Instances and Images Guide
Managing Instances and Images
概要
Preface
Making open source more inclusive
Red Hat is committed to replacing problematic language in our code, documentation, and web properties. We are beginning with these four terms: master, slave, blacklist, and whitelist. Because of the enormity of this endeavor, these changes will be implemented gradually over several upcoming releases. For more details, see our CTO Chris Wright’s message.
第1章 Image service
You can manage images and storage in Red Hat OpenStack Platform (RHOSP).
A virtual machine image is a file that contains a virtual disk with a bootable operating system installed. Virtual machine images are supported in different formats. The following formats are available in RHOSP:
-
RAW- Unstructured disk image format. -
QCOW2- Disk format supported by QEMU emulator. This format includes QCOW2v3 (sometimes referred to as QCOW3), which requires QEMU 1.1 or higher. -
ISO- Sector-by-sector copy of the data on a disk, stored in a binary file. -
AKI- Indicates an Amazon Kernel Image. -
AMI- Indicates an Amazon Machine Image. -
ARI- Indicates an Amazon RAMDisk Image. -
VDI- Disk format supported by VirtualBox virtual machine monitor and the QEMU emulator. -
VHD- Common disk format used by virtual machine monitors from VMware, VirtualBox, and others. -
VMDK- Disk format supported by many common virtual machine monitors. -
PLOOP- A disk format supported and used by Virtuozzo to run OS containers. -
OVA- Indicates that what is stored in the Image service (glance) is an OVA tar archive file. -
DOCKER- Indicates that what is stored in the Image service (glance) is a Docker tar archive of the container file system.
Because ISO files contain bootable file systems with an installed operating system, you can use ISO files in the same way that you use other virtual machine image files.
To download the official Red Hat Enterprise Linux cloud images, your account must have a valid Red Hat Enterprise Linux subscription:
If you are not logged in to the Customer Portal, a prompt opens where you must enter your Red Hat account credentials.
1.1. Understanding and optimizing the Image service
You can use the following Red Hat OpenStack Platform (RHOSP) Image service (glance) features to manage and optimize images and storage in your RHOSP deployment.
1.1.1. Supported Image service (glance) back ends
The following Image service (glance) back end scenarios are supported:
- RBD is the default back end when you use Ceph. For more information, see Configuring Ceph Storage in the Advanced Overcloud Customization guide.
- Object Storage (swift). For more information, see Using an External Object Storage Cluster in the Advanced Overcloud Customization guide.
Block Storage (cinder). For more information, see Configuring cinder back end for the Image service in the Advanced Overcloud Customization guide.
- Note
- The Image service uses the Block Storage type and back end as the default.
NFS. For more information, see Configuring NFS Storage in the Advanced Overcloud Customization guide.
重要Although NFS is a supported Image service deployment option, more robust options are available.
NFS is not native to the Image service. When you mount an NFS share on the Image service, the Image service does not manage the operation. The Image service writes data to the file system but is unaware that the back end is an NFS share.
In this type of deployment, the Image service cannot retry a request if the share fails. This means that when a failure occurs on the back end, the store might enter read-only mode, or it might continue to write data to the local file system, in which case you risk data loss. To recover from this situation, you must ensure that the share is mounted and in sync, and then restart the Image service. For these reasons, Red Hat does not recommend NFS as an Image service back end.
However, if you do choose to use NFS as an Image service back end, some of the following best practices can help to mitigate risks:
- Use a production-grade NFS back end.
- Ensure that a Layer 2 connection is established between Controller nodes and the NFS back end.
- Include monitoring and alerts for the mounted share.
Set underlying FS permissions.
- Ensure that the user and the group that the glance-api process runs on do not have write permissions on the mount point at the local file system. This means that the process can detect possible mount failure and put the store into read-only mode during a write attempt.
- The write permissions must be present in the shared file system that you use as a store.
1.1.2. Image signing and verification
Image signing and verification protects image integrity and authenticity by enabling deployers to sign images and save the signatures and public key certificates as image properties.
By taking advantage of this feature, you can:
- Sign an image using your private key and upload the image, the signature, and a reference to your public key certificate (the verification metadata). The Image service then verifies that the signature is valid.
- Create an image in the Compute service, have the Compute service sign the image, and upload the image and its verification metadata. The Image service again verifies that the signature is valid.
- Request a signed image in the Compute service. The Image service provides the image and its verification metadata, allowing the Compute service to validate the image before booting it.
For information on image signing and verification, refer to the Validate Glance Images chapter of the Manage Secrets with OpenStack Key Manager Guide.
1.1.3. Image conversion
Image conversion converts images by calling the task API while importing an image.
As part of the import workflow, a plugin provides the image conversion. This plugin can be activated or deactivated based on the deployer configuration. Therefore, the deployer needs to specify the preferred format of images for the deployment.
Internally, the Image service receives the bits of the image in a particular format. These bits are stored in a temporary location. The plugin is then triggered to convert the image to the target format and move it to a final destination. When the task is finished, the temporary location is deleted. As a result, the format uploaded initially is not retained by the Image service.
For more information about image conversion, see Enabling image conversion.
You can trigger the conversion only when you import an image. Conversion does not run when you upload an image. For example:
$ glance image-create-via-import \
--disk-format qcow2 \
--container-format bare \
--name <name> \
--visibility public \
--import-method web-download \
--uri <http://server/image.qcow2>1.1.4. Image introspection
Every image format comes with a set of metadata embedded inside the image itself. For example, a stream optimized vmdk would contain the following parameters:
$ head -20 so-disk.vmdk
# Disk DescriptorFile
version=1
CID=d5a0bce5
parentCID=ffffffff
createType="streamOptimized"
# Extent description
RDONLY 209714 SPARSE "generated-stream.vmdk"
# The Disk Data Base
#DDB
ddb.adapterType = "buslogic"
ddb.geometry.cylinders = "102"
ddb.geometry.heads = "64"
ddb.geometry.sectors = "32"
ddb.virtualHWVersion = "4"
By introspecting this vmdk, you can know that the disk_type is streamOptimized, and the adapter_type is buslogic. These metadata parameters are useful for the consumer of the image. In Compute, the workflow to instantiate a streamOptimized disk is different from the one to instantiate a flat disk. This new feature allows metadata extraction. You can achieve image introspection by calling the task API while you import the image. An administrator can override metadata settings.
1.1.5. Interoperable image import
The OpenStack Image service (glance) provides two methods to import images by using the interoperable image import workflow:
-
web-download(default) for importing images from a URI -
glance-directfor importing from a local file system
1.2. Managing images
The OpenStack Image service (glance) provides discovery, registration, and delivery services for disk and server images. It provides the ability to copy or snapshot a server image, and immediately store it. You can use stored images as a template to get new servers up and running quickly and more consistently than installing a server operating system and individually configuring services.
1.2.1. Creating an image
Manually create Red Hat OpenStack Platform (RHOSP) compatible images in the QCOW2 format by using Red Hat Enterprise Linux 7 ISO files, Red Hat Enterprise Linux 6 ISO files, or Windows ISO files.
1.2.1.1. Using a KVM guest image with Red Hat OpenStack Platform
You can use a ready RHEL KVM guest QCOW2 image:
These images are configured with cloud-init and must take advantage of ec2-compatible metadata services for provisioning SSH keys to function properly.
Ready Windows KVM guest QCOW2 images are not available.
For the KVM guest images:
-
The
rootaccount in the image is disabled, butsudoaccess is granted to a special user namedcloud-user. -
There is no
rootpassword set for this image.
The root password is locked in /etc/shadow by placing !! in the second field.
For a RHOSP instance, it is recommended that you generate an ssh keypair from the RHOSP dashboard or command line and use that key combination to perform an SSH public authentication to the instance as root.
When the instance is launched, this public key is injected to it. You can then use the private key you downloaded while you created the keypair to authenticate.
If you do not want to use keypairs, you can use the admin password that you can set in the procedure to inject an admin password, see Injecting an admin password into an instance.
If you want to create custom Red Hat Enterprise Linux or Windows images, see:
1.2.1.2. Creating custom Red Hat Enterprise Linux or Windows images
Prerequisites
- Linux host machine to create an image. This can be any machine on which you can install and run the Linux packages.
-
libvirt, virt-manager (run command
yum groupinstall -y @virtualization). This installs all packages necessary to create a guest operating system. -
Libguestfs tools (run command
yum install -y libguestfs-tools-c). This installs a set of tools to access and modify virtual machine images. - A Red Hat Enterprise Linux 7 or 6 ISO file (see RHEL 7.2 Binary DVD or RHEL 6.8 Binary DVD) or a Windows ISO file. If you do not have a Windows ISO file, visit the Microsoft TechNet Evaluation Center and download an evaluation image.
-
A text editor if you want to change the
kickstartfiles (RHEL only).
If you install the libguestfs-tools package on the undercloud, disable iscsid.socket to avoid port conflicts with the tripleo_iscsid service on the undercloud:
$ sudo systemctl disable --now iscsid.socket
In the following procedures, you must run all commands with the [root@host]# prompt on your host machine.
1.2.1.2.1. Creating a Red Hat Enterprise Linux 7 image
Manually create a Red Hat OpenStack Platform (RHOSP) compatible image in the QCOW2 format by using a Red Hat Enterprise Linux 7 ISO file.
Procedure
Start the installation using
virt-install:[root@host]# qemu-img create -f qcow2 rhel7.qcow2 8G [root@host]# virt-install --virt-type kvm --name rhel7 --ram 2048 \ --cdrom /tmp/rhel-server-7.2-x86_64-dvd.iso \ --disk rhel7.qcow2,format=qcow2 \ --network=bridge:virbr0 --graphics vnc,listen=0.0.0.0 \ --noautoconsole --os-type=linux --os-variant=rhel7This launches an instance and starts the installation process.
注記If the instance does not launch automatically, run the
virt-viewercommand to view the console:[root@host]# virt-viewer rhel7Configure the virtual machine as follows:
-
At the initial Installer boot menu, choose the
Install Red Hat Enterprise Linux 7.X option. - Choose the appropriate Language and Keyboard options.
- When prompted about which type of devices your installation uses, choose Auto-detected installation media.
- When prompted about which type of installation destination, choose Local Standard Disks. For other storage options, choose Automatically configure partitioning.
- For software selection, choose Minimal Install.
-
For network and host name, choose
eth0for network and choose ahostnamefor your device. The default host name islocalhost.localdomain. -
Choose the
rootpassword. The installation process completes and the Complete! screen appears.
-
At the initial Installer boot menu, choose the
- After the installation is complete, reboot the instance and log in as the root user.
Update the
/etc/sysconfig/network-scripts/ifcfg-eth0file so that it contains only the following values:TYPE=Ethernet DEVICE=eth0 ONBOOT=yes BOOTPROTO=dhcp NM_CONTROLLED=no- Reboot the machine.
Register the machine with the Content Delivery Network.
# sudo subscription-manager register # sudo subscription-manager attach --pool=Valid-Pool-Number-123456 # sudo subscription-manager repos --enable=rhel-7-server-rpmsUpdate the system:
# yum -y updateInstall the
cloud-initpackages:# yum install -y cloud-utils-growpart cloud-initEdit the
/etc/cloud/cloud.cfgconfiguration file and undercloud_init_modulesadd:- resolv-confThe
resolv-confoption automatically configures theresolv.confwhen an instance boots for the first time. This file contains information related to the instance such asnameservers,domainand other options.Add the following line to
/etc/sysconfig/networkto avoid problems accessing the EC2 metadata service:NOZEROCONF=yesTo ensure the console messages appear in the
Logtab on the dashboard and thenova console-logoutput, add the following boot option to the/etc/default/grubfile:GRUB_CMDLINE_LINUX_DEFAULT="console=tty0 console=ttyS0,115200n8"Run the
grub2-mkconfigcommand:# grub2-mkconfig -o /boot/grub2/grub.cfgThe output is as follows:
Generating grub configuration file ... Found linux image: /boot/vmlinuz-3.10.0-229.7.2.el7.x86_64 Found initrd image: /boot/initramfs-3.10.0-229.7.2.el7.x86_64.img Found linux image: /boot/vmlinuz-3.10.0-121.el7.x86_64 Found initrd image: /boot/initramfs-3.10.0-121.el7.x86_64.img Found linux image: /boot/vmlinuz-0-rescue-b82a3044fb384a3f9aeacf883474428b Found initrd image: /boot/initramfs-0-rescue-b82a3044fb384a3f9aeacf883474428b.img doneUn-register the virtual machine so that the resulting image does not contain the same subscription details for every instance cloned based on it:
# subscription-manager repos --disable=* # subscription-manager unregister # yum clean allPower off the instance:
# poweroffUse the
virt-sysprepcommand to reset and clean the image so that it can be used to create instances without issues:[root@host]# virt-sysprep -d rhel7Reduce image size by using the
virt-sparsifycommand. This command converts any free space within the disk image back to free space within the host:[root@host]# virt-sparsify --compress /tmp/rhel7.qcow2 rhel7-cloud.qcow2This creates a new
rhel7-cloud.qcow2file in the location from where the command is run.
The rhel7-cloud.qcow2 image file is ready to be uploaded to the Image service. For more information about using the dashboard to upload this image to your RHOSP deployment, see Upload an Image.
1.2.1.2.2. Creating a Red Hat Enterprise Linux 6 image
Manually create a Red Hat OpenStack Platform (RHOSP) compatible image in the QCOW2 format by using a Red Hat Enterprise Linux 6 ISO file.
Procedure
Use
virt-installto start the installation:[root@host]# qemu-img create -f qcow2 rhel6.qcow2 4G [root@host]# virt-install --connect=qemu:///system --network=bridge:virbr0 \ --name=rhel6 --os-type linux --os-variant rhel6 \ --disk path=rhel6.qcow2,format=qcow2,size=10,cache=none \ --ram 4096 --vcpus=2 --check-cpu --accelerate \ --hvm --cdrom=rhel-server-6.8-x86_64-dvd.isoThis launches an instance and starts the installation process.
注記If the instance does not launch automatically, run the
virt-viewercommand to view the console:[root@host]# virt-viewer rhel6Configure the virtual machines as follows:
At the initial Installer boot menu, choose the Install or upgrade an existing system option. Follow the installation prompts. Accept the defaults.
The installer checks for the disc and lets you decide whether you want to test your installation media before installation. Select OK to run the test or Skip to proceed without testing.
- Choose the appropriate Language and Keyboard options.
- When prompted about which type of devices your installation uses, choose Basic Storage Devices.
-
Choose a
hostnamefor your device. The default host name islocalhost.localdomain. -
Set timezone and
rootpassword. - Based on the space on the disk, choose the type of installation.
- Choose the Basic Server install, which installs an SSH server.
- The installation process completes and Congratulations, your Red Hat Enterprise Linux installation is complete screen appears.
-
Reboot the instance and log in as the
rootuser. Update the
/etc/sysconfig/network-scripts/ifcfg-eth0file so it only contains the following values:TYPE=Ethernet DEVICE=eth0 ONBOOT=yes BOOTPROTO=dhcp NM_CONTROLLED=no- Reboot the machine.
Register the machine with the Content Delivery Network:
# sudo subscription-manager register # sudo subscription-manager attach --pool=Valid-Pool-Number-123456 # sudo subscription-manager repos --enable=rhel-6-server-rpmsUpdate the system:
# yum -y updateInstall the
cloud-initpackages:# yum install -y cloud-utils-growpart cloud-initEdit the
/etc/cloud/cloud.cfgconfiguration file and undercloud_init_modulesadd:- resolv-confThe
resolv-confoption automatically configures theresolv.confconfiguration file when an instance boots for the first time. This file contains information related to the instance such asnameservers,domain, and other options.To prevent network issues, create the
/etc/udev/rules.d/75-persistent-net-generator.rulesfile as follows:# echo "#" > /etc/udev/rules.d/75-persistent-net-generator.rulesThis prevents
/etc/udev/rules.d/70-persistent-net.rulesfile from being created. If/etc/udev/rules.d/70-persistent-net.rulesis created, networking might not function correctly when booting from snapshots (the network interface is created aseth1rather thaneth0and IP address is not assigned).Add the following line to
/etc/sysconfig/networkto avoid problems accessing the EC2 metadata service:NOZEROCONF=yesTo ensure the console messages appear in the
Logtab on the dashboard and thenova console-logoutput, add the following boot option to the/etc/grub.conf:console=tty0 console=ttyS0,115200n8Un-register the virtual machine so that the resulting image does not contain the same subscription details for every instance cloned based on it:
# subscription-manager repos --disable=* # subscription-manager unregister # yum clean allPower off the instance:
# poweroffUse the
virt-sysprepcommand to reset and clean the image so that it can be used to create instances without issues:[root@host]# virt-sysprep -d rhel6Reduce image size by using the
virt-sparsifycommand. This command converts any free space within the disk image back to free space within the host:[root@host]# virt-sparsify --compress rhel6.qcow2 rhel6-cloud.qcow2This creates a new
rhel6-cloud.qcow2file in the location from where the command is run.注記You must manually resize the partitions of instances based on the image in accordance with the disk space in the flavor that is applied to the instance.
The rhel6-cloud.qcow2 image file is ready to upload to the Image service. For more information about using the dashboard to upload this image to your RHOSP deployment, see Upload an Image
1.2.1.2.3. Creating a Windows image
Manually create a Red Hat OpenStack Platform (RHOSP) compatible image in the QCOW2 format by using a Windows ISO file.
Procedure
Use
virt-installto start the installation:[root@host]# virt-install --name=<name> \ --disk size=<size> \ --cdrom=<path>` \ --os-type=windows \ --network=bridge:virbr0 \ --graphics spice \ --ram=<RAM>Replace the values of the
virt-installparameters as follows:-
<name>— the name of the Windows guest. -
<size>— disk size in GB. -
<path>— the path to the Windows installation ISO file. <RAM>— the requested amount of RAM in MB.注記The
--os-type=windowsparameter ensures that the clock is configured correctly for the Windows guest, and enables its Hyper-V enlightenment features.virt-installsaves the guest image as/var/lib/libvirt/images/<name>.qcow2by default. If you want to keep the guest image elsewhere, change the parameter of the--diskoption as follows:--disk path=<filename>,size=<size>Replace <filename> with the name of the file that stores the guest image, and optionally its path, for example,
path=win8.qcow2,size=8creates an 8 GB file namedwin8.qcow2in the current working directory.ヒントIf the guest does not launch automatically, run the
virt-viewercommand to view the console:[root@host]# virt-viewer <name>
-
- Installation of Windows systems is beyond the scope of this document. For instructions about how to install Windows, see the relevant Microsoft documentation.
-
To allow the newly installed Windows system to use the virtualized hardware, you might need to install
virtio driversin it. To so do, first install thevirtio-winpackage on the host system. This package contains the virtio ISO image, which you must attach as a CD-ROM drive to the Windows guest. See Chapter 8. KVM Para-virtualized (virtio) Drivers in the Virtualization Deployment and Administration Guide for detailed instructions on how to install thevirtio-winpackage, add the virtio ISO image to the guest, and install the virtio drivers. To complete the configuration, download and execute Cloudbase-Init on the Windows system. At the end of the installation of Cloudbase-Init, select the
Run SysprepandShutdowncheck boxes. TheSyspreptool makes the guest unique by generating an OS ID, which certain Microsoft services use.重要Red Hat does not provide technical support for Cloudbase-Init. If you encounter an issue, contact Cloudbase Solutions.
When the Windows system shuts down, the <name>_.qcow2 image file is ready to upload to the Image service. For more information about using the dashboard or the command line to upload this image to your RHOSP deployment, see Uploading an Image.
libosinfo data
The Compute service has deprecated support for using libosinfo data to set default device models. Instead, use the following image metadata properties to configure the optimal virtual hardware for an instance:
-
os_distro -
os_version -
hw_cdrom_bus -
hw_disk_bus -
hw_scsi_model -
hw_vif_model -
hw_video_model -
hypervisor_type
For more information about these metadata properties, see 付録A Image configuration parameters.
1.2.2. Uploading an image
Procedure
- In the dashboard, select Project > Compute > Images.
- Click Create Image.
- Complete the values, and click Create Image when finished.
| Field | Notes |
|---|---|
| Name | Name for the image. The name must be unique within the project. |
| Description | Brief description to identify the image. |
| Image Source | Image source: Image Location or Image File. Based on your selection, the next field is displayed. |
| Image Location or Image File |
|
| Format | Image format (for example, qcow2). |
| Architecture | Image architecture. For example, use i686 for a 32-bit architecture or x86_64 for a 64-bit architecture. |
| Minimum Disk (GB) | Minimum disk size required to boot the image. If this field is not specified, the default value is 0 (no minimum). |
| Minimum RAM (MB) | Minimum memory size required to boot the image. If this field is not specified, the default value is 0 (no minimum). |
| Public | If selected, makes the image public to all users with access to the project. |
| Protected | If selected, ensures only users with specific permissions can delete this image. |
When the image has been successfully uploaded, its status is changed to active, which indicates that the image is available for use. The Image service can handle even large images that take a long time to upload, longer than the lifetime of the Identity service token which was used to initiate the upload. This is due to the fact that the Image service first creates a trust with the Identity service so that a new token can be obtained and used when the upload is complete and the status of the image is to be updated.
You can also use the glance image-create command with the --property option to upload an image. More values are available on the command line. For a complete list of available metadata properties, see Image Configuration Parameters.
1.2.3. Updating an image
Procedure
- In the dashboard, select Project > Compute > Images.
Click Edit Image from the list.
注記The Edit Image option is available only when you log in as an
adminuser. When you log in as ademouser, you have the option to Launch an instance or Create Volume.- Update the fields and click Update Image when finished. You can update the following values - name, description, kernel ID, ramdisk ID, architecture, format, minimum disk, minimum RAM, public, protected.
- Click the menu and select Update Metadata option.
- Specify metadata by adding items from the left column to the right one. In the left column, there are metadata definitions from the Image Service Metadata Catalog. Select Other to add metadata with the key of your choice and click Save when finished.
You can also use the glance image-update command with the --property option to update an image. More values are available on the command line. For a complete list of available metadata properties, see Image Configuration Parameters.
1.2.4. Importing an image
You can import images into the Image service (glance) by using web-download to import an image from a URI and glance-direct to import an image from a local file system. The web-download option is enabled by default.
Import methods are configured by the cloud administrator. Run the glance import-info command to list available import options.
1.2.4.1. Importing from a remote URI
You can use the web-download method to copy an image from a remote URI by using a two-stage process. First, an image record is created and then the image is retrieved from a URI. This method provides a more secure way to import images than the deprecated copy-from method used in Image API v1.
Procedure
Create an image and specify the URI of the image to import.
$ glance image-create --uri <URI>You can monitor the availability of the image:
$ openstack image show <image_id> command.Replace the ID with the one provided during image creation.
1.2.4.2. Importing from a local volume
The glance-direct method creates an image record, which generates an image ID. After the image is uploaded to the service from a local volume, it is stored in a staging area and is made active after it passes any configured checks. The glance-direct method requires a shared staging area when used in a highly available (HA) configuration.
Image uploads that use the glance-direct method fail in an HA environment if a common staging area is not present. In an HA active-active environment, API calls are distributed to the Image service controllers. The download API call can be sent to a different controller than the API call to upload the image. For more information about configuring the staging area, see Storage Configuration in the Advanced Overcloud Customization Guide.
The glance-direct method uses the following calls to import an image:
-
glance image-create -
glance image-stage -
glance image-import
Procedure
You can use the
glance image-create-via-importcommand to perform all three of these calls in one command:$ glance image-create-via-import --container-format <format> --disk-format <disk_format> --name <name> --file <path_to_image>After the image moves from the staging area to the back end location, the image is listed. However, it might take some time for the image to become active.
You can monitor the availability of the image:
$ openstack image show <image_id> command.Replace the ID with the one provided during image creation.
1.2.5. Deleting an image
Procedure
- In the dashboard, select Project > Compute > Images.
- Select the image you want to delete and click Delete Images.
1.2.6. Enabling image conversion
With the GlanceImageImportPlugins parameter enabled, you can upload a QCOW2 image, and the Image service converts it to RAW.
Procedure
To enable image conversion, create an environment file that contains the following parameter value and include the new environment file with any other environment files that are relevant to your deployment by using the
-eoption in theopenstack overcloud deploycommand:parameter_defaults: GlanceImageImportPlugins:'image_conversion'
1.2.7. Converting an image to RAW format
Red Hat Ceph can store, but does not support using, QCOW2 images to host virtual machine (VM) disks.
When you upload a QCOW2 image and create a VM from it, the compute node downloads the image, converts the image to RAW, and uploads it back into Ceph, which can then use it. This process affects the time it takes to create VMs, especially during parallel VM creation.
For example, when you create multiple VMs simultaneously, uploading the converted image to the Ceph cluster might impact already running workloads. The upload process can starve those workloads of IOPS and impede storage responsiveness.
To boot VMs in Ceph more efficiently (ephemeral back end or boot from volume), the Image service image format must be RAW.
Procedure
Converting an image to RAW might yield an image that is larger in size than the original QCOW2 image file. Run the following command before the conversion to determine the final RAW image size:
qemu-img info <image>.qcow2Convert an image from QCOW2 to RAW format:
qemu-img convert -p -f qcow2 -O raw <original_qcow2_image>.qcow2 <new_raw_image>.raw
1.2.7.1. Configuring the Image service to accept only RAW and ISO
You can configure the Image service to accept only RAW and ISO image formats.
Procedure
Add an additional environment file that contains the following content in the
openstack overcloud deploycommand with your other environment files:parameter_defaults: ExtraConfig: glance::config::api_config: image_format/disk_formats: value: "raw,iso"
1.2.8. Storing an image in RAW format
Procedure
With the
GlanceImageImportPluginsparameter enabled, run the following command to upload aQCOW2image and automatically convert it toRAWformat.$ glance image-create-via-import \ --disk-format qcow2 \ --container-format bare \ --name <name> \ --visibility public \ --import-method web-download \ --uri <http://server/image.qcow2>-
Replace
<name>with the name of the image; this is the name that appears inopenstack image list. -
For
--uri, replace<http://server/image.qcow2>with the location and file name of the QCOW2 image.
This example command creates the image record and imports it by using the web-download method. The glance-api downloads the image from the --uri location during the import process. If web-download is not available, glanceclient cannot automatically download the image data. Run the glance import-info command to list the available image import methods.
第2章 Configuring the Compute (nova) service
Use environment files to customize the Compute (nova) service. Puppet generates and stores this configuration in the /var/lib/config-data/puppet-generated/<nova_container>/etc/nova/nova.conf file. Use the following configuration methods to customize the Compute service configuration:
Heat parameters - as detailed in the Compute (nova) Parameters section in the Overcloud Parameters guide. For example:
parameter_defaults: NovaSchedulerDefaultFilters: AggregateInstanceExtraSpecsFilter,RetryFilter,ComputeFilter,ComputeCapabilitiesFilter,ImagePropertiesFilter NovaNfsEnabled: true NovaNfsShare: '192.0.2.254:/export/nova' NovaNfsOptions: 'context=system_u:object_r:nfs_t:s0' NovaNfsVersion: '4.2'Puppet parameters - as defined in
/etc/puppet/modules/nova/manifests/*:parameter_defaults: ComputeExtraConfig: nova::compute::force_raw_images: True注記Only use this method if an equivalent heat parameter does not exist.
Manual hieradata overrides - for customizing parameters when no heat or Puppet parameter exists. For example, the following sets the
disk_allocation_ratioin the[DEFAULT]section on the Compute role:parameter_defaults: ComputeExtraConfig: nova::config::nova_config: DEFAULT/disk_allocation_ratio: value: '2.0'
If a heat parameter exists, it must be used instead of the Puppet parameter; if a Puppet parameter exists, but not a heat parameter, then the Puppet parameter must be used instead of the manual override method. The manual override method must only be used if there is no equivalent heat or Puppet parameter.
Follow the guidance in Identifying Parameters to Modify to determine if a heat or Puppet parameter is available for customizing a particular configuration.
See Parameters in the Advanced Overcloud Customization guide for further details on configuring overcloud services.
2.1. Configuring memory for overallocation
When you use memory overcommit (NovaRAMAllocationRatio >= 1.0), you need to deploy your overcloud with enough swap space to support the allocation ratio.
If your NovaRAMAllocationRatio parameter is set to < 1, follow the RHEL recommendations for swap size. For more information, see Recommended system swap space in the RHEL Managing Storage Devices guide.
Prerequisites
- You have calculated the swap size your node requires. For more information, see 「Calculating swap size」.
Procedure
Copy the
/usr/share/openstack-tripleo-heat-templates/environments/enable-swap.yamlfile to your environment file directory:$ cp /usr/share/openstack-tripleo-heat-templates/environments/enable-swap.yaml /home/stack/templates/enable-swap.yamlConfigure the swap size by adding the following parameters to your
enable-swap.yamlfile:parameter_defaults: swap_size_megabytes: <swap size in MB> swap_path: <full path to location of swap, default: /swap>To apply this configuration, add the
enable_swap.yamlenvironment file to the stack with your other environment files and deploy the overcloud:(undercloud) $ openstack overcloud deploy --templates \ -e [your environment files] \ -e /home/stack/templates/enable-swap.yaml \
2.2. Calculating reserved host memory on Compute nodes
To determine the total amount of RAM to reserve for host processes, you need to allocate enough memory for each of the following:
- The resources that run on the node, for instance, OSD consumes 3 GB of memory.
- The emulator overhead required to visualize instances on a host.
- The hypervisor for each instance.
After you calculate the additional demands on memory, use the following formula to help you determine the amount of memory to reserve for host processes on each node:
NovaReservedHostMemory = total_RAM - ( (vm_no * (avg_instance_size + overhead)) + (resource1 * resource_ram) + (resource _n_ * resource_ram))-
Replace
vm_nowith the number of instances. -
Replace
avg_instance_sizewith the average amount of memory each instance can use. -
Replace
overheadwith the hypervisor overhead required for each instance. -
Replace
resource1with the number of a resource type on the node. -
Replace
resource_ramwith the amount of RAM each resource of this type requires.
2.3. Calculating swap size
The allocated swap size must be large enough to handle any memory overcommit. You can use the following formulas to calculate the swap size your node requires:
-
overcommit_ratio =
NovaRAMAllocationRatio- 1 -
Minimum swap size (MB) =
(total_RAM * overcommit_ratio) + RHEL_min_swap -
Recommended (maximum) swap size (MB) =
total_RAM * (overcommit_ratio + percentage_of_RAM_to_use_for_swap)
The percentage_of_RAM_to_use_for_swap variable creates a buffer to account for QEMU overhead and any other resources consumed by the operating system or host services.
For instance, to use 25% of the available RAM for swap, with 64GB total RAM, and NovaRAMAllocationRatio set to 1:
- Recommended (maximum) swap size = 64000 MB * (0 + 0.25) = 16000 MB
For information on how to calculate the NovaReservedHostMemory value, see 「Calculating reserved host memory on Compute nodes」.
For information on how to determine the RHEL_min_swap value, see Recommended system swap space in the RHEL Managing Storage Devices guide.
第3章 Configuring OpenStack Compute storage
This chapter describes the architecture for the back-end storage of images in OpenStack Compute (nova), and provides basic configuration options.
3.1. Architecture overview
In Red Hat OpenStack Platform, the OpenStack Compute service uses the KVM hypervisor to execute compute workloads. The libvirt driver handles all interactions with KVM, and enables the creation of virtual machines.
Two types of libvirt storage must be considered for Compute:
- Base image, which is a cached and formatted copy of the Image service image.
-
Instance disk, which is created using the
libvirtbase and is the back end for the virtual machine instance. Instance disk data can be stored either in Compute’s ephemeral storage (using thelibvirtbase) or in persistent storage (for example, using Block Storage).
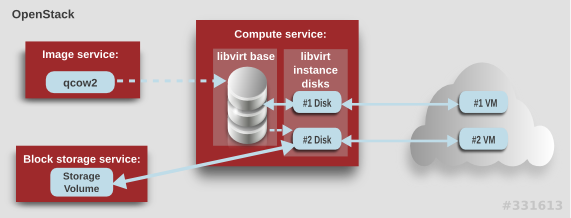
The steps that Compute takes to create a virtual machine instance are:
-
Cache the Image service’s backing image as the
libvirtbase. - Convert the base image to the raw format (if configured).
- Resize the base image to match the VM’s flavor specifications.
- Use the base image to create the libvirt instance disk.
In the diagram above, the #1 instance disk uses ephemeral storage; the #2 disk uses a block-storage volume.
Ephemeral storage is an empty, unformatted, additional disk available to an instance. This storage value is defined by the instance flavor. The value provided by the user must be less than or equal to the ephemeral value defined for the flavor. The default value is 0, meaning no ephemeral storage is created.
The ephemeral disk appears in the same way as a plugged-in hard drive or thumb drive. It is available as a block device which you can check using the lsblk command. You can format it, mount it, and use it however you normally would a block device. There is no way to preserve or reference that disk beyond the instance it is attached to.
Block storage volume is persistant storage available to an instance regardless of the state of the running instance.
3.2. Configuration
You can configure performance tuning and security for your virtual disks by customizing the Compute (nova) configuration files. Compute is configured in custom environment files and Heat templates using the parameters detailed in the Compute (nova) Parameters section in the Overcloud Parameters guide. This configuration is generated and stored in the /var/lib/config-data/puppet-generated/<nova_container>/etc/nova/nova.conf file, as detailed in the following table.
| Section | Parameter | Description | Default |
|---|---|---|---|
| [DEFAULT] |
|
Whether to convert a
Converting the base to raw uses more space for any image that could have been used directly by the hypervisor (for example, a qcow2 image). If you have a system with slower I/O or less available space, you might want to specify false, trading the higher CPU requirements of compression for that of minimized input bandwidth.
Raw base images are always used with |
|
| [DEFAULT] |
|
Whether to use CoW (Copy on Write) images for
| true |
| [DEFAULT] |
|
Preallocation mode for
Even when not using CoW instance disks, the copy each VM gets is sparse and so the VM may fail unexpectedly at run time with ENOSPC. By running | none |
| [DEFAULT] |
|
Whether to enable direct resizing of the base image by accessing the image over a block device (boolean). This is only necessary for images with older versions of Because this parameter enables the direct mounting of images which might otherwise be disabled for security reasons, it is not enabled by default. |
|
| [DEFAULT] |
|
The default format that is used for a new ephemeral volume. Value can be: |
|
| [DEFAULT] |
|
Number of seconds to wait between runs of the image cache manager, which impacts base caching on libvirt compute nodes. This period is used in the auto removal of unused cached images (see |
|
| [DEFAULT] |
|
Whether to enable the automatic removal of unused base images (checked every |
|
| [DEFAULT] |
|
How old an unused base image must be before being removed from the |
|
|
[ |
|
Image type to use for |
|
3.3. Enabling service tokens between the Compute service and the Block Storage service
As an administrator, if you want to prevent user request token timeouts when attaching or detaching volumes, you must enable service tokens on all overcloud nodes that run the Compute (nova) service or the Block Storage (cinder) service.
Procedure
-
Create an environment file to configure the service tokens, such as
service_tokens.yaml. Add the following configuration parameters to the service token environment file:
parameter_defaults: ComputeExtraConfig: nova::config::nova_config: service_user/send_service_user_token: value: true service_user/username: value: nova service_user/auth_strategy: value: keystone service_user/auth_type: value: password service_user/password: value: "%{hiera('nova::placement::password')}" service_user/auth_url: value: "%{hiera('nova::placement::auth_url')}" service_user/user_domain_name: value: "Default" service_user/project_name: value: "%{hiera('nova::placement::project_name')}" service_user/project_default_name: value: "Default" ControllerExtraConfig: nova::config::nova_config: keystone_authtoken/service_token_roles_required: value: true keystone_authtoken/service_token_roles: value: admin service_user/send_service_user_token: value: true service_user/username: value: nova service_user/auth_strategy: value: keystone service_user/auth_type: value: password service_user/password: value: "%{hiera('nova::keystone::authtoken::password')}" service_user/auth_url: value: "%{hiera('nova::keystone::authtoken::auth_url')}" service_user/user_domain_name: value: "%{hiera('nova::keystone::authtoken::user_domain_name')}" service_user/project_name: value: "%{hiera('nova::keystone::authtoken::project_name')}" service_user/project_domain_name: value: "%{hiera('nova::keystone::authtoken::project_domain_name')}" cinder::config::cinder_config: keystone_authtoken/service_token_roles_required: value: true keystone_authtoken/service_token_roles: value: admin service_user/send_service_user_token: value: true service_user/username: value: cinder service_user/auth_strategy: value: keystone service_user/auth_type: value: password service_user/password: value: "%{hiera('cinder::keystone::authtoken::password')}" service_user/auth_url: value: "%{hiera('cinder::keystone::authtoken::auth_url')}" service_user/user_domain_name: value: "%{hiera('cinder::keystone::authtoken::user_domain_name')}" service_user/project_name: value: "%{hiera('cinder::keystone::authtoken::project_name')}" service_user/project_domain_name: value: "%{hiera('cinder::keystone::authtoken::project_domain_name')}" BlockStorageExtraConfig: cinder::config::cinder_config: keystone_authtoken/service_token_roles_required: value: true keystone_authtoken/service_token_roles: value: admin service_user/send_service_user_token: value: true service_user/username: value: cinder service_user/auth_strategy: value: keystone service_user/auth_type: value: password service_user/password: value: "%{hiera('cinder::keystone::authtoken::password')}" service_user/auth_url: value: "%{hiera('cinder::keystone::authtoken::auth_url')}" service_user/user_domain_name: value: "%{hiera('cinder::keystone::authtoken::user_domain_name')}" service_user/project_name: value: "%{hiera('cinder::keystone::authtoken::project_name')}" service_user/project_domain_name: value: "%{hiera('cinder::keystone::authtoken::project_domain_name')}"Add the service token environment file to the stack with your other environment files and deploy the overcloud:
(undercloud)$ openstack overcloud deploy --templates \ -e [your environment files] \ -e /home/stack/templates/service_tokens.yaml \
第4章 Virtual machine instances
OpenStack Compute (nova) is the central component that provides virtual machines on demand. Compute interacts with the Identity service (keystone) for authentication, the Image service (glance) for images to launch instances, and the dashboard service for the user and administrative interface.
With Red Hat OpenStack Platform (RHOSP) you can easily manage virtual machine instances in the cloud. The Compute service creates, schedules, and manages instances, and exposes this functionality to other OpenStack components. This chapter discusses these procedures along with procedures to add components like key pairs, security groups, host aggregates and flavors. The term instance in OpenStack means a virtual machine instance.
4.1. Managing instances
Before you can create an instance, you need to ensure certain other OpenStack components (for example, a network, key pair and an image or a volume as the boot source) are available for the instance.
This section discusses the procedures to add these components, create and manage an instance. Managing an instance refers to updating, and logging in to an instance, viewing how the instances are being used, resizing or deleting them.
4.1.1. Adding components
Use the following sections to create a network, key pair and upload an image or volume source. Use these components when you create an instance that is not available by default. You must also create a new security group to allow SSH access to the user.
- In the dashboard, select Project.
- Select Network > Networks, and ensure there is a private network to which you can attach the new instance (to create a network, see Creating a Network section in the Networking Guide).
- Select Compute > Access & Security > Key Pairs, and ensure there is a key pair (to create a key pair, see 「Creating a key pair」).
Ensure that you have either an image or a volume that can you can use as a boot source:
- To view boot-source images, select the Images tab (to create an image, see 「Creating an image」).
- To view boot-source volumes, select the Volumes tab (to create a volume, see Create a Volume in the Storage Guide).
- Select Compute > Access & Security > Security Groups, and ensure you have created a security group rule (to create a security group, see Project Security Management in the Users and Identity Management Guide).
4.1.2. Launching an instance
Launch one or more instances from the dashboard.
Instances are launched by default using the Launch Instance form. However, you can also enable a Launch Instance wizard that simplifies the steps required. For more information, see 付録B Enabling the launch instance wizard.
- In the dashboard, select Project > Compute > Instances.
- Click Launch Instance.
- Complete the fields (* indicates a required field), and click Launch.
One or more instances are created and launched based on the options provided.
It is not possible to launch an instance with a Block Storage (cinder) volume if the root disk size is larger than the HDD of the Compute node. Use one of the following workarounds to allow an instance to be launched with a Block Storage volume:
- Use a flavor with the root disk and ephemeral disk set to 0.
-
Remove
DiskFilterfrom theNovaSchedulerDefaultFiltersconfiguration.
4.1.2.1. Launching instance options
The following table outlines the options available when you use the Launch Instance form to launch a new instance. The same options are also available in the Launch instance wizard.
| Tab | Field | Notes |
|---|---|---|
| Project and User | Project | Select the project from the list. |
| User | Select the user from the list. | |
| Details | Availability Zone | Zones are logical groupings of cloud resources in which you can place your instance. If you are unsure, use the default zone (for more information, see 「Managing host aggregates」). |
| Instance Name | A name to identify your instance. | |
| Flavor | The flavor determines what resources to give the instance, for example, memory. For default flavor allocations and information about creating new flavors, see 「Managing flavors」. | |
| Instance Count | The number of instances to create with these parameters. 1 is preselected. | |
| Instance Boot Source | Depending on the item selected, new fields are displayed to select the source:
| |
| Access and Security | Key Pair | The specified key pair is injected into the instance and is used to remotely access the instance using SSH (if neither a direct login information or a static key pair is provided). Usually one key pair per project is created. |
| Security Groups | Security groups contain firewall rules which filter the type and direction of the instance network traffic. For more information about configuring groups, see Project Security Management in the Users and Identity Management Guide). | |
| Networking | Selected Networks | You must select at least one network. Instances are typically assigned to a private network, and then later given a floating IP address to enable external access. |
| Post-Creation | Customization Script Source | You can provide either a set of commands or a script file, which runs after the instance is booted (for example, to set the instance host name or a user password). If Direct Input is selected, write your commands in the Script Data field; otherwise, specify your script file. 注記
Any script that starts with |
| Advanced Options | Disk Partition | By default, the instance is built as a single partition and dynamically resized as needed. However, you can choose to manually configure the partitions yourself. |
| Configuration Drive | If selected, OpenStack writes metadata to a read-only configuration drive that is attached to the instance when it boots (instead of to Compute’s metadata service). After the instance has booted, you can mount this drive to view its contents and provide files to the instance. |
4.1.3. Updating an instance
You can update an instance by selecting Project > Compute > Instances, and selecting an action for that instance in the Actions column. Use actions to manipulate the instance in a number of ways:
| Action | Description |
|---|---|
| Create Snapshot | Snapshots preserve the disk state of a running instance. You can create a snapshot to migrate the instance, as well as to preserve backup copies. |
| Associate/Disassociate Floating IP | You must associate an instance with a floating IP (external) address before it can communicate with external networks, or be reached by external users. Because there are a limited number of external addresses in your external subnets, it is recommended that you disassociate any unused addresses. |
| Edit Instance | Update the instance’s name and associated security groups. |
| Edit Security Groups | Add and remove security groups to or from this instance using the list of available security groups (for more information on configuring groups, see Project Security Management in the Users and Identity Management Guide). |
| Console | View the instance console in the browser for easy access to the instance. |
| View Log | View the most recent section of the instance console log. When opened, you can view the full log by clicking View Full Log. |
| Pause/Resume Instance | Immediately pause the instance (you are not asked for confirmation); the state of the instance is stored in memory (RAM). |
| Suspend/Resume Instance | Immediately suspend the instance (you are not asked for confirmation); like hibernation, the state of the instance is kept on disk. |
| Resize Instance | Display the Resize Instance window (see 「Resizing an instance」). |
| Soft Reboot | Gracefully stop and restart the instance. A soft reboot attempts to gracefully shut down all processes before restarting the instance. |
| Hard Reboot |
Stop and restart the instance. A hard reboot effectively shuts down the |
| Shut Off Instance | Gracefully stop the instance. |
| Rebuild Instance | Use new image and disk-partition options to rebuild the image (shut down, re-image, and re-boot the instance). If encountering operating system issues, this option is easier to try than terminating the instance and starting from the beginning. |
| Terminate Instance | Permanently destroy the instance (you are asked for confirmation). |
You can create and allocate an external IP address, see 「Creating, assigning, and releasing floating IP addresses」
4.1.4. Resizing an instance
To resize an instance (memory or CPU count), you must select a new flavor for the instance that has the right capacity. If you are increasing the size, remember to first ensure that the host has enough space.
- Ensure communication between hosts by setting up each host with SSH key authentication so that Compute can use SSH to move disks to other hosts. For example, Compute nodes can share the same SSH key.
Enable resizing on the original host by setting the
allow_resize_to_same_hostparameter toTruefor the Controller role.注記The
allow_resize_to_same_hostparameter does not resize the instance on the same host. Even if the parameter equalsTrueon all Compute nodes, the scheduler does not force the instance to resize on the same host. This is the expected behavior.- In the dashboard, select Project > Compute > Instances.
- Click the instance’s Actions arrow, and select Resize Instance.
- Select a new flavor in the New Flavor field.
If you want to manually partition the instance when it launches (results in a faster build time):
- Select Advanced Options.
- In the Disk Partition field, select Manual.
- Click Resize.
4.1.5. Connecting to an instance
You can access an instance console by using the dashboard or the command-line interface. You can also directly connect to the serial port of an instance so that you can debug even if the network connection fails.
4.1.5.1. Accessing an instance console by using the dashboard
You can connect to the instance console from the dashboard.
Procedure
- In the dashboard, select Compute > Instances.
-
Click the instance’s More button and select Console.
- Log in using the image’s user name and password (for example, a CirrOS image uses cirros/cubswin:)).
4.1.5.2. Accessing an instance console by using the CLI
You can connect directly to the VNC console for an instance by entering the VNC console URL in a browser.
Procedure
To display the VNC console URL for an instance, enter the following command:
$ openstack console url show <vm_name> +-------+------------------------------------------------------+ | Field | Value | +-------+------------------------------------------------------+ | type | novnc | | url | http://172.25.250.50:6080/vnc_auto.html?token= | | | 962dfd71-f047-43d3-89a5-13cb88261eb9 | +-------+-------------------------------------------------------+- To connect directly to the VNC console, enter the displayed URL in a browser.
4.1.6. Viewing instance usage
The following usage statistics are available:
Per Project
To view instance usage per project, select Project > Compute > Overview. A usage summary is immediately displayed for all project instances.
You can also view statistics for a specific period of time by specifying the date range and clicking Submit.
Per Hypervisor
If logged in as an administrator, you can also view information for all projects. Click Admin > System and select one of the tabs. For example, the Resource Usage tab offers a way to view reports for a distinct time period. You might also click Hypervisors to view your current vCPU, memory, or disk statistics.
注記The
vCPU Usagevalue (x of y) reflects the number of total vCPUs of all virtual machines (x) and the total number of hypervisor cores (y).
4.1.7. Deleting an instance
- In the dashboard, select Project > Compute > Instances, and select your instance.
- Click Terminate Instance.
Deleting an instance does not delete its attached volumes; you must do this separately (see Delete a Volume in the Storage Guide).
4.1.8. Managing multiple instances simultaneously
If you need to start multiple instances at the same time (for example, those that were down for compute or controller maintenance) you can do so easily at Project > Compute > Instances:
- Click the check boxes in the first column for the instances that you want to start. If you want to select all of the instances, click the check box in the first row in the table.
- Click More Actions above the table and select Start Instances.
Similarly, you can shut off or soft reboot multiple instances by selecting the respective actions.
4.2. Managing instance security
You can manage access to an instance by assigning it the correct security group (set of firewall rules) and key pair (enables SSH user access). Further, you can assign a floating IP address to an instance to enable external network access. The sections below outline how to create and manage key pairs, security groups, floating IP addresses and logging in to an instance using SSH. There is also a procedure for injecting an admin password in to an instance.
For information on managing security groups, see Project Security Management in the Users and Identity Management Guide.
4.2.1. Managing key pairs
Key pairs provide SSH access to the instances. Each time a key pair is generated, its certificate is downloaded to the local machine and can be distributed to users. Typically, one key pair is created for each project (and used for multiple instances).
You can also import an existing key pair into OpenStack.
4.2.1.1. Creating a key pair
- In the dashboard, select Project > Compute > Access & Security.
- On the Key Pairs tab, click Create Key Pair.
- Specify a name in the Key Pair Name field, and click Create Key Pair.
When the key pair is created, a key pair file is automatically downloaded through the browser. Save this file for later connections from external machines. For command-line SSH connections, you can load this file into SSH by executing:
# ssh-add ~/.ssh/os-key.pem4.2.1.2. Importing a key pair
- In the dashboard, select Project > Compute > Access & Security.
- On the Key Pairs tab, click Import Key Pair.
- Specify a name in the Key Pair Name field, and copy and paste the contents of your public key into the Public Key field.
- Click Import Key Pair.
4.2.1.3. Deleting a key pair
- In the dashboard, select Project > Compute > Access & Security.
- On the Key Pairs tab, click the key’s Delete Key Pair button.
4.2.2. Creating a security group
Security groups are sets of IP filter rules that can be assigned to project instances, and which define networking access to the instance. Security group are project specific; project members can edit the default rules for their security group and add new rule sets.
- In the dashboard, select the Project tab, and click Compute > Access & Security.
- On the Security Groups tab, click + Create Security Group.
- Provide a name and description for the group, and click Create Security Group.
For more information on managing project security, see Project Security Management in the Users and Identity Management Guide.
4.2.3. Creating, assigning, and releasing floating IP addresses
By default, an instance is given an internal IP address when it is first created. However, you can enable access through the public network by creating and assigning a floating IP address (external address). You can change an instance’s associated IP address regardless of the instance’s state.
Projects have a limited range of floating IP address that can be used (by default, the limit is 50), so you should release these addresses for reuse when they are no longer needed. Floating IP addresses can only be allocated from an existing floating IP pool, see Creating Floating IP Pools in the Networking Guide.
4.2.3.1. Allocating a floating IP to the project
- In the dashboard, select Project > Compute > Access & Security.
- On the Floating IPs tab, click Allocate IP to Project.
- Select a network from which to allocate the IP address in the Pool field.
- Click Allocate IP.
4.2.3.2. Assigning a floating IP
- In the dashboard, select Project > Compute > Access & Security.
- On the Floating IPs tab, click the address' Associate button.
Select the address to be assigned in the IP address field.
注記If no addresses are available, you can click the
+button to create a new address.- Select the instance to be associated in the Port to be Associated field. An instance can only be associated with one floating IP address.
- Click Associate.
4.2.3.3. Releasing a floating IP
- In the dashboard, select Project > Compute > Access & Security.
- On the Floating IPs tab, click the address' menu arrow (next to the Associate/Disassociate button).
- Select Release Floating IP.
4.2.4. Logging in to an instance
Prerequisites:
- Ensure that the instance’s security group has an SSH rule (see Project Security Management in the Users and Identity Management Guide).
- Ensure the instance has a floating IP address (external address) assigned to it (see 「Creating, assigning, and releasing floating IP addresses」).
- Obtain the instance’s key-pair certificate. The certificate is downloaded when the key pair is created; if you did not create the key pair yourself, ask your administrator (see 「Managing key pairs」).
To first load the key pair file into SSH, and then use ssh without naming it:
Change the permissions of the generated key-pair certificate.
$ chmod 600 os-key.pemCheck whether
ssh-agentis already running:# ps -ef | grep ssh-agentIf not already running, start it up with:
# eval `ssh-agent`On your local machine, load the key-pair certificate into SSH. For example:
$ ssh-add ~/.ssh/os-key.pem- You can now SSH into the file with the user supplied by the image.
The following example command shows how to SSH into the Red Hat Enterprise Linux guest image with the user cloud-user:
$ ssh cloud-user@192.0.2.24You can also use the certificate directly. For example:
$ ssh -i /myDir/os-key.pem cloud-user@192.0.2.244.2.5. Injecting an admin password into an instance
You can inject an admin (root) password into an instance using the following procedure.
In the
/etc/openstack-dashboard/local_settingsfile, set thechange_set_passwordparameter value toTrue.can_set_password: TrueSet the
inject_passwordparameter to "True" in your Compute environment file.inject_password=trueRestart the Compute service.
# service nova-compute restart
When you use the nova boot command to launch a new instance, the output of the command displays an adminPass parameter. You can use this password to log into the instance as the root user.
The Compute service overwrites the password value in the /etc/shadow file for the root user. This procedure can also be used to activate the root account for the KVM guest images. For more information on how to use KVM guest images, see 「Using a KVM guest image with Red Hat OpenStack Platform」
You can also set a custom password from the dashboard. To enable this, run the following command after you have set can_set_password parameter to true.
# systemctl restart httpd.service
The newly added admin password fields are as follows:
These fields can be used when you launch or rebuild an instance.
4.3. Managing flavors
Each created instance is given a flavor (resource template), which determines the instance’s size and capacity. Flavors can also specify secondary ephemeral storage, swap disk, metadata to restrict usage, or special project access (none of the default flavors have these additional attributes defined).
| Name | vCPUs | RAM | Root Disk Size |
|---|---|---|---|
| m1.tiny | 1 | 512 MB | 1 GB |
| m1.small | 1 | 2048 MB | 20 GB |
| m1.medium | 2 | 4096 MB | 40 GB |
| m1.large | 4 | 8192 MB | 80 GB |
| m1.xlarge | 8 | 16384 MB | 160 GB |
The majority of end users will be able to use the default flavors. However, you can create and manage specialized flavors. For example, you can:
- Change default memory and capacity to suit the underlying hardware needs.
- Add metadata to force a specific I/O rate for the instance or to match a host aggregate.
Behavior set using image properties overrides behavior set using flavors (for more information, see 「Managing images」).
4.3.1. Updating configuration permissions
By default, only administrators can create flavors or view the complete flavor list (select Admin > System > Flavors). To allow all users to configure flavors, specify the following in the /etc/nova/policy.json file (nova-api server):
"compute_extension:flavormanage": "",
4.3.2. Creating a flavor
- As an admin user in the dashboard, select Admin > System > Flavors.
Click Create Flavor, and specify the following fields:
Expand 表4.4 Flavor Options Tab Field Description Flavor Information
Name
Unique name.
ID
Unique ID. The default value,
auto, generates a UUID4 value, but you can also manually specify an integer or UUID4 value.VCPUs
Number of virtual CPUs.
RAM (MB)
Memory (in megabytes).
Root Disk (GB)
Ephemeral disk size (in gigabytes); to use the native image size, specify
0. This disk is not used if Instance Boot Source=Boot from Volume.Epehemeral Disk (GB)
Secondary ephemeral disk size (in gigabytes) available to an instance. This disk is destroyed when an instance is deleted.
The default value is
0, which implies that no ephemeral disk is created.Swap Disk (MB)
Swap disk size (in megabytes).
Flavor Access
Selected Projects
Projects which can use the flavor. If no projects are selected, all projects have access (
Public=Yes).- Click Create Flavor.
4.3.3. Updating general attributes
- As an admin user in the dashboard, select Admin > System > Flavors.
- Click the flavor’s Edit Flavor button.
- Update the values, and click Save.
4.3.4. Updating flavor metadata
In addition to editing general attributes, you can add metadata to a flavor (extra_specs), which can help fine-tune instance usage. For example, you might want to set the maximum-allowed bandwidth or disk writes.
- Pre-defined keys determine hardware support or quotas. Pre-defined keys are limited by the hypervisor you are using (for libvirt, see 表4.5「Libvirt Metadata」).
-
Both pre-defined and user-defined keys can determine instance scheduling. For example, you might specify
SpecialComp=True; any instance with this flavor can then only run in a host aggregate with the same key-value combination in its metadata (see 「Managing host aggregates」).
4.3.4.1. Viewing metadata
- As an admin user in the dashboard, select Admin > System > Flavors.
-
Click the flavor’s Metadata link (
YesorNo). All current values are listed on the right-hand side under Existing Metadata.
4.3.4.2. Adding metadata
You specify a flavor’s metadata using a key/value pair.
- As an admin user in the dashboard, select Admin > System > Flavors.
-
Click the flavor’s Metadata link (
YesorNo). All current values are listed on the right-hand side under Existing Metadata. - Under Available Metadata, click on the Other field, and specify the key you want to add (see 表4.5「Libvirt Metadata」).
- Click the + button; you can now view the new key under Existing Metadata.
Fill in the key’s value in its right-hand field.

- When finished with adding key-value pairs, click Save.
| Key | Description |
|---|---|
|
| Action that configures support limits per instance. Valid actions are:
Example: |
|
| Definition of NUMA topology for the instance. For flavors whose RAM and vCPU allocations are larger than the size of NUMA nodes in the compute hosts, defining NUMA topology enables hosts to better utilize NUMA and improve performance of the guest OS. NUMA definitions defined through the flavor override image definitions. Valid definitions are:
注記
If the values of Example when the instance has 8 vCPUs and 4GB RAM:
The scheduler looks for a host with 2 NUMA nodes with the ability to run 6 CPUs + 3072 MB, or 3 GB, of RAM on one node, and 2 CPUS + 1024 MB, or 1 GB, of RAM on another node. If a host has a single NUMA node with capability to run 8 CPUs and 4 GB of RAM, it will not be considered a valid match. |
|
| An instance watchdog device can be used to trigger an action if the instance somehow fails (or hangs). Valid actions are:
Example: |
|
| You can use this parameter to specify the NUMA affinity policy for PCI passthrough devices and SR-IOV interfaces. Set to one of the following valid values:
Example: |
|
|
A random-number generator device can be added to an instance using its image properties (see If the device has been added, valid actions are:
Example: |
|
| Maximum permitted RAM to be allowed for video devices (in MB).
Example: |
|
| Enforcing limit for the instance. Valid options are:
Example: In addition, the VMware driver supports the following quota options, which control upper and lower limits for CPUs, RAM, disks, and networks, as well as shares, which can be used to control relative allocation of available resources among tenants:
|
4.4. Managing host aggregates
A single Compute deployment can be partitioned into logical groups for performance or administrative purposes. OpenStack uses the following terms:
Host aggregates - A host aggregate creates logical units in a OpenStack deployment by grouping together hosts. Aggregates are assigned Compute hosts and associated metadata; a host can be in more than one host aggregate. Only administrators can see or create host aggregates.
An aggregate’s metadata is commonly used to provide information for use with the Compute scheduler (for example, limiting specific flavors or images to a subset of hosts). Metadata specified in a host aggregate will limit the use of that host to any instance that has the same metadata specified in its flavor.
Administrators can use host aggregates to handle load balancing, enforce physical isolation (or redundancy), group servers with common attributes, or separate out classes of hardware. When you create an aggregate, a zone name must be specified, and it is this name which is presented to the end user.
Availability zones - An availability zone is the end-user view of a host aggregate. An end user cannot view which hosts make up the zone, nor see the zone’s metadata; the user can only see the zone’s name.
End users can be directed to use specific zones which have been configured with certain capabilities or within certain areas.
4.4.1. Enabling host aggregate scheduling
By default, host-aggregate metadata is not used to filter instance usage. You must update the Compute scheduler’s configuration to enable metadata usage:
- Open your Compute environment file.
Add the following values to the
NovaSchedulerDefaultFiltersparameter, if they are not already present:AggregateInstanceExtraSpecsFilterfor host aggregate metadata.注記Scoped specifications must be used for setting flavor
extra_specswhen specifying bothAggregateInstanceExtraSpecsFilterandComputeCapabilitiesFilterfilters as values of the sameNovaSchedulerDefaultFiltersparameter, otherwise theComputeCapabilitiesFilterwill fail to select a suitable host. See 表4.7「Scheduling Filters」 for further details.-
AvailabilityZoneFilterfor availability zone host specification when launching an instance.
- Save the configuration file.
- Deploy the overcloud.
4.4.2. Viewing availability zones or host aggregates
As an admin user in the dashboard, select Admin > System > Host Aggregates. All currently defined aggregates are listed in the Host Aggregates section; all zones are in the Availability Zones section.
4.4.3. Adding a host aggregate
- As an admin user in the dashboard, select Admin > System > Host Aggregates. All currently defined aggregates are listed in the Host Aggregates section.
- Click Create Host Aggregate.
- Add a name for the aggregate in the Name field, and a name by which the end user should see it in the Availability Zone field.
- Click Manage Hosts within Aggregate.
- Select a host for use by clicking its + icon.
- Click Create Host Aggregate.
4.4.4. Updating a host aggregate
- As an admin user in the dashboard, select Admin > System > Host Aggregates. All currently defined aggregates are listed in the Host Aggregates section.
To update the instance’s Name or Availability zone:
- Click the aggregate’s Edit Host Aggregate button.
- Update the Name or Availability Zone field, and click Save.
To update the instance’s Assigned hosts:
- Click the aggregate’s arrow icon under Actions.
- Click Manage Hosts.
- Change a host’s assignment by clicking its + or - icon.
- When finished, click Save.
To update the instance’s Metadata:
- Click the aggregate’s arrow icon under Actions.
- Click the Update Metadata button. All current values are listed on the right-hand side under Existing Metadata.
- Under Available Metadata, click on the Other field, and specify the key you want to add. Use predefined keys (see 表4.6「Host Aggregate Metadata」) or add your own (which will only be valid if exactly the same key is set in an instance’s flavor).
Click the + button; you can now view the new key under Existing Metadata.
注記Remove a key by clicking its - icon.
Click Save.
Expand 表4.6 Host Aggregate Metadata Key Description filter_tenant_idIf specified, the aggregate only hosts this tenant (project). Depends on the
AggregateMultiTenancyIsolationfilter being set for the Compute scheduler.
4.4.5. Deleting a host aggregate
- As an admin user in the dashboard, select Admin > System > Host Aggregates. All currently defined aggregates are listed in the Host Aggregates section.
Remove all assigned hosts from the aggregate:
- Click the aggregate’s arrow icon under Actions.
- Click Manage Hosts.
- Remove all hosts by clicking their - icon.
- When finished, click Save.
- Click the aggregate’s arrow icon under Actions.
- Click Delete Host Aggregate in this and the next dialog screen.
4.5. Scheduling hosts
The Compute scheduling service determines on which host (or host aggregate), an instance will be placed. As an administrator, you can influence where the scheduler will place an instance. For example, you might want to limit scheduling to hosts in a certain group or with the right RAM.
You can configure the following components:
- Filters - Determine the initial set of hosts on which an instance might be placed (see 「Configuring scheduling filters」).
- Weights - When filtering is complete, the resulting set of hosts are prioritized using the weighting system. The highest weight has the highest priority (see 「Configuring scheduling weights」).
-
Scheduler service - There are a number of configuration options in the
/var/lib/config-data/puppet-generated/<nova_container>/etc/nova/nova.conffile (on the scheduler host), which determine how the scheduler executes its tasks, and handles weights and filters.
In the following diagram, both host 1 and 3 are eligible after filtering. Host 1 has the highest weight and therefore has the highest priority for scheduling.

4.5.1. Configuring scheduling filters
You define the filters you want the scheduler to use by adding or removing filters from the NovaSchedulerDefaultFilters parameter in your Compute environment file.
The default configuration runs the following filters in the scheduler:
- RetryFilter
- AvailabilityZoneFilter
- ComputeFilter
- ComputeCapabilitiesFilter
- ImagePropertiesFilter
- ServerGroupAntiAffinityFilter
- ServerGroupAffinityFilter
Some filters use information in parameters passed to the instance in:
-
The
nova bootcommand. - The instance’s flavor (see 「Updating flavor metadata」)
- The instance’s image (see 付録A Image configuration parameters).
The following table lists all the available filters.
| Filter | Description |
|---|---|
|
| Only passes hosts in host aggregates whose metadata matches the instance’s image metadata; only valid if a host aggregate is specified for the instance. For more information, see 「Creating an image」. |
|
| Metadata in the host aggregate must match the host’s flavor metadata. For more information, see 「Updating flavor metadata」. |
|
This filter can only be specified in the same
| |
|
|
A host with the specified 注記 The tenant can still place instances on other hosts. |
|
| Passes all available hosts (however, does not disable other filters). |
|
| Filters using the instance’s specified availability zone. |
|
|
Ensures Compute metadata is read correctly. Anything before the |
|
| Passes only hosts that are operational and enabled. |
|
|
Enables an instance to build on a host that is different from one or more specified hosts. Specify |
|
| Only passes hosts that match the instance’s image properties. For more information, see 「Creating an image」. |
|
|
Passes only isolated hosts running isolated images that are specified using |
|
| Recognises and uses an instance’s custom JSON filters:
|
|
The filter is specified as a query hint in the
| |
|
|
Use this filter to limit scheduling to Compute nodes that report the metrics configured by using To use this filter, add the following configuration to your Compute environment file:
By default, the Compute scheduling service updates the metrics every 60 seconds. To ensure the metrics are up-to-date, you can increase the frequency at which the metrics data is refreshed using the |
|
| Filters out hosts based on its NUMA topology. If the instance has no topology defined, any host can be used. The filter tries to match the exact NUMA topology of the instance to those of the host (it does not attempt to pack the instance onto the host). The filter also looks at the standard over-subscription limits for each NUMA node, and provides limits to the compute host accordingly. |
|
|
Filters out hosts that have failed a scheduling attempt; valid if |
|
|
Passes one or more specified hosts; specify hosts for the instance using the |
|
| Only passes hosts for a specific server group:
|
|
| Only passes hosts in a server group that do not already host an instance:
|
|
|
Only passes hosts on the specified IP subnet range specified by the instance’s cidr and
|
4.5.2. Configuring scheduling weights
Hosts can be weighted for scheduling; the host with the largest weight (after filtering) is selected. All weighers are given a multiplier that is applied after normalising the node’s weight. A node’s weight is calculated as:
w1_multiplier * norm(w1) + w2_multiplier * norm(w2) + ...You can configure weight options in the Compute node’s configuration file.
| Configuration option | Description |
|---|---|
|
| Use this parameter to configure which of the following attributes to use for calculating the weight of each host:
Type: String |
|
| Use this parameter to specify the multiplier to use to weigh hosts based on the available RAM. Set to a positive value to prefer hosts with more available RAM, which spreads instances across many hosts. Set to a negative value to prefer hosts with less available RAM, which fills up (stacks) hosts as much as possible before scheduling to a less-used host. The absolute value, whether positive or negative, controls how strong the RAM weigher is relative to other weighers.
By default, the scheduler spreads instances across all hosts evenly ( Type: Floating point |
|
| Use this parameter to specify the multiplier to use to weigh hosts based on the available disk space. Set to a positive value to prefer hosts with more available disk space, which spreads instances across many hosts. Set to a negative value to prefer hosts with less available disk space, which fills up (stacks) hosts as much as possible before scheduling to a less-used host. The absolute value, whether positive or negative, controls how strong the disk weigher is relative to other weighers.
By default, the scheduler spreads instances across all hosts evenly ( Type: Floating point |
|
| Use this parameter to specify the multiplier to use to weigh hosts based on the available vCPUs. Set to a positive value to prefer hosts with more available vCPUs, which spreads instances across many hosts. Set to a negative value to prefer hosts with less available vCPUs, which fills up (stacks) hosts as much as possible before scheduling to a less-used host. The absolute value, whether positive or negative, controls how strong the vCPU weigher is relative to other weighers.
By default, the scheduler spreads instances across all hosts evenly ( Type: Floating point |
|
| Use this parameter to specify the multiplier to use to weigh hosts based on the host workload. Set to a negative value to prefer hosts with lighter workloads, which distributes the workload across more hosts. Set to a positive value to prefer hosts with heavier workloads, which schedules instances onto hosts that are already busy. The absolute value, whether positive or negative, controls how strong the I/O operations weigher is relative to other weighers.
By default, the scheduler distributes the workload across more hosts ( Type: Floating point |
|
| Use this parameter to specify the multiplier to use to weigh hosts based on recent build failures. Set to a positive value to increase the significance of build failures recently reported by the host. Hosts with recent build failures are then less likely to be chosen.
Set to Default: 1000000.0 Type: Floating point |
|
| Use this parameter to specify the multiplier to use to weigh hosts during a cross-cell move. This option determines how much weight is placed on a host which is within the same source cell when moving an instance. By default, the scheduler prefers hosts within the same source cell when migrating an instance. Set to a positive value to prefer hosts within the same cell the instance is currently running. Set to a negative value to prefer hosts located in a different cell from that where the instance is currently running. Default: 1000000.0 Type: Floating point |
|
| Use this parameter to specify the multiplier to use to weigh hosts based on the number of PCI devices on the host and the number of PCI devices requested by an instance. If an instance requests PCI devices, then the more PCI devices a Compute node has the higher the weight allocated to the Compute node. For example, if there are three hosts available, one with a single PCI device, one with multiple PCI devices and one without any PCI devices, then the Compute scheduler prioritizes these hosts based on the demands of the instance. The first host should be preferred if the instance requests one PCI device, the second host if the instance requires multiple PCI devices and the third host if the instance does not request a PCI device. Configure this option to prevent non-PCI instances from occupying resources on hosts with PCI devices. Default: 1.0 Type: Positive floating point |
|
| Use this parameter to specify the size of the subset of filtered hosts from which to select the host. Must be set to at least 1. A value of 1 selects the first host returned by the weighing functions. Any value less than 1 is ignored and 1 is used instead. Set to a value greater than 1 to prevent multiple scheduler processes handling similar requests selecting the same host, creating a potential race condition. By selecting a host randomly from the N hosts that best fit the request, the chance of a conflict is reduced. However, the higher you set this value, the less optimal the chosen host may be for a given request. Default: 1 Type: Integer |
|
| Use this parameter to specify the multiplier to use to weigh hosts for group soft-affinity. Default: 1.0 Type: Positive floating point |
|
| Use this parameter to specify the multiplier to use to weigh hosts for group soft-anti-affinity. Default: 1.0 Type: Positive floating point |
|
|
Use this parameter to specify the multiplier to use for weighting metrics. By default, Set to a number greater than 1.0 to increase the effect of the metric on the overall weight. Set to a number between 0.0 and 1.0 to reduce the effect of the metric on the overall weight. Set to 0.0 to ignore the metric value and return the value of the ‘weight_of_unavailable’ option. Set to a negative number to prioritize the host with lower metrics, and stack instances in hosts. Default: 1.0 Type: Floating point |
|
| Use this parameter to specify the metrics to use for weighting, and the ratio to use to calculate the weight of each metric. Valid metric names:
Example:
Type: Comma-separated list of |
|
|
Use this parameter to specify how to handle configured
Type: Boolean |
|
|
Use this parameter to specify the weight to use if any Default: -10000.0 Type: Floating point |
4.5.3. Reserving NUMA nodes with PCI devices
Compute uses the filter scheduler to prioritize hosts with PCI devices for instances requesting PCI. The hosts are weighted using the PCIWeigher option, based on the number of PCI devices available on the host and the number of PCI devices requested by an instance. If an instance requests PCI devices, then the hosts with more PCI devices are allocated a higher weight than the others. If an instance is not requesting PCI devices, then prioritization does not take place.
This feature is especially useful in the following cases:
- As an operator, if you want to reserve nodes with PCI devices (typically expensive and with limited resources) for guest instances that request them.
- As a user launching instances, you want to ensure that PCI devices are available when required.
For this value to be considered, one of the following values must be added to the NovaSchedulerDefaultFilters parameter in your Compute environment file: PciPassthroughFilter or NUMATopologyFilter.
The pci_weight_multiplier configuration option must be a positive value.
4.6. Managing instance snapshots
You can use an instance snapshot to create a new image from an instance. This is very convenient for upgrading base images or for taking a published image and customizing it for local use.
The difference between an image that you upload directly to the Image service and an image that you create by snapshot is that an image created by snapshot has additional properties in the Image service database. These properties are in the image_properties table and include the following parameters:
| Name | Value |
|---|---|
| image_type | snapshot |
| instance_uuid | <uuid_of_instance_that_was_snapshotted> |
| base_image_ref | <uuid_of_original_image_of_instance_that_was_snapshotted> |
| image_location | snapshot |
Use snapshots to create new instances based on that snapshot, and potentially restore an instance to that state. You can perform this action while the instance is running.
By default, a snapshot is accessible to the users and projects that were selected while launching an instance that the snapshot is based on.
4.6.1. Creating an instance snapshot
If you intend to use an instance snapshot as a template to create new instances, you must ensure that the disk state is consistent. Before you create a snapshot, set the snapshot image metadata property os_require_quiesce=yes:
$ openstack image set --property os_require_quiesce=yes <image_id>
For this to work, the guest must have the qemu-guest-agent package installed, and the image must be created with the metadata property parameter hw_qemu_guest_agent=yes set.:
$ openstack image create \
--disk-format raw \
--container-format bare \
--file <file_name> \
--is-public True \
--property hw_qemu_guest_agent=yes \
--progress \
--name <name>
If you unconditionally enable the hw_qemu_guest_agent=yes parameter, then you are adding another device to the guest. This consumes a PCI slot, and limits the number of other devices you can allocate to the guest. It also causes Windows guests to display a warning message about an unknown hardware device.
For these reasons, setting the hw_qemu_guest_agent=yes parameter is optional, and you must use the parameter only for images that require the QEMU guest agent.
- In the dashboard, select Project > Compute > Instances.
- Select the instance from which you want to create a snapshot.
- In the Actions column, click Create Snapshot.
In the Create Snapshot dialog, enter a name for the snapshot and click Create Snapshot.
The Images category now shows the instance snapshot.
To launch an instance from a snapshot, select the snapshot and click Launch.
4.6.2. Managing a snapshot
- In the dashboard, select Project > Images.
- All snapshots you created, appear under the Project option.
For every snapshot you create, you can perform the following functions, using the dropdown list:
- Use the Create Volume option to create a volume and entering the values for volume name, description, image source, volume type, size and availability zone. For more information, see Create a Volume in the Storage Guide.
- Use the Edit Image option to update the snapshot image by updating the values for name, description, Kernel ID, Ramdisk ID, Architecture, Format, Minimum Disk (GB), Minimum RAM (MB), public or private. For more information, see 「Updating an image」.
- Use the Delete Image option to delete the snapshot.
4.6.3. Rebuilding an instance to a state in a snapshot
In an event that you delete an instance on which a snapshot is based, the snapshot still stores the instance ID. You can check this information by using the nova image-list command and use the snapshot to restore the instance.
- In the dashboard, select Project > Compute > Images.
- Select the snapshot from which you want to restore the instance.
- In the Actions column, click Launch Instance.
- In the Launch Instance dialog, enter a name and the other details for the instance and click Launch.
For more information on launching an instance, see 「Launching an instance」.
4.6.4. Consistent snapshots
Previously, file systems had to be quiesced manually (fsfreeze) before taking a snapshot of active instances for consistent backups.
The Compute libvirt driver automatically requests the QEMU Guest Agent to freeze the file systems (and applications if fsfreeze-hook is installed) during an image snapshot. Support for quiescing file systems enables scheduled, automatic snapshots at the block device level.
This feature is valid only if the QEMU Guest Agent is installed (qemu-ga) and the image metadata enables the agent (hw_qemu_guest_agent=yes).
Do not use snapshots as a substitute for system backups.
4.7. Using rescue mode for instances
Compute has a method to reboot a virtual machine in rescue mode. Rescue mode provides a mechanism for access when the virtual machine image renders the instance inaccessible. A rescue virtual machine allows a user to fix their virtual machine by accessing the instance with a new root password. This feature is useful if the file system of an instance is corrupted. By default, rescue mode starts an instance from the initial image attaching the current boot disk as a secondary one.
4.7.1. Preparing an image for a rescue mode instance
Due to the fact that both the boot disk and the disk for rescue mode have same UUID, sometimes the virtual machine can be booted from the boot disk instead of the disk for rescue mode.
To avoid this issue, you should create a new image as rescue image based on the procedure in 「Creating an image」:
The rescue image is stored in glance and configured in the nova.conf as a default, or you can select when you do the rescue.
4.7.1.1. Rescuing an image that uses ext4 file system
When the base image uses ext4 file system, you can create a rescue image from it by using the following procedure:
Change the
UUIDto a random value by using thetune2fscommand:# tune2fs -U random /dev/<device_node>Replace
<device_node>with the root device node, for example,sdaorvda.Verify the details of the file system, including the new UUID:
# tune2fs -l-
Update the
/etc/fstabto use the new UUID. You might need to repeat this for any additional partitions that you have that are mounted in thefstabby UUID. -
Update the
/boot/grub2/grub.conffile and update the UUID parameter with the new UUID of the root disk. - Shut down and use this image as your rescue image. This causes the rescue image to have a new random UUID that does not conflict with the instance that you are rescuing.
The XFS file system cannot change the UUID of the root device on the running virtual machine. Reboot the virtual machine until the virtual machine is launched from the disk for rescue mode.
4.7.2. Adding the rescue image to the OpenStack Image service
When you have completed modifying the UUID of your image, use the following commands to add the generated rescue image to the OpenStack Image service:
Add the rescue image to the Image service:
# openstack image create --name <image_name> --disk-format qcow2 \ --container-format bare --is-public True --file <image_path>Replace
<image_name>with the name of the image and<image_path>with the location of the image.Use the
image listcommand to obtain the<image_id>required to launch an instance in the rescue mode.# openstack image list
You can also upload an image by using the OpenStack Dashboard, see 「Uploading an image」.
4.7.3. Launching an instance in rescue mode
Because you need to rescue an instance with a specific image, rather than the default one, use the
--imageparameter:# openstack server rescue --image <image> <instance>-
Replace
<image>with the name or ID of the image you want to use. -
Replace
<instance>with the name or ID of the instance that you want to rescue.
注記For more information on rescuing an instance, see https://access.redhat.com/documentation/en-us/red_hat_openstack_platform/16.1/html/instances_and_images_guide/assembly-managing-an-instance_instances#rescuing-an-instance_instances
By default, the instance has 60 seconds to shut down. You can override the timeout value on a per image basis by using the image metadata setting
os_shutdown_timeoutto specify the time that different types of operating systems require to shut down cleanly.-
Replace
- Reboot the virtual machine.
-
Confirm the status of the virtual machine is RESCUE on the controller node by using
nova listcommand or by using dashboard. - Log in to the new virtual machine dashboard by using the password for rescue mode.
You can now make the necessary changes to your instance to fix any issues.
4.7.4. Unrescuing an instance
You can unrescue the fixed instance to restart it from the boot disk.
Execute the following commands on the controller node.
# nova unrescue <virtual_machine_id>Here
<virtual_machine_id>is ID of a virtual machine that you want to unrescue.
The status of your instance returns to ACTIVE after the unrescue operation has completed successfully. :leveloffset: +3
4.8. Creating a customized instance
Cloud users can specify additional data to use when they launch an instance, such as a shell script that the instance runs on boot. The cloud user can use the following methods to pass data to instances:
- User data
-
Use to include instructions in the instance launch command for
cloud-initto execute. - Instance metadata
- A list of key-value pairs that you can specify when you create or update an instance.
You can access the additional data passed to the instance by using a config drive or the metadata service.
- Config drive
-
You can attach a config drive to an instance when it boots. The config drive is presented to the instance as a read-only drive. The instance can mount this drive and read files from it. You can use the config drive as a source for
cloud-initinformation. Config drives are useful when combined withcloud-initfor server bootstrapping, and when you want to pass large files to your instances. For example, you can configurecloud-initto automatically mount the config drive and run the setup scripts during the initial instance boot. Config drives are created with the volume label ofconfig-2, and attached to the instance when it boots. The contents of any additional files passed to the config drive are added to theuser_datafile in theopenstack/{version}/directory of the config drive.cloud-initretrieves the user data from this file. - Metadata service
-
Uses a REST API to retrieve data specific to an instance. Instances access this service at
169.254.169.254or atfe80::a9fe:a9fe.
cloud-init can use both a config drive and the metadata service to consume the additional data for customizing an instance. The cloud-init package supports several data input formats. Shell scripts and the cloud-config format are the most common input formats:
-
Shell scripts: The data declaration begins with
#!orContent-Type: text/x-shellscript. Shell scripts are invoked last in the boot process. -
cloud-configformat: The data declaration begins with#cloud-configorContent-Type: text/cloud-config.cloud-configfiles must be valid YAML to be parsed and executed bycloud-init.
cloud-init has a maximum user data size of 16384 bytes for data passed to an instance. You cannot change the size limit, therefore use gzip compression when you need to exceed the size limit.
4.8.1. Customizing an instance by using user data
You can use user data to include instructions in the instance launch command. cloud-init executes these commands to customize the instance as the last step in the boot process.
Procedure
Create a file with instructions for
cloud-init. For example, create a bash script that installs and enables a web server on the instance:$ vim /home/scripts/install_httpd #!/bin/bash yum -y install httpd python-psycopg2 systemctl enable httpd --nowLaunch an instance with the
--user-dataoption to pass the bash script:$ openstack server create \ --image rhel8 \ --flavor default \ --nic net-id=web-server-network \ --security-group default \ --key-name web-server-keypair \ --user-data /home/scripts/install_httpd \ --wait web-server-instanceWhen the instance state is active, attach a floating IP address:
$ openstack floating ip create web-server-network $ openstack server add floating ip web-server-instance 172.25.250.123Log in to the instance with SSH:
$ ssh -i ~/.ssh/web-server-keypair cloud-user@172.25.250.123Check that the customization was successfully performed. For example, to check that the web server has been installed and enabled, enter the following command:
$ curl http://localhost | grep Test <title>Test Page for the Apache HTTP Server on Red Hat Enterprise Linux</title> <h1>Red Hat Enterprise Linux <strong>Test Page</strong></h1>Review the
/var/log/cloud-init.logfile for relevant messages, such as whether or not thecloud-initexecuted:$ sudo less /var/log/cloud-init.log ...output omitted... ...util.py[DEBUG]: Cloud-init v. 0.7.9 finished at Sat, 23 Jun 2018 02:26:02 +0000. Datasource DataSourceOpenStack [net,ver=2]. Up 21.25 seconds
4.8.2. Customizing an instance by using metadata
You can use instance metadata to specify the properties of an instance in the instance launch command.
Procedure
Launch an instance with the
--property <key=value>option. For example, to mark the instance as a webserver, set the following property:$ openstack server create \ --image rhel8 \ --flavor default \ --property role=webservers \ --wait web-server-instanceOptional: Add an additional property to the instance after it is created, for example:
$ openstack server set \ --property region=emea \ --wait web-server-instance
4.8.3. Customizing an instance by using a config drive
You can create a config drive for an instance that is attached during the instance boot process. You can pass content to the config drive that the config drive makes available to the instance.
Procedure
Enable the config drive, and specify a file that contains content that you want to make available in the config drive. For example, the following command creates a new instance named
config-drive-instanceand attaches a config drive that contains the contents of the filemy-user-data.txt:(overcloud)$ openstack server create --flavor m1.tiny \ --config-drive true \ --user-data ./my-user-data.txt \ --image cirros config-drive-instanceThis command creates the config drive with the volume label of
config-2, which is attached to the instance when it boots, and adds the contents ofmy-user-data.txtto theuser_datafile in theopenstack/{version}/directory of the config drive.- Log in to the instance.
Mount the config drive:
If the instance OS uses
udev:# mkdir -p /mnt/config # mount /dev/disk/by-label/config-2 /mnt/configIf the instance OS does not use
udev, you need to first identify the block device that corresponds to the config drive:# blkid -t LABEL="config-2" -odevice /dev/vdb # mkdir -p /mnt/config # mount /dev/vdb /mnt/config
第5章 Migrating virtual machine instances between Compute nodes
You sometimes need to migrate instances from one Compute node to another Compute node in the overcloud, to perform maintenance, rebalance the workload, or replace a failed or failing node.
- Compute node maintenance
- If you need to temporarily take a Compute node out of service, for instance, to perform hardware maintenance or repair, kernel upgrades and software updates, you can migrate instances running on the Compute node to another Compute node.
- Failing Compute node
- If a Compute node is about to fail and you need to service it or replace it, you can migrate instances from the failing Compute node to a healthy Compute node.
- Failed Compute nodes
- If a Compute node has already failed, you can evacuate the instances. You can rebuild instances from the original image on another Compute node, using the same name, UUID, network addresses, and any other allocated resources the instance had before the Compute node failed.
- Workload rebalancing
- You can migrate one or more instances to another Compute node to rebalance the workload. For example, you can consolidate instances on a Compute node to conserve power, migrate instances to a Compute node that is physically closer to other networked resources to reduce latency, or distribute instances across Compute nodes to avoid hot spots and increase resiliency.
Director configures all Compute nodes to provide secure migration. All Compute nodes also require a shared SSH key to provide the users of each host with access to other Compute nodes during the migration process. Director creates this key using the OS::TripleO::Services::NovaCompute composable service. This composable service is one of the main services included on all Compute roles by default. For more information, see Composable Services and Custom Roles in the Advanced Overcloud Customization guide.
If you have a functioning Compute node, and you want to make a copy of an instance for backup purposes, or to copy the instance to a different environment, follow the procedure in Importing virtual machines into the overcloud in the Director Installation and Usage guide.
5.1. Migration types
Red Hat OpenStack Platform (RHOSP) supports the following types of migration.
Cold migration
Cold migration, or non-live migration, involves shutting down a running instance before migrating it from the source Compute node to the destination Compute node.
Cold migration involves some downtime for the instance. The migrated instance maintains access to the same volumes and IP addresses.
Cold migration requires that both the source and destination Compute nodes are running.
Live migration
Live migration involves moving the instance from the source Compute node to the destination Compute node without shutting it down, and while maintaining state consistency.
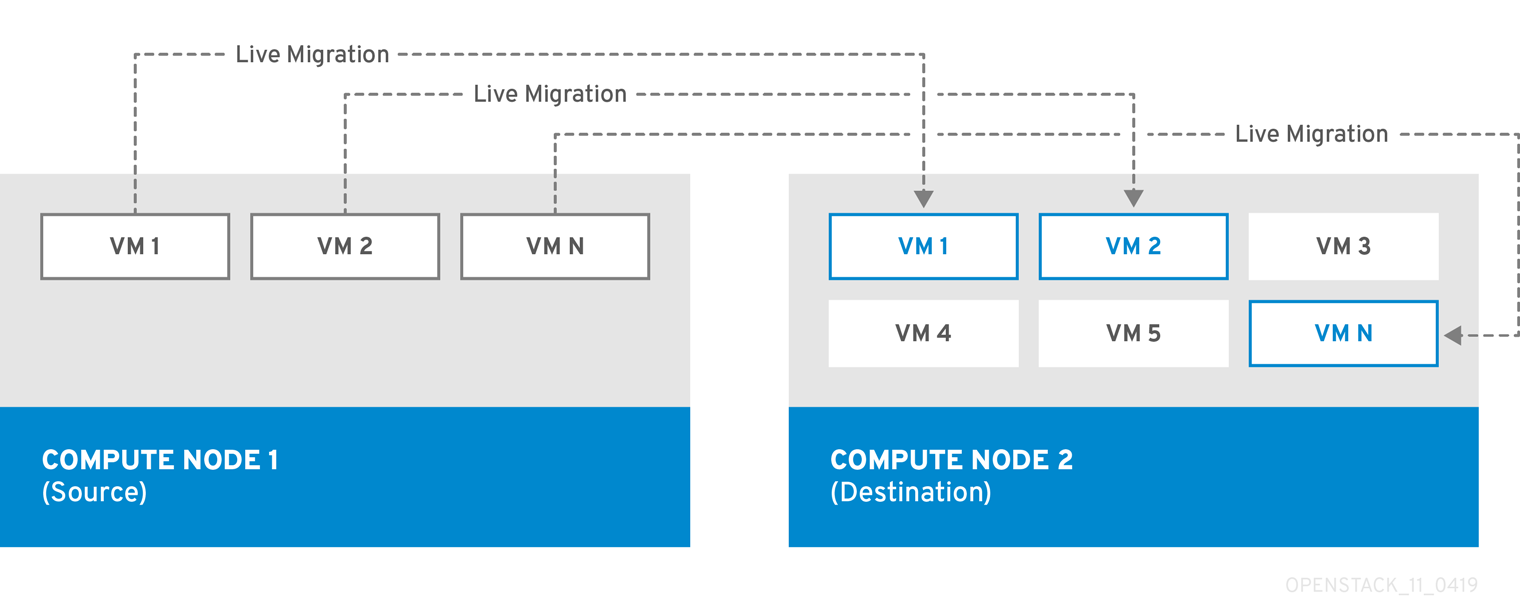
Live migrating an instance involves little or no perceptible downtime. In some cases, instances cannot use live migration. For more information, see Migration Constraints.
Live migration requires that both the source and destination Compute nodes are running.
Evacuation
If you need to migrate instances because the source Compute node has already failed, you can evacuate the instances.
5.2. Migration constraints
In some cases, migrating instances involves additional constraints. Migration constraints typically arise with block migration, configuration disks, or when one or more instances access physical hardware on the Compute node.
CPU constraints
The source and destination Compute nodes must have the same CPU architecture. For example, Red Hat does not support migrating an instance from an x86_64 CPU to a ppc64le CPU. In some cases, the CPU of the source and destination Compute node must match exactly, such as instances that use CPU host passthrough. In all cases, the CPU features of the destination node must be a superset of the CPU features on the source node. Using CPU pinning introduces additional constraints. For more information, see Live migration constraints.
Memory constraints
The destination Compute node must have sufficient available RAM. Memory oversubscription can cause migration to fail. Additionally, instances that use a NUMA topology must have sufficient available RAM on the same NUMA node on the destination Compute node.
Block migration constraints
Migrating instances that use disks that are stored locally on a Compute node takes significantly longer than migrating volume-backed instances that use shared storage, such as Red Hat Ceph Storage. This latency arises because OpenStack Compute (nova) migrates local disks block-by-block between the Compute nodes over the control plane network by default. By contrast, volume-backed instances that use shared storage, such as Red Hat Ceph Storage, do not have to migrate the volumes, because each Compute node already has access to the shared storage.
Network congestion in the control plane network caused by migrating local disks or instances that consume large amounts of RAM might impact the performance of other systems that use the control plane network, such as RabbitMQ.
Read-only drive migration constraints
Migrating a drive is supported only if the drive has both read and write capabilities. For example, OpenStack Compute (nova) cannot migrate a CD-ROM drive or a read-only config drive. However, OpenStack Compute (nova) can migrate a drive with both read and write capabilities, including a config drive with a drive format such as vfat.
Live migration constraints
- Migration between RHEL minor versions
In general, you can live migrate an instance between RHEL minor versions when the instance machine type version on the source Compute node is equal to or less than that of the destination Compute node. For example, you cannot live migrate an instance with a RHEL-7.6 machine type running on a RHEL-7.6 Compute node to a RHEL-7.5 Compute node, because the RHEL-7.5 Compute node does not know of the RHEL-7.6 machine type.
However, if you do not set a machine type explicitly, the instance receives the default machine type and live migration can succeed across supported RHEL minor versions. For example, you can live migrate an instance that has the default machine type, RHEL-7.6, from a RHEL-7.8 Compute node to a RHEL-7.7 Compute node.
- No new operations during migration
- To achieve state consistency between the copies of the instance on the source and destination nodes, RHOSP must prevent new operations during live migration. Otherwise, live migration might take a long time or potentially never end if writes to memory occur faster than live migration can replicate the state of the memory.
- NUMA, CPU pinning, huge pages and DPDK
OpenStack Compute can live migrate an instance that uses NUMA, CPU pinning or DPDK when the environment meets the following conditions:
-
The destination Compute node must have sufficient capacity on the same NUMA node that the instance uses on the source Compute node. For example, if an instance uses
NUMA 0onovercloud-compute-0, to live migrate the instance toovercloud-compute-1, you must ensure thatovercloud-compute-1has sufficient capacity onNUMA 0to support the instance. -
NovaEnableNUMALiveMigrationis set to "True" in the Compute configuration. This parameter is enabled by default only when the Compute host is configured for an OVS-DPDK deployment. -
The
NovaSchedulerDefaultFiltersparameter in the Compute configuration must include the valuesAggregateInstanceExtraSpecsFilterandNUMATopologyFilter. - CPU Pinning: When a flavor uses CPU pinning, the flavor implicitly introduces a NUMA topology to the instance and maps its CPUs and memory to specific host CPUs and memory. The difference between a simple NUMA topology and CPU pinning is that NUMA uses a range of CPU cores, whereas CPU pinning uses specific CPU cores. For more information, see Configuring CPU pinning with NUMA. To live migrate instances that use CPU pinning, the destination host must be empty and must have equivalent hardware.
-
Data Plane Development Kit (DPDK): When an instance uses DPDK, such as an instance running Open vSwitch with
dpdk-netdev, the instance also uses huge pages. Huge pages impose a NUMA topology such that OpenStack Compute (nova) pins the instance to a NUMA node. When you migrate instances that use DPDK, the destination Compute node must have an identical hardware specification and configuration as the source Compute node. Additionally, there must not be any instances running on the destination Compute node to ensure that it preserves the NUMA topology of the source Compute node.
-
The destination Compute node must have sufficient capacity on the same NUMA node that the instance uses on the source Compute node. For example, if an instance uses
Constraints that preclude live migration
Live migration is not possible when the instance is configured for the following features:
- Single-root Input/Output Virtualization (SR-IOV): You can assign SR-IOV Virtual Functions (VFs) to instances. However, this prevents live migration. Unlike a regular network device, an SR-IOV VF network device does not have a permanent unique MAC address. The VF network device receives a new MAC address each time the Compute node reboots, or when the scheduler migrates the instance to a new Compute node. Consequently, OpenStack Compute cannot live migrate instances that use SR-IOV. You must cold migrate instances that use SR-IOV.
- PCI passthrough: QEMU/KVM hypervisors support attaching PCI devices on the Compute node to an instance. Use PCI passthrough to give an instance exclusive access to PCI devices, which appear and behave as if they are physically attached to the operating system of the instance. However, because PCI passthrough involves physical addresses, OpenStack Compute does not support live migration of instances using PCI passthrough.
5.3. Preparing to migrate
Before you migrate one or more instances, you need to determine the Compute node names and the IDs of the instances to migrate.
Procedure
Identify the source Compute node host name and the destination Compute node host name:
(undercloud)$ source ~/overcloudrc (overcloud)$ openstack compute service listList the instances on the source Compute node and locate the ID of the instance or instances that you want to migrate:
(overcloud)$ openstack server list --host <source> --all-projectsReplace
<source>with the name or ID of the source Compute node.Optional: To shut down the source Compute node for maintenance, disable the source Compute node from the undercloud to ensure that the scheduler does not attempt to assign new instances to the source Compute node during maintenance:
(overcloud)$ source ~/stackrc (undercloud)$ openstack compute service set <source> nova-compute --disableReplace
<source>with the name or ID of the source Compute node.
If you are not migrating NUMA, CPU-pinned or DPDK instances, you are now ready to perform the migration. Follow the required procedure detailed in Cold migrating an instance or Live migrating an instance.
If you are migrating NUMA, CPU-pinned or DPDK instances, you need to prepare the destination node. Complete the procedure detailed in 「Additional preparation for DPDK instances」.
5.4. Additional preparation for DPDK instances
If you are migrating NUMA, CPU-pinned or DPDK instances, you need to prepare the destination node.
Procedure
If the destination Compute node for NUMA, CPU-pinned or DPDK instances is not disabled, disable it to prevent the scheduler from assigning instances to the node:
(overcloud)$ openstack compute service set <dest> nova-compute --disableReplace
<dest>with the name or ID of the destination Compute node.Ensure that the destination Compute node has no instances, except for instances that you previously migrated from the source Compute node when you migrated multiple DPDK or NUMA instances:
(overcloud)$ openstack server list --host <dest> --all-projectsReplace
<dest>with the name or ID of the destination Compute node.Ensure that the destination Compute node has sufficient resources to run the NUMA, CPU-pinned or DPDK instance:
(overcloud)$ openstack host show <dest> $ ssh <dest> $ numactl --hardware $ exitReplace
<dest>with the name or ID of the destination Compute node.To discover NUMA information about the source or destination Compute nodes, run the following commands:
$ ssh root@overcloud-compute-n # lscpu && lscpu | grep NUMA # virsh nodeinfo # virsh capabilities # exitUse
sshto connect toovercloud-compute-nwhereovercloud-compute-nis the source or destination Compute node.If you do not know if an instance uses NUMA, check the flavor of the instance:
(overcloud)$ openstack server list -c Name -c Flavor --name <vm> (overcloud)$ openstack flavor show <flavor>-
Replace
<vm>with the name or ID of the instance. Replace
<flavor>with the name or ID of the flavor.-
If the
propertiesfield includeshw:mem_page_sizewith a value other thanany, such as2MB,2048or1GB, the instance has a NUMA topology. -
If the
propertiesfield includesaggregate_instance_extra_specs:pinned='true', the instance uses CPU pinning. -
If the
propertiesfield includeshw:numa_nodes, the OpenStack Compute (nova) service restricts the instance to a specific NUMA node.
-
If the
-
Replace
For each instance that uses NUMA, you can retrieve information about the NUMA topology from the underlying Compute node so that you can verify that the NUMA topology on the destination Compute node reflects the NUMA topology of the source Compute node after migration is complete. You can use the following commands to perform this check:
To view details about NUMA and CPU pinning, run the following command:
$ ssh root@overcloud-compute-n # virsh vcpuinfo <vm>Replace
<vm>with the name of the instance.To view details about which NUMA node the instance is using, run the following command:
$ ssh root@overcloud-compute-n # virsh numatune <vm>Replace
<vm>with the name of the instance.
5.5. Cold migrating an instance
Cold migrating an instance involves stopping the instance and moving it to another Compute node. Cold migration facilitates migration scenarios that live migrating cannot facilitate, such as migrating instances that use PCI passthrough or Single-Root Input/Output Virtualization (SR-IOV). The scheduler automatically selects the destination Compute node. For more information, see Migration Constraints.
During cold migrations, the Compute service rebuilds the migrated instances from scratch, and adjusts the machine type to the machine type of the destination Compute node. Therefore, if you cold migrate an instance with a RHEL-7.5 machine type running on a RHEL-7.5 Compute node, to a RHEL-7.6 Compute node, the migrated instance on the destination Compute node will have a RHEL-7.6 machine type.
Procedure
To cold migrate an instance, run the following command to power off and move the instance:
(overcloud)$ openstack server migrate <vm> --wait-
Replace
<vm>with the name or ID of the instance to migrate. -
Specify the
--block-migrationflag if migrating a locally stored volume.
-
Replace
- Wait for migration to complete. See Checking migration status to check the status of the migration.
Check the status of the instance:
(overcloud)$ openstack server list --all-projectsA status of "VERIFY_RESIZE" indicates you need to confirm or revert the migration:
If the migration worked as expected, confirm it:
(overcloud)$ openstack server resize --confirm <vm>`Replace
<vm>with the name or ID of the instance to migrate. A status of "ACTIVE" indicates that the instance is ready to use.If the migration did not work as expected, revert it:
(overcloud)$ openstack server resize --revert <vm>`Replace
<vm>with the name or ID of the instance.
Restart the instance:
(overcloud)$ openstack server start <vm>Replace
<vm>with the name or ID of the instance.
When you finish migrating the instances, proceed to Completing the migration.
5.6. Live migrating an instance
Live migration moves an instance from a source Compute node to a destination Compute node with a minimal amount of downtime. Live migration might not be appropriate for all instances. For more information, see 「Migration constraints」.
Live migrations preserve the instance machine type on the destination Compute node. Therefore, if you live migrate an instance with a RHEL-7.5 machine type running on a RHEL-7.5 Compute node, to a RHEL-7.6 Compute node, the migrated instance on the destination Compute node retains the RHEL-7.5 machine type. To change the machine type, you must set the image metadata property hw_machine_type, or set the NovaHWMachineType parameter on each Compute node.
Procedure
To live migrate an instance, specify the instance and the destination Compute node:
(overcloud)$ openstack server migrate <vm> --live <dest> --wait-
Replace
<vm>with the name or ID of the instance. Replace
<dest>with the name or ID of the destination Compute node.注記The
openstack server migratecommand covers migrating instances with shared storage, which is the default. Specify the--block-migrationflag to migrate a locally stored volume:(overcloud)$ openstack server migrate <vm> --live <dest> --wait --block-migration
-
Replace
Confirm that the instance is migrating:
$ openstack server show <vm> +----------------------+--------------------------------------+ | Field | Value | +----------------------+--------------------------------------+ | ... | ... | | status | MIGRATING | | ... | ... | +----------------------+--------------------------------------+- Wait for migration to complete. See Checking migration status to check the status of the migration.
Check the status of the instance to confirm if the migration was successful:
(overcloud)$ openstack server list --host <dest> --all-projectsReplace
<dest>with the name or ID of the destination Compute node.Optional: For instances that use NUMA, CPU-pinning, or DPDK, retrieve information about the NUMA topology from a Compute node to compare it with the NUMA topology that you retrieved during the preparing to migrate procedure. Comparing the NUMA topologies of the source and destination Compute nodes ensures that the source and destination Compute nodes use the same NUMA topology.
To view details about NUMA and CPU pinning, run the following command:
$ ssh root@overcloud-compute-n # virsh vcpuinfo <vm>-
Replace
overcloud-compute-nwith the host name of the Compute node. -
Replace
<vm>with the name of the instance.
-
Replace
To view details about which NUMA node the instance is using, run the following command:
$ ssh root@overcloud-compute-n # virsh numatune <vm>-
Replace
overcloud-compute-nwith the host name of the Compute node. -
Replace
<vm>with the name or ID of the instance.
-
Replace
When you finish migrating the instances, proceed to Completing the migration.
5.7. Checking migration status
Migration involves several state transitions before migration is complete. During a healthy migration, the migration state typically transitions as follows:
- Queued: The Compute service has accepted the request to migrate an instance, and migration is pending.
- Preparing: The Compute service is preparing to migrate the instance.
- Running: The Compute service is migrating the instance.
- Post-migrating: The Compute service has built the instance on the destination Compute node and is releasing resources on the source Compute node.
- Completed: The Compute service has completed migrating the instance and finished releasing resources on the source Compute node.
Procedure
Retrieve the list of migration IDs for the instance:
$ nova server-migration-list <vm> +----+-------------+----------- (...) | Id | Source Node | Dest Node | (...) +----+-------------+-----------+ (...) | 2 | - | - | (...) +----+-------------+-----------+ (...)Replace
<vm>with the name or ID of the instance.Show the status of the migration:
$ nova server-migration-show <vm> <migration-id>-
Replace
<vm>with the name or ID of the instance. Replace
<migration-id>with the ID of the migration.Running the
nova server-migration-showcommand returns the following example output:+------------------------+--------------------------------------+ | Property | Value | +------------------------+--------------------------------------+ | created_at | 2017-03-08T02:53:06.000000 | | dest_compute | controller | | dest_host | - | | dest_node | - | | disk_processed_bytes | 0 | | disk_remaining_bytes | 0 | | disk_total_bytes | 0 | | id | 2 | | memory_processed_bytes | 65502513 | | memory_remaining_bytes | 786427904 | | memory_total_bytes | 1091379200 | | server_uuid | d1df1b5a-70c4-4fed-98b7-423362f2c47c | | source_compute | compute2 | | source_node | - | | status | running | | updated_at | 2017-03-08T02:53:47.000000 | +------------------------+--------------------------------------+ヒントThe OpenStack Compute service measures progress of the migration by the number of remaining memory bytes to copy. If this number does not decrease over time, the migration might be unable to complete, and the Compute service might abort it.
-
Replace
Sometimes instance migration can take a long time or encounter errors. For more information, see 「Troubleshooting migration」.
5.8. Completing the migration
After you migrate one or more instances, you need to re-enable the source Compute nodes from the undercloud to ensure that the scheduler can assign new instances to the source Compute node. For migrated instances that use DPDK, you must also re-enable the destination Compute node from the undercloud.
Procedure
Re-enable the source Compute node:
(overcloud)$ source ~/stackrc (undercloud)$ openstack compute service set <source> nova-compute --enableReplace
<source>with the host name of the source Compute node.Optional: For instances that use DPDK, re-enable the destination Compute node from the undercloud:
(undercloud)$ openstack compute service set <dest> nova-compute --enableReplace
<dest>with the host name of the destination Compute node.
5.9. Evacuating an instance
If you want to move an instance from a dead or shut-down Compute node to a new host in the same environment, you can evacuate it. The evacuate process rebuilds the instance on another Compute node. If the instance uses shared storage, the instance root disk is not rebuilt during the evacuate process, as the disk remains accessible by the destination Compute node. If the instance does not use shared storage, then the instance root disk is also rebuilt on the destination Compute node.
-
You can only perform an evacuation when the Compute node is fenced, and the API reports that the state of the Compute node is "down" or "forced-down". If the Compute node is not reported as "down" or "forced-down", the
evacuatecommand fails. - To perform an evacuation, you must be a cloud administrator.
- During evacuations, the Compute service rebuilds the evacuated instances from scratch, and adjusts the machine type to the machine type of the destination Compute node. Therefore, if you evacuate an instance with a RHEL-7.5 machine type running on a RHEL-7.5 Compute node, to a RHEL-7.6 Compute node, the migrated instance on the destination Compute node will have a RHEL-7.6 machine type.
5.9.1. Evacuating one instance
You can evacuate instances one at a time.
Procedure
- Log onto the failed Compute node as an administrator.
Disable the Compute node:
(overcloud)[stack@director ~]$ openstack compute service set \ <host> <service> --disable-
Replace
<host>with the name of the Compute node to evacuate the instance from. -
Replace
<service>with the name of the service to disable, for examplenova-compute.
-
Replace
To evacuate an instance, run the following command:
(overcloud)[stack@director ~]$ nova evacuate [--password <pass>] <vm> [dest]-
Replace
<pass>with the admin password to set for the evacuated instance. If a password is not specified, a random password is generated and output when the evacuation is complete. -
Replace
<vm>with the name or ID of the instance to evacuate. Replace
[dest]with the name of the Compute node to evacuate the instance to. If you do not specify the destination Compute node, the Compute scheduler selects one for you. You can find possible Compute nodes by using the following command:(overcloud)[stack@director ~]$ openstack hypervisor list
-
Replace
5.9.2. Evacuating all instances on a host
You can evacuate all instances on a specified Compute node.
Procedure
- Log onto the failed Compute node as an administrator.
Disable the Compute node:
(overcloud)[stack@director ~]$ openstack compute service set \ <host> <service> --disable-
Replace
<host>with the name of the Compute node to evacuate the instances from. -
Replace
<service>with the name of the service to disable, for examplenova-compute.
-
Replace
Evacuate all instances on a specified Compute node:
(overcloud)[stack@director ~]$ nova host-evacuate [--target_host <dest>] [--force] <host>Replace
<dest>with the name of the destination Compute node to evacuate the instances to. If you do not specify the destination, the Compute scheduler selects one for you. You can find possible Compute nodes by using the following command:(overcloud)[stack@director ~]$ openstack hypervisor list-
Replace
<host>with the name of the Compute node to evacuate the instances from.
5.10. Troubleshooting migration
The following issues can arise during instance migration:
- The migration process encounters errors.
- The migration process never ends.
- Performance of the instance degrades after migration.
5.10.1. Errors during migration
The following issues can send the migration operation into an error state:
- Running a cluster with different versions of Red Hat OpenStack Platform (RHOSP).
- Specifying an instance ID that cannot be found.
-
The instance you are trying to migrate is in an
errorstate. - The Compute service is shutting down.
- A race condition occurs.
-
Live migration enters a
failedstate.
When live migration enters a failed state, it is typically followed by an error state. The following common issues can cause a failed state:
- A destination Compute host is not available.
- A scheduler exception occurs.
- The rebuild process fails due to insufficient computing resources.
- A server group check fails.
- The instance on the source Compute node gets deleted before migration to the destination Compute node is complete.
5.10.2. Never-ending live migration
Live migration can fail to complete, which leaves migration in a perpetual running state. A common reason for a live migration that never completes is that client requests to the instance running on the source Compute node create changes that occur faster than the Compute service can replicate them to the destination Compute node.
Use one of the following methods to address this situation:
- Abort the live migration.
- Force the live migration to complete.
Aborting live migration
If the instance state changes faster than the migration procedure can copy it to the destination node, and you do not want to temporarily suspend the instance operations, you can abort the live migration.
Procedure
Retrieve the list of migrations for the instance:
$ nova server-migration-list <vm>Replace
<vm>with the name or ID of the instance.Abort the live migration:
$ nova live-migration-abort <vm> <migration-id>-
Replace
<vm>with the name or ID of the instance. -
Replace
<migration-id>with the ID of the migration.
-
Replace
Forcing live migration to complete
If the instance state changes faster than the migration procedure can copy it to the destination node, and you want to temporarily suspend the instance operations to force migration to complete, you can force the live migration procedure to complete.
Forcing live migration to complete might lead to perceptible downtime.
Procedure
Retrieve the list of migrations for the instance:
$ nova server-migration-list <vm>Replace
<vm>with the name or ID of the instance.Force the live migration to complete:
$ nova live-migration-force-complete <vm> <migration-id>-
Replace
<vm>with the name or ID of the instance. -
Replace
<migration-id>with the ID of the migration.
-
Replace
5.10.3. Instance performance degrades after migration
For instances that use a NUMA topology, the source and destination Compute nodes must have the same NUMA topology and configuration. The NUMA topology of the destination Compute node must have sufficient resources available. If the NUMA configuration between the source and destination Compute nodes is not the same, it is possible that live migration succeeds while the instance performance degrades. For example, if the source Compute node maps NIC 1 to NUMA node 0, but the destination Compute node maps NIC 1 to NUMA node 5, after migration the instance might route network traffic from a first CPU across the bus to a second CPU with NUMA node 5 to route traffic to NIC 1. This can result in expected behavior, but degraded performance. Similarly, if NUMA node 0 on the source Compute node has sufficient available CPU and RAM, but NUMA node 0 on the destination Compute node already has instances using some of the resources, the instance might run correctly but suffer performance degradation. For more information, see 「Migration constraints」.
第6章 Configuring PCI passthrough
You can use PCI passthrough to attach a physical PCI device, such as a graphics card or a network device, to an instance. If you use PCI passthrough for a device, the instance reserves exclusive access to the device for performing tasks, and the device is not available to the host.
Using PCI passthrough with routed provider networks
The Compute service does not support single networks that span multiple provider networks. When a network contains multiple physical networks, the Compute service only uses the first physical network. Therefore, if you are using routed provider networks you must use the same physical_network name across all the Compute nodes.
If you use routed provider networks with VLAN or flat networks, you must use the same physical_network name for all segments. You then create multiple segments for the network and map the segments to the appropriate subnets.
To enable your cloud users to create instances with PCI devices attached, you must complete the following:
- Designate Compute nodes for PCI passthrough.
- Configure the Compute nodes for PCI passthrough that have the required PCI devices.
- Deploy the overcloud.
- Create a flavor for launching instances with PCI devices attached.
Prerequisites
- The Compute nodes have the required PCI devices.
6.1. Designating Compute nodes for PCI passthrough
To designate Compute nodes for instances with physical PCI devices attached, you must:
- create a new role file to configure the PCI passthrough role
- configure a new overcloud flavor for PCI passthrough to use to tag the Compute nodes for PCI passthrough
Procedure
Generate a new roles data file named
roles_data_pci_passthrough.yamlthat includes theController,Compute, andComputePCIroles:(undercloud)$ openstack overcloud roles \ generate -o /home/stack/templates/roles_data_pci_passthrough.yaml \ Compute:ComputePCI Compute ControllerOpen
roles_data_pci_passthrough.yamland edit or add the following parameters and sections:Expand Section/Parameter Current value New value Role comment
Role: ComputeRole: ComputePCIRole name
name: Computename: ComputePCIdescriptionBasic Compute Node rolePCI Passthrough Compute Node roleHostnameFormatDefault%stackname%-novacompute-%index%%stackname%-novacomputepci-%index%deprecated_nic_config_namecompute.yamlcompute-pci-passthrough.yaml-
Register the PCI passthrough Compute nodes for the overcloud by adding them to your node definition template,
node.jsonornode.yaml. For more information, see Registering nodes for the overcloud in the Director Installation and Usage guide. Inspect the node hardware:
(undercloud)$ openstack overcloud node introspect \ --all-manageable --provideFor more information, see Inspecting the hardware of nodes in the Director Installation and Usage guide.
Create the
compute-pci-passthroughbare metal flavor to use to tag nodes that you want to designate for PCI passthrough:(undercloud)$ openstack flavor create --id auto \ --ram <ram_size_mb> --disk <disk_size_gb> \ --vcpus <no_vcpus> compute-pci-passthrough-
Replace
<ram_size_mb>with the RAM of the bare metal node, in MB. -
Replace
<disk_size_gb>with the size of the disk on the bare metal node, in GB. Replace
<no_vcpus>with the number of CPUs on the bare metal node.注記These properties are not used for scheduling instances. However, the Compute scheduler does use the disk size to determine the root partition size.
-
Replace
Tag each bare metal node that you want to designate for PCI passthrough with a custom PCI passthrough resource class:
(undercloud)$ openstack baremetal node set \ --resource-class baremetal.PCI-PASSTHROUGH <node>Replace
<node>with the ID of the bare metal node.Associate the
compute-pci-passthroughflavor with the custom PCI passthrough resource class:(undercloud)$ openstack flavor set \ --property resources:CUSTOM_BAREMETAL_PCI_PASSTHROUGH=1 \ compute-pci-passthroughTo determine the name of a custom resource class that corresponds to a resource class of a Bare Metal service node, convert the resource class to uppercase, replace all punctuation with an underscore, and prefix with
CUSTOM_.注記A flavor can request only one instance of a bare metal resource class.
Set the following flavor properties to prevent the Compute scheduler from using the bare metal flavor properties to schedule instances:
(undercloud)$ openstack flavor set \ --property resources:VCPU=0 --property resources:MEMORY_MB=0 \ --property resources:DISK_GB=0 compute-pci-passthroughAdd the following parameters to the
node-info.yamlfile to specify the number of PCI passthrough Compute nodes, and the flavor to use for the PCI passthrough designated Compute nodes:parameter_defaults: OvercloudComputePCIFlavor: compute-pci-passthrough ComputePCICount: 3To verify that the role was created, enter the following command:
(undercloud)$ openstack overcloud profiles list
6.2. Configuring a PCI passthrough Compute node
To enable your cloud users to create instances with PCI devices attached, you must configure both the Compute nodes that have the PCI devices and the Controller nodes.
Procedure
-
Create an environment file to configure the Controller node on the overcloud for PCI passthrough, for example,
pci_passthrough_controller.yaml. Add
PciPassthroughFilterto theNovaSchedulerDefaultFiltersparameter inpci_passthrough_controller.yaml:parameter_defaults: NovaSchedulerDefaultFilters: ['AvailabilityZoneFilter','ComputeFilter','ComputeCapabilitiesFilter','ImagePropertiesFilter','ServerGroupAntiAffinityFilter','ServerGroupAffinityFilter','PciPassthroughFilter','NUMATopologyFilter']To specify the PCI alias for the devices on the Controller node, add the following configuration to
pci_passthrough_controller.yaml:parameter_defaults: ... ControllerExtraConfig: nova::pci::aliases: - name: "a1" product_id: "1572" vendor_id: "8086" device_type: "type-PF"For more information about configuring the
device_typefield, see PCI passthrough device type field.注記If the
nova-apiservice is running in a role different from theControllerrole, replaceControllerExtraConfigwith the user role in the format<Role>ExtraConfig.Optional: To set a default NUMA affinity policy for PCI passthrough devices, add
numa_policyto thenova::pci::aliases:configuration from step 3:parameter_defaults: ... ControllerExtraConfig: nova::pci::aliases: - name: "a1" product_id: "1572" vendor_id: "8086" device_type: "type-PF" numa_policy: "preferred"-
To configure the Compute node on the overcloud for PCI passthrough, create an environment file, for example,
pci_passthrough_compute.yaml. To specify the available PCIs for the devices on the Compute node, use the
vendor_idandproduct_idoptions to add all matching PCI devices to the pool of PCI devices available for passthrough to instances. For example, to add all Intel® Ethernet Controller X710 devices to the pool of PCI devices available for passthrough to instances, add the following configuration topci_passthrough_compute.yaml:parameter_defaults: ... ComputePCIParameters: NovaPCIPassthrough: - vendor_id: "8086" product_id: "1572"For more information about how to configure
NovaPCIPassthrough, see Guidelines for configuringNovaPCIPassthrough.You must create a copy of the PCI alias on the Compute node for instance migration and resize operations. To specify the PCI alias for the devices on the PCI passthrough Compute node, add the following to
pci_passthrough_compute.yaml:parameter_defaults: ... ComputePCIExtraConfig: nova::pci::aliases: - name: "a1" product_id: "1572" vendor_id: "8086" device_type: "type-PF"注記The Compute node aliases must be identical to the aliases on the Controller node. Therefore, if you added
numa_affinitytonova::pci::aliasesinpci_passthrough_controller.yaml, then you must also add it tonova::pci::aliasesinpci_passthrough_compute.yaml.To enable IOMMU in the server BIOS of the Compute nodes to support PCI passthrough, add the
KernelArgsparameter topci_passthrough_compute.yaml. For example, use the followingKernalArgssettings to enable an Intel IOMMU:parameter_defaults: ... ComputePCIParameters: KernelArgs: "intel_iommu=on iommu=pt"To enable an AMD IOMMU, set
KernelArgsto"amd_iommu=on iommu=pt".Add your custom environment files to the stack with your other environment files and deploy the overcloud:
(undercloud)$ openstack overcloud deploy --templates \ -e [your environment files] \ -e /home/stack/templates/pci_passthrough_controller.yaml \ -e /home/stack/templates/pci_passthrough_compute.yaml \Create and configure the flavors that your cloud users can use to request the PCI devices. The following example requests two devices, each with a vendor ID of
8086and a product ID of1572, using the alias defined in step 7:(overcloud)# openstack flavor set \ --property "pci_passthrough:alias"="a1:2" device_passthrough
Verification
Create an instance with a PCI passthrough device:
# openstack server create --flavor device_passthrough \ --image <image> --wait test-pci- Log in to the instance as a cloud user. For more information, see Log in to an Instance.
To verify that the PCI device is accessible from the instance, enter the following command from the instance:
$ lspci -nn | grep <device_name>
6.3. PCI passthrough device type field
The Compute service categorizes PCI devices into one of three types, depending on the capabilities the devices report. The following lists the valid values that you can set the device_type field to:
type-PF- The device supports SR-IOV and is the parent or root device. Specify this device type to passthrough a device that supports SR-IOV in its entirety.
type-VF- The device is a child device of a device that supports SR-IOV.
type-PCI-
The device does not support SR-IOV. This is the default device type if the
device_typefield is not set.
You must configure the Compute and Controller nodes with the same device_type.
6.4. Guidelines for configuring NovaPCIPassthrough
-
Do not use the
devnameparameter when configuring PCI passthrough, as the device name of a NIC can change. Instead, usevendor_idandproduct_idbecause they are more stable, or use theaddressof the NIC. -
To use the
product_idparameter to pass through a Physical Function (PF), you must also specify theaddressof the PF. However, you can use just theaddressparameter to specify PFs, because the address is unique on each host. -
To pass through all the Virtual Functions (VFs) you must specify only the
product_idandvendor_id. You must also specify theaddressif you are using SRIOV for NIC partitioning and you are running OVS on a VF. -
To pass through only the VFs for a PF but not the PF itself, you can use the
addressparameter to specify the PCI address of the PF andproduct_idto specify the product ID of the VF.
第7章 Database cleaning
The Compute service includes an administrative tool, nova-manage, that you can use to perform deployment, upgrade, clean-up, and maintenance-related tasks, such as applying database schemas, performing online data migrations during an upgrade, and managing and cleaning up the database.
Director automates the following database management tasks on the overcloud by using cron:
- Archives deleted instance records by moving the deleted rows from the production tables to shadow tables.
- Purges deleted rows from the shadow tables after archiving is complete.
7.1. Configuring database management
The cron jobs use default settings to perform database management tasks. By default, the database archiving cron jobs run daily at 00:01, and the database purging cron jobs run daily at 05:00, both with a jitter between 0 and 3600 seconds. You can modify these settings as required by using heat parameters.
Procedure
- Open your Compute environment file.
Add the heat parameter that controls the cron job that you want to add or modify. For example, to purge the shadow tables immediately after they are archived, set the following parameter to "True":
parameter_defaults: … NovaCronArchiveDeleteRowsPurge: TrueFor a complete list of the heat parameters to manage database cron jobs, see Configuration options for Openstack Compute (nova) automated database management.
- Save the updates to your Compute environment file.
Add your Compute environment file to the stack with your other environment files and deploy the overcloud:
(undercloud)$ openstack overcloud deploy --templates \ -e [your environment files] \ -e /home/stack/templates/<compute_environment_file>.yaml
7.2. Configuration options for OpenStack Compute (nova) automated database management
Use the following heat parameters to enable and modify the automated cron jobs that manage the database.
| Parameter | Description |
|---|---|
|
| Set this parameter to "True" to archive deleted instance records from all cells.
Default value: |
|
| Use this parameter to archive deleted instance records based on their age in days.
Set to
Default value: |
|
| Use this parameter to configure the file for logging deleted instance records.
Default value: |
|
| Use this parameter to configure the hour at which to run the cron command to move deleted instance records to another table.
Default value: |
|
| Use this parameter to configure the maximum delay, in seconds, before moving deleted instance records to another table.
Default value: |
|
| Use this parameter to configure the maximum number of deleted instance records that can be moved to another table.
Default value: |
|
| Use this parameter to configure the minute past the hour at which to run the cron command to move deleted instance records to another table.
Default value: |
|
| Use this parameter to configure on which day of the month to run the cron command to move deleted instance records to another table.
Default value: |
|
| Use this parameter to configure in which month to run the cron command to move deleted instance records to another table.
Default value: |
|
| Set this parameter to "True" to purge shadow tables immediately after scheduled archiving.
Default value: |
|
| Set this parameter to "True" to continue to move deleted instance records to another table until all records are moved.
Default value: |
|
| Use this parameter to configure the user that owns the crontab that archives deleted instance records and that has access to the log file the crontab uses.
Default value: |
|
| Use this parameter to configure on which day of the week to run the cron command to move deleted instance records to another table.
Default value: |
|
| Use this parameter to purge shadow tables based on their age in days.
Set to
Default value: |
|
| Set this parameter to "True" to purge shadow tables from all cells.
Default value: |
|
| Use this parameter to configure the file for logging purged shadow tables.
Default value: |
|
| Use this parameter to configure the hour at which to run the cron command to purge shadow tables.
Default value: |
|
| Use this parameter to configure the maximum delay, in seconds, before purging shadow tables.
Default value: |
|
| Use this parameter to configure the minute past the hour at which to run the cron command to purge shadow tables.
Default value: |
|
| Use this parameter to configure in which month to run the cron command to purge the shadow tables.
Default value: |
|
| Use this parameter to configure on which day of the month to run the cron command to purge the shadow tables.
Default value: |
|
| Use this parameter to configure the user that owns the crontab that purges the shadow tables and that has access to the log file the crontab uses.
Default value: |
|
| Use this parameter to enable verbose logging in the log file for purged shadow tables.
Default value: |
|
| Use this parameter to configure on which day of the week to run the cron command to purge the shadow tables.
Default value: |
第8章 Configuring Compute nodes for performance
You can configure the scheduling and placement of instances for optimal performance by creating customized flavors to target specialized workloads, including Network Functions Virtualization (NFV), and High Performance Computing (HPC).
Use the following features to tune your instances for optimal performance:
- CPU pinning: Pin virtual CPUs to physical CPUs.
- Emulator threads: Pin emulator threads associated with the instance to physical CPUs.
- Huge pages: Tune instance memory allocation policies both for normal memory (4k pages) and huge pages (2 MB or 1 GB pages).
Configuring any of these features creates an implicit NUMA topology on the instance if there is no NUMA topology already present.
For more information about NFV and hyper-converged infrastructure (HCI) deployments, see Deploying an overcloud with HCI and DPDK in the Network Functions Virtualization Planning and Configuration Guide.
8.1. Configuring CPU pinning with NUMA
This chapter describes how to use NUMA topology awareness to configure an OpenStack environment on systems with a NUMA architecture. The procedures detailed in this chapter show you how to pin virtual machines (VMs) to dedicated CPU cores, which improves scheduling and VM performance.
Background information about NUMA is available in the following article: What is NUMA and how does it work on Linux?
The following diagram provides an example of a two-node NUMA system and the way the CPU cores and memory pages are made available:
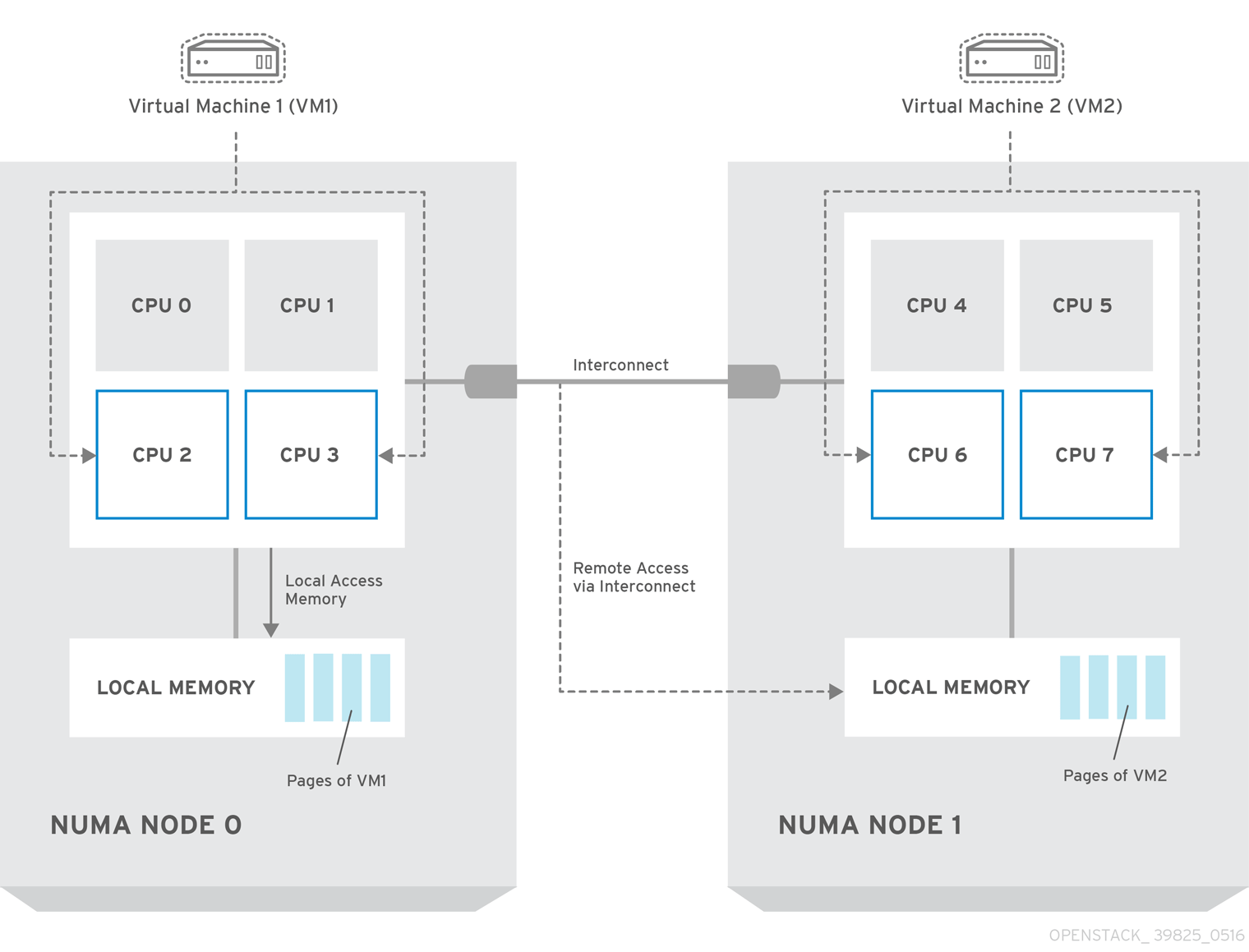
Remote memory available via Interconnect is accessed only if VM1 from NUMA node 0 has a CPU core in NUMA node 1. In this case, the memory of NUMA node 1 will act as local for the third CPU core of VM1 (for example, if VM1 is allocated with CPU 4 in the diagram above), but at the same time, it will act as remote memory for the other CPU cores of the same VM.
For more details on NUMA tuning with libvirt, see the Virtualization Tuning and Optimization Guide.
8.1.1. Compute node configuration
The exact configuration depends on the NUMA topology of your host system. However, you must reserve some CPU cores across all the NUMA nodes for host processes and let the rest of the CPU cores handle your virtual machines (VMs). The following example illustrates the layout of eight CPU cores evenly spread across two NUMA nodes.
| Node 0 | Node 1 | |||
|---|---|---|---|---|
| Host processes | Core 0 | Core 1 | Core 4 | Core 5 |
| Instances | Core 2 | Core 3 | Core 6 | Core 7 |
Determine the number of cores to reserve for host processes by observing the performance of the host under typical workloads.
Procedure
Reserve CPU cores for the VMs by setting the
NovaVcpuPinSetconfiguration in the Compute environment file:NovaVcpuPinSet: 2,3,6,7Set the
NovaReservedHostMemoryoption in the same file to the amount of RAM to reserve for host processes. For example, if you want to reserve 512 MB, use:NovaReservedHostMemory: 512To ensure that host processes do not run on the CPU cores reserved for VMs, set the parameter
IsolCpusListin the Compute environment file to the CPU cores you have reserved for VMs. Specify the value of theIsolCpusListparameter using a list of CPU indices, or ranges separated by a whitespace. For example:IsolCpusList: 2 3 6 7注記The
IsolCpusListparameter andisolcpusparameter are different parameters for separate purposes:-
IsolCpusList: Use this heat parameter to setisolated_coresintuned.confusing thecpu-partitioningprofile. -
isolcpus: This is a Kernel boot parameter that you set with theKernelArgsheat parameter.
Do not use the
IsolCpusListparameter and theisolcpusparameter interchangeably.ヒントTo set
IsolCpusListin non-NFV roles, you must configureKernelArgsandIsolCpusList, and include the/usr/share/openstack-tripleo-heat-templates/environments/host-config-and-reboot.yamlenvironment file in the overcloud deployment. Contact Red Hat Support if you plan to deploy withconfig-download, and configureIsolCpusListfor non-NFV roles.-
To apply this configuration, deploy the overcloud:
(undercloud) $ openstack overcloud deploy --templates \ -e /home/stack/templates/<compute_environment_file>.yaml
8.1.2. Configuring emulator threads to run on dedicated physical CPU
The Compute scheduler determines the CPU resource utilization and places instances based on the number of virtual CPUs (vCPUs) in the flavor. There are a number of hypervisor operations that are performed on the host, on behalf of the guest instance, for example, with QEMU, there are threads used for the QEMU main event loop, asynchronous I/O operations and so on and these operations need to be accounted and scheduled separately.
The libvirt driver implements a generic placement policy for KVM which allows QEMU emulator threads to float across the same physical CPUs (pCPUs) that the vCPUs are running on. This leads to the emulator threads using time borrowed from the vCPUs operations. When you need a guest to have dedicated vCPU allocation, it is necessary to allocate one or more pCPUs for emulator threads. It is therefore necessary to describe to the scheduler any other CPU usage that might be associated with a guest and account for that during placement.
In an NFV deployment, to avoid packet loss, you have to make sure that the vCPUs are never preempted.
Before you enable the emulator threads placement policy on a flavor, check that the following heat parameters are defined as follows:
-
NovaComputeCpuSharedSet: Set this parameter to a list of CPUs defined to run emulator threads. -
NovaSchedulerDefaultFilters: IncludeNUMATopologyFilterin the list of defined filters.
You can define or change heat parameter values on an active cluster, and then redeploy for those changes to take effect.
To isolate emulator threads, you must use a flavor configured as follows:
# openstack flavor set FLAVOR-NAME \
--property hw:cpu_policy=dedicated \
--property hw:emulator_threads_policy=share8.1.3. Scheduler configuration
Procedure
- Open your Compute environment file.
Add the following values to the
NovaSchedulerDefaultFiltersparameter, if they are not already present:-
NUMATopologyFilter -
AggregateInstanceExtraSpecsFilter
-
- Save the configuration file.
- Deploy the overcloud.
8.1.4. Aggregate and flavor configuration
Configure host aggregates to deploy instances that use CPU pinning on different hosts from instances that do not, to avoid unpinned instances using the resourcing requirements of pinned instances.
Do not deploy instances with NUMA topology on the same hosts as instances that do not have NUMA topology.
Prepare your OpenStack environment for running virtual machine instances pinned to specific resources by completing the following steps on a system with the Compute CLI.
Procedure
Load the
admincredentials:source ~/keystonerc_adminCreate an aggregate for the hosts that will receive pinning requests:
nova aggregate-create <aggregate-name-pinned>Enable the pinning by editing the metadata for the aggregate:
nova aggregate-set-metadata <aggregate-pinned-UUID> pinned=trueCreate an aggregate for other hosts:
nova aggregate-create <aggregate-name-unpinned>Edit the metadata for this aggregate accordingly:
nova aggregate-set-metadata <aggregate-unpinned-UUID> pinned=falseChange your existing flavors' specifications to this one:
for i in $(nova flavor-list | cut -f 2 -d ' ' | grep -o '[0-9]*'); do nova flavor-key $i set "aggregate_instance_extra_specs:pinned"="false"; doneCreate a flavor for the hosts that will receive pinning requests:
nova flavor-create <flavor-name-pinned> <flavor-ID> <RAM> <disk-size> <vCPUs>Where:
-
<flavor-ID>- Set toautoif you wantnovato generate a UUID. -
<RAM>- Specify the required RAM in MB. -
<disk-size>- Specify the required disk size in GB. -
<vCPUs>- The number of virtual CPUs that you want to reserve.
-
Set the
hw:cpu_policyspecification of this flavor todedicatedso as to require dedicated resources, which enables CPU pinning, and also thehw:cpu_thread_policyspecification torequire, which places each vCPU on thread siblings:nova flavor-key <flavor-name-pinned> set hw:cpu_policy=dedicated nova flavor-key <flavor-name-pinned> set hw:cpu_thread_policy=require注記If the host does not have an SMT architecture or enough CPU cores with free thread siblings, scheduling will fail. If such behavior is undesired, or if your hosts simply do not have an SMT architecture, do not use the
hw:cpu_thread_policyspecification, or set it topreferinstead ofrequire. The (default)preferpolicy ensures that thread siblings are used when available.Set the
aggregate_instance_extra_specs:pinnedspecification to "true" to ensure that instances based on this flavor have this specification in their aggregate metadata:nova flavor-key <flavor-name-pinned> set aggregate_instance_extra_specs:pinned=trueAdd some hosts to the new aggregates:
nova aggregate-add-host <aggregate-pinned-UUID> <host_name> nova aggregate-add-host <aggregate-unpinned-UUID> <host_name>Boot an instance using the new flavor:
nova boot --image <image-name> --flavor <flavor-name-pinned> <server-name>To verify that the new server has been placed correctly, run the following command and check for
OS-EXT-SRV-ATTR:hypervisor_hostnamein the output:nova show <server-name>
8.2. Configuring huge pages on the Compute node
Configure the Compute node to enable instances to request huge pages.
Procedure
Configure the amount of huge page memory to reserve on each NUMA node for processes that are not instances:
parameter_defaults: NovaReservedHugePages: ["node:0,size:2048,count:64","node:1,size:1GB,count:1"]Where:
Expand Attribute
Description
size
The size of the allocated huge page. Valid values: * 2048 (for 2MB) * 1GB
count
The number of huge pages used by OVS per NUMA node. For example, for 4096 of socket memory used by Open vSwitch, set this to 2.
(Optional) To allow instances to allocate 1GB huge pages, configure the CPU feature flags,
cpu_model_extra_flags, to include "pdpe1gb":parameter_defaults: ComputeExtraConfig: nova::compute::libvirt::libvirt_cpu_mode: 'custom' nova::compute::libvirt::libvirt_cpu_model: 'Haswell-noTSX' nova::compute::libvirt::libvirt_cpu_model_extra_flags: 'vmx, pdpe1gb'注記- CPU feature flags do not need to be configured to allow instances to only request 2 MB huge pages.
- You can only allocate 1G huge pages to an instance if the host supports 1G huge page allocation.
-
You only need to set
cpu_model_extra_flagstopdpe1gbwhencpu_modeis set tohost-modelorcustom. -
If the host supports
pdpe1gb, andhost-passthroughis used as thecpu_mode, then you do not need to setpdpe1gbas acpu_model_extra_flags. Thepdpe1gbflag is only included in Opteron_G4 and Opteron_G5 CPU models, it is not included in any of the Intel CPU models supported by QEMU. - To mitigate for CPU hardware issues, such as Microarchitectural Data Sampling (MDS), you might need to configure other CPU flags. For more information, see RHOS Mitigation for MDS ("Microarchitectural Data Sampling") Security Flaws.
To avoid loss of performance after applying Meltdown protection, configure the CPU feature flags,
cpu_model_extra_flags, to include "+pcid":parameter_defaults: ComputeExtraConfig: nova::compute::libvirt::libvirt_cpu_mode: 'custom' nova::compute::libvirt::libvirt_cpu_model: 'Haswell-noTSX' nova::compute::libvirt::libvirt_cpu_model_extra_flags: 'vmx, pdpe1gb, +pcid'ヒントFor more information, see Reducing the performance impact of Meltdown CVE fixes for OpenStack guests with "PCID" CPU feature flag.
-
Add
NUMATopologyFilterto theNovaSchedulerDefaultFiltersparameter in each Compute environment file, if not already present. Apply this huge page configuration by adding the environment file(s) to your deployment command and deploying the overcloud:
(undercloud) $ openstack overcloud deploy --templates \ -e [your environment files] -e /home/stack/templates/<compute_environment_file>.yaml
8.2.1. Allocating huge pages to instances
Create a flavor with the hw:mem_page_size extra specification key to specify that the instance should use huge pages.
Prerequisites
- The Compute node is configured for huge pages. For more information, see Configuring huge pages on the Compute node.
Procedure
Create a flavor for instances that require huge pages:
$ openstack flavor create --ram <size-mb> --disk <size-gb> --vcpus <no_reserved_vcpus> huge_pagesSet the flavor for huge pages:
$ openstack flavor set huge_pages --property hw:mem_page_size=1GBValid values for
hw:mem_page_size:-
large- Selects the largest page size supported on the host, which may be 2 MB or 1 GB on x86_64 systems. -
small- (Default) Selects the smallest page size supported on the host. On x86_64 systems this is 4 kB (normal pages). -
any- Selects the largest available huge page size, as determined by the libvirt driver. - <pagesize>: (string) Set an explicit page size if the workload has specific requirements. Use an integer value for the page size in KB, or any standard suffix. For example: 4KB, 2MB, 2048, 1GB.
-
Create an instance using the new flavor:
$ openstack server create --flavor huge_pages --image <image> huge_pages_instance
Validation
The scheduler identifies a host with enough free huge pages of the required size to back the memory of the instance. If the scheduler is unable to find a host and NUMA node with enough pages, then the request will fail with a NoValidHost error.
第9章 Adding metadata to instances
The Compute (nova) service uses metadata to pass configuration information to instances on launch. The instance can access the metadata by using a config drive or the metadata service.
- Config drive
- Config drives are special drives that you can attach to an instance when it boots. The config drive is presented to the instance as a read-only drive. The instance can mount this drive and read files from it to get information that is normally available through the metadata service.
- Metadata service
-
The Compute service provides the metadata service as a REST API, which can be used to retrieve data specific to an instance. Instances access this service at
169.254.169.254or atfe80::a9fe:a9fe.
9.1. Types of instance metadata
Cloud users, cloud administrators, and the Compute service can pass metadata to instances:
- Cloud user provided data
- Cloud users can specify additional data to use when they launch an instance, such as a shell script that the instance runs on boot. The cloud user can pass data to instances by using the user data feature, and by passing key-value pairs as required properties when creating or updating an instance.
- Cloud administrator provided data
The RHOSP administrator uses the vendordata feature to pass data to instances. The Compute service provides the vendordata modules
StaticJSONandDynamicJSONto allow administrators to pass metadata to instances:-
StaticJSON: (Default) Use for metadata that is the same for all instances. -
DynamicJSON: Use for metadata that is different for each instance. This module makes a request to an external REST service to determine what metadata to add to an instance.
Vendordata configuration is located in one of the following read-only files on the instance:
-
/openstack/{version}/vendor_data.json -
/openstack/{version}/vendor_data2.json
-
- Compute service provided data
- The Compute service uses its internal implementation of the metadata service to pass information to the instance, such as the requested hostname for the instance, and the availability zone the instance is in. This happens by default and requires no configuration by the cloud user or administrator.
9.2. Adding a config drive to all instances
As an administrator, you can configure the Compute service to always create a config drive for instances, and populate the config drive with metadata that is specific to your deployment. For example, you might use a config drive for the following reasons:
- To pass a networking configuration when your deployment does not use DHCP to assign IP addresses to instances. You can pass the IP address configuration for the instance through the config drive, which the instance can mount and access before you configure the network settings for the instance.
- To pass data to an instance that is not known to the user starting the instance, for example, a cryptographic token to be used to register the instance with Active Directory post boot.
- To create a local cached disk read to manage the load of instance requests, which reduces the impact of instances accessing the metadata servers regularly to check in and build facts.
Any instance operating system that is capable of mounting an ISO 9660 or VFAT file system can use the config drive.
Procedure
- Open your Compute environment file.
To always attach a config drive when launching an instance, set the following parameter to
True:parameter_defaults: ComputeExtraConfig: nova::compute::force_config_drive: 'true'Optional: To change the format of the config drive from the default value of
iso9660tovfat, add theconfig_drive_formatparameter to your configuration:parameter_defaults: ComputeExtraConfig: nova::compute::force_config_drive: 'true' nova::compute::config_drive_format: vfat- Save the updates to your Compute environment file.
Add your Compute environment file to the stack with your other environment files and deploy the overcloud:
(undercloud)$ openstack overcloud deploy --templates \ -e [your environment files] \ -e /home/stack/templates/<compute_environment_file>.yaml \
Verification
Create an instance:
(overcloud)$ openstack server create --flavor m1.tiny \ --image cirros test-config-drive-instance- Log in to the instance.
Mount the config drive:
If the instance OS uses
udev:# mkdir -p /mnt/config # mount /dev/disk/by-label/config-2 /mnt/configIf the instance OS does not use
udev, you need to first identify the block device that corresponds to the config drive:# blkid -t LABEL="config-2" -odevice /dev/vdb # mkdir -p /mnt/config # mount /dev/vdb /mnt/config
-
Inspect the files in the mounted config drive directory,
mnt/config/openstack/{version}/, for your metadata.
9.3. Adding static metadata to instances
You can make static metadata available to all instances in your deployment.
Procedure
- Create the JSON file for the metadata.
- Open your Compute environment file.
Add the path to the JSON file to your environment file:
parameter_defaults: ComputeExtraConfig: nova::config::nova_config: ... api/vendordata_jsonfile_path: value: <path_to_the_JSON_file>- Save the updates to your Compute environment file.
Add your Compute environment file to the stack with your other environment files and deploy the overcloud:
(undercloud)$ openstack overcloud deploy --templates \ -e [your environment files] \ -e /home/stack/templates/<compute_environment_file>.yaml \
9.4. Adding dynamic metadata to instances
You can configure your deployment to create instance-specific metadata, and make the metadata available to that instance through a JSON file.
You can use dynamic metadata on the undercloud to integrate director with a Red Hat Identity Management (IdM) server. An IdM server can be used as a certificate authority and manage the overcloud certificates when SSL/TLS is enabled on the overcloud. For more information, see Add the undercloud to IdM.
Procedure
- Open your Compute environment file.
Add
DynamicJSONto the vendordata provider module:parameter_defaults: ComputeExtraConfig: nova::config::nova_config: ... api/vendordata_providers: value: StaticJSON,DynamicJSONSpecify the REST services to contact to generate the metadata. You can specify as many target REST services as required, for example:
parameter_defaults: ComputeExtraConfig: nova::config::nova_config: ... api/vendordata_providers: value: StaticJSON,DynamicJSON api/vendordata_dynamic_targets: value: target1@http://127.0.0.1:125 api/vendordata_dynamic_targets: value: target2@http://127.0.0.1:126The Compute service generates the JSON file,
vendordata2.json, to contain the metadata retrieved from the configured target services, and stores it in the config drive directory.注記Do not use the same name for a target service more than once.
- Save the updates to your Compute environment file.
Add your Compute environment file to the stack with your other environment files and deploy the overcloud:
(undercloud)$ openstack overcloud deploy --templates \ -e [your environment files] \ -e /home/stack/templates/<compute_environment_file>.yaml \
第10章 Configuring Real-Time Compute
In some use-cases, you might need instances on your Compute nodes to adhere to low-latency policies and perform real-time processing. Real-time Compute nodes include a real-time capable kernel, specific virtualization modules, and optimized deployment parameters, to facilitate real-time processing requirements and minimize latency.
The process to enable Real-time Compute includes:
- configuring the BIOS settings of the Compute nodes
- building a real-time image with real-time kernel and Real-Time KVM (RT-KVM) kernel module
-
assigning the
ComputeRealTimerole to the Compute nodes
For a use-case example of Real-time Compute deployment for NFV workloads, see the Example: Configuring OVS-DPDK with ODL and VXLAN tunnelling section in the Network Functions Virtualization Planning and Configuration Guide.
10.1. Preparing Your Compute Nodes for Real-Time
Real-time Compute nodes are supported only with Red Hat Enterprise Linux version 7.5 or later.
Before you can deploy Real-time Compute in your overcloud, you must enable Red Hat Enterprise Linux Real-Time KVM (RT-KVM), configure your BIOS to support real-time, and build the real-time image.
Prerequisites
- You must use Red Hat certified servers for your RT-KVM Compute nodes. See Red Hat Enterprise Linux for Real Time 7 certified servers for details.
You must enable the
rhel-7-server-nfv-rpmsrepository for RT-KVM to build the real-time image.注記You need a separate subscription to Red Hat OpenStack Platform for Real Time before you can access this repository. For details on managing repositories and subscriptions for your undercloud, see the Registering and updating your undercloud section in the Director Installation and Usage guide.
To check which packages will be installed from the repository, run the following command:
$ yum repo-pkgs rhel-7-server-nfv-rpms list Loaded plugins: product-id, search-disabled-repos, subscription-manager Available Packages kernel-rt.x86_64 3.10.0-693.21.1.rt56.639.el7 rhel-7-server-nfv-rpms kernel-rt-debug.x86_64 3.10.0-693.21.1.rt56.639.el7 rhel-7-server-nfv-rpms kernel-rt-debug-devel.x86_64 3.10.0-693.21.1.rt56.639.el7 rhel-7-server-nfv-rpms kernel-rt-debug-kvm.x86_64 3.10.0-693.21.1.rt56.639.el7 rhel-7-server-nfv-rpms kernel-rt-devel.x86_64 3.10.0-693.21.1.rt56.639.el7 rhel-7-server-nfv-rpms kernel-rt-doc.noarch 3.10.0-693.21.1.rt56.639.el7 rhel-7-server-nfv-rpms kernel-rt-kvm.x86_64 3.10.0-693.21.1.rt56.639.el7 rhel-7-server-nfv-rpms [ output omitted…]
Building the real-time image
To build the overcloud image for Real-time Compute nodes:
Install the
libguestfs-toolspackage on the undercloud to get thevirt-customizetool:(undercloud) [stack@undercloud-0 ~]$ sudo yum install libguestfs-tools重要If you install the
libguestfs-toolspackage on the undercloud, disableiscsid.socketto avoid port conflicts with thetripleo_iscsidservice on the undercloud:$ sudo systemctl disable --now iscsid.socketExtract the images:
(undercloud) [stack@undercloud-0 ~]$ tar -xf /usr/share/rhosp-director-images/overcloud-full.tar (undercloud) [stack@undercloud-0 ~]$ tar -xf /usr/share/rhosp-director-images/ironic-python-agent.tarCopy the default image:
(undercloud) [stack@undercloud-0 ~]$ cp overcloud-full.qcow2 overcloud-realtime-compute.qcow2Register the image and configure the required subscriptions:
(undercloud) [stack@undercloud-0 ~]$ virt-customize -a overcloud-realtime-compute.qcow2 --run-command 'subscription-manager register --username=[username] --password=[password]' [ 0.0] Examining the guest ... [ 10.0] Setting a random seed [ 10.0] Running: subscription-manager register --username=[username] --password=[password] [ 24.0] Finishing offReplace the
usernameandpasswordvalues with your Red Hat customer account details. For general information about building a Real-time overcloud image, see the Modifying the Red Hat Enterprise Linux OpenStack Platform Overcloud Image with virt-customize knowledgebase article.Find the SKU of the Red Hat OpenStack Platform for Real Time subscription. The SKU might be located on a system that is already registered to the Red Hat Subscription Manager with the same account and credentials. For example:
$ sudo subscription-manager listAttach the Red Hat OpenStack Platform for Real Time subscription to the image:
(undercloud) [stack@undercloud-0 ~]$ virt-customize -a overcloud-realtime-compute.qcow2 --run-command 'subscription-manager attach --pool [subscription-pool]'Create a script to configure
rton the image:(undercloud) [stack@undercloud-0 ~]$ cat rt.sh #!/bin/bash set -eux subscription-manager repos --enable=rhel-7-server-rpms --enable=rhel-7-server-openstack-13-rpms --enable=rhel-7-server-nfv-rpms yum -v -y --setopt=protected_packages= erase kernel.$(uname -m) yum -v -y install kernel-rt kernel-rt-kvm tuned-profiles-nfv-host # END OF SCRIPTRun the script to configure the real-time image:
(undercloud) [stack@undercloud-0 ~]$ virt-customize -a overcloud-realtime-compute.qcow2 -v --run rt.sh 2>&1 | tee virt-customize.logRe-label SELinux:
(undercloud) [stack@undercloud-0 ~]$ virt-customize -a overcloud-realtime-compute.qcow2 --selinux-relabelExtract
vmlinuzandinitrd:(undercloud) [stack@undercloud-0 ~]$ mkdir image (undercloud) [stack@undercloud-0 ~]$ guestmount -a overcloud-realtime-compute.qcow2 -i --ro image (undercloud) [stack@undercloud-0 ~]$ cp image/boot/vmlinuz-3.10.0-862.rt56.804.el7.x86_64 ./overcloud-realtime-compute.vmlinuz (undercloud) [stack@undercloud-0 ~]$ cp image/boot/initramfs-3.10.0-862.rt56.804.el7.x86_64.img ./overcloud-realtime-compute.initrd (undercloud) [stack@undercloud-0 ~]$ guestunmount image注記The software version in the
vmlinuzandinitramfsfilenames vary with the kernel version.Upload the image:
(undercloud) [stack@undercloud-0 ~]$ openstack overcloud image upload --update-existing --os-image-name overcloud-realtime-compute.qcow2
You now have a real-time image you can use with the ComputeRealTime composable role on select Compute nodes.
Modifying BIOS settings on Real-time Compute nodes
To reduce latency on your Real-time Compute nodes, you must modify the BIOS settings in the Compute nodes. You should disable all options for the following components in your Compute node BIOS settings:
- Power Management
- Hyper-Threading
- CPU sleep states
- Logical processors
See Setting BIOS parameters for descriptions of these settings and the impact of disabling them. See your hardware manufacturer documentation for complete details on how to change BIOS settings.
10.2. Deploying the Real-time Compute Role
Red Hat OpenStack Platform Director provides the template for the ComputeRealTime role, which you can then use to deploy Real-time Compute nodes. However, you must perform additional steps to designate Compute nodes for real-time.
Based on the /usr/share/openstack-tripleo-heat-templates/environments/compute-real-time-example.yaml file, create a compute-real-time.yaml environment file that sets the parameters for the
ComputeRealTimerole.cp /usr/share/openstack-tripleo-heat-templates/environments/compute-real-time-example.yaml /home/stack/templates/compute-real-time.yamlThe file must include values for the following parameters:
-
IsolCpusListandNovaVcpuPinSet. List of isolated CPU cores and virtual CPU pins to reserve for real-time workloads. This value depends on the CPU hardware of your Real-time Compute nodes. -
KernelArgs. Arguments to pass to the kernel of the Real-time Compute nodes. For example, you can usedefault_hugepagesz=1G hugepagesz=1G hugepages=<number_of_1G_pages_to_reserve> hugepagesz=2M hugepages=<number_of_2M_pages>to define the memory requirements of guests that have huge pages with multiple sizes. In this example, the default size is 1GB but you can also reserve 2M huge pages.
-
Add the
ComputeRealTimerole to your roles data file and regenerate the file. For example:$ openstack overcloud roles generate -o /home/stack/templates/rt_roles_data.yaml Controller Compute ComputeRealTimeThis command generates a
ComputeRealTimerole with contents similar to the following example, and also sets theImageDefaultoption toovercloud-realtime-compute.############################################################### # Role: ComputeRealTime # ############################################################### - name: ComputeRealTime description: | Compute role that is optimized for real-time behaviour. When using this role it is mandatory that an overcloud-realtime-compute image is available and the role specific parameters IsolCpusList and NovaVcpuPinSet are set accordingly to the hardware of the real-time compute nodes. CountDefault: 1 networks: - InternalApi - Tenant - Storage HostnameFormatDefault: '%stackname%-computerealtime-%index%' disable_upgrade_deployment: True ImageDefault: overcloud-realtime-compute RoleParametersDefault: TunedProfileName: "realtime-virtual-host" KernelArgs: "" # these must be set in an environment file or similar IsolCpusList: "" # according to the hardware of real-time nodes NovaVcpuPinSet: "" # ServicesDefault: - OS::TripleO::Services::Aide - OS::TripleO::Services::AuditD - OS::TripleO::Services::CACerts - OS::TripleO::Services::CephClient - OS::TripleO::Services::CephExternal - OS::TripleO::Services::CertmongerUser - OS::TripleO::Services::Collectd - OS::TripleO::Services::ComputeCeilometerAgent - OS::TripleO::Services::ComputeNeutronCorePlugin - OS::TripleO::Services::ComputeNeutronL3Agent - OS::TripleO::Services::ComputeNeutronMetadataAgent - OS::TripleO::Services::ComputeNeutronOvsAgent - OS::TripleO::Services::Docker - OS::TripleO::Services::Fluentd - OS::TripleO::Services::Ipsec - OS::TripleO::Services::Iscsid - OS::TripleO::Services::Kernel - OS::TripleO::Services::LoginDefs - OS::TripleO::Services::MySQLClient - OS::TripleO::Services::NeutronBgpVpnBagpipe - OS::TripleO::Services::NeutronLinuxbridgeAgent - OS::TripleO::Services::NeutronVppAgent - OS::TripleO::Services::NovaCompute - OS::TripleO::Services::NovaLibvirt - OS::TripleO::Services::NovaMigrationTarget - OS::TripleO::Services::Ntp - OS::TripleO::Services::ContainersLogrotateCrond - OS::TripleO::Services::OpenDaylightOvs - OS::TripleO::Services::Rhsm - OS::TripleO::Services::RsyslogSidecar - OS::TripleO::Services::Securetty - OS::TripleO::Services::SensuClient - OS::TripleO::Services::SkydiveAgent - OS::TripleO::Services::Snmp - OS::TripleO::Services::Sshd - OS::TripleO::Services::Timezone - OS::TripleO::Services::TripleoFirewall - OS::TripleO::Services::TripleoPackages - OS::TripleO::Services::Vpp - OS::TripleO::Services::OVNController - OS::TripleO::Services::OVNMetadataAgent - OS::TripleO::Services::PtpFor general information about custom roles and about the roles-data.yaml, see the Roles section.
Create the
compute-realtimeflavor to tag nodes that you want to designate for real-time workloads. For example:$ source ~/stackrc $ openstack flavor create --id auto --ram 6144 --disk 40 --vcpus 4 compute-realtime $ openstack flavor set --property "cpu_arch"="x86_64" --property "capabilities:boot_option"="local" --property "capabilities:profile"="compute-realtime" compute-realtimeTag each node that you want to designate for real-time workloads with the
compute-realtimeprofile.$ openstack baremetal node set --property capabilities='profile:compute-realtime,boot_option:local' <NODE UUID>Map the
ComputeRealTimerole to thecompute-realtimeflavor by creating an environment file with the following content:parameter_defaults: OvercloudComputeRealTimeFlavor: compute-realtimeRun the
openstack overcloud deploycommand with the-eoption and specify all the environment files that you created, as well as the new roles file. For example:$ openstack overcloud deploy -r /home/stack/templates/rt~/my_roles_data.yaml -e /home/stack/templates/compute-real-time.yaml <FLAVOR_ENV_FILE>注記If you want to run additional real-time instances on the same Compute node, you can change the priority of the instances in the
realtime_schedule_priorityparemeter in the nova.conf file.
10.3. Sample Deployment and Testing Scenario
The following example procedure uses a simple single-node deployment to test that the environment variables and other supporting configuration is set up correctly. Actual performance results might vary, depending on the number of nodes and guests that you deploy in your cloud.
Create the
compute-real-time.yamlfile with the following parameters:parameter_defaults: ComputeRealTimeParameters: IsolCpusList: "1" NovaVcpuPinSet: "1" KernelArgs: "default_hugepagesz=1G hugepagesz=1G hugepages=16"Create a new
rt_roles_data.yamlfile with theComputeRealTimerole.$ openstack overcloud roles generate -o ~/rt_roles_data.yaml Controller ComputeRealTimeDeploy the overcloud, adding both your new real-time roles data file and your real-time environment file to the stack along with your other environment files:
(undercloud) $ openstack overcloud deploy --templates \ -r /home/stack/rt_roles_data.yaml -e [your environment files] -e /home/stack/templates/compute-real-time.yamlThis command deploys one Controller node and one Real-time Compute node.
Log into the Real-time Compute node and check the following parameters. Replace
<...>with the values of the relevant parameters from thecompute-real-time.yaml.[root@overcloud-computerealtime-0 ~]# uname -a Linux overcloud-computerealtime-0 3.10.0-693.11.1.rt56.632.el7.x86_64 #1 SMP PREEMPT RT Wed Dec 13 13:37:53 UTC 2017 x86_64 x86_64 x86_64 GNU/Linux [root@overcloud-computerealtime-0 ~]# cat /proc/cmdline BOOT_IMAGE=/boot/vmlinuz-3.10.0-693.11.1.rt56.632.el7.x86_64 root=UUID=45ae42d0-58e7-44fe-b5b1-993fe97b760f ro console=tty0 crashkernel=auto console=ttyS0,115200 default_hugepagesz=1G hugepagesz=1G hugepages=16 [root@overcloud-computerealtime-0 ~]# tuned-adm active Current active profile: realtime-virtual-host [root@overcloud-computerealtime-0 ~]# grep ^isolated_cores /etc/tuned/realtime-virtual-host-variables.conf isolated_cores=<IsolCpusList> [root@overcloud-computerealtime-0 ~]# cat /usr/lib/tuned/realtime-virtual-host/lapic_timer_adv_ns X (X != 0) [root@overcloud-computerealtime-0 ~]# cat /sys/module/kvm/parameters/lapic_timer_advance_ns X (X != 0) [root@overcloud-computerealtime-0 ~]# cat /sys/devices/system/node/node0/hugepages/hugepages-1048576kB/nr_hugepages X (X != 0) [root@overcloud-computerealtime-0 ~]# grep ^vcpu_pin_set /var/lib/config-data/puppet-generated/nova_libvirt/etc/nova/nova.conf vcpu_pin_set=<NovaVcpuPinSet>
10.4. Launching and Tuning Real-Time Instances
After you deploy and configure Real-time Compute nodes, you can launch real-time instances on those nodes. You can further configure these real-time instances with CPU pinning, NUMA topologies, and huge pages.
Configuring a real-time policy for instances
A real-time policy prioritizes real-time instances and minimizes latency during peak workload times. To set this policy, add the following parameters to the compute-realtime flavor.
$ openstack flavor set compute-realtime \
--property hw:cpu_realtime=yes
--property hw:cpu_realtime_mask=^0Launching a real-time instance
-
Make sure that the
compute-realtimeflavor exists on the overcloud, as described in the Deploying the Real-time Compute Role section. Launch the real-time instance.
# openstack server create --image <rhel> --flavor r1.small --nic net-id=<dpdk-net> test-rtIf you have administrator access to the Compute host, you can optionally verify that the instance uses the assigned emulator threads.
# virsh dumpxml <instance-id> | grep vcpu -A1 <vcpu placement='static'>4</vcpu> <cputune> <vcpupin vcpu='0' cpuset='1'/> <vcpupin vcpu='1' cpuset='3'/> <vcpupin vcpu='2' cpuset='5'/> <vcpupin vcpu='3' cpuset='7'/> <emulatorpin cpuset='0-1'/> <vcpusched vcpus='2-3' scheduler='fifo' priority='1'/> </cputune>
Pinning CPUs and setting emulator thread policy
To ensure that there are enough CPUs on each Real-time Compute node for real-time workloads, you need to pin at least one virtual CPU (vCPU) for an instance to a physical CPU (pCPUs) on the host. The emulator threads for that vCPU then remain dedicated to that pCPU.
-
Set the
emulator_thread_policyparameter toisolate. For example:
# openstack flavor set --property hw:emulator_threads_policy=isolate-
Configure your flavor to use a dedicated CPU policy. To do so, set the
hw:cpu_policyparameter todedicatedon the flavor. For example:
# openstack flavor set --property hw:cpu_policy=dedicated 99Make sure that your resources quota has enough pCPUs for the Real-time Compute nodes to consume.
For general information about CPU pinning, see the CPU Pinning chapter.
Optimizing your network configuration
Depending on the needs of your deployment, you might need to set parameters in the network-environment.yaml file to tune your network for certain real-time workloads.
To review an example configuration optimized for OVS-DPDK, see the Configuring OVS-DPDK with RT-KVM section of the Network Functions Virtualization Planning and Configuration Guide.
Configuring huge pages
It is recommended to set the default huge pages size to 1GB. Otherwise, TLB flushes might create jitter in the vCPU execution.
To set the huge pages size for the compute-realtime flavor, run the following command:
openstack flavor set compute-realtime --property hw:mem_page_size=largeFor general information about using huge pages, see the Running DPDK applications web page.
第11章 Configuring virtual GPUs for instances
To support GPU-based rendering on your instances, you can define and manage virtual GPU (vGPU) resources according to your available physical GPU devices and your hypervisor type. You can use this configuration to divide the rendering workloads between all your physical GPU devices more effectively, and to have more control over scheduling your vGPU-enabled instances.
To enable vGPU in OpenStack Compute, create flavors that your cloud users can use to create Red Hat Enterprise Linux (RHEL) instances with vGPU devices. Each instance can then support GPU workloads with virtual GPU devices that correspond to the physical GPU devices.
The OpenStack Compute service tracks the number of vGPU devices that are available for each GPU profile you define on each host. The Compute service schedules instances to these hosts based on the flavor, attaches the devices, and monitors usage on an ongoing basis. When an instance is deleted, the Compute service adds the vGPU devices back to the available pool.
11.1. Supported configurations and limitations
Supported GPU cards
For a list of supported NVIDIA GPU cards, see Virtual GPU Software Supported Products on the NVIDIA website.
Limitations when using vGPU devices
- You can enable only one vGPU type on each Compute node.
- Each instance can use only one vGPU resource.
- Live migration of vGPU between hosts is not supported.
- Suspend operations on a vGPU-enabled instance is not supported due to a libvirt limitation. Instead, you can snapshot or shelve the instance.
- Resize and cold migration operations on an instance with a vGPU flavor does not automatically re-allocate the vGPU resources to the instance. After you resize or migrate the instance, you must rebuild it manually to re-allocate the vGPU resources.
- By default, vGPU types on Compute hosts are not exposed to API users. To grant access, add the hosts to a host aggregate. For more information, see 「Managing host aggregates」.
- If you use NVIDIA accelerator hardware, you must comply with the NVIDIA licensing requirements. For example, NVIDIA vGPU GRID requires a licensing server. For more information about the NVIDIA licensing requirements, see NVIDIA License Server Release Notes on the NVIDIA website.
11.2. Configuring vGPU on the Compute nodes
To enable your cloud users to create instances that use a virtual GPU (vGPU), you must configure the Compute nodes that have the physical GPUs:
- Build a custom GPU-enabled overcloud image.
- Prepare the GPU role, profile, and flavor for designating Compute nodes for vGPU.
- Configure the Compute node for vGPU.
- Deploy the overcloud.
To use an NVIDIA GRID vGPU, you must comply with the NVIDIA GRID licensing requirements and you must have the URL of your self-hosted license server. For more information, see the NVIDIA License Server Release Notes web page.
11.2.1. Building a custom GPU overcloud image
Perform the following steps on the director node to install the NVIDIA GRID host driver on an overcloud Compute image and upload the image to the OpenStack Image service (glance).
Procedure
Copy the overcloud image and add the
gpusuffix to the copied image.$ cp overcloud-full.qcow2 overcloud-full-gpu.qcow2Install an ISO image generator tool from YUM.
$ sudo yum install genisoimage -yDownload the NVIDIA GRID host driver RPM package that corresponds to your GPU device from the NVIDIA website. To determine which driver you need, see the NVIDIA Driver Downloads Portal.
注記You must be a registered NVIDIA customer to download the drivers from the portal.
Create an ISO image from the driver RPM package and save the image in the
nvidia-hostdirectory.$ genisoimage -o nvidia-host.iso -R -J -V NVIDIA nvidia-host/ I: -input-charset not specified, using utf-8 (detected in locale settings) 9.06% done, estimate finish Wed Oct 31 11:24:46 2018 18.08% done, estimate finish Wed Oct 31 11:24:46 2018 27.14% done, estimate finish Wed Oct 31 11:24:46 2018 36.17% done, estimate finish Wed Oct 31 11:24:46 2018 45.22% done, estimate finish Wed Oct 31 11:24:46 2018 54.25% done, estimate finish Wed Oct 31 11:24:46 2018 63.31% done, estimate finish Wed Oct 31 11:24:46 2018 72.34% done, estimate finish Wed Oct 31 11:24:46 2018 81.39% done, estimate finish Wed Oct 31 11:24:46 2018 90.42% done, estimate finish Wed Oct 31 11:24:46 2018 99.48% done, estimate finish Wed Oct 31 11:24:46 2018 Total translation table size: 0 Total rockridge attributes bytes: 358 Total directory bytes: 0 Path table size(bytes): 10 Max brk space used 0 55297 extents written (108 MB)Create a driver installation script that also disables the nouveau driver and generates a new initramfs. The following example script,
install_nvidia.sh, disables the nouveau driver, generates a new initramfs, and installs the NVIDIA GRID host driver on the overcloud image:#/bin/bash cat <<EOF >/etc/modprobe.d/disable-nouveau.conf blacklist nouveau options nouveau modeset=0 EOF echo 'omit_drivers+=" nouveau "' > /etc/dracut.conf.d/disable-nouveau.conf dracut -f # NVIDIA GRID package mkdir /tmp/mount mount LABEL=NVIDIA /tmp/mount rpm -ivh /tmp/mount/<host_driver>.rpm-
Replace
<host_driver>with the host driver downloaded in step 3.
-
Replace
Customize the overcloud image by attaching the ISO image that you generated in step 4, and running the driver installation script that you created in step 5:
$ virt-customize --attach nvidia-packages.iso -a overcloud-full-gpu.qcow2 -v --run install_nvidia.sh [ 0.0] Examining the guest ... libguestfs: launch: program=virt-customize libguestfs: launch: version=1.36.10rhel=8,release=6.el8_5.2,libvirt libguestfs: launch: backend registered: unix libguestfs: launch: backend registered: uml libguestfs: launch: backend registered: libvirtRelabel the customized image with SELinux:
$ virt-customize -a overcloud-full-gpu.qcow2 --selinux-relabel [ 0.0] Examining the guest ... [ 2.2] Setting a random seed [ 2.2] SELinux relabelling [ 27.4] Finishing offPrepare the custom image files for upload to the OpenStack Image Service:
$ mkdir /var/image/x86_64/image $ guestmount -a overcloud-full-gpu.qcow2 -i --ro image $ cp image/boot/vmlinuz-3.10.0-862.14.4.el8.x86_64 ./overcloud-full-gpu.vmlinuz $ cp image/boot/initramfs-3.10.0-862.14.4.el8.x86_64.img ./overcloud-full-gpu.initrdFrom the undercloud, upload the custom image to the OpenStack Image Service:
(undercloud) $ openstack overcloud image upload --update-existing --os-image-name overcloud-full-gpu.qcow2
11.2.2. Designating Compute nodes for vGPU
To designate Compute nodes for vGPU workloads, you must create a new role file to configure the vGPU role, and configure a new flavor to use to tag the GPU-enabled Compute nodes.
Procedure
To create the new
ComputeGpurole file, copy the file/usr/share/openstack-tripleo-heat-templates/roles/Compute.yamlto/usr/share/openstack-tripleo-heat-templates/roles/ComputeGpu.yamland edit or add the following file sections:Expand 表11.1 ComputeGpu role file edits Section/Parameter Current value New value Role comment
Role: ComputeRole: ComputeGpuRole name
name: Computename: ComputeGpudescriptionBasic Compute Node roleGPU Compute Node roleImageDefaultn/a
overcloud-full-gpuHostnameFormatDefault-compute--computegpu-deprecated_nic_config_namecompute.yamlcompute-gpu.yamlThe following example shows the
ComputeGpurole details:##################################################################### # Role: ComputeGpu # ##################################################################### - name: ComputeGpu description: | GPU Compute Node role CountDefault: 1 ImageDefault: overcloud-full-gpu networks: - InternalApi - Tenant - Storage HostnameFormatDefault: '%stackname%-computegpu-%index%' RoleParametersDefault: TunedProfileName: "virtual-host" # Deprecated & backward-compatible values (FIXME: Make parameters consistent) # Set uses_deprecated_params to True if any deprecated params are used. uses_deprecated_params: True deprecated_param_image: 'NovaImage' deprecated_param_extraconfig: 'NovaComputeExtraConfig' deprecated_param_metadata: 'NovaComputeServerMetadata' deprecated_param_scheduler_hints: 'NovaComputeSchedulerHints' deprecated_param_ips: 'NovaComputeIPs' deprecated_server_resource_name: 'NovaCompute' deprecated_nic_config_name: 'compute-gpu.yaml' ServicesDefault: - OS::TripleO::Services::Aide - OS::TripleO::Services::AuditD - OS::TripleO::Services::CACerts - OS::TripleO::Services::CephClient - OS::TripleO::Services::CephExternal - OS::TripleO::Services::CertmongerUser - OS::TripleO::Services::Collectd - OS::TripleO::Services::ComputeCeilometerAgent - OS::TripleO::Services::ComputeNeutronCorePlugin - OS::TripleO::Services::ComputeNeutronL3Agent - OS::TripleO::Services::ComputeNeutronMetadataAgent - OS::TripleO::Services::ComputeNeutronOvsAgent - OS::TripleO::Services::Docker - OS::TripleO::Services::Fluentd - OS::TripleO::Services::Ipsec - OS::TripleO::Services::Iscsid - OS::TripleO::Services::Kernel - OS::TripleO::Services::LoginDefs - OS::TripleO::Services::MetricsQdr - OS::TripleO::Services::MySQLClient - OS::TripleO::Services::NeutronBgpVpnBagpipe - OS::TripleO::Services::NeutronLinuxbridgeAgent - OS::TripleO::Services::NeutronVppAgent - OS::TripleO::Services::NovaCompute - OS::TripleO::Services::NovaLibvirt - OS::TripleO::Services::NovaLibvirtGuests - OS::TripleO::Services::NovaMigrationTarget - OS::TripleO::Services::Ntp - OS::TripleO::Services::ContainersLogrotateCrond - OS::TripleO::Services::OpenDaylightOvs - OS::TripleO::Services::Rhsm - OS::TripleO::Services::RsyslogSidecar - OS::TripleO::Services::Securetty - OS::TripleO::Services::SensuClient - OS::TripleO::Services::SkydiveAgent - OS::TripleO::Services::Snmp - OS::TripleO::Services::Sshd - OS::TripleO::Services::Timezone - OS::TripleO::Services::TripleoFirewall - OS::TripleO::Services::TripleoPackages - OS::TripleO::Services::Tuned - OS::TripleO::Services::Vpp - OS::TripleO::Services::OVNController - OS::TripleO::Services::OVNMetadataAgent - OS::TripleO::Services::PtpGenerate a new roles data file named
roles_data_gpu.yamlthat includes theController,Compute, andComputeGpuroles:(undercloud) [stack@director templates]$ openstack overcloud roles \ generate -o /home/stack/templates/roles_data_gpu.yaml \ ComputeGpu Compute Controller- Register the node for the overcloud. For more information, see Registering nodes for the overcloud in the Director Installation and Usage guide.
- Inspect the node hardware. For more information, see Inspecting the hardware of nodes in the Director Installation and Usage guide.
Create the
compute-vgpu-nvidiaflavor to use to tag nodes that you want to designate for vGPU workloads:(undercloud) [stack@director templates]$ openstack flavor create --id auto --ram 6144 --disk 40 --vcpus 4 compute-vgpu-nvidia +----------------------------+--------------------------------------+ | Field | Value | +----------------------------+--------------------------------------+ | OS-FLV-DISABLED:disabled | False | | OS-FLV-EXT-DATA:ephemeral | 0 | | disk | 40 | | id | 9cb47954-be00-47c6-a57f-44db35be3e69 | | name | compute-vgpu-nvidia | | os-flavor-access:is_public | True | | properties | | | ram | 6144 | | rxtx_factor | 1.0 | | swap | | | vcpus | 4 | +----------------------------+--------------------------------------+Tag each node that you want to designate for GPU workloads with the
compute-vgpu-nvidiaprofile.(undercloud) [stack@director templates]$ openstack baremetal node set --property capabilities='profile:compute-vgpu-nvidia,boot_option:local' <node>Replace
<node>with the ID of the baremetal node.To verify the role is created, enter the following command:
(undercloud) [stack@director templates]$ openstack overcloud profiles list
11.2.3. Configuring the Compute node for vGPU and deploying the overcloud
You need to retrieve and assign the vGPU type that corresponds to the physical GPU device in your environment, and prepare the environment files to configure the Compute node for vGPU.
Procedure
- Install Red Hat Enterprise Linux and the NVIDIA GRID driver on a temporary Compute node and launch the node. For more information about installing the NVIDIA GRID driver, see 「Building a custom GPU overcloud image」.
On the Compute node, locate the vGPU type of the physical GPU device that you want to enable. For libvirt, virtual GPUs are mediated devices, or
mdevtype devices. To discover the supportedmdevdevices, enter the following command:[root@overcloud-computegpu-0 ~]# ls /sys/class/mdev_bus/0000\:06\:00.0/mdev_supported_types/ nvidia-11 nvidia-12 nvidia-13 nvidia-14 nvidia-15 nvidia-16 nvidia-17 nvidia-18 nvidia-19 nvidia-20 nvidia-21 nvidia-210 nvidia-22 [root@overcloud-computegpu-0 ~]# cat /sys/class/mdev_bus/0000\:06\:00.0/mdev_supported_types/nvidia-18/description num_heads=4, frl_config=60, framebuffer=2048M, max_resolution=4096x2160, max_instance=4Add the
compute-gpu.yamlfile to thenetwork-environment.yamlfile:resource_registry: OS::TripleO::Compute::Net::SoftwareConfig: /home/stack/templates/nic-configs/compute.yaml OS::TripleO::ComputeGpu::Net::SoftwareConfig: /home/stack/templates/nic-configs/compute-gpu.yaml OS::TripleO::Controller::Net::SoftwareConfig: /home/stack/templates/nic-configs/controller.yaml #OS::TripleO::AllNodes::Validation: OS::Heat::NoneAdd the following parameters to the
node-info.yamlfile to specify the number of GPU-enabled Compute nodes, and the flavor to use for the vGPU-designated Compute nodes:parameter_defaults: OvercloudControllerFlavor: control OvercloudComputeFlavor: compute OvercloudComputeGpuFlavor: compute-vgpu-nvidia ControllerCount: 1 ComputeCount: 0 ComputeGpuCount: 3 #set to the no of GPU nodes you haveCreate a
gpu.yamlfile to specify the vGPU type of your GPU device:parameter_defaults: ComputeGpuExtraConfig: nova::compute::vgpu::enabled_vgpu_types: - nvidia-18注記Each physical GPU supports only one virtual GPU type. If you specify multiple vGPU types in this property, only the first type is used.
Deploy the overcloud, adding your new role and environment files to the stack along with your other environment files:
(undercloud) $ openstack overcloud deploy --templates \ -r /home/stack/templates/roles_data_gpu.yaml -e /home/stack/templates/node-info.yaml -e /home/stack/templates/network-environment.yaml -e [your environment files] -e /home/stack/templates/gpu.yaml
11.3. Creating the vGPU image and flavor
To enable your cloud users to create instances that use a virtual GPU (vGPU), you can define a custom vGPU-enabled image, and you can create a vGPU flavor.
11.3.1. Creating a custom GPU instance image
After you deploy the overcloud with GPU-enabled Compute nodes, you can create a custom vGPU-enabled instance image with the NVIDIA GRID guest driver and license file.
Procedure
Create an instance with the hardware and software profile that your vGPU instances require:
(overcloud) [stack@director ~]$ openstack server create --flavor <flavor> --image <image> temp_vgpu_instance-
Replace
<flavor>with the name or ID of the flavor that has the hardware profile that your vGPU instances require. For information on default flavors, see Manage flavors. -
Replace
<image>with the name or ID of the image that has the software profile that your vGPU instances require. For information on downloading RHEL cloud images, see Image service.
-
Replace
- Log in to the instance as a cloud-user. For more information, see Log in to an Instance.
-
Create the
gridd.confNVIDIA GRID license file on the instance, following the NVIDIA guidance: Licensing an NVIDIA vGPU on Linux by Using a Configuration File. Install the GPU driver on the instance. For more information about installing an NVIDIA driver, see Installing the NVIDIA vGPU Software Graphics Driver on Linux.
注記Use the
hw_video_modelimage property to define the GPU driver type. You can choosenoneif you want to disable the emulated GPUs for your vGPU instances. For more information about supported drivers, see 付録A Image configuration parameters.Create an image snapshot of the instance:
(overcloud) [stack@director ~]$ openstack server image create --name vgpu_image temp_vgpu_instance- Optional: Delete the instance.
11.3.2. Creating a vGPU flavor for instances
After you deploy the overcloud with GPU-enabled Compute nodes, you can create a custom flavor that your cloud users can use to launch instances for GPU workloads.
Procedure
Create an NVIDIA GPU flavor. For example:
(overcloud) [stack@virtlab-director2 ~]$ openstack flavor create --vcpus 6 --ram 8192 --disk 100 m1.small-gpu +----------------------------+--------------------------------------+ | Field | Value | +----------------------------+--------------------------------------+ | OS-FLV-DISABLED:disabled | False | | OS-FLV-EXT-DATA:ephemeral | 0 | | disk | 100 | | id | a27b14dd-c42d-4084-9b6a-225555876f68 | | name | m1.small-gpu | | os-flavor-access:is_public | True | | properties | | | ram | 8192 | | rxtx_factor | 1.0 | | swap | | | vcpus | 6 | +----------------------------+--------------------------------------+Assign a vGPU resource to the flavor that you created. You can assign only one vGPU for each instance.
(overcloud) [stack@virtlab-director2 ~]$ openstack flavor set m1.small-gpu --property "resources:VGPU=1" (overcloud) [stack@virtlab-director2 ~]$ openstack flavor show m1.small-gpu +----------------------------+--------------------------------------+ | Field | Value | +----------------------------+--------------------------------------+ | OS-FLV-DISABLED:disabled | False | | OS-FLV-EXT-DATA:ephemeral | 0 | | access_project_ids | None | | disk | 100 | | id | a27b14dd-c42d-4084-9b6a-225555876f68 | | name | m1.small-gpu | | os-flavor-access:is_public | True | | properties | resources:VGPU='1' | | ram | 8192 | | rxtx_factor | 1.0 | | swap | | | vcpus | 6 | +----------------------------+--------------------------------------+
11.3.3. Launching a vGPU instance
You can create a GPU-enabled instance for GPU workloads.
Procedure
Create an instance using a GPU flavor and image. For example:
(overcloud) [stack@virtlab-director2 ~]$ openstack server create --flavor m1.small-gpu --image vgpu_image --security-group web --nic net-id=internal0 --key-name lambda vgpu-instance- Log in to the instance as a cloud-user. For more information, see Log in to an Instance.
To verify that the GPU is accessible from the instance, run the following command from the instance:
$ lspci -nn | grep <gpu_name>
11.4. Enabling PCI passthrough for a GPU device
You can use PCI passthrough to attach a physical PCI device, such as a graphics card, to an instance. If you use PCI passthrough for a device, the instance reserves exclusive access to the device for performing tasks, and the device is not available to the host.
Prerequisites
-
The
pciutilspackage is installed on the physical servers that have the PCI cards. - The GPU driver is available to install on the GPU instances. For more information, see 「Building a custom GPU overcloud image」.
Procedure
To determine the vendor ID and product ID for each passthrough device type, run the following command on the physical server that has the PCI cards:
# lspci -nn | grep -i <gpu_name>For example, to determine the vendor and product ID for an NVIDIA GPU, run the following command:
# lspci -nn | grep -i nvidia 3b:00.0 3D controller [0302]: NVIDIA Corporation TU104GL [Tesla T4] [10de:1eb8] (rev a1) d8:00.0 3D controller [0302]: NVIDIA Corporation TU104GL [Tesla T4] [10de:1db4] (rev a1)-
To configure the Controller node on the overcloud for PCI passthrough, create an environment file, for example,
pci_passthru_controller.yaml. Add
PciPassthroughFilterto theNovaSchedulerDefaultFiltersparameter inpci_passthru_controller.yaml:parameter_defaults: NovaSchedulerDefaultFilters: ['RetryFilter','AvailabilityZoneFilter','ComputeFilter','ComputeCapabilitiesFilter','ImagePropertiesFilter','ServerGroupAntiAffinityFilter','ServerGroupAffinityFilter','PciPassthroughFilter','NUMATopologyFilter']To specify the PCI alias for the devices on the Controller node, add the following to
pci_passthru_controller.yaml:ControllerExtraConfig: nova::pci::aliases: - name: "t4" product_id: "1eb8" vendor_id: "10de" - name: "v100" product_id: "1db4" vendor_id: "10de"注記If the
nova-apiservice is running in a role other than the Controller, then replaceControllerExtraConfigwith the user role, in the format<Role>ExtraConfig.-
To configure the Compute node on the overcloud for PCI passthrough, create an environment file, for example,
pci_passthru_compute.yaml. To specify the available PCIs for the devices on the Compute node, add the following to
pci_passthru_compute.yaml:parameter_defaults: NovaPCIPassthrough: - vendor_id: "10de" product_id: "1eb8"To enable IOMMU in the server BIOS of the Compute nodes to support PCI passthrough, add the
KernelArgsparameter topci_passthru_compute.yaml:parameter_defaults: ... ComputeParameters: KernelArgs: "intel_iommu=on iommu=pt"Deploy the overcloud, adding your custom environment files to the stack along with your other environment files:
(undercloud) $ openstack overcloud deploy --templates \ -e [your environment files] -e /home/stack/templates/pci_passthru_controller.yaml -e /home/stack/templates/pci_passthru_compute.yamlConfigure a flavor to request the PCI devices. The following example requests two devices, each with a vendor ID of
10deand a product ID of13f2:# openstack flavor set m1.large --property "pci_passthrough:alias"="t4:2"
Verification
Create an instance with a PCI passthrough device:
# openstack server create --flavor m1.large --image rhelgpu --wait test-pci- Log in to the instance as a cloud user.
Install the GPU driver on the instance. For example, run the following script to install an NVIDIA driver:
$ sh NVIDIA-Linux-x86_64-430.24-grid.runTo verify that the GPU is accessible from the instance, enter the following command from the instance:
$ lspci -nn | grep <gpu_name>To check the NVIDIA System Management Interface status, run the following command from the instance:
$ nvidia-smiExample output:
----------------------------------------------------------------------------- | NVIDIA-SMI 440.33.01 Driver Version: 440.33.01 CUDA Version: 10.2 | |---------------------------------------------------------------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | |===========================================================================| | 0 Tesla T4 Off | 00000000:01:00.0 Off | 0 | | N/A 43C P0 20W / 70W | 0MiB / 15109MiB | 0% Default | --------------------------------------------------------------------------- ----------------------------------------------------------------------------- | Processes: GPU Memory | | GPU PID Type Process name Usage | |=============================================================================| | No running processes found | -----------------------------------------------------------------------------
付録A Image configuration parameters
You can use the following keys with the property option for both the glance image-update and glance image-create commands. For example:
$ glance image-update <image_uuid> --property architecture=x86_64If you set an image property that conflicts with the same property on the flavor then either the flavor property is used, or an error is raised. There are some exceptions to this behavior for legacy compatibility.
| Specific to | Key | Description | Supported values |
|---|---|---|---|
| All |
|
The CPU architecture that must be supported by the hypervisor. For example, |
|
| All |
| The hypervisor type. |
|
| All |
| For snapshot images, this is the UUID of the server used to create this image. | Valid server UUID |
| All |
| The ID of an image stored in the Image Service that must be used as the kernel when booting an AMI-style image. | Valid image ID |
| All |
| The common name of the operating system distribution in lowercase. |
|
| All |
| The operating system version as specified by the distributor. | Version number (for example, "11.10") |
| All |
| The ID of image stored in the Image Service that should be used as the ramdisk when booting an AMI-style image. | Valid image ID |
| All |
| The virtual machine mode. This represents the host/guest ABI (application binary interface) used for the virtual machine. |
|
| libvirt API driver |
| Specifies the type of disk controller to attach disk devices to. |
|
| libvirt API driver |
| Specifies the type of disk controller to attach CD-ROM devices to. |
|
| libvirt API driver |
| Number of NUMA nodes to expose to the instance (does not override flavor definition). | Integer. For a detailed example of NUMA-topology definition, see the hw:NUMA_def key in Add Metadata. |
| libvirt API driver |
| Mapping of vCPUs N-M to NUMA node 0 (does not override flavor definition). | Comma-separated list of integers. |
| libvirt API driver |
| Mapping of vCPUs N-M to NUMA node 1 (does not override flavor definition). | Comma-separated list of integers. |
| libvirt API driver |
| Mapping N MB of RAM to NUMA node 0 (does not override flavor definition). | Integer |
| libvirt API driver |
| Mapping N MB of RAM to NUMA node 1 (does not override flavor definition). | Integer |
| libvirt API driver |
|
Guest agent support. If set to |
|
| libvirt API driver |
| Adds a random-number generator device to the image’s instances. The cloud administrator can enable and control device behavior by configuring the instance’s flavor. By default:
|
|
| libvirt API driver |
| Enables the use of VirtIO SCSI (virtio-scsi) to provide block device access for compute instances; by default, instances use VirtIO Block (virtio-blk). VirtIO SCSI is a para-virtualized SCSI controller device that provides improved scalability and performance, and supports advanced SCSI hardware. |
|
| libvirt API driver |
| The video device driver to use in virtual machine instances. | List of supported drivers, in order of precedence:
|
| libvirt API driver |
|
Maximum RAM for the video image. Used only if a | Integer in MB (for example, 64) |
| libvirt API driver |
|
Enables a virtual hardware watchdog device that carries out the specified action if the server hangs. The watchdog uses the i6300esb device (emulating a PCI Intel 6300ESB). If |
|
| libvirt API driver |
| The kernel command line to be used by the libvirt driver, instead of the default. For Linux Containers (LXC), the value is used as arguments for initialization. This key is valid only for Amazon kernel, ramdisk, or machine images (aki, ari, or ami). | |
| libvirt API driver and VMware API driver |
| Specifies the model of virtual network interface device to use. | The valid options depend on the configured hypervisor.
|
| VMware API driver |
| The virtual SCSI or IDE controller used by the hypervisor. |
|
| VMware API driver |
|
A VMware GuestID which describes the operating system installed in the image. This value is passed to the hypervisor when creating a virtual machine. If not specified, the key defaults to | For more information, see Images with VMware vSphere. |
| VMware API driver |
| Currently unused. |
|
| XenAPI driver |
|
If true, the root partition on the disk is automatically resized before the instance boots. This value is only taken into account by the Compute service when using a Xen-based hypervisor with the XenAPI driver. The Compute service will only attempt to resize if there is a single partition on the image, and only if the partition is in |
|
| libvirt API driver and XenAPI driver |
|
The operating system installed on the image. The XenAPI driver contains logic that takes different actions depending on the value of the |
|
付録B Enabling the launch instance wizard
There are two methods that you can use to launch instances from the dashboard:
- The Launch Instance form
- The Launch Instance wizard
The Launch Instance form is enabled by default, but you can enable the Launch Instance wizard at any time. You can also enable both the Launch Instance form and the Launch Instance wizard at the same time. The Launch Instance wizard simplifies the steps required to create instances.
Edit
/etc/openstack-dashboard/local_settingsfile, and add the following values:LAUNCH_INSTANCE_LEGACY_ENABLED = False LAUNCH_INSTANCE_NG_ENABLED = TrueRestart the httpd service:
# systemctl restart httpd
The preferences for the Launch Instance form and Launch Instance wizard are updated.
If you enabled only one of these options, the Launch Instance button in the dashboard opens that option by default. If you enabled both options, two Launch Instance buttons are displayed in the dashboard, with the button on the left opening the Launch Instance wizard and the button on the right opening the Launch Instance form.