RHEL での論理ボリュームの重複排除および圧縮
LVM に VDO をデプロイしてストレージ容量を増やす
概要
Red Hat ドキュメントへのフィードバック (英語のみ)
Red Hat ドキュメントに関するご意見やご感想をお寄せください。また、改善点があればお知らせください。
Jira からのフィードバック送信 (アカウントが必要)
- Jira の Web サイトにログインします。
- 上部のナビゲーションバーで Create をクリックします。
- Summary フィールドにわかりやすいタイトルを入力します。
- Description フィールドに、ドキュメントの改善に関するご意見を記入してください。ドキュメントの該当部分へのリンクも追加してください。
- ダイアログの下部にある Create をクリックします。
第1章 LVM 上の VDO の概要
Virtual Data Optimizer (VDO) 機能は、ストレージ用にインラインのブロックレベルの重複排除、圧縮、およびシンプロビジョニングを提供します。VDO は、LVM シンプロビジョニングボリュームと同様に、論理ボリュームマネージャー (LVM) 論理ボリューム (LV) の一種として管理できます。
LVM 上の VDO ボリューム (LVM-VDO) には、次のコンポーネントが含まれます。
- VDO プール LV
- これは、VDO LV のデータを保存、重複排除、および圧縮するバッキング物理デバイスです。VDO プール LV は、VDO ボリュームの物理サイズを設定します。これは、VDO がディスクに保存できるデータ量です。
- 現在、各 VDO プール LV は 1 つの VDO LV のみを保持できます。そのため、VDO は VDO LV ごとに重複排除と圧縮を行います。別々の LV に保存されている重複データは、同じ VDO ボリュームのデータ最適化の恩恵を受けません。
- VDO LV
- これは、VDO プール LV 上にプロビジョニングされた仮想デバイスです。VDO LV は、VDO ボリュームのプロビジョニングされた論理サイズを設定します。これは、重複排除と圧縮が行われる前にアプリケーションがボリュームに書き込みできるデータ量です。
- kvdo
- Linux Device Mapper 層に読み込まれるカーネルモジュールは、重複排除、圧縮、シンプロビジョニングされたブロックストレージボリュームを提供します。
-
kvdoモジュールは、VDO プール LV が VDO LV を作成するために使用するブロックデバイスを公開します。その後、VDO LV がシステムによって使用されます。 -
kvdoは、VDO ボリュームからデータ論理ブロックを読み取る要求を受信すると、要求された論理ブロックを基礎となる物理ブロックにマッピングし、要求したデータを読み取って返します。 -
kvdoは、データのブロックを VDO ボリュームに書き込む要求を受信すると、最初にその要求が DISCARD または TRIM 要求であるかどうか、またはデータが均一にゼロであるかどうかを確認します。これらの条件のいずれかが満たされた場合、kvdoはブロックマップを更新し、要求を承認します。そうでない場合は、VDO はデータを処理して最適化します。 - kvdo モジュールは、ボリュームの Universal Deduplication Service (UDS) インデックスを内部的に利用し、受信したデータの重複を分析します。UDS は、新しいデータごとに、そのデータが以前に保存されたデータと同一であるかどうかを確認します。インデックスで一致が見つかった場合、ストレージシステムはその一致の正確性を検証し、内部参照を更新して、同じ情報を複数回保存しないようにすることができます。
LVM シンプロビジョニング実装の構造をすでに理解している場合は、次の表を参照して、VDO のさまざまな側面がシステムにどのように提示されるかを理解してください。
| 物理デバイス | プロビジョニングされるデバイス | |
|---|---|---|
| LVM 上の VDO | VDO プール LV | VDO LV |
| LVM シンプロビジョニング | シンプール | シンボリューム |
VDO はシンプロビジョニングされているため、ファイルシステムとアプリケーションは使用中の論理領域のみを認識し、実際に使用可能な物理領域は認識しません。スクリプトを使用して、使用可能な物理領域を監視し、使用量がしきい値を超えた場合にアラートを生成します。利用可能な VDO スペースの監視については、VDO の監視 セクションを参照してください。
第2章 LVM-VDO の要件
LVM 上の VDO には、配置とシステムリソースに関する特定の要件があります。
2.1. VDO メモリー要件
各 VDO ボリュームには、2 つの異なるメモリー要件があります。
- VDO モジュール
VDO には、固定メモリー 38 MB と変動用に容量を確保する必要があります。
- 設定済みのブロックマップキャッシュサイズ 1 MB ごとに 1.15 MB のメモリー。ブロックマップキャッシュには、最低 150 MB の RAM が必要です。
- 1 TB の論理領域ごとに 1.6 MB のメモリー。
- ボリュームが管理する物理ストレージの 1 TB ごとに 268 MB のメモリー。
- UDS インデックス
Universal Deduplication Service (UDS) には、最低 250 MB のメモリーが必要です。このメモリー量は、重複排除が使用するデフォルトの容量です。この値は、インデックスに必要なストレージ容量にも影響するため、VDO ボリュームをフォーマットするときに設定できます。
UDS インデックスに必要なメモリーは、インデックスタイプと、重複排除ウィンドウに必要なサイズで決定されます。重複排除ウィンドウとは、VDO が一致するブロックをチェックできる、以前に書き込まれたデータの量です。
Expand インデックスタイプ 重複排除ウィンドウ デンス
RAM 1 GB あたり 1 TB
スパース
RAM 1 GB あたり 10 TB
注記デフォルト設定である 2 GB のスラブサイズと 0.25 のデンスインデックスを使用した場合、VDO ボリュームの最小ディスク使用量として、約 4.7 GB が必要です。これにより、0% の重複排除または圧縮で書き込むための 2 GB 弱の物理データが提供されます。
ここでの最小ディスク使用量は、デフォルトのスラブサイズとデンスインデックスの合計です。
2.2. スパースインデックスとデンスインデックスの違い
UDS のスパースインデックス機能は、データの時間的な局所性を利用し、最も関連性の高いインデックスエントリーのみをメモリー内に保持することを試みるものです。スパースインデックスを使用すると、UDS は同じ量のメモリーを使用しながら、デンスインデックスよりも 10 倍大きい重複排除ウィンドウを維持できます。スパースインデックスでは、メタデータ用に 10 倍の物理領域が必要です。
スパースインデックスを使用すると対象範囲が広くなりますが、デンスインデックスの方が提供する重複排除アドバイスが多くなります。ほとんどのワークロードでは、メモリー量が同じであれば、デンスインデックスとスパースインデックスの重複排除率の差はごくわずかです。
2.3. VDO ストレージの領域要件
VDO ボリュームを設定して、最大 256 TB の物理ストレージを使用するように設定できます。データを格納するのに使用できるのは、物理ストレージの一部のみです。
VDO では、2 種類の VDO メタデータと UDS インデックスにストレージが必要です。次の計算を使用して、VDO 管理ボリュームの使用可能なサイズを決定します。
- 最初のタイプの VDO メタデータは、4 GB の 物理ストレージ ごとに約 1 MB を使用し、スラブごとにさらに 1 MB を使用します。
- 2 番目のタイプの VDO メタデータは、論理ストレージ 1 GB ごとに約 1.25 MB を消費し、最も近いスラブに切り上げられます。
- UDS インデックスに必要なストレージの容量は、インデックスの種類と、インデックスに割り当てられている RAM の容量によって異なります。RAM 1 GB ごとに、dense の UDS インデックスはストレージを 17 GB 使用し、sparse の UDS インデックスはストレージを 170 GB 使用します。
2.4. 物理サイズ別の VDO 要件の例
以下の表は、基盤となるボリュームの物理サイズに基づいた、VDO のシステム要件の概算を示しています。それぞれの表には、プライマリーストレージ、バックアップストレージなどの、目的のデプロイメントに適した要件が記載されています。
正確な数値は、VDO ボリュームの設定により異なります。
- プライマリーストレージのデプロイメント
プライマリーストレージの場合、UDS インデックスのサイズは、物理サイズの 0.01% から 25% になります。
Expand 表2.1 プライマリーストレージのストレージとメモリーの設定例 物理サイズ メモリー使用率: UDS メモリー使用率: VDO ディスク使用率 インデックスタイプ 1 TB
250 MB
472 MB
2.5 GB
デンス
10 TB
1 GB
3 GB
10 GB
デンス
250 MB
22 GB
スパース
50 TB
1 GB
14 GB
85 GB
スパース
100 TB
3 GB
27 GB
255 GB
スパース
256 TB
5 GB
69 GB
425 GB
スパース
- バックアップストレージのデプロイメント
バックアップストレージの場合、重複排除ウィンドウをバックアップセットよりも大きくする必要があります。将来的にバックアップセットまたは物理サイズが増大すると予想される場合は、それを考慮してインデックスサイズを設定してください。
Expand 表2.2 バックアップストレージのストレージとメモリーの設定例 重複排除ウィンドウ メモリー使用率: UDS ディスク使用量 インデックスタイプ 1 TB
250 MB
2.5 GB
デンス
10 TB
2 GB
21 GB
デンス
50 TB
2 GB
170 GB
スパース
100 TB
4 GB
340 GB
スパース
256 TB
8 GB
700 GB
スパース
2.5. ストレージスタックでの LVM-VDO の配置
特定のストレージレイヤーを VDO 論理ボリュームの下に配置し、他のストレージレイヤーをその上に配置する必要があります。
シックプロビジョニングの層を VDO の上に配置することもできますが、その場合はシックプロビジョニングの保証に頼ることができません。VDO 層はシンプロビジョニングされているため、シンプロビジョニングの影響は、すべての層に及びます。VDO ボリュームを監視しない場合には、VDO の上にあるシックプロビジョニングのボリュームで、物理領域が不足する可能性があります。
次のレイヤーのサポートされている配置は VDO の下にあるため、VDO の上に配置しないでください。
- DM Multipath
- DM Crypt
- ソフトウェア RAID (LVM または MD RAID)
以下の設定はサポートされていません。
- ループバックデバイスの上に VDO を配置する
- VDO の上に暗号化されたボリュームを配置する
- VDO ボリュームにパーティションを作成する
- VDO ボリュームの上に RAID (LVM RAID、MD RAID、またはその他のタイプ) を配置する
- LVM-VDO に Ceph ストレージをデプロイする
2.6. LVM-VDO のデプロイメントシナリオ
LVM 上の VDO (LVM-VDO) は、さまざまな方法でデプロイして、以下に対して、重複排除したストレージを提供できます。
- ブロックアクセス
- ファイルアクセス
- ローカルストレージ
- リモートストレージ
LVM-VDO は、通常の論理ボリューム (LV) として重複排除したストレージを公開するため、そのストレージを標準ファイルシステム、iSCSI および FC のターゲットドライバーとともに、または統合ストレージとして使用できます。
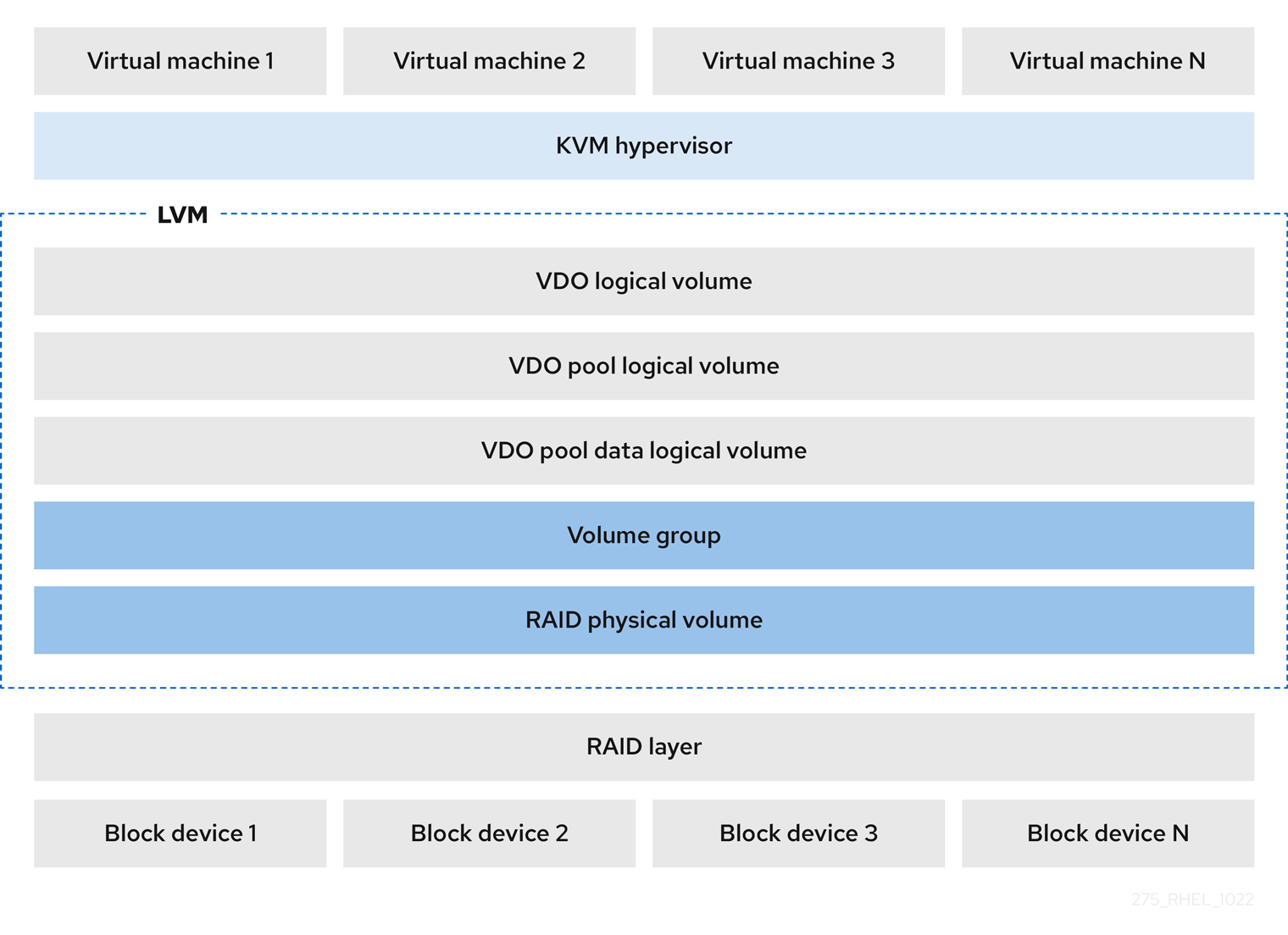
- KVM
LVM-VDO は、Direct Attached Storage を使用して設定された KVM サーバーにデプロイできます。
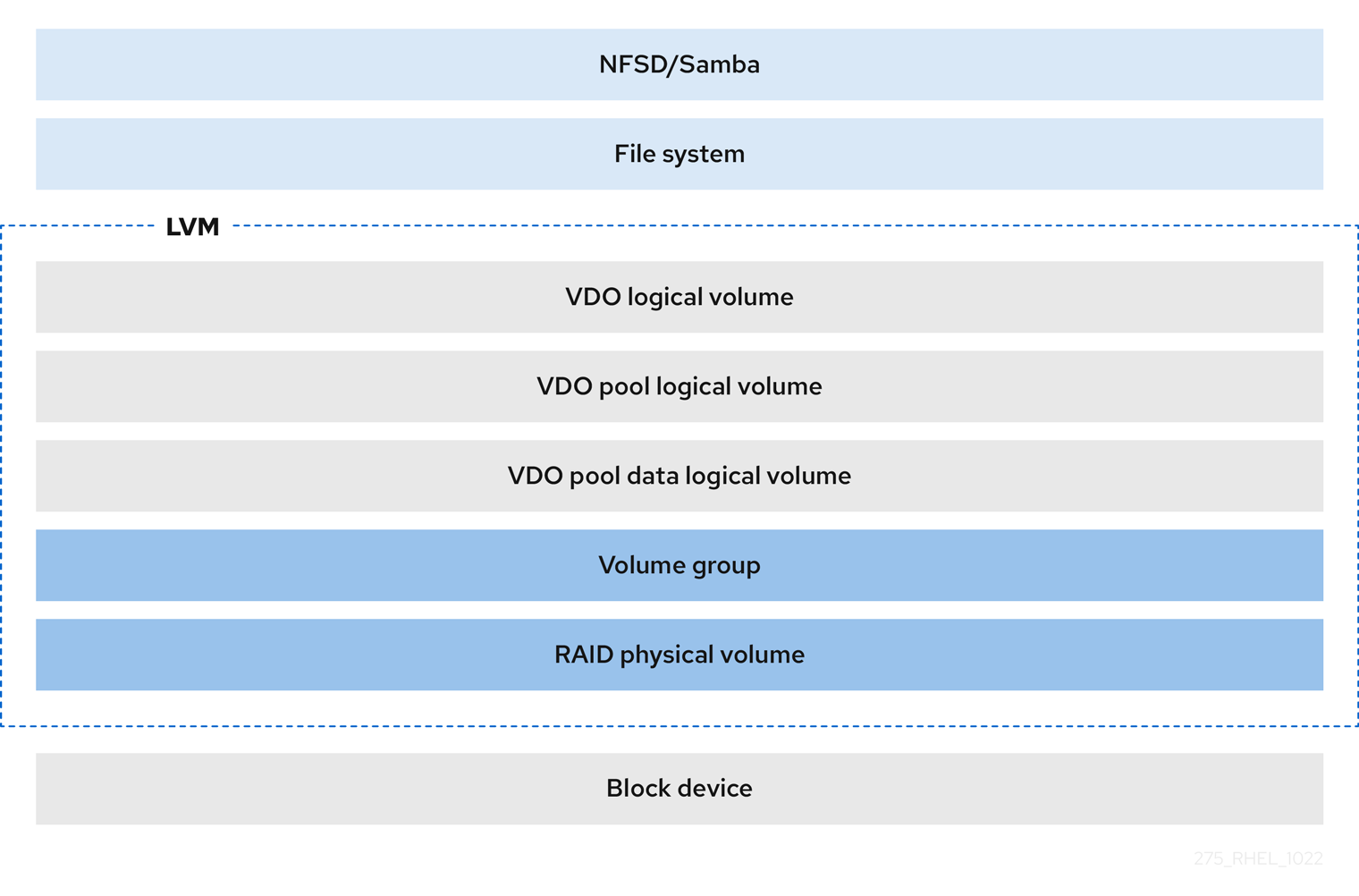
- ファイルシステム
VDO LV 上にファイルシステムを作成し、NFS サーバーまたは Samba を使用して NFS または CIFS ユーザーに公開できます。
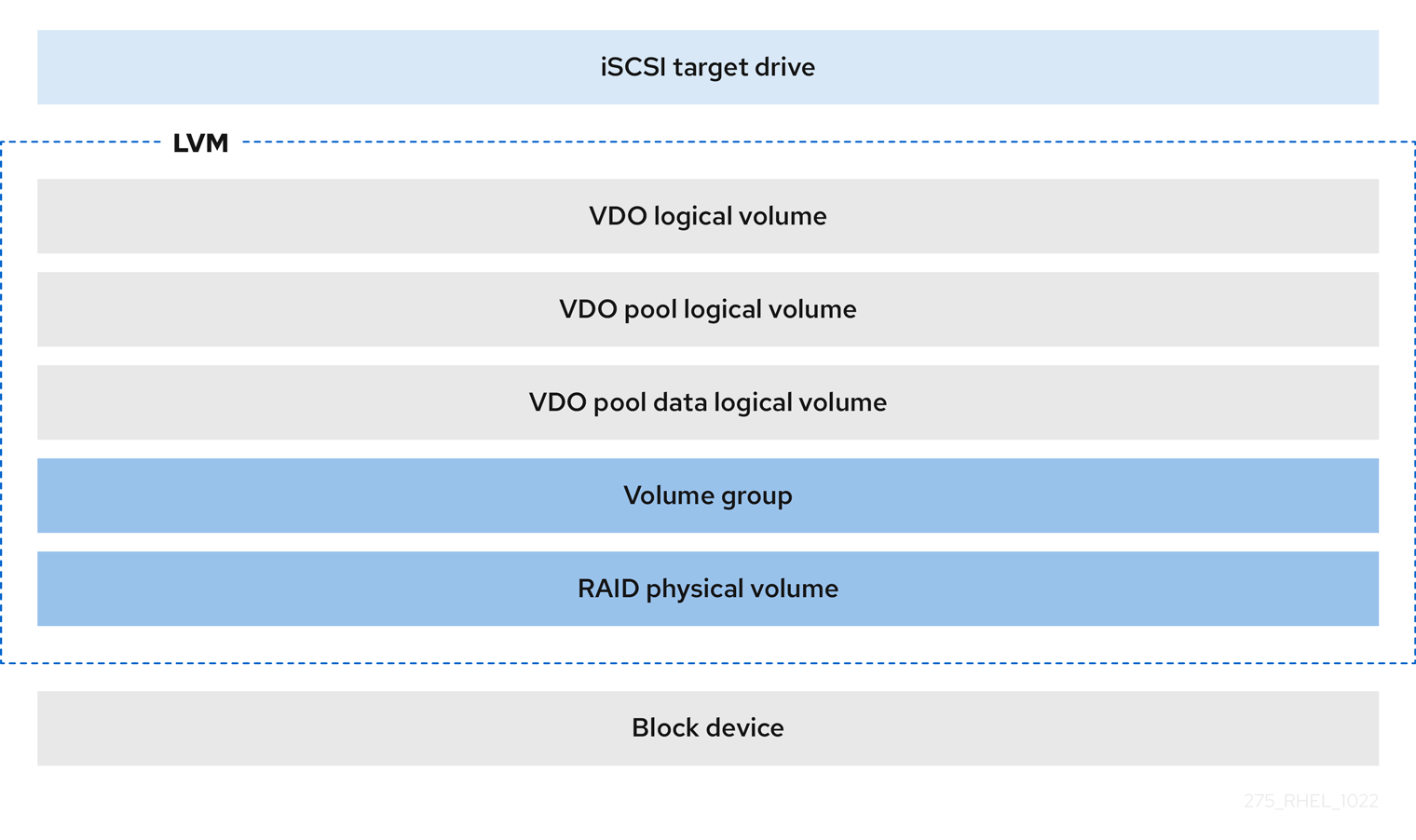
- iSCSI ターゲット
VDO LV 全体を、iSCSI ターゲットとしてリモート iSCSI イニシエーターにエクスポートできます。
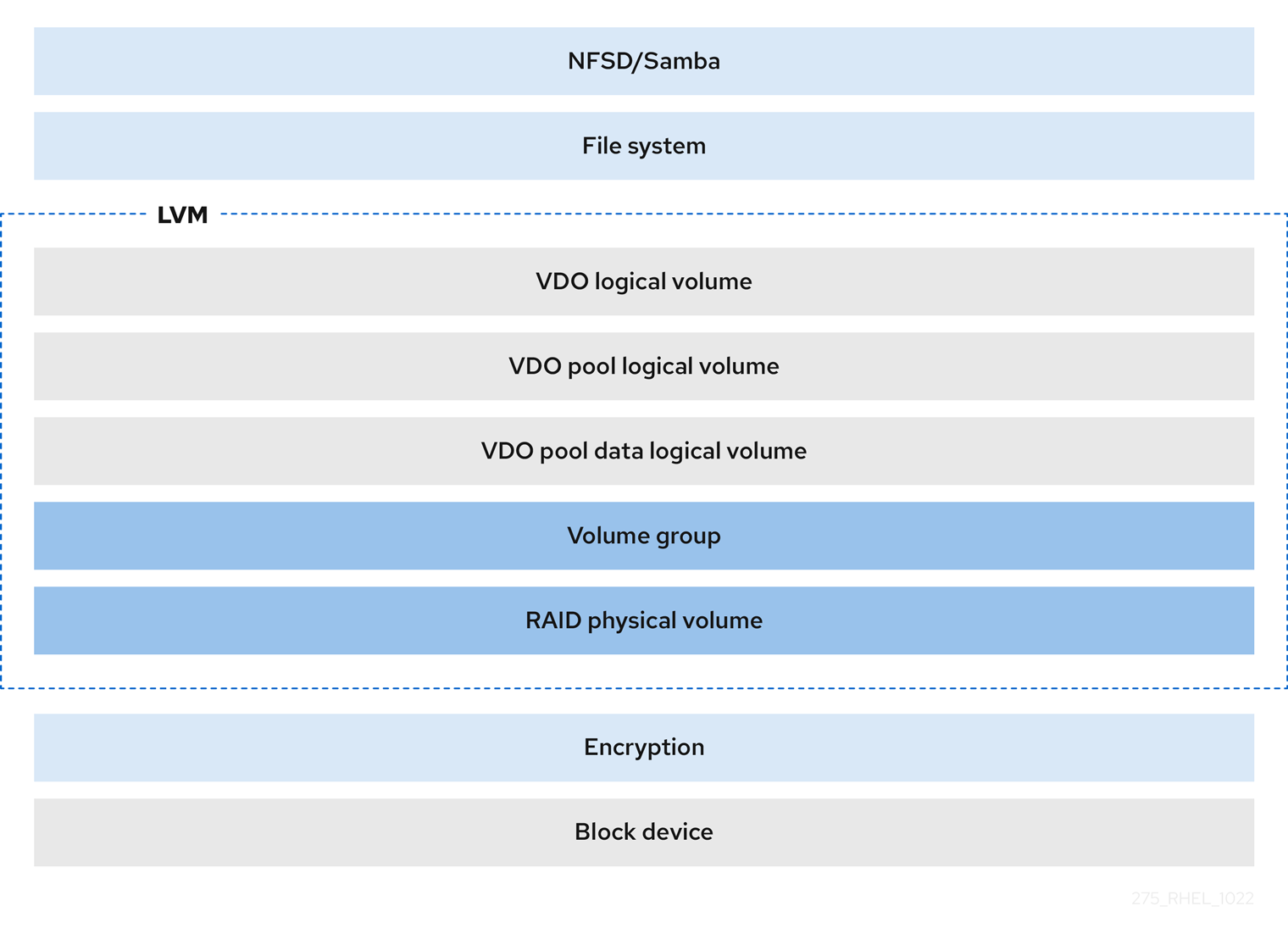
- 暗号化
DM Crypt などのデバイスマッパー (DM) メカニズムは VDO と互換性があります。VDO LV ボリュームを暗号化すると、データのセキュリティーを確保しながら、VDO LV より上のファイルシステムを重複排除できます。
重要VDO LV の上に暗号化層を適用しても、データの重複排除はほとんど行われません。VDO が重複ブロックを排除する前に、暗号化によって重複ブロックが変更されます。
暗号化層は常に VDO LV の下に配置してください。
第3章 重複排除および圧縮された論理ボリュームの作成
VDO 機能を使用してデータの重複排除と圧縮を行う LVM 論理ボリュームを作成できます。
3.1. LVM-VDO ボリュームの物理サイズおよび論理サイズ
VDO ではサイズの定義が異なります。
- 物理サイズ
これは、VDO プール LV に割り当てられた物理エクステントと同じサイズです。VDO は、以下の目的でこのストレージを使用します。
- 重複排除および圧縮される可能性があるユーザーデータ
- UDS インデックスなどの VDO メタデータ
- 利用可能な物理サイズ
これは、VDO がユーザーデータに使用できる物理サイズの一部です。
これは、物理サイズからメタデータのサイズを引いたものに相当し、スラブサイズの倍数に切り捨てられます。
- 論理サイズ
これは、VDO LV がアプリケーションに提示するプロビジョニングされたサイズです。通常、これは利用可能な物理サイズよりも大きくなります。VDO は現在、絶対最大論理サイズ 4 PB の物理ボリュームの最大 254 倍の論理サイズに対応します。
VDO 論理ボリューム (LV) をセットアップする際には、VDO LV が提示する論理ストレージのサイズを指定します。アクティブな仮想マシン (VM) またはコンテナーをホストする場合は、10:1 の論理対物理比率でプロビジョニングストレージを使用します。たとえば、1 TB の物理ストレージを使用している場合は、それを 10 TB の論理ストレージとして提示します。
--virtualsizeオプションを指定しないと、VDO はボリュームを1:1の比率でプロビジョニングします。たとえば、VDO LV を 20 GB の VDO プール LV 上に配置すると、VDO はデフォルトのインデックスサイズが使用されている場合に UDS インデックス用に 2.5 GB を確保します。残りの 17.5 GB は、VDO メタデータおよびユーザーデータに提供されます。そのため、使用可能なストレージは 17.5 GB 以下になります。実際の VDO ボリュームを設定するメタデータにより、これよりも少なくなる可能性があります。
3.2. VDO のスラブサイズ
VDO ボリュームの物理ストレージは、複数のスラブに分割されます。各スラブは、物理領域における連続した領域です。特定のボリュームのスラブはすべて同じサイズで、128 MB の 2 のべき乗倍のサイズ (最大 32 GB) になります。
小規模なテストシステムで VDO を評価しやすくするため、デフォルトのスラブサイズは 2 GB です。1 つの VDO ボリュームには、最大 8192 個のスラブを含めることができます。したがって、デフォルト設定の 2 GB のスラブを使用する場合、許可される物理ストレージは最大 16 TB です。32 GB のスラブを使用する場合、許可される物理ストレージは最大 256 TB です。VDO は常に少なくとも 1 つのスラブ全体をメタデータ用に予約します。そのため、この予約されたスラブをユーザーデータの保存に使用することはできません。
スラブサイズは、VDO ボリュームのパフォーマンスには影響しません。
| 物理ボリュームのサイズ | 推奨されるスラブサイズ |
|---|---|
| 10-99 GB | 1 GB |
| 100 GB - 1 TB | 2 GB |
| 2-256 TB | 32 GB |
デフォルト設定である 2 GB のスラブサイズと 0.25 のデンスインデックスを使用した場合、VDO ボリュームの最小ディスク使用量として、約 4.7 GB が必要です。これにより、0% の重複排除または圧縮で書き込むための 2 GB 弱の物理データが提供されます。
ここでの最小ディスク使用量は、デフォルトのスラブサイズとデンスインデックスの合計です。
lvcreate コマンドに --vdosettings 'vdo_slab_size_mb=size-in-megabytes' オプションを指定することで、スラブサイズを制御できます。
3.3. VDO のインストール
VDO ボリュームの作成、マウント、管理に必要な VDO ソフトウェアをインストールできます。
手順
VDO ソフトウェアをインストールします。
# dnf install lvm2 kmod-kvdo vdo
3.4. LVM-VDO ボリュームの作成とマウント
lvcreate コマンドを使用して、VDO プール LV 上に VDO 論理ボリューム (LV) を作成できます。
LVM-VDO の名前 (vdo1 など) を選択します。システム上の各 LVM-VDO には、異なる名前とデバイスを使用する必要があります。
前提条件
- VDO ソフトウェアをインストールしている。詳細は、VDO のインストール を参照してください。
- 空きストレージ容量を持つ LVM ボリュームグループがシステムに存在する。
手順
LVM-VDO を作成します。
# lvcreate --type vdo \ --name vdo1 \ --size 1T \ --virtualsize 10T \ vg-name1Tを物理サイズに置き換えます。物理サイズが 16 TiB を超える場合は、以下のオプションを指定して、ボリューム上のスラブサイズを 32 GiB に増やします。--vdosettings 'vdo_slab_size_mb=32768'物理サイズが 16 TiB を超える場合にデフォルトのスラブサイズ 2 GiB を使用すると、
lvcreateコマンドは次のエラーで失敗します。ERROR - vdoformat: formatVDO failed on '/dev/device': VDO Status: Exceeds maximum number of slabs supported10Tを LVM-VDO が提供する論理ストレージに置き換えます。vg-nameを LVM-VDO を配置する既存の LVM ボリュームグループの名前に置き換えます。重要LVM-VDO ボリュームの作成に失敗した場合は、
lvremove vg-nameを使用してボリュームを削除します。失敗の理由によっては、2 つの強制オプション (-ff) を追加する必要もあります。LVM-VDO 上にファイルシステムを作成します。
XFS ファイルシステムの場合:
# mkfs.xfs -K /dev/vg-name/vdo-nameext4 ファイルシステムの場合:
# mkfs.ext4 -E nodiscard /dev/vg-name/vdo-name
LVM-VDO ボリュームにファイルシステムをマウントします。
ファイルシステムを永続的にマウントするには、
/etc/fstabファイルに次の行を追加します。/dev/vg-name/vdo-name mount-point <file-system-type> defaults 0 0<file-system-type> を
xfsやext4などのファイルシステムに置き換えます。ファイルシステムを手動でマウントするには、
mountコマンドを使用します。# mount /dev/vg-name/vdo-name mount-point
LVM-VDO ボリュームが、iSCSI などのネットワークを必要とするブロックデバイスに配置されている場合は、_netdev マウントオプションを追加します。iSCSI や、ネットワークを必要とするその他のブロックデバイスの _netdev マウントオプションに関する情報は、systemd.mount(5) の man ページを参照してください。
検証
LVM-VDO ボリュームが作成されたことを確認します。
# lvs
3.5. storage RHEL システムロールを使用して LVM-VDO ボリュームを設定する
storage RHEL システムロールを使用して、圧縮と重複排除を有効にした LVM 上の VDO ボリューム (LVM-VDO) を作成できます。
storage システムロールが LVM VDO を使用するため、プールごとに作成できるボリュームは 1 つだけです。
前提条件
- コントロールノードと管理対象ノードの準備が完了している。
- 管理対象ノードで Playbook を実行できるユーザーとしてコントロールノードにログインしている。
-
管理対象ノードへの接続に使用するアカウントに、そのノードに対する
sudo権限がある。
手順
次の内容を含む Playbook ファイル (例:
~/playbook.yml) を作成します。--- - name: Manage local storage hosts: managed-node-01.example.com tasks: - name: Create LVM-VDO volume under volume group 'myvg' ansible.builtin.include_role: name: redhat.rhel_system_roles.storage vars: storage_pools: - name: myvg disks: - /dev/sdb volumes: - name: mylv1 compression: true deduplication: true vdo_pool_size: 10 GiB size: 30 GiB mount_point: /mnt/app/sharedサンプル Playbook で指定されている設定は次のとおりです。
vdo_pool_size: <size>- デバイス上でボリュームが占める実際のサイズ。サイズは、10 GiB など、人間が判読できる形式で指定できます。単位を指定しない場合、デフォルトでバイト単位に設定されます。
size: <size>- VDO ボリュームの仮想サイズ。
Playbook で使用されるすべての変数の詳細は、コントロールノードの
/usr/share/ansible/roles/rhel-system-roles.storage/README.mdファイルを参照してください。Playbook の構文を検証します。
$ ansible-playbook --syntax-check ~/playbook.ymlこのコマンドは構文を検証するだけであり、有効だが不適切な設定から保護するものではないことに注意してください。
Playbook を実行します。
$ ansible-playbook ~/playbook.yml
検証
圧縮と重複排除の現在のステータスを表示します。
$ ansible managed-node-01.example.com -m command -a 'lvs -o+vdo_compression,vdo_compression_state,vdo_deduplication,vdo_index_state' LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert VDOCompression VDOCompressionState VDODeduplication VDOIndexState mylv1 myvg vwi-a-v--- 3.00t vpool0 enabled online enabled online
3.6. Web コンソールで LVM-VDO ボリュームを作成する
RHEL Web コンソールで LVM-VDO ボリュームを作成します。
前提条件
- RHEL 9 Web コンソールがインストールされている。
- cockpit サービスが有効になっている。
ユーザーアカウントが Web コンソールにログインできる。
手順は、Web コンソールのインストールおよび有効化 を参照してください。
-
cockpit-storagedパッケージがシステムにインストールされている。 - LVM-VDO ボリュームを作成するための LVM2 グループを作成している。
手順
RHEL 9 Web コンソールにログインします。
詳細は、Web コンソールへのログイン を参照してください。
- パネルで、Storage をクリックします。
- LVM-VDO ボリュームを作成する LVM2 グループのメニューボタン [⋮] をクリックし、Create new logical volume をクリックします。
- Name フィールドに、スペースなしで LVM-VDO ボリュームの名前を入力します。
- Purpose ドロップダウンリストから、VDO filesystem volume を選択します。
- Size スライダーで、LVM-VDO ボリュームの物理サイズをセットアップします。
Logical size スライダーで、LVM-VDO ボリュームのサイズをセットアップします。LVM-VDO ボリュームを作成する目的を考慮した上で、10 回以上拡張することも可能です。
- アクティブな仮想マシンまたはコンテナーストレージの場合は、使用する論理のサイズを、ボリュームの物理サイズの 10 倍になるようにします。
- オブジェクトストレージの場合は、使用する論理のサイズを、ボリュームの物理サイズの 3 倍になるようにします。
- Options リストで、Compression および Deduplication を選択します。
- をクリックします。
検証
- ストレージ セクションに新しい LVM-VDO ボリュームが表示されていることを確認します。
3.7. Web コンソールで LVM-VDO ボリュームをフォーマットする
LVM-VDO ボリュームは物理ドライブとして機能します。これらを使用するには、ファイルシステムでフォーマットする必要があります。
フォーマットするとボリューム上のすべてのデータが消去されます。
前提条件
- RHEL 9 Web コンソールがインストールされている。
- cockpit サービスが有効になっている。
ユーザーアカウントが Web コンソールにログインできる。
手順は、Web コンソールのインストールおよび有効化 を参照してください。
-
cockpit-storagedパッケージがシステムにインストールされている。 - LVM-VDO ボリュームを作成している。
手順
RHEL 9 Web コンソールにログインします。
詳細は、Web コンソールへのログイン を参照してください。
- パネルで、Storage をクリックします。
- フォーマットする LVM-VDO ボリュームがある LVM2 ボリュームグループをクリックし、LVM-VDO ボリュームのメニューボタン [⋮] をクリックします。
- ドロップダウンメニューで、Format をクリックします。
- Name フィールドに、論理ボリューム名を入力します。
- Mount Point フィールドにマウントパスを入力します。
- Type ドロップダウンリストからファイルシステムを選択します。
- オプション: ディスクに機密データが含まれており、それを書き換えたい場合は、Overwrite existing data with zeros を選択します。それ以外の場合、Web コンソールはディスクヘッダーのみを書き換えます。
- Encryption ドロップダウンリストから、暗号化のタイプを選択します。
- At boot ドロップダウンリストから、ボリュームをマウントするタイミングを選択します。
Mount options リストで、適切な設定を選択します。
- ボリュームを読み取り専用論理ボリュームとしてマウントする場合は、Mount read only チェックボックスを選択にします。
- デフォルトのマウントオプションを変更する場合は、Custom mount options チェックボックスをオンにしてマウントオプションを追加します。
LVM-VDO ボリュームをフォーマットします。
- LVM-VDO ボリュームをフォーマットしてマウントする場合は、 をクリックします。
- パーティションのみをフォーマットする場合は、 をクリックします。
検証
- Storage タブと LVM2 ボリュームグループタブで、フォーマットされた LVM-VDO ボリュームの詳細を確認します。
3.8. Web コンソールで LVM-VDO ボリュームを拡張する
RHEL 9 Web コンソールで LVM-VDO ボリュームを拡張します。
前提条件
- RHEL 9 Web コンソールがインストールされている。
- cockpit サービスが有効になっている。
ユーザーアカウントが Web コンソールにログインできる。
手順は、Web コンソールのインストールおよび有効化 を参照してください。
-
cockpit-storagedパッケージがシステムにインストールされている。 - LVM-VDO ボリュームを作成している。
手順
RHEL 9 Web コンソールにログインします。
詳細は、Web コンソールへのログイン を参照してください。
- パネルで、Storage をクリックします。
- VDO Devices ボックスで LVM-VDO ボリュームをクリックします。
- LVM-VDO ボリュームの詳細で、 をクリックします。
- Grow logical size of VDO ダイアログボックスで、LVM-VDO ボリュームの論理サイズを増やします。
- Grow をクリックします。
検証
- 正常に変更されたことを確認するには、LVM-VDO ボリュームの詳細で新しいサイズを確認します。
3.9. LVM-VDO ボリュームの圧縮設定の変更
デフォルトでは、VDO プールの論理ボリューム (LV) の圧縮が有効になっています。CPU 使用量を抑えるために、これを無効にできます。lvchange コマンドを使用して、圧縮を有効または無効にします。
前提条件
- LVM-VDO ボリュームがシステム上にある。
手順
論理ボリュームの圧縮ステータスを確認します。
# lvs -o+vdo_compression,vdo_compression_state LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert VDOCompression VDOCompressionState vdo_name vg_name vwi-a-v--- 1.00t vpool0 0.00 enabled online vpool0 vg_name dwi------- <15.00g 20.03 enabled onlineVDOPoolLV の圧縮を無効にします。
# lvchange --compression n vg-name/vdopoolname圧縮を有効にする場合は、
nオプションではなくyオプションを使用します。
検証
圧縮の現在のステータスを表示します。
# lvs -o+vdo_compression,vdo_compression_state LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert VDOCompression VDOCompressionState vdo_name vg_name vwi-a-v--- 1.00t vpool0 0.00 offline vpool0 vg_name dwi------- <15.00g 20.03 offline
3.10. LVM-VDO ボリュームの重複排除設定の変更
デフォルトでは、VDO プールの論理ボリューム (LV) の重複排除が有効になっています。メモリーの使用量を抑えるために、重複排除を無効にできます。lvchange コマンドを使用して、重複排除を有効または無効にします。
VDO が進行中の並行 I/O 操作を処理する方法に基づき、VDO ボリュームはそれらの操作内で重複データを識別し続けます。たとえば、仮想マシンのクローン操作が進行中で、VDO ボリュームに多数の重複ブロックが近接している場合でも、重複排除を使用することでボリュームのスペースをある程度節約できます。ボリュームのインデックス状態はプロセスに影響しません。
前提条件
- LVM-VDO ボリュームがシステム上にある。
手順
論理ボリュームの重複排除ステータスを確認します。
# lvs -o+vdo_deduplication,vdo_index_state LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert VDODeduplication VDOIndexState vdo_name vg_name vwi-a-v--- 1.00t vpool0 0.00 enabled online vpool0 vg_name dwi------- <15.00g 20.03 enabled onlineVDOPoolLV の重複排除を無効にします。
# lvchange --deduplication n vg-name/vdopoolname重複排除を有効にする場合は、
nオプションではなくyオプションを使用します。
検証
重複排除の現在のステータスを表示します。
# lvs -o+vdo_deduplication,vdo_index_state LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert VDODeduplication VDOIndexState vdo_name vg_name vwi-a-v--- 1.00t vpool0 0.00 closed vpool0 vg_name dwi------- <15.00g 20.03 closed
3.11. シンプロビジョニングされた LVM-VDO ボリュームの管理
LVM-VDO ボリュームの物理領域の使用率が 100% に近づいている状況に対処するために、将来の物理領域の拡張に備えてシンプロビジョニングされた LVM-VDO ボリュームを設定できます。たとえば、lvcreate 操作で -l 100%FREE を使用する代わりに、'95%FREE' を使用して、必要に応じて後で回復できるように予約領域を確保します。同じ方法を使用して、次の問題を解決できます。
- ボリュームの領域が不足している
- ファイルシステムが読み取り専用モードになる
- ボリュームにより ENOSPC が報告される
LVM-VDO ボリューム上の物理領域使用率が高い場合に対処する最善の方法は、未使用のファイルを削除し、オンライン破棄または fstrim プログラムを使用して、これらの未使用のファイルによって使用されているブロックを破棄することです。LVM-VDO ボリュームの物理領域は、8192 スラブまでしか拡張できません。これは、デフォルトのスラブサイズが 2 GB の LVM-VDO ボリュームの場合は 16 TB、最大スラブサイズが 32 GB の LVM-VDO ボリュームの場合は 256 TB です。
以下のすべての手順で、myvg と myvdo を、それぞれボリュームグループ名および LVM-VDO 名に置き換えます。
前提条件
- VDO ソフトウェアをインストールしている。詳細は、VDO のインストール を参照してください。
- 空きストレージ容量を持つ LVM ボリュームグループがシステムに存在する。
-
lvcreate --type vdo --name myvdo myvg -l percentage-of-free-space-in-vg --virtualsize virtual-size-of-vdoコマンドを使用した、シンプロビジョニングされた LVM-VDO ボリューム。詳細は、LVM-VDO ボリュームの作成とマウント を参照してください。
手順
シンプロビジョニングされた LVM-VDO ボリュームの最適な論理サイズを決定します。
# vdostats myvg-vpool0-vpool Device 1K-blocks Used Available Use% Space saving% myvg-vpool0-vpool 104856576 29664088 75192488 28% 69%領域の節約率を計算するには、以下の式を使用します。
Savings ratio = 1 / (1 - Space saving%)この例では、次のようになります。
-
約 80 GB のデータセットでは、約
3.22:1の領域削減率が得られます。 - データセットのサイズにこの比率を乗算すると、潜在的な論理サイズが得られます。同じ領域節約率でより多くのデータが LVM-VDO ボリュームに書き込まれる場合、これは 256 GB になります。
- この数を 200 GB まで下げると、同じ領域節約率の場合、空き物理領域に安全なマージンを確保できる論理サイズになります。
-
約 80 GB のデータセットでは、約
LVM-VDO ボリューム内の空き物理領域を監視します。
# vdostats myvg-vpool0-vpoolこのコマンドを定期的に実行すると、LVM-VDO ボリュームの使用済みおよび空き物理領域を監視できます。
オプション: 利用可能な
/usr/share/doc/vdo/examples/monitor/monitor_check_vdostats_physicalSpace.plスクリプトを使用して、LVM-VDO ボリュームの物理領域の使用状況に関する警告を表示します。# /usr/share/doc/vdo/examples/monitor/monitor_check_vdostats_physicalSpace.pl myvg-vpool0-vpoolLVM-VDO ボリュームを作成すると、
dmeventdモニタリングサービスは、LVM-VDO ボリューム内の物理領域の使用状況を監視します。これは、LVM-VDO ボリュームが作成または起動されるとデフォルトで有効になります。LVM-VDO ボリュームのモニタリング中に、
journalctlコマンドを使用して、ログ内のdmeventdの出力を表示します。lvm[8331]: Monitoring VDO pool myvg-vpool0-vpool. ... lvm[8331]: WARNING: VDO pool myvg-vpool0-vpool is now 84.63% full. lvm[8331]: WARNING: VDO pool myvg-vpool0-vpool is now 91.01% full. lvm[8331]: WARNING: VDO pool myvg-vpool0-vpool is now 97.34% full.利用可能な物理領域がほとんどない LVM-VDO ボリュームを修復します。LVM-VDO ボリュームに物理領域を追加できても、ボリュームを拡張する前に領域がいっぱいになった場合は、そのボリュームへの I/O を一時的に停止する必要があるかもしれません。
ボリュームへの I/O を一時的に停止するには、以下の手順を実行します。LVM-VDO ボリューム myvdo には、/users/homeDir パスにマウントされたファイルシステムが含まれています。
ファイルシステムをフリーズします。
# xfs_freeze -f /users/homeDir # vgextend myvg /dev/vdc2 # lvextend -L new-size myvg/vpool0 # xfs_freeze -u /users/homeDirファイルシステムをアンマウントします。
# umount /users/homeDir # vgextend myvg /dev/vdc2 # lvextend -L new-size myvg/vpool0 # mount -o discard /dev/myvg/myvdo /users/homeDir注記キャッシュされたデータを含むファイルシステムをアンマウントまたはフリーズすると、キャッシュされたデータの書き込みが発生し、LVM-VDO ボリュームの物理領域がいっぱいになる可能性があります。LVM-VDO ボリュームの空き物理領域の監視しきい値を設定する場合は、キャッシュされたファイルシステムデータの最大量を考慮してください。
ファイルシステムが使用しなくなったブロックは、
fstrimユーティリティーを使用してクリーンアップできます。VDO ボリュームにマウントしたファイルシステムに対してfstrimを実行すると、そのボリュームの空き物理領域が増える可能性があります。fstrimユーティリティーは、LVM-VDO ボリュームに破棄を送信します。これは、以前使用したブロックへの参照を削除するために使用されます。これらのブロックのいずれかが単一参照されている場合は、物理領域が使用可能になります。VDO の統計情報を確認して、現在の空き領域の量を確認します。
# vdostats --human-readable myvg-vpool0-vpool Device Size Used Available Use% Space saving% myvg-vpool0-vpool 100.0G 95.0G 5.0G 95% 73%未使用のブロックを破棄します。
# fstrim /users/homeDirLVM-VDO ボリュームの空き物理領域を表示します。
# vdostats --human-readable myvg-vpool0-vpool Device Size Used Available Use% Space saving% myvg-vpool0-vpool 100.0G 30.0G 70.0G 30% 43%この例では、ファイルシステムで
fstrimを実行した後、LVM-VDO ボリュームで使用する物理領域 65 G が破棄によって回収されました。注記重複排除と圧縮のレベルが低いボリュームを破棄すると、重複排除と圧縮のレベルが高いボリュームを破棄するよりも、物理領域を回収できます。重複排除と圧縮のレベルが高いボリュームでは、物理領域を回収するために、未使用のブロックを破棄するだけでなく、より詳細なクリーンアップが必要になる可能性があります。
第4章 LVM-VDO ボリュームの縮小オプション
LVM-VDO ボリュームで使用可能なさまざまなトリムオプションは、以下のとおりです。
discard-
オンラインブロック破棄操作を実行して、未使用のブロックを自動的に破棄します。すぐに破棄する場合は、
mount -o discardコマンドを使用します。 fstrim- 定期的に破棄を実行します。管理者は追加のプロセスをスケジュールして監視する必要があります。
現在、未使用のブロックを破棄する場合は、discard マウントオプションではなく、fstrim アプリケーションを使用することが推奨されています。discard オプションは、パフォーマンスに非常に大きな影響を及ぼす可能性があるためです。そのため、nodiscard がデフォルトになっています。
4.1. LVM-VDO ボリュームでの discard マウントオプションの有効化
LVM-VDO ボリュームで discard オプションを有効にできます。
前提条件
- LVM-VDO ボリュームがシステム上にある。
手順
ボリュームの
discardオプションを有効にします。# mount -o discard /dev/vg-name/vdo-name mount-point
4.2. 定期的な TRIM 操作の設定
システム上でスケジュールされた TRIM 操作を有効化できます。
前提条件
- LVM-VDO ボリュームがシステム上にある。
手順
タイマーを有効にして起動します。
# systemctl enable --now fstrim.timer
検証
タイマーが有効化されていることを確認します。
# systemctl list-timers fstrim.timer NEXT LEFT LAST PASSED UNIT ACTIVATES Mon 2021-05-10 00:00:00 EDT 5 days left n/a n/a fstrim.timer fstrim.service
fstrim.timer は、マウントされているすべてのファイルシステムで実行されるため、VDO ボリュームへの参照は表示されません。
第5章 LVM-VDO パフォーマンスの最適化
VDO カーネルドライバーは、複数のスレッドを使用してタスクを高速化します。1 つのスレッドが I/O リクエストのすべてを実行するのではなく、作業を小さく分割し、異なるスレッドに割り当てます。これらのスレッドは、リクエストを処理する際に相互に通信します。このようにして、1 つのスレッドで、頻繁にロックやロック解除を行うことなく共有データを処理できます。
1 つのスレッドがタスクを完了した時点で、VDO はすでに別のタスクを用意しています。これにより、スレッドがビジー状態に保たれ、タスクの切り替えにかかる時間が短縮されます。VDO は、キューへの I/O 操作の追加や重複排除インデックスへのメッセージの処理など、低速のタスクにも別のスレッドを使用します。
5.1. VDO スレッドの種類
VDO は、さまざまなスレッドタイプを使用して特定の操作を処理します。
- 論理ゾーンスレッド (
kvdo:logQ) - VDO デバイスのユーザーに提示される論理ブロック番号 (LBN) と、基盤となるストレージシステムの物理ブロック番号 (PBN) の間のマッピングを維持します。また、同じブロックへの同時書き込みも防止します。論理スレッドは、読み取り操作と書き込み操作の両方でアクティブになります。処理は通常均等に分散されますが、特定のアクセスパターンにより、1 つのスレッドに作業が集中する場合があります。たとえば、特定のブロックマップページ内の LBN に頻繁にアクセスすると、1 つの論理スレッドがそれらすべての操作を処理する可能性があります。
- 物理ゾーンスレッド (
kvdo:physQ) - 書き込み操作中にデータブロックの割り当てと参照カウントを処理します。
- I/O 送信スレッド (
kvdo:bioQ) -
VDO からストレージシステムへのブロック I/O (
bio) 操作の転送を処理します。これらのスレッドは、他の VDO スレッドからの I/O リクエストを処理し、基盤となるデバイスドライバーに渡します。これらのスレッドは、デバイス関連のデータ構造と対話し、デバイスドライバーカーネルスレッドのリクエストを作成し、デバイスリクエストキューがいっぱいになって I/O リクエストがブロックされた場合の遅延を防ぎます。 - CPU 処理スレッド (
kvdo:cpuQ) - 他のスレッドタイプによって管理されるデータ構造をブロックしない、またはそのようなデータ構造への排他的アクセスを必要としない、CPU を集中的に使用するタスクを処理します。これらのタスクには、ハッシュ値の計算とデータブロックの圧縮が含まれます。
- I/O 完了通知スレッド (
kvdo:ackQ) - I/O リクエストの完了を、カーネルページキャッシュやダイレクト I/O を実行するアプリケーションスレッドなどの上位コンポーネントに通知します。メモリー競合への影響と CPU 使用率は、カーネルレベルのコードによる影響を受けます。
- ハッシュゾーンスレッド (
kvdo:hashQ) - 一致するハッシュを使用して I/O リクエストを調整し、潜在的な重複排除タスクを処理します。重複排除リクエストを作成および管理しますが、重要な計算は実行しません。通常、ハッシュゾーンスレッドは 1 つで十分です。
- 重複排除スレッド (
kvdo:dedupeQ) - I/O リクエストを処理し、重複排除インデックスと通信します。この作業はブロッキング状態を防ぐために別のスレッドで実行されます。また、インデックスがすぐに応答しない場合に重複排除をスキップするタイムアウトメカニズムも備えています。重複排除スレッドは VDO デバイスごとに 1 つだけ存在します。
- ジャーナルスレッド (
kvdo:journalQ) - リカバリージャーナルを更新し、ジャーナルブロックの書き込みをスケジュールします。このタスクを複数のスレッドに分割することはできません。ジャーナルスレッドは VDO デバイスごとに 1 つだけ存在します。
- パッカースレッド (
kvdo:packerQ) - 圧縮が有効になっている場合、書き込み操作中に機能します。CPU スレッドから圧縮されたデータブロックを収集して、無駄な領域を削減します。パッカースレッドは VDO デバイスごとに 1 つだけ存在します。
5.2. パフォーマンスのボトルネックの特定
VDO パフォーマンスのボトルネックを特定することは、システム効率を最適化するために重要です。実行できる主要な手順の 1 つは、ボトルネックが CPU、メモリー、バッキングストレージの速度のうちどこにあるのかを判断することです。最も遅いコンポーネントを特定したら、パフォーマンスを向上させる戦略を立てることができます。
パフォーマンス低下の根本原因がハードウェアの問題ではないことを確認するには、ストレージスタックで VDO を使用した場合と使用しない場合のテストを実行します。
VDO の journalQ スレッドは、特に VDO ボリュームが書き込み操作を処理している場合には、必然的にボトルネックになります。別のスレッドタイプの使用率が journalQ スレッドよりも高いことが判明した場合、当該タイプのスレッドをさらに追加することでこの問題を修正できます。
5.2.1. top による VDO パフォーマンスの分析
top ユーティリティーを使用して、VDO スレッドのパフォーマンスを調べることができます。
top などのツールは、生産的な CPU サイクルと、キャッシュまたはメモリーの遅延により停止したサイクルを区別できません。このようなツールは、キャッシュの競合と、低速なメモリーアクセスを実際の動作として解釈します。ノード間でスレッドを移動すると、1 秒あたりの操作数が増加した一方で、CPU 使用率が低下したように見えることがあります。
手順
個々のスレッドを表示します。
$ top -H- f キーを押してフィールドマネージャーを表示します。
-
(↓) キーを使用して
P = Last Used Cpu (SMP)フィールドに移動します。 -
スペースバーを押して、
P = Last Used Cpu (SMP)フィールドを選択します。 -
q キーを押してフィールドマネージャーを閉じます。
topユーティリティーは、個々のコアの CPU 負荷を表示し、各プロセスまたはスレッドが最近使用した CPU を示します。1 を押すと、CPU ごとの統計情報に切り替えることができます。
5.2.2. top 結果の解釈
VDO スレッドのパフォーマンスを分析する際には、次の表を使用して top ユーティリティーの結果を解釈してください。
| 値 | 説明 | 提案 |
|---|---|---|
| スレッドまたは CPU 使用率が 70% を超えている。 | スレッドまたは CPU がオーバーロード状態です。実際の作業を伴わずに CPU 上でスケジュールされている VDO スレッドにより、使用率が高くなっている可能性があります。この状況は、過度のハードウェア割り込み、メモリーの競合、またはリソースの競合によって発生する可能性があります。 | このコアを実行するタイプのスレッドの数を増やします。 |
|
| コアがタスクをアクティブに処理しています。 | アクションは不要です。 |
|
| コアが標準の処理作業を実行しています。 | パフォーマンスを向上させるには、コアを追加します。NUMA の競合を回避します。 |
| コアがオーバーコミットされています。 | カーネルスレッドとデバイス割り込み処理を別のコアに再割り当てします。 |
| VDO が、ストレージシステムを I/O リクエストで常にビジー状態に保っています。 [b] | CPU 使用率が非常に低い場合は、I/O 送信スレッドの数を減らします。 |
|
|
VDO に、必要以上の |
|
| I/O リクエストあたりの CPU 使用率が高い。 | スレッドが増えると、I/O リクエストごとの CPU 使用率が増加します。 | CPU、メモリー、またはロックの競合がないか確認します。 |
[a]
数パーセントを超えた値
[b]
この状態は、ストレージシステムが複数のリクエストを処理できる場合、またはリクエストの処理が効率的である場合には適切です。
| ||
5.2.3. perf による VDO パフォーマンスの分析
perf ユーティリティーを使用して、VDO の CPU パフォーマンスを確認できます。
前提条件
-
perfパッケージがインストールされている。
手順
パフォーマンスプロファイルを表示します。
# perf topperfの結果を解釈して CPU パフォーマンスを分析します。Expand 表5.2 perf の結果の解釈 値 説明 提案 kvdo:bioQスレッドがスピンロックを取得するために過度にサイクルを費やす。VDO の下のデバイスドライバーで過度の競合が発生している可能性があります。
kvdo:bioQスレッドの数を減らします。CPU 使用率が高い。
NUMA ノード間で競合が生じています。
プロセッサーが対応している場合は、
stalled-cycles-backend、cache-misses、およびnode-load-missesなどのカウンターを確認します。ミス率が高いと、他のツールで CPU 使用率が高い場合と同様にストールが発生する場合があり、競合の可能性があります。VDO カーネルスレッドの CPU アフィニティーまたは割り込みハンドラーの IRQ アフィニティーを実装して、処理作業を単一ノードに制限します。
5.2.4. sar による VDO パフォーマンスの分析
sar ユーティリティーを使用すると、VDO パフォーマンスに関する定期レポートを作成できます。
すべてのブロックデバイスドライバーが sar ユーティリティーに必要なデータを提供できるわけではありません。たとえば、MD RAID などのデバイスは %util 値を報告しません。
前提条件
sysstatユーティリティーをインストールします。# dnf install sysstat
手順
ディスク I/O 統計情報を 1 秒間隔で表示します。
$ sar -d 1sarの結果を解釈して VDO パフォーマンスを分析します。Expand 表5.3 sar の結果の解釈 値 説明 提案 -
基盤となるストレージデバイスの
%util値が 100% を大きく下回っている。 - VDO が 100% でビジー状態である。
-
bioQスレッドが大量の CPU 時間を使用している。
VDO の
bioQスレッドが高速デバイスに対して少なすぎます。bioQスレッドを追加します。bioQスレッドを追加すると、スピンロックの競合により、特定のストレージドライバーの速度が低下する可能性があることに注意してください。-
基盤となるストレージデバイスの
5.3. VDO スレッドの再分配
VDO は、リクエストを処理するときに、さまざまなタスクにさまざまなスレッドプールを使用します。最適なパフォーマンスは、各プールのスレッド数を適切に設定することに依存します。適切なスレッド数は、利用可能なストレージ、CPU リソース、ワークロードの種類によって異なります。VDO の作業を複数のスレッドに分散して、VDO パフォーマンスを向上させることができます。
VDO は、並列処理を通じてパフォーマンスを最大化することを目的としています。利用可能な CPU リソースやボトルネックの根本原因などの要因に応じて、ボトルネックになっているタスクに対してより多くのスレッドを割り当てることで、パフォーマンスを向上できます。スレッド使用率が高い (70 - 80% 以上) と遅延が発生する可能性があります。したがって、スレッド数を増やすことが役立ちます。ただし、スレッド数が多すぎるとパフォーマンスが低下し、追加のコストが発生する可能性があります。
最適なパフォーマンスを得るには、次のアクションを実行します。
- 予想されるさまざまなワークロードで VDO をテストし、パフォーマンスを評価して最適化します。
- 使用率が 50% を超えるプールのスレッド数を増やします。
- 個々のスレッドの使用率が低くても、全体の使用率が 50% を超える場合は、VDO で使用できるコアの数を増やします。
5.3.1. NUMA ノード全体での VDO スレッドのグループ化
NUMA ノードをまたぐメモリーへのアクセスは、ローカルメモリーアクセスよりも遅くなります。コアがノード内の最終レベルのキャッシュを共有する Intel プロセッサーでは、単一ノード内でデータが共有される場合よりもノード間でデータが共有される場合に、キャッシュの問題が顕著になります。多くの VDO カーネルスレッドは排他的なデータ構造を管理する一方、しばしば I/O リクエストに関するメッセージを交換します。VDO スレッドが複数のノードに分散している場合や、スケジューラーがノード間でスレッドを再割り当てする場合、競合が発生する可能性があります。具体的には、複数のノードが同じリソースを求めて競合する可能性があります。
特定のスレッドを同じ NUMA ノードにグループ化することで、VDO のパフォーマンスを向上させることができます。
- 関連するスレッドの 1 つの NUMA ノードへのグループ化
-
I/O 完了通知 (
ackQ) スレッド 上位レベルの I/O 送信スレッド:
- ダイレクト I/O を処理するユーザーモードスレッド
- カーネルページキャッシュフラッシュスレッド
-
I/O 完了通知 (
- デバイスアクセスの最適化
-
デバイスアクセスのタイミングが NUMA ノード間で異なる場合は、ストレージデバイスコントローラーに最も近いノードで
bioQスレッドを実行します。
-
デバイスアクセスのタイミングが NUMA ノード間で異なる場合は、ストレージデバイスコントローラーに最も近いノードで
- 競合の最小化
-
I/O 送信とストレージデバイスの割り込み処理を、
logQまたはphysQスレッドと同じノードで実行します。 - 同じノードで他の VDO 関連の作業を実行します。
-
1 つのノードがすべての VDO 作業を処理できない場合は、メモリー競合を考慮してスレッドを他のノードに移動します。たとえば、処理に割り込むデバイスと
bioQスレッドを他のノードに移動します。
-
I/O 送信とストレージデバイスの割り込み処理を、
5.3.2. CPU アフィニティーの設定
VDO スレッドの CPU アフィニティーを調整すると、特定のストレージデバイスドライバーでの VDO パフォーマンスを向上させることができます。
ストレージデバイスドライバーの割り込み (IRQ) ハンドラーが大きな作業を実行し、ドライバーがスレッド化された IRQ ハンドラーを使用しない場合、VDO パフォーマンスを最適化するシステムスケジューラーの機能が制限される可能性があります。
最適なパフォーマンスを得るには、次のアクションを実行します。
-
コアがオーバーロード状態になった場合は特定のコアを IRQ 処理専用にし、VDO スレッドアフィニティーを調整します。
%hi値が他のコアよりも数パーセント以上高い場合、コアはオーバーロード状態になっています。 -
ビジーな IRQ コアでは、
kvdo:journalQスレッドなどのシングルトン VDO スレッドを実行しないようにします。 - 他のスレッドタイプも、IRQ でビジーなコアでは実行しないようにします (個々の CPU 使用率が高い場合のみ)。
この設定は、システムを再起動すると元に戻ります。
手順
CPU アフィニティーを設定します。
# taskset -c <cpu-numbers> -p <process-id><cpu-numbers>は、プロセスを割り当てる CPU 番号のコンマ区切りのリストに置き換えます。<process-id>は、CPU アフィニティーを設定する実行中のプロセスの ID に置き換えます。例5.1 CPU コア 1 および 2 に
kvdoプロセスの CPU アフィニティーを設定する例# for pid in `ps -eo pid,comm | grep kvdo | awk '{ print $1 }'` do taskset -c "1,2" -p $pid done
検証
アフィニティーセットを表示します。
# taskset -p <cpu-numbers> -p <process-id><cpu-numbers>は、プロセスを割り当てる CPU 番号のコンマ区切りのリストに置き換えます。<process-id>は、CPU アフィニティーを設定する実行中のプロセスの ID に置き換えます。
5.4. パフォーマンスを向上させるためのブロックマップキャッシュサイズの増加
LVM-VDO ボリュームのキャッシュサイズを増やすことで、読み取りおよび書き込みのパフォーマンスを向上させることができます。
読み取りおよび書き込みの待ち時間が長い場合、またはアプリケーション要件と一致しない大量のデータをストレージから読み取る場合、キャッシュサイズを調整する必要がある可能性があります。
ブロックマップキャッシュを増やすと、キャッシュは指定したメモリー量に加えて、さらに 15% のメモリーを使用します。キャッシュサイズが大きいほど RAM の使用量が増え、システム全体の安定性に影響します。
次の例は、システムのキャッシュサイズを 128 MB から 640 MB に変更する方法を示しています。
手順
LVM-VDO ボリュームの現在のキャッシュサイズを確認します。
# lvs -o vdo_block_map_cache_size VDOBlockMapCacheSize 128.00m 128.00mLVM-VDO ボリュームを非アクティブ化します。
# lvchange -an vg_name/vdo_volumeLVM-VDO 設定を変更します。
# lvchange --vdosettings "block_map_cache_size_mb=640" vg_name/vdo_volume640を、メガバイト単位の新しいキャッシュサイズに置き換えます。注記キャッシュサイズは 128 MB - 16 TB の範囲内に含まれる 4096 の倍数で、論理スレッドあたり少なくとも 16 MB である必要があります。変更は、次回 LVM-VDO デバイスが起動されたときに有効になります。すでに実行されているデバイスは影響を受けません。
LVM-VDO ボリュームをアクティブ化します。
# lvchange -ay vg_name/vdo_volume
検証
現在の LVM-VDO ボリューム設定を確認します。
# lvs -o vdo_block_map_cache_size vg_name/vdo_volume VDOBlockMapCacheSize 640.00m
5.5. 破棄操作の高速化
VDO は、システム上のすべての VDO デバイスの DISCARD (TRIM) セクターの最大許容サイズを設定します。デフォルトのサイズは 8 セクターで、1 つの 4-KiB ブロックに相当します。DISCARD サイズを増やすと、破棄操作の速度が大幅に向上します。ただし、破棄のパフォーマンス向上は、他の書き込み操作の速度維持とトレードオフの関係にあります。
最適な DISCARD サイズは、ストレージスタックによって異なります。DISCARD セクターが非常に大きい場合でも非常に小さい場合でも、パフォーマンスが低下する可能性があります。さまざまな値で実験を行い、満足のいく結果が得られる値を見つけてください。
ローカルファイルシステムを保存する LVM-VDO ボリュームの場合、デフォルト設定である 8 セクターの DISCARD サイズの使用が最適です。SCSI ターゲットとして機能する LVM-VDO ボリュームの場合、2048 セクター (1 MB の破棄に相当) など、適度に大きな DISCARD サイズが最適に機能します。最大 DISCARD サイズが 10240 セクター (5 MB の破棄に相当) を超えないようにすることを推奨します。サイズを選択するときは、8 の倍数であることを確認してください。8 セクターより小さい場合、VDO は破棄を効果的に処理できない可能性があります。
手順
DISCARD セクターの新しい最大サイズを設定します。
# echo <number-of-sectors> > /sys/kvdo/max_discard_sectors<number-of-sectors>はセクタ数に置き換えます。この設定は再起動するまで維持されます。オプション: DISCARD セクターへの変更を再起動後も永続的に保持するには、カスタム
systemdサービスを作成します。次の内容で新しい
/etc/systemd/system/max_discard_sectors.serviceファイルを作成します。[Unit] Description=Set maximum DISCARD sector [Service] ExecStart=/usr/bin/echo <number-of-sectors> > /sys/kvdo/max_discard_sectors [Install] WantedBy=multi-user.target<number-of-sectors>はセクタ数に置き換えます。- ファイルを保存して終了します。
サービスファイルをリロードします。
# systemctl daemon-reload新しいサービスを有効にします。
# systemctl enable max_discard_sectors.service
検証
オプション: スケーリングガバナーの変更を永続化した場合は、
max_discard_sectors.serviceが有効になっているか確認します。# systemctl is-enabled max_discard_sectors.service
5.6. CPU 周波数スケーリングの最適化
デフォルトでは、RHEL は CPU 周波数スケーリングを使用して、CPU に大きな負荷がかかっていないときに電力を節約し、発熱を軽減します。省電力よりもパフォーマンスを優先する場合は、最大クロック速度で動作するように CPU を設定できます。これにより、CPU はデータの重複排除と圧縮のプロセスを最大限の効率で処理できるようになります。CPU を最高周波数で実行することで、リソースを大量に消費する操作をより迅速に実行できるようになり、データ削減とストレージ最適化の点で LVM-VDO の全体的なパフォーマンスが向上する可能性があります。
高パフォーマンス向けに CPU 周波数スケーリングをチューニングすると、消費電力と発熱が増加する可能性があります。システムの冷却が不十分な場合、これにより過熱が引き起こされてサーマルスロットルが発生し、パフォーマンスの向上が制限される可能性があります。
手順
利用可能な CPU ガバナーを表示します。
$ cpupower frequency-info -gパフォーマンスを優先するようにスケーリングガバナーを変更します。
# cpupower frequency-set -g performanceこの設定は再起動するまで維持されます。
オプション: スケーリングガバナーの変更を再起動後も永続的に保持するには、カスタム
systemdサービスを作成します。次の内容で新しい
/etc/systemd/system/cpufreq.serviceファイルを作成します。[Unit] Description=Set CPU scaling governor to performance [Service] ExecStart=/usr/bin/cpupower frequency-set -g performance [Install] WantedBy=multi-user.target- ファイルを保存して終了します。
サービスファイルをリロードします。
# systemctl daemon-reload新しいサービスを有効にします。
# systemctl enable cpufreq.service
検証
現在使用されている CPU 周波数ポリシーを表示します。
$ cpupower frequency-info -pオプション: スケーリングガバナーの変更を永続化した場合は、
cpufreq.serviceが有効になっているか確認します。# systemctl is-enabled cpufreq.service