アーキテクチャーガイド
製品、コンポーネント、およびアーキテクチャーの例の概要
概要
はじめに
Red Hat OpenStack Platform は、Red Hat Enterprise Linux 上にプライベートまたはパブリックの Infrastructure-as-a-Service (IaaS) クラウドを構築するための基盤を提供します。これにより、スケーラビリティーが高く、耐障害性に優れたプラットフォームをクラウド対応のワークロード開発に利用できます。
Red Hat OpenStack Platform は、利用可能な物理ハードウェアをプライベート、パブリック、またはハイブリッドのクラウドプラットフォームに変換できるようにパッケージされています。これには以下のコンポーネントが含まれます。
- 完全に分散されたオブジェクトストレージ
- 永続的なブロックレベルのストレージ
- 仮想マシンのプロビジョニングエンジンおよびイメージストレージ
- 認証および承認メカニズム
- 統合されたネットワーク
- ユーザーおよび管理者がアクセス可能な Web ブラウザーベースのインターフェイス
- 本ガイドのコンポーネントに関する参考情報は、5章デプロイメント情報 を参照してください。
- 完全な Red Hat OpenStack Platform ドキュメントスイートは Red Hat OpenStack Platform ドキュメント を参照してください。
第1章 コンポーネント
Red Hat OpenStack Platform IaaS クラウドは、コンピューティング、ストレージ、ネットワークのリソースを制御するために相互に対話するサービスのコレクションとして実装されます。クラウドは、Web ベースのダッシュボードまたはコマンドラインクライアントで管理されます。これにより、管理者は OpenStack リソースの制御、プロビジョニング、自動化を行うことができます。OpenStack は、クラウドの全ユーザーが利用できる豊富な API も提供しています。
以下の図は、OpenStack のコアサービスとそれらの相互関係の俯瞰的な概要を示しています。

以下の表には、上図に示した各コンポーネントについての簡単な説明と、それぞれのセクションへのリンクをまとめています。
| サービス | コード | 説明 | 場所 | |
|---|---|---|---|---|
|
| Dashboard | horizon | OpenStack の各サービスの管理に使用する Web ブラウザーベースのダッシュボード | |
|
| Identity | keystone | OpenStack サービスを認証および承認し、ユーザー/プロジェクト/ロールを管理する一元化されたサービス | |
|
| OpenStack Networking | neutron | OpenStack サービスのインターフェイス間の接続性を提供します。 | |
|
| Block Storage | cinder | 仮想マシン用の永続的な Block Storage ボリュームを管理します。 | |
|
| Compute | nova | ハイパーバイザーノードで実行されている仮想マシンの管理とプロビジョニングを行います。 | |
|
| Image | glance | 仮想マシンイメージやボリュームのスナップショットなどのリソースの保管に使用するレジストリーサービス | |
|
| Object Storage | swift | ユーザーによるファイルおよび任意のデータの保管/取得を可能にします。 | |
|
| Telemetry | ceilometer | クラウドリソースの計測値を提供します。 | |
|
| Orchestration | heat | リソーススタックの自動作成をサポートする、テンプレートベースのオーケストレーションエンジン |









各 OpenStack サービスには、Linux サービスおよびその他のコンポーネントの機能グループが含まれています。たとえば、glance-api および glance-registry Linux サービスは MariaDB データベースとともに Image サービスを実装します。OpenStack サービスに含まれるサードパーティーのコンポーネントに関する情報は、「サードパーティーのコンポーネント」を参照してください。
追加サービスは以下のとおりです。
- 「OpenStack Bare Metal Provisioning (ironic)」 - さまざまなハードウェアベンダーで物理マシン(ベアメタル)をプロビジョニングできます。
- 「OpenStack Database-as-a-Service (trove)」 - ユーザーはリレーショナルデータベースエンジンと非リレーショナルデータベースエンジンをデプロイし、複雑なデータベース管理タスクを処理できます。
- 「OpenStack Data Processing (sahara)」 - ユーザーが OpenStack で Hadoop クラスターをプロビジョニングおよび管理できます。
1.1. ネットワーク
1.1.1. OpenStack Networking (neutron)
OpenStack Networking は、OpenStack クラウド内の仮想ネットワークインフラストラクチャーの作成と管理を処理します。インフラストラクチャー要素にはネットワーク、サブネット、ルーターなどが含まれます。また、ファイアウォールや仮想プライベートネットワーク (VPN) などの高度なサービスもデプロイすることができます。
OpenStack Networking は、クラウド管理者向けに、どの物理システムで実行する個々のサービスを柔軟に決定するかを提供します。すべてのサービスデーモンは、評価目的で、1 つの物理ホストで実行できます。あるいは、各サービスに一意の物理ホストを割り当てるか、複数のホストにレプリケートして冗長性を提供できます。
OpenStack Networking はソフトウェア定義であるため、新規 IP アドレスの作成や割り当てなど、ネットワークのニーズの変化にリアルタイムで対応することができます。
OpenStack Networking の利点は以下のとおりです。
- ユーザーは、ネットワークを作成し、トラフィックを制御し、サーバーとデバイスを 1 つまたは複数のネットワークに接続できます。
- 柔軟なネットワークモデルは、ネットワークボリュームとテナンシーに適合できます。
- IP アドレスは専用または Floating にすることができます。ここで、Floating IP は動的トラフィックの再ルーティングに使用できます。
- VLAN ネットワークを使用する場合は、最大 4094 VLAN (4094 ネットワーク)を使用できます。ここで、4094 = 2^12 (minus 2 unavailable)ネットワークアドレスを使用できます。これは、12 ビットヘッダー制限によって課されます。
- VXLAN トンネルベースのネットワークを使用する場合、VNI (仮想ネットワーク識別子)は 24 ビットのヘッダーを使用できます。これにより、基本的に約 1,600万個の固有のアドレス/ネットワークが許可されます。
| コンポーネント | 説明 |
|---|---|
| ネットワークエージェント | それぞれの OpenStack ノードで実行され、ノードの仮想マシンおよび Open vSwitch などのネットワークサービス用のローカルネットワーク設定を実行します。 |
| neutron-dhcp-agent | テナントネットワークに DHCP サービスを提供するエージェント。 |
| neutron-ml2 | ネットワークドライバーを管理し、Open vSwitch や Ryu ネットワークなどのネットワークサービス用のルーティングとスイッチングサービスを提供するプラグイン。 |
| neutron-server | ユーザーの要求を管理し、Networking API を公開する Python デーモン。デフォルトのサーバー設定は、特定のネットワークメカニズムセットを持つプラグインを使用して Networking API を実装します。 openvswitch プラグインや linuxbridge プラグインなどの一部のプラグインは、ネイティブの Linux ネットワークメカニズムを使用し、外部デバイスまたは SDN コントローラーとの他のプラグインインターフェイスを使用します。 |
| neutron | API にアクセスするためのコマンドラインクライアント。 |
OpenStack Networking サービスおよびエージェントの配置は、ネットワーク要件によって異なります。以下の図は、コントローラーのない共通のデプロイメントモデルの例を示しています。このモデルは、専用の OpenStack Networking ノードおよびテナントネットワークを利用します。
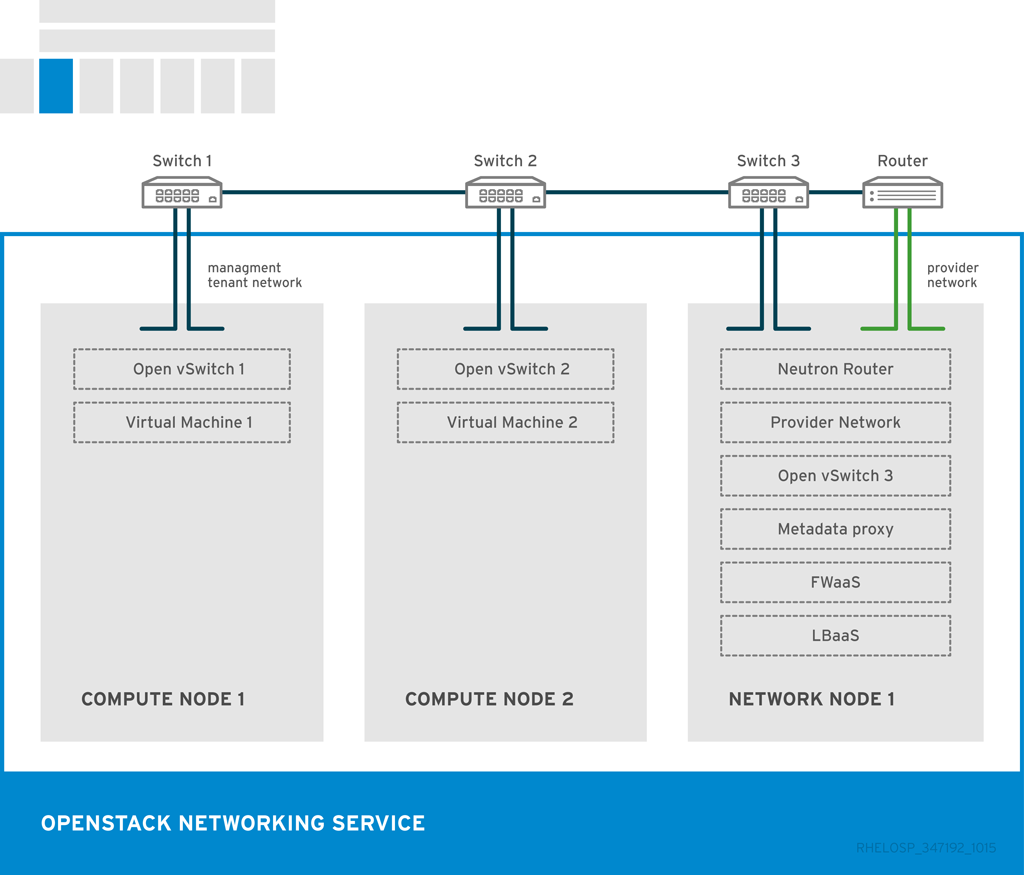
この例は、次の Networking サービスの設定を示しています。
2 台のコンピュートノードは Open vSwitch (ovs-agent)を実行し、1 つの OpenStack Networking ノードが以下のネットワーク機能を実行します。
- L3 ルーティング
- DHCP
- FWaaS や LBaaS などのサービスを含む NAT
- コンピュートノードにはそれぞれ 2 つの物理ネットワークカードがあります。1 つのカードがテナントトラフィックを処理し、他のカードでは接続を管理します。
- OpenStack Networking ノードに、プロバイダートラフィック専用の 3 番目のネットワークカードがあります。
1.2. ストレージ
「OpenStack Block Storage (cinder)」
「OpenStack Object Storage (swift)」
「OpenStack Database-as-a-Service (trove)」
1.2.1. OpenStack Block Storage (cinder)
OpenStack Block Storage サービスは、仮想ハードドライブの永続的なブロックストレージ管理機能を提供します。Block Storage により、ユーザーはブロックデバイスの作成/削除やサーバーへの Block Device の接続を管理することができます。
実際のデバイスの割り当て/割り当て解除は、Compute サービスとの統合により処理されます。リージョンおよびゾーンを使用して、分散ブロックストレージホストを処理できます。
Block Storage は、データベースのストレージや拡張可能なファイルシステムなど、パフォーマンスの影響を受けやすいシナリオで使用できます。また、raw のブロックレベルのストレージにアクセスできるサーバーとして使用することもできます。また、ボリュームスナップショットを作成してデータを復元したり、新しいブロックストレージボリュームを作成したりできます。スナップショットはドライバーのサポートに依存します。
OpenStack Block Storage の利点は以下のとおりです。
- ボリュームおよびスナップショットの作成、一覧表示、および削除。
- 実行中の仮想マシンへのボリュームのアタッチおよび割り当て解除。
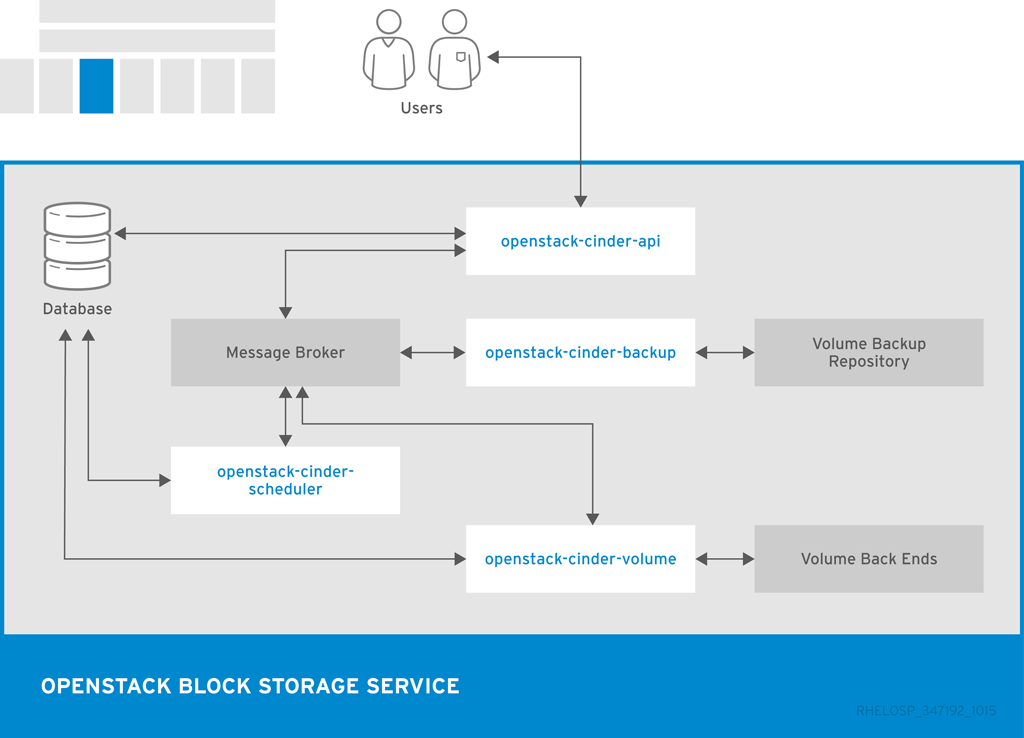
ボリューム、スケジューラー、API などのメインの Block Storage サービスは実稼働環境で同じ場所に配置できますが、ボリュームサービスのインスタンスを複数デプロイして API およびスケジューラーサービスのインスタンスを管理する方が一般的です。
| コンポーネント | 説明 |
|---|---|
| openstack-cinder-api | 要求に応答し、メッセージキューに配置します。リクエストを受け取ると、API サービスはアイデンティティー要件を満たしていることを確認し、要求を必要なブロックストレージアクションを含むメッセージに変換します。その後、メッセージはメッセージブローカーに送信され、他の Block Storage サービスによって処理されます。 |
| openstack-cinder-backup | Block Storage ボリュームを外部ストレージリポジトリーにバックアップします。デフォルトでは、OpenStack は Object Storage サービスを使用してバックアップを保存します。Ceph または NFS バックエンドをバックアップのストレージリポジトリーとして使用することもできます。 |
| openstack-cinder-scheduler | キューにタスクを割り当て、プロビジョニングボリュームサーバーを決定します。スケジューラーサービスはメッセージキューから要求を読み取り、どのブロックストレージホストが要求されたアクションを実行するかを決定します。その後、スケジューラーは選択したホストの openstack-cinder-volume サービスと通信し、要求を処理する。 |
| openstack-cinder-volume | 仮想マシンのストレージを指定します。ボリュームサービスは、ブロックストレージデバイスとの対話を管理します。スケジューラーから要求が到達すると、ボリュームサービスはボリュームを作成、変更、または削除できます。ボリュームサービスには、NFS、Red Hat Storage、Dell EqualLogic などのブロックストレージデバイスと対話するための複数のドライバーが含まれています。 |
| cinder | Block Storage API にアクセスするためのコマンドラインクライアント。 |
以下の図は、Block Storage API、スケジューラー、ボリュームサービス、およびその他の OpenStack コンポーネントの関係を示しています。
1.2.2. OpenStack Object Storage (swift)
Object Storage サービスは、HTTP 経由でアクセス可能な、大量データ用のストレージシステムを提供します。ビデオ、イメージ、メールのメッセージ、ファイル、仮想マシンイメージなどの静的エンティティーをすべて保管することができます。オブジェクトは、各ファイルの拡張属性に保管されているメタデータとともに、下層のファイルシステムにバイナリーとして保管されます。
Object Storage 分散アーキテクチャーは、ソフトウェアベースのデータのレプリケーションによる水平スケーリングおよびフェイルオーバーの冗長性をサポートします。このサービスは非同期および最終的な一貫性のレプリケーションをサポートするため、複数のデータセンターデプロイメントで使用できます。
OpenStack Object Storage の利点は以下のとおりです。
- ストレージレプリカは、停止時にオブジェクトの状態を維持します。少なくとも 3 つのレプリカが推奨されます。
- ストレージゾーンホストレプリカ。ゾーンにより、特定のオブジェクトの各レプリカを個別に保存できます。ゾーンは、個々のディスクドライブ、アレイ、サーバー、サーバーのラック、またはデータセンター全体を表す場合があります。
- ストレージ領域は、ロケーション別にゾーンをグループ化できます。リージョンには、通常同じ地理的領域にあるサーバーまたはサーバーファームを含めることができます。リージョンには、Object Storage サービスのインストールごとに個別の API エンドポイントがあり、個別のサービスを分離することができます。
オブジェクトストレージは、データベースおよび設定ファイルとして機能するリング .gz ファイルを使用します。これらのファイルには、すべてのストレージデバイスの詳細と、保存されたエンティティーから各ファイルの物理的な場所へのマッピングが含まれます。したがって、リングファイルを使用して、特定のデータの場所を判断できます。各オブジェクト、アカウント、およびコンテナーサーバーには、一意のリングファイルがあります。
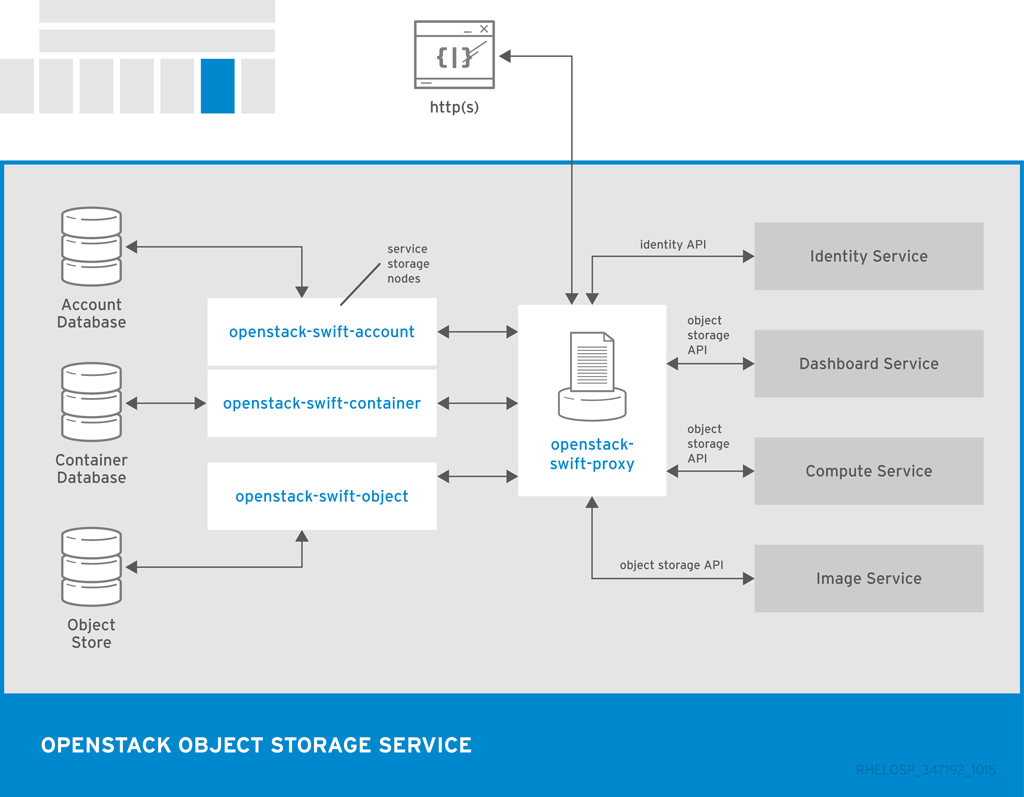
Object Storage サービスは、他の OpenStack サービスとコンポーネントに依存してアクションを実行します。たとえば、Identity サービス(keystone)、rsync デーモン、およびロードバランサーがすべて必要です。
| コンポーネント | 説明 |
|---|---|
| openstack-swift-account | アカウントデータベースでコンテナーの一覧を処理します。 |
| openstack-swift-container | コンテナーデータベースを含む特定のコンテナーに含まれるオブジェクトの一覧を処理します。 |
| openstack-swift-object | オブジェクトを格納、取得、および削除します。 |
| openstack-swift-proxy | パブリック API を公開し、認証およびルーティング要求を行います。オブジェクトは、スプールせずにプロキシーサーバーを介してユーザーにストリーミングされます。 |
| swift | Object Storage API にアクセスするためのコマンドラインクライアント。 |
| Housekeeping | コンポーネント | 説明 |
|---|---|---|
| 監査 |
| Object Storage アカウント、コンテナー、およびオブジェクトの整合性を検証し、データの破損から保護するのに役立ちます。 |
| レプリケーション |
| ガベージコレクションを含む、オブジェクトストレージクラスター全体で一貫したレプリケーションと利用可能なレプリケーションを確保します。 |
| 更新 |
| 失敗した更新を特定して再試行する。 |
以下の図は、Object Storage が他の OpenStack サービス、データベース、ブローカーとの対話に使用する主なインターフェイスを示しています。
1.2.3. OpenStack Database-as-a-Service (trove)
DEPRECATION NOTICE: Red Hat OpenStack Platform 10 以降、OpenStack Trove サービスは Red Hat OpenStack Platform ディストリビューションに含まれなくなります。お客様に実稼働に対応した DBaaS サービスを提供するために、信頼できるパートナーと協力しています。このオプションの詳細については、営業アカウントマネージャーにお問い合わせください。
この機能は、本リリースでは テクノロジープレビュー として提供しているため、Red Hat では全面的にはサポートしていません。これは、テスト用途にのみご利用いただく機能です。実稼働環境にはデプロイしないでください。テクノロジープレビュー機能の詳細は、対象範囲の詳細 を参照してください。
OpenStack Database-as-a-Service では、ユーザーはさまざまなリレーショナルデータベースおよび非リレーショナルデータベースを選択、プロビジョニング、および操作することができ、より複雑なデータベース管理タスクを標準で処理できます。
OpenStack Database-as-a-Service には、以下のような利点があります。
- ユーザーおよびデータベース管理者は、クラウドで複数のデータベースインスタンスをプロビジョニングおよび管理できます。
- デプロイメント、設定、パッチ適用、バックアップ、復元、監視などの複雑な管理タスクを自動化しつつ、高性能のリソース分離。
| コンポーネント | 説明 |
|---|---|
| openstack-trove-api | Database-as-a-Service インスタンスをプロビジョニングおよび管理するための JSON および XML をサポートする RESTful API。 |
| openstack-trove-conductor | ホストで実行され、ホストに関する情報を更新する要求でゲストインスタンスからメッセージを受信します。要求には、インスタンスのステータスまたはバックアップの現在のステータスを含めることができます。 openstack-trove-conductor を使用すると、ゲストインスタンスはホストデータベースに直接接続する必要はありません。このサービスは、メッセージバスを介して RPC メッセージをリッスンし、要求された操作を実行します。 |
| openstack-trove-guestagent | ゲストインスタンスで実行され、ホストデータベースで直接操作を管理および実行します。openstack-trove-guestagent は、メッセージバスを介して RPC メッセージをリッスンし、要求された操作を実行します。 |
| openstack-trove-taskmanager | インスタンスの作成、インスタンスのライフサイクルの管理、データベースインスタンスでの操作などのタスクを行います。 |
| trove | Database-as-a-Service API にアクセスするためのコマンドラインクライアント。 |
以下の図は、Database-as-a-Service と他の OpenStack サービスの関係を示しています。

- OpenStack Database-as-a-Service はデフォルトの OpenStack チャネルから利用できますが、コンポーネントを手動でインストールして設定する必要があります。
1.3. 仮想マシン、イメージ、およびテンプレート
「OpenStack Bare Metal Provisioning (ironic)」
「OpenStack Orchestration (heat)」
「OpenStack Data Processing (sahara)」
1.3.1. OpenStack Compute (nova)
OpenStack Compute サービスは、オンデマンドで仮想マシンを提供する、OpenStack クラウドの中核です。Compute は、下層の仮想化メカニズムと対話するドライバーを定義し、他の OpenStack コンポーネントに機能を公開することにより、仮想マシンが一式のノード上で実行されるようにスケジュールします。
Compute は、KVM をハイパーバイザーとして使用する libvirt ドライバー libvirtd をサポートします。ハイパーバイザーは仮想マシンを作成し、ノードからノードへのライブマイグレーションを可能にします。ベアメタルマシンをプロビジョニングするには、「OpenStack Bare Metal Provisioning (ironic)」 も使用できます。
Compute は Identity サービスと対話してインスタンスおよびデータベースアクセスを認証し、Image サービスを使用してイメージにアクセスしてインスタンスを起動し、ダッシュボードサービスを使用してユーザーおよび管理インターフェイスを提供します。
プロジェクトおよびユーザーがイメージへのアクセスを制限し、プロジェクトおよびユーザーのクォータ(単一ユーザーが作成することのできるインスタンス数など)を指定できます。
Red Hat OpenStack Platform クラウドをデプロイする場合には、さまざまなカテゴリーに従ってクラウドを分類することができます。
- リージョン
Identity サービスでカタログされる各サービスは、サービスリージョン(通常は地理的な場所とサービスエンドポイント)で識別されます。複数のコンピュートノードを持つクラウドでは、リージョンはサービスを分離できるようにします。
また、リージョンを使用して、高いレベルの障害耐性を維持しながら、Compute のインストール間でインフラストラクチャーを共有することもできます。
- セル(テクノロジープレビュー)
コンピュートホストは、セルと呼ばれるグループにパーティショニングして、大規模なデプロイメントや地理的に個別のインストールを処理することができます。セルは、API セル と呼ばれるトップレベルセルであるツリーで設定されます。このツリーでは、nova-api サービスが実行されますが、nova-compute サービスはありません。
ツリーの各子セルは、nova-api サービスではなく、他のすべての一般的な nova-* サービスを実行します。各セルには、個別のメッセージキューとデータベースサービスがあり、API セルと子セル間の通信を管理する nova-cells サービスも実行します。
セルの利点は次のとおりです。
- 単一の API サーバーを使用して、複数の Compute インストールへのアクセスを制御することができます。
- セルレベルでの追加のスケジューリングレベルを利用すると、ホストのスケジューリングとは異なり、仮想マシンの実行時に柔軟性と制御性が向上します。
この機能は、本リリースでは テクノロジープレビュー として提供しているため、Red Hat では全面的にはサポートしていません。これは、テスト用途にのみご利用いただく機能です。実稼働環境にはデプロイしないでください。テクノロジープレビュー機能の詳細は、対象範囲の詳細 を参照してください。
- Host Aggregates and Availability Zone
1 つの Compute デプロイメントを論理グループにパーティション分割することができます。ストレージやネットワークなどの共通のリソースを共有するホストの複数のグループや、信頼済みコンピューティングハードウェアなどの特別なプロパティーを共有するグループを複数作成できます。
管理者に、グループは割り当てられたコンピュートノードと関連するメタデータと共にホストアグリゲートとして表示されます。Host Aggregate メタデータは、通常、特定のフレーバーやイメージをホストのサブセットに制限するなど、openstack-nova-scheduler アクションの情報を提供するために使用されます。
ユーザーに、グループはアベイラビリティーゾーンとして表示されます。ユーザーは、グループメタデータを表示したり、ゾーン内のホストの一覧を表示したりできません。
集約値またはゾーンの利点は次のとおりです。
- 負荷分散とインスタンスの分散。
- ゾーン間の物理的な分離と冗長性。別の電源供給またはネットワーク機器で実装されます。
- 共通の属性を持つサーバーのグループにラベリング。
- 異なるハードウェアのクラスの分離
| コンポーネント | 説明 |
|---|---|
| openstack-nova-api | 要求を処理し、インスタンスの起動等の Compute サービスへのアクセスを提供します。 |
| openstack-nova-cert | 証明書マネージャーを提供します。 |
| openstack-nova-compute | 各ノードで実行され、仮想インスタンスを作成および終了します。Compute サービスはハイパーバイザーと対話して新規インスタンスを起動し、インスタンスの状態がコンピュートデータベースで維持されるようにします。 |
| openstack-nova-conductor | コンピュートノードのデータベースアクセスをサポートし、セキュリティー上のリスクを軽減します。 |
| openstack-nova-consoleauth | コンソール認証を処理します。 |
| openstack-nova-network | OpenStack Networking の代わりに機能でき、プライベートおよびパブリックアクセスの基本的なネットワークトラフィックを処理することができるネットワークサービス。OpenStack Networking と Compute Networking を比較するには、2章Networking In-Depthを参照してください。 |
| openstack-nova-novncproxy | VNC コンソールで仮想マシンにアクセスできるようにするブラウザー用の VNC プロキシーを提供します。 |
| openstack-nova-scheduler | 設定された重みおよびフィルターに基づいて、新しい仮想マシンのリクエストを正しいノードにディスパッチします。 |
| nova | Compute API にアクセスするためのコマンドラインクライアント。 |
以下の図は、Compute サービスと他の OpenStack コンポーネントの関係を示しています。

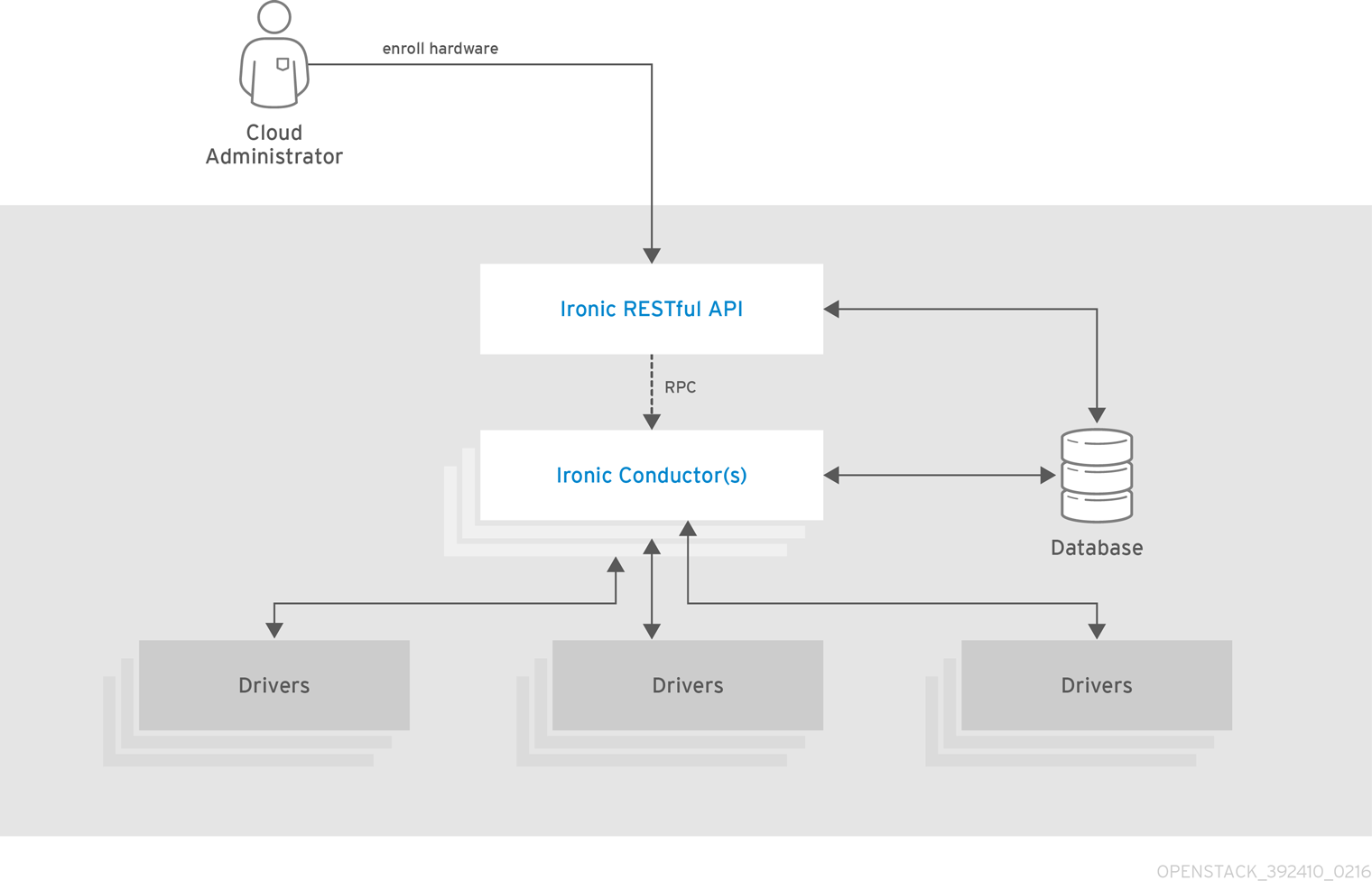
1.3.2. OpenStack Bare Metal Provisioning (ironic)
OpenStack Bare Metal Provisioning により、ハードウェア固有のドライバーを使用するさまざまなハードウェアベンダーの製品で物理マシンまたはベアメタルマシンのプロビジョニングを行うことができます。Bare Metal Provisioning は Compute サービスと統合して、仮想マシンのプロビジョニングと同じ方法で、ベアメタルマシンのプロビジョニングを行い、bare-metal-to-trusted-tenant のユースケースの解決策を提供します。
OpenStack Baremetal Provisioning には、以下のような利点があります。
- Hadoop クラスターはベアメタルマシンにデプロイすることができます。
- ハイパースケールおよび高パフォーマンスコンピューティング(HPC)クラスターをデプロイすることができます。
- 仮想マシンに敏感であるアプリケーションのデータベースホストを使用できます。
Bare Metal Provisioning は、スケジューリングとクォータの管理に Compute サービスを使用し、認証に Identity サービスを使用します。インスタンスイメージは、KVM ではなく Bare Metal Provisioning をサポートするように設定する必要があります。
以下の図は、物理サーバーがプロビジョニングされているときに Ironic と他の OpenStack サービスがどのように対話するかを示しています。

| コンポーネント | 説明 |
|---|---|
| openstack-ironic-api | 要求を処理し、ベアメタルノード上のコンピュートリソースへのアクセスを提供します。 |
| openstack-ironic-conductor | ハードウェアおよび ironic データベースと直接対話し、要求されたアクションおよび定期的なアクションを処理します。複数のコンダクターを作成して、異なるハードウェアドライバーと対話できます。 |
| ironic | Bare Metal Provisioning API にアクセスするためのコマンドラインクライアント。 |
Ironic API を以下の図に示します。
1.3.3. OpenStack Image (glance)
OpenStack Image は、仮想ディスクイメージのレジストリーとして機能します。ユーザーは、新規イメージを追加したり、既存のサーバーのスナップショットを作成して直ちに保存したりすることができます。スナップショットはバックアップ用、またはサーバーを新規作成するためのテンプレートとして使用できます。
登録されたイメージは、Object Storage サービスや、単純なファイルシステムや外部の Web サーバーなどの他の場所に保存できます。
次のイメージディスク形式がサポートされています。
- Aki/ami/ari (Amazon カーネル、ramdisk、またはマシンイメージ)
- ISO (CD などの光ディスク用のアーカイブ形式)
- qcow2 (Qemu/KVM、Copy on Write をサポートしています)
- raw (非構造化形式)
- VHD (Hyper-V)、VMware、Xen、Microsoft、VirtualBox などのベンダーの仮想マシンモニターに共通です。
- VDI (Qemu/VirtualBox)
- VMDK (VMware)
コンテナーの形式は、Image サービスで登録することもできます。コンテナー形式は、イメージに保存する仮想マシンメタデータのタイプおよび詳細レベルを決定します。
以下のコンテナー形式がサポートされています。
- ベアメタル(メタデータなし)
- OVA (OVA tar アーカイブ)
- OVF (OVF 形式)
- Aki/ami/ari (Amazon カーネル、ramdisk、またはマシンイメージ)
| コンポーネント | 説明 |
|---|---|
| openstack-glance-api | ストレージバックエンドと対話して、イメージ取得およびストレージのリクエストを処理します。API は openstack-glance-registry を使用してイメージ情報を取得します。レジストリーサービスに直接アクセスすることはできません。 |
| openstack-glance-registry | 各イメージのすべてのメタデータを管理します。 |
| glance | Image API にアクセスするためのコマンドラインクライアント。 |
以下の図は、Image サービスが Image データベースからイメージを登録して取得するために使用する主なインターフェイスを示しています。

1.3.4. OpenStack Orchestration (heat)
OpenStack Orchestration は、ストレージ、ネットワーク、インスタンス、アプリケーションなどのクラウドリソースを作成および管理するためのテンプレートを提供します。テンプレートは、リソースのコレクションであるスタックの作成に使用されます。
たとえば、インスタンス、フローティング IP、ボリューム、セキュリティーグループ、またはユーザーのテンプレートを作成できます。Orchestration は、1 つのモジュラーテンプレートや、自動スケーリングや基本的な高可用性などの機能を使用して、すべての OpenStack コアサービスへのアクセスを提供します。
OpenStack Orchestration には、以下のような利点があります。
- 単一のテンプレートは、基盤となるすべてのサービス API へのアクセスを提供します。
- テンプレートはモジュール式およびリソース指向です。
- テンプレートは、ネストされたスタックなど、再帰的に定義し、再利用することができます。その後、クラウドインフラストラクチャーは、モジュール式な方法で定義および再利用できます。
- リソース実装はプラグ可能で、カスタムリソースを許可します。
- リソースは自動スケーリングを行うことができるため、使用状況に基づいてクラスターから追加または削除できます。
- 基本的な高可用性機能を利用できます。
| コンポーネント | 説明 |
|---|---|
| openstack-heat-api | RPC 経由で openstack-heat-engine サービスにリクエストを送信して API リクエストを処理する OpenStack-native REST API |
| openstack-heat-api-cfn | RPC 経由で openstack-heat-engine サービスに要求を送信することにより、API 要求を処理する AWS CloudFormation と互換性のあるオプションの AWS-Query API。 |
| openstack-heat-engine | テンプレートの起動をオーケストレーションし、API コンシューマーのイベントを生成します。 |
| openstack-heat-cfntools | メタデータの更新を処理し、カスタムフックを実行する cfn-hup などのヘルパースクリプトのパッケージ化。 |
| heat | Orchestration API と通信して AWS CloudFormation API を実行するコマンドラインツールです。 |
次の図は、2 つの新規インスタンスとローカルネットワークの新規スタックを作成するために Orchestration サービスが使用する主なインターフェイスを示しています。
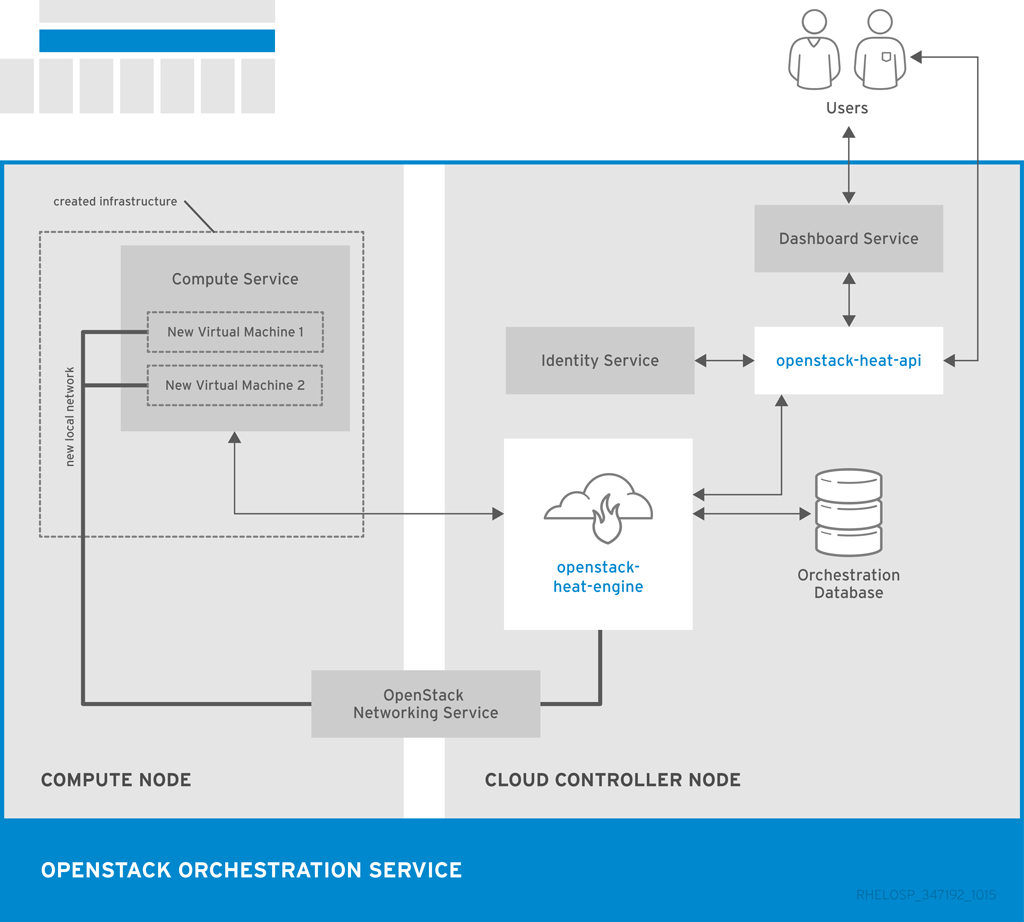
1.3.5. OpenStack Data Processing (sahara)
OpenStack Data Processing により、OpenStack 上の Hadoop クラスターのプロビジョニングと管理を行うことができます。Hadoop は、クラスター内の大量の構造化/非構造化データを保管および分析します。
Hadoop クラスター は、Hadoop Distributed File System (HDFS)、Hadoop の MapReduce (MR)フレームワークを実行しているコンピュートサーバー、またはその両方を実行するストレージサーバーとして機能するサーバーのグループです。
Hadoop クラスター内のサーバーは同じネットワークに置く必要がありますが、メモリーやディスクを共有する必要はありません。したがって、既存のサーバーの互換性に影響を与えることなく、サーバーおよびクラスターを追加または削除できます。
Hadoop のコンピューティングサーバーとストレージサーバーは共存するため、保存されたデータの高速分析が可能になります。すべてのタスクはサーバー全体で分割され、ローカルサーバーリソースを使用します。
OpenStack データ処理の利点には、以下が含まれます。
- Identity サービスはユーザーを認証し、Hadoop クラスターでユーザーセキュリティーを提供できます。
- Compute サービスはクラスターインスタンスをプロビジョニングできます。
- Image サービスはクラスターインスタンスを保管することができます。この場合、各インスタンスにはオペレーティングシステムと HDFS が含まれます。
- オブジェクトストレージサービスを使用して、Hadoop ジョブプロセスのデータを保存できます。
- テンプレートを使用すると、クラスターの作成と設定を行うことができます。ユーザーは、カスタムテンプレートを作成するか、クラスターの作成中にパラメーターを上書きすることで、設定パラメーターを変更できます。ノードは Node Group テンプレートを使用してグループ化され、クラスターテンプレートは Node Groups を組み合わせます。
- ジョブは、Hadoop クラスターでタスクを実行するために使用できます。ジョブバイナリーは実行可能なコードを保存し、データソースは入出力の場所と必要な認証情報を保存します。
データ処理は、Cloudera (CDH)と Hortonworks Data Platform (HDP)ディストリビューションと、Apache Ambari などのベンダー固有の管理ツールをサポートしています。OpenStack Dashboard またはコマンドラインツールを使用して、クラスターをプロビジョニングおよび管理できます。
| コンポーネント | 説明 |
|---|---|
| openstack-sahara-all | API およびエンジンサービスを処理するレガシーパッケージ。 |
| openstack-sahara-api | API 要求を処理し、Data Processing サービスへのアクセスを提供します。 |
| openstack-sahara-engine | クラスター要求とデータ配信を処理するプロビジョニングエンジン。 |
| sahara | Data Processing API にアクセスするためのコマンドラインクライアント。 |
次の図は、Data Processing サービスが Hadoop クラスターのプロビジョニングと管理に使用する主なインターフェイスを示しています。
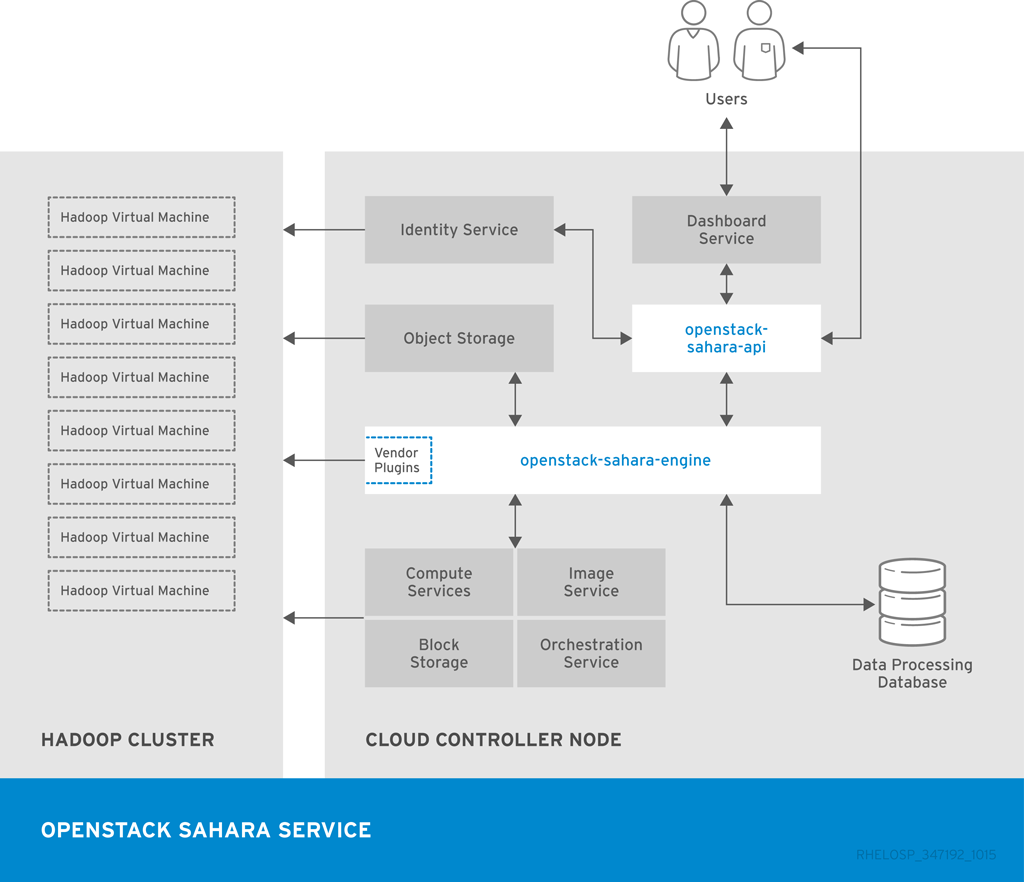
1.4. Identity Management
1.4.1. OpenStack Identity (keystone)
OpenStack Identity は、全 OpenStack コンポーネントに対してユーザーの認証と承認を提供します。Identity は、ユーザー名/パスワード認証情報、トークンベースのシステム、AWS 式のログインなど複数の認証メカニズムをサポートしています。
デフォルトでは、Identity サービスはトークン、カタログ、ポリシー、および ID 情報に MariaDB バックエンドを使用します。このバックエンドは、開発環境または小規模なユーザーセットを認証する場合に推奨されます。LDAP や SQL などの複数の ID バックエンドを同時に使用することもできます。トークンの永続性に memcache または Redis を使用することもできます。
ID は、SAML とのフェデレーションをサポートします。フェデレーションアイデンティティーは、アイデンティティープロバイダー(IdP)と、アイデンティティーがエンドユーザーに提供するサービスとの間の信頼を確立します。
フェデレーションされた Identity と同時のバックエンドには、Eventlet デプロイメントではなく、Identity API v3 および Apache HTTPD のデプロイメントが必要です。
OpenStack Identity の利点は以下のとおりです。
- 名前やパスワードなどの関連情報を含む、ユーザーアカウント管理。カスタムユーザーに加えて、ユーザーはカタログサービスごとに定義する必要があります。たとえば、Image サービス用に glance ユーザーを定義する必要があります。
- テナントまたはプロジェクト、管理。テナントは、ユーザーグループ、プロジェクト、または組織にすることができます。
- ロールの管理。ロールによってユーザーの権限が決まります。たとえば、ロールはセールスの繰り返し権限とマネージャーのパーミッションを区別する場合があります。
- ドメイン管理。ドメインは、Identity サービスエンティティーの管理境界を決定し、マルチテナンシーをサポートします。ドメインは、ユーザー、グループ、テナントのグループ化を表します。ドメインには複数のテナントを持たせることができ、複数の同時 Identity プロバイダーを使用する場合は、各プロバイダーに 1 つのドメインがあります。
| コンポーネント | 説明 |
|---|---|
| openstack-keystone | Identity サービスを、管理およびパブリック API とともに提供します。Identity API v2 および API v3 の両方がサポートされています。 |
| keystone | Identity API にアクセスするためのコマンドラインクライアント。 |
以下の図は、Identity が他の OpenStack コンポーネントでユーザーを認証するために使用する基本的な認証フローを示しています。

1.5. ユーザーインターフェイス
「OpenStack Dashboard (horizon)」
「OpenStack Telemetry (ceilometer)」
1.5.1. OpenStack Dashboard (horizon)
OpenStack Dashboard は、ユーザーおよび管理者がインスタンスの作成/起動やネットワークの管理、アクセス制御の設定などの操作を行うためのグラフィカルユーザーインターフェイスを提供します。
Dashboard サービスは、プロジェクト、管理、設定のデフォルトダッシュボードを提供します。Dashboard は、モジュール型設計により、課金、モニタリング、追加の管理ツールなどの他の製品と連結することができます。
次のイメージは、Admin Dashboard の Compute パネルの例を示しています。
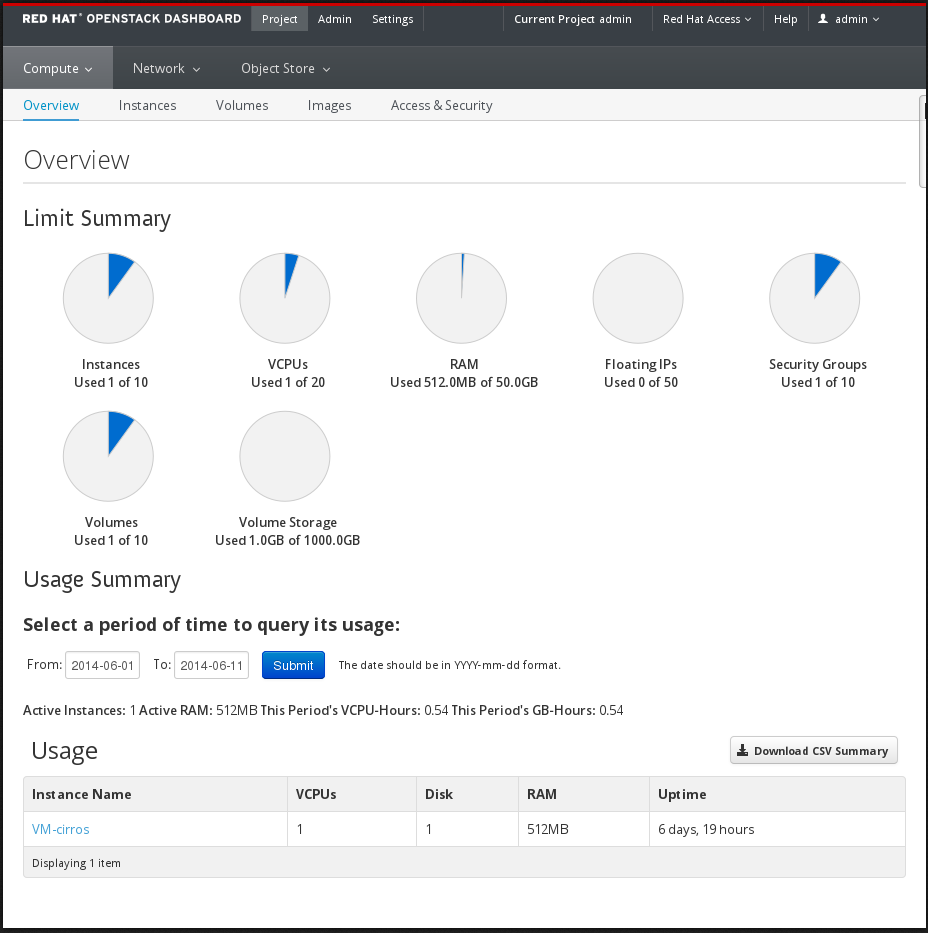
ダッシュボードにログインするユーザーのロールによって、利用可能なダッシュボードおよびパネルが決まります。
| コンポーネント | 説明 |
|---|---|
| openstack-dashboard | 任意の Web ブラウザーからダッシュボードへのアクセスを提供する Django Web アプリケーション。 |
| Apache HTTP サーバー(httpd サービス) | アプリケーションをホストします。 |
次の図は、ダッシュボードアーキテクチャーの概要を示しています。

この例は、以下の対話を示しています。
- OpenStack Identity サービスはユーザーを認証および承認します。
- セッションバックエンドがデータベースサービスを提供します。
- httpd サービスは、Web アプリケーションおよび API 呼び出し用にその他すべての OpenStack サービスをホストします。
1.5.2. OpenStack Telemetry (ceilometer)
OpenStack Telemetry は、OpenStack をベースとするクラウドのユーザーレベルの使用状況データを提供します。データは、顧客の課金、システムの監視、警告に使用することができます。Telemetry は既存の OpenStack コンポーネント (例: Compute の使用イベント) や libvirt などの OpenStack インフラストラクチャーリソースのポーリングにより送信される通知からデータを収集することができます。
Telemetry には、信頼できるメッセージングシステムを介して認証されたエージェントと通信してデータを収集および集約するストレージデーモンが含まれます。さらに、サービスは、新しいモニターの追加に使用できるプラグインシステムを使用します。API サーバー、中央エージェント、データストアサービス、およびコレクターエージェントを異なるホストにデプロイできます。
サービスは、MongoDB データベースを使用して収集したデータを保存します。コレクターエージェントと API サーバーのみがデータベースにアクセスできます。
| コンポーネント | 説明 |
|---|---|
| openstack-ceilometer-alarm-evaluator | アラームで状態遷移をトリガーします。 |
| openstack-ceilometer-alarm-notifier | アラームがトリガーされたときにアクションを実行します。 |
| openstack-ceilometer-api | 1 つまたは複数の中央管理サーバーで実行され、データベース内のデータへのアクセスを提供します。 |
| openstack-ceilometer-central | 中央の管理サーバーで実行され、インスタンスまたはコンピュートノードとは独立したリソースに関する使用率の統計値をポーリングします。エージェントは水平スケーリングできないため、このサービスのインスタンスを一度に 1 つだけ実行できます。 |
| openstack-ceilometer-collector | 1 つ以上の中央管理サーバーで実行され、メッセージキューを監視します。各コレクターは、通知メッセージを Telemetry メッセージに処理して変換し、関連するトピックを使用してメッセージをメッセージバスに送り返します。 テレメトリーメッセージは、変更せずにデータストアに書き込まれます。ceilometer-alarm-evaluator サービスと同様に、ceilometer-api サービスへの AMQP または REST 呼び出しに基づいているため、これらのエージェントを実行する場所を選択できます。 |
| openstack-ceilometer-compute | 各コンピュートノードで実行され、リソースの使用状況の統計値をポーリングします。各 nova-compute ノードには、ceilometer-compute エージェントがデプロイされ、実行されている必要があります。 |
| openstack-ceilometer-notification | さまざまな OpenStack サービスからコレクターサービスにメトリックをプッシュします。 |
| ceilometer | Telemetry API にアクセスするためのコマンドラインクライアント。 |
以下の図は、Telemetry サービスで使用されるインターフェイスを示しています。

1.6. サードパーティーのコンポーネント
1.6.1. サードパーティーのコンポーネント
一部の Red Hat OpenStack Platform コンポーネントは、サードパーティーのデータベース、サービス、およびツールを使用します。
1.6.1.1. データベース
- MariaDB は、Red Hat Enterprise Linux に同梱されるデフォルトのデータベースです。MariaDB を使用すると、Red Hat はオープンソースコミュニティーで開発されたオープンソースソフトウェアを完全にサポートできます。Telemetry 以外の各 OpenStack コンポーネントには、実行中の MariaDB サービスが必要です。したがって、完全な OpenStack クラウドサービスをデプロイする前に、またはスタンドアロンの OpenStack コンポーネントをインストールする前に、MariaDB をデプロイする必要があります。
- Telemetry サービスは、MongoDB データベースを使用して、コレクターエージェントから収集した使用状況データを保存します。コレクターエージェントと API サーバーのみがデータベースにアクセスできます。
1.6.1.2. メッセージング
RabbitMQ は、AMQP 標準をベースとした堅牢なオープンソースメッセージングシステムです。RabbitMQ は、幅広い商用サポートを備えた多くのエンタープライズシステムで使用される高パフォーマンスのメッセージブローカーです。Red Hat OpenStack Platform では、RabbitMQ はデフォルトで推奨されるメッセージブローカーです。
RabbitMQ は、キュー、分散、セキュリティー、管理、クラスタリング、フェデレーションなどの OpenStack トランザクションを管理します。また、高可用性およびクラスタリングのシナリオでも重要なロールを果たします。
1.6.1.3. 外部キャッシング
memcached や Redis などのキャッシュ用の外部アプリケーションは、永続性や共有ストレージを提供し、データベースの負荷を軽減することで動的な Web アプリケーションの高速化を行います。外部キャッシングは、さまざまな OpenStack コンポーネントによって使用されます。以下に例を示します。
- Object Storage サービスは、各クライアントがそれぞれの対話を再認証する代わりに、memcached を使用して認証されたクライアントをキャッシュします。
- デフォルトでは、ダッシュボードはセッションストレージに memcached を使用します。
- Identity サービスは、トークンの永続性に Redis または memcached を使用します。
第2章 Networking In-Depth
2.1. 基本的なネットワークの仕組み
ネットワークは、コンピューター間で情報を移動することで設定されます。最も基本的なレベルでは、ネットワークインターフェイスカード(NIC)がインストールされている 2 台のマシン間でケーブルを実行することで実行されます。OSI ネットワークモデルに注目すると、これはレイヤー 1 になります。
会話に 2 台以上のコンピューターを使用する場合は、スイッチ と呼ばれるデバイスを追加して、この設定をスケールアウトする必要があります。スイッチは、追加のマシンを接続する複数のイーサネットポートを持つ専用デバイスです。この構成は、ローカルエリアネットワーク(LAN)と呼ばれます。
スイッチは OSI モデルをレイヤー 2 に移動し、下位レイヤー 1 よりも多くのインテリジェンスを適用します。各 NIC には、ハードウェアに割り当てられた一意の MAC アドレスがあり、この番号により、同じスイッチに接続されているマシンが相互に認識できるようになります。
スイッチは、どの MAC アドレスがどのポートに結線されているかのリストを管理するので、コンピューター間でデータ送信を試みる際に、スイッチは各 NIC が配置されている場所を認識し、ネットワークトラフィックを正しい宛先に転送するように回路を調整します。
2.1.1. 複数の LAN の接続
2 つの別個のスイッチで 2 つの LAN を使用する場合は、次の方法で 2 つの LAN を接続して互いに情報を共有できます。
- トランクケーブル
- 2 つのスイッチは、トランクケーブルと呼ばれる物理ケーブルで直接接続できます。この設定では、トランクケーブルの各エンドを各スイッチのポートに接続し、それらのポートをトランクポートとして定義します。これで、2 つのスイッチが 1 つの大きな論理スイッチとして機能し、接続されているコンピューター間で正常に検出できるようになります。このオプションはあまりスケーラブルではなく、オーバーヘッドによって直接リンクするスイッチが長くなります。
- ルーター
各スイッチからケーブルを接続するには、ルーターと呼ばれるデバイスを使用できます。その結果、ルーターは両方のスイッチに設定されているネットワークを認識します。ルーターに接続する各スイッチはインターフェイスになり、そのネットワークのデフォルトゲートウェイとして知られる IP アドレスが割り当てられます。デフォルトゲートウェイのデフォルトとは、送信先のコンピューターがデータ転送元と同じ LAN 上にないことが明らかな場合に、トラフィックが送信される宛先であることを意味します。
各コンピューターでこのデフォルトゲートウェイを設定した後に、トラフィック送信のために、他のネットワーク上の他のすべてのコンピューターを認識する必要はありません。トラフィックはデフォルトゲートウェイに送信され、ルーターはそこから処理します。ルーターは、どのネットワークがどのインターフェイスに存在するかを認識するため、パケットを目的の宛先に送信できます。ルーティングは、OSI モデルのレイヤー 3 で機能し、IP アドレスやサブネットなどの一般的な概念を利用します。
この概念は、インターネット自体が機能する仕組みです。異なる組織により実行される多くの別個のネットワークは、すべてスイッチおよびルーターを使用して相互接続されています。正しいデフォルトゲートウェイに従うようにしてください。トラフィックは最終的に移動先に到達します。
2.1.2. VLAN
仮想ローカルエリアネットワーク(VLAN)を使用すると、同じスイッチ上で動作するコンピューターのネットワークトラフィックを分割することができます。異なるネットワークのメンバーであるようにポートを設定することで、スイッチを論理的に分割することができます。この設定により、ポートがミニ LAN になり、セキュリティーの目的でトラフィックを分割できるようになります。
たとえば、スイッチに 24 個のポートがある場合、ポート 1 - 6 を VLAN200 に、ポート 7-18 が VLAN201 に属するポートを定義できます。VLAN200 に接続されているコンピューターは、VLAN201 のコンピューターと完全に分離され、直接通信できなくなります。2 つの VLAN 間のトラフィックはすべて、2 つの別個の物理スイッチであるかのようにルーターを通過する必要があります。また、ファイアウォールでセキュリティーを強化することで、相互に通信できる VLAN を判断することもできます。
2.1.3. ファイアウォール
ファイアウォールは、IP ルーティングと同じ OSI レイヤーで動作します。多くの場合、それらはルーターと同じネットワークセグメントにあり、すべてのネットワーク間のトラフィックを制御します。ファイアウォールは、ネットワークに出入りできないトラフィックを規定する事前定義済みのルールセットを使用します。これらのルールは細かくすることができます。たとえば、VLAN 200 上のサーバーが VLAN201 上のコンピューターとのみ通信できるルールを定義でき、その後の水曜日ではしか、トラフィックが Web (HTTP)で、一方向に移動するルールを定義できます。
これらのルールを強制するために、一部のファイアウォールはステートフルパケット検査(SPI)も実行します。ここで、パケットの内容を調べて、それらが要求するものであることを確認します。ハッカーは、マスカレードが他のトラフィックとして送信することで、データを排出することが知られています。SPI は、その脅威を緩和するのに役立つ 1 つのメソッドです。
2.1.4. ブリッジ
ネットワークブリッジは、OSI モデルの同じレベル 2 で動作するスイッチですが、ルーターと同様に別個のネットワークを接続することのみが対象です。
2.2. OpenStack のネットワーク
OpenStack クラウドにおけるネットワークの基本概念すべて(サービスや設定で定義されていることを除く)これは、Software-Defined Networking (SDN)として知られています。仮想スイッチ(Open vSwitch)およびルーター(l3-agent)により、インスタンスが相互に通信できるようにし、物理ネットワークを使用して外部と通信できるようにします。Open vSwitch ブリッジは、仮想ポートをインスタンスに割り当て、物理ネットワークにまたがるスパンして送受信トラフィックを許可します。
2.3. ネットワークバックエンドの選択
Red Hat OpenStack Platform は、Nova ネットワーク(nova-network)と OpenStack Networking ( neutron)の 2 つの異なるネットワークバックエンドを提供します。
Nova のネットワークは OpenStack テクノロジーのロードマップで非推奨となりましたが、まだ利用可能です。OpenStack Networking は、OpenStack forward-looking ロードマップの中核となるソフトウェア定義ネットワーク(SDN)コンポーネントとみなされ、アクティブな開発段階となっています。
Nova ネットワークと OpenStack ネットワーク間の移行パスはありません。したがって、Nova ネットワークをデプロイして、将来的に OpenStack Networking に移行する予定の場合には、すべてのネットワークおよび設定を手動で移行する必要があります。この移行により、ネットワークが停止する可能性があります。
2.3.1. OpenStack Networking (neutron)を選択するタイミング
- overlay ネットワークソリューションが必要な場合。OpenStack Networking は、仮想マシンのトラフィックの分離に GRE または VXLAN トンネリングをサポートします。GRE または VXLAN では、ネットワークファブリックに VLAN を設定する必要はなく、物理ネットワークからの唯一の要件は、ノード間で IP 接続を提供することです。さらに、VXLAN または GRE では、802.1q VLAN ID の 4094 の制限よりもはるかに大きな固有 ID の理論上の一意の ID 制限が可能です。比較することで、Nova ネットワーキングは 802.1q VLAN 上でネットワークの分離をベースとし、GRE または VXLAN でのトンネリングをサポートしません。
- テナント間で IP アドレスが重複している場合OpenStack Networking は、Linux カーネルのネットワーク名前空間機能を使用します。これにより、重複や干渉のリスクなしに、同じコンピュートノード上の 192.168.100/24 などの同じサブネット範囲を使用することができます。これは、大規模なマルチテナンシーのデプロイメントに推奨されます。比較すると、Nova ネットワークは、すべてのテナントで使用されるサブネットには留意する必要のあるフラットトポロジーのみをサポートします。
Red Hat 認定のサードパーティーの OpenStack Networking プラグインが必要な場合デフォルトでは、Red Hat Enterprise Linux OpenStack Platform 5 以降では、Open vSwitch (OVS)メカニズムドライバーを備えたオープンソースの ML2 コアプラグインを使用します。物理ネットワークファブリックおよびその他のネットワーク要件に基づいて、デフォルトの ML2/Open vSwitch ドライバーの代わりにサードパーティーの OpenStack Networking プラグインをデプロイできます。
注記Red Hat は、Red Hat OpenStack Platform に対してより多くの OpenStack Networking プラグインを認定するためのパートナー認定プログラムの改善を常に取り組んでいます。認定プログラムと認定 OpenStack Networking プラグインの詳細は、http://marketplace.redhat.comを参照してください。
- VPNaaS (VPNaaS)、Firewall-as-a-service (FWaaS)、または Load-Balancing-as-a-service (LBaaS)が必要な場合。これらのネットワークサービスは OpenStack Networking でのみ利用でき、Nova ネットワークでは使用できません。ダッシュボードでは、テナントは管理者の介入なしにこれらのサービスを管理できます。
2.3.2. Nova ネットワーキング(nova-network)を選択するタイミング
- デプロイメントにフラット(タグなし)または VLAN (802.1q タグ付き)ネットワークが必要な場合。この種のデプロイメントは、理論上のスケール制限の 4094 VLAN ID は通常、物理スイッチの制限よりも高いので、管理要件とプロビジョニングの要件に対応することを意味します。ノード間で必要な VLAN セットをトランク接続するには、物理ネットワークで特定の設定が必要です。
- デプロイでテナント間で IP アドレスが重複している必要がない場合。通常、これは小規模なプライベートデプロイメントでのみ推奨されます。
- ソフトウェア定義ネットワーク(SDN)ソリューションが必要ない場合、または物理ネットワークファブリックと対話する機能が必要ない場合。
- セルフサービスの VPN、ファイアウォール、または負荷分散サービスが必要ない場合。
2.4. 高度な OpenStack Networking の概念
2.4.1. レイヤー 3 高可用性
OpenStack Networking は、集中型ネットワークノード(仮想ネットワークコンポーネントをホストする機能専用の物理サーバー)上で仮想ルーターをホストします。これらの仮想ルーターは、仮想マシンとの間のトラフィックを転送し、環境の継続的な接続に不可欠です。多くの理由で物理サーバーが停止する可能性があるため、ネットワークノードが使用できなくなった場合に仮想マシンの停止に対して脆弱になる可能性があります。
OpenStack Networking はレイヤー 3 高可用性を使用してこの脆弱性を軽減し、業界標準の VRRP を実装して仮想ルーターと Floating IP アドレスを保護します。レイヤー 3 高可用性により、テナントの仮想ルーターは複数の物理ネットワークノードに無作為に分散され、1 つのルーターがアクティブなルーターとして指定され、1 つのルーターがスタンバイルーターとして指定され、アクティブなルーターをホストするネットワークノードが停止した場合に引き継ぐ準備が整います。
レイヤー 3 は、この機能が機能する OSI モデルのセクションを指し、ルーティングおよび IP アドレス指定を保護することができることを意味します。
詳細は、Networking Guide のLayer 3 High Availability セクションを参照してください。
2.4.2. Load Balancing-as-a-Service (LBaaS)
Load Balancing-as-a-Service (LBaaS)は、受信したネットワーク要求を指定のインスタンス間で均等に分散できるようにします。この分散により、ワークロードがインスタンス間で共有され、システムリソースをより効果的に使用できます。受け取った要求は、以下の負荷分散メソッドの 1 つを使用して分散されます。
- ラウンドロビン
- 複数のインスタンス間で要求を均等にローテーションします。
- ソース IP
- 一意のソース IP アドレスからの要求は、常に同じインスタンスに転送されます。
- 最小限の接続
- アクティブな接続の数が最も少ないインスタンスにリクエストを割り当てます。
詳細は、ネットワークガイド の Load Balancing-as-a-Service の設定セクションを参照してください。
2.4.3. IPv6
OpenStack Networking はテナントネットワークの IPv6 アドレスをサポートしているため、IPv6 アドレスを仮想マシンに動的に割り当てることができます。また、OpenStack Networking は物理ルーター上で SLAAC と統合することができます。これにより、仮想マシンは既存の DHCP インフラストラクチャーから IPv6 アドレスを受け取ることができます。
詳細は、ネットワークガイドの IPv6 セクションを参照してください。
第3章 設計
本項では、Red Hat OpenStack Platform デプロイメントを設計する際の技術的および運用上の考慮事項について説明します。
本ガイドのすべてのアーキテクチャー例は、KVM ハイパーバイザーを使用して Red Hat Enterprise Linux 7.2 に OpenStack Platform をデプロイすることを前提としています。
3.1. プランニングモデル
Red Hat OpenStack Platform デプロイメントを設計する場合、プロジェクトの期間はデプロイメントの設定やリソースの割り当てに影響を及ぼす可能性があります。プランニングモデルごとに、異なる目標を達成する場合があるため、異なる考慮事項が必要です。
3.1.1. 短期モデル(3 カ月)
短期間の容量計画や予測を実行するには、以下のメトリクスの記録をキャプチャーすることを検討してください。
- vCPU の合計数
- vRAM 割り当ての合計
- I/O によるレイテンシー
- ネットワークトラフィック
- コンピュート負荷
- ストレージの割り当て
vCPU、vRAM、およびレイテンシーメトリクスは、容量計画で最もアクセス可能です。これらの詳細を使用すると、標準の 2 次回帰を適用し、次の 3 カ月をカバーする使用可能な容量予測を受け取ることができます。この見積もりを使用して、追加のハードウェアをデプロイする必要があるかどうかを判断します。
3.1.2. 中間モデル(6 カ月)
このモデルでは反復を確認し、予測傾向と実際の使用量から偏差を予測する必要があります。この情報は、標準の統計ツールを使用して、または Nash-Sutcliffe などの特殊な分析モデルで分析できます。傾向は、2 次回帰を使用して計算することもできます。
vCPU と vRAM のメトリックを単一のメトリクスとして扱うと、複数のインスタンスフレーバーを持つデプロイメントでは、vRAM および vCPU の使用をより簡単に相関させることができます。
3.1.3. 長期モデル(1 年)
リソースの合計使用量は 1 年間で異なる可能性があり、通常は元の長期容量推定値によって偏差が発生します。したがって、2 次回帰は、特に使用が周期的な場合に、キャパシティー予測には不十分な測定となる可能性があります。
長期デプロイメントを計画する際には、1 年以上にわたるデータに基づいた容量計画モデルが、少なくとも最初の派生値に適合する必要があります。利用パターンによっては、周波数分析が必要になる場合があります。
3.2. コンピュートリソース
コンピュートリソースは OpenStack クラウドの中核となります。したがって、Red Hat OpenStack Platform のデプロイメントを設計する場合は、物理および仮想リソースの割り当て、分散、フェイルオーバー、および追加のデバイスを考慮することを推奨します。
3.2.1. 一般的な考慮事項
- 各ハイパーバイザーのプロセッサー、メモリー、およびストレージの数
プロセッサーコアおよびスレッドの数は、コンピュートノード上で実行できるワーカースレッドの数に直接影響を与えます。したがって、サービスに基づいて、すべてのサービスのバランスの取れたインフラストラクチャーに基づいて設計を決定する必要があります。
ワークロードプロファイルに応じて、後でクラウドに追加のコンピュートリソースプールを追加できます。場合によっては、特定のインスタンスフレーバーでの需要は、個々のハードウェア設計を正当化しない可能性があり、代わりに商品化されたシステムが優先されます。
いずれの場合も、共通のインスタンス要求に対応することができるハードウェアリソースを割り当てて、設計を開始します。アーキテクチャー全体にハードウェア設計を追加する場合は、後でこれを行うことができます。
- プロセッサータイプ
ハードウェア設計では、特に異なるプロセッサーの機能とパフォーマンス特性を比較する場合に、プロセッサーの選択が重要な考慮事項となります。
プロセッサーには、ハードウェア支援型仮想化やメモリーのページング、EPT シャドウテクノロジーなどの仮想化コンピュートホスト専用の機能を含めることができます。これらの機能は、クラウド仮想マシンのパフォーマンスに大きく影響する可能性があります。
- リソースノード
- クラウド内のハイパーバイザー以外のリソースノードの Compute 要件を考慮する必要があります。リソースノードには、Object Storage、Block Storage、および Networking サービスを実行するコントローラーノードおよびノードが含まれます。
- リソースプール
オンデマンドで提供されるリソースのプールを複数割り当てる Compute 設計を使用します。この設計は、クラウドでのアプリケーションリソース使用量を最大化します。各リソースプールは、インスタンスまたはフレーバーのグループの特定のフレーバーにサービスする必要があります。
複数のリソースプールを設計することで、インスタンスがコンピュートハイパーバイザーにスケジュールされるたびに、ノードリソースの各セットが割り当てられ、利用可能なハードウェアの使用を最大化することができます。通常、これは bin packing と呼ばれます。
リソースプール内のノード間で一貫性のあるハードウェア設計を使用すると、bin パックをサポートするのにも役立ちます。コンピュートリソースプール用に選択したハードウェアノードは、共通のプロセッサー、メモリー、およびストレージレイアウトを共有する必要があります。一般的なハードウェア設計を選択すると、デプロイメント、サポート、およびノードのライフサイクルのメンテナンスが容易になります。
- オーバーコミット率
OpenStack では、ユーザーはコンピュートノードで CPU および RAM をオーバーコミットすることができます。これは、クラウドで実行されるインスタンスの数を増やすのに役立ちます。ただし、オーバーコミットすると、インスタンスのパフォーマンスが低下する可能性があります。
オーバーコミット率は、利用可能な仮想リソースと利用可能な物理リソースの割合です。
- デフォルトの CPU 割り当て比率は、16:1 では、スケジューラーはすべての物理コアに最大 16 個の仮想コアを割り当てます。たとえば、物理ノードに 12 コアがある場合、スケジューラーは最大 192 個の仮想コアを割り当てることができます。インスタンスごとに 4 つの仮想コアの通常のフレーバー定義により、この比率では物理ノード上で 48 つのインスタンスを提供することができます。
- デフォルトの RAM 割り当て比率の 1.5:1 は、インスタンスに関連付けられた RAM の合計量が物理ノード上では 1.5 倍未満の場合に、スケジューラーはインスタンスを物理ノードに割り当てることを意味します。
設計フェーズで CPU とメモリーのオーバーコミット率を調整することは、コンピュートノードのハードウェアレイアウトに直接影響を与えるので、重要です。ハードウェアノードを、インスタンスに対するコンピュートリソースプールとして設計する場合には、ノードで利用可能なプロセッサーコアの数だけでなく、十分な容量で実行されるサービスインスタンスに必要なディスクおよびメモリーも検討してください。
たとえば、m1.small インスタンスは 1 つの vCPU、20 GB の一時ストレージ、および 2,048 MB のメモリーを使用します。それぞれ 10 コアで 2 つの CPU を搭載したサーバーの場合、ハイパースレッディングをオンにします。
- デフォルトの CPU オーバーコミット比率が 16:1 の場合、合計 m1.small インスタンスに対して 640 (2 × 10 × 16)が許可されます。
- デフォルトのメモリーが 1.5:1 の場合は、サーバーに 853 GB (640 × 2,048 MB / 1.5)以上の RAM が必要です。
メモリー用のノードのサイジング時には、オペレーティングシステムおよびサービスのニーズに必要とされる追加のメモリーも考慮することが重要です。
3.2.2. Flavors
作成する各インスタンスには、インスタンスのサイズや容量を決定するフレーバーまたはリソースのテンプレートが提供されます。フレーバーは、セカンダリー一時ストレージ、スワップディスク、使用量を制限するメタデータ、または特別なプロジェクトアクセスを指定することもできます。デフォルトのフレーバーには、これらの追加属性が定義されていません。インスタンスのフレーバーにより、容量予測が可能です。これは、一般的なユースケースは予測されるサイズで、アドホックにはサイズ設定ではないためです。
仮想マシンを物理ホストにパックしやすくするために、フレーバーのデフォルト選択で、すべてのディメンションにおいて、最大のフレーバーのサイズを半分(合計)します。フレーバーには、vCPU の半分、vRAM の半分、エフェメラルディスク領域の半分があります。後続の最大のフレーバーはそれぞれ、前のフレーバーの半分になります。
次の図は、汎用的なコンピューティング設計と、CPU 最適化のパックされたサーバーでのフレーバー割り当てを視覚的に示しています。
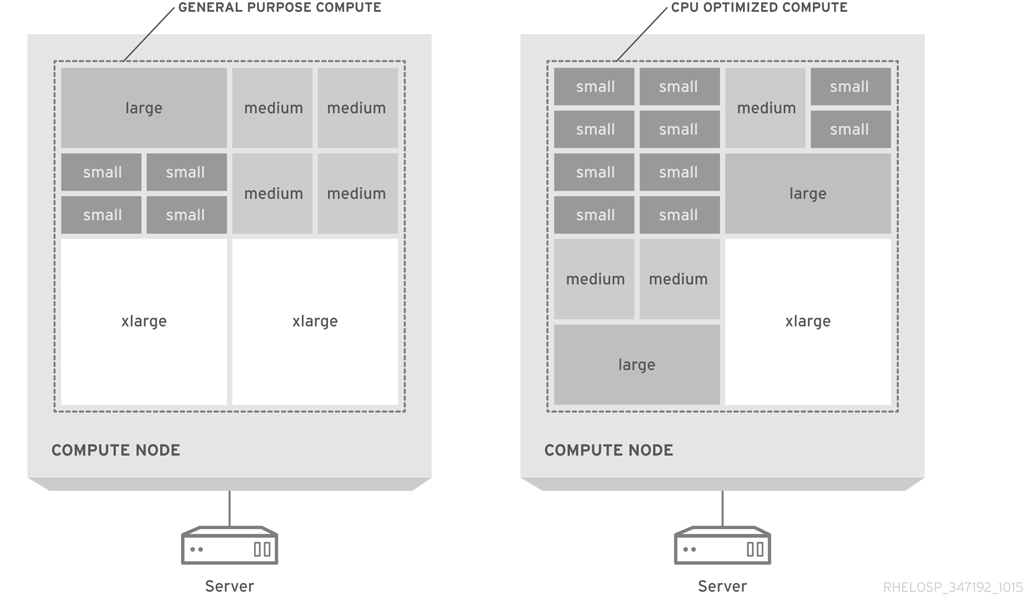
デフォルトのフレーバーは、コモディティーサーバーハードウェアの典型的な設定に適しています。使用率を最大化するには、フレーバーをカスタマイズしたり、新規フレーバーを作成してインスタンスサイズを利用可能なハードウェアに合わせたりする必要がある場合があります。
可能であれば、フレーバーを各フレーバーの 1 つの仮想 CPU に制限します。タイプ 1 ハイパーバイザーは、1 つの vCPU で設定された仮想マシンにとって、CPU 時間をより簡単にスケジュールできることに注意してください。たとえば、4 vCPU で設定されている仮想マシンに CPU 時間をスケジュールするハイパーバイザーは、タスクが 1 つの vCPU のみを実行する必要がある場合でも、4 つの物理コアが使用可能になるまで待機する必要があります。
ワークロードの特徴は、特に CPU、RAM、または HDD 要件の異なる比率をタスクの場合に、ハードウェアの選択とフレーバーの設定にも影響を与える可能性があります。フレーバーに関する情報は、インスタンスおよびイメージの管理 を 参照してください。
3.2.3. vCPU から物理への CPU コア比率
Red Hat OpenStack Platform のデフォルトの割り当て率は、物理(ハイパースレッディング)またはハイパースレッドごとに 16 vCPU です。
次の表に、システム用に予約されている 4GB など、使用可能な合計メモリーに基づいて物理ホストで適切に実行できる仮想マシンの最大数を示します。
| 合計 RAM | 仮想マシン | 合計仮想 CPU |
|---|---|---|
| 64 GB | 14 | 56 |
| 96 GB | 20 | 80 |
| 128 GB | 29 | 116 |
たとえば、60 インスタンスの最初の greenfields 表現を計画するには、3+1 コンピュートノードが必要です。通常、メモリーのボトルネックは CPU のボトルネックよりも一般的です。ただし、必要に応じて割り当て比率を物理コアごとに 8 vCPU に下げることができます。
3.2.4. メモリーのオーバーヘッド
KVM ハイパーバイザーには、共有不可能なメモリーなど、少量の仮想マシンメモリーのオーバーヘッドが必要です。QEMU/KVM システムの共有可能なメモリーは、各ハイパーバイザーで 200 MB に丸めることができます。
| vRAM | 物理メモリー使用量(平均) |
|---|---|
| 256 | 310 |
| 512 | 610 |
| 1024 | 1080 |
| 2048 | 2120 |
| 4096 | 4180 |
通常、仮想マシンごとに 100MB のハイパーバイザーのオーバーヘッドを予測できます。
3.2.5. オーバーサブスクリプション
メモリーは、ハイパーバイザーのデプロイメントの制限要素です。各物理ホストで実行できる仮想マシンの数は、ホストがアクセスできるメモリーの量によって制限されます。たとえば、256 GB の RAM、200 1 GB を超えるインスタンスを持つクアッドコア CPU をデプロイすると、パフォーマンスが低下します。したがって、インスタンス全体に分散するには、CPU コアとメモリーの最適な比率を慎重に決定する必要があります。
3.2.6. 密度
- インスタンスの密度
- コンピュート重視アーキテクチャーでは、インスタンスの密度は低くなります。つまり、CPU と RAM の過剰比も低くなります。特に設計でデュアルソケットハードウェア設計が使用されている場合は、インスタンスの密度が低い場合に、予想されるスケールをサポートするために、より多くのホストが必要になる場合があります。
- ホストの密度
- クアッドソケットプラットフォームを使用して、デュアルソケット設計のより高いホスト数に対応できます。このプラットフォームによりホストの密度が低下し、ラック数が増えます。この構成は、ネットワーク要件や電源接続の数に影響し、コロケーションの要件にも影響を及ぼす可能性があります。
- パワーと協調密度
- パワーと協調の密度の削減は、古いインフラストラクチャーを持つデータセンターにとって重要な考慮事項です。たとえば、2U、3U、または 4U サーバー設計の電源および協調密度の要件は、ホストの密度が低いため、ブレード、sled、または 1U サーバー設計よりも低い場合があります。
3.2.7. Compute ハードウェア
- ブレードサーバー
- ほとんどのブレードサーバーは、デュアルソケット、マルチコア CPU に対応します。CPU の制限を超えないようにするには、フル幅 または 全 負荷のブレードを選択します。これらのブレードタイプはサーバー密度を低下させることもできます。たとえば、HP BladeSystem や Dell PowerEdge M1000e などの高密度ブレードサーバーは、10 個のラックユニットでのみ最大 16 個のサーバーをサポートします。半次ブレードは、高密度のブレードとして 2 倍になり、第 10 のラックユニットごとに 8 台のサーバーしかありません。
- 1U サーバー
1U のラックマウント済みサーバー(ラックユニットを 1 つだけ使用する)は、ブレードサーバーソリューションよりも高いサーバー密度を提供する場合があります。1 つのラックに 40 台のユニットを 1U サーバーで使用すると、ラック(ToR)スイッチの上の領域を確保できます。比較すると、32 個のフル幅ブレードサーバーしか使用できません。1 つのラックでのみ使用できます。
ただし、主要なベンダーの 1U サーバーには、デュアルソケット、マルチコア CPU 設定のみがあります。1U のラックマウントフォーム要素でより高い CPU 設定をサポートするには、システムを元の設計メーカー(ODM)または第 2 層の製造元から購入します。
- 2U サーバー
- 2U ラックマウントサーバーでは、クアッドソケット、マルチコア CPU のサポートが提供されますが、サーバー密度は対応する減少です。2U のラックマウント済みサーバーは、1U のラックマウント済みサーバーが提供する密度の半分を提供します。
- 大規模なサーバー
- 4U サーバーなど、ラックマウントが大きいサーバーでは、多くの場合、高い CPU 容量が提供され、通常は 4 つ以上の CPU ソケットに対応します。これらのサーバーは拡張性が高くなっていますが、サーバーの密度が大幅に低く、多くの場合、より高価です。
- sled servers
あるサーバーは、単一の 2U または 3U ロボットで、複数の独立したサーバーをサポートするラックマウントサーバーです。これらのサーバーは、一般的な 1U または 2U のラックマウントされたサーバーよりも高い密度を提供します。
たとえば、多くのサーバーでは、合計 8 つの CPU ソケットに対して 2U に 4 つの独立したデュアルソケットノードを提供します。ただし、個々のノードでのデュアルソケットの制限については、追加のコストと設定の複雑さを補正するには十分ではない場合があります。
3.2.8. 追加デバイス
コンピュートノード用に、以下のような追加デバイスを検討する場合があります。
- 高性能コンピューティングジョブのグラフィックス処理ユニット(GPU)。
-
暗号化ルーチンのエントロピー不足を避ける、ハードウェアベースの乱数ジェネレーター。インスタンスイメージの属性と共に、乱数ジェネレーターデバイスをインスタンスに追加することができます。
/dev/randomはデフォルトのエントロピーソースです。 - データベース管理システムの読み取り/書き込み時間を最大化する一時ストレージ用の SSD。
- ホストアグリゲートは、ハードウェア類似点など、同様の特性を共有するホストをまとめてグループ化することで機能します。クラウドデプロイメントに固有のハードウェアを追加すると、各ノードのコストが追加される可能性があるため、すべてのコンピュートノードに追加のカスタマイズが必要であるか、またはサブセットのみが必要であるかを検討してください。
3.3. ストレージリソース
クラウドを設計する場合には、選択したストレージソリューションが、パフォーマンス、容量、可用性、相互運用性などのデプロイメントの重要な側面に影響します。
ストレージソリューションを選択する際には、次の要素を考慮してください。
3.3.1. 一般的な留意事項
- アプリケーション
アプリケーションは、クラウドストレージソリューションを効果的に使用するために、基盤となるストレージサブシステムを認識する必要があります。ネイティブで利用可能なレプリケーションが利用できない場合、操作担当者は、レプリケーションサービスを提供するようにアプリケーションを設定できる必要があります。
基盤となるストレージシステムを検出できるアプリケーションは、さまざまなインフラストラクチャーで機能し、基盤となるインフラストラクチャーの違いに関係なく、同じ基本的な動作を持ちます。
- I/O
入力出力パフォーマンスのベンチマークは、予想されるパフォーマンスレベルのベースラインを提供します。ベンチマーク結果データは、異なる負荷での動作をモデル化するのに役立ち、適切なアーキテクチャーを設計するのに役立ちます。
アーキテクチャーのライフサイクル中のスクリプト化されたベンチマークは、異なるタイミングでシステムの正常性を記録するのに役立ちます。スクリプト化されたベンチマークからのデータは、組織のニーズの範囲とより深い理解を支援します。
- 相互運用性
- 選択するハードウェアまたはストレージ管理プラットフォームが、KVM ハイパーバイザーなど、OpenStack コンポーネントと相互運用可能であるようにしてください。これは、短期間のインスタンスストレージに使用できるかどうかに影響します。
- セキュリティー
- データセキュリティー設計は、SLA、法的要件、業界規制、およびシステムまたは担当者に必要な認定に基づいて、さまざまな側面に集中できます。データのタイプに基づいて、HIPPA、ISO9000、または SOX に準拠することを検討してください。特定の組織では、アクセス制御レベルも考慮する必要があります。
3.3.2. OpenStack Object Storage (swift)
- 可用性
オブジェクトストレージリソースプールを設計して、オブジェクトデータに必要な可用性レベルを提供します。必要なレプリカの数に対応するように、ラックレベルとゾーンレベルの設計を検討してください。レプリカ数は 3 です。データの各レプリカは、特定のゾーンに対応する独立した電力、色付け、およびネットワークリソースを持つ個別のアベイラビリティーゾーンに存在する必要があります。
OpenStack Object Storage サービスは、特定の数のデータレプリカをリソースノード上のオブジェクトとして配置します。これらのレプリカは、クラスター内のすべてのノードに存在する一貫したハッシュリングに基づいてクラスター全体に分散されます。さらに、オブジェクトノードに保存されたデータへのアクセスを提供する Object Storage プロキシーサーバーのプールで、各アベイラビリティーゾーンにサービスを提供する必要があります。
レプリカの数に対して最低限必要な正常な応答を提供するのに十分な数のゾーンで Object Storage システムを設計します。たとえば、Swift クラスターに 3 つのレプリカを設定する場合、Object Storage クラスター内で設定するためのゾーンの推奨される数は 5 です。
より少ないゾーンでソリューションをデプロイすることはできますが、一部のデータは利用できず、クラスターに保存されている一部のオブジェクトへの API リクエストが失敗する場合があります。したがって、Object Storage クラスターのゾーンの数を考慮して、必ず考慮してください。
各リージョンのオブジェクトプロキシーは、ローカルの読み取りおよび書き込みアフィニティーを利用して、ローカルストレージリソースが可能な限りオブジェクトへのアクセスを容易にします。プロキシーサービスが複数のゾーンに分散されるようにするには、アップストリームの負荷分散をデプロイする必要があります。場合によっては、サービスの地理的な配布を支援するために、サードパーティーのソリューションが必要になる場合があります。
Object Storage クラスター内のゾーンは論理分割であり、単一のディスク、ノード、ノードのコレクション、複数のラック、または複数の DC で設定できます。利用可能な冗長なストレージシステムを提供する際に、Object Storage クラスターをスケーリングできるようにする必要があります。特定のゾーン内のストレージの設計に影響を与える可能性のあるレプリカ、保持、およびその他の要素について、異なる要件でストレージポリシーを設定する必要がある場合があります。
- ノードのストレージ
OpenStack Object Storage のハードウェアリソースを設計する場合の主な目標は、各リソースノードのストレージ量を最大化することを主な目標とし、さらにテラバイトあたりのコストを最小限に抑えることです。これには、多数の回転ディスクを保持できるサーバーを利用することが多くなります。2U サーバーフォームファクターを使用すると、ストレージが接続されているか、多数のドライブを保持する外部シャーシでも使用できます。
OpenStack Object Storage の一貫性とパーティション耐性の特性により、特殊なデータレプリケーションデバイスを必要とせずに、データが最新の状態に保たれ、ハードウェアの障害が維持されます。
- パフォーマンス
- オブジェクトストレージノードは、要求の数がクラスターのパフォーマンスを妨げないように設計する必要があります。オブジェクトストレージサービスはチャットプロトコルです。したがって、コア数が多い複数のプロセッサーを使用すると、IO リクエストがサーバーに対応していないようにします。
- 重み付けとコスト
OpenStack Object Storage は、swift リング内の重み付けとドライブを混在させ、一致する機能を提供します。swift ストレージクラスターを設計する場合は、最もコスト効果の高いストレージソリューションを使用できます。
多くのサーバーシャーシは、ラックスペースの 4U に 60 個以上のドライブを保持することができます。したがって、テラバイトあたりの最適なコストで、各ラックユニットのストレージの量を最大化できます。ただし、オブジェクトストレージノードで RAID コントローラーを使用することは推奨されません。
- スケーリング
ストレージソリューションを設計する場合は、Object Storage サービスが必要とする最大パーティションのべき乗を決定する必要があります。これにより、作成できるパーティションの最大数が決まります。オブジェクトストレージは、データをストレージクラスター全体に分散しますが、各パーティションは複数のディスクにまたがることができません。したがって、パーティションの最大数は、ディスクの数を超えることはできません。
たとえば、最初のディスクと 3 つのパーティションのべき乗があるシステムでは、8 つのパーティション(23)パーティションを保持できます。2 番目のディスクを追加すると、各ディスクに 4 つのパーティションを保持できます。パーティションごとの 1 つの制限は、このシステムに 8 つ以上のディスクを割り当てることができず、そのスケーラビリティが制限されることを意味します。ただし、最初のディスクと、パーティションのべき乗が 10 のシステムでは、最大 1024 (210)パーティションを使用できます。
システムバックエンドストレージ容量を増やすと、パーティションはストレージノード全体でデータを再分散します。場合によっては、このレプリケーションは非常に大きなデータセットで設定される場合があります。このような場合は、データへのテナントアクセスと競合しないバックエンドレプリケーションリンクを使用する必要があります。
より多くのテナントがクラスター内のデータへのアクセスを開始し、データセットが増加する場合には、データアクセスリクエストにフロントエンドの帯域幅を追加する必要があります。Object Storage クラスターにフロントエンド帯域幅を追加するには、テナントがデータへのアクセスを取得できるようにするオブジェクトストレージプロキシーと、プロキシー層のスケーリングを可能にする高可用性ソリューションを設計する必要があります。
クラスター内に保存されたデータにアクセスするためにテナントとコンシューマーが使用するフロントエンド負荷分散レイヤーを設計する必要があります。この負荷分散レイヤーは、ゾーン、リージョン、または地理的な境界に分散できます。
プロキシーサーバーとストレージノードの間で要求するネットワークリソースに、帯域幅および容量を追加する必要がある場合があります。したがって、ストレージノードとプロキシーサーバーへのアクセスを提供するネットワークアーキテクチャーはスケーラブルである必要があります。
3.3.3. OpenStack Block Storage (cinder)
- 可用性と冗長性
アプリケーションの 1 秒あたりの入出力(IOPS)要求により、RAID コントローラーを使用するかどうかと、必要な RAID レベルが決定されます。冗長性には、RAID 5、RAID 6 などの冗長 RAID 設定を使用する必要があります。ブロックストレージボリュームの自動レプリケーションなど、特殊な機能によっては、より高い需要に対応するためにサードパーティーのプラグインやエンタープライズブロックストレージソリューションが必要になる場合があります。
Block Storage に極端な需要がある環境では、複数のストレージプールを使用する必要があります。各デバイスプールは、そのプール内のすべてのハードウェアノードで同様のハードウェア設計とディスク設定が必要です。この設計により、アプリケーションは、さまざまな冗長性、可用性、およびパフォーマンス特性を持つさまざまな Block Storage プールにアクセスできます。
ネットワークアーキテクチャーは、インスタンスが利用可能なストレージリソースを使用するために必要な East-West 帯域幅も考慮する必要があります。選択したネットワークデバイスは、大量のデータを転送するジャンボフレームをサポートする必要があります。ネットワークリソースの負荷を軽減するために、インスタンスと Block Storage リソース間の接続を提供するために、さらに専用のバックエンドストレージネットワークを作成しないといけない場合があります。
複数のストレージプールをデプロイする場合は、リソースノード全体でストレージをプロビジョニングする Block Storage スケジューラーへの影響を考慮する必要があります。アプリケーションが、特定のネットワーク、電源、および共存するインフラストラクチャーを持つ複数のリージョンにボリュームをスケジュールできることを確認します。この設計により、テナントは複数のアベイラビリティーゾーンに分散されるフォールトトレランスアプリケーションをビルドできます。
Block Storage リソースノードに加えて、ストレージノードをプロビジョニングしてアクセスを提供する API および関連サービスの高可用性および冗長性を設計することが重要です。REST API サービスの高可用性を実現するために、ハードウェアまたはソフトウェアロードバランサーのレイヤーを設計し、中断しないサービスを提供する必要があります。
Block Storage ボリュームの状態を処理し、保存するバックエンドサービスサービスへのアクセスを提供するために、追加の負荷分散レイヤーをデプロイする必要がある場合があります。MariaDB や Galera 等の Block Storage データベースを保存するために、高可用性データベースソリューションを設計する必要があります。
- 割り当てられたストレージ
Block Storage サービスは、ハードウェアベンダーが開発したプラグインドライバーを使用するエンタープライズストレージソリューションを利用できます。OpenStack Block Storage と共に追加設定なしで提供される多数のエンタープライズプラグインは、サードパーティーのチャネルで利用できます。
汎用クラウドは通常、Block Storage ノードの大部分で直接接続されたストレージを使用します。したがって、追加のレベルのサービスをテナントに提供する必要がある場合があります。これらのレベルは、エンタープライズストレージソリューションのみが提供することができます。
- パフォーマンス
- より高いパフォーマンスが必要な場合は、高パフォーマンスの RAID ボリュームを使用できます。パフォーマンスが極端な場合は、高速ソリッドステートドライブ(SSD)ディスクを使用できます。
- Pools
- Block Storage プールでは、テナントがアプリケーションに適切なストレージソリューションを選択できるようにする必要があります。異なるタイプの複数のストレージプールを作成し、Block Storage サービス用の高度なストレージスケジューラーを設定することで、さまざまなパフォーマンスレベルと冗長性オプションを備えたストレージサービスの大規模なカタログをテナントに提供できます。
- スケーリング
Block Storage プールをアップグレードして、Block Storage サービス全体を中断することなくストレージ容量を追加できます。適切なハードウェアおよびソフトウェアをインストールおよび設定して、プールにノードを追加します。次に、メッセージバスを使用して適切なストレージプールに報告するように新規ノードを設定できます。
Block Storage ノードは、スケジューラーサービスにノードの可用性を報告するため、新規ノードがオンラインになり利用可能な場合に、テナントは新しいストレージリソースをすぐに使用できます。
インスタンスからの Block Storage への要求が、利用可能なネットワーク帯域幅を使い切られる場合があります。したがって、Block Storage リソースをサービスするようにネットワークインフラストラクチャーを設計して、容量と帯域幅をシームレスに追加する必要があります。
これには、ダウンストリームデバイスに容量を追加するための動的ルーティングプロトコルまたは高度なネットワークソリューションが必要になることがよくあります。フロントエンドおよびバックエンドストレージネットワーク設計には、容量と帯域幅を迅速かつ簡単に追加する機能が含まれている必要があります。
3.3.4. ストレージハードウェア
- Capacity
ノードハードウェアはクラウドサービスに十分なストレージをサポートする必要があり、デプロイ後に容量を追加できるようにする必要があります。ハードウェアノードは、RAID コントローラーカードに信頼のない多数の不安価なディスクをサポートする必要があります。
また、ハードウェアベースのストレージパフォーマンスと冗長性を提供するために、ハードウェアノードも高速ストレージソリューションと RAID コントローラーカードをサポートできる必要があります。破損したアレイを自動的に修復するハードウェア RAID コントローラーを選択すると、パフォーマンスが低下したストレージデバイスまたは破棄されたストレージデバイスの置き換えおよび修復に役立ちます。
- 接続性
- ストレージソリューションでイーサネット以外のストレージプロトコルを使用する場合は、ハードウェアがこれらのプロトコルを処理できることを確認してください。集中型のストレージアレイを選択する場合は、ハイパーバイザーがイメージストレージ用にそのストレージアレイに接続できることを確認してください。
- コスト
- ストレージは、全体的なシステムコストの大部分になる可能性があります。ベンダーのサポートが必要な場合は、商用ストレージソリューションが推奨されますが、費用が上がります。最初の金融の収益を最小限に抑える必要がある場合は、コモディティハードウェアに基づいてシステムを設計できます。ただし、初期保存により、サポートコストが増加し、互換性のリスクが高くなる可能性があります。
- 直接アタッチされたストレージ
- 直接接続ストレージ(DAS)は、サーバーハードウェアの選択に影響し、ホストの密度、インスタンスの密度、電源密度、OS ハイパーバイザー、管理ツールに影響します。
- スケーラビリティー
- スケーラビリティは、OpenStack クラウドで重要な考慮事項です。実装の最終目的サイズの予測が困難な場合があります。拡大およびユーザー需要に対応するために、初期デプロイメントを拡張することを検討してください。
- 拡張性
拡張性は、ストレージソリューションの主なアーキテクチャー係数です。50 PB に展開されるストレージソリューションは、10 PB まで拡張できるソリューションよりも拡張可能です。このメトリクスはスケーラビリティーとは異なります。これは、ワークロードの増加時のソリューションのパフォーマンス測定値です。
たとえば、開発プラットフォームクラウドのストレージアーキテクチャーでは、商用製品クラウドと同じ拡張性とスケーラビリティーが不要な場合があります。
- フォールトトレランス
オブジェクトストレージリソースノードには、ハードウェアのフォールトトレランスまたは RAID コントローラーは必要ありません。Object Storage サービスはデフォルトでゾーン間でレプリケーションを提供するため、Object Storage ハードウェアでのフォールトトレランスを計画する必要はありません。
ブロックストレージノード、コンピュートノード、およびクラウドコントローラーには、ハードウェア RAID コントローラーとさまざまなレベルの RAID 設定を使用するハードウェアレベルでフォールトトレランスを組み込む必要があります。RAID のレベルは、クラウドのパフォーマンスおよび可用性の要件と一致している必要があります。
- 場所
- インスタンスとイメージストレージの地理的な場所は、アーキテクチャー設計に影響を及ぼす可能性があります。
- パフォーマンス
Object Storage サービスを実行するディスクは、高速で実行されるディスクである必要はありません。したがって、ストレージのテラバイトあたりのコスト効率を最大化することができます。ただし、Block Storage サービスを実行するディスクは、高パフォーマンスの Block Storage プールを提供するために SSD またはフラッシュストレージを必要とする可能性のあるパフォーマンス重視機能を使用する必要があります。
インスタンスに使用する短期ディスクのストレージパフォーマンスも考慮する必要があります。コンピュートプールで短期的なストレージの使用率が必要な場合や、非常に高いパフォーマンスが必要な場合には、Block Storage 用にデプロイするソリューションと同様のハードウェアソリューションをデプロイする必要があります。
- サーバータイプ
- DAS を含むスケールアウトストレージアーキテクチャーは、サーバーハードウェアの選択に影響します。このアーキテクチャーは、ホストの密度、インスタンスの密度、電力密度、OS ハイパーバイザー、管理ツールなどにも影響します。
3.3.5. Ceph Storage
外部ストレージ用に Ceph を検討する場合、Ceph クラスターバックエンドのサイズを変更して、予想される同時仮想マシンの数を妥当なレイテンシーで処理する必要があります。許容可能なサービスレベルは、書き込み操作のために 20 ミリ秒以内に I/O 操作の 99% を維持し、読み取り操作では 10 ミリ秒未満に維持できます。
各 Rados Block Device (RBD)の最大帯域幅を設定するか、保証された最小コミットを設定して、I/O スパイクを他の仮想マシンから分離することができます。
3.4. ネットワークリソース
クラウドデプロイメントのハイパーバイザーでは、ネットワークの可用性が非常に重要です。たとえば、ハイパーバイザーが各ノードで少数の仮想マシン(VM)のみをサポートし、アプリケーションが高速ネットワークを必要としない場合は、1 つまたは 2 つの 1GB のイーサネットリンクを使用できます。ただし、アプリケーションで高速ネットワークが必要な場合や、ハイパーバイザーが各ノードに多くの仮想マシンをサポートする場合は、1 つまたは 2 つの 10GB のイーサネットリンクが推奨されます。
標準的なクラウドデプロイメントでは、通常、従来のコアネットワークトポロジーに必要なものよりも多くのピアから排他的ピア通信を使用します。VM はクラスター全体でランダムにプロビジョニングされますが、これらの仮想マシンは、同じネットワーク上にあるかのように相互に通信する必要があります。この要件は、エッジとネットワークのコア間のリンクが過剰にサブスクライブしているため、ネットワークの速度が低下し、従来のコアネットワークトポロジーでパケットロスを引き起こす可能性があります。
3.4.1. サービスの分離
OpenStack クラウドには従来、複数のネットワークセグメントがありました。各セグメントは、クラウド内のリソースへのアクセスを、オペレーターとテナントに提供します。ネットワークサービスには、他のネットワークとは別のネットワーク通信パスも必要です。サービスを別々のネットワークに分割すると、機密データを保護し、サービスへのアクセスから保護できます。
最小限推奨されるサフィゲーションには、以下のネットワークセグメントが含まれます。
- クラウド REST API にアクセスするためにテナントとオペレーターが使用するパブリックネットワークセグメント。通常、クラウド内のコントローラーノードと swift プロキシーのみが、このネットワークセグメントに接続する必要があります。場合によっては、このネットワークセグメントがハードウェアロードバランサーや他のネットワークデバイスがサービスを提供することもあります。
クラウド管理者がハードウェアリソースを管理し、ソフトウェアおよびサービスを新しいハードウェアにデプロイする設定管理ツールによって使用される管理ネットワークセグメント。場合によっては、このネットワークセグメントは、相互に通信する必要のあるメッセージバスやデータベースサービスなど、内部サービスにも使用される場合があります。
このネットワークセグメントのセキュリティー要件により、このネットワークを不正アクセスから保護することが推奨されます。このネットワークセグメントは通常、クラウド内のすべてのハードウェアノードと通信する必要があります。
アプリケーションとコンシューマーが物理ネットワークへのアクセスを提供し、ユーザーがクラウドで実行しているアプリケーションにアクセスするために使用するアプリケーションネットワークセグメント。このネットワークは、パブリックネットワークセグメントから分離する必要があり、クラウドのハードウェアリソースと直接通信しないでください。
このネットワークセグメントは、アプリケーションデータをクラウド外の物理ネットワークに転送するコンピュートリソースノードおよびネットワークゲートウェイサービスによる通信に使用できます。
3.4.2. ネットワークタイプを選択します。
選択するネットワーク種別は、クラウドネットワークアーキテクチャーの設計において重要なロールを果たします。
- OpenStack Networking (neutron)は、OpenStack forward-looking ロードマップの中核となるソフトウェア定義ネットワーク(SDN)のコンポーネントで、現在開発中です。
- コンピューティングネットワーク(nova-network)は、OpenStack テクノロジーのロードマップでは非推奨でしたが、現在はまだ利用可能です。
コンピュートネットワークと OpenStack Networking の間に移行パスはありません。したがって、コンピュートネットワークをデプロイする場合には、OpenStack Networking にアップグレードすることはできません。また、ネットワーク種別間の移行は手動で行う必要があり、ネットワークの停止が必要になります。
3.4.2.1. OpenStack Networking (neutron)を選択するタイミング
以下の機能のいずれかが必要な場合は、OpenStack Networking を選択します。
Overlay ネットワークソリューション。OpenStack Networking は、仮想マシンのトラフィックの分離に GRE および VXLAN トンネリングをサポートします。GRE または VXLAN は、ネットワークファブリック上の VLAN 設定を必要としません。ノード間で IP 接続を提供するのに物理ネットワークのみを必要とします。
また、VXLAN または GRE では、802.1q VLAN 上の 4094 固有の ID 制限と比較して、理論上の固有 ID の 1,600万固有の ID を許可します。コンピューティングネットワークは、802.1q VLAN でネットワークの分離をベースとし、GRE または VXLAN によるトンネリングをサポートしません。
テナント間で IP アドレスが重複している。OpenStack Networking は、Linux カーネルのネットワーク名前空間機能を使用します。これにより、重複や干渉のリスクなしに、同じコンピュートノード上の 192.168.100/24 などの同じサブネット範囲を使用することができます。この機能は、大規模なマルチテナンシーのデプロイメントに適しています。
比較により、コンピュートネットワークは、すべてのテナントが使用するサブネットを認識しておく必要のあるフラットトポロジーのみを提供します。
Red Hat 認定のサードパーティーの OpenStack Networking プラグイン。デフォルトでは、Red Hat OpenStack Platform はオープンソースの ML2 コアプラグインと Open vSwitch (OVS)メカニズムドライバーを使用します。OpenStack Networking のモジュラー構造では、物理ネットワークファブリックやその他のネットワーク要件に基づいて、デフォルトの ML2/Open vSwitch ドライバーの代わりに、サードパーティーの OpenStack Networking プラグインをデプロイすることができます。
Red Hat は、パートナー認定プログラムを拡張して、Red Hat OpenStack Platform 用のより多くの OpenStack Networking プラグインを認定しています。認定プログラムの詳細と、認定された OpenStack Networking プラグインのリストは、http://marketplace.redhat.comを参照してください。
- VPN-as-a-service (VPNaaS)、Firewall-as-a-service (FWaaS)、または Load-Balancing-as-a-service (LBaaS)。これらのネットワークサービスは OpenStack Networking でのみ利用でき、コンピュートネットワークでは使用できません。ダッシュボードでは、テナントは管理者の介入なしにこれらのサービスを管理できます。
3.4.2.2. Compute Networking (nova-network)を選択するタイミング
Compute Networking (nova-network)サービスは、主に 2 つのモードで動作するレイヤー 2 ネットワークサービスです。これらのモードは、VLAN の使用方法によって異なります。
- フラットネットワークモード。クラウド全体のすべてのネットワークハードウェアノードおよびデバイスは、アプリケーションデータへのアクセスを提供する単一のレイヤー 2 ネットワークセグメントに接続されます。
- VLAN セグメンテーションモード。クラウド内のネットワークデバイスが VLAN によるセグメンテーションをサポートする場合、クラウド内の各テナントには、物理ネットワーク上の VLAN にマッピングされたネットワークサブネットが割り当てられます。クラウド設計が複数のテナントをサポートし、コンピュートネットワークを使用する必要がある場合は、このモードを使用する必要があります。
コンピューティングネットワークは、クラウドオペレーターによってのみ管理されます。テナントはネットワークリソースを制御できません。テナントがネットワークセグメントやサブネット等のネットワークリソースを管理および作成する必要がある場合は、インスタンスへのネットワークアクセスを提供するために OpenStack Networking サービスをインストールする必要があります。
次の場合は、Compute Networking を選択します。
- デプロイメントに、フラットなタグなしネットワークまたはタグ付けされた VLAN 802.1q ネットワークが必要な場合ネットワークトポロジーは理論的なスケールを 4094 の VLAN ID に制限し、物理スイッチは通常はるかに少ない数をサポートすることに注意してください。このネットワークにより、管理およびプロビジョニングの制限も軽減されます。ノード間で必要な VLAN セットをトランク接続するようにネットワークを手動で設定する必要があります。
- デプロイでテナント間で IP アドレスが重複している必要がない場合。これは通常、小規模なプライベートデプロイメントにのみ適しています。
- Software Defined Networking (SDN)ソリューションや物理ネットワークファブリックとの対話機能が必要ない場合。
- セルフサービスの VPN、ファイアウォール、または負荷分散サービスが必要ない場合。
3.4.3. 一般的な留意事項
- セキュリティー
ネットワークサービスを分離し、トラフィックが不要な場所を越えずに適切な宛先に流れるようにします。
以下の要素の例を見てみましょう。
- ファイアウォール
- 分離したテナントネットワークを結合するためのオーバーレイ相互接続
- 特定のネットワークを介したルーティングまたは回避
ネットワークがハイパーバイザーにアタッチされると、セキュリティーの脆弱性が漏洩する可能性があります。ハイパーバイザーが侵入するのを軽減するには、他のシステムから複数のネットワークを切り離し、ネットワークのインスタンスを専用のコンピュートノードにスケジュールします。このように分離することで、攻撃者は侵害されたインスタンスからネットワークにアクセスするのを防ぐことができます。
- 容量のプランニング
- クラウドネットワークには、容量と拡張管理が必要です。容量計画には、ネットワーク回路の購入や、数カ月または数週間で測定できるリードタイムのハードウェアを含めることができます。
- 複雑性
- 複雑なネットワーク設計は、保守とトラブルシューティングが難しい場合があります。デバイスレベルの設定はメンテナンスに関する懸念が容易になり、自動化されたツールはオーバーレイネットワークを処理できますが、機能と特殊ハードウェア間の非分割的な相互接続を回避または文書化して、停止を防ぎます。
- 設定エラー
- 誤った IP アドレス、VLAN、またはルーターを設定すると、ネットワーク領域やクラウドインフラストラクチャー全体でも停止する可能性があります。ネットワーク設定を自動化し、ネットワークの可用性を妨げる Operator エラーを最小限に抑えることができます。
- 標準以外の機能
ベンダー固有の機能を利用するようにクラウドネットワークを設定すると、追加のリスクが発生する可能性があります。
たとえば、マルチリンクアグリゲーション(MLAG)を使用して、ネットワークのアグリゲータースイッチレベルで冗長性を提供することができます。MLAG は標準の集約形式ではなく、各ベンダーはその機能のプロプライエタリーフレーバーを実装します。スイッチベンダー間で MLAG アーキテクチャーは相互運用できないため、ベンダーのロックが発生し、ネットワークコンポーネントのアップグレード時に遅延や問題が発生する可能性があります。
- 単一障害点
- ネットワークに、アップストリームリンクが 1 つしかないために、SPOF (Single Point Failure)があり、電源が 1 つしかない場合は、障害が発生した場合にネットワークが停止する可能性があります。
- チューニング
- リンクロス、パケットロス、パケットステルム、ブロードキャストステルム、ループを最小限に抑えるようにクラウドネットワークを設定します。
3.4.4. ネットワークハードウェア
ネットワークハードウェアがすべての実装に適用できる OpenStack クラウドをサポートするための、単一のベストプラクティスアーキテクチャーはありません。ネットワークハードウェアを選択する際の主要な考慮事項は次のとおりです。
- 可用性
中断されないクラウドノードのアクセスを確保するには、ネットワークアーキテクチャーは単一障害点を特定し、適切な冗長性またはフォールトトレランスを提供する必要があります。
- ネットワークの冗長性は、冗長な電源供給またはペアスイッチを追加することで実現できます。
- ネットワークインフラストラクチャーでは、LACP、VRRP などのネットワークプロトコルを使用して、高可用性ネットワーク接続を実現することができます。
- OpenStack API とクラウド内の他のサービスが高可用性であることを確認するには、ネットワークアーキテクチャー内で負荷分散ソリューションを設計する必要があります。
- 接続性
- OpenStack クラウド内のすべてのノードには、ネットワーク接続が必要です。場合によっては、ノードが複数のネットワークセグメントにアクセスする必要がある場合があります。設計には、クラウドのすべての north-south および east-west トラフィックに十分なリソースが含まれるように、十分なネットワーク容量と帯域幅を含める必要があります。
- ポート
設計には、必要なポートを持つネットワークハードウェアが必要です。
- ポートの提供に必要な物理領域があることを確認します。コンピュートまたはストレージコンポーネント用により多くのラックスペースを残すため、ポートの密度が高くなることが優先されます。適切なポートの可用性は、障害ドメインを防ぎ、電力密度を支援します。より高い密度のスイッチはより高価で、ネットワークが必要ない場合は、ネットワークをオーバー署名しないことが重要です。
- ネットワークハードウェアは、提案されたネットワーク速度をサポートしている必要があります。たとえば、1 GbE、10 GbE、または 40 GbE (または 100 GbE)です。
- Power
- 選択したネットワークハードウェアに必要な電源が物理データセンターが提供することを確認します。たとえば、リーフアンドスピーンのファブリックまたは行末(EoR)スイッチのスパインスイッチでは、十分な電力が得られない可能性があります。
- スケーラビリティー
- ネットワーク設計には、スケーラブルな物理ネットワークおよび論理ネットワーク設計が含まれている必要があります。ネットワークハードウェアは、ハードウェアノードが必要とするインターフェイスの種類と速度を提供する必要があります。
3.5. パフォーマンス
OpenStack デプロイメントのパフォーマンスは、インフラストラクチャーサービスとコントローラーサービスに関連する複数の要因によって異なります。ユーザー要件は、ネットワークパフォーマンス、コンピュートリソースのパフォーマンス、およびストレージシステムのパフォーマンスに分割できます。
これらのシステムが低速ではない状態で一貫して動作する場合でも、システムの過去のパフォーマンスベースラインを保持するようにしてください。利用可能なベースライン情報は、パフォーマンスの問題が発生し、比較目的でデータが必要な場合に役立つリファレンスです。
「OpenStack Telemetry (ceilometer)」 に加え、外部ソフトウェアを使用してパフォーマンスを追跡することもできます。Red Hat OpenStack Platform の Operational Tools リポジトリーには、以下のツールが含まれています。
3.5.1. ネットワークパフォーマンス
ネットワーク要件は、パフォーマンス機能を決定するのに役立ちます。たとえば、小規模なデプロイメントでは 1 ギガビットイーサネット(GbE)ネットワークを使用する可能性があり、複数の部門に対応する大容量インストールや、多くのユーザーが 10 GbE ネットワークを使用する必要があります。
実行中のインスタンスのパフォーマンスは、これらのネットワーク速度により制限される可能性があります。ネットワーク機能の組み合わせを実行する OpenStack 環境を設計することができます。異なるインターフェイス速度を利用することで、OpenStack 環境のユーザーは目的に合ったネットワークを選択できます。
たとえば、Web アプリケーションインスタンスは、1 GbE 機能を持つ OpenStack Networking を使用してパブリックネットワーク上で実行でき、バックエンドデータベースは、10 GbE 機能を備えた OpenStack Networking ネットワークを使用して、そのデータを複製できます。場合によっては、設計にはリンクアグリゲーションを組み込むことで、スループットを向上させることができます。
クラウド API にフロントエンドサービスを提供するハードウェアロードバランサーを実装することで、ネットワークパフォーマンスを向上させることができます。ハードウェアロードバランサーは、必要に応じて SSL ターミネーションを実行することもできます。SSL オフロードを実装する場合は、選択したデバイスの SSL オフロード機能を確認することが重要です。
3.5.2. コンピュートノードのパフォーマンス
CPU、メモリー、ディスクタイプなど、コンピュートノードで使用されるハードウェア仕様は、インスタンスのパフォーマンスに直接影響を及ぼします。OpenStack サービスの調整可能なパラメーターは、パフォーマンスに直接影響を与える可能性があります。
たとえば、OpenStack Compute のデフォルトのオーバーコミット率は、CPU の場合は 16:1、メモリーの場合は 1.5 です。これらの比率が高いと、noisy-neighbor アクティビティーが増える可能性があります。このシナリオを回避し、使用状況が増加したら環境を監視するように、コンピュート環境のサイズを慎重に検討する必要があります。
3.5.3. Block Storage Hosts のパフォーマンス
Block Storage は、NetApp または EMC などのエンタープライズバックエンドシステムや Ceph 等のスケールアウトストレージを使用する、または Block Storage ノードで直接接続されたストレージの機能を利用できます。
Block Storage をデプロイして、トラフィックがホストネットワークを通過できるようにすることができます。これは影響を受ける可能性があり、フロントサイド API トラフィックのパフォーマンスに悪影響を受ける可能性があります。したがって、コントローラーおよびコンピュートホスト上の専用のインターフェイスでデータストレージネットワークを使用することを検討してください。
3.5.4. オブジェクトストレージホストのパフォーマンス
ユーザーは通常、ハードウェアロードバランサーの背後で実行されるプロキシーサービスを介してオブジェクトストレージにアクセスします。デフォルトで、高度に回復性のあるストレージシステムは、保存されたデータを複製します。これにより、システム全体のパフォーマンスに影響を与える可能性があります。この場合、ストレージネットワークアーキテクチャー全体で 10 GbE 以上のネットワーク容量が推奨されます。
3.5.5. コントローラーノード
コントローラーノードは、エンドユーザーに管理サービスを提供し、クラウド操作の内部にあるサービスを提供します。コントローラーインフラストラクチャーを実行するために使用されるハードウェアを慎重に設計することが重要です。
コントローラーは、サービス間のシステムメッセージング用にメッセージキューサービスを実行します。メッセージングのパフォーマンスの問題により、インスタンスのスピンアップや削除、新しいストレージボリュームのプロビジョニング、およびネットワークリソースの管理などの運用機能が遅延する可能性があります。これらの遅延は、特に自動スケーリング機能を使用する場合に、アプリケーションが一部の状態に対応する能力に悪影響を与える可能性があります。
また、コントローラーノードが複数の同時ユーザーのワークロードを処理できるようにする必要があります。顧客のサービスの信頼性を向上させるために、API および Horizon サービスの負荷を確実にテストしてください。
OpenStack Identity サービス(keystone)を考慮することが重要です。OpenStack Identity サービス(keystone)は、すべてのサービスを内部的に OpenStack およびエンドユーザーに提供します。このサービスにより、サイズが適切に行われない場合、全体的なパフォーマンスが低下する可能性があります。
監視が重要なメトリクスには以下が含まれます。
- イメージディスクの使用率
- Compute API への応答時間
3.6. メンテナンスとサポート
インストールをサポートおよび維持するには、OpenStack クラウド管理では、アーキテクチャー設計を理解するために運用スタッフが必要です。操作とエンジニアリングスタッフ間のスキルレベルとロールの分離は、インストールのサイズと目的によって異なります。
- 大規模なクラウドサービスプロバイダー、またはテレコネクトプロバイダーは、特別にトレードされた専用操作組織によって管理される可能性が高くなります。
- 実装は、エンジニアリング、設計、および操作を組み合わせる必要があるサポートスタッフに依存する可能性が高くなります。
設計に操作のオーバーヘッドを軽減する機能を組み込む場合は、一部の運用機能を自動化できる可能性があります。
設計内容は、サービスレベルアグリーメント(SLA)の条件によって直接影響を受けます。SLA は、サービスの可用性レベルを定義し、契約上の義務を満たさない場合は通常ペナルティーを含みます。設計に影響する SLA 用語には、以下が含まれます。
- API の可用性は、複数のインフラストラクチャーサービスと高可用性ロードバランサーを意味することを保証します。
- ネットワークアップタイムは、スイッチ設計に影響があり、冗長なスイッチと電源を必要とする可能性があることを保証します。
- ネットワークの分離または追加のセキュリティーメカニズムを簡素化するネットワークポリシー要件。
3.6.1. バックアップ
設計は、バックアップおよび復元ストラテジー、データ評価または階層的なストレージ管理、保持戦略、データの配置、およびワークフローの自動化の影響を受ける可能性があります。
3.6.2. ダウンタイム
効果的なクラウドアーキテクチャーは以下をサポートする必要があります。
- 計画停止時間(maintenance)
- 予定外のダウンタイム(システム障害)
たとえば、コンピュートホストに障害が発生した場合、インスタンスはスナップショットから復元されるか、インスタンスを再起動することができます。ただし、高可用性については、共有ストレージや信頼性の高い移行パスの設計などの追加のサポートサービスをデプロイする必要がある場合があります。
3.7. 可用性
OpenStack は、少なくとも 2 つのサーバーを使用する場合、高可用性のデプロイメントを提供できます。サーバーは、RabbitMQ メッセージキューサービスおよび MariaDB データベースサービスからすべてのサービスを実行できます。
クラウド内でサービスをスケーリングする場合、バックエンドサービスもスケーリングする必要があります。サーバーの使用状況と応答時間、およびシステムの負荷テストの監視と報告は、スケーリングの決定に役立ちます。
- 単一障害点を避けるために、OpenStack サービスは複数のサーバーにまたがってデプロイする必要があります。これらのサービスをメンバーとして複数の OpenStack サーバーを持つ高可用性ロードバランサーの背後に配置すると、API の可用性を実現できます。
- デプロイメントに十分なバックアップ機能があることを確認します。たとえば、高可用性を使用する 2 つのインフラストラクチャーコントローラーノードを持つデプロイメントでは、1 つのコントローラーが失われた場合でも、もう一方のコントローラーからクラウドサービスを実行できます。
- OpenStack インフラストラクチャーはサービスを提供することが必須であり、特に SLA を操作する場合には常に利用可能でなければなりません。コアインフラストラクチャーに必要な電源のスイッチ、ルート、および冗長性の数や、可用性の高いスイッチインフラストラクチャーに多様なルートを提供するためにネットワークの関連ボンディングを検討します。使用するネットワークバックエンドのタイプに特に注意してください。ネットワークバックエンドの選択方法は、2章Networking In-Depthを参照してください。
- ライブマイグレーション用にコンピュートホストを設定しておらず、コンピュートホストに障害が発生すると、コンピュートインスタンスとそのインスタンスに保存されているデータはすべて失われる可能性があります。コンピュートホストのアップタイムを確保するには、エンタープライズストレージまたは OpenStack Block ストレージで共有ファイルシステムを使用できます。
外部ソフトウェアを使用して、サービスの可用性またはしきい値の制限を確認し、適切なアラームを設定することができます。Red Hat OpenStack Platform の Operational Tools リポジトリーには以下が含まれます。
OpenStack で高可用性を使用するリファレンスアーキテクチャーについては、Ceph Storage を使用した高可用性 Red Hat OpenStack Platform 6 のデプロイ を参照してください。
3.8. セキュリティー
セキュリティードメインには、共通の信頼要件を共有し、1 つのシステムで期待するユーザー、アプリケーション、サーバー、またはネットワークが含まれます。セキュリティードメインは通常、同じ認証および承認の要件とユーザーを使用します。
一般的なセキュリティードメインのカテゴリーは、パブリック、ゲスト、管理、およびデータです。ドメインは、個別に OpenStack のデプロイメントにマッピングすることも、組み合わせてマッピングすることもできます。たとえば、一部のデプロイメントトポロジーは、ゲストとデータドメインを 1 つの物理ネットワークで組み合わせ、別の場合は物理的に分離しています。それぞれのケースでは、クラウドオペレーターが関連するセキュリティー上の懸念を認識する必要があります。
セキュリティードメインは、特定の OpenStack デプロイメントトポロジーにマッピングする必要があります。ドメインとドメイン信頼要件は、クラウドインスタンスがパブリック、プライベート、またはハイブリッドであるかによって異なります。
- パブリックドメイン
- クラウドインフラストラクチャーの完全に信頼されていない領域。パブリックドメインは、権限を持たないネットワーク全体またはネットワークとしてインターネットを参照できます。このドメインは、常に信頼されていないと見なされます。
- ゲストドメイン
通常、コンピュートインスタンス間のトラフィックに使用され、クラウド上のインスタンスによって生成されるコンピューティングデータを処理しますが、API 呼び出しなどのクラウドの操作をサポートするサービスには処理しません。
インスタンスの使用状況を厳密に制御しないパブリッククラウドプロバイダーおよびプライベートクラウドプロバイダー、またはインスタンスへの無制限のインターネットアクセスを許可する場合は、このドメインが信頼できないと見なす必要があります。プライベートクラウドプロバイダーはこのネットワークを内部とみなし、インスタンスとすべてのクラウドテナントの信頼をアサートするコントロールでのみ信頼されている場合があります。
- 管理ドメイン
- サービスが相互に対話するドメイン。このドメインは、コントロールプレーン として知られています。このドメインのネットワークは、設定パラメーター、ユーザー名、パスワードなどの機密データを転送します。ほとんどのデプロイメントでは、このドメインは信頼されていると見なされます。
- データドメイン
- ストレージサービスがデータを転送しているドメイン。このドメインにまたがるほとんどのデータには整合性と機密性の要件が高く、デプロイメントのタイプに応じても強力な可用性要件がある場合があります。このネットワークの信頼レベルは、他のデプロイメントの決定によって異なります。
OpenStack をプライベートクラウドとしてエンタープライズにデプロイする場合、デプロイメントは通常ファイアウォールの背後で、既存のシステムを使用する信頼できるネットワーク内部にあります。クラウドのユーザーは通常、会社が定義するセキュリティー要件に拘束されている従業員です。このデプロイメントは、ほとんどのセキュリティードメインが信頼できることを意味します。
ただし、OpenStack を一般向けのロールでデプロイする場合には、ドメインの信頼レベルに関して仮定を立てることができず、攻撃ベクトルが大幅に増加します。たとえば、API エンドポイントと基盤となるソフトウェアは、不正アクセスを取得したり、サービスへのアクセスを妨害したりする悪意のある人物に対して脆弱になります。これらの攻撃は、データ、機能、および評判の損失につながる可能性があります。これらのサービスは、監査と適切なフィルタリングを使用して保護する必要があります。
パブリッククラウドとプライベートクラウドの両方でシステムのユーザーを管理する場合にも注意が必要です。Identity サービスは、OpenStack 内のユーザー管理を容易にする LDAP などの外部 ID バックエンドを使用することができます。ユーザー認証要求にはユーザー名、パスワード、認証トークンなどの機密情報が含まれるため、SSL の終了を実行するハードウェアの背後に API サービスを配置する必要があります。
3.9. 追加ソフトウェア
一般的な OpenStack デプロイメントには、OpenStack 固有のコンポーネントおよび 「サードパーティーのコンポーネント」 が含まれます。補助ソフトウェアには、クラスタリング、ロギング、モニタリング、およびアラート用のソフトウェアを含めることができます。そのため、デプロイメント設計は、CPU、RAM、ストレージ、ネットワーク帯域幅などの追加のリソース消費に対応する必要があります。
クラウドを設計するときは、次の要素を考慮してください。
- データベースおよびメッセージング
基盤となるメッセージキュープロバイダーは、必要なコントローラーサービスの数や、回復性の高いデータベース機能を提供するテクノロジーに影響を及ぼす可能性があります。たとえば、Galera で MariaDB を使用する場合、サービスのレプリケーションはクォーラムに依存します。したがって、基盤となるデータベースは、障害の発生した Galera ノードの復旧に対応するために少なくとも 3 つのノードで設定される必要があります。
ソフトウェア機能をサポートするようにノード数を増やす場合は、ラックスペースとスイッチポート密度の両方を考慮してください。
- 外部キャッシュ
Memcached は分散メモリーオブジェクトキャッシュシステムであり、Redis はキー/値のストアです。両方のシステムをクラウドにデプロイして、Identity サービスの負荷を軽減できます。たとえば、memcached サービス はトークンをキャッシュし、分散キャッシングシステムを使用して基礎となる認証システムからのボトルネックを軽減するのに役立ちます。
memcached または Redis を使用しても、これらのサービスは通常 OpenStack サービスを提供するインフラストラクチャーノードにデプロイされるため、アーキテクチャーの全体的な設計には影響しません。
- 負荷分散
多くの汎用デプロイメントでは、ハードウェアロードバランサーを使用して可用性の高い API アクセスと SSL ターミネーションを提供しますが、HAProxy などのソフトウェアソリューションも考慮することができます。ソフトウェア定義のロードバランシング実装も高可用性であることを確認する必要があります。
Keepalived や Corosync を使用する Pacemaker などのソリューションで、ソフトウェア定義の高可用性を設定できます。Pacemaker および Corosync は、OpenStack 環境の特定のサービスに基づいて、アクティブ/アクティブまたはアクティブ/パッシブの高可用性設定を提供できます。
これらのアプリケーションは、2 つ以上のノードを含むデプロイメントを必要とし、いずれかのコントローラーノードがスタンバイモードでサービスを実行できるため、設計に影響する可能性があります。
- ロギングとモニタリング
解析を容易にするために、ログを一元的に保存する必要があります。ログデータアナリティクスエンジンは、一般的な問題に警告して修正するメカニズムに関する自動化や問題通知も提供することができます。
ツールは、アーキテクチャー設計の既存のソフトウェアおよびハードウェアをサポートする限り、基本的な OpenStack ログに加えて、外部ロギングまたはモニタリングソフトウェアを使用できます。Red Hat OpenStack Platform の Operational Tools リポジトリーには、以下のツールが含まれています。
3.10. 計画ツール
Cloud Resource Calculator ツールは、容量の要件を計算するのに役立ちます。
ツールを使用するには、ハードウェアの情報をスプレッドシートに入力します。次に、このツールは、フレーバーのバリエーションを含め、利用可能なインスタンス数の計算された推定値を表示します。
このツールは、ユーザーの利便性のためにのみ提供されています。Red Hat では正式にサポートされていません。
第4章 アーキテクチャーの例
本章では、Red Hat OpenStack Platform デプロイメントのアーキテクチャー例への参照を説明します。
本ガイドのすべてのアーキテクチャー例は、KVM ハイパーバイザーを使用して Red Hat Enterprise Linux 7.2 に OpenStack Platform をデプロイすることを前提としています。
4.1. 概要
通常、デプロイメントはパフォーマンスまたは機能をベースにしています。デプロイメントは、デプロイされたインフラストラクチャーをベースとすることもできます。
| 例 | 説明 |
|---|---|
| 特定の技術的または環境的なニーズが不明な場合に使用する一般的な高可用性クラウド。このアーキテクチャータイプは柔軟性があり、単一の OpenStack コンポーネントのサイズを強調せず、特定の環境に限定されません。 | |
| コンピューティングを重視するクラウドで、特にコンピューティング集約型ワークロードをサポートするもの。コンピュート集約型のワークロードは、重要なデータ計算、暗号化、復号化など、CPU を大量に使用する場合があります。また、インメモリーキャッシングやデータベースサーバーなどの RAM を大量に消費するか、CPU 集約型および RAM 集約型の両方を意味します。通常、ストレージ集約型やネットワークを多用する意味ではありません。高性能のコンピュートリソースが必要な場合は、このアーキテクチャー種別を選択できます。 | |
| Hadoop クラスターなどの大規模なデータセットの管理と分析用に設計されたパフォーマンス重視のストレージシステム。このアーキテクチャー種別では、OpenStack は Hadoop と統合して、ストレージバックエンドとして Ceph に Hadoop クラスターを管理します。 | |
| データベース IO 要件が増加し、ソリッドステートドライブ(SSD)を使用してデータを処理することを前提とします。このアーキテクチャーは、既存のストレージ環境に使用できます。 | |
| OpenStack デプロイメントで一般的に使用されるクラウドベースのファイルストレージおよび共有サービス。このアーキテクチャータイプは、クラウドバックアップアプリケーションを使用します。ここでは、クラウドトラフィックの受信データは送信データよりも高くなります。 | |
| 大規模な Web アプリケーション用のハードウェアベースの負荷分散クラスター。このアーキテクチャータイプは、SSL オフロード機能を提供し、テナントネットワークに接続して、アドレス消費を減らし、Web アプリケーションの水平スケーリングを行います。 |
4.2. General-Purpose アーキテクチャー
特定の技術的または環境的なニーズが不明な場合は、一般的な高可用性クラウドをデプロイできます。この柔軟なアーキテクチャー種別は、単一の OpenStack コンポーネントのサイズを強調せず、特定の環境に限定されません。
このアーキテクチャータイプは、以下のような潜在的なユースケースの 80% に対応します。
- シンプルなデータベース
- Web アプリケーションランタイム環境
- 共有アプリケーションの開発環境
- テスト環境
- スケールアップの追加ではなく、スケールアウト機能を必要とする環境
このアーキテクチャータイプは、セキュリティーを強化する必要があるクラウドドメインには推奨されません。
インストールおよびデプロイメントのドキュメントは、5章デプロイメント情報 を参照してください。
4.2.1. ユースケースの例
オンライン分類された広告会社では、プライベートクラウドに Apache Tomcat、Nginx、MariaDB を含む Web アプリケーションを実行します。ポリシーの要件を満たすために、クラウドインフラストラクチャーは会社のデータセンター内で実行されます。
会社には予測可能な負荷要件がありますが、需要の夜間に合わせてスケーリングが必要です。現在の環境には、オープンソースの API 環境を実行する会社の目標に柔軟性がありません。
現在の環境は、以下のコンポーネントで設定されています。
- Nginx と Tomcat の 120 から 140 インストールの間に、2 つの vCPU と 4 GB のメモリーがある
- それぞれ 4 つの vCPU と 8 GB の RAM を備えた 3 ノードの MariaDB および Galera クラスター。Pacemaker は、Galera ノードの管理に使用されます。
会社は、ハードウェアロードバランサーと、Web サイトを提供する複数の Web アプリケーションを実行します。環境オーケストレーションは、スクリプトと Puppet の組み合わせを使用します。この Web サイトでは、アーカイブが必要な日に大量のログデータが生成されます。
4.2.2. 設計について
この例のアーキテクチャーには、3 台のコントローラーノードと少なくとも 8 つのコンピュートノードが含まれます。静的オブジェクトには OpenStack Object Storage を使用し、その他すべてのストレージのニーズには OpenStack Block Storage を使用します。
OpenStack インフラストラクチャーコンポーネントが高可用性を確保するために、ノードは Red Hat Enterprise Linux の Pacemaker アドオンを HAProxy と共に使用します。
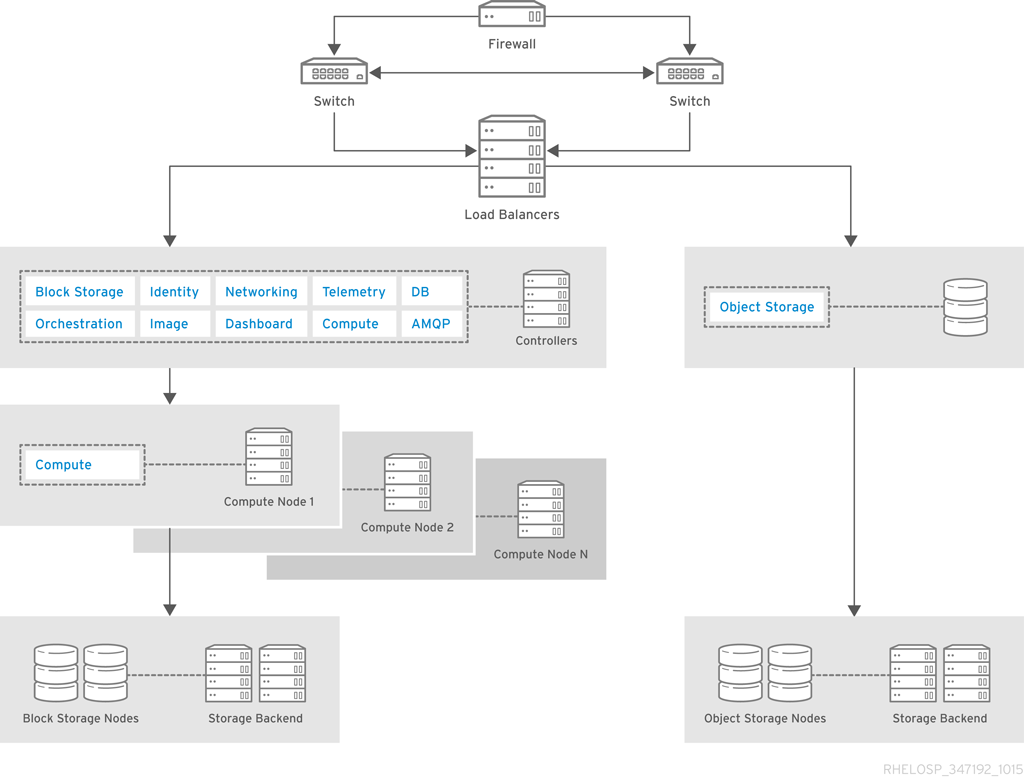
アーキテクチャーには、以下のコンポーネントが含まれます。
- パブリック向けネットワーク接続用のファイアウォール、スイッチ、およびハードウェアロードバランサー。
- Image、Identity、および Networking を実行する OpenStack コントローラーサービスと、サポートサービス MariaDB および RabbitMQ の組み合わせこれらのサービスは、少なくとも 3 つのコントローラーノードで高可用性向けに設定されます。
- クラウドノードは、Red Hat Enterprise Linux 用の Pacemaker アドオンを使用して高可用性用に設定されています。
- コンピュートノードは、永続ストレージを必要とするインスタンス用に OpenStack Block Storage を使用します。
- イメージなどの静的オブジェクトを提供する OpenStack Object Storage
4.2.3. アーキテクチャーコンポーネント
| コンポーネント | 説明 |
|---|---|
| Block Storage | インスタンスの永続ストレージ。 |
| Compute コントローラーサービス | コンピュート管理およびコントローラー上で実行されるスケジューリングサービス。 |
| Dashboard | OpenStack 管理用の Web コンソール。 |
| Identity | ユーザーとテナントの基本認証および承認 |
| イメージ | インスタンスの起動およびスナップショットの管理に使用するイメージを保存します。 |
| MariaDB | すべての OpenStack コンポーネントのデータベース。MariaDB サーバーインスタンスは、NetApp や Solidfire などの共有エンタープライズストレージにデータを格納します。MariaDB インスタンスに障害が発生した場合には、ストレージを別のインスタンスに再接続し、Galera クラスターに再参加する必要があります。 |
| ネットワーク | プラグインおよび Networking API を使用してハードウェアロードバランサーを制御します。OpenStack Object Storage を増やす場合は、ネットワークの帯域幅の要件を考慮する必要があります。OpenStack Object Storage は、10 GbE 以上のネットワーク接続で実行することを推奨します。 |
| オブジェクトストレージ | Web アプリケーションサーバーからログを処理およびアーカイブします。Object Storage を使用して、OpenStack Object Storage コンテナーから静的な Web コンテンツを移動したり、OpenStack イメージが管理するイメージをバックアップしたりすることもできます。 |
| テレメトリー | 他の OpenStack サービスの監視およびレポート。 |
4.2.4. コンピュートノードの要件
Compute サービスがそれぞれのコンピュートノードにインストールされている。
この汎用アーキテクチャーは 140 Web インスタンスまで実行でき、少数の MariaDB インスタンスは 292 vCPU と 584 GB RAM を必要とします。ハイパースレッディングを備えたデュアルソケット 16 進コア Intel CPU を備えた一般的な 1U サーバーでは、CPU のオーバーコミットの比率が 2:1 個と仮定すると、このアーキテクチャーには 8 つのコンピュートノードが必要です。
Web アプリケーションインスタンスは、各コンピュートノード上のローカルストレージから実行されます。Web アプリケーションインスタンスはステートレスであるため、インスタンスの 1 つに障害が発生した場合は、アプリケーションは実行を継続できます。
4.2.5. ストレージ要件
ストレージの場合は、サーバーで直接接続されたストレージでスケールアウトソリューションを使用します。たとえば、グリッド 結合ソリューションと同様の方法でコンピュートホストにストレージを入力することも、ブロックストレージだけを提供する専用ホストにも反映することができます。
コンピュートホストにストレージをデプロイする場合は、ハードウェアがストレージおよびコンピュートサービスを処理できることを確認します。
4.3. Compute-Focused アーキテクチャー
セルは、本リリースでは テクノロジープレビュー として提供されているため、Red Hat では全面的にはサポートしていません。これらは、テスト目的にのみご利用いただく機能で、実稼働環境にデプロイすべきではありません。テクノロジープレビュー機能の詳細は、対象範囲の詳細 を参照してください。
コンピュート中心のクラウドは、データ計算または暗号化と復号化などの CPU を集中的に使用するワークロード、インメモリーキャッシュやデータベースサーバーなどの RAM を集中的に使用するワークロード、またはその両方をサポートします。このアーキテクチャータイプは、通常、ストレージを集中的に使用するものではなく、コンピュートリソースの電力を必要とするお客様に対応します。
コンピュートワークロードには、以下のユースケースが含まれます。
- 高性能コンピューティング(HPC)
- Hadoop またはその他の分散データストアを使用したビッグデータ解析
- 継続的インテグレーションまたは継続的デプロイメント(CI/CD)
- Platform-as-a-Service (PaaS)
- ネットワーク機能仮想化(NFV)のシグナル処理
クラウドは通常、永続的なブロックストレージを必要とするアプリケーションをホストしないため、コンピュート中心の OpenStack クラウドは通常は raw ブロックストレージサービスを使用しません。インフラストラクチャーコンポーネントは共有されないため、ワークロードは必要な数の利用可能なリソースを使用できます。インフラストラクチャーコンポーネントも高可用性である必要があります。この設計はロードバランサーを使用します。HAProxy も使用できます。
インストールおよびデプロイメントのドキュメントは、5章デプロイメント情報 を参照してください。
4.3.1. ユースケースの例
組織は、調査プロジェクト用に HPC を提供します。ヨーロッパの 2 つの既存のコンピューティングセンターに 3 番目のコンピュートセンターを追加する必要があります。
以下の表には、追加する各コンピュートセンターの要件をまとめています。
| Data Center | 概算容量 |
|---|---|
| geneva、Switzerland |
|
| Budapest, Hungary |
|
4.3.2. 設計について
このアーキテクチャーでは、セルを使用してコンピュートリソースを分離し、異なるデータセンター間で透過的なスケーリングを行います。この決定は、セキュリティーグループおよびライブマイグレーションのサポートに影響します。さらに、セル全体でフレーバーなどの一部の設定要素を手動でレプリケーションする必要があります。ただし、セルは、ユーザーに単一のパブリック API エンドポイントを公開する間に必要なスケールを提供します。
クラウドは、元の 2 つのデータセンターのそれぞれにコンピュートセルを使用し、新しいデータセンターを追加するたびに新しいコンピュートセルを作成します。各セルには、コンピュートリソースをさらに分離する 3 つのアベイラビリティゾーンと、高可用性のためにミラーリングされたキューを持つクラスタリング用に設定された 3 つ以上の RabbitMQ メッセージブローカーが含まれます。
HAProxy ロードバランサーの背後に存在する API セルは、Switzerland のデータセンターにあります。API セルは、セルスケジューラーのカスタマイズされたバリエーションを使用して、API コールをコンピュートセルに転送します。カスタマイズにより、特定のワークロードを特定のデータセンターまたはセル RAM の可用性に基づいてすべてのデータセンターにルーティングできるようになります。
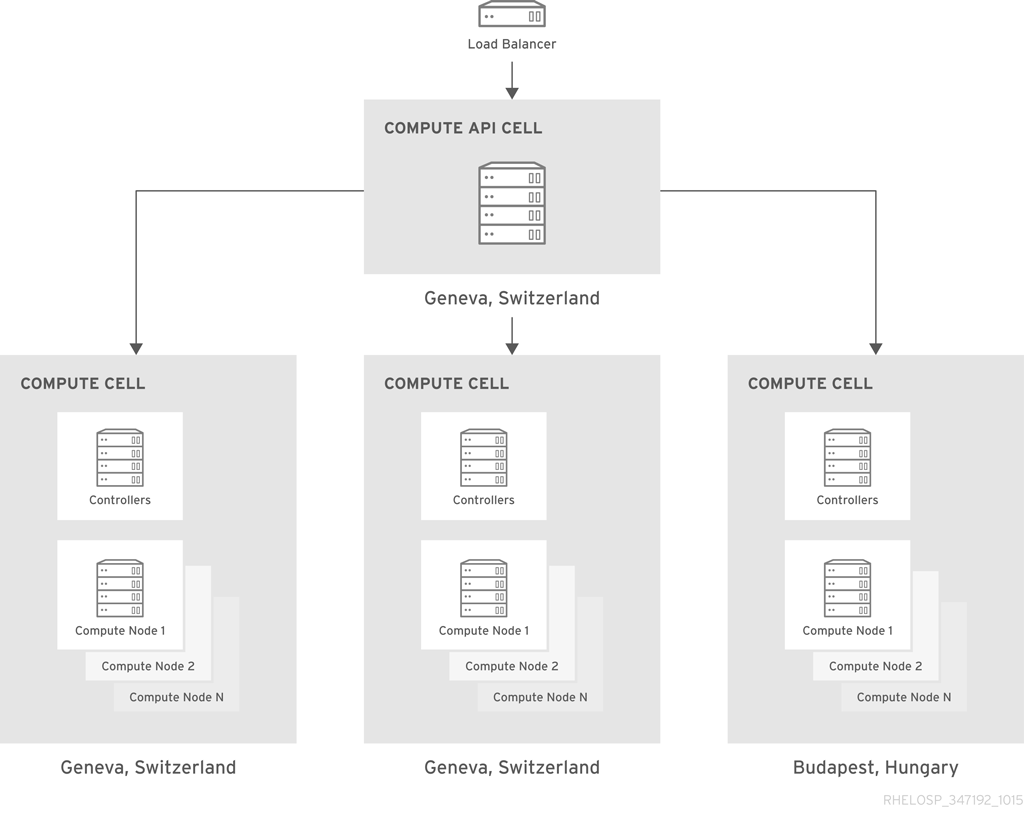
フィルターを使用して、セルでの配置を処理する Compute スケジューラーをカスタマイズすることもできます。たとえば、ImagePropertiesFilter は、ゲストが実行するオペレーティングシステム(Linux、Windows など)に基づいて特別な処理を行います。
中央データベースチームは、NetApp ストレージバックエンドを使用したアクティブ/パッシブ設定の各セルの SQL データベースサーバーを管理します。バックアップは 6 時間ごとに実行されます。
4.3.3. アーキテクチャーコンポーネント
| コンポーネント | 説明 |
|---|---|
| コンピュート | コンピュート管理およびスケジューリングサービスは、コントローラーで実行されます。Compute サービスは、各コンピュートノードでも実行されます。 |
| ダッシュボードサービス | OpenStack 管理用の GUI。 |
| Identity サービス | 基本的な認証および承認機能。 |
| Image サービス | API セルで実行され、小さな Linux イメージセットを維持し、オーケストレーションツールがアプリケーションを配置することができます。 |
| ネットワーク | ネットワークサービス。OpenStack Networking の詳細は、2章Networking In-Depthを参照してください。 |
| モニタリング | Telemetry サービスはメータリングを実行し、シャード化され、複製された MongoDB バックエンドでプロジェクトクォータを調整します。API 負荷を分散するには、Telemetry がクエリーできる子セルに openstack-nova-api サービスのインスタンスをデプロイする必要があります。このデプロイメントには、子セル内で Identity や Image などのサポートサービスを設定する必要もあります。キャプチャーする特定の重要なメトリクスには、Compute API への Image ディスクの使用率と応答時間が含まれます。 |
| オーケストレーションサービス | 新しいインスタンスを自動的にデプロイおよびテストします。 |
| Telemetry Service | オーケストレーションの自動スケーリング機能をサポートします。 |
| オブジェクトストレージ | 3 つの PB Ceph クラスターを使用してオブジェクトを保存します。 |
4.3.4. 設計に関する考慮事項
3章設計 で説明されている 「コンピュートリソース」 およびコンピュートノードの設計に関する考慮事項で説明されている基本的な設計に関する考慮事項に加えて、コンピュート集約型アーキテクチャーには以下の項目を考慮する必要があります。
- ワークロード
短期的なワークロードには、継続的インテグレーションと継続的デプロイメント(CI-CD)ジョブが含まれており、同時に多数のコンピューティングインスタンスが作成され、一連のコンピュート集約型タスクが実行されます。次に、環境は、インスタンスを終了する前に、各インスタンスの結果またはアーティファクトを長期ストレージにコピーします。
Hadoop クラスターや HPC クラスターなどの長期的なワークロードは、通常、大規模なデータセットを受け取り、それらのデータセットで計算作業を実行してから、長期ストレージに結果をプッシュします。計算作業が終了すると、インスタンスは別のジョブを受け取るまでアイドル状態になります。有効期間の長いワークロードの環境は、多くの場合、より複雑になりますが、ジョブ間でアクティブに保つことで、これらの環境の構築コストを補正できます。
コンピューティング中心の OpenStack クラウドのワークロードには、通常、Hadoop と HDFS を使用する点を除き、永続的なブロックストレージは必要ありません。共有ファイルシステムまたはオブジェクトストアは、初期データセットを維持し、計算結果を保存するための宛先として機能します。入力出力(IO)のオーバーヘッドを回避することで、ワークロードのパフォーマンスを大幅に強化できます。データセットのサイズによっては、オブジェクトストアまたは共有ファイルシステムをスケーリングする必要がある場合があります。
- 拡張計画
クラウドユーザーは、必要に応じて新規リソースへの即時アクセスを想定しています。したがって、通常の使用量と、リソース需要の突然的なスパイクを計画する必要があります。安定せずに計画すると、クラウドのオーバーサブスクリプションが予期せず発生する可能性があります。積極的に計画を立てることで、クラウドの不要な運用やメンテナンスコストの不正使用が予測できない状況が生じる可能性があります。
拡張計画における重要な要素は、時間経過に伴うクラウド使用量の傾向の分析です。クラウドの平均速度や容量ではなく、サービスを提供する一貫性を測定します。この情報は、容量パフォーマンスのモデル化や、クラウドの現在および将来の容量を決定するのに役立ちます。
ソフトウェアの監視については、「追加ソフトウェア」 を参照してください。
- CPU および RAM
現在、一般的なサーバーには、最大 12 個のコアを持つ CPU が含まれています。さらに、一部の Intel CPU はハイパースレッディングテクノロジー(HTT)をサポートしているため、コア容量が 2 倍になります。したがって、HTT を使用する複数の CPU をサポートするサーバーは、利用可能なコア数を掛けます。HTT は、Intel CPU での並列化を向上するために使用される Intel プロプライエタリー同時マルチスレッド実装です。マルチスレッドアプリケーションのパフォーマンスを向上させるために、HTT を有効にすることを検討してください。
CPU で HTT を有効にする方法は、ユースケースによって異なります。たとえば、HTT を無効にすると、集中的なコンピューティング環境に役立ちます。HTT の有無にかかわらず、ローカルワークロードのパフォーマンステストを実行すると、どのオプションが特定のケースに適しているかを判断するのに役立ちます。
- 容量のプランニング
以下のストラテジーの 1 つまたは複数を使用して、コンピューティング環境に容量を追加できます。
クラウドに容量を追加して水平スケーリングします。ライブマイグレーション機能が中断される可能性を減らすために、追加のノードで同じ CPU または同様の CPU を使用する必要があります。ハイパーバイザーホストのスケールアウトは、ネットワークおよびその他のデータセンターリソースにも影響します。ラック容量に達した場合や、ネットワークスイッチを追加する必要がある場合は、この点を考慮してください。
注記ノードを適切なアベイラビリティーゾーンおよびホストアグリゲートに配置するために必要な追加の作業に注意してください。
- 使用量の増加をサポートするために内部コンピュートホストコンポーネントの容量を増やすことで垂直スケーリングします。たとえば、CPU をより多くのコアに置き換えるか、サーバーの RAM を増やすことができます。
平均ワークロードを評価し、必要な場合は、オーバーコミットの比率を調整して、コンピュート環境で実行可能なインスタンスの数を増やします。
重要計算対象の OpenStack 設計アーキテクチャーの CPU のオーバーコミット率を増やしないでください。CPU のオーバーコミット比率を変更すると、CPU リソースを必要とする他のノードとの競合が発生する可能性があります。
- Compute ハードウェア
計算した OpenStack クラウドは、プロセッサーとメモリーリソースに関して非常に需要です。したがって、より多くの CPU ソケット、より多くの CPU コア、より多くの RAM を優先できるサーバーハードウェアを優先する必要があります。
このアーキテクチャーでは、ネットワーク接続とストレージ容量が重要ではありません。ハードウェアは、最低限のユーザー要件を満たすのに十分なネットワーク接続とストレージ容量を提供する必要がありますが、ストレージおよびネットワークコンポーネントは主に計算クラスターにデータセットを読み込み、一貫したパフォーマンスを必要としません。
- ストレージハードウェア
オープンソースソフトウェアでコモディティハードウェアを使用してストレージアレイを構築することはできますが、それをデプロイするために専門的な専門知識が必要になる可能性があります。サーバーで直接接続されたストレージと共にスケールアウトストレージソリューションを使用することもできますが、サーバーハードウェアがストレージソリューションをサポートしていることを確認する必要があります。
ストレージハードウェアを設計するときは、次の要素を考慮してください。
- 可用性。インスタンスの可用性が高く、またはホスト間での移行が可能である必要がある場合は、一時インスタンスデータに共有ストレージファイルシステムを使用して、ノードに障害が発生した場合にコンピュートサービスが中断しないようにします。
- レイテンシーソリッドステートドライブ(SSD)ディスクを使用して、インスタンスのストレージレイテンシーを最小限に抑え、CPU の遅延を減らし、パフォーマンスを向上させます。ベースとなるディスクサブシステムのパフォーマンスを向上させるには、コンピュートホストで RAID コントローラーカードを使用することを検討してください。
- Performance通常、コンピュート中心のクラウドにはストレージに対する主要なデータ I/O は必要ありませんが、ストレージのパフォーマンスは考慮すべき重要な要素となります。ストレージ I/O 要求のレイテンシーを監視することで、ストレージハードウェアのパフォーマンスを測定できます。コンピューティング集約型のワークロードによっては、ストレージからデータをフェッチしながら、CPU の経験を最小限に抑えると、アプリケーションの全体的なパフォーマンスが大幅に向上します。
- 拡張性。ストレージソリューションの最大容量を決定します。たとえば、50 PB に拡大するソリューションは、10PB にのみ拡張されるソリューションよりも拡張できます。このメトリクスは、スケーラビリティーに関連しますが、スケーラビリティーは拡張する際のソリューションパフォーマンスの計測値です。
- 接続性。接続はストレージソリューションの要件を満たしている必要があります。集中型ストレージアレイを選択した場合は、ハイパーバイザーをストレージアレイに接続する方法を決定します。接続性は、レイテンシーとパフォーマンスに影響を及ぼす可能性があります。したがって、ネットワークの特性を使用することで、環境の全体的なパフォーマンスを向上させるレイテンシーが最小限に抑えられます。
- ネットワークハードウェア
2章Networking In-Depth で説明されている基本的なネットワークに関する考慮事項に加えて、次の要素を考慮してください。
- 必要なポート数は、ネットワーク設計に必要な物理領域に影響します。たとえば、1U サーバーの各ポートに 10 GbE 容量のポートを提供するスイッチは、2U サーバーのポートごとに 10 GbE 容量の 24 ポートを提供するスイッチよりも、ポート密度が高くなります。ポートの密度が高いため、コンピュートまたはストレージコンポーネントのラック領域が多くなります。障害ドメインと電源密度も考慮する必要があります。より高価な場合ですが、機能要件を超えてネットワークを設計すべきではないため、高密度のスイッチも検討することができます。
- リーフ対応モデルなど、容量や帯域幅の追加に役立つスケーラブルなネットワークモデルでネットワークアーキテクチャーを設計する必要があります。このタイプのネットワーク設計では、帯域幅を追加したり、ギアの追加ラックにスケールアウトしたりできます。
- 必要なポート数、ポート速度、ポート密度をサポートするネットワークハードウェアを選択することが重要になります。また、ワークロードの需要が増えると将来の増加も許容します。また、ネットワークアーキテクチャーのどこで冗長性を提供することが重要であるかを評価することも重要です。ネットワークの可用性と冗長性が向上します。そのため、追加のコストと、冗長なネットワークスイッチとホストレベルでのボンディングインターフェイスの利点を比較する必要があります。
4.4. Storage-Focused アーキテクチャー
「Storage-Focused アーキテクチャーの考慮事項」
4.4.1. Storage-Focused アーキテクチャータイプ
クラウドストレージモデルは、データを物理ストレージデバイスの論理プールに格納します。このアーキテクチャーは、多くの場合、統合ストレージクラウドと呼ばれます。
クラウドストレージは通常、ホストされたオブジェクトストレージサービスを指します。ただし、用語には、サービスとして利用可能な他のタイプのデータストレージも含めることができます。OpenStack は、Block Storage (cinder)と Object Storage (swift)の両方を提供します。クラウドストレージは通常仮想インフラストラクチャーで実行され、インターフェイスアクセシビリティ性、スケーラビリティー、スケーラビリティー、マルチテナンシー、およびメーター化されたリソースの幅広いクラウドコンピューティングと類似しています。
オンプレミスまたはオンプレミスのクラウドストレージサービスを使用できます。クラウドストレージは冗長性とデータの分散に対して高い耐障害性があり、バージョン化されたコピーでは高い耐久性があり、一貫したデータレプリケーションを実行できます。
クラウドストレージアプリケーションの例には、以下が含まれます。
- アクティブなアーカイブ、バックアップ、および階層的なストレージ管理
- プライベートDropBox サービスなどの一般的なコンテンツのストレージと同期
- 並列ファイルシステムを使用したデータ解析
- ソーシャルメディアバックエンドストレージなどのサービス用の非構造化データストア
- 永続ブロックストレージ
- オペレーティングシステムとアプリケーションイメージストア
- メディアストリーミング
- データベース
- コンテンツ配信
- クラウドストレージピアリング
OpenStack Storage のサービスについての詳しい情報は、「OpenStack Object Storage (swift)」 および 「OpenStack Block Storage (cinder)」 を参照してください。
4.4.2. データ分析アーキテクチャー
大規模なデータセットの分析は、ストレージシステムのパフォーマンスに大きく依存します。並列ファイルシステムは、高パフォーマンスのデータ処理を提供する可能性があり、大規模なパフォーマンスに重点を置いたシステムに推奨されます。
インストールおよびデプロイメントのドキュメントは、5章デプロイメント情報 を参照してください。
4.4.2.1. 設計について
OpenStack Data Processing (sahara)は Hadoop と統合され、クラウド内の Hadoop クラスターを管理します。以下の図は、高パフォーマンスの要件を持つ OpenStack ストアを示しています。
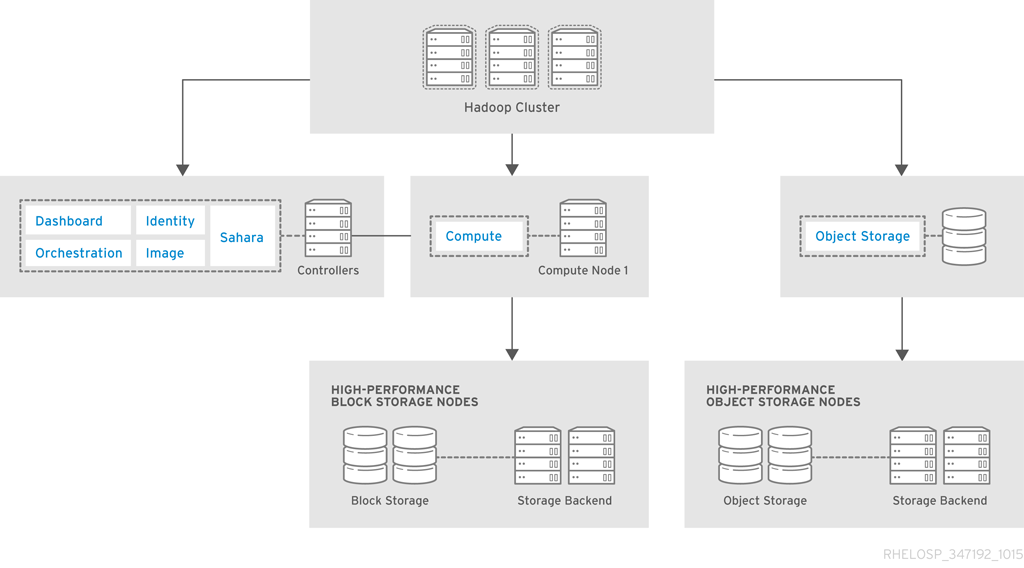
ハードウェア要件と設定は、「高性能データベースアーキテクチャー」 で説明されている高性能アーキテクチャーと似ています。この例では、アーキテクチャーは Ceph Swift 互換の REST インターフェイスを使用してキャッシュプールに接続し、利用可能なプールの高速化を可能にします。
4.4.2.2. アーキテクチャーコンポーネント
| コンポーネント | 説明 |
|---|---|
| コンピュート | コンピュート管理およびスケジューリングサービスは、コントローラーで実行されます。Compute サービスは、各コンピュートノードでも実行されます。 |
| Dashboard | OpenStack 管理用の Web コンソール。 |
| Identity | 基本的な認証および承認機能。 |
| イメージ | インスタンスの起動およびスナップショットの管理に使用するイメージを保存します。このサービスはコントローラーで実行され、イメージの小さなセットを提供します。 |
| ネットワーク | ネットワークサービス。OpenStack Networking の詳細は、2章Networking In-Depthを参照してください。 |
| テレメトリー | 他の OpenStack サービスの監視およびレポート。このサービスを使用して、インスタンスの使用状況を監視し、プロジェクトクォータを調整します。 |
| オブジェクトストレージ | Hadoop バックエンドでデータを保存します。 |
| Block Storage | Hadoop バックエンドでボリュームを保存します。 |
| Orchestration | インスタンスおよびブロックストレージボリュームのテンプレートを管理します。このサービスを使用して、自動スケーリング用の Telemetry を使用して、ストレージ集約型処理用に追加のインスタンスを起動します。 |
4.4.2.3. クラウドの要件
| 要件 | 説明 |
|---|---|
| パフォーマンス | パフォーマンスを向上させるために、ディスクアクティビティーをキャッシュする特別なソリューションを選択できます。 |
| セキュリティー | 転送中および保管中のデータの両方を保護する必要があります。 |
| ストレージの近接性 | ハイパフォーマンスや大容量のストレージスペースを提供するには、各ハイパーバイザーに接続したり、中央のストレージデバイスから提供したりする必要がある場合があります。 |
4.4.2.4. 設計に関する考慮事項
3章設計 で説明されている基本的な設計に関する考慮事項に加えて、「Storage-Focused アーキテクチャーの考慮事項」 で説明されている考慮事項にも従う必要があります。
4.4.3. 高性能データベースアーキテクチャー
データベースアーキテクチャーは、高パフォーマンスストレージバックエンドの恩恵を受けます。エンタープライズストレージは必須ではありませんが、多くの環境には、OpenStack クラウドがバックエンドとして使用できるストレージが含まれます。
ストレージプールを作成して、インスタンスおよびオブジェクトインターフェイス用に OpenStack Block Storage をブロックデバイスに提供することができます。このアーキテクチャーの例では、データベース I/O 要件が高く、高速 SSD プールから必要なストレージがあります。
4.4.3.1. 設計について
ストレージシステムは、従来のストレージアレイで SSD のセットが対応する LUN を使用し、OpenStack Block Storage 統合または Ceph などのストレージプラットフォームを使用します。
このシステムは、追加のパフォーマンス機能を提供します。データベースの例では、SSD プールの一部が、データベースサーバーへのブロックデバイスとして機能できます。高パフォーマンス分析の例では、インライン SSD キャッシュレイヤーが REST インターフェイスを加速します。

この例では、Ceph は、分散ストレージクラスターからのブロックレベルのストレージに加えて、Swift 互換の REST インターフェイスを提供します。これは非常に柔軟であり、自己修復や自動バランシングなどの機能を備えた操作のコストを削減できます。使用可能な領域の量を最大化するために、イレイジャーコーディングされたプールを推奨します。
イレイジャーコード化されたプールには、計算要件が高く、オブジェクトで許可される操作に関する制限など、特別な考慮事項が必要です。イレイジャーコードプールは部分的な書き込みに対応していません。
4.4.3.2. アーキテクチャーコンポーネント
| コンポーネント | 説明 |
|---|---|
| コンピュート | コンピュート管理およびスケジューリングサービスは、コントローラーで実行されます。Compute サービスは、各コンピュートノードでも実行されます。 |
| Dashboard | OpenStack 管理用の Web コンソール。 |
| Identity | 基本的な認証および承認機能。 |
| イメージ | インスタンスの起動およびスナップショットの管理に使用するイメージを保存します。このサービスはコントローラーで実行され、イメージの小さなセットを提供します。 |
| ネットワーク | ネットワークサービス。OpenStack Networking の詳細は、2章Networking In-Depthを参照してください。 |
| テレメトリー | 他の OpenStack サービスの監視およびレポート。このサービスを使用して、インスタンスの使用状況を監視し、プロジェクトクォータを調整します。 |
| モニタリング | プロジェクトクォータを調整する目的で Telemetry サービスを使用し、メータリングを実行します。 |
| オブジェクトストレージ | Ceph バックエンドでデータを保存します。 |
| Block Storage | Ceph バックエンドでボリュームを保存します。 |
| Orchestration | インスタンスおよびブロックストレージボリュームのテンプレートを管理します。このサービスを使用して、自動スケーリング用の Telemetry を使用して、ストレージ集約型処理用に追加のインスタンスを起動します。 |
4.4.3.3. ハードウェアの要件
SSD キャッシュレイヤーを使用して、ブロックデバイスをハイパーバイザーに直接リンクするか、またはインスタンスにリンクすることができます。REST インターフェイスは、SSD キャッシュシステムをインラインキャッシュとして使用することもできます。
| コンポーネント | 要件 | ネットワーク |
|---|---|---|
| 10 GbE 水平的にスケーラブルなスパイン/リーフ型バックエンドストレージとフロントエンドネットワーク | ストレージハードウェア | * レイヤー 24x1 TB SSD のキャッシュ用の 5 つのストレージサーバー * サーバーごとに 12x4 TB ディスクを持つストレージサーバー 10 台。3 レプリカ後に約 160 TB の使用可能な領域の合計 480 TB に等しくなります。 |
4.4.3.4. 設計に関する考慮事項
3章設計 で説明されている基本的な設計に関する考慮事項に加えて、「Storage-Focused アーキテクチャーの考慮事項」 で説明されている考慮事項にも従う必要があります。
4.4.4. Storage-Focused アーキテクチャーの考慮事項
3章設計 で説明されている基本的な設計に関する考慮事項、「ストレージリソース」 で説明されているストレージノード設計に関する考慮事項に加えて、ストレージ集約型アーキテクチャーについては、以下の項目を考慮する必要があります。
- 接続性
- 接続がストレージソリューションの要件と一致していることを確認します。集中型ストレージアレイを選択した場合は、ハイパーバイザーをアレイに接続する方法を決定します。接続性は、レイテンシーとパフォーマンスに影響を及ぼす可能性があります。ネットワークの特性によって、設計の全体的なパフォーマンスを向上させるレイテンシーが最小限に抑えられていることを確認します。
- 密度
- インスタンスの密度ストレージ重視アーキテクチャーでは、インスタンスの密度および CPU/RAM のオーバーサブスクリプションは低くなります。特に設計でデュアルソケットハードウェア設計を使用している場合は、予想されるスケールをサポートするホストが多い必要があります。
- ホストの密度。高いホスト数に対応するには、クアッドソケットプラットフォームを使用します。このプラットフォームにより、ホストの密度が低下し、ラック数が増えます。この設定は、電源接続の数に影響し、ネットワークおよびコロケーションの要件にも影響します。
- パワーとコロリング。電源および協調密度の要件は、ブレード、sled、または 1U サーバー設計よりも 2U、3U サーバー、または 4U サーバーで低くなる場合があります。この設定は、古いインフラストラクチャーを持つデータセンターに推奨されます。
- 柔軟性
- 組織では、オンプレミスとオンプレミスのクラウドストレージオプションのいずれかを柔軟に選択できます。たとえば、運用の継続性、災害復旧、セキュリティー、および記録保持法、規制、およびポリシーは、ストレージプロバイダーのコスト効率に影響を与えます。
- レイテンシー
- ソリッドステートドライブ(SSD)は、インスタンスストレージのレイテンシーを最小限に抑え、ストレージレイテンシーが発生する可能性がある CPU の遅延を減らすことができます。コンピュートホストで RAID コントローラーカードを使用することから得点を評価し、基盤となるディスクサブシステムのパフォーマンスを向上させます。
- モニターおよびアラート
モニタリングおよびアラートサービスは、ストレージリソースへの需要が高いクラウド環境で重要です。これらのサービスは、ストレージシステムの正常性とパフォーマンスに関するリアルタイムビューを提供します。統合管理コンソール、または SNMP データを視覚化する他のダッシュボードは、ストレージクラスターの問題を検出し、解決するのに役立ちます。
ストレージ中心のクラウド設計には、以下が含まれている必要があります。
- 温度や非表示などの物理ハードウェアや環境リソースの監視。
- 利用可能なストレージ、メモリー、CPU など、ストレージリソースのモニタリング。
- 高度なストレージパフォーマンスデータを監視して、ストレージシステムが想定どおりに実行されるようにします。
- ストレージへのアクセスに影響するサービス中断についてネットワークリソースを監視する。
- 一元化されたログ収集およびログ分析機能。
- 問題を追跡するためのチケットシステム、またはチケットシステムとの統合。
- ストレージの発生時に問題を解決できる責任のあるチームまたは自動化システムのアラートと通知。
- ネットワークオペレーションセンター(NOC)スタッフは、問題を解決するために常に利用できます。
- スケーリング
- ストレージ中心の OpenStack アーキテクチャーは、スケールアウトではなく、スケールアップに集中する必要があります。コスト、電気、物理ラック、フォアスペース、サポート保証、および管理性などの要因に基づいて、より大きなホストの数を少なくするか、小さいホストの数を少なくするかを決定する必要があります。
4.5. Network-Focused アーキテクチャー
「Network-Focused Architecture の考慮事項」
4.5.1. Network-Focused アーキテクチャータイプ
すべての OpenStack デプロイメントは、サービスベースの性質上、正しく機能するためにネットワーク通信に依存しています。ただし、ネットワーク設定の方が重要であり、追加の設計に関する考慮事項が必要になる場合があります。
以下の表は、ネットワーク中心の一般的なアーキテクチャーについて説明しています。これらのアーキテクチャーは、信頼できるネットワークインフラストラクチャーと、ユーザーとアプリケーションの要件を満たすサービスに依存します。
| アーキテクチャー | 説明 |
|---|---|
| ビッグデータ | ビッグデータの管理と収集に使用されるクラウドは、ネットワークリソースに大きな需要をもたらします。ビッグデータは多くの場合、データの部分的なレプリカを使用して、大規模な分散クラウド上で整合性を維持します。大量のネットワークリソースを必要とするビッグデータアプリケーションは、Hadoop、Cassandra、NuoDB、Riak、またはその他の NoSQL や分散データベースなどです。 |
| コンテンツ配信ネットワーク (CDN) | CDN を使用すると、ビデオのストリーミング、写真グラフの表示、ホストの Web 会議、多数のエンドユーザーによる分散クラウドベースのデータリポジトリーへのアクセスを行うことができます。ネットワーク設定は、インスタンスのレイテンシー、帯域幅、および分散に影響します。コンテンツの提供とパフォーマンスに影響を与えるその他の要因には、バックエンドシステムのネットワークスループット、リソースの場所、WAN アーキテクチャー、キャッシュ方法などがあります。 |
| 高可用性 (HA) | HA 環境は、サイト間のデータのレプリケーションを維持するネットワークのサイジングに依存します。あるサイトが使用できなくなった場合、元のサイトがサービスに戻るまで、追加のサイトにより負荷に対応できます。追加の負荷を処理するためにネットワーク容量のサイズを設定することが重要です。 |
| 高性能コンピューティング (HPC) | HPC 環境では、クラウドクラスターのニーズに対応するために、追加のトラフィックフローと使用状況パターンを考慮する必要があります。HPC は、ネットワーク内の分散コンピューティングのために East-West トラフィックパターンが高くなっていますが、アプリケーションによっては、ネットワーク内でのノースサウストラフィックが大幅に行われる可能性もあります。 |
| 高速または大量のトランザクションシステム | これらのアプリケーションタイプは、ネットワークジッターおよび遅延の影響を受けます。環境の例には、金融システム、クレジットカード取引アプリケーション、取引システムが含まれます。これらのアーキテクチャーは、データ配信効率を最大化するために、north-south トラフィックで大量の East-west トラフィックを分散する必要があります。これらのシステムの多くは、大規模で高性能のデータベースバックエンドにアクセスする必要があります。 |
| ネットワーク管理機能 | DNS、NTP、SNMP などのバックエンドネットワークサービスの配信をサポートする環境。内部ネットワーク管理にこれらのサービスを使用できます。 |
| ネットワークサービスオファリング | サービスをサポートするために顧客がアクセスするネットワークツールを実行する環境。たとえば、VPN、MPLS プライベートネットワーク、GRE トンネルなどです。 |
| 仮想デスクトップインフラストラクチャー(VDI) | VDI システムは、ネットワークの輻輳、レイテンシー、およびジッターの影響を受けます。VDI にはアップストリームトラフィックとダウンストリームのトラフィックが必要で、キャッシュに依存してアプリケーションをエンドユーザーに配信することはできません。 |
| voice over IP (VoIP) | VoIP システムは、ネットワークの輻輳、レイテンシー、およびジッターの影響を受けます。VoIP システムには対称的なトラフィックパターンがあり、最適なパフォーマンスのためにネットワーク QoS (Quality of Service)が必要です。さらに、アクティブキュー管理を実装して、音声およびマルチメディアコンテンツを配信できます。ユーザーは、レイテンシーおよびジッターの変動に敏感であり、非常に低いレベルで検出できます。 |
| ビデオまたは Web 会議 | 会議システムは、ネットワークの輻輳、レイテンシー、およびジッターの影響を受けます。ビデオ会議システムでは対称的なトラフィックパターンがありますが、ネットワークが MPLS プライベートネットワークでホストされていない場合、システムはネットワーク QoS (Quality of Service)を使用してパフォーマンスを向上できません。VoIP と同様に、これらのシステムのユーザーは、低レベルであってもネットワークのパフォーマンス問題に気づくことができます。 |
| Web ポータルまたはサービス | Web サーバーはクラウドサービスでは一般的なアプリケーションであり、ネットワーク要件を理解する必要があります。ユーザー要求を満たし、最小限のレイテンシーで Web ページを提供するためにネットワークはスケールアウトする必要があります。ポータルアーキテクチャーの詳細に応じて、アーキテクチャーを計画するときに内部 east-west および north-south ネットワーク帯域幅を考慮する必要があります。 |
4.5.2. クラウドストレージとバックアップアーキテクチャー
このアーキテクチャーは、ファイルストレージおよびファイル共有を提供するクラウド向けです。このストレージ中心のユースケースを検討する場合もありますが、ネットワーク側の要件ではネットワーク中心のユースケースになります。
インストールおよびデプロイメントのドキュメントは、5章デプロイメント情報 を参照してください。
4.5.2.1. 設計について
次のクラウドバックアップアプリケーションのワークロードには、ネットワークに影響を与える 2 つの具体的な動作があります。
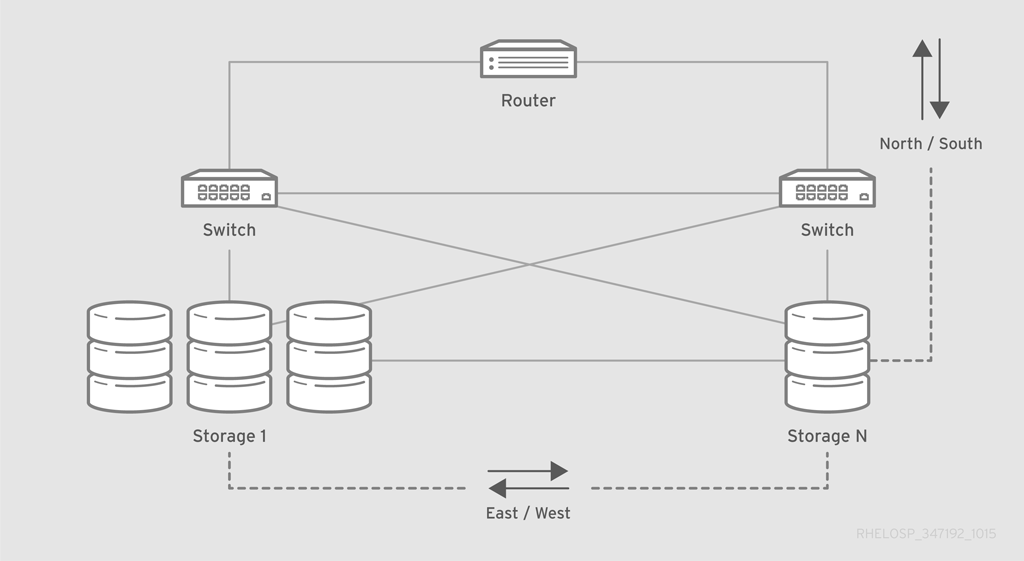
このワークロードには、外部向けサービスと内部レプリケーションアプリケーションが含まれるため、north-south および east-west トラフィックに関する考慮事項が必要です。
- North-south トラフィック
North-south トラフィックは、クラウドとの間で移動するデータで設定されます。ユーザーがコンテンツをアップロードおよび保存すると、そのコンテンツはサウスバウンドを OpenStack 環境に移動します。ユーザーがコンテンツをダウンロードすると、そのコンテンツは OpenStack 環境からノースバウンドを移動します。
このサービスは主にバックアップサービスとして動作するため、ほとんどのトラフィックはサウスバウンドを環境に移動します。このような状況では、OpenStack 環境に入るトラフィックは環境外に出るトラフィックよりも多いため、ネットワークを非対称にダウンストリームに設定する必要があります。
- East-west トラフィック
- East-west トラフィックは、環境内で移動するデータで設定されます。レプリケーションは任意のノードから行われ、複数のノードがアルゴリズムでターゲットとなる可能性があるため、このトラフィックは完全な対称になる可能性があります。ただし、このトラフィックは north-south トラフィックに干渉する可能性があります。
4.5.2.2. アーキテクチャーコンポーネント
| コンポーネント | 説明 |
|---|---|
| コンピュート | コンピュート管理およびスケジューリングサービスは、コントローラーで実行されます。Compute サービスは、各コンピュートノードでも実行されます。 |
| Dashboard | OpenStack 管理用の Web コンソール。 |
| Identity | 基本的な認証および承認機能。 |
| イメージ | インスタンスの起動およびスナップショットの管理に使用するイメージを保存します。このサービスはコントローラーで実行され、イメージの小さなセットを提供します。 |
| ネットワーク | ネットワークサービス。OpenStack Networking の詳細は、2章Networking In-Depthを参照してください。 |
| オブジェクトストレージ | バックアップのコンテンツを保存します。 |
| テレメトリー | 他の OpenStack サービスの監視およびレポート。 |
4.5.2.3. 設計に関する考慮事項
3章設計 で説明されている基本的な設計に関する考慮事項に加えて、「Network-Focused Architecture の考慮事項」 で説明されている考慮事項にも従う必要があります。
4.5.3. 大規模な Web アプリケーションのアーキテクチャー
このアーキテクチャーは、バーストの水平方向にスケーリングし、インスタンス数が高いものを生成する大規模な Web アプリケーション用です。アプリケーションでは、データを保護するために SSL 接続が必要であり、個々のサーバーへの接続を失うことはできません。
インストールおよびデプロイメントのドキュメントは、5章デプロイメント情報 を参照してください。
4.5.3.1. 設計について
次の図は、このワークロードの設計例を示しています。
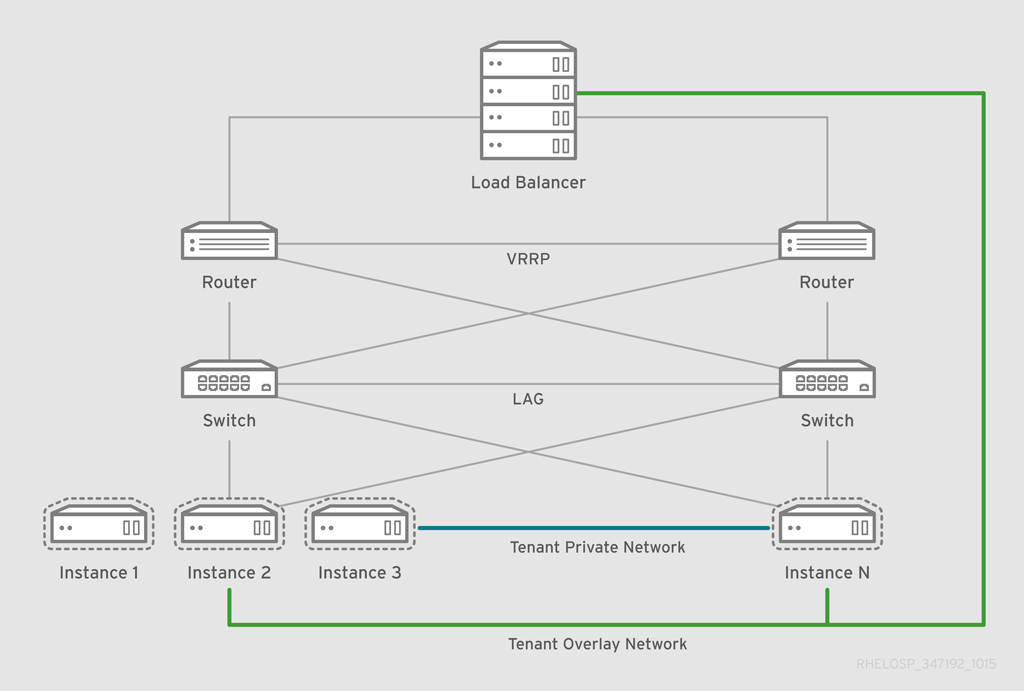
この設計には、以下のコンポーネントとワークフローが含まれます。
- ハードウェアロードバランサーは、SSL オフロード機能を提供し、テナントネットワークに接続してアドレス消費を減らします。
- ロードバランサーは、アプリケーションの仮想 IP (VIP)にサービスを提供する間にルーティングアーキテクチャーにリンクします。
- ルーターとロードバランサーは、アプリケーションテナントネットワークの GRE トンネル ID と、テナントサブネットにある IP アドレス(アドレスプールの外)を使用します。この設定により、ロードバランサーはパブリック IP アドレスを消費せずにアプリケーション HTTP サーバーと通信できるようになります。
4.5.3.2. アーキテクチャーコンポーネント
Web サービスのアーキテクチャーは、多くのオプションとオプションのコンポーネントで設定できます。したがって、このアーキテクチャーは複数の OpenStack 設計で使用できます。ただし、ほとんどの Web スケールワークロードを処理するために、いくつかの主要コンポーネントをデプロイする必要があります。
| コンポーネント | 説明 |
|---|---|
| コンピュート | コンピュート管理およびスケジューリングサービスは、コントローラーで実行されます。Compute サービスは、各コンピュートノードでも実行されます。 |
| Dashboard | OpenStack 管理用の Web コンソール。 |
| Identity | 基本的な認証および承認機能。 |
| イメージ | インスタンスの起動およびスナップショットの管理に使用するイメージを保存します。このサービスはコントローラーで実行され、イメージの小さなセットを提供します。 |
| ネットワーク | ネットワークサービス。分割されたネットワーク設定は、プライベートテナントネットワークに存在するデータベースと互換性があります。データベースは大量のブロードキャストトラフィックを出力せず、コンテンツのために他のデータベースに相互接続する必要がある場合があります。 |
| Orchestration | スケールアウト時に使用するインスタンステンプレートを管理します。トラフィックのバースト中に、このテンプレートを使用します。 |
| テレメトリー | 他の OpenStack サービスの監視およびレポート。このサービスを使用して、インスタンスの使用状況を監視し、Orchestration サービスからインスタンステンプレートを呼び出します。 |
| オブジェクトストレージ | バックアップのコンテンツを保存します。 |
4.5.3.3. 設計に関する考慮事項
3章設計 で説明されている基本的な設計に関する考慮事項に加えて、「Network-Focused Architecture の考慮事項」 で説明されている考慮事項にも従う必要があります。
4.5.4. Network-Focused Architecture の考慮事項
3章設計および2章Networking In-Depthで説明されているネットワークノード設計に関する基本的な設計に関する考慮事項に加えて、次の項目をネットワーク集約型アーキテクチャー向けに考慮する必要があります。
- 外部の依存関係
以下の外部ネットワークコンポーネントの使用を検討してください。
- ワークロードを分散したり、特定の機能を読み込んだりするハードウェアロードバランサー
- 動的ルーティングを実装する外部デバイス
OpenStack Networking はトンネリング機能を提供しますが、ネットワーキング管理リージョンに制限されています。OpenStack リージョンを超えて別のリージョンや外部システムにトンネルを拡張するには、OpenStack 外部のトンネルを実装するか、トンネル管理システムを使用してトンネルまたはオーバーレイを外部トンネルにマッピングします。
- 最大伝送単位 (MTU)
一部のワークロードでは、大量のデータを転送するため、より大きな MTU が必要です。ビデオストリーミングやストレージレプリケーションなどのアプリケーションにネットワークサービスを提供する場合は、可能な限り、OpenStack ハードウェアノードとジャンボフレームをサポートするネットワーク機器を設定します。この設定により、利用可能な帯域幅の使用率を最大化します。
パケットを通過するパス全体でジャンボフレームを設定します。1 つのネットワークコンポーネントがジャンボフレームを処理できない場合、パス全体がデフォルトの MTU に戻ります。
- NAT の使用
固定パブリック IP の代わりに Floating IP が必要な場合は、NAT を使用する必要があります。たとえば、DHCP サーバーの IP にマッピングされた DHCP リレーを使用します。この場合、新規インスタンスごとにレガシーまたは外部システムを再設定するのではなく、インフラストラクチャーを自動化してターゲット IP を新規インスタンスに適用することが容易になります。
OpenStack Networking で管理される Floating IP の NAT は、ハイパーバイザーにあります。ただし、他のバージョンの NAT が他の場所で実行されている可能性があります。IPv4 アドレスが足りなくなった場合には、以下の方法を使用して、OpenStack の外部にある欠点を軽減することができます。
- OpenStack のロードバランサーをインスタンスとして、または外部からサービスとして実行します。OpenStack Load-Balancer-as-a-Service (LBaaS)は、HAproxy などの負荷分散ソフトウェアを内部で管理できます。このサービスは仮想 IP (VIP)アドレスを管理しますが、HAproxy インスタンスからのデュアルホーム接続は、パブリックネットワークを、すべてのコンテンツサーバーをホストするテナントプライベートネットワークに接続します。
- ロードバランサーを使用して VIP を提供し、外部メソッドまたはプライベートアドレスを使用してテナントオーバーレイネットワークに接続します。
場合によっては、インスタンスで IPv6 アドレスのみを使用し、NAT64 や DNS64 などの NAT ベースの移行テクノロジーを提供するために、インスタンスまたは外部サービスを操作することが望ましい場合があります。この設定では、IPv4 アドレスを使用する一方で、グローバルにルーティング可能な IPv6 アドレスが提供されます。
- Quality of Service (QoS)
QoS は、ネットワークのパフォーマンスが低下するため、優先度の高いパケットにインスタントサービスを提供するため、ネットワーク集約型のワークロードに影響します。Voice over IP (VoIP)などのアプリケーションでは、通常、継続的な操作に差別化されたサービスコードポイントが必要です。
また、混合ワークロードに QoS を使用して、バックアップサービス、ビデオ会議、ファイル共有などの優先度の低い高帯域幅アプリケーションが、他のワークロードの継続的な操作に必要な帯域幅をブロックするのを防ぐこともできます。
ファイルストレージトラフィックを ベストエフォート や scavenger などの低いクラストラフィックとしてタグ付けして、優先度の高いトラフィックがネットワークを通過できるようにすることができます。クラウド内のリージョンが地理的に分散されている場合は、WAN 最適化を使用してレイテンシーまたはパケットロスを削減することもできます。
- ワークロード
ルーティングとスイッチングアーキテクチャーは、ネットワークレベルの冗長性を必要とするワークロードに対応する必要があります。設定は、選択したネットワークハードウェア、選択したハードウェアパフォーマンス、およびネットワークモデルによって異なります。例としては、Link Aggregation (LAG)や Hot Standby Router Protocol (HSRP)などがあります。
ワークロードはオーバーレイネットワークの有効性にも影響します。アプリケーションネットワーク接続が小規模、有効期間の短い、またはバースト性である場合、動的オーバーレイを実行すると、ネットワークが処理するパケットと同じ量の帯域幅を生成できます。また、オーバーレイは、ハイパーバイザーで問題を引き起こすのに十分なレイテンシーを発生させる可能性があり、1 回あたりのパケットおよび 1 秒あたりの接続速度でパフォーマンスが低下する可能性があります。
デフォルトでは、オーバーレイにはワークロードに依存するセカンダリー full-mesh オプションが含まれています。たとえば、ほとんどの Web サービスアプリケーションでは、完全なメッシュオーバーレイネットワークに関する大きな問題がなく、一部のネットワーク監視ツールまたはストレージレプリケーションワークロードには、スループットまたは過剰なブロードキャストトラフィックに関するパフォーマンスの問題があります。
第5章 デプロイメント情報
以下の表には、本ガイドに記載したコンポーネントの参考情報をまとめています。
Red Hat OpenStack Platform のその他のマニュアルは https://access.redhat.com/documentation/ja-JP/Red_Hat_OpenStack_Platform/を参照してください。
| コンポーネント | 参考情報 |
|---|---|
| Red Hat Enterprise Linux | Red Hat OpenStack Platform は、Red Hat Enterprise Linux 7.2 以降でサポートされています。Red Hat Enterprise Linux のインストールに関する情報は、https://access.redhat.com/site/documentation/en-US/Red_Hat_Enterprise_Linux/ にある該当するインストールガイドを参照してください。 |
| OpenStack | OpenStack のコンポーネントとそれらの依存関係をインストールするには、Red Hat OpenStack Platform director を使用します。director では、基本的な OpenStack アンダークラウド を使用して、最終的な オーバークラウド の OpenStack ノードのプロビジョニングと管理を行います。 アンダークラウドのインストールには、デプロイするオーバークラウドに必要な環境に加えて、追加のホストマシンが 1 台必要となる点に注意してください。詳細な手順は、Red Hat OpenStack Platform Director Installation and Usage を参照してください。 |
| High Availability | 追加の高可用性コンポーネント(例:HAProxy)の設定については、Ceph Storage を使用した高可用性 Red Hat OpenStack Platform 6 のデプロイ を参照し てください。 ライブマイグレーションの設定に関する情報は、インスタンスおよびイメージの管理 を参照してください。 |
| LBasS | Load Balancing-as-a-Service を使用するには、ネットワークガイドの Load Balancing-as-a-Service の設定を参照してください。 |
| Pacemaker | Pacemaker は Red Hat Enterprise Linux にアドオンとして統合されています。高可用性用の Red Hat Enterprise Linux を設定するには、High Availability アドオンの概要 を参照してください。 |