このコンテンツは選択した言語では利用できません。
Maintaining Red Hat Hyperconverged Infrastructure for Virtualization
Common maintenance tasks for Red Hat Hyperconverged Infrastructure for Virtualization
Abstract
Part I. Configuration tasks
Chapter 1. Add compute and storage resources
Red Hat Hyperconverged Infrastructure for Virtualization (RHHI for Virtualization) can be scaled to 6, 9, or 12 nodes.
You can add compute and storage resources in several ways:
You can also increase the space available on your existing nodes to expand storage without expanding compute resources.
1.1. Creating new bricks using ansible
If you want to create bricks on a lot of hosts at once, you can automate the process by creating an ansible playbook. Follow this process to create and run a playbook that creates, formats, and mounts bricks for use in a hyperconverged environment.
Prerequisites
Install the physical machines to host your new bricks.
Follow the instructions in Install Physical Host Machines.
Configure key-based SSH authentication without a password between all nodes.
Configure this from the node that is running the Web Console to all new nodes, and from the first new node to all other new nodes.
ImportantRHHI for Virtualization expects key-based SSH authentication without a password between these nodes for both IP addresses and FQDNs. Ensure that you configure key-based SSH authentication between these machines for the IP address and FQDN of all storage and management network interfaces.
Follow the instructions in Using key-based authentication to configure key-based SSH authentication without a password.
- Verify that your hosts do not use a Virtual Disk Optimization (VDO) layer. If you have a VDO layer, use Section 1.2, “Creating new bricks above VDO layer using ansible” instead.
Procedure
Create an
inventoryfileCreate a new
inventoryfile in the/etc/ansible/roles/gluster.infra/playbooksdirectory using the following example.This file lists the hosts on which to create new bricks.
Example
inventoryfile[hosts] server4.example.com server5.example.com server6.example.com
Create a
bricks.ymlvariables fileCreate a new
bricks.ymlfile in the/etc/ansible/roles/gluster.infra/playbooksdirectory using the following example.This file defines the underlying storage infrastructure and settings to be created or used on each host.
Example
bricks.ymlvariable file# gluster_infra_disktype # Set a disk type. Options: JBOD, RAID6, RAID10 - Default: JBOD gluster_infra_disktype: RAID10 # gluster_infra_dalign # Dataalignment, for JBOD default is 256K if not provided. # For RAID{6,10} dataalignment is computed by multiplying # gluster_infra_diskcount and gluster_infra_stripe_unit_size. gluster_infra_dalign: 256K # gluster_infra_diskcount # Required only for RAID6 and RAID10. gluster_infra_diskcount: 10 # gluster_infra_stripe_unit_size # Required only in case of RAID6 and RAID10. Stripe unit size always in KiB, do # not provide the trailing `K' in the value. gluster_infra_stripe_unit_size: 128 # gluster_infra_volume_groups # Variables for creating volume group gluster_infra_volume_groups: - { vgname: 'vg_vdb', pvname: '/dev/vdb' } - { vgname: 'vg_vdc', pvname: '/dev/vdc' } # gluster_infra_thick_lvs # Variable for thick lv creation gluster_infra_thick_lvs: - { vgname: 'vg_vdb', lvname: 'vg_vdb_thicklv1', size: '10G' } # gluster_infra_thinpools # thinpoolname is optional, if not provided `vgname' followed by _thinpool is # used for name. poolmetadatasize is optional, default 16G is used gluster_infra_thinpools: - {vgname: 'vg_vdb', thinpoolname: 'foo_thinpool', thinpoolsize: '10G', poolmetadatasize: '1G' } - {vgname: 'vg_vdc', thinpoolname: 'bar_thinpool', thinpoolsize: '20G', poolmetadatasize: '1G' } # gluster_infra_lv_logicalvols # Thinvolumes for the brick. `thinpoolname' is optional, if omitted `vgname' # followed by _thinpool is used gluster_infra_lv_logicalvols: - { vgname: 'vg_vdb', thinpool: 'foo_thinpool', lvname: 'vg_vdb_thinlv', lvsize: '500G' } - { vgname: 'vg_vdc', thinpool: 'bar_thinpool', lvname: 'vg_vdc_thinlv', lvsize: '500G' } # Setting up cache using SSD disks gluster_infra_cache_vars: - { vgname: 'vg_vdb', cachedisk: '/dev/vdd', cachethinpoolname: 'foo_thinpool', cachelvname: 'cachelv', cachelvsize: '20G', cachemetalvname: 'cachemeta', cachemetalvsize: '100M', cachemode: 'writethrough' } # gluster_infra_mount_devices gluster_infra_mount_devices: - { path: '/rhgs/thicklv', vgname: 'vg_vdb', lvname: 'vg_vdb_thicklv1' } - { path: '/rhgs/thinlv1', vgname: 'vg_vdb', lvname: 'vg_vdb_thinlv' } - { path: '/rhgs/thinlv2', vgname: 'vg_vdc', lvname: 'vg_vdc_thinlv' }ImportantIf the
path:defined does not begin with/rhgsthe bricks are not detected automatically by the Administration Portal. Synchronize the host storage after running thecreate_brick.ymlplaybook to add the new bricks to the Administration Portal.Create a
create_brick.ymlplaybook fileCreate a new
create_brick.ymlfile in the/etc/ansible/roles/gluster.infra/playbooksdirectory using the following example.This file defines the work involved in creating a brick using the
gluster.infrarole and the variable file you created above.Example
create_brick.ymlplaybook file--- - name: Create a GlusterFS brick on the servers remote_user: root hosts: all gather_facts: false vars_files: - bricks.yml roles: - gluster.infraExecute the playbook
Run the following command from the
/etc/ansible/roles/gluster.infra/playbooksdirectory to run the playbook you created using the inventory and the variables files you defined above.# ansible-playbook -i inventory create_brick.yml
Verify that your bricks are available
- Click Compute → Hosts and select the host.
Click Storage Devices and check the list of storage devices for your new bricks.
If you cannot see your new bricks, click Sync and wait for them to appear in the list of storage devices.
1.2. Creating new bricks above VDO layer using ansible
If you want to create bricks on a lot of hosts at once, you can automate the process by creating an ansible playbook.
Prerequisites
Install the physical machines to host your new bricks.
Follow the instructions in Install Physical Host Machines.
Configure key-based SSH authentication without a password between all nodes.
Configure this from the node that is running the Web Console to all new nodes, and from the first new node to all other new nodes.
ImportantRHHI for Virtualization expects key-based SSH authentication without a password between these nodes for both IP addresses and FQDNs. Ensure that you configure key-based SSH authentication between these machines for the IP address and FQDN of all storage and management network interfaces.
Follow the instructions in Using key-based authentication to configure key-based SSH authentication without a password.
- Verify that your hosts use a Virtual Disk Optimization (VDO) layer. If you do not have a VDO layer, use Section 1.1, “Creating new bricks using ansible” instead.
Procedure
Create an
inventoryfileCreate a new
inventoryfile in the/etc/ansible/roles/gluster.infra/playbooksdirectory using the following example.This file lists the hosts on which to create new bricks.
Example
inventoryfile[hosts] server4.example.com server5.example.com server6.example.com
Create a
bricks.ymlvariables fileCreate a new
bricks.ymlfile in the/etc/ansible/roles/gluster.infra/playbooksdirectory using the following example.This file defines the underlying storage infrastructure and settings to be created or used on each host.
Example
vdo_bricks.ymlvariable file# gluster_infra_disktype # Set a disk type. Options: JBOD, RAID6, RAID10 - Default: JBOD gluster_infra_disktype: RAID10 # gluster_infra_dalign # Dataalignment, for JBOD default is 256K if not provided. # For RAID{6,10} dataalignment is computed by multiplying # gluster_infra_diskcount and gluster_infra_stripe_unit_size. gluster_infra_dalign: 256K # gluster_infra_diskcount # Required only for RAID6 and RAID10. gluster_infra_diskcount: 10 # gluster_infra_stripe_unit_size # Required only in case of RAID6 and RAID10. Stripe unit size always in KiB, do # not provide the trailing `K' in the value. gluster_infra_stripe_unit_size: 128 # VDO creation gluster_infra_vdo: - { name: 'hc_vdo_1', device: '/dev/vdb' } - { name: 'hc_vdo_2', device: '/dev/vdc' } # gluster_infra_volume_groups # Variables for creating volume group gluster_infra_volume_groups: - { vgname: 'vg_vdb', pvname: '/dev/mapper/hc_vdo_1' } - { vgname: 'vg_vdc', pvname: '/dev/mapper/hc_vdo_2' } # gluster_infra_thick_lvs # Variable for thick lv creation gluster_infra_thick_lvs: - { vgname: 'vg_vdb', lvname: 'vg_vdb_thicklv1', size: '10G' } # gluster_infra_thinpools # thinpoolname is optional, if not provided `vgname' followed by _thinpool is # used for name. poolmetadatasize is optional, default 16G is used gluster_infra_thinpools: - {vgname: 'vg_vdb', thinpoolname: 'foo_thinpool', thinpoolsize: '10G', poolmetadatasize: '1G' } - {vgname: 'vg_vdc', thinpoolname: 'bar_thinpool', thinpoolsize: '20G', poolmetadatasize: '1G' } # gluster_infra_lv_logicalvols # Thinvolumes for the brick. `thinpoolname' is optional, if omitted `vgname' # followed by _thinpool is used gluster_infra_lv_logicalvols: - { vgname: 'vg_vdb', thinpool: 'foo_thinpool', lvname: 'vg_vdb_thinlv', lvsize: '500G' } - { vgname: 'vg_vdc', thinpool: 'bar_thinpool', lvname: 'vg_vdc_thinlv', lvsize: '500G' } # gluster_infra_mount_devices gluster_infra_mount_devices: - { path: '/rhgs/thicklv', vgname: 'vg_vdb', lvname: 'vg_vdb_thicklv1' } - { path: '/rhgs/thinlv1', vgname: 'vg_vdb', lvname: 'vg_vdb_thinlv' } - { path: '/rhgs/thinlv2', vgname: 'vg_vdc', lvname: 'vg_vdc_thinlv' }ImportantIf the
path:defined does not begin with/rhgsthe bricks are not detected automatically by the Administration Portal. Synchronize the host storage after running thecreate_brick.ymlplaybook to add the new bricks to the Administration Portal.Create a
create_brick.ymlplaybook fileCreate a new
create_brick.ymlfile in the/etc/ansible/roles/gluster.infra/playbooksdirectory using the following example.This file defines the work involved in creating a brick using the
gluster.infrarole and the variable file you created above.Example
create_brick.ymlplaybook file--- - name: Create a GlusterFS brick on the servers remote_user: root hosts: all gather_facts: false vars_files: - vdo_bricks.yml roles: - gluster.infraExecute the playbook
Run the following command from the
/etc/ansible/roles/gluster.infra/playbooksdirectory to run the playbook you created using the inventory and the variables files you defined above.# ansible-playbook -i inventory create_brick.yml
Verify that your bricks are available
- Click Compute → Hosts and select the host.
Click Storage Devices and check the list of storage devices for your new bricks.
If you cannot see your new bricks, click Sync and wait for them to appear in the list of storage devices.
1.3. Expanding volume from Red Hat Virtualization Manager
Follow this section to expand an existing volume across new bricks on new hyperconverged nodes.
Prerequisites
- Verify that your scaling plans are supported: Requirements for scaling.
- If your existing deployment uses certificates signed by a Certificate Authority for encryption, prepare the certificates required for the new nodes.
Install three physical machines to serve as the new hyperconverged nodes.
Follow the instructions in Install Physical Host Machines.
Configure key-based SSH authentication without a password.
Configure this from the node that is running the Web Console to all new nodes, and from the first new node to all other new nodes.
ImportantRHHI for Virtualization expects key-based SSH authentication without a password between these nodes for both IP addresses and FQDNs. Ensure that you configure key-based SSH authentication between these machines for the IP address and FQDN of all storage and management network interfaces.
Follow the instructions in Using key-based authentication to configure key-based SSH authentication without a password.
Procedure
Create new bricks
Create the bricks on the servers you want to expand your volume across by following the instructions in Creating bricks using ansible or Creating bricks above a VDO layer using ansible depending on your requirements.
ImportantIf the
path:defined does not begin with/rhgsthe bricks are not detected automatically by the Administration Portal. Synchronize the host storage after running thecreate_brick.ymlplaybook to synchronize the new bricks to the Administration Portal.- Click Compute → Hosts and select the host.
- Click Storage Devices.
- Click Sync.
Repeat for each host that has new bricks.
Add new bricks to the volume
- Log in to RHV Administration Console.
- Click Storage → Volumes and select the volume to expand.
- Click the Bricks tab.
- Click Add. The Add Bricks window opens.
Add new bricks.
- Select the brick host from the Host dropdown menu.
- Select the brick to add from the Brick Directory dropdown menu and click Add.
- When all bricks are listed, click OK to add bricks to the volume.
The volume automatically syncs the new bricks.
1.4. Expanding the hyperconverged cluster by adding a new volume on new nodes using the Web Console
Follow these instructions to use the Web Console to expand your hyperconverged cluster with a new volume on new nodes.
Prerequisites
- Verify that your scaling plans are supported: Requirements for scaling.
- If your existing deployment uses certificates signed by a Certificate Authority for encryption, prepare the certificates that will be required for the new nodes.
Install three physical machines to serve as the new hyperconverged nodes.
Follow the instructions in Deploying Red Hat Hyperconverged Infrastructure for Virtualization.
Configure key-based SSH authentication without a password.
Configure this from the node that is running the Web Console to all new nodes, and from the first new node to all other new nodes.
ImportantRHHI for Virtualization expects key-based SSH authentication without a password between these nodes for both IP addresses and FQDNs. Ensure that you configure key-based SSH authentication between these machines for the IP address and FQDN of all storage and management network interfaces.
Follow the instructions in Using key-based authentication to configure key-based SSH authentication without a password.
Procedure
- Log in to the Web Console.
- Click Virtualization → Hosted Engine and then click Manage Gluster.
Click Expand Cluster. The Gluster Deployment window opens.
On the Hosts tab, enter the FQDN or IP address of the new hyperconverged nodes and click Next.

On the Volumes tab, specify the details of the volume you want to create.
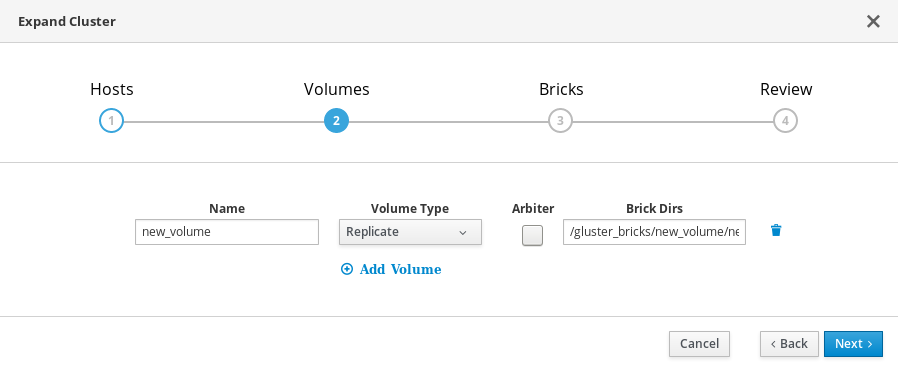
On the Bricks tab, specify the details of the disks to be used to create the Gluster volume.
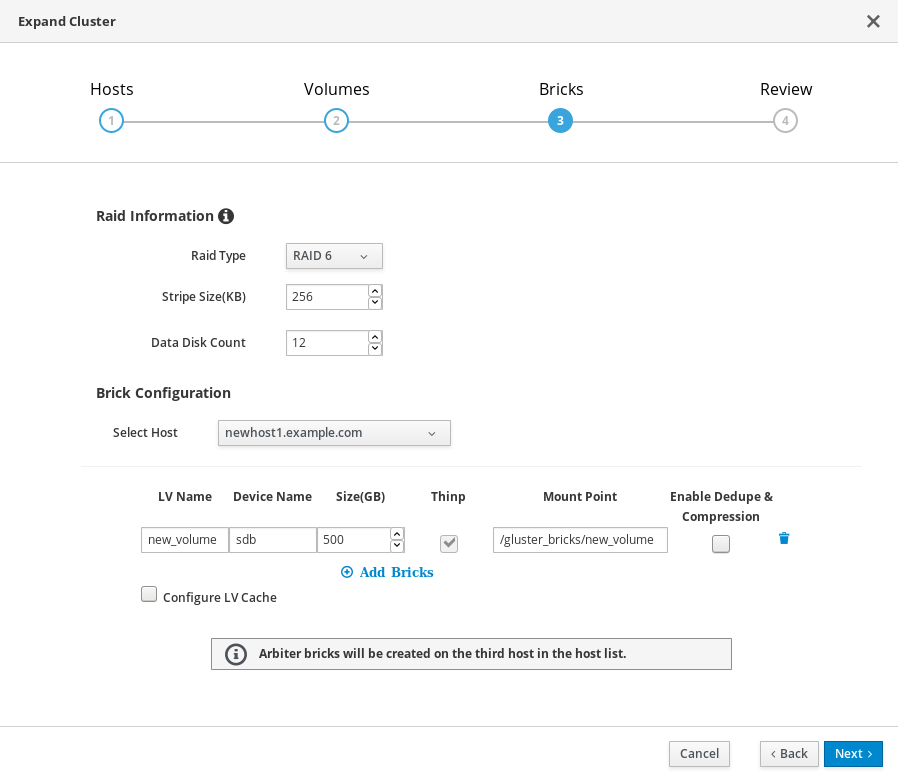
On the Review tab, check the generated file for any problems. When you are satisfied, click Deploy.
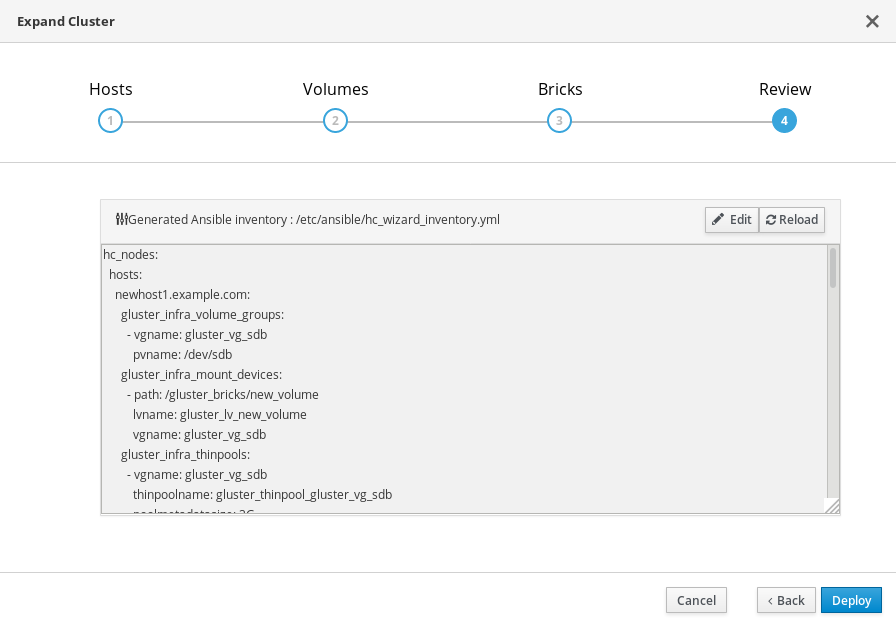
Deployment takes some time to complete. The following screen appears when the cluster has been successfully expanded.

Chapter 2. Configure high availability using fencing policies
Fencing allows a cluster to enforce performance and availability policies and react to unexpected host failures by automatically rebooting hyperconverged hosts.
Several policies specific to Red Hat Gluster Storage must be enabled to ensure that fencing activities do not disrupt storage services in a Red Hat Hyperconverged (RHHI for Virtualization) Infrastructure deployment.
This requires enabling and configuring fencing at both the cluster level and at the host level. See the following sections for details.
2.1. Configuring Fencing Policies in the Cluster
- In the Administration Portal, click Compute → Clusters.
- Select the cluster and click Edit. The Edit Cluster window opens.
- Click the Fencing policy tab.
- Check the Enable fencing checkbox.
Check the checkboxes for at least the following fencing policies:
- Skip fencing if gluster bricks are up
- Skip fencing if gluster quorum not met
See Appendix A, Fencing Policies for Red Hat Gluster Storage for details on the effects of these policies.
- Click OK to save settings.
2.2. Configuring Fencing Parameters on the Hosts
- In the Administration Portal, click Compute → Hosts.
- Select the host to configure, and click Edit to open the Edit Host window.
Click the Power Management tab.
Figure 2.1. Power Management Settings
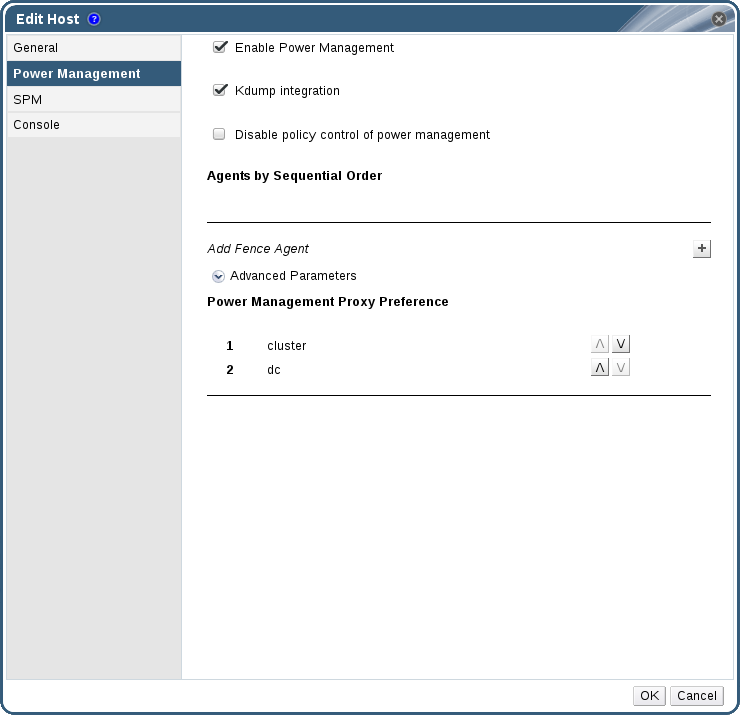
- Check the Enable Power Management check box. This enables other fields on the tab.
Check the Kdump integration check box to prevent the host from fencing while performing a kernel crash dump.
ImportantWhen you enable Kdump integration on an existing host, the host must be reinstalled for kdump to be configured. See Chapter 12, Reinstalling a hyperconverged host for instructions on reinstalling a host.
Click the plus (+) button to add a new power management device. The Edit fence agent window opens.
Figure 2.2. Edit fence agent
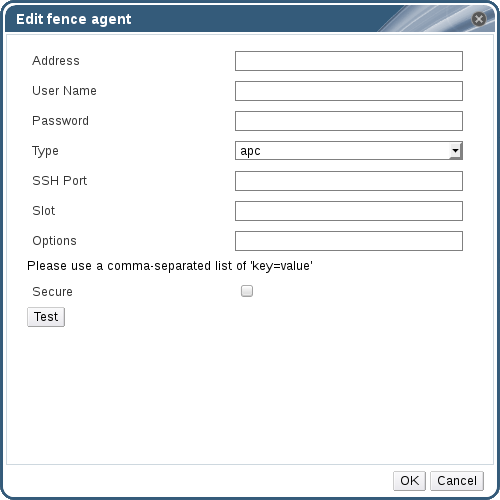
- Enter the Address, User Name, and Password of the power management device.
- Select the power management device Type from the drop-down list.
- Enter the SSH Port number used by the power management device to communicate with the host.
- Enter the Slot number used to identify the blade of the power management device.
- Enter the Options for the power management device. Use a comma-separated list of key=value entries.
- Check the Secure check box to enable the power management device to connect securely to the host.
Click the Test button to ensure the settings are correct. Test Succeeded, Host Status is: on displays upon successful verification.
WarningPower management parameters (userid, password, options, etc.) are tested by Red Hat Virtualization Manager in two situations: during setup, and when parameter values are manually changed in Red Hat Virtualization Manager. If you choose to ignore alerts about incorrect parameters, or if the parameters are changed on the power management hardware without the corresponding change in Red Hat Virtualization Manager, fencing is likely to fail.
- Click OK to finish adding the fence agent.
- Click OK to save your host configuration.
You are returned to the list of hosts. Note that the exclamation mark (!) next to the host’s name has now disappeared, signifying that power management has been successfully configured.
Chapter 3. Configuring backup and recovery options
This chapter explains how to add disaster recovery capabilities to your Red Hat Hyperconverged Infrastructure for Virtualization deployment so that you can restore your cluster to a working state after a disk or server failure.
3.1. Prerequisites
3.1.1. Prerequisites for geo-replication
Be aware of the following requirements and limitations when configuring geo-replication:
- One geo-replicated volume only
- Red Hat Hyperconverged Infrastructure for Virtualization (RHHI for Virtualization) supports only one geo-replicated volume. Red Hat recommends backing up the volume that stores the data of your virtual machines, as this is usually contains the most valuable data.
- Two different managers required
- The source and destination volumes for geo-replication must be managed by different instances of Red Hat Virtualization Manager.
3.1.2. Prerequisites for failover and failback configuration
- Versions must match between environments
- Ensure that the primary and secondary environments have the same version of Red Hat Virtualization Manager, with identical data center compatibility versions, cluster compatibility versions, and PostgreSQL versions.
- No virtual machine disks in the hosted engine storage domain
- The storage domain used by the hosted engine virtual machine is not failed over, so any virtual machine disks in this storage domain will be lost.
- Execute Ansible playbooks manually from a separate master node
- Generate and execute Ansible playbooks manually from a separate machine that acts as an Ansible master node.
3.2. Supported backup and recovery configurations
There are two supported ways to add disaster recovery capabilities to your Red Hat Hyperconverged Infrastructure for Virtualization deployment.
- Configure backing up to a secondary volume only
Regularly synchronizing your data to a remote secondary volume helps to ensure that your data is not lost in the event of disk or server failure.
This option is suitable if the following statements are true of your deployment.
- You require only a backup of your data for disaster recovery.
- You do not require highly available storage.
- You do not want to maintain a secondary cluster.
- You are willing to manually restore your data and reconfigure your backup solution after a failure has occurred.
Follow the instructions in Configuring backup to a secondary volume to configure this option.
- Configure failing over to and failing back from a secondary cluster
This option provides failover and failback capabilities in addition to backing up data on a remote volume. Configuring failover of your primary cluster’s operations and storage domains to a secondary cluster helps to ensure that your data remains available in event of disk or server failure in the primary cluster.
This option is suitable if the following statements are true of your deployment.
- You require highly available storage.
- You are willing to maintain a secondary cluster.
- You do not want to manually restore your data or reconfigure your backup solution after a failure has occurred.
Follow the instructions in Configuring failover to and failback from a secondary cluster to configure this option.
Red Hat recommends that you configure at least a backup volume for production deployments.
3.3. Configuring backup to a secondary volume
This section covers how to back up a gluster volume to a secondary gluster volume using geo-replication.
To do this, you must:
- Ensure that all prerequisites are met.
- Create a suitable volume to use as a geo-replication target.
- Configure a geo-replication session between the source volume and the target volume.
- Schedule the geo-replication process.
3.3.1. Prerequisites
3.3.1.2. Match encryption on source and target volumes
If encryption is enabled on the volume that you want to back up, encryption must also be enabled on the volume that will hold your backed up data.
See Configure Encryption with Transport Layer Security (TLS/SSL) for details.
3.3.2. Create a suitable target volume for geo-replication
Prepare a secondary gluster volume to hold the geo-replicated copy of your source volume. This target volume should be in a separate cluster, hosted at a separate site, so that the risk of source and target volumes being affected by the same outages is minimised.
Ensure that the target volume for geo-replication has sharding enabled. Run the following command on any node that hosts the target volume to enable sharding on that volume.
# gluster volume set <volname> features.shard enable
3.3.3. Configuring geo-replication for backing up volumes
3.3.3.1. Creating a geo-replication session
A geo-replication session is required to replicate data from an active source volume to a passive target volume.
Only rsync based geo-replication is supported with Red Hat Hyperconverged Infrastructure for Virtualization.
Create a common
pem pubfile.Run the following command on a source node that has key-based SSH authentication without a password configured to the target nodes.
# gluster system:: execute gsec_create
Create the geo-replication session
Run the following command to create a geo-replication session between the source and target volumes, using the created
pem pubfile for authentication.# gluster volume geo-replication <SOURCE_VOL> <TARGET_NODE>::<TARGET_VOL> create push-pem
For example, the following command creates a geo-replication session from a source volume prodvol to a target volume called backupvol, which is hosted by backup.example.com.
# gluster volume geo-replication prodvol backup.example.com::backupvol create push-pem
By default this command verifies that the target volume is a valid target with available space. You can append the
forceoption to the command to ignore failed verification.Configure a meta-volume
This relies on the source volume having shared storage configured, as described in Prerequisites.
# gluster volume geo-replication <SOURCE_VOL> <TARGET_HOST>::<TARGET_VOL> config use_meta_volume true
Do not start the geo-replication session. Starting the geo-replication session begins replication from your source volume to your target volume.
3.3.3.2. Verifying creation of a geo-replication session
- Log in to the Administration Portal on any source node.
- Click Storage → Volumes.
Check the Info column for the geo-replication icon.
If this icon is present, geo-replication has been configured for that volume.
If this icon is not present, try synchronizing the volume.
3.3.3.3. Synchronizing volume state using the Administration Portal
- Log in to the Administration Portal.
- Click Compute → Volumes.
- Select the volume that you want to synchronize.
- Click the Geo-replication sub-tab.
- Click Sync.
3.3.4. Scheduling regular backups using geo-replication
- Log in to the Administration Portal on any source node.
- Click Storage → Domains.
- Click the name of the storage domain that you want to back up.
- Click the Remote Data Sync Setup subtab.
Click Setup.
The Setup Remote Data Synchronization window opens.
- In the Geo-replicated to field, select the backup target.
In the Recurrence field, select a recurrence interval type.
Valid values are WEEKLY with at least one weekday checkbox selected, or DAILY.
In the Hours and Minutes field, specify the time to start synchronizing.
NoteThis time is based on the Hosted Engine’s timezone.
- Click OK.
- Check the Events subtab for the source volume at the time you specified to verify that synchronization works correctly.
3.4. Configuring failover to and failback from a secondary cluster
This section covers how to configure your cluster to fail over to a remote secondary cluster in the event of server failure.
To do this, you must:
- Configure backing up to a remote volume.
- Create a suitable cluster to use as a failover target.
- Prepare a mapping file for the source and target clusters.
- Prepare a failover playbook.
- Prepare a cleanup playbook for the primary cluster.
- Prepare a failback playbook.
3.4.1. Creating a secondary cluster for failover
Install and configure a secondary cluster that can be used in place of the primary cluster in the event of failure.
This secondary cluster can be either of the following configurations:
- Red Hat Hyperconverged Infrastructure
- See Deploying Red Hat Hyperconverged Infrastructure for details.
- Red Hat Gluster Storage configured for use as a Red Hat Virtualization storage domain
- See Configuring Red Hat Virtualization with Red Hat Gluster Storage for details. Note that creating a storage domain is not necessary for this use case; the storage domain is imported as part of the failover process.
The storage on the secondary cluster must not be attached to a data center, so that it can be added to the secondary site’s data center during the failover process.
3.4.2. Creating a mapping file between source and target clusters
Follow this section to create a file that maps the storage in your source cluster to the storage in your target cluster.
Red Hat recommends that you create this file immediately after you first deploy your storage, and keep it up to date as your deployment changes. This helps to ensure that everything in your cluster fails over safely in the event of disaster.
Create a playbook to generate the mapping file.
Create a playbook that passes information about your cluster to the
oVirt.disaster-recoveryrole, using thesite,username,password, andcavariables.Red Hat recommends creating this file in the
/usr/share/ansible/roles/oVirt.disaster-recoverydirectory of the server that providesansibleand manages failover and failback.Example playbook file: dr-ovirt-setup.yml
--- - name: Collect mapping variables hosts: localhost connection: local vars: site: https://example.engine.redhat.com/ovirt-engine/api username: admin@internal password: my_password ca: /etc/pki/ovirt-engine/ca.pem var_file: disaster_recovery_vars.yml roles: - oVirt.disaster-recoveryGenerate the mapping file by running the playbook with the
generate_mappingtag.# ansible-playbook dr-ovirt-setup.yml --tags "generate_mapping"
This creates the mapping file,
disaster_recovery_vars.yml.Edit
disaster_recovery_vars.ymland add information about the secondary cluster.See Appendix A: Mapping File Attributes in the Red Hat Virtualization Disaster Recovery Guide for detailed information about attributes used in the mapping file.
3.4.3. Creating a failover playbook between source and target clusters
Create a playbook file that passes the lists of hyperconverged hosts to use as a failover source and target to the oVirt.disaster-recovery role, using the dr_target_host and dr_source_map variables.
Red Hat recommends creating this file in the /usr/share/ansible/roles/oVirt.disaster-recovery directory of the server that provides ansible and manages failover and failback.
Example playbook file: dr-rhv-failover.yml
---
- name: Failover RHV
hosts: localhost
connection: local
vars:
dr_target_host: secondary
dr_source_map: primary
vars_files:
- disaster_recovery_vars.yml
- passwords.yml
roles:
- oVirt.disaster-recovery
For information about executing failover, see Failing over to a secondary cluster.
3.4.4. Creating a failover cleanup playbook for your primary cluster
Create a playbook file that cleans up your primary cluster so that you can use it as a failback target.
Red Hat recommends creating this file in the /usr/share/ansible/roles/oVirt.disaster-recovery directory of the server that provides ansible and manages failover and failback.
Example playbook file: dr-cleanup.yml
---
- name: Clean RHV
hosts: localhost
connection: local
vars:
dr_source_map: primary
vars_files:
- disaster_recovery_vars.yml
roles:
- oVirt.disaster-recovery
For information about executing failback, see Failing back to a primary cluster.
3.4.5. Create a failback playbook between source and target clusters
Create a playbook file that passes the lists of hyperconverged hosts to use as a failback source and target to the oVirt.disaster-recovery role, using the dr_target_host and dr_source_map variables.
Red Hat recommends creating this file in the /usr/share/ansible/roles/oVirt.disaster-recovery directory of the server that provides ansible and manages failover and failback.
Example playbook file: dr-rhv-failback.yml
---
- name: Failback RHV
hosts: localhost
connection: local
vars:
dr_target_host: primary
dr_source_map: secondary
vars_files:
- disaster_recovery_vars.yml
- passwords.yml
roles:
- oVirt.disaster-recovery
For information about executing failback, see Failing back to a primary cluster.
Chapter 4. Configure encryption with Transport Layer Security (TLS/SSL)
Transport Layer Security (TLS/SSL) can be used to encrypt management and storage layer communications between nodes. This helps ensure that your data remains private.
Encryption can be configured using either self-signed certificates or certificates signed by a Certificate Authority.
This document assumes that you want to enable encryption on an existing deployment. However, encryption can also be configured as part of the deployment process. See Deploying Red Hat Hyperconverged Infrastructure for Virtualization for details: https://access.redhat.com/documentation/en-us/red_hat_hyperconverged_infrastructure_for_virtualization/1.6/html/deploying_red_hat_hyperconverged_infrastructure_for_virtualization/.
4.1. Configuring TLS/SSL using self-signed certificates
Enabling or disabling encryption is a disruptive process that requires virtual machines and the Hosted Engine to be shut down.
Shut down all virtual machines
See Shutting Down a Virtual Machine in the Red Hat Virtualization documentation for details: https://access.redhat.com/documentation/en-us/red_hat_virtualization/4.3/html/virtual_machine_management_guide/chap-administrative_tasks.
Move all storage domains except the hosted engine storage domain into Maintenance mode
See Moving Storage Domains to Maintenance Mode in the Red Hat Virtualization documentation for details: https://access.redhat.com/documentation/en-us/red_hat_virtualization/4.3/html/administration_guide/sect-storage_tasks.
Move the hosted engine into global maintenance mode
Run the following command on the hyperconverged host that hosts the hosted engine:
# hosted-engine --set-maintenance --mode=global
Shut down the hosted engine virtual machine
Run the following command on the hyperconverged host that hosts the hosted engine:
# hosted-engine --vm-shutdown
Verify that the hosted engine has shut down by running the following command:
# hosted-engine --vm-status
Stop all high availability services
Run the following command on all hyperconverged hosts:
# systemctl stop ovirt-ha-agent # systemctl stop ovirt-ha-broker
Unmount the hosted engine storage domain from all hyperconverged hosts
# hosted-engine --disconnect-storage
Verify that all volumes are unmounted
On each hyperconverged host, verify that all gluster volumes are no longer mounted.
# mount
Prepare self-signed certificates
Follow Procedure 23.1. Preparing a self-signed certificate in the Red Hat Gluster Storage Administration Guide: Preparing Certificates.
Stop all volumes
# gluster v stop <VolumeName>
Restart glusterd on all nodes
# systemctl restart glusterd
Enable TLS/SSL encryption on all volumes
# gluster volume set <volname> client.ssl on # gluster volume set <volname> server.ssl on
Specify access permissions on all hosts
# gluster volume set <volname> auth.ssl-allow "host1,host2,host3"
Start all volumes
# gluster v start <VolumeName>
Verify that no TLS/SSL errors occurred
Check the /var/log/glusterfs/glusterd.log file on each physical machine to ensure that no TLS/SSL related errors occurred, and setup completed successfully.
Start all high availability services
Run the following commands on all hyperconverged hosts:
# systemctl start ovirt-ha-agent # systemctl start ovirt-ha-broker
Move the hosted engine out of Global Maintenance mode
# hosted-engine --set-maintenance --mode=none
The hosted engine starts automatically after a short wait.
Wait for nodes to synchronize
Run the following command on the first hyperconverged host to check synchronization status. If engine status is listed as unknown stale-data, synchronization requires several more minutes to complete.
The following output indicates completed synchronization.
# hosted-engine --vm-status | grep 'Engine status' Engine status : {"health": "good", "vm": "up", "detail": "up"} Engine status : {"reason": "vm not running on this host", "health": "bad", "vm": "down", "detail": "unknown"} Engine status : {"reason": "vm not running on this host", "health": "bad", "vm": "down", "detail": "unknown"}Activate all storage domains
Activate the master storage domain first, followed by all other storage domains.
For details on activating storage domains, see Activating Storage Domains from Maintenance Mode in the Red Hat Virtualization documentation: https://access.redhat.com/documentation/en-us/red_hat_virtualization/4.3/html/administration_guide/sect-storage_tasks.
Start all virtual machines
See Starting a Virtual Machine in the Red Hat Virtualization documentation for details: https://access.redhat.com/documentation/en-us/red_hat_virtualization/4.3/html/virtual_machine_management_guide/sect-starting_the_virtual_machine.
4.2. Configuring TLS/SSL using Certificate Authority signed certificates
Enabling or disabling encryption is a disruptive process that requires virtual machines and the Hosted Engine to be shut down.
Ensure that you have appropriate certificates signed by a Certificate Authority before proceeding. Obtaining certificates is outside the scope of this document, but further details are available in the Red Hat Gluster Storage Administration Guide: https://access.redhat.com/documentation/en-us/red_hat_gluster_storage/3.4/html/administration_guide/chap-network_encryption#chap-Network_Encryption-Prereqs.
Shut down all virtual machines
See Shutting Down a Virtual Machine in the Red Hat Virtualization documentation for details: https://access.redhat.com/documentation/en-us/red_hat_virtualization/4.3/html/virtual_machine_management_guide/chap-administrative_tasks.
Move all storage domains except the hosted engine storage domain into Maintenance mode
See Moving Storage Domains to Maintenance Mode in the Red Hat Virtualization documentation for details: https://access.redhat.com/documentation/en-us/red_hat_virtualization/4.3/html/administration_guide/sect-storage_tasks.
Move the hosted engine into global maintenance mode
Run the following command on the hyperconverged host that hosts the hosted engine:
# hosted-engine --set-maintenance --mode=global
Shut down the hosted engine virtual machine
Run the following command on the hyperconverged host that hosts the hosted engine:
# hosted-engine --vm-shutdown
Verify that the hosted engine has shut down by running the following command:
# hosted-engine --vm-status
Stop all high availability services
Run the following command on all hyperconverged hosts:
# systemctl stop ovirt-ha-agent # systemctl stop ovirt-ha-broker
Unmount the hosted engine storage domain from all hyperconverged hosts
# hosted-engine --disconnect-storage
Verify that all volumes are unmounted
On each hyperconverged host, verify that all gluster volumes are no longer mounted.
# mount
Configure Certificate Authority signed encryption
ImportantEnsure that you have appropriate certificates signed by a Certificate Authority before proceeding. Obtaining certificates is outside the scope of this document.
Place certificates in the following locations on all nodes.
- /etc/ssl/glusterfs.key
- The node’s private key.
- /etc/ssl/glusterfs.pem
- The certificate signed by the Certificate Authority, which becomes the node’s certificate.
- /etc/ssl/glusterfs.ca
- The Certificate Authority’s certificate.
Stop all volumes
# gluster v stop <VolumeName>
Restart glusterd on all nodes
# systemctl restart glusterd
Enable TLS/SSL encryption on all volumes
# gluster volume set <volname> client.ssl on # gluster volume set <volname> server.ssl on
Specify access permissions on all hosts
# gluster volume set <volname> auth.ssl-allow "host1,host2,host3"
Start all volumes
# gluster v start <VolumeName>
Verify that no TLS/SSL errors occurred
Check the /var/log/glusterfs/glusterd.log file on each physical machine to ensure that no TLS/SSL related errors occurred, and setup completed successfully.
Start all high availability services
Run the following commands on all hyperconverged hosts:
# systemctl start ovirt-ha-agent # systemctl start ovirt-ha-broker
Move the hosted engine out of Global Maintenance mode
# hosted-engine --set-maintenance --mode=none
The hosted engine starts automatically after a short wait.
Wait for nodes to synchronize
Run the following command on the first hyperconverged host to check synchronization status. If engine status is listed as unknown stale-data, synchronization requires several more minutes to complete.
The following output indicates completed synchronization.
# hosted-engine --vm-status | grep 'Engine status' Engine status : {"health": "good", "vm": "up", "detail": "up"} Engine status : {"reason": "vm not running on this host", "health": "bad", "vm": "down", "detail": "unknown"} Engine status : {"reason": "vm not running on this host", "health": "bad", "vm": "down", "detail": "unknown"}Activate all storage domains
Activate the master storage domain first, followed by all other storage domains.
For details on activating storage domains, see Activating Storage Domains from Maintenance Mode in the Red Hat Virtualization documentation: https://access.redhat.com/documentation/en-us/red_hat_virtualization/4.3/html/administration_guide/sect-storage_tasks.
Start all virtual machines
See Starting a Virtual Machine in the Red Hat Virtualization documentation for details: https://access.redhat.com/documentation/en-us/red_hat_virtualization/4.3/html/virtual_machine_management_guide/sect-starting_the_virtual_machine.
Chapter 5. Configure performance improvements
Some deployments benefit from additional configuration to achieve optimal performance. This section covers recommended additional configuration for certain deployments.
5.1. Improving volume performance by changing shard size
The default value of the shard-block-size parameter changed from 4MB to 64MB between Red Hat Hyperconverged Infrastructure for Virtualization version 1.0 and 1.1. This means that all new volumes are created with a shard-block-size value of 64MB. However, existing volumes retain the original shard-block-size value of 4MB.
There is no safe way to modify the shard-block-size value on volumes that contain data. Because shard block size applies only to writes that occur after the value is set, attempting to change the value on a volume that contains data results in a mixed shard block size, which results in poor performance.
This section shows you how to safely modify the shard block size on an existing volume after upgrading to Red Hat Hyperconverged Infrastructure for Virtualization 1.1 or higher, in order to take advantage of the performance benefits of a larger shard size.
5.1.1. Changing shard size on replicated volumes
Create an inventory file
Create an inventory file called
normal_replicated_inventory.ymlbased on the following example.Replace
host1,host2, andhost3with the FQDNs of your hosts, and edit device details to match your environment.Example
normal_replicated_inventory.ymlinventory filehc_nodes: hosts: # Host1 host1: # Dedupe & Compression config # If logicalsize >= 1000G then slabsize=32G else slabsize=2G #gluster_infra_vdo: # - { name: 'vdo_sdb', device: '/dev/sdb', logicalsize: '3000G', emulate512: 'on', slabsize: '32G', # blockmapcachesize: '128M', readcachesize: '20M', readcache: 'enabled', writepolicy: 'auto' } # With Dedupe & Compression #gluster_infra_volume_groups: # - vgname: <volgroup_name> # pvname: /dev/mapper/vdo_sdb # Without Dedupe & Compression gluster_infra_volume_groups: - vgname: <volgroup_name> pvname: /dev/sdb gluster_infra_mount_devices: - path: <brick_mountpoint> lvname: <lv_name> vgname: <volgroup_name> gluster_infra_thinpools: - {vgname: '<volgroup_name>', thinpoolname: 'thinpool_<volgroup_name>', thinpoolsize: '500G', poolmetadatasize: '4G'} gluster_infra_lv_logicalvols: - vgname: <volgroup_name> thinpool: thinpool_<volgroup_name> lvname: <lv_name> lvsize: <size>G # Mount the devices gluster_infra_mount_devices: - { path: '<brick_mountpoint>', vgname: <volgroup_name>, lvname: <lv_name> } #Host2 host2: # Dedupe & Compression config # If logicalsize >= 1000G then slabsize=32G else slabsize=2G #gluster_infra_vdo: # - { name: 'vdo_sdb', device: '/dev/sdb', logicalsize: '3000G', emulate512: 'on', slabsize: '32G', # blockmapcachesize: '128M', readcachesize: '20M', readcache: 'enabled', writepolicy: 'auto' } # With Dedupe & Compression #gluster_infra_volume_groups: # - vgname: <volgroup_name> # pvname: /dev/mapper/vdo_sdb # Without Dedupe & Compression gluster_infra_volume_groups: - vgname: <volgroup_name> pvname: /dev/sdb gluster_infra_mount_devices: - path: <brick_mountpoint> lvname: <lv_name> vgname: <volgroup_name> gluster_infra_thinpools: - {vgname: '<volgroup_name>', thinpoolname: 'thinpool_<volgroup_name>', thinpoolsize: '500G', poolmetadatasize: '4G'} gluster_infra_lv_logicalvols: - vgname: <volgroup_name> thinpool: thinpool_<volgroup_name> lvname: <lv_name> lvsize: <size>G # Mount the devices gluster_infra_mount_devices: - { path: '<brick_mountpoint>', vgname: <volgroup_name>, lvname: <lv_name> } #Host3 host3: # Dedupe & Compression config # If logicalsize >= 1000G then slabsize=32G else slabsize=2G #gluster_infra_vdo: # - { name: 'vdo_sdb', device: '/dev/sdb', logicalsize: '3000G', emulate512: 'on', slabsize: '32G', # blockmapcachesize: '128M', readcachesize: '20M', readcache: 'enabled', writepolicy: 'auto' } # With Dedupe & Compression #gluster_infra_volume_groups: # - vgname: <volgroup_name> # pvname: /dev/mapper/vdo_sdb # Without Dedupe & Compression gluster_infra_volume_groups: - vgname: <volgroup_name> pvname: /dev/sdb gluster_infra_mount_devices: - path: <brick_mountpoint> lvname: <lv_name> vgname: <volgroup_name> gluster_infra_thinpools: - {vgname: '<volgroup_name>', thinpoolname: 'thinpool_<volgroup_name>', thinpoolsize: '500G', poolmetadatasize: '4G'} gluster_infra_lv_logicalvols: - vgname: <volgroup_name> thinpool: thinpool_<volgroup_name> lvname: <lv_name> lvsize: <size>G # Mount the devices gluster_infra_mount_devices: - { path: '<brick_mountpoint>', vgname: <volgroup_name>, lvname: <lv_name> } # Common configurations vars: cluster_nodes: - host1 - host2 - host3 gluster_features_hci_cluster: "{{ cluster_nodes }}" gluster_features_hci_volumes: - { volname: 'data', brick: '<brick_mountpoint>' } gluster_features_hci_volume_options: { group: 'virt', storage.owner-uid: '36', storage.owner-gid: '36', network.ping-timeout: '30', performance.strict-o-direct: 'on', network.remote-dio: 'off', cluster.granular-entry-heal: 'enable', features.shard-block-size: '64MB' }Create the
normal_replicated.ymlplaybookCreate a
normal_replicated.ymlplaybook file using the following example:Example
normal_replicated.ymlplaybook--- # Safely changing the shard block size parameter value for normal replicated volume - name: Changing the shard block size hosts: hc_nodes remote_user: root gather_facts: no any_errors_fatal: true roles: - gluster.infra - gluster.featuresRun the playbook
ansible-playbook -i normal_replicated_inventory.yml normal_replicated.yml
5.1.2. Changing shard size on arbitrated volumes
Create an inventory file
Create an inventory file called
arbitrated_replicated_inventory.ymlbased on the following example.Replace
host1,host2, andhost3with the FQDNs of your hosts, and edit device details to match your environment.Example
arbitrated_replicated_inventory.ymlinventory filehc_nodes: hosts: # Host1 host1: # Dedupe & Compression config # If logicalsize >= 1000G then slabsize=32G else slabsize=2G #gluster_infra_vdo: # - { name: 'vdo_sdb', device: '/dev/sdb', logicalsize: '3000G', emulate512: 'on', slabsize: '32G', # blockmapcachesize: '128M', readcachesize: '20M', readcache: 'enabled', writepolicy: 'auto' } # With Dedupe & Compression #gluster_infra_volume_groups: # - vgname: <volgroup_name> # pvname: /dev/mapper/vdo_sdb # Without Dedupe & Compression gluster_infra_volume_groups: - vgname: <volgroup_name> pvname: /dev/sdb gluster_infra_mount_devices: - path: <brick_mountpoint> lvname: <lv_name> vgname: <volgroup_name> - path: <brick_mountpoint> lvname: <lv_name> vgname: <volgroup_name> gluster_infra_thinpools: - {vgname: '<volgroup_name>', thinpoolname: 'thinpool_<volgroup_name>', thinpoolsize: '500G', poolmetadatasize: '4G'} gluster_infra_lv_logicalvols: - vgname: <volgroup_name> thinpool: thinpool_<volgroup_name> lvname: <lv_name> lvsize: <size>G - vgname: <volgroup_name> thinpool: thinpool_<volgroup_name> lvname: <lv_name> lvsize: <size>G # Mount the devices gluster_infra_mount_devices: - { path: '<brick_mountpoint>', vgname: <volgroup_name>, lvname: <lv_name> } - { path: '<brick_mountpoint>', vgname: <volgroup_name>, lvname: <lv_name> } #Host2 host2: # Dedupe & Compression config # If logicalsize >= 1000G then slabsize=32G else slabsize=2G #gluster_infra_vdo: # - { name: 'vdo_sdb', device: '/dev/sdb', logicalsize: '3000G', emulate512: 'on', slabsize: '32G', # blockmapcachesize: '128M', readcachesize: '20M', readcache: 'enabled', writepolicy: 'auto' } # With Dedupe & Compression #gluster_infra_volume_groups: # - vgname: <volgroup_name> # pvname: /dev/mapper/vdo_sdb # Without Dedupe & Compression gluster_infra_volume_groups: - vgname: <volgroup_name> pvname: /dev/sdb gluster_infra_mount_devices: - path: <brick_mountpoint> lvname: <lv_name> vgname: <volgroup_name> - path: <brick_mountpoint> lvname: <lv_name> vgname: <volgroup_name> gluster_infra_thinpools: - {vgname: '<volgroup_name>', thinpoolname: 'thinpool_<volgroup_name>', thinpoolsize: '500G', poolmetadatasize: '4G'} gluster_infra_lv_logicalvols: - vgname: <volgroup_name> thinpool: thinpool_<volgroup_name> lvname: <lv_name> lvsize: <size>G - vgname: <volgroup_name> thinpool: thinpool_<volgroup_name> lvname: <lv_name> lvsize: <size>G # Mount the devices gluster_infra_mount_devices: - { path: '<brick_mountpoint>', vgname: <volgroup_name>, lvname: <lv_name> } - { path: '<brick_mountpoint>', vgname: <volgroup_name>, lvname: <lv_name> } #Host3 host3: # Dedupe & Compression config # If logicalsize >= 1000G then slabsize=32G else slabsize=2G #gluster_infra_vdo: # - { name: 'vdo_sdb', device: '/dev/sdb', logicalsize: '3000G', emulate512: 'on', slabsize: '32G', # blockmapcachesize: '128M', readcachesize: '20M', readcache: 'enabled', writepolicy: 'auto' } # With Dedupe & Compression #gluster_infra_volume_groups: # - vgname: <volgroup_name> # pvname: /dev/mapper/vdo_sdb # Without Dedupe & Compression gluster_infra_volume_groups: - vgname: <volgroup_name> pvname: /dev/sdb gluster_infra_mount_devices: - path: <brick_mountpoint> lvname: <lv_name> vgname: <volgroup_name> gluster_infra_thinpools: - {vgname: '<volgroup_name>', thinpoolname: 'thinpool_<volgroup_name>', thinpoolsize: '500G', poolmetadatasize: '4G'} gluster_infra_lv_logicalvols: - vgname: <volgroup_name> thinpool: thinpool_<volgroup_name> lvname: <lv_name> lvsize: <size>G # Mount the devices gluster_infra_mount_devices: - { path: '<brick_mountpoint>', vgname: <volgroup_name>, lvname: <lv_name> } # Common configurations vars: cluster_nodes: - host1 - host2 - host3 gluster_features_hci_cluster: "{{ cluster_nodes }}" gluster_features_hci_volumes: - { volname: 'data_one', brick: '<brick_mountpoint>', arbiter: 1 } gluster_features_hci_volume_options: { group: 'virt', storage.owner-uid: '36', storage.owner-gid: '36', network.ping-timeout: '30', performance.strict-o-direct: 'on', network.remote-dio: 'off', cluster.granular-entry-heal: 'enable', features.shard-block-size: '64MB', server.ssl: 'on', client.ssl: 'on', auth.ssl-allow: '<host1>;<host2>;<host3>' }Create the
arbitrated_replicated.ymlplaybookCreate a
arbitrated_replicated.ymlplaybook file using the following example:Example
arbitrated_replicated.ymlplaybook--- # Safely changing the shard block size parameter value for arbitrated replicated volume - name: Changing the shard block size hosts: hc_nodes remote_user: root gather_facts: no any_errors_fatal: true roles: - gluster.infra - gluster.featuresRun the playbook
ansible-playbook -i arbitrated_replicated_inventory.yml arbitrated_replicated.yml
5.2. Configuring a logical volume cache (lvmcache) for an existing volume
If your main storage devices are not Solid State Disks (SSDs), Red Hat recommends configuring a logical volume cache (lvmcache) to achieve the required performance for Red Hat Hyperconverged Infrastructure for Virtualization deployments.
Create inventory file
Create an inventory file called
cache_inventory.ymlbased on the example below.Replace
<host1>,<host2>, and<host3>with the FQDNs of the hosts on which to configure the cache.Replace the following values throughout the file.
- <slow_device>,<fast_device>
-
Specify the device to which the cache should attach, followed by the cache device, as a comma-delimited list, for example,
cachedisk: '/dev/sdb,/dev/sde'. - <fast_device_name>
-
Specify the name of the cache logical volume to create, for example,
cachelv_thinpool_gluster_vg_sde - <fast_device_thinpool>
-
Specify the name of the cache thin pool to create, for example,
gluster_thinpool_gluster_vg_sde.
Example cache_inventory.yml file
hc_nodes: hosts: # Host1 <host1>: gluster_infra_cache_vars: - vgname: gluster_vg_sdb cachedisk: '<slow_device>,<fast_device>' cachelvname: <fast_device_name> cachethinpoolname: <fast_device_thinpool> cachelvsize: '10G' cachemode: writethrough #Host2 <host2>: gluster_infra_cache_vars: - vgname: gluster_vg_sdb cachedisk: '<slow_device>,<fast_device>' cachelvname: <fast_device_name> cachethinpoolname: <fast_device_thinpool> cachelvsize: '10G' cachemode: writethrough #Host3 <host3>: gluster_infra_cache_vars: - vgname: gluster_vg_sdb cachedisk: '<slow_device>,<fast_device>' cachelvname: <fast_device_name> cachethinpoolname: <fast_device_thinpool> cachelvsize: '10G' cachemode: writethroughCreate a playbook file
Create an ansible playbook file named
lvm_cache.yml.Example lvm_cache.yml file
--- # Create LVM Cache - name: Setup LVM Cache hosts: hc_nodes remote_user: root gather_facts: no any_errors_fatal: true roles: - gluster.infraRun the playbook with the
cachesetuptagRun the following command to apply the configuration specified in
lvm_cache.ymlto the hosts and devices specified incache_inventory.yml.ansible-playbook -i cache_inventory.yml lvm_cache.yml --tags cachesetup
Chapter 6. Configure monitoring
6.1. Configuring event notifications
To configure which notifications you want to be displayed in the Administration Portal, see Configuring Event Notifications in the Administration Portal in the Red Hat Virtualization 4.3 Administration Guide.
Part II. Maintenance tasks
Chapter 7. Basic Operations
Some basic operations are required for many administrative and troubleshooting tasks. This section covers how to safely perform basic tasks like shutting down and starting up the hyperconverged cluster.
7.1. Creating a shutdown playbook
A hyperconverged environment must be shut down in a particular order. The simplest way to do this is to create a shutdown playbook that can be run from the Hosted Engine virtual machine.
The ovirt.shutdown_env role enables Global Maintenance Mode, and initiates shutdown for all virtual machines and hosts in the cluster. Host shutdown is asynchronous. The playbook terminates before hyperconverged hosts are actually shut down.
Prerequisites
Ensure that the
ovirt.shutdown_envansible role is available on the Hosted Engine virtual machine.# yum install ovirt-ansible-shutdown-env -y
Procedure
- Log in to the Hosted Engine virtual machine.
Create a shutdown playbook for your environment.
Use the following template to create the playbook file.
-
Replace
ovirt-engine.example.comwith the FQDN of your Hosted Engine virtual machine. -
Replace
123456with the password for theadmin@internalaccount.
Example playbook file: shutdown_rhhi-v.yml
--- - name: oVirt shutdown environment hosts: localhost connection: local gather_facts: false vars: engine_url: https://ovirt-engine.example.com/ovirt-engine/api engine_user: admin@internal engine_password: 123456 engine_cafile: /etc/pki/ovirt-engine/ca.pem roles: - ovirt.shutdown_env-
Replace
7.2. Shutting down RHHI for Virtualization
A hyperconverged environment must be shut down in a particular order. Use an Ansible playbook to automate this process and ensure that your environment is shut down safely.
Prerequisites
- Create a shutdown playbook as described in Creating a shutdown playbook
Ensure that the
ovirt.shutdown_envansible role is available on the Hosted Engine virtual machine.# yum install ovirt-ansible-shutdown-env -y
Procedure
Run the shutdown playbook against the Hosted Engine virtual machine.
# ansible-playbook -i localhost <shutdown_rhhi-v.yml>
7.3. Starting up a hyperconverged cluster
Starting up a hyperconverged cluster is more complex than starting up a traditional compute or storage cluster. Follow these instructions to start up your hyperconverged cluster safely.
- Power on all hosts in the cluster.
Ensure that the required services are available.
Verify that the
glusterdservice started correctly on all hosts.# systemctl status glusterd ● glusterd.service - GlusterFS, a clustered file-system server Loaded: loaded (/usr/lib/systemd/system/glusterd.service; enabled; vendor preset: disabled) Drop-In: /etc/systemd/system/glusterd.service.d └─99-cpu.conf Active: active (running) since Wed 2018-07-18 11:15:03 IST; 3min 48s ago [...]If glusterd is not started, start it.
# systemctl start glusterd
Verify that host networks are available and hosts have IP addresses assigned to the required interfaces.
# ip addr show
Verify that all hosts are part of the storage cluster (listed as Peer in Cluster (Connected)).
# gluster peer status Number of Peers: 2 Hostname: 10.70.37.101 Uuid: 773f1140-68f7-4861-a996-b1ba97586257 State: Peer in Cluster (Connected) Hostname: 10.70.37.102 Uuid: fc4e7339-9a09-4a44-aa91-64dde2fe8d15 State: Peer in Cluster (Connected)
Verify that all bricks are shown as online.
# gluster volume status engine Status of volume: engine Gluster process TCP Port RDMA Port Online Pid ------------------------------------------------------------------------------ Brick 10.70.37.28:/gluster_bricks/engine/en gine 49153 0 Y 23160 Brick 10.70.37.29:/gluster_bricks/engine/en gine 49160 0 Y 12392 Brick 10.70.37.30:/gluster_bricks/engine/en gine 49157 0 Y 15200 Self-heal Daemon on localhost N/A N/A Y 23008 Self-heal Daemon on 10.70.37.30 N/A N/A Y 10905 Self-heal Daemon on 10.70.37.29 N/A N/A Y 13568 Task Status of Volume engine ------------------------------------------------------------------------------ There are no active volume tasks
Start the hosted engine virtual machine.
Run the following command on the host that you want to be the hosted engine node.
# hosted-engine --vm-start
Verify that the hosted engine virtual machine has started correctly.
# hosted-engine --vm-status
Take the hosted engine virtual machine out of Global Maintenance mode.
- Log in to the Administration Portal.
- Click Compute → Hosts and select the hosted engine node.
- Click ⋮ → Disable Global HA Maintenance.
Start any other virtual machines using the Web Console.
- Click Compute → Virtualization.
- Select any virtual machines you want to start and click Run.
Chapter 8. Upgrading to Red Hat Hyperconverged Infrastructure for Virtualization 1.6
Upgrading involves moving from one version of a product to a newer major release of the same product. This section shows you how to upgrade to Red Hat Hyperconverged Infrastructure for Virtualization 1.6 from version 1.5.
From a component standpoint, this involves the following:
- Upgrading the Hosted Engine virtual machine to Red Hat Virtualization Manager version 4.3.
- Upgrading the physical hosts to Red Hat Virtualization 4.3.
8.1. Major changes in version 1.6
Be aware of the following differences between Red Hat Hyperconverged Infrastructure for Virtualization 1.6 and previous versions:
- Ansible-based deployment and management
- RHHI for Virtualization now uses Ansible playbooks for all deployment and management tasks. Documentation has been updated accordingly.
- Expand volumes across more than 3 nodes
- Volumes can now span across 3, 6, 9, or 12 nodes. See Volume Types for support details. See Expanding an existing volume across more hyperconverged nodes for instructions on expanding existing volumes across more nodes.
- RHHI for Virtualization sizing tool
- Visit the RHHI for Virtualization Sizing Tool, enter your deployment requirements and click Solve to receive an example configuration with suggested nodes, memory, and resource commitments for your deployment.
8.2. Upgrade workflow
Red Hat Hyperconverged Infrastructure for Virtualization is a software solution comprised of several different components. Upgrade the components in the following order to minimize disruption to your deployment:
8.3. Preparing to upgrade
8.3.1. Update to the latest version of the previous release
Ensure that you are using the latest version (4.2.8) of Red Hat Virtualization Manager 4.2 on the hosted engine virtual machine, and the latest version of Red Hat Virtualization 4.2 on the hosted engine node.
See the Red Hat Virtualization Self-Hosted Engine Guide for the Red Hat Virtualization 4.3 update process.
Do not proceed with the following prerequisites until you have updated to the latest version of Red Hat Virtualization 4.2.
8.3.2. Update subscriptions
You can check which repositories a machine has access to by running the following command as the root user:
# subscription-manager repos --list-enabled
Verify that the Hosted Engine virtual machine is subscribed to the following repositories:
-
rhel-7-server-rhv-4.3-manager-rpms -
rhel-7-server-rhv-4-manager-tools-rpms -
rhel-7-server-rpms -
rhel-7-server-supplementary-rpms -
jb-eap-7-for-rhel-7-server-rpms -
rhel-7-server-ansible-2-rpms
-
Verify that the Hosted Engine virtual machine is not subscribed to previous versions of the required repositories.
-
rhel-7-server-rhv-4.3-manager-rpmsreplaces therhel-7-server-rhv-4.2-manager-rpmsrepository
-
Subscribe a machine to a repository by running the following command on that machine:
# subscription-manager repos --enable=<repository>
8.3.3. Verify that data is not currently being synchronized using geo-replication
- Click the Tasks tab at the bottom right of the Manager. Ensure that there are no ongoing tasks related to Data Synchronization. If data synchronization tasks are present, wait until they are complete before beginning the update.
Stop all geo-replication sessions so that synchronization will not occur during the update. Click the Geo-replication subtab and select the session that you want to stop, then click Stop.
Alternatively, run the following command to stop a geo-replication session:
# gluster volume geo-replication <MASTER_VOL> <SLAVE_HOST>::<SLAVE_VOL> stop
8.4. Upgrading Red Hat Hyperconverged Infrastructure for Virtualization
8.4.1. Upgrading the Hosted Engine virtual machine
Place the cluster into Global Maintenance mode
- Log in to the Web Console.
- Click Virtualization → Hosted Engine.
- Click Put this cluster into global maintenance.
Upgrade Red Hat Virtualization Manager.
- Log in to the Hosted Engine virtual machine.
Upgrade the setup packages:
# yum update ovirt*setup\*
Run
engine-setupand follow the prompts to upgrade the Manager.This process can take a while and cannot be aborted, so Red Hat recommends running it inside a
screensession. See How to use the screen command for more information about this function.Upgrade all other packages.
# yum update
Reboot the Hosted Engine virtual machine to ensure all updates are applied.
# reboot
Restart the Hosted Engine virtual machine.
- Log in to any hyperconverged host.
Start the Hosted Engine virtual machine.
# hosted-engine --vm-start
Verify the status of the Hosted Engine virtual machine.
# hosted-engine --vm-status
Remove the cluster from Global Maintenance mode.
- Log in to the Web Console.
- Click Virtualization → Hosted Engine.
- Click Remove this cluster from global maintenance.
8.4.2. Upgrading the hyperconverged hosts
If you are upgrading a host from Red Hat Virtualization 4.2.7 or 4.2.7-1, ensure that the hosted engine virtual machine is not running on that host during the upgrade process. This is related to a bug introduced in Red Hat Enterprise Linux 7.6, BZ#1641798, which affects these versions of Red Hat Virtualization.
To work around this issue, stop the hosted engine virtual machine before upgrading a host, and start it on another host.
[root@host1] # hosted-engine --vm-shutdown
[root@host2] # hosted-engine --vm-start
Upgrade one host at a time
Perform the following steps on one hyperconverged host at a time.
Upgrade the hyperconverged host.
- In the Manager, click Compute → Hosts and select a node.
- Click Installation → Upgrade.
Click OK to confirm the upgrade.
Wait for the upgrade to complete, and for the host to become available again.
Verify self-healing is complete before upgrading the next host.
- Click the name of the host.
- Click the Bricks tab.
-
Verify that the Self-Heal Info column of all bricks is listed as
OKbefore upgrading the next host.
Update cluster compatibility
When all hosts are upgraded, update cluster compatibility setting.
-
In the Manager, click Cluster and select the cluster (
Default). - Click Edit.
-
Update the value of Cluster compatibility to
4.3and save. Restart all virtual machines
This ensures that the new cluster compatibility setting takes effect.
- Click Compute → Virtual Machines and select a running virtual machine.
- Click Reboot.
Click OK in the Reboot Virtual Machine(s) confirmation window.
The Status of the virtual machine changes to
Reboot In Progressbefore returning toUp.
-
In the Manager, click Cluster and select the cluster (
Troubleshooting
-
If upgrading a hyperconverged host fails because of a conflict with the
rhvm-appliancepackage, log in to the hyperconverged host and follow the steps in RHV: RHV-H Upgrade failed before continuing.
Chapter 9. Monitoring Red Hat Hyperconverged Infrastructure for Virtualization
9.1. Monitoring Virtual Data Optimizer (VDO)
Monitoring VDO helps in understanding when the physical storage is running out of space. Physical space in VDO needs to be monitored like thin provisioned storage. VDO devices should use thin provisioning because more logical space will be available and VDO space will be used in a more effective way. By default thin provisioning is enabled and it can be unchecked as required.
You can check available blocks, used space, and device information by clicking on View Details.
9.1.1. Monitoring VDO using the command line interface
There are several options for monitoring VDO using the command line interface.
- The
vdostatscommand -
This command displays volume statistics including available blocks, number of blocks used, device name, percentage of physical blocks saved, and percentage of physical blocks on a VDO volume. For more information on vdostats, see the manual page:
man vdostats. - The
vdo statuscommand - This command reports VDO system and volume status in YAML format.
- The
/sys/kvdo/<vdo_volume>/statisticsdirectory -
Files in this directory include volume statistics for VDO. You can read these files instead of using the
vdostatscommand.
9.1.2. Monitoring VDO using the Web Console
Events related to VDO usage are displayed under the Notifications tab. Events provide information about the physical space remaining on the VDO volume, and keep you up to date about whether more physical space is needed.
| Type | Text | Actions |
|---|---|---|
| Warn | Warning, low confirmed disk space. StorageDomainName domain has DiskSpace GB of confirmed free space. |
|
Chapter 10. Freeing space on thinly-provisioned logical volumes using fstrim
You can manually run fstrim to return unused logical volume space to the thin pool so that it is available for other logical volumes.
Red Hat recommends running fstrim daily.
Prerequisites
Verify that the thin pool logical volume supports discard behavior.
Discard is supported if the output of the following command for the underlying device is not zero.
# cat /sys/block/<device>/queue/discard_max_bytes
Procedure
Run
fstrimto restore physical space to the thin pool.# fstrim -v <mountpoint>
For example, the following command discards any unused space it finds on the logical volume mounted at
/gluster_bricks/data/data, and provides verbose output (-v).# fstrim -v /gluster_bricks/data/data
Additional resources
- See Scheduling a recurring job using cron for information on configuring an automatically recurring task.
Chapter 11. Add hyperconverged hosts to Red Hat Virtualization Manager
Follow this process to allow Red Hat Virtualization Manager to manage an existing hyperconverged host.
- Log in to the Administration Portal.
- Click Compute → Hosts.
- Click New. The New Host window opens.
On the General tab, specify the following details about your hyperconverged host.
-
Host Cluster -
Name -
Hostname -
Password
-
-
On the General tab, click the Advanced Parameters dropdown, and uncheck the
Automatically configure host firewallcheckbox. - Click OK.
Chapter 12. Reinstalling a hyperconverged host
Some configuration changes require a hyperconverged host to be reinstalled before the configuration change can take effect. Follow these steps to reinstall a hyperconverged host.
- Log in to the Administration Portal.
- Click Compute → Hosts.
- Select the host and click Management > Maintenance > OK to place this host in Maintenance mode.
- Click Installation > Reinstall to open the Reinstall window.
- On the General tab, uncheck the Automatically Configure Host firewall checkbox.
-
On the Hosted Engine tab, set the value of Choose hosted engine deployment action to
Deploy. - Click OK to reinstall the host.
Chapter 13. Replacing hosts
13.1. Replacing the primary hyperconverged host using ansible
Follow this section to replace the hyperconverged host that you used to perform all deployment operations.
When self-signed encryption is enabled, replacing a node is a disruptive process that requires virtual machines and the Hosted Engine to be shut down.
- (Optional) If encryption using a Certificate Authority is enabled, follow the steps under Expanding Volumes in the Network Encryption chapter of the Red Hat Gluster Storage 3.4 Administration Guide.
Move the server to be replaced into Maintenance mode.
- In the Administration Portal, click Compute → Hosts and select the host to replace.
- Click Management → Maintenance and click OK to move the host to Maintenance mode.
Install the replacement host
Follow the instructions in Deploying Red Hat Hyperconverged Infrastructure for Virtualization for Virtualization to install the physical machine and configure storage on the new host.
Configure the replacement host
Follow the instructions in Section 13.3, “Preparing a replacement hyperconverged host using ansible”.
(Optional) If encryption with self-signed certificates is enabled:
- Generate the private key and self-signed certificate on the replacement host. See the Red Hat Gluster Storage Administration Guide for details: https://access.redhat.com/documentation/en-us/red_hat_gluster_storage/3.4/html/administration_guide/chap-network_encryption#chap-Network_Encryption-Prereqs.
On a healthy host, create a copy of the
/etc/ssl/glusterfs.cafile.# cp /etc/ssl/glusterfs.ca /etc/ssl/glusterfs.ca.bk
-
Append the new host’s certificate to the content of the original
/etc/ssl/glusterfs.cafile. -
Distribute the
/etc/ssl/glusterfs.cafile to all hosts in the cluster, including the new host. Run the following command on the replacement host to enable management encryption:
# touch /var/lib/glusterd/secure-access
Include the new host in the value of the
auth.ssl-allowvolume option by running the following command for each volume.# gluster volume set <volname> auth.ssl-allow "<old_host1>,<old_host2>,<new_host>"
Restart the glusterd service on all hosts.
# systemctl restart glusterd
- Follow the steps in Section 4.1, “Configuring TLS/SSL using self-signed certificates” to remount all gluster processes.
Add the replacement host to the cluster.
Run the following command from any host already in the cluster.
# gluster peer probe <new_host>
Move the Hosted Engine into Maintenance mode:
# hosted-engine --set-maintenance --mode=global
Stop the ovirt-engine service.
# systemctl stop ovirt-engine
Update the database.
# hosted-engine --set-shared-config storage <new_host_IP>:/engine
Start the ovirt-engine service.
# systemctl start ovirt-engine
- Stop all virtual machines except the Hosted Engine.
- Move all storage domains except the Hosted Engine domain into Maintenance mode.
Stop the Hosted Engine virtual machine.
Run the following command on the existing server that hosts the Hosted Engine.
# hosted-engine --vm-shutdown
Stop high availability services on all hosts.
# systemctl stop ovirt-ha-agent # systemctl stop ovirt-ha-broker
Disconnect Hosted Engine storage from the hyperconverged host.
Run the following command on the existing server that hosts the Hosted Engine.
# hosted-engine --disconnect-storage
Update the Hosted Engine configuration file.
Edit the storage parameter in the
/etc/ovirt-hosted-engine/hosted-engine.conffile to use the replacement host.storage=<new_server_IP>:/engine
NoteTo configure the Hosted Engine for new hosts, use the command:
# hosted-engine --set-shared-config storage <new_server_IP>:/engine
Restart high availability services on all hosts.
# systemctl restart ovirt-ha-agent # systemctl restart ovirt-ha-broker
Reboot the existing and replacement hosts.
Wait until all hosts are available before continuing.
Take the Hosted Engine out of Maintenance mode.
# hosted-engine --set-maintenance --mode=none
Verify that the replacement host is used.
On all hyperconverged hosts, verify that the engine volume is mounted from the replacement host by checking the IP address in the output of the
mountcommand.Activate storage domains.
Verify that storage domains mount using the IP address of the replacement host.
Using the RHV Management UI, add the replacement host.
Specify that the replacement host be used to host the Hosted Engine.
Move the replacement host into Maintenance mode.
# hosted-engine --set-maintenance --mode=global
Reboot the replacement host.
Wait until the host is back online before continuing.
Activate the replacement host from the RHV Management UI.
Ensure that all volumes are mounted using the IP address of the replacement host.
Replace engine volume brick.
Replace the brick on the old host that belongs to the
enginevolume with a new brick on the replacement host.- Click Storage → Volumes and select the volume.
- Click the Bricks subtab.
- Select the brick to replace, and then click Replace brick.
- Select the host that hosts the brick being replaced.
- In the Replace brick window, provide the path to the new brick.
Remove the old host.
- Click Compute → Hosts and select the old host.
- Click Management → Maintenance to move the host to maintenance mode.
- Click Remove. The Remove Host(s) confirmation dialog appears.
- If there are still volume bricks on this host, or the host is non-responsive, check the Force Remove checkbox.
- Click OK.
Detach the old host from the cluster.
# gluster peer detach <old_host_IP> force
On the replacement host, run the following command to remove metadata from the previous host.
# hosted-engine --clean-metadata --host-id=<old_host_id> --force-clean
13.2. Replacing other hyperconverged hosts using ansible
There are two options for replacing a hyperconverged host that is not the first host:
- Replace the host with a new host that has a different fully-qualified domain name by following the instructions in Section 13.2.1, “Replacing a hyperconverged host to use a different FQDN”.
- Replace the host with a new host that has the same fully-qualified domain name by following the instructions in Section 13.2.2, “Replacing a hyperconverged host to use the same FQDN”.
Follow the instructions in whichever section is appropriate for your deployment.
13.2.1. Replacing a hyperconverged host to use a different FQDN
When self-signed encryption is enabled, replacing a node is a disruptive process that requires virtual machines and the Hosted Engine to be shut down.
Install the replacement host
Follow the instructions in Deploying Red Hat Hyperconverged Infrastructure for Virtualization for Virtualization to install the physical machine.
Stop any existing geo-replication sessions
# gluster volume geo-replication MASTER_VOL SLAVE_HOST::SLAVE_VOL stop
For further information, see the Red Hat Gluster Storage Administration Guide: https://access.redhat.com/documentation/en-us/red_hat_gluster_storage/3.4/html/administration_guide/sect-starting_geo-replication#Stopping_a_Geo-replication_Session.
Move the host to be replaced into Maintenance mode
Perform the following steps in the Administration Portal:
- Click Compute → Hosts and select the hyperconverged host in the results list.
- Click Management → Maintenance and click OK to move the host to Maintenance mode.
Prepare the replacement host
Configure key-based SSH authentication without a password
Configure key-based SSH authentication without a password from a physical machine still in the cluster to the replacement host. For details, see https://access.redhat.com/documentation/en-us/red_hat_hyperconverged_infrastructure_for_virtualization/1.6/html/deploying_red_hat_hyperconverged_infrastructure_for_virtualization/task-configure-key-based-ssh-auth.
Prepare the replacement host
Follow the instructions in Section 13.3, “Preparing a replacement hyperconverged host using ansible”.
Create replacement brick directories
Ensure the new directories are owned by the
vdsmuser and thekvmgroup.# mkdir /gluster_bricks/engine/engine # chmod vdsm:kvm /gluster_bricks/engine/engine # mkdir /gluster_bricks/data/data # chmod vdsm:kvm /gluster_bricks/data/data # mkdir /gluster_bricks/vmstore/vmstore # chmod vdsm:kvm /gluster_bricks/vmstore/vmstore
(Optional) If encryption is enabled
Generate the private key and self-signed certificate on the new server using the steps in the Red Hat Gluster Storage Administration Guide: https://access.redhat.com/documentation/en-us/red_hat_gluster_storage/3.4/html/administration_guide/chap-network_encryption#chap-Network_Encryption-Prereqs.
If encryption using a Certificate Authority is enabled, follow the steps under Expanding Volumes in the Network Encryption chapter of the Red Hat Gluster Storage 3.4 Administration Guide.
Add the new host’s certificate to existing certificates.
-
On a healthy host, make a backup copy of the
/etc/ssl/glusterfs.cafile. -
Add the new host’s certificate to the
/etc/ssl/glusterfs.cafile on the healthy host. -
Distribute the updated
/etc/ssl/glusterfs.cafile to all other hosts, including the new host.
-
On a healthy host, make a backup copy of the
Enable management encryption
Run the following command on the new host to enable management encryption:
# touch /var/lib/glusterd/secure-access
Include the new host in the value of the
auth.ssl-allowvolume option by running the following command for each volume.# gluster volume set <volname> auth.ssl-allow "<old_host1>,<old_host2>,<new_host>"
Restart the glusterd service on all hosts
# systemctl restart glusterd
- If encryption uses self-signed certificates, follow the steps in Section 4.1, “Configuring TLS/SSL using self-signed certificates” to remount all gluster processes.
Add the new host to the existing cluster
Run the following command from one of the healthy hosts:
# gluster peer probe <new_host>
Add the new host to the existing cluster
- Click Compute → Hosts and then click New to open the New Host dialog.
- Provide a Name, Address, and Password for the new host.
- Uncheck the Automatically configure host firewall checkbox, as firewall rules are already configured by gdeploy.
-
In the Hosted Engine tab of the New Host dialog, set the value of Choose hosted engine deployment action to
Deploy. - Click OK.
- When the host is available, click the name of the new host.
- Click the Network Interfaces subtab and then click Setup Host Networks. The Setup Host Networks dialog appears.
Drag and drop the network you created for gluster to the IP associated with this host, and click OK.
See the Red Hat Virtualization 4.3 Self-Hosted Engine Guide for further details: https://access.redhat.com/documentation/en-us/red_hat_virtualization/4.3/html/self-hosted_engine_guide/chap-installing_additional_hosts_to_a_self-hosted_environment.
Configure and mount shared storage on the new host
# cp /etc/fstab /etc/fstab.bk # echo "<new_host>:/gluster_shared_storage /var/run/gluster/shared_storage/ glusterfs defaults 0 0" >> /etc/fstab # mount /gluster_shared_storage
Replace the old brick with the brick on the new host
- In the Administration Portal, click Storage → Volumes and select the volume.
- Click the Bricks subtab.
- Select the brick that you want to replace and click Replace Brick. The Replace Brick dialog appears.
- Specify the Host and the Brick Directory of the new brick.
- Verify that brick heal completes successfully.
- Click Compute → Hosts.
Select the old host and click Remove.
Use
gluster peer statusto verify that that the old host is no longer part of the cluster. If the old host is still present in the status output, run the following command to forcibly remove it:# gluster peer detach <old_host> force
Clean old host metadata.
# hosted-engine --clean-metadata --host-id=<old_host_id> --force-clean
Set up new SSH keys for geo-replication of new brick.
# gluster system:: execute gsec_create
Recreate geo-replication session and distribute new SSH keys.
# gluster volume geo-replication <MASTER_VOL> <SLAVE_HOST>::<SLAVE_VOL> create push-pem force
Start the geo-replication session.
# gluster volume geo-replication <MASTER_VOL> <SLAVE_HOST>::<SLAVE_VOL> start
13.2.2. Replacing a hyperconverged host to use the same FQDN
When self-signed encryption is enabled, replacing a node is a disruptive process that requires virtual machines and the Hosted Engine to be shut down.
- (Optional) If encryption using a Certificate Authority is enabled, follow the steps under Expanding Volumes in the Network Encryption chapter of the Red Hat Gluster Storage 3.4 Administration Guide.
Move the host to be replaced into Maintenance mode
- In the Administration Portal, click Compute → Hosts and select the hyperconverged host.
- Click Management → Maintenance.
- Click OK to move the host to Maintenance mode.
Install the replacement host
Follow the instructions in Deploying Red Hat Hyperconverged Infrastructure for Virtualization for Virtualization to install the physical machine and configure storage on the new host.
Configure the replacement host
Follow the instructions in Section 13.3, “Preparing a replacement hyperconverged host using ansible”.
(Optional) If encryption with self-signed certificates is enabled
- Generate the private key and self-signed certificate on the replacement host. See the Red Hat Gluster Storage Administration Guide for details: https://access.redhat.com/documentation/en-us/red_hat_gluster_storage/3.4/html/administration_guide/chap-network_encryption#chap-Network_Encryption-Prereqs.
On a healthy host, make a backup copy of the
/etc/ssl/glusterfs.cafile:# cp /etc/ssl/glusterfs.ca /etc/ssl/glusterfs.ca.bk
-
Append the new host’s certificate to the content of the
/etc/ssl/glusterfs.cafile. -
Distribute the
/etc/ssl/glusterfs.cafile to all hosts in the cluster, including the new host. Run the following command on the replacement host to enable management encryption:
# touch /var/lib/glusterd/secure-access
Replace the host machine
Follow the instructions in the Red Hat Gluster Storage Administration Guide to replace the host: https://access.redhat.com/documentation/en-us/red_hat_gluster_storage/3.4/html/administration_guide/sect-replacing_hosts#Replacing_a_Host_Machine_with_the_Same_Hostname.
Restart the glusterd service on all hosts
# systemctl restart glusterd
Verify that all hosts reconnect
# gluster peer status
- (Optional) If encryption uses self-signed certificates, follow the steps in Section 4.1, “Configuring TLS/SSL using self-signed certificates” to remount all gluster processes.
Verify that all hosts reconnect and that brick heal completes successfully
# gluster peer status
Refresh fingerprint
- In the Administration Portal, click Compute → Hosts and select the new host.
- Click Edit.
- Click Advanced Parameters on the General tab.
- Click fetch to fetch the fingerprint from the host.
- Click OK.
- Click Installation → Reinstall and provide the root password when prompted.
- On the Hosted Engine tab set the value of Choose hosted engine deployment action to Deploy.
Attach the gluster network to the host
- Click Compute → Hosts and click the name of the host.
- Click the Network Interfaces subtab and then click Setup Host Networks.
- Drag and drop the newly created network to the correct interface.
- Ensure that the Verify connectivity between Host and Engine checkbox is checked.
- Ensure that the Save network configuration checkbox is checked.
- Click OK to save.
Verify the health of the network
Click the Network Interfaces tab and check the state of the host’s network. If the network interface enters an "Out of sync" state or does not have an IP Address, click Management → Refresh Capabilities.
13.3. Preparing a replacement hyperconverged host using ansible
Follow this process to replace a hyperconverged host in the cluster.
Prerequisites
- Ensure that the host you intend to replace is not associated with the FQDN that you want to use for the new host.
- Ensure that the new host is associated with the FQDN you want it to use.
Procedure
Create
node_prep_inventory.ymlinventory fileCreate an inventory file called
node_prep_inventory.yml, based on the following example.Replace
host1with the FQDN that you want to use for the new host, and device details with details appropriate for your host.Example
node_prep_inventory.ymlfilehc_nodes: hosts: # New host newhost.example.com: # Dedupe & Compression config # If logicalsize >= 1000G then slabsize=32G else slabsize=2G #gluster_infra_vdo: # - { name: 'vdo_sdc', device: '/dev/sdc', logicalsize: '3000G', emulate512: 'on', slabsize: '32G', # blockmapcachesize: '128M', readcachesize: '20M', readcache: 'enabled', writepolicy: 'auto' } # With Dedupe & Compression #gluster_infra_volume_groups: # - vgname: gluster_vg_sdc # pvname: /dev/mapper/vdo_sdc # Without Dedupe & Compression gluster_infra_volume_groups: - vgname: gluster_vg_sdc pvname: /dev/sdc gluster_infra_mount_devices: - path: /gluster_bricks/engine lvname: gluster_lv_engine vgname: gluster_vg_sdc - path: /gluster_bricks/data lvname: gluster_lv_data vgname: gluster_vg_sdc - path: /gluster_bricks/vmstore lvname: gluster_lv_vmstore vgname: gluster_vg_sdc gluster_infra_thinpools: - {vgname: 'gluster_vg_sdc', thinpoolname: 'thinpool_gluster_vg_sdc', thinpoolsize: '500G', poolmetadatasize: '4G'} # This is optional gluster_infra_cache_vars: - vgname: gluster_vg_sdc cachedisk: /dev/sde cachelvname: cachelv_thinpool_vg_sdc cachethinpoolname: thinpool_gluster_vg_sdc # cachethinpoolname is equal to the already created thinpool which you want to attach cachelvsize: '10G' cachemetalvsize: '2G' cachemetalvname: cache_thinpool_vg_sdc cachemode: writethrough gluster_infra_thick_lvs: - vgname: gluster_vg_sdc lvname: gluster_lv_engine size: 100G gluster_infra_lv_logicalvols: - vgname: gluster_vg_sdc thinpool: thinpool_gluster_vg_sdc lvname: gluster_lv_data lvsize: 500G - vgname: gluster_vg_sdc thinpool: thinpool_gluster_vg_sdc lvname: gluster_lv_vmstore lvsize: 500G # Mount the devices gluster_infra_mount_devices: - { path: '/gluster_bricks/data', vgname: gluster_vg_sdc, lvname: gluster_lv_data } - { path: '/gluster_bricks/vmstore', vgname: gluster_vg_sdc, lvname: gluster_lv_vmstore } - { path: '/gluster_bricks/engine', vgname: gluster_vg_sdc, lvname: gluster_lv_engine } # Common configurations vars: # Firewall setup gluster_infra_fw_ports: - 2049/tcp - 54321/tcp - 5900/tcp - 5900-6923/tcp - 5666/tcp - 16514/tcp gluster_infra_fw_permanent: true gluster_infra_fw_state: enabled gluster_infra_fw_zone: public gluster_infra_fw_services: - glusterfs gluster_infra_disktype: RAID6 gluster_infra_diskcount: 12 gluster_infra_stripe_unit_size: 128Create
node_prep.ymlplaybookCreate a
node_prep.ymlplaybook file based on the following example.Example
node_prep.ymlplaybook--- # Prepare Node for replace - name: Setup backend hosts: hc_nodes remote_user: root gather_facts: no any_errors_fatal: true roles: - gluster.infra - gluster.featuresRun
node_prep.ymlplaybook# ansible-playbook -i node_prep_inventory.yml node_prep.yml
Chapter 14. Recovering from disaster
This chapter explains how to restore your cluster to a working state after a disk or server failure.
You must have configured disaster recovery options previously in order to use this chapter. See Configuring backup and recovery options for details.
14.1. Manually restoring data from a backup volume
This section covers how to restore data from a remote backup volume to a freshly installed replacement deployment of Red Hat Hyperconverged Infrastructure for Virtualization.
To do this, you must:
- Install and configure a replacement deployment according to the instructions in Deploying Red Hat Hyperconverged Infrastructure for Virtualization.
14.1.1. Restoring a volume from a geo-replicated backup
Install and configure a replacement Hyperconverged Infrastructure deployment
For instructions, refer to Deploying Red Hat Hyperconverged Infrastructure for Virtualization: https://access.redhat.com/documentation/en-us/red_hat_hyperconverged_infrastructure_for_virtualization/1.6/html/deploying_red_hat_hyperconverged_infrastructure_for_virtualization/.
Import the backup of the storage domain
From the new Hyperconverged Infrastructure deployment, in the Administration Portal:
- Click Storage → Domains.
- Click Import Domain. The Import Pre-Configured Domain window opens.
- In the Storage Type field, specify GlusterFS.
- In the Name field, specify a name for the new volume that will be created from the backup volume.
- In the Path field, specify the path to the backup volume.
Click OK. The following warning appears, with any active data centers listed below:
This operation might be unrecoverable and destructive! Storage Domain(s) are already attached to a Data Center. Approving this operation might cause data corruption if both Data Centers are active.
- Check the Approve operation checkbox and click OK.
Determine a list of virtual machines to import
Determine the imported domain’s identifier by running the following command:
# curl -v -k -X GET -u "admin@internal:password" -H "Accept: application/xml" https://$ENGINE_FQDN/ovirt-engine/api/storagedomains/
For example:
# curl -v -k -X GET -u "admin@example.com:mybadpassword" -H "Accept: application/xml" https://10.0.2.1/ovirt-engine/api/storagedomains/
Determine the list of unregistered disks by running the following command:
# curl -v -k -X GET -u "admin@internal:password" -H "Accept: application/xml" "https://$ENGINE_FQDN/ovirt-engine/api/storagedomains/DOMAIN_ID/vms;unregistered"
For example:
# curl -v -k -X GET -u "admin@example.com:mybadpassword" -H "Accept: application/xml" "https://10.0.2.1/ovirt-engine/api/storagedomains/5e1a37cf-933d-424c-8e3d-eb9e40b690a7/vms;unregistered"
Perform a partial import of each virtual machine to the storage domain
Determine cluster identifier
The following command returns the cluster identifier.
# curl -v -k -X GET -u "admin@internal:password" -H "Accept: application/xml" https://$ENGINE_FQDN/ovirt-engine/api/clusters/
For example:
# curl -v -k -X GET -u "admin@example:mybadpassword" -H "Accept: application/xml" https://10.0.2.1/ovirt-engine/api/clusters/
Import the virtual machines
The following command imports a virtual machine without requiring all disks to be available in the storage domain.
# curl -v -k -u 'admin@internal:password' -H "Content-type: application/xml" -d '<action> <cluster id="CLUSTER_ID"></cluster> <allow_partial_import>true</allow_partial_import> </action>' "https://ENGINE_FQDN/ovirt-engine/api/storagedomains/DOMAIN_ID/vms/VM_ID/register"
For example:
# curl -v -k -u 'admin@example.com:mybadpassword' -H "Content-type: application/xml" -d '<action> <cluster id="bf5a9e9e-5b52-4b0d-aeba-4ee4493f1072"></cluster> <allow_partial_import>true</allow_partial_import> </action>' "https://10.0.2.1/ovirt-engine/api/storagedomains/8d21980a-a50b-45e9-9f32-cd8d2424882e/e164f8c6-769a-4cbd-ac2a-ef322c2c5f30/register"
For further information, see the Red Hat Virtualization REST API Guide: https://access.redhat.com/documentation/en-us/red_hat_virtualization/4.3/html/rest_api_guide/.
Migrate the partially imported disks to the new storage domain
In the Administration Portal, click Storage → Disks, and Click the Move Disk option. Move the imported disks from the synced volume to the replacement cluster’s storage domain. For further information, see the Red Hat Virtualization Administration Guide.
Attach the restored disks to the new virtual machines
Follow the instructions in the Red Hat Virtualization Virtual Machine Management Guide to attach the replacement disks to each virtual machine.
14.2. Failing over to a secondary cluster
This section covers how to fail over from your primary cluster to a remote secondary cluster in the event of server failure.
- Configure failover to a remote cluster.
- Verify that the mapping file for the source and target clusters remains accurate.
Run the failover playbook with the
fail_overtag.# ansible-playbook dr-rhv-failover.yml --tags "fail_over"
14.3. Failing back to a primary cluster
This section covers how to fail back from your secondary cluster to the primary cluster after you have corrected the cause of a server failure.
Prepare the primary cluster for failback by running the cleanup playbook with the
clean_enginetag.# ansible-playbook dr-cleanup.yml --tags "clean_engine"
- Verify that the mapping file for the source and target clusters remains accurate.
Execute failback by running the failback playbook with the
fail_backtag.# ansible-playbook dr-cleanup.yml --tags "fail_back"
14.4. Stopping a geo-replication session using RHV Manager
Stop a geo-replication session when you want to prevent data being replicated from an active source volume to a passive target volume via geo-replication.
Verify that data is not currently being synchronized
Click the Tasks icon at the top right of the Manager, and review the Tasks page.
Ensure that there are no ongoing tasks related to Data Synchronization.
If data synchronization tasks are present, wait until they are complete.
Stop the geo-replication session
- Click Storage → Volumes.
- Click the name of the volume that you want to prevent geo-replicating.
- Click the Geo-replication subtab.
- Select the session that you want to stop, then click Stop.
14.5. Turning off scheduled backups by deleting the geo-replication schedule
You can stop scheduled backups via geo-replication by deleting the geo-replication schedule.
- Log in to the Administration Portal on any source node.
- Click Storage → Domains.
- Click the name of the storage domain that you want to back up.
- Click the Remote Data Sync Setup subtab.
Click Setup.
The Setup Remote Data Synchronization window opens.
- In the Recurrence field, select a recurrence interval type of NONE and click OK.
(Optional) Remove the geo-replication session
Run the following command from the geo-replication master node:
# gluster volume geo-replication MASTER_VOL SLAVE_HOST::SLAVE_VOL delete
You can also run this command with the
reset-sync-timeparameter. For further information about this parameter and deleting a geo-replication session, see Deleting a Geo-replication Session in the Red Hat Gluster Storage 3.4 Administration Guide.
Part III. Reference material
Appendix A. Fencing Policies for Red Hat Gluster Storage
The following fencing policies are required for Red Hat Hyperconverged Infrastructure for Virtualization (RHHI for Virtualization) deployments. They ensure that hosts are not shut down in situations where brick processes are still running, or when shutting down the host would remove the volume’s ability to reach a quorum.
These policies can be set in the New Cluster or Edit Cluster window in the Administration Portal when Red Hat Gluster Storage functionality is enabled.
- Skip fencing if gluster bricks are up
- Fencing is skipped if bricks are running and can be reached from other peers.
- Skip fencing if gluster quorum not met
- Fencing is skipped if bricks are running and shutting down the host will cause loss of quorum
These policies are checked after all other fencing policies when determining whether a node is fenced.
Additional fencing policies may be useful for your deployment. For further details about fencing, see the Red Hat Virtualization Technical Reference: https://access.redhat.com/documentation/en-us/red_hat_virtualization/4.3/html/technical_reference/fencing.
Appendix B. Glossary of terms
B.1. Virtualization terms
- Administration Portal
- A web user interface provided by Red Hat Virtualization Manager, based on the oVirt engine web user interface. It allows administrators to manage and monitor cluster resources like networks, storage domains, and virtual machine templates.
- Hosted Engine
- The instance of Red Hat Virtualization Manager that manages RHHI for Virtualization.
- Hosted Engine virtual machine
- The virtual machine that acts as Red Hat Virtualization Manager. The Hosted Engine virtual machine runs on a virtualization host that is managed by the instance of Red Hat Virtualization Manager that is running on the Hosted Engine virtual machine.
- Manager node
- A virtualization host that runs Red Hat Virtualization Manager directly, rather than running it in a Hosted Engine virtual machine.
- Red Hat Enterprise Linux host
- A physical machine installed with Red Hat Enterprise Linux plus additional packages to provide the same capabilities as a Red Hat Virtualization host. This type of host is not supported for use with RHHI for Virtualization.
- Red Hat Virtualization
- An operating system and management interface for virtualizing resources, processes, and applications for Linux and Microsoft Windows workloads.
- Red Hat Virtualization host
- A physical machine installed with Red Hat Virtualization that provides the physical resources to support the virtualization of resources, processes, and applications for Linux and Microsoft Windows workloads. This is the only type of host supported with RHHI for Virtualization.
- Red Hat Virtualization Manager
- A server that runs the management and monitoring capabilities of Red Hat Virtualization.
- Self-Hosted Engine node
- A virtualization host that contains the Hosted Engine virtual machine. All hosts in a RHHI for Virtualization deployment are capable of becoming Self-Hosted Engine nodes, but there is only one Self-Hosted Engine node at a time.
- storage domain
- A named collection of images, templates, snapshots, and metadata. A storage domain can be comprised of block devices or file systems. Storage domains are attached to data centers in order to provide access to the collection of images, templates, and so on to hosts in the data center.
- virtualization host
- A physical machine with the ability to virtualize physical resources, processes, and applications for client access.
- VM Portal
- A web user interface provided by Red Hat Virtualization Manager. It allows users to manage and monitor virtual machines.
B.2. Storage terms
- brick
- An exported directory on a server in a trusted storage pool.
- cache logical volume
- A small, fast logical volume used to improve the performance of a large, slow logical volume.
- geo-replication
- One way asynchronous replication of data from a source Gluster volume to a target volume. Geo-replication works across local and wide area networks as well as the Internet. The target volume can be a Gluster volume in a different trusted storage pool, or another type of storage.
- gluster volume
- A logical group of bricks that can be configured to distribute, replicate, or disperse data according to workload requirements.
- logical volume management (LVM)
- A method of combining physical disks into larger virtual partitions. Physical volumes are placed in volume groups to form a pool of storage that can be divided into logical volumes as needed.
- Red Hat Gluster Storage
- An operating system based on Red Hat Enterprise Linux with additional packages that provide support for distributed, software-defined storage.
- source volume
- The Gluster volume that data is being copied from during geo-replication.
- storage host
- A physical machine that provides storage for client access.
- target volume
- The Gluster volume or other storage volume that data is being copied to during geo-replication.
- thin provisioning
- Provisioning storage such that only the space that is required is allocated at creation time, with further space being allocated dynamically according to need over time.
- thick provisioning
- Provisioning storage such that all space is allocated at creation time, regardless of whether that space is required immediately.
- trusted storage pool
- A group of Red Hat Gluster Storage servers that recognise each other as trusted peers.
B.3. Hyperconverged Infrastructure terms
- Red Hat Hyperconverged Infrastructure (RHHI) for Virtualization
- RHHI for Virtualization is a single product that provides both virtual compute and virtual storage resources. Red Hat Virtualization and Red Hat Gluster Storage are installed in a converged configuration, where the services of both products are available on each physical machine in a cluster.
- hyperconverged host
- A physical machine that provides physical storage, which is virtualized and consumed by virtualized processes and applications run on the same host. All hosts installed with RHHI for Virtualization are hyperconverged hosts.
- Web Console
- The web user interface for deploying, managing, and monitoring RHHI for Virtualization. The Web Console is provided by the the Web Console service and plugins for Red Hat Virtualization Manager.