Fuse Online でのアプリケーションの統合
さまざまなアプリケーションとサービスとの間でデータを共有したいビジネスユーザー向け
概要
前書き
Red Hat Fuse は、分散型のクラウドネイティブな統合ソリューションで、選択できる多くのアーキテクチャー、デプロイメント、およびツールを提供します。Fuse Online は Red Hat の web ベースの Fuse ディストリビューションです。Syndesis は Fuse Online のオープンソースプロジェクトです。Fuse Online は OpenShift Online、OpenShift Dedicated、および OpenShift Container Platform で実行されます。
本ガイドでは、Fuse Online の Web インターフェースを使用してアプリケーションを統合するための情報および手順を提供します。本書では以下の内容を取り上げます。
サンプルインテグレーションを作成して Fuse Online を使用する方法の詳細は、「Sample Integration Tutorials」を参照してください。
サポートを利用するには、Fuse Online の左ナビゲーションパネルで Support をクリックするか、右上の
 をクリックしてから Support を選択 します。
をクリックしてから Support を選択 します。
第1章 Fuse Online の概要
Fuse Online では、アプリケーションやサービスからのデータを取得し、必要な場合はそのデータで操作することができます。さらに、データを全く異なるアプリケーションやサービスに送信することもできます。そのためにコーディングは必要ありません。
Fuse Online の概要は以下のトピックで取り上げます。
1.1. Fuse Online の仕組み
Fuse Online は、コードを作成せずに複数の異なるアプリケーションやサービスの統合を可能にする Web ブラウザーインターフェースを提供します。また、複雑なユースケースで必要な場合にコードを導入できる機能も提供します。
Fuse Online では、異なるアプリケーション間でのデータ転送を有効にできます。たとえば、ビジネスアナリストは Fuse Online を使用して、お客様がメンションされているツイートをキャプチャーし、Twitter から取得したデータを利用して Salesforce アカウントを更新できます。別の例として、株式取引の提案を行うサービスが挙げられます。Fuse Online を使用すると、対象株式の売買に関する提案をキャプチャーし、この提案を株式移転を自動化するサービスに転送することができます。
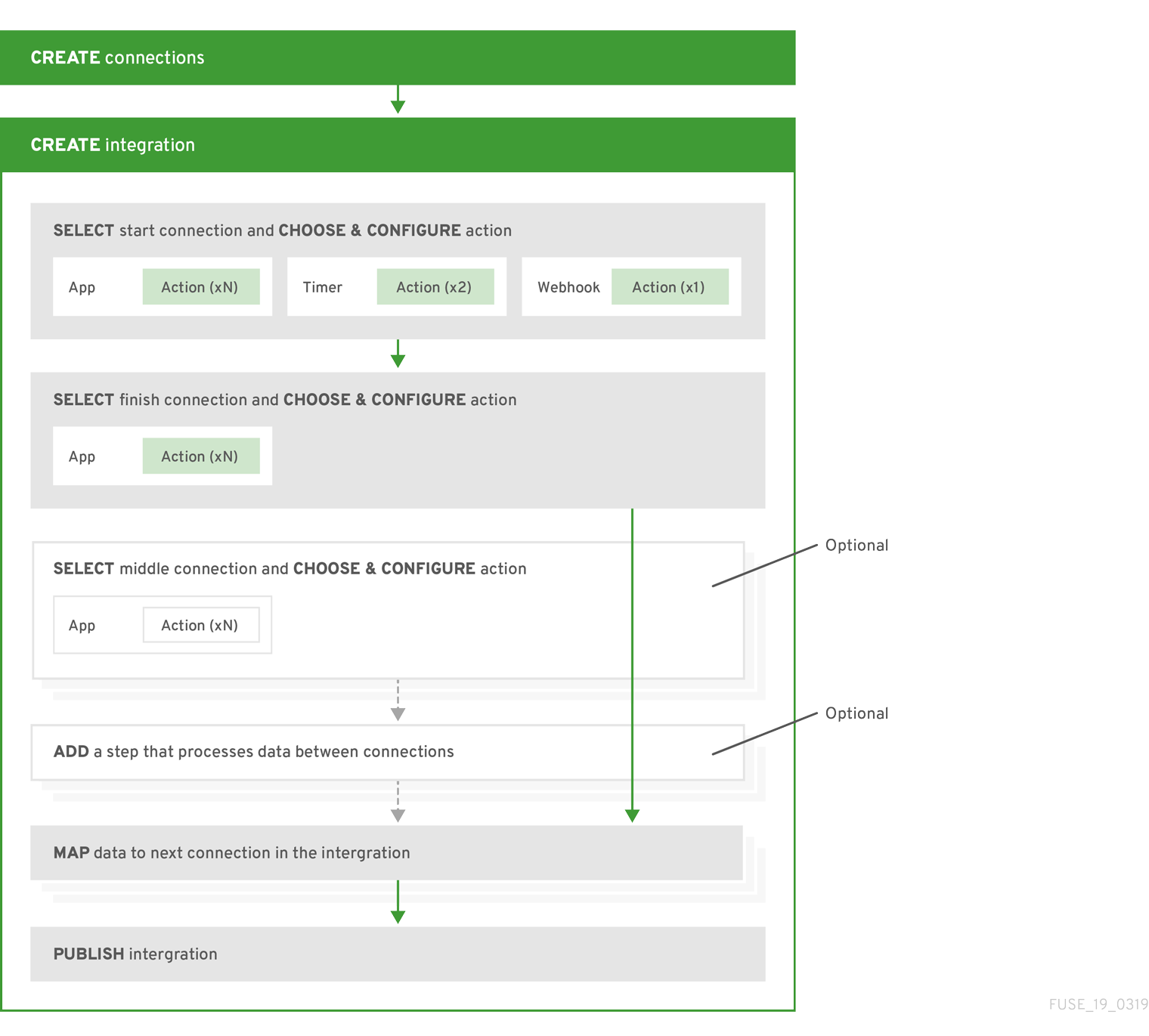
シンプルなインテグレーションを作成および実行するため主なステップは次のとおりです。
- 統合する各アプリケーションへのコネクションを作成します。
最初のコネクションを選択します。これは、別のアプリケーションと共有するデータが含まれるアプリケーションへのコネクションです。
または、HTTP リクエストを受け入れるタイマーまたは Webhook でインテグレーションを開始できます。
- 最後のコネクションを選択します。これは、最初のコネクションからデータを受け取ってインテグレーションを完了するアプリケーションへのコネクションです。
- 最初のコネクションのデータフィールドを最後のコネクションのデータフィールドにマップします。
- インテグレーションに名前を付けます。
- Publish をクリックし、インテグレーションの実行を開始します。
この他のインテグレーションの 1 つに API プロバイダーインテグレーションがあります。API プロバイダーインテグレーションでは、REST API クライアントはインテグレーションの実行をトリガーするコマンドを呼び出しできます。API プロバイダーインテグレーションを作成および実行するには、OpenAPI 2.0 ドキュメントを Fuse Online にアップロードします。このドキュメントは、クライアントが呼び出しできるオペレーションを指定します。オペレーションを実行する、コネクションやステップ (データマッパーステップやフィルターステップなど) のフローを、各オペレーションに対して指定および設定します。シンプルなインテグレーションごとに 1 つのプライマリーフローがあります。API プロバイダーインテグレーションの場合は、オペレーションごとに 1 つのプライマリーフローがあります。
Fuse Online のダッシュボードでは、インテグレーションを監視および管理できます。実行しているインテグレーションを確認でき、インテグレーションを開始、停止、および編集できます。
1.2. Fuse Online の対象ユーザー
Fuse Online の対象ユーザーは、異なるアプリケーション間でデータを共有するためにコードを作成したくないビジネスユーザー (財務、人事、マーケティングなどの関係者) です。このようなユーザーは、さまざまな SaaS (Software-as-a-Service) を使用することにより、ビジネス要件、ワークフロー、および関連データについて理解します。
ビジネスユーザーは Fuse Online を使用して以下を行うことができます。
- 所属企業の名前がメンションされたツイートをキャプチャーし、それが知らないソースからのツイートである場合は Salesforce 環境で新しい連絡先を作成します。
- Salesforce のリード更新を特定し、SQL ストアドプロシージャーを実行して、関連するデータベースを最新の状態に維持します。
- AMQ ブローカーが受け取るオーダーをサブスクライブし、カスタム API でこれらのオーダーを操作します。
- Amazon S3 バケットからデータを取得し、Dropbox フォルダーに追加します。
これは、ビジネスユーザーがコードを作成せずに行える例の一部です。
1.3. Fuse Online を使用する利点
Fuse Online には多くの利点があります。
- コードを作成せずに異なるアプリケーションやサービスからデータを統合します。
- パブリッククラウドの OpenShift Online や、オンサイトの OpenShift Container Platform でインテグレーションを実行できます。
- ビジュアルデータマッパーを使用して、あるアプリケーションのデータフィールドを別のアプリケーションのデータフィールドにマップします。
- オープンソースソフトウェアの利点をすべて活用します。機能の拡張やインターフェースのカスタマイズが可能です。統合するアプリケーションやサービスのコネクターを Fuse Online が提供しない場合は、開発者が必要なコネクターを作成できます。
1.4. Fuse Online コンストラクトの説明
Fuse Online を使用するには、コネクター、コネクション、アクション、ステップ、およびフローを使用してインテグレーションを作成します。これらのコンストラクトの基本を理解すると便利です。
Fuse Online の各インストールは Fuse Online 環境と呼ばれます。Red Hat が Fuse Online 環境をインストールおよび管理する場合、OpenShift Online または OpenShift Dedicated 上で実行されます。ユーザーが Fuse Online 環境をインストールおよび管理する場合、通常は OpenShift Container Platform で実行されますが、OpenShift Dedicated で実行することもできます。
インテグレーション
Fuse Online には、シンプルなインテグレーションと API プロバイダーインテグレーションがあります。
シンプルなインテグレーションは、Fuse Online が実行する順序付けされたステップです。これには、以下が含まれます。
- アプリケーションに接続し、インテグレーションを開始するステップ。このコネクションは、インテグレーションが操作する初期データを提供します。後続のコネクションは追加のデータを提供できます。
- アプリケーションに接続し、インテグレーションを完了するためのステップ。このコネクションは、以前のステップから出力されたデータをすべて受け取り、インテグレーションを終了します。
最初と最後のコネクションの間にアプリケーションに接続する任意の追加ステップ。追加のコネクションがどのインテグレーションステップにあるかによって、追加のコネクションは以下のいずれかまたはすべてを実行できます。
- 操作するインテグレーションの追加データを提供します。
- インテグレーションデータを処理します。
- 処理結果をインテグレーションに出力します。
- コネクションとアプリケーション間のデータで操作する任意のステップ。通常、前のコネクションのデータフィールドを次のコネクションが使用するデータフィールドにマップするステップがあります。
API プロバイダーインテグレーションは、OpenAPI スキーマを提供した REST API サービスをパブリッシュします。REST API クライアントからの呼び出しによって、API プロバイダーインテグレーションの実行がトリガーされます。呼び出しは、REST API が実装するすべてのオペレーションを呼び出すことができます。シンプルなインテグレーションには実行のプライマリーフローが 1 つあります。API プロバイダーインテグレーションの場合は、オペレーションごとに 1 つのプライマリーフローがあります。各オペレーションフローは、インテグレーションの作成時にそのオペレーションのフローに追加したステップに応じて、アプリケーションに接続し、データを処理します。各オペレーションフローは、呼び出しがインテグレーションの実行をトリガーしたクライアントに指定する応答を返して終了します。
コネクター
Fuse Online はコネクターのセットを提供します。コネクターは、データの取得元また送信先となる特定のアプリケーションを示します。各コネクターは、その特定のアプリケーションへのコネクションを作成するためのテンプレートです。たとえば、Salesforce コネクターを使用して、Salesforce へのコネクションを作成します。
接続するアプリケーションは、OAuth プロトコルを使用してユーザーを認証することがあります。この場合、Fuse Online 環境をそのアプリケーションにアクセスできるクライアントとして登録します。登録は、アプリケーションのコネクターに関連付けられます。OAuth を使用する各アプリケーションに 1 度だけ特定の Fuse Online 環境を登録する必要があります。登録は、コネクターから作成する各コネクションまで適用されます。
Fuse Online が必要なコネクターを提供しない場合、開発者が必要なコネクターを作成できます。
コネクション
インテグレーションを作成する前に、データの取得元また送信先となる各アプリケーションまたはサービスへのコネクションを作成する必要があります。コネクションを作成するには、コネクターを選択して、設定情報を追加します。たとえば、インテグレーションで AMQ ブローカーに接続するには、AMQ コネクターを選択してコネクションを作成し、プロンプトにしたがって接続するブローカーと、コネクションに使用するアカウントを特定します。
コネクションは、作成されたコネクターの特定のインスタンスの 1 つです。1 つのコネクターから複数のコネクションを作成できます。たとえば、AMQ コネクターを使用して、各コネクションが異なるブローカーにアクセスする 3 つの AMQ コネクションを作成できます。
シンプルなインテグレーションを作成するには、インテグレーションを開始するコネクションとインテグレーションを終了するコネクションを選択します。また任意で、追加のアプリケーションにアクセスするためのコネクションを 1 つ以上選択します。各オペレーションフローに 1 つ以上のコネクションを追加して API プロバイダーインテグレーションを作成できます。任意の数のインテグレーションおよびオペレーションフローが同じコネクションを使用できます。特定のインテグレーションまたはフローは、同じコネクションを複数回使用できます。
詳細は「アプリケーションへの接続」を参照してください。
アクション
インテグレーションでは、各コネクションは必ず 1 つのアクションを実行します。インテグレーションの作成時に、フローに追加するコネクションを選択し、コネクションが実行するアクションを選択します。たとえば、Salesforce コネクションをフローに追加するときに、Salesforce アカウントの作成、Salesforce アカウントの更新、および Salesforce の検索が含まれ、それに限定されないアクションのセットから選択します。
一部のアクションには追加の設定が必要で、Fuse Online は必要な情報を要求します。
ステップ
シンプルなインテグレーションは、順序付けされたステップのセットです。API プロバイダーインテグレーションでは、各オペレーションフローが順序付けされたステップのセットになります。
各ステップはデータで操作します。ステップによっては、Fuse Online 外部のアプリケーションまたはサービスに接続しながらデータ上で操作するものもあります。これらのステップはコネクションです。コネクションの間に、Fuse Online のデータで操作する他のステップがある場合があります。通常、ステップのセットには、前のコネクションで使用されたデータフィールドをフローの次のコネクションで使用されるデータフィールドにマップするステップが含まれます。シンプルなインテグレーションの最初のコネクション以外では、各ステップは前のステップから受け取るデータで操作します。
Fuse Online は、コネクションの間でデータを操作するため、以下を行うステップを提供します。
- あるアプリケーションのデータフィールドを別のアプリケーションのデータフィールドにマップします。
- データをフィルターし、処理中のデータがユーザー定義の基準と合ったときのみインテグレーションが継続されるようにします。
- レコードのコレクションを個別のレコードに分割して、Fuse Online が各レコードに対して 1 度後続のステップをイテレーティブに実行するようにします。
- 個別のレコードをコレクションに集計し、Fuse Online がコレクションに対して 1 度後続のステップを実行するようにします。
- Freemaker、Mustache、または Velocity テンプレートにデータを挿入して、同等で一貫性のある出力を生成します。
- Fuse Online が自動的に提供するデフォルトのログ以外の情報をログに記録します。
カスタムステップを提供するエクステンションをアップロードすると、Fuse Online に組み込まれない方法でコネクションの間のデータを操作できます。「エクステンションの開発」を参照してください。
フロー
フローは、インテグレーションが実行する順序付けされたステップのセットです。
シンプルなインテグレーションには、1 つのプライマリーフローがあります。API プロバイダーインテグレーションの場合は、REST API が定義するオペレーションごとに 1 つのプライマリーフローがあります。各オペレーションのプライマリーフローは、そのオペレーションの呼び出しを処理するステップのセットです。
プライマリーフローには条件付きフローを追加できます。インテグレーションは、指定した条件を評価し、関連付けられたフローを実行するかどうかを決定します。
フローでは、各ステップは前のステップから出力されたデータで操作できます。フローに必要なステップを判断するには、「インテグレーションの計画」を参照してください。
第2章 インテグレーション作成の準備方法
インテグレーションを作成するためのワークフローを計画および理解すると、必要に応じたインテグレーションの作成に役立ちます。インテグレーション作成の準備に関する情報は、以下を参照してください。
2.1. インテグレーションの計画に関する注意点
インテグレーションを作成する前に、以下を検討してください。
インテグレーションの実行をトリガーする方法。
- タイマーを設定して、指定した間隔で実行をトリガーするか。
- HTTP リクエストを送信するか。
アプリケーションに接続してデータを取得するか。
- そのアプリケーションで、データを取得するアクションを何がトリガーするか。たとえば、Twitter からデータを取得して開始するインテグレーションは Twitter のメンションでトリガーすることが可能です。
- 対象となるデータフィールド。
- このアプリケーションにアクセスするために Fuse Online が使用するクレデンシャル。
オペレーションのフローの実行をトリガーする REST API 呼び出しをクライアントが実行できるよう、REST API サービスをパブリッシュするか。
- サービスの OpenAPI スキーマがすでに定義されているか。
- 定義されていない場合、サービスがどのオペレーションを定義するか。
シンプルなインテグレーションを終了するには、以下を検討します。
- データを受信するアプリケーションがあるか、または情報をインテグレーションのログに送信するか。
- アプリケーションにデータを送信する場合、インテグレーションが実行するアクションは何か。
- 対象となるデータフィールド。
- このアプリケーションにアクセスするために Fuse Online が使用するクレデンシャル。
フローのステップのセットでは、以下を検討します。
他のアプリケーションにアクセスする必要があるか。アクセスする必要がある他のアプリケーションに対して、以下を検討します。
- フローが接続する必要のあるアプリケーション。
- コネクションが実行するアクション。
- 対象となるデータフィールド。
- コネクションがこのアプリケーションに接続するために使用するクレデンシャル。
フローがコネクション間のデータで操作する必要があるか。以下に例を示します。
- フローは操作するデータをフィルターするか。
- フィールド名がソースアプリケーションとターゲットアプリケーションで異なるか。異なる場合はデータマッピングが必要です。
- フローがコレクションで操作するか。操作する場合、フローがデータマッパーを使用してコレクションを処理できるか、またはフローがコレクションを個別のレコードに分割する必要があるか。フローはレコードをコレクションに集約する必要があるか。
- テンプレートはデータを一貫した形式で出力するのに便利であるか。
- 処理中のメッセージに関する情報をインテグレーションのログに送信するか。
- フローはカスタマイズされた方法にてデータで操作する必要があるか。
- インテグレーションデータの内容に応じて実行フローを変更する必要があるか。よって、条件付きフローが必要であるか。
2.2. シンプルなインテグレーションを作成するための一般的なワークフロー
Fuse Online コンソールにログインしたら、統合するアプリケーションへのコネクションを作成できます。統合する各アプリケーションと、OAuth プロトコルを使用する各アプリケーションでは、Fuse Online をそのアプリケーションのクライアントとして登録します。登録する必要のあるアプリケーションには以下が含まれます。
- Dropbox
- Google アプリケーション (Gmail、カレンダー、およびスプレッドシート)
- Salesforce
- SAP Concur
これらのアプリケーションを登録すると、シンプルなインテグレーションを作成するためのワークフローは次のようになります。
その他のリソース
2.3. Salesforce からデータベースへシンプルなインテグレーションを作成するためのワークフローの例
Fuse Online を使用してシンプルなインテグレーションを作成するためのワークフローを理解するには、「Sample Integration Tutorials」の手順にしたがってサンプルインテグレーションを作成するのが最も効果的です。
以下の図は、Salesforce からデータベースへのサンプルインテグレーションを作成するためのワークフローを表しています。
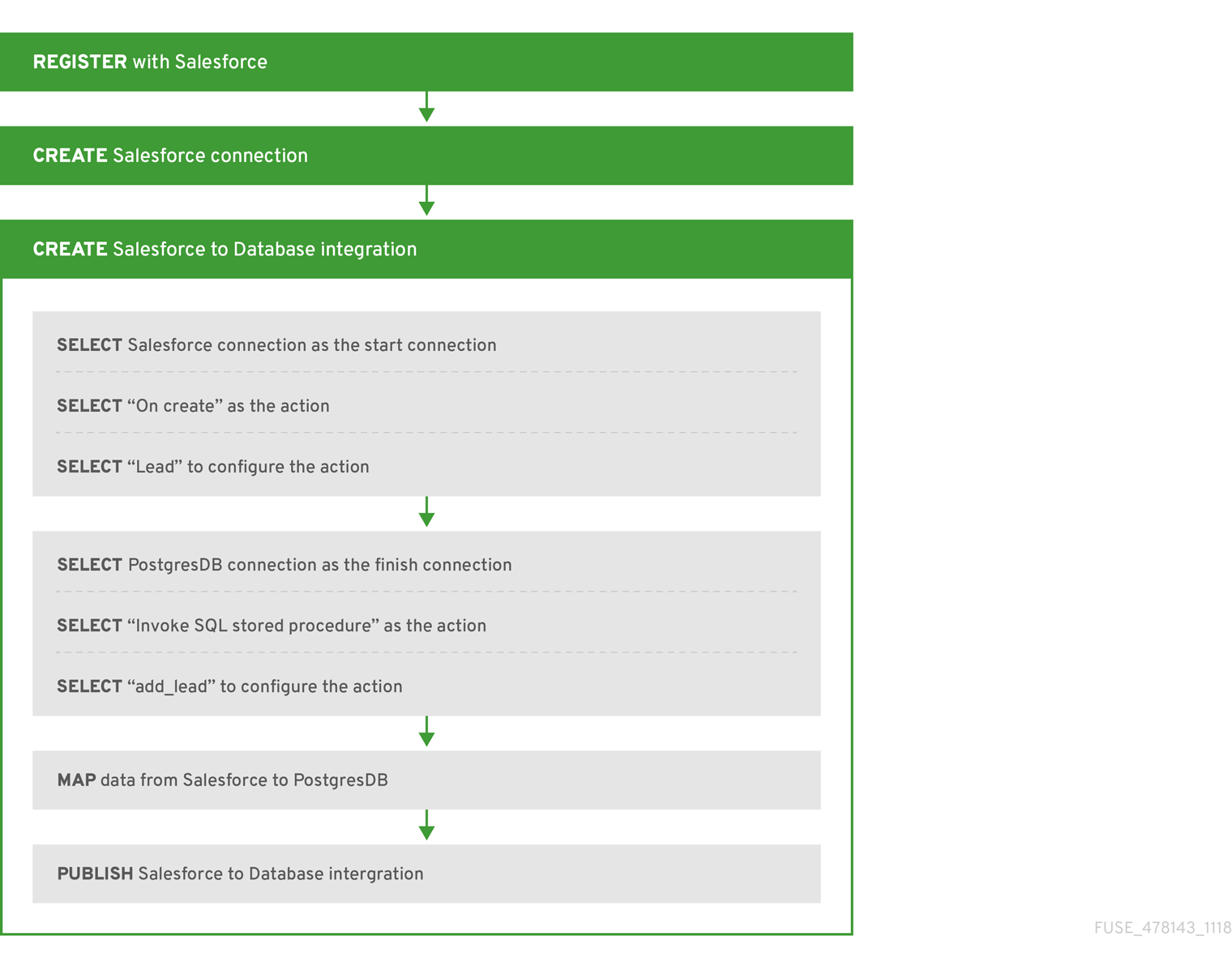
インテグレーションをパブリッシュした後、インテグレーションを実行する準備ができていれば Fuse Online ダッシュボードのインテグレーション名の横に Running が表示されます。
第3章 Fuse Online を初めて使用するときに想定される手順
OpenShift Online の Fuse Online へのアクセスを有効にするために、Red Hat はリンクを提供します。このリンクをクリックすると、Red Hat OpenShift Online Log In ページが表示され、Red Hat アカウントを使用してログインするよう指示されます。ログインすると、Fuse Online から OpenShift Online アカウントへのアクセスを承認するよう要求されます。
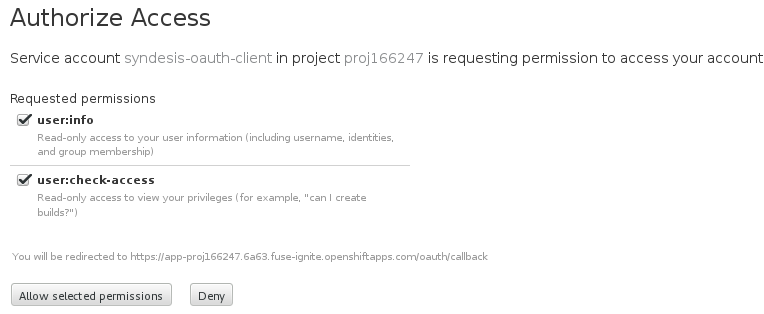
Allow selected permissions をクリックします。これは一度だけ行います。次回、「Welcome to the Red Hat Fuse Online Evaluation」メールメッセージにある Fuse Online アクセスリンクをクリックすると、Fuse Online が即座に表示されます。
Fuse Online on OpenShift Container Platform を使用するには、『Fuse Online でのアプリケーションの統合』の最後にあるインストール手順にしたがいます。
Red Hat は、以下のブラウザーで Fuse Online の使用をサポートします。
- Chrome
- Firefox
第4章 統合するアプリケーションへのコネクション
統合するアプリケーションに接続するための主なステップは次のとおりです。
- 統合する各アプリケーションまたはサービスへのコネクションを作成します。
- 統合する各アプリケーションへのコネクションを持つインテグレーションを作成します。
コネクションの作成手順は、アプリケーションまたはサービスごとに異なります。各種のコネクションを作成し、特定のインテグレーション向けに設定するための詳細は、『Fuse Online のアプリケーションおよびサービスへの接続』を参照してください。
コネクションの一般的な情報は以下を参照してください。
4.1. Fuse Online からアプリケーションへのコネクションの作成
コネクションを作成するには、接続するアプリケーションのコネクターを選択し、入力フィールドに値を入力して、そのアプリケーションへのコネクションを設定します。提供する必要のある設定の詳細は、アプリケーションごとに異なります。コネクションの設定後、このコネクションと同じアプリケーションへの別のコネクションを区別できる名前を付けます。任意で、コネクションの詳細を指定できます。
同じコネクターを使用して、そのアプリケーションへのコネクションをいくつでも作成することができます。たとえば、AMQ コネクターを使用して 3 つのコネクションを作成することが可能です。各 AMQ コネクションは異なるブローカーを指定することが可能です。
例については、以下を参照してください。
4.2. 承認取得のための一般的な手順
インテグレーションでは、アクセス要求の認証に OAuth プロトコルを使用するアプリケーションに接続する場合があります。これには、そのアプリケーションにアクセスするために Fuse Online のインストールを登録する必要があります。登録により、Fuse Online インストールから該当するアプリケーションへのすべてのコネクションが承認されます。たとえば、Fuse Online インストールを Salesforce に登録する場合、Fuse Online インストールから Salesforce へのすべてのコネクションは、登録によって提供された同じ Salesforce クライアント ID と 同じ Salesforce クライアントシークレットを使用します。
Fuse Online 環境ごとに、OAuth を使用するアプリケーション 1 つにつき Fuse Online をクライアントとする 1 つの登録のみが必要です。この登録により、複数のコネクションを作成でき、コネクションごとに違うユーザークレデンシャルを使用できます。
接続する OAuth アプリケーションによって特定のステップは異なりますが、登録は常にクライアント ID とクライアントシークレットで Fuse Online 環境を提供します。アプリケーションによっては、クライアント ID およびクライアントシークレットに別のラベルを使用することがあります。たとえば、Salesforce はコンシューマーキーとコンシューマーシークレットを生成します。
OAuth アプリケーションによっては、登録が提供するクライアント ID およびクライアントシークレットを追加するため、Fuse Online が Settings ページにエントリーを提供することがあります。これに該当するアプリケーションを確認するには、Fuse Online の左パネルで Settings をクリックします。
前提条件
- Fuse Online の Settings ページに、OAuth プロトコルを使用してアクセスを承認するアプリケーションのエントリーがあります。
手順の概要
- Fuse Online の OAuth Application Management ページで、Fuse Online を登録するアプリケーションのエントリーを展開します。これにより、クライアント ID およびクライアントシークレットのフィールドが表示されます。
-
OAuth Application Management ページの上部付近に表示されている
During registration, enter this callback URL:の URL をクリップボードにコピーします。 - 別のブラウザータブで、登録するアプリケーションの Web サイトに移動し、クライアント ID とシークレットを取得するのに必要なステップを実行します。これらのステップの 1 つで、Fuse Online 環境のコールバック URL を入力する必要があります。クリップボードにコピーした URL を 2 つ目のステップで貼り付けます。
- Fuse Online の Settings ページにクライアント ID とクライアントシークレットを貼り付け、設定を保存します。
その他のリソース
Settings ページにエントリーがあるアプリケーションを登録する例:
- Fuse Online の Settings ページにエントリーのないアプリケーションを登録する例: Fuse Online を Dropbox クライアントとして登録
- OAuth プロトコルを使用するアプリケーションへのアクセスを許可するカスタムコネクターの使用に関する情報: カスタムコネクターからコネクションを作成
4.3. コネクションの検証
OAuth を使用するアプリケーションにアクセスするために Fuse Online の承認を取得した後、そのアプリケーションへのコネクションを 1 つ以上作成できます。OAuth アプリケーションへのコネクションを作成する場合、Fuse Online はそのコネクションを検証し、承認が取得されていることを確認します。いつでもコネクションを再度検証し、承認が有効であることを確認できます。
OAuth アプリケーションによっては、有効期限のあるアクセストークンを付与することがあります。アクセストークンの期限が切れた場合、アプリケーションに再接続して新しいアクセストークンを取得できます。
OAuth を使用するコネクションを検証するか、OAuth アプリケーションの新しいアクセストークンを取得するには、以下を実行します。
- 左側のパネルで Connections をクリックします。
- 検証するコネクション、または新しいアクセストークンを取得するコネクションをクリックします。
- コネクションの詳細ページで、Validate または Reconnect をクリックします。
検証または再接続に失敗した場合は、アプリケーションまたはサービスプロバイダーを確認し、アプリケーションの OAuth キー、ID、トークン、またはシークレットが有効であるか判断します。アイテムが期限切れになったり、取り消された可能性があります。
OAuth アイテムが無効になったり、期限切れや取り消しになった場合は、新しい値を取得し、アプリケーションの Fuse Online 設定に貼り付けます。コネクションが検証されなかったアプリケーションの登録については、「Fuse Online のアプリケーションおよびサービスへの接続」の手順を参照してください。更新された設定が導入されたら、上記の手順にしたがって更新されたコネクションを検証します。検証に成功し、このコネクションを使用しているインテグレーションが実行されている場合は、インテグレーションを再起動します。インテグレーションを再起動するには、停止してから開始します。
検証に失敗し、再接続が失敗したものの、サービスプロバイダーですべてが有効であると見られる場合は、アプリケーションで Fuse Online 環境を登録してから、コネクションを再作成します。Fuse Online は再作成時にコネクションを検証します。コネクションを再作成し、コネクションを使用しているインテグレーションがある場合、インテグレーションを編集して古いコネクションを削除し、新しいコネクションを追加する必要があります。インテグレーションが実行されている場合、これを停止してから再起動する必要があります。
4.4. インテグレーションへのコネクションの追加
コネクションをシンプルなインテグレーションやオペレーションフローに追加する場合、Fuse Online はコネクションのアプリケーション接続時に実行できるアクションのリストを表示します。必ず 1 つのアクションを選択する必要があります。実行中のインテグレーションでは、各コネクションは選択したアクションのみを実行します。たとえば、Twitter コネクションをインテグレーションの最初のコネクションとして追加した場合、Twitter で Twitter ハンドルがメンションされたツイートを監視する Mention アクションを選択することがあります。
一部のアクションを選択すると、アクションを設定する 1 つまたは複数のパラメーターの指定を要求されます。たとえば、Salesforce コネクションをインテグレーションに追加し、On create アクションを選択する場合、リードや取引先責任者など対象となるオブジェクトの種類を示す必要があります。
4.5. コネクション情報の表示および編集方法
コネクションの作成後、Fuse Online は内部識別子をコネクションに割り当てます。この識別子は変更しません。コネクションの名前、説明、または設定値を変更でき、Fuse Online は同じコネクションとして認識します。
コネクションに関する情報を表示および編集する方法は 2 つあります。
- 左側のパネルで Connections をクリックし、詳細を表示するコネクションをクリックします。
左側のパネルで Integrations をクリックし、インテグレーションを表示してその Summary ページを確認します。インテグレーションのフローダイアグラムでは以下を行います。
- シンプルなインテグレーションの場合は、コネクションアイコンをクリックしてそのコネクションの詳細を表示します。
-
API プロバイダーインテグレーションの場合は
 をクリックし、インテグレーションのオペレーションリストを表示します。詳細を表示するコネクションが含まれるフローがあるオペレーションをクリックします。
をクリックし、インテグレーションのオペレーションリストを表示します。詳細を表示するコネクションが含まれるフローがあるオペレーションをクリックします。
Connection Details ページで、編集するコネクションのフィールドの横にある
 をクリックして、そのフィールドを編集します。コネクションによっては、設定フィールドの下にある Edit をクリックして設定値を変更します。値を変更したら必ず Save をクリックしてください。
をクリックして、そのフィールドを編集します。コネクションによっては、設定フィールドの下にある Edit をクリックして設定値を変更します。値を変更したら必ず Save をクリックしてください。
実行中のインテグレーションで使用されるコネクションを更新する場合、インテグレーションを再パブリッシュする必要があります。
アクセスを許可する OAuth プロトコルを使用するアプリケーションへのコネクションでは、コネクションが使用するログインクレデンシャルを変更することはできません。アプリケーションに接続し、異なるログインクレデンシャルを使用するには、新しいコネクションを作成する必要があります。
4.6. カスタムコネクターからコネクションを作成
カスタムコネクターを定義するエクステンションをアップロードした後、カスタムコネクターを使用できます。Fuse Online が提供するコネクターを使用してコネクションを作成する方法と同様に、カスタムコネクターを使用してコネクションを作成します。
カスタムコネクターは、OAuth プロトコルを使用するアプリケーションのカスタムコネクターであることがあります。このようなコネクターからコネクションを作成する前に、コネクターのアプリケーションにアクセスするための Fuse Online 環境を登録する必要があります。これは、コネクターのアプリケーションのインターフェースで行います。Fuse Online 環境を登録する方法の詳細は、アプリケーションによって異なります。
たとえば、カスタムのコネクターを使用して Yammer へのコネクションを作成する場合に、Yammer 内に新規アプリケーションを作成して、Fuse Online 環境を登録する必要があります。登録によって、Fuse Online の Yammer クライアント ID と Fuse Online の Yammer クライアントシークレットの値が提供されます。Fuse Online 環境から Yammer へのコネクションは、この 2 つの値を提供する必要があります。
アプリケーションによっては、この 2 つの値にコンシューマー ID やコンシューマーシークレットなどの異なる名前を使用する場合があるため注意してください。
Fuse Online 環境を登録した後に、アプリケーションへのコネクションを作成できます。コネクションを設定するとき、クライアント ID およびクライアントシークレットを入力するためのパラメーターが必要になります。これらのパラメーターを利用できない場合は、エクステンションの開発者に連絡し、クライアント ID とクライアントシークレットの指定を可能にする更新済みのエクステンションを依頼する必要があります。
第5章 インテグレーションの作成
計画と準備が完了したら、インテグレーションを作成します。Fuse Online の Web インターフェースでは、Create Integrationをクリックすると、手順にしたがってインテグレーションを作成できます。
前提条件
- インテグレーションの計画に関する注意点
作成するインテグレーションの種類に応じて、以下を行います。
インテグレーションを作成するための情報および手順は以下を参照してください。
5.1. インテグレーション作成の準備
インテグレーション作成の準備を開始するには、「インテグレーションの計画に関する注意点」に記載されている質問への回答を参照します。インテグレーションを計画したら、インテグレーションの作成前に以下を行う必要があります。
接続するアプリケーションが OAuth プロトコルを使用するかどうかを判別します。OAuth を使用する各アプリケーションでは、Fuse Online をそのアプリケーションへのアクセスが許可されるクライアントとして登録します。OAuth プロトコルを使用するアプリケーションには以下が含まれます。
- Dropbox
- Google アプリケーション (Gmail、カレンダー、およびスプレッドシート)
- Salesforce
- SAP Concur
- 接続するアプリケーションが HTTP Basic 認証を使用するかどうかを判別します。HTTP Basic 認証を使用する各アプリケーションにアクセスするためのユーザー名およびパスワードを特定します。コネクションを作成する際に、この情報を提供する必要があります。
- 統合するアプリケーションごとにコネクションを作成します。
5.2. インテグレーション実行トリガーの代替
インテグレーションの作成時、インテグレーションの実行をトリガーする方法はインテグレーションの最初のステップによって決定されます。インテグレーションの最初のステップは以下のいずれかになります。
アプリケーションまたはサービスへのコネクション。特定のアプリケーションやサービスのコネクションを設定します。以下に例を示します。
- Twitter へのコネクションはツイートを監視でき、ツイートに指定のテキストが含まれている場合にシンプルなインテグレーションの実行をトリガーできます。
- Salesforce へのコネクションは、新しいリードが作成されたときにシンプルなインテグレーションの実行をトリガーできます。
- AWS S3 へのコネクションは、特定のバケットを定期的にポーリングでき、バケットにファイルが含まれる場合にシンプルなインテグレーションの実行をトリガーできます。
-
タイマー。Fuse Online は、シンプルなインテグレーションの実行を指定した間隔でトリガーします。これは、簡単なタイマーまたは
cronジョブになります。 -
Webhook。クライアントは、HTTP
GETまたはPOSTリクエストを Fuse Online が公開する HTTP エンドポイントに送信できます。リクエストはシンプルなインテグレーションの実行をトリガーします。 - API プロバイダー。API プロバイダーインテグレーションは、REST API サービスから開始します。この REST API サービスは、API プロバイダーインテグレーションの作成時に提供する OpenAPI 2.0 ドキュメントによって定義されます。API プロバイダーインテグレーションをパブリッシュした後、Fuse Online は REST API サービスを OpenShift にデプロイします。インテグレーションエンドポイントにネットワークアクセスできるクライアントは、インテグレーションの実行をトリガーできます。
5.3. シンプルなインテグレーションを作成する手順
Fuse Online では手順にしたがってシンプルなインテグレーションを作成できます。最初のコネクション、最後のコネクション、途中のコネクション (任意)、およびその他のステップを選択するよう促されます。インテグレーションが完了したら、パブリッシュして稼働するか、保存して後でパブリッシュすることができます。
API プロバイダーインテグレーションを作成する手順の詳細は、「API プロバイダーインテグレーションの作成」 を参照してください。
前提条件
- インテグレーションのステップが計画済みである必要があります。
- このインテグレーションで接続する各アプリケーションまたはサービスへのコネクションが作成済みである必要があります。
手順
- Fuse Online の左パネルで Integrationsをクリックします。
- 右上の Create Integration をクリックします。
最初のコネクションを追加および設定します。
- Choose a connection ページで、インテグレーションを開始するために使用するコネクションをクリックします。このインテグレーションの稼働時に、Fuse Online はこのアプリケーションに接続し、インテグレーションが操作するデータを取得します。
- Choose an action ページで、このコネクションが実行するアクションを選択します。使用できるアクションはコネクションごとに異なります。
- アクションを設定するページで、フィールドに値を入力します。
- 任意で、コネクションにデータタイプの指定が必要な場合は、Next をクリックしてアクションの出入力タイプを指定するよう要求されます。
- Next をクリックして、最初のコネクションを追加します。
アプリケーションに接続する代わりに、指定した間隔でインテグレーションの実行をトリガーするタイマーや、HTTP リクエストを許可する Webhook を最初のコネクションとすることが可能です。
最初のコネクションの選択および設定後、Fuse Online は最後のコネクションを選択するよう要求します。
最後のコネクションを選択および設定します。
- Choose a connection ページで、インテグレーションを完了するために使用するコネクションをクリックします。このインテグレーションの稼働中に、Fuse Online はインテグレーションが操作するデータでこのアプリケーションに接続します。
- Choose an action ページで、このコネクションが実行するアクションを選択します。使用できるアクションはコネクションごとに異なります。
- アクションを設定するページで、フィールドに値を入力します。
- 任意で、コネクションにデータタイプの指定が必要な場合は、Next をクリックしてアクションの出入力タイプを指定するよう要求されます。
- Next をクリックして、最後のコネクションを追加します。
アプリケーションに接続する代わりに、最後のコネクションはインテグレーションが処理したメッセージに関する情報をインテグレーションのログに送信できます。これには、Fuse Online が最後のコネクションの選択を要求したときに Log を選択します。
- 必要に応じて、最初のコネクションと最後のコネクションとの間に 1 つ以上のコネクションを追加します。コネクションごとにアクションを選択し、必要な設定詳細を入力します。
- 必要に応じて、コネクション間のインテグレーションデータで操作する 1 つ以上のステップを追加します。「コネクション間のステップの追加」を参照してください。
-
インテグレーションビジュアライゼーションで、
 アイコンを見つけます。この警告は、このコネクションの前にデータマッパーステップが必要なことを示しています。必要なデータマッパーステップを追加します。
アイコンを見つけます。この警告は、このコネクションの前にデータマッパーステップが必要なことを示しています。必要なデータマッパーステップを追加します。
- インテグレーションに必要なステップがすべて含まれている場合は、インテグレーションの実行を開始するかどうかに応じて Save または Publish をクリックします。
- Name フィールドに、このインテグレーションを別のインテグレーションと区別する名前を入力します。
- 必要に応じて、: Description フィールドに説明を入力します。たとえば、このインテグレーションが実行することを説明できます。
インテグレーションの実行を開始する準備ができたら、Save and publish をクリックします。
Fuse Online にはインテグレーションの概要が表示されます。Fuse Online がパブリッシュの処理中であることが分かります。インテグレーションの状態が Runningになるまでに多少時間がかかる可能性があります。
インテグレーションをパブリッシュしない場合は、Save クリックします。Fuse Online はインテグレーションを保存し、フロービジュアライゼーションを表示します。編集を続行できます。または、ページの上部のパンくずリストで Integrations をクリックし、インテグレーションの一覧を表示します。保存してもインテグレーションがパブリッシュされない場合は、Stopped がインテグレーションのエントリーに表示されます。
5.4. インテグレーションの実行をトリガーするためタイマーコネクションを追加
指定のスケジュールに応じてシンプルなインテグレーションの実行をトリガーするには、タイマーコネクションをシンプルなインテグレーションの最初のコネクションとして追加します。タイマーコネクションをフローの途中やフローの最後に追加することはできません。
手順
- Fuse Online で左側にある Integrations をクリックします。
- 右上の Create Integration をクリックします。
Choose a connection ページで Timer をクリックします。
Fuse Online は Timer コネクションを提供するため、タイマーコネクションを作成する必要はありません。
Choose an action ページで Cron または Simple を選択します。
-
cronタイマーには、インテグレーションの実行をトリガーするスケジュールを指定するcron式が必要です。 -
期間とその時間単位の指定を要求されます (例:
5 seconds、1 hour)。使用可能な単位はミリ秒 (milliseconds)、秒 (seconds)、分 (minutes)、時間 (hours)、および日 (days) です。
-
-
追加するタイマーのタイプに応じて、
cron式または選択した時間単位の期間を入力します。 - Next をクリックして Timer コネクションをインテグレーションの最初のコネクションとして追加します。
5.5. フローでコレクションを処理する方法
コネクションは、すべて同じタイプの複数の値が含まれるコレクションを返すことがあります。コネクションがコレクションを返すと、フローは以下を含む複数の方法でコレクションで操作できます。
- 各ステップを 1 度、コレクションに実行します。
- 各ステップを 1 度、コレクションの各要素に実行します。
- 一部のステップを 1 度、コレクションに実行し、他のステップを 1 度、コレクションの各要素に実行します。
フローのコレクションでの操作方法を決定するには、フローが接続するアプリケーション、それらのアプリケーションがコレクションに対応できるかどうか、およびフローが達成することを知っている必要があります。その後、以下の情報を使用して、コレクションを処理するフローにステップを追加できます。
5.5.1. コレクションの処理
フローがコレクションを処理する最も簡単な方法は、データマッパーを使用してソースコレクションにあるフィールドをターゲットコレクションにあるフィールドにマップすることです。多くのフローでは、これだけが必要になります。たとえば、フローはデータベースから社員のレコードのコレクションを取得し、それらのレコードをスプレッドシートに挿入します。データマッパーステップは、データベースコネクションと Google スプレッドシートコネクションの間でデータベースフィールドを Google スプレッドシートフィールドにマップします。ソースとターゲットはコレクションであるため、Fuse Online がフローを実行すると、Google スプレッドシートコネクションを 1 度呼び出します。この呼び出しで、Fuse Online はレコードを繰り返し処理し、スプレッドシートが適切に入力されます。
フローによっては、コレクションを個別のオブジェクトに分割する必要がある場合があります。たとえば、データベースに接続し、特定の日付までに割り当てられた休暇を取らないと休暇が失効してしまう社員のコレクションを取得する場合など考えられます。その後、フローはこれらの各社員にメール通知を送信する必要があります。このフローでは、データベースコネクションの後に分割ステップ (split step) を追加します。その後、社員のレコードのソースフィールドを、メッセージを送信する Gmail コネクションのターゲットフィールドにマップする、データマッパーステップを追加します。Fuse Online がフローを実行すると、データマッパーステップと Gmail コネクションを社員ごとに 1 度実行します。
場合によっては、フローのコレクションを分割し、フローがコレクションの各要素に一部のステップを 1 度実行した後、フローをコレクションで再度操作したいことがあります。前述の例について考えてみましょう。Gmail コネクションでメッセージを各従業員に送信した後に、通知済みの従業員一覧をスプレッドシートに追加すると仮定します。このシナリオでは、Gmail コネクションの後に、集約の手順を追加して、従業員名のコレクションを作成します。次に、ソースコレクションのフィールドをターゲット Google スプレッドシートコネクションのフィールドにマップするデータマッパーステップを追加します。Fuse Online がフローを実行すると、新しいデータマッパーステップと Google スプレッドシートコネクションをコレクションに 1 度実行します。
これが、フローのコレクションを処理する最も一般的なシナリオになります。ただし、より複雑な処理も可能です。たとえば、コレクションの要素自体がコレクションである場合、分割および集約ステップを他の分割および集約ステップ内で入れ子にすることができます。
5.5.2. データマッパーを使用したコレクションの処理
フローでは、ステップがコレクションを出力し、フローの後続のコネクションはコレクションを入力として想定する場合、データマッパーを使用してフローがどのようにコレクションを処理するかを指定できます。
ステップがコレクションを出力すると、フロービジュアライゼーションはステップの詳細で Collection を表示します。以下に例を示します。
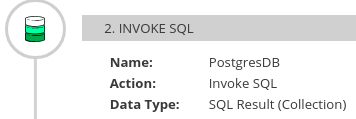
データマッパーステップを、コレクションを提供するステップの後およびマッピングを必要とするステップの前に追加します。フローでこのデータマッパーステップが必要な場所は、フローの他のステップによって異なります。以下のイメージは、ソースコレクションフィールドからターゲットコレクションフィールドへのマッピングを示しています。
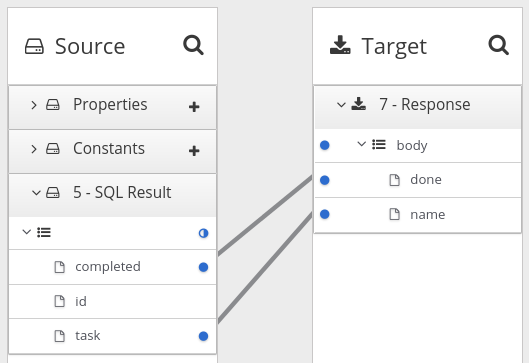
ソースおよびターゲットパネルで、データマッパーは
![]() を表示し、コレクションを示します。ソースコレクションまたはターゲットコレクションにプリミティブタイプのみが含まれる場合、データマッパーはコレクションフィールドを表示する必要がないため表示しません。コレクション自体をマップ元またはマップ先としてマップすることができます。
を表示し、コレクションを示します。ソースコレクションまたはターゲットコレクションにプリミティブタイプのみが含まれる場合、データマッパーはコレクションフィールドを表示する必要がないため表示しません。コレクション自体をマップ元またはマップ先としてマップすることができます。
コレクションに複数のプリミティブタイプが含まれる場合や、複雑なタイプが 1 つ以上含まれている場合、データマッパーはコレクションの子フィールドを表示します。各フィールドをマップ元またはマップ先とすることができます。しかし、入れ子のコレクションをマップ元またはマップ先とすることはできません。
Fuse Online がフローを実行すると、ソースコレクション要素を繰り返し処理し、ターゲットコレクション要素が入力されます。1 つ以上のソースコレクションフィールドをターゲットコレクションまたはターゲットコレクションフィールドにマップする場合、ターゲットコレクション要素にはマップされたフィールドのみの値が含まれます。
ソースコレクションまたはソースコレクションのフィールドをコレクションではないターゲットフィールドにマップする場合、Fuse Online がフローを実行するときにソースコレクションの最後の要素のみから値を割り当てます。コレクションの他の要素は、そのマッピングステップで無視されます。しかし、後続のマッピングステップはソースコレクションのすべての要素にアクセスできます。
コネクションが JSON または Java ドキュメントに定義されたコレクションを返すと、データマッパーは通常コレクションとしてソースドキュメントを処理できます。
5.5.3. 分割ステップの追加
フローの実行中に、コネクションがオブジェクトのコレクションを返すと、Fuse Online はコレクションに後続のステップを 1 度実行します。コレクションにある各オブジェクトに後続のステップを 1 度実行する場合は、分割ステップを追加します。たとえば、Google スプレッドシートコネクションは行オブジェクトのコレクションを返します。行ごとに後続のステップを 1 度実行するには、Google スプレッドシートコネクションの後に分割ステップを追加します。
分割ステップへの入力が常にコレクションであるようにしてください。分割ステップが、コレクションタイプではないソースドキュメントを取得する場合、ステップは空白文字で入力を分割します。たとえば、Fuse Online は「Hello world!」の入力を「Hello」と「world!」という 2 つの要素に分割し、これらの要素をフローの次のステップに渡します。特に XML データはコレクションタイプではありません。
前提条件
- フローを作成または編集することになります。
- フローに必要なコネクションがすべて存在する必要があります。
- フロービジュアライゼーションでは、ソースデータを取得するコネクションはデータが (Collection) であると示します。
手順
-
フロービジュアライゼーションの分割ステップを追加する場所で
 をクリックします。
をクリックします。
- Split をクリックします。このステップに設定は必要ありません。
- Next をクリックします。
関連情報
通常、データマッパーステップを追加する前に、分割ステップと集約ステップを追加します。これは、データがコレクションまたは個々のオブジェクトであるかがマッピングに影響するためです。データマッパーステップを追加して分割ステップを追加する場合、通常はマッピングをやり直す必要があります。同様に、分割または集約ステップを削除する場合もマッピングをやり直す必要があります。
5.5.4. 集約ステップの追加
フローに、Fuse Online が個別のオブジェクトからコレクションを作成する、集約ステップを追加します。実行中、Fuse Online は集約ステップの後に各オブジェクトに対して後続のステップを 1 度実行せずに、コレクションに対して後続のステップを 1 度実行します。
集約ステップをフローに追加するかどうかを決定する場合は、フローのコネクションを考慮してください。分割ステップの後、Fuse Online は後続の各コネクションに対して、フローのデータの各要素のために 1 度アプリケーションに接続します。コネクションによっては、複数回接続するよりも 1 度接続した方が望ましいことがあります。
前提条件
- フローを作成または編集することになります。
- フローに必要なコネクションがすべて存在する必要があります。
- 前の手順でコレクションを個別のオブジェクトに分割している必要があります。
手順
-
フロービジュアライゼーションの、集約ステップをフローに追加する場所で
をクリックします。
- Aggregate をクリックします。このステップに設定は必要ありません。
- Next をクリックします。
関連情報
通常、データマッパーステップを追加する前に、分割および集約ステップを追加します。これは、データがコレクションまたは個々のオブジェクトであるかがマッピングに影響するためです。データマッパーステップを追加して集約ステップを追加する場合、通常はマッピングをやり直す必要があります。同様に、集約ステップを削除する場合もマッピングをやり直す必要があります。
5.5.5. フローでコレクションを処理する例
このシンプルなインテグレーションは、Fuse Online によって提供されるサンプルデータベースからタスクのコレクションを取得します。フローはコレクションを個別のタスクオブジェクトに分割し、これらのオブジェクトをフィルターして実行されたタスクを見つけます。その後、フローは完了したタスクをコレクションで集約し、そのコレクションのフィールドをスプレッドシートのフィールドにマップします。完了したタスクのリストをスプレッドシートに追加して終了します。
以下の手順は、このシンプルなインテグレーションを作成する方法を説明します。
前提条件
- Google スプレッドシートコネクションが作成済みである必要があります。
- Google スプレッドシートコネクションがアクセスするアカウントに、データベースレコードを受信するスプレッドシートがある必要があります。
手順
- Create Integration をクリックします。
最初のコネクションを追加します。
- Choose a connection ページで PostgresDB をクリックします。
- Choose an action ページで Periodic SQL Invocation を選択します。
-
SQL Statement フィールドに
select * from todoを入力し、Next をクリックします。
このコネクションは、タスクオブジェクトのコレクションを返します。
最後のコネクションを追加します。
- Choose a connection ページで、Google スプレッドシートコネクションをクリックします。
- Choose an action ページで Append values to a sheet を選択します。
- SpreadsheetId フィールドにスプレッドシートの ID を入力し、タスクの一覧を追加します。
-
Range フィールドに
A:Bを値を追加するターゲット列として入力します。最初のコラムである A はタスク ID のコラムです。次のコラムである B は、タスク名のコラムです。 - Major Dimension と Value Input Option のデフォルト値を受け入れ、Next をクリックします。
Google スプレッドシートコネクションは、コレクションの各要素をスプレッドシートに追加してフローを終了します。
フローに分割ステップを追加します。
- フロービジュアライゼーションで、プラス記号をクリックします。
- Split をクリックします。
フローが分割ステップを実行した後、結果は個別のタスクオブジェクトのセットになります。Fuse Online は、各タスクオブジェクトに対してフローの後続ステップを 1 度実行します。
フィルターステップをフローに追加します。
- フロービジュアライゼーションにて、分割ステップの後でプラスマークをクリックします。
Basic Filter をクリックし、以下のようにフィルターを設定します。
-
最初のフィールドをクリックし、評価するデータが含まれるフィールドの名前である
completedを選択します。 - 2 つ目のフィールドに、completed フィールドの値が満たさなければならない条件として equals を選択します。
-
3 番目のフィールドに、completed フィールドになければならない値として
1を指定します。1は、タスクが完了したことを示します。
-
最初のフィールドをクリックし、評価するデータが含まれるフィールドの名前である
- Next をクリックします。
実行中、フローは各タスクオブジェクトに対してフィルターステップを 1 度実行します。結果は、個別の完了したタスクオブジェクトのセットになります。
集約ステップをフローに追加します。
- フロービジュアライゼーションにて、フィルターステップの後でプラス記号をクリックします。
- Aggregate をクリックします。
結果セットには、完了したタスクごとに要素が含まれるコレクションが含まれるようになりました。
データマッパーステップをフローに追加します。
- フロービジュアライゼーションにて、集約ステップの後でプラスマークをクリックします。
Data Mapper をクリックし、以下のフィールドを SQL 結果ソースのコレクションから Google スプレッドシートのターゲットコレクションにマップします。
- id から A
- task から B
- Done をクリックします。
- Publish をクリックします。
結果
インテグレーションの実行時に、毎分サンプルデータベースからタスクを取得し、完了したタスクをスプレッドシートの最初のシートに追加します。インテグレーションは、タスク ID を最初の列である A にマップし、タスク名を 2 番目の列である B にマップします。
5.6. コネクション間のステップの追加
必須ではありませんが、必要なコネクションをすべてプライマリーフローに追加してから、フローが実行するプロセスにしたがって、コネクションの間に追加ステップを追加することが推奨されます。フローでは、各ステップは以前のコネクションおよび以前のステップから取得したデータで操作します。結果となるデータは、フローの次のステップで利用できます。
多くの場合、コネクションから受け取ったデータフィールドを、フローの次のコネクションが操作できるデータフィールドにマップする必要があります。すべてのコネクションをフローに追加したら、フロービジュアライゼーションを確認します。入力データで操作する前にデータマッピングを必要とする各コネクションに対し、Fuse Online は
 を表示します。このアイコンをクリックして、Data Type Mismatch: Add a data mapper step before this connection to resolve the difference. を表示します。
を表示します。このアイコンをクリックして、Data Type Mismatch: Add a data mapper step before this connection to resolve the difference. を表示します。
メッセージのリンクをクリックして、データマッパーステップを追加および指定する Configure Mapper ページを表示します。しかし、必要な他のステップを追加してから、データマッパーステップを最後に追加することが推奨されます。
5.7. 条件付き実行フローの追加
統合開発中、Conditional Flows (条件付きフロー) ステップをフローに追加して 1 つ以上の条件を追加できます。条件ごとに、ステップをその条件のみに関連する条件付きフローに追加します。インテグレーションの実行中、前のインテグレーションステップが Conditional Flows ステップに渡す各メッセージに対して、Conditional Flows ステップは、Fuse Online ページで定義する Conditional Flows ステップの追加順序でメッセージコンテンツを指定の条件に対して評価します。
条件付き実行フローの追加は、テクノロジープレビュー機能です。テクノロジープレビューの機能は、Red Hat の本番環境のサービスレベルアグリーメント (SLA) ではサポートされず、機能的に完全ではないことがあるため、Red Hat は本番環境での使用は推奨しません。Red Hat では、これらについて実稼働環境での使用を推奨していません。テクノロジープレビューの機能は、最新の製品機能をいち早く提供して、開発段階で機能のテストやフィードバックの提供を可能にするために提供されます。Red Hat のテクノロジープレビュー機能のサポート範囲に関する詳細は、「https://access.redhat.com/ja/support/offerings/techpreview」を参照してください。
true に評価される最初の式では、インテグレーションは式に関連する条件付きフローを実行します。条件が true に評価されず、デフォルトの条件付きフローがある場合は、インテグレーションはそのフローを実行します。条件が true に評価されず、デフォルトの条件付きフローがない場合、インテグレーションは条件付きフローを実行しません。
条件付きフローの実行後、または true に評価される式とデフォルトの条件フローがない場合は、インテグレーションはプライマリーフローの次のステップを実行します。
たとえば、SQL データベースに接続し、社員の有給休暇 (PTO、Paid Time Off) データを取得するインテグレーションについて考えてみましょう。返されたデータは以下を示します。
- 特定日までに PTO を消化しないと失効する可能性がある社員。
- 付与分を超える PTO を使用した社員。
- 時間の制限なく PTO を使える残りの社員。
Conditional Flows ステップでは、このインテグレーションの例は条件ごとに 2 つの条件と 1 つの条件付き実行フローを定義できます。
- PTO が特定の数を超えた場合、特定日までに消化しないと失効する可能性がある PTO があることを意味します。インテグレーションは、該当する社員にメールを送信するフローを実行します。メールには、消化する必要がある PTO の時間数または日数と、失効日が含まれます。
- PTO が負の値の場合、付与分を超える PTO が使用されたこと意味します。インテグレーションは、該当する社員にメールを送信するフローを実行します。メールには、社員が取得した過剰分の PTO が含まれ、PTO の付与が再開される日付が指定されます。
さらに、このインテグレーションには、これらの条件を 1 つも満たさない入力に対してインテグレーションが実行するデフォルトの条件付きフローを追加することができます。このインテグレーションの例は、PTO が負の値ではなく、指定の数を超えない社員にデフォルトの条件付きフローを実行します。このフローは、社員が使用できる PTO の時間数または日数を示すステートメントを該当する社員にメールで送信します。
前提条件
- プライマリーフローを作成または編集することになります。これがシンプルなインテグレーションである場合、最初と最後のコネクションが追加されている必要があります。Conditional Flows ステップを条件付きフローに追加することはできません。
- Conditional Flows ステップへの入力は、個別のメッセージである必要があります。インテグレーションビジュアリゼーションで、前のステップの Data Type が (Collection) である場合、分割 ステップを追加します。
- 追加する Conditional Flows ステップにインテグレーションが渡すメッセージに含まれるフィールドを熟知している必要があります。
- Camel Simple Expression 言語を熟知するか、評価する条件の式が提供されている必要があります。
- 条件付きフローに追加する各コネクションが作成されている必要があります。
手順
-
インテグレーションビジュアライゼーションの、Conditional Flows ステップを追加する場所で
をクリックします。
- Conditional Flows をクリックします。
Configure Conditional Flows ページで、以下の条件を 1 つまたは複数定義します。
最初の When フィールドに Camel Simple Expression を入力します。たとえば以下の式は、メッセージの本文に
160を超えるptoフィールドが含まれている場合に true に評価します。${body.pto} > 160この式が true に評価されると、インテグレーションはこの条件で作成および関連付けする条件付きフローを実行します。
注記条件付きフローステップが以下のようなフローの 1 つにある場合は、式に追加のプロパティーを指定する必要があります。
- API プロバイダーインテグレーションのオペレーションフロー。
- Webhook コネクションで始まるシンプルなインテグレーション。
- カスタム REST API コネクションで始まるシンプルなインテグレーション。
これらのフローでは、Fuse Online は
bodyプロパティー内で実際のメッセージコンテンツをラッピングします。これは、Conditional Flows ステップへの入力にbodyプロパティーが含まれ、このプロパティーに実際のメッセージコンテンツが含まれる別のbodyプロパティーが含まれることを意味します。そのため、このようなフローの 1 つにある条件付きフローステップの式に、bodyのインスタンスを 2 つを指定する必要があります。たとえば、入力メッセージのptoフィールドにあるコンテンツを評価するとします。この場合、以下のように式を指定します。${body.body.pto} > 160${body.body.pto} > 160Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 必要に応じて、Add another condition をクリックし、前のステップを繰り返します。定義する追加条件ごとに、この作業を行います。
- 必要に応じて、条件フィールドの右にある上矢印または下矢印をクリックして、定義された条件をインテグレーションで評価する順序を変更します。
必要に応じて、デフォルトの条件付きフローとする場合は Use a default flow をクリックします。
実行中に Use a default flow を選択した場合、指定した条件に true となるものがなければ、インテグレーションはデフォルトの条件付きフローを実行します。実行中に Use a default flow を選択しなかった場合、指定した条件に true となるものがなければ、この Conditional Flows ステップに続くステップで、インテグレーションの実行が継続されます。
- Apply をクリックし、定義した条件の一覧を表示します。
- Done をクリックして、新しい Flows ナビゲーション制御があるプライマリーフローを上部に表示します。
条件ごとにフローを定義します。
インテグレーションビジュアライゼーションで、フローを定義する条件に対して Open Flow をクリックします。
Fuse Online は、ページ上部付近にその条件を表示します。条件付きフロービジュアライゼーションは、すべての条件付きフローにある Flow Start ステップおよび Flow End ステップを表示します。
-
フロービジュアライゼーションの、この条件付きフローにステップを追加する箇所で
をクリックします。
追加するステップをクリックします。プライマリーフローに追加できるコネクションまたはステップを追加できます。
Flow Start ステップからの出力は、この Conditional Flows ステップの前にあるプライマリーフローステップからの出力と常に同じです。たとえば、フィルターステップまたはデータマッパーステップをこの条件付きフローに追加する場合、利用可能なフィールドはプライマリーフローで利用可能なフィールドと同じになります。
- 必要に応じて手順を設定します。
- この条件付きフローに追加するステップごとに、前述の 3 つの手順を繰り返します。
- ページ上部の Flow フィールドで、下矢印をクリックし、Back to primary flow をクリックします。これにより、条件付きフローが保存され、プライマリーフローが表示されます。
- ステップ 4 の最初に戻り、作成する条件付きフローごとにステップ 4 の手順を繰り返します。
結果
プライマリーフローには、Conditional Flows ステップで定義した条件ごとに条件付きフローが存在します。Use a default flow オプションを選択した場合、プライマリーフローにはデフォルトの条件付きフローも存在します。
実行中、Conditional Flows ステップは true となる最初の条件に関連する条件付きフローを実行します。その後、インテグレーションによって Conditional Flows ステップに続くステップが実行されます。
true となる条件がない場合、Conditional Flows ステップはデフォルトの条件付きフローを実行します。その後、インテグレーションによって Conditional Flows ステップに続くステップが実行されます。
以下の条件を両方満たすとします。
- true となる条件がない
- デフォルトの条件付きフローがない
この場合、インテグレーションは Conditional Flows ステップに続くステップを実行します。
5.8. データマッパーステップの追加
ほぼすべてのインテグレーションにはデータマッピングが必要になります。データマッパーステップは、前のコネクションおよびその他のステップのデータフィールドからフローの次のコネクションが操作できるデータフィールドにマップします。たとえば、インテグレーションデータに Name フィールドが含まれ、フローの次のコネクションに CustomerName フィールドがある場合、ソースの Name フィールドをターゲットの CustomerName フィールドにマップする必要があります。
前提条件
フローを作成または編集することになります。
手順
-
フロービジュアライゼーションの、データマッパーステップを追加する箇所で
をクリックします。
- Data Mapper をクリックして、データマッパーキャンバスにソースおよびターゲットフィールドを表示します。
次のステップ
「インテグレーションデータを次のコネクションのフィールドにマッピング」を参照してください。
5.9. 基本のフィルターステップの追加
ステップのフローを追加して、フローが操作するデータをフィルターできます。フィルターステップでは、Fuse Online はデータを検査し、コンテンツが定義した基準を満たしている場合にのみ継続されます。たとえば、Twitter からデータを取得するフローでは、「Red Hat」が含まれるツイートのみ操作して、実行の継続を指定できます。
前提条件
- フローには必要なコネクションがすべて含まれている必要があります。
- フローを作成または編集することになります。
手順
-
フロービジュアライゼーションの、フィルターステップを追加する箇所で
をクリックします。
- Basic Filter をクリックします。
Configure Basic Filter Step ページの Continue only if incoming data match フィールドで以下を行います。
- 定義されたすべてのルールを満たす必要があるデフォルトを使用します。
- あるいは、ANY of the following を選択して、1 つのルールのみを満たす必要があることを示します。
フィルタールールを定義します。
The data you want to evaluate: フィルターが評価する内容が含まれるフィールドの名前を入力します。たとえば、ステップに送信されるデータがご自分の Twitter ハンドルをメンションするツイートで構成されるとします。また、ツイートに特定の内容が含まれる場合のみ実行を継続するとします。ツイートは
textという名前のフィールドにあるためtextを最初のフィールドの値として入力または選択します。フィールドの値は以下の方法で定義できます。
- 入力を開始します。data name フィールドには、ポップアップボックスに補完の候補が表示される自動補完機能があります。ボックスから適切な候補を選択します。
- フィールドをクリックします。ドロップダウンボックスが表示され、利用可能なフィールドのリストが表示されます。リストから対象のフィールドを選択します。
- Must meet this condition: ドロップダウンボックスから条件を選択します。デフォルト設定は Contains です。実行を継続するには、このフィールドで選択する条件が、3 つ目のフィールドに入力する値に対して true である必要があります。
- For this value: フィルターする値を入力します。たとえば、Twitter フィードからの特定製品のメンションを操作する場合は、ここに製品名を入力します。
必要に応じて、+ Add another rule クリックして、別のルールを定義します。
エントリーの横にあるごみ箱アイコンをクリックすると、ルールを削除できます。
- フィルターステップが完了したら、Done をクリックしてフローに追加します。
その他のリソース
基本のフィルターステップに必要なフィルターを定義できない場合は、「高度なフィルターステップの追加」を参照してください。
5.10. 高度なフィルターステップの追加
フィルターステップでは、Fuse Online はデータを検査し、コンテンツが定義した基準を満たしている場合にのみフローの実行を継続します。基本のフィルターステップでは必要なフィルターを定義できない場合は、高度なフィルターステップを追加します。
前提条件
- フローには必要なコネクションがすべて含まれている必要があります。
- フローを作成または編集することになります。
- Camel Simple Expression 言語を熟知するか、フィルター言語が提供されている必要があります。
手順
-
フロービジュアライゼーションの上級なフィルターステップを追加する場所で
をクリックします。
- Advanced Filter をクリックします。
編集ボックスで Camel Simple Expression 言語を使用してフィルター式を指定します。たとえば、メッセージヘッダーの
typeフィールドがwidgetに設定されている場合、以下の式は true に評価されます。${in.header.type} == 'widget'${in.header.type} == 'widget'Copy to Clipboard Copied! Toggle word wrap Toggle overflow 以下の例では、メッセージのボディーに
titleフィールドが含まれる場合に式が true に評価されます。${in.body.title}${in.body.title}Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Next をクリックして、高度なフィルターステップをフローに追加します。
フローでの追加プロパティーの指定
式では、高度なフィルターステップが以下のようなフローの場合、追加のプロパティーを指定する必要があります。
- API プロバイダーインテグレーションのオペレーションフロー。
- Webhook コネクションで始まるシンプルなインテグレーション。
- カスタム REST API コネクションで始まるシンプルなインテグレーション。
これらのフローでは、Fuse Online は body プロパティー内で実際のメッセージコンテンツをラッピングします。これは、高度なフィルターへの入力に body プロパティーが含まれ、このプロパティーには実際のメッセージコンテンツが含まれる別の body プロパティーが含まれることを意味します。そのため、このようなフローの 1 つにある高度なフィルター式に、body のインスタンスを 2 つを指定する必要があります。たとえば、入力メッセージの completed フィールドにあるコンテンツを評価するとします。この場合、以下のように式を指定します。
${body.body.completed} = 1
${body.body.completed} = 15.11. テンプレートステップの追加
フローでは、テンプレートステップはソースからデータを取得し、Fuse Online にアップロードするテンプレートで定義された形式に挿入します。テンプレートステップの利点は、指定した一貫性のある形式でデータの出力を提供できることです。
テンプレートでは、プレースホルダーを定義して静的テキストを指定します。フローの作成時に、テンプレートステップを追加してソースフィールドをテンプレートプレースホルダーにマップし、テンプレートコンテンツをフローの次のステップにマップします。Fuse Online がフローを実行するとき、マップされたソースフィールドにある値がテンプレートのインスタンスに挿入されるため、フローの次のステップで利用できるようになります。
フローにテンプレートステップが含まれる場合、そのフローの唯一のテンプレートステップとなる可能性が高くなります。ただし、フローに複数のテンプレートステップを含めることも可能です。
Fuse Online は、Freemarker、Mustache、および Velocity のテンプレートをサポートします。
前提条件
- フローを作成または編集する必要があります。
- シンプルなインテグレーションを作成する場合は、すでに最初と最後のコネクションがある必要があります。
手順
-
フロービジュアライゼーションのテンプレートステップを追加する場所で
をクリックします。
- Template をクリックします。Upload Template ページが開きます。
- Freemarker、Mustache、または Velocity をテンプレートタイプとして指定します。
テンプレートを定義するには、以下のいずれかを行います。
- テンプレートファイルまたはテンプレートを作成するために編集するテキストが含まれるファイルを、テンプレートエディターにドラグアンドドロップします。
- browse to upload をクリックしてファイルを選択し、アップロードします。
- テンプレートエディターで、テンプレートを定義します。
-
テンプレートエディターでは、テンプレートが Fuse Online で使用できるようにしてください。有効なテンプレートの例は、この手順の後に記載されています。Fuse Online では、構文エラーが含まれる行の左側に
 が表示されます。構文エラーインジケーターにマウスオーバーすると、エラーを解決するためのヒントが表示されます。
が表示されます。構文エラーインジケーターにマウスオーバーすると、エラーを解決するためのヒントが表示されます。
Done をクリックして、フローにテンプレートステップを追加します。
Done ボタンが有効でない場合は、修正する必要のある構文エラーが 1 つ以上存在します。
テンプレートステップへの入力は、JSON オブジェクトの形式である必要があります。そのため、データマッピングステップをテンプレートステップの前に追加する必要があります。
テンプレートステップの前にデータマッパーステップを追加するには、以下を行います。
-
フロービジュアライゼーションで、先ほど追加したテンプレートステップの直前にある
をクリックします。
- Data Mapper をクリックします。
データマッパーで、ソースフィールドを各テンプレートプレースホルダーフィールドにマップします。
たとえば、この手順の後に記載されているテンプレート例を使用して、ソースフィールドを以下のテンプレートフィールドにマップします。
-
time -
name -
text
-
- 右上の Done をクリックし、データマッパーステップをフローに追加します。
テンプレートステップからの出力は常に JSON オブジェクトになります。そのため、テンプレートステップの後にデータマッパーステップを追加する必要があります。
-
フロービジュアライゼーションで、先ほど追加したテンプレートステップの直前にある
テンプレートステップの後にデータマッパーステップを追加するには、以下を行います。
-
フロービジュアライゼーションで、先ほど追加したテンプレートステップの直後にある
をクリックします。
- Data Mapper をクリックします。
- データマッパーで、テンプレートの message フィールドをターゲットフィールドにマップします。message フィールドには常にソースフィールドをテンプレートに挿入した結果が含まれます。たとえば、フローの次のコネクションが Gmail コネクションで、テンプレートステップの結果を Gmail メッセージの内容として送信するとします。これには、message ソースフィールドを text ターゲットフィールドにマップします。
- 右上の Done をクリックします。
-
フロービジュアライゼーションで、先ほど追加したテンプレートステップの直後にある
テンプレートの例
Mustache テンプレートの例:
At {{time}}, {{name}} tweeted:
{{text}}
At {{time}}, {{name}} tweeted:
{{text}}Freemarker および Velocity では、以下のテンプレート例がサポートされます。
At ${time}, ${name} tweeted:
${text}
At ${time}, ${name} tweeted:
${text}Velocity では、以下の例のようにかっこを使用しない構文もサポートされます。
At $time, $name tweeted: $text
At $time, $name tweeted:
$text
プレースホルダーに . (ピリオド) を使用することはできません。
その他のリソース
フィールドのマッピングに関する詳細は、「インテグレーションデータを次のコネクションのフィールドにマッピング」を参照してください。
5.12. カスタムステップの追加
Fuse Online がフローで必要なステップを提供しない場合、開発者はエクステンションでカスタムステップを 1 つ以上定義できます。カスタムステップは、フローのコネクション間のデータで操作します。
カスタムステップは、組み込みのステップを追加するのと同じ方法でフローに追加します。シンプルなインテグレーションでは、最初と最後のコネクションを選択し、必要に応じて他のコネクションを追加した後、追加のステップを追加します。API プロバイダーインテグレーションでは、フローがカスタムステップを実行するオペレーションを選択し、必要に応じてコネクションをフローに追加した後、他のステップを追加します。ステップを追加すると、Fuse Online はフローの前のステップから受信するデータで操作します。
前提条件
- Fuse Online にカスタムステップのエクステンションがアップロードされている必要があります。「カスタム機能の使用」を参照してください。
- フローを作成または編集することになります。
- フローに必要なコネクションがすべて存在する必要があります。
手順
-
フロービジュアライゼーションのカスタムステップを追加する場所で
をクリックします。
追加するカスタムステップをクリックします。
使用できるステップには、Fuse Online 環境にアップロードされたエクステンションで定義されたカスタムステップが含まれます。
- ステップの実行に必要な情報のプロンプトに応答します。この情報はカスタムステップごとに異なります。
第6章 REST API 呼び出しによってトリガーされるインテグレーションの作成
必要時にインテグレーションの実行をトリガーするには、ユーザーが提供した REST API サービスでインテグレーションを開始します。この方法で開始するインテグレーションは、API プロバイダーインテグレーション と呼ばれます。API プロバイダーインテグレーションでは、REST API クライアントはインテグレーションの実行をトリガーするコマンドを呼び出しできます。
Fuse Online が API プロバイダーインテグレーションをパブリッシュすると、インテグレーションエンドポイントにネットワークアクセスできるクライアントはすべてインテグレーションの実行をトリガーできます。
Fuse Online on OpenShift Container Platform をオンサイトで稼働している場合、Fuse Online サーバーを設定して Red Hat 3scale の API プロバイダーインテグレーション API の検出を有効にすることができます。デフォルトでは、Fuse Online は 3scale と使用するために API プロバイダーインテグレーションの API サービス定義にアノテーションを付けますが、これらの API を 3scale の自動検出に公開しません。3scale の検出が行われないと、アクセス制御が行われません。3scale の検出を使用すると、アクセスポリシーを設定したり、管理を一元化でき、API プロバイダーインテグレーション API の高可用性を提供することもできます。詳細は、Red Hat 3scale のドキュメントページ の API Gateway に関するドキュメントを参照してください。
「Configuring Fuse Online to enable 3scale discovery of APIs」も参照してください。
API プロバイダーインテグレーションを作成するための情報および手順は以下を参照してください。
6.1. API プロバイダーインテグレーションを作成する利点、概要、およびワークフロー
API プロバイダーインテグレーションは、REST API サービスから開始します。この REST API サービスは、API プロバイダーインテグレーションの作成時に提供する OpenAPI 2.0 ドキュメントによって定義されます。API プロバイダーインテグレーションをパブリッシュした後、Fuse Online は REST API サービスを OpenShift にデプロイします。API プロバイダーインテグレーションの利点は、REST API クライアントがインテグレーションの実行をトリガーする呼び出しを実行できることです。
複数の実行フロー
API プロバイダーインテグレーションには、フローと呼ばれる複数の実行パスがあります。OpenAPI ドキュメントが定義する各オペレーションには独自のフローがあります。Fuse Online では、OpenAPI ドキュメントが定義する各オペレーションに対して、コネクションおよびその他のステップをそのオペレーションの実行フローに追加します。これらのステップは、特定のオペレーションに必要なデータを処理します。
実行フローの例
たとえば、Fuse Online によって利用可能になった REST API サービスを呼び出す人事アプリケーションがあるとします。新しい従業員を追加する操作が呼び出されたとします。この呼び出しを処理する操作のフローは、以下のとおりです。
- 新入社員のハードウェアに関する経費報告書を作成するアプリケーションに接続します。
- 新しいハードウェアを設定するための社内チケットを追加する SQL データベースに接続します。
- 新入社員にオリエンテーションの情報を提供するメッセージを送信する Google メールに接続します。
実行をトリガーする方法
インテグレーションの実行をトリガーする REST API を呼び出す方法は複数あります。これには以下が含まれます。
- データ入力を取得し、呼び出しを生成する Web ブラウザーページ。
-
curlユーティリティーなどの REST API を明示的に呼び出すアプリケーション。 - REST API を呼び出す他の API (Webhook など)。
フローを編集する方法
以下を行って、各オペレーションのフローを編集できます。
- データを処理する必要があるアプリケーションにコネクションを追加します。
- 分割、集計、およびデータマッピングステップを含む、コネクション間のステップを追加します。
- フローを終了する HTTP 応答の戻りコードを変更します。この応答は、インテグレーションの実行をトリガーした呼び出しを実行したアプリケーションに送信されます。
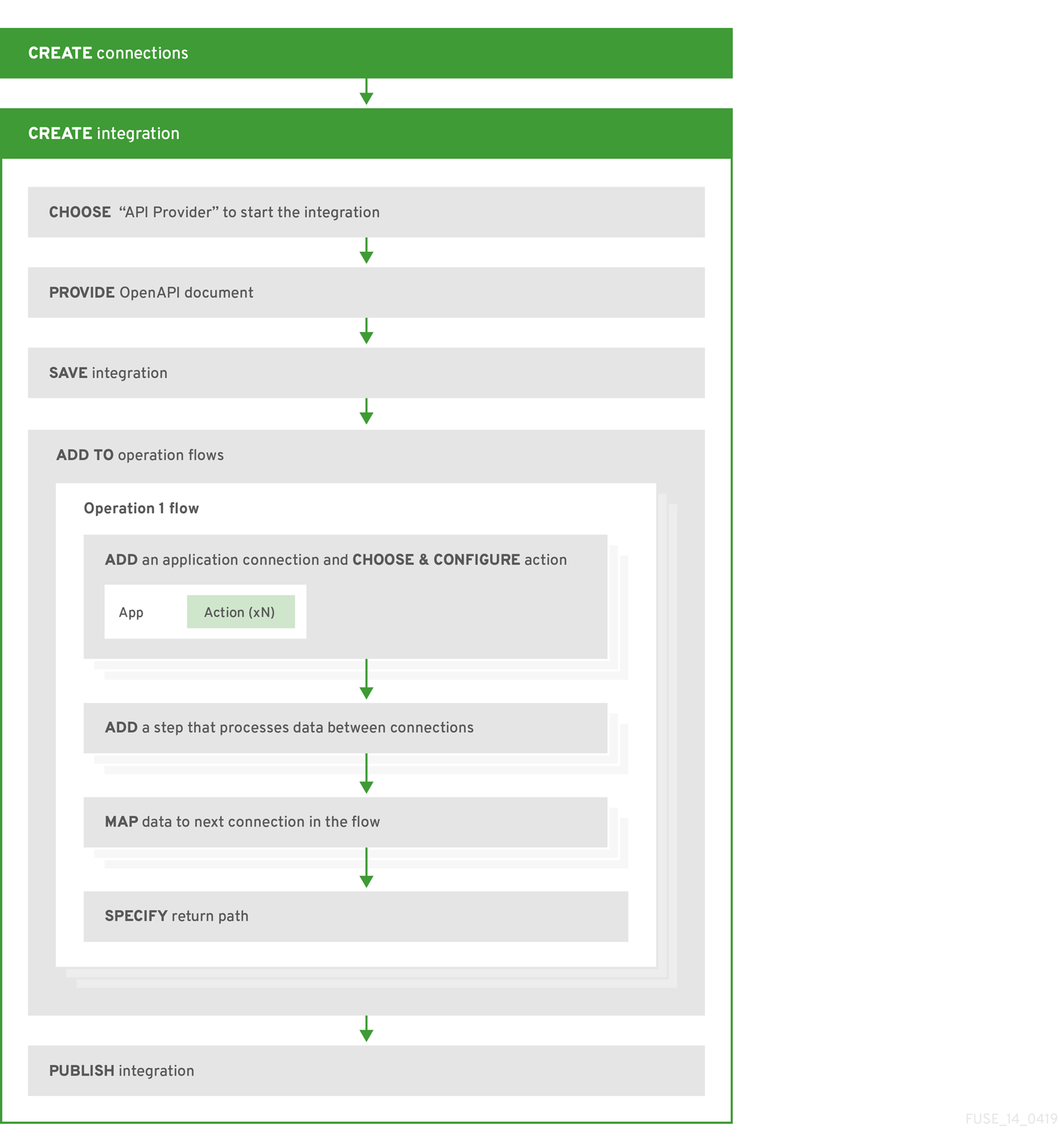
API プロバイダーインテグレーションを作成するためのワークフロー
API プロバイダーインテグレーションを作成するための 一般的な ワークフローを以下の図に示します。
API プロバイダーインテグレーションのパブリッシュ
API プロバイダーインテグレーションをパブリッシュした後、Fuse Online はインテグレーションの summary ページに REST API サービスの外部 URL を表示します。この外部 URL は、クライアントが REST API サービスを呼び出すために使用するベース URL です。
API プロバイダーインテグレーションのテスト
API プロバイダーインテグレーションのフローをテストするには、curl ユーティリティーを使用できます。たとえば、以下の curl コマンドによって Get Task by ID オペレーションのフローの実行がトリガーされるとします。HTTP GET コマンドはデフォルトのリクエストであるため、GET を指定する必要はありません。URL の最後の部分は、取得するタスクの ID を指定します。
curl -k https://i-task-api-proj319352.6a63.fuse-ignite.openshiftapps.com/api/todo/1
curl -k https://i-task-api-proj319352.6a63.fuse-ignite.openshiftapps.com/api/todo/16.2. OpenAPI オペレーションを API プロバイダーインテグレーションフローと関連させる方法
API プロバイダーインテグレーションの OpenAPI ドキュメントは、REST API クライアントが呼び出しできるオペレーションを定義します。各 OpenAPI オペレーションには、独自の API プロバイダーインテグレーションフローがあります。そのため、各オペレーションは独自の REST API サービス URL を持つこともできます。各 URL は API サービスのベース URL で定義され、任意でサブパスによって定義されます。REST API 呼び出しは、オペレーションの URL を指定し、そのオペレーションのフローの実行をトリガーします。
OpenAPI ドキュメントは、REST API サービス URL への呼び出しに指定できる HTTP 動詞 (GET、POST、DELETE など) を決定します。API プロバイダー URL への呼び出しの例は、API プロバイダークイックスタートの例を試すための手順 を参照してください。
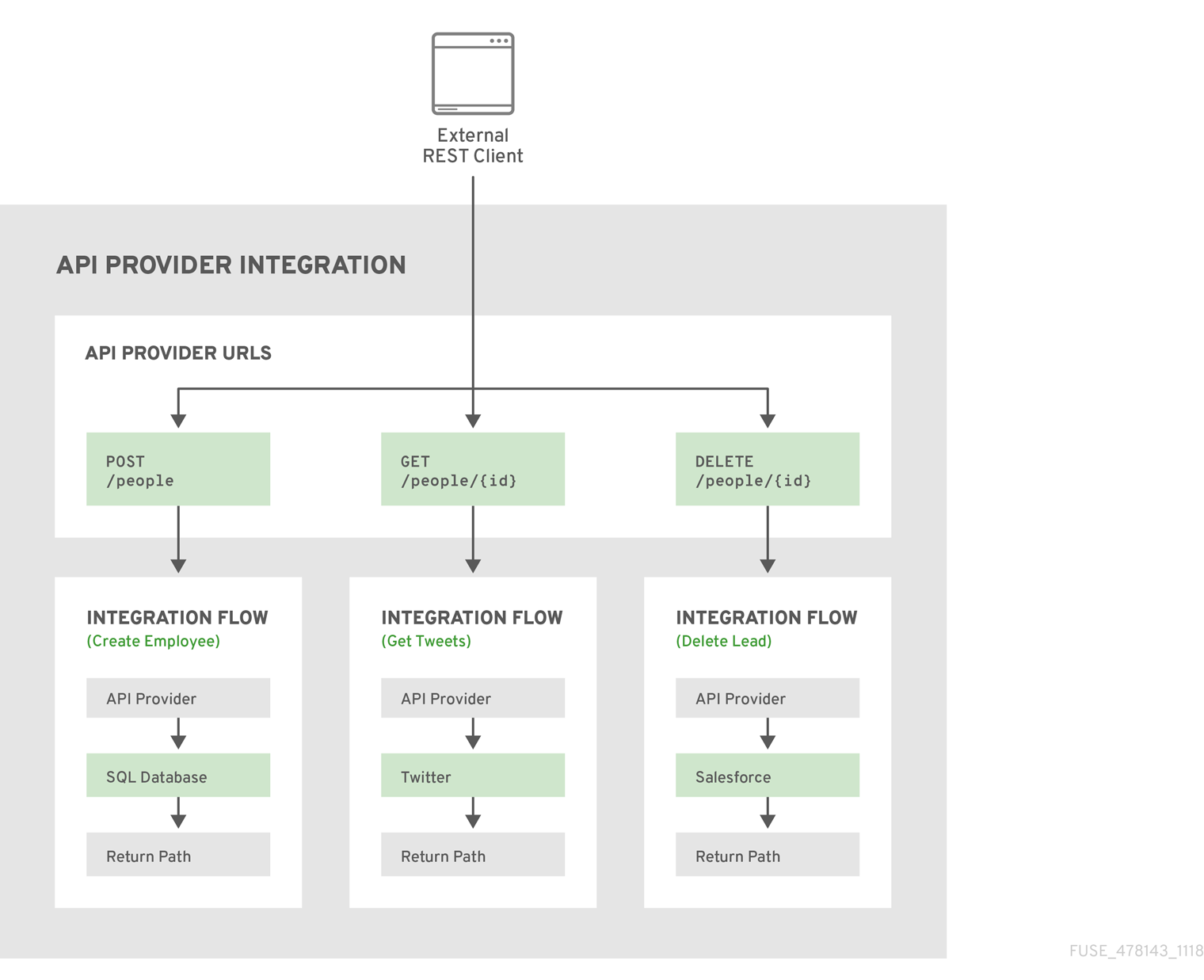
API プロバイダーインテグレーションの例
以下の図は、人に関するデータを処理する API プロバイダーインテグレーションを示しています。外部の REST API クライアントは、API プロバイダーインテグレーションによってデプロイされた REST API URL を呼び出します。URL が呼び出されると、1 つの REST オペレーションに対するフローの実行がトリガーされます。この API プロバイダーインテグレーションには 3 つのフローがあります。各フローは、Fuse Online で利用可能なすべてのコネクションまたはステップを使用できます。REST API とそのフローは、1 つの OpenShift Pod にデプロイされる Fuse Online API プロバイダーインテグレーションの 1 つです。
API プロバイダーインテグレーションの作成時における OpenAPI ドキュメントの編集
API プロバイダーインテグレーションの OpenAPI 2.0 ドキュメントを指定した後、API オペレーションの実行フローを定義するときに必要に応じてドキュメントを更新できます。これには、API プロバイダーインテグレーションを編集するページの右上にある View/Edit API Definition をクリックします。これにより、Apicurito エディターに OpenAPI ドキュメントが表示されます。ドキュメントを編集および保存し、Fuse Online で変更が反映されるようにします。
OpenAPI ドキュメントの編集時に以下を考慮します。
同期化の
operationIdプロパティー。Apicurito エディターの OpenAPI ドキュメントのバージョンと、Fuse Online インテグレーションエディターの OpenAPI ドキュメントのバージョンの同期は、ドキュメントに定義される各オペレーションに割り当てられた一意な
operationIdプロパティーに応じて行われます。特定のoperationIdプロパティー値を各オペレーションに割り当てるか、Fuse Online が自動生成する値を使用します。リクエストと応答の定義
オペレーションのリクエストおよび応答を定義する JSON スキーマを各オペレーションの定義に提供できます。Fuse Online は以下のように JSON スキーマを使用します。
- オペレーションの入力および出力データシェイプのベースとして使用します。
- データマッパーでオペレーションフィールドを表示するために使用します。
循環スキーマ参照がない
API プロバイダーインテグレーションオペレーションの JSON スキーマにはスキーマの循環参照を含めることはできません。たとえば、リクエストまたは応答ボディーを指定する JSON スキーマは、そのスキーマ自体を全体的に参照することはできず、中間スキーマを介してそのスキーマ自体を部分的に参照することもできません。
6.3. API プロバイダーインテグレーションの作成
API プロバイダーインテグレーションを作成するには、インテグレーションが実行できるオペレーションを定義する OpenAPI ドキュメント (.json、.yaml、または .yml ファイル) を提供します。Fuse Online は各オペレーションの実行フローを作成します。各オペレーションのフローを編集し、そのオペレーションの要件に応じてインテグレーションデータを処理するコネクションおよびステップを追加します。
前提条件
インテグレーションが実行する REST API オペレーションの OpenAPI ドキュメントを提供または定義できる必要があります。
検証するには、API プロバイダークイックスタートの OpenAPI ドキュメントである
task-api.jsonファイルをダウンロード します。Fuse Online が OpenAPI ドキュメントの提供を要求したときに、このファイルをアップロードできます。- 各 OpenAPI オペレーションのフローが計画されている必要があります。
- オペレーションのフローを追加する各アプリケーションまたはサービスのコネクションが作成済みである必要があります。
手順
- Fuse Online の左ナビゲーションパネルで Integrations をクリックします。
- 右上の Create Integration をクリックします。
- Choose a connection ページで API Provider をクリックします。
Start integration with an API call ページで以下を行います。
- REST API オペレーションを定義する OpenAPI 2.0 ドキュメントがある場合は、OpenAPI ドキュメントをアップロードします。
- OpenAPI 2.0 ドキュメントを定義する必要がある場合は、Create を選択します。
Next をクリックします。
ドキュメントをアップロードした場合は、これを確認または編集します。
- Review/Edit をクリックして Apicurito エディターを開きます。
- 必要に応じて確認や編集を行います。
- 右上の Save または Cancel をクリックし、エディターを閉じます。
- Next をクリックします。
ドキュメントを作成する場合は、Fuse Online が開く Apicurito エディターで以下を行います。
- OpenAPI ドキュメントを定義します。
- 右上の Save をクリックし、エディターを閉じます。
- Next をクリックします。
Apicurito エディターの使用に関する詳細は、「Design and develop an API definition with API Designer」を参照してください。
結果
Fuse Online は OpenAPI ドキュメントが定義するオペレーションの一覧を表示します。
次のステップ
それぞれのオペレーションでは、そのオペレーションを実行するフローを定義します。
6.4. API プロバイダーインテグレーションのオペレーションフローの作成
REST API サービスを定義する OpenAPI ドキュメントは、サービスが実行できるオペレーションを定義します。API プロバイダーインテグレーションの作成後、各オペレーションのフローを編集できます。
各オペレーションには必ず 1 つのフローがあります。オペレーションフローでは、コネクションを他のアプリケーションやサービスに追加でき、コネクション間のデータで操作するステップも追加できます。
オペレーションフローへ追加すると、API プロバイダーインテグレーションがベースとする OpenAPI ドキュメントの更新が必要であることがあります。これには、API プロバイダーインテグレーションを編集するページの右上にある View/Edit API Definition をクリックします。これにより、Apicurito エディターにドキュメントが表示されます。OpenAPI 定義では、各オペレーションに固有の operationId プロパティーがある限り、Apicurito に更新を保存することができ、Fuse Online は API プロバイダーインテグレーションのフロー定義を同期して更新が反映されるようにすることができます。
前提条件
- API プロバイダーインテグレーションを作成し、名前を付け、保存している必要があります。
- オペレーションフローが接続する各アプリケーションまたはサービスへのコネクションが作成済みである必要があります。詳細は、コネクションの作成に関する情報 を参照してください。
- Fuse Online は API が定義するオペレーションのリストを表示します。
手順
- Operations リストページで、編集するフローのオペレーションに対して Create flow をクリックします。
このフローに追加する各コネクションに対して以下を行います。
- フロービジュアライゼーションで、プラス記号をクリックしてその場所にコネクションを追加します。
- 使用するコネクションをクリックします。
- コネクションが実行するアクションを選択します。
- ラベルが付いたフィールドにデータを入力して、アクションを設定します。
- Next をクリックします。
フローに必要なコネクションをすべて追加してから、続行します。
このオペレーションフローでコネクション間のデータを処理するには、以下を行います。
- フロービジュアライゼーションで、ステップを追加する場所にあるプラス記号をクリックします。
- 追加するステップをクリックします。
- ラベル付が付いたフィールドにデータを入力して、ステップを設定します。
Next をクリックします。
ヘルプは「コネクション間のステップの追加」を参照してください。
コネクションの間のデータを処理する別のステップを追加する場合は、この手順のサブセットを繰り返します。
データを次のコネクションのフィールドにマップします。
-
フロービジュアライゼーションで、コネクションが受信データを処理できないことを示す、データタイプ不一致の
アイコンを確認します。ここでは、データマッパーステップを追加する必要があります。
フロービジュアライゼーションの各データ不一致アイコンに対して以下を行います。
- そのステップの直前にあるプラスマークをクリックします。
- Data Mapper をクリックします。
- 必要なマッピングを定義します。詳細は「インテグレーションデータを次のコネクションのフィールドにマッピング」を参照してください。
- Done をクリックして、データマッパーステップをフローに追加します。
-
フロービジュアライゼーションで、コネクションが受信データを処理できないことを示す、データタイプ不一致の
フロービジュアライゼーションの、Provided API Return Path ステップで Configure をクリックします。
すべての API プロバイダーインテグレーションは、オペレーションフローの実行をトリガーした REST API の呼び出し元に応答を送信することで、各オペレーションフローを終了します。応答には、ここで設定される戻りコードが含まれます。
本リリースでは、API 呼び出しによってこのフローの実行がトリガーされる場合は、戻りコードはこのステップで指定されるコードになります。エラー処理は、今後のリリースでサポートされる予定です。
フローのデフォルトの戻りコードである 501 Not implemented を使用するか、以下のように別の戻りコードを指定します。
- Return Code 入力フィールドをクリックすると、可能な戻りコードのリストが表示されます。
- 該当の戻りコードまでスクロールし、クリックします。
- Next をクリックします。
このフローに、必要なコネクションとステップがすべてあり、データの不一致アイコンがない場合や、フローを編集しない場合は、以下の 1 つを行います。
- Publish: インテグレーションの実行を開始するには、右上の Publish をクリックします。これにより、インテグレーションがビルドされ、REST API サービスが OpenShift にデプロイされます。さらにインテグレーションが実行できるようになります。オペレーションフローの作成を完了するときやオペレーションフローを編集するときに、インテグレーションをパブリッシュできます。
- Save: オペレーションのリストを表示するには、右上の Save をクリックします。
- Operation : 別のオペレーションフローを編集するには、ページ上部のパンくずリストで Operation ドロップダウンメニューを表示し、編集するフローのオペレーションをクリックします。Fuse Online は、編集しているフローの現在の状態を保存します。
この手順を繰り返して、別のオペレーションフローを編集します。
次のステップ
API プロバイダーインテグレーションが OpenShift Online または OpenShift Dedicated 上の Fuse Online で稼働している場合、curl ユーティリティーを使用すると想定どおりに動作していることを確認できます。この例については、API プロバイダークイックスタートの説明を参照してください。
API プロバイダーインテグレーションが OpenShift Container Platform 上の Fuse Online で稼働している場合、管理者は CONTROLLERS_EXPOSE_VIA3SCALE 環境変数を true に設定し、Red Hat 3scale でインテグレーションの API を検出できるようにした可能性があります。この環境変数が true に設定されると、Fuse Online は API プロバイダーインテグレーションの外部 URL を提供しません。インテグレーションをテストする場合は、3scale の管理者に協力を依頼してください。
6.5. API プロバイダークイックスタートインテグレーションの例の設定およびパブリッシュ
Fuse Online は、Fuse Online 環境にインポートできる API プロバイダークイックスタートインテグレーションを提供します。このクイックスタートには、タスク管理 API の OpenAPI ドキュメントが含まれています。クイックスタートインテグレーションをインポートした後、戻りコードを設定し、インテグレーションをパブリッシュします。以下の手順の完了後、Task API インテグレーションは稼働状態になり、実行される準備が整います。
API プロバイダークイックスタートは、API プロバイダーインテグレーションを設定、パブリッシュ、およびテストする方法を短時間で理解するのに役立ちます。しかし、API プロバイダーインテグレーションが便利であることを実証する実際の例ではありません。実例として、Fuse Online をすでに使用して、複数のシンプルなインテグレーションをパブリッシュしている場合に、このようなインテグレーションの実行をトリガーするために、OpenAPI ドキュメントを定義できます。これには、パブリッシュ済みのシンプルなインテグレーションとほぼ同じになるように、各 OpenAPI オペレーションのフローを編集します。
前提条件
- Fuse Online がブラウザーで開かれている必要があります。
手順
Task API クイックスタートインテグレーションをインポートします。
-
https://github.com/syndesisio/syndesis-quickstarts/tree/1.6/api-provider にアクセスし、
TaskAPI-export.zipをダウンロードします。 - Fuse Online の左側のナビゲーションパネルで Integrations をクリックします。
- 右上の Import をクリックします。
-
ダウンロードした
TaskAPI-export.zipファイルをドラッグアンドドロップします。Fuse Online は、ファイルが正常にインポートされたことを示します。 - 左側のナビゲーションパネルで Integrations をクリックし、先ほどインポートした Task API インテグレーションのエントリーを表示します。このエントリーは、設定が必要であることを示します。
-
https://github.com/syndesisio/syndesis-quickstarts/tree/1.6/api-provider にアクセスし、
Task API インテグレーションを設定します。
- Task API エントリーをクリックして、インテグレーションの概要を表示します。
- 右上にある Edit Integration をクリックし、この API が提供するオペレーションのリストを表示します。
Create Task オペレーションのフローで、1 つのステップを更新します。
Task オペレーションの POST エントリーで、Create flow をクリックし、そのフローのビジュアライゼーションを表示します。
コネクションとステップはすでにこのフローに追加されています。オペレーションフロービジュアライゼーションで、ステップの設定を表示するには、その Configure ボタンをクリックします。Cancel または Next をクリックしてフロービジュアライゼーションに戻ります。1 つのステップの設定を確認したら、別のステップの Configure をクリックし、その設定を確認します。データベースコネクションをクリックすると、実行する SQL ステートメントを確認できます。
- オペレーションフロービジュアライゼーションで、フローの最後のステップである Provided API Return Path ステップの Configure をクリックします。スクロールダウンして確認する必要がある場合があります。
- Return Code 入力フィールドをクリックし、スクロールして 201 Created を選択します。
- Next をクリックします。
- 右上の Save をクリックします。
Delete Task for ID オペレーションのフローで、1 つのステップを更新します。
Delete Task for ID オペレーションの Delete エントリーで、Create flow をクリックし、そのフローのビジュアライゼーションを表示します。
このオペレーションフローには、データマッパーステップと Fuse Online によって提供されるサンプルデータベースへのコネクションがあります。オペレーションフロービジュアライゼーションで、データベースコネクションの Configure をクリックし、実行する SQL ステートメントを表示します。
- Next または Cancel をクリックします。
- オペレーションフロービジュアライゼーションで、フローの最後のステップである Provided API Return Path ステップの Configure をクリックします。
- Return Code 入力フィールドをクリックし、スクロールして 200 OK を選択します。
- Next をクリックします。
- 右上の Save をクリックします。
Get Task by ID オペレーションのフローで、1 つのステップを更新します。
Get Task by ID オペレーションの GET エントリーで、Create flow をクリックし、そのフローのビジュアライゼーションを表示します。
このオペレーションフローには、2 つのデータマッパーステップ、Fuse Online によって提供されるサンプルデータベースへのコネクション 1 つ、および 1 つのログステップがあります。
- オペレーションフロービジュアライゼーションで、ステップの Configure ボタンをクリックし、その設定を表示します。ステップの設定を確認したら、Next または Cancel をクリックします。この作業を必要なステップすべてに行います。
- オペレーションフロービジュアライゼーションで、フローの最後のステップである Provided API Return Path ステップの Configure をクリックします。
- Return Code 入力フィールドをクリックし、スクロールして 200 OK を選択します。
- Next をクリックします。
右上の Publishをクリックし、Save and publish をクリックします。
Fuse Online は、このインテグレーションの概要ページを表示し、アセンブル、ビルド、デプロイ、およびインテグレーションの実行中にパブリッシュの進捗を表示します。
Task API インテグレーション概要ページに Running が表示されると、Fuse Online は Task API サービスの外部 URL を表示します。以下のような URL が表示されます。
https://i-task-api-proj319352.6a63.fuse-ignite.openshiftapps.com/api/これは、Task API サービスを利用できる場所を示しています。REST API 呼び出しは、このベース URL で始まる URL を指定します。
Fuse Online を OpenShift Container Platform で使用し、外部 URL がインテグレーションの概要ページにない場合、
CONTROLLERS_EXPOSE_VIA3SCALE環境変数が true に設定されています。この API プロバイダーインテグレーションをテストする場合は、3scale の管理者に協力を依頼してください。
6.6. API プロバイダークイックスタートインテグレーションの例のテスト
Fuse Online の Task API クイックスタートインテグレーションの稼働時に、HTTP リクエストを Task API サービスに送信する curl ユーティリティーコマンドを呼び出すことができます。HTTP リクエストを指定する方法によって呼び出しがトリガーするフローが判断されます。
前提条件
- Fuse Online は、Task API インテグレーションが Running 状態であることを示す必要があります。
- Fuse Online 環境が OCP で実行している場合、Fuse Online は API を 3scale に公開するように設定されていません。
手順
- Fuse Online の左側のナビゲーションパネルで Integrations をクリックします。
- Task API インテグレーションをクリックし、その概要を表示します。
- インテグレーションの外部 URL をコピーします。
ターミナルで以下のようなコマンドを実行し、インテグレーションの外部 URL を
externalURL環境変数に割り当てます。必ず、このサンプルコマンドの URL を、コピーした URL に置き換え、末尾に/apiを追加するようにしてください。export externalURL="https://i-task-api-proj319352.6a63.fuse-ignite.openshiftapps.com/api"`
export externalURL="https://i-task-api-proj319352.6a63.fuse-ignite.openshiftapps.com/api"`Copy to Clipboard Copied! Toggle word wrap Toggle overflow Create Task オペレーションに対してフローの実行をトリガーする
curlコマンドを実行します。curl -k --header "Content-Type: application/json" --request POST --data '{ "task":"my new task!"}' $externalURL/todocurl -k --header "Content-Type: application/json" --request POST --data '{ "task":"my new task!"}' $externalURL/todoCopy to Clipboard Copied! Toggle word wrap Toggle overflow -
-kを指定すると、サーバーコネクションがセキュアでなくてもcurlは続行および動作します。 -
--headerは、コマンドが JSON 形式のデータを送信することを示します。 -
--requestは、データを格納する HTTPPOSTコマンドを指定します。 -
--dataは、保存する JSON 形式のコンテンツを指定します。この例では、クォータは{ "task":"my new task!"}です。 $externalURL/todoは呼び出す URL です。このコマンドは、HTTP
POSTリクエストを、Create Task オペレーションのフローの実行をトリガーする Task API サービスに送信します。フロー実行により、新しいタスクがサンプルデータベースに追加され、以下のようなメッセージを返して実行された内容を示します。
{"completed":false,"id":1,"task":"my new task!"}{"completed":false,"id":1,"task":"my new task!"}Copy to Clipboard Copied! Toggle word wrap Toggle overflow -
Get Task by ID オペレーションに対してフローの実行をトリガーする
curlコマンドを実行します。curl -k $externalURL/todo/1
curl -k $externalURL/todo/1Copy to Clipboard Copied! Toggle word wrap Toggle overflow タスクを取得するには、
curlコマンドに URL のみを指定する必要があります。HTTPGETコマンドはデフォルトのリクエストです。URL の最後の部分は、取得するタスクの ID を指定します。Delete Task for ID オペレーションのフローの実行をトリガーする
curlコマンドを実行します。curl -k -X DELETE $externalURL/todo/1
curl -k -X DELETE $externalURL/todo/1Copy to Clipboard Copied! Toggle word wrap Toggle overflow このコマンドは、ID でタスクを取得したコマンドと同じ URL で HTTP
DELETEコマンドを実行します。
第7章 HTTP リクエスト (Webhook) によってトリガーされるインテグレーションの作成
HTTP GET または POST リクエストを Fuse Online が公開する HTTP エンドポイントに送信して、シンプルなインテグレーションの実行をトリガーできます。詳細は以下のトピックを参照してください。
7.1. Fuse Online Webhook を使用するための一般的な手順
HTTP GET または POST リクエストでインテグレーションの実行をトリガーするには、以下を行う必要があります。
-
GETまたはPOSTリクエストを Fuse Online に送信するかどうかを決定します。 - このリクエストを処理するようインテグレーションを計画します。
インテグレーションを終了するコネクションを作成します。
Fuse Online は、最初のコネクションとして使用する Webhook コネクションを提供します。
- インテグレーションに追加する他のコネクションを作成します。
インテグレーションを作成します。
- Webhook コネクションを最初のコネクションとして追加します。
最後のコネクションを追加した後、インテグレーションで必要な他のコネクションを追加します。最後のコネクションと途中のコネクションは、インテグレーションの実行をトリガーする HTTP リクエストを処理します。目的を達成するために最も適切な HTTP リクエストを選択および指定するのはユーザー自身です。これには以下を考慮してください。
- 取得または更新するデータが含まれるアプリケーションへのコネクションを追加します。
-
GETリクエストは、キー/値パラメーターの指定に限定されます。 -
POSTリクエストは、XML や JSON インスタンスなどの任意のボディーを提供します。 -
Fuse Online は HTTP ステータスヘッダーのみを返し、データは返しません。そのため、
GETリクエストによってトリガーされるインテグレーションや、データを取得せずにデータを更新するインテグレーションを定義できます。同様に、POSTリクエストによってトリガーされるインテグレーションや、データを更新せずにデータを取得するインテグレーションを定義することもできます。
Webhook コネクションの後にデータマッパーステップを追加します。
GETリクエストでは、HTTP リクエストのパラメーターフィールドを次のコネクションのデータフィールドにマップします。POSTリクエストの場合、JSON インスタンス、JSON スキーマ、XML インスタンス、または SML スキーマを渡して、リクエストに出力データシェイプを指定した可能性があります。指定しなかった場合は、Webhook コネクションをインテグレーションの最初のコネクションとして追加します。指定しないと、Webhook コネクションの出力データタイプのデフォルトは JSON 形式になります。- インテグレーションに必要な他のステップを追加します。
- インテグレーションをパブリッシュし、Running 状態になるまで待ちます。
- インテグレーション概要ページに移動し、Fuse Online が提供する外部 URL をコピーします。
-
外部 URL を編集して、
GETまたはPOSTリクエストを作成します。 -
HTTP
GETまたはPOSTリクエストを Fuse Online に送信するアプリケーションを実装します。
7.2. HTTP リクエストがトリガー可能なインテグレーションの作成
HTTP GET または POST リクエストでインテグレーションの実行をトリガーするには、Webhook コネクションをインテグレーションの最初のコネクションとして追加します。
手順
- Fuse Online パネルの左側にある Integrations をクリックします。
- Create Integration をクリックします。
- Choose a connection ページで Webhook コネクションをクリックします。
Choose an action ページで Incoming Webhook アクションを選択します。
Webhook Configuration ページで、Fuse Online はこのインテグレーションのために生成した Webhook トークンを表示します。
HTTP リクエストを作成するとき、このトークンは URL の最後の部分になります。このインテグレーションをパブリッシュし、稼働状態になった後、Fuse Online はこのトークンが末尾にある Fuse Online 外部 URL を表示します。
- Next をクリックします。
Specify Output Data Type ページで以下を行います。
- Select Type フィールドをクリックし、JSON schema を選択します。
- Definition フィールドに、HTTP リクエストでパラメーターのデータタイプを定義する JSON スキーマを貼り付けます。「リクエストパラメーターを指定するための JSON スキーマ」を参照してください。
- Data Type Name フィールドに、このデータタイプの名前を指定します。これは任意のフィールドですが、名前を指定すると、データマッパーの Sources リストに表示されるため、フィールドを正しくマップしやすくなります。
- 必要に応じて、このデータタイプを区別するための情報を Data Type Description フィールドに入力します。
- Next をクリックします。
- 最後のコネクションをインテグレーションに追加します。
- 必要な他のコネクションを追加します。
- 必要な他のステップを追加します。
- 最初のコネクションの直後に、データマッパーステップを追加します。
- Publish をクリックし、インテグレーションの名前を付け、必要に応じて説明を追加した後、 Save and publish をクリックします。
7.3. Fuse Online による HTTP リクエストの処理方法
HTTP GET または POST リクエストを指定して、シンプルなインテグレーションの実行をトリガーできます。通常 GET リクエストはデータを取得し、POST リクエストはデータを更新しますが、いずれかのリクエストを使用して、いずれかのオペレーションを行うインテグレーションをトリガーできます。リクエストのパラメーターはすべてインテグレーションの次のコネクションにあるデータフィールドへのマッピングに利用できます。詳細は「リクエストパラメーターを指定するための JSON スキーマ」を参照してください。
Webhook コネクションは受信するデータのみをインテグレーションの次のコネクションに渡します。Fuse Online が HTTP リクエストを受信すると、以下を行います。
-
HTTP ステータスヘッダーを要求元に返します。リクエストがインテグレーションの実行を正常にトリガーした場合、Fuse Online の戻りコードは
201になります。リクエストがインテグレーション実行のトリガーに失敗した場合、戻りコードは5xxになります。 - 他のデータを要求元に返しません。ステータスヘッダーが含まれる 応答 の HTTP ボディーにはデータがありません。
- リクエストのデータをインテグレーションの次のコネクションに渡します。
そのため、GET リクエストによってトリガーされるシンプルなインテグレーションや、データを取得せずにデータを更新するインテグレーションを定義できます。同様に、POST リクエストによってトリガーされるシンプルなインテグレーションや、データを更新せずにデータを取得するインテグレーションを定義することもできます。
7.4. Fuse Online Webhook を呼び出す HTTP クライアントのガイドライン
HTTP リクエストを Fuse Online に送信するクライアントを実装する場合、実装は以下を行う必要があります。
-
GETまたはPOSTリクエストを作成する URL を作成するため、Fuse Online が提供する外部 URL に追加します。 -
URL リクエストに、
io:syndesis:webhookJSON スキーマに準拠するデータタイプを持つ、HTTP ヘッダーとクエリーパラメーターの値を指定します。「リクエストパラメーターを指定するための JSON スキーマ」を参照してください。ヘッダーとクエリーパラメーターがこのデータタイプの指定に準拠する場合、パラメーターフィールドをインテグレーションの次のコネクションが処理できるフィールドにマップできます。 -
リクエストに成功した場合、返された成功コード
201を処理します。 -
リクエストに失敗した場合、HTTP の
5xxエラーコードを処理します。 - Fuse Online からの他の応答を想定しません。そのため、リクエストを送信しても戻りコード以外の戻りデータは直接要求元のクライアントに返されません。
7.5. リクエストパラメーターを指定するための JSON スキーマ
インテグレーションでは、通常 HTTP リクエストのヘッダーおよびクエリーパラメーターをインテグレーションの次のコネクションで処理できるデータフィールドにマップします。これを可能にするには、Webhook コネクションをインテグレーションに追加するときに、以下の構造を持つ JSON スキーマの出力データタイプを指定します。
必要なデータ構造を追加するには、HTTP リクエストの JSON インスタンスで以下を行います。
HTTP クライアントが送信するデータはすべてインテグレーションで利用できますが、Webhook コネクションのデータシェイプがこの JSON スキーマに準拠する場合はクエリーパラメーターとボディーのコンテンツをマッピングに使用できます。
例は 「HTTP リクエストの指定方法」を参照してください。
7.6. HTTP リクエストの指定方法
以下の例は、Fuse Online Webhook に HTTP リクエストを指定する方法を示しています。
Webhook における HTTP ボディーのみの POST リクエストの例
Webhook コネクションで開始し、Fuse Online が提供するデータベースの Todo テーブルの行を作成するインテグレーションについて考えます。

このインテグレーションの作成中、Webhook の最初のコネクションを追加するときに {"todo":"text"} がコンテンツにある JSON インスタンスで出力データタイプを指定します。
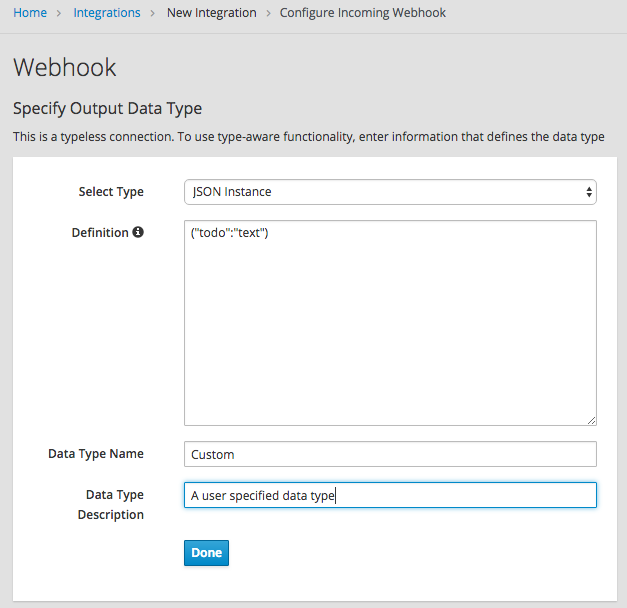
PostgresDB コネクションを最後のコネクションとして追加するとき、Invoke SQL アクションを選択し、この SQL ステートメントを指定します。
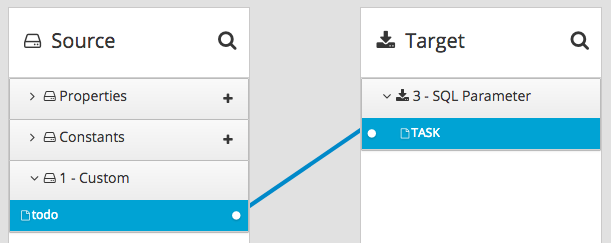
INSERT INTO TODO (TASK) VALUES (:#TASK)
データベースコネクションを追加した後、マッピングステップを追加します。
インテグレーションを保存し、パブリッシュします。実行中に Fuse Online が提供する外部 URL をコピーできます。
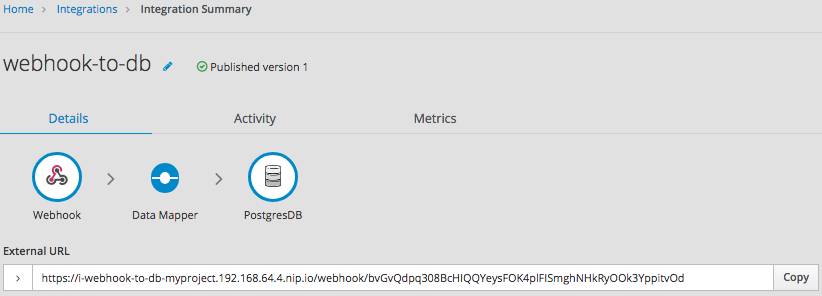
外部 URL の一部を理解するため、以下の URL の例を見てください。
https://i-webhook-to-db-myproject.192.168.64.4.nip.io/webhook/bvGvQdpq308BcHIQQYeysFOK4plFISmghNHkRyOOk3YppitvOd
| 値 | 説明 |
|---|---|
|
| Fuse Online は常にこの値を URL の最初に挿入します。 |
|
| インテグレーションの名前。 |
|
| インテグレーションを実行している Pod が含まれる OpenShift namespace。 |
|
| OpenShift 用に設定された DNS ドメイン。これは、Webhook を提供している Fuse Online 環境を示しています。 |
|
| 各 Webhook コネクション URL に表示されます。 |
|
| Webhook コネクションをインテグレーションに追加するときに Fuse Online が提供する Webhook コネクショントークン。トークンは、URL を識別しにくくすることでセキュリティーを提供する無作為の文字列です。これにより、該当の送信者以外がリクエストを送信できないようにします。 リクエストでは、Fuse Online が提供するトークンを指定するか、独自のトークンを定義します。独自に定義する場合は、必ず簡単に推測できないものにしてください。 |
外部 URL が確認できたら、Fuse Online はインテグレーションの名前、OpenShift namespace の名前、および OpenShift DNS ドメインからホスト名を作成します。Fuse Online は使用できない文字を削除し、空白文字をハイフンに変換します。上記の外部 URL の例では、ホスト名は次のようになります。
https://i-webhook-to-db-myproject.192.168.64.4.nip.io
curl を使用して Webhook を呼び出すには、コマンドを以下のように指定します。
curl -H 'Content-Type: application/json' -d '{"todo":"from webhook"}' https://i-webhook-to-db-myproject.192.168.64.4.nip.io/webhook/bvGvQdpq308BcHIQQYeysFOK4plFISmghNHkRyOOk3YppitvOd
-
-Hオプションは HTTPContent-Typeヘッダーを指定します。 -
-dオプションは、デフォルトで HTTP メソッドをPOSTに設定します。
このコマンドの実行により、インテグレーションがトリガーされます。データベースの最後のコネクションは新しいタスクをタスクテーブルに挿入します。これを確認するには、たとえば https://todo-myproject.192.168.64.4.nip.io で https://todo-myproject.192.168.64.4.nip.io アプリケーションを表示し、Update をクリックします。from webhook が新しいタスクとして表示されるはずです。
Webhook におけるクエリーパラメーターでの POST リクエストの例
この例では、前述の例と同じインテグレーションを使用します。
しかし、この例では以下のコンテンツを持つ JSON スキーマを指定して Webhook コネクションの出力データタイプを定義します。
この JSON スキーマでは以下を行います。
-
idがio.syndesis.webhookに設定される必要があります。 -
parametersセクションは HTTP クエリーパラメーターを指定する必要があります。 -
bodyセクションはボディーのコンテンツを指定し、必要に応じて複雑に指定することができます。たとえば、入れ子のプロパティーやアレイを定義できます。
これは、Webhook コネクターがインテグレーションの次のステップのコンテンツを準備するために必要な情報を提供します。
curl を使用して HTTP リクエストを送信するには、以下のようなコマンドを呼び出します。
curl -H 'Content-Type: application/json' -d '{"company":"Gadgets","email":"sales@gadgets.com","phone":"+1-202-555-0152"}'https://i-webhook-params-to-db-myproject.192.168.42.235.nip.io/webhook/ZYWrhaW7dVk097vNsLX3YJ1GyxUFMFRteLpw0z4O69MW7d2Kjg?source=web&status=new
Webhook コネクションがこのリクエストを受信すると、以下のような JSON インスタンスを作成します。
この JSON インスタンスが以下のマッピングを有効にします。
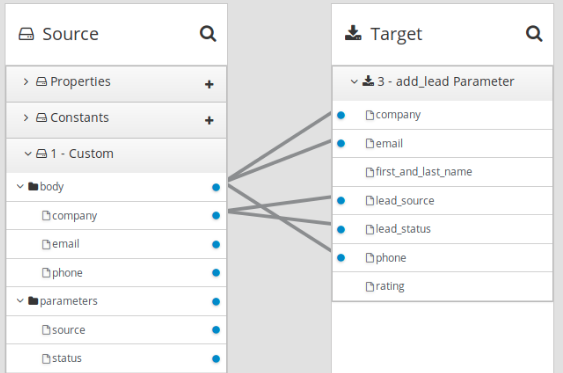
Webhook での GET の例
入力データを提供しない GET リクエストでインテグレーションをトリガーするには、Webhook コネクションの出力データシェイプを、定義 '{}' を持つ JSON インスタンスとして指定します。その後、クエリーパラメーターを指定しない以下の curl コマンドを呼び出すことができます。
curl 'https://i-webhook-params-to-db-myproject.192.168.42.235.nip.io/webhook/ZYWrhaW7dVk097vNsLX3YJ1GyxUFMFRteLpw0z4O69MW7d2Kjg'
前述の POST の例を変更して、クエリーパラメーターがありボディーはない GET リクエストを送信します。Webhook コネクションの出力データシェイプを、以下の定義を持つ JSON スキーマとして指定します。
以下の curl コマンドは GET リクエストを送信します。
curl 'https://i-webhook-params-to-db-myproject.192.168.42.235.nip.io/webhook/ZYWrhaW7dVk097vNsLX3YJ1GyxUFMFRteLpw0z4O69MW7d2Kjg?source=web&status=new'`
第8章 インテグレーションデータを次のコネクションのフィールドにマッピング
ほとんどのフローでは、すでに取得または処理された不データフィールドを、フローの次のコネクションで処理できるデータフィールドにマップする必要があります。Fuse Online は、これを行うためにデータマッパーを提供します。フローで、データフィールドをマップする必要がある各場所に、データマッパーステップを追加します。データフィールドをマッピングする詳細については、以下を参照してください。
- 「データマッピングが必要な場所を特定」
- 「マップするデータフィールドの検索」
- 「1 つのソースフィールドを 1 つのターゲットフィールドへマッピング」
- 「フィールドを組み合わせまたは分割する場合の不足または不必要なデータの例」
- 「複数のソースフィールドを 1 つのターゲットフィールドに組み合わせる」
- 「1 つのソースフィールドを複数のターゲットフィールドに分割」
- 「データマッパーを使用したコレクションの処理」
- 「コレクションと非コレクション間のマッピング」
- 「ソースまたはターゲットデータの変換」
- 「条件のマッピングへの適用」
- 「ステップでのマッピングの表示」
- 「利用可能な変換の説明」
- 「データマッピングのトラブルシューティング」
8.1. データマッピングが必要な場所を特定
Fuse Online は、フローにデータマッピングが必要な場所を示す警告アイコンを表示します。
前提条件
- フローを作成または編集することになります。
- フローには必要なコネクションがすべて含まれている必要があります。
手順
-
フロービジュアライゼーションで、
アイコンを見つけます。
- アイコンをクリックして Data Type Mismatch 通知を確認します。
- メッセージで Add a data mapping step をクリックし、データマッパーを表示します。
8.2. マップするデータフィールドの検索
比較的ステップの数が少ないフローでは、データフィールドのマッピングは簡単で感覚的に行うことができます。より複雑なフローや、大量のデータフィールドを処理するフローでは、データマッパーの処理方法に関する背景が分かればソースからターゲットへのマッピングがより簡単になります。
データマッパーはデータフィールドの列を 2 つ表示します。
- Sources は、フローのこれまでのステップすべてで取得または処理されたデータフィールドの一覧です。
- Target は、フローの次のコネクションが予期して処理できるデータフィールドの一覧です。
マップするデータフィールドを素早く検索するには、以下のいずれかを行います。
検索します。
Sources パネルと Target パネルには、それぞれに上部に検索フィールドがあります。検索フィールドが表示されていない場合は、Sources または Target パネルの右上にある
 をクリックします。
をクリックします。
マップするフィールドの名前を入力します。
これには、Configure Mapper ページの右上にあるプラスマークをクリックして Mapping Details パネルを表示します。Sources セクションに、ソースフィールドの名前を入力します。Target セクションに、マップ先のフィールドの名前を入力します。
フォルダーを展開したり折りたたんで、表示するフィールドを制限します。
特定のステップで利用可能なデータフィールドを表示するには、そのステップのフォルダーを展開します。
手順をフローに追加すると、ステップに番号が割り当てられ、Fuse Online がステップを処理する順番を示します。データマッパーステップを追加する場合、ステップ番号は Sources パネルと Target パネルのフォルダーラベルに表示されます。
フォルダーラベルには、ステップによって出力されるデータタイプの名前も表示されます。Twitter、Salesforce、SQL などのアプリケーションへのコネクションでは、独自のデータタイプを定義します。Amazon S3、AMQ、AMQP、Dropbox、FTP/SFTP などのアプリケーションに接続するには、コネクションをフローに追加するときにコネクションの入力および出力タイプを定義し、コネクションが実行するアクションを選択します。データタイプを指定するときに、タイプに名前を付けます。指定したタイプ名は、データマッパーのフォルダー名として表示されます。データタイプの宣言時に説明を指定した場合は、マッパーの step フォルダーにマウスオーバーするとタイプの説明が表示されます。
8.3. 1 つのソースフィールドを 1 つのターゲットフィールドへマッピング
1 つのソースフィールドを 1 つのターゲットフィールドにマップするのがデフォルトのマッピング動作です。たとえば、Name フィールドを CustomerName フィールドにマップします。
手順
Sources パネルで、マップ元となるデータフィールドをクリックします。
ステップを展開して、提供されるデータフィールドを表示する必要がある場合があります。
ソースフィールドが多数ある場合は、
をクリックして対象のフィールドを検索し、検索フィールドにデータフィールドの名前を入力します。
Target パネルで、マップ先のデータフィールドをクリックします。
データマッパーは、先ほど選択した 2 つのフィールドを接続する行を表示します。
必要に応じて、データマッピングの結果をプレビューします。これは、マッピングに変換を追加する場合や、マッピングにタイプ変換が必要な場合に便利です。
-
データマッパーの右上で
 をクリックし、Show Mapping Preview を選択して、ソースフィールドにテキスト入力フィールドを表示し、ターゲットフィールドに読み取り専用結果フィールドを表示します。
をクリックし、Show Mapping Preview を選択して、ソースフィールドにテキスト入力フィールドを表示し、ターゲットフィールドに読み取り専用結果フィールドを表示します。
- ソースフィールドのデータ入力フィールドにテキストを入力します。
- このテキストボックスの外部をどこかクリックし、ターゲットフィールドの読み取り専用フィールドにマッピングの結果を表示します。
- 任意で、変換の結果を確認するには、Mapping Details パネルに変換を追加します。
-
を再度クリックし、Show Mapping Preview を選択して、プレビューフィールドを非表示にします。
-
データマッパーの右上で
任意で、マッピングが定義されていることを確認するには、右上の
 をクリックし、定義されたマッピングを表示します。
をクリックし、定義されたマッピングを表示します。
このビューでデータマッピングの結果をプレビューすることもできます。プレビューフィールドが表示されない場合は、
をクリックし、Show Mapping Preview を選択します。前の手順で説明したデータを入力します。定義されたマッピングの表では、プレビューフィールドは選択したマッピングでのみ表示されます。別のマッピングのプレビューフィールドを表示するには、そのマッピングを表示します。
を再度クリックし、データフィールドパネルを表示します。
- 右上の Done をクリックし、データマッパーステップをインテグレーションに追加します。
代替手順
1 つのソースフィールドを 1 つのターゲットフィールドにマップする別の方法を以下に示します。
- Configure Mapper ページで、右上のプラスマークをクリックし、Mapping Details パネルを表示します。
- Sources セクションに、ソースフィールドの名前を入力します。
- Action セクションで、デフォルトの Map アクションを受け入れます。
- Target セクションで、マップ先のフィールドの名前を入力し、Enter をクリックします。
8.4. フィールドを組み合わせまたは分割する場合の不足または不必要なデータの例
データマッピングでは、ソースまたはターゲットフィールドに複合データが含まれている場合に、不足しているデータや不必要なデータを特定する必要がある可能性があります。たとえば、以下のような形式の long_address フィールドがあるとします。
number street apartment city state zip zip+4 country
long_address フィールドを number、street、city、state、および zip の別々のフィールドに分割するとします。これを行うには、long_address をソースフィールドとして選択し、ターゲットフィールドを選択します。次に、ソースフィールドの不要なパーツがある場所に、パディングフィールドを追加します。この例では、不要なパーツは apartment、zip+4、および country になります。
不要なパーツを特定するには、これらのパーツの順番を知っておく必要があります。順番は、複合フィールドにある内容の各パーツのインデックスを示します。たとえば、long_address フィールドには順番が付けられたパーツが 8 つあります。インデックスの各パーツの順番は次のようになり、1 で始まります。
| 1 | number |
| 2 | street |
| 3 | apartment |
| 4 | city |
| 5 | state |
| 6 | zip |
| 7 | zip+4 |
| 8 | country |
データマッパーで apartment、zip+4、および country が不足していると識別するには、インデックス 3、7、および 8 にパディングフィールドを追加します。「複数のソースフィールドを 1 つのターゲットフィールドに組み合わせる」を参照してください。
number、street、city、state、および zip のソースフィールドを long_address ターゲットフィールドに組み合わせることにします。さらに、apartment、zip+4、および country の内容を提供するソースフィールドがないとします。データマッパーで、これらのフィールドが不足していると特定する必要があります。ここでも、インデックス 3、7、および 8 にパディングフィールドを追加します。「1 つのソースフィールドを複数のターゲットフィールドに分割」を参照してください。
8.5. 複数のソースフィールドを 1 つのターゲットフィールドに組み合わせる
データマッパーステップでは、複数のソースフィールドを 1 つの複合ターゲットフィールドに組み合わせることができます。たとえば、FirstName および LastName フィールドを CustomerName にマップできます。
前提条件
ターゲットフィールドでは、この複合フィールドの各パーツのコンテンツタイプ、コンテンツの各パーツの順番およびインデックス、および空白やコンマなどのパーツの区切り文字を知っている必要があります。「フィールドを組み合わせまたは分割する場合の不足または不必要なデータの例」を参照してください。
手順
- Target パネルで、複数のソースフィールドをマップするフィールドをクリックします。
Sources パネルに、ターゲットフィールドにマップするフィールドが含まれるフィールドがある場合は、そのコンテナーフィールドをクリックし、含まれるすべてのフィールドをターゲットフィールドにマップします。
各ソースフィールドを個別に選択するには、ターゲットフィールドに組み合わせる最初のフィールドをクリックします。ターゲットフィールドに組み合わせる他の各フィールドにマウスオーバーし、CTRL-Mouse1 (MacOS では CMD-Mouse1) を押します。
作業が完了したら、各ソースフィールドからターゲットフィールドへの線が表示されるはずです。
- Mapping Details パネルの Separator フィールドで、データマッパーが異なるソースフィールドからのコンテンツの間に挿入する文字を許可または選択します。デフォルトは空白文字です。
Mapping Details パネルの Sourcesの下にあるソースフィールドの順番が、複合ターゲットフィールドの対応するコンテンツと同じになるようにしてください。
必要な場合は、同じ順番になるようにソースフィールドをドラッグアンドドロップします。データマッパーは新しい順番を反映するためにインデックス番号を自動的に更新します。
ソースフィールドを複合ターゲットフィールドの各パーツにマップした場合は、次のステップを省略します。
ターゲットフィールドがマップできないデータを想定する場合、Mapping Details パネルで各ソースフィールドのインデックスを編集し、複合ターゲットフィールドの対応するデータのインデックスと同じになるようにします。データマッパーは、不足しているデータを示すために、必要に応じてパディングフィールドを自動的に追加します。
誤って余分なパディングフィールドを作成した場合は、余分なパディングフィールドのごみ箱アイコンをクリックして削除します。
必要に応じて、データマッピングの結果をプレビューします。
-
データマッパーの右上にある
をクリックします。Show Mapping Preview を選択して、テキスト入力フィールドを現在選択しているマッピングの各ソースフィールドに表示し、読み取り専用結果フィールドを現在選択しているマッピングのターゲットフィールドに表示します。
ソースデータ入力フィールドにテキストを入力します。テキストボックスの外部をクリックし、ターゲットフィールドの読み取り専用フィールドにマッピングの結果を表示します。
ソースフィールドの順序を変更したり、マッピングに変換を追加すると、ターゲットフィールドの結果フィールドにこれが反映されます。データマッパーがエラーを検出すると、Mapping Details パネルの上部に情報メッセージが表示されます。
-
を再度クリックし、Show Mapping Preview を選択して、プレビューフィールドを非表示にします。
プレビューフィールドを再表示すると、入力したデータはデータマッパーが終了するまでそのまま存在します。
-
データマッパーの右上にある
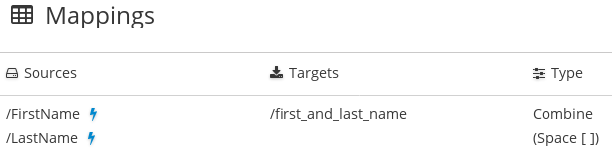
マッピングが適切に定義されていることを確認するには、右上の
をクリックし、このステップで定義されたマッピングを表示します。複数のソースフィールドの値を 1 つのターゲットフィールドに組み合わせるマッピングは次のようになります。
このビューでは、マッピングの結果をプレビューすることもできます。
をクリックし、 Show Mapping Preview を選択して、先ほどのステップの説明どおりにテキストを入力します。プレビューフィールドは選択したマッピングのみに表示されます。表の別のマッピングをクリックして、そのプレビューフィールドを表示します。
8.6. 1 つのソースフィールドを複数のターゲットフィールドに分割
データマッパーステップでは、複合ソースフィールドを複数のターゲットフィールドに分割できます。たとえば、Name フィールドを FirstName および LastName フィールドにマップします。
前提条件
ソースフィールドでは、この複合フィールドの各パーツのコンテンツタイプ、コンテンツの各パーツの順番およびインデックス、および空白やコンマなどのパーツの区切り文字を知っている必要があります。「フィールドを組み合わせまたは分割する場合の不足または不必要なデータの例」を参照してください。
手順
- Sources パネルで、分割するコンテンツのあるフィールドをクリックします。
- Target パネルで、ソースフィールドデータを区切る最初のフィールドをクリックします。
Target パネルで、ソースフィールドのデータの一部を含める追加の各ターゲットフィールドにマウスオーバーし、CTRL-Mouse1 (MacOS では CMD-Mouse1) を押して選択します。
ターゲットフィールドの選択を終了すると、ソースフィールドから各ターゲットフィールドへの線が表示されるはずです。
- Mapping Details パネルの Separator フィールドで、ソースフィールドの値を区切る場所を示すソースフィールドの文字を許可または選択します。デフォルトは空白文字です。
Mapping Details パネルの Targets の下にあるターゲットフィールドの順番が、複合ソースフィールドの対応するコンテンツと同じになるようにしてください。
必要な場合は、同じ順番になるようにターゲットフィールドをドラッグアンドドロップします。データマッパーは新しい順番を反映するためにインデックス番号を自動的に更新します。
複合ソースフィールドの各パーツをターゲットフィールドにマップした場合は、次のステップを省略します。
ソースフィールドに、不必要なデータが含まれる場合は、Mapping Details パネルで、各ターゲットフィールドのインデックスを編集して、複合ソースフィールドの対応するデータのインデックスと同じになるようにします。データマッパーは、不要なデータを示すため、必要に応じてパディングフィールドを自動的に追加します。
必要に応じて、データマッピングの結果をプレビューします。
-
データマッパーの右上で
をクリックし、Show Mapping Preview を選択して、ソースフィールドにテキスト入力フィールドを表示し、各ターゲットフィールドに読み取り専用結果フィールドを表示します。
ソースフィールドのデータ入力フィールドにテキストを入力します。フィールドのパーツの間には必ず区切り文字を入力してください。テキストボックスの外部をクリックし、ターゲットフィールドの読み取り専用フィールドにマッピングの結果を表示します。
ターゲットフィールドの順序を変更したり、ターゲットフィールドに変換を追加すると、ターゲットフィールドの結果フィールドにこれが反映されます。データマッパーがエラーを検出すると、Mapping Details パネルの上部に情報メッセージが表示されます。
-
を再度クリックし、Show Mapping Preview を選択して、プレビューフィールドを非表示にします。
プレビューフィールドを再表示すると、入力したデータはデータマッパーが終了するまでそのまま存在します。
-
データマッパーの右上で
マッピングが適切に定義されていることを確認するには、
をクリックし、このステップで定義されたマッピングを表示します。ソースフィールドの値を複数のターゲットフィールドに分割するマッピングは次のようになります。
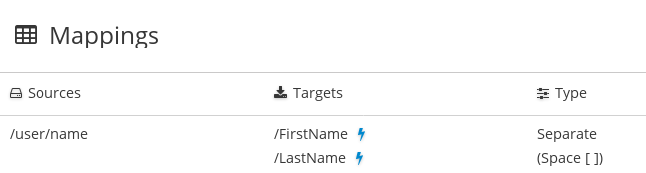
このビューでは、マッピングの結果をプレビューすることもできます。
をクリックし、 Show Mapping Preview を選択して、先ほどのステップの説明どおりにテキストを入力します。プレビューフィールドは選択したマッピングのみに表示されます。表の別のマッピングをクリックして、そのプレビューフィールドを表示します。
8.7. データマッパーを使用したコレクションの処理
フローでは、ステップがコレクションを出力し、フローの後続のコネクションはコレクションを入力として想定する場合、データマッパーを使用してフローがどのようにコレクションを処理するかを指定できます。
ステップがコレクションを出力すると、フロービジュアライゼーションはステップの詳細で Collection を表示します。以下に例を示します。
データマッパーステップを、コレクションを提供するステップの後およびマッピングを必要とするステップの前に追加します。フローでこのデータマッパーステップが必要な場所は、フローの他のステップによって異なります。以下のイメージは、ソースコレクションフィールドからターゲットコレクションフィールドへのマッピングを示しています。
ソースおよびターゲットパネルで、データマッパーは
![]() を表示し、コレクションを示します。ソースコレクションまたはターゲットコレクションにプリミティブタイプのみが含まれる場合、データマッパーはコレクションフィールドを表示する必要がないため表示しません。コレクション自体をマップ元またはマップ先としてマップすることができます。
を表示し、コレクションを示します。ソースコレクションまたはターゲットコレクションにプリミティブタイプのみが含まれる場合、データマッパーはコレクションフィールドを表示する必要がないため表示しません。コレクション自体をマップ元またはマップ先としてマップすることができます。
コレクションに複数のプリミティブタイプが含まれる場合や、複雑なタイプが 1 つ以上含まれている場合、データマッパーはコレクションの子フィールドを表示します。各フィールドをマップ元またはマップ先とすることができます。しかし、入れ子のコレクションをマップ元またはマップ先とすることはできません。
Fuse Online がフローを実行すると、ソースコレクション要素を繰り返し処理し、ターゲットコレクション要素が入力されます。1 つ以上のソースコレクションフィールドをターゲットコレクションまたはターゲットコレクションフィールドにマップする場合、ターゲットコレクション要素にはマップされたフィールドのみの値が含まれます。
ソースコレクションまたはソースコレクションのフィールドをコレクションではないターゲットフィールドにマップする場合、Fuse Online がフローを実行するときにソースコレクションの最後の要素のみから値を割り当てます。コレクションの他の要素は、そのマッピングステップで無視されます。しかし、後続のマッピングステップはソースコレクションのすべての要素にアクセスできます。
コネクションが JSON または Java ドキュメントに定義されたコレクションを返すと、データマッパーは通常コレクションとしてソースドキュメントを処理できます。
8.8. コレクションと非コレクション間のマッピング
データマッパーの Source および Target パネルには以下があります。
-
 はコレクションを示します。コレクションにプリミティブタイプが含まれる場合は、コレクションをマップ元またはマップ先として直接マッピングできます。コレクションに 2 つ以上の異なるタイプが含まれる場合、データマッパーはコレクションの子フィールドを表示し、コレクションのフィールドをマップ元またはマップ先としてマッピングできます。
はコレクションを示します。コレクションにプリミティブタイプが含まれる場合は、コレクションをマップ元またはマップ先として直接マッピングできます。コレクションに 2 つ以上の異なるタイプが含まれる場合、データマッパーはコレクションの子フィールドを表示し、コレクションのフィールドをマップ元またはマップ先としてマッピングできます。
-
 は、コンプレックスタイプの拡張可能なコンテナーを示します。コンプレックスタイプには、異なるタイプの複数のフィールドが含まれます。コンプレックスタイプのフィールドは、アレイなどのコレクションのタイプにすることができます。コンプレックスタイプのコンテナー自体をマップすることはできません。コンプレックスタイプにあるフィールドのみをマップできます。
は、コンプレックスタイプの拡張可能なコンテナーを示します。コンプレックスタイプには、異なるタイプの複数のフィールドが含まれます。コンプレックスタイプのフィールドは、アレイなどのコレクションのタイプにすることができます。コンプレックスタイプのコンテナー自体をマップすることはできません。コンプレックスタイプにあるフィールドのみをマップできます。
データマッパーの右上にある (COMPLEX)、STRING、および INTEGER などのデータタイプの表示を切り替えるには、
をクリックし、Show Type をクリックします。
以下の表は、コレクションフィールドとコレクション以外のフィールドとの間のマッピングにおけるデフォルトの動作を示しています。
| マップ元ソース | マップ先ターゲット | 実行中 |
|---|---|---|
| コレクション。(データマッパーには子フィールドは表示されない) | コレクションにないフィールド。 | データマッパーはソースコレクションの最後の要素にある値をターゲットフィールドにマップします。 |
| コレクションにあるフィールド。 | コレクションにないフィールド。 | データマッパーは、ソースコレクションの最後の要素にあるマップされたフィールドの値をターゲットフィールドにマップします。 |
| コレクションにないフィールド。 | コレクション。(データマッパーには子フィールドは表示されない) | データマッパーは、マップされたソースフィールドの値をコレクションの最初の要素 (唯一の要素) にマップします。 |
| コレクションにないフィールド。 | コレクションにあるフィールド。 | データマッパーは、マップされたソースフィールドの値をコレクションの最初の要素 (唯一の要素) にマップします。 |
マップしないフィールドがソースコレクションに含まれている場合、これらのフィールドはフローにある後続のステップでも使用できます。
コレクションフィールドからマップする場合のデフォルト動作の変更
コレクションフィールドからコレクションでないフィールドにマップする場合、ターゲットフィールドがその値をソースコレクションの最後の要素から取得するのがデフォルトの動作になります。このデフォルトの動作は、以下の方法で変更できます。
-
選択する要素からマップするには、Item At 変換をソースに適用し、インデックスを指定します。たとえば、コレクションの最初の要素にある値をマップするには、インデックスに
0を指定します。 ソースコレクションにあるすべての要素の値をマップするには、Concatenate 変換をソースコレクションまたはソースコレクションフィールドにマップし、必要に応じて区切り文字を指定します。デフォルトの区切り文字は空白文字です。たとえば、以下のソースコレクションについて考えてみましょう。
- 最初の要素では、city フィールドの値は Boston です。
- 2 つ目の要素では、city フィールドの値は Paris です。
- 3 つ目の要素では、city フィールドの値は Tokyo です。
実行中、データマッパーはターゲットフィールドに
Boston Paris Tokyoを入力します。
コレクションでないフィールドからマップする場合のデフォルト動作の変更
コレクションでないフィールドからコレクションフィールドにマップする場合、コレクションでないソースフィールド値を持つ要素がターゲットコレクションに含まれるのがデフォルトの動作になります。ソースフィールドに同じ区切り文字で区切られた一連の値が含まれる場合、デフォルトの動作を変更できます。たとえば、以下が含まれるコレクションでないソース cities フィールドについて考えてみましょう。
Boston Paris Tokyo
これを、ターゲットコレクションまたはコレクションのターゲットフィールドにマップします。ソース cities フィールドで Split 変換を追加します。実行中、データマッパーはスペースの区切り文字で cities フィールドの値を分割します。結果として、3 つの要素が含まれる 1 つのコレクションが作成されます。最初の要素では、city フィールドの値は Bostonです。2 つ目の要素では、city フィールドの値は Paris です。3 つ目の要素では、city フィールドの値は Tokyo です。
8.9. ソースまたはターゲットデータの変換
マッピングの定義後、データマッパーでマッピングのフィールドを変換できます。データフィールドの変換は、データの格納方法を定義します。たとえば、Capitalize 変換を指定して、データ値の最初の文字が大文字になるようにすることができます。
手順
- フィールドをマップします。これは、1 対 1 のマッピング、組み合わせのマッピング、または分割のマッピングになります。
- Mapping Details パネルの Sources または Targets にある変換するフィールドのボックスで、ごみ箱を指す矢印をクリックします。データマッパーが実行する変換を選択するフィールドが表示されます。
- このフィールドをクリックして変換のリストを表示します。
- 実行する変換をクリックします。
- 変換に入力パラメーターが必要な場合は、該当する入力フィールドに指定します。
- 別の変換を追加するには、ごみ箱を指す矢印を再度クリックします。
その他のリソース
8.10. 条件のマッピングへの適用
インテグレーションによっては、条件処理をマッピングに追加すると便利なものがあります。たとえば、ソースの zip コードフィールドに、ターゲットの zip コードフィールドをマッピングすると仮定し、ソースの zip コードフィールドが空白の場合には、ターゲットのフィールドに 99999 と入力することにします。これを実行するには、ソースの zip コードフィールドをテストして、空かどうかを判断するための式を指定し、空の場合は 99999 をターゲットの zip コードフィールドにマップします。
条件のマッピングへの適用はテクノロジープレビュー機能です。テクノロジープレビュー機能は、Red Hat の本番環境のサービスレベルアグリーメント (SLA) ではサポートされず、機能的に完全ではないことがあるため、Red Hat は本番環境での使用は推奨しません。Red Hat では、これらについて実稼働環境での使用を推奨していません。テクノロジープレビューの機能は、最新の製品機能をいち早く提供して、開発段階で機能のテストやフィードバックの提供を可能にするために提供されます。Red Hat のテクノロジープレビュー機能のサポート範囲に関する詳細は、https://access.redhat.com/ja/support/offerings/techpreview を参照してください。
データマッパーがサポートする式は Microsoft Excel の式と似ていますが、Microsoft Excel のすべての式構文をサポートしていません。
各マッピングにはゼロまたは 1 つの条件を定義できます。
以下の手順は、条件をマッピングに適用できるようにします。マッピングと条件に応じて、最も作業がしやすい順番で必要なステップを実行することができます。
前提条件
- データマッパー ステップでフィールドをマッピングします。
- Microsoft Excel 式に詳しいか、マッピングに適用する条件付きの式がある必要があります。
手順
データタイプが表示されない場合は、
をクリックした後、Show Types をクリックして表示します。
これは、条件を指定するための要件ではありませんが、データタイプを表示すると便利です。
条件を適用するマッピングを作成するか、現在選択しているマッピングが条件を適用するマッピングであることを確認します。たとえば、以下のマッピングについて考えてみましょう。
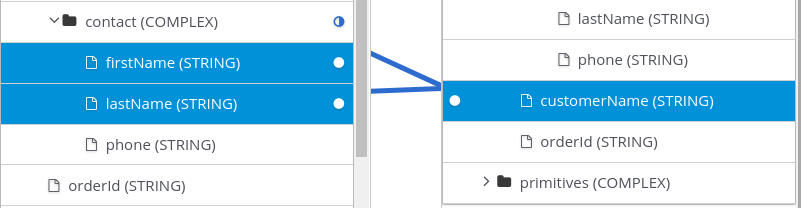
右上の
 をクリックして条件式入力フィールドを表示します。
をクリックして条件式入力フィールドを表示します。
データマッパーは、式フィールドに現在のマッピングにあるソースフィールドの名前を自動的に表示します。以下に例を示します。

式入力フィールドでは、ソースフィールドの順序は、マッピングの作成時に選択した順序になります。これは、データマッパーがこの順序でフィールド値を連結し、結果をターゲットフィールドに挿入するのがデフォルトのマッピング動作であるため、重要になります。この例では、このマッピングの作成では、最初に
lastNameが選択されてからfirstNameが選択されます。式入力フィールドを編集して、データマッパーがマッピングに適用する条件式を指定します。サポートされる条件式の詳細は、次の手順に従います。
式を指定する際に、以下を実行できます。
-
@を入力してフィールドの名前の入力を開始します。データマッパーは入力内容に一致するフィールドのリストを表示します。式に指定するフィールドを選択します。 フィールドをマッピングキャンバスから式入力フィールドにドラッグします。
フィールド名を式に追加するとき、データマッパーはそのフィールドをマッピングに追加します。たとえば、以下の条件式について考えてみましょう。

実行中、データマッパーによって
lastNameが空であると判断されると、firstname フィールドのみをfirstNameフィールドのみをターゲットcustomerNameフィールドにマップします。lastNameフィールドに値が含まれ、空でない場合、データマッパーはソースのorderIdおよびphoneフィールドの値を連結し、結果をcustomerNameフィールドに挿入します。(以下の例は論理の仕組みを示していますが、lastNameフィールドに値があるときは、データマッパーと使って単にマッピングを実行し、他の値をターゲットにマップしない可能性が高いため、実践的な例とは言えません。)この例では、式の入力後にデータマッピングは次のようになります。

条件式で式が適用されるマッピングにあるフィールド名を削除すると、データマッパーはそのフィールドをマッピングから削除します。つまり、マッピングのすべてのフィールド名は条件式にある必要があります。
-
-
マッピングプレビューフィールドが表示されていない場合は、
をクリックした後に Show Mapping Preview をクリックして表示します。
- ソースのプレビュー入力フィールドにサンプルデータを入力して、ターゲットフィールドが正しい値であることを確認します。
必要に応じて、マッピングにある 1 つ以上のソースまたはターゲットフィールドに変換を適用します。
- Mapping Details パネルで、変換を適用するフィールドを見つけます。
- 下にある Add Transformation をクリックします。
- データマッパーが実行する変換をクリックします。
- 必要な場合は入力パラメーターを指定します。
たとえば、この手順と同じマッピングで Mapping Details パネルにて
Uppercase変換をfirstNameフィールドに適用できます。これをテストするには、firstNameフィールドのプレビュー入力フィールドにデータを入力します。- 必要に応じて条件式を編集して、目的の結果を取得します。
条件式でサポートされる関数
ISEMPTY(source-field-name1 [+ source-field-name2])ISEMPTY()関数の結果はブール値です。条件を適用するマッピングのソースフィールドの名前である引数を最低でも 1 つ指定します。指定したソースフィールドが空の場合、ISEMPTY()関数は true を返します。必要に応じて、次の例のように + (連結) 演算子を追加のフィールドと追加します。
ISEMPTY(lastName + firstName)この式は、ソースフィールドの
lastNameとfirstNameが両方空の場合に true に評価されます。多くの場合、
ISEMPTY()関数はIF()関数の最初の引数になります。IF(boolean-expression, then, else)boolean-expressionが true に評価されると、データマッパーはthenを返します。boolean-expressionが false に評価されると、データマッパーはelseを返します。3 つの引数がすべて必要です。最後の引数は null にすることができます。つまり、boolean-expressionが false に評価されると何もマッピングされません。たとえば、
customerNameターゲットフィールでlastNameおよびfirstNameソースフィールドを組み合わせるマッピングについて考えてみましょう。この条件式を指定できます。IF (ISEMPTY(lastName), firstName, lastName + ‘,’ + firstName )実行中、データマッパーは
lastNameフィールドを評価します。-
lastNameフィールドが空で、ISEMPTY(lastName)が true を返す場合、データマッパーはfirstNameの値のみをターゲットcustomerNameフィールドに挿入します。 lastNameフィールドに値が含まれ、ISEMPTY(lastName)が false を返す場合、データマッパーはfirstNameの値とコンマの後にlastNameの値をターゲットのcustomerNameフィールドにマップします。この式の 3 つ目の引数が null であった場合の動作について考えてみましょう。
IF (ISEMPTY(lastName), firstName, null )実行中、データマッパーは
lastNameフィールドを評価します。-
前の例のように、
lastNameフィールドが空で、ISEMPTY(lastName)が true を返す場合、データマッパーはfirstNameの値のみをターゲットのcustomerNameフィールドに挿入します。 -
しかし、3 つ目の引数が null であり、
lastNameフィールドに値が含まれ、ISEMPTY(lastName)が false を返す場合は、データマッパーはターゲットのcustomerNameフィールドに何もマップしません。
-
| 演算子 | 説明 |
|
| 数値の値または連結文字列値を加算します。 |
|
| 1 つの数値を別の数値から減算します。 |
|
| 数値を乗算します。 |
|
| 数値を除算します。 |
|
| 左と右のオペランドが両方 true の場合に true を返します。各オペランドは、ブール値を返す必要があります。 |
|
| 左のオペランド、右のオペランド、または両方のオペランドが true の場合に true を返します。各オペランドは、ブール値を返す必要があります。 |
|
| Not (否定) |
|
| 左の数値オペランドが右の数値のオペランドよりも大きい場合に true を返します。 |
|
< | 左の数値オペランドが右の数値のオペランドよりも小さい場合に true を返します。 |
|
| 左の数値オペランドと右の数値のオペランドが同じ場合に true を返します。 |
8.11. ステップでのマッピングの表示
データマッパーステップを追加または編集する間に、このステップにすでに定義されたマッピングを表示できます。これにより、正しいマッピングがあるかどうかを確認できます。
前提条件
- インテグレーションを作成または更新することになります。
- データマッパーステップを追加することになります。よって、データマッパーは表示されます。
手順
-
右上の
をクリックします。
-
マッピングのリストを解除し、ソースおよびターゲットフィールドを再表示するには、
を再度クリックします。
8.12. 利用可能な変換の説明
以下の表では利用可能な変換について説明します。日付と時刻のタイプは、これらの概念のいずれの形式にも汎用的に参照されます。よって、数字には integer、long、double などが含まれます。日付には date、Time、ZonedDateTime などが含まれます。
| 変換 | 入力タイプ | 出力タイプ | パラメーター(* = 必須) | 説明 |
|---|---|---|---|---|
|
| number | number | なし | 数字の絶対値を返します。 |
|
| date | date |
| 日付に日を追加します。デフォルトは 0 日です。 |
|
| date | date |
| 日付に秒数を追加します。デフォルトは 0 秒です。 |
|
| 文字列 | 文字列 | 文字列 | 文字列の最後に文字列を追加します。デフォルトでは、何も追加しません。 |
|
| 文字列 | 文字列 | なし | 空白を削除し、最初の単語を小文字にし、その後の各単語の最初の文字を大文字にして、キャメルケースを用いた文字列に変換します。 |
|
| 文字列 | 文字列 | なし | 文字列の最初の文字を大文字にします。 |
|
| number | number | なし | 数字の整数上限を返します。 |
|
| any | ブール値 |
| フィールドに指定された値が含まれる場合、true を返します。 |
|
| number | number |
|
範囲を表す数値を別の単位に変換します。From Unit および To Unit メニューから |
|
| number | number |
|
距離を表す数値を別の単位に変換します。From Unit および To Unit メニューから |
|
| number | number |
|
質量を表す数値を別の単位に変換します。From Unit および To Unit メニューから |
|
| number | number |
|
体積を表す数値を別の単位に変換します。From Unit および To Unit メニューから |
|
| date | number | なし | 日付に対応する週 (1 から 7) を返します。 |
|
| date | number | なし | 日付に対応する年間通算日 (1 から 366) を返します。 |
|
| 文字列 | ブール値 |
|
文字列が指定の |
|
| any | ブール値 |
|
フィールドが指定の |
|
| 文字列 | 文字列 | なし | ファイル名を表す文字列から、ドットなしでファイル拡張子を返します。 |
|
| number | number | なし | 数字の整数下限を返します。 |
|
| any | 文字列 |
|
|
|
|
string | number |
|
パラメーター文字列の最初の文字である、入力文字列の文字のインデックスを返します。パラメーター文字列が見つからないと |
|
| any | ブール値 | なし | フィールドが null の場合、true を返します。 |
|
|
string | number |
|
パラメーター文字列の最後の文字である、入力文字列の文字のインデックスを返します。パラメーター文字列が見つからないと |
|
| any | number | なし |
フィールドの長さを返し、フィールドが null の場合は |
|
| 文字列 | 文字列 | なし | 文字列を小文字に変換します。 |
|
| 文字列 | 文字列 | なし | 連続した空白文字を単一のスペースに置き換え、文字列の前後にある空白文字を切り取ります。 |
|
| 文字列 | 文字列 |
|
|
|
| 文字列 | 文字列 |
|
|
|
| 文字列 | 文字列 |
|
|
|
| 文字列 | 文字列 |
|
文字列で、提供された一致する文字列をすべて提供された |
|
| 文字列 | 文字列 |
|
文字列で、最初に見つかった指定の |
|
| number | number | なし | 数字の四捨五入した整数を返します。 |
|
| 文字列 | 文字列 | なし | 空白文字、コロン (:)、アンダーライン (_)、プラス記号 (+)、および等号 (=) をハイフン (-) に置き換えます。 |
|
| 文字列 | 文字列 | なし | 空白文字、コロン (:)、ハイフン (-)、プラス記号 (+)、および等号 (=) をアンダーライン (_) に置き換えます。 |
|
| 文字列 | ブール値 |
| 文字列が指定の文字列で始まり、両方の文字列で大文字と小文字が同じである場合に true を返します。 |
|
| 文字列 | 文字列 |
|
指定された |
|
| 文字列 | 文字列 |
|
指定された |
|
| 文字列 | 文字列 |
|
指定された |
|
| 文字列 | 文字列 | なし | 文字列の前後にある空白文字を削除します。 |
|
| 文字列 | 文字列 | なし | 文字列の前にある空白文字を削除します。 |
|
| 文字列 | 文字列 | なし | 文字列の後にある空白文字を削除します。 |
|
| 文字列 | 文字列 | なし | 文字列を大文字に変換します。 |
8.13. データマッピングのトラブルシューティング
すでにマップされたフィールドに影響するデータシェイプの変更により、データマッパーがドキュメントをロードできない場合があります。このような場合、影響を受けるフィールドをマップするデータマッパーステップを編集しようとすると、データマッパーはソースおよびターゲットパネルを表示できません。その代わりに、ドキュメントのロードまたは検索が不可能であることを示すエラーが表示されます。エラーメッセージは、以下のメッセージの 1 つのようになります。
-
Data Mapper UI Initialization Error: Could not load document '-La_rwMD_ggphAW6nE9o': undefined undefined -
Could not find document for mapped field 'last_name' at URI atlas:json:-LaX4LMC1CfVJYp3JXM6
このデータマッパーステップを削除し、更新されたフィールドをマップする新しいデータマッパーステップに置き換える必要があります。
マップされたフィールドのデータシェイプを変更するには、必ずマッピングをやり直す必要がありますが、常にデータマッパーステップを削除する必要はありません。たとえば、XML インスタンスが入力データシェイプを指定し、ユーザーが要素の名前を変更すると、データマッパーは古いフィールド名をマップ元またはマップ先とするマッピングを削除します。更新された名前でフィールドをマップ先またはマップ元としてマッピングする必要があります。
以下の方法で、マップされたフィールドのデータシェイプを変更できます。
API プロバイダーインテグレーションでフローの編集中に、オペレーションを定義する OpenAPI ドキュメントを編集します。
オペレーションの応答のデータシェイプを変更すると、データマッパーがドキュメントをロードできなくなります。
フローでは、以下に記載されているコネクションの 1 つの入力データタイプや出力データタイプを編集します。
- Amazon S3
- AMQ
- AMQP
- Dropbox
- FTP/SFTP
- HTTP/HTTPS
- Kafka
- IRC
- MQTT
第9章 インテグレーションの管理
一般的なセットアップには、Fuse Online 開発環境、Fuse Online テスト環境、および Fuse Online デプロイメント環境が含まれます。そのため、Fuse Online は Fuse Online 環境からインテグレーションをエクスポートし、そのインテグレーションを別の Fuse Online 環境にインポートする機能を提供します。インテグレーションの管理に関する情報と手順は、特に記述がない限り、各種の Fuse Online 環境で同じになります。
インテグレーションの管理に役立つ情報は、以下を参照してください。
9.1. インテグレーションのライフサイクルの処理
インテグレーションを作成およびパブリッシュした後に、インテグレーションの動作を更新する必要がある場合があります。パブリッシュされたインテグレーションのドラフトを編集し、実行中のバージョンを更新されたバージョンに置き換えることができます。そのため、Fuse Online はインテグレーションごとに、複数のバージョンと各バージョンの状態を維持します。インテグレーションのバージョンや状態を理解することは、インテグレーションの管理に役立ちます。
インテグレーションのバージョンの説明
各 Fuse Online 環境では、インテグレーションごとに複数のバージョンを保持できます。複数のインテグレーションバージョンをサポートすることには、以下のような利点があります。
- 適切に動作しないバージョンをパブリッシュした場合、インテグレーションの適切なバージョンに戻して実行することができます。これには、適切に動作しないバージョンを停止して、適切に動作するバージョンを起動します。
- 要件またはツールの変更に応じて、インテグレーションを段階的に更新できます。新しいインテグレーションを作成する必要はありません。
Fuse Online は、インテグレーションの新しいバージョンが実行されるたびに、新しいバージョン番号を割り当てます。たとえば、Twitter to Salesforce Sample Integration をパブリッシュをすると仮定します。実行後に、インテグレーションを更新して、別のアカウントを使用して Twitter に接続します。その後、更新されたインテグレーションを公開します。Fuse Online は実行中のバージョンのインテグレーションを停止し、インクリメントされたバージョン番号でインテグレーションの更新されたバージョンをパブリッシュします。
実行されていた最初のインテグレーションはバージョン 1 になります。現在稼働している更新されたインテグレーションはバージョン 2 になります。バージョン 2 を編集し (たとえば、別のアカウントを使用して Salesforce に接続するためなど)、そのバージョンをパブリッシュする場合、インテグレーションのバージョン 3 になります。
インテグレーションのドラフトバージョンは必ず 1 つになります。Fuse Online には、インテグレーションのドラフトバージョンの定義がありますが、このバージョンのインテグレーションを実行することはありません。インテグレーションのドラフトバージョンには数字がありません。インテグレーションの編集時に、インテグレーションのドラフトバージョンを更新します。
Fuse Online では、インテグレーションの概要ページでインテグレーションのバージョンリストを確認することができます。このページを表示するには、左側のナビゲーションパネルで Integrations をクリックします。対象のインテグレーションのエントリーで、View をクリックします。
インテグレーション状態の説明
Fuse Online では、インテグレーションのバージョンリストで、各エントリーがそのバージョンの状態を示します。それは以下の 1 つになります。
| 状態 | 説明 |
| Running | Running バージョンが実行されています。これはサービスです。インテグレーションの 1 つのバージョンのみを稼働することができます。つまり、1 度に 1 つのバージョンのみが Running 状態になることができます。 |
| Stopped | Stopped バージョンは実行していません。インテグレーションのドラフトバージョンは Stopped 状態になります。ある時点で実行されていたインテグレーションが停止されると Stopped 状態になります。 このインテグレーションで Running 状態のバージョンがない場合、停止されたバージョンを起動できます。 |
| Pending | Pending のバージョンは移行中です。Fuse Online はこのバージョンのインテグレーションの開始処理中または停止処理中のいずれかになりますが、インテグレーションは実行または停止されていません。 |
| Error |
Error 状態にあるインテグレーションバージョンは、起動中または実行中に OpenShift エラーが発生しました。そのエラーによって起動または実行が停止されました。これが発生した場合、適切に実行される以前のインテグレーションバージョンを開始してください。または、テクニカルサポートにお問い合わせください。これには、Fuse Online ページの右上にある
|
9.2. インテグレーションを使用可能および使用不可能にする
インテグレーションの作成後、これをドラフトとして保存したり、パブリッシュして実行を開始することができます。インテグレーションをパブリッシュする場合、Fuse Online は必要なリソースをアセンブルし、インテグレーションランタイムをビルドします。さらに、インテグレーションを実行する OpenShift Pod をデプロイし、インテグレーションの実行を開始します。
いつでも、ボタンをクリックしてインテグレーションの実行を停止することができます。インテグレーションを再度開始した場合、Fuse Online には必要なものがすでに揃っているため、パブリッシュして初めて実行したときよりも開始に時間がかかりません。
最初にインテグレーションのバージョンを開始するプロセスは、インテグレーションのパブリッシュと呼ばれます。詳細は以下のトピックを参照してください。
9.2.1. インテグレーションのパブリッシュ
初めてインテグレーションのバージョンを実行するには、パブリッシュします。インテグレーションをパブリッシュするとインテグレーションランタイムがビルドおよびデプロイされます。インテグレーションは実行を開始します。インテグレーションをパブリッシュした後、停止および再起動することができます。インテグレーションの 1 つのバージョンを 1 度に実行することができます。
パブリッシュの代替
最初にインテグレーションを実行するには、以下の 1 つを実行してパブリッシュします。
- インテグレーションの作成または編集手順の最後で、右上の Publish をクリックします。
インテグレーションのドラフトバージョンをパブリッシュします。
- Fuse Online パネルの左側にある Integrations をクリックします。
-
インテグレーションのリストで、ドラフトエントリーの右側の
 をクリックし、Publish を選択します。
をクリックし、Publish を選択します。
パブリッシュの進捗
Fuse Online は、複数のステージがあるパブリッシュプロセスの進捗を表示します。
- Assembling は、インテグレーションのビルドに必要な Pod リソースを作成します。
- Building は、インテグレーションをデプロイするための準備をします。
- Deploying は、インテグレーションを実行する Pod のデプロイメントを待ちます。
- Starting は、Pod がインテグレーションの実行を開始するまで待機します。
- Deployed はインテグレーションが実行されていることを示します。
起動中に View Logs をクリックすると、起動時の情報を提供する OpenShift ログを表示できます。
パブリッシュ後のインテグレーション状態
インテグレーションのパブリッシュが完了すると、Running 状態がインテグレーション名の横に表示されます。Pod がインテグレーションを実行している状態になります。
9.2.2. インテグレーションの停止
インテグレーションごとに、稼働中のバージョンが必ず 1 つ存在します。実行中のバージョンが Running 状態になります。いつでも、インテグレーションの実行を停止できます。
前提条件
停止するインテグレーションは Running 状態になります。
手順
- Fuse Online パネルの左側にある Integrations をクリックします。
- インテグレーションのリストで、実行を停止するインテグレーションのエントリーを特定します。このエントリーは、このインテグレーションが Running 状態であることを示しています。
-
このインテグレーションのエントリーの右端にある
をクリックし、Stop を選択します。
結果
Fuse Online がインテグレーションの実行を停止します。インテグレーションリストのインテグレーションのエントリーで、Stopping が表示された後に Stopped が表示されます。
9.2.3. インテグレーションの開始
インテグレーションを初めて開始するプロセスは、インテグレーションの実行前に Fuse Online がインテグレーションランタイムを構築する必要があるため、インテグレーションをパブリッシュすると呼ばれます。いつでも、インテグレーションの実行を停止して、再度開始できます。
前提条件
起動するインテグレーションが Stopped 状態である必要があります。
手順
- 左のナビゲーションパネルで Integrations をクリックします。
-
インテグレーションのリストで、開始するインテグレーションのエントリーの右にある
をクリックします。
- Start を選択します。
結果
Fuse Online は、そのインテグレーションバージョンの状態として Starting を表示し、インテグレーションが再度稼働したときに Running を表示します。
9.2.4. インテグレーションの旧バージョンの再起動
思うように動作しないインテグレーションをパブリッシュする可能性があります。このような場合、適切に動作しないバージョンを停止し、以前パブリッシュした適切に実行されるバージョンに置き換えます。
前提条件
- 稼働しているバージョンのインテグレーションを停止する必要があります。
- 別のバージョンのインテグレーションがあり、それを実行する必要があります。
手順
- 左側のパネルで Integrations をクリックし、この環境のインテグレーションの一覧を表示します。
- 旧バージョンをパブリッシュするインテグレーションのエントリーをクリックします。Fuse Online はインテグレーションのバージョンリストを表示します。
-
実行しているバージョンのエントリーで、右端にある
をクリックし、Stop を選択します。
- OK をクリックして、このバージョンの実行を停止することを確認します。
- ページの上部付近にあるインテグレーション名のの右側に Stopped が表示されるまで待ちます。
そのまま旧バージョンをパブリッシュする場合は、次の手順を飛ばします。また、旧バージョンをパブリッシュする前に、更新することもできます。
-
更新するインテグレーションバージョンのエントリーで、右端の
をクリックし、Replace Draft を選択します。
- 必要に応じてインテグレーションを更新します。
- 更新が完了したら、右上の Publishをクリックし、再度 Publish をクリックして確認します。これは、次の 2 つのステップの代わりになります。
-
更新するインテグレーションバージョンのエントリーで、右端の
-
そのまま旧バージョンをパブリッシュする場合は、再度実行を開始するインテグレーションバージョンのエントリーで、右端の
をクリックし、Start を選択します。
- Start をクリックして、このバージョンのインテグレーションを開始することを確認します。
結果
Fuse Online はインテグレーションを開始します。これには数分かかります。インテグレーションの稼働時、Running version n がインテグレーション名の右側に表示されます。
9.3. インテグレーションの実行に関するログ情報
Fuse Online は、インテグレーションの実行ごとに、以下のアクティビティー情報をフローの各ステップに提供します。
- ステップが実行された日付と時刻
- ステップの実行にかかった時間
- 実行が成功したかどうか
- 実行に成功しなかった場合のエラーメッセージ
Fuse Online でこの情報を表示するには、インテグレーションの概要を表示して Activity タブをクリックします。
インテグレーション実行に関する詳細を取得するには、インテグレーションフローにログステップを追加して、インテグレーションが処理するメッセージに関する情報をログに記録します。ログステップは、インテグレーションが受信する各メッセージに対して、以下を 1 つまたは複数提供できます。
- メッセージのヘッダーを含む、メッセージに関するメタデータを提供するメッセージのコンテキスト。
- メッセージの内容を提供するメッセージのボディー。
- 明示的に指定するテキストまたは Apache Camel Simple language 式の評価で指定するテキスト。
これまでのリリースで使用できたログコネクションは、インテグレーションに追加されなくなりました。ログコネクションの代わりにログステップを追加します。
前提条件
- フローを作成または編集することになります。Fuse Online でインテグレーションを追加するよう要求されます。または、Fuse Online で最後のコネクションを選択するよう要求されます。
手順
- フロービジュアライゼーションにて、ログステップを追加する場所でプラス記号をクリックします。Fuse Online が最後のコネクションを選択するよう要求する場合は、このステップをスキップします。
- Log をクリックします。
Configure Log Step ページで、ログするコンテンツを選択します。Custom Text を選択した場合、テキスト入力フィールドに以下のいずれかを入力します。
- ログするテキスト
- Camel Simple 言語式
式を入力すると、Fuse Online は式を解決し、生成されたテキストをログに記録します。
- ログステップ設定が完了したら、Next をクリックしてフローにステップを追加します。
次のステップ
フローの完了後にインテグレーションをパブリッシュすると、新しいログステップからの出力が表示されます。
その他のリソース
ログステップのあるフローの実行後、ログステップからの出力はインテグレーションの Activity タブに表示されます。「インテグレーションアクティビティー情報の表示」を参照してください。
9.4. インテグレーションの監視
Fuse Online は、インテグレーションの実行を監視するさまざまな方法を提供します。以下を参照してください。
9.4.1. インテグレーション履歴の表示
Fuse Online はインテグレーションの各バージョンを維持します。各インテグレーションのバージョンのリストを常に確認できます。
手順
- 左側のパネルで Integrations をクリックし、環境のインテグレーションの一覧を表示します。
- バージョンを表示するインテグレーションのエントリーの右側にある View をクリックします。
結果
表示されるページの History セクションに、インテグレーションのバージョンがリストされます。
 アイコンは、正常に稼働している最新バージョンである現在のバージョンを特定します。各バージョンの最後に起動した日付も確認できます。
アイコンは、正常に稼働している最新バージョンである現在のバージョンを特定します。各バージョンの最後に起動した日付も確認できます。
特定のバージョンを編集、開始、または停止するには、バージョンのエントリーの右にある
をクリックします。実行するオペレーションを選択します。
9.4.2. インテグレーションのアクティビティーに関する情報の表示
Fuse Online はインテグレーションの実行ごとにアクティビティーの情報を提供します。この情報はインテグレーションのログの一部です。フローの各ステップに対して、Fuse Online は以下を提供します。
- ステップが実行された日付と時刻
- ステップの実行にかかった時間
- 実行が成功したかどうか
- 実行に成功しなかった場合のエラーメッセージ
この情報はいつでも確認することができます。
前提条件
- アクティビティー情報を表示する現在稼働中のインテグレーションまたは過去に稼働していたインテグレーションが存在する必要があります。
- このインテグレーションは、1 回以上実行されている必要があります。
手順
- 左側のパネルで Integrations をクリックします。
- アクティビティー情報を表示するインテグレーションのエントリーの右側にある View をクリックします。
- インテグレーションの概要ページで Activity をクリックします。
- 必要に応じて、日付フィルターやキーワードフィルターを入力して、表示する実行を制限します。
- アクティビティー情報を表示するインテグレーションの実行をクリックします。
その他のリソース
- ログステップをインテグレーションに追加すると、いずれかのステップの間で追加情報を取得できます。ログステップは、受信する各メッセージに関する情報を提供し、指定するカスタムテキストを提供できます。ログステップを追加する場合、アクティビティー情報を表示するインテグレーションの実行を拡張すると、インテグレーションのステップの 1 つとして表示されます。他のステップの Fuse Online 情報を表示するように、ログステップの Fuse Online 情報を表示します。「インテグレーションの実行に関するログ情報」を参照してください。
9.4.3. 特定インテグレーションのメトリクスの表示
Fuse Online は、各インテグレーションに以下のメトリクスを提供します。
- Total Errors は、過去 30 日以内にこのインテグレーションのすべての実行で発生したランタイムエラーの数を示します。
- Last Processed は、このインテグレーションが最後にメッセージを処理した日時を表示します。メッセージが正常に処理されたり、エラーが含まれたりする可能性があります。
- メッセージのTotal Messagesは、過去 30 日以内にこのインテグレーションの実行がすべて処理したメッセージの数になります。これには、メッセージの失敗が含まれます。
- Uptime は、このインテグレーションがいつ実行を開始したかと、エラーなで実行を続けている期間を示します。
前提条件
メトリクスを表示するインテグレーションが稼働している必要があります。
手順
- 左側のパネルで Integrations をクリックします。
- メトリクスを表示するインテグレーションのエントリーの右側にある View をクリックします。
- インテグレーションの概要ページで Metrics をクリックします。
9.4.4. Fuse Online 環境のメトリクスの表示
Fuse Online 環境のメトリクスが Fuse Online のホームページに表示されます。
手順
左側のパネルで Home をクリックします。
結果
Fuse Online は以下のメトリクスを 5 秒ごとに更新します。
- この環境に定義されているインテグレーション数、稼働中のインテグレーションの数、停止されたインテグレーションの数、および保留中のインテグレーションの数。Fuse Online は、保留中のインテグレーションを停止または開始します。赤いバツ印は、実行を停止したエラーが発生した稼働状態だったインテグレーションを示しています。
- この環境で定義されたコネクションの数。
- 過去 30 日以内にこの環境でインテグレーションによって処理されたメッセージの合計数。これには、現在は稼働していない可能性のあるインテグレーションや、この環境から削除された可能性のあるインテグレーションによって処理されたメッセージも含まれます。
- アップタイムは、稼働中のインテグレーションが 1 つ以上存在した期間を示します。アップタイム開始時の日付および時間も表示されます。
9.5. インテグレーションのテスト
作成したインテグレーションが Fuse Online の開発環境で正しく稼働した後、そのインテグレーションを別の Fuse Online 環境で実行し、テストする場合があります。
前提条件
- Fuse Online 開発環境と Fuse Online テスト環境が必要です。
- Fuse Online の開発環境で、正しく稼働しているインテグレーションが存在する必要があります。
手順
- インテグレーションを別の環境にコピーする 方法を確認します。
- 開発環境からインテグレーションをエクスポートします。「インテグレーションのエクスポート」を参照してください。
- インテグレーションをテスト環境にインポートします。「インテグレーションのインポート」を参照してください。
9.6. インテグレーション実行のトラブルシューティングに関するヒント
インテグレーションの動作が停止したら、アクティビティーおよび履歴の詳細を確認してください。「インテグレーションアクティビティー情報の表示」および「インテグレーション履歴の表示」を参照してください。
OAuth を使用するアプリケーションへのコネクションでは、アプリケーションのアクセストークンが期限切れであることを示すエラーメッセージが表示されることがあります。場合によっては、403 - Access denied というメッセージが表示されることがあります。メッセージの情報は、インテグレーションが接続しているアプリケーションによって異なります。この場合、アプリケーションへ再接続し、インテグレーションを再パブリッシュします。
- 左側のパネルで Integrations をクリックします。
- インテグレーションのリストで、実行が停止したインテグレーションのエントリーの右側にある View をクリックします。
インテグレーションの概要ページのフロービジュアライゼーションで、再接続するアプリケーションのアイコンをクリックします。
これが API プロバイダーインテグレーションの場合、インテグレーションの概要ページでそのフローアイコンをクリックし、オペレーションのリストを表示します。次に、パスに障害のあるコネクションが含まれるオペレーションをクリックし、オペレーションのパスビジュアライゼーションで障害のあるコネクションをクリックします。
- コネクションの詳細ページで、Reconnect をクリックします。
アプリケーションの OAuth ワークフローのプロンプトに応答します。
Fuse Online は、そのアプリケーションへのアクセスが承認されたことを示すメッセージを表示します。アプリケーションによっては、これに数秒かかることがありますが、より長期間かかることもあります。
- アプリケーションを再接続した後、インテグレーションを起動します。
再接続が適切に行われない場合は、以下を試行します。
- Fuse Online をアプリケーションのクライアントとして再登録します。「承認取得のための一般的な手順」を参照してください。
- 新しいコネクションを作成します。
古いコネクションを使用していた各インテグレーションを編集します。
- 古いコネクションを削除します。
- 新しいコネクションに置き換えます。
- 更新された各インテグレーションをパブリッシュします。
9.7. インテグレーションの更新
インテグレーションの作成後、ステップを追加、編集、または削除するためにインテグレーションを更新する必要があります。
前提条件
Fuse Online 環境では、更新するインテグレーションのバージョンがある必要があります。
手順
- Fuse Online パネルの左側にある Integrations をクリックします。
- インテグレーションのリストで、更新するインテグレーションの View をクリックします。
インテグレーションの概要ページで、右上隅の Edit Integration をクリックします。
これがシンプルなインテグレーションである場合、Fuse Online はインテグレーションのフローを表示します。これが API プロバイダーインテグレーションである場合、Fuse Online はオペレーションリストを表示します。特定のオペレーションのフローを更新するには、オペレーションの右にある Create flow または Edit flow をクリックして、そのフローを表示します。
必要に応じてフローを更新します。
- ステップを追加するには、フロービジュアライゼーションで、ステップを追加する場所のプラス記号をクリックします。その後、追加するステップを表すカードをクリックします。
-
ステップを削除するには、フロービジュアライゼーションで削除するステップの
 をクリックします。
をクリックします。
- ステップの設定を変更する場合は、フロービジュアライゼーションで更新するステップの Configure をクリックします。設定ページで、必要に応じてパラメーター設定を更新します。
9.8. インテグレーションの削除
インテグレーションの削除後、Fuse Online はそのインテグレーションの履歴を保持します。削除されたインテグレーションのバージョンをインポートする場合、Fuse Online は削除されたインテグレーションの履歴をインポートされたインテグレーションと関連付けます。
手順
- Fuse Online パネルの左側にある Integrations をクリックします。
-
インテグレーションのリストで、開始するインテグレーションのエントリーの右にある
をクリックし、Delete を選択します。
- ポップアップの OK をクリックし、インテグレーションの削除を確認します。
9.9. インテグレーションの別の環境へのコピー
開発、ステージング、および実稼働環境全体でインテグレーションを実行するには、インテグレーションをエクスポートおよびインポートします。環境は、すべて単一の OpenShift クラスターに配置することができ、複数の OpenShift クラスター全体に分散することもできます。
ここで説明する手順では、Fuse Online コンソールでインテグレーションをエクスポートおよびインポートします。
Fuse Online をオンサイトで OpenShift Container Platform 上で実行している場合、特定のインテグレーションをエクスポートおよびインポートする必要がある CI/CD (Continuous Integration/Continuous Deployment) パイプラインが存在する場合があります。これを行う方法については、「Using external tools to export/import integrations for CI/CD」を参照してください。
以下を参照してください。
9.9.1. インテグレーションのコピー
各 Fuse Online インストールは、インテグレーションのエクスポート元となる環境です。インテグレーションのエクスポートによって、異なる Fuse Online 環境でインテグレーションを再作成するのに必要な情報が含まれる zip ファイルがダウンロードされます。
環境では、各インテグレーションは 1 つの Draft バージョンのみを持つことができます。
インテグレーションのインポート結果は以下によって異なります。
- インテグレーションが以前インポートされたかどうか。
- インテグレーションが使用するコネクションが以前インポートされたかどうか。
Fuse Online は、各インテグレーションと各コネクションの内部 ID を使用し、インポート先の環境にすでに存在するかどうかを判断します。インテグレーション名またはコネクション名を変更する場合、Fuse Online は異なる名前を持つ同じインテグレーションまたはコネクションとして認識します。
以下の表は、インレグレーションのインポートで可能な結果を表しています。
| インポートする環境 | インポートオペレーションによる動作 |
|---|---|
| インテグレーションはこれまでインポートされていない。 | インテグレーションを作成します。インテグレーションは Draft 状態です。 |
| インテグレーションは以前インポートされた。 | Fuse Online はインテグレーションを更新します。更新されたインテグレーションは Draft 状態です。このインテグレーションの Draft バージョンがある場合、これは失われます。 |
| インポートされたインテグレーションは、インポートオペレーションの前に環境に存在しなかったコネクションを使用する。 | Fuse Online は、シークレット以外が同じ設定のコネクションを作成します。新しいコネクションを確認する必要があります。コネクションが新しい環境に対して完全に設定されていない場合、不足している設定を追加する必要があります。たとえばこのような場合、Fuse Online 環境をコネクションがアクセスするアプリケーションのクライアントとして登録し、シークレットの設定を取得する必要がある場合があります。 |
9.9.2. インテグレーションのエクスポート
Fuse Online がインテグレーションをエクスポートする場合、zip ファイルをローカルの Downloads フォルダーにダウンロードします。この zip ファイルには、異なる Fuse Online 環境でインテグレーションを再作成するために必要な情報が含まれます。
インテグレーションのエクスポートは、インテグレーションをバックアップする方法でもあります。しかし、Fuse Online はインテグレーションのバージョンを維持するため、バックアップコピーを保持するのにインテグレーションのエクスポートは必要ありません。
手順
- Fuse Online の左パネルで Integrations をクリックします。
- インテグレーションのリストで、エクスポートするインテグレーションのエントリーを特定します。
-
エントリーの右側にある
をクリックし、Export を選択します。
次のステップ
インテグレーションを別の Fuse Online 環境にインポートするには、その環境を開いて、エクスポートした zip ファイルをインポートします。
9.9.3. インテグレーションのインポート
Fuse Online 環境で、別の Fuse Online 環境からエクスポートされたインテグレーションをインポートできます。インテグレーションのエクスポートは、インテグレーションをインポートするためにアップロードする zip ファイルをダウンロードします。
前提条件
- 別の Fuse Online 環境からエクスポートされたインテグレーションが含まれる zip ファイルが必要です。
手順
- インテグレーションをインポートする Fuse Online 環境を開きます。
- 左側のパネルで Integrations をクリックします。
- 右上の Import をクリックします。
エクスポートしたインテグレーション zip ファイルを 1 つまたは複数ドラッグアンドドロップするか、エクスポートしたインテグレーションが含まれる zip ファイルに移動して選択します。
Fuse Online はファイルをインポートし、適切にインポートが完了したときにメッセージを表示します。
- 左側のパネルで Integrations をクリックします。
- インテグレーションのリストで、インポートしたインテグレーションのエントリーにある View をクリックします。
- 設定が必要な通知がある場合は、インテグレーションの概要の右上にある Edit integration をクリックします。
設定が必要な各コネクションに対して、以下を行います。
- Configure ボタンをクリックして詳細を表示します。
- 必要に応じてコネクションの詳細を入力または変更します。このページのすべてのフィールドが正しく、セキュリティー設定のみが必要になることがあります。
- Next をクリックします。
左側のパネルで Settings をクリックします。
Settings ページには、OAuth プロトコルを使用するアプリケーションのエントリーが表示されます。
設定が必要で、OAuth プロトコルを使用するアプリケーションにアクセスする各コネクションに対して、Fuse Online 環境をアプリケーションに登録します。手順はアプリケーションごとに異なります。以下の該当するトピックを参照してください。
- 左側のパネルで Connections をクリックし、設定が必要なコネクションがないことを確認します。
- 左側のパネルで Integrations をクリックします。インテグレーションのリストでは、インポートされたインテグレーションはエントリーの左上隅に緑の三角が表示されます。
-
インテグレーションのリストで、インポートしたインテグレーションのエントリーの右側にある
をクリックし、Edit を選択します。
- 右上の Save をクリックするか、インポートしたインテグレーションの実行を開始する場合は Publish をクリックします。Fuse Online は、インテグレーションをドラフトとして保存するか、パブリッシュするかに関わらず、更新されたコネクションを使用するようインテグレーションを更新します。
第10章 Fuse Online のカスタマイズ
Fuse Online は、一般的なアプリケーションやサービスへの接続に使用できるコネクターを多数提供します。一般的な方法でデータを処理する組み込みの手順も複数あります。しかし、Fuse Online が必要な機能を提供しない場合は、要件について開発者と話し合う必要があります。経験のある開発者は、以下を提供してインテグレーションのカスタマイズに協力できます。
REST API クライアントのコネクターを作成するために Fuse Online が使用できる OpenAPI ドキュメント
このスキーマを Fuse Online にアップロードすると、Fuse Online はスキーマにしたがってコネクターを作成します。その後、コネクターを使用してインテグレーションに追加できるコネクションを作成します。たとえば、多くのインターネットショップの Web サイトは、開発者が OpenAPI ドキュメントでキャプチャーできる REST API クライアントインターフェースを提供します。
REST API サービスを定義する OpenAPI ドキュメント。
このスキーマを Fuse Online にアップロードします。Fuse Online は API サービスを利用可能にし、API 呼び出しの URL を提供します。これにより、API 呼び出しでインテグレーションの実行をトリガー できます。
Fuse Online エクステンションを実装する
JARファイル。エクステンションは以下の 1 つになります。- コネクション間のインテグレーションデータを操作する 1 つ以上のステップ。
- アプリケーションまたはサービスのコネクター。
プロプライエタリー SQL データベースの JDBC ドライバーなどのライブラリーリソース。
この
JARファイルを Fuse Online にアップロードすると、Fuse Online はエクステンションによって提供されるカスタム機能を利用可能にします。
詳細は以下のトピックを参照してください。
10.1. REST API クライアントコネクターの開発
Fuse Online は、HTTP (Hypertext Transfer Protocol) をサポートする REST API (Representational State Transfer Application Programming Interface) のコネクターを作成できます。これには、接続する REST API を記述する有効な OpenAPI 2.0 ドキュメントが Fuse Online に必要です。API サービスプロバイダーが OpenAPI ドキュメントを利用可能にしない場合、経験のある開発者が OpenAPI ドキュメントを作成する必要があります。
REST API コネクターを開発するための情報および手順は、以下を参照してください。
10.1.1. REST API クライアントコネクターの要件
OpenAPI スキーマを Fuse Online にアップロードすると、REST API へのコネクターが利用可能になります。コネクターを選択すると REST API クライアントコネクションを作成できます。その後、新しいインテグレーションを作成し、REST API クライアントコネクションを追加するか、既存のインテグレーションを編集して REST API クライアントコネクションを追加します。
Fuse Online コネクターは OAuth 2.0、HTTP の BASIC 認証、および API キーをサポートします。REST API へのアクセスに TLS (Transport Layer Security) が必要な場合、API は認められた認証局 (CA) が発行する有効な証明書を使用する必要があります。
OAuth を使用する REST API には、クライアントコールバック URL を入力とする承認 URL が必要です。Fuse Online がコネクターを作成した後、コネクターを使用してコネクションを作成する前に、その URL にアクセスして Fuse Online 環境を REST API のクライアントとして登録する必要があります。これにより、Fuse Online 環境による REST API へのアクセスが承認されます。登録の一環として、Fuse Online コールバック URL を提供します。詳細は、「Fuse Online のアプリケーションおよびサービスへの接続、Fuse Online を REST API クライアントとして登録」の説明を参照してください。
OAuth を使用する REST API では、Fuse Online は承認の取得に Authorization Code Grant フローのみをサポートします。コネクターを作成するためにアップロードする OpenAPI ドキュメントの securityDefinitions オブジェクトで、flow 属性を accessCode に設定する必要があります。例を以下に示します。
flow を implicit、password、または application に設定しないでください。
REST API クライアントコネクターの OpenAPI スキーマは、循環 (Cyclic) スキーマ参照を持つことができません。たとえば、リクエストまたは応答ボディーを指定する JSON スキーマは、そのスキーマ自体を全体的に参照することはできず、任意数の中間スキーマを介してそれ自体を部分的に参照することもできません。
Fuse Online は、HTTP 2.0 プロトコルをサポートする REST API のコネクターを作成できません。
10.1.2. REST API クライアントコネクターの OpenAPI スキーマのガイドライン
Fuse Online が REST API クライアントコネクターを作成するとき、OpenAPI ドキュメントの各リソースオペレーションをコネクションアクションにマップします。アクション名とアクションの説明は、OpenAPI ドキュメントのドキュメントから提供されます。
OpenAPI ドキュメントが提供する詳細が多いほど、API への接続時に Fuse Online が提供するサポートも多くなります。たとえば、API 定義はリクエストおよび応答のデータタイプを宣言する必要はありません。タイプ宣言がない場合、Fuse Online は対応するコネクションアクションをタイプレス (タイプがない) として定義します。ただし、インテグレーションでは、タイプレスアクションを実行する API コネクションの直前および直後に、データマッピングステップを追加することはできません。
これに対処するには、OpenAPI ドキュメントにより多くの情報を追加します。API コネクションが実行するアクションにマップする OpenAPI リソースオペレーションを特定します。OpenAPI ドキュメントにて、各オペレーションのリクエストおよび応答タイプを指定する YAML または JSON スキーマがあることを確認します。
スキーマをアップロードした後、OpenAPI ドキュメントをベースとした API 設計のビジュアルエディターである Apicurito で、スキーマを確認および編集する機会が与えられます。詳細の追加や更新の保存を行うことができ、Fuse Online は更新に対応する API クライアントコネクターを作成します。Fuse Online がクライアントコネクターを作成した後、OpenAPI ドキュメントを編集できなくなります。変更を実装するには、新しいクライアントコネクターを作成する必要があります。
API の OpenAPI ドキュメントが、application/json コンテンツタイプおよび application/xml コンテンツタイプのサポートを宣言する場合、コネクターは JSON 形式を使用します。OpenAPI ドキュメントが、application/json および application/xml の両方を定義する consumes または produces パラメーターを指定する場合、コネクターは JSON 形式を使用します。
10.1.3. クライアントクレデンシャルをパラメーターで提供
Fuse Online が OAuth2 アプリケーションへアクセスするための承認の取得を試みると、HTTP Basic 認証を使用してクライアントのクレデンシャルを提供します。必要な場合は、このデフォルトの動作を変更し、Fuse Online が HTTP Basic 認証を使用する代わりに、クライアントクレデンシャルをパラメーターとしてプロバイダーに渡すことができます。これは、OAuth アクセストークンの取得に使用される tokenUrl エイドポイントの使用に影響します。
これは テクノロジープレビュー 機能です。
Fuse Online がクライアントクレデンシャルをパラメーターとして渡すよう指定するには、OpenAPI ドキュメントの securityDefinitions セクションで、設定が true の x-authorize-using-parameters ベンダーエクステンションを追加します。以下の例では、最後の行は x-authorize-using-parameters を指定しています。
x-authorize-using-parameters ベンダーエクステンションの設定は true または false です。
-
trueは、クライアントクレデンシャルがパラメーターであることを示しています。 -
デフォルトは
falseで、Fuse Online は HTTP Basic 認証を使用してクライアントクレデンシャルを提供します。
10.1.4. アクセストークンの自動更新
アクセストークンに有効期限がある場合、そのトークンを使用してアプリケーションに接続する Fuse Online インテグレーションは、トークンの期限が切れると、正常に実行を停止します。新しいアクセストークンを取得するには、アプリケーションに再接続するか、アプリケーションで再登録する必要があります。
必要な場合は、このデフォルトの動作を変更し、Fuse Online が以下の状況で新しいアクセストークンを自動的にリクエストできるようにします。
- 期限切れになった場合。
- 指定した HTTP 応答ステータスコードが受信された場合。
これは テクノロジープレビュー 機能です。
前述の状況で Fuse Online が新しいアクセストークンを自動的に取得するよう指定するには、OpenAPI ドキュメントの securityDefinitions セクションで x-refresh-token-retry-statuses ベンダーエクステンションを追加します。このエクステンションの設定は、HTTP 応答ステータスコードを指定するコンマ区切りのリストです。アクセストークンの期限が切れたり、Fuse Online が OAuth2 プロバイダーから受信したメッセージにこれらの応答ステータスコードの 1 つがある場合、Fuse Online は自動的に新しいアクセストークンの取得を試みます。以下の例では、最後の行は x-refresh-token-retry-statuses を指定しています。
場合によっては API オペレーションが失敗し、その失敗によりアクセストークンが更新されます。この場合、新しいアクセストークンの取得に成功しても、API オペレーションが失敗します。つまり、Fuse Online は新しいアクセストークンを受信した後に、失敗した API オペレーションを再試行しません。
10.2. REST API クライアントコネクターの追加および管理
Fuse Online は OpenAPI ドキュメントから REST API クライアントコネクターを作成できます。OpenAPI ドキュメントの内容に関する情報は「REST API クライアントコネクターの開発」を参照してください。
REST API クライアントコネクターを追加および管理するための情報および手順は以下を参照してください。
REST API クライアントコネクターの作成後、このコネクターを使用するには「Fuse Online のアプリケーションおよびサービスへの接続、REST API への接続」の詳細を参照してください。
10.2.1. REST API クライアントコネクターの作成
OpenAPI ドキュメントをアップロードし、Fuse Online が REST API クライアントコネクターを作成できるようにします。
前提条件
Fuse Online が作成するコネクターの OpenAPI ドキュメントが必要です。
手順
- Fuse Online のナビゲーションパネルで、Customizations > API Client Connectors をクリックします。すでに利用可能な API クライアントコネクターが表示されます。
- Create API Connector をクリックします。
Create API Client Connector ページで、以下のいずれかを行います。
- 点線のボックスをクリックし、アップロードする OpenAPI ファイルを選択します。
- Use a URL 選択し、入力フィールドに OpenAPI ドキュメントの URL を貼り付けます。
Next をクリックします。無効なコンテンツや不足しているコンテンツがある場合、必要な修正に関する情報が Fuse Online に表示されます。アップロードする別の OpenAPI ファイルを選択するか、Cancel をクリックします。OpenAPI ファイルを訂正し、更新されたファイルをアップロードします。
スキーマが有効な場合、Fuse Online はコネクターが提供するアクションの概要を表示します。これには、アクション定義に関するエラーおよび警告が含まれる可能性があります。
アクションの概要が適切であれば Next をクリックします。
OpenAPI ドキュメントを訂正する場合は、右下の Review/Edit をクリックして Apicurito エディターを開きます。必要に応じてスキーマを更新します。右上の Save クリックし、更新を新しい API クライアントコネクターに反映します。Next をクリックして API クライアントコネクターの作成を続行します。
Apicurito の使用に関する詳細は、「Designing and developing an API definition with Apicurito」を参照してください。
OpenAPI ドキュメントの URL を提供する場合、Fuse Online はドキュメントをアップロードできても、開いて編集できないことがあります。通常、これはファイルのホストの設定が原因です。スキーマを開いて編集するには、ファイルのホストに以下が必要です。
-
httpsURL(httpURL は動作しません) - 有効な CORS。
-
API のセキュリティー要件を示します。Fuse Online は OpenAPI 定義を読み取り、API のセキュリティー要件を満たすためにコネクターの設定に必要な情報を判断します。Fuse Online は以下のいずれかを表示できます。
- No Security (セキュリティーなし)
- HTTP Basic Authorization (HTTP Basic 認証) - API サービスが HTTP Basic 認証を使用する場合は、このチェックボックスを選択します。後で、このコネクターを使用してコネクションを作成するときに、Fuse Online はユーザー名とパスワードの入力を要求します。
OAuth 2.0 — Fuse Online は以下を入力するよう要求します。
- Authorization URL は、Fuse Online を API のクライアントとして登録する場所です。登録によって Fuse Online の API へのアクセスが承認されます。『Fuse Online のアプリケーションおよびサービスへの接続』の「Fuse Online を REST API クライアントとして登録」を参照してください。OpenAPI ドキュメントまたは API の他のドキュメントはこの URL を指定する必要があります。指定しない場合、サービスプロバイダーに連絡してこの URL を取得する必要があります。
- OAuth 承認には、アクセストークン URL が必要です。この場合も、OpenAPI ドキュメントまたは API の他のドキュメントがこの URL を提供する必要があります。提供しない場合、サービスプロバイダーに連絡する必要があります。
- API Key - API サービスに API キーが必要な場合、Fuse Online はコネクターの作成に必要な情報を要求します。プロンプトは OpenAPI 定義に基づきます。たとえば、API キーがメッセージヘッダーまたはクエリーパラメーターにあるかを示す必要がある可能性があります。OpenAPI 定義が API キーのセキュリティーと他のセキュリティータイプを指定する場合、チェックボックスを選択し、このコネクターを基にしてコネクションに API キーセキュリティーを使用することを示します。後で、このコネクターを使用してコネクションを作成するときに、Fuse Online は API キーの値を入力するよう要求します。
Next をクリックします。Fuse Online は OpenAPI ドキュメントによって示されるコネクターの名前、説明、ホスト、およびベース URL を表示します。このコネクターから作成するコネクションの場合は以下を行います。
-
Fuse Online は、コネクションのエンドポイントを定義するため、ホストおよびベース URL 値を連結します。たとえば、ホストが
https://example.comで、ベース URL が/api/v1の場合、コネクションエンドポイントはhttps://example.com/api/v1になります。 - Fuse Online は OpenAPI ドキュメントをデータマッピングステップに適用します。OpenAPI ドキュメントが複数のスキーマをサポートする場合、Fuse Online は TLS (HTTPS) スキーマを使用します。
-
Fuse Online は、コネクションのエンドポイントを定義するため、ホストおよびベース URL 値を連結します。たとえば、ホストが
- コネクターの詳細を確認し、必要に応じてコネクターのアイコンをアップロードします。アイコンをアップロードしない場合、Fuse Online はアイコンを生成します。後でアイコンをアップロードできます。Fuse Online でインテグレーションのフローが表示されるときに、コネクターから作成されたコネクションを表すコネクターのアイコンが表示されます。
OpenAPI ファイルから取得した値を上書きするには、変更するフィールド値を編集します。
重要Fuse Online がコネクターを作成した後、これを変更することはできません。変更を反映にするには、Fuse Online が新しいコネクターを作成できるよう、更新された OpenAPI ドキュメントをアップロードしたり、同じスキーマをアップロードして Apicurito で変更する必要があります。その後、新しい API クライアントコネクターを作成するプロセスを続行します。
- コネクターの詳細に満足したら、Create API Connector をクリックします。Fuse Online は他のコネクターを持つ新しいコネクターを表示します。
次のステップ
新しい API コネクターの使用に関する詳細は「Fuse Online のアプリケーションおよびサービスへの接続、REST API への接続」を参照してください。
10.2.2. 新規コネクターを作成して API クライアントコネクターを更新
API クライアントコネクターを作成した OpenAPI ドキュメントに更新があり、API クライアントコネクターがそれらの更新を使用するようにするには、新しい API クライアントコネクターを作成する必要があります。API クライアントコネクターを直接更新することはできません。新しい API クライアントコネクターの作成後に、そのコネクターを使用して新しいコネクションを作成し、古いコネクターから作成されたコネクションを使用する各インテグレーションを編集します。
前提条件
以下のいずれかを行う準備をする必要があります。
- 更新された OpenAPI ドキュメントをアップロードします。
- 古いスキーマを再度アップロードし、Apicurito で更新します。
手順
更新された OpenAPI ドキュメントを基にして新しい API クライアントコネクターを作成します。古いコネクターと新しいコネクターを区別しやすくするため、コネクター名またはコネクターの説明にバージョン番号を指定することもできます。
「REST API クライアントコネクターの作成」を参照してください。
- 新しいコネクターから新しいコネクションを作成します。ここでも、古いコネクターから作成されたコネクションと、新しいコネクターから作成されたコネクションを簡単に区別できるようにすることができます。コネクション名またはコネクションの説明のバージョン番号を使用すると便利です。
- 古いコネクションを削除し、新しいコネクションを追加して、古いコネクターから作成されたコネクションを使用する各インテグレーションを編集します。
- 更新された各インテグレーションをパブリッシュします。
- 必須ではありませんが、古いコネクターおよびコネクションを削除することが推奨されます。
10.2.3. API クライアントコネクターの削除
コネクターから作成されたコネクションがある場合や、このコネクションがインテグレーションで使用される場合は、コネクターを削除することはできません。API クライアントコネクターの削除後、そのコネクターから作成されたコネクションを使用することはできません。
手順
- 左側のパネルで Customizations > API Client Connectors をクリックします。
- 削除するコネクター名の右側にある Delete をクリックします。
- コネクターを削除する場合は、確認ポップアップの Delete をクリックします。
10.3. Fuse Online エクステンションの開発
Fuse Online がインテグレーションの作成に必要な機能を提供しない場合、開発者が必要な動作を提供するエクステンションを作成することができます。Syndesis エクステンションリポジトリー https://github.com/syndesisio/syndesis-extensions にエクステンションの例が含まれています。
ビジネスインテグレーターは、エクステンションを作成する開発者と要件を共有します。開発者は、エクステンションが含まれる .jar ファイルを提供します。ビジネスインテグレーターは Fuse Onlineに .jar ファイルをアップロードして、カスタムコネクター、カスタムステップ、またはライブラリーリソースを Fuse Online で使用できるようにします。
Red Hat Developer Studio への Fuse Tooling プラグインは、ステップのエクステンションまたはコネクターのエクステンションの開発に役立つウィザードを提供します。Developer Studio またはその他の IDE で、ステップエクステンションまたはコネクターエクステンションを開発するかどうかは、個人的に選択できます。Developer Studio プラグインの使用に関する詳細は、「Developing extensions for Fuse Online integration」を参照してください。
選択した IDE でエクステンションを開発するための手順の概要、要件の説明、および追加の例については以下を参照してください。
10.3.1. エクステンション開発の一般的な手順
エクステンションの開発を開始する前に、実行する必要のあるタスクについて理解しておく必要があります。
前提条件
インテグレーション Pod は、フラットなクラスパスを持つ Java プロセスで実行されます。バージョンの競合を避けるため、エクステンションが使用する依存関係が、以下のすべてのソースからインポートされた BOM (Bill of Materials) に対応することを確認してください。
-
org.springframework.boot:spring-boot-dependencies:$SPRING_BOOT_VERSION -
org.apache.camel:camel-spring-boot-dependencies:$CAMEL_VERSION -
io.syndesis.integration:integration-bom:$SYNDESIS_VERSION
インポートされた BOM の一部ではない追加の依存関係がある場合、以下を行う必要があります。
-
libディレクトリーにあるエクステンション JAR ファイルでパッケージ化する必要があります。 -
エクステンションの JSON 記述子ファイルの
dependenciesプロパティーから省略します。
手順
- 拡張された機能の動作の理解します。機能要件を理解するために、ビジネスの関係者と話し合います。
- ステップエクステンション、コネクターエクステンション、またはライブラリーエクステンションを開発する必要があるかどうかを判断します。
- エクステンションを開発する Maven プロジェクトを設定します。
ステップエクステンションを開発する場合は以下を行います。
-
Camel ルートとして実装するか、または Syndesis
StepAPI を使用して実装するかを決定します。Syndesis API に関する情報は http://javadoc.io/doc/io.syndesis.extension/extension-api を参照してください。 -
Camel ルートとしてエクステンションを実装する場合は、XML フラグメント、
RouteBuilderクラス、または Bean を実装するかどうかを決定します。 -
Maven プロジェクトで、
schemaVersion、エクステンションname、extensionIdなどの必要なメタデータを指定します。
-
Camel ルートとして実装するか、または Syndesis
- 機能を実装するクラスを作成します。
-
依存関係をプロジェクトの
pom.xmlファイルに追加します。 コネクターおよびライブラリーエクステンションと、XML に実装するステップエクステンションに、エクステンションを定義する JSON ファイルを作成します。
Java に実装するステップエクステンションでは、Maven プロジェクトで対応するデータ構造の値を指定するときに Maven は JSON エクステンション定義ファイルを生成できます。
- Maven を実行してエクステンションを構築し、エクステンションの JAR ファイルを作成します。
- JAR ファイルを Fuse Online 開発環境にアップロードして、エクステンションをテストします。
- エクステンションをパッケージ化する JAR ファイルを Fuse Online 本番環境にアップロードするビジネス関係者に、そのファイルを提供します。JAR ファイルを提供するときに、Fuse Online の Web インターフェースに表示される情報以外の設定について、ビジネス関係者に説明します。
10.3.2. エクステンションの種類の説明
エクステンションは以下のいずれかを定義します。
- コネクション間のインテグレーションデータを操作する 1 つ以上のカスタムステップ。各カスタムステップは 1 つのアクションを実行します。これは、ステップエクステンションです。
- インテグレーションランタイムが使用するライブラリーリソース。たとえば、ライブラリーエクステンションは、Oracle などのプロプライエタリー SQL データベースに接続するための JDBC ドライバーを提供できます。
統合する特定のアプリケーションまたはサービスへのコネクションを作成するための単一のカスタムコネクター。これは、コネクターエクステンションです。
注記Fuse Online は OpenAPI ドキュメントを使用して REST API クライアントのコネクターを作成できます。「REST API クライアントコネクターの開発」を参照してください。
ビジネスインテグレーターは、エクステンションを作成する開発者と要件を共有します。開発者は、エクステンションが含まれる .jar ファイルを提供します。ビジネスインテグレーターは Fuse Online で .jar ファイルをアップロードし、カスタムコネクター、カスタムステップ、または Fuse Online 内で使用できるライブラリーリソースを作成します。
Fuse Online にアップロードするエクステンション .jar ファイルには、常に 1 つのエクステンションが含まれます。
コネクション間のデータを操作するステップを提供するエクステンションのアップロード例および使用例については、 AMQ から REST API へのサンプルインテグレーションのチュートリアル を参照してください。
10.3.3. エクステンションコンテンツおよび構造の概要
エクステンションとは、.jar ファイルにパッケージ化されるクラス、依存関係、およびリソースのコレクションです。
Fuse Online は Spring Boot を使用してエクステンションをロードします。そのため、Spring Boot の実行可能な JAR 形式に従い、エクステンションをパッケージ化する必要があります。たとえば、ZipEntry.STORED() を使用して、ネストされた JAR ファイルを保存するようにします。
エクステンションをパッケージ化する .jar ファイルの構造は次のとおりです。
10.3.4. エクステンション定義の JSON ファイルの要件
各エクステンションには、名前、説明、サポートされるアクション、依存関係などのデータ構造の値を指定してエクステンションを定義する .json ファイルが必要です。以下の表は、Maven がエクステンション定義 JSON ファイルを生成するかどうかと、必要になるデータ構造をエクステンションタイプ別に示しています。
| エクステンションタイプ | Maven によるエクステンション定義の生成 | 必要なデータ構造 |
|---|---|---|
| Java のステップエクステンション | 可能 |
|
| XML のステップエクステンション | 不可能 |
|
| コネクターエクステンション | 不可能 |
|
| ライブラリーエクステンション | 不可能 |
|
* dependencies の指定は必ずしも必要ではありませんが、ほとんどの場合で指定の必要な依存関係が存在します。
通常、エクステンション定義ファイルのレイアウトは次のようになります。
- schemaVersion は、エクステンション定義スキーマのバージョンを定義します。Syndesis は内部的に schemaVersion を使用して、エクステンション定義を内部モデルにマップする方法を決定します。これにより、古いバージョンの Syndesis に対して開発されたエクステンションを、より新しいバージョンの Syndesis にデプロイすることが可能になります。
- name は、エクステンションの名前です。Fuse Online にエクステンションをアップロードするときに、この名前が表示されます。
- description は、指定する便利な情報です。Fuse Online はこの値を操作しません。
- version は、エクステンションへの更新を区別するのに便利です。Fuse Online はこの値を操作しません。
- extensionId は、エクステンションの一意の ID を定義します。これは、少なくとも Syndesis 環境全体で一意である必要があります。
extensionType は、エクステンションが提供するものを Syndesis に示します。Syndesis バージョン 1.3 時点で、以下のエクステンションタイプがサポートされます。
-
Steps -
Connectors -
Libraries
-
コネクターエクステンションのトップレベルで properties が必要です。このオブジェクトは、Fuse Online ユーザーがコネクターを選択してコネクションを作成する時に Fuse Online で何を表示するかを制御します。この
propertiesオブジェクトには、コネクションを作成するための各フォームコントロールのプロパティーセットが含まれます。以下に例を示します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow コネクターエクステンションでは、ネストされた
propertiesオブジェクトはコネクションアクションを設定するための HTML フォームコントロールを定義します。ステップエクステンションでは、actionsオブジェクトにpropertiesオブジェクトが含まれます。propertiesオブジェクトは、ステップを設定するための各フォームコントロールのプロパティーセットを定義します。「ユーザーインターフェースプロパティーの説明」も参照してください。actions はコネクターが実行できるオペレーションや、コネクション間のステップが実行できるオペレーションを定義します。コネクターおよびステップエクステンションのみが指定するアクションを使用します。アクションの指定形式は以下のようになります。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow - id は、アクションの一意の ID です。これは、少なくとも Syndesis 環境内で一意である必要があります。
- name は、Fuse Online に表示されるアクション名です。インテグレーターは、この値をコネクションアクションの名前またはコネクション間のインテグレーションデータを操作するステップの名前として解釈します。
- description は、Fuse Online に表示されるアクションの説明です。インテグレーターがアクションの動作を理解するよう、このフィールドを使用します。
- actionType は、アクションがコネクションまたはコネクション間のステップによって実行されるかどうかを示します。
-
descriptor は、
kind、entrypoint、inputDataType、およびoutputDatatypeなどのネストされた属性を指定します。
dependencies は、このエクステンションが必要とする Fuse Online が提供するリソースを定義します。
以下のように依存関係を定義します。
{ "type": "MAVEN", "id" : "org.apache.camel:camel-telegram:jar:2.21.0" }{ "type": "MAVEN", "id" : "org.apache.camel:camel-telegram:jar:2.21.0" }Copy to Clipboard Copied! Toggle word wrap Toggle overflow - type は依存関係のタイプを示します。MAVEN を指定します。(他のタイプは今後サポートされる予定です)
- id は、Maven 依存関係 (Maven GAV) の ID です。
10.3.5. ユーザーインターフェースプロパティーの説明
コネクターエクステンションおよびステップエクステンションで、エクステンション定義 JSON ファイルまたは Java クラスファイルにユーザーインターフェースプロパティーを指定します。これらのプロパティーの設定は、Fuse Online ユーザーがコネクションの作成、コネクションアクションの設定、またはエクステンションによって提供されるステップの設定を行うときに Fuse Online が表示する HTML フォームコントロールを定義します。
Fuse Online コンソールのエクステンションのユーザーインターフェースに表示する各フォームコントロールのプロパティーを指定する必要があります。各フォームコントロールで、一部またはすべてのプロパティーを任意の順序で指定します。
ユーザーインターフェースプロパティーの指定例
IRC コネクターの一部である JSON ファイルでは、トップレベルの properties オブジェクトは、Fuse Online ユーザーがコネクションを作成するための IRC コネクターを選択した後に HTML フォームコントロールを定義します。3 つのフォームコントロールには、hostname、password、および port の 3 つのセットのプロパティー定義があります。
これらのプロパティー指定を基にして、Fuse Online ユーザーが IRC コネクターを選択すると、Fuse Online に以下のダイアログが表示されます。ユーザーが 2 つの必須フィールドに値を入力し、Next をクリックすると、Fuse Online は Fuse Online ユーザーが入力する値で IRC コネクションを作成します。
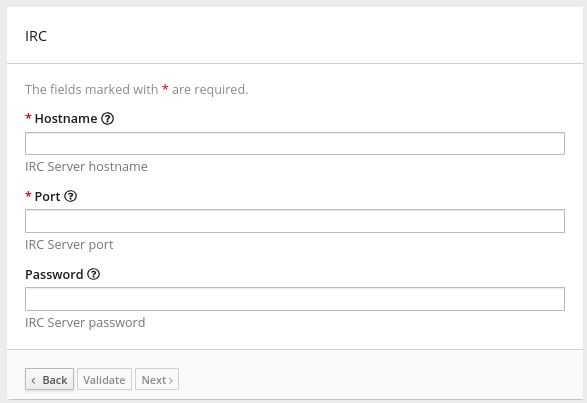
エクステンション定義 JSON ファイルの properties オブジェクト
コネクターエクステンションでは以下が行われます。
-
トップレベルの
propertiesオブジェクトが必要です。このオブジェクトは、Fuse Online ユーザーがコネクターを選択してコネクションを作成する時に Fuse Online で何を表示するかを制御します。このpropertiesオブジェクトには、コネクションを作成するための各フォームコントロールのプロパティーセットが含まれます。 -
actionsオブジェクトでは、アクションごとにpropertiesオブジェクトがあります。これらのpropertiesオブジェクトごとに、そのアクションを設定するための各フォームコントロールのプロパティーセットがあります。
ステップエクステンションでは、actions オブジェクトに properties オブジェクトが含まれます。properties オブジェクトは、ステップを設定するための各フォームコントロールのプロパティーセットを定義します。JSON 階層は、以下のようになります。
Java ファイルのユーザーインターフェースプロパティー
Java ファイルでユーザーインターフェースのフォームコントロールを定義するには、コネクション、アクション、またはステップのユーザー設定を定義する各クラスファイルに io.syndesis.extension.api.annotations.ConfigurationProperty をインポートします。Fuse Online コンソールが表示する各フォームコントロールに対して、@ConfigurationProperty アノテーションと後続のプロパティーリストを指定します。指定できるプロパティーに関する詳細は、このセクションの最後にあるユーザーインターフェースプロパティーの参照テーブルを参照してください。
以下のコードは、単一のフォームコントロールのプロパティー定義を表しています。このコードは、RouteBuilder で Camel ルートを開発する例になります。
以下のコードは、2 つのコントロールのプロパティー定義を表しています。このコードは、Syndesis Step API をした例です。
コントロールフォーム入力タイプの説明
各 HTML フォームコントロールのプロパティーセットでは、type プロパティーが Fuse Online が表示するフォームコントロールの入力タイプを定義します。HTML フォームの入力タイプに関する詳細は、https://www.w3schools.com/html/html_form_input_types.asp を参照してください。
以下の表に、Fuse Online フォームコントロールの可能な入力タイプを示します。制御のプロパティーのセットで、不明な type の値を指定すると、Fuse Online は 1行のテキストを許可する入力フィールドを表示します。デフォルトは "type": "text" です。
type プロパティーの値 | HTML | Fuse Online が表示するもの |
|---|---|---|
|
|
| ユーザーが選択可能または不可能なチェックボックス。 |
|
|
Fuse Online ユーザーが時間の単位を選択できるようにするカスタム制御。ミリ秒、秒、分、時、または日を選択できます。また、ユーザーは番号を入力し、Fuse Online はミリ秒数を返します。例: | |
|
|
| このフィールドは Fuse Online コンソールに表示されません。他のプロパティーを使用して、テキストデータなどのこのフィールドに関連するデータを指定できます。Fuse Online ユーザーはこのデータを表示または変更できませんが、ユーザーが Fuse Online ページの View Source を選択すると、ソース表示に非表示のフィールドが表示されます。そのため、セキュリティーの目的で非表示フィールドを使用しないでください。 |
|
|
| 数字を許可する入力フィールドです。 |
|
|
| ユーザーが入力する文字を通常はアスタリスクでマスクする入力フィールド。 |
|
|
|
フォームコントロールの |
|
|
| 1 行のテキストを許可する入力フィールド。 |
|
|
| textarea 要素が使用されます。 |
コントロールフォームのユーザーインターフェースプロパティーの説明
コネクターまたはステップエクステンションでは、Fuse Online コンソールに表示される各 HTML フォームコントロールに対して、以下の表に説明があるプロパティーを 1 つ以上指定できます。HTML フォームの入力タイプに関する詳細は、https://www.w3schools.com/html/html_form_input_types.asp を参照してください。
| プロパティー名 | タイプ | 説明 |
|---|---|---|
|
| 文字列 | Fuse Online が表示するフォームコントロールの種類を制御します。詳細は、前述の表を参照してください。 |
|
| number |
|
|
| 文字列 |
設定された場合、値はフォームコントロール要素の HTML |
|
| array |
|
|
|
|
Fuse Online は、最初にこの値をフォームフィールドに表示します。 |
|
| 文字列 | 設定されている場合、Fuse Online はこの値をフォームコントロールの下に表示します。通常、これはコントロールに関する短い便利なメッセージです。 |
|
| 文字列 | Fuse Online はこの値を表示します。 |
|
| array |
設定した場合、Fuse Online は |
|
| 文字列 |
設定されている場合、表示名の横に |
|
| number |
|
|
| number |
|
|
| ブール値 |
|
|
| number |
Fuse Online コンソールでの制御の順序を決定します。Fuse Online は昇順を適用します。つまり、 |
|
| 文字列 | 設定された場合、ユーザーに想定される入力を分かりやすく示すため、この値を薄いフォントで入力フィールドに表示します。 |
|
| ブール値 |
|
|
| number |
|
|
| ブール値 |
指定された場合、Fuse Online はコントロールの |
10.3.6. エクステンションをサポートする Maven プラグインの説明
extension-maven-plugin は、エクステンションを有効な Spring Boot モジュールとしてパッケージ化し、エクステンションの開発をサポートします。Java に実装するステップエクステンションでは、このプラグインでエクステンション定義 JSON ファイルを生成できます。
Maven プロジェクトの pom.xml ファイルに、以下のプラグイン宣言を追加します。
extension-maven-plugin は以下のゴールを定義します。
generate-metadata は、生成された JAR ファイルに含まれる JSON エクステンション定義ファイルを以下のように生成します。
Maven は
META-INF/syndesis/syndesis-extension-definition.jsonファイルにあるデータ構造の指定から開始します (このファイルがある場合)。XML でコーディングする場合、エクステンション定義 JSON ファイルを独自に定義する必要があり、そのファイルに必要なデータ構造をすべて指定する必要があります。
コネクターまたはライブラリーエクステンションを開発する場合、エクステンション定義 JSON ファイルを独自に定義する必要があり、そのファイルに必要なデータ構造をすべて指定する必要があります。
Java でステップエクステンションを開発する場合、以下を行うことが可能です。
- エクステンション定義 JSON ファイルをユーザー自身が作成します。
- Java コードで、必要なデータ構造すべてを定義するアノテーションを指定します。ユーザーはエクステンション定義 JSON ファイルを作成しません。
- エクステンション定義 JSON ファイルを作成し、一部のデータ構造を指定します。
- Java で開発するステップエクステンションの場合、Maven はコードアノテーションから、不足している指定を取得します。
-
Maven は、scope が
providedで、extension-bomを介して管理される依存関係を指定する、依存関係リストを追加します。
repackage-extension はエクステンションをパッケージ化します。
-
extension-bomを介して管理されない依存関係および関連する推移的依存関係は、生成された JAR のlibフォルダーにあります。 -
ライブラリーエクステンションの場合、scope が
systemの依存関係は、生成された JAR のlibフォルダーにあります。
-
たとえば、Maven プロジェクトに以下の pom.xml ファイルがあるとします。
この pom.xml ファイルを基にすると、生成されたエクステンション定義 JSON ファイルは以下のようになります。
生成されたアーカイブの構造と内容は次のようになります。
10.3.7. エクステンションでデータシェイプを指定する方法
データシェイプは、データマッパーによって使用されるデータタイプメタデータを保持します。データマッパーはこのメタデータを、データマッパーユーザーインターフェースでソースおよびターゲットデータフィールドを表示するために使用する内部ドキュメントに変換します。コネクターまたはカスタムステップのエクステンション定義 JSON ファイルでは、各アクションの指定が入力データシェイプ (inputDataShape) および出力データシェイプ (outputDataShape) を定義します。
エクステンションを開発する場合、データマッパーがソースおよびターゲットフィールドを正しく処理および表示できるようにするデータシェイププロパティーを指定することが重要になります。以下のデータシェイププロパティーは、データマッパーの動作に影響します。
-
kind -
type -
specification -
name -
description
kind プロパティー
データシェイプ kind プロパティーは DataShapeKinds 列挙によって表されます。kind プロパティーで使用可能な値は次のとおりです。
javaは、データタイプが Java クラスによって表されることを示します。typeプロパティーの完全修飾クラス名を指定して、"kind": "java"宣言に従います。以下に例を示します。"outputDataShape": { "kind": "java", "type": "org.apache.camel.component.telegram.model.IncomingMessage" },"outputDataShape": { "kind": "java", "type": "org.apache.camel.component.telegram.model.IncomingMessage" },Copy to Clipboard Copied! Toggle word wrap Toggle overflow json-schemaはデータタイプが JSON スキーマによって表されることを示します。kindがjson-schemaに設定された場合、JSON スキーマをデータシェイプのspecificationプロパティーの値として指定します。以下に例を示します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow SAP Concur コネクターのコードには、JSON スキーマによって指定されるデータシェイプの例 が含まれています。
json-instanceは、データタイプが JSON インスタンスで表されることを示しています。kindがjson-instanceに設定された場合、JSON インスタンスをデータシェイプのspecificationプロパティーの値として指定します。以下に例を示します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow xml-schemaは、データタイプが XML スキーマで表されることを示しています。kindがxml-schemaに設定された場合、XML スキーマをデータシェイプのspecificationプロパティーの値として指定します。以下に例を示します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow xml-instanceは、データタイプが XML インスタンスによって表されることを示しています。kindがxml-instanceに設定された場合、XML インスタンスをデータシェイプのspecificationプロパティーの値として指定します。以下に例を示します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow anyは、データタイプが構造化されていないことを示します。たとえば、バイト配列やフリーフォーマットテキストであることがあります。データマッパーは、kindプロパティーがanyに設定されている場合にデータシェイプを無視します。つまり、データはデータマッパーに表示されないため、このデータとフィールドの間にマッピングを作成することはできません。しかし、
kindプロパティーがanyに設定された場合、カスタムコネクターから作成したコネクションを設定するときに、Fuse Online は入力および出力データタイプを指定するよう要求します。これは、コネクションをインテグレーションに追加するときに発生します。データシェイプのスキーマの種類、指定するスキーマの種類に対応するドキュメント、およびデータタイプの名前を指定できます。-
noneはデータタイプがないことを示します。入力データシェイプでは、コネクションまたはステップがデータを読み取らないことを示します。出力データシェイプでは、コネクションまたはステップがデータを変更しないことを示します。たとえば、入力メッセージボディーが出力メッセージボディーに転送される場合は、kindプロパティーをnoneに設定すると、データが通過することを意味します。データマッパーは、kindがnoneに設定された場合にデータシェイプを無視します。つまり、データはデータマッパーに表示されないため、このデータとフィールドの間にマッピングを作成することはできません。
type プロパティー
kind プロパティーの値が java の場合、"kind": "java" 宣言の後に完全修飾 Java クラス名を指定する type 宣言が続きます。以下に例を示します。
"outputDataShape": {
"kind": "java",
"type": "org.apache.camel.component.telegram.model.IncomingMessage"
},
"outputDataShape": {
"kind": "java",
"type": "org.apache.camel.component.telegram.model.IncomingMessage"
},
kind プロパティーが java 以外に設定された場合、type プロパティーの設定は無視されます。
specification プロパティー
kind プロパティーの設定は、以下の表のように、specification プロパティーの設定を決定します。
kind プロパティーの設定 | specification プロパティーの設定 |
|---|---|
|
| Java インスペクションの結果。
Java で作成する各エクステンションに、
Java で記述されたステップエクステンションの場合、 |
|
| 実際の JSON スキーマのドキュメント。設定をドキュメントへの参照とすることはできず、参照の手段として JSON スキーマが他の JSON スキーマドキュメントを示すことはできません。 |
|
| サンプルデータが含まれる実際の JSON ドキュメント。データマッパーは、サンプルデータからデータタイプを取得します。この設定をドキュメントへの参照とすることはできません。 |
|
| 実際の XML スキーマドキュメント。設定をドキュメントへの参照とすることはできず、参照の手段として XML スキーマが他の XML スキーマドキュメントを示すことはできません。 |
|
| 実際の XML インスタンスドキュメントです。この設定をドキュメントへの参照とすることはできません。 |
|
|
|
|
|
|
name プロパティー
データシェイプの name プロパティーは、データタイプの人間が判読できる名前を指定します。データマッパーは、この名前をデータフィールドのラベルとしてユーザーインターフェースに表示します。以下のイメージの Twitter Mention は、name プロパティーの値が表示される場所の例になります。
この名前は、Fuse Online フロービジュアライゼーションのデータタイプインジケーターにも表示されます。
description プロパティー
データシェイプの description プロパティーは、データマッパーユーザーインターフェースのデータタイプ名にカーソルを合わせたときにツールチップとして表示されるテキストを指定します。
10.3.8. ステップエクステンションの開発例
ステップエクステンションは、1 つまたは複数のカスタムステップを実装します。各カスタムステップは、コネクション間のインテグレーションデータを処理するために 1 つのアクションを実装します。以下の例は、ステップエクステンション開発の代替を示します。
Syndesis は、syndesis-extension-plugin とともに使用できる、カスタム Java アノテーションを提供します。ステップエクステンションまたはコネクターエクステンションを Java で実装する場合、Maven がアクション定義をエクステンション定義 JSON ファイルに追加できるようにするアノテーションを指定できます。アノテーションの処理を有効にするには、以下の依存関係を Maven プロジェクトに追加します。
<dependency> <groupId>io.syndesis.extension</groupId> <artifactId>extension-annotation-processor</artifactId> <optional>true</optional> </dependency>
<dependency>
<groupId>io.syndesis.extension</groupId>
<artifactId>extension-annotation-processor</artifactId>
<optional>true</optional>
</dependency>
Spring Boot はインテグレーションランタイムであるため、Bean を Camel コンテキストにインジェクトするには、Spring Boot の標準の方法に従う必要があります。たとえば、自動設定クラスを作成 し、Bean を作成します。ただし、デフォルトの動作では、エクステンションコードはパッケージスキャンの対象ではありません。したがって、ステップエクステンションの META-INF/spring.factories ファイルを作成し、内容を追加する必要があります。
10.3.8.1. XML フラグメントでの Camel ルートの開発例
カスタムステップを開発するには、direct などの入力がある Camel ルートである XML フラグメントとして、アクションを実装できます。Syndesis ランタイムは、このルートを他の Camel ルートを呼び出す同じ方法で呼び出します。
たとえば、任意の接頭辞を持つメッセージのボディーをログに記録するステップを作成する場合に以下の XML はこれを行う Camel ルートを定義します。
XML でエクステンションを開発する場合は、エクステンション定義 JSON ファイルを独自に作成する必要があります。この XML フラグメントに対し、src/main/resources/META-INF/syndesis/syndesis-extension-definition.json ファイルは以下のようにアクションを定義できます。
- 1
- アクションのタイプは
ENDPOINTです。ランタイムは、Camel エンドポイントを呼び出して、このカスタムステップによって提供されるアクションを実行します。 - 2
- 呼び出す Camel エンドポイントは
direct:logです。これはルートのfrom指定です。 - 3
- これは、XML フラグメントの場所になります。
- 4
- これらは、このカスタムステップでアクションが定義したプロパティーで、このステップをインテグレーションに追加するインテグレーターに公開します。Fuse Online では、インテグレーターがユーザーインターフェースで指定する値は、プロパティーと同じ名前を持つメッセージヘッダーにマップされます。この例では、インテグレーターは Log Prefix 表示名を持つ 1 つの入力フィールドを確認できます。詳細は「ユーザーインターフェースプロパティーの説明」を参照してください。
Syndesis は、完全な Camel XML 設定をサポートしません。Syndesis は <routes> タグのみをサポートします。
10.3.8.2. RouteBuilder を使った Camel ルートの開発例
カスタムステップを実装するには、RouteBuilder クラスを利用してアクションを Camel ルートとして開発します。このようなルートには、direct などの入力があります。Syndesis は、他の Camel ルートの呼び出しと同じ方法でこのルートを呼び出します。
任意の接頭辞でメッセージのボディーをログに記録するステップを作成する例を実装するには、以下のように記述します。
- 1
@Actionアノテーションは、アクション定義を示します。- 2
@ConfigurationPropertyアノテーションは、ユーザーインターフェースのフォームコントロールの定義を示します。詳細は「ユーザーインターフェースプロパティーの説明」を参照してください。- 3
- これはアクションの実装です。
この Java コードは Syndesis アノテーションを使用するため、extension-maven-plugin はアクション定義を自動的に生成できます。エクステンション定義 JSON ファイルのアクション定義は以下のようになります。
- 1
- アクションのタイプは
ENDPOINTです。ランタイムは Camel エンドポイントを呼び出して、このステップが実装するアクションを実行します。 - 2
- これが呼び出す Camel エンドポイントです。これはルートの
from指定です。 - 3
- これは、
RoutesBuilderを実装するクラスです。 - 4
- これらは、このカスタムステップでアクションが定義したプロパティーで、このステップをインテグレーションに追加するインテグレーターに公開します。Fuse Online では、インテグレーターがユーザーインターフェースで指定する値は、プロパティーと同じ名前を持つメッセージヘッダーにマップされます。この例では、インテグレーターは Log Prefix 表示名を持つ 1 つの入力フィールドを確認できます。詳細は「ユーザーインターフェースプロパティーの説明」を参照してください。
10.3.8.3. RouteBuilder および Spring Boot を使った Camel ルートの開発例
RouteBuilder クラスと Spring Boot を利用してアクションを Camel ルートとして開発します。この例では、Spring Boot は RouteBuilder オブジェクトを Camel コンテキストに登録するファシリティーです。Syndesis は、他の Camel ルートの呼び出しと同じ方法でこのルートを呼び出します。
任意の接頭辞でメッセージのボディーをログに記録するステップを作成する例を実装するには、以下のように記述します。
- 1
@Actionアノテーションは、アクション定義を示します。- 2
@ConfigurationPropertyアノテーションは、ユーザーインターフェースのフォームコントロールの定義を示します。詳細は「ユーザーインターフェースプロパティーの説明」を参照してください。- 3
RouteBuilderオブジェクトを Bean として登録します。- 4
- これはアクションの実装です。
この Java コードは Syndesis アノテーションを使用するため、extension-maven-plugin はアクション定義を自動的に生成できます。エクステンション定義 JSON ファイルのアクション定義は以下のようになります。
- 1
- アクションのタイプは
ENDPOINTです。ランタイムは Camel エンドポイントを呼び出して、このステップが実装するアクションを実行します。 - 2
- これが呼び出す Camel エンドポイントです。これはルートの
from指定です。 - 3
- これらは、このカスタムステップでアクションが定義したプロパティーで、このステップをインテグレーションに追加するインテグレーターに公開します。Fuse Online では、インテグレーターがユーザーインターフェースで指定する値は、プロパティーと同じ名前を持つメッセージヘッダーにマップされます。この例では、インテグレーターは Log Prefix 表示名を持つ 1 つの入力フィールドを確認できます。詳細は「ユーザーインターフェースプロパティーの説明」を参照してください。
Spring Boot が設定クラスを検出できるようにするには、以下のように META-INF/spring.factories という名前のファイルにこれらのクラスを記載する必要があります。
org.springframework.boot.autoconfigure.EnableAutoConfiguration=com.company.ActionsConfiguration
Spring Boot では、設定クラスに最終的に登録するすべての Bean を Camel コンテキストで利用できます。詳細は、独自の自動設定を作成するための Spring Boot ドキュメントを参照してください。
10.3.8.4. Camel Bean の使用例
アクションを Camel Bean プロセッサーとして開発すると、カスタムステップを実装できます。任意の接頭辞でメッセージのボディーをログに記録するステップを作成する例を実装するには、以下のように記述します。
- 1
- これは、アクションを実装する関数です。
この Java コードは Syndesis アノテーションを使用するため、extension-maven-plugin はアクション定義を自動的に生成できます。エクステンション定義 JSON ファイルのアクション定義は以下のようになります。
- 1
- アクションのタイプは
BEANです。ランタイムは、Camel Bean プロセッサーを呼び出して、このカスタムステップのアクションを実行します。 - 2
- この Camel Bean を呼び出します。
- 3
- これらは、このカスタムステップでアクションが定義したプロパティーで、このステップをインテグレーションに追加するインテグレーターに公開します。Fuse Online では、インテグレーターがユーザーインターフェースで指定する値は、プロパティーと同じ名前を持つメッセージヘッダーにマップされます。この例では、インテグレーターは Log Prefix 表示名を持つ 1 つの入力フィールドを確認できます。詳細は「ユーザーインターフェースプロパティーの説明」を参照してください。
Bean を使用する場合、交換ヘッダーからユーザープロパティーを取得する代わりに、ユーザープロパティーを Bean にインジェクトすると便利である可能性があります。これには、インジェクトするプロパティーに getter および setter メソッドを実装します。アクション実装は以下のようになります。
10.3.8.5. Syndesis Step API の使用例
Syndesis Step API を使用することで、カスタムステップを実装できます。これにより、ランタイムルートの作成と対話することが可能になります。ProcessorDefinition クラスによって提供されるすべてのメソッドを使用でき、さらに複雑なルートを作成できます。Syndesis API に関する情報は http://javadoc.io/doc/io.syndesis.extension/extension-api を参照してください。
以下は、スプリットアクションを実装するために Syndesis Step API を使用するステップエクステンションの例になります。
- 1
- これは、カスタムステップが実行するアクションの実装です。
この Java コードは Syndesis アノテーションを使用するため、extension-maven-plugin はアクション定義を自動的に生成できます。エクステンション定義 JSON ファイルのアクション定義は以下のようになります。
その他のリソース
ユーザーインターフェースプロパティーの詳細は「ユーザーインターフェースプロパティーの説明」を参照してください。
10.3.9. コネクターエクステンションの開発例
Fuse Online が、インテグレーションで接続するアプリケーションやサービスのコネクターを提供しない場合、経験のある開発者は Fuse Online に新しいコネクターを提供するエクステンションを作成できます。
コネクターエクステンションでは、Java コードからエクステンション定義 JSON ファイルを自動的に生成できません。
コネクターは基本的に Camel コンポーネントのプロキシーになります。コネクターは基盤のコンポーネントを設定し、エクステンション定義で定義されるオプションや、Fuse Online Web インターフェースが収集するユーザー提供のオプションに応じてエンドポイントを作成します。
コネクターエクステンションの定義は、以下の追加のデータ構造を使用して、ステップエクステンションに必要なエクステンション定義を拡張します。
componentSchemeコネクターが使用する Camel コンポーネントを定義します。コネクターまたはアクションに
componentSchemeを設定できます。componentSchemeをコネクターとアクションの両方に設定した場合、アクションの設定が優先されます。connectorCustomizersComponentProxyCustomizer クラスを実装するクラスの一覧を指定します。各クラスはコネクターの動作をカスタマイズします。たとえば、クラスはプロパティーが基礎となるコンポーネントやエンドポイントに適用される前にプロパティーを操作したり、クラスは事前または事後のエンドポイントロジックを追加する場合があります。各クラスに対して、
com.mycomponent.MyCustomizerのように実装の完全クラス名を指定します。connectorCustomizersはアクションおよびコネクターに設定できます。Fuse Online は設定に応じて、カスタマイザーを最初にコネクターに適用した後、アクションに適用します。connectorFactory基盤のコンポーネント/エンドポイントの作成や設定を行う、ComponentProxyFactory クラスを実装するクラスを定義します。実装の完全クラス名を指定します。コネクターまたはアクションに
connectorFactoryを設定できます。アクションには優先順位があります。
カスタマイザーの例
以下のカスタマイザーの例は、個別のオプションから DataSource を設定します。
プロパティーのインジェクト例
カスタマイザーが Java Bean の慣例に従う場合、以下のようにプロパティーもインジェクトできます (前述の例を編集)。
カスタマイザーを使用した before/after 論理の設定
以下の例のように、カスタマイザーを使用して before/after 論理を設定できます。
ComponentProxyComponent の動作のカスタマイズ
ComponentProxyFactory クラスは、基礎となるコンポーネント/エイドポイントの作成や設定を行います。ComponentProxyFactory が作成する ComponentProxyComponent オブジェクトの動作をカスタマイズするには、以下のメソッドのいずれかをオーバーライドします。
createDelegateComponent()Syndesis は、プロキシーの開始時にこのメソッドを呼び出し、最終的に
componentSchemeオプションによって定義されたスキームでコンポーネントの専用インスタンスを作成します。このメソッドのデフォルトの動作は、いずれかのコネクター/アクションオプションがコンポーネントレベルで適用されるかどうかを判断します。同じオプションをエンドポイントに適用できない場合のみ、メソッドによってカスタムコンポーネントインスタンスが作成され、適用可能なオプションに応じて設定されます。
configureDelegateComponent()`Syndesis は、委譲されたコンポーネントインスタンスの追加の動作を設定するためにカスタムコンポーネントインスタンスが作成された場合に限り、このメソッドを呼び出します。
createDelegateEndpoint()Syndesis は、プロキシーがエンドポイントを作成するときにこのメソッドを呼び出し、デフォルトで Camel カタログファシリティーを使用してエンドポイントを作成します。
configureDelegateEndpoint()委譲されたエンドポイントの作成後に、Syndesis がこのメソッドを呼び出し、委譲されたエンドポイントインスタンスの追加動作を設定します。以下に例を示します。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
10.3.10. ライブラリーエクステンションの開発方法
ライブラリーエクステンションは、インテグレーションがランタイムに必要なリソースを提供します。ライブラリーエクステンションは、ステップやコネクターを Fuse Online に提供しません。
ライブラリーエクステンションのサポートは拡大中です。本リリースでは、Fuse Online Web インターフェースは以下を行います。
- インテグレーションを作成するときに、インテグレーションに含まれる必要があるライブラリーエクステンションを選択できません。
-
データベースコネクションをインテグレーションに追加するとき、Fuse Online は
jdbc-driverタグがあるすべてのエクステンションをインテグレーションランタイムに追加します。
ライブラリーエクステンションは、いかなるアクションも定義しません。以下は、ライブラリーエクステンションの定義例になります。
ライブラリーエクステンションの構造は、アクションがないこと以外は、ステップまたはコネクターエクステンションの構造と同じです。
ライブラリーエクステンションを作成する Maven プロジェクトで、Maven リポジトリーから使用できない依存関係を追加するには、以下のように system 依存関係を指定します。
10.3.11. JDBC ドライバーライブラリーエクステンションの作成
Apache Derby、MySQL、および PostgreSQL 以外の SQL データベースに接続するには、接続するデータベースの JDBC ドライバーをラップするライブラリーエクステンションを作成します。Fuse Online にこのエクステンションをアップロードした後、Fuse Online が提供する Database コネクターはドライバーにアクセスしてプロプライエタリーデータベースへのコネクションを検証および作成することができます。特定のデータベースに新しいコネクターを作成しません。
Syndesis オープンソースコミュニティーは、JDBC ドライバーをラップするエクステンションを作成するためのプロジェクトを提供します。
エクステンションで 1 つのドライバーのみをパッケージ化します。これにより、特定のデータベースを管理する一環として、エクステンションの管理が容易になります。ただし、複数のドライバーをラップするライブラリーエクステンションを作成することは可能です。
前提条件
Syndesis プロジェクトを使用するには、GitHub アカウントが必要です。
手順
以下のいずれかを行って、接続するデータベースの JDBC ドライバーへアクセスできるようにします。
- ドライバーが Maven リポジトリーにあることを確認します。
- ドライバーをダウンロードします。
- ブラウザーのタブで https://github.com/syndesisio/syndesis-extensions にアクセスします。
-
syndesis-extensionsリポジトリーを GitHub アカウントにフォークします。 - フォークからローカルのクローンを作成します。
syndesis-extensionsのクローンで以下を行います。-
このドライバーが Maven リポジトリーにない場合、
syndesis-library-jdbc-driver/libフォルダーにコピーします。 syndesis-library-jdbc-driver/pom.xmlファイルを編集します。-
Name要素の値を更新し、このエクステンションに選択する名前にします。 -
Description要素の値を更新し、このエクステンションに関する便利な情報を提供します。 -
このドライバーが Maven リポジトリーにある場合は、その Maven リポジトリーへの参照が
pom.xmlファイルにあることを確認します。 -
pom.xmlファイルの残りの内容を確認し、必要に応じて関連するメタデータを変更します。
-
-
syndesis-library-jdbc-driverフォルダーで、mvn clean packageを実行してエクステンションを構築します。
-
このドライバーが Maven リポジトリーにない場合、
生成された .jar ファイルは syndesis-library-jdbc-driver/target フォルダーにあります。Fuse Online にアップロードするこの .jar ファイルを提供します。
現在 Fuse Online には、インテグレーションに含まれる必要があるライブラリーエクステンションを選択する方法がありません。データベースコネクションをインテグレーションに追加するとき、Fuse Online は jdbc-driver タグがあるすべてのエクステンションをインテグレーションランタイムに追加します。これは、今後のリリースで改善される予定です。
10.4. エクステンションの追加および管理
エクステンションを使用すると、Fuse Online にカスタマイズを追加できるため、アプリケーションを好きなように統合できます。エクステンションで提供されるカスタマイズを使い始めた後、これらのカスタマイズを使用するインテグレーションを特定できます。これは、エクステンションを更新または削除する前に便利です。
詳細は以下のトピックを参照してください。
10.4.1. カスタム機能の使用
インテグレーションでカスタム機能を使用できるようにするには、エクステンションを Fuse Online にアップロードします。
前提条件
-
開発者によって、Fuse Online エクステンションが含まれる
.jarファイルが提供済みである必要があります。
手順
- Fuse Online の左パネルで Customizations > Extensions をクリックします。
- Import Extension をクリックします。
アップロードするエクステンションが含まれる
.jarファイルをドラッグアンドドロップまたは選択します。Fuse Online は、ファイルにエクステンションが含まれることを即座に検証しようとします。問題がある場合、Fuse Online はエラーに関するメッセージを表示します。エクステンションの開発者と協力して、更新された
.jarファイルを取得する必要があります。取得後、そのファイルをアップロードします。エクステンションの詳細を確認します。
Fuse Online はファイルの検証後、エクステンションの名前、ID、説明、およびタイプを抽出および表示します。タイプは、カスタムコネクター、コネクション間のデータを操作する 1 つ以上のカスタムステップ、またはプロプライエタリーデータの JDBC ドライバーをエクステンションが定義するかどうかを示します。JDBC ドライバーを提供するエクステンションは、ライブラリーエクステンションと呼ばれます。
コネクターエクステンションの場合、Fuse Online はこのカスタムコネクターから作成されたコネクションで使用できるアクションを表示します。エクステンションでは、開発者は、このコネクターから作成されたアプリケーションコネクションを表すために Fuse Online が使用するアイコンを提供することがあります。このアイコンは、エクステンションの詳細ページには表示されませんが、カスタムコネクターからコネクションを作成すると表示されます。エクステンションの開発者がエクステンションのアイコンを指定しなかった場合、Fuse Online はアイコンを生成します。
ステップエクステンションでは、Fuse Online はエクステンションが定義する各カスタムステップの名前を表示します。
ライブラリーエクステンションでは、このエクステンションに以前にアップロードした新しいバージョンの JDBC ドライバーが含まれている場合は、クラスパスから古いバージョンを削除する必要があります。クラスパスにあるのは、このドライバーの 1 つのバージョンのみで、アップロードする新しいドライバーへの参照があることを確認します。稼働中のインテグレーションや、古いドライバーを基にしてコネクションを使用するインテグレーションは影響を受けません。作成する新しいコネクションは新しいドライバーを使用します。古いドライバーで作成されたコネクションがあるインテグレーションを開始する場合、Fuse Online は代わりに新しいドライバーを自動的に使用します。
- Import Extension をクリックします。Fuse Online はカスタムコネクターまたはカスタムステップを使用できるようにし、エクステンションの詳細ページを表示します。
その他のリソース
10.4.2. エクステンションを使用するインテグレーションの特定
エクステンションを更新または削除する前に、そのエクステンションが提供するカスタマイズを使用するインテグレーションを特定する必要があります。
手順
- Fuse Online の左パネルで Customizations > Extensions をクリックします。
- エクステンションの一覧で、更新または削除するエクステンションのエントリーを見つけ、Details ボタンをクリックします。
結果
Fuse Online は、エクステンションに関する詳細を表示します。これには、エクステンションが提供するカスタマイズを使用するインテグレーションのリストが含まれます。
10.4.3. エクステンションの更新
開発者がエクステンションを更新する場合、更新された .jar ファイルをアップロードし、インテグレーションで更新を実装することができます。
前提条件
開発者は、以前にアップロードしたエクステンションの更新された .jar ファイルを提供する必要があります。
手順
- Fuse Online の左側のパネルで Customizations > Extensions をクリックします。
- 更新するエクステンションのエントリーの右側にある Update をクリックします。
-
点線のボックスをクリックして、更新された
.jarファイルに移動および選択し、Open をクリックします。 - エクステンションの詳細が正しいことを確認し、Import Extension をクリックします。
- 更新されたエクステンションの詳細ページで、エクステンションに定義されたコネクターまたはカスタムステップを使用するインテグレーションを特定します。
更新されたエクステンションからカスタムコネクターまたはカスタムステップを使用する各インテグレーションを更新するのに何が必要であるかを確認するのはユーザー次第です。少なくとも、更新されたエクステンションに定義されたカスタマイズを使用する各インテグレーションを再パブリッシュする必要があります。
インテグレーションを編集し、カスタマイズの設定詳細を変更または追加する必要が場合があります。インテグレーションの更新方法を理解するには、エクステンションの開発者と対話する必要があります。
10.4.4. エクステンションの削除
実行中のインテグレーションがエクステンションによって提供されるステップを使用したり、エクステンションによって提供されたコネクターから作成されたコネクションを使用しても、そのエクステンションを削除できます。エクステンションの削除後に、そのエクステンションによって提供されたカスタマイズを使用するインテグレーションを開始することはできません。
手順
- Fuse Online の左パネルで Customizations > Extensions をクリックします。
- エクステンションの一覧で、削除するエクステンションのエントリーを見つけ、エントリーの右側に表示される Delete をクリックします。
結果
削除するエクステンションによって提供されるカスタマイズを使用する、停止したインテグレーションまたは下書きのインテグレーションが存在する可能性があります。このようなインテグレーションを実行するには、インテグレーションを編集して、カスタマイズを削除する必要があります。
その他のリソース