클러스터 구성
OpenShift Container Platform 3.11 설치 및 구성
초록
1장. 개요
이 가이드에서는 설치 후 OpenShift Container Platform 클러스터에 사용할 수 있는 추가 구성 옵션에 대해 설명합니다.
2장. 레지스트리 설정
2.1. 내부 레지스트리 개요
2.1.1. 레지스트리 정보
OpenShift Container Platform은 소스 코드에서 컨테이너 이미지를 빌드하고 배포하며 라이프사이클을 관리할 수 있습니다. 이를 활성화하기 위해 OpenShift Container Platform은 OpenShift Container Platform 환경에 배포하여 이미지를 로컬로 관리할 수 있는 내부 통합 컨테이너 이미지 레지스트리 를 제공합니다.
2.1.2. 통합 또는 독립 실행형 레지스트리
전체 OpenShift Container Platform 클러스터를 처음 설치하는 동안 설치 프로세스 중에 레지스트리가 자동으로 배포되었을 수 있습니다. 레지스트리 구성이 없거나 레지스트리 구성을 추가로 사용자 지정하려면 기존 클러스터에 레지스트리 배포를 참조하십시오.
전체 OpenShift Container Platform 클러스터의 통합 일부로 실행하도록 배포할 수는 있지만 OpenShift Container Platform 레지스트리는 독립 실행형 컨테이너 이미지 레지스트리로 별도로 설치할 수 있습니다.
독립 실행형 레지스트리를 설치하려면 독립 실행형 레지스트리 설치를 따르십시오. 이 설치 경로는 레지스트리와 특수 웹 콘솔을 실행하는 올인원 클러스터를 배포합니다.
2.2. 기존 클러스터에 레지스트리 배포
2.2.1. 개요
OpenShift Container Platform 클러스터를 처음 설치하는 동안 통합 레지스트리가 자동으로 배포되지 않았거나 더 이상 성공적으로 실행되지 않고 기존 클러스터에 다시 배포해야 하는 경우 다음 섹션을 참조하십시오.
독립 실행형 레지스트리 를 설치한 경우에는 이 주제가 필요하지 않습니다.
2.2.2. 레지스트리 호스트 이름 설정
레지스트리가 내부 및 외부 참조 모두에 대해 로 알려진 호스트 이름과 포트를 구성할 수 있습니다. 이렇게 하면 이미지 스트림은 이미지의 호스트 이름 기반 푸시 및 가져오기 사양을 제공하므로, 이미지 소비자가 레지스트리 서비스 IP의 변경 사항과 이미지 스트림과 참조를 이식할 수 있습니다.
클러스터 내에서 레지스트리를 참조하는 데 사용되는 호스트 이름을 설정하려면 마스터 구성 파일의 imagePolicyConfig 섹션에 internalRegistryHostname 을 설정합니다. 외부 호스트 이름은 동일한 위치에 externalRegistryHostname 값을 설정하여 제어됩니다.
이미지 정책 구성
imagePolicyConfig:
internalRegistryHostname: docker-registry.default.svc.cluster.local:5000
externalRegistryHostname: docker-registry.mycompany.com
레지스트리 자체는 동일한 내부 호스트 이름 값으로 구성해야 합니다. 이 작업은 레지스트리 배포 구성에서 REGISTRY_OPENSHIFT_SERVER_ADDR 환경 변수를 설정하거나 레지스트리 구성의 OpenShift 섹션에서 값을 설정하여 수행할 수 있습니다.
레지스트리에 TLS를 활성화한 경우 서버 인증서에 레지스트리를 참조할 것으로 예상되는 호스트 이름이 포함되어야 합니다. 서버 인증서에 호스트 이름을 추가하는 방법은 레지스트리 보안을 참조하십시오.
2.2.3. 레지스트리 배포
통합 컨테이너 이미지 레지스트리를 배포하려면 클러스터 관리자 권한이 있는 사용자로 oc adm registry 명령을 사용합니다. 예를 들면 다음과 같습니다.
$ oc adm registry --config=/etc/origin/master/admin.kubeconfig \
--service-account=registry \
--images='registry.redhat.io/openshift3/ose-${component}:${version}' 그러면 docker-registry 라는 서비스와 배포 구성이 생성됩니다. 성공적으로 배포되면 docker-registry-1-cpty9 와 유사한 이름으로 포드가 생성됩니다.
레지스트리 생성 시 지정할 수 있는 전체 옵션 목록을 보려면 다음을 수행합니다.
$ oc adm registry --help
--fs-group 의 값은 레지스트리에서 사용하는 SCC에서 허용해야 합니다(일반적으로 restricted SCC).
2.2.4. 레지스트리를 DaemonSet으로 배포
oc adm registry 명령을 사용하여 --daemonset 옵션을 사용하여 레지스트리를 DaemonSet 으로 배포합니다.
DaemonSet은 노드가 생성될 때 지정된 Pod 복사본이 포함되어 있는지 확인합니다. 노드를 제거하면 Pod가 가비지 수집됩니다.
DaemonSet에 대한 자세한 내용은 Daemonsets 사용을 참조하십시오.
2.2.5. 레지스트리 컴퓨팅 리소스
기본적으로 레지스트리는 컴퓨팅 리소스 요청 또는 제한에 대한 설정 없이 생성됩니다. 프로덕션의 경우 레지스트리의 배포 구성을 업데이트하여 레지스트리의 리소스 요청 및 제한을 설정하는 것이 좋습니다. 그렇지 않으면 레지스트리 포드가 BestEffort 포드 로 간주됩니다.
요청 및 제한 구성에 대한 자세한 내용은 Compute Resources 를 참조하십시오.
2.2.6. 레지스트리 스토리지
레지스트리는 컨테이너 이미지와 메타데이터를 저장합니다. 레지스트리를 사용하여 포드를 배포하면 Pod가 종료되면 삭제된 임시 볼륨을 사용합니다. 누구나 레지스트리로 빌드 또는 푸시한 이미지가 사라집니다.
이 섹션에는 지원되는 레지스트리 스토리지 드라이버가 나열되어 있습니다. 자세한 내용은 컨테이너 이미지 레지스트리 설명서를 참조하십시오.
다음 목록에는 레지스트리의 구성 파일에서 구성해야 하는 스토리지 드라이버가 포함되어 있습니다.
- 파일 시스템. 파일 시스템이 기본값이며 구성할 필요가 없습니다.
- S3. 자세한 내용은 CloudFront 구성 설명서를 참조하십시오.
- OpenStack Swift
- Google Cloud Storage(GCS)
- Microsoft Azure
- Aliyun OSS
일반 레지스트리 스토리지 구성 옵션이 지원됩니다. 자세한 내용은 컨테이너 이미지 레지스트리 설명서를 참조하십시오.
다음 스토리지 옵션은 파일 시스템 드라이버를 통해 구성해야 합니다.
지원되는 영구 스토리지 드라이버에 대한 자세한 내용은 영구 스토리지 및 영구 스토리지 예제 구성을 참조하십시오.
2.2.6.1. 프로덕션 사용
프로덕션 용도 의 경우 원격 볼륨을 연결하거나 선택한 영구 스토리지 방법을 정의 및 사용합니다.
예를 들어 기존 영구 볼륨 클레임을 사용하려면 다음을 수행합니다.
$ oc set volume deploymentconfigs/docker-registry --add --name=registry-storage -t pvc \
--claim-name=<pvc_name> --overwrite테스트 결과 RHEL NFS 서버를 컨테이너 이미지 레지스트리의 스토리지 백엔드로 사용하는 데 문제가 있는 것으로 표시됩니다. 여기에는 OpenShift Container Registry 및 Quay가 포함됩니다. 따라서 RHEL NFS 서버를 사용하여 핵심 서비스에서 사용하는 PV를 백업하는 것은 권장되지 않습니다.
마켓플레이스의 다른 NFS 구현에는 이러한 문제가 나타나지 않을 수 있습니다. 이러한 OpenShift 핵심 구성 요소에 대해 완료된 테스트에 대한 자세한 내용은 개별 NFS 구현 벤더에 문의하십시오.
2.2.6.1.1. Amazon S3을 스토리지 백엔드로 사용
내부 컨테이너 이미지 레지스트리와 함께 Amazon Simple Storage Service 스토리지를 사용하는 옵션도 있습니다. AWS 관리 콘솔을 통해 관리할 수 있는 보안 클라우드 스토리지입니다. 이를 사용하려면 레지스트리의 구성 파일을 수동으로 편집하여 레지스트리 포드에 마운트해야 합니다. 그러나 구성을 시작하기 전에 업스트림의 권장 단계를 확인합니다.
기본 YAML 구성 파일을 기본으로 사용하고 storage 섹션의 filesystem 항목을 다음과 같은 s3 항목으로 바꿉니다. 결과 스토리지 섹션은 다음과 같을 수 있습니다.
storage:
cache:
layerinfo: inmemory
delete:
enabled: true
s3:
accesskey: awsaccesskey
secretkey: awssecretkey
region: us-west-1
regionendpoint: http://myobjects.local
bucket: bucketname
encrypt: true
keyid: mykeyid
secure: true
v4auth: false
chunksize: 5242880
rootdirectory: /s3/object/name/prefix모든 s3 구성 옵션은 업스트림 드라이버 참조 문서에 설명되어 있습니다.
레지스트리 구성을 재정의하면 구성 파일을 포드에 마운트하는 추가 단계를 거칩니다.
레지스트리가 S3 스토리지 백엔드에서 실행되면 보고된 문제가 있습니다.
사용 중인 통합 레지스트리에서 지원하지 않는 S3 리전을 사용하려면 S3 드라이버 구성을 참조하십시오.
2.2.6.2. 비생산 사용
프로덕션 환경 이외의 용도의 경우 --mount-host=<path> 옵션을 사용하여 레지스트리에서 영구 스토리지에 사용할 디렉터리를 지정할 수 있습니다. 그런 다음 지정된 <path> 에 레지스트리 볼륨이 host-mount로 생성됩니다.
mount -host 옵션은 레지스트리 컨테이너가 있는 노드의 디렉터리를 마운트합니다. docker-registry 배포 구성을 확장하는 경우 레지스트리 포드와 컨테이너가 서로 다른 노드에서 실행될 수 있으므로 각각 고유한 로컬 스토리지가 있는 두 개 이상의 레지스트리 컨테이너가 생성될 수 있습니다. 이로 인해 요청이 최종적으로 전달되는 컨테이너에 따라 동일한 이미지를 반복적으로 가져오는 요청이 항상 성공하지는 않을 수 있으므로 예측할 수 없는 동작이 발생합니다.
mount -host 옵션을 사용하려면 레지스트리 컨테이너를 권한 있는 모드로 실행해야 합니다. 이는 --mount-host 를 지정하면 자동으로 활성화됩니다. 그러나 일부 Pod가 기본적으로 권한 있는 컨테이너를 실행할 수 있는 것은 아닙니다. 이 옵션을 계속 사용하려면 레지스트리를 생성하고 설치 중에 생성된 레지스트리 서비스 계정을 사용하도록 지정합니다.
$ oc adm registry --service-account=registry \
--config=/etc/origin/master/admin.kubeconfig \
--images='registry.redhat.io/openshift3/ose-${component}:${version}' \
--mount-host=<path>- 1
- OpenShift Container Platform의 올바른 이미지를 가져오는 데 필요합니다.
${component}및${version}은 설치 중에 동적으로 교체됩니다.
컨테이너 이미지 레지스트리 포드는 사용자 1001 로 실행됩니다. 이 사용자는 호스트 디렉터리에 쓸 수 있어야 합니다. 다음 명령을 사용하여 디렉터리 소유권을 사용자 ID 1001 로 변경해야 할 수 있습니다.
$ sudo chown 1001:root <path>2.2.7. 레지스트리 콘솔 활성화
OpenShift Container Platform은 통합 레지스트리에 웹 기반 인터페이스를 제공합니다. 이 레지스트리 콘솔은 이미지 검색 및 관리를 위한 선택적 구성 요소입니다. 포드로 실행되는 상태 비저장 서비스로 배포됩니다.
OpenShift Container Platform을 독립 실행형 레지스트리로 설치한 경우 레지스트리 콘솔은 이미 배포되어 설치 중에 자동으로 보호됩니다.
Cockpit이 이미 실행 중인 경우 레지스트리 콘솔과 포트 충돌(기본적으로 9090)을 방지하려면 계속 진행하기 전에 Cockpit을 종료해야 합니다.
2.2.7.1. 레지스트리 콘솔 배포
먼저 레지스트리를 공개해야 합니다.
default 프로젝트에 패스스루 경로를 만듭니다. 다음 단계에서 레지스트리 콘솔 애플리케이션을 생성할 때 이 작업이 필요합니다.
$ oc create route passthrough --service registry-console \ --port registry-console \ -n default레지스트리 콘솔 애플리케이션을 배포합니다.
<openshift_oauth_url>을 OpenShift Container Platform OAuth 공급자의 URL로 바꿉니다. 일반적으로 마스터입니다.$ oc new-app -n default --template=registry-console \ -p OPENSHIFT_OAUTH_PROVIDER_URL="https://<openshift_oauth_url>:8443" \ -p REGISTRY_HOST=$(oc get route docker-registry -n default --template='{{ .spec.host }}') \ -p COCKPIT_KUBE_URL=$(oc get route registry-console -n default --template='https://{{ .spec.host }}')참고레지스트리 콘솔에 로그인하려고 할 때 리디렉션 URL이 잘못되면
oc get oauthclients를 사용하여 OAuth 클라이언트를 확인합니다.- 마지막으로 웹 브라우저를 사용하여 경로 URI를 사용하여 콘솔을 확인합니다.
2.2.7.2. 레지스트리 콘솔 보안
기본적으로 레지스트리 콘솔 배포의 단계에 따라 레지스트리 콘솔에서 자체 서명 TLS 인증서를 생성합니다. 자세한 내용은 레지스트리 콘솔 문제 해결을 참조하십시오.
다음 단계를 사용하여 조직의 서명 인증서를 보안 볼륨으로 추가합니다. 이는 인증서를 oc 클라이언트 호스트에서 사용할 수 있다고 가정합니다.
인증서와 키가 포함된 .cert 파일을 만듭니다. 다음과 같이 파일을 포맷합니다.
- 서버 인증서 및 중간 인증 기관을 위한 하나 이상의 BEGIN CERTIFICATE 블록
BEGIN PRIVATE KEY 또는 키와 유사한 블록입니다. 키를 암호화할 수 없습니다
예를 들면 다음과 같습니다.
-----BEGIN CERTIFICATE----- MIIDUzCCAjugAwIBAgIJAPXW+CuNYS6QMA0GCSqGSIb3DQEBCwUAMD8xKTAnBgNV BAoMIGI0OGE2NGNkNmMwNTQ1YThhZTgxOTEzZDE5YmJjMmRjMRIwEAYDVQQDDAls ... -----END CERTIFICATE----- -----BEGIN CERTIFICATE----- MIIDUzCCAjugAwIBAgIJAPXW+CuNYS6QMA0GCSqGSIb3DQEBCwUAMD8xKTAnBgNV BAoMIGI0OGE2NGNkNmMwNTQ1YThhZTgxOTEzZDE5YmJjMmRjMRIwEAYDVQQDDAls ... -----END CERTIFICATE----- -----BEGIN PRIVATE KEY----- MIIEvgIBADANBgkqhkiG9w0BAQEFAASCBKgwggSkAgEAAoIBAQCyOJ5garOYw0sm 8TBCDSqQ/H1awGMzDYdB11xuHHsxYS2VepPMzMzryHR137I4dGFLhvdTvJUH8lUS ... -----END PRIVATE KEY-----보안 레지스트리에는 다음 SAN(주체 대체 이름) 목록이 포함되어야 합니다.
두 개의 서비스 호스트 이름.
예를 들면 다음과 같습니다.
docker-registry.default.svc.cluster.local docker-registry.default.svc서비스 IP 주소.
예를 들면 다음과 같습니다.
172.30.124.220다음 명령을 사용하여 컨테이너 이미지 레지스트리 서비스 IP 주소를 가져옵니다.
oc get service docker-registry --template='{{.spec.clusterIP}}'공개 호스트 이름.
예를 들면 다음과 같습니다.
docker-registry-default.apps.example.com다음 명령을 사용하여 컨테이너 이미지 레지스트리 공개 호스트 이름을 가져옵니다.
oc get route docker-registry --template '{{.spec.host}}'예를 들어 서버 인증서에는 다음과 유사한 SAN 세부 정보가 포함되어야 합니다.
X509v3 Subject Alternative Name: DNS:docker-registry-public.openshift.com, DNS:docker-registry.default.svc, DNS:docker-registry.default.svc.cluster.local, DNS:172.30.2.98, IP Address:172.30.2.98레지스트리 콘솔은 /etc/cockpit/ws-certs.d 디렉터리에서 인증서를 로드합니다. 마지막 파일에는 .cert 확장자가 알파벳순으로 사용됩니다. 따라서 .cert 파일에는 OpenSSL 스타일로 포맷된 PEM 블록이 2개 이상 포함되어야 합니다.
인증서를 찾을 수 없는 경우,
openssl명령을 사용하여 자체 서명된 인증서가 생성되고 0-self-signed.cert 파일에 저장됩니다.
시크릿을 생성합니다.
$ oc create secret generic console-secret \ --from-file=/path/to/console.certregistry-console 배포 구성에 보안을 추가합니다.
$ oc set volume dc/registry-console --add --type=secret \ --secret-name=console-secret -m /etc/cockpit/ws-certs.d이렇게 하면 레지스트리 콘솔의 새 배포가 트리거되어 서명된 인증서가 포함됩니다.
2.2.7.3. 레지스트리 콘솔 문제 해결
2.2.7.3.1. 디버그 모드
레지스트리 콘솔 디버그 모드는 환경 변수를 사용하여 활성화됩니다. 다음 명령은 디버그 모드로 레지스트리 콘솔을 재배포합니다.
$ oc set env dc registry-console G_MESSAGES_DEBUG=cockpit-ws,cockpit-wrapper디버그 모드를 활성화하면 더 자세한 로깅이 레지스트리 콘솔의 Pod 로그에 표시될 수 있습니다.
2.2.7.3.2. SSL 인증서 경로 표시
레지스트리 콘솔에서 사용 중인 인증서를 확인하려면 콘솔 포드 내부에서 명령을 실행할 수 있습니다.
default 프로젝트의 Pod를 나열하고 레지스트리 콘솔의 Pod 이름을 찾습니다.
$ oc get pods -n default NAME READY STATUS RESTARTS AGE registry-console-1-rssrw 1/1 Running 0 1d이전 명령에서 포드 이름을 사용하여 cockpit-ws 프로세스에서 사용 중인 인증서 경로를 가져옵니다. 이 예에서는 자동 생성 인증서를 사용하는 콘솔을 보여줍니다.
$ oc exec registry-console-1-rssrw remotectl certificate certificate: /etc/cockpit/ws-certs.d/0-self-signed.cert
2.3. 레지스트리에 액세스
2.3.1. 로그 보기
컨테이너 이미지 레지스트리의 로그를 보려면 배포 구성과 함께 oc logs 명령을 사용합니다.
$ oc logs dc/docker-registry
2015-05-01T19:48:36.300593110Z time="2015-05-01T19:48:36Z" level=info msg="version=v2.0.0+unknown"
2015-05-01T19:48:36.303294724Z time="2015-05-01T19:48:36Z" level=info msg="redis not configured" instance.id=9ed6c43d-23ee-453f-9a4b-031fea646002
2015-05-01T19:48:36.303422845Z time="2015-05-01T19:48:36Z" level=info msg="using inmemory layerinfo cache" instance.id=9ed6c43d-23ee-453f-9a4b-031fea646002
2015-05-01T19:48:36.303433991Z time="2015-05-01T19:48:36Z" level=info msg="Using OpenShift Auth handler"
2015-05-01T19:48:36.303439084Z time="2015-05-01T19:48:36Z" level=info msg="listening on :5000" instance.id=9ed6c43d-23ee-453f-9a4b-031fea6460022.3.2. 파일 스토리지
태그 및 이미지 메타데이터는 OpenShift Container Platform에 저장되지만 레지스트리는 /registry 의 레지스트리 컨테이너에 마운트된 볼륨에 계층 및 서명 데이터를 저장합니다. oc exec 는 권한 있는 컨테이너에서 작동하지 않으므로 레지스트리의 콘텐츠를 보려면 레지스트리 Pod의 컨테이너에 수동으로 SSH를 적용한 다음 컨테이너 자체에서 docker exec 를 실행해야 합니다.
현재 Pod를 나열하여 컨테이너 이미지 레지스트리의 포드 이름을 찾습니다.
# oc get pods그런 다음
oc describe를 사용하여 컨테이너를 실행하는 노드의 호스트 이름을 찾습니다.# oc describe pod <pod_name>원하는 노드에 로그인합니다.
# ssh node.example.com노드 호스트의 default 프로젝트에서 실행 중인 컨테이너를 나열하고 컨테이너 이미지 레지스트리의 컨테이너 ID를 확인합니다.
# docker ps --filter=name=registry_docker-registry.*_default_oc rsh명령을 사용하여 레지스트리 콘텐츠를 나열합니다.# oc rsh dc/docker-registry find /registry /registry/docker /registry/docker/registry /registry/docker/registry/v2 /registry/docker/registry/v2/blobs1 /registry/docker/registry/v2/blobs/sha256 /registry/docker/registry/v2/blobs/sha256/ed /registry/docker/registry/v2/blobs/sha256/ed/ede17b139a271d6b1331ca3d83c648c24f92cece5f89d95ac6c34ce751111810 /registry/docker/registry/v2/blobs/sha256/ed/ede17b139a271d6b1331ca3d83c648c24f92cece5f89d95ac6c34ce751111810/data2 /registry/docker/registry/v2/blobs/sha256/a3 /registry/docker/registry/v2/blobs/sha256/a3/a3ed95caeb02ffe68cdd9fd84406680ae93d633cb16422d00e8a7c22955b46d4 /registry/docker/registry/v2/blobs/sha256/a3/a3ed95caeb02ffe68cdd9fd84406680ae93d633cb16422d00e8a7c22955b46d4/data /registry/docker/registry/v2/blobs/sha256/f7 /registry/docker/registry/v2/blobs/sha256/f7/f72a00a23f01987b42cb26f259582bb33502bdb0fcf5011e03c60577c4284845 /registry/docker/registry/v2/blobs/sha256/f7/f72a00a23f01987b42cb26f259582bb33502bdb0fcf5011e03c60577c4284845/data /registry/docker/registry/v2/repositories3 /registry/docker/registry/v2/repositories/p1 /registry/docker/registry/v2/repositories/p1/pause4 /registry/docker/registry/v2/repositories/p1/pause/_manifests /registry/docker/registry/v2/repositories/p1/pause/_manifests/revisions /registry/docker/registry/v2/repositories/p1/pause/_manifests/revisions/sha256 /registry/docker/registry/v2/repositories/p1/pause/_manifests/revisions/sha256/e9a2ac6418981897b399d3709f1b4a6d2723cd38a4909215ce2752a5c068b1cf /registry/docker/registry/v2/repositories/p1/pause/_manifests/revisions/sha256/e9a2ac6418981897b399d3709f1b4a6d2723cd38a4909215ce2752a5c068b1cf/signatures5 /registry/docker/registry/v2/repositories/p1/pause/_manifests/revisions/sha256/e9a2ac6418981897b399d3709f1b4a6d2723cd38a4909215ce2752a5c068b1cf/signatures/sha256 /registry/docker/registry/v2/repositories/p1/pause/_manifests/revisions/sha256/e9a2ac6418981897b399d3709f1b4a6d2723cd38a4909215ce2752a5c068b1cf/signatures/sha256/ede17b139a271d6b1331ca3d83c648c24f92cece5f89d95ac6c34ce751111810 /registry/docker/registry/v2/repositories/p1/pause/_manifests/revisions/sha256/e9a2ac6418981897b399d3709f1b4a6d2723cd38a4909215ce2752a5c068b1cf/signatures/sha256/ede17b139a271d6b1331ca3d83c648c24f92cece5f89d95ac6c34ce751111810/link6 /registry/docker/registry/v2/repositories/p1/pause/_uploads7 /registry/docker/registry/v2/repositories/p1/pause/_layers8 /registry/docker/registry/v2/repositories/p1/pause/_layers/sha256 /registry/docker/registry/v2/repositories/p1/pause/_layers/sha256/a3ed95caeb02ffe68cdd9fd84406680ae93d633cb16422d00e8a7c22955b46d4 /registry/docker/registry/v2/repositories/p1/pause/_layers/sha256/a3ed95caeb02ffe68cdd9fd84406680ae93d633cb16422d00e8a7c22955b46d4/link9 /registry/docker/registry/v2/repositories/p1/pause/_layers/sha256/f72a00a23f01987b42cb26f259582bb33502bdb0fcf5011e03c60577c4284845 /registry/docker/registry/v2/repositories/p1/pause/_layers/sha256/f72a00a23f01987b42cb26f259582bb33502bdb0fcf5011e03c60577c4284845/link- 1
- 이 디렉터리는 모든 계층과 서명을 Blob으로 저장합니다.
- 2
- 이 파일에는 Blob의 내용이 포함되어 있습니다.
- 3
- 이 디렉터리는 모든 이미지 리포지토리를 저장합니다.
- 4
- 이 디렉터리는 단일 이미지 리포지토리 p1/pause 를 위한 것입니다.
- 5
- 이 디렉터리에는 특정 이미지 매니페스트 버전에 대한 서명이 포함되어 있습니다.
- 6
- 이 파일에는 서명 데이터가 포함된 Blob에 대한 참조가 포함되어 있습니다.
- 7
- 이 디렉터리에는 현재 지정된 리포지토리에 대해 업로드 및 스테이징된 모든 계층이 포함되어 있습니다.
- 8
- 이 디렉터리에는 이 리포지토리가 참조하는 모든 계층에 대한 링크가 포함되어 있습니다.
- 9
- 이 파일에는 이미지를 통해 이 리포지토리에 연결된 특정 계층에 대한 참조가 포함되어 있습니다.
2.3.3. 직접 레지스트리 액세스
고급 용도의 경우 레지스트리에 직접 액세스하여 docker 명령을 호출할 수 있습니다. 이를 통해 docker push 또는 docker pull과 같은 작업을 사용하여 통합 레지스트리에서 이미지를 직접 푸시 하거나 가져올 수 있습니다. 이렇게 하려면 docker login 명령을 사용하여 레지스트리에 로그인해야 합니다. 수행할 수있는 작업은 다음 섹션에 설명된대로 사용자 권한에 따라 달라집니다.
2.3.3.1. 사용자 요구 사항
직접 레지스트리에 액세스하려면 원하는 사용량에 따라 사용하는 사용자가 다음을 충족해야 합니다.
직접 액세스하기 위해 선호하는 ID 공급자에 대한 일반 사용자가 있어야 합니다. 일반 사용자는 레지스트리에 로그인하는 데 필요한 액세스 토큰을 생성할 수 있습니다. system:admin 과 같은 시스템 사용자는 액세스 토큰을 가져올 수 없으므로 레지스트리에 직접 액세스할 수 없습니다.
예를 들어
HTPASSWD인증을 사용하는 경우 다음 명령을 사용하여 하나를 생성할 수 있습니다.# htpasswd /etc/origin/master/htpasswd <user_name>예를 들어
docker pull명령을 사용하는 경우 이미지를 가져오려면 사용자에게 registry-viewer 역할이 있어야 합니다. 이 역할을 추가하려면 다음을 수행합니다.$ oc policy add-role-to-user registry-viewer <user_name>예를 들어
docker push 명령을 사용할 때 이미지를 작성하거나 푸시하려면 사용자에게 registry-editor 역할이 있어야 합니다. 이 역할을 추가하려면 다음을 수행합니다.$ oc policy add-role-to-user registry-editor <user_name>
사용자 권한에 대한 자세한 내용은 역할 바인딩 관리를 참조하십시오.
2.3.3.2. 레지스트리에 로그인
사용자가 직접 레지스트리에 액세스하는 데 필요한 사전 요구 사항을 충족하는지 확인합니다.
레지스트리에 직접 로그인하려면 다음을 수행합니다.
일반 사용자로 OpenShift Container Platform에 로그인했는지 확인하십시오.
$ oc login액세스 토큰을 사용하여 컨테이너 이미지 레지스트리에 로그인합니다.
docker login -u openshift -p $(oc whoami -t) <registry_ip>:<port>
사용자 이름에 모든 값을 전달할 수 있으며 토큰에는 필요한 모든 정보가 포함되어 있습니다. 콜론이 포함된 사용자 이름을 전달하면 로그인이 실패합니다.
2.3.3.3. 이미지 내보내기 및 가져오기
레지스트리에 로그인한 후 레지스트리에 대해 docker pull 및 docker push 작업을 수행할 수 있습니다.
모든 이미지를 가져올 수 있지만 system:registry 역할이 추가된 경우 프로젝트의 레지스트리에만 이미지를 푸시할 수 있습니다.
다음 예제에서는 다음을 사용합니다.
| 구성 요소 | 값 |
| <registry_ip> |
|
| <port> |
|
| <project> |
|
| <image> |
|
| <tag> |
생략됨 (기본값 |
모든 이미지를 가져옵니다.
$ docker pull docker.io/busybox<registry_ip>:<port>/<project>/<image>형식으로 새 이미지에 태그를 지정합니다. OpenShift Container Platform이 레지스트리에 이미지를 올바르게 배치하고 나중에 액세스할 수 있도록 프로젝트 이름이 이 풀 사양에 표시되어야 합니다.$ docker tag docker.io/busybox 172.30.124.220:5000/openshift/busybox참고일반 사용자에게는 지정된 프로젝트에 대한 system:image-builder 역할이 있어야 사용자가 이미지를 작성하거나 푸시할 수 있습니다. 그렇지 않으면 다음 단계의
docker push가 실패합니다. 테스트를 위해 busybox 이미지를 푸시하는 새 프로젝트를 만들 수 있습니다.새로 태그가 지정된 이미지를 레지스트리로 푸시합니다.
$ docker push 172.30.124.220:5000/openshift/busybox ... cf2616975b4a: Image successfully pushed Digest: sha256:3662dd821983bc4326bee12caec61367e7fb6f6a3ee547cbaff98f77403cab55
2.3.4. 레지스트리 지표에 액세스
OpenShift Container 레지스트리는 Prometheus 메트릭에 대한 엔드 포인트를 제공합니다. Prometheus는 독립형 오픈 소스 시스템 모니터링 및 경고 툴킷입니다.
메트릭은 레지스트리 엔드 포인트의 /extensions/v2/metrics 경로에 표시됩니다. 그러나 이 경로를 먼저 활성화해야 합니다. 자세한 내용은 확장 레지스트리 구성을 참조하십시오.
다음은 지표 쿼리의 간단한 예입니다.
$ curl -s -u <user>:<secret> \
http://172.30.30.30:5000/extensions/v2/metrics | grep openshift | head -n 10
# HELP openshift_build_info A metric with a constant '1' value labeled by major, minor, git commit & git version from which OpenShift was built.
# TYPE openshift_build_info gauge
openshift_build_info{gitCommit="67275e1",gitVersion="v3.6.0-alpha.1+67275e1-803",major="3",minor="6+"} 1
# HELP openshift_registry_request_duration_seconds Request latency summary in microseconds for each operation
# TYPE openshift_registry_request_duration_seconds summary
openshift_registry_request_duration_seconds{name="test/origin-pod",operation="blobstore.create",quantile="0.5"} 0
openshift_registry_request_duration_seconds{name="test/origin-pod",operation="blobstore.create",quantile="0.9"} 0
openshift_registry_request_duration_seconds{name="test/origin-pod",operation="blobstore.create",quantile="0.99"} 0
openshift_registry_request_duration_seconds_sum{name="test/origin-pod",operation="blobstore.create"} 0
openshift_registry_request_duration_seconds_count{name="test/origin-pod",operation="blobstore.create"} 5
지표에 액세스하는 또 다른 방법은 클러스터 역할을 사용하는 것입니다. 끝점을 활성화해야 하지만 <secret> 을 지정할 필요가 없습니다. 메트릭을 담당하는 구성 파일의 일부는 다음과 같아야합니다.
openshift:
version: 1.0
metrics:
enabled: true
...메트릭에 액세스할 클러스터 역할이 아직 없는 경우 클러스터 역할을 생성해야 합니다.
$ cat <<EOF |
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: prometheus-scraper
rules:
- apiGroups:
- image.openshift.io
resources:
- registry/metrics
verbs:
- get
EOF
oc create -f -이 역할을 사용자에게 추가하려면 다음 명령을 실행합니다.
$ oc adm policy add-cluster-role-to-user prometheus-scraper <username>고급 쿼리 및 권장 시각화 프로그램은 업스트림 Prometheus 설명서 를 참조하십시오.
2.4. 레지스트리 보안 및 노출
2.4.1. 개요
기본적으로 OpenShift Container Platform 레지스트리는 TLS를 통해 트래픽을 제공하도록 클러스터 설치 중에 보호됩니다. 또한 서비스를 외부에 노출하기 위해 기본적으로 패스스루 경로가 생성됩니다.
어떠한 이유로 레지스트리가 보안 또는 노출되지 않은 경우 수동으로 이렇게 하는 방법에 대한 단계는 다음 섹션을 참조하십시오.
2.4.2. 수동으로 레지스트리 보안
TLS를 통해 트래픽을 제공하도록 레지스트리를 수동으로 보호하려면 다음을 수행합니다.
- 레지스트리를 배포합니다.
레지스트리의 서비스 IP 및 포트를 가져옵니다.
$ oc get svc/docker-registry NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE docker-registry ClusterIP 172.30.82.152 <none> 5000/TCP 1d기존 서버 인증서를 사용하거나 지정된 CA에서 서명한 지정된 IP 및 호스트 이름에 유효한 키와 서버 인증서를 생성할 수 있습니다. 레지스트리 서비스 IP 및 docker-registry.default.svc.cluster.local 호스트 이름에 대한 서버 인증서를 생성하려면 Ansible 호스트 인벤토리 파일에 나열된 첫 번째 마스터(기본값 /etc/ansible/hosts )에서 다음 명령을 실행합니다.
$ oc adm ca create-server-cert \ --signer-cert=/etc/origin/master/ca.crt \ --signer-key=/etc/origin/master/ca.key \ --signer-serial=/etc/origin/master/ca.serial.txt \ --hostnames='docker-registry.default.svc.cluster.local,docker-registry.default.svc,172.30.124.220' \ --cert=/etc/secrets/registry.crt \ --key=/etc/secrets/registry.key라우터가 외부에 노출되는 경우
--hostnames플래그에 공용 경로 호스트 이름을 추가합니다.--hostnames='mydocker-registry.example.com,docker-registry.default.svc.cluster.local,172.30.124.220 \외부에서 액세스할 수 있도록 기본 인증서 업데이트에 대한 자세한 내용은 레지스트리 및 라우터 인증서 재배포 를 참조하십시오.
참고oc adm ca create-server-cert명령은 2년 동안 유효한 인증서를 생성합니다. 이는--expire-days옵션으로 변경할 수 있지만 보안상의 이유로 이 값보다 커지지 않는 것이 좋습니다.레지스트리 인증서의 보안을 생성합니다.
$ oc create secret generic registry-certificates \ --from-file=/etc/secrets/registry.crt \ --from-file=/etc/secrets/registry.key레지스트리 Pod의 서비스 계정에 보안을 추가합니다( 기본 서비스 계정 포함).
$ oc secrets link registry registry-certificates $ oc secrets link default registry-certificates참고시크릿을 참조하는 서비스 계정에만 제한하는 것은 기본적으로 비활성화되어 있습니다. 즉, 마스터 구성 파일에서
serviceAccountConfig.limitSecretReferences가false(기본 설정)로 설정되면 서비스에 시크릿을 연결할 필요가 없습니다.docker-registry서비스를 일시 중지합니다.$ oc rollout pause dc/docker-registry레지스트리 배포 구성에 시크릿 볼륨을 추가합니다.
$ oc set volume dc/docker-registry --add --type=secret \ --secret-name=registry-certificates -m /etc/secrets레지스트리 배포 구성에 다음 환경 변수를 추가하여 TLS를 활성화합니다.
$ oc set env dc/docker-registry \ REGISTRY_HTTP_TLS_CERTIFICATE=/etc/secrets/registry.crt \ REGISTRY_HTTP_TLS_KEY=/etc/secrets/registry.key자세한 내용은 Docker 문서의 레지스트리 구성 섹션 을 참조하십시오.
HTTP에서 HTTPS로 레지스트리의 활성 프로브에 사용된 스키마를 업데이트합니다.
$ oc patch dc/docker-registry -p '{"spec": {"template": {"spec": {"containers":[{ "name":"registry", "livenessProbe": {"httpGet": {"scheme":"HTTPS"}} }]}}}}'처음에 OpenShift Container Platform 3.2 이상에 레지스트리가 배포된 경우 레지스트리의 준비 상태 프로브에 사용된 체계를 HTTP에서 HTTPS로 업데이트합니다.
$ oc patch dc/docker-registry -p '{"spec": {"template": {"spec": {"containers":[{ "name":"registry", "readinessProbe": {"httpGet": {"scheme":"HTTPS"}} }]}}}}'docker-registry서비스를 다시 시작합니다.$ oc rollout resume dc/docker-registry레지스트리가 TLS 모드에서 실행 중인지 확인합니다. 최신 docker-registry 배포가 완료될 때까지 기다린 후 레지스트리 컨테이너의 Docker 로그를 확인합니다.
:5000, tls에서 수신대기할 항목을 찾아야 합니다.$ oc logs dc/docker-registry | grep tls time="2015-05-27T05:05:53Z" level=info msg="listening on :5000, tls" instance.id=deeba528-c478-41f5-b751-dc48e4935fc2Docker 인증서 디렉터리에 CA 인증서를 복사합니다. 클러스터의 모든 노드에서 이 작업을 수행해야 합니다.
$ dcertsdir=/etc/docker/certs.d $ destdir_addr=$dcertsdir/172.30.124.220:5000 $ destdir_name=$dcertsdir/docker-registry.default.svc.cluster.local:5000 $ sudo mkdir -p $destdir_addr $destdir_name $ sudo cp ca.crt $destdir_addr1 $ sudo cp ca.crt $destdir_name- 1
- ca.crt 파일은 마스터의 /etc/origin/master/ca.crt 의 사본입니다.
인증을 사용하는 경우 일부 버전의
docker에서도 OS 수준에서 인증서를 신뢰하도록 클러스터를 구성해야 합니다.인증서를 복사합니다.
$ cp /etc/origin/master/ca.crt /etc/pki/ca-trust/source/anchors/myregistrydomain.com.crt다음을 실행합니다.
$ update-ca-trust enable
/etc/sysconfig/docker 파일에서 이 특정 레지스트리에 대해서만
--insecure-registry옵션을 제거합니다. 그런 다음 데몬을 다시 로드하고 docker 서비스를 다시 시작하여 이 구성 변경을 반영합니다.$ sudo systemctl daemon-reload $ sudo systemctl restart dockerdocker클라이언트 연결을 확인합니다. 레지스트리에서docker push를 실행하거나 레지스트리에서docker pull을 실행하면 성공해야 합니다. 레지스트리에 로그인 했는지 확인합니다.$ docker tag|push <registry/image> <internal_registry/project/image>예를 들면 다음과 같습니다.
$ docker pull busybox $ docker tag docker.io/busybox 172.30.124.220:5000/openshift/busybox $ docker push 172.30.124.220:5000/openshift/busybox ... cf2616975b4a: Image successfully pushed Digest: sha256:3662dd821983bc4326bee12caec61367e7fb6f6a3ee547cbaff98f77403cab55
2.4.3. 수동으로 보안 레지스트리 노출
OpenShift Container Platform 클러스터 내에서 OpenShift Container Platform 레지스트리에 로그인하는 대신 먼저 레지스트리를 보안한 다음 경로로 노출하여 외부에서 액세스할 수 있습니다. 이를 통해 라우팅 주소를 사용하여 클러스터 외부에서 레지스트리에 로그인하고 라우팅 호스트를 사용하여 이미지에 태그를 지정하거나 푸시할 수 있습니다.
다음 각 전제 조건 단계는 일반적인 클러스터 설치 중에 기본적으로 수행됩니다. 해당 노드가 없는 경우 수동으로 수행합니다.
초기 클러스터 설치 중에 레지스트리에 대해 기본적으로 passthrough 경로가 생성되어야 합니다.
경로가 있는지 확인합니다.
$ oc get route/docker-registry -o yaml apiVersion: v1 kind: Route metadata: name: docker-registry spec: host: <host>1 to: kind: Service name: docker-registry2 tls: termination: passthrough3 참고보안 레지스트리 노출에도 재암호화 경로가 지원됩니다.
존재하지 않는 경우 레지스트리를 경로의 서비스로 지정하여
oc create route passthrough명령을 통해 경로를 만듭니다. 기본적으로 생성된 경로의 이름은 서비스 이름과 동일합니다.docker-registry 서비스 세부 정보를 가져옵니다.
$ oc get svc NAME CLUSTER_IP EXTERNAL_IP PORT(S) SELECTOR AGE docker-registry 172.30.69.167 <none> 5000/TCP docker-registry=default 4h kubernetes 172.30.0.1 <none> 443/TCP,53/UDP,53/TCP <none> 4h router 172.30.172.132 <none> 80/TCP router=router 4h경로를 생성합니다.
$ oc create route passthrough \ --service=docker-registry \1 --hostname=<host> route "docker-registry" created2
다음으로 호스트가 이미지를 푸시하고 가져올 수 있도록 호스트 시스템의 레지스트리에 사용되는 인증서를 신뢰해야 합니다. 레지스트리를 보호할 때 참조된 인증서가 생성되었습니다.
$ sudo mkdir -p /etc/docker/certs.d/<host> $ sudo cp <ca_certificate_file> /etc/docker/certs.d/<host> $ sudo systemctl restart docker레지스트리 보안 정보를 사용하여 레지스트리에 로그인합니다. 그러나 이번에는 서비스 IP가 아닌 경로에 사용된 호스트 이름을 가리킵니다. 보안 및 노출된 레지스트리에 로그인할 때
docker login명령에서 레지스트리를 지정해야 합니다.# docker login -e user@company.com \ -u f83j5h6 \ -p Ju1PeM47R0B92Lk3AZp-bWJSck2F7aGCiZ66aFGZrs2 \ <host>이제 경로 호스트를 사용하여 이미지에 태그를 지정하고 내보낼 수 있습니다. 예를 들어
test라는 프로젝트에서busybox이미지에 태그를 지정하고 푸시하려면 다음을 수행합니다.$ oc get imagestreams -n test NAME DOCKER REPO TAGS UPDATED $ docker pull busybox $ docker tag busybox <host>/test/busybox $ docker push <host>/test/busybox The push refers to a repository [<host>/test/busybox] (len: 1) 8c2e06607696: Image already exists 6ce2e90b0bc7: Image successfully pushed cf2616975b4a: Image successfully pushed Digest: sha256:6c7e676d76921031532d7d9c0394d0da7c2906f4cb4c049904c4031147d8ca31 $ docker pull <host>/test/busybox latest: Pulling from <host>/test/busybox cf2616975b4a: Already exists 6ce2e90b0bc7: Already exists 8c2e06607696: Already exists Digest: sha256:6c7e676d76921031532d7d9c0394d0da7c2906f4cb4c049904c4031147d8ca31 Status: Image is up to date for <host>/test/busybox:latest $ oc get imagestreams -n test NAME DOCKER REPO TAGS UPDATED busybox 172.30.11.215:5000/test/busybox latest 2 seconds ago참고이미지 스트림에는 경로 이름과 포트가 아닌 레지스트리 서비스의 IP 주소 및 포트가 있습니다. 자세한 내용은
oc get imagestreams를 참조하십시오.
2.4.4. 수동으로 비보안 레지스트리 노출
레지스트리를 공개하기 위해 레지스트리를 보호하는 대신 비 프로덕션 OpenShift Container Platform 환경에 비보안 레지스트리를 노출하면 됩니다. 이를 통해 SSL 인증서를 사용하지 않고 레지스트리에 대한 외부 경로를 보유할 수 있습니다.
비 프로덕션 환경만 외부 액세스에 비보안 레지스트리를 노출해야 합니다.
비보안 레지스트리를 공개하려면 다음을 수행합니다.
레지스트리를 공개합니다.
# oc expose service docker-registry --hostname=<hostname> -n default이렇게 하면 다음 JSON 파일이 생성됩니다.
apiVersion: v1 kind: Route metadata: creationTimestamp: null labels: docker-registry: default name: docker-registry spec: host: registry.example.com port: targetPort: "5000" to: kind: Service name: docker-registry status: {}경로가 성공적으로 생성되었는지 확인합니다.
# oc get route NAME HOST/PORT PATH SERVICE LABELS INSECURE POLICY TLS TERMINATION docker-registry registry.example.com docker-registry docker-registry=default레지스트리의 상태를 확인합니다.
$ curl -v http://registry.example.com/healthzHTTP 200/OK 메시지가 예상됩니다.
레지스트리를 노출한 후
OPTIONS항목에 포트 번호를 추가하여 /etc/sysconfig/docker 파일을 업데이트합니다. 예를 들면 다음과 같습니다.OPTIONS='--selinux-enabled --insecure-registry=172.30.0.0/16 --insecure-registry registry.example.com:80'중요위의 옵션은 로그인하려는 클라이언트에 추가해야 합니다.
또한 Docker가 클라이언트에서 실행되고 있는지 확인합니다.
비보안 및 노출된 레지스트리에 로그인할 때 docker login 명령에서 레지스트리를 지정해야 합니다. 예를 들면 다음과 같습니다.
# docker login -e user@company.com \
-u f83j5h6 \
-p Ju1PeM47R0B92Lk3AZp-bWJSck2F7aGCiZ66aFGZrs2 \
<host>2.5. 확장 레지스트리 구성
2.5.1. 레지스트리 IP 주소 유지 관리
OpenShift Container Platform은 서비스 IP 주소로 통합 레지스트리를 참조하므로 docker-registry 서비스를 삭제하고 다시 생성하는 경우 새 서비스에서 이전 IP 주소를 다시 사용하도록 정렬하여 완전히 투명한 전환을 보장할 수 있습니다. 새 IP 주소를 방지할 수 없는 경우 마스터만 재부팅하여 클러스터 중단을 최소화할 수 있습니다.
- 주소 다시 사용
- IP 주소를 다시 사용하려면 기존 docker-registry 서비스의 IP 주소를 삭제하기 전에 저장하고 새로 할당된 IP 주소를 새 docker-registry 서비스에 저장된 IP 주소로 교체해야 합니다.
서비스에 대한
clusterIP를 기록합니다.$ oc get svc/docker-registry -o yaml | grep clusterIP:서비스를 삭제합니다.
$ oc delete svc/docker-registry dc/docker-registryregistry.yaml에서 레지스트리 정의를 생성하여
<options>를 프로덕션 사용 섹션의 3단계에 사용된 항목으로 바꿉니다.$ oc adm registry <options> -o yaml > registry.yaml-
registry.yaml 을 편집하고, 여기에서
서비스를찾은 다음,clusterIP를 1단계에 명시된 주소로 변경합니다. 수정된 registry .yaml을 사용하여 레지스트리를 생성합니다.
$ oc create -f registry.yaml
- 마스터 재부팅
- IP 주소를 다시 사용할 수 없는 경우 이전 IP 주소가 포함된 가져오기 사양을 사용하는 작업이 실패합니다. 클러스터 중단을 최소화하려면 마스터를 재부팅해야 합니다.
# master-restart api
# master-restart controllers이렇게 하면 이전 IP 주소를 포함하는 이전 레지스트리 URL이 캐시에서 지워집니다.
Pod에 불필요한 다운타임이 발생하고 실제로 캐시를 지우지 않으므로 전체 클러스터를 재부팅하지 않는 것이 좋습니다.
2.5.2. 외부 레지스트리 검색 목록 구성
/etc/containers/registries.conf 파일을 사용하여 컨테이너 이미지를 검색할 Docker 레지스트리 목록을 생성할 수 있습니다.
/etc/containers/registries.conf 파일은 사용자가 myimage:latest 와 같은 이미지 단축 이름을 사용하여 이미지를 가져올 때 OpenShift Container Platform에서 검색해야 하는 레지스트리 서버 목록입니다. 검색 순서를 사용자 지정하고, 보안 및 비보안 레지스트리를 지정하고, 차단된 레지스트리 목록을 정의할 수 있습니다. OpenShift Container Platform은 차단된 목록의 레지스트리를 검색하거나 가져올 수 없습니다.
예를 들어 사용자가 myimage:latest 이미지를 가져오려는 경우 OpenShift Container Platform은 myimage:latest 를 찾을 때까지 목록에 표시되는 순서대로 레지스트리를 검색합니다.
레지스트리 검색 목록을 사용하면 OpenShift Container Platform 사용자가 다운로드할 수 있는 이미지 및 템플릿 세트를 큐레이션할 수 있습니다. 이러한 이미지를 하나 이상의 Docker 레지스트리에 배치하고 레지스트리를 목록에 추가한 다음 해당 이미지를 클러스터로 가져올 수 있습니다.
레지스트리 검색 목록을 사용하는 경우 OpenShift Container Platform은 검색 목록에 없는 레지스트리에서 이미지를 가져오지 않습니다.
레지스트리 검색 목록을 구성하려면 다음을 수행합니다.
필요에 따라 /etc/containers/registries.conf 파일을 편집하여 다음 매개변수를 추가하거나 편집합니다.
[registries.search]1 registries = ["reg1.example.com", "reg2.example.com"] [registries.insecure]2 registries = ["reg3.example.com"] [registries.block]3 registries = ['docker.io']
2.5.3. 레지스트리 호스트 이름 설정
레지스트리가 내부 및 외부 참조 모두에 대해 로 알려진 호스트 이름과 포트를 구성할 수 있습니다. 이렇게 하면 이미지 스트림은 이미지의 호스트 이름 기반 푸시 및 가져오기 사양을 제공하므로, 이미지 소비자가 레지스트리 서비스 IP의 변경 사항과 이미지 스트림과 참조를 이식할 수 있습니다.
클러스터 내에서 레지스트리를 참조하는 데 사용되는 호스트 이름을 설정하려면 마스터 구성 파일의 imagePolicyConfig 섹션에 internalRegistryHostname 을 설정합니다. 외부 호스트 이름은 동일한 위치에 externalRegistryHostname 값을 설정하여 제어됩니다.
이미지 정책 구성
imagePolicyConfig:
internalRegistryHostname: docker-registry.default.svc.cluster.local:5000
externalRegistryHostname: docker-registry.mycompany.com
레지스트리 자체는 동일한 내부 호스트 이름 값으로 구성해야 합니다. 이 작업은 레지스트리 배포 구성에서 REGISTRY_OPENSHIFT_SERVER_ADDR 환경 변수를 설정하거나 레지스트리 구성의 OpenShift 섹션에서 값을 설정하여 수행할 수 있습니다.
레지스트리에 TLS를 활성화한 경우 서버 인증서에 레지스트리를 참조할 것으로 예상되는 호스트 이름이 포함되어야 합니다. 서버 인증서에 호스트 이름을 추가하는 방법은 레지스트리 보안을 참조하십시오.
2.5.4. 레지스트리 설정 덮어쓰기
실행 중인 레지스트리 컨테이너의 /config.yml 에 기본적으로 있는 통합 레지스트리의 기본 구성을 자체 사용자 지정 구성으로 재정의할 수 있습니다.
이 파일의 업스트림 구성 옵션은 환경 변수를 사용하여 재정의할 수도 있습니다. 미들웨어 섹션 은 환경 변수를 사용하여 재정의할 수 있는 몇 가지 옵션만 있으므로 예외입니다. 특정 구성 옵션을 재정의하는 방법을 알아봅니다.
레지스트리 구성 파일의 관리를 직접 활성화하고 ConfigMap 을 사용하여 업데이트된 구성을 배포하려면 다음을 수행합니다.
- 레지스트리를 배포합니다.
필요에 따라 레지스트리 구성 파일을 로컬로 편집합니다. 레지스트리에 배포된 초기 YAML 파일은 아래에 제공됩니다. 지원되는 옵션 검토.
레지스트리 설정 파일
version: 0.1 log: level: debug http: addr: :5000 storage: cache: blobdescriptor: inmemory filesystem: rootdirectory: /registry delete: enabled: true auth: openshift: realm: openshift middleware: registry: - name: openshift repository: - name: openshift options: acceptschema2: true pullthrough: true enforcequota: false projectcachettl: 1m blobrepositorycachettl: 10m storage: - name: openshift openshift: version: 1.0 metrics: enabled: false secret: <secret>이 디렉터리의 각 파일의 콘텐츠를 보관하는
ConfigMap을 생성합니다.$ oc create configmap registry-config \ --from-file=</path/to/custom/registry/config.yml>/registry-config ConfigMap을 레지스트리 배포 구성에 볼륨으로 추가하여 /etc/docker/registry/ 에 사용자 정의 구성 파일을 마운트합니다.
$ oc set volume dc/docker-registry --add --type=configmap \ --configmap-name=registry-config -m /etc/docker/registry/레지스트리의 배포 구성에 다음 환경 변수를 추가하여 이전 단계의 구성 경로를 참조하도록 레지스트리를 업데이트합니다.
$ oc set env dc/docker-registry \ REGISTRY_CONFIGURATION_PATH=/etc/docker/registry/config.yml
이 작업은 원하는 구성을 수행하기 위해 반복 프로세스로 수행할 수 있습니다. 예를 들어 문제를 해결하는 동안 구성이 일시적으로 업데이트되어 디버그 모드가 될 수 있습니다.
기존 구성을 업데이트하려면 다음을 수행합니다.
이 절차에서는 현재 배포된 레지스트리 구성을 덮어씁니다.
- 로컬 레지스트리 구성 파일 config.yml 을 편집합니다.
registry-config configmap을 삭제합니다.
$ oc delete configmap registry-config업데이트된 구성 파일을 참조하도록 configmap을 다시 생성합니다.
$ oc create configmap registry-config\ --from-file=</path/to/custom/registry/config.yml>/업데이트된 구성을 읽기 위해 레지스트리를 재배포합니다.
$ oc rollout latest docker-registry
소스 제어 리포지토리의 구성 파일을 유지 관리합니다.
2.5.5. 레지스트리 구성 참조
업스트림 Docker 배포 라이브러리에는 다양한 구성 옵션을 사용할 수 있습니다. 일부 구성 옵션이 지원되거나 활성화되지는 않습니다. 레지스트리 구성을 재정의할 때 이 섹션을 참조로 사용합니다.
이 파일의 업스트림 구성 옵션은 환경 변수를 사용하여 재정의할 수도 있습니다. 그러나 미들웨어 섹션 은 환경 변수를 사용하여 재정의 되지 않을 수 있습니다. 특정 구성 옵션을 재정의하는 방법을 알아봅니다.
2.5.5.1. log
업스트림 옵션이 지원됩니다.
예제:
log:
level: debug
formatter: text
fields:
service: registry
environment: staging2.5.5.2. 후크
메일 후크는 지원되지 않습니다.
2.5.5.3. 스토리지
이 섹션에는 지원되는 레지스트리 스토리지 드라이버가 나열되어 있습니다. 자세한 내용은 컨테이너 이미지 레지스트리 설명서를 참조하십시오.
다음 목록에는 레지스트리의 구성 파일에서 구성해야 하는 스토리지 드라이버가 포함되어 있습니다.
- 파일 시스템. 파일 시스템이 기본값이며 구성할 필요가 없습니다.
- S3. 자세한 내용은 CloudFront 구성 설명서를 참조하십시오.
- OpenStack Swift
- Google Cloud Storage(GCS)
- Microsoft Azure
- Aliyun OSS
일반 레지스트리 스토리지 구성 옵션이 지원됩니다. 자세한 내용은 컨테이너 이미지 레지스트리 설명서를 참조하십시오.
다음 스토리지 옵션은 파일 시스템 드라이버를 통해 구성해야 합니다.
지원되는 영구 스토리지 드라이버에 대한 자세한 내용은 영구 스토리지 및 영구 스토리지 예제 구성을 참조하십시오.
일반 스토리지 구성 옵션
storage:
delete:
enabled: true
redirect:
disable: false
cache:
blobdescriptor: inmemory
maintenance:
uploadpurging:
enabled: true
age: 168h
interval: 24h
dryrun: false
readonly:
enabled: false- 1
- 이미지 정리 가 제대로 작동하려면 이 항목이 필요합니다.
2.5.5.4. auth
인증 옵션은 변경할 수 없습니다. openshift 확장 기능은 지원되는 유일한 옵션입니다.
auth:
openshift:
realm: openshift2.5.5.5. 미들웨어
리포지토리 미들웨어 확장을 사용하면 OpenShift Container Platform 및 이미지 프록시와의 상호 작용을 담당하는 OpenShift Container Platform 미들웨어를 구성할 수 있습니다.
middleware:
registry:
- name: openshift
repository:
- name: openshift
options:
acceptschema2: true
pullthrough: true
mirrorpullthrough: true
enforcequota: false
projectcachettl: 1m
blobrepositorycachettl: 10m
storage:
- name: openshift - 1 2 9
- 이러한 항목은 필수 항목입니다. 이를 통해 필요한 구성 요소가 로드됩니다. 이러한 값은 변경하지 않아야 합니다.
- 3
- 레지스트리에 내보내는 동안 매니페스트 스키마 v2 를 저장할 수 있습니다. 자세한 내용은 아래를 참조하십시오.
- 4
- 레지스트리가 원격 Blob의 프록시 역할을 할 수 있습니다. 자세한 내용은 아래를 참조하십시오.
- 5
- 나중에 빠른 액세스를 위해 원격 레지스트리에서 레지스트리 캐시 Blob을 제공할 수 있습니다. 미러링은 Blob이 처음으로 액세스할 때 시작됩니다. pullthrough 를 비활성화하면 옵션이 적용되지 않습니다.
- 6
- 타겟 프로젝트에 정의된 크기 제한을 초과하는 Blob 업로드를 방지합니다.
- 7
- 레지스트리에 캐시된 제한에 대한 만료 시간 제한입니다. 값이 낮을수록 제한 변경 사항이 레지스트리에 전파되는 데 걸리는 시간이 줄어듭니다. 그러나 레지스트리는 서버의 제한을 더 자주 쿼리하므로 푸시 속도가 느려집니다.
- 8
- Blob과 리포지토리 간의 기억되는 연결에 대한 만료 시간 제한. 값이 클수록 빠른 조회 가능성이 높으며 더 효율적인 레지스트리 작업입니다. 반면 메모리 사용량은 증가하며 더 이상 액세스할 권한이 없는 사용자에게 이미지 계층을 제공할 위험이 있습니다.
2.5.5.5.1. S3 드라이버 설정
사용 중인 통합 레지스트리에서 지원하지 않는 S3 리전을 사용하려면 지역 검증 오류가 발생하지 않도록 regionendpoint 를 지정할 수 있습니다.
Amazon Simple Storage Service Storage 사용에 대한 자세한 내용은 Amazon S3을 스토리지 백엔드로 참조하십시오.
예를 들면 다음과 같습니다.
version: 0.1
log:
level: debug
http:
addr: :5000
storage:
cache:
blobdescriptor: inmemory
delete:
enabled: true
s3:
accesskey: BJKMSZBRESWJQXRWMAEQ
secretkey: 5ah5I91SNXbeoUXXDasFtadRqOdy62JzlnOW1goS
bucket: docker.myregistry.com
region: eu-west-3
regionendpoint: https://s3.eu-west-3.amazonaws.com
auth:
openshift:
realm: openshift
middleware:
registry:
- name: openshift
repository:
- name: openshift
storage:
- name: openshift
region 및 region endpoint 필드가 일관되게 표시되는지 확인합니다. 통합 레지스트리가 시작되지만 S3 스토리지에 아무 것도 읽거나 쓸 수 없습니다.
리전엔드 포인트는 Amazon S3과 다른 S3 스토리지를 사용하는 경우에도 유용할 수 있습니다.
2.5.5.5.2. CloudFront Middleware
AWS, uuid CDN 스토리지 공급자를 지원하기 위해 EventListener 미들웨어 확장을 추가할 수 있습니다. CloudFront 미들웨어로 이미지 컨텐츠의 배포를 가속화할 수 있습니다. Blob은 전 세계 여러 에지 위치에 배포됩니다. 클라이언트는 항상 대기 시간이 가장 짧은 에지로 이동합니다.
다음은 CloudFront 미들웨어를 사용한 S3 스토리지 드라이버의 최소 구성 예입니다.
version: 0.1
log:
level: debug
http:
addr: :5000
storage:
cache:
blobdescriptor: inmemory
delete:
enabled: true
s3:
accesskey: BJKMSZBRESWJQXRWMAEQ
secretkey: 5ah5I91SNXbeoUXXDasFtadRqOdy62JzlnOW1goS
region: us-east-1
bucket: docker.myregistry.com
auth:
openshift:
realm: openshift
middleware:
registry:
- name: openshift
repository:
- name: openshift
storage:
- name: cloudfront
options:
baseurl: https://jrpbyn0k5k88bi.cloudfront.net/
privatekey: /etc/docker/cloudfront-ABCEDFGHIJKLMNOPQRST.pem
keypairid: ABCEDFGHIJKLMNOPQRST
- name: openshift2.5.5.5.3. 미들웨어 구성 옵션 덮어쓰기
미들웨어 섹션은 환경 변수를 사용하여 재정의할 수 없습니다. 하지만 몇 가지 예외가 있습니다. 예를 들면 다음과 같습니다.
middleware:
repository:
- name: openshift
options:
acceptschema2: true
pullthrough: true
mirrorpullthrough: true
enforcequota: false
projectcachettl: 1m
blobrepositorycachettl: 10m - 1
- 매니페스트 붙여넣기 요청에서 매니페스트 스키마 v2를 수락할 수 있는 부울 환경 변수
REGISTRY_MIDDLE_REPOSITORY_OPENSHIFT_ACCEPTSCHEMA2로 재정의할 수 있는 구성 옵션입니다. 인식된 값은true및false입니다(아래의 다른 모든 부울 변수에 적용됩니다). - 2
- 원격 리포지토리에 프록시 모드를 활성화하는 부울 환경 변수
REGISTRY_MIDDLE_REPOSITORY_OPENSHIFT_PULLTHROUGH로 재정의할 수 있는 구성 옵션입니다. - 3
- 부울 환경 변수
REGISTRY_MIDDLE_REPOSITORY_OPENSHIFT_MIRRORPULLTHROUGH로 재정의할 수 있는 구성 옵션으로, 원격 Blob을 제공하는 경우 레지스트리에서 Blob을 로컬로 미러링하도록 지시합니다. - 4
- 할당량 적용을 켜거나 끌 수 있는 부울 환경 변수
REGISTRY_MIDDLE_REPOSITORY_OPENSHIFT_ENFORCEQUOTA로 재정의할 수 있는 구성 옵션입니다. 기본적으로 할당량 적용은 꺼져 있습니다. - 5
REGISTRY_MIDDLEWARE_REPOSITORY_OPENSHIFT_PROJECTCACHETTL환경 변수로 재정의할 수 있는 구성 옵션으로 프로젝트 할당량 오브젝트에 대한 제거 시간 제한을 지정합니다. 유효한 기간 문자열(예:2m)이 걸립니다. 비어 있는 경우 기본 시간 초과가 발생합니다.0(0m)이면 캐싱이 비활성화됩니다.- 6
- 환경 변수
REGISTRY_MIDDLEWARE_REPOSITORY_OPENSHIFT_BLOBREPOSITORYCACHETTL으로 재정의할 수 있는 구성 옵션으로 blob과 리포지토리를 포함하는 연결에 대한 제거 시간 제한을 지정합니다. 값의 형식은projectcachettl사례와 동일합니다.
2.5.5.5.4. 이미지 Pullthrough
활성화된 경우 blob이 로컬로 존재하지 않는 한 레지스트리는 원격 레지스트리에서 요청된 Blob 가져오기를 시도합니다. 원격 후보는 클라이언트에서 가져온 이미지 스트림 상태에 저장된 DockerImage 항목에서 계산됩니다. 이러한 항목의 모든 원격 레지스트리 참조는 Blob을 찾을 때까지 차례로 시도됩니다.
pullthrough는 이미지 스트림 태그가 가져오는 이미지에 대해 존재하는 경우에만 발생합니다. 예를 들어 가져온 이미지가 docker-registry.default.svc:5000/yourproject/yourimage:prod 인 경우 레지스트리는 your project 프로젝트에서 라는 이미지 스트림 태그를 찾습니다. 이미지를 찾으면 해당 이미지 스트림 태그와 연결된 your image:proddockerImageReference 를 사용하여 이미지를 가져오려고 합니다.
pullthrough를 수행할 때 레지스트리는 참조되는 이미지 스트림 태그와 연결된 프로젝트에서 찾은 가져오기 자격 증명을 사용합니다. 이 기능을 사용하면 이미지를 참조하는 이미지 스트림 태그에 액세스할 수 있는 인증 정보가 없는 레지스트리에 있는 이미지를 가져올 수도 있습니다.
가져오기를 수행하는 외부 레지스트리를 신뢰하기 위한 적절한 인증서가 레지스트리에 있는지 확인해야 합니다. 인증서를 포드의 /etc/pki/tls/certs 디렉터리에 배치해야 합니다. 구성 맵 또는 시크릿 을 사용하여 인증서를 마운트할 수 있습니다. 전체 /etc/pki/tls/certs 디렉토리를 교체해야 합니다. 새 인증서를 포함하고 마운트하는 시크릿 또는 구성 맵에 시스템 인증서를 교체해야 합니다.
기본적으로 이미지 스트림 태그는 소스 의 참조 정책 유형을 사용합니다. 즉, 이미지 스트림 참조가 이미지 가져오기 사양으로 확인되면 사용된 사양이 이미지 소스를 가리킵니다. 외부 레지스트리에서 호스팅되는 이미지의 경우 외부 레지스트리가 되며, 결과적으로 리소스는 외부 레지스트리에서 이미지를 참조하고 가져옵니다. 예를 들어 registry.redhat.io/openshift3/jenkins-2-rhel7 및 pullthrough는 적용되지 않습니다. 이미지 스트림을 참조하는 리소스가 내부 레지스트리를 가리키는 가져오기 사양을 사용하도록 하려면 이미지 스트림 태그에서 참조 정책 유형을 Local 으로 사용해야 합니다. 자세한 내용은 참조 정책에서 확인할 수 있습니다.
이 기능은 기본적으로 활성화되어 있습니다. 그러나 구성 옵션을 사용하여 비활성화할 수 있습니다.
기본적으로 mirrorpullthrough 를 비활성화하지 않는 한 이러한 방식으로 제공되는 모든 원격 Blob은 후속 빠른 액세스를 위해 로컬에 저장됩니다. 이 미러링 기능의 단점은 스토리지 사용량이 증가합니다.
클라이언트가 Blob의 한 바이트 이상을 가져오려고 할 때 미러링이 시작됩니다. 실제로 필요하기 전에 특정 이미지를 통합 레지스트리로 미리 가져오려면 다음 명령을 실행합니다.
$ oc get imagestreamtag/${IS}:${TAG} -o jsonpath='{ .image.dockerImageLayers[*].name }' | \
xargs -n1 -I {} curl -H "Range: bytes=0-1" -u user:${TOKEN} \
http://${REGISTRY_IP}:${PORT}/v2/default/mysql/blobs/{}이 OpenShift Container Platform 미러링 기능은 유사하지만 고유한 기능인 캐시 기능을 통해 업스트림 레지스트리 가져오기 와 혼동해서는 안 됩니다.
2.5.5.5.5. 매니페스트 스키마 v2 지원
각 이미지에 해당 Blob, 실행 지침 및 추가 메타데이터를 설명하는 매니페스트가 있습니다. 매니페스트는 버전이 지정되며 각 버전은 시간이 지남에 따라 구조와 필드가 서로 다릅니다. 동일한 이미지는 여러 매니페스트 버전으로 표시할 수 있습니다. 하지만 각 버전에는 다른 다이제스트가 있습니다.
레지스트리는 현재 매니페스트 v2 스키마 1 (schema1) 및 매니페스트 v2 스키마 2( schema 2)를 지원합니다. 전자는 더 이상 사용되지 않지만 연장된 시간 동안 지원됩니다.
기본 구성은 schema2 를 저장하는 것입니다.
다양한 Docker 클라이언트와의 호환성 문제가 주의해야 합니다.
- 버전 1.9 이상의 Docker 클라이언트는 schema1 만 지원합니다. 이 클라이언트 풀 또는 푸시는 이 레거시 스키마의 모든 매니페스트입니다.
- 버전 1.10의 Docker 클라이언트는 schema 1 및 schema 2 를 모두 지원합니다. 최신 스키마를 지원하는 경우 기본적으로 후자를 레지스트리로 푸시합니다.
schema1 이 있는 이미지를 저장하는 레지스트리는 항상 변경되지 않은 상태로 클라이언트로 반환됩니다. Schema2 는 변경되지 않고 최신 Docker 클라이언트로만 전송됩니다. 이전 버전의 경우 on-the-fly를 schema1 로 변환합니다.
이것은 큰 결과를 가져옵니다. 예를 들어 최신 Docker 클라이언트에서 레지스트리에 푸시된 이미지를 다이제스트에서 이전 Docker에서 가져올 수 없습니다. 저장된 이미지의 매니페스트는 schema2 이고 다이제스트를 사용하여 이 매니페스트 버전만 가져올 수 있기 때문입니다.
모든 레지스트리 클라이언트가 schema2 를 지원한다고 확신하면 레지스트리에서 안전하게 지원을 활성화할 수 있습니다. 특정 옵션은 위의 미들웨어 구성 참조를 참조하십시오.
2.5.5.6. OpenShift
이 섹션에서는 OpenShift Container Platform과 관련된 기능에 대한 전역 설정 구성을 검토합니다. 향후 릴리스에서는 Middleware 섹션의 openshift관련 설정이 더 이상 사용되지 않습니다.
현재 이 섹션에서는 레지스트리 메트릭 컬렉션을 구성할 수 있습니다.
openshift:
version: 1.0
server:
addr: docker-registry.default.svc
metrics:
enabled: false
secret: <secret>
requests:
read:
maxrunning: 10
maxinqueue: 10
maxwaitinqueue 2m
write:
maxrunning: 10
maxinqueue: 10
maxwaitinqueue 2m - 1
- 이 섹션의 구성 버전을 지정하는 필수 항목입니다. 지원되는 유일한 값은
1.0입니다. - 2
- 레지스트리의 호스트 이름입니다. 마스터에 구성된 동일한 값으로 설정해야 합니다. 환경 변수
REGISTRY_OPENSHIFT_SERVER_ADDR로 재정의할 수 있습니다. - 3
- 지표 컬렉션을 활성화하려면
true로 설정할 수 있습니다. 부울 환경 변수REGISTRY_OPENSHIFT_METRICS_ENABLED로 재정의할 수 있습니다. - 4
- 클라이언트 요청을 인증하는 데 사용되는 시크릿입니다. 지표 클라이언트는
권한 부여헤더에서 전달자 토큰으로 사용해야 합니다. 환경 변수REGISTRY_OPENSHIFT_METRICS_SECRET로 재정의할 수 있습니다. - 5
- 최대 동시 가져오기 요청 수입니다. 환경 변수
REGISTRY_OPENSHIFT_REQUESTS_READ_MAXRUNNING으로 재정의할 수 있습니다. 0은 제한이 없음을 나타냅니다. - 6
- 대기 중인 최대 가져오기 요청 수입니다. 환경 변수
REGISTRY_OPENSHIFT_REQUESTS_READ_MAXINQUEUE로 재정의할 수 있습니다. 0은 제한이 없음을 나타냅니다. - 7
- 가져오기 요청이 거부되기 전에 대기열에서 대기할 수 있는 최대 시간입니다. 환경 변수
REGISTRY_OPENSHIFT_REQUESTS_READ_MAXWAITINQUEUE로 재정의할 수 있습니다. 0은 제한이 없음을 나타냅니다. - 8
- 최대 동시 푸시 요청 수입니다. 환경 변수
REGISTRY_OPENSHIFT_REQUESTS_WRITE_MAXRUNNING으로 재정의할 수 있습니다. 0은 제한이 없음을 나타냅니다. - 9
- 대기 중인 최대 푸시 요청 수입니다. 환경 변수
REGISTRY_OPENSHIFT_REQUESTS_WRITE_MAXINQUEUE로 재정의할 수 있습니다. 0은 제한이 없음을 나타냅니다. - 10
- 내보내기 요청이 거부되기 전에 대기열에서 대기할 수 있는 최대 시간입니다. 환경 변수
REGISTRY_OPENSHIFT_REQUESTS_WRITE_MAXWAITINQUEUE로 재정의할 수 있습니다. 0은 제한이 없음을 나타냅니다.
사용 정보는 레지스트리 지표 액세스를 참조하십시오.
2.5.5.7. 보고
보고는 지원되지 않습니다.
2.5.5.8. HTTP
업스트림 옵션이 지원됩니다. 환경 변수를 통해 이러한 설정을 변경하는 방법을 알아봅니다. tls 섹션만 변경해야 합니다. 예를 들면 다음과 같습니다.
http:
addr: :5000
tls:
certificate: /etc/secrets/registry.crt
key: /etc/secrets/registry.key2.5.5.9. 알림
업스트림 옵션이 지원됩니다. REST API 참조 는 보다 포괄적인 통합 옵션을 제공합니다.
예제:
notifications:
endpoints:
- name: registry
disabled: false
url: https://url:port/path
headers:
Accept:
- text/plain
timeout: 500
threshold: 5
backoff: 10002.5.5.10. Redis
Redis는 지원되지 않습니다.
2.5.5.11. 상태
업스트림 옵션이 지원됩니다. 레지스트리 배포 구성은 /healthz 에서 통합된 상태 점검을 제공합니다.
2.5.5.12. proxy
프록시 설정은 활성화해서는 안 됩니다. 이 기능은 OpenShift Container Platform 리포지토리 미들웨어 확장,pullthrough: true 로 제공됩니다.
2.5.5.13. 캐시
통합 레지스트리는 데이터를 적극적으로 캐시하여 외부 리소스 속도가 느린 호출 수를 줄입니다. 두 개의 캐시가 있습니다.
- Blob 메타데이터를 캐시하는 데 사용되는 스토리지 캐시입니다. 이 캐시에는 만료 시간이 없으며 명시적으로 삭제될 때까지 데이터가 있습니다.
- 애플리케이션 캐시에는 Blob과 리포지토리 간의 연결이 포함됩니다. 이 캐시의 데이터에는 만료 시간이 있습니다.
캐시를 완전히 해제하려면 구성을 변경해야 합니다.
version: 0.1
log:
level: debug
http:
addr: :5000
storage:
cache:
blobdescriptor: ""
openshift:
version: 1.0
cache:
disabled: true
blobrepositoryttl: 10m2.6. 확인된 문제
2.6.1. 개요
다음은 통합 레지스트리를 배포하거나 사용할 때 알려진 문제입니다.
2.6.2. 레지스트리 가져오기를 사용한 동시 빌드
로컬 docker-registry 배포에서는 추가 로드를 사용합니다. 기본적으로 registry.redhat.io 의 콘텐츠를 캐시합니다. STI 빌드용 registry.redhat.io 의 이미지가 로컬 레지스트리에 저장됩니다. 로컬 docker-registry 에서 가져오기를 시도합니다. 결과적으로 극도의 동시 빌드로 인해 가져오기에 대한 시간 초과가 발생하고 빌드가 실패할 수 있는 상황이 있습니다. 문제를 완화하려면 docker-registry 배포를 둘 이상의 복제본으로 스케일링합니다. 빌더 Pod의 로그에서 시간 초과를 확인합니다.
2.6.3. 공유 NFS 볼륨을 사용하여 확장 레지스트리가 포함된 이미지 푸시 오류
공유 NFS 볼륨과 함께 확장된 레지스트리를 사용하는 경우 이미지를 푸시하는 동안 다음 오류 중 하나가 표시될 수 있습니다.
-
다이제스트 유효하지 않음: 제공된 다이제스트가 업로드된 콘텐츠와 일치하지 않습니다 -
Blob 업로드 알 수 없음 -
Blob 업로드가 잘못되었습니다
이러한 오류는 Docker에서 이미지를 푸시하려고 할 때 내부 레지스트리 서비스에서 반환됩니다. 이러한 원인은 노드에서 파일 속성의 동기화에서 발생합니다. NFS 클라이언트 측 캐싱, 네트워크 대기 시간 및 계층 크기와 같은 요인은 모두 기본 라운드 로빈 로드 밸런싱 구성을 사용하여 이미지를 푸시할 때 발생할 수 있는 잠재적인 오류에 기여할 수 있습니다.
다음 단계를 수행하여 이러한 실패 가능성을 최소화할 수 있습니다.
docker-registry 서비스의
sessionAffinity가ClientIP로 설정되어 있는지 확인합니다.$ oc get svc/docker-registry --template='{{.spec.sessionAffinity}}'그러면 최근 OpenShift Container Platform 버전에서 기본값인
ClientIP가 반환되어야 합니다. 그렇지 않은 경우 변경합니다.$ oc patch svc/docker-registry -p '{"spec":{"sessionAffinity": "ClientIP"}}'-
NFS 서버에 있는 레지스트리 볼륨의 NFS 내보내기 줄에
no_wdelay옵션이 나열되어 있는지 확인합니다.no_wdelay옵션을 사용하면 서버가 쓰기를 지연시키지 못하므로 레지스트리 요구 사항인 쓰기 후 읽기 일관성이 크게 향상됩니다.
테스트 결과 RHEL NFS 서버를 컨테이너 이미지 레지스트리의 스토리지 백엔드로 사용하는 데 문제가 있는 것으로 표시됩니다. 여기에는 OpenShift Container Registry 및 Quay가 포함됩니다. 따라서 RHEL NFS 서버를 사용하여 핵심 서비스에서 사용하는 PV를 백업하는 것은 권장되지 않습니다.
마켓플레이스의 다른 NFS 구현에는 이러한 문제가 나타나지 않을 수 있습니다. 이러한 OpenShift 핵심 구성 요소에 대해 완료된 테스트에 대한 자세한 내용은 개별 NFS 구현 벤더에 문의하십시오.
2.6.4. "not found" 오류로 내부 관리 이미지 가져오기 실패
이 오류는 가져온 이미지를 가져오는 이미지 스트림과 다른 이미지 스트림으로 푸시할 때 발생합니다. 이는 빌드된 이미지를 임의의 이미지 스트림으로 다시 태그하기 때문에 발생합니다.
$ oc tag srcimagestream:latest anyproject/pullimagestream:latest그런 다음 다음과 같은 이미지 참조를 사용하여 Playbook에서 가져오십시오.
internal.registry.url:5000/anyproject/pullimagestream:latest수동 Docker 가져오기 동안 유사한 오류가 발생합니다.
Error: image anyproject/pullimagestream:latest not found이 문제를 방지하려면 내부 관리 이미지의 태그 지정을 완전히 방지하거나 빌드된 이미지를 원하는 네임스페이스에 수동으로 다시 푸시합니다.
2.6.5. S3 스토리지에서 "500개의 내부 서버 오류"로 이미지 푸시 실패
레지스트리가 S3 스토리지 백엔드에서 실행될 때 보고되는 문제가 있습니다. 컨테이너 이미지 레지스트리로 푸시하는 데 다음 오류가 발생하는 경우가 있습니다.
Received unexpected HTTP status: 500 Internal Server Error이 문제를 디버깅하려면 레지스트리 로그를 확인해야 합니다. 여기에서 실패한 푸시 시 발생하는 유사한 오류 메시지를 찾습니다.
time="2016-03-30T15:01:21.22287816-04:00" level=error msg="unknown error completing upload: driver.Error{DriverName:\"s3\", Enclosed:(*url.Error)(0xc20901cea0)}" http.request.method=PUT
...
time="2016-03-30T15:01:21.493067808-04:00" level=error msg="response completed with error" err.code=UNKNOWN err.detail="s3: Put https://s3.amazonaws.com/oso-tsi-docker/registry/docker/registry/v2/blobs/sha256/ab/abe5af443833d60cf672e2ac57589410dddec060ed725d3e676f1865af63d2e2/data: EOF" err.message="unknown error" http.request.method=PUT
...
time="2016-04-02T07:01:46.056520049-04:00" level=error msg="error putting into main store: s3: The request signature we calculated does not match the signature you provided. Check your key and signing method." http.request.method=PUT
atest이러한 오류가 표시되면 Amazon S3 지원에 문의하십시오. 지역이나 특정 버킷에 문제가 있을 수 있습니다.
2.6.6. 이미지 정리 실패
이미지를 정리할 때 다음 오류가 발생하면 다음을 수행합니다.
BLOB sha256:49638d540b2b62f3b01c388e9d8134c55493b1fa659ed84e97cb59b87a6b8e6c error deleting blob레지스트리 로그에 는 다음 정보가 포함되어 있습니다.
error deleting blob \"sha256:49638d540b2b62f3b01c388e9d8134c55493b1fa659ed84e97cb59b87a6b8e6c\": operation unsupported
즉, 사용자 지정 구성 파일에는 storage 섹션에 필수 항목, 즉 storage:delete:enabled 가 true로 설정되어 있지 않습니다. 이미지를 추가하고 레지스트리를 다시 배포한 다음 이미지 정리 작업을 반복합니다.
3장. 라우터 설정
3.1. 라우터 개요
3.1.1. 라우터 정보
클러스터로 트래픽을 가져오는 방법은 여러 가지가 있습니다. 가장 일반적인 방법은 OpenShift Container Platform 라우터 를 OpenShift Container Platform 설치의 서비스로 향하는 외부 트래픽의 진입 지점으로 사용하는 것입니다.
OpenShift Container Platform은 다음 라우터 플러그인을 제공하고 지원합니다.
- HAProxy 템플릿 라우터 는 기본 플러그인입니다. openshift3/ose-haproxy-router 이미지를 사용하여 OpenShift Container Platform의 컨테이너 내부에서 템플릿 라우터 플러그인과 함께 HAProxy 인스턴스를 실행합니다. 현재 SNI를 통해 HTTP(S) 트래픽 및 TLS 지원 트래픽을 지원합니다. 개인 IP에서만 수신 대기하는 대부분의 컨테이너와 달리 라우터의 컨테이너는 호스트 네트워크 인터페이스에서 수신 대기합니다. 라우터는 경로 이름에 대한 외부 요청을 경로와 연결된 서비스로 식별된 실제 포드의 IP로 프록시합니다.
- F5 라우터 는 사용자 환경의 기존 F5 BIG-IP® 시스템과 통합되어 경로를 동기화합니다. F5 iControl REST API를 사용하려면 F5 BIG-IP® 버전 11.4 이상이 필요합니다.
- 기본 HAProxy 라우터 배포
- 사용자 지정 HAProxy 라우터 배포
- PROXY 프로토콜을 사용하도록 HAProxy 라우터 구성
- 경로 시간 제한 구성
3.1.2. 라우터 서비스 계정
OpenShift Container Platform 클러스터를 배포하기 전에 클러스터 설치 중에 자동으로 생성되는 라우터의 서비스 계정이 있어야 합니다. 이 서비스 계정에는 호스트 포트를 지정할 수 있는 SCC( 보안 컨텍스트 제약 조건)에 대한 권한이 있습니다.
3.1.2.1. 액세스 권한 레이블
예를 들어 라우터 shard 생성 시 네임스페이스 레이블을 사용하는 경우 라우터 의 서비스 계정에 cluster-reader 권한이 있어야 합니다.
$ oc adm policy add-cluster-role-to-user \
cluster-reader \
system:serviceaccount:default:router서비스 계정이 있는 경우 기본 HAProxy 라우터 또는 사용자 지정된 HAProxy 라우터설치를 진행할 수 있습니다.
3.2. 기본 HAProxy 라우터 사용
3.2.1. 개요
oc adm router 명령은 새 설치에서 라우터를 설정하는 작업을 간소화하기 위해 관리자 CLI와 함께 제공됩니다. oc adm router 명령은 서비스 및 배포 구성 오브젝트를 만듭니다. service -account 옵션을 사용하여 라우터가 마스터에 연결하는 데 사용할 서비스 계정을 지정합니다.
라우터 서비스 계정은 사전에 생성하거나 oc adm router --service-account 명령으로 만들 수 있습니다.
OpenShift Container Platform 구성 요소 간 모든 형식의 통신은 TLS에 의해 보호되며 다양한 인증서 및 인증 방법을 사용합니다. default -certificate .pem 형식 파일을 제공하거나 oc adm router 명령으로 파일을 생성할 수 있습니다. 경로가 생성되면 사용자는 라우터가 경로를 처리할 때 사용할 경로 인증서를 제공할 수 있습니다.
라우터를 삭제할 때 배포 구성, 서비스 및 시크릿도 삭제되었는지 확인합니다.
라우터는 특정 노드에 배포됩니다. 따라서 클러스터 관리자와 외부 네트워크 관리자가 라우터를 실행할 IP 주소와 라우터에서 처리할 트래픽을 보다 쉽게 조정할 수 있습니다. 라우터는 노드 선택기를 사용하여 특정 노드에 배포됩니다.
oc adm 라우터를 사용하여 생성된 라우터 포드에는 노드가 배포될 라우터 포드를 충족해야 한다는 기본 리소스 요청이 있습니다. 인프라 구성 요소의 안정성을 높이기 위해 기본 리소스 요청은 리소스 요청 없이 포드 위의 라우터 Pod의 QoS 계층을 늘리는 데 사용됩니다. 기본값은 배포되는 기본 라우터에 필요한 관찰된 최소 리소스를 나타내며 라우터 배포 구성에서 편집할 수 있으며 라우터 부하에 따라 늘릴 수 있습니다.
3.2.2. 라우터 생성
라우터가 없는 경우 다음을 실행하여 라우터를 생성합니다.
$ oc adm router <router_name> --replicas=<number> --service-account=router --extended-logging=true
고가용성 구성이 생성되지 않는 한 --replicas 는 일반적으로 1 입니다.
--extended-logging=true 는 HAProxy에서 생성한 로그를 syslog 컨테이너로 전달하도록 라우터를 구성합니다.
라우터의 호스트 IP 주소를 찾으려면 다음을 수행합니다.
$ oc get po <router-pod> --template={{.status.hostIP}}라우터 shard를 사용하여 라우터가 특정 네임스페이스 또는 경로로 필터링되었는지 확인하거나 라우터 생성 후 환경 변수를 설정할 수도 있습니다. 이 경우 각 shard에 대한 라우터를 생성합니다.
3.2.3. 기타 기본 라우터 명령
- 기본 라우터 확인
- router라는 기본 라우터 서비스 계정은 클러스터 설치 중에 자동으로 생성됩니다. 이 계정이 이미 있는지 확인하려면 다음을 수행하십시오.
$ oc adm router --dry-run --service-account=router- 기본 라우터 보기
- 기본 라우터가 생성된 경우 어떻게 표시되는지 확인하려면 다음을 수행하십시오.
$ oc adm router --dry-run -o yaml --service-account=router- HAProxy 로그를 전달하도록 라우터 구성
-
HAProxy에서 생성된 로그를 rsyslog 사이드카 컨테이너로 전달하도록 라우터를 구성할 수 있습니다. extended
-logging=true매개 변수는 syslog 컨테이너를 추가하여 HAProxy 로그를 표준 출력에 전달합니다.
$ oc adm router --extended-logging=true
다음 예제는 --extended-logging=true 를 사용하는 라우터의 구성입니다.
$ oc get pod router-1-xhdb9 -o yaml
apiVersion: v1
kind: Pod
spec:
containers:
- env:
....
- name: ROUTER_SYSLOG_ADDRESS
value: /var/lib/rsyslog/rsyslog.sock
....
- command:
- /sbin/rsyslogd
- -n
- -i
- /tmp/rsyslog.pid
- -f
- /etc/rsyslog/rsyslog.conf
image: registry.redhat.io/openshift3/ose-haproxy-router:v3.11.188
imagePullPolicy: IfNotPresent
name: syslog다음 명령을 사용하여 HAProxy 로그를 확인합니다.
$ oc set env dc/test-router ROUTER_LOG_LEVEL=info
$ oc logs -f <pod-name> -c syslog HAProxy 로그는 다음 형식을 취합니다.
2020-04-14T03:05:36.629527+00:00 test-311-node-1 haproxy[43]: 10.0.151.166:59594 [14/Apr/2020:03:05:36.627] fe_no_sni~ be_secure:openshift-console:console/pod:console-b475748cb-t6qkq:console:10.128.0.5:8443 0/0/1/1/2 200 393 - - --NI 2/1/0/1/0 0/0 "HEAD / HTTP/1.1"
2020-04-14T03:05:36.633024+00:00 test-311-node-1 haproxy[43]: 10.0.151.166:59594 [14/Apr/2020:03:05:36.528] public_ssl be_no_sni/fe_no_sni 95/1/104 2793 -- 1/1/0/0/0 0/0- 라벨이 지정된 노드에 라우터 배포
- 지정된 노드 레이블 과 일치하는 모든 노드에 라우터를 배포하려면 다음을 수행합니다.
$ oc adm router <router_name> --replicas=<number> --selector=<label> \
--service-account=router
예를 들어 router 이라는 라우터를 생성하고 node-role.kubernetes.io/infra=true로 레이블이 지정된 노드에 배치하려면 다음을 수행합니다.
$ oc adm router router --replicas=1 --selector='node-role.kubernetes.io/infra=true' \
--service-account=router
클러스터 설치 중에 openshift_router_selector 및 openshift_registry_selector Ansible 설정은 기본적으로 node-role.kubernetes.io/infra=true 로 설정됩니다. 기본 라우터 및 레지스트리는 노드가 node-role.kubernetes.io/infra=true 레이블과 일치하는 경우에만 자동으로 배포됩니다.
라벨 업데이트에 대한 자세한 내용은 노드에서 라벨 업데이트를 참조하십시오.
스케줄러 정책에 따라 여러 개의 인스턴스가 여러 호스트에서 생성됩니다.
- 다른 라우터 이미지 사용
- 다른 라우터 이미지를 사용하고 사용되는 라우터 구성을 보려면 다음을 수행합니다.
$ oc adm router <router_name> -o <format> --images=<image> \
--service-account=router예를 들면 다음과 같습니다.
$ oc adm router region-west -o yaml --images=myrepo/somerouter:mytag \
--service-account=router3.2.4. 특정 라우터로 경로 필터링
ROUTE_LABELS 환경 변수를 사용하면 특정 라우터에서만 사용하도록 경로를 필터링할 수 있습니다.
예를 들어 여러 라우터와 100개의 경로가 있는 경우 레이블을 경로에 연결하여 한 라우터에서 이를 처리하도록 하는 반면 나머지는 다른 라우터에서 처리할 수 있습니다.
라우터를 만든 후
ROUTE_LABELS환경 변수를 사용하여 라우터에 태그를 지정합니다.$ oc set env dc/<router=name> ROUTE_LABELS="key=value"원하는 경로에 라벨을 추가합니다.
oc label route <route=name> key=value레이블이 경로에 연결되었는지 확인하려면 경로 구성을 확인합니다.
$ oc describe route/<route_name>
- 최대 동시 연결 수 설정
-
라우터는 기본적으로 최대 20000개의 연결을 처리할 수 있습니다. 요구 사항에 따라 해당 제한을 변경할 수 있습니다. 연결이 너무 적으면 상태 점검이 작동하지 않으므로 불필요한 재시작이 발생합니다. 최대 연결 수를 지원하도록 시스템을 구성해야 합니다.
'sysctl fs.nr_open'및'sysctl fs.file-max'에 표시된 제한은 충분히 커야 합니다. 그렇지 않으면 HAproxy가 시작되지 않습니다.
라우터가 생성되면 --max-connections= 옵션은 원하는 제한을 설정합니다.
$ oc adm router --max-connections=10000 ....
라우터의 배포 구성에서 ROUTER_MAX_CONNECTIONS 환경 변수를 편집하여 값을 변경합니다. 라우터 포드는 새 값으로 다시 시작됩니다. ROUTER_MAX_CONNECTIONS 가 없으면 기본값 20000이 사용됩니다.
연결에는 프론트엔드 및 내부 백엔드가 포함됩니다. 두 개의 커넥션으로 계산됩니다. 생성하려는 연결 수보다 두 배로 ROUTER_MAX_CONNECTIONS 를 설정해야 합니다.
3.2.5. HAProxy Strict SNI
HAProxy S tric-sni 는 라우터 배포 구성의 ROUTER_STRICT_SNI 환경 변수를 통해 제어할 수 있습니다. 또한 --strict-sni 명령줄 옵션을 사용하여 라우터를 만들 때 설정할 수 있습니다.
$ oc adm router --strict-sni3.2.6. TLS 암호 제품군
라우터를 만들 때 --ciphers 옵션을 사용하여 라우터 암호화 제품군 을 설정합니다.
$ oc adm router --ciphers=modern ....
값은 modern,intermediate 또는 old 이며 기본값은 intermediate 입니다. 또는 ":"로 구분된 암호 집합을 제공할 수 있습니다. 암호는 다음을 통해 표시되는 세트의 암호여야 합니다.
$ openssl ciphers
또는 기존 라우터에 ROUTER_CIPHERS 환경 변수를 사용합니다.
3.2.7. 상호 TLS 인증
라우터 및 백엔드 서비스에 대한 클라이언트 액세스는 상호 TLS 인증을 사용하여 제한할 수 있습니다. 라우터는 인증된 세트에 없는 클라이언트의 요청을 거부합니다. 상호 TLS 인증은 클라이언트 인증서에 구현되며 인증서를 발급한 CA(인증 기관), 인증서 폐기 목록 및/또는 모든 인증 대상 필터를 기반으로 제어할 수 있습니다. 라우터를 생성할 때 상호 tls 구성 옵션 -- mutual-tls-auth, --mutual-tls-auth-ca, --mutual-tls-auth-filter 를 사용합니다.
$ oc adm router --mutual-tls-auth=required \
--mutual-tls-auth-ca=/local/path/to/cacerts.pem ....
mutual -tls-auth 값은 required,optional 또는 none 이며 기본값으로 none 입니다. mutual -tls-auth-ca 값은 하나 이상의 CA 인증서가 포함된 파일을 지정합니다. 이러한 CA 인증서는 라우터에서 클라이언트의 인증서를 확인하는 데 사용됩니다.
mutual -tls-auth-crl 을 사용하면 인증서 취소 목록을 지정하여 인증서(유효한 인증 기관에서 발급)가 취소된 경우를 처리할 수 있습니다.
$ oc adm router --mutual-tls-auth=required \
--mutual-tls-auth-ca=/local/path/to/cacerts.pem \
--mutual-tls-auth-filter='^/CN=my.org/ST=CA/C=US/O=Security/OU=OSE$' \
....
인증서 제목에 따라 --mutual-tls-auth-filter 값을 사용하여 세분화된 액세스 제어에 사용할 수 있습니다. 값은 인증서 제목과 일치하는 데 사용되는 정규식입니다.
위의 상호 TLS 인증 필터 예제는 인증서 제목과 정확히 일치하는 제한적인 정규 표현식(regex)( regex ) 살펴봅니다. 덜 제한적인 정규 표현식을 사용하기로 결정한 경우 유효한 것으로 간주되는 CA에서 발급한 인증서와 일치할 수 있다는 점에 유의하십시오. 또한 발급한 인증서를 더 세부적으로 제어할 수 있도록 --mutual-tls-auth-ca 옵션을 사용하는 것이 좋습니다.
mutual -tls-auth=required 를 사용하면 인증된 클라이언트 만 백엔드 리소스에 액세스할 수 있습니다. 즉, 클라이언트가 인증 정보( 클라이언트 인증서라고 함)를 항상 제공해야 합니다. 상호 TLS 인증을 선택하도록 하려면 --mutual-tls-auth=optional 을 사용합니다(또는 none 을 사용하여 이를 비활성화 - 기본값임). 여기서 선택사항 은 인증 정보를 제공하는 클라이언트가 인증 정보를 제공하지 않아도 되며 클라이언트가 인증 정보를 제공하는 경우 X-SSL* HTTP 헤더의 백엔드로만 전달됩니다.
$ oc adm router --mutual-tls-auth=optional \
--mutual-tls-auth-ca=/local/path/to/cacerts.pem \
....
상호 TLS 인증 지원이 활성화된 경우( --mutual-tls-auth 플래그에 필수 또는 선택적 값 사용) 클라이언트 인증 정보는 X-SSL* HTTP 헤더 형식의 백엔드로 전달됩니다.
X-SSL* HTTP 헤더 X-SSL-Client-DN: 인증서 제목의 전체 고유 이름(DN)의 예. X-SSL-Client-NotBefore: YYMMDDhhmmss[Z] 형식의 클라이언트 인증서 시작 날짜입니다. X-SSL-Client-NotAfter: YYMMDDhhmmss[Z] 형식의 클라이언트 인증서 종료일입니다. X-SSL-Client-SHA1: 클라이언트 인증서의 SHA-1 지문입니다. X-SSL-Client-DER: 클라이언트 인증서에 대한 전체 액세스를 제공합니다. base-64 형식으로 인코딩된 DER 형식 클라이언트 인증서를 포함합니다.
3.2.8. 고가용성 라우터
IP 페일오버를 사용하여 OpenShift Container Platform 클러스터에 고가용성 라우터를 설정 할 수 있습니다. 이 설정에는 여러 노드에 여러 개의 복제본이 있으므로 현재 노드에 장애가 발생한 경우 장애 조치(failover) 소프트웨어로 전환할 수 있습니다.
3.2.9. 라우터 서비스 포트 사용자 정의
환경 변수 ROUTER_SERVICE_HTTP_PORT 및 ROUTER_SERVICE_HTTPS_PORT 를 설정하여 템플릿 라우터가 바인딩하는 서비스 포트를 사용자 지정할 수 있습니다. 이 작업은 템플릿 라우터를 만든 다음 배포 구성을 편집하여 수행할 수 있습니다.
다음 예제에서는 0 개의 복제본을 사용하여 라우터 배포를 생성하고 라우터 서비스 HTTP 및 HTTPS 포트를 사용자 지정한 다음 적절하게 확장합니다(복제본 1 개로).
$ oc adm router --replicas=0 --ports='10080:10080,10443:10443'
$ oc set env dc/router ROUTER_SERVICE_HTTP_PORT=10080 \
ROUTER_SERVICE_HTTPS_PORT=10443
$ oc scale dc/router --replicas=1- 1
- 컨테이너 네트워킹 모드
--host-network=false를 사용하는 라우터에 노출된 포트가 적절하게 설정되었는지 확인합니다.
템플릿 라우터 서비스 포트를 사용자 지정하는 경우 라우터 포드가 실행되는 노드에 방화벽(Ansible 또는 iptables 을 통해 또는 firewall-cmd를 통해 사용하는 기타 사용자 지정 방법)에서 해당 사용자 지정 포트가 열려 있는지 확인해야 합니다.
다음은 iptables 를 사용하여 사용자 지정 라우터 서비스 포트를 여는 예입니다.
$ iptables -A OS_FIREWALL_ALLOW -p tcp --dport 10080 -j ACCEPT
$ iptables -A OS_FIREWALL_ALLOW -p tcp --dport 10443 -j ACCEPT3.2.10. 여러 라우터로 작업
관리자는 동일한 정의로 여러 라우터를 만들어 동일한 경로 집합을 제공할 수 있습니다. 각 라우터는 다른 노드에 있으며 다른 IP 주소를 가집니다. 네트워크 관리자는 각 노드에 원하는 트래픽을 가져와야 합니다.
클러스터에 라우팅 부하를 분산하고 다른 라우터 또는 shard 에 테넌트를 분리하도록 여러 라우터를 그룹화할 수 있습니다. 그룹의 각 라우터 또는 shard는 라우터의 선택기를 기반으로 경로를 허용합니다. 관리자는 ROUTE_LABELS 를 사용하여 전체 클러스터에 shard를 생성할 수 있습니다. 사용자는 NAMESPACE_LABELS 를 사용하여 네임스페이스(프로젝트)에서 shard를 생성할 수 있습니다.
3.2.11. 배포 구성에 노드 선택기 추가
특정 라우터를 특정 노드에 배포하려면 다음 두 단계가 필요합니다.
원하는 노드에 레이블을 추가합니다.
$ oc label node 10.254.254.28 "router=first"라우터 배포 구성에 노드 선택기를 추가합니다.
$ oc edit dc <deploymentConfigName>라벨에 해당하는 키와 값이 있는
template.spec.nodeSelector필드를 추가합니다.... template: metadata: creationTimestamp: null labels: router: router1 spec: nodeSelector:1 router: "first" ...- 1
- 키 및 값은 각각
router=first 레이블에 해당하는 라우터와레이블입니다.첫번째
3.2.12. 라우터 공유 공간 사용
라우터 분할 에서는 NAMESPACE_LABELS 및 ROUTE_LABELS 를 사용하여 라우터 네임스페이스와 경로를 필터링합니다. 이를 통해 경로의 하위 집합을 여러 라우터 배포에 배포할 수 있습니다. 오버레이되지 않은 하위 집합을 사용하면 경로 집합을 효과적으로 분할할 수 있습니다. 또는 겹치는 경로 하위 집합으로 구성된 shard를 정의할 수 있습니다.
기본적으로 라우터는 모든 프로젝트(네임스페이스) 에서 모든 경로를 선택합니다. 분할에는 경로 또는 네임스페이스에 레이블을 추가하고 라우터에 라벨 선택기를 추가합니다. 각 라우터 shard는 특정 레이블 선택기 집합에서 선택한 경로로 구성되거나 특정 레이블 선택기 세트에서 선택한 네임스페이스에 속합니다.
라우터 서비스 계정에는 다른 네임스페이스의 라벨에 액세스할 수 있도록 [클러스터 리더] 권한이 설정되어 있어야 합니다.
라우터 공유 및 DNS
요청을 원하는 shard로 라우팅하려면 외부 DNS 서버가 필요하므로 관리자는 프로젝트의 각 라우터에 대해 별도의 DNS 항목을 만들어야 합니다. 라우터는 알 수 없는 경로를 다른 라우터로 전달하지 않습니다.
다음 예제를 고려하십시오.
-
라우터 A는 호스트 192.168.0.5에 있으며
*.foo.com이 있는 경로가 있습니다. -
라우터 B는 호스트 192.168.1.9에 있으며
*.example.com이 있는 경로가 있습니다.
별도의 DNS 항목은 *.foo.com을 라우터 A를 호스팅하는 노드로 확인하고 *.example.com을 라우터 B를 호스팅하는 노드로 확인해야 합니다.
-
*.foo.com A IN 192.168.0.5 -
*.example.com A IN 192.168.1.9
라우터 공유 예
이 섹션에서는 네임스페이스 및 경로 레이블을 사용하여 라우터 분할에 대해 설명합니다.
그림 3.1. 네임 스페이스 레이블 기반 라우터 공유

네임스페이스 라벨 선택기를 사용하여 라우터를 구성합니다.
$ oc set env dc/router NAMESPACE_LABELS="router=r1"라우터에는 네임스페이스에 선택기가 있으므로 라우터는 일치하는 네임스페이스에 대해서만 경로를 처리합니다. 이 선택기가 네임스페이스와 일치하도록 하려면 그에 따라 네임스페이스에 라벨을 지정합니다.
$ oc label namespace default "router=r1"이제 default 네임스페이스에 경로를 생성하는 경우 기본 라우터에서 경로를 사용할 수 있습니다.
$ oc create -f route1.yaml새 프로젝트(namespace)를 생성하고 경로를 만듭니다.
route2:$ oc new-project p1 $ oc create -f route2.yaml라우터에서 경로를 사용할 수 없습니다.
router=r
1을 사용하여 네임스페이스 p1에 레이블을 지정합니다.$ oc label namespace p1 "router=r1"
이 레이블을 추가하면 라우터에서 경로를 사용할 수 있습니다.
- 예제
라우터 배포 pin
ops-router는 레이블 선택기NAMESPACE_LABELS="name in (finance, ops)"으로구성되고 라우터 배포dev-router는 레이블 선택기NAMESPACE_LABELS="name=dev"로 구성됩니다.모든 경로가
name=finance, name=ops,라는 레이블이 지정된 네임스페이스에 있는 경우 이 구성은 두 라우터 배포 간에 경로를 효과적으로 배포합니다.name=dev위의 시나리오에서 분할은 중복되는 하위 집합이 없는 파티션의 특별한 사례가 됩니다. 경로는 라우터 shard 간에 나뉩니다.
경로 선택 기준은 경로 배포 방법을 결정합니다. 라우터 배포에서 경로의 중복된 하위 집합을 가질 수 있습니다.
- 예제
위의 예에 있는
pinops외에도 라벨 선택기-router및 dev-routerNAMESPACE_LABELS="name (dev, ops)"으로 구성된devops-router도 있습니다.name=dev 또는레이블이 지정된 네임스페이스의 경로는 이제 두 개의 서로 다른 라우터 배포에서 서비스를 제공합니다. 이 경우에는 네임스페이스 레이블을 기반으로 라우터 공유를 기반으로 하는 절차에 설명된 대로 경로의 중복된 하위 집합을 정의한 사례가 됩니다.name=ops또한 더 복잡한 라우팅 규칙을 만들 수 있으므로 우선 순위가 더 높은 트래픽이 전용 conf
ops-router로 전환할 수 있으며 우선 순위가 낮은 트래픽을devops-router로 보낼 수 있습니다.
경로 레이블을 기반으로 하는 라우터 공유
NAMESPACE_LABELS 를 사용하면 프로젝트를 서비스하고 해당 프로젝트에서 모든 경로를 선택할 수 있지만 경로 자체와 연결된 다른 기준에 따라 경로를 분할할 수 있습니다. ROUTE_LABELS 선택기를 사용하면 경로 자체를 슬라이스 앤 드롭할 수 있습니다.
- 예제
라우터 배포
prod-router는 레이블 선택기ROUTE_LABELS="mydeployment=prod"로 구성되고 라우터 배포devtest-router는 레이블 선택기ROUTE_LABELS="mydeployment in (dev, test)"로 구성됩니다.이 구성 파티션은 네임스페이스와 관계없이 경로의 레이블에 따라 두 라우터 배포 간에 라우팅됩니다.
이 예제에서는 서비스할 모든 경로에
"mydeployment=<tag>"라는 레이블이 지정되어 있다고 가정합니다.
3.2.12.1. 라우터 공유 파일 생성
이 섹션에서는 라우터 분할의 고급 예를 설명합니다. 다양한 라벨이 있는 26개의 경로(이름: ) 가 있다고 가정합니다.
경로에 가능한 레이블
sla=high geo=east hw=modest dept=finance
sla=medium geo=west hw=strong dept=dev
sla=low dept=ops이러한 레이블은 서비스 수준 계약, 지리적 위치, 하드웨어 요구 사항, 부서 등의 개념을 나타냅니다. 경로에는 각 열에서 최대 하나의 레이블이 있을 수 있습니다. 일부 경로에는 다른 레이블이 있거나 레이블이 전혀 없을 수 있습니다.
| 이름 | SLA | geo | HW | Dept | 기타 레이블 |
|---|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
| ||
|
|
|
|
| ||
|
|
|
|
| ||
|
|
|
|
| ||
|
|
|
|
다음은 oc adm router, oc shard를 만드는 방법을 보여주는 모바일 스크립트 mkshard 입니다.
set env 및 oc scale 을 함께 사용하여 라우터
#!/bin/bash
# Usage: mkshard ID SELECTION-EXPRESSION
id=$1
sel="$2"
router=router-shard-$id
oc adm router $router --replicas=0
dc=dc/router-shard-$id
oc set env $dc ROUTE_LABELS="$sel"
oc scale $dc --replicas=3 mkshard 를 여러 번 실행하면 여러 라우터가 생성됩니다.
| 라우터 | 선택 표현식 | 라우트 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
3.2.12.2. 라우터 공유 파일 수정
라우터 shard는 레이블을 기반으로 한 생성자이므로 oc 레이블을통해 레이블(oc label ) 또는 선택 표현식(oc set env를 통해)을 수정할 수 있습니다.
이 섹션에서는 라우터 공유 생성 섹션에서 시작된 예제를 확장하여 선택 표현식을 변경하는 방법을 보여줍니다.
다음은 새 선택 표현식을 사용하도록 기존 라우터를 수정하는 편리한 스크립트 modshard 입니다.
#!/bin/bash
# Usage: modshard ID SELECTION-EXPRESSION...
id=$1
shift
router=router-shard-$id
dc=dc/$router
oc scale $dc --replicas=0
oc set env $dc "$@"
oc scale $dc --replicas=3
modshard 에서는 router-shard-<id> 의 배포 전략이 롤링 인 경우 oc scale 명령이 필요하지 않습니다.
예를 들어 router-shard-3 의 부서를 확장하여 ops 및 dev 를 포함하려면 다음을 수행합니다.
$ modshard 3 ROUTE_LABELS='dept in (dev, ops)'
그 결과 router-shard-3 이 이제 g cd - s(g^- k 및 lcd - s 의 결합된 집합)를 선택합니다.
이 예제에서는 이 예제 시나리오에 세 개의 부서만 있으며 shard에서 나가도록 부서를 지정하여 이전 예제와 동일한 결과를 얻을 수 있음을 고려합니다.
$ modshard 3 ROUTE_LABELS='dept != finance'
이 예제에서는 쉼표로 구분된 세 가지 특성을 지정하며 결과적으로 b 만 선택됩니다.
$ modshard 3 ROUTE_LABELS='hw=strong,type=dynamic,geo=west'
경로 레이블이 포함된 ROUTE_LABELS 와 유사하게 NAMESPACE_LABELS 환경 변수를 사용하여 경로 네임스페이스의 레이블을 기반으로 경로를 선택할 수 있습니다. 이 예제에서는 router-shard-3 을 수정하여 네임스페이스에 라벨 frequency=weekly 가 있는 경로를 제공합니다.
$ modshard 3 NAMESPACE_LABELS='frequency=weekly'
마지막 예제에서는 ROUTE_LABELS 와 NAMESPACE_LABELS 를 결합하여 라벨이 sla=low 인 경로를 선택하고 네임스페이스에 라벨 frequency=weekly 가 있습니다.
$ modshard 3 \
NAMESPACE_LABELS='frequency=weekly' \
ROUTE_LABELS='sla=low'3.2.13. 라우터의 호스트 이름 찾기
서비스를 노출할 때 외부 사용자가 애플리케이션에 액세스하는 데 사용하는 DNS 이름과 동일한 경로를 사용할 수 있습니다. 외부 네트워크의 네트워크 관리자는 호스트 이름이 경로를 허용한 라우터의 이름으로 확인되어야 합니다. 사용자는 이 호스트 이름을 가리키는 CNAME으로 DNS를 설정할 수 있습니다. 그러나 사용자는 라우터의 호스트 이름을 알지 못할 수 있습니다. 알 수 없는 경우 클러스터 관리자는 이를 제공할 수 있습니다.
클러스터 관리자는 라우터를 만들 때 라우터의 정식 호스트 이름과 함께 --router-canonical-hostname 옵션을 사용할 수 있습니다. 예를 들면 다음과 같습니다.
# oc adm router myrouter --router-canonical-hostname="rtr.example.com"
이렇게 하면 라우터의 호스트 이름이 포함된 라우터 배포 구성에 ROUTER_CANONICAL_HOSTNAME 환경 변수가 생성됩니다.
이미 존재하는 라우터의 경우 클러스터 관리자는 라우터의 배포 구성을 편집하고 ROUTER_CANONICAL_HOSTNAME 환경 변수를 추가할 수 있습니다.
spec:
template:
spec:
containers:
- env:
- name: ROUTER_CANONICAL_HOSTNAME
value: rtr.example.com
ROUTER_CANONICAL_HOSTNAME 값은 경로를 승인한 모든 라우터의 경로 상태에 표시됩니다. 라우터를 다시 로드할 때마다 경로 상태가 새로 고쳐집니다.
사용자가 경로를 만들면 모든 활성 라우터가 경로를 평가하고 조건이 충족되면 이를 승인합니다. ROUTER_CANONICAL_HOSTNAME 환경 변수를 정의하는 라우터에서 경로를 허용하면 라우터에서 routerCanonicalHostname 필드에 값을 경로 상태에 배치합니다. 사용자는 경로 상태를 검사하여 라우터가 경로를 허용했는지 확인하고, 목록에서 라우터를 선택하고, 네트워크 관리자에게 전달할 라우터의 호스트 이름을 찾을 수 있습니다.
status:
ingress:
conditions:
lastTransitionTime: 2016-12-07T15:20:57Z
status: "True"
type: Admitted
host: hello.in.mycloud.com
routerCanonicalHostname: rtr.example.com
routerName: myrouter
wildcardPolicy: None
oc describe 는 사용 가능한 경우 호스트 이름을 포함합니다.
$ oc describe route/hello-route3
...
Requested Host: hello.in.mycloud.com exposed on router myroute (host rtr.example.com) 12 minutes ago
사용자는 위의 정보를 사용하여 DNS 관리자에게 경로의 호스트 hello.in.mycloud.com에서 라우터의 정식 호스트 이름 그러면 rtr.example.com 으로 CNAME을 설정하도록 요청할 수 있습니다.hello.in.mycloud.com 에 대한 트래픽이 사용자의 애플리케이션에 도달하게 됩니다.
3.2.14. 기본 라우팅 하위 도메인 사용자 지정
마스터 구성 파일(기본적으로 /etc/origin/master/master-config.yaml 파일)을 수정하여 해당 환경의 기본 라우팅 하위 도메인으로 사용되는 접미사를 사용자 지정할 수 있습니다. 호스트 이름을 지정하지 않는 경로는 이 기본 라우팅 하위 도메인을 사용하여 생성됩니다.
다음 예제에서는 구성된 접미사를 v3.openshift.test로 설정하는 방법을 보여줍니다.
routingConfig:
subdomain: v3.openshift.test이 변경 사항을 적용하려면 마스터가 실행 중인 경우 다시 시작해야 합니다.
위 구성을 실행하는 OpenShift Container Platform 마스터에서 mynamespace 네임스페이스에 호스트 이름을 추가하지 않고 no-route-hostname 이라는 경로의 예를 위해 생성된 호스트 이름은 다음과 같습니다.
no-route-hostname-mynamespace.v3.openshift.test3.2.15. 사용자 지정 라우팅 하위 도메인으로 경로 호스트 이름 강제
관리자가 모든 경로를 특정 라우팅 하위 도메인으로 제한하려는 경우 --force-subdomain 옵션을 oc adm router 명령에 전달할 수 있습니다. 이렇게 하면 라우터가 경로에 지정된 호스트 이름을 재정의하고 --force-subdomain 옵션에 제공된 템플릿을 기반으로 합니다.
다음 예제에서는 라우터를 실행하여 사용자 지정 하위 도메인 템플릿 ${name}-${namespace}.apps.example.com 을 사용하여 경로 호스트 이름을 재정의합니다.
$ oc adm router --force-subdomain='${name}-${namespace}.apps.example.com'3.2.16. 와일드카드 인증서 사용
인증서가 포함되지 않은 TLS 지원 경로에서는 라우터의 기본 인증서를 대신 사용합니다. 대부분의 경우 이 인증서는 신뢰할 수 있는 인증 기관에서 제공해야 하지만 편의를 위해 OpenShift Container Platform CA를 사용하여 인증서를 생성할 수 있습니다. 예를 들면 다음과 같습니다.
$ CA=/etc/origin/master
$ oc adm ca create-server-cert --signer-cert=$CA/ca.crt \
--signer-key=$CA/ca.key --signer-serial=$CA/ca.serial.txt \
--hostnames='*.cloudapps.example.com' \
--cert=cloudapps.crt --key=cloudapps.key
oc adm ca create-server-cert 명령은 2년 동안 유효한 인증서를 생성합니다. 이는 --expire-days 옵션으로 변경할 수 있지만 보안상의 이유로 이 값보다 커지지 않는 것이 좋습니다.
기본적으로 /etc/ansible/hosts 에서 Ansible 호스트 인벤토리 파일에 나열된 첫 번째 마스터에서만 oc adm 명령을 실행합니다.
라우터는 인증서와 키가 단일 파일에서 PEM 형식이어야 합니다.
$ cat cloudapps.crt cloudapps.key $CA/ca.crt > cloudapps.router.pem
여기에서 --default-cert 플래그를 사용할 수 있습니다.
$ oc adm router --default-cert=cloudapps.router.pem --service-account=router브라우저는 한 레벨의 하위 도메인에 유효한 와일드카드만 고려합니다. 이 예에서는 인증서가. cloudapps.example.com에 유효하지만, a. b.cloudapps.example.com에는 적용되지 않습니다.
3.2.17. 수동으로 인증서 재배포
라우터 인증서를 수동으로 재배포하려면 다음을 수행합니다.
기본 라우터 인증서가 포함된 보안이 라우터에 추가되었는지 확인합니다.
$ oc set volume dc/router deploymentconfigs/router secret/router-certs as server-certificate mounted at /etc/pki/tls/private인증서가 추가되면 다음 단계를 건너뛰고 보안을 덮어씁니다.
다음 변수
DEFAULT_CERTIFICATE_DIR에 대해 설정된 기본 인증서 디렉터리가 있는지 확인합니다.$ oc set env dc/router --list DEFAULT_CERTIFICATE_DIR=/etc/pki/tls/private그렇지 않은 경우 다음 명령을 사용하여 디렉터리를 생성합니다.
$ oc set env dc/router DEFAULT_CERTIFICATE_DIR=/etc/pki/tls/private인증서를 PEM 형식으로 내보냅니다.
$ cat custom-router.key custom-router.crt custom-ca.crt > custom-router.crt라우터 인증서 보안을 덮어쓰거나 생성합니다.
인증서 보안이 라우터에 추가되면 보안을 덮어씁니다. 그렇지 않은 경우 새 시크릿을 생성합니다.
보안을 덮어쓰려면 다음 명령을 실행합니다.
$ oc create secret generic router-certs --from-file=tls.crt=custom-router.crt --from-file=tls.key=custom-router.key --type=kubernetes.io/tls -o json --dry-run | oc replace -f -새 보안을 생성하려면 다음 명령을 실행합니다.
$ oc create secret generic router-certs --from-file=tls.crt=custom-router.crt --from-file=tls.key=custom-router.key --type=kubernetes.io/tls $ oc set volume dc/router --add --mount-path=/etc/pki/tls/private --secret-name='router-certs' --name router-certs라우터를 배포합니다.
$ oc rollout latest dc/router
3.2.18. 보안 경로 사용
현재는 암호로 보호되는 키 파일이 지원되지 않습니다. HAProxy는 시작 시 암호를 묻는 메시지를 표시하며 이 프로세스를 자동화할 방법이 없습니다. 키 파일에서 암호를 제거하려면 다음을 실행합니다.
# openssl rsa -in <passwordProtectedKey.key> -out <new.key>다음은 트래픽이 대상에 프록시되기 전에 라우터에서 TLS 종료와 함께 보안 에지 종료 경로를 사용하는 방법에 대한 예입니다. 보안 에지 종료 경로는 TLS 인증서 및 키 정보를 지정합니다. TLS 인증서는 라우터 프런트엔드에서 제공합니다.
먼저 라우터 인스턴스를 시작합니다.
# oc adm router --replicas=1 --service-account=router
다음으로 에지 보안 경로에 사용할 개인 키 csr 및 인증서를 만듭니다. 이 작업을 수행하는 방법에 대한 지침은 인증 기관 및 공급자에 따라 다릅니다. www.example.test 도메인의 간단한 자체 서명 인증서는 아래 표시된 예제를 참조하십시오.
# sudo openssl genrsa -out example-test.key 2048
#
# sudo openssl req -new -key example-test.key -out example-test.csr \
-subj "/C=US/ST=CA/L=Mountain View/O=OS3/OU=Eng/CN=www.example.test"
#
# sudo openssl x509 -req -days 366 -in example-test.csr \
-signkey example-test.key -out example-test.crt위의 인증서와 키를 사용하여 경로를 생성합니다.
$ oc create route edge --service=my-service \
--hostname=www.example.test \
--key=example-test.key --cert=example-test.crt
route "my-service" created해당 정의를 살펴보겠습니다.
$ oc get route/my-service -o yaml
apiVersion: v1
kind: Route
metadata:
name: my-service
spec:
host: www.example.test
to:
kind: Service
name: my-service
tls:
termination: edge
key: |
-----BEGIN PRIVATE KEY-----
[...]
-----END PRIVATE KEY-----
certificate: |
-----BEGIN CERTIFICATE-----
[...]
-----END CERTIFICATE-----
www.example.test 에 대한 DNS 항목이 라우터 인스턴스를 가리키는지 확인하고 도메인의 경로를 사용할 수 있어야 합니다. 아래 예제에서는 로컬 확인자와 함께 curl을 사용하여 DNS 조회를 시뮬레이션합니다.
# routerip="4.1.1.1" # replace with IP address of one of your router instances.
# curl -k --resolve www.example.test:443:$routerip https://www.example.test/3.2.19. 와일드 카드 경로 사용(하위 도메인의 경우)
HAProxy 라우터는 와일드카드 경로를 지원하며, 이 경로는 ROUTER_ALLOW_WILDCARD_ROUTES 환경 변수를 true 로 설정하여 활성화됩니다. 라우터 승인 검사를 통과하는 와일드카드 정책이 Subdomain 인 모든 경로는 HAProxy 라우터에서 서비스를 제공합니다. 그런 다음 HAProxy 라우터는 경로의 와일드카드 정책에 따라 연결된 서비스(경로용)를 노출합니다.
경로의 와일드카드 정책을 변경하려면 경로를 제거하고 업데이트된 와일드카드 정책으로 다시 생성해야 합니다. 경로의 .yaml 파일에서 경로의 와일드카드 정책만 편집하는 것은 작동하지 않습니다.
$ oc adm router --replicas=0 ...
$ oc set env dc/router ROUTER_ALLOW_WILDCARD_ROUTES=true
$ oc scale dc/router --replicas=1와일드카드 경로에 사용할 웹 콘솔을 구성하는 방법을 알아봅니다.
보안 와일드카드 에지 종료 경로 사용
이 예에서는 트래픽이 대상으로 프록시되기 전에 라우터에서 발생하는 TLS 종료를 반영합니다. 하위 도메인 example.org( )의 모든 호스트에 전송된 트래픽은 노출된 서비스로 프록시됩니다.
*.example.org
보안 에지 종료 경로는 TLS 인증서 및 키 정보를 지정합니다. TLS 인증서는 하위 도메인(*.example.org)과 일치하는 모든 호스트의 라우터 프런트엔드에서 제공합니다.
라우터 인스턴스를 시작합니다.
$ oc adm router --replicas=0 --service-account=router $ oc set env dc/router ROUTER_ALLOW_WILDCARD_ROUTES=true $ oc scale dc/router --replicas=1엣지 보안 경로에 대한 개인 키, CSR(인증서 서명 요청) 및 인증서를 만듭니다.
이 작업을 수행하는 방법에 대한 지침은 인증 기관 및 공급자에 따라 다릅니다.
*.example.test라는 도메인의 간단한 자체 서명 인증서는 다음 예제를 참조하십시오.# sudo openssl genrsa -out example-test.key 2048 # # sudo openssl req -new -key example-test.key -out example-test.csr \ -subj "/C=US/ST=CA/L=Mountain View/O=OS3/OU=Eng/CN=*.example.test" # # sudo openssl x509 -req -days 366 -in example-test.csr \ -signkey example-test.key -out example-test.crt위의 인증서 및 키를 사용하여 와일드카드 경로를 생성합니다.
$ cat > route.yaml <<REOF apiVersion: v1 kind: Route metadata: name: my-service spec: host: www.example.test wildcardPolicy: Subdomain to: kind: Service name: my-service tls: termination: edge key: "$(perl -pe 's/\n/\\n/' example-test.key)" certificate: "$(perl -pe 's/\n/\\n/' example-test.cert)" REOF $ oc create -f route.yaml*.example.test에 대한 DNS 항목이 라우터 인스턴스를 가리키는지 확인하고 도메인의 경로를 사용할 수 있는지 확인합니다.이 예제에서는 로컬 확인자와 함께
curl을 사용하여 DNS 조회를 시뮬레이션합니다.# routerip="4.1.1.1" # replace with IP address of one of your router instances. # curl -k --resolve www.example.test:443:$routerip https://www.example.test/ # curl -k --resolve abc.example.test:443:$routerip https://abc.example.test/ # curl -k --resolve anyname.example.test:443:$routerip https://anyname.example.test/
와일드카드 경로(ROUTER_ALLOW_WILDCARD_ROUTES 가 true로 설정됨)를 허용하는 라우터의 경우 와일드카드 경로와 연결된 하위 도메인의 소유권에 대한 몇 가지 주의 사항이 있습니다.
와일드카드 경로 이전에는 다른 클레임에 대해 경로가 가장 오래된 네임스페이스를 사용하는 호스트 이름에 대한 소유권을 기반으로 했습니다. 예를 들어, 1. example.test 에 대한 클레임이 있는 네임스페이스 ns1 의 경로 r1은 경로 r2 가 경로 r 2보다 오래된 의 다른 경로 r경우 네임스페이스 ns22 에 대해 상이합니다.
또한 다른 네임스페이스의 경로는 오버레이되지 않은 호스트 이름을 요청할 수 있었습니다. 예를 들어 네임스페이스 ns1 의 routerone은 www.example.test 를 클레임하고 네임스페이스 d2 의 다른 경로 rtwo 는 c3po.example.test 를 클레임할 수 있습니다.
동일한 하위 도메인을 클레임하는 와일드카드 경로(위예제에서 example.test )가 없는 경우에도 마찬가지입니다.
그러나 와일드카드 경로는 하위 도메인(\ *.example.test 형식의 호스트 이름) 내의 모든 호스트 이름을 요청해야 합니다. 와일드카드 경로의 클레임은 해당 하위 도메인의 가장 오래된 경로(예.test)가 와일드카드 경로와 동일한 네임스페이스에 있는지 여부에 따라 허용 또는 거부됩니다. 가장 오래된 경로는 일반 경로 또는 와일드카드 경로일 수 있습니다.
예를 들어, owner.example.test 라는 호스트를 요청한 ns1 네임스페이스에 경로 eldest 가 이미 있고 나중에 해당 하위 도메인의 경로(예.test)에 요청하는 새 와일드카드 경로 와일드카드 경로가 추가된 경우 와일드카드 경로의 클레임은소유경로와 동일한 네임스페이스(ns1)인 경우에만 허용됩니다.
다음 예제에서는 와일드카드 경로 클레임이 성공 또는 실패하는 다양한 시나리오를 보여줍니다.
아래 예제에서 와일드카드 경로를 허용하는 라우터는 와일드카드 경로가 하위 도메인을 요청하지 않은 한 하위 도메인 example.test 에 있는 호스트에 대한 비 오버레이 클레임을 허용합니다.
$ oc adm router ...
$ oc set env dc/router ROUTER_ALLOW_WILDCARD_ROUTES=true
$ oc project ns1
$ oc expose service myservice --hostname=owner.example.test
$ oc expose service myservice --hostname=aname.example.test
$ oc expose service myservice --hostname=bname.example.test
$ oc project ns2
$ oc expose service anotherservice --hostname=second.example.test
$ oc expose service anotherservice --hostname=cname.example.test
$ oc project otherns
$ oc expose service thirdservice --hostname=emmy.example.test
$ oc expose service thirdservice --hostname=webby.example.test
아래 예제에서 와일드카드 경로를 허용하는 라우터에서는 소유자.example.test 또는 소유 네임스페이스는 aname.example.example.test 에 대한 클레임을 성공적으로 허용하지 않습니다.ns1 입니다.
$ oc adm router ...
$ oc set env dc/router ROUTER_ALLOW_WILDCARD_ROUTES=true
$ oc project ns1
$ oc expose service myservice --hostname=owner.example.test
$ oc expose service myservice --hostname=aname.example.test
$ oc project ns2
$ oc expose service secondservice --hostname=bname.example.test
$ oc expose service secondservice --hostname=cname.example.test
$ # Router will not allow this claim with a different path name `/p1` as
$ # namespace `ns1` has an older route claiming host `aname.example.test`.
$ oc expose service secondservice --hostname=aname.example.test --path="/p1"
$ # Router will not allow this claim as namespace `ns1` has an older route
$ # claiming host name `owner.example.test`.
$ oc expose service secondservice --hostname=owner.example.test
$ oc project otherns
$ # Router will not allow this claim as namespace `ns1` has an older route
$ # claiming host name `aname.example.test`.
$ oc expose service thirdservice --hostname=aname.example.test
아래 예제에서 와일드카드 경로를 허용하는 라우터를 사용하면 소유 네임스페이스가 ns1 이고 와일드카드 경로는 동일한 네임스페이스에 속하므로 '\*.example.test.test 클레임이 성공합니다.
$ oc adm router ...
$ oc set env dc/router ROUTER_ALLOW_WILDCARD_ROUTES=true
$ oc project ns1
$ oc expose service myservice --hostname=owner.example.test
$ # Reusing the route.yaml from the previous example.
$ # spec:
$ # host: www.example.test
$ # wildcardPolicy: Subdomain
$ oc create -f route.yaml # router will allow this claim.
아래 예에서 와일드카드 경로를 허용하는 라우터에서는 소유 네임스페이스가 ns1 이고 와일드카드 경로는 다른 네임 스페이스에 속하므로 '\*.example.test.test에 대한 클레임이 성공하지 못합니다 .
$ oc adm router ...
$ oc set env dc/router ROUTER_ALLOW_WILDCARD_ROUTES=true
$ oc project ns1
$ oc expose service myservice --hostname=owner.example.test
$ # Switch to a different namespace/project.
$ oc project cyclone
$ # Reusing the route.yaml from a prior example.
$ # spec:
$ # host: www.example.test
$ # wildcardPolicy: Subdomain
$ oc create -f route.yaml # router will deny (_NOT_ allow) this claim.마찬가지로 와일드카드 경로가 있는 네임스페이스에서 하위 도메인을 요청하면 해당 네임스페이스 내 경로만 동일한 하위 도메인의 호스트를 요청할 수 있습니다.
아래 예제에서 와일드카드 경로가 subdomain example.test 인 네임스페이스 ns1 의 경로가 있으면 네임스페이스 ns1 의 경로만 동일한 하위 도메인의 호스트를 요청할 수 있습니다.
$ oc adm router ...
$ oc set env dc/router ROUTER_ALLOW_WILDCARD_ROUTES=true
$ oc project ns1
$ oc expose service myservice --hostname=owner.example.test
$ oc project otherns
$ # namespace `otherns` is allowed to claim for other.example.test
$ oc expose service otherservice --hostname=other.example.test
$ oc project ns1
$ # Reusing the route.yaml from the previous example.
$ # spec:
$ # host: www.example.test
$ # wildcardPolicy: Subdomain
$ oc create -f route.yaml # Router will allow this claim.
$ # In addition, route in namespace otherns will lose its claim to host
$ # `other.example.test` due to the wildcard route claiming the subdomain.
$ # namespace `ns1` is allowed to claim for deux.example.test
$ oc expose service mysecondservice --hostname=deux.example.test
$ # namespace `ns1` is allowed to claim for deux.example.test with path /p1
$ oc expose service mythirdservice --hostname=deux.example.test --path="/p1"
$ oc project otherns
$ # namespace `otherns` is not allowed to claim for deux.example.test
$ # with a different path '/otherpath'
$ oc expose service otherservice --hostname=deux.example.test --path="/otherpath"
$ # namespace `otherns` is not allowed to claim for owner.example.test
$ oc expose service yetanotherservice --hostname=owner.example.test
$ # namespace `otherns` is not allowed to claim for unclaimed.example.test
$ oc expose service yetanotherservice --hostname=unclaimed.example.test
아래 예제에서는 소유자 경로가 삭제되고 소유권이 네임스페이스 내에서 전달되는 다양한 시나리오가 표시되어 있습니다. 네임스페이스 ns1 에 호스트를 클레임하는 경로에는 eldest .example.test 가 있지만 해당 네임스페이스의 와일드카드 경로는 하위 도메인 example.test 를 요청할 수 있습니다. 호스트 eldest .example.test 의 경로가 삭제되면 다음 가장 오래된 경로 senior.example.test 가 가장 오래된 경로가 되며 다른 경로에는 영향을 주지 않습니다. 호스트 senior.example.test 의 경로가 삭제되면 가장 오래된 다음 경로 junior.example.test 가 가장 오래된 경로가 되고 와일드카드 경로 클레임자를 차단합니다.
$ oc adm router ...
$ oc set env dc/router ROUTER_ALLOW_WILDCARD_ROUTES=true
$ oc project ns1
$ oc expose service myservice --hostname=eldest.example.test
$ oc expose service seniorservice --hostname=senior.example.test
$ oc project otherns
$ # namespace `otherns` is allowed to claim for other.example.test
$ oc expose service juniorservice --hostname=junior.example.test
$ oc project ns1
$ # Reusing the route.yaml from the previous example.
$ # spec:
$ # host: www.example.test
$ # wildcardPolicy: Subdomain
$ oc create -f route.yaml # Router will allow this claim.
$ # In addition, route in namespace otherns will lose its claim to host
$ # `junior.example.test` due to the wildcard route claiming the subdomain.
$ # namespace `ns1` is allowed to claim for dos.example.test
$ oc expose service mysecondservice --hostname=dos.example.test
$ # Delete route for host `eldest.example.test`, the next oldest route is
$ # the one claiming `senior.example.test`, so route claims are unaffacted.
$ oc delete route myservice
$ # Delete route for host `senior.example.test`, the next oldest route is
$ # the one claiming `junior.example.test` in another namespace, so claims
$ # for a wildcard route would be affected. The route for the host
$ # `dos.example.test` would be unaffected as there are no other wildcard
$ # claimants blocking it.
$ oc delete route seniorservice3.2.20. 컨테이너 네트워크 스택 사용
OpenShift Container Platform 라우터는 컨테이너 내부에서 실행되며 기본 동작은 호스트의 네트워크 스택을 사용하는 것입니다(즉, 라우터 컨테이너가 실행되는 노드). 이 기본 동작은 원격 클라이언트의 네트워크 트래픽이 대상 서비스 및 컨테이너에 도달하기 위해 사용자 공간을 통해 여러 개의 홉을 수행하지 않아도 되므로 성능에 도움이 됩니다.
또한 이 기본 동작을 사용하면 라우터에서 노드의 IP 주소를 가져오는 대신 원격 연결의 실제 소스 IP 주소를 가져올 수 있습니다. 이 기능은 원래 IP를 기반으로 수신 규칙을 정의하고, 고정 세션을 지원하고, 다른 용도에서 트래픽을 모니터링하는 데 유용합니다.
이 호스트 네트워크 동작은 --host-network 라우터 명령줄 옵션으로 제어되며 기본 동작은 --host-network=true 를 사용하는 것과 동일합니다. 컨테이너 네트워크 스택을 사용하여 라우터를 실행하려면 라우터를 만들 때 --host-network=false 옵션을 사용합니다. 예를 들면 다음과 같습니다.
$ oc adm router --service-account=router --host-network=false내부적으로 라우터 컨테이너는 외부 네트워크가 라우터와 통신할 수 있도록 80 및 443 포트를 게시해야 합니다.
컨테이너 네트워크 스택으로 실행하면 라우터에서 연결의 소스 IP 주소가 실제 원격 IP 주소가 아니라 노드의 NATed IP 주소가 되도록 합니다.
다중 테넌트 네트워크 격리 를 사용하는 OpenShift Container Platform 클러스터에서 --host-network=false 옵션과 함께 기본이 아닌 네임스페이스의 라우터는 클러스터의 모든 경로를 로드하지만, 네트워크 격리로 인해 네임스페이스의 경로에 연결할 수 없습니다. host -network=true 옵션을 사용하면 경로에서 컨테이너 네트워크를 바이패스하고 클러스터의 모든 Pod에 액세스할 수 있습니다. 이 경우 격리가 필요한 경우 네임스페이스 전체에서 경로를 추가하지 마십시오.
3.2.21. 동적 구성 관리자 사용
동적 구성 관리자를 지원하도록 HAProxy 라우터를 구성할 수 있습니다.
동적 구성 관리자는 HAProxy를 다시 로드하지 않고도 특정 유형의 경로를 온라인으로 제공합니다. 경로 및 엔드포인트 추가|deletion|업데이트 와 같은 경로 및 엔드포인트 라이프사이클 이벤트를 처리합니다.
ROUTER_HAPROXY_CONFIG_MANAGER 환경 변수를 true 로 설정하여 동적 구성 관리자를 활성화합니다.
$ oc set env dc/<router_name> ROUTER_HAPROXY_CONFIG_MANAGER='true'동적 구성 관리자가 HAProxy를 동적으로 구성할 수 없는 경우 구성을 다시 작성하고 HAProxy 프로세스를 다시 로드합니다. 예를 들어 새 경로에 사용자 지정 시간 초과와 같은 사용자 지정 주석이 있거나 경로에 사용자 지정 TLS 구성이 필요한 경우입니다.
동적 구성은 사전 할당된 경로 및 백엔드 서버 풀과 함께 HAProxy 소켓 및 구성 API를 사용합니다. 경로 청사진을 사용하여 사전 할당된 경로 풀이 생성됩니다. 기본 청사진 집합은 사용자 지정 TLS 구성 및 통과 경로 없이 비보안 경로, 에지 보안 경로를 지원합니다.
재암호화 경로에는 사용자 지정 TLS 구성 정보가 필요하므로 동적 구성 관리자와 함께 사용하려면 추가 구성이 필요합니다.
ROUTER_BLUEPRINT_ROUTE_ NAMESPACE를 설정하고 선택적으로 ROUTER_BLUEPRINT_ 환경 변수를 설정하여 동적 구성 관리자가 사용할 수 있는 청사진을 확장합니다.
ROUTE_ LABELS
청사진 경로 네임스페이스의 모든 경로 또는 경로 레이블은 기본 청사진 세트와 유사한 사용자 지정 청사진으로 처리됩니다. 여기에는 사용자 정의 TLS 구성으로 사용자 정의 주석 또는 경로를 사용하는 재암호화 경로 또는 경로가 포함됩니다.
다음 절차에서는 세 개의 경로 오브젝트, 즉 reencrypt-blueprint, annotated- edge-blueprint 및 annotated- unsecured-blueprint 를 생성했다고 가정합니다. 다양한 경로 유형 오브젝트의 예는 경로 유형을 참조하십시오.
절차
새 프로젝트를 생성합니다.
$ oc new-project namespace_name새 경로를 만듭니다. 이 메서드는 기존 서비스를 노출합니다.
$ oc create route edge edge_route_name --key=/path/to/key.pem \ --cert=/path/to/cert.pem --service=<service> --port=8443경로에 레이블을 지정합니다.
$ oc label route edge_route_name type=route_label_1경로 오브젝트 정의에서 세 가지 다른 경로를 만듭니다. 모두
type=route_label_1 라벨을갖습니다.$ oc create -f reencrypt-blueprint.yaml $ oc create -f annotated-edge-blueprint.yaml $ oc create -f annotated-unsecured-blueprint.json경로에서 레이블을 제거하여 청사진 경로로 사용하지 않도록 할 수도 있습니다. 예를 들어
주석이 있는 비보안 청사진이 청사진 경로로 사용되지 않도록하려면 다음을 수행합니다.$ oc label route annotated-unsecured-blueprint type-블루프린트 풀에 사용할 새 라우터를 생성합니다.
$ oc adm router새 라우터의 환경 변수를 설정합니다.
$ oc set env dc/router ROUTER_HAPROXY_CONFIG_MANAGER=true \ ROUTER_BLUEPRINT_ROUTE_NAMESPACE=namespace_name \ ROUTER_BLUEPRINT_ROUTE_LABELS="type=route_label_1"type=route_label_1 라벨이 있는 네임스페이스 또는 프로젝트의 모든 경로를 처리하여 사용자 지정 청사진으로 사용할 수 있습니다.namespace_name해당
namespace_name에서 일반적으로와 같이 경로를 관리하여 청사진을 추가, 업데이트 또는 제거할 수도 있습니다. 동적 구성 관리자는 라우터가 경로 및서비스를 감시하는 방법과 유사하게.네임스페이스 namespace_name의경로변경 사항을 감시합니다사전 할당된 경로 및 백엔드 서버의 풀 크기는 기본값인
ROUTER_BLUEPRINT_ROUTE_POOL_SIZE와 기본값인5,기본값인ROUTER_MAX_DYNAMIC_SERVERS를 사용하여 제어할 수 있습니다. 또한 동적 구성 관리자의 변경 사항이 디스크에 커밋되는 빈도를 제어할 수 있습니다. 이 경우 HAProxy 구성을 다시 작성하고 HAProxy 프로세스가 다시 로드됩니다. 기본값은 1시간 또는 3600초 또는 동적 구성 관리자가 풀 공간이 부족할 때입니다.COMMIT_INTERVAL환경 변수는 다음 설정을 제어합니다.$ oc set env dc/router -c router ROUTER_BLUEPRINT_ROUTE_POOL_SIZE=20 \ ROUTER_MAX_DYNAMIC_SERVERS=3 COMMIT_INTERVAL=6h이 예제에서는 각 청사진 경로의 풀 크기를
20으로 늘리고, 동적 서버 수를3으로 줄이며, 커밋 간격을6시간으로 늘립니다.
3.2.22. 라우터 지표 노출
HAProxy 라우터 지표 는 기본적으로 외부 지표 수집 및 집계 시스템(예: Prometheus, statsd)에서 사용할 수 있도록 Prometheus 형식에 노출되거나 게시됩니다. 지표는 브라우저 또는 CSV 다운로드에서 볼 수 있도록 자체 HTML 형식으로 HAProxy 라우터 에서 직접 사용할 수도 있습니다. 이러한 지표에는 HAProxy 기본 지표 및 일부 컨트롤러 지표가 포함됩니다.
다음 명령을 사용하여 라우터를 생성할 때 OpenShift Container Platform에서는 기본적으로 1936년까지 통계 포트의 Prometheus 형식으로 지표를 사용할 수 있습니다.
$ oc adm router --service-account=routerPrometheus 형식의 원시 통계를 추출하려면 다음 명령을 실행합니다.
curl <user>:<password>@<router_IP>:<STATS_PORT>예를 들면 다음과 같습니다.
$ curl admin:sLzdR6SgDJ@10.254.254.35:1936/metrics라우터 서비스 주석에서 메트릭에 액세스하는 데 필요한 정보를 가져올 수 있습니다.
$ oc edit service <router-name> apiVersion: v1 kind: Service metadata: annotations: prometheus.io/port: "1936" prometheus.io/scrape: "true" prometheus.openshift.io/password: IImoDqON02 prometheus.openshift.io/username: adminprometheus.io/port는 기본적으로 1936년 통계 포트입니다. 액세스를 허용하도록 방화벽을 구성해야 할 수도 있습니다. 이전 사용자 이름 및 암호를 사용하여 지표에 액세스합니다. 경로는 /metrics 입니다.$ curl <user>:<password>@<router_IP>:<STATS_PORT> for example: $ curl admin:sLzdR6SgDJ@10.254.254.35:1936/metrics ... # HELP haproxy_backend_connections_total Total number of connections. # TYPE haproxy_backend_connections_total gauge haproxy_backend_connections_total{backend="http",namespace="default",route="hello-route"} 0 haproxy_backend_connections_total{backend="http",namespace="default",route="hello-route-alt"} 0 haproxy_backend_connections_total{backend="http",namespace="default",route="hello-route01"} 0 ... # HELP haproxy_exporter_server_threshold Number of servers tracked and the current threshold value. # TYPE haproxy_exporter_server_threshold gauge haproxy_exporter_server_threshold{type="current"} 11 haproxy_exporter_server_threshold{type="limit"} 500 ... # HELP haproxy_frontend_bytes_in_total Current total of incoming bytes. # TYPE haproxy_frontend_bytes_in_total gauge haproxy_frontend_bytes_in_total{frontend="fe_no_sni"} 0 haproxy_frontend_bytes_in_total{frontend="fe_sni"} 0 haproxy_frontend_bytes_in_total{frontend="public"} 119070 ... # HELP haproxy_server_bytes_in_total Current total of incoming bytes. # TYPE haproxy_server_bytes_in_total gauge haproxy_server_bytes_in_total{namespace="",pod="",route="",server="fe_no_sni",service=""} 0 haproxy_server_bytes_in_total{namespace="",pod="",route="",server="fe_sni",service=""} 0 haproxy_server_bytes_in_total{namespace="default",pod="docker-registry-5-nk5fz",route="docker-registry",server="10.130.0.89:5000",service="docker-registry"} 0 haproxy_server_bytes_in_total{namespace="default",pod="hello-rc-vkjqx",route="hello-route",server="10.130.0.90:8080",service="hello-svc-1"} 0 ...브라우저에서 메트릭을 가져오려면 다음을 수행합니다.
라우터 배포 구성 파일에서 다음 환경 변수를 삭제합니다.
$ oc edit dc router - name: ROUTER_LISTEN_ADDR value: 0.0.0.0:1936 - name: ROUTER_METRICS_TYPE value: haproxy라우터 준비 프로브를 패치하여 haproxy 라우터에서 현재 제공하는 활성 프로브와 동일한 경로를 사용합니다.
$ oc patch dc router -p '"spec": {"template": {"spec": {"containers": [{"name": "router","readinessProbe": {"httpGet": {"path": "/healthz"}}}]}}}'브라우저에서 다음 URL을 사용하여 stats 창을 시작합니다. 여기서
STATS_PORT값은 기본적으로1936입니다.http://admin:<Password>@<router_IP>:<STATS_PORT>URL에
;csv를 추가하여 CSV 형식으로 통계를 가져올 수 있습니다.예를 들면 다음과 같습니다.
http://admin:<Password>@<router_IP>:1936;csv라우터 IP, 관리자 이름 및 암호를 가져오려면 다음을 수행합니다.
oc describe pod <router_pod>
메트릭 컬렉션을 비활성화하려면 다음을 수행합니다.
$ oc adm router --service-account=router --stats-port=0
3.2.23. 대규모 클러스터에 대한 ARP 캐시 튜닝
다수의 경로가 있는 OpenShift Container Platform 클러스터에서는 기본적으로 65536 인 net.ipv4.neigh.default.gc_thresh3 값보다 큰 경로가 있는 OpenShift Container Platform 클러스터에서 라우터 Pod를 실행하는 클러스터의 각 노드에서 sysctl 변수의 기본값을 늘려 ARP 캐시에 더 많은 항목을 허용해야 합니다.
문제가 발생하면 커널 메시지가 다음과 유사합니다.
[ 1738.811139] net_ratelimit: 1045 callbacks suppressed
[ 1743.823136] net_ratelimit: 293 callbacks suppressed
이 문제가 발생하면 oc 명령이 다음 오류로 인해 실패할 수 있습니다.
Unable to connect to the server: dial tcp: lookup <hostname> on <ip>:<port>: write udp <ip>:<port>-><ip>:<port>: write: invalid argumentIPv4의 실제 ARP 항목을 확인하려면 다음을 실행합니다.
# ip -4 neigh show nud all | wc -l
숫자가 net.ipv4.neigh.default.gc_thresh3 임계값에 접근하기 시작하면 값을 늘립니다. 다음을 실행하여 현재 값을 가져옵니다.
# sysctl net.ipv4.neigh.default.gc_thresh1
net.ipv4.neigh.default.gc_thresh1 = 128
# sysctl net.ipv4.neigh.default.gc_thresh2
net.ipv4.neigh.default.gc_thresh2 = 512
# sysctl net.ipv4.neigh.default.gc_thresh3
net.ipv4.neigh.default.gc_thresh3 = 1024다음 sysctl은 변수를 OpenShift Container Platform 현재 기본값으로 설정합니다.
# sysctl net.ipv4.neigh.default.gc_thresh1=8192
# sysctl net.ipv4.neigh.default.gc_thresh2=32768
# sysctl net.ipv4.neigh.default.gc_thresh3=65536이러한 설정을 영구적으로 설정하려면 이 문서를 참조하십시오.
3.2.24. 가상 공격에 대한 보호
DHCP http-request 를 기본 HAProxy 라우터 이미지에 추가하여 DDoS(Distributed-of-service) 공격(예: slowloris) 공격으로부터 배포를 보호합니다.
# and the haproxy stats socket is available at /var/run/haproxy.stats
global
stats socket ./haproxy.stats level admin
defaults
option http-server-close
mode http
timeout http-request 5s
timeout connect 5s
timeout server 10s
timeout client 30s- 1
- 시간 제한 http-request 가 최대 5초로 설정됩니다. HAProxy는 전체 HTTP 요청을 보낼 클라이언트 5초 *를 제공합니다. 그렇지 않으면 HAProxy가 *an 오류로 연결을 종료합니다.
또한 환경 변수 ROUTER_SLOWLORIS_TIMEOUT 이 설정되면 클라이언트가 전체 HTTP 요청을 보내야 하는 시간을 제한합니다. 그렇지 않으면 HAProxy가 연결을 종료합니다.
환경 변수를 설정하면 라우터 배포 구성의 일부로 정보를 캡처할 수 있으며 템플릿을 수동으로 수정할 필요가 없지만 HAProxy 설정을 수동으로 추가하려면 라우터 포드를 다시 빌드하고 라우터 템플릿 파일을 유지 관리해야 합니다.
주석을 사용하면 HAProxy 템플릿 라우터에서 다음을 제한하는 기능을 포함하여 기본 사항이 적용됩니다.
- 동시 TCP 연결 수
- 클라이언트가 TCP 연결을 요청할 수 있는 비율
- HTTP 요청을 작성할 수 있는 비율
애플리케이션은 트래픽 패턴이 매우 다를 수 있으므로 경로별로 활성화됩니다.
| 설정 | 설명 |
|---|---|
|
| 설정을 구성할 수 있습니다(예: true 로 설정된 경우). |
|
| 이 경로의 동일한 IP 주소로 만들 수 있는 동시 TCP 연결 수입니다. |
|
| 클라이언트 IP에서 열 수 있는 TCP 연결 수입니다. |
|
| 클라이언트 IP에서 3초 내에 생성할 수 있는 HTTP 요청 수입니다. |
3.2.25. HAProxy 스레드 활성화
--threads 플래그로 활성화된 스레드입니다. 이 플래그는 HAProxy 라우터에서 사용할 스레드 수를 지정합니다.
3.3. 사용자 지정된 HAProxy 라우터 배포
3.3.1. 개요
기본 HAProxy 라우터는 대부분의 사용자의 요구 사항을 충족하기 위한 것입니다. 그러나 HAProxy의 모든 기능을 노출하지는 않습니다. 따라서 사용자가 자신의 요구에 맞게 라우터를 수정해야 할 수 있습니다.
애플리케이션 백엔드 내에서 새 기능을 구현하거나 현재 작업을 수정해야 할 수 있습니다. 라우터 플러그인은 이 사용자 지정에 필요한 모든 기능을 제공합니다.
라우터 포드는 템플릿 파일을 사용하여 필요한 HAProxy 구성 파일을 생성합니다. 템플릿 파일은 golang 템플릿 입니다. 템플릿을 처리할 때 라우터는 라우터의 배포 구성, 허용된 경로 집합 및 일부 도우미 기능을 포함하여 OpenShift Container Platform 정보에 액세스할 수 있습니다.
라우터 포드가 시작되고 다시 로드될 때마다 HAProxy 구성 파일을 생성한 다음 HAProxy를 시작합니다. HAProxy 구성 설명서 에서는 HAProxy의 모든 기능과 유효한 구성 파일을 구성하는 방법을 설명합니다.
configMap 을 사용하여 라우터 Pod에 새 템플릿을 추가할 수 있습니다. 이 방법을 사용하면 configMap 을 라우터 Pod의 볼륨으로 마운트하도록 라우터 배포 구성이 수정되었습니다. TEMPLATE_FILE 환경 변수는 라우터 포드에서 템플릿 파일의 전체 경로 이름으로 설정됩니다.
OpenShift Container Platform을 업그레이드한 후에도 라우터 템플릿 사용자 정의가 계속 작동하는지 보장하지 않습니다.
또한 라우터 템플릿 사용자 지정을 실행 중인 라우터의 템플릿 버전에 적용해야 합니다.
또는 사용자 지정 라우터 이미지를 빌드하여 일부 또는 전체 라우터를 배포할 때 사용할 수 있습니다. 모든 라우터에서 동일한 이미지를 실행할 필요가 없습니다. 이렇게 하려면 haproxy-template.config 파일을 수정하고 라우터 이미지를 다시 빌드 합니다. 새 이미지는 클러스터의 Docker 리포지토리로 푸시되고 라우터의 배포 구성 이미지: 필드가 새 이름으로 업데이트됩니다. 클러스터가 업데이트되면 이미지를 다시 빌드하고 푸시해야 합니다.
두 경우 모두 라우터 포드는 템플릿 파일로 시작합니다.
3.3.2. 라우터 구성 템플릿 가져오기
HAProxy 템플릿 파일은 상당히 크고 복잡합니다. 일부 변경의 경우 전체 교체를 작성하지 않고 기존 템플릿을 수정하는 것이 더 쉬울 수 있습니다. 라우터 Pod를 참조하여 master에서 이를 실행하여 실행 중인 라우터에서 haproxy-config.template 파일을 가져올 수 있습니다.
# oc get po
NAME READY STATUS RESTARTS AGE
router-2-40fc3 1/1 Running 0 11d
# oc exec router-2-40fc3 cat haproxy-config.template > haproxy-config.template
# oc exec router-2-40fc3 cat haproxy.config > haproxy.config또는 라우터를 실행 중인 노드에 로그인할 수도 있습니다.
# docker run --rm --interactive=true --tty --entrypoint=cat \
registry.redhat.io/openshift3/ose-haproxy-router:v{product-version} haproxy-config.template이미지 이름은 컨테이너 이미지의 입니다.
사용자 지정된 템플릿의 기반으로 사용할 수 있도록 이 콘텐츠를 파일에 저장합니다. 저장된 haproxy.config 는 실제로 실행 중인 항목을 표시합니다.
3.3.3. 라우터 구성 템플릿 수정
3.3.3.1. 배경
템플릿은 golang 템플릿 을 기반으로 합니다. 라우터 배포 구성의 환경 변수, 아래 설명된 모든 구성 정보 및 라우터 제공 도우미 기능을 참조할 수 있습니다.
템플릿 파일의 구조가 생성된 HAProxy 구성 파일을 미러링합니다. 템플릿이 처리되면 {{"으로 묶지 않는 모든 것이 구성 파일에 직접 복사됩니다. {{'로 묶인 문구는 "}}" 에 대해 평가됩니다. 결과 텍스트(있는 경우)가 구성 파일에 복사됩니다.
3.3.3.2. Go Template Actions
는 처리된 템플릿을 포함할 파일의 이름을 정의합니다.
{{define "/var/lib/haproxy/conf/haproxy.config"}}pipeline{{end}}| 함수 | 의미 |
|---|---|
|
| 유효한 엔드포인트 목록을 반환합니다. 작업이 "축소"되면 끝점 순서가 임의화됩니다. |
|
| 포드에서 명명된 환경 변수를 가져옵니다. 정의되지 않았거나 비어 있지 않은 경우 선택적 두 번째 인수를 반환합니다. 그렇지 않으면 빈 문자열을 반환합니다. |
|
| 첫 번째 인수는 정규 표현식이 포함된 문자열이며, 두 번째 인수는 테스트할 변수입니다. 첫 번째 인수로 제공된 정규 표현식이 두 번째 인수로 제공된 문자열과 일치하는지 여부를 나타내는 부울 값을 반환합니다. |
|
| 지정된 변수가 정수인지 여부를 결정합니다. |
|
| 지정된 문자열을 허용된 문자열 목록과 비교합니다. 목록을 통해 첫 번째 일치 스캔을 오른쪽으로 반환합니다. |
|
| 지정된 문자열을 허용된 문자열 목록과 비교합니다. 문자열이 허용된 값인 경우 "true"를 반환하고, 그렇지 않으면 false를 반환합니다. |
|
| 경로 호스트(및 경로)와 일치하는 정규식을 생성합니다. 첫 번째 인수는 호스트 이름, 두 번째 인수는 경로이며, 세 번째 인수는 와일드카드 부울입니다. |
|
| 인증서 제공/결합에 사용할 호스트 이름을 생성합니다. 첫 번째 인수는 호스트 이름이고 두 번째 인수는 와일드카드 부울입니다. |
|
| 주어진 변수에 "true"가 포함되어 있는지 확인합니다. |
이러한 기능은 HAProxy 템플릿 라우터 플러그인에서 제공합니다.
3.3.3.3. 라우터 제공 정보
이 섹션에서는 템플릿에서 라우터를 사용할 수 있도록 하는 OpenShift Container Platform 정보를 검토합니다. 라우터 구성 매개 변수는 HAProxy 라우터 플러그인이 제공되는 데이터 집합입니다. 필드는 (점) .Fieldname 을 통해 액세스합니다.
라우터 구성 매개 변수 아래의 테이블은 다양한 필드의 정의에서 확장됩니다. 특히 .State 에는 허용된 경로 집합이 있습니다.
| 필드 | 유형 | 설명 |
|---|---|---|
|
| string | 파일이 작성될 디렉토리, 기본값은 /var/lib/containers/router입니다. |
|
|
| 경로. |
|
|
| 서비스 조회. |
|
| string | pem 형식의 기본 인증서의 전체 경로 이름입니다. |
|
|
| 동료. |
|
| string | 통계를 표시할 사용자 이름(템플릿에서 지원하는 경우). |
|
| string | 로 통계를 표시할 암호입니다(템플릿에서 지원하는 경우). |
|
| int | 로 통계를 노출할 포트입니다(템플릿에서 지원하는 경우). |
|
| 부울 | 라우터가 기본 포트를 바인딩해야 하는지 여부입니다. |
| 필드 | 유형 | 설명 |
|---|---|---|
|
| string | 경로의 사용자 지정 이름입니다. |
|
| string | 경로의 네임스페이스입니다. |
|
| string |
호스트 이름입니다. 예: |
|
| string |
선택적 경로입니다. 예를 들어, |
|
|
| 이 백엔드에 대한 종료 정책은 매핑 파일 및 라우터 구성을 구동합니다. |
|
|
| 이 백엔드를 보호하는 데 사용되는 인증서입니다. 인증서 ID로 키됩니다. |
|
|
| 유지해야 하는 구성 상태를 나타냅니다. |
|
| string | 사용자가 노출하려는 포트를 나타냅니다. 비어 있는 경우 서비스에 대해 포트가 선택됩니다. |
|
|
|
에지 종료 경로에 대한 비보안 연결에 대해 원하는 동작을 나타냅니다. |
|
| string | 쿠키 ID를 모호하게 하는 데 사용되는 경로 + 네임스페이스 이름의 해시입니다. |
|
| 부울 | 와일드카드 지원이 필요한 이 서비스 유닛을 나타냅니다. |
|
|
| 이 경로에 연결된 주석입니다. |
|
|
| 이 경로를 지원하는 서비스 컬렉션으로 서비스 이름별로 키 지정되고 맵의 다른 항목과 관련하여 연결된 가중치에 대해 값 매겨집니다. |
|
| int |
가중치가 0이 아닌 |
ServiceAliasConfig 는 서비스의 경로입니다. 호스트 + 경로로 고유하게 식별됩니다. 기본 템플릿은 {{range $cfgIdx, $cfg := .State }} 를 사용하여 경로를 반복합니다. 이러한 {{range}} 블록 내에서 템플릿은 $cfg.Field 를 사용하여 현재 ServiceAliasConfig 의 모든 필드를 참조할 수 있습니다.
| 필드 | 유형 | 설명 |
|---|---|---|
|
| string |
name은 서비스 이름 + 네임스페이스에 해당합니다. |
|
|
| 서비스를 지원하는 엔드포인트입니다. 이는 라우터의 최종 백엔드 구현으로 변환됩니다. |
ServiceUnit 은 서비스 캡슐화, 해당 서비스를 지원하는 엔드포인트, 서비스를 가리키는 경로입니다. 라우터 구성 파일을 생성하도록 지원하는 데이터입니다.
| 필드 | 유형 |
|---|---|
|
| string |
|
| string |
|
| string |
|
| string |
|
| string |
|
| string |
|
| 부울 |
엔드포인트 는 Kubernetes 엔드포인트의 내부 표현입니다.
| 필드 | 유형 | 설명 |
|---|---|---|
|
| string |
공개/개인 키 쌍을 나타냅니다. ID로 식별되며 파일 이름이 됩니다. CA 인증서에는 |
|
| string | 이 구성에 필요한 파일이 디스크에 지속되었음을 나타냅니다. 유효한 값: "saved", "". |
| 필드 | 유형 | 설명 |
|---|---|---|
| ID | string | |
| 내용 | string | 인증서입니다. |
| PrivateKey | string | 개인 키입니다. |
| 필드 | 유형 | 설명 |
|---|---|---|
|
| string | 보안 통신을 중지할 위치를 지정합니다. |
|
| string | 안전하지 않은 경로 연결에 대해 원하는 동작을 나타냅니다. 각 라우터에서 노출할 포트를 자체적으로 결정할 수 있지만 일반적으로 포트 80입니다. |
TLSTerminationType 및 InsecureEdgeTerminationPolicyType 은 보안 통신을 중지할 위치를 지정합니다.
| 상수 | 현재의 | 의미 |
|---|---|---|
|
|
| 에지 라우터에서 암호화를 종료합니다. |
|
|
| 대상에서 암호화를 종료하면 대상에서 트래픽의 암호를 해독합니다. |
|
|
| 에지 라우터에서 암호화를 종료하고 대상에서 제공하는 새 인증서로 다시 암호화합니다. |
| 유형 | 의미 |
|---|---|
|
| 트래픽은 비보안 포트의 서버로 전송됩니다(기본값). |
|
| 비보안 포트에는 트래픽이 허용되지 않습니다. |
|
| 클라이언트는 보안 포트로 리디렉션됩니다. |
none(")은 Disable (비활성화)과 동일합니다.
3.3.3.4. 주석
각 경로에는 주석이 연결될 수 있습니다. 각 주석은 이름과 값일 뿐입니다.
apiVersion: v1
kind: Route
metadata:
annotations:
haproxy.router.openshift.io/timeout: 5500ms
[...]
이름은 기존 주석과 충돌하지 않는 항목이 될 수 있습니다. 값은 모든 문자열입니다. 문자열에는 공백으로 구분된 여러 개의 토큰이 있을 수 있습니다. 예를 들면 aa bb cc 입니다. 템플릿은 {{index}} 을 사용하여 주석 값을 추출합니다. 예를 들면 다음과 같습니다.
{{$balanceAlgo := index $cfg.Annotations "haproxy.router.openshift.io/balance"}}이는 상호 클라이언트 권한 부여에 이를 사용하는 방법의 예입니다.
{{ with $cnList := index $cfg.Annotations "whiteListCertCommonName" }}
{{ if ne $cnList "" }}
acl test ssl_c_s_dn(CN) -m str {{ $cnList }}
http-request deny if !test
{{ end }}
{{ end }}그런 다음 이 명령을 사용하여 화이트리스트 CN을 처리할 수 있습니다.
$ oc annotate route <route-name> --overwrite whiteListCertCommonName="CN1 CN2 CN3"자세한 내용은 경로별 주석 을 참조하십시오.
3.3.3.5. 환경 변수
템플릿은 라우터 포드에 존재하는 모든 환경 변수를 사용할 수 있습니다. 환경 변수는 배포 구성에서 설정할 수 있습니다. 새 환경 변수를 추가할 수 있습니다.
env 기능은 참조합니다.
{{env "ROUTER_MAX_CONNECTIONS" "20000"}}
첫 번째 문자열은 변수이며, 두 번째 문자열은 변수가 누락되거나 nil 이 없을 때 기본값입니다. ROUTER_MAX_CONNECTIONS 가 설정되지 않았거나 nil 인 경우 20000이 사용됩니다. 환경 변수는 키가 환경 변수 이름이고 콘텐츠가 변수의 값인 맵입니다.
자세한 내용은 경로별 환경 변수를 참조하십시오.
3.3.3.6. 사용 예
다음은 HAProxy 템플릿 파일을 기반으로 하는 간단한 템플릿입니다.
코멘트로 시작하십시오.
{{/*
Here is a small example of how to work with templates
taken from the HAProxy template file.
*/}}템플릿에서 원하는 수의 출력 파일을 만들 수 있습니다. define 구문을 사용하여 출력 파일을 만듭니다. 파일 이름은 정의할 인수로 지정되며, 내부에 있는 블록은 일치하는 끝까지 모두 파일의 내용으로 작성됩니다.
{{ define "/var/lib/haproxy/conf/haproxy.config" }}
global
{{ end }}
위의 는 global 을 /var/lib/haproxy/conf/haproxy.config 파일에 복사한 다음 파일을 닫습니다.
환경 변수를 기반으로 로깅을 설정합니다.
{{ with (env "ROUTER_SYSLOG_ADDRESS" "") }}
log {{.}} {{env "ROUTER_LOG_FACILITY" "local1"}} {{env "ROUTER_LOG_LEVEL" "warning"}}
{{ end }}
env 함수는 환경 변수의 값을 추출합니다. 환경 변수가 정의되지 않았거나 nil 이 없으면 두 번째 인수가 반환됩니다.
with 구문을 사용하여 블록 내에서 "."( 점)의 값을 와 함께 에 인수로 제공됩니다. 를 사용하여 nil 에 대한 Dot를 테스트합니다. nil 이 아니면 절이 종료 까지 처리됩니다. 위의 경우 ROUTER_SYSLOG_ADDRESS 에 /var/log/msg, ROUTER_LOG_FACILITY 가 정의되지 않은 경우 ROUTER_LOG_LEVEL 에 info 가 포함되어 있다고 가정합니다. 다음은 출력 파일에 복사됩니다.
log /var/log/msg local1 info
허용되는 각 경로는 구성 파일에서 행 생성을 종료합니다. 범위를 사용하여 허용된 경로를 통과합니다.
{{ range $cfgIdx, $cfg := .State }}
backend be_http_{{$cfgIdx}}
{{end}}
.state 는 ServiceAliasConfig 의 맵입니다. 키는 경로 이름입니다. 범위는 맵을 통과하며, 통과할 때마다 키로 $cfgIdx 를 설정하고 경로를 설명하는 ServiceAliasConfig 를 가리키도록 $cfg Idx를 설정합니다. myroute 라는 두 개의 경로와 hisroute 가 있는 경우 위의 경로는 다음을 출력 파일에 복사합니다.
backend be_http_myroute
backend be_http_hisroute
Route Annotations, $cfg.Annotations 는 주석 이름이 키이고 content 문자열이 값으로 있는 맵이기도 합니다. 경로에는 원하는 만큼 많은 주석이 있을 수 있으며, 이 사용은 템플릿 작성자가 정의합니다. 사용자는 주석을 경로에 코딩하고 템플릿 작성자는 주석을 처리하도록 HAProxy 템플릿을 사용자 지정합니다.
일반적인 사용은 주석을 인덱싱하여 값을 가져오는 것입니다.
{{$balanceAlgo := index $cfg.Annotations "haproxy.router.openshift.io/balance"}}
인덱스는 지정된 주석에 대한 값을 추출합니다(있는 경우). 따라서 $balanceAlgo 에는 주석 또는 nil 과 연결된 문자열이 포함됩니다. 위와 같이nil 이 아닌 문자열을 테스트하고 구문을 사용하여 해당 문자열을 작동할 수 있습니다.
{{ with $balanceAlgo }}
balance $balanceAlgo
{{ end }}
여기서 $balanceAlgo 가 nil 이 아닌 경우$balanceAlgo 가 출력 파일에 복사됩니다.
두 번째 예에서 주석에 설정된 시간 제한 값에 따라 서버 시간 초과를 설정합니다.
$value := index $cfg.Annotations "haproxy.router.openshift.io/timeout"
이제 $ 값을 평가하여 올바르게 구성된 문자열이 포함되어 있는지 확인할 수 있습니다. matchPattern 함수는 정규 표현식을 수락하고 인수가 표현식을 만족하는 경우 true 를 반환합니다.
matchPattern "[1-9][0-9]*(us\|ms\|s\|m\|h\|d)?" $value
이 경우 5000ms 가 허용되지만 7y 는 허용되지 않습니다. 결과는 테스트에서 사용할 수 있습니다.
{{if (matchPattern "[1-9][0-9]*(us\|ms\|s\|m\|h\|d)?" $value) }}
timeout server {{$value}}
{{ end }}토큰과 일치시키는 데 사용할 수도 있습니다.
matchPattern "roundrobin|leastconn|source" $balanceAlgo
또는 matchValues 를 사용하여 토큰과 일치시킬 수 있습니다.
matchValues $balanceAlgo "roundrobin" "leastconn" "source"3.3.4. ConfigMap을 사용하여 라우터 구성 템플릿 교체
ConfigMap 을 사용하여 라우터 이미지를 다시 빌드하지 않고 라우터 인스턴스를 사용자 지정할 수 있습니다. haproxy-config.template, reload-haproxy 및 기타 스크립트는 라우터 환경 변수 생성 및 수정뿐만 아니라 수정할 수 있습니다.
- 위에서 설명한 대로 수정할 haproxy-config.template 을 복사합니다. 원하는 대로 수정합니다.
ConfigMap을 생성합니다.
$ oc create configmap customrouter --from-file=haproxy-config.templatecustomrouterConfigMap에 수정된 haproxy-config.template 파일의 사본이 포함됩니다.ConfigMap을 파일로 마운트하고
TEMPLATE_FILE환경 변수를 가리키도록 라우터 배포 구성을 수정합니다. 이 작업은oc set env및oc set volume명령을 사용하거나 라우터 배포 구성을 편집하여 수행할 수 있습니다.oc명령 사용$ oc set volume dc/router --add --overwrite \ --name=config-volume \ --mount-path=/var/lib/haproxy/conf/custom \ --source='{"configMap": { "name": "customrouter"}}' $ oc set env dc/router \ TEMPLATE_FILE=/var/lib/haproxy/conf/custom/haproxy-config.template- 라우터 배포 구성 편집
oc edit dc 라우터를 사용하여 텍스트 편집기로 라우터 배포 구성을 편집합니다.... - name: STATS_USERNAME value: admin - name: TEMPLATE_FILE1 value: /var/lib/haproxy/conf/custom/haproxy-config.template image: openshift/origin-haproxy-routerp ... terminationMessagePath: /dev/termination-log volumeMounts:2 - mountPath: /var/lib/haproxy/conf/custom name: config-volume dnsPolicy: ClusterFirst ... terminationGracePeriodSeconds: 30 volumes:3 - configMap: name: customrouter name: config-volume ...변경 사항을 저장하고 편집기를 종료합니다. 그러면 라우터가 다시 시작됩니다.
3.3.5. 스틱 테이블 사용
다음 예제 사용자 지정은 고가용성 라우팅 설정에서 사용하여 피어 간에 동기화되는 고정 테이블을 사용할 수 있습니다.
피어 섹션 추가
피어 간에 고정 테이블을 동기화하려면 HAProxy 구성에 peers 섹션을 정의해야 합니다. 이 섹션에서는 HAProxy가 피어를 식별하고 연결하는 방법을 결정합니다. 플러그인은 .PeerEndpoints 변수 아래의 템플릿에 데이터를 제공하여 라우터 서비스의 멤버를 쉽게 식별할 수 있도록 합니다. 다음을 추가하여 라우터 이미지 내의 haproxy-config.template 파일에 peer 섹션을 추가할 수 있습니다.
{{ if (len .PeerEndpoints) gt 0 }}
peers openshift_peers
{{ range $endpointID, $endpoint := .PeerEndpoints }}
peer {{$endpoint.TargetName}} {{$endpoint.IP}}:1937
{{ end }}
{{ end }}다시 로드 스크립트 변경
stick-tables를 사용하는 경우 HAProxy에 peer 섹션의 로컬 호스트 이름을 고려해야 하는 사항을 지시하는 옵션이 있습니다. 엔드포인트를 만들 때 플러그인은 TargetName 을 엔드포인트의 TargetRef.Name 값으로 설정합니다. TargetRef 를 설정하지 않으면 TargetName 을 IP 주소로 설정합니다. TargetRef.Name 은 Kubernetes 호스트 이름에 해당하므로, -L 옵션을 reload-haproxy 스크립트에 추가하여 피어 섹션에서 로컬 호스트를 식별할 수 있습니다.
peer_name=$HOSTNAME
if [ -n "$old_pid" ]; then
/usr/sbin/haproxy -f $config_file -p $pid_file -L $peer_name -sf $old_pid
else
/usr/sbin/haproxy -f $config_file -p $pid_file -L $peer_name
fi- 1
- 피어 섹션에서 사용되는 엔드포인트 대상 이름과 일치해야 합니다.
백엔드 수정
마지막으로 백엔드 내에서 고정 테이블을 사용하려면 HAProxy 구성을 수정하여 stick-tables 및 peer 세트를 사용할 수 있습니다. 다음은 고정 테이블을 사용하도록 TCP 연결의 기존 백엔드를 변경하는 예입니다.
{{ if eq $cfg.TLSTermination "passthrough" }}
backend be_tcp_{{$cfgIdx}}
balance leastconn
timeout check 5000ms
stick-table type ip size 1m expire 5m{{ if (len $.PeerEndpoints) gt 0 }} peers openshift_peers {{ end }}
stick on src
{{ range $endpointID, $endpoint := $serviceUnit.EndpointTable }}
server {{$endpointID}} {{$endpoint.IP}}:{{$endpoint.Port}} check inter 5000ms
{{ end }}
{{ end }}이 수정 후 라우터를 다시 빌드할 수 있습니다.
3.3.6. 라우터 다시 빌드
라우터를 다시 빌드하려면 실행 중인 라우터에 있는 여러 파일의 복사본이 필요합니다. 작업 디렉토리를 만들고 라우터에서 파일을 복사합니다.
# mkdir - myrouter/conf
# cd myrouter
# oc get po
NAME READY STATUS RESTARTS AGE
router-2-40fc3 1/1 Running 0 11d
# oc exec router-2-40fc3 cat haproxy-config.template > conf/haproxy-config.template
# oc exec router-2-40fc3 cat error-page-503.http > conf/error-page-503.http
# oc exec router-2-40fc3 cat default_pub_keys.pem > conf/default_pub_keys.pem
# oc exec router-2-40fc3 cat ../Dockerfile > Dockerfile
# oc exec router-2-40fc3 cat ../reload-haproxy > reload-haproxy이러한 파일을 편집하거나 바꿀 수 있습니다. 그러나 conf/haproxy-config.template 및 reload-haproxy 가 수정될 가능성이 가장 높습니다.
파일을 업데이트한 후 다음을 수행합니다.
# docker build -t openshift/origin-haproxy-router-myversion .
# docker tag openshift/origin-haproxy-router-myversion 172.30.243.98:5000/openshift/haproxy-router-myversion
# docker push 172.30.243.98:5000/openshift/origin-haproxy-router-pc:latest
새 라우터를 사용하려면 image: 문자열을 변경하거나 oc adm router 명령에 배포 구성을 편집합니다.
--images=<repo>/<image>:<tag> 플래그를 추가하여 라우터
변경 사항을 디버깅할 때 imagePullPolicy를 설정하는 것이 좋습니다. always 배포 구성에서 각 Pod 생성 시 이미지를 강제로 가져옵니다. 디버깅이 완료되면 imagePullPolicy로 다시 변경할 수 있습니다. ifNotPresent 각 Pod에서 풀을 시작하지 않도록 합니다.
3.4. PROXY 프로토콜을 사용하도록 HAProxy 라우터 구성
3.4.1. 개요
기본적으로 HAProxy 라우터에서는 HTTP를 사용하도록 들어오는 연결이 안전하지 않은 에지 및 재암호화 경로에 대해 예상합니다. 그러나 PROXY 프로토콜을 사용하여 들어오는 요청을 예상하도록 라우터를 구성할 수 있습니다. 이 주제에서는 PROXY 프로토콜을 사용하도록 HAProxy 라우터 및 외부 로드 밸런서를 구성하는 방법에 대해 설명합니다.
3.4.2. PROXY 프로토콜을 사용하는 이유는 무엇입니까?
프록시 서버 또는 로드 밸런서와 같은 중간 서비스에서 HTTP 요청을 전달하는 경우 이 정보를 후속 중간 및 궁극적으로 요청이 전달되는 백엔드 서비스에 제공하기 위해 요청의 "Forwarded" 헤더에 연결의 소스 주소를 추가합니다. 그러나 연결이 암호화되면 중간자는 "Forwarded" 헤더를 수정할 수 없습니다. 이 경우 HTTP 헤더는 요청이 전달될 때 원래 소스 주소를 정확하게 전달하지 않습니다.
이 문제를 해결하기 위해 일부 로드 밸런서는 PROXY 프로토콜을 사용하여 HTTP 요청을 단순히 HTTP 전달을 위한 대안으로 캡슐화합니다. 캡슐화를 사용하면 전달된 요청 자체를 수정하지 않고도 로드 밸런서에서 요청에 정보를 추가할 수 있습니다. 특히, 이는 암호화된 연결을 전달할 때도 로드 밸런서에서 소스 주소를 통신할 수 있음을 의미합니다.
HAProxy 라우터는 PROXY 프로토콜을 수락하고 HTTP 요청을 분리하도록 구성할 수 있습니다. 라우터는 에지 및 재암호화 경로의 암호화를 종료하므로 라우터는 요청에서 "Forwarded" HTTP 헤더(및 관련 HTTP 헤더)를 업데이트하여 PROXY 프로토콜을 사용하여 통신하는 모든 소스 주소를 추가할 수 있습니다.
PROXY 프로토콜과 HTTP는 호환되지 않으며 혼합할 수 없습니다. 라우터 앞의 로드 밸런서를 사용하는 경우 둘 다 PROXY 프로토콜 또는 HTTP를 사용해야 합니다. 하나의 프로토콜을 사용하도록 구성하면 다른 프로토콜을 사용하도록 다른 프로토콜을 사용하면 라우팅이 실패합니다.
3.4.3. PROXY 프로토콜 사용
기본적으로 HAProxy 라우터에서는 PROXY 프로토콜을 사용하지 않습니다. 라우터는 들어오는 연결에 PROXY 프로토콜을 예상하도록 ROUTER_USE_PROXY_PROTOCOL 환경 변수를 사용하여 구성할 수 있습니다.
PROXY 프로토콜 활성화
$ oc set env dc/router ROUTER_USE_PROXY_PROTOCOL=true
PROXY 프로토콜을 비활성화하려면 변수를 true 또는 TRUE 이외의 값으로 설정합니다.
PROXY 프로토콜 비활성화
$ oc set env dc/router ROUTER_USE_PROXY_PROTOCOL=false라우터에서 PROXY 프로토콜을 활성화하는 경우 PROXY 프로토콜을 사용하도록 라우터 앞에 로드 밸런서를 구성해야 합니다. 다음은 PROXY 프로토콜을 사용하도록 Amazon의 ELB(Elastic Load Balancer) 서비스를 구성하는 예입니다. 이 예에서는 ELB가 포트 80(HTTP), 443(HTTPS) 및 5000(이미지 레지스트리의 경우)을 하나 이상의 EC2 인스턴스에서 실행되는 라우터로 전달한다고 가정합니다.
PROXY 프로토콜을 사용하도록 Amazon ELB 구성
후속 단계를 간소화하려면 먼저 몇 가지 쉘 변수를 설정합니다.
$ lb='infra-lb'1 $ instances=( 'i-079b4096c654f563c' )2 $ secgroups=( 'sg-e1760186' )3 $ subnets=( 'subnet-cf57c596' )4 그런 다음 적절한 리스너, 보안 그룹 및 서브넷을 사용하여 ELB를 만듭니다.
참고HTTP 프로토콜이 아닌 TCP 프로토콜을 사용하도록 모든 리스너를 구성해야 합니다.
$ aws elb create-load-balancer --load-balancer-name "$lb" \ --listeners \ 'Protocol=TCP,LoadBalancerPort=80,InstanceProtocol=TCP,InstancePort=80' \ 'Protocol=TCP,LoadBalancerPort=443,InstanceProtocol=TCP,InstancePort=443' \ 'Protocol=TCP,LoadBalancerPort=5000,InstanceProtocol=TCP,InstancePort=5000' \ --security-groups $secgroups \ --subnets $subnets { "DNSName": "infra-lb-2006263232.us-east-1.elb.amazonaws.com" }ELB에 라우터 인스턴스 또는 인스턴스를 등록합니다.
$ aws elb register-instances-with-load-balancer --load-balancer-name "$lb" \ --instances $instances { "Instances": [ { "InstanceId": "i-079b4096c654f563c" } ] }ELB의 상태 점검을 구성합니다.
$ aws elb configure-health-check --load-balancer-name "$lb" \ --health-check 'Target=HTTP:1936/healthz,Interval=30,UnhealthyThreshold=2,HealthyThreshold=2,Timeout=5' { "HealthCheck": { "HealthyThreshold": 2, "Interval": 30, "Target": "HTTP:1936/healthz", "Timeout": 5, "UnhealthyThreshold": 2 } }마지막으로
ProxyProtocol특성이 활성화된 로드 밸런서 정책을 생성하고 ELB의 TCP 포트 80 및 443에서 구성합니다.$ aws elb create-load-balancer-policy --load-balancer-name "$lb" \ --policy-name "${lb}-ProxyProtocol-policy" \ --policy-type-name 'ProxyProtocolPolicyType' \ --policy-attributes 'AttributeName=ProxyProtocol,AttributeValue=true' $ for port in 80 443 do aws elb set-load-balancer-policies-for-backend-server \ --load-balancer-name "$lb" \ --instance-port "$port" \ --policy-names "${lb}-ProxyProtocol-policy" done
설정 확인
다음과 같이 로드 밸런서를 검사하여 구성이 올바른지 확인할 수 있습니다.
$ aws elb describe-load-balancers --load-balancer-name "$lb" |
jq '.LoadBalancerDescriptions| [.[]|.ListenerDescriptions]'
[
[
{
"Listener": {
"InstancePort": 80,
"LoadBalancerPort": 80,
"Protocol": "TCP",
"InstanceProtocol": "TCP"
},
"PolicyNames": ["infra-lb-ProxyProtocol-policy"]
},
{
"Listener": {
"InstancePort": 443,
"LoadBalancerPort": 443,
"Protocol": "TCP",
"InstanceProtocol": "TCP"
},
"PolicyNames": ["infra-lb-ProxyProtocol-policy"]
},
{
"Listener": {
"InstancePort": 5000,
"LoadBalancerPort": 5000,
"Protocol": "TCP",
"InstanceProtocol": "TCP"
},
"PolicyNames": []
}
]
]또는 ELB가 이미 구성되어 있지만 PROXY 프로토콜을 사용하도록 구성되지 않은 경우 HTTP 대신 TCP 프로토콜을 사용하도록 기존 리스너를 변경해야 합니다(TCP 포트 443은 이미 TCP 프로토콜을 사용해야 함).
$ aws elb delete-load-balancer-listeners --load-balancer-name "$lb" \
--load-balancer-ports 80
$ aws elb create-load-balancer-listeners --load-balancer-name "$lb" \
--listeners 'Protocol=TCP,LoadBalancerPort=80,InstanceProtocol=TCP,InstancePort=80'프로토콜 업데이트 확인
다음과 같이 프로토콜이 업데이트되었는지 확인합니다.
$ aws elb describe-load-balancers --load-balancer-name "$lb" |
jq '[.LoadBalancerDescriptions[]|.ListenerDescriptions]'
[
[
{
"Listener": {
"InstancePort": 443,
"LoadBalancerPort": 443,
"Protocol": "TCP",
"InstanceProtocol": "TCP"
},
"PolicyNames": []
},
{
"Listener": {
"InstancePort": 5000,
"LoadBalancerPort": 5000,
"Protocol": "TCP",
"InstanceProtocol": "TCP"
},
"PolicyNames": []
},
{
"Listener": {
"InstancePort": 80,
"LoadBalancerPort": 80,
"Protocol": "TCP",
"InstanceProtocol": "TCP"
},
"PolicyNames": []
}
]
]- 1
- TCP 포트 80의 리스너를 포함한 모든 리스너는 TCP 프로토콜을 사용해야 합니다.
그런 다음 로드 밸런서 정책을 만들고 위의 5단계에 설명된 대로 ELB에 추가합니다.
4장. Red Hat CloudForms 배포
4.1. OpenShift Container Platform에 Red Hat CloudForms 배포
4.1.1. 소개
OpenShift Container Platform 설치 프로그램에는 OpenShift Container Platform에 Red Hat CloudForms 4.6(CloudForms Management Engine 5.9 또는 CFME)을 배포하기 위한 Ansible 역할 openshift-management 및 플레이북이 포함되어 있습니다.
현재 구현은 OpenShift Container Platform 3.6 설명서에 설명된 대로 Red Hat CloudForms 4.5의 기술 프리뷰 배포 프로세스와 호환되지 않습니다.
OpenShift Container Platform에 Red Hat CloudForms를 배포할 때 다음과 같은 두 가지 주요 결정을 내릴 수 있습니다.
- 외부 또는 컨테이너화된( 포드화된) PostgreSQL 데이터베이스를 원하십니까?
- PV(영구 볼륨)를 지원하는 스토리지 클래스는 무엇입니까?
첫 번째 결정에서는 Red Hat CloudForms가 사용할 PostgreSQL 데이터베이스의 위치에 따라 두 가지 방법 중 하나로 Red Hat CloudForms를 배포할 수 있습니다.
| 배포 변형 | 설명 |
|---|---|
| 완전히 컨테이너화된 | 모든 애플리케이션 서비스 및 PostgreSQL 데이터베이스는 OpenShift Container Platform에서 포드로 실행됩니다. |
| 외부 데이터베이스 | 애플리케이션은 외부 호스팅 PostgreSQL 데이터베이스 서버를 활용하는 반면, 다른 모든 서비스는 OpenShift Container Platform에서 포드로 실행됩니다. |
두 번째 결정을 위해 openshift-management 역할은 많은 기본 배포 매개 변수를 재정의하기 위한 사용자 지정 옵션을 제공합니다. 여기에는 PV를 백업하는 스토리지 클래스 옵션이 포함됩니다.
| 스토리지 클래스 | 설명 |
|---|---|
| NFS(기본값) | 클러스터의 로컬, |
| NFS 외부 | 스토리지 어플라이언스와 같은 다른 곳에 NFS |
| 클라우드 공급자 | 클라우드 공급자(Google Cloud Engine, Amazon Web Services 또는 Microsoft Azure)의 자동 스토리지 프로비저닝 사용 |
| 사전 구성 (고급) | 미리 모든 것을 생성했다고 가정합니다. |
이 가이드의 주제에는 OpenShift Container Platform에서 Red Hat CloudForms를 실행하기 위한 요구 사항, 사용 가능한 구성 변수에 대한 설명, 초기 OpenShift Container Platform 설치 중 또는 클러스터가 프로비저닝된 후 설치 프로그램 실행에 대한 지침이 포함되어 있습니다.
4.2. OpenShift Container Platform의 Red Hat CloudForms 요구 사항
기본 요구 사항은 아래 표에 나열되어 있습니다. 이러한 매개 변수는 템플릿 매개 변수를 사용자 지정하여 재정의할 수 있습니다.
이러한 요구 사항이 충족되지 않는 경우 애플리케이션 성능에 문제가 있거나 배포에 실패할 수도 있습니다.
| 항목 | 요구 사항 | 설명 | 사용자 정의 매개 변수 |
|---|---|---|---|
| 애플리케이션 메모리 | ✓ 4.0 GI | 애플리케이션에 필요한 최소 메모리 |
|
| 애플리케이션 스토리지 | ✓ 5.0 GI | 애플리케이션에 필요한 최소 PV 크기 |
|
| PostgreSQL 메모리 | ✓ 6.0 GI | 데이터베이스에 필요한 최소 메모리 |
|
| PostgreSQL Storage | ✓15.0 GI | 데이터베이스에 필요한 최소 PV 크기 |
|
| 클러스터 호스트 | ≥ 3 | 클러스터의 호스트 수 | 해당 없음 |
이러한 요구 사항을 요약하려면 다음을 수행합니다.
- 여러 클러스터 노드가 있어야 합니다.
- 클러스터 노드에는 사용 가능한 메모리가 많이 있어야 합니다.
- 로컬 또는 클라우드 공급자에 여러GiB의 스토리지를 사용할 수 있어야 합니다.
- 템플릿 매개 변수에 재정의 값을 제공하여 PV 크기를 변경할 수 있습니다.
4.3. 역할 변수 구성
4.3.1. 개요
다음 섹션에서는 설치 프로그램을 실행할 때 Red Hat CloudForms 설치 동작을 제어하는 데 사용되는 Ansible 인벤토리 파일에서 사용할 수 있는 역할 변수에 대해 설명합니다.
4.3.2. 일반 변수
| Variable | 필수 항목 | Default | 설명 |
|---|---|---|---|
|
| 없음 |
|
애플리케이션을 설치하려면 부울을 |
|
| 있음 |
|
설치할 Red Hat CloudForms의 배포 변형. 컨테이너화된 데이터베이스의 |
|
| 없음 |
| Red Hat CloudForms 설치를 위한 네임스페이스(프로젝트). |
|
| 없음 |
| 네임스페이스(프로젝트) 설명. |
|
| 없음 |
| 기본 관리 사용자 이름. 이 값을 변경해도 사용자 이름은 변경되지 않습니다. 이미 이름을 변경했으며 통합 스크립트(예: 컨테이너 공급업체 추가스크립트)를 실행 중인 경우에만 이 값을 변경합니다. |
|
| 없음 |
| 기본 관리 암호. 이 값을 변경해도 암호가 변경되지 않습니다. 이미 암호를 변경했으며 통합 스크립트(예: 컨테이너 공급업체 추가)를 실행 중인 경우에만 이 값을 변경합니다. |
4.3.3. 템플릿 매개변수 사용자 정의
openshift_management_template_parameters Ansible 역할 변수를 사용하여 애플리케이션 또는 PV 템플릿에서 재정의하려는 템플릿 매개변수를 지정할 수 있습니다.
예를 들어 PostgreSQL 포드의 메모리 요구 사항을 줄이려는 경우 다음을 설정할 수 있습니다.
openshift_management_template_parameters={'POSTGRESQL_MEM_REQ': '1Gi'}
Red Hat CloudForms 템플릿이 처리되면 POSTGRESQL_MEM_REQ 템플릿 매개변수 값에 1Gi 가 사용됩니다.
일부 템플릿 매개 변수가 두 템플릿 변형(컨테이너화된 또는 외부 데이터베이스)에 있는 것은 아닙니다. 예를 들어 podified 데이터베이스 템플릿에는 POSTGRESQL_MEM_REQ 매개 변수가 있지만 포드가 필요한 데이터베이스가 없기 때문에 이러한 매개 변수가 외부 db 템플릿에 존재하지 않습니다.
따라서 템플릿 매개 변수를 재정의하는 경우 주의하십시오. 템플릿에 정의되지 않은 매개 변수를 포함하면 오류가 발생합니다. Unsure the Management App is created 작업 중에 오류가 발생하면 설치 프로그램을 다시 실행하기 전에 제거 스크립트를 먼저 실행합니다.
4.3.4. 데이터베이스 변수
4.3.4.1. 컨테이너화된 (Podified) 데이터베이스
cfme-template.yaml 파일의 POSTGRES 템플릿 매개 변수는 인벤토리 파일의 _* 또는 DATABASE_*openshift_management_template_parameters 해시를 통해 사용자 지정할 수 있습니다.
4.3.4.2. 외부 데이터베이스
cfme-template-ext-db.yaml 파일의 POSTGRES 템플릿 매개 변수는 인벤토리 파일의 _* 또는 DATABASE_*openshift_management_template_parameters 해시를 통해 사용자 지정할 수 있습니다.
외부 PostgreSQL 데이터베이스를 사용하려면 데이터베이스 연결 매개 변수를 제공해야 합니다. 인벤토리의 openshift_management_template_parameters 매개변수에 필요한 연결 키를 설정해야 합니다. 다음 키가 필요합니다.
-
DATABASE_USER -
DATABASE_PASSWORD -
DATABASE_IP -
DATABASE_PORT(최대 PostgreSQL 서버는 포트5432에서 실행됩니다) -
DATABASE_NAME
외부 데이터베이스에서 PostgreSQL 9.5를 실행 중이거나 CloudForms 애플리케이션을 성공적으로 배포할 수 없는지 확인합니다.
인벤토리에는 다음과 유사한 행이 포함됩니다.
[OSEv3:vars]
openshift_management_app_template=cfme-template-ext-db
openshift_management_template_parameters={'DATABASE_USER': 'root', 'DATABASE_PASSWORD': 'mypassword', 'DATABASE_IP': '10.10.10.10', 'DATABASE_PORT': '5432', 'DATABASE_NAME': 'cfme'}- 1
openshift_management_app_template매개 변수를cfme-template-ext-db로 설정합니다.
4.3.5. 스토리지 클래스 변수
| Variable | 필수 항목 | Default | 설명 |
|---|---|---|---|
|
| 없음 |
|
사용할 스토리지 유형입니다. 옵션은 |
|
| 없음 |
|
NetApp 어플라이언스와 같은 외부 NFS 서버를 사용하는 경우 여기에 호스트 이름을 설정해야 합니다. 외부 NFS를 사용하지 않는 경우 값을 |
|
| 없음 |
| 외부 NFS를 사용하는 경우 내보내기 위치로 기본 경로를 설정할 수 있습니다. 로컬 NFS의 경우 로컬 NFS 내보내기에 사용되는 기본 경로를 변경하려면 이 값을 변경할 수도 있습니다. |
|
| 없음 |
|
인벤토리에 |
4.3.5.1. NFS(기본값)
NFS 스토리지 클래스는 개념 증명 및 테스트 배포에 가장 적합합니다. 배포를 위한 기본 스토리지 클래스이기도 합니다. 이 선택에는 추가 구성이 필요하지 않습니다.
이 스토리지 클래스는 클러스터 호스트에서 NFS를 구성합니다(기본적으로 인벤토리 파일의 첫 번째 마스터) 필수 PV를 백업하도록 합니다. 애플리케이션에는 PV가 필요하며 데이터베이스(외부에서 호스팅될 수 있음)에는 1초가 필요할 수 있습니다. PV의 최소 필수 크기는 Red Hat CloudForms 애플리케이션의 경우 5GiB이고 PostgreSQL 데이터베이스에는 15GiB입니다(NFS용으로 특별히 사용되는 경우 볼륨 또는 파티션에서 사용 가능한 최소 공간 20GiB).
사용자 지정은 다음 역할 변수를 통해 제공됩니다.
-
openshift_management_storage_nfs_base_dir -
openshift_management_storage_nfs_local_hostname
4.3.5.2. NFS 외부
외부 NFS는 필요한 PV에 내보내기를 제공하기 위해 사전 구성된 NFS 서버에 간결합니다. 외부 NFS의 경우 cfme-app 및 cfme-db (컨테이너 데이터베이스용) 내보내기가 있어야 합니다.
구성은 다음 역할 변수를 통해 제공됩니다.
-
openshift_management_storage_nfs_external_hostname -
openshift_management_storage_nfs_base_dir
openshift_management_storage_nfs_external_hostname 매개 변수를 외부 NFS 서버의 호스트 이름 또는 IP로 설정해야 합니다.
/exports 가 내보내기에 대한 상위 디렉터리가 아닌 경우 openshift_management_storage_nfs_base_dir 매개 변수를 통해 기본 디렉터리를 설정해야 합니다.
예를 들어 서버 내보내기가 /exports/hosted/prod/cfme-app 인 경우 openshift_management_storage_nfs_base_dir=/exports/hosted/prod 를 설정해야 합니다.
4.3.5.3. 클라우드 공급자
스토리지 클래스에 OpenShift Container Platform 클라우드 공급자 통합을 사용하는 경우 Red Hat CloudForms는 클라우드 공급자 스토리지를 사용하여 필요한 PV를 백업할 수도 있습니다. 이 기능이 작동하려면 선택한 클라우드 공급자와 관련된 openshift_cloudprovider_kind 변수(AWS 또는 GCE의 경우) 및 모든 관련 매개변수를 구성해야 합니다.
이 스토리지 클래스를 사용하여 애플리케이션이 생성되면 구성된 클라우드 프로바이더 스토리지 통합을 사용하여 필요한 PV가 자동으로 프로비저닝됩니다.
이 스토리지 클래스의 동작을 구성하는 추가 변수는 없습니다.
4.3.5.4. 사전 구성(고급)
사전 구성된 스토리지 클래스는 사용자가 수행하는 작업을 정확하게 알고 모든 스토리지 요구 사항이 미리 관리되었음을 의미합니다. 일반적으로 올바르게 크기가 지정된 PV를 이미 생성했습니다. 설치 프로그램은 스토리지 설정을 수정하지 않습니다.
이 스토리지 클래스의 동작을 구성하는 추가 변수는 없습니다.
4.4. 설치 프로그램 실행
4.4.1. OpenShift Container Platform 설치 중 또는 이후에 Red Hat CloudForms 배포
초기 OpenShift Container Platform 설치 중 또는 클러스터가 프로비저닝된 후 Red Hat CloudForms를 배포할 수 있습니다.
[OSEv3:vars]섹션 아래의 인벤토리 파일에서openshift_management_install_management가true로 설정되어 있는지 확인합니다.[OSEv3:vars] openshift_management_install_management=true- 역할 변수 구성에 설명된 대로 인벤토리 파일에서 다른 Red Hat CloudForms 역할 변수를 설정합니다. 이를 지원하는 리소스는 Example Inventory Files 에서 제공됩니다.
OpenShift Container Platform이 이미 프로비저닝되었는지 여부에 따라 실행할 플레이북을 선택합니다.
- OpenShift Container Platform 클러스터를 동시에 설치할 때 Red Hat CloudForms를 설치하려면 설치 플레이북 실행에 설명된 대로 표준 config.yml 플레이북을 호출 하여 OpenShift Container Platform 클러스터 및 Red Hat CloudForms 설치를 시작합니다.
이미 프로비저닝된 OpenShift Container Platform 클러스터에 Red Hat CloudForms를 설치하려면 플레이북 디렉터리로 변경하고 Red Hat CloudForms 플레이북을 직접 호출하여 설치를 시작합니다.
$ cd /usr/share/ansible/openshift-ansible $ ansible-playbook -v [-i /path/to/inventory] \ playbooks/openshift-management/config.yml
4.4.2. 인벤토리 파일 예
다음 섹션에서는 시작하는 데 도움이 되는 OpenShift Container Platform의 Red Hat CloudForms의 다양한 구성을 보여주는 인벤토리 파일의 예를 보여줍니다.
전체 변수 설명은 역할 변수 구성을 참조하십시오.
4.4.2.1. 모든 기본값
이 예제는 모든 기본값과 선택 사항을 사용하는 가장 간단한 예입니다. 따라서 완전히 컨테이너화된 Red Hat CloudForms가 설치됩니다. 모든 애플리케이션 구성 요소 및 PostgreSQL 데이터베이스는 OpenShift Container Platform에서 포드로 생성됩니다.
[OSEv3:vars]
openshift_management_app_template=cfme-template4.4.2.2. 외부 NFS 스토리지
이는 클러스터에서 로컬 NFS 서비스를 사용하는 대신 기존 외부 NFS 서버(예: 스토리지 어플라이언스)를 사용하는 경우를 제외하고 이전 예제와 같습니다. 두 개의 새 매개변수를 확인합니다.
[OSEv3:vars]
openshift_management_app_template=cfme-template
openshift_management_storage_class=nfs_external
openshift_management_storage_nfs_external_hostname=nfs.example.com 외부 NFS 호스트에서 /exports/hosted/prod 와 같은 다른 상위 디렉터리 아래에 디렉터리를 내보내는 경우 다음 추가 변수를 추가합니다.
openshift_management_storage_nfs_base_dir=/exports/hosted/prod4.4.2.3. PV 크기 덮어쓰기
이 예제에서는 PV(영구 볼륨) 크기를 재정의합니다. PV 크기는 openshift_management_template_parameters 를 통해 설정해야 애플리케이션 및 데이터베이스에서 생성된 PV에 대한 클레임을 만들 수 있습니다.
[OSEv3:vars]
openshift_management_app_template=cfme-template
openshift_management_template_parameters={'APPLICATION_VOLUME_CAPACITY': '10Gi', 'DATABASE_VOLUME_CAPACITY': '25Gi'}4.4.2.4. 메모리 요구 사항 재정의
테스트 또는 개념 증명 설치에서는 애플리케이션 및 데이터베이스 메모리 요구 사항을 용량에 맞게 줄여야 할 수도 있습니다. 메모리 제한을 줄이면 성능이 저하되거나 애플리케이션을 초기화하는 데 완전한 오류가 발생할 수 있습니다.
[OSEv3:vars]
openshift_management_app_template=cfme-template
openshift_management_template_parameters={'APPLICATION_MEM_REQ': '3000Mi', 'POSTGRESQL_MEM_REQ': '1Gi', 'ANSIBLE_MEM_REQ': '512Mi'}
이 예제에서는 설치 프로그램에서 APPLICATION_MEM_REQ 매개 변수를 사용하여 애플리케이션 템플릿을 3000Mi 로 설정하고POSTGRESQL_MEM_REQ 를 1Gi 로 설정하고 ANSIBLE_MEM_REQ 를 512Mi 로 설정하도록 지시합니다.
이러한 매개변수는 이전 예제의 PV 크기 재정의에 표시된 매개변수와 결합할 수 있습니다.
4.4.2.5. 외부 PostgreSQL 데이터베이스
외부 데이터베이스를 사용하려면 openshift_management_app_template 매개변수 값을 로 변경해야 합니다.
cfme-template -ext-db
또한 openshift_management_template_parameters 변수를 사용하여 데이터베이스 연결 정보를 제공해야 합니다. 자세한 내용은 역할 변수 구성을 참조하십시오.
[OSEv3:vars]
openshift_management_app_template=cfme-template-ext-db
openshift_management_template_parameters={'DATABASE_USER': 'root', 'DATABASE_PASSWORD': 'mypassword', 'DATABASE_IP': '10.10.10.10', 'DATABASE_PORT': '5432', 'DATABASE_NAME': 'cfme'}PostgreSQL 9.5를 실행 중이거나 애플리케이션을 성공적으로 배포할 수 없는지 확인합니다.
4.5. 컨테이너 공급자 통합 활성화
4.5.1. 단일 컨테이너 공급자 추가
설치 프로그램 실행에 설명된 대로 OpenShift Container Platform에 Red Hat CloudForms를 배포한 후 컨테이너 공급자 통합을 활성화하는 두 가지 방법이 있습니다. OpenShift Container Platform을 컨테이너 공급자로 수동으로 추가하거나 이 역할에 포함된 플레이북을 시도할 수 있습니다.
4.5.1.1. 수동으로 추가
OpenShift Container Platform 클러스터를 컨테이너 공급자로 수동으로 추가하는 방법은 다음 Red Hat CloudForms 설명서를 참조하십시오.
4.5.1.2. 자동으로 추가
자동화된 컨테이너 프로바이더 통합은 이 역할에 포함된 플레이북을 사용하여 수행할 수 있습니다.
이 플레이북은 다음과 같습니다.
- 필요한 인증 시크릿을 수집합니다.
- Red Hat CloudForms 애플리케이션 및 클러스터 API로 공용 경로를 찾습니다.
- REST 호출을 만들어 OpenShift Container Platform 클러스터를 컨테이너 공급자로 추가합니다.
플레이북 디렉터리로 변경하고 컨테이너 공급자 플레이북을 실행합니다.
$ cd /usr/share/ansible/openshift-ansible
$ ansible-playbook -v [-i /path/to/inventory] \
openshift-management/add_container_provider.yml4.5.2. 다중 컨테이너 공급자
현재 OpenShift Container Platform 클러스터를 Red Hat CloudForms 배포에 통합하는 플레이북을 제공할 뿐 아니라, 이 역할에는 임의의 Red Hat CloudForms 서버에서 여러 컨테이너 플랫폼을 컨테이너 공급자로 추가할 수 있는 스크립트가 포함되어 있습니다. 컨테이너 플랫폼은 OpenShift Container Platform 또는 OpenShift Origin일 수 있습니다.
여러 프로바이더 스크립트를 사용하려면 플레이북을 실행할 때 CLI에서 EXTRA_VARS 매개 변수를 수동으로 구성하고 설정해야 합니다.
4.5.2.1. 스크립트 준비
여러 공급자 스크립트를 준비하려면 다음 수동 구성을 완료합니다.
- /usr/share/ansible/openshift-ansible/roles/openshift_management/files/examples/container_providers.yml 예제(예: /tmp/cp.yml )를 복사합니다. 이 파일을 수정합니다.
-
Red Hat CloudForms 이름 또는 암호를 변경한 경우 복사한 container_providers.yml 파일의
management_server키에서hostname,user및password매개 변수를 업데이트합니다. 컨테이너 공급자로 추가할 각
컨테이너 플랫폼 클러스터에 대한 container_providers키 아래에 항목을 입력합니다.다음 매개변수를 구성해야 합니다.
-
auth_key-cluster-admin권한이 있는 서비스 계정의 토큰입니다. -
hostname- 클러스터 API를 가리키는 호스트 이름입니다. 각 컨테이너 공급자에는 고유한 호스트 이름이 있어야 합니다. -
Name(이름) - Red Hat CloudForms 서버 컨테이너 공급업체 개요 페이지에 표시할 클러스터의 이름입니다. 고유해야 합니다.
작은 정보클러스터에서
auth_key전달자 토큰을 가져오려면 다음을 수행합니다.$ oc serviceaccounts get-token -n management-infra management-admin-
선택적으로 다음 매개변수를 구성할 수 있습니다.
-
포트- 컨테이너 플랫폼 클러스터가8443이외의 포트에서 API를 실행하는 경우 이 키를 업데이트합니다. -
엔드포인트- SSL 확인(verify_ssl)을 활성화하거나 검증 설정을ssl-with-validation으로 변경할 수 있습니다. 현재 사용자 정의 신뢰할 수 있는 CA 인증서에 대한 지원은 제공되지 않습니다.
-
4.5.2.1.1. 예제
예를 들어 다음 시나리오를 고려하십시오.
- container_providers.yml 파일을 /tmp/cp.yml 에 복사했습니다.
- 두 개의 OpenShift Container Platform 클러스터를 추가하려고 합니다.
-
Red Hat CloudForms 서버는
mgmt.example.com에서 실행됩니다.
이 시나리오의 경우 다음과 같이 /tmp/cp.yml 을 사용자 지정합니다.
container_providers:
- connection_configurations:
- authentication: {auth_key: "<token>", authtype: bearer, type: AuthToken}
endpoint: {role: default, security_protocol: ssl-without-validation, verify_ssl: 0}
hostname: "<provider_hostname1>"
name: <display_name1>
port: 8443
type: "ManageIQ::Providers::Openshift::ContainerManager"
- connection_configurations:
- authentication: {auth_key: "<token>", authtype: bearer, type: AuthToken}
endpoint: {role: default, security_protocol: ssl-without-validation, verify_ssl: 0}
hostname: "<provider_hostname2>"
name: <display_name2>
port: 8443
type: "ManageIQ::Providers::Openshift::ContainerManager"
management_server:
hostname: "<hostname>"
user: <user_name>
password: <password>4.5.2.2. 플레이북 실행
다중 공급자 통합 스크립트를 실행하려면 컨테이너 프로바이더 구성 파일의 경로를 ansible-playbook 명령에 대한 EXTRA_VARS 매개 변수로 제공해야 합니다. -e (또는 --extra-vars) 매개 변수를 사용하여 container_providers_config 를 구성 파일 경로로 설정합니다. 플레이북 디렉터리로 변경하고 플레이북을 실행합니다.
$ cd /usr/share/ansible/openshift-ansible
$ ansible-playbook -v [-i /path/to/inventory] \
-e container_providers_config=/tmp/cp.yml \
playbooks/openshift-management/add_many_container_providers.yml
플레이북이 완료되면 Red Hat CloudForms 서비스에서 두 개의 새 컨테이너 프로바이더를 찾을 수 있습니다. 컴퓨팅 → 컨테이너 → 공급자 페이지로 이동하여 개요를 확인합니다.
4.5.3. 공급자 새로 고침
하나 이상의 컨테이너 공급업체를 추가한 후 Red Hat CloudForms에서 새 공급업체를 새로 고쳐 컨테이너 공급업체 및 관리 중인 컨테이너에 대한 모든 최신 데이터를 가져와야 합니다. 이를 위해서는 Red Hat CloudForms 웹 콘솔의 각 공급업체로 이동한 후 각각 새로 고침 버튼을 클릭해야 합니다.
단계는 다음 Red Hat CloudForms 설명서를 참조하십시오.
4.6. Red Hat CloudForms 설치 제거
4.6.1. 설치 제거 Playbook 실행
OpenShift Container Platform에서 배포된 Red Hat CloudForms 설치를 제거 및 제거하려면 플레이북 디렉터리로 변경하고 uninstall.yml 플레이북을 실행합니다.
$ cd /usr/share/ansible/openshift-ansible
$ ansible-playbook -v [-i /path/to/inventory] \
playbooks/openshift-management/uninstall.ymlNFS 내보내기 정의 및 NFS 내보내기에 저장된 데이터는 자동으로 제거되지 않습니다. 새 배포를 초기화하기 전에 이전 애플리케이션 또는 데이터베이스 배포의 데이터를 수동으로 삭제해야 합니다.
4.6.2. 문제 해결
이전 PostgreSQL 데이터를 지우지 않으면 캐스케이딩 오류가 발생할 수 있으므로 postgresql Pod가 크래시 루프백 상태가 됩니다. 그러면 cfme 포드가 시작되지 않습니다. 크래시 루프백오프 의 원인은 이전 배포 중에 생성된 데이터베이스 NFS 내보내기에 대한 잘못된 파일 권한 때문입니다.
계속하려면 PostgreSQL 내보내기에서 모든 데이터를 지우고 포드(배포자 포드가 아님)를 삭제합니다. 예를 들어 다음 Pod가 있는 경우 다음을 수행합니다.
$ oc get pods
NAME READY STATUS RESTARTS AGE
httpd-1-cx7fk 1/1 Running 1 21h
cfme-0 0/1 Running 1 21h
memcached-1-vkc7p 1/1 Running 1 21h
postgresql-1-deploy 1/1 Running 1 21h
postgresql-1-6w2t4 0/1 CrashLoopBackOff 1 21h그런 다음 다음을 수행합니다.
- 데이터베이스 NFS 내보내기에서 데이터를 지웁니다.
다음을 실행합니다.
$ oc delete postgresql-1-6w2t4
PostgreSQL 배포자 포드는 삭제한 포드를 교체하기 위해 새 postgresql 포드를 확장하려고 합니다. postgresql 포드가 실행되면 cfme 포드에서 차단을 중지하고 애플리케이션 초기화를 시작합니다.
5장. Prometheus 클러스터 모니터링
5.1. 개요
OpenShift Container Platform에는 Prometheus 오픈 소스 프로젝트 및 광범위한 에코시스템을 기반으로 하는 사전 구성된 자체 업데이트 모니터링 스택이 포함되어 있습니다. 클러스터 구성 요소의 모니터링을 제공하며, 발생하는 모든 문제와 Grafana 대시보드 세트에 대해 클러스터 관리자에게 즉시 알리는 일련의 경고가 포함되어 있습니다.
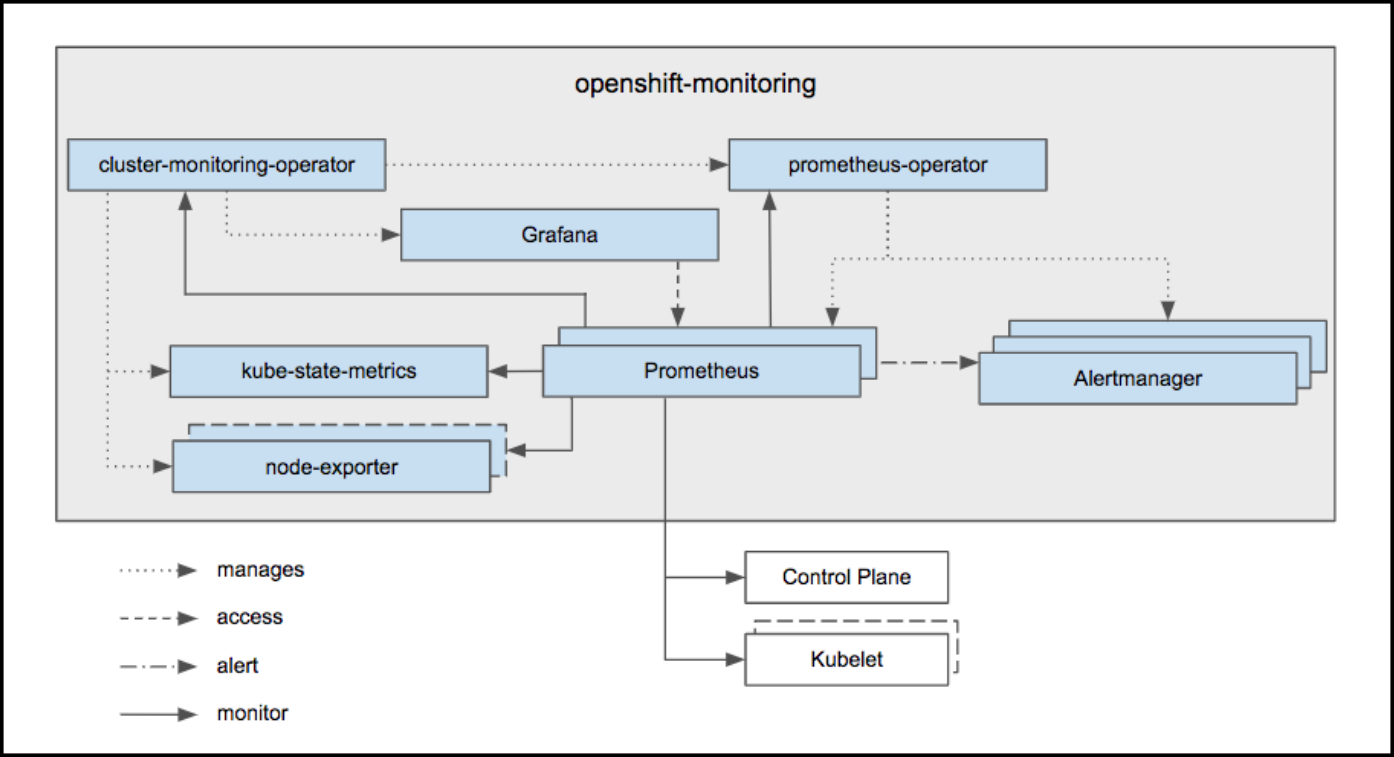
위의 다이어그램에 표시된 모니터링 스택의 핵심에는 배포된 모니터링 구성 요소 및 리소스를 감시하는 OpenShift Container Platform CMO(Cluster Monitoring Operator)가 있으며 항상 최신 상태인지 확인합니다.
Prometheus Operator(PO)는 Prometheus 및 Alertmanager 인스턴스를 생성, 구성 및 관리합니다. 또한 친숙한 Kubernetes 라벨 쿼리를 기반으로 모니터링 대상 구성을 자동으로 생성합니다.
OpenShift Container Platform Monitoring에는 Prometheus 및 Alertmanager 외에도 node-exporter 및 kube- state-metrics 도 포함됩니다. node-exporter는 모든 노드에 배포된 에이전트로 관련 지표를 수집할 수 있습니다. kube-state-metrics 내보내기 에이전트는 Kubernetes 오브젝트를 Prometheus에서 사용할 수 있는 지표로 변환합니다.
클러스터 모니터링의 일부로 모니터링되는 대상은 다음과 같습니다.
- Prometheus 자체
- Prometheus-Operator
- cluster-monitoring-operator
- Alertmanager 클러스터 인스턴스
- Kubernetes apiserver
- kubelets (kubelet includess cAdvisor for per container metrics)
- kube-controllers
- kube-state-metrics
- node-exporter
- etcd ( etcd 모니터링이 활성화된 경우)
이러한 모든 구성 요소가 자동으로 업데이트됩니다.
OpenShift Container Platform Cluster Monitoring Operator에 대한 자세한 내용은 Cluster Monitoring Operator GitHub 프로젝트를 참조하십시오.
호환성이 보장된 업데이트를 제공하기 위해 OpenShift Container Platform 모니터링 스택의 구성은 명시적으로 사용 가능한 옵션으로 제한됩니다.
5.2. OpenShift Container Platform 클러스터 모니터링 구성
OpenShift Container Platform Ansible openshift_cluster_monitoring_operator 역할은 인벤토리 파일의 변수를 사용하여 Cluster Monitoring Operator를 구성하고 배포합니다.
| Variable | 설명 |
|---|---|
|
|
|
|
|
각 Prometheus 인스턴스의 영구 볼륨 클레임 크기입니다. 이 변수는 |
|
|
각 Alertmanager 인스턴스의 영구 볼륨 클레임 크기입니다. 이 변수는 |
|
|
Pod가 특정 레이블이 있는 노드에 배치되도록 원하는 기존 노드 선택기 로 설정합니다. 기본값은 |
|
| Alertmanager 구성. |
|
|
Prometheus의 시계열 데이터의 영구 스토리지를 활성화합니다. 이 변수는 기본적으로 |
|
|
Alertmanager 알림 및 음소거의 영구 스토리지를 활성화합니다. 이 변수는 기본적으로 |
|
|
|
|
|
|
5.2.1. 모니터링 사전 요구 사항
모니터링 스택은 추가 리소스 요구 사항을 적용합니다. 자세한 내용은 컴퓨팅 리소스 권장 사항을 참조하십시오.
5.2.2. 모니터링 스택 설치
모니터링 스택은 기본적으로 OpenShift Container Platform과 함께 설치됩니다. 설치되지 않도록 할 수 있습니다. 이를 수행하려면 Ansible 인벤토리 파일에서 이 변수를 false로 설정합니다.
openshift_cluster_monitoring_operator_install
다음을 실행하여 수행할 수 있습니다.
$ ansible-playbook [-i </path/to/inventory>] <OPENSHIFT_ANSIBLE_DIR>/playbooks/openshift-monitoring/config.yml \
-e openshift_cluster_monitoring_operator_install=False
Ansible 디렉터리의 일반적인 경로는 /usr/share/ansible/openshift-ansible/ 입니다. 이 경우 구성 파일의 경로는 /usr/share/ansible/openshift-ansible/playbooks/openshift-monitoring/config.yml 입니다.
5.2.3. 영구 스토리지
영구저장장치를 사용하여 클러스터 모니터링을 실행하면 메트릭이 영구 볼륨에 저장되며 Pod가 다시 시작되거나 재생성될 수 있습니다. 데이터 손실에서 메트릭 또는 경고 데이터가 필요한 경우 이상적입니다. 프로덕션 환경의 경우 블록 스토리지 기술을 사용하여 영구 스토리지를 구성하는 것이 좋습니다.
5.2.3.1. 영구 스토리지 활성화
기본적으로 Prometheus 시계열 데이터 및 Alertmanager 알림 및 음소거에 대해 영구 스토리지가 비활성화됩니다. 클러스터 중 하나를 영구적으로 저장하거나 둘 다 저장하도록 구성할 수 있습니다.
Prometheus 시계열 데이터의 영구 스토리지를 활성화하려면 Ansible 인벤토리 파일에서 이 변수를
true로 설정합니다.openshift_cluster_monitoring_operator_prometheus_storage_enabledAlertmanager 알림 및 음소거의 영구 스토리지를 활성화하려면 Ansible 인벤토리 파일에서 이 변수를
true로 설정합니다.openshift_cluster_monitoring_operator_alertmanager_storage_enabled
5.2.3.2. 스토리지가 필요한 정도 확인
필요한 스토리지의 양은 Pod 수에 따라 달라집니다. 관리자는 디스크가 가득 차지 않도록 충분한 스토리지를 전담해야 합니다. 영구 스토리지의 시스템 요구 사항에 대한 자세한 내용은 Cluster Monitoring Operator 용량 계획을 참조하십시오.
5.2.3.3. 영구 스토리지 크기 설정
Prometheus 및 Alertmanager에 대한 영구 볼륨 클레임의 크기를 지정하려면 다음 Ansible 변수를 변경합니다.
-
openshift_cluster_monitoring_operator_prometheus_storage_capacity(default: 50Gi) -
openshift_cluster_monitoring_operator_alertmanager_storage_capacity(default: 2Gi)
이러한 각 변수는 해당 storage_enabled 변수가 true 로 설정된 경우에만 적용됩니다.
5.2.3.4. 충분한 영구 볼륨 할당
동적으로 프로비저닝된 스토리지를 사용하지 않는 경우 PVC에서 각 복제본에 대해 하나의 PV인 PV(영구 볼륨)를 요청할 준비가 되어 있는지 확인해야 합니다. Prometheus에는 두 개의 복제본이 있으며 Alertmanager에는 세 개의 복제본이 있으며, PV는 5개입니다.
5.2.3.5. 동적으로 프로비저닝된 스토리지 활성화
정적으로 프로비저닝된 스토리지 대신 동적으로 프로비저닝된 스토리지를 사용할 수 있습니다. 자세한 내용은 동적 볼륨 프로비저닝 을 참조하십시오.
Prometheus 및 Alertmanager의 동적 스토리지를 활성화하려면 Ansible 인벤토리 파일에서 다음 매개변수를 true 로 설정합니다.
-
openshift_cluster_monitoring_operator_prometheus_storage_enabled(기본값: false) -
openshift_cluster_monitoring_operator_alertmanager_storage_enabled(기본값: false)
동적 스토리지를 활성화한 후 Ansible 인벤토리 파일의 다음 매개변수에 있는 각 구성 요소에 대한 영구 볼륨 클레임의 스토리지 클래스를 설정할 수도 있습니다.
-
openshift_cluster_monitoring_operator_prometheus_storage_class_name(default: "") -
openshift_cluster_monitoring_operator_alertmanager_storage_class_name(default: "")
이러한 각 변수는 해당 storage_enabled 변수가 true 로 설정된 경우에만 적용됩니다.
5.2.4. 지원되는 구성
지원되는 OpenShift Container Platform 모니터링 구성 방법은 이 가이드에 설명된 옵션을 사용하여 구성하는 것입니다. 이러한 명시적 구성 옵션 외에도 스택에 추가 구성을 삽입할 수 있습니다. 그러나 구성 패러다임은 Prometheus 릴리스에서 변경될 수 있으며 이러한 경우는 모든 구성 가능성이 제어되는 경우에만 정상적으로 처리할 수 있기 때문에 지원되지 않습니다.
명시적으로 지원되지 않는 경우는 다음과 같습니다.
-
openshift-monitoring네임스페이스에 추가ServiceMonitor오브젝트를 생성하여 클러스터 모니터링 Prometheus 인스턴스 스크랩을 대상으로 확장합니다. 이로 인해 처리할 수 없는 충돌 및 로드 차이점이 발생할 수 있으므로 Prometheus 설정을 불안정할 수 있습니다. -
클러스터 모니터링 Prometheus 인스턴스에 추가 경고 및 기록 규칙이 포함되도록 하는 추가
ConfigMap오브젝트를 생성합니다. Prometheus 2.0에는 새 규칙 파일 구문이 제공되므로 이 동작은 적용 시 중단되는 동작을 발생시키는 것으로 알려져 있습니다.
5.3. Alertmanager 구성
Alertmanager는 들어오는 경고를 관리합니다. 여기에는 이메일, PagerDuty 및 HipChat과 같은 방법을 통해 알림 전송이 포함됩니다.
OpenShift Container Platform Monitoring Alertmanager 클러스터의 기본 구성은 다음과 같습니다.
global:
resolve_timeout: 5m
route:
group_wait: 30s
group_interval: 5m
repeat_interval: 12h
receiver: default
routes:
- match:
alertname: DeadMansSwitch
repeat_interval: 5m
receiver: deadmansswitch
receivers:
- name: default
- name: deadmansswitch
이 구성은 openshift_cluster_monitoring _operator 를 사용하여 덮어쓸 수 있습니다.
역할의 Ansible 변수 openshift_cluster_monitoring_operator_alertmanager_ config
다음 예제에서는 알림을 위해 PagerDuty 를 구성합니다. service_key 를 검색하는 방법을 알아보려면 Alertmanager 에 대한 PagerDuty 문서를 참조하십시오.
openshift_cluster_monitoring_operator_alertmanager_config: |+
global:
resolve_timeout: 5m
route:
group_wait: 30s
group_interval: 5m
repeat_interval: 12h
receiver: default
routes:
- match:
alertname: DeadMansSwitch
repeat_interval: 5m
receiver: deadmansswitch
- match:
service: example-app
routes:
- match:
severity: critical
receiver: team-frontend-page
receivers:
- name: default
- name: deadmansswitch
- name: team-frontend-page
pagerduty_configs:
- service_key: "<key>"
하위 경로는 critical 의 심각도가 있는 경고에서만 일치하고 team-frontend-page 라는 수신자를 사용하여 전송합니다. 이름에서 알 수 있듯이 중요한 경고에 대해 다른 사람을 호출해야 합니다. 다양한 경고 수신자를 통한 경고 구성은 Alertmanager 설정을 참조하십시오.
5.3.1. 배달된 사람의 스위치
OpenShift Container Platform 모니터링에는 모니터링 인프라를 사용할 수 있도록 잘못된 버전의 스위치가 포함되어 있습니다.
배달 못 한 사람의 스위치는 항상 트리거되는 간단한 Prometheus 경고 규칙입니다. Alertmanager는 배달된 사람의 스위치에 대한 알림을 지속적으로 이 기능을 지원하는 알림 프로바이더로 보냅니다. 또한 Alertmanager와 알림 프로바이더 간의 통신이 작동하는지 확인합니다.
이 메커니즘은 모니터링 시스템 자체가 중단될 때 알림을 발행하도록 PagerDuty에서 지원합니다. 자세한 내용은 아래 Dead man의 switch PagerDuty 를 참조하십시오.
5.3.2. 경고 그룹화
Alertmanager에 대해 경고가 실행된 후 논리적으로 그룹화하는 방법을 확인하도록 구성해야 합니다.
이 예에서는 프론트엔드 팀의 경고 라우팅을 반영하기 위해 새 경로가 추가됩니다.
절차
새 경로 추가. 원본 경로 아래에 여러 경로를 추가하여 일반적으로 알림 수신자를 정의할 수 있습니다. 다음 예제에서는 일치 항목을 사용하여 서비스
example-app에서 들어오는 경고만 사용됩니다.global: resolve_timeout: 5m route: group_wait: 30s group_interval: 5m repeat_interval: 12h receiver: default routes: - match: alertname: DeadMansSwitch repeat_interval: 5m receiver: deadmansswitch - match: service: example-app routes: - match: severity: critical receiver: team-frontend-page receivers: - name: default - name: deadmansswitch하위 경로는 심각도가
critical인 경고에서만 일치하고team-frontend-page라는 수신자를 사용하여 전송합니다. 이름에서 알 수 있듯이 중요한 경고에 대해 다른 사람을 호출해야 합니다.
5.3.3. dead man의 스위치 PagerDuty
PagerDuty 는 Dead Man's Snitch 라는 통합을 통해 이 메커니즘을 지원합니다. PagerDuty 구성을 기본 deadmansswitch 수신자에 추가하면 됩니다. 위에서 설명한 프로세스를 사용하여 이 구성을 추가합니다.
Dead man의 스위치 경고가 15분 동안 자동으로 작동될 경우 운영자를 호출하도록 Dead Man의 Snitch를 구성합니다. 기본 Alertmanager 설정을 사용하면 5분마다 Dead man의 스위치 경고가 반복됩니다. 15분 후에 Dead Man의 Snitch가 트리거되면 알림이 2번 이상 실패했음을 나타냅니다.
PagerDuty를 위한 Dead Man의 Snitch 구성 방법 알아보기.
5.3.4. 경고 규칙
OpenShift Container Platform 클러스터 모니터링에는 기본적으로 구성된 다음 경고 규칙이 제공됩니다. 현재는 사용자 지정 경고 규칙을 추가할 수 없습니다.
일부 경고 규칙에는 이름이 동일합니다. 이것은 의도적입니다. 임계값이 다르거나 심각도가 다르거나 둘 다 있는 동일한 이벤트에 대해 경고합니다. 억제 규칙을 사용하면 심각도가 더 높은 심각도가 실행되면 더 낮은 심각도가 억제됩니다.
경고 규칙에 대한 자세한 내용은 구성 파일을 참조하십시오.
| 경고 | 심각도 | 설명 |
|---|---|---|
|
|
| Cluster Monitoring Operator에서 X% 오류가 발생했습니다. |
|
|
| Alertmanager가 Prometheus 대상 검색에서 사라졌습니다. |
|
|
| ClusterMonitoringOperator가 Prometheus 대상 검색에서 사라졌습니다. |
|
|
| KubeAPI가 Prometheus 대상 검색에서 사라졌습니다. |
|
|
| kubecontrollermanager가 Prometheus 대상 검색에서 사라졌습니다. |
|
|
| kubescheduler가 Prometheus 대상 검색에서 사라졌습니다. |
|
|
| KubeStateMetrics는 Prometheus 대상 검색에서 사라졌습니다. |
|
|
| kubelet이 Prometheus 대상 검색에서 사라졌습니다. |
|
|
| NodeExporter는 Prometheus 대상 검색에서 사라졌습니다. |
|
|
| Prometheus는 Prometheus 대상 검색에서 사라졌습니다. |
|
|
| prometheusOperator는 Prometheus 대상 검색에서 사라졌습니다. |
|
|
| 네임스페이스/포드 (컨테이너)가 재시작 시간 / 초 |
|
|
| 네임 스페이스/Pod 가 준비되지 않았습니다. |
|
|
| 배포 네임 스페이스/배포 생성 불일치 |
|
|
| 배포 네임 스페이스/배포 복제본 불일치 |
|
|
| StatefulSet 네임 스페이스/StatefulSet 복제본 불일치 |
|
|
| StatefulSet 네임 스페이스/StatefulSet 생성 불일치 |
|
|
| 원하는 Pod의 X%만 예약되고 데몬 세트 네임 스페이스/DaemonSet준비가 완료되었습니다. |
|
|
| daemonset 네임스페이스/DaemonSet 의 여러 Pod는 예약되지 않습니다. |
|
|
| 데몬 세트 네임스페이스/DaemonSet 의 여러 Pod가 실행되지 않아야 하는 위치입니다. |
|
|
| CronJob 네임스페이스/CronJob 은 완료하는 데 1시간 이상 걸립니다. |
|
|
| 작업 네임스페이스/Job 을 완료하는 데 1시간 이상 걸립니다. |
|
|
| 작업 네임스페이스/Job 을 완료하지 못했습니다. |
|
|
| Pod에서 과다 할당된 CPU 리소스 요청은 노드 오류를 허용하지 않습니다. |
|
|
| Pod에서 과다 할당된 메모리 리소스 요청은 노드 오류를 허용하지 않습니다. |
|
|
| 네임스페이스에서 과다 할당된 CPU 리소스 요청 할당량입니다. |
|
|
| 네임스페이스에서 과다 할당된 메모리 리소스 요청 할당량입니다. |
|
|
| 네임스페이스 네임스페이스에서 리소스의 X% 사용. |
|
|
| 네임스페이스에서 PersistentVolumeClaim 이 클레임한 영구 볼륨은 X% 가 사용 가능합니다. |
|
|
| 최근 샘플링에 따라 네임스페이스에서 PersistentVolumeClaim에서 클레임 한 영구 볼륨은 4일 내에 채워질 것으로 예상됩니다. 현재 X 바이트를 사용할 수 있습니다. |
|
|
| 노드 가 1시간 이상 준비되지 않았습니다 |
|
|
| X 버전의 Kubernetes 구성 요소가 실행되고 있습니다. |
|
|
| Kubernetes API 서버 클라이언트 '작업/인스턴스'에 X% 오류가 발생했습니다. |
|
|
| Kubernetes API 서버 클라이언트 '작업/인스턴스'에 X 오류/초가 발생했습니다. |
|
|
| kubelet 인스턴스는 110개 제한에 가까운 X Pod를 실행하고 있습니다. |
|
|
| API 서버에는 Verb Resource 의 X 초의 99번째 백분위 대기 시간이 있습니다. |
|
|
| API 서버에는 Verb Resource 의 X 초의 99번째 백분위 대기 시간이 있습니다. |
|
|
| API 서버가 요청의 X%에 대해 오류가 발생했습니다. |
|
|
| API 서버가 요청의 X%에 대해 오류가 발생했습니다. |
|
|
| Kubernetes API 인증서가 7일 이내에 만료됩니다. |
|
|
| Kubernetes API 인증서가 1일 이내에 만료됩니다. |
|
|
|
요약: 동기화되지 않은 구성. 설명: Alertmanager 클러스터 |
|
|
| 요약: Alertmanager의 설정을 다시 로드하지 못했습니다. 설명: Alertmanager 설정을 다시 로드하지 못했습니다. Namespace/Pod 에 실패했습니다. |
|
|
| 요약: 대상은 다운됩니다. 설명: 작업 대상의 X%가 다운되었습니다. |
|
|
| 요약: 경고 DeadMansSwitch. 설명: DeadMansSwitch는 전체 경고 파이프라인이 작동하는지 확인합니다. |
|
|
| 노드 내보내기 네임스페이스/Pod 의 장치 장치가 다음 24시간 내에 완전히 실행됩니다. |
|
|
| 다음 2시간 내에 node -exporter 네임스페이스/Pod 의 장치 장치가 완전히 실행됩니다. |
|
|
| 요약: Prometheus 구성을 다시 로드하지 못했습니다. 설명: Namespace/Pod에 대해 Prometheus 구성을 다시 로드하지 못했습니다 |
|
|
| 요약: Prometheus의 경고 알림 대기열이 완전히 실행됩니다. 설명: Prometheus의 경고 알림 대기열이 네임 스페이스/Pod에 대해 전체 실행 중입니다 |
|
|
| 요약: Prometheus에서 경고를 보내는 동안 오류가 발생했습니다. 설명: Prometheus 네임스페이스/Pod 에서 Alertmanager로 경고를 보내는 동안 오류 발생 |
|
|
| 요약: Prometheus에서 경고를 보내는 동안 오류가 발생했습니다. 설명: Prometheus 네임스페이스/Pod 에서 Alertmanager로 경고를 보내는 동안 오류 발생 |
|
|
| 요약: Prometheus는 Alertmanagers에 연결되어 있지 않습니다. 설명: Prometheus 네임 스페이스/Pod 가 Alertmanagers에 연결되어 있지 않습니다 |
|
|
| 요약: Prometheus는 디스크에서 데이터 블록을 다시 로드하는 데 문제가 있습니다. 설명: 인스턴스의 작업에 는 지난 4시간 동안 X 다시 로드 오류가 발생했습니다. |
|
|
| 요약: Prometheus는 샘플 블록을 압축하는 데 문제가 있습니다. 설명: 인스턴스의 작업에 는 지난 4시간 동안 X 압축 오류가 발생했습니다. |
|
|
| 요약: Prometheus write-ahead 로그가 손상되었습니다. 설명: 인스턴스의 작업에 는 WAL( write-ahead) 로그가 손상되었습니다. |
|
|
| 요약: Prometheus는 샘플을 수집하지 않습니다. 설명: Prometheus 네임스페이스/Pod 가 샘플을 수집하지 않습니다. |
|
|
| 요약: Prometheus에는 거부된 많은 샘플이 있습니다. 설명: 네임스페이스/Pod 에는 중복 타임스탬프로 인해 거부되지만 다른 값이 있습니다. |
|
|
| etcd 클러스터 "Job": insufficient members(X). |
|
|
| etcd 클러스터 "작업": 멤버 인스턴스는 리더가 없습니다. |
|
|
| etcd 클러스터 "작업": 인스턴스 인스턴스는 지난 1 시간 이내에 X 리더 변경 사항을 보았습니다. |
|
|
| etcd 클러스터 "작업": etcd 인스턴스 인스턴스에서 GRPC_Method 에 대한 요청의 x%가 실패했습니다. |
|
|
| etcd 클러스터 "작업": etcd 인스턴스 인스턴스에서 GRPC_Method 에 대한 요청의 x%가 실패했습니다. |
|
|
| etcd 클러스터 "작업": GRPC_Method 에 대한 gRPC 요청은 etcd 인스턴스 _Instance에서 X_s를 가져옵니다. |
|
|
| etcd 클러스터 "작업": To 와 멤버 통신이 etcd 인스턴스 _Instance에서 X_s를 가져옵니다. |
|
|
| etcd 클러스터 "작업": etcd 인스턴스 인스턴스의 마지막 1시간 내에 제안 오류가 발생합니다. |
|
|
| etcd 클러스터 "작업": 99번째 백분율 fync 기간은 etcd 인스턴스에서 X_s입니다. _Instance. |
|
|
| etcd 클러스터 "작업": etcd 인스턴스에서 X_s의 99번째 백분위 커밋 기간(_I) _Instance. |
|
|
| 작업 인스턴스 인스턴스에서 파일 설명자가 곧 소진됩니다 |
|
|
| 작업 인스턴스 인스턴스에서 파일 설명자가 곧 소진됩니다 |
5.4. etcd 모니터링 구성
etcd 서비스가 올바르게 실행되지 않으면 전체 OpenShift Container Platform 클러스터가 성공적으로 작동하지 않을 수 있습니다. 따라서 etcd 모니터링을 구성하는 것이 좋습니다.
다음 단계에 따라 etcd 모니터링을 구성하십시오.
절차
모니터링 스택이 실행 중인지 확인합니다.
$ oc -n openshift-monitoring get pods NAME READY STATUS RESTARTS AGE alertmanager-main-0 3/3 Running 0 34m alertmanager-main-1 3/3 Running 0 33m alertmanager-main-2 3/3 Running 0 33m cluster-monitoring-operator-67b8797d79-sphxj 1/1 Running 0 36m grafana-c66997f-pxrf7 2/2 Running 0 37s kube-state-metrics-7449d589bc-rt4mq 3/3 Running 0 33m node-exporter-5tt4f 2/2 Running 0 33m node-exporter-b2mrp 2/2 Running 0 33m node-exporter-fd52p 2/2 Running 0 33m node-exporter-hfqgv 2/2 Running 0 33m prometheus-k8s-0 4/4 Running 1 35m prometheus-k8s-1 0/4 ContainerCreating 0 21s prometheus-operator-6c9fddd47f-9jfgk 1/1 Running 0 36m클러스터 모니터링 스택의 구성 파일을 엽니다.
$ oc -n openshift-monitoring edit configmap cluster-monitoring-configconfig.yaml: |+에서etcd섹션을 추가합니다.마스터 노드의 정적 Pod에서
etcd를 실행하는 경우 선택기를 사용하여etcd노드를 지정할 수 있습니다.... data: config.yaml: |+ ... etcd: targets: selector: openshift.io/component: etcd openshift.io/control-plane: "true"별도의 호스트에서
etcd를 실행하는 경우 IP 주소를 사용하여 노드를 지정해야 합니다.... data: config.yaml: |+ ... etcd: targets: ips: - "127.0.0.1" - "127.0.0.2" - "127.0.0.3"etcd노드의 IP 주소가 변경되면 이 목록을 업데이트해야 합니다.
etcd서비스 모니터가 실행 중인지 확인합니다.$ oc -n openshift-monitoring get servicemonitor NAME AGE alertmanager 35m etcd 1m1 kube-apiserver 36m kube-controllers 36m kube-state-metrics 34m kubelet 36m node-exporter 34m prometheus 36m prometheus-operator 37m- 1
etcd서비스 모니터입니다.
etcd서비스 모니터를 시작하는 데 최대 1분이 걸릴 수 있습니다.이제 웹 인터페이스로 이동하여
etcd모니터링 상태에 대한 자세한 정보를 확인할 수 있습니다.URL을 가져오려면 다음을 실행합니다.
$ oc -n openshift-monitoring get routes NAME HOST/PORT PATH SERVICES PORT TERMINATION WILDCARD ... prometheus-k8s prometheus-k8s-openshift-monitoring.apps.msvistun.origin-gce.dev.openshift.com prometheus-k8s web reencrypt None-
https를 사용하여prometheus-k8s에 대해 나열된 URL로 이동합니다. 로그인합니다.
사용자가
cluster-monitoring-view역할에 속하는지 확인합니다. 이 역할은 클러스터 모니터링 UI를 볼 수 있는 액세스를 제공합니다.예를 들어 사용자
developer를 cluster-monitoring-view역할에 추가하려면 다음을 실행합니다.$ oc adm policy add-cluster-role-to-user cluster-monitoring-view developer-
웹 인터페이스에서
cluster-monitoring-view역할에 속하는 사용자로 로그인합니다. Status(상태 )를 클릭한 다음 Targets(대상) 를 클릭합니다.
etcd 항목이 표시되면 etcd가 모니터링됩니다.
etcd가 모니터링되는 동안 Prometheus는 아직etcd에 대해 인증할 수 없으므로 메트릭을 수집할 수 없습니다.etcd에 대해 Prometheus 인증을 구성하려면 다음을 수행합니다.마스터 노드의
/etc/etcd/ca/ca.crt및/etc/etcd/ca/ca.key자격 증명 파일을 로컬 시스템으로 복사합니다.$ ssh -i gcp-dev/ssh-privatekey cloud-user@35.237.54.213다음 내용을 사용하여
openssl.cnf파일을 생성합니다.[ req ] req_extensions = v3_req distinguished_name = req_distinguished_name [ req_distinguished_name ] [ v3_req ] basicConstraints = CA:FALSE keyUsage = nonRepudiation, keyEncipherment, digitalSignature extendedKeyUsage=serverAuth, clientAuthetcd.key개인 키 파일을 생성합니다.$ openssl genrsa -out etcd.key 2048etcd.csr인증서 서명 요청 파일을 생성합니다.$ openssl req -new -key etcd.key -out etcd.csr -subj "/CN=etcd" -config openssl.cnfetcd.crt인증서 파일을 생성합니다.$ openssl x509 -req -in etcd.csr -CA ca.crt -CAkey ca.key -CAcreateserial -out etcd.crt -days 365 -extensions v3_req -extfile openssl.cnf인증 정보를 OpenShift Container Platform에서 사용하는 형식으로 설정합니다.
$ cat <<-EOF > etcd-cert-secret.yaml apiVersion: v1 data: etcd-client-ca.crt: "$(cat ca.crt | base64 --wrap=0)" etcd-client.crt: "$(cat etcd.crt | base64 --wrap=0)" etcd-client.key: "$(cat etcd.key | base64 --wrap=0)" kind: Secret metadata: name: kube-etcd-client-certs namespace: openshift-monitoring type: Opaque EOF이렇게 하면 etcd-cert-secret.yaml 파일이 생성됩니다.
인증 정보 파일을 클러스터에 적용합니다.
$ oc apply -f etcd-cert-secret.yaml
인증을 구성했으므로 웹 인터페이스의 Targets(대상) 페이지를 다시 방문하십시오.
etcd가 올바르게 모니터링되고 있는지 확인합니다. 변경 사항을 적용하는 데 몇 분이 걸릴 수 있습니다.
OpenShift Container Platform을 업데이트할 때
etcd모니터링을 자동으로 업데이트하려면 Ansible 인벤토리 파일에서 이 변수를true로 설정합니다.openshift_cluster_monitoring_operator_etcd_enabled=true별도의 호스트에서
etcd를 실행하는 경우 다음 Ansible 변수를 사용하여 IP 주소로 노드를 지정합니다.openshift_cluster_monitoring_operator_etcd_hosts=[<address1>, <address2>, ...]etcd노드의 IP 주소가 변경되면 이 목록을 업데이트해야 합니다.
5.5. Prometheus, Alertmanager 및 Grafana에 액세스
OpenShift Container Platform 모니터링에는 클러스터 모니터링을 위한 Prometheus 인스턴스와 중앙 Alertmanager 클러스터가 포함되어 있습니다. OpenShift Container Platform Monitoring에는 Prometheus 및 Alertmanager 외에도 클러스터 모니터링 문제 해결을 위한 사전 빌드된 대시보드뿐만 아니라 Grafana 인스턴스도 포함되어 있습니다. 대시보드와 함께 모니터링 스택을 통해 제공되는 Grafana 인스턴스는 읽기 전용입니다.
Prometheus, Alertmanager 및 Grafana 웹 UI에 액세스하는 데 필요한 주소를 가져오려면 다음을 수행합니다.
절차
다음 명령을 실행합니다.
$ oc -n openshift-monitoring get routes NAME HOST/PORT alertmanager-main alertmanager-main-openshift-monitoring.apps._url_.openshift.com grafana grafana-openshift-monitoring.apps._url_.openshift.com prometheus-k8s prometheus-k8s-openshift-monitoring.apps._url_.openshift.comhttps://앞에 이러한 주소를 추가해야 합니다. 암호화되지 않은 연결을 사용하여 웹 UI에 액세스할 수 없습니다.-
인증은 OpenShift Container Platform ID에 대해 수행되며 OpenShift Container Platform의 다른 곳에서 사용되는 것과 동일한 자격 증명 또는 인증 수단을 사용합니다. cluster
-monitoring-view 클러스터역할과 같은 모든 네임스페이스에 대한 읽기 액세스 권한이 있는 역할을 사용해야 합니다.
6장. Red Hat 레지스트리에 액세스 및 구성
6.1. 인증 활성화 Red Hat 레지스트리
Red Hat Container Catalog를 통해 사용할 수 있는 모든 컨테이너 이미지는 이미지 레지스트리인 registry.access.redhat.com 에 호스팅됩니다. OpenShift Container Platform 3.11 Red Hat Container Catalog를 registry.access.redhat.com에서 로 이동했습니다.
registry. redhat.io
새 레지스트리 registry.redhat.io 는 OpenShift Container Platform의 이미지 및 호스팅 콘텐츠에 액세스할 수 있는 인증이 필요합니다. 새 레지스트리로 마이그레이션한 후 기존 레지스트리를 일정 기간 동안 사용할 수 있습니다.
OpenShift Container Platform은 registry.redhat.io에서 이미지를 가져 오므로 이를 사용할 수 있도록 클러스터를 설정해야합니다.
새 레지스트리는 다음과 같은 방법으로 인증에 표준 OAuth 메커니즘을 사용합니다.
- 인증 토큰: 관리자가 생성한 토큰은 시스템에 컨테이너 이미지 레지스트리에 대한 인증 기능을 제공하는 서비스 계정입니다. 서비스 계정은 사용자 계정 변경의 영향을 받지 않으므로 인증에 토큰을 사용하는 것은 안정적이고 유연한 인증 방법입니다. 이는 프로덕션 클러스터에 대해 지원되는 유일한 인증 옵션입니다.
-
웹 사용자 이름 및 암호: 이는
access.redhat.com과 같은 리소스에 로그인하는 데 사용하는 표준 인증 정보 집합입니다. OpenShift Container Platform에서 이 인증 방법을 사용할 수는 있지만 프로덕션 배포에는 지원되지 않습니다. 이 인증 방법은 OpenShift Container Platform 외부의 독립형 프로젝트에서만 사용해야합니다.
사용자 이름 및 암호 또는 인증 토큰 중 하나의 자격 증명으로 Docker 로그인을 사용하여 새 레지스트리의 콘텐츠에 액세스할 수 있습니다.
모든 이미지 스트림은 새 레지스트리를 가리킵니다. 새 레지스트리에는 액세스에 대한 인증이 필요하므로 OpenShift 네임스페이스에 imagestreamsecret 이라는 새 시크릿이 있습니다.
다음 두 위치에 인증 정보를 배치해야 합니다.
- OpenShift 네임 스페이스: OpenShift 네임스페이스의 이미지 스트림을 가져올 수 있도록 인증 정보가 OpenShift 네임스페이스에 있어야 합니다.
- 호스트: Kubernetes에서 이미지를 가져올 때 호스트의 인증 정보를 사용하므로 호스트에 인증 정보가 있어야합니다.
새 레지스트리에 액세스하려면 다음을 수행합니다.
-
이미지 가져오기 시크릿
imagestreamsecret이 OpenShift 네임스페이스에 있는지 확인합니다. 해당 시크릿에는 새 레지스트리에 액세스할 수 있는 인증 정보가 있습니다. -
모든 클러스터 노드에 마스터에서 복사된
/var/lib/origin/.docker/config.json이 Red Hat 레지스트리에 액세스할 수 있도록 합니다.
6.1.1. 사용자 계정 생성
Red Hat 제품에 대한 권한이 있는 Red Hat 고객인 경우 해당 사용자 자격 증명이 있는 계정이 있습니다. Red Hat 고객 포털에 로그인하는 데 사용하는 사용자 이름과 암호입니다.
계정이 없는 경우 다음 옵션 중 하나에 등록하여 무료로 계정을 얻을 수 있습니다.
- Red Hat 개발자 프로그램. 이 계정은 개발자 도구 및 프로그램에 대한 액세스를 제공합니다.
- 30일 평가판 서브스크립션. 이 계정은 일부 Red Hat 소프트웨어 제품에 액세스할 수 있는 30일 평가판 서브스크립션을 제공합니다.
6.1.2. Red Hat 레지스트리에 대한 서비스 계정 및 인증 토큰 생성
조직에서 공유 계정을 관리하는 경우 토큰을 생성해야 합니다. 관리자는 조직과 연결된 모든 토큰을 생성, 보기 및 삭제할 수 있습니다.
사전 요구 사항
- 사용자 인증 정보
절차
Docker 로그인을 완료하기 위해 토큰을 생성하려면 다음을 수행합니다.
-
registry.redhat.io로 이동합니다. - RHN(Red Hat Network) 사용자 이름과 암호로 로그인합니다.
메시지가 표시되면 조건 수락.
- 즉시 약관을 수락하라는 메시지가 표시되지 않으면 다음 단계를 진행하면 메시지가 표시됩니다.
레지스트리 서비스 계정 페이지에서 서비스 계정 생성을클릭합니다.
- 서비스 계정의 이름을 입력합니다. 앞에 임의의 문자열이 붙습니다.
- 설명을 입력합니다.
- 생성을 클릭합니다.
- 서비스 계정으로 다시 이동합니다.
- 생성한 서비스 계정을 클릭합니다.
- 앞에 있는 문자열을 포함하여 사용자 이름을 복사합니다.
- 토큰을 복사합니다.
6.1.3. 설치 및 업그레이드를 위한 레지스트리 인증 정보 관리
Ansible 설치 프로그램을 사용하여 설치 또는 업그레이드 중에 레지스트리 자격 증명을 관리할 수도 있습니다.
이렇게 하면 다음 설정이 설정됩니다.
-
OpenShift 네임스페이스의
imagestreamsecret. - 모든 노드의 자격 증명.
openshift_examples_registryurl 또는 에 기본값 oreg_url registry.redhat.io 를 사용하는 경우 Ansible 설치 프로그램에서 자격 증명이 필요합니다.
사전 요구 사항
- 사용자 인증 정보
- 서비스 계정
- 서비스 계정 토큰
절차
Ansible 설치 프로그램을 사용하여 설치 또는 업그레이드 중에 레지스트리 인증 정보를 관리하려면 다음을 수행합니다.
-
설치 또는 업그레이드 중에 설치 프로그램 인벤토리에
oreg_auth_user및oreg_auth_password변수를 지정합니다.
토큰을 생성한 경우 oreg_auth_password 를 토큰 값으로 설정합니다.
인증된 추가 레지스트리에 액세스해야 하는 클러스터는 openshift_additional_registry_credentials 를 설정하여 레지스트리 목록을 구성할 수 있습니다. 각 레지스트리에는 host 및 password 값이 필요하며 user를 설정하여 사용자 이름을 지정할 수 있습니다. 기본적으로 지정된 인증 정보는 지정된 레지스트리에서 이미지 openshift3/ose-pod 를 검사하여 유효성을 검사합니다.
대체 이미지를 지정하려면 다음 중 하나를 수행합니다.
-
test_image를 설정합니다. -
test_login을 False로 설정하여 자격 증명 유효성 검사를 비활성화합니다.
레지스트리가 안전하지 않은 경우 tls_verify 를 False로 설정합니다.
이 목록의 모든 자격 증명에는 OpenShift 네임스페이스에서 생성된 imagestreamsecret 과 모든 노드에 배포된 자격 증명이 있습니다.
예를 들면 다음과 같습니다.
openshift_additional_registry_credentials=[{'host':'registry.example.com','user':'name','password':'pass1','test_login':'False'},{'host':'registry2.example.com','password':'token12345','tls_verify':'False','test_image':'mongodb/mongodb'}]6.1.4. Red Hat 레지스트리의 서비스 계정 사용
서비스 계정을 생성하고 Red Hat 레지스트리에 대해 생성된 토큰을 생성한 후에는 추가 작업을 수행할 수 있습니다.
이 섹션에서는 설치 및 업그레이드를 위한 레지스트리 자격 증명 관리 섹션에 설명된 인벤토리 변수를 제공하여 설치 중에 자동으로 수행할 수 있는 수동 단계를 제공합니다.
사전 요구 사항
- 사용자 인증 정보
- 서비스 계정
- 서비스 계정 토큰
절차
레지스트리 서비스 계정 페이지에서 계정 이름을 클릭합니다. 여기에서 다음 작업을 수행할 수 있습니다.
- 토큰 정보 탭에서 사용자 이름( 임의 문자열이 앞에 추가한 이름) 및 암호(토큰)를 볼 수 있습니다. 이 탭에서 토큰을 다시 생성할 수 있습니다.
OpenShift Secret 탭에서 다음을 수행할 수 있습니다.
- 탭에서 링크를 클릭하여 시크릿을 다운로드합니다.
클러스터에 보안을 제출합니다.
# oc create -f <account-name>-secret.yml --namespace=openshift다음과 같이
imagePullSecrets필드를 사용하여 Kubernetes Pod 구성에 보안에 대한 참조를 추가하여 Kubernetes 구성을 업데이트합니다.apiVersion: v1 kind: Pod metadata: name: somepod namespace: all spec: containers: - name: web image: registry.redhat.io/REPONAME imagePullSecrets: - name: <numerical-string-account-name>-pull-secret
Docker 로그인 탭에서
docker login을 실행할 수 있습니다. 예를 들면 다음과 같습니다.# docker login -u='<numerical-string|account-name>' -p=<token>성공적으로 로그인한 후
~/.docker/config.json을/var/lib/origin/.docker/config.json에 복사하고 노드를 다시 시작합니다.# cp -r ~/.docker /var/lib/origin/ systemctl restart atomic-openshift-nodeDocker 구성 탭에서 다음을 수행할 수 있습니다.
- 탭에서 링크를 클릭하여 자격 증명 구성을 다운로드합니다.
Docker 구성 디렉터리에 파일을 배치하여 디스크에 구성을 작성합니다. 이렇게 하면 기존 자격 증명을 덮어씁니다. 예를 들면 다음과 같습니다.
# mv <account-name>-auth.json ~/.docker/config.json
7장. 마스터 및 노드 구성
7.1. 설치 후 마스터 및 노드 구성 사용자 정의
openshift start 명령(마스터 서버용) 및 hyperkube 명령(노드 서버용)은 개발 또는 실험 환경에서 서버를 시작하기에 충분한 제한된 인수 세트를 사용합니다. 그러나 이러한 인수는 프로덕션 환경에 필요한 전체 구성 및 보안 옵션 세트를 설명하고 제어하는 데 충분하지 않습니다.
마스터 구성 파일, /etc/origin/master/master-config.yaml 및 노드 구성 맵에 이러한 옵션을 제공해야 합니다. 이러한 파일은 기본 플러그인 덮어쓰기, etcd에 연결, 서비스 계정 자동 생성, 이미지 이름 구축, 프로젝트 요청 사용자 지정, 볼륨 플러그인 구성 등의 옵션을 정의합니다.
이 주제에서는 OpenShift Container Platform 마스터 및 노드 호스트를 사용자 지정하는 데 사용할 수 있는 옵션에 대해 설명하고 설치 후 구성을 변경하는 방법을 보여줍니다.
이러한 파일은 기본값 없이 완전히 지정됩니다. 따라서 빈 값은 해당 매개 변수에 빈 값으로 시작하려고 함을 나타냅니다. 이렇게 하면 구성이 정확히 무엇인지 쉽게 이유할 수 있지만 지정할 모든 옵션을 기억하기가 어렵습니다. 이를 용이하게 하기 위해 --write-config 옵션으로 구성 파일을 만든 다음 --config 옵션과 함께 사용할 수 있습니다 .
7.2. 설치 종속성
프로덕션 환경은 표준 클러스터 설치 프로세스를 사용하여 설치해야 합니다. 프로덕션 환경에서는 HA(고가용성 )의 목적으로 여러 마스터를 사용하는 것이 좋습니다. 마스터 3개로 구성된 클러스터 아키텍처를 사용하는 것이 권장되며, HAproxy 가 권장되는 솔루션입니다.
마스터 호스트에 etcd가 설치된 경우 etcd가 권한이 있는 마스터를 결정할 수 없기 때문에 3개 이상의 마스터를 사용하도록 클러스터를 구성해야 합니다. 마스터 두 개만 성공적으로 실행하는 유일한 방법은 마스터 이외의 호스트에 etcd를 설치하는 것입니다.
7.3. 마스터 및 노드 구성
마스터 및 노드 구성 파일을 구성하는 데 사용하는 방법은 OpenShift Container Platform 클러스터를 설치하는 데 사용된 방법과 일치해야 합니다. 표준 클러스터 설치 프로세스를 수행한 경우 Ansible 인벤토리 파일에서 구성을 변경합니다.
7.4. Ansible을 사용하여 구성 변경
이 섹션에서는 Ansible에 대해 익숙한 것으로 가정합니다.
사용 가능한 호스트 구성 옵션의 일부만 Ansible에 노출됩니다. OpenShift Container Platform을 설치한 후 Ansible은 대체된 일부 값을 사용하여 인벤토리 파일을 생성합니다. 이 인벤토리 파일을 수정하고 Ansible 설치 프로그램 플레이북을 다시 실행하는 방법은 OpenShift Container Platform 클러스터를 사용자 지정하는 방법입니다.
OpenShift Container Platform은 Ansible 플레이북 및 인벤토리 파일을 사용하여 클러스터 설치를 위해 Ansible 사용을 지원하지만 Puppet,Chef 또는 Salt 등의 다른 관리 툴도 사용할 수 있습니다.
사용 사례: HTPasswd 인증을 사용하도록 클러스터 구성
- 이 사용 사례에서는 플레이북에서 참조하는 모든 노드에 SSH 키를 이미 설정했다고 가정합니다.
htpasswd유틸리티는httpd-tools패키지에 있습니다.# yum install httpd-tools
Ansible 인벤토리를 수정하고 구성을 변경하려면 다음을 수행합니다.
- ./hosts 인벤토리 파일을 엽니다.
파일의
[OSEv3:vars]섹션에 다음 새 변수를 추가합니다.# htpasswd auth openshift_master_identity_providers=[{'name': 'htpasswd_auth', 'login': 'true', 'challenge': 'true', 'kind': 'HTPasswdPasswordIdentityProvider'}] # Defining htpasswd users #openshift_master_htpasswd_users={'<name>': '<hashed-password>', '<name>': '<hashed-password>'} # or #openshift_master_htpasswd_file=/etc/origin/master/htpasswdHTPasswd 인증의 경우
openshift_master_identity_providers변수는 인증 유형을 활성화합니다. HTPasswd를 사용하는 세 가지 인증 옵션을 구성할 수 있습니다.-
/etc/origin/만 지정합니다.master/htpasswd가 이미 구성되어 있으며 호스트에 있는 경우 openshift_master_identity_providers -
로컬 htpasswd 파일을 호스트에 복사하려면
openshift_master_identity을 둘 다 지정합니다._providers및 openshift_master_htpasswd_file -
openshift_master_identity_providers및openshift_master_htpasswd_users를 둘 다 지정하여 호스트에서 새 htpasswd 파일을 생성합니다.
OpenShift Container Platform에는 HTPasswd 인증을 구성하는 데 해시된 암호가 필요하므로 다음 섹션에 표시된 대로
htpasswd명령을 사용하여 사용자의 해시된 암호를 생성하거나 사용자와 연결된 해시된 암호를 사용하여 플랫 파일을 생성할 수 있습니다.다음 예제에서는 인증 방법을 기본에서
모든 설정을 거부하고, 지정된 파일을사용하여jsmith및bloblaw사용자에 대한 사용자 ID 및 암호를 생성합니다.# htpasswd auth openshift_master_identity_providers=[{'name': 'htpasswd_auth', 'login': 'true', 'challenge': 'true', 'kind': 'HTPasswdPasswordIdentityProvider'}] # Defining htpasswd users openshift_master_htpasswd_users={'jsmith': '$apr1$wIwXkFLI$bAygtKGmPOqaJftB', 'bloblaw': '7IRJ$2ODmeLoxf4I6sUEKfiA$2aDJqLJe'} # or #openshift_master_htpasswd_file=/etc/origin/master/htpasswd-
이러한 수정 사항을 적용하기 위해 ansible 플레이북을 다시 실행합니다.
$ ansible-playbook -b -i ./hosts ~/src/openshift-ansible/playbooks/deploy_cluster.yml플레이북은 구성을 업데이트하고 OpenShift Container Platform 마스터 서비스를 다시 시작하여 변경 사항을 적용합니다.
이제 Ansible을 사용하여 마스터 및 노드 구성 파일을 수정했지만 간단한 사용 사례일 뿐입니다. 여기에서 Ansible에 노출되는 마스터 및 노드 구성 옵션을 확인하고 고유한 Ansible 인벤토리를 사용자 지정할 수 있습니다.
7.4.1. htpasswd 명령 사용
HTPasswd 인증을 사용하도록 OpenShift Container Platform 클러스터를 구성하려면 인벤토리 파일에 포함하려면 해시된 암호가 있는 사용자가 하나 이상 필요합니다.
다음을 수행할 수 있습니다.
- 사용자 이름과 암호를 생성하여 ./hosts 인벤토리 파일에 직접 추가합니다.
- 플랫 파일을 만들어 자격 증명을 ./hosts 인벤토리 파일에 전달합니다.
사용자 및 해시된 암호를 생성하려면 다음을 수행합니다.
다음 명령을 실행하여 지정된 사용자를 추가합니다.
$ htpasswd -n <user_name>참고명령줄에 암호를 제공하기 위해
-b옵션을 포함할 수 있습니다.$ htpasswd -nb <user_name> <password>사용자에 대해 일반 텍스트 암호를 입력하고 확인합니다.
예를 들면 다음과 같습니다.
$ htpasswd -n myuser New password: Re-type new password: myuser:$apr1$vdW.cI3j$WSKIOzUPs6Q이 명령에서는 해시된 버전의 암호를 생성합니다.
그런 다음 HTPasswd 인증을 구성할 때 해시된 암호를 사용할 수 있습니다. 해시된 암호는 : 뒤에 있는 문자열입니다. 위의 예에서 다음을 입력합니다.
openshift_master_htpasswd_users={'myuser': '$apr1$wIwXkFLI$bAygtISk2eKGmqaJftB'}사용자 이름과 해시된 암호로 플랫 파일을 생성하려면 다음을 수행합니다.
다음 명령을 실행합니다.
$ htpasswd -c /etc/origin/master/htpasswd <user_name>참고명령줄에 암호를 제공하기 위해
-b옵션을 포함할 수 있습니다.$ htpasswd -c -b <user_name> <password>사용자에 대해 일반 텍스트 암호를 입력하고 확인합니다.
예를 들면 다음과 같습니다.
htpasswd -c /etc/origin/master/htpasswd user1 New password: Re-type new password: Adding password for user user1명령은 사용자 이름과 해시된 사용자 암호의 버전을 포함하는 파일을 생성합니다.
그런 다음 HTPasswd 인증을 구성할 때 암호 파일을 사용할 수 있습니다.
htpasswd 명령에 대한 자세한 내용은 HTPasswd Identity Provider 를 참조하십시오.
7.5. 수동 구성 변경
사용 사례: HTPasswd 인증을 사용하도록 클러스터 구성
구성 파일을 수동으로 수정하려면 다음을 수행합니다.
- 수정할 구성 파일을 엽니다. 이 경우에는 /etc/origin/master/master-config.yaml 파일입니다.
파일의
identityProviders스탠자에 다음 새 변수를 추가합니다.oauthConfig: ... identityProviders: - name: my_htpasswd_provider challenge: true login: true mappingMethod: claim provider: apiVersion: v1 kind: HTPasswdPasswordIdentityProvider file: /etc/origin/master/htpasswd- 변경 사항을 저장하고 파일을 종료합니다.
변경 사항을 적용하려면 마스터를 다시 시작하십시오.
# master-restart api # master-restart controllers
이제 마스터와 노드 구성 파일을 수동으로 수정했지만 간단한 사용 사례일 뿐입니다. 여기에서 모든 마스터 및 노드 구성 옵션을 확인하고 추가 수정을 수행하여 자체 클러스터를 추가로 사용자 지정할 수 있습니다.
클러스터에서 노드를 수정하려면 필요에 따라 노드 구성 맵을 업데이트합니다. node-config.yaml 파일을 수동으로 편집하지 마십시오.
7.6. 마스터 구성 파일
이 섹션에서는 master-config.yaml 파일에 언급된 매개변수를 검토합니다.
새 마스터 구성 파일을 생성하여 설치된 OpenShift Container Platform 버전에 유효한 옵션을 확인할 수 있습니다.
master-config.yaml 파일을 수정할 때마다 변경 사항을 적용하려면 마스터를 다시 시작해야 합니다. OpenShift Container Platform 서비스 재시작을 참조하십시오.
7.6.1. 승인 제어 구성
| 매개변수 이름 | 설명 |
|---|---|
|
| 승인 제어 플러그인 구성이 포함되어 있습니다. OpenShift Container Platform에는 API 오브젝트를 생성하거나 수정할 때마다 트리거되는 승인 컨트롤러 플러그인의 구성 가능한 목록이 있습니다. 이 옵션을 사용하면 기본 플러그인 목록을 재정의할 수 있습니다(예: 일부 플러그인 비활성화, 다른 플러그인 추가, 순서 변경, 구성 지정). 플러그인 목록과 해당 구성은 모두 Ansible에서 제어할 수 있습니다. |
|
|
API 서버의 명령줄 인수와 일치하는 Kube API 서버로 직접 전달될 키-값 쌍입니다. 이러한 값은 마이그레이션되지 않지만 존재하지 않는 값을 참조하면 서버가 시작되지 않습니다. 이러한 값은 |
|
|
컨트롤러 관리자의 명령줄 인수와 일치하는 Kube 컨트롤러 관리자에 직접 전달될 키-값 쌍입니다. 이러한 값은 마이그레이션되지 않지만 존재하지 않는 값을 참조하면 서버가 시작되지 않습니다. 이러한 값은 |
|
|
다양한 승인 플러그인을 활성화하거나 비활성화하는 데 사용됩니다. 이 유형이 |
|
| 승인 제어 플러그인별로 구성 파일을 지정할 수 있습니다. |
|
| 마스터에 설치할 승인 제어 플러그인 이름 목록입니다. 순서가 매우 중요합니다. 비어 있는 경우 기본 플러그인 목록이 사용됩니다. |
|
|
스케줄러의 명령줄 인수와 일치하는 Kube 스케줄러로 직접 전달할 키-값 쌍입니다. 이러한 값은 마이그레이션되지 않지만 존재하지 않는 값을 참조하면 서버가 시작되지 않습니다. 이러한 값은 |
7.6.2. 자산 구성
| 매개변수 이름 | 설명 |
|---|---|
|
| 해당하는 경우 자산 서버는 정의된 매개 변수를 기반으로 시작됩니다. 예를 들면 다음과 같습니다. |
|
|
다른 호스트 이름을 사용하여 웹 애플리케이션에서 API 서버에 액세스하려면 구성 필드에 |
|
| 시작할 수 없는 기능 목록입니다. 이 값을 null 로 설정할 수 있습니다. 누구나 기능을 수동으로 비활성화하고 권장되지 않는 경우가 많습니다. |
|
| 하위 컨텍스트 아래에 있는 자산 서버 파일 시스템에서 제공할 파일입니다. |
|
| true 로 설정하면 자산 서버에 시작 시가 아닌 모든 요청에 대해 확장 스크립트 및 스타일시트를 다시 로드하도록 지시합니다. 서버를 변경할 때마다 서버를 다시 시작하지 않고도 확장 프로그램을 개발할 수 있습니다. |
|
|
글로벌 변수 |
|
| 웹 콘솔이 로드될 때 스크립트로 로드할 자산 서버 파일의 파일 경로입니다. |
|
| 웹 콘솔이 로드될 때 스타일 시트로 로드할 자산 서버 파일의 파일 경로입니다. |
|
| 로깅을 위한 공용 엔드포인트(선택 사항). |
|
| 웹 콘솔에서 로그아웃한 후 웹 브라우저를 로 리디렉션하는 절대 URL(선택 사항)입니다. 지정하지 않으면 기본 제공 로그아웃 페이지가 표시됩니다. |
|
| 웹 콘솔에서 OpenShift Container Platform 서버에 액세스하는 방법. |
|
| 지표의 공용 엔드포인트(선택 사항). |
|
| 자산 서버의 URL입니다. |
7.6.3. 인증 및 권한 부여 구성
| 매개변수 이름 | 설명 |
|---|---|
|
| 인증 및 권한 부여 구성 옵션이 있습니다. |
|
| 는 캐시해야 하는 인증 결과 수를 나타냅니다. 0인 경우 기본 캐시 크기가 사용됩니다. |
|
| 권한 부여 결과를 캐시해야 하는 기간을 나타냅니다. 유효한 기간 문자열(예:)이 사용됩니다. "5m"). 비어 있는 경우 기본 시간 초과가 발생합니다. 0인 경우(예:). "0m"), 캐싱이 비활성화됩니다. |
7.6.4. 컨트롤러 구성
| 매개변수 이름 | 설명 |
|---|---|
|
|
시작해야 하는 컨트롤러 목록입니다. none 으로 설정하면 자동으로 시작되지 않습니다. 기본값은 *이며 모든 컨트롤러를 시작합니다. *를 사용할 때는 이름 앞에 |
|
|
컨트롤러 선택을 활성화하여 마스터에 컨트롤러가 시작되기 전에 리스를 획득하고 이 값으로 정의된 몇 초 내에 갱신하도록 지시합니다. 이 값을 부정적으로 설정하면 |
|
| 마스터에 컨트롤러를 자동으로 시작하지 않도록 지시하지만, 대신 서버에 대한 알림이 수신될 때까지 기다린 후 이를 시작하도록 지시합니다. |
7.6.5. etcd 구성
| 매개변수 이름 | 설명 |
|---|---|
|
| etcd에 대한 클라이언트 연결에 대해 공개된 host:port입니다. |
|
| etcd에 연결하는 방법에 대한 정보가 포함되어 있습니다. etcd가 임베디드 또는 임베드되지 않은 것으로 실행되는지 여부 및 호스트를 지정합니다. 나머지 구성은 Ansible 인벤토리에서 처리합니다. 예를 들면 다음과 같습니다. |
|
| 해당하는 경우 정의된 매개변수를 기반으로 etcd가 시작됩니다. 예를 들면 다음과 같습니다. |
|
| API 리소스가 etcd에 저장되는 방법에 대한 정보가 포함되어 있습니다. 이러한 값은 etcd가 클러스터의 백업 저장소인 경우에만 관련이 있습니다. |
|
| Kubernetes 리소스가 루트로 제공될 etcd 내 경로입니다. 이 값은 변경되는 경우 etcd 의 기존 개체가 더 이상 존재하지 않음을 의미합니다. 기본값은 kubernetes.io 입니다. |
|
| etcd 의 Kubernetes 리소스를 직렬화해야 하는 API 버전입니다. 이 값은 etcd에서 읽은 모든 클라이언트에 새 버전을 읽을 수 있는 코드가 있어야 합니다. |
|
| OpenShift Container Platform 리소스가 루트로 제공될 etcd 내 경로입니다. 이 값은 변경되는 경우 etcd의 기존 개체가 더 이상 존재하지 않음을 의미합니다. 기본값은 openshift.io 입니다. |
|
| etcd 의 OS 리소스를 직렬화해야 하는 API 버전입니다. 이 값은 etcd 에서 읽은 모든 클라이언트에 새 버전을 읽을 수 있는 코드가 있어야 합니다. |
|
| etcd 에 대한 피어 연결의 공개된 host:port입니다. |
|
| etcd 피어 서비스를 시작하는 방법을 설명합니다. |
|
| 서비스 제공을 시작하는 방법을 설명합니다. 예를 들면 다음과 같습니다. |
|
| etcd 스토리지 디렉터리의 경로입니다. |
7.6.6. 설정 부여
| 매개변수 이름 | 설명 |
|---|---|
|
| 보조금 처리 방법을 설명합니다. |
|
| 클라이언트 권한 부여 요청을 자동 승인합니다. |
|
| 클라이언트 권한 부여 요청을 자동 거부합니다. |
|
| 사용자에게 새 클라이언트 권한 부여 요청을 승인하라는 메시지를 표시합니다. |
|
| OAuth 클라이언트가 부여를 요청할 때 사용할 기본 전략을 결정합니다.이 방법은 특정 OAuth 클라이언트가 자체 전략을 제공하지 않는 경우에만 사용됩니다. 유효한 권한 부여 처리 방법은 다음과 같습니다.
|
7.6.7. 이미지 설정
| 매개변수 이름 | 설명 |
|---|---|
|
| 시스템 구성 요소에 대해 빌드할 이름의 형식입니다. |
|
| 레지스트리에서 latest 태그를 가져올지 여부를 결정합니다. |
7.6.8. 이미지 정책 구성
| 매개변수 이름 | 설명 |
|---|---|
|
| 비활성화할 이미지의 예약된 백그라운드 가져오기를 허용합니다. |
|
| 사용자가 Docker 리포지토리를 대량으로 가져올 때 가져오는 이미지 수를 제어합니다. 사용자가 실수로 많은 이미지를 가져오지 못하도록 하려면 이 숫자는 기본값 5로 설정됩니다. 제한 없이 -1 을 설정합니다. |
|
| 분당 백그라운드로 가져올 예약된 최대 이미지 스트림 수입니다. 기본값은 60입니다. |
|
| 백그라운드 가져오기로 예약된 이미지 스트림을 업스트림 리포지토리에 대해 확인할 수 있는 최소 시간(초)입니다. 기본값은 15분입니다. |
|
| 일반 사용자가 이미지를 가져올 수 있는 Docker 레지스트리를 제한합니다. 이 목록을 유효한 Docker 이미지를 포함하고 싶은 레지스트리로 설정하고 애플리케이션을 가져올 수 있도록 설정합니다. 이미지 또는 API를 통해 ImageStreamMappings를 생성할 수 있는 사용자는 이 정책의 영향을 받지 않습니다. 일반적으로 관리자 또는 시스템 통합에만 이러한 권한이 부여됩니다. |
|
| 이미지 스트림 가져오기 중에 신뢰할 수 있는 추가 인증 기관을 나열하는 PEM 인코딩 파일에 대한 파일 경로를 지정합니다. 이 파일은 API 서버 프로세스에서 액세스할 수 있어야 합니다. 클러스터 설치 방법에 따라 파일을 API 서버 포드에 마운트해야 할 수 있습니다. |
|
|
기본 내부 이미지 레지스트리의 호스트 이름을 설정합니다. 값은 |
|
|
ExternalRegistryHostname은 기본 외부 이미지 레지스트리의 호스트 이름을 설정합니다. 외부 호스트 이름은 이미지 레지스트리가 외부에 노출되는 경우에만 설정되어야 합니다. 값은 ImageStreams의 |
7.6.9. Kubernetes 마스터 구성
| 매개변수 이름 | 설명 |
|---|---|
|
| 시작 시 활성화해야 하는 API 수준 목록, 예제로 v1. |
|
|
그룹을 비활성화해야 하는 버전(또는 |
|
| kubelet에 연결하는 방법에 대한 정보가 포함되어 있습니다. |
|
| kubelet의 KubernetesMasterConfig에 연결하는 방법에 대한 정보가 포함되어 있습니다. 해당하는 경우 이 프로세스로 kubernetes 마스터를 시작합니다. |
|
| 실행해야 하는 예상 마스터 수입니다. 이 값은 기본값은 1이며 양의 정수로 설정되거나 -1로 설정된 경우 클러스터의 일부임을 나타냅니다. |
|
|
Kubernetes 리소스의 공용 IP 주소입니다. 비어 있는 경우 |
|
| 이 노드를 마스터에 연결하는 방법을 설명하는 .kubeconfig 파일의 파일 이름입니다. |
|
|
실패한 노드에서 Pod를 삭제하기 위한 유예 기간을 제어합니다. 유효한 기간 문자열을 사용합니다. 비어 있는 경우 기본 Pod 제거 시간 초과가 발생합니다. 기본값은 |
|
| Pod로 프록시할 때 사용할 클라이언트 인증서/키를 지정합니다. 예: |
|
| 호스트에서 서비스 공용 포트를 할당하는 데 사용할 범위입니다. 기본값 30000-32767. |
|
| 서비스 IP 할당에 사용할 서브넷입니다. |
|
| 정적으로 알려진 노드 목록입니다. |
7.6.10. 네트워크 설정
IPv4 주소 공간은 노드의 모든 사용자가 공유하므로 다음 매개 변수에서 CIDR을 신중하게 선택합니다. OpenShift Container Platform은 IPv4 주소 공간의 CIDR을 자체적으로 사용할 수 있도록 예약하고 외부 사용자와 클러스터 간에 공유되는 주소를 위해 IPv4 주소 공간의 CIDR을 예약합니다.
| 매개변수 이름 | 설명 |
|---|---|
|
| 글로벌 오버레이 네트워크의 L3 공간을 지정하는 CIDR 문자열입니다. 이는 클러스터 네트워킹의 내부용으로 예약되어 있습니다. |
|
|
서비스 외부 IP 필드에 허용되는 값을 제어합니다. 비어 있는 경우 |
|
| 각 호스트의 서브넷에 할당할 비트 수입니다. 예를 들어 8은 호스트의 /24 네트워크를 의미합니다. |
|
|
베어 메탈의 LoadBalancer 유형의 서비스에 대해 수신 IP를 할당하는 범위를 제어합니다. 할당될 단일 CIDR이 포함될 수 있습니다. 기본적으로 |
|
| 각 호스트의 서브넷에 할당할 비트 수입니다. 예를 들어 8은 호스트의 /24 네트워크를 의미합니다. |
|
| 컴파일된 네트워크 플러그인으로 전달하려면 다음을 수행합니다. 여기에 있는 대부분의 옵션은 Ansible 인벤토리에서 제어할 수 있습니다.
예를 들면 다음과 같습니다. |
|
| 사용할 네트워크 플러그인의 이름입니다. |
|
| 서비스 네트워크를 지정하는 CIDR 문자열입니다. |
7.6.11. OAuth 인증 구성
| 매개변수 이름 | 설명 |
|---|---|
|
| 단일 공급업체만 있는 경우에도 프로바이더 선택 페이지가 렌더링되도록 강제 적용합니다. |
|
| 외부 액세스를 위해 유효한 클라이언트 리디렉션 URL을 구축하는 데 사용됩니다. |
|
| 인증 중 오류 페이지를 렌더링하거나 흐름을 부여하는 데 사용되는 이동 템플릿이 포함된 파일의 경로입니다. 지정되지 않은 경우 기본 오류 페이지가 사용됩니다. |
|
| 사용자가 자신을 식별할 수 있는 순서가 지정된 방법 목록. |
|
| 로그인 페이지를 렌더링하는 데 사용되는 이동 템플릿이 포함된 파일의 경로입니다. 지정되지 않은 경우 기본 로그인 페이지가 사용됩니다. |
|
|
|
|
| 외부 액세스를 위해 유효한 클라이언트 리디렉션 URL을 구축하는 데 사용됩니다. |
|
| 액세스 토큰의 권한 부여 코드를 교환하도록 server-to-server 호출을 만드는 데 사용됩니다. |
|
| 해당하는 경우 정의된 매개 변수를 기반으로 /oauth 엔드포인트가 시작됩니다. 예를 들면 다음과 같습니다. |
|
| 로그인 페이지와 같은 페이지를 사용자 지정할 수 있습니다. |
|
| 공급자 선택 페이지를 렌더링하는 데 사용되는 이동 템플릿을 포함하는 파일의 경로입니다. 지정되지 않은 경우 기본 공급자 선택 페이지가 사용됩니다. |
|
| 세션 구성에 대한 정보를 보유합니다. |
|
| 로그인 페이지와 같은 페이지를 사용자 지정할 수 있습니다. |
|
| 권한 부여 및 액세스 토큰에 대한 옵션이 포함되어 있습니다. |
7.6.12. 프로젝트 설정
| 매개변수 이름 | 설명 |
|---|---|
|
| 기본 프로젝트 노드 레이블 선택기가 있습니다. |
|
| 프로젝트 생성 및 기본값에 대한 정보가 있습니다.
|
|
| 프로젝트 요청 API 엔드포인트를 통해 프로젝트를 요청할 수 없는 경우 사용자에게 제공되는 문자열입니다. |
|
| projectrequest 에 응답하여 프로젝트를 생성하는 데 사용할 템플릿입니다. 이는 namespace/template 형식이며 선택 사항입니다. 지정하지 않으면 기본 템플릿이 사용됩니다. |
7.6.13. 스케줄러 구성
| 매개변수 이름 | 설명 |
|---|---|
|
| 스케줄러 설정 방법을 설명하는 파일을 가리킵니다. 비어 있는 경우 기본 스케줄링 규칙을 가져옵니다. |
7.6.14. 보안 할당자 설정
| 매개변수 이름 | 설명 |
|---|---|
|
|
네임스페이스에 할당할 MCS 카테고리 범위를 정의합니다. 형식은 |
|
| 프로젝트에 대한 UID 및 MCS 라벨의 자동 할당을 제어합니다. nil인 경우 할당이 비활성화됩니다. |
|
| 프로젝트에 자동으로 할당할 전체 Unix 사용자 ID(UID)와 각 네임스페이스가 가져오는 블록 크기를 정의합니다. 예를 들어 1000-1999/10은 네임스페이스당 10개의 UID를 할당하며 공간이 부족하기 전에 최대 100개의 블록을 할당할 수 있습니다. 기본값은 10k 블록의 10억에서 20억 개(사용자 네임스페이스가 시작된 후 컨테이너 이미지의 예상되는 크기)에서 할당하는 것입니다. |
7.6.15. 서비스 계정 구성
| 매개변수 이름 | 설명 |
|---|---|
|
| 서비스 계정이 명시적으로 참조하지 않고 네임스페이스의 보안을 참조할 수 있는지 여부를 제어합니다. |
|
|
모든 네임스페이스에서 자동으로 생성될 서비스 계정 이름 목록입니다. 이름을 지정하지 않으면 |
|
| TLS 연결을 마스터로 다시 확인하는 CA입니다. 서비스 계정 컨트롤러는 마스터 연결을 확인할 수 있도록 이 파일의 콘텐츠를 포드에 자동으로 삽입합니다. |
|
|
서비스 계정 토큰에 서명하는 데 사용되는 PEM 인코딩 개인 RSA 키가 포함된 파일입니다. 개인 키가 지정되지 않은 경우 서비스 계정 |
|
| 각각 PEM 인코딩 공개 RSA 키가 포함된 파일 목록입니다. 파일에 개인 키가 포함된 경우 키의 공용 부분이 사용됩니다. 공개 키 목록은 제시된 서비스 계정 토큰을 확인하는 데 사용됩니다. 각 키는 목록이 고갈되거나 확인이 성공할 때까지 순서대로 시도됩니다. 키가 지정되지 않은 경우 서비스 계정 인증을 사용할 수 없습니다. |
|
| 서비스 계정과 관련된 옵션이 있습니다.
|
7.6.16. 정보 구성 제공
| 매개변수 이름 | 설명 |
|---|---|
|
| 마스터의 DNS 서버가 쿼리에 반복적으로 응답하도록 허용합니다. 열린 확인자는 DNS 증폭 공격에 사용할 수 있으며 마스터 DNS는 공용 네트워크에서 액세스할 수 없어야 합니다. |
|
| 제공할 ip:port 입니다. |
|
| 이미지 가져오기를 위한 제한 및 동작을 제어합니다. |
|
| PEM 인코딩 인증서가 포함된 파일입니다. |
|
| 보안 트래픽 제공을 위한 TLS 인증서 정보. |
|
| 들어오는 클라이언트 인증서를 인식하는 모든 서명자의 인증서 번들입니다. |
|
| 해당하는 경우 정의된 매개 변수를 기반으로 DNS 서버를 시작합니다. 예를 들면 다음과 같습니다. |
|
| 도메인 접미사가 있습니다. |
|
| IP를 보유합니다. |
|
|
|
|
| 마스터 연결에 사용되는 클라이언트 연결에 대한 재정의를 제공합니다. 이 매개변수는 지원되지 않습니다. QPS 및 버스트 값을 설정하려면 노드 QPS 및 버스트 값 설정을 참조하십시오. |
|
| 서버에 허용되는 동시 요청 수입니다. 0인 경우 제한 없음. |
|
| 특정 호스트 이름에 대한 요청을 보호하는 데 사용할 인증서 목록입니다. |
|
| 요청의 시간 초과 전 시간(초)입니다. 기본값은 60분입니다. -1인 경우 요청에 제한이 없습니다. |
|
| 자산에 대한 HTTP 제공 정보. |
7.6.17. 볼륨 설정
| 매개변수 이름 | 설명 |
|---|---|
|
| 동적 프로비저닝을 활성화하거나 비활성화하는 부울입니다. 기본값은 true 입니다. |
| FSGroup |
각 FSGroup의 각 노드에서 로컬 스토리지 할당량 을 활성화합니다. 현재 이는 emptyDir 볼륨에 대해서만 구현되며 기본 |
|
| 마스터 노드에서 볼륨 플러그인을 구성하는 옵션이 포함되어 있습니다. |
|
| 노드에 볼륨을 구성하는 옵션이 포함되어 있습니다. |
|
| 노드에 볼륨 플러그인을 구성하는 옵션이 포함되어 있습니다.
|
|
|
볼륨이 에 저장된 디렉터리입니다. 이 값을 변경하려면 |
7.6.18. 기본 감사
감사는 개별 사용자, 관리자 또는 시스템의 기타 구성 요소가 시스템에 영향을 준 활동 시퀀스를 설명하는 보안 관련 레코드 집합을 제공합니다.
감사는 API 서버 수준에서 작동하며 서버로 들어오는 모든 요청을 기록합니다. 각 감사 로그에는 두 개의 항목이 포함되어 있습니다.
다음이 포함된 요청 행입니다.
- 응답 행과 일치시킬 수 있는 고유 ID ( #2 참조)
- 요청의 소스 IP
- HTTP 메서드가 호출되고 있습니다.
- 작업을 호출하는 원래 사용자
-
가장된 작업 사용자 (
자체의미) -
가장된 작업 그룹 (룩
업의미 사용자 그룹) - 요청 또는 <none>의 네임스페이스
- 요청된 URI
다음이 포함된 응답 행:
- #1의 고유 ID
- 응답 코드
사용자 admin 에서 Pod 목록을 요청하는 출력의 예:
AUDIT: id="5c3b8227-4af9-4322-8a71-542231c3887b" ip="127.0.0.1" method="GET" user="admin" as="<self>" asgroups="<lookup>" namespace="default" uri="/api/v1/namespaces/default/pods"
AUDIT: id="5c3b8227-4af9-4322-8a71-542231c3887b" response="200"7.6.18.1. 기본 감사 활성화
다음 절차에서는 기본 감사 후 설치를 활성화합니다.
고급 감사는 설치 중에 활성화해야 합니다.
다음 예와 같이 모든 마스터 노드에서 /etc/origin/master/master-config.yaml 파일을 편집합니다.
auditConfig: auditFilePath: "/var/log/origin/audit-ocp.log" enabled: true maximumFileRetentionDays: 14 maximumFileSizeMegabytes: 500 maximumRetainedFiles: 15클러스터에서 API Pod를 재시작합니다.
# /usr/local/bin/master-restart api
설치 중에 기본 감사를 활성화하려면 다음 변수 선언을 인벤토리 파일에 추가합니다. 값을 적절하게 조정합니다.
openshift_master_audit_config={"enabled": true, "auditFilePath": "/var/lib/origin/openpaas-oscp-audit.log", "maximumFileRetentionDays": 14, "maximumFileSizeMegabytes": 500, "maximumRetainedFiles": 5}감사 구성은 다음 매개변수를 사용합니다.
| 매개변수 이름 | 설명 |
|---|---|
|
|
감사 로그를 활성화하거나 비활성화하는 부울입니다. 기본값은 |
|
| 요청을 로깅해야 하는 파일 경로입니다. 설정되지 않으면 로그가 마스터 로그에 인쇄됩니다. |
|
| 파일 이름에 인코딩된 타임스탬프를 기반으로 이전 감사 로그 파일을 유지하는 최대 기간(일)을 지정합니다. |
|
| 유지할 이전 감사 로그 파일의 최대 수를 지정합니다. |
|
| 순환되기 전에 로그 파일의 최대 크기(MB)를 지정합니다. 기본값은 100MB입니다. |
감사 구성 예
auditConfig:
auditFilePath: "/var/log/origin/audit-ocp.log"
enabled: true
maximumFileRetentionDays: 14
maximumFileSizeMegabytes: 500
maximumRetainedFiles: 15
auditFilePath 매개변수를 정의하면 디렉터리가 없는 경우 생성됩니다.
7.6.19. 고급 감사
고급 감사 기능은 세부적인 이벤트 필터링 및 여러 출력 백엔드를 포함하여 기본 감사 기능에 비해 몇 가지 개선 사항을 제공합니다.
고급 감사 기능을 활성화하려면 감사 정책 파일을 생성하고 openshift_master_audit_ config 및 매개변수에 다음 값을 지정합니다.
openshift_master_audit _policyfile
openshift_master_audit_config={"enabled": true, "auditFilePath": "/var/log/origin/audit-ocp.log", "maximumFileRetentionDays": 14, "maximumFileSizeMegabytes": 500, "maximumRetainedFiles": 5, "policyFile": "/etc/origin/master/adv-audit.yaml", "logFormat":"json"}
openshift_master_audit_policyfile="/<path>/adv-audit.yaml"클러스터를 설치하고 클러스터 인벤토리 파일에 위치를 지정하기 전에 adv-audit.yaml 파일을 생성해야 합니다.
다음 테이블에는 사용할 수 있는 추가 옵션이 나와 있습니다.
| 매개변수 이름 | 설명 |
|---|---|
|
| 감사 정책 구성을 정의하는 파일의 경로입니다. |
|
| 포함된 감사 정책 구성. |
|
|
저장된 감사 로그의 형식을 지정합니다. 허용되는 값은 |
|
|
이벤트가 전송되는 감사 Webhook 구성을 정의하는 |
|
|
감사 이벤트를 보내는 전략을 지정합니다. 허용되는 값은 |
고급 감사 기능을 활성화하려면 감사 정책 규칙을 설명하는 policyFile 또는 policyConfiguration 을 제공해야 합니다.
감사 정책 구성 샘플
apiVersion: audit.k8s.io/v1beta1
kind: Policy
rules:
# Do not log watch requests by the "system:kube-proxy" on endpoints or services
- level: None
users: ["system:kube-proxy"]
verbs: ["watch"]
resources:
- group: ""
resources: ["endpoints", "services"]
# Do not log authenticated requests to certain non-resource URL paths.
- level: None
userGroups: ["system:authenticated"]
nonResourceURLs:
- "/api*" # Wildcard matching.
- "/version"
# Log the request body of configmap changes in kube-system.
- level: Request
resources:
- group: "" # core API group
resources: ["configmaps"]
# This rule only applies to resources in the "kube-system" namespace.
# The empty string "" can be used to select non-namespaced resources.
namespaces: ["kube-system"]
# Log configmap and secret changes in all other namespaces at the metadata level.
- level: Metadata
resources:
- group: "" # core API group
resources: ["secrets", "configmaps"]
# Log all other resources in core and extensions at the request level.
- level: Request
resources:
- group: "" # core API group
- group: "extensions" # Version of group should NOT be included.
# A catch-all rule to log all other requests at the Metadata level.
- level: Metadata
# Log login failures from the web console or CLI. Review the logs and refine your policies.
- level: Metadata
nonResourceURLs:
- /login*
- /oauth* - 1 8
- 모든 이벤트를 로깅할 수 있는 네 가지 레벨은 다음과 같습니다.
-
none- 이 규칙과 일치하는 이벤트를 기록하지 마십시오. -
메타데이터- 요청 메타데이터(사용자, 타임스탬프, 리소스, 동사 등)를 로그하지만 요청 또는 응답 본문은 제공하지 않습니다. 이 수준은 기본 감사에서 사용되는 것과 동일한 수준입니다. -
request
-이벤트 메타데이터 및 요청 본문을 기록하지만 응답 본문은 기록하지 않습니다. -
RequestResponse- 이벤트 메타데이터, 요청 및 응답 본문을 기록합니다.
-
- 2
- 규칙이 적용되는 사용자 목록입니다. 빈 목록은 모든 사용자를 의미합니다.
- 3
- 이 규칙이 적용되는 동사 목록입니다. 빈 목록은 모든 동사를 의미합니다. API 요청(
get,list,watch,create,update,patch, delete,deletecollection, proxy 등)과 관련된 Kubernetes 동사입니다. - 4
- 규칙이 적용되는 리소스 목록입니다. 빈 목록은 모든 리소스를 의미합니다. 각 리소스는 Kubernetes 코어 API, 배치, build.openshift.io 등에 대한 빈 및 해당 그룹의 리소스 목록(예: Kubernetes 코어 API의 빈)에 할당되는 그룹으로 지정됩니다.
- 5
- 규칙이 적용되는 그룹 목록입니다. 빈 목록은 모든 그룹을 의미합니다.
- 6
- 규칙이 적용되는 리소스가 아닌 URL 목록입니다.
- 7
- 규칙이 적용되는 네임스페이스 목록입니다. 빈 목록은 모든 네임스페이스를 의미합니다.
- 9
- 웹 콘솔에서 사용하는 엔드포인트.
- 10
- CLI에서 사용하는 엔드포인트입니다.
고급 감사에 대한 자세한 내용은 Kubernetes 문서를 참조하십시오.
7.6.20. etcd의 TLS 암호 지정
마스터 서버와 etcd 서버 간의 통신에 사용할 지원되는 TLS 암호를 지정할 수 있습니다.
각 etcd 노드에서 etcd를 업그레이드하십시오.
# yum update etcd iptables-servicesetcd 버전이 3.2.22 이상인지 확인합니다.
# etcd --version etcd Version: 3.2.22각 마스터 호스트에서
/etc/origin/master/master-config.yaml 파일에서 활성화할 암호를 지정합니다.servingInfo: ... minTLSVersion: VersionTLS12 cipherSuites: - TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256 - TLS_RSA_WITH_AES_256_CBC_SHA - TLS_RSA_WITH_AES_128_CBC_SHA ...각 마스터 호스트에서 마스터 서비스를 다시 시작합니다.
# master-restart api # master-restart controllers암호가 적용되었는지 확인합니다. 예를 들어 TLSv1.2 암호화
ECDHE-RSA-AES128-GCM-SHA256의 경우 다음 명령을 실행합니다.# openssl s_client -connect etcd1.example.com:23791 CONNECTED(00000003) depth=0 CN = etcd1.example.com verify error:num=20:unable to get local issuer certificate verify return:1 depth=0 CN = etcd1.example.com verify error:num=21:unable to verify the first certificate verify return:1 139905367488400:error:14094412:SSL routines:ssl3_read_bytes:sslv3 alert bad certificate:s3_pkt.c:1493:SSL alert number 42 139905367488400:error:140790E5:SSL routines:ssl23_write:ssl handshake failure:s23_lib.c:177: --- Certificate chain 0 s:/CN=etcd1.example.com i:/CN=etcd-signer@1529635004 --- Server certificate -----BEGIN CERTIFICATE----- MIIEkjCCAnqgAwIBAgIBATANBgkqhkiG9w0BAQsFADAhMR8wHQYDVQQDDBZldGNk ........ .... eif87qttt0Sl1vS8DG1KQO1oOBlNkg== -----END CERTIFICATE----- subject=/CN=etcd1.example.com issuer=/CN=etcd-signer@1529635004 --- Acceptable client certificate CA names /CN=etcd-signer@1529635004 Client Certificate Types: RSA sign, ECDSA sign Requested Signature Algorithms: RSA+SHA256:ECDSA+SHA256:RSA+SHA384:ECDSA+SHA384:RSA+SHA1:ECDSA+SHA1 Shared Requested Signature Algorithms: RSA+SHA256:ECDSA+SHA256:RSA+SHA384:ECDSA+SHA384:RSA+SHA1:ECDSA+SHA1 Peer signing digest: SHA384 Server Temp Key: ECDH, P-256, 256 bits --- SSL handshake has read 1666 bytes and written 138 bytes --- New, TLSv1/SSLv3, Cipher is ECDHE-RSA-AES128-GCM-SHA256 Server public key is 2048 bit Secure Renegotiation IS supported Compression: NONE Expansion: NONE No ALPN negotiated SSL-Session: Protocol : TLSv1.2 Cipher : ECDHE-RSA-AES128-GCM-SHA256 Session-ID: Session-ID-ctx: Master-Key: 1EFA00A91EE5FC5EDDCFC67C8ECD060D44FD3EB23D834EDED929E4B74536F273C0F9299935E5504B562CD56E76ED208D Key-Arg : None Krb5 Principal: None PSK identity: None PSK identity hint: None Start Time: 1529651744 Timeout : 300 (sec) Verify return code: 21 (unable to verify the first certificate)- 1
etcd1.example.com은 etcd 호스트의 이름입니다.
7.7. 노드 설정 파일
설치 중에 OpenShift Container Platform은 각 노드 그룹에 대해 openshift-node 프로젝트에 configmap을 생성합니다.
- node-config-master
- node-config-infra
- node-config-compute
- node-config-all-in-one
- node-config-master-infra
기존 노드를 구성하려면 적절한 구성 맵을 편집합니다. 각 노드의 동기화 Pod 는 구성 맵의 변경 사항을 감시합니다. 설치하는 동안 동기화 Pod는 동기화 Daemonsets 를 사용하고 노드 구성 매개 변수가 있는 /etc/origin/node/node-config.yaml 파일이 각 노드에 추가됩니다. 동기화 Pod에서 구성 맵 변경 사항을 탐지하면 해당 노드 그룹의 모든 노드에서 node-config.yaml 을 업데이트하고 적절한 노드에서 atomic-openshift-node.service 를 다시 시작합니다.
$ oc get cm -n openshift-node출력 예
NAME DATA AGE
node-config-all-in-one 1 1d
node-config-compute 1 1d
node-config-infra 1 1d
node-config-master 1 1d
node-config-master-infra 1 1dnode-config-compute 그룹의 구성 맵 샘플
apiVersion: v1
authConfig:
authenticationCacheSize: 1000
authenticationCacheTTL: 5m
authorizationCacheSize: 1000
authorizationCacheTTL: 5m
dnsBindAddress: 127.0.0.1:53
dnsDomain: cluster.local
dnsIP: 0.0.0.0
dnsNameservers: null
dnsRecursiveResolvConf: /etc/origin/node/resolv.conf
dockerConfig:
dockerShimRootDirectory: /var/lib/dockershim
dockerShimSocket: /var/run/dockershim.sock
execHandlerName: native
enableUnidling: true
imageConfig:
format: registry.reg-aws.openshift.com/openshift3/ose-${component}:${version}
latest: false
iptablesSyncPeriod: 30s
kind: NodeConfig
kubeletArguments:
bootstrap-kubeconfig:
- /etc/origin/node/bootstrap.kubeconfig
cert-dir:
- /etc/origin/node/certificates
cloud-config:
- /etc/origin/cloudprovider/aws.conf
cloud-provider:
- aws
enable-controller-attach-detach:
- 'true'
feature-gates:
- RotateKubeletClientCertificate=true,RotateKubeletServerCertificate=true
node-labels:
- node-role.kubernetes.io/compute=true
pod-manifest-path:
- /etc/origin/node/pods
rotate-certificates:
- 'true'
masterClientConnectionOverrides:
acceptContentTypes: application/vnd.kubernetes.protobuf,application/json
burst: 40
contentType: application/vnd.kubernetes.protobuf
qps: 20
masterKubeConfig: node.kubeconfig
networkConfig:
mtu: 8951
networkPluginName: redhat/openshift-ovs-subnet
servingInfo:
bindAddress: 0.0.0.0:10250
bindNetwork: tcp4
clientCA: client-ca.crt
volumeConfig:
localQuota:
perFSGroup: null
volumeDirectory: /var/lib/origin/openshift.local.volumes- 1
- 인증 및 권한 부여 구성 옵션.
- 2
- 포드의 /etc/resolv.conf 앞에 추가되는 IP 주소.
- 3
- Kubelet의 명령줄 인수 와 일치하는 Kubelet에 직접 전달되는 키 값 쌍입니다.
- 4
- Pod 매니페스트 파일 또는 디렉터리의 경로입니다. 디렉터리에는 하나 이상의 매니페스트 파일이 포함되어야 합니다. OpenShift Container Platform은 매니페스트 파일을 사용하여 노드에 Pod를 생성합니다.
- 5
- 노드의 Pod 네트워크 설정입니다.
- 6
- 소프트웨어 정의 네트워크(SDN) 플러그인. ovs
-subnet 플러그인의 경우 redhat/openshift-ovs-subnet, ovs -multitenant 플러그인의 경우 redhat/openshift-ovs-multitenant 또는 ovs -networkpolicy 플러그인의 경우 redhat/openshift-ovs-networkpolicy 로 설정합니다. - 7
- 노드의 인증서 정보입니다.
- 8
- 선택 사항: PEM 인코딩 인증서 번들. 설정한 경우 요청 헤더에서 사용자 이름을 확인하기 전에 지정된 파일의 인증 기관에 대해 유효한 클라이언트 인증서를 제공하고 검증해야 합니다.
/etc/origin/node/node-config.yaml 파일을 수동으로 수정하지 마십시오.
노드 구성 파일에는 노드 리소스가 결정됩니다. 자세한 내용은 클러스터 관리자 안내서의 노드 리소스 할당 섹션을 참조하십시오.
7.7.1. Pod 및 노드 구성
| 매개변수 이름 | 설명 |
|---|---|
|
| OpenShift Container Platform 노드를 시작하는 완전히 지정된 구성입니다. |
|
| 클러스터에서 이 특정 노드를 식별하는 데 사용되는 값입니다. 가능한 경우 이는 정규화된 호스트 이름이어야 합니다. 정적 노드 집합을 마스터에 설명하는 경우 이 값은 목록의 값 중 하나와 일치해야 합니다. |
7.7.2. Docker 구성
| 매개변수 이름 | 설명 |
|---|---|
|
| true인 경우 kubelet은 Docker의 오류를 무시합니다. 즉, docker가 시작되지 않은 시스템에서 노드를 시작할 수 있습니다. |
|
| Docker 관련 구성 옵션 포함 |
|
| 컨테이너에서 명령을 실행하는 데 사용할 핸들러입니다. |
7.7.3. 로컬 스토리지 구성
XFS 할당량 하위 시스템을 사용하여 각 노드에서 시크릿 및 구성 맵과 같은 emptyDir 볼륨에 따라 emptyDir 볼륨 및 볼륨 크기를 제한할 수 있습니다.
XFS 파일 시스템의 emptyDir 볼륨 크기를 제한하려면 openshift-node 프로젝트에서 node-config-compute 구성 맵을 사용하여 각각의 고유한 FSGroup 에 대한 로컬 볼륨 할당량을 구성합니다.
apiVersion: kubelet.config.openshift.io/v1
kind: VolumeConfig
localQuota:
perFSGroup: 1Gi - 1
- 노드에서 로컬 볼륨 할당량을 제어하는 옵션이 포함되어 있습니다.
- 2
- 이 값을 노드당 [FSGroup]당 원하는 할당량(예:
1Gi,512Mi등)을 나타내는 리소스 수량으로 설정합니다. volumeDirectory 가grpquota옵션으로 마운트된 XFS 파일 시스템에 있어야 합니다. 일치하는 보안 컨텍스트 제약 조건 fsGroup 유형을MustRunAs로 설정해야 합니다.
요청을 RunAsAny 와 일치하는 요청을 나타내는 FSGroup이 지정되지 않은 경우 할당량 애플리케이션을 건너뜁니다.
/etc/origin/node/volume-config.yaml 파일을 직접 편집하지 마십시오. 파일은 node-config-compute 구성 맵에서 생성됩니다. node-config-compute 구성 맵을 사용하여 volume-config.yaml 파일에서 매개 변수를 생성하거나 편집합니다.
7.7.4. QPS(초당 노드 쿼리) 제한 및 버스트 값 설정
kubelet이 API 서버와 통신하는 속도는 qps 및 버스트 값에 따라 다릅니다. 각 노드에서 실행 중인 포드가 제한된 경우 기본값이 충분합니다. 노드에 CPU 및 메모리 리소스가 충분한 경우 /etc/origin/node/node-config.yaml 파일에서 qps 및 burst 값을 수정할 수 있습니다.
kubeletArguments:
kube-api-qps:
- "20"
kube-api-burst:
- "40"위의 qps 및 burst 값은 OpenShift Container Platform의 기본값입니다.
| 매개변수 이름 | 설명 |
|---|---|
|
|
Kubelet이 APIServer와 통신하는 QPS 속도입니다. 기본값은 |
|
|
Kubelet이 APIServer와 통신하는 버스트 비율입니다. 기본값은 |
|
| 컨테이너에서 명령을 실행하는 데 사용할 핸들러입니다. |
7.7.5. Docker 1.9+를 사용한 병렬 이미지 가져오기
Docker 1.9+를 사용하는 경우 한 번에 하나씩 이미지를 가져오는 것이므로 병렬 이미지 가져오기 활성화를 고려할 수 있습니다.
Docker 1.9 이전의 데이터 손상에 발생할 수 있는 문제가 있습니다. 그러나 1.9부터는 손상 문제가 해결되어 병렬 풀로 전환하는 것이 안전합니다.
kubeletArguments:
serialize-image-pulls:
- "false" - 1
- 병렬 풀을 비활성화하려면
true로 변경합니다. 기본 구성입니다.
7.8. 암호 및 기타 중요한 데이터
일부 인증 구성의 경우 LDAP bindPassword 또는 OAuth clientSecret 값이 필요합니다. 마스터 구성 파일에 이러한 값을 직접 지정하는 대신, 이러한 값은 환경 변수, 외부 파일 또는 암호화된 파일로 제공될 수 있습니다.
환경 변수 예
bindPassword:
env: BIND_PASSWORD_ENV_VAR_NAME외부 파일 예
bindPassword:
file: bindPassword.txt암호화된 외부 파일 예
bindPassword:
file: bindPassword.encrypted
keyFile: bindPassword.key위의 예에 대해 암호화된 파일 및 키 파일을 생성하려면 다음을 수행합니다.
$ oc adm ca encrypt --genkey=bindPassword.key --out=bindPassword.encrypted
> Data to encrypt: B1ndPass0rd!
기본적으로 /etc/ansible/hosts 에서 Ansible 호스트 인벤토리 파일에 나열된 첫 번째 마스터에서만 oc adm 명령을 실행합니다.
암호화된 데이터는 암호 해독 키만큼 안전합니다. 파일 시스템 권한을 제한하고 키 파일에 대한 액세스 권한을 제한하려면 주의해야 합니다.
7.9. 새 구성 파일 생성
처음부터 OpenShift Container Platform 구성을 정의할 때 새 구성 파일을 생성하여 시작합니다.
마스터 호스트 구성 파일의 경우 openshift start 명령을 --write-config 옵션과 함께 사용하여 구성 파일을 작성합니다. 노드 호스트의 경우 oc adm create-node-config 명령을 사용하여 구성 파일을 작성합니다.
다음 명령은 관련 시작 구성 파일, 인증서 파일 및 기타 필요한 파일을 지정된 --write-config 또는 -- node-dir 디렉터리에 작성합니다.
생성된 인증서 파일은 2년 동안 유효하지만 CA(인증 기관) 인증서는 5년 동안 유효합니다. 이는 expire-days 및 옵션을 사용하여 변경할 수 있지만 보안상의 이유로 이러한 값보다 크게 만들지 않는 것이 좋습니다.
--signer- expire-days
지정된 디렉토리에서 올인원 서버(동일한 호스트에 있는 마스터 및 노드)에 대한 구성 파일을 생성하려면 다음을 실행합니다.
$ openshift start --write-config=/openshift.local.config지정된 디렉터리에 마스터 구성 파일 및 기타 필수 파일을 생성하려면 다음을 수행합니다.
$ openshift start master --write-config=/openshift.local.config/master지정된 디렉터리에 노드 구성 파일 및 기타 관련 파일을 생성하려면 다음을 수행합니다.
$ oc adm create-node-config \
--node-dir=/openshift.local.config/node-<node_hostname> \
--node=<node_hostname> \
--hostnames=<node_hostname>,<ip_address> \
--certificate-authority="/path/to/ca.crt" \
--signer-cert="/path/to/ca.crt" \
--signer-key="/path/to/ca.key"
--signer-serial="/path/to/ca.serial.txt"
--node-client-certificate-authority="/path/to/ca.crt"
노드 구성 파일을 만들 때 --hostnames 옵션에는 서버 인증서가 유효할 모든 호스트 이름 또는 IP 주소의 쉼표로 구분된 목록이 허용됩니다.
7.10. 구성 파일을 사용하여 서버 시작
마스터 및 노드 구성 파일을 사양에 수정한 후 를 인수로 지정하여 서버를 시작할 때 사용할 수 있습니다. 구성 파일을 지정하는 경우 전달하는 다른 명령줄 옵션이 적용되지 않습니다.
클러스터에서 노드를 수정하려면 필요에 따라 노드 구성 맵을 업데이트합니다. node-config.yaml 파일을 수동으로 편집하지 마십시오.
마스터 구성 파일을 사용하여 마스터 서버를 시작합니다.
$ openshift start master \ --config=/openshift.local.config/master/master-config.yaml노드 구성 파일과 node. kubeconfig 파일을 사용하여 네트워크 프록시 및 SDN 플러그인을 시작합니다.
$ openshift start network \ --config=/openshift.local.config/node-<node_hostname>/node-config.yaml \ --kubeconfig=/openshift.local.config/node-<node_hostname>/node.kubeconfig노드 구성 파일을 사용하여 노드 서버를 시작합니다.
$ hyperkube kubelet \ $(/usr/bin/openshift-node-config \ --config=/openshift.local.config/node-<node_hostname>/node-config.yaml)
7.11. 마스터 및 노드 로그 보기
OpenShift Container Platform은 노드에 systemd-journald.service를 사용하고 마스터를 위해 라는 스크립트를 사용하여 디버깅을 위해 로그 메시지를 수집합니다.
master- logs
웹 콘솔에 표시되는 행 수는 5000으로 하드 코딩되어 있으며 변경할 수 없습니다. 전체 로그를 보려면 CLI를 사용합니다.
로깅은 다음과 같이 Kubernetes 로깅 규칙에 따라 5개의 로그 메시지 심각도를 사용합니다.
| 옵션 | 설명 |
|---|---|
| 0 | 오류 및 경고 만 |
| 2 | 일반 정보 |
| 4 | 디버깅 수준 정보 |
| 6 | API 수준 디버깅 정보(요청/응답) |
| 8 | 본문 수준 API 디버깅 정보 |
필요한 경우 마스터 또는 노드의 로그 수준을 독립적으로 변경할 수 있습니다.
노드 로그 보기
노드 시스템의 로그를 보려면 다음 명령을 실행합니다.
# journalctl -r -u <journal_name>
r 옵션을 사용하여 최신 항목을 먼저 표시합니다.
마스터 로그 보기
마스터 구성 요소의 로그를 보려면 다음 명령을 실행합니다.
# /usr/local/bin/master-logs <component> <container>예를 들면 다음과 같습니다.
# /usr/local/bin/master-logs controllers controllers
# /usr/local/bin/master-logs api api
# /usr/local/bin/master-logs etcd etcd마스터 로그를 파일로 리디렉션
마스터 로그인 출력을 파일로 리디렉션하려면 다음 명령을 실행합니다.
master-logs api api 2> file7.11.1. 로깅 수준 구성
노드의 master 또는 /etc/ sysconfig/atomic-openshift-node 파일의 /etc/origin/master/master/env 파일에서 DEBUG_LOGLEVEL 옵션을 설정하여 로깅되는 INFO 메시지를 제어할 수 있습니다. 모든 메시지를 수집하도록 로그를 구성하면 해석하기 어려워지고 과도한 공간을 차지할 수 있는 대용량 로그가 발생할 수 있습니다. 클러스터를 디버깅해야 하는 경우에만 모든 메시지를 수집합니다.
FATAL, ERROR, WARNING 및 일부 INFO 심각도가 있는 메시지는 로그 구성에 관계없이 로그에 표시됩니다.
로깅 수준을 변경하려면 다음을 수행합니다.
- 노드의 마스터 또는 /etc/ sysconfig/atomic-openshift-node 파일의 /etc/origin/ master/master.env 파일을 편집합니다.
DEBUG_LOGLEVEL(로그 수준 옵션) 필드에 Log Level Options (로그 수준 옵션) 테이블의 값을 입력합니다.예를 들면 다음과 같습니다.
DEBUG_LOGLEVEL=4- 마스터 또는 노드 호스트를 적절하게 다시 시작합니다. OpenShift Container Platform 서비스 재시작을 참조하십시오.
재시작 후 모든 새 로그 메시지는 새 설정을 준수합니다. 이전 메시지는 변경되지 않습니다.
기본 로그 수준은 표준 클러스터 설치 프로세스를 사용하여 설정할 수 있습니다. 자세한 내용은 클러스터 변수를 참조하십시오.
다음 예제는 다양한 로그 수준에서 리디렉션된 마스터 로그 파일의 발췌 내용입니다. 이러한 예에서 시스템 정보가 제거되었습니다.
loglevel=2에서 master-logs api api 2> 파일 출력 발췌
W1022 15:08:09.787705 1 server.go:79] Unable to keep dnsmasq up to date, 0.0.0.0:8053 must point to port 53
I1022 15:08:09.787894 1 logs.go:49] skydns: ready for queries on cluster.local. for tcp4://0.0.0.0:8053 [rcache 0]
I1022 15:08:09.787913 1 logs.go:49] skydns: ready for queries on cluster.local. for udp4://0.0.0.0:8053 [rcache 0]
I1022 15:08:09.889022 1 dns_server.go:63] DNS listening at 0.0.0.0:8053
I1022 15:08:09.893156 1 feature_gate.go:190] feature gates: map[AdvancedAuditing:true]
I1022 15:08:09.893500 1 master.go:431] Starting OAuth2 API at /oauth
I1022 15:08:09.914759 1 master.go:431] Starting OAuth2 API at /oauth
I1022 15:08:09.942349 1 master.go:431] Starting OAuth2 API at /oauth
W1022 15:08:09.977088 1 swagger.go:38] No API exists for predefined swagger description /oapi/v1
W1022 15:08:09.977176 1 swagger.go:38] No API exists for predefined swagger description /api/v1
[restful] 2018/10/22 15:08:09 log.go:33: [restful/swagger] listing is available at https://openshift.com:443/swaggerapi
[restful] 2018/10/22 15:08:09 log.go:33: [restful/swagger] https://openshift.com:443/swaggerui/ is mapped to folder /swagger-ui/
I1022 15:08:10.231405 1 master.go:431] Starting OAuth2 API at /oauth
W1022 15:08:10.259523 1 swagger.go:38] No API exists for predefined swagger description /oapi/v1
W1022 15:08:10.259555 1 swagger.go:38] No API exists for predefined swagger description /api/v1
I1022 15:08:23.895493 1 logs.go:49] http: TLS handshake error from 10.10.94.10:46322: EOF
I1022 15:08:24.449577 1 crdregistration_controller.go:110] Starting crd-autoregister controller
I1022 15:08:24.449916 1 controller_utils.go:1019] Waiting for caches to sync for crd-autoregister controller
I1022 15:08:24.496147 1 logs.go:49] http: TLS handshake error from 127.0.0.1:39140: EOF
I1022 15:08:24.821198 1 cache.go:39] Caches are synced for APIServiceRegistrationController controller
I1022 15:08:24.833022 1 cache.go:39] Caches are synced for AvailableConditionController controller
I1022 15:08:24.865087 1 controller.go:537] quota admission added evaluator for: { events}
I1022 15:08:24.865393 1 logs.go:49] http: TLS handshake error from 127.0.0.1:39162: read tcp4 127.0.0.1:443->127.0.0.1:39162: read: connection reset by peer
I1022 15:08:24.966917 1 controller_utils.go:1026] Caches are synced for crd-autoregister controller
I1022 15:08:24.967961 1 autoregister_controller.go:136] Starting autoregister controller
I1022 15:08:24.967977 1 cache.go:32] Waiting for caches to sync for autoregister controller
I1022 15:08:25.015924 1 controller.go:537] quota admission added evaluator for: { serviceaccounts}
I1022 15:08:25.077984 1 cache.go:39] Caches are synced for autoregister controller
W1022 15:08:25.304265 1 lease_endpoint_reconciler.go:176] Resetting endpoints for master service "kubernetes" to [10.10.94.10]
E1022 15:08:25.472536 1 memcache.go:153] couldn't get resource list for servicecatalog.k8s.io/v1beta1: the server could not find the requested resource
E1022 15:08:25.550888 1 memcache.go:153] couldn't get resource list for servicecatalog.k8s.io/v1beta1: the server could not find the requested resource
I1022 15:08:29.480691 1 healthz.go:72] /healthz/log check
I1022 15:08:30.981999 1 controller.go:105] OpenAPI AggregationController: Processing item v1beta1.servicecatalog.k8s.io
E1022 15:08:30.990914 1 controller.go:111] loading OpenAPI spec for "v1beta1.servicecatalog.k8s.io" failed with: OpenAPI spec does not exists
I1022 15:08:30.990965 1 controller.go:119] OpenAPI AggregationController: action for item v1beta1.servicecatalog.k8s.io: Rate Limited Requeue.
I1022 15:08:31.530473 1 trace.go:76] Trace[1253590531]: "Get /api/v1/namespaces/openshift-infra/serviceaccounts/serviceaccount-controller" (started: 2018-10-22 15:08:30.868387562 +0000 UTC m=+24.277041043) (total time: 661.981642ms):
Trace[1253590531]: [661.903178ms] [661.89217ms] About to write a response
I1022 15:08:31.531366 1 trace.go:76] Trace[83808472]: "Get /api/v1/namespaces/aws-sb/secrets/aws-servicebroker" (started: 2018-10-22 15:08:30.831296749 +0000 UTC m=+24.239950203) (total time: 700.049245ms):loglevel=4에서 master-logs api api 2> 파일 출력 발췌
I1022 15:08:09.746980 1 plugins.go:149] Loaded 1 admission controller(s) successfully in the following order: AlwaysDeny.
I1022 15:08:09.747597 1 plugins.go:149] Loaded 1 admission controller(s) successfully in the following order: ResourceQuota.
I1022 15:08:09.748038 1 plugins.go:149] Loaded 1 admission controller(s) successfully in the following order: openshift.io/ClusterResourceQuota.
I1022 15:08:09.786771 1 start_master.go:458] Starting master on 0.0.0.0:443 (v3.10.45)
I1022 15:08:09.786798 1 start_master.go:459] Public master address is https://openshift.com:443
I1022 15:08:09.786844 1 start_master.go:463] Using images from "registry.access.redhat.com/openshift3/ose-<component>:v3.10.45"
W1022 15:08:09.787046 1 dns_server.go:37] Binding DNS on port 8053 instead of 53, which may not be resolvable from all clients
W1022 15:08:09.787705 1 server.go:79] Unable to keep dnsmasq up to date, 0.0.0.0:8053 must point to port 53
I1022 15:08:09.787894 1 logs.go:49] skydns: ready for queries on cluster.local. for tcp4://0.0.0.0:8053 [rcache 0]
I1022 15:08:09.787913 1 logs.go:49] skydns: ready for queries on cluster.local. for udp4://0.0.0.0:8053 [rcache 0]
I1022 15:08:09.889022 1 dns_server.go:63] DNS listening at 0.0.0.0:8053
I1022 15:08:09.893156 1 feature_gate.go:190] feature gates: map[AdvancedAuditing:true]
I1022 15:08:09.893500 1 master.go:431] Starting OAuth2 API at /oauth
I1022 15:08:09.914759 1 master.go:431] Starting OAuth2 API at /oauth
I1022 15:08:09.942349 1 master.go:431] Starting OAuth2 API at /oauth
W1022 15:08:09.977088 1 swagger.go:38] No API exists for predefined swagger description /oapi/v1
W1022 15:08:09.977176 1 swagger.go:38] No API exists for predefined swagger description /api/v1
[restful] 2018/10/22 15:08:09 log.go:33: [restful/swagger] listing is available at https://openshift.com:443/swaggerapi
[restful] 2018/10/22 15:08:09 log.go:33: [restful/swagger] https://openshift.com:443/swaggerui/ is mapped to folder /swagger-ui/
I1022 15:08:10.231405 1 master.go:431] Starting OAuth2 API at /oauth
W1022 15:08:10.259523 1 swagger.go:38] No API exists for predefined swagger description /oapi/v1
W1022 15:08:10.259555 1 swagger.go:38] No API exists for predefined swagger description /api/v1
[restful] 2018/10/22 15:08:10 log.go:33: [restful/swagger] listing is available at https://openshift.com:443/swaggerapi
[restful] 2018/10/22 15:08:10 log.go:33: [restful/swagger] https://openshift.com:443/swaggerui/ is mapped to folder /swagger-ui/
I1022 15:08:10.444303 1 master.go:431] Starting OAuth2 API at /oauth
W1022 15:08:10.492409 1 swagger.go:38] No API exists for predefined swagger description /oapi/v1
W1022 15:08:10.492507 1 swagger.go:38] No API exists for predefined swagger description /api/v1
[restful] 2018/10/22 15:08:10 log.go:33: [restful/swagger] listing is available at https://openshift.com:443/swaggerapi
[restful] 2018/10/22 15:08:10 log.go:33: [restful/swagger] https://openshift.com:443/swaggerui/ is mapped to folder /swagger-ui/
I1022 15:08:10.774824 1 master.go:431] Starting OAuth2 API at /oauth
I1022 15:08:23.808685 1 logs.go:49] http: TLS handshake error from 10.128.0.11:39206: EOF
I1022 15:08:23.815311 1 logs.go:49] http: TLS handshake error from 10.128.0.14:53054: EOF
I1022 15:08:23.822286 1 customresource_discovery_controller.go:174] Starting DiscoveryController
I1022 15:08:23.822349 1 naming_controller.go:276] Starting NamingConditionController
I1022 15:08:23.822705 1 logs.go:49] http: TLS handshake error from 10.128.0.14:53056: EOF
+24.277041043) (total time: 661.981642ms):
Trace[1253590531]: [661.903178ms] [661.89217ms] About to write a response
I1022 15:08:31.531366 1 trace.go:76] Trace[83808472]: "Get /api/v1/namespaces/aws-sb/secrets/aws-servicebroker" (started: 2018-10-22 15:08:30.831296749 +0000 UTC m=+24.239950203) (total time: 700.049245ms):
Trace[83808472]: [700.049245ms] [700.04027ms] END
I1022 15:08:31.531695 1 trace.go:76] Trace[1916801734]: "Get /api/v1/namespaces/aws-sb/secrets/aws-servicebroker" (started: 2018-10-22 15:08:31.031163449 +0000 UTC m=+24.439816907) (total time: 500.514208ms):
Trace[1916801734]: [500.514208ms] [500.505008ms] END
I1022 15:08:44.675371 1 healthz.go:72] /healthz/log check
I1022 15:08:46.589759 1 controller.go:537] quota admission added evaluator for: { endpoints}
I1022 15:08:46.621270 1 controller.go:537] quota admission added evaluator for: { endpoints}
I1022 15:08:57.159494 1 healthz.go:72] /healthz/log check
I1022 15:09:07.161315 1 healthz.go:72] /healthz/log check
I1022 15:09:16.297982 1 trace.go:76] Trace[2001108522]: "GuaranteedUpdate etcd3: *core.Node" (started: 2018-10-22 15:09:15.139820419 +0000 UTC m=+68.548473981) (total time: 1.158128974s):
Trace[2001108522]: [1.158012755s] [1.156496534s] Transaction committed
I1022 15:09:16.298165 1 trace.go:76] Trace[1124283912]: "Patch /api/v1/nodes/master-0.com/status" (started: 2018-10-22 15:09:15.139695483 +0000 UTC m=+68.548348970) (total time: 1.158434318s):
Trace[1124283912]: [1.158328853s] [1.15713683s] Object stored in database
I1022 15:09:16.298761 1 trace.go:76] Trace[24963576]: "GuaranteedUpdate etcd3: *core.Node" (started: 2018-10-22 15:09:15.13159057 +0000 UTC m=+68.540244112) (total time: 1.167151224s):
Trace[24963576]: [1.167106144s] [1.165570379s] Transaction committed
I1022 15:09:16.298882 1 trace.go:76] Trace[222129183]: "Patch /api/v1/nodes/node-0.com/status" (started: 2018-10-22 15:09:15.131269234 +0000 UTC m=+68.539922722) (total time: 1.167595526s):
Trace[222129183]: [1.167517296s] [1.166135605s] Object stored in databaseloglevel=8에서 master-logs api api 2> 파일 출력 발췌
1022 15:11:58.829357 1 plugins.go:84] Registered admission plugin "NamespaceLifecycle"
I1022 15:11:58.839967 1 plugins.go:84] Registered admission plugin "Initializers"
I1022 15:11:58.839994 1 plugins.go:84] Registered admission plugin "ValidatingAdmissionWebhook"
I1022 15:11:58.840012 1 plugins.go:84] Registered admission plugin "MutatingAdmissionWebhook"
I1022 15:11:58.840025 1 plugins.go:84] Registered admission plugin "AlwaysAdmit"
I1022 15:11:58.840082 1 plugins.go:84] Registered admission plugin "AlwaysPullImages"
I1022 15:11:58.840105 1 plugins.go:84] Registered admission plugin "LimitPodHardAntiAffinityTopology"
I1022 15:11:58.840126 1 plugins.go:84] Registered admission plugin "DefaultTolerationSeconds"
I1022 15:11:58.840146 1 plugins.go:84] Registered admission plugin "AlwaysDeny"
I1022 15:11:58.840176 1 plugins.go:84] Registered admission plugin "EventRateLimit"
I1022 15:11:59.850825 1 feature_gate.go:190] feature gates: map[AdvancedAuditing:true]
I1022 15:11:59.859108 1 register.go:154] Admission plugin AlwaysAdmit is not enabled. It will not be started.
I1022 15:11:59.859284 1 plugins.go:149] Loaded 1 admission controller(s) successfully in the following order: AlwaysAdmit.
I1022 15:11:59.859809 1 register.go:154] Admission plugin NamespaceAutoProvision is not enabled. It will not be started.
I1022 15:11:59.859939 1 plugins.go:149] Loaded 1 admission controller(s) successfully in the following order: NamespaceAutoProvision.
I1022 15:11:59.860594 1 register.go:154] Admission plugin NamespaceExists is not enabled. It will not be started.
I1022 15:11:59.860778 1 plugins.go:149] Loaded 1 admission controller(s) successfully in the following order: NamespaceExists.
I1022 15:11:59.863999 1 plugins.go:149] Loaded 1 admission controller(s) successfully in the following order: NamespaceLifecycle.
I1022 15:11:59.864626 1 register.go:154] Admission plugin EventRateLimit is not enabled. It will not be started.
I1022 15:11:59.864768 1 plugins.go:149] Loaded 1 admission controller(s) successfully in the following order: EventRateLimit.
I1022 15:11:59.865259 1 register.go:154] Admission plugin ProjectRequestLimit is not enabled. It will not be started.
I1022 15:11:59.865376 1 plugins.go:149] Loaded 1 admission controller(s) successfully in the following order: ProjectRequestLimit.
I1022 15:11:59.866126 1 plugins.go:149] Loaded 1 admission controller(s) successfully in the following order: OriginNamespaceLifecycle.
I1022 15:11:59.866709 1 register.go:154] Admission plugin openshift.io/RestrictSubjectBindings is not enabled. It will not be started.
I1022 15:11:59.866761 1 plugins.go:149] Loaded 1 admission controller(s) successfully in the following order: openshift.io/RestrictSubjectBindings.
I1022 15:11:59.867304 1 plugins.go:149] Loaded 1 admission controller(s) successfully in the following order: openshift.io/JenkinsBootstrapper.
I1022 15:11:59.867823 1 plugins.go:149] Loaded 1 admission controller(s) successfully in the following order: openshift.io/BuildConfigSecretInjector.
I1022 15:12:00.015273 1 master_config.go:476] Initializing cache sizes based on 0MB limit
I1022 15:12:00.015896 1 master_config.go:539] Using the lease endpoint reconciler with TTL=15s and interval=10s
I1022 15:12:00.018396 1 storage_factory.go:285] storing { apiServerIPInfo} in v1, reading as __internal from storagebackend.Config{Type:"etcd3", Prefix:"kubernetes.io", ServerList:[]string{"https://master-0.com:2379"}, KeyFile:"/etc/origin/master/master.etcd-client.key", CertFile:"/etc/origin/master/master.etcd-client.crt", CAFile:"/etc/origin/master/master.etcd-ca.crt", Quorum:true, Paging:true, DeserializationCacheSize:0, Codec:runtime.Codec(nil), Transformer:value.Transformer(nil), CompactionInterval:300000000000, CountMetricPollPeriod:60000000000}
I1022 15:12:00.037710 1 storage_factory.go:285] storing { endpoints} in v1, reading as __internal from storagebackend.Config{Type:"etcd3", Prefix:"kubernetes.io", ServerList:[]string{"https://master-0.com:2379"}, KeyFile:"/etc/origin/master/master.etcd-client.key", CertFile:"/etc/origin/master/master.etcd-client.crt", CAFile:"/etc/origin/master/master.etcd-ca.crt", Quorum:true, Paging:true, DeserializationCacheSize:0, Codec:runtime.Codec(nil), Transformer:value.Transformer(nil), CompactionInterval:300000000000, CountMetricPollPeriod:60000000000}
I1022 15:12:00.054112 1 compact.go:54] compactor already exists for endpoints [https://master-0.com:2379]
I1022 15:12:00.054678 1 start_master.go:458] Starting master on 0.0.0.0:443 (v3.10.45)
I1022 15:12:00.054755 1 start_master.go:459] Public master address is https://openshift.com:443
I1022 15:12:00.054837 1 start_master.go:463] Using images from "registry.access.redhat.com/openshift3/ose-<component>:v3.10.45"
W1022 15:12:00.056957 1 dns_server.go:37] Binding DNS on port 8053 instead of 53, which may not be resolvable from all clients
W1022 15:12:00.065497 1 server.go:79] Unable to keep dnsmasq up to date, 0.0.0.0:8053 must point to port 53
I1022 15:12:00.066061 1 logs.go:49] skydns: ready for queries on cluster.local. for tcp4://0.0.0.0:8053 [rcache 0]
I1022 15:12:00.066265 1 logs.go:49] skydns: ready for queries on cluster.local. for udp4://0.0.0.0:8053 [rcache 0]
I1022 15:12:00.158725 1 dns_server.go:63] DNS listening at 0.0.0.0:8053
I1022 15:12:00.167910 1 htpasswd.go:118] Loading htpasswd file /etc/origin/master/htpasswd...
I1022 15:12:00.168182 1 htpasswd.go:118] Loading htpasswd file /etc/origin/master/htpasswd...
I1022 15:12:00.231233 1 storage_factory.go:285] storing {apps.openshift.io deploymentconfigs} in apps.openshift.io/v1, reading as apps.openshift.io/__internal from storagebackend.Config{Type:"etcd3", Prefix:"openshift.io", ServerList:[]string{"https://master-0.com:2379"}, KeyFile:"/etc/origin/master/master.etcd-client.key", CertFile:"/etc/origin/master/master.etcd-client.crt", CAFile:"/etc/origin/master/master.etcd-ca.crt", Quorum:true, Paging:true, DeserializationCacheSize:0, Codec:runtime.Codec(nil), Transformer:value.Transformer(nil), CompactionInterval:300000000000, CountMetricPollPeriod:60000000000}
I1022 15:12:00.248136 1 compact.go:54] compactor already exists for endpoints [https://master-0.com:2379]
I1022 15:12:00.248697 1 store.go:1391] Monitoring deploymentconfigs.apps.openshift.io count at <storage-prefix>//deploymentconfigs
W1022 15:12:00.256861 1 swagger.go:38] No API exists for predefined swagger description /oapi/v1
W1022 15:12:00.258106 1 swagger.go:38] No API exists for predefined swagger description /api/v17.12. 마스터 및 노드 서비스 재시작
마스터 또는 노드 구성 변경 사항을 적용하려면 각 서비스를 다시 시작해야 합니다.
마스터 구성 변경 사항을 다시 로드하려면 master -restart 명령을 사용하여 컨트롤 플레인 정적 Pod에서 실행 중인 마스터 서비스를 다시 시작합니다.
# master-restart api
# master-restart controllers노드 구성 변경 사항을 다시 로드하려면 노드 호스트에서 노드 서비스를 다시 시작합니다.
# systemctl restart atomic-openshift-node8장. OpenShift Ansible 브로커 구성
8.1. 개요
OpenShift Ansible 브로커 (OAB)를 클러스터에 배포하면 시작 시 로드된 브로커의 구성 파일에 의해 해당 동작이 크게 지정됩니다. 브로커의 구성은 브로커의 네임스페이스(기본적으로openshift-ansible-service-broker )에 ConfigMap 오브젝트로 저장됩니다.
OpenShift Ansible 브로커 구성 파일의 예
registry:
- type: dockerhub
name: docker
url: https://registry.hub.docker.com
org: <dockerhub_org>
fail_on_error: false
- type: rhcc
name: rhcc
url: https://registry.redhat.io
fail_on_error: true
white_list:
- "^foo.*-apb$"
- ".*-apb$"
black_list:
- "bar.*-apb$"
- "^my-apb$"
- type: local_openshift
name: lo
namespaces:
- openshift
white_list:
- ".*-apb$"
dao:
etcd_host: localhost
etcd_port: 2379
log:
logfile: /var/log/ansible-service-broker/asb.log
stdout: true
level: debug
color: true
openshift:
host: ""
ca_file: ""
bearer_token_file: ""
image_pull_policy: IfNotPresent
sandbox_role: "edit"
keep_namespace: false
keep_namespace_on_error: true
broker:
bootstrap_on_startup: true
dev_broker: true
launch_apb_on_bind: false
recovery: true
output_request: true
ssl_cert_key: /path/to/key
ssl_cert: /path/to/cert
refresh_interval: "600s"
auth:
- type: basic
enabled: true
secrets:
- title: Database credentials
secret: db_creds
apb_name: dh-rhscl-postgresql-apb8.2. Red Hat Partner Connect Registry에서 인증
자동화 브로커를 구성하기 전에 Red Hat Partner Connect를 사용하려면 OpenShift Container Platform 클러스터의 모든 노드에서 다음 명령을 실행해야 합니다.
$ docker --config=/var/lib/origin/.docker login -u <registry-user> -p <registry-password> registry.connect.redhat.com8.3. OpenShift Ansible 브로커 구성 수정
배포 후 OAB의 기본 브로커 구성을 수정하려면 다음을 수행합니다.
OAB 네임스페이스에서 cluster -admin 권한이 있는 사용자로 broker- config ConfigMap 오브젝트를 편집합니다.
$ oc edit configmap broker-config -n openshift-ansible-service-broker업데이트를 저장한 후 변경 사항을 적용하려면 OAB의 배포 구성을 다시 배포합니다.
$ oc rollout latest dc/asb -n openshift-ansible-service-broker
8.4. 레지스트리 설정
registry 섹션을 사용하면 브로커가 APB를 확인해야 하는 레지스트리를 정의할 수 있습니다.
| 필드 | 설명 | 필수 항목 |
|---|---|---|
|
| 레지스트리의 이름입니다. 이 레지스트리에서 APB를 식별하는 데 브로커가 사용합니다. | Y |
|
|
레지스트리에 인증하기 위한 사용자 이름입니다. | N |
|
|
레지스트리에 인증하기 위한 암호입니다. | N |
|
|
브로커가 | N |
|
|
읽을 레지스트리 자격 증명을 저장하는 시크릿 또는 파일의 이름입니다. |
N은 |
|
| 이미지가 포함된 네임스페이스 또는 조직입니다. | N |
|
|
레지스트리 유형입니다. 사용 가능한 어댑터는 | Y |
|
|
| N |
|
|
이미지 정보를 검색하는 데 사용되는 URL입니다. | N |
|
| 이 레지스트리가 실패하면 부트스트랩 요청이 실패하는 경우 요청합니다. 는 다른 레지스트리 로드의 실행을 중지합니다. | N |
|
|
를 통해 허용해야 하는 이미지 이름을 정의하는 데 사용되는 정규식 목록입니다. APB를 카탈로그에 추가할 수 있도록 허용하려면 화이트 목록이 있어야 합니다. 레지스트리의 모든 APB를 검색하려는 경우 가장 허용적인 정규 표현식은 | N |
|
| 를 통해 허용하지 않아야 하는 이미지 이름을 정의하는 데 사용되는 정규식 목록입니다. 자세한 내용은 APB 필터링 을 참조하십시오. | N |
|
| OpenShift Container Registry와 함께 사용할 이미지 목록입니다. | N |
8.4.1. 프로덕션 또는 개발
프로덕션 브로커 구성은 RHCC(Red Hat Container Catalog)와 같은 신뢰할 수 있는 컨테이너 배포 레지스트리를 가리키도록 설계되었습니다.
registry:
- name: rhcc
type: rhcc
url: https://registry.redhat.io
tag: v3.11
white_list:
- ".*-apb$"
- type: local_openshift
name: localregistry
namespaces:
- openshift
white_list: []
그러나 개발 브로커 구성은 주로 브로커에서 작업하는 개발자가 사용합니다. 개발자 설정을 활성화하려면 레지스트리 이름을 dev 로 설정하고 broker 섹션의 dev_broker 필드를 true로 설정합니다.
registry:
name: devbroker:
dev_broker: true8.4.2. 레지스트리 자격 증명 저장
브로커 구성은 브로커가 레지스트리 자격 증명을 읽는 방법을 결정합니다. 다음과 같이 사용자 에서 읽고 registry 섹션의 값을 전달할 수 있습니다.
registry:
- name: isv
type: openshift
url: https://registry.connect.redhat.com
user: <user>
pass: <password>
이러한 자격 증명에 공개적으로 액세스할 수 없도록 하려면 레지스트리 섹션의 auth_type 필드를 시크릿 또는 파일 유형으로 설정할 수 있습니다. secret 유형은 브로커의 네임스페이스의 보안을 사용하도록 레지스트리를 구성하는 반면, 파일 유형은 볼륨으로 마운트된 시크릿을 사용하도록 레지스트리를 구성합니다.
보안 또는 파일 유형을 사용하려면 다음을 수행합니다.
연결된 보안에
사용자 이름및암호가정의되어 있어야 합니다. 시크릿을 사용하는 경우 보안을 읽을 때openshift-ansible-service-broker네임스페이스가 있는지 확인해야 합니다.예를 들어 reg-creds.yaml 파일을 생성합니다.
$ cat reg-creds.yaml --- username: <user_name> password: <password>openshift-ansible-service-broker네임스페이스에서 이 파일에서 시크릿을 생성합니다.$ oc create secret generic \ registry-credentials-secret \ --from-file reg-creds.yaml \ -n openshift-ansible-service-broker시크릿또는파일유형을 사용할지 여부를 선택합니다.보안유형을 사용하려면 다음을 수행합니다.브로커 구성에서
auth_type을secret으로 설정하고auth_name을 보안 이름으로 설정합니다.registry: - name: isv type: openshift url: https://registry.connect.redhat.com auth_type: secret auth_name: registry-credentials-secret보안이 있는 네임스페이스를 설정합니다.
openshift: namespace: openshift-ansible-service-broker
파일유형을 사용하려면 다음을 수행합니다.asb배포 구성을 편집하여 파일을 /tmp/registry-credentials/reg-creds.yaml에 마운트합니다.$ oc edit dc/asb -n openshift-ansible-service-brokercontainers.volumeMounts섹션에 다음을 추가합니다.volumeMounts: - mountPath: /tmp/registry-credentials name: reg-authvolumes섹션에서 다음을 추가합니다.volumes: - name: reg-auth secret: defaultMode: 420 secretName: registry-credentials-secret브로커 구성에서
auth_type을file로 설정하고auth_type을 파일의 위치로 설정합니다.registry: - name: isv type: openshift url: https://registry.connect.redhat.com auth_type: file auth_name: /tmp/registry-credentials/reg-creds.yaml
8.4.3. APB 필터링
브로커 구성 내의 레지스트리 기반으로 설정된 white_list 또는 매개변수의 조합을 사용하여 이미지 이름으로 APB를 필터링할 수 있습니다.
black_list
두 명령 모두 일치 여부를 확인하기 위해 지정된 레지스트리에 대해 검색된 총 APB 집합에 대해 실행할 정규 표현식의 선택적 목록입니다.
| 존재 | 허용됨 | 차단됨 |
|---|---|---|
| 허용 목록만 | 목록의 regex와 일치합니다. | 일치하지 않는 APB. |
| 블랙리스트만 | 일치하지 않는 모든 APB. | 목록의 regex와 일치하는 APB. |
| 모두 있음 | 허용 목록에 regex와 일치하지만 블랙리스트에는 일치하지 않습니다. | 블랙리스트의 regex와 일치하는 APB. |
| 없음 | 레지스트리의 APB가 없습니다. | 해당 레지스트리의 모든 APB. |
예를 들면 다음과 같습니다.
화이트리스트만
white_list:
- "foo.*-apb$"
- "^my-apb$"
이 경우 foo.*-apb$ 에서 일치하는 항목과 my-apb 만 허용됩니다. 다른 모든 APB는 거부됩니다.
블랙리스트만
black_list:
- "bar.*-apb$"
- "^foobar-apb$"
이 경우 bar.*-apb$ 및 foobar-apb 만 일치하는 항목만 차단됩니다. 기타 모든 APB는 다음을 통해 허용됩니다.
화이트리스트 및 블랙리스트
white_list:
- "foo.*-apb$"
- "^my-apb$"
black_list:
- "^foo-rootkit-apb$"
여기에서 foo-rootkit-apb 는 허용 목록의 일치에도 불구하고 블랙리스트에 의해 특별히 차단됩니다. 화이트리스트 일치 항목이 재정의되기 때문입니다.
그렇지 않으면 foo.*-apb$ 및 my-apb 와 일치하는 항목만 를 통해 허용됩니다.
브로커 구성 레지스트리 섹션의 예:
registry:
- type: dockerhub
name: dockerhub
url: https://registry.hub.docker.com
user: <user>
pass: <password>
org: <org>
white_list:
- "foo.*-apb$"
- "^my-apb$"
black_list:
- "bar.*-apb$"
- "^foobar-apb$"8.4.4. mock Registry
mock 레지스트리는 로컬 APB 사양을 읽는 데 유용합니다. 레지스트리로 이미지 사양을 검색하는 대신 로컬 사양 목록을 사용합니다. mock 레지스트리를 사용하도록 레지스트리의 이름을 mock으로 설정합니다.
registry:
- name: mock
type: mock8.4.5. DockerHub 레지스트리
dockerhub 유형을 사용하면 DockerHub의 특정 조직에서 APB를 로드할 수 있습니다. 예를 들어 ansibleplaybookbundle 조직입니다.
registry:
- name: dockerhub
type: dockerhub
org: ansibleplaybookbundle
user: <user>
pass: <password>
white_list:
- ".*-apb$"8.4.6. Ansible Galaxy 레지스트리
galaxy 유형을 사용하면 Ansible Galaxy 에서 APB 역할을 사용할 수 있습니다. 조직을 선택적으로 지정할 수도 있습니다.
registry:
- name: galaxy
type: galaxy
# Optional:
# org: ansibleplaybookbundle
runner: docker.io/ansibleplaybookbundle/apb-base:latest
white_list:
- ".*$"8.4.7. 로컬 OpenShift Container Registry
local_openshift 유형을 사용하면 OpenShift Container Platform 클러스터 내부의 OpenShift Container Registry에서 APB를 로드할 수 있습니다. 게시된 APB를 찾고자 하는 네임스페이스를 구성할 수 있습니다.
registry:
- type: local_openshift
name: lo
namespaces:
- openshift
white_list:
- ".*-apb$"8.4.8. Red Hat Container Catalog Registry
rhcc 유형을 사용하면 RHCC(Red Hat Container Catalog ) 레지스트리에 게시된 APB를 로드할 수 있습니다.
registry:
- name: rhcc
type: rhcc
url: https://registry.redhat.io
white_list:
- ".*-apb$"8.4.9. Red Hat Partner Connect Registry
Red Hat Container Catalog의 타사 이미지는 Red Hat Partner Connect Registry (https://registry.connect.redhat.com) 에서 제공됩니다. partner_rhcc 유형을 사용하면 브로커가 파트너 레지스트리에서 부트스트랩되어 APB 목록을 검색하고 사양을 로드할 수 있습니다. 파트너 레지스트리는 유효한 Red Hat 고객 포털 사용자 이름과 암호를 사용하여 이미지를 가져오려면 인증이 필요합니다.
registry:
- name: partner_reg
type: partner_rhcc
url: https://registry.connect.redhat.com
user: <registry_user>
pass: <registry_password>
white_list:
- ".*-apb$"파트너 레지스트리에 인증이 필요하므로 파트너 레지스트리 URL을 사용하도록 브로커를 구성하려면 다음 수동 단계도 필요합니다.
OpenShift Container Platform 클러스터의 모든 노드에서 다음 명령을 실행합니다.
# docker --config=/var/lib/origin/.docker \ login -u <registry_user> -p <registry_password> \ registry.connect.redhat.com
8.4.10. Helm 차트 레지스트리
helm 유형을 사용하면 Helm 차트 리포지터리의 Helm 차트를 사용할 수 있습니다.
registry:
- name: stable
type: helm
url: "https://kubernetes-charts.storage.googleapis.com"
runner: "docker.io/automationbroker/helm-runner:latest"
white_list:
- ".*"안정적인 리포지터리의 많은 Helm 차트는 OpenShift Container Platform과 함께 사용하기에 적합하지 않으며 이를 사용하는 경우 오류와 함께 실패합니다.
8.4.11. API V2 Docker 레지스트리
apiv2 유형을 사용하면 Docker Registry HTTP API V2 프로토콜을 구현하는 Docker 레지스트리의 이미지를 사용할 수 있습니다.
registry:
- name: <registry_name>
type: apiv2
url: <registry_url>
user: <registry-user>
pass: <registry-password>
white_list:
- ".*-apb$"레지스트리에 이미지 가져오기에 대한 인증이 필요한 경우 기존 클러스터의 모든 노드에서 다음 명령을 실행하여 수행할 수 있습니다.
$ docker --config=/var/lib/origin/.docker login -u <registry-user> -p <registry-password> <registry_url>8.4.12. Quay Docker 레지스트리
quay 유형을 사용하면 CoreOS Quay 레지스트리에 게시된 APB를 로드할 수 있습니다. 인증 토큰이 제공되면 토큰이 액세스하도록 구성된 프라이빗 리포지토리가 로드됩니다. 지정된 조직의 공용 리포지토리에 토큰을 로드할 필요가 없습니다.
registry:
- name: quay_reg
type: quay
url: https://quay.io
token: <for_private_repos>
org: <your_org>
white_list:
- ".*-apb$"Quay 레지스트리에 이미지 가져오기에 대한 인증이 필요한 경우 기존 클러스터의 모든 노드에서 다음 명령을 실행하여 수행할 수 있습니다.
$ docker --config=/var/lib/origin/.docker login -u <registry-user> -p <registry-password> quay.io8.4.13. 다중 레지스트리
둘 이상의 레지스트리를 사용하여 APB를 논리 조직으로 분리하고 동일한 브로커에서 관리할 수 있습니다. 레지스트리에는 비어 있지 않은 고유한 이름이 있어야 합니다. 고유한 이름이 없는 경우 서비스 브로커가 문제를 알리는 오류 메시지로 시작하지 못합니다.
registry:
- name: dockerhub
type: dockerhub
org: ansibleplaybookbundle
user: <user>
pass: <password>
white_list:
- ".*-apb$"
- name: rhcc
type: rhcc
url: <rhcc_url>
white_list:
- ".*-apb$"8.5. 브로커 인증
브로커는 브로커에 연결할 때 호출자가 각 요청에 대해 Basic Auth 또는 Bearer Auth 자격 증명을 제공해야 하는 인증을 지원합니다. curl 을 사용하면 다음과 같이 간단합니다.
-u <user_name>:<password>또는
-h "Authorization: bearer <token>명령을 실행합니다. 서비스 카탈로그는 사용자 이름 및 암호 조합 또는 전달자 토큰이 포함된 시크릿을 사용하여 구성해야 합니다.
8.5.1. 기본 인증
기본 인증 사용을 활성화하려면 브로커 구성에서 다음을 설정합니다.
broker:
...
auth:
- type: basic
enabled: true 8.5.1.1. 배포 템플릿 및 시크릿
일반적으로 브로커는 배포 템플릿에서 ConfigMap 을 사용하여 구성됩니다. 파일 구성과 동일한 방식으로 인증 구성을 제공합니다.
다음은 배포 템플릿의 예입니다.
auth:
- type: basic
enabled: ${ENABLE_BASIC_AUTH}Basic Auth(기본 인증)의 또 다른 부분은 브로커에 대해 인증하는 데 사용되는 사용자 이름과 암호입니다. 기본 인증 구현은 다양한 백엔드 서비스에서 지원할 수 있지만 현재 지원되는 구현은 비밀 에서 지원합니다. /var/run/asb_auth 위치의 볼륨 마운트를 통해 시크릿을 Pod에 삽입해야 합니다. 여기서 브로커가 사용자 이름과 암호를 읽습니다.
배포 템플릿에서 보안을 지정해야 합니다. 예를 들면 다음과 같습니다.
- apiVersion: v1
kind: Secret
metadata:
name: asb-auth-secret
namespace: openshift-ansible-service-broker
data:
username: ${BROKER_USER}
password: ${BROKER_PASS}
시크릿에는 사용자 이름과 암호가 포함되어야 합니다. 값은 base64로 인코딩되어야 합니다. 해당 항목의 값을 생성하는 가장 쉬운 방법은 echo 및 base64 명령을 사용하는 것입니다.
$ echo -n admin | base64
YWRtaW4=- 1
- n
옵션은매우 중요합니다.
이제 이 시크릿을 볼륨 마운트를 통해 Pod에 삽입해야 합니다. 이는 배포 템플릿에서도 구성됩니다.
spec:
serviceAccount: asb
containers:
- image: ${BROKER_IMAGE}
name: asb
imagePullPolicy: IfNotPresent
volumeMounts:
...
- name: asb-auth-volume
mountPath: /var/run/asb-auth
그런 다음 volumes 섹션에서 보안을 마운트합니다.
volumes:
...
- name: asb-auth-volume
secret:
secretName: asb-auth-secret위의 경우 /var/run/asb-auth 에 있는 볼륨 마운트가 생성됩니다. 이 볼륨에는 두 개의 파일, 즉 asb-auth-secret 보안에서 작성한 사용자 이름과 암호가 있습니다.
8.5.1.2. 서비스 카탈로그 및 브로커 통신 구성
이제 브로커가 Basic Auth를 사용하도록 구성되었으므로 서비스 카탈로그에 브로커와 통신하는 방법을 알려야 합니다. 이 작업은 브로커 리소스의 authInfo 섹션에서 수행합니다.
다음은 서비스 카탈로그에서 브로커 리소스를 생성하는 예입니다. 사양은 브로커가 수신 대기 중인 URL을 서비스 카탈로그에 알려줍니다. authInfo 는 인증 정보를 얻기 위해 읽을 시크릿을 알려줍니다.
apiVersion: servicecatalog.k8s.io/v1alpha1
kind: Broker
metadata:
name: ansible-service-broker
spec:
url: https://asb-1338-openshift-ansible-service-broker.172.17.0.1.nip.io
authInfo:
basicAuthSecret:
namespace: openshift-ansible-service-broker
name: asb-auth-secret서비스 카탈로그의 v0.0.17부터 브로커 리소스 구성이 변경됩니다.
apiVersion: servicecatalog.k8s.io/v1alpha1
kind: ServiceBroker
metadata:
name: ansible-service-broker
spec:
url: https://asb-1338-openshift-ansible-service-broker.172.17.0.1.nip.io
authInfo:
basic:
secretRef:
namespace: openshift-ansible-service-broker
name: asb-auth-secret8.5.2. 전달자 인증
기본적으로 인증을 지정하지 않으면 브로커는 전달자 토큰 인증(Bearer Auth)을 사용합니다. 전달자 Auth는 Kubernetes apiserver 라이브러리에서 위임된 인증을 사용합니다.
이 구성은 Kubernetes RBAC 역할 및 역할 바인딩을 통해 URL 접두사에 액세스 권한을 부여합니다. 브로커가 url_prefix를 지정하기 위해 구성 옵션 을 추가했습니다. 이 값은 기본값은 cluster_ urlopenshift-ansible-service-broker 입니다.
클러스터 역할 예
- apiVersion: authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: access-asb-role
rules:
- nonResourceURLs: ["/ansible-service-broker", "/ansible-service-broker/*"]
verbs: ["get", "post", "put", "patch", "delete"]8.5.2.1. 배포 템플릿 및 시크릿
다음은 서비스 카탈로그에서 사용할 수 있는 시크릿을 생성하는 예입니다. 이 예제에서는 access-asb-role 역할이 이미 생성되었다고 가정합니다. 배포 템플릿에서:
- apiVersion: v1
kind: ServiceAccount
metadata:
name: ansibleservicebroker-client
namespace: openshift-ansible-service-broker
- apiVersion: authorization.openshift.io/v1
kind: ClusterRoleBinding
metadata:
name: ansibleservicebroker-client
subjects:
- kind: ServiceAccount
name: ansibleservicebroker-client
namespace: openshift-ansible-service-broker
roleRef:
kind: ClusterRole
name: access-asb-role
- apiVersion: v1
kind: Secret
metadata:
name: ansibleservicebroker-client
annotations:
kubernetes.io/service-account.name: ansibleservicebroker-client
type: kubernetes.io/service-account-token위의 예제에서는 access -asb-role에 대한 액세스 권한을 부여하고 해당 서비스 계정 토큰에 대한 시크릿을 생성하는 서비스 계정을 생성합니다.
8.5.2.2. 서비스 카탈로그 및 브로커 통신 구성
이제 브로커가 Bearer Auth 토큰을 사용하도록 구성되었으므로 서비스 카탈로그에 브로커와 통신하는 방법을 알려야 합니다. 이 작업은 브로커 리소스의 authInfo 섹션에서 수행합니다.
다음은 서비스 카탈로그에서 브로커 리소스를 생성하는 예입니다. 사양은 브로커가 수신 대기 중인 URL을 서비스 카탈로그에 알려줍니다. authInfo 는 인증 정보를 얻기 위해 읽을 시크릿을 알려줍니다.
apiVersion: servicecatalog.k8s.io/v1alpha1
kind: ServiceBroker
metadata:
name: ansible-service-broker
spec:
url: https://asb.openshift-ansible-service-broker.svc:1338${BROKER_URL_PREFIX}/
authInfo:
bearer:
secretRef:
kind: Secret
namespace: openshift-ansible-service-broker
name: ansibleservicebroker-client8.6. DAO 구성
| 필드 | 설명 | 필수 항목 |
|---|---|---|
|
| etcd 호스트의 URL입니다. | Y |
|
|
| Y |
8.7. 로그 설정
| 필드 | 설명 | 필수 항목 |
|---|---|---|
|
| 브로커의 로그를 작성할 위치. | Y |
|
| stdout에 로그를 작성합니다. | Y |
|
| 로그 출력 수준입니다. | Y |
|
| 로그를 컬러링합니다. | Y |
8.8. OpenShift Configuration
| 필드 | 설명 | 필수 항목 |
|---|---|---|
|
| OpenShift Container Platform 호스트. | N |
|
| 인증 기관 파일의 위치입니다. | N |
|
| 사용할 전달자 토큰의 위치. | N |
|
| 이미지를 가져올 시기입니다. | Y |
|
| 브로커가 배포된 네임스페이스입니다. 시크릿을 통해 매개 변수 값을 전달하는 것과 같은 항목에 중요합니다. | Y |
|
| APB 샌드박스 환경에 제공하는 역할. | Y |
|
| 항상 APB 실행 후 네임스페이스를 유지합니다. | N |
|
| APB 실행에 오류가 있는 후 네임스페이스를 유지합니다. | N |
8.9. 브로커 구성
broker 섹션에서는 브로커 에 어떤 기능을 활성화 및 비활성화해야 하는지 알려줍니다. 또한 전체 기능을 사용할 수 있는 디스크에서 파일을 찾을 위치를 브로커에게 알려줍니다.
| 필드 | 설명 | 기본값 | 필수 항목 |
|---|---|---|---|
|
| 개발 경로에 액세스할 수 있도록 허용합니다. |
| N |
|
| bind를 no-op로 허용합니다. |
| N |
|
| 시작 시 브로커가 부트스트랩을 시도하도록 허용합니다. 는 구성된 레지스트리에서 APB를 검색합니다. |
| N |
|
| etcd에 명시된 보류 중인 작업을 처리하여 브로커가 자체적으로 복구하도록 허용합니다. |
| N |
|
| 더 쉬운 디버깅을 위해 브로커가 들어오는 대로 로그 파일에 요청을 출력하도록 허용합니다. |
| N |
|
| 브로커에 TLS 키 파일을 찾을 위치를 알려줍니다. 설정되지 않은 경우 API 서버는 새로 생성을 시도합니다. |
| N |
|
| 브로커에 TLS .crt 파일을 찾을 위치를 알립니다. 설정되지 않은 경우 API 서버는 새로 생성을 시도합니다. |
| N |
|
| 새 이미지 사양의 레지스트리를 쿼리하는 간격입니다. |
| N |
|
| 브로커가 APB를 실행하는 동안 사용자의 권한을 에스컬레이션할 수 있습니다. |
| N |
|
| 브로커가 예상하는 URL의 접두사를 설정합니다. |
| N |
비동기 바인딩 및 바인딩 해제는 실험적 기능이며 기본적으로 지원되지 않거나 활성화되지 않습니다. 비동기 바인딩이 없으면 launch_apb_on_bind 를 true 로 설정하면 bind 작업이 시간 초과되고 재시도를 확장합니다. 브로커는 다른 매개변수와 동일한 바인드 요청이므로 "409 충돌"으로 처리합니다.
8.10. 보안 구성
secrets 섹션에서는 브로커 네임스페이스의 보안과 브로커가 실행하는 APB 간 연결을 생성합니다. 브로커는 이러한 규칙을 사용하여 실행 중인 APB에 시크릿을 마운트하므로 사용자가 카탈로그 또는 사용자에게 공개하지 않고 시크릿을 사용하여 매개 변수를 전달할 수 있습니다.
섹션은 각 항목에 다음 구조가 있는 목록입니다.
| 필드 | 설명 | 필수 항목 |
|---|---|---|
|
| 규칙의 제목입니다. 이는 디스플레이 및 출력 용도로만 사용됩니다. | Y |
|
|
지정된 보안과 연결할 APB의 이름입니다. 이는 정규화된 이름( | Y |
|
| 매개변수를 가져올 시크릿의 이름입니다. | Y |
create_broker_secret.py 파일을 다운로드하여 이 구성 섹션을 생성하고 포맷할 수 있습니다.
secrets:
- title: Database credentials
secret: db_creds
apb_name: dh-rhscl-postgresql-apb8.11. 프록시 뒤의 실행
프록시된 OpenShift Container Platform 클러스터 내부에서 OAB를 실행하는 경우 핵심 개념을 이해하고 외부 네트워크 액세스에 사용되는 프록시 컨텍스트 내에서 고려해야 합니다.
개요를 통해 브로커 자체는 클러스터 내에서 Pod로 실행됩니다. 레지스트리 구성 방법에 따라 외부 네트워크 액세스 요구 사항이 있습니다.
8.11.1. 레지스트리 어댑터 화이트리스트
브로커의 구성된 레지스트리 어댑터는 성공적으로 부트스트랩하고 원격 APB 매니페스트를 로드하기 위해 외부 레지스트리와 통신할 수 있어야 합니다. 이러한 요청은 프록시를 통해 만들 수 있지만 프록시는 필요한 원격 호스트에 액세스할 수 있어야 합니다.
필요한 허용된 호스트의 예:
| 레지스트리 어댑터 유형 | 허용된 호스트 |
|---|---|
|
|
|
|
|
|
8.11.2. Ansible을 사용하여 프록시 기반 브로커 구성
초기 설치 중에 프록시 뒤에서 실행되도록 OpenShift Container Platform 클러스터를 구성하는 경우 OAB가 배포될 때 프록시뒤에서 실행되도록 OpenShift Container Platform 클러스터를 구성합니다.
- 이러한 클러스터 전체 프록시 설정을 자동으로 상속합니다.
-
cidr필드 및serviceNetworkCIDR을 포함하여 필수NO_PROXY목록을 생성합니다.
또한 추가 구성이 필요하지 않습니다.
8.11.3. 수동으로 프록시 종속 브로커 구성
초기 설치 중 또는 배포하기 전에 클러스터의 글로벌 프록시 옵션이 구성되지 않았거나 글로벌 프록시 설정을 수정한 경우 프록시를 통해 외부 액세스를 위해 브로커를 수동으로 구성해야 합니다.
프록시 뒤에서 OAB를 실행하기 전에 HTTP 프록시 작업을 검토하고 프록시 뒤에서 실행되도록 클러스터가 적절하게 구성되었는지 확인합니다.
특히 내부 클러스터 요청을 프록시 하지 않도록 클러스터를 구성해야 합니다. 일반적으로 다음과 같은
NO_PROXY설정으로 구성됩니다..cluster.local,.svc,<serviceNetworkCIDR_value>,<master_IP>,<master_domain>,.default다른 원하는
NO_PROXY설정 외에. 자세한 내용은 NO_PROXY 구성을 참조하십시오.참고버전 또는 v1 APB를 배포하는 브로커도
NO_PROXY목록에172.30.0.1을 추가해야 합니다. v2 이전 APB는 비밀 교환이 아닌execHTTP 요청을 통해 APB Pod를 실행할 수 있는 인증 정보를 추출했습니다. OpenShift Container Platform 3.9 이전의 클러스터에서 실험적 프록시 지원이 포함된 브로커를 실행하지 않는 한, 이 문제를 걱정할 필요가 없습니다.cluster-admin 권한이
있는사용자로 브로커의 deployment를 편집합니다.$ oc edit dc/asb -n openshift-ansible-service-broker다음 환경 변수를 설정합니다.
-
HTTP_PROXY -
HTTPS_PROXY -
NO_PROXY
참고자세한 내용은 Pod에서 프록시 환경 변수 설정을 참조하십시오.
-
업데이트를 저장한 후 변경 사항을 적용하려면 OAB의 배포 구성을 다시 배포합니다.
$ oc rollout latest dc/asb -n openshift-ansible-service-broker
8.11.4. Pod에서 프록시 환경 변수 설정
APB 포드 자체도 프록시를 통해 외부 액세스가 필요할 수 있습니다. 브로커에 프록시 구성이 있는 것을 인식하는 경우 이러한 환경 변수를 생성하는 APB Pod에 투명하게 적용합니다. APB 내에서 사용된 모듈이 환경 변수를 통해 프록시 구성을 참조하는 한 APB도 이러한 설정을 사용하여 작업을 수행합니다.
마지막으로, APB에서 생성한 서비스도 프록시를 통해 외부 네트워크 액세스가 필요할 수 있습니다. 자체 실행 환경에서 인식하는 경우 이러한 환경 변수를 명시적으로 설정 하도록 APB를 작성하거나 클러스터 운영자가 환경에 삽입하기 위해 필요한 서비스를 수동으로 수정해야 합니다.
9장. 기존 클러스터에 호스트 추가
9.1. 호스트 추가
scaleup.yml 플레이북을 실행하여 클러스터에 새 호스트를 추가할 수 있습니다. 이 플레이북은 마스터를 쿼리하고 새 호스트에 대한 새 인증서를 생성 및 배포한 다음 새 호스트에서만 구성 플레이북을 실행합니다. scaleup.yml 플레이북을 실행하기 전에 사전 요구 사항 호스트 준비 단계를 모두 완료합니다.
scaleup.yml 플레이북은 새 호스트만 구성합니다. 마스터 서비스에서 NO_PROXY 를 업데이트하지 않으며 마스터 서비스를 다시 시작하지 않습니다.
scaleup.yml 플레이북을 실행하려면 현재 클러스터 구성을 나타내는 기존 인벤토리 파일(예: /etc/ansible/hosts )이 있어야 합니다. 이전에 atomic-openshift-installer 명령을 사용하여 설치를 실행하는 경우 설치 프로그램에서 생성한 마지막 인벤토리 파일의 ~/.config/openshift/hosts 를 확인하고 해당 파일을 인벤토리 파일로 사용할 수 있습니다. 필요에 따라 이 파일을 수정할 수 있습니다. 그런 다음 ansible-playbook 을 실행할 때 -i 를 사용하여 파일 위치를 지정해야 합니다.
권장되는 최대 노드 수는 클러스터 최대값 섹션을 참조하십시오.
절차
openshift-ansible 패키지를 업데이트하여 최신 플레이북이 있는지 확인합니다.
# yum update openshift-ansible/etc/ansible/hosts 파일을 편집하고 new_<host_type> 을 [OSEv3:children] 섹션에 추가합니다. 예를 들어 새 노드 호스트를 추가하려면 new_nodes 를 추가합니다.
[OSEv3:children] masters nodes new_nodes새 마스터 호스트를 추가하려면 new_masters 를 추가합니다.
[new_<host_type>] 섹션을 생성하여 새 호스트에 대한 호스트 정보를 지정합니다. 새 노드 추가의 다음 예에 표시된 대로 이 섹션을 기존 섹션처럼 포맷합니다.
[nodes] master[1:3].example.com node1.example.com openshift_node_group_name='node-config-compute' node2.example.com openshift_node_group_name='node-config-compute' infra-node1.example.com openshift_node_group_name='node-config-infra' infra-node2.example.com openshift_node_group_name='node-config-infra' [new_nodes] node3.example.com openshift_node_group_name='node-config-infra'자세한 옵션은 호스트 변수 구성을 참조하십시오.
새 마스터 호스트를 추가할 때 [new_masters] 섹션과 [new_nodes] 섹션 모두에 호스트를 추가하여 새 마스터 호스트가 OpenShift SDN의 일부인지 확인합니다.
[masters] master[1:2].example.com [new_masters] master3.example.com [nodes] master[1:2].example.com node1.example.com openshift_node_group_name='node-config-compute' node2.example.com openshift_node_group_name='node-config-compute' infra-node1.example.com openshift_node_group_name='node-config-infra' infra-node2.example.com openshift_node_group_name='node-config-infra' [new_nodes] master3.example.com중요node-role.kubernetes.io/infra=true레이블을 사용하여 마스터 호스트에 레이블을 지정하고 다른 전용 인프라 노드가 없는 경우, 항목에openshift_schedulable=true를 추가하여 호스트를 예약 가능으로 명시적으로 표시해야 합니다. 그렇지 않으면 레지스트리 및 라우터 포드를 아무 위치에 배치할 수 없습니다.플레이북 디렉터리로 변경하고 openshift_node_group.yml 플레이북을 실행합니다. 인벤토리 파일이 기본값 /etc/ansible/hosts 이외의 위치에 있는 경우
-i옵션을 사용하여 위치를 지정합니다.$ cd /usr/share/ansible/openshift-ansible $ ansible-playbook [-i /path/to/file] \ playbooks/openshift-master/openshift_node_group.yml이렇게 하면 새 노드 그룹에 대한 ConfigMap이 생성되고 궁극적으로 호스트에서 노드의 구성 파일이 생성됩니다.
참고openshift_node_group.yaml 플레이북을 실행하면 새 노드만 업데이트됩니다. 클러스터의 기존 노드를 업데이트하기 위해 실행할 수 없습니다.
scaleup.yml 플레이북을 실행합니다. 인벤토리 파일이 기본값 /etc/ansible/hosts 이외의 위치에 있는 경우
-i옵션을 사용하여 위치를 지정합니다.추가 노드의 경우 다음을 수행합니다.
$ ansible-playbook [-i /path/to/file] \ playbooks/openshift-node/scaleup.yml추가 마스터의 경우 다음을 수행합니다.
$ ansible-playbook [-i /path/to/file] \ playbooks/openshift-master/scaleup.yml
클러스터에 EFK 스택을 배포한 경우 node 레이블을
logging-infra-fluentd=true로 설정합니다.# oc label node/new-node.example.com logging-infra-fluentd=true- 플레이북이 실행된 후 설치를 확인합니다.
[new_<host_type>] 섹션에서 정의한 호스트를 적절한 섹션으로 이동합니다. 이러한 호스트를 이동하면 이 인벤토리 파일을 사용하는 후속 플레이북 실행에서 노드를 올바르게 처리합니다. [new_<host_type>] 섹션은 비어 있습니다. 예를 들어 새 노드를 추가할 때 다음을 수행합니다.
[nodes] master[1:3].example.com node1.example.com openshift_node_group_name='node-config-compute' node2.example.com openshift_node_group_name='node-config-compute' node3.example.com openshift_node_group_name='node-config-compute' infra-node1.example.com openshift_node_group_name='node-config-infra' infra-node2.example.com openshift_node_group_name='node-config-infra' [new_nodes]
9.2. 기존 클러스터에 etcd 호스트 추가
etcd 확장 플레이북을 실행하여 클러스터에 새 etcd 호스트를 추가할 수 있습니다. 이 플레이북은 마스터를 쿼리하고 새 호스트에 대한 새 인증서를 생성 및 배포한 다음 새 호스트에서만 구성 플레이북을 실행합니다. etcd scaleup.yml 플레이북을 실행하기 전에 사전 요구 사항 호스트 준비 단계를 모두 완료합니다.
이러한 단계는 Ansible 인벤토리의 설정을 클러스터와 동기화합니다. 로컬 변경 사항이 Ansible 인벤토리에 표시되는지 확인합니다.
기존 클러스터에 etcd 호스트를 추가하려면 다음을 수행합니다.
openshift-ansible 패키지를 업데이트하여 최신 플레이북이 있는지 확인합니다.
# yum update openshift-ansible/etc/ansible/hosts 파일을 편집하고 new_<host_type> 을 [OSEv3:children] 그룹에 추가하고 new_<host_type> 그룹 아래에 호스트를 추가합니다. 예를 들어 새 etcd를 추가하려면 new_etcd 를 추가합니다.
[OSEv3:children] masters nodes etcd new_etcd [etcd] etcd1.example.com etcd2.example.com [new_etcd] etcd3.example.com플레이북 디렉터리로 변경하고 openshift_node_group.yml 플레이북을 실행합니다. 인벤토리 파일이 기본값 /etc/ansible/hosts 이외의 위치에 있는 경우
-i옵션을 사용하여 위치를 지정합니다.$ cd /usr/share/ansible/openshift-ansible $ ansible-playbook [-i /path/to/file] \ playbooks/openshift-master/openshift_node_group.yml이렇게 하면 새 노드 그룹에 대한 ConfigMap이 생성되고 궁극적으로 호스트에서 노드의 구성 파일이 생성됩니다.
참고openshift_node_group.yaml 플레이북을 실행하면 새 노드만 업데이트됩니다. 클러스터의 기존 노드를 업데이트하기 위해 실행할 수 없습니다.
etcd scaleup.yml 플레이북을 실행합니다. 인벤토리 파일이 기본값 /etc/ansible/hosts 이외의 위치에 있는 경우
-i옵션을 사용하여 위치를 지정합니다.$ ansible-playbook [-i /path/to/file] \ playbooks/openshift-etcd/scaleup.yml- 플레이북이 성공적으로 완료되면 설치를 확인합니다.
9.3. 기존 마스터를 etcd로 교체
시스템을 다른 데이터 센터로 마이그레이션하고 할당된 네트워크와 IP가 변경되는 경우 다음 단계를 따르십시오.
OpenShift Container Platform 버전 3.11의 초기 릴리스에서는 scaleup.yml 플레이북이 etcd를 확장하지 않습니다. 이는 OpenShift Container Platform 3.11.59 이상에서 해결되었습니다.
-
마스터 추가. 해당 프로세스의 3단계에서
[new_masters] 및에 새 데이터 센터의 호스트를 추가하고 openshift_node_group.yml 플레이북을 실행하고 master scaleup.yml 플레이북을 실행합니다.[new_nodes] - 동일한 호스트를 etcd 섹션에 배치하고 openshift_node_group.yml 플레이북을 실행한 다음 etcd scaleup.yml 플레이북을 실행합니다.
호스트가 추가되었는지 확인합니다.
# oc get nodes마스터 호스트 IP가 추가되었는지 확인합니다.
# oc get ep kubernetesetcd가 추가되었는지 확인합니다.
ETCDCTL_API값은 사용 중인 버전에 따라 다릅니다.# source /etc/etcd/etcd.conf # ETCDCTL_API=2 etcdctl --cert-file=$ETCD_PEER_CERT_FILE --key-file=$ETCD_PEER_KEY_FILE \ --ca-file=/etc/etcd/ca.crt --endpoints=$ETCD_LISTEN_CLIENT_URLS member list/etc/origin/master/ca.serial.txt 디렉터리의 /etc/origin/master 디렉토리를 inventory 파일에 먼저 나열된 새 마스터 호스트로 복사합니다. 기본적으로 이는 /etc/ansible/hosts 입니다.
- etcd 호스트를 제거합니다.
- /etc/etcd/ca 디렉터리를 인벤토리 파일에 먼저 나열된 새 etcd 호스트로 복사합니다. 기본적으로 이는 /etc/ansible/hosts 입니다.
master-config.yaml 파일에서 이전 etcd 클라이언트를 제거합니다.
# grep etcdClientInfo -A 11 /etc/origin/master/master-config.yaml마스터를 다시 시작하십시오.
# master-restart api # master-restart controllers클러스터에서 이전 etcd 멤버를 제거합니다.
ETCDCTL_API값은 사용 중인 버전에 따라 다릅니다.# source /etc/etcd/etcd.conf # ETCDCTL_API=2 etcdctl --cert-file=$ETCD_PEER_CERT_FILE --key-file=$ETCD_PEER_KEY_FILE \ --ca-file=/etc/etcd/ca.crt --endpoints=$ETCD_LISTEN_CLIENT_URLS member list위 명령의 출력에서 ID를 사용하고 ID를 사용하여 이전 멤버를 제거합니다.
# etcdctl --cert-file=$ETCD_PEER_CERT_FILE --key-file=$ETCD_PEER_KEY_FILE \ --ca-file=/etc/etcd/ca.crt --endpoints=$ETCD_LISTEN_CLIENT_URL member remove 1609b5a3a078c227etcd pod 정의를 제거하여 이전 etcd 호스트에서 etcd 서비스를 중지합니다.
# mkdir -p /etc/origin/node/pods-stopped # mv /etc/origin/node/pods/* /etc/origin/node/pods-stopped/정적 포드 dir /etc/origin/node/pods에서 정의 파일을 이동하여 이전 마스터 API 및 컨트롤러 서비스를 종료합니다.
# mkdir -p /etc/origin/node/pods/disabled # mv /etc/origin/node/pods/controller.yaml /etc/origin/node/pods/disabled/:- 기본 설치 프로세스 중 기본적으로 로드 밸런서 장치로 설치된 HA 프록시 구성에서 마스터 노드를 제거합니다.
- 시스템을 해제합니다.
포드 정의를 제거하고 호스트를 재부팅하여 마스터에서 노드 서비스를 중지합니다.
# mkdir -p /etc/origin/node/pods-stopped # mv /etc/origin/node/pods/* /etc/origin/node/pods-stopped/ # reboot노드 리소스를 삭제합니다.
# oc delete node
9.4. 노드 마이그레이션
노드를 개별적으로 또는 그룹(2, 5, 10 등)으로 마이그레이션할 수 있으며, 노드상의 서비스가 실행 및 확장되는 방식에 따라 노드를 개별적으로 마이그레이션할 수 있습니다.
- 마이그레이션 노드 또는 노드의 경우 새 데이터 센터에서 노드에 사용할 새 VM을 프로비저닝합니다.
- 새 노드를 추가하려면 인프라를 확장합니다. 새 노드의 레이블이 올바르게 설정되어 새 API 서버가 로드 밸런서에 추가되고 트래픽을 성공적으로 제공하는지 확인합니다.
평가 및 축소.
- 현재 노드(기존 데이터 센터에 있음)를 예약하지 않은 상태로 표시합니다.
- 노드의 포드가 다른 노드로 예약되도록 노드를 비웁니다.
- 비워진 서비스가 새 노드에서 실행 중인지 확인합니다.
노드를 제거합니다.
- 노드가 비어 있고 실행 중인 프로세스가 없는지 확인합니다.
- 서비스를 중지하거나 노드를 삭제합니다.
10장. 기본 이미지 스트림 및 템플릿 추가
10.1. 개요
x86_64 아키텍처가 있는 서버에 OpenShift Container Platform을 설치한 경우 클러스터에 유용한 Red Hat 제공 이미지 스트림 및 템플릿 세트가 포함되어 개발자가 새 애플리케이션을 쉽게 생성할 수 있습니다. 기본적으로 클러스터 설치 프로세스에서는 모든 사용자에게 보기 액세스 권한이 있는 기본 글로벌 프로젝트인 openshift 프로젝트에 이러한 세트를 자동으로 생성합니다.
IBM POWER 아키텍처가 있는 서버에 OpenShift Container Platform을 설치하는 경우 클러스터에 이미지 스트림과 템플릿 을 추가할 수 있습니다.
10.2. 서브스크립션 유형별 제공
Red Hat 계정에 대한 활성 서브스크립션에 따라 다음 이미지 스트림 및 템플릿 세트가 Red Hat에서 제공하고 지원합니다. 자세한 서브스크립션 정보는 Red Hat 영업 담당자에게 문의하십시오.
10.2.1. OpenShift Container Platform 서브스크립션
이미지 스트림 및 템플릿의 핵심 세트는 활성 OpenShift Container Platform 서브스크립션 에서 제공되고 지원됩니다. 여기에는 다음과 같은 기술이 포함됩니다.
| 유형 | 기술 |
|---|---|
| 언어 및 프레임워크 | |
| 데이터베이스 | |
| 미들웨어 서비스 | |
| 기타 서비스 |
10.2.2. xPaaS 미들웨어 애드온 서브스크립션
xPaaS 미들웨어 이미지에 대한 지원은 각 xPaaS 제품에 대해 별도의 서브스크립션인 xPaaS 미들웨어 애드온 서브스크립션을 통해 제공됩니다. 계정에서 관련 서브스크립션이 활성화되어 있으면 다음 기술에 대해 이미지 스트림과 템플릿이 제공되고 지원됩니다.
10.3. 시작하기 전
이 항목에서 작업을 수행하기 전에 다음 중 하나를 수행하여 이러한 이미지 스트림과 템플릿이 OpenShift Container Platform 클러스터에 이미 등록되어 있는지 확인합니다.
- 웹 콘솔에 로그인하고 Add to Project (프로젝트에 추가)를 클릭합니다.
CLI를 사용하여 openshift 프로젝트에 사용할 수 있도록 나열합니다.
$ oc get is -n openshift $ oc get templates -n openshift
기본 이미지 스트림과 템플릿이 제거되거나 변경된 경우 이 항목에 따라 기본 오브젝트를 직접 생성할 수 있습니다. 그렇지 않으면 다음 지침이 필요하지 않습니다.
10.4. 사전 요구 사항
기본 이미지 스트림 및 템플릿을 생성하려면 먼저 다음을 수행합니다.
- 통합된 컨테이너 이미지 레지스트리 서비스는 OpenShift Container Platform 설치에 배포해야 합니다.
-
기본 openshift 프로젝트에서 작동하므로 cluster-admin 권한으로
oc create명령을 실행할 수 있어야 합니다. - openshift-ansible RPM 패키지가 설치되어 있어야 합니다. 자세한 내용은 소프트웨어 사전 요구 사항을 참조하십시오.
-
IBM POWER8 또는 IBM POWER9 서버에 온프레미스 설치의 경우
openshift네임스페이스에registry.redhat.io의 시크릿을 생성합니다. 이미지 스트림과 템플릿을 포함하는 디렉터리에 대한 쉘 변수를 정의합니다. 이렇게 하면 다음 섹션의 명령이 크게 단축됩니다. 이 작업을 수행하려면 다음을 수행합니다.
- x86_64 서버에 클라우드 설치 및 온프레미스 설치의 경우:
$ IMAGESTREAMDIR="/usr/share/ansible/openshift-ansible/roles/openshift_examples/files/examples/x86_64/image-streams"; \
XPAASSTREAMDIR="/usr/share/ansible/openshift-ansible/roles/openshift_examples/files/examples/x86_64/xpaas-streams"; \
XPAASTEMPLATES="/usr/share/ansible/openshift-ansible/roles/openshift_examples/files/examples/x86_64/xpaas-templates"; \
DBTEMPLATES="/usr/share/ansible/openshift-ansible/roles/openshift_examples/files/examples/x86_64/db-templates"; \
QSTEMPLATES="/usr/share/ansible/openshift-ansible/roles/openshift_examples/files/examples/x86_64/quickstart-templates"- IBM POWER8 또는 IBM POWER9 서버에 온프레미스 설치의 경우 다음을 수행합니다.
IMAGESTREAMDIR="/usr/share/ansible/openshift-ansible/roles/openshift_examples/files/examples/ppc64le/image-streams"; \
DBTEMPLATES="/usr/share/ansible/openshift-ansible/roles/openshift_examples/files/examples/ppc64le/db-templates"; \
QSTEMPLATES="/usr/share/ansible/openshift-ansible/roles/openshift_examples/files/examples/ppc64le/quickstart-templates"10.5. OpenShift Container Platform 이미지의 이미지 스트림 생성
Red Hat Subscription Manager를 사용하여 노드 호스트를 서브스크립션하고 RHEL (Red Hat Enterprise Linux) 7 기반 이미지를 사용한 코어 이미지 스트림 세트를 사용하려는 경우 다음을 수행하십시오.
$ oc create -f $IMAGESTREAMDIR/image-streams-rhel7.json -n openshift또는 CentOS 7 기반 이미지를 사용하는 이미지 스트림의 코어 세트를 생성하려면 다음을 수행합니다.
$ oc create -f $IMAGESTREAMDIR/image-streams-centos7.json -n openshiftCentOS 및 RHEL 이미지 스트림 세트를 모두 생성할 수 없습니다. 동일한 이름을 사용하기 때문입니다. 사용자가 두 가지 이미지 스트림 세트를 모두 사용할 수 있도록 하려면 다른 프로젝트에서 하나의 세트를 생성하거나 파일 중 하나를 편집하고 이미지 스트림 이름을 수정하여 고유하게 만듭니다.
10.6. xPaaS 미들웨어 이미지용 이미지 스트림 생성
xPaaS Middleware 이미지 스트림은 JBoss EAP, JBoss JWS, JBoss A-MQ,OpenShift의 Red Hat Fuse,Decision Server,JBoss Data Virtualization 및 JBoss Data Grid 이미지를 제공합니다. 제공된 템플릿을 사용하여 이러한 플랫폼에 대한 애플리케이션을 빌드하는 데 사용할 수 있습니다.
이미지 스트림의 xPaaS Middleware 세트를 생성하려면 다음을 수행합니다.
$ oc create -f $XPAASSTREAMDIR/jboss-image-streams.json -n openshift이러한 이미지 스트림에서 참조하는 이미지에 액세스하려면 관련 xPaaS Middleware 서브스크립션이 필요합니다.
10.7. 데이터베이스 서비스 템플릿 생성
데이터베이스 서비스 템플릿을 사용하면 다른 구성 요소에서 사용할 수 있는 데이터베이스 이미지를 쉽게 실행할 수 있습니다. 각 데이터베이스(MongoDB, MySQL, PostgreSQL)에 대해 두 개의 템플릿이 정의됩니다.
한 템플릿은 컨테이너의 임시 스토리지를 사용하므로, 예를 들어 포드가 이동하는 경우 컨테이너를 다시 시작하면 저장된 데이터가 손실됩니다. 이 템플릿은 데모용으로만 사용해야 합니다.
다른 템플릿은 스토리지용 영구 볼륨을 정의하지만, 영구 볼륨을 구성하려면 OpenShift Container Platform을 설치해야 합니다.
데이터베이스 템플릿의 코어 세트를 생성하려면 다음을 수행합니다.
$ oc create -f $DBTEMPLATES -n openshift템플릿을 만든 후에는 사용자가 다양한 템플릿을 쉽게 인스턴스화하여 데이터베이스 배포에 빠르게 액세스할 수 있습니다.
10.8. 인스턴트 앱 및 빠른 시작 템플릿 생성
인스턴트 앱 및 빠른 시작 템플릿은 실행 중인 애플리케이션의 전체 오브젝트 세트를 정의합니다. 여기에는 다음이 포함됩니다.
또한 일부 템플릿은 애플리케이션에서 데이터베이스 작업을 수행할 수 있도록 데이터베이스 배포 및 서비스를 정의합니다.
데이터베이스를 정의하는 템플릿은 데이터베이스 콘텐츠에 임시 스토리지를 사용합니다. 어떤 이유로든 데이터베이스 포드가 다시 시작되면 데이터베이스 데이터가 모두 손실되므로 이러한 템플릿은 설명용으로만 사용해야 합니다.
사용자는 이러한 템플릿을 사용하여 OpenShift Container Platform과 함께 제공되는 다양한 언어 이미지를 사용하여 전체 애플리케이션을 쉽게 인스턴스화할 수 있습니다. 또한 인스턴스화 중에 샘플 리포지토리가 아닌 자체 리포지토리에서 소스를 빌드하도록 템플릿 매개 변수를 사용자 지정할 수 있으므로, 새 애플리케이션을 간단하게 빌드할 수 있습니다.
핵심 Instant App 및 빠른 시작 템플릿을 생성하려면 다음을 수행합니다.
$ oc create -f $QSTEMPLATES -n openshift다음을 실행하여 등록할 수 있는 다양한 xPaaS Middleware 제품(JBossEAP, JBoss JWS, JBoss A-MQ,Red Hat Fuse on OpenShift,Decision Server 및 JBoss Data Grid)을 사용하여 애플리케이션을 생성하는 템플릿도 있습니다.
$ oc create -f $XPAASTEMPLATES -n openshiftxPaaS Middleware 템플릿에는 xPaaS Middleware 이미지 스트림이 필요하며, 이 스트림에는 관련 xPaaS Middleware 서브스크립션이 필요합니다.
데이터베이스를 정의하는 템플릿은 데이터베이스 콘텐츠에 임시 스토리지를 사용합니다. 어떤 이유로든 데이터베이스 포드가 다시 시작되면 데이터베이스 데이터가 모두 손실되므로 이러한 템플릿은 설명용으로만 사용해야 합니다.
10.9. 어떻게 해야 합니까?
이러한 아티팩트가 생성되면 개발자가 웹 콘솔에 로그인하고 템플릿에서 생성하는 흐름을 따를 수 있습니다. 데이터베이스 또는 애플리케이션 템플릿을 선택하여 현재 프로젝트에서 실행 중인 데이터베이스 서비스 또는 애플리케이션을 생성할 수 있습니다. 일부 애플리케이션 템플릿은 자체 데이터베이스 서비스를 정의합니다.
예제 애플리케이션은 SOURCE_REPOSITORY_URL 매개 변수 값에 표시된 대로 기본적으로 템플릿에서 참조되는 GitHub 리포지토리에서 모두 빌드됩니다. 이러한 리포지토리는 분기할 수 있으며 템플릿에서 생성할 때 포크를 SOURCE_REPOSITORY_URL 매개변수 값으로 제공할 수 있습니다. 이를 통해 개발자가 자체 애플리케이션을 만드는 것을 실험할 수 있습니다.
이러한 지침에 대해 개발자 가이드의 개발자 가이드에서 개발자에게 인스턴트 앱 및 빠른 시작 템플릿 사용 섹션으로 안내할 수 있습니다.
11장. 사용자 정의 인증서 구성
11.1. 개요
관리자는 OpenShift Container Platform API 및 웹 콘솔의 공용 호스트 이름에 대해 사용자 정의 제공 인증서를 구성할 수 있습니다. 이는 클러스터를 설치하는 동안 수행하거나 설치 후 구성할 수 있습니다.
11.2. 인증서 체인 구성
인증서 체인을 사용하는 경우 모든 인증서를 수동으로 명명된 하나의 인증서 파일에 연결해야 합니다. 이러한 인증서는 다음 순서로 지정해야 합니다.
- OpenShift Container Platform 마스터 호스트 인증서
- 중간 CA 인증서
- 루트 CA 인증서
- 타사 인증서
이 인증서 체인을 생성하려면 인증서를 공통 파일에 연결합니다. 각 인증서에 대해 이 명령을 실행하고 이전에 정의된 순서에 해당하는지 확인해야 합니다.
$ cat <certificate>.pem >> ca-chain.cert.pem11.3. 설치 중 사용자 정의 인증서 구성
클러스터 설치 중에 인벤토리 파일에서 구성할 수 있는 openshift_master_named_certificates 및 openshift_master_overwrite_named_certificates 매개변수를 사용하여 사용자 지정 인증서를 구성할 수 있습니다. Ansible을 사용하여 사용자 지정 인증서 구성에 대한 자세한 내용을 확인할 수 있습니다.
사용자 정의 인증서 구성 매개 변수
openshift_master_overwrite_named_certificates=true
openshift_master_named_certificates=[{"certfile": "/path/on/host/to/crt-file", "keyfile": "/path/on/host/to/key-file", "names": ["public-master-host.com"], "cafile": "/path/on/host/to/ca-file"}]
openshift_hosted_router_certificate={"certfile": "/path/on/host/to/app-crt-file", "keyfile": "/path/on/host/to/app-key-file", "cafile": "/path/on/host/to/app-ca-file"} - 1
openshift_master_named_certificates매개변수 값을 제공하는 경우 이 매개변수를true로 설정합니다.- 2
- 3
- 라우터 와일드카드 인증서를 프로비저닝합니다.
마스터 API 인증서의 매개변수 예:
openshift_master_overwrite_named_certificates=true
openshift_master_named_certificates=[{"names": ["master.148.251.233.173.nip.io"], "certfile": "/home/cloud-user/master.148.251.233.173.nip.io.cert.pem", "keyfile": "/home/cloud-user/master.148.251.233.173.nip.io.key.pem", "cafile": "/home/cloud-user/master-bundle.cert.pem"}]라우터 와일드카드 인증서의 예제 매개 변수:
openshift_hosted_router_certificate={"certfile": "/home/cloud-user/star-apps.148.251.233.173.nip.io.cert.pem", "keyfile": "/home/cloud-user/star-apps.148.251.233.173.nip.io.key.pem", "cafile": "/home/cloud-user/ca-chain.cert.pem"}11.4. 웹 콘솔 또는 CLI에 대한 사용자 정의 인증서 구성
마스터 구성 파일의 servingInfo 섹션을 통해 웹 콘솔 및 CLI에 대한 사용자 정의 인증서를 지정할 수 있습니다.
-
servingInfo.namedCertificates섹션에서는 웹 콘솔의 사용자 지정 인증서를 제공합니다. -
servingInfo섹션은 CLI 및 기타 API 호출에 대한 사용자 정의 인증서를 제공합니다.
이러한 방식으로 여러 인증서를 구성할 수 있으며 각 인증서를 여러 호스트 이름, 여러 라우터 또는 OpenShift Container Platform 이미지 레지스트리와 연결할 수 있습니다.
기본 인증서는 namedCertificates 외에 servingInfo.certFile 및 servingInfo.keyFile 구성 섹션에서 구성해야 합니다.
namedCertificates 섹션은 /etc/origin/master/master-config .yaml 파일의 masterPublicURL 및 oauthConfig.assetPublicURL 설정과 연결된 호스트 이름에 대해서만 구성해야 합니다. masterURL과 연결된 호스트 이름에 사용자 정의 제공 인증서를 사용하면 인프라 구성 요소가 내부 호스트를 사용하여 마스터 API에 연결하려고 하므로 TLS 오류가 발생합니다.
masterURL
사용자 정의 인증서 구성
servingInfo:
logoutURL: ""
masterPublicURL: https://openshift.example.com:8443
publicURL: https://openshift.example.com:8443/console/
bindAddress: 0.0.0.0:8443
bindNetwork: tcp4
certFile: master.server.crt
clientCA: ""
keyFile: master.server.key
maxRequestsInFlight: 0
requestTimeoutSeconds: 0
namedCertificates:
- certFile: wildcard.example.com.crt
keyFile: wildcard.example.com.key
names:
- "openshift.example.com"
metricsPublicURL: "https://metrics.os.example.com/hawkular/metrics"
Ansible 인벤토리 파일의 openshift_master_cluster_public 매개 변수는 기본적으로 _hostname 및 openshift_master_cluster_hostname/etc/ansible/hosts 여야 합니다. 동일한 경우 명명된 인증서가 실패하므로 다시 설치해야 합니다.
# Native HA with External LB VIPs
openshift_master_cluster_hostname=internal.paas.example.com
openshift_master_cluster_public_hostname=external.paas.example.comOpenShift Container Platform에서 DNS를 사용하는 방법에 대한 자세한 내용은 DNS 설치 사전 요구 사항을 참조하십시오.
이 방법을 사용하면 OpenShift Container Platform에서 생성한 자체 서명 인증서를 활용하고 필요에 따라 개별 구성 요소에 사용자 정의 신뢰할 수 있는 인증서를 추가할 수 있습니다.
내부 인프라 인증서는 자체 서명된 상태로 유지되며 일부 보안 또는 PKI 팀에서 잘못된 사례로 인식될 수 있습니다. 그러나 이러한 인증서를 신뢰하는 유일한 클라이언트는 클러스터 내의 다른 구성 요소이므로 여기서 위험은 최소화됩니다. 모든 외부 사용자와 시스템은 신뢰할 수 있는 사용자 정의 인증서를 사용합니다.
상대 경로는 마스터 구성 파일의 위치에 따라 확인됩니다. 서버를 다시 시작하여 구성 변경 사항을 가져옵니다.
11.5. 사용자 지정 마스터 호스트 인증서 구성
OpenShift Container Platform의 외부 사용자와의 신뢰할 수 있는 연결을 용이하게 하기 위해 기본적으로 /etc/ansible/hosts 의 openshift_master_cluster_public_hostname 매개변수에 제공된 도메인 이름과 일치하는 명명된 인증서를 프로비저닝할 수 있습니다.
Ansible에서 액세스할 수 있는 디렉터리에 이 인증서를 배치하고 다음과 같이 Ansible 인벤토리 파일에서 경로를 추가해야 합니다.
openshift_master_named_certificates=[{"certfile": "/path/to/console.ocp-c1.myorg.com.crt", "keyfile": "/path/to/console.ocp-c1.myorg.com.key", "names": ["console.ocp-c1.myorg.com"]}]매개변수 값은 다음과 같습니다.
- certFile 은 OpenShift Container Platform 사용자 정의 마스터 API 인증서가 포함된 파일의 경로입니다.
- keyfile 은 OpenShift Container Platform 사용자 정의 마스터 API 인증서 키가 포함된 파일의 경로입니다.
- name 은 클러스터 공용 호스트 이름입니다.
파일 경로는 Ansible이 실행되는 시스템에 로컬로 있어야 합니다. 인증서는 마스터 호스트에 복사되며 /etc/origin/master 디렉터리에 배포됩니다.
레지스트리를 보호할 때 서비스 호스트 이름과 IP 주소를 레지스트리의 서버 인증서에 추가합니다. SAN(주체 대체 이름)에는 다음이 포함되어야 합니다.
두 개의 서비스 호스트 이름:
docker-registry.default.svc.cluster.local docker-registry.default.svc서비스 IP 주소.
예를 들면 다음과 같습니다.
172.30.252.46다음 명령을 사용하여 컨테이너 이미지 레지스트리 서비스 IP 주소를 가져옵니다.
oc get service docker-registry --template='{{.spec.clusterIP}}'공개 호스트 이름.
docker-registry-default.apps.example.com다음 명령을 사용하여 컨테이너 이미지 레지스트리 공개 호스트 이름을 가져옵니다.
oc get route docker-registry --template '{{.spec.host}}'
예를 들어 서버 인증서에는 다음과 유사한 SAN 세부 정보가 포함되어야 합니다.
X509v3 Subject Alternative Name:
DNS:docker-registry-public.openshift.com, DNS:docker-registry.default.svc, DNS:docker-registry.default.svc.cluster.local, DNS:172.30.2.98, IP Address:172.30.2.9811.6. 기본 라우터에 대한 사용자 정의 와일드카드 인증서 구성
기본 와일드카드 인증서를 사용하여 OpenShift Container Platform 기본 라우터를 구성할 수 있습니다. 기본 와일드카드 인증서는 사용자 정의 인증서 없이도 기본 암호화를 사용하도록 OpenShift Container Platform에 배포된 애플리케이션에 편리한 방법을 제공합니다.
기본 와일드카드 인증서는 프로덕션 환경 이외의 환경에만 권장됩니다.
기본 와일드카드 인증서를 구성하려면 *.<app_domain>에 유효한 인증서를 프로비저닝합니다. 여기서 <app_domain> 은 Ansible 인벤토리 파일에서 기본적으로 /etc/ansible/hosts 의 openshift_master_default_subdomain 값입니다. 프로비저닝되고 나면 Ansible 호스트에 인증서, 키 및 ca 인증서 파일을 배치하고 Ansible 인벤토리 파일에 다음 행을 추가합니다.
openshift_hosted_router_certificate={"certfile": "/path/to/apps.c1-ocp.myorg.com.crt", "keyfile": "/path/to/apps.c1-ocp.myorg.com.key", "cafile": "/path/to/apps.c1-ocp.myorg.com.ca.crt"}예를 들면 다음과 같습니다.
openshift_hosted_router_certificate={"certfile": "/home/cloud-user/star-apps.148.251.233.173.nip.io.cert.pem", "keyfile": "/home/cloud-user/star-apps.148.251.233.173.nip.io.key.pem", "cafile": "/home/cloud-user/ca-chain.cert.pem"}매개변수 값은 다음과 같습니다.
- cert File은 OpenShift Container Platform 라우터 와일드카드 인증서가 포함된 파일의 경로입니다.
- keyfile 은 OpenShift Container Platform 라우터 와일드카드 인증서 키가 포함된 파일의 경로입니다.
- CAfile 은 이 키 및 인증서의 루트 CA가 포함된 파일의 경로입니다. 중간 CA가 사용 중인 경우 파일에 중간 및 루트 CA가 모두 포함되어야 합니다.
이러한 인증서 파일이 OpenShift Container Platform 클러스터를 처음 사용하는 경우 플레이북 디렉터리로 변경하고 Ansible deploy_router.yml 플레이북을 실행하여 해당 파일을 OpenShift Container Platform 구성 파일에 추가합니다. 플레이북은 인증서 파일을 /etc/origin/master/ 디렉터리에 추가합니다.
# ansible-playbook [-i /path/to/inventory] \
/usr/share/ansible/openshift-ansible/playbooks/openshift-hosted/deploy_router.yml예를 들어 인증서가 새 인증서가 아닌 경우 기존 인증서를 변경하거나 만료된 인증서를 교체하려는 경우 플레이북 디렉터리로 변경하고 다음 플레이북을 실행합니다.
ansible-playbook /usr/share/ansible/openshift-ansible/playbooks/redeploy-certificates.yml이 플레이북을 실행하려면 인증서 이름을 변경하지 않아야 합니다. 인증서 이름이 변경되면 인증서가 새로운 것처럼 Ansible deploy_cluster.yml 플레이북을 다시 실행합니다.
11.7. 이미지 레지스트리에 대한 사용자 정의 인증서 구성
OpenShift Container Platform 이미지 레지스트리는 빌드 및 배포를 용이하게 하는 내부 서비스입니다. 레지스트리와의 통신은 대부분 OpenShift Container Platform의 내부 구성 요소에 의해 처리됩니다. 따라서 레지스트리 서비스 자체에서 사용하는 인증서를 교체할 필요가 없습니다.
그러나 기본적으로 레지스트리는 경로를 사용하여 외부 시스템 및 사용자가 이미지를 가져오고 내보낼 수 있습니다. 자체 서명 된 내부 인증서를 사용하는 대신 외부 사용자에게 제공되는 사용자 정의 인증서와 함께 재암호화 경로를 사용할 수 있습니다.
이를 구성하려면 기본적으로 /etc/ansible/hosts 파일을 Ansible 인벤토리 파일의 [OSEv3:vars] 섹션에 다음 코드 행 을 추가합니다. 레지스트리 경로와 함께 사용할 인증서를 지정합니다.
openshift_hosted_registry_routehost=registry.apps.c1-ocp.myorg.com
openshift_hosted_registry_routecertificates={"certfile": "/path/to/registry.apps.c1-ocp.myorg.com.crt", "keyfile": "/path/to/registry.apps.c1-ocp.myorg.com.key", "cafile": "/path/to/registry.apps.c1-ocp.myorg.com-ca.crt"}
openshift_hosted_registry_routetermination=reencrypt - 1
- 레지스트리의 호스트 이름입니다.
- 2
- cacert,cert 및 키 파일의 위치.
- cert File은 OpenShift Container Platform 레지스트리 인증서가 포함된 파일의 경로입니다.
- keyfile 은 OpenShift Container Platform 레지스트리 인증서 키가 포함된 파일의 경로입니다.
- CAfile 은 이 키 및 인증서의 루트 CA가 포함된 파일의 경로입니다. 중간 CA가 사용 중인 경우 파일에 중간 및 루트 CA가 모두 포함되어야 합니다.
- 3
- 암호화가 수행되는 위치를 지정합니다.
-
에지 라우터에서 암호화를 종료하고 대상에서
제공하는새 인증서로 다시 암호화하려면 re-encrypt 경로로 재암호화되도록 설정합니다. -
대상에서 암호화를 종료하려면
passthrough로 설정합니다. 대상은 트래픽의 암호 해독을 담당합니다.
-
에지 라우터에서 암호화를 종료하고 대상에서
11.8. 로드 밸런서에 대한 사용자 정의 인증서 구성
OpenShift Container Platform 클러스터에서 기본 로드 밸런서 또는 엔터프라이즈 수준 로드 밸런서를 사용하는 경우 사용자 정의 인증서를 사용하여 공개 서명된 사용자 정의 인증서를 사용하여 외부에서 웹 콘솔 및 API를 사용할 수 있습니다. 내부 끝점의 기존 내부 인증서를 남겨 두십시오.
다음과 같은 방식으로 사용자 정의 인증서를 사용하도록 OpenShift Container Platform을 구성하려면 다음을 수행합니다.
마스터 구성 파일의
servingInfo섹션을 편집합니다.servingInfo: logoutURL: "" masterPublicURL: https://openshift.example.com:8443 publicURL: https://openshift.example.com:8443/console/ bindAddress: 0.0.0.0:8443 bindNetwork: tcp4 certFile: master.server.crt clientCA: "" keyFile: master.server.key maxRequestsInFlight: 0 requestTimeoutSeconds: 0 namedCertificates: - certFile: wildcard.example.com.crt1 keyFile: wildcard.example.com.key2 names: - "openshift.example.com" metricsPublicURL: "https://metrics.os.example.com/hawkular/metrics"참고masterPublicURL 및설정과 연결된 호스트 이름에 대해서만oauthConfig.assetPublicURLnamedCertificates섹션을 구성합니다. masterURL과 연결된 호스트 이름에 사용자 지정 제공 인증서를 사용하면 인프라 구성 요소가 내부masterURL호스트를 사용하여 마스터 API에 연결하려고 할 때 TLS 오류가 발생합니다.Ansible 인벤토리 파일에서
openshift_master_cluster_public매개변수(기본적으로 /etc/ansible/hosts )를 지정합니다. 이러한 값은 달라야 합니다. 동일한 경우 명명된 인증서가 실패합니다._hostname및 openshift_master_cluster_hostname# Native HA with External LB VIPs openshift_master_cluster_hostname=paas.example.com1 openshift_master_cluster_public_hostname=public.paas.example.com2
로드 밸런서 환경에 대한 자세한 내용은 공급자 및 사용자 정의 인증서 SSL 종료(프로덕션) 의 OpenShift Container Platform 참조 아키텍처를 참조하십시오.
11.9. 클러스터에 사용자 정의 인증서 재구성
기존 OpenShift Container Platform 클러스터에 사용자 정의 마스터 및 사용자 정의 라우터 인증서를 다시 작성할 수 있습니다.
11.9.1. 클러스터에 사용자 정의 마스터 인증서 재구성
사용자 정의 인증서를 다시 설정하려면 :
-
Ansible 인벤토리 파일을 편집하여
openshift_master_overwrite_named_certificates=true를 설정합니다. openshift_master_named_certificates매개변수를 사용하여 인증서 경로를 지정합니다.openshift_master_overwrite_named_certificates=true openshift_master_named_certificates=[{"certfile": "/path/on/host/to/crt-file", "keyfile": "/path/on/host/to/key-file", "names": ["public-master-host.com"], "cafile": "/path/on/host/to/ca-file"}]1 플레이북 디렉터리로 변경하고 다음 플레이북을 실행합니다.
ansible-playbook /usr/share/ansible/openshift-ansible/playbooks/redeploy-certificates.yml명명된 인증서를 사용하는 경우:
- 각 마스터 노드의 master-config.yaml 파일에서 인증서 매개변수를 업데이트합니다.
OpenShift Container Platform 마스터 서비스를 다시 시작하여 변경 사항을 적용합니다.
# master-restart api # master-restart controllers
11.9.2. 클러스터에 사용자 정의 라우터 인증서 수정
사용자 정의 라우터 인증서를 다시 설정하려면 다음을 수행합니다.
-
Ansible 인벤토리 파일을 편집하여
openshift_master_overwrite_named_certificates=true를 설정합니다. openshift_hosted_router_certificate매개변수를 사용하여 인증서 경로를 지정합니다.openshift_master_overwrite_named_certificates=true openshift_hosted_router_certificate={"certfile": "/path/on/host/to/app-crt-file", "keyfile": "/path/on/host/to/app-key-file", "cafile": "/path/on/host/to/app-ca-file"}1 - 1
- 라우터 와일드카드 인증서 의 경로입니다.
플레이북 디렉터리로 변경하고 다음 플레이북을 실행합니다.
$ cd /usr/share/ansible/openshift-ansible $ ansible-playbook playbooks/openshift-hosted/redeploy-router-certificates.yml
11.10. 다른 구성 요소에서 사용자 지정 인증서 사용
로깅 및 지표와 같은 다른 구성 요소에서 사용자 정의 인증서를 사용하는 방법에 대한 자세한 내용은 인증서 관리를 참조하십시오.
12장. 인증서 재배포
12.1. 개요
OpenShift Container Platform은 인증서를 사용하여 다음 구성 요소에 대한 보안 연결을 제공합니다.
- 마스터(API 서버 및 컨트롤러)
- etcd
- 노드
- 레지스트리
- 라우터
설치 프로그램에 제공된 Ansible 플레이북을 사용하여 클러스터 인증서의 만료 날짜를 자동으로 확인할 수 있습니다. 또한 이러한 인증서의 백업 및 재배포를 자동화하기 위해 플레이북이 제공되므로 일반적인 인증서 오류를 수정할 수 있습니다.
인증서를 재배포할 수 있는 사용 사례는 다음과 같습니다.
- 설치 프로그램에서 잘못된 호스트 이름을 감지하고 문제가 너무 늦어졌습니다.
- 인증서가 만료되어 업데이트해야 합니다.
- 새 CA가 있고 대신 인증서를 사용하여 인증서를 생성하려고 합니다.
12.2. 인증서 만료 확인
설치 프로그램을 사용하여 구성 가능 기간 내에 만료된 인증서에 대해 경고하고 이미 만료된 인증서에 대해 알릴 수 있습니다. 인증서 만료 플레이북에서는 Ansible 역할 openshift_certificate_expiry 를 사용합니다.
역할에서 검사한 인증서는 다음과 같습니다.
- 마스터 및 노드 서비스 인증서
- etcd 보안의 라우터 및 레지스트리 서비스 인증서
- cluster-admin 사용자를 위한 master, node, 라우터, 레지스트리 및 kubeconfig 파일
- etcd 인증서 (포함 포함)
모든 OpenShift TLS 인증서 만료 날짜를 나열 하는 방법을 알아봅니다.
12.2.1. 역할 변수
openshift_certificate_expiry 역할은 다음 변수를 사용합니다.
| 변수 이름 | 기본값 | 설명 |
|---|---|---|
|
|
| 기본 OpenShift Container Platform 구성 디렉터리입니다. |
|
|
| 지금까지 며칠 동안 만료될 플래그 인증서입니다. |
|
|
| 결과에 정상(만료되지 않음) 및 비경고 인증서를 포함합니다. |
| 변수 이름 | 기본값 | 설명 |
|---|---|---|
|
|
| 만료 확인 결과에 대한 HTML 보고서를 생성합니다. |
|
|
| HTML 보고서를 저장하기 위한 전체 경로입니다. 기본값은 보고서 파일의 홈 디렉터리 및 타임스탬프 접미사로 구성됩니다. |
|
|
| 만료 확인 결과를 JSON 파일로 저장합니다. |
|
|
| JSON 보고서를 저장하는 전체 경로입니다. 기본값은 보고서 파일의 홈 디렉터리 및 타임스탬프 접미사로 구성됩니다. |
12.2.2. 인증서 만료 플레이북 실행
OpenShift Container Platform 설치 프로그램은 openshift_certificate_expiry 역할에 대한 다양한 구성 세트를 사용하여 인증서 만료 플레이북 세트를 제공합니다.
이러한 플레이북은 클러스터를 나타내는 인벤토리 파일과 함께 사용해야 합니다. 최상의 결과를 얻으려면 -v 옵션을 사용하여 ansible-playbook 을 실행합니다.
easy-mode.yaml 예제 플레이북을 사용하면 필요에 따라 사양에 맞게 조정하기 전에 역할을 시도할 수 있습니다. 이 플레이북은 다음과 같습니다.
- $HOME 디렉터리에 JSON 및 스타일화된 HTML 보고서를 생성합니다.
- 경고 창을 매우 크게 설정하므로 거의 항상 결과를 얻을 수 있습니다.
- 결과에 모든 인증서(healthy 또는 not)를 포함합니다.
플레이북 디렉터리로 변경하고 easy-mode.yaml 플레이북을 실행합니다.
$ cd /usr/share/ansible/openshift-ansible
$ ansible-playbook -v -i <inventory_file> \
playbooks/openshift-checks/certificate_expiry/easy-mode.yaml기타 예제 플레이북
다른 예제 플레이북은 /usr/share/ansible/openshift-ansible/playbooks/certificate_expiry/ 디렉터리에서 직접 실행하는 데 사용할 수도 있습니다.
| 파일 이름 | 사용법 |
|---|---|
| default.yaml |
|
| html_and_json_default_paths.yaml | 기본 경로에 HTML 및 JSON 아티팩트를 생성합니다. |
| longer_warning_period.yaml | 만료 경고 창을 1500일로 변경합니다. |
| longer-warning-period-json-results.yaml | 만료 경고 창을 1500일로 변경하고 결과를 JSON 파일로 저장합니다. |
다음 예제 플레이북을 실행하려면 다음을 수행합니다.
$ cd /usr/share/ansible/openshift-ansible
$ ansible-playbook -v -i <inventory_file> \
playbooks/openshift-checks/certificate_expiry/<playbook>12.2.3. 출력 형식
위에서 설명한 것처럼 검사 보고서를 포맷하는 방법은 두 가지가 있습니다. 시스템 구문 분석을 위한 JSON 형식 또는 간편한 스탬밍을 위한 스타일화된 HTML 페이지로 되어 있습니다.
HTML 보고서
HTML 보고서의 예는 설치 프로그램에서 제공됩니다. 브라우저에서 다음 파일을 열어 볼 수 있습니다.
/usr/share/ansible/openshift-ansible/roles/openshift_certificate_expiry/examples/cert-expiry-report.html
JSON 보고서
저장된 JSON 결과에는 data 및 summary 이라는 두 개의 최상위 키가 있습니다.
data 키는 검사한 각 호스트의 이름이며 값은 각 호스트에서 식별된 인증서의 검사 결과입니다.
요약 키는 총 인증서 수를 요약하는 해시입니다.
- 전체 클러스터에서 검사
- OK입니다.
- 구성된 경고 창 내에서 만료
- 이미 만료되었습니다
전체 JSON 보고서의 예는 /usr/share/ansible/openshift-ansible/roles/openshift_certificate_expiry/examples/cert-expiry-report.json 을 참조하십시오.
JSON 데이터의 요약은 다양한 명령줄 도구를 사용하여 경고 또는 만료 여부를 쉽게 확인할 수 있습니다. 예를 들어 grep 을 사용하여 summary 이라는 단어를 찾아서 일치(-A2) 뒤에 두 행을 출력할 수 있습니다.
$ grep -A2 summary $HOME/cert-expiry-report.yyyymmddTHHMMSS.json
"summary": {
"warning": 16,
"expired": 0
사용 가능한 경우 jq 도구를 사용하여 특정 값을 선택할 수도 있습니다. 아래의 처음 두 예제는 하나의 값( 경고 또는 만료 됨)만 선택하는 방법을 보여줍니다. 세 번째 예제는 두 값을 한 번에 선택하는 방법을 보여줍니다.
$ jq '.summary.warning' $HOME/cert-expiry-report.yyyymmddTHHMMSS.json
16
$ jq '.summary.expired' $HOME/cert-expiry-report.yyyymmddTHHMMSS.json
0
$ jq '.summary.warning,.summary.expired' $HOME/cert-expiry-report.yyyymmddTHHMMSS.json
16
012.3. 인증서 재배포
재배포 플레이북은 컨트롤 플레인 서비스를 다시 시작하여 클러스터 다운 타임을 일으킬 수 있습니다. 하나의 서비스에 오류가 발생하면 플레이북이 실패하고 클러스터 상태에 영향을 줄 수 있습니다. 플레이북이 실패하는 경우 문제를 수동으로 해결하고 플레이북을 다시 시작해야 할 수 있습니다. 플레이북은 성공하려면 모든 작업을 순차적으로 완료해야 합니다.
다음 플레이북을 사용하여 모든 관련 호스트에 마스터, etcd, 노드, 레지스트리 및 라우터 인증서를 재배포합니다. 현재 CA를 사용하여 모든 인증서를 한 번에 다시 배포하거나, 특정 구성 요소에 대해서만 인증서를 재배포하거나, 새로 생성된 또는 사용자 지정 CA를 자체적으로 재배포할 수 있습니다.
인증서 만료 플레이북과 마찬가지로 이러한 플레이북은 클러스터를 나타내는 인벤토리 파일을 사용하여 실행해야 합니다.
특히 인벤토리는 현재 클러스터 구성과 일치하도록 다음 변수를 통해 설정된 모든 호스트 이름 및 IP 주소를 지정하거나 재정의해야 합니다.
-
openshift_public_hostname -
openshift_public_ip -
openshift_master_cluster_hostname -
openshift_master_cluster_public_hostname
필요한 플레이북은 다음을 통해 제공됩니다.
# yum install openshift-ansible다시 배포하는 동안 자동으로 생성된 인증서의 유효 기간(제한 기간)도 Ansible을 통해 구성할 수 있습니다. 인증서 유효성성 구성을 참조하십시오.
OpenShift Container Platform CA 및 etcd 인증서는 5년 후에 만료됩니다. 서명된 OpenShift Container Platform 인증서는 2년 후에 만료됩니다.
12.3.1. 현재 OpenShift Container Platform 및 etcd CA를 사용하여 모든 인증서 재배포
redeploy-certificates.yml 플레이북은 OpenShift Container Platform CA 인증서를 다시 생성하지 않습니다. 새 마스터, etcd, 노드, 레지스트리 및 라우터 인증서는 새 인증서에 서명하기 위해 현재 CA 인증서를 사용하여 생성됩니다.
여기에는 다음의 직렬 재시작도 포함됩니다.
- etcd
- 마스터 서비스
- 노드 서비스
현재 OpenShift Container Platform CA를 사용하여 마스터, etcd 및 노드 인증서를 재배포하려면 플레이북 디렉터리로 변경하고 인벤토리 파일을 지정하여 이 플레이북을 실행합니다.
$ cd /usr/share/ansible/openshift-ansible
$ ansible-playbook -i <inventory_file> \
playbooks/redeploy-certificates.yml
OpenShift Container Platform CA가 openshift-master/redeploy-openshift-ca.yml 플레이북 으로 재배포된 경우 이 명령에 -e openshift_redeploy_openshift_ca=true 를 추가해야 합니다.
12.3.2. 새 또는 사용자 지정 OpenShift Container Platform CA 재배포
openshift-master/redeploy-openshift-ca.yml 플레이북은 새 CA 인증서를 생성하고 client kubeconfig 파일 및 신뢰할 수 있는 CA의 노드 데이터베이스(CA-trust)를 포함한 모든 구성 요소에 업데이트된 번들을 배포하여 OpenShift Container Platform CA 인증서를 재배포합니다.
여기에는 다음의 직렬 재시작도 포함됩니다.
- 마스터 서비스
- 노드 서비스
- docker
또한 OpenShift Container Platform에서 생성한 CA를 사용하는 대신 인증서를 재배포할 때 사용자 정의 CA 인증서를 지정할 수 있습니다.
마스터 서비스가 다시 시작되면 마스터의 제공 인증서가 동일하고 레지스트리 및 라우터가 여전히 유효한 CA이기 때문에 레지스트리 및 라우터가 마스터와 계속 통신할 수 있습니다.
새로 생성된 또는 사용자 정의 CA를 재배포하려면 다음을 수행합니다.
사용자 지정 CA를 사용하려면 인벤토리 파일에 다음 변수를 설정합니다. 현재 CA를 사용하려면 이 단계를 건너뜁니다.
# Configure custom ca certificate # NOTE: CA certificate will not be replaced with existing clusters. # This option may only be specified when creating a new cluster or # when redeploying cluster certificates with the redeploy-certificates # playbook. openshift_master_ca_certificate={'certfile': '</path/to/ca.crt>', 'keyfile': '</path/to/ca.key>'}중간 CA에서 CA 인증서를 발급하는 경우 하위 인증서의 유효성을 검사하기 위해 번들된 인증서에 CA에 대한 전체 체인(중간 및 루트 인증서)이 포함되어야 합니다.
예를 들면 다음과 같습니다.
$ cat intermediate/certs/intermediate.cert.pem \ certs/ca.cert.pem >> intermediate/certs/ca-chain.cert.pem플레이북 디렉터리로 변경하고 인벤토리 파일을 지정하여 openshift-master/redeploy-openshift-ca.yml 플레이북을 실행합니다.
$ cd /usr/share/ansible/openshift-ansible $ ansible-playbook -i <inventory_file> \ playbooks/openshift-master/redeploy-openshift-ca.yml새 OpenShift Container Platform CA가 구현된 상태에서 모든 구성 요소의 새 CA에서 서명한 인증서를 재배포할 때마다 redeploy-certificates.yml 플레이북 을 사용합니다.
중요새 OpenShift Container Platform CA가 있는 후 redeploy-certificates.yml 플레이북을 사용하는 경우
-e openshift_redeploy_openshift_ca=true를 플레이북 명령에 추가해야 합니다.
12.3.3. 새 etcd CA 재배포
openshift-etcd/redeploy-ca.yml 플레이북은 새 CA 인증서를 생성하고 업데이트된 번들을 모든 etcd 피어 및 마스터 클라이언트에 배포하여 etcd CA 인증서를 재배포합니다.
여기에는 다음의 직렬 재시작도 포함됩니다.
- etcd
- 마스터 서비스
새로 생성된 etcd CA를 재배포하려면 다음을 수행합니다.
인벤토리 파일을 지정하여 openshift-etcd/redeploy-ca.yml 플레이북을 실행합니다.
$ cd /usr/share/ansible/openshift-ansible $ ansible-playbook -i <inventory_file> \ playbooks/openshift-etcd/redeploy-ca.yml
playbooks/openshift-etcd/redeploy-ca.yml 플레이북을 처음 실행하면 CA 서명자가 포함된 압축 번들이 /etc/etcd/etcd_ca.tgz 로 유지됩니다. 새 etcd 인증서를 생성하는 데 CA 서명자가 필요하므로 백업하는 것이 중요합니다.
플레이북이 다시 실행되는 경우 예방 조치로 디스크에서 이 번들을 덮어쓰지 않습니다. 플레이북을 다시 실행하려면 이 경로에서 번들을 백업하고 이동한 다음 플레이북을 실행합니다.
새 etcd CA를 배치하면 etcd 피어 및 마스터 클라이언트의 새 etcd CA에서 서명한 인증서를 재배포할 때마다 재량에 따라 openshift-etcd/redeploy-certificates.yml 플레이북 을 사용할 수 있습니다. 또는 redeploy-certificates.yml 플레이북을 사용하여 etcd 피어 및 마스터 클라이언트 외에도 OpenShift Container Platform 구성 요소에 대한 인증서를 재배포할 수 있습니다.
etcd 인증서 재배포로 인해 직렬 를 모든 마스터 호스트에 복사할 수 있습니다.
12.3.4. 마스터 및 웹 콘솔 인증서 재배포
openshift-master/redeploy-certificates.yml 플레이북은 마스터 인증서 및 웹 콘솔 인증서를 재배포합니다. 여기에는 마스터 서비스의 직렬 재시작도 포함됩니다.
마스터 인증서 및 웹 콘솔 인증서를 재배포하려면 플레이북 디렉터리로 변경하고 인벤토리 파일을 지정하여 이 플레이북을 실행합니다.
$ cd /usr/share/ansible/openshift-ansible
$ ansible-playbook -i <inventory_file> \
playbooks/openshift-master/redeploy-certificates.yml
명명된 인증서를 사용하는 경우 각 마스터 노드의 master-config.yaml 파일에서 명명된 인증서 매개변수를 업데이트해야 합니다. 필요한 경우 certFile 매개변수에 제공되는 인증서 파일의 인증서 체인 을 구성하는 필수 파일을 모두 연결합니다.
그런 다음 OpenShift Container Platform 마스터 서비스를 다시 시작하여 변경 사항을 적용합니다.
이 플레이북을 실행한 후에는 서비스 제공 인증서가 포함된 기존 시크릿을 삭제하거나 적절한 서비스에 주석을 제거 및 다시 추가하여 서비스 서명 인증서 또는 키 쌍을 다시 생성해야 합니다.
필요한 경우 서비스 서명자 인증서의 재배포를 건너뛰도록 인벤토리 파일에 openshift_redeploy_service_signer=false 매개변수를 설정할 수 있습니다. 인벤토리 파일에서 openshift_redeploy_openshift_ca=true 및 openshift_redeploy_service_signer=true 를 설정하면 마스터 인증서를 재배포할 때 서비스 서명 인증서가 재배포됩니다. openshift_redeploy_openshift_ca=false 를 설정하거나 매개변수를 생략하면 서비스 서명자 인증서가 재배포되지 않습니다.
12.3.5. 이름이 지정된 인증서만 재배포
openshift-master/redeploy-named-certificates.yml 플레이북은 명명된 인증서만 다시 배포합니다. 이 플레이북을 실행하면 마스터 서비스의 직렬 재시작도 완료합니다.
명명된 인증서만 재배포하려면 플레이북이 포함된 디렉터리로 변경하고 이 플레이북을 실행합니다.
$ cd /usr/share/ansible/openshift-ansible
$ ansible-playbook -i <inventory_file> \
playbooks/openshift-master/redeploy-named-certificates.yml
ansible 인벤토리 파일의 _ openshift_master_named_certificates_ 매개 변수에는 master-config.yaml 파일과 동일한 이름의 인증서가 포함되어야 합니다. certfile 및 의 이름이 변경되면 각 마스터 노드의 master-config.yaml 파일에서 명명된 인증서 매개 변수를 업데이트하고 keyfile api 및 컨트롤러 서비스를 다시 시작해야 합니다. 전체 ca 체인이 있는 cafile 이 /etc/origin/master/ca-bundle.crt 에 추가됩니다.
12.3.6. etcd 인증서 재배포만
openshift-etcd/redeploy-certificates.yml 플레이북은 마스터 클라이언트 인증서를 포함한 etcd 인증서만 재배포합니다.
여기에는 다음의 직렬 재시작도 포함됩니다.
- etcd
- 마스터 서비스.
etcd 인증서를 재배포하려면 플레이북 디렉터리로 변경하고 인벤토리 파일을 지정하여 이 플레이북을 실행합니다.
$ cd /usr/share/ansible/openshift-ansible
$ ansible-playbook -i <inventory_file> \
playbooks/openshift-etcd/redeploy-certificates.yml12.3.7. 노드 인증서 재배포
기본적으로 노드 인증서는 1년 동안 유효합니다. OpenShift Container Platform은 만료될 때 노드 인증서를 자동으로 순환합니다. 자동 승인이 구성되지 않은 경우 CSR(인증서 서명 요청)을 수동으로 승인해야 합니다.
CA 인증서가 변경되었으므로 인증서를 재배포해야 하는 경우 -e openshift_ redeploy_openshift_ca=true 플래그와 함께 playbook/redeploy-certificates.yml 플레이북을 사용할 수 있습니다. 자세한 내용은 현재 OpenShift Container Platform 및 etcd CA를 사용하여 모든 인증서 재배포 를 참조하십시오. 이 플레이북을 실행하면 CSR이 자동으로 승인됩니다.
12.3.8. 레지스트리 또는 라우터 인증서만 재배포
openshift-hosted/redeploy-registry-certificates.yml 및 openshift-hosted/redeploy-router-certificates.yml 플레이북은 레지스트리 및 라우터의 설치 관리자 생성 인증서를 대체합니다. 이러한 구성 요소에 사용자 정의 인증서가 사용 중인 경우 사용자 정의 레지스트리 또는 라우터 인증서 재배포 를 참조하여 수동으로 교체합니다.
12.3.8.1. 레지스트리 인증서만 재배포
레지스트리 인증서를 재배포하려면 플레이북 디렉터리로 변경하고 인벤토리 파일을 지정하여 다음 플레이북을 실행합니다.
$ cd /usr/share/ansible/openshift-ansible
$ ansible-playbook -i <inventory_file> \
playbooks/openshift-hosted/redeploy-registry-certificates.yml12.3.8.2. 라우터 인증서만 재배포
라우터 인증서를 재배포하려면 플레이북 디렉터리로 변경하고 인벤토리 파일을 지정하여 다음 플레이북을 실행합니다.
$ cd /usr/share/ansible/openshift-ansible
$ ansible-playbook -i <inventory_file> \
playbooks/openshift-hosted/redeploy-router-certificates.yml12.3.9. 사용자 정의 레지스트리 또는 라우터 인증서 재배포
재배포된 CA로 인해 노드를 비우면 레지스트리 및 라우터 포드가 다시 시작됩니다. 레지스트리 및 라우터 인증서도 새 CA로 재배포되지 않은 경우 이전 인증서를 사용하여 마스터에 연결할 수 없기 때문에 중단될 수 있습니다.
12.3.9.1. 수동으로 레지스트리 인증서 재배포
레지스트리 인증서를 수동으로 재배포하려면 registry -certificates라는 보안에 새 레지스트리 인증서를 추가한 다음 레지스트리를 다시 배포해야 합니다.
다음 단계의 나머지 부분에서
기본프로젝트로 전환합니다.$ oc project defaultOpenShift Container Platform 3.1 이하에서 레지스트리가 처음 생성된 경우에도 여전히 환경 변수를 사용하여 인증서를 저장하는 것일 수 있습니다(보안 사용을 위해 더 이상 사용되지 않음).
다음을 실행하고
OPENSHIFT_CA_DATA, OPENSHIFT_CERT_DATA,환경 변수를 찾습니다.OPENSHIFT_KEY_DATA$ oc set env dc/docker-registry --list존재하지 않는 경우 이 단계를 건너뜁니다. 이러한 경우 다음
ClusterRoleBinding을 생성합니다.$ cat <<EOF | apiVersion: v1 groupNames: null kind: ClusterRoleBinding metadata: creationTimestamp: null name: registry-registry-role roleRef: kind: ClusterRole name: system:registry subjects: - kind: ServiceAccount name: registry namespace: default userNames: - system:serviceaccount:default:registry EOF oc create -f -그런 다음 다음을 실행하여 환경 변수를 제거합니다.
$ oc set env dc/docker-registry OPENSHIFT_CA_DATA- OPENSHIFT_CERT_DATA- OPENSHIFT_KEY_DATA- OPENSHIFT_MASTER-
이후 명령을 덜 복잡하게 만들도록 다음 환경 변수를 로컬로 설정합니다.
$ REGISTRY_IP=`oc get service docker-registry -o jsonpath='{.spec.clusterIP}'` $ REGISTRY_HOSTNAME=`oc get route/docker-registry -o jsonpath='{.spec.host}'`새 레지스트리 인증서를 생성합니다.
$ oc adm ca create-server-cert \ --signer-cert=/etc/origin/master/ca.crt \ --signer-key=/etc/origin/master/ca.key \ --hostnames=$REGISTRY_IP,docker-registry.default.svc,docker-registry.default.svc.cluster.local,$REGISTRY_HOSTNAME \ --cert=/etc/origin/master/registry.crt \ --key=/etc/origin/master/registry.key \ --signer-serial=/etc/origin/master/ca.serial.txt기본적으로 /etc/ansible/hosts 에서 Ansible 호스트 인벤토리 파일에 나열된 첫 번째 마스터에서만
oc adm명령을 실행합니다.새
레지스트리 인증서로 registry-certificates보안을 업데이트합니다.$ oc create secret generic registry-certificates \ --from-file=/etc/origin/master/registry.crt,/etc/origin/master/registry.key \ -o json --dry-run | oc replace -f -레지스트리를 재배포합니다.
$ oc rollout latest dc/docker-registry
12.3.9.2. 수동으로 라우터 인증서 재배포
라우터 인증서를 수동으로 재배포하려면 router -certs라는 보안에 새 라우터 인증서를 추가한 다음 라우터 를 다시 배포해야 합니다.
다음 단계의 나머지 부분에서
기본프로젝트로 전환합니다.$ oc project default라우터가 처음 OpenShift Container Platform 3.1 이하에서 생성된 경우에도 환경 변수를 사용하여 서비스 제공 인증서 보안을 사용하는 대신 더 이상 사용되지 않는 인증서를 저장할 수 있습니다.
다음 명령을 실행하고
OPENSHIFT_CA_DATA,환경 변수를 찾습니다.OPENSHIFT_CERT_DATA,OPENSHIFT_KEY_DATA$ oc set env dc/router --list이러한 변수가 있는 경우 다음
ClusterRoleBinding을 생성합니다.$ cat <<EOF | apiVersion: v1 groupNames: null kind: ClusterRoleBinding metadata: creationTimestamp: null name: router-router-role roleRef: kind: ClusterRole name: system:router subjects: - kind: ServiceAccount name: router namespace: default userNames: - system:serviceaccount:default:router EOF oc create -f -이러한 변수가 있는 경우 다음 명령을 실행하여 제거합니다.
$ oc set env dc/router OPENSHIFT_CA_DATA- OPENSHIFT_CERT_DATA- OPENSHIFT_KEY_DATA- OPENSHIFT_MASTER-
인증서를 가져옵니다.
- 외부 CA(인증 기관)를 사용하여 인증서에 서명하는 경우 새 인증서를 생성하여 내부 프로세스에 따라 OpenShift Container Platform에 제공합니다.
내부 OpenShift Container Platform CA를 사용하여 인증서에 서명하는 경우 다음 명령을 실행합니다.
중요다음 명령은 내부 서명된 인증서를 생성합니다. OpenShift Container Platform CA를 신뢰하는 클라이언트만 신뢰합니다.
$ cd /root $ mkdir cert ; cd cert $ oc adm ca create-server-cert \ --signer-cert=/etc/origin/master/ca.crt \ --signer-key=/etc/origin/master/ca.key \ --signer-serial=/etc/origin/master/ca.serial.txt \ --hostnames='*.hostnames.for.the.certificate' \ --cert=router.crt \ --key=router.key \이러한 명령은 다음 파일을 생성합니다.
- router.crt 라는 새 인증서.
- 서명 CA 인증서 체인의 사본인 /etc/origin/master/ca.crt. 중간 CA를 사용하는 경우 이 체인에는 인증서가 2개 이상 포함될 수 있습니다.
- router.key 라는 해당 개인 키입니다.
생성된 인증서를 연결하는 새 파일을 생성합니다.
$ cat router.crt /etc/origin/master/ca.crt router.key > router.pem참고이 단계는 OpenShift CA에서 서명한 인증서를 사용하는 경우에만 유효합니다. 사용자 정의 인증서를 사용하는 경우
/etc/origin/master/ca.crt대신 올바른 CA 체인이 있는 파일을 사용해야 합니다.새 보안을 생성하기 전에 현재 보안을 백업하십시오.
$ oc get -o yaml --export secret router-certs > ~/old-router-certs-secret.yaml새 인증서와 키를 보유할 새 시크릿을 생성하고 기존 보안의 콘텐츠를 교체합니다.
$ oc create secret tls router-certs --cert=router.pem \1 --key=router.key -o json --dry-run | \ oc replace -f -- 1
- router.pem 은 사용자가 생성한 인증서의 연결을 포함하는 파일입니다.
라우터를 재배포합니다.
$ oc rollout latest dc/router라우터를 처음 배포할 때 router
-metrics-tls라는 서비스 제공 인증서 보안을 자동으로 생성하는 라우터 의 서비스에주석이 추가됩니다.router-metrics-tls인증서를 수동으로 재배포하려면 시크릿을 삭제하고, 라우터 서비스에 주석을 제거 및 다시 추가한 다음 router-metrics-tls보안을 다시 배포하여 서비스 제공 인증서를 다시 트리거할 수 있습니다.라우터서비스에서 다음 주석을 제거합니다.$ oc annotate service router \ service.alpha.openshift.io/serving-cert-secret-name- \ service.alpha.openshift.io/serving-cert-signed-by-기존
router-metrics-tls시크릿을 제거합니다.$ oc delete secret router-metrics-tls주석을 다시 추가합니다.
$ oc annotate service router \ service.alpha.openshift.io/serving-cert-secret-name=router-metrics-tls
12.4. 인증서 서명 요청 관리
클러스터 관리자는 CSR(인증서 서명 요청)을 검토하고 인증서 서명 요청을 승인하거나 거부할 수 있습니다.
12.4.1. 인증서 서명 요청 검토
CSR(인증서 서명 요청) 목록을 검토할 수 있습니다.
현재 CSR의 목록을 가져옵니다.
$ oc get csrCSR의 세부 정보를 보고 CSR이 유효한지 확인합니다.
$ oc describe csr <csr_name>1 - 1
<csr_name>은 현재 CSR 목록에 있는 CSR의 이름입니다.
12.4.2. 인증서 서명 요청 승인
oc certificate approve 명령을 사용하여 CSR(인증서 서명 요청)을 수동으로 승인할 수 있습니다.
CSR을 승인합니다.
$ oc adm certificate approve <csr_name>1 - 1
<csr_name>은 현재 CSR 목록에 있는 CSR의 이름입니다.
보류 중인 모든 CSR을 승인합니다.
$ oc get csr -o go-template='{{range .items}}{{if not .status}}{{.metadata.name}}{{"\n"}}{{end}}{{end}}' | xargs oc adm certificate approve
12.4.3. 인증서 서명 요청 거부
oc certificate deny 명령을 사용하여 CSR(인증서 서명 요청)을 수동으로 거부할 수 있습니다.
CSR을 거부합니다.
$ oc adm certificate deny <csr_name>1 - 1
<csr_name>은 현재 CSR 목록에 있는 CSR의 이름입니다.
12.4.4. 인증서 서명 요청 자동 승인 구성
클러스터를 설치할 때 Ansible 인벤토리 파일에 다음 매개변수를 추가하여 노드 인증서 서명 요청(CSR)의 자동 승인을 구성할 수 있습니다.
openshift_master_bootstrap_auto_approve=true이 매개변수를 추가하면 부트스트랩 자격 증명을 사용하거나 관리자의 개입 없이 동일한 호스트 이름을 가진 이전에 인증된 노드에서 생성된 모든 CSR을 승인할 수 있습니다.
자세한 내용은 클러스터 변수 구성을 참조하십시오.
13장. 인증 및 사용자 에이전트 구성
13.1. 개요
OpenShift Container Platform 마스터 에는 내장 OAuth 서버가 포함되어 있습니다. 개발자와 관리자는 OAuth 액세스 토큰을 가져와 API에 자신을 인증합니다.
관리자는 마스터 구성 파일을 사용하여 OAuth를 구성하여 ID 공급자를 지정할 수 있습니다. 클러스터 설치 중에 ID 공급자를 구성하는 것이 좋지만 설치 후 구성할 수 있습니다.
/, :, %를 포함하는 OpenShift Container Platform 사용자 이름은 지원되지 않습니다.
기본적으로 Deny All identity 프로바이더는 모든 사용자 이름 및 암호에 대한 액세스를 거부하는 데 사용됩니다. 액세스를 허용하려면 다른 ID 공급자를 선택하고 마스터 구성 파일을 적절하게 구성해야 합니다(기본적으로 /etc/origin/master/master-config.yaml 에 있음).
구성 파일 없이 마스터를 실행하면 기본적으로 Allow All Identity 프로바이더가 사용되므로 비어 있지 않은 사용자 이름과 암호가 모두 로그인할 수 있습니다. 이는 테스트 목적으로 유용합니다. 다른 ID 프로바이더를 사용하거나 토큰을 수정하거나부여 또는 세션 옵션을 수정하려면 구성 파일에서 마스터를 실행해야 합니다.
외부 사용자로 설정을 관리하려면 역할을 할당해야 합니다.
ID 공급자를 변경한 후 변경 사항을 적용하려면 마스터 서비스를 다시 시작해야 합니다.
# master-restart api
# master-restart controllers13.2. ID 공급자 매개변수
모든 ID 공급자에는 공통적으로 네 가지 매개 변수가 있습니다.
| 매개변수 | 설명 |
|---|---|
|
| 공급자 사용자 이름에 접두어로 공급자 이름을 지정하여 ID 이름을 만듭니다. |
|
|
브라우저 클라이언트에 대한 CSV(Cross-site Request Forgery) 공격을 방지하기 위해 |
|
|
사용자를 ID 공급자의 로그인으로 리디렉션하기 전에 브랜드 페이지로 전송하려면 마스터 구성 파일에서 |
|
| 사용자가 로그인할 때 새 ID를 사용자에게 매핑하는 방법을 정의합니다. 다음 값 중 하나를 입력하십시오.
|
ID 공급자를 추가하거나 변경할 때 mappingMethod 매개변수를 add로 설정하면 새 공급자의 ID를 기존 사용자에게 매핑할 수 있습니다.
13.3. ID 공급자 구성
OpenShift Container Platform은 동일한 ID 공급자에 대해 여러 LDAP 서버를 구성할 수 없습니다. 그러나 LDAP 페일오버 와 같은 더 복잡한 구성을 위해 기본 인증을 확장할 수 있습니다.
이러한 매개변수를 사용하여 설치 중 또는 설치 후 ID 공급자를 정의할 수 있습니다.
13.3.1. Ansible을 사용하여 ID 공급자 구성
초기 클러스터 설치의 경우 기본적으로 Deny All Identity 프로바이더가 구성되어 있지만, 인벤토리 파일에 openshift_master_identity_providers 매개변수를 구성하여 설치 중에 재정의할 수 있습니다. OAuth 구성의 세션 옵션은 인벤토리 파일에서도 구성할 수 있습니다.
Ansible을 사용한 ID 공급자 구성 예
# htpasswd auth
openshift_master_identity_providers=[{'name': 'htpasswd_auth', 'login': 'true', 'challenge': 'true', 'kind': 'HTPasswdPasswordIdentityProvider'}]
# Defining htpasswd users
#openshift_master_htpasswd_users={'user1': '<pre-hashed password>', 'user2': '<pre-hashed password>'}
# or
#openshift_master_htpasswd_file=/etc/origin/master/htpasswd
# Allow all auth
#openshift_master_identity_providers=[{'name': 'allow_all', 'login': 'true', 'challenge': 'true', 'kind': 'AllowAllPasswordIdentityProvider'}]
# LDAP auth
#openshift_master_identity_providers=[{'name': 'my_ldap_provider', 'challenge': 'true', 'login': 'true', 'kind': 'LDAPPasswordIdentityProvider', 'attributes': {'id': ['dn'], 'email': ['mail'], 'name': ['cn'], 'preferredUsername': ['uid']}, 'bindDN': '', 'bindPassword': '', 'insecure': 'false', 'url': 'ldap://ldap.example.com:389/ou=users,dc=example,dc=com?uid'}]
# Configuring the ldap ca certificate
#openshift_master_ldap_ca=<ca text>
# or
#openshift_master_ldap_ca_file=<path to local ca file to use>
# Available variables for configuring certificates for other identity providers:
#openshift_master_openid_ca
#openshift_master_openid_ca_file
#openshift_master_request_header_ca
#openshift_master_request_header_ca_file - 1
- LDAP ID 공급자에 대해서만
openshift_master_identity_providers매개변수에서 'insecure': 'true'를 지정한 경우 CA 인증서를 생략할 수 있습니다. - 2 3 4
- 플레이북을 실행하는 호스트에서 파일을 지정하면 해당 콘텐츠가 /etc/origin/master/<identity_provider_name>_<identity_provider_type>_ca.crt 파일에 복사됩니다. ID 공급자 이름은
openshift_master_identity_providers매개변수,ldap,openid또는request_header의 값입니다. CA 텍스트 또는 로컬 CA 파일의 경로를 지정하지 않으면 이 위치에 CA 인증서를 배치해야 합니다. 여러 ID 공급자를 지정하는 경우 이 위치에 각 공급자에 대한 CA 인증서를 수동으로 배치해야 합니다. 이 위치를 변경할 수 없습니다.
여러 ID 공급자를 지정할 수 있습니다. 이 경우 각 ID 공급자의 CA 인증서를 /etc/origin/master/ 디렉터리에 배치해야 합니다. 예를 들어 openshift_master_identity_providers 값에 다음 공급자를 포함합니다.
openshift_master_identity_providers:
- name: foo
provider:
kind: OpenIDIdentityProvider
...
- name: bar
provider:
kind: OpenIDIdentityProvider
...
- name: baz
provider:
kind: RequestHeaderIdentityProvider
...해당 ID 공급자의 CA 인증서를 다음 파일에 배치해야 합니다.
- /etc/origin/master/foo_openid_ca.crt
- /etc/origin/master/bar_openid_ca.crt
- /etc/origin/master/baz_requestheader_ca.crt
13.3.2. 마스터 구성 파일에서 ID 공급자 구성
마스터 구성 파일을 수정하여 원하는 ID 공급자를 사용하여 인증에 대한 마스터 호스트를 구성할 수 있습니다.
예 13.1. 마스터 구성 파일의 ID 공급자 구성 예
...
oauthConfig:
identityProviders:
- name: htpasswd_auth
challenge: true
login: true
mappingMethod: "claim"
...
기본 클레임 값으로 설정하면 ID가 이전에 존재하는 사용자 이름에 매핑되면 OAuth가 실패합니다.
13.3.2.1. lookup 매핑 방법을 사용할 때 수동으로 사용자를 프로비저닝합니다.
조회 매핑 방법을 사용하면 API를 통해 외부 시스템에서 사용자 프로비저닝을 수행합니다. 일반적으로 ID는 로그인 중에 사용자에게 자동으로 매핑됩니다. 'lookup' 매핑 방법은 이 자동 매핑을 자동으로 비활성화하므로 사용자를 수동으로 프로비저닝해야 합니다.
ID 오브젝트에 대한 자세한 내용은 ID 사용자 API obejct를 참조하십시오.
조회 매핑 방법을 사용하는 경우 ID 공급자를 구성한 후 각 사용자에 대해 다음 단계를 사용합니다.
OpenShift Container Platform 사용자를 생성합니다(아직 생성하지 않은 경우).
$ oc create user <username>예를 들어 다음 명령은 OpenShift Container Platform 사용자
bob을 생성합니다.$ oc create user bobOpenShift Container Platform ID를 만듭니다(아직 생성하지 않은 경우). ID 공급자의 이름과 ID 공급자의 범위에서 이 ID를 고유하게 표시하는 이름을 사용합니다.
$ oc create identity <identity-provider>:<user-id-from-identity-provider><identity-provider>는 아래 적절한 ID 공급자 섹션에 표시된 대로 마스터 구성의 ID 프로바이더 이름입니다.예를 들어 다음 명령은 ID 프로바이더
ldap_provider 및 ID 공급자 사용자 이름를 사용하여 ID를 생성합니다.bob_s$ oc create identity ldap_provider:bob_s생성된 사용자 및 ID에 대한 사용자/ID 매핑을 생성합니다.
$ oc create useridentitymapping <identity-provider>:<user-id-from-identity-provider> <username>예를 들어 다음 명령은 ID를 사용자에게 매핑합니다.
$ oc create useridentitymapping ldap_provider:bob_s bob
13.3.3. 모두 허용
비어 있지 않은 사용자 이름과 암호가 로그인할 수 있도록 identityProviders 스탠자에서 AllowAllPasswordIdentityProvider 를 설정합니다.
예 13.2. AllowAllPasswordIdentityProvider를 사용한 마스터 구성
oauthConfig:
...
identityProviders:
- name: my_allow_provider
challenge: true
login: true
mappingMethod: claim
provider:
apiVersion: v1
kind: AllowAllPasswordIdentityProvider- 1
- 이 공급자 이름은 공급자 사용자 이름에 접두어로 지정되어 ID 이름을 형성합니다.
- 2
true인경우 웹 이외의 클라이언트(예: CLI)의 인증되지 않은 토큰 요청이 이 프로바이더의WWW-Authenticate 챌린지헤더가 전송됩니다.- 3
true인경우 웹 콘솔과 같은 웹 클라이언트의 인증되지 않은 토큰 요청은 이 프로바이더가 지원하는 로그인 페이지로 리디렉션됩니다.- 4
- 위에서 설명한 대로 이 프로바이더의 ID와 사용자 오브젝트 간의 매핑 설정 방법을 제어합니다.
13.3.4. 모두 거부
identityProviders 스탠자에서 DenyAllPasswordIdentityProvider 를 설정하여 모든 사용자 이름과 암호에 대한 액세스를 거부합니다.
예 13.3. DenyAllPasswordIdentityProvider를 사용한 마스터 구성
oauthConfig:
...
identityProviders:
- name: my_deny_provider
challenge: true
login: true
mappingMethod: claim
provider:
apiVersion: v1
kind: DenyAllPasswordIdentityProvider- 1
- 이 공급자 이름은 공급자 사용자 이름에 접두어로 지정되어 ID 이름을 형성합니다.
- 2
true인경우 웹 이외의 클라이언트(예: CLI)의 인증되지 않은 토큰 요청이 이 프로바이더의WWW-Authenticate 챌린지헤더가 전송됩니다.- 3
true인경우 웹 콘솔과 같은 웹 클라이언트의 인증되지 않은 토큰 요청은 이 프로바이더가 지원하는 로그인 페이지로 리디렉션됩니다.- 4
- 위에서 설명한 대로 이 프로바이더의 ID와 사용자 오브젝트 간의 매핑 설정 방법을 제어합니다.
13.3.5. HTPasswd
identityProviders 스탠자에서 HTPasswdPasswordIdentityProvider 를 설정하여 htpasswd 를 사용하여 생성된 플랫 파일에 대해 사용자 이름과 암호의 유효성을 검사합니다.
htpasswd 유틸리티는 httpd-tools 패키지에 있습니다.
# yum install httpd-tools
OpenShift Container Platform은 Bcrypt, SHA-1 및 MD5 암호화 해시 함수를 지원하며 MD5는 htpasswd 의 기본값입니다. 일반 텍스트, 암호화된 텍스트 및 기타 해시 함수는 현재 지원되지 않습니다.
서버를 다시 시작하지 않고도 수정 시간이 변경되면 플랫 파일이 다시 읽습니다.
OpenShift Container Platform 마스터 API는 이제 정적 포드로 실행되므로 컨테이너에서 읽을 수 있도록 /etc/origin/master/ 에서 HTPasswdPasswordIdentityProvider htpasswd 파일을 생성해야 합니다.
htpasswd 명령을 사용하려면 다음을 수행합니다.
사용자 이름과 해시된 암호로 플랫 파일을 생성하려면 다음을 실행합니다.
$ htpasswd -c /etc/origin/master/htpasswd <user_name>그런 다음 사용자의 일반 텍스트 암호를 입력하고 확인합니다. 이 명령에서는 해시된 버전의 암호를 생성합니다.
예를 들면 다음과 같습니다.
htpasswd -c /etc/origin/master/htpasswd user1 New password: Re-type new password: Adding password for user user1참고명령줄에 암호를 제공하기 위해
-b옵션을 포함할 수 있습니다.$ htpasswd -c -b <user_name> <password>예를 들면 다음과 같습니다.
$ htpasswd -c -b file user1 MyPassword! Adding password for user user1
파일에 로그인을 추가하거나 업데이트하려면 다음을 실행합니다.
$ htpasswd /etc/origin/master/htpasswd <user_name>파일에서 로그인을 제거하려면 다음을 실행합니다.
$ htpasswd -D /etc/origin/master/htpasswd <user_name>
예 13.4. HTPasswdPasswordIdentityProvider를 사용한 마스터 구성
oauthConfig:
...
identityProviders:
- name: my_htpasswd_provider
challenge: true
login: true
mappingMethod: claim
provider:
apiVersion: v1
kind: HTPasswdPasswordIdentityProvider
file: /etc/origin/master/htpasswd 13.3.6. Keystone
Keystone은 ID, 토큰, 카탈로그 및 정책 서비스를 제공하는 OpenStack 프로젝트입니다. OpenShift Container Platform 클러스터를 Keystone과 통합하여 사용자를 내부 데이터베이스에 저장하도록 구성된 OpenStack Keystone v3 서버와 공유 인증을 활성화할 수 있습니다. 이 구성을 통해 사용자는 Keystone 자격 증명을 사용하여 OpenShift Container Platform에 로그인할 수 있습니다.
새 OpenShift Container Platform 사용자가 Keystone 사용자 이름 또는 고유한 Keystone ID를 기반으로 하도록 Keystone과의 통합을 구성할 수 있습니다. 두 방법 모두 사용자는 Keystone 사용자 이름과 암호를 입력하여 로그인합니다. OpenShift Container Platform 사용자가 Keystone ID를 사용하면 더 안전합니다. Keystone 사용자를 삭제하고 그 사용자 이름으로 새 Keystone 사용자를 생성하는 경우, 새 사용자는 이전 사용자의 리소스에 액세스할 수 있습니다.
13.3.6.1. 마스터에서 인증 구성
다음과 같은 사항이 있을 수 있습니다.
Openshift 설치를 이미 완료한 다음 /etc/origin/master/master-config.yaml 파일을 새 디렉토리(예:)로 복사합니다.
$ cd /etc/origin/master $ mkdir keystoneconfig; cp master-config.yaml keystoneconfigOpenShift Container Platform을 아직 설치하지 않은 다음 OpenShift Container Platform API 서버를 시작하여 (미래) OpenShift Container Platform 마스터의 호스트 이름과 start 명령으로 생성한 구성 파일을 저장할 디렉터리를 지정합니다.
$ openshift start master --public-master=<apiserver> --write-config=<directory>예를 들면 다음과 같습니다.
$ openshift start master --public-master=https://myapiserver.com:8443 --write-config=keystoneconfig참고Ansible을 사용하여 설치하는 경우
identityProvider구성을 Ansible 플레이북에 추가해야 합니다. 다음 단계를 사용하여 Ansible을 사용하여 설치한 후 수동으로 구성을 수정하는 경우 설치 도구 또는 업그레이드를 다시 실행할 때마다 수정 사항이 손실됩니다.
새 keystoneconfig/master-config.yaml 파일의
identityProviders스탠자를 편집하고 예제KeystonePasswordIdentityProvider구성을 복사하여 기존 스탠자를 교체합니다.oauthConfig: ... identityProviders: - name: my_keystone_provider1 challenge: true2 login: true3 mappingMethod: claim4 provider: apiVersion: v1 kind: KeystonePasswordIdentityProvider domainName: default5 url: http://keystone.example.com:50006 ca: ca.pem7 certFile: keystone.pem8 keyFile: keystonekey.pem9 useKeystoneIdentity: false10 - 1
- 이 공급자 이름은 공급자 사용자 이름에 접두어로 지정되어 ID 이름을 형성합니다.
- 2
true인경우 웹 이외의 클라이언트(예: CLI)의 인증되지 않은 토큰 요청이 이 프로바이더의WWW-Authenticate 챌린지헤더가 전송됩니다.- 3
true인경우 웹 콘솔과 같은 웹 클라이언트의 인증되지 않은 토큰 요청은 이 프로바이더가 지원하는 로그인 페이지로 리디렉션됩니다.- 4
- 위에서 설명한 대로 이 프로바이더의 ID와 사용자 오브젝트 간의 매핑 설정 방법을 제어합니다.
- 5
- Keystone 도메인 이름. Keystone에서는 사용자 이름이 도메인에 따라 다릅니다. 단일 도메인만 지원됩니다.
- 6
- Keystone 서버 연결에 사용하는 URL입니다(필수).
- 7
- 선택 사항: 구성된 URL에 대한 서버 인증서의 유효성을 검사하는 데 사용할 인증서 번들입니다.
- 8
- 선택 사항: 구성된 URL에 요청할 때 제공할 클라이언트 인증서입니다.
- 9
- 클라이언트 인증서의 키입니다.
certFile이 지정된 경우 필수 항목입니다. - 10
true인경우, Keystone 사용자 이름이 아닌 Keystone ID에서 사용자를 인증합니다. 사용자 이름으로 인증하려면false로 설정합니다.
identityProviders스탠자를 다음과 같이 수정합니다.-
Keystone 서버와 일치하도록 공급업체
이름("my_keystone_provider")을 변경합니다. 이 이름은 공급자 사용자 이름에 접두어로 지정되어 ID 이름을 형성합니다. -
필요한 경우
mappingMethod를 변경하여 공급자의 ID와 사용자 오브젝트 간의 매핑 설정 방법을 제어합니다. -
domainName을 OpenStack Keystone 서버의 도메인 이름으로 변경합니다. Keystone에서 사용자 이름은 도메인에 따라 다릅니다. 단일 도메인만 지원됩니다. -
OpenStack Keystone 서버에 연결하는 데 사용할
URL을 지정합니다. -
선택적으로 Keystone 사용자 이름 대신 Keystone ID로 사용자를 인증
하려면 useKeystoneIdentity를true로 설정합니다. -
선택적으로 구성된 URL의 서버 인증서의 유효성을 검사하기 위해 사용할
ca를 인증서 번들로 변경합니다. -
선택적으로 구성된 URL에 요청할 때
certFile을 클라이언트 인증서로 변경합니다. -
certFile이 지정된 경우keyFile을 클라이언트 인증서의 키로 변경해야 합니다.
-
Keystone 서버와 일치하도록 공급업체
- 변경 사항을 저장하고 파일을 종료합니다.
방금 수정한 구성 파일을 지정하여 OpenShift Container Platform API 서버를 시작합니다.
$ openshift start master --config=<path/to/modified/config>/master-config.yaml
구성되면 OpenShift Container Platform 웹 콘솔에 로그인하는 모든 사용자에게 Keystone 자격 증명을 사용하여 로그인하라는 메시지가 표시됩니다.
13.3.6.2. Keystone 인증을 사용하여 사용자 생성
외부 인증 공급자(이 경우 Keystone)와 통합할 때 OpenShift Container Platform에서 사용자를 생성하지 않습니다. Keystone은 레코드 시스템입니다. 즉, 사용자가 Keystone 데이터베이스에 정의되어 있으며 구성된 인증 서버에 대해 유효한 Keystone 사용자 이름이 있는 모든 사용자가 로그인할 수 있습니다.
OpenShift Container Platform에 사용자를 추가하려면 사용자가 Keystone 데이터베이스에 있어야 하며 필요한 경우 사용자의 새 Keystone 계정을 만들어야 합니다.
13.3.6.3. 사용자 확인
하나 이상의 사용자가 로그인하면 oc get users 를 실행하여 사용자 목록을 보고 사용자가 성공적으로 생성되었는지 확인할 수 있습니다.
예 13.5. oc get users 명령의 출력
$ oc get users
NAME UID FULL NAME IDENTITIES
bobsmith a0c1d95c-1cb5-11e6-a04a-002186a28631 Bob Smith keystone:bobsmith - 1
- OpenShift Container Platform의 ID는 Keystone 사용자 이름에 접두사가 지정된 ID 공급자 이름으로 구성됩니다.
13.3.7. LDAP 인증
단순 바인드 인증을 사용하여 LDAPv3 서버에 대해 사용자 이름과 암호의 유효성을 검사하도록 를 설정합니다.
identityProviders 스탠자에서 LDAPPasswordIdentityProvider
다음 단계를 따르지 않고 LDAP 서버에 장애 조치가 필요한 경우 LDAP 페일오버를 위해 SSSD를 구성하여 기본 인증 방법을 확장합니다.
LDAP 디렉터리는 인증 중 제공된 사용자 이름과 일치하는 항목으로 검색됩니다. 고유한 일치 항목이 1개 발견되는 경우 해당 항목의 고유 이름(DN)과 제공된 암호를 사용하여 단순 바인딩이 시도됩니다.
다음 단계를 수행합니다.
-
구성된
URL의 속성 및 필터를 사용자가 입력한 사용자 이름과 결합하여 검색 필터를 생성합니다. - 생성된 필터를 사용하여 디렉터리를 검색합니다. 검색에서 정확히 하나의 항목을 반환하지 않으면 액세스를 거부합니다.
- 검색에서 검색된 항목의 DN과 사용자 제공 암호를 사용하여 LDAP 서버에 바인딩합니다.
- 바인딩에 실패하면 액세스를 거부합니다.
- 바인딩이 성공하면 구성된 속성을 ID, 이메일 주소, 표시 이름, 기본 사용자 이름으로 사용하여 ID를 빌드합니다.
구성된 URL은 RFC 2255 URL이며, 사용할 LDAP 호스트 및 검색 매개변수를 지정합니다. URL 구문은 다음과 같습니다.
ldap://host:port/basedn?attribute?scope?filter위 예의 경우 다음을 수행합니다.
| URL 구성 요소 | 설명 |
|---|---|
|
|
일반 LDAP의 경우 |
|
|
LDAP 서버의 이름 및 포트입니다. ldap의 경우 기본값은 |
|
| 모든 검색을 시작해야 하는 디렉터리 분기의 DN입니다. 적어도 디렉터리 트리의 맨 위에 있어야 하지만 디렉터리에 하위 트리를 지정할 수도 있습니다. |
|
|
검색할 속성입니다. RFC 2255에서는 쉼표로 구분된 속성 목록을 사용할 수 있지만 제공되는 속성 수와 관계없이 첫 번째 속성만 사용됩니다. 속성이 제공되지 않는 경우 기본값은 |
|
|
검색 범위입니다. |
|
|
유효한 LDAP 검색 필터입니다. 제공하지 않는 경우 기본값은 |
검색을 수행할 때 속성, 필터, 제공된 사용자 이름을 결합하여 다음과 같은 검색 필터가 생성됩니다.
(&(<filter>)(<attribute>=<username>))예를 들어 다음과 같은 URL을 살펴보십시오.
ldap://ldap.example.com/o=Acme?cn?sub?(enabled=true)
클라이언트가 사용자 이름 bob을 사용하여 연결을 시도하는 경우 결과 검색 필터는 (&(enabled=true)(cn=bob))입니다.
LDAP 디렉터리에서 검색에 인증이 필요한 경우 항목을 검색하는 데 사용할 bindDN 및 bindPassword를 지정하십시오.
LDAPPasswordIdentityProvider를 사용한 마스터 구성
oauthConfig:
...
identityProviders:
- name: "my_ldap_provider"
challenge: true
login: true
mappingMethod: claim
provider:
apiVersion: v1
kind: LDAPPasswordIdentityProvider
attributes:
id:
- dn
email:
- mail
name:
- cn
preferredUsername:
- uid
bindDN: ""
bindPassword: ""
ca: my-ldap-ca-bundle.crt
insecure: false
url: "ldap://ldap.example.com/ou=users,dc=acme,dc=com?uid" - 1
- 이 공급자 이름은 반환된 사용자 ID 앞에 접두어로 지정되어 ID 이름을 형성합니다.
- 2
true인경우 웹 이외의 클라이언트(예: CLI)의 인증되지 않은 토큰 요청이 이 프로바이더의WWW-Authenticate 챌린지헤더가 전송됩니다.- 3
true인경우 웹 콘솔과 같은 웹 클라이언트의 인증되지 않은 토큰 요청은 이 프로바이더가 지원하는 로그인 페이지로 리디렉션됩니다.- 4
- 위에서 설명한 대로 이 프로바이더의 ID와 사용자 오브젝트 간의 매핑 설정 방법을 제어합니다.
- 5
- ID로 사용할 속성 목록입니다. 비어 있지 않은 첫 번째 속성이 사용됩니다. 하나 이상의 속성이 필요합니다. 나열된 어떤 속성에도 값이 없는 경우 인증이 실패합니다.
- 6
- 이메일 주소로 사용할 속성 목록입니다. 비어 있지 않은 첫 번째 속성이 사용됩니다.
- 7
- 표시 이름으로 사용할 속성 목록입니다. 비어 있지 않은 첫 번째 속성이 사용됩니다.
- 8
- 이 ID에 대해 사용자를 프로비저닝할 때 기본 사용자 이름으로 사용할 속성 목록입니다. 비어 있지 않은 첫 번째 속성이 사용됩니다.
- 9
- 검색 단계에서 바인딩하는 데 사용할 선택적 DN입니다.
- 10
- 검색 단계에서 바인딩하는 데 사용할 선택적 암호입니다. 이 값은 환경 변수, 외부 파일 또는 암호화된 파일에서 도 제공할 수 있습니다.
- 11
- 구성된 URL에 대한 서버 인증서의 유효성을 검사하는 데 사용할 인증서 번들입니다. 이 파일의 내용은 /etc/origin/master/<identity_provider_name>_ldap_ca.crt 파일에 복사됩니다. ID 공급자 이름은
openshift_master_identity_providers매개변수의 값입니다. CA 텍스트 또는 로컬 CA 파일의 경로를 지정하지 않으면/etc/origin/master/디렉터리에 CA 인증서를 배치해야 합니다. 여러 ID 공급자를 지정하는 경우/etc/origin/master/디렉터리에 각 공급자의 CA 인증서를 수동으로 배치해야 합니다. 이 위치를 변경할 수 없습니다. 인증서 번들 정의는insecure: false가 인벤토리 파일에 설정된 경우에만 적용됩니다. - 12
true인 경우 서버에 TLS 연결이 이루어지지 않습니다.false인 경우ldaps://URL은 TLS를 사용하여 연결되고,ldap://URL은 TLS로 업그레이드됩니다.- 13
- 위에 설명된 대로 사용할 LDAP 호스트 및 검색 매개변수를 지정하는 RFC 2255 URL입니다.
LDAP 통합을 위해 사용자를 허용 목록에 추가하려면 lookup 매핑 방법을 사용하십시오. LDAP에서 로그인하려면 클러스터 관리자가 각 LDAP 사용자에 대한 ID 및 사용자 오브젝트를 생성해야 합니다.
13.3.8. 기본 인증(원격)
기본 인증은 사용자가 원격 ID 공급자에 대해 검증된 인증 정보를 사용하여 OpenShift Container Platform에 로그인할 수 있는 일반 백엔드 통합 메커니즘입니다.
기본 인증은 일반적이므로 이 ID 공급자를 고급 인증 구성에 사용할 수 있습니다. LDAP 페일오버를 구성하거나 컨테이너화된 기본 인증 리포지토리를 다른 고급 원격 기본 인증 구성의 시작점으로 사용할 수 있습니다.
기본 인증은 원격 서버에 대한 HTTPS 연결을 통해 잠재적인 사용자 ID 및 암호 스누핑 및 중간자 공격을 방지해야 합니다.
BasicAuthPasswordIdentityProvider 가 구성된 상태에서 사용자는 사용자 이름과 암호를 OpenShift Container Platform으로 전송한 다음, server-to-server 요청을 만들어 자격 증명을 기본 인증 헤더로 전달하여 원격 서버에 대해 해당 자격 증명의 유효성을 검사합니다. 이를 위해서는 사용자가 로그인하는 동안 사용자의 자격 증명을 OpenShift Container Platform에 보내야 합니다.
이 작업은 사용자 이름/암호 로그인 메커니즘에서만 작동하며, OpenShift Container Platform에서 원격 인증 서버에 네트워크를 요청할 수 있어야 합니다.
identityProviders 스탠자에서 BasicAuthPasswordIdentityProvider 를 설정하여 서버 대 서버 기본 인증 요청을 사용하여 원격 서버에 대해 사용자 이름과 암호를 검증합니다. 사용자 이름과 암호는 기본 인증으로 보호되고 JSON을 반환하는 원격 URL과 비교하여 유효성을 검사합니다.
401 응답은 인증 실패를 나타냅니다.
200 이외의 상태 또는 비어 있지 않은 "error" 키는 오류를 나타냅니다.
{"error":"Error message"}
sub(제목) 키가 200인 태는 실행 성공을 나타냅니다.
{"sub":"userid"} - 1
- 제목은 인증된 사용자에게 고유해야 하며 수정할 수 없어야 합니다.
성공적인 응답은 선택적으로 다음과 같은 추가 데이터를 제공할 수 있습니다.
name키를 사용하는 표시 이름. 예를 들면 다음과 같습니다.{"sub":"userid", "name": "User Name", ...}email키를 사용하는 이메일 주소. 예를 들면 다음과 같습니다.{"sub":"userid", "email":"user@example.com", ...}preferred_username키를 사용하는 기본 사용자 이름. 변경 불가능한 고유 주체가 데이터베이스 키 또는 UID이고 더 읽기 쉬운 이름이 존재하는 경우 유용합니다. 인증된 ID에 대해 OpenShift Container Platform 사용자를 프로비저닝할 때 힌트로 사용됩니다. 예를 들면 다음과 같습니다.{"sub":"014fbff9a07c", "preferred_username":"bob", ...}
13.3.8.1. 마스터에서 인증 구성
다음과 같은 사항이 있을 수 있습니다.
Openshift 설치를 이미 완료한 다음 /etc/origin/master/master-config.yaml 파일을 새 디렉토리(예:)로 복사합니다.
$ mkdir basicauthconfig; cp master-config.yaml basicauthconfigOpenShift Container Platform을 아직 설치하지 않은 다음 OpenShift Container Platform API 서버를 시작하여 (미래) OpenShift Container Platform 마스터의 호스트 이름과 start 명령으로 생성한 구성 파일을 저장할 디렉터리를 지정합니다.
$ openshift start master --public-master=<apiserver> --write-config=<directory>예를 들면 다음과 같습니다.
$ openshift start master --public-master=https://myapiserver.com:8443 --write-config=basicauthconfig참고Ansible을 사용하여 설치하는 경우
identityProvider구성을 Ansible 플레이북에 추가해야 합니다. 다음 단계를 사용하여 Ansible을 사용하여 설치한 후 수동으로 구성을 수정하는 경우 설치 도구 또는 업그레이드를 다시 실행할 때마다 수정 사항이 손실됩니다.
새 master-config.yaml 파일의
identityProviders스탠자를 편집하고BasicAuthPasswordIdentityProvider구성을 복사하여 기존 스탠자를 교체합니다.oauthConfig: ... identityProviders: - name: my_remote_basic_auth_provider1 challenge: true2 login: true3 mappingMethod: claim4 provider: apiVersion: v1 kind: BasicAuthPasswordIdentityProvider url: https://www.example.com/remote-idp5 ca: /path/to/ca.file6 certFile: /path/to/client.crt7 keyFile: /path/to/client.key8 - 1
- 이 공급자 이름은 반환된 사용자 ID 앞에 접두어로 지정되어 ID 이름을 형성합니다.
- 2
true인경우 웹 이외의 클라이언트(예: CLI)의 인증되지 않은 토큰 요청이 이 프로바이더의WWW-Authenticate 챌린지헤더가 전송됩니다.- 3
true인경우 웹 콘솔과 같은 웹 클라이언트의 인증되지 않은 토큰 요청은 이 프로바이더가 지원하는 로그인 페이지로 리디렉션됩니다.- 4
- 위에서 설명한 대로 이 프로바이더의 ID와 사용자 오브젝트 간의 매핑 설정 방법을 제어합니다.
- 5
- 기본 인증 헤더에서 인증 정보를 수락하는 URL.
- 6
- 선택 사항: 구성된 URL에 대한 서버 인증서의 유효성을 검사하는 데 사용할 인증서 번들입니다.
- 7
- 선택 사항: 구성된 URL에 요청할 때 제공할 클라이언트 인증서입니다.
- 8
- 클라이언트 인증서의 키입니다.
certFile이 지정된 경우 필수 항목입니다.
identityProviders스탠자를 다음과 같이 수정합니다.-
공급자
이름을배포와 관련된 고유한 이름으로 설정합니다. 이 이름은 반환된 사용자 ID 앞에 접두어로 지정되어 ID 이름을 형성합니다. -
필요한 경우
mappingMethod를 설정하여 공급자의 ID와 사용자 오브젝트 간의 매핑 설정 방법을 제어합니다. -
기본 인증 헤더에서 자격 증명을 수락하는 서버에 연결하는 데 사용할 HTTPS
URL을 지정합니다. -
선택적으로 구성된 URL에 대한 서버 인증서의 유효성을 검사하기 위해 사용할 인증서 번들로
ca를 설정하거나 시스템에서 신뢰할 수 있는 루트를 사용하도록 비워 둡니다. -
선택적으로 구성된 URL에 요청할 때
certFile을 클라이언트 인증서로 제거하거나 설정합니다. -
certFile이 지정된 경우keyFile을 클라이언트 인증서의 키로 설정해야 합니다.
- 변경 사항을 저장하고 파일을 종료합니다.
방금 수정한 구성 파일을 지정하여 OpenShift Container Platform API 서버를 시작합니다.
$ openshift start master --config=<path/to/modified/config>/master-config.yaml
구성되면 OpenShift Container Platform 웹 콘솔에 로그인하는 모든 사용자에게 기본 인증 자격 증명을 사용하여 로그인하라는 메시지가 표시됩니다.
13.3.8.2. 문제 해결
가장 일반적인 문제는 백엔드 서버에 대한 네트워크 연결과 관련이 있습니다. 간단한 디버깅을 위해 마스터에서 curl 명령을 실행합니다. 성공적인 로그인을 테스트하려면 다음 예제 명령에서 <user> 및 <password>를 유효한 자격 증명으로 교체하십시오. 잘못된 로그인을 테스트하려면 잘못된 인증 정보로 대체합니다.
curl --cacert /path/to/ca.crt --cert /path/to/client.crt --key /path/to/client.key -u <user>:<password> -v https://www.example.com/remote-idp성공적인 응답
sub(제목) 키가 200인 태는 실행 성공을 나타냅니다.
{"sub":"userid"}제목은 인증된 사용자에게 고유해야 하며 수정할 수 없어야 합니다.
성공적인 응답은 선택적으로 다음과 같은 추가 데이터를 제공할 수 있습니다.
name키를 사용하는 표시 이름:{"sub":"userid", "name": "User Name", ...}email키를 사용하는 이메일 주소:{"sub":"userid", "email":"user@example.com", ...}preferred_username키를 사용하는 기본 사용자 이름:{"sub":"014fbff9a07c", "preferred_username":"bob", ...}preferred_username은 변경 불가능한 고유한 제목이 데이터베이스 키 또는 UID이고 더 읽기 쉬운 이름이 존재하는 경우 유용합니다. 인증된 ID에 대해 OpenShift Container Platform 사용자를 프로비저닝할 때 힌트로 사용됩니다.
실패한 응답
-
401응답은 인증 실패를 나타냅니다. -
200이외의 상태 또는 비어 있지 않은 "error" 키는 오류({"error":"Error message"})를 나타냅니다.
13.3.9. 요청 헤더
identityProviders 스탠자에 RequestHeaderIdentityProvider 를 설정하여 X-Remote-User 와 같은 요청 헤더 값에서 사용자를 식별합니다. 일반적으로 요청 헤더 값을 설정하는 인증 프록시와 함께 사용됩니다. 이는 관리자가 OpenShift Enterprise 2의 원격 사용자 플러그인이 Kerberos, LDAP 및 기타 여러 형태의 엔터프라이즈 인증 기능을 제공하는 방법과 유사합니다.
커뮤니티 지원 SAML 인증과 같은 고급 구성에도 요청 헤더 ID 공급자를 사용할 수 있습니다. Red Hat에서는 SAML 인증을 지원하지 않습니다.
사용자가 이 ID 공급자를 사용하여 인증하려면 인증 프록시를 통해 https://<master>/oauth/authorize (및 하위 경로)에 액세스해야 합니다. 이를 수행하려면 https://<master>/oauth/authorize 로 프록시하는 프록시 끝점으로 OAuth 토큰의 인증되지 않은 요청을 리디렉션하도록 OAuth 서버를 구성합니다.
브라우저 기반 로그인 flows가 필요한 클라이언트의 인증되지 않은 요청을 리디렉션하려면 다음을 수행합니다.
-
login매개 변수를true로 설정합니다. -
provider.loginURL매개변수를 대화형 클라이언트를 인증하는 인증 프록시 URL로 설정한 다음 요청을https://<master>/oauth/authorize로 프록시합니다.
WWW 인증 챌린지가 예상되는 클라이언트의 인증되지 않은 요청을 리디렉션하려면 다음을 수행합니다.
-
challenge매개 변수를true로 설정합니다. -
provider.challengeURL매개변수를WWW 인증 챌린지가 예상되는 클라이언트를 인증하는 인증 프록시 URL로 설정한 다음 요청을https://<master>/oauth/authorize로 프록시합니다.
provider.challengeURL 및 provider.loginURL 매개변수는 URL 조회 부분에 다음 토큰을 포함할 수 있습니다.
${url}은 현재 URL로 교체되며 쿼리 매개변수에서 안전하도록 이스케이프됩니다.예:
https://www.example.com/sso-login?then=${url}${query}는 이스케이프 처리되지 않은 현재 쿼리 문자열로 교체됩니다.예:
https://www.example.com/auth-proxy/oauth/authorize?${query}
OAuth 서버에 도달할 인증되지 않은 요청이 예상되는 경우 이 ID 프로바이더에 대해 clientCA 매개 변수를 설정해야 하므로 요청 헤더를 사용자 이름에 대해 들어오는 요청이 유효한 클라이언트 인증서에 대해 확인되도록 해야 합니다. 그러지 않으면 요청 헤더를 설정하는 것만으로 OAuth 서버에 대한 모든 직접 요청이 이 공급자의 ID를 가장할 수 있습니다.
RequestHeaderIdentityProvider를 사용한 마스터 구성
oauthConfig:
...
identityProviders:
- name: my_request_header_provider
challenge: true
login: true
mappingMethod: claim
provider:
apiVersion: v1
kind: RequestHeaderIdentityProvider
challengeURL: "https://www.example.com/challenging-proxy/oauth/authorize?${query}"
loginURL: "https://www.example.com/login-proxy/oauth/authorize?${query}"
clientCA: /path/to/client-ca.file
clientCommonNames:
- my-auth-proxy
headers:
- X-Remote-User
- SSO-User
emailHeaders:
- X-Remote-User-Email
nameHeaders:
- X-Remote-User-Display-Name
preferredUsernameHeaders:
- X-Remote-User-Login- 1
- 이 공급자 이름은 요청 헤더에서 사용자 이름 앞에 접두어로 지정되어 ID 이름을 형성합니다.
- 2
RequestHeaderIdentityProvider는 구성된 챌린지 URL로 리디렉션하여WWW-Authenticate 챌린지를요청하는 클라이언트에만 응답할 수있습니다. 구성된 URL은WWW-Authenticate 챌린지에 응답해야 합니다.- 3
RequestHeaderIdentityProvider는 구성된 로그인 URL로 리디렉션하여 로그인 흐름을 요청하는 클라이언트에만 응답할 수있습니다. 구성된 URL은 로그인 흐름을 사용하여 응답해야 합니다.- 4
- 위에서 설명한 대로 이 프로바이더의 ID와 사용자 오브젝트 간의 매핑 설정 방법을 제어합니다.
- 5
- 선택 사항: 인증되지 않은
/oauth/authorize요청을 리디렉션할 URL로,WWW-Authenticate 챌린지를예상하는 클라이언트를 인증한 다음https://<master>/oauth/authorize로 프록시합니다.${url}은(는) 현재 URL로 교체되고 쿼리 매개 변수에서 안전하도록 이스케이프됩니다.${query}는 현재 쿼리 문자열로 교체됩니다. - 6
- 선택 사항: 인증되지 않은
/oauth/authorize요청을 로 리디렉션하는 URL로, 브라우저 기반 클라이언트를 인증한 다음 해당 요청을https://<master>/oauth/authorize로 프록시합니다. OAuth 승인 흐름이 제대로 작동하려면https://<master>/oauth/authorize로 프록시되는 URL은/authorize(후행 슬래시 없음)로 끝나야 하며 프록시 하위 경로도 작동합니다.${url}은 현재 URL로 교체되고 쿼리 매개변수에서 안전하도록 이스케이프됩니다.${query}는 현재 쿼리 문자열로 교체됩니다. - 7
- 선택 사항: PEM 인코딩 인증서 번들. 설정한 경우 요청 헤더에서 사용자 이름을 확인하기 전에 지정된 파일의 인증 기관에 대해 유효한 클라이언트 인증서를 제공하고 검증해야 합니다.
- 8
- 선택 사항: 공통 이름(
cn) 목록. 설정된 경우 요청 헤더에서 사용자 이름을 확인하기 전에 지정된 목록에 공통 이름(cn)이 있는 유효한 클라이언트 인증서를 제공해야 합니다. 비어 있는 경우 모든 공통 이름이 허용됩니다.clientCA와 함께만 사용할 수 있습니다. - 9
- 사용자 ID에 대해 순서대로 확인할 헤더 이름입니다. 값을 포함하는 첫 번째 헤더가 ID로 사용됩니다. 필수 항목이며 대소문자를 구분하지 않습니다.
- 10
- 이메일 주소를 순서대로 확인할 헤더 이름입니다. 값을 포함하는 첫 번째 헤더가 이메일 주소로 사용됩니다. 선택 항목이며 대소문자를 구분하지 않습니다.
- 11
- 표시 이름을 순서대로 확인할 헤더 이름입니다. 값을 포함하는 첫 번째 헤더가 표시 이름으로 사용됩니다. 선택 항목이며 대소문자를 구분하지 않습니다.
- 12
headers에 지정된 헤더에서 결정된 불변 ID와 다른 경우, 기본 사용자 이름을 순서대로 확인하는 헤더 이름입니다. 값이 포 된 첫 번째 헤더는 프로비저닝시 기본 사용자 이름으로 사용됩니다. 선택 항목이며 대소문자를 구분하지 않습니다.
Microsoft Windows에서 SSPI 연결 지원
Microsoft Windows에서 SSPI 연결 지원을 사용하는 것은 기술 프리뷰 기능입니다. 기술 프리뷰 기능은 Red Hat 프로덕션 서비스 수준 계약(SLA)에서 지원하지 않으며, 기능상 완전하지 않을 수 있어 프로덕션에 사용하지 않는 것이 좋습니다. 이러한 기능을 사용하면 향후 제품 기능을 조기에 이용할 수 있어 개발 과정에서 고객이 기능을 테스트하고 피드백을 제공할 수 있습니다.
Red Hat 기술 프리뷰 기능 지원 범위에 대한 자세한 내용은 https://access.redhat.com/support/offerings/techpreview/를 참조하십시오.
버전 3.11부터
oc는 Microsft Windows에서 SSO 흐름을 허용하기 위해 보안 지원 공급자 인터페이스(SSPI)를 지원합니다. 요청 헤더 ID 공급자를 GSSAPI 지원 프록시와 함께 사용하여 Active Directory 서버를 OpenShift Container Platform에 연결하는 경우, 사용자가 도메인에 가입된 Microsoft Windows 컴퓨터에서 oc 명령줄 인터페이스를 사용하여 OpenShift Container Platform을 자동으로 인증할 수 있습니다.
요청 헤더를 사용한 Apache 인증
이 예제에서는 마스터와 동일한 호스트에서 인증 프록시를 구성합니다. 프록시와 마스터를 동일한 호스트에 보유하는 것은 편의성일 뿐이며 사용자 환경에 적합하지 않을 수 있습니다. 예를 들어 마스터에서 이미 라우터를 실행 중인 경우 포트 443을 사용할 수 없습니다.
또한 이 참조 구성은 Apache의 mod_auth_gssapi 를 사용하지만 필수는 없으며 다음 요구 사항을 충족하는 경우 다른 프록시를 쉽게 사용할 수 있습니다.
-
스푸핑을 방지하기 위해 클라이언트 요청에서
X-Remote-User헤더를 차단합니다. -
RequestHeaderIdentityProvider구성에서 클라이언트 인증서 인증을 시행합니다. -
챌린지 flow를 사용하여 모든 인증 요청에
X-Csrf-Token헤더를 설정해야 합니다. -
/oauth/authorize엔드포인트와 해당 하위 경로만 프록시해야 하며 백엔드 서버가 클라이언트를 올바른 위치로 보낼 수 있도록 리디렉션을 다시 작성해서는 안 됩니다. https://<master>/oauth/authorize로 프록시되는 URL은(후행 슬래시 없음)로 끝나야 합니다. 예를 들면 다음과 같습니다./authorize-
https://proxy.example.com/login-proxy/authorize?…→HTTPS://<master>/oauth/authorize?…
-
https://<master>/oauth/authorize로 프록시되는 URL의 하위 경로는https://<master>/oauth/authorize 하위 경로로 프록시되어야 합니다. 예를 들면 다음과 같습니다.-
https://proxy.example.com/login-proxy/authorize/approve?…→HTTPS://<master>/oauth/authorize/approve?…
-
사전 요구 사항 설치
선택적 채널에서 mod_auth_gssapi 모듈을 가져옵니다. 다음 패키지를 설치합니다.
# yum install -y httpd mod_ssl mod_session apr-util-openssl mod_auth_gssapi신뢰할 수 있는 헤더를 제출하는 요청을 검증하는 CA를 생성합니다. 이 CA는 마스터의 ID 공급자 구성에서
clientCA의 파일 이름으로 사용해야 합니다.# oc adm ca create-signer-cert \ --cert='/etc/origin/master/proxyca.crt' \ --key='/etc/origin/master/proxyca.key' \ --name='openshift-proxy-signer@1432232228' \ --serial='/etc/origin/master/proxyca.serial.txt'참고oc adm ca create-signer-cert명령은 5년 동안 유효한 인증서를 생성합니다. 이는--expire-days옵션으로 변경할 수 있지만 보안상의 이유로 이 값보다 커지지 않는 것이 좋습니다.기본적으로 /etc/ansible/hosts 에서 Ansible 호스트 인벤토리 파일에 나열된 첫 번째 마스터에서만
oc adm명령을 실행합니다.프록시의 클라이언트 인증서를 생성합니다. 이 작업은 x509 인증서 툴링을 사용하여 수행할 수 있습니다. 편의를 위해
oc admCLI를 사용할 수 있습니다.# oc adm create-api-client-config \ --certificate-authority='/etc/origin/master/proxyca.crt' \ --client-dir='/etc/origin/master/proxy' \ --signer-cert='/etc/origin/master/proxyca.crt' \ --signer-key='/etc/origin/master/proxyca.key' \ --signer-serial='/etc/origin/master/proxyca.serial.txt' \ --user='system:proxy'1 # pushd /etc/origin/master # cp master.server.crt /etc/pki/tls/certs/localhost.crt2 # cp master.server.key /etc/pki/tls/private/localhost.key # cp ca.crt /etc/pki/CA/certs/ca.crt # cat proxy/system\:proxy.crt \ proxy/system\:proxy.key > \ /etc/pki/tls/certs/authproxy.pem # popd- 1
- 사용자 이름은 무엇이든 될 수 있지만 로그에 표시될 때 설명이 포함된 이름을 지정하는 것이 유용합니다.
- 2
- 마스터와 다른 호스트 이름에서 인증 프록시를 실행하는 경우 위에 표시된 대로 기본 마스터 인증서를 사용하는 대신 호스트 이름과 일치하는 인증서를 생성하는 것이 중요합니다. /etc/origin/master/master-config.yaml 파일의
masterPublicURL값은SSLCertificateFile에 지정된 인증서의 X509v3 주체 대체이름에 포함되어야 합니다. 새 인증서를 만들어야 하는 경우oc adm ca create-server-cert명령을 사용할 수 있습니다.
참고oc adm create-api-client-config명령은 2년 동안 유효한 인증서를 생성합니다. 이는--expire-days옵션으로 변경할 수 있지만 보안상의 이유로 이 값보다 커지지 않는 것이 좋습니다. 기본적으로 /etc/ansible/hosts 에서 Ansible 호스트 인벤토리 파일에 나열된 첫 번째 마스터에서만oc adm명령을 실행합니다.
Apache 구성
이 프록시는 마스터와 동일한 호스트에 상주할 필요가 없습니다. 클라이언트 인증서를 사용하여 X-Remote-User 헤더를 신뢰하도록 구성된 마스터에 연결합니다.
-
Apache 구성에 대한 인증서를 생성합니다.
SSLProxyMachineCertificateFile매개변수 값으로 지정하는 인증서는 서버에 프록시를 인증하는 데 사용되는 프록시의 클라이언트 인증서입니다. 확장 키 유형으로TLS 웹 클라이언트 인증을 사용해야 합니다. Apache 구성을 생성합니다. 다음 템플릿을 사용하여 필요한 설정 및 값을 제공하십시오.
중요템플릿을 신중하게 검토하고 환경에 맞게 내용을 사용자 정의하십시오.
LoadModule request_module modules/mod_request.so LoadModule auth_gssapi_module modules/mod_auth_gssapi.so # Some Apache configurations might require these modules. # LoadModule auth_form_module modules/mod_auth_form.so # LoadModule session_module modules/mod_session.so # Nothing needs to be served over HTTP. This virtual host simply redirects to # HTTPS. <VirtualHost *:80> DocumentRoot /var/www/html RewriteEngine On RewriteRule ^(.*)$ https://%{HTTP_HOST}$1 [R,L] </VirtualHost> <VirtualHost *:443> # This needs to match the certificates you generated. See the CN and X509v3 # Subject Alternative Name in the output of: # openssl x509 -text -in /etc/pki/tls/certs/localhost.crt ServerName www.example.com DocumentRoot /var/www/html SSLEngine on SSLCertificateFile /etc/pki/tls/certs/localhost.crt SSLCertificateKeyFile /etc/pki/tls/private/localhost.key SSLCACertificateFile /etc/pki/CA/certs/ca.crt SSLProxyEngine on SSLProxyCACertificateFile /etc/pki/CA/certs/ca.crt # It's critical to enforce client certificates on the Master. Otherwise # requests could spoof the X-Remote-User header by accessing the Master's # /oauth/authorize endpoint directly. SSLProxyMachineCertificateFile /etc/pki/tls/certs/authproxy.pem # Send all requests to the console RewriteEngine On RewriteRule ^/console(.*)$ https://%{HTTP_HOST}:8443/console$1 [R,L] # In order to using the challenging-proxy an X-Csrf-Token must be present. RewriteCond %{REQUEST_URI} ^/challenging-proxy RewriteCond %{HTTP:X-Csrf-Token} ^$ [NC] RewriteRule ^.* - [F,L] <Location /challenging-proxy/oauth/authorize> # Insert your backend server name/ip here. ProxyPass https://[MASTER]:8443/oauth/authorize AuthName "SSO Login" # For Kerberos AuthType GSSAPI Require valid-user RequestHeader set X-Remote-User %{REMOTE_USER}s GssapiCredStore keytab:/etc/httpd/protected/auth-proxy.keytab # Enable the following if you want to allow users to fallback # to password based authntication when they do not have a client # configured to perform kerberos authentication GssapiBasicAuth On # For ldap: # AuthBasicProvider ldap # AuthLDAPURL "ldap://ldap.example.com:389/ou=People,dc=my-domain,dc=com?uid?sub?(objectClass=*)" # It's possible to remove the mod_auth_gssapi usage and replace it with # something like mod_auth_mellon, which only supports the login flow. </Location> <Location /login-proxy/oauth/authorize> # Insert your backend server name/ip here. ProxyPass https://[MASTER]:8443/oauth/authorize AuthName "SSO Login" AuthType GSSAPI Require valid-user RequestHeader set X-Remote-User %{REMOTE_USER}s env=REMOTE_USER GssapiCredStore keytab:/etc/httpd/protected/auth-proxy.keytab # Enable the following if you want to allow users to fallback # to password based authntication when they do not have a client # configured to perform kerberos authentication GssapiBasicAuth On ErrorDocument 401 /login.html </Location> </VirtualHost> RequestHeader unset X-Remote-User
마스터 구성
/etc/origin/master/master-config.yaml 파일의 identityProviders 스탠자도 업데이트해야 합니다.
identityProviders:
- name: requestheader
challenge: true
login: true
provider:
apiVersion: v1
kind: RequestHeaderIdentityProvider
challengeURL: "https://[MASTER]/challenging-proxy/oauth/authorize?${query}"
loginURL: "https://[MASTER]/login-proxy/oauth/authorize?${query}"
clientCA: /etc/origin/master/proxyca.crt
headers:
- X-Remote-User서비스 재시작
마지막으로 다음 서비스를 다시 시작하십시오.
# systemctl restart httpd
# master-restart api
# master-restart controllers구성 확인
프록시를 바이패스하여 테스트합니다. 올바른 클라이언트 인증서 및 헤더를 제공하는 경우 토큰을 요청할 수 있습니다.
# curl -L -k -H "X-Remote-User: joe" \ --cert /etc/pki/tls/certs/authproxy.pem \ https://[MASTER]:8443/oauth/token/request클라이언트 인증서를 제공하지 않으면 요청이 거부되어야 합니다.
# curl -L -k -H "X-Remote-User: joe" \ https://[MASTER]:8443/oauth/token/request구성된
challengeURL로의 리디렉션이 표시됩니다(추가 쿼리 매개 변수 포함).# curl -k -v -H 'X-Csrf-Token: 1' \ '<masterPublicURL>/oauth/authorize?client_id=openshift-challenging-client&response_type=token'WWW-Authenticate 기본 챌린지, 협상 챌린지 또는 두 가지 챌린지가 있는 401 응답이 표시되어야 합니다.# curl -k -v -H 'X-Csrf-Token: 1' \ '<redirected challengeURL from step 3 +query>'Kerberos 티켓을 사용하거나 사용하지 않고
oc명령행에 로그인을 테스트합니다.kinit를 사용하여 Kerberos 티켓을 생성한 경우 이를 삭제합니다.# kdestroy -c cache_name1 - 1
- Kerberos 캐시의 이름을 제공합니다.
Kerberos 자격 증명을 사용하여
oc명령줄에 로그인합니다.# oc login프롬프트에 Kerberos 사용자 이름과 암호를 입력합니다.
oc명령줄에서 로그아웃합니다.# oc logoutKerberos 인증 정보를 사용하여 티켓을 받습니다.
# kinit프롬프트에 Kerberos 사용자 이름과 암호를 입력합니다.
oc명령줄에 로그인할 수 있는지 확인합니다.# oc login구성이 올바르면 별도의 인증 정보를 입력하지 않아도 로그인할 수 있습니다.
13.3.10. GitHub 및 GitHub Enterprise
GitHub는 OAuth를 사용하며 OpenShift Container Platform 클러스터를 통합하여 해당 OAuth 인증을 사용할 수 있습니다. OAuth를 사용하면 OpenShift Container Platform과 GitHub 또는 GitHub Enterprise 간의 토큰 교환 flow가 용이해집니다.
GitHub 통합을 사용하여 GitHub 또는 GitHub Enterprise에 연결할 수 있습니다. GitHub Enterprise 통합의 경우 인스턴스의 호스트 이름을 제공해야 하며, 서버에 대한 요청에 사용할 ca 인증서 번들을 선택적으로 제공할 수 있습니다.
다음 단계는 별도로 명시하지 않는 한 GitHub 및 GitHub Enterprise에 모두 적용됩니다.
GitHub 인증을 구성하면 사용자가 GitHub 자격 증명을 사용하여 OpenShift Container Platform에 로그인할 수 있습니다. GitHub 사용자 ID가 있는 사람이 OpenShift Container Platform 클러스터에 로그인하지 못하도록 특정 GitHub 조직의 사용자만 액세스할 수 있도록 제한할 수 있습니다.
13.3.10.1. GitHub에서 애플리케이션 등록
애플리케이션을 등록합니다.
- GitHub의 경우 설정 → 개발자 설정 → 새 OAuth 애플리케이션 등록을 클릭합니다.
- GitHub Enterprise의 경우 GitHub Enterprise 홈페이지로 이동한 다음 Settings → Developer settings → Register a new application을 클릭합니다.
-
애플리케이션 이름(예:
My OpenShift Install)을 입력합니다. -
https://myapiserver.com:8443과 같은 홈페이지 URL을 입력합니다. - 필요한 경우 애플리케이션 설명을 입력합니다.
권한 부여 콜백 URL을 입력합니다. 여기서 URL 끝에는 이 항목의 다음 섹션에서 구성하는 마스터 구성 파일의
identityProviders스탠자에 정의된 ID 공급자 이름이 포함됩니다.<apiserver>/oauth2callback/<identityProviderName>예를 들면 다음과 같습니다.
https://myapiserver.com:8443/oauth2callback/github/- Register application을 클릭합니다. GitHub에서 클라이언트 ID와 클라이언트 보안을 제공합니다. 이러한 값을 복사하여 마스터 구성 파일에 붙여넣을 수 있도록 이 창을 열어 둡니다.
13.3.10.2. 마스터에서 인증 구성
다음과 같은 사항이 있을 수 있습니다.
OpenShift Container Platform을 이미 설치한 다음 /etc/origin/master/master-config.yaml 파일을 새 디렉터리에 복사합니다. 예를 들면 다음과 같습니다.
$ cd /etc/origin/master $ mkdir githubconfig; cp master-config.yaml githubconfigOpenShift Container Platform을 아직 설치하지 않은 다음 OpenShift Container Platform API 서버를 시작하여 (미래) OpenShift Container Platform 마스터의 호스트 이름과 start 명령으로 생성한 구성 파일을 저장할 디렉터리를 지정합니다.
$ openshift start master --public-master=<apiserver> --write-config=<directory>예를 들면 다음과 같습니다.
$ openshift start master --public-master=https://myapiserver.com:8443 --write-config=githubconfig참고Ansible을 사용하여 설치하는 경우
identityProvider구성을 Ansible 플레이북에 추가해야 합니다. 다음 단계를 사용하여 Ansible을 사용하여 설치한 후 수동으로 구성을 수정하는 경우 설치 도구 또는 업그레이드를 다시 실행할 때마다 수정 사항이 손실됩니다.참고openshift start master를 자체적으로 사용하면 호스트 이름을 자동으로 감지하지만 GitHub에서 애플리케이션을 등록할 때 지정한 정확한 호스트 이름으로 리디렉션할 수 있어야 합니다. 따라서 ID가 잘못된 주소로 리디렉션될 수 있으므로 자동으로 탐지할 수 없습니다. 대신 웹 브라우저가 OpenShift Container Platform 클러스터와 상호 작용하는 데 사용하는 호스트 이름을 지정해야 합니다.
새 master-config.yaml 파일의
identityProviders스탠자를 편집하고GitHubIdentityProvider구성 예제를 복사하여 기존 스탠자를 교체합니다.oauthConfig: ... identityProviders: - name: github1 challenge: false2 login: true3 mappingMethod: claim4 provider: apiVersion: v1 kind: GitHubIdentityProvider ca: ...5 clientID: ...6 clientSecret: ...7 hostname: ...8 organizations:9 - myorganization1 - myorganization2 teams:10 - myorganization1/team-a - myorganization2/team-b- 1
- 이 공급자 이름은 GitHub 숫자 사용자 ID 앞에 접두어로 지정되어 ID 이름을 형성합니다. 콜백 URL을 빌드하는 데에도 사용됩니다.
- 2
GitHubIdentityProvider는WWW-Authenticate 챌린지를 보내는 데 사용할 수 없습니다.- 3
true인경우 웹 콘솔과 같은 웹 클라이언트의 인증되지 않은 토큰 요청이 GitHub로 리디렉션되어 로그인합니다.- 4
- 위에서 설명한 대로 이 프로바이더의 ID와 사용자 오브젝트 간의 매핑 설정 방법을 제어합니다.
- 5
- GitHub Enterprise의 경우 CA는 서버에 요청할 때 사용할 수 있는 신뢰할 수 있는 인증 기관 번들입니다. 기본 시스템 루트 인증서를 사용하려면 이 매개변수를 생략합니다. GitHub의 경우 이 매개변수를 생략합니다.
- 6
- 등록된 GitHub OAuth 애플리케이션의 클라이언트 ID. 애플리케이션은
<master>/oauth2callback/<identityProviderName>의 콜백 URL을 사용하여 구성해야 합니다. - 7
- GitHub에서 발행한 클라이언트 시크릿입니다. 이 값은 환경 변수, 외부 파일 또는 암호화된 파일에서 도 제공할 수 있습니다.
- 8
- GitHub Enterprise의 경우 인스턴스의 호스트 이름(예:
example.com)을 제공해야 합니다. 이 값은 /setup/settings 파일의 GitHub Enterprise호스트 이름값과 일치해야 하며 포트 번호를 포함할 수 없습니다. GitHub의 경우 이 매개변수를 생략합니다. - 9
- 조직 선택 목록. 지정된 경우 나열된 조직 중 하나 이상의 멤버인 GitHub 사용자만 로그인할 수 있습니다.
clientID에 구성된 GitHub OAuth 애플리케이션이 조직의 소유가 아닌 경우 조직 소유자가 이 옵션을 사용하려면 타사 액세스 권한을 부여해야 합니다. 이러한 작업은 조직 관리자가 GitHub를 처음 로그인하는 동안 또는 GitHub 조직 설정에서 수행할 수 있습니다.teams필드와 함께 사용할 수 없습니다. - 10
- 팀 선택 목록. 지정된 경우 나열된 팀 중 하나 이상의 멤버인 GitHub 사용자만 로그인할 수 있습니다.
clientID에 구성된 GitHub OAuth 애플리케이션이 팀의 조직에서 소유하지 않는 경우 조직 소유자는 이 옵션을 사용하려면 타사 액세스 권한을 부여해야 합니다. 이러한 작업은 조직 관리자가 GitHub를 처음 로그인하는 동안 또는 GitHub 조직 설정에서 수행할 수 있습니다.organizations필드와 함께 사용할 수 없습니다.
identityProviders스탠자를 다음과 같이 수정합니다.GitHub에서 구성한 콜백 URL과 일치하도록 프로바이더
이름을변경합니다.예를 들어 콜백 URL을
https://myapiserver.com:8443/oauth2callback/github/로 정의한 경우이름은github여야 합니다.-
이전에 등록한 GitHub에서
clientID를 클라이언트 ID로 변경합니다. -
clientSecret을 이전에 등록한 GitHub에서 클라이언트 보안으로 변경합니다. -
인증
하기 위해
- 변경 사항을 저장하고 파일을 종료합니다.
방금 수정한 구성 파일을 지정하여 OpenShift Container Platform API 서버를 시작합니다.
$ openshift start master --config=<path/to/modified/config>/master-config.yaml
구성되고 나면 OpenShift Container Platform 웹 콘솔에 로그인하는 모든 사용자에게 GitHub 자격 증명을 사용하여 로그인하라는 메시지가 표시됩니다. 첫 번째 로그인 시 사용자는 GitHub에서 OpenShift Container Platform에서 사용자 이름, 암호 및 조직 멤버십을 사용할 수 있도록 애플리케이션 권한 부여를 클릭해야 합니다. 그런 다음 사용자는 다시 웹 콘솔로 리디렉션됩니다.
13.3.10.3. GitHub 인증으로 사용자 생성
외부 인증 공급자(이 경우 GitHub)와 통합할 때 OpenShift Container Platform에서 사용자를 생성하지 않습니다. GitHub 또는 GitHub Enterprise는 사용자가 GitHub에서 정의하며 지정된 조직에 속한 모든 사용자가 로그인할 수 있음을 나타내는 레코드 시스템입니다.
OpenShift Container Platform에 사용자를 추가하려면 해당 사용자를 GitHub 또는 GitHub Enterprise의 승인된 조직에 추가해야 하며 필요한 경우 사용자에 대한 새 GitHub 계정을 생성해야 합니다.
13.3.10.4. 사용자 확인
하나 이상의 사용자가 로그인하면 oc get users 를 실행하여 사용자 목록을 보고 사용자가 성공적으로 생성되었는지 확인할 수 있습니다.
예 13.6. oc get users 명령의 출력
$ oc get users
NAME UID FULL NAME IDENTITIES
bobsmith 433b5641-066f-11e6-a6d8-acfc32c1ca87 Bob Smith github:873654 - 1
- OpenShift Container Platform의 ID는 ID 공급자 이름과 GitHub의 내부 숫자 사용자 ID로 구성됩니다. 이렇게 하면 사용자가 GitHub 사용자 이름 또는 이메일을 변경해도 GitHub 계정에 연결된 자격 증명을 사용하는 대신 OpenShift Container Platform에 로그인할 수 있습니다. 이렇게 하면 안정적인 로그인이 생성됩니다.
13.3.11. GitLab
GitLab .com 또는 기타 GitLab 인스턴스를 ID 프로바이더로 사용하도록 를 설정합니다. GitLab 버전 7.7.0~11.0을 사용하는 경우 OAuth 통합을 사용하여 연결합니다. GitLab 버전 11.1 이상을 사용하는 경우 OAuth 대신 OpenID Connect(OIDC)를 사용하여 연결할 수 있습니다.
identityProviders 스탠자에서 GitLabIdentityProvider
예 13.7. GitLabIdentityProvider를 사용한 마스터 구성
oauthConfig:
...
identityProviders:
- name: gitlab
challenge: true
login: true
mappingMethod: claim
provider:
apiVersion: v1
kind: GitLabIdentityProvider
legacy:
url: ...
clientID: ...
clientSecret: ...
ca: ... - 1
- 이 공급자 이름은 GitLab 숫자 사용자 ID 앞에 접두어로 지정되어 ID 이름을 형성합니다. 콜백 URL을 빌드하는 데에도 사용됩니다.
- 2
true인경우 웹 이외의 클라이언트(예: CLI)의 인증되지 않은 토큰 요청이 이 프로바이더의WWW-Authenticate 챌린지헤더가 전송됩니다. 이를 통해 Resource Owner Password 자격 증명이 흐름을 부여하여 GitLab에서 액세스 토큰을 가져옵니다.- 3
true인경우 웹 콘솔과 같은 웹 클라이언트의 인증되지 않은 토큰 요청이 GitLab으로 리디렉션되어 로그인합니다.- 4
- 위에서 설명한 대로 이 프로바이더의 ID와 사용자 오브젝트 간의 매핑 설정 방법을 제어합니다.
- 5
- OAuth 또는 OIDC를 인증 프로바이더로 사용할지 여부를 결정합니다. OIDC를 사용하려면 OAuth 및
false를 사용하려면true로 설정합니다. OIDC를 사용하려면 GitLab.com 또는 GitLab 버전 11.1 이상을 사용해야 합니다. 값을 제공하지 않으면 OAuth는 GitLab 인스턴스에 연결하는 데 사용되며 OIDC는 GitLab.com에 연결하는 데 사용됩니다. - 6
- GitLab 공급자의 호스트 URL.
https://gitlab.com/또는 기타 자체 호스팅 GitLab 인스턴스일 수 있습니다. - 7
- 등록된 GitLab OAuth 애플리케이션의 클라이언트 ID. 애플리케이션은
<master>/oauth2callback/<identityProviderName>의 콜백 URL을 사용하여 구성해야 합니다. - 8
- GitLab에서 발행한 클라이언트 시크릿입니다. 이 값은 환경 변수, 외부 파일 또는 암호화된 파일에서 도 제공할 수 있습니다.
- 9
- CA는 GitLab 인스턴스에 요청할 때 사용할 신뢰할 수 있는 인증 기관 번들입니다. 비어있는 경우 기본 시스템 루트가 사용됩니다.
13.3.12. Google
Google의 OpenID Connect 통합을 사용하여 Google을 ID 공급자로 사용하도록 를 설정합니다.
identityProviders 스탠자에서 Google IdentityProvider
Google을 ID 공급자로 사용하려면 사용자가 <master>/oauth/token/request를 통해 토큰을 가져와서 명령행 도구에서 사용해야 합니다.
Google을 ID 공급자로 사용하면 모든 Google 사용자가 서버 인증을 수행할 수 있습니다. 아래 표시된 대로 hostedDomain 구성 속성을 사용하여 특정 호스팅 도메인의 멤버 인증을 제한할 수 있습니다.
예 13.8. GoogleIdentityProvider를 사용한 마스터 구성
oauthConfig:
...
identityProviders:
- name: google
challenge: false
login: true
mappingMethod: claim
provider:
apiVersion: v1
kind: GoogleIdentityProvider
clientID: ...
clientSecret: ...
hostedDomain: "" - 1
- 이 공급자 이름은 Google 숫자 사용자 ID 앞에 접두어로 지정되어 ID 이름을 형성합니다. 리디렉션 URL을 빌드하는 데에도 사용됩니다.
- 2
GoogleIdentityProvider는WWW 인증 챌린지를 보내는 데 사용할 수 없습니다.- 3
true인경우 웹 콘솔과 같은 웹 클라이언트의 인증되지 않은 토큰 요청이 Google으로 리디렉션되어 로그인합니다.- 4
- 위에서 설명한 대로 이 프로바이더의 ID와 사용자 오브젝트 간의 매핑 설정 방법을 제어합니다.
- 5
- 등록된 Google 프로젝트의 클라이언트 ID. 프로젝트는
<master>/oauth2callback/<identityProviderName>의 리디렉션 URI를 사용하여 구성해야 합니다. - 6
- Google에서 발행한 클라이언트 비밀. 이 값은 환경 변수, 외부 파일 또는 암호화된 파일에서 도 제공할 수 있습니다.
- 7
- 로그인 계정을 제한하는 선택적 호스트 도메인 입니다. 비어있는 경우 모든 Google 계정을 인증할 수 있습니다.
13.3.13. OpenID 연결
인증 코드 흐름을 사용하여 OpenID Connect ID 프로바이더와 통합하도록 를 설정합니다.
identityProviders 스탠자에서 OpenIDIdentityProvider
OpenShift Container Platform의 OpenID Connect ID 공급자로 Red Hat Single Sign-On을 구성할 수 있습니다.
ID 토큰 및 UserInfo 암호 해독은 지원되지 않습니다.
기본적으로 openid 범위가 요청됩니다. 필요한 경우 extraScopes 필드에 추가 범위를 지정할 수 있습니다.
클레임은 OpenID ID 공급자에서 반환하는 JWT id_token 및 지정된 경우 UserInfo URL에서 반환하는 JSON에서 읽습니다.
사용자 ID로 사용할 하나 이상의 클레임을 구성해야 합니다. 표준 ID 클레임은 sub입니다.
또한 사용자의 기본 사용자 이름, 표시 이름, 이메일 주소로 사용할 클레임을 나타낼 수도 있습니다. 여러 클레임이 지정되는 경우 비어 있지 않은 값이 있는 첫 번째 클레임이 사용됩니다. 표준 클레임은 다음과 같습니다.
|
| "Subject identifier(주체 식별자)"의 줄임말입니다. 발행자에서 사용자의 원격 ID입니다. |
|
|
사용자를 프로비저닝할 때 사용하는 기본 사용자 이름입니다. 사용자가 사용하고자 하는 약칭입니다(예: |
|
| 이메일 주소입니다. |
|
| 표시 이름입니다. |
자세한 내용은 OpenID 클레임 설명서를 참조하십시오.
OpenID Connect ID 공급자를 사용하려면 사용자가 <master>/oauth/token/request를 통해 토큰을 가져와서 명령행 도구에서 사용해야 합니다.
OpenIDIdentityProvider를 사용한 표준 마스터 구성
oauthConfig:
...
identityProviders:
- name: my_openid_connect
challenge: true
login: true
mappingMethod: claim
provider:
apiVersion: v1
kind: OpenIDIdentityProvider
clientID: ...
clientSecret: ...
claims:
id:
- sub
preferredUsername:
- preferred_username
name:
- name
email:
- email
urls:
authorize: https://myidp.example.com/oauth2/authorize
token: https://myidp.example.com/oauth2/token - 1
- 이 공급자 이름은 ID 클레임 값 앞에 접두어로 지정되어 ID 이름을 형성합니다. 리디렉션 URL을 빌드하는 데에도 사용됩니다.
- 2
true인경우 웹 이외의 클라이언트(예: CLI)의 인증되지 않은 토큰 요청이 이 프로바이더의WWW-Authenticate 챌린지헤더가 전송됩니다. 이를 위해 OpenID 프로바이더가 Resource Owner Password 자격 증명에 flows 를 지원해야 합니다.- 3
true인경우 웹 콘솔과 같은 웹 클라이언트의 인증되지 않은 토큰 요청은 로그인할 인증 URL로 리디렉션됩니다.- 4
- 위에서 설명한 대로 이 프로바이더의 ID와 사용자 오브젝트 간의 매핑 설정 방법을 제어합니다.
- 5
- OpenID 공급자에 등록된 클라이언트의 클라이언트 ID. 클라이언트를
<master>/oauth2callback/<identityProviderName>으로 리디렉션할 수 있어야 합니다. - 6
- 클라이언트 비밀입니다. 이 값은 환경 변수, 외부 파일 또는 암호화된 파일에서 도 제공할 수 있습니다.
- 7
- ID로 사용할 클레임 목록입니다. 비어 있지 않은 첫 번째 클레임이 사용됩니다. 클레임이 한 개 이상 있어야 합니다. 나열된 클레임에 값이 없으면 인증이 실패합니다. 예를 들어, 여기서는 반환된
id_token의sub클레임 값을 사용자의 ID로 사용합니다. - 8
- OpenID 사양에 설명된 권한 부여 엔드포인트.
https를 사용해야 합니다. - 9
- OpenID 사양에 설명된 토큰 엔드포인트.
https를 사용해야 합니다.
사용자 정의 인증서 번들, 추가 범위, 추가 권한 부여 요청 매개변수 및 userInfo URL도 지정할 수 있습니다.
예 13.9. OpenIDIdentityProvider를 사용한 전체 마스터 구성
oauthConfig:
...
identityProviders:
- name: my_openid_connect
challenge: false
login: true
mappingMethod: claim
provider:
apiVersion: v1
kind: OpenIDIdentityProvider
clientID: ...
clientSecret: ...
ca: my-openid-ca-bundle.crt
extraScopes:
- email
- profile
extraAuthorizeParameters:
include_granted_scopes: "true"
claims:
id:
- custom_id_claim
- sub
preferredUsername:
- preferred_username
- email
name:
- nickname
- given_name
- name
email:
- custom_email_claim
- email
urls:
authorize: https://myidp.example.com/oauth2/authorize
token: https://myidp.example.com/oauth2/token
userInfo: https://myidp.example.com/oauth2/userinfo - 1
- 구성된 URL에 대한 서버 인증서의 유효성을 검사하는 데 사용할 인증서 번들입니다. 비어 있는 경우 시스템에서 신뢰할 수 있는 루트가 사용됩니다.
- 2
- 권한 부여 토큰 요청 중 openid 범위 외에 요청할 선택적 범위 목록입니다.
- 3
- 권한 부여 토큰 요청에 추가할 추가 매개변수의 선택적 맵입니다.
- 4
- ID로 사용할 클레임 목록입니다. 비어 있지 않은 첫 번째 클레임이 사용됩니다. 클레임이 한 개 이상 있어야 합니다. 나열된 클레임에 값이 없으면 인증이 실패합니다.
- 5
- 이 ID에 대해 사용자를 프로비저닝할 때 기본 사용자 이름으로 사용할 클레임 목록입니다. 비어 있지 않은 첫 번째 클레임이 사용됩니다.
- 6
- 표시 이름으로 사용할 클레임 목록입니다. 비어 있지 않은 첫 번째 클레임이 사용됩니다.
- 7
- 이메일 주소로 사용할 클레임 목록입니다. 비어 있지 않은 첫 번째 클레임이 사용됩니다.
- 8
- OpenID 사양에 설명된 UserInfo Endpoint 입니다.
https를 사용해야 합니다.
13.4. 토큰 옵션
OAuth 서버는 두 종류의 토큰을 생성합니다.
| 액세스 토큰 | API에 대한 액세스 권한을 부여하는 장기 토큰입니다. |
| 코드 인증 | 액세스 토큰으로 교환하는 용도로만 사용하는 단기 토큰입니다. |
tokenConfig 스탠자를 사용하여 토큰 옵션을 설정합니다.
예 13.10. 마스터 구성 토큰 옵션
13.5. 부여 옵션
OAuth 서버에서 사용자가 이전에 권한을 부여하지 않은 클라이언트에 대한 토큰 요청을 수신하는 경우, OAuth 서버에서 수행하는 조치는 OAuth 클라이언트의 권한 부여 전략에 따라 결정됩니다.
토큰을 요청하는 OAuth 클라이언트가 자체 부여 전략을 제공하지 않으면 서버 전체 기본 전략이 사용됩니다. 기본 전략을 구성하려면 grantConfig 스탠자에서 메서드 값을 설정합니다. 메서드에 유효한 값은 다음과 같습니다.
|
| 부여를 자동 승인하고 요청을 다시 시도합니다. |
|
| 사용자에게 부여를 승인하거나 거부하도록 요청합니다. |
|
| 부여를 자동 거부하고 클라이언트에 오류 오류를 반환합니다. |
예 13.11. 마스터 구성 부여 옵션
oauthConfig:
...
grantConfig:
method: auto13.6. 세션 옵션
OAuth 서버는 로그인 및 리디렉션 흐름 중에 서명되고 암호화된 쿠키 기반 세션을 사용합니다.
sessionConfig 스탠자를 사용하여 세션 옵션을 설정합니다.
예 13.12. 마스터 구성 세션 옵션
oauthConfig:
...
sessionConfig:
sessionMaxAgeSeconds: 300
sessionName: ssn
sessionSecretsFile: "..." - 1
- 세션의 최대 사용 기간을 제어합니다. 토큰 요청이 완료되면 세션 자동 만료. 자동 승인이 활성화되지 않은 경우 사용자가 클라이언트 권한 부여 요청을 승인하거나 거부할 것으로 예상되는 한 세션이 지속되어야 합니다.
- 2
- 세션을 저장하는 데 사용되는 쿠키의 이름입니다.
- 3
- 직렬화된
세션Secrets 오브젝트가포함된 파일 이름입니다. 비어 있는 경우 각 서버를 시작할 때 임의의 서명 및 암호화 보안이 생성됩니다.
sessionSecretsFile 이 지정되지 않은 경우 마스터 서버를 시작할 때마다 임의의 서명 및 암호화 보안이 생성됩니다. 즉, 진행 중인 모든 로그인 시 마스터가 다시 시작되면 세션이 무효화됩니다. 또한 다른 마스터 중 하나에서 생성된 세션을 디코딩할 수 없음을 의미합니다.
사용할 서명 및 암호화 보안을 지정하려면 sessionSecretsFile을 지정합니다. 이를 통해 구성 파일에서 시크릿 값을 분리하고, 디버깅을 위해 구성 파일을 배포 가능 상태로 유지할 수 있습니다.
sessionSecretsFile 에서 여러 보안을 지정하여 회전을 활성화할 수 있습니다. 새 세션은 목록의 첫 번째 비밀을 사용하여 서명되고 암호화됩니다. 기존 세션은 성공할 때까지 각 시크릿에서 암호 해독하고 인증합니다.
예 13.13. 세션 시크릿 설정:
apiVersion: v1
kind: SessionSecrets
secrets:
- authentication: "..."
encryption: "..."
- authentication: "..."
encryption: "..."
...13.7. 사용자 에이전트와 CLI 버전 불일치 방지
OpenShift Container Platform은 애플리케이션 개발자의 CLI가 OpenShift Container Platform API에 액세스하지 못하도록 하는 데 사용할 수 있는 사용자 에이전트를 구현합니다.
OpenShift Container Platform CLI의 사용자 에이전트는 OpenShift Container Platform 내의 값 집합으로 구성됩니다.
<command>/<version>+<git_commit> (<platform>/<architecture>) <client>/<git_commit>예를 들어 다음과 같은 경우를 예로 들 수 있습니다.
-
<command> =
oc -
<version> = 클라이언트 버전입니다. 예:
v3.3.0/api의 쿠버네티스 API에 대한 요청은 쿠버네티스 버전을 수신하고,/oapi의 OpenShift Container Platform API에 대한 요청은 OpenShift Container Platform 버전(oc version에 따라 지정됨)을 수신합니다. -
<platform> =
linux -
<architecture> =
amd64 -
<client> =
/api의 쿠버네티스 API에 대한 요청인지 아니면/oapi의 OpenShift Container Platform API에 대한 요청인지에 따라openshift또는kubernetes -
<git_commit> = 클라이언트 버전의 Git 커밋(예:
f034127)
사용자 에이전트는 다음과 같습니다.
oc/v3.3.0+f034127 (linux/amd64) openshift/f034127마스터 구성 파일 /etc/origin/master/master-config.yaml 에서 사용자 에이전트를 구성해야 합니다. 구성을 적용하려면 API 서버를 다시 시작하십시오.
$ /usr/local/bin/master-restart api
OpenShift Container Platform 관리자는 마스터 구성의 userAgentMatching 구성 설정을 사용하여 클라이언트가 API에 액세스하지 못하도록 할 수 있습니다. 따라서 클라이언트가 특정 라이브러리 또는 바이너리를 사용하는 경우 API에 액세스할 수 없게 됩니다.
다음 사용자 에이전트 예제에서는 Kubernetes 1.2 클라이언트 바이너리, OpenShift Origin 1.1.3 바이너리 및 POST 및 PUT httpVerbs 를 거부합니다.
policyConfig:
userAgentMatchingConfig:
defaultRejectionMessage: "Your client is too old. Go to https://example.org to update it."
deniedClients:
- regex: '\w+/v(?:(?:1\.1\.1)|(?:1\.0\.1)) \(.+/.+\) openshift/\w{7}'
- regex: '\w+/v(?:1\.1\.3) \(.+/.+\) openshift/\w{7}'
httpVerbs:
- POST
- PUT
- regex: '\w+/v1\.2\.0 \(.+/.+\) kubernetes/\w{7}'
httpVerbs:
- POST
- PUT
requiredClients: null관리자는 예상 클라이언트와 정확히 일치하지 않는 클라이언트를 거부할 수도 있습니다.
policyConfig:
userAgentMatchingConfig:
defaultRejectionMessage: "Your client is too old. Go to https://example.org to update it."
deniedClients: []
requiredClients:
- regex: '\w+/v1\.1\.3 \(.+/.+\) openshift/\w{7}'
- regex: '\w+/v1\.2\.0 \(.+/.+\) kubernetes/\w{7}'
httpVerbs:
- POST
- PUT
허용된 클라이언트 집합에 포함되는 클라이언트를 거부하려면 deniedClients 및 값을 함께 사용합니다. 다음 예제에서는 1.13을 제외한 모든 1.X 클라이언트 바이너리를 허용합니다.
requiredClients
policyConfig:
userAgentMatchingConfig:
defaultRejectionMessage: "Your client is too old. Go to https://example.org to update it."
deniedClients:
- regex: '\w+/v1\.13.0\+\w{7} \(.+/.+\) openshift/\w{7}'
- regex: '\w+/v1\.13.0\+\w{7} \(.+/.+\) kubernetes/\w{7}'
requiredClients:
- regex: '\w+/v1\.[1-9][1-9].[0-9]\+\w{7} \(.+/.+\) openshift/\w{7}'
- regex: '\w+/v1\.[1-9][1-9].[0-9]\+\w{7} \(.+/.+\) kubernetes/\w{7}'클라이언트의 사용자 에이전트가 구성이 일치하지 않으면 오류가 발생합니다. 변경 요청이 일치하는지 확인하려면 허용 목록을 적용합니다. 규칙은 특정 동사에 매핑되므로 변경 요청을 금지하는 동시에 요청을 변경하지 않을 수 있습니다.
14장. LDAP와 그룹 동기화
14.1. 개요
OpenShift Container Platform 관리자는 그룹을 사용하여 사용자를 관리하고 권한을 변경하며 협업을 개선할 수 있습니다. 조직에서 이미 사용자 그룹을 생성하여 LDAP 서버에 저장했을 수 있습니다. OpenShift Container Platform은 이러한 LDAP 레코드를 내부 OpenShift Container Platform 레코드와 동기화하므로 한 곳에서 그룹을 관리할 수 있습니다. OpenShift Container Platform은 현재 그룹 멤버십을 정의하는 세 가지 공통 스키마를 사용하여 LDAP 서버와 그룹 동기화를 지원합니다. RFC 2307, Active Directory 및 보강된 Active Directory.
그룹을 동기화하려면 cluster-admin 권한이 있어야 합니다.
14.2. LDAP 동기화 구성
LDAP 동기화를 실행하려면 동기화 구성 파일이 필요합니다. 이 파일에는 LDAP 클라이언트 구성 세부 정보가 포함되어 있습니다.
- LDAP 서버 연결에 필요한 구성
- LDAP 서버에서 사용되는 스키마에 종속된 동기화 구성 옵션
동기화 구성 파일에는 OpenShift Container Platform 그룹 이름을 LDAP 서버의 그룹에 매핑하는 관리자 정의 이름 매핑 목록이 포함될 수 있습니다.
14.2.1. LDAP 클라이언트 구성
LDAP 클라이언트 구성
url: ldap://10.0.0.0:389
bindDN: cn=admin,dc=example,dc=com
bindPassword: password
insecure: false
ca: my-ldap-ca-bundle.crt - 1
- 연결 프로토콜, 데이터베이스를 호스팅하는 LDAP 서버의 IP 주소, 연결할 포트로
scheme://host:port형식으로 되어 있습니다. - 2
- 바인딩 DN으로 사용할 선택적 고유 이름(DN)입니다. OpenShift Container Platform에서는 동기화 작업을 위한 항목을 검색하는 데 높은 권한이 필요한 경우 이 고유 이름을 사용합니다.
- 3
- 바인딩에 사용할 선택적 암호입니다. OpenShift Container Platform에서는 동기화 작업을 위한 항목을 검색하는 데 높은 권한이 필요한 경우 이 암호를 사용합니다. 이 값은 환경 변수, 외부 파일 또는 암호화된 파일에서 도 제공할 수 있습니다.
- 4
false인 경우 보안 LDAP(ldaps://) URL이 TLS를 사용하여 연결되고 안전하지 않은 LDAP(ldap://) URL은 TLS로 업그레이드됩니다.true인경우ldaps://URL을 지정하지 않는 한 서버에 TLS 연결이 이루어지지 않습니다. 이 경우 URL은 계속 TLS를 사용하여 연결을 시도합니다.- 5
- 구성된 URL에 대한 서버 인증서의 유효성을 확인하는 데 사용할 인증서 번들입니다. 비어있는 경우 OpenShift Container Platform은 시스템에서 신뢰하는 루트를 사용합니다.
insecure가false로 설정된 경우에만 적용됩니다.
14.2.2. LDAP 쿼리 정의
동기화 구성은 동기화에 필요한 항목에 대한 LDAP 쿼리 정의로 구성됩니다. LDAP 쿼리의 특정 정의는 LDAP 서버에 멤버십 정보를 저장하는 데 사용하는 스키마에 따라 다릅니다.
LDAP 쿼리 정의
baseDN: ou=users,dc=example,dc=com
scope: sub
derefAliases: never
timeout: 0
filter: (objectClass=inetOrgPerson)
pageSize: 0 - 1
- 모든 검색이 시작되는 디렉터리 분기의 DN(고유 이름)입니다. 디렉터리 트리의 최상위를 지정해야 하지만 디렉터리의 하위 트리를 지정할 수도 있습니다.
- 2
- 3
- LDAP 트리의 별칭에 관한 검색 동작입니다. 유효한 값은
never,search,base또는always입니다. 값이 정의되지 않은 경우 기본값은always역참조 별칭으로 설정됩니다. 역참조 동작에 대한 설명은 아래 표에서 확인할 수 있습니다. - 4
- 클라이언트에서 검색할 수 있는 시간 제한(초)입니다. 값이 0이면 클라이언트 쪽 제한이 적용되지 않습니다.
- 5
- 유효한 LDAP 검색 필터입니다. 정의되지 않은 경우 기본값은
(objectClass=*)입니다. - 6
- 서버 응답 페이지의 최대 크기 옵션으로, LDAP 항목으로 측정합니다. 0으로 설정하면 응답 페이지에 크기 제한이 없습니다. 클라이언트 또는 서버에서 기본적으로 허용하는 것보다 쿼리에서 더 많은 항목을 반환하는 경우, 페이징 크기를 설정해야 합니다.
| LDAP 검색 범위 | 설명 |
|---|---|
|
| 쿼리의 기본 DN에 의해 지정된 오브젝트만 고려합니다. |
|
| 쿼리의 기본 DN과 동일한 수준의 트리에 있는 모든 오브젝트를 고려합니다. |
|
| 쿼리에 대해 제공된 기본 DN을 기반으로 하는 전체 하위 트리를 고려합니다. |
| 역참조 동작 | 설명 |
|---|---|
|
| LDAP 트리에 있는 별칭을 역참조하지 않도록 합니다. |
|
| 검색하는 동안 역참조 별칭만 발견되었습니다. |
|
| 기본 오브젝트를 찾는 동안 별칭만 역참조합니다. |
|
| 항상 LDAP 트리에 있는 모든 별칭을 역참조합니다. |
14.2.3. 사용자 정의 이름 매핑
사용자 정의 이름 매핑은 OpenShift Container Platform 그룹의 이름을 LDAP 서버에서 그룹을 식별하는 고유 식별자에 명시적으로 매핑합니다. 매핑에서는 일반 YAML 구문을 사용합니다. 사용자 정의 매핑은 LDAP 서버의 모든 그룹에 대한 항목을 포함하거나 그룹의 하위 집합만 포함할 수 있습니다. LDAP 서버에 사용자 정의 이름 매핑이 없는 그룹이 있는 경우, 동기화 중 기본 동작은 OpenShift Container Platform 그룹 이름으로 지정된 속성을 사용하는 것입니다.
사용자 정의 이름 매핑
groupUIDNameMapping:
"cn=group1,ou=groups,dc=example,dc=com": firstgroup
"cn=group2,ou=groups,dc=example,dc=com": secondgroup
"cn=group3,ou=groups,dc=example,dc=com": thirdgroup14.3. LDAP 동기화 실행
동기화 구성 파일을 만든 후에는 동기화 가 시작될 수 있습니다. 관리자는 OpenShift Container Platform을 통해 동일한 서버에서 다양한 동기화 유형을 수행할 수 있습니다.
기본적으로 모든 그룹 동기화 또는 정리 작업은 시험 실행이므로 OpenShift Container Platform 그룹 레코드를 변경하려면 sync-groups 명령에 --confirm 플래그를 설정해야 합니다.
LDAP 서버의 모든 그룹을 OpenShift Container Platform과 동기화하려면 다음을 실행합니다.
$ oc adm groups sync --sync-config=config.yaml --confirm구성 파일에 지정된 LDAP 서버의 그룹에 해당하는 OpenShift Container Platform의 모든 그룹을 동기화하려면 다음을 수행합니다.
$ oc adm groups sync --type=openshift --sync-config=config.yaml --confirmOpenShift Container Platform과 LDAP 그룹의 하위 집합을 동기화하려면 허용 목록 파일, 블랙리스트 파일 또는 둘 다를 사용할 수 있습니다.
차단 목록 파일, 허용 목록 파일 또는 허용 목록 리터럴을 조합하여 사용할 수 있습니다. 허용 목록 및 차단 목록 파일에는 한 줄에 하나의 고유한 그룹 식별자를 포함해야 하며, 명령 자체에 허용 목록 리터럴을 직접 포함할 수 있습니다. 이러한 지침은 OpenShift Container Platform에 이미 존재하는 그룹뿐만 아니라 LDAP 서버에 있는 그룹에도 적용됩니다.
$ oc adm groups sync --whitelist=<whitelist_file> \
--sync-config=config.yaml \
--confirm
$ oc adm groups sync --blacklist=<blacklist_file> \
--sync-config=config.yaml \
--confirm
$ oc adm groups sync <group_unique_identifier> \
--sync-config=config.yaml \
--confirm
$ oc adm groups sync <group_unique_identifier> \
--whitelist=<whitelist_file> \
--blacklist=<blacklist_file> \
--sync-config=config.yaml \
--confirm
$ oc adm groups sync --type=openshift \
--whitelist=<whitelist_file> \
--sync-config=config.yaml \
--confirm14.4. 그룹 정리 작업 실행
그룹을 생성한 LDAP 서버의 레코드가 더 이상 존재하지 않는 경우, 관리자는 OpenShift Container Platform 레코드에서 그룹을 제거하도록 선택할 수도 있습니다. 정리 작업에서는 동기화 작업에 사용되는 것과 동일한 동기화 구성 파일과 허용 또는 차단 목록을 허용합니다. 자세한 내용은 그룹 정리 섹션에서 확인할 수 있습니다.
14.5. 동기화 예
이 섹션에는 RFC 2307,Active Directory 및 보강된 Active Directory 스키마의 예가 포함되어 있습니다. 다음 예제는 두 개의 멤버가 있는 admins 라는 그룹을 동기화합니다. Jane 와 Jim. 각 예제에서는 다음을 설명합니다.
- 그룹 및 사용자를 LDAP 서버에 추가하는 방법
- LDAP 동기화 구성 파일의 내용
- 동기화 후 OpenShift Container Platform에 생성되는 결과 그룹 레코드
이러한 예에서는 모든 사용자를 해당 그룹의 직접 멤버로 가정합니다. 특히, 어떠한 그룹도 다른 그룹의 멤버가 될 수 없습니다. 중첩 그룹을 동기화하는 방법에 대한 자세한 내용은 중첩 멤버십 동기화 예제 를 참조하십시오.
14.5.1. RFC 2307 스키마를 사용하여 그룹 동기화
RFC 2307 스키마에서는 사용자(Jane 및 Jim)와 그룹 모두 LDAP 서버에 최상위 항목으로 존재하며, 그룹 멤버십은 그룹 속성에 저장됩니다. 다음의 ldif 조각에서는 이 스키마의 사용자 및 그룹을 정의합니다.
RFC 2307 스키마를 사용하는 LDAP 항목: rfc2307.ldif
dn: ou=users,dc=example,dc=com
objectClass: organizationalUnit
ou: users
dn: cn=Jane,ou=users,dc=example,dc=com
objectClass: person
objectClass: organizationalPerson
objectClass: inetOrgPerson
cn: Jane
sn: Smith
displayName: Jane Smith
mail: jane.smith@example.com
dn: cn=Jim,ou=users,dc=example,dc=com
objectClass: person
objectClass: organizationalPerson
objectClass: inetOrgPerson
cn: Jim
sn: Adams
displayName: Jim Adams
mail: jim.adams@example.com
dn: ou=groups,dc=example,dc=com
objectClass: organizationalUnit
ou: groups
dn: cn=admins,ou=groups,dc=example,dc=com
objectClass: groupOfNames
cn: admins
owner: cn=admin,dc=example,dc=com
description: System Administrators
member: cn=Jane,ou=users,dc=example,dc=com
member: cn=Jim,ou=users,dc=example,dc=com이 그룹을 동기화하려면 먼저 구성 파일을 생성해야 합니다. RFC 2307 스키마를 사용하려면 사용자 항목 및 그룹 항목에 대한 LDAP 쿼리 정의와 내부 OpenShift Container Platform 레코드에서 해당 항목을 표시하는 데 사용할 속성을 제공해야 합니다.
명확히 하기 위해, OpenShift Container Platform에서 생성한 그룹의 경우 사용자용 필드 또는 관리자용 필드에 가급적 고유 이름 이외의 속성을 사용해야 합니다. 예를 들면 이메일로 OpenShift Container Platform 그룹의 사용자를 구분하고, 그룹 이름을 공통 이름으로 사용합니다. 다음 구성 파일에서는 이러한 관계를 생성합니다.
사용자 정의 이름 매핑을 사용하는 경우 구성 파일이 다릅니다.
RFC 2307 스키마를 사용하는 LDAP 동기화 구성: rfc2307_config.yaml
kind: LDAPSyncConfig
apiVersion: v1
url: ldap://LDAP_SERVICE_IP:389
insecure: false
rfc2307:
groupsQuery:
baseDN: "ou=groups,dc=example,dc=com"
scope: sub
derefAliases: never
pageSize: 0
groupUIDAttribute: dn
groupNameAttributes: [ cn ]
groupMembershipAttributes: [ member ]
usersQuery:
baseDN: "ou=users,dc=example,dc=com"
scope: sub
derefAliases: never
pageSize: 0
userUIDAttribute: dn
userNameAttributes: [ uid ]
tolerateMemberNotFoundErrors: false
tolerateMemberOutOfScopeErrors: false- 1
- 이 그룹의 레코드가 저장된 LDAP 서버의 IP 주소 및 호스트입니다.
- 2
false인 경우 보안 LDAP(ldaps://) URL이 TLS를 사용하여 연결되고 안전하지 않은 LDAP(ldap://) URL은 TLS로 업그레이드됩니다.true인경우ldaps://URL을 지정하지 않는 한 서버에 TLS 연결이 이루어지지 않습니다. 이 경우 URL은 계속 TLS를 사용하여 연결을 시도합니다.- 3
- LDAP 서버에서 그룹을 고유하게 식별하는 속성입니다. groupUIDAttribute로 DN을 사용할 때는
groupsQuery필터를 지정할 수 없습니다. 세분화된 필터링의 경우 허용 목록 / 블랙리스트 메서드를 사용합니다. - 4
- 그룹 이름으로 사용할 속성입니다.
- 5
- 멤버십 정보를 저장하는 그룹의 속성입니다.
- 6
- LDAP 서버에서 사용자를 고유하게 식별하는 속성입니다. userUIDAttribute로 DN을 사용할 때는
usersQuery필터를 지정할 수 없습니다. 세분화된 필터링의 경우 허용 목록 / 블랙리스트 메서드를 사용합니다. - 7
- OpenShift Container Platform 그룹 레코드에서 사용자 이름으로 사용할 속성입니다.
rfc2307_config.yaml 파일과의 동기화를 실행하려면 다음을 수행합니다.
$ oc adm groups sync --sync-config=rfc2307_config.yaml --confirmOpenShift Container Platform은 위 동기화 작업의 결과로 다음과 같은 그룹 레코드를 만듭니다.
rfc2307_config.yaml 파일을 사용하여 생성된 OpenShift Container Platform 그룹
apiVersion: user.openshift.io/v1
kind: Group
metadata:
annotations:
openshift.io/ldap.sync-time: 2015-10-13T10:08:38-0400
openshift.io/ldap.uid: cn=admins,ou=groups,dc=example,dc=com
openshift.io/ldap.url: LDAP_SERVER_IP:389
creationTimestamp:
name: admins
users:
- jane.smith@example.com
- jim.adams@example.com14.5.1.1. 사용자 정의 이름 매핑이 포함된 RFC2307
사용자 정의 이름 매핑과 그룹을 동기화하면 구성 파일이 이러한 매핑을 포함하도록 아래와 같이 변경됩니다.
사용자 정의 이름 매핑과 RFC 2307 스키마를 사용하는 LDAP 동기화 구성: rfc2307_config_user_defined.yaml
kind: LDAPSyncConfig
apiVersion: v1
groupUIDNameMapping:
"cn=admins,ou=groups,dc=example,dc=com": Administrators
rfc2307:
groupsQuery:
baseDN: "ou=groups,dc=example,dc=com"
scope: sub
derefAliases: never
pageSize: 0
groupUIDAttribute: dn
groupNameAttributes: [ cn ]
groupMembershipAttributes: [ member ]
usersQuery:
baseDN: "ou=users,dc=example,dc=com"
scope: sub
derefAliases: never
pageSize: 0
userUIDAttribute: dn
userNameAttributes: [ uid ]
tolerateMemberNotFoundErrors: false
tolerateMemberOutOfScopeErrors: false- 1
- 사용자 정의 이름 매핑입니다.
- 2
- 사용자 정의 이름 매핑에서 키에 사용되는 고유 식별자 속성입니다. groupUIDAttribute로 DN을 사용할 때는
groupsQuery필터를 지정할 수 없습니다. 세분화된 필터링의 경우 허용 목록 / 블랙리스트 메서드를 사용합니다. - 3
- 사용자 정의 이름 매핑에 고유 식별자가 없는 경우 OpenShift Container Platform 그룹의 이름을 지정하는 속성입니다.
- 4
- LDAP 서버에서 사용자를 고유하게 식별하는 속성입니다. userUIDAttribute로 DN을 사용할 때는
usersQuery필터를 지정할 수 없습니다. 세분화된 필터링의 경우 허용 목록 / 블랙리스트 메서드를 사용합니다.
rfc2307_config_user_defined.yaml 파일과의 동기화를 실행하려면 다음을 수행합니다.
$ oc adm groups sync --sync-config=rfc2307_config_user_defined.yaml --confirmOpenShift Container Platform은 위 동기화 작업의 결과로 다음과 같은 그룹 레코드를 만듭니다.
rfc2307_config_user_defined.yaml 파일을 사용하여 생성된 OpenShift Container Platform 그룹
apiVersion: user.openshift.io/v1
kind: Group
metadata:
annotations:
openshift.io/ldap.sync-time: 2015-10-13T10:08:38-0400
openshift.io/ldap.uid: cn=admins,ou=groups,dc=example,dc=com
openshift.io/ldap.url: LDAP_SERVER_IP:389
creationTimestamp:
name: Administrators
users:
- jane.smith@example.com
- jim.adams@example.com- 1
- 사용자 정의 이름 매핑에 의해 지정된 그룹의 이름입니다.
14.5.2. RFC 2307을 사용자 정의 오류 허용 오차와 함께 사용하여 그룹 동기화
기본적으로 동기화 중인 그룹에 멤버 쿼리에 정의된 범위를 벗어나는 항목이 있는 멤버가 포함된 경우, 그룹 동기화에 오류가 발생하여 실패합니다.
Error determining LDAP group membership for "<group>": membership lookup for user "<user>" in group "<group>" failed because of "search for entry with dn="<user-dn>" would search outside of the base dn specified (dn="<base-dn>")".
이는 대부분 usersQuery 필드에 baseDN 이 잘못 구성되었음을 나타냅니다. 그러나 baseDN에에 의도적으로 일부 그룹 멤버가 포함되어 있지 않은 경우, tolerateMemberOutOfScopeErrors:true를 설정하면 그룹을 계속 동기화할 수 있습니다. 범위를 벗어난 멤버는 무시됩니다.
마찬가지로 그룹 동기화 프로세스에서 그룹 멤버를 찾지 못하면 오류와 함께 실패합니다.
Error determining LDAP group membership for "<group>": membership lookup for user "<user>" in group "<group>" failed because of "search for entry with base dn="<user-dn>" refers to a non-existent entry".
Error determining LDAP group membership for "<group>": membership lookup for user "<user>" in group "<group>" failed because of "search for entry with base dn="<user-dn>" and filter "<filter>" did not return any results".
이는 종종 usersQuery 필드가 잘못 구성된 것을 나타냅니다. 그러나 그룹에 누락된 것으로 알려진 멤버 항목이 포함된 경우, tolerateMemberNotFoundErrors:true로 설정하면 그룹을 계속 동기화할 수 있습니다. 문제가 있는 멤버는 무시됩니다.
LDAP 그룹 동기화에 오류 허용을 사용하면 동기화 프로세스에서 문제가 있는 멤버 항목을 무시합니다. LDAP 그룹 동기화가 올바르게 구성되어 있지 않으면 동기화된 OpenShift Container Platform 그룹에서 멤버가 누락될 수 있습니다.
그룹 멤버십에 문제가 있는 RFC 2307 스키마를 사용하는 LDAP 항목: rfc2307_problematic_users.ldif
dn: ou=users,dc=example,dc=com
objectClass: organizationalUnit
ou: users
dn: cn=Jane,ou=users,dc=example,dc=com
objectClass: person
objectClass: organizationalPerson
objectClass: inetOrgPerson
cn: Jane
sn: Smith
displayName: Jane Smith
mail: jane.smith@example.com
dn: cn=Jim,ou=users,dc=example,dc=com
objectClass: person
objectClass: organizationalPerson
objectClass: inetOrgPerson
cn: Jim
sn: Adams
displayName: Jim Adams
mail: jim.adams@example.com
dn: ou=groups,dc=example,dc=com
objectClass: organizationalUnit
ou: groups
dn: cn=admins,ou=groups,dc=example,dc=com
objectClass: groupOfNames
cn: admins
owner: cn=admin,dc=example,dc=com
description: System Administrators
member: cn=Jane,ou=users,dc=example,dc=com
member: cn=Jim,ou=users,dc=example,dc=com
member: cn=INVALID,ou=users,dc=example,dc=com
member: cn=Jim,ou=OUTOFSCOPE,dc=example,dc=com 위 예제의 오류를 허용하려면 동기화 구성 파일에 다음을 추가해야 합니다.
오류를 허용하는 RFC 2307 스키마를 사용하는 LDAP 동기화 구성: rfc2307_config_tolerating.yaml
kind: LDAPSyncConfig
apiVersion: v1
url: ldap://LDAP_SERVICE_IP:389
rfc2307:
groupsQuery:
baseDN: "ou=groups,dc=example,dc=com"
scope: sub
derefAliases: never
groupUIDAttribute: dn
groupNameAttributes: [ cn ]
groupMembershipAttributes: [ member ]
usersQuery:
baseDN: "ou=users,dc=example,dc=com"
scope: sub
derefAliases: never
userUIDAttribute: dn
userNameAttributes: [ uid ]
tolerateMemberNotFoundErrors: true
tolerateMemberOutOfScopeErrors: true - 2
true인 경우 동기화 작업에서는 일부 멤버가 없는 그룹을 허용하고 LDAP 항목이 없는 멤버를 무시합니다. 그룹 멤버를 찾을 수 없는 경우 동기화 작업의 기본 동작은 실패하는 것입니다.- 3
true인 경우 동기화 작업에서는 일부 멤버가usersQuery기본 DN에 지정된 사용자 범위를 벗어나는 그룹을 허용하고, 멤버 조회 범위를 벗어나는 멤버를 무시합니다. 그룹 멤버가 범위를 벗어나는 경우 동기화 작업의 기본 동작은 실패하는 것입니다.- 1
- LDAP 서버에서 사용자를 고유하게 식별하는 속성입니다. userUIDAttribute로 DN을 사용할 때는
usersQuery필터를 지정할 수 없습니다. 세분화된 필터링의 경우 허용 목록 / 블랙리스트 메서드를 사용합니다.
rfc2307_config_tolerating.yaml 파일과의 동기화를 실행하려면 다음을 수행합니다.
$ oc adm groups sync --sync-config=rfc2307_config_tolerating.yaml --confirmOpenShift Container Platform은 위 동기화 작업의 결과로 다음과 같은 그룹 레코드를 만듭니다.
rfc2307_config.yaml 파일을 사용하여 생성된 OpenShift Container Platform 그룹
apiVersion: user.openshift.io/v1
kind: Group
metadata:
annotations:
openshift.io/ldap.sync-time: 2015-10-13T10:08:38-0400
openshift.io/ldap.uid: cn=admins,ou=groups,dc=example,dc=com
openshift.io/ldap.url: LDAP_SERVER_IP:389
creationTimestamp:
name: admins
users:
- jane.smith@example.com
- jim.adams@example.com- 1
- 동기화 파일에서 지정한 대로 그룹 멤버에 해당하는 사용자입니다. 조회에 허용되는 오류가 발생한 멤버가 없습니다.
14.5.3. Active Directory를 사용하여 그룹 동기화
Active Directory 스키마에서는 두 사용자(Jane 및 Jim) 모두 LDAP 서버에 최상위 항목으로 존재하며, 그룹 멤버십은 사용자 속성에 저장됩니다. 다음의 ldif 조각에서는 이 스키마의 사용자 및 그룹을 정의합니다.
Active Directory 스키마를 사용하는 LDAP 항목: active_directory.ldif
dn: ou=users,dc=example,dc=com
objectClass: organizationalUnit
ou: users
dn: cn=Jane,ou=users,dc=example,dc=com
objectClass: person
objectClass: organizationalPerson
objectClass: inetOrgPerson
objectClass: testPerson
cn: Jane
sn: Smith
displayName: Jane Smith
mail: jane.smith@example.com
memberOf: admins
dn: cn=Jim,ou=users,dc=example,dc=com
objectClass: person
objectClass: organizationalPerson
objectClass: inetOrgPerson
objectClass: testPerson
cn: Jim
sn: Adams
displayName: Jim Adams
mail: jim.adams@example.com
memberOf: admins- 1
- 사용자의 그룹 멤버십은 사용자의 속성으로 나열되며, 그룹은 서버에 항목으로 존재하지 않습니다.
memberOf속성이 사용자의 리터럴 속성이 아닐 수도 있습니다. 일부 LDAP 서버에서는 검색 중 생성되어 클라이언트에 반환되지만 데이터베이스에는 커밋되지 않습니다.
이 그룹을 동기화하려면 먼저 구성 파일을 생성해야 합니다. Active Directory 스키마를 사용하려면 사용자 항목에 대한 LDAP 쿼리 정의와 내부 OpenShift Container Platform 그룹 레코드에서 해당 항목을 표시하는 속성을 제공해야 합니다.
명확히 하기 위해, OpenShift Container Platform에서 생성한 그룹의 경우 사용자용 필드 또는 관리자용 필드에 가급적 고유 이름 이외의 속성을 사용해야 합니다. 예를 들면 OpenShift Container Platform 그룹의 사용자는 이메일로 구분하지만, 그룹 이름은 LDAP 서버의 그룹 이름에 따라 정의합니다. 다음 구성 파일에서는 이러한 관계를 생성합니다.
Active Directory 스키마를 사용하는 LDAP 동기화 구성: active_directory_config.yaml
kind: LDAPSyncConfig
apiVersion: v1
url: ldap://LDAP_SERVICE_IP:389
activeDirectory:
usersQuery:
baseDN: "ou=users,dc=example,dc=com"
scope: sub
derefAliases: never
filter: (objectclass=inetOrgPerson)
pageSize: 0
userNameAttributes: [ uid ]
groupMembershipAttributes: [ memberOf ] active_directory_config.yaml 파일과의 동기화를 실행하려면 다음을 수행합니다.
$ oc adm groups sync --sync-config=active_directory_config.yaml --confirmOpenShift Container Platform은 위 동기화 작업의 결과로 다음과 같은 그룹 레코드를 만듭니다.
active_directory_config.yaml 파일을 사용하여 생성된 OpenShift Container Platform 그룹
apiVersion: user.openshift.io/v1
kind: Group
metadata:
annotations:
openshift.io/ldap.sync-time: 2015-10-13T10:08:38-0400
openshift.io/ldap.uid: admins
openshift.io/ldap.url: LDAP_SERVER_IP:389
creationTimestamp:
name: admins
users:
- jane.smith@example.com
- jim.adams@example.com14.5.4. 보강된 Active Directory를 사용하여 그룹 동기화
보강된 Active Directory 스키마에서는 사용자(Jane 및 Jim)와 그룹 모두 LDAP 서버에 최상위 항목으로 존재하며, 그룹 멤버십은 사용자 속성에 저장됩니다. 다음의 ldif 조각에서는 이 스키마의 사용자 및 그룹을 정의합니다.
보강된 Active Directory 스키마를 사용하는 LDAP 항목: augmented_active_directory.ldif
dn: ou=users,dc=example,dc=com
objectClass: organizationalUnit
ou: users
dn: cn=Jane,ou=users,dc=example,dc=com
objectClass: person
objectClass: organizationalPerson
objectClass: inetOrgPerson
objectClass: testPerson
cn: Jane
sn: Smith
displayName: Jane Smith
mail: jane.smith@example.com
memberOf: cn=admins,ou=groups,dc=example,dc=com
dn: cn=Jim,ou=users,dc=example,dc=com
objectClass: person
objectClass: organizationalPerson
objectClass: inetOrgPerson
objectClass: testPerson
cn: Jim
sn: Adams
displayName: Jim Adams
mail: jim.adams@example.com
memberOf: cn=admins,ou=groups,dc=example,dc=com
dn: ou=groups,dc=example,dc=com
objectClass: organizationalUnit
ou: groups
dn: cn=admins,ou=groups,dc=example,dc=com
objectClass: groupOfNames
cn: admins
owner: cn=admin,dc=example,dc=com
description: System Administrators
member: cn=Jane,ou=users,dc=example,dc=com
member: cn=Jim,ou=users,dc=example,dc=com이 그룹을 동기화하려면 먼저 구성 파일을 생성해야 합니다. 보강된 Active Directory 스키마를 사용하려면 사용자 항목 및 그룹 항목에 대한 LDAP 쿼리 정의와 내부 OpenShift Container Platform 그룹 레코드에서 해당 항목을 표시하는 속성을 제공해야 합니다.
명확히 하기 위해, OpenShift Container Platform에서 생성한 그룹의 경우 사용자용 필드 또는 관리자용 필드에 가급적 고유 이름 이외의 속성을 사용해야 합니다. 예를 들면 이메일로 OpenShift Container Platform 그룹의 사용자를 구분하고, 그룹 이름을 공통 이름으로 사용합니다. 다음 구성 파일에서는 이러한 관계를 생성합니다.
보강된 Active Directory 스키마를 사용하는 LDAP 동기화 구성: augmented_active_directory_config.yaml
kind: LDAPSyncConfig
apiVersion: v1
url: ldap://LDAP_SERVICE_IP:389
augmentedActiveDirectory:
groupsQuery:
baseDN: "ou=groups,dc=example,dc=com"
scope: sub
derefAliases: never
pageSize: 0
groupUIDAttribute: dn
groupNameAttributes: [ cn ]
usersQuery:
baseDN: "ou=users,dc=example,dc=com"
scope: sub
derefAliases: never
filter: (objectclass=inetOrgPerson)
pageSize: 0
userNameAttributes: [ uid ]
groupMembershipAttributes: [ memberOf ] - 1
- LDAP 서버에서 그룹을 고유하게 식별하는 속성입니다. groupUIDAttribute로 DN을 사용할 때는
groupsQuery필터를 지정할 수 없습니다. 세분화된 필터링의 경우 허용 목록 / 블랙리스트 메서드를 사용합니다. - 2
- 그룹 이름으로 사용할 속성입니다.
- 3
- OpenShift Container Platform 그룹 레코드에서 사용자 이름으로 사용할 속성입니다.
- 4
- 멤버십 정보를 저장하는 사용자 속성입니다.
augmented_active_directory_config.yaml 파일과의 동기화를 실행하려면 다음을 수행합니다.
$ oc adm groups sync --sync-config=augmented_active_directory_config.yaml --confirmOpenShift Container Platform은 위 동기화 작업의 결과로 다음과 같은 그룹 레코드를 만듭니다.
augmented_active_directory_config.yaml 파일을 사용하여 생성된 OpenShift 그룹
apiVersion: user.openshift.io/v1
kind: Group
metadata:
annotations:
openshift.io/ldap.sync-time: 2015-10-13T10:08:38-0400
openshift.io/ldap.uid: cn=admins,ou=groups,dc=example,dc=com
openshift.io/ldap.url: LDAP_SERVER_IP:389
creationTimestamp:
name: admins
users:
- jane.smith@example.com
- jim.adams@example.com14.6. 중첩 멤버십 동기화 예
OpenShift Container Platform의 그룹은 중첩되지 않습니다. 데이터를 사용하려면 LDAP 서버에서 그룹 멤버십을 평면화해야 합니다. Microsoft의 Active Directory 서버에서는 OID 1.2.840.113556.1.4.1941이 있는 LDAP_MATCHING_RULE_IN_CHAIN 규칙을 통해 이 기능을 지원합니다. 또한 이 일치 규칙을 사용하는 경우에는 명시적으로 허용된 그룹 만 동기화할 수 있습니다.
이 섹션에는 한 명의 사용자 Jane과 하나의 그룹 otheradmins가 멤버인 admins라는 그룹을 동기화하는 보강된 Active Directory 스키마에 대한 예가 있습니다. otheradmins 그룹에는 하나의 사용자 멤버가 있습니다. Jim. 이 예제에서는 다음을 설명합니다.
- 그룹 및 사용자를 LDAP 서버에 추가하는 방법
- LDAP 동기화 구성 파일의 내용
- 동기화 후 OpenShift Container Platform에 생성되는 결과 그룹 레코드
보강된 Active Directory 스키마에서는 사용자(Jane 및 Jim)와 그룹 모두 LDAP 서버에 최상위 항목으로 존재하며, 그룹 멤버십은 사용자 또는 그룹 속성에 저장됩니다. 다음의 ldif 조각에서는 이 스키마의 사용자 및 그룹을 정의합니다.
보강된 Active Directory 스키마를 중첩 멤버와 함께 사용하는 LDAP 항목: augmented_active_directory_nested.ldif
dn: ou=users,dc=example,dc=com
objectClass: organizationalUnit
ou: users
dn: cn=Jane,ou=users,dc=example,dc=com
objectClass: person
objectClass: organizationalPerson
objectClass: inetOrgPerson
objectClass: testPerson
cn: Jane
sn: Smith
displayName: Jane Smith
mail: jane.smith@example.com
memberOf: cn=admins,ou=groups,dc=example,dc=com
dn: cn=Jim,ou=users,dc=example,dc=com
objectClass: person
objectClass: organizationalPerson
objectClass: inetOrgPerson
objectClass: testPerson
cn: Jim
sn: Adams
displayName: Jim Adams
mail: jim.adams@example.com
memberOf: cn=otheradmins,ou=groups,dc=example,dc=com
dn: ou=groups,dc=example,dc=com
objectClass: organizationalUnit
ou: groups
dn: cn=admins,ou=groups,dc=example,dc=com
objectClass: group
cn: admins
owner: cn=admin,dc=example,dc=com
description: System Administrators
member: cn=Jane,ou=users,dc=example,dc=com
member: cn=otheradmins,ou=groups,dc=example,dc=com
dn: cn=otheradmins,ou=groups,dc=example,dc=com
objectClass: group
cn: otheradmins
owner: cn=admin,dc=example,dc=com
description: Other System Administrators
memberOf: cn=admins,ou=groups,dc=example,dc=com
member: cn=Jim,ou=users,dc=example,dc=com중첩 그룹을 Active Directory와 동기화하려면 사용자 항목 및 그룹 항목에 대한 LDAP 쿼리 정의와 내부 OpenShift Container Platform 그룹 레코드에서 해당 항목을 표시하는 속성을 제공해야 합니다. 또한 이 구성에는 특정 변경이 필요합니다.
-
oc adm groups sync명령은 그룹을 명시적으로 허용해야 합니다. -
LDAP_MATCHING_RULE_IN_CHAIN규칙을 준수하려면 사용자의groupMembershipAttributes에"memberOf:1.2.840.113556.1.4.1941:"이 포함되어야 합니다. -
groupUIDAttribute를dn으로 설정해야 합니다. groupsQuery의 경우-
filter를 설정하지 않아야 합니다. -
유효한
derefAliases를 설정해야 합니다. -
해당 값이 무시되므로
baseDN을 설정하지 않아야 합니다. -
해당 값이 무시되므로
scope를 설정하지 않아야 합니다.
-
명확히 하기 위해, OpenShift Container Platform에서 생성한 그룹의 경우 사용자용 필드 또는 관리자용 필드에 가급적 고유 이름 이외의 속성을 사용해야 합니다. 예를 들면 이메일로 OpenShift Container Platform 그룹의 사용자를 구분하고, 그룹 이름을 공통 이름으로 사용합니다. 다음 구성 파일에서는 이러한 관계를 생성합니다.
중첩 멤버와 함께 보강된 Active Directory 스키마를 사용하는 LDAP 동기화 구성: augmented_active_directory_config_nested.yaml
kind: LDAPSyncConfig
apiVersion: v1
url: ldap://LDAP_SERVICE_IP:389
augmentedActiveDirectory:
groupsQuery:
derefAliases: never
pageSize: 0
groupUIDAttribute: dn
groupNameAttributes: [ cn ]
usersQuery:
baseDN: "ou=users,dc=example,dc=com"
scope: sub
derefAliases: never
filter: (objectclass=inetOrgPerson)
pageSize: 0
userNameAttributes: [ uid ]
groupMembershipAttributes: [ "memberOf:1.2.840.113556.1.4.1941:" ] - 1
groupsQuery필터를 지정할 수 없습니다.groupsQuery기본 DN 및 범위 값이 무시됩니다.groupsQuery에서 유효한derefAliases를 설정해야 합니다.- 2
- LDAP 서버에서 그룹을 고유하게 식별하는 속성입니다.
dn으로 설정해야 합니다. - 3
- 그룹 이름으로 사용할 속성입니다.
- 4
- OpenShift Container Platform 그룹 레코드에서 사용자 이름으로 사용할 속성입니다.
uid또는sAMAccountName은 대부분의 설치에서 선호됩니다. - 5
- 멤버십 정보를 저장하는 사용자 속성입니다.
LDAP_MATCHING_RULE_IN_CHAIN사용에 유의하십시오.
augmented_active_directory_config_nested.yaml 파일과의 동기화를 실행하려면 다음을 수행합니다.
$ oc adm groups sync \
'cn=admins,ou=groups,dc=example,dc=com' \
--sync-config=augmented_active_directory_config_nested.yaml \
--confirm
cn=admins,ou=groups,dc=example,dc=com 그룹을 명시적으로 허용해야 합니다.
OpenShift Container Platform은 위 동기화 작업의 결과로 다음과 같은 그룹 레코드를 만듭니다.
augmented_active_directory_config_nested.yaml 파일을 사용하여 생성된 OpenShift 그룹
apiVersion: user.openshift.io/v1
kind: Group
metadata:
annotations:
openshift.io/ldap.sync-time: 2015-10-13T10:08:38-0400
openshift.io/ldap.uid: cn=admins,ou=groups,dc=example,dc=com
openshift.io/ldap.url: LDAP_SERVER_IP:389
creationTimestamp:
name: admins
users:
- jane.smith@example.com
- jim.adams@example.com14.7. LDAP 동기화 구성 사양
구성 파일의 오브젝트 사양은 다음과 같습니다. 필드는 스키마 오브젝트에 따라 달라집니다. 예를 들어 v1.ActiveDirectoryConfig 에는 groupsQuery 필드가 없지만 v1.RFC2307Config 및 v1.AugmentedActiveDirectoryConfig 는 둘 다입니다.
바이너리 속성은 지원되지 않습니다. LDAP 서버에서 제공하는 모든 속성 데이터는 UTF-8 인코딩 문자열 형식이어야 합니다. 예를 들면 objectGUID와 같은 바이너리 속성을 ID 속성으로 사용하지 마십시오. 그 대신 sAMAccountName 또는 userPrincipalName과 같은 문자열 속성을 사용해야 합니다.
14.7.1. v1.LDAPSyncConfig
LDAPSyncConfig에는 LDAP 그룹 동기화를 정의하는 데 필요한 구성 옵션이 있습니다.
| 이름 | 설명 | 스키마 |
|---|---|---|
|
| 이 오브젝트가 나타내는 REST 리소스에 해당하는 문자열 값입니다. 서버는 클라이언트에서 요청을 제출한 끝점에서 이를 유추할 수 있습니다. CamelCase로 업데이트할 수 없습니다. 자세한 정보: https://github.com/kubernetes/community/blob/master/contributors/devel/api-conventions.md#types-kinds | string |
|
| 버전이 지정된 이 오브젝트 표현의 스키마를 정의합니다. 서버는 인식된 스키마를 최신 내부 값으로 변환해야 하며, 인식되지 않는 값을 거부할 수 있습니다. 자세한 정보: https://github.com/kubernetes/community/blob/master/contributors/devel/api-conventions.md#resources | 문자열 |
|
|
호스트는 연결할 LDAP 서버의 스키마, 호스트 및 포트입니다( | 문자열 |
|
| LDAP 서버에 바인딩할 선택적 DN입니다. | 문자열 |
|
| 검색 단계에서 바인딩할 선택적 암호입니다. | |
|
|
| 부울 |
|
| 서버에 요청할 때 사용하는 신뢰할 수 있는 인증 기관 번들 옵션입니다. 비어있는 경우 기본 시스템 루트가 사용됩니다. | 문자열 |
|
| LDAP 그룹 UID를 OpenShift Container Platform 그룹 이름에 직접 매핑하는 옵션입니다. | 오브젝트 |
|
| RFC2307과 유사한 방식으로 설정된 LDAP 서버에서 데이터를 추출하는 구성이 있습니다. 최상위 그룹 및 사용자 항목이 있고 멤버를 나열하는 그룹 항목 다중값 속성에 따라 그룹 멤버십이 결정됩니다. | |
|
| Active Directory 방식과 유사한 방식으로 설정된 LDAP 서버에서 데이터를 추출하는 구성이 있습니다. 최상위 사용자 항목이 있고 멤버가 속한 그룹을 나열하는 멤버 다중값 속성에 따라 그룹 멤버십이 결정됩니다. | |
|
| 위에서 설명한 Active Directory 방식과 유사한 방식으로 설정된 LDAP 서버에서 데이터를 추출하는 구성이 있습니다. 단, 최상위 그룹 항목이 존재하고 여기에 그룹 멤버십이 아닌 메타데이터를 보관합니다. |
14.7.2. v1.StringSource
StringSource를 사용하면 문자열을 인라인으로 지정하거나 환경 변수 또는 파일을 통해 외부에서 지정할 수 있습니다. 문자열 값만 포함하는 경우 간단한 JSON 문자열로 마샬링됩니다.
| 이름 | 설명 | 스키마 |
|---|---|---|
|
|
일반 텍스트 값 또는 | 문자열 |
|
|
일반 텍스트 값을 포함하는 환경 변수 또는 | 문자열 |
|
|
일반 텍스트 값이 포함된 파일 또는 | 문자열 |
|
| 값을 해독하는 데 사용할 키가 들어 있는 파일을 참조합니다. | 문자열 |
14.7.3. v1.LDAPQuery
LDAPQuery에는 LDAP 쿼리를 빌드하는 데 필요한 옵션이 있습니다.
| 이름 | 설명 | 스키마 |
|---|---|---|
|
| 모든 검색을 시작하는 디렉터리 분기의 DN입니다. | 문자열 |
|
|
검색의 (선택 사항) 범위입니다. | 문자열 |
|
|
별칭과 관련된 검색의 (선택 사항) 동작입니다. 별칭을 역참조하지 | 문자열 |
|
|
응답 대기를 종료하기 전에 서버에 대한 요청을 처리 중 상태로 유지할 수 있는 시간(초)이 있습니다. 이 값이 | 정수 |
|
| 기본 DN이 있는 LDAP 서버에서 관련 항목을 모두 검색하는 유효한 LDAP 검색 필터입니다. | 문자열 |
|
|
LDAP 항목으로 측정한 최대 기본 페이지 크기입니다. 페이지 크기가 | 정수 |
14.7.4. v1.RFC2307Config
RFC2307Config에는 RFC2307 스키마를 사용하여 LDAP 그룹 동기화에서 LDAP 서버와 상호 작용하는 방식을 정의하는 데 필요한 구성 옵션이 있습니다.
| 이름 | 설명 | 스키마 |
|---|---|---|
|
| 그룹 항목을 반환하는 LDAP 쿼리용 템플릿이 있습니다. | |
|
|
고유 식별자로 해석되는 LDAP 그룹 항목의 속성을 정의합니다( | 문자열 |
|
| OpenShift Container Platform 그룹에 사용할 이름으로 해석되는 LDAP 그룹 항목의 속성을 정의합니다. | 문자열 배열 |
|
|
멤버로 해석되는 LDAP 그룹 항목의 속성을 정의합니다. 해당 속성에 포함된 값을 | 문자열 배열 |
|
| 사용자 항목을 반환하는 LDAP 쿼리용 템플릿이 있습니다. | |
|
|
고유 식별자로 해석되는 LDAP 사용자 항목의 속성을 정의합니다. | 문자열 |
|
|
OpenShift Container Platform 사용자 이름으로 사용할 LDAP 사용자 항목의 속성을 순서대로 정의합니다. 값이 비어 있지 않은 첫 번째 속성이 사용됩니다. 이 값은 | 문자열 배열 |
|
|
누락된 사용자 항목이 있는 경우 LDAP 동기화 작업의 동작을 결정합니다. | 부울 |
|
|
범위를 벗어난 사용자 항목이 있는 경우 LDAP 동기화 작업의 동작을 결정합니다. | 부울 |
14.7.5. v1.ActiveDirectoryConfig
ActiveDirectoryConfig에는 Active Directory 스키마를 사용하여 LDAP 그룹 동기화에서 LDAP 서버와 상호 작용하는 방식을 정의하는 데 필요한 구성 옵션이 있습니다.
| 이름 | 설명 | 스키마 |
|---|---|---|
|
| 사용자 항목을 반환하는 LDAP 쿼리용 템플릿이 있습니다. | |
|
|
OpenShift Container Platform 사용자 이름으로 해석되는 LDAP 사용자 항목의 속성을 정의합니다. OpenShift Container Platform 그룹 레코드에서 사용자 이름으로 사용할 속성입니다. | 문자열 배열 |
|
| 멤버가 속한 그룹으로 해석되는 LDAP 사용자 항목의 속성을 정의합니다. | 문자열 배열 |
14.7.6. v1.AugmentedActiveDirectoryConfig
AugmentedActiveDirectoryConfig에는 보강된 Active Directory 스키마를 사용하여 LDAP 그룹 동기화에서 LDAP 서버와 상호 작용하는 방식을 정의하는 데 필요한 구성 옵션이 있습니다.
| 이름 | 설명 | 스키마 |
|---|---|---|
|
| 사용자 항목을 반환하는 LDAP 쿼리용 템플릿이 있습니다. | |
|
|
OpenShift Container Platform 사용자 이름으로 해석되는 LDAP 사용자 항목의 속성을 정의합니다. OpenShift Container Platform 그룹 레코드에서 사용자 이름으로 사용할 속성입니다. | 문자열 배열 |
|
| 멤버가 속한 그룹으로 해석되는 LDAP 사용자 항목의 속성을 정의합니다. | 문자열 배열 |
|
| 그룹 항목을 반환하는 LDAP 쿼리용 템플릿이 있습니다. | |
|
|
고유 식별자로 해석되는 LDAP 그룹 항목의 속성을 정의합니다( | 문자열 |
|
| OpenShift Container Platform 그룹에 사용할 이름으로 해석되는 LDAP 그룹 항목의 속성을 정의합니다. | 문자열 배열 |
15장. LDAP 페일오버 구성
OpenShift Container Platform은 LDAP(Lightweight Directory Access Protocol) 설정에 사용할 인증 공급자를 제공하지만 단일 LDAP 서버에만 연결할 수 있습니다. OpenShift Container Platform을 설치하는 동안 LDAP 페일오버를 위해 하나의 LDAP 서버가 실패하는 경우 클러스터에 액세스할 수 있도록 SSSD(System Security Services Daemon)를 구성할 수 있습니다.
이 구성의 설정은 고급이며 OpenShift Container Platform이 와 통신하기 위해 원격 기본 인증 서버 라고도 하는 별도의 인증 서버가 필요합니다. 웹 콘솔에 표시할 수 있도록 이메일 주소와 같은 추가 속성을 OpenShift Container Platform에 전달하도록 이 서버를 구성합니다.
이 주제에서는 전용 물리적 시스템 또는 VM(가상 시스템)에서 이 설정을 완료하는 방법에 대해 설명하지만 컨테이너에서 SSSD를 구성할 수도 있습니다.
이 주제의 모든 섹션을 완료해야 합니다.
15.1. 기본 원격 인증 구성을 위한 사전 요구 사항
설정을 시작하기 전에 LDAP 서버에 대한 다음 정보를 알아야 합니다.
- 디렉터리 서버가 FreeIPA, Active Directory 또는 다른 LDAP 솔루션에 의해 구동되는지 여부.
- LDAP 서버의 URI(Uniform Resource Identifier)입니다(예: ldap.example.com ).
- LDAP 서버의 CA 인증서 위치입니다.
- LDAP 서버가 사용자 그룹의 RFC 2307 또는 RFC2307bis에 해당하는지 여부.
서버를 준비합니다.
remote-basic.example.com: 원격 기본 인증 서버로 사용할 VM입니다.
- Red Hat Enterprise Linux 7.0 이상과 같이 이 서버에 SSSD 버전 1.12.0이 포함된 운영 체제를 선택합니다.
openshift.example.com: OpenShift Container Platform의 새 설치입니다.
- 이 클러스터에 대해 구성된 인증 방법이 없어야 합니다.
- 이 클러스터에서 OpenShift Container Platform을 시작하지 마십시오.
15.2. 원격 기본 인증 서버를 사용하여 인증서 생성 및 공유
기본적으로 /etc/ansible/hosts 로 Ansible 호스트 인벤토리 파일에 나열된 첫 번째 마스터 호스트에서 다음 단계를 완료합니다.
원격 기본 인증 서버와 OpenShift Container Platform 간의 통신이 신뢰할 수 있도록 하기 위해 이 설정의 다른 단계에서 사용할 일련의 TLS(Transport Layer Security) 인증서를 생성합니다. 다음 명령을 실행합니다.
# openshift start \ --public-master=https://openshift.example.com:8443 \ --write-config=/etc/origin/출력에는 /etc/origin/master/ca.crt 및 /etc/origin/master/ca.key 서명 인증서가 포함됩니다.
서명 인증서를 사용하여 원격 기본 인증 서버에서 사용할 키를 생성합니다.
# mkdir -p /etc/origin/remote-basic/ # oc adm ca create-server-cert \ --cert='/etc/origin/remote-basic/remote-basic.example.com.crt' \ --key='/etc/origin/remote-basic/remote-basic.example.com.key' \ --hostnames=remote-basic.example.com \1 --signer-cert='/etc/origin/master/ca.crt' \ --signer-key='/etc/origin/master/ca.key' \ --signer-serial='/etc/origin/master/ca.serial.txt'- 1
- 원격 기본 인증 서버에 액세스해야 하는 모든 호스트 이름 및 인터페이스 IP 주소의 쉼표로 구분된 목록입니다.
참고생성하는 인증서 파일은 2년 동안 유효합니다.
--expire-days 및값을 변경하여 이 기간을 변경할 수 있지만 보안상의 이유로 730보다 크게 만들지 마십시오.--signer-expire-days중요원격 기본 인증 서버에 액세스해야 하는 모든 호스트 이름 및 인터페이스 IP 주소를 나열하지 않으면 HTTPS 연결이 실패합니다.
필요한 인증서와 키를 원격 기본 인증 서버에 복사합니다.
# scp /etc/origin/master/ca.crt \ root@remote-basic.example.com:/etc/pki/CA/certs/ # scp /etc/origin/remote-basic/remote-basic.example.com.crt \ root@remote-basic.example.com:/etc/pki/tls/certs/ # scp /etc/origin/remote-basic/remote-basic.example.com.key \ root@remote-basic.example.com:/etc/pki/tls/private/
15.3. LDAP 페일오버를 위한 SSSD 구성
원격 기본 인증 서버에서 다음 단계를 완료합니다.
이메일 주소 및 표시 이름과 같은 속성을 검색하도록 SSSD를 구성하고 웹 인터페이스에 표시하도록 OpenShift Container Platform에 전달할 수 있습니다. 다음 단계에서는 OpenShift Container Platform에 이메일 주소를 제공하도록 SSSD를 구성합니다.
필요한 SSSD 및 웹 서버 구성 요소를 설치합니다.
# yum install -y sssd \ sssd-dbus \ realmd \ httpd \ mod_session \ mod_ssl \ mod_lookup_identity \ mod_authnz_pam \ php \ mod_phpLDAP 서버에 대해 이 VM을 인증하도록 SSSD를 설정합니다. LDAP 서버가 FreeIPA 또는 Active Directory 환경인 경우 realmd 를 사용하여 이 시스템을 도메인에 연결합니다.
# realm join ldap.example.com고급 케이스는 시스템 수준 인증 가이드를 참조하십시오.
- SSSD를 사용하여 LDAP의 장애 조치(failover) 상황을 관리하려면 ldap_uri 행의 /etc/sssd/sssd.conf 파일에 항목을 더 추가합니다. FreeIPA에 등록된 시스템은 DNS SRV 레코드를 사용하여 장애 조치(failover)를 자동으로 처리할 수 있습니다.
/etc/sssd /sssd.conf 파일의 [domain/DOMAINNAME] 섹션을 수정하고 이 속성을 추가합니다.
[domain/example.com] ... ldap_user_extra_attrs = mail1 - 1
- LDAP 솔루션에 대한 이메일 주소를 검색하려면 올바른 속성을 지정합니다. IPA의 경우
mail을 지정합니다. 다른 LDAP 솔루션에서는email과 같은 다른 특성을 사용할 수 있습니다.
/etc/sssd/sssd.conf 파일의 domain 매개 변수에 [domain/DOMAINNAME] 섹션에 나열된 도메인 이름만 포함되어 있는지 확인합니다.
domains = example.comApache에 email 속성을 검색할 수 있는 권한을 부여합니다. /etc/sssd/sssd.conf 파일의 [ifp] 섹션에 다음 행을 추가합니다.
[ifp] user_attributes = +mail allowed_uids = apache, root모든 변경 사항이 제대로 적용되었는지 확인하려면 SSSD를 다시 시작하십시오.
$ systemctl restart sssd.service사용자 정보를 올바르게 검색할 수 있는지 테스트합니다.
$ getent passwd <username> username:*:12345:12345:Example User:/home/username:/usr/bin/bash지정한 mail 속성이 도메인에서 이메일 주소를 반환하는지 확인합니다.
# dbus-send --print-reply --system --dest=org.freedesktop.sssd.infopipe \ /org/freedesktop/sssd/infopipe org.freedesktop.sssd.infopipe.GetUserAttr \ string:username \1 array:string:mail2 method return time=1528091855.672691 sender=:1.2787 -> destination=:1.2795 serial=13 reply_serial=2 array [ dict entry( string "mail" variant array [ string "username@example.com" ] ) ]- VM에 LDAP 사용자로 로그인하고 LDAP 자격 증명을 사용하여 로그인할 수 있는지 확인합니다. 로컬 콘솔 또는 SSH와 같은 원격 서비스를 사용하여 로그인할 수 있습니다.
기본적으로 모든 사용자는 LDAP 자격 증명을 사용하여 원격 기본 인증 서버에 로그인할 수 있습니다. 이 동작을 변경할 수 있습니다.
- IPA 참여 시스템을 사용하는 경우 호스트 기반 액세스 제어를 구성합니다.
- Active Directory에 가입된 시스템을 사용하는 경우 그룹 정책 오브젝트를 사용합니다.
- 다른 경우에는 SSSD 구성 설명서를 참조하십시오.
15.4. SSSD를 사용하도록 Apache 구성
다음 내용이 포함된 /etc/pam.d/openshift 파일을 만듭니다.
auth required pam_sss.so account required pam_sss.so이 구성을 사용하면 플러그형 인증 모듈인 PAM이 pam_sss.so 를 사용하여 openshift 스택에 대한 인증 및 액세스 요청이 발행될 때 인증 및 액세스 제어를 결정할 수 있습니다.
/etc/httpd/conf.modules.d/55-authnz_pam.conf 파일을 편집하고 다음 행의 주석 처리를 해제합니다.
LoadModule authnz_pam_module modules/mod_authnz_pam.so원격 기본 인증을 위해 Apache httpd.conf 파일을 구성하려면 /etc/httpd/ conf.d 디렉터리에 openshift-remote-basic-auth.conf 파일을 만듭니다. 다음 템플릿을 사용하여 필요한 설정 및 값을 제공하십시오.
중요템플릿을 신중하게 검토하고 환경에 맞게 내용을 사용자 정의하십시오.
LoadModule request_module modules/mod_request.so LoadModule php7_module modules/libphp7.so # Nothing needs to be served over HTTP. This virtual host simply redirects to # HTTPS. <VirtualHost *:80> DocumentRoot /var/www/html RewriteEngine On RewriteRule ^(.*)$ https://%{HTTP_HOST}$1 [R,L] </VirtualHost> <VirtualHost *:443> # This needs to match the certificates you generated. See the CN and X509v3 # Subject Alternative Name in the output of: # openssl x509 -text -in /etc/pki/tls/certs/remote-basic.example.com.crt ServerName remote-basic.example.com DocumentRoot /var/www/html # Secure all connections with TLS SSLEngine on SSLCertificateFile /etc/pki/tls/certs/remote-basic.example.com.crt SSLCertificateKeyFile /etc/pki/tls/private/remote-basic.example.com.key SSLCACertificateFile /etc/pki/CA/certs/ca.crt # Require that TLS clients provide a valid certificate SSLVerifyClient require SSLVerifyDepth 10 # Other SSL options that may be useful # SSLCertificateChainFile ... # SSLCARevocationFile ... # Send logs to a specific location to make them easier to find ErrorLog logs/remote_basic_error_log TransferLog logs/remote_basic_access_log LogLevel warn # PHP script that turns the Apache REMOTE_USER env var # into a JSON formatted response that OpenShift understands <Location /check_user.php> # all requests not using SSL are denied SSLRequireSSL # denies access when SSLRequireSSL is applied SSLOptions +StrictRequire # Require both a valid basic auth user (so REMOTE_USER is always set) # and that the CN of the TLS client matches that of the OpenShift master <RequireAll> Require valid-user Require expr %{SSL_CLIENT_S_DN_CN} == 'system:openshift-master' </RequireAll> # Use basic auth since OpenShift will call this endpoint with a basic challenge AuthType Basic AuthName openshift AuthBasicProvider PAM AuthPAMService openshift # Store attributes in environment variables. Specify the email attribute that # you confirmed. LookupOutput Env LookupUserAttr mail REMOTE_USER_MAIL LookupUserGECOS REMOTE_USER_DISPLAY_NAME # Other options that might be useful # While REMOTE_USER is used as the sub field and serves as the immutable ID, # REMOTE_USER_PREFERRED_USERNAME could be used to have a different username # LookupUserAttr <attr_name> REMOTE_USER_PREFERRED_USERNAME # Group support may be added in a future release # LookupUserGroupsIter REMOTE_USER_GROUP </Location> # Deny everything else <Location ~ "^((?!\/check_user\.php).)*$"> Deny from all </Location> </VirtualHost>check_user.php 스크립트를 /var/www/html 디렉터리에 생성합니다. 다음 코드를 포함합니다.
<?php // Get the user based on the Apache var, this should always be // set because we 'Require valid-user' in the configuration $user = apache_getenv('REMOTE_USER'); // However, we assume it may not be set and // build an error response by default $data = array( 'error' => 'remote PAM authentication failed' ); // Build a success response if we have a user if (!empty($user)) { $data = array( 'sub' => $user ); // Map of optional environment variables to optional JSON fields $env_map = array( 'REMOTE_USER_MAIL' => 'email', 'REMOTE_USER_DISPLAY_NAME' => 'name', 'REMOTE_USER_PREFERRED_USERNAME' => 'preferred_username' ); // Add all non-empty environment variables to JSON data foreach ($env_map as $env_name => $json_name) { $env_data = apache_getenv($env_name); if (!empty($env_data)) { $data[$json_name] = $env_data; } } } // We always output JSON from this script header('Content-Type: application/json', true); // Write the response as JSON echo json_encode($data); ?>Apache를 활성화하여 모듈을 로드합니다. /etc/httpd/conf.modules.d/55-lookup_identity.conf 파일을 수정하고 다음 행의 주석을 제거합니다.
LoadModule lookup_identity_module modules/mod_lookup_identity.soSElinux가 Apache가 D-BUS를 통해 SSSD에 연결할 수 있도록 SELinux 부울을 설정합니다.
# setsebool -P httpd_dbus_sssd onSELinux가 Apache가 PAM 하위 시스템에 연결할 수 있음을 알리도록 부울을 설정합니다.
# setsebool -P allow_httpd_mod_auth_pam onApache 시작:
# systemctl start httpd.service
15.5. SSSD를 기본 원격 인증 서버로 사용하도록 OpenShift Container Platform 구성
생성한 새 ID 공급자를 사용하도록 클러스터의 기본 구성을 수정합니다. Ansible 호스트 인벤토리 파일에 나열된 첫 번째 마스터 호스트에서 다음 단계를 완료합니다.
- /etc/origin/master/master-config.yaml 파일을 엽니다.
identityProviders 섹션을 찾아 다음 코드로 바꿉니다.
identityProviders: - name: sssd challenge: true login: true mappingMethod: claim provider: apiVersion: v1 kind: BasicAuthPasswordIdentityProvider url: https://remote-basic.example.com/check_user.php ca: /etc/origin/master/ca.crt certFile: /etc/origin/master/openshift-master.crt keyFile: /etc/origin/master/openshift-master.key업데이트된 구성으로 OpenShift Container Platform을 다시 시작하십시오.
# /usr/local/bin/master-restart api api # /usr/local/bin/master-restart controllers controllersocCLI를 사용하여 로그인을 테스트합니다.$ oc login https://openshift.example.com:8443유효한 LDAP 자격 증명을 사용해서만 로그인할 수 있습니다.
ID를 나열하고 각 사용자 이름에 이메일 주소가 표시되는지 확인합니다. 다음 명령을 실행합니다.
$ oc get identity -o yaml
16장. SDN 구성
16.1. 개요
OpenShift SDN은 OpenShift Container Platform 클러스터에서 포드 간 통신을 활성화하여 포드 네트워크를 설정합니다. 현재 3개의 SDN 플러그인 (ovs-subnet,ovs- multitenant 및 ovs-networkpolicy)을 사용할 수 있으며 포드 네트워크 구성을 위한 다양한 방법을 제공합니다.
16.2. 사용 가능한 SDN 공급자
업스트림 Kubernetes 프로젝트에는 기본 네트워크 솔루션이 제공되지 않습니다. 대신 Kubernetes는 네트워크 공급자가 고유한 SDN 솔루션과 통합할 수 있도록 CNI(컨테이너 네트워크 인터페이스)를 개발했습니다.
Red Hat은 즉시 사용할 수 있는 여러 개의 OpenShift SDN 플러그인과 타사 플러그인이 있습니다.
Red Hat은 제품의 인타이틀먼트 프로세스를 통해 SDN 플러그인에 대한 지원 프로세스를 포함하여 Kubernetes CNI 인터페이스를 통해 OpenShift Container Platform에서 SDN 네트워크 솔루션을 인증하기 위해 여러 SDN 공급자와 협력했습니다. OpenShift를 사용하여 지원 사례를 열 경우 Red Hat은 두 회사가 고객의 요구를 충족하는 데 참여하도록 교환 프로세스를 원활하게 수행할 수 있습니다.
다음 SDN 솔루션은 타사 벤더에서 직접 OpenShift Container Platform에서 검증 및 지원됩니다.
- Cisco ACI(™)
- Juniper Contrail(™)
- collectd Nuage(™)
- Tigerakonco(™)
- VMware NSX-T(™)
OpenShift Container Platform에 VMware NSX-T(™) 설치
VMware NSX-T(™)는 클라우드 네이티브 애플리케이션 환경을 구축하기 위한 SDN 및 보안 인프라를 제공합니다. vSphere 하이퍼바이저(ESX) 외에도 이러한 환경에는 KVM 및 기본 퍼블릭 클라우드가 포함됩니다.
현재 통합을 수행하려면 NSX-T 및 OpenShift Container Platform을 새로 설치해야 합니다. 현재 NSX-T 버전 2.4가 지원되며 현재 ESXi 및 KVM 하이퍼바이저 사용만 지원합니다.
자세한 내용은 OpenShift - 설치 및 관리 가이드는 NSX-T 컨테이너 플러그인을 참조하십시오.
16.3. Ansible을 사용하여 Pod 네트워크 구성
초기 클러스터 설치의 경우 ovs-subnet 플러그인은 기본적으로 설치 및 구성되지만, Ansible 인벤토리 파일에서 구성할 수 있는 os_sdn_network_plugin_name 매개 변수를 사용하여 설치 중에 재정의할 수 있습니다.
예를 들어 표준 ovs-subnet 플러그인을 재정의하고 대신 ovs-multitenant 플러그인을 사용하려면 다음을 수행합니다.
# Configure the multi-tenant SDN plugin (default is 'redhat/openshift-ovs-subnet')
os_sdn_network_plugin_name='redhat/openshift-ovs-multitenant'인벤토리 파일에 설정할 수 있는 네트워킹 관련 Ansible 변수에 대한 설명은 클러스터 변수 구성을 참조하십시오.
16.4. 마스터에서 Pod 네트워크 구성
클러스터 관리자는 마스터 구성 파일의 network Config 섹션에 있는 매개 변수를 수정하여 마스터 호스트에서 Pod 네트워크 설정을 제어할 수 있습니다(기본적으로 /etc/origin/master/master-config.yaml 에 있음).
단일 CIDR에 대한 Pod 네트워크 구성
networkConfig:
clusterNetworks:
- cidr: 10.128.0.0/14
hostSubnetLength: 9
networkPluginName: "redhat/openshift-ovs-subnet"
serviceNetworkCIDR: 172.30.0.0/16
또는 범위와 hostSubnetLength 를 사용하여 clusterNetworks 필드에 별도의 범위를 추가하여 여러 CIDR 범위가 있는 Pod 네트워크를 생성할 수 있습니다.
여러 범위를 한 번에 사용할 수 있으며 범위를 확장하거나 축소할 수 있습니다. 노드를 비우고 노드를 삭제하고 다시 생성하여 노드를 한 범위에서 다른 범위로 이동할 수 있습니다. 자세한 내용은 노드 관리 섹션을 참조하십시오. 노드 할당은 나열된 순서로 수행되며 범위가 가득 차면 목록의 다음 단계로 이동합니다.
여러 CIDR에 대한 Pod 네트워크 구성
networkConfig:
clusterNetworks:
- cidr: 10.128.0.0/14
hostSubnetLength: 9
- cidr: 10.132.0.0/14
hostSubnetLength: 9
externalIPNetworkCIDRs: null
hostSubnetLength: 9
ingressIPNetworkCIDR: 172.29.0.0/16
networkPluginName: redhat/openshift-ovs-multitenant
serviceNetworkCIDR: 172.30.0.0/16
clusterNetworks 값에 요소를 추가하거나 노드가 해당 CIDR 범위를 사용하지 않는 경우 제거할 수 있습니다.
hostSubnetLength 값은 클러스터를 처음 생성한 후에 변경할 수 없으며, cidr 필드는 노드가 범위 내에서 할당되어 있는 경우에만 원래 네트워크가 포함된 더 큰 네트워크로만 변경할 수 있으며 serviceNetworkCIDR 은 확장할 수 있습니다. 예를 들어 10.128.0.0/14 의 일반적인 값을 지정하는 경우 cidr 을 10.128.0.0/9 (즉, 전체 네트워크 상반기 10)로 변경할 수 있지만 원래 값 겹치지 않기 때문에 10.64.0.0/16 으로 변경할 수 있습니다.
serviceNetworkCIDR 을 172.30.0.0/16 에서 172.30.0.0/15 로 변경할 수 있지만 원래 범위가 완전히 새 범위 내에 있더라도 원래 범위가 CIDR을 시작해야 하기 때문에 172.28.0.0/14 는 변경할 수 없습니다. 자세한 내용은 서비스 네트워크 확장을 참조하십시오.
변경 사항을 적용하려면 API 및 마스터 서비스를 다시 시작해야 합니다.
$ master-restart api
$ master-restart controllers마스터 서비스를 다시 시작한 후에는 구성을 노드로 전파해야 합니다. 각 노드에서 atomic-openshift-node 서비스와 ovs Pod를 다시 시작해야 합니다. 다운 타임을 방지하려면 노드 관리에 정의된 단계를 피하고 한 번에 각 노드 또는 노드 그룹에 대해 다음 절차에 설명하십시오.
노드를 예약 불가능으로 표시합니다.
# oc adm manage-node <node1> <node2> --schedulable=false노드를 드레이닝합니다.
# oc adm drain <node1> <node2>노드를 재시작합니다.
# reboot노드를 다시 예약 가능으로 표시합니다.
# oc adm manage-node <node1> <node2> --schedulable
16.5. 클러스터 네트워크의 VXLAN PORT 변경
클러스터 관리자는 시스템에서 사용하는 VXLAN 포트를 변경할 수 있습니다.
실행 중인 clusternetwork 오브젝트의 VXLAN 포트를 변경할 수 없기 때문에 기존 네트워크 구성을 삭제하고 마스터 구성 파일에서 vxlanPort 변수를 편집하여 새 구성을 생성해야 합니다.
기존
clusternetwork를 삭제합니다.# oc delete clusternetwork default기본적으로 새
clusternetwork를 생성하여 /etc/origin/master/master-config.yaml 에 있는 마스터 구성 파일을 편집합니다.networkConfig: clusterNetworks: - cidr: 10.128.0.0/14 hostSubnetLength: 9 - cidr: 10.132.0.0/14 hostSubnetLength: 9 externalIPNetworkCIDRs: null hostSubnetLength: 9 ingressIPNetworkCIDR: 172.29.0.0/16 networkPluginName: redhat/openshift-ovs-multitenant serviceNetworkCIDR: 172.30.0.0/16 vxlanPort: 48891 - 1
- VXLAN 포트에 노드에서 사용하는 값으로 설정합니다. 1-65535 사이의 정수일 수 있습니다. 기본값은
4789입니다.
각 클러스터 노드의 iptables 규칙에 새 포트를 추가합니다.
# iptables -A OS_FIREWALL_ALLOW -p udp -m state --state NEW -m udp --dport 4889 -j ACCEPT1 - 1
4889는 마스터 구성 파일에서 설정한vxlanPort값입니다.
마스터 서비스를 다시 시작하십시오.
# master-restart api # master-restart controllers이전 SDN Pod를 삭제하여 새 Pod를 새 변경 사항으로 전파합니다.
# oc delete pod -l app=sdn -n openshift-sdn
16.6. 노드에서 Pod 네트워크 구성
클러스터 관리자는 적절한 노드 구성 맵의 network Config 섹션에서 매개변수를 수정하여 노드에서Pod 네트워크 설정을 제어할 수 있습니다.
networkConfig:
mtu: 1450
networkPluginName: "redhat/openshift-ovs-subnet" OpenShift Container Platform SDN에 포함되는 모든 마스터 및 노드에서 MTU 크기를 변경해야 합니다. 또한 tun0 인터페이스의 MTU 크기는 클러스터에 속하는 모든 노드에서 같아야 합니다.
16.7. 서비스 네트워크 확장
서비스 네트워크의 주소 부족 상태인 경우 현재 범위가 새 범위의 시작 위치에 있는지 확인하는 한 범위를 확장할 수 있습니다.
서비스 네트워크는 확장만 할 수 있으며 변경할 수 없거나 계약할 수 없습니다.
-
모든 마스터의 구성 파일에서
serviceNetworkCIDR및servicesSubnet매개 변수를 변경합니다 (기본적으로/etc/origin/master/master-config.yaml )./다음에 나오는 숫자만 더 작은 숫자로 변경합니다. clusterNetwork 기본오브젝트를 삭제합니다.$ oc delete clusternetwork default모든 마스터에서 컨트롤러 구성 요소를 다시 시작하십시오.
# master-restart controllersAnsible 인벤토리 파일의
openshift_portal_net변수 값을 새 CIDR로 업데이트합니다.# Configure SDN cluster network and kubernetes service CIDR blocks. These # network blocks should be private and should not conflict with network blocks # in your infrastructure that pods may require access to. Can not be changed # after deployment. openshift_portal_net=172.30.0.0/<new_CIDR_range>
클러스터의 각 노드에 대해 다음 단계를 완료합니다.
- 노드를 예약 불가능으로 표시합니다.
- 노드에서 포드를 비웁니다.
- 노드를 재부팅합니다.
- 노드를 다시 사용 가능하게 되면 노드를 다시 예약 가능으로 표시합니다.
16.8. SDN 플러그인 간 마이그레이션
하나의 SDN 플러그인을 이미 사용하고 있으며 다른 버전으로 전환하려면 다음을 수행하십시오.
-
구성 파일의 모든 마스터와 노드에서
networkPluginName매개 변수를 변경합니다. 모든 마스터에서 API 및 마스터 서비스를 다시 시작하십시오.
# master-restart api # master-restart controllers모든 마스터와 노드에서 노드 서비스를 중지합니다.
# systemctl stop atomic-openshift-node.serviceOpenShift SDN 플러그인 간에 전환하는 경우 모든 마스터와 노드에서 OpenShift SDN을 다시 시작합니다.
oc delete pod --all -n openshift-sdn모든 마스터 및 노드에서 노드 서비스를 다시 시작하십시오.
# systemctl restart atomic-openshift-node.serviceOpenShift SDN 플러그인에서 타사 플러그인으로 전환하는 경우 OpenShift SDN 특정 아티팩트를 정리합니다.
$ oc delete clusternetwork --all $ oc delete hostsubnets --all $ oc delete netnamespaces --all
또한 ovs-multitenant 로 전환한 후 사용자는 더 이상 서비스 카탈로그를 사용하여 서비스를 프로비저닝할 수 없습니다. openshift-monitoring 에도 동일한 내용이 적용됩니다. 이 문제를 해결하려면 다음 프로젝트를 전역으로 설정합니다.
$ oc adm pod-network make-projects-global kube-service-catalog
$ oc adm pod-network make-projects-global openshift-monitoring이러한 명령이 Ansible 플레이북의 일부로 실행되었기 때문에 클러스터가 ovs-multitenant 를 사용하여 처음 설치되면 이 문제가 나타나지 않습니다.
ovs-subnet에서 ovs- multitenant OpenShift SDN 플러그인으로 전환하면 클러스터의 모든 기존 프로젝트가 완전히 격리됩니다(할당된 고유 VNID). 클러스터 관리자는 관리자 CLI를 사용하여 프로젝트 네트워크를 수정 하도록 선택할 수 있습니다.
다음을 실행하여 VNID를 확인합니다.
$ oc get netnamespace16.8.1. ovs-multitenant에서 ovs-networkpolicy로 마이그레이션
v1 NetworkPolicy 기능은 OpenShift Container Platform에서만 사용할 수 있습니다. 즉, OpenShift Container Platform에서는 송신 정책 유형, IPBlock 및 podSelector 와 namespaceSelector 를 결합할 수 없습니다.
클러스터와의 통신을 중단할 수 있으므로 기본 OpenShift Container Platform 프로젝트에 NetworkPolicy 기능을 적용하지 마십시오.
SDN 플러그인 간 마이그레이션 섹션에서 위의 일반 플러그인 마이그레이션 단계 외에도 ovs- multitenant 플러그인에서 ovs- networkpolicy 플러그인으로 마이그레이션할 때 한 가지 추가 단계가 있습니다. 모든 네임스페이스에 고유한 NetID 가 있는지 확인해야 합니다. 즉 , 이전에 참여하거나 프로젝트를 전역으로 만든 경우 ovs-networkpolicy 플러그인으로 전환하기 전에 해당 프로젝트를 실행 취소하거나 NetworkPolicy 오브젝트가 올바르게 작동하지 않을 수 있습니다.
도우미 스크립트는 NetID의 수정을 통해 NetworkPolicy 오브젝트를 생성하여 이전에 격리된 네임스페이스를 격리하고 이전에 연결된 네임스페이스 간 연결을 활성화합니다.
다음 단계를 사용하여 ovs- multitenant 플러그인을 계속 실행하는 동안 이 도우미 스크립트를 사용하여 ovs- networkpolicy 플러그인으로 마이그레이션합니다.
스크립트를 다운로드하고 실행 파일 권한을 추가합니다.
$ curl -O https://raw.githubusercontent.com/openshift/origin/release-3.11/contrib/migration/migrate-network-policy.sh $ chmod a+x migrate-network-policy.sh스크립트를 실행합니다(클러스터 관리자 역할 필요).
$ ./migrate-network-policy.sh
이 스크립트를 실행하면 모든 네임스페이스가 다른 모든 네임스페이스에서 완전히 격리되므로 ovs-networkpolicy 플러그인으로의 마이그레이션을 완료해야 다른 네임스페이스의 Pod 간 연결이 실패합니다.
새로 생성된 네임스페이스에서 기본적으로 동일한 정책도 포함하려는 경우 마이그레이션 스크립트에서 생성한 default-deny 및 정책과 일치하는 기본 NetworkPolicy 오브젝트 를 설정할 수 있습니다.
allow-from-global- namespaces
스크립트 실패 또는 기타 오류가 있거나 나중에 ovs-multitenant 플러그인으로 되돌리도록 결정한 경우 마이그레이션 되지 않은 스크립트를 사용할 수 있습니다. 이 스크립트는 마이그레이션 스크립트에서 변경한 내용을 실행 취소하고 이전에 가입한 네임스페이스를 다시 결합합니다.
16.9. 클러스터 네트워크에 대한 외부 액세스
OpenShift Container Platform 외부 호스트에 클러스터 네트워크에 액세스해야 하는 경우 다음 두 가지 옵션이 있습니다.
- 호스트를 OpenShift Container Platform 노드로 구성하지만 마스터에서 컨테이너를 예약하지 않도록 예약할 수 없음으로 표시합니다.
- 호스트와 클러스터 네트워크에 있는 호스트 간에 터널을 만듭니다.
두 옵션 모두 에지 로드 밸런서에서 OpenShift SDN 내의 컨테이너로의 라우팅 을 구성하는 설명서의 실제 사용 사례의 일부로 제공됩니다.
16.10. Flannel 사용
OpenShift Container Platform은 기본 SDN에 대한 대안으로 flannel- 기반 네트워킹을 설치하기 위한 Ansible 플레이북도 제공합니다. 이는 Red Hat OpenStack Platform과 같은 SDN에도 의존하고 두 플랫폼을 통해 패킷을 캡슐화하지 않으려는 클라우드 공급자 플랫폼에서 OpenShift Container Platform을 실행하는 경우 유용합니다.
Flannel은 공간의 인접 하위 집합을 각 인스턴스에 할당하는 모든 컨테이너에 단일 IP 네트워크 공간을 사용합니다. 따라서 컨테이너가 동일한 네트워크 공간에 있는 IP 주소에 접속하지 못하게 할 수 없습니다. 이 경우 한 애플리케이션의 컨테이너를 격리하는 데 네트워크를 사용할 수 없기 때문에 멀티 테넌시가 중단됩니다.
내부 네트워크의 mutli-tenancy 격리 또는 성능을 선호하는지 여부에 따라 OpenShift SDN(다중 테넌시)과 flannel(performance) 중에서 선택할 때 적절한 선택을 결정해야 합니다.
Flannel은 Red Hat OpenStack Platform의 OpenShift Container Platform에서만 지원됩니다.
현재 버전의 Neutron은 기본적으로 포트에 포트 보안을 적용합니다. 이렇게 하면 포트 자체에서 MAC 주소와 다른 MAC 주소로 패킷을 보내거나 받는 것을 방지할 수 있습니다. Flannel은 가상 MAC 및 IP 주소를 만들고 포트에서 패킷을 전송하고 수신해야 하므로 flannel 트래픽을 전송하는 포트에서 포트 보안을 비활성화해야 합니다.
OpenShift Container Platform 클러스터 내에서 flannel을 활성화하려면 다음을 수행합니다.
Neutron 포트 보안 제어는 Flannel과 호환되도록 구성해야 합니다. Red Hat OpenStack Platform의 기본 구성에서는
port_security의 사용자 제어를 비활성화합니다. 사용자가 개별포트에서 port_security설정을 제어할 수 있도록 Neutron을 구성합니다.Neutron 서버에서 다음을 /etc/neutron/plugins/ml2/ml2_conf.ini 파일에 추가합니다.
[ml2] ... extension_drivers = port_security그런 다음 Neutron 서비스를 다시 시작하십시오.
service neutron-dhcp-agent restart service neutron-ovs-cleanup restart service neutron-metadata-agentrestart service neutron-l3-agent restart service neutron-plugin-openvswitch-agent restart service neutron-vpn-agent restart service neutron-server restart
Red Hat OpenStack Platform에서 OpenShift Container Platform 인스턴스를 생성할 때 컨테이너 네트워크 플란널 인터페이스가 될 포트에서 포트 보안 및 보안 그룹을 모두 비활성화합니다.
neutron port-update $port --no-security-groups --port-security-enabled=False참고Flannel은 etcd에서 정보를 수집하여 노드의 서브넷을 구성하고 할당합니다. 따라서 etcd 호스트에 연결된 보안 그룹은 노드에서 포트 2379/tcp로의 액세스를 허용해야 하며 노드 보안 그룹은 etcd 호스트의 해당 포트에 대한 송신 통신을 허용해야 합니다.
설치를 실행하기 전에 Ansible 인벤토리 파일에서 다음 변수를 설정합니다.
openshift_use_openshift_sdn=false1 openshift_use_flannel=true2 flannel_interface=eth0선택적으로
flannel_interface변수를 사용하여 호스트 간 통신에 사용할 인터페이스를 지정할 수 있습니다. 이 변수가 없으면 OpenShift Container Platform 설치에 기본 인터페이스가 사용됩니다.참고flannel을 사용하는 Pod 및 서비스의 사용자 지정 네트워킹 CIDR이 향후 릴리스에서 지원됩니다. BZ#1473858
OpenShift Container Platform을 설치한 후 모든 OpenShift Container Platform 노드에 iptables 규칙 세트를 추가합니다.
iptables -A DOCKER -p all -j ACCEPT iptables -t nat -A POSTROUTING -o eth1 -j MASQUERADE/etc/sysconfig/iptables 에서 이러한 변경 사항을 지속하려면 모든 노드에서 다음 명령을 사용합니다.
cp /etc/sysconfig/iptables{,.orig} sh -c "tac /etc/sysconfig/iptables.orig | sed -e '0,/:DOCKER -/ s/:DOCKER -/:DOCKER ACCEPT/' | awk '"\!"p && /POSTROUTING/{print \"-A POSTROUTING -o eth1 -j MASQUERADE\"; p=1} 1' | tac > /etc/sysconfig/iptables"참고iptables-save명령은 모든 현재 in memory iptables 규칙을 저장합니다. 그러나 Docker, Kubernetes 및 OpenShift Container Platform은 지속되도록 설계되지 않은 많은 iptables 규칙(서비스 등)을 생성하므로 이러한 규칙을 저장하는 것이 문제가 될 수 있습니다.
OpenShift Container Platform 트래픽의 나머지 부분에서 컨테이너 트래픽을 분리하려면 격리된 테넌트 네트워크를 생성하고 모든 노드를 연결하는 것이 좋습니다. 다른 네트워크 인터페이스(eth1)를 사용하는 경우 /etc/sysconfig/network-scripts/ifcfg-eth1 파일을 통해 부팅 시 시작되도록 인터페이스를 구성해야 합니다.
DEVICE=eth1
TYPE=Ethernet
BOOTPROTO=dhcp
ONBOOT=yes
DEFTROUTE=no
PEERDNS=no17장. Nuage SDN 구성
17.1. Nuage SDN 및 OpenShift Container Platform
Nuage Networks VSP(가상화된 서비스 플랫폼)는 IT 작업을 간소화하고 OpenShift Container Platform의 기본 네트워킹 기능을 확장하는 컨테이너 환경에 가상 네트워킹 및 SDN(소프트웨어 정의 네트워킹) 인프라를 제공합니다.
Nuage Networks VSP는 OpenShift Container Platform에서 실행되는 Docker 기반 애플리케이션을 지원하여 포드와 기존 워크로드 간의 가상 네트워크 프로비저닝을 가속화하고 전체 클라우드 인프라에서 보안 정책을 활성화합니다. VSP를 사용하면 보안 어플라이언스를 자동화하여 컨테이너 애플리케이션에 대한 세분화된 보안 및 마이크로 세분화 정책이 포함될 수 있습니다.
VSP를 OpenShift Container Platform 애플리케이션 워크플로와 통합하면 DevOps 팀이 직면하는 네트워크 지연을 제거하여 비즈니스 애플리케이션을 빠르게 켜고 업데이트할 수 있습니다. VSP는 사용자가 정책 기반 자동화를 사용하여 사용 편의성 또는 완전한 제어를 선택할 수 있는 시나리오를 수용하기 위해 OpenShift Container Platform을 통해 다양한 워크플로우를 지원합니다.
VSP 를 OpenShift Container Platform과 통합하는 방법에 대한 자세한 내용은 네트워킹을 참조하십시오.
17.2. 개발자 워크플로
이 워크플로는 개발자 환경에서 사용되며 네트워킹을 설정하는 데 개발자가 거의 입력하지 않아야 합니다. 이 워크플로에서 nuage-openshift-monitor 는 OpenShift Container Platform 프로젝트에서 생성된 포드에 적절한 정책 및 네트워킹을 제공하는 데 필요한 VSP 구성(Zone, Subnets 등)을 생성합니다. 프로젝트가 생성되면 nuage-openshift-monitor 를 통해 해당 프로젝트의 기본 영역 및 기본 서브넷이 생성됩니다. 지정된 프로젝트에 대해 생성된 기본 서브넷이 제거되면 nuage-openshift-monitor 는 동적으로 추가 서브넷을 생성합니다.
각 OpenShift Container Platform 프로젝트에 대해 별도의 VSP 영역이 생성되어 프로젝트 간 격리가 수행됩니다.
17.3. 작업 워크플로
이 워크플로는 운영 팀에서 애플리케이션을 배포하는 데 사용됩니다. 이 워크플로에서는 애플리케이션을 배포하기 위해 조직에서 설정한 규칙에 따라 네트워크 및 보안 정책을 VSD에 먼저 구성합니다. 관리자는 잠재적으로 여러 영역과 서브넷을 생성하고 레이블을 사용하여 동일한 프로젝트에 매핑할 수 있습니다. Pod를 회전하는 동안 사용자는 Nuage 레이블을 사용하여 Pod에 연결해야 하는 네트워크와 여기에 적용해야 하는 네트워크 정책을 지정할 수 있습니다. 이를 통해 프로젝트 간 트래픽과 프로젝트 내 트래픽을 세부적으로 제어할 수 있는 배포를 허용합니다. 예를 들어 프로젝트별로 프로젝트 간 통신이 활성화됩니다. 이는 프로젝트를 공유 프로젝트에 배포된 공통 서비스에 연결하는 데 사용할 수 있습니다.
17.4. 설치
OpenShift Container Platform과의 VSP 통합은 VM(가상 머신) 및 베어 메탈 OpenShift Container Platform 설치에 모두 작동합니다.
HA(고가용성) 환경을 여러 마스터와 여러 노드로 구성할 수 있습니다.
다중 마스터 모드의 Nuage VSP 통합은 이 섹션에 설명된 기본 HA 구성 방법만 지원합니다. 이 값은 모든 부하 분산 솔루션과 결합될 수 있으며 기본값은 HAProxy입니다. 인벤토리 파일에는 3개의 마스터 호스트, 노드, etcd 서버 및 모든 마스터 호스트에서 마스터 API의 균형을 맞추기 위해 HAProxy로 작동하는 호스트가 포함되어 있습니다. HAProxy 호스트는 Ansible에서 HAProxy를 부하 분산 솔루션으로 자동으로 설치하고 구성할 수 있도록 인벤토리 파일의 [lb] 섹션에 정의됩니다.
Ansible 노드 파일에서 네트워크 플러그인으로 Nuage VSP를 설정하려면 다음 매개 변수를 지정해야 합니다.
# Create and OSEv3 group that contains masters, nodes, load-balancers, and etcd hosts
masters
nodes
etcd
lb
# Nuage specific parameters
openshift_use_openshift_sdn=False
openshift_use_nuage=True
os_sdn_network_plugin_name='nuage/vsp-openshift'
openshift_node_proxy_mode='userspace'
# VSP related parameters
vsd_api_url=https://192.168.103.200:8443
vsp_version=v4_0
enterprise=nuage
domain=openshift
vsc_active_ip=192.168.103.201
vsc_standby_ip=192.168.103.202
uplink_interface=eth0
# rpm locations
nuage_openshift_rpm=http://location_of_rpm_server/openshift/RPMS/x86_64/nuage-openshift-monitor-4.0.X.1830.el7.centos.x86_64.rpm
vrs_rpm=http://location_of_rpm_server/openshift/RPMS/x86_64/nuage-openvswitch-4.0.X.225.el7.x86_64.rpm
plugin_rpm=http://location_of_rpm_server/openshift/RPMS/x86_64/vsp-openshift-4.0.X1830.el7.centos.x86_64.rpm
# Required for Nuage Monitor REST server and HA
openshift_master_cluster_method=native
openshift_master_cluster_hostname=lb.nuageopenshift.com
openshift_master_cluster_public_hostname=lb.nuageopenshift.com
nuage_openshift_monitor_rest_server_port=9443
# Optional parameters
nuage_interface_mtu=1460
nuage_master_adminusername='admin's user-name'
nuage_master_adminuserpasswd='admin's password'
nuage_master_cspadminpasswd='csp admin password'
nuage_openshift_monitor_log_dir=/var/log/nuage-openshift-monitor
# Required for brownfield install (where a {product-title} cluster exists without Nuage as the networking plugin)
nuage_dockker_bridge=lbr0
# Specify master hosts
[masters]
fqdn_of_master_1
fqdn_of_master_2
fqdn_of_master_3
# Specify load balancer host
[lb]
fqdn_of_load_balancer18장. NSX-T SDN 구성
18.1. NSX-T SDN 및 OpenShift Container Platform
VMware NSX-T Data Center ™는 IT 작업을 간소화하고 기본 OpenShift Container Platform 네트워킹 기능을 확장하는 컨테이너 환경에 대한 고급 소프트웨어 정의 네트워킹(SDN), 보안 및 가시성을 제공합니다.
NSX-T Data Center는 여러 클러스터에서 가상 머신, 베어 메탈 및 컨테이너 워크로드를 지원합니다. 이를 통해 조직은 전체 환경에서 단일 SDN을 사용하여 완벽한 가시성을 얻을 수 있습니다.
NSX-T가 OpenShift Container Platform과 통합하는 방법에 대한 자세한 내용은 NSX-T SDN in Available SDN 플러그인을 참조하십시오.
18.2. 토폴로지 예
일반적인 사용 사례 중 하나는 실제 시스템을 가상 환경과 연결하는 Tier-0(T0) 라우터와 OpenShift Container Platform VM의 기본 게이트웨이 역할을 하는 Tier-1(T1) 라우터를 사용하는 것입니다.
각 VM에는 두 개의 vNIC가 있습니다. 한 vNIC는 VM에 액세스하기 위해 Management Logical Switch에 연결합니다. 다른 vNIC는 덤프 논리 스위치에 연결하고 nsx-node-agent 에서 Pod 네트워킹을 업링크하는 데 사용됩니다. 자세한 내용은 OpenShift의 NSX 컨테이너 플러그인을 참조하십시오.
OpenShift Container Platform 경로를 구성하는 데 사용되는 LoadBalancer 및 모든 프로젝트 T1 라우터 및 논리 스위치는 OpenShift Container Platform 설치 중에 자동으로 생성됩니다.
이 토폴로지에서 기본 OpenShift Container Platform HAProxy 라우터는 Grafana, Prometheus, Console, Service Catalog 등과 같은 모든 인프라 구성 요소에 사용됩니다. HAProxy에서 호스트 네트워크 네임스페이스를 사용하므로 인프라 구성 요소의 DNS 레코드가 인프라 노드 IP 주소를 가리키는지 확인합니다. 이는 인프라 경로에서 작동하지만 인프라 노드 관리 IP를 외부에 노출하지 않도록 애플리케이션별 경로를 NSX-T LoadBalancer에 배포합니다.
이 예제 토폴로지에서는 세 개의 OpenShift Container Platform 마스터 가상 머신과 OpenShift Container Platform 작업자 가상 머신 4개를 사용한다고 가정합니다(인프라의 경우 2개, 컴퓨팅에는 2개).
18.3. VMware NSX-T 설치
사전 요구 사항
ESXi 호스트 요구 사항:
OpenShift Container Platform 노드 VM을 호스팅하는 ESXi 서버는 NSX-T 전송 노드여야 합니다.
그림 18.1. 일반적인 고가용성 환경을 위해 전송 노드를 해제하는 NSX UI:
DNS 요구 사항:
-
와일드카드가 있는 DNS 서버에 새 항목을 인프라 노드에 추가해야 합니다. 그러면 NSX-T 또는 기타 타사 LoadBalancer에 의한 로드 밸런싱이 가능합니다. 아래
hosts파일에서 항목은openshift_master_default_subdomain변수로 정의합니다. -
openshift_master_cluster_
hostname 및변수로 DNS 서버를 업데이트해야 합니다.openshift_master_cluster_public_hostname
-
와일드카드가 있는 DNS 서버에 새 항목을 인프라 노드에 추가해야 합니다. 그러면 NSX-T 또는 기타 타사 LoadBalancer에 의한 로드 밸런싱이 가능합니다. 아래
가상 머신 요구 사항:
- OpenShift Container Platform 노드 VM에는 두 개의 vNIC가 있어야 합니다.
- 관리 vNIC는 관리 T1 라우터에 업링크된 논리 스위치에 연결되어 있어야 합니다.
NSX Container Plug-in(NCP)에서 특정 OpenShift Container Platform 노드에서 실행 중인 모든 Pod의 상위 VIF로 사용해야 하는 포트를 알 수 있도록 모든 VM의 두 번째 vNIC에 NSX-T 태그가 지정되어야 합니다. 태그는 다음과 같아야 합니다.
{'ncp/node_name': 'node_name'} {'ncp/cluster': 'cluster_name'}다음 이미지는 모든 노드에 대한 NSX UI의 태그 방법을 보여줍니다. 대규모 클러스터의 경우 API 호출을 사용하거나 Ansible을 사용하여 태깅을 자동화할 수 있습니다.
그림 18.2. NSX UI dislaying 노드 태그

NSX UI의 태그 순서는 API와 반대입니다. 노드 이름은 kubelet과 정확히 동일해야 하며 클러스터 이름은 Ansible 호스트 파일의
nsx_openshift_cluster_name과 같아야 합니다. 모든 노드의 두 번째 vNIC에 적절한 태그가 적용되었는지 확인합니다.
NSX-T 요구 사항:
NSX에서 다음 사전 요구 사항을 충족해야 합니다.
- Tier-0 라우터.
- 오버레이 전송 영역.
- POD 네트워킹을 위한 IP 블록.
- 선택적으로 라우팅(NoNAT) POD 네트워킹을 위한 IP 블록입니다.
- SNAT용 IP 풀. 기본적으로 Pod 네트워킹 IP 블록에서 프로젝트별로 지정된 서브넷은 NSX-T 내에서만 라우팅할 수 있습니다. NCP는 이 IP 풀을 사용하여 외부에 대한 연결을 제공합니다.
- dFW(Distributed Firewall)의 Top 및 Bottom firewall 섹션(옵션). NCP는 이 두 섹션 사이에 Kubernetes 네트워크 정책 규칙을 배치합니다.
-
Open vSwitch 및 CNI 플러그인 RPM은 OpenShift Container Platform 노드 VM에서 연결할 수 있는 HTTP 서버에서 호스팅해야 합니다(
이예에서는 http://websrv.example.com). 해당 파일은 NCP Tar 파일에 포함되어 있으며, VMware에서 NSX Container Plug-in 2.4.0 다운로드 에서 다운로드할 수 있습니다.
OpenShift Container Platform 요구사항:
다음 명령을 실행하여 OpenShift Container Platform에 필요한 소프트웨어 패키지를 설치합니다.
$ ansible-playbook -i hosts openshift-ansible/playbooks/prerequisites.yml- NCP 컨테이너 이미지가 모든 노드에서 로컬로 다운로드되었는지 확인합니다.
prerequisites
.yml플레이북이 실행된 후 모든 노드에서 다음 명령을 실행하여xxx를 NCP 빌드 버전으로 교체합니다.$ docker load -i nsx-ncp-rhel-xxx.tar예를 들면 다음과 같습니다.
$ docker load -i nsx-ncp-rhel-2.4.0.12511604.tar이미지 이름을 가져와서 다시 태그를 지정합니다.
$ docker images $ docker image tag registry.local/xxxxx/nsx-ncp-rhel nsx-ncp1 - 1
xxx를 NCP 빌드 버전으로 바꿉니다. 예를 들면 다음과 같습니다.
docker image tag registry.local/2.4.0.12511604/nsx-ncp-rhel nsx-ncpOpenShift Container Platform Ansible 호스트 파일에서 다음 매개변수를 지정하여 NSX-T를 네트워크 플러그인으로 설정합니다.
[OSEv3:children] masters nodes etcd [OSEv3:vars] ansible_ssh_user=root openshift_deployment_type=origin openshift_master_identity_providers=[{'name': 'htpasswd_auth', 'login': 'true', 'challenge': 'true', 'kind': 'HTPasswdPasswordIdentityProvider'}] openshift_master_htpasswd_users={"admin" : "$apr1$H0QeP6oX$HHdscz5gqMdtTcT5eoCJ20"} openshift_master_default_subdomain=demo.example.com openshift_use_nsx=true os_sdn_network_plugin_name=cni openshift_use_openshift_sdn=false openshift_node_sdn_mtu=1500 openshift_master_cluster_method=native openshift_master_cluster_hostname=master01.example.com openshift_master_cluster_public_hostname=master01.example.com openshift_hosted_manage_registry=true openshift_hosted_manage_router=true openshift_enable_service_catalog=true openshift_cluster_monitoring_operator_install=true openshift_web_console_install=true openshift_console_install=true # NSX-T specific configuration #nsx_use_loadbalancer=false nsx_openshift_cluster_name='cluster01' nsx_api_managers='nsxmgr.example.com' nsx_api_user='nsx_admin' nsx_api_password='nsx_api_password_example' nsx_tier0_router='LR-Tier-0' nsx_overlay_transport_zone='TZ-Overlay' nsx_container_ip_block='pod-networking' nsx_no_snat_ip_block='pod-nonat' nsx_external_ip_pool='pod-external' nsx_top_fw_section='containers-top' nsx_bottom_fw_section='containers-bottom' nsx_ovs_uplink_port='ens224' nsx_cni_url='http://websrv.example.com/nsx-cni-buildversion.x86_64.rpm' nsx_ovs_url='http://websrv.example.com/openvswitch-buildversion.rhel75-1.x86_64.rpm' nsx_kmod_ovs_url='http://websrv.example.com/kmod-openvswitch-buildversion.rhel75-1.el7.x86_64.rpm' nsx_insecure_ssl=true # vSphere Cloud Provider #openshift_cloudprovider_kind=vsphere #openshift_cloudprovider_vsphere_username='administrator@example.com' #openshift_cloudprovider_vsphere_password='viadmin_password' #openshift_cloudprovider_vsphere_host='vcsa.example.com' #openshift_cloudprovider_vsphere_datacenter='Example-Datacenter' #openshift_cloudprovider_vsphere_cluster='example-Cluster' #openshift_cloudprovider_vsphere_resource_pool='ocp' #openshift_cloudprovider_vsphere_datastore='example-Datastore-name' #openshift_cloudprovider_vsphere_folder='ocp' [masters] master01.example.com master02.example.com master03.example.com [etcd] master01.example.com master02.example.com master03.example.com [nodes] master01.example.com ansible_ssh_host=192.168.220.2 openshift_node_group_name='node-config-master' master02.example.com ansible_ssh_host=192.168.220.3 openshift_node_group_name='node-config-master' master03.example.com ansible_ssh_host=192.168.220.4 openshift_node_group_name='node-config-master' node01.example.com ansible_ssh_host=192.168.220.5 openshift_node_group_name='node-config-infra' node02.example.com ansible_ssh_host=192.168.220.6 openshift_node_group_name='node-config-infra' node03.example.com ansible_ssh_host=192.168.220.7 openshift_node_group_name='node-config-compute' node04.example.com ansible_ssh_host=192.168.220.8 openshift_node_group_name='node-config-compute'OpenShift Container Platform 설치 매개변수에 대한 자세한 내용은 인벤토리 파일 구성을 참조하십시오.
절차
모든 사전 요구 사항을 충족한 후 NSX 데이터 센터 및 OpenShift Container Platform을 배포할 수 있습니다.
OpenShift Container Platform 클러스터를 배포합니다.
$ ansible-playbook -i hosts openshift-ansible/playbooks/deploy_cluster.ymlOpenShift Container Platform 설치에 대한 자세한 내용은 OpenShift Container Platform 설치를 참조하십시오.
설치가 완료되면 NCP 및 nsx-node-agent Pod가 실행 중인지 확인합니다.
$ oc get pods -o wide -n nsx-system NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE nsx-ncp-5sggt 1/1 Running 0 1h 192.168.220.8 node04.example.com <none> nsx-node-agent-b8nkm 2/2 Running 0 1h 192.168.220.5 node01.example.com <none> nsx-node-agent-cldks 2/2 Running 0 2h 192.168.220.8 node04.example.com <none> nsx-node-agent-m2p5l 2/2 Running 28 3h 192.168.220.4 master03.example.com <none> nsx-node-agent-pcfd5 2/2 Running 0 1h 192.168.220.7 node03.example.com <none> nsx-node-agent-ptwnq 2/2 Running 26 3h 192.168.220.2 master01.example.com <none> nsx-node-agent-xgh5q 2/2 Running 26 3h 192.168.220.3 master02.example.com <none>
18.4. OpenShift Container Platform 배포 후 NSX-T 확인
OpenShift Container Platform을 설치하고 NCP 및 nsx-node-agent-* Pod를 확인한 후 다음을 수행합니다.
라우팅을 확인합니다. 설치 중에 Tier-1 라우터가 생성되었으며 Tier-0 라우터에 연결되어 있는지 확인합니다.
그림 18.3. T1 라우터 표시 NSX UI 비활성화
네트워크 추적플로 및 가시성을 관찰합니다. 예를 들어 'console'과 'grafana' 간 연결을 확인합니다.
Pod, 프로젝트, 가상 머신 및 외부 서비스 간의 통신 보안 및 최적화에 대한 자세한 내용은 다음 예제를 참조하십시오.
그림 18.4. 네트워크 추적 흐름을 보여주는 NSX UI 디레이딩
부하 분산을 확인합니다. NSX-T 데이터 센터는 다음 예와 같이 로드 밸런서 및 Ingress 컨트롤러 기능을 제공합니다.
그림 18.5. 로드 밸런서를 표시하는 NSX UI 비활성화
추가 구성 및 옵션은 VMware NSX-T v2.4 OpenShift 플러그인 설명서를 참조하십시오.
19장. Kuryr SDN 구성
19.1. Kuryr SDN 및 OpenShift Container Platform
Kuryr (또는 구체적으로 Kuryr-Kubernetes)는 CNI 및 OpenStack Neutron 을 사용하여 빌드된 SDN 솔루션입니다. 이 솔루션의 장점은 광범위한 Neutron SDN 백엔드를 사용하고 Kubernetes Pod와 OpenStack VM(가상 시스템) 간의 상호 연결을 제공할 수 있다는 것입니다.
Kuryr-Kubernetes 및 OpenShift Container Platform 통합은 주로 OpenStack VM에서 실행되는 OpenShift Container Platform 클러스터를 위해 설계되었습니다. Kuryr-Kubernetes 구성 요소는 kuryr 네임스페이스의 OpenShift Container Platform에 Pod로 설치됩니다.
-
kuryr-controller -
인프라노드에 설치된 단일 서비스 인스턴스입니다. OpenShift Container Platform에서 배포로모델링. -
kuryr-cni - 각 OpenShift Container Platform 노드에서 Kuryr를 CNI 드라이버로 설치하고 구성하는 컨테이너입니다. OpenShift Container Platform에서
DaemonSet으로 모델링.
Kuryr 컨트롤러는 OpenShift API 서버에서 Pod, 서비스 및 네임스페이스 생성, 업데이트 및 삭제 이벤트를 감시합니다. OpenShift Container Platform API 호출을 Neutron 및 Octavia의 해당 개체에 매핑합니다. 즉 Neutron 트렁크 포트 기능을 구현하는 모든 네트워크 솔루션을 사용하여 Kuryr를 통해 OpenShift Container Platform을 지원할 수 있습니다. 여기에는 OVS 및 OVN과 같은 오픈 소스 솔루션과 Neutron 호환 상용 SDN이 포함됩니다.
19.2. Kuryr SDN 설치
OpenStack 클라우드에 Kuryr SDN을 설치하려면 OpenStack 구성 설명서에 설명된 단계를 따라야 합니다.
19.3. 검증
OpenShift Container Platform 설치가 완료되면 Kuryr Pod가 성공적으로 배포되었는지 확인할 수 있습니다.
$ oc -n kuryr get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE
kuryr-cni-ds-66kt2 2/2 Running 0 3d 192.168.99.14 infra-node-0.openshift.example.com
kuryr-cni-ds-ggcpz 2/2 Running 0 3d 192.168.99.16 master-0.openshift.example.com
kuryr-cni-ds-mhzjt 2/2 Running 0 3d 192.168.99.6 app-node-1.openshift.example.com
kuryr-cni-ds-njctb 2/2 Running 0 3d 192.168.99.12 app-node-0.openshift.example.com
kuryr-cni-ds-v8hp8 2/2 Running 0 3d 192.168.99.5 infra-node-1.openshift.example.com
kuryr-controller-59fc7f478b-qwk4k 1/1 Running 0 3d 192.168.99.5 infra-node-1.openshift.example.com
Kuryr-cni Pod는 모든 OpenShift Container Platform 노드에서 실행됩니다. 단일 kuryr-controller 인스턴스는 모든 인프라 노드에서 실행됩니다.
Kuryr SDN이 활성화되면 네트워크 정책 및 노드 포트 서비스가 지원되지 않습니다.
20장. AWS(Amazon Web Services)에 대한 구성
20.1. 개요
애플리케이션 데이터의 영구 스토리지로 AWS 볼륨을 사용하는 등 AWS EC2 인프라에 액세스하도록 OpenShift Container Platform을 구성할 수 있습니다. AWS를 구성한 후 OpenShift Container Platform 호스트에서 일부 추가 구성을 완료해야 합니다.
20.1.1. AWS(Amazon Web Services)에 대한 권한 부여 구성
권한 AWS 인스턴스에는 OpenShift Container Platform에서 로드 밸런서 및 스토리지를 요청하고 관리할 수 있도록 액세스 및 비밀 키 또는 인스턴스에 할당된 IAM 역할을 사용하여 프로그래밍 액세스가 있는 IAM 계정이 필요합니다.
IAM 계정 또는 IAM 역할에는 다음과 같은 정책 권한이 있어야 전체 클라우드 공급자 기능을 사용할 수 있습니다.
{
"Version": "2012-10-17",
"Statement": [
{
"Action": [
"ec2:DescribeVolume*",
"ec2:CreateVolume",
"ec2:CreateTags",
"ec2:DescribeInstances",
"ec2:AttachVolume",
"ec2:DetachVolume",
"ec2:DeleteVolume",
"ec2:DescribeSubnets",
"ec2:CreateSecurityGroup",
"ec2:DescribeSecurityGroups",
"ec2:DeleteSecurityGroup",
"ec2:DescribeRouteTables",
"ec2:AuthorizeSecurityGroupIngress",
"ec2:RevokeSecurityGroupIngress",
"elasticloadbalancing:DescribeTags",
"elasticloadbalancing:CreateLoadBalancerListeners",
"elasticloadbalancing:ConfigureHealthCheck",
"elasticloadbalancing:DeleteLoadBalancerListeners",
"elasticloadbalancing:RegisterInstancesWithLoadBalancer",
"elasticloadbalancing:DescribeLoadBalancers",
"elasticloadbalancing:CreateLoadBalancer",
"elasticloadbalancing:DeleteLoadBalancer",
"elasticloadbalancing:ModifyLoadBalancerAttributes",
"elasticloadbalancing:DescribeLoadBalancerAttributes"
],
"Resource": "*",
"Effect": "Allow",
"Sid": "1"
}
]
}aws iam put-role-policy \
--role-name openshift-role \
--policy-name openshift-admin \
--policy-document file: //openshift_iam_policyaws iam put-user-policy \
--user-name openshift-admin \
--policy-name openshift-admin \
--policy-document file: //openshift_iam_policy
OpenShift 노드 인스턴스에는 ec2:DescribeInstance 권한만 필요하지만 설치 프로그램에서는 단일 AWS 액세스 키와 시크릿만 정의할 수 있습니다. 이는 IAM 역할을 사용하여 바이패스하고 위의 권한을 마스터 인스턴스에 할당하고 노드에 ec2:DescribeInstance 를 할당할 수 있습니다.
20.1.1.1. 설치 시 OpenShift Container Platform 클라우드 공급자 구성
절차
액세스 및 비밀 키가 있는 IAM 계정을 사용하여 Amazon Web Services 클라우드 공급자를 구성하려면 다음 값을 인벤토리에 추가합니다.
[OSEv3:vars]
openshift_cloudprovider_kind=aws
openshift_clusterid=openshift
openshift_cloudprovider_aws_access_key=AKIAJ6VLBLISADPBUA
openshift_cloudprovider_aws_secret_key=g/8PmDNYHVSQn0BQE+xtsHzbaZaGYjGNzhbdgwjH IAM 역할을 사용하여 Amazon Web Services 클라우드 공급자를 구성하려면 인벤토리에 다음 값을 추가합니다.
[source,yaml]
----
[OSEv3:vars]
openshift_cloudprovider_kind=aws
openshift_clusterid=openshift
----
<1> A tag assigned to all resources (instances, load balancers, vpc, etc) used for OpenShift.NOTE: The IAM role takes the place of needing an access and secret key.20.1.1.2. 설치 후 OpenShift Container Platform 클라우드 공급자 구성
Amazon Web Services 클라우드 공급자 값을 설치할 때 설치 시 제공하지 않은 경우 설치 후 구성을 정의하고 생성할 수 있습니다. 단계에 따라 구성 파일을 구성하고 AWS용 OpenShift Container Platform 마스터 수동 구성 마스터 및 노드를 수동으로 구성합니다.
-
모든 마스터 호스트, 노드 호스트 및 서브넷에는
kubernetes.io/cluster/<clusterid>,Value=(owned|shared)태그가 있어야 합니다. 한 보안 그룹(노드에 연결된 그룹)에는
kubernetes.io/cluster/<clusterid>,Value=(owned|shared)태그가 있어야 합니다.-
kubernetes.io/cluster/<clusterid>,Value=(owned|shared)태그 또는 ELB(Elastic Load Balancing) 태그로 모든 보안 그룹에 태그를 지정하지 마십시오.
-
20.2. 보안 그룹 구성
AWS에 OpenShift Container Platform을 설치할 때 적절한 보안 그룹을 설정해야 합니다.
설치에 실패하지 않고 보안 그룹에 있어야 하는 일부 포트입니다. 설치하려는 클러스터 구성에 따라 더 많은 항목이 필요할 수 있습니다. 자세한 내용은 보안 그룹을 적절하게 조정하려면 Required Ports (필수 포트)를 참조하십시오.
| 모든 OpenShift Container Platform 호스트 |
|
| etcd 보안 그룹 |
|
| 마스터 보안 그룹 |
|
| 노드 보안 그룹 |
|
| 인프라 노드(OpenShift Container Platform 라우터를 호스팅할 수 있는 노드) |
|
| CRI-O |
CRIO를 사용하는 경우 |
마스터 및/또는 라우터의 부하 분산을 위해 외부 로드 밸런서(ELB)를 구성하는 경우 ELB에 대한 Ingress 및 Egress 보안 그룹도 적절하게 구성해야 합니다.
20.2.1. 감지된 IP 주소 및 호스트 이름 덮어쓰기
AWS에서 변수를 재정의해야 하는 상황은 다음과 같습니다.
| Variable | 사용법 |
|---|---|
|
|
사용자는 DNS 호스트 이름과 |
|
| 네트워크 인터페이스가 여러 개 구성되어 있으며 기본값이 아닌 다른 인터페이스 하나를 사용하려고 합니다. |
|
|
|
|
|
|
특히 EC2 호스트의 경우 DNS 호스트 이름과 DNS 확인이 활성화된 VPC에 배포해야 합니다.
20.2.1.1. AWS(Amazon Web Services)용 OpenShift Container Platform 레지스트리 구성
AWS(Amazon Web Services)는 OpenShift Container Platform이 OpenShift Container Platform 컨테이너 레지스트리를 사용하여 컨테이너 이미지를 저장하는 데 사용할 수 있는 오브젝트 클라우드 스토리지를 제공합니다.
자세한 내용은 Amazon S3 을 참조하십시오.
사전 요구 사항
OpenShift Container Platform은 이미지 스토리지에 S3를 사용합니다. 설치 프로그램에서 레지스트리를 구성할 수 있도록 프로그램 액세스 권한이 있는 S3 버킷, IAM 정책 및 IAM 사용자를 생성해야 합니다.
아래 예제에서는 awscli를 사용하여 us-east-1 의 지역에서 openshift-registry-storage 라는 이름으로 버킷을 생성합니다.
# aws s3api create-bucket \
--bucket openshift-registry-storage \
--region us-east-1기본 정책
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:ListBucket",
"s3:GetBucketLocation",
"s3:ListBucketMultipartUploads"
],
"Resource": "arn:aws:s3:::S3_BUCKET_NAME"
},
{
"Effect": "Allow",
"Action": [
"s3:PutObject",
"s3:GetObject",
"s3:DeleteObject",
"s3:ListMultipartUploadParts",
"s3:AbortMultipartUpload"
],
"Resource": "arn:aws:s3:::S3_BUCKET_NAME/*"
}
]
}20.2.1.1.1. S3을 사용하도록 OpenShift Container Platform 인벤토리 구성
절차
S3 버킷 및 IAM 사용자를 사용하도록 레지스트리에 대한 Ansible 인벤토리를 구성하려면 다음을 수행합니다.
[OSEv3:vars]
# AWS Registry Configuration
openshift_hosted_manage_registry=true
openshift_hosted_registry_storage_kind=object
openshift_hosted_registry_storage_provider=s3
openshift_hosted_registry_storage_s3_accesskey=AKIAJ6VLREDHATSPBUA
openshift_hosted_registry_storage_s3_secretkey=g/8PmTYDQVGssFWWFvfawHpDbZyGkjGNZhbWQpjH
openshift_hosted_registry_storage_s3_bucket=openshift-registry-storage
openshift_hosted_registry_storage_s3_region=us-east-1
openshift_hosted_registry_storage_s3_chunksize=26214400
openshift_hosted_registry_storage_s3_rootdirectory=/registry
openshift_hosted_registry_storage_s3_encrypt=false
openshift_hosted_registry_storage_s3_kmskeyid=aws_kms_key_id
openshift_hosted_registry_pullthrough=true
openshift_hosted_registry_acceptschema2=true
openshift_hosted_registry_enforcequota=true
openshift_hosted_registry_replicas=320.2.1.1.2. S3를 사용하도록 OpenShift Container Platform 레지스트리 수동 구성
AWS(Amazon Web Services) S3 오브젝트 스토리지를 사용하려면 레지스트리의 구성 파일을 편집하고 레지스트리 Pod에 마운트합니다.
절차
현재 config.yml 을 내보냅니다 :
$ oc get secret registry-config \ -o jsonpath='{.data.config\.yml}' -n default | base64 -d \ >> config.yml.old이전 config.yml에서 새 구성 파일을 만듭니다.
$ cp config.yml.old config.ymlS3 매개 변수를 포함하도록 파일을 편집합니다. 레지스트리 구성 파일의
스토리지섹션에서 accountname, accountkey, 컨테이너 및 영역을 지정합니다.storage: delete: enabled: true cache: blobdescriptor: inmemory s3: accesskey: AKIAJ6VLREDHATSPBUA1 secretkey: g/8PmTYDQVGssFWWFvfawHpDbZyGkjGNZhbWQpjH2 region: us-east-13 bucket: openshift-registry-storage4 encrypt: False secure: true v4auth: true rootdirectory: /registry5 chunksize: "26214400"registry-config시크릿을 삭제합니다.$ oc delete secret registry-config -n default업데이트된 구성 파일을 참조하도록 보안을 다시 생성합니다.
$ oc create secret generic registry-config \ --from-file=config.yml -n default업데이트된 구성을 읽기 위해 레지스트리를 재배포합니다.
$ oc rollout latest docker-registry -n default
20.2.1.1.3. 레지스트리에서 S3 스토리지를 사용하고 있는지 확인
레지스트리가 Amazon S3 스토리지를 사용하고 있는지 확인하려면 다음을 수행합니다.
절차
레지스트리 배포가 완료되면 레지스트리
deploymentconfig는 registry-storage를 AWS S3 대신emptydir로 설명하지만 AWS S3 버킷의 구성은 보안docker-config에 상주합니다.docker-config시크릿은 레지스트리 오브젝트 스토리지에 AWS S3을 사용할 때 모든 매개 변수를 제공하는REGISTRY_CONFIGURATION_PATH에 마운트합니다.$ oc describe dc docker-registry -n default ... Environment: REGISTRY_HTTP_ADDR: :5000 REGISTRY_HTTP_NET: tcp REGISTRY_HTTP_SECRET: SPLR83SDsPaGbGuwSMDfnDwrDRvGf6YXl4h9JQrToQU= REGISTRY_MIDDLEWARE_REPOSITORY_OPENSHIFT_ENFORCEQUOTA: false REGISTRY_HTTP_TLS_KEY: /etc/secrets/registry.key OPENSHIFT_DEFAULT_REGISTRY: docker-registry.default.svc:5000 REGISTRY_CONFIGURATION_PATH: /etc/registry/config.yml REGISTRY_OPENSHIFT_SERVER_ADDR: docker-registry.default.svc:5000 REGISTRY_HTTP_TLS_CERTIFICATE: /etc/secrets/registry.crt Mounts: /etc/registry from docker-config (rw) /etc/secrets from registry-certificates (rw) /registry from registry-storage (rw) Volumes: registry-storage: Type: EmptyDir (a temporary directory that shares a pod's lifetime)1 Medium: registry-certificates: Type: Secret (a volume populated by a Secret) SecretName: registry-certificates Optional: false docker-config: Type: Secret (a volume populated by a Secret) SecretName: registry-config Optional: false ....- 1
- Pod의 수명을 공유하는 임시 디렉터리입니다.
/registry 마운트 지점이 비어 있는지 확인합니다.
$ oc exec \ $(oc get pod -l deploymentconfig=docker-registry \ -o=jsonpath='{.items[0].metadata.name}') -i -t -- ls -l /registry total 0비어 있는 경우 S3 구성이
registry-config보안에 정의되어 있기 때문입니다.$ oc describe secret registry-config Name: registry-config Namespace: default Labels: <none> Annotations: <none> Type: Opaque Data ==== config.yml: 398 bytes설치 프로그램에서 설치 설명서의 Storage 에 표시된 대로 확장 레지스트리 기능을 사용하여 원하는 구성으로 config.yml 파일을 생성합니다. 스토리지 버킷 구성이 저장된
storage섹션을 포함하여 구성 파일을 보려면 다음을 수행합니다.$ oc exec \ $(oc get pod -l deploymentconfig=docker-registry \ -o=jsonpath='{.items[0].metadata.name}') \ cat /etc/registry/config.yml version: 0.1 log: level: debug http: addr: :5000 storage: delete: enabled: true cache: blobdescriptor: inmemory s3: accesskey: AKIAJ6VLREDHATSPBUA secretkey: g/8PmTYDQVGssFWWFvfawHpDbZyGkjGNZhbWQpjH region: us-east-1 bucket: openshift-registry-storage encrypt: False secure: true v4auth: true rootdirectory: /registry chunksize: "26214400" auth: openshift: realm: openshift middleware: registry: - name: openshift repository: - name: openshift options: pullthrough: true acceptschema2: true enforcequota: true storage: - name: openshift또는 시크릿을 볼 수 있습니다.
$ oc get secret registry-config -o jsonpath='{.data.config\.yml}' | base64 -d version: 0.1 log: level: debug http: addr: :5000 storage: delete: enabled: true cache: blobdescriptor: inmemory s3: accesskey: AKIAJ6VLREDHATSPBUA secretkey: g/8PmTYDQVGssFWWFvfawHpDbZyGkjGNZhbWQpjH region: us-east-1 bucket: openshift-registry-storage encrypt: False secure: true v4auth: true rootdirectory: /registry chunksize: "26214400" auth: openshift: realm: openshift middleware: registry: - name: openshift repository: - name: openshift options: pullthrough: true acceptschema2: true enforcequota: true storage: - name: openshift
emptyDir 볼륨을 사용하는 경우 /registry 마운트 지점은 다음과 같이 표시됩니다.
$ oc exec \
$(oc get pod -l deploymentconfig=docker-registry \
-o=jsonpath='{.items[0].metadata.name}') -i -t -- df -h /registry
Filesystem Size Used Avail Use% Mounted on
/dev/sdc 100G 226M 30G 1% /registry
$ oc exec \
$(oc get pod -l deploymentconfig=docker-registry \
-o=jsonpath='{.items[0].metadata.name}') -i -t -- ls -l /registry
total 0
drwxr-sr-x. 3 1000000000 1000000000 22 Jun 19 12:24 docker20.3. AWS 변수 구성
필요한 AWS 변수를 설정하려면 마스터와 노드 모두에서 다음 콘텐츠를 사용하여 /etc/origin/cloudprovider/aws.conf 파일을 생성합니다.
[Global]
Zone = us-east-1c - 1
- AWS 인스턴스의 가용성 영역과 EBS 볼륨이 상주하는 위치입니다. 이 정보는 AWS 관리 콘솔에서 가져옵니다.
20.4. AWS용 OpenShift Container Platform 구성
다음 두 가지 방법으로 OpenShift Container Platform에서 AWS 구성을 설정할 수 있습니다.
- Ansible 사용 또는
- 수동으로.
20.4.1. Ansible을 사용하여 AWS용 OpenShift Container Platform 구성
클러스터 설치 중에 인벤토리 파일에서 구성할 수 있는 openshift_cloudprovider_aws_access_key,openshift_cloudprovider_aws_secret_key,openshift_cloudprovider_kind,openshift_clusterid 매개변수를 사용하여 AWS를 구성할 수 있습니다.
Ansible을 사용한 AWS 구성 예
# Cloud Provider Configuration
#
# Note: You may make use of environment variables rather than store
# sensitive configuration within the ansible inventory.
# For example:
#openshift_cloudprovider_aws_access_key="{{ lookup('env','AWS_ACCESS_KEY_ID') }}"
#openshift_cloudprovider_aws_secret_key="{{ lookup('env','AWS_SECRET_ACCESS_KEY') }}"
#
#openshift_clusterid=unique_identifier_per_availablility_zone
#
# AWS (Using API Credentials)
#openshift_cloudprovider_kind=aws
#openshift_cloudprovider_aws_access_key=aws_access_key_id
#openshift_cloudprovider_aws_secret_key=aws_secret_access_key
#
# AWS (Using IAM Profiles)
#openshift_cloudprovider_kind=aws
# Note: IAM roles must exist before launching the instances.Ansible이 AWS를 구성하면 다음 파일에 필요한 변경 작업을 자동으로 수행합니다.
- /etc/origin/cloudprovider/aws.conf
- /etc/origin/master/master-config.yaml
- /etc/origin/node/node-config.yaml
20.4.2. AWS용 OpenShift Container Platform 마스터 수동 구성
모든 마스터(기본적으로/etc/origin/master/master-config.yaml )에서 마스터 구성 파일을 편집하거나 생성하고 apiServerArguments 및 섹션의 내용을 업데이트합니다.
controllerArguments
kubernetesMasterConfig:
...
apiServerArguments:
cloud-provider:
- "aws"
cloud-config:
- "/etc/origin/cloudprovider/aws.conf"
controllerArguments:
cloud-provider:
- "aws"
cloud-config:
- "/etc/origin/cloudprovider/aws.conf"
현재 클라우드 공급자 통합이 제대로 작동하려면 nodeName 이 AWS의 인스턴스 이름과 일치해야 합니다. 이름은 RFC1123과 호환되어야 합니다.
컨테이너화된 설치를 트리거하면 /etc/origin 및 / var/lib/origin 의 디렉터리만 마스터 및 노드 컨테이너에 마운트됩니다. 따라서 aws.conf 는 /etc/ 대신 /etc/origin/ 에 있어야 합니다.
20.4.3. AWS용 OpenShift Container Platform 노드 수동 구성
적절한 노드 구성 맵을 편집하고 kubeletArguments 섹션의 내용을 업데이트합니다.
kubeletArguments:
cloud-provider:
- "aws"
cloud-config:
- "/etc/origin/cloudprovider/aws.conf"컨테이너화된 설치를 트리거하면 /etc/origin 및 / var/lib/origin 의 디렉터리만 마스터 및 노드 컨테이너에 마운트됩니다. 따라서 aws.conf 는 /etc/ 대신 /etc/origin/ 에 있어야 합니다.
20.4.4. 수동으로 키 값 액세스 쌍 설정
다음 환경 변수가 masters의 /etc/origin/master/master.env 파일에 설정되어 있고 노드의 /etc/sysconfig/atomic-openshift-node 파일에 설정되어 있는지 확인합니다.
AWS_ACCESS_KEY_ID=<key_ID>
AWS_SECRET_ACCESS_KEY=<secret_key>AWS IAM 사용자를 설정할 때 액세스 키를 가져옵니다.
20.5. 구성 변경 사항 적용
모든 마스터 및 노드 호스트에서 OpenShift Container Platform 서비스를 시작하거나 다시 시작하여 구성 변경 사항을 적용하려면 OpenShift Container Platform 서비스 재시작을 참조하십시오.
# master-restart api
# master-restart controllers
# systemctl restart atomic-openshift-nodeKubernetes 아키텍처에서는 클라우드 공급자의 끝점이 안정적인 것으로 예상합니다. 클라우드 공급자가 중단되면 kubelet에서 OpenShift Container Platform이 재시작되지 않습니다. 기본 클라우드 공급자 끝점이 안정적이지 않은 경우 클라우드 공급자 통합을 사용하는 클러스터를 설치하지 마십시오. 베어 메탈 환경인 것처럼 클러스터를 설치합니다. 설치된 클러스터에서 클라우드 공급자 통합을 설정하거나 해제하는 것은 권장되지 않습니다. 그러나 해당 시나리오를 사용할 수 없는 경우 다음 프로세스를 완료합니다.
클라우드 프로바이더를 사용하지 않고 클라우드 프로바이더를 사용하여 전환하면 오류 메시지가 생성됩니다. 노드가 externalID (클라우드 공급업체가 사용되지 않은 경우)로 호스트 이름을 사용하지 않고 전환하여 클라우드 프로바이더의 instance-id (클라우드 공급자가 지정하는 내용)를 사용하도록 전환하므로 클라우드 프로바이더를 추가하는 경우 노드 삭제를 시도합니다. 이 문제를 해결하려면 다음을 수행합니다.
- 클러스터 관리자로 CLI에 로그인합니다.
기존 노드 라벨을 확인하고 백업합니다.
$ oc describe node <node_name> | grep -Poz '(?s)Labels.*\n.*(?=Taints)'노드를 삭제합니다.
$ oc delete node <node_name>각 노드 호스트에서 OpenShift Container Platform 서비스를 다시 시작합니다.
# systemctl restart atomic-openshift-node- 이전에 보유한 각 노드에 레이블을 다시 추가합니다.
20.6. AWS의 클러스터 레이블 지정
AWS 공급자 자격 증명을 구성하는 경우 모든 호스트에 레이블이 지정되어 있는지 확인해야 합니다.
클러스터와 연결된 리소스를 올바르게 식별하려면 kubernetes.io/cluster/<clusterid> 키를 사용하여 리소스에 태그를 지정합니다.
-
<clusterid>는 클러스터의 고유한 이름입니다.
노드가 클러스터에만 속하는 경우 해당 값을 owned로 설정하거나 다른 시스템과 공유되는 리소스인 경우 shared로 설정합니다.
kubernetes.io/cluster/<clusterid>,Value=(owned|shared) 태그로 모든 리소스를 태그하면 여러 영역 또는 여러 클러스터에 잠재적인 문제가 발생하지 않습니다.
OpenShift Container Platform의 레이블 지정 및 태그 지정에 대한 자세한 내용은 Pod 및 서비스를 참조하십시오.
20.6.1. 태그가 필요한 리소스
태그해야 하는 4가지 유형의 리소스가 있습니다.
- 인스턴스
- 보안 그룹
- 로드 밸런서
- EBS 볼륨
20.6.2. 기존 클러스터 태그
클러스터는 kubernetes.io/cluster/<clusterid>,Value=(owned|shared) 태그 값을 사용하여 AWS 클러스터에 속하는 리소스를 결정합니다. 즉, 모든 관련 리소스에 해당 키에 대해 동일한 값을 사용하여 kubernetes.io/cluster/<clusterid>,Value=(owned|shared) 태그로 레이블이 지정되어야 합니다. 이러한 리소스는 다음과 같습니다.
- 모든 호스트.
- AWS 인스턴스에서 사용할 모든 관련 로드 밸런서.
모든 EBS 볼륨. 태그가 지정해야 하는 EBS 볼륨은 다음을 사용하여 찾을 수 있습니다.
$ oc get pv -o json|jq '.items[].spec.awsElasticBlockStore.volumeID'AWS 인스턴스와 함께 사용할 모든 관련 보안 그룹입니다.
참고kubernetes.io/cluster/<name>,Value=<clusterid>태그로 기존 보안 그룹을 태그하지 마십시오. 그렇지 않으면 ELB(Elastic Load Balancing)에서 로드 밸런서를 생성할 수 없습니다.
리소스에 태그를 지정한 후 마스터의 마스터 서비스를 다시 시작하고 모든 노드에서 노드 서비스를 다시 시작합니다. 구성 적용 섹션 을 참조하십시오.
20.6.3. Red Hat OpenShift Container Storage 정보
RHOCS(Red Hat OpenShift Container Storage)는 사내 또는 하이브리드 클라우드에 있는 OpenShift Container Platform의 영구 스토리지 공급자입니다. RHOCS는 Red Hat 스토리지 솔루션으로 OpenShift Container Platform(컨버지드) 또는 OpenShift Container Platform(독립적인)에 설치되어 있는지 여부에 관계없이 배포, 관리 및 모니터링을 위해 OpenShift Container Platform과 완전히 통합됩니다. OpenShift Container Storage는 단일 가용성 영역 또는 노드로 국한되지 않으므로 중단 후에도 유지될 수 있습니다. RHOCS를 사용하는 전체 지침은 RH OCS3.11 배포 가이드에서 확인할 수 있습니다.
21장. Red Hat Virtualization 구성
bastion 가상 머신을 생성하고 이를 사용하여 OpenShift Container Platform을 설치하여 Red Hat Virtualization용 OpenShift Container Platform을 구성할 수 있습니다.
21.1. bastion 가상 머신 생성
Red Hat Virtualization에서 bastion 가상 머신을 생성하여 OpenShift Container Platform을 설치합니다.
절차
- SSH를 사용하여 Manager 시스템에 로그인합니다.
- 설치 파일에 임시 bastion 설치 디렉터리(예: /bastion_installation )를 만듭니다.
ansible-vault를 사용하여 암호화된 /bastion_installation/secure_vars.yaml 파일을 생성하고 암호를 기록합니다.# ansible-vault create secure_vars.yamlsecure_vars.yaml 파일에 다음 매개변수 값을 추가합니다.
engine_password: <Manager_password>1 bastion_root_password: <bastion_root_password>2 rhsub_user: <Red_Hat_Subscription_Manager_username>3 rhsub_pass: <Red_Hat_Subscription_Manager_password> rhsub_pool: <Red_Hat_Subscription_Manager_pool_id>4 root_password: <OpenShift_node_root_password>5 engine_cafile: <RHVM_CA_certificate>6 oreg_auth_user: <image_registry_authentication_username>7 oreg_auth_password: <image_registry_authentication_password>- 1
- 관리 포털에 로그인하기 위한 암호.
- 2
- bastion 가상 시스템의 루트 암호입니다.
- 3
- Red Hat Subscription Manager 자격 증명.
- 4
- Red Hat Virtualization Manager 서브스크립션 풀의 풀 ID.
- 5
- OpenShift Container Platform 루트 암호.
- 6
- Red Hat Virtualization Manager CA 인증서. Manager 시스템에서 플레이북을 실행하지 않는 경우
engine_cafile값이 필요합니다. Manager CA 인증서의 기본 위치는 /etc/pki/ovirt-engine/ca.pem 입니다. - 7
- 인증이 필요한 이미지 레지스트리를 사용하는 경우 인증 정보를 추가합니다.
- 파일을 저장합니다.
Red Hat Enterprise Linux KVM 게스트 이미지 다운로드 링크를 가져옵니다.
- Red Hat 고객 포털로 이동합니다. Red Hat Enterprise Linux 다운로드.
- Product Software(제품 소프트웨어 ) 탭에서 Red Hat Enterprise Linux KVM 게스트 이미지를 찾습니다.
지금 다운로드를 마우스 오른쪽 버튼으로 클릭하고 링크를 복사한 다음 저장합니다.
링크는 시간에 민감하며 bastion 가상 시스템을 생성하기 전에 복사해야 합니다.
다음 콘텐츠를 사용하여 /bastion_installation/create-bastion-machine-playbook.yaml 파일을 생성하고 매개변수 값을 업데이트합니다.
--- - name: Create a bastion machine hosts: localhost connection: local gather_facts: false no_log: true roles: - oVirt.image-template - oVirt.vm-infra no_log: true vars: engine_url: https://_Manager_FQDN_/ovirt-engine/api1 engine_user: <admin@internal> engine_password: "{{ engine_password }}" engine_cafile: /etc/pki/ovirt-engine/ca.pem qcow_url: <RHEL_KVM_guest_image_download_link>2 template_cluster: Default template_name: rhelguest7 template_memory: 4GiB template_cpu: 2 wait_for_ip: true debug_vm_create: false vms: - name: rhel-bastion cluster: "{{ template_cluster }}" profile: cores: 2 template: "{{ template_name }}" root_password: "{{ root_password }}" ssh_key: "{{ lookup('file', '/root/.ssh/id_rsa_ssh_ocp_admin.pub') }}" state: running cloud_init: custom_script: | rh_subscription: username: "{{ rhsub_user }}" password: "{{ rhsub_pass }}" auto-attach: true disable-repo: ['*'] # 'rhel-7-server-rhv-4.2-manager-rpms' supports RHV 4.2 and 4.3 enable-repo: ['rhel-7-server-rpms', 'rhel-7-server-extras-rpms', 'rhel-7-server-ansible-2.7-rpms', 'rhel-7-server-ose-3.11-rpms', 'rhel-7-server-supplementary-rpms', 'rhel-7-server-rhv-4.2-manager-rpms'] packages: - ansible - ovirt-ansible-roles - openshift-ansible - python-ovirt-engine-sdk4 pre_tasks: - name: Create an ssh key-pair for OpenShift admin user: name: root generate_ssh_key: yes ssh_key_file: .ssh/id_rsa_ssh_ocp_admin roles: - oVirt.image-template - oVirt.vm-infra - name: post installation tasks on the bastion machine hosts: rhel-bastion tasks: - name: create ovirt-engine PKI dir file: state: directory dest: /etc/pki/ovirt-engine/ - name: Copy the engine ca cert to the bastion machine copy: src: "{{ engine_cafile }}" dest: "{{ engine_cafile }}" - name: Copy the secured vars to the bastion machine copy: src: secure_vars.yaml dest: secure_vars.yaml decrypt: false - file: state: directory path: /root/.ssh - name: copy the OpenShift_admin keypair to the bastion machine copy: src: "{{ item }}" dest: "{{ item }}" mode: 0600 with_items: - /root/.ssh/id_rsa_ssh_ocp_admin - /root/.ssh/id_rsa_ssh_ocp_admin.pub- 1
- 관리자 시스템의 FQDN.
- 2
<qcow_url>은 Red Hat Enterprise Linux KVM 게스트 이미지의 다운로드 링크입니다. Red Hat Enterprise Linux KVM 게스트 이미지 에는 이 플레이북에 필요한cloud-init패키지가 포함되어 있습니다. Red Hat Enterprise Linux를 사용하지 않는 경우, 이 플레이북을 실행하기 전에cloud-init패키지를 다운로드하여 수동으로 설치합니다.
bastion 가상 머신을 생성합니다.
# ansible-playbook -i localhost create-bastion-machine-playbook.yaml -e @secure_vars.yaml --ask-vault-pass- 관리 포털에 로그인합니다.
- → (가상 시스템) 를 클릭하여 rhel-bastion 가상 시스템이 성공적으로 생성되었는지 확인합니다.
21.2. bastion 가상 머신으로 OpenShift Container Platform 설치
Red Hat Virtualization에서 bastion 가상 머신을 사용하여 OpenShift Container Platform을 설치합니다.
절차
- rhel-bastion 에 로그인합니다.
다음 내용이 포함된 install_ocp.yaml 파일을 생성합니다.
--- - name: Openshift on RHV hosts: localhost connection: local gather_facts: false vars_files: - vars.yaml - secure_vars.yaml pre_tasks: - ovirt_auth: url: "{{ engine_url }}" username: "{{ engine_user }}" password: "{{ engine_password }}" insecure: "{{ engine_insecure }}" ca_file: "{{ engine_cafile | default(omit) }}" roles: - role: openshift_ovirt - import_playbook: setup_dns.yaml - import_playbook: /usr/share/ansible/openshift-ansible/playbooks/prerequisites.yml - import_playbook: /usr/share/ansible/openshift-ansible/playbooks/openshift-node/network_manager.yml - import_playbook: /usr/share/ansible/openshift-ansible/playbooks/deploy_cluster.yml다음 내용이 포함된 setup_dns.yaml 파일을 생성합니다.
- hosts: masters strategy: free tasks: - shell: "echo {{ ansible_default_ipv4.address }} {{ inventory_hostname }} etcd.{{ inventory_hostname.split('.', 1)[1] }} openshift-master.{{ inventory_hostname.split('.', 1)[1] }} openshift-public-master.{{ inventory_hostname.split('.', 1)[1] }} docker-registry-default.apps.{{ inventory_hostname.split('.', 1)[1] }} webconsole.openshift-web-console.svc registry-console-default.apps.{{ inventory_hostname.split('.', 1)[1] }} >> /etc/hosts" when: openshift_ovirt_all_in_one is defined | ternary((openshift_ovirt_all_in_one | bool), false)다음 콘텐츠를 포함하는 /etc/ansible/openshift_3_11.hosts Ansible 인벤토리 파일을 생성합니다.
[workstation] localhost ansible_connection=local [all:vars] openshift_ovirt_dns_zone="{{ public_hosted_zone }}" openshift_web_console_install=true openshift_master_overwrite_named_certificates=true openshift_master_cluster_hostname="openshift-master.{{ public_hosted_zone }}" openshift_master_cluster_public_hostname="openshift-public-master.{{ public_hosted_zone }}" openshift_master_default_subdomain="{{ public_hosted_zone }}" openshift_public_hostname="{{openshift_master_cluster_public_hostname}}" openshift_deployment_type=openshift-enterprise openshift_service_catalog_image_version="{{ openshift_image_tag }}" [OSEv3:vars] # General variables debug_level=1 containerized=false ansible_ssh_user=root os_firewall_use_firewalld=true openshift_enable_excluders=false openshift_install_examples=false openshift_clock_enabled=true openshift_debug_level="{{ debug_level }}" openshift_node_debug_level="{{ node_debug_level | default(debug_level,true) }}" osn_storage_plugin_deps=[] openshift_master_bootstrap_auto_approve=true openshift_master_bootstrap_auto_approver_node_selector={"node-role.kubernetes.io/master":"true"} osm_controller_args={"experimental-cluster-signing-duration": ["20m"]} osm_default_node_selector="node-role.kubernetes.io/compute=true" openshift_enable_service_catalog=false # Docker container_runtime_docker_storage_type=overlay2 openshift_docker_use_system_container=false [OSEv3:children] nodes masters etcd lb [masters] [nodes] [etcd] [lb]Red Hat Enterprise Linux KVM 게스트 이미지 다운로드 링크를 가져옵니다.
- Red Hat 고객 포털로 이동합니다. Red Hat Enterprise Linux 다운로드.
- Product Software(제품 소프트웨어 ) 탭에서 Red Hat Enterprise Linux KVM 게스트 이미지를 찾습니다.
지금 다운로드를 마우스 오른쪽 버튼으로 클릭하고 링크를 복사한 다음 저장합니다.
bastion 가상 시스템을 생성할 때 복사한 링크를 사용하지 마십시오. 다운로드 링크는 시간에 민감하며 설치 플레이북을 실행하기 전에 복사해야 합니다.
다음 콘텐츠를 사용하여 vars.yaml 파일을 생성하고 매개 변수 값을 업데이트합니다.
--- # For detailed documentation of variables, see # openshift_ovirt: https://github.com/openshift/openshift-ansible/tree/master/roles/openshift_ovirt#role-variables # openshift installation: https://github.com/openshift/openshift-ansible/tree/master/inventory engine_url: https://<Manager_FQDN>/ovirt-engine/api1 engine_user: admin@internal engine_password: "{{ engine_password }}" engine_insecure: false engine_cafile: /etc/pki/ovirt-engine/ca.pem openshift_ovirt_vm_manifest: - name: 'master' count: 1 profile: 'master_vm' - name: 'compute' count: 0 profile: 'node_vm' - name: 'lb' count: 0 profile: 'node_vm' - name: 'etcd' count: 0 profile: 'node_vm' - name: infra count: 0 profile: node_vm # Currently, only all-in-one installation (`openshift_ovirt_all_in_one: true`) is supported. # Multi-node installation (master and node VMs installed separately) will be supported in a future release. openshift_ovirt_all_in_one: true openshift_ovirt_cluster: Default openshift_ovirt_data_store: data openshift_ovirt_ssh_key: "{{ lookup('file', '/root/.ssh/id_rsa_ssh_ocp_admin.pub') }}" public_hosted_zone: # Uncomment to disable install-time checks, for smaller scale installations #openshift_disable_check: memory_availability,disk_availability,docker_image_availability qcow_url: <RHEL_KVM_guest_image_download_link>2 image_path: /var/tmp template_name: rhelguest7 template_cluster: "{{ openshift_ovirt_cluster }}" template_memory: 4GiB template_cpu: 1 template_disk_storage: "{{ openshift_ovirt_data_store }}" template_disk_size: 100GiB template_nics: - name: nic1 profile_name: ovirtmgmt interface: virtio debug_vm_create: false wait_for_ip: true vm_infra_wait_for_ip_retries: 30 vm_infra_wait_for_ip_delay: 20 node_item: &node_item cluster: "{{ openshift_ovirt_cluster }}" template: "{{ template_name }}" memory: "8GiB" cores: "2" high_availability: true disks: - name: docker size: 15GiB interface: virtio storage_domain: "{{ openshift_ovirt_data_store }}" - name: openshift size: 30GiB interface: virtio storage_domain: "{{ openshift_ovirt_data_store }}" state: running cloud_init: root_password: "{{ root_password }}" authorized_ssh_keys: "{{ openshift_ovirt_ssh_key }}" custom_script: "{{ cloud_init_script_node | to_nice_yaml }}" openshift_ovirt_vm_profile: master_vm: <<: *node_item memory: 16GiB cores: "{{ vm_cores | default(4) }}" disks: - name: docker size: 15GiB interface: virtio storage_domain: "{{ openshift_ovirt_data_store }}" - name: openshift_local size: 30GiB interface: virtio storage_domain: "{{ openshift_ovirt_data_store }}" - name: etcd size: 25GiB interface: virtio storage_domain: "{{ openshift_ovirt_data_store }}" cloud_init: root_password: "{{ root_password }}" authorized_ssh_keys: "{{ openshift_ovirt_ssh_key }}" custom_script: "{{ cloud_init_script_master | to_nice_yaml }}" node_vm: <<: *node_item etcd_vm: <<: *node_item lb_vm: <<: *node_item cloud_init_script_node: &cloud_init_script_node packages: - ovirt-guest-agent runcmd: - sed -i 's/# ignored_nics =.*/ignored_nics = docker0 tun0 /' /etc/ovirt-guest-agent.conf - systemctl enable ovirt-guest-agent - systemctl start ovirt-guest-agent - mkdir -p /var/lib/docker - mkdir -p /var/lib/origin/openshift.local.volumes - /usr/sbin/mkfs.xfs -L dockerlv /dev/vdb - /usr/sbin/mkfs.xfs -L ocplv /dev/vdc mounts: - [ '/dev/vdb', '/var/lib/docker', 'xfs', 'defaults,gquota' ] - [ '/dev/vdc', '/var/lib/origin/openshift.local.volumes', 'xfs', 'defaults,gquota' ] power_state: mode: reboot message: cloud init finished - boot and install openshift condition: True cloud_init_script_master: <<: *cloud_init_script_node runcmd: - sed -i 's/# ignored_nics =.*/ignored_nics = docker0 tun0 /' /etc/ovirt-guest-agent.conf - systemctl enable ovirt-guest-agent - systemctl start ovirt-guest-agent - mkdir -p /var/lib/docker - mkdir -p /var/lib/origin/openshift.local.volumes - mkdir -p /var/lib/etcd - /usr/sbin/mkfs.xfs -L dockerlv /dev/vdb - /usr/sbin/mkfs.xfs -L ocplv /dev/vdc - /usr/sbin/mkfs.xfs -L etcdlv /dev/vdd mounts: - [ '/dev/vdb', '/var/lib/docker', 'xfs', 'defaults,gquota' ] - [ '/dev/vdc', '/var/lib/origin/openshift.local.volumes', 'xfs', 'defaults,gquota' ] - [ '/dev/vdd', '/var/lib/etcd', 'xfs', 'defaults,gquota' ]- 1
- 관리자 시스템의 FQDN.
- 2
<qcow_url>은 Red Hat Enterprise Linux KVM 게스트 이미지의 다운로드 링크입니다. Red Hat Enterprise Linux KVM 게스트 이미지 에는 이 플레이북에 필요한cloud-init패키지가 포함되어 있습니다. Red Hat Enterprise Linux를 사용하지 않는 경우, 이 플레이북을 실행하기 전에cloud-init패키지를 다운로드하여 수동으로 설치합니다.
OpenShift Container Platform을 설치합니다.
# export ANSIBLE_ROLES_PATH="/usr/share/ansible/roles/:/usr/share/ansible/openshift-ansible/roles" # export ANSIBLE_JINJA2_EXTENSIONS="jinja2.ext.do" # ansible-playbook -i /etc/ansible/openshift_3_11.hosts install_ocp.yaml -e @vars.yaml -e @secure_vars.yaml --ask-vault-pass- 각 인프라 인스턴스에 대해 라우터의 DNS 항목을 만듭니다.
- 라우터에서 애플리케이션에 트래픽을 전달할 수 있도록 라운드 로빈 라우팅을 구성합니다.
- OpenShift Container Platform 웹 콘솔의 DNS 항목을 생성합니다.
- 로드 밸런서 노드의 IP 주소를 지정합니다.
22장. OpenStack 구성
22.1. 개요
OpenStack 에 배포되는 경우 애플리케이션 데이터를 위한 영구 스토리지로 OpenStack Cinder 볼륨을 사용하는 등 OpenStack 인프라에 액세스하도록 OpenShift Container Platform을 구성할 수 있습니다.
OpenShift Container Platform 3.11은 Red Hat OpenStack Platform 13에서 사용할 수 있습니다.
최신 OpenShift Container Platform 릴리스는 최신 Red Hat OpenStack Platform 장기 릴리스 및 중간 릴리스를 모두 지원합니다. OpenShift Container Platform 및 Red Hat OpenStack Platform의 릴리스 주기는 다르며 테스트된 버전은 두 제품의 릴리스 날짜에 따라 향후 달라질 수 있습니다.
22.2. 시작하기 전에
22.2.1. OpenShift Container Platform SDN
기본 OpenShift Container Platform SDN은 OpenShiftSDN 입니다. Kuryr SDN 을 사용하는 또 다른 옵션이 있습니다.
22.2.2. Kuryr SDN
Kuryr는 Neutron 및 Octavia를 사용하여 Pod 및 서비스에 네트워킹을 제공하는 CNI 플러그인입니다. 주로 OpenStack 가상 시스템에서 실행되는 OpenShift Container Platform 클러스터용으로 설계되었습니다. Kuryr는 OpenShift Container Platform Pod를 OpenStack SDN에 연결하여 네트워크 성능을 향상시킵니다. 또한 OpenShift Container Platform Pod와 OpenStack 가상 인스턴스 간의 상호 연결성을 제공합니다.
Kuryr는 OpenStack 네트워크를 통해 캡슐화된 OpenShift SDN을 실행하는 등 이중 캡슐화를 방지하기 위해 캡슐화된 OpenStack 테넌트 네트워크에 OpenShift Container Platform 배포를 권장합니다. Kuryr는 VXLAN, GRE 또는 GENEVE가 필요할 때마다 권장됩니다.
반대로 Kuryr 구현은 다음과 같은 경우 의미가 없습니다.
- 프로바이더 네트워크, 테넌트 VLAN 또는 Cisco ACI 또는 Juniper Contrail와 같은 타사 상용 SDN을 사용합니다.
- 배포에서는 몇 개의 하이퍼바이저 또는 OpenShift Container Platform 가상 머신 노드에서 많은 서비스를 사용합니다. 각 OpenShift Container Platform 서비스는 필요한 로드 밸런서를 호스팅하는 OpenStack에서 Octavia Amphora 가상 머신을 생성합니다.
Kuryr SDN을 활성화하려면 환경이 다음 요구사항을 충족해야 합니다.
- OpenStack 13 이상 실행
- Octavia가 있는 오버클라우드
- Neutron 트렁크 포트 확장 활성화
- ML2/OVS Neutron 드라이버를 사용하는 경우 ovs-hybrid 대신 OpenvSwitch 방화벽 드라이버를 사용해야 합니다.
OpenStack 13.0.13에서 Kuryr를 사용하려면 Kuryr 컨테이너 이미지는 버전 3.11.306 이상이어야 합니다.
22.2.3. OpenShift Container Platform 사전 요구 사항
OpenShift Container Platform을 성공적으로 배포하려면 많은 사전 요구 사항이 필요합니다. Ansible을 사용하여 OpenShift Container Platform을 실제로 설치하기 전에 인프라 및 호스트 구성 단계 집합으로 구성됩니다. 다음 후속 섹션에서는 OpenStack 환경의 OpenShift Container Platform에 필요한 사전 요구 사항 및 구성 변경 사항에 대한 자세한 내용은 자세히 설명합니다.
이 참조 환경의 모든 OpenStack CLI 명령은 director 노드의 다른 노드 내에서 CLI openstack 명령을 사용하여 실행됩니다. 명령은 패키지가 Ansible 버전 2.6 이상과 충돌하지 않도록 다른 노드에서 실행됩니다. 지정된 리포지토리에 다음 패키지를 설치해야 합니다.
예제:
Set Up Repositories 에서 rhel-7-server-openstack-13-tools-rpms 및 필요한 OpenShift Container Platform 리포지토리를 활성화합니다.
$ sudo subscription-manager repos \
--enable rhel-7-server-openstack-{rhosp_version}-tools-rpms \
--enable rhel-7-server-openstack-14-tools-rpms
$ sudo subscription-manager repo-override --repo=rhel-7-server-openstack-14-tools-rpms --add=includepkgs:"python2-openstacksdk.* python2-keystoneauth1.* python2-os-service-types.*"
$ sudo yum install -y python2-openstackclient python2-heatclient python2-octaviaclient ansible
패키지가 최소한 다음 버전인지 확인합니다( rpm -q <package_name>사용).
-
python2-openstackclient-3.14.1.-1 -
python2-heatclient1.14.0-1 -
python2-octaviaclient1.4.0-1 -
python2-openstacksdk0.17.2
22.2.3.1. Octavia 활성화: LBaaS(OpenStack Load Balancing as a Service)
Octavia는 외부 들어오는 트래픽을 로드하고 애플리케이션에 대한 OpenShift Container Platform 마스터 서비스의 단일 보기를 제공하기 위해 OpenShift Container Platform과 함께 사용하는 것이 권장되는 지원되는 로드 밸런서 솔루션입니다.
Octavia를 활성화하려면 OpenStack overcloud 설치 중에 Octavia 서비스를 포함하거나 오버클라우드가 이미 존재하는 경우 업그레이드해야 합니다. 다음 단계에서는 Octavia 활성화의 기본 사용자 지정되지 않은 단계를 제공하고 오버클라우드 정리 또는 오버클라우드 업데이트에 모두 적용합니다.
다음 단계는 Octavia를 처리할 때 OpenStack 배포 중에 필요한 주요 부분만 다룹니다. 자세한 내용은 OpenStack 설치 설명서를 참조하십시오. 레지스트리 방법도 다를 수 있습니다. 자세한 내용은 레지스트리 메서드 설명서를 참조하십시오. 이 예에서는 로컬 레지스트리 방법을 사용했습니다.
로컬 레지스트리를 사용하는 경우 이미지를 레지스트리에 업로드할 템플릿을 생성합니다. 아래에 표시된 예.
(undercloud) $ openstack overcloud container image prepare \
-e /usr/share/openstack-tripleo-heat-templates/environments/services-docker/octavia.yaml \
--namespace=registry.access.redhat.com/rhosp13 \
--push-destination=<local-ip-from-undercloud.conf>:8787 \
--prefix=openstack- \
--tag-from-label {version}-{release} \
--output-env-file=/home/stack/templates/overcloud_images.yaml \
--output-images-file /home/stack/local_registry_images.yaml생성된 local_registry_images.yaml 에 Octavia 이미지가 포함되어 있는지 확인합니다.
로컬 레지스트리 파일의 Octavia 이미지
...
- imagename: registry.access.redhat.com/rhosp13/openstack-octavia-api:13.0-43
push_destination: <local-ip-from-undercloud.conf>:8787
- imagename: registry.access.redhat.com/rhosp13/openstack-octavia-health-manager:13.0-45
push_destination: <local-ip-from-undercloud.conf>:8787
- imagename: registry.access.redhat.com/rhosp13/openstack-octavia-housekeeping:13.0-45
push_destination: <local-ip-from-undercloud.conf>:8787
- imagename: registry.access.redhat.com/rhosp13/openstack-octavia-worker:13.0-44
push_destination: <local-ip-from-undercloud.conf>:8787Octavia 컨테이너 버전은 설치된 특정 Red Hat OpenStack Platform 릴리스에 따라 달라집니다.
다음 단계에서는 registry.redhat.io 에서 언더클라우드 노드로 컨테이너 이미지를 가져옵니다. 이 프로세스는 네트워크 및 Undercloud 디스크의 속도에 따라 다소 시간이 걸릴 수 있습니다.
(undercloud) $ sudo openstack overcloud container image upload \
--config-file /home/stack/local_registry_images.yaml \
--verboseOpenShift API에 액세스하는 데 Octavia 로드 밸런서를 사용하므로 연결에 대한 리스너 기본 시간 초과를 늘려야 합니다. 기본 제한 시간은 50초입니다. 다음 파일을 오버클라우드 배포 명령에 전달하여 시간 초과를 20분으로 늘립니다.
(undercloud) $ cat octavia_timeouts.yaml
parameter_defaults:
OctaviaTimeoutClientData: 1200000
OctaviaTimeoutMemberData: 1200000이는 Red Hat OpenStack Platform 14 이상에서는 필요하지 않습니다.
Octavia를 사용하여 오버클라우드 환경을 설치하거나 업데이트합니다.
openstack overcloud deploy --templates \
.
.
.
-e /usr/share/openstack-tripleo-heat-templates/environments/services-docker/octavia.yaml \
-e octavia_timeouts.yaml
.
.
.위의 명령에는 Octavia와 연결된 파일만 포함됩니다. 이 명령은 OpenStack의 특정 설치에 따라 달라집니다. 자세한 내용은 공식 OpenStack 설명서를 참조하십시오. Octavia 설치 사용자 지정에 대한 자세한 내용은 Director를 사용하여 Octavia 설치를 참조하십시오.
Kuryr SDN을 사용하는 경우 Neutron에서 오버클라우드 설치에 "trunk" 확장 기능을 활성화해야 합니다. 이 기능은 기본적으로 Director 배포에서 활성화됩니다. Neutron 백엔드가 ML2/OVS인 경우 기본 ovs-hybrid 대신 openvswitch 방화벽을 사용합니다. 백엔드가 ML2/OVN인 경우에는 수정하지 않아도 됩니다.
22.2.3.2. OpenStack 사용자 계정, 프로젝트 및 역할 생성
OpenShift Container Platform을 설치하기 전에 RHOSP(Red Hat OpenStack Platform) 환경에는 OpenShift Container Platform을 설치할 OpenStack 인스턴스를 저장하는 테넌트 라고 하는 프로젝트가 필요합니다. 이 프로젝트에는 사용자의 소유권과 해당 사용자의 역할을 _member_ 로 설정해야 합니다.
다음 단계에서는 위의 작업을 수행하는 방법을 보여줍니다.
OpenStack 오버클라우드 관리자로서,
RHOSP 인스턴스를 저장할 프로젝트(테넌트)를 생성합니다.
$ openstack project create <project>이전에 생성한 프로젝트의 소유권이 있는 RHOSP 사용자를 생성합니다.
$ openstack user create --password <password> <username>사용자의 역할을 설정합니다.
$ openstack role add --user <username> --project <project> _member_
새 RH OSP 프로젝트에 할당된 기본 할당량은 OpenShift Container Platform 설치에 충분하지 않습니다. 할당량을 최소 30개의 보안 그룹, 200개의 보안 그룹 규칙 및 200개의 포트로 늘립니다.
$ openstack quota set --secgroups 30 --secgroup-rules 200 --ports 200 <project>
- 1
<project>는 수정할 프로젝트 이름을 지정합니다.
22.2.3.3. Kuryr SDN에 대한 추가 단계
Kuryr SDN이 활성화된 경우 특히 네임스페이스 격리를 사용하는 경우 다음 최소 요구 사항을 충족하도록 프로젝트의 할당량을 늘립니다.
- 300개의 보안 그룹 - 각 네임 스페이스에 하나씩 각 로드 밸런서에 대해 추가
- 150개의 네트워크 - 각 네임 스페이스에 하나씩
- 150 서브넷 - 각 네임 스페이스에 하나씩
- 500개의 보안 그룹 규칙
- 500 포트 - Pod당 하나의 포트 및 풀 생성 속도를 높이기 위한 추가 포트
이는 글로벌 권장 사항이 아닙니다. 요구 사항에 맞게 할당량을 조정합니다.
네임스페이스 격리를 사용하는 경우 각 네임스페이스에 새 네트워크와 서브넷이 제공됩니다. 또한 네임스페이스의 Pod 간 트래픽을 활성화하기 위해 보안 그룹이 생성됩니다.
$ openstack quota set --networks 150 --subnets 150 --secgroups 300 --secgroup-rules 500 --ports 500 <project>
- 1
<project>는 수정할 프로젝트 이름을 지정합니다.
네임스페이스 분리를 활성화한 경우 프로젝트를 생성한 후 프로젝트 ID를 the octavia.conf 구성 파일에 추가해야 합니다. 이 단계를 수행하면 필요한 LoadBalancer 보안 그룹이 해당 프로젝트에 속하고 네임스페이스 간에 서비스 격리를 적용하도록 업데이트할 수 있습니다.
프로젝트 ID 가져오기
$ openstack project show *<project>* +-------------+----------------------------------+ | Field | Value | +-------------+----------------------------------+ | description | | | domain_id | default | | enabled | True | | id | PROJECT_ID | | is_domain | False | | name | *<project>* | | parent_id | default | | tags | [] | +-------------+----------------------------------+컨트롤러에서 프로젝트 ID를 [filename]octavia.conf에 추가하고 octavia worker를 다시 시작합니다.
$ source stackrc # undercloud credentials $ openstack server list +--------------------------------------+--------------+--------+-----------------------+----------------+------------+ │ | ID | Name | Status | Networks | Image | Flavor | │ +--------------------------------------+--------------+--------+-----------------------+----------------+------------+ │ | 6bef8e73-2ba5-4860-a0b1-3937f8ca7e01 | controller-0 | ACTIVE | ctlplane=192.168.24.8 | overcloud-full | controller | │ | dda3173a-ab26-47f8-a2dc-8473b4a67ab9 | compute-0 | ACTIVE | ctlplane=192.168.24.6 | overcloud-full | compute | │ +--------------------------------------+--------------+--------+-----------------------+----------------+------------+ $ ssh heat-admin@192.168.24.8 # ssh into the controller(s) controller-0$ vi /var/lib/config-data/puppet-generated/octavia/etc/octavia/octavia.conf [controller_worker] # List of project ids that are allowed to have Load balancer security groups # belonging to them. amp_secgroup_allowed_projects = PROJECT_ID controller-0$ sudo docker restart octavia_worker
22.2.3.4. RC 파일 구성
프로젝트를 구성하면 OpenStack 관리자가 OpenShift Container Platform 환경을 구현하는 사용자에게 필요한 모든 정보가 포함된 RC 파일을 생성할 수 있습니다.
예제 RC 파일:
$ cat path/to/examplerc
# Clear any old environment that may conflict.
for key in $( set | awk '{FS="="} /^OS_/ {print $1}' ); do unset $key ; done
export OS_PROJECT_DOMAIN_NAME=Default
export OS_USER_DOMAIN_NAME=Default
export OS_PROJECT_NAME=<project-name>
export OS_USERNAME=<username>
export OS_PASSWORD=<password>
export OS_AUTH_URL=http://<ip>:5000//v3
export OS_CLOUDNAME=<cloud-name>
export OS_IDENTITY_API_VERSION=3
# Add OS_CLOUDNAME to PS1
if [ -z "${CLOUDPROMPT_ENABLED:-}" ]; then
export PS1=${PS1:-""}
export PS1=\${OS_CLOUDNAME:+"(\$OS_CLOUDNAME)"}\ $PS1
export CLOUDPROMPT_ENABLED=1
fi동일한 도메인을 참조하는 한 기본값에서 _OS_PROJECT_DOMAIN_NAME 및 _OS_USER_DOMAIN_NAME을 변경합니다.
OpenStack director 노드 또는 워크스테이션에서 OpenShift Container Platform 환경을 구현하는 사용자로 다음과 같이 인증 정보를 가져와야 합니다.
$ source path/to/examplerc22.2.3.5. OpenStack 플레이버 만들기
OpenStack 내에서 플레이버는 Nova 컴퓨팅 인스턴스의 계산, 메모리 및 스토리지 용량을 정의하여 가상 서버의 크기를 정의합니다. 이 참조 아키텍처 내의 기본 이미지는 Red Hat Enterprise Linux 7.5이므로, m1.node 및 m1.master 크기 플레이버는 표 22.1. “OpenShift에 대한 최소 시스템 요구 사항” 에 표시된 대로 다음 사양을 사용하여 생성됩니다.
최소 시스템 요구 사항은 클러스터를 실행하기에 충분하지만 성능을 향상시키기 위해 마스터 노드에서 vCPU를 늘리는 것이 좋습니다. 또한 etcd가 마스터 노드에 공동 배치된 경우 더 많은 메모리를 사용하는 것이 좋습니다.
| 노드 유형 | CPU | RAM | 루트 디스크 | 플레이버 |
|---|---|---|---|---|
| 마스터 | 4 | 16GB | 45GB |
|
| 노드 | 1 | 8GB | 20GB |
|
OpenStack 관리자로서,
$ openstack flavor create <flavor_name> \
--id auto \
--ram <ram_in_MB> \
--disk <disk_in_GB> \
--vcpus <num_vcpus>아래 예는 이 참조 환경 내에서 플레이버 생성을 보여줍니다.
$ openstack flavor create m1.master \
--id auto \
--ram 16384 \
--disk 45 \
--vcpus 4
$ openstack flavor create m1.node \
--id auto \
--ram 8192 \
--disk 20 \
--vcpus 1OpenStack 관리자 권한에 액세스하여 새 플레이버를 생성할 수 없는 경우 표 22.1. “OpenShift에 대한 최소 시스템 요구 사항” 의 요구 사항을 충족하는 OpenStack 환경 내의 기존 플레이버를 사용합니다.
다음을 통한 OpenStack 플레이버 확인:
$ openstack flavor list22.2.3.6. OpenStack 키 쌍 생성
Red Hat OpenStack Platform은 cloud-init 를 사용하여 인스턴스에 대한 ssh 액세스를 허용하도록 생성될 때 각 인스턴스에 ssh 공개 키를 배치합니다. Red Hat OpenStack Platform은 사용자가 개인 키를 보유할 것으로 예상합니다.
개인 키를 분실하면 인스턴스에 액세스할 수 없게 됩니다.
키 쌍을 생성하려면 다음 명령을 사용합니다.
$ openstack keypair create <keypair-name> > /path/to/<keypair-name>.pem키 쌍 생성은 다음을 통해 수행할 수 있습니다.
$ openstack keypair list
키 쌍이 생성되면 권한을 600 으로 설정하여 파일의 소유자만 해당 파일을 읽고 쓸 수 있습니다.
$ chmod 600 /path/to/<keypair-name>.pem22.2.3.7. OpenShift Container Platform용 DNS 설정
DNS 서비스는 OpenShift Container Platform 환경에서 중요한 구성 요소입니다. DNS 공급자에 관계없이 다양한 OpenShift Container Platform 구성 요소를 충족하기 위해 조직에 특정 레코드가 있어야 합니다.
/etc/hosts 를 사용하는 것이 올바르지 않으므로 적절한 DNS 서비스가 있어야 합니다.
DNS의 키 시크릿을 사용하여 OpenShift Ansible 설치 프로그램에 정보를 제공할 수 있으며 대상 인스턴스 및 다양한 OpenShift Container Platform 구성 요소에 대한 A 레코드를 자동으로 추가할 수 있습니다. 이 프로세스 설정은 나중에 OpenShift Ansible 설치 프로그램을 구성할 때 설명합니다.
DNS 서버에 대한 액세스가 예상됩니다. 액세스 권한에 대한 지원을 위해 Red Hat Labs DNS 도우미 를 사용할 수 있습니다.
애플리케이션 DNS
OpenShift에서 제공하는 애플리케이션은 포트 80/TCP 및 443/TCP의 라우터에서 액세스할 수 있습니다. 라우터는 와일드카드 레코드를 사용하여 특정 하위 도메인의 모든 호스트 이름을 각 이름에 별도의 레코드 없이 동일한 IP 주소에 매핑합니다.
이를 통해 OpenShift Container Platform은 해당 하위 도메인에 있는 한 임의의 이름을 가진 애플리케이션을 추가할 수 있습니다.
예를 들어 *.apps.example.com의 와일드카드 레코드로 인해 에 대한 DNS 이름 조회가 동일한 IP 주소를 반환합니다. tax. apps.example.com 및 home- goods. apps.example.com10.19.x.y. 모든 트래픽이 OpenShift 라우터로 전달됩니다. 라우터는 쿼리의 HTTP 헤더를 검사하고 올바른 대상으로 전달합니다.
Octavia와 같은 로드 밸런서를 사용하면 호스트 주소가 10.19.x.y인 경우 와일드카드 DNS 레코드를 다음과 같이 추가할 수 있습니다.
| IP 주소 | 호스트 이름 | 목적 |
|---|---|---|
| 10.19.x.y |
| 애플리케이션 웹 서비스에 대한 사용자 액세스 |
22.2.3.8. OpenStack을 통한 OpenShift Container Platform 네트워크 생성
이 세그먼트에 설명된 대로 Red Hat OpenStack Platform에 OpenShift Container Platform을 배포할 때 요구 사항은 공용 및 내부 네트워크 2개입니다.
공용 네트워크
공용 네트워크는 외부 액세스가 포함되어 있으며 외부에서 연결할 수 있는 네트워크입니다. 공용 네트워크 생성은 OpenStack 관리자만 수행할 수 있습니다.
다음 명령은 공용 네트워크 액세스를 위한 OpenStack 프로바이더 네트워크를 생성하는 예를 제공합니다.
OpenStack 관리자(overcloudrc 액세스)로,
$ source /path/to/examplerc
$ openstack network create <public-net-name> \
--external \
--provider-network-type flat \
--provider-physical-network datacentre
$ openstack subnet create <public-subnet-name> \
--network <public-net-name> \
--dhcp \
--allocation-pool start=<float_start_ip>,end=<float_end_ip> \
--gateway <ip> \
--subnet-range <CIDR>네트워크와 서브넷을 만든 후에는 다음을 통해 확인합니다.
$ openstack network list
$ openstack subnet list
<float_start_ip> 및 <float_end_ip> 는 공용 네트워크에 레이블이 지정된 네트워크에 제공되는 연결된 유동 IP 풀입니다. CIDR(Classless Inter-Domain Routing)은 <ip>/<routing_prefix> 형식(예: 10.0.0.1/24)을 사용합니다.
내부 네트워크
내부 네트워크는 네트워크를 설정하는 동안 라우터를 통해 공용 네트워크에 연결됩니다. 이렇게 하면 내부 네트워크에 연결된 각 Red Hat OpenStack Platform 인스턴스가 공용 네트워크에서 공용 네트워크에서 유동 IP를 요청할 수 있습니다. 내부 네트워크는 openshift_openstack_private_network_name 을 설정하여 OpenShift Ansible 설치 프로그램에서 자동으로 생성됩니다. OpenShift Ansible 설치 프로그램에 필요한 변경 사항에 대한 자세한 내용은 나중에 설명합니다.
22.2.3.9. OpenStack 배포 호스트 보안 그룹 생성
OpenStack 네트워킹을 사용하면 네트워크의 각 인스턴스에 적용할 수 있는 인바운드 및 아웃바운드 트래픽 필터를 정의할 수 있습니다. 이를 통해 사용자는 인스턴스 서비스의 기능에 따라 각 인스턴스로 네트워크 트래픽을 제한할 수 있으며 호스트 기반 필터링에 의존하지 않습니다. OpenShift Ansible 설치 프로그램은 배포 호스트를 제외하고 OpenShift Container Platform 클러스터의 일부인 각 호스트 유형에 필요한 모든 포트 및 서비스의 올바른 생성을 처리합니다.
다음 명령은 배포 호스트에 대해 설정된 규칙 없이 빈 보안 그룹을 만듭니다.
$ source path/to/examplerc
$ openstack security group create <deployment-sg-name>보안 그룹 생성을 확인합니다.
$ openstack security group listDeployment Host Security Group
배포 인스턴스는 인바운드 ssh 만 허용하면 됩니다. 이 인스턴스는 OpenShift Container Platform 환경을 배포, 모니터링 및 관리할 수 있는 안정적인 기반을 제공하기 위해 존재합니다.
| 포트/프로토콜 | Service | 원격 소스 | 목적 |
|---|---|---|---|
| ICMP | ICMP | Any | ping, traceroute 등을 허용합니다. |
| 22/TCP | SSH | Any | 보안 쉘 로그인 |
위의 보안 그룹 규칙은 다음과 같습니다.
$ source /path/to/examplerc
$ openstack security group rule create \
--ingress \
--protocol icmp \
<deployment-sg-name>
$ openstack security group rule create \
--ingress \
--protocol tcp \
--dst-port 22 \
<deployment-sg-name>보안 그룹 규칙은 다음과 같습니다.
$ openstack security group rule list <deployment-sg-name>
+--------------------------------------+-------------+-----------+------------+-----------------------+
| ID | IP Protocol | IP Range | Port Range | Remote Security Group |
+--------------------------------------+-------------+-----------+------------+-----------------------+
| 7971fc03-4bfe-4153-8bde-5ae0f93e94a8 | icmp | 0.0.0.0/0 | | None |
| b8508884-e82b-4ee3-9f36-f57e1803e4a4 | None | None | | None |
| cb914caf-3e84-48e2-8a01-c23e61855bf6 | tcp | 0.0.0.0/0 | 22:22 | None |
| e8764c02-526e-453f-b978-c5ea757c3ac5 | None | None | | None |
+--------------------------------------+-------------+-----------+------------+-----------------------+22.2.3.10. OpenStack Cinder 볼륨
OpenStack 블록 스토리지는 cinder 서비스를 통해 영구적인 블록 스토리지 관리를 제공합니다. 블록 스토리지를 사용하면 OpenStack 사용자가 다른 OpenStack 인스턴스에 연결할 수 있는 볼륨을 만들 수 있습니다.
22.2.3.10.1. Docker 볼륨
마스터 및 노드 인스턴스에는 Docker 이미지를 저장할 볼륨이 포함되어 있습니다. 볼륨의 목적은 큰 이미지 또는 컨테이너가 기존 노드의 노드 성능이나 능력을 손상시키지 않도록 하는 것입니다.
컨테이너를 실행하려면 최소 15GB의 Docker 볼륨이 필요합니다. 이렇게 하려면 각 노드가 실행할 컨테이너 크기와 수에 따라 조정해야 합니다.
docker 볼륨은 openshift_openstack_docker_volume_size 변수를 통해 OpenShift Ansible 설치 프로그램에서 생성합니다. OpenShift Ansible 설치 프로그램에 필요한 변경 사항에 대한 자세한 내용은 나중에 설명합니다.
22.2.3.10.2. 레지스트리 볼륨
OpenShift 이미지 레지스트리에는 레지스트리가 다른 노드로 마이그레이션해야 하는 경우 이미지를 저장하려면 cinder 볼륨이 필요합니다. 다음 단계에서는 OpenStack을 통해 이미지 레지스트리를 생성하는 방법을 보여줍니다. 볼륨이 생성되면 나중에 설명된 대로 openshift_hosted_registry_storage_openstack_volumeID 매개 변수를 통해 OpenShift Ansible Installer OSEv3.yml 파일에 볼륨 ID가 포함됩니다.
$ source /path/to/examplerc
$ openstack volume create --size <volume-size-in-GB> <registry-name>레지스트리 볼륨 크기는 최소 30GB여야 합니다.
볼륨 생성을 확인합니다.
$ openstack volume list
----------------------------------------+------------------------------------------------+
| ID | Name | Status | Size | Attached to |
+--------------------------------------+-------------------------------------------------+
| d65209f0-9061-4cd8-8827-ae6e2253a18d | <registry-name>| available | 30 | |
+--------------------------------------+-------------------------------------------------+22.2.3.11. 배포 인스턴스 생성 및 구성
배포 인스턴스의 역할은 OpenShift Container Platform의 배포 및 관리를 위한 유틸리티 호스트 역할을 하는 것입니다.
배포 호스트 네트워크 및 라우터 생성
인스턴스를 만들기 전에 배포 호스트와의 통신을 위해 내부 네트워크 및 라우터를 만들어야 합니다. 다음 명령은 해당 네트워크 및 라우터를 생성합니다.
$ source path/to/examplerc
$ openstack network create <deployment-net-name>
$ openstack subnet create --network <deployment-net-name> \
--subnet-range <subnet_range> \
--dns-nameserver <dns-ip> \
<deployment-subnet-name>
$ openstack router create <deployment-router-name>
$ openstack router set --external-gateway <public-net-name> <deployment-router-name>
$ openstack router add subnet <deployment-router-name> <deployment-subnet-name>배포 인스턴스 배포
네트워크 및 보안 그룹을 만든 상태에서 인스턴스를 배포합니다.
$ domain=<domain>
$ netid1=$(openstack network show <deployment-net-name> -f value -c id)
$ openstack server create \
--nic net-id=$netid1 \
--flavor <flavor> \
--image <image> \
--key-name <keypair> \
--security-group <deployment-sg-name> \
deployment.$domain
m1.small 플레이버가 기본적으로 없는 경우 1 vCPU 및 2GB RAM의 요구 사항을 충족하는 기존 플레이버를 사용합니다.
배포 인스턴스에 유동 IP 생성 및 추가
배포 인스턴스가 생성되면 유동 IP를 만든 다음 인스턴스에 할당해야 합니다. 다음은 예를 보여줍니다.
$ source /path/to/examplerc
$ openstack floating ip create <public-network-name>
+---------------------+--------------------------------------+
| Field | Value |
+---------------------+--------------------------------------+
| created_at | 2017-08-24T22:44:03Z |
| description | |
| fixed_ip_address | None |
| floating_ip_address | 10.20.120.150 |
| floating_network_id | 084884f9-d9d2-477a-bae7-26dbb4ff1873 |
| headers | |
| id | 2bc06e39-1efb-453e-8642-39f910ac8fd1 |
| port_id | None |
| project_id | ca304dfee9a04597b16d253efd0e2332 |
| project_id | ca304dfee9a04597b16d253efd0e2332 |
| revision_number | 1 |
| router_id | None |
| status | DOWN |
| updated_at | 2017-08-24T22:44:03Z |
+---------------------+--------------------------------------+
위 출력 내에서 floating_ip_address 필드에 유동 IP 10.20.120.150 이 생성되었음을 표시합니다. 이 IP를 배포 인스턴스에 할당하려면 다음 명령을 실행합니다.
$ source /path/to/examplerc
$ openstack server add floating ip <deployment-instance-name> <ip>
예를 들어, instance deployment.example.com 에 IP 10.20.120.150 이 할당되는 경우 명령은 다음과 같습니다.
$ source /path/to/examplerc
$ openstack server add floating ip deployment.example.com 10.20.120.150배포 호스트에 RC 파일 추가
배포 호스트가 있으면 이전에 만든 RC 파일을 다음과 같이 scp 를 통해 배포 호스트에 복사합니다.
scp <rc-file-deployment-host> cloud-user@<ip>:/home/cloud-user/22.2.3.12. OpenShift Container Platform에 대한 배포 호스트 구성
다음 하위 섹션에서는 배포 인스턴스를 올바르게 구성하는 데 필요한 모든 단계를 설명합니다.
Deployment Host를 Jumphost로 사용하도록 ~/.ssh/config 구성
OpenShift Container Platform 환경에 쉽게 연결하려면 다음 단계를 따르십시오.
개인 키가 <keypair-name>.pem인 OpenStack director 노드 또는 로컬 워크스테이션에서 다음을 수행합니다.
$ exec ssh-agent bash
$ ssh-add /path/to/<keypair-name>.pem
Identity added: /path/to/<keypair-name>.pem (/path/to/<keypair-name>.pem)
~/.ssh/config 파일에 추가합니다.
Host deployment
HostName <deployment_fqdn_hostname OR IP address>
User cloud-user
IdentityFile /path/to/<keypair-name>.pem
ForwardAgent yes
인증 에이전트 연결 전달을 활성화하는 -A 옵션을 사용하여 배포 호스트에 SSH 로 연결합니다.
권한이 ~/.ssh/config 파일의 소유자에 대해서만 읽기 전용인지 확인합니다.
$ chmod 600 ~/.ssh/config$ ssh -A cloud-user@deployment
배포 호스트에 로그인한 후 SSH_AUTH_SOCK를 확인하여 ssh 에이전트 전달이 작동하는지 확인합니다.
$ echo "$SSH_AUTH_SOCK"
/tmp/ssh-NDFDQD02qB/agent.1387서브스크립션 관리자 및 OpenShift Container Platform 리포지토리 활성화
배포 인스턴스 내에서 Red Hat Subscription Manager에 등록합니다. 이 작업은 인증 정보를 사용하여 수행할 수 있습니다.
$ sudo subscription-manager register --username <user> --password '<password>'또는 활성화 키를 사용할 수 있습니다.
$ sudo subscription-manager register --org="<org_id>" --activationkey=<keyname>등록되고 나면 다음과 같이 다음 리포지토리를 활성화합니다.
$ sudo subscription-manager repos \
--enable="rhel-7-server-rpms" \
--enable="rhel-7-server-extras-rpms" \
--enable="rhel-7-server-ose-3.11-rpms" \
--enable="rhel-7-server-ansible-2.6-rpms" \
--enable="rhel-7-server-openstack-13-rpms" \
--enable="rhel-7-server-openstack-13-tools-rpms"활성화할 적절한 OpenShift Container Platform 리포지토리 및 Ansible 버전을 확인하려면 Set Up Repositories(리포지토리 설정)를 참조하십시오. 위의 파일은 샘플일 뿐입니다.
배포 호스트에 필요한 패키지
다음 패키지를 배포 호스트에 설치해야 합니다.
다음 패키지를 설치합니다.
-
openshift-ansible -
python-openstackclient -
python2-heatclient -
python2-octaviaclient -
python2-shade -
python-dns -
Git -
Ansible
$ sudo yum -y install openshift-ansible python-openstackclient python2-heatclient python2-octaviaclient python2-shade python-dns git ansibleAnsible 구성
Ansible 은 배포 인스턴스에 설치되어 마스터 및 노드 인스턴스에서 OpenShift Container Platform 환경의 등록, 설치 및 배포를 수행합니다.
플레이북을 실행하기 전에 배포하려는 환경을 반영하도록 ansible.cfg 파일을 생성하는 것이 중요합니다.
$ cat ~/ansible.cfg
[defaults]
forks = 20
host_key_checking = False
remote_user = openshift
gathering = smart
fact_caching = jsonfile
fact_caching_connection = $HOME/ansible/facts
fact_caching_timeout = 600
log_path = $HOME/ansible.log
nocows = 1
callback_whitelist = profile_tasks
inventory = /usr/share/ansible/openshift-ansible/playbooks/openstack/inventory.py,/home/cloud-user/inventory
[ssh_connection]
ssh_args = -o ControlMaster=auto -o ControlPersist=600s -o UserKnownHostsFile=/dev/null -o StrictHostKeyChecking=false
control_path = %(directory)s/%%h-%%r
pipelining = True
timeout = 10
[persistent_connection]
connect_timeout = 30
connect_retries = 30
connect_interval = 1다음 매개 변수 값은 ansible.cfg 파일에 중요합니다.
-
remote_user는 사용자 openshift 로 유지되어야 합니다. - inventory 매개 변수는 두 인벤토리 사이에 공백이 없도록 합니다.
예: inventory = path/to/inventory1,path/to/inventory2
위의 코드 블록은 파일의 기본값을 덮어쓸 수 있습니다. 배포 인스턴스에 복사된 키 쌍으로 <keypair-name>을 채워야 합니다.
인벤토리 폴더는 22.3.1절. “프로비저닝을 위한 인벤토리 준비” 에 생성됩니다.
OpenShift Authentication
OpenShift Container Platform은 다양한 인증 플랫폼을 사용할 수 있는 기능을 제공합니다. 인증 옵션 목록은 인증 및 사용자 에이전트 구성에서 사용할 수 있습니다.
기본 ID 프로바이더를 구성하는 것은 모두 거부되므로 중요합니다.
22.3. OpenShift Ansible 플레이북을 사용하여 OpenShift Container Platform 인스턴스 프로비저닝
배포 호스트의 생성 및 구성이 완료되면 Ansible을 사용하여 OpenShift Container Platform 배포를 위한 환경을 준비합니다. 다음 하위 섹션에서 Ansible이 구성되고 특정 YAML 파일이 OpenStack 배포 시 OpenShift Container Platform을 성공적으로 수행하도록 수정됩니다.
22.3.1. 프로비저닝을 위한 인벤토리 준비
이전 단계를 통해 openshift-ansible 패키지를 설치하면 배포 호스트의 cloud 디렉터리가 있습니다.
-user 홈 디렉터리에 복사할 sample- inventory
배포 호스트에서
$ cp -r /usr/share/ansible/openshift-ansible/playbooks/openstack/sample-inventory/ ~/inventory이 인벤토리 디렉터리 내에서 all.yml 파일에는 RHOCP 인스턴스를 성공적으로 프로비저닝하기 위해 설정해야 하는 다양한 매개 변수가 모두 포함되어 있습니다. OSEv3.yml 파일에는 all.yml 파일에 필요한 몇 가지 참조와 사용자 지정할 수 있는 모든 사용 가능한 OpenShift Container Platform 클러스터 매개변수가 포함되어 있습니다.
22.3.1.1. OpenShiftSDN All YAML file
all.yml 파일에는 특정 요구 사항에 맞게 수정할 수 있는 많은 옵션이 있습니다. 이 파일에서 수집한 정보는 OpenShift Container Platform을 성공적으로 배포하는 데 필요한 인스턴스의 프로비저닝 부분에 사용됩니다. 이러한 내용을 신중하게 검토하는 것이 중요합니다. 이 문서에서는 All YAML 파일의 압축된 버전을 제공하고 성공적인 배포를 위해 설정해야 하는 가장 중요한 매개 변수에 중점을 둡니다.
$ cat ~/inventory/group_vars/all.yml
---
openshift_openstack_clusterid: "openshift"
openshift_openstack_public_dns_domain: *"example.com"*
openshift_openstack_dns_nameservers: *["10.19.115.228"]*
openshift_openstack_public_hostname_suffix: "-public"
openshift_openstack_nsupdate_zone: "{{ openshift_openstack_public_dns_domain }}"
openshift_openstack_keypair_name: *"openshift"*
openshift_openstack_external_network_name: *"public"*
openshift_openstack_default_image_name: *"rhel75"*
## Optional (Recommended) - This removes the need for floating IPs
## on the OpenShift Cluster nodes
openshift_openstack_node_subnet_name: *<deployment-subnet-name>*
openshift_openstack_router_name: *<deployment-router-name>*
openshift_openstack_master_floating_ip: *false*
openshift_openstack_infra_floating_ip: *false*
openshift_openstack_compute_floating_ip: *false*
## End of Optional Floating IP section
openshift_openstack_num_masters: *3*
openshift_openstack_num_infra: *3*
openshift_openstack_num_cns: *0*
openshift_openstack_num_nodes: *2*
openshift_openstack_master_flavor: *"m1.master"*
openshift_openstack_default_flavor: *"m1.node"*
openshift_openstack_use_lbaas_load_balancer: *true*
openshift_openstack_docker_volume_size: "15"
# # Roll-your-own DNS
*openshift_openstack_external_nsupdate_keys:*
public:
*key_secret: '/alb8h0EAFWvb4i+CMA12w=='*
*key_name: "update-key"*
*key_algorithm: 'hmac-md5'*
*server: '<ip-of-DNS>'*
private:
*key_secret: '/alb8h0EAFWvb4i+CMA12w=='*
*key_name: "update-key"*
*key_algorithm: 'hmac-md5'*
*server: '<ip-of-DNS>'*
ansible_user: openshift
## cloud config
openshift_openstack_disable_root: true
openshift_openstack_user: openshift외부 DNS 서버를 사용하므로 private 및 public 섹션에서는 DNS 서버가 OpenStack 환경에 있지 않으므로 DNS 서버의 공용 IP 주소를 사용합니다.
별표(*)로 묶은 위의 값은 OpenStack 환경과 DNS 서버를 기반으로 수정해야 합니다.
모든 YAML 파일의 DNS 부분을 올바르게 수정하려면 DNS 서버에 로그인하고 다음 명령을 수행하여 키 이름, 키 알고리즘 및 키 시크릿을 캡처합니다.
$ ssh <ip-of-DNS>
$ sudo -i
# cat /etc/named/<key-name.key>
key "update-key" {
algorithm hmac-md5;
secret "/alb8h0EAFWvb4i+CMA02w==";
};키 이름은 다를 수 있으며 위의 이름은 예시일 뿐입니다.
22.3.1.2. KuryrSDN 모든 YAML 파일
다음 all.yml 파일은 기본 OpenShiftSDN 대신 Kuryr SDN을 활성화합니다. 아래 예제는 축소된 버전이므로 기본 템플릿을 주의 깊게 검토하는 것이 중요합니다.
$ cat ~/inventory/group_vars/all.yml
---
openshift_openstack_clusterid: "openshift"
openshift_openstack_public_dns_domain: *"example.com"*
openshift_openstack_dns_nameservers: *["10.19.115.228"]*
openshift_openstack_public_hostname_suffix: "-public"
openshift_openstack_nsupdate_zone: "{{ openshift_openstack_public_dns_domain }}"
openshift_openstack_keypair_name: *"openshift"*
openshift_openstack_external_network_name: *"public"*
openshift_openstack_default_image_name: *"rhel75"*
## Optional (Recommended) - This removes the need for floating IPs
## on the OpenShift Cluster nodes
openshift_openstack_node_subnet_name: *<deployment-subnet-name>*
openshift_openstack_router_name: *<deployment-router-name>*
openshift_openstack_master_floating_ip: *false*
openshift_openstack_infra_floating_ip: *false*
openshift_openstack_compute_floating_ip: *false*
## End of Optional Floating IP section
openshift_openstack_num_masters: *3*
openshift_openstack_num_infra: *3*
openshift_openstack_num_cns: *0*
openshift_openstack_num_nodes: *2*
openshift_openstack_master_flavor: *"m1.master"*
openshift_openstack_default_flavor: *"m1.node"*
## Kuryr configuration
openshift_use_kuryr: True
openshift_use_openshift_sdn: False
use_trunk_ports: True
os_sdn_network_plugin_name: cni
openshift_node_proxy_mode: userspace
kuryr_openstack_pool_driver: nested
openshift_kuryr_precreate_subports: 5
kuryr_openstack_public_net_id: *<public_ID>*
# To disable namespace isolation, comment out the next 2 lines
openshift_kuryr_subnet_driver: namespace
openshift_kuryr_sg_driver: namespace
# If you enable namespace isolation, `default` and `openshift-monitoring` become the
# global namespaces. Global namespaces can access all namespaces. All
# namespaces can access global namespaces.
# To make other namespaces global, include them here:
kuryr_openstack_global_namespaces: default,openshift-monitoring
# If OpenStack cloud endpoints are accessible over HTTPS, provide the CA certificate
kuryr_openstack_ca: *<path-to-ca-certificate>*
openshift_master_open_ports:
- service: dns tcp
port: 53/tcp
- service: dns udp
port: 53/udp
openshift_node_open_ports:
- service: dns tcp
port: 53/tcp
- service: dns udp
port: 53/udp
# To set the pod network CIDR range, uncomment the following property and set its value:
#
# openshift_openstack_kuryr_pod_subnet_prefixlen: 24
#
# The subnet prefix length value must be smaller than the CIDR value that is
# set in the inventory file as openshift_openstack_kuryr_pod_subnet_cidr.
# By default, this value is /24.
# openshift_portal_net is the range that OpenShift services and their associated Octavia
# load balancer VIPs use. Amphora VMs use Neutron ports in the range that is defined by
# openshift_openstack_kuryr_service_pool_start and openshift_openstack_kuryr_service_pool_end.
#
# The value of openshift_portal_net in the OSEv3.yml file must be within the range that is
# defined by openshift_openstack_kuryr_service_subnet_cidr. This range must be half
# of openshift_openstack_kuryr_service_subnet_cidr's range. This practice ensures that
# openshift_portal_net does not overlap with the range that load balancers' VMs use, which is
# defined by openshift_openstack_kuryr_service_pool_start and openshift_openstack_kuryr_service_pool_end.
#
# For reference only, copy the value in the next line from OSEv3.yml:
# openshift_portal_net: *"172.30.0.0/16"*
openshift_openstack_kuryr_service_subnet_cidr: *"172.30.0.0/15"*
openshift_openstack_kuryr_service_pool_start: *"172.31.0.1"*
openshift_openstack_kuryr_service_pool_end: *"172.31.255.253"*
# End of Kuryr configuration
openshift_openstack_use_lbaas_load_balancer: *true*
openshift_openstack_docker_volume_size: "15"
# # Roll-your-own DNS
*openshift_openstack_external_nsupdate_keys:*
public:
*key_secret: '/alb8h0EAFWvb4i+CMA12w=='*
*key_name: "update-key"*
*key_algorithm: 'hmac-md5'*
*server: '<ip-of-DNS>'*
private:
*key_secret: '/alb8h0EAFWvb4i+CMA12w=='*
*key_name: "update-key"*
*key_algorithm: 'hmac-md5'*
*server: '<ip-of-DNS>'*
ansible_user: openshift
## cloud config
openshift_openstack_disable_root: true
openshift_openstack_user: openshift네임스페이스 격리를 사용하는 경우 Kuryr-controller는 각 네임스페이스에 대해 새 Neutron 네트워크 및 서브넷을 생성합니다.
Kuryr SDN이 활성화되면 네트워크 정책 및 노드 포트 서비스가 지원되지 않습니다.
Kuryr가 활성화되면 OpenStack Octavia Amphora VM을 통해 OpenShift Container Platform 서비스가 구현됩니다.
Octavia는 UDP 로드 밸런싱을 지원하지 않습니다. UDP 포트를 노출하는 서비스는 지원되지 않습니다.
22.3.1.2.1. 글로벌 네임 스페이스 액세스 구성
The kuryr_openstack_global_namespace 매개 변수에는 글로벌 네임스페이스를 정의하는 목록이 포함되어 있습니다. 기본적으로 default 및 openshift-monitoring 네임스페이스만 이 목록에 포함되어 있습니다.
OpenShift Container Platform 3.11의 이전 z-release에서 업그레이드하는 경우 글로벌 네임스페이스의 다른 네임스페이스에 대한 액세스는 보안 그룹 *-allow_from_default 에서 제어합니다.
remote_group_id 규칙은 글로벌 네임스페이스에서 다른 네임스페이스에 대한 액세스를 제어할 수 있지만 를 사용하면 확장 및 연결 문제가 발생할 수 있습니다. 이러한 문제를 방지하려면 *_allow_from 를 사용하지 마십시오.
_default에서 remote_ idip_prefix로 remote_ group_
명령줄에서 네트워크의
subnetCIDR값을 검색합니다.$ oc get kuryrnets ns-default -o yaml | grep subnetCIDR subnetCIDR: 10.11.13.0/24이 범위에 대한 TCP 및 UDP 규칙을 생성합니다.
$ openstack security group rule create --remote-ip 10.11.13.0/24 --protocol tcp openshift-ansible-openshift.example.com-allow_from_default $ openstack security group rule create --remote-ip 10.11.13.0/24 --protocol udp openshift-ansible-openshift.example.com-allow_from_defaultremote_group_id를 사용하는 보안 그룹 규칙을 제거합니다.$ openstack security group show *-allow_from_default | grep remote_group_id $ openstack security group rule delete REMOTE_GROUP_ID
| Variable | 설명 |
|---|---|
| openshift_openstack_clusterid | 클러스터 ID 이름 |
| openshift_openstack_public_dns_domain | 퍼블릭 DNS 도메인 이름 |
| openshift_openstack_dns_nameservers | DNS 이름 서버의 IP |
| openshift_openstack_public_hostname_suffix | 공용 및 개인용 DNS 레코드의 노드 호스트 이름에 접미사를 추가합니다. |
| openshift_openstack_nsupdate_zone | OCP 인스턴스 IP를 사용하여 업데이트할 영역 |
| openshift_openstack_keypair_name | OCP 인스턴스에 로그인하는 데 사용되는 키 쌍 이름 |
| openshift_openstack_external_network_name | OpenStack 공용 네트워크 이름 |
| openshift_openstack_default_image_name | OCP 인스턴스에 사용되는 OpenStack 이미지 |
| openshift_openstack_num_masters | 배포할 마스터 노드 수 |
| openshift_openstack_num_infra | 배포할 인프라 노드 수 |
| openshift_openstack_num_cns | 배포할 컨테이너 네이티브 스토리지 노드 수 |
| openshift_openstack_num_nodes | 배포할 애플리케이션 노드 수 |
| openshift_openstack_master_flavor | 마스터 인스턴스에 사용되는 OpenStack 플레이버의 이름 |
| openshift_openstack_default_flavor | 특정 플레이버가 지정되지 않은 경우 모든 인스턴스에 사용되는 Openstack 플레이버의 이름입니다. |
| openshift_openstack_use_lbaas_load_balancer | Octavia 로드 밸런서를 활성화하는 부울 값 (Octavia를 설치해야 함) |
| openshift_openstack_docker_volume_size | Docker 볼륨의 최소 크기(필수 변수) |
| openshift_openstack_external_nsupdate_keys | 인스턴스 IP 주소로 DNS 업데이트 |
| ansible_user | OpenShift Container Platform을 배포하는 데 사용되는 Ansible 사용자입니다. "openshift"는 필수 이름이므로 변경해서는 안 됩니다. |
| openshift_openstack_disable_root | 루트 액세스를 비활성화하는 부울 값 |
| openshift_openstack_user | 이 사용자로 생성된 OCP 인스턴스 |
| openshift_openstack_node_subnet_name | 배포에 사용할 기존 OpenShift 서브넷의 이름입니다. 이는 배포 호스트에 사용되는 서브넷 이름과 같아야 합니다. |
| openshift_openstack_router_name | 배포에 사용할 기존 OpenShift 라우터의 이름입니다. 이는 배포 호스트에 사용된 라우터 이름과 같아야 합니다. |
| openshift_openstack_master_floating_ip |
기본값은 |
| openshift_openstack_infra_floating_ip |
기본값은 |
| openshift_openstack_compute_floating_ip |
기본값은 |
| openshift_use_openshift_sdn |
openshift-sdn을 비활성화하려면 |
| openshift_use_kuryr |
kuryr sdn을 사용하려면 |
| use_trunk_ports |
트렁크 포트가 있는 OpenStack VM을 생성하려면 |
| os_sdn_network_plugin_name |
SDN 동작 선택. kuryr에 대해 to |
| openshift_node_proxy_mode |
Kuryr의 |
| openshift_master_open_ports | Kuryr를 사용할 때 VM에서 열 포트 |
| kuryr_openstack_public_net_id | Kuryr의 필요성. FIP가 가져오는 퍼블릭 OpenStack 네트워크의 ID |
| openshift_kuryr_subnet_driver |
Kuryr 서브넷 드라이버. |
| openshift_kuryr_sg_driver |
Kuryr 보안 그룹 드라이버. 네임스페이스 격리를 위한 |
| kuryr_openstack_global_namespaces |
네임스페이스 격리에 사용할 글로벌 네임스페이스입니다. 기본값은 |
| kuryr_openstack_ca | 클라우드의 CA 인증서 경로입니다. HTTPS를 통해 OpenStack 클라우드 엔드포인트에 액세스할 수 있는 경우 필요합니다. |
22.3.1.3. OSEv3 YAML 파일
OSEv3 YAML 파일은 OpenShift 설치와 관련된 다른 매개 변수 및 사용자 지정을 모두 지정합니다.
다음은 성공적인 배포에 필요한 모든 변수가 포함된 파일의 축소 버전입니다. 특정 OpenShift Container Platform 배포에 필요한 사용자 지정에 따라 추가 변수가 필요할 수 있습니다.
$ cat ~/inventory/group_vars/OSEv3.yml
---
openshift_deployment_type: openshift-enterprise
openshift_release: v3.11
oreg_url: registry.access.redhat.com/openshift3/ose-${component}:${version}
openshift_examples_modify_imagestreams: true
oreg_auth_user: <oreg_auth_user>
oreg_auth_password: <oreg_auth_pw>
# The following is required if you want to deploy the Operator Lifecycle Manager (OLM)
openshift_additional_registry_credentials: [{'host':'registry.connect.redhat.com','user':'REGISTRYCONNECTUSER','password':'REGISTRYCONNECTPASSWORD','test_image':'mongodb/enterprise-operator:0.3.2'}]
openshift_master_default_subdomain: "apps.{{ (openshift_openstack_clusterid|trim == '') | ternary(openshift_openstack_public_dns_domain, openshift_openstack_clusterid + '.' + openshift_openstack_public_dns_domain) }}"
openshift_master_cluster_public_hostname: "console.{{ (openshift_openstack_clusterid|trim == '') | ternary(openshift_openstack_public_dns_domain, openshift_openstack_clusterid + '.' + openshift_openstack_public_dns_domain) }}"
#OpenStack Credentials:
openshift_cloudprovider_kind: openstack
openshift_cloudprovider_openstack_auth_url: "{{ lookup('env','OS_AUTH_URL') }}"
openshift_cloudprovider_openstack_username: "{{ lookup('env','OS_USERNAME') }}"
openshift_cloudprovider_openstack_password: "{{ lookup('env','OS_PASSWORD') }}"
openshift_cloudprovider_openstack_tenant_name: "{{ lookup('env','OS_PROJECT_NAME') }}"
openshift_cloudprovider_openstack_blockstorage_version: v2
openshift_cloudprovider_openstack_domain_name: "{{ lookup('env','OS_USER_DOMAIN_NAME') }}"
openshift_cloudprovider_openstack_conf_file: <path_to_local_openstack_configuration_file>
#Use Cinder volume for Openshift registry:
openshift_hosted_registry_storage_kind: openstack
openshift_hosted_registry_storage_access_modes: ['ReadWriteOnce']
openshift_hosted_registry_storage_openstack_filesystem: xfs
openshift_hosted_registry_storage_volume_size: 30Gi
openshift_hosted_registry_storage_openstack_volumeID: d65209f0-9061-4cd8-8827-ae6e2253a18d
openshift_hostname_check: false
ansible_become: true
#Setting SDN (defaults to ovs-networkpolicy) not part of OSEv3.yml
#For more info, on which to choose, visit:
#https://docs.openshift.com/container-platform/3.11/architecture/networking/sdn.html#overview
networkPluginName: redhat/ovs-networkpolicy
#networkPluginName: redhat/ovs-multitenant
#Configuring identity providers with Ansible
#For initial cluster installations, the Deny All identity provider is configured
#by default. It is recommended to be configured with either htpasswd
#authentication, LDAP authentication, or Allowing all authentication (not recommended)
#For more info, visit:
#https://docs.openshift.com/container-platform/3.10/install_config/configuring_authentication.html#identity-providers-ansible
#Example of Allowing All
#openshift_master_identity_providers: [{'name': 'allow_all', 'login': 'true', 'challenge': 'true', 'kind': 'AllowAllPasswordIdentityProvider'}]
#Optional Metrics (uncomment below lines for installation)
#openshift_metrics_install_metrics: true
#openshift_metrics_cassandra_storage_type: dynamic
#openshift_metrics_storage_volume_size: 25Gi
#openshift_metrics_cassandra_nodeselector: {"node-role.kubernetes.io/infra":"true"}
#openshift_metrics_hawkular_nodeselector: {"node-role.kubernetes.io/infra":"true"}
#openshift_metrics_heapster_nodeselector: {"node-role.kubernetes.io/infra":"true"}
#Optional Aggregated Logging (uncomment below lines for installation)
#openshift_logging_install_logging: true
#openshift_logging_es_pvc_dynamic: true
#openshift_logging_es_pvc_size: 30Gi
#openshift_logging_es_cluster_size: 3
#openshift_logging_es_number_of_replicas: 1
#openshift_logging_es_nodeselector: {"node-role.kubernetes.io/infra":"true"}
#openshift_logging_kibana_nodeselector: {"node-role.kubernetes.io/infra":"true"}
#openshift_logging_curator_nodeselector: {"node-role.kubernetes.io/infra":"true"}나열된 변수에 대한 자세한 내용은 OpenShift-Ansible 호스트 인벤토리 예제를 참조하십시오.
22.3.2. OpenStack 사전 요구 사항 플레이북
OpenShift Container Platform Ansible 설치 프로그램은 OpenStack 인스턴스의 모든 프로비저닝 단계가 충족되었는지 확인하는 플레이북을 제공합니다.
플레이북을 실행하기 전에 RC 파일의 소스를 확인하십시오.
$ source path/to/examplerc
배포 호스트에서 ansible-playbook 명령을 통해 모든 사전 요구 사항이 prerequisites .yml 플레이북을 사용하여 충족되는지 확인합니다.
$ ansible-playbook /usr/share/ansible/openshift-ansible/playbooks/openstack/openshift-cluster/prerequisites.yml사전 요구 사항 플레이북이 성공적으로 완료되면 다음과 같이 프로비저닝 플레이북을 실행합니다.
$ ansible-playbook /usr/share/ansible/openshift-ansible/playbooks/openstack/openshift-cluster/provision.ymlprovision.yml 을 조기에 오류가 발생하면 OpenStack 스택의 상태를 확인하고 완료될 때까지 기다립니다.
$ watch openstack stack list
+--------------------------------------+-------------------+--------------------+----------------------+--------------+
| ID | Stack Name | Stack Status | Creation Time | Updated Time |
+--------------------------------------+-------------------+--------------------+----------------------+--------------+
| 87cb6d1c-8516-40fc-892b-49ad5cb87fac | openshift-cluster | CREATE_IN_PROGRESS | 2018-08-20T23:44:46Z | None |
+--------------------------------------+-------------------+--------------------+----------------------+--------------+
스택에 CREATE_IN_PROGRESS 가 표시되면 스택이 CREATE_COMPLETE 와 같은 최종 결과와 함께 완료될 때까지 기다립니다. 스택이 성공적으로 완료되면 provision.yml 플레이북을 다시 실행하여 필요한 모든 추가 단계를 완료합니다.
스택에 CREATE_FAILED 가 표시되면 다음 명령을 실행하여 오류의 원인을 확인하십시오.
$ openstack stack failures list openshift-cluster22.3.3. 스택 이름 설정
기본적으로 OpenShift Container Platform 클러스터용으로 OpenStack에서 생성한 Heat 스택의 이름은 openshift-cluster 입니다. 다른 이름을 사용하려면 플레이북을 실행하기 전에 OPENSHIFT_CLUSTER 환경 변수를 설정해야 합니다.
$ export OPENSHIFT_CLUSTER=openshift.example.com
기본이 아닌 스택 이름을 사용하고 openshift-ansible 플레이북을 실행하여 배포를 업데이트하는 경우 오류를 방지하려면 OPENSHIFT_CLUSTER 를 스택 이름으로 설정해야 합니다.
22.4. 서브스크립션 관리자 OpenShift Container Platform 인스턴스 등록
노드가 성공적으로 프로비저닝되면 다음 단계는 OpenShift Container Platform 설치에 필요한 모든 패키지를 설치하기 위해 subscription-manager 를 통해 모든 노드가 성공적으로 등록되었는지 확인하는 것입니다. 단순성을 위해 repos.yml 파일이 생성 및 제공되었습니다.
$ cat ~/repos.yml
---
- name: Enable the proper repositories for OpenShift installation
hosts: OSEv3
become: yes
tasks:
- name: Register with activationkey and consume subscriptions matching Red Hat Cloud Suite or Red Hat OpenShift Container Platform
redhat_subscription:
state: present
activationkey: <key-name>
org_id: <orig_id>
pool: '^(Red Hat Cloud Suite|Red Hat OpenShift Container Platform)$'
- name: Disable all current repositories
rhsm_repository:
name: '*'
state: disabled
- name: Enable Repositories
rhsm_repository:
name: "{{ item }}"
state: enabled
with_items:
- rhel-7-server-rpms
- rhel-7-server-extras-rpms
- rhel-7-server-ansible-2.6-rpms
- rhel-7-server-ose-3.11-rpmsSet Up Repositories(리포지토리 설정)를 참조하여 활성화할 적절한 리포지토리와 버전을 확인합니다. 위의 파일은 샘플일 뿐입니다.
repos.yml 을 사용하여 ansible-playbook 명령을 실행합니다.
$ ansible-playbook repos.yml
위 예제에서는 리포지토리를 비활성화하고 활성화하는 모든 등록에 Ansible의 redhat 모듈을 사용합니다. 이 특정 예에서는 Red Hat 활성화 키를 사용합니다. 활성화 키가 없는 경우 예제에 표시된 대로 사용자 이름 및 암호를 사용하여 수정하려면 Ansible _subscription 및rhsm_repositoryredhat_subscription 모듈을 방문하여 수정해야 합니다. https://docs.ansible.com/ansible/2.6/modules/redhat_subscription_module.html
redhat_subscription 모듈이 특정 노드에서 실패할 수 있습니다. 이 문제가 발생하면 subscription-manager 를 사용하여 OpenShift Container Platform 인스턴스를 수동으로 등록하십시오.
22.5. Ansible Playbook을 사용하여 OpenShift Container Platform 설치
OpenStack 인스턴스가 프로비저닝되면 초점이 설치 OpenShift Container Platform으로 바뀝니다. 설치 및 구성은 OpenShift RPM 패키지에서 제공하는 일련의 Ansible 플레이북 및 역할을 통해 수행됩니다. 이전에 구성한 OSEv3.yml 파일을 검토하여 모든 옵션이 올바르게 설정되었는지 확인합니다.
설치 프로그램 플레이북을 실행하기 전에 다음을 통해 모든 {rhocp} 사전 요구 사항을 충족하는지 확인합니다.
$ ansible-playbook /usr/share/ansible/openshift-ansible/playbooks/prerequisites.yml설치 프로그램 플레이북을 실행하여 Red Hat OpenShift Container Platform을 설치합니다.
$ ansible-playbook /usr/share/ansible/openshift-ansible/playbooks/openstack/openshift-cluster/install.ymlOpenShift Container Platform 버전 3.11은 RH OSP 14 및 RH OSP 13에서 지원됩니다. OpenShift Container Platform 버전 3.10은 RH OSP 13에서 지원됩니다.
22.6. 기존 OpenShift Container Platform 환경에 구성 변경 사항 적용
모든 마스터 및 노드 호스트에서 OpenShift Container Platform 서비스를 시작하거나 다시 시작하여 구성 변경 사항을 적용하려면 OpenShift Container Platform 서비스 재시작을 참조하십시오.
# master-restart api
# master-restart controllers
# systemctl restart atomic-openshift-nodeKubernetes 아키텍처에서는 클라우드 공급자의 끝점이 안정적인 것으로 예상합니다. 클라우드 공급자가 중단되면 kubelet에서 OpenShift Container Platform이 재시작되지 않습니다. 기본 클라우드 공급자 끝점이 안정적이지 않은 경우 클라우드 공급자 통합을 사용하는 클러스터를 설치하지 마십시오. 베어 메탈 환경인 것처럼 클러스터를 설치합니다. 설치된 클러스터에서 클라우드 공급자 통합을 설정하거나 해제하는 것은 권장되지 않습니다. 그러나 해당 시나리오를 사용할 수 없는 경우 다음 프로세스를 완료합니다.
클라우드 프로바이더를 사용하지 않고 클라우드 프로바이더를 사용하여 전환하면 오류 메시지가 생성됩니다. 노드가 externalID (클라우드 공급업체가 사용되지 않은 경우)로 호스트 이름을 사용하지 않고 전환하여 클라우드 프로바이더의 instance-id (클라우드 공급자가 지정하는 내용)를 사용하도록 전환하므로 클라우드 프로바이더를 추가하는 경우 노드 삭제를 시도합니다. 이 문제를 해결하려면 다음을 수행합니다.
- 클러스터 관리자로 CLI에 로그인합니다.
기존 노드 라벨을 확인하고 백업합니다.
$ oc describe node <node_name> | grep -Poz '(?s)Labels.*\n.*(?=Taints)'노드를 삭제합니다.
$ oc delete node <node_name>각 노드 호스트에서 OpenShift Container Platform 서비스를 다시 시작합니다.
# systemctl restart atomic-openshift-node- 이전에 보유한 각 노드에 레이블을 다시 추가합니다.
22.6.1. 기존 OpenShift 환경에서 OpenStack 변수 구성
필요한 OpenStack 변수를 설정하려면 마스터 및 노드 모두에서 모든 OpenShift Container Platform 호스트에서 다음 콘텐츠를 사용하여 /etc/origin/cloudprovider/openstack.conf 파일을 수정합니다.
[Global]
auth-url = <OS_AUTH_URL>
username = <OS_USERNAME>
password = <password>
domain-id = <OS_USER_DOMAIN_ID>
tenant-id = <OS_TENANT_ID>
region = <OS_REGION_NAME>
[LoadBalancer]
subnet-id = <UUID of the load balancer subnet>
OpenStack 구성에 일반적으로 사용되는 OS_ 변수 값은 OpenStack 관리자에게 문의하십시오.
22.6.2. 동적으로 생성된 OpenStack PV의 영역 레이블 구성
관리자는 동적으로 생성된 OpenStack PV의 영역 레이블을 구성할 수 있습니다. 이 옵션은 예를 들어 Cinder 영역과 많은 계산 영역만 있는 경우 OpenStack Cinder 영역 이름이 계산 영역 이름과 일치하지 않는 경우 유용합니다. 관리자는 Cinder 볼륨을 동적으로 만든 다음 레이블을 확인할 수 있습니다.
PV의 영역 레이블을 보려면 다음을 수행합니다.
# oc get pv --show-labels
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE LABELS
pvc-1faa6f93-64ac-11e8-930c-fa163e3c373c 1Gi RWO Delete Bound openshift-node/pvc1 standard 12s failure-domain.beta.kubernetes.io/zone=nova
기본 설정이 활성화됩니다. oc get pv --show-labels 명령을 사용하면 failure-domain.beta.kubernetes.io/zone=nova 레이블이 반환됩니다.
영역 레이블을 비활성화하려면 다음을 추가하여 openstack.conf 파일을 업데이트합니다.
[BlockStorage]
ignore-volume-az = yes마스터 서비스를 다시 시작한 후 생성된 PV에는 영역 레이블이 없습니다.
23장. Google Compute Engine 구성
애플리케이션 데이터의 영구 스토리지로 GCE 볼륨을 사용하는 등 기존 Google Compute Engine(GCE) 인프라에 액세스하도록 OpenShift Container Platform을 구성할 수 있습니다.
23.1. 시작하기 전
23.1.1. Google Cloud Platform에 대한 권한 부여 구성
역할
OpenShift Container Platform용 GCP를 구성하려면 다음 GCP 역할이 필요합니다.
|
| 서비스 계정, 클라우드 스토리지, 인스턴스, 이미지, 템플릿, 클라우드 DNS 항목을 만들고 로드 밸런서 및 상태 점검을 배포하는 데 필요합니다. |
사용자가 테스트 단계 중에 환경을 재배포해야 하는 경우에도 삭제 권한이 필요할 수 있습니다.
GCP 오브젝트를 배포할 때 개인 사용자를 사용하지 않도록 서비스 계정을 생성할 수도 있습니다.
역할 구성 방법에 대한 단계를 포함하여 자세한 내용은 GCP 문서의 역할 이해 섹션 을 참조하십시오.
범위 및 서비스 계정
GCP는 범위를 사용하여 리소스 내에서 작업을 수행할 인증된 ID가 있는지 확인합니다. 예를 들어, 읽기 전용 범위 액세스 토큰이 있는 애플리케이션 A는 읽기 전용 액세스 토큰만 읽을 수 있지만, 읽기-쓰기 범위 액세스 토큰이 있는 애플리케이션 B는 데이터를 읽고 수정할 수 있습니다.
범위는 GCP API 수준에서 https://www.googleapis.com/auth/compute.readonly 로 정의됩니다.
--scopes=[SCOPE,…를 사용하여 범위를 지정할 수 있습니다.] 인스턴스를 생성할 때 옵션을 선택하거나, 인스턴스가 GCP API에 액세스하지 않으려면 --no-scopes 옵션을 사용하여 범위 없이 인스턴스를 생성할 수 있습니다.
자세한 내용은 GCP 문서의 범위 섹션 을 참조하십시오.
모든 GCP 프로젝트에는 기본 [PROJECT_NUMBER]-compute@developer.gserviceaccount.com 서비스 계정이 프로젝트 편집기 권한이 있습니다.
기본적으로 새로 생성된 인스턴스는 다음 액세스 범위를 사용하여 기본 서비스 계정으로 실행되도록 자동으로 활성화됩니다.
- https://www.googleapis.com/auth/devstorage.read_only
- https://www.googleapis.com/auth/logging.write
- https://www.googleapis.com/auth/monitoring.write
- https://www.googleapis.com/auth/pubsub
- https://www.googleapis.com/auth/service.management.readonly
- https://www.googleapis.com/auth/servicecontrol
- https://www.googleapis.com/auth/trace.append
- https://www.googleapis.com/auth/bigquery
- https://www.googleapis.com/auth/cloud-platform
- https://www.googleapis.com/auth/compute.readonly
- https://www.googleapis.com/auth/compute
- https://www.googleapis.com/auth/datastore
- https://www.googleapis.com/auth/logging.write
- https://www.googleapis.com/auth/monitoring
- https://www.googleapis.com/auth/monitoring.write
- https://www.googleapis.com/auth/servicecontrol
- https://www.googleapis.com/auth/service.management.readonly
- https://www.googleapis.com/auth/sqlservice.admin
- https://www.googleapis.com/auth/devstorage.full_control
- https://www.googleapis.com/auth/devstorage.read_only
- https://www.googleapis.com/auth/devstorage.read_write
- https://www.googleapis.com/auth/taskqueue
- https://www.googleapis.com/auth/userinfo.email
인스턴스를 만들 때 --service-account=SERVICE_ACCOUNT 옵션을 사용하여 다른 서비스 계정을 지정하거나 gcloud CLI를 사용하여 --no-service-account 옵션을 사용하여 인스턴스의 서비스 계정을 명시적으로 비활성화할 수 있습니다.
자세한 내용은 GCP 문서의 새 서비스 계정 생성 섹션 을 참조하십시오.
23.1.2. Google Compute Engine 오브젝트
OpenShift Container Platform과 GCE(Google Compute Engine)를 통합하려면 다음과 같은 구성 요소 또는 서비스가 필요합니다.
- GCP 프로젝트
- GCP 프로젝트는 모든 GCP 서비스를 생성, 활성화 및 사용하기 위한 기반을 구성하는 기본 수준입니다. 여기에는 API 관리, 청구 활성화, 협업자 추가 및 제거, 권한 관리 등이 포함됩니다.
자세한 내용은 GCP 문서의 프로젝트 리소스 섹션 을 참조하십시오.
프로젝트 ID는 고유한 식별자이며 프로젝트 ID는 모든 Google 클라우드 엔진에서 고유해야 합니다. 즉, 이전에 해당 ID가 있는 프로젝트를 생성한 경우 myproject 를 프로젝트 ID로 사용할 수 없습니다.
- 청구
- 청구가 계정에 첨부되지 않는 한 새 리소스를 만들 수 없습니다. 새 프로젝트는 기존 프로젝트에 연결하거나 새 정보를 입력할 수 있습니다.
자세한 내용은 GCP 문서의 청구 계정 생성, 수정 또는 닫기 를 참조하십시오.
- 클라우드 ID 및 액세스 관리
- OpenShift Container Platform을 배포하려면 적절한 권한이 필요합니다. 사용자는 서비스 계정, 클라우드 스토리지, 인스턴스, 이미지, 템플릿, 클라우드 DNS 항목, 로드 밸런서 및 상태 점검을 배포할 수 있어야 합니다. 또한 삭제 권한은 테스트 중에 환경을 재배포할 수 있도록 유용합니다.
특정 권한이 있는 서비스 계정을 생성한 다음 일반 사용자 대신 인프라 구성 요소를 배포하는 데 사용할 수 있습니다. 역할을 생성하여 다른 사용자 또는 서비스 계정에 대한 액세스를 제한할 수도 있습니다.
GCP 인스턴스는 서비스 계정을 사용하여 애플리케이션이 GCP API를 호출할 수 있도록 허용합니다. 예를 들어 OpenShift Container Platform 노드 호스트는 GCP 디스크 API를 호출하여 영구 볼륨을 애플리케이션에 제공할 수 있습니다.
IAM 서비스를 사용하여 다양한 인프라, 서비스 리소스 및 세분화된 역할에 대한 액세스 제어를 사용할 수 있습니다. 자세한 내용은 GCP 문서의 클라우드 액세스 개요 섹션을 참조하십시오.
- SSH 키
- 생성된 인스턴스에서 SSH를 사용하여 로그인할 수 있도록 GCP는 인증 키로 SSH 공개 키를 삽입합니다. 인스턴스 또는 프로젝트별로 SSH 키를 구성할 수 있습니다.
기존 SSH 키를 사용할 수 있습니다. GCP 메타데이터는 SSH 액세스를 허용하기 위해 인스턴스에 부팅 시 삽입되는 SSH 키를 저장하는 데 도움이 될 수 있습니다.
자세한 내용은 GCP 문서의 메타데이터 섹션 을 참조하십시오.
- GCP 지역 및 영역
- GCP에는 지역 및 가용 영역을 다루는 글로벌 인프라가 있습니다. 다른 영역에 GCP에 OpenShift Container Platform을 배포하면 단일 장애 지점을 방지하는 데 도움이 될 수 있지만 스토리지와 관련하여 몇 가지 주의 사항이 있습니다.
GCP 디스크는 영역 내에서 생성됩니다. 따라서 OpenShift Container Platform 노드 호스트가 "A" 영역에서 다운되고 Pod가 영역 "B"로 이동하면 디스크가 다른 영역에 있으므로 영구 스토리지를 해당 Pod에 연결할 수 없습니다.
OpenShift Container Platform을 설치하기 전에 다중 영역 OpenShift Container Platform 환경의 단일 영역 배포가 중요한 결정입니다. 다중 영역 환경을 배포하는 경우 권장되는 설정은 단일 지역에서 세 개의 다른 영역을 사용하는 것입니다.
자세한 내용은 지역 및 영역에 대한 GCP 문서 및 여러 영역에 대한 Kubernetes 설명서 를 참조하십시오.
- 외부 IP 주소
- GCP 인스턴스가 인터넷과 통신할 수 있도록 외부 IP 주소를 인스턴스에 연결해야 합니다. 또한 가상 프라이빗 클라우드(VPC) 네트워크 외부에서 GCP에 배포된 인스턴스와 통신하려면 외부 IP 주소가 필요합니다.
인터넷 액세스를 위해 외부 IP 주소를 요구하는 것은 공급자의 제한입니다. 필요하지 않은 경우 인스턴스에서 들어오는 외부 트래픽을 차단하도록 방화벽 규칙을 구성할 수 있습니다.
자세한 내용은 외부 IP 주소에 대한 GCP 설명서 를 참조하십시오.
- 클라우드 DNS
- GCP 클라우드 DNS는 GCP DNS 서버를 사용하여 도메인 이름을 글로벌 DNS에 게시하는 데 사용되는 DNS 서비스입니다.
퍼블릭 클라우드 DNS 영역에는 Google의 "도메인" 서비스 또는 타사 공급자를 통해 구입한 도메인 이름이 필요합니다. 영역을 생성할 때 Google에서 제공하는 이름 서버를 등록 기관에 추가해야 합니다.
자세한 내용은 클라우드 DNS에 대한 GCP 설명서 를 참조하십시오.
GCP VPC 네트워크에는 내부 호스트 이름을 자동으로 확인하는 내부 DNS 서비스가 있습니다.
인스턴스의 내부 정규화된 도메인 이름(FQDN)은 [HOST_NAME].c.[PROJECT_ID].internal 형식을 따릅니다.
자세한 내용은 내부 DNS의 GCP 문서를 참조하십시오.
- 로드 밸런싱
- GCP 로드 밸런싱 서비스를 사용하면 GCP 클라우드의 여러 인스턴스에 트래픽을 분산할 수 있습니다.
로드 밸런싱에는 5가지 유형이 있습니다.
HTTPS 및 TCP 프록시 로드 밸런싱은 /healthz 상태를 확인하는 마스터 노드에 대한 HTTPS 상태 점검을 사용하는 유일한 옵션입니다.
HTTPS 로드 밸런싱에는 사용자 지정 인증서가 필요하므로 이 구현에서는 TCP 프록시 로드 밸런싱을 사용하여 프로세스를 간소화합니다.
자세한 내용은 로드 밸런싱에 대한 GCP 문서를 참조하십시오.
- 인스턴스 크기
- OpenShift Container Platform 환경에 성공하려면 몇 가지 최소 하드웨어 요구 사항이 필요합니다.
| Role | 크기 |
|---|---|
| Master |
|
| 노드 |
|
GCP를 사용하면 다양한 요구 사항에 맞게 사용자 정의 인스턴스 크기를 생성할 수 있습니다. 자세한 내용은 머신 유형 및 OpenShift Container Platform 최소 하드웨어 요구 사항을 사용하여 인스턴스 크기를 참조하십시오. 인스턴스 크기에 대한 자세한 내용은 머신 유형 및 OpenShift Container Platform 최소 하드웨어 요구 사항을 참조하십시오.
- 스토리지 옵션
기본적으로 각 GCP 인스턴스에는 운영 체제를 포함하는 작은 루트 영구 디스크가 있습니다. 인스턴스에서 실행 중인 애플리케이션에 더 많은 스토리지 공간이 필요한 경우 인스턴스에 스토리지 옵션을 추가할 수 있습니다.
- 표준 영구 디스크
- SSD 영구 디스크
- 로컬 SSD
- 클라우드 스토리지 버킷
자세한 내용은 스토리지 옵션에 대한 GCP 설명서를 참조하십시오.
23.2. GCE용 OpenShift Container Platform 구성
다음 두 가지 방법으로 GCE용 OpenShift Container Platform을 구성할 수 있습니다.
23.2.1. 옵션 1: Ansible을 사용하여 GCP용 OpenShift Container Platform 구성
설치 시 또는 설치 후 Ansible 인벤토리 파일을 수정하여 GCP(Google Compute Platform)용 OpenShift Container Platform을 구성할 수 있습니다.
절차
기본 네트워크 이름을 사용하지 않는 경우
openshift_cloudprovider_kind,openshift_매개변수와 다중 영역 배포용 선택적gcp_project및 openshift_gcp_prefixopenshift_gcp을 정의해야 합니다._multizone및 openshift_gcp_network_name설치 시 Ansible 인벤토리 파일에 다음 섹션을 추가하여 GCP용 OpenShift Container Platform 환경을 구성합니다.
[OSEv3:vars] openshift_cloudprovider_kind=gce openshift_gcp_project=<projectid>1 openshift_gcp_prefix=<uid>2 openshift_gcp_multizone=False3 openshift_gcp_network_name=<network name>4 Ansible을 사용하여 설치하면 GCP 환경에 맞게 다음 파일을 생성하고 구성합니다.
- /etc/origin/cloudprovider/gce.conf
- /etc/origin/master/master-config.yaml
- /etc/origin/node/node-config.yaml
-
GCP를 사용하여 로드 밸런서 서비스를 실행하는 경우 Compute Engine VM 노드 인스턴스에
ocp접미사가 필요합니다. 예를 들어openshift_gcp_prefix매개변수 값이 mycluster로 설정된 경우myclusterocp 선택적으로 다중 영역 지원을 구성할 수 있습니다.
클러스터 설치 프로세스는 기본적으로 단일 영역 지원을 구성하지만 단일 실패 지점을 방지하기 위해 여러 영역에 대해 를 구성할 수 있습니다.
GCP 디스크는 영역 내에 생성되므로 다양한 영역에 OpenShift Container Platform을 배포하면 스토리지에 문제가 발생할 수 있습니다. OpenShift Container Platform 노드 호스트가 "A" 영역에서 다운되고 Pod가 "B" 영역으로 이동하면 디스크가 이제 다른 영역에 있으므로 영구 스토리지를 해당 Pod에 연결할 수 없습니다. 자세한 내용은 Kubernetes 설명서의 다중 영역 제한 사항을 참조하십시오.
Ansible 인벤토리 파일을 사용하여 다중 영역 지원을 활성화하려면 다음 매개 변수를 추가합니다.
[OSEv3:vars] openshift_gcp_multizone=true단일 영역 지원으로 돌아가려면
openshift_gcp_multizone값을false로 설정하고 Ansible 인벤토리 파일을 다시 실행합니다.
23.2.2. 옵션 2: GCE용 OpenShift Container Platform 수동 구성
23.2.2.1. GCE에 대한 마스터 호스트 수동 구성
모든 마스터 호스트에서 다음 절차를 수행합니다.
절차
기본적으로
/etc/origin/master/master-config.yaml에 있는 마스터 구성 파일의apiServer섹션에 GCE 매개변수를 추가합니다.Arguments및 controllerArgumentsapiServerArguments: cloud-provider: - "gce" cloud-config: - "/etc/origin/cloudprovider/gce.conf" controllerArguments: cloud-provider: - "gce" cloud-config: - "/etc/origin/cloudprovider/gce.conf"Ansible을 사용하여 GCP용 OpenShift Container Platform을 구성하면 /etc/origin/cloudprovider/gce.conf 파일이 자동으로 생성됩니다. GCP용 OpenShift Container Platform을 수동으로 구성하므로 파일을 생성하고 다음을 입력해야 합니다.
[Global] project-id = <project-id>1 network-name = <network-name>2 node-tags = <node-tags>3 node-instance-prefix = <instance-prefix>4 multizone = true5 - 1
- 기존 인스턴스가 실행 중인 GCP 프로젝트 ID를 제공합니다.
- 2
- 네트워크 이름을 기본값을 사용하지 않는 경우 제공합니다.
- 3
- GCP 노드의 태그를 제공합니다. 접미사로
ocp를 포함해야 합니다. 예를 들어node-instance-prefix매개변수 값이mycluster로 설정된 경우 노드에태그를 지정해야 합니다.myclusterocp - 4
- OpenShift Container Platform 클러스터를 식별하는 고유한 문자열을 제공합니다.
- 5
- GCP에서 다중 영역 배포를 트리거하려면
true로 설정합니다. 기본적으로False로 설정합니다.
클러스터 설치 프로세스는 기본적으로 단일 영역 지원을 구성합니다.
다른 영역에 GCP에 OpenShift Container Platform을 배포하면 단일 실패 지점을 방지하는 데 유용할 수 있지만 스토리지에 문제가 발생할 수 있습니다. 이는 GCP 디스크가 영역 내에 생성되기 때문입니다. OpenShift Container Platform 노드 호스트가 "A" 영역에서 다운되고 Pod를 "B" 영역으로 이동해야 하는 경우 디스크가 이제 다른 영역에 있으므로 영구 스토리지를 해당 Pod에 연결할 수 없습니다. 자세한 내용은 Kubernetes 설명서의 다중 영역 제한 사항을 참조하십시오.
중요GCP를 사용하여 로드 밸런서 서비스를 실행하려면 Compute Engine VM 노드 인스턴스에
ocp접미사<openshift_gcp_prefix>ocp가 필요합니다. 예를 들어openshift_gcp_prefix매개변수 값이 mycluster로 설정된 경우myclusterocpOpenShift Container Platform 호스트 서비스를 다시 시작하십시오.
# master-restart api # master-restart controllers # systemctl restart atomic-openshift-node
단일 영역 지원으로 돌아가려면 다중 영역 값을 false 로 설정하고 마스터 및 노드 호스트 서비스를 다시 시작합니다.
23.2.2.2. GCE에 대한 노드 호스트 수동 구성
모든 노드 호스트에서 다음을 수행합니다.
절차
적절한 노드 구성 맵을 편집하고
kubeletArguments섹션의 내용을 업데이트합니다.kubeletArguments: cloud-provider: - "gce" cloud-config: - "/etc/origin/cloudprovider/gce.conf"중요클라우드 공급자 통합이 제대로 작동하려면
nodeName이 GCP의 인스턴스 이름과 일치해야 합니다. 이름은 RFC1123과 호환되어야 합니다.모든 노드에서 OpenShift Container Platform 서비스를 다시 시작합니다.
# systemctl restart atomic-openshift-node
23.2.3. GCP용 OpenShift Container Platform 레지스트리 구성
GCP(Google Cloud Platform)는 OpenShift Container Platform이 OpenShift Container Platform 컨테이너 이미지 레지스트리를 사용하여 컨테이너 이미지를 저장하는 데 사용할 수 있는 오브젝트 클라우드 스토리지를 제공합니다.
자세한 내용은 GCP 문서의 Cloud Storage를 참조하십시오.
사전 요구 사항
설치하기 전에 레지스트리 이미지를 호스팅할 버킷을 생성해야 합니다. 다음 명령은 구성된 서비스 계정을 사용하여 지역 버킷을 생성합니다.
gsutil mb -c regional -l <region> gs://ocp-registry-bucket
cat <<EOF > labels.json
{
"ocp-cluster": "mycluster"
}
EOF
gsutil label set labels.json gs://ocp-registry-bucket
rm -f labels.json버킷 데이터는 기본적으로 Google 관리 키를 사용하여 자동으로 암호화됩니다. 데이터를 암호화하기 위해 다른 키를 지정하려면 GCP에서 사용할 수 있는 데이터 암호화 옵션을 참조하십시오.
자세한 내용은 스토리지 버킷 생성 설명서 를 참조하십시오.
절차
GCP(Google Cloud Storage) 버킷을 사용하도록 레지스트리에 대한 Ansible 인벤토리 파일을 구성하려면 다음을 수행합니다.
[OSEv3:vars]
# GCP Provider Configuration
openshift_hosted_registry_storage_provider=gcs
openshift_hosted_registry_storage_kind=object
openshift_hosted_registry_replicas=1
openshift_hosted_registry_storage_gcs_bucket=<bucket_name>
openshift_hosted_registry_storage_gcs_keyfile=<bucket_keyfile>
openshift_hosted_registry_storage_gcs_rootdirectory=<registry_directory> 자세한 내용은 GCP 문서의 Cloud Storage를 참조하십시오.
23.2.3.1. GCP용 OpenShift Container Platform 레지스트리 수동 구성
GCP 오브젝트 스토리지를 사용하려면 레지스트리의 구성 파일을 편집하고 레지스트리 Pod에 마운트합니다.
스토리지 드라이버 구성 파일에 대한 자세한 내용은 Google Cloud Storage Driver 설명서 를 참조하십시오.
절차
현재 /etc/registry/config.yml 파일을 내보냅니다.
$ oc get secret registry-config \ -o jsonpath='{.data.config\.yml}' -n default | base64 -d \ >> config.yml.old이전 /etc/registry/config.yml 파일에서 새 구성 파일을 만듭니다.
$ cp config.yml.old config.ymlGCP 매개변수를 포함하도록 파일을 편집합니다. 레지스트리 구성 파일의
스토리지섹션에서 버킷 및 키 파일을 지정합니다.storage: delete: enabled: true cache: blobdescriptor: inmemory gcs: bucket: ocp-registry1 keyfile: mykeyfile2 registry-config시크릿을 삭제합니다.$ oc delete secret registry-config -n default업데이트된 구성 파일을 참조하도록 보안을 다시 생성합니다.
$ oc create secret generic registry-config \ --from-file=config.yml -n default업데이트된 구성을 읽기 위해 레지스트리를 재배포합니다.
$ oc rollout latest docker-registry -n default
23.2.3.1.1. 레지스트리에서 GCP 오브젝트 스토리지를 사용하고 있는지 확인합니다.
레지스트리에서 GCP 버킷 스토리지를 사용하는지 확인하려면 다음을 수행합니다.
절차
GCP 스토리지를 사용하여 레지스트리를 성공적으로 배포한 후 레지스트리
deploymentconfig는 레지스트리가 GCP 버킷 스토리지 대신emptydir을 사용하는 경우 정보를 표시하지 않습니다.$ oc describe dc docker-registry -n default ... Mounts: ... /registry from registry-storage (rw) Volumes: registry-storage: Type: EmptyDir1 ...- 1
- Pod의 수명을 공유하는 임시 디렉터리입니다.
/registry 마운트 지점이 비어 있는지 확인합니다. 이는 볼륨 GCP 스토리지에서 사용할 볼륨입니다.
$ oc exec \ $(oc get pod -l deploymentconfig=docker-registry \ -o=jsonpath='{.items[0].metadata.name}') -i -t -- ls -l /registry total 0비어 있는 경우 GCP 버킷 구성이
registry-config시크릿에서 수행되기 때문입니다.$ oc describe secret registry-config Name: registry-config Namespace: default Labels: <none> Annotations: <none> Type: Opaque Data ==== config.yml: 398 bytes설치 프로그램에서 설치 설명서의 Storage 에 표시된 대로 확장 레지스트리 기능을 사용하여 원하는 구성으로 config.yml 파일을 생성합니다. 스토리지 버킷 구성이 저장된
storage섹션을 포함하여 구성 파일을 보려면 다음을 수행합니다.$ oc exec \ $(oc get pod -l deploymentconfig=docker-registry \ -o=jsonpath='{.items[0].metadata.name}') \ cat /etc/registry/config.yml version: 0.1 log: level: debug http: addr: :5000 storage: delete: enabled: true cache: blobdescriptor: inmemory gcs: bucket: ocp-registry auth: openshift: realm: openshift middleware: registry: - name: openshift repository: - name: openshift options: pullthrough: True acceptschema2: True enforcequota: False storage: - name: openshift또는 시크릿을 볼 수 있습니다.
$ oc get secret registry-config -o jsonpath='{.data.config\.yml}' | base64 -d version: 0.1 log: level: debug http: addr: :5000 storage: delete: enabled: true cache: blobdescriptor: inmemory gcs: bucket: ocp-registry auth: openshift: realm: openshift middleware: registry: - name: openshift repository: - name: openshift options: pullthrough: True acceptschema2: True enforcequota: False storage: - name: openshiftGCP 콘솔에서 스토리지를 본 다음 브라우저를 클릭하고 버킷 을 선택하거나
gsutil명령을 실행하여 이미지 내보내기에 성공했는지 확인할 수 있습니다.$ gsutil ls gs://ocp-registry/ gs://ocp-registry/docker/ $ gsutil du gs://ocp-registry/ 7660385 gs://ocp-registry/docker/registry/v2/blobs/sha256/03/033565e6892e5cc6dd03187d00a4575720a928db111274e0fbf31b410a093c10/data 7660385 gs://ocp-registry/docker/registry/v2/blobs/sha256/03/033565e6892e5cc6dd03187d00a4575720a928db111274e0fbf31b410a093c10/ 7660385 gs://ocp-registry/docker/registry/v2/blobs/sha256/03/ ...
emptyDir 볼륨을 사용하는 경우 /registry 마운트 지점은 다음과 유사합니다.
$ oc exec \
$(oc get pod -l deploymentconfig=docker-registry \
-o=jsonpath='{.items[0].metadata.name}') -i -t -- df -h /registry
Filesystem Size Used Avail Use% Mounted on
/dev/sdc 30G 226M 30G 1% /registry
$ oc exec \
$(oc get pod -l deploymentconfig=docker-registry \
-o=jsonpath='{.items[0].metadata.name}') -i -t -- ls -l /registry
total 0
drwxr-sr-x. 3 1000000000 1000000000 22 Jun 19 12:24 docker23.2.4. GCP 스토리지를 사용하도록 OpenShift Container Platform 구성
OpenShift Container Platform은 영구 볼륨 메커니즘을 사용하여 GCP 스토리지를 사용할 수 있습니다. OpenShift Container Platform은 GCP에 디스크를 생성하고 올바른 인스턴스에 디스크를 연결합니다.
GCP 디스크는 ReadWriteOnce 액세스 모드이므로 단일 노드에서 볼륨을 읽기-쓰기로 마운트할 수 있습니다. 자세한 내용은 아키텍처 가이드의 액세스 모드 섹션 을 참조하십시오.
절차
gce-pd프로비저너를 사용할 때 OpenShift Container Platform은 다음스토리지 클래스를생성하고 Ansible 인벤토리에서openshift_cloudprovider_kind=gce및openshift_gcp_*변수를 사용하는 경우입니다. 그렇지 않으면 Ansible을 사용하지 않고 OpenShift Container Platform을 구성하고스토리지 클래스가 설치 시 생성되지 않은경우 수동으로 생성할 수 있습니다.$ oc get --export storageclass standard -o yaml apiVersion: storage.k8s.io/v1 kind: StorageClass metadata: annotations: storageclass.kubernetes.io/is-default-class: "true" creationTimestamp: null name: standard selfLink: /apis/storage.k8s.io/v1/storageclasses/standard parameters: type: pd-standard provisioner: kubernetes.io/gce-pd reclaimPolicy: Delete이전 단계에 표시된 스토리지 클래스를 사용하여 PV를 요청한 후 OpenShift Container Platform은 GCP 인프라에 디스크를 생성합니다. 디스크가 생성되었는지 확인하려면 다음을 수행합니다.
$ gcloud compute disks list | grep kubernetes kubernetes-dynamic-pvc-10ded514-7625-11e8-8c52-42010af00003 us-west1-b 10 pd-standard READY
23.2.5. Red Hat OpenShift Container Storage 정보
RHOCS(Red Hat OpenShift Container Storage)는 사내 또는 하이브리드 클라우드에 있는 OpenShift Container Platform의 영구 스토리지 공급자입니다. RHOCS는 Red Hat 스토리지 솔루션으로 OpenShift Container Platform(컨버지드) 또는 OpenShift Container Platform(독립적인)에 설치되어 있는지 여부에 관계없이 배포, 관리 및 모니터링을 위해 OpenShift Container Platform과 완전히 통합됩니다. OpenShift Container Storage는 단일 가용성 영역 또는 노드로 국한되지 않으므로 중단 후에도 유지될 수 있습니다. RHOCS를 사용하는 전체 지침은 RH OCS3.11 배포 가이드에서 확인할 수 있습니다.
23.3. GCP 외부 로드 밸런서를 서비스로 사용
LoadBalancer 서비스를 사용하여 외부에서 서비스를 노출하여 GCP 로드 밸런서를 사용하도록 OpenShift Container Platform을 구성할 수 있습니다. OpenShift Container Platform은 GCP에 로드 밸런서를 생성하고 필요한 방화벽 규칙을 생성합니다.
절차
새 애플리케이션을 생성합니다.
$ oc new-app openshift/hello-openshift로드 밸런서 서비스를 노출합니다.
$ oc expose dc hello-openshift --name='hello-openshift-external' --type='LoadBalancer'이 명령은 다음 예와 유사한
LoadBalancer서비스를 생성합니다.apiVersion: v1 kind: Service metadata: labels: app: hello-openshift name: hello-openshift-external spec: externalTrafficPolicy: Cluster ports: - name: port-1 nodePort: 30714 port: 8080 protocol: TCP targetPort: 8080 - name: port-2 nodePort: 30122 port: 8888 protocol: TCP targetPort: 8888 selector: app: hello-openshift deploymentconfig: hello-openshift sessionAffinity: None type: LoadBalancer서비스가 생성되었는지 확인하려면 다음을 수행하십시오.
$ oc get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE hello-openshift ClusterIP 172.30.62.10 <none> 8080/TCP,8888/TCP 20m hello-openshift-external LoadBalancer 172.30.147.214 35.230.97.224 8080:31521/TCP,8888:30843/TCP 19mLoadBalancer유형 및 외부 IP 값은 서비스에서 애플리케이션을 노출하기 위해 GCP 로드 밸런서를 사용하고 있음을 나타냅니다.
OpenShift Container Platform은 다음과 같은 GCP 인프라에 필요한 오브젝트를 생성합니다.
방화벽 규칙:
$ gcloud compute firewall-rules list | grep k8s k8s-4612931a3a47c204-node-http-hc my-net INGRESS 1000 tcp:10256 k8s-fw-a1a8afaa7762811e88c5242010af0000 my-net INGRESS 1000 tcp:8080,tcp:8888참고이러한 방화벽 규칙은
<openshift_gcp_prefix>ocp태그가 지정된 인스턴스에 적용됩니다. 예를 들어openshift_gcp_prefix매개변수 값이 mycluster로 설정된 경우myclusterocp상태 점검:
$ gcloud compute http-health-checks list | grep k8s k8s-4612931a3a47c204-node 10256 /healthz로드 밸런서:
$ gcloud compute target-pools list | grep k8s a1a8afaa7762811e88c5242010af0000 us-west1 NONE k8s-4612931a3a47c204-node $ gcloud compute forwarding-rules list | grep a1a8afaa7762811e88c5242010af0000 a1a8afaa7762811e88c5242010af0000 us-west1 35.230.97.224 TCP us-west1/targetPools/a1a8afaa7762811e88c5242010af0000
로드 밸런서가 올바르게 구성되었는지 확인하려면 외부 호스트에서 다음 명령을 실행합니다.
$ curl 35.230.97.224:8080
Hello OpenShift!24장. Azure 구성
영구 애플리케이션 데이터에 Microsoft Azure 로드 밸런서 및 디스크를 사용하도록 OpenShift Container Platform을 구성할 수 있습니다.
24.1. 시작하기 전
24.1.1. Microsoft Azure에 대한 권한 부여 구성
Azure 역할
OpenShift Container Platform을 위해 Microsoft Azure를 구성하려면 다음 Microsoft Azure 역할이 필요합니다.
| 기여자 | 모든 유형의 Microsoft Azure 리소스를 생성하고 관리합니다. |
Classic 서브스크립션 관리자 역할 및 를 참조하십시오. Azure RBAC 역할 및. Azure AD 관리자 역할 설명서 자세한 내용은.
권한
OpenShift Container Platform을 위해 Microsoft Azure를 구성하려면 서비스 주체가 필요하며, 이를 통해 영구 스토리지용 Kubernetes 서비스 로드 밸런서 및 디스크를 생성하고 관리할 수 있습니다. 서비스 주체 값은 설치 시 정의되고 OpenShift Container Platform 마스터 및 노드 호스트의 /etc/origin/cloudprovider/azure.conf 에 있는 Azure 구성 파일에 배포됩니다.
절차
Azure CLI를 사용하여 계정 서브스크립션 ID를 가져옵니다.
# az account list [ { "cloudName": "AzureCloud", "id": "<subscription>",1 "isDefault": false, "name": "Pay-As-You-Go", "state": "Enabled", "tenantId": "<tenant-id>", "user": { "name": "admin@example.com", "type": "user" } ]- 1
- 새 권한을 생성하는 데 사용할 서브스크립션 ID입니다.
기여자의 Microsoft Azure 역할과 Microsoft Azure 서브스크립션 및 리소스 그룹의 범위를 사용하여 서비스 주체를 생성합니다. 인벤토리를 정의할 때 사용할 이러한 값의 출력을 기록합니다. 아래 값 대신 이전 단계의
<subscription>값을 사용합니다.# az ad sp create-for-rbac --name openshiftcloudprovider \ --password <secret> --role contributor \ --scopes /subscriptions/<subscription>/resourceGroups/<resource-group> Retrying role assignment creation: 1/36 Retrying role assignment creation: 2/36 { "appId": "<app-id>", "displayName": "ocpcloudprovider", "name": "http://ocpcloudprovider", "password": "<secret>", "tenant": "<tenant-id>" }
24.1.2. Microsoft Azure 오브젝트 구성
OpenShift Container Platform을 Microsoft Azure와 통합하려면 다음과 같은 구성 요소 또는 서비스에서 가용성이 높고 완전한 기능을 갖춘 환경을 생성해야 합니다.
적절한 양의 인스턴스를 시작할 수 있도록 하려면 인스턴스를 만들기 전에 Microsoft에서 CPU 할당량 증가를 요청합니다.
- 리소스 그룹
- 리소스 그룹에는 네트워킹, 로드 밸런서, 가상 시스템 및 DNS를 포함하여 배포를 위한 모든 Microsoft Azure 구성 요소가 포함되어 있습니다. 리소스 그룹에 쿼터 및 권한을 적용하여 Microsoft Azure에 배포된 리소스를 제어하고 관리할 수 있습니다. 리소스 그룹은 지리적 지역별로 생성 및 정의됩니다. OpenShift Container Platform 환경에 생성된 모든 리소스는 동일한 지역 리전과 동일한 리소스 그룹 내에 있어야 합니다.
자세한 내용은 Azure Resource Manager 개요 를 참조하십시오.
- Azure Virtual Networks
- Azure 가상 네트워크는 Azure 클라우드 네트워크를 서로 분리하는 데 사용됩니다. 인스턴스 및 로드 밸런서는 가상 네트워크를 사용하여 상호 간에 그리고 인터넷으로부터의 통신을 허용합니다. 가상 네트워크를 사용하면 리소스 그룹 내의 구성 요소에서 사용할 하나 이상의 서브넷을 만들 수 있습니다. 또한 가상 네트워크를 다양한 VPN 서비스에 연결하여 온프레미스 서비스와 통신할 수 있습니다.
자세한 내용은 Azure Virtual Network? 를 참조하십시오.
- Azure DNS
- Azure는 내부 및 인터넷에 액세스할 수 있는 호스트 이름 및 로드 밸런서 확인을 제공하는 관리형 DNS 서비스를 제공합니다. 참조 환경에서는 DNS 영역을 사용하여 세 개의 DNS A 레코드를 호스팅하여 공용 IP를 OpenShift Container Platform 리소스 및 bastion으로 매핑할 수 있습니다.
자세한 내용은 Azure DNS란 무엇입니까? 를 참조하십시오.
- 로드 밸런싱
- Azure 로드 밸런서를 사용하면 Azure 환경 내의 가상 시스템에서 실행되는 서비스의 확장 및 고가용성을 위해 네트워크 연결을 사용할 수 있습니다.
- 스토리지 계정
-
스토리지 계정을 사용하면 가상 시스템과 같은 리소스가 Microsoft Azure에서 제공하는 다양한 스토리지 구성 요소에 액세스할 수 있습니다. 설치하는 동안 스토리지 계정은 OpenShift Container Platform 레지스트리에 사용되는 오브젝트 기반
Blob스토리지의 위치를 정의합니다.
자세한 내용은 Azure Storage 소개 또는 레지스트리에 대한 스토리지 계정을 생성하는 단계는 OpenShift Container Platform 레지스트리 구성 섹션 을 참조하십시오.
- 서비스 주체
- Azure는 Azure 내에서 구성 요소를 액세스, 관리 또는 생성하는 서비스 계정을 생성할 수 있는 기능을 제공합니다. 서비스 계정은 특정 서비스에 대한 API 액세스 권한을 부여합니다. 예를 들어 서비스 주체는 Kubernetes 또는 OpenShift Container Platform 인스턴스가 영구 스토리지 및 로드 밸런서를 요청할 수 있습니다. 서비스 주체는 특정 기능에 대해 인스턴스 또는 사용자에게 세밀한 액세스를 제공할 수 있습니다.
자세한 내용은 Azure Active Directory의 애플리케이션 및 서비스 주체 오브젝트 를 참조하십시오.
- 가용성 세트
- 가용성 세트를 사용하면 배포된 VM이 클러스터의 여러 격리된 하드웨어 노드에 분산됩니다. 배포는 클라우드 프로바이더 하드웨어에서 유지 관리가 수행될 때 인스턴스가 모두 하나의 노드에서 실행되지 않도록 하는 데 도움이 됩니다.
인스턴스를 역할에 따라 다른 가용성 세트로 분할해야 합니다. 예를 들어 3개의 마스터 호스트, 인프라 호스트를 포함하는 하나의 가용성 세트, 애플리케이션 호스트를 포함하는 하나의 가용성 세트를 포함하는 하나의 가용성 집합이 있습니다. 이를 통해 분할 및 OpenShift Container Platform 내에서 외부 로드 밸런서를 사용할 수 있습니다.
자세한 내용은 Linux 가상 시스템의 가용성 관리를 참조하십시오.
- 네트워크 보안 그룹
- NSG(Network Security Groups)는 Azure Virtual Network 내에서 배포된 리소스에 대한 트래픽을 허용하거나 거부하는 규칙 목록을 제공합니다. NSG는 숫자 우선 순위 값과 규칙을 사용하여 서로 통신할 수 있는 항목을 정의합니다. 가상 네트워크 내에서, 로드 밸런서 또는 모든 위치에서 통신이 발생할 수 있는 위치를 제한할 수 있습니다.
우선 순위 값을 사용하면 관리자가 포트 통신이 허용되거나 발생할 수 없는 순서에 따라 세분화된 값을 부여할 수 있습니다.
자세한 내용은 가상 네트워크 계획을 참조하십시오.
- 인스턴스 크기
- OpenShift Container Platform 환경에 성공하려면 몇 가지 최소 하드웨어 요구 사항이 필요합니다.
자세한 내용은 OpenShift Container Platform 설명서 또는 클라우드 서비스의 크기에서 최소 Hadware 요구 사항 섹션 을 참조하십시오.
24.2. Azure 구성 파일
Azure용 OpenShift Container Platform을 구성하려면 각 노드 호스트에 /etc/azure/azure.conf 파일이 필요합니다.
파일이 없으면 생성할 수 있습니다.
tenantId: <>
subscriptionId: <>
aadClientId: <>
aadClientSecret: <>
aadTenantId: <>
resourceGroup: <>
cloud: <>
location: <>
vnetName: <>
securityGroupName: <>
primaryAvailabilitySetName: <> - 1
- 클러스터가 배포된 서브스크립션의 AAD 테넌트 ID입니다.
- 2
- 클러스터가 배포된 Azure 서브스크립션 ID입니다.
- 3
- RBAC 액세스 권한이 있는 AAD 애플리케이션의 클라이언트 ID로 Azure RM API와 통신합니다.
- 4
- RBAC 액세스 권한이 있는 AAD 애플리케이션의 클라이언트 시크릿으로 Azure RM API와 통신합니다.
- 5
- 이 값이 테넌트 ID(선택 사항)와 같은지 확인합니다.
- 6
- Azure VM이 속하는 Azure 리소스 그룹 이름입니다.
- 7
- 특정 클라우드 지역. 예를 들면
AzurePublicCloud입니다. - 8
- 소형 스타일 Azure 리전입니다. 예를 들어
southeastasia(선택 사항). - 9
- 인스턴스가 포함된 가상 네트워크 및 로드 밸런서 생성 시 사용됩니다.
- 10
- 인스턴스 및 로드 밸런서와 연결된 보안 그룹 이름입니다.
- 11
- 로드 밸런서와 같은 리소스를 생성할 때 사용할 가용성 설정(선택 사항).
인스턴스에 액세스하는 데 사용되는 NIC는 internal-dns-name 세트가 있어야 합니다. 그렇지 않으면 노드가 클러스터에 다시 참여하지 못하고, 빌드 로그를 콘솔에 표시하며 oc rsh 가 올바르게 작동하지 않습니다.
24.3. Microsoft Azure의 OpenShift Container Platform의 인벤토리 예
아래 예제 인벤토리에서는 다음 항목이 생성되었다고 가정합니다.
- 리소스 그룹
- Azure 가상 네트워크
- 필요한 OpenShift Container Platform 포트를 포함하는 하나 이상의 네트워크 보안 그룹
- 스토리지 계정
- 서비스 주체
- 로드 밸런서 두 개
- 라우터 및 OpenShift Container Platform 웹 콘솔의 경우 두 개 이상의 DNS 항목
- 3개의 가용성 세트
- 마스터 인스턴스 세 개
- 인프라 인스턴스 세 개
- 하나 이상의 애플리케이션 인스턴스
아래 인벤토리는 기본 스토리지 클래스를 사용하여 서비스 주체가 관리하는 지표, 로깅 및 서비스 카탈로그 구성 요소에서 사용할 영구 볼륨을 생성합니다. 레지스트리는 Microsoft Azure Blob 스토리지를 사용합니다.
Microsoft Azure 인스턴스에서 관리 디스크를 사용하는 경우 인벤토리에 다음 변수를 제공합니다.
openshift_storageclass_parameters={'kind': 'managed', 'storageaccounttype': 'Premium_LRS'}
또는
openshift_storageclass_parameters={'kind': 'managed', 'storageaccounttype': 'Standard_LRS'}
이렇게 하면 스토리지 클래스에서 배포된 인스턴스와 관련된 PV 의 올바른 디스크 유형을 생성할 수 있습니다. 관리되지 않는 디스크를 사용하는 경우 스토리지 클래스 는 PV에 대해 무시되지 않은 디스크를 만들 수 있도록 공유 매개 변수를 사용합니다.
[OSEv3:children]
masters
etcd
nodes
[OSEv3:vars]
ansible_ssh_user=cloud-user
ansible_become=true
openshift_cloudprovider_kind=azure
#cloudprovider
openshift_cloudprovider_kind=azure
openshift_cloudprovider_azure_client_id=v9c97ead-1v7E-4175-93e3-623211bed834
openshift_cloudprovider_azure_client_secret=s3r3tR3gistryN0special
openshift_cloudprovider_azure_tenant_id=422r3f91-21fe-4esb-vad5-d96dfeooee5d
openshift_cloudprovider_azure_subscription_id=6003c1c9-d10d-4366-86cc-e3ddddcooe2d
openshift_cloudprovider_azure_resource_group=openshift
openshift_cloudprovider_azure_location=eastus
#endcloudprovider
oreg_auth_user=service_account
oreg_auth_password=service_account_token
openshift_master_api_port=443
openshift_master_console_port=443
openshift_hosted_router_replicas=3
openshift_hosted_registry_replicas=1
openshift_master_cluster_method=native
openshift_master_cluster_hostname=openshift-master.example.com
openshift_master_cluster_public_hostname=openshift-master.example.com
openshift_master_default_subdomain=apps.openshift.example.com
openshift_deployment_type=openshift-enterprise
openshift_master_identity_providers=[{'name': 'idm', 'challenge': 'true', 'login': 'true', 'kind': 'LDAPPasswordIdentityProvider', 'attributes': {'id': ['dn'], 'email': ['mail'], 'name': ['cn'], 'preferredUsername': ['uid']}, 'bindDN': 'uid=admin,cn=users,cn=accounts,dc=example,dc=com', 'bindPassword': 'ldapadmin', 'ca': '/etc/origin/master/ca.crt', 'insecure': 'false', 'url': 'ldap://ldap.example.com/cn=users,cn=accounts,dc=example,dc=com?uid?sub?(memberOf=cn=ose-user,cn=groups,cn=accounts,dc=example,dc=com)'}]
networkPluginName=redhat/ovs-networkpolicy
openshift_examples_modify_imagestreams=true
# Storage Class change to use managed storage
openshift_storageclass_parameters={'kind': 'managed', 'storageaccounttype': 'Standard_LRS'}
# service catalog
openshift_enable_service_catalog=true
openshift_hosted_etcd_storage_kind=dynamic
openshift_hosted_etcd_storage_volume_name=etcd-vol
openshift_hosted_etcd_storage_access_modes=["ReadWriteOnce"]
openshift_hosted_etcd_storage_volume_size=SC_STORAGE
openshift_hosted_etcd_storage_labels={'storage': 'etcd'}
# metrics
openshift_metrics_install_metrics=true
openshift_metrics_cassandra_storage_type=dynamic
openshift_metrics_storage_volume_size=20Gi
openshift_metrics_hawkular_nodeselector={"node-role.kubernetes.io/infra": "true"}
openshift_metrics_cassandra_nodeselector={"node-role.kubernetes.io/infra": "true"}
openshift_metrics_heapster_nodeselector={"node-role.kubernetes.io/infra": "true"}
# logging
openshift_logging_install_logging=true
openshift_logging_es_pvc_dynamic=true
openshift_logging_storage_volume_size=50Gi
openshift_logging_kibana_nodeselector={"node-role.kubernetes.io/infra": "true"}
openshift_logging_curator_nodeselector={"node-role.kubernetes.io/infra": "true"}
openshift_logging_es_nodeselector={"node-role.kubernetes.io/infra": "true"}
# Setup azure blob registry storage
openshift_hosted_registry_storage_kind=object
openshift_hosted_registry_storage_azure_blob_accountkey=uZdkVlbca6xzwBqK8VDz15/loLUoc8I6cPfP31ZS+QOSxL6ylWT6CLrcadSqvtNTMgztxH4CGjYfVnRNUhvMiA==
openshift_hosted_registry_storage_provider=azure_blob
openshift_hosted_registry_storage_azure_blob_accountname=registry
openshift_hosted_registry_storage_azure_blob_container=registry
openshift_hosted_registry_storage_azure_blob_realm=core.windows.net
[masters]
ocp-master-1
ocp-master-2
ocp-master-3
[etcd]
ocp-master-1
ocp-master-2
ocp-master-3
[nodes]
ocp-master-1 openshift_node_group_name="node-config-master"
ocp-master-2 openshift_node_group_name="node-config-master"
ocp-master-3 openshift_node_group_name="node-config-master"
ocp-infra-1 openshift_node_group_name="node-config-infra"
ocp-infra-2 openshift_node_group_name="node-config-infra"
ocp-infra-3 openshift_node_group_name="node-config-infra"
ocp-app-1 openshift_node_group_name="node-config-compute"- 1 2
- 기본 컨테이너 이미지 레지스트리와 같이 인증이 필요한 컨테이너 레지스트리를 사용하는 경우 해당 계정의 인증 정보를 지정합니다. Red Hat 레지스트리 액세스 및 구성을 참조하십시오.
24.4. Microsoft Azure용 OpenShift Container Platform 구성
다음 두 가지 방법으로 Microsoft Azure용 OpenShift Container Platform을 구성할 수 있습니다.
24.4.1. Ansible을 사용하여 Azure용 OpenShift Container Platform 구성
설치 시 Azure용 OpenShift Container Platform을 구성할 수 있습니다.
기본적으로 /etc/ansible/hosts 에 있는 Ansible 인벤토리 파일에 다음을 추가하여 Microsoft Azure의 OpenShift Container Platform 환경을 구성합니다.
[OSEv3:vars]
openshift_cloudprovider_kind=azure
openshift_cloudprovider_azure_client_id=<app_ID>
openshift_cloudprovider_azure_client_secret=<secret>
openshift_cloudprovider_azure_tenant_id=<tenant_ID>
openshift_cloudprovider_azure_subscription_id=<subscription>
openshift_cloudprovider_azure_resource_group=<resource_group>
openshift_cloudprovider_azure_location=<location> Ansible을 사용하여 설치하면 Microsoft Azure 환경에 맞게 다음 파일을 생성하고 구성합니다.
- /etc/origin/cloudprovider/azure.conf
- /etc/origin/master/master-config.yaml
- /etc/origin/node/node-config.yaml
24.4.2. Microsoft Azure용 OpenShift Container Platform 수동 구성
24.4.2.1. Microsoft Azure에 대한 마스터 호스트 수동 구성
모든 마스터 호스트에서 다음을 수행합니다.
절차
기본적으로 모든 마스터에서
/etc/origin/master/master-config.yaml에 있는 마스터 구성 파일을 편집하고apiServerArguments 및섹션의 내용을 업데이트합니다.controllerArgumentskubernetesMasterConfig: ... apiServerArguments: cloud-provider: - "azure" cloud-config: - "/etc/origin/cloudprovider/azure.conf" controllerArguments: cloud-provider: - "azure" cloud-config: - "/etc/origin/cloudprovider/azure.conf"중요컨테이너화된 설치를 트리거하면 /etc/origin 및 /var/lib/origin 디렉터리만 마스터 및 노드 컨테이너에 마운트됩니다. 따라서 master-config.yaml 이 /etc/ 대신 /etc/origin/master 디렉토리에 있는지 확인합니다.
Ansible을 사용하여 Microsoft Azure용 OpenShift Container Platform을 구성하면
/etc/origin/cloudprovider/azure.conf파일이 자동으로 생성됩니다. Microsoft Azure용 OpenShift Container Platform을 수동으로 구성하므로 모든 노드 인스턴스에서 파일을 생성하고 다음을 포함해야 합니다.tenantId: <tenant_ID>1 subscriptionId: <subscription>2 aadClientId: <app_ID>3 aadClientSecret: <secret>4 aadTenantId: <tenant_ID>5 resourceGroup: <resource_group>6 location: <location>7 OpenShift Container Platform 마스터 서비스를 다시 시작하십시오.
# master-restart api # master-restart controllers
24.4.2.2. Microsoft Azure의 노드 호스트 수동 구성
모든 노드 호스트에서 다음을 수행합니다.
절차
적절한 노드 구성 맵을 편집하고
kubeletArguments섹션의 내용을 업데이트합니다.kubeletArguments: cloud-provider: - "azure" cloud-config: - "/etc/origin/cloudprovider/azure.conf"중요인스턴스에 액세스하는 데 사용되는 NIC는 내부 DNS 이름이 설정되어야 합니다. 그렇지 않으면 노드가 클러스터에 다시 참여하지 못하고, 콘솔에 빌드 로그를 표시하지 않으므로
oc rsh가 올바르게 작동하지 않습니다.모든 노드에서 OpenShift Container Platform 서비스를 다시 시작하십시오.
# systemctl restart atomic-openshift-node
24.4.3. Microsoft Azure용 OpenShift Container Platform 레지스트리 구성
Microsoft Azure는 OpenShift Container Platform이 OpenShift Container Platform 컨테이너 이미지 레지스트리를 사용하여 컨테이너 이미지를 저장하는 데 사용할 수 있는 오브젝트 클라우드 스토리지를 제공합니다.
자세한 내용은 Azure 문서의 Cloud Storage를 참조하십시오.
Ansible을 사용하거나 레지스트리 구성 파일을 구성하여 레지스트리를 수동으로 구성할 수 있습니다.
사전 요구 사항
설치하기 전에 레지스트리 이미지를 호스팅할 스토리지 계정을 생성해야 합니다. 다음 명령은 이미지 스토리지에 설치하는 동안 사용되는 스토리지 계정을 생성합니다.
Microsoft Azure Blob 스토리지를 사용하여 컨테이너 이미지를 저장할 수 있습니다. OpenShift Container Platform 레지스트리는 Blob 스토리지를 사용하여 관리자의 개입 없이 레지스트리의 크기를 동적으로 확장할 수 있습니다.
Azure 스토리지 계정을 생성합니다.
az storage account create --name <account_name> \ --resource-group <resource_group> \ --location <location> \ --sku Standard_LRS이렇게 하면 계정 키가 생성됩니다. 계정 키를 보려면 다음을 수행합니다.
az storage account keys list \ --account-name <account-name> \ --resource-group <resource-group> \ --output table KeyName Permissions Value key1 Full <account-key> key2 Full <extra-account-key>
OpenShift Container Platform 레지스트리 구성에는 하나의 계정 키 값만 필요합니다.
옵션 1: Ansible을 사용하여 Azure용 OpenShift Container Platform 레지스트리 구성
절차
스토리지 계정을 사용하도록 레지스트리에 대한 Ansible 인벤토리를 구성합니다.
[OSEv3:vars] # Azure Registry Configuration openshift_hosted_registry_replicas=11 openshift_hosted_registry_storage_kind=object openshift_hosted_registry_storage_azure_blob_accountkey=<account_key>2 openshift_hosted_registry_storage_provider=azure_blob openshift_hosted_registry_storage_azure_blob_accountname=<account_name>3 openshift_hosted_registry_storage_azure_blob_container=<registry>4 openshift_hosted_registry_storage_azure_blob_realm=core.windows.net
옵션 2: Microsoft Azure용 OpenShift Container Platform 레지스트리 수동 구성
Microsoft Azure 오브젝트 스토리지를 사용하려면 레지스트리의 구성 파일을 편집하고 레지스트리 포드에 마운트합니다.
절차
현재 config.yml 을 내보냅니다 :
$ oc get secret registry-config \ -o jsonpath='{.data.config\.yml}' -n default | base64 -d \ >> config.yml.old이전 config.yml에서 새 구성 파일을 만듭니다.
$ cp config.yml.old config.ymlAzure 매개변수를 포함하도록 파일을 편집합니다.
storage: delete: enabled: true cache: blobdescriptor: inmemory azure: accountname: <account-name>1 accountkey: <account-key>2 container: registry3 realm: core.windows.net4 registry-config시크릿을 삭제합니다.$ oc delete secret registry-config -n default업데이트된 구성 파일을 참조하도록 보안을 다시 생성합니다.
$ oc create secret generic registry-config \ --from-file=config.yml -n default업데이트된 구성을 읽기 위해 레지스트리를 재배포합니다.
$ oc rollout latest docker-registry -n default
레지스트리에서 Blob 오브젝트 스토리지를 사용하고 있는지 확인
레지스트리에서 Microsoft Azure Blob 스토리지를 사용하는지 확인하려면 다음을 수행합니다.
절차
레지스트리 배포가 완료되면 레지스트리
deploymentconfig에 Microsoft Azure Blob 스토리지 대신emptydir을 사용하는 것이 항상 표시됩니다.$ oc describe dc docker-registry -n default ... Mounts: ... /registry from registry-storage (rw) Volumes: registry-storage: Type: EmptyDir1 ...- 1
- Pod의 수명을 공유하는 임시 디렉터리입니다.
/registry 마운트 지점이 비어 있는지 확인합니다. Microsoft Azure 스토리지에서 사용할 볼륨입니다.
$ oc exec \ $(oc get pod -l deploymentconfig=docker-registry \ -o=jsonpath='{.items[0].metadata.name}') -i -t -- ls -l /registry total 0비어 있는 경우 Microsoft Azure blob 구성이
registry-config시크릿에서 수행되기 때문입니다.$ oc describe secret registry-config Name: registry-config Namespace: default Labels: <none> Annotations: <none> Type: Opaque Data ==== config.yml: 398 bytes설치 프로그램에서 설치 설명서의 Storage 에 표시된 대로 확장 레지스트리 기능을 사용하여 원하는 구성으로 config.yml 파일을 생성합니다. 스토리지 버킷 구성이 저장된
storage섹션을 포함하여 구성 파일을 보려면 다음을 수행합니다.$ oc exec \ $(oc get pod -l deploymentconfig=docker-registry \ -o=jsonpath='{.items[0].metadata.name}') \ cat /etc/registry/config.yml version: 0.1 log: level: debug http: addr: :5000 storage: delete: enabled: true cache: blobdescriptor: inmemory azure: accountname: registry accountkey: uZekVBJBa6xzwAqK8EDz15/hoHUoc8I6cPfP31ZS+QOSxLfo7WT7CLrVPKaqvtNTMgztxH7CGjYfpFRNUhvMiA== container: registry realm: core.windows.net auth: openshift: realm: openshift middleware: registry: - name: openshift repository: - name: openshift options: pullthrough: True acceptschema2: True enforcequota: False storage: - name: openshift또는 시크릿을 볼 수 있습니다.
$ oc get secret registry-config -o jsonpath='{.data.config\.yml}' | base64 -d version: 0.1 log: level: debug http: addr: :5000 storage: delete: enabled: true cache: blobdescriptor: inmemory azure: accountname: registry accountkey: uZekVBJBa6xzwAqK8EDz15/hoHUoc8I6cPfP31ZS+QOSxLfo7WT7CLrVPKaqvtNTMgztxH7CGjYfpFRNUhvMiA== container: registry realm: core.windows.net auth: openshift: realm: openshift middleware: registry: - name: openshift repository: - name: openshift options: pullthrough: True acceptschema2: True enforcequota: False storage: - name: openshift
emptyDir 볼륨을 사용하는 경우 /registry 마운트 지점은 다음과 같이 표시됩니다.
$ oc exec \
$(oc get pod -l deploymentconfig=docker-registry \
-o=jsonpath='{.items[0].metadata.name}') -i -t -- df -h /registry
Filesystem Size Used Avail Use% Mounted on
/dev/sdc 30G 226M 30G 1% /registry
$ oc exec \
$(oc get pod -l deploymentconfig=docker-registry \
-o=jsonpath='{.items[0].metadata.name}') -i -t -- ls -l /registry
total 0
drwxr-sr-x. 3 1000000000 1000000000 22 Jun 19 12:24 docker24.4.4. Microsoft Azure 스토리지를 사용하도록 OpenShift Container Platform 구성
OpenShift Container Platform은 영구 볼륨 메커니즘을 사용하여 Microsoft Azure 스토리지를 사용할 수 있습니다. OpenShift Container Platform은 리소스 그룹에 디스크를 생성하고 올바른 인스턴스에 디스크를 연결합니다.
절차
다음
스토리지 클래스는 Ansible 인벤토리의 openshift_cloudprovider_kind=azure 및변수를 사용하여 설치 시 Azure 클라우드 공급자를 구성할 때 생성됩니다.openshift_cloud_provider_azure$ oc get --export storageclass azure-standard -o yaml apiVersion: storage.k8s.io/v1 kind: StorageClass metadata: annotations: storageclass.kubernetes.io/is-default-class: "true" creationTimestamp: null name: azure-standard parameters: kind: Shared storageaccounttype: Standard_LRS provisioner: kubernetes.io/azure-disk reclaimPolicy: Delete volumeBindingMode: ImmediateOpenShift Container Platform 및 Microsoft Azure 통합을 활성화하는 데 Ansible을 사용하지 않은 경우
스토리지 클래스를수동으로 생성할 수 있습니다. 자세한 내용은 동적 프로비저닝 및 스토리지 클래스 생성 섹션을 참조하십시오.-
현재 기본
스토리지 클래스종류는공유되므로 Microsoft Azure 인스턴스에서 관리되지 않는 디스크를 사용해야 합니다.openshift_storageclass_parameters={'kind'를 제공하여 인스턴스에서 관리 디스크를 사용하도록 허용하여 선택적으로 이를 수정할 수 있습니다. 'Managed', 'storageaccounttype': 'Premium_LRS'}또는openshift_storageclass_parameters={'kind': 'Managed', 'storageaccounttype': 'Standard_LRS'}설치 시 Ansible 인벤토리 파일의 변수입니다.
Microsoft Azure 디스크는 ReadWriteOnce 액세스 모드이므로 단일 노드에서 볼륨을 읽기-쓰기로 마운트할 수 있습니다. 자세한 내용은 아키텍처 가이드의 액세스 모드 섹션 을 참조하십시오.
24.4.5. Red Hat OpenShift Container Storage 정보
RHOCS(Red Hat OpenShift Container Storage)는 사내 또는 하이브리드 클라우드에 있는 OpenShift Container Platform의 영구 스토리지 공급자입니다. RHOCS는 Red Hat 스토리지 솔루션으로 OpenShift Container Platform(컨버지드) 또는 OpenShift Container Platform(독립적인)에 설치되어 있는지 여부에 관계없이 배포, 관리 및 모니터링을 위해 OpenShift Container Platform과 완전히 통합됩니다. OpenShift Container Storage는 단일 가용성 영역 또는 노드로 국한되지 않으므로 중단 후에도 유지될 수 있습니다. RHOCS를 사용하는 전체 지침은 RH OCS3.11 배포 가이드에서 확인할 수 있습니다.
24.5. Microsoft Azure 외부 로드 밸런서를 서비스로 사용
OpenShift Container Platform은 LoadBalancer 서비스를 사용하여 외부에서 서비스를 노출하여 Microsoft Azure 로드 밸런서를 활용할 수 있습니다. OpenShift Container Platform은 Microsoft Azure에 로드 밸런서를 생성하고 적절한 방화벽 규칙을 생성합니다.
현재 버그로 인해 추가 변수가 Microsoft Azure 인프라에 포함되어 클라우드 프로바이더로 사용하고 외부 로드 밸런서로 사용할 때 추가 변수가 포함됩니다. 자세한 내용은 다음을 참조하십시오.
사전 요구 사항
/etc/origin/cloudprovider/azure.conf 에 있는 Azure 구성 파일이 적절한 오브젝트로 올바르게 구성되었는지 확인합니다. /etc/origin/cloudprovider/azure.conf 파일의 예는 Microsoft Azure용 OpenShift Container Platform 수동 구성 섹션 을 참조하십시오.
값이 추가되면 모든 호스트에서 OpenShift Container Platform 서비스를 다시 시작하십시오.
# systemctl restart atomic-openshift-node
# master-restart api
# master-restart controllers24.5.1. 로드 밸런서를 사용하여 샘플 애플리케이션 배포
절차
새 애플리케이션을 생성합니다.
$ oc new-app openshift/hello-openshift로드 밸런서 서비스를 노출합니다.
$ oc expose dc hello-openshift --name='hello-openshift-external' --type='LoadBalancer'이렇게 하면 다음과 유사한
Loadbalancer서비스가 생성됩니다.apiVersion: v1 kind: Service metadata: labels: app: hello-openshift name: hello-openshift-external spec: externalTrafficPolicy: Cluster ports: - name: port-1 nodePort: 30714 port: 8080 protocol: TCP targetPort: 8080 - name: port-2 nodePort: 30122 port: 8888 protocol: TCP targetPort: 8888 selector: app: hello-openshift deploymentconfig: hello-openshift sessionAffinity: None type: LoadBalancer서비스가 생성되었는지 확인합니다.
$ oc get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE hello-openshift ClusterIP 172.30.223.255 <none> 8080/TCP,8888/TCP 1m hello-openshift-external LoadBalancer 172.30.99.54 40.121.42.180 8080:30714/TCP,8888:30122/TCP 4mLoadBalancer유형 및External-IP필드는 서비스에서 애플리케이션을 노출하기 위해 Microsoft Azure 로드 밸런서를 사용하고 있음을 나타냅니다.
이렇게 하면 Azure 인프라에 다음과 같은 필수 오브젝트가 생성됩니다.
로드 밸런서:
az network lb list -o table Location Name ProvisioningState ResourceGroup ResourceGuid ---------- ----------- ------------------- --------------- ------------------------------------ eastus kubernetes Succeeded refarch-azr 30ec1980-b7f5-407e-aa4f-e570f06f168d eastus OcpMasterLB Succeeded refarch-azr acb537b2-8a1a-45d2-aae1-ea9eabfaea4a eastus OcpRouterLB Succeeded refarch-azr 39087c4c-a5dc-457e-a5e6-b25359244422
로드 밸런서가 올바르게 구성되었는지 확인하려면 외부 호스트에서 다음을 실행합니다.
$ curl 40.121.42.180:8080
Hello OpenShift!- 1
- 를 위의
EXTERNAL-IP확인 단계의 값과 포트 번호로 바꿉니다.
25장. VMware vSphere 구성
VMware vSphere VMDK를 로 사용하여 PersistentVolume을 백업하도록 OpenShift Container Platform을 구성할 수 있습니다. 이 구성에는 애플리케이션 데이터의 영구 스토리지로 VMware vSphere VMDK를 사용하는 작업이 포함될 수 있습니다.
vSphere Cloud Provider는 OpenShift Container Platform에서 vSphere 관리 스토리지를 사용할 수 있으며 Kubernetes가 사용하는 모든 스토리지를 지원합니다.
- PersistentVolume(PV)
- PVC(PersistentVolumesClaim)
- StorageClass
상태 저장 컨테이너화된 애플리케이션에서 요청한 영구 볼륨은 VMware vSAN, VVOL, VMFS 또는 NFS 데이터 저장소에 프로비저닝할 수 있습니다.
Kubernetes PV는 Pod 사양으로 정의됩니다. 동적 프로비저닝을 사용하는 경우 정적 프로비저닝 또는 PVC를 사용하는 경우 VMDK 파일을 직접 참조할 수 있습니다.
vSphere 클라우드 공급자의 최신 업데이트는 Kubernetes용 vSphere Storage에 있습니다.
25.1. 시작하기 전
25.1.1. 요구 사항
VMware vSphere
독립 실행형 ESXi는 지원되지 않습니다.
- 완전한 VMware Validate Design 을 지원하려면 vSphere 버전 6.0.x 최소 권장 버전 6.7 U1b가 필요합니다.
VSAN, VMFS 및 NFS 지원.
- VSAN 지원은 vCenter 한 개의 클러스터로 제한됩니다.
OpenShift Container Platform 3.11이 지원되며 vSphere 7 클러스터에 배포됩니다. vSphere in-tree 스토리지 드라이버를 사용하는 경우 vSAN, VMFS 및 NFS 스토리지 옵션도 지원됩니다.
사전 요구 사항
각 Node VM에 VMware Tools를 설치해야 합니다. 자세한 내용은 VMware 툴 설치를 참조하십시오.
추가 구성 및 문제 해결을 위해 오픈 소스 VMware govm ¢ CLI 툴을 사용할 수 있습니다. 예를 들어 다음 govc CLI 구성을 참조하십시오.
export GOVC_URL='vCenter IP OR FQDN'
export GOVC_USERNAME='vCenter User'
export GOVC_PASSWORD='vCenter Password'
export GOVC_INSECURE=125.1.1.1. 권한
vSphere 클라우드 공급업체에 역할을 생성하고 할당합니다. 필요한 권한 집합이 있는 vCenter 사용자가 필요합니다.
일반적으로 vSphere Cloud Provider에 지정된 vSphere 사용자에게는 다음과 같은 권한이 있어야 합니다.
-
폴더,, 데이터 저장소 클러스터 등과 같은 노드 VM의 상위 엔터티에 대한 권한을호스트, 데이터센터, 데이터 저장소 폴더읽습니다. -
vsphere권한 - 테스트 VM을 생성하고 삭제하는 데 사용됩니다..conf 정의 리소스 풀에 대한 VirtualMachine.Inventory.Create/Delete
사용자 지정 역할, 사용자 및 역할 할당을 생성하는 단계는 vSphere 문서 센터를 참조하십시오.
vSphere Cloud Provider는 여러 vCenter에 걸쳐 있는 OpenShift Container Platform 클러스터를 지원합니다. 위의 모든 권한이 모든 vCenter에 대해 올바르게 설정되었는지 확인합니다.
동적 영구 볼륨 생성은 권장되는 방법입니다.
| 역할 | 권한 | 엔터티 | 하위 항목으로 권한 부여 |
|---|---|---|---|
| manage-k8s-node-vms | Resource.AssignVMToPool, VirtualMachine.Config.AddExistingDisk, VirtualMachine.Config.AddNewDisk, VirtualMachine.Config.AddRemoveDevice, VirtualMachine.Config.RemoveDisk, VirtualMachine.Inventory.Create, VirtualMachine.Inventory.Delete, VirtualMachine.Config.Settings | 클러스터, 호스트, VM 폴더 | 있음 |
| manage-k8s-volumes | Datastore.AllocateSpace, Datastore.FileManagement (낮은 파일 작업) | 데이터 저장소 | 없음 |
| k8s-system-read-and-spbm-profile-view | storageProfile.View (프로파일 기반 스토리지 뷰) | vCenter | 없음 |
| 읽기 전용 (기존 기본 역할) | System.Anonymous, System.Read, System.View | 데이터센터, 데이터 저장소 클러스터, 데이터 저장소 스토리지 폴더 | 없음 |
정적으로 프로비저닝된 PV와 바인딩할 PVC를 생성하고 삭제하도록 회수 정책을 설정하는 경우 manage-k8s-volumes 역할에만 Datastore.FileManagement가 필요합니다. PVC가 삭제되면 정적으로 프로비저닝된 PV도 삭제됩니다.
| 역할 | 권한 | 엔터티 | 북마크로 전파 |
|---|---|---|---|
| manage-k8s-node-vms | VirtualMachine.Config.AddExistingDisk, VirtualMachine.Config.AddNewDisk, VirtualMachine.Config.AddRemoveDevice, VirtualMachine.Config.RemoveDisk | VM 폴더 | 있음 |
| manage-k8s-volumes | Datastore.FileManagement (낮은 파일 작업) | 데이터 저장소 | 없음 |
| 읽기 전용 (기존 기본 역할) | System.Anonymous, System.Read, System.View | vCenter, 데이터 센터, 데이터 저장소 클러스터, 데이터 저장소 스토리지 폴더, 클러스터, 호스트 | 없음… |
절차
- VM 폴더를 생성하고 OpenShift Container Platform 노드 VM을 이 폴더로 이동합니다.
각 Node VM에 대해
disk.EnableUUID매개변수를true로 설정합니다. 이 설정을 사용하면 VMware vSphere의 VMDK(가상 머신 디스크)가 항상 VM에 일관된 UUID를 표시하여 디스크를 올바르게 마운트할 수 있습니다.클러스터에 참여할 모든 VM 노드에는
disk.EnableUUID매개 변수가true로 설정되어 있어야 합니다. 이 값을 설정하려면 vSphere 콘솔 또는govcCLI 툴에 대한 단계를 따르십시오.- vSphere HTML 클라이언트에서 VM 속성 → VM 옵션 → 고급 → 구성 매개 변수 → disk .enableUUID=TRUE로 이동합니다.
또는 govc CLI를 사용하여 Node VM 경로를 찾습니다.
$govc ls /datacenter/vm/<vm-folder-name>모든 VM에 대해
disk.EnableUUID를true로 설정합니다.$govc vm.change -e="disk.enableUUID=1" -vm='VM Path'
가상 머신 템플릿에서 OpenShift Container Platform 노드 VM이 생성되는 경우 템플릿 VM에서 disk.EnableUUID=1 을 설정할 수 있습니다. 이 템플릿에서 복제한 VM은 이 속성을 상속받습니다.
25.1.1.2. vMotion으로 OpenShift Container Platform 사용
OpenShift Container Platform은 일반적으로 compute-only vMotion 을 지원합니다. 스토리지 vMotion을 사용하면 문제가 발생할 수 있으며 지원되지 않습니다.
포드에서 vSphere 볼륨을 사용하는 경우 데이터 저장소를 통해 VM을 마이그레이션하면 수동으로 또는 스토리지 vMotion을 통해 VM을 마이그레이션하면 OpenShift Container Platform 영구 볼륨(PV) 개체 내에서 잘못된 참조가 발생합니다. 이러한 참조는 영향을 받는 포드가 시작되지 않게 하고 데이터 손실을 초래할 수 있습니다.
마찬가지로 OpenShift Container Platform은 데이터 저장소에서 VMDK의 선택적 마이그레이션을 지원하지 않으며 VM 프로비저닝 또는 PV의 동적 또는 정적 프로비저닝을 위해 데이터 저장소 클러스터의 일부 또는 PV의 동적 또는 정적 프로비저닝을 위해 데이터 저장소 클러스터의 일부인 데이터 저장소를 사용하는 경우도 있습니다.
25.2. vSphere용 OpenShift Container Platform 구성
다음 두 가지 방법으로 vSphere용 OpenShift Container Platform을 구성할 수 있습니다.
25.2.1. 옵션 1: Ansible을 사용하여 vSphere용 OpenShift Container Platform 구성
Ansible 인벤토리 파일을 수정하여 VMware vSphere(VCP)용 OpenShift Container Platform을 구성할 수 있습니다. 설치하기 전에 또는 기존 클러스터에 이러한 변경을 수행할 수 있습니다.
절차
Ansible 인벤토리 파일에 다음을 추가합니다.
[OSEv3:vars] openshift_cloudprovider_kind=vsphere openshift_cloudprovider_vsphere_username=administrator@vsphere.local1 openshift_cloudprovider_vsphere_password=<password> openshift_cloudprovider_vsphere_host=10.x.y.322 openshift_cloudprovider_vsphere_datacenter=<Datacenter>3 openshift_cloudprovider_vsphere_datastore=<Datastore>4 deploy_cluster.yml플레이북을 실행합니다.$ ansible-playbook -i <inventory_file> \ playbooks/deploy_cluster.yml
Ansible을 사용하여 설치하면 vSphere 환경에 맞게 다음 파일을 생성하고 구성합니다.
- /etc/origin/cloudprovider/vsphere.conf
- /etc/origin/master/master-config.yaml
- /etc/origin/node/node-config.yaml
참조로 전체 인벤토리는 다음과 같이 표시됩니다.
OpenShift Container Platform에서 영구 볼륨의 데이터 저장소에서 VMDK와 같은 vSphere 리소스를 생성하려면 openshift_cloudprovider_vsphere_ 값이 필요합니다.
$ cat /etc/ansible/hosts
[OSEv3:children]
ansible
masters
infras
apps
etcd
nodes
lb
[OSEv3:vars]
become=yes
ansible_become=yes
ansible_user=root
oreg_auth_user=service_account
oreg_auth_password=service_account_token
openshift_deployment_type=openshift-enterprise
# Required per https://access.redhat.com/solutions/3480921
oreg_url=registry.access.redhat.com/openshift3/ose-${component}:${version}
openshift_examples_modify_imagestreams=true
# vSphere Cloud provider
openshift_cloudprovider_kind=vsphere
openshift_cloudprovider_vsphere_username="administrator@vsphere.local"
openshift_cloudprovider_vsphere_password="password"
openshift_cloudprovider_vsphere_host="vcsa65-dc1.example.com"
openshift_cloudprovider_vsphere_datacenter=Datacenter
openshift_cloudprovider_vsphere_cluster=Cluster
openshift_cloudprovider_vsphere_resource_pool=ResourcePool
openshift_cloudprovider_vsphere_datastore="datastore"
openshift_cloudprovider_vsphere_folder="folder"
# Service catalog
openshift_hosted_etcd_storage_kind=dynamic
openshift_hosted_etcd_storage_volume_name=etcd-vol
openshift_hosted_etcd_storage_access_modes=["ReadWriteOnce"]
openshift_hosted_etcd_storage_volume_size=1G
openshift_hosted_etcd_storage_labels={'storage': 'etcd'}
openshift_master_ldap_ca_file=/home/cloud-user/mycert.crt
openshift_master_identity_providers=[{'name': 'idm', 'challenge': 'true', 'login': 'true', 'kind': 'LDAPPasswordIdentityProvider', 'attributes': {'id': ['dn'], 'email': ['mail'], 'name': ['cn'], 'preferredUsername': ['uid']}, 'bindDN': 'uid=admin,cn=users,cn=accounts,dc=example,dc=com', 'bindPassword': 'ldapadmin', 'ca': '/etc/origin/master/ca.crt', 'insecure': 'false', 'url': 'ldap://ldap.example.com/cn=users,cn=accounts,dc=example,dc=com?uid?sub?(memberOf=cn=ose-user,cn=groups,cn=accounts,dc=openshift,dc=com)'}]
# Setup vsphere registry storage
openshift_hosted_registry_storage_kind=vsphere
openshift_hosted_registry_storage_access_modes=['ReadWriteOnce']
openshift_hosted_registry_storage_annotations=['volume.beta.kubernetes.io/storage-provisioner: kubernetes.io/vsphere-volume']
openshift_hosted_registry_replicas=1
openshift_hosted_router_replicas=3
openshift_master_cluster_method=native
openshift_node_local_quota_per_fsgroup=512Mi
default_subdomain=example.com
openshift_master_cluster_hostname=openshift.example.com
openshift_master_cluster_public_hostname=openshift.example.com
openshift_master_default_subdomain=apps.example.com
os_sdn_network_plugin_name='redhat/openshift-ovs-networkpolicy'
osm_use_cockpit=true
# Red Hat subscription name and password
rhsub_user=username
rhsub_pass=password
rhsub_pool=8a85f9815e9b371b015e9b501d081d4b
# metrics
openshift_metrics_install_metrics=true
openshift_metrics_storage_kind=dynamic
openshift_metrics_storage_volume_size=25Gi
# logging
openshift_logging_install_logging=true
openshift_logging_es_pvc_dynamic=true
openshift_logging_es_pvc_size=30Gi
openshift_logging_elasticsearch_storage_type=pvc
openshift_logging_es_cluster_size=1
openshift_logging_es_nodeselector={"node-role.kubernetes.io/infra": "true"}
openshift_logging_kibana_nodeselector={"node-role.kubernetes.io/infra": "true"}
openshift_logging_curator_nodeselector={"node-role.kubernetes.io/infra": "true"}
openshift_logging_fluentd_nodeselector={"node-role.kubernetes.io/infra": "true"}
openshift_logging_storage_kind=dynamic
#registry
openshift_public_hostname=openshift.example.com
[ansible]
localhost
[masters]
master-0.example.com vm_name=master-0 ipv4addr=10.x.y.103
master-1.example.com vm_name=master-1 ipv4addr=10.x.y.104
master-2.example.com vm_name=master-2 ipv4addr=10.x.y.105
[infras]
infra-0.example.com vm_name=infra-0 ipv4addr=10.x.y.100
infra-1.example.com vm_name=infra-1 ipv4addr=10.x.y.101
infra-2.example.com vm_name=infra-2 ipv4addr=10.x.y.102
[apps]
app-0.example.com vm_name=app-0 ipv4addr=10.x.y.106
app-1.example.com vm_name=app-1 ipv4addr=10.x.y.107
app-2.example.com vm_name=app-2 ipv4addr=10.x.y.108
[etcd]
master-0.example.com
master-1.example.com
master-2.example.com
[lb]
haproxy-0.example.com vm_name=haproxy-0 ipv4addr=10.x.y.200
[nodes]
master-0.example.com openshift_node_group_name="node-config-master" openshift_schedulable=true
master-1.example.com openshift_node_group_name="node-config-master" openshift_schedulable=true
master-2.example.com openshift_node_group_name="node-config-master" openshift_schedulable=true
infra-0.example.com openshift_node_group_name="node-config-infra"
infra-1.example.com openshift_node_group_name="node-config-infra"
infra-2.example.com openshift_node_group_name="node-config-infra"
app-0.example.com openshift_node_group_name="node-config-compute"
app-1.example.com openshift_node_group_name="node-config-compute"
app-2.example.com openshift_node_group_name="node-config-compute"- 1 2
- 기본 컨테이너 이미지 레지스트리와 같이 인증이 필요한 컨테이너 레지스트리를 사용하는 경우 해당 계정의 인증 정보를 지정합니다. Red Hat 레지스트리 액세스 및 구성을 참조하십시오.
vSphere VM 환경 배포는 Red Hat에서 공식적으로 지원하지 않지만 구성할 수 있습니다.
25.2.2. 옵션 2: vSphere용 OpenShift Container Platform 수동 구성
25.2.2.1. vSphere에 대한 마스터 호스트 수동 구성
모든 마스터 호스트에서 다음을 수행합니다.
절차
기본적으로 모든 마스터에서 /etc/origin/master/master-config.yaml 에서 마스터 구성 파일을 편집하고
apiServerArguments 및섹션의 내용을 업데이트합니다.controllerArgumentskubernetesMasterConfig: ... apiServerArguments: cloud-provider: - "vsphere" cloud-config: - "/etc/origin/cloudprovider/vsphere.conf" controllerArguments: cloud-provider: - "vsphere" cloud-config: - "/etc/origin/cloudprovider/vsphere.conf"중요컨테이너화된 설치를 트리거하면 /etc/origin 및 /var/lib/origin 디렉터리만 마스터 및 노드 컨테이너에 마운트됩니다. 따라서 master-config.yaml 은 /etc/ 대신 /etc/origin/master 에 있어야 합니다.
Ansible을 사용하여 vSphere용 OpenShift Container Platform을 구성하면 /etc/origin/cloudprovider/vsphere.conf 파일이 자동으로 생성됩니다. vSphere용 OpenShift Container Platform을 수동으로 구성하므로 파일을 생성해야 합니다. 파일을 생성하기 전에 여러 vCenter 영역을 원하는지 여부를 결정합니다.
클러스터 설치 프로세스는 기본적으로 단일 영역 또는 단일 vCenter를 구성합니다. 그러나 vSphere에 여러 영역에 OpenShift Container Platform을 배포하면 단일 장애 지점을 방지하는 데 유용할 수 있지만 영역 전체에서 공유 스토리지가 필요합니다. OpenShift Container Platform 노드 호스트가 "A" 영역에서 다운되고 Pod를 "B" 영역으로 이동해야 하는 경우. 자세한 내용은 Kubernetes 설명서의 여러 영역에서 실행을 참조하십시오.
단일 vCenter 서버를 구성하려면 /etc/origin/cloudprovider/vsphere.conf 파일에 다음 형식을 사용하십시오.
[Global]1 user = "myusername"2 password = "mypassword"3 port = "443"4 insecure-flag = "1"5 datacenters = "mydatacenter"6 [VirtualCenter "10.10.0.2"]7 user = "myvCenterusername" password = "password" [Workspace]8 server = "10.10.0.2"9 datacenter = "mydatacenter" folder = "path/to/vms"10 default-datastore = "shared-datastore"11 resourcepool-path = "myresourcepoolpath"12 [Disk] scsicontrollertype = pvscsi13 [Network] public-network = "VM Network"14 - 1
[Global] 섹션에 설정된 속성은 개별 [VirtualCenter]섹션의 설정에서 재정의하지 않는 한 지정된 모든 vcenters에 사용됩니다.- 2
- vSphere 클라우드 공급자의 vCenter 사용자 이름.
- 3
- 지정된 사용자의 vCenter 암호입니다.
- 4
- 선택 사항: vCenter 서버의 포트 번호입니다. 기본값은 포트
443입니다. - 5
- vCenter가 자체 서명된 인증서를 사용하는 경우
1로 설정합니다. - 6
- Node VM이 배포되는 데이터 센터의 이름입니다.
- 7
- 이 가상 센터의 특정
[Global]속성을 재정의합니다. 가능한 설정은[Port],[user],[insecure-flag],[datacenters]입니다. 지정되지 않은 모든 설정은[Global]섹션에서 가져옵니다. - 8
- 다양한 vSphere Cloud Provider 기능에 사용되는 속성을 설정합니다. 예를 들어 동적 프로비저닝, 스토리지 프로필 기반 볼륨 프로비저닝 등이 있습니다.
- 9
- vCenter 서버의 IP 주소 또는 FQDN입니다.
- 10
- 노드 VM의 VM 디렉터리 경로입니다.
- 11
- 스토리지 클래스 또는 동적 프로비저닝을 사용하여 프로비저닝 볼륨에 사용할 데이터 저장소의 이름으로 설정합니다. OpenShift Container Platform 3.9 이전에는 데이터 저장소가 스토리지 디렉터리에 있거나 데이터 저장소 클러스터의 멤버인 경우 전체 경로가 필요합니다.
- 12
- 선택 사항: 스토리지 프로필 기반 볼륨 프로비저닝을 위한 더미 VM을 생성해야 하는 리소스 풀의 경로로 설정합니다.
- 13
- SCSI 컨트롤러 유형으로 VMDK가 VM에 로 연결됩니다.
- 14
- vSphere의 네트워크 포트 그룹으로 설정하여 기본적으로 VM 네트워크라고 하는 노드에 액세스합니다. 이는 Kubernetes에 등록된 노드 호스트의 ExternalIP입니다.
여러 vCenter 서버를 구성하려면 /etc/origin/cloudprovider/vsphere.conf 파일에 다음 형식을 사용하십시오.
[Global]1 user = "myusername"2 password = "mypassword"3 port = "443"4 insecure-flag = "1"5 datacenters = "us-east, us-west"6 [VirtualCenter "10.10.0.2"]7 user = "myvCenterusername" password = "password" [VirtualCenter "10.10.0.3"] port = "448" insecure-flag = "0" [Workspace]8 server = "10.10.0.2"9 datacenter = "mydatacenter" folder = "path/to/vms"10 default-datastore = "shared-datastore"11 resourcepool-path = "myresourcepoolpath"12 [Disk] scsicontrollertype = pvscsi13 [Network] public-network = "VM Network"14 - 1
[Global] 섹션에 설정된 속성은 개별 [VirtualCenter]섹션의 설정에서 재정의하지 않는 한 지정된 모든 vcenters에 사용됩니다.- 2
- vSphere 클라우드 공급자의 vCenter 사용자 이름.
- 3
- 지정된 사용자의 vCenter 암호입니다.
- 4
- 선택 사항: vCenter 서버의 포트 번호입니다. 기본값은 포트
443입니다. - 5
- vCenter가 자체 서명된 인증서를 사용하는 경우
1로 설정합니다. - 6
- 노드 VM이 배포되는 데이터 센터의 이름입니다.
- 7
- 이 가상 센터의 특정
[Global]속성을 재정의합니다. 가능한 설정은[Port],[user],[insecure-flag],[datacenters]입니다. 지정되지 않은 모든 설정은[Global]섹션에서 가져옵니다. - 8
- 다양한 vSphere Cloud Provider 기능에 사용되는 속성을 설정합니다. 예를 들어 동적 프로비저닝, 스토리지 프로필 기반 볼륨 프로비저닝 등이 있습니다.
- 9
- 클라우드 공급자가 통신하는 vCenter 서버의 IP 주소 또는 FQDN입니다.
- 10
- 노드 VM의 VM 디렉터리 경로입니다.
- 11
- 스토리지 클래스 또는 동적 프로비저닝을 사용하여 프로비저닝 볼륨에 사용할 데이터 저장소의 이름으로 설정합니다. OpenShift Container Platform 3.9 이전에는 데이터 저장소가 스토리지 디렉터리에 있거나 데이터 저장소 클러스터의 멤버인 경우 전체 경로가 필요합니다.
- 12
- 선택 사항: 스토리지 프로필 기반 볼륨 프로비저닝을 위한 더미 VM을 생성해야 하는 리소스 풀의 경로로 설정합니다.
- 13
- SCSI 컨트롤러 유형으로 VMDK가 VM에 로 연결됩니다.
- 14
- vSphere의 네트워크 포트 그룹으로 설정하여 기본적으로 VM 네트워크라고 하는 노드에 액세스합니다. 이는 Kubernetes에 등록된 노드 호스트의 ExternalIP입니다.
OpenShift Container Platform 호스트 서비스를 다시 시작하십시오.
# master-restart api # master-restart controllers # systemctl restart atomic-openshift-node
25.2.2.2. vSphere의 노드 호스트 수동 구성
모든 노드 호스트에서 다음을 수행합니다.
절차
vSphere용 OpenShift Container Platform 노드를 구성하려면 다음을 수행합니다.
적절한 노드 구성 맵을 편집하고
kubeletArguments섹션의 내용을 업데이트합니다.kubeletArguments: cloud-provider: - "vsphere" cloud-config: - "/etc/origin/cloudprovider/vsphere.conf"중요클라우드 공급자 통합이 제대로 작동하려면
nodeName이 vSphere의 VM 이름과 일치해야 합니다. 이름은 RFC1123과 호환되어야 합니다.모든 노드에서 OpenShift Container Platform 서비스를 다시 시작합니다.
# systemctl restart atomic-openshift-node
25.2.2.3. 구성 변경 사항 적용
모든 마스터 및 노드 호스트에서 OpenShift Container Platform 서비스를 시작하거나 다시 시작하여 구성 변경 사항을 적용하려면 OpenShift Container Platform 서비스 재시작을 참조하십시오.
# master-restart api
# master-restart controllers
# systemctl restart atomic-openshift-nodeKubernetes 아키텍처에서는 클라우드 공급자의 끝점이 안정적인 것으로 예상합니다. 클라우드 공급자가 중단되면 kubelet에서 OpenShift Container Platform이 재시작되지 않습니다. 기본 클라우드 공급자 끝점이 안정적이지 않은 경우 클라우드 공급자 통합을 사용하는 클러스터를 설치하지 마십시오. 베어 메탈 환경인 것처럼 클러스터를 설치합니다. 설치된 클러스터에서 클라우드 공급자 통합을 설정하거나 해제하는 것은 권장되지 않습니다. 그러나 해당 시나리오를 사용할 수 없는 경우 다음 프로세스를 완료합니다.
클라우드 프로바이더를 사용하지 않고 클라우드 프로바이더를 사용하여 전환하면 오류 메시지가 생성됩니다. 노드가 externalID (클라우드 공급업체가 사용되지 않은 경우)로 호스트 이름을 사용하지 않고 전환하여 클라우드 프로바이더의 instance-id (클라우드 공급자가 지정하는 내용)를 사용하도록 전환하므로 클라우드 프로바이더를 추가하는 경우 노드 삭제를 시도합니다. 이 문제를 해결하려면 다음을 수행합니다.
- 클러스터 관리자로 CLI에 로그인합니다.
기존 노드 라벨을 확인하고 백업합니다.
$ oc describe node <node_name> | grep -Poz '(?s)Labels.*\n.*(?=Taints)'노드를 삭제합니다.
$ oc delete node <node_name>각 노드 호스트에서 OpenShift Container Platform 서비스를 다시 시작합니다.
# systemctl restart atomic-openshift-node- 이전에 보유한 각 노드에 레이블을 다시 추가합니다.
25.3. vSphere 스토리지를 사용하도록 OpenShift Container Platform 구성
OpenShift Container Platform은 VMware vSphere의 VMDK(가상 머신 디스크) 볼륨을 지원합니다. VMware vSphere 를 사용하여 영구 스토리지로 OpenShift Container Platform 클러스터를 프로비저닝할 수 있습니다. Kubernetes 및 VMware vSphere에 대해 어느 정도 익숙한 것으로 가정합니다.
OpenShift Container Platform은 vSphere에서 디스크를 생성하고 올바른 인스턴스에 디스크를 연결합니다.
OpenShift Container Platform PV(영구 볼륨) 프레임워크를 사용하면 관리자가 영구 스토리지로 클러스터를 프로비저닝하고 사용자가 기본 인프라에 대한 지식 없이도 해당 리소스를 요청할 수 있습니다. vSphere VMDK 볼륨은 동적으로 프로비저닝 할 수 있습니다.
PV는 단일 프로젝트 또는 네임스페이스에 바인딩되지 않으며 OpenShift Container Platform 클러스터에서 공유할 수 있습니다. 그러나 PV 클레임 은 프로젝트 또는 네임스페이스에 고유하며 사용자가 요청할 수 있습니다.
인프라의 스토리지의 고가용성은 기본 스토리지 공급자가 담당합니다.
사전 요구 사항
vSphere를 사용하여 PV를 생성하기 전에 OpenShift Container Platform 클러스터가 다음 요구사항을 충족하는지 확인하십시오.
- OpenShift Container Platform을 vSphere에 대해 먼저 구성해야 합니다.
- 인프라의 각 노드 호스트는 vSphere VM 이름과 일치해야 합니다.
- 각 노드 호스트는 동일한 리소스 그룹에 있어야 합니다.
25.3.1. 동적으로 VMware vSphere 볼륨 프로비저닝
동적으로 VMware vSphere 볼륨을 프로비저닝하는 것이 좋습니다.
클러스터를 프로비저닝할 때 Ansible 인벤토리 파일에
openshift_cloudprovider변수를 지정하지 않은 경우_kind=vsphere및 openshift_vsphere_*vsphere-volume프로비전 프로그램을 사용하려면 다음StorageClass를수동으로 생성해야 합니다.$ oc get --export storageclass vsphere-standard -o yaml kind: StorageClass apiVersion: storage.k8s.io/v1 metadata: name: "vsphere-standard"1 provisioner: kubernetes.io/vsphere-volume2 parameters: diskformat: thin3 datastore: "YourvSphereDatastoreName"4 reclaimPolicy: Delete이전 단계에 표시된 StorageClass를 사용하여 PV를 요청한 후 OpenShift Container Platform은 vSphere 인프라에 VMDK 디스크를 자동으로 생성합니다. 디스크가 생성되었는지 확인하려면 vSphere에서 Datastore 브라우저를 사용합니다.
참고vSphere-volume 디스크는
ReadWriteOnce액세스 모드이므로 단일 노드에서 볼륨을 읽기-쓰기로 마운트할 수 있습니다. 자세한 내용은 아키텍처 가이드의 액세스 모드 섹션 을 참조하십시오.
25.3.2. 정적으로 프로비저닝 VMware vSphere 볼륨
OpenShift Container Platform에서 볼륨으로 마운트하기 전에 기본 인프라에 스토리지가 있어야 합니다. OpenShift Container Platform이 vSphere에 구성되었는지 확인한 후 OpenShift Container Platform 및 vSphere에 필요한 모든 것이 VM 폴더 경로, 파일 시스템 유형 및 영구 볼륨 API 입니다.
25.3.2.1. 영구 볼륨 생성
PV 오브젝트 정의를 정의합니다(예: vsphere-pv.yaml ).
apiVersion: v1 kind: PersistentVolume metadata: name: pv00011 spec: capacity: storage: 2Gi2 accessModes: - ReadWriteOnce persistentVolumeReclaimPolicy: Retain vsphereVolume:3 volumePath: "[datastore1] volumes/myDisk"4 fsType: ext45 - 1
- 볼륨의 이름입니다. PV 클레임 또는 Pod에서 식별하는 방식이어야 합니다.
- 2
- 이 볼륨에 할당된 스토리지의 용량입니다.
- 3
- 사용 중인 볼륨 유형입니다. 이 예에서는
vsphereVolume을 사용합니다. 레이블은 vSphere VMDK 볼륨을 Pod에 마운트하는 데 사용됩니다. 볼륨의 내용은 마운트 해제 시 보존됩니다. 볼륨 유형은 VMFS 및 VSAN 데이터 저장소를 지원합니다. - 4
- 사용할 기존 VMDK 볼륨입니다. 다음과 같이 데이터 저장소 이름을 볼륨 정의에 대괄호([])로 묶어야 합니다.
- 5
- 마운트할 파일 시스템 유형입니다. 예:
ext4,xfs또는 기타 파일 시스템.
중요볼륨이 포맷되고 프로비저닝된 후
fsType매개변수 값을 변경하면 데이터가 손실되고 Pod 오류가 발생할 수 있습니다.PV를 만듭니다.
$ oc create -f vsphere-pv.yaml persistentvolume "pv0001" createdPV가 생성되었는지 확인합니다.
$ oc get pv NAME LABELS CAPACITY ACCESSMODES STATUS CLAIM REASON AGE pv0001 <none> 2Gi RWO Available 2s
이제 PV 클레임을 사용하여 스토리지를 요청할 수 있으며 이제 PV 를 사용할 수 있습니다.
PV 클레임은 사용자의 네임스페이스에만 존재하며 동일한 네임스페이스 내의 Pod에서만 참조할 수 있습니다. 다른 네임스페이스에서 PV에 액세스하려고 하면 Pod가 실패합니다.
25.3.2.2. VMware vSphere 볼륨 포맷
OpenShift Container Platform이 볼륨을 마운트하고 컨테이너에 전달하기 전에 PV 정의의 fsType 매개변수에 의해 지정된 파일 시스템이 볼륨에 포함되어 있는지 확인합니다. 장치가 파일 시스템으로 포맷되지 않으면 장치의 모든 데이터가 삭제되고 장치는 지정된 파일 시스템에서 자동으로 포맷됩니다.
OpenShift Container Platform은 처음 사용하기 전에 포맷되므로 vSphere 볼륨을 PV로 사용할 수 있습니다.
25.4. vSphere용 OpenShift Container Platform 레지스트리 구성
25.4.1. Ansible을 사용하여 vSphere용 OpenShift Container Platform 레지스트리 구성
절차
레지스트리에서 vSphere 볼륨을 사용하도록 Ansible 인벤토리를 구성하려면 다음을 수행합니다.
[OSEv3:vars]
# vSphere Provider Configuration
openshift_hosted_registry_storage_kind=vsphere
openshift_hosted_registry_storage_access_modes=['ReadWriteOnce']
openshift_hosted_registry_storage_annotations=['volume.beta.kubernetes.io/storage-provisioner: kubernetes.io/vsphere-volume']
openshift_hosted_registry_replicas=1 위의 구성 파일의 괄호가 필요합니다.
25.4.2. OpenShift Container Platform 레지스트리용 스토리지 동적 프로비저닝
vSphere 볼륨 스토리지를 사용하려면 레지스트리의 구성 파일을 편집하고 레지스트리 Pod에 마운트합니다.
절차
vSphere 볼륨에서 새 구성 파일을 생성합니다.
kind: PersistentVolumeClaim apiVersion: v1 metadata: name: vsphere-registry-storage annotations: volume.beta.kubernetes.io/storage-class: vsphere-standard spec: accessModes: - ReadWriteOnce resources: requests: storage: 30GiOpenShift Container Platform에서 파일을 생성합니다.
$ oc create -f pvc-registry.yaml새 PVC를 사용하도록 볼륨 구성을 업데이트합니다.
$ oc set volume dc docker-registry --add --name=registry-storage -t \ pvc --claim-name=vsphere-registry-storage --overwrite업데이트된 구성을 읽기 위해 레지스트리를 재배포합니다.
$ oc rollout latest docker-registry -n default볼륨이 할당되었는지 확인합니다.
$ oc set volume dc docker-registry -n default
25.4.3. OpenShift Container Platform 레지스트리용 스토리지 수동 프로비저닝
다음 명령을 실행하면 StorageClass 를 사용할 수 없거나 사용되지 않는 경우 레지스트리의 스토리지를 생성하는 데 사용되는 스토리지가 수동으로 생성됩니다.
# VMFS
cd /vmfs/volumes/datastore1/
mkdir kubevols # Not needed but good hygiene
# VSAN
cd /vmfs/volumes/vsanDatastore/
/usr/lib/vmware/osfs/bin/osfs-mkdir kubevols # Needed
cd kubevols
vmkfstools -c 25G registry.vmdk25.4.4. Red Hat OpenShift Container Storage 정보
RHOCS(Red Hat OpenShift Container Storage)는 사내 또는 하이브리드 클라우드에 있는 OpenShift Container Platform의 영구 스토리지 공급자입니다. RHOCS는 Red Hat 스토리지 솔루션으로 OpenShift Container Platform(컨버지드) 또는 OpenShift Container Platform(독립적인)에 설치되어 있는지 여부에 관계없이 배포, 관리 및 모니터링을 위해 OpenShift Container Platform과 완전히 통합됩니다. OpenShift Container Storage는 단일 가용성 영역 또는 노드로 국한되지 않으므로 중단 후에도 유지될 수 있습니다. RHOCS를 사용하는 전체 지침은 RH OCS3.11 배포 가이드에서 확인할 수 있습니다.
25.5. 영구 볼륨 백업
OpenShift Container Platform은 클러스터의 모든 노드에서 볼륨을 자유롭게 연결 및 분리하기 위해 새 볼륨을 독립 영구 디스크로 프로비저닝합니다. 따라서 스냅샷을 사용하는 볼륨을 백업할 수 없습니다.
PV 백업을 생성하려면 다음을 수행합니다.
- PV를 사용하여 애플리케이션을 중지합니다.
- 영구 디스크를 복제합니다.
- 애플리케이션을 다시 시작합니다.
- 복제된 디스크의 백업을 생성합니다.
- 복제된 디스크를 삭제합니다.
26장. 로컬 볼륨 구성
26.1. 개요
애플리케이션 데이터의 로컬 볼륨에 액세스하도록 OpenShift Container Platform을 구성할 수 있습니다.
로컬 볼륨은 원시 블록 장치를 포함하여 로컬로 마운트된 파일 시스템을 나타내는 PV(영구 볼륨)입니다. 원시 장치는 실제 장치에 대한 더 직접 경로를 제공하며 애플리케이션이 해당 물리적 장치에 대한 I/O 작업 타이밍을 더 많이 제어할 수 있도록 합니다. 이렇게 하면 원시 장치가 일반적으로 고유한 캐싱을 수행하는 데이터베이스 관리 시스템과 같은 복잡한 애플리케이션에 적합합니다. 로컬 볼륨에는 다음과 같은 몇 가지 고유한 기능이 있습니다. 로컬 볼륨 PV를 사용하는 모든 Pod는 로컬 볼륨이 마운트된 노드에 예약됩니다.
또한 로컬 볼륨에는 로컬 마운트 장치에 대한 PV를 자동으로 생성하는 프로비저너가 포함되어 있습니다. 이 프로비저너는 현재 사전 구성된 디렉토리만 검사합니다. 이 프로비저너는 볼륨을 동적으로 프로비저닝할 수 없지만 이 기능은 향후 릴리스에서 구현될 수 있습니다.
로컬 볼륨 프로비저너를 사용하면 OpenShift Container Platform 내에서 로컬 스토리지를 사용할 수 있으며 다음을 지원합니다.
- 볼륨
- PVs
로컬 볼륨은 기술 프리뷰 기능 전용입니다. 기술 프리뷰 기능은 Red Hat 프로덕션 서비스 수준 계약(SLA)에서 지원하지 않으며, 기능상 완전하지 않을 수 있어 프로덕션에 사용하지 않는 것이 좋습니다. 이러한 기능을 사용하면 향후 제품 기능을 조기에 이용할 수 있어 개발 과정에서 고객이 기능을 테스트하고 피드백을 제공할 수 있습니다. Red Hat 기술 프리뷰 기능 지원 범위에 대한 자세한 내용은 https://access.redhat.com/support/offerings/techpreview/를 참조하십시오.
26.2. 로컬 볼륨 마운트
OpenShift Container Platform에서 PV로 사용하기 전에 모든 로컬 볼륨을 수동으로 마운트해야 합니다.
로컬 볼륨을 마운트하려면 다음을 수행합니다.
모든 볼륨을 /mnt/local-storage/<storage-class-name>/<volume> 경로에 마운트합니다. 관리자는 디스크 파티션 또는 LVM과 같은 방법을 사용하여 필요에 따라 로컬 장치를 생성하고, 해당 장치에 적합한 파일 시스템을 만들고, 스크립트 또는
/etc/fstab항목을 사용하여 이러한 장치를 마운트해야 합니다.# device name # mount point # FS # options # extra /dev/sdb1 /mnt/local-storage/ssd/disk1 ext4 defaults 1 2 /dev/sdb2 /mnt/local-storage/ssd/disk2 ext4 defaults 1 2 /dev/sdb3 /mnt/local-storage/ssd/disk3 ext4 defaults 1 2 /dev/sdc1 /mnt/local-storage/hdd/disk1 ext4 defaults 1 2 /dev/sdc2 /mnt/local-storage/hdd/disk2 ext4 defaults 1 2컨테이너 내에서 실행 중인 프로세스에 모든 볼륨에 액세스할 수 있도록 합니다. 마운트된 파일 시스템의 레이블을 변경하여 다음을 허용할 수 있습니다. 예를 들면 다음과 같습니다.
--- $ chcon -R unconfined_u:object_r:svirt_sandbox_file_t:s0 /mnt/local-storage/ ---
26.3. 로컬 프로비저너 구성
OpenShift Container Platform은 외부 프로비저너에 따라 로컬 장치에 대한 PV를 생성하고 재사용을 활성화하는 데 사용하지 않는 경우 PV를 정리합니다.
- 로컬 볼륨 프로비저너는 대부분의 프로비저너와 다르며 동적 프로비저닝을 지원하지 않습니다.
- 로컬 볼륨 프로비저너를 사용하려면 관리자가 각 노드에서 로컬 볼륨을 미리 구성하고 검색 디렉터리에 마운트해야 합니다. 그런 다음 프로비저너는 각 볼륨의 PV를 만들고 정리하여 볼륨을 관리합니다.
로컬 프로비저너를 구성하려면 다음을 수행합니다.
스토리지 클래스와 디렉터리를 연결하도록 ConfigMap을 사용하여 외부 프로비저너를 구성합니다. 이 구성은 프로비저너를 배포하기 전에 만들어야 합니다. 예를 들면 다음과 같습니다.
apiVersion: v1 kind: ConfigMap metadata: name: local-volume-config data: storageClassMap: | local-ssd:1 hostDir: /mnt/local-storage/ssd2 mountDir: /mnt/local-storage/ssd3 local-hdd: hostDir: /mnt/local-storage/hdd mountDir: /mnt/local-storage/hdd-
(선택 사항) 로컬 볼륨 프로비전 프로그램 및 해당 구성에 대한 독립 실행형 네임스페이스를 생성합니다(예:
oc new-project local-storage).
이 구성을 사용하면 프로비저너에서 다음을 생성합니다.
-
/mnt/local
-storage/ssd 디렉터리에 마운트된 모든 하위 디렉터리에 대해 스토리지 클래스 local-ssd 가 있는 하나의 PV -
/mnt/local
-storage/hdd 디렉터리에 마운트된 모든 하위 디렉터리에 대해 스토리지 클래스 local-hdd 가 있는 하나의 PV
26.4. 로컬 프로비저너 배포
프로비저너를 시작하기 전에 모든 로컬 장치를 마운트하고 스토리지 클래스 및 디렉터리를 사용하여 ConfigMap을 생성합니다.
로컬 프로비저너를 배포하려면 다음을 수행합니다.
- local-storage-provisioner-template.yaml 파일에서 로컬 프로비저너를 설치합니다.
hostPath 볼륨을 사용하고 SELinux 컨텍스트를 사용하여 로컬 볼륨을 모니터링, 관리 및 정리할 수 있는 root 사용자로 포드를 실행할 수 있는 서비스 계정을 생성합니다.
$ oc create serviceaccount local-storage-admin $ oc adm policy add-scc-to-user privileged -z local-storage-admin프로비저너 포드가 모든 Pod에서 생성한 로컬 볼륨의 콘텐츠를 삭제하도록 하려면 root 권한 및 SELinux 컨텍스트가 필요합니다. hostPath는 호스트의 /mnt/local-storage 경로에 액세스해야 합니다.
템플릿을 설치합니다.
$ oc create -f https://raw.githubusercontent.com/openshift/origin/release-3.11/examples/storage-examples/local-examples/local-storage-provisioner-template.yamlCONFIGMAP,SERVICE_ACCOUNT,매개변수 값을 지정하여 템플릿 인스턴스화.NAMESPACE및PROVISIONER_IMAGE$ oc new-app -p CONFIGMAP=local-volume-config \ -p SERVICE_ACCOUNT=local-storage-admin \ -p NAMESPACE=local-storage \ -p PROVISIONER_IMAGE=registry.redhat.io/openshift3/local-storage-provisioner:v3.11 \1 local-storage-provisioner- 1
- OpenShift Container Platform 버전 번호(예:
v3.11)를 입력합니다.
필요한 스토리지 클래스를 추가합니다.
$ oc create -f ./storage-class-ssd.yaml $ oc create -f ./storage-class-hdd.yaml예를 들면 다음과 같습니다.
storage-class-ssd.yaml
apiVersion: storage.k8s.io/v1 kind: StorageClass metadata: name: local-ssd provisioner: kubernetes.io/no-provisioner volumeBindingMode: WaitForFirstConsumerstorage-class-hdd.yaml
apiVersion: storage.k8s.io/v1 kind: StorageClass metadata: name: local-hdd provisioner: kubernetes.io/no-provisioner volumeBindingMode: WaitForFirstConsumer
기타 구성 가능한 옵션은 로컬 스토리지 프로비저너 템플릿을 참조하십시오. 이 템플릿은 모든 노드에서 Pod를 실행하는 DaemonSet을 생성합니다. Pod는 ConfigMap에 지정된 디렉터리를 감시하고 PV를 자동으로 생성합니다.
프로비저너는 PV가 릴리스될 때 수정된 디렉터리에서 모든 데이터를 제거하므로 루트 권한으로 실행됩니다.
26.5. 새 장치 추가
새 장치를 추가하는 것은 반자동입니다. 프로비저너는 구성된 디렉터리에서 새 마운트를 주기적으로 확인합니다. 관리자는 새 하위 디렉터리를 생성하고, 장치를 마운트하며, Pod에서 SELinux 레이블을 적용하여 장치를 사용하도록 허용해야 합니다. 예를 들면 다음과 같습니다.
$ chcon -R unconfined_u:object_r:svirt_sandbox_file_t:s0 /mnt/local-storage/이러한 단계를 생략하면 잘못된 PV가 생성될 수 있습니다.
26.6. 원시 블록 장치 구성
로컬 볼륨 프로비저너를 사용하여 원시 블록 장치를 정적으로 프로비저닝할 수 있습니다. 이 기능은 기본적으로 비활성화되어 있으며 추가 구성이 필요합니다.
원시 블록 장치를 구성하려면 다음을 수행합니다.
모든 마스터에서
BlockVolume기능 게이트를 활성화합니다. 모든 마스터(기본적으로/etc/origin/master/master-config.yaml )에서 마스터 구성 파일을 편집하거나 생성한 후apiServerArguments 및섹션에controllerArgumentsBlockVolume=true를 추가합니다.apiServerArguments: feature-gates: - BlockVolume=true ... controllerArguments: feature-gates: - BlockVolume=true ...노드 구성 ConfigMap을 편집하여 모든 노드에서 기능 게이트를 활성화합니다.
$ oc edit configmap node-config-compute --namespace openshift-node $ oc edit configmap node-config-master --namespace openshift-node $ oc edit configmap node-config-infra --namespace openshift-node예를 들면 모든 ConfigMap에
kubeletArguments의 기능 게이트 배열에BlockVolume=true가 포함되어 있는지 확인합니다.노드 configmap feature-gates 설정
kubeletArguments: feature-gates: - RotateKubeletClientCertificate=true,RotateKubeletServerCertificate=true,BlockVolume=true- 마스터를 다시 시작합니다. 구성이 변경되면 노드가 자동으로 다시 시작됩니다. 이 작업은 몇 분 정도 걸릴 수 있습니다.
26.6.1. 원시 블록 장치 준비
프로비저너를 시작하기 전에 Pod에서 사용할 수 있는 모든 원시 블록 장치를 /mnt/local-storage/<storage 클래스> 디렉터리 구조에 연결합니다. 예를 들어 /dev/dm-36 디렉토리를 사용할 수 있도록 하려면 다음을 수행합니다.
/mnt/local-storage 에 장치 스토리지 클래스의 디렉토리를 생성합니다.
$ mkdir -p /mnt/local-storage/block-devices장치를 가리키는 심볼릭 링크를 만듭니다.
$ ln -s /dev/dm-36 dm-uuid-LVM-1234참고가능한 이름 충돌을 방지하려면 심볼릭 링크의 이름과 /dev/disk/ by-uuid 또는 /dev/disk/by- id 디렉토리의 링크와 동일한 이름을 사용합니다.
프로비저너를 구성하는 ConfigMap을 생성하거나 업데이트합니다.
apiVersion: v1 kind: ConfigMap metadata: name: local-volume-config data: storageClassMap: | block-devices:1 hostDir: /mnt/local-storage/block-devices2 mountDir: /mnt/local-storage/block-devices3 장치의
SELinux레이블과 /mnt/local-storage/ 를 변경합니다.$ chcon -R unconfined_u:object_r:svirt_sandbox_file_t:s0 /mnt/local-storage/ $ chcon unconfined_u:object_r:svirt_sandbox_file_t:s0 /dev/dm-36원시 블록 장치에 대한 스토리지 클래스를 생성합니다.
apiVersion: storage.k8s.io/v1 kind: StorageClass metadata: name: block-devices provisioner: kubernetes.io/no-provisioner volumeBindingMode: WaitForFirstConsumer
프로비저너에서 블록 장치 /dev/dm-36 을 사용할 준비가 되었으며 PV로 프로비저닝되었습니다.
26.6.2. 원시 블록 장치 프로비저너 배포
원시 블록 장치에 대한 프로비저너 배포는 로컬 볼륨에 프로비저너를 배포하는 것과 유사합니다. 두 가지 차이점이 있습니다.
- 프로비저너는 권한 있는 컨테이너에서 실행해야 합니다.
- 프로비저너는 호스트에서 /dev 파일 시스템에 액세스할 수 있어야 합니다.
원시 블록 장치에 대한 프로비저너를 배포하려면 다음을 수행합니다.
- local-storage-provisioner-template.yaml 파일에서 템플릿을 다운로드합니다.
템플릿을 편집합니다.
컨테이너 사양의
securityContext의privileged속성을true로 설정합니다.... containers: ... name: provisioner ... securityContext: privileged: true ...hostPath를 사용하여 /dev/ 파일 시스템을 컨테이너에 마운트합니다.... containers: ... name: provisioner ... volumeMounts: - mountPath: /dev name: dev ... volumes: - hostPath: path: /dev name: dev ...
수정된 YAML 파일에서 템플릿을 생성합니다.
$ oc create -f local-storage-provisioner-template.yaml프로비저너를 시작합니다.
$ oc new-app -p CONFIGMAP=local-volume-config \ -p SERVICE_ACCOUNT=local-storage-admin \ -p NAMESPACE=local-storage \ -p PROVISIONER_IMAGE=registry.redhat.io/openshift3/local-storage-provisioner:v3.11 \ local-storage-provisioner
26.6.3. 원시 블록 장치 영구 볼륨 사용
Pod에서 원시 블록 장치를 사용하려면 volumeMode: 가 Block 으로 설정된 PVC(영구 볼륨 클레임)를 block-devices 로 설정합니다. 예를 들면 다음과 같습니다.
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: block-pvc
spec:
storageClassName: block-devices
accessModes:
- ReadWriteOnce
volumeMode: Block
resources:
requests:
storage: 1Gi원시 블록 장치 PVC를 사용하는 Pod
apiVersion: v1
kind: Pod
metadata:
name: busybox-test
labels:
name: busybox-test
spec:
restartPolicy: Never
containers:
- resources:
limits :
cpu: 0.5
image: gcr.io/google_containers/busybox
command:
- "/bin/sh"
- "-c"
- "while true; do date; sleep 1; done"
name: busybox
volumeDevices:
- name: vol
devicePath: /dev/xvda
volumes:
- name: vol
persistentVolumeClaim:
claimName: block-pvc볼륨은 Pod에 마운트되지 않지만 /dev/xvda 원시 블록 장치로 노출됩니다.
27장. 영구 스토리지 구성
27.1. 개요
Kubernetes 영구 볼륨 프레임워크를 사용하면 환경에서 사용 가능한 네트워크 스토리지를 사용하여 영구 스토리지로 OpenShift Container Platform 클러스터를 프로비저닝할 수 있습니다. 이 작업은 애플리케이션 요구 사항에 따라 초기 OpenShift Container Platform 설치를 완료한 후 사용자가 기본 인프라에 대한 지식이 없어 해당 리소스를 요청하는 방법을 제공합니다.
다음 주제에서는 지원되는 다음 볼륨 플러그인을 사용하여 OpenShift Container Platform에서 영구 볼륨을 구성하는 방법을 보여줍니다.
27.2. NFS를 사용하는 영구 스토리지
27.2.1. 개요
OpenShift Container Platform 클러스터는 NFS를 사용하여 영구 스토리지로 프로비저닝할 수 있습니다. PV(영구 볼륨) 및 PVC(영구 볼륨 클레임)는 프로젝트 전체에서 볼륨을 공유하는 편리한 방법을 제공합니다. PV 정의에 포함된 NFS 관련 정보는 포드 정의에 직접 정의할 수 있지만 이렇게 하면 볼륨이 별도의 클러스터 리소스로 생성되지 않으므로 볼륨이 충돌하기 쉽습니다.
이 주제에서는 NFS 영구 스토리지 유형을 사용하는 방법에 대해 설명합니다. OpenShift Container Platform 및 NFS 에 대해 어느 정도 익숙한 것이 좋습니다. 일반적으로 OpenShift Container Platform PV(영구 볼륨) 프레임워크에 대한 자세한 내용은 영구 스토리지 개념 주제를 참조하십시오.
27.2.2. 프로비저닝
OpenShift Container Platform에서 볼륨으로 마운트하기 전에 기본 인프라에 스토리지가 있어야 합니다. NFS 볼륨을 프로비저닝하려면, NFS 서버 목록 및 내보내기 경로만 있으면 됩니다.
먼저 PV에 대한 오브젝트 정의를 생성해야 합니다.
예 27.1. NFS를 사용하는 PV 오브젝트 정의
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv0001
spec:
capacity:
storage: 5Gi
accessModes:
- ReadWriteOnce
nfs:
path: /tmp
server: 172.17.0.2
persistentVolumeReclaimPolicy: Retain - 1
- 볼륨의 이름입니다. 이는 다양한
oc <command> pod에서 PV ID입니다. - 2
- 이 볼륨에 할당된 스토리지의 용량입니다.
- 3
- 볼륨에 대한 액세스를 제어하는 것으로 표시되지만 실제로 레이블에 사용되며 PVC를 PV에 연결하는 데 사용됩니다. 현재는 access
Modes를 기반으로 하는 액세스규칙이 적용되지 않습니다. - 4
- 사용 중인 볼륨 유형으로, 이 경우에는 nfs 플러그인입니다.
- 5
- NFS 서버에서 내보낸 경로입니다.
- 6
- NFS 서버의 호스트 이름 또는 IP 주소입니다.
- 7
- PV의 회수 정책입니다. 이는 클레임에서 해제될 때 볼륨에 발생하는 작업을 정의합니다. 리소스 회수를 참조하십시오.
각 NFS 볼륨은 클러스터의 모든 스케줄링 가능한 노드에서 마운트할 수 있어야 합니다.
정의를 파일에 저장합니다(예: nfs-pv.yaml ). PV를 생성합니다.
$ oc create -f nfs-pv.yaml
persistentvolume "pv0001" createdPV가 생성되었는지 확인합니다.
# oc get pv
NAME LABELS CAPACITY ACCESSMODES STATUS CLAIM REASON AGE
pv0001 <none> 5368709120 RWO Available 31s다음 단계에서는 새 PV에 바인딩하는 PVC를 생성할 수 있습니다.
예 27.2. PVC 오브젝트 정의
정의를 파일에 저장하고(예: nfs-claim.yaml ) PVC를 생성합니다.
# oc create -f nfs-claim.yaml27.2.3. 디스크 할당량 적용
디스크 파티션을 사용하여 디스크 할당량 및 크기 제약 조건을 적용할 수 있습니다. 각 파티션은 자체 내보내기일 수 있습니다. 각 내보내기는 1개의 PV입니다. OpenShift Container Platform은 PV에 고유한 이름을 적용하지만 NFS 볼륨 서버와 경로의 고유성은 관리자에 따라 다릅니다.
이렇게 하면 개발자가 특정 용량(예: 10Gi)에 의해 영구 스토리지를 요청하고 해당 볼륨과 동등한 용량과 일치시킬 수 있습니다.
27.2.4. NFS 볼륨 보안
이 섹션에서는 일치하는 권한 및 SELinux 고려 사항을 포함하여 NFS 볼륨 보안에 대해 설명합니다. 사용자는 POSIX 권한, 프로세스 UID, 추가 그룹 및 SELinux의 기본 사항을 이해하고 있어야 합니다.
NFS 볼륨을 구현하기 전에 전체 볼륨 보안 주제를 참조하십시오.
개발자는 포드 정의의 볼륨 섹션에서 이름으로 PVC 또는 NFS 볼륨 플러그인을 직접 참조하여 NFS 스토리지를 요청합니다.
NFS 서버의 /etc/exports 파일에는 액세스 가능한 NFS 디렉토리가 포함되어 있습니다. 대상 NFS 디렉터리에는 POSIX 소유자 및 그룹 ID가 있습니다. OpenShift Container Platform NFS 플러그인은 내보낸 NFS 디렉터리에 있는 동일한 POSIX 소유권 및 권한과 함께 컨테이너의 NFS 디렉터리를 마운트합니다. 그러나 컨테이너는 원하는 동작인 NFS 마운트의 소유자와 동일한 유효 UID로 실행되지 않습니다.
예를 들어, 대상 NFS 디렉터리가 NFS 서버에 다음과 같이 표시되는 경우:
# ls -lZ /opt/nfs -d
drwxrws---. nfsnobody 5555 unconfined_u:object_r:usr_t:s0 /opt/nfs
# id nfsnobody
uid=65534(nfsnobody) gid=65534(nfsnobody) groups=65534(nfsnobody)그러면 컨테이너가 SELinux 레이블과 일치해야 하며 65534 (nfsnobody 소유자)의 UID 또는 디렉터리에 액세스하려면 보조 그룹에서 5555 와 함께 실행해야 합니다.
65534의 소유자 ID가 예제로 사용됩니다. NFS의 root_squash는 루트 (0) 를 nfsnobody (5534)에 매핑하지만 NFS 내보내기에는 임의의 소유자 ID가 있을 수 있습니다. NFS 내보내기에는 소유자 65534가 필요하지 않습니다.
27.2.4.1. 그룹 ID
NFS 액세스를 처리하는 권장 방법(NFS 내보내기에 대한 권한을 변경하는 옵션이 아님 가정)은 보조 그룹을 사용하는 것입니다. OpenShift Container Platform의 추가 그룹은 공유 스토리지에 사용되며 NFS가 그 예입니다. 반대로 Ceph RBD 또는 iSCSI와 같은 블록 스토리지는 포드의 securityContext 에 있는 fsGroup SCC 전략과 fsGroup 값을 사용합니다.
일반적으로 사용자 ID를 사용하는 대신 추가 그룹 ID를 사용하여 영구 스토리지에 액세스하는 것이 좋습니다. 보충 그룹은 전체 볼륨 보안 주제에서 자세히 다룹니다.
위에 표시된 대상 NFS 디렉터리 의 그룹 ID는 5555이므로 Pod는 Pod 수준 securityContext 정의에서 supplementalGroups 를 사용하여 해당 그룹 ID를 정의할 수 있습니다. 예를 들면 다음과 같습니다.
spec:
containers:
- name:
...
securityContext:
supplementalGroups: [5555]
Pod의 요구 사항을 충족할 수 있는 사용자 지정 SCC가 없는 경우 Pod는 restricted SCC와 일치할 수 있습니다. 이 SCC에는 supplementalGroups 전략이 RunAsAny 로 설정되어 있습니다. 즉, 범위를 확인하지 않고 제공된 그룹 ID가 허용됩니다.
그 결과 위의 Pod에서 승인이 전달 및 실행됩니다. 그러나 그룹 ID 범위 확인이 필요한 경우 Pod 보안 및 사용자 지정 SCC에 설명된 대로 사용자 지정 SCC 가 권장되는 솔루션입니다. 최소 및 최대 그룹 ID가 정의되고, 그룹 ID 범위 검사가 적용되며, 5555 그룹 ID가 허용되도록 사용자 지정 SCC를 생성할 수 있습니다.
사용자 정의 SCC를 사용하려면 먼저 적절한 서비스 계정에 추가해야 합니다. 예를 들어 Pod 사양에 다른 값이 지정된 경우를 제외하고 지정된 프로젝트에서 기본 서비스 계정을 사용합니다. 자세한 내용은 사용자, 그룹 또는 프로젝트에 SCC 추가를 참조하십시오.
27.2.4.2. 사용자 ID
사용자 ID는 컨테이너 이미지 또는 포드 정의에 정의할 수 있습니다. 전체 볼륨 보안 주제에서는 사용자 ID를 기반으로 스토리지 액세스를 제어하는 작업을 다루며 NFS 영구 스토리지를 설정하려면 먼저 읽어야 합니다.
일반적으로 사용자 ID를 사용하는 대신 추가 그룹 ID 를 사용하여 영구 스토리지에 액세스하는 것이 좋습니다.
위에 표시된 예제 NFS 디렉터리에서 컨테이너에는 65534(지금 그룹 ID를 무시)로 설정된 UID가 있어야 하므로 다음을 포드 정의에 추가할 수 있습니다.
spec:
containers:
- name:
...
securityContext:
runAsUser: 65534 기본 프로젝트 및 restricted SCC를 가정하면 Pod의 요청된 사용자 ID 65534가 허용되지 않으므로 Pod가 실패합니다. Pod는 다음과 같은 이유로 실패합니다.
- 65534를 사용자 ID로 요청합니다.
- Pod에서 사용할 수 있는 모든 SCC를 검사하여 65534의 사용자 ID를 허용하는 SCC를 확인합니다(실제로 SCC의 모든 정책이 확인되지만 여기에서 초점은 사용자 ID에 있음).
-
사용 가능한 모든 SCC는
runAsUser전략에 MustRunAsRange 를 사용하므로 UID 범위 검사가 필요합니다. - 65534는 SCC 또는 프로젝트의 사용자 ID 범위에 포함되지 않습니다.
일반적으로 사전 정의된 SCC를 수정하지 않는 것이 좋습니다. 이 상황을 수정하는 기본 방법은 전체 볼륨 보안 항목에 설명된 대로 사용자 지정 SCC를 만드는 것입니다. 최소 및 최대 사용자 ID가 정의되고, UID 범위 검사가 계속 적용되며 65534의 UID가 허용되도록 사용자 지정 SCC를 만들 수 있습니다.
사용자 정의 SCC를 사용하려면 먼저 적절한 서비스 계정에 추가해야 합니다. 예를 들어 Pod 사양에 다른 값이 지정된 경우를 제외하고 지정된 프로젝트에서 기본 서비스 계정을 사용합니다. 자세한 내용은 사용자, 그룹 또는 프로젝트에 SCC 추가를 참조하십시오.
27.2.4.3. SELinux
SELinux를 사용하여 스토리지 액세스 제어에 대한 자세한 내용은 전체 볼륨 보안 주제를 참조하십시오.
기본적으로 SELinux는 포드에서 원격 NFS 서버로 쓰기를 허용하지 않습니다. NFS 볼륨이 올바르게 마운트되지만 읽기 전용입니다.
각 노드에서 SELinux를 강제 적용하여 NFS 볼륨에 쓰기를 활성화하려면 다음을 실행합니다.
# setsebool -P virt_use_nfs 1
위의 -P 옵션을 사용하면 재부팅 사이에 부울이 지속됩니다.
virt_use_nfs 부울은 docker-selinux 패키지에서 정의합니다. 이 부울이 정의되지 않았음을 나타내는 오류가 표시되면 이 패키지가 설치되었는지 확인합니다.
27.2.4.4. 내보내기 설정
임의의 컨테이너 사용자가 볼륨을 읽고 쓸 수 있도록 하려면 NFS 서버의 내보낸 각 볼륨이 다음 조건을 준수해야 합니다.
각 내보내기는 다음과 같아야 합니다.
/<example_fs> *(rw,root_squash)마운트 옵션으로 트래픽을 허용하도록 방화벽을 구성해야 합니다.
NFSv4의 경우 기본 포트
2049(nfs)를 구성합니다.NFSv4
# iptables -I INPUT 1 -p tcp --dport 2049 -j ACCEPTNFSv3의 경우 구성할 포트 3개가 있습니다.
2049(NFS),20048(mountd) 및111(portmapper).NFSv3
# iptables -I INPUT 1 -p tcp --dport 2049 -j ACCEPT # iptables -I INPUT 1 -p tcp --dport 20048 -j ACCEPT # iptables -I INPUT 1 -p tcp --dport 111 -j ACCEPT
-
대상 포드에서 액세스할 수 있도록 NFS 내보내기 및 디렉터리를 설정해야 합니다. 컨테이너의 기본 UID에서 소유하도록 내보내기를 설정하거나 위의 그룹 ID에 표시된 대로
supplementalGroups를 사용하여 포드 그룹 액세스 권한을 제공합니다. 추가 포드 보안 정보는 전체 볼륨 보안 주제를 참조하십시오.
27.2.5. 리소스 회수
NFS는 OpenShift Container Platform Recyclable 플러그인 인터페이스를 구현합니다. 자동 프로세스는 각 영구 볼륨에 설정된 정책에 따라 복구 작업을 처리합니다.
기본적으로 PV는 Retain으로 설정됩니다.
PV에 대한 클레임이 릴리스되면(즉, PVC가 삭제됨) PV 오브젝트를 다시 사용하면 안 됩니다. 대신 원래 볼륨과 동일한 기본 볼륨 세부 정보를 사용하여 새 PV를 생성해야 합니다.
예를 들어, 관리자가 이름이 nfs1인 PV를 생성합니다.
apiVersion: v1
kind: PersistentVolume
metadata:
name: nfs1
spec:
capacity:
storage: 1Mi
accessModes:
- ReadWriteMany
nfs:
server: 192.168.1.1
path: "/"
사용자가 PVC1을 생성하여 nfs1에 바인딩합니다. 그런 다음 사용자가 PVC1 을 삭제하여 nfs1 에 클레임을 해제하여 nfs1 이 릴리스 됩니다. 관리자가 동일한 NFS 공유를 사용하려면 동일한 NFS 서버 세부 정보를 사용하여 새 PV를 생성해야 하지만 다른 PV 이름을 사용해야 합니다.
apiVersion: v1
kind: PersistentVolume
metadata:
name: nfs2
spec:
capacity:
storage: 1Mi
accessModes:
- ReadWriteMany
nfs:
server: 192.168.1.1
path: "/"
원래 PV를 삭제하고 동일한 이름으로 다시 생성하는 것은 권장되지 않습니다. Released에서 Available로 PV의 상태를 수동으로 변경하면 오류가 발생하거나 데이터가 손실될 수 있습니다.
27.2.6. 자동화
클러스터는 다음과 같은 방식으로 NFS를 사용하여 영구 스토리지로 프로비저닝할 수 있습니다.
- 디스크 파티션을 사용하여 스토리지 할당량을 적용합니다.
- 볼륨을 클레임이 있는 프로젝트로 제한하여 보안을 적용합니다.
- 각 PV에 대해 삭제된 리소스의 재사용 을 구성합니다.
스크립트를 사용하여 이전 작업을 자동화할 수 있는 방법은 여러 가지가 있습니다. OpenShift Container Platform 3.11 릴리스와 관련된 Ansible 플레이북 예제 를 사용하여 시작할 수 있습니다.
27.2.7. 추가 구성 및 문제 해결
사용되는 NFS 버전과 구성 방법에 따라 적절한 내보내기 및 보안 매핑에 필요한 추가 구성 단계가 있을 수 있습니다. 다음은 적용되는 몇 가지입니다.
| NFSv4 마운트에서 소유권이 nobody:nobody인 모든 파일이 올바르게 표시되지 않습니다. |
|
| NFSv4에서 ID 매핑 비활성화 |
|
27.3. Red Hat Gluster Storage를 사용하는 영구 스토리지
27.3.1. 개요
OpenShift Container Platform에 영구 스토리지 및 동적 프로비저닝을 제공하도록 Red Hat Gluster Storage를 구성할 수 있습니다. OpenShift Container Platform(통합 모드) 내에서 컨테이너화되고 자체 노드(독립모드)에서 컨테이너화되지 않을 수 있습니다.
27.3.1.1. 통합 모드
통합 모드를 사용하면 Red Hat Gluster Storage가 OpenShift Container Platform 노드에서 직접 컨테이너화됩니다. 이를 통해 계산 및 스토리지 인스턴스를 동일한 하드웨어 집합에서 예약하고 실행할 수 있습니다.
그림 27.1. 아키텍처 - 통합 모드

통합 모드는 Red Hat Gluster Storage 3.4에서 사용할 수 있습니다. 추가 설명서는 OpenShift Container Platform의 통합 모드를 참조하십시오.
27.3.1.2. 독립 모드
독립 모드를 사용하면 Red Hat Gluster Storage는 자체 전용 노드에서 실행되며 GlusterFS 볼륨 관리 REST 서비스인 heketi 인스턴스에서 관리합니다. 이 heketi 서비스는 독립 실행형이 아닌 컨테이너화된 상태로 실행해야 합니다. 컨테이너화를 통해 서비스에 고가용성을 제공하는 쉬운 메커니즘을 사용할 수 있습니다. 이 문서에서는 컨테이너화된 heketi 구성을 중점적으로 설명합니다.
27.3.1.3. 독립형 Red Hat Gluster Storage
사용자 환경에서 독립 실행형 Red Hat Gluster Storage 클러스터를 사용할 수 있는 경우 OpenShift Container Platform의 GlusterFS 볼륨 플러그인을 사용하여 해당 클러스터에서 볼륨을 사용할 수 있습니다. 이 솔루션은 애플리케이션이 전용 계산 노드, OpenShift Container Platform 클러스터 및 자체 전용 노드에서 스토리지를 제공하는 일반적인 배포입니다.
그림 27.2. 아키텍처 - OpenShift Container Platform의 GlusterFS 볼륨 플러그인을 사용하는 독립 실행형 Red Hat Gluster Storage 클러스터

Red Hat Gluster Storage에 대한 자세한 내용은 Red Hat Gluster Storage 설치 가이드 및 Red Hat Gluster Storage 관리 가이드를 참조하십시오.
인프라의 스토리지의 고가용성은 기본 스토리지 공급자가 담당합니다.
27.3.1.4. GlusterFS 볼륨
GlusterFS 볼륨은 POSIX 호환 파일 시스템을 제공하며 클러스터의 하나 이상의 노드에서 하나 이상의 "bricks"로 구성됩니다. brick은 지정된 스토리지 노드의 디렉터리이며 일반적으로 블록 스토리지 장치의 마운트 지점입니다. GlusterFS는 해당 볼륨 구성별로 지정된 볼륨의 brick에서 파일의 배포 및 복제를 처리합니다.
create, delete 및 resize와 같은 대부분의 일반적인 볼륨 관리 작업에 heketi를 사용하는 것이 좋습니다. OpenShift Container Platform은 GlusterFS 프로비저너를 사용할 때 heketi가 존재할 것으로 예상합니다. 기본적으로 heketi는 3개의 배열 복제본인 볼륨을 생성합니다. 이 볼륨은 각 파일에 3개의 서로 다른 노드에 세 개의 복사본이 있는 볼륨입니다. 따라서 heketi에서 사용할 모든 Red Hat Gluster Storage 클러스터에 3개 이상의 노드를 사용할 수 있는 것이 좋습니다.
GlusterFS 볼륨에 사용할 수 있는 많은 기능이 있지만 이 설명서의 범위를 벗어납니다.
27.3.1.5. Gluster-block 볼륨
Gluster-block 볼륨은 iSCSI를 통해 마운트할 수 있는 볼륨입니다. 이 작업은 기존 GlusterFS 볼륨에 파일을 만든 다음 iSCSI 대상을 통해 해당 파일을 블록 장치로 제공하여 수행됩니다. 이러한 GlusterFS 볼륨을 블록 호스팅 볼륨이라고 합니다.
Gluster-block 볼륨은 일종의 장단점이 있습니다. iSCSI 대상으로 사용되기 때문에 gluster-block 볼륨은 여러 노드/클라이언트에서 마운트할 수 있는 GlusterFS 볼륨과 달리 한 번에 하나의 노드/클라이언트만 마운트할 수 있습니다. 그러나 백엔드에 파일이 있으면 GlusterFS 볼륨에 일반적으로 비용이 많이 드는 작업(예: 메타데이터 조회)을 GlusterFS 볼륨(예: 읽기 및 쓰기)에서 훨씬 더 빠른 작업으로 변환할 수 있습니다. 이로 인해 특정 워크로드에 대해 잠재적으로 성능이 크게 향상됩니다.
OpenShift Container Storage 및 OpenShift Container Platform 상호 운용성에 대한 자세한 내용은 링크를 참조하십시오. OpenShift Container Storage 및 OpenShift Container Platform 상호 운용성 매트릭스.
27.3.1.6. Gluster S3 스토리지
Gluster S3 서비스를 사용하면 사용자 애플리케이션이 S3 인터페이스를 통해 GlusterFS 스토리지에 액세스할 수 있습니다. 서비스는 두 개의 GlusterFS 볼륨에 바인딩합니다. 하나는 개체 데이터와 오브젝트 메타데이터용용이며, 수신되는 S3 REST 요청을 볼륨의 파일 시스템 작업으로 변환합니다. 서비스를 OpenShift Container Platform 내에서 포드로 실행하는 것이 좋습니다.
현재 Gluster S3 서비스의 사용 및 설치는 기술 검토 단계에 있습니다.
27.3.2. 고려 사항
이 섹션에서는 OpenShift Container Platform에서 Red Hat Gluster Storage를 사용할 때 고려해야 하는 몇 가지 주제에 대해 설명합니다.
27.3.2.1. 소프트웨어 요구 사항
GlusterFS 볼륨에 액세스하려면 예약 가능한 모든 노드에서 mount.glusterfs 명령을 사용할 수 있어야 합니다. RPM 기반 시스템의 경우 glusterfs-fuse 패키지를 설치해야 합니다.
# yum install glusterfs-fuse이 패키지는 모든 RHEL 시스템에 설치됩니다. 하지만 서버가 x86_64 아키텍처를 사용하는 경우 Red Hat Gluster Storage에서 사용 가능한 최신 버전으로 업데이트하는 것이 좋습니다. 이를 수행하려면 다음 RPM 리포지토리를 활성화해야 합니다.
# subscription-manager repos --enable=rh-gluster-3-client-for-rhel-7-server-rpmsglusterfs-fuse 가 노드에 이미 설치된 경우 최신 버전이 설치되어 있는지 확인합니다.
# yum update glusterfs-fuse27.3.2.2. 하드웨어 요구 사항
통합 모드 또는 독립 모드 클러스터에서 사용되는 모든 노드는 스토리지 노드로 간주됩니다. 단일 노드는 여러 그룹에 있을 수 없지만 스토리지 노드를 별도의 클러스터 그룹으로 그룹화할 수 있습니다. 각 스토리지 노드 그룹에 대해 다음을 수행합니다.
- 스토리지 Gluster 볼륨 유형 옵션을 기반으로 그룹당 하나 이상의 스토리지 노드가 필요합니다.
각 스토리지 노드에는 최소 8GB의 RAM이 있어야 합니다. 이는 Red Hat Gluster Storage 포드와 기타 애플리케이션 및 기본 운영 체제를 실행할 수 있도록 허용하기 위한 것입니다.
- 또한 각 GlusterFS 볼륨은 스토리지 클러스터의 모든 스토리지 노드에서 약 30MB의 메모리를 사용합니다. 총 RAM 용량은 원하는 동시 볼륨 또는 예상 볼륨 수에 따라 결정되어야 합니다.
각 스토리지 노드에는 현재 데이터 또는 메타데이터가 없는 원시 블록 장치가 하나 이상 있어야 합니다. 이러한 블록 장치는 GlusterFS 스토리지의 전체에서 사용됩니다. 다음이 없는지 확인합니다.
- 파티션 테이블 (GPT 또는 MSDOS)
- 파일 시스템 또는 보조 파일 시스템 서명
- 이전 볼륨 그룹 및 논리 볼륨의 LVM2 서명
- LVM2 물리 볼륨의 LVM2 메타데이터
의심스러운 경우
wipefs -a <device>는 위의 항목을 지웁니다.
인프라 애플리케이션(예: OpenShift Container Registry)용 스토리지 전용 클러스터와 일반 애플리케이션을 위한 스토리지 전용의 두 클러스터를 계획하는 것이 좋습니다. 이 작업에는 총 6개의 스토리지 노드가 필요합니다. 이 권장 사항은 I/O 및 볼륨 생성의 성능에 잠재적 영향을 미치지 않도록 합니다.
27.3.2.3. 스토리지 크기 조정
모든 GlusterFS 클러스터는 해당 스토리지를 사용할 예상 애플리케이션의 요구 사항에 따라 크기를 조정해야 합니다. 예를 들어 OpenShift Logging 및 OpenShift 지표 모두에 사용할 수 있는 크기 조정 가이드가 있습니다.
고려해야 할 몇 가지 추가 사항은 다음과 같습니다.
각 통합 모드 또는 독립 모드 클러스터의 기본 동작은 3방향 복제를 사용하여 GlusterFS 볼륨을 생성하는 것입니다. 따라서 계획할 총 스토리지는 필요한 용량 시간 3배여야 합니다.
-
예를 들어 각 heketi 인스턴스는 크기가 2GB인
heketidbstorage볼륨을 생성하므로 스토리지 클러스터의 3개 노드에 총 6GB의 원시 스토리지가 필요합니다. 이 용량은 항상 필요하며 크기 조정을 고려해야 합니다. - 통합된 OpenShift Container Registry와 같은 애플리케이션은 애플리케이션의 여러 인스턴스에서 단일 GlusterFS 볼륨을 공유합니다.
-
예를 들어 각 heketi 인스턴스는 크기가 2GB인
Gluster-block 볼륨에는 지정된 블록 볼륨 용량의 전체 크기를 유지하기에 충분한 용량이 있는 GlusterFS 블록 호스팅 볼륨이 있어야 합니다.
- 기본적으로 이러한 블록 호스팅 볼륨이 없으면 설정된 크기로 자동으로 생성됩니다. 이 크기의 기본값은 100GB입니다. 클러스터에 새 블록 호스팅 볼륨을 생성하는 공간이 충분하지 않으면 블록 볼륨 생성에 실패합니다. 자동 생성 동작과 자동 생성된 볼륨 크기를 모두 구성할 수 있습니다.
- OpenShift Logging 및 OpenShift Metrics와 같이 gluster-block 볼륨을 사용하는 여러 인스턴스가 있는 애플리케이션에서는 인스턴스당 하나의 볼륨을 사용합니다.
- Gluster S3 서비스는 두 개의 GlusterFS 볼륨에 바인딩됩니다. 기본 클러스터 설치에서 이러한 볼륨은 각각 1GB이며 총 6GB의 원시 스토리지를 사용합니다.
27.3.2.4. 볼륨 작업 동작
생성 및 삭제와 같은 볼륨 작업은 다양한 환경 환경에서 영향을 받을 수 있으며 이로 인해 애플리케이션에도 영향을 줄 수 있습니다.
애플리케이션 포드에서 동적으로 프로비저닝된 GlusterFS PVC(영구 볼륨 클레임)를 요청하는 경우 볼륨이 생성되고 해당 PVC에 바인딩되도록 추가 시간을 고려해야 할 수 있습니다. 이는 애플리케이션 포드의 시작 시간에 영향을 미칩니다.
참고GlusterFS 볼륨 생성 시간은 볼륨 수에 따라 선형으로 확장됩니다. 예를 들어 권장 하드웨어 사양을 사용하여 클러스터에 100개의 볼륨을 지정하는 경우 각 볼륨은 Pod를 생성, 할당 및 바인딩하는 데 약 6초가 걸렸습니다.
PVC가 삭제되면 해당 조치가 기본 GlusterFS 볼륨의 삭제를 트리거합니다.
oc get pvc출력에서 PVC는 즉시 사라집니다. 이는 볼륨이 완전히 삭제되었음을 의미하지는 않습니다. GlusterFS 볼륨은heketi-cli 볼륨 목록 및대한 명령줄 출력에 표시되지 않는 경우에만 삭제된 것으로 간주할 수 있습니다.gluster 볼륨 목록에참고GlusterFS 볼륨을 삭제하고 해당 스토리지를 재활용하는 시간은 활성 GlusterFS 볼륨 수에 따라 선형으로 확장되며. 보류 중인 볼륨 삭제는 실행 중인 애플리케이션에 영향을 미치지 않지만 스토리지 관리자는 특히 대규모 리소스 소비를 튜닝할 때 걸리는 시간을 예상할 수 있어야 합니다.
27.3.2.5. 볼륨 보안
이 섹션에서는 HAIX(Portable Operating System Interface) 권한 및 SELinux 고려 사항을 포함하여 Red Hat Gluster Storage 볼륨 보안을 다룹니다. 볼륨 보안, POSIX 권한 및 SELinux의 기본 사항을 이해해야 합니다.
OpenShift Container Storage 3.11에서는 영구 볼륨에 대한 보안 액세스 제어를 보장하기 위해 SSL 암호화를 활성화해야 합니다.
자세한 내용은 Red Hat OpenShift Container Storage 3.11 운영 가이드를 참조하십시오.
27.3.2.5.1. POSIX 권한
Red Hat Gluster Storage 볼륨은 POSIX 호환 파일 시스템을 제공합니다. 따라서 chmod 및 chown 과 같은 표준 명령줄 도구를 사용하여 액세스 권한을 관리할 수 있습니다.
통합 모드 및 독립 모드의 경우 볼륨 생성 시 볼륨의 루트를 소유할 그룹 ID를 지정할 수도 있습니다. 정적 프로비저닝의 경우 heketi-cli 볼륨 생성 명령의 일부로 지정합니다.
$ heketi-cli volume create --size=100 --gid=10001000이 볼륨과 연결된 PersistentVolume은 PersistentVolume을 사용하는 Pod에서 파일 시스템에 액세스할 수 있도록 그룹 ID로 주석을 달아야 합니다. 이 주석은 다음과 같은 형식을 취합니다.
pv.beta.kubernetes.io/gid: "<GID>" ---
동적 프로비저닝의 경우 프로비저너에서 그룹 ID를 자동으로 생성하고 적용합니다. gidMin 및 gid Max StorageClass 매개변수를 사용하여 이 그룹 ID를 선택하는 범위를 제어할 수 있습니다( 동적 프로비저닝참조). 배포 프로그램은 생성된 PersistentVolume에 그룹 ID에 주석을 답니다.
27.3.2.5.2. SELinux
기본적으로 SELinux는 포드에서 원격 Red Hat Gluster Storage 서버로 쓰기를 허용하지 않습니다. 에서 SELinux를 사용하여 Red Hat Gluster Storage 볼륨에 쓰기를 활성화하려면 GlusterFS를 실행하는 각 노드에서 다음을 실행합니다.
$ sudo setsebool -P virt_sandbox_use_fusefs on
$ sudo setsebool -P virt_use_fusefs on- 1
- P
옵션을 사용하면재부팅 사이에 부울이 지속됩니다.
virt_sandbox_use_fusefs 부울은 docker-selinux 패키지에서 정의합니다. 정의되지 않았다는 오류가 표시되면 이 패키지가 설치되어 있는지 확인합니다.
Atomic Host를 사용하는 경우 Atomic Host를 업그레이드할 때 SELinux 부울이 지워집니다. Atomic Host를 업그레이드할 때 이러한 부울 값을 다시 설정해야 합니다.
27.3.3. 지원 요구 사항
지원되는 Red Hat Gluster Storage 및 OpenShift Container Platform 통합을 생성하려면 다음 요구 사항을 충족해야 합니다.
독립 모드 또는 독립형 Red Hat Gluster Storage의 경우:
- 최소 버전: Red Hat Gluster Storage 3.4
- 모든 Red Hat Gluster Storage 노드에는 Red Hat Network 채널 및 서브스크립션 관리자 리포지토리에 대한 유효한 서브스크립션이 있어야 합니다.
- Red Hat Gluster Storage 노드는 계획 Red Hat Gluster Storage 설치에 지정된 요구 사항을 준수해야 합니다.
- Red Hat Gluster Storage 노드는 최신 패치 및 업그레이드를 완전히 최신 상태로 유지해야 합니다. 최신 버전으로 업그레이드하려면 Red Hat Gluster Storage 설치 가이드를 참조하십시오.
- 각 Red Hat Gluster Storage 노드에 대해 FQDN(정규화된 도메인 이름)을 설정해야 합니다. 올바른 DNS 레코드가 있고 정방향 및 역방향 DNS 조회를 통해 FQDN을 확인할 수 있는지 확인합니다.
27.3.4. 설치
독립 실행형 Red Hat Gluster Storage의 경우 OpenShift Container Platform과 함께 사용하는 데 필요한 구성 요소 설치가 없습니다. OpenShift Container Platform에는 기본 제공 GlusterFS 볼륨 드라이버가 제공되어 기존 클러스터에서 기존 볼륨을 사용할 수 있습니다. 기존 볼륨을 사용하는 방법에 대한 자세한 내용은 프로비저닝 을 참조하십시오.
통합 모드 및 독립 모드의 경우 클러스터 설치 프로세스를 사용하여 필요한 구성 요소를 설치하는 것이 좋습니다.
27.3.4.1. 독립 모드: Red Hat Gluster Storage 노드 설치
독립 모드의 경우 각 Red Hat Gluster Storage 노드에는 적절한 시스템 구성(예: 방화벽 포트, 커널 모듈)이 있어야 하며 Red Hat Gluster Storage 서비스가 실행 중이어야 합니다. 서비스는 추가로 구성되지 않아야 하며 신뢰할 수 있는 스토리지 풀을 구성하지 않아야 합니다.
Red Hat Gluster Storage 노드의 설치는 이 문서의 범위를 벗어납니다. 자세한 내용은 Set Up independent mode 를 참조하십시오.
27.3.4.2. 설치 프로그램 사용
glusterfs 및 glusterfs _registry 노드 그룹에 별도의 노드를 사용합니다. 각 인스턴스는 독립적으로 관리 되므로 별도의 Gluster 인스턴스여야 합니다. glusterfs 및 glusterfs _registry 노드 그룹에 동일한 노드를 사용하면 배포에 실패합니다.
클러스터 설치 프로세스를 사용하여 두 개의 GlusterFS 노드 그룹 중 하나 또는 둘 다를 설치할 수 있습니다.
-
glusterfs: 사용자 애플리케이션에서 사용할 일반 스토리지 클러스터. -
glusterfs_registry: 통합된 OpenShift Container Registry와 같은 인프라 애플리케이션에서 사용할 전용 스토리지 클러스터입니다.
I/O 및 볼륨 생성의 성능에 잠재적 영향을 주지 않도록 두 그룹을 모두 배포하는 것이 좋습니다. 이 두 가지는 모두 인벤토리 호스트 파일에 정의되어 있습니다.
스토리지 클러스터를 정의하려면 [OSEv3:children] 그룹에 관련 이름을 포함하여 유사한 명명된 그룹을 생성합니다. 그런 다음, 그룹 을 노드 정보로 채웁니다.
[OSEv3:children] 그룹에서 masters,nodes,etcd, glusterfs 및 glusterfs _registry 스토리지 클러스터를 추가합니다.
그룹을 생성하고 채운 후 [OSEv3:vars] 그룹에 더 많은 매개변수 값을 정의하여 클러스터를 구성합니다. 변수는 다음 예와 같이 GlusterFS 클러스터와 상호 작용하며 인벤토리 파일에 저장됩니다.
-
GlusterFS변수는openshift_storage_glusterfs_로 시작합니다. -
glusterfs_registry변수는openshift_storage_glusterfs_registry_로 시작합니다.
인벤토리 파일의 다음 예제에서는 두 개의 GlusterFS 노드 그룹을 배포할 때 변수 사용을 보여줍니다.
`[OSEv3:children]
masters
nodes
etcd
glusterfs
glusterfs_registry`
[OSEv3:vars]
install_method=rpm
os_update=false
install_update_docker=true
docker_storage_driver=devicemapper
ansible_ssh_user=root
openshift_release=v3.11
oreg_url=registry.access.redhat.com/openshift3/ose-${component}:v3.11
#openshift_cockpit_deployer_image='registry.redhat.io/openshift3/registry-console:v3.11'
openshift_docker_insecure_registries=registry.access.redhat.com
openshift_deployment_type=openshift-enterprise
openshift_web_console_install=true
openshift_enable_service_catalog=false
osm_use_cockpit=false
osm_cockpit_plugins=['cockpit-kubernetes']
debug_level=5
openshift_set_hostname=true
openshift_override_hostname_check=true
openshift_disable_check=docker_image_availability
openshift_check_min_host_disk_gb=2
openshift_check_min_host_memory_gb=1
openshift_portal_net=172.31.0.0/16
openshift_master_cluster_method=native
openshift_clock_enabled=true
openshift_use_openshift_sdn=true
openshift_master_dynamic_provisioning_enabled=true
# logging
openshift_logging_install_logging=true
openshift_logging_es_pvc_dynamic=true
openshift_logging_kibana_nodeselector={"node-role.kubernetes.io/infra": "true"}
openshift_logging_curator_nodeselector={"node-role.kubernetes.io/infra": "true"}
openshift_logging_es_nodeselector={"node-role.kubernetes.io/infra": "true"}
openshift_logging_es_pvc_size=20Gi
openshift_logging_es_pvc_storage_class_name="glusterfs-registry-block"
# metrics
openshift_metrics_install_metrics=true
openshift_metrics_storage_kind=dynamic
openshift_metrics_hawkular_nodeselector={"node-role.kubernetes.io/infra": "true"}
openshift_metrics_cassandra_nodeselector={"node-role.kubernetes.io/infra": "true"}
openshift_metrics_heapster_nodeselector={"node-role.kubernetes.io/infra": "true"}
openshift_metrics_storage_volume_size=20Gi
openshift_metrics_cassandra_pvc_storage_class_name="glusterfs-registry-block"
# glusterfs
openshift_storage_glusterfs_timeout=900
openshift_storage_glusterfs_namespace=glusterfs
openshift_storage_glusterfs_storageclass=true
openshift_storage_glusterfs_storageclass_default=false
openshift_storage_glusterfs_block_storageclass=true
openshift_storage_glusterfs_block_storageclass_default=false
openshift_storage_glusterfs_block_deploy=true
openshift_storage_glusterfs_block_host_vol_create=true
openshift_storage_glusterfs_block_host_vol_size=100
# glusterfs_registry
openshift_storage_glusterfs_registry_namespace=glusterfs-registry
openshift_storage_glusterfs_registry_storageclass=true
openshift_storage_glusterfs_registry_storageclass_default=false
openshift_storage_glusterfs_registry_block_storageclass=true
openshift_storage_glusterfs_registry_block_storageclass_default=false
openshift_storage_glusterfs_registry_block_deploy=true
openshift_storage_glusterfs_registry_block_host_vol_create=true
openshift_storage_glusterfs_registry_block_host_vol_size=100
# glusterfs_registry_storage
openshift_hosted_registry_storage_kind=glusterfs
openshift_hosted_registry_storage_volume_size=20Gi
openshift_hosted_registry_selector="node-role.kubernetes.io/infra=true"
openshift_storage_glusterfs_heketi_admin_key='adminkey'
openshift_storage_glusterfs_heketi_user_key='heketiuserkey'
openshift_storage_glusterfs_image='registry.access.redhat.com/rhgs3/rhgs-server-rhel7:v3.11'
openshift_storage_glusterfs_heketi_image='registry.access.redhat.com/rhgs3/rhgs-volmanager-rhel7:v3.11'
openshift_storage_glusterfs_block_image='registry.access.redhat.com/rhgs3/rhgs-gluster-block-prov-rhel7:v3.11'
openshift_master_cluster_hostname=node101.redhat.com
openshift_master_cluster_public_hostname=node101.redhat.com
[masters]
node101.redhat.com
[etcd]
node101.redhat.com
[nodes]
node101.redhat.com openshift_node_group_name="node-config-master"
node102.redhat.com openshift_node_group_name="node-config-infra"
node103.redhat.com openshift_node_group_name="node-config-compute"
node104.redhat.com openshift_node_group_name="node-config-compute"
node105.redhat.com openshift_node_group_name="node-config-compute"
node106.redhat.com openshift_node_group_name="node-config-compute"
node107.redhat.com openshift_node_group_name="node-config-compute"
node108.redhat.com openshift_node_group_name="node-config-compute"
[glusterfs]
node103.redhat.com glusterfs_zone=1 glusterfs_devices='["/dev/sdd"]'
node104.redhat.com glusterfs_zone=2 glusterfs_devices='["/dev/sdd"]'
node105.redhat.com glusterfs_zone=3 glusterfs_devices='["/dev/sdd"]'
[glusterfs_registry]
node106.redhat.com glusterfs_zone=1 glusterfs_devices='["/dev/sdd"]'
node107.redhat.com glusterfs_zone=2 glusterfs_devices='["/dev/sdd"]'
node108.redhat.com glusterfs_zone=3 glusterfs_devices='["/dev/sdd"]'27.3.4.2.1. 호스트 변수
glusterfs 및 glusterfs _registry 그룹의 각 호스트에는 glusterfs_devices 변수가 정의되어 있어야 합니다. 이 변수는 GlusterFS 클러스터의 일부로 관리할 블록 장치 목록을 정의합니다. 하나 이상의 장치가 있어야 하며 파티션이나 LVM PV가 없어야 합니다.
각 호스트에 대해 다음 변수를 정의할 수도 있습니다. 이러한 변수가 정의된 경우 이러한 변수는 호스트 구성을 GlusterFS 노드로 추가로 제어합니다.
-
glusterfs_cluster: 이 노드가 속하는 클러스터의 ID입니다. -
glusterfs_hostname: 내부 GlusterFS 통신에 사용할 호스트 이름 또는 IP 주소입니다. -
glusterfs_ip: 포드가 GlusterFS 노드와 통신하는 데 사용하는 IP 주소입니다. -
glusterfs_zone: 노드의 영역 번호입니다. 클러스터 내에서 영역은 GlusterFS 볼륨의 brick을 배포하는 방법을 결정합니다.
27.3.4.2.2. 역할 변수
신규 또는 기존 OpenShift Container Platform 클러스터에 GlusterFS 클러스터의 통합을 제어하기 위해 인벤토리 파일에 저장된 여러 역할 변수를 정의할 수도 있습니다. 각 역할 변수에는 선택적으로 통합된 Docker 레지스트리의 스토리지로 사용할 별도의 GlusterFS 클러스터를 구성하는 해당 변수도 있습니다.
27.3.4.2.3. 이미지 이름 및 버전 태그 변수
다른 OpenShift Container Platform 버전이 있는 클러스터가 중단된 후 OpenShift Container Platform Pod가 업그레이드되지 않도록 컨테이너화된 모든 구성 요소에 대한 이미지 이름 및 버전 태그를 지정하는 것이 좋습니다. 이러한 변수는 다음과 같습니다.
-
openshift_storage_glusterfs_image -
openshift_storage_glusterfs_block_image -
openshift_storage_glusterfs_s3_image -
openshift_storage_glusterfs_heketi_image
gluster-block 및 gluster- s3의 이미지 변수는 해당 배포 변수( _block_deploy 및 로 끝나는 변수)가 true인 경우에만 필요합니다.
_s3_deploy
배포에 성공하려면 유효한 이미지 태그가 필요합니다. 인벤토리 파일의 다음 변수에 대한 상호 운용성 매트릭스에 설명된 대로 <tag> 를 OpenShift Container Platform 3.11과 호환되는 Red Hat Gluster Storage 버전으로 교체합니다.
-
openshift_storage_glusterfs_image=registry.redhat.io/rhgs3/rhgs-server-rhel7:<tag> -
openshift_storage_glusterfs_block_image=registry.redhat.io/rhgs3/rhgs-gluster-block-prov-rhel7:<tag> -
openshift_storage_glusterfs_s3_image=registry.redhat.io/rhgs3/rhgs-s3-server-rhel7:<tag> -
openshift_storage_glusterfs_heketi_image=registry.redhat.io/rhgs3/rhgs-volmanager-rhel7:<tag> -
openshift_storage_glusterfs_registry_image=registry.redhat.io/rhgs3/rhgs-server-rhel7:<tag> -
openshift_storage_glusterfs_block_registry_image=registry.redhat.io/rhgs3/rhgs-gluster-block-prov-rhel7:<tag> -
openshift_storage_glusterfs_s3_registry_image=registry.redhat.io/rhgs3/rhgs-s3-server-rhel7:<tag> -
openshift_storage_glusterfs_heketi_registry_image=registry.redhat.io/rhgs3/rhgs-volmanager-rhel7:<tag>
전체 변수 목록은 GitHub의 GlusterFS 역할 README 를 참조하십시오.
변수가 구성되면 설치 환경에 따라 여러 플레이북을 사용할 수 있습니다.
클러스터 설치를 위한 기본 플레이북을 사용하여 OpenShift Container Platform의 초기 설치와 함께 GlusterFS 클러스터를 배포할 수 있습니다.
- 여기에는 GlusterFS 스토리지를 사용하는 통합 OpenShift Container Registry 배포가 포함됩니다.
- 여기에는 현재 별도의 단계이므로 OpenShift Logging 또는 OpenShift Metrics는 포함되지 않습니다. 자세한 내용은 OpenShift Logging 및 Metrics의 통합 모드를 참조하십시오.
-
playbooks/openshift-glusterfs/config.yml을 사용하여 기존 OpenShift Container Platform 설치에 클러스터를 배포할 수 있습니다. playbooks/openshift-glusterfs/registry.yml을 사용하여 기존 OpenShift Container Platform 설치에 클러스터를 배포할 수 있습니다. 또한 GlusterFS 스토리지를 사용하는 통합 OpenShift Container Registry도 배포합니다.중요OpenShift Container Platform 클러스터에는 기존 레지스트리가 없어야 합니다.
playbooks/openshift-glusterfs/uninstall.yml을 사용하여 인벤토리 호스트 파일의 구성과 일치하는 기존 클러스터를 제거할 수 있습니다. 이 기능은 구성 오류로 인해 배포가 실패한 경우 OpenShift Container Platform 환경을 정리하는 데 유용합니다.참고GlusterFS 플레이북은 멱등이 되도록 보장되지 않습니다.
참고현재 전체 GlusterFS 설치(디스크 데이터 포함)를 삭제하고 처음부터 다시 시작하지 않고 주어진 설치에 대해 플레이북을 실행하는 것은 현재 지원되지 않습니다.
27.3.4.2.4. 예제: 기본 통합 모드 설치
인벤토리 파일의
[OSEv3:vars]섹션에 다음 변수를 포함하고 구성에 필요한 대로 조정합니다.[OSEv3:vars] ... openshift_storage_glusterfs_namespace=app-storage openshift_storage_glusterfs_storageclass=true openshift_storage_glusterfs_storageclass_default=false openshift_storage_glusterfs_block_deploy=true openshift_storage_glusterfs_block_host_vol_size=100 openshift_storage_glusterfs_block_storageclass=true openshift_storage_glusterfs_block_storageclass_default=false[OSEv3:children]섹션에glusterfs를 추가하여[glusterfs]그룹을 활성화합니다.[OSEv3:children] masters nodes glusterfsGlusterFS 스토리지를 호스팅할 각 스토리지 노드의 항목으로
[glusterfs]섹션을 추가합니다. 각 노드에서glusterfs_devices를 GlusterFS 클러스터의 일부로 완전히 관리되는 원시 블록 장치 목록으로 설정합니다. 장치가 하나 이상 나열되어야 합니다. 각 장치는 파티션 또는 LVM PV가 없는 베어 상태여야 합니다. 변수를 지정하려면 다음 형식을 사용합니다.<hostname_or_ip> glusterfs_devices='[ "</path/to/device1/>", "</path/to/device2>", ... ]'예를 들면 다음과 같습니다.
[glusterfs] node11.example.com glusterfs_devices='[ "/dev/xvdc", "/dev/xvdd" ]' node12.example.com glusterfs_devices='[ "/dev/xvdc", "/dev/xvdd" ]' node13.example.com glusterfs_devices='[ "/dev/xvdc", "/dev/xvdd" ]'[glusterfs]아래에 나열된 호스트를[nodes]그룹에 추가합니다.[nodes] ... node11.example.com openshift_node_group_name="node-config-compute" node12.example.com openshift_node_group_name="node-config-compute" node13.example.com openshift_node_group_name="node-config-compute"참고앞의 단계에서는 인벤토리 파일에 추가해야 하는 일부 옵션만 제공합니다. 전체 인벤토리 파일을 사용하여 Red Hat Gluster Storage를 배포합니다.
플레이북 디렉터리로 변경하고 설치 플레이북을 실행합니다. 인벤토리 파일의 상대 경로를 옵션으로 제공합니다.
새로운 OpenShift Container Platform 설치의 경우 다음을 수행합니다.
$ cd /usr/share/ansible/openshift-ansible $ ansible-playbook -i <path_to_inventory_file> playbooks/prerequisites.yml $ ansible-playbook -i <path_to_inventory_file> playbooks/deploy_cluster.yml기존 OpenShift Container Platform 클러스터에 설치하려면 다음을 수행합니다.
$ cd /usr/share/ansible/openshift-ansible $ ansible-playbook -i <path_to_inventory_file> playbooks/openshift-glusterfs/config.yml
27.3.4.2.5. 예제: 기본 독립 모드 설치
인벤토리 파일의
[OSEv3:vars]섹션에 다음 변수를 포함하고 구성에 필요한 대로 조정합니다.[OSEv3:vars] ... openshift_storage_glusterfs_namespace=app-storage openshift_storage_glusterfs_storageclass=true openshift_storage_glusterfs_storageclass_default=false openshift_storage_glusterfs_block_deploy=true openshift_storage_glusterfs_block_host_vol_size=100 openshift_storage_glusterfs_block_storageclass=true openshift_storage_glusterfs_block_storageclass_default=false openshift_storage_glusterfs_is_native=false openshift_storage_glusterfs_heketi_is_native=true openshift_storage_glusterfs_heketi_executor=ssh openshift_storage_glusterfs_heketi_ssh_port=22 openshift_storage_glusterfs_heketi_ssh_user=root openshift_storage_glusterfs_heketi_ssh_sudo=false openshift_storage_glusterfs_heketi_ssh_keyfile="/root/.ssh/id_rsa"[OSEv3:children]섹션에glusterfs를 추가하여[glusterfs]그룹을 활성화합니다.[OSEv3:children] masters nodes glusterfsGlusterFS 스토리지를 호스팅할 각 스토리지 노드의 항목으로
[glusterfs]섹션을 추가합니다. 각 노드에서glusterfs_devices를 GlusterFS 클러스터의 일부로 완전히 관리되는 원시 블록 장치 목록으로 설정합니다. 장치가 하나 이상 나열되어야 합니다. 각 장치는 파티션 또는 LVM PV가 없는 베어 상태여야 합니다. 또한glusterfs_ip를 노드의 IP 주소로 설정합니다. 변수를 지정하려면 다음 형식을 사용합니다.<hostname_or_ip> glusterfs_ip=<ip_address> glusterfs_devices='[ "</path/to/device1/>", "</path/to/device2>", ... ]'예를 들면 다음과 같습니다.
[glusterfs] gluster1.example.com glusterfs_ip=192.168.10.11 glusterfs_devices='[ "/dev/xvdc", "/dev/xvdd" ]' gluster2.example.com glusterfs_ip=192.168.10.12 glusterfs_devices='[ "/dev/xvdc", "/dev/xvdd" ]' gluster3.example.com glusterfs_ip=192.168.10.13 glusterfs_devices='[ "/dev/xvdc", "/dev/xvdd" ]'참고앞의 단계에서는 인벤토리 파일에 추가해야 하는 일부 옵션만 제공합니다. 전체 인벤토리 파일을 사용하여 Red Hat Gluster Storage를 배포합니다.
플레이북 디렉터리로 변경하고 설치 플레이북을 실행합니다. 인벤토리 파일의 상대 경로를 옵션으로 제공합니다.
새로운 OpenShift Container Platform 설치의 경우 다음을 수행합니다.
$ cd /usr/share/ansible/openshift-ansible $ ansible-playbook -i <path_to_inventory_file> playbooks/prerequisites.yml $ ansible-playbook -i <path_to_inventory_file> playbooks/deploy_cluster.yml기존 OpenShift Container Platform 클러스터에 설치하려면 다음을 수행합니다.
$ cd /usr/share/ansible/openshift-ansible $ ansible-playbook -i <path_to_inventory_file> playbooks/openshift-glusterfs/config.yml
27.3.4.2.6. 예: 통합 OpenShift Container Registry를 사용한 통합 모드
인벤토리 파일에서
[OSEv3:vars]섹션 아래에 다음 변수를 설정하고 구성에 필요한 대로 조정합니다.[OSEv3:vars] ... openshift_hosted_registry_storage_kind=glusterfs1 openshift_hosted_registry_storage_volume_size=5Gi openshift_hosted_registry_selector='node-role.kubernetes.io/infra=true'- 1
- 인프라 노드에서 통합된 OpenShift Container Registry를 실행하는 것이 좋습니다. 인프라 노드는 관리자가 OpenShift Container Platform 클러스터에 서비스를 제공하기 위해 배포한 애플리케이션을 실행하는 전용 노드입니다.
[OSEv3:children]섹션에glusterfs_registry를 추가하여[glusterfs_registry]그룹을 활성화합니다.[OSEv3:children] masters nodes glusterfs_registryGlusterFS 스토리지를 호스팅할 각 스토리지 노드에 대한 항목으로
[glusterfs_registry]섹션을 추가합니다. 각 노드에서glusterfs_devices를 GlusterFS 클러스터의 일부로 완전히 관리되는 원시 블록 장치 목록으로 설정합니다. 장치가 하나 이상 나열되어야 합니다. 각 장치는 파티션 또는 LVM PV가 없는 베어 상태여야 합니다. 변수를 지정하려면 다음 형식을 사용합니다.<hostname_or_ip> glusterfs_devices='[ "</path/to/device1/>", "</path/to/device2>", ... ]'예를 들면 다음과 같습니다.
[glusterfs_registry] node11.example.com glusterfs_devices='[ "/dev/xvdc", "/dev/xvdd" ]' node12.example.com glusterfs_devices='[ "/dev/xvdc", "/dev/xvdd" ]' node13.example.com glusterfs_devices='[ "/dev/xvdc", "/dev/xvdd" ]'[glusterfs_registry]아래에 나열된 호스트를[nodes]그룹에 추가합니다.[nodes] ... node11.example.com openshift_node_group_name="node-config-infra" node12.example.com openshift_node_group_name="node-config-infra" node13.example.com openshift_node_group_name="node-config-infra"참고앞의 단계에서는 인벤토리 파일에 추가해야 하는 일부 옵션만 제공합니다. 전체 인벤토리 파일을 사용하여 Red Hat Gluster Storage를 배포합니다.
플레이북 디렉터리로 변경하고 설치 플레이북을 실행합니다. 인벤토리 파일의 상대 경로를 옵션으로 제공합니다.
새로운 OpenShift Container Platform 설치의 경우 다음을 수행합니다.
$ cd /usr/share/ansible/openshift-ansible $ ansible-playbook -i <path_to_inventory_file> playbooks/prerequisites.yml $ ansible-playbook -i <path_to_inventory_file> playbooks/deploy_cluster.yml기존 OpenShift Container Platform 클러스터에 설치하려면 다음을 수행합니다.
$ cd /usr/share/ansible/openshift-ansible $ ansible-playbook -i <path_to_inventory_file> playbooks/openshift-glusterfs/config.yml
27.3.4.2.7. 예: OpenShift 로깅 및 메트릭을 위한 통합 모드
인벤토리 파일에서
[OSEv3:vars]섹션 아래에 다음 변수를 설정하고 구성에 필요한 대로 조정합니다.[OSEv3:vars] ... openshift_metrics_install_metrics=true openshift_metrics_hawkular_nodeselector={"node-role.kubernetes.io/infra": "true"}1 openshift_metrics_cassandra_nodeselector={"node-role.kubernetes.io/infra": "true"}2 openshift_metrics_heapster_nodeselector={"node-role.kubernetes.io/infra": "true"}3 openshift_metrics_storage_kind=dynamic openshift_metrics_storage_volume_size=10Gi openshift_metrics_cassandra_pvc_storage_class_name="glusterfs-registry-block"4 openshift_logging_install_logging=true openshift_logging_kibana_nodeselector={"node-role.kubernetes.io/infra": "true"}5 openshift_logging_curator_nodeselector={"node-role.kubernetes.io/infra": "true"}6 openshift_logging_es_nodeselector={"node-role.kubernetes.io/infra": "true"}7 openshift_logging_storage_kind=dynamic openshift_logging_es_pvc_size=10Gi8 openshift_logging_elasticsearch_storage_type=pvc9 openshift_logging_es_pvc_storage_class_name="glusterfs-registry-block"10 openshift_storage_glusterfs_registry_namespace=infra-storage openshift_storage_glusterfs_registry_block_deploy=true openshift_storage_glusterfs_registry_block_host_vol_size=100 openshift_storage_glusterfs_registry_block_storageclass=true openshift_storage_glusterfs_registry_block_storageclass_default=false- 1 2 3 5 6 7
- 관리자가 OpenShift Container Platform 클러스터에 서비스를 제공하기 위해 배포한 애플리케이션인 "인프라" 애플리케이션 전용 노드에서 통합된 OpenShift Container Registry, Logging 및 Metrics를 실행하는 것이 좋습니다.
- 4 10
- 로깅 및 지표에 사용할 StorageClass를 지정합니다. 이 이름은 대상 GlusterFS 클러스터의 이름(예:
glusterfs-<name>-block)에서 생성됩니다. 이 예제에서는 기본값은registry입니다. - 8
- OpenShift Logging에서는 PVC 크기를 지정해야 합니다. 제공된 값은 권장 사항이 아닌 예시일 뿐입니다.
- 9
- 영구 Elasticsearch 스토리지를 사용하는 경우 스토리지 유형을
pvc로 설정합니다.
참고이러한 변수 및 기타 변수에 대한 자세한 내용은 GlusterFS 역할 README 를 참조하십시오.
[OSEv3:children]섹션에glusterfs_registry를 추가하여[glusterfs_registry]그룹을 활성화합니다.[OSEv3:children] masters nodes glusterfs_registryGlusterFS 스토리지를 호스팅할 각 스토리지 노드에 대한 항목으로
[glusterfs_registry]섹션을 추가합니다. 각 노드에서glusterfs_devices를 GlusterFS 클러스터의 일부로 완전히 관리되는 원시 블록 장치 목록으로 설정합니다. 장치가 하나 이상 나열되어야 합니다. 각 장치는 파티션 또는 LVM PV가 없는 베어 상태여야 합니다. 변수를 지정하려면 다음 형식을 사용합니다.<hostname_or_ip> glusterfs_devices='[ "</path/to/device1/>", "</path/to/device2>", ... ]'예를 들면 다음과 같습니다.
[glusterfs_registry] node11.example.com glusterfs_devices='[ "/dev/xvdc", "/dev/xvdd" ]' node12.example.com glusterfs_devices='[ "/dev/xvdc", "/dev/xvdd" ]' node13.example.com glusterfs_devices='[ "/dev/xvdc", "/dev/xvdd" ]'[glusterfs_registry]아래에 나열된 호스트를[nodes]그룹에 추가합니다.[nodes] ... node11.example.com openshift_node_group_name="node-config-infra" node12.example.com openshift_node_group_name="node-config-infra" node13.example.com openshift_node_group_name="node-config-infra"참고앞의 단계에서는 인벤토리 파일에 추가해야 하는 일부 옵션만 제공합니다. 전체 인벤토리 파일을 사용하여 Red Hat Gluster Storage를 배포합니다.
플레이북 디렉터리로 변경하고 설치 플레이북을 실행합니다. 인벤토리 파일의 상대 경로를 옵션으로 제공합니다.
새로운 OpenShift Container Platform 설치의 경우 다음을 수행합니다.
$ cd /usr/share/ansible/openshift-ansible $ ansible-playbook -i <path_to_inventory_file> playbooks/prerequisites.yml $ ansible-playbook -i <path_to_inventory_file> playbooks/deploy_cluster.yml기존 OpenShift Container Platform 클러스터에 설치하려면 다음을 수행합니다.
$ cd /usr/share/ansible/openshift-ansible $ ansible-playbook -i <path_to_inventory_file> playbooks/openshift-glusterfs/config.yml
27.3.4.2.8. 예: 애플리케이션, 레지스트리, 로깅 및 메트릭을 위한 통합 모드
인벤토리 파일에서
[OSEv3:vars]섹션 아래에 다음 변수를 설정하고 구성에 필요한 대로 조정합니다.[OSEv3:vars] ... openshift_hosted_registry_storage_kind=glusterfs1 openshift_hosted_registry_storage_volume_size=5Gi openshift_hosted_registry_selector='node-role.kubernetes.io/infra=true' openshift_metrics_install_metrics=true openshift_metrics_hawkular_nodeselector={"node-role.kubernetes.io/infra": "true"}2 openshift_metrics_cassandra_nodeselector={"node-role.kubernetes.io/infra": "true"}3 openshift_metrics_heapster_nodeselector={"node-role.kubernetes.io/infra": "true"}4 openshift_metrics_storage_kind=dynamic openshift_metrics_storage_volume_size=10Gi openshift_metrics_cassandra_pvc_storage_class_name="glusterfs-registry-block"5 openshift_logging_install_logging=true openshift_logging_kibana_nodeselector={"node-role.kubernetes.io/infra": "true"}6 openshift_logging_curator_nodeselector={"node-role.kubernetes.io/infra": "true"}7 openshift_logging_es_nodeselector={"node-role.kubernetes.io/infra": "true"}8 openshift_logging_storage_kind=dynamic openshift_logging_es_pvc_size=10Gi9 openshift_logging_elasticsearch_storage_type=pvc10 openshift_logging_es_pvc_storage_class_name="glusterfs-registry-block"11 openshift_storage_glusterfs_namespace=app-storage openshift_storage_glusterfs_storageclass=true openshift_storage_glusterfs_storageclass_default=false openshift_storage_glusterfs_block_deploy=true openshift_storage_glusterfs_block_host_vol_size=10012 openshift_storage_glusterfs_block_storageclass=true openshift_storage_glusterfs_block_storageclass_default=false openshift_storage_glusterfs_registry_namespace=infra-storage openshift_storage_glusterfs_registry_block_deploy=true openshift_storage_glusterfs_registry_block_host_vol_size=100 openshift_storage_glusterfs_registry_block_storageclass=true openshift_storage_glusterfs_registry_block_storageclass_default=false- 1 2 3 4 6 7 8
- 인프라 노드에서 통합된 OpenShift Container Registry, Logging 및 Metrics를 실행하는 것이 좋습니다. 인프라 노드는 관리자가 OpenShift Container Platform 클러스터에 서비스를 제공하기 위해 배포한 애플리케이션을 실행하는 전용 노드입니다.
- 5 11
- 로깅 및 지표에 사용할 StorageClass를 지정합니다. 이 이름은 대상 GlusterFS 클러스터의 이름(예:
glusterfs-<name>-block)에서 생성됩니다. 이 예에서<name>은 기본값은registry입니다. - 9
- OpenShift Logging에는 PVC 크기를 지정해야 합니다. 제공된 값은 권장 사항이 아닌 예시일 뿐입니다.
- 10
- 영구 Elasticsearch 스토리지를 사용하는 경우 스토리지 유형을
pvc로 설정합니다. - 12
- glusterblock 볼륨을 호스팅하도록 자동으로 생성되는 GlusterFS 볼륨의 크기(GB)입니다. 이 변수는 glusterblock volume create 요청에 사용할 수 있는 공간이 충분하지 않은 경우에만 사용됩니다. 이 값은 더 큰 GlusterFS 블록 호스팅 볼륨을 수동으로 생성하지 않는 한 glusterblock 볼륨 크기에 대한 상한을 나타냅니다.
[OSEv3:children]섹션에glusterfs및 glusterfs_registry를 추가하여[glusterfs]및[glusterfs_registry]그룹을 활성화합니다.[OSEv3:children] ... glusterfs glusterfs_registryGlusterFS 스토리지를 호스트할 각 스토리지 노드에 대한 항목이 있는
[glusterfs]및 [glusterfs_registry]glusterfs_devices를 GlusterFS 클러스터의 일부로 완전히 관리되는 원시 블록 장치 목록으로 설정합니다. 장치가 하나 이상 나열되어야 합니다. 각 장치는 파티션 또는 LVM PV가 없는 베어 상태여야 합니다. 변수를 지정하려면 다음 형식을 사용합니다.<hostname_or_ip> glusterfs_devices='[ "</path/to/device1/>", "</path/to/device2>", ... ]'예를 들면 다음과 같습니다.
[glusterfs] node11.example.com glusterfs_devices='[ "/dev/xvdc", "/dev/xvdd" ]' node12.example.com glusterfs_devices='[ "/dev/xvdc", "/dev/xvdd" ]' node13.example.com glusterfs_devices='[ "/dev/xvdc", "/dev/xvdd" ]' [glusterfs_registry] node14.example.com glusterfs_devices='[ "/dev/xvdc", "/dev/xvdd" ]' node15.example.com glusterfs_devices='[ "/dev/xvdc", "/dev/xvdd" ]' node16.example.com glusterfs_devices='[ "/dev/xvdc", "/dev/xvdd" ]'[glusterfs] 및에 나열된 호스트를[glusterfs_registry][nodes]그룹에 추가합니다.[nodes] ... node11.example.com openshift_node_group_name='node-config-compute'1 node12.example.com openshift_node_group_name='node-config-compute'2 node13.example.com openshift_node_group_name='node-config-compute'3 node14.example.com openshift_node_group_name='node-config-infra'"4 node15.example.com openshift_node_group_name='node-config-infra'"5 node16.example.com openshift_node_group_name='node-config-infra'"6 참고앞의 단계에서는 인벤토리 파일에 추가해야 하는 일부 옵션만 제공합니다. 전체 인벤토리 파일을 사용하여 Red Hat Gluster Storage를 배포합니다.
플레이북 디렉터리로 변경하고 설치 플레이북을 실행합니다. 인벤토리 파일의 상대 경로를 옵션으로 제공합니다.
새로운 OpenShift Container Platform 설치의 경우 다음을 수행합니다.
$ cd /usr/share/ansible/openshift-ansible $ ansible-playbook -i <path_to_inventory_file> playbooks/prerequisites.yml $ ansible-playbook -i <path_to_inventory_file> playbooks/deploy_cluster.yml기존 OpenShift Container Platform 클러스터에 설치하려면 다음을 수행합니다.
$ cd /usr/share/ansible/openshift-ansible $ ansible-playbook -i <path_to_inventory_file> playbooks/openshift-glusterfs/config.yml
27.3.4.2.9. 예: 애플리케이션, 레지스트리, 로깅 및 메트릭에 대한 독립 모드
인벤토리 파일에서
[OSEv3:vars]섹션 아래에 다음 변수를 설정하고 구성에 필요한 대로 조정합니다.[OSEv3:vars] ... openshift_hosted_registry_storage_kind=glusterfs1 openshift_hosted_registry_storage_volume_size=5Gi openshift_hosted_registry_selector='node-role.kubernetes.io/infra=true' openshift_metrics_install_metrics=true openshift_metrics_hawkular_nodeselector={"node-role.kubernetes.io/infra": "true"}2 openshift_metrics_cassandra_nodeselector={"node-role.kubernetes.io/infra": "true"}3 openshift_metrics_heapster_nodeselector={"node-role.kubernetes.io/infra": "true"}4 openshift_metrics_storage_kind=dynamic openshift_metrics_storage_volume_size=10Gi openshift_metrics_cassandra_pvc_storage_class_name="glusterfs-registry-block"5 openshift_logging_install_logging=true openshift_logging_kibana_nodeselector={"node-role.kubernetes.io/infra": "true"}6 openshift_logging_curator_nodeselector={"node-role.kubernetes.io/infra": "true"}7 openshift_logging_es_nodeselector={"node-role.kubernetes.io/infra": "true"}8 openshift_logging_storage_kind=dynamic openshift_logging_es_pvc_size=10Gi9 openshift_logging_elasticsearch_storage_type10 openshift_logging_es_pvc_storage_class_name="glusterfs-registry-block"11 openshift_storage_glusterfs_namespace=app-storage openshift_storage_glusterfs_storageclass=true openshift_storage_glusterfs_storageclass_default=false openshift_storage_glusterfs_block_deploy=true openshift_storage_glusterfs_block_host_vol_size=10012 openshift_storage_glusterfs_block_storageclass=true openshift_storage_glusterfs_block_storageclass_default=false openshift_storage_glusterfs_is_native=false openshift_storage_glusterfs_heketi_is_native=true openshift_storage_glusterfs_heketi_executor=ssh openshift_storage_glusterfs_heketi_ssh_port=22 openshift_storage_glusterfs_heketi_ssh_user=root openshift_storage_glusterfs_heketi_ssh_sudo=false openshift_storage_glusterfs_heketi_ssh_keyfile="/root/.ssh/id_rsa" openshift_storage_glusterfs_registry_namespace=infra-storage openshift_storage_glusterfs_registry_block_deploy=true openshift_storage_glusterfs_registry_block_host_vol_size=100 openshift_storage_glusterfs_registry_block_storageclass=true openshift_storage_glusterfs_registry_block_storageclass_default=false openshift_storage_glusterfs_registry_is_native=false openshift_storage_glusterfs_registry_heketi_is_native=true openshift_storage_glusterfs_registry_heketi_executor=ssh openshift_storage_glusterfs_registry_heketi_ssh_port=22 openshift_storage_glusterfs_registry_heketi_ssh_user=root openshift_storage_glusterfs_registry_heketi_ssh_sudo=false openshift_storage_glusterfs_registry_heketi_ssh_keyfile="/root/.ssh/id_rsa"- 1 2 3 4 6 7 8
- 관리자가 OpenShift Container Platform 클러스터에 서비스를 제공하기 위해 배포한 애플리케이션인 "인프라" 애플리케이션 전용 노드에서 통합 OpenShift Container Registry를 실행하는 것이 좋습니다. 인프라 애플리케이션의 노드를 선택하고 레이블을 지정하는 관리자만 사용할 수 있습니다.
- 5 11
- 로깅 및 지표에 사용할 StorageClass를 지정합니다. 이 이름은 대상 GlusterFS 클러스터의 이름(예:
glusterfs-<name>-block)에서 생성됩니다. 이 예제에서는 기본값은registry입니다. - 9
- OpenShift Logging에서는 PVC 크기를 지정해야 합니다. 제공된 값은 권장 사항이 아닌 예시일 뿐입니다.
- 10
- 영구 Elasticsearch 스토리지를 사용하는 경우 스토리지 유형을
pvc로 설정합니다. - 12
- glusterblock 볼륨을 호스팅하도록 자동으로 생성되는 GlusterFS 볼륨의 크기(GB)입니다. 이 변수는 glusterblock volume create 요청에 사용할 수 있는 공간이 충분하지 않은 경우에만 사용됩니다. 이 값은 더 큰 GlusterFS 블록 호스팅 볼륨을 수동으로 생성하지 않는 한 glusterblock 볼륨 크기에 대한 상한을 나타냅니다.
[OSEv3:children]섹션에glusterfs및 glusterfs_registry를 추가하여[glusterfs]및[glusterfs_registry]그룹을 활성화합니다.[OSEv3:children] ... glusterfs glusterfs_registryGlusterFS 스토리지를 호스트할 각 스토리지 노드에 대한 항목이 있는
[glusterfs]및 [glusterfs_registry]glusterfs_devices를 GlusterFS 클러스터의 일부로 완전히 관리되는 원시 블록 장치 목록으로 설정합니다. 장치가 하나 이상 나열되어야 합니다. 각 장치는 파티션 또는 LVM PV가 없는 베어 상태여야 합니다. 또한glusterfs_ip를 노드의 IP 주소로 설정합니다. 변수를 지정하려면 다음 형식을 사용합니다.<hostname_or_ip> glusterfs_ip=<ip_address> glusterfs_devices='[ "</path/to/device1/>", "</path/to/device2>", ... ]'예를 들면 다음과 같습니다.
[glusterfs] gluster1.example.com glusterfs_ip=192.168.10.11 glusterfs_devices='[ "/dev/xvdc", "/dev/xvdd" ]' gluster2.example.com glusterfs_ip=192.168.10.12 glusterfs_devices='[ "/dev/xvdc", "/dev/xvdd" ]' gluster3.example.com glusterfs_ip=192.168.10.13 glusterfs_devices='[ "/dev/xvdc", "/dev/xvdd" ]' [glusterfs_registry] gluster4.example.com glusterfs_ip=192.168.10.14 glusterfs_devices='[ "/dev/xvdc", "/dev/xvdd" ]' gluster5.example.com glusterfs_ip=192.168.10.15 glusterfs_devices='[ "/dev/xvdc", "/dev/xvdd" ]' gluster6.example.com glusterfs_ip=192.168.10.16 glusterfs_devices='[ "/dev/xvdc", "/dev/xvdd" ]'참고앞의 단계에서는 인벤토리 파일에 추가해야 하는 일부 옵션만 제공합니다. 전체 인벤토리 파일을 사용하여 Red Hat Gluster Storage를 배포합니다.
플레이북 디렉터리로 변경하고 설치 플레이북을 실행합니다. 인벤토리 파일의 상대 경로를 옵션으로 제공합니다.
새로운 OpenShift Container Platform 설치의 경우 다음을 수행합니다.
$ cd /usr/share/ansible/openshift-ansible $ ansible-playbook -i <path_to_inventory_file> playbooks/prerequisites.yml $ ansible-playbook -i <path_to_inventory_file> playbooks/deploy_cluster.yml기존 OpenShift Container Platform 클러스터에 설치하려면 다음을 수행합니다.
$ cd /usr/share/ansible/openshift-ansible $ ansible-playbook -i <path_to_inventory_file> playbooks/openshift-glusterfs/config.yml
27.3.5. 통합 모드 제거
통합 모드의 경우 OpenShift Container Platform 설치에는 클러스터에서 모든 리소스 및 아티팩트를 제거하는 플레이북이 제공됩니다. 플레이북을 사용하려면 통합 모드의 대상 인스턴스를 설치하고, 플레이북 디렉터리로 변경하고, 다음 플레이북을 실행하는 데 사용된 원본 인벤토리 파일을 제공합니다.
$ cd /usr/share/ansible/openshift-ansible
$ ansible-playbook -i <path_to_inventory_file> playbooks/openshift-glusterfs/uninstall.yml
또한 플레이북은 활성화 시 Red Hat Gluster Storage 백엔드 스토리지에 사용된 블록 장치의 모든 데이터를 삭제하는 openshift_storage_glusterfs_wipe 라는 변수 사용을 지원합니다. openshift_storage_glusterfs_wipe 변수를 사용하려면 플레이북 디렉터리로 변경하고 다음 플레이북을 실행합니다.
$ cd /usr/share/ansible/openshift-ansible
$ ansible-playbook -i <path_to_inventory_file> -e \
"openshift_storage_glusterfs_wipe=true" \
playbooks/openshift-glusterfs/uninstall.yml이 절차에서는 데이터를 삭제합니다. 주의해서 진행하십시오.
27.3.6. 프로비저닝
GlusterFS 볼륨은 정적 또는 동적으로 프로비저닝할 수 있습니다. 정적 프로비저닝은 모든 구성에서 사용할 수 있습니다. 통합 모드와 독립 모드만 동적 프로비저닝을 지원합니다.
27.3.6.1. 정적 프로비저닝
-
정적 프로비저닝을 활성화하려면 먼저 GlusterFS 볼륨을 만듭니다.
heketi를 사용하여 이 작업을 수행하는 방법에 대한 자세한 내용은 Red Hat Gluster Storage 관리 가이드를 참조하십시오. 이 예에서는 볼륨의 이름은-climyVol1로 지정됩니다. gluster-endpoints.yaml에서 다음 서비스 및 엔드포인트를 정의합니다.--- apiVersion: v1 kind: Service metadata: name: glusterfs-cluster1 spec: ports: - port: 1 --- apiVersion: v1 kind: Endpoints metadata: name: glusterfs-cluster2 subsets: - addresses: - ip: 192.168.122.2213 ports: - port: 14 - addresses: - ip: 192.168.122.2225 ports: - port: 16 - addresses: - ip: 192.168.122.2237 ports: - port: 18 OpenShift Container Platform 마스터 호스트에서 서비스 및 엔드포인트를 생성합니다.
$ oc create -f gluster-endpoints.yaml service "glusterfs-cluster" created endpoints "glusterfs-cluster" created서비스 및 엔드포인트가 생성되었는지 확인합니다.
$ oc get services NAME CLUSTER_IP EXTERNAL_IP PORT(S) SELECTOR AGE glusterfs-cluster 172.30.205.34 <none> 1/TCP <none> 44s $ oc get endpoints NAME ENDPOINTS AGE docker-registry 10.1.0.3:5000 4h glusterfs-cluster 192.168.122.221:1,192.168.122.222:1,192.168.122.223:1 11s kubernetes 172.16.35.3:8443 4d참고엔드포인트는 프로젝트별로 고유합니다. GlusterFS 볼륨에 액세스하는 각 프로젝트에는 고유한 엔드포인트가 필요합니다.
볼륨에 액세스하려면 볼륨의 파일 시스템에 액세스할 수 있는 UID(사용자 ID) 또는 그룹 ID(GID)를 사용하여 컨테이너를 실행해야 합니다. 이 정보는 다음과 같은 방식으로 검색할 수 있습니다.
$ mkdir -p /mnt/glusterfs/myVol1 $ mount -t glusterfs 192.168.122.221:/myVol1 /mnt/glusterfs/myVol1 $ ls -lnZ /mnt/glusterfs/ drwxrwx---. 592 590 system_u:object_r:fusefs_t:s0 myVol11 2 gluster-pv.yaml에서 다음 PV(PersistentVolume)를 정의합니다.apiVersion: v1 kind: PersistentVolume metadata: name: gluster-default-volume1 annotations: pv.beta.kubernetes.io/gid: "590"2 spec: capacity: storage: 2Gi3 accessModes:4 - ReadWriteMany glusterfs: endpoints: glusterfs-cluster5 path: myVol16 readOnly: false persistentVolumeReclaimPolicy: RetainOpenShift Container Platform 마스터 호스트에서 PV를 생성합니다.
$ oc create -f gluster-pv.yamlPV가 생성되었는지 확인합니다.
$ oc get pv NAME LABELS CAPACITY ACCESSMODES STATUS CLAIM REASON AGE gluster-default-volume <none> 2147483648 RWX Available 2sgluster-claim.yaml에서 새 PV에 바인딩할 PVC(PersistentVolumeClaim)를 생성합니다.apiVersion: v1 kind: PersistentVolumeClaim metadata: name: gluster-claim1 spec: accessModes: - ReadWriteMany2 resources: requests: storage: 1Gi3 OpenShift Container Platform 마스터 호스트에서 PVC를 생성합니다.
$ oc create -f gluster-claim.yamlPV 및 PVC가 바인딩되었는지 확인합니다.
$ oc get pv NAME LABELS CAPACITY ACCESSMODES STATUS CLAIM REASON AGE gluster-pv <none> 1Gi RWX Available gluster-claim 37s $ oc get pvc NAME LABELS STATUS VOLUME CAPACITY ACCESSMODES AGE gluster-claim <none> Bound gluster-pv 1Gi RWX 24s
PVC는 프로젝트별로 고유합니다. GlusterFS 볼륨에 액세스하는 각 프로젝트에는 자체 PVC가 필요합니다. PV는 단일 프로젝트에 바인딩되지 않으므로 여러 프로젝트의 PVC가 동일한 PV를 참조할 수 있습니다.
27.3.6.2. 동적 프로비저닝
동적 프로비저닝을 사용하려면 먼저
StorageClass오브젝트 정의를 생성합니다. 아래 정의는 OpenShift Container Platform을 사용하기 위해 이 예제에 필요한 최소 요구 사항을 기반으로 합니다. 추가 매개변수 및 사양 정의는 동적 프로비저닝 및 스토리지 클래스 생성을 참조하십시오.kind: StorageClass apiVersion: storage.k8s.io/v1 metadata: name: glusterfs provisioner: kubernetes.io/glusterfs parameters: resturl: "http://10.42.0.0:8080"1 restauthenabled: "false"2 OpenShift Container Platform 마스터 호스트에서 StorageClass를 생성합니다.
# oc create -f gluster-storage-class.yaml storageclass "glusterfs" created새로 생성된 StorageClass를 사용하여 PVC를 만듭니다. 예를 들면 다음과 같습니다.
apiVersion: v1 kind: PersistentVolumeClaim metadata: name: gluster1 spec: accessModes: - ReadWriteMany resources: requests: storage: 30Gi storageClassName: glusterfsOpenShift Container Platform 마스터 호스트에서 PVC를 생성합니다.
# oc create -f glusterfs-dyn-pvc.yaml persistentvolumeclaim "gluster1" createdPVC를 보고 볼륨이 동적으로 생성되어 PVC에 바인딩되었는지 확인합니다.
# oc get pvc NAME STATUS VOLUME CAPACITY ACCESSMODES STORAGECLASS AGE gluster1 Bound pvc-78852230-d8e2-11e6-a3fa-0800279cf26f 30Gi RWX glusterfs 42s
27.4. OpenStack Cinder를 사용하는 영구 스토리지
27.4.1. 개요
OpenStack Cinder 를 사용하여 영구 스토리지로 OpenShift Container Platform 클러스터를 프로비저닝할 수 있습니다. Kubernetes 및 OpenStack에 대해 어느 정도 익숙한 것으로 가정합니다.
Cinder를 사용하여 PV(영구 볼륨)를 만들기 전에 OpenStack용 OpenShift Container Platform을 구성합니다.
Kubernetes 영구 볼륨 프레임워크를 사용하면 관리자가 영구 스토리지로 클러스터를 프로비저닝하고 사용자가 기본 인프라에 대한 지식 없이도 해당 리소스를 요청할 수 있습니다. OpenStack Cinder 볼륨을 동적으로 프로비저닝 할 수 있습니다.
영구 볼륨은 단일 프로젝트 또는 네임스페이스에 바인딩되지 않으며, OpenShift Container Platform 클러스터에서 공유할 수 있습니다. 그러나 영구 볼륨 클레임 은 프로젝트 또는 네임스페이스에 고유하며 사용자가 요청할 수 있습니다.
인프라의 스토리지의 고가용성은 기본 스토리지 공급자가 담당합니다.
27.4.2. Cinder PV 프로비저닝
OpenShift Container Platform에서 볼륨으로 마운트하기 전에 기본 인프라에 스토리지가 있어야 합니다. OpenShift Container Platform이 OpenStack에 대해 구성되었는지 확인한 후 Cinder에 필요한 모든 것이 Cinder 볼륨 ID 및 the PersistentVolume API입니다.
27.4.2.1. 영구 볼륨 생성
OpenShift Container Platform에서 생성하기 전에 오브젝트 정의에서 PV를 정의해야 합니다.
오브젝트 정의를 파일에 저장합니다(예: cinder-pv.yaml ):
apiVersion: "v1" kind: "PersistentVolume" metadata: name: "pv0001"1 spec: capacity: storage: "5Gi"2 accessModes: - "ReadWriteOnce" cinder:3 fsType: "ext3"4 volumeID: "f37a03aa-6212-4c62-a805-9ce139fab180"5 중요볼륨이 포맷되고 프로비저닝된 후에는 the
fstype매개변수 값을 변경하지 마십시오. 이 값을 변경하면 데이터가 손실되고 Pod 오류가 발생할 수 있습니다.영구 볼륨을 생성합니다.
# oc create -f cinder-pv.yaml persistentvolume "pv0001" created영구 볼륨이 있는지 확인합니다.
# oc get pv NAME LABELS CAPACITY ACCESSMODES STATUS CLAIM REASON AGE pv0001 <none> 5Gi RWO Available 2s
그러면 사용자가 영구 볼륨 클레임을 사용하여 스토리지를 요청할 수 있으므로 이제 새 영구 볼륨을 활용할 수 있습니다.
영구 볼륨 클레임은 사용자의 네임스페이스에만 존재하며 동일한 네임스페이스 내의 Pod에서 참조할 수 있습니다. 다른 네임스페이스에서 영구 볼륨 클레임에 액세스하려고 하면 Pod가 실패합니다.
27.4.2.2. Cinder PV 형식
OpenShift Container Platform이 볼륨을 마운트하고 컨테이너에 전달하기 전에 영구 볼륨 정의에서 fsType 매개변수에 의해 지정된 파일 시스템이 포함되어 있는지 확인합니다. 장치가 파일 시스템으로 포맷되지 않으면 장치의 모든 데이터가 삭제되고 장치는 지정된 파일 시스템에서 자동으로 포맷됩니다.
이를 통해 OpenShift Container Platform이 처음 사용하기 전에 형식화되기 때문에 형식화되지 않은 Cinder 볼륨을 영구 볼륨으로 사용할 수 있습니다.
27.4.2.3. Cinder 볼륨 보안
애플리케이션에서 Cinder PV를 사용하는 경우 배포 구성에 대한 보안을 구성합니다.
Cinder 볼륨을 구현하기 전에 볼륨 보안 정보를 검토합니다.
-
적절한
fsGroup전략을 사용하는 SCC 를 만듭니다. 서비스 계정을 생성하고 SCC에 추가합니다.
[source,bash] $ oc create serviceaccount <service_account> $ oc adm policy add-scc-to-user <new_scc> -z <service_account> -n <project>애플리케이션 배포 구성에서 서비스 계정 이름과
securityContext를 입력합니다.apiVersion: v1 kind: ReplicationController metadata: name: frontend-1 spec: replicas: 11 selector:2 name: frontend template:3 metadata: labels:4 name: frontend5 spec: containers: - image: openshift/hello-openshift name: helloworld ports: - containerPort: 8080 protocol: TCP restartPolicy: Always serviceAccountName: <service_account>6 securityContext: fsGroup: 77777
27.4.2.4. Cinder 볼륨 제한
기본적으로 클러스터의 각 노드에 최대 256개의 Cinder 볼륨을 연결할 수 있습니다. 이 제한을 변경하려면 다음을 수행합니다.
KUBE_MAX_PD_VOLS환경 변수를 정수로 설정합니다. 예를 들어/etc/origin/master/master.env에서 :KUBE_MAX_PD_VOLS=26명령줄에서 API 서비스를 다시 시작합니다.
# master-restart api명령줄에서 컨트롤러 서비스를 다시 시작합니다.
# master-restart controllers
27.5. Ceph Rados Block Device (RBD)를 사용하는 영구 스토리지
27.5.1. 개요
OpenShift Container Platform 클러스터는 Ceph RBD를 사용하여 영구 스토리지로 프로비저닝할 수 있습니다.
PV(영구 볼륨) 및 PVC(영구 볼륨 클레임)는 단일 프로젝트에서 볼륨을 공유할 수 있습니다. PV 정의에 포함된 Ceph RBD 관련 정보는 포드 정의에 직접 정의할 수 있지만 이렇게 하면 볼륨이 별도의 클러스터 리소스로 생성되지 않으므로 볼륨이 충돌하기 쉽습니다.
이 주제에서는 OpenShift Container Platform 및 Ceph RBD에 대해 어느 정도 익숙한 것으로 간주합니다. 일반적으로 OpenShift Container Platform PV(영구 볼륨) 프레임워크에 대한 자세한 내용은 영구 스토리지 개념 주제를 참조하십시오.
이 문서 전반에서 프로젝트와 네임스페이스 가 서로 바꿔 사용할 수 있습니다. 관계에 대한 자세한 내용은 프로젝트 및 사용자를 참조하십시오.
인프라의 스토리지의 고가용성은 기본 스토리지 공급자가 담당합니다.
27.5.2. 프로비저닝
Ceph 볼륨을 프로비저닝하려면 다음이 필요합니다.
- 기본 인프라의 기존 스토리지 장치.
- OpenShift Container Platform 시크릿 오브젝트에서 사용할 Ceph 키입니다.
- Ceph 이미지 이름입니다.
- 블록 스토리지 상단에 있는 파일 시스템 유형(예: ext4).
클러스터의 각 예약 가능 OpenShift Container Platform 노드에 Ceph 공통이 설치되어 있어야 합니다.
# yum install ceph-common
27.5.2.1. Ceph 시크릿 생성
시크릿 구성에 권한 부여 키를 정의한 다음 OpenShift Container Platform에서 사용하기 위해 base64로 변환됩니다.
Ceph 스토리지를 사용하여 영구 볼륨을 백업하려면 PVC 및 포드와 동일한 프로젝트에 시크릿을 생성해야 합니다. 시크릿은 단순히 기본 프로젝트에 있을 수 없습니다.
Ceph MON 노드에서
ceph auth get-key를 실행하여client.admin 사용자의 키 값을 표시합니다.apiVersion: v1 kind: Secret metadata: name: ceph-secret data: key: QVFBOFF2SlZheUJQRVJBQWgvS2cwT1laQUhPQno3akZwekxxdGc9PQ== type: kubernetes.io/rbd보안 정의를 파일에 저장합니다(예: ceph-secret.yaml ).
$ oc create -f ceph-secret.yaml보안이 생성되었는지 확인합니다.
# oc get secret ceph-secret NAME TYPE DATA AGE ceph-secret kubernetes.io/rbd 1 23d
27.5.2.2. 영구 볼륨 생성
개발자는 포드 사양의 volumes 섹션에서 직접 PVC 또는 Gluster 볼륨 플러그인을 참조하여 Ceph RBD 스토리지를 요청합니다. PVC는 사용자의 네임스페이스에만 존재하며 동일한 네임스페이스 내의 Pod에서만 참조할 수 있습니다. 다른 네임스페이스에서 PV에 액세스하려고 하면 Pod가 실패합니다.
OpenShift Container Platform에서 생성하기 전에 오브젝트 정의에 PV를 정의합니다.
예 27.3. Ceph RBD를 사용한 영구 볼륨 오브젝트 정의
apiVersion: v1 kind: PersistentVolume metadata: name: ceph-pv1 spec: capacity: storage: 2Gi2 accessModes: - ReadWriteOnce3 rbd:4 monitors:5 - 192.168.122.133:6789 pool: rbd image: ceph-image user: admin secretRef: name: ceph-secret6 fsType: ext47 readOnly: false persistentVolumeReclaimPolicy: Retain- 1
- Pod 정의에서 참조하거나 다양한
oc볼륨 명령에 표시되는 PV의 이름입니다. - 2
- 이 볼륨에 할당된 스토리지의 용량입니다.
- 3
accessModes는 PV 및 PVC와 일치하는 라벨로 사용됩니다. 현재는 액세스 제어 형식을 정의하지 않습니다. 모든 블록 스토리지는 단일 사용자(비공유 스토리지)로 정의됩니다.- 4
- 사용 중인 볼륨 유형(이 경우 rbd 플러그인).
- 5
- Ceph 모니터 IP 주소 및 포트의 배열입니다.
- 6
- OpenShift Container Platform에서 Ceph 서버로 보안 연결을 생성하는 데 사용되는 Ceph 시크릿입니다.
- 7
- Ceph RBD 블록 장치에 마운트된 파일 시스템 유형입니다.
중요볼륨이 포맷되고 프로비저닝된 후 the
fstype매개변수 값을 변경하면 데이터가 손실되고 Pod 오류가 발생할 수 있습니다.정의를 파일에 저장합니다(예: ceph-pv.yaml ). PV를 생성합니다.
# oc create -f ceph-pv.yaml영구 볼륨이 생성되었는지 확인합니다.
# oc get pv NAME LABELS CAPACITY ACCESSMODES STATUS CLAIM REASON AGE ceph-pv <none> 2147483648 RWO Available 2s새 PV에 바인딩할 PVC를 생성합니다.
정의를 파일에 저장합니다(예: ceph-claim.yaml ).
# oc create -f ceph-claim.yaml
27.5.3. Ceph 볼륨 보안
Ceph RBD 볼륨을 구현하기 전에 전체 볼륨 보안 주제를 참조하십시오.
공유 볼륨(NFS 및 GlusterFS)과 블록 볼륨(Ceph RBD, iSCSI, 대부분의 클라우드 스토리지)의 중요한 차이점은 포드 정의 또는 컨테이너 이미지에 정의된 사용자 및 그룹 ID가 대상 물리 스토리지에 적용된다는 것입니다. 이를 블록 장치의 소유권 관리라고 합니다. 예를 들어 Ceph RBD 마운트에 소유자가 123 이고 그룹 ID가 567 로 설정되어 있고 포드에서 runAsUser를 222 로 정의하고 fsGroup 을 7777로 정의하는 경우 Ceph RBD 물리적 마운트의 소유권이 222:7777 로 변경됩니다.
사용자 및 그룹 ID가 Pod 사양에 정의되어 있지 않더라도 결과 Pod에 일치하는 SCC 또는 해당 프로젝트를 기반으로 이러한 ID에 대한 기본값이 정의되어 있을 수 있습니다. 자세한 내용은 SCC 및 기본값의 스토리지 측면을 다루는 전체 볼륨 보안 주제를 참조하십시오.
포드는 Pod의 securityContext 정의에서 fsGroup 스탠자를 사용하여 Ceph RBD 볼륨의 그룹 소유권을 정의합니다.
27.6. AWS Elastic Block Store를 사용하는 영구 스토리지
27.6.1. 개요
OpenShift Container Platform은 AWS EBS(Elastic Block Store volume)를 지원합니다. AWS EC2 를 사용하여 영구 스토리지로 OpenShift Container Platform 클러스터를 프로비저닝할 수 있습니다. Kubernetes 및 AWS에 대해 어느 정도 익숙한 것으로 가정합니다.
AWS를 사용하여 영구 볼륨을 생성하기 전에 OpenShift Container Platform은 AWS ElasticBlockStore에 대해 먼저 올바르게 구성해야 합니다.
Kubernetes 영구 볼륨 프레임워크를 사용하면 관리자가 영구 스토리지로 클러스터를 프로비저닝하고 사용자가 기본 인프라에 대한 지식 없이도 해당 리소스를 요청할 수 있습니다. AWS Elastic Block Store 볼륨은 동적으로 프로비저닝 할 수 있습니다. 영구 볼륨은 단일 프로젝트 또는 네임스페이스에 바인딩되지 않으며, OpenShift Container Platform 클러스터에서 공유할 수 있습니다. 그러나 영구 볼륨 클레임 은 프로젝트 또는 네임스페이스에 고유하며 사용자가 요청할 수 있습니다.
인프라의 스토리지의 고가용성은 기본 스토리지 공급자가 담당합니다.
27.6.2. 프로비저닝
OpenShift Container Platform에서 볼륨으로 마운트하기 전에 기본 인프라에 스토리지가 있어야 합니다. OpenShift가 AWS Elastic Block Store에 대해 구성되었는지 확인한 후 OpenShift 및 AWS에 필요한 모든 것이 AWS EBS 볼륨 ID 및 the PersistentVolume API입니다.
27.6.2.1. 영구 볼륨 생성
OpenShift Container Platform에서 생성하기 전에 오브젝트 정의에서 영구 볼륨을 정의해야 합니다.
예 27.5. AWS를 사용하는 영구 볼륨 오브젝트 정의
apiVersion: "v1"
kind: "PersistentVolume"
metadata:
name: "pv0001"
spec:
capacity:
storage: "5Gi"
accessModes:
- "ReadWriteOnce"
awsElasticBlockStore:
fsType: "ext4"
volumeID: "vol-f37a03aa"
볼륨이 포맷되고 프로비저닝된 후 the fstype 매개변수 값을 변경하면 데이터가 손실되고 Pod 오류가 발생할 수 있습니다.
정의를 파일에 저장합니다(예: aws-pv.yaml ) 영구 볼륨을 생성합니다.
# oc create -f aws-pv.yaml
persistentvolume "pv0001" created영구 볼륨이 생성되었는지 확인합니다.
# oc get pv
NAME LABELS CAPACITY ACCESSMODES STATUS CLAIM REASON AGE
pv0001 <none> 5Gi RWO Available 2s그러면 사용자가 영구 볼륨 클레임을 사용하여 스토리지를 요청할 수 있으므로 이제 새 영구 볼륨을 활용할 수 있습니다.
영구 볼륨 클레임은 사용자의 네임스페이스에만 존재하며 동일한 네임스페이스 내의 Pod에서만 참조할 수 있습니다. 다른 네임스페이스에서 영구 볼륨에 액세스하려고 하면 포드가 실패합니다.
27.6.2.2. 볼륨 형식
OpenShift Container Platform이 볼륨을 마운트하고 컨테이너에 전달하기 전에 영구 볼륨 정의에서 fsType 매개변수에 의해 지정된 파일 시스템이 포함되어 있는지 확인합니다. 장치가 파일 시스템으로 포맷되지 않으면 장치의 모든 데이터가 삭제되고 장치는 지정된 파일 시스템에서 자동으로 포맷됩니다.
이를 통해 OpenShift Container Platform이 처음 사용하기 전에 포맷되기 때문에 형식화되지 않은 AWS 볼륨을 영구 볼륨으로 사용할 수 있습니다.
27.6.2.3. 노드의 최대 EBS 볼륨 수
기본적으로 OpenShift Container Platform은 노드 1개에 연결된 최대 39개의 EBS 볼륨을 지원합니다. 이 제한은 AWS 볼륨 제한 과 일치합니다.
환경 변수 KUBE_MAX_PD_VOLS 를 설정하여 OpenShift Container Platform을 더 제한하도록 구성할 수 있습니다. 그러나 AWS에는 연결된 장치에 대한 특정 명명 체계(AWS 장치 명명)가 필요하며 최대 52개 볼륨만 지원합니다. 이렇게 하면 OpenShift Container Platform을 통해 노드에 연결할 수 있는 볼륨 수가 52개로 제한됩니다.
27.7. GCE 영구 디스크를 사용하는 영구 스토리지
27.7.1. 개요
OpenShift Container Platform은 gcePD(GCE 영구 디스크 볼륨)를 지원합니다. GCE 를 사용하여 영구 스토리지로 OpenShift Container Platform 클러스터를 프로비저닝할 수 있습니다. Kubernetes 및 GCE에 대해 어느 정도 익숙한 것으로 가정합니다.
GCE를 사용하여 영구 볼륨을 생성하기 전에 OpenShift Container Platform이 GCE 영구 디스크에 대해 먼저 올바르게 구성해야 합니다.
Kubernetes 영구 볼륨 프레임워크를 사용하면 관리자가 영구 스토리지로 클러스터를 프로비저닝하고 사용자가 기본 인프라에 대한 지식 없이도 해당 리소스를 요청할 수 있습니다. GCE 영구 디스크 볼륨은 동적으로 프로비저닝 할 수 있습니다. 영구 볼륨은 단일 프로젝트 또는 네임스페이스에 바인딩되지 않으며, OpenShift Container Platform 클러스터에서 공유할 수 있습니다. 그러나 영구 볼륨 클레임 은 프로젝트 또는 네임스페이스에 고유하며 사용자가 요청할 수 있습니다.
인프라의 스토리지의 고가용성은 기본 스토리지 공급자가 담당합니다.
27.7.2. 프로비저닝
OpenShift Container Platform에서 볼륨으로 마운트하기 전에 기본 인프라에 스토리지가 있어야 합니다. OpenShift Container Platform이 GCE PersistentDisk에 대해 구성되었는지 확인한 후 OpenShift Container Platform 및 GCE에 필요한 모든 것이 GCE 영구 디스크 볼륨 ID 및 the PersistentVolume API입니다.
27.7.2.1. 영구 볼륨 생성
OpenShift Container Platform에서 생성하기 전에 오브젝트 정의에서 영구 볼륨을 정의해야 합니다.
예 27.6. GCE를 사용하는 영구 볼륨 오브젝트 정의
apiVersion: "v1"
kind: "PersistentVolume"
metadata:
name: "pv0001"
spec:
capacity:
storage: "5Gi"
accessModes:
- "ReadWriteOnce"
gcePersistentDisk:
fsType: "ext4"
pdName: "pd-disk-1"
볼륨이 포맷되고 프로비저닝된 후 fstype 매개변수 값을 변경하면 데이터가 손실되고 Pod 오류가 발생할 수 있습니다.
정의를 파일에 저장합니다(예: gce-pv.yaml ).
# oc create -f gce-pv.yaml
persistentvolume "pv0001" created영구 볼륨이 생성되었는지 확인합니다.
# oc get pv
NAME LABELS CAPACITY ACCESSMODES STATUS CLAIM REASON AGE
pv0001 <none> 5Gi RWO Available 2s그러면 사용자가 영구 볼륨 클레임을 사용하여 스토리지를 요청할 수 있으므로 이제 새 영구 볼륨을 활용할 수 있습니다.
영구 볼륨 클레임은 사용자의 네임스페이스에만 존재하며 동일한 네임스페이스 내의 Pod에서만 참조할 수 있습니다. 다른 네임스페이스에서 영구 볼륨에 액세스하려고 하면 포드가 실패합니다.
27.7.2.2. 볼륨 형식
OpenShift Container Platform이 볼륨을 마운트하고 컨테이너에 전달하기 전에 영구 볼륨 정의에 fsType 매개변수에 의해 지정된 파일 시스템이 포함되어 있는지 확인합니다. 장치가 파일 시스템으로 포맷되지 않으면 장치의 모든 데이터가 삭제되고 장치는 지정된 파일 시스템에서 자동으로 포맷됩니다.
이를 통해 OpenShift Container Platform이 처음 사용하기 전에 형식화되므로 형식화되지 않은 GCE 볼륨을 영구 볼륨으로 사용할 수 있습니다.
27.8. iSCSI를 사용하는 영구 스토리지
27.8.1. 개요
iSCSI 를 사용하여 영구 스토리지로 OpenShift Container Platform 클러스터를 프로비저닝할 수 있습니다. Kubernetes 및 iSCSI에 대해 어느 정도 익숙한 것으로 가정합니다.
Kubernetes 영구 볼륨 프레임워크를 사용하면 관리자가 영구 스토리지로 클러스터를 프로비저닝하고 사용자가 기본 인프라에 대한 지식 없이도 해당 리소스를 요청할 수 있습니다.
인프라의 스토리지의 고가용성은 기본 스토리지 공급자가 담당합니다.
27.8.2. 프로비저닝
OpenShift Container Platform에서 볼륨으로 마운트하기 전에 기본 인프라에 스토리지가 있는지 확인합니다. iSCSI에 필요한 것은 iSCSI 대상 포털, 유효한 IQN(iSCSI Qualified Name), 유효한 LUN 번호, 파일 시스템 유형 및 PersistentVolume API입니다.
선택적으로 다중 경로 포털 및 CHAP(챌린지 Handshake Authentication Protocol) 구성을 제공할 수 있습니다.
예 27.7. 영구 볼륨 오브젝트 정의
apiVersion: v1
kind: PersistentVolume
metadata:
name: iscsi-pv
spec:
capacity:
storage: 1Gi
accessModes:
- ReadWriteOnce
iscsi:
targetPortal: 10.16.154.81:3260
portals: ['10.16.154.82:3260', '10.16.154.83:3260']
iqn: iqn.2014-12.example.server:storage.target00
lun: 0
fsType: 'ext4'
readOnly: false
chapAuthDiscovery: true
chapAuthSession: true
secretRef:
name: chap-secret27.8.2.1. 디스크 할당량 적용
LUN 파티션을 사용하여 디스크 할당량 및 크기 제약 조건을 강제 적용합니다. 각 LUN은 1개의 영구 볼륨입니다. Kubernetes는 영구 볼륨에 고유 이름을 강제 적용합니다.
이렇게 하면 최종 사용자가 특정 용량(예: 10Gi)에 의해 영구 스토리지를 요청하고 해당 볼륨과 동등한 용량과 일치시킬 수 있습니다.
27.8.2.2. iSCSI 볼륨 보안
사용자는 PersistentVolumeClaim 을 사용하여 스토리지를 요청합니다. 이 클레임은 사용자의 네임스페이스에만 존재하며, 동일한 네임스페이스 내의 Pod에서만 참조할 수 있습니다. 네임스페이스에서 영구 볼륨에 대한 액세스를 시도하면 Pod가 실패하게 됩니다.
각 iSCSI LUN은 클러스터의 모든 노드에서 액세스할 수 있어야 합니다.
27.8.2.3. iSCSI Multipathing
iSCSI 기반 스토리지의 경우 두 개 이상의 대상 포털 IP 주소에 동일한 IQN을 사용하여 여러 경로를 구성할 수 있습니다. 경로의 구성 요소 중 하나 이상에 실패하면 다중 경로를 통해 영구 볼륨에 액세스할 수 있습니다.
Pod 사양에서 다중 경로를 지정하려면 portals 필드를 사용합니다. 예를 들면 다음과 같습니다.
apiVersion: v1
kind: PersistentVolume
metadata:
name: iscsi-pv
spec:
capacity:
storage: 1Gi
accessModes:
- ReadWriteOnce
iscsi:
targetPortal: 10.0.0.1:3260
portals: ['10.0.2.16:3260', '10.0.2.17:3260', '10.0.2.18:3260']
iqn: iqn.2016-04.test.com:storage.target00
lun: 0
fsType: ext4
readOnly: false- 1
portals필드를 사용하여 추가 대상 포털을 추가합니다.
27.8.2.4. iSCSI 사용자 지정 이니시에이터 IQN
iSCSI 대상이 특정 IQN으로 제한되는 경우 사용자 정의 이니시에이터 IQN(iSCSI Qualified Name)을 구성하지만 iSCSI PV가 연결된 노드는 이러한 IQN을 갖는 것이 보장되지 않습니다.
사용자 지정 이니시에이터 IQN을 지정하려면 initiatorName 필드를 사용합니다.
apiVersion: v1
kind: PersistentVolume
metadata:
name: iscsi-pv
spec:
capacity:
storage: 1Gi
accessModes:
- ReadWriteOnce
iscsi:
targetPortal: 10.0.0.1:3260
portals: ['10.0.2.16:3260', '10.0.2.17:3260', '10.0.2.18:3260']
iqn: iqn.2016-04.test.com:storage.target00
lun: 0
initiatorName: iqn.2016-04.test.com:custom.iqn
fsType: ext4
readOnly: false- 1
- 추가 사용자 지정 이니시에이터 IQN을 추가하려면
initiatorName필드를 사용합니다.
27.9. 파이버 채널을 사용하는 영구 스토리지
27.9.1. 개요
FC( 파이버 채널 )를 사용하여 영구 스토리지로 OpenShift Container Platform 클러스터를 프로비저닝할 수 있습니다. Kubernetes 및 FC에 대해 어느 정도 익숙한 것으로 가정합니다.
Kubernetes 영구 볼륨 프레임워크를 사용하면 관리자가 영구 스토리지로 클러스터를 프로비저닝하고 사용자가 기본 인프라에 대한 지식 없이도 해당 리소스를 요청할 수 있습니다.
인프라의 스토리지의 고가용성은 기본 스토리지 공급자가 담당합니다.
27.9.2. 프로비저닝
OpenShift Container Platform에서 볼륨으로 마운트하기 전에 기본 인프라에 스토리지가 있어야 합니다. FC 영구 스토리지에 필요한 모든 것이 PersistentVolume API, wwids 또는 (유효한 targetWWNs lun 번호가 있는 targetWWN) 및 fsType 입니다. 영구 볼륨과 LUN은 일대일 매핑됩니다.
영구 볼륨 오브젝트 정의
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv0001
spec:
capacity:
storage: 1Gi
accessModes:
- ReadWriteOnce
fc:
wwids: [scsi-3600508b400105e210000900000490000]
targetWWNs: ['500a0981891b8dc5', '500a0981991b8dc5']
lun: 2
fsType: ext4- 1
- 선택 사항: WWID(WWID). FC
wwids또는 FCtargetWWN 및lun의 조합 중 하나를 설정해야 하지만 둘 다 동시에 설정할 수는 없습니다. FC WWID 식별자는 WWNs 타겟을 통해 권장되며 모든 스토리지 장치에 대해 고유하고 장치에 액세스하는 데 사용되는 경로와 별개이기 때문입니다. WWID 식별자는 장치 식별 Vital Product Data(0x83 페이지) 또는 유닛 일련 번호)를 검색하기 위해 SCSI Inquiry를 발행하여 가져올 수 있습니다. FC WWID는 다양한 시스템에서 장치에 액세스하는 경우에도 장치 경로가 변경되더라도 디스크의 데이터를 참조하기 위해(0x80페이지/dev/disk/by-id/로 식별됩니다. - 2 3
- 선택 사항: WWN(WWN). FC
wwids또는 FCtargetWWN 및lun의 조합 중 하나를 설정해야 하지만 둘 다 동시에 설정할 수는 없습니다. FC WWID 식별자는 WWNs 타겟을 통해 권장되며 모든 스토리지 장치에 대해 고유하고 장치에 액세스하는 데 사용되는 경로와 별개이기 때문입니다. FC WWN은/dev/disk/by-path/pci-<identifier>-fc-0x<wwn>-lun-<lun_#>로 식별되지만 최대< WWN>(0x포함) 및 그 다음에는-(하이픈)를 포함합니다.
볼륨이 포맷되고 프로비저닝된 후 the fstype 매개변수 값을 변경하면 데이터가 손실되고 Pod 오류가 발생할 수 있습니다.
27.9.2.1. 디스크 할당량 적용
LUN 파티션을 사용하여 디스크 할당량 및 크기 제약 조건을 강제 적용합니다. 각 LUN은 1개의 영구 볼륨입니다. Kubernetes는 영구 볼륨에 고유 이름을 강제 적용합니다.
이렇게 하면 최종 사용자가 10Gi와 같은 특정 용량에 의해 영구 스토리지를 요청할 수 있으며 해당 볼륨과 동등한 용량과 일치시킬 수 있습니다.
27.9.2.2. 파이버 채널 볼륨 보안
사용자는 PersistentVolumeClaim 을 사용하여 스토리지를 요청합니다. 이 클레임은 사용자의 네임스페이스에만 존재하며 동일한 네임스페이스 내의 Pod에서만 참조할 수 있습니다. 네임스페이스에서 영구 볼륨 클레임에 대한 액세스를 시도하면 Pod가 실패하게 됩니다.
각 FC LUN은 클러스터의 모든 노드에서 액세스할 수 있어야 합니다.
27.10. Azure 디스크를 사용하는 영구 스토리지
27.10.1. 개요
OpenShift Container Platform은 Microsoft Azure Disk 볼륨을 지원합니다. Azure를 사용하여 영구 스토리지로 OpenShift Container Platform 클러스터를 프로비저닝할 수 있습니다. Kubernetes 및 Azure에 대해 어느 정도 익숙한 것으로 가정합니다.
Kubernetes 영구 볼륨 프레임워크를 사용하면 관리자가 영구 스토리지로 클러스터를 프로비저닝하고 사용자가 기본 인프라에 대한 지식 없이도 해당 리소스를 요청할 수 있습니다.
Azure 디스크 볼륨은 동적으로 프로비저닝 할 수 있습니다. 영구 볼륨은 단일 프로젝트 또는 네임스페이스에 바인딩되지 않으며, OpenShift Container Platform 클러스터에서 공유할 수 있습니다. 그러나 영구 볼륨 클레임 은 프로젝트 또는 네임스페이스에 고유하며 사용자가 요청할 수 있습니다.
인프라의 스토리지의 고가용성은 기본 스토리지 공급자가 담당합니다.
27.10.2. 사전 요구 사항
Azure를 사용하여 영구 볼륨을 생성하기 전에 OpenShift Container Platform 클러스터가 다음 요구 사항을 충족하는지 확인하십시오.
- OpenShift Container Platform을 Azure Disk에 대해 먼저 구성해야 합니다.
- 인프라의 각 노드 호스트는 Azure 가상 머신 이름과 일치해야 합니다.
- 각 노드 호스트는 동일한 리소스 그룹에 있어야 합니다.
27.10.3. 프로비저닝
OpenShift Container Platform에서 볼륨으로 마운트하기 전에 기본 인프라에 스토리지가 있어야 합니다. OpenShift Container Platform이 Azure 디스크에 대해 구성되었는지 확인한 후 OpenShift Container Platform 및 Azure에 필요한 모든 것이 Azure Disk Name 및 Disk URI 및 the PersistentVolume API입니다.
27.10.4. 지역 클라우드에 대한 Azure Disk 구성
Azure에는 인스턴스를 배포할 여러 리전이 있습니다. 원하는 지역을 지정하려면 azure.conf 파일에 다음을 추가합니다.
cloud: <region>리전은 다음 중 하나일 수 있습니다.
-
독일어 클라우드:
AZUREGERMANCLOUD -
중국 클라우드:
AZURECHINACLOUD -
퍼블릭 클라우드:
AZUREPUBLICCLOUD -
미국 클라우드:
AZUREUSGOVERNMENTCLOUD
27.10.4.1. 영구 볼륨 생성
OpenShift Container Platform에서 생성하기 전에 오브젝트 정의에서 영구 볼륨을 정의해야 합니다.
예 27.8. Azure를 사용하는 영구 볼륨 오브젝트 정의
apiVersion: "v1"
kind: "PersistentVolume"
metadata:
name: "pv0001"
spec:
capacity:
storage: "5Gi"
accessModes:
- "ReadWriteOnce"
azureDisk:
diskName: test2.vhd
diskURI: https://someacount.blob.core.windows.net/vhds/test2.vhd
cachingMode: ReadWrite
fsType: ext4
readOnly: false - 1
- 볼륨의 이름입니다. 이는 영구 볼륨 클레임 을 통해 또는 Pod에서 식별되는 방법입니다.
- 2
- 이 볼륨에 할당된 스토리지의 용량입니다.
- 3
- 이는 사용 중인 볼륨 유형(이 예에서는azureDisk 플러그인)을 정의합니다.
- 4
- Blob 스토리지의 데이터 디스크 이름입니다.
- 5
- Blob 스토리지에 있는 데이터 디스크의 URI입니다.
- 6
- 호스트 캐싱 모드: none, ReadOnly 또는 ReadWrite.
- 7
- 마운트할 파일 시스템 유형(예:
ext4,xfs등). - 8
- 기본값은
false(읽기/쓰기)입니다.여기서 읽기전용으로VolumeMounts에서ReadOnly설정을 강제 적용합니다.
볼륨이 포맷되고 프로비저닝된 후 fsType 매개변수 값을 변경하면 데이터가 손실되고 Pod 오류가 발생할 수 있습니다.
정의를 파일에 저장합니다(예: azure-pv.yaml ) 영구 볼륨을 생성합니다.
# oc create -f azure-pv.yaml persistentvolume "pv0001" created영구 볼륨이 생성되었는지 확인합니다.
# oc get pv NAME LABELS CAPACITY ACCESSMODES STATUS CLAIM REASON AGE pv0001 <none> 5Gi RWO Available 2s
이제 새 영구 볼륨을 사용할 수 있는 영구 볼륨 클레임을 사용하여 스토리지를 요청할 수 있습니다.
Azure 디스크 PVC를 통해 마운트된 볼륨이 있는 Pod의 경우 새 노드에 Pod를 예약하는 데 몇 분이 걸립니다. 2~3분 정도 기다린 후 Disk Detach(디스크 분리) 작업을 완료한 다음 새 배포를 시작합니다. Disk Detach 작업을 완료하기 전에 새 Pod 생성 요청이 시작되면 Pod 생성에 의해 시작된 Disk Attach 작업이 실패하여 Pod 생성에 실패합니다.
영구 볼륨 클레임은 사용자의 네임스페이스에만 존재하며 동일한 네임스페이스 내의 Pod에서만 참조할 수 있습니다. 다른 네임스페이스에서 영구 볼륨에 액세스하려고 하면 포드가 실패합니다.
27.10.4.2. 볼륨 형식
OpenShift Container Platform이 볼륨을 마운트하고 컨테이너에 전달하기 전에 영구 볼륨 정의에 fsType 매개변수에 의해 지정된 파일 시스템이 포함되어 있는지 확인합니다. 장치가 파일 시스템으로 포맷되지 않으면 장치의 모든 데이터가 삭제되고 장치는 지정된 파일 시스템에서 자동으로 포맷됩니다.
이를 통해 OpenShift Container Platform이 처음 사용하기 전에 포맷되기 때문에 형식화되지 않은 Azure 볼륨을 영구 볼륨으로 사용할 수 있습니다.
27.11. Azure 파일을 사용하는 영구 스토리지
27.11.1. 개요
OpenShift Container Platform은 Microsoft Azure File 볼륨을 지원합니다. Azure를 사용하여 영구 스토리지로 OpenShift Container Platform 클러스터를 프로비저닝할 수 있습니다. Kubernetes 및 Azure에 대해 어느 정도 익숙한 것으로 가정합니다.
인프라의 스토리지의 고가용성은 기본 스토리지 공급자가 담당합니다.
27.11.2. 시작하기 전
모든 노드에
samba-client,samba-common,cifs-utils를 설치합니다.$ sudo yum install samba-client samba-common cifs-utils모든 노드에서 SELinux 부울을 활성화합니다.
$ /usr/sbin/setsebool -P virt_use_samba on $ /usr/sbin/setsebool -P virt_sandbox_use_samba onmount명령을 실행하여dir_mode 및권한을 확인합니다. 예를 들면 다음과 같습니다.file_mode$ mount
dir_mode 및 file_mode 권한이 0755로 설정된 경우 기본값 0755 를 0777 또는 0775 로 변경합니다. 이 수동 단계는 OpenShift Container Platform 3.9의 기본 dir_mode 및 file_mode 권한이 0777 에서 0755 로 변경되었으므로 필요합니다. 다음 예제에서는 변경된 값이 있는 구성 파일을 보여줍니다.
Azure File 사용시 고려 사항
다음 파일 시스템 기능은 Azure File에서 지원하지 않습니다.
- 심볼릭 링크
- 하드 링크
- 확장 속성
- 스파스 파일
- 명명된 파이프
또한 Azure File이 마운트되는 디렉터리의 소유자 ID (UID)는 컨테이너의 프로세스 UID와 다릅니다.
지원되지 않는 파일 시스템 기능을 사용하는 컨테이너 이미지를 사용하는 경우 환경에서 불안정할 수 있습니다. PostgreSQL 및 MySQL의 컨테이너는 Azure File과 함께 사용할 때 문제가 있는 것으로 알려져 있습니다.
Azure File에서 MySQL을 사용하는 해결 방법
MySQL 컨테이너를 사용하는 경우 마운트된 디렉터리 UID와 컨테이너 프로세스 UID 간의 파일 소유권 불일치에 대한 해결 방법으로 PV 구성을 수정해야 합니다. PV 구성 파일을 다음과 같이 변경합니다.
PV 구성 파일의
runAsUser변수에 Azure File 마운트된 디렉터리 UID를 지정합니다.spec: containers: ... securityContext: runAsUser: <mounted_dir_uid>PV 구성 파일에서
mountOptions아래에 컨테이너 프로세스 UID를 지정합니다.mountOptions: - dir_mode=0700 - file_mode=0600 - uid=<container_process_uid> - gid=0
27.11.3. 구성 파일 예
다음 예제 구성 파일에는 Azure File을 사용하여 PV 구성이 표시됩니다.
PV 구성 파일 예
apiVersion: "v1"
kind: "PersistentVolume"
metadata:
name: "azpv"
spec:
capacity:
storage: "1Gi"
accessModes:
- "ReadWriteMany"
azureFile:
secretName: azure-secret
shareName: azftest
readOnly: false
mountOptions:
- dir_mode=0777
- file_mode=0777다음 예제 구성 파일은 Azure File을 사용하여 스토리지 클래스를 표시합니다.
스토리지 클래스 구성 파일 예
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: azurefile
provisioner: kubernetes.io/azure-file
mountOptions:
- dir_mode=0777
- file_mode=0777
parameters:
storageAccount: ocp39str
location: centralus27.11.4. 지역 클라우드에 대한 Azure File 구성
Azure Disk는 여러 지역 클라우드와 호환되는 반면 Azure File은 끝점이 하드 코딩되어 있기 때문에 Azure 공용 클라우드만 지원합니다.
27.11.5. Azure 스토리지 계정 시크릿 생성
시크릿 구성에 Azure Storage 계정 이름과 키를 정의한 다음 OpenShift Container Platform에서 사용하기 위해 base64로 변환됩니다.
Azure 스토리지 계정 이름과 키를 가져오고 base64로 인코딩합니다.
apiVersion: v1 kind: Secret metadata: name: azure-secret type: Opaque data: azurestorageaccountname: azhzdGVzdA== azurestorageaccountkey: eElGMXpKYm5ub2pGTE1Ta0JwNTBteDAyckhzTUsyc2pVN21GdDRMMTNob0I3ZHJBYUo4akQ2K0E0NDNqSm9nVjd5MkZVT2hRQ1dQbU02WWFOSHk3cWc9PQ==비밀 정의를 파일에 저장합니다(예: azure-secret.yaml ).
$ oc create -f azure-secret.yaml보안이 생성되었는지 확인합니다.
$ oc get secret azure-secret NAME TYPE DATA AGE azure-secret Opaque 1 23dOpenShift Container Platform에서 생성하기 전에 오브젝트 정의에 PV를 정의합니다.
Azure File을 사용한 PV 오브젝트 정의 예
apiVersion: "v1" kind: "PersistentVolume" metadata: name: "pv0001"1 spec: capacity: storage: "5Gi"2 accessModes: - "ReadWriteMany" azureFile:3 secretName: azure-secret4 shareName: example5 readOnly: false6 정의를 파일에 저장합니다(예: azure-file-pv.yaml ) PV를 생성합니다.
$ oc create -f azure-file-pv.yaml persistentvolume "pv0001" createdPV가 생성되었는지 확인합니다.
$ oc get pv NAME LABELS CAPACITY ACCESSMODES STATUS CLAIM REASON AGE pv0001 <none> 5Gi RWM Available 2s
이제 PV 클레임을 사용하여 스토리지를 요청할 수 있으며 이제 새 PV를 사용할 수 있습니다.
PV 클레임은 사용자의 네임스페이스에만 존재하며 동일한 네임스페이스 내의 Pod에서만 참조할 수 있습니다. 다른 네임스페이스에서 PV에 액세스하려고 하면 Pod가 실패합니다.
27.12. FlexVolume 플러그인을 사용하는 영구 스토리지
27.12.1. 개요
OpenShift Container Platform에는 다양한 스토리지 기술을 사용하기 위해 기본 제공 볼륨 플러그인이 있습니다. 플러그인이 내장되지 않은 백엔드의 스토리지를 사용하려면 FlexVolume 드라이버를 통해 OpenShift Container Platform을 확장하고 애플리케이션에 영구 스토리지를 제공할 수 있습니다.
27.12.2. FlexVolume 드라이버
FlexVolume 드라이버는 마스터와 노드 모두 클러스터의 모든 머신에 있는 잘 정의된 디렉터리에 있는 실행 파일입니다. flexVolume 을 소스로 사용하여 a PersistentVolume 에서 표시하는 볼륨을 연결, 분리, 마운트 또는 마운트해야 할 때마다 OpenShift Container Platform은 FlexVolume 드라이버를 호출합니다.
드라이버의 첫 번째 명령줄 인수는 항상 작업 이름입니다. 다른 매개 변수는 각 작업에 따라 다릅니다. 대부분의 작업에서는 JSON(JavaScript Object Notation) 문자열을 매개변수로 사용합니다. 이 매개변수는 전체 JSON 문자열이며 JSON 데이터가 있는 파일 이름은 아닙니다.
FlexVolume 드라이버에는 다음이 포함됩니다.
-
모든
flexVolume.options. -
fsType및readwrite와 같은kubernetes.io/접두사가 붙은flexVolume의 일부 옵션. -
설정된 경우,
kubernetes.io/secret/이 접두사로 사용되는 참조된 시크릿의 콘텐츠
FlexVolume 드라이버 JSON 입력 예
{
"fooServer": "192.168.0.1:1234",
"fooVolumeName": "bar",
"kubernetes.io/fsType": "ext4",
"kubernetes.io/readwrite": "ro",
"kubernetes.io/secret/<key name>": "<key value>",
"kubernetes.io/secret/<another key name>": "<another key value>",
}OpenShift Container Platform은 드라이버의 표준 출력에서 JSON 데이터를 예상합니다. 지정하지 않으면, 출력이 작업 결과를 설명합니다.
FlexVolume 드라이버 기본 출력
{
"status": "<Success/Failure/Not supported>",
"message": "<Reason for success/failure>"
}
드라이버의 종료 코드는 성공의 경우 0이고 오류의 경우 1이어야 합니다.
작업은 멱등이어야 합니다. 즉, 이미 연결된 볼륨의 첨부 또는 이미 마운트된 볼륨의 마운팅으로 인해 작업이 성공적으로 수행되어야 합니다.
FlexVolume 드라이버는 다음 두 가지 모드로 작동할 수 있습니다.
attach/detach 작업은 OpenShift Container Platform 마스터에서 노드에 볼륨을 연결하고 노드에서 볼륨을 분리하는 데 사용됩니다. 이는 노드가 어떠한 이유로도 응답하지 않을 때 유용합니다. 그런 다음 마스터는 노드의 모든 포드를 종료하고 해당 포드에서 모든 볼륨을 분리한 다음, 원래 노드에 연결할 수 없는 상태에서 애플리케이션을 다시 시작하도록 다른 노드에 볼륨을 연결할 수 있습니다.
일부 스토리지 백엔드가 다른 시스템에서 볼륨의 마스터 시작 분리를 지원하는 것은 아닙니다.
27.12.2.1. 마스터 시작 attach/detach가 있는 FlexVolume 드라이버
마스터 제어 연결/분리를 지원하는 FlexVolume 드라이버는 다음 작업을 구현해야 합니다.
init드라이버를 초기화합니다. 이는 마스터와 노드를 초기화하는 동안 호출됩니다.
- 인수: 없음
- 실행 위치: master, node
- 예상 출력: 기본 JSON
getvolumename볼륨의 고유 이름을 반환합니다. 후속
분리호출에서<volume-name>으로 사용되므로 이 이름은 모든 마스터 및 노드 간에 일관성을 유지해야 합니다.<volume-name>의 모든/문자는 자동으로~로 바뀝니다.-
인수:
<json> - 실행 위치: master, node
예상 출력: 기본 JSON +
volumeName:{ "status": "Success", "message": "", "volumeName": "foo-volume-bar"1 }- 1
- 스토리지 백엔드
foo의 볼륨의 고유 이름입니다.
-
인수:
attachJSON으로 표시된 볼륨을 지정된 노드에 연결합니다. 이 작업은 알려진 경우 노드의 장치 이름을 반환해야 합니다(실행 전에 스토리지 백엔드에서 할당한 경우). 장치를 알 수 없는 경우 이후
waitforattach작업을 통해 노드에서 장치를 찾아야 합니다.-
인수:
<json><node-name> - 실행 위치: master
예상 출력: 알려진 경우 기본 JSON +
장치:{ "status": "Success", "message": "", "device": "/dev/xvda"1 }- 1
- 알려진 경우 노드의 장치 이름입니다.
-
인수:
waitforattach볼륨이 노드에 완전히 연결되고 해당 장치가 표시될 때까지 기다립니다. 이전
연결작업이<device-name>을 반환한 경우 입력 매개 변수로 제공됩니다. 그렇지 않으면<device-name>이 비어 있으며 작업에서 노드에서 장치를 찾아야 합니다.-
인수:
<device-name><json> - 실행 위치: 노드
예상 출력: 기본 JSON +
장치{ "status": "Success", "message": "", "device": "/dev/xvda"1 }- 1
- 노드의 장치 이름입니다.
-
인수:
분리노드에서 지정된 볼륨을 분리합니다.
<volume-name>은getvolumename작업에서 반환한 장치의 이름입니다.<volume-name>의 모든/문자는 자동으로~로 바뀝니다.-
인수:
<volume-name><node-name> - 실행 위치: master
- 예상 출력: 기본 JSON
-
인수:
isattached볼륨이 노드에 연결되어 있는지 확인합니다.
-
인수:
<json><node-name> - 실행 위치: master
예상 출력: 기본 JSON +
연결{ "status": "Success", "message": "", "attached": true1 }- 1
- 노드에 볼륨 연결 상태입니다.
-
인수:
mountdevice볼륨의 장치를 디렉터리에 마운트합니다.
<device-name>은 이전waitforattach작업에서 반환한 장치의 이름입니다.-
인수:
<mount-dir><device-name><json> - 실행 위치: 노드
- 예상 출력: 기본 JSON
-
인수:
unmountdevice디렉터리에서 볼륨의 장치를 마운트 해제합니다.
-
인수:
<mount-dir> - 실행 위치: 노드
-
인수:
다른 모든 작업은 {"status":를 사용하여 JSON을 반환해야 합니다: "지원되지 않음"} 코드 1 을 종료합니다.
마스터 시작 연결/분리 작업은 기본적으로 활성화됩니다. 활성화하지 않으면 볼륨을 연결하거나 분리해야 하는 노드에 의해 attach/detach 작업이 시작됩니다. FlexVolume 드라이버 호출의 모든 매개변수와 구문은 두 경우 모두 동일합니다.
27.12.2.2. 마스터 시작 연결/분리 없는 FlexVolume 드라이버
마스터 제어 연결/분리를 지원하지 않는 FlexVolume 드라이버는 노드에서만 실행되며 다음 작업을 구현해야 합니다.
init드라이버를 초기화합니다. 이는 모든 노드를 초기화하는 동안 호출됩니다.
- 인수: 없음
- 실행 위치: 노드
- 예상 출력: 기본 JSON
Mount디렉터리에 볼륨을 마운트합니다. 여기에는 노드에 볼륨 연결, 장치를 찾은 다음 장치를 마운트하는 등 볼륨을 마운트하는 데 필요한 모든 항목이 포함될 수 있습니다.
-
인수:
<mount-dir><json> - 실행 위치: 노드
- 예상 출력: 기본 JSON
-
인수:
unmount디렉터리에서 볼륨의 마운트를 해제합니다. 여기에는 노드에서 볼륨 분리와 같이 마운트 해제한 후 볼륨을 정리하는 데 필요한 항목이 포함됩니다.
-
인수:
<mount-dir> - 실행 위치: 노드
- 예상 출력: 기본 JSON
-
인수:
다른 모든 작업은 {"status":를 사용하여 JSON을 반환해야 합니다: "지원되지 않음"} 코드 1 을 종료합니다.
27.12.3. FlexVolume 드라이버 설치
FlexVolume 드라이버를 설치하려면 다음을 수행합니다.
- 실행 가능한 파일이 클러스터의 모든 마스터와 노드에 있는지 확인합니다.
- 볼륨 플러그인 경로에 실행 가능 파일 /usr/libexec/kubernetes/kubelet-plugins/volume/exec/<vendor>~<driver>/<driver>를 배치합니다.
예를 들어 foo 스토리지용 FlexVolume 드라이버를 설치하려면 실행 파일을 /usr/libexec/kubernetes/kubelet-plugins/volume/exec/openshift.com~foo/foo 에 배치합니다.
OpenShift Container Platform 3.11에서 controller-manager 가 정적 포드로 실행되므로 attach 및 detach 작업을 수행하는 FlexVolume 바이너리 파일은 외부 종속성 없이 자체 포함된 실행 파일이어야 합니다.
Atomic 호스트에서 FlexVolume 플러그인 디렉터리의 기본 위치는 /etc/origin/kubelet-plugins/ 입니다. 클러스터의 모든 마스터와 노드의 /etc/origin/kubelet-plugins/volume/exec/<vendor>~<driver>/<driver> 디렉터리에 FlexVolume 실행 파일을 배치해야 합니다.
27.12.4. FlexVolume 드라이버를 사용한 스토리지 사용
PersistentVolume 오브젝트를 사용하여 설치된 스토리지를 참조합니다. OpenShift Container Platform의 each PersistentVolume 오브젝트는 스토리지 백엔드에서 하나의 스토리지 자산(일반적으로 볼륨)을 나타냅니다.
FlexVolume 드라이버를 사용한 영구 볼륨 오브젝트 정의 예
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv0001
spec:
capacity:
storage: 1Gi
accessModes:
- ReadWriteOnce
flexVolume:
driver: openshift.com/foo
fsType: "ext4"
secretRef: foo-secret
readOnly: true
options:
fooServer: 192.168.0.1:1234
fooVolumeName: bar- 1
- 볼륨의 이름입니다. 영구 볼륨 클레임 을 통해 또는 Pod에서 식별되는 방법입니다. 이 이름은 백엔드 스토리지의 볼륨 이름과 다를 수 있습니다.
- 2
- 이 볼륨에 할당된 스토리지의 용량입니다.
- 3
- 드라이버의 이름입니다. 이 필드는 필수입니다.
- 4
- 볼륨에 존재하는 파일 시스템입니다. 이 필드는 선택 사항입니다.
- 5
- 시크릿에 대한 참조입니다. 이 시크릿의 키와 값은 호출 시 FlexVolume 드라이버에 제공됩니다. 이 필드는 선택 사항입니다.
- 6
- 읽기 전용 플래그입니다. 이 필드는 선택 사항입니다.
- 7
- FlexVolume 드라이버에 대한 추가 옵션입니다.
options필드에 있는 사용자가 지정한 플래그 외에도 다음 플래그도 실행 파일에 전달됩니다.
"fsType":"<FS type>",
"readwrite":"<rw>",
"secret/key1":"<secret1>"
...
"secret/keyN":"<secretN>"시크릿은 호출을 마운트/마운트 해제하는 데만 전달됩니다.
27.13. 영구 스토리지에 VMware vSphere 볼륨 사용
27.13.1. 개요
OpenShift Container Platform은 VMware vSphere의 VMDK(가상 머신 디스크) 볼륨을 지원합니다. VMware vSphere 를 사용하여 영구 스토리지로 OpenShift Container Platform 클러스터를 프로비저닝할 수 있습니다. Kubernetes 및 VMware vSphere에 대해 어느 정도 익숙한 것으로 가정합니다.
OpenShift Container Platform은 vSphere에서 디스크를 생성하고 올바른 인스턴스에 디스크를 연결합니다.
OpenShift Container Platform PV(영구 볼륨) 프레임워크를 사용하면 관리자가 영구 스토리지로 클러스터를 프로비저닝하고 사용자가 기본 인프라에 대한 지식 없이도 해당 리소스를 요청할 수 있습니다. vSphere VMDK 볼륨은 동적으로 프로비저닝 할 수 있습니다.
PV는 단일 프로젝트 또는 네임스페이스에 바인딩되지 않으며 OpenShift Container Platform 클러스터에서 공유할 수 있습니다. 그러나 PV 클레임 은 프로젝트 또는 네임스페이스에 고유하며 사용자가 요청할 수 있습니다.
인프라의 스토리지의 고가용성은 기본 스토리지 공급자가 담당합니다.
사전 요구 사항
vSphere를 사용하여 PV를 생성하기 전에 OpenShift Container Platform 클러스터가 다음 요구사항을 충족하는지 확인하십시오.
- OpenShift Container Platform을 vSphere에 대해 먼저 구성해야 합니다.
- 인프라의 각 노드 호스트는 vSphere VM 이름과 일치해야 합니다.
- 각 노드 호스트는 동일한 리소스 그룹에 있어야 합니다.
27.13.2. 동적으로 VMware vSphere 볼륨 프로비저닝
동적으로 VMware vSphere 볼륨을 프로비저닝하는 것이 좋습니다.
클러스터를 프로비저닝할 때 Ansible 인벤토리 파일에
openshift_cloudprovider변수를 지정하지 않은 경우_kind=vsphere및 openshift_vsphere_*vsphere-volume프로비전 프로그램을 사용하려면 다음StorageClass를수동으로 생성해야 합니다.$ oc get --export storageclass vsphere-standard -o yaml kind: StorageClass apiVersion: storage.k8s.io/v1 metadata: name: "vsphere-standard"1 provisioner: kubernetes.io/vsphere-volume2 parameters: diskformat: thin3 datastore: "YourvSphereDatastoreName"4 reclaimPolicy: Delete이전 단계에 표시된 StorageClass를 사용하여 PV를 요청한 후 OpenShift Container Platform은 vSphere 인프라에 VMDK 디스크를 자동으로 생성합니다. 디스크가 생성되었는지 확인하려면 vSphere에서 Datastore 브라우저를 사용합니다.
참고vSphere-volume 디스크는
ReadWriteOnce액세스 모드이므로 단일 노드에서 볼륨을 읽기-쓰기로 마운트할 수 있습니다. 자세한 내용은 아키텍처 가이드의 액세스 모드 섹션 을 참조하십시오.
27.13.3. 정적으로 프로비저닝 VMware vSphere 볼륨
OpenShift Container Platform에서 볼륨으로 마운트하기 전에 기본 인프라에 스토리지가 있어야 합니다. OpenShift Container Platform이 vSphere에 구성되었는지 확인한 후 OpenShift Container Platform 및 vSphere에 필요한 모든 것이 VM 폴더 경로, 파일 시스템 유형 및 영구 볼륨 API 입니다.
27.13.3.1. VMDK 생성
사용하기 전에 다음 방법 중 하나를 사용하여 VMDK를 만듭니다.
vmkfstools:SSH(Secure Shell)를 통해 ESX에 액세스한 후 다음 명령을 사용하여 VMDK 볼륨을 생성합니다.
vmkfstools -c 40G /vmfs/volumes/DatastoreName/volumes/myDisk.vmdkvmware-vdiskmanager를 사용하여 생성합니다.shell vmware-vdiskmanager -c -t 0 -s 40GB -a lsilogic myDisk.vmdk
27.13.3.2. 영구 볼륨 생성
PV 오브젝트 정의를 정의합니다(예: vsphere-pv.yaml ).
apiVersion: v1 kind: PersistentVolume metadata: name: pv00011 spec: capacity: storage: 2Gi2 accessModes: - ReadWriteOnce persistentVolumeReclaimPolicy: Retain vsphereVolume:3 volumePath: "[datastore1] volumes/myDisk"4 fsType: ext45 - 1
- 볼륨의 이름입니다. PV 클레임 또는 Pod에서 식별하는 방식이어야 합니다.
- 2
- 이 볼륨에 할당된 스토리지의 용량입니다.
- 3
- 사용 중인 볼륨 유형입니다. 이 예에서는
vsphereVolume을 사용합니다. 레이블은 vSphere VMDK 볼륨을 Pod에 마운트하는 데 사용됩니다. 볼륨의 내용은 마운트 해제 시 보존됩니다. 볼륨 유형은 VMFS 및 VSAN 데이터 저장소를 지원합니다. - 4
- 사용할 기존 VMDK 볼륨입니다. 다음과 같이 데이터 저장소 이름을 볼륨 정의에 대괄호([])로 묶어야 합니다.
- 5
- 마운트할 파일 시스템 유형입니다. 예:
ext4,xfs또는 기타 파일 시스템.
중요볼륨이 포맷되고 프로비저닝된 후
fsType매개변수 값을 변경하면 데이터가 손실되고 Pod 오류가 발생할 수 있습니다.PV를 만듭니다.
$ oc create -f vsphere-pv.yaml persistentvolume "pv0001" createdPV가 생성되었는지 확인합니다.
$ oc get pv NAME LABELS CAPACITY ACCESSMODES STATUS CLAIM REASON AGE pv0001 <none> 2Gi RWO Available 2s
이제 PV 클레임을 사용하여 스토리지를 요청할 수 있으며 이제 PV 를 사용할 수 있습니다.
PV 클레임은 사용자의 네임스페이스에만 존재하며 동일한 네임스페이스 내의 Pod에서만 참조할 수 있습니다. 다른 네임스페이스에서 PV에 액세스하려고 하면 Pod가 실패합니다.
27.13.3.3. VMware vSphere 볼륨 포맷
OpenShift Container Platform이 볼륨을 마운트하고 컨테이너에 전달하기 전에 PV 정의의 fsType 매개변수에 의해 지정된 파일 시스템이 볼륨에 포함되어 있는지 확인합니다. 장치가 파일 시스템으로 포맷되지 않으면 장치의 모든 데이터가 삭제되고 장치는 지정된 파일 시스템에서 자동으로 포맷됩니다.
OpenShift Container Platform은 처음 사용하기 전에 포맷되므로 vSphere 볼륨을 PV로 사용할 수 있습니다.
27.14. 로컬 볼륨을 사용하는 영구 스토리지
27.14.1. 개요
OpenShift Container Platform 클러스터는 로컬 볼륨을 사용하여 영구 스토리지로 프로비저닝할 수 있습니다. 로컬 영구 볼륨을 사용하면 표준 PVC 인터페이스를 사용하여 디스크, 파티션 또는 디렉터리와 같은 로컬 스토리지 장치에 액세스할 수 있습니다.
시스템에서 볼륨의 노드 제약 조건을 인식하므로 로컬 볼륨을 노드에 수동으로 예약하지 않고 사용할 수 있습니다. 그러나 로컬 볼륨은 여전히 기본 노드의 가용성에 따라 달라지며 일부 애플리케이션에는 적합하지 않습니다.
로컬 볼륨은 알파 기능이며 향후 OpenShift Container Platform 릴리스에서 변경될 수 있습니다. 알려진 문제 및 해결 방법에 대한 자세한 내용은 기능 상태(로컬 볼륨) 섹션을 참조하십시오.
로컬 볼륨은 정적으로 생성된 영구 볼륨으로만 사용할 수 있습니다.
27.14.2. 프로비저닝
OpenShift Container Platform에서 볼륨으로 마운트하기 전에 기본 인프라에 스토리지가 있어야 합니다. the PersistentVolume API를 사용하기 전에 OpenShift Container Platform이 로컬 볼륨 용으로 구성되어 있는지 확인합니다.
27.14.3. 로컬 영구 볼륨 생성
오브젝트 정의에 영구 볼륨을 정의합니다.
apiVersion: v1
kind: PersistentVolume
metadata:
name: example-local-pv
spec:
capacity:
storage: 5Gi
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Delete
storageClassName: local-storage
local:
path: /mnt/disks/ssd1
nodeAffinity:
required:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- my-node27.14.4. 로컬 영구 볼륨 클레임 생성
오브젝트 정의에 영구 볼륨 클레임을 정의합니다.
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: example-local-claim
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 5Gi
storageClassName: local-storage 27.14.5. 기능 상태
작동 방식:
- 노드 선호도로 디렉터리를 지정하여 PV 생성.
- 이전에 언급된 PV에 바인딩된 PVC를 사용하는 Pod는 항상 해당 노드에 예약됩니다.
- 로컬 디렉터리를 검색하고 PV를 생성, 정리 및 삭제하는 외부 정적 프로비저너 데몬 세트.
작동하지 않는 내용:
- 단일 Pod의 여러 로컬 PVC.
PVC 바인딩은 Pod 스케줄링 요구 사항을 고려하지 않으며 하위 최적화 또는 잘못된 결정을 내릴 수 있습니다.
해결방법:
- 로컬 볼륨이 필요한 해당 포드를 먼저 실행합니다.
- Pod에 우선 순위가 높습니다.
- 보류 중인 Pod에 대해 PVC를 바인딩 해제하는 임시 컨트롤러를 실행합니다.
외부 프로비저너를 시작한 후 마운트를 추가하면 외부 프로비저너가 올바른 마운트의 공간을 감지할 수 없습니다.
해결방법:
- 새 마운트 지점을 추가하기 전에 먼저 daemonset를 중지하고 새 마운트 지점을 추가한 다음 daemonset을 시작합니다.
-
동일한 PVC를 사용하는 여러 Pod가 다른
fsgroup을 지정하면 fsGroup충돌이발생합니다.
27.15. CSI(Container Storage Interface)를 사용한 영구 스토리지
27.15.1. 개요
CSI(Container Storage Interface)를 사용하면 OpenShift Container Platform에서 CSI 인터페이스를 영구 스토리지로 구현하는 스토리지 백엔드의 스토리지를 사용할 수 있습니다.
CSI 볼륨은 현재 기술 프리뷰에 있으며 프로덕션 워크로드에는 적합하지 않습니다. CSI 볼륨은 향후 OpenShift Container Platform 릴리스에서 변경될 수 있습니다. 기술 프리뷰 기능은 Red Hat 프로덕션 서비스 수준 계약(SLA)에서 지원하지 않으며, 기능상 완전하지 않을 수 있어 프로덕션에 사용하지 않는 것이 좋습니다. 이러한 기능을 사용하면 향후 제품 기능을 조기에 이용할 수 있어 개발 과정에서 고객이 기능을 테스트하고 피드백을 제공할 수 있습니다.
링크 참조:https://access.redhat.com/support/offerings/techpreview/[Red Hat
OpenShift Container Platform은 CSI 드라이버를 제공되지 않습니다. 커뮤니티 또는 스토리지 벤더가 제공하는 CSI 드라이버를 사용하는 것이 좋습니다.
OpenShift Container Platform 3.11은 CSI 사양 의 버전 0.2.0을 지원합니다.
27.15.2. 아키텍처
CSI 드라이버는 일반적으로 컨테이너 이미지로 제공됩니다. 이러한 컨테이너는 OpenShift Container Platform이 실행되는 위치를 인식하지 못합니다. OpenShift Container Platform에서 CSI 호환 스토리지 백엔드를 사용하려면 클러스터 관리자가 OpenShift Container Platform과 스토리지 드라이버 간의 브리지 역할을 하는 여러 구성 요소를 배포해야 합니다.
다음 다이어그램에서는 OpenShift Container Platform 클러스터의 Pod에서 실행되는 구성 요소에 대한 상위 수준 개요를 설명합니다.

다양한 스토리지 백엔드에 대해 여러 CSI 드라이버를 실행할 수 있습니다. 각 드라이버에는 드라이버 및 CSI 등록 기관과 함께 자체 외부 컨트롤러의 배포 및 DaemonSet이 필요합니다.
27.15.2.1. 외부 CSI 컨트롤러
외부 CSI 컨트롤러는 3개의 컨테이너가 포함된 1개 이상의 Pod를 배포하는 배포입니다.
-
OpenShift Container Platform의
attach및detach호출을 CSI 드라이버에 대한 해당ControllerPublish 및 ControllerUnpublish호출로 변환하는 외부 CSI 연결 컨테이너 -
OpenShift Container Platform의
provision및delete호출을 CSI 드라이버에 대한 해당CreateVolume 및호출로 변환하는 외부 CSI 프로비저너 컨테이너DeleteVolume - CSI 드라이버 컨테이너
CSI 연결 및 CSI 프로비저너 컨테이너는 UNIX 도메인 소켓을 사용하여 CSI 드라이버 컨테이너와 통신하므로 CSI 통신이 Pod를 종료하지 않도록 합니다. Pod 외부에서 CSI 드라이버에 액세스할 수 없습니다.
attach, 분리, provision 및 삭제 작업에는 일반적으로 스토리지 백엔드에 인증 정보를 사용하기 위해 CSI 드라이버가 필요합니다. 컴퓨팅 노드의 심각한 보안 위반 시 인증 정보가 사용자 프로세스에 유출되지 않도록 인프라 노드에서 CSI 컨트롤러 Pod를 실행합니다.
외부 연결은 타사 attach/detach 작업을 지원하지 않는 CSI 드라이버에서도 실행해야 합니다. 외부 연결은 CSI 드라이버에 ControllerPublish 또는 ControllerUnpublish 작업을 발행하지 않습니다. 그러나 필요한 OpenShift Container Platform 연결 API를 구현하려면 실행해야 합니다.
27.15.2.2. CSI 드라이버 데몬 세트
마지막으로 CSI 드라이버 DaemonSet은 OpenShift Container Platform이 CSI 드라이버에서 제공하는 스토리지를 노드에 마운트하고 사용자 워크로드(포드)에서 PV(영구 볼륨)로 사용할 수 있는 모든 노드에서 Pod를 실행합니다. CSI 드라이버가 설치된 Pod에는 다음 컨테이너가 포함되어 있습니다.
-
CSI 드라이버 등록 기관: CSI 드라이버를 노드에서 실행 중인
openshift-node서비스에 등록합니다. 노드에서 실행되는openshift-node프로세스는 노드에서 사용 가능한 UNIX 도메인 소켓을 사용하여 CSI 드라이버와 직접 연결합니다. - CSI 드라이버.
노드에 배포된 CSI 드라이버에는 스토리지 백엔드에 최대한 적은 수의 인증 정보가 있어야 합니다. OpenShift Container Platform은 NodePublish / NodeUnpublish 및 Node Stage/ NodeUnstage (구현된 경우)와 같은 CSI 호출의 노드 플러그인 세트만 사용합니다.
27.15.3. 배포 예
OpenShift Container Platform은 CSI 드라이버가 설치되지 않으므로 다음 예제에서는 OpenShift Container Platform에서 OpenStack Cinder용 커뮤니티 드라이버를 배포하는 방법을 보여줍니다.
CSI 구성 요소가 실행될 새 프로젝트와 구성 요소를 실행할 새 서비스 계정을 생성합니다. 명시적 노드 선택기는 마스터 노드에서도 CSI 드라이버와 함께 Daemonset을 실행하는 데 사용됩니다.
# oc adm new-project csi --node-selector="" Now using project "csi" on server "https://example.com:8443". # oc create serviceaccount cinder-csi serviceaccount "cinder-csi" created # oc adm policy add-scc-to-user privileged system:serviceaccount:csi:cinder-csi scc "privileged" added to: ["system:serviceaccount:csi:cinder-csi"]이 YAML 파일을 적용하여 CSI 드라이버와 함께 외부 CSI 연결 및 프로비저너 및 DaemonSet을 사용하여 배포를 생성합니다.
# This YAML file contains all API objects that are necessary to run Cinder CSI # driver. # # In production, this needs to be in separate files, e.g. service account and # role and role binding needs to be created once. # # It serves as an example of how to use external attacher and external provisioner # images that are shipped with OpenShift Container Platform with a community CSI driver. kind: ClusterRole apiVersion: rbac.authorization.k8s.io/v1 metadata: name: cinder-csi-role rules: - apiGroups: [""] resources: ["persistentvolumes"] verbs: ["create", "delete", "get", "list", "watch", "update", "patch"] - apiGroups: [""] resources: ["events"] verbs: ["create", "get", "list", "watch", "update", "patch"] - apiGroups: [""] resources: ["persistentvolumeclaims"] verbs: ["get", "list", "watch", "update", "patch"] - apiGroups: [""] resources: ["nodes"] verbs: ["get", "list", "watch", "update", "patch"] - apiGroups: ["storage.k8s.io"] resources: ["storageclasses"] verbs: ["get", "list", "watch"] - apiGroups: ["storage.k8s.io"] resources: ["volumeattachments"] verbs: ["get", "list", "watch", "update", "patch"] - apiGroups: [""] resources: ["configmaps"] verbs: ["get", "list", "watch", "create", "update", "patch"] --- kind: ClusterRoleBinding apiVersion: rbac.authorization.k8s.io/v1 metadata: name: cinder-csi-role subjects: - kind: ServiceAccount name: cinder-csi namespace: csi roleRef: kind: ClusterRole name: cinder-csi-role apiGroup: rbac.authorization.k8s.io --- apiVersion: v1 data: cloud.conf: W0dsb2JhbF0KYXV0aC11cmwgPSBodHRwczovL2V4YW1wbGUuY29tOjEzMDAwL3YyLjAvCnVzZXJuYW1lID0gYWxhZGRpbgpwYXNzd29yZCA9IG9wZW5zZXNhbWUKdGVuYW50LWlkID0gZTBmYTg1YjZhMDY0NDM5NTlkMmQzYjQ5NzE3NGJlZDYKcmVnaW9uID0gcmVnaW9uT25lCg==1 kind: Secret metadata: creationTimestamp: null name: cloudconfig --- kind: Deployment apiVersion: apps/v1 metadata: name: cinder-csi-controller spec: replicas: 2 selector: matchLabels: app: cinder-csi-controllers template: metadata: labels: app: cinder-csi-controllers spec: serviceAccount: cinder-csi containers: - name: csi-attacher image: registry.redhat.io/openshift3/csi-attacher:v3.11 args: - "--v=5" - "--csi-address=$(ADDRESS)" - "--leader-election" - "--leader-election-namespace=$(MY_NAMESPACE)" - "--leader-election-identity=$(MY_NAME)" env: - name: MY_NAME valueFrom: fieldRef: fieldPath: metadata.name - name: MY_NAMESPACE valueFrom: fieldRef: fieldPath: metadata.namespace - name: ADDRESS value: /csi/csi.sock volumeMounts: - name: socket-dir mountPath: /csi - name: csi-provisioner image: registry.redhat.io/openshift3/csi-provisioner:v3.11 args: - "--v=5" - "--provisioner=csi-cinderplugin" - "--csi-address=$(ADDRESS)" env: - name: ADDRESS value: /csi/csi.sock volumeMounts: - name: socket-dir mountPath: /csi - name: cinder-driver image: quay.io/jsafrane/cinder-csi-plugin command: [ "/bin/cinder-csi-plugin" ] args: - "--nodeid=$(NODEID)" - "--endpoint=unix://$(ADDRESS)" - "--cloud-config=/etc/cloudconfig/cloud.conf" env: - name: NODEID valueFrom: fieldRef: fieldPath: spec.nodeName - name: ADDRESS value: /csi/csi.sock volumeMounts: - name: socket-dir mountPath: /csi - name: cloudconfig mountPath: /etc/cloudconfig volumes: - name: socket-dir emptyDir: - name: cloudconfig secret: secretName: cloudconfig --- kind: DaemonSet apiVersion: apps/v1 metadata: name: cinder-csi-ds spec: selector: matchLabels: app: cinder-csi-driver template: metadata: labels: app: cinder-csi-driver spec:2 serviceAccount: cinder-csi containers: - name: csi-driver-registrar image: registry.redhat.io/openshift3/csi-driver-registrar:v3.11 securityContext: privileged: true args: - "--v=5" - "--csi-address=$(ADDRESS)" env: - name: ADDRESS value: /csi/csi.sock - name: KUBE_NODE_NAME valueFrom: fieldRef: fieldPath: spec.nodeName volumeMounts: - name: socket-dir mountPath: /csi - name: cinder-driver securityContext: privileged: true capabilities: add: ["SYS_ADMIN"] allowPrivilegeEscalation: true image: quay.io/jsafrane/cinder-csi-plugin command: [ "/bin/cinder-csi-plugin" ] args: - "--nodeid=$(NODEID)" - "--endpoint=unix://$(ADDRESS)" - "--cloud-config=/etc/cloudconfig/cloud.conf" env: - name: NODEID valueFrom: fieldRef: fieldPath: spec.nodeName - name: ADDRESS value: /csi/csi.sock volumeMounts: - name: socket-dir mountPath: /csi - name: cloudconfig mountPath: /etc/cloudconfig - name: mountpoint-dir mountPath: /var/lib/origin/openshift.local.volumes/pods/ mountPropagation: "Bidirectional" - name: cloud-metadata mountPath: /var/lib/cloud/data/ - name: dev mountPath: /dev volumes: - name: cloud-metadata hostPath: path: /var/lib/cloud/data/ - name: socket-dir hostPath: path: /var/lib/kubelet/plugins/csi-cinderplugin type: DirectoryOrCreate - name: mountpoint-dir hostPath: path: /var/lib/origin/openshift.local.volumes/pods/ type: Directory - name: cloudconfig secret: secretName: cloudconfig - name: dev hostPath: path: /dev- 1
- OpenStack 구성에 설명된 대로 OpenStack 배포를 위해
cloud.conf로 바꿉니다. 예를 들어oc create secret generic cloudconfig --from-file cloud.conf --dry-run -o yaml을 사용하여 보안을 생성할 수 있습니다. - 2
- 선택적으로 CSI 드라이버 Pod 템플릿에
nodeSelector를 추가하여 CSI 드라이버가 시작되는 노드를 구성합니다. 선택기와 일치하는 노드만 CSI 드라이버에서 제공하는 볼륨을 사용하는 Pod를 실행합니다.nodeSelector없이 드라이버는 클러스터의 모든 노드에서 실행됩니다.
27.15.4. 동적 프로비저닝
영구 스토리지의 동적 프로비저닝은 CSI 드라이버 및 기본 스토리지 백엔드의 기능에 따라 다릅니다. CSI 드라이버 공급자는 OpenShift Container Platform에서 StorageClass 및 구성에 사용할 수 있는 매개변수를 생성하는 방법을 설명해야 합니다.
OpenStack Cinder 예제에서 볼 수 있듯이 이 StorageClass를 배포하여 동적 프로비저닝을 활성화할 수 있습니다. 다음 예제에서는 설치된 CSI 드라이버에서 특수 스토리지 클래스가 필요하지 않은 모든 PVC를 프로비저닝하는 새 기본 스토리지 클래스를 생성합니다.
# oc create -f - << EOF
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: cinder
annotations:
storageclass.kubernetes.io/is-default-class: "true"
provisioner: csi-cinderplugin
parameters:
EOF27.15.5. 사용법
CSI 드라이버가 배포되고 동적 프로비저닝을 위한 StorageClass가 생성되면 OpenShift Container Platform에서 CSI를 사용할 준비가 됩니다. 다음 예제에서는 템플릿을 변경하지 않고 기본 MySQL 템플릿을 설치합니다.
# oc new-app mysql-persistent
--> Deploying template "openshift/mysql-persistent" to project default
...
# oc get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
mysql Bound kubernetes-dynamic-pv-3271ffcb4e1811e8 1Gi RWO cinder 3s27.16. OpenStack Manila를 사용하는 영구 스토리지
27.16.1. 개요
OpenStack Manila를 사용한 PV(영구 볼륨) 프로비저닝은 기술 프리뷰 기능 전용입니다. 기술 프리뷰 기능은 Red Hat 프로덕션 서비스 수준 계약(SLA)에서 지원하지 않으며, 기능상 완전하지 않을 수 있어 프로덕션에 사용하지 않는 것이 좋습니다. 이러한 기능을 사용하면 향후 제품 기능을 조기에 이용할 수 있어 개발 과정에서 고객이 기능을 테스트하고 피드백을 제공할 수 있습니다.
Red Hat 기술 프리뷰 기능 지원 범위에 대한 자세한 내용은 https://access.redhat.com/support/offerings/techpreview/를 참조하십시오.
OpenShift Container Platform은 OpenStack Manila 공유 파일 시스템 서비스를 사용하여 PV를 프로비저닝할 수 있습니다.
OpenStack Manila 서비스가 올바르게 설정되었으며 OpenShift Container Platform 클러스터에서 액세스할 수 있다고 가정합니다. NFS 공유 유형만 프로비저닝할 수 있습니다.
PV, PVC (영구 볼륨 클레임), 동적 프로비저닝 및 RBAC 권한 부여 에 대해 숙지하는 것이 좋습니다.
27.16.2. 설치 및 설정
기능은 외부 프로비저너에서 제공합니다. OpenShift Container Platform 클러스터에 설치하고 구성해야 합니다.
27.16.2.1. 외부 프로비저너 시작
외부 프로비저너 서비스는 컨테이너 이미지로 배포되며, 일반적으로 OpenShift Container Platform 클러스터에서 실행할 수 있습니다.
API 오브젝트를 관리하는 컨테이너를 허용하려면 필수 역할 기반 액세스 제어(RBAC) 규칙을 클러스터 관리자로 구성합니다.
ServiceAccount를 생성합니다.apiVersion: v1 kind: ServiceAccount metadata: name: manila-provisioner-runnerClusterRole을 생성합니다.kind: ClusterRole apiVersion: rbac.authorization.k8s.io/v1 metadata: name: manila-provisioner-role rules: - apiGroups: [""] resources: ["persistentvolumes"] verbs: ["get", "list", "watch", "create", "delete"] - apiGroups: [""] resources: ["persistentvolumeclaims"] verbs: ["get", "list", "watch", "update"] - apiGroups: ["storage.k8s.io"] resources: ["storageclasses"] verbs: ["get", "list", "watch"] - apiGroups: [""] resources: ["events"] verbs: ["list", "watch", "create", "update", "patch"]ClusterRoleBinding을 통해 규칙을 바인딩합니다.apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: manila-provisioner roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: manila-provisioner-role subjects: - kind: ServiceAccount name: manila-provisioner-runner namespace: default새
스토리지클래스를 만듭니다.apiVersion: storage.k8s.io/v1 kind: StorageClass metadata: name: "manila-share" provisioner: "externalstorage.k8s.io/manila" parameters: type: "default"1 zones: "nova"2 - 1
- 볼륨에 프로비저너가 만들 Manila 공유 유형입니다.
- 2
- 볼륨이 생성될 수 있는 Manila 가용 영역 세트입니다.
환경 변수를 사용하여 Manila servicesvic에 연결, 인증 및 권한을 부여하도록 프로비저너를 구성합니다. 다음 목록에서 설치 환경 변수의 적절한 조합을 선택합니다.
OS_USERNAME
OS_PASSWORD
OS_AUTH_URL
OS_DOMAIN_NAME
OS_TENANT_NAMEOS_USERID
OS_PASSWORD
OS_AUTH_URL
OS_TENANT_IDOS_USERNAME
OS_PASSWORD
OS_AUTH_URL
OS_DOMAIN_ID
OS_TENANT_NAMEOS_USERNAME
OS_PASSWORD
OS_AUTH_URL
OS_DOMAIN_ID
OS_TENANT_ID
변수를 프로비저너에 전달하려면 Secret (시크릿)을 사용합니다. 다음 예는 첫 번째 변수 조합에 대해 구성된 보안을 보여줍니다.
apiVersion: v1
kind: Secret
metadata:
name: manila-provisioner-env
type: Opaque
data:
os_username: <base64 encoded Manila username>
os_password: <base64 encoded password>
os_auth_url: <base64 encoded OpenStack Keystone URL>
os_domain_name: <base64 encoded Manila service Domain>
os_tenant_name: <base64 encoded Manila service Tenant/Project name>
최신 OpenStack 버전에서는 "테넌트" 대신 "프로젝트"를 사용합니다. 그러나 프로비저너에서 사용하는 환경 변수는 이름에 TENANT를 사용해야 합니다.
마지막 단계는 배포를 사용하여 프로비저너 자체를 시작하는 것입니다.
kind: Deployment
apiVersion: extensions/v1beta1
metadata:
name: manila-provisioner
spec:
replicas: 1
strategy:
type: Recreate
template:
metadata:
labels:
app: manila-provisioner
spec:
serviceAccountName: manila-provisioner-runner
containers:
- image: "registry.redhat.io/openshift3/manila-provisioner:latest"
imagePullPolicy: "IfNotPresent"
name: manila-provisioner
env:
- name: "OS_USERNAME"
valueFrom:
secretKeyRef:
name: manila-provisioner-env
key: os_username
- name: "OS_PASSWORD"
valueFrom:
secretKeyRef:
name: manila-provisioner-env
key: os_password
- name: "OS_AUTH_URL"
valueFrom:
secretKeyRef:
name: manila-provisioner-env
key: os_auth_url
- name: "OS_DOMAIN_NAME"
valueFrom:
secretKeyRef:
name: manila-provisioner-env
key: os_domain_name
- name: "OS_TENANT_NAME"
valueFrom:
secretKeyRef:
name: manila-provisioner-env
key: os_tenant_name27.16.3. 사용법
프로비저너가 실행되면 PVC 및 해당 StorageClass를 사용하여 PV를 프로비저닝할 수 있습니다.
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: manila-nfs-pvc
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 2G
storageClassName: manila-share
그러면 PersistentVolumeClaim 이 새로 배포된 Manila 공유에서 지원하는 a PersistentVolume 에 바인딩됩니다. PersistentVolumeClaim 과 이후에 PersistentVolume 이 삭제되면 프로비저너는 Manila 공유를 삭제하고 내보내기 취소합니다.
27.17. 동적 프로비저닝 및 스토리지 클래스 생성
27.17.1. 개요
StorageClass 리소스 오브젝트는 요청할 수 있는 스토리지를 설명하고 분류할 뿐 아니라 필요에 따라 동적으로 프로비저닝된 스토리지에 대한 매개변수를 전달하는 수단을 제공합니다. StorageClass 객체는 다른 수준의 스토리지 및 스토리지에 대한 액세스를 제어하기 위한 관리 메커니즘으로 사용될 수 있습니다. 클러스터 관리자(cluster-admin) 또는스토리지 관리자(스토리지 관리자)는 사용자가 기본 스토리지 볼륨 소스에 대한 지식이 없어도 요청할 수 있는 StorageClass 오브젝트를 정의하고 생성합니다.
OpenShift Container Platform 영구 볼륨 프레임워크를 사용하면 이 기능을 사용할 수 있으며 관리자는 영구 스토리지로 클러스터를 프로비저닝할 수 있습니다. 또한 이 프레임 워크를 통해 사용자는 기본 인프라에 대한 지식이 없어도 해당 리소스를 요청할 수 있습니다.
OpenShift Container Platform에서 많은 스토리지 유형을 영구 볼륨으로 사용할 수 있습니다. 관리자가 이를 모두 정적으로 프로비저닝할 수 있지만 일부 스토리지 유형은 기본 제공자 및 플러그인 API를 사용하여 동적으로 만들 수 있습니다.
동적 프로비저닝을 활성화하려면 openshift_master_dynamic_provisioning_enabled 변수를 Ansible 인벤토리 파일의 [OSEv3:vars] 섹션에 추가하고 해당 값을 True 로 설정합니다.
[OSEv3:vars]
openshift_master_dynamic_provisioning_enabled=True27.17.2. 동적으로 프로비저닝된 플러그인
OpenShift Container Platform은 다음과 같은 프로비저너 플러그인을 제공합니다. 이 플러그인에는 클러스터의 구성된 공급자 API를 사용하여 새 스토리지 리소스를 생성하는 동적 프로비저닝에 대한 일반 구현이 있습니다.
| 스토리지 유형 | 프로비저너 플러그인 이름 | 필수 설정 | 참고 |
|---|---|---|---|
| OpenStack Cinder |
| ||
| AWS Elastic Block Store (EBS) |
|
다른 영역에서 여러 클러스터를 사용할 때 동적 프로비저닝의 경우 각 노드에 | |
| GCE Persistent Disk (gcePD) |
| 다중 영역 구성에서는 현재 클러스터에서 노드가 없는 영역에서 PV가 생성되지 않도록 GCE 프로젝트당 하나의 Openshift 클러스터를 실행하는 것이 좋습니다. | |
| GlusterFS |
| ||
| Ceph RBD |
| ||
| NetApp에서 Trident |
| NetApp ONTAP, SolidFire 및 E-Series 스토리지용 스토리지 오케스트레이터. | |
|
| |||
| Azure Disk |
|
선택한 프로비저너 플러그인에는 관련 문서에 따라 클라우드, 호스트 또는 타사 공급자를 구성해야 합니다.
27.17.3. StorageClass 정의
StorageClass 오브젝트는 현재 전역 범위 오브젝트이며 cluster -admin 또는 사용자가 생성해야 합니다.
storage-admin
GCE 및 AWS의 경우 OpenShift Container Platform 설치 중에 기본 StorageClass가 생성됩니다. 기본 StorageClass를 변경하거나 삭제할 수 있습니다.
현재 지원되는 플러그인은 6개입니다. 다음 섹션에서는 StorageClass 의 기본 오브젝트 정의 및 지원되는 각 플러그인 유형에 대한 특정 예를 설명합니다.
27.17.3.1. 기본 StorageClass 개체 정의
StorageClass Basic 개체 정의
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: foo
annotations:
...
provisioner: kubernetes.io/plug-in-type
parameters:
param1: value
...
paramN: value27.17.3.2. StorageClass 주석
StorageClass 를 클러스터 전체 기본값으로 설정하려면 다음을 수행합니다.
storageclass.kubernetes.io/is-default-class: "true"이렇게 하면 특정 볼륨을 지정하지 않는 모든 PVC(영구 볼륨 클레임)가 기본 StorageClass를 통해 자동으로 프로비저닝됩니다.
베타 주석 storageclass.beta.kubernetes.io/is-default-class 가 여전히 작동 중입니다. 그러나 향후 릴리스에서는 제거될 예정입니다.
StorageClass 설명을 설정하려면 다음을 수행합니다.
kubernetes.io/description: My StorageClass Description27.17.3.3. OpenStack Cinder 오브젝트 정의
cinder-storageclass.yaml
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: gold
provisioner: kubernetes.io/cinder
parameters:
type: fast
availability: nova
fsType: ext4 27.17.3.4. AWS ElasticBlockStore (EBS) 객체 정의
aws-ebs-storageclass.yaml
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: slow
provisioner: kubernetes.io/aws-ebs
parameters:
type: io1
zone: us-east-1d
iopsPerGB: "10"
encrypted: "true"
kmsKeyId: keyvalue
fsType: ext4 - 1
- 2
- AWS 영역. 영역을 지정하지 않으면 일반적으로 OpenShift Container Platform 클러스터에 노드가 있는 모든 활성 영역에서 볼륨이 라운드 로빈됩니다. zone 및 zones 매개 변수를 동시에 사용하면 안 됩니다.
- 3
- for io1 볼륨만. GiB마다 초당 I/O 작업 수입니다. AWS 볼륨 플러그인은 이 값과 요청된 볼륨 크기를 곱하여 볼륨의 IOPS를 계산합니다. 값의 상한은 AWS가 지원하는 최대치인 20,000 IOPS입니다. 자세한 내용은 AWS 설명서 를 참조하십시오.
- 4
- EBS 볼륨을 암호화할지 여부를 나타냅니다. 유효한 값은
true또는false입니다. - 5
- 선택 사항: 볼륨을 암호화할 때 사용할 키의 전체 ARN입니다. 값을 지정하지 않는 경우에도
encypted가true로 설정되어 있는 경우 AWS가 키를 생성합니다. 유효한 ARN 값은 AWS 설명서 를 참조하십시오. - 6
- 동적으로 프로비저닝된 볼륨에서 생성된 파일 시스템입니다. 이 값은 동적으로 프로비저닝된 영구 볼륨의
fsType필드에 복사되며 볼륨이 처음 마운트될 때 파일 시스템이 작성됩니다. 기본값은ext4입니다.
27.17.3.5. GCE PersistentDisk (gcePD) 오브젝트 정의
gce-pd-storageclass.yaml
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: slow
provisioner: kubernetes.io/gce-pd
parameters:
type: pd-standard
zone: us-central1-a
zones: us-central1-a, us-central1-b, us-east1-b
fsType: ext4 - 1
pd-standard또는pd-ssd중 하나를 선택합니다. 기본값은pd-ssd입니다.- 2
- GCE 영역. 영역을 지정하지 않으면 일반적으로 OpenShift Container Platform 클러스터에 노드가 있는 모든 활성 영역에서 볼륨이 라운드 로빈됩니다. zone 및 zones 매개 변수를 동시에 사용하면 안 됩니다.
- 3
- 쉼표로 구분된 GCE 영역 목록입니다. 영역을 지정하지 않으면 일반적으로 OpenShift Container Platform 클러스터에 노드가 있는 모든 활성 영역에서 볼륨이 라운드 로빈됩니다. zone 및 zones 매개 변수를 동시에 사용하면 안 됩니다.
- 4
- 동적으로 프로비저닝된 볼륨에서 생성된 파일 시스템입니다. 이 값은 동적으로 프로비저닝된 영구 볼륨의
fsType필드에 복사되며 볼륨이 처음 마운트될 때 파일 시스템이 작성됩니다. 기본값은ext4입니다.
27.17.3.6. GlusterFS 오브젝트 정의
glusterfs-storageclass.yaml
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: slow
provisioner: kubernetes.io/glusterfs
parameters:
resturl: http://127.0.0.1:8081
restuser: admin
secretName: heketi-secret
secretNamespace: default
gidMin: "40000"
gidMax: "50000"
volumeoptions: group metadata-cache, nl-cache on
volumetype: replicate:3
volumenameprefix: custom - 1
- 나열되어야 하는 필수 매개 변수와 몇 가지 선택적 매개 변수가 나열됩니다. 추가 매개변수는 스토리지 클래스 등록을 참조하십시오.
- 2
- 필요할 때 GlusterFS 볼륨을 프로비저닝하는 heketi (Gluster 볼륨 관리 REST 서비스) URL. 일반 형식은
{http/https}://{IPaddress}:{Port}여야 합니다. GlusterFS 동적 프로비저너에 대한 필수 매개 변수입니다. OpenShift Container Platform에서 heketi 서비스가 라우팅 가능한 서비스로 노출되면 FQDN(정규화된 도메인 이름) 및 heketi 서비스 URL을 확인할 수 있습니다. - 3
- 볼륨을 만들 수 있는 액세스 권한이 있는 heketi 사용자. 일반적으로 "admin".
- 4
- heketi와 통신할 때 사용할 사용자 암호가 포함된 시크릿 식별. 선택 사항입니다.
secretNamespace 및 secretName이 모두 생략될 때 비어 있는 암호가 사용됩니다. 제공된 보안 유형은"kubernetes.io/glusterfs"유형이어야 합니다. - 5
- 언급된
secretName의 네임스페이스입니다. 선택 사항입니다.secretNamespace 및 secretName이 모두 생략될 때 비어 있는 암호가 사용됩니다. 제공된 보안 유형은"kubernetes.io/glusterfs"유형이어야 합니다. - 6
- 선택 사항: 이 StorageClass의 볼륨에 대한 최소 GID 범위 값입니다.
- 7
- 선택 사항: 이 StorageClass의 볼륨에 대한 GID 범위의 최대 값입니다.
- 8
- 선택 사항: 새로 생성된 볼륨에 대한 옵션. 성능 튜닝을 허용합니다. GlusterFS 볼륨 옵션에 대한 자세한 내용은 볼륨 옵션 튜닝 을 참조하십시오.
- 9
- 선택 사항: 사용할 볼륨 유형입니다.
- 10
- 선택 사항:
<volumenameprefix>_<namespace>_<claimname>_UUID형식을 사용하여 사용자 정의 볼륨 이름 지원을 활성화합니다. 이 storageClass를 사용하여 프로젝트project1에myclaim이라는 새 PVC를 생성하는 경우 볼륨 이름은custom-project1-myclaim-UUID가 됩니다.
gidMin 및 gidMax 값을 지정하지 않으면 기본값은 각각 2000 및 2147483647입니다. 동적으로 프로비저닝된 각 볼륨에는 이 범위(gidMin-gidMax)에 GID가 부여됩니다. 이 GID는 각 볼륨이 삭제될 때 풀에서 릴리스됩니다. GID 풀은 StorageClass당입니다. 두 개 이상의 스토리지 클래스에 겹치는 GID 범위가 있는 경우 프로비저너에서 디스패치하는 중복 GID가 있을 수 있습니다.
heketi 인증을 사용하는 경우 관리자 키가 포함된 시크릿도 있어야 합니다.
heketi-secret.yaml
apiVersion: v1
kind: Secret
metadata:
name: heketi-secret
namespace: default
data:
key: bXlwYXNzd29yZA==
type: kubernetes.io/glusterfs- 1
- base64로 인코딩된 암호(예:
echo -n "mypassword" | base64
PV가 동적으로 프로비저닝되면 GlusterFS 플러그인에서 끝점과 gluster-dynamic-<claimname> 이라는 헤드리스 서비스를 자동으로 생성합니다. PVC가 삭제되면 이러한 동적 리소스가 자동으로 삭제됩니다.
27.17.3.7. Ceph RBD 개체 정의
ceph-storageclass.yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: fast
provisioner: kubernetes.io/rbd
parameters:
monitors: 10.16.153.105:6789
adminId: admin
adminSecretName: ceph-secret
adminSecretNamespace: kube-system
pool: kube
userId: kube
userSecretName: ceph-secret-user
fsType: ext4 - 1
- 쉼표로 구분된 Ceph 모니터. 필수 항목입니다.
- 2
- 풀에 이미지를 만들 수 있는 Ceph 클라이언트 ID입니다. 기본값은 "admin"입니다.
- 3
adminId의 시크릿 이름. 필수 항목입니다. 제공된 보안에는 유형 "kubernetes.io/rbd"가 있어야 합니다.- 4
adminSecret의 네임스페이스입니다. 기본값은 "default"입니다.- 5
- Ceph RBD 풀. 기본값은 "rbd"입니다.
- 6
- Ceph RBD 이미지를 매핑하는 데 사용되는 Ceph 클라이언트 ID입니다. 기본값은
adminId와 동일합니다. - 7
- Ceph RBD 이미지를 매핑하는
userId의 Ceph Secret 이름입니다. PVC와 동일한 네임스페이스에 있어야 합니다. 필수 항목입니다. - 8
- 동적으로 프로비저닝된 볼륨에서 생성된 파일 시스템입니다. 이 값은 동적으로 프로비저닝된 영구 볼륨의
fsType필드에 복사되며 볼륨이 처음 마운트될 때 파일 시스템이 작성됩니다. 기본값은ext4입니다.
27.17.3.8. Trident 개체 정의
Trident.yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: gold
provisioner: netapp.io/trident
parameters:
media: "ssd"
provisioningType: "thin"
snapshots: "true"Trident은 등록된 스토리지 풀마다 선택 기준으로 매개 변수를 사용합니다. Trident 자체는 별도로 구성됩니다.
- 1
- OpenShift Container Platform을 사용한 평가판 설치에 대한 자세한 내용은 Trident 설명서 를 참조하십시오.
- 2
- 지원되는 매개변수에 대한 자세한 내용은 Trident 설명서의 스토리지 속성 섹션을 참조하십시오.
27.17.3.9. VMware vSphere 오브젝트 정의
vsphere-storageclass.yaml
kind: StorageClass
apiVersion: storage.k8s.io/v1beta1
metadata:
name: slow
provisioner: kubernetes.io/vsphere-volume
parameters:
diskformat: thin - 1
- OpenShift Container Platform과 함께 VMWare vSphere를 사용하는 방법에 대한 자세한 내용은 VMWare vSphere 설명서 를 참조하십시오.
- 2
Diskformat:thin,zeroedthick및eagerzeroedthick. 자세한 내용은 vSphere 설명서를 참조하십시오. 기본값:thin
27.17.3.10. Azure File 객체 정의
Azure 파일 동적 프로비저닝을 구성하려면 다음을 수행합니다.
사용자 프로젝트에서 역할을 생성합니다.
$ cat azf-role.yaml apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: system:controller:persistent-volume-binder namespace: <user's project name> rules: - apiGroups: [""] resources: ["secrets"] verbs: ["create", "get", "delete"]kube-system프로젝트에서persistent-volume-binder서비스 계정에 대한 역할 바인딩을 생성합니다.$ cat azf-rolebind.yaml apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: system:controller:persistent-volume-binder namespace: <user's project> roleRef: apiGroup: rbac.authorization.k8s.io kind: Role name: system:controller:persistent-volume-binder subjects: - kind: ServiceAccount name: persistent-volume-binder namespace: kube-system서비스 계정을 사용자 프로젝트에
admin으로 추가합니다.$ oc policy add-role-to-user admin system:serviceaccount:kube-system:persistent-volume-binder -n <user's project>Azure 파일의 스토리지 클래스를 생성합니다.
$ cat azfsc.yaml | oc create -f - kind: StorageClass apiVersion: storage.k8s.io/v1 metadata: name: azfsc provisioner: kubernetes.io/azure-file mountOptions: - dir_mode=0777 - file_mode=0777
이제 이 스토리지 클래스를 사용하는 PVC를 생성할 수 있습니다.
27.17.3.11. Azure Disk 오브젝트 정의
azure-advanced-disk-storageclass.yaml
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: slow
provisioner: kubernetes.io/azure-disk
parameters:
storageAccount: azure_storage_account_name
storageaccounttype: Standard_LRS
kind: Dedicated - 1
- Azure 스토리지 계정을 생성합니다. 클러스터와 동일한 리소스 그룹에 존재해야합니다. 스토리지 계정을 지정하면
location이 무시됩니다. 스토리지 계정을 지정하지 않으면 클러스터와 동일한 리소스 그룹에 새 스토리지 계정이 생성됩니다.storageAccount를 지정하는 경우kind값은Dedicated이어야합니다. - 2
- Azure 스토리지 계정 SKU층입니다. 기본값은 비어 있습니다. 참고: 프리미엄 VM은 Standard_LRS 및 Premium_LRS 디스크를 모두 연결할 수 있으며 표준 VM은 Standard_LRS 디스크만 연결할 수 있으며, 관리형 VM은 관리 디스크만 연결할 수 있으며 관리되지 않는 VM은 관리되지 않는 디스크만 연결할 수 있습니다.
- 3
- 가능한 값은
Shared(기본값),Dedicated및Managed입니다.-
kind가Shared로 설정된 경우 Azure는 클러스터와 동일한 리소스 그룹에 있는 일부 공유 스토리지 계정에서 관리되지 않는 디스크를 만듭니다. -
kind가Managed로 설정된 경우 Azure는 새 관리 디스크를 만듭니다. kind가Dedicated로 설정되고storageAccount가 지정된 경우 Azure는 클러스터와 동일한 리소스 그룹에서 새로운 관리되지 않는 디스크에 대해 지정된 스토리지 계정을 사용합니다. 이 기능이 작동하려면 다음 사항이 전제가 되어야 합니다.- 지정된 스토리지 계정이 같은 지역에 있어야합니다.
- Azure Cloud Provider는 스토리지 계정에 대한 쓰기 권한이 있어야합니다.
-
kind가Dedicated로 설정되어 있고storageAccount가 지정되지 않은 경우 Azure는 클러스터와 동일한 리소스 그룹에 새로운 관리되지 않는 디스크에 대한 새로운 전용 스토리지 계정을 만듭니다.
-
Azure StorageClass는 OpenShift Container Platform 버전 3.7에서 수정되었습니다. 이전 버전에서 업그레이드한 경우 다음 중 하나를 수행합니다.
-
업그레이드 전에 Azure StorageClass를 계속 사용하는
전용 속성 kind:를 지정합니다. 또는, -
azure.conf 파일에 location 매개변수(예: "location": "southcentralus")를 추가하여 기본 속성kind: shared를 사용합니다. 이렇게 하면 나중에 사용할 새 스토리지 계정이 생성됩니다.
27.17.4. 기본 StorageClass 변경
GCE 및 AWS를 사용하는 경우 다음 프로세스를 사용하여 기본 StorageClass를 변경합니다.
StorageClass 목록을 표시합니다.
$ oc get storageclass NAME TYPE gp2 (default) kubernetes.io/aws-ebs1 standard kubernetes.io/gce-pd- 1
(default)은 기본 StorageClass를 나타냅니다.
기본 StorageClass에 대해 주석
storageclass.kubernetes.io/is-default-class의 값을false로 변경합니다.$ oc patch storageclass gp2 -p '{"metadata": {"annotations": \ {"storageclass.kubernetes.io/is-default-class": "false"}}}'주석을
storageclass.kubernetes.io/is-default-class=true로 추가하거나 수정하여 다른 StorageClass를 기본값으로 설정합니다.$ oc patch storageclass standard -p '{"metadata": {"annotations": \ {"storageclass.kubernetes.io/is-default-class": "true"}}}'
두 개 이상의 StorageClass가 기본값으로 표시되면 storageClassName 이 명시적으로 지정된 경우에만 PVC를 생성할 수 있습니다. 따라서 하나의 StorageClass만 기본값으로 설정해야 합니다.
변경 사항을 확인합니다.
$ oc get storageclass NAME TYPE gp2 kubernetes.io/aws-ebs standard (default) kubernetes.io/gce-pd
27.17.5. 추가 정보 및 예
27.18. 볼륨 보안
27.18.1. 개요
이 주제에서는 볼륨 보안과 관련된 포드 보안에 대한 일반적인 가이드를 제공합니다. Pod 수준 보안에 대한 자세한 내용은 보안 컨텍스트 제약 조건(SCC) 및 보안 컨텍스트 제약 조건의 주제를 참조하십시오. 일반적으로 OpenShift Container Platform PV(영구 볼륨) 프레임워크에 대한 자세한 내용은 영구 스토리지 개념 주제를 참조하십시오.
영구 스토리지에 액세스하려면 클러스터 및/또는 스토리지 관리자와 최종 개발자 간의 조정이 필요합니다. 클러스터 관리자가 PV를 생성하여 기본 물리 스토리지를 추상화합니다. 개발자는 Pod를 생성하고 용량과 같은 기준에 따라 PV에 바인딩하는 PVC(선택 사항)를 생성합니다.
동일한 프로젝트 내의 여러 PVC(영구 볼륨 클레임)는 동일한 PV에 바인딩할 수 있습니다. 그러나 PVC가 PV에 바인딩되면 해당 PV는 첫 번째 클레임 프로젝트 외부의 클레임에서 바인딩할 수 없습니다. 여러 프로젝트에서 기본 스토리지에 액세스해야 하는 경우 각 프로젝트에는 동일한 물리 스토리지를 가리킬 수 있는 자체 PV가 필요합니다. 이러한 의미에서는 바인딩된 PV가 프로젝트에 연결됩니다. 자세한 PV 및 PVC 예제는 영구 볼륨을 사용하여 WordPress 및 MySQL 배포 예를 참조하십시오.
클러스터 관리자의 경우 PV에 대한 Pod 액세스 권한을 부여하려면 다음을 수행해야 합니다.
- 실제 스토리지에 할당된 그룹 ID 및/또는 사용자 ID를 알 수 있습니다.
- SELinux 고려 사항 이해
- 이러한 ID가 포드의 요구 사항과 일치하는 SCC 및/또는 프로젝트에 대해 정의된 법률 ID 범위 내에서 허용되는지 확인합니다.
그룹 ID, 사용자 ID 및 SELinux 값은 포드 정의의 SecurityContext 섹션에 정의됩니다. 그룹 ID는 Pod에 전역적으로 적용되며 포드에 정의된 모든 컨테이너에 적용됩니다. 사용자 ID는 글로벌이거나 각 컨테이너에 따라 다를 수도 있습니다. 4개의 섹션은 볼륨에 대한 액세스를 제어합니다.
27.18.2. SCC, 기본값, 허용된 범위
SCC는 포드에 기본 사용자 ID, fsGroup ID, 보조 그룹 ID 및 SELinux 레이블이 부여되는지 여부에 영향을 미칩니다. 또한 포드 정의에 제공된 ID 또는 이미지에서 제공된 ID가 허용되는 ID 범위에 대해 검증되는지 여부에 영향을 미칩니다. 검증이 필요하고 실패하면 Pod도 실패합니다.
SCC는 runAsUser,supplementalGroups 및 fsGroup 과 같은 전략을 정의합니다. 이러한 전략은 Pod가 권한 부여되었는지 확인하는 데 도움이 됩니다. RunAsAny 로 설정된 전략 값은 기본적으로 포드가 해당 전략과 관련하여 원하는 작업을 수행할 수 있음을 나타냅니다. 해당 전략에 대한 권한을 건너뛰고 해당 전략을 기반으로 OpenShift Container Platform 기본값이 생성되지 않습니다. 따라서 결과 컨테이너의 ID 및 SELinux 레이블은 OpenShift Container Platform 정책 대신 컨테이너 기본값을 기반으로 합니다.
RunAsAny 를 간략하게 요약하려면 다음을 수행합니다.
- 포드 정의(또는 이미지)에 정의된 모든 ID가 허용됩니다.
- 포드 정의(및 이미지)에 ID가 없으면 컨테이너에서 Docker에 대한 루트 (0)인 ID를 할당합니다.
- SELinux 레이블이 정의되어 있지 않으므로 Docker에서 고유한 레이블을 할당합니다.
이러한 이유로 일반 개발자가 SCC에 액세스할 수 없도록 ID 관련 전략에 대한 RunAsAny 가 있는 SCC를 보호해야 합니다. 반면 MustRunAs 또는 MustRunAs Range 로 설정된 SCC 전략은 ID 검증(ID 관련 전략의 경우)을 트리거하고 해당 값을 Pod 정의 또는 이미지에 직접 제공하지 않은 경우 OpenShift Container Platform에서 기본값을 컨테이너에 제공합니다.
RunAsAny FSGroup 전략을 사용하여 SCC에 액세스할 수 있도록 허용하면 사용자가 블록 장치에 액세스할 수 없습니다. 포드는 블록 장치를 인계받으려면 fsGroup 을 지정해야 합니다. 일반적으로 SCC FSGroup 전략이 MustRunAs 로 설정된 경우 이 작업이 수행됩니다. 사용자 Pod에 RunAsAny FSGroup 전략이 있는 SCC가 할당되면 사용자가 자체를 지정해야 한다는 것을 확인할 때까지 권한 거부 오류가 발생할 수 있습니다.
fsGroup
SCC는 허용되는 ID(사용자 또는 그룹)의 범위를 정의할 수 있습니다. 범위 검사가 필요한 경우(예: MustRunAs사용) 허용 범위는 SCC에 정의되지 않은 경우 프로젝트에서 ID 범위를 결정합니다. 따라서 프로젝트에서 허용되는 ID 범위를 지원합니다. 그러나 SCC와 달리 프로젝트는 runAsUser 와 같은 전략을 정의하지 않습니다.
허용되는 범위는 컨테이너 ID에 대한 경계를 정의하기 때 뿐만 아니라 범위 내의 최소 값이 문제의 ID 기본값이 되기 때문에 유용합니다. 예를 들어 SCC ID 전략 값이 MustRunAs 이면 ID 범위의 최소 값이 100 이고 포드 정의에는 ID가 없으며 이 ID의 기본값으로 100이 제공됩니다.
Pod 승인의 일부로 Pod에서 사용할 수 있는 SCC를 검사하여 Pod의 요청과 가장 잘 일치하도록 우선순위 순서에 따라 가장 제한적입니다. SCC의 전략 유형을 RunAsAny로 설정하는 것은 제한적이지 않지만 MustRunAs 유형은 더 제한적입니다. 이러한 모든 전략이 평가됩니다. Pod에 할당된 SCC를 보려면 oc get pod 명령을 사용합니다.
# oc get pod <pod_name> -o yaml
...
metadata:
annotations:
openshift.io/scc: nfs-scc
name: nfs-pod1
namespace: default
...- 1
- 포드에서 사용하는 SCC의 이름입니다(이 경우 사용자 지정 SCC).
- 2
- Pod의 이름입니다.
- 3
- 프로젝트 이름입니다. OpenShift Container Platform의 "네임스페이스"는 "프로젝트"와 교환할 수 있습니다. 자세한 내용은 프로젝트 및 사용자를 참조하십시오.
포드와 일치하는 SCC를 즉시 알 수 없으므로 위의 명령은 라이브 컨테이너에서 UID, 추가 그룹 및 SELinux 레이블 변경을 이해하는 데 매우 유용할 수 있습니다.
전략이 RunAsAny 로 설정된 모든 SCC를 사용하면 해당 전략의 특정 값을 포드 정의(및/또는 이미지)에 정의할 수 있습니다. 이 값이 사용자 ID(runAsUser)에 적용되는 경우 컨테이너가 root로 실행되지 않도록 SCC에 대한 액세스를 제한해야 합니다.
포드는 종종 restricted SCC와 일치하기 때문에 이 관련 보안을 알고 있어야 합니다. restricted SCC에는 다음과 같은 특징이 있습니다.
-
runAsUser전략이 MustRunAsRange 로 설정되어 있기 때문에 사용자 ID가 제한됩니다. 이렇게 하면 사용자 ID가 검증됩니다. -
허용되는 사용자 ID 범위가 SCC에 정의되어 있지 않기 때문에 (자세한 내용은 oc get -o yaml --export scc restricted' 참조) 프로젝트의
openshift.io/sa.scc.uid-range범위는 범위 검사 및 필요한 경우 기본 ID에 사용됩니다. -
Pod 정의에 사용자 ID가 지정되지 않고 일치하는 SCC의
runAsUser가 MustRunAsRange 로 설정된 경우 기본 사용자 ID가 생성됩니다. -
프로젝트의 기본 MCS 레이블을 사용하는 SELinux 레이블(SELinux
Context가 MustRunAs로 설정됨)이 필요합니다. -
fsGroupID는 MustRunAs 로 설정되어 있는FSGroup전략으로 인해 단일 값으로 제한됩니다. 사용할 값이 지정된 첫 번째 범위의 최소 값임을 나타냅니다. -
허용 가능한
fsGroupID 범위가 SCC에 정의되지 않으므로 프로젝트의 최소openshift.io/sa.scc.supplemental-groups범위(또는 사용자 ID에 사용되는 것과 동일한 범위)는 검증 및 필요한 경우 기본 ID에 사용됩니다. -
Pod에
fsGroupID가 지정되지 않고 일치하는 SCC의FSID가 생성됩니다.Group이 MustRunAs 로 설정된 경우 기본 fsGroup -
범위를 확인할 필요가 없으므로 임의의 보조 그룹 ID가 허용됩니다. 이는
supplementalGroups전략이 RunAsAny 로 설정된 결과입니다. - 위의 두 그룹 전략의 RunAsAny 로 인해 기본 보충 그룹은 실행 중인 포드에 대해 생성되지 않습니다. 따라서 포드 정의에 또는 이미지에서 그룹이 정의되지 않은 경우 컨테이너에는 보충 그룹이 사전 정의되어 있지 않습니다.
다음은 SCC와 프로젝트의 상호 작용을 요약하는 기본 프로젝트 및 사용자 지정 SCC(my-custom-scc)를 보여줍니다.
$ oc get project default -o yaml
...
metadata:
annotations:
openshift.io/sa.scc.mcs: s0:c1,c0
openshift.io/sa.scc.supplemental-groups: 1000000000/10000
openshift.io/sa.scc.uid-range: 1000000000/10000
$ oc get scc my-custom-scc -o yaml
...
fsGroup:
type: MustRunAs
ranges:
- min: 5000
max: 6000
runAsUser:
type: MustRunAsRange
uidRangeMin: 1000100000
uidRangeMax: 1000100999
seLinuxContext:
type: MustRunAs
SELinuxOptions:
user: <selinux-user-name>
role: ...
type: ...
level: ...
supplementalGroups:
type: MustRunAs
ranges:
- min: 5000
max: 6000- 1
- 기본값은 프로젝트 이름입니다.
- 2
- 기본값은 해당 SCC 전략이 RunAsAny 가 아닌 경우에만 생성됩니다.
- 3
- 포드 정의 또는 SCC에 정의되지 않은 경우 SELinux 기본값입니다.
- 4
- 허용되는 그룹 ID 범위. ID 검증은 SCC 전략이 RunAsAny 인 경우에만 발생합니다. 범위를 두 개 이상 지정할 수 있으며 쉼표로 구분할 수 있습니다. 지원되는 형식은 아래를 참조하십시오.
- 5
- <4> 와 동일하지만 사용자 ID의 경우입니다. 또한 단일 사용자 ID 범위만 지원됩니다.
- 6 10
- MustRunAs 는 그룹 ID 범위 검사를 시행하고 컨테이너의 그룹 기본값을 제공합니다. 이 SCC 정의를 기반으로 기본값은 5000(최소 ID 값)입니다. SCC에서 범위를 생략하면 기본값은 1000000000(프로젝트에서 파생됨)입니다. 지원되는 다른 유형 RunAsAny 는 범위 확인을 수행하지 않으므로 그룹 ID를 허용하고 기본 그룹을 생성하지 않습니다.
- 7
- MustRunAsRange 는 사용자 ID 범위 검사를 시행하고 UID 기본값을 제공합니다. 이 SCC를 기반으로 기본 UID는 1000100000(최소 값)입니다. SCC에서 최소 및 최대 범위를 생략하면 기본 사용자 ID는 1000000000(프로젝트에서 파생됨)입니다. MustRunAsNonRoot 및 RunAsAny 는 기타 지원되는 유형입니다. 대상 스토리지에 필요한 사용자 ID를 포함하도록 허용되는 ID 범위를 정의할 수 있습니다.
- 8
- MustRunAs 로 설정하면 SCC의 SELinux 옵션 또는 프로젝트에 정의된 MCS 기본값으로 컨테이너가 생성됩니다. RunAsAny 유형은 SELinux 컨텍스트가 필요하지 않으며 포드에 정의되지 않은 경우 컨테이너에 설정되어 있지 않음을 나타냅니다.
- 9
- SELinux 사용자 이름, 역할 이름, 유형 및 레이블을 여기에 정의할 수 있습니다.
허용되는 범위에는 두 가지 형식이 지원됩니다.
-
M은시작 ID이고N은 카운트이므로, 범위는M+N-1을 통해 M이 됩니다. -
m
-N. 여기서M은 다시 시작 ID이고N은 최종 ID입니다. 기본 그룹 ID는 첫 번째 범위의 시작 ID이며, 이 프로젝트에서1000000000입니다. SCC에서 최소 그룹 ID를 정의하지 않은 경우 프로젝트의 기본 ID가 적용됩니다.
27.18.3. 보충 그룹
보조 그룹을 사용하기 전에 SCC, 기본값, 허용된 범위를 읽습니다.
보충 그룹은 일반 Linux 그룹입니다. 프로세스가 Linux에서 실행되면 UID, GID 및 하나 이상의 보조 그룹이 있습니다. 이러한 특성은 컨테이너의 기본 프로세스에 대해 설정할 수 있습니다. supplementalGroups ID는 일반적으로 NFS 및 GlusterFS와 같은 공유 스토리지에 대한 액세스를 제어하는 데 사용되지만, fsGroup 은 Ceph RBD, iSCSI 등의 블록 스토리지에 대한 액세스를 제어하는 데 사용됩니다.
OpenShift Container Platform 공유 스토리지 플러그인은 마운트의 POSIX 권한이 대상 스토리지의 권한과 일치하도록 볼륨을 마운트합니다. 예를 들어 대상 스토리지의 소유자 ID가 1234 이고 그룹 ID가 5678 이면 호스트 노드와 컨테이너에 있는 마운트에 동일한 ID가 있게 됩니다. 따라서 볼륨에 액세스하려면 컨테이너의 기본 프로세스가 해당 ID 중 하나 또는 둘 다와 일치해야 합니다.
예를 들어 다음 NFS 내보내기를 살펴봅니다.
OpenShift Container Platform 노드에서 다음을 수행합니다.
showmount 는 NFS 서버의 rpcbind 및 rpc .mount 에서 사용하는 포트에 액세스해야 합니다.
# showmount -e <nfs-server-ip-or-hostname>
Export list for f21-nfs.vm:
/opt/nfs *NFS 서버에서 다음을 수행합니다.
# cat /etc/exports
/opt/nfs *(rw,sync,root_squash)
...
# ls -lZ /opt/nfs -d
drwx------. 1000100001 5555 unconfined_u:object_r:usr_t:s0 /opt/nfs/opt/nfs/ 내보내기는 UID 1000100001 및 그룹 5555 로 액세스할 수 있습니다. 일반적으로 컨테이너는 root로 실행하면 안 됩니다. 따라서 이 NFS 예제에서 UID 1000100001 으로 실행되지 않고 그룹 5555 가 NFS 내보내기에 액세스할 수 없는 멤버가 아닌 컨테이너는 NFS 내보내기에 액세스할 수 없습니다.
포드와 일치하는 SCC에서는 특정 사용자 ID를 지정할 수 없으므로 보충 그룹을 사용하면 포드에 스토리지 액세스 권한을 부여할 수 있습니다. 예를 들어 위의 내보내기에 대한 NFS 액세스 권한을 부여하려면 Pod 정의에 5555 그룹을 정의할 수 있습니다.
apiVersion: v1
kind: Pod
...
spec:
containers:
- name: ...
volumeMounts:
- name: nfs
mountPath: /usr/share/...
securityContext:
supplementalGroups: [5555]
volumes:
- name: nfs
nfs:
server: <nfs_server_ip_or_host>
path: /opt/nfs - 1
- 볼륨 마운트의 이름입니다.
volumes섹션의 이름과 일치해야 합니다. - 2
- 컨테이너에 표시되는 NFS 내보내기 경로.
- 3
- 포드 글로벌 보안 컨텍스트. 포드 내의 모든 컨테이너에 적용됩니다. 각 컨테이너는
securityContext를 정의할 수도 있지만 그룹 ID는 포드에 전역적이며 개별 컨테이너에 대해 정의할 수 없습니다. - 4
- ID 배열인 보조 그룹은 5555로 설정됩니다. 이렇게 하면 그룹에 내보내기에 대한 액세스 권한이 부여됩니다.
- 5
- 볼륨 이름입니다.
volumeMounts섹션의 이름과 일치해야 합니다. - 6
- NFS 서버의 실제 NFS 내보내기 경로입니다.
위의 포드의 모든 컨테이너(일치 SCC 또는 프로젝트를 사용하면 5555그룹이 허용됨)는 5555 그룹의 멤버이며 컨테이너의 사용자 ID와 관계없이 볼륨에 액세스할 수 있습니다. 그러나 위의 가정은 매우 중요합니다. SCC가 허용되는 그룹 ID 범위를 정의하지 않고 그룹 ID 유효성 검사(Supplemental Groups 가 MustRunAs로 설정된 결과)를 대신 지정해야 하는 경우가 있습니다. 이는 restricted SCC의 경우가 아닙니다. 프로젝트가 이 NFS 내보내기에 액세스하도록 사용자 지정되지 않은 한 프로젝트는 5555 의 그룹 ID를 허용하지 않습니다. 따라서 이 시나리오에서는 5555 의 그룹 ID가 SCC의 허용된 그룹 ID 범위 내에 없으므로 위의 Pod가 실패합니다.
보충 그룹 및 사용자 지정 SCC
이전 예제의 상황을 해결하기 위해 다음과 같이 사용자 정의 SCC를 생성할 수 있습니다.
- 최소 및 최대 그룹 ID가 정의됩니다.
- ID 범위 검사가 강제 적용됨
- 5555 의 그룹 ID가 허용됩니다.
사전 정의된 SCC를 수정하거나 사전 정의된 프로젝트에서 허용되는 ID 범위를 변경하는 대신 새 SCC를 생성하는 것이 좋습니다.
새 SCC를 생성하는 가장 쉬운 방법은 기존 SCC를 내보내고 YAML 파일을 사용자 지정하여 새 SCC의 요구 사항을 충족하는 것입니다. 예를 들면 다음과 같습니다.
restricted SCC를 새 SCC의 템플릿으로 사용합니다.
$ oc get -o yaml --export scc restricted > new-scc.yaml- new-scc.yaml 파일을 원하는 사양으로 편집합니다.
새 SCC를 생성합니다.
$ oc create -f new-scc.yaml
oc edit scc 명령을 사용하여 인스턴스화된 SCC를 수정할 수 있습니다.
다음은 nfs-scc 라는 새 SCC의 일부입니다.
$ oc get -o yaml --export scc nfs-scc
allowHostDirVolumePlugin: false
...
kind: SecurityContextConstraints
metadata:
...
name: nfs-scc
priority: 9
...
supplementalGroups:
type: MustRunAs
ranges:
- min: 5000
max: 6000
...- 1
allow부울은 restricted SCC와 동일합니다.- 2
- 새 SCC의 이름입니다.
- 3
- 숫자로 큰 숫자가 우선 순위가 높습니다. nil 또는 omitted가 가장 낮은 우선 순위입니다. 우선순위가 높은 SCC가 더 낮은 우선 순위 SCC보다 먼저 정렬되므로 새 Pod를 일치시킬 가능성이 더 높습니다.
- 4
supplementalGroups는 전략이며 MustRunAs 로 설정되어 있으므로 그룹 ID 검사가 필요합니다.- 5
- 여러 범위가 지원됩니다. 여기서 허용되는 그룹 ID 범위는 5000 ~ 5999이며 기본 보조 그룹은 5000입니다.
이전에 표시된 동일한 Pod가 이 새 SCC에 대해 실행되는 경우(물론 포드는 새 SCC와 일치), 포드 정의에 제공된 5555 그룹이 이제 사용자 지정 SCC에서 허용되므로 시작됩니다.
27.18.4. fsGroup
보조 그룹을 사용하기 전에 SCC, 기본값, 허용된 범위를 읽습니다.
fsGroup 은 Pod의 "파일 시스템 그룹" ID를 정의하며, 이는 컨테이너의 보조 그룹에 추가됩니다. supplementalGroups ID는 공유 스토리지에 적용되지만 fsGroup ID는 블록 스토리지에 사용됩니다.
Ceph RBD, iSCSI 및 다양한 클라우드 스토리지와 같은 블록 스토리지는 일반적으로 직접 또는 PVC를 사용하여 블록 스토리지 볼륨을 요청한 단일 포드 전용입니다. 공유 스토리지와 달리 블록 스토리지는 포드에서 인계받습니다. 즉 포드 정의 또는 이미지에 제공된 사용자 및 그룹 ID가 실제 물리적 블록 장치에 적용됩니다. 일반적으로 블록 스토리지는 공유되지 않습니다.
fsGroup 정의는 다음 Pod 정의 내용에서 아래에 표시됩니다.
kind: Pod
...
spec:
containers:
- name: ...
securityContext:
fsGroup: 5555
...
supplementalGroups 와 마찬가지로, 위의 포드의 모든 컨테이너(동일한 SCC 또는 프로젝트가 5555그룹이 허용된다고 가정)는 5555 그룹의 멤버이며 컨테이너의 사용자 ID에 관계없이 블록 볼륨에 액세스할 수 있습니다. 포드가 fsGroup 전략이 MustRunAs 인 restricted SCC와 일치하면 포드가 실행되지 않습니다. 그러나 SCC에 fsGroup 전략이 RunAsAny 로 설정된 경우 모든 fsGroup ID(5555 포함)가 허용됩니다. SCC에 fsGroup 전략이 RunAsAny 로 설정되어 있고 fsGroup ID가 지정되지 않은 경우 블록 스토리지의 "계산"이 발생하지 않고 Pod에 대한 사용 권한이 거부될 수 있습니다.
fsGroups 및 사용자 지정 SCC
이전 예제의 상황을 해결하기 위해 다음과 같이 사용자 정의 SCC를 생성할 수 있습니다.
- 최소 및 최대 그룹 ID가 정의됩니다.
- ID 범위 검사가 강제 적용됨
- 5555 의 그룹 ID가 허용됩니다.
사전 정의된 SCC를 수정하거나 사전 정의된 프로젝트에서 허용되는 ID 범위를 변경하는 대신 새 SCC를 생성하는 것이 좋습니다.
새 SCC 정의의 다음 내용을 고려하십시오.
# oc get -o yaml --export scc new-scc
...
kind: SecurityContextConstraints
...
fsGroup:
type: MustRunAs
ranges:
- max: 6000
min: 5000
...- 1
- MustRunAs 는 그룹 ID 범위 검사를 트리거하지만 RunAsAny 는 범위 검사가 필요하지 않습니다.
- 2
- 허용되는 그룹 ID의 범위는 5000 ~ 5999를 포함합니다. 여러 범위가 지원되지만 사용되지 않습니다. 여기서 허용되는 그룹 ID 범위는 5000 ~ 5999이며 기본
fsGroup은 5000입니다. - 3
- 최소 값(또는 전체 범위)은 SCC에서 생략할 수 있으므로 기본값을 검사하고 생성하는 범위가 프로젝트의
openshift.io/sa.scc.supplemental-groups범위로 지연됩니다.fsGroup및supplementalGroups는 프로젝트에서 동일한 그룹 필드를 사용합니다.fsGroup에는 별도의 범위가 없습니다.
위에 표시된 포드가 이 새 SCC에 대해 실행되는 경우(물론 포드는 새 SCC와 일치), 포드 정의에 제공된 5555 그룹이 사용자 지정 SCC에서 허용되므로 시작됩니다. 또한 포드는 블록 장치를 "수수"하므로 Pod 외부의 프로세스에서 블록 스토리지를 볼 때 실제로 5555 가 그룹 ID로 지정됩니다.
블록 소유권을 지원하는 볼륨 목록은 다음과 같습니다.
- AWS Elastic Block Store
- OpenStack Cinder
- Ceph RBD
- GCE 영구 디스크
- iSCSI
- emptyDir
이 목록은 잠재적으로 불완전합니다.
27.18.5. 사용자 ID
보조 그룹을 사용하기 전에 SCC, 기본값, 허용된 범위를 읽습니다.
사용자 ID는 컨테이너 이미지 또는 포드 정의에 정의할 수 있습니다. 포드 정의에서 단일 사용자 ID는 모든 컨테이너에 전역적으로 정의되거나 개별 컨테이너(또는 둘 다)에 따라 정의할 수 있습니다. 사용자 ID는 아래 Pod 정의 조각에 표시된 대로 제공됩니다.
spec:
containers:
- name: ...
securityContext:
runAsUser: 1000100001
위의 ID 1000100001은 컨테이너에 따라 다르며 내보내기의 소유자 ID와 일치합니다. NFS 내보내기의 소유자 ID가 54321 인 경우 해당 번호가 포드 정의에 사용됩니다. 컨테이너 정의 외부의 securityContext 를 지정하면 포드의 모든 컨테이너에 ID가 전역적으로 지정됩니다.
그룹 ID와 유사하게 SCC 및/또는 프로젝트에 설정된 정책에 따라 사용자 ID를 검증할 수 있습니다. SCC의 runAsUser 전략이 RunAsAny 로 설정된 경우 포드 정의 또는 이미지에 정의된 모든 사용자 ID가 허용됩니다.
이는 UID 0(루트 )도 허용됩니다.
대신 runAsUser 전략이 MustRunAsRange 로 설정된 경우 제공된 사용자 ID가 허용되는 ID 범위에 대해 검증됩니다. 포드에 사용자 ID가 제공되지 않으면 기본 ID가 허용되는 사용자 ID 범위의 최소 값으로 설정됩니다.
이전 NFS 예제 로 돌아가서 컨테이너에는 위의 포드 조각에 표시되는 1000100001 으로 설정된 UID가 필요합니다. 기본 프로젝트 및 restricted SCC를 가정하면 Pod의 요청된 사용자 ID 1000100001이 허용되지 않으므로 Pod가 실패합니다. 다음과 같은 이유로 Pod가 실패합니다.
- 사용자 ID로 1000100001 을 요청합니다.
-
사용 가능한 모든 SCC는
runAsUser전략에 MustRunAsRange 를 사용하므로 UID 범위 검사가 필요하고 - 1000100001 은 SCC 또는 프로젝트의 사용자 ID 범위에 포함되지 않습니다.
이 상황을 해결하기 위해 적절한 사용자 ID 범위를 사용하여 새 SCC를 만들 수 있습니다. 새 프로젝트는 적절한 사용자 ID 범위를 정의하여 만들 수도 있습니다. 더 적은 우선 순위의 다른 옵션도 있습니다.
- 제한된 SCC는 최소 및 최대 사용자 ID 범위 내에 1000100001 을 포함하도록 수정할 수 있습니다. 가능한 경우 사전 정의된 SCC를 수정하지 않도록 해야 하므로 이 방법은 권장되지 않습니다.
-
runAsUser값에 RunAsAny 를 사용하도록 restricted SCC를 수정하여 ID 범위 확인을 제거할 수 있습니다. 컨테이너를 root로 실행할 수 있으므로 이 방법은 권장되지 않습니다. - 기본 프로젝트의 UID 범위는 1000100001 의 사용자 ID를 허용하도록 변경할 수 있습니다. 단일 사용자 ID 범위만 지정할 수 있고 범위가 변경되면 다른 Pod가 실행되지 않을 수 있으므로 일반적으로 이 방법은 권장되지 않습니다.
사용자 ID 및 사용자 지정 SCC
가능한 경우 사전 정의된 SCC를 수정하지 않는 것이 좋습니다. 기본 방법은 조직의 보안 요구 사항에 더 적합한 사용자 지정 SCC 를 생성하거나 원하는 사용자 ID를 지원하는 새 프로젝트를 생성하는 것입니다.
이전 예제의 상황을 해결하기 위해 다음과 같이 사용자 정의 SCC를 생성할 수 있습니다.
- 최소 및 최대 사용자 ID가 정의됩니다.
- UID 범위 검사는 계속 적용되며
- 1000100001 의 UID가 허용됩니다.
예를 들면 다음과 같습니다.
$ oc get -o yaml --export scc nfs-scc
allowHostDirVolumePlugin: false
...
kind: SecurityContextConstraints
metadata:
...
name: nfs-scc
priority: 9
requiredDropCapabilities: null
runAsUser:
type: MustRunAsRange
uidRangeMax: 1000100001
uidRangeMin: 1000100001
...
이제 runAsUser를 사용합니다. 이전 포드 정의 조각에 표시된 1000100001 의 Pod는 새 nfs-scc 와 일치하며 UID 1000100001으로 실행할 수 있습니다.
27.18.6. SELinux 옵션
권한 있는 SCC를 제외한 사전 정의된 모든 SCC는 seLinuxContext 를 MustRunAs 로 설정합니다. 따라서 포드의 요구 사항과 일치할 가능성이 가장 높은 SCC는 포드에서 SELinux 정책을 사용하도록 강제 적용합니다. 포드에서 사용하는 SELinux 정책은 포드 자체, 이미지, SCC 또는 프로젝트(기본값 제공)에 정의할 수 있습니다.
SELinux 레이블은 Pod의 securityContext.seLinuxOptions 섹션에 정의할 수 있으며 사용자,역할,유형 및 수준을 지원합니다.
이 주제에서는 Level 및 MCS 레이블이 서로 바꿔 사용할 수 있습니다.
...
securityContext:
seLinuxOptions:
level: "s0:c123,c456"
...다음은 SCC 및 기본 프로젝트의 내용입니다.
$ oc get -o yaml --export scc scc-name
...
seLinuxContext:
type: MustRunAs
# oc get -o yaml --export namespace default
...
metadata:
annotations:
openshift.io/sa.scc.mcs: s0:c1,c0
...
권한 있는 SCC를 제외한 사전 정의된 모든 SCC는 seLinuxContext 를 MustRunAs 로 설정합니다. 이렇게 하면 Pod에서 포드 정의, 이미지 또는 기본값으로 정의할 수 있는 MCS 레이블을 사용합니다.
SCC는 SELinux 레이블을 필요로 하는지 여부를 결정하고 기본 레이블을 제공할 수 있습니다. seLinuxContext 전략이 MustRunAs 로 설정되고 Pod(또는 이미지)가 레이블을 정의하지 않으면 OpenShift Container Platform은 기본적으로 SCC 자체 또는 프로젝트에서 선택한 레이블로 설정됩니다.
seLinuxContext 가 RunAsAny 로 설정된 경우 기본 레이블이 제공되지 않으며 컨테이너에서 최종 레이블을 결정합니다. Docker의 경우 컨테이너는 고유한 MCS 레이블을 사용하므로 기존 스토리지 마운트의 레이블과 일치하지 않을 수 있습니다. 지정된 레이블에서 액세스할 수 있도록 SELinux 관리를 지원하는 볼륨과 해당 레이블만 제외되는 방식에 따라 레이블이 다시 지정됩니다.
이는 권한이 없는 컨테이너에 대한 두 가지를 의미합니다.
-
볼륨에는 권한이 없는 컨테이너에서 액세스할 수 있는 유형이 제공됩니다. 이 유형은 일반적으로 RHEL(Red Hat Enterprise Linux) 버전 7.5 이상에서
container_file_t입니다. 이 유형은 볼륨을 컨테이너 콘텐츠로 처리합니다. 이전 RHEL 버전인 RHEL 7.4, 7.3 등에서 볼륨에svirt_sandbox_file_t유형이 지정됩니다. -
수준을지정하면 볼륨에 지정된 MCS 레이블이 지정됩니다.
Pod에서 볼륨에 액세스하려면 Pod에 볼륨의 두 카테고리가 모두 있어야 합니다. 따라서 s0:c1,c2 가 있는 Pod는 s0:c1,c2 를 사용하여 볼륨에 액세스할 수 있습니다. s0 이 있는 볼륨은 모든 포드에서 액세스할 수 있습니다.
포드가 권한 부여에 실패하거나 권한 오류로 인해 스토리지 마운트가 실패하는 경우 SELinux 강제를 방해할 가능성이 있습니다. 이를 확인하는 한 가지 방법은 다음을 실행하는 것입니다.
# ausearch -m avc --start recent그러면 AVC(Access Vector Cache) 오류에 대한 로그 파일이 검사됩니다.
27.19. selector-Label 볼륨 바인딩
27.19.1. 개요
이 가이드에서는 선택기 및 레이블 속성을 통해 PVC(영구 볼륨 클레임)를 영구 볼륨(PV)에 바인딩하는 데 필요한 단계를 제공합니다. 일반 사용자는 선택기 및 레이블을 구현하여 클러스터 관리자가 정의한 식별자로 프로비저닝된 스토리지를 대상으로 지정할 수 있습니다.
27.19.2. 동기부여
정적으로 프로비저닝된 스토리지의 경우 PVC를 배포하고 바인딩하기 위해 PV의 식별 특성을 알고자 하는 개발자는 영구 스토리지를 필요로 합니다. 이로 인해 몇 가지 문제가 있는 상황이 발생합니다. 일반 사용자는 클러스터 관리자에게 PVC를 배포하거나 PV 값을 제공해야 할 수 있습니다. PV 속성만으로는 스토리지 볼륨의 용도를 전달하지 않으며, 볼륨을 그룹화할 수 있는 방법을 제공하지 않습니다.
선택기 및 레이블 특성은 설명 및 사용자 지정 태그로 볼륨을 식별하는 방법으로 클러스터 관리자에게 제공하여 사용자로부터 PV 세부 정보를 추상화하는 데 사용할 수 있습니다. selector-label 바인딩 방법을 통해 사용자는 관리자가 정의한 라벨을 아는 데만 필요합니다.
selector-label 기능은 현재 정적으로 프로비저닝된 스토리지에만 사용할 수 있으며 현재는 동적으로 프로비저닝된 스토리지를 위해 구현되지 않습니다.
27.19.3. Deployment
이 섹션에서는 PVC를 정의하고 배포하는 방법을 검토합니다.
27.19.3.1. 사전 요구 사항
- 실행 중인 OpenShift Container Platform 3.3 이상 클러스터
- 지원되는 스토리지 공급자가제공하는 볼륨
- cluster-admin 역할 바인딩이 있는 사용자
27.19.3.2. 영구 볼륨 및 클레임 정의
cluster-admin 사용자로 PV를 정의합니다. 이 예제에서는 GlusterFS 볼륨을 사용합니다. 공급자의 구성에 적합한 스토리지 공급자를 참조하십시오.
예 27.9. 레이블이 있는 영구 볼륨
apiVersion: v1 kind: PersistentVolume metadata: name: gluster-volume labels:1 volume-type: ssd aws-availability-zone: us-east-1 spec: capacity: storage: 2Gi accessModes: - ReadWriteMany glusterfs: endpoints: glusterfs-cluster path: myVol1 readOnly: false persistentVolumeReclaimPolicy: Retain- 1
- PV를 사용할 수 있다고 가정하면 선택기가 모든 PV 레이블과 일치하는 PVC가 바인딩됩니다.
PVC를 정의합니다.
예 27.10. 선택기를 사용한 영구 볼륨 클레임
27.19.3.3. 선택 사항: PVC를 특정 PV에 바인딩
PV 이름 또는 선택기를 지정하지 않는 PVC는 PV와 일치합니다.
클러스터 관리자로 PVC를 특정 PV에 바인딩하려면 다음을 수행합니다.
-
PV 이름을 알고 있으면
pvc.spec.volumeName을 사용합니다. PV 레이블을 알고 있으면
pvc.spec.selector를 사용합니다.선택기를 지정하면 PVC에 특정 라벨이 있어야 합니다.
27.19.3.4. 선택 사항: 특정 PVC에 PV 예약
특정 작업에 대해 PV를 예약하려면 특정 스토리지 클래스를 생성하거나 PV를 PVC에 사전 바인딩하는 두 가지 옵션이 있습니다.
스토리지 클래스의 이름을 지정하여 PV의 특정 스토리지 클래스를 요청합니다.
다음 리소스는 StorageClass를 구성하는 데 사용하는 필수 값을 보여줍니다. 이 예에서는 AWS ElasticBlockStore (EBS) 객체 정의를 사용합니다.
예 27.11. EBS의 StorageClass 정의
kind: StorageClass apiVersion: storage.k8s.io/v1 metadata: name: kafka provisioner: kubernetes.io/aws-ebs ...중요멀티 테넌트 환경에 필요한 경우 할당량 정의를 사용하여 스토리지 클래스와 PV만 특정 네임스페이스에 예약합니다.
PVC 네임스페이스 및 이름을 사용하여 PV를 PVC에 사전 바인딩합니다. 이와 같이 정의된 PV는 다음 예와 같이 지정된 PVC에만 바인딩되며 그 외에는 아무 것도 바인딩합니다.
예 27.12. PV 정의의 claimRef
apiVersion: v1 kind: PersistentVolume metadata: name: mktg-ops--kafka--kafka-broker01 spec: capacity: storage: 15Gi accessModes: - ReadWriteOnce claimRef: apiVersion: v1 kind: PersistentVolumeClaim name: kafka-broker01 namespace: default ...
27.19.3.5. 영구 볼륨 및 클레임 배포
cluster-admin 사용자로 영구 볼륨을 생성합니다.
예 27.13. 영구 볼륨 만들기
# oc create -f gluster-pv.yaml
persistentVolume "gluster-volume" created
# oc get pv
NAME LABELS CAPACITY ACCESSMODES STATUS CLAIM REASON AGE
gluster-volume map[] 2147483648 RWX Available 2sPV가 생성되면 선택기가 모든 레이블과 일치하는 모든 사용자가 해당 PVC를 생성할 수 있습니다.
예 27.14. 영구 볼륨 클레임 생성
# oc create -f gluster-pvc.yaml
persistentVolumeClaim "gluster-claim" created
# oc get pvc
NAME LABELS STATUS VOLUME
gluster-claim Bound gluster-volume27.20. 컨트롤러 관리 연결 및 분리 활성화
27.20.1. 개요
기본적으로 클러스터의 마스터에서 실행되는 컨트롤러는 자체 볼륨 연결 및 분리 작업을 관리하는 대신 노드 집합을 대신하여 볼륨 연결 및 분리 작업을 관리합니다.
컨트롤러 관리 연결 및 분리에는 다음과 같은 이점이 있습니다.
- 노드가 손실되면 컨트롤러에서 연결된 볼륨을 분리하고 다른 위치로 다시 연결할 수 있습니다.
- 연결 및 분리를 위한 자격 증명은 모든 노드에 존재하여 보안을 강화할 필요가 없습니다.
27.20.2. 첨부 파일 및 분리 관리 기능 확인
노드가 volumes.kubernetes.io/controller-managed-attach-detach 주석을 자체적으로 설정한 경우 컨트롤러에서 attach 및 detach 작업을 관리합니다. 컨트롤러는 이 주석의 모든 노드를 자동으로 검사하고 존재 여부에 따라 작동합니다. 따라서 이 주석의 노드를 검사하여 컨트롤러 관리 연결 및 분리가 활성화되었는지 확인할 수 있습니다.
노드가 컨트롤러에서 관리되는 연결 및 분리를 추가로 선택하도록 하려면 다음 행을 사용하여 로그를 검색할 수 있습니다.
Setting node annotation to enable volume controller attach/detach위의 행을 찾을 수 없는 경우 로그에는 다음을 포함해야 합니다.
Controller attach/detach is disabled for this node; Kubelet will attach and detach volumes
컨트롤러의 끝에서 특정 노드의 attach 및 detach 작업을 관리하고 있는지 확인하려면 먼저 로깅 수준을 4 로 설정해야 합니다. 그런 다음 다음 행을 찾을 수 있습니다.
processVolumesInUse for node <node_hostname>로그를 보고 로깅 수준을 구성하는 방법에 대한 자세한 내용은 로깅 수준 구성을 참조하십시오.
27.20.3. 컨트롤러 관리 연결 및 분리를 사용하도록 노드 구성
컨트롤러 관리 연결 및 분리는 자체 노드 수준 연결 및 분리 관리를 선택 및 비활성화하도록 개별 노드를 구성하여 수행합니다. 편집할 노드 구성 파일에 대한 자세한 내용은 노드 구성 파일을 참조하십시오.
kubeletArguments:
enable-controller-attach-detach:
- "true"노드를 구성하고 나면 설정을 적용하려면 노드를 다시 시작해야 합니다.
27.21. 영구 볼륨 스냅샷
27.21.1. 개요
영구 볼륨 스냅샷은 기술 프리뷰 기능입니다. 기술 프리뷰 기능은 Red Hat 프로덕션 서비스 수준 계약(SLA)에서 지원하지 않으며, 기능상 완전하지 않을 수 있어 프로덕션에 사용하지 않는 것이 좋습니다. 이러한 기능을 사용하면 향후 제품 기능을 조기에 이용할 수 있어 개발 과정에서 고객이 기능을 테스트하고 피드백을 제공할 수 있습니다.
Red Hat 기술 프리뷰 기능 지원 범위에 대한 자세한 내용은 https://access.redhat.com/support/offerings/techpreview/를 참조하십시오.
많은 스토리지 시스템은 데이터 손실을 방지하기 위해 PV(영구 볼륨)의 "snapshots"를 생성할 수 있는 기능을 제공합니다. 외부 스냅샷 컨트롤러 및 프로비저너는 OpenShift Container Platform 클러스터에서 기능을 사용하고 OpenShift Container Platform API를 통해 볼륨 스냅샷을 처리하는 방법을 제공합니다.
이 문서에서는 OpenShift Container Platform의 볼륨 스냅샷 지원의 현재 상태를 설명합니다. PV, PVC (영구 볼륨 클레임) 및 동적 프로비저닝에 대해 숙지하는 것이 좋습니다.
27.21.2. 기능
-
PersistentVolumeClaim에 바인딩된 aPersistentVolume의 스냅샷 생성 -
기존
VolumeSnapshots나열 -
기존
VolumeSnapshot삭제 -
기존
VolumeSnapshot에서 newPersistentVolume생성 Supported
PersistentVolume유형:- AWS Elastic Block Store (EBS)
- GCP(Google Compute Engine) PD(Persistent Disk)
27.21.3. 설치 및 설정
외부 컨트롤러 및 프로비저너는 볼륨 스냅샷을 제공하는 외부 구성 요소입니다. 이러한 외부 구성 요소는 클러스터에서 실행됩니다. 컨트롤러는 볼륨 스냅샷에서 이벤트를 생성, 삭제 및 보고합니다. 프로비저너는 볼륨 스냅샷에서 new PersistentVolumes 를 생성합니다. 자세한 내용은 Create Snapshot and Restore Snapshot 에서 참조하십시오.
27.21.3.1. 외부 컨트롤러 및 프로비저너 시작
외부 컨트롤러 및 프로비저너 서비스는 컨테이너 이미지로 배포되며, 일반적으로 OpenShift Container Platform 클러스터에서 실행할 수 있습니다. 컨트롤러와 프로비저너용 RPM 버전도 있습니다.
API 오브젝트를 관리하는 컨테이너를 허용하려면 관리자가 필요한 역할 기반 액세스 제어(RBAC) 규칙을 구성해야 합니다.
ServiceAccount및ClusterRole을 생성합니다.apiVersion: v1 kind: ServiceAccount metadata: name: snapshot-controller-runner kind: ClusterRole apiVersion: rbac.authorization.k8s.io/v1 metadata: name: snapshot-controller-role rules: - apiGroups: [""] resources: ["persistentvolumes"] verbs: ["get", "list", "watch", "create", "delete"] - apiGroups: [""] resources: ["persistentvolumeclaims"] verbs: ["get", "list", "watch", "update"] - apiGroups: ["storage.k8s.io"] resources: ["storageclasses"] verbs: ["get", "list", "watch"] - apiGroups: [""] resources: ["events"] verbs: ["list", "watch", "create", "update", "patch"] - apiGroups: ["apiextensions.k8s.io"] resources: ["customresourcedefinitions"] verbs: ["create", "list", "watch", "delete"] - apiGroups: ["volumesnapshot.external-storage.k8s.io"] resources: ["volumesnapshots"] verbs: ["get", "list", "watch", "create", "update", "patch", "delete"] - apiGroups: ["volumesnapshot.external-storage.k8s.io"] resources: ["volumesnapshotdatas"] verbs: ["get", "list", "watch", "create", "update", "patch", "delete"]ClusterRoleBinding을 통해 규칙을 바인딩합니다.apiVersion: rbac.authorization.k8s.io/v1beta1 kind: ClusterRoleBinding metadata: name: snapshot-controller roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: snapshot-controller-role subjects: - kind: ServiceAccount name: snapshot-controller-runner namespace: default
외부 컨트롤러 및 프로비저너가 AWS(Amazon Web Services)에 배포된 경우 액세스 키를 사용하여 인증할 수 있어야 합니다. 관리자는 Pod에 인증 정보를 제공하기 위해 새 보안을 생성합니다.
apiVersion: v1
kind: Secret
metadata:
name: awskeys
type: Opaque
data:
access-key-id: <base64 encoded AWS_ACCESS_KEY_ID>
secret-access-key: <base64 encoded AWS_SECRET_ACCESS_KEY>외부 컨트롤러 및 프로비저너 컨테이너의 AWS 배포(두 Pod 컨테이너 모두 시크릿을 사용하여 AWS 클라우드 공급자 API에 액세스).
kind: Deployment
apiVersion: extensions/v1beta1
metadata:
name: snapshot-controller
spec:
replicas: 1
strategy:
type: Recreate
template:
metadata:
labels:
app: snapshot-controller
spec:
serviceAccountName: snapshot-controller-runner
containers:
- name: snapshot-controller
image: "registry.redhat.io/openshift3/snapshot-controller:latest"
imagePullPolicy: "IfNotPresent"
args: ["-cloudprovider", "aws"]
env:
- name: AWS_ACCESS_KEY_ID
valueFrom:
secretKeyRef:
name: awskeys
key: access-key-id
- name: AWS_SECRET_ACCESS_KEY
valueFrom:
secretKeyRef:
name: awskeys
key: secret-access-key
- name: snapshot-provisioner
image: "registry.redhat.io/openshift3/snapshot-provisioner:latest"
imagePullPolicy: "IfNotPresent"
args: ["-cloudprovider", "aws"]
env:
- name: AWS_ACCESS_KEY_ID
valueFrom:
secretKeyRef:
name: awskeys
key: access-key-id
- name: AWS_SECRET_ACCESS_KEY
valueFrom:
secretKeyRef:
name: awskeys
key: secret-access-keyGCE의 경우 시크릿을 사용하여 GCE 클라우드 공급자 API에 액세스할 필요가 없습니다. 관리자는 배포를 진행할 수 있습니다.
kind: Deployment
apiVersion: extensions/v1beta1
metadata:
name: snapshot-controller
spec:
replicas: 1
strategy:
type: Recreate
template:
metadata:
labels:
app: snapshot-controller
spec:
serviceAccountName: snapshot-controller-runner
containers:
- name: snapshot-controller
image: "registry.redhat.io/openshift3/snapshot-controller:latest"
imagePullPolicy: "IfNotPresent"
args: ["-cloudprovider", "gce"]
- name: snapshot-provisioner
image: "registry.redhat.io/openshift3/snapshot-provisioner:latest"
imagePullPolicy: "IfNotPresent"
args: ["-cloudprovider", "gce"]27.21.3.2. 스냅샷 사용자 관리
클러스터 구성에 따라 관리자가 아닌 사용자가 API 서버의 VolumeSnapshot 오브젝트를 조작할 수 있도록 허용해야 할 수 있습니다. 이 작업은 특정 사용자 또는 그룹에 바인딩된 ClusterRole 을 생성하여 수행할 수 있습니다.
예를 들어 사용자 'alice'가 클러스터의 스냅샷으로 작동한다고 가정합니다. 클러스터 관리자가 다음 단계를 완료합니다.
새
ClusterRole을 정의합니다.apiVersion: v1 kind: ClusterRole metadata: name: volumesnapshot-admin rules: - apiGroups: - "volumesnapshot.external-storage.k8s.io" attributeRestrictions: null resources: - volumesnapshots verbs: - create - delete - deletecollection - get - list - patch - update - watchClusterRoleBinding오브젝트를 생성하여 사용자 'alice'에 클러스터 역할을 바인딩합니다.apiVersion: rbac.authorization.k8s.io/v1beta1 kind: ClusterRoleBinding metadata: name: volumesnapshot-admin roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: volumesnapshot-admin subjects: - kind: User name: alice
이는 API 액세스 구성의 예입니다. VolumeSnapshot 오브젝트는 다른 OpenShift Container Platform API 오브젝트와 유사하게 작동합니다. API RBAC 관리에 대한 자세한 내용은 API 액세스 제어 설명서 를 참조하십시오.
27.21.4. 볼륨 스냅샷 및 볼륨 스냅샷 데이터 라이프사이클
27.21.4.1. 영구 볼륨 클레임 및 영구 볼륨
PersistentVolumeClaim 은 a PersistentVolume 에 바인딩됩니다. The PersistentVolume 유형은 스냅샷에서 지원되는 영구 볼륨 유형 중 하나여야 합니다.
27.21.4.1.1. 스냅샷 프로모션
스토리지 클래스를 생성하려면 다음을 수행합니다.
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: snapshot-promoter
provisioner: volumesnapshot.external-storage.k8s.io/snapshot-promoter
이 StorageClass 는 이전에 생성된 VolumeSnapshot 에서 a PersistentVolume 을 복원하는 데 필요합니다.
27.21.4.2. 스냅샷 만들기
PV의 스냅샷을 생성하려면 새 VolumeSnapshot 오브젝트를 생성합니다.
apiVersion: volumesnapshot.external-storage.k8s.io/v1
kind: VolumeSnapshot
metadata:
name: snapshot-demo
spec:
persistentVolumeClaimName: ebs-pvc
persistentVolumeClaimName 은 a PersistentVolume 에 바인딩된 PersistentVolumeClaim 의 이름입니다. 이 특정 PV는 스냅샷이 생성됩니다.
그런 다음 VolumeSnapshotData 오브젝트가 VolumeSnapshot 에 따라 자동으로 생성됩니다. VolumeSnapshot과 VolumeSnapshot Data 간의 관계는 PersistentVolumeClaim 과 PersistentVolume 간의 관계와 유사합니다.
PV 유형에 따라 작업이 VolumeSnapshot 상태로 반영되는 여러 단계를 수행할 수 있습니다.
-
새
VolumeSnapshot오브젝트가 생성됩니다. -
컨트롤러에서 스냅샷 작업을 시작합니다. snapshotted
PersistentVolume을 사용하려면 애플리케이션이 일시 중지되어야 할 수 있습니다. -
스토리지 시스템은 스냅샷 생성을 완료하고(스냅샷은 "cut") snapshotted
PersistentVolume을 일반 작업으로 돌아갈 수 있습니다. 스냅샷 자체는 아직 준비되지 않았습니다. 마지막 상태 조건은 상태 값이True인Pending유형입니다. 실제 스냅샷을 나타내도록 새VolumeSnapshotData오브젝트가 생성됩니다. -
새로 만든 스냅샷이 완료되어 사용할 준비가 되었습니다. 마지막 상태 조건은 상태 값이
True인Ready유형입니다.
사용자의 책임은 데이터 일관성을 보장합니다(포드/애플리케이션 중지, 캐시 플러시, 파일 시스템 중지 등).
오류가 발생하는 경우 VolumeSnapshot 상태에 Error 조건이 추가됩니다.
VolumeSnapshot 상태를 표시하려면 다음을 수행합니다.
$ oc get volumesnapshot -o yaml상태가 표시됩니다.
apiVersion: volumesnapshot.external-storage.k8s.io/v1
kind: VolumeSnapshot
metadata:
clusterName: ""
creationTimestamp: 2017-09-19T13:58:28Z
generation: 0
labels:
Timestamp: "1505829508178510973"
name: snapshot-demo
namespace: default
resourceVersion: "780"
selfLink: /apis/volumesnapshot.external-storage.k8s.io/v1/namespaces/default/volumesnapshots/snapshot-demo
uid: 9cc5da57-9d42-11e7-9b25-90b11c132b3f
spec:
persistentVolumeClaimName: ebs-pvc
snapshotDataName: k8s-volume-snapshot-9cc8813e-9d42-11e7-8bed-90b11c132b3f
status:
conditions:
- lastTransitionTime: null
message: Snapshot created successfully
reason: ""
status: "True"
type: Ready
creationTimestamp: null27.21.4.3. 스냅샷 복원
VolumeSnapshot 에서 PV를 복원하려면 PVC를 생성합니다.
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: snapshot-pv-provisioning-demo
annotations:
snapshot.alpha.kubernetes.io/snapshot: snapshot-demo
spec:
storageClassName: snapshot-promoter
annotations:snapshot.alpha.kubernetes.io/snapshot 은 복원 할 VolumeSnapshot 의 이름입니다. storageClassName: StorageClass 는 관리자가 VolumeSnapshots 를 복원하기 위해 생성합니다.
new PersistentVolume 이 생성되어 PersistentVolumeClaim 에 바인딩됩니다. 이 프로세스는 PV 유형에 따라 몇 분이 걸릴 수 있습니다.
27.21.4.4. 스냅샷 삭제
snapshot-demo 를 삭제하려면 다음을 수행합니다.
$ oc delete volumesnapshot/snapshot-demo
VolumeSnapshot에 바인딩된 가 자동으로 삭제됩니다.
VolumeSnapshot Data
27.22. hostPath 사용
OpenShift Container Platform 클러스터의 hostPath 볼륨은 호스트 노드의 파일 또는 디렉터리를 Pod에 마운트합니다. 대부분의 Pod에는 hostPath 볼륨이 필요하지 않지만 애플리케이션에 필요한 빠른 옵션을 제공합니다.
클러스터 관리자는 권한으로 실행되도록 Pod를 구성해야 합니다. 이를 통해 동일한 노드의 Pod에 액세스 권한이 부여됩니다.
27.22.1. 개요
OpenShift Container Platform은 단일 노드 클러스터에서 개발 및 테스트를 위해 hostPath 마운트를 지원합니다.
프로덕션 클러스터에서는 hostPath 를 사용하지 않습니다. 대신 클러스터 관리자가 GCE 영구 디스크 볼륨 또는 Amazon EBS 볼륨과 같은 네트워크 리소스를 프로비저닝합니다. 네트워크 리소스는 스토리지 클래스 사용을 지원하여 동적 프로비저닝을 설정합니다.
hostPath 볼륨은 정적으로 프로비저닝해야 합니다.
27.22.2. Pod 사양에서 hostPath 볼륨 구성
hostPath 볼륨을 사용하여 노드의 읽기-쓰기 파일에 액세스할 수 있습니다. 이 기능은 내부에서 호스트를 구성하고 모니터링할 수 있는 포드에 유용할 수 있습니다. 또한 hostPath 볼륨을 사용하여 mount Propagation을 사용하여 호스트에 볼륨을 마운트 할 수 있습니다.
포드에서 호스트의 파일을 읽고 쓸 수 있으므로 hostPath 볼륨 사용은 위험할 수 있습니다. 주의해서 진행하십시오.
PersistentVolume 오브젝트가 아닌 Pod 사양에 hostPath 볼륨을 직접 지정하는 것이 좋습니다. 이는 포드가 노드를 구성할 때 액세스하는 데 필요한 경로를 이미 알고 있기 때문에 유용합니다.
절차
권한 있는 Pod를 생성합니다.
apiVersion: v1 kind: Pod metadata: name: pod-name spec: containers: ... securityContext: privileged: true volumeMounts: - mountPath: /host/etc/motd.confg1 name: hostpath-privileged ... volumes: - name: hostpath-privileged hostPath: path: /etc/motd.confg2
이 예에서 Pod는 /etc/motd.confg 내의 호스트 경로를 로 확인할 수 있습니다. 따라서 호스트에 직접 액세스하지 않고 /host/etc/motd.confg motd 를 구성할 수 있습니다.
27.22.3. 정적으로 hostPath 볼륨을 프로비저닝
hostPath 볼륨을 사용하는 Pod는 수동 또는 정적 프로비저닝에서 참조해야 합니다.
hostPath 에서 영구 볼륨을 사용하는 것은 사용 가능한 영구 스토리지가 없는 경우에만 사용해야 합니다.
절차
PV(영구 볼륨)를 정의합니다.
PersistentVolume오브젝트 정의를 사용하여pv.yaml파일을 생성합니다.apiVersion: v1 kind: PersistentVolume metadata: name: task-pv-volume1 labels: type: local spec: storageClassName: manual2 capacity: storage: 5Gi accessModes: - ReadWriteOnce3 persistentVolumeReclaimPolicy: Retain hostPath: path: "/mnt/data"4 파일에서 PV를 생성합니다.
$ oc create -f pv.yamlPVC(영구 볼륨 클레임)를 정의합니다.
PersistentVolumeClaim오브젝트 정의를 사용하여pvc.yaml파일을 생성합니다.apiVersion: v1 kind: PersistentVolumeClaim metadata: name: task-pvc-volume spec: accessModes: - ReadWriteOnce resources: requests: storage: 1Gi storageClassName: manual파일에서 PVC를 생성합니다.
$ oc create -f pvc.yaml
27.22.4. 권한이 있는 Pod에서 hostPath 공유 마운트
영구 볼륨 클레임이 생성되면 애플리케이션에서 포드 내부에서 사용할 수 있습니다. 다음 예시는 Pod 내부에서 이 공유를 마운트하는 방법을 보여줍니다.
사전 요구 사항
-
기본
hostPath공유에 매핑된 영구 볼륨 클레임이 있습니다.
절차
기존 영구 볼륨 클레임을 마운트하는 권한이 있는 Pod를 생성합니다.
apiVersion: v1 kind: Pod metadata: name: pod-name1 spec: containers: ... securityContext: privileged: true2 volumeMounts: - mountPath: /data3 name: hostpath-privileged ... securityContext: {} volumes: - name: hostpath-privileged persistentVolumeClaim: claimName: task-pvc-volume4
27.22.5. 추가 리소스
28장. 영구 스토리지 예
28.1. 개요
다음 섹션에서는 일반적인 스토리지 사용 사례 설정 및 구성에 대한 자세한 종합 지침을 제공합니다. 이 예제에서는 영구 볼륨과 해당 보안의 관리 및 시스템에 대한 볼륨 클레임 방법을 모두 다룹니다.
28.3. Ceph RBD를 사용한 전체 예
28.3.1. 개요
이 주제에서는 기존 Ceph 클러스터를 OpenShift Container Platform 영구 저장소로 사용하는 포괄적인 예를 제공합니다. 작동하는 Ceph 클러스터가 이미 설정되어 있다고 가정합니다. 그렇지 않은 경우 Red Hat Ceph Storage 개요 를 참조하십시오.
Ceph Rados 블록 장치를 사용하는 영구 스토리지는 영구 볼륨(PV), PVC(영구 볼륨 클레임) 및 Ceph RBD를 영구 스토리지로 사용하는 방법을 설명합니다.
모두 oc… 명령은 OpenShift Container Platform 마스터 호스트에서 실행됩니다.
28.3.2. ceph-common 패키지 설치
ceph-common 라이브러리는 예약 가능한 모든 OpenShift Container Platform 노드에 설치해야 합니다.
OpenShift Container Platform 올인원 호스트는 Pod 워크로드를 실행하는 데 자주 사용되지 않으므로 예약 가능한 노드로 포함되지 않습니다.
# yum install -y ceph-common28.3.3. Ceph 시크릿 생성
ceph auth get-key 명령은 Ceph MON 노드에서 실행되어 client.admin 사용자의 키 값을 표시합니다.
예 28.5. Ceph 시크릿 정의
apiVersion: v1
kind: Secret
metadata:
name: ceph-secret
data:
key: QVFBOFF2SlZheUJQRVJBQWgvS2cwT1laQUhPQno3akZwekxxdGc9PQ==
type: kubernetes.io/rbd 보안 정의를 파일에 저장합니다(예: ceph-secret.yaml ).
$ oc create -f ceph-secret.yaml
secret "ceph-secret" created보안이 생성되었는지 확인합니다.
# oc get secret ceph-secret
NAME TYPE DATA AGE
ceph-secret kubernetes.io/rbd 1 23d28.3.4. 영구 볼륨 생성
다음으로 OpenShift Container Platform에서 PV 오브젝트를 생성하기 전에 영구 볼륨 파일을 정의합니다.
예 28.6. Ceph RBD를 사용한 영구 볼륨 오브젝트 정의
apiVersion: v1
kind: PersistentVolume
metadata:
name: ceph-pv
spec:
capacity:
storage: 2Gi
accessModes:
- ReadWriteOnce
rbd:
monitors:
- 192.168.122.133:6789
pool: rbd
image: ceph-image
user: admin
secretRef:
name: ceph-secret
fsType: ext4
readOnly: false
persistentVolumeReclaimPolicy: Retain- 1
- 포드 정의에서 참조하거나 다양한
oc볼륨 명령에 표시되는 PV의 이름입니다. - 2
- 이 볼륨에 할당된 스토리지의 용량입니다.
- 3
accessModes는 PV 및 PVC와 일치하는 라벨로 사용됩니다. 현재는 액세스 제어 형식을 정의하지 않습니다. 모든 블록 스토리지는 단일 사용자(비공유 스토리지)로 정의됩니다.- 4
- 이는 사용 중인 볼륨 유형을 정의합니다. 이 경우 rbd 플러그인이 정의됩니다.
- 5
- Ceph 모니터 IP 주소와 포트의 배열입니다.
- 6
- 이는 위에서 정의한 Ceph 비밀입니다. OpenShift Container Platform에서 Ceph 서버로의 보안 연결을 생성하는 데 사용됩니다.
- 7
- Ceph RBD 블록 장치에 마운트된 파일 시스템 유형입니다.
PV 정의를 파일에 저장합니다(예: ceph-pv.yaml ).
# oc create -f ceph-pv.yaml
persistentvolume "ceph-pv" created영구 볼륨이 생성되었는지 확인합니다.
# oc get pv
NAME LABELS CAPACITY ACCESSMODES STATUS CLAIM REASON AGE
ceph-pv <none> 2147483648 RWO Available 2s28.3.5. 영구 볼륨 클레임 생성
PVC(영구 볼륨 클레임)는 원하는 액세스 모드 및 스토리지 용량을 지정합니다. 현재는 이러한 두 특성만 기반으로 PVC가 단일 PV에 바인딩됩니다. PV가 PVC에 바인드되면 해당 PV는 기본적으로 PVC의 프로젝트에 연결되며 다른 PVC에 바인딩할 수 없습니다. PV 및 PVC에는 일대일 매핑이 있습니다. 그러나 동일한 프로젝트의 여러 포드에서 동일한 PVC를 사용할 수 있습니다.
예 28.7. PVC 오브젝트 정의
PVC 정의를 파일에 저장합니다(예: ceph-claim.yaml ).
# oc create -f ceph-claim.yaml
persistentvolumeclaim "ceph-claim" created
#and verify the PVC was created and bound to the expected PV:
# oc get pvc
NAME LABELS STATUS VOLUME CAPACITY ACCESSMODES AGE
ceph-claim <none> Bound ceph-pv 1Gi RWX 21s
- 1
- 클레임이 ceph-pv PV에 바인딩되었습니다.
28.3.6. Pod 생성
포드 정의 파일 또는 템플릿 파일을 사용하여 포드를 정의할 수 있습니다. 다음은 단일 컨테이너를 생성하고 읽기-쓰기 액세스를 위해 Ceph RBD 볼륨을 마운트하는 Pod 사양입니다.
예 28.8. Pod 오브젝트 정의
apiVersion: v1
kind: Pod
metadata:
name: ceph-pod1
spec:
containers:
- name: ceph-busybox
image: busybox
command: ["sleep", "60000"]
volumeMounts:
- name: ceph-vol1
mountPath: /usr/share/busybox
readOnly: false
volumes:
- name: ceph-vol1
persistentVolumeClaim:
claimName: ceph-claim 포드 정의를 파일에 저장하고(예: ceph-pod1.yaml ) Pod를 생성합니다.
# oc create -f ceph-pod1.yaml
pod "ceph-pod1" created
#verify pod was created
# oc get pod
NAME READY STATUS RESTARTS AGE
ceph-pod1 1/1 Running 0 2m
- 1
- 1분 정도 경과하면 포드 상태가 Running 이 됩니다.
28.3.7. 그룹 및 소유자 ID 정의(선택 사항)
Ceph RBD와 같은 블록 스토리지를 사용하는 경우 실제 블록 스토리지는 포드에서 관리합니다. 포드에 정의된 그룹 ID는 컨테이너 내부에 Ceph RBD 마운트의 그룹 ID와 실제 스토리지 자체의 그룹 ID가 됩니다. 따라서 일반적으로 Pod 사양에 그룹 ID를 정의할 필요가 없습니다. 그러나 그룹 ID가 필요한 경우 다음 Pod 정의 내용과 같이 fsGroup 을 사용하여 정의할 수 있습니다.
28.3.8. 프로젝트의 기본값으로 ceph-user-secret 설정
모든 프로젝트에서 영구 스토리지를 사용할 수 있도록 하려면 기본 프로젝트 템플릿을 수정해야 합니다. 기본 프로젝트 템플릿을 수정하는 방법에 대한 자세한 내용을 확인할 수 있습니다. 기본 프로젝트 템플릿을 수정하는 방법에 대해 자세히 알아보십시오. 이 파일을 기본 프로젝트 템플릿에 추가하면 Ceph 클러스터에 대한 프로젝트 액세스 권한을 생성하는 데 액세스할 수 있는 모든 사용자가 허용됩니다.
기본 프로젝트 예
...
apiVersion: v1
kind: Template
metadata:
creationTimestamp: null
name: project-request
objects:
- apiVersion: v1
kind: Project
metadata:
annotations:
openshift.io/description: ${PROJECT_DESCRIPTION}
openshift.io/display-name: ${PROJECT_DISPLAYNAME}
openshift.io/requester: ${PROJECT_REQUESTING_USER}
creationTimestamp: null
name: ${PROJECT_NAME}
spec: {}
status: {}
- apiVersion: v1
kind: Secret
metadata:
name: ceph-user-secret
data:
key: yoursupersecretbase64keygoeshere
type:
kubernetes.io/rbd
...- 1
- 여기에 Ceph 사용자 키를 base64 형식으로 배치합니다.
28.4. Ceph RBD를 사용하여 동적 프로비저닝
28.4.1. 개요
이 주제에서는 OpenShift Container Platform 영구 스토리지에 기존 Ceph 클러스터를 사용하는 전체 예제를 제공합니다. 작동하는 Ceph 클러스터가 이미 설정되어 있다고 가정합니다. 그렇지 않은 경우 Red Hat Ceph Storage 개요 를 참조하십시오.
Ceph Rados 블록 장치를 사용하는 영구 스토리지에서는 PV(영구 볼륨), PVC(영구 볼륨 클레임) 및 Ceph Rados Block Device(RBD)를 영구 스토리지로 사용하는 방법에 대한 설명을 제공합니다.
-
OpenShift Container Platform 마스터 호스트에서 모든
oc명령을 실행합니다. - OpenShift Container Platform 올인원 호스트는 Pod 워크로드를 실행하는 데 자주 사용되지 않으므로 예약 가능한 노드로 포함되지 않습니다.
28.4.2. 동적 볼륨을 위한 풀 생성
최신 ceph-common 패키지를 설치합니다.
yum install -y ceph-common참고ceph-common라이브러리는예약 가능한 모든OpenShift Container Platform 노드에 설치해야 합니다.관리자 또는 MON 노드에서 동적 볼륨에 대한 새 풀을 생성합니다. 예를 들면 다음과 같습니다.
$ ceph osd pool create kube 1024 $ ceph auth get-or-create client.kube mon 'allow r, allow command "osd blacklist"' osd 'allow class-read object_prefix rbd_children, allow rwx pool=kube' -o ceph.client.kube.keyring참고RBD의 기본 풀을 사용하는 것은 옵션이지만 권장되지는 않습니다.
28.4.3. 동적 영구 스토리지에 기존 Ceph 클러스터 사용
동적 영구 스토리지에 기존 Ceph 클러스터를 사용하려면 다음을 수행합니다.
client.admin base64 인코딩 키를 생성합니다.
$ ceph auth get client.adminCeph 시크릿 정의 예
apiVersion: v1 kind: Secret metadata: name: ceph-secret namespace: kube-system data: key: QVFBOFF2SlZheUJQRVJBQWgvS2cwT1laQUhPQno3akZwekxxdGc9PQ==1 type: kubernetes.io/rbd2 client.admin의 Ceph 시크릿을 생성합니다.
$ oc create -f ceph-secret.yaml secret "ceph-secret" created보안이 생성되었는지 확인합니다.
$ oc get secret ceph-secret NAME TYPE DATA AGE ceph-secret kubernetes.io/rbd 1 5d스토리지 클래스를 생성합니다.
$ oc create -f ceph-storageclass.yaml storageclass "dynamic" createdCeph 스토리지 클래스 예
apiVersion: storage.k8s.io/v1beta1 kind: StorageClass metadata: name: dynamic annotations: storageclass.kubernetes.io/is-default-class: "true" provisioner: kubernetes.io/rbd parameters: monitors: 192.168.1.11:6789,192.168.1.12:6789,192.168.1.13:67891 adminId: admin2 adminSecretName: ceph-secret3 adminSecretNamespace: kube-system4 pool: kube5 userId: kube6 userSecretName: ceph-user-secret7 - 1
- 쉼표로 구분된 IP 주소 Ceph 모니터 목록입니다. 이 값은 필수입니다.
- 2
- 풀에 이미지를 만들 수 있는 Ceph 클라이언트 ID입니다. 기본값은
admin입니다. - 3
adminId의 시크릿 이름입니다. 이 값은 필수입니다. 제공하는 시크릿에는kubernetes.io/rbd가 있어야 합니다.- 4
adminSecret의 네임스페이스입니다. 기본값은default입니다.- 5
- Ceph RBD 풀. 기본값은
rbd이지만 이 값은 권장되지 않습니다. - 6
- Ceph RBD 이미지를 매핑하는 데 사용되는 Ceph 클라이언트 ID입니다. 기본값은
adminId의 시크릿 이름과 동일합니다. - 7
- Ceph RBD 이미지를 매핑하는
userId의 Ceph 시크릿 이름입니다. PVC와 동일한 네임스페이스에 있어야 합니다. 새 프로젝트에서 Ceph 보안을 기본값으로 설정하는 경우 이 매개변수 값을 제공해야 합니다.
스토리지 클래스가 생성되었는지 확인합니다.
$ oc get storageclasses NAME TYPE dynamic (default) kubernetes.io/rbdPVC 오브젝트 정의를 생성합니다.
PVC 오브젝트 정의 예
kind: PersistentVolumeClaim apiVersion: v1 metadata: name: ceph-claim-dynamic spec: accessModes:1 - ReadWriteOnce resources: requests: storage: 2Gi2 PVC를 만듭니다.
$ oc create -f ceph-pvc.yaml persistentvolumeclaim "ceph-claim-dynamic" createdPVC가 생성되어 예상 PV에 바인드되었는지 확인합니다.
$ oc get pvc NAME STATUS VOLUME CAPACITY ACCESSMODES AGE ceph-claim Bound pvc-f548d663-3cac-11e7-9937-0024e8650c7a 2Gi RWO 1mPod 오브젝트 정의를 생성합니다.
Pod 오브젝트 정의 예
apiVersion: v1 kind: Pod metadata: name: ceph-pod11 spec: containers: - name: ceph-busybox image: busybox2 command: ["sleep", "60000"] volumeMounts: - name: ceph-vol13 mountPath: /usr/share/busybox4 readOnly: false volumes: - name: ceph-vol1 persistentVolumeClaim: claimName: ceph-claim-dynamic5 Pod를 생성합니다.
$ oc create -f ceph-pod1.yaml pod "ceph-pod1" createdPod가 생성되었는지 확인합니다.
$ oc get pod NAME READY STATUS RESTARTS AGE ceph-pod1 1/1 Running 0 2m
1분 정도 경과하면 포드 상태가 Running 으로 변경됩니다.
28.4.4. ceph-user-secret을 프로젝트의 기본값으로 설정
모든 프로젝트에서 영구 스토리지를 사용하려면 기본 프로젝트 템플릿을 수정해야 합니다. 이 파일을 기본 프로젝트 템플릿에 추가하면 Ceph 클러스터에 대한 프로젝트 액세스 권한을 생성하는 데 액세스할 수 있는 모든 사용자가 허용됩니다. 자세한 내용은 기본 프로젝트 템플릿 수정을 참조하십시오.
기본 프로젝트 예
...
apiVersion: v1
kind: Template
metadata:
creationTimestamp: null
name: project-request
objects:
- apiVersion: v1
kind: Project
metadata:
annotations:
openshift.io/description: ${PROJECT_DESCRIPTION}
openshift.io/display-name: ${PROJECT_DISPLAYNAME}
openshift.io/requester: ${PROJECT_REQUESTING_USER}
creationTimestamp: null
name: ${PROJECT_NAME}
spec: {}
status: {}
- apiVersion: v1
kind: Secret
metadata:
name: ceph-user-secret
data:
key: QVFCbEV4OVpmaGJtQ0JBQW55d2Z0NHZtcS96cE42SW1JVUQvekE9PQ==
type:
kubernetes.io/rbd
...- 1
- 여기에 Ceph 사용자 키를 base64 형식으로 배치합니다.
28.5. GlusterFS를 사용한 전체 예
28.5.1. 개요
이 주제에서는 기존 통합 모드, 독립 모드 또는 독립 실행형 Red Hat Gluster Storage 클러스터를 OpenShift Container Platform의 영구 스토리지로 사용하는 방법에 대한 포괄적인 예를 제공합니다. 작동하는 Red Hat Gluster Storage 클러스터가 이미 설정되어 있다고 가정합니다. 통합 모드 또는 독립 모드 설치에 도움이 되는 경우 Red Hat Gluster Storage를 사용하여 영구 스토리지를 참조하십시오. 독립형 Red Hat Gluster Storage는 Red Hat Gluster Storage 관리 가이드를 참조하십시오.
GlusterFS 볼륨을 동적으로 프로비저닝하는 방법에 대한 엔드 투 엔드 예는 동적 프로비저닝을 위해 GlusterFS를 사용한 전체 예제를 참조하십시오.
모든 oc 명령은 OpenShift Container Platform 마스터 호스트에서 실행됩니다.
28.5.2. 사전 요구 사항
GlusterFS 볼륨에 액세스하려면 예약 가능한 모든 노드에서 mount.glusterfs 명령을 사용할 수 있어야 합니다. RPM 기반 시스템의 경우 glusterfs-fuse 패키지를 설치해야 합니다.
# yum install glusterfs-fuse이 패키지는 모든 RHEL 시스템에 설치됩니다. 하지만 서버가 x86_64 아키텍처를 사용하는 경우 Red Hat Gluster Storage에서 사용 가능한 최신 버전으로 업데이트하는 것이 좋습니다. 이를 수행하려면 다음 RPM 리포지토리를 활성화해야 합니다.
# subscription-manager repos --enable=rh-gluster-3-client-for-rhel-7-server-rpmsglusterfs-fuse 가 노드에 이미 설치된 경우 최신 버전이 설치되어 있는지 확인합니다.
# yum update glusterfs-fuse기본적으로 SELinux는 포드에서 원격 Red Hat Gluster Storage 서버로 쓰기를 허용하지 않습니다. 에서 SELinux를 사용하여 Red Hat Gluster Storage 볼륨에 쓰기를 활성화하려면 GlusterFS를 실행하는 각 노드에서 다음을 실행합니다.
$ sudo setsebool -P virt_sandbox_use_fusefs on
$ sudo setsebool -P virt_use_fusefs on- 1
- P
옵션을 사용하면재부팅 사이에 부울이 지속됩니다.
virt_sandbox_use_fusefs 부울은 docker-selinux 패키지에서 정의합니다. 정의되지 않았다는 오류가 표시되면 이 패키지가 설치되어 있는지 확인합니다.
Atomic Host를 사용하는 경우 Atomic Host를 업그레이드할 때 SELinux 부울이 지워집니다. Atomic Host를 업그레이드할 때 이러한 부울 값을 다시 설정해야 합니다.
28.5.3. 정적 프로비저닝
-
정적 프로비저닝을 활성화하려면 먼저 GlusterFS 볼륨을 만듭니다.
heketi를 사용하여 이 작업을 수행하는 방법에 대한 자세한 내용은 Red Hat Gluster Storage 관리 가이드를 참조하십시오. 이 예에서는 볼륨의 이름은-climyVol1로 지정됩니다. gluster-endpoints.yaml에서 다음 서비스 및 엔드포인트를 정의합니다.--- apiVersion: v1 kind: Service metadata: name: glusterfs-cluster1 spec: ports: - port: 1 --- apiVersion: v1 kind: Endpoints metadata: name: glusterfs-cluster2 subsets: - addresses: - ip: 192.168.122.2213 ports: - port: 14 - addresses: - ip: 192.168.122.2225 ports: - port: 16 - addresses: - ip: 192.168.122.2237 ports: - port: 18 OpenShift Container Platform 마스터 호스트에서 서비스 및 엔드포인트를 생성합니다.
$ oc create -f gluster-endpoints.yaml service "glusterfs-cluster" created endpoints "glusterfs-cluster" created서비스 및 엔드포인트가 생성되었는지 확인합니다.
$ oc get services NAME CLUSTER_IP EXTERNAL_IP PORT(S) SELECTOR AGE glusterfs-cluster 172.30.205.34 <none> 1/TCP <none> 44s $ oc get endpoints NAME ENDPOINTS AGE docker-registry 10.1.0.3:5000 4h glusterfs-cluster 192.168.122.221:1,192.168.122.222:1,192.168.122.223:1 11s kubernetes 172.16.35.3:8443 4d참고엔드포인트는 프로젝트별로 고유합니다. GlusterFS 볼륨에 액세스하는 각 프로젝트에는 고유한 엔드포인트가 필요합니다.
볼륨에 액세스하려면 볼륨의 파일 시스템에 액세스할 수 있는 UID(사용자 ID) 또는 그룹 ID(GID)를 사용하여 컨테이너를 실행해야 합니다. 이 정보는 다음과 같은 방식으로 검색할 수 있습니다.
$ mkdir -p /mnt/glusterfs/myVol1 $ mount -t glusterfs 192.168.122.221:/myVol1 /mnt/glusterfs/myVol1 $ ls -lnZ /mnt/glusterfs/ drwxrwx---. 592 590 system_u:object_r:fusefs_t:s0 myVol11 2 gluster-pv.yaml에서 다음 PV(PersistentVolume)를 정의합니다.apiVersion: v1 kind: PersistentVolume metadata: name: gluster-default-volume1 annotations: pv.beta.kubernetes.io/gid: "590"2 spec: capacity: storage: 2Gi3 accessModes:4 - ReadWriteMany glusterfs: endpoints: glusterfs-cluster5 path: myVol16 readOnly: false persistentVolumeReclaimPolicy: RetainOpenShift Container Platform 마스터 호스트에서 PV를 생성합니다.
$ oc create -f gluster-pv.yamlPV가 생성되었는지 확인합니다.
$ oc get pv NAME LABELS CAPACITY ACCESSMODES STATUS CLAIM REASON AGE gluster-default-volume <none> 2147483648 RWX Available 2sgluster-claim.yaml에서 새 PV에 바인딩할 PVC(PersistentVolumeClaim)를 생성합니다.apiVersion: v1 kind: PersistentVolumeClaim metadata: name: gluster-claim1 spec: accessModes: - ReadWriteMany2 resources: requests: storage: 1Gi3 OpenShift Container Platform 마스터 호스트에서 PVC를 생성합니다.
$ oc create -f gluster-claim.yamlPV 및 PVC가 바인딩되었는지 확인합니다.
$ oc get pv NAME LABELS CAPACITY ACCESSMODES STATUS CLAIM REASON AGE gluster-pv <none> 1Gi RWX Available gluster-claim 37s $ oc get pvc NAME LABELS STATUS VOLUME CAPACITY ACCESSMODES AGE gluster-claim <none> Bound gluster-pv 1Gi RWX 24s
PVC는 프로젝트별로 고유합니다. GlusterFS 볼륨에 액세스하는 각 프로젝트에는 자체 PVC가 필요합니다. PV는 단일 프로젝트에 바인딩되지 않으므로 여러 프로젝트의 PVC가 동일한 PV를 참조할 수 있습니다.
28.5.4. 스토리지 사용
이때 PVC에 바인딩된 GlusterFS 볼륨이 동적으로 생성됩니다. 이제 Pod에서 이 PVC를 사용할 수 있습니다.
Pod 오브젝트 정의를 생성합니다.
apiVersion: v1 kind: Pod metadata: name: hello-openshift-pod labels: name: hello-openshift-pod spec: containers: - name: hello-openshift-pod image: openshift/hello-openshift ports: - name: web containerPort: 80 volumeMounts: - name: gluster-vol1 mountPath: /usr/share/nginx/html readOnly: false volumes: - name: gluster-vol1 persistentVolumeClaim: claimName: gluster11 - 1
- 이전 단계에서 생성한 PVC의 이름입니다.
OpenShift Container Platform 마스터 호스트에서 Pod를 생성합니다.
# oc create -f hello-openshift-pod.yaml pod "hello-openshift-pod" created포드를 확인합니다. 이미지를 다운로드해야 하는 경우 이미지를 다운로드해야 하므로 몇 분 정도 기다립니다.
# oc get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE hello-openshift-pod 1/1 Running 0 9m 10.38.0.0 node1oc exec를 컨테이너로 실행하고 Pod의mountPath정의에 index.html 파일을 생성합니다.$ oc exec -ti hello-openshift-pod /bin/sh $ cd /usr/share/nginx/html $ echo 'Hello OpenShift!!!' > index.html $ ls index.html $ exit이제 Pod의 URL을
curl합니다.# curl http://10.38.0.0 Hello OpenShift!!!Pod를 삭제하고 다시 생성한 다음 표시될 때까지 기다립니다.
# oc delete pod hello-openshift-pod pod "hello-openshift-pod" deleted # oc create -f hello-openshift-pod.yaml pod "hello-openshift-pod" created # oc get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE hello-openshift-pod 1/1 Running 0 9m 10.37.0.0 node1이제 포드를 다시
curl로 지정하면 이전과 동일한 데이터가 계속 있어야 합니다. IP 주소가 변경될 수 있습니다.# curl http://10.37.0.0 Hello OpenShift!!!모든 노드에서 다음을 수행하여 index.html 파일이 GlusterFS 스토리지에 작성되었는지 확인합니다.
$ mount | grep heketi /dev/mapper/VolGroup00-LogVol00 on /var/lib/heketi type xfs (rw,relatime,seclabel,attr2,inode64,noquota) /dev/mapper/vg_f92e09091f6b20ab12b02a2513e4ed90-brick_1e730a5462c352835055018e1874e578 on /var/lib/heketi/mounts/vg_f92e09091f6b20ab12b02a2513e4ed90/brick_1e730a5462c352835055018e1874e578 type xfs (rw,noatime,seclabel,nouuid,attr2,inode64,logbsize=256k,sunit=512,swidth=512,noquota) /dev/mapper/vg_f92e09091f6b20ab12b02a2513e4ed90-brick_d8c06e606ff4cc29ccb9d018c73ee292 on /var/lib/heketi/mounts/vg_f92e09091f6b20ab12b02a2513e4ed90/brick_d8c06e606ff4cc29ccb9d018c73ee292 type xfs (rw,noatime,seclabel,nouuid,attr2,inode64,logbsize=256k,sunit=512,swidth=512,noquota) $ cd /var/lib/heketi/mounts/vg_f92e09091f6b20ab12b02a2513e4ed90/brick_d8c06e606ff4cc29ccb9d018c73ee292/brick $ ls index.html $ cat index.html Hello OpenShift!!!
28.6. 동적 프로비저닝에 GlusterFS를 사용한 전체 예
28.6.1. 개요
이 주제에서는 기존 통합 모드, 독립 모드 또는 독립 실행형 Red Hat Gluster Storage 클러스터를 OpenShift Container Platform의 동적 영구 스토리지로 사용하는 방법에 대한 포괄적인 예를 제공합니다. 작동하는 Red Hat Gluster Storage 클러스터가 이미 설정되어 있다고 가정합니다. 통합 모드 또는 독립 모드 설치에 도움이 되는 경우 Red Hat Gluster Storage를 사용하여 영구 스토리지를 참조하십시오. 독립형 Red Hat Gluster Storage는 Red Hat Gluster Storage 관리 가이드를 참조하십시오.
모든 oc 명령은 OpenShift Container Platform 마스터 호스트에서 실행됩니다.
28.6.2. 사전 요구 사항
GlusterFS 볼륨에 액세스하려면 예약 가능한 모든 노드에서 mount.glusterfs 명령을 사용할 수 있어야 합니다. RPM 기반 시스템의 경우 glusterfs-fuse 패키지를 설치해야 합니다.
# yum install glusterfs-fuse이 패키지는 모든 RHEL 시스템에 설치됩니다. 하지만 서버가 x86_64 아키텍처를 사용하는 경우 Red Hat Gluster Storage에서 사용 가능한 최신 버전으로 업데이트하는 것이 좋습니다. 이를 수행하려면 다음 RPM 리포지토리를 활성화해야 합니다.
# subscription-manager repos --enable=rh-gluster-3-client-for-rhel-7-server-rpmsglusterfs-fuse 가 노드에 이미 설치된 경우 최신 버전이 설치되어 있는지 확인합니다.
# yum update glusterfs-fuse기본적으로 SELinux는 포드에서 원격 Red Hat Gluster Storage 서버로 쓰기를 허용하지 않습니다. 에서 SELinux를 사용하여 Red Hat Gluster Storage 볼륨에 쓰기를 활성화하려면 GlusterFS를 실행하는 각 노드에서 다음을 실행합니다.
$ sudo setsebool -P virt_sandbox_use_fusefs on
$ sudo setsebool -P virt_use_fusefs on- 1
- P
옵션을 사용하면재부팅 사이에 부울이 지속됩니다.
virt_sandbox_use_fusefs 부울은 docker-selinux 패키지에서 정의합니다. 정의되지 않았다는 오류가 표시되면 이 패키지가 설치되어 있는지 확인합니다.
Atomic Host를 사용하는 경우 Atomic Host를 업그레이드할 때 SELinux 부울이 지워집니다. Atomic Host를 업그레이드할 때 이러한 부울 값을 다시 설정해야 합니다.
28.6.3. 동적 프로비저닝
동적 프로비저닝을 사용하려면 먼저
StorageClass오브젝트 정의를 생성합니다. 아래 정의는 OpenShift Container Platform을 사용하기 위해 이 예제에 필요한 최소 요구 사항을 기반으로 합니다. 추가 매개변수 및 사양 정의는 동적 프로비저닝 및 스토리지 클래스 생성을 참조하십시오.kind: StorageClass apiVersion: storage.k8s.io/v1 metadata: name: glusterfs provisioner: kubernetes.io/glusterfs parameters: resturl: "http://10.42.0.0:8080"1 restauthenabled: "false"2 OpenShift Container Platform 마스터 호스트에서 StorageClass를 생성합니다.
# oc create -f gluster-storage-class.yaml storageclass "glusterfs" created새로 생성된 StorageClass를 사용하여 PVC를 만듭니다. 예를 들면 다음과 같습니다.
apiVersion: v1 kind: PersistentVolumeClaim metadata: name: gluster1 spec: accessModes: - ReadWriteMany resources: requests: storage: 30Gi storageClassName: glusterfsOpenShift Container Platform 마스터 호스트에서 PVC를 생성합니다.
# oc create -f glusterfs-dyn-pvc.yaml persistentvolumeclaim "gluster1" createdPVC를 보고 볼륨이 동적으로 생성되어 PVC에 바인딩되었는지 확인합니다.
# oc get pvc NAME STATUS VOLUME CAPACITY ACCESSMODES STORAGECLASS AGE gluster1 Bound pvc-78852230-d8e2-11e6-a3fa-0800279cf26f 30Gi RWX glusterfs 42s
28.6.4. 스토리지 사용
이때 PVC에 바인딩된 GlusterFS 볼륨이 동적으로 생성됩니다. 이제 Pod에서 이 PVC를 사용할 수 있습니다.
Pod 오브젝트 정의를 생성합니다.
apiVersion: v1 kind: Pod metadata: name: hello-openshift-pod labels: name: hello-openshift-pod spec: containers: - name: hello-openshift-pod image: openshift/hello-openshift ports: - name: web containerPort: 80 volumeMounts: - name: gluster-vol1 mountPath: /usr/share/nginx/html readOnly: false volumes: - name: gluster-vol1 persistentVolumeClaim: claimName: gluster11 - 1
- 이전 단계에서 생성한 PVC의 이름입니다.
OpenShift Container Platform 마스터 호스트에서 Pod를 생성합니다.
# oc create -f hello-openshift-pod.yaml pod "hello-openshift-pod" created포드를 확인합니다. 이미지를 다운로드해야 하는 경우 이미지를 다운로드해야 하므로 몇 분 정도 기다립니다.
# oc get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE hello-openshift-pod 1/1 Running 0 9m 10.38.0.0 node1oc exec를 컨테이너로 실행하고 Pod의mountPath정의에 index.html 파일을 생성합니다.$ oc exec -ti hello-openshift-pod /bin/sh $ cd /usr/share/nginx/html $ echo 'Hello OpenShift!!!' > index.html $ ls index.html $ exit이제 Pod의 URL을
curl합니다.# curl http://10.38.0.0 Hello OpenShift!!!Pod를 삭제하고 다시 생성한 다음 표시될 때까지 기다립니다.
# oc delete pod hello-openshift-pod pod "hello-openshift-pod" deleted # oc create -f hello-openshift-pod.yaml pod "hello-openshift-pod" created # oc get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE hello-openshift-pod 1/1 Running 0 9m 10.37.0.0 node1이제 포드를 다시
curl로 지정하면 이전과 동일한 데이터가 계속 있어야 합니다. IP 주소가 변경될 수 있습니다.# curl http://10.37.0.0 Hello OpenShift!!!모든 노드에서 다음을 수행하여 index.html 파일이 GlusterFS 스토리지에 작성되었는지 확인합니다.
$ mount | grep heketi /dev/mapper/VolGroup00-LogVol00 on /var/lib/heketi type xfs (rw,relatime,seclabel,attr2,inode64,noquota) /dev/mapper/vg_f92e09091f6b20ab12b02a2513e4ed90-brick_1e730a5462c352835055018e1874e578 on /var/lib/heketi/mounts/vg_f92e09091f6b20ab12b02a2513e4ed90/brick_1e730a5462c352835055018e1874e578 type xfs (rw,noatime,seclabel,nouuid,attr2,inode64,logbsize=256k,sunit=512,swidth=512,noquota) /dev/mapper/vg_f92e09091f6b20ab12b02a2513e4ed90-brick_d8c06e606ff4cc29ccb9d018c73ee292 on /var/lib/heketi/mounts/vg_f92e09091f6b20ab12b02a2513e4ed90/brick_d8c06e606ff4cc29ccb9d018c73ee292 type xfs (rw,noatime,seclabel,nouuid,attr2,inode64,logbsize=256k,sunit=512,swidth=512,noquota) $ cd /var/lib/heketi/mounts/vg_f92e09091f6b20ab12b02a2513e4ed90/brick_d8c06e606ff4cc29ccb9d018c73ee292/brick $ ls index.html $ cat index.html Hello OpenShift!!!
28.7. 권한이 있는 Pod에서 볼륨 마운트
28.7.1. 개요
권한 있는 SCC(보안 컨텍스트 제약 조건)가 연결된 Pod에 영구 볼륨을 마운트할 수 있습니다.
이 주제에서는 권한 있는 포드에 볼륨을 마운트하기 위한 샘플 사용 사례로 GlusterFS를 사용하지만 지원되는 스토리지 플러그인을 사용하도록 조정할 수 있습니다.
28.7.2. 사전 요구 사항
- 기존 Gluster 볼륨.
- GlusterFS-fuse 가 모든 호스트에 설치되어 있습니다.
GlusterFS 정의:
- 엔드포인트 및 서비스:gluster-endpoints-service.yaml 및 gluster-endpoints.yaml
- 영구 볼륨:gluster-pv.yaml
- 영구 볼륨 클레임:gluster-pvc.yaml
- 권한 있는 Pod:gluster-S3-pod.yaml
-
cluster-admin 역할 바인딩이 있는 사용자. 이 가이드의 경우 해당 사용자를
admin이라고 합니다.
28.7.3. 영구 볼륨 생성
PersistentVolume 을 생성하면 프로젝트와 관계없이 사용자가 스토리지에 액세스할 수 있습니다.
admin으로 서비스, 끝점 오브젝트 및 영구 볼륨을 생성합니다.
$ oc create -f gluster-endpoints-service.yaml $ oc create -f gluster-endpoints.yaml $ oc create -f gluster-pv.yaml오브젝트가 생성되었는지 확인합니다.
$ oc get svc NAME CLUSTER_IP EXTERNAL_IP PORT(S) SELECTOR AGE gluster-cluster 172.30.151.58 <none> 1/TCP <none> 24s$ oc get ep NAME ENDPOINTS AGE gluster-cluster 192.168.59.102:1,192.168.59.103:1 2m$ oc get pv NAME LABELS CAPACITY ACCESSMODES STATUS CLAIM REASON AGE gluster-default-volume <none> 2Gi RWX Available 2d
28.7.4. 정규 사용자 생성
일반 사용자를 권한 있는 SCC(또는 SCC에 지정된 그룹 액세스)에 추가하면 권한 있는 Pod를 실행할 수 있습니다.
admin으로 SCC에 사용자를 추가합니다.
$ oc adm policy add-scc-to-user privileged <username>일반 사용자로 로그인합니다.
$ oc login -u <username> -p <password>그런 다음 새 프로젝트를 생성합니다.
$ oc new-project <project_name>
28.7.5. 영구 볼륨 클레임 생성
일반 사용자로 PersistentVolumeClaim 을 생성하여 볼륨에 액세스합니다.
$ oc create -f gluster-pvc.yaml -n <project_name>클레임에 액세스할 Pod를 정의합니다.
예 28.10. Pod 정의
apiVersion: v1 id: gluster-S3-pvc kind: Pod metadata: name: gluster-nginx-priv spec: containers: - name: gluster-nginx-priv image: fedora/nginx volumeMounts: - mountPath: /mnt/gluster1 name: gluster-volume-claim securityContext: privileged: true volumes: - name: gluster-volume-claim persistentVolumeClaim: claimName: gluster-claim2 Pod를 생성할 때 마운트 디렉터리가 생성되고 볼륨이 해당 마운트 지점에 연결됩니다.
일반 사용자로 정의에서 Pod를 생성합니다.
$ oc create -f gluster-S3-pod.yamlPod가 성공적으로 생성되었는지 확인합니다.
$ oc get pods NAME READY STATUS RESTARTS AGE gluster-S3-pod 1/1 Running 0 36m포드가 생성하는 데 몇 분이 걸릴 수 있습니다.
28.7.6. 설정 확인
28.7.6.1. Pod SCC 확인
Pod 구성을 내보냅니다.
$ oc get -o yaml --export pod <pod_name>출력을 검사합니다.
openshift.io/scc의 값이privileged인지 확인합니다.예 28.11. 슬라이프 내보내기
metadata: annotations: openshift.io/scc: privileged
28.7.6.2. 마운트 확인
Pod에 액세스하여 볼륨이 마운트되었는지 확인합니다.
$ oc rsh <pod_name> [root@gluster-S3-pvc /]# mountGluster 볼륨의 출력을 검사합니다.
예 28.12. 볼륨 마운트
192.168.59.102:gv0 on /mnt/gluster type fuse.gluster (rw,relatime,user_id=0,group_id=0,default_permissions,allow_other,max_read=131072)
28.8. 전달 마운트
28.8.1. 개요
마운트 전파를 사용하면 컨테이너에서 마운트한 볼륨을 동일한 Pod의 다른 컨테이너 또는 동일한 노드의 다른 Pod로 공유할 수 있습니다.
28.8.2. 값
볼륨 마운트 전파는 Container.volumeMounts 의 mountPropagation 필드에 의해 제어됩니다. 해당 값은 다음과 같습니다.
-
none- 이 볼륨 마운트는 호스트에서 이 볼륨 또는 하위 디렉토리에 마운트된 후속 마운트를 받지 않습니다. 마찬가지로, 컨테이너에서 생성한 마운트가 호스트에 표시되지 않습니다. 이는 기본 모드이며 Linux 커널의개인마운트 전파와 동일합니다. -
HostToContainer- 이 볼륨 마운트는 이 볼륨 또는 하위 디렉토리에 마운트된 모든 후속 마운트를 받습니다. 즉, 호스트가 볼륨 마운트 내부에 있는 항목을 마운트하면 컨테이너가 마운트된 것을 인식합니다. 이 모드는 Linux 커널의rslave마운트 전파와 동일합니다. -
양방향- 이 볼륨 마운트는HostToContainer마운트와 동일하게 작동합니다. 또한 컨테이너에서 생성한 모든 볼륨 마운트는 동일한 볼륨을 사용하는 모든 포드의 모든 컨테이너와 호스트로 다시 전파됩니다. 이 모드의 일반적인 사용 사례는 FlexVolume 또는 CSI 드라이버가 있는 Pod 또는hostPath볼륨을 사용하여 호스트에 항목을 마운트해야 하는 Pod입니다. 이 모드는 Linux 커널의rshared마운트 전파와 동일합니다.
양방향 마운트 전파는 위험할 수 있습니다. 호스트 운영 체제를 손상시킬 수 있으므로 권한 있는 컨테이너에서만 허용됩니다. Linux 커널 동작을 잘 알고 있는 것이 좋습니다. 또한 Pod의 컨테이너에서 생성한 볼륨 마운트는 종료 시 컨테이너에서 삭제하거나 마운트 해제해야 합니다.
28.8.3. 설정
CoreOS, Red Hat Enterprise Linux/Centos 또는 Ubuntu와 같은 일부 배포에서 마운트 전파가 제대로 작동하려면 Docker에서 마운트 공유를 올바르게 구성해야 합니다.
절차
Docker의 systemd 서비스 파일을 편집합니다. 다음과 같이
MountFlags를 설정합니다.MountFlags=shared또는
MountFlags=slave(있는 경우)를 제거합니다.Docker 데몬을 다시 시작하십시오.
$ sudo systemctl daemon-reload $ sudo systemctl restart docker
28.9. 통합 OpenShift Container Registry를 GlusterFS로 전환
28.9.1. 개요
이 주제에서는 통합 OpenShift Container Registry에 GlusterFS 볼륨을 연결하는 방법을 검토합니다. 이 작업은 통합 모드, 독립 실행형 모드 또는 독립형 Red Hat Gluster Storage로 수행할 수 있습니다. 레지스트리가 이미 시작되었으며 볼륨이 생성되었다고 가정합니다.
28.9.2. 사전 요구 사항
- 스토리지를 구성하지 않고 배포된 기존 레지스트리 입니다.
- 기존 GlusterFS 볼륨
- 예약 가능한 모든 노드에 GlusterFS -fuse 설치.
cluster-admin 역할 바인딩이 있는 사용자.
- 이 가이드의 경우 해당 사용자는 admin 입니다.
모든 oc 명령은 마스터 노드에서 admin 사용자로 실행됩니다.
28.9.3. GlusterFS PersistentVolumeClaim 수동 프로비저닝
-
정적 프로비저닝을 활성화하려면 먼저 GlusterFS 볼륨을 만듭니다.
heketi를 사용하여 이 작업을 수행하는 방법에 대한 자세한 내용은 Red Hat Gluster Storage 관리 가이드를 참조하십시오. 이 예에서는 볼륨의 이름은-climyVol1로 지정됩니다. gluster-endpoints.yaml에서 다음 서비스 및 엔드포인트를 정의합니다.--- apiVersion: v1 kind: Service metadata: name: glusterfs-cluster1 spec: ports: - port: 1 --- apiVersion: v1 kind: Endpoints metadata: name: glusterfs-cluster2 subsets: - addresses: - ip: 192.168.122.2213 ports: - port: 14 - addresses: - ip: 192.168.122.2225 ports: - port: 16 - addresses: - ip: 192.168.122.2237 ports: - port: 18 OpenShift Container Platform 마스터 호스트에서 서비스 및 엔드포인트를 생성합니다.
$ oc create -f gluster-endpoints.yaml service "glusterfs-cluster" created endpoints "glusterfs-cluster" created서비스 및 엔드포인트가 생성되었는지 확인합니다.
$ oc get services NAME CLUSTER_IP EXTERNAL_IP PORT(S) SELECTOR AGE glusterfs-cluster 172.30.205.34 <none> 1/TCP <none> 44s $ oc get endpoints NAME ENDPOINTS AGE docker-registry 10.1.0.3:5000 4h glusterfs-cluster 192.168.122.221:1,192.168.122.222:1,192.168.122.223:1 11s kubernetes 172.16.35.3:8443 4d참고엔드포인트는 프로젝트별로 고유합니다. GlusterFS 볼륨에 액세스하는 각 프로젝트에는 고유한 엔드포인트가 필요합니다.
볼륨에 액세스하려면 볼륨의 파일 시스템에 액세스할 수 있는 UID(사용자 ID) 또는 그룹 ID(GID)를 사용하여 컨테이너를 실행해야 합니다. 이 정보는 다음과 같은 방식으로 검색할 수 있습니다.
$ mkdir -p /mnt/glusterfs/myVol1 $ mount -t glusterfs 192.168.122.221:/myVol1 /mnt/glusterfs/myVol1 $ ls -lnZ /mnt/glusterfs/ drwxrwx---. 592 590 system_u:object_r:fusefs_t:s0 myVol11 2 gluster-pv.yaml에서 다음 PV(PersistentVolume)를 정의합니다.apiVersion: v1 kind: PersistentVolume metadata: name: gluster-default-volume1 annotations: pv.beta.kubernetes.io/gid: "590"2 spec: capacity: storage: 2Gi3 accessModes:4 - ReadWriteMany glusterfs: endpoints: glusterfs-cluster5 path: myVol16 readOnly: false persistentVolumeReclaimPolicy: RetainOpenShift Container Platform 마스터 호스트에서 PV를 생성합니다.
$ oc create -f gluster-pv.yamlPV가 생성되었는지 확인합니다.
$ oc get pv NAME LABELS CAPACITY ACCESSMODES STATUS CLAIM REASON AGE gluster-default-volume <none> 2147483648 RWX Available 2sgluster-claim.yaml에서 새 PV에 바인딩할 PVC(PersistentVolumeClaim)를 생성합니다.apiVersion: v1 kind: PersistentVolumeClaim metadata: name: gluster-claim1 spec: accessModes: - ReadWriteMany2 resources: requests: storage: 1Gi3 OpenShift Container Platform 마스터 호스트에서 PVC를 생성합니다.
$ oc create -f gluster-claim.yamlPV 및 PVC가 바인딩되었는지 확인합니다.
$ oc get pv NAME LABELS CAPACITY ACCESSMODES STATUS CLAIM REASON AGE gluster-pv <none> 1Gi RWX Available gluster-claim 37s $ oc get pvc NAME LABELS STATUS VOLUME CAPACITY ACCESSMODES AGE gluster-claim <none> Bound gluster-pv 1Gi RWX 24s
PVC는 프로젝트별로 고유합니다. GlusterFS 볼륨에 액세스하는 각 프로젝트에는 자체 PVC가 필요합니다. PV는 단일 프로젝트에 바인딩되지 않으므로 여러 프로젝트의 PVC가 동일한 PV를 참조할 수 있습니다.
28.9.4. PersistentVolumeClaim을 레지스트리에 연결합니다.
계속 진행하기 전에 docker-registry 서비스가 실행 중인지 확인합니다.
$ oc get svc
NAME CLUSTER_IP EXTERNAL_IP PORT(S) SELECTOR AGE
docker-registry 172.30.167.194 <none> 5000/TCP docker-registry=default 18mdocker-registry 서비스 또는 관련 포드가 실행 중이지 않은 경우 계속하기 전에 문제 해결에 대한 레지스트리 설정 지침을 참조하십시오.
그런 다음 PVC를 연결합니다.
$ oc set volume deploymentconfigs/docker-registry --add --name=registry-storage -t pvc \
--claim-name=gluster-claim --overwrite레지스트리를 설정하면 OpenShift Container Registry 사용에 대한 자세한 정보가 제공됩니다.
28.10. 라벨을 통한 영구 볼륨 바인딩
28.10.1. 개요
이 주제에서는 PV에 레이블을 정의하고 PVC에서 일치하는 선택기를 일치시켜 PVC( 영구 볼륨 클레임) 를 PV(영구 볼륨 클레임) 에 바인딩하기 위한 엔드 투 엔드 예를 제공합니다. 이 기능은 모든 스토리지 옵션에 사용할 수 있습니다. OpenShift Container Platform 클러스터에 PVC에서 바인딩할 수 있는 영구 스토리지 리소스가 포함되어 있다고 가정합니다.
레이블 및 선택기에 대한 참고 사항
레이블은 오브젝트 사양의 일부로 사용자 정의 태그(키-값 쌍)를 지원하는 OpenShift Container Platform 기능입니다. 주요 목적은 동일한 레이블을 정의하여 오브젝트의 임의 그룹을 활성화하는 것입니다. 그런 다음 선택기에서 이러한 라벨을 대상으로 지정하여 모든 오브젝트와 지정된 레이블 값과 일치시킬 수 있습니다. 이 기능은 PVC가 PV에 바인딩할 수 있도록 하는 기능입니다. 라벨에 대한 자세한 내용은 Pod 및 Service를 참조하십시오.
이 예제에서는 수정된 GlusterFS PV 및 PVC 사양을 사용합니다. 그러나 선택기 및 레이블 구현은 모든 스토리지 옵션에서 일반적으로 사용됩니다. 고유한 구성에 대해 자세히 알아보려면 볼륨 공급자에 대한 관련 스토리지 옵션을 참조하십시오.
28.10.1.1. 가정
다음과 같은 결과가 있다고 가정합니다.
- 마스터 및 노드가 하나 이상 있는 기존 OpenShift Container Platform 클러스터
- 하나 이상의 지원되는 스토리지 볼륨
- cluster-admin 권한이 있는 사용자
28.10.2. 사양 정의
이러한 사양은 GlusterFS 에 맞게 조정됩니다. 고유한 구성에 대해 자세히 알아보려면 볼륨 공급자에 대한 관련 스토리지 옵션을 참조하십시오.
28.10.2.1. 레이블이 있는 영구 볼륨
예 28.13. glusterfs-pv.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: gluster-volume
labels:
storage-tier: gold
aws-availability-zone: us-east-1
spec:
capacity:
storage: 2Gi
accessModes:
- ReadWriteMany
glusterfs:
endpoints: glusterfs-cluster
path: myVol1
readOnly: false
persistentVolumeReclaimPolicy: Retain28.10.2.2. 선택기를 사용한 영구 볼륨 클레임
선택기 스탠자가 있는 클레임(아래 예제 참조)은 기존, Unclaimed 및 비prebound PV와 일치하려고 합니다. PVC 선택기가 있으면 PV의 용량을 무시합니다. 그러나 일치하는 기준에는 여전히 accessModes 가 고려됩니다.
클레임이 선택기 스탠자에 포함된 모든 키-값 쌍과 일치해야 합니다. 클레임과 일치하는 PV가 없으면 PVC는 바인딩되지 않은 상태로 유지됩니다(보류 중). 나중에 PV를 생성할 수 있으며 클레임이 레이블이 일치하는지 자동으로 확인합니다.
예 28.14. glusterfs-pvc.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: gluster-claim
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 1Gi
selector:
matchLabels:
storage-tier: gold
aws-availability-zone: us-east-1- 1
- 선택기 스탠자는 이 클레임과 일치하도록 PV에 필요한 모든 레이블을 정의합니다.
28.10.2.3. 볼륨 엔드 포인트
PV를 Gluster 볼륨에 연결하려면 오브젝트를 생성하기 전에 끝점을 구성해야 합니다.
예 28.15. glusterfs-ep.yaml
apiVersion: v1
kind: Endpoints
metadata:
name: glusterfs-cluster
subsets:
- addresses:
- ip: 192.168.122.221
ports:
- port: 1
- addresses:
- ip: 192.168.122.222
ports:
- port: 128.10.2.4. PV, PVC, 엔드포인트 배포
이 예에서는 oc 명령을 cluster -admin 권한 있는 사용자로 실행합니다. 프로덕션 환경에서 클러스터 클라이언트는 PVC를 정의하고 생성할 것으로 예상될 수 있습니다.
# oc create -f glusterfs-ep.yaml
endpoints "glusterfs-cluster" created
# oc create -f glusterfs-pv.yaml
persistentvolume "gluster-volume" created
# oc create -f glusterfs-pvc.yaml
persistentvolumeclaim "gluster-claim" created마지막으로 PV 및 PVC가 성공적으로 바인딩되었는지 확인합니다.
# oc get pv,pvc
NAME CAPACITY ACCESSMODES STATUS CLAIM REASON AGE
gluster-volume 2Gi RWX Bound gfs-trial/gluster-claim 7s
NAME STATUS VOLUME CAPACITY ACCESSMODES AGE
gluster-claim Bound gluster-volume 2Gi RWX 7sPVC는 프로젝트에 로컬인 반면 PV는 클러스터 전체의 글로벌 리소스입니다. 개발자 및 비관리자 사용자는 사용 가능한 PV의 전체(또는 임의의)를 볼 수 있는 권한이 없을 수 있습니다.
28.11. 동적 프로비저닝을 위해 스토리지 클래스 사용
28.11.1. 개요
이 예제에서는 GCE(Google Cloud Platform Compute Engine)를 사용한 StorageClass의 다양한 구성 및 동적 프로비저닝 시나리오에 대해 설명합니다. 이 예제에서는 Kubernetes, GCE, Persistent Disks 및 OpenShift Container Platform에 대해 어느 정도 익숙한 것으로 가정하고 GCE를 사용하도록 올바르게 구성되어 있다고 가정합니다.
28.11.2. 시나리오 1: 두 가지 유형의 스토리지 클래스를 사용하는 기본 동적 프로비저닝
스토리지 클래스를 사용하여 스토리지 수준 및 사용량을 구분하고 설명할 수 있습니다. 이 경우 cluster-admin 또는 storage -admin 은 GCE에서 두 개의 개별 스토리지 클래스를 설정합니다.
-
slow: 순차적 데이터 운영에 적합하며 저렴하고 효율적이며 최적화되었습니다(읽기 및 쓰기가 더 낮음) -
fast: 임의 IOPS 및 지속 처리량을 높도록 최적화 (빠른 읽기 및 쓰기)
이러한 StorageClass를 생성하면 cluster -admin 또는 을 사용하여 사용자가 StorageClass 의 특정 수준 또는 서비스를 요청하는 클레임을 생성할 수 있습니다.
storage-admin
예 28.16. StorageClass Slow 오브젝트 정의
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: slow
provisioner: kubernetes.io/gce-pd
parameters:
type: pd-standard
zone: us-east1-d 예 28.17. 스토리지 클래스 빠른 오브젝트 정의
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: fast
provisioner: kubernetes.io/gce-pd
parameters:
type: pd-ssd
zone: us-east1-d
cluster-admin 또는 storage-admin 으로 두 정의를 모두 YAML 파일로 저장합니다. 예를 들어 slow-gce.yaml 및 fast-gce.yaml 입니다. 그런 다음 StorageClasses를 만듭니다.
# oc create -f slow-gce.yaml
storageclass "slow" created
# oc create -f fast-gce.yaml
storageclass "fast" created
# oc get storageclass
NAME TYPE
fast kubernetes.io/gce-pd
slow kubernetes.io/gce-pd
cluster-admin 또는 storage-admin 사용자는 올바른 StorageClass 이름을 올바른 사용자, 그룹 및 프로젝트로 중계합니다.
일반 사용자로 새 프로젝트를 생성합니다.
# oc new-project rh-eng
클레임 YAML 정의를 생성하여 파일에 저장합니다(pvc-fast.yaml).
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc-engineering
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 10Gi
storageClassName: fast
oc create 명령으로 클레임을 추가합니다.
# oc create -f pvc-fast.yaml
persistentvolumeclaim "pvc-engineering" created클레임이 바인딩되었는지 확인합니다.
# oc get pvc
NAME STATUS VOLUME CAPACITY ACCESSMODES AGE
pvc-engineering Bound pvc-e9b4fef7-8bf7-11e6-9962-42010af00004 10Gi RWX 2m이 클레임은 rh-eng 프로젝트에 생성 및 바인딩되었으므로 동일한 프로젝트의 모든 사용자가 공유할 수 있습니다.
cluster-admin 또는 storage -admin 사용자로 최근 동적으로 프로비저닝된 PV(영구 볼륨)를 확인합니다.
# oc get pv
NAME CAPACITY ACCESSMODES RECLAIMPOLICY STATUS CLAIM REASON AGE
pvc-e9b4fef7-8bf7-11e6-9962-42010af00004 10Gi RWX Delete Bound rh-eng/pvc-engineering 5m동적으로 프로비저닝된 모든 볼륨에서 RECLAIMPOLICY 는 기본적으로 Delete 입니다. 즉, 볼륨은 클레임이 시스템에 남아 있는 경우에만 유지됩니다. 클레임을 삭제하면 볼륨도 삭제되고 볼륨의 모든 데이터가 손실됩니다.
마지막으로 GCE 콘솔을 확인합니다. 새 디스크가 생성되었으며 사용할 준비가 되었습니다.
kubernetes-dynamic-pvc-e9b4fef7-8bf7-11e6-9962-42010af00004 SSD persistent disk 10 GB us-east1-d이제 Pod에서 영구 볼륨 클레임을 참조하고 볼륨 사용을 시작할 수 있습니다.
28.11.3. 시나리오 2: 클러스터에 대한 기본 StorageClass 동작을 활성화하는 방법
이 예에서 cluster-admin 또는 storage-admin 은 클레임에 StorageClass 를 암시적으로 지정하지 않는 다른 모든 사용자와 프로젝트에 기본 스토리지 클래스를 활성화합니다. 이는 클러스터 전체에서 특수 StorageClass 를 설정하거나 통신할 필요 없이 cluster -admin이 스토리지 볼륨을 쉽게 관리하는 데 유용합니다.
-admin 또는 storage
이 예제는 28.11.2절. “시나리오 1: 두 가지 유형의 스토리지 클래스를 사용하는 기본 동적 프로비저닝 ” 를 기반으로 빌드됩니다. cluster-admin 또는 storage-admin 은 기본 StorageClass 로 지정을 위해 다른 스토리지 클래스를 생성합니다.
예 28.18. 기본 StorageClass 오브젝트 정의
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: generic
annotations:
storageclass.kubernetes.io/is-default-class: "true"
provisioner: kubernetes.io/gce-pd
parameters:
type: pd-standard
zone: us-east1-d
cluster-admin 또는 storage-admin 이 정의를 YAML 파일(generic-gce.yaml)에 저장한 다음 StorageClasses를 생성합니다.
# oc create -f generic-gce.yaml
storageclass "generic" created
# oc get storageclass
NAME TYPE
generic kubernetes.io/gce-pd
fast kubernetes.io/gce-pd
slow kubernetes.io/gce-pd
일반 사용자로 StorageClass 요구 사항 없이 새 클레임 정의를 생성하여 파일(generic-pvc.yaml)에 저장합니다.
예 28.19. 기본 스토리지 클레임 오브젝트 정의
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc-engineering2
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 5Gi이를 실행하고 클레임이 바인딩되었는지 확인합니다.
# oc create -f generic-pvc.yaml
persistentvolumeclaim "pvc-engineering2" created
3s
# oc get pvc
NAME STATUS VOLUME CAPACITY ACCESSMODES AGE
pvc-engineering Bound pvc-e9b4fef7-8bf7-11e6-9962-42010af00004 10Gi RWX 41m
pvc-engineering2 Bound pvc-a9f70544-8bfd-11e6-9962-42010af00004 5Gi RWX 7s - 1
PVC-engineering2는 기본적으로 동적으로 프로비저닝된 볼륨에 바인딩됩니다.
cluster-admin 또는 storage-admin 으로 지금까지 정의된 영구 볼륨을 확인합니다.
# oc get pv
NAME CAPACITY ACCESSMODES RECLAIMPOLICY STATUS CLAIM REASON AGE
pvc-a9f70544-8bfd-11e6-9962-42010af00004 5Gi RWX Delete Bound rh-eng/pvc-engineering2 5m
pvc-ba4612ce-8b4d-11e6-9962-42010af00004 5Gi RWO Delete Bound mytest/gce-dyn-claim1 21h
pvc-e9b4fef7-8bf7-11e6-9962-42010af00004 10Gi RWX Delete Bound rh-eng/pvc-engineering 46m - 1
- 이 PV는 기본 StorageClass 의 기본 동적 볼륨에 바인딩되었습니다.
- 2
- 이 PV는 빠른 스토리지 클래스 와 함께 28.11.2절. “시나리오 1: 두 가지 유형의 스토리지 클래스를 사용하는 기본 동적 프로비저닝 ” 의 첫 번째 PVC에 바인딩되었습니다.
GCE (동일적으로 프로비저닝되지 않음)를 사용하여 수동으로 프로비저닝된 디스크를 생성합니다. 그런 다음 새 GCE 디스크(pv-manual-gce.yaml)에 연결하는 영구 볼륨을 만듭니다.
예 28.20. 수동 PV 오브젝트 정의
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv-manual-gce
spec:
capacity:
storage: 35Gi
accessModes:
- ReadWriteMany
gcePersistentDisk:
readOnly: false
pdName: the-newly-created-gce-PD
fsType: ext4오브젝트 정의 파일을 실행합니다.
# oc create -f pv-manual-gce.yaml
이제 PV를 다시 확인합니다. pv-manual-gce 볼륨이 Available(사용 가능 )인지 확인합니다.
# oc get pv
NAME CAPACITY ACCESSMODES RECLAIMPOLICY STATUS CLAIM REASON AGE
pv-manual-gce 35Gi RWX Retain Available 4s
pvc-a9f70544-8bfd-11e6-9962-42010af00004 5Gi RWX Delete Bound rh-eng/pvc-engineering2 12m
pvc-ba4612ce-8b4d-11e6-9962-42010af00004 5Gi RWO Delete Bound mytest/gce-dyn-claim1 21h
pvc-e9b4fef7-8bf7-11e6-9962-42010af00004 10Gi RWX Delete Bound rh-eng/pvc-engineering 53m
이제 generic-pvc.yaml PVC 정의와 동일한 다른 클레임을 생성하되 이름을 변경하고 스토리지 클래스 이름을 설정하지 마십시오.
예 28.21. Claim 오브젝트 정의
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc-engineering3
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 15Gi이 인스턴스에서 기본 StorageClass 가 활성화되므로 수동으로 생성된 PV가 클레임 요청을 충족하지 않습니다. 사용자는 동적으로 프로비저닝된 새 영구 볼륨을 받습니다.
# oc get pvc
NAME STATUS VOLUME CAPACITY ACCESSMODES AGE
pvc-engineering Bound pvc-e9b4fef7-8bf7-11e6-9962-42010af00004 10Gi RWX 1h
pvc-engineering2 Bound pvc-a9f70544-8bfd-11e6-9962-42010af00004 5Gi RWX 19m
pvc-engineering3 Bound pvc-6fa8e73b-8c00-11e6-9962-42010af00004 15Gi RWX 6s이 시스템에서 기본 StorageClass 가 활성화되므로 수동으로 생성된 영구 볼륨이 위의 클레임에 의해 바인딩되고 새 동적 프로비저닝 볼륨이 바인딩되지 않도록 하려면 기본 StorageClass 에 PV를 생성해야 합니다.
이 시스템에서 기본 StorageClass 가 활성화되어 있으므로 수동으로 생성된 영구 볼륨의 기본 StorageClass 에서 PV를 생성하여 위의 클레임에 바인딩되고 클레임에 바인딩된 새 동적 프로비저닝 볼륨이 없어야 합니다.
이 문제를 해결하려면 cluster-admin 또는 storage-admin 사용자가 다른 GCE 디스크를 생성하거나 첫 번째 수동 PV를 삭제하고 필요한 경우 StorageClass 이름(pv-manual-gce2.yaml)을 할당하는 PV 오브젝트 정의를 사용해야 합니다.
예 28.22. 기본 StorageClass 이름이 있는 수동 PV 사양
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv-manual-gce2
spec:
capacity:
storage: 35Gi
accessModes:
- ReadWriteMany
gcePersistentDisk:
readOnly: false
pdName: the-newly-created-gce-PD
fsType: ext4
storageClassName: generic - 1
- 이전에 생성된 일반 스토리지 클래스 의 이름입니다.
오브젝트 정의 파일을 실행합니다.
# oc create -f pv-manual-gce2.yamlPV를 나열합니다.
# oc get pv
NAME CAPACITY ACCESSMODES RECLAIMPOLICY STATUS CLAIM REASON AGE
pv-manual-gce 35Gi RWX Retain Available 4s
pv-manual-gce2 35Gi RWX Retain Bound rh-eng/pvc-engineering3 4s
pvc-a9f70544-8bfd-11e6-9962-42010af00004 5Gi RWX Delete Bound rh-eng/pvc-engineering2 12m
pvc-ba4612ce-8b4d-11e6-9962-42010af00004 5Gi RWO Delete Bound mytest/gce-dyn-claim1 21h
pvc-e9b4fef7-8bf7-11e6-9962-42010af00004 10Gi RWX Delete Bound rh-eng/pvc-engineering 53m기본적으로 동적으로 프로비저닝된 모든 볼륨의 RECLAIMPOLICICICY of Delete 가 있습니다. PVC가 동적으로 PV에 바인딩되면 GCE 볼륨이 삭제되고 모든 데이터가 손실됩니다. 그러나 수동으로 생성된 PV에는 기본 Re CLAIMPOLICICY 가 Retain 이 있습니다.
28.12. 기존 레거시 스토리지에 스토리지 클래스 사용
28.12.1. 개요
이 예에서는 레거시 데이터 볼륨이 존재하며 cluster-admin 또는 storage-admin 은 특정 프로젝트에서 사용할 수 있도록 설정해야 합니다. 스토리지 클래스를 사용하면 StorageClass 이름에 대해 클레임과 정확히 일치하는 값이 있어야 하므로 클레임에서 이 볼륨에 액세스할 수 있는 다른 사용자와 프로젝트가 발생할 가능성이 줄어듭니다. 이 예제에서는 동적 프로비저닝도 비활성화합니다. 이 예제에서는 다음을 가정합니다.
- OpenShift Container Platform, GCE, 영구 디스크에 대해 어느 정도 익숙한 경우
- OpenShift Container Platform이 GCE를 사용하도록 올바르게 구성되어 있습니다.
28.12.1.1. 시나리오 1: 레거시 데이터로 스토리지 클래스를 기존 영구 볼륨에 연결
cluster-admin 또는 storage-admin 으로 기록 금융 데이터에 대한 StorageClass 를 정의하고 생성합니다.
예 28.23. 스토리지 클래스 finance-history 오브젝트 정의
정의를 YAML 파일(finance-history-storageclass.yaml)에 저장하고 StorageClass 를 만듭니다.
# oc create -f finance-history-storageclass.yaml
storageclass "finance-history" created
# oc get storageclass
NAME TYPE
finance-history no-provisioning
cluster-admin 또는 storage-admin 사용자는 올바른 StorageClass 이름을 올바른 사용자, 그룹 및 프로젝트로 중계합니다.
StorageClass 가 있습니다. cluster-admin 또는 storage-admin 은 StorageClass 에 사용할 영구 볼륨(PV)을 생성할 수 있습니다. 새 GCE 디스크(gce-pv.yaml)에 연결하는 GCE(동적 프로비저닝되지 않음) 및 영구 볼륨을 사용하여 수동으로 프로비저닝된 디스크를 생성합니다.
예 28.24. 재무 기록 PV 오브젝트
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv-finance-history
spec:
capacity:
storage: 35Gi
accessModes:
- ReadWriteMany
gcePersistentDisk:
readOnly: false
pdName: the-existing-PD-volume-name-that-contains-the-valuable-data
fsType: ext4
storageClassName: finance-history
cluster-admin 또는 storage-admin 으로 PV를 생성하고 확인합니다.
# oc create -f gce-pv.yaml
persistentvolume "pv-finance-history" created
# oc get pv
NAME CAPACITY ACCESSMODES RECLAIMPOLICY STATUS CLAIM REASON AGE
pv-finance-history 35Gi RWX Retain Available 2d
pv-finance-history Available(사용 가능)이 있으며 사용할 준비가 되어 있습니다.
사용자로 PVC(영구 볼륨 클레임)를 YAML 파일로 생성하고 올바른 StorageClass 이름을 지정합니다.
예 28.25. finance-history 오브젝트 정의 클레임
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc-finance-history
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 20Gi
storageClassName: finance-history - 1
- StorageClass 이름은 정확히 일치해야 합니다. 그렇지 않으면 클레임이 삭제되거나 이름과 일치하는 다른 StorageClass 가 생성될 때까지 바인딩되지 않습니다.
PVC 및 PV를 생성하고 보고 바인딩되었는지 확인합니다.
# oc create -f pvc-finance-history.yaml
persistentvolumeclaim "pvc-finance-history" created
# oc get pvc
NAME STATUS VOLUME CAPACITY ACCESSMODES AGE
pvc-finance-history Bound pv-finance-history 35Gi RWX 9m
# oc get pv (cluster/storage-admin)
NAME CAPACITY ACCESSMODES RECLAIMPOLICY STATUS CLAIM REASON AGE
pv-finance-history 35Gi RWX Retain Bound default/pvc-finance-history 5m기존 데이터( 동적 프로비저닝 없음) 및 동적 프로비저닝에 대해 동일한 클러스터에서 StorageClass 를 사용할 수 있습니다 .
28.13. 통합 컨테이너 이미지 레지스트리용 Azure Blob 스토리지 구성
28.13.1. 개요
이 주제에서는 OpenShift 통합 컨테이너 이미지 레지스트리를 위한 Microsoft Azure Blob Storage 를 구성하는 방법을 검토합니다.
28.13.2. 시작하기 전
- Microsoft Azure Portal, Microsoft Azure CLI 또는 Microsoft Azure Storage Explorer를 사용하여 스토리지 컨테이너를 생성합니다. 스토리지 계정 이름, 스토리지 계정 키 및 컨테이너 이름을 기록해 둡니다.
- 통합 컨테이너 이미지 레지스트리 가 배포되지 않은 경우 배포합니다.
28.13.3. 레지스트리 설정 덮어쓰기
새 레지스트리 Pod를 생성하고 이전 Pod를 자동으로 교체하려면 다음을 수행합니다.
registry config.yaml이라는 새 레지스트리 구성 파일을 생성하고 다음 정보를 추가합니다.
version: 0.1 log: level: debug http: addr: :5000 storage: cache: blobdescriptor: inmemory delete: enabled: true azure:1 accountname: azureblobacc accountkey: azureblobacckey container: azureblobname realm: core.windows.net2 auth: openshift: realm: openshift middleware: registry: - name: openshift repository: - name: openshift options: acceptschema2: false pullthrough: true enforcequota: false projectcachettl: 1m blobrepositorycachettl: 10m storage: - name: openshift새 레지스트리 구성을 생성합니다.
$ oc create secret generic registry-config --from-file=config.yaml=registryconfig.yaml보안을 추가합니다.
$ oc set volume dc/docker-registry --add --type=secret \ --secret-name=registry-config -m /etc/docker/registry/REGISTRY_CONFIGURATION_PATH환경 변수를 설정합니다.$ oc set env dc/docker-registry \ REGISTRY_CONFIGURATION_PATH=/etc/docker/registry/config.yaml레지스트리 구성을 이미 생성한 경우 다음을 수행합니다.
보안을 삭제합니다.
$ oc delete secret registry-config새 레지스트리 구성을 생성합니다.
$ oc create secret generic registry-config --from-file=config.yaml=registryconfig.yaml새 롤아웃을 시작하여 구성을 업데이트합니다.
$ oc rollout latest docker-registry
29장. 임시 스토리지 구성
29.1. 개요
OpenShift Container Platform은 Pod 및 컨테이너 작업 데이터의 임시 스토리지를 관리할 수 있도록 구성할 수 있습니다. 컨테이너는 쓰기 가능한 계층, 로그 디렉터리, EmptyDir 볼륨을 활용할 수 있지만 여기에 설명된 대로 이 스토리지에는 여러 제한 사항이 적용되었습니다.
임시 스토리지 관리를 통해 관리자는 개별 포드 및 컨테이너에서 사용하는 리소스를 제한하고 포드 및 컨테이너에서 이러한 임시 스토리지 사용에 대한 요청 및 제한을 지정할 수 있습니다. 이는 기술 프리뷰이며 기본적으로 비활성화되어 있습니다.
이 기술 프리뷰는 OpenShift Container Platform에서 로컬 스토리지를 사용할 수 있도록 하는 메커니즘을 변경하지 않습니다. 기존 메커니즘, 루트 디렉터리 또는 런타임 디렉터리는 계속 적용됩니다. 이 기술 프리뷰는 이 리소스의 사용을 관리하는 메커니즘만 제공합니다.
29.2. 임시 스토리지 활성화
임시 스토리지를 활성화하려면 다음을 수행합니다.
기본적으로 모든 마스터 /etc/origin/master/master-config.yaml 에서 마스터 구성 파일을 편집하거나 생성한 후
apiServerArguments 및섹션에controllerArgumentsLocalStorageCapacityIsolation=true를 추가합니다.apiServerArguments: feature-gates: - LocalStorageCapacityIsolation=true ... controllerArguments: feature-gates: - LocalStorageCapacityIsolation=true ...모든 노드의 ConfigMap을 편집하여 명령줄에서 LocalStorageCapacityIsolation을 활성화합니다. 다음과 같이 편집해야 하는 ConfigMap을 식별할 수 있습니다.
$ oc get cm -n openshift-node NAME DATA AGE node-config-compute 1 52m node-config-infra 1 52m node-config-master 1 52m이러한 각 맵,
node-config-compute,node-config-infra및node-config-master에 대해 기능 게이트를 추가해야 합니다.oc edit cm node-config-master -n openshift-node이미
feature-gates:선언이 있는 경우 다음 텍스트를 기능 게이트 목록에 추가합니다.,LocalStorageCapacityIsolation=truefeature-gates:선언이 없는 경우 다음 섹션을 추가합니다.feature-gates: - LocalStorageCapacityIsolation=true-
node-config-compute,node-config-infra및 기타 ConfigMaps에 대해 반복합니다. - OpenShift Container Platform을 재시작하고 apiserver를 실행하는 컨테이너를 삭제합니다.
이러한 단계를 생략하면 임시 스토리지 관리가 활성화되지 않을 수 있습니다.
30장. HTTP 프록시 작업
30.1. 개요
프로덕션 환경에서는 인터넷에 대한 직접 액세스를 거부하고 대신 HTTP 또는 HTTPS 프록시를 제공합니다. 이러한 프록시를 사용하도록 OpenShift Container Platform을 구성하는 것은 구성 또는 JSON 파일에서 표준 환경 변수를 설정하는 것만큼 간단할 수 있습니다. 이는 클러스터를 설치하는 동안 수행하거나 설치 후 구성할 수 있습니다.
프록시 구성은 클러스터의 각 호스트에서 동일해야 합니다. 따라서 프록시를 설정하거나 수정할 때 각 OpenShift Container Platform 호스트의 파일을 동일한 값으로 업데이트해야 합니다. 그런 다음 클러스터의 각 호스트에서 OpenShift Container Platform 서비스를 다시 시작해야 합니다.
NO_PROXY,HTTP_PROXY 및 HTTPS_PROXY 환경 변수는 각 호스트의 /etc/origin/master/master/master.env 및 /etc/ sysconfig/atomic-openshift-node 파일에서 찾을 수 있습니다.
30.2. NO_PROXY 구성
NO_PROXY 환경 변수는 OpenShift Container Platform에서 관리하는 모든 OpenShift Container Platform 구성 요소 및 모든 IP 주소를 나열합니다.
CIDR을 허용하는 OpenShift 서비스에서 NO_PROXY 는 쉼표로 구분된 호스트, IP 주소 또는 IP 범위를 CIDR 형식으로 표시합니다.
- 마스터 호스트의 경우
- 노드 호스트 이름
- 마스터 IP 또는 호스트 이름
- etcd 호스트의 IP 주소
- 노드 호스트의 경우
- 마스터 IP 또는 호스트 이름
- Docker 서비스의 경우
- 레지스트리 서비스 IP 및 호스트 이름
-
Registry service URL
docker-registry.default.svc.cluster.local - 레지스트리 경로 호스트 이름 (생성된 경우)
Docker를 사용하는 경우 Docker는 쉼표로 구분된 호스트, 도메인 확장 또는 IP 주소 목록을 허용하지만 OpenShift 서비스에서만 수락하는 CIDR 형식으로 IP 범위를 허용하지 않습니다. 'no_proxy' 변수에는 프록시를 사용하지 않아야 하는 쉼표로 구분된 도메인 확장 목록이 포함되어야 합니다.
예를 들어 no_proxy 가 . school.edu 로 설정된 경우 프록시는 특정 학교의 문서를 검색하는 데 사용되지 않습니다.
NO_PROXY 에는 master-config.yaml 파일에 있는 대로 SDN 네트워크 및 서비스 IP 주소도 포함되어 있습니다.
/etc/origin/master/master-config.yaml
networkConfig:
clusterNetworks:
- cidr: 10.1.0.0/16
hostSubnetLength: 9
serviceNetworkCIDR: 172.30.0.0/16
OpenShift Container Platform은 * 를 도메인 접미사에 연결된 와일드카드로 허용하지 않습니다. 예를 들어 다음이 허용됩니다.
NO_PROXY=.example.com그러나 다음 사항은 아닙니다.
NO_PROXY=*.example.com
NO_PROXY 가 허용하는 유일한 와일드카드는 모든 호스트와 일치하고 프록시를 효과적으로 비활성화하는 단일 * 문자입니다.
이 목록의 각 이름은 호스트 이름을 접미사 또는 호스트 이름 자체로 포함하는 도메인과 일치합니다.
노드를 확장할 때 호스트 이름 목록이 아닌 도메인 이름을 사용합니다.
예를 들어 example.com 은 example.com,example.com:80, www.example.com 과 일치합니다.
30.3. 프록시 호스트 구성
OpenShift Container Platform 제어 파일에서 프록시 환경 변수를 편집합니다. 클러스터의 모든 파일이 올바른지 확인합니다.
HTTP_PROXY=http://<user>:<password>@<ip_addr>:<port>/ HTTPS_PROXY=https://<user>:<password>@<ip_addr>:<port>/ NO_PROXY=master.hostname.example.com,10.1.0.0/16,172.30.0.0/161 - 1
- 호스트 이름 및 CIDR을 지원합니다. 기본적으로 SDN 네트워크 및 서비스 IP 범위
10.1.0.0/16,172.30.0.0/16을 포함해야 합니다.
마스터 또는 노드 호스트를 다시 시작하십시오.
# master-restart api # master-restart controllers # systemctl restart atomic-openshift-node
30.4. Ansible을 사용하여 프록시에 대한 호스트 구성
클러스터를 설치하는 동안 인벤토리 파일에서 구성할 수 있는 openshift_ 환경 변수를 구성할 수 있습니다.
no PROXY_proxy, openshift_ _PROXY 및 HTTPS_http_proxy 및 openshift_ https_proxy 매개변수를 사용하여 NO_PROXY, HTTP
Ansible을 사용한 프록시 구성 예
# Global Proxy Configuration
# These options configure HTTP_PROXY, HTTPS_PROXY, and NOPROXY environment
# variables for docker and master services.
openshift_http_proxy=http://<user>:<password>@<ip_addr>:<port>
openshift_https_proxy=https://<user>:<password>@<ip_addr>:<port>
openshift_no_proxy='.hosts.example.com,some-host.com'
#
# Most environments do not require a proxy between OpenShift masters, nodes, and
# etcd hosts. So automatically add those host names to the openshift_no_proxy list.
# If all of your hosts share a common domain you may wish to disable this and
# specify that domain above.
# openshift_generate_no_proxy_hosts=TrueAnsible 매개 변수를 사용하여 빌드에 대해 구성할 수 있는 추가 프록시 설정이 있습니다. 예를 들면 다음과 같습니다.
openshift_builddefaults_git_http_proxy 및 openshift_builddefaults_git_https_proxy 매개변수를 사용하면 Git 복제에 프록시를 사용할수 있습니다.
openshift_builddefaults_http_proxy 및 openshift_builddefaults_https_proxy 매개 변수를 사용하면 Docker 빌드 전략 및 사용자 지정 빌드 전략 프로세스에서 환경 변수를 사용할 수 있습니다.
30.5. Docker Pull 프록시
OpenShift Container Platform 노드 호스트는 Docker 레지스트리에 푸시 및 풀 작업을 수행해야 합니다. 노드가 액세스하기 위해 프록시가 필요하지 않은 레지스트리가 있는 경우 다음을 사용하여 NO_PROXY 매개변수를 포함합니다.
- 레지스트리의 호스트 이름
- 레지스트리 서비스의 IP 주소
- 서비스 이름입니다.
이렇게 하면 해당 레지스트리를 블랙리스트로 지정하고 외부 HTTP 프록시를 유일한 옵션으로 남겨 둡니다.
다음을 실행하여 레지스트리 서비스의 IP 주소
docker_registy_ip를 검색합니다.$ oc describe svc/docker-registry -n default Name: docker-registry Namespace: default Labels: docker-registry=default Selector: docker-registry=default Type: ClusterIP IP: 172.30.163.1831 Port: 5000-tcp 5000/TCP Endpoints: 10.1.0.40:5000 Session Affinity: ClientIP No events.- 1
- 레지스트리 서비스 IP.
/etc/sysconfig/docker 파일을 편집하고 쉘 형식으로
NO_PROXY변수를 추가하여<docker_registry_ip>를 이전 단계의 IP 주소로 바꿉니다.HTTP_PROXY=http://<user>:<password>@<ip_addr>:<port>/ HTTPS_PROXY=https://<user>:<password>@<ip_addr>:<port>/ NO_PROXY=master.hostname.example.com,<docker_registry_ip>,docker-registry.default.svc.cluster.localDocker 서비스를 다시 시작하십시오.
# systemctl restart docker
30.6. 프록시 기반 Maven 사용
프록시와 함께 Maven을 사용하려면 HTTP_PROXY_NONPROXYHOSTS 변수를 사용해야 합니다.
프록시 뒤에서 Maven을 설정하는 단계를 포함하여 Red Hat JBoss Enterprise Application Platform용 OpenShift Container Platform 환경을 구성하는 방법에 대한 정보는 OpenShift용 Red Hat JBoss Enterprise Application Platform 문서를 참조하십시오.
30.7. 프록시에 대한 S2I 빌드 구성
S2I 빌드는 다양한 위치에서 종속성을 가져옵니다. .s2i/environment 파일을 사용하여 간단한 쉘 변수를 지정할 수 있으며, OpenShift Container Platform은 빌드 이미지를 볼 때 이에 따라 반응합니다.
다음은 예제 값을 사용하여 지원되는 프록시 환경 변수입니다.
HTTP_PROXY=http://USERNAME:PASSWORD@10.0.1.1:8080/
HTTPS_PROXY=https://USERNAME:PASSWORD@10.0.0.1:8080/
NO_PROXY=master.hostname.example.com30.8. 프록시의 기본 템플릿 구성
기본적으로 OpenShift Container Platform에서 사용할 수 있는 예제 템플릿에 는 HTTP 프록시 설정이 포함되지 않습니다. 이러한 템플릿을 기반으로 하는 기존 애플리케이션의 경우 애플리케이션 빌드 구성의 source 섹션을 수정하고 프록시 설정을 추가합니다.
...
source:
type: Git
git:
uri: https://github.com/openshift/ruby-hello-world
httpProxy: http://proxy.example.com
httpsProxy: https://proxy.example.com
noProxy: somedomain.com, otherdomain.com
...이는 Git 복제에 프록시를 사용하는 프로세스와 유사합니다.
30.9. Pod에서 프록시 환경 변수 설정
배포 구성에서 templates. spec.containers 스탠자에 NO 환경 변수를 설정하여 프록시 연결 정보를 전달할 수 있습니다. 런타임 시 Pod 프록시를 구성하기에도 동일한 작업을 수행할 수 있습니다.
_PROXY 및 HTTPS_PROXY_PROXY, HTTP
...
containers:
- env:
- name: "HTTP_PROXY"
value: "http://<user>:<password>@<ip_addr>:<port>"
...
oc set env 명령을 사용하여 새 환경 변수로 기존 배포 구성을 업데이트할 수도 있습니다.
$ oc set env dc/frontend HTTP_PROXY=http://<user>:<password>@<ip_addr>:<port>OpenShift Container Platform 인스턴스에 ConfigChange 트리거가 설정된 경우 변경 사항이 자동으로 수행됩니다. 그렇지 않으면 변경 사항을 적용하기 위해 애플리케이션을 수동으로 재배포합니다.
30.10. Git 리포지토리 액세스
프록시를 사용해서만 Git 리포지토리에 액세스할 수 있는 경우 BuildConfig 의 source 섹션에서 사용할 프록시를 정의할 수 있습니다. 사용할 HTTP 및 HTTPS 프록시를 둘 다 구성할 수 있습니다. 두 필드 모두 선택 사항입니다. 프록시를 수행할 수 없는 도메인도 NoProxy 필드를 통해 지정할 수 있습니다.
이를 위해서는 소스 URI에서 HTTP 또는 HTTPS 프로토콜을 사용해야 합니다.
source:
git:
uri: "https://github.com/openshift/ruby-hello-world"
httpProxy: http://proxy.example.com
httpsProxy: https://proxy.example.com
noProxy: somedomain.com, otherdomain.com31장. 글로벌 빌드 기본값 및 덮어쓰기 구성
31.1. 개요
개발자는 Git 복제에 대한 프록시 구성과 같은 프로젝트 내의 특정 빌드 구성에서 설정을 정의할 수 있습니다. 관리자는 개발자가 각 빌드 구성에 특정 설정을 정의해야 하는 대신 승인 제어 플러그인을 사용하여 전역 빌드 기본값을 구성하고 빌드에서 이러한 설정을 자동으로 사용하는 재정의를 수행할 수 있습니다.
이러한 플러그인의 설정은 빌드 프로세스 중에만 사용되지만 빌드 구성 또는 빌드 자체에는 설정되지 않습니다. 플러그인을 통해 설정을 구성하면 관리자는 언제든지 글로벌 구성을 변경하고 기존 빌드 구성 또는 빌드에서 다시 실행되는 빌드에 새 설정이 할당됩니다.
-
BuildDefaults승인 제어 플러그인을 사용하면 관리자가 Git HTTP 및 HTTPS 프록시와 같은 설정에 대한 글로벌 기본값과 기본 환경 변수를 설정할 수 있습니다. 이러한 기본값은 특정 빌드에 대해 구성된 값을 덮어쓰지 않습니다. 그러나 이러한 값이 빌드 정의에 없으면 기본값으로 설정됩니다. BuildOverrides승인 제어 플러그인을 사용하면 관리자가 빌드에 저장된 값과 관계없이 빌드의 설정을 재정의할 수 있습니다.플러그인은 현재 빌드 전략에서
forcePull플래그 재정의를 지원하여 빌드 중에 레지스트리에서 로컬 이미지를 강제로 새로 고칩니다. 즉, 빌드가 시작될 때마다 액세스 점검이 이미지에서 수행되므로 사용자가 가져올 수 있는 이미지만 사용할 수 있습니다. 강제 새로 고침에서는 빌드에 대한 멀티 테넌시를 제공합니다. 그러나 빌드 노드에 저장된 이미지의 로컬 캐시를 더 이상 사용할 수 없습니다. 항상 레지스트리에 액세스할 수 있어야 합니다.빌드된 모든 이미지에 이미지 레이블 세트를 적용하도록 플러그인을 구성할 수도 있습니다.
BuildOverrides승인 제어 플러그인 및 재정의할 수 있는 값 구성에 대한 자세한 내용은 글로벌 빌드 오버라이드 수동 설정을 참조하십시오.
기본 노드 선택기와 BuildDefaults 또는 BuildOverrides 승인 플러그인은 다음과 같이 함께 작동합니다.
-
마스터 구성 파일의
projectConfig.defaultNodeSelector필드에 정의된 기본 프로젝트 노드 선택기는 지정된nodeSelector값이 없는 모든 프로젝트에 생성된 Pod에 적용됩니다. 이러한 설정은BuildDefaults 또는nodeselector가 설정되지 않은 클러스터에서BuildOverridesnodeSelector="null"을 사용하여 빌드에 적용됩니다. -
클러스터 전체 기본 빌드 노드 선택기인
admissionConfig.pluginConfig.BuildDefaults.configuration.nodeSelector는 빌드 구성에nodeSelector="null"매개변수가 설정된 경우에만 적용됩니다.nodeSelector=null이 기본 설정입니다. 기본 프로젝트 또는 클러스터 수준 노드 선택기를 사용하면 기본 설정이
BuildDefaults 또는승인 플러그인에 설정된 빌드 노드 선택기에 AND로 추가됩니다. 이러한 설정은 빌드가BuildOverridesBuildOverrides노드 선택기 및 프로젝트 기본 노드 선택기를 충족하는 노드에만 예약됨을 의미합니다.참고RunOnceDuration 플러그인을 사용하여 빌드 Pod를 실행할 수 있는 기간에 대한 하드 제한을 정의할 수 있습니다.
31.2. 글로벌 빌드 기본값 설정
글로벌 빌드 기본값은 다음 두 가지 방법으로 설정할 수 있습니다.
31.2.1. Ansible을 사용하여 글로벌 빌드 기본값 구성
클러스터를 설치하는 동안 인벤토리 파일에서 구성할 수 있는 다음 매개변수를 사용하여 BuildDefaults 플러그인을 구성할 수 있습니다.
-
openshift_builddefaults_http_proxy -
openshift_builddefaults_https_proxy -
openshift_builddefaults_no_proxy -
openshift_builddefaults_git_http_proxy -
openshift_builddefaults_git_https_proxy -
openshift_builddefaults_git_no_proxy -
openshift_builddefaults_image_labels -
openshift_builddefaults_nodeselectors -
openshift_builddefaults_annotations -
openshift_builddefaults_resources_requests_cpu -
openshift_builddefaults_resources_requests_memory -
openshift_builddefaults_resources_limits_cpu -
openshift_builddefaults_resources_limits_memory
예 31.1. Ansible을 사용한 빌드 기본값 구성 예
# These options configure the BuildDefaults admission controller which injects
# configuration into Builds. Proxy related values will default to the global proxy
# config values. You only need to set these if they differ from the global proxy settings.
openshift_builddefaults_http_proxy=http://USER:PASSWORD@HOST:PORT
openshift_builddefaults_https_proxy=https://USER:PASSWORD@HOST:PORT
openshift_builddefaults_no_proxy=mycorp.com
openshift_builddefaults_git_http_proxy=http://USER:PASSWORD@HOST:PORT
openshift_builddefaults_git_https_proxy=https://USER:PASSWORD@HOST:PORT
openshift_builddefaults_git_no_proxy=mycorp.com
openshift_builddefaults_image_labels=[{'name':'imagelabelname1','value':'imagelabelvalue1'}]
openshift_builddefaults_nodeselectors={'nodelabel1':'nodelabelvalue1'}
openshift_builddefaults_annotations={'annotationkey1':'annotationvalue1'}
openshift_builddefaults_resources_requests_cpu=100m
openshift_builddefaults_resources_requests_memory=256Mi
openshift_builddefaults_resources_limits_cpu=1000m
openshift_builddefaults_resources_limits_memory=512Mi
# Or you may optionally define your own build defaults configuration serialized as json
#openshift_builddefaults_json='{"BuildDefaults":{"configuration":{"apiVersion":"v1","env":[{"name":"HTTP_PROXY","value":"http://proxy.example.com.redhat.com:3128"},{"name":"NO_PROXY","value":"ose3-master.example.com"}],"gitHTTPProxy":"http://proxy.example.com:3128","gitNoProxy":"ose3-master.example.com","kind":"BuildDefaultsConfig"}}}'31.2.2. 수동으로 글로벌 빌드 기본값 설정
BuildDefaults 플러그인을 구성하려면 다음을 수행합니다.
마스터 노드의 /etc/origin/master/master-config.yaml 파일에 구성을 추가합니다.
admissionConfig: pluginConfig: BuildDefaults: configuration: apiVersion: v1 kind: BuildDefaultsConfig gitHTTPProxy: http://my.proxy:80801 gitHTTPSProxy: https://my.proxy:84432 gitNoProxy: somedomain.com, otherdomain.com3 env: - name: HTTP_PROXY4 value: http://my.proxy:8080 - name: HTTPS_PROXY5 value: https://my.proxy:8443 - name: BUILD_LOGLEVEL6 value: 4 - name: CUSTOM_VAR7 value: custom_value imageLabels: - name: url8 value: https://containers.example.org - name: vendor value: ExampleCorp Ltd. nodeSelector:9 key1: value1 key2: value2 annotations:10 key1: value1 key2: value2 resources:11 requests: cpu: "100m" memory: "256Mi" limits: cpu: "100m" memory: "256Mi"- 1
- Git 리포지토리에서 소스 코드를 복제할 때 사용할 HTTP 프록시를 설정합니다.
- 2
- Git 리포지토리에서 소스 코드를 복제할 때 사용할 HTTPS 프록시를 설정합니다.
- 3
- 프록시를 수행하지 않아야 하는 도메인 목록을 설정합니다.
- 4
- 빌드 중 사용할 HTTP 프록시를 설정하는 기본 환경 변수입니다. 이 매개 변수는 assemble 및 build 단계에서 종속성을 다운로드하는 데 사용할 수 있습니다.
- 5
- 빌드 중 사용할 HTTPS 프록시를 설정하는 기본 환경 변수입니다. 이 매개 변수는 assemble 및 build 단계에서 종속성을 다운로드하는 데 사용할 수 있습니다.
- 6
- 빌드 중 빌드 로그 수준을 설정하는 기본 환경 변수입니다.
- 7
- 모든 빌드에 추가 기본 환경 변수.
- 8
- 빌드된 모든 이미지에 적용할 레이블입니다. 사용자는
BuildConfig에서 이를 재정의할 수 있습니다. - 9
- 빌드 포드는
key1=value2 및레이블이 있는 노드에서만 실행됩니다. 사용자는 해당 빌드에key2=value2대해 다른 nodeSelector세트를 정의할 수 있습니다. 이 경우 이러한 값이 무시됩니다. - 10
- 빌드 Pod에는 이러한 주석이 추가됩니다.
- 11
BuildConfig에 관련 리소스가 정의되지 않은 경우 기본 리소스를 빌드 Pod로 설정합니다.
변경 사항을 적용하려면 마스터 서비스를 다시 시작하십시오.
# master-restart api # master-restart controllers
31.3. 글로벌 빌드 덮어쓰기 설정
다음과 같은 두 가지 방법으로 글로벌 빌드를 덮어쓸 수 있습니다.
31.3.1. Ansible을 사용하여 글로벌 빌드 덮어쓰기 구성
클러스터를 설치하는 동안 인벤토리 파일에서 구성할 수 있는 다음 매개변수를 사용하여 BuildOverrides 플러그인을 구성할 수 있습니다.
-
openshift_buildoverrides_force_pull -
openshift_buildoverrides_image_labels -
openshift_buildoverrides_nodeselectors -
openshift_buildoverrides_annotations -
openshift_buildoverrides_tolerations
예 31.2. Ansible을 사용하여 빌드 덮어쓰기 구성의 예
# These options configure the BuildOverrides admission controller which injects
# configuration into Builds.
openshift_buildoverrides_force_pull=true
openshift_buildoverrides_image_labels=[{'name':'imagelabelname1','value':'imagelabelvalue1'}]
openshift_buildoverrides_nodeselectors={'nodelabel1':'nodelabelvalue1'}
openshift_buildoverrides_annotations={'annotationkey1':'annotationvalue1'}
openshift_buildoverrides_tolerations=[{'key':'mykey1','value':'myvalue1','effect':'NoSchedule','operator':'Equal'}]
# Or you may optionally define your own build overrides configuration serialized as json
#openshift_buildoverrides_json='{"BuildOverrides":{"configuration":{"apiVersion":"v1","kind":"BuildOverridesConfig","forcePull":"true","tolerations":[{'key':'mykey1','value':'myvalue1','effect':'NoSchedule','operator':'Equal'}]}}}'
BuildOverrides 플러그인을 사용하여 허용 오차를 덮어쓰려면 BuildOverrides 노드 선택기를 사용해야 합니다.
31.3.2. 수동으로 글로벌 빌드 오버라이드 설정
BuildOverrides 플러그인을 구성하려면 다음을 수행합니다.
masters의 /etc/origin/master/master-config.yaml 파일에 구성을 추가합니다.
admissionConfig: pluginConfig: BuildOverrides: configuration: apiVersion: v1 kind: BuildOverridesConfig forcePull: true1 imageLabels: - name: distribution-scope2 value: private nodeSelector:3 key1: value1 key2: value2 annotations:4 key1: value1 key2: value2 tolerations:5 - key: mykey1 value: myvalue1 effect: NoSchedule operator: Equal - key: mykey2 value: myvalue2 effect: NoExecute operator: Equal- 1
- 빌드를 시작하기 전에 모든 빌드가 빌더 이미지와 소스 이미지를 가져오도록 강제 적용합니다.
- 2
- 빌드된 모든 이미지에 적용할 추가 레이블입니다. 여기에 정의된 라벨은
BuildConfig에 정의된 라벨보다 우선합니다. - 3
- 빌드 포드는
key1=value2 및레이블이 있는 노드에서만 실행됩니다. 사용자는 추가 키/값 라벨을 정의하여 빌드가 실행되는 노드 집합을 추가로 제한할 수 있지만 노드에 는 이러한 레이블이 있어야 합니다.key2=value2 - 4
- 빌드 Pod에는 이러한 주석이 추가됩니다.
- 5
- 빌드 Pod에는 여기에 나열된 것으로 재정의된 기존 허용 오차가 있습니다.
참고BuildOverrides플러그인을 사용하여 허용 오차를 덮어쓰려면BuildOverrides노드 선택기를 사용해야 합니다.변경 사항을 적용하려면 마스터 서비스를 다시 시작하십시오.
# master-restart api # master-restart controllers
32장. 파이프라인 실행 구성
32.1. 개요
사용자가 Pipeline 빌드 전략을 사용하여 빌드 구성을 처음 생성할 때 OpenShift Container Platform은 openshift 네임스페이스에서 jenkins-ephemeral 이라는 템플릿을 찾아 사용자 프로젝트 내에서 인스턴스화합니다. OpenShift Container Platform과 함께 제공되는 jenkins-ephemeral 템플릿은 인스턴스화 시 생성됩니다.
- 공식 OpenShift Container Platform Jenkins 이미지를 사용하는 Jenkins에 대한 배포 구성
- Jenkins 배포에 액세스하기 위한 서비스 및 경로
- 새 Jenkins 서비스 계정
- 프로젝트에 대한 서비스 계정 편집 액세스 권한을 부여하는 역할 바인딩
클러스터 관리자는 기본 제공 템플릿의 콘텐츠를 수정하거나 클러스터를 다른 템플릿 위치로 보내 클러스터 구성을 편집하여 생성되는 항목을 제어할 수 있습니다.
기본 템플릿의 내용을 수정하려면 다음을 수행합니다.
$ oc edit template jenkins-ephemeral -n openshift
Jenkins에 영구 스토리지를 사용하는 jenkins-persistent 템플릿과 같은 다른 템플릿을 사용하려면 마스터 구성 파일에 다음을 추가합니다.
jenkinsPipelineConfig:
autoProvisionEnabled: true
templateNamespace: openshift
templateName: jenkins-persistent
serviceName: jenkins-persistent-svc
parameters:
key1: value1
key2: value2
파이프라인 빌드 구성이 생성되면 OpenShift Container Platform은 Service Name과 일치하는 서비스를 찾습니다. 즉, 프로젝트에서 고유하도록 serviceName 을 선택해야 합니다. 서비스를 찾을 수 없는 경우 OpenShift Container Platform은 jenkinsPipelineConfig 템플릿을 인스턴스화합니다. 이 기능이 바람직하지 않은 경우(예: OpenShift Container Platform 외부에서 Jenkins 서버를 사용하려는 경우) 본인에 따라 몇 가지 작업을 수행할 수 있습니다.
-
클러스터 관리자인 경우
autoProvisionEnabled를false로 설정하면 됩니다. 그러면 클러스터에서 자동 프로비저닝이 비활성화됩니다. -
권한이 없는 사용자인 경우 OpenShift Container Platform이 사용할 서비스를 생성해야 합니다. 서비스 이름은
jenkinsPipelineConfig의serviceName클러스터 구성 값과 일치해야 합니다. 기본값은jenkins입니다. 프로젝트 외부에서 Jenkins 서버를 실행 중이므로 자동 프로비저닝을 비활성화하는 경우 이 새 서비스를 기존 Jenkins 서버를 가리키는 것이 좋습니다. 다음 내용을 참조하십시오. 외부 서비스 통합
후자의 옵션을 사용하여 선택한 프로젝트에서만 자동 프로비저닝을 비활성화할 수도 있습니다.
32.2. OpenShift Jenkins 클라이언트 플러그인
OpenShift Jenkins 클라이언트 플러그인은 Jenkins 플러그인으로, OpenShift API 서버와의 풍부한 상호 작용을 위해 읽기 쉽고 간결하며 포괄적이며 유창한 Jenkins 파이프라인 구문을 제공하기 위한 것입니다. 플러그인은 스크립트를 실행하는 노드에서 사용할 수 있어야 하는 OpenShift 명령줄 도구(oc)를 활용합니다.
플러그인 설치 및 구성에 대한 자세한 내용은 공식 문서를 참조하는 아래 링크를 사용하십시오.
개발자들은 이 플러그인 사용에 대한 정보를 찾고 있습니까? 해당하는 경우 OpenShift Pipeline 개요 를 참조하십시오.
32.3. OpenShift Jenkins Sync Plugin
이 Jenkins 플러그인은 OpenShift BuildConfig를 유지하고 Jenkins 작업 및 빌드와 동기화된 오브젝트를 빌드합니다.
OpenShift jenkins 동기화 플러그인은 다음을 제공합니다.
- Jenkins에서 동적 작업/실행 생성.
- ImageStreams, ImageStreamTags 또는 ConfigMaps에서 슬레이브 Pod 템플릿 동적 생성.
- 환경 변수 삽입
- OpenShift 웹 콘솔의 파이프라인 시각화.
- Jenkins Git 플러그인과의 통합으로 OpenShift 빌드의 커밋 정보를 Jenkins git 플러그인으로 전달합니다.
이 플러그인에 대한 자세한 내용은 다음을 참조하십시오.
33장. 경로 시간 제한 구성
OpenShift Container Platform을 설치하고 라우터를 배포한 후 느린 백엔드의 경우 SLA(Service Level Availability) 목적에 필요한 대로 서비스가 짧은 시간 초과가 필요한 경우 기존 경로에 대한 기본 시간 초과를 구성할 수 있습니다.
oc annotate 명령을 사용하여 경로에 시간 초과를 추가합니다.
# oc annotate route <route_name> \
--overwrite haproxy.router.openshift.io/timeout=<timeout><time_unit>
예를 들어 myroute 라는 경로를 2초의 시간 제한으로 설정하려면 다음을 수행합니다.
# oc annotate route myroute --overwrite haproxy.router.openshift.io/timeout=2s지원되는 시간 단위는 마이크로초(us), 밀리초(ms), 초(s), 분(m), 시간(h) 또는 일(d)입니다.
34장. 네이티브 컨테이너 라우팅 구성
34.1. 네트워크 개요
다음은 일반적인 네트워크 설정을 설명합니다.
- 11.11.0.0/16은 컨테이너 네트워크입니다.
- 11.11.x.0/24 서브넷은 각 노드용으로 예약되어 Docker Linux 브리지에 할당됩니다.
- 각 노드에는 로컬 서브넷을 제외하고 11.11.0.0/16 범위의 모든 항목에 도달하기 위한 라우터 경로가 있습니다.
- 라우터에는 각 노드의 경로가 있으므로 올바른 노드로 이동할 수 있습니다.
- 네트워크 토폴로지를 수정하지 않는 한, 새 노드를 추가할 때 기존 노드를 변경할 필요가 없습니다.
- 각 노드에서 IP 전달이 활성화됩니다.
다음 다이어그램에서는 이 항목에 설명된 컨테이너 네트워킹 설정을 보여줍니다. 두 개의 네트워크 인터페이스 카드가 있는 Linux 노드 1개가 라우터, 2개의 스위치 및 이러한 스위치에 연결된 노드 3개를 사용합니다.
34.2. 기본 컨테이너 라우팅 구성
기존 스위치 및 라우터와 Linux에서 커널 네트워킹 스택을 사용하여 컨테이너 네트워킹을 설정할 수 있습니다.
네트워크 관리자는 클러스터에 새 노드를 추가할 때 라우터 또는 라우터를 수정할 스크립트를 수정하거나 생성해야 합니다.
모든 유형의 라우터와 함께 사용하도록 이 프로세스를 조정할 수 있습니다.
34.3. 컨테이너 네트워킹을 위한 노드 설정
사용되지 않은 11.11.x.0/24 서브넷 IP 주소를 노드의 Linux 브리지에 할당합니다.
# brctl addbr lbr0 # ip addr add 11.11.1.1/24 dev lbr0 # ip link set dev lbr0 up새 브리지를 사용하도록 Docker 시작 스크립트를 수정합니다. 기본적으로 시작 스크립트는
/etc/sysconfig/docker파일입니다.# docker -d -b lbr0 --other-options11.11.0.0/16 네트워크의 라우터에 경로를 추가합니다.
# ip route add 11.11.0.0/16 via 192.168.2.2 dev p3p1노드에서 IP 전달을 활성화합니다.
# sysctl -w net.ipv4.ip_forward=1
34.4. 컨테이너 네트워킹용 라우터 설정
다음 절차에서는 여러 NIC가 있는 Linux 상자를 라우터로 사용한다고 가정합니다. 특정 라우터의 구문을 사용하도록 필요에 따라 단계를 수정합니다.
라우터에서 IP 전달을 활성화합니다.
# sysctl -w net.ipv4.ip_forward=1클러스터에 추가된 각 노드의 경로를 추가합니다.
# ip route add <node_subnet> via <node_ip_address> dev <interface through which node is L2 accessible> # ip route add 11.11.1.0/24 via 192.168.2.1 dev p3p1 # ip route add 11.11.2.0/24 via 192.168.3.3 dev p3p2 # ip route add 11.11.3.0/24 via 192.168.3.4 dev p3p2
35장. 에지 로드 밸런서에서 라우팅
35.1. 개요
OpenShift Container Platform 클러스터 내부의 Pod 는 클러스터 네트워크의 IP 주소를 통해서만 연결할 수 있습니다. 에지 로드 밸런서를 사용하여 외부 네트워크의 트래픽을 허용하고 OpenShift Container Platform 클러스터 내부의 포드로 트래픽을 프록시할 수 있습니다. 로드 밸런서가 클러스터 네트워크의 일부가 아닌 경우 내부 클러스터 네트워크에 에지 로드 밸런서에 액세스할 수 없으므로 라우팅이 장애물이 됩니다.
OpenShift Container Platform 클러스터에서 OpenShift Container Platform SDN 을 클러스터 네트워킹 솔루션으로 사용하는 이 문제를 해결하려면 Pod에 대한 네트워크 액세스를 수행하는 두 가지 방법이 있습니다.
35.2. SDN에 로드 밸런서 포함
가능한 경우 OpenShift SDN을 네트워킹 플러그인으로 사용하는 로드 밸런서 자체에서 OpenShift Container Platform 노드 인스턴스를 실행합니다. 이렇게 하면 에지 시스템은 클러스터에 상주하는 포드 및 노드에 액세스 권한을 제공하도록 SDN에서 자동으로 구성하는 자체 Open vSwitch 브리지를 가져옵니다. 라우팅 테이블은 포드가 생성 및 삭제될 때 SDN에서 동적으로 구성되므로 라우팅 소프트웨어가 포드에 도달할 수 있습니다.
로드 밸런서 자체에 Pod가 종료되지 않도록 로드 밸런서 머신을 예약 불가 노드로 표시합니다.
$ oc adm manage-node <load_balancer_hostname> --schedulable=false로드 밸런서가 컨테이너로 패키징되는 경우 OpenShift Container Platform과 통합하는 것이 더 쉽습니다. 호스트 포트가 노출된 포드로 로드 밸런서를 실행하기만 하면 됩니다. OpenShift Container Platform에서 사전 패키징된 HAProxy 라우터 는 정확히 이러한 방식으로 실행됩니다.
35.3. Ramp 노드를 사용하여 터널 설정
이전 솔루션은 가능한 경우도 있습니다. 예를 들어 F5®는 호환되지 않는 사용자 지정 Linux 커널 및 배포를 사용하기 때문에 F5 BIG-IP ® 호스트에서 OpenShift Container Platform 노드 인스턴스 또는 OpenShift Container Platform SDN을 실행할 수 없습니다.
대신 F5 BIG-IP® 가 Pod에 도달할 수 있도록 클러스터 네트워크 내에서 기존 노드를 확대 노드로 선택하고 F5 BIG-IP® 호스트와 지정된 확장 노드 간에 터널을 설정할 수 있습니다. 그렇지 않으면 일반 OpenShift Container Platform 노드이므로 확장 노드에는 클러스터 네트워크의 모든 노드에 있는 모든 Pod로 트래픽을 라우팅하는 데 필요한 구성이 있습니다. 따라서 확장 노드는 F5 BIG-IP® 호스트가 전체 클러스터 네트워크에 액세스할 수 있는 게이트웨이의 역할을 가정합니다.
다음은 F5 BIG-IP® 호스트와 지정된 확장 노드 간에 ipip 터널을 설정하는 예입니다.
F5 BIG-IP® 호스트에서 다음을 수행합니다.
다음 변수를 설정합니다.
# F5_IP=10.3.89.661 # RAMP_IP=10.3.89.892 # TUNNEL_IP1=10.3.91.2163 # CLUSTER_NETWORK=10.128.0.0/144 이전 경로, 자체, 터널 및 SNAT 풀을 삭제합니다.
# tmsh delete net route $CLUSTER_NETWORK || true # tmsh delete net self SDN || true # tmsh delete net tunnels tunnel SDN || true # tmsh delete ltm snatpool SDN_snatpool || true새 터널, 셀프, 경로 및 SNAT 풀을 생성하고 가상 서버에서 SNAT 풀을 사용합니다.
# tmsh create net tunnels tunnel SDN \ \{ description "OpenShift SDN" local-address \ $F5_IP profile ipip remote-address $RAMP_IP \} # tmsh create net self SDN \{ address \ ${TUNNEL_IP1}/24 allow-service all vlan SDN \} # tmsh create net route $CLUSTER_NETWORK interface SDN # tmsh create ltm snatpool SDN_snatpool members add { $TUNNEL_IP1 } # tmsh modify ltm virtual ose-vserver source-address-translation { type snat pool SDN_snatpool } # tmsh modify ltm virtual https-ose-vserver source-address-translation { type snat pool SDN_snatpool }
업그레이드 노드에서 다음을 수행합니다.
다음은 지속되지 않는 구성을 만듭니다. 즉, 확대기 노드 또는 openvswitch 서비스를 다시 시작하면 설정이 사라집니다.
다음 변수를 설정합니다.
# F5_IP=10.3.89.66 # TUNNEL_IP1=10.3.91.216 # TUNNEL_IP2=10.3.91.2171 # CLUSTER_NETWORK=10.128.0.0/142 이전 터널을 삭제합니다.
# ip tunnel del tun1 || true적합한 L2 연결 인터페이스(예 : eth0)를 사용하여 확장기 노드에서 ipip 터널을 생성합니다.
# ip tunnel add tun1 mode ipip \ remote $F5_IP dev eth0 # ip addr add $TUNNEL_IP2 dev tun1 # ip link set tun1 up # ip route add $TUNNEL_IP1 dev tun1 # ping -c 5 $TUNNEL_IP1SDN 서브넷에서 사용하지 않는 IP를 사용하여 터널 IP를 조정합니다.
# source /run/openshift-sdn/config.env # tap1=$(ip -o -4 addr list tun0 | awk '{print $4}' | cut -d/ -f1 | head -n 1) # subaddr=$(echo ${OPENSHIFT_SDN_TAP1_ADDR:-"$tap1"} | cut -d "." -f 1,2,3) # export RAMP_SDN_IP=${subaddr}.254이
RAMP_SDN_IP를 tun0 (로컬 SDN의 게이트웨이)에 추가 주소로 할당합니다.# ip addr add ${RAMP_SDN_IP} dev tun0SNAT에 대한 OVS 규칙을 수정합니다.
# ipflowopts="cookie=0x999,ip" # arpflowopts="cookie=0x999, table=0, arp" # # ovs-ofctl -O OpenFlow13 add-flow br0 \ "${ipflowopts},nw_src=${TUNNEL_IP1},actions=mod_nw_src:${RAMP_SDN_IP},resubmit(,0)" # ovs-ofctl -O OpenFlow13 add-flow br0 \ "${ipflowopts},nw_dst=${RAMP_SDN_IP},actions=mod_nw_dst:${TUNNEL_IP1},resubmit(,0)" # ovs-ofctl -O OpenFlow13 add-flow br0 \ "${arpflowopts}, arp_tpa=${RAMP_SDN_IP}, actions=output:2" # ovs-ofctl -O OpenFlow13 add-flow br0 \ "${arpflowopts}, priority=200, in_port=2, arp_spa=${RAMP_SDN_IP}, arp_tpa=${CLUSTER_NETWORK}, actions=goto_table:30" # ovs-ofctl -O OpenFlow13 add-flow br0 \ "arp, table=5, priority=300, arp_tpa=${RAMP_SDN_IP}, actions=output:2" # ovs-ofctl -O OpenFlow13 add-flow br0 \ "ip,table=5,priority=300,nw_dst=${RAMP_SDN_IP},actions=output:2" # ovs-ofctl -O OpenFlow13 add-flow br0 "${ipflowopts},nw_dst=${TUNNEL_IP1},actions=output:2"선택적으로 고가용성으로 확장기 노드를 구성하지 않으려는 경우, 업그레이드 노드를 예약할 수 없음으로 표시합니다. 다음 섹션을 따르고 고가용성 확장 노드 생성을 계획하는 경우 이 단계를 건너뜁니다.
$ oc adm manage-node <ramp_node_hostname> --schedulable=false
35.3.1. 가용성이 높은 Ramp 노드 구성
keepalived 를 내부적으로 사용하는 OpenShift Container Platform의 ipfailover 기능을 사용하여 확장 노드를 F5 BIG-IP®의 관점에서 고가용성으로 사용할 수 있습니다. 이를 위해 먼저 동일한 L2 서브넷에서 두 개의 노드(예: ramp-node-1 및 ramp-node-2) 를 가져옵니다.
그런 다음 가상 IP 또는 VIP 에 사용할 동일한 서브넷 내에서 할당되지 않은 일부 IP 주소를 선택합니다. F5 BIG- IP®에서 터널을 구성할 RAMP_ IP 변수로 설정됩니다.
예를 들어 10.20.30.0/24 서브넷을 확대 노드에 사용하고 있고 10.20.30.2 를 ramp-node-1 및 10.20.30.3 으로 할당했다고 가정합니다. VIP의 경우 동일한 10.20.30.0/24 서브넷에서 할당되지 않은 주소를 선택합니다(예: 10.20.30.4). 그런 다음 ipfailover 를 구성하려면 f5rampnode 와 같은 레이블을 사용하여 두 노드를 모두 표시합니다.
$ oc label node ramp-node-1 f5rampnode=true
$ oc label node ramp-node-2 f5rampnode=trueipfailover 설명서 의 지침과 유사하게 서비스 계정을 생성하여 권한이 있는 SCC에 추가해야 합니다. 먼저 f5ipfailover 서비스 계정을 생성합니다.
$ oc create serviceaccount f5ipfailover -n default다음으로 f5ipfailover 서비스를 권한 있는 SCC에 추가할 수 있습니다. 기본 네임스페이스의 f5ipfailover 를 권한 있는 SCC에 추가하려면 다음을 실행합니다.
$ oc adm policy add-scc-to-user privileged system:serviceaccount:default:f5ipfailover
마지막으로 선택한 VIP(RAM P_IP 변수) 및 f5ipfailover 서비스 계정을 사용하여 ip failover 를 구성하고 이전에 설정한 f5rampnode 레이블을 사용하여 VIP를 두 노드에 할당합니다.
# RAMP_IP=10.20.30.4
# IFNAME=eth0
# oc adm ipfailover <name-tag> \
--virtual-ips=$RAMP_IP \
--interface=$IFNAME \
--watch-port=0 \
--replicas=2 \
--service-account=f5ipfailover \
--selector='f5rampnode=true'- 1
RAMP_IP를 구성해야 하는 인터페이스입니다.
위의 설정을 사용하면 현재 할당되어 있는 업그레이드 노드 호스트가 실패하면 VIP(RAM P_IP 변수)가 자동으로 다시 할당됩니다.
36장. 컨테이너 로그 집계
36.1. 개요
OpenShift Container Platform 클러스터 관리자는 EFK 스택을 배포하여 다양한 OpenShift Container Platform 서비스에 대한 로그를 집계할 수 있습니다. 애플리케이션 개발자는 보기 액세스 권한이 있는 프로젝트의 로그를 볼 수 있습니다. EFK 스택은 여러 컨테이너에서 제공되거나 삭제된 포드까지도 호스트 및 애플리케이션에서 로그를 집계합니다.
EFK 스택은 ELK 스택 의 수정된 버전이며 다음으로 구성됩니다.
- Elasticsearch (ES): 모든 로그가 저장되는 오브젝트 저장소입니다.
- Fluentd: 노드에서 로그를 수집하여 Elasticsearch에 제공합니다.
- Kibana: Elasticsearch용 웹 UI입니다.
클러스터에 배포한 후 스택은 모든 노드 및 프로젝트의 로그를 Elasticsearch로 집계하고 Kibana UI를 제공하여 모든 로그를 확인합니다. 클러스터 관리자는 모든 로그를 볼 수 있지만 애플리케이션 개발자는 볼 권한이 있는 프로젝트의 로그만 볼 수 있습니다. 스택 구성 요소는 안전하게 통신합니다.
Docker Container Logs 관리는 json-file 로깅 드라이버 옵션을 사용하여 컨테이너 로그를 관리하고 노드 디스크를 채우지 않도록 합니다.
36.2. 배포 전 구성
- Ansible 플레이북은 집계된 로깅을 배포 및 업그레이드하는 데 사용할 수 있습니다. 클러스터 설치 가이드를 숙지해야 합니다. 이는 Ansible 사용을 준비하는 데 필요한 정보를 제공하며 구성에 대한 정보를 포함합니다. 매개 변수는 EFK 스택의 다양한 영역을 구성하기 위해 Ansible 인벤토리 파일에 추가됩니다.
- 크기 조정 지침을 검토하여 배포를 구성하는 것이 가장 적합한지 확인합니다.
- 클러스터의 라우터를 배포했는지 확인합니다.
- Elasticsearch 에 필요한 스토리지가 있는지 확인합니다. 각 Elasticsearch 노드에는 자체 스토리지 볼륨이 필요합니다. 자세한 내용은 Elasticsearch 를 참조하십시오.
-
고가용성 Elasticsearch 가 필요한지 확인합니다. 고가용성 환경에는 각각 다른 호스트에 있는 Elasticsearch 노드가 3개 이상 필요합니다. 기본적으로 OpenShift Container Platform은 각 인덱스에 대해 하나의 shard와 해당 shard의 복제본 0개를 생성합니다. 고가용성에는 각 shard의 여러 복제본도 필요합니다. 고가용성을 생성하려면
openshift_logging_es_number_of_replicasAnsible 변수를1보다 큰 값으로 설정합니다. 자세한 내용은 Elasticsearch 를 참조하십시오.
36.3. 로깅 Ansible 변수 지정
인벤토리 호스트 파일에서 EFK 배포에 대한 매개변수를 지정하여 기본 매개변수 값을 재정의할 수 있습니다.
매개변수를 선택하기 전에 Elasticsearch 및 Fluentd 섹션을 읽습니다.
기본적으로 Elasticsearch 서비스는 클러스터의 노드 간 TCP 통신에 포트 9300을 사용합니다.
| 매개변수 | 설명 |
|---|---|
|
|
로깅을 설치하려면 |
|
|
|
|
| Kubernetes 마스터의 URL입니다. 공용으로 액세스할 필요는 없지만 클러스터 내에서 액세스할 수 있어야 합니다. 예를 들면 https://<PRIVATE-MASTER-URL>:8443 입니다. |
|
|
일반적인 설치 제거는 다시 설치 중에 원하지 않는 데이터 손실을 방지하기 위해 PVC를 유지합니다. Ansible 플레이북이 PVC를 포함한 모든 로깅 영구 데이터를 완전히 제거할 수 있도록 하려면 |
|
|
|
|
|
Eventrouter의 이미지 버전입니다. 예: |
|
| 로깅 이벤트 라우터의 이미지 버전입니다. |
|
|
이벤트 라우터, 지원되는 |
|
|
|
|
|
기본값은 |
|
|
이벤트 라우터에 할당할 최소 CPU 양입니다. 기본값은 |
|
|
eventrouter Pod의 메모리 제한입니다. 기본값은 |
|
|
eventrouter 가 배포되는 프로젝트입니다. 기본값은 중요
프로젝트를 |
|
| 인증된 레지스트리에서 구성 요소 이미지를 가져오는 데 사용할 기존 풀 시크릿의 이름을 지정합니다. |
|
|
Curator의 이미지 버전입니다. 예: |
|
| 기본 최소 사용 기간(일 수) Curator는 로그 레코드를 삭제하는 데 를 사용합니다. |
|
| Curator(날짜)의 시간이 실행됩니다. |
|
| 분량의 Curator가 실행됩니다. |
|
|
시간대 Curator는 런타임 시간을 파악하는 데 를 사용합니다. tzselect(8) 또는 timedatectl(1) "Region/Locality" 형식의 문자열로 시간대를 제공합니다(예: |
|
| Curator의 스크립트 로그 수준입니다. |
|
| Curator 프로세스의 로그 수준입니다. |
|
| Curator에 할당할 CPU 양입니다. |
|
| Curator에 할당할 메모리 양입니다. |
|
| Curator 인스턴스를 배포하는 데 적합한 노드를 지정하는 노드 선택기입니다. |
|
|
|
|
|
|
|
|
업그레이드가 |
|
|
Kibana의 이미지 버전입니다. 예: |
|
| Kibana에 도달할 웹 클라이언트의 외부 호스트 이름입니다. |
|
| Kibana에 할당할 CPU 양입니다. |
|
| Kibana에 할당할 메모리 양입니다. |
|
|
Kibana 프록시의 이미지 버전입니다. 예: |
|
|
|
|
| Kibana 프록시에 할당할 CPU 양입니다. |
|
| Kibana 프록시에 할당할 메모리 양입니다. |
|
| Kibana를 확장해야 하는 노드 수입니다. |
|
| Kibana 인스턴스 배포에 적합한 노드를 지정하는 노드 선택기입니다. |
|
| Kibana 배포 구성에 추가할 환경 변수 맵입니다. 예를 들면 {"ELASTœEARCH_REQUESTTIMEOUT":"30000"}입니다. |
|
| Kibana 경로를 생성할 때 사용할 공개 키입니다. |
|
| Kibana 경로를 생성할 때 키와 일치하는 인증서입니다. |
|
| 선택 사항: Kibana 경로를 생성할 때 사용되는 키 및 인증서와 함께 사용할 CA입니다. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Elasticsearch를 재암호화 경로로 노출하려면 |
|
|
경로 및 TLS 서버 인증서에 사용할 외부를 향한 호스트 이름입니다. 기본값은
예를 들어 |
|
| Elasticsearch가 외부 TLS 서버 인증서에 사용하는 인증서의 위치입니다. 기본값은 생성된 인증서입니다. |
|
| Elasticsearch가 외부 TLS 서버 인증서에 사용하는 키의 위치입니다. 기본값은 생성된 키입니다. |
|
| CA 인증서 Elasticsearch의 위치는 외부 TLS 서버 인증서에 사용합니다. 기본값은 내부 CA입니다. |
|
|
Elasticsearch를 재암호화 경로로 노출하려면 |
|
|
경로 및 TLS 서버 인증서에 사용할 외부를 향한 호스트 이름입니다. 기본값은
예를 들어 |
|
| Elasticsearch가 외부 TLS 서버 인증서에 사용하는 인증서의 위치입니다. 기본값은 생성된 인증서입니다. |
|
| Elasticsearch가 외부 TLS 서버 인증서에 사용하는 키의 위치입니다. 기본값은 생성된 키입니다. |
|
| CA 인증서 Elasticsearch의 위치는 외부 TLS 서버 인증서에 사용합니다. 기본값은 내부 CA입니다. |
|
|
Fluentd의 이미지 버전입니다. 예: |
|
| Fluentd 인스턴스 배포에 적합한 노드를 지정하는 노드 선택기입니다. Fluentd가 로그를 실행하고 수집하기 전에 Fluentd를 실행해야 하는 모든 노드(일반적으로 모두)는 이 레이블이 있어야 합니다.
설치 후 집계된 로깅 클러스터를 확장하는 경우 설치의 일부로 Fluentd 노드 선택기 레이블을 지속된 노드 레이블 목록에 추가하는 것이 좋습니다 . |
|
| Fluentd Pod의 CPU 제한입니다. |
|
| Fluentd Pod의 메모리 제한입니다. |
|
|
Fluentd가 처음 시작될 때 저널 헤드에서 읽어야 하는 경우 |
|
|
Fluentd를 배포하기 위해 레이블이 지정된 노드 목록입니다. 기본값은 ['--all']을 사용하여 모든 노드에 레이블을 지정하는 것입니다. null 값은 |
|
|
|
|
|
감사 로그 파일의 위치. 기본값은 |
|
|
감사 로그 파일의 Fluentd |
|
|
레코드의 |
|
|
|
|
|
|
|
|
업그레이드가 |
|
|
|
|
|
|
|
|
|
|
|
openshift_logging_fluentd_merge_json_log를 사용할 |
|
|
|
|
|
|
|
|
|
|
| Fluentd가 로그를 보내야 하는 Elasticsearch 서비스의 이름입니다. |
|
| Fluentd가 로그를 보내야 하는 Elasticsearch 서비스의 포트입니다. |
|
|
CA Fluentd의 위치는 |
|
|
Fluentd가 |
|
|
Fluentd가 |
|
| 배포할 Elasticsearch 노드입니다. 고가용성에는 3개 이상 필요합니다. |
|
| Elasticsearch 클러스터의 CPU 제한 양입니다. |
|
| Elasticsearch 인스턴스당 예약할 RAM 크기입니다. 최소 512M이어야 합니다. 가능한 접미사는 G,g, M,m입니다. |
|
|
새 인덱스마다 기본 shard당 복제본 수입니다. 기본값은 '0'입니다. 프로덕션 클러스터에는 최소 |
|
|
ES에서 생성된 모든 새 인덱스의 기본 shard 수입니다. 기본값은 |
|
| 특정 PV를 선택하기 위해 PVC에 추가된 키/값 맵입니다. |
|
|
백업 스토리지를 동적으로 프로비저닝하려면 매개 변수 값을
|
|
|
기본이 아닌 스토리지 클래스를 사용하려면 |
|
|
Elasticsearch 인스턴스별로 생성할 영구 볼륨 클레임의 크기입니다. 예: 100G. 생략하면 PVC가 생성되지 않으며 대신 임시 볼륨이 사용됩니다. 이 매개변수를 설정하면 로깅 설치 프로그램에서
|
|
|
Elasticsearch의 이미지 버전입니다. 예: |
|
|
Elasticsearch 스토리지 유형을 설정합니다. 영구 Elasticsearch 스토리지를 사용하는 경우 로깅 설치 프로그램에서 이 값을 |
|
|
Elasticsearch 노드의 스토리지로 사용할 영구 볼륨 클레임 이름의 접두사입니다. 숫자는 logging-es-1 과 같이 노드당 추가됩니다. 아직 존재하지 않는 경우 크기가
|
|
| Elasticsearch가 복구를 시도하기 전에 대기하는 시간입니다. 지원되는 시간 단위는 초(s) 또는 분(m)입니다. |
|
| Elasticsearch 스토리지 볼륨에 액세스할 수 있는 추가 그룹 ID 수입니다. 백업 볼륨은 이 그룹 ID의 액세스를 허용해야 합니다. |
|
|
Elasticsearch 노드를 배포하는 데 적합한 대상을 결정하는 맵으로 지정된 노드 선택기입니다. 이 맵을 사용하여 이러한 인스턴스를 실행에 예약되거나 최적화된 노드에 배치합니다. 예를 들어 선택기는 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Elasticsearch 노드 배포에 적합한 노드를 지정하는 노드 선택기입니다. 이러한 인스턴스를 예약하거나 실행하도록 최적화한 노드에 이러한 인스턴스를 배치하는 데 사용할 수 있습니다. 예를 들어 선택기는 |
|
|
기본값
적절한 액세스 권한이 없는 경우 클러스터 관리자에게 문의하십시오. |
|
|
Ansible 플레이북이 지정된 Elasticsearch 노드를 업그레이드한 후 Elasticsearch 클러스터가 녹색 상태가 될 때까지 기다리는 시간을 조정합니다. 대규모 shard(50GB 이상)를 초기화하는 데 60분 이상 걸릴 수 있으므로 Ansible 플레이북에서 업그레이드 절차를 중단합니다. 기본값은 |
|
| Kibana 인스턴스 배포에 적합한 노드를 지정하는 노드 선택기입니다. |
|
| Curator 인스턴스를 배포하는 데 적합한 노드를 지정하는 노드 선택기입니다. |
|
|
|
사용자 정의 인증서
배포 프로세스 중에 생성된 변수를 사용하는 대신 다음 인벤토리 변수를 사용하여 사용자 정의 인증서를 지정할 수 있습니다. 이러한 인증서는 사용자의 브라우저와 Kibana 간의 통신을 암호화하고 보호하는 데 사용됩니다. 보안 관련 파일은 제공되지 않는 경우 생성됩니다.
| 파일 이름 | 설명 |
|---|---|
|
| Kibana 서버의 브라우저 관련 인증서입니다. |
|
| 브라우저를 향한 Kibana 인증서와 함께 사용할 키입니다. |
|
| Kibana 인증서가 있는 브라우저에 사용할 CA 파일의 제어 노드의 절대 경로입니다. |
|
| Ops Kibana 서버의 브라우저 방향 인증서입니다. |
|
| 브라우저에 대한 Ops Kibana 인증서와 함께 사용할 키입니다. |
|
| ops Kibana 인증서가 가리키는 브라우저에 사용할 CA 파일의 제어 노드의 절대 경로입니다. |
이러한 인증서를 재배포해야 하는 경우 EFK 인증서 재배포 를 참조하십시오.
36.4. EFK 스택 배포
EFK 스택은 Ansible 플레이북을 사용하여 EFK 구성 요소에 배포합니다. 기본 인벤토리 파일을 사용하여 기본 OpenShift Ansible 위치에서 플레이북을 실행합니다.
$ cd /usr/share/ansible/openshift-ansible
$ ansible-playbook [-i </path/to/inventory>] \
playbooks/openshift-logging/config.yml
플레이북을 실행하면 openshift-logging 프로젝트에 배포된 Secrets, ServiceAccounts 및 DeploymentConfigs와 같은 스택을 지원하는 데 필요한 모든 리소스가 배포됩니다. 플레이북은 스택이 실행될 때까지 구성 요소 포드를 배포합니다. 대기 단계가 실패하면 배포가 계속 성공할 수 있습니다. 레지스트리에서 구성 요소 이미지를 검색하여 최대 몇 분 정도 걸릴 수 있습니다. 다음을 사용하여 프로세스를 확인할 수 있습니다.
$ oc get pods -w
logging-curator-1541129400-l5h77 0/1 Running 0 11h
logging-es-data-master-ecu30lr4-1-deploy 0/1 Running 0 11h
logging-fluentd-2lgwn 1/1 Running 0 11h
logging-fluentd-lmvms 1/1 Running 0 11h
logging-fluentd-p9nd7 1/1 Running 0 11h
logging-kibana-1-zk94k 2/2 Running 0 11h 'oc get pods -o wide 명령을 사용하여 Fluentd Pod가 배포된 노드를 확인할 수 있습니다.
$ oc get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE
logging-es-data-master-5av030lk-1-2x494 2/2 Running 0 38m 154.128.0.80 ip-153-12-8-6.wef.internal <none>
logging-fluentd-lqdxg 1/1 Running 0 2m 154.128.0.85 ip-153-12-8-6.wef.internal <none>
logging-kibana-1-gj5kc 2/2 Running 0 39m 154.128.0.77 ip-153-12-8-6.wef.internal <none>결국 Running(실행 중 ) 상태가 됩니다. 관련 이벤트를 검색하여 배포 중에 Pod 상태에 대한 자세한 내용은 다음을 수행합니다.
$ oc describe pods/<pod_name>Pod가 성공적으로 실행되지 않는 경우 로그를 확인합니다.
$ oc logs -f <pod_name>36.5. 배포 이해 및 조정
이 섹션에서는 배포된 구성 요소를 설정할 수 있는 조정에 대해 설명합니다.
36.5.1. ops 클러스터
default,openshift 및 openshift -infra 프로젝트의 로그는 자동으로 집계되어 Kibana 인터페이스에서 .operations 항목으로 그룹화됩니다.
EFK 스택을 배포한 프로젝트(여기에 설명된 대로로깅 )는 .operations 로 집계 되지 않으며 ID 아래에 있습니다.
인벤토리 파일에서 openshift_logging_use_ops 를 true 로 설정하면 Fluentd는 기본 Elasticsearch 클러스터와 노드 시스템 로그와 프로젝트 기본값,openshift, openshift -infra 로 정의된 작업 로그를 위해 예약된 다른 클러스터 간에 로그를 분할하도록 구성됩니다. 따라서 별도의 Elasticsearch 클러스터, 별도의 Kibana 및 별도의 Curator가 작업 로그를 인덱싱, 액세스 및 관리하기 위해 배포됩니다. 이러한 배포는 -ops 를 포함하는 이름으로 설정됩니다. 이 옵션을 활성화하는 경우 별도의 배포를 염두에 두십시오. 다음 설명은 대부분 -ops 를 포함하도록 이름이 변경된 경우에만 작업 클러스터에 적용됩니다.
36.5.2. Elasticsearch
Elasticsearch(ES) 는 모든 로그가 저장되는 오브젝트 저장소입니다.
Elasticsearch는 각각 인덱스 라고 하는 데이터 저장소로 로그 데이터를 구성합니다. Elasticsearch는 각 인덱스를 shards 라는 여러 조각으로 세분화하여 클러스터의 Elasticsearch 노드 세트에 분산됩니다. replicas 라는 shard의 복사본을 만들도록 Elasticsearch를 구성할 수 있습니다. Elasticsearch는 또한 Elactisearch 노드에 복제본을 분배합니다. shard와 복제본의 조합은 장애에 대한 중복성과 복원력을 제공하기 위한 것입니다. 예를 들어 하나의 복제본을 사용하여 인덱스에 대해 세 개의 shard를 구성하는 경우 Elasticsearch는 해당 인덱스에 대해 총 6개의 shard(기본 샤드 3개와 복제본 3개를 백업으로 생성합니다.
OpenShift Container Platform 로깅 설치 프로그램은 각 Elasticsearch 노드가 자체 스토리지 볼륨이 포함된 고유한 배포 구성을 사용하여 배포되도록 합니다. 로깅 시스템에 추가하는 각 Elasticsearch 노드에 대한 추가 배포 구성을 생성할 수 있습니다. 설치하는 동안 openshift_logging_es_cluster_size Ansible 변수를 사용하여 Elasticsearch 노드 수를 지정할 수 있습니다.
또는 인벤토리 파일의 openshift_logging_es_cluster_size 를 수정하고 로깅 플레이북을 다시 실행하여 기존 클러스터를 확장할 수 있습니다. 추가 클러스터링 매개 변수는 수정할 수 있으며 로깅 Ansible 변수 지정 에서 설명합니다.
아래 지침에 따라 스토리지 및 네트워크 위치 선택과 관련된 고려 사항은 Elastic 문서를 참조하십시오.
고가용성 Elasticsearch 환경에 는 각각 다른 호스트에 있는 3개 이상의 Elasticsearch 노드가 필요하며, 복제본을 생성하려면 openshift_logging_es_number_of_replicas Ansible 변수를 1 개 이상의 값으로 설정해야 합니다.
모든 Elasticsearch 배포 보기
현재 Elasticsearch 배포를 모두 보려면 다음을 수행합니다.
$ oc get dc --selector logging-infra=elasticsearch고가용성을 위한 Elasticsearch 구성
고가용성 Elasticsearch 환경에는 각각 다른 호스트에 있는 3개 이상의 Elasticsearch 노드가 필요하며, 복제본을 생성하려면 openshift_logging_es_number_of_replicas Ansible 변수를 1 개 이상의 값으로 설정해야 합니다.
다음 시나리오를 3개의 Elasticsearch 노드가 있는 OpenShift Container Platform 클러스터의 가이드로 사용합니다.
-
openshift_logging_es_number_of_replicas를1로 설정하면 두 노드에 클러스터에 있는 모든 Elasticsearch 데이터의 복사본이 있습니다. 이렇게 하면 Elasticsearch 데이터가 있는 노드가 중단되면 다른 노드에 클러스터의 모든 Elasticsearch 데이터 복사본이 있습니다. openshift_logging_es_number_of_replicas를3으로 설정하면 4개의 노드에 클러스터에 있는 모든 Elasticsearch 데이터의 복사본이 있습니다. 이렇게 하면 Elasticsearch 데이터가 있는 노드 3개가 다운되면 한 노드에 클러스터의 모든 Elasticsearch 데이터 복사본이 있습니다.이 시나리오에서는 여러 Elasticsearch 노드가 중단되면 Elasticsearch 상태가 RED가 되고 새로운 Elasticsearch shard가 할당되지 않았습니다. 그러나 고가용성으로 인해 Elasticsearch 데이터가 손실되지 않습니다.
고가용성과 성능에는 장단점이 있습니다. 예를 들어 openshift_logging_es_number_of_replicas=2 및 openshift_logging_es_number_of_shards=3 을 보유하려면 Elasticsearch에서 클러스터의 노드 간에 shard 데이터를 복제하는 중요한 리소스를 사용해야 합니다. 또한 복제본을 더 많이 사용하려면 각 노드에서 데이터 스토리지 요구 사항을 두 배 늘리거나 이동해야 하므로 Elasticsearch에 영구 스토리지를 계획할 때 고려해야 합니다.
공유 수 구성 시 고려 사항
openshift_logging_es_number_of_shards 매개변수의 경우 다음을 고려하십시오.
-
더 높은 성능을 위해 shard 수를 늘립니다. 예를 들어 3개의 노드 클러스터에서
openshift_logging_es_number_of_shards=3을설정합니다. 이렇게 하면 각 인덱스가 3개의 파트(스하드)로 분할되고 인덱스를 처리하기 위한 로드가 3개의 노드 전체에 분산됩니다. - 다수의 프로젝트가 있는 경우 클러스터에 몇 만 개 이상의 shard가 있는 경우 성능 저하가 표시될 수 있습니다. shard 수를 줄이거나 큐레이션 시간을 줄입니다.
-
매우 큰 인덱스가 적은 경우
openshift_logging_es_number_of_shards=3이상을 구성할 수 있습니다. Elasticsearch는 50GB 미만의 최대 shard 크기를 사용하는 것이 좋습니다.
노드 선택기
Elasticsearch는 많은 리소스를 사용할 수 있기 때문에 클러스터의 모든 구성원은 서로 짧은 대기 시간 네트워크 연결이 있어야 하며 원격 스토리지에 대한 연결이 짧아야 합니다. 노드 선택기 를 사용하여 전용 노드 또는 클러스터 내 전용 리전에 인스턴스를 지시하여 확인합니다.
노드 선택기를 구성하려면 인벤토리 파일에서 openshift_logging_es_nodeselector 구성 옵션을 지정합니다. 이는 모든 Elasticsearch 배포에 적용됩니다. 노드 선택기를 개별화해야 하는 경우 배포 후 각 배포 구성을 수동으로 편집해야 합니다. 노드 선택기는 python 호환 dict로 지정됩니다. 예를 들면 {"node-type":"infra", "region":"east"} 입니다.
36.5.2.1. 영구 Elasticsearch 스토리지
기본적으로 openshift_logging Ansible 역할은 Pod를 다시 시작할 때 Pod의 모든 데이터가 손실되는 임시 배포를 생성합니다.
프로덕션 환경의 경우 각 Elasticsearch 배포 구성에 영구 스토리지 볼륨이 필요합니다. 기존 영구 볼륨 클레임 을 지정하거나 OpenShift Container Platform에서 이를 생성할 수 있습니다.
기존 PVC 사용. 배포에 대해 고유한 PVC를 생성하는 경우 OpenShift Container Platform은 이러한 PVC를 사용합니다.
openshift_logging_es_pvc_prefix설정과 일치하도록 PVC의 이름을 지정합니다. 기본값은logging-es입니다. 각 PVC에 이름을 추가한 시퀀스 번호(logging-es-0, logging-es-1, logging-es-2등)를 할당합니다.OpenShift Container Platform에서 PVC를 생성할 수 있습니다. Elsaticsearch의 PVC가 없는 경우 OpenShift Container Platform은 Ansible 인벤토리 파일의 매개 변수를 기반으로 PVC를 생성합니다.
Expand 매개변수 설명 openshift_logging_es_pvc_sizePVC 요청 크기를 지정합니다.
openshift_logging_elasticsearch_storage_type스토리지 유형을
pvc로 지정합니다.참고선택적 매개변수입니다.
openshift_logging_es_pvc_size매개변수를 0보다 큰 값으로 설정하면 로깅 설치 프로그램에서 이 매개변수를 기본적으로 자동으로pvc로 설정합니다.openshift_logging_es_pvc_prefix선택적으로 PVC에 대한 사용자 지정 접두사를 지정합니다.
예를 들면 다음과 같습니다.
openshift_logging_elasticsearch_storage_type=pvc openshift_logging_es_pvc_size=104802308Ki openshift_logging_es_pvc_prefix=es-logging
동적으로 프로비저닝된 PV 를 사용하는 경우 OpenShift Container Platform 로깅 설치 프로그램은 기본 스토리지 클래스 또는 openshift_logging_elasticsearch_pvc_storage_class_name 매개변수로 지정된 PVC를 사용하는 PVC를 생성합니다.
NFS 스토리지를 사용하는 경우 OpenShift Container Platform 설치 프로그램은 openshift_logging_storage_* 매개 변수를 기반으로 영구 볼륨을 생성하고 OpenShift Container Platform 로깅 설치 프로그램은 openshift_logging_es_pvc_* 매개변수를 사용하여 PVC를 생성합니다. EFK에서 영구 볼륨을 사용하려면 올바른 매개변수를 지정해야 합니다. 또한 로깅 설치 프로그램에서 코어 인프라를 사용하여 NFS 설치를 차단하므로 Ansible 인벤토리 파일에서 openshift_enable_unsupported_configurations=true 매개 변수를 설정합니다.
Lucene은 NFS가 제공하지 않는 파일 시스템 동작을 사용하므로 NFS 스토리지를 볼륨 또는 영구 볼륨으로 사용하거나 Gluster와 같은 NAS를 사용하는 것은 Elasticsearch 스토리지에서 지원되지 않습니다. 데이터 손상 및 기타 문제가 발생할 수 있습니다.
환경에 NFS 스토리지가 필요한 경우 다음 방법 중 하나를 사용합니다.
36.5.2.1.1. NFS를 영구 볼륨으로 사용
자동으로 프로비저닝된 영구 볼륨 또는 사전 정의된 NFS 볼륨을 사용하여 NFS를 배포할 수 있습니다.
자세한 내용은 두 개의 개별 컨테이너에서 사용하기 위해 공유 스토리지를 활용하기 위해 두 개의 영구 볼륨 클레임에서 NFS 마운트 공유를 참조하십시오.
자동 프로비저닝된 NFS 사용
NFS를 자동으로 프로비저닝하는 영구 볼륨으로 NFS를 사용하려면 다음을 수행합니다.
다음 줄을 Ansible 인벤토리 파일에 추가하여 NFS 자동 프로비저닝 스토리지 클래스를 생성하고 백업 스토리지를 동적으로 프로비저닝합니다.
openshift_logging_es_pvc_storage_class_name=$nfsclass openshift_logging_es_pvc_dynamic=true다음 명령을 사용하여 로깅 플레이북을 사용하여 NFS 볼륨을 배포합니다.
ansible-playbook /usr/share/ansible/openshift-ansible/playbooks/openshift-logging/config.yml다음 단계를 사용하여 PVC를 생성합니다.
Ansible 인벤토리 파일을 편집하여 PVC 크기를 설정합니다.
openshift_logging_es_pvc_size=50Gi참고로깅 플레이북은 크기를 기반으로 볼륨을 선택하고 다른 영구 볼륨의 크기가 동일한 경우 예기치 않은 볼륨을 사용할 수 있습니다.
다음 명령을 사용하여 Ansible deploy_cluster.yml 플레이북을 다시 실행합니다.
ansible-playbook /usr/share/ansible/openshift-ansible/playbooks/deploy_cluster.yml설치 프로그램 플레이북은
openshift_logging_storage변수를 기반으로 NFS 볼륨을 생성합니다.
사전 정의된 NFS 볼륨 사용
기존 NFS 볼륨을 사용하여 OpenShift Container Platform 클러스터와 함께 로깅을 배포하려면 다음을 수행합니다.
Ansible 인벤토리 파일을 편집하여 NFS 볼륨을 구성하고 PVC 크기를 설정합니다.
openshift_logging_storage_kind=nfs openshift_logging_storage_access_modes=['ReadWriteOnce'] openshift_logging_storage_nfs_directory=/share1 openshift_logging_storage_nfs_options='*(rw,root_squash)'2 openshift_logging_storage_labels={'storage': 'logging'} openshift_logging_elasticsearch_storage_type=pvc openshift_logging_es_pvc_size=10Gi openshift_logging_es_pvc_storage_class_name='' openshift_logging_es_pvc_dynamic=true openshift_logging_es_pvc_prefix=logging다음 명령을 사용하여 EFK 스택을 재배포합니다.
ansible-playbook /usr/share/ansible/openshift-ansible/playbooks/deploy_cluster.yml
36.5.2.1.2. NFS를 로컬 스토리지로 사용
NFS 서버에서 대규모 파일을 할당하고 파일을 노드에 마운트할 수 있습니다. 그런 다음 파일을 호스트 경로 장치로 사용할 수 있습니다.
$ mount -F nfs nfserver:/nfs/storage/elasticsearch-1 /usr/local/es-storage
$ chown 1000:1000 /usr/local/es-storage그런 다음 아래 설명된 대로 /usr/local/es-storage 를 호스트 마운트로 사용합니다. 다른 백업 파일을 Elasticsearch 노드의 스토리지로 사용합니다.
이 루프백은 노드의 OpenShift Container Platform 외부에서 수동으로 유지 관리해야 합니다. 컨테이너 내부에서 유지 관리해서는 안 됩니다.
각 노드 호스트에서 로컬 디스크 볼륨(사용 가능한 경우)을 Elasticsearch 복제본의 스토리지로 사용할 수 있습니다. 이 작업을 수행하려면 다음과 같이 몇 가지 준비가 필요합니다.
관련 서비스 계정에 로컬 볼륨을 마운트하고 편집할 수 있는 권한이 있어야 합니다.
$ oc adm policy add-scc-to-user privileged \ system:serviceaccount:openshift-logging:aggregated-logging-elasticsearch참고이전 버전의 OpenShift Container Platform에서 업그레이드한 경우 로깅
프로젝트에클러스터 로깅이 설치되었을 수 있습니다. 그에 따라 서비스 계정을 조정해야 합니다.예를 들면 다음과 같은 권한을 클레임하려면 각 Elasticsearch 노드 정의를 패치해야 합니다.
$ for dc in $(oc get deploymentconfig --selector component=es -o name); do oc scale $dc --replicas=0 oc patch $dc \ -p '{"spec":{"template":{"spec":{"containers":[{"name":"elasticsearch","securityContext":{"privileged": true}}]}}}}' done- 로컬 스토리지를 사용하려면 Elasticsearch 복제본이 올바른 노드에 있어야 하며 해당 노드가 일정 기간 동안 중단되어도 이동하지 않아야 합니다. 이를 위해서는 각 Elasticsearch 복제본에 관리자가 스토리지를 할당한 노드에 고유한 노드 선택기를 제공해야 합니다. 노드 선택기를 구성하려면 각 Elasticsearch 배포 구성을 편집하여 nodeSelector 섹션을 추가하거나 편집하여 원하는 각 노드에 적용한 고유한 라벨을 지정합니다.
apiVersion: v1
kind: DeploymentConfig
spec:
template:
spec:
nodeSelector:
logging-es-node: "1" - 1
- 이 레이블은 해당 레이블이 있는 단일 노드(이 경우
logging-es-node=1)를 통해 복제본을 고유하게 식별해야 합니다.- 각 필수 노드에 대한 노드 선택기를 생성합니다.
-
oc label명령을 사용하여 필요한 수의 노드에 레이블을 적용합니다.
예를 들어 배포에 세 개의 인프라 노드가 있는 경우 다음과 같이 해당 노드의 레이블을 추가할 수 있습니다.
$ oc label node <nodename1> logging-es-node=0
$ oc label node <nodename2> logging-es-node=1
$ oc label node <nodename3> logging-es-node=2노드에 라벨을 추가하는 방법에 대한 자세한 내용은 노드의 라벨 업데이트를 참조하십시오.
노드 선택기를 자동으로 적용하려면 oc patch 명령을 대신 사용할 수 있습니다.
$ oc patch dc/logging-es-<suffix> \
-p '{"spec":{"template":{"spec":{"nodeSelector":{"logging-es-node":"0"}}}}}'이러한 단계를 완료하고 나면 각 복제본에 로컬 호스트 마운트를 적용할 수 있습니다. 다음 예제에서는 스토리지가 각 노드의 동일한 경로에 마운트되었다고 가정합니다.
$ for dc in $(oc get deploymentconfig --selector component=es -o name); do
oc set volume $dc \
--add --overwrite --name=elasticsearch-storage \
--type=hostPath --path=/usr/local/es-storage
oc rollout latest $dc
oc scale $dc --replicas=1
done36.5.2.1.3. Elasticsearch의 hostPath 스토리지 구성
Elasticsearch의 hostPath 스토리지를 사용하여 OpenShift Container Platform 클러스터를 프로비저닝할 수 있습니다.
각 노드 호스트에서 로컬 디스크 볼륨을 Elasticsearch 복제본의 스토리지로 사용하려면 다음을 수행합니다.
로컬 Elasticsearch 스토리지의 각 인프라 노드에 로컬 마운트 지점을 생성합니다.
$ mkdir /usr/local/es-storageElasticsearch 볼륨에서 파일 시스템을 생성합니다.
$ mkfs.ext4 /dev/xxxelasticsearch 볼륨을 마운트합니다.
$ mount /dev/xxx /usr/local/es-storage/etc/fstab에 다음 행을 추가합니다.$ /dev/xxx /usr/local/es-storage ext4마운트 지점의 소유권을 변경합니다.
$ chown 1000:1000 /usr/local/es-storage관련 서비스 계정에 로컬 볼륨을 마운트하고 편집할 권한을 부여합니다.
$ oc adm policy add-scc-to-user privileged \ system:serviceaccount:openshift-logging:aggregated-logging-elasticsearch참고이전 버전의 OpenShift Container Platform에서 업그레이드한 경우 로깅
프로젝트에클러스터 로깅이 설치되었을 수 있습니다. 그에 따라 서비스 계정을 조정해야 합니다.권한을 요청하려면 예제에 표시된 대로 Ops 클러스터에
--selector 구성 요소=es-ops를 지정하는 각 Elasticsearch 복제본 정의를 패치합니다.$ for dc in $(oc get deploymentconfig --selector component=es -o name); do oc scale $dc --replicas=0 oc patch $dc \ -p '{"spec":{"template":{"spec":{"containers":[{"name":"elasticsearch","securityContext":{"privileged": true}}]}}}}' done올바른 노드에서 Elasticsearch 복제본을 찾아 로컬 스토리지를 사용하고 해당 노드가 일정 시간 동안 중단되는 경우에도 해당 복제본을 이동하지 않습니다. 노드 위치를 지정하려면 각 Elasticsearch 복제본에 관리자가 스토리지를 할당한 노드에 고유한 노드 선택기를 지정합니다.
노드 선택기를 구성하려면 각 Elasticsearch 배포 구성을 편집하거나
nodeSelector섹션을 추가하거나 편집하여 원하는 각 노드에 적용한 고유한 라벨을 지정합니다.apiVersion: v1 kind: DeploymentConfig spec: template: spec: nodeSelector: logging-es-node: "1"레이블은 해당 레이블이 있는 단일 노드(이 경우
logging-es-node=1)를 통해 복제본을 고유하게 식별해야 합니다.각 필수 노드에 대한 노드 선택기를 생성합니다.
oc label명령을 사용하여 필요한 수의 노드에 레이블을 적용합니다.예를 들어 배포에 세 개의 인프라 노드가 있는 경우 다음과 같이 해당 노드의 레이블을 추가할 수 있습니다.
$ oc label node <nodename1> logging-es-node=0 $ oc label node <nodename2> logging-es-node=1 $ oc label node <nodename3> logging-es-node=2노드 선택기의 애플리케이션을 자동화하려면 다음과 같이
oc명령을 사용합니다.label 명령 대신 ocpatch$ oc patch dc/logging-es-<suffix> \ -p '{"spec":{"template":{"spec":{"nodeSelector":{"logging-es-node":"1"}}}}}'이러한 단계를 완료하고 나면 각 복제본에 로컬 호스트 마운트를 적용할 수 있습니다. 다음 예제에서는 스토리지가 각 노드의 동일한 경로에 마운트된 것으로 가정하고 Ops 클러스터에 대해
--selector component=es-ops를 지정합니다.$ for dc in $(oc get deploymentconfig --selector component=es -o name); do oc set volume $dc \ --add --overwrite --name=elasticsearch-storage \ --type=hostPath --path=/usr/local/es-storage oc rollout latest $dc oc scale $dc --replicas=1 done
36.5.2.1.4. Elasticsearch의 규모 변경
클러스터에서 Elasticsearch 노드 수를 확장해야 하는 경우 추가할 각 Elasticsearch 노드에 대한 배포 구성을 생성할 수 있습니다.
영구 볼륨의 특성과 Elasticsearch가 해당 데이터를 저장하고 클러스터를 복구하도록 구성된 방식 때문에 Elasticsearch 배포 구성에서 노드를 간단하게 늘릴 수 없습니다.
Elasticsearch의 규모를 변경하는 가장 간단한 방법은 인벤토리 호스트 파일을 수정하고 이전에 설명한 대로 로깅 플레이북을 다시 실행하는 것입니다. 배포를 위해 영구 스토리지를 제공한 경우 이 작업을 중단해서는 안 됩니다.
로깅 플레이북을 사용하여 Elasticsearch 클러스터의 크기를 조정하는 것은 새로운 openshift_logging_es_cluster_size 값이 클러스터의 현재 Elasticsearch 노드 수(확장됨)보다 큰 경우에만 가능합니다.
36.5.2.1.5. Elasticsearch 복제본 수 변경
인벤토리 호스트 파일에서 openshift_logging_es_number_of_replicas 값을 편집하고 이전에 설명한 대로 로깅 플레이북을 다시 실행하여 Elasticsearch 복제본의 수를 변경할 수 있습니다.
변경 사항은 새 인덱스에만 적용됩니다. 기존 인덱스는 이전 복제본 수를 계속 사용합니다. 예를 들어 인덱스 수를 3에서 2로 변경하는 경우 클러스터는 새 인덱스에 대해 2개의 복제본과 기존 인덱스의 경우 복제본 3개를 사용합니다.
다음 명령을 실행하여 기존 인덱스의 복제본 수를 수정할 수 있습니다.
$ oc exec -c elasticsearch $pod -- es_util --query=project.* -d '{"index":{"number_of_replicas":"2"}}' - 1
- 기존 인덱스에 사용할 복제본 수를 지정합니다.
36.5.2.1.6. Elasticsearch를 경로로 노출
기본적으로 OpenShift 집계 로깅과 함께 배포된 Elasticsearch는 로깅 클러스터 외부에서 액세스할 수 없습니다. 데이터에 액세스하려는 도구에 대해 Elasticsearch에 대한 외부 액세스에 대한 경로를 활성화할 수 있습니다.
OpenShift 토큰을 사용하여 Elasticsearch에 액세스할 수 있으며 서버 인증서를 생성할 때 외부 Elasticsearch 및 Elasticsearch Ops 호스트 이름을 제공할 수 있습니다( Kibana와 비슷함).
Elasticsearch를 재암호화 경로로 액세스하려면 다음 변수를 정의합니다.
openshift_logging_es_allow_external=True openshift_logging_es_hostname=elasticsearch.example.com플레이북 디렉터리로 변경하고 다음 Ansible 플레이북을 실행합니다.
$ cd /usr/share/ansible/openshift-ansible $ ansible-playbook [-i </path/to/inventory>] \ playbooks/openshift-logging/config.ymlElasticsearch에 원격으로 로그인하려면 요청에 세 개의 HTTP 헤더가 포함되어야 합니다.
Authorization: Bearer $token X-Proxy-Remote-User: $username X-Forwarded-For: $ip_address로그에 액세스하려면 프로젝트에 액세스할 수 있어야 합니다. 예를 들면 다음과 같습니다.
$ oc login <user1> $ oc new-project <user1project> $ oc new-app <httpd-example>요청에 사용할 이 ServiceAccount의 토큰을 가져와야 합니다.
$ token=$(oc whoami -t)이전에 구성된 토큰을 사용하여 노출된 경로를 통해 Elasticsearch에 액세스할 수 있어야 합니다.
$ curl -k -H "Authorization: Bearer $token" -H "X-Proxy-Remote-User: $(oc whoami)" -H "X-Forwarded-For: 127.0.0.1" https://es.example.test/project.my-project.*/_search?q=level:err | python -mjson.tool
36.5.3. fluentd
Fluentd는 노드 레이블 선택기에 따라 노드를 배포하는 DaemonSet으로 배포되며, 인벤토리 매개변수 openshift_logging_fluentd_nodeselector 로 지정할 수 있으며 기본값은 logging-infra-fluentd 입니다. OpenShift 클러스터 설치의 일부로 Fluentd 노드 선택기를 지속된 노드 레이블 목록에 추가하는 것이 좋습니다.
Fluentd는 시스템 로그 소스로 journald 를 사용합니다. 운영 체제, 컨테이너 런타임 및 OpenShift의 로그 메시지입니다.
사용 가능한 컨테이너 런타임은 로그 메시지의 소스를 식별하기 위한 최소한의 정보를 제공합니다. 로그 수집 및 로그 정규화는 Pod가 삭제되고 라벨 또는 주석과 같은 API 서버에서 추가 메타데이터를 검색할 수 없는 후에 발생할 수 있습니다.
로그 수집기가 로그를 완료하기 전에 지정된 이름과 네임스페이스가 있는 Pod를 삭제하면 로그 메시지를 유사한 이름의 Pod 및 네임스페이스와 구분할 수 없습니다. 이로 인해 로그를 인덱싱하고 포드를 배포한 사용자가 소유하지 않은 인덱스에 주석을 달 수 있습니다.
사용 가능한 컨테이너 런타임은 로그 메시지의 소스를 식별할 수 있는 최소한의 정보를 제공하며, 고유한 개별 로그 메시지 또는 그러한 메시지의 소스 추적을 보장하지 않습니다.
OpenShift Container Platform 3.9 이상을 설치하면 json-file 을 기본 로그 드라이버로 사용하지만 OpenShift Container Platform 3.7에서 업그레이드된 환경에서는 기존 journald 로그 드라이버 구성이 유지됩니다. json-file 로그 드라이버를 사용하는 것이 좋습니다. 기존 로그 드라이버 구성을 json-file 로 변경하려면 집계된 로깅 드라이버 변경 에서 참조하십시오.
Fluentd 로그 보기
로그를 보는 방법은 LOGGING_FILE_PATH 설정에 따라 다릅니다.
LOGGING_FILE_PATH가 파일을 가리키는 경우 logs 유틸리티를 사용하여 Fluentd 로그 파일의 콘텐츠를 출력합니다.oc exec <pod> -- logs1 - 1
- Fluentd Pod의 이름을 지정합니다.
로그앞에 있는 공간을 확인합니다.
예를 들면 다음과 같습니다.
oc exec logging-fluentd-lmvms -- logs가장 오래된 로그부터 로그 파일의 내용이 출력됩니다. 로그에 기록되는 내용을 추적하려면
-f옵션을 사용합니다.LOGGING_FILE_PATH=console을 사용하는 경우 Fluentd는 로그를 기본 위치인/var/log/fluentd/fluentd.log에 씁니다.oc logs -f <pod_name>명령을 사용하여 로그를 검색할 수 있습니다.예를 들면 다음과 같습니다
oc logs -f fluentd.log
Fluentd 로그 위치 구성
Fluentd는 기본적으로 /var/log/fluentd/fluentd.log 또는 LOGGING_FILE_PATH 환경 변수를 기반으로 지정된 파일에 로그를 작성합니다.
Fluentd 로그의 기본 출력 위치를 변경하려면 기본 인벤토리 파일에서 LOGGING_FILE_PATH 매개변수를 사용합니다. 특정 파일을 지정하거나 Fluentd 기본 위치를 사용할 수 있습니다.
LOGGING_FILE_PATH=console
LOGGING_FILE_PATH=<path-to-log/fluentd.log> 이러한 매개변수를 변경한 후 로깅 설치 프로그램 플레이북을 다시 실행합니다.
$ cd /usr/share/ansible/openshift-ansible
$ ansible-playbook [-i </path/to/inventory>] \
playbooks/openshift-logging/config.ymlFluentd 로그 순환 구성
현재 Fluentd 로그 파일이 지정된 크기에 도달하면 OpenShift Container Platform의 이름이 fluentd.log 로그 파일의 이름을 자동으로 변경하여 새 로깅 데이터를 수집할 수 있습니다. 로그 회전은 기본적으로 활성화되어 있습니다.
다음 예에서는 최대 로그 크기가 1Mb이고 로그 4개를 유지해야 하는 클러스터의 로그를 보여줍니다. fluentd.log 가 1Mb에 도달하면 OpenShift Container Platform은 현재 fluentd.log.4 를 삭제하고 각 Fluentd 로그의 이름을 차례로 변경하고 새 fluentd.log 를 생성합니다.
fluentd.log 0b
fluentd.log.1 1Mb
fluentd.log.2 1Mb
fluentd.log.3 1Mb
fluentd.log.4 1MbFluentd 로그 파일의 크기와 환경 변수를 사용하여 OpenShift Container Platform이 유지되는 이름 변경 파일 수를 제어할 수 있습니다.
| 매개변수 | 설명 |
|---|---|
|
| 바이트에 있는 단일 Fluentd 로그 파일의 최대 크기입니다. flientd.log 파일의 크기가 이 값을 초과하면 OpenShift Container Platform에서 fluentd.log.* 파일의 이름을 변경하고 새 fluentd.log 를 생성합니다. 기본값은 1024000(1MB)입니다. |
|
|
Fluentd가 삭제하기 전에 유지되는 로그 수입니다. 기본값은 |
예를 들면 다음과 같습니다.
$ oc set env ds/logging-fluentd LOGGING_FILE_AGE=30 LOGGING_FILE_SIZE=1024000"
LOGGING_FILE_PATH=console 을 설정하여 로그 회전을 끕니다. 이로 인해 Fluentd는 Fluentd 기본 위치인 /var/log/fluentd/fluentd.log에 로그를 작성합니다. 여기에서 oc logs -f <pod_name> 명령을 사용하여 검색할 수 있습니다.
$ oc set env ds/fluentd LOGGING_FILE_PATH=consoleMERGE_JSON_LOG를 사용하여 로그의 JSON 구문 분석 비활성화
기본적으로 Fluentd는 로그 메시지가 JSON 형식인지 확인하고 메시지를 Elasticsearch에 게시된 JSON 페이로드 문서에 병합합니다.
JSON 구문 분석을 사용할 때 다음과 같은 결과가 나타날 수 있습니다.
- 일치하지 않는 유형 매핑으로 인해 Elasticsearch가 문서를 거부하여 로그 손실
- 거부 메시지로 인한 버퍼 스토리지 누수
- 동일한 이름의 필드의 데이터를 덮어씁니다.
이러한 문제 일부를 완화하는 방법에 대한 자세한 내용은 로그 수집기에서 로그를 정규화하는 방법을 참조하십시오.
이러한 문제를 방지하거나 로그에서 JSON을 구문 분석할 필요가 없는 경우 JSON 구문 분석을 비활성화할 수 있습니다.
JSON 구문 분석을 비활성화하려면 다음을 수행합니다.
다음 명령을 실행합니다.
oc set env ds/logging-fluentd MERGE_JSON_LOG=false1 - 1
- 이 기능을 비활성화하려면 이 값을
false로 설정하거나 이 기능을 활성화하려면true로 설정합니다.
Ansible을 실행할 때마다 이 설정이 적용되도록 하려면 Ansible 인벤토리에
openshift_logging_fluentd_merge_json_log="false"를 추가합니다.
로그 수집기에서 로그를 정규화하는 방법 구성
클러스터 로깅은 데이터베이스 스키마와 같은 특정 데이터 모델을 사용하여 로그 레코드와 해당 메타데이터를 로깅 저장소에 저장합니다. 데이터에는 몇 가지 제한 사항이 있습니다.
-
실제 로그 메시지를 포함하는
"message"필드가 있어야 합니다. -
RFC 3339 형식의 로그 레코드 타임스탬프가 포함된
"@timestamp"필드가 있어야 합니다. -
로그 수준(예:
err,info,unknown등)이 있는"level"필드가 있어야 합니다.
데이터 모델에 대한 자세한 내용은 Exported Fields를 참조하십시오.
이러한 요구 사항으로 인해 다양한 하위 시스템에서 수집된 로그 데이터로 충돌과 불일치가 발생할 수 있습니다.
예를 들어 MERGE_JSON_LOG 기능(MERGE_JSON_LOG=true) 기능을 사용하는 경우 애플리케이션이 JSON에 출력을 기록하고 Elasticsearch에서 데이터를 자동으로 구문 분석하여 인덱싱하도록 하는 것이 매우 유용할 수 있습니다. 그러나 이로 인해 다음과 같은 여러 문제가 발생합니다.
- 필드 이름은 비워 둘 수 있거나 Elasticsearch에서 부적절한 문자를 포함할 수 있습니다.
- 동일한 네임 스페이스의 다른 애플리케이션이 다른 값 데이터 유형의 동일한 필드 이름을 출력할 수 있습니다.
- 애플리케이션은 너무 많은 필드를 발송할 수 있습니다.
- 필드는 클러스터 로깅 기본 제공 필드와 충돌할 수 있습니다.
다음 표에서 Fluentd 로그 수집기 데몬 세트를 편집하고 환경 변수를 설정하여 클러스터 로깅이 서로 다른 소스에서 필드를 처리하는 방법을 구성할 수 있습니다.
정의되지 않은 필드. ViaQ 데이터 모델을 알 수 없는 필드를 정의되지 않은 필드라고 합니다. 분산된 시스템의 로그 데이터에는 정의되지 않은 필드가 포함될 수 있습니다. 데이터 모델을 사용하려면 모든 최상위 필드를 정의하고 설명할 필요가 있습니다.
매개 변수를 사용하여 OpenShift Container Platform이 잘 알려진 최상위 필드와 충돌하지 않도록
정의되지 않은필드를 정의되지 않은 최상위 필드로 이동하는 방법을 구성합니다. 정의되지 않은 필드를 최상위 필드에 추가하고 다른 필드를정의되지않은 컨테이너로 이동할 수 있습니다.정의되지 않은 필드의 특수 문자를 교체하고 정의되지 않은 필드를 JSON 문자열 표현으로 변환할 수도 있습니다. JSON 문자열로 변환하면 나중에 값을 검색하고 맵 또는 배열로 변환할 수 있도록 값의 구조를 유지합니다.
-
숫자 및 부울과 같은 간단한 스칼라 값은 따옴표가 지정된 문자열로 변경됩니다. 예를 들면 다음과 같습니다.
10은"10"이 됩니다.3.1415가"3.141"가 되고,false는"false"가 됩니다. -
맵/사전 값 및 배열 값은 JSON 문자열 표현으로 변환됩니다.
"mapfield":{"key":"value"}는"mapfield":"{\"key\":\"value\"}"및"arrayfield":[1,2,"three"]가"arrayfield":"[1,2,\"three\"]가 됩니다.
-
숫자 및 부울과 같은 간단한 스칼라 값은 따옴표가 지정된 문자열로 변경됩니다. 예를 들면 다음과 같습니다.
정의된 필드. 정의된 필드는 로그의 최상위 수준에 표시됩니다. 정의된 필드를 구성할 수 있습니다.
CDM_DEFAULT_KEEP_FIELDS매개 변수를 통해 정의된 기본 최상위 필드는CEE,time,@timestamp,aushape,ci_job,collectd,docker, fedora-ci,fedora-ci입니다.file,foreman,geoip,hostname,ipaddr4,ipaddr6,kubernetes,level,message,namespace_name,namespace_uuid,offset,openstack,ovirt,pid,pipeline_metadata,service,systemd,태그,testcase,tlog,viaq_msg_id.${CDM_DEFAULT_KEEP_FIELDS} 또는(으)로 이동합니다. 이러한 매개변수에 대한 자세한 내용은 아래 표를 참조하십시오.${CDM_EXTRA_KEEP_FIELDS}에 포함되지 않은 필드는CDM_USE_NAME}UNDEFINED_NAME}(이)가true인 경우 ${CDM_UNDEFINED_참고CDM_DEFAULT_KEEP_FIELDS매개 변수는 고급 사용자 전용 또는 Red Hat 지원에 의해 지시된 경우입니다.- 빈 필드. 빈 필드에는 데이터가 없습니다. 로그에서 유지할 빈 필드를 결정할 수 있습니다.
| 매개 변수 | 정의 | 예제 |
|---|---|---|
|
|
|
|
|
| 비어 있는 경우에도 CSV 형식으로 유지할 필드를 지정합니다. 정의되지 않은 빈 필드가 삭제됩니다. 기본값은 "message"입니다. 빈 메시지를 유지합니다. |
|
|
|
정의되지 않은 필드를 정의되지 않은 |
|
|
|
|
|
|
|
정의되지 않은 필드 수가 이 수보다 크면 모든 정의되지 않은 필드가 JSON 문자열 표현으로 변환되고
알림: 이 매개변수는 |
|
|
|
정의되지 않은 모든 필드를 JSON 문자열 표시로 변환하려면 |
|
|
|
정의되지 않은 필드에서 점 문자 '.' 대신 사용할 문자를 지정합니다. |
|
Fluentd 로그 수집기 데몬 세트 및 CDM 매개변수를 true로 설정하면 Elasticsearch 400 오류가 표시될 수 있습니다. _UNDEFINED_TO_STRING 환경 변수에서 MERGE_JSON_ LOGMERGE_JSON_LOG=true 인 경우 로그 수집기는 문자열 이외의 데이터 유형에 필드를 추가합니다. CDM_UNDEFINED_TO_STRING=true 를 설정하면 로그 수집기에서 해당 필드를 문자열 값으로 추가하려고 시도하여 Elasticsearch 400 오류가 발생합니다. 로그 수집기가 다음 날 로그의 인덱스를 롤오버할 때 오류가 지워집니다.
로그 수집기는 인덱스를 롤오버할 때 완전히 새 인덱스를 생성합니다. 필드 정의가 업데이트되고 400 오류가 발생하지 않습니다. 자세한 내용은 Setting MERGE_JSON_LOG 및 CDM_UNDEFINED_TO_STRING 을 참조하십시오.
정의되지 않은 빈 필드 처리를 구성하려면 logging-fluentd daemonset를 편집합니다.
필요에 따라 필드를 처리하는 방법을 구성합니다.
-
CDM_EXTRA_KEEP_FIELDS를 사용하여 이동할 필드를 지정합니다. -
CSV 형식의
CDM_KEEP_EMPTY_FIELDS매개변수에 유지할 빈 필드를 지정합니다.
-
필요에 따라 정의되지 않은 필드를 처리하는 방법을 구성합니다.
-
정의되지 않은 필드를 최상위 수준의 정의되지 않은 필드로 이동하려면
CDM_USE_UNDEFINED를true로설정합니다. -
CDM_UNDEFINED_NAME매개 변수를 사용하여 정의되지 않은 필드의 이름을 지정합니다. -
CDM_UNDEFINED_MAX_NUM_FIELDS를 기본값-1이외의 값으로 설정하여 단일 레코드에서 정의되지 않은 필드 수에 상한값을 설정합니다.
-
정의되지 않은 필드를 최상위 수준의 정의되지 않은 필드로 이동하려면
-
정의되지 않은 필드 이름의 문자를 다른
문자로변경하려면CDM_UNDEFINED_DOT_REPLACE_CHAR을 지정합니다. 예를 들어CDM_UNDEFINED_DOT_REPLACE_CHAR=@@@@@@인 경우, 필드가foo@@@bar@@baz로 변환됩니다. -
정의되지 않은 필드를 JSON 문자열 표현으로 변환하려면
UNDEFINED_TO_STRING을true로 설정합니다.
CDM_UNDEFINED_TO_STRING 또는 매개변수를 구성하는 경우 CDM_ UNDEFINED_MAX_NUM_FIELDSCDM_UNDEFINED_NAME 을 사용하여 정의되지 않은 필드 이름을 변경합니다. CDM_UNDEFINED_TO_STRING 또는 가 정의되지 않은 필드의 값 유형을 변경할 수 있기 때문에 이 필드가 필요합니다. CDM_ UNDEFINED_MAX_NUM_FIELDSCDM_UNDEFINED_TO_STRING 또는 CDM_UNDEFINED_MAX_NUM_FIELDS 가 true로 설정되어 로그에 정의되지 않은 필드가 더 많은 경우 값 유형은 문자열이 됩니다. Elasticsearch는 JSON에서 JSON 문자열로 값 유형이 변경되면 레코드 수락을 중지합니다.
예를 들어 CDM_UNDEFINED_TO_STRING 이 false 이거나 CDM_UNDEFINED_MAX_NUM_FIELDS 가 기본값인 경우 정의되지 않은 필드의 값 유형은 json 입니다. CDM_UNDEFINED_MAX_NUM_FIELDS 를 default 이외의 값으로 변경하고 로그에 정의되지 않은 필드가 더 많은 경우 값 유형은 문자열(JSON 문자열 )이 됩니다. 값 유형이 변경되면 Elasticsearch는 레코드 수락을 중지합니다.
MERGE_JSON_LOG 및 CDM_UNDEFINED_TO_STRING 설정
MERGE_JSON_LOG 및 환경 변수를 CDM_ UNDEFINED_TO_STRINGtrue로 설정하면 Elasticsearch 400 오류가 발생할 수 있습니다. MERGE_JSON_LOG=true 인 경우 로그 수집기는 문자열 이외의 데이터 유형에 필드를 추가합니다. CDM_UNDEFINED_TO_STRING=true 를 설정하면 Fluentd가 해당 필드를 문자열 값으로 추가하려고 시도하여 Elasticsearch 400 오류가 발생합니다. 다음 날 인덱스가 롤오버될 때 오류가 지워집니다.
Fluentd가 다음 날의 로그에 대한 인덱스를 롤오버하면 완전히 새 인덱스가 생성됩니다. 필드 정의가 업데이트되고 400 오류가 발생하지 않습니다.
스키마 위반, 손상된 데이터 등 하드 오류가 있는 레코드는 재시도할 수 없습니다. 로그 수집기는 오류 처리를 위해 레코드를 전송합니다. Fluentd 구성에 <label @ERROR> 섹션을 추가하는 경우 마지막 <label> 으로 필요에 따라 이러한 레코드를 처리할 수 있습니다.
예를 들면 다음과 같습니다.
data:
fluent.conf:
....
<label @ERROR>
<match **>
@type file
path /var/log/fluent/dlq
time_slice_format %Y%m%d
time_slice_wait 10m
time_format %Y%m%dT%H%M%S%z
compress gzip
</match>
</label>이 섹션에서는 Elasticsearch 배달 못 한 큐(DLQ) 파일에 오류 레코드를 작성합니다. 파일 출력에 대한 자세한 내용은 fluentd 문서를 참조하십시오.
그런 다음 파일을 편집하여 레코드를 수동으로 정리하고 Elasticsearch /_bulk 인덱스 API와 함께 사용하도록 파일을 편집하고 cURL을 사용하여 해당 레코드를 추가할 수 있습니다. Elasticsearch 대량 API에 대한 자세한 내용은 Elasticsearch 설명서를 참조하십시오.
여러 줄 Docker 로그에 참여
Docker 로그 부분 조각에서 전체 로그 레코드를 재구성하도록 Fluentd를 구성할 수 있습니다. 이 기능을 활성화하면 Fluentd는 여러 줄의 Docker 로그를 읽고 재구축하며 누락된 데이터가 없는 Elasticsearch에 로그를 하나의 레코드로 저장합니다.
그러나 이 기능을 사용하면 성능 저하가 발생할 수 있으므로 기능은 기본적으로 꺼져 수동으로 활성화해야 합니다.
다음 Fluentd 환경 변수는 여러 줄의 Docker 로그를 처리하도록 클러스터 로깅을 구성합니다.
| 매개변수 | 설명 |
|---|---|
| USE_MULTILINE_JSON |
|
| USE_MULTILINE_JOURNAL |
the |
다음 명령을 사용하여 사용 중인 로그 드라이버를 확인할 수 있습니다.
$ docker info | grep -i log다음 중 하나는 출력입니다.
Logging Driver: json-fileLogging Driver: journald여러 줄의 Docker 로그 처리를 활성화하려면 다음을 수행합니다.
다음 명령을 사용하여 여러 줄의 Docker 로그를 활성화합니다.
json-file로그 드라이버의 경우 다음을 수행합니다.oc set env daemonset/logging-fluentd USE_MULTILINE_JSON=truethe
journald로그 드라이버의 경우:oc set env daemonset/logging-fluentd USE_MULTILINE_JOURNAL=true
클러스터 재시작의 Fluentd Pod입니다.
외부 로그 집계기로 로그를 보내도록 Fluentd 구성
secure-forward 플러그인을 사용하여 기본 Elasticsearch 외에도 로그 사본을 외부 로그 집계기로 전송하도록 Fluentd를 구성할 수 있습니다. 여기에서 로컬 호스팅 Fluentd가 처리한 후 로그 레코드를 추가로 처리할 수 있습니다.
클라이언트 인증서로 secure_foward 플러그인을 구성할 수 없습니다. 인증은 SSL/TLS 프로토콜을 통해 실행할 수 있지만 shared_key 및 대상 Fluentd 를 secure_foward 입력 플러그인을 사용하여 구성해야 합니다.
로깅 배포는 외부 집계기를 구성하기 위해 Fluentd 구성 맵에 secure-forward.conf 섹션을 제공합니다.
<store>
@type secure_forward
self_hostname pod-${HOSTNAME}
shared_key thisisasharedkey
secure yes
enable_strict_verification yes
ca_cert_path /etc/fluent/keys/your_ca_cert
ca_private_key_path /etc/fluent/keys/your_private_key
ca_private_key_passphrase passphrase
<server>
host ose1.example.com
port 24284
</server>
<server>
host ose2.example.com
port 24284
standby
</server>
<server>
host ose3.example.com
port 24284
standby
</server>
</store>
이 작업은 oc edit 명령을 사용하여 업데이트할 수 있습니다.
$ oc edit configmap/logging-fluentd
secure-forward.conf 에서 사용할 인증서는 Fluentd Pod에 마운트된 기존 보안에 추가할 수 있습니다. your_ca_cert 및 your_private_key 값은 configmap/logging-fluentd 의 secure-forward.conf 에 지정된 값과 일치해야 합니다.
$ oc patch secrets/logging-fluentd --type=json \
--patch "[{'op':'add','path':'/data/your_ca_cert','value':'$(base64 -w 0 /path/to/your_ca_cert.pem)'}]"
$ oc patch secrets/logging-fluentd --type=json \
--patch "[{'op':'add','path':'/data/your_private_key','value':'$(base64 -w 0 /path/to/your_private_key.pem)'}]"
your_private_key 를 일반 이름으로 바꿉니다. 이것은 호스트 시스템의 경로가 아닌 JSON 경로에 대한 링크입니다.
외부 집계기를 구성할 때 Fluentd에서 메시지를 안전하게 수락할 수 있어야 합니다.
외부 집계기가 또 다른 Fluentd 서버인 경우 fluent-plugin-secure-forward 플러그인이 설치되어 있어야 하며 입력 플러그인을 사용해야 합니다.
<source>
@type secure_forward
self_hostname ${HOSTNAME}
bind 0.0.0.0
port 24284
shared_key thisisasharedkey
secure yes
cert_path /path/for/certificate/cert.pem
private_key_path /path/for/certificate/key.pem
private_key_passphrase secret_foo_bar_baz
</source>
fluent-plugin-secure-forward 리포지토리에서 fluent-plugin-secure-forward 플러그인을 설정하는 방법에 대한 추가 설명을 확인할 수 있습니다.
Fluentd에서 API 서버로 연결 수 감소
MUX 는 기술 프리뷰 기능 전용입니다. 기술 프리뷰 기능은 Red Hat 프로덕션 서비스 수준 계약(SLA)에서 지원하지 않으며, 기능상 완전하지 않을 수 있어 프로덕션에 사용하지 않는 것이 좋습니다. 이러한 기능을 사용하면 향후 제품 기능을 조기에 이용할 수 있어 개발 과정에서 고객이 기능을 테스트하고 피드백을 제공할 수 있습니다.
Red Hat 기술 프리뷰 기능 지원 범위에 대한 자세한 내용은 https://access.redhat.com/support/offerings/techpreview/를 참조하십시오.
MUX 는 Secure Forward listener 서비스입니다.
| 매개변수 | 설명 |
|---|---|
|
|
기본값은 |
|
|
|
|
|
기본값은 |
|
|
기본 is |
|
| 24284 |
|
| 500M |
|
| 2Gi |
|
|
기본 is |
|
|
기본값은 비어 있으므로 추가 네임스페이스가 external |
Fluentd의 제한 로그
특히 상세한 프로젝트의 경우 관리자는 처리하기 전에 Fluentd에서 로그를 읽는 비율을 제한할 수 있습니다.
제한은 구성된 프로젝트의 뒤처진 로그 집계에 기여할 수 있습니다. Fluentd가 발견되기 전에 Pod를 삭제하면 로그 항목이 손실될 수 있습니다.
systemd 저널을 로그 소스로 사용할 때는 제한이 작동하지 않습니다. 제한 구현은 각 프로젝트의 개별 로그 파일 읽기를 제한하는 데 따라 다릅니다. 저널에서 읽을 때 하나의 로그 소스만 있고 로그 파일이 없으므로 파일 기반 제한은 사용할 수 없습니다. Fluentd 프로세스로 읽은 로그 항목을 제한하는 방법은 없습니다.
제한해야 하는 프로젝트를 Fluentd에 알리려면 배포 후 ConfigMap에서 스로틀 구성을 편집합니다.
$ oc edit configmap/logging-fluentdthrottle-config.yaml 키 형식은 프로젝트 이름과 각 노드에서 로그를 읽는 원하는 속도가 포함된 YAML 파일입니다. 기본값은 노드당 한 번에 1000행입니다. 예를 들면 다음과 같습니다.
- 프로젝트
project-name:
read_lines_limit: 50
second-project-name:
read_lines_limit: 100- 로깅
logging:
read_lines_limit: 500
test-project:
read_lines_limit: 10
.operations:
read_lines_limit: 100Fluentd를 변경하려면 구성을 변경하고 Fluentd Pod를 다시 시작하여 변경 사항을 적용합니다. Elasticsearch를 변경하려면 먼저 Fluentd를 축소한 다음 Elasticsearch를 0으로 축소해야 합니다. 변경을 수행한 후 Elasticsearch를 먼저 스케일링한 다음 Fluentd를 원래 설정으로 다시 조정합니다.
Elasticsearch를 0으로 확장하려면 다음을 수행합니다.
$ oc scale --replicas=0 dc/<ELASTICSEARCH_DC>daemonset 구성에서 nodeSelector를 0과 일치하도록 변경합니다.
Fluentd 노드 선택기를 가져옵니다.
$ oc get ds logging-fluentd -o yaml |grep -A 1 Selector
nodeSelector:
logging-infra-fluentd: "true"oc patch 명령을 사용하여 daemonset nodeSelector를 수정합니다.
$ oc patch ds logging-fluentd -p '{"spec":{"template":{"spec":{"nodeSelector":{"nonexistlabel":"true"}}}}}'Fluentd 노드 선택기를 가져옵니다.
$ oc get ds logging-fluentd -o yaml |grep -A 1 Selector
nodeSelector:
"nonexistlabel: "true"Elasticsearch를 0에서 백업합니다.
$ oc scale --replicas=# dc/<ELASTICSEARCH_DC>daemonset 구성의 nodeSelector를 logging-infra-fluentd: "true"로 다시 변경합니다.
oc patch 명령을 사용하여 daemonset nodeSelector를 수정합니다.
oc patch ds logging-fluentd -p '{"spec":{"template":{"spec":{"nodeSelector":{"logging-infra-fluentd":"true"}}}}}'버퍼 Chunk 제한 튜닝
Fluentd 로거가 많은 로그를 유지할 수 없는 경우 메모리 사용량을 줄이고 데이터 손실을 방지하기 위해 파일 버퍼링으로 전환해야 합니다.
Fluentd buffer_chunk_limit 는 기본값 8m 이 있는 환경 변수 BUFFER_SIZE_LIMIT 로 결정됩니다. 출력당 파일 버퍼 크기는 기본값이 256Mi 인 환경 변수 FILE_BUFFER_LIMIT 로 결정됩니다. 영구 볼륨 크기는 FILE_BUFFER_LIMIT 보다 커야 합니다.
Fluentd 및 Mux Pod에서 영구 볼륨 /var/lib/fluentd 는 PVC 또는 hostmount에서 준비해야 합니다(예:). 그런 다음 해당 영역은 파일 버퍼에 사용됩니다.
buffer_type 및 buffer_path 는 다음과 같이 Fluentd 구성 파일에 구성됩니다.
$ egrep "buffer_type|buffer_path" *.conf
output-es-config.conf:
buffer_type file
buffer_path `/var/lib/fluentd/buffer-output-es-config`
output-es-ops-config.conf:
buffer_type file
buffer_path `/var/lib/fluentd/buffer-output-es-ops-config`
filter-pre-mux-client.conf:
buffer_type file
buffer_path `/var/lib/fluentd/buffer-mux-client`
Fluentd buffer_queue_limit 는 variable BUFFER_QUEUE_LIMIT 의 값입니다. 이 값은 기본적으로 32 입니다.
환경 변수 BUFFER_QUEUE_LIMIT 은 (FILE_BUFFER_LIMIT / (number_of_outputs * BUFFER_SIZE_LIMIT) 로 계산됩니다.
BUFFER_QUE_LIMIT 변수에 기본 값 세트가 있는 경우:
-
FILE_BUFFER_LIMIT = 256Mi -
number_of_outputs = 1 -
BUFFER_SIZE_LIMIT = 8Mi
buffer_queue_limit 값은 32 가 됩니다. buffer_queue_limit 를 변경하려면 FILE_BUFFER_LIMIT 값을 변경해야 합니다.
이 공식에서 number_of_outputs 는 모든 로그 가 단일 리소스에 전송되고 추가 리소스마다 1 씩 증가합니다. 예를 들어 number_of_outputs 값은 다음과 같습니다.
-
1- 모든 로그가 단일 ElasticSearch Pod로 전송되는 경우 -
2- 애플리케이션 로그가 ElasticSearch Pod로 전송되고 ops 로그가 다른 ElasticSearch Pod로 전송되는 경우 -
4- 애플리케이션 로그가 ElasticSearch Pod로 전송되면 ops 로그가 다른 ElasticSearch Pod로 전송되고 둘 다 다른 Fluentd 인스턴스로 전달됩니다.
36.5.4. Kibana
OpenShift Container Platform 웹 콘솔에서 Kibana 콘솔에 액세스하려면 master webconsole-config configmap 파일에 loggingPublicURL 매개변수를 추가합니다(kiban a-hostname 매개변수). 값은 HTTPS URL이어야 합니다.
...
clusterInfo:
...
loggingPublicURL: "https://kibana.example.com"
...
loggingPublicURL 매개변수를 설정하면 찾아보기 → Pod → <pod_name> → 로그 탭 아래 OpenShift Container Platform 웹 콘솔에서 View Archive (아카이브 보기) 버튼이 생성됩니다. 이 링크는 Kibana 콘솔에 연결됩니다.
유효한 로그인 쿠키가 만료되면 Kibana 콘솔에 로그인해야 합니다(예: 로그인해야 합니다.
- 첫 번째 사용
- 로그아웃 후
중복성을 위해 Kibana 배포를 일반적인 대로 확장할 수 있습니다.
$ oc scale dc/logging-kibana --replicas=2
로깅 플레이북의 여러 실행에서 확장이 지속되도록 하려면 인벤토리 파일의 openshift_logging_kibana_replica_count 를 업데이트해야 합니다.
openshift_logging_kibana_hostname 변수로 지정된 사이트를 방문하여 사용자 인터페이스를 확인할 수 있습니다.
Kibana에 대한 자세한 내용은 Kibana 설명서 를 참조하십시오.
Kibana 시각화
Kibana Visualize를 사용하면 컨테이너 및 Pod 로그를 모니터링하기 위한 시각화 및 대시보드를 생성할 수 있으므로 관리자 사용자(Cluster-admin 또는 cluster-reader)는 배포, 네임스페이스, Pod 및 컨테이너별로 로그를 볼 수 있습니다.
Kibana 시각화는 Elasticsearch 및 ES-OPS Pod 내부에 있으며 해당 Pod 내에서 실행해야 합니다. 대시보드 및 기타 Kibana UI 오브젝트를 로드하려면 먼저 대시보드를 추가하려는 사용자로 Kibana에 로그인한 다음 로그아웃해야 합니다. 그러면 다음 단계에서 사용하는 필수 사용자별 구성이 생성됩니다. 그런 다음 다음을 실행합니다.
$ oc exec <$espod> -- es_load_kibana_ui_objects <user-name>
여기서 $espod 는 Elasticsearch Pod 중 하나입니다.
Kibana 시각화에 사용자 지정 필드 추가
OpenShift Container Platform 클러스터가 Elasticsearch .operations.* 또는 에 정의되지 않은 사용자 정의 필드가 포함된 JSON 형식으로 로그를 생성하는 경우 Kibana에서 사용자 정의 필드를 사용할 수 없기 때문에 이러한 필드를 사용하여 시각화를 생성할 수 없습니다.
project.*
그러나 Elasticsearch 인덱스에 사용자 정의 필드를 추가하면 Kibana 시각화에서 사용할 Kibana 인덱스 패턴에 필드를 추가할 수 있습니다.
사용자 정의 필드는 템플릿이 업데이트된 후 생성된 인덱스에만 적용됩니다.
Kibana 시각화에 사용자 정의 필드를 추가하려면 다음을 수행합니다.
Elasticsearch 인덱스 템플릿에 사용자 정의 필드를 추가합니다.
-
필드를 추가할 Elasticsearch 인덱스(
.operations.* 또는인덱스)를 결정합니다. 사용자 지정 필드가 있는 특정 프로젝트가 있는 경우 프로젝트의 특정 인덱스에 필드를 추가합니다(예:project.*project.this-project-has-time-fields.*). 다음과 유사한 사용자 지정 필드에 대한 JSON 파일을 생성합니다.
예를 들면 다음과 같습니다.
{ "order": 20, "mappings": { "_default_": { "properties": { "mytimefield1": {1 "doc_values": true, "format": "yyyy-MM-dd HH:mm:ss,SSSZ||yyyy-MM-dd'T'HH:mm:ss.SSSSSSZ||yyyy-MM-dd'T'HH:mm:ssZ||dateOptionalTime", "index": "not_analyzed", "type": "date" }, "mytimefield2": { "doc_values": true, "format": "yyyy-MM-dd HH:mm:ss,SSSZ||yyyy-MM-dd'T'HH:mm:ss.SSSSSSZ||yyyy-MM-dd'T'HH:mm:ssZ||dateOptionalTime", "index": "not_analyzed", "type": "date" } } } }, "template": "project.<project-name>.*"2 }openshift-loggin프로젝트로 변경합니다.$ oc project openshift-loggingElasticsearch Pod 중 하나의 이름을 가져옵니다.
$ oc get -n logging pods -l component=es NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE logging-es-data-master-5av030lk-1-2x494 2/2 Running 0 38m 154.128.0.80 ip-153-12-8-6.wef.internal <none>JSON 파일을 Elasticsearch 포드로 로드합니다.
$ cat <json-file-name> | \1 oc exec -n logging -i -c elasticsearch <es-pod-name> -- \2 curl -s -k --cert /etc/elasticsearch/secret/admin-cert \ --key /etc/elasticsearch/secret/admin-key \ https://localhost:9200/_template/<json-file-name> -XPUT -d@- | \3 python -mjson.tool{ "acknowledged": true }별도의 OPS 클러스터가 있는 경우 es-ops Elasticsearch Pod 중 하나의 이름을 가져옵니다.
$ oc get -n logging pods -l component=es-ops NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE logging-es-ops-data-master-o7nhcbo4-5-b7stm 2/2 Running 0 38m 154.128.0.80 ip-153-12-8-6.wef.internal <none>JSON 파일을 es-ops Elasticsearch Pod로 로드합니다.
$ cat <json-file-name> | \1 oc exec -n logging -i -c elasticsearch <esops-pod-name> -- \2 curl -s -k --cert /etc/elasticsearch/secret/admin-cert \ --key /etc/elasticsearch/secret/admin-key \ https://localhost:9200/_template/<json-file-name> -XPUT -d@- | \3 python -mjson.tool출력은 다음과 유사합니다.
{ "acknowledged": true }인덱스가 업데이트되었는지 확인합니다.
oc exec -n logging -i -c elasticsearch <es-pod-name> -- \1 curl -s -k --cert /etc/elasticsearch/secret/admin-cert \ --key /etc/elasticsearch/secret/admin-key \ https://localhost:9200/project.*/_search?sort=<custom-field>:desc | \2 python -mjson.tool명령은 정렬된 사용자 지정 필드의 인덱스 레코드를 내림차순으로 출력합니다.
참고설정이 기존 인덱스에는 적용되지 않습니다. 설정을 기존 인덱스에 적용하려면 re-index를 수행합니다.
-
필드를 추가할 Elasticsearch 인덱스(
Kibana에 사용자 정의 필드를 추가합니다.
Elasticsearch 컨테이너에서 기존 인덱스 패턴 파일을 가져옵니다.
$ mkdir index_patterns $ cd index_patterns $ oc project openshift-logging $ for espod in $( oc get pods -l component=es -o jsonpath='{.items[*].metadata.name}' ) ; do > for ff in $( oc exec -c elasticsearch <es-pod-name> -- ls /usr/share/elasticsearch/index_patterns ) ; do > oc exec -c elasticsearch <es-pod-name> -- cat /usr/share/elasticsearch/index_patterns/$ff > $ff > done > break > done인덱스 패턴 파일은 /usr/share/elasticsearch/index_patterns 디렉터리에 다운로드됩니다.
예를 들면 다음과 같습니다.
index_patterns $ ls com.redhat.viaq-openshift.index-pattern.json해당 인덱스 패턴 파일을 편집하여 각 사용자 정의 필드의 정의를
필드값에 추가합니다.예를 들면 다음과 같습니다.
{\"count\": 0, \"name\": \"mytimefield2\", \"searchable\": true, \"aggregatable\": true, \"readFromDocValues\": true, \"type\": \"date\", \"scripted\": false},정의에는 시각화에 사용하려면
\"searchable\": true 및\"aggregatable\": true,매개변수가 포함되어야 합니다. 데이터 유형은 위에서 추가한 Elasticsearch 필드 정의에 일치해야 합니다. 예를 들어숫자유형인 Elasticsearch에myfield필드를 추가한 경우myfield를 Kibana에문자열유형으로 추가할 수 없습니다.인덱스 패턴 파일에서 Kibana 인덱스 패턴의 이름을 인덱스 패턴 파일에 추가합니다.
예를 들어, 작업을 사용하려면\ * 인덱스 패턴은 다음과 같습니다.
"title": "*operations.*"project.MYNAMESPACE.\* 인덱스 패턴을 사용하려면 다음을 수행합니다.
"title": "project.MYNAMESPACE.*"사용자 이름을 식별하고 사용자 이름의 해시 값을 가져옵니다. 인덱스 패턴은 사용자 이름의 해시를 사용하여 저장됩니다. 다음 두 명령을 순서대로 실행합니다.
$ get_hash() { > printf "%s" "$1" | sha1sum | awk '{print $1}' > }$ get_hash admin d0aeb5660fc2140aec35850c4da997인덱스 패턴 파일을 Elasticsearch에 적용합니다.
cat com.redhat.viaq-openshift.index-pattern.json | \1 oc exec -i -c elasticsearch <espod-name> -- es_util \ --query=".kibana.<user-hash>/index-pattern/<index>" -XPUT --data-binary @- | \2 python -mjson.tool예를 들면 다음과 같습니다.
cat index-pattern.json | \ oc exec -i -c elasticsearch mypod-23-gb9pl -- es_util \ --query=".kibana.d0aeb5660fc2140aec35850c4da997/index-pattern/project.MYNAMESPACE.*" -XPUT --data-binary @- | \ python -mjson.tool출력은 다음과 유사합니다.
{ "_id": ".operations.*", "_index": ".kibana.d0aeb5660fc2140aec35850c4da997", "_shards": { "failed": 0, "successful": 2, "total": 2 }, "_type": "index-pattern", "_version": 1, "created": true, "result": "created" }- 사용 가능한 필드 목록과 관리 → 인덱스 패턴 페이지의 필드 목록에 사용자 정의 필드 가 표시되도록 Kibana 콘솔을 종료하고 다시 시작합니다.
36.5.5. Curator
관리자는 Curator를 사용하여 프로젝트별로 예약된 Elasticsearch 유지 관리 작업을 자동으로 수행할 수 있습니다. 구성을 기반으로 매일 작업을 수행하도록 예약됩니다. Elasticsearch 클러스터당 하나의 Curator Pod만 권장됩니다. Curator Pod는 cronjob에 명시된 시간에만 실행되며 Pod는 완료 시 종료됩니다. Curator는 다음 구조의 YAML 구성 파일을 통해 구성됩니다.
시간대는 Curator Pod가 실행되는 호스트 노드를 기반으로 설정됩니다.
$PROJECT_NAME:
$ACTION:
$UNIT: $VALUE
$PROJECT_NAME:
$ACTION:
$UNIT: $VALUE
...사용 가능한 매개변수는 다음과 같습니다.
| 변수 이름 | 설명 |
|---|---|
|
|
myapp-devel과 같은 프로젝트의 실제 이름입니다. OpenShift Container Platform 작업 로그의 경우 프로젝트 이름으로 이름 |
|
|
수행할 작업으로, 현재 |
|
|
|
|
| 단위 수의 정수입니다. |
|
|
|
|
| 프로젝트 이름과 일치하는 정규식 목록입니다. |
|
| 작은 따옴표로 묶은 유효하고 올바르게 이스케이프 된 정규 표현식 패턴입니다. |
예를 들어 Curator를 다음과 같이 구성하려면
-
myapp-dev 프로젝트에서
1 day이 지난 인덱스 삭제 -
1 week가 지난 myapp-qe 프로젝트에서 인덱스 삭제 -
8 weeks가 지난 작업 로그 삭제 -
31 days이 지난 후 다른 모든 프로젝트 인덱스 삭제 - '^project\..+\-dev.*$' regex와 일치하는 1일이 지난 인덱스 삭제
- '^project\..+\-test.*$' regex와 일치하는 2일이 지난 인덱스 삭제
다음을 사용하십시오.
config.yaml: |
myapp-dev:
delete:
days: 1
myapp-qe:
delete:
weeks: 1
.operations:
delete:
weeks: 8
.defaults:
delete:
days: 31
.regex:
- pattern: '^project\..+\-dev\..*$'
delete:
days: 1
- pattern: '^project\..+\-test\..*$'
delete:
days: 2
작업에 대해 $UNIT으로 months을 사용하면 Curator는 현재 달의 현재 날짜가 아니라 현재 달의 첫 날부터 계산을 시작합니다. 예를 들어 오늘이 4월 15일이고 오늘보다 2개월 지난 인덱스를 삭제하려는 경우(삭제: 개월: 2) Curator는 2월 15일 이전의 인덱스를 삭제하지 않습니다. 2월 1일 이전의 인덱스를 삭제합니다. 즉, 현재 달의 첫날로 되돌아간 다음 해당 날짜로부터 총 두 달 전으로 되돌아갑니다. Curator를 정확하게 사용하려면 일(예: 삭제: days)을 사용하는 것이 좋습니다. 30).
36.5.5.1. Curator 작업 파일 사용
OpenShift Container Platform 사용자 정의 구성 파일 형식을 설정하면 내부 인덱스가 실수로 삭제되지 않습니다.
작업 파일을 사용하려면 Curator 구성에 제외 규칙을 추가하여 이러한 인덱스를 유지합니다. 필요한 모든 패턴을 수동으로 추가해야 합니다.
actions.yaml: |
actions:
action: delete_indices
description: be careful!
filters:
- exclude: false
kind: regex
filtertype: pattern
value: '^project\.myapp\..*$'
- direction: older
filtertype: age
source: name
timestring: '%Y.%m.%d'
unit_count: 7
unit: days
options:
continue_if_exception: false
timeout_override: '300'
ignore_empty_list: true
action: delete_indices
description: be careful!
filters:
- exclude: false
kind: regex
filtertype: pattern
value: '^\.operations\..*$'
- direction: older
filtertype: age
source: name
timestring: '%Y.%m.%d'
unit_count: 56
unit: days
options:
continue_if_exception: false
timeout_override: '300'
ignore_empty_list: true
action: delete_indices
description: be careful!
filters:
- exclude: true
kind: regex
filtertype: pattern
value: '^project\.myapp\..*$|^\.operations\..*$|^\.searchguard\..*$|^\.kibana$'
- direction: older
filtertype: age
source: name
timestring: '%Y.%m.%d'
unit_count: 30
unit: days
options:
continue_if_exception: false
timeout_override: '300'
ignore_empty_list: true36.5.5.2. Curator 설정 생성
openshift_logging Ansible 역할은 Curator가 해당 구성을 읽는 ConfigMap을 제공합니다. 이 ConfigMap을 편집하거나 교체하여 Curator를 다시 구성할 수 있습니다. 현재 logging-curator ConfigMap은 ops 및 비ops Curator 인스턴스를 구성하는 데 사용됩니다. any .operations 구성은 애플리케이션 로그 구성과 동일한 위치에 있습니다.
Curator 구성을 생성하려면 배포된 ConfigMap에서 구성을 편집합니다.
$ oc edit configmap/logging-curator또는 cronjob에서 작업을 수동으로 생성합니다.
oc create job --from=cronjob/logging-curator <job_name>스크립팅된 배포의 경우 설치 프로그램에서 생성한 구성 파일을 복사하고 새 OpenShift Container Platform 사용자 정의 구성을 생성합니다.
$ oc extract configmap/logging-curator --keys=curator5.yaml,config.yaml --to=/my/config edit /my/config/curator5.yaml edit /my/config/config.yaml $ oc delete configmap logging-curator ; sleep 1 $ oc create configmap logging-curator \ --from-file=curator5.yaml=/my/config/curator5.yaml \ --from-file=config.yaml=/my/config/config.yaml \ ; sleep 1또는 작업 파일을 사용하는 경우 :
$ oc extract configmap/logging-curator --keys=curator5.yaml,actions.yaml --to=/my/config edit /my/config/curator5.yaml edit /my/config/actions.yaml $ oc delete configmap logging-curator ; sleep 1 $ oc create configmap logging-curator \ --from-file=curator5.yaml=/my/config/curator5.yaml \ --from-file=actions.yaml=/my/config/actions.yaml \ ; sleep 1
다음 예약된 작업은 이 구성을 사용합니다.
다음 명령을 사용하여 cronjob을 제어할 수 있습니다.
# suspend cronjob
oc patch cronjob logging-curator -p '{"spec":{"suspend":true}}'
# resume cronjob
oc patch cronjob logging-curator -p '{"spec":{"suspend":false}}
# change cronjob schedule
oc patch cronjob logging-curator -p '{"spec":{"schedule":"0 0 * * *"}}' 36.6. 정리
배포 중에 생성된 모든 항목을 제거합니다.
$ cd /usr/share/ansible/openshift-ansible
$ ansible-playbook [-i </path/to/inventory>] \
playbooks/openshift-logging/config.yml \
-e openshift_logging_install_logging=False36.7. 외부 Elasticsearch 인스턴스에 로그 전송
Fluentd는 Elasticsearch 배포 구성의 ES_HOST,ES_PORT,OPS_HOST 및 OPS_PORT 환경 변수 값으로 로그를 보냅니다. 애플리케이션 로그는 ES_HOST 대상으로 전송되고 작업 로그는 OPS_HOST 로 이동합니다.
AWS Elasticsearch 인스턴스로 직접 로그를 보내는 것은 지원되지 않습니다. Fluentd Secure Forward 를 사용하여 사용자가 제어하고 fluent-plugin-aws-elasticsearch-service 플러그인으로 구성된 Fluentd 인스턴스로 로그를 보냅니다.
특정 Elasticsearch 인스턴스로 로그를 보내려면 배포 구성을 편집하고 위의 변수 값을 원하는 인스턴스로 교체합니다.
$ oc edit ds/<daemon_set>
애플리케이션 및 작업 로그를 모두 포함하는 외부 Elasticsearch 인스턴스의 경우 ES_HOST 및 를 동일한 대상으로 설정하여 OPS_ HOSTES_PORT 및 도 동일한 값으로 설정할 수 있습니다.
OPS_PORT
제공된 Elasticsearch 인스턴스와 마찬가지로 상호 TLS 구성만 지원됩니다. 클라이언트 키, 클라이언트 인증서 및 CA를 사용하여 로깅 영향 보안을 패치하거나 다시 생성합니다.
제공된 Kibana 및 Elasticsearch 이미지를 사용하지 않는 경우 동일한 다중 테넌트 기능이 없으며 데이터는 특정 프로젝트에 대한 사용자 액세스 권한으로 제한되지 않습니다.
36.8. 외부 Syslog 서버로 로그 전송
호스트의 fluent-plugin-remote-syslog 플러그인을 사용하여 외부 syslog 서버로 로그를 보냅니다.
logging -fluentd 또는 daemonsets에서 환경 변수를 설정합니다.
logging- mux
- name: REMOTE_SYSLOG_HOST
value: host1
- name: REMOTE_SYSLOG_HOST_BACKUP
value: host2
- name: REMOTE_SYSLOG_PORT_BACKUP
value: 5555- 1
- 원하는 원격 syslog 호스트입니다. 각 호스트에 필요합니다.
이 예제에서는 두 개의 대상을 빌드합니다. host1 의 syslog 서버는 514 의 기본 포트에서 메시지를 수신하는 반면 host2 는 포트 5555 에서 동일한 메시지를 받습니다.
또는 logging -fluentd 또는 ConfigMaps에서 자체 사용자 정의 fluent.conf 를 구성할 수 있습니다.
logging- mux
Fluentd 환경 변수
| 매개변수 | 설명 |
|---|---|
|
|
기본값은 |
|
| (필수) 원격 syslog 서버의 호스트 이름 또는 IP 주소입니다. |
|
|
연결할 포트 번호입니다. 기본값은 |
|
|
syslog 심각도 수준을 설정합니다. 기본값은 |
|
|
syslog 기능을 설정합니다. 기본값은 |
|
|
기본값은 |
|
|
태그에서 접두사를 제거하고 기본값은 |
|
| 지정된 경우 이 필드를 레코드를 조회하는 키로 사용하여 syslog 메시지에 태그를 설정합니다. |
|
| 지정된 경우 이 필드를 레코드를 조회하는 키로 사용하여 syslog 메시지에 페이로드를 설정합니다. |
|
|
전송 계층 프로토콜 유형을 설정합니다. 기본값은 TCP 프로토콜을 설정하는 |
이 구현은 안전하지 않으며 연결 시 스누핑을 보장할 수 없는 환경에서만 사용해야 합니다.
Fluentd 로깅 Ansible 변수
| 매개변수 | 설명 |
|---|---|
|
|
기본값은 |
|
| 원격 syslog 서버의 호스트 이름 또는 IP 주소, 이는 필수입니다. |
|
|
연결할 포트 번호, 기본값은 |
|
|
syslog 심각도 수준을 설정합니다. 기본값은 |
|
|
syslog 기능을 설정합니다. 기본값은 |
|
|
기본값은 |
|
|
태그에서 접두사를 제거하고 기본값은 |
|
| 문자열이 지정되면 이 필드를 레코드를 조회하는 키로 사용하여 syslog 메시지에 태그를 설정합니다. |
|
| 문자열이 지정되면 이 필드를 레코드를 조회하는 키로 사용하여 syslog 메시지에 페이로드를 설정합니다. |
MUX 로깅 Ansible 변수
| 매개변수 | 설명 |
|---|---|
|
|
기본값은 |
|
| 원격 syslog 서버의 호스트 이름 또는 IP 주소, 이는 필수입니다. |
|
|
연결할 포트 번호, 기본값은 |
|
|
syslog 심각도 수준을 설정합니다. 기본값은 |
|
|
syslog 기능을 설정합니다. 기본값은 |
|
|
기본값은 |
|
|
태그에서 접두사를 제거하고 기본값은 |
|
| 문자열이 지정되면 이 필드를 레코드를 조회하는 키로 사용하여 syslog 메시지에 태그를 설정합니다. |
|
| 문자열이 지정되면 이 필드를 레코드를 조회하는 키로 사용하여 syslog 메시지에 페이로드를 설정합니다. |
36.9. 관리 Elasticsearch 작업 수행
로깅 버전 3.2.0부터 Elasticsearch에서 통신하고 관리 작업을 수행하는 데 사용할 수 있는 관리자 인증서, 키 및 CA는 logging-elasticsearch 시크릿 내에 제공됩니다.
EFK 설치에서 다음을 제공하는지 여부를 확인하려면 다음을 실행합니다.
$ oc describe secret logging-elasticsearch- 유지 관리를 수행하려는 클러스터에 있는 Elasticsearch Pod에 연결합니다.
클러스터에서 Pod를 찾으려면 다음 중 하나를 사용합니다.
$ oc get pods -l component=es -o name | head -1 $ oc get pods -l component=es-ops -o name | head -1Pod에 연결합니다.
$ oc rsh <your_Elasticsearch_pod>Elasticsearch 컨테이너에 연결되면 시크릿에서 마운트된 인증서를 사용하여 지표 API 설명서에 따라 Elasticsearch와 통신할 수 있습니다.
Fluentd는 인덱스 형식 프로젝트를 사용하여 Elasticsearch로 로그를 보냅니다.{project_name}.{project_uuid}.YYYY.MM.DD 여기서 YYYY.MM.DD는 로그 레코드의 날짜입니다.
예를 들어, 2016년 6월 15일부터 uuid 3b3594fa-2ccd-11e6-acb7-0eb6b35eaee3 를 사용하여 openshift-logging 프로젝트의 모든 로그를 삭제하려면 다음을 실행합니다.
$ curl --key /etc/elasticsearch/secret/admin-key \ --cert /etc/elasticsearch/secret/admin-cert \ --cacert /etc/elasticsearch/secret/admin-ca -XDELETE \ "https://localhost:9200/project.logging.3b3594fa-2ccd-11e6-acb7-0eb6b35eaee3.2016.06.15"
36.10. EFK 인증서 재배포
Ansible 플레이북을 사용하여 설치/업그레이드 플레이북을 실행할 필요 없이 EFK 스택에 대한 인증서 교체를 수행할 수 있습니다.
이 플레이북은 현재 인증서 파일을 삭제하고, 새 EFK 인증서를 생성하고, 인증서 보안을 업데이트하며, Kibana 및 Elasticsearch를 다시 시작하여 해당 구성 요소가 업데이트된 인증서에서 읽도록 합니다.
EFK 인증서를 재배포하려면 다음을 수행합니다.
Ansible 플레이북을 사용하여 EFK 인증서를 재배포합니다.
$ cd /usr/share/ansible/openshift-ansible $ ansible-playbook playbooks/openshift-logging/redeploy-certificates.yml
36.11. 집계된 로깅 드라이버 변경
집계된 로깅의 경우 json-file 로그 드라이버를 사용하는 것이 좋습니다.
json-file 드라이버를 사용하는 경우 Docker 버전 docker-1.12.6-55.gitc4618fb.el7_4를 사용 중인지 확인합니다.
Fluentd는 /etc/docker/ daemon.json 및 /etc/sysconfig/docker 파일을 확인하여 Docker가 사용 중인 드라이버를 결정합니다.
Docker info 명령과 함께 사용 중인 드라이버를 확인할 수 있습니다.
# docker info | grep Logging
Logging Driver: journald
json-file 로 변경하려면 다음을 수행합니다.
/etc/sysconfig/docker 또는 /etc/docker/daemon.json 파일을 수정합니다.
예를 들면 다음과 같습니다.
# cat /etc/sysconfig/docker OPTIONS=' --selinux-enabled --log-driver=json-file --log-opt max-size=1M --log-opt max-file=3 --signature-verification=False' cat /etc/docker/daemon.json { "log-driver": "json-file", "log-opts": { "max-size": "1M", "max-file": "1" } }Docker 서비스를 다시 시작하십시오.
systemctl restart dockerFluentd를 다시 시작합니다.
주의12개 이상의 노드에서 Fluentd를 한 번에 다시 시작하면 Kubernetes 스케줄러에 큰 부하가 생성됩니다. 다음 지침을 사용하여 Fluentd를 다시 시작할 때 주의하십시오.
Fluentd를 다시 시작하는 방법은 두 가지가 있습니다. 단일 노드 또는 노드 세트에서 Fluentd를 다시 시작하거나 모든 노드에서 시작할 수 있습니다.
다음 단계에서는 노드 또는 노드 세트에서 Fluentd를 다시 시작하는 방법을 보여줍니다.
Fluentd가 실행 중인 노드를 나열합니다.
$ oc get nodes -l logging-infra-fluentd=true각 노드에 대해 라벨을 제거하고 Fluentd를 종료합니다.
$ oc label node $node logging-infra-fluentd-Fluentd가 꺼져 있는지 확인합니다.
$ oc get pods -l component=fluentd각 노드에 Fluentd를 다시 시작합니다.
$ oc label node $node logging-infra-fluentd=true
다음 단계에서는 Fluentd 모든 노드를 다시 시작하는 방법을 보여줍니다.
모든 노드에서 Fluentd를 끕니다.
$ oc label node -l logging-infra-fluentd=true --overwrite logging-infra-fluentd=falseFluentd가 꺼져 있는지 확인합니다.
$ oc get pods -l component=fluentd모든 노드에서 Fluentd를 다시 시작합니다.
$ oc label node -l logging-infra-fluentd=false --overwrite logging-infra-fluentd=trueFluentd가 있는지 확인합니다.
$ oc get pods -l component=fluentd
36.12. 수동 Elasticsearch 롤아웃
OpenShift Container Platform 3.7부터 집계된 로깅 스택은 Elasticsearch Deployment Config 오브젝트를 업데이트하여 더 이상 구성 변경 트리거를 사용하지 않도록 합니다. 즉, dc 에 대한 변경으로 인해 자동 롤아웃이 발생하지 않습니다. 이는 클러스터 구성원을 다시 시작할 때 과도한 shard 리밸런싱을 생성할 수 있는 Elasticsearch 클러스터에서 의도하지 않은 재시작을 방지하는 것이었습니다.
이 섹션에서는 두 가지 재시작 절차인 rolling-restart 및 full-restart 를 제공합니다. 롤링 재시작을 통해 가동 중지 시간(세 개의 마스터 구성) 없이 Elasticsearch 클러스터에 적절한 변경 사항을 적용하고 전체 재시작은 기존 데이터에 위험 없이 안전하게 주요 변경 사항을 적용합니다.
36.12.1. Elasticsearch 롤링 클러스터 재시작 수행
다음과 같은 변경 사항이 있는 경우 롤링 재시작이 권장됩니다.
- Elasticsearch Pod가 실행되는 노드를 재부팅해야 합니다.
- logging-elasticsearch configmap
- logging-es-* 배포 구성
- 새 이미지 배포 또는 업그레이드
이는 권장되는 재시작 정책입니다.
openshift_logging_use_ops 가 True 로 구성된 경우 Elasticsearch 클러스터에 대해 작업을 반복해야 합니다.
의도적으로 노드를 중단할 때 shard 밸런싱을 방지합니다.
$ oc exec -c elasticsearch <any_es_pod_in_the_cluster> -- \ curl -s \ --cacert /etc/elasticsearch/secret/admin-ca \ --cert /etc/elasticsearch/secret/admin-cert \ --key /etc/elasticsearch/secret/admin-key \ -XPUT 'https://localhost:9200/_cluster/settings' \ -d '{ "transient": { "cluster.routing.allocation.enable" : "none" } }'완료되면 Elasticsearch 클러스터의 각
dc에 대해oc rollout latest를 실행하여 최신 버전의dc오브젝트를 배포합니다.$ oc rollout latest <dc_name>새 포드가 배포됩니다. 포드에 2개의 컨테이너가 준비되면 다음
dc로 이동할 수 있습니다.클러스터의 모든 'dc's가 롤아웃되면 shard 밸런싱을 다시 활성화합니다.
$ oc exec -c elasticsearch <any_es_pod_in_the_cluster> -- \ curl -s \ --cacert /etc/elasticsearch/secret/admin-ca \ --cert /etc/elasticsearch/secret/admin-cert \ --key /etc/elasticsearch/secret/admin-key \ -XPUT 'https://localhost:9200/_cluster/settings' \ -d '{ "transient": { "cluster.routing.allocation.enable" : "all" } }'
36.12.2. Elasticsearch 전체 클러스터 재시작 수행
변경 프로세스 중에 데이터 무결성을 위험할 수 있는 Elasticsearch의 주요 버전 또는 기타 변경 사항을 변경할 때 전체 재시작이 권장됩니다.
openshift_logging_use_ops 가 True 로 구성된 경우 Elasticsearch 클러스터에 대해 작업을 반복해야 합니다.
logging-es-ops 서비스를 변경할 때 구성 요소는 패치 대신 "es-ops-blocked" 및 "es-ops"를 사용합니다.
중단되는 동안 Elasticsearch 클러스터와의 모든 외부 통신을 비활성화합니다. 더 이상 Elasticsearch Pod가 실행 중이지 않도록 클러스터 외
로깅 서비스(예:)를 편집합니다.logging-es, logging-es-ops$ oc patch svc/logging-es -p '{"spec":{"selector":{"component":"es-blocked","provider":"openshift"}}}'shard 동기화 플러시를 수행하여 종료하기 전에 디스크에 쓰기 대기 중인 작업이 없는지 확인하십시오.
$ oc exec -c elasticsearch <any_es_pod_in_the_cluster> -- \ curl -s \ --cacert /etc/elasticsearch/secret/admin-ca \ --cert /etc/elasticsearch/secret/admin-cert \ --key /etc/elasticsearch/secret/admin-key \ -XPOST 'https://localhost:9200/_flush/synced'의도적으로 노드를 중단할 때 shard 밸런싱을 방지합니다.
$ oc exec -c elasticsearch <any_es_pod_in_the_cluster> -- \ curl -s \ --cacert /etc/elasticsearch/secret/admin-ca \ --cert /etc/elasticsearch/secret/admin-cert \ --key /etc/elasticsearch/secret/admin-key \ -XPUT 'https://localhost:9200/_cluster/settings' \ -d '{ "transient": { "cluster.routing.allocation.enable" : "none" } }'완료되면 Elasticsearch 클러스터의 각
dc에 대해 모든 노드를 축소합니다.$ oc scale dc <dc_name> --replicas=0축소가 완료되면 Elasticsearch 클러스터의
dc마다oc rollout latest를 실행하여 최신 버전의dc오브젝트를 배포합니다.$ oc rollout latest <dc_name>새 포드가 배포됩니다. 포드에 2개의 컨테이너가 준비되면 다음
dc로 이동할 수 있습니다.배포가 완료되면 Elasticsearch 클러스터의 각
dc에 대해 노드를 확장합니다.$ oc scale dc <dc_name> --replicas=1확장이 완료되면 ES 클러스터에 대한 모든 외부 통신을 활성화합니다. Elasticsearch Pod가 다시 실행 중인지 일치하도록 클러스터 외
로깅 서비스(예:)를 편집합니다.logging-es, logging-es-ops$ oc patch svc/logging-es -p '{"spec":{"selector":{"component":"es","provider":"openshift"}}}'
36.13. EFK 문제 해결
다음은 클러스터 로깅 배포에서 일반적으로 식별되는 여러 문제에 대한 정보를 해결합니다.
36.13.3. Kibana
다음과 같은 문제 해결 문제는 EFK 스택의 Kibana 구성 요소에 적용됩니다.
Kibana에 로그인 반복
Kibana 콘솔을 시작하고 성공적으로 로그인하면 잘못 Kibana로 리디렉션되어 로그인 화면으로 즉시 리디렉션됩니다.
이 문제의 원인은 Kibana 앞의 OAuth2 프록시가 유효한 클라이언트로 식별하기 위해 마스터의 OAuth2 서버와 시크릿을 공유해야 한다는 것입니다. 이 문제는 보안이 일치하지 않음을 나타낼 수 있습니다. 노출될 수 있는 방식으로 이 문제를 보고하지 않습니다.
이 문제는 로깅을 두 번 이상 배포할 때 발생할 수 있습니다. 예를 들어 초기 배포를 수정하고 Kibana에서 사용하는 시크릿 이 교체되는 동안 일치하는 마스터 oauthclient 항목이 교체되지 않습니다.
다음을 수행할 수 있습니다.
$ oc delete oauthclient/kibana-proxy
openshift-ansible 지침에 따라 openshift_logging 역할을 다시 실행합니다. 이렇게 하면 oauthclient가 대체되고 다음에 성공적으로 로그인한 다음 로그인이 반복되지 않아야 합니다.
*"error":"invalid\_request" on login*Kibana의 로그인 오류
Kibana 콘솔을 방문하려고 하면 대신 브라우저 오류가 발생할 수 있습니다.
{"error":"invalid_request","error_description":"The request is missing a required parameter,
includes an invalid parameter value, includes a parameter more than once, or is otherwise malformed."}이 문제는 OAuth2 클라이언트와 서버 간의 불일치로 인해 발생할 수 있습니다. 클라이언트의 반환 주소는 허용 목록에 있어야 로그인 후 서버가 안전하게 다시 리디렉션될 수 있습니다. 불일치가 있는 경우 오류 메시지가 표시됩니다.
이 문제는 이전 배포에서 oauthclient 항목 링링으로 인해 발생할 수 있습니다. 이 경우 대체할 수 있습니다.
$ oc delete oauthclient/kibana-proxy
openshift-ansible 지침에 따라 openshift_logging 역할을 다시 실행하면 oauthclient 항목이 대체됩니다. Kibana 콘솔로 돌아가서 다시 로그인합니다.
문제가 지속되면 OAuth 클라이언트에 나열된 URL에서 Kibana에 액세스하고 있는지 확인하십시오. 이 문제는 표준 443 HTTPS 포트 대신 1443과 같은 전달 포트에서 URL에 액세스하면 발생할 수 있습니다.
oauthclient 를 편집하여 서버 화이트리스트를 조정할 수 있습니다.
$ oc edit oauthclient/kibana-proxy실제로 사용 중인 주소를 포함하도록 수락된 리디렉션 URI 목록을 편집합니다. 저장하고 종료한 후 오류가 해결됩니다.
Kibana 액세스에 503 오류 표시
Kibana 콘솔을 볼 때 프록시 오류가 발생하면 다음 두 가지 문제 중 하나로 인해 발생할 수 있습니다.
Kibana가 Pod를 인식하지 못할 수 있습니다. ElasticSearch가 시작 속도가 느리면 Kibana가 ElasticSearch에 도달하려고 할 수 있으며 Kibana가 활성 상태라고 생각하지 않습니다. 관련 서비스에 끝점이 있는지 확인할 수 있습니다.
$ oc describe service logging-kibana Name: logging-kibana [...] Endpoints: <none>Kibana Pod가 활성화되어 있으면 끝점이 나열되어야 합니다. 그렇지 않은 경우 Kibana Pod 및 배포 상태를 확인합니다.
Kibana 서비스에 액세스하기 위한 명명된 경로가 마스킹될 수 있습니다.
하나의 프로젝트에서 테스트 배포를 수행한 다음 첫 번째 배포를 완전히 제거하지 않고 다른 프로젝트에 배포할 경우에 발생할 수 있습니다. 여러 경로가 동일한 대상으로 전송되면 기본 라우터는 처음 생성된 대상으로만 라우팅합니다. 문제가 있는 경로가 여러 위치에 정의되어 있는지 확인하십시오.
$ oc get route --all-namespaces --selector logging-infra=support NAMESPACE NAME HOST/PORT PATH SERVICE logging kibana kibana.example.com logging-kibana logging kibana-ops kibana-ops.example.com logging-kibana-ops이 예에서는 중복되는 경로가 없습니다.
37장. 로깅 크기 조정 가이드라인 집계
37.1. 개요
Elasticsearch, Fluentd 및 Kibana (EFK) 스택은 OpenShift Container Platform 설치 내부에서 실행되는 노드 및 애플리케이션에서 로그를 집계합니다. 배포한 후에는 Fluentd 를 사용하여 모든 노드의 로그와 포드를 Elasticsearch(ES) 로 집계합니다. 또한 사용자와 관리자가 집계된 데이터를 사용하여 풍부한 시각화 및 대시보드를 생성할 수 있는 중앙 집중식 Kibana 웹 UI를 제공합니다.
37.2. 설치
OpenShift Container Platform에서 집계 로깅 스택을 설치하는 일반적인 절차는 컨테이너 로그 집계에 설명되어 있습니다. 설치 가이드를 수행하는 동안 다음과 같은 몇 가지 중요한 사항에 유의해야 합니다.
로깅 Pod가 클러스터에 균등하게 분배되려면 프로젝트를 생성할 때 비어 있는 노드 선택기 를 사용해야 합니다.
$ oc adm new-project logging --node-selector=""나중에 수행되는 노드 레이블링과 함께 로깅 프로젝트 전체에서 Pod 배치를 제어합니다.
Elasticsearch(ES)는 노드 장애에 대한 복원력을 위해 3개 이상의 클러스터 크기로 배포해야 합니다. 이는 인벤토리 호스트 파일에서 openshift_logging_es_cluster_size 매개 변수를 설정하여 지정합니다.
매개 변수 전체 목록은 Ansible 변수를 참조하십시오.
Kibana에는 브라우저가 액세스하는 데 사용할 수 있는 호스트 이름이 필요합니다. 예를 들어 랩탑에서 실행되는 웹 브라우저에서 Kibana에 액세스하려면 Kibana의 DNS 별칭을 회사 이름 서비스에 추가해야 할 수 있습니다. 로깅 배포는 "인프라" 노드 또는 OpenShift 라우터가 실행될 때마다 Kibana에 대한 경로를 생성합니다. Kibana 호스트 이름 별칭은 이 시스템을 가리켜야 합니다. 이 호스트 이름은 Ansible openshift_logging_kibana_hostname 변수로 지정됩니다.
설치는 레지스트리에서 이미지를 이미 검색했는지 여부와 클러스터 크기에 따라 다소 시간이 걸릴 수 있습니다.
openshift-logging 프로젝트에서 oc get all 을 사용하여 배포를 확인할 수 있습니다.
$ oc get all
NAME REVISION REPLICAS TRIGGERED BY
logging-curator 1 1
logging-es-6cvk237t 1 1
logging-es-e5x4t4ai 1 1
logging-es-xmwvnorv 1 1
logging-kibana 1 1
NAME DESIRED CURRENT AGE
logging-curator-1 1 1 3d
logging-es-6cvk237t-1 1 1 3d
logging-es-e5x4t4ai-1 1 1 3d
logging-es-xmwvnorv-1 1 1 3d
logging-kibana-1 1 1 3d
NAME HOST/PORT PATH SERVICE TERMINATION LABELS
logging-kibana kibana.example.com logging-kibana reencrypt component=support,logging-infra=support,provider=openshift
logging-kibana-ops kibana-ops.example.com logging-kibana-ops reencrypt component=support,logging-infra=support,provider=openshift
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
logging-es 172.24.155.177 <none> 9200/TCP 3d
logging-es-cluster None <none> 9300/TCP 3d
logging-es-ops 172.27.197.57 <none> 9200/TCP 3d
logging-es-ops-cluster None <none> 9300/TCP 3d
logging-kibana 172.27.224.55 <none> 443/TCP 3d
logging-kibana-ops 172.25.117.77 <none> 443/TCP 3d
NAME READY STATUS RESTARTS AGE
logging-curator-1-6s7wy 1/1 Running 0 3d
logging-deployer-un6ut 0/1 Completed 0 3d
logging-es-6cvk237t-1-cnpw3 1/1 Running 0 3d
logging-es-e5x4t4ai-1-v933h 1/1 Running 0 3d
logging-es-xmwvnorv-1-adr5x 1/1 Running 0 3d
logging-fluentd-156xn 1/1 Running 0 3d
logging-fluentd-40biz 1/1 Running 0 3d
logging-fluentd-8k847 1/1 Running 0 3d다음과 유사한 설정으로 끝나야 합니다.
$ oc get pods -o wide
NAME READY STATUS RESTARTS AGE NODE
logging-curator-1-6s7wy 1/1 Running 0 3d ip-172-31-24-239.us-west-2.compute.internal
logging-deployer-un6ut 0/1 Completed 0 3d ip-172-31-6-152.us-west-2.compute.internal
logging-es-6cvk237t-1-cnpw3 1/1 Running 0 3d ip-172-31-24-238.us-west-2.compute.internal
logging-es-e5x4t4ai-1-v933h 1/1 Running 0 3d ip-172-31-24-235.us-west-2.compute.internal
logging-es-xmwvnorv-1-adr5x 1/1 Running 0 3d ip-172-31-24-233.us-west-2.compute.internal
logging-fluentd-156xn 1/1 Running 0 3d ip-172-31-24-241.us-west-2.compute.internal
logging-fluentd-40biz 1/1 Running 0 3d ip-172-31-24-236.us-west-2.compute.internal
logging-fluentd-8k847 1/1 Running 0 3d ip-172-31-24-237.us-west-2.compute.internal
logging-fluentd-9a3qx 1/1 Running 0 3d ip-172-31-24-231.us-west-2.compute.internal
logging-fluentd-abvgj 1/1 Running 0 3d ip-172-31-24-228.us-west-2.compute.internal
logging-fluentd-bh74n 1/1 Running 0 3d ip-172-31-24-238.us-west-2.compute.internal
...
...
기본적으로 각 ES 인스턴스에 할당된 RAM의 크기는 16GB입니다. openshift_logging_es_memory_limit 는 openshift-ansible 호스트 인벤토리 파일에서 사용되는 매개 변수입니다. 이 값의 절반은 개별 elasticsearch Pod java 프로세스 힙 크기로 전달됩니다.
37.2.1. 대규모 클러스터
100개 이상의 노드에서 먼저 docker pull registry.redhat.io/openshift3/logging-fluentd:v3.11 에서 로깅 이미지를 미리 가져오는 것이 좋습니다. 로깅 인프라 Pod(Elasticsearch, Kibana 및 Curator)를 배포한 후 노드 레이블은 한 번에 20개의 노드 단계에서 수행해야 합니다. 예를 들면 다음과 같습니다.
간단한 반복문 사용:
$ while read node; do oc label nodes $node logging-infra-fluentd=true; done < 20_fluentd.lst다음 작업도 수행합니다.
$ oc label nodes 10.10.0.{100..119} logging-infra-fluentd=true그룹의 노드에 레이블을 지정하면 OpenShift 로깅에서 사용하는 DaemonSet이 진행되므로 이미지 레지스트리와 같은 공유 리소스의 경합을 방지하는 데 도움이 됩니다.
"CrashLoopBackOff | ImagePullFailed | Error" 문제가 발생하는지 확인하십시오. oc logs <pod>, oc describe pod <pod> 및 oc get event 는 유용한 진단 명령입니다.
37.3. systemd-journald 및 rsyslog
RHEL(Red Hat Enterprise Linux) 7에서 systemd-journald.socket 단위는 부팅 프로세스 중에 /dev/log 를 만든 다음 입력을 systemd-journald.service 에 전달합니다. 모든 syslog() 호출은 저널로 이동합니다.
systemd-journald 의 기본 속도 제한으로 인해 Fluentd가 읽을 수 있기 전에 일부 시스템 로그가 삭제됩니다. 이를 방지하려면 /etc/systemd/journald.conf 파일에 다음을 추가합니다.
# Disable rate limiting
RateLimitInterval=1s
RateLimitBurst=10000
Storage=volatile
Compress=no
MaxRetentionSec=30s그런 다음 서비스를 다시 시작합니다.
$ systemctl restart systemd-journald.service
$ systemctl restart rsyslog.service이러한 설정은 대량으로 업로드하는 버스티 특성에 대한 계정입니다.
속도 제한을 제거한 후 이전에 제한되었던 메시지를 처리할 때 시스템 로깅 데몬에서 CPU 사용률이 증가할 수 있습니다.
37.4. EFK 로깅 확장
첫 번째 배포 시 원하는 스케일링을 나타내지 않으면 업데이트된 openshift_logging_es_cluster_size 값으로 인벤토리 파일을 업데이트한 후 Ansible 로깅 플레이북을 다시 실행하면 클러스터를 조정하는 가장 적은 방법이 있습니다. 자세한 내용은 관리 Elasticsearch 운영 수행 섹션을 참조하십시오.
고가용성 Elasticsearch 환경에 는 각각 다른 호스트에 있는 3개 이상의 Elasticsearch 노드가 필요하며, 복제본을 생성하려면 openshift_logging_es_number_of_replicas Ansible 변수를 1 개 이상의 값으로 설정해야 합니다.
37.4.1. 마스터 이벤트는 로그로 EFK로 집계됩니다.
eventrouter Pod는 Kubernetes API의 이벤트를 스크랩하고 STDOUT 으로 출력됩니다. fluentd 플러그인은 로그 메시지를 변환하고 Elasticsearch(ES)로 전송합니다.
openshift_logging_install_eventrouter 를 true 로 설정하여 활성화합니다. 기본적으로 꺼져 있습니다. 이벤트 라우터 는 기본 네임스페이스에 배포됩니다. 수집된 정보는 ES의 작업 인덱스에 있으며 클러스터 관리자만 시각적 액세스가 가능합니다.
37.5. 스토리지 고려 사항
Elasticsearch 인덱스는 shard 및 해당 복제본의 컬렉션입니다. ES는 내부적으로 고가용성을 구현하므로 하드웨어 기반 미러링 RAID 변형을 사용할 필요가 거의 없습니다. RAID 0은 여전히 전체 디스크 성능을 향상하는 데 사용할 수 있습니다.
각 Elasticsearch 배포 구성에 영구 볼륨이 추가됩니다. OpenShift Container Platform에서는 일반적으로 영구 볼륨 클레임 을 통해 달성됩니다.
PVC의 이름은 openshift_logging_es_pvc_prefix 설정을 기반으로 합니다. 자세한 내용은 영구 Elasticsearch 스토리지를 참조하십시오.
Fluentd는 systemd 저널 및 /var/lib/docker/containers/*.log 의 모든 로그를 Elasticsearch에 제공합니다. 자세히 알아보기.
최상의 성능을 얻으려면 로컬 SSD 드라이브가 권장됩니다. RHEL(Red Hat Enterprise Linux) 7에서 데드라인 IO 스케줄러는 SATA 디스크를 제외한 모든 블록 장치의 기본값입니다. SATA 디스크의 경우 기본 IO 스케줄러는 cfq 입니다.
ES의 스토리지 크기 조정은 인덱스를 최적화하는 방법에 크게 따라 달라집니다. 따라서 필요한 데이터 양을 미리 생각하고 애플리케이션 로그 데이터를 집계하는 것을 고려하십시오. 일부 Elasticsearch 사용자는 절대 스토리지 소비를 항상 약 50%에서 70% 미만으로 유지해야 한다는 것을 발견했습니다. 이는 대규모 병합 작업 중에 Elasticsearch가 응답하지 않는 것을 방지합니다.
38장. 클러스터 지표 활성화
38.1. 개요
kubelet 은 Heapster 를 통해 백엔드에 수집 및 저장할 수 있는 지표를 노출합니다.
OpenShift Container Platform 관리자는 하나의 사용자 인터페이스에서 모든 컨테이너 및 구성 요소에서 클러스터의 지표를 볼 수 있습니다.
이전 버전의 OpenShift Container Platform에서는 Heapster의 메트릭을 사용하여 수평 Pod 자동 스케일러를 구성했습니다. 이제 수평 Pod 자동 스케일러가 OpenShift Container Platform 지표 서버의 지표를 사용합니다. 자세한 내용은 Horizontal Pod Autoscaler 사용에 대한 요구 사항을 참조하십시오.
이 주제에서는 데이터를 Cassandra 데이터베이스에 영구적으로 저장하는 지표 엔진으로 Hawkular Metrics 를 사용하는 방법에 대해 설명합니다. 이 지표가 구성되면 OpenShift Container Platform 웹 콘솔에서 CPU, 메모리 및 네트워크 기반 지표를 볼 수 있습니다.
Heapster는 마스터 서버에서 모든 노드 목록을 검색한 다음 /stats 엔드포인트를 통해 각 노드에 개별적으로 연결합니다. 여기에서 Heapster는 CPU, 메모리 및 네트워크 사용량에 대한 지표를 스크랩한 다음 Hawkular Metrics로 내보냅니다.
kubelet에서 사용할 수 있는 스토리지 볼륨 지표는 /stats 끝점을 통해 사용할 수 없지만 /metrics 끝점을 통해 사용할 수 있습니다. 자세한 내용은 Prometheus Monitoring 을 참조하십시오.
웹 콘솔에서 개별 포드를 찾으면 메모리 및 CPU에 대한 별도의 스클라인 차트가 표시됩니다. 표시되는 시간 범위를 선택할 수 있으며, 이 차트는 30초마다 자동으로 업데이트됩니다. 포드에 컨테이너가 여러 개 있는 경우 특정 컨테이너를 선택하여 지표를 표시할 수 있습니다.
프로젝트에 대한 리소스 제한이 정의된 경우 각 포드에 도넛형 차트가 표시될 수도 있습니다. 도넛형 차트는 리소스 제한에 대한 사용량을 표시합니다. 예를 들면 다음과 같습니다. 145 200MiB로 사용할 수 있으며 도넛형 차트에 55MiB가 사용됨.
38.2. 시작하기 전
Ansible 플레이북을 사용하여 클러스터 지표를 배포하고 업그레이드할 수 있습니다. 클러스터 설치 가이드를 숙지해야 합니다. 이는 Ansible 사용을 준비하는 데 필요한 정보를 제공하며 구성에 대한 정보를 포함합니다. 매개 변수가 Ansible 인벤토리 파일에 추가되어 클러스터 지표의 다양한 영역을 구성합니다.
다음은 기본값을 수정하기 위해 Ansible 인벤토리 파일에 추가할 수 있는 다양한 영역과 매개 변수에 대해 설명합니다.
38.3. 메트릭 데이터 스토리지
지표 데이터를 영구 스토리지 또는 임시 Pod 볼륨에 저장할 수 있습니다.
38.3.1. 영구 스토리지
영구저장장치를 사용하여 OpenShift Container Platform 클러스터 지표를 실행하면 메트릭이 영구 볼륨에 저장되며 Pod가 다시 시작되거나 재생성될 수 있습니다. 데이터 손실에서 지표 데이터를 보호해야 하는 경우 이상적입니다. 프로덕션 환경의 경우 지표 포드에 대한 영구 스토리지를 구성하는 것이 좋습니다.
Cassandra 스토리지의 크기 요구 사항은 포드 수에 따라 달라집니다. 관리자는 크기 요구 사항이 설정에 충분한지 확인하고 디스크가 가득 차지 않도록 사용량을 모니터링해야 합니다. 영구 볼륨 클레임의 크기는 기본적으로 10GB로 설정된 openshift_metrics_cassandra_pvc_size ansible 변수로 지정됩니다.
동적으로 프로비저닝된 영구 볼륨 을 사용하려면 openshift_metrics_cassandra_storage_type 변수를 인벤토리 파일에서 dynamic 로 설정합니다.
38.3.2. 클러스터 메트릭에 대한 용량 계획
openshift_metrics Ansible 역할을 실행한 후 oc get pods 의 출력은 다음과 유사합니다.
# oc get pods -n openshift-infra
NAME READY STATUS RESTARTS AGE
hawkular-cassandra-1-l5y4g 1/1 Running 0 17h
hawkular-metrics-1t9so 1/1 Running 0 17h
heapster-febru 1/1 Running 0 17h
OpenShift Container Platform 지표는 openshift_metrics_cassandra_limits_memory 설정으로 배포되는 Cassandra 데이터베이스를 사용하여 저장됩니다. 2G; Cassandra 시작 스크립트에 의해 결정된 대로 사용 가능한 메모리를 기반으로 이 값을 추가로 조정할 수 있습니다. 이 값은 대부분의 OpenShift Container Platform 지표 설치를 다루지만 환경 변수를 사용하면 클러스터 지표를 배포하기 전에 Cassandra Dockerfile에서 힙 새 생성 크기인 HEAP_NEWSIZE 와 함께 MAX _HEAP_SIZE를 수정할 수 있습니다.
기본적으로 지표 데이터는 7일 동안 저장됩니다. 7일 후 Cassandra는 가장 오래된 지표 데이터를 제거하기 시작합니다. 삭제된 포드 및 프로젝트의 지표 데이터는 자동으로 삭제되지 않습니다. 데이터는 7일이 지난 후에만 제거됩니다.
예 38.1. 10개의 노드 및 1000개의 Pod에 의해 변경되는 데이터
10개의 노드 및 1000개의 포드를 포함하는 테스트 시나리오에서는 24시간 동안 2.5GB의 지표 데이터를 누적했습니다. 따라서 이 시나리오의 지표 데이터에 대한 용량 계획 공식은 다음과 같습니다.
(2.5~10 9) ✓1000- 24) ✓ 106 = 포드당 ~0.125MB/시간.
예 38.2. 120개의 노드 및 10,000개의 Pod에 의해 변경되는 데이터
120개의 노드 및 10000개의 포드를 포함하는 테스트 시나리오에서는 24시간 동안 25GB의 지표 데이터를 누적했습니다. 따라서 이 시나리오의 지표 데이터에 대한 용량 계획 공식은 다음과 같습니다.
((11.410~10 9) - 1000-1000- 24) - 106 = 0.475 MB/시간
| 1000개의 Pod | Pod 10,000개 | |
|---|---|---|
| 24시간 이상 누적된 Cassandra 스토리지 데이터(기본 메트릭 매개변수) | 2.5GB | 11.4GB |
openshift_metrics_ duration의 기본값은 7일이고 openshift_metrics _ resolution의 경우 30초가 유지되면 Cassandra 포드의 매주 스토리지 요구 사항은 다음과 같습니다.
| 1000개의 Pod | Pod 10,000개 | |
|---|---|---|
| 7일 동안 누적된 Cassandra 스토리지 데이터(기본 지표 매개 변수) | 20GB | 90GB |
이전 표에서는 예기치 않은 모니터링된 Pod 사용량을 버퍼로 예상 스토리지 공간에 추가 10%가 추가되었습니다.
Cassandra가 지속된 볼륨이 충분한 공간이 부족하면 데이터 손실이 발생합니다.
클러스터 지표가 영구 스토리지에서 작동하려면 영구 볼륨에 ReadWriteOnce 액세스 모드가 있는지 확인합니다. 이 모드가 활성 상태가 아닌 경우 영구 볼륨 클레임은 영구 볼륨을 찾을 수 없으며 Cassandra가 시작되지 않습니다.
지표 구성 요소와 함께 영구 스토리지를 사용하려면 충분한 크기의 영구 볼륨을 사용할 수 있는지 확인합니다. 영구 볼륨 클레임 생성은 OpenShift Ansible openshift_metrics 역할에서 처리합니다.
OpenShift Container Platform 지표는 동적으로 프로비저닝된 영구 볼륨도 지원합니다. 이 기능을 OpenShift Container Platform 지표와 함께 사용하려면 openshift_metrics_cassandra_storage_type 값을 동적으로 설정해야 합니다. EBS, GCE, Cinder 스토리지 백엔드를 사용하여 영구 볼륨을 동적으로 프로비저닝할 수 있습니다.
성능 구성 및 클러스터 지표 포드 확장에 대한 자세한 내용은 클러스터 지표 확장 주제를 참조하십시오.
| 노드 수 | Pod 수 | Cassandra 스토리지 성장 속도 | 매일 Cassandra 스토리지 증가 | 주당 Cassandra 스토리지 증가 |
|---|---|---|---|---|
| 210 | 10500 | 시간당 500MB | 15GB | 75GB |
| 990 | 11000 | 시간당 1GB | 30GB | 210GB |
위 계산에서는 스토리지 요구 사항이 계산된 값을 초과하지 않도록 예상 크기의 약 20%가 오버헤드로 추가되었습니다.
METRICS_DURATION 및 METRICS_RESOLUTION 값이 기본값(각각7 일 및 15 초)에 유지되는 경우 위의 값과 같이 매주 Cassandra 스토리지 크기 재심사를 계획하는 것이 안전합니다.
OpenShift Container Platform 지표는 Cassandra 데이터베이스를 지표 데이터의 데이터 저장소로 사용하므로, 지표 설정 프로세스 중에 USE_PERSISTANT_STORAGE=true 가 설정된 경우 PV 가 네트워크 스토리지에 있고 NFS가 기본값으로 지정됩니다. 그러나 Cassandra 설명서에 따라 네트워크 스토리지를 Cassandra와 함께 사용하는 것은 권장되지 않습니다.
알려진 문제 및 제한 사항
테스트 결과 heapster 지표 구성 요소가 최대 25,000개의 Pod를 처리할 수 있습니다. 포드 양이 해당 수를 초과하는 경우 Heapster는 지표 처리에서 뒤처지기 때문에 지표 그래프가 더 이상 나타나지 않습니다. Heapster가 메트릭을 수집할 수 있는 Pod 및 대체 지표 수집 솔루션의 업스트림 개발을 위한 Pod 수를 늘리는 작업이 진행 중입니다.
38.3.3. 영구적이지 않은 스토리지
비영구 스토리지를 사용하여 OpenShift Container Platform 클러스터 지표를 실행하면 Pod가 삭제될 때 저장된 지표가 모두 삭제됩니다. 비영구적 데이터를 사용하여 클러스터 지표를 실행하는 것이 훨씬 쉬운 반면 비영구적 데이터로 실행하면 영구 데이터가 손실될 위험이 있습니다. 그러나 메트릭은 다시 시작하는 컨테이너를 계속 유지할 수 있습니다.
비영구 스토리지를 사용하려면 인벤토리 파일에서 openshift_metrics_cassandra_storage_type 변수를 emptydir 으로 설정해야 합니다.
비영구 스토리지를 사용하는 경우 메트릭 데이터는 Cassandra 포드가 실행되는 노드의 /var/lib/origin/openshift.local.volumes/pods 에 메트릭 스토리지를 수용하기에 충분한 여유 공간이 있는지 확인합니다.
38.4. 메트릭 Ansible 역할
OpenShift Container Platform Ansible openshift_metrics 역할은 Ansible 인벤토리 구성 파일의 변수를 사용하여 모든 지표 구성 요소를 구성하고 배포합니다.
38.4.1. 지표 Ansible 변수 지정
OpenShift Ansible에 포함된 openshift_metrics 역할은 클러스터 지표를 배포하는 작업을 정의합니다. 다음은 재정의해야 하는 경우 인벤토리 파일에 추가할 수 있는 역할 변수 목록입니다.
| Variable | 설명 |
|---|---|
|
|
|
|
| 구성 요소를 배포한 후 지표 클러스터를 시작합니다. |
|
| 재시작을 시도하기 전에 Hawkular Metrics 및 Heapster가 시작될 때까지 대기하는 시간(초)입니다. |
|
| 지표를 제거하기 전에 저장할 일 수입니다. |
|
| 지표를 수집하는 빈도입니다. 숫자 및 시간 식별자로 정의됨: 초(s), 분(m), 시간(h). |
|
|
이 변수를 사용하여 사용할 Cassandra 볼륨의 정확한 이름을 지정합니다. 지정된 이름의 볼륨이 없으면 생성됩니다. 이 변수는 단일 Cassandra 복제본에서만 사용할 수 있습니다. 여러 Cassandra 복제본의 경우 대신 |
|
| Cassandra에 대해 생성된 영구 볼륨 클레임 접두사입니다. 일련 번호가 1부터 시작되는 접두사에 추가됩니다. |
|
| 각 Cassandra 노드의 영구 볼륨 클레임 크기입니다. |
|
|
사용할 스토리지 클래스를 지정합니다. 스토리지 클래스를 명시적으로 설정하려면 |
|
|
임시 스토리지(테스트용)에는 |
|
| 지표 스택의 Cassandra 노드 수입니다. 이 값은 Cassandra 복제 컨트롤러 수를 지정합니다. |
|
|
Cassandra 포드의 메모리 제한입니다. 예를 들어 |
|
|
Cassandra 포드의 CPU 제한입니다. 예를 들어, 값 |
|
|
Cassandra 포드를 요청할 메모리 양입니다. 예를 들어 |
|
|
Cassandra 포드의 CPU 요청입니다. 예를 들어 |
|
| Cassandra에 사용할 보조 스토리지 그룹입니다. |
|
|
Pod가 특정 레이블이 있는 노드에 배치되도록 원하는 기존 노드 선택기 로 설정합니다. 예를 들면 |
|
| Hawkular 인증서에 서명하는 데 사용되는 선택적 CA(인증 기관) 파일입니다. |
|
| Hawkular 지표에 대한 경로를 재암호화하는 데 사용되는 인증서 파일입니다. 인증서에는 경로에서 사용하는 호스트 이름이 포함되어야 합니다. 지정되지 않은 경우 기본 라우터 인증서가 사용됩니다. |
|
| Hawkular 인증서에 사용되는 키 파일입니다. |
|
|
Hawkular 포드를 제한하는 메모리 양입니다. 예를 들어 |
|
|
Hawkular 포드의 CPU 제한입니다. 예를 들어, 값 |
|
| Hawkular 지표의 복제본 수입니다. |
|
|
Hawkular 포드에 요청할 메모리 양입니다. 예를 들어 |
|
|
Hawkular 포드에 대한 CPU 요청입니다. 예를 들어 |
|
|
Pod가 특정 레이블이 있는 노드에 배치되도록 원하는 기존 노드 선택기 로 설정합니다. 예를 들면 |
|
|
허용할 CN의 쉼표로 구분된 목록입니다. 기본적으로 OpenShift 서비스 프록시가 연결할 수 있도록 설정됩니다. 수평 Pod 자동 스케일링 이 제대로 작동하도록 허용하려면 재정의할 때 |
|
|
Heapster 포드를 제한하는 메모리 양입니다. 예를 들어 |
|
|
Heapster 포드의 CPU 제한입니다. 예를 들어, 값 |
|
|
Heapster 포드에 요청할 메모리 양입니다. 예를 들어 |
|
|
Heapster 포드에 대한 CPU 요청입니다. 예를 들어 |
|
| Hawkular Metrics 및 Cassandra 구성 요소 없이 Heapster만 배포합니다. |
|
|
Pod가 특정 레이블이 있는 노드에 배치되도록 원하는 기존 노드 선택기 로 설정합니다. 예를 들면 |
|
|
Hawkular Metrics 경로에 호스트 이름을 사용하므로 |
요청 및 제한을 지정하는 방법에 대한 자세한 내용은 Compute Resources 를 참조하십시오.
Cassandra와 함께 영구 스토리지를 사용하는 경우 관리자가 openshift_metrics_cassandra_pvc_size 변수를 사용하여 클러스터에 충분한 디스크 크기를 설정해야 합니다. 디스크 사용량이 가득 차지 않도록 관리자가 디스크 사용을 모니터링해야 하는 책임이기도 합니다.
Cassandra가 볼륨을 충분한 공간이 부족하면 데이터 손실이 발생합니다.
다른 모든 변수는 선택 사항이며 더 큰 사용자 지정을 허용합니다. 예를 들어, https://kubernetes.default.svc:443 에서 Kubernetes 마스터를 사용할 수 없는 사용자 지정 설치가 있는 경우 대신 openshift_metrics_master_url 매개변수를 사용하여 사용할 값을 지정할 수 있습니다.
38.4.2. 시크릿 사용
OpenShift Container Platform Ansible openshift_metrics 역할은 해당 구성 요소 간에 사용할 자체 서명 인증서를 자동으로 생성하고 Hawkular Metrics 서비스를 노출하는 재암호화 경로를 생성합니다. 이 경로는 웹 콘솔에서 Hawkular Metrics 서비스에 액세스할 수 있도록 허용하는 경로입니다.
웹 콘솔을 실행하는 브라우저가 이 경로를 통해 연결을 신뢰하려면 경로의 인증서를 신뢰해야 합니다. 이는 신뢰할 수 있는 인증 기관에서 서명한 자체 인증서를 제공하여 수행할 수 있습니다. openshift_metrics 역할을 사용하면 자체 인증서를 지정한 다음 경로를 만들 때 사용할 수 있습니다.
자체 인증서를 제공하지 않는 경우 라우터의 기본 인증서가 사용됩니다.
38.4.2.1. 자체 인증서 제공
재암호화 경로에서 사용하는 자체 인증서를 제공하기 위해 인벤토리 파일에서 openshift_ metrics_hawkular_cert, 및 openshift_ metrics_hawkular_keyopenshift_metrics_hawkular_ca 변수를 설정할 수 있습니다.
hawkular-metrics.pem 값은. pem 형식으로 인증서를 포함해야 합니다. hawkular-metrics-ca.cert 시크릿을 통해 이 pem 파일에 서명한 인증 기관의 인증서를 제공해야 할 수도 있습니다.
자세한 내용은 재암호화 경로 설명서를 참조하십시오.
38.5. 지표 구성 요소 배포
모든 지표 구성 요소가 OpenShift Container Platform Ansible을 사용하여 배포 및 구성되므로 한 단계로 모든 항목을 배포할 수 있습니다.
다음 예제에서는 기본 매개 변수를 사용하여 영구 스토리지를 사용하거나 사용하지 않고 지표를 배포하는 방법을 보여줍니다.
Ansible 플레이북을 실행하는 호스트에는 인벤토리에 호스트당 최소 75MiB의 여유 메모리가 있어야 합니다.
업스트림 Kubernetes 규칙에 따라 eth0 의 기본 인터페이스에서만 지표를 수집할 수 있습니다.
예 38.3. 영구 스토리지를 사용하여 배포
다음 명령은 hawkular-metrics.example.com 을 사용하도록 Hawkular Metrics 경로를 설정하고 영구 스토리지를 사용하여 배포됩니다.
사용 가능한 영구 볼륨이 있어야 합니다.
$ ansible-playbook [-i </path/to/inventory>] <OPENSHIFT_ANSIBLE_DIR>/playbooks/openshift-metrics/config.yml \
-e openshift_metrics_install_metrics=True \
-e openshift_metrics_hawkular_hostname=hawkular-metrics.example.com \
-e openshift_metrics_cassandra_storage_type=pv예 38.4. 영구 스토리지없이 배포
다음 명령은 hawkular-metrics.example.com 을 사용하고 영구 스토리지 없이 배포하도록 Hawkular Metrics 경로를 설정합니다.
$ ansible-playbook [-i </path/to/inventory>] <OPENSHIFT_ANSIBLE_DIR>/playbooks/openshift-metrics/config.yml \
-e openshift_metrics_install_metrics=True \
-e openshift_metrics_hawkular_hostname=hawkular-metrics.example.com영구 스토리지 없이 배포되기 때문에 지표 데이터 손실이 발생할 수 있습니다.
38.5.1. 메트릭 진단
는 지표 스택의 상태를 평가하는 데 도움이 되는 몇 가지 지표 진단입니다. 메트릭에 대한 진단을 실행하려면 다음을 수행합니다.
$ oc adm diagnostics MetricsApiProxy38.6. 지표 공개 URL 설정
OpenShift Container Platform 웹 콘솔은 Hawkular Metrics 서비스에서 들어오는 데이터를 사용하여 그래프를 표시합니다. Hawkular Metrics 서비스에 액세스하기 위한 URL은 마스터 webconsole-config configmap 파일의 metricsPublicURL 옵션을 사용하여 구성해야 합니다. 이 URL은 지표 구성 요소를 배포하는 동안 사용되는 openshift_metrics_hawkular_hostname 인벤토리 변수로 생성된 경로에 해당합니다.
콘솔에 액세스하는 브라우저에서 openshift_metrics_hawkular_hostname 을 확인할 수 있어야 합니다.
예를 들어 openshift_metrics_hawkular_hostname 이 hawkular-metrics.example.com 에 해당하는 경우 webconsole-config configmap 파일에서 다음과 같이 변경해야 합니다.
clusterInfo:
...
metricsPublicURL: "https://hawkular-metrics.example.com/hawkular/metrics"webconsole-config configmap 파일을 업데이트하고 저장한 후 활성 프로브 구성에 설정된 지연 후 웹 콘솔 Pod가 다시 시작되며 기본적으로 30초입니다.
OpenShift Container Platform 서버가 백업 및 실행 중이면 Pod 개요 페이지에 지표가 표시됩니다.
자체 서명 인증서를 사용하는 경우 Hawkular Metrics 서비스는 다른 호스트 이름으로 호스팅되며 콘솔과 다른 인증서를 사용합니다. metricsPublicURL 에 지정된 값으로 브라우저 탭을 명시적으로 열고 해당 인증서를 수락해야 할 수 있습니다.
이 문제를 방지하려면 브라우저에서 허용하도록 구성된 인증서를 사용합니다.
38.7. Hawkular Metrics 직접 액세스
더 직접 메트릭에 액세스하고 관리하려면 Hawkular Metrics API 를 사용합니다.
API에서 Hawkular Metrics에 액세스할 때 읽기만 수행할 수 있습니다. 지표 작성은 기본적으로 비활성화되어 있습니다. 개별 사용자도 지표를 작성할 수 있도록 하려면 openshift_metrics_hawkular_user_write_access 변수를 true 로 설정해야 합니다.
그러나 기본 구성을 사용하는 것이 권장되며 지표만 Heapster를 통해 시스템에 입력하도록 하는 것이 좋습니다. 쓰기 액세스가 활성화되면 모든 사용자가 시스템에 지표를 작성할 수 있으므로 성능에 영향을 미치고 Cassandra 디스크 사용량이 예측할 수 없게 증가할 수 있습니다.
Hawkular Metrics 설명서 에서는 API 사용 방법을 다루지만 OpenShift Container Platform에서 사용하도록 구성된 Hawkular Metrics 버전을 처리할 때 몇 가지 차이점이 있습니다.
38.7.1. OpenShift Container Platform 프로젝트 및 Hawkular Tenants
Hawkular Metrics는 다중 테넌트 애플리케이션입니다. OpenShift Container Platform의 프로젝트가 Hawkular Metrics의 테넌트에 해당하도록 구성됩니다.
따라서 MyProject 라는 프로젝트의 메트릭에 액세스하는 경우 Hawkular-Tenant 헤더를 MyProject 로 설정해야 합니다.
시스템 수준 지표를 포함하는 _system 이라는 특수 테넌트도 있습니다. 이를 위해서는 cluster-reader 또는 cluster-admin 수준 권한이 필요합니다.
38.7.2. 권한 부여
Hawkular Metrics 서비스는 OpenShift Container Platform에 대해 사용자를 인증하여 사용자가 액세스하려는 프로젝트에 액세스할 수 있는지 확인합니다.
Hawkular Metrics는 클라이언트의 전달자 토큰을 수락하고 SubjectAccessReview 를 사용하여 OpenShift Container Platform 서버로 해당 토큰을 확인합니다. 사용자에게 프로젝트에 대한 적절한 읽기 권한이 있는 경우 해당 프로젝트의 지표를 읽을 수 있습니다. _system 테넌트의 경우 이 테넌트에서 읽기를 요청하는 사용자에게 cluster-reader 권한이 있어야 합니다.
Hawkular Metrics API에 액세스할 때 Authorization 헤더에 전달자 토큰을 전달해야 합니다.
38.8. OpenShift Container Platform 클러스터 지표 포드 스케일링
클러스터 지표 기능 확장에 대한 정보는 확장 및 성능 가이드를 참조하십시오.
38.9. 정리
다음 단계를 수행하여 OpenShift Container Platform Ansible openshift_metrics 역할에서 배포한 모든 항목을 제거할 수 있습니다.
$ ansible-playbook [-i </path/to/inventory>] <OPENSHIFT_ANSIBLE_DIR>/playbooks/openshift-metrics/config.yml \
-e openshift_metrics_install_metrics=False39장. 웹 콘솔 사용자 정의
39.1. 개요
관리자는 확장 기능을 사용하여 웹 콘솔을 사용자 지정할 수 있습니다. 그러면 웹 콘솔이 로드될 때 스크립트를 실행하고 사용자 지정 스타일시트를 로드할 수 있습니다. 확장 스크립트를 사용하면 웹 콘솔의 기본 동작을 재정의하고 필요에 맞게 사용자 지정할 수 있습니다.
예를 들어 확장 스크립트는 회사의 브랜딩을 추가하거나 회사별 기능을 추가하는 데 사용할 수 있습니다. 이를 위한 일반적인 사용 사례는 다양한 환경에 맞게 재 브랜딩 또는 화이트 라벨링입니다. 동일한 확장 코드를 사용할 수 있지만 웹 콘솔을 변경하는 설정을 제공할 수 있습니다.
아래에 설명되지 않은 웹 콘솔 스타일이나 동작을 광범위하게 변경해야 합니다. 스크립트 또는 스타일시트를 추가하는 동안 웹 콘솔 마크업 및 향후 버전의 동작 변경으로 업그레이드 시 상당한 사용자 지정 작업이 필요할 수 있습니다.
39.2. 확장 스크립트 및 스타일시트 로드
브라우저에서 URL에 액세스할 수 있는 한 https:// URL에서 확장 스크립트 및 스타일시트를 호스팅할 수 있습니다. 파일은 공개적으로 액세스 가능한 경로를 사용하거나 OpenShift Container Platform 외부의 다른 서버에 있는 플랫폼의 Pod에서 호스팅할 수 있습니다.
스크립트 및 스타일시트를 추가하려면 openshift-web ConfigMap을 편집합니다. 웹 콘솔 구성은 ConfigMap의 -console 네임스페이스에서 webconsole- configwebconsole-config.yaml 키에서 사용할 수 있습니다.
$ oc edit configmap/webconsole-config -n openshift-web-console
스크립트를 추가하려면 extensions.scriptURLs 속성을 업데이트합니다. 값은 URL 배열입니다.
스타일시트를 추가하려면 extensions.stylesheetURLs 속성을 업데이트합니다. 값은 URL 배열입니다.
extensions.stylesheetURLs 설정 예
apiVersion: v1
kind: ConfigMap
data:
webconsole-config.yaml: |
apiVersion: webconsole.config.openshift.io/v1
extensions:
scriptURLs:
- https://example.com/scripts/menu-customization.js
- https://example.com/scripts/nav-customization.js
stylesheetURLs:
- https://example.com/styles/logo.css
- https://example.com/styles/custom-styles.css
[...]ConfigMap을 저장하면 몇 분 내에 새 확장 파일에 대해 웹 콘솔 컨테이너가 자동으로 업데이트됩니다.
스크립트와 스타일시트는 올바른 콘텐츠 유형으로 제공되거나 브라우저에서 실행되지 않습니다. 스크립트는 Content-Type: application/javascript s 및 Content-Type: text/css 가 포함된 스타일시트를 통해 제공되어야 합니다.
IIFE(Inmmediately Invoked Function Expression)로 확장 스크립트를 래핑하는 것이 좋습니다. 이렇게 하면 웹 콘솔 또는 다른 확장 기능에서 사용하는 이름과 충돌하는 전역 변수를 생성하지 않습니다. 예를 들면 다음과 같습니다.
(function() {
// Put your extension code here...
}());다음 섹션의 예제에서는 웹 콘솔을 사용자 지정할 수 있는 일반적인 방법을 보여줍니다.
추가 확장 예제는 GitHub의 OpenShift Origin 리포지토리에서 사용할 수 있습니다.
39.2.1. 확장 속성 설정
특정 확장자가 있지만 각 환경에 대해 다른 텍스트를 사용하려는 경우 웹 콘솔 구성에서 환경을 정의하고 환경 전반에서 동일한 확장 스크립트를 사용할 수 있습니다.
확장 속성을 추가하려면 openshift-web ConfigMap을 편집합니다. 웹 콘솔 구성은 ConfigMap의 -console 네임스페이스에서 webconsole- configwebconsole-config.yaml 키에서 사용할 수 있습니다.
$ oc edit configmap/webconsole-config -n openshift-web-console
키-값 쌍의 맵인 extensions.properties 값을 업데이트합니다.
apiVersion: v1
kind: ConfigMap
data:
webconsole-config.yaml: |
apiVersion: webconsole.config.openshift.io/v1
extensions:
[...]
properties:
doc_url: https://docs.openshift.com
key1: value1
key2: value2
[...]그러면 다음 코드가 실행된 것처럼 확장에서 액세스할 수 있는 전역 변수가 생성됩니다.
window.OPENSHIFT_EXTENSION_PROPERTIES = {
doc_url: "https://docs.openshift.com",
key1: "value1",
key2: "value2"
}39.3. 외부 로깅 솔루션에 대한 확장 옵션
확장 옵션을 사용하여 OpenShift Container Platform의 EFK 로깅 스택을 사용하는 대신 외부 로깅 솔루션에 연결할 수 있습니다.
'use strict';
angular.module("mylinkextensions", ['openshiftConsole'])
.run(function(extensionRegistry) {
extensionRegistry.add('log-links', _.spread(function(resource, options) {
return {
type: 'dom',
node: '<span><a href="https://extension-point.example.com">' + resource.metadata.name + '</a><span class="action-divider">|</span></span>'
};
}));
});
hawtioPluginLoader.addModule("mylinkextensions");확장 스크립트 및 스타일시트 로드 에 설명된 대로 스크립트를 추가합니다.
39.4. 안내에 따른 둘러보기 사용자 정의 및 비활성화
사용자가 특정 브라우저에서 처음 로그인할 때 가이드 둘러보기가 나타납니다. 새 사용자에 대해 auto_launch 를 활성화할 수 있습니다.
window.OPENSHIFT_CONSTANTS.GUIDED_TOURS.landing_page_tour.auto_launch = true;확장 스크립트 및 스타일시트 로드 에 설명된 대로 스크립트를 추가합니다.
39.5. 문서 링크 사용자 정의
랜딩 페이지의 설명서 링크를 사용할 수 있습니다. window.OPENSHIFT_CONSTANTS.CATALOG_HELP_RESOURCES 는 제목과 href 를 포함하는 개체 배열입니다. 이러한 값은 링크로 전환됩니다. 배열을 완전히 재정의하거나, 추가 링크를 푸시하거나, 기존 링크의 속성을 수정할 수 있습니다. 예를 들면 다음과 같습니다.
window.OPENSHIFT_CONSTANTS.CATALOG_HELP_RESOURCES.links.push({
title: 'Blog',
href: 'https://blog.openshift.com'
});확장 스크립트 및 스타일시트 로드 에 설명된 대로 스크립트를 추가합니다.
39.6. 로고 사용자 정의
다음 스타일은 웹 콘솔 헤더의 로고를 변경합니다.
#header-logo {
background-image: url("https://www.example.com/images/logo.png");
width: 190px;
height: 20px;
}example.com URL을 실제 이미지의 URL로 바꾸고 너비와 높이를 조정합니다. 이상적인 높이는 20px 입니다.
39.7. 멤버십 화이트리스트 사용자 정의
멤버십 페이지의 기본 허용 목록에는 admin,basic-user,edit 등과 같은 클러스터 역할의 하위 집합이 표시됩니다. 또한 프로젝트 내에 정의된 사용자 지정 역할을 표시합니다.
예를 들어 사용자 지정 클러스터 역할 세트를 허용 목록에 추가하려면 다음을 수행합니다.
window.OPENSHIFT_CONSTANTS.MEMBERSHIP_WHITELIST = [
"admin",
"basic-user",
"edit",
"system:deployer",
"system:image-builder",
"system:image-puller",
"system:image-pusher",
"view",
"custom-role-1",
"custom-role-2"
];확장 스크립트 및 스타일시트 로드 에 설명된 대로 스크립트를 추가합니다.
39.8. 문서로 링크 변경
외부 설명서 링크는 웹 콘솔의 다양한 섹션에 표시됩니다. 다음 예제에서는 설명서에 대한 제공된 두 링크의 URL을 변경합니다.
window.OPENSHIFT_CONSTANTS.HELP['get_started_cli'] = "https://example.com/doc1.html";
window.OPENSHIFT_CONSTANTS.HELP['basic_cli_operations'] = "https://example.com/doc2.html";또는 모든 문서 링크의 기본 URL을 변경할 수 있습니다.
이 예에서는 기본 도움말 URL https://example.com/docs/welcome/index.html 이 생성됩니다.
window.OPENSHIFT_CONSTANTS.HELP_BASE_URL = "https://example.com/docs/"; - 1
- 경로는
/로 끝나야 합니다.
확장 스크립트 및 스타일시트 로드 에 설명된 대로 스크립트를 추가합니다.
39.9. CLI 다운로드 링크 추가 또는 변경
웹 콘솔의 정보 페이지에서는 CLI(명령줄 인터페이스) 툴에 대한 다운로드 링크를 제공합니다. 이러한 링크는 링크 텍스트와 URL을 모두 제공하여 파일 패키지 또는 실제 패키지를 가리키는 외부 페이지를 가리키도록 선택할 수 있습니다.
예를 들어 다운로드할 수 있는 패키지를 직접 가리키려면 링크 텍스트는 패키지 플랫폼입니다.
window.OPENSHIFT_CONSTANTS.CLI = {
"Linux (32 bits)": "https://<cdn>/openshift-client-tools-linux-32bit.tar.gz",
"Linux (64 bits)": "https://<cdn>/openshift-client-tools-linux-64bit.tar.gz",
"Windows": "https://<cdn>/openshift-client-tools-windows.zip",
"Mac OS X": "https://<cdn>/openshift-client-tools-mac.zip"
};또는 실제 다운로드 패키지를 최신 릴리스 링크 텍스트와 연결하는 페이지를 가리키려면 다음을 수행합니다.
window.OPENSHIFT_CONSTANTS.CLI = {
"Latest Release": "https://<cdn>/openshift-client-tools/latest.html"
};확장 스크립트 및 스타일시트 로드 에 설명된 대로 스크립트를 추가합니다.
39.9.1. 정보 페이지 사용자 정의
웹 콘솔의 사용자 지정 정보 페이지를 제공하려면 다음을 수행합니다.
다음과 같은 확장자를 작성합니다.
angular .module('aboutPageExtension', ['openshiftConsole']) .config(function($routeProvider) { $routeProvider .when('/about', { templateUrl: 'https://example.com/extensions/about/about.html', controller: 'AboutController' }); } ); hawtioPluginLoader.addModule('aboutPageExtension');사용자 지정 템플릿을 작성합니다.
사용 중인 OpenShift Container Platform 릴리스에서 about.html 의 버전에서 시작합니다. 템플릿 내에는 두 개의 angular 범위 변수, 즉
version.master.openshift 및가 있습니다.version.master.kubernetes웹 콘솔에 올바른 CORS(Cross-Origin Resource Sharing) 응답 헤더를 사용하여 URL에서 템플릿을 호스팅합니다.
-
웹 콘솔 도메인에서 요청을 허용하도록
Access-Control-Allow-Origin응답을 설정합니다. -
GET을 포함하도록Access-Control-Allow-Methods를 설정합니다. -
Access-Control-Allow-Headers를Content-Type을 포함하도록 설정합니다.
-
웹 콘솔 도메인에서 요청을 허용하도록
또는 AngularJS $templateCache 를 사용하여 JavaScript에 템플릿을 직접 포함할 수 있습니다.
확장 스크립트 및 스타일시트 로드 에 설명된 대로 스크립트를 추가합니다.
39.11. 기능화된 애플리케이션 구성
웹 콘솔에는 시작 페이지 카탈로그에 주요 애플리케이션 링크 선택 목록이 있습니다. 페이지 상단에 표시되며 아이콘, 제목, 간단한 설명 및 링크를 가질 수 있습니다.
// Add featured applications to the top of the catalog.
window.OPENSHIFT_CONSTANTS.SAAS_OFFERINGS = [{
title: "Dashboard", // The text label
icon: "fa fa-dashboard", // The icon you want to appear
url: "http://example.com/dashboard", // Where to go when this item is clicked
description: "Open application dashboard." // Short description
}, {
title: "System Status",
icon: "fa fa-heartbeat",
url: "http://example.com/status",
description: "View system alerts and outages."
}, {
title: "Manage Account",
icon: "pficon pficon-user",
url: "http://example.com/account",
description: "Update email address or password."
}];확장 스크립트 및 스타일시트 로드 에 설명된 대로 스크립트를 추가합니다.
39.12. 카탈로그 카테고리 구성
카탈로그 카테고리는 웹 콘솔 카탈로그 랜딩 페이지에서 항목 표시를 구성합니다. 각 범주에는 하나 이상의 하위 범주가 있습니다. 일치하는 하위 범주 태그에 나열된 태그가 포함된 경우 빌더 이미지, 템플릿 또는 서비스는 하위 범주로 그룹화되며 항목이 하위 범주로 표시될 수 있습니다. 범주 및 하위 범주는 최소한 하나의 항목이 포함된 경우에만 표시됩니다.
카탈로그 카테고리에 대한 중요한 사용자 정의는 사용자 환경에 영향을 줄 수 있으며 신중하게 고려해야 합니다. 기존 카테고리 항목을 수정하는 경우 향후 업그레이드에서 이 사용자 지정을 업데이트해야 할 수 있습니다.
// Find the Languages category.
var category = _.find(window.OPENSHIFT_CONSTANTS.SERVICE_CATALOG_CATEGORIES,
{ id: 'languages' });
// Add Go as a new subcategory under Languages.
category.subCategories.splice(2,0,{ // Insert at the third spot.
// Required. Must be unique.
id: "go",
// Required.
label: "Go",
// Optional. If specified, defines a unique icon for this item.
icon: "icon-go-gopher",
// Required. Items matching any tag will appear in this subcategory.
tags: [
"go",
"golang"
]
});
// Add a Featured category as the first category tab.
window.OPENSHIFT_CONSTANTS.SERVICE_CATALOG_CATEGORIES.unshift({
// Required. Must be unique.
id: "featured",
// Required
label: "Featured",
subCategories: [
{
// Required. Must be unique.
id: "go",
// Required.
label: "Go",
// Optional. If specified, defines a unique icon for this item.
icon: "icon-go-gopher",
// Required. Items matching any tag will appear in this subcategory.
tags: [
"go",
"golang"
]
},
{
// Required. Must be unique.
id: "jenkins",
// Required.
label: "Jenkins",
// Optional. If specified, defines a unique icon for this item.
icon: "icon-jenkins",
// Required. Items matching any tag will appear in this subcategory.
tags: [
"jenkins"
]
}
]
});확장 스크립트 및 스타일시트 로드 에 설명된 대로 스크립트를 추가합니다.
39.13. 할당량 알림 메시지 구성
사용자가 할당량에 도달할 때마다 할당량 알림이 notification drawer로 전송됩니다. 할당량 리소스 유형별로 사용자 지정 할당량 알림 메시지를 알림에 추가할 수 있습니다. 예를 들면 다음과 같습니다.
Your project is over quota. It is using 200% of 2 cores CPU (Limit). Upgrade
to <a href='https://www.openshift.com'>OpenShift Online Pro</a> if you need
additional resources."Upgrade to…"알림의 일부는 사용자 지정 메시지이며 추가 리소스에 대한 링크와 같은 HTML을 포함할 수 있습니다.
할당량 메시지가 HTML 마크업이므로 모든 특수 문자가 HTML에 대해 올바르게 이스케이프되어야 합니다.
확장 스크립트에서 window.OPENSHIFT_CONSTANTS.QUOTA_NOTIFICATION_MESSAGE 속성을 설정하여 각 리소스에 대한 메시지를 사용자 지정합니다.
// Set custom notification messages per quota type/key
window.OPENSHIFT_CONSTANTS.QUOTA_NOTIFICATION_MESSAGE = {
'pods': 'Upgrade to <a href="https://www.openshift.com">OpenShift Online Pro</a> if you need additional resources.',
'limits.memory': 'Upgrade to <a href="https://www.openshift.com">OpenShift Online Pro</a> if you need additional resources.'
};확장 스크립트 및 스타일시트 로드 에 설명된 대로 스크립트를 추가합니다.
39.14. URL 네임스페이스 화이트리스트에서 생성 구성
URL에서 생성 은 OPENSHIFT_CONSTANTS.CREATE_FROM_URL_WHITELIST 에 명시적으로 지정된 네임스페이스에서 이미지 스트림 또는 템플릿에서만 작동합니다. 허용 목록에 네임스페이스를 추가하려면 다음 단계를 따르십시오.
OpenShift 는 기본적으로 화이트리스트에 포함되어 있습니다. 제거하지 마십시오.
// Add a namespace containing the image streams and/or templates
window.OPENSHIFT_CONSTANTS.CREATE_FROM_URL_WHITELIST.push(
'shared-stuff'
);확장 스크립트 및 스타일시트 로드 에 설명된 대로 스크립트를 추가합니다.
39.15. 복사 로그인 명령 비활성화
웹 콘솔을 사용하면 현재 액세스 토큰을 포함한 로그인 명령을 사용자 메뉴 및 명령줄 도구 페이지의 클립보드로 복사할 수 있습니다. 이 기능은 사용자의 액세스 토큰이 복사된 명령에 포함되지 않도록 변경할 수 있습니다.
// Do not copy the user's access token in the copy login command.
window.OPENSHIFT_CONSTANTS.DISABLE_COPY_LOGIN_COMMAND = true;확장 스크립트 및 스타일시트 로드 에 설명된 대로 스크립트를 추가합니다.
39.15.1. 와일드카드 경로 활성화
라우터에 와일드카드 경로를 활성화한 경우 웹 콘솔에서 와일드카드 경로를 활성화할 수도 있습니다. 이를 통해 사용자는 경로를 생성할 때 *.example.com 과 같은 별표로 시작하는 호스트 이름을 입력할 수 있습니다. 와일드카드 경로를 활성화하려면 다음을 수행합니다.
window.OPENSHIFT_CONSTANTS.DISABLE_WILDCARD_ROUTES = false;확장 스크립트 및 스타일시트 로드 에 설명된 대로 스크립트를 추가합니다.
39.16. 로그인 페이지 사용자 정의
웹 콘솔의 로그인 페이지와 로그인 공급자 선택 페이지를 변경할 수도 있습니다. 다음 명령을 실행하여 수정할 수 있는 템플릿을 만듭니다.
$ oc adm create-login-template > login-template.html
$ oc adm create-provider-selection-template > provider-selection-template.html파일을 편집하여 스타일을 변경하거나 콘텐츠를 추가하지만 중괄호 내에서 필수 매개 변수를 제거하지 않도록 주의하십시오.
사용자 정의 로그인 페이지 또는 공급자 선택 페이지를 사용하려면 마스터 구성 파일에서 다음 옵션을 설정합니다.
oauthConfig:
...
templates:
login: /path/to/login-template.html
providerSelection: /path/to/provider-selection-template.html상대 경로는 마스터 구성 파일을 기준으로 확인합니다. 이 구성을 변경한 후 서버를 다시 시작해야 합니다.
로그인 공급자가 여러 개 구성되어 있거나 master-config.yaml 파일의 alwaysshowProviderSelection 옵션이 true 로 설정된 경우 사용자의 토큰이 OpenShift Container Platform에 만료될 때마다 사용자에게 다른 작업을 진행하기 전에 이 사용자 지정 페이지가 표시됩니다.
39.16.1. 사용 예
사용자 정의 로그인 페이지를 사용하여 서비스 약관 정보를 작성할 수 있습니다. 또한 GitHub 또는 Google과 같은 타사 로그인 공급자를 사용하여 인증 프로바이더로 리디렉션되기 전에 신뢰하는 브랜드 페이지를 사용자에게 표시하는 데 유용할 수 있습니다.
39.17. OAuth 오류 페이지 사용자 정의
인증 중에 오류가 발생하면 표시된 페이지를 변경할 수 있습니다.
다음 명령을 실행하여 수정할 수 있는 템플릿을 생성합니다.
$ oc adm create-error-template > error-template.html파일을 편집하여 스타일을 변경하거나 내용을 추가합니다.
템플릿에서
Error(오류) 및 ErrorCode(오류 코드) 변수를 사용할 수 있습니다. 사용자 정의 오류 페이지를 사용하려면 마스터 구성 파일에서 다음 옵션을 설정합니다.oauthConfig: ... templates: error: /path/to/error-template.html상대 경로는 마스터 구성 파일을 기준으로 확인합니다.
- 이 구성을 변경한 후 서버를 다시 시작해야 합니다.
39.18. 로그아웃 URL 변경
webconsole-config ConfigMap에서 clusterInfo.logoutPublicURL 매개변수를 수정하여 콘솔 사용자가 콘솔에서 로그아웃할 때 전송되는 위치를 변경할 수 있습니다.
$ oc edit configmap/webconsole-config -n openshift-web-console
다음은 로그 아웃 URL을 https://www.example.com/logout로 변경하는 예입니다.:
apiVersion: v1
kind: ConfigMap
data:
webconsole-config.yaml: |
apiVersion: webconsole.config.openshift.io/v1
clusterInfo:
[...]
logoutPublicURL: "https://www.example.com/logout"
[...]이는 Single Sign-On 세션을 삭제하기 위해 외부 URL을 방문해야 하는 Request Header 및 OAuth 또는 OpenID ID 공급자로 인증할 때 유용할 수 있습니다.
39.19. Ansible을 사용하여 웹 콘솔 사용자 지정 구성
클러스터 설치 중에 인벤토리 파일에서 구성할 수 있는 다음 매개 변수를 사용하여 웹 콘솔에 대한 많은 수정 사항을 구성할 수 있습니다.
Ansible을 사용하여 웹 콘솔 사용자 지정 예
# Configure `clusterInfo.logoutPublicURL` in the web console configuration
# See: https://docs.openshift.com/enterprise/latest/install_config/web_console_customization.html#changing-the-logout-url
#openshift_master_logout_url=https://example.com/logout
# Configure extension scripts for web console customization
# See: https://docs.openshift.com/enterprise/latest/install_config/web_console_customization.html#loading-custom-scripts-and-stylesheets
#openshift_web_console_extension_script_urls=['https://example.com/scripts/menu-customization.js','https://example.com/scripts/nav-customization.js']
# Configure extension stylesheets for web console customization
# See: https://docs.openshift.com/enterprise/latest/install_config/web_console_customization.html#loading-custom-scripts-and-stylesheets
#openshift_web_console_extension_stylesheet_urls=['https://example.com/styles/logo.css','https://example.com/styles/custom-styles.css']
# Configure a custom login template in the master config
# See: https://docs.openshift.com/enterprise/latest/install_config/web_console_customization.html#customizing-the-login-page
#openshift_master_oauth_templates={'login': '/path/to/login-template.html'}
# Configure `clusterInfo.metricsPublicURL` in the web console configuration for cluster metrics. Ansible is also able to configure metrics for you.
# See: https://docs.openshift.com/enterprise/latest/install_config/cluster_metrics.html
#openshift_master_metrics_public_url=https://hawkular-metrics.example.com/hawkular/metrics
# Configure `clusterInfo.loggingPublicURL` in the web console configuration for aggregate logging. Ansible is also able to install logging for you.
# See: https://docs.openshift.com/enterprise/latest/install_config/aggregate_logging.html
#openshift_master_logging_public_url=https://kibana.example.com39.20. 웹 콘솔 URL 포트 및 인증서 변경
사용자가 웹 콘솔 URL에 액세스할 때 사용자 정의 인증서가 제공되도록 하려면 인증서와 URL을 master-config.yaml 파일의 namedCertificates 섹션에 추가합니다. 자세한 내용은 웹 콘솔 또는 CLI에 대한 사용자 정의 인증서 구성을 참조하십시오.
웹 콘솔의 리디렉션 URL을 설정하거나 수정하려면 openshift-web-console oauthclient를 수정합니다.
$ oc edit oauthclient openshift-web-console
사용자가 올바르게 리디렉션되도록 하려면 openshift-web-console configmap 의 PublicUrls 를 업데이트합니다.
$ oc edit configmap/webconsole-config -n openshift-web-console
그런 다음 consolePublicURL 의 값을 업데이트합니다.
40장. 외부 영구 볼륨 프로비저너 배포
40.1. 개요
OpenShift Container Platform에서 AWS EFS의 외부 프로비저너는 기술 프리뷰 기능입니다. 기술 프리뷰 기능은 Red Hat 프로덕션 서비스 수준 계약(SLA)에서 지원되지 않으며 기능적으로 완전하지 않을 수 있으며 프로덕션에 사용하지 않는 것이 좋습니다. 이러한 기능을 사용하면 향후 제품 기능을 조기에 이용할 수 있어 개발 과정에서 고객이 기능을 테스트하고 피드백을 제공할 수 있습니다. 자세한 내용은 Red Hat 기술 프리뷰 기능 지원 범위를 참조하십시오.
외부 프로비저너는 특정 스토리지 프로바이더에 대해 동적 프로비저닝을 활성화하는 애플리케이션입니다. 외부 프로비저너는 OpenShift Container Platform에서 제공하는 프로비저너 플러그인과 함께 실행할 수 있으며 동적 프로비저닝 및 스토리지 클래스 생성 섹션에 설명된 대로 StorageClass 오브젝트가 구성되는 것과 유사한 방식으로 구성됩니다. 이러한 프로비저너는 외부에 있기 때문에 OpenShift Container Platform과 독립적으로 배포 및 업데이트할 수 있습니다.
40.2. 시작하기 전
Ansible 플레이북은 외부 배포 프로그램을 배포하고 업그레이드할 수도 있습니다.
계속 진행하기 전에 클러스터 지표 구성 및 클러스터 로깅 구성 섹션을 숙지합니다.
40.2.1. 외부 배포자 Ansible 역할
OpenShift Ansible openshift_provisioners 역할은 Ansible 인벤토리 파일의 변수를 사용하여 외부 배포 프로그램을 구성하고 배포합니다. 각 설치 변수를 true 로 재정의하여 설치할 프로비저너 를 지정해야 합니다.
40.2.2. 외부 프로비저너 Ansible 변수
다음은 설치 변수가 true 인 모든 프로비저너에 적용되는 역할 변수 목록입니다.
| Variable | 설명 |
|---|---|
|
|
|
|
|
구성 요소 이미지의 접두사입니다. 예를 들어 defaults를 |
|
|
구성 요소 이미지의 버전입니다. 예를 들어 |
|
|
프로비저너를 배포할 프로젝트입니다. 기본값은 |
40.2.3. AWS EFS 프로비저너 Ansible 변수
AWS EFS 프로비저너는 지정된 EFS 파일 시스템의 디렉터리에 동적으로 생성된 디렉터리가 지원하는 NFS PV 를 동적으로 프로비저닝합니다. AWS EFS Provisioner Ansible 변수를 구성하려면 다음 요구 사항을 충족해야 합니다.
- AmazonElasticFileSystemReadOnlyAccess 정책으로 할당된 IAM 사용자.
- 클러스터 리전의 EFS 파일 시스템입니다.
- 모든 노드(클러스터 리전의 모든 영역에서)가 파일 시스템 DNS 이름으로 EFS 파일 시스템을 마운트할 수 있도록 대상 및 보안 그룹을 마운트합니다.
| Variable | 설명 |
|---|---|
|
|
EFS 파일 시스템의 파일 시스템 ID (예: |
|
| EFS 파일 시스템의 Amazon EC2 리전입니다. |
|
| IAM 사용자의 AWS 액세스 키입니다(지정한 EFS 파일 시스템이 있는지 확인하기 위해). |
|
| IAM 사용자의 AWS 시크릿 액세스 키(지정된 EFS 파일 시스템이 있는지 확인하기 위해). |
| Variable | 설명 |
|---|---|
|
|
|
|
|
EFS 프로비저너가 생성한 각 PV를 백업할 디렉터리를 생성하는 EFS 파일 시스템의 디렉터리 경로입니다. EFS 프로비저너에서 존재하고 마운트할 수 있어야 합니다. 기본값은 |
|
|
StorageClasses 가 지정하는 |
|
|
포드가 배치될 노드를 선택하는 라벨 맵입니다. 예: |
|
|
EFS 파일 시스템에 쓰기 권한이 필요한 경우 포드를 제공하는 보조 그룹입니다. 기본값은 |
40.3. 프로비저너 배포
OpenShift Ansible 변수에 지정된 구성에 따라 한 번에 모든 배포 프로그램을 한 번에 하나씩 배포할 수 있습니다. 다음 예제에서는 지정된 프로비저너를 배포한 다음 해당 StorageClass 를 생성 및 구성하는 방법을 보여줍니다.
40.3.1. AWS EFS 프로비저너 배포
다음 명령은 EFS 볼륨의 디렉터리를 /data/persistentvolumes 로 설정합니다. 이 디렉터리는 파일 시스템에 있어야 하며 프로비저너 Pod에서 마운트하고 쓸 수 있어야 합니다. 플레이북 디렉터리로 변경하고 다음 플레이북을 실행합니다.
$ cd /usr/share/ansible/openshift-ansible
$ ansible-playbook -v -i <inventory_file> \
playbooks/openshift-provisioners/config.yml \
-e openshift_provisioners_install_provisioners=True \
-e openshift_provisioners_efs=True \
-e openshift_provisioners_efs_fsid=fs-47a2c22e \
-e openshift_provisioners_efs_region=us-west-2 \
-e openshift_provisioners_efs_aws_access_key_id=AKIAIOSFODNN7EXAMPLE \
-e openshift_provisioners_efs_aws_secret_access_key=wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY \
-e openshift_provisioners_efs_path=/data/persistentvolumes40.3.1.1. AWS EFS 오브젝트 정의
aws-efs-storageclass.yaml
kind: StorageClass
apiVersion: storage.k8s.io/v1beta1
metadata:
name: slow
provisioner: openshift.org/aws-efs
parameters:
gidMin: "40000"
gidMax: "50000"
동적으로 프로비저닝된 각 NFS 디렉터리에는 gidMin - gidMax 범위의 고유한 GID 소유자가 할당됩니다. 지정하지 않으면 gidMin 의 기본값은 2000 이고 gidMax 의 기본값은 2147483647 입니다. 클레임을 통해 프로비저닝된 볼륨을 사용하는 모든 Pod는 필요한 GID를 보충 그룹으로 자동 실행하며 볼륨에 읽고 쓸 수 있습니다. 보조 그룹(root로 실행 중이지 않음)이 없는 기타 마운터는 볼륨에 읽거나 쓸 수 없습니다. NFS 액세스를 관리하는 추가 그룹을 사용하는 방법에 대한 자세한 내용은 NFS 볼륨 보안 주제의 그룹 ID 섹션을 참조하십시오.
40.4. 정리
다음 명령을 실행하여 OpenShift Ansible openshift_provisioners 역할에서 배포한 모든 항목을 제거할 수 있습니다.
$ cd /usr/share/ansible/openshift-ansible
$ ansible-playbook -v -i <inventory_file> \
playbooks/openshift-provisioners/config.yml \
-e openshift_provisioners_install_provisioners=False41장. Operator 프레임워크 설치(기술 프리뷰)
Red Hat은 Operator라는 Kubernetes 네이티브 애플리케이션을 보다 효율적이고 자동화하며 확장 가능한 방식으로 관리하도록 설계된 오픈 소스 툴킷인 Operator Framework 를 발표했습니다.
다음 섹션에서는 클러스터 관리자로 OpenShift Container Platform 3.11에서 Technology Preview Operator Framework를 수행하는 데 필요한 지침을 제공합니다.
Operator 프레임워크는 기술 프리뷰 기능입니다. 기술 프리뷰 기능은 Red Hat 프로덕션 서비스 수준 계약(SLA)에서 지원하지 않으며, 기능상 완전하지 않을 수 있어 프로덕션에 사용하지 않는 것이 좋습니다. 이러한 기능을 사용하면 향후 제품 기능을 조기에 이용할 수 있어 개발 과정에서 고객이 기능을 테스트하고 피드백을 제공할 수 있습니다.
Red Hat 기술 프리뷰 기능 지원 범위에 대한 자세한 내용은 https://access.redhat.com/support/offerings/techpreview/를 참조하십시오.
41.1. 기술 프리뷰란 무엇입니까?
Technology Preview Operator Framework는 클러스터 관리자가 OpenShift Container Platform 클러스터에서 실행되는 Operator에 대한 액세스 권한을 설치, 업그레이드 및 부여하는 데 도움이 되는 OLM(Operator Lifecycle Manager) 을 설치합니다.
OpenShift Container Platform 웹 콘솔은 클러스터 관리자가 Operator를 설치할 수 있도록 새 관리 화면과 클러스터에서 사용 가능한 Operator 카탈로그를 사용할 수 있는 액세스 권한을 특정 프로젝트에 부여합니다.
개발자의 경우 분야별 전문가가 아니어도 셀프서비스 경험을 통해 데이터베이스, 모니터링, 빅 데이터 서비스의 인스턴스를 프로비저닝하고 구성할 수 있습니다. Operator에서 해당 지식을 제공하기 때문입니다.
그림 41.1. Operator 카탈로그 소스
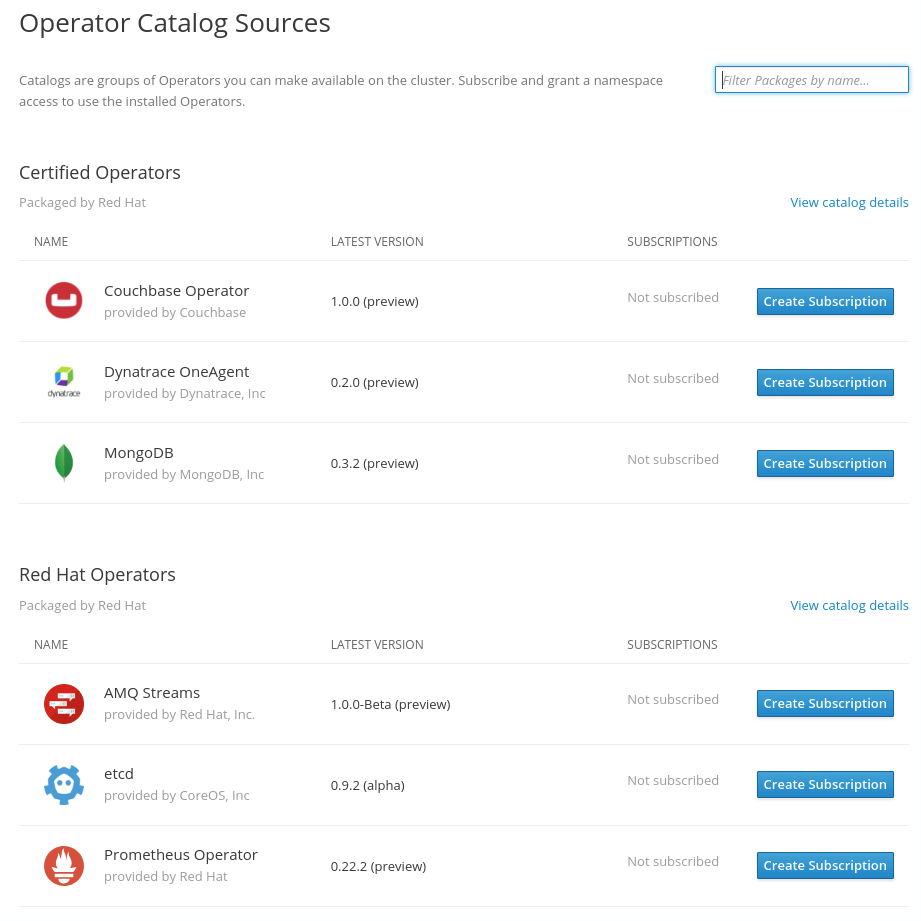
스크린샷은 주요 소프트웨어 벤더에서 파트너 Operator의 사전 로드된 카탈로그 소스를 볼 수 있습니다.
- Couchbase Operator
- Couchbase는 관계형 데이터베이스에 사용된 표형 관계를 제외하고 모델링된 데이터의 저장 및 검색을 위한 메커니즘을 제공하는 NoSQL 데이터베이스를 제공합니다. OpenShift Container Platform 3.11에서 Couchbase에서 지원하는 개발자 프리뷰로 사용할 수 있는 Operator를 사용하면 OpenShift Container Platform에서 기본적으로 Couchbase 배포를 실행할 수 있습니다. NoSQL 클러스터를 설치하고 보다 효율적으로 장애 조치할 수 있습니다.
- 기본값은trace Operator입니다.
- trace 애플리케이션 모니터링은 실시간으로 성능 지표를 제공하며 문제를 자동으로 탐지하고 진단하는 데 도움이 될 수 있습니다. Operator는 컨테이너 중심 모니터링 스택을 더 쉽게 설치하고 해당 스택을trace 모니터링 클라우드에 다시 연결하여 사용자 정의 리소스를 모니터링하고 원하는 상태를 지속적으로 모니터링합니다.
- MongoDB Operator
- MongoDB는 JSON과 같은 유연한 문서에 데이터를 저장하는 분산 트랜잭션 데이터베이스입니다. Operator는 프로덕션 가능 복제본 세트와 분할된 클러스터와 독립 실행형 dev/test 인스턴스를 모두 배포할 수 있습니다. MongoDB Ops Manager와 함께 작동하므로 모든 클러스터가 운영 모범 사례에 따라 배포됩니다.
또한 다음과 같은 Red Hat 제공 Operator가 포함되어 있습니다.
- Red Hat AMQ Streams Operator
- Red Hat AMQ Streams는 Apache Kafka 프로젝트를 기반으로 하는 대규모 확장이 가능한 분산형 고성능 데이터 스트리밍 플랫폼입니다. 마이크로 서비스 및 기타 애플리케이션에서 매우 높은 처리량과 매우 짧은 대기 시간으로 데이터를 공유할 수 있는 분산 백본을 제공합니다.
- etcd Operator
- etcd는 머신 클러스터 전체에 데이터를 저장할 수 있는 안정적인 방법을 제공하는 분산형 키-값 저장소입니다. 이 Operator를 사용하면 etcd 클러스터를 생성, 구성 및 관리하는 간단한 선언적 구성을 사용하여 etcd의 복잡성을 구성하고 관리할 수 있습니다.
- Prometheus Operator
- Prometheus는 70%F 내의 Kubernetes와 공동 호스팅되는 클라우드 네이티브 모니터링 시스템입니다. 이 Operator에는 생성/삭제, 간단한 구성, 레이블을 통한 모니터링 대상 구성의 자동 생성 등의 일반적인 작업을 처리하는 애플리케이션 도메인 지식이 포함되어 있습니다.
41.2. Ansible을 사용하여 Operator Lifecycle Manager 설치
클러스터를 설치한 후 Technology Preview Operator Framework를 설치하려면 OpenShift Container Platform openshift-ansible 설치 프로그램에서 포함된 플레이북을 사용할 수 있습니다.
또는 초기 클러스터 설치 중에 Technology Preview Operator Framework를 설치할 수 있습니다. 별도의 지침은 인벤토리 파일 구성을 참조하십시오.
사전 요구 사항
- 기존 OpenShift Container Platform 3.11 클러스터
-
cluster
-admin 권한이 있는 계정을 사용하여 클러스터에대한 액세스 -
최신
openshift-ansible설치 프로그램에서 제공하는 Ansible 플레이북
절차
OpenShift Container Platform 클러스터를 설치하고 관리하는 데 사용되는 인벤토리 파일에서
[OSEv3:vars]섹션에openshift_additional_registry_credentials변수를 추가하고 Operator 컨테이너를 가져오는 데 필요한 인증 정보를 설정합니다.openshift_additional_registry_credentials=[{'host':'registry.connect.redhat.com','user':'<your_user_name>','password':'<your_password>','test_image':'mongodb/enterprise-operator:0.3.2'}]https://access.redhat.com 에서 Red Hat 고객 포털에 로그인하는 데 사용하는 자격 증명으로
사용자및암호를설정합니다.test_image는 제공한 자격 증명을 테스트하는 데 사용할 이미지를 나타냅니다.플레이북 디렉터리로 변경하고 인벤토리 파일을 사용하여 레지스트리 권한 부여 플레이북을 실행하여 이전 단계의 자격 증명을 사용하여 노드를 인증합니다.
$ cd /usr/share/ansible/openshift-ansible $ ansible-playbook -i <inventory_file> \ playbooks/updates/registry_auth.yml플레이북 디렉터리로 변경하고 인벤토리 파일을 사용하여 OLM 설치 플레이북을 실행합니다.
$ cd /usr/share/ansible/openshift-ansible $ ansible-playbook -i <inventory_file> \ playbooks/olm/config.yml브라우저를 사용하여 클러스터의 웹 콘솔로 이동합니다. 이제 페이지 왼쪽에 있는 탐색에서 새 섹션을 사용할 수 있어야 합니다.
그림 41.2. 새 Operator 탐색 섹션
여기에서 Operator를 설치하고 프로젝트에 대한 액세스 권한을 부여한 다음 모든 환경에 대한 인스턴스를 시작할 수 있습니다.
41.3. 첫 번째 Operator 시작
이 섹션에서는 Couchbase Operator를 사용하여 새 Couchbase 클러스터를 생성하는 방법을 안내합니다.
사전 요구 사항
- 기술 프리뷰 OLM이 활성화된 OpenShift Container Platform 3.11
-
cluster
-admin 권한이 있는 계정을 사용하여 클러스터에대한 액세스 - Couchbase Operator가 Operator 카탈로그에 로드(기본적으로 기술 프리뷰 OLM을 사용하여 로드됨)
절차
-
클러스터 관리자(cluster
-admin역할의 사용자)로 이 절차를 위해 OpenShift Container Platform 웹 콘솔에 새 프로젝트를 생성합니다. 이 예에서는 couchbase-test 라는 프로젝트를 사용합니다. 프로젝트 내에서 Operator 설치는 Subscription 오브젝트를 통해 수행됩니다. 이 오브젝트는 클러스터 관리자가 전체 클러스터에서 생성하고 관리할 수 있습니다. 사용 가능한 서브스크립션을 보려면 드롭다운 메뉴에서 클러스터 콘솔로 이동한 다음 왼쪽 탐색의 Operator → Catalog Sources 화면으로 이동합니다.
참고프로젝트에서 서브스크립션을 보고, 만들고, 관리할 수 있도록 추가 사용자를 활성화하려면 해당 프로젝트에 대한
admin및view역할과operator-lifecycle-manager프로젝트에 대한view역할이 있어야 합니다. 클러스터 관리자는 다음 명령을 사용하여 이러한 역할을 추가할 수 있습니다.$ oc policy add-role-to-user admin <user> -n <target_project> $ oc policy add-role-to-user view <user> -n <target_project> $ oc policy add-role-to-user view <user> -n operator-lifecycle-manager이 환경은 OLM의 향후 릴리스에서 간소화될 예정입니다.
웹 콘솔 또는 CLI에서 Couchbase 카탈로그 소스에 원하는 프로젝트를 등록합니다.
다음 방법 중 하나를 선택합니다.
- 웹 콘솔 방법의 경우 원하는 프로젝트가 표시되는지 확인하고 이 화면에서 Create Subscription on an Operator를 클릭하여 프로젝트에 설치합니다.
CLI 메서드의 경우 다음 정의를 사용하여 YAML 파일을 생성합니다.
couchbase-subscription.yaml 파일
apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: generateName: couchbase-enterprise- namespace: couchbase-test1 spec: source: certified-operators name: couchbase-enterprise startingCSV: couchbase-operator.v1.0.0 channel: preview- 1
metadata섹션의namespace필드가 원하는 프로젝트로 설정되어 있는지 확인합니다.
그런 다음 CLI를 사용하여 서브스크립션을 생성합니다.
$ oc create -f couchbase-subscription.yaml
서브스크립션이 생성되면 카탈로그 사용자가 Operator에서 제공한 소프트웨어를 시작하는 데 사용할 수 있는 Cluster Service Versions (클러스터 서비스 버전) 화면에 표시됩니다. 이 Operator의 기능에 대한 자세한 내용을 보려면 Couchbase Operator를 클릭합니다.
그림 41.3. Couchbase Operator 개요
Couchbase 클러스터를 만들기 전에 수퍼 사용자 계정에 대한 자격 증명을 보유한 웹 콘솔 또는 CLI를 사용하여 다음 정의로 시크릿을 생성합니다. Operator는 시작 시 이를 읽고 다음 세부 사항을 사용하여 데이터베이스를 구성합니다.
Couchbase 시크릿
apiVersion: v1 kind: Secret metadata: name: couchbase-admin-creds namespace: couchbase-test1 type: Opaque stringData: username: admin password: password- 1
metadata섹션의namespace필드가 원하는 프로젝트로 설정되어 있는지 확인합니다.
다음 방법 중 하나를 선택합니다.
- 웹 콘솔 방법의 경우 왼쪽 탐색에서 워크로드 → 시크릿 을 클릭한 다음 생성을 클릭하고 YAML에서 Secret 을 선택하여 시크릿 정의를 입력합니다.
CLI 메서드의 경우 시크릿 정의를 YAML 파일(예: couchbase-secret.yaml)에 저장하고 CLI를 사용하여 원하는 프로젝트에서 생성합니다.
$ oc create -f couchbase-secret.yaml
새 Couchbase 클러스터를 만듭니다.
참고지정된 프로젝트에서
edit역할을 가진 모든 사용자는 클라우드 서비스와 마찬가지로 셀프 서비스 방식으로 프로젝트에 이미 설치된 Operator가 관리하는 애플리케이션 인스턴스(이 예에서는 Couchbase 클러스터)를 생성, 관리 및 삭제할 수 있습니다. 이 기능을 사용하여 추가 사용자를 활성화하려면 클러스터 관리자가 다음 명령을 사용하여 역할을 추가할 수 있습니다.$ oc policy add-role-to-user edit <user> -n <target_project>웹 콘솔의 Cluster Service Versions (클러스터 서비스 버전) 섹션에서 Operator의 Overview (개요) 화면에서 Create Couchbase Operator를 클릭하여 새
CouchbaseCluster오브젝트 생성을 시작합니다. 이 오브젝트는 클러스터에서 Operator를 사용할 수 있는 새로운 유형입니다. 이 오브젝트는 내장된Deployment또는ReplicaSet오브젝트와 유사하지만 Couchbase 관리와 관련된 논리를 포함합니다.작은 정보Create Couchbase Operator 단추를 클릭하면 처음으로 404 오류가 표시될 수 있습니다. 이는 알려진 문제입니다. 해결 방법으로 이 페이지를 새로 고쳐 계속합니다. (BZ#1609731)
웹 콘솔에는 최소 시작 템플릿이 포함되어 있지만 Operator 에서 지원하는 모든 기능에 대한 Couchbase 문서를 읽을 수 있습니다.
그림 41.4. Couchbase 클러스터 생성

관리자인증 정보가 포함된 보안 이름을 구성해야 합니다.apiVersion: couchbase.com/v1 kind: CouchbaseCluster metadata: name: cb-example namespace: couchbase-test spec: authSecret: couchbase-admin-creds baseImage: registry.connect.redhat.com/couchbase/server [...]- 오브젝트 정의를 완료하면 웹 콘솔에서 Create(생성 )를 클릭하거나 CLI를 사용하여 오브젝트를 생성합니다. 그러면 Operator에서 Couchbase 클러스터의 Pod, 서비스 및 기타 구성 요소를 시작합니다.
이제 Operator에서 자동으로 생성 및 구성하는 여러 리소스가 프로젝트에 포함됩니다.
그림 41.5. Couchbase 클러스터 세부 정보
Resources(리소스 ) 탭을 클릭하여 프로젝트의 다른 포드에서 데이터베이스에 액세스할 수 있는 Kubernetes 서비스가 생성되었는지 확인합니다.
cb-example서비스를 사용하여 시크릿에 저장된 자격 증명을 사용하여 데이터베이스에 연결할 수 있습니다. 다른 애플리케이션 포드는 이 시크릿을 마운트 및 사용할 수 있으며 서비스와 통신할 수 있습니다.
이제 Pod가 비정상 상태가 되거나 클러스터의 노드 간에 마이그레이션될 때 오류에 반응하고 데이터를 리밸런싱할 Couchbase의 내결함성 설치가 있습니다. 가장 중요한 것은 클러스터 관리자 또는 개발자가 고급 구성을 제공하여 이 데이터베이스 클러스터를 쉽게 가져올 수 있다는 점입니다. Couchbase 클러스터링 또는 페일오버의 미묘한 지식이 필요하지 않습니다.
공식 Couchbase 설명서에서 Couchbase Autonomous Operator의 기능에 대해 자세히 알아보십시오.
41.4. 참여하기
OpenShift 팀은 Operator 프레임워크를 사용한 경험과 Operator로 제공될 서비스 제안에 대한 제안을 듣고자 합니다.
mailto:openshift-operators@redhat.com 로 이메일을 보내 팀에 문의할 수 있습니다.
42장. Operator Lifecycle Manager 설치 제거
클러스터를 설치한 후 OpenShift Container Platform openshift-ansible 설치 프로그램을 사용하여 Operator Lifecycle Manager를 제거할 수 있습니다.
42.1. Ansible을 사용하여 Operator Lifecycle Manager 설치 제거
클러스터를 설치한 후 OpenShift Container Platform openshift-ansible 설치 프로그램과 함께 이 절차를 사용하여 Technology Preview Operator 프레임워크를 제거할 수 있습니다.
Technology Preview Operator Framework를 설치 제거하려면 먼저 다음 사전 요구 사항을 확인해야 합니다.
- 기존 OpenShift Container Platform 3.11 클러스터
-
cluster
-admin 권한이 있는 계정을 사용하여 클러스터에대한 액세스 최신
openshift-ansible설치 프로그램에서 제공하는 Ansible 플레이북config.yml플레이북에 다음 변수를 추가합니다.operator_lifecycle_manager_install=false operator_lifecycle_manager_remove=true플레이북 디렉터리로 변경합니다.
$ cd /usr/share/ansible/openshift-ansible인벤토리 파일을 사용하여 OLM 설치 플레이북을 실행하여 OLM을 제거합니다.
$ ansible-playbook -i <inventory_file> playbooks/olm/config.yml