 「作成に失敗したボリュームの削除」 を参照してください。 - ファイルシステムを作成します。
- XFS ファイルシステムの場合:
#mkfs.xfs -K /dev/mapper/vdo_name - ext4 ファイルシステムの場合:
#mkfs.ext4 -E nodiscard /dev/mapper/vdo_name
- ファイルシステムをマウントします。
#mkdir -m 1777 /mnt/vdo_name#mount /dev/mapper/vdo_name /mnt/vdo_name - ファイルシステムが自動的にマウントされるように設定するには、
/etc/fstabファイルまたは systemd マウントユニットを使用します。/etc/fstab設定ファイルを使用する場合は、以下のいずれかの行をファイルに追加します。- XFS ファイルシステムの場合:
/dev/mapper/vdo_name /mnt/vdo_name xfs defaults,_netdev,x-systemd.device-timeout=0,x-systemd.requires=vdo.service 0 0
- ext4 ファイルシステムの場合:
/dev/mapper/vdo_name /mnt/vdo_name ext4 defaults,_netdev,x-systemd.device-timeout=0,x-systemd.requires=vdo.service 0 0
- systemd ユニットを使用する場合は、適切なファイル名で systemd マウントユニットファイルを作成します。VDO ボリュームのマウントポイントには、以下の内容で
/etc/systemd/system/mnt-vdo_name.mountファイルを作成します。[Unit] Description = VDO unit file to mount file system name = vdo_name.mount Requires = vdo.service After = multi-user.target Conflicts = umount.target [Mount] What = /dev/mapper/vdo_name Where = /mnt/vdo_name Type = xfs [Install] WantedBy = multi-user.target
systemd ユニットファイルの例は、/usr/share/doc/vdo/examples/systemd/VDO.mount.exampleにもインストールされます。
- VDO デバイスのファイルシステムで
discard機能を有効にします。バッチ操作とオンライン操作の両方が VDO で機能します。discard機能の設定方法の詳細は、「未使用ブロックの破棄」 を参照してください。
30.3.4. VDO の監視
# vdostats --human-readable
Device 1K-blocks Used Available Use% Space saving%
/dev/mapper/node1osd1 926.5G 21.0G 905.5G 2% 73%
/dev/mapper/node1osd2 926.5G 28.2G 898.3G 3% 64%
Oct 2 17:13:39 system lvm[13863]: Monitoring VDO pool vdo_name. Oct 2 17:27:39 system lvm[13863]: WARNING: VDO pool vdo_name is now 80.69% full. Oct 2 17:28:19 system lvm[13863]: WARNING: VDO pool vdo_name is now 85.25% full. Oct 2 17:29:39 system lvm[13863]: WARNING: VDO pool vdo_name is now 90.64% full. Oct 2 17:30:29 system lvm[13863]: WARNING: VDO pool vdo_name is now 96.07% full.
30.3.5. デプロイメントの例
KVM を使用した VDO デプロイメント
図30.2 KVM を使用した VDO デプロイメント

その他のデプロイメントシナリオ
30.4. VDO の管理
30.4.1. VDO の起動または停止
#vdo start --name=my_vdo#vdo start --all
#vdo stop --name=my_vdo#vdo stop --all
- ボリュームは、UDS インデックスの 1GiB ごとに、約 1 GiB のデータを常に書き込みます。
- スパースの UDS インデックスを使用すると、ボリュームはブロックマップキャッシュのサイズと、スラブごとに最大 8MiB のデータ量を書き込みます。
- 同期モードでは、シャットダウンの前に VDO により確認されたすべての書き込みが再構築されます。
- 非同期モードでは、最後に確認されたフラッシュ要求の前に確認されたすべての書き込みが再構築されます。
30.4.2. VDO 書き込みモードの選択
sync、async、および auto の 3 つの書き込みモードに対応します。
- VDO が
syncモードの場合、上記のレイヤーは write コマンドが永続ストレージにデータを書き込むことを想定します。したがって、このモードは、ファイルシステムやアプリケーションには必要ありません。FLUSH リクエストまたは FUA (強制ユニットアクセス) リクエストを発行すると、データは、重要な点で持続します。VDO は、書き込みコマンドの完了時にデータが永続ストレージに書き込まれることを保証する場合にのみsyncmode に設定する必要があります。つまり、ストレージには揮発性の書き込みキャッシュがないか、ライトスルーキャッシュが存在する必要があります。 - VDO が
asyncモードの場合、書き込みコマンドが確認されると、データが永続ストレージに書き込まれる保証はありません。ファイルシステムまたはアプリケーションは、各トランザクションの重要な点でデータの永続性を保証するために、FLUSH リクエストまたは FUA リクエストを発行する必要があります。write コマンドの完了時に、基礎となるストレージが永続ストレージにデータを書き込むことを保証しない場合は、VDO をasyncモードに設定する必要があります。つまり、ストレージに揮発性のライトバックキャッシュがある場合です。デバイスが揮発性キャッシュを使用するかどうかを確認する方法は、「揮発性キャッシュの確認」 を参照してください。警告VDO が非同期モードで実行されている場合は、ACID (Atomicity, Consistency, Isolation, Durability)に準拠していません。VDO ボリュームの上に ACID コンプライアンスを想定するアプリケーションまたはファイルシステムがある場合、asyncモードにより予期しないデータ損失が発生する可能性があります。 autoモードは、各デバイスの特性に基づいてsyncまたはasyncを自動的に選択します。以下はデフォルトのオプションになります。
--writePolicy を使用します。これは、「VDO ボリュームの作成」 のように VDO ボリュームを作成する場合、または changeWritePolicy サブコマンドを使用して既存の VDO ボリュームを変更する場合に指定できます。
# vdo changeWritePolicy --writePolicy=sync|async|auto --name=vdo_name揮発性キャッシュの確認
/sys/block/block_device/device/scsi_disk/identifier/cache_type sysfs ファイルを読み込みます。以下に例を示します。
- デバイス
sdaには、ライトバックキャッシュ が あることを示します。$cat '/sys/block/sda/device/scsi_disk/7:0:0:0/cache_type' write back - デバイス
sdbには、ライトバックキャッシュが ない ことを示します。$cat '/sys/block/sdb/device/scsi_disk/1:2:0:0/cache_type' None
sd 7:0:0:0: [sda] Write cache: enabled, read cache: enabled, doesn't support DPO or FUA sd 1:2:0:0: [sdb] Write cache: disabled, read cache: disabled, supports DPO and FUA
sdaデバイスのasyncモードsdbデバイスの同期モード
cache_type の値が none または で書き込みを 行う 場合は、sync 書き込みポリシーを使用するように VDO を設定する必要があります。
30.4.3. VDO ボリュームの削除
# vdo remove --name=my_vdo30.4.3.1. 作成に失敗したボリュームの削除
vdo ユーティリティーが VDO ボリュームを作成しているときに障害が発生した場合、ボリュームは中間状態のままになります。これは、システムがクラッシュしたり、電源に障害が発生したり、管理者が実行中の vdo create コマンドを中断したりした場合に発生する可能性があります。
--force オプションを使用して、作成に失敗したボリュームを削除します。
# vdo remove --force --name=my_vdo--force オプションが必要となります。--force オプションを指定しないと、vdo remove コマンドが失敗し、以下のメッセージが表示されます。
[...] A previous operation failed. Recovery from the failure either failed or was interrupted. Add '--force' to 'remove' to perform the following cleanup. Steps to clean up VDO my_vdo: umount -f /dev/mapper/my_vdo udevadm settle dmsetup remove my_vdo vdo: ERROR - VDO volume my_vdo previous operation (create) is incomplete
30.4.4. UDS インデックスの設定
--indexMem=size オプションを使用してインデックスメモリーのサイズを指定して決定されます。使用するディスク領域は、自動的に決定されます。
--sparseIndex=enabled --indexMem=0.25 オプションを vdo create コマンドに指定します。この設定により、2.5 TB の重複排除ウィンドウが作成されます (つまり、2.5 TB の履歴が記録されます)。ほとんどのユースケースでは、2.5 TB の重複排除ウィンドウは、サイズが 10 TB までのストレージプールを重複排除するのに適しています。
30.4.5. シャットダウンが適切に行われない場合の VDO ボリュームの復旧
- VDO が同期ストレージで実行され、書き込みポリシーが を
同期すると、ボリュームに書き込まれたすべてのデータが完全に復元されます。 - 書き込みポリシーが
asyncの場合、一部の書き込みは、VDO にFLUSHコマンドを送信するか、FUAフラグでタグ付けされた書き込み I/O (ユニットアクセスの実施)を行っても、書き込みが永続化されない場合に復元されないことがあります。これは、fsync、fdatasync、sync、またはumountなどのデータ整合性操作を呼び出すことで、ユーザーモードから実行されます。
30.4.5.1. オンライン復旧
使用中のブロックやブロックの 空きブロック など、いくつかの統計が利用できなくなります。この統計は、再構築が完了すると利用可能になります。
30.4.5.2. 再構築の強制
operating mode 属性は、VDO ボリュームが読み取り専用モードかどうかを示します。)
# vdo stop --name=my_vdo--forceRebuild オプションを使用してボリュームを再起動します。
# vdo start --name=my_vdo --forceRebuild30.4.6. システム起動時に VDO ボリュームを自動的に起動する
vdo systemd ユニットは、アクティブ化 された として設定されているすべての VDO デバイスを自動的に起動します。
- 特定のボリュームを無効にするには、以下のコマンドを実行します。
#vdo deactivate --name=my_vdo - すべてのボリュームを無効にするには、以下のコマンドを実行します。
#vdo deactivate --all
- 特定のボリュームを有効にするには、以下のコマンドを実行します。
#vdo activate --name=my_vdo - すべてのボリュームを有効にするには、以下のコマンドを実行します。
#vdo activate --all
--activate=disabled オプションを追加して、自動的に起動しない VDO ボリュームを作成することもできます。
- LVM の下位層を最初に起動する必要があります (ほとんどのシステムでは、LVM2 パッケージのインストール時に、この層の起動が自動的に設定されます)。
- その後、
vdosystemd ユニットを起動する必要があります。 - 最後に、現在実行している VDO ボリュームに、LVM ボリュームやその他のサービスを起動するために、追加のスクリプトを実行する必要があります。
30.4.7. 重複排除の無効化と再有効化
- VDO ボリュームでの重複排除を停止するには、以下のコマンドを使用します。
#vdo disableDeduplication --name=my_vdoこれにより、関連付けられている UDS インデックスが停止し、重複排除がアクティブでないことを VDO ボリュームに通知します。 - VDO ボリュームでの重複排除を再起動するには、以下のコマンドを使用します。
#vdo enableDeduplication --name=my_vdoこれにより、関連する UDS インデックスが再起動し、重複排除が再度アクティブであることを VDO ボリュームに通知します。
--deduplication=disabled オプションを vdo create コマンドに追加することで、新しい VDO ボリュームを作成するときに重複排除を無効にすることもできます。
30.4.8. 圧縮の使用
30.4.8.1. 導入部分
30.4.8.2. 圧縮の有効化と無効化
--compression=disabled オプションを vdo create コマンドに追加することで圧縮を無効にできます。
- VDO ボリュームで圧縮を停止するには、次のコマンドを使用します。
#vdo disableCompression --name=my_vdo - 再び起動するには、以下のコマンドを使用します。
#vdo enableCompression --name=my_vdo
30.4.9. 空き領域の管理
vdostats ユーティリティーを使用して決定できます。詳細は、「vdostats」 を参照してください。このユーティリティーのデフォルト出力には、Linux df ユーティリティーと同様の形式で、実行中のすべての VDO ボリュームの情報が一覧表示されます。以下に例を示します。
Device 1K-blocks Used Available Use% /dev/mapper/my_vdo 211812352 105906176 105906176 50%
Oct 2 17:13:39 system lvm[13863]: Monitoring VDO pool my_vdo. Oct 2 17:27:39 system lvm[13863]: WARNING: VDO pool my_vdo is now 80.69% full. Oct 2 17:28:19 system lvm[13863]: WARNING: VDO pool my_vdo is now 85.25% full. Oct 2 17:29:39 system lvm[13863]: WARNING: VDO pool my_vdo is now 90.64% full. Oct 2 17:30:29 system lvm[13863]: WARNING: VDO pool my_vdo is now 96.07% full.
ファイルシステムの領域の回収
DISCARD、TRIM、または UNMAP コマンドを使用してブロックが解放されていることを伝えない限り、VDO は領域を回収できません。DISCARD、TRIM、または UNMAP を使用しないファイルシステムの場合、バイナリーゼロで設定されるファイルを保存し、そのファイルを削除することで、空き領域を手動で再利用できます。
DISCARD 要求を発行するように設定できます。
- リアルタイム廃棄 (オンライン廃棄またはインライン廃棄)
- リアルタイム破棄を有効にすると、ユーザーがファイルを削除して領域を解放するたびに、ファイルシステムはブロック層に
REQ_DISCARD要求を送信します。VDO はこの要求を受け取り、ブロックが共有されていないことを前提として、空きプールに領域を戻します。オンライン破棄に対応するファイルシステムの場合、マウント時にdiscardオプションを設定することで有効にできます。 - バッチ破棄
- バッチ破棄は、ユーザーが開始する操作であり、ファイルシステムが未使用のブロックをブロックレイヤー (VDO) に通知します。これは、ファイルシステムに
FITRIMと呼ばれるioctl要求を送信することで実現されます。fstrimユーティリティー(cronなど)を使用して、このioctlをファイルシステムに送信できます。
discard 機能の詳細は、「未使用ブロックの破棄」 を参照してください。
ファイルシステムがない場合の領域の確保
REQ_DISCARD コマンドに対応し、領域を解放するために適切な論理ブロックアドレスで VDO に要求を転送します。他のボリュームマネージャーを使用している場合は、REQ_DISCARD もサポートする必要があります。もしくは、SCSI デバイスの場合は UNMAP、または ATA デバイスの場合は TRIM をサポートする必要もあります。
ファイバーチャネルまたはイーサネットネットワーク上の領域の確保
UNMAP コマンドを使用して、シンプロビジョニングされたストレージターゲット上の領域を解放できますが、SCSI ターゲットフレームワークは、このコマンドのサポートをアドバタイズするように設定する必要があります。通常、これはこのボリュームで シンプロビジョニング を有効にすることで行われます。UNMAP への対応は、Linux ベースの SCSI イニシエーターで確認できます。
# sg_vpd --page=0xb0 /dev/device30.4.10. 論理ボリュームのサイズの拡大
# vdo growLogical --name=my_vdo --vdoLogicalSize=new_logical_size
30.4.11. 物理ボリュームのサイズの拡大
- 基になるデバイスのサイズを大きくします。正確な手順は、デバイスの種類によって異なります。たとえば、MBR パーティションのサイズを変更するには、「fdisk でのパーティションのサイズ変更」 の説明に従って
fdiskユーティリティーを使用します。 growPhysicalを使用して、新しい物理ストレージ領域を VDO ボリュームに追加します。#vdo growPhysical --name=my_vdo
30.4.12. Ansible を使用した VDO の自動化
- Ansible ドキュメント: https://docs.ansible.com/
- VDO Ansible モジュールのドキュメント https://docs.ansible.com/ansible/latest/modules/vdo_module.html
30.5. デプロイメントシナリオ
30.5.1. iSCSI ターゲット
図30.3 重複排除したブロックストレージターゲット

30.5.2. ファイルシステム
図30.4 重複排除した NAS

30.5.3. LVM
LV1 から LV4)が、重複排除されたストレージプールから作成されます。この方法で、VDO は、基となる重複排除ストレージプールへのマルチプロトコルの統合ブロック/ファイルアクセスに対応できます。
図30.5 重複排除された統合ストレージ
30.5.4. 暗号化
図30.6 暗号化での VDO の使用

30.6. VDO のチューニング
30.6.1. VDO チューニングの概要
30.6.2. VDO アーキテクチャーの背景
- 論理ゾーンスレッド
- 文字列
kvdo:logQを含むプロセス名を持つ 論理 スレッドは、VDO デバイスのユーザーに提示される論理ブロック番号(LBN)と、基盤となるストレージシステムの物理ブロック番号(PBN)との間のマッピングを維持します。また、同じブロックに書き込もうとする 2 つの I/O 操作が同時に処理されないように、ロックを実装します。論理ゾーンスレッドは、読み取り操作と書き込み操作の両方でアクティブになります。LBN はチャンクに分割され (ブロックマップページ は 3MB 以上の LBN を含む)、このチャンクはスレッド間で分割されるゾーンにグループ化されます。処理はスレッド間でかなり均等に分散させる必要がありますが、一部の不運なアクセスパターンでは、作業が 1 つのスレッドまたは別のスレッドに集中する場合があります。たとえば、特定のブロックマップページ内の LBN に頻繁にアクセスすると、論理スレッドの 1 つがそれらのすべての操作を処理します。論理ゾーンスレッドの数は、vdo コマンドの--vdoLogicalThreads=thread countオプションを使用して制御できます。 - 物理ゾーンスレッド
- 物理、または
kvdo:physQのスレッドは、データブロックの割り当てを管理し、参照カウントを維持します。これらは書き込み操作時にアクティブになります。LBN と同様、PBN は スラブ と呼ばれるチャンクに分割され、さらにゾーンに分割され、処理負荷を分散するワーカースレッドに割り当てられます。物理ゾーンスレッドの数は、vdo コマンドの--vdoPhysicalThreads=thread countオプションを使用して制御できます。 - I/O 送信スレッド
kvdo:bioQスレッドは、VDO からストレージシステムにブロック I/O (bio)操作を送信します。これらは、他の VDO スレッドによってキューに入れられた I/O 要求を受け取り、それらを基盤となるデバイスドライバーに渡します。このようなスレッドは、デバイスに関連付けられたデータ構造と通信し、データ構造を更新したり、デバイスドライバーのカーネルスレッドを処理するように要求を設定したりできます。基礎となるデバイスのリクエストキューが満杯になると、I/O リクエストの送信がブロックされる可能性があるため、この作業は専用のスレッドで行われ、処理の遅延を回避します。psユーティリティーまたはトップユーティリティーによってこれらのスレッドが頻繁にD状態に表示される場合、VDO は頻繁にストレージシステムを I/O 要求でビジー状態に保ちます。これは、一部の SSD のように、ストレージシステムが複数のリクエストを並行して処理できる場合、またはリクエスト処理がパイプライン化されている場合に一般的に適しています。この期間にスレッドの CPU 使用率が非常に低い場合は、I/O 送信スレッドの数を減らすことができます。CPU 使用率およびメモリー競合は、VDO の下にあるデバイスドライバーにより異なります。スレッドが追加されるにつれて I/O 要求あたりの CPU 使用率が増加する場合は、それらのデバイスドライバーの CPU、メモリー、またはロックの競合を確認してください。I/O 送信スレッドの数は、vdo コマンドの--vdoBioThreads=thread countオプションを使用して制御できます。- CPU 処理スレッド
kvdo:cpuQスレッドは、ハッシュ値の計算や、他のスレッドタイプに関連付けられたデータ構造への排他的アクセスをブロックしないデータブロックの圧縮など、CPU 集約型作業を実行するために存在します。CPU 処理スレッドの数は、vdo コマンドの--vdoCpuThreads=thread countオプションを使用して制御できます。- I/O 確認スレッド
kvdo:ackQスレッドは、VDO (カーネルページキャッシュ、ダイレクト I/O を実行するアプリケーションプログラムスレッドなど)にコールバックを発行して、I/O 要求の完了を報告します。CPU 時間の要件およびメモリーの競合は、この他のカーネルレベルのコードに依存します。確認応答スレッドの数は、vdo コマンドの--vdoAckThreads=thread countオプションを使用して制御できます。- スケーラビリティーのない VDO カーネルスレッド:
- 重複排除スレッド
kvdo:dedupeQスレッドは、キューに入れられた I/O 要求を受け取り、UDS に接続します。サーバーが要求を十分に迅速に処理できない場合、またはカーネルメモリーが他のシステムアクティビティーによって制約されている場合、ソケットバッファーがいっぱいになる可能性があることから、この作業は別のスレッドによって実行され、スレッドがブロックされた場合でも、他の VDO 処理を続行できます。また、長い遅延 (数秒) 後に I/O 要求をスキップするタイムアウトメカニズムもあります。- ジャーナルスレッド
kvdo:journalQスレッドはリカバリージャーナルを更新し、書き込み用にジャーナルブロックをスケジュールします。VDO デバイスは 1 つのジャーナルのみを使用するため、この作業はスレッド間では分割できません。- パッカースレッド
- 圧縮が有効な場合に書き込みパスでアクティブな
kvdo:packerQスレッドは、無駄なスペースを最小限に抑えるためにkvdo:cpuQスレッドによって圧縮されたデータブロックを収集します。VDO デバイスごとに 1 つのパッカーデータ構造があり、これにより 1 つのパッカースレッドがあります。
30.6.3. 調整する値
30.6.3.1. CPU/メモリー
30.6.3.1.1. 論理、物理、cpu、ack スレッド数
30.6.3.1.2. CPU アフィニティーおよび NUMA
taskset ユーティリティーを使用して 1 つのノードで VDO スレッドを収集します。他の VDO 関連の作業も同じノードで実行できる場合は、競合がさらに減少する可能性があります。この場合、処理に対する要求に対応するために、あるノードで CPU パワーが足りないと、別のノードに移動するスレッドを選択する際に、メモリーの競合を考慮する必要があります。たとえば、ストレージデバイスのドライバーが保持するデータ構造が多数ある場合は、デバイスの割り込み処理と VDO の I/O 送信 (デバイスのドライバーコードを呼び出す bio スレッド) の両方を別のノードに移動させると便利です。I/O 確認スレッド(ack スレッド)と上位レベルの I/O 送信スレッド(ダイレクト I/O を実行するユーザーモードスレッド、またはカーネルのページキャッシュ フラッシュ スレッド)をペアにしておくこともお勧めします。
30.6.3.1.3. 周波数のスロットル調整
/sys/devices/system/cpu/cpu*/cpufreq/scaling_governor ファイルに文字列の performance を書き込むと、より良い結果が生じる可能性があります。これらの sysfs ノードが存在しない場合は、Linux またはシステムの BIOS により、CPU 周波数管理を設定するための他のオプションが提供される場合があります。
30.6.3.2. キャッシュ
30.6.3.2.1. ブロックマップキャッシュ
--blockMapCacheSize=megabytes
オプションを使用して増やすことができます。より大きなキャッシュを使用すると、ランダムアクセスワークロードに大きなメリットがもたらされる可能性があります。
30.6.3.2.2. 読み取りキャッシュ
--readCache={enabled | disabled}
オプションは、読み取りキャッシュを使用するかどうかを制御します。これを有効にした場合、キャッシュの最小サイズは 8 MB ですが、
--readCacheSize=megabytes
オプションで増やすことができます。読み取りキャッシュの管理には若干のオーバーヘッドが発生するため、ストレージシステムが十分に高速であれば、パフォーマンスが向上しない可能性があります。読み取りキャッシュはデフォルトで無効になっています。
30.6.3.3. ストレージシステム I/O
30.6.3.3.1. Bio スレッド
30.6.3.3.2. IRQ の処理
%hi インジケーター)。その場合は、IRQ 処理を特定のコアに割り当て、VDO カーネルスレッドの CPU アフィニティーを調整して、そのコアで実行しないようにすると役立つ場合があります。
30.6.3.4. 最大破棄セクター
/sys/kvdo/max_discard_sectors で調整できます。デフォルトは 8 セクター (つまり 4KB ブロック 1 つ) です。より大きなサイズを指定することもできますが、VDO はループで一度に 1 ブロックずつ処理し、破棄された 1 つのブロックのメタデータの更新がジャーナルに書き込まれ、次のブロックで開始する前にディスクにフラッシュされるようにします。
30.6.4. ボトルネックの特定
top や ps などのユーティリティーで見られるように、スレッドまたは CPU の使用率が 70% を超える場合は、通常、1 つのスレッドまたは 1 つの CPU に多くの作業が集中していることを意味します。ただし、場合によっては、VDO スレッドが CPU で実行されるようにスケジュールされていても、実際には作業が行われなかったことを意味する場合があります。このシナリオは、過度のハードウェア割り込みハンドラー処理、コアまたは NUMA ノード間のメモリー競合、またはスピンロックの競合で発生する可能性があります。
top ユーティリティーを使用してシステムパフォーマンスを調べる場合、Red Hat は top -H を実行してすべてのプロセススレッドを個別に表示し、1 f j キーを入力し、その後に Enter/Return キーを入力することをお勧めします。top コマンドは、個々の CPU コアの負荷を表示し、各プロセスまたはスレッドが最後に実行された CPU を識別します。この情報により、以下の洞察が得られます。
- コアに
%id(idle)と%wa(waiting-for-I/O)の値が少ない場合、ある種の作業でビジー状態が保たれています。 - コアの
%hi値が非常に低い場合、そのコアは通常の処理作業を行い、カーネルスケジューラーによって負荷分散されています。そのセットにコアを追加すると、NUMA の競合が発生しない限り、負荷が軽減される可能性があります。 - コアの
%hiが数パーセントを超え、そのコアに割り当てられているスレッドは 1 つだけで、%idと%waがゼロの場合、コアはオーバーコミットされ、スケジューラーは状況に対処していません。この場合は、カーネルスレッドやデバイスの割り込み処理を別のコアに保持するために再割り当てする必要があります。
perf ユーティリティーは、多くの CPU のパフォーマンスカウンターを調べることができます。Red Hat は、perf top サブコマンドを開始点として使用して、スレッドまたはプロセッサーが実行する作業を調べることをお勧めします。たとえば、bioQ スレッドがスピンロックの取得を試行する多くのサイクルを費やしている場合、VDO 未満のデバイスドライバーで競合が多すぎる可能性があり、bioQ スレッドの数を減らすと状況が軽減される可能性があります。CPU 使用率が高い場合(スピンロックの取得など)は、たとえば bioQ スレッドとデバイス割り込みハンドラーが異なるノードで実行されている場合など、NUMA ノード間の競合を示している可能性があります。プロセッサーがそれらをサポートしている場合、stalled-cycles-backend、cache-misses、および node-load-misses などのカウンターが重要になる可能性があります。
sar ユーティリティーは、複数のシステム統計に関する定期的なレポートを提供できます。sar -d 1 コマンドは、ブロックデバイス使用率レベル(少なくとも 1 つの I/O 操作が進行中である割合)とキューの長さ(I/O 要求の待機数)を 1 秒に 1 回報告します。ただし、すべてのブロックデバイスドライバーがそのような情報を報告できるわけではないため、sar の有用性は、使用中のデバイスドライバーに依存する可能性があります。
30.7. VDO コマンド
30.7.1. vdo
kvdo コンポーネントと UDS コンポーネントの両方を管理します。
概要
vdo { activate | changeWritePolicy | create | deactivate | disableCompression | disableDeduplication | enableCompression | enableDeduplication | growLogical | growPhysical | list | modify | printConfigFile | remove | start | status | stop }
[ options... ]
サブコマンド
| サブコマンド | 説明 |
|---|---|
作成
|
VDO ボリュームと、その関連インデックスを作成し、使用できるようにします。
−−activate=disabled を指定すると、VDO ボリュームが作成されますが、使用できません。--force が指定されていない場合は、既存のファイルシステムまたはフォーマットされた VDO ボリュームを上書きしません。このコマンドは、root 権限で実行する必要があります。適用可能なオプションは以下のとおりです。
|
remove
|
停止している 1 つまたは複数の VDO ボリュームと関連するインデックスを削除します。このコマンドは、root 権限で実行する必要があります。適用可能なオプションは以下のとおりです。
|
start
|
停止、アクティブ化されている 1 つ以上の VDO ボリュームおよび関連サービスを開始します。このコマンドは、root 権限で実行する必要があります。適用可能なオプションは以下のとおりです。
|
stop
|
1 つ以上の VDO ボリュームおよび関連サービスの実行を停止します。このコマンドは、root 権限で実行する必要があります。適用可能なオプションは以下のとおりです。
|
activate
|
1 つ以上の VDO ボリュームをアクティブにします。アクティブなボリュームは、
start
|
deactivate
|
1 つ以上の VDO ボリュームを非アクティブにします。アクティブでないボリュームは、
start
|
status
|
VDO システムとボリュームのステータスを YAML 形式で報告します。このコマンドは root 権限を必要としませんが、root 権限なしで実行すると、情報は不完全になります。適用可能なオプションは以下のとおりです。
|
リスト
|
起動している VDO ボリュームのリストを表示します。
--all を指定すると、起動したボリュームと、起動していないボリュームの両方が表示されます。このコマンドは、root 権限で実行する必要があります。適用可能なオプションは以下のとおりです。
|
modify
|
1 つまたはすべての VDO ボリュームの設定パラメーターを変更します。変更は、次に VDO デバイスを起動したときに有効になります。すでに実行中のデバイスには影響しません。適用可能なオプションは以下のとおりです。
|
changeWritePolicy
|
実行中の 1 つまたはすべての VDO ボリュームの書き込みポリシーを変更します。このコマンドは、root 権限で実行する必要があります。
|
enableDeduplication
|
1 つ以上の VDO ボリュームでの重複排除を有効にします。このコマンドは、root 権限で実行する必要があります。適用可能なオプションは以下のとおりです。
|
disableDeduplication
|
1 つ以上の VDO ボリュームでの重複排除を無効にします。このコマンドは、root 権限で実行する必要があります。適用可能なオプションは以下のとおりです。
|
enableCompression
|
1 つ以上の VDO ボリュームで圧縮を有効にします。VDO ボリュームが実行中の場合は、すぐに有効になります。VDO ボリュームで圧縮を実行していない場合は、次に VDO ボリュームを起動したときに圧縮が有効になります。このコマンドは、root 権限で実行する必要があります。適用可能なオプションは以下のとおりです。
|
disableCompression
|
1 つ以上の VDO ボリュームでの圧縮を無効にします。VDO ボリュームが実行中の場合は、すぐに有効になります。VDO ボリュームで圧縮を実行していない場合は、次に VDO ボリュームを起動したときに圧縮が無効になります。このコマンドは、root 権限で実行する必要があります。適用可能なオプションは以下のとおりです。
|
growLogical
|
VDO ボリュームに論理領域を追加します。ボリュームが存在し、実行されている必要があります。このコマンドは、root 権限で実行する必要があります。適用可能なオプションは以下のとおりです。
|
growPhysical
|
VDO ボリュームに物理領域を追加します。ボリュームが存在し、実行されている必要があります。このコマンドは、root 権限で実行する必要があります。適用可能なオプションは以下のとおりです。
|
printConfigFile
|
設定ファイルを
stdout に出力します。このコマンドには、root 権限が必要です。適用可能なオプションは以下のとおりです。
|
オプション
| オプション | 説明 |
|---|---|
--indexMem=gigabytes
| UDS サーバーメモリーの量をギガバイト単位で指定します。デフォルトサイズは 1GB です。特殊な 10 進数の値である 0.25、0.5、0.75 は、正の整数として使用できます。 |
--sparseIndex={enabled | disabled}
| スパースインデックス作成を有効または無効にします。デフォルトでは が 無効に なります。 |
--all
| このコマンドを、設定した VDO ボリュームすべてに適用する必要があることを示しています。--name と併用しないでください。 |
--blockMapCacheSize=megabytes
| ブロックマップページのキャッシュに割り当てるメモリーの量を指定します。値は、4096 の倍数にする必要があります。B(ytes)、K(ilobytes)、M(egabytes)、G(igabytes)、T(テラバイト)、P(トリアバイト)、または E(xabytes)の接尾辞が付いた値の使用はオプションです。接尾辞が指定されていない場合、値はメガバイトとして解釈されます。デフォルトは 128M です。値は 128M 以上、16T 未満にする必要があります。メモリーオーバーヘッドは 15% であることに注意してください。 |
--blockMapPeriod=period
| キャッシュされたページがディスクにフラッシュされる前に蓄積される可能性のあるブロックマップ更新の数を決定する 1 から 16380 までの値。値を大きくすると、通常の操作中のパフォーマンスが低下しますが、クラッシュ後の回復時間が短くなります。デフォルト値は 16380 です。このパラメーターを調整する前に、RedHat の担当者に相談してください。 |
--compression={enabled | disabled}
| VDO デバイス内での圧縮を有効または無効にします。デフォルトでは有効になっています。パフォーマンスを最大化するため、または圧縮される可能性が低いデータの処理を高速化するために、必要に応じて圧縮を無効にすることができます。 |
--confFile=file
| 別の設定ファイルを指定します。デフォルトは /etc/vdoconf.yml です。 |
--deduplication={enabled | disabled}
| VDO デバイス内での重複排除を有効または無効にします。デフォルトでは が 有効 です。データの重複排除率が高くないと予想されるが、圧縮が必要な場合は、重複排除を無効にすることができます。 |
--emulate512={enabled | disabled}
| 512 バイトのブロックデバイスエミュレーションモードを有効にします。デフォルトでは が 無効に なります。 |
--force
| VDO ボリュームを停止する前に、マウントされたファイルシステムをアンマウントします。 |
--forceRebuild
| 読み取り専用の VDO ボリュームを開始する前に、オフラインでの再構築を強制して、オンラインに戻して使用できるようにします。このオプションを使用すると、データの損失や破損が生じる可能性があります。 |
--help
| vdo ユーティリティーのドキュメントを表示します。 |
--logfile=pathname
| このスクリプトのログメッセージの出力先となるファイルを指定します。警告メッセージおよびエラーメッセージは、常に syslog にも記録されます。 |
--name=volume
| 指定した VDO ボリュームで動作します。--all と併用しないでください。 |
--device=device
| VDO ストレージに使用するデバイスの絶対パスを指定します。 |
--activate={enabled | disabled}
| 引数 disabled は、VDO ボリュームのみを作成することを示します。ボリュームは起動されたり、有効化されたりしません。デフォルトでは が 有効 です。 |
--vdoAckThreads=thread count
| 要求された VDOI/O 操作の完了を確認するために使用するスレッドの数を指定します。デフォルトは 1 です。値は 0 以上、100 以下である必要があります。 |
--vdoBioRotationInterval=I/O count
| 作業を次のスレッドに転送する前に、bio 送信スレッドごとにキューに入れる I/O 操作の数を指定します。デフォルトは 64 です。値は 1 以上、1024 以下である必要があります。 |
--vdoBioThreads=thread count
| ストレージデバイスへの I/O 操作の送信に使用するスレッド数を指定します。最小は 1 で、最大は 100 です。デフォルトは 4 です。値は 1 以上、100 以下である必要があります。 |
--vdoCpuThreads=thread count
| ハッシュや圧縮など、CPU を集中的に使用する作業に使用するスレッドの数を指定します。デフォルトは 2 です。値は 1 以上、100 以下である必要があります。 |
--vdoHashZoneThreads=thread count
| ブロックデータから計算したハッシュ値に基づいて、VDO 処理の一部を細分化するスレッド数を指定します。デフォルトは 1 です。値は 0 以上、100 以下である必要があります。vdoHashZoneThreads、vdoLogicalThreads、および vdoPhysicalThreads は、すべてゼロであるか、すべてゼロ以外の値にする必要があります。 |
--vdoLogicalThreads=thread count
| ブロックデータから計算したハッシュ値に基づいて、VDO 処理の一部を細分化するスレッド数を指定します。この値は、0 以上、100 以下である必要があります。論理スレッド数が 9 以上の場合は、ブロックマップキャッシュのサイズも明示的に指定する必要があります。vdoHashZoneThreads、vdoLogicalThreads、および vdoPhysicalThreads は、すべてゼロにするか、すべてゼロ以外にする必要があります。デフォルトでは 1 回です。 |
--vdoLogLevel=level
| VDO ドライバーログレベル (critical、error、warning、notice、info、または debug) を指定します。レベルでは大文字と小文字が区別されます。デフォルトは info です。 |
--vdoLogicalSize=megabytes
| 論理 VDO ボリュームのサイズをメガバイト単位で指定します。S(ectors)、B(ytes)、K(ilobytes)、M(egabytes)、G(igabytes)、T(テラバイト)、P(etabytes)、または E(xabytes)の接尾辞が付いた値の使用はオプションです。ボリュームのオーバープロビジョニングに使用されます。これはデフォルトでストレージデバイスのサイズになります。 |
--vdoPhysicalThreads=thread count
| 物理ブロックアドレスに基づいて、VDO 処理の一部を細分化するスレッド数を指定します。この値は、0 以上、16 以下である必要があります。最初のスレッド以降にスレッドを追加するたびに、さらに 10 MB の RAM を使用します。vdoPhysicalThreads、vdoHashZoneThreads、および vdoLogicalThreads は、すべてゼロにするか、すべてゼロ以外にする必要があります。デフォルトでは 1 回です。 |
--readCache={enabled | disabled}
| VDO デバイス内の読み取りキャッシュを有効または無効にします。デフォルトは disabled です。書き込みワークロードで重複排除のレベルが高いことが予想される場合、または高圧縮性のデータの読み取り集中型ワークロードの場合は、キャッシュを有効にする必要があります。 |
--readCacheSize=megabytes
| 追加の VDO デバイス読み取りキャッシュサイズをメガバイト単位で指定します。この領域は、システム定義の最小領域に追加されます。B(ytes)、K(ilobytes)、M(egabytes)、G(igabytes)、T(テラバイト)、P(トリアバイト)、または E(xabytes)の接尾辞が付いた値の使用はオプションです。デフォルトは 0M です。bio スレッドごとに、指定された読み取りキャッシュの MB ごとに 1.12 MB のメモリーが使用されます。 |
--vdoSlabSize=megabytes
| VDO が拡張される増分のサイズを指定します。サイズを小さくすると、収納可能な物理サイズの合計が制約されます。128M から 32G の間の 2 の累乗である必要があります。デフォルトは 2G です。S(ectors)、B(ytes)、K(ilobytes)、M(egabytes)、G(igabytes)、T(テラバイト)、P(etabytes)、または E(xabytes)の接尾辞が付いた値の使用はオプションです。接尾辞を使用しない場合、この値はメガバイトとして解釈されます。 |
--verbose
| コマンドを実行する前に出力します。 |
--writePolicy={ auto | sync | async }
| 書き込みポリシーを指定します。
|
status
サブコマンドは、YAML 形式で、次の情報を返します。キーは以下のように分割されます。
| キー | 説明 | |
|---|---|---|
| VDO のステータス | このキーの情報には、ホストの名前とステータス照会が行われている日時が含まれます。この領域で報告されるパラメーターは以下のとおりです。 | |
| ノード | VDO が実行しているシステムのホスト名。 | |
| 日付 | vdo status コマンドを実行した日時。 | |
| カーネルモジュール | このキーの情報は、設定されたカーネルをカバーします。 | |
| Loaded | カーネルモジュールが読み込まれているかどうか (True または False)。 | |
| バージョン情報 | 設定されている kvdo のバージョンに関する情報。 | |
| 設定 | このキーの情報は、VDO 設定ファイルの場所とステータスをカバーします。 | |
| ファイル | VDO 設定ファイルの場所。 | |
| 最終更新日 | VDO 設定ファイルの最終更新日。 | |
| VDO | すべての VDO ボリュームの設定情報を提供します。各 VDO ボリュームで報告されるパラメーターは以下のとおりです。 | |
| ブロックサイズ | VDO ボリュームのブロックサイズ (バイト単位)。 | |
| 512 バイトエミュレーション | ボリュームが 512 バイトのエミュレーションモードで実行しているかどうかを示します。 | |
| 重複排除の有効化 | ボリュームで重複排除が有効かどうか。 | |
| 論理サイズ | VDO ボリュームの論理サイズ。 | |
| 物理サイズ | VDO ボリュームの基本となる物理ストレージのサイズ。 | |
| 書き込みポリシー | 書き込みポリシーの設定値 (sync または async)。 | |
| VDO 統計 | vdostats ユーティリティーの出力。 | |
30.7.2. vdostats
vdostats ユーティリティーは、Linux df ユーティリティーと同様の形式で、設定(または指定した)デバイスごとの統計情報を表示します。
vdostats ユーティリティーの出力が不完全になる可能性があります。
概要
vdostats [ --verbose | --human-readable | --si | --all ] [ --version ] [ device ...]
オプション
| オプション | 説明 |
|---|---|
--verbose
|
1 つ (または複数) の VDO デバイスの使用率とブロック I/O (bios) 統計を表示します。詳しくは 表30.9「vdostats --詳細な出力」 をご覧ください。
|
--human-readable
| ブロック値を読み取り可能な形式で表示します (ベース 2: 1 KB = 210 bytes = 1024 バイト)。 |
--si
| --si オプションは、--human-readable オプションの出力を SI ユニットを使用するように変更します (ベース 10: 1KB = 103 バイト = 1000 バイト)。--human-readable オプションが指定されていない場合は、--si オプションが無効になります。 |
--all
| このオプションは、後方互換性のためにのみ使用されます。これは、--verbose オプションと同等になりました。 |
--version
| vdostats のバージョンを表示します。 |
device ...
| 報告する 1 つ以上の特定のボリュームを指定します。この引数を省略すると、vdostats はすべてのデバイスでレポートします。 |
出力
Device 1K-blocks Used Available Use% Space Saving% /dev/mapper/my_vdo 1932562432 427698104 1504864328 22% 21%
| 項目 | 説明 |
|---|---|
| Device | VDO ボリュームへのパス。 |
| 1K-blocks | VDO ボリュームに割り当てられている 1K ブロックの合計数 (= 物理ボリュームサイズ * ブロックサイズ / 1024) |
| Used | VDO ボリュームで使用されている 1K ブロックの合計数 (= 使用されている物理ブロック * ブロックサイズ / 1024) |
| Available | VDO ボリュームで利用可能な 1K ブロックの合計数 (= 空き物理ブロック * ブロックサイズ / 1024) |
| Use% | VDO ボリュームで使用されている物理ブロックの割合 (= 使用済みブロック / 割り当て済みブロック * 100) |
| Space Saving% | VDO ボリュームに保存されている物理ブロックの割合 (= [使用されている論理ブロック - 使用されている物理ブロック] / 使用されている論理ブロック) |
--human-readable オプションでは、ブロックカウントを従来の単位 (1 KB = 1024 バイト) に変換します。
Device Size Used Available Use% Space Saving% /dev/mapper/my_vdo 1.8T 407.9G 1.4T 22% 21%
--human-readable オプションおよび --si オプションは、ブロックカウントを SI ユニット (1 KB = 1000 バイト) に変換します。
Device Size Used Available Use% Space Saving% /dev/mapper/my_vdo 2.0T 438G 1.5T 22% 21%
--verbose (表30.9「vdostats --詳細な出力」) オプションは、1 つ (またはすべて) の VDO デバイスの YAML 形式で VDO デバイス統計情報を表示します。
| 項目 | 説明 |
|---|---|
| Version | この統計のバージョン。 |
| Release version | VDO のリリースバージョン。 |
| Data blocks used | VDO ボリュームがデータを保存するために現在使用している物理ブロックの数。 |
| Overhead blocks used | VDO メタデータを保存するために VDO ボリュームが現在使用している物理ブロックの数。 |
| Logical blocks used | 現在マッピングされている論理ブロックの数。 |
| Physical blocks | VDO ボリュームに割り当てられている物理ブロックの合計数。 |
| Logical blocks | VDO ボリュームでマッピングできる論理ブロックの最大数。 |
| 1K-blocks | VDO ボリュームに割り当てられている 1K ブロックの合計数 (= 物理ボリュームサイズ * ブロックサイズ / 1024) |
| 1K-blocks used | VDO ボリュームで使用されている 1K ブロックの合計数 (= 使用されている物理ブロック * ブロックサイズ / 1024) |
| 1K-blocks available | VDO ボリュームで利用可能な 1K ブロックの合計数 (= 空き物理ブロック * ブロックサイズ / 1024) |
| Used percent | VDO ボリュームで使用されている物理ブロックの割合 (= 使用済みブロック / 割り当て済みブロック * 100) |
| Saving percent | VDO ボリュームに保存されている物理ブロックの割合 (= [使用されている論理ブロック - 使用されている物理ブロック] / 使用されている論理ブロック) |
| Block map cache size | ブロックマップキャッシュのサイズ (バイト単位)。 |
| Write policy | アクティブな書き込みポリシー (同期または非同期)。これは、vdo changeWritePolicy --writePolicy=auto|sync|async で設定されます。 |
| Block size | VDO ボリュームのブロックサイズ (バイト単位)。 |
| Completed recovery count | VDO ボリュームが不完全なシャットダウンから復旧した回数。 |
| Read-only recovery count | VDO ボリュームが、(vdo start --forceRebuild を介して) 読み取り専用モードから復元された回数。 |
| Operating mode | VDO ボリュームが通常どおり動作しているか、復旧モードであるか、読み取り専用モードであるかを示します。 |
| Recovery progress (%) | オンライン復旧の進捗状況を示します。またはボリュームが復旧モードでない場合はN/A を示します。 |
| Compressed fragments written | VDO ボリュームが最後に再起動してから書き込まれた圧縮フラグメントの数。 |
| Compressed blocks written | VDO ボリュームを最後に再起動してから書き込まれた圧縮データの物理ブロックの数。 |
| Compressed fragments in packer | まだ書き込まれていない、処理中の圧縮フラグメントの数。 |
| Slab count | スラブの合計数。 |
| Slabs opened | ブロックがこれまでに割り当てられたスラブの総数。 |
| Slabs reopened | VDO が開始されてからスラブが再開された回数。 |
| Journal disk full count | リカバリージャーナルがいっぱいであったために、要求がリカバリージャーナル項目を作成できなかった回数。 |
| Journal commits requested count | リカバリージャーナルがスラブジャーナルをコミットするように要求した回数。 |
| Journal entries batching | 開始されたジャーナルエントリーの書き込み数から、書き込まれたジャーナルエントリーの数を引いた数。 |
| Journal entries started | メモリー内で作成されたジャーナルエントリーの数。 |
| Journal entries writing | 送信された書き込みのジャーナルエントリーの数から、ストレージにコミットされたジャーナルエントリーの数を引いたもの。 |
| Journal entries written | 書き込みが発行されたジャーナルエントリーの合計数。 |
| Journal entries committed | ストレージに書き込まれたジャーナルエントリーの数。 |
| Journal blocks batching | 開始したジャーナルブロックの書き込み数から、書き込まれたジャーナルブロックの数を引いた数。 |
| Journal blocks started | メモリー内でタッチされたジャーナルブロックの数。 |
| Journal blocks writing | 書き込まれたジャーナルブロックの数 (アクティブメモリー内のメタデータを使用) からコミットされたジャーナルブロックの数を引いた数。 |
| Journal entries written | 書き込みが発行されたジャーナルブロックの合計数。 |
| Journal blocks committed | ストレージに書き込まれたジャーナルブロックの数。 |
| Slab journal disk full count | オンディスクスラブジャーナルがいっぱいになった回数。 |
| Slab journal flush count | フラッシュしきい値を超えるスラブジャーナルにエントリーが追加された回数。 |
| Slab journal blocked count | ブロックしきい値を超えたスラブジャーナルにエントリーが追加された回数。 |
| Slab journal blocks written | 発行されたスラブジャーナルブロック書き込みの数。 |
| Slab journal tail busy count | 書き込み要求がスラブジャーナル書き込みの待機をブロックした回数。 |
| Slab summary blocks written | 発行されたスラブサマリーブロック書き込みの数。 |
| Reference blocks written | 発行された参照ブロック書き込みの数。 |
| Block map dirty pages | ブロックマップキャッシュ内のダーティーページ数。 |
| Block map clean pages | ブロックマップキャッシュ内のクリーンなページ数。 |
| ブロックマップの空きページ | ブロックマップキャッシュの空きページ数。 |
| Block map failed pages | 書き込みエラーがあるブロックマップキャッシュページの数。 |
| Block map incoming pages | キャッシュに読み込まれているブロックマップキャッシュページの数。 |
| Block map outgoing pages | 書き込まれているブロックマップキャッシュページの数。 |
| Block map cache pressure | 必要に時に空きページが利用できなかった回数。 |
| Block map read count | ブロックマップページ読み取りの合計数。 |
| Block map write count | ブロックマップページへの書き込みの合計数。 |
| Block map failed reads | ブロックマップの読み取りエラーの合計数。 |
| Block map failed writes | ブロックマップの書き込みエラーの合計数。 |
| Block map reclaimed | 回収されたブロックマップページの合計数。 |
| Block map read outgoing | 書き込み中のページのブロックマップ読み取りの合計数。 |
| Block map found in cache | ブロックマップキャッシュヒットの合計数。 |
| Block map discard required | ページを破棄する必要があったブロックマップ要求の合計数。 |
| Block map wait for page | ページを待つ必要があった要求の合計数。 |
| Block map fetch required | ページフェッチを必要としたリクエストの合計数。 |
| Block map pages loaded | ページフェッチの合計数。 |
| Block map pages saved | 保存したページの合計数。 |
| Block map flush count | ブロックマップが発行したフラッシュの合計数。 |
| Invalid advice PBN count | インデックスが無効なアドバイスを返した回数 |
| No space error count. | VDO ボリュームの領域が不足しているために失敗した書き込み要求の数。 |
| Read only error count | VDO ボリュームが読み取り専用モードであるために失敗した書き込み要求の数。 |
| Instance | VDO インスタンス。 |
| 512 byte emulation | 512 バイトのエミュレーションがボリュームでオンまたはオフになるかを示します。 |
| Current VDO IO requests in progress. | VDO が現在処理している I/O 要求の数。 |
| Maximum VDO IO requests in progress | VDO が処理した同時 I/O 要求の最大数。 |
| Current dedupe queries | 現在実行中の重複排除クエリーの数。 |
| Maximum dedupe queries | 起動時の重複排除クエリーの最大数。 |
| Dedupe advice valid | 重複排除のアドバイスが正しかった回数。 |
| Dedupe advice stale | 重複排除のアドバイスが間違っていた回数。 |
| Dedupe advice timeouts | 重複排除クエリーがタイムアウトした回数。 |
| Flush out | VDO が基盤となるストレージに送信したフラッシュ要求の数。 |
| Bios in...Bios in partial...Bios out...Bios meta...Bios journal...Bios page cache...Bios out completed...Bio meta completed...Bios journal completed...Bios page cache completed...Bios acknowledged...Bios acknowledged partial...Bios in progress... |
これらの統計は、特定のフラグを持つ各カテゴリーの BIOS の数をカウントします。カテゴリーは以下のとおりです。
フラグには、以下の 3 つのタイプがあります。
|
| 読み取りキャッシュアクセス | VDO が読み取りキャッシュを検索した回数。 |
| 読み取りキャッシュのヒット | 読み取りキャッシュのヒット数。 |
30.8. /sysの統計ファイル
/sys/kvdo/volume_name/statistics ディレクトリーのファイルから読み込むことができます。ここで、volume_name は、VDO ボリュームの名前になります。これにより、vdostats ユーティリティーによって生成されたデータへの別のインターフェイスが提供されます。これは、シェルスクリプトおよび管理ソフトウェアによるアクセスに適しています。
statistics ディレクトリーにファイルがあります。これらの追加の統計ファイルは、将来のリリースでサポートされることは保証されていません。
| ファイル | 説明 |
|---|---|
dataBlocksUsed | VDO ボリュームがデータを保存するために現在使用している物理ブロックの数。 |
logicalBlocksUsed | 現在マッピングされている論理ブロックの数。 |
physicalBlocks | VDO ボリュームに割り当てられている物理ブロックの合計数。 |
logicalBlocks | VDO ボリュームでマッピングできる論理ブロックの最大数。 |
モード | VDO ボリュームが通常どおり動作しているか、復旧モードであるか、読み取り専用モードであるかを示します。 |
第31章 VDO 評価
31.1. 導入部分
- VDO 固有の設定可能なプロパティー (エンドユーザーアプリケーションのパフォーマンスチューニング)
- ネイティブ 4KB ブロックデバイスである場合の影響
- アクセスパターンと、重複排除および圧縮のディストリビューションへの応答
- 高負荷環境でのパフォーマンス (非常に重要)
- アプリケーションに基づいて、コスト、容量、パフォーマンスを分析します
31.1.1. 期待と成果
- エンジニアが、テストデバイスから最適な応答を導く設定を特定する際に役立ちます。
- 製品の設定ミスを防ぐため、基本的なチューニングパラメーターの概要を説明します。
- 実際のアプリケーションの結果と比較するための参照として、パフォーマンス結果ポートフォリオを作成します。
- さまざまなワークロードがパフォーマンスやデータ効率にどのように影響するかを特定します。
- VDO 実装により、市場投入までの時間を短縮します。
31.2. テスト環境の準備
31.2.1. システム設定
- 利用可能な CPU コアの数およびタイプ。これは、
tasksetユーティリティーを使用して制御できます。 - 利用可能なメモリーと、取り付けられているメモリーの合計。
- ストレージデバイスの設定
- Linux カーネルバージョン。Red Hat Enterprise Linux 7 では、提供される Linux カーネルバージョンは 1 つのみであることに注意してください。
- インストールされているパッケージ
31.2.2. VDO 設定
- パーティション設定スキーム
- VDO ボリュームで使用されるファイルシステム
- VDO ボリュームに割り当てられた物理ストレージのサイズ
- 作成した論理 VDO ボリュームのサイズ
- スパースまたはデンスインデックス
- メモリーサイズの UDS インデックス
- VDO のスレッド設定
31.2.3. ワークロード
- テストデータを生成するのに使用するツールの種類
- 同時クライアントの数
- 書き込まれたデータ内の重複する 4KB ブロックの量
- 読み書きのパターン
- ワーキングセットのサイズ
31.2.4. 対応しているシステム設定
- 柔軟な I/O テスター バージョン 2.08 以降。fio パッケージから入手できます。
sysstatバージョン 8.1.2-2 以降。sysstat パッケージから入手できます。
31.2.5. テスト前のシステム準備
- システム設定
- CPU が最も高いパフォーマンス設定で実行していることを確認します。
- BIOS 設定または Linux の
cpupowerユーティリティーを使用して、可能であれば頻度のスケーリングを無効にします。 - 最大スループットを実現できる場合は、Turbo モードを有効にします。Turbo モードでは、テスト結果に多少のばらつきが生じますが、Turbo なしのテストと同等以上のパフォーマンスを発揮します。
- Linux 設定
- ディスクベースのソリューションの場合、Linux は、キューに入っている複数の読み取り/書き込み要求を処理するための I/O スケジューラーアルゴリズムを複数提供します。デフォルトでは、Red Hat Enterprise Linux は CFQ (完全に公平なキューイング) スケジューラーを使用します。これは、多くの状況でローテーションディスク (ハードディスク) のアクセスを改善する方法で要求を調整します。代わりに、ローテーションディスクに Deadline スケジューラーを使用することを推奨します。Red Hat ラボテストでスループットとレイテンシーが改善されることが分かりました。デバイス設定を次のように変更します。
# echo "deadline" > /sys/block/device/queue/scheduler
- フラッシュベースのソリューションの場合、
noopスケジューラーは、Red Hat ラボテストで優れたランダムアクセススループットとレイテンシーを示します。デバイス設定を次のように変更します。# echo "noop" > /sys/block/device/queue/scheduler
- ストレージデバイスの設定ファイルシステム (ext4、XFS など) は、パフォーマンスに固有の影響を与える可能性があります。それらはしばしばパフォーマンス測定を歪め、結果に対する VDO の影響を分離することを困難にします。妥当な場合は、raw ブロックデバイスでパフォーマンスを測定することを推奨します。使用できない場合は、ターゲットの実装で使用されるファイルシステムを使用してデバイスをフォーマットします。
31.2.6. VDO の内部構造
31.2.7. VDO の最適化
高負荷
同期と非同期書き込みポリシーの比較
# vdo status --name=my_vdo
メタデータのキャッシュ
VDO マルチスレッディングの設定
データコンテンツ
31.2.8. 読み取りパフォーマンスのテストに関する特別な考慮事項
- 4KB のブロックに 書き込まれたことがない 場合、VDO はストレージへの I/O を実行せず、即座にゼロブロックで応答します。
- 4KB のブロックに 書き込まれているが、すべてゼロが含まれている 場合、VDO はストレージへの I/O を実行せず、すぐにゼロブロックで応答します。
31.2.9. クロストーク
31.3. データ効率のテスト手順
テスト環境
- 1 つ以上の Linux 物理ブロックデバイスが使用できる。
- ターゲットブロックデバイス(例:
/dev/sdb)が 512 GB を超える。 - 柔軟な I/O テスター(
fio)バージョン 2.1.1 以降がインストールされている。 - VDO がインストールされている。
- 使用される Linux ビルド (カーネルビルド番号を含む)。
- rpm -qa コマンドから取得した、インストールされているパッケージの完全なリスト。
- 完全なシステム仕様:
- CPU タイプと数量(
/proc/cpuinfoで入手可能) - インストールされたメモリーと、ベース OS の実行後に利用可能な量(
/proc/meminfoで使用可能)。 - 使用されているドライブコントローラーのタイプ
- 使用されているディスクのタイプと数量
- 実行中のプロセスの完全なリスト( ps aux など)。
- VDO で使用するために作成された物理ボリュームおよびボリュームグループの名前(pvs および vgs の一覧)。
- VDO ボリューム (存在する場合) のフォーマットに使用されるファイルシステム。
- マウントされたディレクトリーの権限。
/etc/vdoconf.yamlの内容。- VDO ファイルの場所。
ワークロード
fio の 2 つのユーティリティーの使用が推奨されます。
fio を使用します。評価を成功させるためには、引数を理解することが重要です。
| 引数 | 説明 | 値 |
|---|---|---|
--size | fio がジョブごとにターゲットに送信するデータの量 (以下の numjobs を参照)。 | 100 GB |
--bs | fio が生成する各読み取り/書き込み要求のブロックサイズ。Red Hat は、デフォルトの 4KB の VDO と一致する 4KB のブロックサイズを推奨します。 | 4k |
--numjobs |
fio がベンチマークを実行するために作成するジョブの数。
各ジョブは、
--size パラメーターで指定した量のデータを送信します。
1 番目のジョブは、
--offset パラメーターで指定したオフセットでデバイスにデータを送信します。後続のジョブでは、--offset_increment パラメーターが指定されていない限り、ディスクの同じ領域に書き込みます (上書き)。これは、前のジョブがその値で開始した場所からそれぞれのジョブをオフセットします。フラッシュメモリーでピークパフォーマンスを実現するには、最低 2 つのジョブが推奨されます。通常、1 つのジョブで、ローテーションを行うディスク (HDD) のスループットをいっぱいにできます。
|
1 (HDD)
2 (SSD)
|
--thread | fio ジョブをフォークするのではなく、スレッドで実行するように指示します。これにより、コンテキストスイッチを制限することでパフォーマンスが向上する可能性があります。 | <N/A> |
--ioengine |
Linux では、fio を使用してテストできる I/O エンジンが複数あります。Red Hat テストでは、非同期のバッファーなしエンジン (
libaio) が使用されます。別のエンジンに興味がある場合は、Red Hat セールスエンジニアに相談してください。
Linux
libaioエンジンは、1 つ以上のプロセスが同時にランダムな要求を行っているワークロードを評価するために使用されます。libaio は、データが取得される前に、単一のスレッドから複数のリクエストを非同期で作成できるようにします。これにより、リクエストが同期エンジンを介して多くのスレッドによって提供された場合に必要となるコンテキストスイッチの数が制限されます。
| libaio |
--direct |
設定すると、direct は、Linux カーネルのページキャッシュをバイパスしてデバイスにリクエストを送信できるようにします。
Libaio Engine:
libaio は、direct を有効 (=1) にして使用する必要があります。そうしないと、カーネルが、すべての I/O 要求で sync API に頼る可能性があります。
| 1 (libaio) |
--iodepth |
任意の時点で実行している I/O バッファーの数。
通常、高い
iodepth の場合、無作為な読み取りまたは書き込みのパフォーマンスが向上します。深度が高い場合は、コントローラーは常にバッチ処理を要求できます。ただし、iodepth を高く設定しすぎる (通常は 1K を超える) と、望ましくないレイテンシーが発生する場合があります。Red Hat は、128 から 512 までの iodepth を推奨していますが、最後の値はトレードオフであり、アプリケーションがレイテンシーを許容する方法によって異なります。
| 128 (最小値) |
--iodepth_batch_submit | iodepth バッファープールが空になり始めるときに作成される I/O の数。このパラメーターは、テスト中の I/O からバッファー作成へのタスクの切り替えを制限します。 | 16 |
--iodepth_batch_complete | 一括処理 (iodepth_batch_complete) を送信するまでに完了する I/O の数。このパラメーターは、テスト中の I/O からバッファー作成へのタスクの切り替えを制限します。 | 16 |
--gtod_reduce | レイテンシーを計算する時刻の呼び出しを無効にします。この設定は、無効 (=0) にするとスループットが低下するため、レイテンシー測定が必要でない限り有効 (=1) にしてください。 | 1 |
31.3.1. VDO テストボリュームの設定
1.512GB の物理ボリュームに、論理サイズが 1TB の VDO ボリュームを作成する
- VDO ボリュームを作成します。
- 同期ストレージで VDO の
asyncモードをテストするには、--writePolicy=asyncオプションを使用して非同期ボリュームを作成します。# vdo create --name=vdo0 --device=/dev/sdb \ --vdoLogicalSize=1T --writePolicy=async --verbose - 同期ストレージで VDO
同期モードをテストするには、--writePolicy=syncオプションを使用して同期ボリュームを作成します。# vdo create --name=vdo0 --device=/dev/sdb \ --vdoLogicalSize=1T --writePolicy=sync --verbose
- 新しいデバイスを XFS または ext4 ファイルシステムでフォーマットします。
- XFS の場合:
# mkfs.xfs -K /dev/mapper/vdo0
- ext4 の場合:
# mkfs.ext4 -E nodiscard /dev/mapper/vdo0
- フォーマットしたデバイスをマウントします。
# mkdir /mnt/VDOVolume # mount /dev/mapper/vdo0 /mnt/VDOVolume && \ chmod a+rwx /mnt/VDOVolume
31.3.2. VDO の効率のテスト
2.VDO ボリュームの読み取りと書き込みのテスト
- VDO ボリュームに 32GB のランダムデータを書き込みます。
$ dd if=/dev/urandom of=/mnt/VDOVolume/testfile bs=4096 count=8388608
- VDO ボリュームからデータを読み込み、VDO ボリュームではない別の場所に書き込みます。
$ dd if=/mnt/VDOVolume/testfile of=/home/user/testfile bs=4096
diffを使用して、2 つのファイルを比較します。この場合、ファイルが同じであることが報告されます。$ diff -s /mnt/VDOVolume/testfile /home/user/testfile
- ファイルを VDO ボリュームの 2 番目の場所にコピーします。
$ dd if=/home/user/testfile of=/mnt/VDOVolume/testfile2 bs=4096
- 3 番目のファイルと 2 番目のファイルを比較します。これは、ファイルが同じであることを報告するはずです。
$ diff -s /mnt/VDOVolume/testfile2 /home/user/testfile
3.VDO ボリュームの削除
- VDO ボリュームに作成されたファイルシステムをアンマウントします。
# umount /mnt/VDOVolume
- コマンドを実行して、システムから VDO ボリューム
vdo0を削除します。# vdo remove --name=vdo0
- ボリュームが削除されたことを確認します。VDO パーティションの vdo リストにはリスト がないはずです。
# vdo list --all | grep vdo
4.重複排除の計測
- 「VDO テストボリュームの設定」に従って、VDO ボリュームを作成してマウントします。
vdo1からvdo10までの VDO ボリュームに 10 個のディレクトリーを作成し、テストデータセットのコピーを 10 個保持します。$ mkdir /mnt/VDOVolume/vdo{01..10}- ファイルシステムに応じて使用されているディスク領域を調べます。
$ df -h /mnt/VDOVolume Filesystem Size Used Avail Use% Mounted on /dev/mapper/vdo0 1.5T 198M 1.4T 1% /mnt/VDOVolume
結果をリストまとめることを検討してください。統計 ベアファイルシステム シード後 10 回コピーした後 使用されるファイルシステムのサイズ 198 MB 使用されている VDO データ 使用されている VDO 論理 - 次のコマンドを実行して、値を記録します。"Data blocks used" は、VDO で実行している物理デバイスのユーザーデータが使用しているブロック数です。"Logical blocks used" は、最適化前に使用したブロック数になります。これは、計測の開始点として使用されます。
# vdostats --verbose | grep "blocks used" data blocks used : 1090 overhead blocks used : 538846 logical blocks used : 6059434
- VDO ボリュームのトップレベルに、データソースファイルを作成します。
$ dd if=/dev/urandom of=/mnt/VDOVolume/sourcefile bs=4096 count=1048576 4294967296 bytes (4.3 GB) copied, 540.538 s, 7.9 MB/s
- 使用中の物理ディスク領域の量を再度調べます。これは、ちょうど書き込まれたファイルのサイズに応じて、使用されているブロック数の増加を示しているはずです。
$ df -h /mnt/VDOVolume Filesystem Size Used Avail Use% Mounted on /dev/mapper/vdo0 1.5T 4.2G 1.4T 1% /mnt/VDOVolume
# vdostats --verbose | grep "blocks used" data blocks used : 1050093 (increased by 4GB) overhead blocks used : 538846 (Did not change) logical blocks used : 7108036 (increased by 4GB)
- 10 個のサブディレクトリーのそれぞれにファイルをコピーします。
$ for i in {01..10}; do cp /mnt/VDOVolume/sourcefile /mnt/VDOVolume/vdo$i done - 再度、使用されている物理ディスク領域 (使用されているデータブロック) の量を確認します。この数は、ファイルシステムのジャーナリングとメタデータによるわずかな増加を除いて、上記手順 6 の結果と類似している必要があります。
$ df -h /mnt/VDOVolume Filesystem Size Used Avail Use% Mounted on /dev/mapper/vdo0 1.5T 45G 1.3T 4% /mnt/VDOVolume
# vdostats --verbose | grep "blocks used" data blocks used : 1050836 (increased by 3M) overhead blocks used : 538846 logical blocks used : 17594127 (increased by 41G)
- テストデータを書き込む前に見つかった値から、ファイルシステムが使用する領域の値を減算します。これは、ファイルシステムの観点から、このテストで使用される領域の量です。
- 記録された統計で節約する容量を確認します。注記:次の表では、値は MB/GB に変換されています。vdostats の "blocks" は 4,096 B です。
統計 ベアファイルシステム シード後 10 回コピーした後 使用されるファイルシステムのサイズ 198 MB 4.2 GB 45 GB 使用されている VDO データ 4 MB 4.1 GB 4.1 GB 使用されている VDO 論理 23.6 GB* 27.8 GB 68.7 GB 1.6TB フォーマットドライブ用のファイルシステムのオーバーヘッド
5.圧縮の測定
- 物理サイズおよび論理サイズが 10GB 以上の VDO ボリュームを作成します。重複排除を無効にし、圧縮を有効にするオプションを追加します。
# vdo create --name=vdo0 --device=/dev/sdb \ --vdoLogicalSize=10G --verbose \ --deduplication=disabled --compression=enabled - 転送前に VDO 統計を確認します。使用されているデータブロックと論理ブロックを書き留めておきます (両方ともゼロにする必要があります)。
# vdostats --verbose | grep "blocks used"
- 新しいデバイスを XFS または ext4 ファイルシステムでフォーマットします。
- XFS の場合:
# mkfs.xfs -K /dev/mapper/vdo0
- ext4 の場合:
# mkfs.ext4 -E nodiscard /dev/mapper/vdo0
- フォーマットしたデバイスをマウントします。
# mkdir /mnt/VDOVolume # mount /dev/mapper/vdo0 /mnt/VDOVolume && \ chmod a+rwx /mnt/VDOVolume
- VDO ボリュームを同期して、未完了の圧縮を完了します。
# sync && dmsetup message vdo0 0 sync-dedupe
- VDO 統計を再検証します。使用されている論理ブロック - 使用されているデータブロックは、ファイルシステム単体の圧縮により保存されている 4KB ブロックの数になります。VDO は、ファイルシステムのオーバーヘッドと、実際のユーザーデータを最適化します。
# vdostats --verbose | grep "blocks used"
/libのコンテンツを VDO ボリュームにコピーします。合計サイズを記録します。# cp -vR /lib /mnt/VDOVolume ... sent 152508960 bytes received 60448 bytes 61027763.20 bytes/sec total size is 152293104 speedup is 1.00
- Linux キャッシュと VDO ボリュームを同期します。
# sync && dmsetup message vdo0 0 sync-dedupe
- VDO 統計を再検証します。使用されている論理ブロックおよびデータブロックを確認します。
# vdostats --verbose | grep "blocks used"
- 使用されている論理ブロック - 使用されるデータブロックは、
/libファイルのコピーに使用されるスペースの量(4 KB ブロック単位)を表します。 - 合計サイズ (「4.重複排除の計測」 の表から) - (使用される論理-使用されるデータブロック * 4096) = 圧縮により節約されたバイト数
- VDO ボリュームを削除します。
# umount /mnt/VDOVolume && vdo remove --name=vdo0
6.VDO 圧縮の効率のテスト
- 「VDO テストボリュームの設定」に従って、VDO ボリュームを作成してマウントします。
- 用意したデータセットを試します。
7.TRIM および DISCARD について
TRIM コマンドまたは DISCARD コマンドを送信します。これらのコマンドは、discard マウントオプションを使用してブロックが削除されるたびに送信できます。または、fstrim などのユーティリティーを実行して、どの論理ブロックが使用されていないかを検出し、TRIM または DISCARD コマンドの形式でストレージシステムに情報を送信するようにファイルシステムに指示することで、制御された方法でこれらのコマンドを送信できます。
- 「VDO テストボリュームの設定」 に従って、新しい VDO 論理ボリュームを作成してマウントします。
- ファイルシステムをトリミングして、不要なブロックを削除します (これには長い時間がかかる場合があります)。
# fstrim /mnt/VDOVolume
- 以下を入力して、以下の表に初期状態を記録します。
$ df -m /mnt/VDOVolume
ファイルシステムで使用されている容量を確認し、vdostats を実行して、使用されている物理データブロックと論理データブロックの数を確認します。 - VDO 上で実行中のファイルシステムに、重複しないデータを含む 1 GB ファイルを作成します。
$ dd if=/dev/urandom of=/mnt/VDOVolume/file bs=1M count=1K
次に、同じデータを収集します。ファイルシステムはさらに 1GB を使用する必要があり、使用されるデータブロックと使用される論理ブロックも同様に増加しました。 fstrim /mnt/VDOVolumeを実行し、新しいファイルの作成後に、これが影響を与えないことを確認します。- 1 GB ファイルを削除します。
$ rm /mnt/VDOVolume/file
パラメーターを確認し、記録します。ファイルシステムは、ファイルが削除されたことを認識していますが、ファイルの削除が基礎となるストレージに通知されていないため、物理ブロックまたは論理ブロックの数に変更がありませんでした。 fstrim /mnt/VDOVolumeを実行し、同じパラメーターを記録します。fstrimは、ファイルシステムの空きブロックを検索し、未使用のアドレスの VDO ボリュームに TRIM コマンドを送信します。これにより、関連する論理ブロックが解放され、VDO が TRIM を処理して基礎となる物理ブロックを解放します。Step 使用されているファイル領域 (MB) 使用されているデータブロック 使用されている論理ブロック 初期 1 GB ファイルを追加 fstrimを実行1 GB ファイルを削除 fstrimを実行
fstrim は、多くのブロックを一度に分析して効率を向上させるコマンドラインツールです。別の方法として、マウント時に file system discard オプションを使用する方法があります。discard オプションは、各ファイルシステムブロックの削除後に基礎となるストレージを更新します。これによりスループットは遅くなりますが、使用率認識度は高くなります。未使用のブロックを TRIM または DISCARD する必要性は、VDO に固有のものではないことを理解することも重要です。シンプロビジョニングされたストレージシステムにも同じ課題があります。
31.4. パフォーマンステストの手順
31.4.1. フェーズ 1 - I/O 深さの影響、固定 4KB ブロック
- 4KB I/O および I/O 深度が 1、8、16、32、64、128、256、512、1024 で、フォーコーナーテストを実行します。
- 100% シーケンシャル読み取り (固定 4KB *)
- 100% シーケンシャル書き込み (固定 4KB)
- 100% ランダム読み取り (固定 4KB *)
- 100% ランダム書き込み (固定 4KB **)
* 最初に write fio ジョブを実行して、読み取りテスト中に読み取り可能な領域を事前に入力します。** 4 KB のランダム書き込み I/O の実行後、VDO ボリュームを再作成します。シェルテスト入力要因の例 (書き込み):# for depth in 1 2 4 8 16 32 64 128 256 512 1024 2048; do fio --rw=write --bs=4096 --name=vdo --filename=/dev/mapper/vdo0 \ --ioengine=libaio --numjobs=1 --thread --norandommap --runtime=300\ --direct=1 --iodepth=$depth --scramble_buffers=1 --offset=0 \ --size=100g done - 各データポイントでスループットとレイテンシーを記録してから、グラフ化します。
- テストを繰り返してフォーコーナーテストを完了します:
--rw=randwrite、--rw=read、および--rw=randread.
- この特定のアプライアンスは、シーケンシャル 4 KB I/O 深度 > X の恩恵を受けません。この深度を超えると、帯域幅の利得が減少し、I/O 要求が増えるごとに平均要求レイテンシーが 1:1 に増加します。
- この特定のアプライアンスは、ランダム 4KB の I/O 深度 > Z の恩恵を受けません。この深度を超えると、帯域幅の利得が減少し、追加の I/O 要求ごとに平均要求レイテンシーが 1:1 増加します。
図31.1 I/O 深度分析

図31.2 ランダム書き込みの I/O の増加による遅延応答
31.4.2. フェーズ 2 - I/O リクエストサイズの影響
- 8KB から 1MB の範囲でさまざまなブロックサイズ (2 の累乗) を使用して、固定 I/O 深度で フォーコーナーテストを実行します。読み取る領域を事前に入力し、テストの合間にボリュームを再作成することを忘れないでください。
- I/O 深度を 「フェーズ 1 - I/O 深さの影響、固定 4KB ブロック」 で決定された値に設定します。テスト入力要因の例 (読み取り):
# z=[see previous step] # for iosize in 4 8 16 32 64 128 256 512 1024; do fio --rw=write --bs=$iosize\k --name=vdo --filename=/dev/mapper/vdo0 --ioengine=libaio --numjobs=1 --thread --norandommap --runtime=300 --direct=1 --iodepth=$z --scramble_buffers=1 --offset=0 --size=100g done - 各データポイントでスループットとレイテンシーを記録してから、グラフ化します。
- テストを繰り返してフォーコーナーテストを完了します:
--rw=randwrite、--rw=read、および--rw=randread.
- シーケンシャル書き込みは、要求サイズ Y でピークスループットに達します。この曲線は、設定可能であるか、特定の要求サイズによって自然に支配されるアプリケーションが、パフォーマンスをどのように認識するかを示しています。4KB の I/O はマージの恩恵を受ける可能性があるため、要求サイズが大きいほどスループットが向上することがよくあります。
- シーケンシャル読み取りのスループットは、Z 点で似たようなピークスループットに到達します。これらのピークの後、I/O が完了するまでの全体的な遅延は、追加のスループットなしで増加することに注意してください。このサイズよりも大きな I/O を受け付けないようにデバイスを調整することが推奨されます。
- ランダム読み取りは、ポイント X でピークスループットを達成します。デバイスによっては、大規模なリクエストサイズのランダムアクセスで、ほぼシーケンシャルスループット率を実現する可能性がありますが、純粋なシーケンシャルアクセスと異なる場合は、より多くのペナルティーを受けることになります。
- ランダム書き込みは、ポイント Y でピークスループットを達成します。ランダム書き込みは、重複排除デバイスの相互作用が最も多く、VDO は、特に要求サイズや I/O 深度が大きい場合に高いパフォーマンスを実現します。
図31.3 要求サイズとスループットの分析、および重要な変曲点
31.4.3. フェーズ 3 - 読み取り/書き込み I/O のミキシングの影響
- 固定の I/O 深度、8 KB から 256 KB の範囲の可変ブロックサイズ (2 の累乗)、0% から初めて 10 % 刻みで読み取り率を設定し、フォーコーナーテストを実行します。読み取る領域を事前に入力し、テストの合間にボリュームを再作成することを忘れないでください。
- I/O 深度を 「フェーズ 1 - I/O 深さの影響、固定 4KB ブロック」 で決定された値に設定します。テスト入力要因の例 (読み取り/書き込みの組み合わせ):
# z=[see previous step] # for readmix in 0 10 20 30 40 50 60 70 80 90 100; do for iosize in 4 8 16 32 64 128 256 512 1024; do fio --rw=rw --rwmixread=$readmix --bs=$iosize\k --name=vdo \ --filename=/dev/mapper/vdo0 --ioengine=libaio --numjobs=1 --thread \ --norandommap --runtime=300 --direct=0 --iodepth=$z --scramble_buffers=1 \ --offset=0 --size=100g done done - 各データポイントでスループットとレイテンシーを記録してから、グラフ化します。
図31.4 パフォーマンスは、さまざまな読み取りと書き込みの組み合わせ混合で一貫している

31.4.4. フェーズ 4: アプリケーション環境
# for readmix in 20 50 80; do
for iosize in 4 8 16 32 64 128 256 512 1024; do
fio --rw=rw --rwmixread=$readmix --bsrange=4k-256k --name=vdo \
--filename=/dev/mapper/vdo0 --ioengine=libaio --numjobs=1 --thread \
--norandommap --runtime=300 --direct=0 --iodepth=$iosize \
--scramble_buffers=1 --offset=0 --size=100g
done
done
図31.5 混合環境パフォーマンス
31.5. 問題の報告
- テスト環境の詳細な説明。詳細は 「テスト環境」 を参照してください。
- VDO 設定
- 問題を生成したユースケース
- エラー発生時に実行していたアクション
- コンソールまたは端末におけるエラーメッセージのテキスト
- カーネルログファイル
- カーネルクラッシュダンプ (利用可能な場合)
sosreportの結果で、これは、Linux 全体を記述するデータを取得します。
31.6. まとめ
付録A ストレージ管理に関連する Red Hat カスタマーポータルラボ
SCSI デコーダー
/log/* ファイルまたはログファイルスニペットにデコードするように設計されています。
File System Layout Calculator
root として実行し、必要なファイルシステムを作成します。
LVM RAID Calculator
root として 1 つずつコピーして実行し、必要な LVM を作成します。
iSCSI Helper
Samba Configuration Helper
- をクリックして、基本的なサーバー設定を指定します。
- をクリックして、共有するディレクトリーを追加します。
- をクリックして、接続されたプリンターを個別に追加します。
Multipath Helper
multipath.conf ファイルも提供します。必要な設定が終了したら、サーバーにインストールスクリプトをダウンロードして実行します。
NFS Helper
Multipath Configuration Visualizer
- サーバー側の Host Bus Adapter (HBA)、ローカルデバイス、および iSCSI デバイスを含むホストコンポーネント
- ストレージのストレージコンポーネント
- サーバーとストレージとの間のファブリック、またはイーサネットのコンポーネント
- 上記の全コンポーネントのパス
RHEL Backup and Restore Assistant
dump および restore: ext2、ext3、および ext4 のファイルシステムのバックアップtar および cpio: ファイルやフォルダーをアーカイブまたは復元するため(特にテープドライブをバックアップする場合)。rsync: バックアップ操作の実行および場所間でのファイルとディレクトリーの同期dd: 関連するファイルシステムやオペレーティングシステムとは独立してブロックごとにファイルをコピーする場合。
- 障害回復
- ハードウェアの移行
- パーティションテーブルのバックアップ
- 重要なフォルダーのバックアップ
- 増分バックアップ
- 差分バックアップ
付録B 更新履歴
| 改訂履歴 | |||
|---|---|---|---|
| 改訂 4-10 | Mon Aug 10 2020 | ||
| |||
| 改訂 4-09 | Mon Jan 7 2019 | ||
| |||
| 改訂 4-08 | Mon Oct 23 2018 | ||
| |||
| 改訂 4-07 | Thu Sep 13 2018 | ||
| |||
| 改訂 4-00 | Fri Apr 6 2018 | ||
| |||
| 改訂 3-95 | Thu Apr 5 2018 | ||
| |||
| 改訂 3-93 | Mon Mar 5 2018 | ||
| |||
| 改訂 3-92 | Fri Feb 9 2018 | ||
| |||
| 改訂 3-90 | Wed Dec 6 2017 | ||
| |||
| 改訂 3-86 | Mon Nov 6 2017 | ||
| |||
| 改訂 3-80 | Thu Jul 27 2017 | ||
| |||
| 改訂 3-77 | Wed May 24 2017 | ||
| |||
| 改訂 3-68 | Fri Oct 21 2016 | ||
| |||
| 改訂 3-67 | Fri Jun 17 2016 | ||
| |||
| 改訂 3-64 | Wed Nov 11 2015 | ||
| |||
| 改訂 3-33 | Wed Feb 18 2015 | ||
| |||
| 改訂 3-26 | Wed Jan 21 2015 | ||
| |||
| 改訂 3-22 | Thu Dec 4 2014 | ||
| |||
| 改訂 3-4 | Thu Jul 17 2014 | ||
| |||
| 改訂 3-1 | Tue Jun 3 2014 | ||
| |||
索引
シンボル
- /boot/ ディレクトリー, /boot/ ディレクトリー
- /dev/shm, df コマンド
- /etc/fstab, ext3 ファイルシステムへの変換, /etc/fstabを使用した NFS ファイルシステムのマウント, ファイルシステムのマウント
- /etc/fstab ファイル
- ディスククォータの有効化, クォータの有効化
- /home、/opt、/usr/local には別々のパーティションを用意する
- ストレージをインストールする際の注意点, /home、/opt、/usr/local には別々のパーティションを用意する
- /local/directory (クライアント設定、マウント)
- NFS, NFS クライアントの設定
- /proc
- /proc/devices, /proc 仮想ファイルシステム
- /proc/filesystems, /proc 仮想ファイルシステム
- /proc/mdstat, /proc 仮想ファイルシステム
- /proc/mounts, /proc 仮想ファイルシステム
- /proc/mounts/, /proc 仮想ファイルシステム
- /proc/partitions, /proc 仮想ファイルシステム
- /proc/devices
- 仮想ファイルシステム (/proc), /proc 仮想ファイルシステム
- /proc/filesystems
- 仮想ファイルシステム (/proc), /proc 仮想ファイルシステム
- /proc/mdstat
- 仮想ファイルシステム (/proc), /proc 仮想ファイルシステム
- /proc/mounts
- 仮想ファイルシステム (/proc), /proc 仮想ファイルシステム
- /proc/mounts/
- 仮想ファイルシステム (/proc), /proc 仮想ファイルシステム
- /proc/partitions
- 仮想ファイルシステム (/proc), /proc 仮想ファイルシステム
- /remote/export (クライアント設定、マウント)
- NFS, NFS クライアントの設定
- アンマウント, ファイルシステムのアンマウント
- イニシエーターの実装
- オフロードとインターフェイスのバインディング
- iSCSI, 利用可能な iface 設定の表示
- インストーラーのサポート
- インストールストレージの設定
- /home、/opt、/usr/local には別々のパーティションを用意する, /home、/opt、/usr/local には別々のパーティションを用意する
- DIF/DIX を有効にしているブブロックデバイス, DIF/DIX を有効にしているブロックデバイス
- IBM System Z における DASD デバイスと zFCP デバイス, IBM System Z における DASD デバイスと zFCP デバイス
- iSCSI の検出および設定, iSCSI の検出および設定
- LUKS/dm-crypt の使用、ブロックデバイスの暗号化, LUKS を使用したブロックデバイスの暗号化
- updates, ストレージをインストールする際の注意点
- チャネルコマンドワード (CCW), IBM System Z における DASD デバイスと zFCP デバイス
- 古い BIOS RAID メタデータ, 古い BIOS RAID メタデータ
- 新着情報, ストレージをインストールする際の注意点
- インタラクティブな操作 (xfsrestore)
- XFS, 復元
- インデックスキー
- FS-Cache, FS-Cache
- エキスパートモード (xfs_quota)
- XFS, XFS クォータ管理
- エクスポートしたファイルシステム
- ディスクレスシステム, ディスクレスクライアントのエクスポートしたファイルシステムの設定
- エラーメッセージ
- 書き込みバリア, 書き込みバリアの有効化と無効化
- オフラインステータス
- Linux SCSI レイヤー, SCSI コマンドタイマーおよびデバイスステータスの制御
- オフロードとインターフェイスのバインディング
- オプション (クライアント設定、マウント)
- NFS, NFS クライアントの設定
- オンラインストレージ
- トラブルシューティング, オンラインストレージ設定のトラブルシューティング
- ファイバーチャネル, ファイバーチャネル
- 概要, オンラインストレージ管理
- sysfs, オンラインストレージ管理
- オンライン論理ユニット
- 読み取り/書き込み状態の変更, オンライン論理ユニットの読み取り/書き込み状態の変更
- キャッシュの共有
- FS-Cache, キャッシュの共有
- キャッシュの設定
- FS-Cache, キャッシュの設定
- キャッシュカリング制限
- FS-Cache, キャッシュカリング制限の設定
- キャッシュバックエンド
- FS-Cache, FS-Cache
- クォータの管理
- XFS, XFS クォータ管理
- コヒーレンシーデータ
- FS-Cache, FS-Cache
- コマンドタイマー (SCSI)
- Linux SCSI レイヤー, コマンドタイマー
- サイズ変更
- ext4, ext4 ファイルシステムのサイズ変更
- サイズ変更された論理ユニット、サイズ変更, オンライン論理ユニットのサイズの変更
- サイズ変更した論理ユニット, オンライン論理ユニットのサイズの変更
- サイト設定ファイルの上書き/拡張 (autofs)
- NFS, autofs の設定
- サーバー (クライアント設定、マウント)
- NFS, NFS クライアントの設定
- システム情報
- ファイルシステム, ファイルシステム情報の収集
- /dev/shm, df コマンド
- ストライド (ストライプジオメトリーの指定)
- ext4, Ext4 ファイルシステムの作成
- ストライピング
- RAID, RAID レベルとリニアサポート
- RAID の基礎, RAID (Redundant Array of Independent Disks)
- ストライプジオメトリー
- ext4, Ext4 ファイルシステムの作成
- ストレージの相互接続、スキャン, ストレージの相互接続のスキャン
- ストレージの相互接続のスキャン, ストレージの相互接続のスキャン
- ストレージをインストールする際の注意点
- /home、/opt、/usr/local には別々のパーティションを用意する, /home、/opt、/usr/local には別々のパーティションを用意する
- DIF/DIX を有効にしているブブロックデバイス, DIF/DIX を有効にしているブロックデバイス
- IBM System Z における DASD デバイスと zFCP デバイス, IBM System Z における DASD デバイスと zFCP デバイス
- iSCSI の検出および設定, iSCSI の検出および設定
- LUKS/dm-crypt の使用、ブロックデバイスの暗号化, LUKS を使用したブロックデバイスの暗号化
- updates, ストレージをインストールする際の注意点
- チャネルコマンドワード (CCW), IBM System Z における DASD デバイスと zFCP デバイス
- 古い BIOS RAID メタデータ, 古い BIOS RAID メタデータ
- 新着情報, ストレージをインストールする際の注意点
- ストレージアクセスパラメーター
- I/O のアライメントとサイズ, ストレージアクセスパラメーター
- ストレージデバイスへのパス、削除, ストレージデバイスへのパスの削除
- ストレージデバイスへのパス、追加, ストレージデバイスまたはパスの追加
- ストレージデバイスへのパスの削除, ストレージデバイスへのパスの削除
- ストレージデバイスへのパスの追加, ストレージデバイスまたはパスの追加
- スループットクラス
- ソリッドステートディスク, ソリッドステートディスクのデプロイメントガイドライン
- スレーブマウント, マウントの共有
- スワップ領域, swap 領域
- expanding, スワップ領域の追加
- file
- 作成, スワップファイルの作成, スワップファイルの削除
- LVM2
- 作成, スワップ領域の追加
- 削除中, スワップ領域の削除
- 推奨サイズ, swap 領域
- 移動, Swap 領域の移動
- セッションの実行、以下に関する情報の取得
- iSCSI API, iSCSI API
- ソフトウェア iSCSI
- iSCSI, ソフトウェア iSCSI 用の iface の設定
- オフロードとインターフェイスのバインディング
- iSCSI, ソフトウェア iSCSI 用の iface の設定
- ソフトウェア iSCSI の iface
- オフロードとインターフェイスのバインディング
- iSCSI, ソフトウェア iSCSI 用の iface の設定
- ソフトウェア RAID (参照 RAID)
- ソリッドステートディスク
- deployment, ソリッドステートディスクのデプロイメントガイドライン
- SSD, ソリッドステートディスクのデプロイメントガイドライン
- TRIM コマンド, ソリッドステートディスクのデプロイメントガイドライン
- スループットクラス, ソリッドステートディスクのデプロイメントガイドライン
- デプロイメントのガイドライン, ソリッドステートディスクのデプロイメントガイドライン
- ターゲット
- iSCSI, iSCSI ターゲットへのログイン
- ダイレクトマップサポート (autofs バージョン 5)
- ダンプレベル
- XFS, バックアップ
- ダーティーログ (XFS ファイルシステムを修復)
- XFS, XFS ファイルシステムの修復
- ダーティーログを使用した XFS ファイルシステムの修復
- XFS, XFS ファイルシステムの修復
- チャネルコマンドワード (CCW)
- ストレージをインストールする際の注意点, IBM System Z における DASD デバイスと zFCP デバイス
- ツール (パーティションおよびその他のファイルシステム機能用)
- I/O のアライメントとサイズ, パーティションおよびファイルシステムツール
- ディスククォータ, ディスククォータ
- グループごとに割り当て, グループごとのクォータ割り当て
- ソフト制限, ユーザーごとのクォータ割り当て
- ハード制限, ユーザーごとのクォータ割り当て
- ファイルシステムごとの割り当て, ソフト制限の猶予期間の設定
- ユーザーごとに割り当て, ユーザーごとのクォータ割り当て
- 有効化, ディスククォータの設定, 有効化と無効化
- /etc/fstab、変更, クォータの有効化
- quotacheck、実行中, クォータデータベースファイルの作成
- クォータファイルの作成, クォータデータベースファイルの作成
- 無効化, 有効化と無効化
- 猶予期間, ユーザーごとのクォータ割り当て
- 管理, ディスククォータの管理
- quotacheck コマンド、以下のチェックに使用, クォータの精度維持
- レポート, ディスククォータに関するレポート
- 関連情報, ディスククオータのリファレンス
- ディスクストレージ (参照 ディスククォータ)
- parted (参照 parted)
- ディスクレスクライアントの tftp サービスの設定
- ディスクレスシステム, ディスクレスクライアントの tftp サービスの設定
- ディスクレスクライアント用の DHCP の設定
- ディスクレスシステム, ディスクレスクライアント用の DHCP の設定
- ディスクレスシステム
- DHCP、設定, ディスクレスクライアント用の DHCP の設定
- tftp サービス、設定, ディスクレスクライアントの tftp サービスの設定
- エクスポートしたファイルシステム, ディスクレスクライアントのエクスポートしたファイルシステムの設定
- ネットワークブートサービス, リモートディスクレスシステムの設定
- リモートのディスクレスシステム, リモートディスクレスシステムの設定
- 必要なパッケージ, リモートディスクレスシステムの設定
- ディレクトリー
- /boot/, /boot/ ディレクトリー
- /dev/, /dev/ ディレクトリー
- /etc/, /etc/ ディレクトリー
- /mnt/, /mnt/ ディレクトリー
- /opt/, /opt/ ディレクトリー
- /proc/, /proc/ ディレクトリー
- /srv/, /srv/ ディレクトリー
- /sys/, /sys/ ディレクトリー
- /usr/, /usr/ ディレクトリー
- /var/, /var/ ディレクトリー
- デバイス、削除, ストレージデバイスの削除
- デバイスがブロックされているかどうかの確認
- ファイバーチャネル
- リンクロス動作の変更, ファイバーチャネル
- デバイスのステータス
- Linux SCSI レイヤー, デバイスの状態
- デバイスの削除, ストレージデバイスの削除
- デプロイメントのガイドライン
- ソリッドステートディスク, ソリッドステートディスクのデプロイメントガイドライン
- トラブルシューティング
- オンラインストレージ, オンラインストレージ設定のトラブルシューティング
- ドライバー (ネイティブ)、ファイバーチャネル, ネイティブファイバーチャネルのドライバーおよび機能
- ネイティブのファイバーチャネルドライバー, ネイティブファイバーチャネルのドライバーおよび機能
- ネットワークファイルシステム (参照 NFS)
- ネットワークブートサービス
- ディスクレスシステム, リモートディスクレスシステムの設定
- ハイエンドアレイ
- 書き込みバリア, ハイエンドアレイ
- ハードウェア RAID (参照 RAID)
- ハードウェア RAID コントローラードライバー
- バインド不可能なマウント, マウントの共有
- バックアップ/復元
- バックアップの復元
- XFS, 復元
- バッテリーでバックアップされる書き込みキャッシュ
- 書き込みバリア, バッテリーでバックアップされる書き込みキャッシュ
- パフォーマンスに関する保証
- FS-Cache, パフォーマンスに関する保証
- パラレル NFS
- pNFS, pNFS
- パリティー
- RAID, RAID レベルとリニアサポート
- パーティション
- サイズ変更, fdisk でのパーティションのサイズ変更
- フォーマット
- mkfs , パーティションのフォーマットとラベル付け
- リスト表示, パーティションテーブルの表示
- 作成, パーティションの作成
- 削除中, パーティションの削除
- パーティションテーブル
- 表示する, パーティションテーブルの表示
- ファイバーチャネル
- オンラインストレージ, ファイバーチャネル
- ファイバーチャネル API, ファイバーチャネル API
- ファイバーチャネルドライバー (ネイティブ), ネイティブファイバーチャネルのドライバーおよび機能
- ファイルシステム, ファイルシステム情報の収集
- Btrfs, Btrfs (テクノロジープレビュー)
- ext2 (参照 ext2)
- ext3 (参照 ext3)
- FHS 標準, FHS 組織
- 構造, ファイルシステム構造とメンテナンス
- 組織, FHS 組織
- 階層, ファイルシステム階層標準 (FHS) の概要
- ファイルシステムのタイプ
- ext4, ext4 ファイルシステム
- GFS2, Global File System 2
- XFS, XFS ファイルシステム
- ファイルシステムの修復
- XFS, XFS ファイルシステムの修復
- ファイルシステムサイズの拡大
- XFS, XFS ファイルシステムのサイズの拡大
- ブロックされたデバイスの検証
- ファイバーチャネル
- リンクロス動作の変更, ファイバーチャネル
- ブロックデバイス ioctls (ユーザー空間アクセス)
- I/O のアライメントとサイズ, ブロックデバイス ioctls
- プライベートマウント, マウントの共有
- プロジェクト制限 (設定)
- XFS, プロジェクト制限の設定
- ホスト
- ファイバーチャネル API, ファイバーチャネル API
- ポートの状態 (リモート)、判断
- ファイバーチャネル
- リンクロス動作の変更, ファイバーチャネル
- マウント (クライアント設定)
- NFS, NFS クライアントの設定
- マウントする, ファイルシステムのマウント
- ext4, ext4 ファイルシステムのマウント
- XFS, XFS ファイルシステムのマウント
- マウントポイントの移動, マウントポイントの移動
- ミラーリング
- RAID, RAID レベルとリニアサポート
- ユーザー空間の API ファイル
- ファイバーチャネル API, ファイバーチャネル API
- ユーザー空間アクセス
- I/O のアライメントとサイズ, ユーザー空間アクセス
- リニア RAID
- RAID, RAID レベルとリニアサポート
- リモートのディスクレスシステム
- ディスクレスシステム, リモートディスクレスシステムの設定
- リモートポート
- ファイバーチャネル API, ファイバーチャネル API
- リモートポートの状態、判断
- ファイバーチャネル
- リンクロス動作の変更, ファイバーチャネル
- リモートポートの状態の判断
- ファイバーチャネル
- リンクロス動作の変更, ファイバーチャネル
- リンクロス動作の変更, リンクロス動作の変更
- ファイバーチャネル, ファイバーチャネル
- レイジーマウント/アンマウントのサポート (autofs バージョン 5)
- レコードタイプ
- discovery
- iSCSI, iSCSI 検出設定
- レポート (xfs_quota エキスパートモード)
- XFS, XFS クォータ管理
- ログイン
- iSCSI ターゲット, iSCSI ターゲットへのログイン
- 一時停止中
- XFS, XFS ファイルシステムの一時停止
- 主な特長
- ext4, ext4 ファイルシステム
- XFS, XFS ファイルシステム
- 他のファイルシステムユーティリティー
- 仮想ファイルシステム (/proc)
- /proc/devices, /proc 仮想ファイルシステム
- /proc/filesystems, /proc 仮想ファイルシステム
- /proc/mdstat, /proc 仮想ファイルシステム
- /proc/mounts, /proc 仮想ファイルシステム
- /proc/mounts/, /proc 仮想ファイルシステム
- /proc/partitions, /proc 仮想ファイルシステム
- 仮想マシン用のストレージ, 仮想マシン用のストレージ
- 作成
- ext4, Ext4 ファイルシステムの作成
- XFS, XFS ファイルシステムの作成
- 保存用の LDAP を使用した自動マウント機能マップの保存 (autofs)
- NFS, サイト設定ファイルの上書きまたは拡張
- 個々のユーザー
- volume_key, volume_key を個別のユーザーとして使用する
- 共有サブツリー, マウントの共有
- 共有マウント, マウントの共有
- 利用可能な iface 設定の表示
- オフロードとインターフェイスのバインディング
- iSCSI, 利用可能な iface 設定の表示
- 制限 (xfs_quota エキスパートモード)
- XFS, XFS クォータ管理
- 割り当て機能
- ext4, ext4 ファイルシステム
- XFS, XFS ファイルシステム
- 古い BIOS RAID メタデータ
- ストレージをインストールする際の注意点, 古い BIOS RAID メタデータ
- 実行中のステータス
- Linux SCSI レイヤー, SCSI コマンドタイマーおよびデバイスステータスの制御
- 強化された LDAP サポート (autofs バージョン 5)
- 必要なパッケージ
- FCoE, ファイバーチャネルオーバーイーサネットインターフェイスの設定
- ディスクレスシステム, リモートディスクレスシステムの設定
- 追加/削除
- LUN (論理ユニット番号), rescan-scsi-bus.sh を使用した論理ユニットの追加/削除
- 新着情報
- ストレージをインストールする際の注意点, ストレージをインストールする際の注意点
- 既知の問題
- 追加/削除
- LUN (論理ユニット番号), rescan-scsi-bus.sh の既知の問題
- 書き込みキャッシュ、無効化
- 書き込みバリア, 書き込みキャッシュの無効化
- 書き込みキャッシュの無効化
- 書き込みバリア, 書き込みキャッシュの無効化
- 書き込みバリア
- ext4, ext4 ファイルシステムのマウント
- NFS, NFS
- XFS, 書き込みバリア
- エラーメッセージ, 書き込みバリアの有効化と無効化
- ハイエンドアレイ, ハイエンドアレイ
- バッテリーでバックアップされる書き込みキャッシュ, バッテリーでバックアップされる書き込みキャッシュ
- 定義, 書き込みバリア
- 書き込みキャッシュの無効化, 書き込みキャッシュの無効化
- 書き込みバリアのしくみ, 書き込みバリアのしくみ
- 書き込みバリアの重要性, 書き込みバリアの重要性
- 有効化/無効化, 書き込みバリアの有効化と無効化
- 書き込みバリアのしくみ
- 書き込みバリア, 書き込みバリアのしくみ
- 書き込みバリアの重要性
- 書き込みバリア, 書き込みバリアの重要性
- 最大サイズ
- GFS2, Global File System 2
- 最大サイズ, GFS2 ファイルシステム, Global File System 2
- 有効化/無効化
- 書き込みバリア, 書き込みバリアの有効化と無効化
- 概要, 概要
- オンラインストレージ, オンラインストレージ管理
- 永続的な命名, 永続的な命名
- 特定のセッションのタイムアウト、設定
- iSCSI の設定, 特定セッションのタイムアウトの設定
- 特定セッションのタイムアウト、設定
- iSCSI の設定, 特定セッションのタイムアウトの設定
- 相互接続 (スキャン)
- iSCSI, iSCSI 相互接続のスキャン
- 相互接続のスキャン
- iSCSI, iSCSI 相互接続のスキャン
- 統計情報 (追跡)
- FS-Cache, 統計情報
- 統計情報の追跡
- FS-Cache, 統計情報
- 読み取り/書き込み状態の変更
- オンライン論理ユニット, オンライン論理ユニットの読み取り/書き込み状態の変更
- 追加/削除
- LUN (論理ユニット番号), rescan-scsi-bus.sh を使用した論理ユニットの追加/削除
- 適切な nsswitch 設定 (autofs バージョン 5) の使用
- 階層、ファイルシステム, ファイルシステム階層標準 (FHS) の概要
- 高度な RAID デバイスの作成
- RAID, 高度な RAID デバイスの作成
A
- Anaconda のサポート
- API、iSCSI, iSCSI API
- API、ファイバーチャネル, ファイバーチャネル API
- ATA 規格
- I/O のアライメントとサイズ, ATA
- autofs , autofs, autofs の設定
- (参照 NFS)
- autofs バージョン 5
- autofs マウントポイントごとの複数のマスターマップエントリー (autofs バージョン 5)
B
- bcull (キャッシュカリング制限の設定)
- FS-Cache, キャッシュカリング制限の設定
- brun (キャッシュカリング制限の設定)
- FS-Cache, キャッシュカリング制限の設定
- bstop (キャッシュカリング制限の設定)
- FS-Cache, キャッシュカリング制限の設定
- Btrfs
- ファイルシステム, Btrfs (テクノロジープレビュー)
C
- cachefiles
- FS-Cache, FS-Cache
- cachefilesd
- FS-Cache, キャッシュの設定
- CCW、チャネルコマンドワード
- ストレージをインストールする際の注意点, IBM System Z における DASD デバイスと zFCP デバイス
- changing dev_loss_tmo
- ファイバーチャネル
- リンクロス動作の変更, ファイバーチャネル
- commands
- volume_key, volume_key コマンド
- configuration
- discovery
- iSCSI, iSCSI 検出設定
- cumulative モード (xfsrestore)
- XFS, 復元
D
- debugfs (ext4 ファイルシステムのその他のユーティリティー)
- deployment
- ソリッドステートディスク, ソリッドステートディスクのデプロイメントガイドライン
- dev ディレクトリー, /dev/ ディレクトリー
- Device Mapper を使用したマルチパス設定, DM Multipath
- dev_loss_tmo
- ファイバーチャネル
- リンクロス動作の変更, ファイバーチャネル
- dev_loss_tmo, changing
- ファイバーチャネル
- リンクロス動作の変更, ファイバーチャネル
- df, df コマンド
- DHCP、設定
- ディスクレスシステム, ディスクレスクライアント用の DHCP の設定
- DIF/DIX を有効にしているブブロックデバイス
- ストレージをインストールする際の注意点, DIF/DIX を有効にしているブロックデバイス
- discovery
- iSCSI, iSCSI 検出設定
- dm-multipath
- iSCSI の設定, dm-multipathでの iSCSI 設定
- dmraid
- RAID, dmraid
- dmraid (RAID セットを設定する)
- RAID, dmraid
- du, du コマンド
E
- e2fsck, Ext2 ファイルシステムへの復元
- e2image (ext4 ファイルシステムのその他のユーティリティー)
- e2label
- e2label (ext4 ファイルシステムのその他のユーティリティー)
- etc ディレクトリー, /etc/ ディレクトリー
- ext2
- ext3 からの復元, Ext2 ファイルシステムへの復元
- ext3
- ext2 からの変換, ext3 ファイルシステムへの変換
- features, Ext3 ファイルシステム。
- 作成, Ext3 ファイルシステムの作成
- ext4
- debugfs (ext4 ファイルシステムのその他のユーティリティー), ext4 ファイルシステムのその他のユーティリティー
- e2image (ext4 ファイルシステムのその他のユーティリティー), ext4 ファイルシステムのその他のユーティリティー
- e2label, ext4 ファイルシステムのその他のユーティリティー
- e2label (ext4 ファイルシステムのその他のユーティリティー), ext4 ファイルシステムのその他のユーティリティー
- fsync(), ext4 ファイルシステム
- mkfs.ext4, Ext4 ファイルシステムの作成
- nobarrier マウントオプション, ext4 ファイルシステムのマウント
- quota (ext4 ファイルシステムのその他のユーティリティー), ext4 ファイルシステムのその他のユーティリティー
- resize2fs (resizing ext4), ext4 ファイルシステムのサイズ変更
- stripe-width (ストライプ配列を指定), Ext4 ファイルシステムの作成
- tune2fs (mounting), ext4 ファイルシステムのマウント
- サイズ変更, ext4 ファイルシステムのサイズ変更
- ストライド (ストライプジオメトリーの指定), Ext4 ファイルシステムの作成
- ストライプジオメトリー, Ext4 ファイルシステムの作成
- ファイルシステムのタイプ, ext4 ファイルシステム
- マウントする, ext4 ファイルシステムのマウント
- 主な特長, ext4 ファイルシステム
- 他のファイルシステムユーティリティー, ext4 ファイルシステムのその他のユーティリティー
- 作成, Ext4 ファイルシステムの作成
- 割り当て機能, ext4 ファイルシステム
- 書き込みバリア, ext4 ファイルシステムのマウント
F
- FCoE
- FCoE を使用するためにイーサネットインターフェイスの設定, ファイバーチャネルオーバーイーサネットインターフェイスの設定
- Fibre Channel over Ethernet, ファイバーチャネルオーバーイーサネットインターフェイスの設定
- 必要なパッケージ, ファイバーチャネルオーバーイーサネットインターフェイスの設定
- FCoE を使用するためにイーサネットインターフェイスの設定
- FHS, ファイルシステム階層標準 (FHS) の概要, FHS 組織
- (参照 ファイルシステム)
- Fibre Channel over Ethernet
- findmnt (コマンド)
- マウントのリスト表示, 現在マウントされているファイルシステムのリスト表示
- FS-Cache
- bcull (キャッシュカリング制限の設定), キャッシュカリング制限の設定
- brun (キャッシュカリング制限の設定), キャッシュカリング制限の設定
- bstop (キャッシュカリング制限の設定), キャッシュカリング制限の設定
- cachefiles, FS-Cache
- cachefilesd, キャッシュの設定
- NFS (with の使用), NFS でのキャッシュの使用
- NFS (キャッシュの制限), NFS でのキャッシュの制限
- tune2fs (キャッシュの設定), キャッシュの設定
- インデックスキー, FS-Cache
- キャッシュの共有, キャッシュの共有
- キャッシュの設定, キャッシュの設定
- キャッシュカリング制限, キャッシュカリング制限の設定
- キャッシュバックエンド, FS-Cache
- コヒーレンシーデータ, FS-Cache
- パフォーマンスに関する保証, パフォーマンスに関する保証
- 統計情報 (追跡), 統計情報
- fsync()
- ext4, ext4 ファイルシステム
- XFS, XFS ファイルシステム
G
- GFS2
- gfs2.ko, Global File System 2
- ファイルシステムのタイプ, Global File System 2
- 最大サイズ, Global File System 2
- GFS2 ファイルシステムの最大サイズ, Global File System 2
- gfs2.ko
- GFS2, Global File System 2
- Global File System 2
- gfs2.ko, Global File System 2
- ファイルシステムのタイプ, Global File System 2
- 最大サイズ, Global File System 2
- gquota/gqnoenforce
- XFS, XFS クォータ管理
I
- I/O のアライメントとサイズ, ストレージ I/O アライメントとサイズ
- ATA 規格, ATA
- I/O パラメーターのスタッキング, I/O パラメーターのスタッキング
- Linux I/O スタック, ストレージ I/O アライメントとサイズ
- logical_block_size, ユーザー空間アクセス
- LVM, 論理ボリュームマネージャー
- READ CAPACITY(16), SCSI
- SCSI 規格, SCSI
- sysfs インターフェイス (ユーザー空間アクセス), sysfs インターフェイス
- ストレージアクセスパラメーター, ストレージアクセスパラメーター
- ツール (パーティションおよびその他のファイルシステム機能用), パーティションおよびファイルシステムツール
- ブロックデバイス ioctls (ユーザー空間アクセス), ブロックデバイス ioctls
- ユーザー空間アクセス, ユーザー空間アクセス
- I/O パラメーターのスタッキング
- I/O のアライメントとサイズ, I/O パラメーターのスタッキング
- IBM System Z における DASD デバイスと zFCP デバイス
- ストレージをインストールする際の注意点, IBM System Z における DASD デバイスと zFCP デバイス
- iface (iSCSI オフロードの設定)
- オフロードとインターフェイスのバインディング
- iSCSI, iSCSI オフロード用の iface の設定
- iface のバインディング/バインド解除
- オフロードとインターフェイスのバインディング
- iSCSI, iface のポータルへのバインド/バインド解除
- iface のポータルへのバインド/バインド解除
- オフロードとインターフェイスのバインディング
- iSCSI, iface のポータルへのバインド/バインド解除
- iface 設定
- オフロードとインターフェイスのバインディング
- iSCSI, 利用可能な iface 設定の表示
- iface 設定、表示
- オフロードとインターフェイスのバインディング
- iSCSI, 利用可能な iface 設定の表示
- iSCSI
- discovery, iSCSI 検出設定
- configuration, iSCSI 検出設定
- レコードタイプ, iSCSI 検出設定
- オフロードとインターフェイスのバインディング, iSCSI オフロードおよびインターフェイスバインディングの設定
- iface (iSCSI オフロードの設定), iSCSI オフロード用の iface の設定
- iface のポータルへのバインド/バインド解除, iface のポータルへのバインド/バインド解除
- iface 設定, 利用可能な iface 設定の表示
- iface 設定、表示, 利用可能な iface 設定の表示
- イニシエーターの実装, 利用可能な iface 設定の表示
- ソフトウェア iSCSI, ソフトウェア iSCSI 用の iface の設定
- ソフトウェア iSCSI の iface, ソフトウェア iSCSI 用の iface の設定
- 利用可能な iface 設定の表示, 利用可能な iface 設定の表示
- ソフトウェア iSCSI, ソフトウェア iSCSI 用の iface の設定
- ターゲット, iSCSI ターゲットへのログイン
- ログイン, iSCSI ターゲットへのログイン
- 相互接続のスキャン, iSCSI 相互接続のスキャン
- iSCSI API, iSCSI API
- iSCSI の検出および設定
- ストレージをインストールする際の注意点, iSCSI の検出および設定
- iSCSI ルート
- iSCSI の設定, iSCSI ルート
- iSCSI 論理ユニット、サイズ変更, iSCSI 論理ユニットのサイズを変更
- iSCSI 論理ユニットのサイズ変更, iSCSI 論理ユニットのサイズを変更
L
- levels
- RAID, RAID レベルとリニアサポート
- Linux I/O スタック
- I/O のアライメントとサイズ, ストレージ I/O アライメントとサイズ
- logical_block_size
- I/O のアライメントとサイズ, ユーザー空間アクセス
- LUKS/dm-crypt の使用、ブロックデバイスの暗号化
- ストレージをインストールする際の注意点, LUKS を使用したブロックデバイスの暗号化
- LUN (論理ユニット番号)
- 追加/削除, rescan-scsi-bus.sh を使用した論理ユニットの追加/削除
- rescan-scsi-bus.sh, rescan-scsi-bus.sh を使用した論理ユニットの追加/削除
- 必要なパッケージ, rescan-scsi-bus.sh を使用した論理ユニットの追加/削除
- 既知の問題, rescan-scsi-bus.sh の既知の問題
- LVM
- I/O のアライメントとサイズ, 論理ボリュームマネージャー
M
- mdadm (RAID セットの設定)
- RAID, mdadm
- mdraid
- RAID, mdraid
- mkfs , パーティションのフォーマットとラベル付け
- mkfs.ext4
- ext4, Ext4 ファイルシステムの作成
- mkfs.xfs
- XFS, XFS ファイルシステムの作成
- mnt ディレクトリー, /mnt/ ディレクトリー
- mount (command), mount コマンドの使用
- オプション, マウントオプションの指定
- ファイルシステムのマウント, ファイルシステムのマウント
- マウントのリスト表示, 現在マウントされているファイルシステムのリスト表示
- マウントポイントの移動, マウントポイントの移動
- 共有サブツリー, マウントの共有
N
- NFS
- /etc/fstab , /etc/fstabを使用した NFS ファイルシステムのマウント
- /local/directory (クライアント設定、マウント), NFS クライアントの設定
- /remote/export (クライアント設定、マウント), NFS クライアントの設定
- autofs
- LDAP, LDAP を使用した自動マウント機能マップの格納
- 拡張, サイト設定ファイルの上書きまたは拡張
- 設定, autofs の設定
- autofs バージョン 5, バージョン 4 と比較した autofs バージョン 5 の改善点
- autofs マウントポイントごとの複数のマスターマップエントリー (autofs バージョン 5), バージョン 4 と比較した autofs バージョン 5 の改善点
- client
- autofs , autofs
- マウントオプション, 一般的な NFS マウントオプション
- 設定, NFS クライアントの設定
- condrestart, NFS サーバーの起動と停止
- FS-Cache, NFS でのキャッシュの使用
- NFS と rpcbind のトラブルシューティング, NFS と rpcbindのトラブルシューティング
- RDMA, NFS over RDMA の有効化 (NFSoRDMA)
- rfc2307bis (autofs), LDAP を使用した自動マウント機能マップの格納
- rpcbind , NFS および rpcbind
- security, NFS のセキュア化
- NFSv3 ホストアクセス, AUTH_SYS とエクスポート制御による NFS セキュリティー保護
- status, NFS サーバーの起動と停止
- TCP, NFS の概要
- UDP, NFS の概要
- オプション (クライアント設定、マウント), NFS クライアントの設定
- サイト設定ファイルの上書き/拡張 (autofs), autofs の設定
- サーバー (クライアント設定、マウント), NFS クライアントの設定
- サーバー設定, NFS サーバーの設定
- /etc/exports , /etc/exports 設定ファイル
- exportfs コマンド, exportfs コマンド
- NFSv4 を使用した exportfs コマンド, NFSv4 での exportfs の使用
- セキュリティー
- NFSv4 ホストアクセス, AUTH_GSSを使用した NFS 保護
- ファイル権限, ファイル権限
- ダイレクトマップサポート (autofs バージョン 5), バージョン 4 と比較した autofs バージョン 5 の改善点
- ファイアウォールでの設定, ファイアウォール背後での NFS の実行
- ホスト名の形式, ホスト名の形式
- マウント (クライアント設定), NFS クライアントの設定
- レイジーマウント/アンマウントのサポート (autofs バージョン 5), バージョン 4 と比較した autofs バージョン 5 の改善点
- 仕組み, NFS の概要
- 保存用の LDAP を使用した自動マウント機能マップの保存 (autofs), サイト設定ファイルの上書きまたは拡張
- 停止, NFS サーバーの起動と停止
- 再読み込み, NFS サーバーの起動と停止
- 再起動, NFS サーバーの起動と停止
- 強化された LDAP サポート (autofs バージョン 5), バージョン 4 と比較した autofs バージョン 5 の改善点
- 必要なサービス, 必要なサービス
- 書き込みバリア, NFS
- 概要, Network File System (NFS)
- 起動, NFS サーバーの起動と停止
- 適切な nsswitch 設定 (autofs バージョン 5) の使用, バージョン 4 と比較した autofs バージョン 5 の改善点
- 関連情報, NFS のリファレンス
- インストールされているドキュメント, インストールされているドキュメント
- 便利な Web サイト, 便利な Web サイト
- 関連書籍, 関連書籍
- NFS (with の使用)
- FS-Cache, NFS でのキャッシュの使用
- NFS (キャッシュの制限)
- FS-Cache, NFS でのキャッシュの制限
- NFS でのキャッシュの制限
- FS-Cache, NFS でのキャッシュの制限
- NFS と rpcbind のトラブルシューティング
- nobarrier マウントオプション
- ext4, ext4 ファイルシステムのマウント
- XFS, 書き込みバリア
- NOP-Out 要求
- リンクロスの変更
- iSCSI の設定, NOP-Out 間隔/タイムアウト
- NOP-Outs (無効化)
- iSCSI の設定, iSCSI ルート
- NOP-Outs の無効化
- iSCSI の設定, iSCSI ルート
O
- opt ディレクトリー, /opt/ ディレクトリー
P
- parted , Partitions
- コマンドの表, Partitions
- デバイスの選択, パーティションテーブルの表示
- パーティションのサイズ変更, fdisk でのパーティションのサイズ変更
- パーティションの削除, パーティションの削除
- パーティションを作成する, パーティションの作成
- パーティションテーブルの表示, パーティションテーブルの表示
- 概要, Partitions
- pNFS
- パラレル NFS, pNFS
- pquota/pqnoenforce
- XFS, XFS クォータ管理
- proc ディレクトリー, /proc/ ディレクトリー
Q
- queue_if_no_path
- iSCSI の設定, dm-multipathでの iSCSI 設定
- リンクロスの変更
- iSCSI の設定, replacement_timeout
- quota (ext4 ファイルシステムのその他のユーティリティー)
- quotacheck , クォータデータベースファイルの作成
- quotacheck コマンド
- によるクォータ正確性のチェック, クォータの精度維持
- quotaoff , 有効化と無効化
- quotaon , 有効化と無効化
R
- RAID
- Anaconda のサポート, Anaconda インストーラーでの RAID のサポート
- dmraid, dmraid
- dmraid (RAID セットを設定する), dmraid
- levels, RAID レベルとリニアサポート
- mdadm (RAID セットの設定), mdadm
- mdraid, mdraid
- RAID のサブシステム, Linux RAID サブシステム
- RAID セットの設定, RAID セットの設定
- インストーラーのサポート, Anaconda インストーラーでの RAID のサポート
- ストライピング, RAID レベルとリニアサポート
- ソフトウェア RAID, RAID のタイプ
- ハードウェア RAID, RAID のタイプ
- ハードウェア RAID コントローラードライバー, Linux ハードウェア RAID のコントローラードライバー
- パリティー, RAID レベルとリニアサポート
- ミラーリング, RAID レベルとリニアサポート
- リニア RAID, RAID レベルとリニアサポート
- レベル 0, RAID レベルとリニアサポート
- レベル 1, RAID レベルとリニアサポート
- レベル 4, RAID レベルとリニアサポート
- レベル 5, RAID レベルとリニアサポート
- 使用理由, RAID (Redundant Array of Independent Disks)
- 高度な RAID デバイスの作成, 高度な RAID デバイスの作成
- RAID のサブシステム
- RAID, Linux RAID サブシステム
- RAID セットの設定
- RAID, RAID セットの設定
- RDMA
- READ CAPACITY(16)
- I/O のアライメントとサイズ, SCSI
- Red Hat Enterprise Linux 固有のファイルの場所
- /etc/sysconfig/, 特別な Red Hat Enterprise Linux ファイルの場所
- (参照 sysconfig ディレクトリー)
- /var/cache/yum, 特別な Red Hat Enterprise Linux ファイルの場所
- /var/lib/rpm/, 特別な Red Hat Enterprise Linux ファイルの場所
- replacement_timeout
- リンクロスの変更
- iSCSI の設定, SCSI エラーハンドラー, replacement_timeout
- replacement_timeoutM
- iSCSI の設定, iSCSI ルート
- rescan-scsi-bus.sh
- 追加/削除
- LUN (論理ユニット番号), rescan-scsi-bus.sh を使用した論理ユニットの追加/削除
- resize2fs, Ext2 ファイルシステムへの復元
- resize2fs (resizing ext4)
- ext4, ext4 ファイルシステムのサイズ変更
- rfc2307bis (autofs)
- rpcbind , NFS および rpcbind
- (参照 NFS)
- NFS, NFS と rpcbindのトラブルシューティング
- rpcinfo , NFS と rpcbindのトラブルシューティング
- status, NFS サーバーの起動と停止
- rpcinfo , NFS と rpcbindのトラブルシューティング
S
- SCSI エラーハンドラー
- リンクロスの変更
- iSCSI の設定, SCSI エラーハンドラー
- SCSI コマンドタイマー
- Linux SCSI レイヤー, コマンドタイマー
- SCSI コマンドタイマーとデバイスステータスの制御
- Linux SCSI レイヤー, SCSI コマンドタイマーおよびデバイスステータスの制御
- SCSI 規格
- I/O のアライメントとサイズ, SCSI
- simple モード (xfsrestore)
- XFS, 復元
- SMB (参照 SMB)
- srv ディレクトリー, /srv/ ディレクトリー
- SSD
- ソリッドステートディスク, ソリッドステートディスクのデプロイメントガイドライン
- SSM
- System Storage Manager, System Storage Manager (SSM)
- list コマンド, 検出されたすべてのデバイスに関する情報の表示
- resize コマンド, ボリュームのサイズを大きくする
- snapshot コマンド, スナップショット
- インストール, SSM のインストール
- バックエンド, SSM のバックエンド
- stripe-width (ストライプ配列を指定)
- ext4, Ext4 ファイルシステムの作成
- su (mkfs.xfs サブオプション)
- XFS, XFS ファイルシステムの作成
- sw (mkfs.xfs サブオプション)
- XFS, XFS ファイルシステムの作成
- sys ディレクトリー, /sys/ ディレクトリー
- sysconfig ディレクトリー, 特別な Red Hat Enterprise Linux ファイルの場所
- sysfs
- 概要
- オンラインストレージ, オンラインストレージ管理
- sysfs インターフェイス (ユーザー空間アクセス)
- I/O のアライメントとサイズ, sysfs インターフェイス
- System Storage Manager
- SSM, System Storage Manager (SSM)
- list コマンド, 検出されたすべてのデバイスに関する情報の表示
- resize コマンド, ボリュームのサイズを大きくする
- snapshot コマンド, スナップショット
- インストール, SSM のインストール
- バックエンド, SSM のバックエンド
T
- tftp サービス、設定
- ディスクレスシステム, ディスクレスクライアントの tftp サービスの設定
- transport
- ファイバーチャネル API, ファイバーチャネル API
- TRIM コマンド
- ソリッドステートディスク, ソリッドステートディスクのデプロイメントガイドライン
- tune2fs
- ext2 への復元, Ext2 ファイルシステムへの復元
- ext3 への変換, ext3 ファイルシステムへの変換
- tune2fs (mounting)
- ext4, ext4 ファイルシステムのマウント
- tune2fs (キャッシュの設定)
- FS-Cache, キャッシュの設定
U
- udev ルール(タイムアウト)
- コマンドタイマー (SCSI), コマンドタイマー
- umount, ファイルシステムのアンマウント
- updates
- ストレージをインストールする際の注意点, ストレージをインストールする際の注意点
- uquota/uqnoenforce
- XFS, XFS クォータ管理
- usr ディレクトリー, /usr/ ディレクトリー
V
- var ディレクトリー, /var/ ディレクトリー
- var/lib/rpm/ ディレクトリー, 特別な Red Hat Enterprise Linux ファイルの場所
- var/spool/up2date/ ディレクトリー, 特別な Red Hat Enterprise Linux ファイルの場所
- version
- 新機能
- volume_key
- commands, volume_key コマンド
- 個々のユーザー, volume_key を個別のユーザーとして使用する
W
- World Wide Identifier (WWID)
- 永続的な命名, World Wide Identifier (WWID)
- WWID
- 永続的な命名, World Wide Identifier (WWID)
X
- XFS
- cumulative モード (xfsrestore), 復元
- fsync(), XFS ファイルシステム
- gquota/gqnoenforce, XFS クォータ管理
- mkfs.xfs, XFS ファイルシステムの作成
- nobarrier マウントオプション, 書き込みバリア
- pquota/pqnoenforce, XFS クォータ管理
- simple モード (xfsrestore), 復元
- su (mkfs.xfs サブオプション), XFS ファイルシステムの作成
- sw (mkfs.xfs サブオプション), XFS ファイルシステムの作成
- uquota/uqnoenforce, XFS クォータ管理
- xfsdump, バックアップ
- xfsprogs, XFS ファイルシステムの一時停止
- xfsrestore, 復元
- xfs_admin, XFS ファイルシステムのその他のユーティリティー
- xfs_bmap, XFS ファイルシステムのその他のユーティリティー
- xfs_copy, XFS ファイルシステムのその他のユーティリティー
- xfs_db, XFS ファイルシステムのその他のユーティリティー
- xfs_freeze, XFS ファイルシステムの一時停止
- xfs_fsr, XFS ファイルシステムのその他のユーティリティー
- xfs_growfs, XFS ファイルシステムのサイズの拡大
- xfs_info, XFS ファイルシステムのその他のユーティリティー
- xfs_mdrestore, XFS ファイルシステムのその他のユーティリティー
- xfs_metadump, XFS ファイルシステムのその他のユーティリティー
- xfs_quota, XFS クォータ管理
- xfs_repair, XFS ファイルシステムの修復
- インタラクティブな操作 (xfsrestore), 復元
- エキスパートモード (xfs_quota), XFS クォータ管理
- クォータの管理, XFS クォータ管理
- ダンプレベル, バックアップ
- ダーティーログを使用した XFS ファイルシステムの修復, XFS ファイルシステムの修復
- バックアップ/復元, XFS ファイルシステムのバックアップおよび復元
- ファイルシステムのタイプ, XFS ファイルシステム
- ファイルシステムの修復, XFS ファイルシステムの修復
- ファイルシステムサイズの拡大, XFS ファイルシステムのサイズの拡大
- プロジェクト制限 (設定), プロジェクト制限の設定
- マウントする, XFS ファイルシステムのマウント
- レポート (xfs_quota エキスパートモード), XFS クォータ管理
- 一時停止中, XFS ファイルシステムの一時停止
- 主な特長, XFS ファイルシステム
- 作成, XFS ファイルシステムの作成
- 制限 (xfs_quota エキスパートモード), XFS クォータ管理
- 割り当て機能, XFS ファイルシステム
- 書き込みバリア, 書き込みバリア
- xfsdump
- XFS, バックアップ
- xfsprogs
- XFS, XFS ファイルシステムの一時停止
- xfsrestore
- XFS, 復元
- xfs_admin
- xfs_bmap
- xfs_copy
- xfs_db
- xfs_freeze
- XFS, XFS ファイルシステムの一時停止
- xfs_fsr
- xfs_growfs
- XFS, XFS ファイルシステムのサイズの拡大
- xfs_info
- xfs_mdrestore
- xfs_metadump
- xfs_quota
- XFS, XFS クォータ管理
- xfs_repair
- XFS, XFS ファイルシステムの修復