설치 후 구성
OpenShift Container Platform의 Day 2 운영
초록
1장. 설치 후 구성 개요
OpenShift Container Platform을 설치하면 클러스터 관리자가 다음 구성 요소를 구성하고 사용자 정의할 수 있습니다.
- 머신
- 베어 메탈
- Cluster
- 노드
- 네트워크
- 스토리지
- 사용자
- 경고 및 알림
1.1. 설치 후 구성 작업
설치 후 구성 작업을 수행하여 요구 사항에 맞게 환경을 구성할 수 있습니다.
다음은 이러한 구성에 대한 세부 정보입니다.
-
운영 체제 기능 구성: MCO(Machine Config Operator)는
MachineConfig오브젝트를 관리합니다. MCO를 사용하면 노드 및 사용자 정의 리소스를 구성할 수 있습니다. 베어 메탈 노드 구성: Bare Metal Operator(BMO)를 사용하여 베어 메탈 호스트를 관리할 수 있습니다. BMO는 다음 작업을 완료할 수 있습니다.
- 호스트의 하드웨어 세부 정보를 검사하고 베어 메탈 호스트에 보고합니다.
- 펌웨어를 검사하고 BIOS 설정을 구성합니다.
- 원하는 이미지로 호스트를 프로비저닝합니다.
- 호스트를 프로비저닝하기 전이나 후에 호스트의 디스크 콘텐츠를 정리합니다.
클러스터 기능을 구성합니다. OpenShift Container Platform 클러스터의 다음 기능을 수정할 수 있습니다.
- 이미지 레지스트리
- 네트워킹 구성
- 이미지 빌드 동작
- ID 공급자
- etcd 구성
- 워크로드를 처리할 머신 세트 생성
- 클라우드 공급자 인증 정보 관리
프라이빗 클러스터 구성: 기본적으로 설치 프로그램은 공개적으로 액세스 가능한 DNS 및 끝점을 사용하여 OpenShift Container Platform을 프로비저닝합니다. 내부 네트워크 내에서만 클러스터에 액세스할 수 있도록 하려면 다음 구성 요소를 구성하여 비공개로 설정합니다.
- DNS
- Ingress 컨트롤러
- API 서버
노드 작업 수행: 기본적으로 OpenShift Container Platform은 RHCOS(Red Hat Enterprise Linux CoreOS) 컴퓨팅 머신을 사용합니다. 다음 노드 작업을 수행할 수 있습니다.
- 컴퓨팅 시스템을 추가하고 제거합니다.
- 테인트 및 허용 오차를 추가하고 제거합니다.
- 노드당 최대 Pod 수를 구성합니다.
- 장치 관리자를 활성화합니다.
- 사용자 구성: OAuth 액세스 토큰을 구성하면 사용자가 API에 자신을 인증할 수 있습니다. 다음 작업을 수행하도록 OAuth를 구성할 수 있습니다.
- ID 공급자 지정
- 역할 기반 액세스 제어를 사용하여 사용자에게 권한 정의 및 제공
- OperatorHub에서 Operator 설치
- 경고 알림 구성: 기본적으로 웹 콘솔의 경고 UI에 실행 경고가 표시됩니다. 경고 알림을 외부 시스템으로 보내도록 OpenShift Container Platform을 구성할 수도 있습니다.
2장. 프라이빗 클러스터 설정
OpenShift Container Platform 버전 4.13 클러스터를 설치한 후 일부 핵심 구성 요소를 프라이빗으로 설정할 수 있습니다.
2.1. 프라이빗 클러스터 정보
기본적으로 OpenShift Container Platform은 공개적으로 액세스 가능한 DNS 및 엔드 포인트를 사용하여 프로비저닝됩니다. 프라이빗 클러스터를 배포한 후 DNS, Ingress 컨트롤러 및 API 서버를 프라이빗으로 설정할 수 있습니다.
클러스터에 퍼블릭 서브넷이 있는 경우 관리자가 생성한 로드 밸런서 서비스에 공개적으로 액세스할 수 있습니다. 클러스터 보안을 보장하기 위해 이러한 서비스에 명시적으로 주석이 지정되었는지 확인합니다.
DNS
설치 프로그램이 프로비저닝한 인프라에 OpenShift Container Platform을 설치하는 경우 설치 프로그램은 기존 퍼블릭 영역에 레코드를 만들고 가능한 경우 클러스터 자체 DNS 확인을 위한 프라이빗 영역을 만듭니다. 퍼블릭 영역과 프라이빗 영역 모두에서 설치 프로그램 또는 클러스터는 API 서버에 대한 * .apps, Ingress 개체, api의 DNS 항목을 만듭니다.
퍼블릭 영역과 프라이빗 영역의 * .apps 레코드는 동일하므로 퍼블릭 영역을 삭제하면 프라이빗 영역이 클러스터에 대한 모든 DNS 확인을 완벽하게 제공합니다.
Ingress 컨트롤러
기본 Ingress 개체는 퍼블릭으로 생성되기 때문에 로드 밸런서는 인터넷에 연결되어 퍼블릭 서브넷에서 사용됩니다.
사용자가 사용자 정의 기본 인증서를 구성할 때까지 Ingress Operator가 자리 표시자로 사용될 Ingress Controller의 기본 인증서를 생성합니다. 프로덕션 클러스터에서는 operator가 생성한 기본 인증서를 사용하지 마십시오. Ingress Operator에서는 자체 서명 인증서 또는 생성된 기본 인증서가 순환되지 않습니다. Operator가 생성한 기본 인증서는 구성하는 사용자 정의 기본 인증서의 자리 표시자로 사용됩니다.
API 서버
기본적으로 설치 프로그램은 API 서버가 내부 트래픽 및 외부 트래픽 모두에 사용할 적절한 네트워크로드 밸런서를 만듭니다.
AWS (Amazon Web Services)에서 별도의 퍼블릭 및 프라이빗 로드 밸런서가 생성됩니다. 클러스터에서 사용하기 위해 내부 포트에서 추가 포트를 사용할 수 있다는 점을 제외하고 로드 밸런서는 동일합니다. 설치 프로그램이 API 서버 요구 사항에 따라 로드 밸런서를 자동으로 생성하거나 제거하더라도 클러스터는 이를 관리하거나 유지하지 않습니다. API 서버에 대한 클러스터의 액세스 권한을 유지하는 한 로드 밸런서를 수동으로 변경하거나 이동할 수 있습니다. 퍼블릭 로드 밸런서의 경우 포트 6443이 열려있고 상태 확인은 HTTPS의 / readyz 경로에 대해 설정되어 있습니다.
Google Cloud Platform에서 내부 및 외부 API 트래픽을 모두 관리하기 위해 단일 로드 밸런서가 생성되므로 로드 밸런서를 변경할 필요가 없습니다.
Microsoft Azure에서는 퍼블릭 및 프라이빗 로드 밸런서가 모두 생성됩니다. 그러나 현재 구현에 한계가 있기 때문에 프라이빗 클러스터에서 두 로드 밸런서를 유지합니다.
2.2. 프라이빗 영역에 게시할 DNS 레코드 구성
퍼블릭 또는 프라이빗이든 관계없이 모든 OpenShift Container Platform 클러스터의 경우 DNS 레코드는 기본적으로 퍼블릭 영역에 게시됩니다.
퍼블릭 영역을 클러스터 DNS 구성에서 제거하여 DNS 레코드가 공용으로 노출되지 않도록 할 수 있습니다. 내부 도메인 이름, 내부 IP 주소 또는 조직의 클러스터 수와 같은 중요한 정보를 노출하지 않으려거나 단순히 레코드를 공개적으로 게시하지 않아도 될 수 있습니다. 클러스터 내의 서비스에 연결할 수 있는 모든 클라이언트가 프라이빗 영역의 DNS 레코드가 있는 프라이빗 DNS 서비스를 사용하는 경우 클러스터의 퍼블릭 DNS 레코드가 필요하지 않습니다.
클러스터를 배포한 후 DNS CR(사용자 정의 리소스)을 수정하여 프라이빗 영역만 사용하도록 DNS 를 수정할 수 있습니다. 이러한 방식으로 DNS CR을 수정하면 이후에 생성된 모든 DNS 레코드가 퍼블릭 DNS 서버에 게시되지 않으므로 내부 사용자에게 격리된 DNS 레코드에 대한 지식이 유지됩니다. 이 작업은 클러스터를 비공개로 설정하거나 DNS 레코드를 공개적으로 확인할 수 없는 경우 수행할 수 있습니다.
또는 프라이빗 클러스터에서도 클라이언트가 해당 클러스터에서 실행되는 애플리케이션의 DNS 이름을 확인할 수 있으므로 DNS 레코드에 대한 퍼블릭 영역을 유지할 수 있습니다. 예를 들어 조직에는 공용 인터넷에 연결된 머신이 있고 개인 IP 주소에 연결하기 위해 특정 개인 IP 범위에 대한 VPN 연결을 설정할 수 있습니다. 이러한 시스템의 DNS 조회는 퍼블릭 DNS를 사용하여 해당 서비스의 프라이빗 주소를 확인한 다음 VPN을 통해 프라이빗 주소에 연결합니다.
프로세스
다음 명령을 실행하고 출력을 관찰하여 클러스터의
DNSCR을 확인합니다.$ oc get dnses.config.openshift.io/cluster -o yaml출력 예
apiVersion: config.openshift.io/v1 kind: DNS metadata: creationTimestamp: "2019-10-25T18:27:09Z" generation: 2 name: cluster resourceVersion: "37966" selfLink: /apis/config.openshift.io/v1/dnses/cluster uid: 0e714746-f755-11f9-9cb1-02ff55d8f976 spec: baseDomain: <base_domain> privateZone: tags: Name: <infrastructure_id>-int kubernetes.io/cluster/<infrastructure_id>: owned publicZone: id: Z2XXXXXXXXXXA4 status: {}spec섹션에는 프라이빗 영역과 퍼블릭 영역이 모두 포함되어 있습니다.다음 명령을 실행하여
DNSCR을 패치하여 퍼블릭 영역을 제거합니다.$ oc patch dnses.config.openshift.io/cluster --type=merge --patch='{"spec": {"publicZone": null}}'출력 예
dns.config.openshift.io/cluster patchedIngress Operator는
IngressController오브젝트에 대한DNS레코드를 생성할 때 DNS CR 정의를 참조합니다. 프라이빗 영역만 지정하면 개인 레코드만 생성됩니다.중요퍼블릭 영역을 제거해도 기존 DNS 레코드는 수정되지 않습니다. 더 이상 공개적으로 게시되지 않으려면 이전에 게시된 퍼블릭 DNS 레코드를 수동으로 삭제해야 합니다.
검증
클러스터의
DNSCR을 확인하고 다음 명령을 실행하고 출력을 관찰하여 퍼블릭 영역이 제거되었는지 확인합니다.$ oc get dnses.config.openshift.io/cluster -o yaml출력 예
apiVersion: config.openshift.io/v1 kind: DNS metadata: creationTimestamp: "2019-10-25T18:27:09Z" generation: 2 name: cluster resourceVersion: "37966" selfLink: /apis/config.openshift.io/v1/dnses/cluster uid: 0e714746-f755-11f9-9cb1-02ff55d8f976 spec: baseDomain: <base_domain> privateZone: tags: Name: <infrastructure_id>-int kubernetes.io/cluster/<infrastructure_id>-wfpg4: owned status: {}
2.3. Ingress 컨트롤러를 프라이빗으로 설정
클러스터를 배포한 후 프라이빗 영역만 사용하도록 Ingress 컨트롤러를 변경할 수 있습니다.
프로세스
내부 엔드 포인트만 사용하도록 기본 Ingress 컨트롤러를 변경합니다.
$ oc replace --force --wait --filename - <<EOF apiVersion: operator.openshift.io/v1 kind: IngressController metadata: namespace: openshift-ingress-operator name: default spec: endpointPublishingStrategy: type: LoadBalancerService loadBalancer: scope: Internal EOF출력 예
ingresscontroller.operator.openshift.io "default" deleted ingresscontroller.operator.openshift.io/default replaced퍼블릭 DNS 항목이 제거되고 프라이빗 영역 항목이 업데이트됩니다.
2.4. API 서버를 프라이빗으로 제한
AWS (Amazon Web Services) 또는 Microsoft Azure에 클러스터를 배포한 후 프라이빗 영역만 사용하도록 API 서버를 재구성할 수 있습니다.
전제 조건
-
OpenShift CLI (
oc)를 설치합니다. -
admin권한이 있는 사용자로 웹 콘솔에 액세스합니다.
절차
클라우드 공급자의 웹 포털 또는 콘솔에서 다음 작업을 수행합니다.
적절한 로드 밸런서 구성 요소를 찾아 삭제합니다.
- AWS의 경우 외부 로드 밸런서를 삭제합니다. 프라이빗 영역의 API DNS 항목은 동일한 설정을 사용하는 내부 로드 밸런서를 가리키므로 내부 로드 밸런서를 변경할 필요가 없습니다.
-
Azure의 경우 로드 밸런서의
api-internal규칙을 삭제합니다.
-
퍼블릭 영역의
api.$clustername.$yourdomainDNS 항목을 삭제합니다.
외부 로드 밸런서를 제거합니다.
중요설치 관리자 프로비저닝 인프라(IPI) 클러스터에 대해서만 다음 단계를 실행할 수 있습니다. UPI(사용자 프로비저닝 인프라) 클러스터의 경우 외부 로드 밸런서를 수동으로 제거하거나 비활성화해야 합니다.
클러스터에서 컨트롤 플레인 머신 세트를 사용하는 경우 컨트롤 플레인 머신 세트 사용자 정의 리소스에서 다음 행을 삭제합니다.
providerSpec: value: loadBalancers: - name: lk4pj-ext1 type: network2 - name: lk4pj-int type: network클러스터가 컨트롤 플레인 머신 세트를 사용하지 않는 경우 각 컨트롤 플레인 시스템에서 외부 로드 밸런서를 삭제해야 합니다.
터미널에서 다음 명령을 실행하여 클러스터 시스템을 나열합니다.
$ oc get machine -n openshift-machine-api출력 예
NAME STATE TYPE REGION ZONE AGE lk4pj-master-0 running m4.xlarge us-east-1 us-east-1a 17m lk4pj-master-1 running m4.xlarge us-east-1 us-east-1b 17m lk4pj-master-2 running m4.xlarge us-east-1 us-east-1a 17m lk4pj-worker-us-east-1a-5fzfj running m4.xlarge us-east-1 us-east-1a 15m lk4pj-worker-us-east-1a-vbghs running m4.xlarge us-east-1 us-east-1a 15m lk4pj-worker-us-east-1b-zgpzg running m4.xlarge us-east-1 us-east-1b 15m컨트롤 플레인 시스템에는 이름에
master가 포함되어 있습니다.각 컨트롤 플레인 시스템에서 외부 로드 밸런서를 제거합니다.
다음 명령을 실행하여 컨트롤 플레인 머신 오브젝트를 다음과 같이 편집합니다.
$ oc edit machines -n openshift-machine-api <control_plane_name>1 - 1
- 수정할 컨트롤 플레인 머신 오브젝트의 이름을 지정합니다.
다음 예에 표시된 외부 로드 밸런서를 설명하는 행을 제거합니다.
providerSpec: value: loadBalancers: - name: lk4pj-ext1 type: network2 - name: lk4pj-int type: network- 변경 사항을 저장하고 오브젝트 사양을 종료합니다.
- 각 컨트롤 플레인 시스템에 대해 이 프로세스를 반복합니다.
3장. 베어 메탈 구성
베어 메탈 호스트에 OpenShift Container Platform을 배포할 때 프로비저닝 전이나 후에 호스트를 변경해야 하는 경우가 있습니다. 여기에는 호스트의 하드웨어, 펌웨어 및 펌웨어 세부 정보가 포함될 수 있습니다. 여기에는 포맷 디스크 또는 수정 가능한 펌웨어 설정 변경이 포함될 수 있습니다.
3.1. Bare Metal Operator 정보
BMO( Bare Metal Operator)를 사용하여 클러스터에서 베어 메탈 호스트를 프로비저닝, 관리 및 검사합니다.
BMO는 다음 작업을 완료하기 위해 세 가지 리소스를 사용합니다.
-
BareMetalHost -
HostFirmwareSettings -
FirmwareSchema
BMO는 각 베어 메탈 호스트를 BareMetalHost 사용자 정의 리소스 정의 인스턴스에 매핑하여 클러스터에서 물리적 호스트 인벤토리를 유지 관리합니다. 각 BareMetalHost 리소스에는 하드웨어, 소프트웨어 및 펌웨어 세부 정보가 있습니다. BMO는 클러스터의 베어 메탈 호스트를 지속적으로 검사하여 각 BareMetalHost 리소스에서 해당 호스트의 구성 요소를 정확하게 자세히 설명합니다.
BMO는 또한 HostFirmwareSettings 리소스 및 FirmwareSchema 리소스를 사용하여 베어 메탈 호스트의 펌웨어 사양을 자세히 설명합니다.
BMO는 Ironic API 서비스를 사용하여 클러스터에서 베어 메탈 호스트와의 인터페이스입니다. Ironic 서비스는 호스트의 BMC(Baseboard Management Controller)를 사용하여 시스템과 상호 작용합니다.
BMO를 사용하여 완료할 수 있는 몇 가지 일반적인 작업은 다음과 같습니다.
- 특정 이미지로 클러스터에 베어 메탈 호스트를 프로비저닝
- 프로비저닝 전 또는 프로비저닝 해제 후 호스트의 디스크 콘텐츠 포맷
- 호스트 설정 또는 해제
- 펌웨어 설정 변경
- 호스트의 하드웨어 세부 정보 보기
3.1.1. Bare Metal Operator 아키텍처
BMO( Bare Metal Operator)는 3개의 리소스를 사용하여 클러스터에서 베어 메탈 호스트를 프로비저닝, 관리 및 검사합니다. 다음 다이어그램에서는 이러한 리소스의 아키텍처를 보여줍니다.

BareMetalHost
BareMetalHost 리소스는 물리적 호스트 및 해당 속성을 정의합니다. 베어 메탈 호스트를 클러스터에 프로비저닝하는 경우 해당 호스트의 BareMetalHost 리소스를 정의해야 합니다. 호스트를 지속적으로 관리하기 위해 BareMetalHost 의 정보를 검사하거나 이 정보를 업데이트할 수 있습니다.
BareMetalHost 리소스에는 다음과 같은 프로비저닝 정보가 있습니다.
- 운영 체제 부팅 이미지 또는 사용자 정의 RAM 디스크와 같은 배포 사양
- 프로비저닝 상태
- BMC(Baseboard Management Controller) 주소
- 원하는 전원 상태
BareMetalHost 리소스는 다음과 같은 하드웨어 정보를 제공합니다.
- CPU 수
- NIC의 MAC 주소
- 호스트 스토리지 장치의 크기
- 현재 전원 상태
HostFirmwareSettings
HostFirmwareSettings 리소스를 사용하여 호스트의 펌웨어 설정을 검색하고 관리할 수 있습니다. 호스트가 Available 상태로 이동하면 Ironic 서비스에서 호스트의 펌웨어 설정을 읽고 HostFirmwareSettings 리소스를 생성합니다. BareMetalHost 리소스와 HostFirmwareSettings 리소스 간에 일대일 매핑이 있습니다.
HostFirmwareSettings 리소스를 사용하여 호스트의 펌웨어 사양을 검사하거나 호스트의 펌웨어 사양을 업데이트할 수 있습니다.
HostFirmwareSettings 리소스의 spec 필드를 편집할 때 공급 업체 펌웨어와 관련된 스키마를 준수해야 합니다. 이 스키마는 읽기 전용 FirmwareSchema 리소스에 정의되어 있습니다.
FirmwareSchema
펌웨어 설정은 하드웨어 공급 업체 및 호스트 모델에 따라 다릅니다. FirmwareSchema 리소스는 각 호스트 모델의 각 펌웨어 설정에 대한 유형 및 제한을 포함하는 읽기 전용 리소스입니다. Ironic 서비스를 사용하여 BMC에서 직접 데이터를 가져옵니다. FirmwareSchema 리소스를 사용하면 HostFirmwareSettings 리소스의 spec 필드에 지정할 수 있는 유효한 값을 식별할 수 있습니다.
스키마가 동일한 경우 FirmwareSchema 리소스를 여러 BareMetalHost 리소스에 적용할 수 있습니다.
3.2. BareMetalHost 리소스 정보
Metal3 에는 물리적 호스트 및 해당 속성을 정의하는 BareMetalHost 리소스의 개념이 도입되었습니다. BareMetalHost 리소스에는 다음 두 섹션이 포함되어 있습니다.
-
BareMetalHost사양 -
BareMetalHost상태
3.2.1. BareMetalHost 사양
BareMetalHost 리소스의 spec 섹션은 원하는 호스트의 상태를 정의합니다.
| 매개 변수 | 설명 |
|---|---|
|
|
프로비저닝 및 프로비저닝 해제 중 자동 정리를 활성화 또는 비활성화하는 인터페이스입니다. |
|
|
|
| 호스트 프로비저닝에 사용되는 NIC의 MAC 주소입니다. |
|
|
호스트의 부팅 모드입니다. 기본값은 |
|
|
호스트를 사용하는 다른 리소스에 대한 참조입니다. 다른 리소스가 호스트를 현재 사용하지 않는 경우 비어 있을 수 있습니다. 예를 들어 |
|
| 호스트를 식별하는 데 도움이 되는 사람이 제공하는 문자열입니다. |
|
| 호스트 프로비저닝 및 프로비저닝 해제가 외부에서 관리되는지를 나타내는 부울입니다. 설정한 경우:
|
|
|
베어 메탈 호스트의 BIOS 구성에 대한 정보를 포함합니다. 현재
|
|
|
|
| 네트워크를 설정하기 위해 호스트를 부팅하기 전에 호스트에 연결할 수 있도록 네트워크 구성 데이터 및 해당 네임스페이스가 포함된 보안에 대한 참조입니다. |
|
|
호스트의 전원 켜기( |
| (선택 사항) 베어 메탈 호스트의 RAID 구성에 대한 정보가 포함되어 있습니다. 지정하지 않으면 현재 구성이 유지됩니다. 참고 OpenShift Container Platform 4.13에서는 iRMC 프로토콜만 사용하여 BMC용 하드웨어 RAID를 지원합니다. OpenShift Container Platform 4.13에서는 소프트웨어 RAID를 지원하지 않습니다. 다음 설정 설정을 참조하십시오.
드라이버가 RAID를 지원하지 않음을 나타내는 오류 메시지가 표시되면 |
|
|
3.2.2. BareMetalHost 상태
BareMetalHost 상태는 호스트의 현재 상태를 나타내며 테스트된 인증 정보, 현재 하드웨어 세부 정보 및 기타 정보를 포함합니다.
| 매개 변수 | 설명 |
|---|---|
|
| 시크릿 및 마지막 BMC(Baseboard Management Controller) 인증 정보 세트를 보유한 네임스페이스에 대한 참조로, 시스템에서 작동 상태로 검증할 수 있었습니다. |
|
| 프로비저닝 백엔드에서 보고한 마지막 오류의 세부 정보(있는 경우). |
|
| 호스트가 오류 상태가 된 문제의 클래스를 나타냅니다. 오류 유형은 다음과 같습니다.
|
|
시스템의 CPU의
|
| BIOS 펌웨어 정보를 포함합니다. 예를 들어 하드웨어 벤더 및 버전입니다. |
|
|
| 호스트의 메모리 양(MiB)입니다. |
|
|
|
호스트의 |
|
| 마지막으로 호스트의 상태를 업데이트한 시점의 타임 스탬프입니다. |
|
| 서버의 상태입니다. 상태는 다음 중 하나입니다.
|
|
| 호스트의 전원이 켜졌는지 여부를 나타내는 부울입니다. |
|
|
|
| 프로비저닝 백엔드로 전송된 마지막 BMC 자격 증명 세트를 보유한 시크릿 및 해당 네임스페이스에 대한 참조입니다. |
3.3. BareMetalHost 리소스 가져오기
BareMetalHost 리소스에는 물리적 호스트의 속성이 포함되어 있습니다. 물리적 호스트의 BareMetalHost 리소스를 가져와서 속성을 확인해야 합니다.
절차
BareMetalHost리소스 목록을 가져옵니다.$ oc get bmh -n openshift-machine-api -o yaml참고oc get명령을 사용하여baremetalhost를bmh의 긴 형식으로 사용할 수 있습니다.호스트 목록을 가져옵니다.
$ oc get bmh -n openshift-machine-api특정 호스트의
BareMetalHost리소스를 가져옵니다.$ oc get bmh <host_name> -n openshift-machine-api -o yaml여기서
<host_name>은 호스트 이름입니다.출력 예
apiVersion: metal3.io/v1alpha1 kind: BareMetalHost metadata: creationTimestamp: "2022-06-16T10:48:33Z" finalizers: - baremetalhost.metal3.io generation: 2 name: openshift-worker-0 namespace: openshift-machine-api resourceVersion: "30099" uid: 1513ae9b-e092-409d-be1b-ad08edeb1271 spec: automatedCleaningMode: metadata bmc: address: redfish://10.46.61.19:443/redfish/v1/Systems/1 credentialsName: openshift-worker-0-bmc-secret disableCertificateVerification: true bootMACAddress: 48:df:37:c7:f7:b0 bootMode: UEFI consumerRef: apiVersion: machine.openshift.io/v1beta1 kind: Machine name: ocp-edge-958fk-worker-0-nrfcg namespace: openshift-machine-api customDeploy: method: install_coreos online: true rootDeviceHints: deviceName: /dev/disk/by-id/scsi-<serial_number> userData: name: worker-user-data-managed namespace: openshift-machine-api status: errorCount: 0 errorMessage: "" goodCredentials: credentials: name: openshift-worker-0-bmc-secret namespace: openshift-machine-api credentialsVersion: "16120" hardware: cpu: arch: x86_64 clockMegahertz: 2300 count: 64 flags: - 3dnowprefetch - abm - acpi - adx - aes model: Intel(R) Xeon(R) Gold 5218 CPU @ 2.30GHz firmware: bios: date: 10/26/2020 vendor: HPE version: U30 hostname: openshift-worker-0 nics: - mac: 48:df:37:c7:f7:b3 model: 0x8086 0x1572 name: ens1f3 ramMebibytes: 262144 storage: - hctl: "0:0:0:0" model: VK000960GWTTB name: /dev/disk/by-id/scsi-<serial_number> sizeBytes: 960197124096 type: SSD vendor: ATA systemVendor: manufacturer: HPE productName: ProLiant DL380 Gen10 (868703-B21) serialNumber: CZ200606M3 lastUpdated: "2022-06-16T11:41:42Z" operationalStatus: OK poweredOn: true provisioning: ID: 217baa14-cfcf-4196-b764-744e184a3413 bootMode: UEFI customDeploy: method: install_coreos image: url: "" raid: hardwareRAIDVolumes: null softwareRAIDVolumes: [] rootDeviceHints: deviceName: /dev/disk/by-id/scsi-<serial_number> state: provisioned triedCredentials: credentials: name: openshift-worker-0-bmc-secret namespace: openshift-machine-api credentialsVersion: "16120"
3.4. HostFirmwareSettings 리소스 정보
HostFirmwareSettings 리소스를 사용하여 호스트의 BIOS 설정을 검색하고 관리할 수 있습니다. 호스트가 Available 상태로 이동하면 Ironic에서 호스트의 BIOS 설정을 읽고 HostFirmwareSettings 리소스를 생성합니다. 리소스에는 BMC(Baseboard Management Controller)에서 반환된 전체 BIOS 구성이 포함되어 있습니다. 반면 BareMetalHost 리소스의 펌웨어 필드는 세 개의 벤더 독립적 필드를 반환하는 반면 HostFirmwareSettings 리소스는 일반적으로 호스트당 벤더별 필드의 많은 BIOS 설정으로 구성됩니다.
HostFirmwareSettings 리소스에는 다음 두 섹션이 포함되어 있습니다.
-
HostFirmwareSettings사양입니다. -
HostFirmwareSettings상태
3.4.1. HostFirmwareSettings 사양
HostFirmwareSettings 리소스의 spec 섹션은 원하는 호스트 BIOS 상태를 정의하고 기본적으로 비어 있습니다. Ironic은 spec.settings 섹션의 설정을 사용하여 호스트가 준비 상태가 될 때 BMC(Baseboard Management Controller)를 업데이트합니다. FirmwareSchema 리소스를 사용하여 잘못된 이름/값 쌍을 호스트에 보내지 않도록 합니다. 자세한 내용은 " FirmwareSchema 리소스 정보"를 참조하십시오.
예제
spec:
settings:
ProcTurboMode: Disabled- 1
- 앞의 예에서
spec.settings섹션에는ProcTurboModeBIOS 설정을Disabled로 설정하는 이름/값 쌍이 포함되어 있습니다.
status 섹션에 나열된 정수 매개변수는 문자열로 표시됩니다. 예를 들면 "1" 입니다. spec.settings 섹션에서 정수를 설정할 때 값은 따옴표 없이 정수로 설정되어야 합니다. 예를 들면 1 입니다.
3.4.2. HostFirmwareSettings 상태
상태는 호스트의 BIOS의 현재 상태를 나타냅니다.
| 매개 변수 | 설명 |
|---|---|
|
|
|
펌웨어 설정의
|
|
|
3.5. HostFirmwareSettings 리소스 가져오기
HostFirmwareSettings 리소스에는 물리적 호스트의 공급업체별 BIOS 속성이 포함되어 있습니다. BIOS 속성을 검토하려면 물리적 호스트의 HostFirmwareSettings 리소스를 가져와야 합니다.
절차
HostFirmwareSettings리소스의 자세한 목록을 가져옵니다.$ oc get hfs -n openshift-machine-api -o yaml참고oc get명령과 함께hfs의 긴 형태로hostfirmwaresettings를 사용할 수 있습니다.HostFirmwareSettings리소스 목록을 가져옵니다.$ oc get hfs -n openshift-machine-api특정 호스트에 대한
HostFirmwareSettings리소스 가져오기$ oc get hfs <host_name> -n openshift-machine-api -o yaml여기서
<host_name>은 호스트 이름입니다.
3.6. HostFirmwareSettings 리소스 편집
프로비저닝된 호스트의 HostFirmwareSettings 를 편집할 수 있습니다.
읽기 전용 값을 제외하고 프로비저닝 된 상태에 있는 경우에만 호스트를 편집할 수 있습니다. 외부 프로비저닝 상태의 호스트를 편집할 수 없습니다.
절차
HostFirmwareSettings리소스 목록을 가져옵니다.$ oc get hfs -n openshift-machine-api호스트의
HostFirmwareSettings리소스를 편집합니다.$ oc edit hfs <host_name> -n openshift-machine-api여기서
<host_name>은 프로비저닝된 호스트의 이름입니다. 터미널의 기본 편집기에서HostFirmwareSettings리소스가 열립니다.spec.settings섹션에 이름/값 쌍을 추가합니다.예제
spec: settings: name: value1 - 1
FirmwareSchema리소스를 사용하여 호스트에 사용 가능한 설정을 식별합니다. 읽기 전용 값은 설정할 수 없습니다.
- 변경 사항을 저장하고 편집기를 종료합니다.
호스트의 시스템 이름을 가져옵니다.
$ oc get bmh <host_name> -n openshift-machine name여기서
<host_name>은 호스트 이름입니다. 머신 이름은CONSUMER필드 아래에 표시됩니다.machineset에서 삭제하기 위해 머신에 주석을 답니다.
$ oc annotate machine <machine_name> machine.openshift.io/delete-machine=true -n openshift-machine-api여기서
<machine_name>은 삭제할 머신의 이름입니다.노드 목록을 가져오고 작업자 노드 수를 계산합니다.
$ oc get nodesmachineset를 가져옵니다.
$ oc get machinesets -n openshift-machine-apimachineset를 확장합니다.
$ oc scale machineset <machineset_name> -n openshift-machine-api --replicas=<n-1>여기서 <
machineset_name>은 machineset의 이름이고 <n-1>은 감소된 작업자 노드 수입니다.호스트가
Available상태가 되면 machineset를 확장하여HostFirmwareSettings리소스 변경 사항을 적용합니다.$ oc scale machineset <machineset_name> -n openshift-machine-api --replicas=<n>여기서
<machineset_name>은 machineset의 이름이고 <n>은 작업자 노드 수입니다.
3.7. HostFirmware Settings 리소스가 유효한지 확인
사용자가 HFS( HostFirmwareSetting) 리소스를 변경하기 위해 spec.settings 섹션을 편집하면 Bare Metal Operator(BMO)는 읽기 전용 리소스인 FimwareSchema 리소스에 대한 변경 사항을 검증합니다. 설정이 유효하지 않으면 BMO에서 status.Condition 설정의 Type 값을 False 로 설정하고 이벤트를 생성하여 HFS 리소스에 저장합니다. 다음 절차에 따라 리소스가 유효한지 확인합니다.
절차
HostFirmwareSetting리소스 목록을 가져옵니다.$ oc get hfs -n openshift-machine-api특정 호스트의
HostFirmwareSettings리소스가 유효한지 확인합니다.$ oc describe hfs <host_name> -n openshift-machine-api여기서
<host_name>은 호스트 이름입니다.출력 예
Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal ValidationFailed 2m49s metal3-hostfirmwaresettings-controller Invalid BIOS setting: Setting ProcTurboMode is invalid, unknown enumeration value - Foo중요응답이
ValidationFailed를 반환하는 경우 리소스 구성에 오류가 있으며FirmwareSchema리소스를 준수하도록 값을 업데이트해야 합니다.
3.8. FirmwareSchema 리소스 정보
BIOS 설정은 하드웨어 공급 업체 및 호스트 모델에 따라 다릅니다. FirmwareSchema 리소스는 각 호스트 모델의 각 BIOS 설정에 대한 유형 및 제한이 포함된 읽기 전용 리소스입니다. 데이터는 BMC에서 Ironic까지 직접 가져옵니다. FirmwareSchema 를 사용하면 HostFirmwareSettings 리소스의 spec 필드에 지정할 수 있는 유효한 값을 식별할 수 있습니다. FirmwareSchema 리소스에는 설정 및 제한에서 파생된 고유 식별자가 있습니다. 동일한 호스트 모델은 동일한 FirmwareSchema 식별자를 사용합니다. HostFirmwareSettings 의 여러 인스턴스가 동일한 FirmwareSchema 를 사용할 가능성이 높습니다.
| 매개 변수 | 설명 |
|---|---|
|
|
3.9. FirmwareSchema 리소스 가져오기
각 공급 업체의 호스트 모델에는 서로 다른 BIOS 설정이 있습니다. HostFirmwareSettings 리소스의 spec 섹션을 편집할 때 설정한 이름/값 쌍은 해당 호스트의 펌웨어 스키마를 준수해야 합니다. 유효한 이름/값 쌍을 설정하고 있는지 확인하려면 호스트의 FirmwareSchema 를 가져와서 검토합니다.
절차
FirmwareSchema리소스 인스턴스 목록을 가져오려면 다음을 실행합니다.$ oc get firmwareschema -n openshift-machine-api특정
FirmwareSchema인스턴스를 가져오려면 다음을 실행합니다.$ oc get firmwareschema <instance_name> -n openshift-machine-api -o yaml여기서
<instance_name>은HostFirmwareSettings리소스에 명시된 스키마 인스턴스의 이름입니다(표 3 참조).
4장. OpenShift Container Platform 클러스터에서 다중 아키텍처 컴퓨팅 시스템 구성
다중 아키텍처 컴퓨팅 머신이 있는 OpenShift Container Platform 클러스터는 아키텍처가 다른 컴퓨팅 머신을 지원하는 클러스터입니다. 다중 아키텍처 컴퓨팅 머신이 있는 클러스터는 AWS 또는 Azure 설치 관리자 프로비저닝 인프라 및 x86_64 컨트롤 플레인 시스템이 있는 베어 메탈 사용자 프로비저닝 인프라에서만 사용할 수 있습니다.
클러스터에 여러 아키텍처가 있는 노드가 있는 경우 이미지 아키텍처는 노드 아키텍처와 일치해야 합니다. Pod가 적절한 아키텍처를 사용하여 노드에 할당되고 이미지 아키텍처와 일치하는지 확인해야 합니다. 노드에 Pod를 할당하는 방법에 대한 자세한 내용은 노드에 Pod 할당을 참조하십시오.
다중 아키텍처 컴퓨팅 머신이 있는 클러스터에서 Cluster Samples Operator가 지원되지 않습니다. 이 기능 없이 클러스터를 생성할 수 있습니다. 자세한 내용은 클러스터 기능 활성화를참조하십시오.
단일 아키텍처 클러스터를 다중 아키텍처 컴퓨팅 머신을 지원하는 클러스터로 마이그레이션하는 방법에 대한 자세한 내용은 다중 아키텍처 컴퓨팅 머신이 있는 클러스터로 마이그레이션 을 참조하십시오.
4.1. 클러스터 호환성 확인
서로 다른 아키텍처의 컴퓨팅 노드를 클러스터에 추가하려면 먼저 클러스터가 다중 아키텍처와 호환되는지 확인해야 합니다.
사전 요구 사항
-
OpenShift CLI (
oc)를 설치했습니다.
절차
다음 명령을 실행하여 클러스터가 아키텍처 페이로드를 사용하는지 확인할 수 있습니다.
$ oc adm release info -o json | jq .metadata.metadata
검증
다음 출력이 표시되면 클러스터는 다중 아키텍처 페이로드를 사용하는 것입니다.
$ "release.openshift.io/architecture": "multi"그런 다음 클러스터에 다중 아키텍처 컴퓨팅 노드를 추가할 수 있습니다.
다음 출력이 표시되면 클러스터는 다중 아키텍처 페이로드를 사용하지 않습니다.
$ null다중 아키텍처 컴퓨팅 시스템을 지원하는 클러스터로 클러스터를 마이그레이션하려면 "여러 아키텍처 컴퓨팅 시스템이 있는 클러스터로 마이그레이션"의 절차를 따르십시오.
4.2. Azure에서 다중 아키텍처 컴퓨팅 머신을 사용하여 클러스터 생성
다중 아키텍처 컴퓨팅 머신을 사용하여 Azure 클러스터를 배포하려면 먼저 다중 아키텍처 설치 프로그램 바이너리를 사용하는 단일 아키텍처 Azure 설치 관리자 프로비저닝 클러스터를 생성해야 합니다. Azure 설치에 대한 자세한 내용은 사용자 지정을 사용하여 Azure에 클러스터 설치를 참조하십시오. 그런 다음 ARM64 컴퓨팅 머신 세트를 클러스터에 추가하여 다중 아키텍처 컴퓨팅 머신이 있는 클러스터를 생성할 수 있습니다.
다음 절차에서는 ARM64 부팅 이미지를 생성하고 ARM64 부팅 이미지를 사용하는 Azure 컴퓨팅 머신 세트를 생성하는 방법을 설명합니다. 이를 통해 클러스터에 ARM64 컴퓨팅 노드를 추가하고 필요한 ARM64 가상 머신(VM) 양을 배포합니다.
4.2.1. Azure 이미지 라이브러리를 사용하여 ARM64 부팅 이미지 생성
다음 절차에서는 ARM64 부팅 이미지를 수동으로 생성하는 방법을 설명합니다.
사전 요구 사항
-
Azure CLI(
az)를 설치했습니다. - 다중 아키텍처 설치 프로그램 바이너리를 사용하여 단일 아키텍처 Azure 설치 관리자 프로비저닝 클러스터를 생성하셨습니다.
절차
Azure 계정에 로그인합니다.
$ az login스토리지 계정을 생성하고 scrape
64 가상하드 디스크(VHD)를 스토리지 계정에 업로드합니다. OpenShift Container Platform 설치 프로그램은 리소스 그룹을 생성하지만 부팅 이미지는 사용자 정의 리소스 그룹에 업로드할 수도 있습니다.$ az storage account create -n ${STORAGE_ACCOUNT_NAME} -g ${RESOURCE_GROUP} -l westus --sku Standard_LRS1 - 1
westus오브젝트는 예제 리전입니다.
생성한 스토리지 계정을 사용하여 스토리지 컨테이너를 생성합니다.
$ az storage container create -n ${CONTAINER_NAME} --account-name ${STORAGE_ACCOUNT_NAME}OpenShift Container Platform 설치 프로그램 JSON 파일을 사용하여 URL 및
aarch64VHD 이름을 추출해야 합니다.URL필드를 추출하여 다음 명령을 실행하여RHCOS_VHD_ORIGIN_URL으로 파일 이름으로 설정합니다.$ RHCOS_VHD_ORIGIN_URL=$(oc -n openshift-machine-config-operator get configmap/coreos-bootimages -o jsonpath='{.data.stream}' | jq -r '.architectures.aarch64."rhel-coreos-extensions"."azure-disk".url')aarch64VHD 이름을 추출하고 다음 명령을 실행하여 파일 이름으로BLOB_NAME으로 설정합니다.$ BLOB_NAME=rhcos-$(oc -n openshift-machine-config-operator get configmap/coreos-bootimages -o jsonpath='{.data.stream}' | jq -r '.architectures.aarch64."rhel-coreos-extensions"."azure-disk".release')-azure.aarch64.vhd
공유 액세스 서명(ECDHE) 토큰을 생성합니다. 다음 명령을 사용하여 RHCOS VHD를 스토리지 컨테이너에 업로드하려면 이 토큰을 사용합니다.
$ end=`date -u -d "30 minutes" '+%Y-%m-%dT%H:%MZ'`$ sas=`az storage container generate-sas -n ${CONTAINER_NAME} --account-name ${STORAGE_ACCOUNT_NAME} --https-only --permissions dlrw --expiry $end -o tsv`RHCOS VHD를 스토리지 컨테이너에 복사합니다.
$ az storage blob copy start --account-name ${STORAGE_ACCOUNT_NAME} --sas-token "$sas" \ --source-uri "${RHCOS_VHD_ORIGIN_URL}" \ --destination-blob "${BLOB_NAME}" --destination-container ${CONTAINER_NAME}다음 명령을 사용하여 복사 프로세스의 상태를 확인할 수 있습니다.
$ az storage blob show -c ${CONTAINER_NAME} -n ${BLOB_NAME} --account-name ${STORAGE_ACCOUNT_NAME} | jq .properties.copy출력 예
{ "completionTime": null, "destinationSnapshot": null, "id": "1fd97630-03ca-489a-8c4e-cfe839c9627d", "incrementalCopy": null, "progress": "17179869696/17179869696", "source": "https://rhcos.blob.core.windows.net/imagebucket/rhcos-411.86.202207130959-0-azure.aarch64.vhd", "status": "success",1 "statusDescription": null }- 1
- status 매개변수에
success오브젝트가 표시되면 복사 프로세스가 완료됩니다.
다음 명령을 사용하여 이미지 builder를 생성합니다.
$ az sig create --resource-group ${RESOURCE_GROUP} --gallery-name ${GALLERY_NAME}이미지 Maven을 사용하여 이미지 정의를 생성합니다. 다음 예제 명령에서
rhcos-arm64는 이미지 정의의 이름입니다.$ az sig image-definition create --resource-group ${RESOURCE_GROUP} --gallery-name ${GALLERY_NAME} --gallery-image-definition rhcos-arm64 --publisher RedHat --offer arm --sku arm64 --os-type linux --architecture Arm64 --hyper-v-generation V2VHD의 URL을 가져와서 파일 이름으로
RHCOS_VHD_URL로 설정하려면 다음 명령을 실행합니다.$ RHCOS_VHD_URL=$(az storage blob url --account-name ${STORAGE_ACCOUNT_NAME} -c ${CONTAINER_NAME} -n "${BLOB_NAME}" -o tsv)RHCOS_VHD_URL파일, 스토리지 계정, 리소스 그룹 및 이미지 그룹 을 사용하여 이미지 버전을 생성합니다. 다음 예에서1.0.0은 이미지 버전입니다.$ az sig image-version create --resource-group ${RESOURCE_GROUP} --gallery-name ${GALLERY_NAME} --gallery-image-definition rhcos-arm64 --gallery-image-version 1.0.0 --os-vhd-storage-account ${STORAGE_ACCOUNT_NAME} --os-vhd-uri ${RHCOS_VHD_URL}이제
ARM64부팅 이미지가 생성됩니다. 다음 명령을 사용하여 이미지 ID에 액세스할 수 있습니다.$ az sig image-version show -r $GALLERY_NAME -g $RESOURCE_GROUP -i rhcos-arm64 -e 1.0.0다음 예제 이미지 ID는 컴퓨팅 머신 세트의 reECDHE
ID매개변수에 사용됩니다.resourceID예/resourceGroups/${RESOURCE_GROUP}/providers/Microsoft.Compute/galleries/${GALLERY_NAME}/images/rhcos-arm64/versions/1.0.0
4.2.2. 클러스터에 다중 아키텍처 컴퓨팅 머신 세트 추가
ARM64 컴퓨팅 노드를 클러스터에 추가하려면 ARM64 부팅 이미지를 사용하는 Azure 컴퓨팅 머신 세트를 생성해야 합니다. Azure에서 자체 사용자 지정 컴퓨팅 머신 세트를 생성하려면 "Azure에서 컴퓨팅 머신 세트 생성"을 참조하십시오.
사전 요구 사항
-
OpenShift CLI(
oc)를 설치합니다.
절차
컴퓨팅 머신 세트를 생성하고 다음 명령을 사용하여
resourceID및vmSize매개변수를 수정합니다. 이 컴퓨팅 머신 세트는 클러스터의 machines64작업자 노드를 제어합니다.$ oc create -f arm64-machine-set-0.yamlARM64부팅 이미지가 포함된 샘플 YAML 컴퓨팅 머신 세트apiVersion: machine.openshift.io/v1beta1 kind: MachineSet metadata: labels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> machine.openshift.io/cluster-api-machine-role: worker machine.openshift.io/cluster-api-machine-type: worker name: <infrastructure_id>-arm64-machine-set-0 namespace: openshift-machine-api spec: replicas: 2 selector: matchLabels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> machine.openshift.io/cluster-api-machineset: <infrastructure_id>-arm64-machine-set-0 template: metadata: labels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> machine.openshift.io/cluster-api-machine-role: worker machine.openshift.io/cluster-api-machine-type: worker machine.openshift.io/cluster-api-machineset: <infrastructure_id>-arm64-machine-set-0 spec: lifecycleHooks: {} metadata: {} providerSpec: value: acceleratedNetworking: true apiVersion: machine.openshift.io/v1beta1 credentialsSecret: name: azure-cloud-credentials namespace: openshift-machine-api image: offer: "" publisher: "" resourceID: /resourceGroups/${RESOURCE_GROUP}/providers/Microsoft.Compute/galleries/${GALLERY_NAME}/images/rhcos-arm64/versions/1.0.01 sku: "" version: "" kind: AzureMachineProviderSpec location: <region> managedIdentity: <infrastructure_id>-identity networkResourceGroup: <infrastructure_id>-rg osDisk: diskSettings: {} diskSizeGB: 128 managedDisk: storageAccountType: Premium_LRS osType: Linux publicIP: false publicLoadBalancer: <infrastructure_id> resourceGroup: <infrastructure_id>-rg subnet: <infrastructure_id>-worker-subnet userDataSecret: name: worker-user-data vmSize: Standard_D4ps_v52 vnet: <infrastructure_id>-vnet zone: "<zone>"
검증
다음 명령을 입력하여 새 ARM64 시스템이 실행 중인지 확인합니다.
$ oc get machineset -n openshift-machine-api출력 예
NAME DESIRED CURRENT READY AVAILABLE AGE <infrastructure_id>-arm64-machine-set-0 2 2 2 2 10m다음 명령을 사용하여 노드가 준비되고 예약할 수 있는지 확인할 수 있습니다.
$ oc get nodes
4.3. AWS에서 다중 아키텍처 컴퓨팅 시스템으로 클러스터 생성
다중 아키텍처 컴퓨팅 머신으로 AWS 클러스터를 생성하려면 먼저 다중 아키텍처 설치 프로그램 바이너리를 사용하여 단일 아키텍처 AWS 설치 관리자 프로비저닝 클러스터를 생성해야 합니다. AWS 설치에 대한 자세한 내용은 사용자 지정을 사용하여 AWS에 클러스터 설치를 참조하십시오. 그런 다음 ARM64 컴퓨팅 머신 세트를 AWS 클러스터에 추가할 수 있습니다.
4.3.1. 클러스터에 ARM64 컴퓨팅 머신 세트 추가
다중 아키텍처 컴퓨팅 머신을 사용하여 클러스터를 구성하려면 AWS ARM64 컴퓨팅 머신 세트를 생성해야 합니다. 클러스터에 ARM64 컴퓨팅 노드가 추가되어 클러스터에 다중 아키텍처 컴퓨팅 머신이 추가됩니다.
사전 요구 사항
-
OpenShift CLI(
oc)를 설치합니다. - 설치 프로그램을 사용하여 다중 아키텍처 설치 프로그램 바이너리로 AMD64 단일 아키텍처 AWS 클러스터를 생성했습니다.
절차
컴퓨팅 머신 세트를 생성하고 수정하면 클러스터의 ARM64 컴퓨팅 노드를 제어합니다.
$ oc create -f aws-arm64-machine-set-0.yamlARM64 컴퓨팅 노드를 배포하는 샘플 YAML 컴퓨팅 머신 세트
apiVersion: machine.openshift.io/v1beta1 kind: MachineSet metadata: labels: machine.openshift.io/cluster-api-cluster: <infrastructure_id>1 name: <infrastructure_id>-aws-arm64-machine-set-02 namespace: openshift-machine-api spec: replicas: 1 selector: matchLabels: machine.openshift.io/cluster-api-cluster: <infrastructure_id>3 machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role>-<zone>4 template: metadata: labels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> machine.openshift.io/cluster-api-machine-role: <role>5 machine.openshift.io/cluster-api-machine-type: <role>6 machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role>-<zone>7 spec: metadata: labels: node-role.kubernetes.io/<role>: "" providerSpec: value: ami: id: ami-02a574449d4f4d2808 apiVersion: awsproviderconfig.openshift.io/v1beta1 blockDevices: - ebs: iops: 0 volumeSize: 120 volumeType: gp2 credentialsSecret: name: aws-cloud-credentials deviceIndex: 0 iamInstanceProfile: id: <infrastructure_id>-worker-profile9 instanceType: m6g.xlarge10 kind: AWSMachineProviderConfig placement: availabilityZone: us-east-1a11 region: <region>12 securityGroups: - filters: - name: tag:Name values: - <infrastructure_id>-worker-sg13 subnet: filters: - name: tag:Name values: - <infrastructure_id>-private-<zone> tags: - name: kubernetes.io/cluster/<infrastructure_id>14 value: owned - name: <custom_tag_name> value: <custom_tag_value> userDataSecret: name: worker-user-data- 1 2 3 9 13 14
- 클러스터를 프로비저닝할 때 설정한 클러스터 ID를 기반으로 하는 인프라 ID를 지정합니다. OpenShift CLI 패키지가 설치되어 있으면 다음 명령을 실행하여 인프라 ID를 얻을 수 있습니다.
$ oc get -o jsonpath=‘{.status.infrastructureName}{“\n”}’ infrastructure cluster - 4 7
- 인프라 ID, 역할 노드 레이블 및 영역을 지정합니다.
- 5 6
- 추가할 역할 노드 레이블을 지정합니다.
- 8
- OpenShift Container Platform 노드의 AWS 영역에 대해 ARM64 지원 RHCOS(Red Hat Enterprise Linux CoreOS) Amazon 머신 이미지(AMI)를 지정합니다.
$ oc get configmap/coreos-bootimages \ -n openshift-machine-config-operator \ -o jsonpath='{.data.stream}' | jq \ -r '.architectures.<arch>.images.aws.regions."<region>".image' - 10
- ARM64 지원 머신 유형을 지정합니다. 자세한 내용은 "AWS 64비트 ARM의 테스트 인스턴스 유형"을 참조하십시오.
- 11
- 영역을 지정합니다(예:
us-east-1a). 선택한 영역에 64비트 ARM 시스템을 제공하는지 확인합니다. - 12
- 리전을 지정합니다(예:
us-east-1). 선택한 영역에 64비트 ARM 시스템을 제공하는지 확인합니다.
검증
다음 명령을 입력하여 컴퓨팅 머신 세트 목록을 확인합니다.
$ oc get machineset -n openshift-machine-api생성된 ARM64 머신 세트를 확인할 수 있습니다.
출력 예
NAME DESIRED CURRENT READY AVAILABLE AGE <infrastructure_id>-aws-arm64-machine-set-0 2 2 2 2 10m다음 명령을 사용하여 노드가 준비되고 예약할 수 있는지 확인할 수 있습니다.
$ oc get nodes
4.4. 베어 메탈에서 다중 아키텍처 컴퓨팅 머신으로 클러스터 생성 (기술 프리뷰)
베어 메탈에서 다중 아키텍처 컴퓨팅 머신으로 클러스터를 생성하려면 기존 단일 아키텍처 베어 메탈 클러스터가 있어야 합니다. 베어 메탈 설치에 대한 자세한 내용은 베어 메탈에 사용자 프로비저닝 클러스터 설치를 참조하십시오. 그런 다음 베어 메탈의 OpenShift Container Platform 클러스터에 64비트 ARM 컴퓨팅 머신을 추가할 수 있습니다.
베어 메탈 클러스터에 64비트 ARM 노드를 추가하려면 먼저 다중 아키텍처 페이로드를 사용하는 클러스터를 업그레이드해야 합니다. 다중 아키텍처 페이로드로 마이그레이션하는 방법에 대한 자세한 내용은 다중 아키텍처 컴퓨팅 머신이 있는 클러스터로 마이그레이션 을 참조하십시오.
다음 절차에서는 ISO 이미지 또는 네트워크 PXE 부팅을 사용하여 RHCOS 컴퓨팅 머신을 생성하는 방법을 설명합니다. 그러면 ARM64 노드를 베어 메탈 클러스터에 추가하고 다중 아키텍처 컴퓨팅 머신이 있는 클러스터를 배포할 수 있습니다.
베어 메탈 사용자 프로비저닝 설치에서 다중 아키텍처 컴퓨팅 머신이 있는 클러스터는 기술 프리뷰 기능 전용입니다. 기술 프리뷰 기능은 Red Hat 프로덕션 서비스 수준 계약(SLA)에서 지원되지 않으며 기능적으로 완전하지 않을 수 있습니다. 따라서 프로덕션 환경에서 사용하는 것은 권장하지 않습니다. 이러한 기능을 사용하면 향후 제품 기능을 조기에 이용할 수 있어 개발 과정에서 고객이 기능을 테스트하고 피드백을 제공할 수 있습니다.
Red Hat 기술 프리뷰 기능의 지원 범위에 대한 자세한 내용은 기술 프리뷰 기능 지원 범위를 참조하십시오.
4.4.1. ISO 이미지를 사용하여 RHCOS 머신 생성
ISO 이미지를 사용하여 머신을 생성함으로써 베어 메탈 클러스터에 대해 더 많은 Red Hat Enterprise Linux CoreOS (RHCOS) 컴퓨팅 머신을 생성할 수 있습니다.
사전 요구 사항
- 클러스터의 컴퓨팅 머신에 대한 Ignition 구성 파일의 URL을 가져옵니다. 설치 중에 이 파일은 HTTP 서버에 업로드되어 있어야 합니다.
-
OpenShift CLI(
oc)가 설치되어 있어야 합니다.
절차
다음 명령을 실행하여 클러스터에서 Ignition 구성 파일을 추출합니다.
$ oc extract -n openshift-machine-api secret/worker-user-data-managed --keys=userData --to=- > worker.ign-
내보낸
worker.ignIgnition 구성 파일을 클러스터에서 HTTP 서버로 업로드합니다. 해당 파일의 URL을 기록해 둡니다. URL에서 Ignition 파일을 사용할 수 있는지 확인할 수 있습니다. 다음 예제에서는 컴퓨팅 노드에 대한 Ignition 구성 파일을 가져옵니다.
$ curl -k http://<HTTP_server>/worker.ign다음 명령으로 실행하여 새 머신을 부팅하기 위해 ISO 이미지에 액세스할 수 있습니다.
RHCOS_VHD_ORIGIN_URL=$(oc -n openshift-machine-config-operator get configmap/coreos-bootimages -o jsonpath='{.data.stream}' | jq -r '.architectures.<architecture>.artifacts.metal.formats.iso.disk.location')ISO 파일을 사용하여 추가 컴퓨팅 머신에 RHCOS를 설치합니다. 클러스터를 설치하기 전에 머신을 만들 때 사용한 것과 동일한 방법을 사용합니다.
- ISO 이미지를 디스크에 굽고 직접 부팅합니다.
- LOM 인터페이스에서 ISO 리디렉션을 사용합니다.
옵션을 지정하거나 라이브 부팅 시퀀스를 중단하지 않고 RHCOS ISO 이미지를 부팅합니다. 설치 프로그램이 RHCOS 라이브 환경에서 쉘 프롬프트로 부팅될 때까지 기다립니다.
참고커널 인수를 추가하기 위해 RHCOS 설치 부팅 프로세스를 중단할 수 있습니다. 그러나 이 ISO 프로세스에서는 커널 인수를 추가하는 대신 다음 단계에 설명된 대로
coreos-installer명령을 사용해야 합니다.coreos-installer명령을 실행하고 설치 요구 사항을 충족하는 옵션을 지정합니다. 최소한 노드 유형에 대한 Ignition 구성 파일과 설치할 장치를 가리키는 URL을 지정해야 합니다.$ sudo coreos-installer install --ignition-url=http://<HTTP_server>/<node_type>.ign <device> --ignition-hash=sha512-<digest>1 2 참고TLS를 사용하는 HTTPS 서버를 통해 Ignition 구성 파일을 제공하려는 경우
coreos-installer를 실행하기 전에 내부 인증 기관(CA)을 시스템 신뢰 저장소에 추가할 수 있습니다.다음 예제에서는
/dev/sda장치에 부트스트랩 노드 설치를 초기화합니다. 부트스트랩 노드의 Ignition 구성 파일은 IP 주소 192.168.1.2가 있는 HTTP 웹 서버에서 가져옵니다.$ sudo coreos-installer install --ignition-url=http://192.168.1.2:80/installation_directory/bootstrap.ign /dev/sda --ignition-hash=sha512-a5a2d43879223273c9b60af66b44202a1d1248fc01cf156c46d4a79f552b6bad47bc8cc78ddf0116e80c59d2ea9e32ba53bc807afbca581aa059311def2c3e3b머신 콘솔에서 RHCOS 설치 진행률을 모니터링합니다.
중요OpenShift Container Platform 설치를 시작하기 전에 각 노드에서 성공적으로 설치되었는지 확인합니다. 설치 프로세스를 관찰하면 발생할 수 있는 RHCOS 설치 문제의 원인을 파악하는 데 도움이 될 수 있습니다.
- 계속해서 클러스터에 추가 컴퓨팅 머신을 만듭니다.
4.4.2. PXE 또는 iPXE 부팅을 통해 RHCOS 머신 생성
PXE 또는 iPXE 부팅을 사용하여 베어 메탈 클러스터에 대해 추가 Red Hat Enterprise Linux CoreOS (RHCOS) 컴퓨팅 머신을 생성할 수 있습니다.
사전 요구 사항
- 클러스터의 컴퓨팅 머신에 대한 Ignition 구성 파일의 URL을 가져옵니다. 설치 중에 이 파일은 HTTP 서버에 업로드되어 있어야 합니다.
-
클러스터 설치 중에 HTTP 서버에 업로드 한 RHCOS ISO 이미지, 압축된 메탈 BIOS,
kernel및initramfs파일의 URL을 가져옵니다. - 설치 중에 OpenShift Container Platform 클러스터에 대한 머신을 생성하는 데 사용한 PXE 부팅 인프라에 액세스할 수 있습니다. RHCOS가 설치된 후 로컬 디스크에서 머신을 부팅해야합니다.
-
UEFI를 사용하는 경우 OpenShift Container Platform 설치 중에 수정 한
grub.conf파일에 액세스할 수 있습니다.
절차
RHCOS 이미지의 PXE 또는 iPXE가 올바르게 설치되었는지 확인합니다.
PXE의 경우:
DEFAULT pxeboot TIMEOUT 20 PROMPT 0 LABEL pxeboot KERNEL http://<HTTP_server>/rhcos-<version>-live-kernel-<architecture>1 APPEND initrd=http://<HTTP_server>/rhcos-<version>-live-initramfs.<architecture>.img coreos.inst.install_dev=/dev/sda coreos.inst.ignition_url=http://<HTTP_server>/worker.ign coreos.live.rootfs_url=http://<HTTP_server>/rhcos-<version>-live-rootfs.<architecture>.img2 - 1
- HTTP 서버에 업로드한 라이브
kernel파일의 위치를 지정합니다. - 2
- HTTP 서버에 업로드한 RHCOS 파일의 위치를 지정합니다.
initrd매개변수 값은initramfs파일의 위치이고coreos.inst.ignition_url매개변수 값은 작업자 Ignition 설정 파일의 위치이며coreos.live.rootfs_url매개 변수 값은 라이브rootfs파일의 위치입니다.coreos.inst.ignition_url및coreos.live.rootfs_url매개변수는 HTTP 및 HTTPS만 지원합니다.
참고이 구성은 그래픽 콘솔이 있는 시스템에서 직렬 콘솔 액세스를 활성화하지 않습니다. 다른 콘솔을 구성하려면
APPEND행에 하나 이상의console=인수를 추가합니다. 예를 들어console=tty0 console=ttyS0을 추가하여 첫 번째 PC 직렬 포트를 기본 콘솔로 설정하고 그래픽 콘솔을 보조 콘솔로 설정합니다. 자세한 내용은 Red Hat Enterprise Linux에서 직렬 터미널 및/또는 콘솔 설정 방법을 참조하십시오.iPXE의 경우 (
x86_64+aarch64).kernel http://<HTTP_server>/rhcos-<version>-live-kernel-<architecture> initrd=main coreos.live.rootfs_url=http://<HTTP_server>/rhcos-<version>-live-rootfs.<architecture>.img coreos.inst.install_dev=/dev/sda coreos.inst.ignition_url=http://<HTTP_server>/worker.ign1 2 initrd --name main http://<HTTP_server>/rhcos-<version>-live-initramfs.<architecture>.img3 boot- 1
- HTTP 서버에 업로드한 RHCOS 파일의 위치를 지정합니다.
kernel매개변수 값은kernel파일의 위치이고initrd=main인수는 UEFI 시스템에서 부팅하는 데 필요하며coreos.live.rootfs_url매개변수 값은rootfs파일의 위치이며coreos.inst.ignition_url매개 변수 값은 작업자 Ignition 구성 파일의 위치입니다. - 2
- NIC를 여러 개 사용하는 경우
ip옵션에 단일 인터페이스를 지정합니다. 예를 들어,eno1라는 NIC에서 DHCP를 사용하려면ip=eno1:dhcp를 설정하십시오. - 3
- HTTP 서버에 업로드한
initramfs파일의 위치를 지정합니다.
참고이 구성은 그래픽 콘솔이 있는 시스템에서 직렬 콘솔 액세스를 활성화하지 않습니다. 다른 콘솔을 구성하려면
커널행에 하나 이상의console=인수를 추가합니다. 예를 들어console=tty0 console=ttyS0을 추가하여 첫 번째 PC 직렬 포트를 기본 콘솔로 설정하고 그래픽 콘솔을 보조 콘솔로 설정합니다. 자세한 내용은 How does one set up a serial terminal and/or console in Red Hat Enterprise Linux? 및 "고급 RHCOS 설치 구성" 섹션의 "프로비저닝 콘솔 활성화"를 참조하십시오.참고aarch64아키텍처에서 CoreOS커널을 네트워킹하려면IMAGE_GZIP옵션이 활성화된 iPXE 빌드 버전을 사용해야 합니다. iPXE의IMAGE_GZIP옵션을 참조하십시오.aarch64에서 PXE ( UEFI 및 GRUB을 두 번째 단계로 포함)의 경우 :menuentry 'Install CoreOS' { linux rhcos-<version>-live-kernel-<architecture> coreos.live.rootfs_url=http://<HTTP_server>/rhcos-<version>-live-rootfs.<architecture>.img coreos.inst.install_dev=/dev/sda coreos.inst.ignition_url=http://<HTTP_server>/worker.ign1 2 initrd rhcos-<version>-live-initramfs.<architecture>.img3 }- 1
- HTTP/TFTP 서버에 업로드한 RHCOS 파일의 위치를 지정합니다.
kernel매개변수 값은 TFTP 서버의파일의 위치입니다.coreos.live.rootfs_url매개변수 값은rootfs파일의 위치이며coreos.inst.ignition_url매개변수 값은 HTTP Server의 작업자 Ignition 구성 파일의 위치입니다. - 2
- NIC를 여러 개 사용하는 경우
ip옵션에 단일 인터페이스를 지정합니다. 예를 들어,eno1라는 NIC에서 DHCP를 사용하려면ip=eno1:dhcp를 설정하십시오. - 3
- TFTP 서버에 업로드한
initramfs파일의 위치를 지정합니다.
- PXE 또는 iPXE 인프라를 사용하여 클러스터에 필요한 컴퓨팅 머신을 만듭니다.
4.4.3. 시스템의 인증서 서명 요청 승인
클러스터에 시스템을 추가하면 추가한 시스템별로 보류 중인 인증서 서명 요청(CSR)이 두 개씩 생성됩니다. 이러한 CSR이 승인되었는지 확인해야 하며, 필요한 경우 이를 직접 승인해야 합니다. 클라이언트 요청을 먼저 승인한 다음 서버 요청을 승인해야 합니다.
사전 요구 사항
- 클러스터에 시스템을 추가했습니다.
프로세스
클러스터가 시스템을 인식하는지 확인합니다.
$ oc get nodes출력 예
NAME STATUS ROLES AGE VERSION master-0 Ready master 63m v1.26.0 master-1 Ready master 63m v1.26.0 master-2 Ready master 64m v1.26.0출력에 생성된 모든 시스템이 나열됩니다.
참고이전 출력에는 일부 CSR이 승인될 때까지 컴퓨팅 노드(작업자 노드라고도 함)가 포함되지 않을 수 있습니다.
보류 중인 CSR을 검토하고 클러스터에 추가한 각 시스템에 대해
Pending또는Approved상태의 클라이언트 및 서버 요청이 표시되는지 확인합니다.$ oc get csr출력 예
NAME AGE REQUESTOR CONDITION csr-8b2br 15m system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending csr-8vnps 15m system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending ...예에서는 두 시스템이 클러스터에 참여하고 있습니다. 목록에는 승인된 CSR이 더 많이 나타날 수도 있습니다.
CSR이 승인되지 않은 경우, 추가된 시스템에 대한 모든 보류 중인 CSR이
Pending상태로 전환된 후 클러스터 시스템의 CSR을 승인합니다.참고CSR은 교체 주기가 자동으로 만료되므로 클러스터에 시스템을 추가한 후 1시간 이내에 CSR을 승인하십시오. 한 시간 내에 승인하지 않으면 인증서가 교체되고 각 노드에 대해 두 개 이상의 인증서가 표시됩니다. 이러한 인증서를 모두 승인해야 합니다. 클라이언트 CSR이 승인되면 Kubelet은 인증서에 대한 보조 CSR을 생성하므로 수동 승인이 필요합니다. 그러면 Kubelet에서 동일한 매개변수를 사용하여 새 인증서를 요청하는 경우 인증서 갱신 요청은
machine-approver에 의해 자동으로 승인됩니다.참고베어 메탈 및 기타 사용자 프로비저닝 인프라와 같이 머신 API를 사용하도록 활성화되지 않는 플랫폼에서 실행되는 클러스터의 경우 CSR(Kubelet service Certificate Request)을 자동으로 승인하는 방법을 구현해야 합니다. 요청이 승인되지 않으면 API 서버가 kubelet에 연결될 때 서비스 인증서가 필요하므로
oc exec,oc rsh,oc logs명령을 성공적으로 수행할 수 없습니다. Kubelet 엔드 포인트에 연결하는 모든 작업을 수행하려면 이 인증서 승인이 필요합니다. 이 방법은 새 CSR을 감시하고 CSR이system:node또는system:admin그룹의node-bootstrapper서비스 계정에 의해 제출되었는지 확인하고 노드의 ID를 확인합니다.개별적으로 승인하려면 유효한 CSR 각각에 대해 다음 명령을 실행하십시오.
$ oc adm certificate approve <csr_name>1 - 1
<csr_name>은 현재 CSR 목록에 있는 CSR의 이름입니다.
보류 중인 CSR을 모두 승인하려면 다음 명령을 실행하십시오.
$ oc get csr -o go-template='{{range .items}}{{if not .status}}{{.metadata.name}}{{"\n"}}{{end}}{{end}}' | xargs --no-run-if-empty oc adm certificate approve참고일부 Operator는 일부 CSR이 승인될 때까지 사용할 수 없습니다.
이제 클라이언트 요청이 승인되었으므로 클러스터에 추가한 각 머신의 서버 요청을 검토해야 합니다.
$ oc get csr출력 예
NAME AGE REQUESTOR CONDITION csr-bfd72 5m26s system:node:ip-10-0-50-126.us-east-2.compute.internal Pending csr-c57lv 5m26s system:node:ip-10-0-95-157.us-east-2.compute.internal Pending ...나머지 CSR이 승인되지 않고
Pending상태인 경우 클러스터 머신의 CSR을 승인합니다.개별적으로 승인하려면 유효한 CSR 각각에 대해 다음 명령을 실행하십시오.
$ oc adm certificate approve <csr_name>1 - 1
<csr_name>은 현재 CSR 목록에 있는 CSR의 이름입니다.
보류 중인 CSR을 모두 승인하려면 다음 명령을 실행하십시오.
$ oc get csr -o go-template='{{range .items}}{{if not .status}}{{.metadata.name}}{{"\n"}}{{end}}{{end}}' | xargs oc adm certificate approve
모든 클라이언트 및 서버 CSR이 승인된 후 머신은
Ready상태가 됩니다. 다음 명령을 실행하여 확인합니다.$ oc get nodes출력 예
NAME STATUS ROLES AGE VERSION master-0 Ready master 73m v1.26.0 master-1 Ready master 73m v1.26.0 master-2 Ready master 74m v1.26.0 worker-0 Ready worker 11m v1.26.0 worker-1 Ready worker 11m v1.26.0참고머신이
Ready상태로 전환하는 데 서버 CSR의 승인 후 몇 분이 걸릴 수 있습니다.
추가 정보
- CSR에 대한 자세한 내용은 인증서 서명 요청을 참조하십시오.
4.5. 다중 아키텍처 컴퓨팅 머신의 이미지 스트림에서 매니페스트 목록 가져오기
다중 아키텍처 컴퓨팅 머신이 있는 OpenShift Container Platform 4.13 클러스터에서 클러스터의 이미지 스트림은 매니페스트 목록을 자동으로 가져오지 않습니다. 매니페스트 목록을 가져오려면 기본 importMode 옵션을 PreserveOriginal 옵션으로 수동으로 변경해야 합니다.
사전 요구 사항
-
OpenShift Container Platform CLI(
oc)를 설치했습니다.
절차
다음 예제 명령은
ImageStreamcli-artifacts를 패치하여cli-artifacts:latest이미지 스트림 태그를 매니페스트 목록으로 가져오는 방법을 보여줍니다.$ oc patch is/cli-artifacts -n openshift -p '{"spec":{"tags":[{"name":"latest","importPolicy":{"importMode":"PreserveOriginal"}}]}}'
검증
이미지 스트림 태그를 검사하여 올바르게 가져온 매니페스트 목록을 확인할 수 있습니다. 다음 명령은 특정 태그의 개별 아키텍처 매니페스트를 나열합니다.
$ oc get istag cli-artifacts:latest -n openshift -oyamldockerImageManifests오브젝트가 있으면 매니페스트 목록 가져오기에 성공했습니다.dockerImageManifests오브젝트 출력 예dockerImageManifests: - architecture: amd64 digest: sha256:16d4c96c52923a9968fbfa69425ec703aff711f1db822e4e9788bf5d2bee5d77 manifestSize: 1252 mediaType: application/vnd.docker.distribution.manifest.v2+json os: linux - architecture: arm64 digest: sha256:6ec8ad0d897bcdf727531f7d0b716931728999492709d19d8b09f0d90d57f626 manifestSize: 1252 mediaType: application/vnd.docker.distribution.manifest.v2+json os: linux - architecture: ppc64le digest: sha256:65949e3a80349cdc42acd8c5b34cde6ebc3241eae8daaeea458498fedb359a6a manifestSize: 1252 mediaType: application/vnd.docker.distribution.manifest.v2+json os: linux - architecture: s390x digest: sha256:75f4fa21224b5d5d511bea8f92dfa8e1c00231e5c81ab95e83c3013d245d1719 manifestSize: 1252 mediaType: application/vnd.docker.distribution.manifest.v2+json os: linux
5장. 설치 후 시스템 구성 작업
OpenShift Container Platform 노드에서 실행되는 운영 체제를 변경해야하는 경우가 있습니다. 여기에는 네트워크 시간 서비스 설정 변경, 커널 인수 추가 또는 특정 방식으로 저널 설정이 포함됩니다.
몇 가지 특수 기능 외에도 OpenShift Container Platform 노드에서 운영 체제 대부분의 변경 사항은 Machine Config Operator가 관리하는 MachineConfig 객체를 생성하여 수행할 수 있습니다.
이 섹션의 작업은 Machine Config Operator의 기능을 사용하여 OpenShift Container Platform 노드에서 운영 체제 기능을 구성하는 방법을 설명합니다.
5.1. 머신 구성 Operator 정보
OpenShift Container Platform 4.13은 운영 체제와 클러스터 관리를 모두 통합합니다. 클러스터는 클러스터 노드에서 RHCOS(Red Hat Enterprise Linux CoreOS)에 대한 업데이트를 포함하여 자체 업데이트를 관리하므로 OpenShift Container Platform은 노드 업그레이드 오케스트레이션을 단순화하는 독단적인 라이프사이클 관리 환경을 제공합니다.
OpenShift Container Platform은 3개의 데몬 세트와 컨트롤러를 사용하여 노드 관리를 단순화합니다. 이러한 데몬 세트는 표준 Kubernetes 스타일 구성을 사용하여 호스트에 대한 운영 체제 업데이트 및 구성 변경을 오케스트레이션합니다. 다음이 포함됩니다.
-
컨트롤 플레인에서 머신 업그레이드를 조정하는
machine-config-controller. 모든 클러스터 노드를 모니터링하고 구성 업데이트를 오케스트레이션합니다. -
클러스터의 각 노드에서 실행되며 머신 구성에 정의된 구성으로 MachineConfigController의 지시에 따라 머신을 업데이트하는
machine-config-daemon데몬 세트. 노드가 변경사항을 감지하면 포드를 비우고 업데이트를 적용한 다음 재부팅합니다. 이러한 변경사항은 지정된 머신 구성 및 제어 kubelet 구성을 적용하는 Ignition 구성 파일의 형태로 제공됩니다. 업데이트 자체는 컨테이너로 제공됩니다. 이 프로세스는 OpenShift Container Platform 및 RHCOS 업데이트를 성공적으로 관리하는 데 핵심입니다. -
클러스터에 참여할 때 컨트롤 플레인 노드에 Ignition 구성 파일을 제공하는
machine-config-server데몬 세트.
머신 구성은 Ignition 구성의 서브 세트입니다. machine-config-daemon은 OSTree 업데이트를 수행해야 하는지 아니면 일련의 systemd kubelet 파일 변경, 구성 변경 또는 운영 체제나 OpenShift Container Platform 구성의 기타 변경 사항을 적용해야 하는지 확인하기 위해 머신 구성을 읽습니다.
노드 관리 작업을 수행할 때 KubeletConfig 사용자 정의 리소스(CR)를 생성하거나 수정합니다.
머신 구성을 변경하면 MCO(Machine Config Operator)가 변경 사항을 적용하기 위해 해당 노드를 자동으로 재부팅합니다.
머신 구성 변경사항이 적용된 후 노드가 자동 재부팅되지 않게 하려면 해당 머신 구성 풀에서 spec.paused 필드를 true로 설정하여 자동 부팅 프로세스를 일시중지해야 합니다. 일시 정지되면 spec.paused 필드를 false로 설정하고 노드가 새 구성으로 재부팅될 때까지 머신 구성 변경 사항이 적용되지 않습니다.
다음 수정 사항에서는 노드 재부팅이 트리거되지 않습니다.
MCO가 다음 변경 사항을 감지하면 노드를 드레이닝하거나 재부팅하지 않고 업데이트를 적용합니다.
-
머신 구성의
spec.config.passwd.users.sshAuthorizedKeys매개변수에서 SSH 키 변경 -
openshift-config네임 스페이스에서 글로벌 풀 시크릿 또는 풀 시크릿 관련 변경 사항 -
Kubernetes API Server Operator의
/etc/kubernetes/kubelet-ca.crt인증 기관(CA) 자동 교체
-
머신 구성의
MCO가
ImageDigestMirrorSet,ImageTagMirrorSet또는ImageContentSourcePolicy개체 추가 또는 편집과 같은/etc/containers/registries.conf파일의 변경을 감지하면 해당 노드를 드레이닝하고 변경 사항을 적용하고 노드를 분리합니다. 다음 변경에는 노드 드레이닝이 발생하지 않습니다.-
각 미러에 대해 설정된
pull-from-mirror = "digest-only"매개변수를 사용하여 레지스트리를 추가합니다. -
레지스트리에 설정된
pull-from-mirror = "digest-only"매개변수를 사용하여 미러를 추가합니다. -
unqualified-search-registries목록에 항목이 추가되었습니다.
-
각 미러에 대해 설정된
노드의 구성이 현재 적용된 머신 구성에서 지정하는 것과 완전히 일치하지 않는 경우가 있을 수 있습니다. 이 상태를 구성 드리프트 라고 합니다. MCO(Machine Config Daemon)는 노드에서 구성 드리프트를 정기적으로 확인합니다. MCD가 구성 드리프트를 감지하면 관리자가 노드 구성을 수정할 때까지 MCO는 노드가 저하된 상태로 표시됩니다. 성능이 저하된 노드는 온라인 상태이고 작동하지만 업데이트할 수 없습니다.
5.1.1. 머신 구성 개요
MCO (Machine Config Operator)는 systemd, CRI-O 및 Kubelet, 커널, 네트워크 관리자 및 기타 시스템 기능에 대한 업데이트를 관리합니다. 또한 호스트에 구성 파일을 쓸 수 있는 MachineConfig CRD를 제공합니다( machine-config-operator참조). OpenShift Container Platform 클러스터에 대한 고급 시스템 수준을 변경하려면 MCO의 기능과 다른 구성 요소와 상호 작용하는 방법을 이해하는 것이 중요합니다. MCO, 머신 구성 및 사용 방법에 대해 알아야 할 몇 가지 사항은 다음과 같습니다.
- 머신 구성은 사전순으로 해당 이름의 사전순으로 처리됩니다. 렌더링 컨트롤러는 목록의 첫 번째 머신 구성을 기반으로 사용하고 나머지를 기본 머신 구성에 추가합니다.
- 머신 구성은 OpenShift Container Platform 노드 풀을 나타내는 각 시스템의 운영 체제에서 파일 또는 서비스를 특정하게 변경할 수 있습니다.
MCO는 시스템 풀의 운영 체제에 변경 사항을 적용합니다. 모든 OpenShift Container Platform 클러스터는 작업자 및 컨트롤 플레인 노드 풀로 시작합니다. 역할 레이블을 추가하여 사용자 지정 노드 풀을 구성할 수 있습니다. 예를 들어 애플리케이션에 필요한 특정 하드웨어 기능을 포함하는 작업자 노드의 사용자 정의 풀을 설정할 수 있습니다. 그러나 이 섹션의 예에서는 기본 풀 유형의 변경에 중점을 둡니다.
중요노드는
master또는worker와 같이 유형을 나타내기 위해 여러 레이블을 적용할 수 있지만 단일 머신 구성 풀의 멤버일 수 있습니다.-
머신 구성 변경 후 MCO는
topology.kubernetes.io/zone레이블을 기반으로 영역별로 영향을 받는 노드를 업데이트합니다. 영역에 둘 이상의 노드가 있으면 가장 오래된 노드가 먼저 업데이트됩니다. 베어 메탈 배포에서와 같이 영역을 사용하지 않는 노드의 경우 노드가 사용 기간으로 업그레이드되며 가장 오래된 노드가 먼저 업데이트됩니다. MCO는 머신 구성 풀의maxUnavailable필드에 지정된 노드 수를 한 번에 업데이트합니다. - OpenShift Container Platform을 디스크에 설치하기 전에 일부 머신 구성을 완료해야 합니다. 대부분의 경우 이 작업은 설치 후 머신 구성으로 실행되지 않고 OpenShift Container Platform 설치 프로그램 프로세스에 직접 삽입되는 머신 구성을 생성하여 수행할 수 있습니다. 다른 경우에는 노드별 개별 IP 주소 설정 또는 고급 디스크 파티셔닝과 같은 작업을 수행하기 위해 OpenShift Container Platform 설치 프로그램 시작 시 커널 인수를 전달하는 베어 메탈 설치를 수행해야 할 수 있습니다.
- MCO는 머신 구성에 설정된 항목을 관리합니다. MCO가 충돌하는 파일을 관리하도록 명시적으로 지시하지 않는 한 MCO는 시스템에 대한 수동 변경 사항을 덮어 쓰지 않습니다. 즉, MCO는 사용자가 요청한 특정 업데이트 만 수행하고 전체 노드에 대한 제어를 요구하지 않습니다.
- 노드를 수동으로 변경하지 않는 것이 좋습니다. 노드를 종료하고 새 노드를 시작해야하는 경우 이러한 직접적인 변경 사항이 손실됩니다.
-
MCO는
/etc및/var디렉토리에있는 파일에 쓰는 경우에만 지원됩니다. 하지만 이러한 영역 중 하나에 심볼릭 링크를 사용하여 쓰기 가능해진 일부 디렉토리에 대한 심볼릭 링크도 있습니다./opt및/usr/local디렉토리는 예제입니다. - Ignition은 MachineConfigs에서 사용되는 구성 형식입니다. 자세한 내용은 Ignition Configuration Specification v3.2.0을 참조하십시오.
- Ignition 구성 설정은 OpenShift Container Platform 설치시 직접 제공될 수 있고 MCO가 Ignition 구성을 제공하는 것과 동일한 방식으로 포맷할 수 있지만 MCO는 원래 Ignition 구성이 무엇인지 확인할 방법이 없습니다. 따라서 Ignition 구성 설정을 배포하기 전에 이를 머신 구성에 래핑해야 합니다.
-
MCO에서 관리하는 파일이 MCO 외부에서 변경되면 MCD (Machine Config Daemon)가 노드를
degraded로 설정합니다. 이는 문제가 되는 파일을 덮어 쓰지 않으며 성능이degraded상태에서 계속 작동합니다. -
머신 구성을 사용하는 주요 이유는 OpenShift Container Platform 클러스터의 풀에 새 노드를 추가할 때 적용되기 때문입니다.
machine-api-operator는 새 머신을 프로비저닝하고 MCO가 이를 구성합니다.
MCO는 Ignition을 구성 형식으로 사용합니다. OpenShift Container Platform 4.6은 Ignition 구성 사양 버전 2에서 버전 3으로 이동했습니다.
5.1.1.1. 머신 구성에서 변경 가능한 구성
MCO가 변경할 수 있는 구성 요소의 종류는 다음과 같습니다.
config: Ignition 구성 개체 (Ignition 구성 사양 참조)를 생성하여 다음을 포함하여 OpenShift Container Platform 시스템에서 파일, systemd 서비스 및 기타 기능을 변경할 수 있습니다.
-
Configuration files:
/var또는/etc디렉토리에 파일을 만들거나 덮어 씁니다. - systemd units: systemd 서비스의 상태를 생성 및 설정하거나 추가 설정을 기존 systemd 서비스에 추가합니다.
users and groups: 설치 후 passwd 섹션에서 SSH 키를 변경합니다.
중요-
core사용자만 머신 구성을 사용하여 SSH 키 변경을 지원합니다. - 머신 구성을 사용하여 새 사용자를 추가하는 것은 지원되지 않습니다.
-
-
Configuration files:
- kernelArguments: OpenShift Container Platform 노드가 시작될 때 커널 명령 줄에 인수를 추가합니다.
-
kernelType: 선택 옵션으로 표준 커널 대신 사용할 비표준 커널을 확인합니다. RT 커널 (RAN 용)을 사용하려면
realtime을 사용합니다. 이는 일부 플랫폼에서만 지원됩니다.
- extensions: 사전 패키지화된 소프트웨어를 추가하여 RHCOS 기능을 확장합니다. 이 기능의 경우 사용 가능한 확장에는 usbguard 및 커널 모듈이 포함됩니다.
-
사용자 지정 리소스 (
ContainerRuntime및Kubelet용): 머신 구성 외부에서 MCO는 CRI-O 컨테이너 런타임 설정 (ContainerRuntimeCR) 및 Kubelet 서비스 (KubeletCR)를 변경하기 위해 두 가지 특정 사용자 지정 리소스를 관리합니다.
MCO는 OpenShift Container Platform 노드에서 운영 체제 구성 요소를 변경할 수 있는 유일한 Operator가 아닙니다. 다른 Operator도 운영 체제 수준의 기능을 변경할 수 있습니다. 한 가지 예로 Node Tuning Operator를 사용하여 Tuned 데몬 프로필을 통해 노드 수준 조정을 수행할 수있습니다.
설치 후 수행할 수 있는 MCO 구성 작업은 다음 절차에 포함되어 있습니다. OpenShift Container Platform 설치 중 또는 설치 전에 수행해야 하는 시스템 설정 작업은 RHCOS 베어 메탈 설치에 대한 설명을 참조하십시오.
노드의 구성이 현재 적용된 머신 구성에서 지정하는 것과 완전히 일치하지 않는 경우가 있을 수 있습니다. 이 상태를 구성 드리프트 라고 합니다. MCO(Machine Config Daemon)는 노드에서 구성 드리프트를 정기적으로 확인합니다. MCD가 구성 드리프트를 감지하면 관리자가 노드 구성을 수정할 때까지 MCO는 노드가 저하된 상태로 표시됩니다. 성능이 저하된 노드는 온라인 상태이고 작동하지만 업데이트할 수 없습니다. 구성 드리프트에 대한 자세한 내용은 구성 드리프트 탐지 이해를 참조하십시오.
5.1.1.2. 프로젝트
자세한 내용은 openshift-machine-config-operator GitHub 사이트를 참조하십시오.
5.1.2. Machine Config Operator 노드 드레이닝 동작 이해
머신 구성을 사용하여 새 구성 파일 추가, systemd 장치 또는 커널 인수 수정, SSH 키 업데이트와 같은 시스템 기능을 변경하는 경우 MCO(Machine Config Operator)는 이러한 변경 사항을 적용하고 각 노드가 원하는 구성 상태에 있는지 확인합니다.
변경 후 MCO는 새로 렌더링된 머신 구성을 생성합니다. 대부분의 경우 새로 렌더링된 머신 구성을 적용할 때 Operator는 영향을 받는 모든 노드에 업데이트된 구성이 있을 때까지 영향을 받는 각 노드에서 다음 단계를 수행합니다.
- Cordon. MCO는 추가 워크로드에 대해 노드를 예약할 수 없음으로 표시합니다.
- drain. MCO는 노드에서 실행 중인 모든 워크로드를 종료하여 워크로드를 다른 노드에 다시 예약합니다.
- 적용. MCO는 필요에 따라 새 구성을 노드에 씁니다.
- 재부팅. MCO가 노드를 다시 시작합니다.
- 차단 해제. MCO는 노드를 워크로드에 대해 예약 가능으로 표시합니다.
이 프로세스 전반에 걸쳐 MCO는 머신 구성 풀에 설정된 MaxUnavailable 값을 기반으로 필요한 Pod 수를 유지 관리합니다.
MCO가 마스터 노드에서 Pod를 드레이닝하는 경우 다음 조건을 기록하십시오.
- 단일 노드 OpenShift 클러스터에서 MCO는 드레이닝 작업을 건너뜁니다.
- MCO는 etcd와 같은 서비스로의 간섭을 방지하기 위해 정적 pod를 드레이닝하지 않습니다.
경우에 따라 노드가 드레이닝되지 않습니다. 자세한 내용은 "Machine Config Operator 정보"를 참조하십시오.
컨트롤 플레인 재부팅을 비활성화하여 주기 드레이닝 및 재부팅으로 인한 중단을 완화할 수 있습니다. 자세한 내용은 "Machine Config Operator가 자동으로 재부팅되지 않도록 비활성화"를 참조하십시오.
5.1.3. 구성 드리프트 탐지 이해
노드의 디스크 상태가 머신 구성에 구성된 것과 다른 경우가 있을 수 있습니다. 이를 구성 드리프트 라고 합니다. 예를 들어 클러스터 관리자는 파일, systemd 장치 파일 또는 머신 구성을 통해 구성된 파일 권한을 수동으로 수정할 수 있습니다. 이로 인해 구성 드리프트가 발생합니다. 구성 드리프트는 Machine Config Pool의 노드 또는 머신 구성이 업데이트되는 경우 문제가 발생할 수 있습니다.
MCO(Machine Config Operator)는 MCO(Machine Config Daemon)를 사용하여 노드에서 정기적으로 구성 드리프트가 있는지 확인합니다. 탐지된 경우 MCO는 노드와 MCP(머신 구성 풀)를 Degraded 로 설정하고 오류를 보고합니다. 성능이 저하된 노드는 온라인 상태이고 작동하지만 업데이트할 수 없습니다.
MCD는 다음 각 조건에서 구성 드리프트 탐지를 수행합니다.
- 노드가 부팅될 때
- 머신 구성에 지정된 파일(Ignition 파일 및 systemd 드롭인 단위)이 머신 구성 외부에서 수정되면 파일(Ignition 파일 및 systemd 드롭인 단위)이 모두 수정됩니다.
새 머신 구성을 적용하기 전에
참고노드에 새 머신 구성을 적용하면 MCD에서 구성 드리프트 탐지를 일시적으로 종료합니다. 이 종료는 새 머신 구성이 노드의 머신 구성과 반드시 다르기 때문에 필요합니다. 새 머신 구성이 적용된 후 MCD는 새 머신 구성을 사용하여 구성 드리프트 감지를 다시 시작합니다.
구성 드리프트 탐지를 수행할 때 MCD는 파일 내용과 권한이 현재 적용된 머신 구성에서 지정하는 권한과 완전히 일치하는지 확인합니다. 일반적으로 MCD는 탐지가 트리거된 후 1초 이내에 구성 드리프트를 감지합니다.
MCD가 구성 드리프트를 감지하면 MCD는 다음 작업을 수행합니다.
- 콘솔 로그에 오류 발송
- Kubernetes 이벤트 발송
- 노드에서 추가 탐지를 중지
-
노드 및 MCP의
성능 저하로 설정
MCP를 나열하여 성능이 저하된 노드가 있는지 확인할 수 있습니다.
$ oc get mcp worker
성능 저하된 MCP가 있는 경우 DEGRADEDMACHINECOUNT 필드는 다음 출력과 유사하게 0이 아닙니다.
출력 예
NAME CONFIG UPDATED UPDATING DEGRADED MACHINECOUNT READYMACHINECOUNT UPDATEDMACHINECOUNT DEGRADEDMACHINECOUNT AGE
worker rendered-worker-404caf3180818d8ac1f50c32f14b57c3 False True True 2 1 1 1 5h51m머신 구성 풀을 검사하여 구성 드리프트로 인해 문제가 발생하는지 확인할 수 있습니다.
$ oc describe mcp worker출력 예
...
Last Transition Time: 2021-12-20T18:54:00Z
Message: Node ci-ln-j4h8nkb-72292-pxqxz-worker-a-fjks4 is reporting: "content mismatch for file \"/etc/mco-test-file\""
Reason: 1 nodes are reporting degraded status on sync
Status: True
Type: NodeDegraded
...또는 성능이 저하된 노드를 알고 있는 경우 해당 노드를 검사합니다.
$ oc describe node/ci-ln-j4h8nkb-72292-pxqxz-worker-a-fjks4출력 예
...
Annotations: cloud.network.openshift.io/egress-ipconfig: [{"interface":"nic0","ifaddr":{"ipv4":"10.0.128.0/17"},"capacity":{"ip":10}}]
csi.volume.kubernetes.io/nodeid:
{"pd.csi.storage.gke.io":"projects/openshift-gce-devel-ci/zones/us-central1-a/instances/ci-ln-j4h8nkb-72292-pxqxz-worker-a-fjks4"}
machine.openshift.io/machine: openshift-machine-api/ci-ln-j4h8nkb-72292-pxqxz-worker-a-fjks4
machineconfiguration.openshift.io/controlPlaneTopology: HighlyAvailable
machineconfiguration.openshift.io/currentConfig: rendered-worker-67bd55d0b02b0f659aef33680693a9f9
machineconfiguration.openshift.io/desiredConfig: rendered-worker-67bd55d0b02b0f659aef33680693a9f9
machineconfiguration.openshift.io/reason: content mismatch for file "/etc/mco-test-file"
machineconfiguration.openshift.io/state: Degraded
...
다음 수정 사항 중 하나를 수행하여 구성 드리프트를 수정하고 노드를 Ready 상태로 되돌릴 수 있습니다.
- 노드에 있는 파일의 내용과 파일 권한이 머신 구성에 구성된 것과 일치하는지 확인합니다. 파일 내용을 수동으로 다시 작성하거나 파일 권한을 변경할 수 있습니다.
성능이 저하된 노드에 force 파일을 생성합니다. 강제 파일을 사용하면 MCD가 일반적인 구성 드리프트 탐지를 무시하고 현재 머신 구성을 가져옵니다.
참고노드에서 force 파일을 생성하면 해당 노드가 재부팅됩니다.
5.1.4. Machine config pool 상태 확인
MCO(Machine Config Operator), 하위 구성 요소 및 관리하는 리소스의 상태를 보려면 다음 oc 명령을 사용합니다.
프로세스
각 MCP(머신 구성 풀)에 대해 클러스터에서 사용 가능한 MCO 관리 노드 수를 보려면 다음 명령을 실행합니다.
$ oc get machineconfigpool출력 예
NAME CONFIG UPDATED UPDATING DEGRADED MACHINECOUNT READYMACHINECOUNT UPDATEDMACHINECOUNT DEGRADEDMACHINECOUNT AGE master rendered-master-06c9c4… True False False 3 3 3 0 4h42m worker rendered-worker-f4b64… False True False 3 2 2 0 4h42m다음과 같습니다.
- UPDATED
-
True상태는 MCO가 현재 머신 구성을 해당 MCP의 노드에 적용했음을 나타냅니다. 현재 머신 구성은oc get mcp출력의STATUS필드에 지정됩니다.False상태는 MCP의 노드가 업데이트 중임을 나타냅니다. - 업데이트
-
True상태는MachineConfigPool사용자 정의 리소스에 지정된 대로 MCO가 해당 MCP의 노드 중 하나 이상에 지정된 대로 원하는 머신 구성을 적용함을 나타냅니다. 원하는 머신 구성은 새로 편집된 머신 구성입니다. 업데이트 중인 노드를 예약에 사용할 수 없을 수 있습니다.False상태는 MCP의 모든 노드가 업데이트되었음을 나타냅니다. - DEGRADED
-
True상태는 MCO가 현재 또는 원하는 머신 구성을 해당 MCP의 노드 중 하나 이상에 적용하지 못하거나 구성이 실패함을 나타냅니다. 성능이 저하된 노드는 스케줄링에 사용할 수 없을 수 있습니다.False상태는 MCP의 모든 노드가 준비되었음을 나타냅니다. - MACHINECOUNT
- 해당 MCP의 총 머신 수를 나타냅니다.
- READYMACHINECOUNT
- 예약할 준비가 된 MCP의 총 머신 수를 나타냅니다.
- UPDATEDMACHINECOUNT
- 현재 머신 구성이 있는 MCP의 총 머신 수를 나타냅니다.
- DEGRADEDMACHINECOUNT
- degraded 또는 Unreconcilable으로 표시된 MCP의 총 머신 수를 나타냅니다.
이전 출력에는 컨트롤 플레인 (마스터) 노드와 3 개의 작업자 노드가 있습니다. 컨트롤 플레인 MCP 및 관련 노드가 현재 머신 구성으로 업데이트됩니다. 작업자 MCP의 노드가 원하는 머신 구성으로 업데이트되고 있습니다. 작업자 MCP의 노드 중 두 개가 업데이트되어
UPDATEDMACHINECOUNT가2로 표시된 대로 계속 업데이트됩니다.DEGRADEDMACHINECOUNT가0이고DEGRADED가False인 경우 문제가 없습니다.MCP의 노드가 업데이트되는 동안
CONFIG아래에 나열된 머신 구성은 현재 머신 구성으로, MCP가 업데이트되고 있습니다. 업데이트가 완료되면 나열된 머신 구성이 MCP를 업데이트한 원하는 머신 구성입니다.참고노드가 차단되는 경우 해당 노드는
READYMACHINECOUNT에 포함되지 않지만MACHINECOUNT에 포함됩니다. 또한 MCP 상태는UPDATING으로 설정됩니다. 노드에 현재 머신 구성이 있으므로UPDATEDMACHINECOUNT합계에 계산됩니다.출력 예
NAME CONFIG UPDATED UPDATING DEGRADED MACHINECOUNT READYMACHINECOUNT UPDATEDMACHINECOUNT DEGRADEDMACHINECOUNT AGE master rendered-master-06c9c4… True False False 3 3 3 0 4h42m worker rendered-worker-c1b41a… False True False 3 2 3 0 4h42mMachineConfigPool사용자 정의 리소스를 검사하여 MCP의 노드 상태를 확인하려면 다음 명령을 실행합니다.$ oc describe mcp worker출력 예
... Degraded Machine Count: 0 Machine Count: 3 Observed Generation: 2 Ready Machine Count: 3 Unavailable Machine Count: 0 Updated Machine Count: 3 Events: <none>참고노드가 차단 중이면 노드가
Ready 머신 수에 포함되지 않습니다.Unavailable Machine Count에 포함되어 있습니다:출력 예
... Degraded Machine Count: 0 Machine Count: 3 Observed Generation: 2 Ready Machine Count: 2 Unavailable Machine Count: 1 Updated Machine Count: 3기존
MachineConfig오브젝트를 보려면 다음 명령을 실행합니다.$ oc get machineconfigs출력 예
NAME GENERATEDBYCONTROLLER IGNITIONVERSION AGE 00-master 2c9371fbb673b97a6fe8b1c52... 3.2.0 5h18m 00-worker 2c9371fbb673b97a6fe8b1c52... 3.2.0 5h18m 01-master-container-runtime 2c9371fbb673b97a6fe8b1c52... 3.2.0 5h18m 01-master-kubelet 2c9371fbb673b97a6fe8b1c52… 3.2.0 5h18m ... rendered-master-dde... 2c9371fbb673b97a6fe8b1c52... 3.2.0 5h18m rendered-worker-fde... 2c9371fbb673b97a6fe8b1c52... 3.2.0 5h18mrendered로 나열된MachineConfig오브젝트는 변경하거나 삭제할 수 없습니다.특정 머신 구성의 내용을 보려면 (이 경우
01-master-kubelet) 다음 명령을 실행합니다.$ oc describe machineconfigs 01-master-kubelet명령의 출력에는 이
MachineConfig오브젝트에 구성 파일(cloud.conf및kubelet.conf)과 systemd 서비스(Kubernetes Kubelet)가 모두 포함되어 있음을 보여줍니다.출력 예
Name: 01-master-kubelet ... Spec: Config: Ignition: Version: 3.2.0 Storage: Files: Contents: Source: data:, Mode: 420 Overwrite: true Path: /etc/kubernetes/cloud.conf Contents: Source: data:,kind%3A%20KubeletConfiguration%0AapiVersion%3A%20kubelet.config.k8s.io%2Fv1beta1%0Aauthentication%3A%0A%20%20x509%3A%0A%20%20%20%20clientCAFile%3A%20%2Fetc%2Fkubernetes%2Fkubelet-ca.crt%0A%20%20anonymous... Mode: 420 Overwrite: true Path: /etc/kubernetes/kubelet.conf Systemd: Units: Contents: [Unit] Description=Kubernetes Kubelet Wants=rpc-statd.service network-online.target crio.service After=network-online.target crio.service ExecStart=/usr/bin/hyperkube \ kubelet \ --config=/etc/kubernetes/kubelet.conf \ ...
적용한 머신 구성에서 문제가 발생하면 언제든지 해당 변경 사항을 취소할 수 있습니다. 예를 들어 oc create -f ./myconfig.yaml 을 실행하여 머신 구성을 적용한 경우 다음 명령을 실행하여 해당 머신 구성을 제거할 수 있습니다.
$ oc delete -f ./myconfig.yaml이것이 유일한 문제인 경우 영향을 받는 풀 노드는 성능이 저하되지 않은 상태로 돌아갑니다. 이로 인해 실제로 렌더링된 구성이 이전에 렌더링된 상태로 롤백됩니다.
자체 머신 구성을 클러스터에 추가하는 경우 위의 예에 표시된 명령을 사용하여 해당 상태 및 적용되는 풀의 관련 상태를 확인할 수 있습니다.
5.2. MachineConfig 개체를 사용하여 노드 구성
이 섹션의 작업을 통해 MachineConfig 객체를 생성하여 OpenShift Container Platform 노드에서 실행되는 파일, systemd 단위 파일 및 기타 운영 체제 기능을 변경할 수 있습니다. 머신 구성 사용에 대한 자세한 내용은 SSH 인증 키 업데이트, 이미지 서명 확인,SCTP 활성화 및 OpenShift Container Platform용 iSCSI 이니시에이터 이름 구성 과 관련된 콘텐츠를 참조하십시오.
OpenShift Container Platform은 Ignition 사양 버전 3.2을 지원합니다. 앞으로 생성하는 모든 새로운 머신 구성은 Ignition 사양 버전 3.2를 기반으로 해야합니다. OpenShift Container Platform 클러스터를 업그레이드하는 경우 기존 Ignition 사양 버전 2.x 머신 구성은 사양 버전 3.2로 자동 변환됩니다.
노드의 구성이 현재 적용된 머신 구성에서 지정하는 것과 완전히 일치하지 않는 경우가 있을 수 있습니다. 이 상태를 구성 드리프트 라고 합니다. MCO(Machine Config Daemon)는 노드에서 구성 드리프트를 정기적으로 확인합니다. MCD가 구성 드리프트를 감지하면 관리자가 노드 구성을 수정할 때까지 MCO는 노드가 저하된 상태로 표시됩니다. 성능이 저하된 노드는 온라인 상태이고 작동하지만 업데이트할 수 없습니다. 구성 드리프트에 대한 자세한 내용은 구성 드리프트 감지 이해 를 참조하십시오.
OpenShift Container Platform 노드에 다른 구성 파일을 추가하는 방법의 경우 다음 "chrony 타임 서비스 구성" 프로세스를 모델로 사용하십시오.
5.2.1. chrony 타임 서비스 설정
chrony.conf 파일의 내용을 수정하고 해당 내용을 머신 구성으로 노드에 전달하여 chrony 타임 서비스 (chronyd)에서 사용하는 시간 서버 및 관련 구성을 설정할 수 있습니다.
프로세스
chrony.conf파일의 내용을 포함하여 Butane config를 만듭니다. 예를 들어 작업자 노드에 chrony를 구성하려면99-worker-chrony.bu파일을 만듭니다.참고Butane에 대한 자세한 내용은 “Butane 을 사용하여 머신 구성 생성”을 참조하십시오.
variant: openshift version: 4.13.0 metadata: name: 99-worker-chrony1 labels: machineconfiguration.openshift.io/role: worker2 storage: files: - path: /etc/chrony.conf mode: 06443 overwrite: true contents: inline: | pool 0.rhel.pool.ntp.org iburst4 driftfile /var/lib/chrony/drift makestep 1.0 3 rtcsync logdir /var/log/chrony- 1 2
- 컨트롤 플레인 노드에서 두 위치에 있는
master를worker로 대체합니다. - 3
- 시스템 구성 파일에서
mode필드의 8진수 값 모드를 지정합니다. 파일을 만들고 변경 사항을 적용하면mode가 10진수 값으로 변환됩니다.oc get mc <mc-name> -o yaml명령을 사용하여 YAML 파일을 확인할 수 있습니다. - 4
- DHCP 서버에서 제공하는 것과 같은 유효한 시간 소스를 지정합니다. 다른 방법으로
1.rhel.pool.ntp.org,2.rhel.pool.ntp.org또는3.rhel.pool.ntp.org의 NTP 서버 중 하나를 지정할 수 있습니다.
Butane을 사용하여 노드에 전달할 구성이 포함된
MachineConfig파일99-worker-chrony.yaml을 생성합니다.$ butane 99-worker-chrony.bu -o 99-worker-chrony.yaml다음 두 가지 방법 중 하나로 설정을 적용하십시오.
-
클러스터가 아직 실행되지 않은 경우 매니페스트 파일을 생성한 후
<installation_directory>/openshift디렉터리에MachineConfig개체 파일을 추가한 다음 클러스터를 계속 작성합니다. 클러스터가 이미 실행중인 경우 다음과 같은 파일을 적용합니다.
$ oc apply -f ./99-worker-chrony.yaml
-
클러스터가 아직 실행되지 않은 경우 매니페스트 파일을 생성한 후
5.2.2. chrony 타임 서비스 비활성화
MachineConfig CR(사용자 정의 리소스)을 사용하여 특정 역할이 있는 노드의 chrony 타임 서비스 (chronyd)를 비활성화할 수 있습니다.
사전 요구 사항
-
OpenShift CLI(
oc)를 설치합니다. -
cluster-admin권한이 있는 사용자로 로그인합니다.
프로세스
지정된 노드 역할에 대해
chronyd를 비활성화하는MachineConfigCR을 만듭니다.다음 YAML을
disable-chronyd.yaml파일에 저장합니다.apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: labels: machineconfiguration.openshift.io/role: <node_role>1 name: disable-chronyd spec: config: ignition: version: 3.2.0 systemd: units: - contents: | [Unit] Description=NTP client/server Documentation=man:chronyd(8) man:chrony.conf(5) After=ntpdate.service sntp.service ntpd.service Conflicts=ntpd.service systemd-timesyncd.service ConditionCapability=CAP_SYS_TIME [Service] Type=forking PIDFile=/run/chrony/chronyd.pid EnvironmentFile=-/etc/sysconfig/chronyd ExecStart=/usr/sbin/chronyd $OPTIONS ExecStartPost=/usr/libexec/chrony-helper update-daemon PrivateTmp=yes ProtectHome=yes ProtectSystem=full [Install] WantedBy=multi-user.target enabled: false name: "chronyd.service"- 1
chronyd를 비활성화하려는 노드 역할(예:master)입니다.
다음 명령을 실행하여
MachineConfigCR을 생성합니다.$ oc create -f disable-chronyd.yaml
5.2.3. 노드에 커널 인수 추가
특별한 경우에는 클러스터 노드 세트에 커널 인수를 추가해야 할 수 있습니다. 이 작업을 수행할 때 주의해야 하며 먼저 설정된 인수의 영향을 명확하게 이해하고 있어야합니다.
커널 인수를 잘못 사용하면 시스템이 부팅되지 않을 수 있습니다.
설정할 수 있는 커널 인수의 예는 다음과 같습니다.
-
nosmt: 커널에서 대칭 멀티 스레딩 (SMT)을 비활성화합니다. 멀티 스레딩은 각 CPU마다 여러 개의 논리 스레드를 허용합니다. 멀티 테넌트 환경에서
nosmt를 사용하여 잠재적인 크로스 스레드 공격 위험을 줄일 수 있습니다. SMT를 비활성화하는 것은 기본적으로 성능보다는 보안을 중요시하여 선택하는 것과 같습니다. - systemd.unified_cgroup_hierarchy: Linux 제어 그룹 버전 2 (cgroup v2)를 활성화합니다. cgroup v2는 커널 제어 그룹 의 다음 버전이며 여러 가지 개선 사항을 제공합니다.
enforcing=0: SELinux(Security Enhanced Linux)를 허용 모드에서 실행하도록 구성합니다. 허용 모드에서는 SELinux가 개체에 레이블을 지정하고 로그에 액세스 거부 항목을 내보내는 등 로드된 보안 정책을 적용하는 것처럼 동작하지만 실제로는 어떤 작업도 거부하지 않습니다. 프로덕션 시스템에서 지원되지 않지만 허용 모드는 디버깅에 유용할 수 있습니다.
주의프로덕션에서 RHCOS에서 SELinux를 비활성화하는 것은 지원되지 않습니다. 노드에서 SELinux를 비활성화한 후에는 프로덕션 클러스터에서 다시 프로비저닝해야 합니다.
커널 인수 목록 및 설명은 Kernel.org 커널 매개변수에서 참조하십시오.
다음 프로세스에서는 다음을 식별하는 MachineConfig를 만듭니다.
- 커널 인수를 추가하려는 머신 세트입니다. 이 경우 작업자 역할을 갖는 머신입니다.
- 기존 커널 인수 끝에 추가되는 커널 인수입니다.
- 머신 구성 목록에서 변경 사항이 적용되는 위치를 나타내는 라벨입니다.
사전 요구 사항
- OpenShift Container Platform 클러스터에 대한 관리자 권한을 보유하고 있어야 합니다.
절차
OpenShift Container Platform 클러스터의 기존
MachineConfig오브젝트를 나열하고 머신 구성에 라벨을 지정하는 방법을 결정합니다.$ oc get MachineConfig출력 예
NAME GENERATEDBYCONTROLLER IGNITIONVERSION AGE 00-master 52dd3ba6a9a527fc3ab42afac8d12b693534c8c9 3.2.0 33m 00-worker 52dd3ba6a9a527fc3ab42afac8d12b693534c8c9 3.2.0 33m 01-master-container-runtime 52dd3ba6a9a527fc3ab42afac8d12b693534c8c9 3.2.0 33m 01-master-kubelet 52dd3ba6a9a527fc3ab42afac8d12b693534c8c9 3.2.0 33m 01-worker-container-runtime 52dd3ba6a9a527fc3ab42afac8d12b693534c8c9 3.2.0 33m 01-worker-kubelet 52dd3ba6a9a527fc3ab42afac8d12b693534c8c9 3.2.0 33m 99-master-generated-registries 52dd3ba6a9a527fc3ab42afac8d12b693534c8c9 3.2.0 33m 99-master-ssh 3.2.0 40m 99-worker-generated-registries 52dd3ba6a9a527fc3ab42afac8d12b693534c8c9 3.2.0 33m 99-worker-ssh 3.2.0 40m rendered-master-23e785de7587df95a4b517e0647e5ab7 52dd3ba6a9a527fc3ab42afac8d12b693534c8c9 3.2.0 33m rendered-worker-5d596d9293ca3ea80c896a1191735bb1 52dd3ba6a9a527fc3ab42afac8d12b693534c8c9 3.2.0 33m커널 인수를 식별하는
MachineConfig파일을 만듭니다 (예:05-worker-kernelarg-selinuxpermissive.yaml).apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: labels: machineconfiguration.openshift.io/role: worker1 name: 05-worker-kernelarg-selinuxpermissive2 spec: kernelArguments: - enforcing=03 새 머신 구성을 생성합니다.
$ oc create -f 05-worker-kernelarg-selinuxpermissive.yaml머신 구성에서 새 구성이 추가되었는지 확인합니다.
$ oc get MachineConfig출력 예
NAME GENERATEDBYCONTROLLER IGNITIONVERSION AGE 00-master 52dd3ba6a9a527fc3ab42afac8d12b693534c8c9 3.2.0 33m 00-worker 52dd3ba6a9a527fc3ab42afac8d12b693534c8c9 3.2.0 33m 01-master-container-runtime 52dd3ba6a9a527fc3ab42afac8d12b693534c8c9 3.2.0 33m 01-master-kubelet 52dd3ba6a9a527fc3ab42afac8d12b693534c8c9 3.2.0 33m 01-worker-container-runtime 52dd3ba6a9a527fc3ab42afac8d12b693534c8c9 3.2.0 33m 01-worker-kubelet 52dd3ba6a9a527fc3ab42afac8d12b693534c8c9 3.2.0 33m 05-worker-kernelarg-selinuxpermissive 3.2.0 105s 99-master-generated-registries 52dd3ba6a9a527fc3ab42afac8d12b693534c8c9 3.2.0 33m 99-master-ssh 3.2.0 40m 99-worker-generated-registries 52dd3ba6a9a527fc3ab42afac8d12b693534c8c9 3.2.0 33m 99-worker-ssh 3.2.0 40m rendered-master-23e785de7587df95a4b517e0647e5ab7 52dd3ba6a9a527fc3ab42afac8d12b693534c8c9 3.2.0 33m rendered-worker-5d596d9293ca3ea80c896a1191735bb1 52dd3ba6a9a527fc3ab42afac8d12b693534c8c9 3.2.0 33m노드를 확인합니다.
$ oc get nodes출력 예
NAME STATUS ROLES AGE VERSION ip-10-0-136-161.ec2.internal Ready worker 28m v1.26.0 ip-10-0-136-243.ec2.internal Ready master 34m v1.26.0 ip-10-0-141-105.ec2.internal Ready,SchedulingDisabled worker 28m v1.26.0 ip-10-0-142-249.ec2.internal Ready master 34m v1.26.0 ip-10-0-153-11.ec2.internal Ready worker 28m v1.26.0 ip-10-0-153-150.ec2.internal Ready master 34m v1.26.0변경 사항이 적용되어 있기 때문에 각 작업자 노드의 예약이 비활성화되어 있음을 알 수 있습니다.
작업자 노드 중 하나로 이동하여 커널 명령 행 인수 (호스트의
/proc/cmdline에 있음)를 나열하여 커널 인수가 작동하는지 확인합니다.$ oc debug node/ip-10-0-141-105.ec2.internal출력 예
Starting pod/ip-10-0-141-105ec2internal-debug ... To use host binaries, run `chroot /host` sh-4.2# cat /host/proc/cmdline BOOT_IMAGE=/ostree/rhcos-... console=tty0 console=ttyS0,115200n8 rootflags=defaults,prjquota rw root=UUID=fd0... ostree=/ostree/boot.0/rhcos/16... coreos.oem.id=qemu coreos.oem.id=ec2 ignition.platform.id=ec2 enforcing=0 sh-4.2# exitenforcing=0인수가 다른 커널 인수에 추가된 것을 확인할 수 있습니다.
5.2.4. RHCOS에서 커널 인수로 다중 경로 활성화
RHCOS(Red Hat Enterprise Linux CoreOS)는 기본 디스크에서 다중 경로를 지원하므로 하드웨어 장애에 대한 탄력성이 강화된 호스트 가용성을 높일 수 있습니다. 설치 후 지원은 머신 구성을 통해 다중 경로를 활성화하여 사용할 수 있습니다.
설치 중에 다중 경로를 활성화하는 것은 OpenShift Container Platform 4.8 이상에서 프로비저닝된 노드에 권장됩니다. I/O에서 최적화된 경로로 인해 I/O 시스템 오류가 발생하는 설정에서 설치 시 멀티패스를 활성화해야 합니다. 설치 시 다중 경로를 활성화하는 방법에 대한 자세한 내용은 베어 메탈에 설치 문서의 "RHCOS에서 커널 인수를 사용하여 다중 경로 활성화"를 참조하십시오.
IBM Z 및 IBM® LinuxONE에서는 설치 중에 클러스터를 구성한 경우에만 멀티패스를 활성화할 수 있습니다. 자세한 내용은 IBM Z 및 IBM® LinuxONE에 z/VM으로 클러스터 설치의 "RHCOS 설치 및 OpenShift Container Platform 부트스트랩 프로세스 시작"을 참조하십시오.
다중 경로가 구성된 IBM Power®에서 "vSCSI" 스토리지가 있는 단일 VIOS 호스트에서 OpenShift Container Platform 4.13 클러스터를 설치 후 활동으로 구성하면 다중 경로가 활성화된 CoreOS 노드가 부팅되지 않습니다. 노드에서 하나의 경로만 사용할 수 있으므로 이 동작이 예상됩니다.
전제 조건
- OpenShift Container Platform 클러스터 (버전 4.7 이상)가 실행되고 있어야 합니다.
- 관리 권한이 있는 사용자로 클러스터에 로그인했습니다.
- 멀티패스에 디스크가 활성화되었는지 확인했습니다. 멀티패스는 HBA 어댑터를 통해 SAN에 연결된 호스트에서만 지원됩니다.
절차
컨트롤 플레인 노드에서 다중 경로 설치 후 활성화하려면 다음을 수행합니다.
다음과 같이 클러스터에
master레이블를 추가하도록 지시하고 다중 경로 커널 인수를 식별하는99-master-kargs-mpath.yaml과 같은 머신 구성 파일을 만듭니다.apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: labels: machineconfiguration.openshift.io/role: "master" name: 99-master-kargs-mpath spec: kernelArguments: - 'rd.multipath=default' - 'root=/dev/disk/by-label/dm-mpath-root'
작업자 노드에서 다중 경로 설치 후 활성화하려면 다음을 수행합니다.
다음과 같은
99-worker-kargs-mpath.yaml과 같은 머신 구성 파일을 생성하여 클러스터에worker레이블을 추가하고 다중 경로 커널 인수를 식별합니다.apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: labels: machineconfiguration.openshift.io/role: "worker" name: 99-worker-kargs-mpath spec: kernelArguments: - 'rd.multipath=default' - 'root=/dev/disk/by-label/dm-mpath-root'
이전에 작성한 마스터 또는 작업자 YAML 파일을 사용하여 새 머신 구성을 생성합니다.
$ oc create -f ./99-worker-kargs-mpath.yaml머신 구성에서 새 구성이 추가되었는지 확인합니다.
$ oc get MachineConfig출력 예
NAME GENERATEDBYCONTROLLER IGNITIONVERSION AGE 00-master 52dd3ba6a9a527fc3ab42afac8d12b693534c8c9 3.2.0 33m 00-worker 52dd3ba6a9a527fc3ab42afac8d12b693534c8c9 3.2.0 33m 01-master-container-runtime 52dd3ba6a9a527fc3ab42afac8d12b693534c8c9 3.2.0 33m 01-master-kubelet 52dd3ba6a9a527fc3ab42afac8d12b693534c8c9 3.2.0 33m 01-worker-container-runtime 52dd3ba6a9a527fc3ab42afac8d12b693534c8c9 3.2.0 33m 01-worker-kubelet 52dd3ba6a9a527fc3ab42afac8d12b693534c8c9 3.2.0 33m 99-master-generated-registries 52dd3ba6a9a527fc3ab42afac8d12b693534c8c9 3.2.0 33m 99-master-ssh 3.2.0 40m 99-worker-generated-registries 52dd3ba6a9a527fc3ab42afac8d12b693534c8c9 3.2.0 33m 99-worker-kargs-mpath 52dd3ba6a9a527fc3ab42afac8d12b693534c8c9 3.2.0 105s 99-worker-ssh 3.2.0 40m rendered-master-23e785de7587df95a4b517e0647e5ab7 52dd3ba6a9a527fc3ab42afac8d12b693534c8c9 3.2.0 33m rendered-worker-5d596d9293ca3ea80c896a1191735bb1 52dd3ba6a9a527fc3ab42afac8d12b693534c8c9 3.2.0 33m노드를 확인합니다.
$ oc get nodes출력 예
NAME STATUS ROLES AGE VERSION ip-10-0-136-161.ec2.internal Ready worker 28m v1.26.0 ip-10-0-136-243.ec2.internal Ready master 34m v1.26.0 ip-10-0-141-105.ec2.internal Ready,SchedulingDisabled worker 28m v1.26.0 ip-10-0-142-249.ec2.internal Ready master 34m v1.26.0 ip-10-0-153-11.ec2.internal Ready worker 28m v1.26.0 ip-10-0-153-150.ec2.internal Ready master 34m v1.26.0변경 사항이 적용되어 있기 때문에 각 작업자 노드의 예약이 비활성화되어 있음을 알 수 있습니다.
작업자 노드 중 하나로 이동하여 커널 명령 행 인수 (호스트의
/proc/cmdline에 있음)를 나열하여 커널 인수가 작동하는지 확인합니다.$ oc debug node/ip-10-0-141-105.ec2.internal출력 예
Starting pod/ip-10-0-141-105ec2internal-debug ... To use host binaries, run `chroot /host` sh-4.2# cat /host/proc/cmdline ... rd.multipath=default root=/dev/disk/by-label/dm-mpath-root ... sh-4.2# exit추가된 커널 인수가 표시되어야 합니다.
5.2.5. 노드에 실시간 커널 추가
일부 OpenShift Container Platform 워크로드에는 높은 수준의 결정이 필요합니다. Linux는 실시간 운영 체제가 아니지만 Linux 실시간 커널에는 운영 체제에 실시간 기능을 제공하는 선점 형 스케줄러가 포함되어 있습니다.
OpenShift Container Platform 워크로드에 이러한 실시간 기능이 필요한 경우 머신을 Linux 실시간 커널로 전환할 수 있습니다. OpenShift Container Platform, 4.13의 경우 MachineConfig 객체를 사용하여 이러한 전환을 수행할 수 있습니다. 머신 구성 kernelType 설정을 realtime으로 변경하는 것처럼 간단하지만 변경을 수행하기 전에 몇 가지 고려해야 할 사항이 있습니다.
- 현재 실시간 커널은 작업자 노드에서만 지원되며 RAN (Radio Access Network) 사용만 지원됩니다.
- 다음 단계는 Red Hat Enterprise Linux for Real Time 8에서 인증 된 시스템을 사용하는 베어 메탈 설치에 완전히 지원됩니다.
- OpenShift Container Platform에서 실시간 지원은 특정 서브스크립션으로 제한됩니다.
- 다음 단계는 Google Cloud Platform에서의 사용도 지원됩니다.
사전 요구 사항
- 실행중인 OpenShift Container Platform 클러스터 (버전 4.4 이상)가 있어야합니다.
- 관리 권한이 있는 사용자로 클러스터에 로그인합니다.
절차
실시간 커널의 머신 구성을 만듭니다.
realtime커널 유형의MachineConfig개체가 포함된 YAML 파일 (예:99-worker-realtime.yaml)을 만듭니다. 다음 예에서는 모든 작업자 노드에 대해 실시간 커널을 사용하도록 클러스터에 지시합니다.$ cat << EOF > 99-worker-realtime.yaml apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: labels: machineconfiguration.openshift.io/role: "worker" name: 99-worker-realtime spec: kernelType: realtime EOF머신 구성을 클러스터에 추가합니다. 다음을 입력하여 머신 구성을 클러스터에 추가합니다.
$ oc create -f 99-worker-realtime.yaml실시간 커널을 확인합니다 : 영향을 받는 각 노드가 재부팅되면 클러스터에 로그인하고 다음 명령을 실행하여 실시간 커널이 구성된 노드 세트의 일반 커널을 대체하고 있는지 확인합니다.
$ oc get nodes출력 예
NAME STATUS ROLES AGE VERSION ip-10-0-143-147.us-east-2.compute.internal Ready worker 103m v1.26.0 ip-10-0-146-92.us-east-2.compute.internal Ready worker 101m v1.26.0 ip-10-0-169-2.us-east-2.compute.internal Ready worker 102m v1.26.0$ oc debug node/ip-10-0-143-147.us-east-2.compute.internal출력 예
Starting pod/ip-10-0-143-147us-east-2computeinternal-debug ... To use host binaries, run `chroot /host` sh-4.4# uname -a Linux <worker_node> 4.18.0-147.3.1.rt24.96.el8_1.x86_64 #1 SMP PREEMPT RT Wed Nov 27 18:29:55 UTC 2019 x86_64 x86_64 x86_64 GNU/Linux커널 이름에는
rt및 "PREEMPT RT"라는 텍스트가 포함되어 이것이 실시간 커널임을 나타냅니다.일반 커널로 돌아가려면
MachineConfig객체를 삭제합니다.$ oc delete -f 99-worker-realtime.yaml
5.2.6. journald 설정 구성
OpenShift Container Platform 노드에서 journald 서비스 설정을 구성해야하는 경우 적절한 구성 파일을 수정하고 해당 파일을 머신 구성으로 적절한 노드 풀에 전달하여 이를 수행할 수 있습니다.
이 프로세스에서는 /etc/systemd/journald.conf 파일에서 journald 속도 제한 설정을 수정하고 이를 작업자 노드에 적용하는 방법을 설명합니다. 해당 파일을 사용하는 방법에 대한 정보는 journald.conf man 페이지를 참조하십시오.
사전 요구 사항
- 실행 중인 OpenShift Container Platform 클러스터가 있어야 합니다.
- 관리 권한이 있는 사용자로 클러스터에 로그인합니다.
절차
필요한 설정과 함께
/etc/systemd/journald.conf파일을 포함하는 Butane 구성 파일40-worker-custom-journald.bu를 만듭니다.참고Butane에 대한 자세한 내용은 “Butane 을 사용하여 머신 구성 생성”을 참조하십시오.
variant: openshift version: 4.13.0 metadata: name: 40-worker-custom-journald labels: machineconfiguration.openshift.io/role: worker storage: files: - path: /etc/systemd/journald.conf mode: 0644 overwrite: true contents: inline: | # Disable rate limiting RateLimitInterval=1s RateLimitBurst=10000 Storage=volatile Compress=no MaxRetentionSec=30sButane을 사용하여 작업자 노드로 전달할 구성이 포함된
MachineConfig개체 파일40-worker-custom-journald.yaml을 생성합니다.$ butane 40-worker-custom-journald.bu -o 40-worker-custom-journald.yaml머신 구성을 풀에 적용합니다.
$ oc apply -f 40-worker-custom-journald.yaml새 머신 구성이 적용되고 노드가 저하된 상태에 있는지 확인합니다. 이 작업을 수행하는 데 몇 분 정도 걸릴 수 있습니다. 각 노드에 새 머신 구성이 성공적으로 적용되어 작업자 풀에 진행중인 업데이트가 표시됩니다.
$ oc get machineconfigpool NAME CONFIG UPDATED UPDATING DEGRADED MACHINECOUNT READYMACHINECOUNT UPDATEDMACHINECOUNT DEGRADEDMACHINECOUNT AGE master rendered-master-35 True False False 3 3 3 0 34m worker rendered-worker-d8 False True False 3 1 1 0 34m변경 사항이 적용되었는지 확인하려면 작업자 노드에 로그인합니다.
$ oc get node | grep worker ip-10-0-0-1.us-east-2.compute.internal Ready worker 39m v0.0.0-master+$Format:%h$ $ oc debug node/ip-10-0-0-1.us-east-2.compute.internal Starting pod/ip-10-0-141-142us-east-2computeinternal-debug ... ... sh-4.2# chroot /host sh-4.4# cat /etc/systemd/journald.conf # Disable rate limiting RateLimitInterval=1s RateLimitBurst=10000 Storage=volatile Compress=no MaxRetentionSec=30s sh-4.4# exit
5.2.7. RHCOS에 확장 기능 추가
RHCOS는 모든 플랫폼에서 OpenShift Container Platform 클러스터에 공통적인 기능 세트를 제공하도록 설계된 최소한의 컨테이너 지향 RHEL 운영 체제입니다. RHCOS 시스템에 소프트웨어 패키지를 추가하는 것은 일반적으로 권장되지 않지만 MCO는 RHCOS 노드에 최소한의 기능 세트를 추가하는 데 사용할 수있는 extensions 기능을 제공합니다.
현재 다음과 같은 확장 기능을 사용할 수 있습니다.
-
usbguard:
usbguard확장 기능을 추가하면 간섭적인 USB 장치의 공격으로부터 RHCOS 시스템을 보호합니다. 자세한 내용은 USBGuard를 참조하십시오. -
Kerberos :
kerberos확장을 추가하면 사용자와 머신 모두 관리자가 구성한 영역 및 서비스에 대해 정의된 제한된 액세스 권한을 받을 수 있도록 네트워크에 자신을 식별할 수 있는 메커니즘을 제공합니다. Kerberos 클라이언트를 설정하고 Kerberized NFS 공유를 마운트하는 방법은 Kerberos 사용을 참조하십시오.
다음 프로세서에서는 머신 구성을 사용하여 RHCOS 노드에 하나 이상의 확장 기능을 추가하는 방법을 설명합니다.
사전 요구 사항
- 실행중인 OpenShift Container Platform 클러스터 (버전 4.6 이상)가 있어야합니다.
- 관리 권한이 있는 사용자로 클러스터에 로그인합니다.
절차
확장 기능을 위한 머신 구성을 만듭니다.
MachineConfigextensions개체를 포함하는 YAML 파일 (예 :80-extensions.yaml)을 만듭니다. 이 예에서는 클러스터에usbguard확장 기능을 추가하도록 지시합니다.$ cat << EOF > 80-extensions.yaml apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: labels: machineconfiguration.openshift.io/role: worker name: 80-worker-extensions spec: config: ignition: version: 3.2.0 extensions: - usbguard EOF머신 구성을 클러스터에 추가합니다. 다음을 입력하여 머신 구성을 클러스터에 추가합니다.
$ oc create -f 80-extensions.yaml이렇게하면 모든 작업자 노드에
usbguard의 rpm 패키지가 설치됩니다.확장 기능이 적용되었는지 확인합니다.
$ oc get machineconfig 80-worker-extensions출력 예
NAME GENERATEDBYCONTROLLER IGNITIONVERSION AGE 80-worker-extensions 3.2.0 57s새 머신 구성이 적용되고 노드가 저하된 상태에 있는지 확인합니다. 이 작업을 수행하는 데 몇 분 정도 걸릴 수 있습니다. 각 머신에 새 머신 구성이 성공적으로 적용되면 작업자 풀에 진행중인 업데이트가 표시됩니다.
$ oc get machineconfigpool출력 예
NAME CONFIG UPDATED UPDATING DEGRADED MACHINECOUNT READYMACHINECOUNT UPDATEDMACHINECOUNT DEGRADEDMACHINECOUNT AGE master rendered-master-35 True False False 3 3 3 0 34m worker rendered-worker-d8 False True False 3 1 1 0 34m확장 기능을 확인합니다. 확장 기능이 적용되었는지 확인하려면 다음을 실행하십시오.
$ oc get node | grep worker출력 예
NAME STATUS ROLES AGE VERSION ip-10-0-169-2.us-east-2.compute.internal Ready worker 102m v1.26.0$ oc debug node/ip-10-0-169-2.us-east-2.compute.internal출력 예
... To use host binaries, run `chroot /host` sh-4.4# chroot /host sh-4.4# rpm -q usbguard usbguard-0.7.4-4.el8.x86_64.rpm
5.2.8. 머신 구성 매니페스트에서 사용자 정의 펌웨어 Blob 로드
/usr/lib 의 펌웨어 Blob의 기본 위치는 읽기 전용이므로 검색 경로를 업데이트하여 사용자 지정 펌웨어 Blob을 찾을 수 있습니다. 이렇게 하면 RHCOS에서 Blob을 관리하지 않는 경우 머신 구성 매니페스트에 로컬 펌웨어 Blob을 로드할 수 있습니다.
절차
로컬 스토리지에 루트 소유이고 쓰기 가능하도록 Butane 구성 파일
98-worker-firmware-blob.bu를 생성합니다. 다음 예제에서는 로컬 워크스테이션의 사용자 지정 Blob 파일을/var/lib/firmware의 노드에 배치합니다.참고Butane에 대한 자세한 내용은 “Butane 을 사용하여 머신 구성 생성”을 참조하십시오.
사용자 정의 펌웨어 Blob의 Butane 구성 파일
variant: openshift version: 4.13.0 metadata: labels: machineconfiguration.openshift.io/role: worker name: 98-worker-firmware-blob storage: files: - path: /var/lib/firmware/<package_name>1 contents: local: <package_name>2 mode: 06443 openshift: kernel_arguments: - 'firmware_class.path=/var/lib/firmware'4 - 1
- 펌웨어 패키지가 복사되는 노드의 경로를 설정합니다.
- 2
- Butane을 실행하는 시스템의 로컬 파일 디렉터리에서 읽어오는 콘텐츠가 있는 파일을 지정합니다. 로컬 파일의 경로는
files-dir디렉터리를 기준으로 하며 다음 단계에서 Butane과 함께--files-dir옵션을 사용하여 지정해야 합니다. - 3
- RHCOS 노드에서 파일에 대한 권한을 설정합니다.
0644권한을 설정하는 것이 좋습니다. - 4
firmware_class.path매개변수는 로컬 워크스테이션에서 노드의 루트 파일 시스템으로 복사된 사용자 정의 펌웨어 Blob을 찾을 위치를 사용자 지정합니다. 이 예에서는 사용자 지정 경로로/var/lib/firmware를 사용합니다.
Butane을 실행하여 로컬 워크스테이션
98-worker-firmware-blob.yaml에서 펌웨어 Blob의 사본을 사용하는MachineConfig파일을 생성합니다. 펌웨어 Blob에는 노드로 전달할 구성이 포함되어 있습니다. 다음 예제에서는--files-dir옵션을 사용하여 로컬 파일 또는 파일이 있는 워크스테이션의 디렉터리를 지정합니다.$ butane 98-worker-firmware-blob.bu -o 98-worker-firmware-blob.yaml --files-dir <directory_including_package_name>다음 두 가지 방법 중 하나로 노드에 구성을 적용합니다.
-
클러스터가 아직 실행되지 않은 경우 매니페스트 파일을 생성한 후
<installation_directory>/openshift디렉터리에MachineConfig개체 파일을 추가한 다음 클러스터를 계속 작성합니다. 클러스터가 이미 실행중인 경우 다음과 같은 파일을 적용합니다.
$ oc apply -f 98-worker-firmware-blob.yaml머신 구성을 완료하기 위해
MachineConfig오브젝트 YAML 파일이 생성됩니다.
-
클러스터가 아직 실행되지 않은 경우 매니페스트 파일을 생성한 후
-
향후
MachineConfig오브젝트를 업데이트해야 하는 경우 Butane 구성을 저장합니다.
5.3. MCO 관련 사용자 지정 리소스 구성
MachineConfig 개체를 관리하는 것 외에도 MCO는KubeletConfig 및 ContainerRuntimeConfig의 두 가지 사용자 지정 리소스 (CR)를 관리합니다. 이러한 CR을 사용하면 Kubelet 및 CRI-O 컨테이너 런타임 서비스의 작동 방식에 영향을 주는 노드 수준 설정을 변경할 수 있습니다.
5.3.1. KubeletConfig CRD를 생성하여 kubelet 매개변수 편집
kubelet 구성은 현재 Ignition 구성으로 직렬화되어 있으므로 직접 편집할 수 있습니다. 하지만 MCC(Machine Config Controller)에 새 kubelet-config-controller도 추가되어 있습니다. 이를 통해 KubeletConfig CR(사용자 정의 리소스)을 사용하여 kubelet 매개변수를 편집할 수 있습니다.
kubeletConfig 오브젝트의 필드가 Kubernetes 업스트림에서 kubelet으로 직접 전달되므로 kubelet은 해당 값을 직접 검증합니다. kubeletConfig 오브젝트의 값이 유효하지 않으면 클러스터 노드를 사용할 수 없게 될 수 있습니다. 유효한 값은 Kubernetes 설명서를 참조하십시오.
다음 지침 사항을 고려하십시오.
-
기존
KubeletConfigCR을 편집하여 각 변경 사항에 대한 CR을 생성하는 대신 기존 설정을 수정하거나 새 설정을 추가합니다. 변경 사항을 되돌릴 수 있도록 다른 머신 구성 풀을 수정하거나 임시로 변경하려는 변경 사항만 수정하기 위해 CR을 생성하는 것이 좋습니다. -
해당 풀에 필요한 모든 구성 변경 사항을 사용하여 각 머신 구성 풀에 대해 하나의
KubeletConfigCR을 생성합니다. -
필요에 따라 클러스터당 10개로 제한되는 여러
KubeletConfigCR을 생성합니다. 첫 번째KubeletConfigCR의 경우 MCO(Machine Config Operator)는kubelet에 추가된 머신 구성을 생성합니다. 이후 각 CR을 통해 컨트롤러는 숫자 접미사가 있는 다른kubelet머신 구성을 생성합니다. 예를 들어,-2접미사가 있는kubelet머신 구성이 있는 경우 다음kubelet머신 구성에-3이 추가됩니다.
사용자 정의 머신 구성 풀에 kubelet 또는 컨테이너 런타임 구성을 적용하는 경우 machineConfigSelector 의 사용자 지정 역할은 사용자 정의 머신 구성 풀의 이름과 일치해야 합니다.
예를 들어 다음 사용자 지정 머신 구성 풀의 이름은 infra 이므로 사용자 지정 역할도 infra 여야 합니다.
apiVersion: machineconfiguration.openshift.io/v1
kind: MachineConfigPool
metadata:
name: infra
spec:
machineConfigSelector:
matchExpressions:
- {key: machineconfiguration.openshift.io/role, operator: In, values: [worker,infra]}
# ...
머신 구성을 삭제하려면 제한을 초과하지 않도록 해당 구성을 역순으로 삭제합니다. 예를 들어 kubelet-2 머신 구성을 삭제하기 전에 kubelet-3 머신 구성을 삭제합니다.
kubelet-9 접미사가 있는 머신 구성이 있고 다른 KubeletConfig CR을 생성하는 경우 kubelet 머신 구성이 10개 미만인 경우에도 새 머신 구성이 생성되지 않습니다.
KubeletConfig CR 예
$ oc get kubeletconfigNAME AGE
set-max-pods 15mKubeletConfig 머신 구성 표시 예
$ oc get mc | grep kubelet...
99-worker-generated-kubelet-1 b5c5119de007945b6fe6fb215db3b8e2ceb12511 3.2.0 26m
...다음 프로세스는 작업자 노드의 각 노드에 대한 최대 Pod 수를 구성하는 방법을 보여줍니다.
사전 요구 사항
구성하려는 노드 유형의 정적
MachineConfigPoolCR와 연관된 라벨을 가져옵니다. 다음 중 하나를 실행합니다.Machine config pool을 표시합니다.
$ oc describe machineconfigpool <name>예를 들면 다음과 같습니다.
$ oc describe machineconfigpool worker출력 예
apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfigPool metadata: creationTimestamp: 2019-02-08T14:52:39Z generation: 1 labels: custom-kubelet: set-max-pods1 - 1
- 라벨이 추가되면
labels아래에 표시됩니다.
라벨이 없으면 키/값 쌍을 추가합니다.
$ oc label machineconfigpool worker custom-kubelet=set-max-pods
절차
이 명령은 선택할 수 있는 사용 가능한 머신 구성 오브젝트를 표시합니다.
$ oc get machineconfig기본적으로 두 개의 kubelet 관련 구성은
01-master-kubelet및01-worker-kubelet입니다.노드당 최대 Pod의 현재 값을 확인하려면 다음을 실행합니다.
$ oc describe node <node_name>예를 들면 다음과 같습니다.
$ oc describe node ci-ln-5grqprb-f76d1-ncnqq-worker-a-mdv94Allocatable스탠자에서value: pods: <value>를 찾습니다.출력 예
Allocatable: attachable-volumes-aws-ebs: 25 cpu: 3500m hugepages-1Gi: 0 hugepages-2Mi: 0 memory: 15341844Ki pods: 250작업자 노드에서 노드당 최대 Pod 수를 설정하려면 kubelet 구성이 포함된 사용자 정의 리소스 파일을 생성합니다.
중요특정 머신 구성 풀을 대상으로 하는 kubelet 구성도 종속 풀에 영향을 미칩니다. 예를 들어 작업자 노드가 포함된 풀에 대한 kubelet 구성을 생성하면 인프라 노드가 포함된 풀을 포함한 모든 하위 집합 풀에도 적용됩니다. 이를 방지하려면 작업자 노드만 포함하는 선택 표현식을 사용하여 새 머신 구성 풀을 생성하고 kubelet 구성이 이 새 풀을 대상으로 지정하도록 해야 합니다.
apiVersion: machineconfiguration.openshift.io/v1 kind: KubeletConfig metadata: name: set-max-pods spec: machineConfigPoolSelector: matchLabels: custom-kubelet: set-max-pods1 kubeletConfig: maxPods: 5002 참고kubelet이 API 서버와 통신하는 속도는 QPS(초당 쿼리) 및 버스트 값에 따라 달라집니다. 노드마다 실행되는 Pod 수가 제한된 경우 기본 값인
50(kubeAPIQPS인 경우) 및100(kubeAPIBurst인 경우)이면 충분합니다. 노드에 CPU 및 메모리 리소스가 충분한 경우 kubelet QPS 및 버스트 속도를 업데이트하는 것이 좋습니다.apiVersion: machineconfiguration.openshift.io/v1 kind: KubeletConfig metadata: name: set-max-pods spec: machineConfigPoolSelector: matchLabels: custom-kubelet: set-max-pods kubeletConfig: maxPods: <pod_count> kubeAPIBurst: <burst_rate> kubeAPIQPS: <QPS>라벨을 사용하여 작업자의 머신 구성 풀을 업데이트합니다.
$ oc label machineconfigpool worker custom-kubelet=set-max-podsKubeletConfig오브젝트를 생성합니다.$ oc create -f change-maxPods-cr.yamlKubeletConfig오브젝트가 생성되었는지 확인합니다.$ oc get kubeletconfig출력 예
NAME AGE set-max-pods 15m클러스터의 작업자 노드 수에 따라 작업자 노드가 하나씩 재부팅될 때까지 기다립니다. 작업자 노드가 3개인 클러스터의 경우 약 10~15분이 걸릴 수 있습니다.
변경 사항이 노드에 적용되었는지 확인합니다.
작업자 노드에서
maxPods값이 변경되었는지 확인합니다.$ oc describe node <node_name>Allocatable스탠자를 찾습니다.... Allocatable: attachable-volumes-gce-pd: 127 cpu: 3500m ephemeral-storage: 123201474766 hugepages-1Gi: 0 hugepages-2Mi: 0 memory: 14225400Ki pods: 5001 ...- 1
- 이 예에서
pods매개변수는KubeletConfig오브젝트에 설정한 값을 보고해야 합니다.
KubeletConfig오브젝트에서 변경 사항을 확인합니다.$ oc get kubeletconfigs set-max-pods -o yaml다음 예와 같이
True및type:Success상태가 표시되어야 합니다.spec: kubeletConfig: maxPods: 500 machineConfigPoolSelector: matchLabels: custom-kubelet: set-max-pods status: conditions: - lastTransitionTime: "2021-06-30T17:04:07Z" message: Success status: "True" type: Success
5.3.2. CRI-O 매개 변수를 편집하기 위한 ContainerRuntimeConfig CR 작성
특정 MCP(MCP)와 연결된 노드의 OpenShift Container Platform CRI-O 런타임과 관련된 설정을 변경할 수 있습니다. ContainerRuntimeConfig 사용자 지정 리소스(CR)를 사용하여 구성 값을 설정하고 MCP와 일치하도록 레이블을 추가합니다. 그런 다음 MCO는 업데이트된 값으로 연결된 노드에서 crio.conf 및 storage.conf 구성 파일을 다시 빌드합니다.
ContainerRuntimeConfig CR을 사용하여 구현된 변경 사항을 되돌리려면 CR을 삭제해야 합니다. 머신 구성 풀에서 레이블을 제거해도 변경 사항은 복구되지 않습니다.
ContainerRuntimeConfig CR을 사용하여 다음 설정을 수정할 수 있습니다.
PIDs limit:
ContainerRuntimeConfig에서 PIDs 제한을 설정하면 더 이상 사용되지 않을 것으로 예상됩니다. PIDs 제한이 필요한 경우KubeletConfigCR에서podPidsLimit필드를 사용하는 것이 좋습니다. 기본podPidsLimit값은4096이고 기본pids_limit값은0입니다.podPidsLimit이pids_limit보다 작으면 유효한 컨테이너 PIDs 제한이podPidsLimit에 설정된 값으로 정의됩니다.참고CRI-O 플래그는 컨테이너 cgroup에 적용되며 Kubelet 플래그는 Pod의 cgroup에 설정됩니다. 그에 따라 PID 제한을 조정하십시오.
-
Log level:
logLevel매개변수는 로그 메시지의 상세 수준인 CRI-Olog_level매개변수를 설정합니다. 기본값은info(log_level = info)입니다. 기타 다른 옵션에는fatal,panic,error,warn,debug,trace가 포함됩니다. -
Overlay size:
overlaySize매개변수는 컨테이너 이미지의 최대 크기인 CRI-O Overlay 스토리지 드라이버size매개 변수를 설정합니다. -
Maximum log size:
ContainerRuntimeConfig에서 최대 로그 크기를 설정하면 더 이상 사용되지 않을 것으로 예상됩니다. 최대 로그 크기가 필요한 경우KubeletConfigCR에서containerLogMaxSize필드를 사용하는 것이 좋습니다. -
container runtime:
defaultRuntime매개변수는 컨테이너 런타임을runc또는crun로 설정합니다. 기본값은runc입니다.
각 머신 구성 풀에 대해 해당 풀에 필요한 모든 구성 변경 사항이 포함된 하나의 ContainerRuntimeConfig CR이 있어야 합니다. 모든 풀에 동일한 콘텐츠를 적용하는 경우 모든 풀에 대해 하나의 ContainerRuntimeConfig CR만 있으면 됩니다.
기존 ContainerRuntimeConfig CR을 편집하여 새 CR을 생성하는 대신 기존 설정을 편집하거나 새 설정을 추가할 수도 있습니다. 새 ContainerRuntimeConfig CR을 생성하여 다른 머신 구성 풀을 수정하거나 임시로 변경하려는 경우에만 변경 사항을 되돌릴 수 있도록 하는 것이 좋습니다.
필요에 따라 여러 ContainerRuntimeConfig CR을 생성할 수 있습니다 (클러스터당 10 개 제한). 첫 번째 ContainerRuntimeConfig CR의 경우 MCO는 containerruntime으로 추가된 머신 구성을 생성합니다. 이후 각 CR을 통해 컨트롤러는 숫자 접미사가 포함된 새 containerruntime 머신 구성을 생성합니다. 예를 들어, -2 접미사가 있는 containerruntime 머신 구성이 있는 경우 다음 containerruntime 머신 구성에 -3이 추가됩니다.
머신 구성을 삭제하려면 제한을 초과하지 않도록 해당 구성을 역순으로 삭제해야 합니다. 예를 들어 containerruntime-2 머신 구성을 삭제하기 전에 containerruntime-3 머신 구성을 삭제해야 합니다.
containerruntime-9 접미사가 있는 머신 구성이 있는 경우, 다음 머신 구성에 ContainerRuntimeConfig CR이 추가되고, containerruntime 머신 구성이 10 개 미만이어도 제한을 초과하여 실패합니다.
여러 ContainerRuntimeConfig CR 표시 예
$ oc get ctrcfg출력 예
NAME AGE
ctr-overlay 15m
ctr-level 5m45s여러 containerruntime 머신 구성의 예
$ oc get mc | grep container출력 예
...
01-master-container-runtime b5c5119de007945b6fe6fb215db3b8e2ceb12511 3.2.0 57m
...
01-worker-container-runtime b5c5119de007945b6fe6fb215db3b8e2ceb12511 3.2.0 57m
...
99-worker-generated-containerruntime b5c5119de007945b6fe6fb215db3b8e2ceb12511 3.2.0 26m
99-worker-generated-containerruntime-1 b5c5119de007945b6fe6fb215db3b8e2ceb12511 3.2.0 17m
99-worker-generated-containerruntime-2 b5c5119de007945b6fe6fb215db3b8e2ceb12511 3.2.0 7m26s
...
다음 예제에서는 log_level 필드를 debug 로 설정하고 오버레이 크기를 8GB로 설정합니다.
ContainerRuntimeConfig CR 예
apiVersion: machineconfiguration.openshift.io/v1
kind: ContainerRuntimeConfig
metadata:
name: overlay-size
spec:
machineConfigPoolSelector:
matchLabels:
pools.operator.machineconfiguration.openshift.io/worker: ''
containerRuntimeConfig:
logLevel: debug
overlaySize: 8G
defaultRuntime: "crun" 절차
ContainerRuntimeConfig CR을 사용하여 CRI-O 설정을 변경합니다.
ContainerRuntimeConfigCR의 YAML 파일을 생성합니다.apiVersion: machineconfiguration.openshift.io/v1 kind: ContainerRuntimeConfig metadata: name: overlay-size spec: machineConfigPoolSelector: matchLabels: pools.operator.machineconfiguration.openshift.io/worker: ''1 containerRuntimeConfig:2 logLevel: debug overlaySize: 8GContainerRuntimeConfigCR을 생성합니다.$ oc create -f <file_name>.yamlCR이 생성되었는지 확인합니다.
$ oc get ContainerRuntimeConfig출력 예
NAME AGE overlay-size 3m19s새
containerruntime머신 구성이 생성되었는지 확인합니다.$ oc get machineconfigs | grep containerrun출력 예
99-worker-generated-containerruntime 2c9371fbb673b97a6fe8b1c52691999ed3a1bfc2 3.2.0 31s모두 준비 상태로 표시될 때까지 머신 구성 풀을 모니터링합니다.
$ oc get mcp worker출력 예
NAME CONFIG UPDATED UPDATING DEGRADED MACHINECOUNT READYMACHINECOUNT UPDATEDMACHINECOUNT DEGRADEDMACHINECOUNT AGE worker rendered-worker-169 False True False 3 1 1 0 9h설정이 CRI-O에 적용되었는지 확인하려면 다음을 실행합니다.
머신 구성 풀의 노드에
oc debug세션을 열고chroot /host를 실행합니다.$ oc debug node/<node_name>sh-4.4# chroot /hostcrio.conf파일의 변경 사항을 확인합니다.sh-4.4# crio config | grep 'log_level'출력 예
log_level = "debug"'storage.conf' 파일의 변경 사항을 확인합니다.
sh-4.4# head -n 7 /etc/containers/storage.conf출력 예
[storage] driver = "overlay" runroot = "/var/run/containers/storage" graphroot = "/var/lib/containers/storage" [storage.options] additionalimagestores = [] size = "8G"
5.3.3. CRI-O를 사용하여 오버레이에 대한 기본 최대 컨테이너 루트 파티션 크기 설정
각 컨테이너의 루트 파티션에는 기본 호스트의 사용 가능한 디스크 공간이 모두 표시됩니다. 다음 지침에 따라 모든 컨테이너의 루트 디스크에 대한 최대 파티션 크기를 설정합니다.
최대 오버레이 크기 및 로그 수준과 같은 기타 CRI-O 옵션을 구성하려면 다음 ContainerRuntimeConfig CRD(사용자 정의 리소스 정의)를 생성할 수 있습니다.
apiVersion: machineconfiguration.openshift.io/v1
kind: ContainerRuntimeConfig
metadata:
name: overlay-size
spec:
machineConfigPoolSelector:
matchLabels:
custom-crio: overlay-size
containerRuntimeConfig:
logLevel: debug
overlaySize: 8G절차
구성 오브젝트를 생성합니다.
$ oc apply -f overlaysize.yml새 CRI-O 구성을 작업자 노드에 적용하려면 작업자 머신 구성 풀을 편집합니다.
$ oc edit machineconfigpool workerContainerRuntimeConfigCRD에서 설정한matchLabels이름을 기반으로custom-crio레이블을 추가합니다.apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfigPool metadata: creationTimestamp: "2020-07-09T15:46:34Z" generation: 3 labels: custom-crio: overlay-size machineconfiguration.openshift.io/mco-built-in: ""변경 사항을 저장한 다음 머신 구성을 확인합니다.
$ oc get machineconfigs새로운
99-worker-generated-containerruntime및rendered-worker-xyz오브젝트가 생성됩니다.출력 예
99-worker-generated-containerruntime 4173030d89fbf4a7a0976d1665491a4d9a6e54f1 3.2.0 7m42s rendered-worker-xyz 4173030d89fbf4a7a0976d1665491a4d9a6e54f1 3.2.0 7m36s해당 오브젝트가 생성된 후 적용할 변경 사항이 있는지 머신 구성 풀을 모니터링합니다.
$ oc get mcp worker작업자 노드는
UPDATING을True로 표시하고 머신 수, 업데이트된 수 및 기타 세부 정보를 표시합니다.출력 예
NAME CONFIG UPDATED UPDATING DEGRADED MACHINECOUNT READYMACHINECOUNT UPDATEDMACHINECOUNT DEGRADEDMACHINECOUNT AGE worker rendered-worker-xyz False True False 3 2 2 0 20h완료 후 작업자 노드는
UPDATING에서 다시False로 변환되고UPDATEDMACHINECOUNT의 수는MACHINECOUNT의 수와 일치합니다.출력 예
NAME CONFIG UPDATED UPDATING DEGRADED MACHINECOUNT READYMACHINECOUNT UPDATEDMACHINECOUNT DEGRADEDMACHINECOUNT AGE worker rendered-worker-xyz True False False 3 3 3 0 20h작업자 머신을 보면 새로운 8GB 최대 크기 구성이 모든 작업자에 적용되는 것을 확인할 수 있습니다.
출력 예
head -n 7 /etc/containers/storage.conf [storage] driver = "overlay" runroot = "/var/run/containers/storage" graphroot = "/var/lib/containers/storage" [storage.options] additionalimagestores = [] size = "8G"컨테이너 내부를 보면 루트 파티션이 이제 8GB가 됩니다.
출력 예
~ $ df -h Filesystem Size Used Available Use% Mounted on overlay 8.0G 8.0K 8.0G 0% /
6장. 설치 후 클러스터 작업
OpenShift Container Platform을 한 후 요구 사항에 맞게 클러스터를 추가로 확장하고 사용자 정의할 수 있습니다.
6.1. 사용 가능한 클러스터 사용자 정의
OpenShift Container Platform 클러스터를 배포한 후 대부분의 클러스터 설정 및 사용자 정의가 완료됩니다. 다양한 설정 리소스를 사용할 수 있습니다.
IBM Z에 클러스터를 설치하는 경우 모든 기능을 사용할 수 있는 것은 아닙니다.
설정 리소스를 수정하여 이미지 레지스트리, 네트워킹 설정, 이미지 빌드 동작 및 아이덴티티 제공자와 같은 클러스터의 주요 기능을 설정합니다.
이러한 리소스를 사용하여 기능 제어를 설정하려면 oc explain 명령을 사용합니다. (예: oc explain builds --api-version = config.openshift.io/v1)
6.1.1. 클러스터 설정 리소스
모든 클러스터 설정 리소스는 전체적으로 범위가 지정되고 (네임 스페이스가 아님) cluster라는 이름을 지정할 수 있습니다.
| 리소스 이름 | 설명 |
|---|---|
|
| 인증서 및 인증 기관과 같은 API 서버 구성을 제공합니다. |
|
| 클러스터의 ID 공급자 및 인증 구성을 제어합니다. |
|
| 클러스터의 모든 빌드에 대해 기본 및 강제 구성 을 제어합니다. |
|
| |
|
| 기술 프리뷰 기능을 사용할 수 있도록 FeatureGates 를 활성화합니다. |
|
| 특정 이미지 레지스트리를 처리하는 방법(허용, 허용하지 않음, 비보안, CA 세부 정보)을 설정합니다. |
|
| 경로의 기본 도메인과 같은 라우팅 과 관련된 구성 세부 정보입니다. |
|
| 내부 OAuth 서버 흐름과 관련된 ID 공급자 및 기타 동작을 설정합니다. |
|
| 프로젝트 템플릿을 포함하여 프로젝트를 생성하는 방법을 구성합니다. |
|
| 외부 네트워크 액세스를 필요로 하는 구성 요소에서 사용할 프록시를 정의합니다. 참고: 현재 모든 구성 요소가 이 값을 사용하는 것은 아닙니다. |
|
| 프로필 및 기본 노드 선택기와 같은 스케줄러 동작을 구성합니다. |
6.1.2. Operator 설정 자원
이러한 설정 리소스는 cluster라는 클러스터 범위의 인스턴스로 특정 Operator가 소유한 특정 구성 요소의 동작을 제어합니다.
| 리소스 이름 | 설명 |
|---|---|
|
| 브랜딩 사용자 정의와 같은 콘솔 모양을 제어합니다 |
|
| 공용 라우팅, 로그 수준, 프록시 설정, 리소스 제약 조건, 복제본 수 및 스토리지 유형과 같은 OpenShift 이미지 레지스트리 설정을 구성합니다. |
|
| Samples Operator 를 구성하여 클러스터에 설치된 이미지 스트림 및 템플릿 샘플을 제어합니다. |
6.1.3. 추가 설정 리소스
이러한 설정 리소스는 특정 구성 요소의 단일 인스턴스를 나타냅니다. 경우에 따라 리소스의 여러 인스턴스를 작성하고 여러 인스턴스를 요청할 수 있습니다. 다른 경우 Operator는 특정 네임 스페이스에서 특정 리소스 인스턴스 이름 만 사용할 수 있습니다. 추가 리소스 인스턴스를 생성하는 방법과 시기에 대한 자세한 내용은 구성 요소 별 설명서를 참조하십시오.
| 리소스 이름 | 인스턴스 이름 | 네임 스페이스 | 설명 |
|---|---|---|---|
|
|
|
| Alertmanager 배포 매개변수를 제어합니다. |
|
|
|
| 도메인, 복제본 수, 인증서 및 컨트롤러 배치와 같은 Ingress Operator 동작을 구성합니다. |
6.1.4. 정보 리소스
이러한 리소스를 사용하여 클러스터에 대한 정보를 검색합니다. 일부 구성에서는 이러한 리소스를 직접 편집해야 할 수 있습니다.
| 리소스 이름 | 인스턴스 이름 | 설명 |
|---|---|---|
|
|
|
OpenShift Container Platform 4.13에서는 프로덕션 클러스터에 대한 |
|
|
| 클러스터의 DNS 설정을 변경할 수 없습니다. DNS Operator 상태를 볼 수 있습니다. |
|
|
| 클러스터가 클라우드 공급자와 상호 작용을 가능하게 하는 설정 세부 정보입니다. |
|
|
| 설치 후 클러스터 네트워크를 변경할 수 없습니다. 네트워크를 사용자 지정하려면 프로세스에 따라 설치 중에 네트워크를 사용자 지정합니다. |
6.2. 작업자 노드 추가
OpenShift Container Platform 클러스터를 배포한 후 작업자 노드를 추가하여 클러스터 리소스를 확장할 수 있습니다. 설치 방법과 클러스터 환경에 따라 작업자 노드를 추가할 수 있는 방법은 다양합니다.
6.2.1. 설치 관리자가 프로비저닝한 인프라 클러스터에 작업자 노드 추가
설치 관리자 프로비저닝 인프라 클러스터의 경우 사용 가능한 베어 메탈 호스트 수와 일치하도록 MachineSet 오브젝트를 수동으로 또는 자동으로 확장할 수 있습니다.
베어 메탈 호스트를 추가하려면 모든 네트워크 사전 요구 사항을 구성하고 연결된 baremetalhost 오브젝트를 구성한 다음 작업자 노드를 클러스터에 프로비저닝해야 합니다. 베어 메탈 호스트를 수동으로 추가하거나 웹 콘솔을 사용하여 추가할 수 있습니다.
6.2.2. 사용자 프로비저닝 인프라 클러스터에 작업자 노드 추가
사용자 프로비저닝 인프라 클러스터의 경우 RHEL 또는 RHCOS ISO 이미지를 사용하여 작업자 노드를 추가하고 클러스터 Ignition 구성 파일을 사용하여 클러스터에 연결할 수 있습니다. RHEL 작업자 노드의 경우 다음 예제에서는 Ansible 플레이북을 사용하여 클러스터에 작업자 노드를 추가합니다. RHCOS 작업자 노드의 경우 다음 예제에서는 ISO 이미지와 네트워크 부팅을 사용하여 작업자 노드를 클러스터에 추가합니다.
6.2.3. Assisted Installer에 의해 관리되는 클러스터에 작업자 노드 추가
Assisted Installer에서 관리하는 클러스터의 경우 Red Hat OpenShift Cluster Manager 콘솔인 Assisted Installer REST API를 사용하여 작업자 노드를 추가하거나 ISO 이미지 및 클러스터 Ignition 구성 파일을 사용하여 작업자 노드를 수동으로 추가할 수 있습니다.
6.2.4. Kubernetes의 다중 클러스터 엔진에서 관리하는 클러스터에 작업자 노드 추가
Kubernetes용 멀티 클러스터 엔진에서 관리하는 클러스터의 경우 전용 멀티 클러스터 엔진 콘솔을 사용하여 작업자 노드를 추가할 수 있습니다.
6.3. 작업자 노드 조정
배포 중에 작업자 노드의 크기를 잘못 조정한 경우 하나 이상의 새 컴퓨팅 머신 세트를 생성하여 확장한 다음 제거하기 전에 원래 컴퓨팅 머신 세트를 축소하여 조정할 수 있습니다.
6.3.1. 컴퓨팅 머신 세트와 머신 구성 풀의 차이점
MachineSet 개체는 클라우드 또는 머신 공급자와 관련하여 OpenShift Container Platform 노드를 설명합니다.
MachineConfigPool 개체를 사용하면 MachineConfigController 구성 요소가 업그레이드 컨텍스트에서 시스템의 상태를 정의하고 제공할 수 있습니다.
MachineConfigPool 개체를 사용하여 시스템 구성 풀의 OpenShift Container Platform 노드에 대한 업그레이드 방법을 구성할 수 있습니다.
NodeSelector 개체는 MachineSet에 대한 참조로 대체할 수 있습니다.
6.3.2. 컴퓨팅 머신 세트 수동 스케일링
컴퓨팅 머신 세트에서 머신 인스턴스를 추가하거나 제거하려면 컴퓨팅 머신 세트를 수동으로 스케일링할 수 있습니다.
이는 완전히 자동화된 설치 프로그램에 의해 프로비저닝된 인프라 설치와 관련이 있습니다. 사용자 지정 사용자 프로비저닝 인프라 설치에는 컴퓨팅 머신 세트가 없습니다.
사전 요구 사항
-
OpenShift Container Platform 클러스터 및
oc명령행을 설치합니다. -
cluster-admin권한이 있는 사용자로oc에 로그인합니다.
프로세스
다음 명령을 실행하여 클러스터에 있는 컴퓨팅 머신 세트를 확인합니다.
$ oc get machinesets -n openshift-machine-api컴퓨팅 머신 세트는 <
clusterid>-worker-<aws-region-az> 형식으로 나열됩니다.다음 명령을 실행하여 클러스터에 있는 컴퓨팅 시스템을 확인합니다.
$ oc get machine -n openshift-machine-api다음 명령을 실행하여 삭제할 컴퓨팅 머신에 주석을 설정합니다.
$ oc annotate machine/<machine_name> -n openshift-machine-api machine.openshift.io/delete-machine="true"다음 명령 중 하나를 실행하여 컴퓨팅 머신 세트를 확장합니다.
$ oc scale --replicas=2 machineset <machineset> -n openshift-machine-api또는 다음을 수행합니다.
$ oc edit machineset <machineset> -n openshift-machine-api작은 정보다음 YAML을 적용하여 컴퓨팅 머신 세트를 확장할 수 있습니다.
apiVersion: machine.openshift.io/v1beta1 kind: MachineSet metadata: name: <machineset> namespace: openshift-machine-api spec: replicas: 2컴퓨팅 머신 세트를 확장 또는 축소할 수 있습니다. 새 머신을 사용할 수 있을 때 까지 몇 분 정도 소요됩니다.
중요기본적으로 머신 컨트롤러는 성공할 때까지 머신이 지원하는 노드를 드레이닝하려고 합니다. Pod 중단 예산을 잘못 구성하는 등 일부 상황에서는 드레이닝 작업이 성공하지 못할 수 있습니다. 드레이닝 작업이 실패하면 머신 컨트롤러에서 머신 제거를 진행할 수 없습니다.
특정 머신에서
machine.openshift.io/exclude-node-draining에 주석을 달아 노드 드레이닝을 건너뛸 수 있습니다.
검증
다음 명령을 실행하여 의도한 시스템의 삭제를 확인합니다.
$ oc get machines
6.3.3. 컴퓨팅 머신 세트 삭제 정책
Random, Newest 및 Oldest의 세 가지 삭제 옵션이 지원됩니다. 기본값은 Random 입니다. 따라서 컴퓨팅 머신 세트를 축소할 때 임의의 머신이 선택되어 삭제됩니다. 특정 컴퓨팅 머신 세트를 수정하여 유스 케이스에 따라 삭제 정책을 설정할 수 있습니다.
spec:
deletePolicy: <delete_policy>
replicas: <desired_replica_count>
삭제 정책에 관계없이 관련 머신에 machine.openshift.io/delete-machine=true 주석을 추가하여 특정 머신의 삭제 우선 순위를 지정할 수도 있습니다.
기본적으로 OpenShift Container Platform 라우터 Pod는 작업자에게 배포됩니다. 라우터는 웹 콘솔을 포함한 일부 클러스터 리소스에 액세스해야 하므로 먼저 라우터 Pod를 재배치하지 않는 한 작업자 컴퓨팅 머신 세트를 0 으로 스케일링하지 마십시오.
사용자 정의 컴퓨팅 머신 세트는 특정 노드에서 서비스가 실행되고 작업자 컴퓨팅 머신 세트가 축소될 때 컨트롤러에서 해당 서비스를 무시해야 하는 유스 케이스에 사용할 수 있습니다. 이로 인해 서비스 중단을 피할 수 있습니다.
6.3.4. 기본 클러스터 수준 노드 선택기 생성
Pod의 기본 클러스터 수준 노드 선택기와 노드의 라벨을 함께 사용하면 클러스터에 생성되는 모든 Pod를 특정 노드로 제한할 수 있습니다.
클러스터 수준 노드 선택기를 사용하여 해당 클러스터에서 Pod를 생성하면 OpenShift Container Platform에서 기본 노드 선택기를 Pod에 추가하고 라벨이 일치하는 노드에 Pod를 예약합니다.
Scheduler Operator CR(사용자 정의 리소스)을 편집하여 클러스터 수준 노드 선택기를 구성합니다. 노드, 컴퓨팅 머신 세트 또는 머신 구성에 라벨을 추가합니다. 컴퓨팅 머신 세트에 레이블을 추가하면 노드 또는 머신이 중단되는 경우 새 노드에 라벨이 지정됩니다. 노드 또는 머신이 중단된 경우 노드 또는 머신 구성에 추가된 라벨이 유지되지 않습니다.
Pod에 키/값 쌍을 추가할 수 있습니다. 그러나 기본 키에는 다른 값을 추가할 수 없습니다.
프로세스
기본 클러스터 수준 노드 선택기를 추가하려면 다음을 수행합니다.
Scheduler Operator CR을 편집하여 기본 클러스터 수준 노드 선택기를 추가합니다.
$ oc edit scheduler cluster노드 선택기를 사용하는 Scheduler Operator CR의 예
apiVersion: config.openshift.io/v1 kind: Scheduler metadata: name: cluster ... spec: defaultNodeSelector: type=user-node,region=east1 mastersSchedulable: false- 1
- 적절한
<key>:<value>쌍을 사용하여 노드 선택기를 추가합니다.
변경 후
openshift-kube-apiserver프로젝트의 pod가 재배포될 때까지 기다립니다. 이 작업은 몇 분 정도 걸릴 수 있습니다. 기본 클러스터 수준 노드 선택기는 Pod가 재배포된 후 적용됩니다.컴퓨팅 머신 세트를 사용하거나 노드를 직접 편집하여 노드에 라벨을 추가합니다.
노드를 생성할 때 컴퓨팅 머신 세트에서 관리하는 노드에 라벨을 추가하려면 컴퓨팅 머신 세트를 사용합니다.
다음 명령을 실행하여
MachineSet오브젝트에 라벨을 추가합니다.$ oc patch MachineSet <name> --type='json' -p='[{"op":"add","path":"/spec/template/spec/metadata/labels", "value":{"<key>"="<value>","<key>"="<value>"}}]' -n openshift-machine-api1 - 1
- 각 라벨에
<key>/<value>쌍을 추가합니다.
예를 들면 다음과 같습니다.
$ oc patch MachineSet ci-ln-l8nry52-f76d1-hl7m7-worker-c --type='json' -p='[{"op":"add","path":"/spec/template/spec/metadata/labels", "value":{"type":"user-node","region":"east"}}]' -n openshift-machine-api작은 정보또는 다음 YAML을 적용하여 컴퓨팅 머신 세트에 라벨을 추가할 수 있습니다.
apiVersion: machine.openshift.io/v1beta1 kind: MachineSet metadata: name: <machineset> namespace: openshift-machine-api spec: template: spec: metadata: labels: region: "east" type: "user-node"oc edit명령을 사용하여 라벨이MachineSet오브젝트에 추가되었는지 확인합니다.예를 들면 다음과 같습니다.
$ oc edit MachineSet abc612-msrtw-worker-us-east-1c -n openshift-machine-apiMachineSet오브젝트의 예apiVersion: machine.openshift.io/v1beta1 kind: MachineSet ... spec: ... template: metadata: ... spec: metadata: labels: region: east type: user-node ...0으로 축소하고 노드를 확장하여 해당 컴퓨팅 머신 세트와 관련된 노드를 재배포합니다.예를 들면 다음과 같습니다.
$ oc scale --replicas=0 MachineSet ci-ln-l8nry52-f76d1-hl7m7-worker-c -n openshift-machine-api$ oc scale --replicas=1 MachineSet ci-ln-l8nry52-f76d1-hl7m7-worker-c -n openshift-machine-api노드가 준비되고 사용 가능한 경우
oc get명령을 사용하여 라벨이 노드에 추가되었는지 확인합니다.$ oc get nodes -l <key>=<value>예를 들면 다음과 같습니다.
$ oc get nodes -l type=user-node출력 예
NAME STATUS ROLES AGE VERSION ci-ln-l8nry52-f76d1-hl7m7-worker-c-vmqzp Ready worker 61s v1.26.0
라벨을 노드에 직접 추가합니다.
노드의
Node오브젝트를 편집합니다.$ oc label nodes <name> <key>=<value>예를 들어 노드에 라벨을 지정하려면 다음을 수행합니다.
$ oc label nodes ci-ln-l8nry52-f76d1-hl7m7-worker-b-tgq49 type=user-node region=east작은 정보또는 다음 YAML을 적용하여 노드에 라벨을 추가할 수 있습니다.
kind: Node apiVersion: v1 metadata: name: <node_name> labels: type: "user-node" region: "east"oc get명령을 사용하여 노드에 라벨이 추가되었는지 확인합니다.$ oc get nodes -l <key>=<value>,<key>=<value>예를 들면 다음과 같습니다.
$ oc get nodes -l type=user-node,region=east출력 예
NAME STATUS ROLES AGE VERSION ci-ln-l8nry52-f76d1-hl7m7-worker-b-tgq49 Ready worker 17m v1.26.0
6.3.5. AWS 로컬 영역에서 사용자 워크로드 생성
AWS(Amazon Web Service) 로컬 영역 환경을 생성하고 클러스터를 배포한 후 에지 작업자 노드를 사용하여 로컬 영역 서브넷에 사용자 워크로드를 생성할 수 있습니다.
openshift-installer 가 클러스터를 생성한 후 설치 프로그램은 각 에지 작업자 노드에 대해 NoSchedule 의 테인트 효과를 자동으로 지정합니다. 즉, Pod가 테인트에 대해 지정된 허용 오차와 일치하지 않는 경우 스케줄러에서 새 Pod 또는 배포를 노드에 추가하지 않습니다. 각 노드가 각 로컬 영역 서브넷에 워크로드를 생성하는 방법을 더 잘 제어하도록 테인트를 수정할 수 있습니다.
openshift-installer 는 로컬 영역 서브넷에 있는 각 에지 작업자 노드에 적용되는 node-role.kubernetes.io/edge 및 node-role.kubernetes.io/worker 라벨을 사용하여 컴퓨팅 머신 세트 매니페스트 파일을 생성합니다.
사전 요구 사항
-
OpenShift CLI(
oc)에 액세스할 수 있습니다. - 로컬 영역 서브넷이 정의된 VPC(Virtual Private Cloud)에 클러스터를 배포했습니다.
-
로컬 영역 서브넷의 에지 작업자에 대한 컴퓨팅 머신 세트가
node-role.kubernetes.io/edge에 대한 테인트를 지정했는지 확인했습니다.
절차
로컬 영역 서브넷에서 작동하는 에지 작업자 노드에 배포할 예제 애플리케이션에 대한 배포 리소스 YAML 파일을 생성합니다.
에지 작업자 노드의 테인트와 일치하는 올바른 톨러레이션을 지정해야 합니다.로컬 영역 서브넷에서 작동하는 에지 작업자 노드에 대해 구성된
배포리소스의 예kind: Namespace apiVersion: v1 metadata: name: <local_zone_application_namespace> --- kind: PersistentVolumeClaim apiVersion: v1 metadata: name: <pvc_name> namespace: <local_zone_application_namespace> spec: accessModes: - ReadWriteOnce resources: requests: storage: 10Gi storageClassName: gp2-csi1 volumeMode: Filesystem --- apiVersion: apps/v1 kind: Deployment2 metadata: name: <local_zone_application>3 namespace: <local_zone_application_namespace>4 spec: selector: matchLabels: app: <local_zone_application> replicas: 1 template: metadata: labels: app: <local_zone_application> zone-group: ${ZONE_GROUP_NAME}5 spec: securityContext: seccompProfile: type: RuntimeDefault nodeSelector:6 machine.openshift.io/zone-group: ${ZONE_GROUP_NAME} tolerations:7 - key: "node-role.kubernetes.io/edge" operator: "Equal" value: "" effect: "NoSchedule" containers: - image: openshift/origin-node command: - "/bin/socat" args: - TCP4-LISTEN:8080,reuseaddr,fork - EXEC:'/bin/bash -c \"printf \\\"HTTP/1.0 200 OK\r\n\r\n\\\"; sed -e \\\"/^\r/q\\\"\"' imagePullPolicy: Always name: echoserver ports: - containerPort: 8080 volumeMounts: - mountPath: "/mnt/storage" name: data volumes: - name: data persistentVolumeClaim: claimName: <pvc_name>- 1
storageClassName: 로컬 영역 구성의 경우gp2-csi를 지정해야 합니다.- 2
kind:배포리소스를 정의합니다.- 3
Name: Local Zone 애플리케이션의 이름을 지정합니다. 예를 들면local-zone-demo-app-nyc-1입니다.- 4
namespace:사용자 워크로드를 실행할 AWS 로컬 영역의 네임스페이스를 정의합니다. 예:local-zone-app-nyc-1a.- 5
zone-group: 영역이 속한 그룹을 정의합니다. 예를 들면us-east-1-iah-1입니다.- 6
nodeSelector: 지정된 라벨과 일치하는 에지 작업자 노드를 대상으로 합니다.- 7
tolerations: 로컬 영역 노드의MachineSet매니페스트에 정의된테인트와 일치하는 값을 설정합니다.
노드에 대한
서비스리소스 YAML 파일을 생성합니다. 이 리소스는 대상 에지 작업자 노드의 Pod를 로컬 영역 네트워크 내에서 실행되는 서비스에 노출합니다.로컬 영역 서브넷에서 작동하는 에지 작업자 노드에 대한 구성된
서비스리소스의 예apiVersion: v1 kind: Service1 metadata: name: <local_zone_application> namespace: <local_zone_application_namespace> spec: ports: - port: 80 targetPort: 8080 protocol: TCP type: NodePort selector:2 app: <local_zone_application>
다음 단계
- 선택 사항: AWS Load Balancer(ALB) Operator를 사용하여 공용 네트워크의 로컬 영역 서브넷 내에서 실행되는 서비스에 대상 에지 작업자 노드의 Pod를 노출합니다. AWS Load Balancer Operator 설치를 참조하십시오.
6.4. 작업자 대기 시간 프로필을 사용하여 대기 시간이 긴 환경에서 클러스터 안정성 개선
클러스터 관리자가 플랫폼 확인을 위해 대기 시간 테스트를 수행한 경우 대기 시간이 긴 경우 안정성을 보장하기 위해 클러스터의 작동을 조정해야 할 수 있습니다. 클러스터 관리자는 파일에 기록된 하나의 매개 변수만 변경해야 합니다. 이 매개변수는 감독자 프로세스가 상태를 읽고 클러스터의 상태를 해석하는 방법에 영향을 미치는 매개변수 4개를 제어합니다. 하나의 매개변수만 변경하면 지원 가능한 방식으로 클러스터 튜닝이 제공됩니다.
Kubelet 프로세스는 클러스터 상태를 모니터링하기 위한 시작점을 제공합니다. Kubelet 은 OpenShift Container Platform 클러스터의 모든 노드에 대한 상태 값을 설정합니다. Kubernetes Controller Manager(kube 컨트롤러)는 기본적으로 10초마다 상태 값을 읽습니다. kube 컨트롤러에서 노드 상태 값을 읽을 수 없는 경우 구성된 기간이 지난 후 해당 노드와의 연결이 끊어집니다. 기본 동작은 다음과 같습니다.
-
컨트롤 플레인의 노드 컨트롤러는 노드 상태를
Unhealthy로 업데이트하고 노드Ready조건 'Unknown'을 표시합니다. - 스케줄러는 이에 대한 응답으로 해당 노드에 대한 Pod 예약을 중지합니다.
-
Node Lifecycle Controller는
NoExecute효과가 있는node.kubernetes.io/unreachable테인트를 노드에 추가하고 기본적으로 5분 후에 제거하도록 노드에 Pod를 예약합니다.
이 동작으로 인해 특히 네트워크 엣지에 노드가 있는 경우 특히 네트워크가 대기 시간이 되는 경우 문제가 발생할 수 있습니다. 경우에 따라 네트워크 대기 시간으로 인해 Kubernetes 컨트롤러 관리자에서 정상적인 노드에서 업데이트를 수신하지 못할 수 있습니다. Kubelet 은 노드가 정상이지만 노드에서 Pod를 제거합니다.
이 문제를 방지하려면 작업자 대기 시간 프로필을 사용하여 Kubelet 및 Kubernetes 컨트롤러 관리자가 작업을 수행하기 전에 상태 업데이트를 기다리는 빈도를 조정할 수 있습니다. 이러한 조정은 컨트롤 플레인과 작업자 노드 간의 네트워크 대기 시간이 최적이 아닌 경우 클러스터가 올바르게 실행되도록 하는 데 도움이 됩니다.
이러한 작업자 대기 시간 프로필에는 대기 시간을 높이기 위해 클러스터의 응답을 제어하기 위해 신중하게 조정된 값으로 미리 정의된 세 가지 매개변수 세트가 포함되어 있습니다. 실험적으로 최상의 값을 수동으로 찾을 필요가 없습니다.
클러스터를 설치하거나 클러스터 네트워크에서 대기 시간을 늘리면 언제든지 작업자 대기 시간 프로필을 구성할 수 있습니다.
6.4.1. 작업자 대기 시간 프로필 이해
작업자 대기 시간 프로필은 신중하게 조정된 매개변수의 네 가지 범주입니다. 이러한 값을 구현하는 4개의 매개변수는 node-status-update-frequency,node-monitor-grace-period,default-not-ready-toleration-seconds 및 default-unreachable-toleration-seconds 입니다. 이러한 매개변수는 수동 방법을 사용하여 최상의 값을 결정할 필요 없이 대기 시간 문제에 대한 클러스터의 대응을 제어할 수 있는 값을 사용할 수 있습니다.
이러한 매개변수를 수동으로 설정하는 것은 지원되지 않습니다. 잘못된 매개변수 설정은 클러스터 안정성에 부정적인 영향을 미칩니다.
모든 작업자 대기 시간 프로필은 다음 매개변수를 구성합니다.
- node-status-update-frequency
- kubelet이 API 서버에 노드 상태를 게시하는 빈도를 지정합니다.
- node-monitor-grace-period
-
노드를 비정상적으로 표시하고
node.kubernetes.io/not-ready또는node.kubernetes.io/unreachable테인트를 노드에 추가하기 전에 Kubernetes 컨트롤러 관리자가 kubelet에서 업데이트를 기다리는 시간(초)을 지정합니다. - default-not-ready-toleration-seconds
- 해당 노드에서 Pod를 제거하기 전에 Kube API Server Operator가 기다리는 비정상적인 노드를 표시한 후 시간(초)을 지정합니다.
- default-unreachable-toleration-seconds
- 해당 노드에서 Pod를 제거하기 전에 Kube API Server Operator가 대기할 수 없는 노드를 표시한 후 시간(초)을 지정합니다.
다음 Operator는 작업자 대기 시간 프로필에 대한 변경 사항을 모니터링하고 그에 따라 응답합니다.
-
MCO(Machine Config Operator)는 작업자 노드에서
node-status-update-frequency매개변수를 업데이트합니다. -
Kubernetes 컨트롤러 관리자는 컨트롤 플레인 노드에서
node-monitor-grace-period매개변수를 업데이트합니다. -
Kubernetes API Server Operator는 컨트롤 플레인 노드에서
default-not-ready-toleration-seconds및default-unreachable-toleration-seconds매개변수를 업데이트합니다.
기본 구성이 대부분의 경우 작동하지만 OpenShift Container Platform은 네트워크가 일반적인 것보다 대기 시간이 길어지는 상황에 대해 두 가지 다른 작업자 대기 시간 프로필을 제공합니다. 3개의 작업자 대기 시간 프로파일이 다음 섹션에 설명되어 있습니다.
- 기본 작업자 대기 시간 프로필
Default프로필을 사용하면 각Kubelet이 10초마다 상태를 업데이트합니다(node-status-update-frequency).Kube Controller Manager는 5초마다Kubelet의 상태를 확인합니다(node-monitor-grace-period).Kubernetes 컨트롤러 관리자는
Kubelet비정상을 고려하기 전에Kubelet에서 상태 업데이트를 40초 동안 기다립니다. Kubernetes 컨트롤러 관리자에서 사용할 수 없는 상태가 없는 경우 노드를node.kubernetes.io/not-ready또는node.kubernetes.io/unreachable테인트로 표시하고 해당 노드에서 Pod를 제거합니다.해당 노드의 Pod에
NoExecute테인트가 있는 경우tolerationSeconds에 따라 Pod가 실행됩니다. Pod에 테인트가 없는 경우 300초(Kube API서버의default-not-ready-toleration-seconds및default-unreachable-toleration-seconds설정)가 제거됩니다.Expand 프로필 구성 요소 매개변수 현재의 Default
kubelet
node-status-update-frequency10s
kubelet Controller Manager
node-monitor-grace-period40s
Kubernetes API Server Operator
default-not-ready-toleration-seconds300s
Kubernetes API Server Operator
default-unreachable-toleration-seconds300s
- 중간 수준의 작업자 대기 시간 프로필
네트워크 대기 시간이 보통보다 약간 높은 경우
MediumUpdateAverageReaction프로필을 사용합니다.MediumUpdateAverageReaction프로필은 kubelet 업데이트 빈도를 20초로 줄이고 Kubernetes 컨트롤러 관리자가 해당 업데이트를 2분으로 기다리는 기간을 변경합니다. 해당 노드의 Pod의 Pod 제거 기간은 60초로 단축됩니다. Pod에tolerationSeconds매개변수가 있는 경우 제거 시 해당 매개변수에서 지정한 기간 동안 기다립니다.Kubernetes 컨트롤러 관리자는 노드의 비정상적인 것으로 간주하기 위해 2분 정도 기다립니다. 잠시 후 제거 프로세스가 시작됩니다.
Expand 프로필 구성 요소 매개변수 현재의 MediumUpdateAverageReaction
kubelet
node-status-update-frequency20s
kubelet Controller Manager
node-monitor-grace-period2m
Kubernetes API Server Operator
default-not-ready-toleration-seconds60s
Kubernetes API Server Operator
default-unreachable-toleration-seconds60s
- 짧은 작업자 대기 시간 프로필
네트워크 대기 시간이 매우 높은 경우
LowUpdateSlowReaction프로필을 사용합니다.LowUpdateSlowReaction프로필은 kubelet 업데이트 빈도를 1분으로 줄이고 Kubernetes 컨트롤러 관리자가 해당 업데이트를 5분으로 기다리는 기간을 변경합니다. 해당 노드의 Pod의 Pod 제거 기간은 60초로 단축됩니다. Pod에tolerationSeconds매개변수가 있는 경우 제거 시 해당 매개변수에서 지정한 기간 동안 기다립니다.Kubernetes 컨트롤러 관리자는 노드의 비정상적인 것으로 간주하기 위해 5분 정도 기다립니다. 잠시 후 제거 프로세스가 시작됩니다.
Expand 프로필 구성 요소 매개변수 현재의 LowUpdateSlowReaction
kubelet
node-status-update-frequency1m
kubelet Controller Manager
node-monitor-grace-period5m
Kubernetes API Server Operator
default-not-ready-toleration-seconds60s
Kubernetes API Server Operator
default-unreachable-toleration-seconds60s
6.4.2. 작업자 대기 시간 프로필 사용 및 변경
네트워크 대기 시간을 처리하기 위해 작업자 대기 시간 프로필을 변경하려면 node.config 오브젝트를 편집하여 프로필 이름을 추가합니다. 대기 시간이 증가하거나 감소하면 언제든지 프로필을 변경할 수 있습니다.
한 번에 하나의 작업자 대기 시간 프로필을 이동해야 합니다. 예를 들어 Default 프로필에서 LowUpdateSlowReaction 작업자 대기 시간 프로필로 직접 이동할 수 없습니다. 기본 작업자 대기 시간 프로필에서 먼저 MediumUpdateAverageReaction 프로필로 이동한 다음 LowUpdateSlowReaction 으로 이동해야 합니다. 마찬가지로 Default 프로필로 돌아갈 때 먼저 low 프로필에서 medium 프로필로 이동한 다음 Default 로 이동해야 합니다.
OpenShift Container Platform 클러스터를 설치할 때 작업자 대기 시간 프로필을 구성할 수도 있습니다.
절차
기본 작업자 대기 시간 프로필에서 이동하려면 다음을 수행합니다.
중간 작업자 대기 시간 프로필로 이동합니다.
node.config오브젝트를 편집합니다.$ oc edit nodes.config/clusterspec.workerLatencyProfile: mediumUpdateAverageReaction을 추가합니다.node.config오브젝트의 예apiVersion: config.openshift.io/v1 kind: Node metadata: annotations: include.release.openshift.io/ibm-cloud-managed: "true" include.release.openshift.io/self-managed-high-availability: "true" include.release.openshift.io/single-node-developer: "true" release.openshift.io/create-only: "true" creationTimestamp: "2022-07-08T16:02:51Z" generation: 1 name: cluster ownerReferences: - apiVersion: config.openshift.io/v1 kind: ClusterVersion name: version uid: 36282574-bf9f-409e-a6cd-3032939293eb resourceVersion: "1865" uid: 0c0f7a4c-4307-4187-b591-6155695ac85b spec: workerLatencyProfile: MediumUpdateAverageReaction1 # ...- 1
- 중간 작업자 대기 시간 정책을 지정합니다.
변경 사항이 적용됨에 따라 각 작업자 노드의 스케줄링이 비활성화됩니다.
선택 사항: 짧은 작업자 대기 시간 프로필로 이동합니다.
node.config오브젝트를 편집합니다.$ oc edit nodes.config/clusterspec.workerLatencyProfile값을LowUpdateSlowReaction으로 변경합니다.node.config오브젝트의 예apiVersion: config.openshift.io/v1 kind: Node metadata: annotations: include.release.openshift.io/ibm-cloud-managed: "true" include.release.openshift.io/self-managed-high-availability: "true" include.release.openshift.io/single-node-developer: "true" release.openshift.io/create-only: "true" creationTimestamp: "2022-07-08T16:02:51Z" generation: 1 name: cluster ownerReferences: - apiVersion: config.openshift.io/v1 kind: ClusterVersion name: version uid: 36282574-bf9f-409e-a6cd-3032939293eb resourceVersion: "1865" uid: 0c0f7a4c-4307-4187-b591-6155695ac85b spec: workerLatencyProfile: LowUpdateSlowReaction1 # ...- 1
- 낮은 작업자 대기 시간 정책 사용을 지정합니다.
변경 사항이 적용됨에 따라 각 작업자 노드의 스케줄링이 비활성화됩니다.
검증
모든 노드가
Ready상태로 돌아가면 다음 명령을 사용하여 Kubernetes Controller Manager에서 적용되었는지 확인할 수 있습니다.$ oc get KubeControllerManager -o yaml | grep -i workerlatency -A 5 -B 5출력 예
# ... - lastTransitionTime: "2022-07-11T19:47:10Z" reason: ProfileUpdated status: "False" type: WorkerLatencyProfileProgressing - lastTransitionTime: "2022-07-11T19:47:10Z"1 message: all static pod revision(s) have updated latency profile reason: ProfileUpdated status: "True" type: WorkerLatencyProfileComplete - lastTransitionTime: "2022-07-11T19:20:11Z" reason: AsExpected status: "False" type: WorkerLatencyProfileDegraded - lastTransitionTime: "2022-07-11T19:20:36Z" status: "False" # ...- 1
- 프로필이 적용되고 활성화되도록 지정합니다.
미디어 프로필을 기본값으로 변경하거나 기본값을 medium로 변경하려면 node.config 오브젝트를 편집하고 spec.workerLatencyProfile 매개변수를 적절한 값으로 설정합니다.
6.5. 컨트롤 플레인 시스템 관리
컨트롤 플레인 머신 세트는 컴퓨팅 머신에 제공하는 컴퓨팅 머신 세트와 유사한 컨트롤 플레인 시스템에 대한 관리 기능을 제공합니다. 클러스터에서 컨트롤 플레인 머신 세트의 가용성 및 초기 상태는 클라우드 공급자와 사용자가 설치한 OpenShift Container Platform 버전에 따라 다릅니다. 자세한 내용은 컨트롤 플레인 머신 세트 시작하기를 참조하십시오.
6.6. 프로덕션 환경의 인프라 머신 세트 생성
컴퓨팅 머신 세트를 생성하여 기본 라우터, 통합 컨테이너 이미지 레지스트리, 클러스터 메트릭 및 모니터링용 구성 요소만 호스팅하는 머신을 생성할 수 있습니다. 이러한 인프라 시스템은 환경을 실행하는 데 필요한 총 서브스크립션 수에 포함되지 않습니다.
프로덕션 배포에서는 인프라 구성 요소를 유지하기 위해 세 개 이상의 컴퓨팅 머신 세트를 배포하는 것이 좋습니다. OpenShift Logging 및 Red Hat OpenShift Service Mesh 둘 다 다른 노드에 3개의 인스턴스를 설치해야 하는 Elasticsearch를 배포합니다. 이러한 각 노드는 고가용성을 위해 다른 가용성 영역에 배포할 수 있습니다. 이와 같은 구성에는 각 가용성 영역마다 하나씩 3개의 컴퓨팅 시스템 세트가 필요합니다. 여러 가용성 영역이 없는 글로벌 Azure 리전에서는 가용성 세트를 사용하여 고가용성을 보장할 수 있습니다.
인프라 노드 및 인프라 노드에서 실행할 수 있는 구성 요소에 대한 자세한 내용은 인프라 머신 세트 생성 을 참조하십시오.
인프라 노드를 생성하려면 머신 세트를 사용하거나 노드에 레이블을 할당 하거나 머신 구성 풀을 사용할 수 있습니다.
이러한 절차와 함께 사용할 수 있는 샘플 머신 세트의 경우 다른 클라우드의 머신 세트 생성을 참조하십시오.
모든 인프라 구성 요소에 특정 노드 선택기를 적용하면 OpenShift Container Platform에서 해당 라벨이 있는 노드에 해당 워크로드를 예약합니다.
6.6.1. 컴퓨팅 머신 세트 생성
설치 프로그램에서 생성한 컴퓨팅 머신 세트 외에도 고유한 머신 세트를 생성하여 선택한 특정 워크로드의 머신 컴퓨팅 리소스를 동적으로 관리할 수 있습니다.
사전 요구 사항
- OpenShift Container Platform 클러스터를 배포합니다.
-
OpenShift CLI(
oc)를 설치합니다. -
cluster-admin권한이 있는 사용자로oc에 로그인합니다.
절차
컴퓨팅 머신 세트 CR(사용자 정의 리소스) 샘플이 포함된 새 YAML 파일을 만들고 <
file_name>.yaml이라는 이름을 지정합니다.<clusterID>및<role>매개 변수 값을 설정해야 합니다.선택 사항: 특정 필드에 설정할 값이 확실하지 않은 경우 클러스터에서 기존 컴퓨팅 머신 세트를 확인할 수 있습니다.
클러스터의 컴퓨팅 머신 세트를 나열하려면 다음 명령을 실행합니다.
$ oc get machinesets -n openshift-machine-api출력 예
NAME DESIRED CURRENT READY AVAILABLE AGE agl030519-vplxk-worker-us-east-1a 1 1 1 1 55m agl030519-vplxk-worker-us-east-1b 1 1 1 1 55m agl030519-vplxk-worker-us-east-1c 1 1 1 1 55m agl030519-vplxk-worker-us-east-1d 0 0 55m agl030519-vplxk-worker-us-east-1e 0 0 55m agl030519-vplxk-worker-us-east-1f 0 0 55m특정 컴퓨팅 머신 세트 CR(사용자 정의 리소스)의 값을 보려면 다음 명령을 실행합니다.
$ oc get machineset <machineset_name> \ -n openshift-machine-api -o yaml출력 예
apiVersion: machine.openshift.io/v1beta1 kind: MachineSet metadata: labels: machine.openshift.io/cluster-api-cluster: <infrastructure_id>1 name: <infrastructure_id>-<role>2 namespace: openshift-machine-api spec: replicas: 1 selector: matchLabels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role> template: metadata: labels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> machine.openshift.io/cluster-api-machine-role: <role> machine.openshift.io/cluster-api-machine-type: <role> machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role> spec: providerSpec:3 ...
다음 명령을 실행하여
MachineSetCR을 생성합니다.$ oc create -f <file_name>.yaml
검증
다음 명령을 실행하여 컴퓨팅 머신 세트 목록을 확인합니다.
$ oc get machineset -n openshift-machine-api출력 예
NAME DESIRED CURRENT READY AVAILABLE AGE agl030519-vplxk-infra-us-east-1a 1 1 1 1 11m agl030519-vplxk-worker-us-east-1a 1 1 1 1 55m agl030519-vplxk-worker-us-east-1b 1 1 1 1 55m agl030519-vplxk-worker-us-east-1c 1 1 1 1 55m agl030519-vplxk-worker-us-east-1d 0 0 55m agl030519-vplxk-worker-us-east-1e 0 0 55m agl030519-vplxk-worker-us-east-1f 0 0 55m새 컴퓨팅 머신 세트를 사용할 수 있으면
DESIRED및CURRENT값이 일치합니다. 컴퓨팅 머신 세트를 사용할 수 없는 경우 몇 분 기다렸다가 명령을 다시 실행합니다.
6.6.2. 인프라 노드 생성
설치 관리자 프로비저닝 인프라 환경 또는 머신 API에서 컨트롤 플레인 노드를 관리하는 클러스터의 인프라 머신 세트 생성을 참조하십시오.
클러스터의 요구 사항은 infra 노드라고도 불리는 인프라를 프로비저닝해야 합니다. 설치 프로그램은 컨트롤 플레인 및 작업자 노드에 대한 프로비저닝만 제공합니다. 작업자 노드는 레이블을 통해 인프라 노드 또는 애플리케이션 ( app, app 이라고도 함)으로 지정할 수 있습니다.
절차
애플리케이션 노드 역할을 수행할 작업자 노드에 레이블을 추가합니다.
$ oc label node <node-name> node-role.kubernetes.io/app=""인프라 노드 역할을 수행할 작업자 노드에 레이블을 추가합니다.
$ oc label node <node-name> node-role.kubernetes.io/infra=""해당 노드에
infra역할 및app역할이 있는지 확인합니다.$ oc get nodes기본 클러스터 수준 노드 선택기를 생성합니다. 기본 노드 선택기는 모든 네임스페이스에서 생성된 Pod에 적용됩니다. 이렇게 하면 Pod의 기존 노드 선택기와 교차점이 생성되어 Pod의 선택기가 추가로 제한됩니다.
중요기본 노드 선택기 키가 Pod 라벨 키와 충돌하는 경우 기본 노드 선택기가 적용되지 않습니다.
그러나 Pod를 예약할 수 없게 만들 수 있는 기본 노드 선택기를 설정하지 마십시오. 예를 들어 Pod의 라벨이
node-role.kubernetes.io/master=""와 같은 다른 노드 역할로 설정된 경우 기본 노드 선택기를node-role.kubernetes.io/infra=""와 같은 특정 노드 역할로 설정하면 Pod를 예약할 수 없게 될 수 있습니다. 따라서 기본 노드 선택기를 특정 노드 역할로 설정할 때 주의해야 합니다.또는 프로젝트 노드 선택기를 사용하여 클러스터 수준 노드 선택기 키 충돌을 방지할 수 있습니다.
Scheduler오브젝트를 편집합니다.$ oc edit scheduler cluster적절한 노드 선택기를 사용하여
defaultNodeSelector필드를 추가합니다.apiVersion: config.openshift.io/v1 kind: Scheduler metadata: name: cluster spec: defaultNodeSelector: node-role.kubernetes.io/infra=""1 # ...- 1
- 이 예제 노드 선택기는 기본적으로 인프라 노드에 Pod를 배포합니다.
- 파일을 저장하여 변경 사항을 적용합니다.
이제 인프라 리소스를 새로 레이블이 지정된 인프라 노드로 이동할 수 있습니다.
6.6.3. 인프라 머신의 머신 구성 풀 생성
전용 구성을 위한 인프라 머신이 필요한 경우 인프라 풀을 생성해야 합니다.
절차
특정 레이블이 있는 인프라 노드로 할당하려는 노드에 레이블을 추가합니다.
$ oc label node <node_name> <label>$ oc label node ci-ln-n8mqwr2-f76d1-xscn2-worker-c-6fmtx node-role.kubernetes.io/infra=작업자 역할과 사용자 지정 역할을 모두 포함하는 머신 구성 풀을 머신 구성 선택기로 생성합니다.
$ cat infra.mcp.yaml출력 예
apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfigPool metadata: name: infra spec: machineConfigSelector: matchExpressions: - {key: machineconfiguration.openshift.io/role, operator: In, values: [worker,infra]}1 nodeSelector: matchLabels: node-role.kubernetes.io/infra: ""2 참고사용자 지정 머신 구성 풀은 작업자 풀의 머신 구성을 상속합니다. 사용자 지정 풀은 작업자 풀을 대상으로 하는 머신 구성을 사용하지만 사용자 지정 풀을 대상으로 하는 변경 사항만 배포할 수 있는 기능을 추가합니다. 사용자 지정 풀은 작업자 풀에서 리소스를 상속하므로 작업자 풀을 변경하면 사용자 지정 풀에도 영향을 줍니다.
YAML 파일이 있으면 머신 구성 풀을 생성할 수 있습니다.
$ oc create -f infra.mcp.yaml머신 구성을 확인하고 인프라 구성이 성공적으로 렌더링되었는지 확인합니다.
$ oc get machineconfig출력 예
NAME GENERATEDBYCONTROLLER IGNITIONVERSION CREATED 00-master 365c1cfd14de5b0e3b85e0fc815b0060f36ab955 3.2.0 31d 00-worker 365c1cfd14de5b0e3b85e0fc815b0060f36ab955 3.2.0 31d 01-master-container-runtime 365c1cfd14de5b0e3b85e0fc815b0060f36ab955 3.2.0 31d 01-master-kubelet 365c1cfd14de5b0e3b85e0fc815b0060f36ab955 3.2.0 31d 01-worker-container-runtime 365c1cfd14de5b0e3b85e0fc815b0060f36ab955 3.2.0 31d 01-worker-kubelet 365c1cfd14de5b0e3b85e0fc815b0060f36ab955 3.2.0 31d 99-master-1ae2a1e0-a115-11e9-8f14-005056899d54-registries 365c1cfd14de5b0e3b85e0fc815b0060f36ab955 3.2.0 31d 99-master-ssh 3.2.0 31d 99-worker-1ae64748-a115-11e9-8f14-005056899d54-registries 365c1cfd14de5b0e3b85e0fc815b0060f36ab955 3.2.0 31d 99-worker-ssh 3.2.0 31d rendered-infra-4e48906dca84ee702959c71a53ee80e7 365c1cfd14de5b0e3b85e0fc815b0060f36ab955 3.2.0 23m rendered-master-072d4b2da7f88162636902b074e9e28e 5b6fb8349a29735e48446d435962dec4547d3090 3.2.0 31d rendered-master-3e88ec72aed3886dec061df60d16d1af 02c07496ba0417b3e12b78fb32baf6293d314f79 3.2.0 31d rendered-master-419bee7de96134963a15fdf9dd473b25 365c1cfd14de5b0e3b85e0fc815b0060f36ab955 3.2.0 17d rendered-master-53f5c91c7661708adce18739cc0f40fb 365c1cfd14de5b0e3b85e0fc815b0060f36ab955 3.2.0 13d rendered-master-a6a357ec18e5bce7f5ac426fc7c5ffcd 365c1cfd14de5b0e3b85e0fc815b0060f36ab955 3.2.0 7d3h rendered-master-dc7f874ec77fc4b969674204332da037 5b6fb8349a29735e48446d435962dec4547d3090 3.2.0 31d rendered-worker-1a75960c52ad18ff5dfa6674eb7e533d 5b6fb8349a29735e48446d435962dec4547d3090 3.2.0 31d rendered-worker-2640531be11ba43c61d72e82dc634ce6 5b6fb8349a29735e48446d435962dec4547d3090 3.2.0 31d rendered-worker-4e48906dca84ee702959c71a53ee80e7 365c1cfd14de5b0e3b85e0fc815b0060f36ab955 3.2.0 7d3h rendered-worker-4f110718fe88e5f349987854a1147755 365c1cfd14de5b0e3b85e0fc815b0060f36ab955 3.2.0 17d rendered-worker-afc758e194d6188677eb837842d3b379 02c07496ba0417b3e12b78fb32baf6293d314f79 3.2.0 31d rendered-worker-daa08cc1e8f5fcdeba24de60cd955cc3 365c1cfd14de5b0e3b85e0fc815b0060f36ab955 3.2.0 13drendered-infra-*접두사가 있는 새 머신 구성이 표시되어야 합니다.선택 사항: 사용자 지정 풀에 변경 사항을 배포하려면
infra와 같은 사용자 지정 풀 이름을 레이블로 사용하는 머신 구성을 생성합니다. 필수 사항은 아니며 지침 용도로만 표시됩니다. 이렇게 하면 인프라 노드에 고유한 사용자 지정 구성을 적용할 수 있습니다.참고새 머신 구성 풀을 생성한 후 MCO는 해당 풀에 대해 새로 렌더링된 구성과 해당 풀의 관련 노드를 다시 부팅하여 새 구성을 적용합니다.
머신 구성을 생성합니다.
$ cat infra.mc.yaml출력 예
apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: name: 51-infra labels: machineconfiguration.openshift.io/role: infra1 spec: config: ignition: version: 3.2.0 storage: files: - path: /etc/infratest mode: 0644 contents: source: data:,infra- 1
- 노드에 추가한 레이블을
nodeSelector로 추가합니다.
머신 구성을 인프라 레이블 노드에 적용합니다.
$ oc create -f infra.mc.yaml
새 머신 구성 풀을 사용할 수 있는지 확인합니다.
$ oc get mcp출력 예
NAME CONFIG UPDATED UPDATING DEGRADED MACHINECOUNT READYMACHINECOUNT UPDATEDMACHINECOUNT DEGRADEDMACHINECOUNT AGE infra rendered-infra-60e35c2e99f42d976e084fa94da4d0fc True False False 1 1 1 0 4m20s master rendered-master-9360fdb895d4c131c7c4bebbae099c90 True False False 3 3 3 0 91m worker rendered-worker-60e35c2e99f42d976e084fa94da4d0fc True False False 2 2 2 0 91m이 예에서는 작업자 노드가 인프라 노드로 변경되었습니다.
6.7. 인프라 노드에 머신 세트 리소스 할당
인프라 머신 세트를 생성 한 후 worker 및 infra 역할이 새 인프라 노드에 적용됩니다. infra 역할이 적용된 노드는 worker 역할이 적용된 경우에도 환경을 실행하는 데 필요한 총 서브스크립션 수에 포함되지 않습니다.
그러나 인프라 노드에 작업자 역할이 할당되면 사용자 워크로드를 의도치 않게 인프라 노드에 할당할 수 있습니다. 이를 방지하려면 제어하려는 pod에 대한 허용 오차를 적용하고 인프라 노드에 테인트를 적용할 수 있습니다.
6.7.1. 테인트 및 허용 오차를 사용하여 인프라 노드 워크로드 바인딩
infra 및 worker 역할이 할당된 인프라 노드가 있는 경우 사용자 워크로드가 할당되지 않도록 노드를 구성해야 합니다.
인프라 노드에 대해 생성된 이중 infra,worker 레이블을 유지하고 테인트 및 허용 오차를 사용하여 사용자 워크로드가 예약된 노드를 관리하는 것이 좋습니다. 노드에서 worker 레이블을 제거하는 경우 이를 관리할 사용자 지정 풀을 생성해야 합니다. master 또는 worker 이외의 레이블이 있는 노드는 사용자 지정 풀없이 MCO에서 인식되지 않습니다. worker 레이블을 유지 관리하면 사용자 정의 레이블을 선택하는 사용자 정의 풀이 없는 경우 기본 작업자 머신 구성 풀에서 노드를 관리할 수 있습니다. infra 레이블은 총 서브스크립션 수에 포함되지 않는 클러스터와 통신합니다.
사전 요구 사항
-
OpenShift Container Platform 클러스터에서 추가
MachineSet개체를 구성합니다.
프로세스
인프라 노드에 테인트를 추가하여 사용자 워크로드를 예약하지 않도록합니다.
노드에 테인트가 있는지 확인합니다.
$ oc describe nodes <node_name>샘플 출력
oc describe node ci-ln-iyhx092-f76d1-nvdfm-worker-b-wln2l Name: ci-ln-iyhx092-f76d1-nvdfm-worker-b-wln2l Roles: worker ... Taints: node-role.kubernetes.io/infra:NoSchedule ...이 예에서는 노드에 테인트가 있음을 보여줍니다. 다음 단계에서 Pod에 허용 오차를 추가할 수 있습니다.
사용자 워크로드를 예약하지 않도록 테인트를 구성하지 않은 경우 다음을 수행합니다.
$ oc adm taint nodes <node_name> <key>=<value>:<effect>예를 들면 다음과 같습니다.
$ oc adm taint nodes node1 node-role.kubernetes.io/infra=reserved:NoSchedule작은 정보다음 YAML을 적용하여 테인트를 추가할 수 있습니다.
kind: Node apiVersion: v1 metadata: name: <node_name> labels: ... spec: taints: - key: node-role.kubernetes.io/infra effect: NoSchedule value: reserved ...이 예에서는 키
node-role.kubernetes.io/infra및 taint 효과NoSchedule이 있는node1에 taint를 배치합니다.NoSchedule효과가 있는 노드는 taint를 허용하는 pod만 예약하지만 기존 pod는 노드에서 예약된 상태를 유지할 수 있습니다.참고descheduler를 사용하면 노드 taint를 위반하는 pod가 클러스터에서 제거될 수 있습니다.
NoSchedule Effect와 위의 테인트와 함께 NoExecute Effect를 사용하여 테인트를 추가합니다.
$ oc adm taint nodes <node_name> <key>=<value>:<effect>예를 들면 다음과 같습니다.
$ oc adm taint nodes node1 node-role.kubernetes.io/infra=reserved:NoExecute작은 정보다음 YAML을 적용하여 테인트를 추가할 수 있습니다.
kind: Node apiVersion: v1 metadata: name: <node_name> labels: ... spec: taints: - key: node-role.kubernetes.io/infra effect: NoExecute value: reserved ...이 예에서는
node-role.kubernetes.io/infra및 taint 효과NoExecute가 있는node1에 taint를 배치합니다.NoExecute효과가 있는 노드는 테인트를 허용하는 Pod만 예약합니다. 이 효과에서는 일치하는 톨러레이션이 없는 노드에서 기존 Pod를 제거합니다.
라우터, 레지스트리 및 모니터링 워크로드와 같이 인프라 노드에서 예약하려는 pod 구성에 대한 허용 오차를 추가합니다. 다음 코드를
Pod개체 사양에 추가합니다.tolerations: - effect: NoSchedule1 key: node-role.kubernetes.io/infra2 value: reserved3 - effect: NoExecute4 key: node-role.kubernetes.io/infra5 operator: Exists6 value: reserved7 이 허용 오차는
oc adm taint명령으로 생성된 taint와 일치합니다. 이 허용 오차가 있는 pod를 인프라 노드에 예약할 수 있습니다.참고OLM을 통해 설치된 Operator의 pod를 인프라 노드로 이동할 수는 없습니다. Operator pod를 이동하는 기능은 각 Operator의 구성에 따라 다릅니다.
- 스케줄러를 사용하여 pod를 인프라 노드에 예약합니다. 자세한 내용은 노드에서 pod 배치 제어에 대한 설명서를 참조하십시오.
6.8. 인프라 머신 세트로 리소스 이동
일부 인프라 리소스는 기본적으로 클러스터에 배포됩니다. 이를 생성한 인프라 머신 세트로 이동할 수 있습니다.
6.8.1. 라우터 이동
라우터 Pod를 다른 컴퓨팅 머신 세트에 배포할 수 있습니다. 기본적으로 Pod는 작업자 노드에 배포됩니다.
사전 요구 사항
- OpenShift Container Platform 클러스터에서 추가 컴퓨팅 머신 세트를 구성합니다.
프로세스
라우터 Operator의
IngressController사용자 정의 리소스를 표시합니다.$ oc get ingresscontroller default -n openshift-ingress-operator -o yaml명령 출력은 다음 예제와 유사합니다.
apiVersion: operator.openshift.io/v1 kind: IngressController metadata: creationTimestamp: 2019-04-18T12:35:39Z finalizers: - ingresscontroller.operator.openshift.io/finalizer-ingresscontroller generation: 1 name: default namespace: openshift-ingress-operator resourceVersion: "11341" selfLink: /apis/operator.openshift.io/v1/namespaces/openshift-ingress-operator/ingresscontrollers/default uid: 79509e05-61d6-11e9-bc55-02ce4781844a spec: {} status: availableReplicas: 2 conditions: - lastTransitionTime: 2019-04-18T12:36:15Z status: "True" type: Available domain: apps.<cluster>.example.com endpointPublishingStrategy: type: LoadBalancerService selector: ingresscontroller.operator.openshift.io/deployment-ingresscontroller=defaultingresscontroller리소스를 편집하고infra레이블을 사용하도록nodeSelector를 변경합니다.$ oc edit ingresscontroller default -n openshift-ingress-operatorspec: nodePlacement: nodeSelector:1 matchLabels: node-role.kubernetes.io/infra: "" tolerations: - effect: NoSchedule key: node-role.kubernetes.io/infra value: reserved - effect: NoExecute key: node-role.kubernetes.io/infra value: reserved- 1
- 적절한 값이 설정된
nodeSelector매개변수를 이동하려는 구성 요소에 추가합니다. 표시된 형식으로nodeSelector를 사용하거나 노드에 지정된 값에 따라<key>: <value>쌍을 사용할 수 있습니다. 인프라 노드에 테인트를 추가한 경우 일치하는 허용 오차도 추가합니다.
라우터 pod가
infra노드에서 실행되고 있는지 확인합니다.라우터 pod 목록을 표시하고 실행중인 pod의 노드 이름을 기록해 둡니다.
$ oc get pod -n openshift-ingress -o wide출력 예
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES router-default-86798b4b5d-bdlvd 1/1 Running 0 28s 10.130.2.4 ip-10-0-217-226.ec2.internal <none> <none> router-default-955d875f4-255g8 0/1 Terminating 0 19h 10.129.2.4 ip-10-0-148-172.ec2.internal <none> <none>이 예에서 실행중인 pod는
ip-10-0-217-226.ec2.internal노드에 있습니다.실행중인 pod의 노드 상태를 표시합니다.
$ oc get node <node_name>1 - 1
- pod 목록에서 얻은
<node_name>을 지정합니다.
출력 예
NAME STATUS ROLES AGE VERSION ip-10-0-217-226.ec2.internal Ready infra,worker 17h v1.26.0역할 목록에
infra가 포함되어 있으므로 pod가 올바른 노드에서 실행됩니다.
6.8.2. 기본 레지스트리 이동
Pod를 다른 노드에 배포하도록 레지스트리 Operator를 구성합니다.
사전 요구 사항
- OpenShift Container Platform 클러스터에서 추가 컴퓨팅 머신 세트를 구성합니다.
프로세스
config/instance개체를 표시합니다.$ oc get configs.imageregistry.operator.openshift.io/cluster -o yaml출력 예
apiVersion: imageregistry.operator.openshift.io/v1 kind: Config metadata: creationTimestamp: 2019-02-05T13:52:05Z finalizers: - imageregistry.operator.openshift.io/finalizer generation: 1 name: cluster resourceVersion: "56174" selfLink: /apis/imageregistry.operator.openshift.io/v1/configs/cluster uid: 36fd3724-294d-11e9-a524-12ffeee2931b spec: httpSecret: d9a012ccd117b1e6616ceccb2c3bb66a5fed1b5e481623 logging: 2 managementState: Managed proxy: {} replicas: 1 requests: read: {} write: {} storage: s3: bucket: image-registry-us-east-1-c92e88cad85b48ec8b312344dff03c82-392c region: us-east-1 status: ...config/instance개체를 편집합니다.$ oc edit configs.imageregistry.operator.openshift.io/clusterspec: affinity: podAntiAffinity: preferredDuringSchedulingIgnoredDuringExecution: - podAffinityTerm: namespaces: - openshift-image-registry topologyKey: kubernetes.io/hostname weight: 100 logLevel: Normal managementState: Managed nodeSelector:1 node-role.kubernetes.io/infra: "" tolerations: - effect: NoSchedule key: node-role.kubernetes.io/infra value: reserved - effect: NoExecute key: node-role.kubernetes.io/infra value: reserved- 1
- 적절한 값이 설정된
nodeSelector매개변수를 이동하려는 구성 요소에 추가합니다. 표시된 형식으로nodeSelector를 사용하거나 노드에 지정된 값에 따라<key>: <value>쌍을 사용할 수 있습니다. 인프라 노드에 테인트를 추가한 경우 일치하는 톨러레이션도 추가합니다.
레지스트리 pod가 인프라 노드로 이동되었는지 검증합니다.
다음 명령을 실행하여 레지스트리 pod가 있는 노드를 식별합니다.
$ oc get pods -o wide -n openshift-image-registry노드에 지정된 레이블이 있는지 확인합니다.
$ oc describe node <node_name>명령 출력을 확인하고
node-role.kubernetes.io/infra가LABELS목록에 있는지 확인합니다.
6.8.3. 모니터링 솔루션 이동
모니터링 스택에는 Prometheus, Thanos Querier, Alertmanager를 비롯한 여러 구성 요소가 포함됩니다. Cluster Monitoring Operator는 이 스택을 관리합니다. 모니터링 스택을 인프라 노드에 재배포하려면 사용자 정의 구성 맵을 생성하고 적용할 수 있습니다.
절차
cluster-monitoring-config구성 맵을 편집하고infra레이블을 사용하도록nodeSelector를 변경합니다.$ oc edit configmap cluster-monitoring-config -n openshift-monitoringapiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: |+ alertmanagerMain: nodeSelector:1 node-role.kubernetes.io/infra: "" tolerations: - key: node-role.kubernetes.io/infra value: reserved effect: NoSchedule - key: node-role.kubernetes.io/infra value: reserved effect: NoExecute prometheusK8s: nodeSelector: node-role.kubernetes.io/infra: "" tolerations: - key: node-role.kubernetes.io/infra value: reserved effect: NoSchedule - key: node-role.kubernetes.io/infra value: reserved effect: NoExecute prometheusOperator: nodeSelector: node-role.kubernetes.io/infra: "" tolerations: - key: node-role.kubernetes.io/infra value: reserved effect: NoSchedule - key: node-role.kubernetes.io/infra value: reserved effect: NoExecute k8sPrometheusAdapter: nodeSelector: node-role.kubernetes.io/infra: "" tolerations: - key: node-role.kubernetes.io/infra value: reserved effect: NoSchedule - key: node-role.kubernetes.io/infra value: reserved effect: NoExecute kubeStateMetrics: nodeSelector: node-role.kubernetes.io/infra: "" tolerations: - key: node-role.kubernetes.io/infra value: reserved effect: NoSchedule - key: node-role.kubernetes.io/infra value: reserved effect: NoExecute telemeterClient: nodeSelector: node-role.kubernetes.io/infra: "" tolerations: - key: node-role.kubernetes.io/infra value: reserved effect: NoSchedule - key: node-role.kubernetes.io/infra value: reserved effect: NoExecute openshiftStateMetrics: nodeSelector: node-role.kubernetes.io/infra: "" tolerations: - key: node-role.kubernetes.io/infra value: reserved effect: NoSchedule - key: node-role.kubernetes.io/infra value: reserved effect: NoExecute thanosQuerier: nodeSelector: node-role.kubernetes.io/infra: "" tolerations: - key: node-role.kubernetes.io/infra value: reserved effect: NoSchedule - key: node-role.kubernetes.io/infra value: reserved effect: NoExecute- 1
- 적절한 값이 설정된
nodeSelector매개변수를 이동하려는 구성 요소에 추가합니다. 표시된 형식으로nodeSelector를 사용하거나 노드에 지정된 값에 따라<key>: <value>쌍을 사용할 수 있습니다. 인프라 노드에 테인트를 추가한 경우 일치하는 톨러레이션도 추가합니다.
모니터링 pod가 새 머신으로 이동하는 것을 확인합니다.
$ watch 'oc get pod -n openshift-monitoring -o wide'구성 요소가
infra노드로 이동하지 않은 경우 이 구성 요소가 있는 pod를 제거합니다.$ oc delete pod -n openshift-monitoring <pod>삭제된 pod의 구성 요소가
infra노드에 다시 생성됩니다.
6.8.4. 로깅 리소스 이동
로깅 리소스 이동에 대한 자세한 내용은 다음을 참조하십시오.
6.9. 클러스터에 자동 스케일링 적용
OpenShift Container Platform 클러스터에 자동 스케일링을 적용하려면클러스터 자동 스케일러를 배포한 다음 클러스터의 각 머신 유형에 대해 머신 자동 스케일러를 배포해야 합니다.
자세한 내용은 OpenShift Container Platform 클러스터에 자동 스케일링 적용에서 참조하십시오.
6.10. Linux cgroup 구성
Linux 제어 그룹 버전 1 (cgroup v1)은 기본적으로 활성화되어 있습니다. node.config 오브젝트를 편집하여 클러스터에서 Linux 제어 그룹 버전 2 (cgroup v2)를 활성화할 수 있습니다. OpenShift Container Platform에서 cgroup v2를 활성화하면 클러스터의 모든 cgroup 버전 1 컨트롤러 및 계층이 비활성화됩니다.
cgroup v2는 Linux cgroup API의 현재 버전입니다. cgroup v2는 통합 계층 구조, 더 안전한 하위 트리 위임, pressure stayll Information 과 같은 새로운 기능, 향상된 리소스 관리 및 격리를 포함하여 cgroup v1에 비해 몇 가지 개선 사항을 제공합니다. 그러나 cgroup v2에는 cgroup v1과 다른 CPU, 메모리, I/O 관리 특성이 있습니다. 따라서 일부 워크로드는 cgroup v2를 실행하는 클러스터의 메모리 또는 CPU 사용량에 약간의 차이가 있을 수 있습니다.
필요에 따라 cgroup v1과 cgroup v2 사이에서 변경할 수 있습니다. 자세한 내용은 이 섹션의 "ECDHE 리소스"의 "노드에서 Linux cgroup 구성"을 참조하십시오.
현재 cgroup v2에서는 CPU 부하 분산을 비활성화하지 않습니다. 따라서 cgroup v2가 활성화된 경우 성능 프로필에서 원하는 동작을 얻지 못할 수 있습니다. 성능 프로필을 사용하는 경우에는 cgroup v2를 활성화하는 것은 권장되지 않습니다.
사전 요구 사항
- 버전 4.12 이상을 사용하는 OpenShift Container Platform 클러스터가 실행 중입니다.
- 관리 권한이 있는 사용자로 클러스터에 로그인했습니다.
절차
노드에서 cgroup v2를 활성화합니다.
node.config오브젝트를 편집합니다.$ oc edit nodes.config/clusterspec.cgroupMode: "v2": 추가 :node.config오브젝트의 예apiVersion: config.openshift.io/v1 kind: Node metadata: annotations: include.release.openshift.io/ibm-cloud-managed: "true" include.release.openshift.io/self-managed-high-availability: "true" include.release.openshift.io/single-node-developer: "true" release.openshift.io/create-only: "true" creationTimestamp: "2022-07-08T16:02:51Z" generation: 1 name: cluster ownerReferences: - apiVersion: config.openshift.io/v1 kind: ClusterVersion name: version uid: 36282574-bf9f-409e-a6cd-3032939293eb resourceVersion: "1865" uid: 0c0f7a4c-4307-4187-b591-6155695ac85b spec: cgroupMode: "v2"1 ...- 1
- cgroup v2를 활성화합니다.
검증
머신 구성에서 새 머신 구성이 추가되었는지 확인합니다.
$ oc get mc출력 예
NAME GENERATEDBYCONTROLLER IGNITIONVERSION AGE 00-master 52dd3ba6a9a527fc3ab42afac8d12b693534c8c9 3.2.0 33m 00-worker 52dd3ba6a9a527fc3ab42afac8d12b693534c8c9 3.2.0 33m 01-master-container-runtime 52dd3ba6a9a527fc3ab42afac8d12b693534c8c9 3.2.0 33m 01-master-kubelet 52dd3ba6a9a527fc3ab42afac8d12b693534c8c9 3.2.0 33m 01-worker-container-runtime 52dd3ba6a9a527fc3ab42afac8d12b693534c8c9 3.2.0 33m 01-worker-kubelet 52dd3ba6a9a527fc3ab42afac8d12b693534c8c9 3.2.0 33m 97-master-generated-kubelet 52dd3ba6a9a527fc3ab42afac8d12b693534c8c9 3.2.0 33m 99-worker-generated-kubelet 52dd3ba6a9a527fc3ab42afac8d12b693534c8c9 3.2.0 33m 99-master-generated-registries 52dd3ba6a9a527fc3ab42afac8d12b693534c8c9 3.2.0 33m 99-master-ssh 3.2.0 40m 99-worker-generated-registries 52dd3ba6a9a527fc3ab42afac8d12b693534c8c9 3.2.0 33m 99-worker-ssh 3.2.0 40m rendered-master-23d4317815a5f854bd3553d689cfe2e9 52dd3ba6a9a527fc3ab42afac8d12b693534c8c9 3.2.0 10s1 rendered-master-23e785de7587df95a4b517e0647e5ab7 52dd3ba6a9a527fc3ab42afac8d12b693534c8c9 3.2.0 33m rendered-worker-5d596d9293ca3ea80c896a1191735bb1 52dd3ba6a9a527fc3ab42afac8d12b693534c8c9 3.2.0 33m rendered-worker-dcc7f1b92892d34db74d6832bcc9ccd4 52dd3ba6a9a527fc3ab42afac8d12b693534c8c9 3.2.0 10s- 1
- 예상대로 새 머신 구성이 생성됩니다.
새 머신 구성에 새
kernelArguments가 추가되었는지 확인합니다.$ oc describe mc <name>cgroup v2 출력 예
apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: labels: machineconfiguration.openshift.io/role: worker name: 05-worker-kernelarg-selinuxpermissive spec: kernelArguments: - systemd_unified_cgroup_hierarchy=11 - cgroup_no_v1="all"2 - psi=13 노드의 스케줄링이 비활성화되어 있는지 확인합니다. 이는 변경 사항이 적용 중임을 나타냅니다.
$ oc get nodes출력 예
NAME STATUS ROLES AGE VERSION ci-ln-fm1qnwt-72292-99kt6-master-0 Ready,SchedulingDisabled master 58m v1.26.0 ci-ln-fm1qnwt-72292-99kt6-master-1 Ready master 58m v1.26.0 ci-ln-fm1qnwt-72292-99kt6-master-2 Ready master 58m v1.26.0 ci-ln-fm1qnwt-72292-99kt6-worker-a-h5gt4 Ready,SchedulingDisabled worker 48m v1.26.0 ci-ln-fm1qnwt-72292-99kt6-worker-b-7vtmd Ready worker 48m v1.26.0 ci-ln-fm1qnwt-72292-99kt6-worker-c-rhzkv Ready worker 48m v1.26.0노드가
Ready상태가 되면 해당 노드의 디버그 세션을 시작합니다.$ oc debug node/<node_name>디버그 쉘 내에서
/host를 root 디렉터리로 설정합니다.sh-4.4# chroot /hostsys/fs/cgroup/cgroup2fs파일이 노드에 있는지 확인합니다. 이 파일은 cgroup v2에 의해 생성됩니다.$ stat -c %T -f /sys/fs/cgroup출력 예
cgroup2fs
6.11. FeatureGate를 사용하여 기술 프리뷰 기능 활성화
FeatureGate 사용자 정의 리소스 (CR)를 편집하여 클러스터의 모든 노드에 대해 현재 기술 프리뷰 기능의 일부를 켤 수 있습니다.
6.11.1. FeatureGate 이해
FeatureGate 사용자 정의 리소스 (CR)를 사용하여 클러스터에서 특정 기능 세트를 활성화할 수 있습니다. 기능 세트는 기본적으로 활성화되어 있지 않은 OpenShift Container Platform 기능 컬렉션입니다.
FeatureGate CR을 사용하여 설정된 다음 기능을 활성화할 수 있습니다.
TechPreviewNoUpgrade이 기능 세트는 현재 기술 프리뷰 기능의 서브 세트입니다. 이 기능 세트를 사용하면 프로덕션 클러스터에서 비활성화된 기능을 유지하면서 테스트 클러스터에서 이러한 기술 프리뷰 기능을 완전히 테스트할 수 있습니다.주의클러스터에서
TechPreviewNoUpgrade기능 세트를 활성화하면 취소할 수 없으며 마이너 버전 업데이트를 방지할 수 없습니다. 프로덕션 클러스터에서 이 기능 세트를 활성화해서는 안 됩니다.기능 세트를 통해 다음과 같은 기술 프리뷰 기능을 활성화할 수 있습니다.
-
외부 클라우드 공급자. vSphere, AWS, Azure 및 GCP에서 클러스터에 대한 외부 클라우드 공급자를 지원합니다. OpenStack에 대한 지원은 GA입니다. 이는 대부분의 사용자가 상호 작용할 필요가 없는 내부 기능입니다. (
ExternalCloudProvider) -
OpenShift 빌드의 공유 리소스 CSI 드라이버 및 CSI 볼륨 빌드. CSI(Container Storage Interface)를 활성화합니다. (
CSIDriverSharedResource) -
CSI 볼륨. OpenShift Container Platform 빌드 시스템에 대한 CSI 볼륨 지원을 활성화합니다. (
빌드CSIVolumes) -
노드의 스왑 메모리입니다. 노드별로 OpenShift Container Platform 워크로드에 대한 스왑 메모리 사용을 활성화합니다. (
NodeSwap) -
OpenStack 시스템 API 공급자. 이 게이트는 영향을 미치지 않으며 향후 릴리스에서 이 기능 세트에서 제거될 예정입니다. (
MachineAPIProviderOpenStack) -
Insights Operator.
InsightsDataGatherCRD를 활성화하여 사용자가 일부 Insights 데이터 수집 옵션을 구성할 수 있습니다. -
Pod 토폴로지 분배 제약 조건입니다. Pod 토폴로지 제약 조건에 대한
matchLabelKeys매개변수를 활성화합니다. 매개변수는 분배를 계산할 Pod를 선택하는 Pod 라벨 키 목록입니다. (MatchLabelKeysInPodTopologySpread) -
소급 기본 스토리지 클래스. PVC가 생성될 때 기본 스토리지 클래스가 없는 경우 OpenShift Container Platform에서 기본 스토리지 클래스를 강제로 PVC에 할당할 수 있습니다. (
RetroactiveDefaultStorageClass) -
Pod 중단 예산 (PDB) 비정상적인 Pod 제거 정책입니다. PDB를 사용할 때 비정상 Pod를 제거로 간주하는 방법을 지정하는 지원을 활성화합니다. (
PDBUnhealthyPodEvictionPolicy) -
동적 리소스 CloudEvent API. 새 API를 사용하여 Pod와 컨테이너 간에 리소스를 요청하고 공유할 수 있습니다. 이는 대부분의 사용자가 상호 작용할 필요가 없는 내부 기능입니다. (
DynamicResourceAllocation) -
Pod 보안 승인 적용 Pod 보안 승인에 대해 제한된 적용 모드를 활성화합니다. 경고만 로깅하는 대신 Pod가 Pod 보안 표준을 위반하는 경우 거부됩니다. (
OpenShiftPodSecurityAdmission)
-
외부 클라우드 공급자. vSphere, AWS, Azure 및 GCP에서 클러스터에 대한 외부 클라우드 공급자를 지원합니다. OpenStack에 대한 지원은 GA입니다. 이는 대부분의 사용자가 상호 작용할 필요가 없는 내부 기능입니다. (
6.11.2. 웹 콘솔을 사용하여 기능 세트 활성화
OpenShift Container Platform 웹 콘솔을 사용하여 FeatureGate CR(사용자 정의 리소스)을 편집하여 클러스터의 모든 노드에 대해 기능 세트를 활성화할 수 있습니다.
프로세스
기능 세트를 활성화하려면 다음을 수행합니다.
- OpenShift Container Platform 웹 콘솔에서 관리 → 사용자 지정 리소스 정의 페이지로 전환합니다.
- 사용자 지정 리소스 정의 페이지에서 FeatureGate를 클릭합니다.
- 사용자 정의 리소스 정의 세부 정보 페이지에서 인스턴스 탭을 클릭합니다.
- 클러스터 기능 게이트를 클릭한 다음 YAML 탭을 클릭합니다.
특정 기능 세트를 추가하려면 클러스터 인스턴스를 편집합니다.
주의클러스터에서
TechPreviewNoUpgrade기능 세트를 활성화하면 취소할 수 없으며 마이너 버전 업데이트를 방지할 수 없습니다. 프로덕션 클러스터에서 이 기능 세트를 활성화해서는 안 됩니다.FeatureGate 사용자 지정 리소스 샘플
apiVersion: config.openshift.io/v1 kind: FeatureGate metadata: name: cluster1 # ... spec: featureSet: TechPreviewNoUpgrade2 변경 사항을 저장하면 새 머신 구성이 생성되고 머신 구성 풀이 업데이트되고 변경 사항이 적용되는 동안 각 노드의 스케줄링이 비활성화됩니다.
검증
노드가 준비 상태로 돌아간 후 노드에서 kubelet.conf 파일을 확인하여 기능 게이트가 활성화되어 있는지 확인할 수 있습니다.
- 웹 콘솔의 관리자 화면에서 컴퓨팅 → 노드로 이동합니다.
- 노드를 선택합니다.
- 노드 세부 정보 페이지에서 터미널 을 클릭합니다.
터미널 창에서 root 디렉토리를
/host:로 변경합니다.sh-4.2# chroot /hostkubelet.conf파일을 확인합니다.sh-4.2# cat /etc/kubernetes/kubelet.conf샘플 출력
# ... featureGates: InsightsOperatorPullingSCA: true, LegacyNodeRoleBehavior: false # ...true로 나열된 기능은 클러스터에서 활성화됩니다.참고나열된 기능은 OpenShift Container Platform 버전에 따라 다릅니다.
6.11.3. CLI를 사용하여 기능 세트 활성화
OpenShift CLI(oc)를 사용하여 FeatureGate CR(사용자 정의 리소스)을 편집하여 클러스터의 모든 노드에 대해 기능 세트를 활성화할 수 있습니다.
사전 요구 사항
-
OpenShift CLI(
oc)가 설치되어 있습니다.
프로세스
기능 세트를 활성화하려면 다음을 수행합니다.
cluster라는FeatureGateCR을 편집합니다.$ oc edit featuregate cluster주의클러스터에서
TechPreviewNoUpgrade기능 세트를 활성화하면 취소할 수 없으며 마이너 버전 업데이트를 방지할 수 없습니다. 프로덕션 클러스터에서 이 기능 세트를 활성화해서는 안 됩니다.FeatureGate 사용자 지정 리소스 샘플
apiVersion: config.openshift.io/v1 kind: FeatureGate metadata: name: cluster1 # ... spec: featureSet: TechPreviewNoUpgrade2 변경 사항을 저장하면 새 머신 구성이 생성되고 머신 구성 풀이 업데이트되고 변경 사항이 적용되는 동안 각 노드의 스케줄링이 비활성화됩니다.
검증
노드가 준비 상태로 돌아간 후 노드에서 kubelet.conf 파일을 확인하여 기능 게이트가 활성화되어 있는지 확인할 수 있습니다.
- 웹 콘솔의 관리자 화면에서 컴퓨팅 → 노드로 이동합니다.
- 노드를 선택합니다.
- 노드 세부 정보 페이지에서 터미널 을 클릭합니다.
터미널 창에서 root 디렉토리를
/host:로 변경합니다.sh-4.2# chroot /hostkubelet.conf파일을 확인합니다.sh-4.2# cat /etc/kubernetes/kubelet.conf샘플 출력
# ... featureGates: InsightsOperatorPullingSCA: true, LegacyNodeRoleBehavior: false # ...true로 나열된 기능은 클러스터에서 활성화됩니다.참고나열된 기능은 OpenShift Container Platform 버전에 따라 다릅니다.
6.12. etcd 작업
etcd를 백업하거나 etcd 암호화를 활성화 또는 비활성화하거나 etcd 데이터 조각 모음을 실행합니다.
6.12.1. etcd 암호화 정보
기본적으로 etcd 데이터는 OpenShift Container Platform에서 암호화되지 않습니다. 클러스터에 etcd 암호화를 사용하여 추가 데이터 보안 계층을 제공할 수 있습니다. 예를 들어 etcd 백업이 잘못된 당사자에게 노출되는 경우 중요한 데이터의 손실을 방지할 수 있습니다.
etcd 암호화를 활성화하면 다음 OpenShift API 서버 및 쿠버네티스 API 서버 리소스가 암호화됩니다.
- 보안
- 구성 맵
- 라우트
- OAuth 액세스 토큰
- OAuth 승인 토큰
etcd 암호화를 활성화하면 암호화 키가 생성됩니다. etcd 백업에서 복원하려면 이 키가 있어야 합니다.
etcd 암호화는 키가 아닌 값만 암호화합니다. 리소스 유형, 네임스페이스 및 오브젝트 이름은 암호화되지 않습니다.
백업 중에 etcd 암호화가 활성화되면 static_kuberesources_<datetimestamp>.tar.gz 파일에 etcd 스냅샷의 암호화 키가 포함되어 있습니다. 보안상의 이유로 이 파일을 etcd 스냅샷과 별도로 저장합니다. 그러나 이 파일은 해당 etcd 스냅샷에서 이전 etcd 상태를 복원하는데 필요합니다.
6.12.2. 지원되는 암호화 유형
OpenShift Container Platform에서 etcd 데이터를 암호화하는 데 다음 암호화 유형이 지원됩니다.
- AES-CBC
- PKCS#7 패딩 및 32바이트 키와 함께 AES-CBC를 사용하여 암호화를 수행합니다. 암호화 키는 매주 순환됩니다.
- AES-GCM
- 임의의 nonce 및 32바이트 키가 있는 AES-GCM을 사용하여 암호화를 수행합니다. 암호화 키는 매주 순환됩니다.
6.12.3. etcd 암호화 활성화
etcd 암호화를 활성화하여 클러스터에서 중요한 리소스를 암호화할 수 있습니다.
초기 암호화 프로세스가 완료될 때까지 etcd 리소스를 백업하지 마십시오. 암호화 프로세스가 완료되지 않으면 백업이 부분적으로만 암호화될 수 있습니다.
etcd 암호화를 활성화하면 다음과 같은 몇 가지 변경이 발생할 수 있습니다.
- etcd 암호화는 몇 가지 리소스의 메모리 사용에 영향을 줄 수 있습니다.
- 리더가 백업을 제공해야 하기 때문에 백업 성능에 일시적인 영향을 미칠 수 있습니다.
- 디스크 I/O는 백업 상태를 수신하는 노드에 영향을 줄 수 있습니다.
AES-GCM 또는 AES-CBC 암호화에서 etcd 데이터베이스를 암호화할 수 있습니다.
한 암호화 유형에서 다른 암호화 유형으로 etcd 데이터베이스를 마이그레이션하려면 API 서버의 spec.encryption.type 필드를 수정할 수 있습니다. etcd 데이터를 새로운 암호화 유형으로 마이그레이션하면 자동으로 수행됩니다.
사전 요구 사항
-
cluster-admin역할의 사용자로 클러스터에 액세스할 수 있어야 합니다.
절차
APIServer오브젝트를 수정합니다.$ oc edit apiserverspec.encryption.type필드를aesgcm또는aescbc로 설정합니다.spec: encryption: type: aesgcm1 - 1
- AES-GCM 암호화를 위한
aesgcm또는 AES-CBC 암호화를 위한aescbc로 설정합니다.
파일을 저장하여 변경 사항을 적용합니다.
암호화 프로세스가 시작됩니다. etcd 데이터베이스의 크기에 따라 이 프로세스를 완료하는 데 20분 이상 걸릴 수 있습니다.
etcd 암호화에 성공했는지 확인합니다.
OpenShift API 서버의
Encrypted상태 조건을 검토하여 해당 리소스가 성공적으로 암호화되었는지 확인합니다.$ oc get openshiftapiserver -o=jsonpath='{range .items[0].status.conditions[?(@.type=="Encrypted")]}{.reason}{"\n"}{.message}{"\n"}'암호화에 성공하면 출력에
EncryptionCompleted가 표시됩니다.EncryptionCompleted All resources encrypted: routes.route.openshift.io출력에
EncryptionInProgress가 표시되는 경우에도 암호화는 계속 진행 중입니다. 몇 분 기다린 후 다시 시도합니다.쿠버네티스 API 서버의
Encrypted상태 조건을 검토하여 해당 리소스가 성공적으로 암호화되었는지 확인합니다.$ oc get kubeapiserver -o=jsonpath='{range .items[0].status.conditions[?(@.type=="Encrypted")]}{.reason}{"\n"}{.message}{"\n"}'암호화에 성공하면 출력에
EncryptionCompleted가 표시됩니다.EncryptionCompleted All resources encrypted: secrets, configmaps출력에
EncryptionInProgress가 표시되는 경우에도 암호화는 계속 진행 중입니다. 몇 분 기다린 후 다시 시도합니다.OpenShift OAuth API 서버의
Encrypted상태 조건을 검토하여 해당 리소스가 성공적으로 암호화되었는지 확인합니다.$ oc get authentication.operator.openshift.io -o=jsonpath='{range .items[0].status.conditions[?(@.type=="Encrypted")]}{.reason}{"\n"}{.message}{"\n"}'암호화에 성공하면 출력에
EncryptionCompleted가 표시됩니다.EncryptionCompleted All resources encrypted: oauthaccesstokens.oauth.openshift.io, oauthauthorizetokens.oauth.openshift.io출력에
EncryptionInProgress가 표시되는 경우에도 암호화는 계속 진행 중입니다. 몇 분 기다린 후 다시 시도합니다.
6.12.4. etcd 암호화 비활성화
클러스터에서 etcd 데이터의 암호화를 비활성화할 수 있습니다.
사전 요구 사항
-
cluster-admin역할의 사용자로 클러스터에 액세스할 수 있어야 합니다.
절차
APIServer오브젝트를 수정합니다.$ oc edit apiserver암호화필드 유형을identity로 설정합니다.spec: encryption: type: identity1 - 1
identity유형이 기본값이며, 이는 암호화가 수행되지 않음을 의미합니다.
파일을 저장하여 변경 사항을 적용합니다.
암호 해독 프로세스가 시작됩니다. 클러스터 크기에 따라 이 프로세스를 완료하는 데 20분 이상 걸릴 수 있습니다.
etcd 암호 해독에 성공했는지 확인합니다.
OpenShift API 서버의
Encrypted상태 조건을 검토하여 해당 리소스의 암호가 성공적으로 해독되었는지 확인합니다.$ oc get openshiftapiserver -o=jsonpath='{range .items[0].status.conditions[?(@.type=="Encrypted")]}{.reason}{"\n"}{.message}{"\n"}'암호 해독에 성공하면 출력에
DecryptionCompleted가 표시됩니다.DecryptionCompleted Encryption mode set to identity and everything is decrypted출력에
DecryptionInProgress가 표시되면 암호 해독이 여전히 진행 중임을 나타냅니다. 몇 분 기다린 후 다시 시도합니다.쿠버네티스 API 서버의
Encrypted상태 조건을 검토하여 해당 리소스의 암호가 성공적으로 해독되었는지 확인합니다.$ oc get kubeapiserver -o=jsonpath='{range .items[0].status.conditions[?(@.type=="Encrypted")]}{.reason}{"\n"}{.message}{"\n"}'암호 해독에 성공하면 출력에
DecryptionCompleted가 표시됩니다.DecryptionCompleted Encryption mode set to identity and everything is decrypted출력에
DecryptionInProgress가 표시되면 암호 해독이 여전히 진행 중임을 나타냅니다. 몇 분 기다린 후 다시 시도합니다.OpenShift API 서버의
Encrypted상태 조건을 검토하여 해당 리소스의 암호가 성공적으로 해독되었는지 확인합니다.$ oc get authentication.operator.openshift.io -o=jsonpath='{range .items[0].status.conditions[?(@.type=="Encrypted")]}{.reason}{"\n"}{.message}{"\n"}'암호 해독에 성공하면 출력에
DecryptionCompleted가 표시됩니다.DecryptionCompleted Encryption mode set to identity and everything is decrypted출력에
DecryptionInProgress가 표시되면 암호 해독이 여전히 진행 중임을 나타냅니다. 몇 분 기다린 후 다시 시도합니다.
6.12.5. etcd 데이터 백업
다음 단계에 따라 etcd 스냅샷을 작성하고 정적 pod의 리소스를 백업하여 etcd 데이터를 백업합니다. 이 백업을 저장하여 etcd를 복원해야하는 경우 나중에 사용할 수 있습니다.
단일 컨트롤 플레인 호스트의 백업만 저장합니다. 클러스터의 각 컨트롤 플레인 호스트에서 백업을 수행하지 마십시오.
사전 요구 사항
-
cluster-admin역할의 사용자로 클러스터에 액세스할 수 있어야 합니다. 클러스터 전체의 프록시가 활성화되어 있는지 확인해야 합니다.
작은 정보oc get proxy cluster -o yaml의 출력을 확인하여 프록시가 사용 가능한지 여부를 확인할 수 있습니다.httpProxy,httpsProxy및noProxy필드에 값이 설정되어 있으면 프록시가 사용됩니다.
절차
컨트롤 플레인 노드의 root로 디버그 세션을 시작합니다.
$ oc debug --as-root node/<node_name>디버그 쉘에서 root 디렉토리를
/host로 변경합니다.sh-4.4# chroot /host클러스터 전체 프록시가 활성화된 경우 다음 명령을 실행하여
NO_PROXY,HTTP_PROXY및HTTPS_PROXY환경 변수를 내보냅니다.$ export HTTP_PROXY=http://<your_proxy.example.com>:8080$ export HTTPS_PROXY=https://<your_proxy.example.com>:8080$ export NO_PROXY=<example.com>디버그 쉘에서
cluster-backup.sh스크립트를 실행하고 백업을 저장할 위치를 전달합니다.작은 정보cluster-backup.sh스크립트는 etcd Cluster Operator의 구성 요소로 유지 관리되며etcdctl snapshot save명령 관련 래퍼입니다.sh-4.4# /usr/local/bin/cluster-backup.sh /home/core/assets/backup스크립트 출력 예
found latest kube-apiserver: /etc/kubernetes/static-pod-resources/kube-apiserver-pod-6 found latest kube-controller-manager: /etc/kubernetes/static-pod-resources/kube-controller-manager-pod-7 found latest kube-scheduler: /etc/kubernetes/static-pod-resources/kube-scheduler-pod-6 found latest etcd: /etc/kubernetes/static-pod-resources/etcd-pod-3 ede95fe6b88b87ba86a03c15e669fb4aa5bf0991c180d3c6895ce72eaade54a1 etcdctl version: 3.4.14 API version: 3.4 {"level":"info","ts":1624647639.0188997,"caller":"snapshot/v3_snapshot.go:119","msg":"created temporary db file","path":"/home/core/assets/backup/snapshot_2021-06-25_190035.db.part"} {"level":"info","ts":"2021-06-25T19:00:39.030Z","caller":"clientv3/maintenance.go:200","msg":"opened snapshot stream; downloading"} {"level":"info","ts":1624647639.0301006,"caller":"snapshot/v3_snapshot.go:127","msg":"fetching snapshot","endpoint":"https://10.0.0.5:2379"} {"level":"info","ts":"2021-06-25T19:00:40.215Z","caller":"clientv3/maintenance.go:208","msg":"completed snapshot read; closing"} {"level":"info","ts":1624647640.6032252,"caller":"snapshot/v3_snapshot.go:142","msg":"fetched snapshot","endpoint":"https://10.0.0.5:2379","size":"114 MB","took":1.584090459} {"level":"info","ts":1624647640.6047094,"caller":"snapshot/v3_snapshot.go:152","msg":"saved","path":"/home/core/assets/backup/snapshot_2021-06-25_190035.db"} Snapshot saved at /home/core/assets/backup/snapshot_2021-06-25_190035.db {"hash":3866667823,"revision":31407,"totalKey":12828,"totalSize":114446336} snapshot db and kube resources are successfully saved to /home/core/assets/backup이 예제에서는 컨트롤 플레인 호스트의
/home/core/assets/backup/디렉토리에 두 개의 파일이 생성됩니다.-
snapshot_<datetimestamp>.db:이 파일은 etcd 스냅샷입니다.cluster-backup.sh스크립트는 유효성을 확인합니다. static_kuberesources_<datetimestamp>.tar.gz: 이 파일에는 정적 pod 리소스가 포함되어 있습니다. etcd 암호화가 활성화되어 있는 경우 etcd 스냅 샷의 암호화 키도 포함됩니다.참고etcd 암호화가 활성화되어 있는 경우 보안상의 이유로 이 두 번째 파일을 etcd 스냅 샷과 별도로 저장하는 것이 좋습니다. 그러나 이 파일은 etcd 스냅 샷에서 복원하는데 필요합니다.
etcd 암호화는 키가 아닌 값만 암호화합니다. 즉, 리소스 유형, 네임 스페이스 및 개체 이름은 암호화되지 않습니다.
-
6.12.6. etcd 데이터 조각 모음
대규모 및 밀도가 높은 클러스터의 경우 키 공간이 너무 커져서 공간 할당량을 초과하면 etcd 성능이 저하될 수 있습니다. etcd를 정기적으로 유지 관리하고 조각 모음하여 데이터 저장소의 공간을 확보합니다. Prometheus에서 etcd 지표를 모니터링하고 필요한 경우 조각 모음을 수행합니다. 그렇지 않으면 etcd에서 키 읽기 및 삭제만 허용하는 유지보수 모드로 클러스터를 배치하는 클러스터 전체 경보를 발생시킬 수 있습니다.
다음 주요 메트릭을 모니터링합니다.
-
etcd_server_quota_backend_bytes는 현재 할당량 제한인 -
etcd_mvcc_db_total_size_in_use_in_bytes는 기록 압축 후 실제 데이터베이스 사용량을 나타냅니다. -
etcd_mvcc_db_total_size_in_bytes.gb는 조각 모음 대기 중인 여유 공간을 포함하여 데이터베이스 크기를 표시합니다.
etcd 기록 압축과 같은 디스크 조각화를 초래하는 이벤트 후 디스크 공간을 회수하기 위해 etcd 데이터를 조각 모음합니다.
기록 압축은 5분마다 자동으로 수행되며 백엔드 데이터베이스에서 공백이 남습니다. 이 분할된 공간은 etcd에서 사용할 수 있지만 호스트 파일 시스템에서 사용할 수 없습니다. 호스트 파일 시스템에서 이 공간을 사용할 수 있도록 etcd 조각을 정리해야 합니다.
조각 모음이 자동으로 수행되지만 수동으로 트리거할 수도 있습니다.
etcd Operator는 클러스터 정보를 사용하여 사용자에게 가장 효율적인 작업을 결정하기 때문에 자동 조각 모음은 대부분의 경우에 적합합니다.
6.12.6.1. 자동 조각 모음
etcd Operator는 디스크 조각 모음을 자동으로 수행합니다. 수동 조작이 필요하지 않습니다.
다음 로그 중 하나를 확인하여 조각 모음 프로세스가 성공했는지 확인합니다.
- etcd 로그
- cluster-etcd-operator Pod
- Operator 상태 오류 로그
자동 조각 모음을 사용하면 Kubernetes 컨트롤러 관리자와 같은 다양한 OpenShift 핵심 구성 요소에서 리더 선택 오류가 발생하여 실패한 구성 요소를 다시 시작할 수 있습니다. 재시작은 무해하며 다음 실행 중인 인스턴스로 장애 조치(failover)를 트리거하거나 다시 시작한 후 구성 요소가 다시 작동을 다시 시작합니다.
성공적인 조각 모음을 위한 로그 출력 예
etcd member has been defragmented: <member_name>, memberID: <member_id>실패한 조각 모음에 대한 로그 출력 예
failed defrag on member: <member_name>, memberID: <member_id>: <error_message>6.12.6.2. 수동 조각 모음
Prometheus 경고는 수동 조각 모음을 사용해야 할 시기를 나타냅니다. 경고는 다음 두 가지 경우에 표시됩니다.
- etcd가 사용 가능한 공간의 50%를 10분 이상 사용하는 경우
- etcd가 총 데이터베이스 크기의 50% 미만을 10분 이상 사용하는 경우
PromQL 표현식을 사용하여 조각 모음을 통해 해제될 etcd 데이터베이스 크기를 확인함으로써 조각 모음이 필요한지 확인할 수도 있습니다. (etcd_mvcc_db_total_size_in_bytes - etcd_mvcc_db_total_size_in_in_bytes)/1024/1024
etcd를 분리하는 것은 차단 작업입니다. 조각화가 완료될 때까지 etcd 멤버는 응답하지 않습니다. 따라서 각 pod의 조각 모음 작업 간에 클러스터가 정상 작동을 재개할 수 있도록 1분 이상 대기해야 합니다.
각 etcd 멤버의 etcd 데이터 조각 모음을 수행하려면 다음 절차를 따릅니다.
사전 요구 사항
-
cluster-admin역할의 사용자로 클러스터에 액세스할 수 있어야 합니다.
절차
리더가 최종 조각화 처리를 수행하므로 어떤 etcd 멤버가 리더인지 확인합니다.
etcd pod 목록을 가져옵니다.
$ oc -n openshift-etcd get pods -l k8s-app=etcd -o wide출력 예
etcd-ip-10-0-159-225.example.redhat.com 3/3 Running 0 175m 10.0.159.225 ip-10-0-159-225.example.redhat.com <none> <none> etcd-ip-10-0-191-37.example.redhat.com 3/3 Running 0 173m 10.0.191.37 ip-10-0-191-37.example.redhat.com <none> <none> etcd-ip-10-0-199-170.example.redhat.com 3/3 Running 0 176m 10.0.199.170 ip-10-0-199-170.example.redhat.com <none> <none>Pod를 선택하고 다음 명령을 실행하여 어떤 etcd 멤버가 리더인지 확인합니다.
$ oc rsh -n openshift-etcd etcd-ip-10-0-159-225.example.redhat.com etcdctl endpoint status --cluster -w table출력 예
Defaulting container name to etcdctl. Use 'oc describe pod/etcd-ip-10-0-159-225.example.redhat.com -n openshift-etcd' to see all of the containers in this pod. +---------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+ | ENDPOINT | ID | VERSION | DB SIZE | IS LEADER | IS LEARNER | RAFT TERM | RAFT INDEX | RAFT APPLIED INDEX | ERRORS | +---------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+ | https://10.0.191.37:2379 | 251cd44483d811c3 | 3.5.9 | 104 MB | false | false | 7 | 91624 | 91624 | | | https://10.0.159.225:2379 | 264c7c58ecbdabee | 3.5.9 | 104 MB | false | false | 7 | 91624 | 91624 | | | https://10.0.199.170:2379 | 9ac311f93915cc79 | 3.5.9 | 104 MB | true | false | 7 | 91624 | 91624 | | +---------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+이 출력의
ISLEADER 열에 따르면https://10.0.199.170:2379엔드 포인트가 리더입니다. 이전 단계의 출력과 이 앤드 포인트가 일치하면 리더의 Pod 이름은etcd-ip-10-0199-170.example.redhat.com입니다.
etcd 멤버를 분리합니다.
실행중인 etcd 컨테이너에 연결하고 리더가 아닌 pod 이름을 전달합니다.
$ oc rsh -n openshift-etcd etcd-ip-10-0-159-225.example.redhat.comETCDCTL_ENDPOINTS환경 변수를 설정 해제합니다.sh-4.4# unset ETCDCTL_ENDPOINTSetcd 멤버를 분리합니다.
sh-4.4# etcdctl --command-timeout=30s --endpoints=https://localhost:2379 defrag출력 예
Finished defragmenting etcd member[https://localhost:2379]시간 초과 오류가 발생하면 명령이 성공할 때까지
--command-timeout의 값을 늘립니다.데이터베이스 크기가 감소되었는지 확인합니다.
sh-4.4# etcdctl endpoint status -w table --cluster출력 예
+---------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+ | ENDPOINT | ID | VERSION | DB SIZE | IS LEADER | IS LEARNER | RAFT TERM | RAFT INDEX | RAFT APPLIED INDEX | ERRORS | +---------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+ | https://10.0.191.37:2379 | 251cd44483d811c3 | 3.5.9 | 104 MB | false | false | 7 | 91624 | 91624 | | | https://10.0.159.225:2379 | 264c7c58ecbdabee | 3.5.9 | 41 MB | false | false | 7 | 91624 | 91624 | |1 | https://10.0.199.170:2379 | 9ac311f93915cc79 | 3.5.9 | 104 MB | true | false | 7 | 91624 | 91624 | | +---------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+이 예에서는 etcd 멤버의 데이터베이스 크기가 시작 크기인 104MB와 달리 현재 41MB임을 보여줍니다.
다음 단계를 반복하여 다른 etcd 멤버에 연결하고 조각 모음을 수행합니다. 항상 리더의 조각 모음을 마지막으로 수행합니다.
etcd pod가 복구될 수 있도록 조각 모음 작업에서 1분 이상 기다립니다. etcd pod가 복구될 때까지 etcd 멤버는 응답하지 않습니다.
공간 할당량을 초과하여
NOSPACE경고가 발생하는 경우 이를 지우십시오.NOSPACE경고가 있는지 확인합니다.sh-4.4# etcdctl alarm list출력 예
memberID:12345678912345678912 alarm:NOSPACE경고를 지웁니다.
sh-4.4# etcdctl alarm disarm
6.12.7. 이전 클러스터 상태로 복원
저장된 etcd 백업을 사용하여 이전 클러스터 상태를 복원하거나 대부분의 컨트롤 플레인 호스트가 손실된 클러스터를 복원할 수 있습니다.
클러스터에서 컨트롤 플레인 머신 세트를 사용하는 경우 보다 간단한 etcd 복구 절차는 "컨트롤 플레인 머신 세트 문제 해결"을 참조하십시오.
클러스터를 복원할 때 동일한 z-stream 릴리스에서 가져온 etcd 백업을 사용해야 합니다. 예를 들어 OpenShift Container Platform 4.7.2 클러스터는 4.7.2에서 가져온 etcd 백업을 사용해야 합니다.
사전 요구 사항
-
설치 중에 사용된 인증서 기반
kubeconfig파일을 통해cluster-admin역할의 사용자로 클러스터에 액세스할 수 있습니다. - 복구 호스트로 사용할 정상적인 컨트롤 플레인 호스트가 있어야 합니다.
- 컨트롤 플레인 호스트에 대한 SSH 액세스.
-
동일한 백업에서 가져온 etcd 스냅샷과 정적 pod 리소스가 모두 포함된 백업 디렉토리입니다. 디렉토리의 파일 이름은
snapshot_<datetimestamp>.db및static_kuberesources_<datetimestamp>.tar.gz형식이어야합니다.
복구되지 않은 컨트롤 플레인 노드의 경우 SSH 연결을 설정하거나 정적 Pod를 중지할 필요가 없습니다. 복구되지 않은 다른 컨트롤 플레인 머신을 하나씩 삭제하고 다시 생성할 수 있습니다.
절차
- 복구 호스트로 사용할 컨트롤 플레인 호스트를 선택합니다. 이는 복구 작업을 실행할 호스트입니다.
복구 호스트를 포함하여 각 컨트롤 플레인 노드에 SSH 연결을 설정합니다.
복구 프로세스가 시작된 후에는 Kubernetes API 서버에 액세스할 수 없으므로 컨트롤 플레인 노드에 액세스할 수 없습니다. 따라서 다른 터미널에서 각 컨트롤 플레인 호스트에 대한 SSH 연결을 설정하는 것이 좋습니다.
중요이 단계를 완료하지 않으면 컨트롤 플레인 호스트에 액세스하여 복구 프로세스를 완료할 수 없으며 이 상태에서 클러스터를 복구할 수 없습니다.
etcd 백업 디렉토리를 복구 컨트롤 플레인 호스트에 복사합니다.
이 단계에서는 etcd 스냅샷 및 정적 pod의 리소스가 포함된
backup디렉터리를 복구 컨트롤 플레인 호스트의/home/core/디렉터리에 복사하는 것을 전제로하고 있습니다.다른 컨트롤 플레인 노드에서 정적 Pod를 중지합니다.
참고복구 호스트에서 정적 Pod를 중지할 필요가 없습니다.
- 복구 호스트가 아닌 컨트롤 플레인 호스트에 액세스합니다.
kubelet 매니페스트 디렉토리에서 기존 etcd pod 파일을 이동합니다.
$ sudo mv -v /etc/kubernetes/manifests/etcd-pod.yaml /tmpetcd pod가 중지되었는지 확인합니다.
$ sudo crictl ps | grep etcd | egrep -v "operator|etcd-guard"이 명령의 출력은 비어 있어야합니다. 비어 있지 않은 경우 몇 분 기다렸다가 다시 확인하십시오.
kubelet 매니페스트 디렉토리에서 기존 Kubernetes API 서버 pod 파일을 이동합니다.
$ sudo mv -v /etc/kubernetes/manifests/kube-apiserver-pod.yaml /tmpKubernetes API 서버 pod가 중지되었는지 확인합니다.
$ sudo crictl ps | grep kube-apiserver | egrep -v "operator|guard"이 명령의 출력은 비어 있어야합니다. 비어 있지 않은 경우 몇 분 기다렸다가 다시 확인하십시오.
etcd 데이터 디렉토리를 다른 위치로 이동합니다.
$ sudo mv -v /var/lib/etcd/ /tmp/etc/kubernetes/manifests/keepalived.yaml파일이 있고 노드가 삭제되면 다음 단계를 따르십시오.kubelet 매니페스트 디렉토리에서
/etc/kubernetes/manifests/keepalived.yaml파일을 이동합니다.$ sudo mv -v /etc/kubernetes/manifests/keepalived.yaml /tmpkeepalived데몬에서 관리하는 컨테이너가 중지되었는지 확인합니다.$ sudo crictl ps --name keepalived이 명령의 출력은 비어 있어야합니다. 비어 있지 않은 경우 몇 분 기다렸다가 다시 확인하십시오.
컨트롤 플레인에 VIP가 할당되어 있는지 확인합니다.
$ ip -o address | egrep '<api_vip>|<ingress_vip>'보고된 각 VIP에 대해 다음 명령을 실행하여 제거합니다.
$ sudo ip address del <reported_vip> dev <reported_vip_device>
- 복구 호스트가 아닌 다른 컨트롤 플레인 호스트에서 이 단계를 반복합니다.
- 복구 컨트롤 플레인 호스트에 액세스합니다.
keepalived데몬이 사용 중인 경우 복구 컨트롤 플레인 노드가 VIP를 소유하고 있는지 확인합니다.$ ip -o address | grep <api_vip>VIP 주소가 있는 경우 출력에 강조 표시됩니다. VIP가 잘못 설정되거나 구성되지 않은 경우 이 명령은 빈 문자열을 반환합니다.
클러스터 전체의 프록시가 활성화되어 있는 경우
NO_PROXY,HTTP_PROXY및https_proxy환경 변수를 내보내고 있는지 확인합니다.작은 정보oc get proxy cluster -o yaml의 출력을 확인하여 프록시가 사용 가능한지 여부를 확인할 수 있습니다.httpProxy,httpsProxy및noProxy필드에 값이 설정되어 있으면 프록시가 사용됩니다.복구 컨트롤 플레인 호스트에서 복원 스크립트를 실행하고 etcd 백업 디렉터리에 경로를 전달합니다.
$ sudo -E /usr/local/bin/cluster-restore.sh /home/core/assets/backup스크립트 출력 예
...stopping kube-scheduler-pod.yaml ...stopping kube-controller-manager-pod.yaml ...stopping etcd-pod.yaml ...stopping kube-apiserver-pod.yaml Waiting for container etcd to stop .complete Waiting for container etcdctl to stop .............................complete Waiting for container etcd-metrics to stop complete Waiting for container kube-controller-manager to stop complete Waiting for container kube-apiserver to stop ..........................................................................................complete Waiting for container kube-scheduler to stop complete Moving etcd data-dir /var/lib/etcd/member to /var/lib/etcd-backup starting restore-etcd static pod starting kube-apiserver-pod.yaml static-pod-resources/kube-apiserver-pod-7/kube-apiserver-pod.yaml starting kube-controller-manager-pod.yaml static-pod-resources/kube-controller-manager-pod-7/kube-controller-manager-pod.yaml starting kube-scheduler-pod.yaml static-pod-resources/kube-scheduler-pod-8/kube-scheduler-pod.yaml참고마지막 etcd 백업 후 노드 인증서가 업데이트된 경우 복원 프로세스에서 노드가
NotReady상태가 될 수 있습니다.노드가
Ready상태인지 확인합니다.다음 명령을 실행합니다.
$ oc get nodes -w샘플 출력
NAME STATUS ROLES AGE VERSION host-172-25-75-28 Ready master 3d20h v1.26.0 host-172-25-75-38 Ready infra,worker 3d20h v1.26.0 host-172-25-75-40 Ready master 3d20h v1.26.0 host-172-25-75-65 Ready master 3d20h v1.26.0 host-172-25-75-74 Ready infra,worker 3d20h v1.26.0 host-172-25-75-79 Ready worker 3d20h v1.26.0 host-172-25-75-86 Ready worker 3d20h v1.26.0 host-172-25-75-98 Ready infra,worker 3d20h v1.26.0모든 노드에서 상태를 보고하는 데 몇 분이 걸릴 수 있습니다.
노드가
NotReady상태에 있는 경우 노드에 로그인하고 각 노드의/var/lib/kubelet/pki디렉터리에서 모든 PEM 파일을 제거합니다. 노드에 SSH를 실행하거나 웹 콘솔에서 터미널 창을 사용할 수 있습니다.$ ssh -i <ssh-key-path> core@<master-hostname>샘플
pki디렉터리sh-4.4# pwd /var/lib/kubelet/pki sh-4.4# ls kubelet-client-2022-04-28-11-24-09.pem kubelet-server-2022-04-28-11-24-15.pem kubelet-client-current.pem kubelet-server-current.pem
모든 컨트롤 플레인 호스트에서 kubelet 서비스를 다시 시작합니다.
복구 호스트에서 다음 명령을 실행합니다.
$ sudo systemctl restart kubelet.service- 다른 모든 컨트롤 플레인 호스트에서 이 단계를 반복합니다.
보류 중인 CSR을 승인합니다.
참고3개의 스케줄링 가능한 컨트롤 플레인 노드로 구성된 단일 노드 클러스터 또는 클러스터와 같이 작업자 노드가 없는 클러스터에는 승인할 보류 중인 CSR이 없습니다. 이 단계에서 나열된 모든 명령을 건너뛸 수 있습니다.
현재 CSR의 목록을 가져옵니다.
$ oc get csr출력 예
NAME AGE SIGNERNAME REQUESTOR CONDITION csr-2s94x 8m3s kubernetes.io/kubelet-serving system:node:<node_name> Pending1 csr-4bd6t 8m3s kubernetes.io/kubelet-serving system:node:<node_name> Pending2 csr-4hl85 13m kubernetes.io/kube-apiserver-client-kubelet system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending3 csr-zhhhp 3m8s kubernetes.io/kube-apiserver-client-kubelet system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending4 ...CSR의 세부 사항을 검토하여 CSR이 유효한지 확인합니다.
$ oc describe csr <csr_name>1 - 1
<csr_name>은 현재 CSR 목록에 있는 CSR의 이름입니다.
각각의 유효한
node-bootstrapperCSR을 승인합니다.$ oc adm certificate approve <csr_name>사용자 프로비저닝 설치의 경우 각 유효한 kubelet 서비스 CSR을 승인합니다.
$ oc adm certificate approve <csr_name>
단일 멤버 컨트롤 플레인이 제대로 시작되었는지 확인합니다.
복구 호스트에서 etcd 컨테이너가 실행 중인지 확인합니다.
$ sudo crictl ps | grep etcd | egrep -v "operator|etcd-guard"출력 예
3ad41b7908e32 36f86e2eeaaffe662df0d21041eb22b8198e0e58abeeae8c743c3e6e977e8009 About a minute ago Running etcd 0 7c05f8af362f0복구 호스트에서 etcd pod가 실행 중인지 확인합니다.
$ oc -n openshift-etcd get pods -l k8s-app=etcd출력 예
NAME READY STATUS RESTARTS AGE etcd-ip-10-0-143-125.ec2.internal 1/1 Running 1 2m47sPending상태에 있거나 출력에 여러 실행중인 etcd pod가 나열되어 있는 경우 몇 분 기다렸다가 다시 확인합니다.
OVNKubernetes네트워크 플러그인을 사용하는 경우 복구 컨트롤 플레인 호스트가 아닌 컨트롤 플레인 호스트와 연결된 노드 오브젝트를 삭제합니다.$ oc delete node <non-recovery-controlplane-host-1> <non-recovery-controlplane-host-2>CNO(Cluster Network Operator)가 OVN-Kubernetes 컨트롤 플레인을 재배포하고 더 이상 복구되지 않은 컨트롤러 IP 주소를 참조하지 않는지 확인합니다. 이 결과를 확인하려면 다음 명령의 출력을 정기적으로 확인하십시오. 다음 단계의 모든 호스트에서 OVN(Open Virtual Network) Kubernetes Pod를 다시 시작하기 전에 빈 결과를 반환할 때까지 기다립니다.
$ oc -n openshift-ovn-kubernetes get ds/ovnkube-master -o yaml | grep -E '<non-recovery_controller_ip_1>|<non-recovery_controller_ip_2>'참고OVN-Kubernetes 컨트롤 플레인을 재배포하고 이전 명령을 사용하여 빈 출력을 반환하는 데 최소 5-10 분이 걸릴 수 있습니다.
OVN-Kubernetes 네트워크 플러그인을 사용하는 경우 모든 호스트에서 OVN(Open Virtual Network) Kubernetes Pod를 다시 시작합니다.
참고승인 Webhook 확인 및 변경은 Pod를 거부할 수 있습니다.
failurePolicy를Fail로 설정하여 추가 Webhook를 추가하는 경우 Pod를 거부하고 복원 프로세스가 실패할 수 있습니다. 클러스터 상태를 복원하는 동안 Webhook를 저장하고 삭제하여 이 문제를 방지할 수 있습니다. 클러스터 상태가 성공적으로 복원되면 Webhook를 다시 활성화할 수 있습니다.또는 클러스터 상태를 복원하는 동안
failurePolicy를Ignore로 일시적으로 설정할 수 있습니다. 클러스터 상태가 성공적으로 복원된 후failurePolicy를Fail로 설정할 수 있습니다.northbound 데이터베이스(nbdb) 및 southbound 데이터베이스(sbdb)를 제거합니다. SSH(Secure Shell)를 사용하여 복구 호스트와 나머지 컨트롤 플레인 노드에 액세스하고 다음 명령을 실행합니다.
$ sudo rm -f /var/lib/ovn/etc/*.db다음 명령을 실행하여 모든 OVN-Kubernetes 컨트롤 플레인 Pod를 삭제합니다.
$ oc delete pods -l app=ovnkube-master -n openshift-ovn-kubernetes다음 명령을 실행하여 OVN-Kubernetes 컨트롤 플레인 Pod가 다시 배포되고
Running상태에 있는지 확인합니다.$ oc get pods -l app=ovnkube-master -n openshift-ovn-kubernetes출력 예
NAME READY STATUS RESTARTS AGE ovnkube-master-nb24h 4/4 Running 0 48s다음 명령을 실행하여 모든
ovnkube-nodePod를 삭제합니다.$ oc get pods -n openshift-ovn-kubernetes -o name | grep ovnkube-node | while read p ; do oc delete $p -n openshift-ovn-kubernetes ; done다음 명령을 실행하여 모든
ovnkube-nodePod가 다시 배포되고Running상태에 있는지 확인합니다.$ oc get pods -n openshift-ovn-kubernetes | grep ovnkube-node
복구되지 않는 다른 컨트롤 플레인 시스템을 삭제하고 하나씩 다시 생성합니다. 머신이 다시 생성되면 새 버전이 강제 생성되고 etcd가 자동으로 확장됩니다.
사용자가 프로비저닝한 베어 메탈 설치를 사용하는 경우 원래 사용했던 것과 동일한 방법을 사용하여 컨트롤 플레인 시스템을 다시 생성할 수 있습니다. 자세한 내용은 " 베어 메탈에 사용자 프로비저닝 클러스터 설치"를 참조하십시오.
주의복구 호스트의 시스템을 삭제하고 다시 생성하지 마십시오.
설치 관리자 프로비저닝 인프라를 실행 중이거나 Machine API를 사용하여 머신을 생성한 경우 다음 단계를 따르십시오.
주의복구 호스트의 시스템을 삭제하고 다시 생성하지 마십시오.
설치 관리자 프로비저닝 인프라에 베어 메탈 설치의 경우 컨트롤 플레인 머신이 다시 생성되지 않습니다. 자세한 내용은 " 베어 메탈 컨트롤 플레인 노드 교체"를 참조하십시오.
손실된 컨트롤 플레인 호스트 중 하나에 대한 머신을 가져옵니다.
cluster-admin 사용자로 클러스터에 액세스할 수 있는 터미널에서 다음 명령을 실행합니다.
$ oc get machines -n openshift-machine-api -o wide출력 예:
NAME PHASE TYPE REGION ZONE AGE NODE PROVIDERID STATE clustername-8qw5l-master-0 Running m4.xlarge us-east-1 us-east-1a 3h37m ip-10-0-131-183.ec2.internal aws:///us-east-1a/i-0ec2782f8287dfb7e stopped1 clustername-8qw5l-master-1 Running m4.xlarge us-east-1 us-east-1b 3h37m ip-10-0-143-125.ec2.internal aws:///us-east-1b/i-096c349b700a19631 running clustername-8qw5l-master-2 Running m4.xlarge us-east-1 us-east-1c 3h37m ip-10-0-154-194.ec2.internal aws:///us-east-1c/i-02626f1dba9ed5bba running clustername-8qw5l-worker-us-east-1a-wbtgd Running m4.large us-east-1 us-east-1a 3h28m ip-10-0-129-226.ec2.internal aws:///us-east-1a/i-010ef6279b4662ced running clustername-8qw5l-worker-us-east-1b-lrdxb Running m4.large us-east-1 us-east-1b 3h28m ip-10-0-144-248.ec2.internal aws:///us-east-1b/i-0cb45ac45a166173b running clustername-8qw5l-worker-us-east-1c-pkg26 Running m4.large us-east-1 us-east-1c 3h28m ip-10-0-170-181.ec2.internal aws:///us-east-1c/i-06861c00007751b0a running- 1
- 이는 손실된 컨트롤 플레인 호스트인
ip-10-0-131-183.ec2.internal의 컨트롤 플레인 시스템입니다.
다음을 실행하여 손실된 컨트롤 플레인 호스트의 시스템을 삭제합니다.
$ oc delete machine -n openshift-machine-api clustername-8qw5l-master-01 - 1
- 손실된 컨트롤 플레인 호스트의 컨트롤 플레인 시스템의 이름을 지정합니다.
손실된 컨트롤 플레인 호스트의 시스템을 삭제한 후 새 시스템이 자동으로 프로비저닝됩니다.
다음을 실행하여 새 시스템이 생성되었는지 확인합니다.
$ oc get machines -n openshift-machine-api -o wide출력 예:
NAME PHASE TYPE REGION ZONE AGE NODE PROVIDERID STATE clustername-8qw5l-master-1 Running m4.xlarge us-east-1 us-east-1b 3h37m ip-10-0-143-125.ec2.internal aws:///us-east-1b/i-096c349b700a19631 running clustername-8qw5l-master-2 Running m4.xlarge us-east-1 us-east-1c 3h37m ip-10-0-154-194.ec2.internal aws:///us-east-1c/i-02626f1dba9ed5bba running clustername-8qw5l-master-3 Provisioning m4.xlarge us-east-1 us-east-1a 85s ip-10-0-173-171.ec2.internal aws:///us-east-1a/i-015b0888fe17bc2c8 running1 clustername-8qw5l-worker-us-east-1a-wbtgd Running m4.large us-east-1 us-east-1a 3h28m ip-10-0-129-226.ec2.internal aws:///us-east-1a/i-010ef6279b4662ced running clustername-8qw5l-worker-us-east-1b-lrdxb Running m4.large us-east-1 us-east-1b 3h28m ip-10-0-144-248.ec2.internal aws:///us-east-1b/i-0cb45ac45a166173b running clustername-8qw5l-worker-us-east-1c-pkg26 Running m4.large us-east-1 us-east-1c 3h28m ip-10-0-170-181.ec2.internal aws:///us-east-1c/i-06861c00007751b0a running- 1
- 새 시스템
clustername-8qw5l-master-3이 생성되고 단계가Provisioning에서Running으로 변경된 후 준비됩니다.
새 시스템을 만드는 데 몇 분이 소요될 수 있습니다. etcd 클러스터 Operator는 머신 또는 노드가 정상 상태로 돌아 오면 자동으로 동기화됩니다.
- 복구 호스트가 아닌 손실된 컨트롤 플레인 호스트에 대해 이 단계를 반복합니다.
다음 명령을 입력하여 쿼럼 가드를 끕니다.
$ oc patch etcd/cluster --type=merge -p '{"spec": {"unsupportedConfigOverrides": {"useUnsupportedUnsafeNonHANonProductionUnstableEtcd": true}}}'이 명령을 사용하면 시크릿을 성공적으로 다시 생성하고 정적 Pod를 롤아웃할 수 있습니다.
복구 호스트 내의 별도의 터미널 창에서 다음 명령을 실행하여 복구
kubeconfig파일을 내보냅니다.$ export KUBECONFIG=/etc/kubernetes/static-pod-resources/kube-apiserver-certs/secrets/node-kubeconfigs/localhost-recovery.kubeconfigetcd를 강제로 재배포합니다.
복구
kubeconfig파일을 내보낸 동일한 터미널 창에서 다음 명령을 실행합니다.$ oc patch etcd cluster -p='{"spec": {"forceRedeploymentReason": "recovery-'"$( date --rfc-3339=ns )"'"}}' --type=merge1 - 1
forceRedeploymentReason값은 고유해야하므로 타임 스탬프가 추가됩니다.
etcd 클러스터 Operator가 재배포를 실행하면 기존 노드가 초기 부트 스트랩 확장과 유사한 새 pod를 사용하기 시작합니다.
다음 명령을 입력하여 쿼럼 가드를 다시 켭니다.
$ oc patch etcd/cluster --type=merge -p '{"spec": {"unsupportedConfigOverrides": null}}'다음 명령을 입력하여
unsupportedConfigOverrides섹션이 오브젝트에서 제거되었는지 확인할 수 있습니다.$ oc get etcd/cluster -oyaml모든 노드가 최신 버전으로 업데이트되었는지 확인합니다.
클러스터에 액세스할 수 있는 터미널에서
cluster-admin사용자로 다음 명령을 실행합니다.$ oc get etcd -o=jsonpath='{range .items[0].status.conditions[?(@.type=="NodeInstallerProgressing")]}{.reason}{"\n"}{.message}{"\n"}'etcd의
NodeInstallerProgressing상태 조건을 확인하고 모든 노드가 최신 버전인지 확인합니다. 업데이트가 성공적으로 실행되면 출력에AllNodesAtLatestRevision이 표시됩니다.AllNodesAtLatestRevision 3 nodes are at revision 71 - 1
- 이 예에서 최신 버전 번호는
7입니다.
출력에
2 nodes are at revision 6; 1 nodes are at revision 7와 같은 여러 버전 번호가 표시되면 이는 업데이트가 아직 진행 중임을 의미합니다. 몇 분 기다린 후 다시 시도합니다.etcd를 재배포한 후 컨트롤 플레인에 새 롤아웃을 강제 실행합니다. kubelet이 내부 로드 밸런서를 사용하여 API 서버에 연결되어 있으므로 Kubernetes API 서버는 다른 노드에 다시 설치됩니다.
cluster-admin사용자로 클러스터에 액세스할 수있는 터미널에서 다음 명령을 실행합니다.Kubernetes API 서버에 대해 새 롤아웃을 강제 적용합니다.
$ oc patch kubeapiserver cluster -p='{"spec": {"forceRedeploymentReason": "recovery-'"$( date --rfc-3339=ns )"'"}}' --type=merge모든 노드가 최신 버전으로 업데이트되었는지 확인합니다.
$ oc get kubeapiserver -o=jsonpath='{range .items[0].status.conditions[?(@.type=="NodeInstallerProgressing")]}{.reason}{"\n"}{.message}{"\n"}'NodeInstallerProgressing상태 조건을 확인하고 모든 노드가 최신 버전인지 확인합니다. 업데이트가 성공적으로 실행되면 출력에AllNodesAtLatestRevision이 표시됩니다.AllNodesAtLatestRevision 3 nodes are at revision 71 - 1
- 이 예에서 최신 버전 번호는
7입니다.
출력에
2 nodes are at revision 6; 1 nodes are at revision 7와 같은 여러 버전 번호가 표시되면 이는 업데이트가 아직 진행 중임을 의미합니다. 몇 분 기다린 후 다시 시도합니다.Kubernetes 컨트롤러 관리자에 대해 새 롤아웃을 강제 적용합니다.
$ oc patch kubecontrollermanager cluster -p='{"spec": {"forceRedeploymentReason": "recovery-'"$( date --rfc-3339=ns )"'"}}' --type=merge모든 노드가 최신 버전으로 업데이트되었는지 확인합니다.
$ oc get kubecontrollermanager -o=jsonpath='{range .items[0].status.conditions[?(@.type=="NodeInstallerProgressing")]}{.reason}{"\n"}{.message}{"\n"}'NodeInstallerProgressing상태 조건을 확인하고 모든 노드가 최신 버전인지 확인합니다. 업데이트가 성공적으로 실행되면 출력에AllNodesAtLatestRevision이 표시됩니다.AllNodesAtLatestRevision 3 nodes are at revision 71 - 1
- 이 예에서 최신 버전 번호는
7입니다.
출력에
2 nodes are at revision 6; 1 nodes are at revision 7와 같은 여러 버전 번호가 표시되면 이는 업데이트가 아직 진행 중임을 의미합니다. 몇 분 기다린 후 다시 시도합니다.Kubernetes 스케줄러에 대해 새 롤아웃을 강제 적용합니다.
$ oc patch kubescheduler cluster -p='{"spec": {"forceRedeploymentReason": "recovery-'"$( date --rfc-3339=ns )"'"}}' --type=merge모든 노드가 최신 버전으로 업데이트되었는지 확인합니다.
$ oc get kubescheduler -o=jsonpath='{range .items[0].status.conditions[?(@.type=="NodeInstallerProgressing")]}{.reason}{"\n"}{.message}{"\n"}'NodeInstallerProgressing상태 조건을 확인하고 모든 노드가 최신 버전인지 확인합니다. 업데이트가 성공적으로 실행되면 출력에AllNodesAtLatestRevision이 표시됩니다.AllNodesAtLatestRevision 3 nodes are at revision 71 - 1
- 이 예에서 최신 버전 번호는
7입니다.
출력에
2 nodes are at revision 6; 1 nodes are at revision 7와 같은 여러 버전 번호가 표시되면 이는 업데이트가 아직 진행 중임을 의미합니다. 몇 분 기다린 후 다시 시도합니다.
모든 컨트롤 플레인 호스트가 클러스터를 시작하여 참여하고 있는지 확인합니다.
클러스터에 액세스할 수 있는 터미널에서
cluster-admin사용자로 다음 명령을 실행합니다.$ oc -n openshift-etcd get pods -l k8s-app=etcd출력 예
etcd-ip-10-0-143-125.ec2.internal 2/2 Running 0 9h etcd-ip-10-0-154-194.ec2.internal 2/2 Running 0 9h etcd-ip-10-0-173-171.ec2.internal 2/2 Running 0 9h
복구 절차에 따라 모든 워크로드가 일반 작업으로 돌아가도록 하려면 Kubernetes API 정보를 저장하는 각 Pod를 다시 시작합니다. 여기에는 라우터, Operator 및 타사 구성 요소와 같은 OpenShift Container Platform 구성 요소가 포함됩니다.
이전 절차 단계를 완료하면 모든 서비스가 복원된 상태로 돌아올 때까지 몇 분 정도 기다려야 할 수 있습니다. 예를 들어, OAuth 서버 pod가 다시 시작될 때까지 oc login을 사용한 인증이 즉시 작동하지 않을 수 있습니다.
즉각적인 인증을 위해 system:admin kubeconfig 파일을 사용하는 것이 좋습니다. 이 방법은 OAuth 토큰에 대해 SSL/TLS 클라이언트 인증서에 대한 인증을 기반으로 합니다. 다음 명령을 실행하여 이 파일로 인증할 수 있습니다.
$ export KUBECONFIG=<installation_directory>/auth/kubeconfig다음 명령을 실행하여 인증된 사용자 이름을 표시합니다.
$ oc whoami6.12.8. 영구 스토리지 상태 복원을 위한 문제 및 해결 방법
OpenShift Container Platform 클러스터에서 모든 형식의 영구저장장치를 사용하는 경우 일반적으로 클러스터의 상태가 etcd 외부에 저장됩니다. StatefulSet 오브젝트에서 실행 중인 Pod 또는 데이터베이스에서 실행 중인 Elasticsearch 클러스터일 수 있습니다. etcd 백업에서 복원하면 OpenShift Container Platform의 워크로드 상태도 복원됩니다. 그러나 etcd 스냅샷이 오래된 경우 상태가 유효하지 않거나 오래되었을 수 있습니다.
PV(영구 볼륨)의 내용은 etcd 스냅샷의 일부가 아닙니다. etcd 스냅샷에서 OpenShift Container Platform 클러스터를 복원할 때 중요하지 않은 워크로드가 중요한 데이터에 액세스할 수 있으며 그 반대의 경우로도 할 수 있습니다.
다음은 사용되지 않는 상태를 생성하는 몇 가지 예제 시나리오입니다.
- MySQL 데이터베이스는 PV 오브젝트에서 지원하는 pod에서 실행됩니다. etcd 스냅샷에서 OpenShift Container Platform을 복원해도 스토리지 공급자의 볼륨을 다시 가져오지 않으며 pod를 반복적으로 시작하려고 하지만 실행 중인 MySQL pod는 생성되지 않습니다. 스토리지 공급자에서 볼륨을 복원한 다음 새 볼륨을 가리키도록 PV를 편집하여 이 Pod를 수동으로 복원해야 합니다.
- Pod P1에서는 노드 X에 연결된 볼륨 A를 사용합니다. 다른 pod가 노드 Y에서 동일한 볼륨을 사용하는 동안 etcd 스냅샷을 가져오는 경우 etcd 복원이 수행되면 해당 볼륨이 여전히 Y 노드에 연결되어 있으므로 Pod P1이 제대로 시작되지 않을 수 있습니다. OpenShift Container Platform은 연결을 인식하지 못하고 자동으로 연결을 분리하지 않습니다. 이 경우 볼륨이 노드 X에 연결된 다음 Pod P1이 시작될 수 있도록 노드 Y에서 볼륨을 수동으로 분리해야 합니다.
- etcd 스냅샷을 만든 후 클라우드 공급자 또는 스토리지 공급자 인증 정보가 업데이트되었습니다. 이로 인해 해당 인증 정보를 사용하는 CSI 드라이버 또는 Operator가 작동하지 않습니다. 해당 드라이버 또는 Operator에 필요한 인증 정보를 수동으로 업데이트해야 할 수 있습니다.
etcd 스냅샷을 만든 후 OpenShift Container Platform 노드에서 장치가 제거되거나 이름이 변경됩니다. Local Storage Operator는
/dev/disk/by-id또는/dev디렉터리에서 관리하는 각 PV에 대한 심볼릭 링크를 생성합니다. 이 경우 로컬 PV가 더 이상 존재하지 않는 장치를 참조할 수 있습니다.이 문제를 해결하려면 관리자가 다음을 수행해야 합니다.
- 잘못된 장치가 있는 PV를 수동으로 제거합니다.
- 각 노드에서 심볼릭 링크를 제거합니다.
-
LocalVolume또는LocalVolumeSet오브젝트를 삭제합니다 (스토리지 → 영구 스토리지 구성 → 로컬 볼륨을 사용하는 영구 스토리지 → Local Storage Operator 리소스 삭제참조).
6.13. Pod 중단 예산
Pod 중단 예산을 이해하고 구성합니다.
6.13.1. Pod 중단 예산을 사용하여 실행 중인 pod 수를 지정하는 방법
Pod 중단 예산을 사용하면 유지보수를 위해 노드를 드레이닝하는 등 작업 중에 Pod에 대한 보안 제약 조건을 지정할 수 있습니다.
PodDisruptionBudget은 동시에 작동해야 하는 최소 복제본 수 또는 백분율을 지정하는 API 오브젝트입니다. 프로젝트에서 이러한 설정은 노드 유지 관리 (예: 클러스터 축소 또는 클러스터 업그레이드) 중에 유용할 수 있으며 (노드 장애 시가 아니라) 자발적으로 제거된 경우에만 적용됩니다.
PodDisruptionBudget 오브젝트의 구성은 다음과 같은 주요 부분으로 구성되어 있습니다.
- 일련의 pod에 대한 라벨 쿼리 기능인 라벨 선택기입니다.
동시에 사용할 수 있어야 하는 최소 pod 수를 지정하는 가용성 수준입니다.
-
minAvailable은 중단 중에도 항상 사용할 수 있어야하는 pod 수입니다. -
maxUnavailable은 중단 중에 사용할 수없는 pod 수입니다.
-
Available 은 condition Ready=True 가 있는 Pod 수를 나타냅니다. ready=True 는 요청을 처리할 수 있는 Pod를 참조하며 일치하는 모든 서비스의 부하 분산 풀에 추가해야 합니다.
maxUnavailable 0 % 또는 0이나 minAvailable의 100 % 혹은 복제본 수와 동일한 값은 허용되지만 이로 인해 노드가 드레인되지 않도록 차단할 수 있습니다.
maxUnavailable 의 기본 설정은 OpenShift Container Platform의 모든 머신 구성 풀에 대해 1 입니다. 이 값을 변경하지 않고 한 번에 하나의 컨트롤 플레인 노드를 업데이트하는 것이 좋습니다. 컨트롤 플레인 풀의 경우 이 값을 3 으로 변경하지 마십시오.
다음을 사용하여 모든 프로젝트에서 pod 중단 예산을 확인할 수 있습니다.
$ oc get poddisruptionbudget --all-namespaces출력 예
NAMESPACE NAME MIN AVAILABLE MAX UNAVAILABLE ALLOWED DISRUPTIONS AGE
openshift-apiserver openshift-apiserver-pdb N/A 1 1 121m
openshift-cloud-controller-manager aws-cloud-controller-manager 1 N/A 1 125m
openshift-cloud-credential-operator pod-identity-webhook 1 N/A 1 117m
openshift-cluster-csi-drivers aws-ebs-csi-driver-controller-pdb N/A 1 1 121m
openshift-cluster-storage-operator csi-snapshot-controller-pdb N/A 1 1 122m
openshift-cluster-storage-operator csi-snapshot-webhook-pdb N/A 1 1 122m
openshift-console console N/A 1 1 116m
#...
PodDisruptionBudget은 시스템에서 최소 minAvailable pod가 실행중인 경우 정상으로 간주됩니다. 이 제한을 초과하는 모든 pod는 제거할 수 있습니다.
Pod 우선 순위 및 선점 설정에 따라 우선 순위가 낮은 pod는 pod 중단 예산 요구 사항을 무시하고 제거될 수 있습니다.
6.13.2. Pod 중단 예산을 사용하여 실행해야 할 pod 수 지정
PodDisruptionBudget 오브젝트를 사용하여 동시에 가동되어야 하는 최소 복제본 수 또는 백분율을 지정할 수 있습니다.
절차
pod 중단 예산을 구성하려면 다음을 수행합니다.
다음과 같은 오브젝트 정의를 사용하여 YAML 파일을 만듭니다.
apiVersion: policy/v11 kind: PodDisruptionBudget metadata: name: my-pdb spec: minAvailable: 22 selector:3 matchLabels: name: my-pod또는 다음을 수행합니다.
apiVersion: policy/v11 kind: PodDisruptionBudget metadata: name: my-pdb spec: maxUnavailable: 25%2 selector:3 matchLabels: name: my-pod다음 명령을 실행하여 오브젝트를 프로젝트에 추가합니다.
$ oc create -f </path/to/file> -n <project_name>
6.13.3. 비정상적인 Pod에 대한 제거 정책 지정
PDB(Pod 중단 예산)를 사용하여 동시에 사용할 수 있어야 하는 Pod 수를 지정하는 경우 제거로 간주되는 비정상적인 Pod에 대한 기준을 정의할 수도 있습니다.
다음 정책 중 하나를 선택할 수 있습니다.
- IfHealthyBudget
- 정상 상태가 아닌 실행 Pod는 보호된 애플리케이션이 손상되지 않은 경우에만 제거할 수 있습니다.
- AlwaysAllow
-
Pod 중단 예산의 기준이 충족되는지 여부에 관계없이 아직 정상 상태가 아닌 실행 Pod를 제거할 수 있습니다. 이 정책은
CrashLoopBackOff상태에 남아 있거나Ready상태를 보고하지 못하는 Pod와 같은 애플리케이션의 문제를 제거하는 데 도움이 될 수 있습니다.
Pod 중단 예산에 대해 비정상적인 Pod 제거 정책을 지정하는 것은 기술 프리뷰 기능 전용입니다. 기술 프리뷰 기능은 Red Hat 프로덕션 서비스 수준 계약(SLA)에서 지원되지 않으며 기능적으로 완전하지 않을 수 있습니다. 따라서 프로덕션 환경에서 사용하는 것은 권장하지 않습니다. 이러한 기능을 사용하면 향후 제품 기능을 조기에 이용할 수 있어 개발 과정에서 고객이 기능을 테스트하고 피드백을 제공할 수 있습니다.
Red Hat 기술 프리뷰 기능의 지원 범위에 대한 자세한 내용은 기술 프리뷰 기능 지원 범위를 참조하십시오.
이 기술 프리뷰 기능을 사용하려면 TechPreviewNoUpgrade 기능 세트를 활성화해야 합니다.
클러스터에서 TechPreviewNoUpgrade 기능 세트를 활성화하면 취소할 수 없으며 마이너 버전 업데이트를 방지할 수 없습니다. 프로덕션 클러스터에서 이 기능 세트를 활성화해서는 안 됩니다.
프로세스
PodDisruptionBudget오브젝트를 정의하는 YAML 파일을 생성하고 비정상 Pod 제거 정책을 지정합니다.pod-disruption-budget.yaml파일 예apiVersion: policy/v1 kind: PodDisruptionBudget metadata: name: my-pdb spec: minAvailable: 2 selector: matchLabels: name: my-pod unhealthyPodEvictionPolicy: AlwaysAllow1 - 1
IfHealthyBudget또는AlwaysAllow를 비정상 Pod 제거 정책으로 선택합니다.unhealthyPodEvictionPolicy필드가 비어 있는 경우 기본값은IfHealthyBudget입니다.
다음 명령을 실행하여
PodDisruptionBudget오브젝트를 생성합니다.$ oc create -f pod-disruption-budget.yaml
AlwaysAllow 비정상적인 Pod 제거 정책이 설정된 PDB를 사용하면 노드를 드레이닝하고 이 PDB에서 방해하는 애플리케이션의 Pod를 제거할 수 있습니다.
6.14. 클라우드 공급자 인증 정보 교체 또는 제거
OpenShift Container Platform을 설치한 후 일부 조직에서는 초기 설치 중에 사용된 클라우드 공급자 인증 정보를 교체하거나 제거해야 합니다.
클러스터가 새 인증 정보를 사용할 수 있도록 하려면 CCO(Cloud Credential Operator) 에서 클라우드 공급자 인증 정보를 관리하는 데 사용하는 시크릿을 업데이트해야 합니다.
6.14.1. Cloud Credential Operator 유틸리티를 사용하여 클라우드 공급자 인증 정보 교체
CCO(Cloud Credential Operator) 유틸리티 ccoctl 에서는 IBM Cloud에 설치된 클러스터의 업데이트를 지원합니다.
6.14.1.1. API 키 교체
기존 서비스 ID에 대한 API 키를 교체하고 해당 시크릿을 업데이트할 수 있습니다.
사전 요구 사항
-
ccoctl바이너리를 구성했습니다. - 라이브 OpenShift Container Platform 클러스터에 기존 서비스 ID가 설치되어 있어야 합니다.
절차
ccoctl유틸리티를 사용하여 서비스 ID에 대한 API 키를 교체하고 시크릿을 업데이트합니다.$ ccoctl <provider_name> refresh-keys \1 --kubeconfig <openshift_kubeconfig_file> \2 --credentials-requests-dir <path_to_credential_requests_directory> \3 --name <name>4 참고클러스터에서
TechPreviewNoUpgrade기능 세트에서 활성화한 기술 프리뷰 기능을 사용하는 경우--enable-tech-preview매개변수를 포함해야 합니다.
6.14.2. 클라우드 공급자 인증 정보를 수동으로 교체
어떠한 이유로 클라우드 공급자 인증 정보가 변경되면 CCO(Cloud Credential Operator)에서 클라우드 공급자 인증 정보를 관리하기 위해 사용하는 시크릿을 수동으로 업데이트해야 합니다.
클라우드 인증 정보를 교체하는 프로세스는 CCO가 사용하도록 구성된 모드에 따라 달라집니다. Mint 모드를 사용하는 클러스터의 인증 정보를 교체한 후 삭제된 인증 정보를 통해 생성된 구성 요소 인증 정보를 수동으로 제거해야 합니다.
사전 요구 사항
클러스터는 다음을 사용하는 CCO 모드로 클라우드 인증 정보 교체를 수동으로 지원하는 플랫폼에 설치됩니다.
- Mint 모드의 경우 AWS(Amazon Web Services) 및 GCP(Google Cloud Platform)가 지원됩니다.
- Passthrough 모드의 경우 AWS(Amazon Web Services), Microsoft Azure, GCP(Google Cloud Platform), RHOSP(Red Hat OpenStack Platform), RHV(Red Hat Virtualization) 및 VMware vSphere가 지원됩니다.
- 클라우드 공급자와 인터페이스에 사용되는 인증 정보를 변경했습니다.
- 새 인증 정보에는 클러스터에서 사용할 수 있도록 구성된 모드 CCO에 대한 충분한 권한이 있습니다.
절차
- 웹 콘솔의 Administrator 모드에서 Workloads → Secrets로 이동합니다.
Secrets 페이지의 표에서 클라우드 공급자의 루트 시크릿을 찾습니다.
Expand 플랫폼 시크릿 이름 AWS
aws-credsAzure
azure-credentialsGCP
gcp-credentialsRHOSP
openstack-credentialsRHV
ovirt-credentialsVMware vSphere
vsphere-creds-
시크릿과 동일한 행에서 옵션 메뉴
 를 클릭하고 시크릿 편집을 선택합니다.
를 클릭하고 시크릿 편집을 선택합니다.
- Value 필드의 내용을 기록합니다. 이 정보를 사용하여 인증서를 업데이트한 후 값이 다른지 확인할 수 있습니다.
- 클라우드 공급자에 대한 새로운 인증 정보를 사용하여 Value 필드의 텍스트를 업데이트한 다음 저장을 클릭합니다.
vSphere CSI Driver Operator가 활성화되어 있지 않은 vSphere 클러스터의 인증 정보를 업데이트하는 경우 Kubernetes 컨트롤러 관리자의 롤아웃을 강제 적용하여 업데이트된 인증 정보를 적용해야 합니다.
참고vSphere CSI Driver Operator가 활성화된 경우 이 단계가 필요하지 않습니다.
업데이트된 vSphere 인증 정보를 적용하려면 OpenShift Container Platform CLI에
cluster-admin역할의 사용자로 로그인하고 다음 명령을 실행합니다.$ oc patch kubecontrollermanager cluster \ -p='{"spec": {"forceRedeploymentReason": "recovery-'"$( date )"'"}}' \ --type=merge인증 정보가 출시되는 동안 Kubernetes Controller Manager Operator의 상태는
Progressing=true로 보고합니다. 상태를 보려면 다음 명령을 실행합니다.$ oc get co kube-controller-manager클러스터의 CCO가 Mint 모드를 사용하도록 구성된 경우 개별
CredentialsRequest오브젝트에서 참조하는 각 구성 요소 시크릿을 삭제합니다.-
cluster-admin역할의 사용자로 OpenShift Container Platform CLI에 로그인합니다. 참조되는 모든 구성 요소 시크릿의 이름과 네임스페이스를 가져옵니다.
$ oc -n openshift-cloud-credential-operator get CredentialsRequest \ -o json | jq -r '.items[] | select (.spec.providerSpec.kind=="<provider_spec>") | .spec.secretRef'여기서
<provider_spec>은 클라우드 공급자의 해당 값입니다.-
AWS:
AWSProviderSpec -
GCP:
GCPProviderSpec
AWS의 부분 예제 출력
{ "name": "ebs-cloud-credentials", "namespace": "openshift-cluster-csi-drivers" } { "name": "cloud-credential-operator-iam-ro-creds", "namespace": "openshift-cloud-credential-operator" }-
AWS:
참조된 각 구성 요소 시크릿을 삭제합니다.
$ oc delete secret <secret_name> \1 -n <secret_namespace>2 AWS 시크릿 삭제 예
$ oc delete secret ebs-cloud-credentials -n openshift-cluster-csi-drivers공급자 콘솔에서 인증 정보를 수동으로 삭제할 필요가 없습니다. 참조된 구성 요소 시크릿을 삭제하면 CCO가 플랫폼에서 기존 인증 정보를 삭제하고 새 인증서를 생성합니다.
-
검증
인증 정보가 변경되었는지 확인하려면 다음을 수행하십시오.
- 웹 콘솔의 Administrator 모드에서 Workloads → Secrets로 이동합니다.
- Value 필드의 내용이 변경되었는지 확인합니다.
6.14.3. 클라우드 공급자 인증 정보 제거
Mint 모드에서 CCO(Cloud Credential Operator)를 사용하여 OpenShift Container Platform 클러스터를 설치한 후 클러스터의 kube-system 네임스페이스에서 관리자 수준 인증 정보 시크릿을 제거할 수 있습니다. 관리자 수준 인증 정보는 업그레이드와 같은 승격된 권한이 필요한 변경 시에만 필요합니다.
z-stream 외 업그레이드 이전에는 관리자 수준 인증 정보를 사용하여 인증 정보 시크릿을 복원해야 합니다. 인증 정보가 없으면 업그레이드가 차단될 수 있습니다.
전제 조건
- 클러스터는 CCO에서 클라우드 인증 정보 제거를 지원하는 플랫폼에 설치되어 있습니다. 지원되는 플랫폼은 AWS 및 GCP입니다.
절차
- 웹 콘솔의 Administrator 모드에서 Workloads → Secrets로 이동합니다.
Secrets 페이지의 표에서 클라우드 공급자의 루트 시크릿을 찾습니다.
Expand 플랫폼 시크릿 이름 AWS
aws-credsGCP
gcp-credentials-
시크릿과 동일한 행에서 옵션 메뉴
를 클릭하고 시크릿 삭제를 선택합니다.
7장. 설치 노드 작업 후
OpenShift Container Platform을 설치한 후 특정 노드 작업을 통해 요구 사항에 맞게 클러스터를 추가로 확장하고 사용자 지정할 수 있습니다.
7.1. OpenShift Container Platform 클러스터에 RHEL 컴퓨팅 머신 추가
RHEL 컴퓨팅 노드를 이해하고 사용합니다.
7.1.1. 클러스터에 RHEL 컴퓨팅 노드 추가 정보
x86_64 아키텍처에서 사용자 프로비저닝 또는 설치 관리자 프로비저닝 인프라 설치를 사용하는 경우 OpenShift Container Platform 4.13에서는 RHEL (Red Hat Enterprise Linux) 머신을 클러스터의 컴퓨팅 머신으로 사용하는 옵션이 있습니다. 클러스터의 컨트롤 플레인 시스템에 RHCOS(Red Hat Enterprise Linux CoreOS) 머신을 사용해야 합니다.
클러스터에서 RHEL 컴퓨팅 머신을 사용하기로 선택한 경우 모든 운영 체제의 라이프 사이클 관리 및 유지 관리를 담당합니다. 시스템 업데이트를 수행하고 패치를 적용하고 기타 필요한 모든 작업을 완료해야 합니다.
설치 관리자 프로비저닝 인프라 클러스터의 경우 설치 관리자 프로비저닝 인프라 클러스터에서 자동으로 확장되어 RHCOS(Red Hat Enterprise Linux CoreOS) 컴퓨팅 머신을 기본적으로 추가하므로 RHEL 컴퓨팅 머신을 수동으로 추가해야 합니다.
- 클러스터의 시스템에서 OpenShift Container Platform을 제거하려면 운영 체제를 제거해야하므로 클러스터에 추가한 모든 RHEL 머신에 전용 하드웨어를 사용해야합니다.
- OpenShift Container Platform 클러스터에 추가한 모든 RHEL 머신에서 스왑 메모리가 비활성화됩니다. 이 머신에서 스왑 메모리를 활성화할 수 없습니다.
7.1.2. RHEL 컴퓨팅 노드의 시스템 요구 사항
OpenShift Container Platform 환경의 RHEL (Red Hat Enterprise Linux) 컴퓨팅 머신 호스트는 다음과 같은 최소 하드웨어 사양 및 시스템 수준 요구 사항을 충족해야합니다.
- Red Hat 계정에 유효한 OpenShift Container Platform 서브스크립션이 있어야합니다. 서브스크립션이 없는 경우 영업 담당자에게 자세한 내용을 문의하십시오.
- 프로덕션 환경에서 예상 워크로드를 지원할 수 있는 컴퓨팅 머신을 제공해야합니다. 클러스터 관리자는 예상 워크로드를 계산하고 오버 헤드에 약 10%를 추가해야합니다. 프로덕션 환경의 경우 노드 호스트 장애가 최대 용량에 영향을 미치지 않도록 충분한 리소스를 할당해야 합니다.
각 시스템은 다음 하드웨어 요구 사항을 충족해야합니다.
- 물리적 또는 가상 시스템 또는 퍼블릭 또는 프라이빗 IaaS에서 실행되는 인스턴스.
기본 OS: RHEL 8.6 이상, "최소" 설치 옵션이 있습니다.
중요OpenShift Container Platform 클러스터에 RHEL 7 컴퓨팅 머신을 추가하는 것은 지원되지 않습니다.
이전에 OpenShift Container Platform 버전에서 지원되는 RHEL 7 컴퓨팅 머신이 있는 경우 RHEL 8로 업그레이드할 수 없습니다. 새 RHEL 8 호스트를 배포해야 하며 이전 RHEL 7 호스트를 제거해야 합니다. 자세한 내용은 "노드 삭제" 섹션을 참조하십시오.
OpenShift Container Platform에서 더 이상 사용되지 않거나 삭제된 주요 기능의 최신 목록은 OpenShift Container Platform 릴리스 노트에서 더 이상 사용되지 않고 삭제된 기능 섹션을 참조하십시오.
- NetworkManager 1.0 이상
- vCPU 1개
- 최소 8GB RAM
-
/var/를 포함하는 파일 시스템의 최소 15GB 하드 디스크 공간 -
/usr/local/bin/을 포함하는 파일 시스템의 최소 1GB 하드 디스크 공간 임시 디렉토리를 포함하는 파일 시스템의 최소 1GB의 하드 디스크 공간 임시 시스템 디렉토리는 Python 표준 라이브러리의 tempfile 모듈에 정의된 규칙에 따라 결정됩니다.
-
각 시스템은 시스템 제공 업체의 추가 요구 사항을 충족해야합니다. 예를 들어 VMware vSphere에 클러스터를 설치하는 경우 스토리지 지침에 따라 디스크를 구성하고
disk.enableUUID=true속성을 설정해야합니다. - 각 시스템은 DNS 확인 가능한 호스트 이름을 사용하여 클러스터의 API 끝점에 액세스할 수 있어야 합니다. 모든 네트워크 보안 액세스 제어는 클러스터의 API 서비스 엔드 포인트에 대한 시스템 액세스를 허용해야합니다.
-
각 시스템은 시스템 제공 업체의 추가 요구 사항을 충족해야합니다. 예를 들어 VMware vSphere에 클러스터를 설치하는 경우 스토리지 지침에 따라 디스크를 구성하고
7.1.2.1. 인증서 서명 요청 관리
사용자가 프로비저닝하는 인프라를 사용하는 경우 자동 시스템 관리 기능으로 인해 클러스터의 액세스가 제한되므로 설치한 후 클러스터 인증서 서명 요청(CSR)을 승인하는 메커니즘을 제공해야 합니다. kube-controller-manager는 kubelet 클라이언트 CSR만 승인합니다. machine-approver는 올바른 시스템에서 발행한 요청인지 확인할 수 없기 때문에 kubelet 자격 증명을 사용하여 요청하는 서비스 인증서의 유효성을 보장할 수 없습니다. kubelet 서비스 인증서 요청의 유효성을 확인하고 요청을 승인할 방법을 결정하여 구현해야 합니다.
7.1.3. Playbook 실행을 위한 머신 준비
RHEL(Red Hat Enterprise Linux)을 운영 체제로 사용하는 컴퓨팅 머신을 OpenShift Container Platform 4.13 클러스터에 추가하려면 먼저 새 노드를 클러스터에 추가하는 Ansible 플레이북을 실행하도록 RHEL 8 머신을 준비해야 합니다. 이 머신은 클러스터의 일부가 아니지만 클러스터에 액세스할 수 있어야합니다.
사전 요구 사항
-
Playbook을 실행하는 머신에 OpenShift CLI (
oc)를 설치합니다. -
cluster-admin권한이 있는 사용자로 로그인합니다.
프로세스
-
클러스터의
kubeconfig파일 및 클러스터를 설치하는 데 사용한 설치 프로그램이 RHEL 8 머신에 있는지 확인합니다. 이를 수행하는 한 가지 방법으로 클러스터 설치에 사용된 머신과 동일한 머신을 사용하는 것입니다. - 컴퓨팅 머신으로 사용하려는 모든 RHEL 호스트에 액세스하도록 머신을 구성합니다. SSH 프록시 또는 VPN을 사용하는 Bastion를 포함하여 회사에서 허용하는 모든 방법을 사용할 수 있습니다.
Playbook을 실행하는 머신에서 모든 RHEL 호스트에 대한 SSH 액세스 권한이있는 사용자를 구성하십시오.
중요SSH 키 기반 인증을 사용하는 경우 SSH 에이전트를 사용하여 키를 관리해야합니다.
아직 등록하지 않은 경우 RHSM으로 머신을 등록하고
OpenShift서브스크립션이 있는 풀을 머신에 연결합니다.RHSM으로 머신를 등록합니다.
# subscription-manager register --username=<user_name> --password=<password>RHSM에서 최신 서브스크립션 데이터를 가져옵니다.
# subscription-manager refresh사용 가능한 서브스크립션을 나열하십시오.
# subscription-manager list --available --matches '*OpenShift*'이전 명령의 출력에서 OpenShift Container Platform 서브스크립션의 풀 ID를 찾아서 이를 연결합니다.
# subscription-manager attach --pool=<pool_id>
OpenShift Container Platform 4.13에 필요한 리포지토리를 활성화합니다.
# subscription-manager repos \ --enable="rhel-8-for-x86_64-baseos-rpms" \ --enable="rhel-8-for-x86_64-appstream-rpms" \ --enable="rhocp-4.13-for-rhel-8-x86_64-rpms"openshift-ansible을 포함한 필수 패키지를 설치합니다.# yum install openshift-ansible openshift-clients jqopenshift-ansible패키지는 설치 프로그램 유틸리티를 제공하고 Ansible, Playbook 및 관련 구성 파일과 같이 RHEL 컴퓨팅 노드를 클러스터에 추가하는데 필요한 다른 패키지를 가져옵니다.openshift-clients는ocCLI를 제공하고jq패키지는 명령 행에서 JSON 출력 표시 방법을 개선할 수 있습니다.
7.1.4. RHEL 컴퓨팅 노드 준비
RHEL (Red Hat Enterprise Linux) 시스템을 OpenShift Container Platform 클러스터에 추가하기 전에 각 호스트를 RHSM (Red Hat Subscription Manager)에 등록하고 활성 OpenShift Container Platform 서브스크립션을 연결하고 필요한 저장소를 활성화해야합니다.
각 호스트에서 RHSM으로 동륵합니다.
# subscription-manager register --username=<user_name> --password=<password>RHSM에서 최신 서브스크립션 데이터를 가져옵니다.
# subscription-manager refresh사용 가능한 서브스크립션을 나열하십시오.
# subscription-manager list --available --matches '*OpenShift*'이전 명령의 출력에서 OpenShift Container Platform 서브스크립션의 풀 ID를 찾아서 이를 연결합니다.
# subscription-manager attach --pool=<pool_id>모든 yum 저장소를 비활성화합니다.
활성화된 모든 RHSM 저장소를 비활성화합니다.
# subscription-manager repos --disable="*"나머지 yum 저장소를 나열하고
repo id아래에 해당 이름을 적어 둡니다.# yum repolistyum-config-manager를 사용하여 나머지 yum 리포지토리를 비활성화합니다.# yum-config-manager --disable <repo_id>또는 모든 리포지토리를 비활성화합니다.
# yum-config-manager --disable \*사용 가능한 리포지토리가 많으면 몇 분의 시간이 소요될 수 있습니다.
OpenShift Container Platform 4.13에 필요한 리포지토리를 활성화합니다.
# subscription-manager repos \ --enable="rhel-8-for-x86_64-baseos-rpms" \ --enable="rhel-8-for-x86_64-appstream-rpms" \ --enable="rhocp-4.13-for-rhel-8-x86_64-rpms" \ --enable="fast-datapath-for-rhel-8-x86_64-rpms"호스트에서 firewalld를 중지하고 비활성화합니다.
# systemctl disable --now firewalld.service참고나중에 firewalld를 활성화할 수 없습니다. 활성화하면 작업자의 OpenShift Container Platform 로그에 액세스할 수 없습니다.
7.1.5. 클러스터에 RHEL 컴퓨팅 머신 추가
Red Hat Enterprise Linux를 운영 체제로 사용하는 컴퓨팅 머신을 OpenShift Container Platform 4.13 클러스터에 추가할 수 있습니다.
사전 요구 사항
- Playbook을 실행하는 머신에 필요한 패키지를 설치하고 필요한 구성이 수행되어 있습니다.
- RHEL 호스트 설치가 준비되어 있습니다.
프로세스
Playbook을 실행할 준비가 되어 있는 머신에서 다음 단계를 수행합니다.
컴퓨팅 머신 호스트 및 필수 변수를 정의하는
/<path>/inventory/hosts라는 Ansible 인벤토리 파일을 만듭니다.[all:vars] ansible_user=root1 #ansible_become=True2 openshift_kubeconfig_path="~/.kube/config"3 [new_workers]4 mycluster-rhel8-0.example.com mycluster-rhel8-1.example.com- 1
- 원격 컴퓨팅 머신에서 Ansible 태스크를 실행하는 사용자 이름을 지정합니다.
- 2
ansible_user의root를 지정하지 않으면ansible_become을True로 설정하고 사용자 sudo 권한을 지정해야합니다.- 3
- 클러스터
kubeconfig파일의 경로와 파일 이름을 지정합니다. - 4
- 클러스터에 추가할 각 RHEL 머신을 나열합니다. 각 호스트에 대해 정규화된 도메인 이름을 지정해야합니다. 이 이름은 클러스터가 시스템에 액세스하는 데 사용하는 호스트 이름이므로 올바른 공용 또는 개인 이름을 설정하여 시스템에 액세스합니다.
Ansible Playbook 디렉토리로 이동합니다.
$ cd /usr/share/ansible/openshift-ansiblePlaybook을 실행합니다.
$ ansible-playbook -i /<path>/inventory/hosts playbooks/scaleup.yml1 - 1
<path>에 대해 생성한 Ansible 인벤토리 파일의 경로를 지정합니다.
7.1.6. Ansible 호스트 파일의 필수 매개 변수
RHEL (Red Hat Enterprise Linux) 컴퓨팅 머신을 클러스터에 추가하기 전에 Ansible 호스트 파일에서 다음 매개 변수를 정의해야합니다.
| 매개변수 | 설명 | 값 |
|---|---|---|
|
| 암호없이 SSH 기반 인증을 허용하는 SSH 사용자입니다. SSH 키 기반 인증을 사용하는 경우 SSH 에이전트를 사용하여 키를 관리해야합니다. |
시스템의 사용자 이름입니다. 기본값은 |
|
|
|
|
|
|
클러스터의 | 구성 파일의 경로 및 이름 |
7.1.7. 선택 사항: 클러스터에서 RHCOS 컴퓨팅 머신 제거
RHEL (Red Hat Enterprise Linux) 컴퓨팅 머신을 클러스터에 추가 한 후 선택 옵션으로 RHCOS (Red Hat Enterprise Linux CoreOS) 컴퓨팅 머신을 제거하여 리소스를 확보할 수 있습니다.
사전 요구 사항
- RHEL 컴퓨팅 머신이 클러스터에 추가되어 있습니다.
절차
머신 목록을 표시하고 RHCOS 컴퓨팅 머신의 노드 이름을 기록합니다.
$ oc get nodes -o wide각 RHCOS 컴퓨팅 머신의 노드를 제거합니다.
oc adm cordon명령을 실행하여 노드를 스케줄 예약 해제로 표시합니다.$ oc adm cordon <node_name>1 - 1
- RHCOS 컴퓨팅 머신의 노드 이름을 지정합니다.
노드에서 모든 pod를 드레인합니다.
$ oc adm drain <node_name> --force --delete-emptydir-data --ignore-daemonsets1 - 1
- 분리 한 RHCOS 컴퓨팅 머신의 노드 이름을 지정합니다.
노드를 제거합니다.
$ oc delete nodes <node_name>1 - 1
- 드레인한 RHCOS 컴퓨팅 머신의 노드 이름을 지정합니다.
컴퓨팅 머신 목록을 확인하고 RHEL 노드만 남아 있는지 확인합니다.
$ oc get nodes -o wide- 클러스터 컴퓨팅 머신의 로드 밸런서에서 RHCOS 머신을 제거합니다. 가상 머신을 삭제하거나 RHCOS 컴퓨팅 머신의 실제 하드웨어를 다시 이미지화 할 수 있습니다.
7.2. OpenShift Container Platform 클러스터에 RHCOS 컴퓨팅 머신 추가
베어 메탈의 OpenShift Container Platform 클러스터에 더 많은 Red Hat Enterprise Linux CoreOS (RHCOS) 컴퓨팅 머신을 추가할 수 있습니다.
베어메탈 인프라에 설치된 클러스터에 컴퓨팅 머신을 추가하기 전에 사용할 RHCOS 머신을 생성해야 합니다. ISO 이미지 또는 네트워크 PXE 부팅을 사용하여 시스템을 생성합니다.
7.2.1. 사전 요구 사항
- 베어 메탈에 클러스터가 설치되어 있어야 합니다.
- 클러스터를 만드는 데 사용한 설치 미디어 및 Red Hat Enterprise Linux CoreOS (RHCOS) 이미지가 있습니다. 이러한 파일이 없는 경우 설치 절차에 따라 파일을 가져와야 합니다.
7.2.2. ISO 이미지를 사용하여 RHCOS 머신 생성
ISO 이미지를 사용하여 머신을 생성함으로써 베어 메탈 클러스터에 대해 더 많은 Red Hat Enterprise Linux CoreOS (RHCOS) 컴퓨팅 머신을 생성할 수 있습니다.
사전 요구 사항
- 클러스터의 컴퓨팅 머신에 대한 Ignition 구성 파일의 URL을 가져옵니다. 설치 중에 이 파일은 HTTP 서버에 업로드되어 있어야 합니다.
-
OpenShift CLI(
oc)가 설치되어 있어야 합니다.
절차
다음 명령을 실행하여 클러스터에서 Ignition 구성 파일을 추출합니다.
$ oc extract -n openshift-machine-api secret/worker-user-data-managed --keys=userData --to=- > worker.ign-
내보낸
worker.ignIgnition 구성 파일을 클러스터에서 HTTP 서버로 업로드합니다. 해당 파일의 URL을 기록해 둡니다. URL에서 Ignition 파일을 사용할 수 있는지 확인할 수 있습니다. 다음 예제에서는 컴퓨팅 노드에 대한 Ignition 구성 파일을 가져옵니다.
$ curl -k http://<HTTP_server>/worker.ign다음 명령으로 실행하여 새 머신을 부팅하기 위해 ISO 이미지에 액세스할 수 있습니다.
RHCOS_VHD_ORIGIN_URL=$(oc -n openshift-machine-config-operator get configmap/coreos-bootimages -o jsonpath='{.data.stream}' | jq -r '.architectures.<architecture>.artifacts.metal.formats.iso.disk.location')ISO 파일을 사용하여 추가 컴퓨팅 머신에 RHCOS를 설치합니다. 클러스터를 설치하기 전에 머신을 만들 때 사용한 것과 동일한 방법을 사용합니다.
- ISO 이미지를 디스크에 굽고 직접 부팅합니다.
- LOM 인터페이스에서 ISO 리디렉션을 사용합니다.
옵션을 지정하거나 라이브 부팅 시퀀스를 중단하지 않고 RHCOS ISO 이미지를 부팅합니다. 설치 프로그램이 RHCOS 라이브 환경에서 쉘 프롬프트로 부팅될 때까지 기다립니다.
참고커널 인수를 추가하기 위해 RHCOS 설치 부팅 프로세스를 중단할 수 있습니다. 그러나 이 ISO 프로세스에서는 커널 인수를 추가하는 대신 다음 단계에 설명된 대로
coreos-installer명령을 사용해야 합니다.coreos-installer명령을 실행하고 설치 요구 사항을 충족하는 옵션을 지정합니다. 최소한 노드 유형에 대한 Ignition 구성 파일과 설치할 장치를 가리키는 URL을 지정해야 합니다.$ sudo coreos-installer install --ignition-url=http://<HTTP_server>/<node_type>.ign <device> --ignition-hash=sha512-<digest>1 2 참고TLS를 사용하는 HTTPS 서버를 통해 Ignition 구성 파일을 제공하려는 경우
coreos-installer를 실행하기 전에 내부 인증 기관(CA)을 시스템 신뢰 저장소에 추가할 수 있습니다.다음 예제에서는
/dev/sda장치에 부트스트랩 노드 설치를 초기화합니다. 부트스트랩 노드의 Ignition 구성 파일은 IP 주소 192.168.1.2가 있는 HTTP 웹 서버에서 가져옵니다.$ sudo coreos-installer install --ignition-url=http://192.168.1.2:80/installation_directory/bootstrap.ign /dev/sda --ignition-hash=sha512-a5a2d43879223273c9b60af66b44202a1d1248fc01cf156c46d4a79f552b6bad47bc8cc78ddf0116e80c59d2ea9e32ba53bc807afbca581aa059311def2c3e3b머신 콘솔에서 RHCOS 설치 진행률을 모니터링합니다.
중요OpenShift Container Platform 설치를 시작하기 전에 각 노드에서 성공적으로 설치되었는지 확인합니다. 설치 프로세스를 관찰하면 발생할 수 있는 RHCOS 설치 문제의 원인을 파악하는 데 도움이 될 수 있습니다.
- 계속해서 클러스터에 추가 컴퓨팅 머신을 만듭니다.
7.2.3. PXE 또는 iPXE 부팅을 통해 RHCOS 머신 생성
PXE 또는 iPXE 부팅을 사용하여 베어 메탈 클러스터에 대해 추가 Red Hat Enterprise Linux CoreOS (RHCOS) 컴퓨팅 머신을 생성할 수 있습니다.
사전 요구 사항
- 클러스터의 컴퓨팅 머신에 대한 Ignition 구성 파일의 URL을 가져옵니다. 설치 중에 이 파일은 HTTP 서버에 업로드되어 있어야 합니다.
-
클러스터 설치 중에 HTTP 서버에 업로드 한 RHCOS ISO 이미지, 압축된 메탈 BIOS,
kernel및initramfs파일의 URL을 가져옵니다. - 설치 중에 OpenShift Container Platform 클러스터에 대한 머신을 생성하는 데 사용한 PXE 부팅 인프라에 액세스할 수 있습니다. RHCOS가 설치된 후 로컬 디스크에서 머신을 부팅해야합니다.
-
UEFI를 사용하는 경우 OpenShift Container Platform 설치 중에 수정 한
grub.conf파일에 액세스할 수 있습니다.
절차
RHCOS 이미지의 PXE 또는 iPXE가 올바르게 설치되었는지 확인합니다.
PXE의 경우:
DEFAULT pxeboot TIMEOUT 20 PROMPT 0 LABEL pxeboot KERNEL http://<HTTP_server>/rhcos-<version>-live-kernel-<architecture>1 APPEND initrd=http://<HTTP_server>/rhcos-<version>-live-initramfs.<architecture>.img coreos.inst.install_dev=/dev/sda coreos.inst.ignition_url=http://<HTTP_server>/worker.ign coreos.live.rootfs_url=http://<HTTP_server>/rhcos-<version>-live-rootfs.<architecture>.img2 - 1
- HTTP 서버에 업로드한 라이브
kernel파일의 위치를 지정합니다. - 2
- HTTP 서버에 업로드한 RHCOS 파일의 위치를 지정합니다.
initrd매개변수 값은initramfs파일의 위치이고coreos.inst.ignition_url매개변수 값은 작업자 Ignition 설정 파일의 위치이며coreos.live.rootfs_url매개 변수 값은 라이브rootfs파일의 위치입니다.coreos.inst.ignition_url및coreos.live.rootfs_url매개변수는 HTTP 및 HTTPS만 지원합니다.
참고이 구성은 그래픽 콘솔이 있는 시스템에서 직렬 콘솔 액세스를 활성화하지 않습니다. 다른 콘솔을 구성하려면
APPEND행에 하나 이상의console=인수를 추가합니다. 예를 들어console=tty0 console=ttyS0을 추가하여 첫 번째 PC 직렬 포트를 기본 콘솔로 설정하고 그래픽 콘솔을 보조 콘솔로 설정합니다. 자세한 내용은 Red Hat Enterprise Linux에서 직렬 터미널 및/또는 콘솔 설정 방법을 참조하십시오.iPXE의 경우 (
x86_64+aarch64).kernel http://<HTTP_server>/rhcos-<version>-live-kernel-<architecture> initrd=main coreos.live.rootfs_url=http://<HTTP_server>/rhcos-<version>-live-rootfs.<architecture>.img coreos.inst.install_dev=/dev/sda coreos.inst.ignition_url=http://<HTTP_server>/worker.ign1 2 initrd --name main http://<HTTP_server>/rhcos-<version>-live-initramfs.<architecture>.img3 boot- 1
- HTTP 서버에 업로드한 RHCOS 파일의 위치를 지정합니다.
kernel매개변수 값은kernel파일의 위치이고initrd=main인수는 UEFI 시스템에서 부팅하는 데 필요하며coreos.live.rootfs_url매개변수 값은rootfs파일의 위치이며coreos.inst.ignition_url매개 변수 값은 작업자 Ignition 구성 파일의 위치입니다. - 2
- NIC를 여러 개 사용하는 경우
ip옵션에 단일 인터페이스를 지정합니다. 예를 들어,eno1라는 NIC에서 DHCP를 사용하려면ip=eno1:dhcp를 설정하십시오. - 3
- HTTP 서버에 업로드한
initramfs파일의 위치를 지정합니다.
참고이 구성은 그래픽 콘솔이 있는 시스템에서 직렬 콘솔 액세스를 활성화하지 않습니다. 다른 콘솔을 구성하려면
커널행에 하나 이상의console=인수를 추가합니다. 예를 들어console=tty0 console=ttyS0을 추가하여 첫 번째 PC 직렬 포트를 기본 콘솔로 설정하고 그래픽 콘솔을 보조 콘솔로 설정합니다. 자세한 내용은 How does one set up a serial terminal and/or console in Red Hat Enterprise Linux? 및 "고급 RHCOS 설치 구성" 섹션의 "프로비저닝 콘솔 활성화"를 참조하십시오.참고aarch64아키텍처에서 CoreOS커널을 네트워킹하려면IMAGE_GZIP옵션이 활성화된 iPXE 빌드 버전을 사용해야 합니다. iPXE의IMAGE_GZIP옵션을 참조하십시오.aarch64에서 PXE ( UEFI 및 GRUB을 두 번째 단계로 포함)의 경우 :menuentry 'Install CoreOS' { linux rhcos-<version>-live-kernel-<architecture> coreos.live.rootfs_url=http://<HTTP_server>/rhcos-<version>-live-rootfs.<architecture>.img coreos.inst.install_dev=/dev/sda coreos.inst.ignition_url=http://<HTTP_server>/worker.ign1 2 initrd rhcos-<version>-live-initramfs.<architecture>.img3 }- 1
- HTTP/TFTP 서버에 업로드한 RHCOS 파일의 위치를 지정합니다.
kernel매개변수 값은 TFTP 서버의파일의 위치입니다.coreos.live.rootfs_url매개변수 값은rootfs파일의 위치이며coreos.inst.ignition_url매개변수 값은 HTTP Server의 작업자 Ignition 구성 파일의 위치입니다. - 2
- NIC를 여러 개 사용하는 경우
ip옵션에 단일 인터페이스를 지정합니다. 예를 들어,eno1라는 NIC에서 DHCP를 사용하려면ip=eno1:dhcp를 설정하십시오. - 3
- TFTP 서버에 업로드한
initramfs파일의 위치를 지정합니다.
- PXE 또는 iPXE 인프라를 사용하여 클러스터에 필요한 컴퓨팅 머신을 만듭니다.
7.2.4. 시스템의 인증서 서명 요청 승인
클러스터에 시스템을 추가하면 추가한 시스템별로 보류 중인 인증서 서명 요청(CSR)이 두 개씩 생성됩니다. 이러한 CSR이 승인되었는지 확인해야 하며, 필요한 경우 이를 직접 승인해야 합니다. 클라이언트 요청을 먼저 승인한 다음 서버 요청을 승인해야 합니다.
사전 요구 사항
- 클러스터에 시스템을 추가했습니다.
프로세스
클러스터가 시스템을 인식하는지 확인합니다.
$ oc get nodes출력 예
NAME STATUS ROLES AGE VERSION master-0 Ready master 63m v1.26.0 master-1 Ready master 63m v1.26.0 master-2 Ready master 64m v1.26.0출력에 생성된 모든 시스템이 나열됩니다.
참고이전 출력에는 일부 CSR이 승인될 때까지 컴퓨팅 노드(작업자 노드라고도 함)가 포함되지 않을 수 있습니다.
보류 중인 CSR을 검토하고 클러스터에 추가한 각 시스템에 대해
Pending또는Approved상태의 클라이언트 및 서버 요청이 표시되는지 확인합니다.$ oc get csr출력 예
NAME AGE REQUESTOR CONDITION csr-8b2br 15m system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending csr-8vnps 15m system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending ...예에서는 두 시스템이 클러스터에 참여하고 있습니다. 목록에는 승인된 CSR이 더 많이 나타날 수도 있습니다.
CSR이 승인되지 않은 경우, 추가된 시스템에 대한 모든 보류 중인 CSR이
Pending상태로 전환된 후 클러스터 시스템의 CSR을 승인합니다.참고CSR은 교체 주기가 자동으로 만료되므로 클러스터에 시스템을 추가한 후 1시간 이내에 CSR을 승인하십시오. 한 시간 내에 승인하지 않으면 인증서가 교체되고 각 노드에 대해 두 개 이상의 인증서가 표시됩니다. 이러한 인증서를 모두 승인해야 합니다. 클라이언트 CSR이 승인되면 Kubelet은 인증서에 대한 보조 CSR을 생성하므로 수동 승인이 필요합니다. 그러면 Kubelet에서 동일한 매개변수를 사용하여 새 인증서를 요청하는 경우 인증서 갱신 요청은
machine-approver에 의해 자동으로 승인됩니다.참고베어 메탈 및 기타 사용자 프로비저닝 인프라와 같이 머신 API를 사용하도록 활성화되지 않는 플랫폼에서 실행되는 클러스터의 경우 CSR(Kubelet service Certificate Request)을 자동으로 승인하는 방법을 구현해야 합니다. 요청이 승인되지 않으면 API 서버가 kubelet에 연결될 때 서비스 인증서가 필요하므로
oc exec,oc rsh,oc logs명령을 성공적으로 수행할 수 없습니다. Kubelet 엔드 포인트에 연결하는 모든 작업을 수행하려면 이 인증서 승인이 필요합니다. 이 방법은 새 CSR을 감시하고 CSR이system:node또는system:admin그룹의node-bootstrapper서비스 계정에 의해 제출되었는지 확인하고 노드의 ID를 확인합니다.개별적으로 승인하려면 유효한 CSR 각각에 대해 다음 명령을 실행하십시오.
$ oc adm certificate approve <csr_name>1 - 1
<csr_name>은 현재 CSR 목록에 있는 CSR의 이름입니다.
보류 중인 CSR을 모두 승인하려면 다음 명령을 실행하십시오.
$ oc get csr -o go-template='{{range .items}}{{if not .status}}{{.metadata.name}}{{"\n"}}{{end}}{{end}}' | xargs --no-run-if-empty oc adm certificate approve참고일부 Operator는 일부 CSR이 승인될 때까지 사용할 수 없습니다.
이제 클라이언트 요청이 승인되었으므로 클러스터에 추가한 각 머신의 서버 요청을 검토해야 합니다.
$ oc get csr출력 예
NAME AGE REQUESTOR CONDITION csr-bfd72 5m26s system:node:ip-10-0-50-126.us-east-2.compute.internal Pending csr-c57lv 5m26s system:node:ip-10-0-95-157.us-east-2.compute.internal Pending ...나머지 CSR이 승인되지 않고
Pending상태인 경우 클러스터 머신의 CSR을 승인합니다.개별적으로 승인하려면 유효한 CSR 각각에 대해 다음 명령을 실행하십시오.
$ oc adm certificate approve <csr_name>1 - 1
<csr_name>은 현재 CSR 목록에 있는 CSR의 이름입니다.
보류 중인 CSR을 모두 승인하려면 다음 명령을 실행하십시오.
$ oc get csr -o go-template='{{range .items}}{{if not .status}}{{.metadata.name}}{{"\n"}}{{end}}{{end}}' | xargs oc adm certificate approve
모든 클라이언트 및 서버 CSR이 승인된 후 머신은
Ready상태가 됩니다. 다음 명령을 실행하여 확인합니다.$ oc get nodes출력 예
NAME STATUS ROLES AGE VERSION master-0 Ready master 73m v1.26.0 master-1 Ready master 73m v1.26.0 master-2 Ready master 74m v1.26.0 worker-0 Ready worker 11m v1.26.0 worker-1 Ready worker 11m v1.26.0참고머신이
Ready상태로 전환하는 데 서버 CSR의 승인 후 몇 분이 걸릴 수 있습니다.
추가 정보
- CSR에 대한 자세한 내용은 인증서 서명 요청을 참조하십시오.
7.2.5. AWS에서 사용자 지정 /var 파티션이 있는 새 RHCOS 작업자 노드 추가
OpenShift Container Platform은 부트스트랩 중에 처리되는 머신 구성을 사용하여 설치 중에 장치 분할을 지원합니다. 그러나 /var 파티션을 사용하는 경우 장치 이름은 설치 시 결정되어야 하며 변경할 수 없습니다. 장치 이름 지정 스키마가 다른 경우 다른 인스턴스 유형을 노드로 추가할 수 없습니다. 예를 들어 m4.large 인스턴스, dev/xvdb 의 기본 AWS 장치 이름으로 /var 파티션을 구성한 경우 기본적으로 m5.large 인스턴스가 /dev/nvme1n1 장치를 사용하므로 AWS m5.large 인스턴스를 직접 추가할 수 없습니다. 다른 이름 지정 스키마로 인해 장치를 파티션하지 못할 수 있습니다.
이 섹션의 절차에서는 설치 시 구성된 것과 다른 장치 이름을 사용하는 인스턴스와 함께 새로운 RHCOS(Red Hat Enterprise Linux CoreOS) 컴퓨팅 노드를 추가하는 방법을 보여줍니다. 사용자 정의 사용자 데이터 시크릿을 생성하고 새 컴퓨팅 머신 세트를 구성합니다. 이러한 단계는 AWS 클러스터에 따라 다릅니다. 이 원칙은 다른 클라우드 배포에도 적용됩니다. 그러나 장치 이름 지정 스키마는 다른 배포마다 다르며 케이스별로 결정되어야 합니다.
절차
명령줄에서
openshift-machine-api네임스페이스로 변경합니다.$ oc project openshift-machine-apiworker-user-data시크릿에서 새 시크릿을 생성합니다.시크릿의
userData섹션을 텍스트 파일로 내보냅니다.$ oc get secret worker-user-data --template='{{index .data.userData | base64decode}}' | jq > userData.txt텍스트 파일을 편집하여 새 노드에 사용하려는 파티션에 대한
스토리지,파일 시스템,systemd스탠자를 추가합니다. 필요에 따라 Ignition 구성 매개변수 를 지정할 수 있습니다.참고ignition스탠자의 값을 변경하지 마십시오.{ "ignition": { "config": { "merge": [ { "source": "https:...." } ] }, "security": { "tls": { "certificateAuthorities": [ { "source": "data:text/plain;charset=utf-8;base64,.....==" } ] } }, "version": "3.2.0" }, "storage": { "disks": [ { "device": "/dev/nvme1n1",1 "partitions": [ { "label": "var", "sizeMiB": 50000,2 "startMiB": 03 } ] } ], "filesystems": [ { "device": "/dev/disk/by-partlabel/var",4 "format": "xfs",5 "path": "/var"6 } ] }, "systemd": { "units": [7 { "contents": "[Unit]\nBefore=local-fs.target\n[Mount]\nWhere=/var\nWhat=/dev/disk/by-partlabel/var\nOptions=defaults,pquota\n[Install]\nWantedBy=local-fs.target\n", "enabled": true, "name": "var.mount" } ] } }- 1
- AWS 블록 장치의 절대 경로를 지정합니다.
- 2
- 데이터 파티션의 크기(MB)를 지정합니다.
- 3
- 메비 바이트 단위의 파티션 시작을 지정합니다. 데이터 파티션을 부트 디스크에 추가할 때 최소 25000MB(메비 바이트)가 권장됩니다. 루트 파일 시스템은 지정된 오프셋까지 사용 가능한 모든 공간을 채우기 위해 자동으로 크기가 조정됩니다. 값이 지정되지 않거나 지정된 값이 권장 최소값보다 작으면 생성되는 루트 파일 시스템의 크기가 너무 작아지고 RHCOS를 나중에 다시 설치할 때 데이터 파티션의 첫 번째 부분을 덮어 쓸 수 있습니다.
- 4
/var파티션의 절대 경로를 지정합니다.- 5
- 파일 시스템 형식을 지정합니다.
- 6
- 루트 파일 시스템이 마운트될 위치와 관련하여 Ignition이 실행되는 동안 파일 시스템의 마운트 지점을 지정합니다. 이는 실제 루트에 마운트되어야 하는 위치와 반드시 동일하지는 않지만 이를 동일하게 만드는 것이 좋습니다.
- 7
/dev/disk/by-partlabel/var장치를/var파티션에 마운트하는 systemd 마운트 장치를 정의합니다.
work-user-data시크릿에서disableTemplating섹션을 텍스트 파일로 추출합니다.$ oc get secret worker-user-data --template='{{index .data.disableTemplating | base64decode}}' | jq > disableTemplating.txt두 개의 텍스트 파일에서 새 사용자 데이터 시크릿 파일을 생성합니다. 이 사용자 데이터 시크릿은
userData.txt파일의 추가 노드 파티션 정보를 새로 생성된 노드에 전달합니다.$ oc create secret generic worker-user-data-x5 --from-file=userData=userData.txt --from-file=disableTemplating=disableTemplating.txt
새 노드의 새 컴퓨팅 머신 세트를 생성합니다.
AWS에 대해 구성된 다음과 유사한 새 컴퓨팅 머신 세트 YAML 파일을 생성합니다. 필요한 파티션과 새로 생성된 사용자 데이터 시크릿을 추가합니다.
작은 정보기존 컴퓨팅 머신 세트를 템플릿으로 사용하고 새 노드에 필요한 대로 매개변수를 변경합니다.
apiVersion: machine.openshift.io/v1beta1 kind: MachineSet metadata: labels: machine.openshift.io/cluster-api-cluster: auto-52-92tf4 name: worker-us-east-2-nvme1n11 namespace: openshift-machine-api spec: replicas: 1 selector: matchLabels: machine.openshift.io/cluster-api-cluster: auto-52-92tf4 machine.openshift.io/cluster-api-machineset: auto-52-92tf4-worker-us-east-2b template: metadata: labels: machine.openshift.io/cluster-api-cluster: auto-52-92tf4 machine.openshift.io/cluster-api-machine-role: worker machine.openshift.io/cluster-api-machine-type: worker machine.openshift.io/cluster-api-machineset: auto-52-92tf4-worker-us-east-2b spec: metadata: {} providerSpec: value: ami: id: ami-0c2dbd95931a apiVersion: awsproviderconfig.openshift.io/v1beta1 blockDevices: - DeviceName: /dev/nvme1n12 ebs: encrypted: true iops: 0 volumeSize: 120 volumeType: gp2 - DeviceName: /dev/nvme1n23 ebs: encrypted: true iops: 0 volumeSize: 50 volumeType: gp2 credentialsSecret: name: aws-cloud-credentials deviceIndex: 0 iamInstanceProfile: id: auto-52-92tf4-worker-profile instanceType: m6i.large kind: AWSMachineProviderConfig metadata: creationTimestamp: null placement: availabilityZone: us-east-2b region: us-east-2 securityGroups: - filters: - name: tag:Name values: - auto-52-92tf4-worker-sg subnet: id: subnet-07a90e5db1 tags: - name: kubernetes.io/cluster/auto-52-92tf4 value: owned userDataSecret: name: worker-user-data-x54 컴퓨팅 머신 세트를 생성합니다.
$ oc create -f <file-name>.yaml시스템을 사용할 수 있게 되는 데 몇 분 정도 걸릴 수 있습니다.
새 파티션과 노드가 생성되었는지 확인합니다.
컴퓨팅 머신 세트가 생성되었는지 확인합니다.
$ oc get machineset출력 예
NAME DESIRED CURRENT READY AVAILABLE AGE ci-ln-2675bt2-76ef8-bdgsc-worker-us-east-1a 1 1 1 1 124m ci-ln-2675bt2-76ef8-bdgsc-worker-us-east-1b 2 2 2 2 124m worker-us-east-2-nvme1n1 1 1 1 1 2m35s1 - 1
- 이는 새로운 컴퓨팅 시스템 세트입니다.
새 노드가 생성되었는지 확인합니다.
$ oc get nodes출력 예
NAME STATUS ROLES AGE VERSION ip-10-0-128-78.ec2.internal Ready worker 117m v1.26.0 ip-10-0-146-113.ec2.internal Ready master 127m v1.26.0 ip-10-0-153-35.ec2.internal Ready worker 118m v1.26.0 ip-10-0-176-58.ec2.internal Ready master 126m v1.26.0 ip-10-0-217-135.ec2.internal Ready worker 2m57s v1.26.01 ip-10-0-225-248.ec2.internal Ready master 127m v1.26.0 ip-10-0-245-59.ec2.internal Ready worker 116m v1.26.0- 1
- 이는 새 노드입니다.
사용자 지정
/var파티션이 새 노드에 생성되었는지 확인합니다.$ oc debug node/<node-name> -- chroot /host lsblk예를 들면 다음과 같습니다.
$ oc debug node/ip-10-0-217-135.ec2.internal -- chroot /host lsblk출력 예
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT nvme0n1 202:0 0 120G 0 disk |-nvme0n1p1 202:1 0 1M 0 part |-nvme0n1p2 202:2 0 127M 0 part |-nvme0n1p3 202:3 0 384M 0 part /boot `-nvme0n1p4 202:4 0 119.5G 0 part /sysroot nvme1n1 202:16 0 50G 0 disk `-nvme1n1p1 202:17 0 48.8G 0 part /var1 - 1
nvme1n1장치는/var파티션에 마운트됩니다.
7.3. 머신 상태 확인
머신 상태 확인을 이해하고 배포합니다.
머신 API가 작동하는 클러스터에서만 고급 머신 관리 및 스케일링 기능을 사용할 수 있습니다. 사용자 프로비저닝 인프라가 있는 클러스터에는 Machine API를 사용하려면 추가 검증 및 구성이 필요합니다.
인프라 플랫폼 유형의 클러스터가 Machine API를 사용할 수 없습니다. 이 제한은 클러스터에 연결된 컴퓨팅 시스템이 기능을 지원하는 플랫폼에 설치된 경우에도 적용됩니다. 이 매개변수는 설치 후 변경할 수 없습니다.
클러스터의 플랫폼 유형을 보려면 다음 명령을 실행합니다.
$ oc get infrastructure cluster -o jsonpath='{.status.platform}'7.3.1. 머신 상태 점검 정보
컴퓨팅 머신 세트 또는 컨트롤 플레인 머신 세트에서 관리하는 머신에만 머신 상태 점검을 적용할 수 있습니다.
머신 상태를 모니터링하기 위해 컨트롤러 구성을 정의할 리소스를 만듭니다. NotReady 상태를 5 분 동안 유지하거나 노드 문제 탐지기(node-problem-detector)에 영구적인 조건을 표시하는 등 검사할 조건과 모니터링할 머신 세트의 레이블을 설정합니다.
MachineHealthCheck 리소스를 관찰하는 컨트롤러에서 정의된 상태를 확인합니다. 머신이 상태 확인에 실패하면 머신이 자동으로 삭제되고 대체할 머신이 만들어집니다. 머신이 삭제되면 machine deleted 이벤트가 표시됩니다.
머신 삭제로 인한 영향을 제한하기 위해 컨트롤러는 한 번에 하나의 노드 만 드레인하고 삭제합니다. 대상 머신 풀에서 허용된 maxUnhealthy 임계값 보다 많은 비정상적인 머신이 있는 경우 수동 개입이 수행될 수 있도록 복구가 중지됩니다.
워크로드 및 요구 사항을 살펴보고 신중하게 시간 초과를 고려하십시오.
- 시간 제한이 길어지면 비정상 머신의 워크로드에 대한 다운타임이 길어질 수 있습니다.
-
시간 초과가 너무 짧으면 수정 루프가 발생할 수 있습니다. 예를 들어
NotReady상태를 확인하는 시간은 머신이 시작 프로세스를 완료할 수 있을 만큼 충분히 길어야 합니다.
검사를 중지하려면 리소스를 제거합니다.
7.3.1.1. 머신 상태 검사 배포 시 제한 사항
머신 상태 점검을 배포하기 전에 고려해야 할 제한 사항은 다음과 같습니다.
- 머신 세트가 소유한 머신만 머신 상태 검사를 통해 업데이트를 적용합니다.
- 머신의 노드가 클러스터에서 제거되면 머신 상태 점검에서 이 머신을 비정상적으로 간주하고 즉시 업데이트를 적용합니다.
-
nodeStartupTimeout후 시스템의 해당 노드가 클러스터에 참여하지 않으면 업데이트가 적용됩니다. -
Machine리소스 단계가Failed하면 즉시 머신에 업데이트를 적용합니다.
7.3.2. MachineHealthCheck 리소스 샘플
베어 메탈 이외의 모든 클라우드 기반 설치 유형에 대한 MachineHealthCheck 리소스는 다음 YAML 파일과 유사합니다.
apiVersion: machine.openshift.io/v1beta1
kind: MachineHealthCheck
metadata:
name: example
namespace: openshift-machine-api
spec:
selector:
matchLabels:
machine.openshift.io/cluster-api-machine-role: <role>
machine.openshift.io/cluster-api-machine-type: <role>
machine.openshift.io/cluster-api-machineset: <cluster_name>-<label>-<zone>
unhealthyConditions:
- type: "Ready"
timeout: "300s"
status: "False"
- type: "Ready"
timeout: "300s"
status: "Unknown"
maxUnhealthy: "40%"
nodeStartupTimeout: "10m" - 1
- 배포할 머신 상태 점검의 이름을 지정합니다.
- 2 3
- 확인할 머신 풀의 레이블을 지정합니다.
- 4
- 추적할 머신 세트를
<cluster_name>-<label>-<zone>형식으로 지정합니다. 예를 들어prod-node-us-east-1a입니다. - 5 6
- 노드 상태에 대한 시간 제한을 지정합니다. 시간 제한 기간 중 상태가 일치되면 머신이 수정됩니다. 시간 제한이 길어지면 비정상 머신의 워크로드에 대한 다운타임이 길어질 수 있습니다.
- 7
- 대상 풀에서 동시에 복구할 수 있는 시스템 수를 지정합니다. 이는 백분율 또는 정수로 설정할 수 있습니다. 비정상 머신의 수가
maxUnhealthy에서의 설정 제한을 초과하면 복구가 수행되지 않습니다. - 8
- 머신 상태가 비정상으로 확인되기 전에 노드가 클러스터에 참여할 때까지 기다려야 하는 시간 초과 기간을 지정합니다.
matchLabels는 예제일 뿐입니다. 특정 요구에 따라 머신 그룹을 매핑해야 합니다.
7.3.2.1. 쇼트 서킷 (Short Circuit) 머신 상태 점검 및 수정
쇼트 서킷(Short-circuiting)은 클러스터가 정상일 때만 머신 상태 점검을 통해 머신을 조정합니다. 쇼트 서킷은 MachineHealthCheck 리소스의 maxUnhealthy 필드를 통해 구성됩니다.
사용자가 시스템을 조정하기 전에 maxUnhealthy 필드 값을 정의하는 경우 MachineHealthCheck는 비정상적으로 결정된 대상 풀 내의 maxUnhealthy 값과 비교합니다. 비정상 머신의 수가 maxUnhealthy 제한을 초과하면 수정을 위한 업데이트가 수행되지 않습니다.
maxUnhealthy가 설정되지 않은 경우 기본값은 100%로 설정되고 클러스터 상태와 관계없이 머신이 수정됩니다.
적절한 maxUnhealthy 값은 배포하는 클러스터의 규모와 MachineHealthCheck에서 다루는 시스템 수에 따라 달라집니다. 예를 들어 maxUnhealthy 값을 사용하여 여러 가용성 영역에서 여러 컴퓨팅 머신 세트를 처리할 수 있으므로 전체 영역을 손실하면 maxUnhealthy 설정이 클러스터 내에서 추가 수정을 방지할 수 있습니다. 여러 가용성 영역이 없는 글로벌 Azure 리전에서는 가용성 세트를 사용하여 고가용성을 보장할 수 있습니다.
컨트롤 플레인에 대해 MachineHealthCheck 리소스를 구성하는 경우 maxUnhealthy 값을 1 로 설정합니다.
이 구성을 사용하면 여러 컨트롤 플레인 머신이 비정상으로 표시되면 머신 상태 점검이 수행되지 않습니다. 비정상적인 여러 컨트롤 플레인 시스템은 etcd 클러스터의 성능이 저하되었거나 실패한 머신을 교체하는 확장 작업이 진행 중임을 나타낼 수 있습니다.
etcd 클러스터가 성능이 저하되면 수동 개입이 필요할 수 있습니다. 스케일링 작업이 진행 중인 경우 머신 상태 점검을 통해 완료할 수 있어야 합니다.
maxUnhealthy 필드는 정수 또는 백분율로 설정할 수 있습니다. maxUnhealthy 값에 따라 다양한 수정을 적용할 수 있습니다.
7.3.2.1.1. 절대 값을 사용하여 maxUnhealthy 설정
maxUnhealthy가 2로 설정된 경우
- 2개 이상의 노드가 비정상인 경우 수정을 위한 업데이트가 수행됩니다.
- 3개 이상의 노드가 비정상이면 수정을 위한 업데이트가 수행되지 않습니다
이러한 값은 머신 상태 점검에서 확인할 수 있는 머신 수와 관련이 없습니다.
7.3.2.1.2. 백분율을 사용하여 maxUnhealthy 설정
maxUnhealthy가 40%로 설정되어 있고 25 대의 시스템이 확인되고 있는 경우 다음을 수행하십시오.
- 10개 이상의 노드가 비정상인 경우 수정을 위한 업데이트가 수행됩니다.
- 11개 이상의 노드가 비정상인 경우 수정을 위한 업데이트가 수행되지 않습니다.
maxUnhealthy가 40%로 설정되어 있고 6 대의 시스템이 확인되고 있는 경우 다음을 수행하십시오.
- 2개 이상의 노드가 비정상인 경우 수정을 위한 업데이트가 수행됩니다.
- 3개 이상의 노드가 비정상이면 수정을 위한 업데이트가 수행되지 않습니다
maxUnhealthy 머신의 백분율이 정수가 아닌 경우 허용되는 머신 수가 반올림됩니다.
7.3.3. 머신 상태 점검 리소스 생성
클러스터의 머신 세트에 대한 MachineHealthCheck 리소스를 생성할 수 있습니다.
컴퓨팅 머신 세트 또는 컨트롤 플레인 머신 세트에서 관리하는 머신에만 머신 상태 점검을 적용할 수 있습니다.
사전 요구 사항
-
oc명령행 인터페이스를 설치합니다.
절차
-
머신 상태 점검 정의가 포함된
healthcheck.yml파일을 생성합니다. healthcheck.yml파일을 클러스터에 적용합니다.$ oc apply -f healthcheck.yml
7.3.4. 컴퓨팅 머신 세트 수동 스케일링
컴퓨팅 머신 세트에서 머신 인스턴스를 추가하거나 제거하려면 컴퓨팅 머신 세트를 수동으로 스케일링할 수 있습니다.
이는 완전히 자동화된 설치 프로그램에 의해 프로비저닝된 인프라 설치와 관련이 있습니다. 사용자 지정 사용자 프로비저닝 인프라 설치에는 컴퓨팅 머신 세트가 없습니다.
사전 요구 사항
-
OpenShift Container Platform 클러스터 및
oc명령행을 설치합니다. -
cluster-admin권한이 있는 사용자로oc에 로그인합니다.
절차
다음 명령을 실행하여 클러스터에 있는 컴퓨팅 머신 세트를 확인합니다.
$ oc get machinesets -n openshift-machine-api컴퓨팅 머신 세트는 <
clusterid>-worker-<aws-region-az> 형식으로 나열됩니다.다음 명령을 실행하여 클러스터에 있는 컴퓨팅 시스템을 확인합니다.
$ oc get machine -n openshift-machine-api다음 명령을 실행하여 삭제할 컴퓨팅 머신에 주석을 설정합니다.
$ oc annotate machine/<machine_name> -n openshift-machine-api machine.openshift.io/delete-machine="true"다음 명령 중 하나를 실행하여 컴퓨팅 머신 세트를 확장합니다.
$ oc scale --replicas=2 machineset <machineset> -n openshift-machine-api또는 다음을 수행합니다.
$ oc edit machineset <machineset> -n openshift-machine-api작은 정보다음 YAML을 적용하여 컴퓨팅 머신 세트를 확장할 수 있습니다.
apiVersion: machine.openshift.io/v1beta1 kind: MachineSet metadata: name: <machineset> namespace: openshift-machine-api spec: replicas: 2컴퓨팅 머신 세트를 확장 또는 축소할 수 있습니다. 새 머신을 사용할 수 있을 때 까지 몇 분 정도 소요됩니다.
중요기본적으로 머신 컨트롤러는 성공할 때까지 머신이 지원하는 노드를 드레이닝하려고 합니다. Pod 중단 예산을 잘못 구성하는 등 일부 상황에서는 드레이닝 작업이 성공하지 못할 수 있습니다. 드레이닝 작업이 실패하면 머신 컨트롤러에서 머신 제거를 진행할 수 없습니다.
특정 머신에서
machine.openshift.io/exclude-node-draining에 주석을 달아 노드 드레이닝을 건너뛸 수 있습니다.
검증
다음 명령을 실행하여 의도한 시스템의 삭제를 확인합니다.
$ oc get machines
7.3.5. 컴퓨팅 머신 세트와 머신 구성 풀의 차이점
MachineSet 개체는 클라우드 또는 머신 공급자와 관련하여 OpenShift Container Platform 노드를 설명합니다.
MachineConfigPool 개체를 사용하면 MachineConfigController 구성 요소가 업그레이드 컨텍스트에서 시스템의 상태를 정의하고 제공할 수 있습니다.
MachineConfigPool 개체를 사용하여 시스템 구성 풀의 OpenShift Container Platform 노드에 대한 업그레이드 방법을 구성할 수 있습니다.
NodeSelector 개체는 MachineSet에 대한 참조로 대체할 수 있습니다.
7.4. 노드 호스트 관련 권장 사례
OpenShift Container Platform 노드 구성 파일에는 중요한 옵션이 포함되어 있습니다. 예를 들어 두 개의 매개변수 podsPerCore 및 maxPods는 하나의 노드에 대해 예약할 수 있는 최대 Pod 수를 제어합니다.
옵션을 둘 다 사용하는 경우 한 노드의 Pod 수는 두 값 중 작은 값으로 제한됩니다. 이 값을 초과하면 다음과 같은 결과가 발생할 수 있습니다.
- CPU 사용률 증가
- Pod 예약 속도 저하
- 노드의 메모리 크기에 따라 메모리 부족 시나리오 발생
- IP 주소 모두 소진
- 리소스 초과 커밋으로 인한 사용자 애플리케이션 성능 저하
Kubernetes의 경우 단일 컨테이너를 보유한 하나의 Pod에서 실제로 두 개의 컨테이너가 사용됩니다. 두 번째 컨테이너는 실제 컨테이너 시작 전 네트워킹 설정에 사용됩니다. 따라서 10개의 Pod를 실행하는 시스템에서는 실제로 20개의 컨테이너가 실행됩니다.
클라우드 공급자의 디스크 IOPS 제한이 CRI-O 및 kubelet에 영향을 미칠 수 있습니다. 노드에서 다수의 I/O 집약적 Pod가 실행되고 있는 경우 오버로드될 수 있습니다. 노드에서 디스크 I/O를 모니터링하고 워크로드에 대해 처리량이 충분한 볼륨을 사용하는 것이 좋습니다.
podsPerCore 매개변수는 노드의 프로세서 코어 수에 따라 노드에서 실행할 수 있는 Pod 수를 설정합니다. 예를 들어 프로세서 코어가 4개인 노드에서 podsPerCore가 10으로 설정된 경우 노드에 허용되는 최대 Pod 수는 40이 됩니다.
kubeletConfig:
podsPerCore: 10
podsPerCore를 0으로 설정하면 이 제한이 비활성화됩니다. 기본값은 0입니다. podsPerCore 매개변수 값은 maxPods 매개변수 값을 초과할 수 없습니다.
maxPods 매개변수는 노드의 속성에 관계없이 노드가 실행할 수 있는 Pod 수를 고정된 값으로 설정합니다.
kubeletConfig:
maxPods: 2507.4.1. KubeletConfig CRD를 생성하여 kubelet 매개변수 편집
kubelet 구성은 현재 Ignition 구성으로 직렬화되어 있으므로 직접 편집할 수 있습니다. 하지만 MCC(Machine Config Controller)에 새 kubelet-config-controller도 추가되어 있습니다. 이를 통해 KubeletConfig CR(사용자 정의 리소스)을 사용하여 kubelet 매개변수를 편집할 수 있습니다.
kubeletConfig 오브젝트의 필드가 Kubernetes 업스트림에서 kubelet으로 직접 전달되므로 kubelet은 해당 값을 직접 검증합니다. kubeletConfig 오브젝트의 값이 유효하지 않으면 클러스터 노드를 사용할 수 없게 될 수 있습니다. 유효한 값은 Kubernetes 설명서를 참조하십시오.
다음 지침 사항을 고려하십시오.
-
기존
KubeletConfigCR을 편집하여 각 변경 사항에 대한 CR을 생성하는 대신 기존 설정을 수정하거나 새 설정을 추가합니다. 변경 사항을 되돌릴 수 있도록 다른 머신 구성 풀을 수정하거나 임시로 변경하려는 변경 사항만 수정하기 위해 CR을 생성하는 것이 좋습니다. -
해당 풀에 필요한 모든 구성 변경 사항을 사용하여 각 머신 구성 풀에 대해 하나의
KubeletConfigCR을 생성합니다. -
필요에 따라 클러스터당 10개로 제한되는 여러
KubeletConfigCR을 생성합니다. 첫 번째KubeletConfigCR의 경우 MCO(Machine Config Operator)는kubelet에 추가된 머신 구성을 생성합니다. 이후 각 CR을 통해 컨트롤러는 숫자 접미사가 있는 다른kubelet머신 구성을 생성합니다. 예를 들어,-2접미사가 있는kubelet머신 구성이 있는 경우 다음kubelet머신 구성에-3이 추가됩니다.
사용자 정의 머신 구성 풀에 kubelet 또는 컨테이너 런타임 구성을 적용하는 경우 machineConfigSelector 의 사용자 지정 역할은 사용자 정의 머신 구성 풀의 이름과 일치해야 합니다.
예를 들어 다음 사용자 지정 머신 구성 풀의 이름은 infra 이므로 사용자 지정 역할도 infra 여야 합니다.
apiVersion: machineconfiguration.openshift.io/v1
kind: MachineConfigPool
metadata:
name: infra
spec:
machineConfigSelector:
matchExpressions:
- {key: machineconfiguration.openshift.io/role, operator: In, values: [worker,infra]}
# ...
머신 구성을 삭제하려면 제한을 초과하지 않도록 해당 구성을 역순으로 삭제합니다. 예를 들어 kubelet-2 머신 구성을 삭제하기 전에 kubelet-3 머신 구성을 삭제합니다.
kubelet-9 접미사가 있는 머신 구성이 있고 다른 KubeletConfig CR을 생성하는 경우 kubelet 머신 구성이 10개 미만인 경우에도 새 머신 구성이 생성되지 않습니다.
KubeletConfig CR 예
$ oc get kubeletconfigNAME AGE
set-max-pods 15mKubeletConfig 머신 구성 표시 예
$ oc get mc | grep kubelet...
99-worker-generated-kubelet-1 b5c5119de007945b6fe6fb215db3b8e2ceb12511 3.2.0 26m
...다음 프로세스는 작업자 노드의 각 노드에 대한 최대 Pod 수를 구성하는 방법을 보여줍니다.
사전 요구 사항
구성하려는 노드 유형의 정적
MachineConfigPoolCR와 연관된 라벨을 가져옵니다. 다음 중 하나를 실행합니다.Machine config pool을 표시합니다.
$ oc describe machineconfigpool <name>예를 들면 다음과 같습니다.
$ oc describe machineconfigpool worker출력 예
apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfigPool metadata: creationTimestamp: 2019-02-08T14:52:39Z generation: 1 labels: custom-kubelet: set-max-pods1 - 1
- 라벨이 추가되면
labels아래에 표시됩니다.
라벨이 없으면 키/값 쌍을 추가합니다.
$ oc label machineconfigpool worker custom-kubelet=set-max-pods
프로세스
이 명령은 선택할 수 있는 사용 가능한 머신 구성 오브젝트를 표시합니다.
$ oc get machineconfig기본적으로 두 개의 kubelet 관련 구성은
01-master-kubelet및01-worker-kubelet입니다.노드당 최대 Pod의 현재 값을 확인하려면 다음을 실행합니다.
$ oc describe node <node_name>예를 들면 다음과 같습니다.
$ oc describe node ci-ln-5grqprb-f76d1-ncnqq-worker-a-mdv94Allocatable스탠자에서value: pods: <value>를 찾습니다.출력 예
Allocatable: attachable-volumes-aws-ebs: 25 cpu: 3500m hugepages-1Gi: 0 hugepages-2Mi: 0 memory: 15341844Ki pods: 250작업자 노드에서 노드당 최대 Pod 수를 설정하려면 kubelet 구성이 포함된 사용자 정의 리소스 파일을 생성합니다.
중요특정 머신 구성 풀을 대상으로 하는 kubelet 구성도 종속 풀에 영향을 미칩니다. 예를 들어 작업자 노드가 포함된 풀에 대한 kubelet 구성을 생성하면 인프라 노드가 포함된 풀을 포함한 모든 하위 집합 풀에도 적용됩니다. 이를 방지하려면 작업자 노드만 포함하는 선택 표현식을 사용하여 새 머신 구성 풀을 생성하고 kubelet 구성이 이 새 풀을 대상으로 지정하도록 해야 합니다.
apiVersion: machineconfiguration.openshift.io/v1 kind: KubeletConfig metadata: name: set-max-pods spec: machineConfigPoolSelector: matchLabels: custom-kubelet: set-max-pods1 kubeletConfig: maxPods: 5002 참고kubelet이 API 서버와 통신하는 속도는 QPS(초당 쿼리) 및 버스트 값에 따라 달라집니다. 노드마다 실행되는 Pod 수가 제한된 경우 기본 값인
50(kubeAPIQPS인 경우) 및100(kubeAPIBurst인 경우)이면 충분합니다. 노드에 CPU 및 메모리 리소스가 충분한 경우 kubelet QPS 및 버스트 속도를 업데이트하는 것이 좋습니다.apiVersion: machineconfiguration.openshift.io/v1 kind: KubeletConfig metadata: name: set-max-pods spec: machineConfigPoolSelector: matchLabels: custom-kubelet: set-max-pods kubeletConfig: maxPods: <pod_count> kubeAPIBurst: <burst_rate> kubeAPIQPS: <QPS>라벨을 사용하여 작업자의 머신 구성 풀을 업데이트합니다.
$ oc label machineconfigpool worker custom-kubelet=set-max-podsKubeletConfig오브젝트를 생성합니다.$ oc create -f change-maxPods-cr.yamlKubeletConfig오브젝트가 생성되었는지 확인합니다.$ oc get kubeletconfig출력 예
NAME AGE set-max-pods 15m클러스터의 작업자 노드 수에 따라 작업자 노드가 하나씩 재부팅될 때까지 기다립니다. 작업자 노드가 3개인 클러스터의 경우 약 10~15분이 걸릴 수 있습니다.
변경 사항이 노드에 적용되었는지 확인합니다.
작업자 노드에서
maxPods값이 변경되었는지 확인합니다.$ oc describe node <node_name>Allocatable스탠자를 찾습니다.... Allocatable: attachable-volumes-gce-pd: 127 cpu: 3500m ephemeral-storage: 123201474766 hugepages-1Gi: 0 hugepages-2Mi: 0 memory: 14225400Ki pods: 5001 ...- 1
- 이 예에서
pods매개변수는KubeletConfig오브젝트에 설정한 값을 보고해야 합니다.
KubeletConfig오브젝트에서 변경 사항을 확인합니다.$ oc get kubeletconfigs set-max-pods -o yaml다음 예와 같이
True및type:Success상태가 표시되어야 합니다.spec: kubeletConfig: maxPods: 500 machineConfigPoolSelector: matchLabels: custom-kubelet: set-max-pods status: conditions: - lastTransitionTime: "2021-06-30T17:04:07Z" message: Success status: "True" type: Success
7.4.3. 컨트롤 플레인 노드 크기 조정
컨트롤 플레인 노드 리소스 요구사항은 클러스터의 노드 및 오브젝트 수에 따라 달라집니다. 다음 컨트롤 플레인 노드 크기 권장 사항은 컨트롤 플레인 밀도 중심 테스트 또는 Cluster-density 의 결과를 기반으로 합니다. 이 테스트에서는 지정된 수의 네임스페이스에서 다음 오브젝트를 생성합니다.
- 이미지 스트림 한 개
- 빌드 1개
-
5 배포:
절전상태의 Pod 복제본 2개, 시크릿 4개, 구성 맵 4개, Downward API 볼륨 1개 - 서비스 5개, 이전 배포 중 하나의 TCP/8080 및 TCP/8443 포트를 가리킵니다.
- 이전 서비스 중 첫 번째를 가리키는 경로 1개
- 2048 임의의 문자열을 포함하는 10개의 보안
- 2048 임의 문자열 문자가 포함된 구성 맵 10개
| 작업자 노드 수 | cluster-density(네임스페이스) | CPU 코어 수 | 메모리(GB) |
|---|---|---|---|
| 24 | 500 | 4 | 16 |
| 120 | 1000 | 8 | 32 |
| 252 | 4000 | 16하지만 OVN-Kubernetes 네트워크 플러그인을 사용하는 경우 24개 | OVN-Kubernetes 네트워크 플러그인을 사용하는 경우 64이지만 128 |
| 501 그러나 OVN-Kubernetes 네트워크 플러그인에서는 테스트되지 않았습니다. | 4000 | 16 | 96 |
위의 표의 데이터는 AWS 상단에서 실행되는 OpenShift Container Platform을 기반으로 하며 r5.4xlarge 인스턴스를 control-plane 노드로 사용하고 m5.2xlarge 인스턴스를 작업자 노드로 사용합니다.
3개의 컨트롤 플레인 노드가 있는 대규모 및 밀도가 높은 클러스터에서는 노드 중 하나가 중지, 재부팅 또는 실패할 때 CPU 및 메모리 사용량이 증가합니다. 전원, 네트워크, 기본 인프라 또는 비용 절감을 위해 클러스터를 종료한 후 클러스터를 다시 시작하는 의도적인 사례로 인해 오류가 발생할 수 있습니다. 나머지 두 컨트롤 플레인 노드는 고가용성이 되기 위해 부하를 처리하여 리소스 사용량을 늘려야 합니다. 이는 컨트롤 플레인 노드가 직렬로 연결, 드레이닝, 재부팅되어 운영 체제 업데이트를 적용하고 컨트롤 플레인 Operator 업데이트를 적용하기 때문에 업그레이드 중에도 이 문제가 발생할 수 있습니다. 단계적 오류를 방지하려면 컨트롤 플레인 노드의 전체 CPU 및 메모리 사용량을 리소스 사용량 급증을 처리할 수 있는 사용 가능한 모든 용량의 60%로 유지합니다. 리소스 부족으로 인한 다운타임을 방지하기 위해 컨트롤 플레인 노드에서 CPU 및 메모리를 늘립니다.
노드 크기 조정은 클러스터의 노드 수와 개체 수에 따라 달라집니다. 또한 클러스터에서 개체가 현재 생성되는지에 따라 달라집니다. 개체 생성 중에 컨트롤 플레인은 개체가 running 단계에 있을 때보다 리소스 사용량 측면에서 더 활성화됩니다.
OLM(Operator Lifecycle Manager)은 컨트롤 플레인 노드에서 실행되며, 메모리 공간은 OLM이 클러스터에서 관리해야 하는 네임스페이스 및 사용자 설치된 Operator 수에 따라 다릅니다. OOM이 종료되지 않도록 컨트를 플레인 노드의 크기를 적절하게 조정해야 합니다. 다음 데이터 지점은 클러스터 최대값 테스트 결과를 기반으로 합니다.
| 네임스페이스 수 | 유휴 상태의 OLM 메모리(GB) | 5명의 사용자 operator가 설치된 OLM 메모리(GB) |
|---|---|---|
| 500 | 0.823 | 1.7 |
| 1000 | 1.2 | 2.5 |
| 1500 | 1.7 | 3.2 |
| 2000 | 2 | 4.4 |
| 3000 | 2.7 | 5.6 |
| 4000 | 3.8 | 7.6 |
| 5000 | 4.2 | 9.02 |
| 6000 | 5.8 | 11.3 |
| 7000 | 6.6 | 12.9 |
| 8000 | 6.9 | 14.8 |
| 9000 | 8 | 17.7 |
| 10,000 | 9.9 | 21.6 |
실행 중인 OpenShift Container Platform 4.13 클러스터에서만 컨트롤 플레인 노드 크기를 수정할 수 있습니다.
- 사용자 프로비저닝 설치 방법으로 설치된 클러스터입니다.
- 설치 관리자 프로비저닝 인프라 설치 방법으로 설치된 AWS 클러스터
- 컨트롤 플레인 머신 세트를 사용하여 컨트롤 플레인 시스템을 관리하는 클러스터입니다.
다른 모든 구성의 경우 총 노드 수를 추정하고 설치 중에 제안된 컨트롤 플레인 노드 크기를 사용해야 합니다.
권장 사항은 OpenShift SDN이 있는 OpenShift Container Platform 클러스터에서 네트워크 플러그인으로 캡처된 데이터 포인트를 기반으로 합니다.
OpenShift Container Platform 3.11 및 이전 버전과 비교하면 OpenShift Container Platform 4.13에서는 기본적으로 CPU 코어의 절반(500밀리코어)이 시스템에 의해 예약되어 있습니다. 이러한 점을 고려하여 크기가 결정됩니다.
7.4.4. CPU 관리자 설정
프로세스
선택사항: 노드에 레이블을 지정합니다.
# oc label node perf-node.example.com cpumanager=trueCPU 관리자를 활성화해야 하는 노드의
MachineConfigPool을 편집합니다. 이 예에서는 모든 작업자의 CPU 관리자가 활성화됩니다.# oc edit machineconfigpool worker작업자 머신 구성 풀에 레이블을 추가합니다.
metadata: creationTimestamp: 2020-xx-xxx generation: 3 labels: custom-kubelet: cpumanager-enabledKubeletConfig,cpumanager-kubeletconfig.yaml, CR(사용자 정의 리소스)을 생성합니다. 이전 단계에서 생성한 레이블을 참조하여 올바른 노드가 새 kubelet 구성으로 업데이트되도록 합니다.machineConfigPoolSelector섹션을 참조하십시오.apiVersion: machineconfiguration.openshift.io/v1 kind: KubeletConfig metadata: name: cpumanager-enabled spec: machineConfigPoolSelector: matchLabels: custom-kubelet: cpumanager-enabled kubeletConfig: cpuManagerPolicy: static1 cpuManagerReconcilePeriod: 5s2 동적 kubelet 구성을 생성합니다.
# oc create -f cpumanager-kubeletconfig.yaml그러면 kubelet 구성에 CPU 관리자 기능이 추가되고 필요한 경우 MCO(Machine Config Operator)가 노드를 재부팅합니다. CPU 관리자를 활성화하는 데는 재부팅이 필요하지 않습니다.
병합된 kubelet 구성을 확인합니다.
# oc get machineconfig 99-worker-XXXXXX-XXXXX-XXXX-XXXXX-kubelet -o json | grep ownerReference -A7출력 예
"ownerReferences": [ { "apiVersion": "machineconfiguration.openshift.io/v1", "kind": "KubeletConfig", "name": "cpumanager-enabled", "uid": "7ed5616d-6b72-11e9-aae1-021e1ce18878" } ]작업자에서 업데이트된
kubelet.conf를 확인합니다.# oc debug node/perf-node.example.com sh-4.2# cat /host/etc/kubernetes/kubelet.conf | grep cpuManager출력 예
cpuManagerPolicy: static1 cpuManagerReconcilePeriod: 5s2 코어를 하나 이상 요청하는 Pod를 생성합니다. 제한 및 요청 둘 다 해당 CPU 값이 정수로 설정되어야 합니다. 해당 숫자는 이 Pod 전용으로 사용할 코어 수입니다.
# cat cpumanager-pod.yaml출력 예
apiVersion: v1 kind: Pod metadata: generateName: cpumanager- spec: containers: - name: cpumanager image: gcr.io/google_containers/pause-amd64:3.0 resources: requests: cpu: 1 memory: "1G" limits: cpu: 1 memory: "1G" nodeSelector: cpumanager: "true"Pod를 생성합니다.
# oc create -f cpumanager-pod.yaml레이블 지정한 노드에 Pod가 예약되어 있는지 검증합니다.
# oc describe pod cpumanager출력 예
Name: cpumanager-6cqz7 Namespace: default Priority: 0 PriorityClassName: <none> Node: perf-node.example.com/xxx.xx.xx.xxx ... Limits: cpu: 1 memory: 1G Requests: cpu: 1 memory: 1G ... QoS Class: Guaranteed Node-Selectors: cpumanager=truecgroups가 올바르게 설정되었는지 검증합니다.pause프로세스의 PID(프로세스 ID)를 가져옵니다.# ├─init.scope │ └─1 /usr/lib/systemd/systemd --switched-root --system --deserialize 17 └─kubepods.slice ├─kubepods-pod69c01f8e_6b74_11e9_ac0f_0a2b62178a22.slice │ ├─crio-b5437308f1a574c542bdf08563b865c0345c8f8c0b0a655612c.scope │ └─32706 /pauseQoS(Quality of Service) 계층
Guaranteed의 Pod는kubepods.slice에 있습니다. 다른 QoS 계층의 Pod는kubepods의 하위cgroups에 있습니다.# cd /sys/fs/cgroup/cpuset/kubepods.slice/kubepods-pod69c01f8e_6b74_11e9_ac0f_0a2b62178a22.slice/crio-b5437308f1ad1a7db0574c542bdf08563b865c0345c86e9585f8c0b0a655612c.scope # for i in `ls cpuset.cpus tasks` ; do echo -n "$i "; cat $i ; done출력 예
cpuset.cpus 1 tasks 32706작업에 허용되는 CPU 목록을 확인합니다.
# grep ^Cpus_allowed_list /proc/32706/status출력 예
Cpus_allowed_list: 1GuaranteedPod용으로 할당된 코어에서는 시스템의 다른 Pod(이 경우burstableQoS 계층의 Pod)를 실행할 수 없는지 검증합니다.# cat /sys/fs/cgroup/cpuset/kubepods.slice/kubepods-besteffort.slice/kubepods-besteffort-podc494a073_6b77_11e9_98c0_06bba5c387ea.slice/crio-c56982f57b75a2420947f0afc6cafe7534c5734efc34157525fa9abbf99e3849.scope/cpuset.cpus 0 # oc describe node perf-node.example.com출력 예
... Capacity: attachable-volumes-aws-ebs: 39 cpu: 2 ephemeral-storage: 124768236Ki hugepages-1Gi: 0 hugepages-2Mi: 0 memory: 8162900Ki pods: 250 Allocatable: attachable-volumes-aws-ebs: 39 cpu: 1500m ephemeral-storage: 124768236Ki hugepages-1Gi: 0 hugepages-2Mi: 0 memory: 7548500Ki pods: 250 ------- ---- ------------ ---------- --------------- ------------- --- default cpumanager-6cqz7 1 (66%) 1 (66%) 1G (12%) 1G (12%) 29m Allocated resources: (Total limits may be over 100 percent, i.e., overcommitted.) Resource Requests Limits -------- -------- ------ cpu 1440m (96%) 1 (66%)이 VM에는 두 개의 CPU 코어가 있습니다.
system-reserved설정은 500밀리코어로 설정되었습니다. 즉,Node Allocatable양이 되는 노드의 전체 용량에서 한 코어의 절반이 감산되었습니다.Allocatable CPU는 1500 밀리코어임을 확인할 수 있습니다. 즉, Pod마다 하나의 전체 코어를 사용하므로 CPU 관리자 Pod 중 하나를 실행할 수 있습니다. 전체 코어는 1000밀리코어에 해당합니다. 두 번째 Pod를 예약하려고 하면 시스템에서 해당 Pod를 수락하지만 Pod가 예약되지 않습니다.NAME READY STATUS RESTARTS AGE cpumanager-6cqz7 1/1 Running 0 33m cpumanager-7qc2t 0/1 Pending 0 11s
7.5. Huge Page
Huge Page를 이해하고 구성합니다.
7.5.1. Huge Page의 기능
메모리는 페이지라는 블록으로 관리됩니다. 대부분의 시스템에서 한 페이지는 4Ki입니다. 1Mi 메모리는 256페이지와 같고 1Gi 메모리는 256,000페이지에 해당합니다. CPU에는 하드웨어에서 이러한 페이지 목록을 관리하는 내장 메모리 관리 장치가 있습니다. TLB(Translation Lookaside Buffer)는 가상-물리적 페이지 매핑에 대한 소규모 하드웨어 캐시입니다. TLB에 하드웨어 명령어로 전달된 가상 주소가 있으면 매핑을 신속하게 확인할 수 있습니다. 가상 주소가 없으면 TLB 누락이 발생하고 시스템에서 소프트웨어 기반 주소 변환 속도가 느려져 성능 문제가 발생합니다. TLB 크기는 고정되어 있으므로 TLB 누락 가능성을 줄이는 유일한 방법은 페이지 크기를 늘리는 것입니다.
대규모 페이지는 4Ki보다 큰 메모리 페이지입니다. x86_64 아키텍처에서 일반적인 대규모 페이지 크기는 2Mi와 1Gi입니다. 다른 아키텍처에서는 크기가 달라집니다. 대규모 페이지를 사용하려면 애플리케이션이 인식할 수 있도록 코드를 작성해야 합니다. THP(투명한 대규모 페이지)에서는 애플리케이션 지식 없이 대규모 페이지 관리를 자동화하려고 하지만 한계가 있습니다. 특히 페이지 크기 2Mi로 제한됩니다. THP에서는 THP 조각 모음 작업으로 인해 메모리 사용률이 높아지거나 조각화가 발생하여 노드에서 성능이 저하될 수 있으며 이로 인해 메모리 페이지가 잠길 수 있습니다. 이러한 이유로 일부 애플리케이션은 THP 대신 사전 할당된 Huge Page를 사용하도록 설계 (또는 권장)할 수 있습니다.
7.5.2. 애플리케이션이 Huge Page를 소비하는 방법
노드에서 대규모 페이지 용량을 보고하려면 노드가 대규모 페이지를 사전 할당해야 합니다. 노드는 단일 크기의 대규모 페이지만 사전 할당할 수 있습니다.
대규모 페이지는 hugepages-<size> 리소스 이름으로 컨테이너 수준 리소스 요구사항에 따라 사용할 수 있습니다. 여기서 크기는 특정 노드에서 지원되는 정수 값이 사용된 가장 간단한 바이너리 표현입니다. 예를 들어 노드에서 2,048KiB 페이지 크기를 지원하는 경우 예약 가능한 리소스 hugepages-2Mi를 공개합니다. CPU 또는 메모리와 달리 대규모 페이지는 초과 커밋을 지원하지 않습니다.
apiVersion: v1
kind: Pod
metadata:
generateName: hugepages-volume-
spec:
containers:
- securityContext:
privileged: true
image: rhel7:latest
command:
- sleep
- inf
name: example
volumeMounts:
- mountPath: /dev/hugepages
name: hugepage
resources:
limits:
hugepages-2Mi: 100Mi
memory: "1Gi"
cpu: "1"
volumes:
- name: hugepage
emptyDir:
medium: HugePages- 1
hugepages의 메모리 양은 할당할 정확한 양으로 지정하십시오. 이 값을hugepages의 메모리 양과 페이지 크기를 곱한 값으로 지정하지 마십시오. 예를 들어 대규모 페이지 크기가 2MB이고 애플리케이션에 100MB의 대규모 페이지 지원 RAM을 사용하려면 50개의 대규모 페이지를 할당합니다. OpenShift Container Platform에서 해당 계산을 처리합니다. 위의 예에서와 같이100MB를 직접 지정할 수 있습니다.
특정 크기의 대규모 페이지 할당
일부 플랫폼에서는 여러 대규모 페이지 크기를 지원합니다. 특정 크기의 대규모 페이지를 할당하려면 대규모 페이지 부팅 명령 매개변수 앞에 대규모 페이지 크기 선택 매개변수 hugepagesz=<size>를 지정합니다. <size> 값은 바이트 단위로 지정해야 하며 스케일링 접미사 [kKmMgG]를 선택적으로 사용할 수 있습니다. 기본 대규모 페이지 크기는 default_hugepagesz=<size> 부팅 매개변수로 정의할 수 있습니다.
대규모 페이지 요구사항
- 대규모 페이지 요청은 제한과 같아야 합니다. 제한은 지정되었으나 요청은 지정되지 않은 경우 제한이 기본값입니다.
- 대규모 페이지는 Pod 범위에서 격리됩니다. 컨테이너 격리는 향후 반복에서 계획됩니다.
-
대규모 페이지에서 지원하는
EmptyDir볼륨은 Pod 요청보다 더 많은 대규모 페이지 메모리를 사용하면 안 됩니다. -
SHM_HUGETLB로shmget()를 통해 대규모 페이지를 사용하는 애플리케이션은 proc/sys/vm/hugetlb_shm_group과 일치하는 보조 그룹을 사용하여 실행되어야 합니다.
7.5.3. 부팅 시 Huge Page 구성
노드는 OpenShift Container Platform 클러스터에서 사용되는 대규모 페이지를 사전 할당해야 합니다. 대규모 페이지 예약은 부팅 시 예약하는 방법과 런타임 시 예약하는 방법 두 가지가 있습니다. 부팅 시 예약은 메모리가 아직 많이 조각화되어 있지 않으므로 성공할 가능성이 높습니다. Node Tuning Operator는 현재 특정 노드에서 대규모 페이지에 대한 부팅 시 할당을 지원합니다.
프로세스
노드 재부팅을 최소화하려면 다음 단계를 순서대로 수행해야 합니다.
동일한 대규모 페이지 설정이 필요한 모든 노드에 하나의 레이블을 지정합니다.
$ oc label node <node_using_hugepages> node-role.kubernetes.io/worker-hp=다음 콘텐츠로 파일을 생성하고 이름을
hugepages-tuned-boottime.yaml로 지정합니다.apiVersion: tuned.openshift.io/v1 kind: Tuned metadata: name: hugepages1 namespace: openshift-cluster-node-tuning-operator spec: profile:2 - data: | [main] summary=Boot time configuration for hugepages include=openshift-node [bootloader] cmdline_openshift_node_hugepages=hugepagesz=2M hugepages=503 name: openshift-node-hugepages recommend: - machineConfigLabels:4 machineconfiguration.openshift.io/role: "worker-hp" priority: 30 profile: openshift-node-hugepagesTuned
hugepages오브젝트를 생성합니다.$ oc create -f hugepages-tuned-boottime.yaml다음 콘텐츠로 파일을 생성하고 이름을
hugepages-mcp.yaml로 지정합니다.apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfigPool metadata: name: worker-hp labels: worker-hp: "" spec: machineConfigSelector: matchExpressions: - {key: machineconfiguration.openshift.io/role, operator: In, values: [worker,worker-hp]} nodeSelector: matchLabels: node-role.kubernetes.io/worker-hp: ""머신 구성 풀을 생성합니다.
$ oc create -f hugepages-mcp.yaml
조각화되지 않은 메모리가 충분한 경우 worker-hp 머신 구성 풀의 모든 노드에 50개의 2Mi 대규모 페이지가 할당되어 있어야 합니다.
$ oc get node <node_using_hugepages> -o jsonpath="{.status.allocatable.hugepages-2Mi}"
100MiTuneD 부트로더 플러그인은 RHCOS(Red Hat Enterprise Linux CoreOS) 작업자 노드만 지원합니다.
7.6. 장치 플러그인 이해
장치 플러그인은 클러스터 전체에서 하드웨어 장치를 소비할 수 있는 일관되고 이식 가능한 솔루션을 제공합니다. 장치 플러그인은 확장 메커니즘을 통해 이러한 장치를 지원하여 컨테이너에서 이러한 장치를 사용할 수 있게 하고 장치의 상태 점검을 제공하며 안전하게 공유합니다.
OpenShift Container Platform은 장치 플러그인 API를 지원하지만 장치 플러그인 컨테이너는 개별 공급 업체에서 지원합니다.
장치 플러그인은 특정 하드웨어 리소스를 관리하는 노드( kubelet외부)에서 실행되는 gRPC 서비스입니다. 모든 장치 플러그인은 다음 원격 프로시저 호출 (RPC)을 지원해야 합니다.
service DevicePlugin {
// GetDevicePluginOptions returns options to be communicated with Device
// Manager
rpc GetDevicePluginOptions(Empty) returns (DevicePluginOptions) {}
// ListAndWatch returns a stream of List of Devices
// Whenever a Device state change or a Device disappears, ListAndWatch
// returns the new list
rpc ListAndWatch(Empty) returns (stream ListAndWatchResponse) {}
// Allocate is called during container creation so that the Device
// Plug-in can run device specific operations and instruct Kubelet
// of the steps to make the Device available in the container
rpc Allocate(AllocateRequest) returns (AllocateResponse) {}
// PreStartcontainer is called, if indicated by Device Plug-in during
// registration phase, before each container start. Device plug-in
// can run device specific operations such as resetting the device
// before making devices available to the container
rpc PreStartcontainer(PreStartcontainerRequest) returns (PreStartcontainerResponse) {}
}장치 플러그인 예
간편한 장치 플러그인 참조 구현을 위해 장치 관리자 코드에 vendor/k8s.io/kubernetes/pkg/kubelet/cm/deviceplugin/device_plugin_stub.go 의 스텁 장치 플러그인이 있습니다.
7.6.1. 장치 플러그인을 배포하는 방법
- 장치 플러그인 배포에는 데몬 세트 접근 방식을 사용하는 것이 좋습니다.
- 시작 시 장치 플러그인은 노드의 /var/lib/kubelet/device-plugin/ 에 UNIX 도메인 소켓을 만들어 장치 관리자의 RPC를 제공하려고 합니다.
- 장치 플러그인은 하드웨어 리소스, 호스트 파일 시스템에 대한 액세스 및 소켓 생성을 관리해야 하므로 권한 있는 보안 컨텍스트에서 실행해야 합니다.
- 배포 단계에 대한 보다 구체적인 세부 정보는 각 장치 플러그인 구현에서 확인할 수 있습니다.
7.6.2. 장치 관리자 이해
장치 관리자는 장치 플러그인이라는 플러그인을 사용하여 특수 노드 하드웨어 리소스를 알리기 위한 메커니즘을 제공합니다.
업스트림 코드 변경없이 특수 하드웨어를 공개할 수 있습니다.
OpenShift Container Platform은 장치 플러그인 API를 지원하지만 장치 플러그인 컨테이너는 개별 공급 업체에서 지원합니다.
장치 관리자는 장치를 확장 리소스(Extended Resources)으로 공개합니다. 사용자 pod는 다른 확장 리소스 를 요청하는 데 사용되는 동일한 제한/요청 메커니즘을 사용하여 장치 관리자에 의해 공개된 장치를 사용할 수 있습니다.
시작시 장치 플러그인은 /var/lib/kubelet/device-plugins/kubelet.sock 에서 Register 를 호출하는 장치 관리자에 직접 등록하고 장치 관리자 요청을 제공하기 위해 /var/lib/kubelet/device-plugins/<plugin>.sock 에서 gRPC 서비스를 시작합니다.
장치 관리자는 새 등록 요청을 처리하는 동안 장치 플러그인 서비스에서 ListAndWatch 원격 프로시저 호출(RPC)을 호출합니다. 이에 대한 응답으로 장치 관리자는 플러그인에서 gRPC 스트림을 통해 장치 오브젝트 목록을 가져옵니다. 장치 관리자는 플러그인에서 새로운 업데이트를 위해 스트림을 모니터링합니다. 플러그인 측에서도 플러그인은 스트림을 열린 상태로 유지하고 장치 상태가 변경될 때마다 동일한 스트리밍 연결을 통해 새 장치 목록이 장치 관리자로 전송됩니다.
새로운 pod 승인 요청을 처리하는 동안 Kubelet은 장치 할당을 위해 요청된 Extended Resources를 장치 관리자에게 전달합니다. 장치 관리자는 데이터베이스에서 해당 플러그인이 존재하는지 확인합니다. 플러그인이 존재하고 로컬 캐시별로 할당 가능한 장치가 있는 경우 Allocate RPC가 특정 장치 플러그인에서 호출됩니다.
또한 장치 플러그인은 드라이버 설치, 장치 초기화 및 장치 재설정과 같은 몇 가지 다른 장치 관련 작업을 수행할 수도 있습니다. 이러한 기능은 구현마다 다릅니다.
7.6.3. 장치 관리자 활성화
장치 관리자는 장치 플러그인을 구현하여 업스트림 코드 변경없이 특수 하드웨어를 사용할 수 있습니다.
장치 관리자는 장치 플러그인이라는 플러그인을 사용하여 특수 노드 하드웨어 리소스를 알리기 위한 메커니즘을 제공합니다.
다음 명령을 입력하여 구성할 노드 유형의 정적
MachineConfigPoolCRD와 연관된 라벨을 가져옵니다. 다음 중 하나를 실행합니다.Machine config를 표시합니다:
# oc describe machineconfig <name>예를 들면 다음과 같습니다.
# oc describe machineconfig 00-worker출력 예
Name: 00-worker Namespace: Labels: machineconfiguration.openshift.io/role=worker1 - 1
- 장치 관리자에 필요한 라벨입니다.
프로세스
구성 변경을 위한 사용자 정의 리소스 (CR)를 만듭니다.
장치 관리자 CR의 설정 예
apiVersion: machineconfiguration.openshift.io/v1 kind: KubeletConfig metadata: name: devicemgr1 spec: machineConfigPoolSelector: matchLabels: machineconfiguration.openshift.io: devicemgr2 kubeletConfig: feature-gates: - DevicePlugins=true3 장치 관리자를 만듭니다.
$ oc create -f devicemgr.yaml출력 예
kubeletconfig.machineconfiguration.openshift.io/devicemgr created- 노드에서 /var/lib/kubelet/device-plugins/kubelet.sock이 작성되었는지 확인하여 장치 관리자가 실제로 사용 가능한지 확인합니다. 이는 장치 관리자의 gRPC 서버가 새 플러그인 등록을 수신하는 UNIX 도메인 소켓입니다. 이 소켓 파일은 장치 관리자가 활성화된 경우에만 Kubelet을 시작할 때 생성됩니다.
7.7. 테인트(Taints) 및 톨러레이션(Tolerations)
테인트(Taints)와 톨러레이션(Tolerations)을 이해하고 사용합니다.
7.7.1. 테인트(Taints) 및 톨러레이션(Tolerations)의 이해
테인트를 사용하면 Pod에 일치하는 허용 오차가 없는 경우 노드에서 Pod 예약을 거부할 수 있습니다.
Node 사양(NodeSpec)을 통해 노드에 테인트를 적용하고 Pod 사양(PodSpec)을 통해 Pod에 허용 오차를 적용합니다. 노드에 테인트를 적용할 때 Pod에서 테인트를 허용할 수 없는 경우 스케줄러에서 해당 노드에 Pod를 배치할 수 없습니다.
노드 사양의 테인트 예
apiVersion: v1
kind: Node
metadata:
name: my-node
#...
spec:
taints:
- effect: NoExecute
key: key1
value: value1
#...Pod 사양의 허용 오차 예
apiVersion: v1
kind: Pod
metadata:
name: my-pod
#...
spec:
tolerations:
- key: "key1"
operator: "Equal"
value: "value1"
effect: "NoExecute"
tolerationSeconds: 3600
#...테인트 및 톨러레이션은 key, value 및 effect로 구성되어 있습니다.
| 매개변수 | 설명 | ||||||
|---|---|---|---|---|---|---|---|
|
|
| ||||||
|
|
| ||||||
|
| 다음 명령 중 하나를 실행합니다.
| ||||||
|
|
|
컨트롤 플레인 노드에
NoSchedule테인트를 추가하는 경우 노드에 기본적으로 추가되는node-role.kubernetes.io/master=:NoSchedule테인트가 있어야 합니다.예를 들면 다음과 같습니다.
apiVersion: v1 kind: Node metadata: annotations: machine.openshift.io/machine: openshift-machine-api/ci-ln-62s7gtb-f76d1-v8jxv-master-0 machineconfiguration.openshift.io/currentConfig: rendered-master-cdc1ab7da414629332cc4c3926e6e59c name: my-node #... spec: taints: - effect: NoSchedule key: node-role.kubernetes.io/master #...
톨러레이션은 테인트와 일치합니다.
operator매개변수가Equal로 설정된 경우:-
key매개변수는 동일합니다. -
value매개변수는 동일합니다. -
effect매개변수는 동일합니다.
-
operator매개변수가Exists로 설정된 경우:-
key매개변수는 동일합니다. -
effect매개변수는 동일합니다.
-
다음 테인트는 OpenShift Container Platform에 빌드됩니다.
-
node.kubernetes.io/not-ready: 노드가 준비 상태에 있지 않습니다. 이는 노드 조건Ready=False에 해당합니다. -
node.kubernetes.io/unreachable: 노드가 노드 컨트롤러에서 연결할 수 없습니다. 이는 노드 조건Ready=Unknown에 해당합니다. -
node.kubernetes.io/memory-pressure: 노드에 메모리 부족 문제가 있습니다. 이는 노드 조건MemoryPressure=True에 해당합니다. -
node.kubernetes.io/disk-pressure: 노드에 디스크 부족 문제가 있습니다. 이는 노드 조건DiskPressure=True에 해당합니다. -
node.kubernetes.io/network-unavailable: 노드 네트워크를 사용할 수 없습니다. -
node.kubernetes.io/unschedulable: 노드를 예약할 수 없습니다. -
node.cloudprovider.kubernetes.io/uninitialized: 노드 컨트롤러가 외부 클라우드 공급자로 시작되면 이 테인트 노드에 사용 불가능으로 표시됩니다. cloud-controller-manager의 컨트롤러가 이 노드를 초기화하면 kubelet이 이 테인트를 제거합니다. node.kubernetes.io/pid-pressure: 노드에 pid 부족이 있습니다. 이는 노드 조건PIDPressure=True에 해당합니다.중요OpenShift Container Platform은 기본 pid.available
evictionHard를 설정하지 않습니다.
7.7.2. 테인트 및 톨러레이션 추가
Pod에 허용 오차를 추가하고 노드에 테인트를 추가하면 노드에 예약하거나 예약하지 않아야 하는 Pod를 노드에서 제어할 수 있습니다. 기존 Pod 및 노드의 경우 먼저 Pod에 허용 오차를 추가한 다음 노드에 테인트를 추가하여 허용 오차를 추가하기 전에 노드에서 Pod가 제거되지 않도록 합니다.
프로세스
tolerations스탠자를 포함하도록Pod사양을 편집하여 Pod에 허용 오차를 추가합니다.Equal 연산자가 있는 Pod 구성 파일 샘플
apiVersion: v1 kind: Pod metadata: name: my-pod #... spec: tolerations: - key: "key1"1 value: "value1" operator: "Equal" effect: "NoExecute" tolerationSeconds: 36002 #...예를 들면 다음과 같습니다.
Exists 연산자가 있는 Pod 구성 파일 샘플
apiVersion: v1 kind: Pod metadata: name: my-pod #... spec: tolerations: - key: "key1" operator: "Exists"1 effect: "NoExecute" tolerationSeconds: 3600 #...- 1
Exists연산자는value를 사용하지 않습니다.
이 예에서는 key
key1, valuevalue1, 테인트 effectNoExecute를 갖는node1에 테인트를 배치합니다.테인트 및 허용 오차 구성 요소 테이블에 설명된 매개변수로 다음 명령을 사용하여 노드에 테인트를 추가합니다.
$ oc adm taint nodes <node_name> <key>=<value>:<effect>예를 들면 다음과 같습니다.
$ oc adm taint nodes node1 key1=value1:NoExecute이 명령은 키가
key1, 값이value1, 효과가NoExecute인node1에 테인트를 배치합니다.참고컨트롤 플레인 노드에
NoSchedule테인트를 추가하는 경우 노드에 기본적으로 추가되는node-role.kubernetes.io/master=:NoSchedule테인트가 있어야 합니다.예를 들면 다음과 같습니다.
apiVersion: v1 kind: Node metadata: annotations: machine.openshift.io/machine: openshift-machine-api/ci-ln-62s7gtb-f76d1-v8jxv-master-0 machineconfiguration.openshift.io/currentConfig: rendered-master-cdc1ab7da414629332cc4c3926e6e59c name: my-node #... spec: taints: - effect: NoSchedule key: node-role.kubernetes.io/master #...Pod의 허용 오차가 노드의 테인트와 일치합니다. 허용 오차 중 하나가 있는 Pod를
node1에 예약할 수 있습니다.
7.7.3. 컴퓨팅 머신 세트를 사용하여 테인트 및 허용 오차 추가
컴퓨팅 머신 세트를 사용하여 노드에 테인트를 추가할 수 있습니다. MachineSet 오브젝트와 연결된 모든 노드는 테인트를 사용하여 업데이트됩니다. 허용 오차는 노드에 직접 추가된 테인트와 동일한 방식으로 컴퓨팅 머신 세트에 의해 추가된 테인트에 응답합니다.
프로세스
tolerations스탠자를 포함하도록Pod사양을 편집하여 Pod에 허용 오차를 추가합니다.Equal연산자가 있는 Pod 구성 파일의 예apiVersion: v1 kind: Pod metadata: name: my-pod #... spec: tolerations: - key: "key1"1 value: "value1" operator: "Equal" effect: "NoExecute" tolerationSeconds: 36002 #...예를 들면 다음과 같습니다.
Exists연산자가 있는 pod 구성 파일의 예apiVersion: v1 kind: Pod metadata: name: my-pod #... spec: tolerations: - key: "key1" operator: "Exists" effect: "NoExecute" tolerationSeconds: 3600 #...MachineSet오브젝트에 테인트를 추가합니다.테인트할 노드의
MachineSetYAML을 편집하거나 새MachineSet오브젝트를 생성할 수 있습니다.$ oc edit machineset <machineset>spec.template.spec섹션에 테인트를 추가합니다.컴퓨팅 머신 세트 사양의 테인트 예
apiVersion: machine.openshift.io/v1beta1 kind: MachineSet metadata: name: my-machineset #... spec: #... template: #... spec: taints: - effect: NoExecute key: key1 value: value1 #...이 예제에서는 키가
key1, 값이value1, 테인트 효과가NoExecute인 테인트를 노드에 배치합니다.컴퓨팅 머신 세트를 0으로 축소합니다.
$ oc scale --replicas=0 machineset <machineset> -n openshift-machine-api작은 정보다음 YAML을 적용하여 컴퓨팅 머신 세트를 확장할 수 있습니다.
apiVersion: machine.openshift.io/v1beta1 kind: MachineSet metadata: name: <machineset> namespace: openshift-machine-api spec: replicas: 0머신이 제거될 때까지 기다립니다.
필요에 따라 컴퓨팅 머신 세트를 확장합니다.
$ oc scale --replicas=2 machineset <machineset> -n openshift-machine-api또는 다음을 수행합니다.
$ oc edit machineset <machineset> -n openshift-machine-api머신이 시작될 때까지 기다립니다. 테인트는
MachineSet오브젝트와 연결된 노드에 추가됩니다.
7.7.4. 테인트 및 톨러레이션을 사용하여 사용자를 노드에 바인딩
특정 사용자 집합에서 독점적으로 사용하도록 노드 세트를 전용으로 지정하려면 해당 Pod에 허용 오차를 추가합니다. 그런 다음 해당 노드에 해당 테인트를 추가합니다. 허용 오차가 있는 Pod는 테인트된 노드 또는 클러스터의 다른 노드를 사용할 수 있습니다.
이렇게 테인트된 노드에만 Pod를 예약하려면 동일한 노드 세트에도 라벨을 추가하고 해당 라벨이 있는 노드에만 Pod를 예약할 수 있도록 Pod에 노드 유사성을 추가합니다.
프로세스
사용자가 해당 노드 만 사용할 수 있도록 노드를 구성하려면 다음을 수행합니다.
해당 노드에 해당 테인트를 추가합니다.
예를 들면 다음과 같습니다.
$ oc adm taint nodes node1 dedicated=groupName:NoSchedule작은 정보다음 YAML을 적용하여 테인트를 추가할 수 있습니다.
kind: Node apiVersion: v1 metadata: name: my-node #... spec: taints: - key: dedicated value: groupName effect: NoSchedule #...- 사용자 정의 승인 컨트롤러를 작성하여 Pod에 허용 오차를 추가합니다.
7.7.5. 테인트 및 톨러레이션을 사용하여 특수 하드웨어로 노드 제어
소규모 노드 하위 집합에 특수 하드웨어가 있는 클러스터에서는 테인트 및 허용 오차를 사용하여 특수 하드웨어가 필요하지 않은 Pod를 해당 노드에서 분리하여 특수 하드웨어가 필요한 Pod를 위해 노드를 남겨 둘 수 있습니다. 또한 특정 노드를 사용하기 위해 특수 하드웨어가 필요한 Pod를 요청할 수도 있습니다.
이 작업은 특수 하드웨어가 필요한 Pod에 허용 오차를 추가하고 특수 하드웨어가 있는 노드를 테인트하여 수행할 수 있습니다.
프로세스
특수 하드웨어가 있는 노드를 특정 Pod용으로 예약하려면 다음을 수행합니다.
특수 하드웨어가 필요한 Pod에 허용 오차를 추가합니다.
예를 들면 다음과 같습니다.
apiVersion: v1 kind: Pod metadata: name: my-pod #... spec: tolerations: - key: "disktype" value: "ssd" operator: "Equal" effect: "NoSchedule" tolerationSeconds: 3600 #...다음 명령 중 하나를 사용하여 특수 하드웨어가 있는 노드에 테인트를 설정합니다.
$ oc adm taint nodes <node-name> disktype=ssd:NoSchedule또는 다음을 수행합니다.
$ oc adm taint nodes <node-name> disktype=ssd:PreferNoSchedule작은 정보다음 YAML을 적용하여 테인트를 추가할 수 있습니다.
kind: Node apiVersion: v1 metadata: name: my_node #... spec: taints: - key: disktype value: ssd effect: PreferNoSchedule #...
7.7.6. 테인트 및 톨러레이션 제거
필요에 따라 노드에서 테인트를 제거하고 Pod에서 톨러레이션을 제거할 수 있습니다. 허용 오차를 추가하려면 먼저 Pod에 허용 오차를 추가한 다음 노드에서 Pod가 제거되지 않도록 노드에 테인트를 추가해야 합니다.
프로세스
테인트 및 톨러레이션을 제거하려면 다음을 수행합니다.
노드에서 테인트를 제거하려면 다음을 수행합니다.
$ oc adm taint nodes <node-name> <key>-예를 들면 다음과 같습니다.
$ oc adm taint nodes ip-10-0-132-248.ec2.internal key1-출력 예
node/ip-10-0-132-248.ec2.internal untaintedPod에서
Pod사양을 편집하여 톨러레이션을 제거합니다.apiVersion: v1 kind: Pod metadata: name: my-pod #... spec: tolerations: - key: "key2" operator: "Exists" effect: "NoExecute" tolerationSeconds: 3600 #...
7.8. 토폴로지 관리자
토폴로지 관리자를 이해하고 사용합니다.
7.8.1. 토폴로지 관리자 정책
토폴로지 관리자는 CPU 관리자 및 장치 관리자와 같은 힌트 공급자로부터 토폴로지 힌트를 수집하고 수집된 힌트로 Pod 리소스를 정렬하는 방법으로 모든 QoS(Quality of Service) 클래스의 Pod 리소스를 정렬합니다.
토폴로지 관리자는 cpumanager-enabled 라는 KubeletConfig CR(사용자 정의 리소스)에서 할당하는 네 가지 할당 정책을 지원합니다.
none정책- 기본 정책으로, 토폴로지 정렬을 수행하지 않습니다.
best-effort정책-
best-effort토폴로지 관리 정책을 사용하는 Pod의 각 컨테이너에서는 kubelet이 각 힌트 공급자를 호출하여 해당 리소스 가용성을 검색합니다. 토폴로지 관리자는 이 정보를 사용하여 해당 컨테이너의 기본 NUMA 노드 선호도를 저장합니다. 선호도를 기본 설정하지 않으면 토폴로지 관리자가 해당 정보를 저장하고 노드에 대해 Pod를 허용합니다. restricted정책-
restricted토폴로지 관리 정책을 사용하는 Pod의 각 컨테이너에서는 kubelet이 각 힌트 공급자를 호출하여 해당 리소스 가용성을 검색합니다. 토폴로지 관리자는 이 정보를 사용하여 해당 컨테이너의 기본 NUMA 노드 선호도를 저장합니다. 선호도를 기본 설정하지 않으면 토폴로지 관리자가 노드에서 이 Pod를 거부합니다. 그러면 Pod는Terminated상태가 되고 Pod 허용 실패가 발생합니다. single-numa-node정책-
single-numa-node토폴로지 관리 정책을 사용하는 Pod의 각 컨테이너에서는 kubelet이 각 힌트 공급자를 호출하여 해당 리소스 가용성을 검색합니다. 토폴로지 관리자는 이 정보를 사용하여 단일 NUMA 노드 선호도가 가능한지 여부를 결정합니다. 가능한 경우 노드에 대해 Pod가 허용됩니다. 단일 NUMA 노드 선호도가 가능하지 않은 경우 토폴로지 관리자가 노드에서 Pod를 거부합니다. 그러면 Pod는 Terminated 상태가 되고 Pod 허용 실패가 발생합니다.
7.8.2. 토폴로지 관리자 설정
토폴로지 관리자를 사용하려면 cpumanager-enabled 라는 KubeletConfig CR(사용자 정의 리소스)에서 할당 정책을 구성해야 합니다. CPU 관리자를 설정한 경우 해당 파일이 존재할 수 있습니다. 파일이 없으면 파일을 생성할 수 있습니다.
사전 요구 사항
-
CPU 관리자 정책을
static으로 구성하십시오.
프로세스
토폴로지 관리자를 활성화하려면 다음을 수행합니다.
사용자 정의 리소스에서 토폴로지 관리자 할당 정책을 구성합니다.
$ oc edit KubeletConfig cpumanager-enabledapiVersion: machineconfiguration.openshift.io/v1 kind: KubeletConfig metadata: name: cpumanager-enabled spec: machineConfigPoolSelector: matchLabels: custom-kubelet: cpumanager-enabled kubeletConfig: cpuManagerPolicy: static1 cpuManagerReconcilePeriod: 5s topologyManagerPolicy: single-numa-node2
7.8.3. Pod와 토폴로지 관리자 정책 간의 상호 작용
아래 Pod 사양의 예는 Pod와 토폴로지 관리자 간 상호 작용을 보여주는 데 도움이 됩니다.
다음 Pod는 리소스 요청 또는 제한이 지정되어 있지 않기 때문에 BestEffort QoS 클래스에서 실행됩니다.
spec:
containers:
- name: nginx
image: nginx
다음 Pod는 요청이 제한보다 작기 때문에 Burstable QoS 클래스에서 실행됩니다.
spec:
containers:
- name: nginx
image: nginx
resources:
limits:
memory: "200Mi"
requests:
memory: "100Mi"
선택한 정책이 none이 아니면 토폴로지 관리자는 이러한 Pod 사양 중 하나를 고려하지 않습니다.
아래 마지막 예의 Pod는 요청이 제한과 동일하기 때문에 Guaranteed QoS 클래스에서 실행됩니다.
spec:
containers:
- name: nginx
image: nginx
resources:
limits:
memory: "200Mi"
cpu: "2"
example.com/device: "1"
requests:
memory: "200Mi"
cpu: "2"
example.com/device: "1"토폴로지 관리자는 이러한 Pod를 고려합니다. 토폴로지 관리자는 포드에 대한 토폴로지 힌트 힌트를 얻으려면 CPU 관리자 및 장치 관리자인 힌트 공급자를 참조합니다.
토폴로지 관리자는 이 정보를 사용하여 이 컨테이너에 가장 적합한 토폴로지를 저장합니다. 이 Pod의 경우 CPU 관리자와 장치 관리자는 리소스 할당 단계에서 이러한 저장된 정보를 사용합니다.
7.9. 리소스 요청 및 과다 할당
각 컴퓨팅 리소스에 대해 컨테이너는 리소스 요청 및 제한을 지정할 수 있습니다. 노드에 요청된 값을 충족할 수 있는 충분한 용량을 확보하기 위한 요청에 따라 스케줄링 결정이 내려집니다. 컨테이너가 제한을 지정하지만 요청을 생략하면 요청은 기본적으로 제한 값으로 설정됩니다. 컨테이너가 노드에서 지정된 제한을 초과할 수 없습니다.
제한 적용은 컴퓨팅 리소스 유형에 따라 다릅니다. 컨테이너가 요청하거나 제한하지 않으면 컨테이너는 리소스 보장이 없는 상태에서 노드로 예약됩니다. 실제로 컨테이너는 가장 낮은 로컬 우선 순위로 사용 가능한 만큼의 지정된 리소스를 소비할 수 있습니다. 리소스가 부족한 상태에서는 리소스 요청을 지정하지 않는 컨테이너에 가장 낮은 수준의 QoS (Quality of Service)가 설정됩니다.
예약은 요청된 리소스를 기반으로하는 반면 할당량 및 하드 제한은 리소스 제한을 나타내며 이는 요청된 리소스보다 높은 값으로 설정할 수 있습니다. 요청과 제한의 차이에 따라 오버 커밋 수준이 결정됩니다. 예를 들어, 컨테이너에 1Gi의 메모리 요청과 2Gi의 메모리 제한이 지정되면 노드에서 사용 가능한 1Gi 요청에 따라 컨테이너가 예약되지만 최대 2Gi를 사용할 수 있습니다. 따라서 이 경우 200% 오버 커밋되는 것입니다.
7.10. Cluster Resource Override Operator를 사용한 클러스터 수준 오버 커밋
Cluster Resource Override Operator는 클러스터의 모든 노드에서 오버 커밋 수준을 제어하고 컨테이너 밀도를 관리할 수 있는 승인Webhook입니다. Operator는 특정 프로젝트의 노드가 정의된 메모리 및 CPU 한계를 초과하는 경우에 대해 제어합니다.
다음 섹션에 설명된대로 OpenShift Container Platform 콘솔 또는 CLI를 사용하여 Cluster Resource Override Operator를 설치해야합니다. 설치하는 동안 다음 예에 표시된 것처럼 오버 커밋 수준을 설정하는 ClusterResourceOverride 사용자 지정 리소스 (CR)를 만듭니다.
apiVersion: operator.autoscaling.openshift.io/v1
kind: ClusterResourceOverride
metadata:
name: cluster
spec:
podResourceOverride:
spec:
memoryRequestToLimitPercent: 50
cpuRequestToLimitPercent: 25
limitCPUToMemoryPercent: 200
# ...- 1
- 이름은
instance이어야 합니다. - 2
- 선택 사항입니다. 컨테이너 메모리 제한이 지정되어 있거나 기본값으로 설정된 경우 메모리 요청이 제한 백분율 (1-100)로 덮어 쓰기됩니다. 기본값은 50입니다.
- 3
- 선택 사항입니다. 컨테이너 CPU 제한이 지정되어 있거나 기본값으로 설정된 경우 CPU 요청이 1-100 사이의 제한 백분율로 덮어 쓰기됩니다. 기본값은 25입니다.
- 4
- 선택 사항입니다. 컨테이너 메모리 제한이 지정되어 있거나 기본값으로 설정된 경우, CPU 제한이 지정되어 있는 경우 메모리 제한의 백분율로 덮어 쓰기됩니다. 1Gi의 RAM을 100 %로 스케일링하는 것은 1 개의 CPU 코어와 같습니다. CPU 요청을 재정의하기 전에 처리됩니다 (설정된 경우). 기본값은 200입니다.
컨테이너에 제한이 설정되어 있지 않은 경우 Cluster Resource Override Operator 덮어 쓰기가 적용되지 않습니다. 프로젝트별 기본 제한이 있는 LimitRange 오브젝트를 생성하거나 Pod 사양에 제한을 구성하여 덮어쓰기를 적용하십시오.
각 프로젝트의 네임 스페이스 오브젝트에 다음 라벨을 적용하여 프로젝트별로 덮어 쓰기를 활성화할 수 있습니다.
apiVersion: v1
kind: Namespace
metadata:
# ...
labels:
clusterresourceoverrides.admission.autoscaling.openshift.io/enabled: "true"
# ...
Operator는 ClusterResourceOverride CR을 감시하고 ClusterResourceOverride 승인 Webhook가 operator와 동일한 네임 스페이스에 설치되어 있는지 확인합니다.
7.10.1. 웹 콘솔을 사용하여 Cluster Resource Override Operator 설치
OpenShift Container Platform 웹 콘솔을 사용하여 Cluster Resource Override Operator를 설치하여 클러스터의 오버 커밋을 제어할 수 있습니다.
사전 요구 사항
-
컨테이너에 제한이 설정되어 있지 않은 경우 Cluster Resource Override Operator에 영향을 주지 않습니다. 덮어쓰기를 적용하려면
LimitRange오브젝트를 사용하여 프로젝트의 기본 제한을 지정하거나Pod사양에 제한을 구성해야 합니다.
절차
OpenShift Container Platform 웹 콘솔을 사용하여 Cluster Resource Override Operator를 설치합니다.
OpenShift Container Platform 웹 콘솔에서 Home → Projects로 이동합니다.
- Create Project를 클릭합니다.
-
clusterresourceoverride-operator를 프로젝트 이름으로 지정합니다. - Create를 클릭합니다.
Operators → OperatorHub로 이동합니다.
- 사용 가능한 Operator 목록에서 ClusterResourceOverride Operator를 선택한 다음 Install을 클릭합니다.
- Operator 설치 페이지에서 설치 모드에 대해 클러스터의 특정 네임스페이스가 선택되어 있는지 확인합니다.
- Installed Namespace에 대해 clusterresourceoverride-operator가 선택되어 있는지 확인합니다.
- Update Channel 및 Approval Strategy를 선택합니다.
- 설치를 클릭합니다.
Installed Operators 페이지에서 ClusterResourceOverride를 클릭합니다.
- ClusterResourceOverride Operator 세부 정보 페이지에서 Create ClusterResourceOverride 를 클릭합니다.
Create ClusterResourceOverride 페이지에서 YAML 보기를 클릭하고 YAML 템플릿을 편집하여 필요에 따라 오버 커밋 값을 설정합니다.
apiVersion: operator.autoscaling.openshift.io/v1 kind: ClusterResourceOverride metadata: name: cluster1 spec: podResourceOverride: spec: memoryRequestToLimitPercent: 502 cpuRequestToLimitPercent: 253 limitCPUToMemoryPercent: 2004 # ...- 1
- 이름은
instance이어야 합니다. - 2
- 선택 사항입니다. 컨테이너 메모리 제한을 덮어 쓰기하는 경우 1-100 사이의 백분율로 지정합니다. 기본값은 50입니다.
- 3
- 선택 사항입니다. 컨테이너 CPU 제한을 덮어 쓰기하는 경우 1-100 사이의 백분율로 지정합니다. 기본값은 25입니다.
- 4
- 선택 사항입니다. 컨테이너 메모리 제한을 덮어 쓰기하는 경우 백분율로 지정합니다 (사용되는 경우). 1Gi의 RAM을 100 %로 스케일링하는 것은 1 개의 CPU 코어와 같습니다. CPU 요청을 덮어 쓰기하기 전에 처리됩니다 (설정된 경우). 기본값은 200입니다.
- Create를 클릭합니다.
클러스터 사용자 정의 리소스 상태를 확인하여 승인 Webhook의 현재 상태를 확인합니다.
- ClusterResourceOverride Operator 페이지에서 cluster를 클릭합니다.
ClusterResourceOverride Details 페이지에서 YAML 을 클릭합니다. webhook 호출 시
mutatingWebhookConfigurationRef섹션이 표시됩니다.apiVersion: operator.autoscaling.openshift.io/v1 kind: ClusterResourceOverride metadata: annotations: kubectl.kubernetes.io/last-applied-configuration: | {"apiVersion":"operator.autoscaling.openshift.io/v1","kind":"ClusterResourceOverride","metadata":{"annotations":{},"name":"cluster"},"spec":{"podResourceOverride":{"spec":{"cpuRequestToLimitPercent":25,"limitCPUToMemoryPercent":200,"memoryRequestToLimitPercent":50}}}} creationTimestamp: "2019-12-18T22:35:02Z" generation: 1 name: cluster resourceVersion: "127622" selfLink: /apis/operator.autoscaling.openshift.io/v1/clusterresourceoverrides/cluster uid: 978fc959-1717-4bd1-97d0-ae00ee111e8d spec: podResourceOverride: spec: cpuRequestToLimitPercent: 25 limitCPUToMemoryPercent: 200 memoryRequestToLimitPercent: 50 status: # ... mutatingWebhookConfigurationRef:1 apiVersion: admissionregistration.k8s.io/v1 kind: MutatingWebhookConfiguration name: clusterresourceoverrides.admission.autoscaling.openshift.io resourceVersion: "127621" uid: 98b3b8ae-d5ce-462b-8ab5-a729ea8f38f3 # ...- 1
ClusterResourceOverride승인 Webhook 참조
7.10.2. CLI를 사용하여 Cluster Resource Override Operator 설치
OpenShift Container Platform CLI를 사용하여 Cluster Resource Override Operator를 설치하면 클러스터의 오버 커밋을 제어할 수 있습니다.
사전 요구 사항
-
컨테이너에 제한이 설정되어 있지 않은 경우 Cluster Resource Override Operator에 영향을 주지 않습니다. 덮어쓰기를 적용하려면
LimitRange오브젝트를 사용하여 프로젝트의 기본 제한을 지정하거나Pod사양에 제한을 구성해야 합니다.
절차
CLI를 사용하여 Cluster Resource Override Operator를 설치하려면 다음을 수행합니다.
Cluster Resource Override Operator의 네임스페이스를 생성합니다.
Cluster Resource Override Operator의
Namespace오브젝트 YAML 파일(예:cro-namespace.yaml)을 생성합니다.apiVersion: v1 kind: Namespace metadata: name: clusterresourceoverride-operator네임스페이스를 생성합니다.
$ oc create -f <file-name>.yaml예를 들면 다음과 같습니다.
$ oc create -f cro-namespace.yaml
Operator 그룹을 생성합니다.
Cluster Resource Override Operator의
OperatorGroup오브젝트 YAML 파일(예: cro-og.yaml)을 생성합니다.apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: name: clusterresourceoverride-operator namespace: clusterresourceoverride-operator spec: targetNamespaces: - clusterresourceoverride-operatorOperator 그룹을 생성합니다.
$ oc create -f <file-name>.yaml예를 들면 다음과 같습니다.
$ oc create -f cro-og.yaml
서브스크립션을 생성합니다.
Cluster Resource Override Operator의
Subscription오브젝트 YAML 파일(예: cro-sub.yaml)을 생성합니다.apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: clusterresourceoverride namespace: clusterresourceoverride-operator spec: channel: "4.13" name: clusterresourceoverride source: redhat-operators sourceNamespace: openshift-marketplace서브스크립션을 생성합니다.
$ oc create -f <file-name>.yaml예를 들면 다음과 같습니다.
$ oc create -f cro-sub.yaml
clusterresourceoverride-operator네임 스페이스에서ClusterResourceOverride사용자 지정 리소스 (CR) 오브젝트를 만듭니다.clusterresourceoverride-operator네임 스페이스로 변경합니다.$ oc project clusterresourceoverride-operatorCluster Resource Override Operator의
ClusterResourceOverride오브젝트 YAML 파일 (예: cro-cr.yaml)을 만듭니다.apiVersion: operator.autoscaling.openshift.io/v1 kind: ClusterResourceOverride metadata: name: cluster1 spec: podResourceOverride: spec: memoryRequestToLimitPercent: 502 cpuRequestToLimitPercent: 253 limitCPUToMemoryPercent: 2004 - 1
- 이름은
instance이어야 합니다. - 2
- 선택 사항입니다. 컨테이너 메모리 제한을 덮어 쓰기하는 경우 1-100 사이의 백분율로 지정합니다. 기본값은 50입니다.
- 3
- 선택 사항입니다. 컨테이너 CPU 제한을 덮어 쓰기하는 경우 1-100 사이의 백분율로 지정합니다. 기본값은 25입니다.
- 4
- 선택 사항입니다. 컨테이너 메모리 제한을 덮어 쓰기하는 경우 백분율로 지정합니다 (사용되는 경우). 1Gi의 RAM을 100 %로 스케일링하는 것은 1 개의 CPU 코어와 같습니다. CPU 요청을 덮어 쓰기하기 전에 처리됩니다 (설정된 경우). 기본값은 200입니다.
ClusterResourceOverride오브젝트를 만듭니다.$ oc create -f <file-name>.yaml예를 들면 다음과 같습니다.
$ oc create -f cro-cr.yaml
클러스터 사용자 정의 리소스의 상태를 확인하여 승인 Webhook의 현재 상태를 확인합니다.
$ oc get clusterresourceoverride cluster -n clusterresourceoverride-operator -o yamlwebhook 호출 시
mutatingWebhookConfigurationRef섹션이 표시됩니다.출력 예
apiVersion: operator.autoscaling.openshift.io/v1 kind: ClusterResourceOverride metadata: annotations: kubectl.kubernetes.io/last-applied-configuration: | {"apiVersion":"operator.autoscaling.openshift.io/v1","kind":"ClusterResourceOverride","metadata":{"annotations":{},"name":"cluster"},"spec":{"podResourceOverride":{"spec":{"cpuRequestToLimitPercent":25,"limitCPUToMemoryPercent":200,"memoryRequestToLimitPercent":50}}}} creationTimestamp: "2019-12-18T22:35:02Z" generation: 1 name: cluster resourceVersion: "127622" selfLink: /apis/operator.autoscaling.openshift.io/v1/clusterresourceoverrides/cluster uid: 978fc959-1717-4bd1-97d0-ae00ee111e8d spec: podResourceOverride: spec: cpuRequestToLimitPercent: 25 limitCPUToMemoryPercent: 200 memoryRequestToLimitPercent: 50 status: # ... mutatingWebhookConfigurationRef:1 apiVersion: admissionregistration.k8s.io/v1 kind: MutatingWebhookConfiguration name: clusterresourceoverrides.admission.autoscaling.openshift.io resourceVersion: "127621" uid: 98b3b8ae-d5ce-462b-8ab5-a729ea8f38f3 # ...- 1
ClusterResourceOverride승인 Webhook 참조
7.10.3. 클러스터 수준 오버 커밋 설정
Cluster Resource Override Operator에는 Operator가 오버 커밋을 제어해야 하는 각 프로젝트에 대한 라벨 및 ClusterResourceOverride 사용자 지정 리소스 (CR)가 필요합니다.
사전 요구 사항
-
컨테이너에 제한이 설정되어 있지 않은 경우 Cluster Resource Override Operator에 영향을 주지 않습니다. 덮어쓰기를 적용하려면
LimitRange오브젝트를 사용하여 프로젝트의 기본 제한을 지정하거나Pod사양에 제한을 구성해야 합니다.
프로세스
클러스터 수준 오버 커밋을 변경하려면 다음을 수행합니다.
ClusterResourceOverrideCR을 편집합니다.apiVersion: operator.autoscaling.openshift.io/v1 kind: ClusterResourceOverride metadata: name: cluster spec: podResourceOverride: spec: memoryRequestToLimitPercent: 501 cpuRequestToLimitPercent: 252 limitCPUToMemoryPercent: 2003 # ...Cluster Resource Override Operator가 오버 커밋을 제어해야 하는 각 프로젝트의 네임 스페이스 오브젝트에 다음 라벨이 추가되었는지 확인합니다.
apiVersion: v1 kind: Namespace metadata: # ... labels: clusterresourceoverrides.admission.autoscaling.openshift.io/enabled: "true"1 # ...- 1
- 이 라벨을 각 프로젝트에 추가합니다.
7.11. 노드 수준 오버 커밋
QoS (Quality of Service) 보장, CPU 제한 또는 리소스 예약과 같은 다양한 방법으로 특정 노드에서 오버 커밋을 제어할 수 있습니다. 특정 노드 및 특정 프로젝트의 오버 커밋을 비활성화할 수도 있습니다.
7.11.1. 컴퓨팅 리소스 및 컨테이너 이해
컴퓨팅 리소스에 대한 노드 적용 동작은 리소스 유형에 따라 다릅니다.
7.11.1.1. 컨테이너의 CPU 요구 이해
컨테이너에 요청된 CPU의 양이 보장되며 컨테이너에서 지정한 한도까지 노드에서 사용 가능한 초과 CPU를 추가로 소비할 수 있습니다. 여러 컨테이너가 초과 CPU를 사용하려고하면 각 컨테이너에서 요청된 CPU 양에 따라 CPU 시간이 분배됩니다.
예를 들어, 한 컨테이너가 500m의 CPU 시간을 요청하고 다른 컨테이너가 250m의 CPU 시간을 요청한 경우 노드에서 사용 가능한 추가 CPU 시간이 2:1 비율로 컨테이너간에 분배됩니다. 컨테이너가 제한을 지정한 경우 지정된 한도를 초과하는 많은 CPU를 사용하지 않도록 제한됩니다. CPU 요청은 Linux 커널에서 CFS 공유 지원을 사용하여 적용됩니다. 기본적으로 CPU 제한은 Linux 커널에서 CFS 할당량 지원을 사용하여 100ms 측정 간격으로 적용되지만 이 기능은 비활성화할 수 있습니다.
7.11.1.2. 컨테이너의 메모리 요구 이해
컨테이너에 요청된 메모리 양이 보장됩니다. 컨테이너는 요청된 메모리보다 많은 메모리를 사용할 수 있지만 요청된 양을 초과하면 노드의 메모리 부족 상태에서 종료될 수 있습니다. 컨테이너가 요청된 메모리보다 적은 메모리를 사용하는 경우 시스템 작업 또는 데몬이 노드의 리소스 예약에 확보된 메모리 보다 더 많은 메모리를 필요로하지 않는 한 컨테이너는 종료되지 않습니다. 컨테이너가 메모리 제한을 지정할 경우 제한 양을 초과하면 즉시 종료됩니다.
7.11.2. 오버커밋 및 QoS (Quality of Service) 클래스 이해
요청이 없는 pod가 예약되어 있거나 해당 노드의 모든 pod에서 제한의 합계가 사용 가능한 머신 용량을 초과하면 노드가 오버 커밋됩니다.
오버 커밋된 환경에서는 노드의 pod가 특정 시점에서 사용 가능한 것보다 더 많은 컴퓨팅 리소스를 사용하려고 할 수 있습니다. 이 경우 노드는 각 pod에 우선 순위를 지정해야합니다. 이러한 결정을 내리는 데 사용되는 기능을 QoS (Quality of Service) 클래스라고 합니다.
Pod는 우선순위가 감소하는 세 가지 QoS 클래스 중 하나로 지정됩니다.
| 우선 순위 | 클래스 이름 | 설명 |
|---|---|---|
| 1 (가장 높음) | Guaranteed | 모든 리소스에 대해 제한 및 요청(선택 사항)이 설정되어 있고(0이 아님) 동일한 경우 Pod는 Guaranteed 로 분류됩니다. |
| 2 | Burstable | 모든 리소스에 대해 요청 및 제한(선택 사항)이 설정되어 있고(0이 아님) 동일하지 않은 경우 Pod는 Burstable 로 분류됩니다. |
| 3 (가장 낮음) | BestEffort | 리소스에 대한 요청 및 제한이 설정되지 않은 경우 Pod는 BestEffort 로 분류됩니다. |
메모리는 압축할 수 없는 리소스이므로 메모리가 부족한 경우 우선 순위가 가장 낮은 컨테이너가 먼저 종료됩니다.
- Guaranteed 컨테이너는 우선 순위가 가장 높은 컨테이너로 간주되며 제한을 초과하거나 시스템의 메모리가 부족하고 제거할 수 있는 우선 순위가 낮은 컨테이너가 없는 경우에만 종료됩니다.
- 시스템 메모리 부족 상태에 있는 Burstable 컨테이너는 제한을 초과하고 다른 BestEffort 컨테이너가 없으면 종료될 수 있습니다.
- BestEffort 컨테이너는 우선 순위가 가장 낮은 컨테이너로 처리됩니다. 시스템에 메모리가 부족한 경우 이러한 컨테이너의 프로세스가 먼저 종료됩니다.
7.11.2.1. Quality of Service (QoS) 계층에서 메모리 예약 방법
qos-reserved 매개변수를 사용하여 특정 QoS 수준에서 pod에 예약된 메모리의 백분율을 지정할 수 있습니다. 이 기능은 요청된 리소스를 예약하여 하위 OoS 클래스의 pod가 고급 QoS 클래스의 pod에서 요청한 리소스를 사용하지 못하도록 합니다.
OpenShift Container Platform은 다음과 같이 qos-reserved 매개변수를 사용합니다.
-
qos-reserved=memory=100%값은Burstable및BestEffortQoS 클래스가 더 높은 QoS 클래스에서 요청한 메모리를 소비하지 못하도록 합니다. 이를 통해BestEffort및Burstable워크로드에서 OOM이 발생할 위험이 증가되어Guaranteed및Burstable워크로드에 대한 메모리 리소스의 보장 수준을 높이는 것이 우선됩니다. -
qos-reserved=memory=50%값은Burstable및BestEffortQoS 클래스가 더 높은 QoS 클래스에서 요청한 메모리의 절반을 소비하는 것을 허용합니다. -
qos-reserved=memory=0%값은Burstable및BestEffortQoS 클래스가 사용 가능한 경우 할당 가능한 최대 노드 양까지 소비하는 것을 허용하지만Guaranteed워크로드가 요청된 메모리에 액세스하지 못할 위험이 높아집니다. 이로 인해 이 기능은 비활성화되어 있습니다.
7.11.3. 스왑 메모리 및 QOS 이해
QoS (Quality of Service) 보장을 유지하기 위해 노드에서 기본적으로 스왑을 비활성화할 수 있습니다. 그렇지 않으면 노드의 물리적 리소스를 초과 구독하여 Pod 배포 중에 Kubernetes 스케줄러가 만드는 리소스에 영향을 미칠 수 있습니다.
예를 들어 2 개의 Guaranteed pod가 메모리 제한에 도달하면 각 컨테이너가 스왑 메모리를 사용할 수 있습니다. 결국 스왑 공간이 충분하지 않으면 시스템의 초과 구독으로 인해 Pod의 프로세스가 종료될 수 있습니다.
스왑을 비활성화하지 못하면 노드에서 MemoryPressure가 발생하고 있음을 인식하지 못하여 Pod가 스케줄링 요청에서 만든 메모리를 받지 못하게 됩니다. 결과적으로 메모리 Pod를 추가로 늘리기 위해 추가 Pod가 노드에 배치되어 궁극적으로 시스템 메모리 부족 (OOM) 이벤트가 발생할 위험이 높아집니다.
스왑이 활성화되면 사용 가능한 메모리에 대한 리소스 부족 처리 제거 임계 값이 예상대로 작동하지 않을 수 있습니다. 리소스 부족 처리를 활용하여 메모리 부족 상태에서 Pod를 노드에서 제거하고 메모리 부족 상태가 아닌 다른 노드에서 일정을 재조정할 수 있도록 합니다.
7.11.4. 노드 과다 할당 이해
오버 커밋된 환경에서는 최상의 시스템 동작을 제공하도록 노드를 올바르게 구성하는 것이 중요합니다.
노드가 시작되면 메모리 관리를 위한 커널 조정 가능한 플래그가 올바르게 설정됩니다. 커널은 실제 메모리가 소진되지 않는 한 메모리 할당에 실패해서는 안됩니다.
이 동작을 확인하기 위해 OpenShift Container Platform은 vm.overcommit_memory 매개변수를 1로 설정하여 기본 운영 체제 설정을 재정의하여 커널이 항상 메모리를 오버 커밋하도록 구성합니다.
OpenShift Container Platform은 vm.panic_on_oom 매개변수를 0으로 설정하여 메모리 부족시 커널이 패닉 상태가되지 않도록 구성합니다. 0으로 설정하면 커널에서 OOM (메모리 부족) 상태일 때 oom_killer를 호출하여 우선 순위에 따라 프로세스를 종료합니다.
노드에서 다음 명령을 실행하여 현재 설정을 볼 수 있습니다.
$ sysctl -a |grep commit출력 예
#...
vm.overcommit_memory = 0
#...$ sysctl -a |grep panic출력 예
#...
vm.panic_on_oom = 0
#...위의 플래그는 이미 노드에 설정되어 있어야하며 추가 조치가 필요하지 않습니다.
각 노드에 대해 다음 구성을 수행할 수도 있습니다.
- CPU CFS 할당량을 사용하여 CPU 제한 비활성화 또는 실행
- 시스템 프로세스의 리소스 예약
- Quality of Service (QoS) 계층에서의 메모리 예약
7.11.5. CPU CFS 할당량을 사용하여 CPU 제한 비활성화 또는 실행
기본적으로 노드는 Linux 커널에서 CFS (Completely Fair Scheduler) 할당량 지원을 사용하여 지정된 CPU 제한을 실행합니다.
CPU 제한 적용을 비활성화한 경우 노드에 미치는 영향을 이해해야 합니다.
- 컨테이너에 CPU 요청이 있는 경우 요청은 Linux 커널의 CFS 공유를 통해 계속 강제 적용됩니다.
- 컨테이너에 CPU 요청은 없지만 CPU 제한이 있는 경우 CPU 요청 기본값이 지정된 CPU 제한으로 설정되며 Linux 커널의 CFS 공유를 통해 강제 적용됩니다.
- 컨테이너에 CPU 요청 및 제한이 모두 있는 경우 Linux 커널의 CFS 공유를 통해 CPU 요청이 강제 적용되며 CPU 제한은 노드에 영향을 미치지 않습니다.
사전 요구 사항
다음 명령을 입력하여 구성할 노드 유형의 정적
MachineConfigPoolCRD와 연관된 라벨을 가져옵니다.$ oc edit machineconfigpool <name>예를 들면 다음과 같습니다.
$ oc edit machineconfigpool worker출력 예
apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfigPool metadata: creationTimestamp: "2022-11-16T15:34:25Z" generation: 4 labels: pools.operator.machineconfiguration.openshift.io/worker: ""1 name: worker- 1
- 레이블이 Labels 아래에 표시됩니다.
작은 정보라벨이 없으면 다음과 같은 키/값 쌍을 추가합니다.
$ oc label machineconfigpool worker custom-kubelet=small-pods
절차
구성 변경을 위한 사용자 정의 리소스 (CR)를 만듭니다.
CPU 제한 비활성화를 위한 설정 예
apiVersion: machineconfiguration.openshift.io/v1 kind: KubeletConfig metadata: name: disable-cpu-units1 spec: machineConfigPoolSelector: matchLabels: pools.operator.machineconfiguration.openshift.io/worker: ""2 kubeletConfig: cpuCfsQuota: false3 다음 명령을 실행하여 CR을 생성합니다.
$ oc create -f <file_name>.yaml
7.11.6. 시스템 프로세스의 리소스 예약
보다 안정적인 스케줄링을 제공하고 노드 리소스 오버 커밋을 최소화하기 위해 각 노드는 클러스터가 작동할 수 있도록 노드에서 실행하는 데 필요한 시스템 데몬에서 사용할 리소스의 일부를 예약할 수 있습니다. 특히 메모리와 같은 압축 불가능한 리소스의 경우 리소스를 예약하는 것이 좋습니다.
절차
pod가 아닌 프로세스의 리소스를 명시적으로 예약하려면 스케줄링에서 사용 가능한 리소스를 지정하여 노드 리소스를 할당합니다. 자세한 내용은 노드의 리소스 할당을 참조하십시오.
7.11.7. 노드의 오버 커밋 비활성화
이를 활성화하면 각 노드에서 오버 커밋을 비활성화할 수 있습니다.
절차
노드에서 오버 커밋을 비활성화하려면 해당 노드에서 다음 명령을 실행합니다.
$ sysctl -w vm.overcommit_memory=07.12. 프로젝트 수준 제한
오버 커밋을 제어하기 위해 오버 커밋을 초과할 수없는 프로젝트의 메모리 및 CPU 제한과 기본값을 지정하여 프로젝트 별 리소스 제한 범위를 설정할 수 있습니다.
프로젝트 수준 리소스 제한에 대한 자세한 내용은 추가 리소스를 참조하십시오.
또는 특정 프로젝트의 오버 커밋을 비활성화할 수 있습니다.
7.12.1. 프로젝트의 오버 커밋 비활성화
이를 활성화하면 프로젝트 별 오버 커밋을 비활성화할 수 있습니다. 예를 들어, 오버 커밋과 독립적으로 인프라 구성 요소를 구성할 수 있습니다.
절차
프로젝트에서 오버 커밋을 비활성화하려면 다음을 실행합니다.
- 네임스페이스 오브젝트 파일을 생성하거나 편집합니다.
다음 주석을 추가합니다.
apiVersion: v1 kind: Namespace metadata: annotations: quota.openshift.io/cluster-resource-override-enabled: "false"1 # ...- 1
- 이 주석을
false로 설정하면 이 네임스페이스에 대한 오버 커밋이 비활성화됩니다.
7.13. 가비지 컬렉션을 사용하여 노드 리소스 해제
가비지 컬렉션을 이해하고 사용합니다.
7.13.1. 가비지 컬렉션을 통해 종료된 컨테이너를 제거하는 방법 이해
컨테이너 가비지 컬렉션에서는 제거 임계 값을 사용하여 종료된 컨테이너를 제거합니다.
가비지 컬렉션에 제거 임계 값이 설정되어 있으면 노드는 API에서 액세스 가능한 모든 pod의 컨테이너를 유지하려고합니다. pod가 삭제된 경우 컨테이너도 삭제됩니다. pod가 삭제되지 않고 제거 임계 값에 도달하지 않는 한 컨테이너는 보존됩니다. 노드가 디스크 부족 (disk pressure) 상태가 되면 컨테이너가 삭제되고 oc logs를 사용하여 해당 로그에 더 이상 액세스할 수 없습니다.
- eviction-soft - 소프트 제거 임계 값은 관리자가 지정한 필수 유예 기간이 있는 제거 임계 값과 일치합니다.
- eviction-hard - 하드 제거 임계 값에 대한 유예 기간이 없으며 감지되는 경우 OpenShift Container Platform은 즉시 작업을 수행합니다.
다음 표에는 제거 임계 값이 나열되어 있습니다.
| 노드 상태 | 제거 신호 | 설명 |
|---|---|---|
| MemoryPressure |
| 노드에서 사용 가능한 메모리입니다. |
| DiskPressure |
|
노드 루트 파일 시스템, |
evictionHard 의 경우 이러한 매개변수를 모두 지정해야 합니다. 모든 매개변수를 지정하지 않으면 지정된 매개변수만 적용되고 가비지 컬렉션이 제대로 작동하지 않습니다.
노드가 소프트 제거 임계 값 상한과 하한 사이에서 변동하고 연관된 유예 기간이 만료되지 않은 경우 해당 노드는 지속적으로 true 와 false 사이에서 변동합니다. 결과적으로 스케줄러는 잘못된 스케줄링 결정을 내릴 수 있습니다.
이러한 변동을 방지하려면 eviction-pressure-transition-period 플래그를 사용하여 OpenShift Container Platform이 부족 상태에서 전환하기 전에 대기해야하는 시간을 제어합니다. OpenShift Container Platform은 false 상태로 전환되기 전에 지정된 기간에 지정된 부족 상태에 대해 제거 임계 값을 충족하도록 설정하지 않습니다.
7.13.2. 가비지 컬렉션을 통해 이미지가 제거되는 방법 이해
이미지 가비지 컬렉션에서는 실행 중인 Pod에서 참조하지 않는 이미지를 제거합니다.
OpenShift Container Platform은 cAdvisor 에서 보고하는 디스크 사용량을 기반으로 노드에서 삭제할 이미지를 결정합니다.
이미지 가비지 컬렉션 정책은 다음 두 가지 조건을 기반으로합니다.
- 이미지 가비지 컬렉션을 트리거하는 디스크 사용량의 백분율 (정수로 표시)입니다. 기본값은 85입니다.
- 이미지 가비지 컬렉션이 해제하려고 하는 디스크 사용량의 백분율 (정수로 표시)입니다. 기본값은 80입니다.
이미지 가비지 컬렉션의 경우 사용자 지정 리소스를 사용하여 다음 변수를 수정할 수 있습니다.
| 설정 | 설명 |
|---|---|
|
| 가비지 컬렉션에 의해 이미지가 제거되기 전에 사용되지 않은 이미지의 최소 보존 기간입니다. 기본값은 2m입니다. |
|
| 이미지 가비지 컬렉션을 트리거하는 정수로 표시되는 디스크 사용량의 백분율입니다. 기본값은 85입니다. |
|
| 이미지 가비지 컬렉션이 해제하려고하는 디스크 사용량의 백분율 (정수로 표시)입니다. 기본값은 80입니다. |
각 가비지 컬렉터 실행으로 두 개의 이미지 목록이 검색됩니다.
- 하나 이상의 Pod에서 현재 실행중인 이미지 목록입니다.
- 호스트에서 사용 가능한 이미지 목록입니다.
새로운 컨테이너가 실행되면 새로운 이미지가 나타납니다. 모든 이미지에는 타임 스탬프가 표시됩니다. 이미지가 실행 중이거나 (위의 첫 번째 목록) 새로 감지된 경우 (위의 두 번째 목록) 현재 시간으로 표시됩니다. 나머지 이미지는 이미 이전 실행에서 표시됩니다. 모든 이미지는 타임 스탬프별로 정렬됩니다.
컬렉션이 시작되면 중지 기준이 충족될 때까지 가장 오래된 이미지가 먼저 삭제됩니다.
7.13.3. 컨테이너 및 이미지의 가비지 컬렉션 구성
관리자는 각 machine config pool마다 kubeletConfig 오브젝트를 생성하여 OpenShift Container Platform이 가비지 컬렉션을 수행하는 방법을 구성할 수 있습니다.
OpenShift Container Platform은 각 머신 구성 풀에 대해 하나의 kubeletConfig 오브젝트만 지원합니다.
다음 중 하나의 조합을 구성할 수 있습니다.
- 소프트 컨테이너 제거
- 하드 컨테이너 제거
- 이미지 제거
컨테이너 가비지 컬렉션에서는 종료된 컨테이너를 제거합니다. 이미지 가비지 컬렉션에서는 실행 중인 Pod에서 참조하지 않는 이미지를 제거합니다.
사전 요구 사항
다음 명령을 입력하여 구성할 노드 유형의 정적
MachineConfigPoolCRD와 연관된 라벨을 가져옵니다.$ oc edit machineconfigpool <name>예를 들면 다음과 같습니다.
$ oc edit machineconfigpool worker출력 예
apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfigPool metadata: creationTimestamp: "2022-11-16T15:34:25Z" generation: 4 labels: pools.operator.machineconfiguration.openshift.io/worker: ""1 name: worker #...- 1
- 레이블이 Labels 아래에 표시됩니다.
작은 정보라벨이 없으면 다음과 같은 키/값 쌍을 추가합니다.
$ oc label machineconfigpool worker custom-kubelet=small-pods
절차
구성 변경을 위한 사용자 정의 리소스 (CR)를 만듭니다.
중요파일 시스템이 하나 있거나
/var/lib/kubelet및/var/lib/containers/가 동일한 파일 시스템에 있는 경우 값이 가장 높은 설정이 먼저 수행되므로 가장 높은 값 트리거 제거가 있는 설정입니다. 파일 시스템에서 제거를 트리거합니다.컨테이너 가비지 컬렉션 CR의 설정 예:
apiVersion: machineconfiguration.openshift.io/v1 kind: KubeletConfig metadata: name: worker-kubeconfig1 spec: machineConfigPoolSelector: matchLabels: pools.operator.machineconfiguration.openshift.io/worker: ""2 kubeletConfig: evictionSoft:3 memory.available: "500Mi"4 nodefs.available: "10%" nodefs.inodesFree: "5%" imagefs.available: "15%" imagefs.inodesFree: "10%" evictionSoftGracePeriod:5 memory.available: "1m30s" nodefs.available: "1m30s" nodefs.inodesFree: "1m30s" imagefs.available: "1m30s" imagefs.inodesFree: "1m30s" evictionHard:6 memory.available: "200Mi" nodefs.available: "5%" nodefs.inodesFree: "4%" imagefs.available: "10%" imagefs.inodesFree: "5%" evictionPressureTransitionPeriod: 0s7 imageMinimumGCAge: 5m8 imageGCHighThresholdPercent: 809 imageGCLowThresholdPercent: 7510 #...- 1
- 오브젝트의 이름입니다.
- 2
- 머신 구성 풀에서 라벨을 지정합니다.
- 3
- 컨테이너 가비지 컬렉션의 경우 eviction:
evictionSoft또는evictionHard입니다. - 4
- 컨테이너 가비지 컬렉션의 경우: 특정 제거 트리거 신호를 기반으로 하는 제거 임계값입니다.
- 5
- 컨테이너 가비지 컬렉션의 경우: 소프트 제거에 대한 grace 기간입니다. 이 매개변수는
eviction-hard에는 적용되지 않습니다. - 6
- 컨테이너 가비지 컬렉션의 경우: 특정 제거 트리거 신호를 기반으로 하는 제거 임계값입니다.
evictionHard의 경우 이러한 매개변수를 모두 지정해야 합니다. 모든 매개변수를 지정하지 않으면 지정된 매개변수만 적용되고 가비지 컬렉션이 제대로 작동하지 않습니다. - 7
- 컨테이너 가비지 컬렉션의 경우: 제거 부족 상태에서 전환되기 전에 대기하는 시간입니다.
- 8
- 이미지 가비지 컬렉션의 경우 이미지 가비지 수집에 의해 이미지가 제거되기 전에 사용되지 않은 이미지의 최소 수명입니다.
- 9
- 이미지 가비지 컬렉션의 경우: 이미지 가비지 컬렉션을 트리거하는 디스크 사용량의 백분율(정수로 표시)입니다.
- 10
- 이미지 가비지 컬렉션의 경우 이미지 가비지 컬렉션이 해제하려고 하는 디스크 사용량의 백분율(정수로 표시)입니다.
다음 명령을 실행하여 CR을 생성합니다.
$ oc create -f <file_name>.yaml예를 들면 다음과 같습니다.
$ oc create -f gc-container.yaml출력 예
kubeletconfig.machineconfiguration.openshift.io/gc-container created
검증
다음 명령을 입력하여 가비지 컬렉션이 활성화되어 있는지 확인합니다. 사용자 지정 리소스에 지정한 Machine Config Pool은 변경 사항이 완전히 구현될 때까지
UPDATING과 함께 'true'로 표시됩니다.$ oc get machineconfigpool출력 예
NAME CONFIG UPDATED UPDATING master rendered-master-546383f80705bd5aeaba93 True False worker rendered-worker-b4c51bb33ccaae6fc4a6a5 False True
7.14. Node Tuning Operator 사용
Node Tuning Operator를 이해하고 사용합니다.
목적
Node Tuning Operator는 TuneD 데몬을 오케스트레이션하고 Performance Profile 컨트롤러를 사용하여 짧은 대기 시간 성능을 실현하여 노드 수준 튜닝을 관리하는 데 도움이 됩니다. 대부분의 고성능 애플리케이션에는 일정 수준의 커널 튜닝이 필요합니다. Node Tuning Operator는 노드 수준 sysctls 사용자에게 통합 관리 인터페이스를 제공하며 사용자의 필요에 따라 지정되는 사용자 정의 튜닝을 추가할 수 있는 유연성을 제공합니다.
Operator는 OpenShift Container Platform의 컨테이너화된 TuneD 데몬을 Kubernetes 데몬 세트로 관리합니다. 클러스터에서 실행되는 모든 컨테이너화된 TuneD 데몬에 사용자 정의 튜닝 사양이 데몬이 이해할 수 있는 형식으로 전달되도록 합니다. 데몬은 클러스터의 모든 노드에서 노드당 하나씩 실행됩니다.
컨테이너화된 TuneD 데몬을 통해 적용되는 노드 수준 설정은 프로필 변경을 트리거하는 이벤트 시 또는 컨테이너화된 TuneD 데몬이 종료 신호를 수신하고 처리하여 정상적으로 종료될 때 롤백됩니다.
Node Tuning Operator는 Performance Profile 컨트롤러를 사용하여 OpenShift Container Platform 애플리케이션에 대해 짧은 대기 시간 성능을 실현하도록 자동 튜닝을 구현합니다.
클러스터 관리자는 다음과 같은 노드 수준 설정을 정의하도록 성능 프로필을 구성합니다.
- 커널을 kernel-rt로 업데이트.
- 하우스키핑을 위한 CPU 선택.
- 워크로드 실행을 위한 CPU 선택.
현재 cgroup v2에서는 CPU 부하 분산을 비활성화하지 않습니다. 따라서 cgroup v2가 활성화된 경우 성능 프로필에서 원하는 동작을 얻지 못할 수 있습니다. 성능 프로필을 사용하는 경우에는 cgroup v2를 활성화하는 것은 권장되지 않습니다.
버전 4.1 이상에서는 Node Tuning Operator가 표준 OpenShift Container Platform 설치에 포함되어 있습니다.
이전 버전의 OpenShift Container Platform에서는 Performance Addon Operator를 사용하여 OpenShift 애플리케이션에 대한 대기 시간을 단축할 수 있도록 자동 튜닝을 구현했습니다. OpenShift Container Platform 4.11 이상에서는 이 기능은 Node Tuning Operator의 일부입니다.
7.14.1. Node Tuning Operator 사양 예에 액세스
이 프로세스를 사용하여 Node Tuning Operator 사양 예에 액세스하십시오.
절차
다음 명령을 실행하여 Node Tuning Operator 사양 예제에 액세스합니다.
oc get tuned.tuned.openshift.io/default -o yaml -n openshift-cluster-node-tuning-operator
기본 CR은 OpenShift Container Platform 플랫폼의 표준 노드 수준 튜닝을 제공하기 위한 것이며 Operator 관리 상태를 설정하는 경우에만 수정할 수 있습니다. Operator는 기본 CR에 대한 다른 모든 사용자 정의 변경사항을 덮어씁니다. 사용자 정의 튜닝의 경우 고유한 Tuned CR을 생성합니다. 새로 생성된 CR은 노드 또는 Pod 라벨 및 프로필 우선 순위에 따라 OpenShift Container Platform 노드에 적용된 기본 CR 및 사용자 정의 튜닝과 결합됩니다.
특정 상황에서는 Pod 라벨에 대한 지원이 필요한 튜닝을 자동으로 제공하는 편리한 방법일 수 있지만 이러한 방법은 권장되지 않으며 특히 대규모 클러스터에서는 이러한 방법을 사용하지 않는 것이 좋습니다. 기본 Tuned CR은 Pod 라벨이 일치되지 않은 상태로 제공됩니다. Pod 라벨이 일치된 상태로 사용자 정의 프로필이 생성되면 해당 시점에 이 기능이 활성화됩니다. Pod 레이블 기능은 Node Tuning Operator의 향후 버전에서 더 이상 사용되지 않습니다.
7.14.2. 사용자 정의 튜닝 사양
Operator의 CR(사용자 정의 리소스)에는 두 가지 주요 섹션이 있습니다. 첫 번째 섹션인 profile:은 TuneD 프로필 및 해당 이름의 목록입니다. 두 번째인 recommend:은 프로필 선택 논리를 정의합니다.
여러 사용자 정의 튜닝 사양은 Operator의 네임스페이스에 여러 CR로 존재할 수 있습니다. 새로운 CR의 존재 또는 오래된 CR의 삭제는 Operator에서 탐지됩니다. 기존의 모든 사용자 정의 튜닝 사양이 병합되고 컨테이너화된 TuneD 데몬의 해당 오브젝트가 업데이트됩니다.
관리 상태
Operator 관리 상태는 기본 Tuned CR을 조정하여 설정됩니다. 기본적으로 Operator는 Managed 상태이며 기본 Tuned CR에는 spec.managementState 필드가 없습니다. Operator 관리 상태에 유효한 값은 다음과 같습니다.
- Managed: 구성 리소스가 업데이트되면 Operator가 해당 피연산자를 업데이트합니다.
- Unmanaged: Operator가 구성 리소스에 대한 변경을 무시합니다.
- Removed: Operator가 프로비저닝한 해당 피연산자 및 리소스를 Operator가 제거합니다.
프로필 데이터
profile: 섹션에는 TuneD 프로필 및 해당 이름이 나열됩니다.
profile:
- name: tuned_profile_1
data: |
# TuneD profile specification
[main]
summary=Description of tuned_profile_1 profile
[sysctl]
net.ipv4.ip_forward=1
# ... other sysctl's or other TuneD daemon plugins supported by the containerized TuneD
# ...
- name: tuned_profile_n
data: |
# TuneD profile specification
[main]
summary=Description of tuned_profile_n profile
# tuned_profile_n profile settings권장 프로필
profile: 선택 논리는 CR의 recommend: 섹션에 의해 정의됩니다. recommend: 섹션은 선택 기준에 따라 프로필을 권장하는 항목의 목록입니다.
recommend:
<recommend-item-1>
# ...
<recommend-item-n>목록의 개별 항목은 다음과 같습니다.
- machineConfigLabels:
<mcLabels>
match:
<match>
priority: <priority>
profile: <tuned_profile_name>
operand:
debug: <bool>
tunedConfig:
reapply_sysctl: <bool> - 1
- 선택 사항입니다.
- 2
- 키/값
MachineConfig라벨 사전입니다. 키는 고유해야 합니다. - 3
- 생략하면 우선 순위가 높은 프로필이 먼저 일치되거나
machineConfigLabels가 설정되어 있지 않으면 프로필이 일치하는 것으로 가정합니다. - 4
- 선택사항 목록입니다.
- 5
- 프로필 순서 지정 우선 순위입니다. 숫자가 작을수록 우선 순위가 높습니다(
0이 가장 높은 우선 순위임). - 6
- 일치에 적용할 TuneD 프로필입니다. 예를 들어
tuned_profile_1이 있습니다. - 7
- 선택적 피연산자 구성입니다.
- 8
- TuneD 데몬에 대해 디버깅을 켜거나 끕니다. 옵션은 on 또는
false의 경우true입니다. 기본값은false입니다. - 9
- TuneD 데몬에 대해
reapply_sysctl기능을 켜거나 끄십시오. on 및 off의 경우옵션이true입니다.
<match>는 다음과 같이 재귀적으로 정의되는 선택사항 목록입니다.
- label: <label_name>
value: <label_value>
type: <label_type>
<match>
<match>를 생략하지 않으면 모든 중첩 <match> 섹션도 true로 평가되어야 합니다. 생략하면 false로 가정하고 해당 <match> 섹션이 있는 프로필을 적용하지 않거나 권장하지 않습니다. 따라서 중첩(하위 <match> 섹션)은 논리 AND 연산자 역할을 합니다. 반대로 <match> 목록의 항목이 일치하면 전체 <match> 목록이 true로 평가됩니다. 따라서 이 목록이 논리 OR 연산자 역할을 합니다.
machineConfigLabels가 정의되면 지정된 recommend: 목록 항목에 대해 머신 구성 풀 기반 일치가 설정됩니다. <mcLabels>는 머신 구성의 라벨을 지정합니다. 머신 구성은 <tuned_profile_name> 프로필에 대해 커널 부팅 매개변수와 같은 호스트 설정을 적용하기 위해 자동으로 생성됩니다. 여기에는 <mcLabels>와 일치하는 머신 구성 선택기가 있는 모든 머신 구성 풀을 찾고 머신 구성 풀이 할당된 모든 노드에서 <tuned_profile_name> 프로필을 설정하는 작업이 포함됩니다. 마스터 및 작업자 역할이 모두 있는 노드를 대상으로 하려면 마스터 역할을 사용해야 합니다.
목록 항목 match 및 machineConfigLabels는 논리 OR 연산자로 연결됩니다. match 항목은 단락 방식으로 먼저 평가됩니다. 따라서 true로 평가되면 machineConfigLabels 항목이 고려되지 않습니다.
머신 구성 풀 기반 일치를 사용하는 경우 동일한 하드웨어 구성을 가진 노드를 동일한 머신 구성 풀로 그룹화하는 것이 좋습니다. 이 방법을 따르지 않으면 TuneD 피연산자가 동일한 머신 구성 풀을 공유하는 두 개 이상의 노드에 대해 충돌하는 커널 매개변수를 계산할 수 있습니다.
예: 노드 또는 Pod 라벨 기반 일치
- match:
- label: tuned.openshift.io/elasticsearch
match:
- label: node-role.kubernetes.io/master
- label: node-role.kubernetes.io/infra
type: pod
priority: 10
profile: openshift-control-plane-es
- match:
- label: node-role.kubernetes.io/master
- label: node-role.kubernetes.io/infra
priority: 20
profile: openshift-control-plane
- priority: 30
profile: openshift-node
위의 CR은 컨테이너화된 TuneD 데몬의 프로필 우선 순위에 따라 recommended.conf 파일로 변환됩니다. 우선 순위가 가장 높은 프로필(10)이 openshift-control-plane-es이므로 이 프로필을 첫 번째로 고려합니다. 지정된 노드에서 실행되는 컨테이너화된 TuneD 데몬은 tuned.openshift.io/elasticsearch 라벨이 설정된 동일한 노드에서 실행되는 Pod가 있는지 확인합니다. 없는 경우 전체 <match> 섹션이 false로 평가됩니다. 라벨이 있는 Pod가 있는 경우 <match> 섹션을 true로 평가하려면 노드 라벨도 node-role.kubernetes.io/master 또는 node-role.kubernetes.io/infra여야 합니다.
우선 순위가 10인 프로필의 라벨이 일치하면 openshift-control-plane-es 프로필이 적용되고 다른 프로필은 고려되지 않습니다. 노드/Pod 라벨 조합이 일치하지 않으면 두 번째로 높은 우선 순위 프로필(openshift-control-plane)이 고려됩니다. 컨테이너화된 TuneD Pod가 node-role.kubernetes.io/master 또는 node-role.kubernetes.io/infra. 라벨이 있는 노드에서 실행되는 경우 이 프로필이 적용됩니다.
마지막으로, openshift-node 프로필은 우선 순위가 가장 낮은 30입니다. 이 프로필에는 <match> 섹션이 없으므로 항상 일치합니다. 지정된 노드에서 우선 순위가 더 높은 다른 프로필이 일치하지 않는 경우 openshift-node 프로필을 설정하는 데 catch-all 프로필 역할을 합니다.
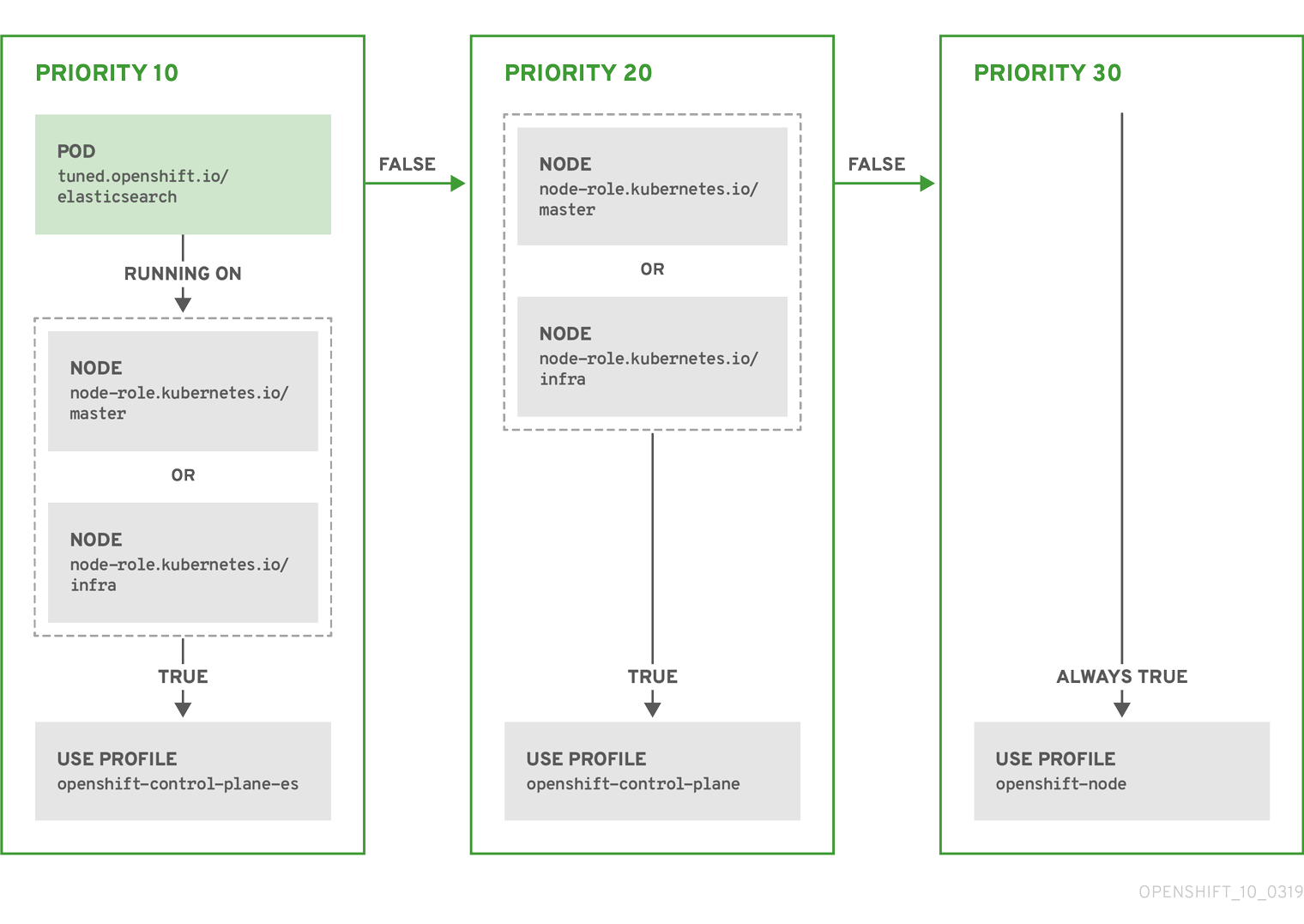
예: 머신 구성 풀 기반 일치
apiVersion: tuned.openshift.io/v1
kind: Tuned
metadata:
name: openshift-node-custom
namespace: openshift-cluster-node-tuning-operator
spec:
profile:
- data: |
[main]
summary=Custom OpenShift node profile with an additional kernel parameter
include=openshift-node
[bootloader]
cmdline_openshift_node_custom=+skew_tick=1
name: openshift-node-custom
recommend:
- machineConfigLabels:
machineconfiguration.openshift.io/role: "worker-custom"
priority: 20
profile: openshift-node-custom노드 재부팅을 최소화하려면 머신 구성 풀의 노드 선택기와 일치하는 라벨로 대상 노드에 라벨을 지정한 후 위의 Tuned CR을 생성하고 마지막으로 사용자 정의 머신 구성 풀을 생성합니다.
클라우드 공급자별 TuneD 프로필
이 기능을 사용하면 모든 클라우드 공급자별 노드에 편리하게 OpenShift Container Platform 클러스터의 특정 클라우드 공급자에 맞게 조정된 TuneD 프로필을 할당할 수 있습니다. 이 작업은 노드 레이블을 추가하거나 노드를 머신 구성 풀로 그룹화하지 않고 수행할 수 있습니다.
이 기능은 spec.providerID 노드 오브젝트 값을 < cloud-provider>://<cloud-provider-specific-id > 형식으로 활용하고 NTO 피연산자 컨테이너에서 < cloud-provider> 값으로 파일을 작성합니다. 그러면 이러한 프로필이 있는 경우 TuneD에서 provider-< /var/lib/tuned/provider cloud-provider > 프로필을 로드하는 데 이 파일의 콘텐츠를 사용합니다.
및 openshift -control-planeopenshift-node 프로필이 모두 설정을 상속하는 openshift 프로필이 이제 조건부 프로파일 로드를 통해 이 기능을 사용하도록 업데이트되었습니다. 현재 NTO 및 TuneD에는 클라우드 공급자별 프로필이 포함되어 있지 않습니다. 그러나 모든 클라우드 공급자별 클러스터 노드에 적용되는 사용자 지정 프로필 provider-<cloud- provider>를 생성할 수 있습니다.
GCE 클라우드 공급자 프로파일의 예
apiVersion: tuned.openshift.io/v1
kind: Tuned
metadata:
name: provider-gce
namespace: openshift-cluster-node-tuning-operator
spec:
profile:
- data: |
[main]
summary=GCE Cloud provider-specific profile
# Your tuning for GCE Cloud provider goes here.
name: provider-gce
프로파일 없음으로 인해 provider-< cloud-provider > 프로필에 지정된 모든 설정은 openshift 프로필 및 해당 하위 프로필에서 덮어씁니다.
7.14.3. 클러스터에 설정된 기본 프로필
다음은 클러스터에 설정된 기본 프로필입니다.
apiVersion: tuned.openshift.io/v1
kind: Tuned
metadata:
name: default
namespace: openshift-cluster-node-tuning-operator
spec:
profile:
- data: |
[main]
summary=Optimize systems running OpenShift (provider specific parent profile)
include=-provider-${f:exec:cat:/var/lib/tuned/provider},openshift
name: openshift
recommend:
- profile: openshift-control-plane
priority: 30
match:
- label: node-role.kubernetes.io/master
- label: node-role.kubernetes.io/infra
- profile: openshift-node
priority: 40
OpenShift Container Platform 4.9부터 모든 OpenShift TuneD 프로필이 TuneD 패키지와 함께 제공됩니다. oc exec 명령을 사용하여 이러한 프로필의 내용을 볼 수 있습니다.
$ oc exec $tuned_pod -n openshift-cluster-node-tuning-operator -- find /usr/lib/tuned/openshift{,-control-plane,-node} -name tuned.conf -exec grep -H ^ {} \;7.14.4. 지원되는 TuneD 데몬 플러그인
Tuned CR의 profile: 섹션에 정의된 사용자 정의 프로필을 사용하는 경우 [main] 섹션을 제외한 다음 TuneD 플러그인이 지원됩니다.
- audio
- cpu
- disk
- eeepc_she
- modules
- mounts
- net
- scheduler
- scsi_host
- selinux
- sysctl
- sysfs
- usb
- video
- vm
- bootloader
일부 플러그인에서 제공하는 동적 튜닝 기능은 지원되지 않습니다. 다음 TuneD 플러그인은 현재 지원되지 않습니다.
- script
- systemd
TuneD 부트로더 플러그인은 RHCOS(Red Hat Enterprise Linux CoreOS) 작업자 노드만 지원합니다.
추가 리소스
7.15. 노드 당 최대 pod 수 구성
podsPerCore 및 maxPods는 노드에 예약할 수 있는 최대 Pod 수를 제어합니다. 두 옵션을 모두 사용하는 경우 두 옵션 중 더 낮은 값이 노드의 Pod 수를 제한합니다.
예를 들어 4 개의 프로세서 코어가 있는 노드에서 podsPerCore가 10으로 설정된 경우 노드에서 허용되는 최대 Pod 수는 40입니다.
사전 요구 사항
다음 명령을 입력하여 구성할 노드 유형의 정적
MachineConfigPoolCRD와 연관된 라벨을 가져옵니다.$ oc edit machineconfigpool <name>예를 들면 다음과 같습니다.
$ oc edit machineconfigpool worker출력 예
apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfigPool metadata: creationTimestamp: "2022-11-16T15:34:25Z" generation: 4 labels: pools.operator.machineconfiguration.openshift.io/worker: ""1 name: worker #...- 1
- 레이블이 Labels 아래에 표시됩니다.
작은 정보라벨이 없으면 다음과 같은 키/값 쌍을 추가합니다.
$ oc label machineconfigpool worker custom-kubelet=small-pods
절차
구성 변경을 위한 사용자 정의 리소스 (CR)를 만듭니다.
max-podsCR의 설정 예apiVersion: machineconfiguration.openshift.io/v1 kind: KubeletConfig metadata: name: set-max-pods1 spec: machineConfigPoolSelector: matchLabels: pools.operator.machineconfiguration.openshift.io/worker: ""2 kubeletConfig: podsPerCore: 103 maxPods: 2504 #...참고podsPerCore를0으로 설정하면 이 제한이 비활성화됩니다.위의 예에서
podsPerCore의 기본값은10이며maxPods의 기본값은250입니다. 즉, 노드에 25 개 이상의 코어가 없으면 기본적으로podsPerCore가 제한 요소가 됩니다.다음 명령을 실행하여 CR을 생성합니다.
$ oc create -f <file_name>.yaml
검증
MachineConfigPoolCRD를 나열하여 변경 사항이 적용되는지 확인합니다. Machine Config Controller에서 변경 사항을 선택하면UPDATING열에True가 보고됩니다.$ oc get machineconfigpools출력 예
NAME CONFIG UPDATED UPDATING DEGRADED master master-9cc2c72f205e103bb534 False False False worker worker-8cecd1236b33ee3f8a5e False True False변경이 완료되면
UPDATED열에True가 보고됩니다.$ oc get machineconfigpools출력 예
NAME CONFIG UPDATED UPDATING DEGRADED master master-9cc2c72f205e103bb534 False True False worker worker-8cecd1236b33ee3f8a5e True False False
8장. 설치 후 네트워크 구성
OpenShift Container Platform을 설치한 후 요구 사항에 맞게 네트워크를 추가로 확장하고 사용자 지정할 수 있습니다.
8.1. Cluster Network Operator 사용
CNO(Cluster Network Operator)를 사용하여 설치 중에 클러스터에 대해 선택한 CNI(Container Network Interface) 네트워크 플러그인을 포함하여 OpenShift Container Platform 클러스터에 클러스터 네트워크 구성 요소를 배포하고 관리할 수 있습니다. 자세한 내용은 OpenShift Container Platform의 Cluster Network Operator 를 참조하십시오.
8.2. 네트워크 구성 작업
8.2.1. 새 프로젝트에 대한 기본 네트워크 정책 만들기
클러스터 관리자는 새 프로젝트를 만들 때 NetworkPolicy 오브젝트를 자동으로 포함하도록 새 프로젝트 템플릿을 수정할 수 있습니다.
8.2.1.1. 새 프로젝트의 템플릿 수정
클러스터 관리자는 사용자 정의 요구 사항을 사용하여 새 프로젝트를 생성하도록 기본 프로젝트 템플릿을 수정할 수 있습니다.
사용자 정의 프로젝트 템플릿을 만들려면:
프로세스
-
cluster-admin권한이 있는 사용자로 로그인합니다. 기본 프로젝트 템플릿을 생성합니다.
$ oc adm create-bootstrap-project-template -o yaml > template.yaml-
텍스트 편집기를 사용하여 오브젝트를 추가하거나 기존 오브젝트를 수정하여 생성된
template.yaml파일을 수정합니다. 프로젝트 템플릿은
openshift-config네임스페이스에서 생성해야 합니다. 수정된 템플릿을 불러옵니다.$ oc create -f template.yaml -n openshift-config웹 콘솔 또는 CLI를 사용하여 프로젝트 구성 리소스를 편집합니다.
웹 콘솔에 액세스:
- 관리 → 클러스터 설정으로 이동합니다.
- Configuration 을 클릭하여 모든 구성 리소스를 확인합니다.
- 프로젝트 항목을 찾아 YAML 편집을 클릭합니다.
CLI 사용:
다음과 같이
project.config.openshift.io/cluster리소스를 편집합니다.$ oc edit project.config.openshift.io/cluster
projectRequestTemplate및name매개변수를 포함하도록spec섹션을 업데이트하고 업로드된 프로젝트 템플릿의 이름을 설정합니다. 기본 이름은project-request입니다.사용자 정의 프로젝트 템플릿이 포함된 프로젝트 구성 리소스
apiVersion: config.openshift.io/v1 kind: Project metadata: # ... spec: projectRequestTemplate: name: <template_name> # ...- 변경 사항을 저장한 후 새 프로젝트를 생성하여 변경 사항이 성공적으로 적용되었는지 확인합니다.
8.2.1.2. 새 프로젝트 템플릿에 네트워크 정책 추가
클러스터 관리자는 네트워크 정책을 새 프로젝트의 기본 템플릿에 추가할 수 있습니다. OpenShift Container Platform은 프로젝트의 템플릿에 지정된 모든 NetworkPolicy 개체를 자동으로 생성합니다.
사전 요구 사항
-
클러스터는
NetworkPolicy오브젝트를 지원하는 기본 CNI 네트워크 플러그인을 사용합니다(예:mode: NetworkPolicy로 설정된 OpenShift SDN 네트워크 플러그인). 이 모드는 OpenShift SDN의 기본값입니다. -
OpenShift CLI(
oc)를 설치합니다. -
cluster-admin권한이 있는 사용자로 클러스터에 로그인해야 합니다. - 새 프로젝트에 대한 사용자 정의 기본 프로젝트 템플릿을 생성해야 합니다.
프로세스
다음 명령을 실행하여 새 프로젝트의 기본 템플릿을 편집합니다.
$ oc edit template <project_template> -n openshift-config<project_template>을 클러스터에 대해 구성한 기본 템플릿의 이름으로 변경합니다. 기본 템플릿 이름은project-request입니다.템플릿에서 각
NetworkPolicy오브젝트를objects매개변수의 요소로 추가합니다.objects매개변수는 하나 이상의 오브젝트 컬렉션을 허용합니다.다음 예제에서
objects매개변수 컬렉션에는 여러NetworkPolicy오브젝트가 포함됩니다.objects: - apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: name: allow-from-same-namespace spec: podSelector: {} ingress: - from: - podSelector: {} - apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: name: allow-from-openshift-ingress spec: ingress: - from: - namespaceSelector: matchLabels: network.openshift.io/policy-group: ingress podSelector: {} policyTypes: - Ingress - apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: name: allow-from-kube-apiserver-operator spec: ingress: - from: - namespaceSelector: matchLabels: kubernetes.io/metadata.name: openshift-kube-apiserver-operator podSelector: matchLabels: app: kube-apiserver-operator policyTypes: - Ingress ...선택 사항: 다음 명령을 실행하여 새 프로젝트를 생성하고 네트워크 정책 오브젝트가 생성되었는지 확인합니다.
새 프로젝트를 생성합니다.
$ oc new-project <project>1 - 1
<project>를 생성중인 프로젝트의 이름으로 변경합니다.
새 프로젝트 템플릿의 네트워크 정책 오브젝트가 새 프로젝트에 있는지 확인합니다.
$ oc get networkpolicy NAME POD-SELECTOR AGE allow-from-openshift-ingress <none> 7s allow-from-same-namespace <none> 7s
9장. 이미지 스트림 및 이미지 레지스트리 구성
현재 풀 시크릿을 교체하거나 새 풀 시크릿을 추가하여 클러스터의 글로벌 풀 시크릿을 업데이트할 수 있습니다. 이 절차는 사용자가 설치 중 사용된 레지스트리보다 이미지를 저장하기 위해 별도의 레지스트리를 사용하는 경우 필요합니다. 자세한 내용은 이미지 풀 시크릿 사용을 참조하십시오.
이미지 스트림 또는 이미지 레지스트리 구성에 대한 자세한 내용은 다음 문서를 참조하십시오.
9.1. 연결이 끊긴 클러스터의 이미지 스트림 구성
연결이 끊긴 환경에 OpenShift Container Platform을 설치한 후 Cluster Samples Operator 및 must-gather 이미지 스트림에 대한 이미지 스트림을 구성합니다.
9.1.1. 미러링을 위한 Cluster Samples Operator 지원
설치 프로세스 중에 OpenShift Container Platform은 openshift-cluster-samples-operator 네임스페이스에 imagestreamtag-to-image라는 구성 맵을 생성합니다. imagestreamtag-to-image 구성 맵에는 각 이미지 스트림 태그에 대한 이미지 채우기 항목이 포함되어 있습니다.
구성 맵의 데이터 필드에 있는 각 항목의 키 형식은 <image_stream_name>_<image_stream_tag_name>입니다.
OpenShift Container Platform의 연결이 끊긴 설치 프로세스 중에 Cluster Samples Operator의 상태가 Removed로 설정됩니다. Managed로 변경하려면 샘플이 설치됩니다.
네트워크 제한 또는 중단된 환경에서 샘플을 사용하려면 네트워크 외부의 서비스에 액세스해야 할 수 있습니다. 일부 예제 서비스에는 GitHub, Maven Central, npm, RubyGems, PyPi 등이 있습니다. 클러스터 샘플 Operator의 오브젝트가 필요한 서비스에 도달할 수 있도록 하는 추가 단계가 있을 수 있습니다.
이 구성 맵을 사용하여 이미지 스트림을 가져오려면 이미지를 미러링해야 하는 이미지 참조로 사용할 수 있습니다.
-
Cluster Samples Operator가
Removed로 설정된 경우 미러링된 레지스트리를 생성하거나 사용할 기존 미러링된 레지스트리를 확인할 수 있습니다. - 새 구성 맵을 가이드로 사용하여 미러링된 레지스트리에 샘플을 미러링합니다.
-
Cluster Samples Operator 구성 개체의
skippedImagestreams필드에 미러링되지 않은 이미지 스트림을 추가합니다. -
Cluster Samples Operator 구성 개체의
samplesRegistry를 미러링된 레지스트리로 설정합니다. -
그런 다음 Cluster Samples Operator를
Managed로 설정하여 미러링된 이미지 스트림을 설치합니다.
9.1.2. 대체 레지스트리 또는 미러링된 레지스트리에서 Cluster Samples Operator 이미지 스트림 사용
Cluster Samples Operator에 의해 관리되는 openshift 네임스페이스에 있는 대부분의 이미지 스트림은 registry.redhat.io의 Red Hat 레지스트리에 있는 이미지를 참조합니다.
설치 페이로드의 일부인 cli, installer, must-gather 및 test 이미지 스트림은 Cluster Samples Operator가 관리하지 않습니다. 이러한 내용은 이 절차에서 다루지 않습니다.
연결이 끊긴 환경에서 Cluster Samples Operator를 Managed 로 설정해야 합니다. 이미지 스트림을 설치하려면 미러링된 레지스트리가 있습니다.
사전 요구 사항
-
cluster-admin역할의 사용자로 클러스터에 액세스할 수 있어야 합니다. - 미러 레지스트리의 풀 시크릿을 생성합니다.
프로세스
미러링할 특정 이미지 스트림의 이미지에 액세스합니다. 예를 들면 다음과 같습니다.
$ oc get is <imagestream> -n openshift -o json | jq .spec.tags[].from.name | grep registry.redhat.io필요한 이미지 스트림과 관련된 registry.redhat.io에서 이미지를 미러링합니다.
$ oc image mirror registry.redhat.io/rhscl/ruby-25-rhel7:latest ${MIRROR_ADDR}/rhscl/ruby-25-rhel7:latest클러스터의 이미지 구성 오브젝트를 생성합니다.
$ oc create configmap registry-config --from-file=${MIRROR_ADDR_HOSTNAME}..5000=$path/ca.crt -n openshift-config클러스터의 이미지 설정 오브젝트에서 미러에 필요한 신뢰할 수 있는 CA를 추가합니다.
$ oc patch image.config.openshift.io/cluster --patch '{"spec":{"additionalTrustedCA":{"name":"registry-config"}}}' --type=merge미러 설정에 정의된 미러 위치의
hostname부분을 포함하도록 Cluster Samples Operator 설정 오브젝트에서samplesRegistry필드를 업데이트합니다.$ oc edit configs.samples.operator.openshift.io -n openshift-cluster-samples-operator참고현재 이미지 스트림 가져오기 프로세스에서 미러 또는 검색 메커니즘이 사용되지 않기 때문에 이 작업이 필요합니다.
Cluster Samples Operator 구성 오브젝트의
skippedImagestreams필드에 미러링되지 않은 이미지 스트림을 추가합니다. 또는 샘플 이미지 스트림을 모두 지원할 필요가 없는 경우 Cluster Samples Operator 구성 오브젝트에서 Cluster Samples Operator를Removed로 설정합니다.참고이미지 스트림 가져오기가 실패했으나 Cluster Samples Operator가 주기적으로 재시도하거나 재시도하지 않는 것처럼 보이면 Cluster Samples Operator는 경고를 발행합니다.
openshift네임스페이스의 여러 템플릿은 이미지 스트림을 참조합니다. 따라서Removed를 사용하여 이미지 스트림과 템플릿을 모두 제거하면 누락된 이미지 스트림으로 인해 기능이 제대로 작동하지 않을 경우 템플릿을 사용할 가능성이 없어집니다.
9.1.3. 지원 데이터 수집을 위해 클러스터 준비
제한된 네트워크를 사용하는 클러스터는 Red Hat 지원을 위한 디버깅 데이터를 수집하기 위해 기본 must-gather 이미지를 가져와야합니다. must-gather 이미지는 기본적으로 가져 오지 않으며 제한된 네트워크의 클러스터는 원격 저장소에서 최신 이미지를 가져 오기 위해 인터넷에 액세스할 수 없습니다.
프로세스
미러 레지스트리의 신뢰할 수 있는 CA를 Cluster Samples Operator 설정의 일부로 클러스터의 이미지 구성 오브젝트에 추가하지 않은 경우 다음 단계를 수행합니다.
클러스터의 이미지 구성 오브젝트를 생성합니다.
$ oc create configmap registry-config --from-file=${MIRROR_ADDR_HOSTNAME}..5000=$path/ca.crt -n openshift-config클러스터의 이미지 설정 오브젝트에서 미러에 필요한 신뢰할 수 있는 CA를 추가합니다.
$ oc patch image.config.openshift.io/cluster --patch '{"spec":{"additionalTrustedCA":{"name":"registry-config"}}}' --type=merge
설치 페이로드에서 기본 must-gather 이미지를 가져옵니다.
$ oc import-image is/must-gather -n openshift
oc adm must-gather 명령을 실행하는 경우 다음 예와 같이 --image 플래그를 사용하고 페이로드 이미지를 가리키십시오.
$ oc adm must-gather --image=$(oc adm release info --image-for must-gather)9.2. Cluster Sample Operator 이미지 스트림 태그의 정기적인 가져오기 구성
새 버전을 사용할 수 있을 때 주기적으로 이미지 스트림 태그를 가져와서 Cluster Sample Operator 이미지의 최신 버전에 항상 액세스할 수 있는지 확인할 수 있습니다.
프로세스
다음 명령을 실행하여
openshift네임스페이스의 모든 이미지 스트림을 가져옵니다.oc get imagestreams -nopenshift다음 명령을 실행하여
openshift네임스페이스에 있는 모든 이미지 스트림의 태그를 가져옵니다.$ oc get is <image-stream-name> -o jsonpath="{range .spec.tags[*]}{.name}{'\t'}{.from.name}{'\n'}{end}" -nopenshift예를 들면 다음과 같습니다.
$ oc get is ubi8-openjdk-17 -o jsonpath="{range .spec.tags[*]}{.name}{'\t'}{.from.name}{'\n'}{end}" -nopenshift출력 예
1.11 registry.access.redhat.com/ubi8/openjdk-17:1.11 1.12 registry.access.redhat.com/ubi8/openjdk-17:1.12다음 명령을 실행하여 이미지 스트림에 있는 각 태그의 이미지를 주기적으로 가져오는 작업을 예약합니다.
$ oc tag <repository/image> <image-stream-name:tag> --scheduled -nopenshift예를 들면 다음과 같습니다.
$ oc tag registry.access.redhat.com/ubi8/openjdk-17:1.11 ubi8-openjdk-17:1.11 --scheduled -nopenshift $ oc tag registry.access.redhat.com/ubi8/openjdk-17:1.12 ubi8-openjdk-17:1.12 --scheduled -nopenshift이 명령은 OpenShift Container Platform이 특정 이미지 스트림 태그를 주기적으로 업데이트하도록 합니다. 이 기간은 기본적으로 15분으로 설정되는 클러스터 전체 설정입니다.
다음 명령을 실행하여 주기적인 가져오기의 스케줄링 상태를 확인합니다.
oc get imagestream <image-stream-name> -o jsonpath="{range .spec.tags[*]}Tag: {.name}{'\t'}Scheduled: {.importPolicy.scheduled}{'\n'}{end}" -nopenshift예를 들면 다음과 같습니다.
oc get imagestream ubi8-openjdk-17 -o jsonpath="{range .spec.tags[*]}Tag: {.name}{'\t'}Scheduled: {.importPolicy.scheduled}{'\n'}{end}" -nopenshift출력 예
Tag: 1.11 Scheduled: true Tag: 1.12 Scheduled: true
10장. 설치 후 스토리지 구성
OpenShift Container Platform을 설치한 후 스토리지 구성을 포함하여 요구 사항에 맞게 클러스터를 추가로 확장하고 사용자 정의할 수 있습니다.
기본적으로 컨테이너는 임시 스토리지 또는 일시적인 로컬 스토리지를 사용하여 작동합니다. 임시 스토리지에는 수명 제한이 있습니다. 데이터를 장기간 저장하려면 영구 스토리지를 구성해야 합니다. 다음 방법 중 하나를 사용하여 스토리지를 구성할 수 있습니다.
- 동적 프로비저닝
- 스토리지 액세스를 포함하여 다양한 스토리지 수준을 제어하는 스토리지 클래스를 정의하고 생성하여 온디맨드 방식으로 스토리지를 동적으로 프로비저닝할 수 있습니다.
- 정적 프로비저닝
- Kubernetes 영구 볼륨을 사용하여 클러스터에서 기존 스토리지를 사용할 수 있습니다. 정적 프로비저닝은 다양한 장치 구성 및 마운트 옵션을 지원할 수 있습니다.
10.1. 동적 프로비저닝
동적 프로비저닝을 사용하면 필요에 따라 스토리지 볼륨을 생성할 수 있으므로 클러스터 관리자가 스토리지를 사전 프로비저닝할 필요가 없습니다. 동적 프로비저닝 을 참조하십시오.
10.1.1. RHV(Red Hat Virtualization) 개체 정의
OpenShift Container Platform은 동적으로 프로비저닝된 영구 볼륨을 생성하는 데 사용되는 ovirt-csi-sc라는 이름의 StorageClass 유형의 기본 오브젝트를 생성합니다.
다양한 구성을 위한 추가 스토리지 클래스를 생성하려면 다음 샘플 YAML에서 설명되는 StorageClass 오브젝트로 파일을 생성하고 저장합니다.
ovirt-storageclass.yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: <storage_class_name>
annotations:
storageclass.kubernetes.io/is-default-class: "<boolean>"
provisioner: csi.ovirt.org
allowVolumeExpansion: <boolean>
reclaimPolicy: Delete
volumeBindingMode: Immediate
parameters:
storageDomainName: <rhv-storage-domain-name>
thinProvisioning: "<boolean>"
csi.storage.k8s.io/fstype: <file_system_type> - 1
- StorageClass의 이름입니다.
- 2
- 스토리지 클래스가 클러스터의 기본 스토리지 클래스인 경우
false로 설정합니다.true로 설정하면 기존 기본 스토리지 클래스를 편집한 후false로 설정해야 합니다. - 3
True는 동적 볼륨 확장을 활성화하고false는 금지합니다.true가 권장됩니다.- 4
- 이 스토리지 클래스의 동적으로 프로비저닝된 영구 볼륨은 이 회수 정책을 사용하여 생성됩니다. 기본 정책은
Delete입니다. - 5
PersistentVolumeClaims를 프로비저닝하고 바인딩하는 방법을 나타냅니다. 설정하지 않으면VolumeBindingImmediate가 사용됩니다. 이 필드는VolumeScheduling기능을 활성화하는 서버에만 적용됩니다.- 6
- 사용할 RHV 스토리지 도메인 이름입니다.
- 7
true인 경우 디스크는 씬 프로비저닝됩니다.false인 경우 디스크가 사전 할당됩니다. 씬 프로비저닝이 권장됩니다.- 8
- 선택 사항: 생성할 파일 시스템 유형입니다. 가능한 값:
ext4(기본값) 또는xfs.
10.2. 권장되는 구성 가능한 스토리지 기술
다음 표에는 지정된 OpenShift Container Platform 클러스터 애플리케이션에 권장되는 구성 가능한 스토리지 기술이 요약되어 있습니다.
| 스토리지 유형 | 블록 | 파일 | 개체 |
|---|---|---|---|
|
1
2 3 Prometheus는 메트릭에 사용되는 기본 기술입니다. 4 물리적 디스크, VM 물리적 디스크, VMDK, NFS를 통한 루프백, AWS EBS 및 Azure Disk에는 적용되지 않습니다.
5 메트릭의 경우 RWX( 6 로깅은 로그 저장소의 영구 스토리지 구성 섹션에서 권장되는 스토리지 솔루션을 검토하십시오. NFS 스토리지를 영구 볼륨으로 사용하거나 Gluster와 같은 NAS를 통해 데이터가 손상될 수 있습니다. 따라서 OpenShift Container Platform Logging에서 Elasticsearch 스토리지 및 10.0.0.1Stack 로그 저장소에 NFS가 지원되지 않습니다. 로그 저장소당 하나의 영구 볼륨 유형을 사용해야 합니다. 7 OpenShift Container Platform의 PV 또는 PVC를 통해서는 오브젝트 스토리지가 사용되지 않습니다. 앱은 오브젝트 스토리지 REST API와 통합해야 합니다. | |||
| ROX1 | 제공됨4 | 제공됨4 | 예 |
| RWX2 | 없음 | 예 | 예 |
| 레지스트리 | 구성 가능 | 구성 가능 | 권장 |
| 확장 레지스트리 | 구성 불가능 | 구성 가능 | 권장 |
| Metrics3 | 권장 | 구성 가능5 | 구성 불가능 |
| Elasticsearch 로깅 | 권장 | 구성 가능6 | 지원되지 않음6 |
| CloudEvent Logging | 구성 불가능 | 구성 불가능 | 권장 |
| 앱 | 권장 | 권장 | 구성 불가능7 |
확장된 레지스트리는 두 개 이상의 포드 복제본이 실행되는 OpenShift 이미지 레지스트리입니다.
10.2.1. 특정 애플리케이션 스토리지 권장 사항
테스트 결과 RHEL(Red Hat Enterprise Linux)의 NFS 서버를 핵심 서비스의 스토리지 백엔드로 사용하는 데 문제가 있는 것으로 표시됩니다. 여기에는 OpenShift Container Registry and Quay, 스토리지 모니터링을 위한 Prometheus, 로깅 스토리지를 위한 Elasticsearch가 포함됩니다. 따라서 RHEL NFS를 사용하여 핵심 서비스에서 사용하는 PV를 백업하는 것은 권장되지 않습니다.
Marketplace의 다른 NFS 구현에는 이러한 문제가 없을 수 있습니다. 이러한 OpenShift Container Platform 핵심 구성 요소에 대해 완료된 테스트에 대한 자세한 내용은 개별 NFS 구현 공급업체에 문의하십시오.
10.2.1.1. 레지스트리
비 확장/HA(고가용성) OpenShift 이미지 레지스트리 클러스터 배포에서는 다음을 수행합니다.
- 스토리지 기술에서 RWX 액세스 모드를 지원할 필요가 없습니다.
- 스토리지 기술에서 쓰기 후 읽기 일관성을 보장해야 합니다.
- 기본 스토리지 기술은 오브젝트 스토리지, 블록 스토리지 순입니다.
- 프로덕션 워크로드가 있는 OpenShift 이미지 레지스트리 클러스터 배포에는 파일 스토리지를 사용하지 않는 것이 좋습니다.
10.2.1.2. 확장 레지스트리
확장/HA OpenShift 이미지 레지스트리 클러스터 배포에서는 다음을 수행합니다.
- 스토리지 기술은 RWX 액세스 모드를 지원해야 합니다.
- 스토리지 기술에서 쓰기 후 읽기 일관성을 보장해야 합니다.
- 기본 스토리지 기술은 오브젝트 스토리지입니다.
- Red Hat OpenShift Data Foundation(ODF), Amazon Simple Storage Service(Amazon S3), GCS(Google Cloud Storage), Microsoft Azure Blob Storage 및 OpenStack Swift가 지원됩니다.
- 오브젝트 스토리지는 S3 또는 Swift와 호환되어야 합니다.
- vSphere, 베어 메탈 설치 등 클라우드 이외의 플랫폼에서는 구성 가능한 유일한 기술이 파일 스토리지입니다.
- 블록 스토리지는 구성 불가능합니다.
- OpenShift Container Platform에서 NFS(Network File System) 스토리지 사용이 지원됩니다. 그러나 확장된 레지스트리와 함께 NFS 스토리지를 사용하면 알려진 문제가 발생할 수 있습니다. 자세한 내용은 프로덕션의 OpenShift 클러스터 내부 구성 요소에 대해 NFS가 지원되는 Red Hat 지식베이스 솔루션을 참조하십시오.
10.2.1.3. 지표
OpenShift Container Platform 호스트 지표 클러스터 배포에서는 다음 사항에 유의합니다.
- 기본 스토리지 기술은 블록 스토리지입니다.
- 오브젝트 스토리지는 구성 불가능합니다.
프로덕션 워크로드가 있는 호스트 지표 클러스터 배포에는 파일 스토리지를 사용하지 않는 것이 좋습니다.
10.2.1.4. 로깅
OpenShift Container Platform 호스트 로깅 클러스터 배포에서는 다음 사항에 유의합니다.
Loki Operator:
- 기본 스토리지 기술은 S3 호환 오브젝트 스토리지입니다.
- 블록 스토리지는 구성 불가능합니다.
OpenShift Elasticsearch Operator:
- 기본 스토리지 기술은 블록 스토리지입니다.
- 오브젝트 스토리지는 지원되지 않습니다.
로깅 버전 5.4.3부터 OpenShift Elasticsearch Operator는 더 이상 사용되지 않으며 향후 릴리스에서 제거될 예정입니다. Red Hat은 현재 릴리스 라이프사이클 동안 이 기능에 대한 버그 수정 및 지원을 제공하지만 이 기능은 더 이상 개선 사항을 받지 않으며 제거됩니다. OpenShift Elasticsearch Operator를 사용하여 기본 로그 스토리지를 관리하는 대신 Loki Operator를 사용할 수 있습니다.
10.2.1.5. 애플리케이션
애플리케이션 사용 사례는 다음 예에 설명된 대로 애플리케이션마다 다릅니다.
- 동적 PV 프로비저닝을 지원하는 스토리지 기술은 마운트 대기 시간이 짧고 정상 클러스터를 지원하는 노드와 관련이 없습니다.
- 애플리케이션 개발자는 애플리케이션의 스토리지 요구사항을 잘 알고 있으며 제공된 스토리지로 애플리케이션을 작동시켜 애플리케이션이 스토리지 계층을 스케일링하거나 스토리지 계층과 상호 작용할 때 문제가 발생하지 않도록 하는 방법을 이해하고 있어야 합니다.
10.2.2. 다른 특정 애플리케이션 스토리지 권장 사항
etcd 와 같은 쓰기 집약적인 워크로드에서는 RAID 구성을 사용하지 않는 것이 좋습니다. RAID 구성으로 etcd 를 실행하는 경우 워크로드에 성능 문제가 발생할 위험이 있을 수 있습니다.
- RHOSP(Red Hat OpenStack Platform) Cinder: RHOSP Cinder는 ROX 액세스 모드 사용 사례에 적합합니다.
- 데이터베이스: 데이터베이스(RDBMS, NoSQL DB 등)는 전용 블록 스토리지를 사용하는 경우 성능이 최대화되는 경향이 있습니다.
- etcd 데이터베이스에는 대규모 클러스터를 활성화하기에 충분한 스토리지와 적절한 성능 용량이 있어야 합니다. 충분한 스토리지 및 고성능 환경을 설정하는 모니터링 및 벤치마킹 툴에 대한 정보는 권장 etcd 관행에 설명되어 있습니다.
10.3. Red Hat OpenShift Data Foundation 배포
Red Hat OpenShift Data Foundation은 사내 또는 하이브리드 클라우드에서 파일, 블록 및 오브젝트 스토리지를 지원하는 OpenShift Container Platform의 영구 스토리지 공급자입니다. Red Hat 스토리지 솔루션인 Red Hat OpenShift Data Foundation은 배포, 관리 및 모니터링을 위해 OpenShift Container Platform과 완전히 통합되어 있습니다. 자세한 내용은 Red Hat OpenShift Data Foundation 설명서를 참조하십시오.
OpenShift Container Platform과 함께 설치된 가상 머신을 호스팅하는 하이퍼컨버지드 노드를 사용하는 가상화용 RHHI(Red Hat Hyperconverged Infrastructure) 상단에 있는 OpenShift Data Foundation은 지원되는 구성이 아닙니다. 지원되는 플랫폼에 대한 자세한 내용은 Red Hat OpenShift Data Foundation 지원 및 상호 운용성 가이드를 참조하십시오.
| Red Hat OpenShift Data Foundation에 대한 정보를 찾고 있는 경우 | 다음 Red Hat OpenShift Data Foundation 문서를 참조하십시오. |
|---|---|
| 새로운 알려진 문제, 중요한 버그 수정 및 기술 미리보기 | |
| 지원되는 워크로드, 레이아웃, 하드웨어 및 소프트웨어 요구 사항, 크기 조정 및 확장 권장 사항 | |
| 외부 Red Hat Ceph Storage 클러스터를 사용하기 위해 OpenShift Data Foundation을 배포하는 방법 | |
| 베어메탈 인프라의 로컬 스토리지에 OpenShift Data Foundation을 배포하는 방법 | |
| Red Hat OpenShift Container Platform VMware vSphere 클러스터에 OpenShift Data Foundation을 배포하는 방법 | |
| 로컬 또는 클라우드 스토리지용 Amazon Web Services를 사용하여 OpenShift Data Foundation을 배포하는 방법 | Deploying OpenShift Data Foundation 4.12 using Amazon Web Services |
| 기존 Red Hat OpenShift Container Platform Google Cloud 클러스터에서 OpenShift Data Foundation을 배포 및 관리하는 방법 | Deploying and managing OpenShift Data Foundation 4.12 using Google Cloud |
| 기존 Red Hat OpenShift Container Platform Azure 클러스터에서 OpenShift Data Foundation을 배포 및 관리하는 방법 | Microsoft Azure를 사용하여 OpenShift Data Foundation 4.12 배포 및 관리 |
| IBM Power 인프라에서 로컬 스토리지를 사용하기 위해 OpenShift Data Foundation을 배포하는 방법 | |
| IBM Z 인프라에서 로컬 스토리지를 사용하기 위해 OpenShift Data Foundation을 배포하는 방법 | |
| 스냅샷 및 복제를 포함하여 Red Hat OpenShift Data Foundation의 핵심 서비스 및 호스팅 애플리케이션에 스토리지 할당 | |
| Multicloud Object Gateway(NooBaa)를 사용하여 하이브리드 클라우드 또는 다중 클라우드 환경에서 스토리지 리소스 관리 | |
| Red Hat OpenShift Data Foundation용 스토리지 장치 안전하게 교체 | |
| Red Hat OpenShift Data Foundation 클러스터에서 안전하게 노드 교체 | |
| Red Hat OpenShift Data Foundation에서 작업 확장 | |
| Red Hat OpenShift Data Foundation 4.12 클러스터 모니터링 | |
| 작업 중 발생한 문제 해결 | |
| OpenShift Container Platform 클러스터를 버전 3에서 버전 4로 마이그레이션 |
11장. 사용자를 위한 준비
OpenShift Container Platform을 설치한 후에는 사용자 준비 단계를 포함하여 요구 사항에 맞게 클러스터를 추가로 확장하고 사용자 정의할 수 있습니다.
11.1. ID 공급자 구성 이해
OpenShift Container Platform 컨트롤 플레인에는 내장 OAuth 서버가 포함되어 있습니다. 개발자와 관리자는 OAuth 액세스 토큰을 가져와 API 인증을 수행합니다.
관리자는 클러스터를 설치한 후 ID 공급자를 지정하도록 OAuth를 구성할 수 있습니다.
11.1.1. OpenShift Container Platform의 ID 공급자 정보
기본적으로는 kubeadmin 사용자만 클러스터에 있습니다. ID 공급자를 지정하려면 해당 ID 공급자를 설명하는 CR(사용자 정의 리소스)을 생성하여 클러스터에 추가해야 합니다.
/, :, %를 포함하는 OpenShift Container Platform 사용자 이름은 지원되지 않습니다.
11.1.2. 지원되는 ID 공급자
다음 유형의 ID 공급자를 구성할 수 있습니다.
| ID 공급자 | 설명 |
|---|---|
|
| |
|
내부 데이터베이스에 사용자를 저장하는 OpenStack Keystone v3 서버와의 공유 인증을 지원하기 위해 OpenShift Container Platform 클러스터를 Keystone과 통합하도록 | |
|
단순 바인드 인증을 사용하여 LDAPv3 서버에 대해 사용자 이름 및 암호의 유효성을 확인하도록 | |
|
사용자가 원격 ID 공급자에 대해 검증된 자격 증명을 사용하여 OpenShift Container Platform에 로그인할 수 있도록 | |
|
| |
|
GitHub 또는 GitHub Enterprise의 OAuth 인증 서버에 대해 사용자 이름 및 암호의 유효성을 확인하도록 | |
|
GitLab.com 또는 기타 GitLab 인스턴스를 ID 공급자로 사용하도록 | |
|
Google의 OpenID Connect 통합을 사용하여 | |
|
인증 코드 Flow를 사용하여 OpenID Connect ID 공급자와 통합하도록 |
ID 공급자를 정의한 후 RBAC를 사용하여 권한을 정의하고 적용할 수 있습니다.
11.1.3. ID 공급자 매개변수
다음 매개변수는 모든 ID 공급자에 공통입니다.
| 매개변수 | 설명 |
|---|---|
|
| 공급자 사용자 이름에 접두어로 공급자 이름을 지정하여 ID 이름을 만듭니다. |
|
| 사용자가 로그인할 때 새 ID를 사용자에게 매핑하는 방법을 정의합니다. 다음 값 중 하나를 입력하십시오.
|
ID 공급자를 추가하거나 변경할 때 mappingMethod 매개변수를 add로 설정하면 새 공급자의 ID를 기존 사용자에게 매핑할 수 있습니다.
11.1.4. ID 공급자 CR 샘플
다음 CR(사용자 정의 리소스)에서는 ID 공급자를 구성하는 데 사용되는 매개변수 및 기본값을 보여줍니다. 이 예에서는 htpasswd ID 공급자를 사용합니다.
ID 공급자 CR 샘플
apiVersion: config.openshift.io/v1
kind: OAuth
metadata:
name: cluster
spec:
identityProviders:
- name: my_identity_provider
mappingMethod: claim
type: HTPasswd
htpasswd:
fileData:
name: htpass-secret 11.2. RBAC를 사용하여 권한 정의 및 적용
역할 기반 액세스 제어를 이해하고 적용합니다.
11.2.1. RBAC 개요
RBAC(역할 기반 액세스 제어) 오브젝트에 따라 사용자가 프로젝트 내에서 지정된 작업을 수행할 수 있는지가 결정됩니다.
클러스터 관리자는 클러스터 역할 및 바인딩을 사용하여 OpenShift Container Platform 플랫폼 자체 및 모든 프로젝트에 대해 다양한 액세스 수준을 보유한 사용자를 제어할 수 있습니다.
개발자는 로컬 역할 및 바인딩을 사용하여 프로젝트에 액세스할 수 있는 사용자를 제어할 수 있습니다. 권한 부여는 인증과 별도의 단계이며, 여기서는 조치를 수행할 사용자의 신원을 파악하는 것이 더 중요합니다.
권한 부여는 다음을 사용하여 관리합니다.
| 권한 부여 오브젝트 | 설명 |
|---|---|
| 규칙 |
오브젝트 집합에 허용되는 동사 집합입니다. 예를 들면 사용자 또는 서비스 계정의 Pod |
| 역할 | 규칙 모음입니다. 사용자와 그룹을 여러 역할에 연결하거나 바인딩할 수 있습니다. |
| 바인딩 | 역할이 있는 사용자 및/또는 그룹 간 연결입니다. |
권한 부여를 제어하는 두 가지 수준의 RBAC 역할 및 바인딩이 있습니다.
| RBAC 수준 | 설명 |
|---|---|
| 클러스터 RBAC | 모든 프로젝트에 적용할 수 있는 역할 및 바인딩입니다. 클러스터 역할은 클러스터 전체에 존재하며 클러스터 역할 바인딩은 클러스터 역할만 참조할 수 있습니다. |
| 지역 RBAC | 지정된 프로젝트에 적용되는 역할 및 바인딩입니다. 로컬 역할은 단일 프로젝트에만 존재하지만 로컬 역할 바인딩은 클러스터 및 로컬 역할을 모두 참조할 수 있습니다. |
클러스터 역할 바인딩은 클러스터 수준에 존재하는 바인딩입니다. 역할 바인딩은 프로젝트 수준에 있습니다. 해당 사용자가 프로젝트를 보려면 로컬 역할 바인딩을 사용하여 클러스터 역할 보기를 사용자에게 바인딩해야 합니다. 클러스터 역할이 특정 상황에 필요한 권한 집합을 제공하지 않는 경우에만 로컬 역할을 생성하십시오.
이러한 2단계 계층 구조로 인해 클러스터 역할로는 여러 프로젝트에서 재사용하고, 로컬 역할로는 개별 프로젝트 내에서 사용자 정의할 수 있습니다.
평가 중에는 클러스터 역할 바인딩과 로컬 역할 바인딩이 모두 사용됩니다. 예를 들면 다음과 같습니다.
- 클러스터 전체의 "허용" 규칙을 확인합니다.
- 로컬 바인딩된 "허용" 규칙을 확인합니다.
- 기본적으로 거부합니다.
11.2.1.1. 기본 클러스터 역할
OpenShift Container Platform에는 클러스터 전체 또는 로컬로 사용자 및 그룹에 바인딩할 수 있는 기본 클러스터 역할 집합이 포함되어 있습니다.
기본 클러스터 역할을 수동으로 수정하지 않는 것이 좋습니다. 이러한 시스템 역할에 대한 수정으로 인해 클러스터가 제대로 작동하지 않을 수 있습니다.
| 기본 클러스터 역할 | 설명 |
|---|---|
|
|
프로젝트 관리자입니다. 로컬 바인딩에 사용되는 경우 |
|
| 프로젝트 및 사용자에 대한 기본 정보를 가져올 수 있는 사용자입니다. |
|
| 모든 프로젝트에서 모든 작업을 수행할 수 있는 슈퍼 유저입니다. 로컬 바인딩을 통해 사용자에게 바인딩하면 할당량은 물론 프로젝트의 모든 리소스에 대한 모든 조치를 완전히 제어할 수 있습니다. |
|
| 기본 클러스터 상태 정보를 가져올 수 있는 사용자입니다. |
|
| 대부분의 오브젝트를 가져오거나 볼 수 있지만 수정할 수는 없는 사용자입니다. |
|
| 프로젝트에서 대부분의 오브젝트를 수정할 수 있지만 역할이나 바인딩을 보거나 수정할 권한은 없는 사용자입니다. |
|
| 자체 프로젝트를 만들 수 있는 사용자입니다. |
|
| 수정할 수는 없지만 프로젝트의 오브젝트를 대부분 볼 수 있는 사용자입니다. 역할 또는 바인딩을 보거나 수정할 수 없습니다. |
로컬 바인딩과 클러스터 바인딩의 차이점에 유의하십시오. 예를 들어 로컬 역할 바인딩을 사용하여 cluster-admin 역할을 사용자에게 바인딩하는 경우, 이 사용자에게 클러스터 관리자 권한이 있는 것처럼 보일 수 있습니다. 사실은 그렇지 않습니다. 프로젝트의 사용자에게 cluster-admin을 바인딩하면 해당 프로젝트에 대해서만 슈퍼 관리자 권한이 사용자에게 부여됩니다. 해당 사용자에게는 클러스터 역할 admin의 권한을 비롯하여 해당 프로젝트에 대한 속도 제한 편집 기능과 같은 몇 가지 추가 권한이 있습니다. 이 바인딩은 실제 클러스터 관리자에게 바인딩된 클러스터 역할 바인딩이 나열되지 않는 웹 콘솔 UI로 인해 혼동될 수 있습니다. 그러나 cluster-admin을 로컬로 바인딩하는 데 사용할 수 있는 로컬 역할 바인딩은 나열됩니다.
아래에는 클러스터 역할, 로컬 역할, 클러스터 역할 바인딩, 로컬 역할 바인딩, 사용자, 그룹, 서비스 계정 간의 관계가 설명되어 있습니다.

get pods/exec,pods/*, get * 규칙은 역할에 적용될 때 실행 권한을 부여합니다. 최소 권한 원칙을 적용하고 사용자 및 에이전트에 필요한 최소 RBAC 권한만 할당합니다. 자세한 내용은 RBAC 규칙 실행 권한을 참조하십시오.
11.2.1.2. 권한 부여 평가
OpenShift Container Platform에서는 다음을 사용하여 권한 부여를 평가합니다.
- ID
- 사용자 이름 및 사용자가 속한 그룹 목록입니다.
- 작업
수행하는 작업입니다. 대부분의 경우 다음으로 구성됩니다.
- 프로젝트: 액세스하는 프로젝트입니다. 프로젝트는 추가 주석이 있는 쿠버네티스 네임스페이스로, 사용자 커뮤니티가 다른 커뮤니티와 별도로 컨텐츠를 구성하고 관리할 수 있습니다.
-
동사: 작업 자체를 나타내며
get,list,create,update,delete,deletecollection또는watch에 해당합니다. - 리소스 이름: 액세스하는 API 끝점입니다.
- 바인딩
- 전체 바인딩 목록으로, 역할이 있는 사용자 또는 그룹 간 연결을 나타냅니다.
OpenShift Container Platform에서는 다음 단계를 사용하여 권한 부여를 평가합니다.
- ID 및 프로젝트 범위 작업은 사용자 또는 해당 그룹에 적용되는 모든 바인딩을 찾는 데 사용됩니다.
- 바인딩은 적용되는 모든 역할을 찾는 데 사용됩니다.
- 역할은 적용되는 모든 규칙을 찾는 데 사용됩니다.
- 일치하는 규칙을 찾기 위해 작업을 각 규칙에 대해 확인합니다.
- 일치하는 규칙이 없으면 기본적으로 작업이 거부됩니다.
사용자 및 그룹을 동시에 여러 역할과 연결하거나 바인딩할 수 있습니다.
프로젝트 관리자는 CLI를 사용하여 각각 연결된 동사 및 리소스 목록을 포함하여 로컬 역할 및 바인딩을 볼 수 있습니다.
프로젝트 관리자에게 바인딩된 클러스터 역할은 로컬 바인딩을 통해 프로젝트에서 제한됩니다. cluster-admin 또는 system:admin에 부여되는 클러스터 역할과 같이 클러스터 전체에 바인딩되지 않습니다.
클러스터 역할은 클러스터 수준에서 정의된 역할이지만 클러스터 수준 또는 프로젝트 수준에서 바인딩할 수 있습니다.
11.2.1.2.1. 클러스터 역할 집계
기본 admin, edit, view 및 cluster-reader 클러스터 역할은 새 규칙이 생성될 때 각 역할에 대한 클러스터 규칙이 동적으로 업데이트되는 클러스터 역할 집계 를 지원합니다. 이 기능은 사용자 정의 리소스를 생성하여 쿠버네티스 API를 확장한 경우에만 관련이 있습니다.
11.2.2. 프로젝트 및 네임스페이스
쿠버네티스 네임스페이스는 클러스터의 리소스 범위를 지정하는 메커니즘을 제공합니다. 쿠버네티스 설명서에 네임스페이스에 대한 자세한 정보가 있습니다.
네임스페이스는 다음에 대한 고유 범위를 제공합니다.
- 기본 이름 지정 충돌을 피하기 위해 이름이 지정된 리소스
- 신뢰할 수 있는 사용자에게 위임된 관리 권한
- 커뮤니티 리소스 사용을 제한하는 기능
시스템에 있는 대부분의 오브젝트는 네임스페이스에 따라 범위가 지정되지만, 노드 및 사용자를 비롯한 일부는 여기에 해당하지 않으며 네임스페이스가 없습니다.
프로젝트는 추가 주석이 있는 쿠버네티스 네임스페이스이며, 일반 사용자용 리소스에 대한 액세스를 관리하는 가장 중요한 수단입니다. 사용자 커뮤니티는 프로젝트를 통해 다른 커뮤니티와 별도로 콘텐츠를 구성하고 관리할 수 있습니다. 사용자는 관리자로부터 프로젝트에 대한 액세스 권한을 부여받아야 합니다. 프로젝트를 생성하도록 허용된 경우 자신의 프로젝트에 액세스할 수 있는 권한이 자동으로 제공됩니다.
프로젝트에는 별도의 name, displayName, description이 있을 수 있습니다.
-
필수 항목인
name은 프로젝트의 고유 식별자이며 CLI 도구 또는 API를 사용할 때 가장 잘 보입니다. 최대 이름 길이는 63자입니다. -
선택적
displayName은 프로젝트가 웹 콘솔에 표시되는 방법입니다(기본값:name). -
선택적
description은 프로젝트에 대한 보다 자세한 설명으로, 웹 콘솔에서도 볼 수 있습니다.
각 프로젝트의 범위는 다음과 같습니다.
| 오브젝트 | 설명 |
|---|---|
|
| Pod, 서비스, 복제 컨트롤러 등입니다. |
|
| 사용자는 오브젝트에서 이 규칙에 대해 작업을 수행할 수 있거나 수행할 수 없습니다. |
|
| 제한할 수 있는 각 종류의 오브젝트에 대한 할당량입니다. |
|
| 서비스 계정은 프로젝트의 오브젝트에 지정된 액세스 권한으로 자동으로 작동합니다. |
클러스터 관리자는 프로젝트를 생성하고 프로젝트에 대한 관리 권한을 사용자 커뮤니티의 모든 멤버에게 위임할 수 있습니다. 클러스터 관리자는 개발자가 자신의 프로젝트를 만들 수 있도록 허용할 수도 있습니다.
개발자와 관리자는 CLI 또는 웹 콘솔을 사용하여 프로젝트와 상호 작용할 수 있습니다.
11.2.3. 기본 프로젝트
OpenShift Container Platform에는 다양한 기본 프로젝트가 제공되며, openshift-로 시작하는 프로젝트가 사용자에게 가장 중요합니다. 이러한 프로젝트는 Pod 및 기타 인프라 구성 요소로 실행되는 마스터 구성 요소를 호스팅합니다. 중요 Pod 주석이 있는 네임스페이스에 생성된 Pod는 중요한 Pod로 간주되며, kubelet의 승인이 보장됩니다. 이러한 네임스페이스에서 마스터 구성 요소용으로 생성된 Pod는 이미 중요로 표시되어 있습니다.
기본 네임스페이스(default, kube-system, kube-public, openshift-node, openshift-infra 및 openshift) 중 하나에서 생성된 Pod에는 SCC를 할당할 수 없습니다. 이러한 네임스페이스는 Pod 또는 서비스를 실행하는 데 사용할 수 없습니다.
11.2.4. 클러스터 역할 및 바인딩 보기
oc CLI에서 oc describe 명령을 사용하여 클러스터 역할 및 바인딩을 볼 수 있습니다.
사전 요구 사항
-
ocCLI를 설치합니다. - 클러스터 역할 및 바인딩을 볼 수 있는 권한을 얻습니다.
cluster-admin 기본 클러스터 역할이 클러스터 전체에서 바인딩된 사용자는 클러스터 역할 및 바인딩 보기를 포함하여 모든 리소스에 대해 모든 작업을 수행할 수 있습니다.
절차
클러스터 역할 및 관련 규칙 집합을 보려면 다음을 수행합니다.
$ oc describe clusterrole.rbac출력 예
Name: admin Labels: kubernetes.io/bootstrapping=rbac-defaults Annotations: rbac.authorization.kubernetes.io/autoupdate: true PolicyRule: Resources Non-Resource URLs Resource Names Verbs --------- ----------------- -------------- ----- .packages.apps.redhat.com [] [] [* create update patch delete get list watch] imagestreams [] [] [create delete deletecollection get list patch update watch create get list watch] imagestreams.image.openshift.io [] [] [create delete deletecollection get list patch update watch create get list watch] secrets [] [] [create delete deletecollection get list patch update watch get list watch create delete deletecollection patch update] buildconfigs/webhooks [] [] [create delete deletecollection get list patch update watch get list watch] buildconfigs [] [] [create delete deletecollection get list patch update watch get list watch] buildlogs [] [] [create delete deletecollection get list patch update watch get list watch] deploymentconfigs/scale [] [] [create delete deletecollection get list patch update watch get list watch] deploymentconfigs [] [] [create delete deletecollection get list patch update watch get list watch] imagestreamimages [] [] [create delete deletecollection get list patch update watch get list watch] imagestreammappings [] [] [create delete deletecollection get list patch update watch get list watch] imagestreamtags [] [] [create delete deletecollection get list patch update watch get list watch] processedtemplates [] [] [create delete deletecollection get list patch update watch get list watch] routes [] [] [create delete deletecollection get list patch update watch get list watch] templateconfigs [] [] [create delete deletecollection get list patch update watch get list watch] templateinstances [] [] [create delete deletecollection get list patch update watch get list watch] templates [] [] [create delete deletecollection get list patch update watch get list watch] deploymentconfigs.apps.openshift.io/scale [] [] [create delete deletecollection get list patch update watch get list watch] deploymentconfigs.apps.openshift.io [] [] [create delete deletecollection get list patch update watch get list watch] buildconfigs.build.openshift.io/webhooks [] [] [create delete deletecollection get list patch update watch get list watch] buildconfigs.build.openshift.io [] [] [create delete deletecollection get list patch update watch get list watch] buildlogs.build.openshift.io [] [] [create delete deletecollection get list patch update watch get list watch] imagestreamimages.image.openshift.io [] [] [create delete deletecollection get list patch update watch get list watch] imagestreammappings.image.openshift.io [] [] [create delete deletecollection get list patch update watch get list watch] imagestreamtags.image.openshift.io [] [] [create delete deletecollection get list patch update watch get list watch] routes.route.openshift.io [] [] [create delete deletecollection get list patch update watch get list watch] processedtemplates.template.openshift.io [] [] [create delete deletecollection get list patch update watch get list watch] templateconfigs.template.openshift.io [] [] [create delete deletecollection get list patch update watch get list watch] templateinstances.template.openshift.io [] [] [create delete deletecollection get list patch update watch get list watch] templates.template.openshift.io [] [] [create delete deletecollection get list patch update watch get list watch] serviceaccounts [] [] [create delete deletecollection get list patch update watch impersonate create delete deletecollection patch update get list watch] imagestreams/secrets [] [] [create delete deletecollection get list patch update watch] rolebindings [] [] [create delete deletecollection get list patch update watch] roles [] [] [create delete deletecollection get list patch update watch] rolebindings.authorization.openshift.io [] [] [create delete deletecollection get list patch update watch] roles.authorization.openshift.io [] [] [create delete deletecollection get list patch update watch] imagestreams.image.openshift.io/secrets [] [] [create delete deletecollection get list patch update watch] rolebindings.rbac.authorization.k8s.io [] [] [create delete deletecollection get list patch update watch] roles.rbac.authorization.k8s.io [] [] [create delete deletecollection get list patch update watch] networkpolicies.extensions [] [] [create delete deletecollection patch update create delete deletecollection get list patch update watch get list watch] networkpolicies.networking.k8s.io [] [] [create delete deletecollection patch update create delete deletecollection get list patch update watch get list watch] configmaps [] [] [create delete deletecollection patch update get list watch] endpoints [] [] [create delete deletecollection patch update get list watch] persistentvolumeclaims [] [] [create delete deletecollection patch update get list watch] pods [] [] [create delete deletecollection patch update get list watch] replicationcontrollers/scale [] [] [create delete deletecollection patch update get list watch] replicationcontrollers [] [] [create delete deletecollection patch update get list watch] services [] [] [create delete deletecollection patch update get list watch] daemonsets.apps [] [] [create delete deletecollection patch update get list watch] deployments.apps/scale [] [] [create delete deletecollection patch update get list watch] deployments.apps [] [] [create delete deletecollection patch update get list watch] replicasets.apps/scale [] [] [create delete deletecollection patch update get list watch] replicasets.apps [] [] [create delete deletecollection patch update get list watch] statefulsets.apps/scale [] [] [create delete deletecollection patch update get list watch] statefulsets.apps [] [] [create delete deletecollection patch update get list watch] horizontalpodautoscalers.autoscaling [] [] [create delete deletecollection patch update get list watch] cronjobs.batch [] [] [create delete deletecollection patch update get list watch] jobs.batch [] [] [create delete deletecollection patch update get list watch] daemonsets.extensions [] [] [create delete deletecollection patch update get list watch] deployments.extensions/scale [] [] [create delete deletecollection patch update get list watch] deployments.extensions [] [] [create delete deletecollection patch update get list watch] ingresses.extensions [] [] [create delete deletecollection patch update get list watch] replicasets.extensions/scale [] [] [create delete deletecollection patch update get list watch] replicasets.extensions [] [] [create delete deletecollection patch update get list watch] replicationcontrollers.extensions/scale [] [] [create delete deletecollection patch update get list watch] poddisruptionbudgets.policy [] [] [create delete deletecollection patch update get list watch] deployments.apps/rollback [] [] [create delete deletecollection patch update] deployments.extensions/rollback [] [] [create delete deletecollection patch update] catalogsources.operators.coreos.com [] [] [create update patch delete get list watch] clusterserviceversions.operators.coreos.com [] [] [create update patch delete get list watch] installplans.operators.coreos.com [] [] [create update patch delete get list watch] packagemanifests.operators.coreos.com [] [] [create update patch delete get list watch] subscriptions.operators.coreos.com [] [] [create update patch delete get list watch] buildconfigs/instantiate [] [] [create] buildconfigs/instantiatebinary [] [] [create] builds/clone [] [] [create] deploymentconfigrollbacks [] [] [create] deploymentconfigs/instantiate [] [] [create] deploymentconfigs/rollback [] [] [create] imagestreamimports [] [] [create] localresourceaccessreviews [] [] [create] localsubjectaccessreviews [] [] [create] podsecuritypolicyreviews [] [] [create] podsecuritypolicyselfsubjectreviews [] [] [create] podsecuritypolicysubjectreviews [] [] [create] resourceaccessreviews [] [] [create] routes/custom-host [] [] [create] subjectaccessreviews [] [] [create] subjectrulesreviews [] [] [create] deploymentconfigrollbacks.apps.openshift.io [] [] [create] deploymentconfigs.apps.openshift.io/instantiate [] [] [create] deploymentconfigs.apps.openshift.io/rollback [] [] [create] localsubjectaccessreviews.authorization.k8s.io [] [] [create] localresourceaccessreviews.authorization.openshift.io [] [] [create] localsubjectaccessreviews.authorization.openshift.io [] [] [create] resourceaccessreviews.authorization.openshift.io [] [] [create] subjectaccessreviews.authorization.openshift.io [] [] [create] subjectrulesreviews.authorization.openshift.io [] [] [create] buildconfigs.build.openshift.io/instantiate [] [] [create] buildconfigs.build.openshift.io/instantiatebinary [] [] [create] builds.build.openshift.io/clone [] [] [create] imagestreamimports.image.openshift.io [] [] [create] routes.route.openshift.io/custom-host [] [] [create] podsecuritypolicyreviews.security.openshift.io [] [] [create] podsecuritypolicyselfsubjectreviews.security.openshift.io [] [] [create] podsecuritypolicysubjectreviews.security.openshift.io [] [] [create] jenkins.build.openshift.io [] [] [edit view view admin edit view] builds [] [] [get create delete deletecollection get list patch update watch get list watch] builds.build.openshift.io [] [] [get create delete deletecollection get list patch update watch get list watch] projects [] [] [get delete get delete get patch update] projects.project.openshift.io [] [] [get delete get delete get patch update] namespaces [] [] [get get list watch] pods/attach [] [] [get list watch create delete deletecollection patch update] pods/exec [] [] [get list watch create delete deletecollection patch update] pods/portforward [] [] [get list watch create delete deletecollection patch update] pods/proxy [] [] [get list watch create delete deletecollection patch update] services/proxy [] [] [get list watch create delete deletecollection patch update] routes/status [] [] [get list watch update] routes.route.openshift.io/status [] [] [get list watch update] appliedclusterresourcequotas [] [] [get list watch] bindings [] [] [get list watch] builds/log [] [] [get list watch] deploymentconfigs/log [] [] [get list watch] deploymentconfigs/status [] [] [get list watch] events [] [] [get list watch] imagestreams/status [] [] [get list watch] limitranges [] [] [get list watch] namespaces/status [] [] [get list watch] pods/log [] [] [get list watch] pods/status [] [] [get list watch] replicationcontrollers/status [] [] [get list watch] resourcequotas/status [] [] [get list watch] resourcequotas [] [] [get list watch] resourcequotausages [] [] [get list watch] rolebindingrestrictions [] [] [get list watch] deploymentconfigs.apps.openshift.io/log [] [] [get list watch] deploymentconfigs.apps.openshift.io/status [] [] [get list watch] controllerrevisions.apps [] [] [get list watch] rolebindingrestrictions.authorization.openshift.io [] [] [get list watch] builds.build.openshift.io/log [] [] [get list watch] imagestreams.image.openshift.io/status [] [] [get list watch] appliedclusterresourcequotas.quota.openshift.io [] [] [get list watch] imagestreams/layers [] [] [get update get] imagestreams.image.openshift.io/layers [] [] [get update get] builds/details [] [] [update] builds.build.openshift.io/details [] [] [update] Name: basic-user Labels: <none> Annotations: openshift.io/description: A user that can get basic information about projects. rbac.authorization.kubernetes.io/autoupdate: true PolicyRule: Resources Non-Resource URLs Resource Names Verbs --------- ----------------- -------------- ----- selfsubjectrulesreviews [] [] [create] selfsubjectaccessreviews.authorization.k8s.io [] [] [create] selfsubjectrulesreviews.authorization.openshift.io [] [] [create] clusterroles.rbac.authorization.k8s.io [] [] [get list watch] clusterroles [] [] [get list] clusterroles.authorization.openshift.io [] [] [get list] storageclasses.storage.k8s.io [] [] [get list] users [] [~] [get] users.user.openshift.io [] [~] [get] projects [] [] [list watch] projects.project.openshift.io [] [] [list watch] projectrequests [] [] [list] projectrequests.project.openshift.io [] [] [list] Name: cluster-admin Labels: kubernetes.io/bootstrapping=rbac-defaults Annotations: rbac.authorization.kubernetes.io/autoupdate: true PolicyRule: Resources Non-Resource URLs Resource Names Verbs --------- ----------------- -------------- ----- *.* [] [] [*] [*] [] [*] ...다양한 역할에 바인딩된 사용자 및 그룹을 표시하는 현재 클러스터 역할 바인딩 집합을 보려면 다음을 수행하십시오.
$ oc describe clusterrolebinding.rbac출력 예
Name: alertmanager-main Labels: <none> Annotations: <none> Role: Kind: ClusterRole Name: alertmanager-main Subjects: Kind Name Namespace ---- ---- --------- ServiceAccount alertmanager-main openshift-monitoring Name: basic-users Labels: <none> Annotations: rbac.authorization.kubernetes.io/autoupdate: true Role: Kind: ClusterRole Name: basic-user Subjects: Kind Name Namespace ---- ---- --------- Group system:authenticated Name: cloud-credential-operator-rolebinding Labels: <none> Annotations: <none> Role: Kind: ClusterRole Name: cloud-credential-operator-role Subjects: Kind Name Namespace ---- ---- --------- ServiceAccount default openshift-cloud-credential-operator Name: cluster-admin Labels: kubernetes.io/bootstrapping=rbac-defaults Annotations: rbac.authorization.kubernetes.io/autoupdate: true Role: Kind: ClusterRole Name: cluster-admin Subjects: Kind Name Namespace ---- ---- --------- Group system:masters Name: cluster-admins Labels: <none> Annotations: rbac.authorization.kubernetes.io/autoupdate: true Role: Kind: ClusterRole Name: cluster-admin Subjects: Kind Name Namespace ---- ---- --------- Group system:cluster-admins User system:admin Name: cluster-api-manager-rolebinding Labels: <none> Annotations: <none> Role: Kind: ClusterRole Name: cluster-api-manager-role Subjects: Kind Name Namespace ---- ---- --------- ServiceAccount default openshift-machine-api ...
11.2.5. 로컬 역할 및 바인딩 보기
oc CLI에서 oc describe 명령을 사용하여 로컬 역할 및 바인딩을 볼 수 있습니다.
사전 요구 사항
-
ocCLI를 설치합니다. 로컬 역할 및 바인딩을 볼 수 있는 권한을 얻습니다.
-
cluster-admin기본 클러스터 역할이 클러스터 전체에서 바인딩된 사용자는 로컬 역할 및 바인딩 보기를 포함하여 모든 리소스에 대해 모든 작업을 수행할 수 있습니다. -
admin기본 클러스터 역할이 로컬로 바인딩된 사용자는 해당 프로젝트의 역할 및 바인딩을 보고 관리할 수 있습니다.
-
절차
현재 프로젝트의 다양한 역할에 바인딩된 사용자 및 그룹을 표시하는 현재의 로컬 역할 바인딩 집합을 보려면 다음을 실행합니다.
$ oc describe rolebinding.rbac다른 프로젝트에 대한 로컬 역할 바인딩을 보려면 명령에
-n플래그를 추가합니다.$ oc describe rolebinding.rbac -n joe-project출력 예
Name: admin Labels: <none> Annotations: <none> Role: Kind: ClusterRole Name: admin Subjects: Kind Name Namespace ---- ---- --------- User kube:admin Name: system:deployers Labels: <none> Annotations: openshift.io/description: Allows deploymentconfigs in this namespace to rollout pods in this namespace. It is auto-managed by a controller; remove subjects to disa... Role: Kind: ClusterRole Name: system:deployer Subjects: Kind Name Namespace ---- ---- --------- ServiceAccount deployer joe-project Name: system:image-builders Labels: <none> Annotations: openshift.io/description: Allows builds in this namespace to push images to this namespace. It is auto-managed by a controller; remove subjects to disable. Role: Kind: ClusterRole Name: system:image-builder Subjects: Kind Name Namespace ---- ---- --------- ServiceAccount builder joe-project Name: system:image-pullers Labels: <none> Annotations: openshift.io/description: Allows all pods in this namespace to pull images from this namespace. It is auto-managed by a controller; remove subjects to disable. Role: Kind: ClusterRole Name: system:image-puller Subjects: Kind Name Namespace ---- ---- --------- Group system:serviceaccounts:joe-project
11.2.6. 사용자 역할 추가
oc adm 관리자 CLI를 사용하여 역할 및 바인딩을 관리할 수 있습니다.
사용자 또는 그룹에 역할을 바인딩하거나 추가하면 역할에 따라 사용자 또는 그룹에 부여되는 액세스 권한이 부여됩니다. oc adm policy 명령을 사용하여 사용자 및 그룹에 역할을 추가하거나 사용자 및 그룹으로부터 역할을 제거할 수 있습니다.
기본 클러스터 역할을 프로젝트의 로컬 사용자 또는 그룹에 바인딩할 수 있습니다.
절차
특정 프로젝트의 사용자에게 역할을 추가합니다.
$ oc adm policy add-role-to-user <role> <user> -n <project>예를 들면 다음을 실행하여
joe프로젝트의alice사용자에게admin역할을 추가할 수 있습니다.$ oc adm policy add-role-to-user admin alice -n joe작은 정보다음 YAML을 적용하여 사용자에게 역할을 추가할 수도 있습니다.
apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: admin-0 namespace: joe roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: admin subjects: - apiGroup: rbac.authorization.k8s.io kind: User name: alice로컬 역할 바인딩을 보고 출력에 추가되었는지 확인합니다.
$ oc describe rolebinding.rbac -n <project>예를 들어,
joe프로젝트의 로컬 역할 바인딩을 보려면 다음을 수행합니다.$ oc describe rolebinding.rbac -n joe출력 예
Name: admin Labels: <none> Annotations: <none> Role: Kind: ClusterRole Name: admin Subjects: Kind Name Namespace ---- ---- --------- User kube:admin Name: admin-0 Labels: <none> Annotations: <none> Role: Kind: ClusterRole Name: admin Subjects: Kind Name Namespace ---- ---- --------- User alice1 Name: system:deployers Labels: <none> Annotations: openshift.io/description: Allows deploymentconfigs in this namespace to rollout pods in this namespace. It is auto-managed by a controller; remove subjects to disa... Role: Kind: ClusterRole Name: system:deployer Subjects: Kind Name Namespace ---- ---- --------- ServiceAccount deployer joe Name: system:image-builders Labels: <none> Annotations: openshift.io/description: Allows builds in this namespace to push images to this namespace. It is auto-managed by a controller; remove subjects to disable. Role: Kind: ClusterRole Name: system:image-builder Subjects: Kind Name Namespace ---- ---- --------- ServiceAccount builder joe Name: system:image-pullers Labels: <none> Annotations: openshift.io/description: Allows all pods in this namespace to pull images from this namespace. It is auto-managed by a controller; remove subjects to disable. Role: Kind: ClusterRole Name: system:image-puller Subjects: Kind Name Namespace ---- ---- --------- Group system:serviceaccounts:joe- 1
alice사용자가adminsRoleBinding에 추가되었습니다.
11.2.7. 로컬 역할 생성
프로젝트의 로컬 역할을 생성하여 이 역할을 사용자에게 바인딩할 수 있습니다.
절차
프로젝트의 로컬 역할을 생성하려면 다음 명령을 실행합니다.
$ oc create role <name> --verb=<verb> --resource=<resource> -n <project>이 명령에서는 다음을 지정합니다.
-
<name>: 로컬 역할 이름 -
<verb>: 역할에 적용할 동사를 쉼표로 구분한 목록 -
<resource>: 역할이 적용되는 리소스 -
<project>: 프로젝트 이름
예를 들어, 사용자가
blue프로젝트의 Pod를 볼 수 있는 로컬 역할을 생성하려면 다음 명령을 실행합니다.$ oc create role podview --verb=get --resource=pod -n blue-
새 역할을 사용자에게 바인딩하려면 다음 명령을 실행합니다.
$ oc adm policy add-role-to-user podview user2 --role-namespace=blue -n blue
11.2.8. 클러스터 역할 생성
클러스터 역할을 만들 수 있습니다.
절차
클러스터 역할을 만들려면 다음 명령을 실행합니다.
$ oc create clusterrole <name> --verb=<verb> --resource=<resource>이 명령에서는 다음을 지정합니다.
-
<name>: 로컬 역할 이름 -
<verb>: 역할에 적용할 동사를 쉼표로 구분한 목록 -
<resource>: 역할이 적용되는 리소스
예를 들어 사용자가 pod를 볼 수 있는 클러스터 역할을 만들려면 다음 명령을 실행합니다.
$ oc create clusterrole podviewonly --verb=get --resource=pod-
11.2.9. 로컬 역할 바인딩 명령
다음 작업을 사용하여 로컬 역할 바인딩에 대한 사용자 또는 그룹의 연결된 역할을 관리하는 경우, -n 플래그를 사용하여 프로젝트를 지정할 수 있습니다. 지정하지 않으면 현재 프로젝트가 사용됩니다.
다음 명령을 사용하여 로컬 RBAC를 관리할 수 있습니다.
| 명령 | 설명 |
|---|---|
|
| 리소스에 작업을 수행할 수 있는 사용자를 나타냅니다. |
|
| 현재 프로젝트에서 지정된 사용자에게 지정된 역할을 바인딩합니다. |
|
| 현재 프로젝트에서 지정된 사용자로부터 지정된 역할을 제거합니다. |
|
| 현재 프로젝트에서 지정된 사용자 및 해당 사용자의 역할을 모두 제거합니다. |
|
| 현재 프로젝트에서 지정된 그룹에 지정된 역할을 바인딩합니다. |
|
| 현재 프로젝트에서 지정된 그룹의 지정된 역할을 제거합니다. |
|
| 현재 프로젝트에서 지정된 그룹과 해당 그룹의 역할을 모두 제거합니다. |
11.2.10. 클러스터 역할 바인딩 명령
다음 작업을 사용하여 클러스터 역할 바인딩을 관리할 수도 있습니다. 클러스터 역할 바인딩에 네임스페이스가 아닌 리소스가 사용되므로 -n 플래그가 해당 작업에 사용되지 않습니다.
| 명령 | 설명 |
|---|---|
|
| 클러스터의 모든 프로젝트에 대해 지정된 사용자에게 지정된 역할을 바인딩합니다. |
|
| 클러스터의 모든 프로젝트에 대해 지정된 사용자로부터 지정된 역할을 제거합니다. |
|
| 클러스터의 모든 프로젝트에 대해 지정된 역할을 지정된 그룹에 바인딩합니다. |
|
| 클러스터의 모든 프로젝트에 대해 지정된 그룹에서 지정된 역할을 제거합니다. |
11.2.11. 클러스터 관리자 생성
클러스터 리소스 수정과 같은 OpenShift Container Platform 클러스터에서 관리자 수준 작업을 수행하려면 cluster-admin 역할이 필요합니다.
사전 요구 사항
- 클러스터 관리자로 정의할 사용자를 생성해야 합니다.
절차
사용자를 클러스터 관리자로 정의합니다.
$ oc adm policy add-cluster-role-to-user cluster-admin <user>
11.3. kubeadmin 사용자
OpenShift Container Platform에서는 설치 프로세스가 완료되면 클러스터 관리자 kubeadmin을 생성합니다.
이 사용자는 cluster-admin 역할이 자동으로 적용되며 클러스터의 루트 사용자로 취급됩니다. 암호는 동적으로 생성되며 OpenShift Container Platform 환경에서 고유합니다. 설치가 완료되면 설치 프로그램의 출력에 암호가 제공됩니다. 예를 들면 다음과 같습니다.
INFO Install complete!
INFO Run 'export KUBECONFIG=<your working directory>/auth/kubeconfig' to manage the cluster with 'oc', the OpenShift CLI.
INFO The cluster is ready when 'oc login -u kubeadmin -p <provided>' succeeds (wait a few minutes).
INFO Access the OpenShift web-console here: https://console-openshift-console.apps.demo1.openshift4-beta-abcorp.com
INFO Login to the console with user: kubeadmin, password: <provided>11.3.1. kubeadmin 사용자 제거
ID 공급자를 정의하고 새 cluster-admin 사용자를 만든 다음 kubeadmin을 제거하여 클러스터 보안을 강화할 수 있습니다.
다른 사용자가 cluster-admin이 되기 전에 이 절차를 수행하는 경우 OpenShift Container Platform을 다시 설치해야 합니다. 이 명령은 취소할 수 없습니다.
사전 요구 사항
- 하나 이상의 ID 공급자를 구성해야 합니다.
-
사용자에게
cluster-admin역할을 추가해야 합니다. - 관리자로 로그인해야 합니다.
절차
kubeadmin시크릿을 제거합니다.$ oc delete secrets kubeadmin -n kube-system
11.4. 미러링된 Operator 카탈로그에서 OperatorHub 채우기
연결이 끊긴 클러스터에 사용하기 위해 Operator 카탈로그를 미러링한 경우 미러링된 카탈로그에서 Operator로 OperatorHub를 채울 수 있습니다. 미러링 프로세스에서 생성된 매니페스트를 사용하여 필요한 ImageContentSourcePolicy 및 CatalogSource 오브젝트를 생성할 수 있습니다.
11.4.1. 사전 요구 사항
11.4.1.1. ImageContentSourcePolicy 오브젝트 생성
Operator 카탈로그 콘텐츠를 미러 레지스트리에 미러링한 후 필요한 ImageContentSourcePolicy (ICSP) 오브젝트를 생성합니다. ICSP 오브젝트는 Operator 매니페스트에 저장된 이미지 참조와 미러링된 레지스트리 간에 변환하도록 노드를 구성합니다.
절차
연결이 끊긴 클러스터에 액세스할 수 있는 호스트에서 매니페스트 디렉터리에
imageContentSourcePolicy.yaml파일을 지정하도록 다음 명령을 실행하여 ICSP를 생성합니다.$ oc create -f <path/to/manifests/dir>/imageContentSourcePolicy.yaml여기서
<path/to/manifests/dir>은 미러링된 콘텐츠의 매니페스트 디렉터리 경로입니다.이제 미러링된 인덱스 이미지 및 Operator 콘텐츠를 참조하도록
CatalogSource오브젝트를 생성할 수 있습니다.
11.4.1.2. 클러스터에 카탈로그 소스 추가
OpenShift Container Platform 클러스터에 카탈로그 소스를 추가하면 사용자를 위한 Operator를 검색하고 설치할 수 있습니다. 클러스터 관리자는 인덱스 이미지를 참조하는 CatalogSource 오브젝트를 생성할 수 있습니다. OperatorHub는 카탈로그 소스를 사용하여 사용자 인터페이스를 채웁니다.
또는 웹 콘솔을 사용하여 카탈로그 소스를 관리할 수 있습니다. 관리 → 클러스터 설정 → 구성 → OperatorHub 페이지에서 개별 소스 를 생성, 업데이트, 삭제, 비활성화 및 활성화할 수 있는 소스 탭을 클릭합니다.
사전 요구 사항
- 인덱스 이미지를 빌드하여 레지스트리로 내보냈습니다.
-
cluster-admin역할의 사용자로 클러스터에 액세스할 수 있어야 합니다.
절차
인덱스 이미지를 참조하는
CatalogSource오브젝트를 생성합니다.oc adm catalog mirror명령을 사용하여 카탈로그를 대상 레지스트리에 미러링한 경우 매니페스트 디렉터리에서 생성된catalogSource.yaml파일을 시작점으로 사용할 수 있습니다.다음을 사양에 맞게 수정하고
catalogsource.yaml파일로 저장합니다.apiVersion: operators.coreos.com/v1alpha1 kind: CatalogSource metadata: name: my-operator-catalog1 namespace: openshift-marketplace2 spec: sourceType: grpc grpcPodConfig: securityContextConfig: <security_mode>3 image: <registry>/<namespace>/redhat-operator-index:v4.134 displayName: My Operator Catalog publisher: <publisher_name>5 updateStrategy: registryPoll:6 interval: 30m- 1
- 레지스트리에 업로드하기 전에 콘텐츠를 로컬 파일에 미러링한 경우 오브젝트를 생성할 때 "잘못된 리소스 이름" 오류가 발생하지 않도록
metadata.name필드에서 백슬래시(/) 문자를 제거합니다. - 2
- 카탈로그 소스를 모든 네임스페이스의 사용자가 전역적으로 사용할 수 있도록 하려면
openshift-marketplace네임스페이스를 지정합니다. 그러지 않으면 카탈로그의 범위가 지정되고 해당 네임스페이스에 대해서만 사용할 수 있도록 다른 네임스페이스를 지정할 수 있습니다. - 3
legacy또는restricted의 값을 지정합니다. 필드가 설정되지 않은 경우 기본값은legacy입니다. 향후 OpenShift Container Platform 릴리스에서는 기본값이제한될 예정입니다.제한된권한으로 카탈로그를 실행할 수 없는 경우 이 필드를 기존로 수동으로 설정하는 것이좋습니다.- 4
- 인덱스 이미지를 지정합니다. 이미지 이름 뒤에 태그를 지정하는 경우 (예:
:v4.13) 카탈로그 소스 Pod는Always라는 이미지 가져오기 정책을 사용합니다. 즉, Pod는 컨테이너를 시작하기 전에 항상 이미지를 가져옵니다. 다이제스트(예:@sha256:<id>)를 지정하는 경우 이미지 가져오기 정책은IfNotPresent입니다. 즉, 노드에 아직 존재하지 않는 경우에만 Pod에서 이미지를 가져옵니다. - 5
- 카탈로그를 게시하는 이름 또는 조직 이름을 지정합니다.
- 6
- 카탈로그 소스는 새 버전을 자동으로 확인하여 최신 상태를 유지할 수 있습니다.
파일을 사용하여
CatalogSource오브젝트를 생성합니다.$ oc apply -f catalogSource.yaml
다음 리소스가 성공적으로 생성되었는지 확인합니다.
Pod를 확인합니다.
$ oc get pods -n openshift-marketplace출력 예
NAME READY STATUS RESTARTS AGE my-operator-catalog-6njx6 1/1 Running 0 28s marketplace-operator-d9f549946-96sgr 1/1 Running 0 26h카탈로그 소스를 확인합니다.
$ oc get catalogsource -n openshift-marketplace출력 예
NAME DISPLAY TYPE PUBLISHER AGE my-operator-catalog My Operator Catalog grpc 5s패키지 매니페스트 확인합니다.
$ oc get packagemanifest -n openshift-marketplace출력 예
NAME CATALOG AGE jaeger-product My Operator Catalog 93s
이제 OpenShift Container Platform 웹 콘솔의 OperatorHub 페이지에서 Operator를 설치할 수 있습니다.
11.5. OperatorHub를 통한 Operator 설치 정보
OperatorHub는 Operator를 검색하는 사용자 인터페이스입니다. 이는 클러스터에 Operator를 설치하고 관리하는 OLM(Operator Lifecycle Manager)과 함께 작동합니다.
클러스터 관리자는 OpenShift Container Platform 웹 콘솔 또는 CLI를 사용하여 OperatorHub에서 Operator를 설치할 수 있습니다. 그런 다음 Operator를 하나 이상의 네임 스페이스에 가입시켜 Operator를 클러스터의 개발자가 사용할 수 있도록 합니다.
설치하는 동안 Operator의 다음 초기 설정을 결정해야합니다.
- 설치 모드
- All namespaces on the cluster (default)를 선택하여 Operator를 모든 네임 스페이스에 설치하거나 사용 가능한 경우 개별 네임 스페이스를 선택하여 선택한 네임 스페이스에만 Operator를 설치합니다. 이 예에서는 모든 사용자와 프로젝트 Operator를 사용할 수 있도록 All namespaces… 선택합니다.
- 업데이트 채널
- 여러 채널을 통해 Operator를 사용할 수있는 경우 구독할 채널을 선택할 수 있습니다. 예를 들어, stable 채널에서 배치하려면 (사용 가능한 경우) 목록에서 해당 채널을 선택합니다.
- 승인 전략
자동 또는 수동 업데이트를 선택할 수 있습니다.
설치된 Operator에 대해 자동 업데이트를 선택하는 경우 선택한 채널에 해당 Operator의 새 버전이 제공되면 OLM(Operator Lifecycle Manager)에서 Operator의 실행 중인 인스턴스를 개입 없이 자동으로 업그레이드합니다.
수동 업데이트를 선택하면 최신 버전의 Operator가 사용 가능할 때 OLM이 업데이트 요청을 작성합니다. 클러스터 관리자는 Operator를 새 버전으로 업데이트하려면 OLM 업데이트 요청을 수동으로 승인해야 합니다.
11.5.1. 웹 콘솔을 사용하여 OperatorHub에서 설치
OpenShift Container Platform 웹 콘솔을 사용하여 OperatorHub에서 Operator를 설치하고 구독할 수 있습니다.
사전 요구 사항
-
cluster-admin권한이 있는 계정을 사용하여 OpenShift Container Platform 클러스터에 액세스할 수 있습니다.
절차
- 웹 콘솔에서 Operators → OperatorHub 페이지로 이동합니다.
원하는 Operator를 찾으려면 키워드를 Filter by keyword 상자에 입력하거나 스크롤합니다. 예를 들어, Jaeger Operator를 찾으려면
jaeger를 입력합니다.인프라 기능에서 옵션을 필터링할 수 있습니다. 예를 들어, 연결이 끊긴 환경 (제한된 네트워크 환경이라고도 함)에서 작업하는 Operator를 표시하려면 Disconnected를 선택합니다.
Operator를 선택하여 추가 정보를 표시합니다.
참고커뮤니티 Operator를 선택하면 Red Hat이 커뮤니티 Operator를 인증하지 않는다고 경고합니다. 계속하기 전에 경고를 확인해야합니다.
- Operator에 대한 정보를 확인하고 Install을 클릭합니다.
Operator 설치 페이지에서 다음을 수행합니다.
다음 명령 중 하나를 선택합니다.
-
All namespaces on the cluster (default)에서는 기본
openshift-operators네임스페이스에 Operator가 설치되므로 Operator가 클러스터의 모든 네임스페이스를 모니터링하고 사용할 수 있습니다. 이 옵션을 항상 사용할 수있는 것은 아닙니다. - A specific namespace on the cluster를 사용하면 Operator를 설치할 특정 단일 네임 스페이스를 선택할 수 있습니다. Operator는 이 단일 네임 스페이스에서만 모니터링 및 사용할 수 있게 됩니다.
-
All namespaces on the cluster (default)에서는 기본
- 업데이트 채널을 선택합니다(사용 가능한 경우).
- 앞에서 설명한 대로 자동 또는 수동 승인 전략을 선택합니다.
이 OpenShift Container Platform 클러스터에서 선택한 네임스페이스에서 Operator를 사용할 수 있도록 하려면 설치를 클릭합니다.
수동 승인 전략을 선택한 경우 설치 계획을 검토하고 승인할 때까지 서브스크립션의 업그레이드 상태가 업그레이드 중으로 유지됩니다.
Install Plan 페이지에서 승인 한 후 subscription 업그레이드 상태가 Up to date로 이동합니다.
- 자동 승인 전략을 선택한 경우 업그레이드 상태가 개입 없이 최신 상태로 확인되어야 합니다.
서브스크립션의 업그레이드 상태가 최신이면 Operator → 설치된 Operator를 선택하여 설치된 Operator의 CSV(클러스터 서비스 버전)가 최종적으로 표시되는지 확인합니다. 상태는 최종적으로 관련 네임스페이스에서 InstallSucceeded로 확인되어야 합니다.
참고모든 네임스페이스… 설치 모드의 경우,
openshift-operators네임스페이스에서 상태가 InstallSucceeded로 확인되지만 다른 네임스페이스에서 확인하면 상태가 복사됨입니다.그렇지 않은 경우 다음을 수행합니다.
-
워크로드 → Pod 페이지의
openshift-operators프로젝트(또는 특정 네임스페이스…설치 모드가 선택된 경우 기타 관련 네임스페이스)에서 문제를 보고하는 모든 Pod의 로그를 확인하여 문제를 추가로 해결합니다.
-
워크로드 → Pod 페이지의
11.5.2. CLI를 사용하여 OperatorHub에서 설치
OpenShift Container Platform 웹 콘솔을 사용하는 대신 CLI를 사용하여 OperatorHub에서 Operator를 설치할 수 있습니다. oc 명령을 사용하여 Subscription 개체를 만들거나 업데이트합니다.
사전 요구 사항
-
cluster-admin권한이 있는 계정을 사용하여 OpenShift Container Platform 클러스터에 액세스할 수 있습니다. -
OpenShift CLI(
oc)가 설치되어 있습니다.
절차
OperatorHub에서 클러스터에 사용 가능한 Operator의 목록을 표시합니다.
$ oc get packagemanifests -n openshift-marketplace출력 예
NAME CATALOG AGE 3scale-operator Red Hat Operators 91m advanced-cluster-management Red Hat Operators 91m amq7-cert-manager Red Hat Operators 91m ... couchbase-enterprise-certified Certified Operators 91m crunchy-postgres-operator Certified Operators 91m mongodb-enterprise Certified Operators 91m ... etcd Community Operators 91m jaeger Community Operators 91m kubefed Community Operators 91m ...필요한 Operator의 카탈로그를 기록해 둡니다.
필요한 Operator를 검사하여 지원되는 설치 모드 및 사용 가능한 채널을 확인합니다.
$ oc describe packagemanifests <operator_name> -n openshift-marketplaceOperatorGroup오브젝트로 정의되는 Operator group에서 Operator group과 동일한 네임스페이스에 있는 모든 Operator에 대해 필요한 RBAC 액세스 권한을 생성할 대상 네임스페이스를 선택합니다.Operator를 서브스크립션하는 네임스페이스에는 Operator의 설치 모드, 즉
AllNamespaces또는SingleNamespace모드와 일치하는 Operator group이 있어야 합니다. 설치하려는 Operator에서AllNamespaces모드를 사용하는 경우openshift-operators네임스페이스에 적절한global-operatorsOperator group이 이미 있습니다.그러나 Operator에서
SingleNamespace모드를 사용하고 적절한 Operator group이 없는 경우 이를 생성해야 합니다.참고-
이 프로세스의 웹 콘솔 버전에서는
SingleNamespace모드를 선택할 때 자동으로OperatorGroup및Subscription개체 생성을 자동으로 처리합니다. - 네임스페이스당 하나의 Operator 그룹만 있을 수 있습니다. 자세한 내용은 "Operator groups"을 참조하십시오.
OperatorGroup개체 YAML 파일을 만듭니다 (예:operatorgroup.yaml).OperatorGroup오브젝트의 예apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: name: <operatorgroup_name> namespace: <namespace> spec: targetNamespaces: - <namespace>주의OLM(Operator Lifecycle Manager)은 각 Operator 그룹에 대해 다음 클러스터 역할을 생성합니다.
-
<operatorgroup_name>-admin -
<operatorgroup_name>-edit -
<operatorgroup_name>-view
Operator group을 수동으로 생성할 때 클러스터의 기존 클러스터 역할 또는 기타 Operator 그룹과 충돌하지 않는 고유한 이름을 지정해야 합니다.
-
OperatorGroup개체를 생성합니다.$ oc apply -f operatorgroup.yaml
-
이 프로세스의 웹 콘솔 버전에서는
Subscription개체 YAML 파일을 생성하여 OpenShift Pipelines Operator에 네임스페이스를 등록합니다(예:sub.yaml).Subscription개체 예apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: <subscription_name> namespace: openshift-operators1 spec: channel: <channel_name>2 name: <operator_name>3 source: redhat-operators4 sourceNamespace: openshift-marketplace5 config: env:6 - name: ARGS value: "-v=10" envFrom:7 - secretRef: name: license-secret volumes:8 - name: <volume_name> configMap: name: <configmap_name> volumeMounts:9 - mountPath: <directory_name> name: <volume_name> tolerations:10 - operator: "Exists" resources:11 requests: memory: "64Mi" cpu: "250m" limits: memory: "128Mi" cpu: "500m" nodeSelector:12 foo: bar- 1
- 기본
AllNamespaces설치 모드 사용량의 경우openshift-operators네임스페이스를 지정합니다. 또는 사용자 지정 글로벌 네임스페이스를 생성한 경우 지정할 수 있습니다. 그 외에는SingleNamespace설치 모드를 사용하도록 관련 단일 네임스페이스를 지정합니다. - 2
- 등록할 채널의 이름입니다.
- 3
- 등록할 Operator의 이름입니다.
- 4
- Operator를 제공하는 카탈로그 소스의 이름입니다.
- 5
- 카탈로그 소스의 네임스페이스입니다. 기본 OperatorHub 카탈로그 소스에는
openshift-marketplace를 사용합니다. - 6
env매개변수는 OLM에서 생성한 포드의 모든 컨테이너에 있어야 하는 환경 변수 목록을 정의합니다.- 7
envFrom매개변수는 컨테이너에서 환경 변수를 채울 소스 목록을 정의합니다.- 8
volumes매개변수는 OLM에서 생성한 Pod에 있어야 하는 볼륨 목록을 정의합니다.- 9
volumeMounts매개변수는 OLM에서 생성한 Pod의 모든 컨테이너에 존재해야 하는 VolumeMount 목록을 정의합니다.volumeMount가 존재하지 않는볼륨을참조하는 경우 OLM은 Operator를 배포하지 못합니다.- 10
tolerations매개변수는 OLM에서 생성한 Pod의 허용 목록을 정의합니다.- 11
resources매개변수는 OLM에서 생성한 Pod의 모든 컨테이너에 대한 리소스 제약 조건을 정의합니다.- 12
nodeSelector매개변수는 OLM에서 생성한 Pod의NodeSelector를 정의합니다.
Subscription오브젝트를 생성합니다.$ oc apply -f sub.yaml이 시점에서 OLM은 이제 선택한 Operator를 인식합니다. Operator의 CSV(클러스터 서비스 버전)가 대상 네임스페이스에 표시되고 Operator에서 제공하는 API를 생성에 사용할 수 있어야 합니다.
12장. 경고 알림 구성
OpenShift Container Platform에서는 경고 규칙에 정의된 조건이 true이면 경고가 실행됩니다. 경고는 클러스터 내에서 일련의 상황이 발생한다는 통지를 제공합니다. 기본적으로 OpenShift Container Platform 웹 콘솔의 알림 UI에서 실행 경고가 표시됩니다. 설치 후 OpenShift Container Platform을 구성하여 외부 시스템에 경고 알림을 보낼 수 있습니다.
12.1. 외부 시스템에 알림 전송
OpenShift Container Platform 4.13에서는 알림 UI에서 실행 경고를 볼 수 있습니다. 알림은 기본적으로 모든 알림 시스템으로 전송되지 않습니다. 다음 수신자 유형으로 알림을 전송하도록 OpenShift Container Platform을 구성할 수 있습니다.
- PagerDuty
- Webhook
- 이메일
- Slack
알림을 수신기로 라우팅하면 오류가 발생할 때 적절한 팀에게 적절한 알림을 보낼 수 있습니다. 예를 들어, 심각한 경고는 즉각적인 주의가 필요하며 일반적으로 개인 또는 문제 대응팀으로 호출됩니다. 심각하지 않은 경고 알림을 제공하는 경고는 즉각적이지 않은 검토를 위해 티켓팅 시스템으로 라우팅할 수 있습니다.
워치독 경고를 사용하여 해당 경고가 제대로 작동하는지 확인
OpenShift Container Platform 모니터링에는 지속적으로 트리거되는 워치독 경고가 포함되어 있습니다. Alertmanager는 구성된 알림 공급자에게 워치독 경고 알림을 반복적으로 보냅니다. 일반적으로 공급자는 워치독 경고를 수신하지 않을 때 관리자에게 알리도록 구성됩니다. 이 메커니즘을 사용하면 Alertmanager와 알림 공급자 간의 모든 통신 문제를 빠르게 식별할 수 있습니다.
12.1.1. 경고 수신자 구성
클러스터의 중요한 문제를 파악할 수 있도록 경고 수신자를 설정할 수 있습니다.
사전 요구 사항
-
cluster-admin클러스터 역할의 사용자로 클러스터에 액세스할 수 있습니다.
절차
관리자 관점에서 관리 → 클러스터 설정 → 구성 → Alertmanager 로 이동합니다.
참고또는 알림 서랍을 통해 동일한 페이지로 이동할 수 있습니다. OpenShift Container Platform 웹 콘솔의 오른쪽 상단에서 호출 아이콘을 선택하고 AlertmanagerReceiverNotConfigured 경고에서 구성을 선택합니다.
- 페이지의 수신자 섹션에서 수신자 만들기 를 클릭합니다.
- 수신자 만들기 양식에서 수신자 이름을 추가하고 목록에서 수신자 유형을 선택합니다.
수신자 구성을 편집합니다.
PagerDuty 수신자의 경우:
- 통합 유형을 선택하고 PagerDuty 통합 키를 추가합니다.
- PagerDuty 설치의 URL을 추가합니다.
- 클라이언트 및 사고 세부 정보 또는 심각도 사양을 편집하려면 고급 구성 표시를 클릭합니다.
Webhook 수신자의 경우:
- HTTP POST 요청이 전송되는 끝점을 추가합니다.
- 해결된 경고를 수신자에게 보내는 기본 옵션을 편집하려면 고급 구성 표시를 클릭합니다.
이메일 수신자의 경우:
- 알림을 받을 이메일 주소를 추가합니다.
- 알림을 전송할 주소, 이메일 전송에 사용되는 스마트 호스트 및 포트 번호, SMTP 서버의 호스트 이름, 인증 세부 정보를 포함하여 SMTP 구성 세부 정보를 추가합니다.
- TLS가 필요한지 여부를 선택합니다.
- 해결된 경고를 수신자에게 보내지 않도록 기본 옵션을 편집하거나 이메일 알림 구성을 편집하려면 고급 설정 표시를 클릭합니다.
Slack 수신자의 경우:
- Slack Webhook의 URL을 추가합니다.
- 알림을 보낼 Slack 채널 또는 사용자 이름을 추가합니다.
- 해결된 경고를 수신자에게 보내지 않도록 기본 옵션을 편집하거나 아이콘 및 사용자 이름 구성을 편집하려면 고급 설정 표시를 선택합니다. 채널 이름과 사용자 이름을 찾고 연결할지 여부를 선택할 수도 있습니다.
기본적으로 모든 선택기와 일치하는 라벨을 사용하여 경고를 수신자에게 보냅니다. 실행 경고에 대한 라벨 값이 수신자로 전송되기 직전에 일치하도록 하려면 다음 단계를 수행합니다.
- 양식의 라우팅 라벨 섹션에 라우팅 라벨 이름과 값을 추가합니다.
- 정규식 을 사용하려면 정규식을 선택합니다.
- 레이블 추가 를 클릭하여 추가 라우팅 라벨을 추가합니다.
- 생성 을 클릭하여 수신자를 생성합니다.
13장. 연결된 클러스터를 연결이 끊긴 클러스터로 변환
OpenShift Container Platform 클러스터를 연결된 클러스터에서 연결이 끊긴 클러스터로 변환해야 하는 몇 가지 시나리오가 있을 수 있습니다.
제한된 클러스터라고도 하는 연결이 끊긴 클러스터에는 인터넷에 활성 연결이 없습니다. 따라서 레지스트리 및 설치 미디어의 콘텐츠를 미러링해야 합니다. 인터넷과 폐쇄 네트워크에 모두 액세스할 수 있는 호스트에 이 미러 레지스트리를 생성하거나 네트워크 경계를 건너뛸 수 있는 장치에 이미지를 복사할 수 있습니다.
이 주제에서는 연결된 기존 클러스터를 연결이 끊긴 클러스터로 변환하는 일반 프로세스에 대해 설명합니다.
13.1. 미러 레지스트리 정보
OpenShift Container Platform 설치 및 후속 제품 업데이트에 Red Hat Quay, JFrog Artifactory, Sonatype Nexus Repository 또는 Harbor와 같은 컨테이너 미러 레지스트리에 필요한 이미지를 미러링할 수 있습니다. 대규모 컨테이너 레지스트리에 액세스할 수 없는 경우 OpenShift Container Platform 서브스크립션에 포함된 소규모 컨테이너 레지스트리인 Red Hat OpenShift에 미러 레지스트리를 사용할 수 있습니다.
Red Hat Quay, the mirror registry for Red Hat OpenShift, Artifactory, Sonatype Nexus Repository, 또는 Harbor와 같이 Docker v2-2를 지원하는 컨테이너 레지스트리를 사용할 수 있습니다. 선택한 레지스트리에 관계없이 인터넷상의 Red Hat 호스팅 사이트의 콘텐츠를 격리된 이미지 레지스트리로 미러링하는 절차는 동일합니다. 콘텐츠를 미러링한 후 미러 레지스트리에서 이 콘텐츠를 검색하도록 각 클러스터를 설정합니다.
OpenShift 이미지 레지스트리는 미러링 프로세스 중에 필요한 태그 없이 푸시를 지원하지 않으므로 대상 레지스트리로 사용할 수 없습니다.
Red Hat OpenShift의 미러 레지스트리가 아닌 컨테이너 레지스트리를 선택하는 경우 프로비저닝하는 클러스터의 모든 시스템에서 액세스할 수 있어야 합니다. 레지스트리에 연결할 수 없는 경우 설치, 업데이트 또는 워크로드 재배치와 같은 일반 작업이 실패할 수 있습니다. 따라서 고가용성 방식으로 미러 레지스트리를 실행해야하며 미러 레지스트리는 최소한 OpenShift Container Platform 클러스터의 프로덕션 환경의 가용성조건에 일치해야 합니다.
미러 레지스트리를 OpenShift Container Platform 이미지로 채우면 다음 두 가지 시나리오를 수행할 수 있습니다. 호스트가 인터넷과 미러 레지스트리에 모두 액세스할 수 있지만 클러스터 노드에 액세스 할 수 없는 경우 해당 머신의 콘텐츠를 직접 미러링할 수 있습니다. 이 프로세스를 connected mirroring(미러링 연결)이라고 합니다. 그러한 호스트가 없는 경우 이미지를 파일 시스템에 미러링한 다음 해당 호스트 또는 이동식 미디어를 제한된 환경에 배치해야 합니다. 이 프로세스를 미러링 연결 해제라고 합니다.
미러링된 레지스트리의 경우 가져온 이미지의 소스를 보려면 CRI-O 로그의 Trying to access 로그 항목을 검토해야 합니다. 노드에서 crictl images 명령을 사용하는 등의 이미지 가져오기 소스를 보는 다른 방법은 미러링되지 않은 이미지 이름을 표시합니다.
Red Hat은 OpenShift Container Platform에서 타사 레지스트리를 테스트하지 않습니다.
13.2. 사전 요구 사항
-
oc클라이언트가 설치되어 있어야 합니다. - 실행 중인 클러스터가 있어야 합니다.
다음 레지스트리 중 하나와 같이 OpenShift Container Platform 클러스터를 호스팅할 위치에서 Docker v2-2 를 지원하는 컨테이너 이미지 레지스트리인 설치된 미러 레지스트리.
Red Hat Quay에 대한 서브스크립션이 있는 경우 개념 증명을 사용하거나 Quay Operator를 사용하여 Red Hat Quay 배포에 대한 설명서를 참조하십시오.
- 이미지를 공유하도록 미러 저장소를 구성해야 합니다. 예를 들어, Red Hat Quay 리포지토리에는 이미지를 공유하기 위해 조직이 필요합니다.
- 필요한 컨테이너 이미지를 얻으려면 인터넷에 액세스합니다.
13.3. 미러링을 위한 클러스터 준비
클러스터 연결을 해제하기 전에 연결이 끊긴 클러스터의 모든 노드에서 연결할 수 있는 미러 레지스트리에 이미지를 미러링하거나 복사해야 합니다. 이미지를 미러링하려면 다음을 통해 클러스터를 준비해야 합니다.
- 미러 레지스트리 인증서를 호스트의 신뢰할 수 있는 CA 목록에 추가합니다.
-
cloud.openshift.com토큰에서 가져온 이미지 가져오기 보안이 포함된.dockerconfigjson파일을 생성합니다.
절차
이미지 미러링을 허용하는 인증 정보 구성:
간단한 PEM 또는 DER 파일 형식의 미러 레지스트리의 CA 인증서를 신뢰할 수 있는 CA 목록에 추가합니다. 예를 들면 다음과 같습니다.
$ cp </path/to/cert.crt> /usr/share/pki/ca-trust-source/anchors/- 다음과 같습니다.,
</path/to/cert.crt> - 로컬 파일 시스템의 인증서 경로를 지정합니다.
- 다음과 같습니다.,
CA 신뢰를 업데이트합니다. 예를 들어 Linux에서는 다음을 수행합니다.
$ update-ca-trust글로벌 가져오기 보안에서
.dockerconfigjson파일을 추출합니다.$ oc extract secret/pull-secret -n openshift-config --confirm --to=.출력 예
.dockerconfigjson.dockerconfigjson파일을 편집하여 미러 레지스트리 및 인증 자격 증명을 추가하고 새 파일로 저장합니다.{"auths":{"<local_registry>": {"auth": "<credentials>","email": "you@example.com"}}},"<registry>:<port>/<namespace>/":{"auth":"<token>"}}}다음과 같습니다.
<local_registry>- 미러 레지스트리가 컨텐츠를 제공하는 데 사용하는 레지스트리 도메인 이름 및 포트(선택사항)를 지정합니다.
auth- 미러 레지스트리의 base64로 인코딩된 사용자 이름 및 암호를 지정합니다.
<registry>:<port>/<namespace>- 미러 레지스트리 세부 정보를 지정합니다.
<token>미러 레지스트리에 대해 base64로 인코딩된
username:password를 지정합니다.예를 들면 다음과 같습니다.
$ {"auths":{"cloud.openshift.com":{"auth":"b3BlbnNoaWZ0Y3UjhGOVZPT0lOMEFaUjdPUzRGTA==","email":"user@example.com"}, "quay.io":{"auth":"b3BlbnNoaWZ0LXJlbGVhc2UtZGOVZPT0lOMEFaUGSTd4VGVGVUjdPUzRGTA==","email":"user@example.com"}, "registry.connect.redhat.com"{"auth":"NTE3MTMwNDB8dWhjLTFEZlN3VHkxOSTd4VGVGVU1MdTpleUpoYkdjaUailA==","email":"user@example.com"}, "registry.redhat.io":{"auth":"NTE3MTMwNDB8dWhjLTFEZlN3VH3BGSTd4VGVGVU1MdTpleUpoYkdjaU9fZw==","email":"user@example.com"}, "registry.svc.ci.openshift.org":{"auth":"dXNlcjpyWjAwWVFjSEJiT2RKVW1pSmg4dW92dGp1SXRxQ3RGN1pwajJhN1ZXeTRV"},"my-registry:5000/my-namespace/":{"auth":"dXNlcm5hbWU6cGFzc3dvcmQ="}}}
13.4. 이미지 미러링
클러스터가 올바르게 구성된 후 외부 리포지토리의 이미지를 미러 리포지토리로 미러링할 수 있습니다.
절차
OLM(Operator Lifecycle Manager) 이미지를 미러링합니다.
$ oc adm catalog mirror registry.redhat.io/redhat/redhat-operator-index:v{product-version} <mirror_registry>:<port>/olm -a <reg_creds>다음과 같습니다.
Product-version-
설치할 OpenShift Container Platform 버전에 해당하는 태그를 지정합니다(예:
4.8). mirror_registry-
대상 레지스트리와 Operator 콘텐츠를 미러링할 네임스페이스의 정규화된 도메인 이름(FQDN)을 지정합니다. 여기서 <
namespace>는 레지스트리의 기존 네임스페이스입니다. reg_creds-
수정된
.dockerconfigjson파일의 위치를 지정합니다.
예를 들면 다음과 같습니다.
$ oc adm catalog mirror registry.redhat.io/redhat/redhat-operator-index:v4.8 mirror.registry.com:443/olm -a ./.dockerconfigjson --index-filter-by-os='.*'다른 Red Hat 제공 Operator의 콘텐츠를 미러링합니다.
$ oc adm catalog mirror <index_image> <mirror_registry>:<port>/<namespace> -a <reg_creds>다음과 같습니다.
index_image- 미러링할 카탈로그의 인덱스 이미지를 지정합니다.
mirror_registry-
대상 레지스트리 및 Operator 콘텐츠를 미러링할 네임스페이스의 FQDN을 지정합니다. 여기서 <
namespace>는 레지스트리의 기존 네임스페이스입니다. reg_creds- 선택 사항: 필요한 경우 레지스트리 자격 증명 파일의 위치를 지정합니다.
예를 들면 다음과 같습니다.
$ oc adm catalog mirror registry.redhat.io/redhat/community-operator-index:v4.8 mirror.registry.com:443/olm -a ./.dockerconfigjson --index-filter-by-os='.*'OpenShift Container Platform 이미지 저장소를 미러링합니다.
$ oc adm release mirror -a .dockerconfigjson --from=quay.io/openshift-release-dev/ocp-release:v<product-version>-<architecture> --to=<local_registry>/<local_repository> --to-release-image=<local_registry>/<local_repository>:v<product-version>-<architecture>다음과 같습니다.
Product-version-
설치할 OpenShift Container Platform 버전에 해당하는 태그(예:
4.8.15-x86_64)를 지정합니다. 아키텍처-
서버의 아키텍처 유형 (예:
x86_64)을 지정합니다. local_registry- 미러 저장소의 레지스트리 도메인 이름을 지정합니다.
local_repository-
레지스트리에 작성할 저장소 이름 (예:
ocp4/openshift4)을 지정합니다.
예를 들면 다음과 같습니다.
$ oc adm release mirror -a .dockerconfigjson --from=quay.io/openshift-release-dev/ocp-release:4.8.15-x86_64 --to=mirror.registry.com:443/ocp/release --to-release-image=mirror.registry.com:443/ocp/release:4.8.15-x86_64출력 예
info: Mirroring 109 images to mirror.registry.com/ocp/release ... mirror.registry.com:443/ ocp/release manifests: sha256:086224cadce475029065a0efc5244923f43fb9bb3bb47637e0aaf1f32b9cad47 -> 4.8.15-x86_64-thanos sha256:0a214f12737cb1cfbec473cc301aa2c289d4837224c9603e99d1e90fc00328db -> 4.8.15-x86_64-kuryr-controller sha256:0cf5fd36ac4b95f9de506623b902118a90ff17a07b663aad5d57c425ca44038c -> 4.8.15-x86_64-pod sha256:0d1c356c26d6e5945a488ab2b050b75a8b838fc948a75c0fa13a9084974680cb -> 4.8.15-x86_64-kube-client-agent ….. sha256:66e37d2532607e6c91eedf23b9600b4db904ce68e92b43c43d5b417ca6c8e63c mirror.registry.com:443/ocp/release:4.5.41-multus-admission-controller sha256:d36efdbf8d5b2cbc4dcdbd64297107d88a31ef6b0ec4a39695915c10db4973f1 mirror.registry.com:443/ocp/release:4.5.41-cluster-kube-scheduler-operator sha256:bd1baa5c8239b23ecdf76819ddb63cd1cd6091119fecdbf1a0db1fb3760321a2 mirror.registry.com:443/ocp/release:4.5.41-aws-machine-controllers info: Mirroring completed in 2.02s (0B/s) Success Update image: mirror.registry.com:443/ocp/release:4.5.41-x86_64 Mirror prefix: mirror.registry.com:443/ocp/release필요에 따라 다른 레지스트리를 미러링합니다.
$ oc image mirror <online_registry>/my/image:latest <mirror_registry>
추가 정보
- Operator 카탈로그 미러링에 대한 자세한 내용은 Operator 카탈로그 미러링을 참조하십시오.
-
oc adm catalog mirror명령에 대한 자세한 내용은 OpenShift CLI 관리자 명령 참조를 참조하십시오.
13.5. 미러 레지스트리의 클러스터 설정
이미지를 미러 레지스트리에 생성하고 미러링한 후 Pod가 미러 레지스트리에서 이미지를 가져올 수 있도록 클러스터를 수정해야 합니다.
다음을 수행해야 합니다.
- 글로벌 풀 시크릿에 미러 레지스트리 인증 정보를 추가합니다.
- 미러 레지스트리 서버 인증서를 클러스터에 추가합니다.
미러 레지스트리를 소스 레지스트리와 연결하는 ICSP(
ImageContentSourcePolicy사용자 지정 리소스)를 생성합니다.클러스터 글로벌 pull-secret에 미러 레지스트리 인증 정보를 추가합니다.
$ oc set data secret/pull-secret -n openshift-config --from-file=.dockerconfigjson=<pull_secret_location>1 - 1
- 새 풀 시크릿 파일의 경로를 제공합니다.
예를 들면 다음과 같습니다.
$ oc set data secret/pull-secret -n openshift-config --from-file=.dockerconfigjson=.mirrorsecretconfigjsonCA 서명 미러 레지스트리 서버 인증서를 클러스터의 노드에 추가합니다.
미러 레지스트리의 서버 인증서가 포함된 구성 맵을 생성
$ oc create configmap <config_map_name> --from-file=<mirror_address_host>..<port>=$path/ca.crt -n openshift-config예를 들면 다음과 같습니다.
S oc create configmap registry-config --from-file=mirror.registry.com..443=/root/certs/ca-chain.cert.pem -n openshift-config구성 맵을 사용하여
image.config.openshift.io/clusterCR(사용자 정의 리소스)을 업데이트합니다. OpenShift Container Platform은 이 CR에 대한 변경 사항을 클러스터의 모든 노드에 적용합니다.$ oc patch image.config.openshift.io/cluster --patch '{"spec":{"additionalTrustedCA":{"name":"<config_map_name>"}}}' --type=merge예를 들면 다음과 같습니다.
$ oc patch image.config.openshift.io/cluster --patch '{"spec":{"additionalTrustedCA":{"name":"registry-config"}}}' --type=merge
ICSP를 생성하여 온라인 레지스트리의 컨테이너 가져오기 요청을 미러 레지스트리로 리디렉션합니다.
ImageContentSourcePolicy사용자 정의 리소스를 생성합니다.apiVersion: operator.openshift.io/v1alpha1 kind: ImageContentSourcePolicy metadata: name: mirror-ocp spec: repositoryDigestMirrors: - mirrors: - mirror.registry.com:443/ocp/release1 source: quay.io/openshift-release-dev/ocp-release2 - mirrors: - mirror.registry.com:443/ocp/release source: quay.io/openshift-release-dev/ocp-v4.0-art-devICSP 오브젝트를 생성합니다.
$ oc create -f registryrepomirror.yaml출력 예
imagecontentsourcepolicy.operator.openshift.io/mirror-ocp createdOpenShift Container Platform은 이 CR에 대한 변경 사항을 클러스터의 모든 노드에 적용합니다.
미러 레지스트리의 인증 정보, CA 및 ICSP가 추가되었는지 확인합니다.
노드에 로그인합니다.
$ oc debug node/<node_name>디버그 쉘 내에서
/host를 root 디렉터리로 설정합니다.sh-4.4# chroot /hostconfig.json파일에서 인증 정보가 있는지 확인합니다.sh-4.4# cat /var/lib/kubelet/config.json출력 예
{"auths":{"brew.registry.redhat.io":{"xx=="},"brewregistry.stage.redhat.io":{"auth":"xxx=="},"mirror.registry.com:443":{"auth":"xx="}}}1 - 1
- 미러 레지스트리 및 인증 정보가 있는지 확인합니다.
certs.d디렉터리로 변경합니다.sh-4.4# cd /etc/docker/certs.d/certs.d디렉터리의 인증서를 나열합니다.sh-4.4# ls출력 예
image-registry.openshift-image-registry.svc.cluster.local:5000 image-registry.openshift-image-registry.svc:5000 mirror.registry.com:4431 - 1
- 미러 레지스트리가 목록에 있는지 확인합니다.
ICSP에서 mirror 레지스트리를
registries.conf파일에 추가했는지 확인합니다.sh-4.4# cat /etc/containers/registries.conf출력 예
unqualified-search-registries = ["registry.access.redhat.com", "docker.io"] [[registry]] prefix = "" location = "quay.io/openshift-release-dev/ocp-release" mirror-by-digest-only = true [[registry.mirror]] location = "mirror.registry.com:443/ocp/release" [[registry]] prefix = "" location = "quay.io/openshift-release-dev/ocp-v4.0-art-dev" mirror-by-digest-only = true [[registry.mirror]] location = "mirror.registry.com:443/ocp/release"registry.mirror매개변수는 미러 레지스트리가 원래 레지스트리보다 먼저 검색됨을 나타냅니다.노드를 종료합니다.
sh-4.4# exit
13.6. 애플리케이션이 계속 작동하는지 확인
네트워크에서 클러스터의 연결을 해제하기 전에 클러스터가 예상대로 작동하고 모든 애플리케이션이 예상대로 작동하는지 확인합니다.
절차
다음 명령을 사용하여 클러스터 상태를 확인합니다.
Pod가 실행 중인지 확인합니다.
$ oc get pods --all-namespaces출력 예
NAMESPACE NAME READY STATUS RESTARTS AGE kube-system apiserver-watcher-ci-ln-47ltxtb-f76d1-mrffg-master-0 1/1 Running 0 39m kube-system apiserver-watcher-ci-ln-47ltxtb-f76d1-mrffg-master-1 1/1 Running 0 39m kube-system apiserver-watcher-ci-ln-47ltxtb-f76d1-mrffg-master-2 1/1 Running 0 39m openshift-apiserver-operator openshift-apiserver-operator-79c7c646fd-5rvr5 1/1 Running 3 45m openshift-apiserver apiserver-b944c4645-q694g 2/2 Running 0 29m openshift-apiserver apiserver-b944c4645-shdxb 2/2 Running 0 31m openshift-apiserver apiserver-b944c4645-x7rf2 2/2 Running 0 33m ...노드가 READY 상태인지 확인합니다.
$ oc get nodes출력 예
NAME STATUS ROLES AGE VERSION ci-ln-47ltxtb-f76d1-mrffg-master-0 Ready master 42m v1.26.0 ci-ln-47ltxtb-f76d1-mrffg-master-1 Ready master 42m v1.26.0 ci-ln-47ltxtb-f76d1-mrffg-master-2 Ready master 42m v1.26.0 ci-ln-47ltxtb-f76d1-mrffg-worker-a-gsxbz Ready worker 35m v1.26.0 ci-ln-47ltxtb-f76d1-mrffg-worker-b-5qqdx Ready worker 35m v1.26.0 ci-ln-47ltxtb-f76d1-mrffg-worker-c-rjkpq Ready worker 34m v1.26.0
13.7. 네트워크에서 클러스터 연결 해제
필요한 모든 리포지토리를 미러링하고 클러스터를 구성하여 연결이 끊긴 클러스터로 작동하면 네트워크에서 클러스터의 연결을 끊을 수 있습니다.
클러스터가 인터넷 연결이 끊어지면 Insights Operator의 성능이 저하됩니다. 복원할 수 있을 때까지 Insights Operator를 일시적으로 비활성화하여 이 문제를 방지할 수 있습니다.
13.8. 성능 저하된 Insights Operator 복원
네트워크에서 클러스터를 연결 해제하면 클러스터가 인터넷 연결이 끊어야 합니다. Insights Operator는 Red Hat Insights 에 액세스해야 하므로 성능이 저하됩니다.
이 주제에서는 성능이 저하된 Insights Operator에서 복구하는 방법을 설명합니다.
절차
.dockerconfigjson파일을 편집하여cloud.openshift.com항목을 제거합니다. 예를 들면 다음과 같습니다."cloud.openshift.com":{"auth":"<hash>","email":"user@example.com"}- 파일을 저장합니다.
편집한
.dockerconfigjson파일을 사용하여 클러스터 보안을 업데이트합니다.$ oc set data secret/pull-secret -n openshift-config --from-file=.dockerconfigjson=./.dockerconfigjsonInsights Operator의 성능이 더 이상 저하되지 않는지 확인합니다.
$ oc get co insights출력 예
NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE insights 4.5.41 True False False 3d
13.9. 네트워크 복원
연결이 끊긴 클러스터를 다시 연결하고 온라인 레지스트리에서 이미지를 가져오려면 클러스터의 ICSP(ImageContentSourcePolicy) 오브젝트를 삭제합니다. ICSP가 없으면 외부 레지스트리에 대한 가져오기 요청이 더 이상 미러 레지스트리로 리디렉션되지 않습니다.
절차
클러스터에서 ICSP 오브젝트를 확인합니다.
$ oc get imagecontentsourcepolicy출력 예
NAME AGE mirror-ocp 6d20h ocp4-index-0 6d18h qe45-index-0 6d15h클러스터 연결을 끊을 때 생성한 모든 ICSP 오브젝트를 삭제합니다.
$ oc delete imagecontentsourcepolicy <icsp_name> <icsp_name> <icsp_name>예를 들면 다음과 같습니다.
$ oc delete imagecontentsourcepolicy mirror-ocp ocp4-index-0 qe45-index-0출력 예
imagecontentsourcepolicy.operator.openshift.io "mirror-ocp" deleted imagecontentsourcepolicy.operator.openshift.io "ocp4-index-0" deleted imagecontentsourcepolicy.operator.openshift.io "qe45-index-0" deleted모든 노드가 재시작될 때까지 기다린 후 READY 상태로 돌아갈 때까지 기다린 후 미러 레지스트리가 아닌
registries.conf파일에 원래 레지스트리를 가리키는지 확인합니다.노드에 로그인합니다.
$ oc debug node/<node_name>디버그 쉘 내에서
/host를 root 디렉터리로 설정합니다.sh-4.4# chroot /hostregistries.conf파일을 검사합니다.sh-4.4# cat /etc/containers/registries.conf출력 예
unqualified-search-registries = ["registry.access.redhat.com", "docker.io"]1 - 1
- 삭제한 ICSP에서 생성한
registry및registry.mirror항목이 제거됩니다.
14장. 클러스터 기능 활성화
클러스터 관리자는 설치 전에 비활성화된 클러스터 기능을 활성화할 수 있습니다.
클러스터 관리자가 클러스터 기능을 활성화한 후에는 비활성화할 수 없습니다.
14.1. 클러스터 기능 보기
클러스터 관리자는 clusterversion 리소스 상태를 사용하여 기능을 볼 수 있습니다.
사전 요구 사항
-
OpenShift CLI(
oc)가 설치되어 있습니다.
절차
클러스터 기능의 상태를 보려면 다음 명령을 실행합니다.
$ oc get clusterversion version -o jsonpath='{.spec.capabilities}{"\n"}{.status.capabilities}{"\n"}'출력 예
{"additionalEnabledCapabilities":["openshift-samples"],"baselineCapabilitySet":"None"} {"enabledCapabilities":["openshift-samples"],"knownCapabilities":["CSISnapshot","Console","Insights","Storage","baremetal","marketplace","openshift-samples"]}
14.2. 기준 기능 세트를 설정하여 클러스터 기능 활성화
클러스터 관리자는 baselineCapabilitySet 을 설정하여 기능을 활성화할 수 있습니다.
사전 요구 사항
-
OpenShift CLI(
oc)가 설치되어 있습니다.
절차
baselineCapabilitySet을 설정하려면 다음 명령을 실행합니다.$ oc patch clusterversion version --type merge -p '{"spec":{"capabilities":{"baselineCapabilitySet":"vCurrent"}}}'1 - 1
baselineCapabilitySet의 경우vCurrent,v4.12,v4.13또는None을 지정할 수 있습니다.
다음 표에서는 baselineCapabilitySet 값을 설명합니다.
| 현재의 | 설명 |
|---|---|
|
| 새 릴리스에 도입된 새로운 기본 기능을 자동으로 추가하려는 경우 이 옵션을 지정합니다. |
|
|
OpenShift Container Platform 4.11의 기본 기능을 활성화하려면 이 옵션을 지정합니다. |
|
|
OpenShift Container Platform 4.12의 기본 기능을 활성화하려면 이 옵션을 지정합니다. |
|
|
OpenShift Container Platform 4.13의 기본 기능을 활성화하려면 이 옵션을 지정합니다. |
|
|
다른 세트가 너무 큰 시기를 지정하고 기능이 필요하지 않거나 |
14.3. 활성화된 기능을 추가로 설정하여 클러스터 기능 활성화
클러스터 관리자는 additionalEnabledCapabilities 를 설정하여 클러스터 기능을 활성화할 수 있습니다.
사전 요구 사항
-
OpenShift CLI(
oc)가 설치되어 있습니다.
절차
다음 명령을 실행하여 활성화된 추가 기능을 확인합니다.
$ oc get clusterversion version -o jsonpath='{.spec.capabilities.additionalEnabledCapabilities}{"\n"}'출력 예
["openshift-samples"]additionalEnabledCapabilities를 설정하려면 다음 명령을 실행합니다.$ oc patch clusterversion/version --type merge -p '{"spec":{"capabilities":{"additionalEnabledCapabilities":["openshift-samples", "marketplace"]}}}'
클러스터에서 이미 활성화된 기능을 비활성화할 수 없습니다. CVO(클러스터 버전 Operator)는 클러스터에서 이미 활성화된 기능을 계속 조정합니다.
기능을 비활성화하려고 하면 CVO에 다이버네트 사양이 표시됩니다.
$ oc get clusterversion version -o jsonpath='{.status.conditions[?(@.type=="ImplicitlyEnabledCapabilities")]}{"\n"}'출력 예
{"lastTransitionTime":"2022-07-22T03:14:35Z","message":"The following capabilities could not be disabled: openshift-samples","reason":"CapabilitiesImplicitlyEnabled","status":"True","type":"ImplicitlyEnabledCapabilities"}
클러스터를 업그레이드하는 동안 지정된 기능을 암시적으로 활성화할 수 있습니다. 업그레이드하기 전에 클러스터에서 리소스가 이미 실행 중인 경우 리소스의 일부인 모든 기능이 활성화됩니다. 예를 들어 클러스터를 업그레이드하는 동안 이미 클러스터에서 실행 중인 리소스가 시스템의 마켓플레이스 기능의 일부로 변경되었습니다. 클러스터 관리자가 마켓플레이스 기능을 명시적으로 활성화하지 않더라도 시스템에 의해 암시적으로 활성화됩니다.
15장. IBM Z 또는 IBM(R) LinuxONE 환경에서 추가 장치 구성
OpenShift Container Platform을 설치한 후 z/VM과 함께 설치된 IBM Z 또는 IBM® LinuxONE 환경에서 클러스터에 대한 추가 장치를 구성할 수 있습니다. 다음 장치를 구성할 수 있습니다.
- 파이버 채널 프로토콜(FCP) 호스트
- FCP LUN
- DASD
- qeth
MCO(Machine Config Operator)를 사용하여 udev 규칙을 추가하거나 장치를 수동으로 구성할 수 있습니다.
여기에 설명된 절차는 z/VM 설치에만 적용됩니다. IBM Z 또는 IBM® LinuxONE 인프라에 RHEL KVM을 사용하여 클러스터를 설치한 경우 KVM 게스트에 장치를 추가한 후 추가 구성이 필요하지 않습니다. 그러나 z/VM 및 RHEL KVM 환경에서 모두 Local Storage Operator 및 Kubernetes NMState Operator를 구성하려면 다음 단계를 적용해야 합니다.
15.1. MCO(Machine Config Operator)를 사용하여 추가 장치 구성
이 섹션의 작업은 MCO(Machine Config Operator) 기능을 사용하여 IBM Z 또는 IBM® LinuxONE 환경에서 추가 장치를 구성하는 방법을 설명합니다. MCO를 사용하여 장치를 구성하는 것은 영구적이지만 컴퓨팅 노드에 대한 특정 구성만 허용합니다. MCO는 컨트롤 플레인 노드가 다른 구성을 갖는 것을 허용하지 않습니다.
사전 요구 사항
- 관리 권한이 있는 사용자로 클러스터에 로그인했습니다.
- z/VM 게스트에서 장치를 사용할 수 있어야 합니다.
- 장치가 이미 연결되어 있습니다.
-
장치는 커널 매개변수에서 설정할 수 있는
cio_ignore목록에 포함되어 있지 않습니다. 다음 YAML을 사용하여
MachineConfig오브젝트 파일을 생성했습니다.apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfigPool metadata: name: worker0 spec: machineConfigSelector: matchExpressions: - {key: machineconfiguration.openshift.io/role, operator: In, values: [worker,worker0]} nodeSelector: matchLabels: node-role.kubernetes.io/worker0: ""
15.1.1. FCP(Fibre Channel Protocol) 호스트 구성
다음은 udev 규칙을 추가하여 NPIV(N_Port Identifier Virtualization)를 사용하여 FCP 호스트 어댑터를 구성하는 방법의 예입니다.
절차
다음 샘플 udev 규칙
441-zfcp-host-0.0.8000.rules를 사용합니다.ACTION=="add", SUBSYSTEM=="ccw", KERNEL=="0.0.8000", DRIVER=="zfcp", GOTO="cfg_zfcp_host_0.0.8000" ACTION=="add", SUBSYSTEM=="drivers", KERNEL=="zfcp", TEST=="[ccw/0.0.8000]", GOTO="cfg_zfcp_host_0.0.8000" GOTO="end_zfcp_host_0.0.8000" LABEL="cfg_zfcp_host_0.0.8000" ATTR{[ccw/0.0.8000]online}="1" LABEL="end_zfcp_host_0.0.8000"다음 명령을 실행하여 규칙을 Base64로 인코딩합니다.
$ base64 /path/to/file/다음 MCO 샘플 프로필을 YAML 파일에 복사합니다.
apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: labels: machineconfiguration.openshift.io/role: worker01 name: 99-worker0-devices spec: config: ignition: version: 3.2.0 storage: files: - contents: source: data:text/plain;base64,<encoded_base64_string>2 filesystem: root mode: 420 path: /etc/udev/rules.d/41-zfcp-host-0.0.8000.rules3
15.1.2. FCP LUN 구성
다음은 udev 규칙을 추가하여 FCP LUN을 구성하는 방법의 예입니다. 새 FCP LUN을 추가하거나 다중 경로로 이미 구성된 LUN에 경로를 추가할 수 있습니다.
절차
다음 샘플 udev 규칙
41-zfcp-lun-0.0.8000:0x500507680d760026:0x00bc000000000000.rules:ACTION=="add", SUBSYSTEMS=="ccw", KERNELS=="0.0.8000", GOTO="start_zfcp_lun_0.0.8207" GOTO="end_zfcp_lun_0.0.8000" LABEL="start_zfcp_lun_0.0.8000" SUBSYSTEM=="fc_remote_ports", ATTR{port_name}=="0x500507680d760026", GOTO="cfg_fc_0.0.8000_0x500507680d760026" GOTO="end_zfcp_lun_0.0.8000" LABEL="cfg_fc_0.0.8000_0x500507680d760026" ATTR{[ccw/0.0.8000]0x500507680d760026/unit_add}="0x00bc000000000000" GOTO="end_zfcp_lun_0.0.8000" LABEL="end_zfcp_lun_0.0.8000"다음 명령을 실행하여 규칙을 Base64로 인코딩합니다.
$ base64 /path/to/file/다음 MCO 샘플 프로필을 YAML 파일에 복사합니다.
apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: labels: machineconfiguration.openshift.io/role: worker01 name: 99-worker0-devices spec: config: ignition: version: 3.2.0 storage: files: - contents: source: data:text/plain;base64,<encoded_base64_string>2 filesystem: root mode: 420 path: /etc/udev/rules.d/41-zfcp-lun-0.0.8000:0x500507680d760026:0x00bc000000000000.rules3
15.1.3. DASD 구성
다음은 udev 규칙을 추가하여 DASD 장치를 구성하는 방법의 예입니다.
절차
다음 샘플 udev 규칙
41-dasd-0.0.4444.rules를 사용합니다.ACTION=="add", SUBSYSTEM=="ccw", KERNEL=="0.0.4444", DRIVER=="dasd-eckd", GOTO="cfg_dasd_eckd_0.0.4444" ACTION=="add", SUBSYSTEM=="drivers", KERNEL=="dasd-eckd", TEST=="[ccw/0.0.4444]", GOTO="cfg_dasd_eckd_0.0.4444" GOTO="end_dasd_eckd_0.0.4444" LABEL="cfg_dasd_eckd_0.0.4444" ATTR{[ccw/0.0.4444]online}="1" LABEL="end_dasd_eckd_0.0.4444"다음 명령을 실행하여 규칙을 Base64로 인코딩합니다.
$ base64 /path/to/file/다음 MCO 샘플 프로필을 YAML 파일에 복사합니다.
apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: labels: machineconfiguration.openshift.io/role: worker01 name: 99-worker0-devices spec: config: ignition: version: 3.2.0 storage: files: - contents: source: data:text/plain;base64,<encoded_base64_string>2 filesystem: root mode: 420 path: /etc/udev/rules.d/41-dasd-eckd-0.0.4444.rules3
15.1.4. qeth 구성
다음은 udev 규칙을 추가하여 qeth 장치를 구성하는 방법의 예입니다.
절차
다음 샘플 udev 규칙
41-qeth-0.0.1000.rules를 사용합니다.ACTION=="add", SUBSYSTEM=="drivers", KERNEL=="qeth", GOTO="group_qeth_0.0.1000" ACTION=="add", SUBSYSTEM=="ccw", KERNEL=="0.0.1000", DRIVER=="qeth", GOTO="group_qeth_0.0.1000" ACTION=="add", SUBSYSTEM=="ccw", KERNEL=="0.0.1001", DRIVER=="qeth", GOTO="group_qeth_0.0.1000" ACTION=="add", SUBSYSTEM=="ccw", KERNEL=="0.0.1002", DRIVER=="qeth", GOTO="group_qeth_0.0.1000" ACTION=="add", SUBSYSTEM=="ccwgroup", KERNEL=="0.0.1000", DRIVER=="qeth", GOTO="cfg_qeth_0.0.1000" GOTO="end_qeth_0.0.1000" LABEL="group_qeth_0.0.1000" TEST=="[ccwgroup/0.0.1000]", GOTO="end_qeth_0.0.1000" TEST!="[ccw/0.0.1000]", GOTO="end_qeth_0.0.1000" TEST!="[ccw/0.0.1001]", GOTO="end_qeth_0.0.1000" TEST!="[ccw/0.0.1002]", GOTO="end_qeth_0.0.1000" ATTR{[drivers/ccwgroup:qeth]group}="0.0.1000,0.0.1001,0.0.1002" GOTO="end_qeth_0.0.1000" LABEL="cfg_qeth_0.0.1000" ATTR{[ccwgroup/0.0.1000]online}="1" LABEL="end_qeth_0.0.1000"다음 명령을 실행하여 규칙을 Base64로 인코딩합니다.
$ base64 /path/to/file/다음 MCO 샘플 프로필을 YAML 파일에 복사합니다.
apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: labels: machineconfiguration.openshift.io/role: worker01 name: 99-worker0-devices spec: config: ignition: version: 3.2.0 storage: files: - contents: source: data:text/plain;base64,<encoded_base64_string>2 filesystem: root mode: 420 path: /etc/udev/rules.d/41-dasd-eckd-0.0.4444.rules3
15.2. 추가 장치 수동 구성
이 섹션의 작업은 IBM Z 또는 IBM® LinuxONE 환경에서 추가 장치를 수동으로 구성하는 방법을 설명합니다. 이 설정 방법은 노드를 재시작해도 유지되지만 OpenShift Container Platform 네이티브는 아니며 노드를 교체하는 경우 단계를 다시 수행해야 합니다.
사전 요구 사항
- 관리 권한이 있는 사용자로 클러스터에 로그인했습니다.
- 노드에서 장치를 사용할 수 있어야 합니다.
- z/VM 환경에서 장치를 z/VM 게스트에 연결해야 합니다.
절차
다음 명령을 실행하여 SSH를 통해 노드에 연결합니다.
$ ssh <user>@<node_ip_address>다음 명령을 실행하여 노드에 대한 디버그 세션을 시작할 수도 있습니다.
$ oc debug node/<node_name>chzdev명령으로 장치를 활성화하려면 다음 명령을 입력합니다.$ sudo chzdev -e 0.0.8000 sudo chzdev -e 1000-1002 sude chzdev -e 4444 sudo chzdev -e 0.0.8000:0x500507680d760026:0x00bc000000000000
15.3. RoCE 네트워크 카드
RoCE(RDMA over Converged Ethernet) 네트워크 카드를 활성화할 필요가 없으며 노드에서 사용 가능할 때마다 Kubernetes NMState Operator로 해당 인터페이스를 구성할 수 있습니다. 예를 들어, RoCE 네트워크 카드는 z/VM 환경에 연결되거나 RHEL KVM 환경에서 전달되는 경우 사용할 수 있습니다.
15.4. FCP LUN 멀티패스 활성화
이 섹션의 작업은 IBM Z 또는 IBM® LinuxONE 환경에서 추가 장치를 수동으로 구성하는 방법을 설명합니다. 이 설정 방법은 노드를 재시작해도 유지되지만 OpenShift Container Platform 네이티브는 아니며 노드를 교체하는 경우 단계를 다시 수행해야 합니다.
IBM Z 및 IBM® LinuxONE에서는 설치 중에 클러스터를 구성한 경우에만 멀티패스를 활성화할 수 있습니다. 자세한 내용은 IBM Z 및 IBM® LinuxONE에 z/VM으로 클러스터 설치의 "RHCOS 설치 및 OpenShift Container Platform 부트스트랩 프로세스 시작"을 참조하십시오.
사전 요구 사항
- 관리 권한이 있는 사용자로 클러스터에 로그인했습니다.
- 위에서 설명한 방법 중 하나를 사용하여 LUN에 대한 여러 경로를 구성했습니다.
절차
다음 명령을 실행하여 SSH를 통해 노드에 연결합니다.
$ ssh <user>@<node_ip_address>다음 명령을 실행하여 노드에 대한 디버그 세션을 시작할 수도 있습니다.
$ oc debug node/<node_name>다중 경로를 활성화하려면 다음 명령을 실행합니다.
$ sudo /sbin/mpathconf --enablemultipathd데몬을 시작하려면 다음 명령을 실행합니다.$ sudo multipath선택 사항:ECDHE로 다중 경로 장치를 포맷하려면 다음 명령을 실행합니다.
$ sudo fdisk /dev/mapper/mpatha
검증
장치가 그룹화되었는지 확인하려면 다음 명령을 실행합니다.
$ sudo multipath -II출력 예
mpatha (20017380030290197) dm-1 IBM,2810XIV size=512G features='1 queue_if_no_path' hwhandler='1 alua' wp=rw -+- policy='service-time 0' prio=50 status=enabled |- 1:0:0:6 sde 68:16 active ready running |- 1:0:1:6 sdf 69:24 active ready running |- 0:0:0:6 sdg 8:80 active ready running `- 0:0:1:6 sdh 66:48 active ready running
16장. RHCOS 이미지 계층 지정
RHCOS(Red Hat Enterprise Linux CoreOS) 이미지 계층 지정을 사용하면 추가 이미지를 기본 이미지에 계층화하여 기본 RHCOS 이미지의 기능을 쉽게 확장할 수 있습니다. 이 계층화는 기본 RHCOS 이미지를 수정하지 않습니다. 대신 모든 RHCOS 기능을 포함하는 사용자 정의 계층 이미지를 생성하고 클러스터의 특정 노드에 기능을 추가합니다.
MachineConfig 오브젝트를 사용하여 Containerfile을 사용하여 사용자 정의 계층 이미지를 생성하고 노드에 적용합니다. Machine Config Operator는 관련 머신 구성의 osImageURL 값에 따라 기본 RHCOS 이미지를 재정의하고 새 이미지를 부팅합니다. 머신 구성을 삭제하여 사용자 정의 계층 이미지를 제거할 수 있으며 MCO는 노드를 다시 기본 RHCOS 이미지로 재부팅할 수 있습니다.
RHCOS 이미지 계층 지정을 사용하면 RPM을 기본 이미지에 설치할 수 있으며 사용자 정의 콘텐츠는 RHCOS와 함께 부팅됩니다. MCO(Machine Config Operator)는 이러한 사용자 정의 계층 이미지를 롤아웃하고 이러한 사용자 정의 컨테이너를 기본 RHCOS 이미지와 동일한 방식으로 모니터링할 수 있습니다. RHCOS 이미지 계층화는 RHCOS 노드 관리 방법에 더 큰 유연성을 제공합니다.
사용자 지정 계층적 콘텐츠로 실시간 커널 및 확장 RPM을 설치하는 것은 권장되지 않습니다. 시스템 구성을 사용하여 설치된 RPM과 이러한 RPM이 충돌할 수 있기 때문입니다. 충돌이 발생하면 머신 구성 RPM을 설치하려고 할 때 MCO가 degraded 상태가 됩니다. 계속하기 전에 머신 구성에서 충돌하는 확장을 제거해야 합니다.
사용자 정의 계층 이미지를 클러스터에 적용하는 즉시 사용자 정의 계층 이미지와 해당 노드의 소유권을 효과적으로 확보할 수 있습니다. Red Hat은 표준 노드에서 기본 RHCOS 이미지를 유지 관리하고 업데이트하는 반면 사용자 정의 계층 이미지를 사용하는 노드에서 이미지를 유지 관리하고 업데이트해야 합니다. 사용자 정의 계층 이미지로 적용한 패키지와 패키지에 발생할 수 있는 문제가 있다고 가정합니다.
사용자 지정 계층 이미지를 적용하려면 OpenShift Container Platform 이미지 및 적용할 RPM을 참조하는 Containerfile을 생성합니다. 그런 다음 결과 사용자 정의 계층 이미지를 이미지 레지스트리로 푸시합니다. 프로덕션 환경 외 OpenShift Container Platform 클러스터에서 새 이미지를 가리키는 대상 노드 풀에 대한 MachineConfig 오브젝트를 생성합니다.
클러스터의 나머지 부분에 설치된 동일한 기본 RHCOS 이미지를 사용합니다. oc adm release info --image-for rhel-coreos 명령을 사용하여 클러스터에 사용된 기본 이미지를 가져옵니다.
RHCOS 이미지 계층 지정을 사용하면 다음 유형의 이미지를 사용하여 사용자 지정 계층 이미지를 생성할 수 있습니다.
OpenShift Container Platform 핫픽스. CEE(Customer Experience and Engagement)를 사용하여 RHCOS 이미지 상단에 핫픽스 패키지를 가져오고 적용할 수 있습니다. 경우에 따라 버그 수정 또는 개선 사항이 공식적인 OpenShift Container Platform 릴리스에 포함되기 전에 필요할 수 있습니다. RHCOS 이미지 계층 지정을 사용하면 공식적으로 릴리스되기 전에 Hotfix를 쉽게 추가하고 기본 RHCOS 이미지가 수정 사항을 통합할 때 핫픽스를 제거할 수 있습니다.
중요일부 핫픽스에는 Red Hat 지원이 필요하며 일반적인 OpenShift Container Platform 지원 적용 범위 또는 라이프 사이클 정책 범위를 벗어납니다.
Hotfix를 원하는 경우 Red Hat Hotfix 정책을 기반으로 제공됩니다. 기본 이미지 상단에 적용하고 프로덕션이 아닌 환경에서 새 사용자 정의 계층화된 이미지를 테스트합니다. 사용자 정의 계층 이미지가 프로덕션에서 안전하게 사용할 수 있다는 것을 만족하면 특정 노드 풀에 자체 일정에 따라 롤아웃할 수 있습니다. 어떠한 이유로든 사용자 정의 계층 이미지를 쉽게 롤백하고 기본 RHCOS를 사용하여 로 돌아갈 수 있습니다.
Hotfix를 적용하려면 Containerfile의 예
# Using a 4.12.0 image FROM quay.io/openshift-release-dev/ocp-v4.0-art-dev@sha256... #Install hotfix rpm RUN rpm-ostree override replace https://example.com/myrepo/haproxy-1.0.16-5.el8.src.rpm && \ rpm-ostree cleanup -m && \ ostree container commitRHEL 패키지. Red Hat 고객 포털(예: chrony, firewalld, iputils)에서 RHEL(Red Hat Enterprise Linux) 패키지를 다운로드할 수 있습니다.
firewalld 유틸리티를 적용할 Containerfile의 예
FROM quay.io/openshift-release-dev/ocp-release@sha256... ADD configure-firewall-playbook.yml . RUN rpm-ostree install firewalld ansible && \ ansible-playbook configure-firewall-playbook.yml && \ rpm -e ansible && \ ostree container commitlibreswan 유틸리티를 적용할 컨테이너 파일의 예
# Get RHCOS base image of target cluster `oc adm release info --image-for rhel-coreos` # hadolint ignore=DL3006 FROM quay.io/openshift-release-dev/ocp-v4.0-art-dev@sha256... # Install our config file COPY my-host-to-host.conf /etc/ipsec.d/ # RHEL entitled host is needed here to access RHEL packages # Install libreswan as extra RHEL package RUN rpm-ostree install libreswan && \ systemctl enable ipsec && \ ostree container commitlibreswan에는 추가 RHEL 패키지가 필요하므로 권한이 부여된 RHEL 호스트에서 이미지를 빌드해야 합니다.
타사 패키지. 다음과 같은 타사 조직에서 RPM을 다운로드하여 설치할 수 있습니다.
- 성능을 향상하거나 기능을 추가하기 위해 엣지 드라이버 및 커널 개선 사항 개선
- 가능한 실제 및 실제 중단을 조사할 수 있는 이해 있는 클라이언트 툴입니다.
- 보안 에이전트.
- 전체 클러스터에 대한 일관된 보기를 제공하는 인벤토리 에이전트입니다.
- SSH 키 관리 패키지.
EPEL의 타사 패키지를 적용하는 Containerfile 예
# Get RHCOS base image of target cluster `oc adm release info --image-for rhel-coreos` # hadolint ignore=DL3006 FROM quay.io/openshift-release-dev/ocp-v4.0-art-dev@sha256... # Install our config file COPY my-host-to-host.conf /etc/ipsec.d/ # RHEL entitled host is needed here to access RHEL packages # Install libreswan as extra RHEL package RUN rpm-ostree install libreswan && \ systemctl enable ipsec && \ ostree container commitRHEL 종속 항목이 있는 타사 패키지를 적용하는 컨테이너 파일의 예
# Get RHCOS base image of target cluster `oc adm release info --image-for rhel-coreos` # hadolint ignore=DL3006 FROM quay.io/openshift-release-dev/ocp-v4.0-art-dev@sha256... # Install our config file COPY my-host-to-host.conf /etc/ipsec.d/ # RHEL entitled host is needed here to access RHEL packages # Install libreswan as extra RHEL package RUN rpm-ostree install libreswan && \ systemctl enable ipsec && \ ostree container commit이 Containerfile은 Linux fish 프로그램을 설치합니다. 어류에는 추가 RHEL 패키지가 필요하므로 이미지를 권한이 부여된 RHEL 호스트에 빌드해야 합니다.
머신 구성을 생성한 후 MCO(Machine Config Operator)는 다음 단계를 수행합니다.
- 지정된 풀 또는 풀에 대한 새 머신 구성을 렌더링합니다.
- 풀 또는 풀의 노드에서 차단 및 드레인 작업을 수행합니다.
- 나머지 머신 구성 매개변수를 노드에 씁니다.
- 사용자 정의 계층화된 이미지를 노드에 적용합니다.
- 새 이미지를 사용하여 노드를 재부팅합니다.
클러스터에 롤아웃하기 전에 프로덕션 환경 외부에서 이미지를 테스트하는 것이 좋습니다.
16.1. RHCOS 사용자 정의 계층 이미지 적용
특정 머신 구성 풀의 노드에서 RHCOS(Red Hat Enterprise Linux CoreOS) 이미지 계층 지정을 쉽게 구성할 수 있습니다. MCO(Machine Config Operator)는 새로운 사용자 정의 계층 이미지로 해당 노드를 재부팅하여 기본 RHCOS(Red Hat Enterprise Linux CoreOS) 이미지를 덮어씁니다.
사용자 정의 계층 이미지를 클러스터에 적용하려면 클러스터가 액세스할 수 있는 리포지토리에 사용자 정의 계층화된 이미지가 있어야 합니다. 그런 다음 사용자 정의 계층 이미지를 가리키는 MachineConfig 오브젝트를 만듭니다. 구성할 각 머신 구성 풀에 대해 별도의 MachineConfig 오브젝트가 필요합니다.
사용자 정의 계층 이미지를 구성하면 OpenShift Container Platform에서 사용자 정의 계층 이미지를 사용하는 노드를 자동으로 업데이트하지 않습니다. 노드를 적절하게 수동으로 업데이트해야 합니다. 사용자 정의 계층을 롤백하면 OpenShift Container Platform에서 노드를 다시 자동으로 업데이트합니다. 사용자 정의 계층 이미지를 사용하는 노드 업데이트에 대한 중요한 정보는 다음 추가 리소스 섹션을 참조하십시오.
사전 요구 사항
태그가 아닌 OpenShift Container Platform 이미지 다이제스트를 기반으로 사용자 정의 계층 이미지를 생성해야 합니다.
참고클러스터의 나머지 부분에 설치된 동일한 기본 RHCOS 이미지를 사용해야 합니다.
oc adm release info --image-for rhel-coreos명령을 사용하여 클러스터에서 사용되는 기본 이미지를 가져옵니다.예를 들어 다음 Containerfile은 OpenShift Container Platform 4.13 이미지에서 사용자 정의 계층 이미지를 생성하고 CentOS 9 Stream의 커널 패키지를 덮어씁니다.
사용자 정의 계층 이미지의 컨테이너 파일의 예
# Using a 4.13.0 image FROM quay.io/openshift-release/ocp-release@sha256...1 #Install hotfix rpm RUN rpm-ostree cliwrap install-to-root / && \2 rpm-ostree override replace http://mirror.stream.centos.org/9-stream/BaseOS/x86_64/os/Packages/kernel-{,core-,modules-,modules-core-,modules-extra-}5.14.0-295.el9.x86_64.rpm && \3 rpm-ostree cleanup -m && \ ostree container commit참고컨테이너 파일을 생성하는 방법에 대한 지침은 이 문서의 범위를 벗어납니다.
-
사용자 정의 계층 이미지를 빌드하는 프로세스는 클러스터 외부에서 수행되므로 Podman 또는 Buildah와 함께
--authfile /path/to/pull-secret옵션을 사용해야 합니다. 또는 이러한 툴에서 가져오기 보안을 자동으로 읽으려면 ~/.docker/config.json ,$XDG_RUNTIME_DIR/containers.json ,.dockercfg .~/.docker/config.json,~/.docker/config.jsondockercfg중 하나에 추가할 수 있습니다. 자세한 내용은containers-auth.json매뉴얼 페이지를 참조하십시오. - 사용자 정의 계층 이미지를 클러스터가 액세스할 수 있는 리포지토리로 내보내야 합니다.
절차
머신 구성 파일을 생성합니다.
다음과 유사한 YAML 파일을 생성합니다.
apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: labels: machineconfiguration.openshift.io/role: worker1 name: os-layer-custom spec: osImageURL: quay.io/my-registry/custom-image@sha256...2 MachineConfig오브젝트를 생성합니다.$ oc create -f <file_name>.yaml중요클러스터에 롤아웃하기 전에 프로덕션 환경 외부에서 이미지를 테스트하는 것이 좋습니다.
검증
다음 점검 중 하나를 수행하여 사용자 정의 계층 이미지가 적용되었는지 확인할 수 있습니다.
새 머신 구성을 사용하여 작업자 머신 구성 풀이 롤아웃되었는지 확인합니다.
새 머신 구성이 생성되었는지 확인합니다.
$ oc get mc샘플 출력
NAME GENERATEDBYCONTROLLER IGNITIONVERSION AGE 00-master 5bdb57489b720096ef912f738b46330a8f577803 3.2.0 95m 00-worker 5bdb57489b720096ef912f738b46330a8f577803 3.2.0 95m 01-master-container-runtime 5bdb57489b720096ef912f738b46330a8f577803 3.2.0 95m 01-master-kubelet 5bdb57489b720096ef912f738b46330a8f577803 3.2.0 95m 01-worker-container-runtime 5bdb57489b720096ef912f738b46330a8f577803 3.2.0 95m 01-worker-kubelet 5bdb57489b720096ef912f738b46330a8f577803 3.2.0 95m 99-master-generated-registries 5bdb57489b720096ef912f738b46330a8f577803 3.2.0 95m 99-master-ssh 3.2.0 98m 99-worker-generated-registries 5bdb57489b720096ef912f738b46330a8f577803 3.2.0 95m 99-worker-ssh 3.2.0 98m os-layer-custom 10s1 rendered-master-15961f1da260f7be141006404d17d39b 5bdb57489b720096ef912f738b46330a8f577803 3.2.0 95m rendered-worker-5aff604cb1381a4fe07feaf1595a797e 5bdb57489b720096ef912f738b46330a8f577803 3.2.0 95m rendered-worker-5de4837625b1cbc237de6b22bc0bc873 5bdb57489b720096ef912f738b46330a8f577803 3.2.0 4s2 새 머신 구성의
osImageURL값이 예상 이미지를 가리키는지 확인합니다.$ oc describe mc rendered-worker-5de4837625b1cbc237de6b22bc0bc873출력 예
Name: rendered-worker-5de4837625b1cbc237de6b22bc0bc873 Namespace: Labels: <none> Annotations: machineconfiguration.openshift.io/generated-by-controller-version: 5bdb57489b720096ef912f738b46330a8f577803 machineconfiguration.openshift.io/release-image-version: {product-version}.0-ec.3 API Version: machineconfiguration.openshift.io/v1 Kind: MachineConfig ... Os Image URL: quay.io/my-registry/custom-image@sha256...연결된 머신 구성 풀이 새 머신 구성으로 업데이트되었는지 확인합니다.
$ oc get mcp샘플 출력
NAME CONFIG UPDATED UPDATING DEGRADED MACHINECOUNT READYMACHINECOUNT UPDATEDMACHINECOUNT DEGRADEDMACHINECOUNT AGE master rendered-master-15961f1da260f7be141006404d17d39b True False False 3 3 3 0 39m worker rendered-worker-5de4837625b1cbc237de6b22bc0bc873 True False False 3 0 0 0 39m1 - 1
UPDATING필드가True이면 머신 구성 풀이 새 머신 구성으로 업데이트됩니다. 이 경우 출력에 나열된 새 머신 구성이 표시되지 않습니다. 필드가False가 되면 작업자 머신 구성 풀이 새 머신 구성에 롤아웃됩니다.
노드의 스케줄링이 비활성화되어 있는지 확인합니다. 이는 변경 사항이 적용 중임을 나타냅니다.
$ oc get nodes출력 예
NAME STATUS ROLES AGE VERSION ip-10-0-148-79.us-west-1.compute.internal Ready worker 32m v1.26.0 ip-10-0-155-125.us-west-1.compute.internal Ready,SchedulingDisabled worker 35m v1.26.0 ip-10-0-170-47.us-west-1.compute.internal Ready control-plane,master 42m v1.26.0 ip-10-0-174-77.us-west-1.compute.internal Ready control-plane,master 42m v1.26.0 ip-10-0-211-49.us-west-1.compute.internal Ready control-plane,master 42m v1.26.0 ip-10-0-218-151.us-west-1.compute.internal Ready worker 31m v1.26.0
노드가
Ready상태가 되면 노드에서 사용자 정의 계층 이미지를 사용하고 있는지 확인합니다.노드에 대한
oc debug세션을 엽니다. 예를 들면 다음과 같습니다.$ oc debug node/ip-10-0-155-125.us-west-1.compute.internal디버그 쉘 내에서
/host를 root 디렉터리로 설정합니다.sh-4.4# chroot /hostrpm-ostree status명령을 실행하여 사용자 정의 계층 이미지가 사용 중인지 확인합니다.sh-4.4# sudo rpm-ostree status출력 예
State: idle Deployments: * ostree-unverified-registry:quay.io/my-registry/... Digest: sha256:...
추가 리소스
16.2. RHCOS 사용자 정의 계층 이미지 제거
특정 머신 구성 풀의 노드에서 RHCOS(Red Hat Enterprise Linux CoreOS) 이미지 계층을 쉽게 되돌릴 수 있습니다. MCO(Machine Config Operator)는 클러스터 기본 RHCOS(Red Hat Enterprise Linux CoreOS) 이미지로 해당 노드를 재부팅하여 사용자 정의 계층 이미지를 덮어씁니다.
클러스터에서 RHCOS(Red Hat Enterprise Linux CoreOS) 사용자 정의 계층화된 이미지를 제거하려면 이미지를 적용한 머신 구성을 삭제해야 합니다.
절차
사용자 정의 계층 이미지를 적용한 머신 구성을 삭제합니다.
$ oc delete mc os-layer-custom머신 구성을 삭제한 후 노드가 재부팅됩니다.
검증
다음 점검 중 하나를 수행하여 사용자 정의 계층 이미지가 제거되었는지 확인할 수 있습니다.
작업자 머신 구성 풀이 이전 머신 구성으로 업데이트되고 있는지 확인합니다.
$ oc get mcp샘플 출력
NAME CONFIG UPDATED UPDATING DEGRADED MACHINECOUNT READYMACHINECOUNT UPDATEDMACHINECOUNT DEGRADEDMACHINECOUNT AGE master rendered-master-6faecdfa1b25c114a58cf178fbaa45e2 True False False 3 3 3 0 39m worker rendered-worker-6b000dbc31aaee63c6a2d56d04cd4c1b False True False 3 0 0 0 39m1 - 1
UPDATING필드가True이면 머신 구성 풀이 이전 머신 구성으로 업데이트됩니다. 필드가False가 되면 작업자 머신 구성 풀이 이전 머신 구성으로 롤아웃됩니다.
노드의 스케줄링이 비활성화되어 있는지 확인합니다. 이는 변경 사항이 적용 중임을 나타냅니다.
$ oc get nodes출력 예
NAME STATUS ROLES AGE VERSION ip-10-0-148-79.us-west-1.compute.internal Ready worker 32m v1.26.0 ip-10-0-155-125.us-west-1.compute.internal Ready,SchedulingDisabled worker 35m v1.26.0 ip-10-0-170-47.us-west-1.compute.internal Ready control-plane,master 42m v1.26.0 ip-10-0-174-77.us-west-1.compute.internal Ready control-plane,master 42m v1.26.0 ip-10-0-211-49.us-west-1.compute.internal Ready control-plane,master 42m v1.26.0 ip-10-0-218-151.us-west-1.compute.internal Ready worker 31m v1.26.0노드가
Ready상태가 되면 노드에서 기본 이미지를 사용하고 있는지 확인합니다.노드에 대한
oc debug세션을 엽니다. 예를 들면 다음과 같습니다.$ oc debug node/ip-10-0-155-125.us-west-1.compute.internal디버그 쉘 내에서
/host를 root 디렉터리로 설정합니다.sh-4.4# chroot /hostrpm-ostree status명령을 실행하여 사용자 정의 계층 이미지가 사용 중인지 확인합니다.sh-4.4# sudo rpm-ostree status출력 예
State: idle Deployments: * ostree-unverified-registry:podman pull quay.io/openshift-release-dev/ocp-release@sha256:e2044c3cfebe0ff3a99fc207ac5efe6e07878ad59fd4ad5e41f88cb016dacd73 Digest: sha256:e2044c3cfebe0ff3a99fc207ac5efe6e07878ad59fd4ad5e41f88cb016dacd73
16.3. RHCOS 사용자 정의 계층 이미지로 업데이트
RHCOS(Red Hat Enterprise Linux CoreOS) 이미지 계층 지정을 구성하면 OpenShift Container Platform에서 더 이상 사용자 정의 계층 이미지를 사용하는 노드 풀을 자동으로 업데이트하지 않습니다. 노드를 적절하게 수동으로 업데이트해야 합니다.
사용자 정의 계층 이미지를 사용하는 노드를 업데이트하려면 다음 일반 단계를 따르십시오.
- 클러스터는 사용자 정의 계층 이미지를 사용하는 노드를 제외하고 버전 x.y.z+1로 자동 업그레이드됩니다.
- 그런 다음 업데이트된 OpenShift Container Platform 이미지 및 이전에 적용한 RPM을 참조하는 새 Containerfile을 생성할 수 있습니다.
- 업데이트된 사용자 정의 계층 이미지를 가리키는 새 머신 구성을 생성합니다.
사용자 정의 계층 이미지로 노드를 업데이트할 필요가 없습니다. 그러나 해당 노드가 현재 OpenShift Container Platform 버전에서 너무 멀리 떨어져 있으면 예기치 않은 결과가 발생할 수 있습니다.
Legal Notice
Copyright © Red Hat
OpenShift documentation is licensed under the Apache License 2.0 (https://www.apache.org/licenses/LICENSE-2.0).
Modified versions must remove all Red Hat trademarks.
Portions adapted from https://github.com/kubernetes-incubator/service-catalog/ with modifications by Red Hat.
Red Hat, Red Hat Enterprise Linux, the Red Hat logo, the Shadowman logo, JBoss, OpenShift, Fedora, the Infinity logo, and RHCE are trademarks of Red Hat, Inc., registered in the United States and other countries.
Linux® is the registered trademark of Linus Torvalds in the United States and other countries.
Java® is a registered trademark of Oracle and/or its affiliates.
XFS® is a trademark of Silicon Graphics International Corp. or its subsidiaries in the United States and/or other countries.
MySQL® is a registered trademark of MySQL AB in the United States, the European Union and other countries.
Node.js® is an official trademark of the OpenJS Foundation.
The OpenStack® Word Mark and OpenStack logo are either registered trademarks/service marks or trademarks/service marks of the OpenStack Foundation, in the United States and other countries and are used with the OpenStack Foundation’s permission. We are not affiliated with, endorsed or sponsored by the OpenStack Foundation, or the OpenStack community.
All other trademarks are the property of their respective owners.