클러스터
클러스터 관리
초록
1장. 다중 클러스터 엔진 Operator가 포함된 클러스터 라이프사이클 개요
멀티 클러스터 엔진 Operator는 OpenShift Container Platform 및 Red Hat Advanced Cluster Management Hub 클러스터에 대한 클러스터 관리 기능을 제공하는 클러스터 라이프사이클 Operator입니다. 허브 클러스터에서 클러스터를 생성 및 관리하고 생성한 클러스터를 제거할 수 있습니다. 또한 클러스터를 hibernate, 재개 및 분리할 수도 있습니다. 다음 문서에서 클러스터 라이프사이클 기능에 대해 자세히 알아보십시오.
지원 매트릭스 에 액세스하여 허브 클러스터 및 관리형 클러스터 요구 사항 및 지원에 대해 알아보십시오.
정보:
- 클러스터는 Hive 리소스와 함께 OpenShift Container Platform 클러스터 설치 프로그램을 사용하여 생성됩니다. OpenShift Container Platform 클러스터 설치 및 구성 시 OpenShift Container Platform 클러스터 설치 및 구성에 대한 자세한 내용은 OpenShift Container Platform 설명서에서 확인할 수 있습니다.
- OpenShift Container Platform 클러스터를 사용하면 다중 클러스터 엔진 Operator를 클러스터 라이프사이클 기능의 독립 실행형 클러스터 관리자로 사용하거나 Red Hat Advanced Cluster Management Hub 클러스터의 일부로 사용할 수 있습니다.
- OpenShift Container Platform만 사용하는 경우 Operator는 서브스크립션에 포함됩니다. OpenShift Container Platform 설명서에서 Kubernetes Operator용 다중 클러스터 엔진 정보를 참조하십시오.
- Red Hat Advanced Cluster Management를 구독하면 설치가 포함된 Operator도 제공됩니다. Red Hat Advanced Cluster Management Hub 클러스터를 사용하여 다른 Kubernetes 클러스터를 생성, 관리 및 모니터링할 수 있습니다. Red Hat Advanced Cluster Management 설치 및 업그레이드 설명서를 참조하십시오.
릴리스 이미지는 클러스터를 생성할 때 사용하는 OpenShift Container Platform 버전입니다. Red Hat Advanced Cluster Management를 사용하여 생성된 클러스터의 경우 릴리스 이미지의 자동 업그레이드를 활성화할 수 있습니다. Red Hat Advanced Cluster Management의 릴리스 이미지에 대한 자세한 내용은 릴리스 이미지를 참조하십시오.
클러스터 라이프사이클 관리 아키텍처의 구성 요소는 클러스터 라이프사이클 아키텍처에 포함되어 있습니다.
1.1. 릴리스 노트
현재 릴리스에 대해 알아보십시오.
더 이상 사용되지 않음: 다중 클러스터 엔진 Operator 2.3 및 이전 버전은 더 이상 지원되지 않습니다. 문서는 사용할 수 있지만 에라타 또는 기타 업데이트는 사용할 수 없습니다.
모범 사례: 최신 버전으로 업그레이드합니다.
현재 지원되는 릴리스 중 하나 또는 제품 문서에 문제가 발생하는 경우 Red Hat 지원팀으로 이동하여 문제를 해결하거나 기술 자료 문서를 보거나 지원 팀과 연결하거나 케이스를 열 수 있습니다. 인증 정보를 사용하여 로그인해야 합니다.
Red Hat 고객 포털 FAQ에서 고객 포털 설명서에 대해 자세히 알아볼 수도 있습니다.
이 문서는 특정 구성 요소 또는 기능이 도입되어 최신 버전의 OpenShift Container Platform에서만 테스트되지 않는 한 가장 빨리 지원되는 OpenShift Container Platform 버전을 참조합니다.
전체 지원 정보는 지원 매트릭스 를 참조하십시오. 라이프 사이클 정보는 Red Hat OpenShift Container Platform 라이프 사이클 정책을 참조하십시오.
1.1.1. 다중 클러스터 엔진 Operator를 사용한 클러스터 라이프사이클의 새로운 기능
중요: 일부 기능 및 구성 요소는 기술 프리뷰로 확인 및 릴리스됩니다.
이 릴리스의 새로운 기능에 대해 자세히 알아보기:
1.1.1.1. 클러스터 라이프사이클
다중 클러스터 엔진 Operator의 클러스터 라이프사이클과 관련된 새로운 기능에 대해 알아보십시오.
- 이제 관리 클러스터가 HTTP 및 HTTPS 프록시 서버를 통해 hub 클러스터와 통신할 수 있도록 클러스터 프록시 애드온의 프록시 설정을 구성할 수 있습니다. 자세한 내용은 클러스터 프록시 애드온 구성 을 참조하십시오.
-
이제
ManagedServiceAccount애드온이 기본적으로 활성화되어 있습니다. 다중 클러스터 엔진 Operator 버전 2.4에서 업그레이드하는 경우 애드온 활성화에 대한 자세한 내용은 ManagedServiceAccount 애드온 활성화를 참조하십시오. - 기술 프리뷰: 이제 중간 구성 요소가 있는 경우에도 다중 클러스터 엔진 Operator 허브 클러스터에서 관리 클러스터를 가져올 수 있도록 서버 URL 및 허브 클러스터 API CA 번들을 사용자 지정할 수 있습니다. 자세한 내용은 서버 URL 사용자 지정 및 허브 클러스터 API CA 번들(기술 프리뷰) 을 참조하십시오.
- 이제 각 요청에서 HTTP/HTTPS 헤더 및 쿼리 매개변수를 전달하여 OS 이미지를 가져올 수 있습니다. 자세한 내용은 연결이 끊긴 환경에서 중앙 인프라 관리 활성화를 참조하십시오.
-
이제 인증을 위해 자체 서명 또는 타사 CA 인증서를 사용하여 TLS가 활성화된 HTTPS
osImages를 저장하고 다운로드할 수 있습니다. 자세한 내용은 연결이 끊긴 환경에서 중앙 인프라 관리 활성화를 참조하십시오.
1.1.1.2. 인증 정보
- 이제 VMware vSphere에서 연결이 끊긴 설치에 통합 콘솔을 사용하여 인증 정보를 생성하도록 Cluster OS 이미지 필드를 구성할 수 있습니다. 자세한 내용은 콘솔을 사용하여 인증 정보 관리를 참조하십시오.
1.1.1.3. 호스팅된 컨트롤 플레인
- 기술 프리뷰: 베어 메탈이 아닌 에이전트 시스템을 사용하여 호스팅된 컨트롤 플레인 클러스터를 프로비저닝할 수 있습니다. 자세한 내용은 베어 메탈 에이전트 머신을 사용하여 호스팅되는 컨트롤 플레인 클러스터 구성 을 참조하십시오.
- 콘솔을 사용하여 KubeVirt 플랫폼으로 호스팅 클러스터를 생성할 수 있습니다. 자세한 내용은 콘솔을 사용하여 호스팅 클러스터 생성을 참조하십시오.
- 이제 추가 네트워크를 구성하고 VM(가상 머신)에 대한 보장된 CPU 액세스를 요청하며 노드 풀의 KubeVirt VM 예약을 관리할 수 있습니다. 자세한 내용은 노드 풀의 추가 네트워크, 보장된 CPU 및 VM 스케줄링 구성을 참조하십시오.
1.1.1.4. Red Hat Advanced Cluster Management 통합
Red Hat Advanced Cluster Management를 설치한 후 Observability를 활성화하면 Grafana 대시보드를 사용하여 호스팅된 컨트롤 플레인 클러스터 용량 추정 및 기존 호스팅 컨트롤 플레인 리소스 사용률을 확인할 수 있습니다. 자세한 내용은 Red Hat Advanced Cluster Management integration 에서 참조하십시오.
1.1.2. 클러스터 라이프사이클의 알려진 문제
다중 클러스터 엔진 Operator가 있는 클러스터 라이프사이클의 알려진 문제를 검토합니다. 다음 목록에는 이 릴리스에 대한 알려진 문제 또는 이전 릴리스에서 계속되는 알려진 문제가 포함되어 있습니다. OpenShift Container Platform 클러스터의 경우 OpenShift Container Platform 릴리스 노트를 참조하십시오.
1.1.2.1. 클러스터 관리
클러스터 라이프사이클 알려진 문제 및 제한 사항은 다중 클러스터 엔진 Operator 문서가 있는 클러스터 라이프사이클의 일부입니다.
1.1.2.1.1. nmstate로 제한
복사 및 붙여넣기 기능을 구성하여 더 빠르게 개발하십시오. assisted-installer 에서 copy-from-mac 기능을 구성하려면 nmstate 정의 인터페이스 및 mac-mapping 인터페이스에 mac-address 를 추가해야 합니다. mac-mapping 인터페이스는 nmstate 정의 인터페이스 외부에 제공됩니다. 따라서 동일한 mac-address 를 두 번 제공해야 합니다.
1.1.2.1.2. Prehook 실패가 호스트된 클러스터 생성에 실패하지 않음
호스팅된 클러스터 생성에 자동화 템플릿을 사용하고 prehook 작업이 실패하면 호스팅된 클러스터 생성이 여전히 진행 중인 것처럼 보입니다. 호스트 클러스터가 완전한 실패 상태로 설계되었으므로 클러스터를 계속 생성하려고 하기 때문에 이는 정상입니다.
1.1.2.1.3. add-on을 제거할 때 관리형 클러스터에 필요한volSync CSV 수동 제거
hub 클러스터에서volSync ManagedClusterAddOn 을 제거하면 관리 클러스터에서volSync Operator 서브스크립션을 제거하지만 CSV(클러스터 서비스 버전)는 제거되지 않습니다. 관리형 클러스터에서 CSV를 제거하려면volSync를 제거하는 각 관리 클러스터에서 다음 명령을 실행합니다.
oc delete csv -n openshift-operators volsync-product.v0.6.0
다른 버전의 CryostatSync가 설치되어 있는 경우 v0.6.0 을 설치된 버전으로 교체합니다.
1.1.2.1.4. 관리형 클러스터 세트를 삭제해도 레이블이 자동으로 제거되지는 않습니다.
ManagedClusterSet 을 삭제한 후 클러스터를 클러스터 세트에 연결하는 각 관리 클러스터에 추가된 레이블은 자동으로 제거되지 않습니다. 삭제된 관리 클러스터 세트에 포함된 각 관리 클러스터에서 레이블을 수동으로 제거합니다. 레이블은 cluster.open-cluster-management.io/clusterset:<ManagedClusterSet Name> 과 유사합니다.
1.1.2.1.5. ClusterClaim 오류
ClusterPool 에 대해 Hive ClusterClaim 을 생성하고 ClusterClaimspec 라이프 사이클 필드를 잘못된 golang 시간 값으로 수동으로 설정하는 경우 제품은 잘못된 형식의 클레임뿐만 아니라 모든 ClusterClaims 이행 및 재조정을 중지합니다.
이 오류가 발생하면 clusterclaim-controller pod 로그에 다음 내용이 표시됩니다. 이 로그는 풀 이름과 유효하지 않은 라이프 사이클이 포함된 특정 예입니다.
E0203 07:10:38.266841 1 reflector.go:138] sigs.k8s.io/controller-runtime/pkg/cache/internal/informers_map.go:224: Failed to watch *v1.ClusterClaim: failed to list *v1.ClusterClaim: v1.ClusterClaimList.Items: []v1.ClusterClaim: v1.ClusterClaim.v1.ClusterClaim.Spec: v1.ClusterClaimSpec.Lifetime: unmarshalerDecoder: time: unknown unit "w" in duration "1w", error found in #10 byte of ...|time":"1w"}},{"apiVe|..., bigger context ...|clusterPoolName":"policy-aas-hubs","lifetime":"1w"}},{"apiVersion":"hive.openshift.io/v1","kind":"Cl|...유효하지 않은 클레임을 삭제할 수 있습니다.
잘못된 클레임이 삭제되면 클레임이 추가 상호 작용 없이 성공적으로 조정되기 시작합니다.
1.1.2.1.6. 제품 채널이 프로비저닝된 클러스터와 동기화되지 않음
clusterimageset 은 fast 채널이지만 프로비저닝된 클러스터는 stable 채널에 있습니다. 현재 제품은 채널을 프로비저닝된 OpenShift Container Platform 클러스터와 동기화하지 않습니다.
OpenShift Container Platform 콘솔에서 올바른 채널로 변경합니다. Administration > Cluster Settings > Details Channel 을 클릭합니다.
1.1.2.1.7. 사용자 정의 CA 인증서가 있는 관리형 클러스터 연결을 복원하면 복원된 허브 클러스터에 실패할 수 있습니다.
사용자 정의 CA 인증서로 클러스터를 관리하는 허브 클러스터의 백업을 복원한 후 관리 클러스터와 hub 클러스터 간의 연결이 실패할 수 있습니다. 이는 복원된 허브 클러스터에서 CA 인증서가 백업되지 않았기 때문입니다. 연결을 복원하려면 관리 클러스터의 네임스페이스에 있는 사용자 정의 CA 인증서 정보를 복원된 허브 클러스터의 < managed_cluster>-admin-kubeconfig 시크릿에 복사합니다.
팁: 백업 사본을 생성하기 전에 이 CA 인증서를 hub 클러스터에 복사하는 경우 백업 사본에 시크릿 정보가 포함됩니다. 나중에 백업 사본을 사용하여 복원하면 허브와 관리 클러스터 간의 연결이 자동으로 완료됩니다.
1.1.2.1.8. local-cluster가 자동으로 다시 생성되지 않을 수 있습니다.
disableHubSelfManagement 를 false 로 설정하는 동안 local-cluster가 삭제되면 MulticlusterHub Operator가 local-cluster를 다시 생성합니다. local-cluster를 분리하면 local-cluster가 자동으로 다시 생성되지 않을 수 있습니다.
이 문제를 해결하려면
MulticlusterHubOperator에서 조사한 리소스를 수정합니다. 다음 예제를 참조하십시오.oc delete deployment multiclusterhub-repo -n <namespace>-
local-cluster를 올바르게 분리하려면
MultiClusterHub에서disableHubSelfManagement를 true로 설정합니다.
1.1.2.1.9. 온-프레미스 클러스터를 만들 때 서브넷을 선택해야 합니다.
콘솔을 사용하여 온-프레미스 클러스터를 만들 때 클러스터에 사용 가능한 서브넷을 선택해야 합니다. 필수 필드로 표시되지 않습니다.
1.1.2.1.10. Infrastructure Operator를 통한 클러스터 프로비저닝 실패
Infrastructure Operator를 사용하여 OpenShift Container Platform 클러스터를 생성할 때 ISO 이미지의 파일 이름이 너무 길 수 있습니다. 긴 이미지 이름을 사용하면 이미지 프로비저닝과 클러스터 프로비저닝이 실패합니다. 이 문제가 있는지 확인하려면 다음 단계를 완료합니다.
다음 명령을 실행하여 프로비저닝 중인 클러스터의 베어 메탈 호스트 정보를 확인합니다.
oc get bmh -n <cluster_provisioning_namespace>describe명령을 실행하여 오류 정보를 확인합니다.oc describe bmh -n <cluster_provisioning_namespace> <bmh_name>다음 예제와 유사한 오류는 파일 이름의 길이가 문제임을 나타냅니다.
Status: Error Count: 1 Error Message: Image provisioning failed: ... [Errno 36] File name too long ...
이 문제가 발생하면 인프라 Operator가 이미지 서비스를 사용하지 않았기 때문에 일반적으로 다음 버전의 OpenShift Container Platform에 있습니다.
- 4.8.17 및 이전 버전
- 4.9.6 이전
이 오류를 방지하려면 OpenShift Container Platform을 버전 4.8.18 이상 또는 4.9.7 이상으로 업그레이드하십시오.
1.1.2.1.11. 호스트 인벤토리를 사용하여 검색 이미지로 부팅하고 호스트를 자동으로 추가할 수 없습니다
검색 이미지로 부팅하고 호스트를 자동으로 추가하기 위해 호스트 인벤토리 또는 InfraEnv 사용자 정의 리소스를 사용할 수 없습니다. BareMetalHost 리소스에 이전 InfraEnv 리소스를 사용한 후 이미지를 직접 부팅하려는 경우 새 InfraEnv 리소스를 생성하여 문제를 해결할 수 있습니다.
1.1.2.1.12. 다른 이름으로 다시 가져온 후 로컬 클러스터 상태 오프라인
실수로 라는 클러스터를 다른 이름으로 다시 가져오려고 하면 local 클러스터의 상태 및 다시 가져오기된 클러스터의 상태가 local-cluster 오프라인으로 표시됩니다.
이 경우 복구하려면 다음 단계를 완료합니다.
hub 클러스터에서 다음 명령을 실행하여 허브 클러스터의 자체 관리 설정을 일시적으로 편집합니다.
oc edit mch -n open-cluster-management multiclusterhub-
spec.disableSelfManagement=true설정을 추가합니다. hub 클러스터에서 다음 명령을 실행하여 local-cluster를 삭제하고 재배포합니다.
oc delete managedcluster local-cluster다음 명령을 입력하여
local-cluster관리 설정을 제거합니다.oc edit mch -n open-cluster-management multiclusterhub-
이전에 추가한
spec.disableSelfManagement=true를 제거합니다.
1.1.2.1.13. 프록시 환경에서 Ansible 자동화를 통한 클러스터 프로비저닝 실패
관리 클러스터를 자동으로 프로비저닝하도록 구성된 자동화 템플릿은 다음 두 조건이 충족되면 실패할 수 있습니다.
- hub 클러스터에는 클러스터 전체 프록시가 활성화되어 있습니다.
- Ansible Automation Platform은 프록시를 통해서만 연결할 수 있습니다.
1.1.2.1.14. klusterlet Operator의 버전은 hub 클러스터와 동일해야 합니다.
klusterlet Operator를 설치하여 관리 클러스터를 가져오는 경우 klusterlet Operator의 버전이 Hub 클러스터 버전과 동일하거나 klusterlet Operator가 작동하지 않아야 합니다.
1.1.2.1.15. 관리되는 클러스터 네임스페이스를 수동으로 삭제할 수 없음
관리 클러스터의 네임스페이스를 수동으로 삭제할 수 없습니다. 관리형 클러스터 네임스페이스는 관리 클러스터를 분리한 후 자동으로 삭제됩니다. 관리 클러스터가 분리되기 전에 관리 클러스터 네임스페이스를 수동으로 삭제하는 경우 관리 클러스터에 관리 클러스터를 삭제한 후 지속적인 종료 상태가 표시됩니다. 이 종료 관리 클러스터를 삭제하려면 분리된 관리 클러스터에서 종료자를 수동으로 제거합니다.
1.1.2.1.16. Hub 클러스터 및 관리형 클러스터 클럭이 동기화되지 않음
Hub 클러스터 및 관리 클러스터 시간이 동기화되지 않아 알 수 없고 결국 몇 분 내에 사용할 수 있습니다. OpenShift Container Platform 허브 클러스터 시간이 올바르게 구성되었는지 확인합니다. 노드 사용자 지정을 참조하십시오.
1.1.2.1.17. 특정 버전의 IBM OpenShift Container Platform Kubernetes Service 클러스터 가져오기는 지원되지 않습니다.
IBM OpenShift Container Platform Kubernetes Service 버전 3.11 클러스터를 가져올 수 없습니다. 이후 버전의 IBM OpenShift Kubernetes Service가 지원됩니다.
1.1.2.1.18. 프로비저닝된 클러스터의 자동 시크릿 업데이트는 지원되지 않습니다.
클라우드 공급자 측에서 클라우드 공급자 액세스 키를 변경하는 경우 다중 클러스터 엔진 Operator 콘솔에서 이 클라우드 공급자에 대한 해당 인증 정보도 업데이트해야 합니다. 이는 관리 클러스터가 호스팅되는 클라우드 공급자에서 인증 정보가 만료되고 관리 클러스터를 삭제하려고 할 때 필요합니다.
1.1.2.1.19. 관리 클러스터의 노드 정보는 검색에서 볼 수 없습니다
hub 클러스터에서 리소스에 대한 맵을 검색합니다. 사용자 RBAC 설정에 따라 사용자가 관리 클러스터의 노드 데이터를 볼 수 없습니다. 검색 결과는 클러스터의 노드 페이지에 표시되는 결과와 다를 수 있습니다.
1.1.2.1.20. 클러스터 제거 프로세스가 완료되지 않음
관리 클러스터를 삭제하면 1시간 후에도 상태가 계속 Destroying 으로 표시되고 클러스터가 삭제되지 않습니다. 이 문제를 해결하려면 다음 단계를 완료합니다.
- 클라우드에 고립된 리소스가 없고 관리 클러스터와 연결된 모든 공급자 리소스가 정리되었는지 수동으로 확인합니다.
다음 명령을 입력하여 제거 중인 관리 클러스터의
ClusterDeployment정보를 엽니다.oc edit clusterdeployment/<mycluster> -n <namespace>mycluster를 제거하려는 관리 클러스터의 이름으로 바꿉니다.namespace를 관리 클러스터의 네임스페이스로 바꿉니다.-
hive.openshift.io/deprovision종료자를 제거하여 클라우드에서 클러스터 리소스를 정리하려는 프로세스를 강제로 중지합니다. -
변경 사항을 저장하고
ClusterDeployment이 사라졌는지 확인합니다. 다음 명령을 실행하여 관리 클러스터의 네임스페이스를 수동으로 제거합니다.
oc delete ns <namespace>namespace를 관리 클러스터의 네임스페이스로 바꿉니다.
Red Hat Advanced Cluster Management 콘솔을 사용하여 OpenShift Container Platform Dedicated 환경에 있는 OpenShift Container Platform 관리 클러스터를 업그레이드할 수 없습니다.
1.1.2.1.22. 작업 관리자 애드온 검색 세부 정보
특정 관리 클러스터에서 특정 리소스의 검색 세부 정보 페이지가 실패할 수 있습니다. 검색하려면 먼저 관리 클러스터의 work-manager 애드온이 Available 상태에 있는지 확인해야 합니다.
Red Hat OpenShift Container Platform 및 비 OpenShift Container Platform 클러스터는 모두 Red Hat Advanced Cluster Management 2.10 이상의 새로 설치를 사용하는 경우 Pod 로그 기능을 지원합니다.
Red Hat Advanced Cluster Management 2.9에서 2.10으로 업그레이드한 경우 OpenShift Container Platform 관리형 클러스터에서 Pod 로그 기능을 사용하려면 ManagedServiceAccount 애드온을 수동으로 활성화해야 합니다. ManagedServiceAccount를 활성화하는 방법을 알아보려면 ManagedServiceAccount 애드온 을 참조하십시오.
또는 ManagedServiceAccount 대신 LoadBalancer 를 사용하여 비 OpenShift Container Platform 관리 클러스터에서 Pod 로그 기능을 활성화할 수 있습니다.
LoadBalancer 를 활성화하려면 다음 단계를 완료합니다.
-
클라우드 공급자에는 서로 다른
LoadBalancer구성이 있습니다. 자세한 내용은 클라우드 공급자 설명서를 참조하십시오. -
managedClusterInfo상태의loggingEndpoint를 확인하여 Red Hat Advanced Cluster Management에서LoadBalancer가 활성화되어 있는지 확인합니다. 다음 명령을 실행하여
loggingEndpoint.IP또는loggingEndpoint.Host에 유효한 IP 주소 또는 호스트 이름이 있는지 확인합니다.oc get managedclusterinfo <clusterName> -n <clusterNamespace> -o json | jq -r '.status.loggingEndpoint'
LoadBalancer 유형에 대한 자세한 내용은 Kubernetes 문서의 서비스 페이지를 참조하십시오.
1.1.2.1.24. OpenShift Container Platform 4.10.z는 프록시 구성이 있는 호스팅된 컨트롤 플레인 클러스터를 지원하지 않습니다.
OpenShift Container Platform 4.10.z에서 클러스터 전체 프록시 구성으로 호스팅 서비스 클러스터를 생성하면 nodeip-configuration.service 서비스가 작업자 노드에서 시작되지 않습니다.
1.1.2.1.25. Azure에서 OpenShift Container Platform 4.11 클러스터를 프로비저닝할 수 없음
Azure에서 OpenShift Container Platform 4.11 클러스터를 프로비저닝하면 인증 Operator 시간 초과 오류로 인해 실패합니다. 이 문제를 해결하려면 install-config.yaml 파일에서 다른 작업자 노드 유형을 사용하거나 vmNetworkingType 매개변수를 Basic 으로 설정합니다. 다음 install-config.yaml 예제를 참조하십시오.
compute:
- hyperthreading: Enabled
name: 'worker'
replicas: 3
platform:
azure:
type: Standard_D2s_v3
osDisk:
diskSizeGB: 128
vmNetworkingType: 'Basic'1.1.2.1.26. 클라이언트가 iPXE 스크립트에 연결할 수 없음
iPXE는 오픈 소스 네트워크 부팅 펌웨어입니다. 자세한 내용은 iPXE 를 참조하십시오.
노드를 부팅할 때 일부 DHCP 서버의 URL 길이 제한이 InfraEnv 사용자 정의 리소스 정의의 ipxeScript URL을 차단하여 콘솔에 다음과 같은 오류 메시지가 표시됩니다.
부팅 가능한 장치 없음
이 문제를 해결하려면 다음 단계를 완료하십시오.
지원 설치를 사용할 때 다음 파일과 유사할 수 있는
bootArtifacts를 노출할 때InfraEnv사용자 정의 리소스 정의를 적용합니다.status: agentLabelSelector: matchLabels: infraenvs.agent-install.openshift.io: qe2 bootArtifacts: initrd: https://assisted-image-service-multicluster-engine.redhat.com/images/0000/pxe-initrd?api_key=0000000&arch=x86_64&version=4.11 ipxeScript: https://assisted-service-multicluster-engine.redhat.com/api/assisted-install/v2/infra-envs/00000/downloads/files?api_key=000000000&file_name=ipxe-script kernel: https://mirror.openshift.com/pub/openshift-v4/x86_64/dependencies/rhcos/4.12/latest/rhcos-live-kernel-x86_64 rootfs: https://mirror.openshift.com/pub/openshift-v4/x86_64/dependencies/rhcos/4.12/latest/rhcos-live-rootfs.x86_64.img-
짧은 URL로
bootArtifacts를 노출하는 프록시 서버를 생성합니다. bootArtifacts를 복사하여 다음 명령을 실행하여 프록시에 추가합니다.for artifact in oc get infraenv qe2 -ojsonpath="{.status.bootArtifacts}" | jq ". | keys[]" | sed "s/\"//g" do curl -k oc get infraenv qe2 -ojsonpath="{.status.bootArtifacts.${artifact}}"` -o $artifact-
libvirt.xml의bootp매개변수에ipxeScript아티팩트 프록시 URL을 추가합니다.
1.1.2.1.27. Red Hat Advanced Cluster Management를 업그레이드한 후 ClusterDeployment 을 삭제할 수 없음
Red Hat Advanced Cluster Management 2.6에서 삭제된 BareMetalAssets API를 사용하는 경우 BareMetalAssets API가 ClusterDeployment 에 바인딩되어 있으므로 Red Hat Advanced Cluster Management 2.7로 업그레이드한 후 ClusterDeployment 을 삭제할 수 없습니다.
이 문제를 해결하려면 Red Hat Advanced Cluster Management 2.7로 업그레이드하기 전에 종료자 를 제거하려면 다음 명령을 실행합니다.
oc patch clusterdeployment <clusterdeployment-name> -p '{"metadata":{"finalizers":null}}' --type=merge1.1.2.1.28. 중앙 인프라 관리 서비스를 사용하여 연결이 끊긴 환경에 배포된 클러스터는 설치되지 않을 수 있습니다.
중앙 인프라 관리 서비스를 사용하여 연결이 끊긴 환경에 클러스터를 배포할 때 클러스터 노드가 설치를 시작하지 못할 수 있습니다.
이 문제는 클러스터가 OpenShift Container Platform 버전 4.12.0에서 4.12.2를 통해 제공되는 Red Hat Enterprise Linux CoreOS 라이브 ISO 이미지에서 생성된 검색 ISO 이미지를 사용하기 때문에 발생합니다. 이미지에는 registry.redhat.io 및 registry.access.redhat.com 에서 소싱한 이미지의 서명이 필요한 제한적인 /etc/containers/policy.json 파일이 포함되어 있습니다. 연결이 끊긴 환경에서 미러링된 이미지에 서명이 미러링되지 않아 검색 시 이미지 풀링이 실패할 수 있습니다. 에이전트 이미지가 클러스터 노드와 연결되지 않아 지원 서비스와의 통신이 실패합니다.
이 문제를 해결하려면 /etc/containers/policy.json 파일을 제한 없이 설정하는 클러스터에 ignition 덮어쓰기를 적용합니다. Ignition 재정의는 InfraEnv 사용자 정의 리소스 정의에서 설정할 수 있습니다. 다음 예제에서는 재정의가 있는 InfraEnv 사용자 정의 리소스 정의를 보여줍니다.
apiVersion: agent-install.openshift.io/v1beta1
kind: InfraEnv
metadata:
name: cluster
namespace: cluster
spec:
ignitionConfigOverride: '{"ignition":{"version":"3.2.0"},"storage":{"files":[{"path":"/etc/containers/policy.json","mode":420,"overwrite":true,"contents":{"source":"data:text/plain;charset=utf-8;base64,ewogICAgImRlZmF1bHQiOiBbCiAgICAgICAgewogICAgICAgICAgICAidHlwZSI6ICJpbnNlY3VyZUFjY2VwdEFueXRoaW5nIgogICAgICAgIH0KICAgIF0sCiAgICAidHJhbnNwb3J0cyI6CiAgICAgICAgewogICAgICAgICAgICAiZG9ja2VyLWRhZW1vbiI6CiAgICAgICAgICAgICAgICB7CiAgICAgICAgICAgICAgICAgICAgIiI6IFt7InR5cGUiOiJpbnNlY3VyZUFjY2VwdEFueXRoaW5nIn1dCiAgICAgICAgICAgICAgICB9CiAgICAgICAgfQp9"}}]}}'다음 예제에서는 생성된 제한되지 않은 파일을 보여줍니다.
{
"default": [
{
"type": "insecureAcceptAnything"
}
],
"transports": {
"docker-daemon": {
"": [
{
"type": "insecureAcceptAnything"
}
]
}
}
}이 설정이 변경되면 클러스터가 설치됩니다.
1.1.2.1.29. 배포 후 관리 클러스터가 Pending 상태로 유지됨
통합 흐름은 기본 프로비저닝 프로세스입니다. Bare Metal Operator(BMO)에 BareMetalHost 리소스를 사용하여 호스트를 라이브 ISO에 연결하는 경우 Ironic Python 에이전트는 다음 작업을 수행합니다.
- 베어 메탈 설치 관리자 프로비저닝-infrastructure에서 단계를 실행합니다.
- 지원 설치 관리자 에이전트를 시작하고 에이전트는 설치 및 프로비저닝 프로세스의 나머지 부분을 처리합니다.
지원 설치 관리자 에이전트가 느리게 시작되고 관리 클러스터를 배포하는 경우 관리 클러스터가 Pending 상태로 중단되고 에이전트 리소스가 없을 수 있습니다. 통합 흐름을 비활성화하여 문제를 해결할 수 있습니다.
중요: 통합 흐름을 비활성화할 때 지원 설치 관리자 에이전트만 라이브 ISO에서 실행되므로 열려 있는 포트 수를 줄이고 Ironic Python 에이전트 에이전트에서 활성화한 기능을 비활성화합니다.
- 디스크 정리 사전 프로비저닝
- iPXE 부팅 펌웨어
- BIOS 구성
통합 흐름을 비활성화하지 않고 활성화하거나 비활성화할 포트 번호를 결정하려면 네트워크 구성 을 참조하십시오.
통합 흐름을 비활성화하려면 다음 단계를 완료합니다.
hub 클러스터에 다음 ConfigMap을 생성합니다.
apiVersion: v1 kind: ConfigMap metadata: name: my-assisted-service-config namespace: multicluster-engine data: ALLOW_CONVERGED_FLOW: "false"1 - 1
- 매개변수 값을 "false"로 설정하면 Ironic Python Agent에서 활성화한 기능도 비활성화합니다.
다음 명령을 실행하여 ConfigMap을 적용합니다.
oc annotate --overwrite AgentServiceConfig agent unsupported.agent-install.openshift.io/assisted-service-configmap=my-assisted-service-config
1.1.2.1.30. ManagedClusterSet API 사양 제한
Clustersets API 를 사용하는 경우 selectorType: LaberSelector 설정은 지원되지 않습니다. selectorType: ExclusiveClusterSetLabel 설정이 지원됩니다.
1.1.2.1.31. Hub 클러스터 통신 제한 사항
hub 클러스터가 관리 클러스터에 도달하거나 통신할 수 없는 경우 다음과 같은 제한 사항이 발생합니다.
- 콘솔을 사용하여 새 관리 클러스터를 생성할 수 없습니다. 명령행 인터페이스를 사용하거나 콘솔에서 수동으로 가져오기 명령 실행 옵션을 사용하여 관리 클러스터를 수동으로 가져올 수 있습니다.
- 콘솔을 사용하여 Application 또는 ApplicationSet을 배포하거나 관리 클러스터를 ArgoCD로 가져오는 경우 hub 클러스터 ArgoCD 컨트롤러는 관리 클러스터 API 서버를 호출합니다. AppSub 또는 ArgoCD 풀 모델을 사용하여 문제를 해결할 수 있습니다.
Pod 로그의 콘솔 페이지가 작동하지 않으며 다음과 유사한 오류 메시지가 표시됩니다.
Error querying resource logs: Service unavailable
1.1.2.1.32. 관리 서비스 계정 애드온 제한 사항
다음은 managed-serviceaccount 애드온에 대한 알려진 문제 및 제한 사항입니다.
1.1.2.1.32.1. installNamespace 필드에는 하나의 값만 있을 수 있습니다.
managed-serviceaccount 애드온을 활성화할 때 ManagedClusterAddOn 리소스의 installNamespace 필드에 값으로 open-cluster-management-agent-addon 이 있어야 합니다. 다른 값은 무시됩니다. managed-serviceaccount 애드온 에이전트는 항상 관리 클러스터의 open-cluster-management-agent-addon 네임스페이스에 배포됩니다.
1.1.2.1.32.2. tolerations 및 nodeSelector 설정은 managed-serviceaccount 에이전트에 영향을 미치지 않습니다.
MultiClusterEngine 및 MultiClusterHub 리소스에 구성된 tolerations 및 nodeSelector 설정은 로컬 클러스터에 배포된 관리-serviceaccount 에이전트에 영향을 미치지 않습니다. 로컬 클러스터에서 managed-serviceaccount 애드온이 항상 필요한 것은 아닙니다.
managed-serviceaccount 애드온이 필요한 경우 다음 단계를 완료하여 문제를 해결할 수 있습니다.
-
addonDeploymentConfig사용자 정의 리소스를 생성합니다. -
로컬 클러스터 및
managed-serviceaccount에이전트의tolerations및nodeSelector값을 설정합니다. -
생성한
addonDeploymentConfig사용자 정의 리소스를 사용하도록 로컬 클러스터 네임스페이스에서managed-serviceaccountManagedClusterAddon을 업데이트합니다.
addonDeploymentConfig 사용자 정의 리소스 를 사용하여 애드온에 대한 허용 오차 및 nodeSelector를 구성하는 방법에 대한 자세한 내용은 klusterlet 애드온에 대한 nodeSelector 및 허용 오차 구성을 참조하십시오.
1.1.2.1.33. KubeVirt 호스트 클러스터의 대량 제거 옵션이 호스팅된 클러스터를 제거하지 않음
KubeVirt 호스팅 클러스터의 콘솔에서 대량 제거 옵션을 사용하면 KubeVirt 호스팅 클러스터가 제거되지 않습니다.
행 작업 드롭다운 메뉴를 사용하여 KubeVirt 호스팅 클러스터를 대신 삭제합니다.
1.1.2.1.34. 클러스터 큐레이터는 OpenShift Container Platform Dedicated 클러스터를 지원하지 않습니다.
ClusterCurator 리소스를 사용하여 OpenShift Container Platform Dedicated 클러스터를 업그레이드하면 클러스터 큐레이터가 OpenShift Container Platform Dedicated 클러스터를 지원하지 않기 때문에 업그레이드가 실패합니다.
1.1.2.1.35. 사용자 정의 수신 도메인이 올바르게 적용되지 않음
관리형 클러스터를 설치하는 동안 ClusterDeployment 리소스를 사용하여 사용자 정의 인그레스 도메인을 지정할 수 있지만, SyncSet 리소스를 사용하여 설치 후에만 변경 사항을 적용합니다. 결과적으로 clusterdeployment.yaml 파일의 spec 필드에 사용자가 지정한 Ingress 도메인이 표시되지만 상태는 여전히 기본 도메인을 표시합니다.
4.16 이전 Red Hat OpenShift Container Platform 버전으로 단일 노드 OpenShift 클러스터를 설치하려면 InfraEnv 사용자 정의 리소스 및 부팅된 호스트에서 단일 노드 OpenShift 클러스터를 설치하기 위해 사용 중인 동일한 OpenShift Container Platform 버전을 사용해야 합니다. 버전이 일치하지 않으면 설치에 실패합니다.
이 문제를 해결하려면 Discovery ISO로 호스트를 부팅하기 전에 InfraEnv 리소스를 편집하고 다음 콘텐츠를 포함합니다.
apiVersion: agent-install.openshift.io/v1beta1
kind: InfraEnv
spec:
osImageVersion: 4.15
osImageVersion 필드는 설치하려는 Red Hat OpenShift Container Platform 클러스터 버전과 일치해야 합니다.
1.1.2.2. 호스팅된 컨트롤 플레인
1.1.2.2.1. 콘솔이 호스트된 클러스터를 Pending 가져오기로 표시
주석 및 ManagedCluster 이름이 일치하지 않으면 콘솔에 클러스터가 Pending 가져오기 로 표시됩니다. 다중 클러스터 엔진 Operator는 클러스터를 사용할 수 없습니다. 주석이 없고 ManagedCluster 이름이 HostedCluster 리소스의 Infra-ID 값과 일치하지 않는 경우에도 동일한 문제가 발생합니다."
1.1.2.2.2. 호스트된 클러스터에 노드 풀을 추가할 때 콘솔이 동일한 버전을 여러 번 나열할 수 있습니다.
콘솔을 사용하여 기존 호스트 클러스터에 새 노드 풀을 추가하면 동일한 버전의 OpenShift Container Platform이 옵션 목록에 두 번 이상 표시될 수 있습니다. 원하는 버전의 목록에서 인스턴스를 선택할 수 있습니다.
1.1.2.2.3. 웹 콘솔은 클러스터에서 제거된 후에도 노드를 나열하고 인프라 환경으로 돌아갑니다.
노드 풀이 작업자가 0개로 축소되면 콘솔의 호스트 목록에는 노드가 준비 됨 상태로 계속 표시됩니다. 다음 두 가지 방법으로 노드 수를 확인할 수 있습니다.
- 콘솔에서 노드 풀로 이동하여 0개의 노드가 있는지 확인합니다.
명령줄 인터페이스에서 다음 명령을 실행합니다.
다음 명령을 실행하여 0개의 노드가 노드 풀에 있는지 확인합니다.
oc get nodepool -A다음 명령을 실행하여 0 노드가 클러스터에 있는지 확인합니다.
oc get nodes --kubeconfig- 다음 명령을 실행하여 0 에이전트가 클러스터에 바인딩된 것으로 보고되었는지 확인합니다.
oc get agents -A
1.1.2.2.4. 듀얼 스택 네트워크에 대해 구성된 호스트 클러스터의 잠재적인 DNS 문제
듀얼 스택 네트워크를 사용하는 환경에서 호스팅 클러스터를 생성할 때 다음과 같은 DNS 관련 문제가 발생할 수 있습니다.
-
service-ca-operatorpod의CrashLoopBackOff상태: Pod가 호스팅된 컨트롤 플레인을 통해 Kubernetes API 서버에 연결하려고 하면kube-system네임스페이스의 데이터 플레인 프록시가 요청을 확인할 수 없기 때문에 Pod는 서버에 연결할 수 없습니다. 이 문제는 HAProxy 설정에서 프런트 엔드에서 IP 주소를 사용하고 백엔드에서 Pod를 확인할 수 없는 DNS 이름을 사용하므로 발생합니다. -
Pod가
ContainerCreating상태로 유지됨:openshift-service-ca-operator에서 DNS pod에 DNS 확인에 필요한metrics-tls시크릿을 생성할 수 없기 때문에 이 문제가 발생합니다. 결과적으로 Pod는 Kubernetes API 서버를 확인할 수 없습니다.
이러한 문제를 해결하려면 듀얼 스택 네트워크의 DNS 구성 지침에 따라 DNS 서버 설정을 구성합니다.
1.1.3. 에라타 업데이트
다중 클러스터 엔진 Operator의 경우 에라타 업데이트가 릴리스될 때 자동으로 적용됩니다.
중요: 참조를 위해 에라타 링크와 GitHub 번호가 콘텐츠에 추가되어 내부적으로 사용될 수 있습니다. 액세스가 필요한 링크는 사용자에게 제공되지 않을 수 있습니다.
1.1.3.1. Errata 2.5.9
- 하나 이상의 제품 컨테이너 이미지에 대한 업데이트를 제공합니다.
1.1.3.2. Errata 2.5.8
- 하나 이상의 제품 컨테이너 이미지에 대한 업데이트를 제공합니다.
1.1.3.3. 에라타 2.5.7
- 하나 이상의 제품 컨테이너 이미지에 대한 업데이트를 제공합니다.
1.1.3.4. 에라타 2.5.6
-
동시에 실행 중인 두 버전의
cluster-proxy-addon의 업그레이드 문제를 해결하여 매니페스트가 서로 재정의되었습니다. (ACM-12411) - 하나 이상의 제품 컨테이너 이미지에 대한 업데이트를 제공합니다.
1.1.3.5. Errata 2.5.5
-
멀티 클러스터 엔진 Operator 버전 2.5.3 또는 버전 2.5.4로 업그레이드한 후 단일 노드 OpenShift 관리 클러스터에
알 수 없는상태가 표시되는 문제가 해결되었습니다. (ACM-12584) - 하나 이상의 제품 컨테이너 이미지에 대한 업데이트를 제공합니다.
1.1.3.6. Errata 2.5.4
- 하나 이상의 제품 컨테이너 이미지에 대한 업데이트를 제공합니다.
1.1.3.7. Errata 2.5.3
-
호스팅된 컨트롤 플레인 클러스터의 기본 모드를
HighAvailability모드로 설정하는 KubeVirt 생성 마법사에 필드를 추가했습니다. (ACM-10580) - 하나 이상의 제품 컨테이너 이미지에 대한 업데이트를 제공합니다.
1.1.3.8. Errata 2.5.2
- 백업 복원 시나리오를 실행하고 Red Hat OpenShift Data Foundation(ODF)용 Regional-DR 솔루션을 사용할 때 데이터 손실을 일으킬 수 있는 문제를 해결합니다. (ACM-10407)
- 하나 이상의 제품 컨테이너 이미지에 대한 업데이트를 제공합니다.
1.1.3.9. Errata 2.5.1
- 하나 이상의 제품 컨테이너 이미지에 대한 업데이트를 제공합니다.
1.1.4. 클러스터 라이프사이클 사용 중단 및 제거
제품의 일부가 다중 클러스터 엔진 Operator에서 더 이상 사용되지 않거나 제거되는 시기를 알아봅니다. 현재 릴리스와 두 개의 이전 릴리스의 테이블에 표시되는 권장 작업 및 세부 사항의 대체 작업을 고려하십시오.
더 이상 사용되지 않음: 다중 클러스터 엔진 Operator 2.3 및 이전 버전은 더 이상 지원되지 않습니다. 문서는 사용할 수 있지만 에라타 또는 기타 업데이트는 사용할 수 없습니다.
모범 사례: 최신 버전으로 업그레이드합니다.
1.1.4.1. API 사용 중단 및 제거
다중 클러스터 엔진 Operator는 API에 대한 Kubernetes 사용 중단 지침을 따릅니다. 해당 정책에 대한 자세한 내용은 Kubernetes 사용 중단 정책을 참조하십시오. 다중 클러스터 엔진 Operator API는 다음 타임라인 외부에서만 더 이상 사용되지 않거나 제거됩니다.
-
모든
V1API는 일반적으로 12개월 또는 3개의 릴리스에서 더 큰 릴리스에서 일반적으로 사용할 수 있습니다. V1 API는 제거되지 않지만 시간 제한 외부에서 더 이상 사용되지 않을 수 있습니다. -
모든
베타API는 일반적으로 9 개월 또는 세 번 릴리스에서 사용할 수 있습니다. 베타 API는 해당 시간 제한 외부에서 제거되지 않습니다. -
모든
알파API는 지원되지 않아도 되지만 사용자에게 도움이 되는 경우 더 이상 사용되지 않거나 제거될 수 있습니다.
1.1.4.1.1. API 사용 중단
| 제품 또는 카테고리 | 영향을 받는 항목 | 버전 | 권장 작업 | 자세한 내용 및 링크 |
|---|---|---|---|---|
| ManagedServiceAccount |
| 2.9 |
| 없음 |
1.1.4.1.2. API 제거
| 제품 또는 카테고리 | 영향을 받는 항목 | 버전 | 권장 작업 | 자세한 내용 및 링크 |
1.1.4.2. deprecations
더 이상 사용되지 않는 구성 요소, 기능 또는 서비스가 지원되지만 더 이상 사용하지 않는 것은 권장되지 않으며 향후 릴리스에서 더 이상 사용되지 않을 수 있습니다. 권장 작업 및 다음 표에 제공되는 세부 사항의 대체 작업을 고려하십시오.
| 제품 또는 카테고리 | 영향을 받는 항목 | 버전 | 권장 작업 | 자세한 내용 및 링크 |
|---|---|---|---|---|
| 클러스터 라이프사이클 | Red Hat Virtualization에서 클러스터 생성 | 2.9 | 없음 | 없음 |
| 클러스터 라이프사이클 | Klusterlet OLM Operator | 2.4 | 없음 | 없음 |
1.1.4.3. 제거
삭제된 항목은 일반적으로 이전 릴리스에서 더 이상 사용되지 않으며 제품에서 더 이상 사용할 수 없는 기능입니다. 제거된 함수에 대한 대안을 사용해야 합니다. 권장 작업 및 다음 표에 제공되는 세부 사항의 대체 작업을 고려하십시오.
| 제품 또는 카테고리 | 영향을 받는 항목 | 버전 | 권장 작업 | 자세한 내용 및 링크 |
1.2. 다중 클러스터 엔진 Operator를 사용하는 클러스터 라이프사이클 정보
Kubernetes Operator용 멀티 클러스터 엔진은 Red Hat OpenShift Container Platform 및 Red Hat Advanced Cluster Management Hub 클러스터를 위한 클러스터 관리 기능을 제공하는 클러스터 라이프사이클 Operator입니다. Red Hat Advanced Cluster Management를 설치한 경우 자동으로 설치되므로 다중 클러스터 엔진 Operator를 설치할 필요가 없습니다.
허브 클러스터 및 관리형 클러스터 요구 사항 및 지원에 대한 자세한 내용과 지원 매트릭스 를 참조하십시오.
계속하려면 다중 클러스터 엔진 Operator 개요를 사용하여 클러스터 라이프사이클에서 나머지 클러스터 라이프 사이클 문서를 참조하십시오.
1.2.1. 콘솔 개요
OpenShift Container Platform 콘솔 플러그인은 OpenShift Container Platform 웹 콘솔에서 사용할 수 있으며 통합할 수 있습니다. 이 기능을 사용하려면 콘솔 플러그인을 계속 활성화해야 합니다. 다중 클러스터 엔진 Operator는 인프라 및 인증 정보 탐색 항목의 특정 콘솔 기능을 표시합니다. Red Hat Advanced Cluster Management를 설치하는 경우 더 많은 콘솔 기능이 표시됩니다.
참고: 플러그인을 활성화하면 드롭다운 메뉴에서 모든 클러스터를 선택하여 클러스터 전환기에서 OpenShift Container Platform 콘솔 내에서 Red Hat Advanced Cluster Management에 액세스할 수 있습니다.
- 플러그인을 비활성화하려면 OpenShift Container Platform 콘솔의 관리자 화면에 있는지 확인합니다.
- 탐색에서 Administration 을 찾고 Cluster Settings 를 클릭한 다음 Configuration 탭을 클릭합니다.
-
구성 리소스 목록에서 웹 콘솔에 대한 클러스터 전체 구성이 포함된
operator.openshift.ioAPI 그룹이 있는 Console 리소스를 클릭합니다. -
콘솔 플러그인 탭을 클릭합니다.
mce플러그인이 나열됩니다. 참고: Red Hat Advanced Cluster Management가 설치된 경우acm로도 나열됩니다. - 표에서 플러그인 상태를 수정합니다. 잠시 후 콘솔을 새로 고침하라는 메시지가 표시됩니다.
1.2.2. 다중 클러스터 엔진 Operator 역할 기반 액세스 제어
RBAC는 콘솔 수준 및 API 수준에서 검증됩니다. 콘솔의 작업은 사용자 액세스 역할 권한에 따라 활성화하거나 비활성화할 수 있습니다. 제품의 특정 라이프사이클에 대한 RBAC에 대한 자세한 내용은 다음 섹션을 참조하십시오.
1.2.2.1. 역할 개요
일부 제품 리소스는 클러스터 전체이며 일부는 네임스페이스 범위입니다. 일관된 액세스 제어를 위해 사용자에게 클러스터 역할 바인딩 및 네임스페이스 역할 바인딩을 적용해야 합니다. 지원되는 다음 역할 정의의 표 목록을 확인합니다.
1.2.2.1.1. 역할 정의 표
| Role | 정의 |
|---|---|
|
|
OpenShift Container Platform 기본 역할입니다. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
admin, edit, view는 OpenShift Container Platform 기본 역할입니다. 이러한 역할에 대한 네임스페이스 범위 바인딩이 있는 사용자는 특정 네임스페이스의 |
중요:
- 모든 사용자는 OpenShift Container Platform에서 프로젝트를 생성할 수 있으므로 네임스페이스에 대한 관리자 역할 권한이 부여됩니다.
-
사용자에게 클러스터에 대한 역할 액세스 권한이 없는 경우 클러스터 이름이 표시되지 않습니다. 클러스터 이름은 다음 기호와 함께 표시됩니다.
-.
RBAC는 콘솔 수준 및 API 수준에서 검증됩니다. 콘솔의 작업은 사용자 액세스 역할 권한에 따라 활성화하거나 비활성화할 수 있습니다. 제품의 특정 라이프사이클에 대한 RBAC에 대한 자세한 내용은 다음 섹션을 참조하십시오.
1.2.2.2. 클러스터 라이프사이클 RBAC
다음 클러스터 라이프사이클 RBAC 작업을 확인합니다.
모든 관리 클러스터에 대한 클러스터 역할 바인딩을 생성하고 관리합니다. 예를 들어 다음 명령을 입력하여 클러스터 역할
open-cluster-management:cluster-manager-admin에 대한 클러스터 역할 바인딩을 생성합니다.oc create clusterrolebinding <role-binding-name> --clusterrole=open-cluster-management:cluster-manager-admin --user=<username>이 역할은 모든 리소스 및 작업에 액세스할 수 있는 슈퍼유저입니다. 클러스터 범위의
관리 클러스터리소스, 관리 클러스터를 관리하는 리소스의 네임스페이스, 이 역할이 있는 네임스페이스의 리소스를 생성할 수 있습니다. 권한 오류를 방지하기 위해 역할연결이 필요한 ID의 사용자 이름을추가해야 할 수 있습니다.다음 명령을 실행하여
cluster-name이라는 관리 클러스터의 클러스터 역할 바인딩을 관리합니다.oc create clusterrolebinding (role-binding-name) --clusterrole=open-cluster-management:admin:<cluster-name> --user=<username>이 역할에는 클러스터 범위의
managedcluster리소스에 대한 읽기 및 쓰기 권한이 있습니다. 이는managedcluster가 네임스페이스 범위 리소스가 아닌 클러스터 범위 리소스이므로 필요합니다.다음 명령을 입력하여 클러스터 역할
admin에 대한 네임스페이스 역할 바인딩을 생성합니다.oc create rolebinding <role-binding-name> -n <cluster-name> --clusterrole=admin --user=<username>이 역할에는 관리 클러스터의 네임스페이스의 리소스에 대한 읽기 및 쓰기 권한이 있습니다.
open-cluster-management:view:<cluster-name> 클러스터 역할에 대한 클러스터 역할 바인딩을 생성하여cluster-name이라는 관리 클러스터를 확인합니다.oc create clusterrolebinding <role-binding-name> --clusterrole=open-cluster-management:view:<cluster-name> --user=<username>이 역할은 클러스터 범위의
managedcluster리소스에 대한 읽기 액세스 권한이 있습니다. 이는managedcluster가 클러스터 범위 리소스이므로 필요합니다.다음 명령을 입력하여 클러스터 역할
뷰에 대한네임스페이스 역할 바인딩을 생성합니다.oc create rolebinding <role-binding-name> -n <cluster-name> --clusterrole=view --user=<username>이 역할에는 관리 클러스터의 네임스페이스의 리소스에 대한 읽기 전용 권한이 있습니다.
다음 명령을 입력하여 액세스할 수 있는 관리 클러스터 목록을 확인합니다.
oc get managedclusters.clusterview.open-cluster-management.io이 명령은 클러스터 관리자 권한이 없는 관리자와 사용자가 사용합니다.
다음 명령을 입력하여 액세스할 수 있는 관리 클러스터 세트 목록을 확인합니다.
oc get managedclustersets.clusterview.open-cluster-management.io이 명령은 클러스터 관리자 권한이 없는 관리자와 사용자가 사용합니다.
1.2.2.2.1. 클러스터 풀 RBAC
다음 클러스터 풀 RBAC 작업을 확인합니다.
클러스터 관리자는 관리 클러스터 세트를 생성하고 그룹에 역할을 추가하여 관리자 권한을 부여하여 클러스터 풀 프로비저닝 클러스터를 사용합니다. 다음 예제를 확인합니다.
다음 명령을 사용하여
server-foundation-clusterset관리 클러스터 세트에관리자권한을 부여합니다.oc adm policy add-cluster-role-to-group open-cluster-management:clusterset-admin:server-foundation-clusterset server-foundation-team-admin다음 명령을 사용하여
server-foundation-clusterset관리 클러스터 세트에보기권한을 부여합니다.oc adm policy add-cluster-role-to-group open-cluster-management:clusterset-view:server-foundation-clusterset server-foundation-team-user
클러스터 풀
server-foundation-clusterpool의 네임스페이스를 만듭니다. 역할 권한을 부여하려면 다음 예제를 확인합니다.다음 명령을 실행하여 server-foundation-
team-에 부여합니다.admin에 대한 관리자 권한을server-foundation-clusterpooloc adm new-project server-foundation-clusterpool oc adm policy add-role-to-group admin server-foundation-team-admin --namespace server-foundation-clusterpool
팀 관리자로 클러스터 세트 레이블
cluster.open-cluster-management.io/clusterset=server-foundation-clusterset를 사용하여ocp46-aws-clusterpool이라는 클러스터 풀을 생성합니다.-
server-foundation-webhook는 클러스터 풀에 클러스터 세트 레이블이 있는지, 사용자가 클러스터 세트에 클러스터 풀을 생성할 수 있는 권한이 있는지 확인합니다. -
server-foundation-controller는server-foundation-team-user의server-foundation-clusterpool네임스페이스에 대한보기권한을 부여합니다.
-
클러스터 풀이 생성되면 클러스터 풀이
클러스터 배포를생성합니다. 자세한 내용은 계속 읽으십시오.-
server-foundation-controller는server-foundation-team-의adminclusterdeployment네임스페이스에 대한 관리자 권한을 부여합니다. server-foundation-controller는server-foundation-team-user에 대한보기권한클러스터 배포네임스페이스를 부여합니다.참고:
team-admin및team-user로clusterpool,clusterdeployment,clusterclaim에 대한관리자권한이 있습니다.
-
1.2.2.2.2. 클러스터 라이프사이클을 위한 콘솔 및 API RBAC 테이블
클러스터 라이프사이클에 대해 다음 콘솔 및 API RBAC 테이블을 확인합니다.
| 리소스 | 관리자 | edit | view |
|---|---|---|---|
| 클러스터 | 읽기, 업데이트, 삭제 | - | 읽기 |
| 클러스터 세트 | get, update, bind, join | 언급되지 않은 편집 역할 | get |
| 관리형 클러스터 | 읽기, 업데이트, 삭제 | 언급된 편집 역할 없음 | get |
| 공급자 연결 | 생성, 읽기, 업데이트 및 삭제 | - | 읽기 |
| API | 관리자 | edit | view |
|---|---|---|---|
|
이 API의 명령에 | 생성, 읽기, 업데이트, 삭제 | 읽기, 업데이트 | 읽기 |
|
이 API의 명령에서 | 읽기 | 읽기 | 읽기 |
|
| 업데이트 | 업데이트 | |
|
이 API의 명령에 | 생성, 읽기, 업데이트, 삭제 | 읽기, 업데이트 | 읽기 |
|
| 읽기 | 읽기 | 읽기 |
|
이 API의 명령에 | 생성, 읽기, 업데이트, 삭제 | 읽기, 업데이트 | 읽기 |
|
| 생성, 읽기, 업데이트, 삭제 | 읽기, 업데이트 | 읽기 |
|
| 생성, 읽기, 업데이트, 삭제 | 읽기, 업데이트 | 읽기 |
|
| 생성, 읽기, 업데이트, 삭제 | 읽기, 업데이트 | 읽기 |
|
| 생성, 읽기, 업데이트, 삭제 | 읽기, 업데이트 | 읽기 |
|
| 생성, 읽기, 업데이트, 삭제 | 읽기, 업데이트 | 읽기 |
|
| 생성, 읽기, 업데이트, 삭제 | 읽기, 업데이트 | 읽기 |
|
| 생성, 읽기, 업데이트, 삭제 | 읽기, 업데이트 | 읽기 |
1.2.2.2.3. 인증 정보 역할 기반 액세스 제어
인증 정보에 대한 액세스는 Kubernetes에서 제어합니다. 인증 정보는 Kubernetes 시크릿으로 저장되고 보호됩니다. 다음 권한은 Red Hat Advanced Cluster Management for Kubernetes의 보안에 적용됩니다.
- 네임스페이스에서 보안을 생성할 수 있는 액세스 권한이 있는 사용자는 인증 정보를 생성할 수 있습니다.
- 네임스페이스에서 시크릿 읽기에 대한 액세스 권한이 있는 사용자는 인증 정보를 볼 수도 있습니다.
-
admin의 Kubernetes 클러스터 역할이 있는 사용자는 시크릿을 생성하고편집할수 있습니다. -
Kubernetes 클러스터 역할의 사용자는 시크릿 내용을 읽을 수 없으므로 시크릿을
볼수 없습니다. 서비스 계정 자격 증명에 액세스할 수 있기 때문입니다.
1.2.3. 네트워크 구성
연결을 허용하도록 네트워크 설정을 구성합니다.
중요: 신뢰할 수 있는 CA 번들은 다중 클러스터 엔진 Operator 네임스페이스에서 사용할 수 있지만 이를 개선하려면 네트워크를 변경해야 합니다. 신뢰할 수 있는 CA 번들 ConfigMap은 기본 이름 trusted-ca-bundle 을 사용합니다. TRUSTED_CA_BUNDLE 이라는 환경 변수에 Operator에 제공하여 이 이름을 변경할 수 있습니다. 자세한 내용은 Red Hat OpenShift Container Platform의 네트워킹 섹션에서 클러스터 전체 프록시 구성 을 참조하십시오.
참고: 관리형 클러스터의 등록 는 프록시를 통과할 수 없는 mTLS 연결을 설정하여 hub 클러스터에서 에이전트 및 작업 에이전트apiserver 와 통신하기 때문에 프록시 설정을 지원하지 않습니다.
다중 클러스터 엔진 Operator 클러스터 네트워킹 요구 사항은 다음 표를 참조하십시오.
| 방향 | 소스 | 대상 | 프로토콜 | 포트 | 설명 |
|---|---|---|---|---|---|
| 관리 클러스터로의 아웃 바운드 |
hub 클러스터의 Hive 및 | 프로비저닝된 관리형 클러스터의 Kubernetes API 서버 | HTTPS | 6443 | 프로비저닝된 관리형 클러스터의 Kubernetes API 서버 |
| 관리 클러스터로의 아웃 바운드 | hub 클러스터의 Ironic 서비스 | 관리 클러스터의 Ironic Python Agent | TCP | 9999 | Ironic Python Agent가 실행 중인 베어 메탈 노드와 Ironic conductor 서비스 간의 통신 |
| 관리 클러스터로의 아웃 바운드 |
hub 클러스터의 |
관리 클러스터의 | TCP | 443 |
|
| 관리 클러스터에서 인바운드 | BMC(Baseboard Management Controller) | Ironic 서비스 옆에 있는 HTTP 서버 | TCP | 6180, 6183 | BMC(Baseboard Management Controller)는 가상 미디어의 경우 포트 6180 및 6183에 액세스합니다. 부팅 펌웨어가 포트 6180에 액세스 |
| 관리 클러스터에서 인바운드 | 관리 클러스터의 Ironic Python Agent | hub 클러스터의 Ironic 서비스 | TCP | 6385 | hub 클러스터에서 Ironic Python Agent와 Ironic 서비스 간 통신 |
| 관리 클러스터에서 인바운드 | 관리 클러스터의 클러스터 프록시 애드온 에이전트 | 클러스터 프록시 ANP 서비스 | TCP | 443 | 관리 클러스터의 클러스터 프록시 애드온 에이전트와 허브 클러스터의 Cluster Proxy 애드온 ANP 서비스 간 통신 |
| 관리 클러스터에서 인바운드 | Klusterlet 에이전트 및 애드온 에이전트 | 허브 클러스터의 Kubernetes API 서버 | HTTPS | 6443 | 관리 클러스터의 다중 클러스터 엔진 Operator 클러스터의 Kubernetes API 서버 |
참고: 관리 클러스터의 klusterlet 에이전트에 직접 연결하는 대신 hub 클러스터의 apiserver 설정에 액세스해야 하는 경우 허브 클러스터와 관리 클러스터 간의 프록시 구성 을 참조하십시오.
1.3. 다중 클러스터 엔진 Operator 설치 및 업그레이드
다중 클러스터 엔진 Operator는 클러스터 플릿 관리를 개선하는 소프트웨어 운영자입니다. 멀티 클러스터 엔진 Operator는 클라우드 및 데이터 센터 전체에서 Red Hat OpenShift Container Platform 및 Kubernetes 클러스터 라이프사이클 관리를 지원합니다.
더 이상 사용되지 않음: 다중 클러스터 엔진 Operator 2.3 및 이전 버전은 더 이상 지원되지 않습니다. 문서는 사용할 수 있지만 에라타 또는 기타 업데이트는 사용할 수 없습니다.
모범 사례: 최신 버전으로 업그레이드합니다.
이 문서는 특정 구성 요소 또는 기능이 도입되어 최신 버전의 OpenShift Container Platform에서만 테스트되지 않는 한 가장 빨리 지원되는 OpenShift Container Platform 버전을 참조합니다.
전체 지원 정보는 지원 매트릭스 를 참조하십시오. 라이프 사이클 정보는 Red Hat OpenShift Container Platform 라이프 사이클 정책을 참조하십시오.
중요: Red Hat Advanced Cluster Management 버전 2.5 이상을 사용하는 경우 Kubernetes Operator용 다중 클러스터 엔진이 클러스터에 이미 설치되어 있습니다.
다음 설명서를 참조하십시오.
1.3.1. 온라인으로 연결하는 동안 설치
다중 클러스터 엔진 Operator는 다중 클러스터 엔진 Operator를 포함하는 구성 요소의 설치, 업그레이드 및 제거를 관리하는 Operator Lifecycle Manager와 함께 설치됩니다.
필수 액세스: 클러스터 관리자
중요:
-
외부 클러스터에 구성된
ManagedCluster리소스가 있는 클러스터에 다중 클러스터 엔진 Operator를 설치할 수 없습니다. 다중 클러스터 엔진 Operator를 설치하려면 먼저 외부 클러스터에서ManagedCluster리소스를 제거해야 합니다. -
OpenShift Container Platform Dedicated 환경의 경우
cluster-admin권한이 있어야 합니다. 기본적으로dedicated-admin역할에는 OpenShift Container Platform Dedicated 환경에서 네임스페이스를 생성하는 데 필요한 권한이 없습니다. - 기본적으로 다중 클러스터 엔진 Operator 구성 요소는 추가 구성없이 OpenShift Container Platform 클러스터의 작업자 노드에 설치됩니다. OpenShift Container Platform OperatorHub 웹 콘솔 인터페이스를 사용하거나 OpenShift Container Platform CLI를 사용하여 다중 클러스터 엔진 Operator를 작업자 노드에 설치할 수 있습니다.
- 인프라 노드를 사용하여 OpenShift Container Platform 클러스터를 구성한 경우 추가 리소스 매개변수와 함께 OpenShift Container Platform CLI를 사용하여 다중 클러스터 엔진 Operator를 해당 인프라 노드에 설치할 수 있습니다. 자세한 내용은 인프라 노드에 다중 클러스터 엔진 설치 섹션을 참조하십시오.
Kubernetes Operator를 위해 OpenShift Container Platform 또는 다중 클러스터 엔진에서 생성하지 않은 Kubernetes 클러스터를 가져오려면 이미지 가져오기 보안을 구성해야 합니다. 이미지 풀 시크릿 및 기타 고급 구성을 구성하는 방법에 대한 자세한 내용은 이 설명서의 고급 구성 섹션에 있는 옵션을 참조하십시오.
1.3.1.1. 사전 요구 사항
Kubernetes Operator용 다중 클러스터 엔진을 설치하기 전에 다음 요구 사항을 참조하십시오.
- Red Hat OpenShift Container Platform 클러스터는 OpenShift Container Platform 콘솔의 OperatorHub 카탈로그에서 다중 클러스터 엔진 Operator에 액세스할 수 있어야 합니다.
- catalog.redhat.com 에 액세스해야 합니다.
-
클러스터에 외부 클러스터에 구성된
ManagedCluster리소스가 없습니다. OpenShift Container Platform 4.13 이상은 환경에 배포되어야 하며 OpenShift Container Platform CLI로 로그인해야 합니다. OpenShift Container Platform에 대한 다음 설치 설명서를 참조하십시오.
-
oc명령을 실행하도록 OpenShift Container Platform CLI(명령줄 인터페이스)를 구성해야 합니다. OpenShift Container Platform CLI 설치 및 구성에 대한 정보는 CLI로 시작하기 를 참조하십시오. - OpenShift Container Platform 권한에서 네임스페이스를 생성할 수 있어야 합니다.
- Operator의 종속 항목에 액세스하려면 인터넷 연결이 있어야 합니다.
OpenShift Container Platform Dedicated 환경에 설치하려면 다음을 참조하십시오.
- OpenShift Container Platform Dedicated 환경이 구성되어 실행되고 있어야 합니다.
-
엔진을 설치하는 OpenShift Container Platform Dedicated 환경에 대한
cluster-admin권한이 있어야 합니다.
- Red Hat OpenShift Container Platform과 함께 제공되는 지원 설치 관리자를 사용하여 관리 클러스터를 생성하려면 요구 사항에 대한 OpenShift Container Platform 설명서의 지원 설치 관리자 준비를 참조하십시오.
1.3.1.2. OpenShift Container Platform 설치 확인
레지스트리 및 스토리지 서비스를 포함하여 지원되는 OpenShift Container Platform 버전이 설치되어 작동해야 합니다. OpenShift Container Platform 설치에 대한 자세한 내용은 OpenShift Container Platform 설명서를 참조하십시오.
- 다중 클러스터 엔진 Operator가 OpenShift Container Platform 클러스터에 아직 설치되지 않았는지 확인합니다. 다중 클러스터 엔진 Operator는 각 OpenShift Container Platform 클러스터에서 하나의 단일 설치만 허용합니다. 설치가 없는 경우 다음 단계를 계속 진행합니다.
OpenShift Container Platform 클러스터가 올바르게 설정되었는지 확인하려면 다음 명령을 사용하여 OpenShift Container Platform 웹 콘솔에 액세스합니다.
kubectl -n openshift-console get route console다음 예제 출력을 참조하십시오.
console console-openshift-console.apps.new-coral.purple-chesterfield.com console https reencrypt/Redirect None-
브라우저에서 URL을 열고 결과를 확인합니다. 콘솔 URL에
console-openshift-console.router.default.svc.cluster.local이 표시되면 OpenShift Container Platform을 설치할 때openshift_master_default_subdomain값을 설정합니다. URL의 다음 예제를 참조하십시오.https://console-openshift-console.apps.new-coral.purple-chesterfield.com.
다중 클러스터 엔진 Operator 설치를 진행할 수 있습니다.
1.3.1.3. OperatorHub 웹 콘솔 인터페이스에서 설치
모범 사례: OpenShift Container Platform 탐색의 관리자 보기에서 OpenShift Container Platform과 함께 제공되는 OperatorHub 웹 콘솔 인터페이스를 설치합니다.
- Operator > OperatorHub 를 선택하여 사용 가능한 Operator 목록에 액세스하고 Kubernetes Operator의 다중 클러스터 엔진을 선택합니다.
-
설치를클릭합니다. Operator 설치 페이지에서 설치 옵션을 선택합니다.
namespace:
- 다중 클러스터 엔진 Operator 엔진은 자체 네임스페이스 또는 프로젝트에 설치해야 합니다.
-
기본적으로 OperatorHub 콘솔 설치 프로세스는
multicluster-engine이라는 네임스페이스를 생성합니다. 모범 사례: 사용 가능한 경우multicluster-engine네임스페이스를 계속 사용합니다. -
이미
multicluster-engine이라는 네임스페이스가 있는 경우 다른 네임스페이스를 선택합니다.
- 채널: 선택한 채널은 설치 중인 릴리스에 해당합니다. 채널을 선택하면 식별된 릴리스를 설치하고 해당 릴리스 내에서 향후 에라타가 업데이트되도록 설정합니다.
승인 전략: 승인 전략은 서브스크립션한 채널 또는 릴리스에 업데이트를 적용하는 데 필요한 인적 상호 작용을 식별합니다.
- 기본적으로 선택한 자동 을 선택하여 해당 릴리스 내의 업데이트가 자동으로 적용되도록 합니다.
- 업데이트를 사용할 수 있을 때 알림을 받으려면 수동 을 선택합니다. 업데이트가 적용되는 시기에 대해 우려 사항이 있는 경우 이 방법을 사용하는 것이 좋습니다.
참고: 다음 마이너 릴리스로 업그레이드하려면 OperatorHub 페이지로 돌아가서 최신 릴리스의 새 채널을 선택해야 합니다.
- 설치를 선택하여 변경 사항을 적용하고 Operator를 생성합니다.
MultiClusterEngine 사용자 정의 리소스를 생성하려면 다음 프로세스를 참조하십시오.
- OpenShift Container Platform 콘솔 탐색에서 Installed Operators > multicluster engine for Kubernetes 를 선택합니다.
- MultiCluster Engine 탭을 선택합니다.
- Create MultiClusterEngine 을 선택합니다.
YAML 파일에서 기본값을 업데이트합니다. 문서의 MultiClusterEngine 고급 구성 섹션의 옵션을 참조하십시오.
- 다음 예제에서는 편집기에 복사할 수 있는 기본 템플릿을 보여줍니다.
apiVersion: multicluster.openshift.io/v1 kind: MultiClusterEngine metadata: name: multiclusterengine spec: {}
생성 을 선택하여 사용자 지정 리소스를 초기화합니다. 다중 클러스터 엔진 Operator 엔진을 빌드하고 시작하는 데 최대 10분이 걸릴 수 있습니다.
MultiClusterEngine 리소스가 생성되면 MultiCluster Engine 탭에서 리소스 상태가
Available(사용 가능)입니다.
1.3.1.4. OpenShift Container Platform CLI에서 설치
Operator 요구 사항이 포함된 다중 클러스터 엔진 Operator 엔진 네임스페이스를 생성합니다. 다음 명령을 실행합니다. 여기서
namespace는 Kubernetes Operator 네임스페이스의 다중 클러스터 엔진의 이름입니다.namespace값은 OpenShift Container Platform 환경에서 Project 라고 할 수 있습니다.oc create namespace <namespace>프로젝트 네임스페이스를 생성한 네임스페이스로 전환합니다. 1단계에서 생성한 Kubernetes Operator 네임스페이스의 다중 클러스터 엔진 이름으로
namespace를 바꿉니다.oc project <namespace>YAML 파일을 생성하여
OperatorGroup리소스를 구성합니다. 각 네임스페이스에는 하나의 operator 그룹만 있을 수 있습니다.default를 operator 그룹의 이름으로 바꿉니다.namespace를 프로젝트 네임스페이스의 이름으로 교체합니다. 다음 예제를 참조하십시오.apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: name: <default> namespace: <namespace> spec: targetNamespaces: - <namespace>다음 명령을 실행하여
OperatorGroup리소스를 생성합니다.operator-group을 생성한 operator 그룹 YAML 파일의 이름으로 교체합니다.oc apply -f <path-to-file>/<operator-group>.yamlYAML 파일을 생성하여 OpenShift Container Platform 서브스크립션을 구성합니다. 파일은 다음 예와 유사해야 합니다.
apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: multicluster-engine spec: sourceNamespace: openshift-marketplace source: redhat-operators channel: stable-2.5 installPlanApproval: Automatic name: multicluster-engine참고: 인프라 노드에 Kubernetes Operator용 다중 클러스터 엔진을 설치하려면 Operator Lifecycle Manager 서브스크립션 추가 구성 섹션을 참조하십시오.
다음 명령을 실행하여 OpenShift Container Platform 서브스크립션을 생성합니다.
서브스크립션을 생성한 서브스크립션 파일의 이름으로 교체합니다.oc apply -f <path-to-file>/<subscription>.yamlYAML 파일을 생성하여
MultiClusterEngine사용자 정의 리소스를 구성합니다. 기본 템플릿은 다음 예와 유사해야 합니다.apiVersion: multicluster.openshift.io/v1 kind: MultiClusterEngine metadata: name: multiclusterengine spec: {}참고: 인프라 노드에 다중 클러스터 엔진 Operator를 설치하는 경우 MultiClusterEngine 사용자 정의 리소스 추가 구성 섹션을 참조하십시오.
다음 명령을 실행하여
MultiClusterEngine사용자 정의 리소스를 생성합니다.custom-resource를 사용자 정의 리소스 파일의 이름으로 교체합니다.oc apply -f <path-to-file>/<custom-resource>.yaml다음 오류와 함께 이 단계가 실패하면 리소스가 계속 생성되고 적용됩니다. 리소스가 생성될 때 몇 분 후에 명령을 다시 실행합니다.
error: unable to recognize "./mce.yaml": no matches for kind "MultiClusterEngine" in version "operator.multicluster-engine.io/v1"다음 명령을 실행하여 사용자 정의 리소스를 가져옵니다. 다음 명령을 실행한 후
MultiClusterEngine사용자 정의 리소스 상태가Available으로 Available로 표시되는 데 최대 10분이 걸릴 수 있습니다.oc get mce -o=jsonpath='{.items[0].status.phase}'
다중 클러스터 엔진 Operator를 다시 설치하고 Pod가 시작되지 않는 경우 이 문제를 해결하기 위한 단계의 재생성 문제 해결을 참조하십시오.
참고:
-
ClusterRoleBinding이 있는ServiceAccount는 다중 클러스터 엔진 Operator 및 다중 클러스터 엔진 Operator를 설치하는 네임스페이스에 대한 액세스 권한이 있는 모든 사용자 인증 정보에 자동으로 클러스터 관리자 권한을 부여합니다.
1.3.1.5. 인프라 노드에 설치
OpenShift Container Platform 클러스터는 승인된 관리 구성 요소를 실행하기 위한 인프라 노드를 포함하도록 구성할 수 있습니다. 인프라 노드에서 구성 요소를 실행하면 해당 관리 구성 요소를 실행하는 노드에 OpenShift Container Platform 서브스크립션 할당량이 할당되지 않습니다.
OpenShift Container Platform 클러스터에 인프라 노드를 추가한 후 OpenShift Container Platform CLI에서 설치 지침을 따르고 Operator Lifecycle Manager 서브스크립션 및 MultiClusterEngine 사용자 정의 리소스에 다음 구성을 추가합니다.
1.3.1.5.1. OpenShift Container Platform 클러스터에 인프라 노드 추가
OpenShift Container Platform 설명서에서 인프라 머신 세트 생성에 설명된 절차를 따르십시오. 인프라 노드는 관리되지 않은 워크로드가 해당 워크로드가 실행되지 않도록 Kubernetes taint 및 레이블 로 구성됩니다.
다중 클러스터 엔진 Operator에서 제공하는 인프라 노드 활성화와 호환되려면 인프라 노드에 다음과 같은 테인트 및 라벨이 적용되어야 합니다.
metadata:
labels:
node-role.kubernetes.io/infra: ""
spec:
taints:
- effect: NoSchedule
key: node-role.kubernetes.io/infra1.3.1.5.2. Operator Lifecycle Manager 서브스크립션 추가 구성
Operator Lifecycle Manager 서브스크립션을 적용하기 전에 다음 추가 구성을 추가합니다.
spec:
config:
nodeSelector:
node-role.kubernetes.io/infra: ""
tolerations:
- key: node-role.kubernetes.io/infra
effect: NoSchedule
operator: Exists1.3.1.5.3. MultiClusterEngine 사용자 정의 리소스 추가 구성
MultiClusterEngine 사용자 정의 리소스를 적용하기 전에 다음 추가 구성을 추가합니다.
spec:
nodeSelector:
node-role.kubernetes.io/infra: ""1.3.2. 연결이 끊긴 네트워크에 설치
인터넷에 연결되지 않은 Red Hat OpenShift Container Platform 클러스터에 다중 클러스터 엔진 Operator를 설치해야 할 수 있습니다. 연결이 끊긴 엔진에 설치하려면 연결된 설치와 동일한 단계가 필요합니다.
중요: 두 제품에서 동일한 관리 구성 요소를 제공하므로 Red Hat Advanced Cluster Management가 설치되지 않은 클러스터에 다중 클러스터 엔진 Operator를 설치합니다. 이전에 Red Hat Advanced Cluster Management를 설치하지 않은 클러스터에 다중 클러스터 엔진 Operator를 설치합니다. Red Hat Advanced Cluster Management 버전 2.5.0 이상을 사용하는 경우 다중 클러스터 엔진 Operator가 클러스터에 이미 설치되어 있습니다.
설치 중에 네트워크에서 직접 액세스하는 대신 설치 중에 패키지 사본을 다운로드하여 설치 중에 액세스해야 합니다.
1.3.2.1. 사전 요구 사항
다중 클러스터 엔진 Operator를 설치하기 전에 다음 요구 사항을 충족해야 합니다.
- Red Hat OpenShift Container Platform 버전 4.13 이상을 환경에 배포해야 하며 CLI(명령줄 인터페이스)를 사용하여 로그인해야 합니다.
catalog.redhat.com 에 액세스해야 합니다.
참고: 베어 메탈 클러스터를 관리하려면 OpenShift Container Platform 버전 4.13 이상이 있어야 합니다.
-
Red Hat OpenShift Container Platform CLI는 버전 4.13 이상이어야 하며
oc명령을 실행하도록 구성해야 합니다. - Red Hat OpenShift Container Platform 권한에서 네임스페이스를 생성할 수 있도록 허용해야 합니다.
- Operator에 대한 종속성을 다운로드하려면 인터넷 연결이 있는 워크스테이션이 있어야 합니다.
1.3.2.2. OpenShift Container Platform 설치 확인
- 레지스트리 및 스토리지 서비스를 포함하여 지원되는 OpenShift Container Platform 버전이 클러스터에 설치되어 작동해야 합니다. OpenShift Container Platform 버전 4.13에 대한 자세한 내용은 OpenShift Container Platform 설명서를 참조하십시오.
연결된 경우 다음 명령을 사용하여 OpenShift Container Platform 웹 콘솔에 액세스하여 OpenShift Container Platform 클러스터가 올바르게 설정되었는지 확인할 수 있습니다.
kubectl -n openshift-console get route console다음 예제 출력을 참조하십시오.
console console-openshift-console.apps.new-coral.purple-chesterfield.com console https reencrypt/Redirect None이 예제의 콘솔 URL은
https:// console-openshift-console.apps.new-coral.purple-chesterfield.com입니다. 브라우저에서 URL을 열고 결과를 확인합니다.콘솔 URL에
console-openshift-console.router.default.svc.cluster.local이 표시되면 OpenShift Container Platform을 설치할 때openshift_master_default_subdomain값을 설정합니다.
1.3.2.3. 연결이 끊긴 환경에 설치
중요: 연결이 끊긴 환경에서 Operator를 설치하려면 필요한 이미지를 미러링 레지스트리에 다운로드해야 합니다. 다운로드하지 않으면 배포 중에 ImagePullBackOff 오류가 표시될 수 있습니다.
다음 단계에 따라 연결이 끊긴 환경에 다중 클러스터 엔진 Operator를 설치합니다.
미러 레지스트리를 생성합니다. 미러 레지스트리가 아직 없는 경우 Red Hat OpenShift Container Platform 설명서의 연결 해제 설치 미러링 주제에서 절차를 완료하여 하나의 레지스트리를 생성합니다.
미러 레지스트리가 이미 있는 경우 기존 레지스트리를 구성하고 사용할 수 있습니다.
참고: 베어 메탈의 경우
install-config.yaml파일에서 연결이 끊긴 레지스트리에 대한 인증서 정보를 제공해야 합니다. 보호된 연결이 끊긴 레지스트리에서 이미지에 액세스하려면 다중 클러스터 엔진 운영자가 레지스트리에 액세스할 수 있도록 인증서 정보를 제공해야 합니다.- 레지스트리에서 인증서 정보를 복사합니다.
-
편집기에서
install-config.yaml파일을 엽니다. -
additionalTrustBundle: |의 항목을 찾습니다. additionalTrustBundle줄 뒤에 인증서 정보를 추가합니다. 결과 콘텐츠는 다음 예와 유사해야 합니다.additionalTrustBundle: | -----BEGIN CERTIFICATE----- certificate_content -----END CERTIFICATE----- sshKey: >-
중요: 다음 Governance 정책이 필요한 경우 연결이 끊긴 이미지 레지스트리에 대한 추가 미러가 필요합니다.
-
Container Security Operator 정책:
registry.redhat.io/quay소스의 이미지를 찾습니다. -
Compliance Operator 정책:
registry.redhat.io/compliance소스의 이미지를 찾습니다. Gatekeeper Operator 정책:
registry.redhat.io/gatekeeper소스에 이미지를 찾습니다.세 가지 연산자 모두에 대한 미러 목록의 다음 예제를 참조하십시오.
- mirrors: - <your_registry>/rhacm2 source: registry.redhat.io/rhacm2 - mirrors: - <your_registry>/quay source: registry.redhat.io/quay - mirrors: - <your_registry>/compliance source: registry.redhat.io/compliance-
Container Security Operator 정책:
-
install-config.yaml파일을 저장합니다. mce-policy.yaml이라는 이름으로ImageContentSourcePolicy가 포함된 YAML 파일을 생성합니다. 참고: 실행 중인 클러스터에서 이 값을 수정하면 모든 노드가 롤링 재시작됩니다.apiVersion: operator.openshift.io/v1alpha1 kind: ImageContentSourcePolicy metadata: name: mce-repo spec: repositoryDigestMirrors: - mirrors: - mirror.registry.com:5000/multicluster-engine source: registry.redhat.io/multicluster-engine다음 명령을 입력하여 ImageContentSourcePolicy 파일을 적용합니다.
oc apply -f mce-policy.yaml연결이 끊긴 Operator Lifecycle Manager Red Hat Operator 및 Community Operator를 활성화합니다.
멀티 클러스터 엔진 Operator는 Operator Lifecycle Manager Red Hat Operator 카탈로그에 포함되어 있습니다.
- Red Hat Operator 카탈로그에 대해 연결이 끊긴 Operator Lifecycle Manager를 구성합니다. Red Hat OpenShift Container Platform 설명서의 제한된 네트워크에서 Operator Lifecycle Manager 사용 주제의 단계를 따르십시오.
- 이제 연결이 끊긴 Operator Lifecycle Manager에 이미지가 있으므로 Operator Lifecycle Manager 카탈로그에서 Kubernetes용 다중 클러스터 엔진 Operator를 계속 설치합니다.
필요한 단계는 온라인에 연결된 동안 설치를 참조하십시오.
1.3.3. 고급 구성
다중 클러스터 엔진 Operator는 필요한 모든 구성 요소를 배포하는 Operator를 사용하여 설치됩니다. 멀티 클러스터 엔진 Operator는 설치 중 또는 설치 후 추가로 구성할 수 있습니다. 고급 구성 옵션에 대해 자세히 알아보십시오.
1.3.3.1. 배포된 구성 요소
MultiClusterEngine 사용자 정의 리소스에 다음 속성 중 하나 이상을 추가합니다.
| 이름 | 설명 | 활성화됨 |
| assisted-service | 최소한의 인프라 사전 요구 사항 및 포괄적인 사전 요구 사항으로 OpenShift Container Platform 설치 | True |
| cluster-lifecycle | OpenShift Container Platform 및 Kubernetes 허브 클러스터를 위한 클러스터 관리 기능 제공 | True |
| cluster-manager | 클러스터 환경 내에서 다양한 클러스터 관련 작업 관리 | True |
| cluster-proxy-addon |
역방향 프록시 서버를 사용하여 허브 및 관리 클러스터에 | True |
| console-mce | 다중 클러스터 엔진 Operator 콘솔 플러그인 활성화 | True |
| discovery | OpenShift Cluster Manager 내에서 새 클러스터를 검색하고 식별합니다. | True |
| Hive | OpenShift Container Platform 클러스터의 초기 구성 프로비저닝 및 수행 | True |
| hypershift | 비용 및 시간 효율성과 클라우드 간 이식성으로 규모에 맞게 OpenShift Container Platform 컨트롤 플레인 호스트 | True |
| hypershift-local-hosting | 로컬 클러스터 환경 내의 로컬 호스팅 기능 활성화 | True |
| local-cluster | 다중 클러스터 엔진 Operator가 배포된 로컬 허브 클러스터의 가져오기 및 자체 관리를 활성화합니다. | True |
| managedserviceacccount | 서비스 계정을 관리 클러스터에 동기화하고 Hub 클러스터로 토큰을 다시 시크릿 리소스로 수집 | False |
| server-foundation | 다중 클러스터 환경 내에서 서버 측 작업에 대한 기본 서비스 제공 | True |
다중 클러스터 엔진 Operator를 클러스터에 설치할 때 나열된 모든 구성 요소가 기본적으로 활성화되어 있는 것은 아닙니다.
MultiClusterEngine 사용자 정의 리소스에 하나 이상의 속성을 추가하여 설치 중 또는 설치 후 다중 클러스터 엔진 Operator를 추가로 구성할 수 있습니다. 추가할 수 있는 속성에 대한 정보를 계속 읽습니다.
1.3.3.2. 콘솔 및 구성 요소 구성
다음 예제는 구성 요소를 활성화하거나 비활성화하는 데 사용할 수 있는 spec.overrides 기본 템플릿을 표시합니다.
apiVersion: operator.open-cluster-management.io/v1
kind: MultiClusterEngine
metadata:
name: multiclusterengine
spec:
overrides:
components:
- name: <name>
enabled: true-
name을 구성 요소의 이름으로 바꿉니다.
또는 다음 명령을 실행할 수 있습니다. namespace 를 프로젝트 및 name 의 이름으로 구성 요소 이름으로 교체합니다.
oc patch MultiClusterEngine <multiclusterengine-name> --type=json -p='[{"op": "add", "path": "/spec/overrides/components/-","value":{"name":"<name>","enabled":true}}]'1.3.3.3. local-cluster 활성화
기본적으로 다중 클러스터 엔진 Operator를 실행하는 클러스터는 자체적으로 관리합니다. 클러스터 관리 자체 없이 다중 클러스터 엔진 Operator를 설치하려면 MultiClusterEngine 섹션의 spec.overrides.components 설정에 다음 값을 지정합니다.
apiVersion: multicluster.openshift.io/v1
kind: MultiClusterEngine
metadata:
name: multiclusterengine
spec:
overrides:
components:
- name: local-cluster
enabled: false-
name값은 hub 클러스터를local-cluster로 식별합니다. -
enabled설정은 기능이 활성화되어 있는지 여부를 지정합니다. 값이true이면 hub 클러스터는 자체적으로 관리합니다. 값이false이면 hub 클러스터에서 자체적으로 관리하지 않습니다.
자체적으로 관리하는 허브 클러스터는 클러스터 목록에서 local-cluster 로 지정됩니다.
1.3.3.4. 사용자 정의 이미지 풀 시크릿
OpenShift Container Platform 또는 다중 클러스터 엔진 Operator에서 생성하지 않은 Kubernetes 클러스터를 가져오려면 배포 레지스트리에서 권한이 있는 콘텐츠에 액세스하기 위해 OpenShift Container Platform pull secret 정보가 포함된 시크릿을 생성합니다.
OpenShift Container Platform 클러스터의 시크릿 요구 사항은 Kubernetes Operator의 OpenShift Container Platform 및 다중 클러스터 엔진에서 자동으로 해결되므로 관리할 다른 유형의 Kubernetes 클러스터를 가져오지 않는 경우 시크릿을 생성할 필요가 없습니다.
중요: 이러한 시크릿은 네임스페이스에 고유하므로 엔진에 사용하는 네임스페이스에 있는지 확인합니다.
- 풀 시크릿 다운로드를 선택하여 cloud.redhat.com/openshift/install/pull-secret 에서 OpenShift Container Platform 풀 시크릿 파일을 다운로드합니다. OpenShift Container Platform 풀 시크릿은 Red Hat Customer Portal ID와 연결되며 모든 Kubernetes 공급자에서 동일합니다.
다음 명령을 실행하여 보안을 생성합니다.
oc create secret generic <secret> -n <namespace> --from-file=.dockerconfigjson=<path-to-pull-secret> --type=kubernetes.io/dockerconfigjson-
secret을 생성하려는 시크릿 이름으로 교체합니다. -
시크릿은
네임스페이스에따라 네임스페이스를 사용하므로 네임스페이스를 프로젝트 네임스페이스로 교체합니다. -
다운로드한 OpenShift Container Platform 풀 시크릿의 경로로
path-to-pull-secret을 교체합니다.
-
다음 예제는 사용자 정의 풀 시크릿을 사용하려는 경우 사용할 spec.imagePullSecret 템플릿을 표시합니다. secret 을 풀 시크릿 이름으로 교체합니다.
apiVersion: multicluster.openshift.io/v1
kind: MultiClusterEngine
metadata:
name: multiclusterengine
spec:
imagePullSecret: <secret>1.3.3.5. 대상 네임스페이스
피연산자는 MultiClusterEngine 사용자 정의 리소스에 위치를 지정하여 지정된 네임스페이스에 설치할 수 있습니다. 이 네임스페이스는 MultiClusterEngine 사용자 정의 리소스의 애플리케이션 시 생성됩니다.
중요: 대상 네임스페이스를 지정하지 않으면 Operator는 multicluster-engine 네임스페이스에 설치하고 MultiClusterEngine 사용자 정의 리소스 사양에 설정합니다.
다음 예제는 대상 네임스페이스를 지정하는 데 사용할 수 있는 spec.targetNamespace 템플릿을 표시합니다. target 을 대상 네임스페이스의 이름으로 교체합니다. 참고: 대상 네임스페이스는 기본 네임스페이스가 될 수 없습니다.
apiVersion: multicluster.openshift.io/v1
kind: MultiClusterEngine
metadata:
name: multiclusterengine
spec:
targetNamespace: <target>1.3.3.6. availabilityConfig
hub 클러스터에는 High 및 Basic 이라는 두 가지 가능성이 있습니다. 기본적으로 허브 클러스터의 가용성은 High 이며 hub 클러스터 구성 요소에 2 의 replicaCount 를 제공합니다. 이는 장애 조치의 경우 더 나은 지원을 제공하지만 기본 가용성보다 많은 리소스를 사용하므로 구성 요소에 1 의 replicaCount 가 제공됩니다.
중요: 단일 노드 OpenShift 클러스터에서 다중 클러스터 엔진 Operator를 사용하는 경우 spec.availabilityConfig 를 Basic 으로 설정합니다.
다음 예제에서는 기본 가용성이 있는 spec.availabilityConfig 템플릿을 보여줍니다.
apiVersion: multicluster.openshift.io/v1
kind: MultiClusterEngine
metadata:
name: multiclusterengine
spec:
availabilityConfig: "Basic"1.3.3.7. nodeSelector
클러스터의 특정 노드에 설치할 MultiClusterEngine 에서 노드 선택기 세트를 정의할 수 있습니다. 다음 예제에서는 node-role.kubernetes.io/infra: 레이블이 있는 노드에 Pod를 할당하는 spec.nodeSelector 를 보여줍니다.
spec:
nodeSelector:
node-role.kubernetes.io/infra: ""1.3.3.8. 허용 오차
허용 오차 목록을 정의하여 MultiClusterEngine 이 클러스터에 정의된 특정 테인트를 허용할 수 있습니다. 다음 예제는 node-role.kubernetes.io/infra 테인트와 일치하는 spec.tolerations 를 보여줍니다.
spec:
tolerations:
- key: node-role.kubernetes.io/infra
effect: NoSchedule
operator: Exists이전 infra-node 허용 오차는 구성에 허용 오차를 지정하지 않고 기본적으로 Pod에 설정됩니다. 구성에서 허용 오차를 사용자 정의하면 이 기본 동작이 대체됩니다.
1.3.3.9. ManagedServiceAccount 애드온
ManagedServiceAccount 애드온을 사용하면 관리 클러스터에서 서비스 계정을 생성하거나 삭제할 수 있습니다. 이 애드온을 사용하여 설치하려면 spec.overrides 의 MultiClusterEngine 사양에 다음을 포함합니다.
apiVersion: multicluster.openshift.io/v1
kind: MultiClusterEngine
metadata:
name: multiclusterengine
spec:
overrides:
components:
- name: managedserviceaccount
enabled: true
명령줄에서 리소스를 편집하고 managedserviceaccount 구성 요소를 enabled: true 로 설정하여 ManagedServiceAccount 애드온을 MultiClusterEngine 을 생성한 후 활성화할 수 있습니다. 또는 다음 명령을 실행하고 <multiclusterengine-name>을 MultiClusterEngine 리소스의 이름으로 교체할 수 있습니다.
oc patch MultiClusterEngine <multiclusterengine-name> --type=json -p='[{"op": "add", "path": "/spec/overrides/components/-","value":{"name":"managedserviceaccount","enabled":true}}]'1.3.4. 설치 제거
Kubernetes Operator에 대한 다중 클러스터 엔진을 설치 제거할 때 프로세스의 두 가지 수준인 사용자 정의 리소스 제거 및 전체 Operator 설치 제거가 표시됩니다. 제거 프로세스를 완료하는 데 최대 5분이 걸릴 수 있습니다.
-
사용자 정의 리소스 제거는
MultiClusterEngine인스턴스의 사용자 정의 리소스를 제거하지만 다른 필요한 Operator 리소스를 제거하는 가장 기본적인 유형의 설치 제거입니다. 이 설치 제거 수준은 동일한 설정 및 구성 요소를 사용하여 다시 설치하려는 경우 유용합니다. - 두 번째 수준은 사용자 정의 리소스 정의와 같은 구성 요소를 제외하고 대부분의 Operator 구성 요소를 제거하는 더 완전한 제거 사항입니다. 이 단계를 계속할 때 사용자 정의 리소스 제거와 함께 제거되지 않은 모든 구성 요소 및 서브스크립션을 제거합니다. 이 제거 후 사용자 정의 리소스를 다시 설치하기 전에 Operator를 다시 설치해야 합니다.
1.3.4.1. 사전 요구 사항: 사용 가능한 서비스 분리
Kubernetes Operator용 다중 클러스터 엔진을 제거하기 전에 해당 엔진에서 관리하는 모든 클러스터를 분리해야 합니다. 오류를 방지하려면 엔진에서 계속 관리하는 모든 클러스터를 분리한 다음 다시 제거하십시오.
관리 클러스터가 연결되어 있는 경우 다음 메시지가 표시될 수 있습니다.
Cannot delete MultiClusterEngine resource because ManagedCluster resource(s) exist클러스터 분리에 대한 자세한 내용은 클러스터 생성 소개에서 공급자의 정보를 선택하여 관리에서 클러스터 제거 섹션을 참조하십시오.
1.3.4.2. 명령을 사용하여 리소스 제거
-
아직 설치되지 않은 경우 OpenShift Container Platform CLI가
oc명령을 실행하도록 구성되어 있는지 확인합니다.oc명령 구성에 대한 자세한 내용은 OpenShift Container Platform 설명서에서 OpenShift CLI 시작하기 를 참조하십시오. 다음 명령을 입력하여 프로젝트 네임스페이스로 변경합니다. namespace 를 프로젝트 네임스페이스의 이름으로 교체합니다.
oc project <namespace>다음 명령을 입력하여
MultiClusterEngine사용자 정의 리소스를 제거합니다.oc delete multiclusterengine --all다음 명령을 입력하여 진행 상황을 볼 수 있습니다.
oc get multiclusterengine -o yaml-
설치된 네임스페이스에서 다중 클러스터 엔진
ClusterServiceVersion을 삭제하려면 다음 명령을 입력합니다.
❯ oc get csv
NAME DISPLAY VERSION REPLACES PHASE
multicluster-engine.v2.0.0 multicluster engine for Kubernetes 2.0.0 Succeeded
❯ oc delete clusterserviceversion multicluster-engine.v2.0.0
❯ oc delete sub multicluster-engine여기에 표시된 CSV 버전은 다를 수 있습니다.
1.3.4.3. 콘솔을 사용하여 구성 요소 삭제
RedHat OpenShift Container Platform 콘솔을 사용하여 설치 제거할 때 Operator를 제거합니다. 콘솔을 사용하여 설치 제거하려면 다음 단계를 완료합니다.
- OpenShift Container Platform 콘솔 탐색에서 Operator > 설치된 Operator > Kubernetes용 멀티 클러스터 엔진을 선택합니다.
MultiClusterEngine사용자 정의 리소스를 제거합니다.- Multiclusterengine 의 탭을 선택합니다.
- MultiClusterEngine 사용자 정의 리소스의 옵션 메뉴를 선택합니다.
- MultiClusterEngine 삭제를 선택합니다.
다음 섹션의 절차에 따라 정리 스크립트를 실행합니다.
팁: Kubernetes Operator 버전에 대해 동일한 다중 클러스터 엔진을 다시 설치하려는 경우 이 절차의 나머지 단계를 건너뛰고 사용자 정의 리소스를 다시 설치할 수 있습니다.
- 설치된 Operator로 이동합니다.
- 옵션 메뉴를 선택하고 Uninstall operator 를 선택하여 Kubernetes_ operator의 _ 다중 클러스터 엔진을 제거합니다.
1.3.4.4. 문제 해결 설치 제거
다중 클러스터 엔진 사용자 정의 리소스가 제거되지 않는 경우 정리 스크립트를 실행하여 나머지 아티팩트를 제거합니다.
다음 스크립트를 파일에 복사합니다.
#!/bin/bash oc delete apiservice v1.admission.cluster.open-cluster-management.io v1.admission.work.open-cluster-management.io oc delete validatingwebhookconfiguration multiclusterengines.multicluster.openshift.io oc delete mce --all
자세한 내용은 Disconnected installation mirroring 에서 참조하십시오.
1.3.5. Red Hat Advanced Cluster Management 통합
Red Hat Advanced Cluster Management가 활성화된 다중 클러스터 엔진 Operator를 사용하는 경우 추가 멀티 클러스터 관리 기능을 활용할 수 있습니다.
1.3.5.1. 사전 요구 사항
Red Hat Advanced Cluster Management 기능과 통합하려면 다음 사전 요구 사항을 참조하십시오.
- Red Hat Advanced Cluster Management를 설치해야 합니다. 설치하려면 설치 및 업그레이드 를 참조하십시오.
1.3.5.2. 관찰 기능 통합
multicluster-observability Pod를 활성화한 후 Red Hat Advanced Cluster Management Observability Grafana 대시보드를 사용하여 호스팅된 컨트롤 플레인에 대한 다음 정보를 볼 수 있습니다.
- ACM > 호스팅 컨트롤 플레인 개요 대시보드를 통해 호스팅되는 컨트롤 플레인, 관련 클러스터 리소스 및 기존 호스팅 컨트롤 플레인의 목록 및 상태에 대한 클러스터 용량 추정치를 확인할 수 있습니다.
- ACM > 리소스 > 개요 페이지에서 액세스할 수 있는 호스팅된 컨트롤 플레인 대시보드를 통해 선택한 호스팅 컨트롤 플레인의 리소스 사용률을 확인할 수 있습니다.
활성화하려면 Observability 서비스 소개 를 참조하십시오.
1.4. 인증 정보 관리
다중 클러스터 엔진 Operator가 있는 클라우드 서비스 공급자에서 Red Hat OpenShift Container Platform 클러스터를 생성하고 관리하려면 인증 정보가 필요합니다. 자격 증명은 클라우드 공급자의 액세스 정보를 저장합니다. 각 공급자 계정에는 단일 공급자의 각 도메인과 마찬가지로 자체 인증 정보가 필요합니다.
클러스터 인증 정보를 생성하고 관리할 수 있습니다. 인증 정보는 Kubernetes 시크릿으로 저장됩니다. 관리 클러스터의 컨트롤러에서 시크릿에 액세스할 수 있도록 보안이 관리되는 클러스터의 네임스페이스에 복사됩니다. 인증 정보가 업데이트되면 관리 클러스터 네임스페이스에서 시크릿 복사본이 자동으로 업데이트됩니다.
참고: 클라우드 공급자 인증 정보의 풀 시크릿, SSH 키 또는 기본 도메인에 대한 변경 사항은 기존 관리 클러스터에 반영되지 않습니다. 원래 인증 정보를 사용하여 이미 프로비저닝되었기 때문입니다.
필요한 액세스: 편집
1.4.1. Amazon Web Services의 인증 정보 생성
다중 클러스터 엔진 Operator 콘솔을 사용하여 AWS(Amazon Web Services)에서 Red Hat OpenShift Container Platform 클러스터를 배포하고 관리하려면 인증 정보가 필요합니다.
필요한 액세스: 편집
참고: 다중 클러스터 엔진 Operator를 사용하여 클러스터를 생성하려면 이 절차를 수행해야 합니다.
1.4.1.1. 사전 요구 사항
인증 정보를 생성하기 전에 다음 사전 요구 사항이 있어야 합니다.
- 배포된 다중 클러스터 엔진 Operator 허브 클러스터
- 다중 클러스터 엔진 Operator 허브 클러스터에 대한 인터넷 액세스를 통해 AWS(Amazon Web Services)에서 Kubernetes 클러스터를 생성할 수 있습니다.
- AWS 로그인 인증 정보: 액세스 키 ID 및 시크릿 액세스 키가 포함됩니다. 보안 인증 정보 이해 및 가져오기를 참조하십시오.
- AWS에 클러스터를 설치할 수 있는 계정 권한 AWS 계정 구성 방법에 대한 지침은 AWS 계정 구성을 참조하십시오.
1.4.1.2. 콘솔을 사용하여 인증 정보 관리
다중 클러스터 엔진 Operator 콘솔에서 인증 정보를 생성하려면 콘솔의 단계를 완료합니다.
탐색 메뉴에서 시작합니다. 인증 정보를 클릭하여 기존 인증 정보 옵션에서 선택합니다. 팁: 편의를 위해 보안을 강화하기 위해 특별히 네임스페이스를 생성하여 인증 정보를 호스팅합니다.
선택적으로 인증 정보에 대한 기본 DNS 도메인 을 추가할 수 있습니다. 기본 DNS 도메인을 인증 정보에 추가하면 이 인증 정보가 있는 클러스터를 생성할 때 올바른 필드에 자동으로 채워집니다. 다음 단계를 참조하십시오.
- AWS 계정의 AWS 액세스 키 ID 를 추가합니다. ID 를 찾으려면 AWS 에 로그인을 참조하십시오.
- 새 AWS Secret Access 키 의 콘텐츠를 제공합니다.
프록시를 활성화하려면 프록시 정보를 입력합니다.
-
HTTP 프록시 URL:
HTTP트래픽의 프록시로 사용해야 하는 URL입니다. -
HTTPS 프록시 URL:
HTTPS트래픽에 사용해야 하는 보안 프록시 URL입니다. 값을 제공하지 않으면 HTTP 및HTTPS모두에HTTP프록시 URL -
프록시 도메인 없음: 프록시를 바이패스해야 하는 쉼표로 구분된 도메인 목록입니다. 마침표로 도메인 이름을 시작합니다
.를 해당 도메인에 있는 모든 하위 도메인을 포함합니다. 모든 대상에 대해 프록시를 바이패스하려면 별표*를 추가합니다. - 추가 신뢰 번들: HTTPS 연결을 프록시하는 데 필요한 하나 이상의 추가 CA 인증서입니다.
-
HTTP 프록시 URL:
- Red Hat OpenShift 풀 시크릿을 입력합니다. 풀 시크릿 을 다운로드하려면 Red Hat OpenShift 풀 시크릿 다운로드를 참조하십시오.
- 클러스터에 연결할 수 있는 SSH 개인 키 및 SSH 공개 키를 추가합니다. 기존 키 쌍을 사용하거나 키 생성 프로그램으로 새 키 쌍을 만들 수 있습니다.
Amazon Web Services에서 클러스터 생성 또는 Amazon Web Services GovCloud에서 클러스터 생성 단계를 완료하여 이 인증 정보를 사용하는 클러스터를 생성할 수 있습니다.
콘솔에서 인증 정보를 편집할 수 있습니다. 이 공급자 연결을 사용하여 클러스터가 생성된 경우 < cluster- > 시크릿이 새 인증 정보로 업데이트됩니다.
namespace>의 <cluster-name>-aws- creds
참고: 인증 정보를 업데이트해도 클러스터 풀 클레임 클러스터에서는 작동하지 않습니다.
인증 정보를 사용하는 클러스터를 더 이상 관리하지 않는 경우 인증 정보를 삭제하여 인증 정보의 정보를 보호합니다. 대규모로 삭제할 작업을 선택하거나 삭제할 인증 정보 옆에 있는 옵션 메뉴를 선택합니다.
1.4.1.2.1. S3 시크릿 생성
Amazon S3(Simple Storage Service) 시크릿을 생성하려면 콘솔에서 다음 작업을 완료합니다.
- Add credential > AWS > S3 Bucket 을 클릭합니다. For Hosted Control Plane 을 클릭하면 이름과 네임스페이스가 제공됩니다.
제공된 다음 필드에 대한 정보를 입력합니다.
-
bucket name: S3 버킷의 이름을 추가합니다. -
AWS
_ACCESS_KEY_ID: AWS 계정의 AWS 액세스 키 ID를 추가합니다. AWS에 로그인하여 ID를 찾습니다. -
AWS
_SECRET_ACCESS_KEY: 새로운 AWS Secret Access 키의 콘텐츠를 제공합니다. -
리전: AWS 리전을 입력합니다.
-
1.4.1.3. API를 사용하여 불투명 보안 생성
API를 사용하여 Amazon Web Services에 대한 불투명 시크릿을 생성하려면 다음 예와 유사한 YAML 프리뷰 창에 YAML 콘텐츠를 적용합니다.
kind: Secret
metadata:
name: <managed-cluster-name>-aws-creds
namespace: <managed-cluster-namespace>
type: Opaque
data:
aws_access_key_id: $(echo -n "${AWS_KEY}" | base64 -w0)
aws_secret_access_key: $(echo -n "${AWS_SECRET}" | base64 -w0)참고:
- 불투명한 시크릿은 콘솔에 표시되지 않습니다.
- opaque 보안은 선택한 관리 클러스터 네임스페이스에서 생성됩니다. Hive는 불투명 시크릿을 사용하여 클러스터를 프로비저닝합니다. Red Hat Advanced Cluster Management 콘솔을 사용하여 클러스터를 프로비저닝할 때 미리 생성된 인증 정보가 opaque 시크릿으로 관리 클러스터 네임스페이스에 복사됩니다.
-
인증 정보에 라벨을 추가하여 콘솔에서 시크릿을 확인합니다. 예를 들어 다음 AWS S3 Bucket
oc 레이블 시크릿에는type=awss3및인증 정보 --from-file=…이 추가됩니다.
oc label secret hypershift-operator-oidc-provider-s3-credentials -n local-cluster "cluster.open-cluster-management.io/type=awss3"
oc label secret hypershift-operator-oidc-provider-s3-credentials -n local-cluster "cluster.open-cluster-management.io/credentials=credentials="1.4.1.4. 추가 리소스
- 보안 인증 정보 이해 및 가져오기를 참조하십시오.
- AWS 계정 구성을 참조하십시오.
- AWS에 로그인합니다.
- Red Hat OpenShift 풀 시크릿을 다운로드합니다.
- 키를 생성하는 방법에 대한 자세한 내용은 클러스터 노드 SSH 액세스에 대한 키 쌍 생성을 참조하십시오.
- Amazon Web Services에서 클러스터 생성 을 참조하십시오.
- Amazon Web Services GovCloud에서 클러스터 생성 을 참조하십시오.
- Amazon Web Services의 인증 정보 생성 으로 돌아갑니다.
1.4.2. Microsoft Azure에 대한 인증 정보 생성
Microsoft Azure 또는 Microsoft Azure Government에서 다중 클러스터 엔진 Operator 콘솔을 사용하여 Red Hat OpenShift Container Platform 클러스터를 생성하고 관리하려면 인증 정보가 필요합니다.
필요한 액세스: 편집
참고: 이 절차는 다중 클러스터 엔진 Operator가 있는 클러스터를 생성하기 위한 사전 요구 사항입니다.
1.4.2.1. 사전 요구 사항
인증 정보를 생성하기 전에 다음 사전 요구 사항이 있어야 합니다.
- 배포된 다중 클러스터 엔진 Operator 허브 클러스터입니다.
- Azure에서 Kubernetes 클러스터를 생성할 수 있도록 다중 클러스터 엔진 Operator 허브 클러스터에 대한 인터넷 액세스
- 기본 도메인 리소스 그룹 및 Azure 서비스 주체 JSON을 포함하는 Azure 로그인 자격 증명입니다. 로그인 인증 정보를 얻으려면 Microsoft Azure Portal 을 참조하십시오.
- Azure에 클러스터를 설치할 수 있는 계정 권한 자세한 내용은 클라우드 서비스 구성 및 Azure 계정 구성을 참조하십시오.
1.4.2.2. 콘솔을 사용하여 인증 정보 관리
다중 클러스터 엔진 Operator 콘솔에서 인증 정보를 생성하려면 콘솔의 단계를 완료합니다. 탐색 메뉴에서 시작합니다. 인증 정보를 클릭하여 기존 인증 정보 옵션에서 선택합니다. 팁: 편의를 위해 보안을 강화하기 위해 특별히 네임스페이스를 생성하여 인증 정보를 호스팅합니다.
- 선택 사항: 인증 정보에 대한 기본 DNS 도메인 을 추가합니다. 기본 DNS 도메인을 인증 정보에 추가하면 이 인증 정보가 있는 클러스터를 생성할 때 올바른 필드에 자동으로 채워집니다.
-
클러스터의 환경이
AzurePublicCloud또는AzureUSGovernmentCloud인지 여부를 선택합니다. Azure Government 환경에 대해 설정이 다르므로 이 설정이 올바르게 설정되어 있는지 확인합니다. - Azure 계정에 대한 기본 도메인 리소스 그룹 이름을 추가합니다. 이 항목은 Azure 계정으로 생성한 리소스 이름입니다. Azure 인터페이스에서 홈 > DNS 영역을 선택하여 기본 도메인 리소스 그룹 이름을 찾을 수 있습니다. Azure CLI를 사용하여 Azure 서비스 주체 생성 을 참조하여 기본 도메인 리소스 그룹 이름을 찾습니다.
클라이언트 ID 의 콘텐츠를 제공합니다. 이 값은 다음 명령을 사용하여 서비스 주체를 생성할 때
appId속성으로 생성됩니다.az ad sp create-for-rbac --role Contributor --name <service_principal> --scopes <subscription_path>service_principal 을 서비스 주체의 이름으로 교체합니다.
클라이언트 시크릿 을 추가합니다. 이 값은 다음 명령을 사용하여 서비스 주체를 생성할 때
password속성으로 생성됩니다.az ad sp create-for-rbac --role Contributor --name <service_principal> --scopes <subscription_path>service_principal 을 서비스 주체의 이름으로 교체합니다.
서브스크립션 ID 를 추가합니다. 이 값은 다음 명령의 출력에 있는
id속성입니다.az account show테넌트 ID 를 추가합니다. 이 값은 다음 명령의 출력에 있는
tenantId속성입니다.az account show프록시를 활성화하려면 프록시 정보를 입력합니다.
-
HTTP 프록시 URL:
HTTP트래픽의 프록시로 사용해야 하는 URL입니다. -
HTTPS 프록시 URL:
HTTPS트래픽에 사용해야 하는 보안 프록시 URL입니다. 값을 제공하지 않으면 HTTP 및HTTPS모두에HTTP프록시 URL -
프록시 도메인 없음: 프록시를 바이패스해야 하는 쉼표로 구분된 도메인 목록입니다. 마침표로 도메인 이름을 시작합니다
.를 해당 도메인에 있는 모든 하위 도메인을 포함합니다. 모든 대상에 대해 프록시를 바이패스하려면 별표*를 추가합니다. - 추가 신뢰 번들: HTTPS 연결을 프록시하는 데 필요한 하나 이상의 추가 CA 인증서입니다.
-
HTTP 프록시 URL:
- Red Hat OpenShift 풀 시크릿 을 입력합니다. 풀 시크릿 을 다운로드하려면 Red Hat OpenShift 풀 시크릿 다운로드를 참조하십시오.
- 클러스터에 연결하는 데 사용할 SSH 개인 키 및 SSH 공개 키를 추가합니다. 기존 키 쌍을 사용하거나 키 생성 프로그램을 사용하여 새 쌍을 만들 수 있습니다.
Microsoft Azure에서 클러스터 생성 단계를 완료하여 이 인증 정보를 사용하는 클러스터를 생성할 수 있습니다.
콘솔에서 인증 정보를 편집할 수 있습니다.
인증 정보를 사용하는 클러스터를 더 이상 관리하지 않는 경우 인증 정보를 삭제하여 인증 정보의 정보를 보호합니다. 대규모로 삭제할 작업을 선택하거나 삭제할 인증 정보 옆에 있는 옵션 메뉴를 선택합니다.
1.4.2.3. API를 사용하여 불투명 보안 생성
콘솔 대신 API를 사용하여 Microsoft Azure에 대한 불투명 시크릿을 생성하려면 다음 예와 유사한 YAML 프리뷰 창에 YAML 콘텐츠를 적용합니다.
kind: Secret
metadata:
name: <managed-cluster-name>-azure-creds
namespace: <managed-cluster-namespace>
type: Opaque
data:
baseDomainResourceGroupName: $(echo -n "${azure_resource_group_name}" | base64 -w0)
osServicePrincipal.json: $(base64 -w0 "${AZURE_CRED_JSON}")참고:
- 불투명한 시크릿은 콘솔에 표시되지 않습니다.
- opaque 보안은 선택한 관리 클러스터 네임스페이스에서 생성됩니다. Hive는 불투명 시크릿을 사용하여 클러스터를 프로비저닝합니다. Red Hat Advanced Cluster Management 콘솔을 사용하여 클러스터를 프로비저닝할 때 미리 생성된 인증 정보가 opaque 시크릿으로 관리 클러스터 네임스페이스에 복사됩니다.
1.4.2.4. 추가 리소스
- Microsoft Azure Portal 을 참조하십시오.
- 클라우드 서비스 구성 방법을 참조하십시오.
- Azure 계정 구성을 참조하십시오.
- Azure CLI를 사용하여 Azure 서비스 주체 생성 을 참조하여 기본 도메인 리소스 그룹 이름을 찾습니다.
- Red Hat OpenShift 풀 시크릿을 다운로드합니다.
- 키를 생성하는 방법에 대한 자세한 내용은 클러스터 노드 SSH 액세스에 대한 키 쌍 생성을 참조하십시오.
- Microsoft Azure에서 클러스터 생성 을 참조하십시오.
- Microsoft Azure의 인증 정보 생성으로 돌아갑니다.
1.4.3. Google Cloud Platform의 인증 정보 생성
다중 클러스터 엔진 Operator 콘솔을 사용하여 GCP(Google Cloud Platform)에서 Red Hat OpenShift Container Platform 클러스터를 생성하고 관리하려면 인증 정보가 필요합니다.
필요한 액세스: 편집
참고: 이 절차는 다중 클러스터 엔진 Operator가 있는 클러스터를 생성하기 위한 사전 요구 사항입니다.
1.4.3.1. 사전 요구 사항
인증 정보를 생성하기 전에 다음 사전 요구 사항이 있어야 합니다.
- 배포된 다중 클러스터 엔진 Operator 허브 클러스터
- GCP에서 Kubernetes 클러스터를 생성할 수 있도록 다중 클러스터 엔진 Operator 허브 클러스터에 대한 인터넷 액세스
- 사용자 Google Cloud Platform 프로젝트 ID 및 Google Cloud Platform 서비스 계정 JSON 키가 포함된 GCP 로그인 인증 정보입니다. 프로젝트 생성 및 관리를 참조하십시오.
- GCP에 클러스터를 설치할 수 있는 계정 권한. 계정 구성 방법에 대한 지침은 GCP 프로젝트 구성을 참조하십시오.
1.4.3.2. 콘솔을 사용하여 인증 정보 관리
다중 클러스터 엔진 Operator 콘솔에서 인증 정보를 생성하려면 콘솔의 단계를 완료합니다.
탐색 메뉴에서 시작합니다. 인증 정보를 클릭하여 기존 인증 정보 옵션에서 선택합니다. 팁: 편의성과 보안을 위해 인증 정보를 호스팅하기 위해 특별히 네임스페이스를 만듭니다.
선택적으로 인증 정보에 대한 기본 DNS 도메인 을 추가할 수 있습니다. 기본 DNS 도메인을 인증 정보에 추가하면 이 인증 정보가 있는 클러스터를 생성할 때 올바른 필드에 자동으로 채워집니다. 다음 단계를 참조하십시오.
- GCP 계정의 Google Cloud Platform 프로젝트 ID 를 추가합니다. 설정을 검색하려면 GCP에 로그인을 참조하십시오.
- Google Cloud Platform 서비스 계정 JSON 키를 추가합니다. 서비스 계정 JSON 키를 생성하려면 서비스 계정 생성 설명서를 참조하십시오. GCP 콘솔의 단계를 따르십시오.
- 새 Google Cloud Platform 서비스 계정 JSON 키 의 콘텐츠를 제공합니다.
프록시를 사용하려면 프록시 정보를 입력합니다.
-
HTTP 프록시 URL:
HTTP트래픽의 프록시로 사용해야 하는 URL입니다. -
HTTPS 프록시 URL:
HTTPS트래픽에 사용해야 하는 보안 프록시 URL입니다. 값을 제공하지 않으면 HTTP 및HTTPS모두에HTTP프록시 URL -
프록시 도메인 없음: 프록시를 바이패스해야 하는 쉼표로 구분된 도메인 목록입니다. 마침표로 도메인 이름을 시작합니다
.를 해당 도메인에 있는 모든 하위 도메인을 포함합니다. 모든 대상에 대해 프록시를 바이패스하려면*를 추가하고 별표를 추가합니다. - 추가 신뢰 번들: HTTPS 연결을 프록시하는 데 필요한 하나 이상의 추가 CA 인증서입니다.
-
HTTP 프록시 URL:
- Red Hat OpenShift 풀 시크릿을 입력합니다. 풀 시크릿 을 다운로드하려면 Red Hat OpenShift 풀 시크릿 다운로드를 참조하십시오.
- 클러스터에 액세스할 수 있도록 SSH 개인 키 및 SSH 공개 키를 추가합니다. 기존 키 쌍을 사용하거나 키 생성 프로그램을 사용하여 새 쌍을 만들 수 있습니다.
Google Cloud Platform에서 클러스터 생성 단계를 완료하여 클러스터를 생성할 때 이 연결을 사용할 수 있습니다.
콘솔에서 인증 정보를 편집할 수 있습니다.
인증 정보를 사용하는 클러스터를 더 이상 관리하지 않는 경우 인증 정보를 삭제하여 인증 정보의 정보를 보호합니다. 대규모로 삭제할 작업을 선택하거나 삭제할 인증 정보 옆에 있는 옵션 메뉴를 선택합니다.
1.4.3.3. API를 사용하여 불투명 보안 생성
콘솔 대신 API를 사용하여 Google Cloud Platform에 대한 불투명 시크릿을 생성하려면 다음 예와 유사한 YAML 프리뷰 창에 YAML 콘텐츠를 적용합니다.
kind: Secret
metadata:
name: <managed-cluster-name>-gcp-creds
namespace: <managed-cluster-namespace>
type: Opaque
data:
osServiceAccount.json: $(base64 -w0 "${GCP_CRED_JSON}")참고:
- 불투명한 시크릿은 콘솔에 표시되지 않습니다.
- opaque 보안은 선택한 관리 클러스터 네임스페이스에서 생성됩니다. Hive는 불투명 시크릿을 사용하여 클러스터를 프로비저닝합니다. Red Hat Advanced Cluster Management 콘솔을 사용하여 클러스터를 프로비저닝할 때 미리 생성된 인증 정보가 opaque 시크릿으로 관리 클러스터 네임스페이스에 복사됩니다.
1.4.3.4. 추가 리소스
- 프로젝트 생성 및 관리를 참조하십시오.
- GCP 프로젝트 구성을 참조하십시오.
- GCP에 로그인합니다.
- 서비스 계정 JSON 키를 생성하려면 서비스 계정 생성 을 참조하십시오.
- Red Hat OpenShift 풀 시크릿을 다운로드합니다.
- 키를 생성하는 방법에 대한 자세한 내용은 클러스터 노드 SSH 액세스에 대한 키 쌍 생성을 참조하십시오.
- Google Cloud Platform에서 클러스터 생성 을 참조하십시오.
Google Cloud Platform의 인증 정보 생성 으로 돌아갑니다.
1.4.4. VMware vSphere의 인증 정보 생성
VMware vSphere에서 Red Hat OpenShift Container Platform 클러스터를 배포하고 관리하려면 다중 클러스터 엔진 Operator 콘솔을 사용하려면 인증 정보가 필요합니다.
필요한 액세스: 편집
참고:
- 다중 클러스터 엔진 Operator로 클러스터를 생성하려면 먼저 VMware vSphere에 대한 인증 정보를 생성해야 합니다.
- OpenShift Container Platform 버전 4.13 이상이 지원됩니다.
1.4.4.1. 사전 요구 사항
인증 정보를 생성하기 전에 다음 사전 요구 사항이 있어야 합니다.
- OpenShift Container Platform 버전 4.13 이상에 배포된 허브 클러스터입니다.
- VMware vSphere에서 Kubernetes 클러스터를 생성할 수 있도록 허브 클러스터에 대한 인터넷 액세스.
설치 관리자 프로비저닝 인프라를 사용하는 경우 OpenShift Container Platform에 대해 구성된 VMware vSphere 로그인 인증 정보 및 vCenter 요구 사항 사용자 지정을 사용하여 vSphere에 클러스터 설치를 참조하십시오. 이러한 인증 정보에는 다음 정보가 포함됩니다.
- vCenter 계정 권한.
- 클러스터 리소스.
- DHCP 사용 가능
- ESXi 호스트는 시간 동기화(예: NTP)입니다.
1.4.4.2. 콘솔을 사용하여 인증 정보 관리
다중 클러스터 엔진 Operator 콘솔에서 인증 정보를 생성하려면 콘솔의 단계를 완료합니다.
탐색 메뉴에서 시작합니다. 인증 정보를 클릭하여 기존 인증 정보 옵션에서 선택합니다. 팁: 편의를 위해 보안을 강화하기 위해 특별히 네임스페이스를 생성하여 인증 정보를 호스팅합니다.
선택적으로 인증 정보에 대한 기본 DNS 도메인 을 추가할 수 있습니다. 기본 DNS 도메인을 인증 정보에 추가하면 이 인증 정보가 있는 클러스터를 생성할 때 올바른 필드에 자동으로 채워집니다. 다음 단계를 참조하십시오.
- VMware vCenter 서버 정규화된 호스트 이름 또는 IP 주소를 추가합니다. 값은 vCenter 서버 루트 CA 인증서에 정의해야 합니다. 가능한 경우 정규화된 호스트 이름을 사용합니다.
- VMware vCenter 사용자 이름을 추가합니다.
- VMware vCenter 암호를 추가합니다.
VMware vCenter 루트 CA 인증서를 추가합니다.
-
VMware vCenter 서버에서 인증서를 사용하여
https://<vCenter_address>/certs/수 있습니다. vCenter_address 를 vCenter 서버의 주소로 바꿉니다.download.zip.zip 패키지에 인증서를 다운로드할 -
download.zip의 패키지를 해제합니다. .0확장자가 있는certs/<platform> 디렉터리의 인증서를 사용합니다.팁:
ls certs/<platform> 명령을 사용하여 플랫폼에 사용 가능한 모든 인증서를 나열할 수 있습니다.&
lt;platform>을 플랫폼의 약어로 바꿉니다.lin,mac또는win.예:
certs/lin/3a343545.0모범 사례:
cat certs/lin/*확장자와 여러 인증서를 연결합니다..0> ca.crt 명령을 실행하여 .0- VMware vSphere 클러스터 이름을 추가합니다.
- VMware vSphere 데이터 센터를 추가합니다.
- VMware vSphere 기본 데이터 저장소를 추가합니다.
- VMware vSphere 디스크 유형을 추가합니다.
- VMware vSphere 폴더 를 추가합니다.
- VMware vSphere 리소스 풀 을 추가합니다.
-
VMware vCenter 서버에서 인증서를 사용하여
연결 해제된 설치의 경우: 필요한 정보를 사용하여 구성 연결이 끊긴 설치 하위 섹션의 필드를 완료합니다.
- Cluster OS image: 이 값에는 Red Hat OpenShift Container Platform 클러스터 머신에 사용할 이미지의 URL이 포함되어 있습니다.
이미지 콘텐츠 소스: 이 값에는 연결이 끊긴 레지스트리 경로가 포함됩니다. 경로에는 연결이 끊긴 설치를 위한 모든 설치 이미지의 호스트 이름, 포트, 리포지토리 경로가 포함됩니다. 예:
repository.com:5000/openshift/ocp-release.경로는
install-config.yaml에서 Red Hat OpenShift Container Platform 릴리스 이미지로 이미지 콘텐츠 소스 정책 매핑을 생성합니다. 예를 들어repository.com:5000은 이imageContentSource콘텐츠를 생성합니다.- mirrors: - registry.example.com:5000/ocp4 source: quay.io/openshift-release-dev/ocp-release-nightly - mirrors: - registry.example.com:5000/ocp4 source: quay.io/openshift-release-dev/ocp-release - mirrors: - registry.example.com:5000/ocp4 source: quay.io/openshift-release-dev/ocp-v4.0-art-dev추가 신뢰 번들: 이 값은 미러 레지스트리에 액세스하는 데 필요한 인증서 파일의 내용을 제공합니다.
참고: 연결이 끊긴 환경에 있는 허브에서 관리 클러스터를 배포하고 자동으로 설치되도록 하려면
YAML편집기를 사용하여 Image Content Source Policy를install-config.yaml파일에 추가합니다. 다음 예제에 샘플 항목이 표시되어 있습니다.- mirrors: - registry.example.com:5000/rhacm2 source: registry.redhat.io/rhacm2
프록시를 활성화하려면 프록시 정보를 입력합니다.
-
HTTP 프록시 URL:
HTTP트래픽의 프록시로 사용해야 하는 URL입니다. -
HTTPS 프록시 URL:
HTTPS트래픽에 사용해야 하는 보안 프록시 URL입니다. 값을 제공하지 않으면 HTTP 및HTTPS모두에HTTP프록시 URL -
프록시 도메인 없음: 프록시를 바이패스해야 하는 쉼표로 구분된 도메인 목록입니다. 마침표로 도메인 이름을 시작합니다
.를 해당 도메인에 있는 모든 하위 도메인을 포함합니다. 모든 대상에 대해 프록시를 바이패스하려면*를 추가하고 별표를 추가합니다. - 추가 신뢰 번들: HTTPS 연결을 프록시하는 데 필요한 하나 이상의 추가 CA 인증서입니다.
-
HTTP 프록시 URL:
- Red Hat OpenShift 풀 시크릿을 입력합니다. 풀 시크릿 을 다운로드하려면 Red Hat OpenShift 풀 시크릿 다운로드를 참조하십시오.
클러스터에 연결할 수 있는 SSH 개인 키 및 SSH 공개 키를 추가합니다.
기존 키 쌍을 사용하거나 키 생성 프로그램으로 새 키 쌍을 만들 수 있습니다.
VMware vSphere에서 클러스터 생성 단계를 완료하여 이 인증 정보를 사용하는 클러스터를 생성할 수 있습니다.
콘솔에서 인증 정보를 편집할 수 있습니다.
인증 정보를 사용하는 클러스터를 더 이상 관리하지 않는 경우 인증 정보를 삭제하여 인증 정보의 정보를 보호합니다. 대규모로 삭제할 작업을 선택하거나 삭제할 인증 정보 옆에 있는 옵션 메뉴를 선택합니다.
1.4.4.3. API를 사용하여 불투명 보안 생성
콘솔 대신 API를 사용하여 VMware vSphere에 대한 불투명 시크릿을 생성하려면 다음 예와 유사한 YAML 프리뷰 창에 YAML 콘텐츠를 적용합니다.
kind: Secret
metadata:
name: <managed-cluster-name>-vsphere-creds
namespace: <managed-cluster-namespace>
type: Opaque
data:
username: $(echo -n "${VMW_USERNAME}" | base64 -w0)
password.json: $(base64 -w0 "${VMW_PASSWORD}")참고:
- 불투명한 시크릿은 콘솔에 표시되지 않습니다.
- opaque 보안은 선택한 관리 클러스터 네임스페이스에서 생성됩니다. Hive는 불투명 시크릿을 사용하여 클러스터를 프로비저닝합니다. Red Hat Advanced Cluster Management 콘솔을 사용하여 클러스터를 프로비저닝할 때 미리 생성된 인증 정보가 opaque 시크릿으로 관리 클러스터 네임스페이스에 복사됩니다.
1.4.4.4. 추가 리소스
- 사용자 지정을 사용하여 vSphere에 클러스터 설치를 참조하십시오.
- Red Hat OpenShift 풀 시크릿을 다운로드합니다.
- 자세한 내용은 클러스터 노드 SSH 액세스에 대한 키 쌍 생성 을 참조하십시오.
- VMware vSphere에서 클러스터 생성 을 참조하십시오.
- VMware vSphere의 인증 정보 생성으로 돌아갑니다.
1.4.5. Red Hat OpenStack의 인증 정보 생성
다중 클러스터 엔진 Operator 콘솔을 사용하여 Red Hat OpenStack Platform에서 Red Hat OpenShift Container Platform 클러스터를 배포하고 관리하려면 인증 정보가 필요합니다.
참고:
- 다중 클러스터 엔진 Operator를 사용하여 클러스터를 생성하려면 Red Hat OpenStack Platform의 인증 정보를 생성해야 합니다.
- OpenShift Container Platform 버전 4.13 이상만 지원됩니다.
1.4.5.1. 사전 요구 사항
인증 정보를 생성하기 전에 다음 사전 요구 사항이 있어야 합니다.
- OpenShift Container Platform 버전 4.13 이상에 배포된 허브 클러스터입니다.
- 허브 클러스터에 대한 인터넷 액세스를 통해 Red Hat OpenStack Platform에서 Kubernetes 클러스터를 생성할 수 있습니다.
- 설치 관리자 프로비저닝 인프라를 사용할 때 OpenShift Container Platform에 대해 구성된 Red Hat OpenStack Platform 로그인 인증 정보 및 Red Hat OpenStack Platform 요구 사항. 사용자 지정을 사용하여 OpenStack에 클러스터 설치를 참조하십시오.
CloudStack API에 액세스하기 위한
clouds.yaml파일을 다운로드하거나 생성합니다.clouds.yaml파일 내에서 다음을 수행합니다.- 사용할 클라우드 인증 섹션 이름을 확인합니다.
- username 행 바로 뒤에 암호에 대한 행을 추가합니다.
1.4.5.2. 콘솔을 사용하여 인증 정보 관리
다중 클러스터 엔진 Operator 콘솔에서 인증 정보를 생성하려면 콘솔의 단계를 완료합니다.
탐색 메뉴에서 시작합니다. 인증 정보를 클릭하여 기존 인증 정보 옵션에서 선택합니다. 보안 및 편의성을 개선하기 위해 특별히 인증 정보를 호스팅하는 네임스페이스를 생성할 수 있습니다.
- 선택 사항: 인증 정보에 대한 기본 DNS 도메인을 추가할 수 있습니다. 기본 DNS 도메인을 추가하면 이 인증 정보를 사용하여 클러스터를 생성할 때 올바른 필드에 자동으로 채워집니다.
-
Red Hat OpenStack Platform
clouds.yaml파일 내용을 추가합니다. password를 포함하여clouds.yaml파일의 내용은 Red Hat OpenStack Platform 서버에 연결하는 데 필요한 정보를 제공합니다. 파일 콘텐츠에는 사용자 이름 직후 새 행에 추가하는 암호가 포함되어야합니다. -
Red Hat OpenStack Platform 클라우드 이름을 추가합니다. 이 항목은 Red Hat OpenStack Platform 서버와의 통신을 설정하는 데 사용할
clouds.yaml의 cloud 섹션에 지정된 이름입니다. -
선택 사항: 내부 인증 기관을 사용하는 구성의 경우 내부 CA 인증서 필드에 인증서를 입력하여 인증서 정보를 사용하여
clouds.yaml을 자동으로 업데이트합니다. 연결이 끊긴 설치의 경우에만 해당: 필요한 정보를 사용하여 구성 연결이 끊긴 설치 하위 섹션의 필드를 완료합니다.
- Cluster OS image: 이 값에는 Red Hat OpenShift Container Platform 클러스터 머신에 사용할 이미지의 URL이 포함되어 있습니다.
이미지 콘텐츠 소스: 이 값에는 연결이 끊긴 레지스트리 경로가 포함됩니다. 경로에는 연결이 끊긴 설치를 위한 모든 설치 이미지의 호스트 이름, 포트, 리포지토리 경로가 포함됩니다. 예:
repository.com:5000/openshift/ocp-release.경로는
install-config.yaml에서 Red Hat OpenShift Container Platform 릴리스 이미지로 이미지 콘텐츠 소스 정책 매핑을 생성합니다. 예를 들어repository.com:5000은 이imageContentSource콘텐츠를 생성합니다.- mirrors: - registry.example.com:5000/ocp4 source: quay.io/openshift-release-dev/ocp-release-nightly - mirrors: - registry.example.com:5000/ocp4 source: quay.io/openshift-release-dev/ocp-release - mirrors: - registry.example.com:5000/ocp4 source: quay.io/openshift-release-dev/ocp-v4.0-art-dev추가 신뢰 번들: 이 값은 미러 레지스트리에 액세스하는 데 필요한 인증서 파일의 내용을 제공합니다.
참고: 연결이 끊긴 환경에 있는 허브에서 관리 클러스터를 배포하고 자동으로 설치되도록 하려면
YAML편집기를 사용하여 Image Content Source Policy를install-config.yaml파일에 추가합니다. 다음 예제에 샘플 항목이 표시되어 있습니다.- mirrors: - registry.example.com:5000/rhacm2 source: registry.redhat.io/rhacm2
프록시를 활성화하려면 프록시 정보를 입력합니다.
-
HTTP 프록시 URL:
HTTP트래픽의 프록시로 사용해야 하는 URL입니다. -
HTTPS 프록시 URL:
HTTPS트래픽에 사용해야 하는 보안 프록시 URL입니다. 값을 제공하지 않으면 HTTP 및HTTPS모두에HTTP프록시 URL -
프록시 도메인 없음: 프록시를 바이패스해야 하는 쉼표로 구분된 도메인 목록입니다. 마침표로 도메인 이름을 시작합니다
.를 해당 도메인에 있는 모든 하위 도메인을 포함합니다. 모든 대상에 대해 프록시를 바이패스하려면 별표*를 추가합니다. - 추가 신뢰 번들: HTTPS 연결을 프록시하는 데 필요한 하나 이상의 추가 CA 인증서입니다.
-
HTTP 프록시 URL:
- Red Hat OpenShift 풀 시크릿을 입력합니다. 풀 시크릿 을 다운로드하려면 Red Hat OpenShift 풀 시크릿 다운로드를 참조하십시오.
- 클러스터에 연결할 수 있는 SSH 개인 키 및 SSH 공개 키를 추가합니다. 기존 키 쌍을 사용하거나 키 생성 프로그램으로 새 키 쌍을 만들 수 있습니다.
- 생성을 클릭합니다.
- 새 인증 정보 를 검토한 다음 추가 를 클릭합니다. 인증 정보를 추가하면 인증 정보 목록에 추가됩니다.
Red Hat OpenStack Platform에서 클러스터 생성 단계를 완료하여 이 인증 정보를 사용하는 클러스터를 생성할 수 있습니다.
콘솔에서 인증 정보를 편집할 수 있습니다.
인증 정보를 사용하는 클러스터를 더 이상 관리하지 않는 경우 인증 정보를 삭제하여 인증 정보의 정보를 보호합니다. 대규모로 삭제할 작업을 선택하거나 삭제할 인증 정보 옆에 있는 옵션 메뉴를 선택합니다.
1.4.5.3. API를 사용하여 불투명 보안 생성
콘솔 대신 API를 사용하여 Red Hat OpenStack Platform에 대한 불투명 시크릿을 생성하려면 다음 예와 유사한 YAML 프리뷰 창에 YAML 콘텐츠를 적용합니다.
kind: Secret
metadata:
name: <managed-cluster-name>-osp-creds
namespace: <managed-cluster-namespace>
type: Opaque
data:
clouds.yaml: $(base64 -w0 "${OSP_CRED_YAML}") cloud: $(echo -n "openstack" | base64 -w0)참고:
- 불투명한 시크릿은 콘솔에 표시되지 않습니다.
- opaque 보안은 선택한 관리 클러스터 네임스페이스에서 생성됩니다. Hive는 불투명 시크릿을 사용하여 클러스터를 프로비저닝합니다. Red Hat Advanced Cluster Management 콘솔을 사용하여 클러스터를 프로비저닝할 때 미리 생성된 인증 정보가 opaque 시크릿으로 관리 클러스터 네임스페이스에 복사됩니다.
1.4.5.4. 추가 리소스
- 사용자 지정을 사용하여 OpenStack에 클러스터 설치를 참조하십시오.
- Red Hat OpenShift 풀 시크릿을 다운로드합니다.
- 자세한 내용은 클러스터 노드 SSH 액세스에 대한 키 쌍 생성 을 참조하십시오.
- Red Hat OpenStack Platform에서 클러스터 생성 을 참조하십시오.
- Red Hat OpenStack에 대한 인증 정보 생성 으로 돌아갑니다.
1.4.6. Red Hat Virtualization의 인증 정보 생성
더 이상 사용되지 않음: Red Hat Virtualization 인증 정보 및 클러스터 생성 기능은 더 이상 사용되지 않으며 더 이상 지원되지 않습니다.
다중 클러스터 엔진 Operator 콘솔을 사용하여 Red Hat Virtualization에서 Red Hat OpenShift Container Platform 클러스터를 배포하고 관리하려면 인증 정보가 필요합니다.
참고: 다중 클러스터 엔진 Operator를 사용하여 클러스터를 생성하려면 이 절차를 수행해야 합니다.
1.4.6.1. 사전 요구 사항
인증 정보를 생성하기 전에 다음 사전 요구 사항이 있어야 합니다.
- OpenShift Container Platform 버전 4.13 이상에 배포된 허브 클러스터입니다.
- 허브 클러스터에 대한 인터넷 액세스를 통해 Red Hat Virtualization에서 Kubernetes 클러스터를 만들 수 있습니다.
구성된 Red Hat Virtualization 환경에 대한 Red Hat Virtualization 로그인 인증 정보. Red Hat Virtualization 설명서의 설치 가이드를 참조하십시오. 다음 목록은 필요한 정보를 보여줍니다.
- ovirt URL
- ovirt FQDN(정규화된 도메인 이름)
- ovirt 사용자 이름
- ovirt 암호
- ovirt CA/Certificate
- 선택 사항: 프록시를 활성화하는 경우 프록시 정보입니다.
- Red Hat OpenShift Container Platform 풀 시크릿 정보. Pull secret 에서 풀 시크릿을 다운로드할 수 있습니다.
- 최종 클러스터의 정보를 전송하는 SSH 개인 키 및 공개 키입니다.
- oVirt에 클러스터를 설치할 수 있는 계정 권한.
1.4.6.2. 콘솔을 사용하여 인증 정보 관리
다중 클러스터 엔진 Operator 콘솔에서 인증 정보를 생성하려면 콘솔의 단계를 완료합니다.
탐색 메뉴에서 시작합니다. 인증 정보를 클릭하여 기존 인증 정보 옵션에서 선택합니다. 팁: 편의를 제공하고 보안을 강화하기 위해 특별히 네임스페이스를 생성하여 인증 정보를 호스팅합니다.
- 새 인증 정보에 대한 기본 정보를 추가합니다. 선택적으로 이 인증 정보를 사용하여 클러스터를 생성할 때 올바른 필드에 자동으로 채워지는 기본 DNS 도메인을 추가할 수 있습니다. 인증 정보에 추가하지 않으면 클러스터를 생성할 때 추가할 수 있습니다.
- Red Hat Virtualization 환경에 필요한 정보를 추가합니다.
프록시를 활성화하려면 프록시 정보를 입력합니다.
-
HTTP 프록시 URL:
HTTP트래픽의 프록시로 사용해야 하는 URL입니다. -
HTTPS 프록시 URL:
HTTPS트래픽을 사용할 때 사용해야 하는 보안 프록시 URL입니다. 값을 제공하지 않으면 HTTP 및HTTPS모두에HTTP프록시 URL -
프록시 도메인 없음: 프록시를 바이패스해야 하는 쉼표로 구분된 도메인 목록입니다. 마침표로 도메인 이름을 시작합니다
.를 해당 도메인에 있는 모든 하위 도메인을 포함합니다. 모든 대상에 대해 프록시를 바이패스하려면 별표*를 추가합니다.
-
HTTP 프록시 URL:
- Red Hat OpenShift Container Platform 풀 시크릿을 입력합니다. Pull secret 에서 풀 시크릿을 다운로드할 수 있습니다.
- 클러스터에 연결할 수 있는 SSH 개인 키 및 SSH 공개 키를 추가합니다. 기존 키 쌍을 사용하거나 키 생성 프로그램을 사용하여 새 키 쌍을 만들 수 있습니다. 자세한 내용은 클러스터 노드 SSH 액세스에 대한 키 쌍 생성 을 참조하십시오.
- 새 인증 정보 를 검토한 다음 추가 를 클릭합니다. 인증 정보를 추가하면 인증 정보 목록에 추가됩니다.
Red Hat Virtualization (더 이상 사용되지 않음)에서 클러스터 생성 단계를 완료하여 이 인증 정보를 사용하는 클러스터를 생성할 수 있습니다.
콘솔에서 인증 정보를 편집할 수 있습니다.
인증 정보를 사용하는 클러스터를 더 이상 관리하지 않는 경우 인증 정보를 삭제하여 인증 정보의 정보를 보호합니다. 대규모로 삭제할 작업을 선택하거나 삭제할 인증 정보 옆에 있는 옵션 메뉴를 선택합니다.
1.4.7. Red Hat OpenShift Cluster Manager의 인증 정보 생성
클러스터를 검색할 수 있도록 OpenShift Cluster Manager 인증 정보를 추가합니다.
필수 액세스: 관리자
1.4.7.1. 사전 요구 사항
console.redhat.com 계정에 액세스해야 합니다. 나중에 console.redhat.com/openshift/token 에서 가져올 수 있는 값이 필요합니다.
1.4.7.2. 콘솔을 사용하여 인증 정보 관리
클러스터를 검색하려면 인증 정보를 추가해야 합니다. 다중 클러스터 엔진 Operator 콘솔에서 인증 정보를 생성하려면 콘솔의 단계를 완료합니다.
탐색 메뉴에서 시작합니다. 인증 정보를 클릭하여 기존 인증 정보 옵션에서 선택합니다. 팁: 편의를 위해 보안을 강화하기 위해 특별히 네임스페이스를 생성하여 인증 정보를 호스팅합니다.
OpenShift Cluster Manager API 토큰은 console.redhat.com/openshift/token 에서 가져올 수 있습니다.
콘솔에서 인증 정보를 편집할 수 있습니다.
인증 정보를 사용하는 클러스터를 더 이상 관리하지 않는 경우 인증 정보를 삭제하여 인증 정보의 정보를 보호합니다. 대규모로 삭제할 작업을 선택하거나 삭제할 인증 정보 옆에 있는 옵션 메뉴를 선택합니다.
인증 정보가 제거되거나 OpenShift Cluster Manager API 토큰이 만료되거나 취소되면 관련 검색 클러스터가 제거됩니다.
1.4.8. Ansible Automation Platform의 인증 정보 생성
다중 클러스터 엔진 Operator 콘솔을 사용하여 Red Hat Ansible Automation Platform을 사용하는 Red Hat OpenShift Container Platform 클러스터를 배포하고 관리하려면 인증 정보가 필요합니다.
필요한 액세스: 편집
참고: 클러스터에서 자동화를 활성화하려면 자동화 템플릿을 생성하기 전에 이 절차를 수행해야 합니다.
1.4.8.1. 사전 요구 사항
인증 정보를 생성하기 전에 다음 사전 요구 사항이 있어야 합니다.
- 배포된 다중 클러스터 엔진 Operator 허브 클러스터
- 다중 클러스터 엔진 Operator 허브 클러스터에 대한 인터넷 액세스
- Ansible Automation Platform 호스트 이름 및 OAuth 토큰이 포함된 Ansible 로그인 인증 정보는 Ansible Automation Platform용 인증 정보를 참조하십시오.
- 허브 클러스터를 설치하고 Ansible을 사용할 수 있는 계정 권한. Ansible 사용자에 대해 자세히 알아보기 .
1.4.8.2. 콘솔을 사용하여 인증 정보 관리
다중 클러스터 엔진 Operator 콘솔에서 인증 정보를 생성하려면 콘솔의 단계를 완료합니다.
탐색 메뉴에서 시작합니다. 인증 정보를 클릭하여 기존 인증 정보 옵션에서 선택합니다. 팁: 편의를 위해 보안을 강화하기 위해 특별히 네임스페이스를 생성하여 인증 정보를 호스팅합니다.
Ansible 인증 정보를 생성할 때 제공하는 Ansible 토큰 및 호스트 URL은 인증 정보를 편집할 때 해당 인증 정보를 사용하는 자동화에 대해 자동으로 업데이트됩니다. 업데이트는 클러스터 라이프사이클, 거버넌스 및 애플리케이션 관리 자동화와 관련된 Ansible 자격 증명을 사용하는 모든 자동화에 복사됩니다. 이렇게 하면 인증 정보를 업데이트한 후 자동화가 계속 실행됩니다.
콘솔에서 인증 정보를 편집할 수 있습니다. Ansible 인증 정보는 인증 정보에서 업데이트할 때 해당 인증 정보를 사용하는 자동화에서 자동으로 업데이트됩니다.
관리 클러스터에서 실행되도록 Ansible Automation Platform 작업 구성 단계를 완료하여 이 인증 정보를 사용하는 Ansible 작업을 생성할 수 있습니다.
인증 정보를 사용하는 클러스터를 더 이상 관리하지 않는 경우 인증 정보를 삭제하여 인증 정보의 정보를 보호합니다. 대규모로 삭제할 작업을 선택하거나 삭제할 인증 정보 옆에 있는 옵션 메뉴를 선택합니다.
1.4.9. 온-프레미스 환경에 대한 인증 정보 생성
온-프레미스 환경에서 Red Hat OpenShift Container Platform 클러스터를 배포하고 관리하려면 콘솔을 사용하는 인증 정보가 필요합니다. 인증 정보는 클러스터에 사용되는 연결을 지정합니다.
필요한 액세스: 편집
1.4.9.1. 사전 요구 사항
인증 정보를 생성하기 전에 다음 사전 요구 사항이 필요합니다.
- 배포된 허브 클러스터입니다.
- 인프라 환경에서 Kubernetes 클러스터를 생성할 수 있도록 허브 클러스터에 대한 인터넷 액세스.
- 연결이 끊긴 환경의 경우 클러스터 생성을 위해 릴리스 이미지를 복사할 수 있는 구성된 미러 레지스트리가 있어야 합니다. 자세한 내용은 OpenShift Container Platform 설명서에서 연결 해제 설치 미러링 을 참조하십시오.
- 온-프레미스 환경에 클러스터 설치를 지원하는 계정 권한.
1.4.9.2. 콘솔을 사용하여 인증 정보 관리
콘솔에서 인증 정보를 생성하려면 콘솔의 단계를 완료합니다.
탐색 메뉴에서 시작합니다. 인증 정보를 클릭하여 기존 인증 정보 옵션에서 선택합니다. 팁: 편의를 위해 보안을 강화하기 위해 특별히 네임스페이스를 생성하여 인증 정보를 호스팅합니다.
- 인증 정보 유형에 대한 호스트 인벤토리 를 선택합니다.
- 선택적으로 인증 정보에 대한 기본 DNS 도메인 을 추가할 수 있습니다. 기본 DNS 도메인을 인증 정보에 추가하면 이 인증 정보가 있는 클러스터를 생성할 때 올바른 필드에 자동으로 채워집니다. DNS 도메인을 추가하지 않으면 클러스터를 생성할 때 추가할 수 있습니다.
- Red Hat OpenShift 풀 시크릿 을 입력합니다. 이 풀 시크릿은 클러스터를 생성하고 이 인증 정보를 지정할 때 자동으로 입력됩니다. Pull secret 에서 풀 시크릿을 다운로드할 수 있습니다. 가져오기 보안에 대한 자세한 내용은 이미지 풀 시크릿 사용을 참조하십시오.
-
SSH 공개 키를입력합니다. 클러스터를 생성하고 이 인증 정보를 지정할 때 이SSH 공개 키도자동으로 입력됩니다. - 추가 를 선택하여 인증 정보를 생성합니다.
온-프레미스 환경에서 클러스터 생성 단계를 완료하여 이 인증 정보를 사용하는 클러스터를 만들 수 있습니다.
인증 정보를 사용하는 클러스터를 더 이상 관리하지 않는 경우 인증 정보를 삭제하여 인증 정보의 정보를 보호합니다. 대규모로 삭제할 작업을 선택하거나 삭제할 인증 정보 옆에 있는 옵션 메뉴를 선택합니다.
1.5. 클러스터 라이프사이클 소개
멀티 클러스터 엔진 Operator는 OpenShift Container Platform 및 Red Hat Advanced Cluster Management Hub 클러스터에 대한 클러스터 관리 기능을 제공하는 클러스터 라이프사이클 Operator입니다. 다중 클러스터 엔진 Operator는 클러스터 관리를 개선하고 클라우드 및 데이터 센터 전체에서 OpenShift Container Platform 클러스터 라이프사이클 관리를 지원하는 소프트웨어 운영자입니다. Red Hat Advanced Cluster Management를 사용하거나 사용하지 않고 다중 클러스터 엔진 Operator를 사용할 수 있습니다. Red Hat Advanced Cluster Management는 멀티 클러스터 엔진 Operator도 자동으로 설치하고 추가 다중 클러스터 기능을 제공합니다.
다음 설명서를 참조하십시오.
- 클러스터 라이프사이클 아키텍처
- 인증 정보 관리 개요
- 호스트 인벤토리 소개
- CLI를 사용하여 클러스터 생성
- 클러스터 생성 중 추가 매니페스트 구성
- Amazon Web Services에서 클러스터 생성
- Amazon Web Services GovCloud에서 클러스터 생성
- Microsoft Azure에 클러스터 생성
- Google Cloud Platform에서 클러스터 생성
- VMware vSphere에서 클러스터 생성
- Red Hat OpenStack Platform에서 클러스터 생성
- Red Hat Virtualization에서 클러스터 생성 (더 이상 사용되지 않음)
- 온프레미스 환경에서 클러스터 생성
- 프록시 환경에서 클러스터 생성
- 클러스터에 액세스
- 관리형 클러스터 확장
- 생성된 클러스터 완화
- 클러스터 프록시 애드온 활성화
- 관리 클러스터에서 실행되도록 Ansible Automation Platform 작업 구성
- 배치
- ManagedServiceAccount 활성화
- 클러스터 라이프사이클 고급 구성
- 관리에서 클러스터 제거
1.5.1. 클러스터 라이프사이클 아키텍처
클러스터 라이프사이클에는 허브 클러스터와 관리 클러스터의 두 가지 유형이 필요합니다.
hub 클러스터는 다중 클러스터 엔진 Operator가 자동으로 설치된 OpenShift Container Platform (또는 Red Hat Advanced Cluster Management) 기본 클러스터입니다. hub 클러스터를 사용하여 다른 Kubernetes 클러스터를 생성, 관리 및 모니터링할 수 있습니다. hub 클러스터에서 관리할 기존 클러스터를 가져오는 동안 hub 클러스터를 사용하여 클러스터를 생성할 수 있습니다.
관리형 클러스터를 생성할 때 Hive 리소스와 함께 Red Hat OpenShift Container Platform 클러스터 설치 프로그램을 사용하여 클러스터가 생성됩니다. OpenShift Container Platform 설치 프로그램을 사용하여 클러스터 설치 프로세스에 대한 자세한 내용은 OpenShift Container Platform 설명서에서 OpenShift Container Platform 클러스터 설치 및 구성 을 읽고 확인할 수 있습니다.
다음 다이어그램은 클러스터 관리를 위해 Kubernetes Operator용 다중 클러스터 엔진과 함께 설치된 구성 요소를 보여줍니다.
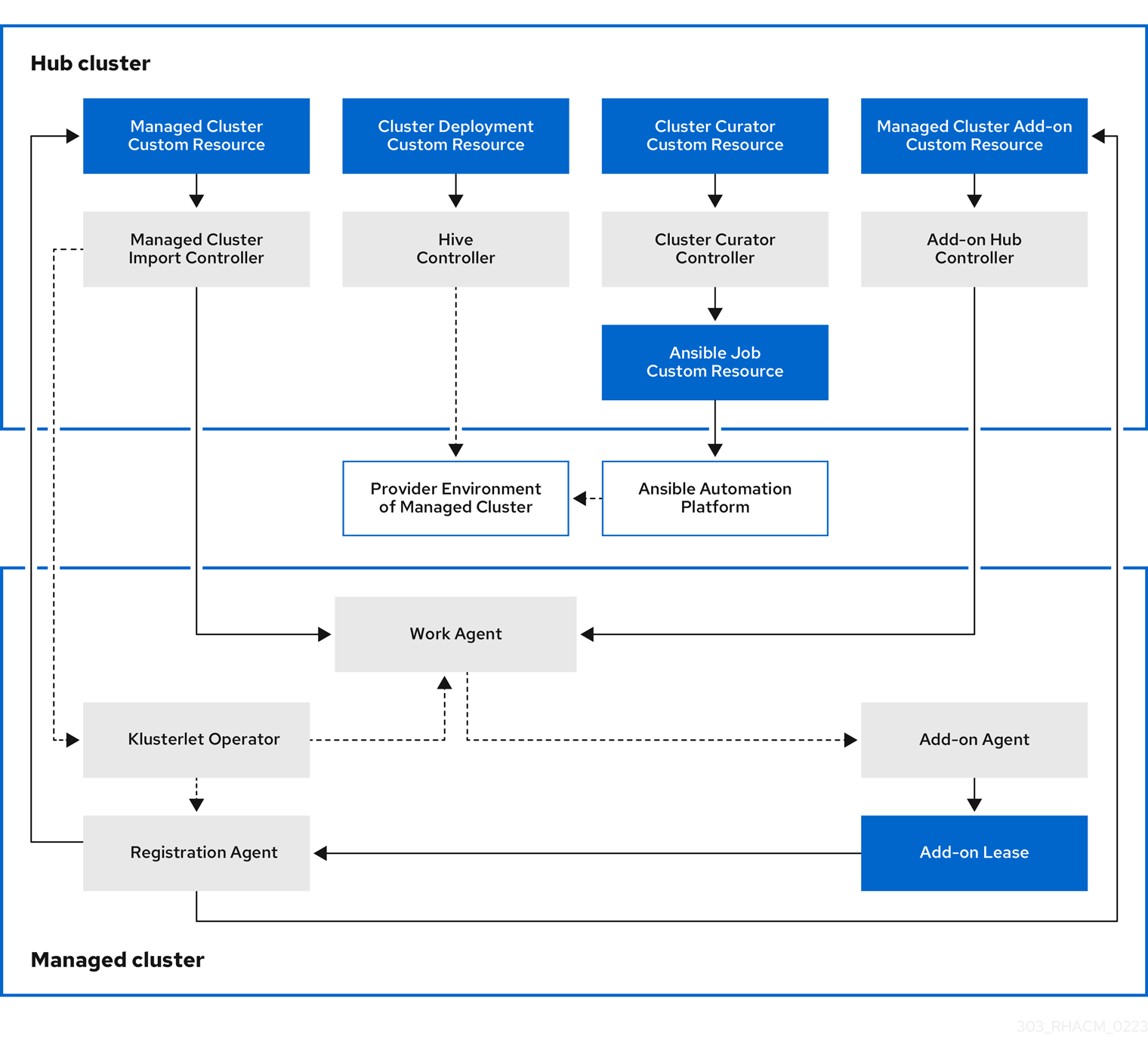
클러스터 라이프사이클 관리 아키텍처의 구성 요소에는 다음 항목이 포함됩니다.
1.5.1.1. hub 클러스터
- 관리 클러스터 가져오기 컨트롤러는 klusterlet Operator를 관리 클러스터에 배포합니다.
- Hive 컨트롤러는 Kubernetes Operator에 다중 클러스터 엔진을 사용하여 생성하는 클러스터를 프로비저닝합니다. Hive 컨트롤러는 Kubernetes Operator를 위해 다중 클러스터 엔진에 의해 생성된 관리형 클러스터도 제거합니다.
- 클러스터 큐레이터 컨트롤러는 관리 클러스터를 생성하거나 업그레이드할 때 클러스터 인프라 환경을 구성하기 위해 pre-hook 또는 post-hook로 Ansible 작업을 생성합니다.
- hub 클러스터에서 관리되는 클러스터 애드온이 활성화되면 허브 클러스터에 해당 애드온 허브 컨트롤러가 배포됩니다. 애드온 허브 컨트롤러는 관리형 클러스터에 애드온 에이전트 를 배포합니다.
1.5.1.2. 관리형 클러스터
- klusterlet Operator 는 관리 클러스터에 등록 및 작업 컨트롤러를 배포합니다.
등록 에이전트 는 관리 클러스터와 관리형 클러스터 애드온을 hub 클러스터에 등록합니다. 또한 등록 에이전트는 관리 클러스터 및 관리 클러스터 애드온의 상태를 유지 관리합니다. 다음 권한은 관리 클러스터가 hub 클러스터에 액세스할 수 있도록 Clusterrole 내에 자동으로 생성됩니다.
- 에이전트가 hub 클러스터에서 관리하는 소유 클러스터를 가져오거나 업데이트할 수 있습니다.
- 에이전트가 hub 클러스터에서 관리하는 소유 클러스터의 상태를 업데이트할 수 있습니다.
- 에이전트가 인증서를 회전하도록 허용
-
에이전트가 reconcile
.k8s.io리스를얻거나업데이트하도록 허용 -
에이전트가 관리 클러스터 애드온을
가져올 수있도록 허용 - 에이전트가 관리 클러스터 애드온의 상태를 업데이트하도록 허용
- 작업 에이전트 는 Add-on Agent를 관리 클러스터에 적용합니다. 관리 클러스터가 hub 클러스터에 액세스할 수 있도록 허용하는 권한은 Clusterrole 내에서 자동으로 생성되고 에이전트가 hub 클러스터에 이벤트를 보낼 수 있습니다.
클러스터를 계속 추가하고 관리하려면 클러스터 라이프사이클 소개 를 참조하십시오.
1.5.2. 이미지 릴리스
클러스터를 빌드할 때 릴리스 이미지가 지정하는 Red Hat OpenShift Container Platform 버전을 사용하십시오. 기본적으로 OpenShift Container Platform은 clusterImageSets 리소스를 사용하여 지원되는 릴리스 이미지 목록을 가져옵니다.
계속 읽고 릴리스 이미지에 대한 자세한 내용을 확인하십시오.
1.5.2.1. 릴리스 이미지 지정
Kubernetes Operator에 다중 클러스터 엔진을 사용하여 공급자에 클러스터를 생성하는 경우 새 클러스터에 사용할 릴리스 이미지를 지정합니다. 릴리스 이미지를 지정하려면 다음 항목을 참조하십시오.
1.5.2.1.1. ClusterImageSets위치
릴리스 이미지를 참조하는 YAML 파일은 acm-hive-openshift-releases GitHub 리포지토리에서 유지 관리됩니다. 파일은 콘솔에서 사용 가능한 릴리스 이미지 목록을 생성하는 데 사용됩니다. 여기에는 OpenShift Container Platform의 최신 빠른 채널 이미지가 포함됩니다.
콘솔에는 세 가지 최신 버전의 OpenShift Container Platform의 최신 릴리스 이미지만 표시됩니다. 예를 들어 콘솔 옵션에 다음 릴리스 이미지가 표시될 수 있습니다.
quay.io/openshift-release-dev/ocp-release:4.13.1-x86_64
콘솔에 최신 릴리스 이미지로 클러스터를 생성하는 데 도움이 되는 최신 버전이 표시됩니다. 특정 버전의 클러스터를 생성해야 하는 경우 이전 릴리스 이미지 버전도 사용할 수 있습니다.
참고: 콘솔에 클러스터를 생성할 때 표시되는 이미지: 'true' 레이블이 있는 이미지만 선택할 수 있습니다. ClusterImageSet 리소스의 이 레이블의 예는 다음 콘텐츠에 제공됩니다. 4.x.1 을 제품의 현재 버전으로 바꿉니다.
apiVersion: hive.openshift.io/v1
kind: ClusterImageSet
metadata:
labels:
channel: fast
visible: 'true'
name: img4.x.1-x86-64-appsub
spec:
releaseImage: quay.io/openshift-release-dev/ocp-release:4.x.1-x86_64추가 릴리스 이미지가 저장되지만 콘솔에는 표시되지 않습니다. 사용 가능한 모든 릴리스 이미지를 보려면 다음 명령을 실행합니다.
oc get clusterimageset
리포지토리에는 릴리스 이미지로 작업할 때 사용하는 디렉터리인 clusterImageSets 디렉터리가 있습니다. clusterImageSets 디렉터리에는 다음과 같은 디렉터리가 있습니다.
- fast: 지원되는 각 OpenShift Container Platform 버전에 대한 최신 버전의 릴리스 이미지를 참조하는 파일이 포함되어 있습니다. 이 폴더의 릴리스 이미지는 테스트, 확인 및 지원됩니다.
릴리스: 각 OpenShift Container Platform 버전 (stable, fast, and candidate 채널)의 모든 릴리스 이미지를 참조하는 파일이 포함되어 있습니다.
참고: 이 릴리스는 모두 테스트된 것이 아니며 안정적인 것으로 확인되었습니다.
stable: 지원되는 각 OpenShift Container Platform 버전에 대해 안정적인 최신 버전의 릴리스 이미지를 참조하는 파일이 포함되어 있습니다.
참고: 기본적으로 현재 릴리스 이미지 목록은 시간마다 한 번씩 업데이트됩니다. 제품을 업그레이드한 후 새 버전의 제품에 권장되는 릴리스 이미지 버전을 반영하는 데 최대 1시간이 걸릴 수 있습니다.
1.5.2.1.2. ClusterImageSets구성
다음 옵션을 사용하여 ClusterImageSet 을 구성할 수 있습니다.
옵션 1: 콘솔에서 클러스터를 만들려면 원하는 특정
ClusterImageSet에 대한 이미지 참조를 지정합니다. 유지를 지정하는 각 새 항목은 향후 모든 클러스터 프로비저닝에 대해 사용할 수 있으며 다음 예제 항목을 참조하십시오.quay.io/openshift-release-dev/ocp-release:4.6.8-x86_64-
옵션 2:
acm-hive-openshift-releasesGitHub 리포지토리에서ClusterImageSetsYAML 파일을 수동으로 생성하고 적용합니다. -
옵션 3: 분기된 GitHub 리포지토리에서
ClusterImageSets의 자동 업데이트를 활성화하려면 cluster-image-set-controller GitHub 리포지토리의README.md를 따릅니다.
1.5.2.1.3. 다른 아키텍처에 클러스터를 배포할 릴리스 이미지 생성
두 아키텍처의 파일이 있는 릴리스 이미지를 수동으로 생성하여 허브 클러스터의 아키텍처와 다른 아키텍처에 클러스터를 생성할 수 있습니다.
예를 들어 ppc64le,aarch64 또는 s390x 아키텍처에서 실행 중인 hub 클러스터에서 x86_64 클러스터를 생성해야 할 수 있습니다. 두 파일 세트를 모두 사용하여 릴리스 이미지를 생성하는 경우 새 릴리스 이미지를 사용하면 OpenShift Container Platform 릴리스 레지스트리에서 다중 아키텍처 이미지 매니페스트를 제공할 수 있으므로 클러스터 생성이 성공합니다.
OpenShift Container Platform 4.13 이상에서는 기본적으로 여러 아키텍처를 지원합니다. 다음 clusterImageSet 을 사용하여 클러스터를 프로비저닝할 수 있습니다. 4.x.0 을 현재 버전으로 바꿉니다.
apiVersion: hive.openshift.io/v1
kind: ClusterImageSet
metadata:
labels:
channel: fast
visible: 'true'
name: img4.x.0-multi-appsub
spec:
releaseImage: quay.io/openshift-release-dev/ocp-release:4.x.0-multi여러 아키텍처를 지원하지 않는 OpenShift Container Platform 이미지의 릴리스 이미지를 생성하려면 아키텍처 유형에 대해 다음 예와 유사한 단계를 완료합니다.
OpenShift Container Platform 릴리스 레지스트리에서
x86_64,s390x,aarch64,ppc64le릴리스 이미지가 포함된 매니페스트 목록을 생성합니다.다음 예제 명령을 실행하여 Quay 리포지토리에서 두 아키텍처 모두에 대한 매니페스트 목록을 가져옵니다.
4.x.1을 제품의 현재 버전으로 바꿉니다.podman pull quay.io/openshift-release-dev/ocp-release:4.x.1-x86_64 podman pull quay.io/openshift-release-dev/ocp-release:4.x.1-ppc64le podman pull quay.io/openshift-release-dev/ocp-release:4.x.1-s390x podman pull quay.io/openshift-release-dev/ocp-release:4.x.1-aarch64다음 명령을 실행하여 이미지를 유지 관리하는 개인 리포지토리에 로그인합니다. &
lt;private-repo>를 리포지토리 경로로 바꿉니다.podman login <private-repo>환경에 적용되는 다음 명령을 실행하여 프라이빗 리포지토리에 릴리스 이미지 매니페스트를 추가합니다.
4.x.1을 제품의 현재 버전으로 바꿉니다. <private-repo>를 리포지토리 경로로 바꿉니다.podman push quay.io/openshift-release-dev/ocp-release:4.x.1-x86_64 <private-repo>/ocp-release:4.x.1-x86_64 podman push quay.io/openshift-release-dev/ocp-release:4.x.1-ppc64le <private-repo>/ocp-release:4.x.1-ppc64le podman push quay.io/openshift-release-dev/ocp-release:4.x.1-s390x <private-repo>/ocp-release:4.x.1-s390x podman push quay.io/openshift-release-dev/ocp-release:4.x.1-aarch64 <private-repo>/ocp-release:4.x.1-aarch64다음 명령을 실행하여 새 정보에 대한 매니페스트를 생성합니다.
podman manifest create mymanifest다음 명령을 실행하여 두 릴리스 이미지에 대한 참조를 매니페스트 목록에 추가합니다.
4.x.1을 제품의 현재 버전으로 바꿉니다. <private-repo>를 리포지토리 경로로 바꿉니다.podman manifest add mymanifest <private-repo>/ocp-release:4.x.1-x86_64 podman manifest add mymanifest <private-repo>/ocp-release:4.x.1-ppc64le podman manifest add mymanifest <private-repo>/ocp-release:4.x.1-s390x podman manifest add mymanifest <private-repo>/ocp-release:4.x.1-aarch64다음 명령을 실행하여 매니페스트 목록의 목록을 기존 매니페스트와 병합합니다. &
lt;private-repo>를 리포지토리 경로로 바꿉니다.4.x.1을 현재 버전으로 바꿉니다.podman manifest push mymanifest docker://<private-repo>/ocp-release:4.x.1
허브 클러스터에서 리포지토리의 매니페스트를 참조하는 릴리스 이미지를 생성합니다.
다음 예와 유사한 정보가 포함된 YAML 파일을 생성합니다. &
lt;private-repo>를 리포지토리 경로로 바꿉니다.4.x.1을 현재 버전으로 바꿉니다.apiVersion: hive.openshift.io/v1 kind: ClusterImageSet metadata: labels: channel: fast visible: "true" name: img4.x.1-appsub spec: releaseImage: <private-repo>/ocp-release:4.x.1허브 클러스터에서 다음 명령을 실행하여 변경 사항을 적용합니다. &
lt;file-name>을 이전 단계에서 생성한 YAML 파일의 이름으로 바꿉니다.oc apply -f <file-name>.yaml
- OpenShift Container Platform 클러스터를 생성할 때 새 릴리스 이미지를 선택합니다.
- Red Hat Advanced Cluster Management 콘솔을 사용하여 관리 클러스터를 배포하는 경우 클러스터 생성 프로세스 중 Architecture 필드에 관리 클러스터의 아키텍처를 지정합니다.
생성 프로세스에서는 병합된 릴리스 이미지를 사용하여 클러스터를 생성합니다.
1.5.2.1.4. 추가 리소스
- 릴리스 이미지를 참조하는 YAML 파일의 acm-hive-openshift-releases GitHub 리포지토리를 참조하십시오.
-
분기된 GitHub 리포지토리에서
ClusterImageSet의 자동 업데이트를 활성화하는 방법을 알아보려면 cluster-image-set-controller GitHub 리포지토리를 참조하십시오.
1.5.2.2. 연결된 경우 사용자 정의 릴리스 이미지 목록 유지
모든 클러스터에 동일한 릴리스 이미지를 사용해야 할 수 있습니다. 단순화하기 위해 클러스터를 생성할 때 사용할 수 있는 고유한 릴리스 이미지 목록을 생성할 수 있습니다. 사용 가능한 릴리스 이미지를 관리하려면 다음 단계를 완료합니다.
- acm-hive-openshift-releases GitHub 를 분기합니다.
-
클러스터를 생성할 때 사용할 수 있는 이미지의 YAML 파일을 추가합니다. Git 콘솔 또는 터미널을 사용하여 이미지를
./clusterImageSets/stable/또는./clusterImageSets/fast/디렉터리에 추가합니다. -
cluster-image-set-git-repo라는multicluster-engine네임스페이스에ConfigMap을 생성합니다. 다음 예제를 참조하지만2.x를 2.5로 바꿉니다.
apiVersion: v1
kind: ConfigMap
metadata:
name: cluster-image-set-git-repo
namespace: multicluster-engine
data:
gitRepoUrl: <forked acm-hive-openshift-releases repository URL>
gitRepoBranch: backplane-<2.x>
gitRepoPath: clusterImageSets
channel: <fast or stable>다음 절차에 따라 분기된 리포지토리에 변경 사항을 병합하여 기본 리포지토리에서 사용 가능한 YAML 파일을 검색할 수 있습니다.
- 분기된 리포지토리에 변경 사항을 커밋하고 병합합니다.
-
acm-hive-openshift-releases리포지토리를 복제한 후 빠른 릴리스 이미지 목록을 동기화하려면cluster-image-set-git-repoConfigMap의 channel 필드를fast로 업데이트합니다. -
안정적인 릴리스 이미지를 동기화하고 표시하려면
cluster-image-set-git-repoConfigMap의 channel 필드 값을stable로 업데이트합니다.
ConfigMap 을 업데이트한 후 사용 가능한 안정적인 릴리스 이미지 목록이 약 1분 내에 현재 사용 가능한 이미지로 업데이트됩니다.
다음 명령을 사용하여 사용 가능한 항목을 나열하고 기본값을 제거할 수 있습니다. &
lt;clusterImageSet_NAME>을 올바른 이름으로 바꿉니다.oc get clusterImageSets oc delete clusterImageSet <clusterImageSet_NAME>
클러스터를 생성할 때 콘솔에서 현재 사용 가능한 릴리스 이미지 목록을 확인합니다.
ConfigMap 을 통해 사용할 수 있는 다른 필드에 대한 자세한 내용은 cluster-image-set-controller GitHub 리포지토리 README를 참조하십시오.
1.5.2.3. 연결이 끊긴 동안 사용자 정의 릴리스 이미지 목록 유지 관리
hub 클러스터에 인터넷 연결이 없는 경우 사용자 정의 릴리스 이미지 목록을 유지 관리해야 하는 경우도 있습니다. 클러스터를 생성할 때 사용 가능한 자체 릴리스 이미지 목록을 생성할 수 있습니다. 연결이 끊긴 동안 사용 가능한 릴리스 이미지를 관리하려면 다음 단계를 완료합니다.
- 연결된 시스템에 있는 동안 acm-hive-openshift-releases GitHub 리포지토리로 이동하여 사용 가능한 클러스터 이미지 세트에 액세스합니다.
-
연결이 끊긴 다중 클러스터 엔진 Operator 클러스터에 액세스할 수 있는 시스템에
clusterImageSets디렉터리를 복사합니다. 관리 클러스터에 적합한 다음 단계를 완료하여 관리 클러스터와 클러스터 이미지 세트와 연결이 끊긴 리포지토리 간의 매핑을 추가합니다.
-
OpenShift Container Platform 관리형 클러스터의 경우
ImageContentSourcePolicy개체를 사용하여 매핑을 완료하는 방법에 대한 자세한 내용은 이미지 레지스트리 저장소 미러링 구성 을 참조하십시오. -
OpenShift Container Platform 클러스터가 아닌 관리형 클러스터의 경우
ManageClusterImageRegistry사용자 정의 리소스 정의를 사용하여 이미지 세트의 위치를 재정의합니다. 매핑에 대한 클러스터를 재정의하는 방법에 대한 정보는 가져오기에서 관리 클러스터에서 레지스트리 이미지 지정을 참조하십시오.
-
OpenShift Container Platform 관리형 클러스터의 경우
-
콘솔 또는 CLI를 사용하여
clusterImageSetYAML 콘텐츠를 수동으로 추가하여 클러스터를 생성할 때 사용할 수 있는 이미지의 YAML 파일을 추가합니다. 이미지를 저장하는 올바른 오프라인 리포지토리를 참조하도록 나머지 OpenShift Container Platform 릴리스 이미지의
clusterImageSetYAML 파일을 수정합니다. 업데이트는spec.releaseImage에서 릴리스 이미지의 오프라인 이미지 레지스트리를 사용하고 다이제스트에서 릴리스 이미지를 참조하는 다음 예와 유사합니다.apiVersion: hive.openshift.io/v1 kind: ClusterImageSet metadata: labels: channel: fast name: img<4.x.x>-x86-64-appsub spec: releaseImage: IMAGE_REGISTRY_IPADDRESS_or__DNSNAME/REPO_PATH/ocp-release@sha256:073a4e46289be25e2a05f5264c8f1d697410db66b960c9ceeddebd1c61e58717- 이미지가 YAML 파일에서 참조되는 오프라인 이미지 레지스트리에 로드되었는지 확인합니다.
다음 명령을 실행하여 이미지 다이제스트를 가져옵니다.
oc adm release info <tagged_openshift_release_image> | grep "Pull From"&
lt;tagged_openshift_release_image>를 지원되는 OpenShift Container Platform 버전에 대한 태그된 이미지로 바꿉니다. 다음 예제 출력을 참조하십시오.Pull From: quay.io/openshift-release-dev/ocp-release@sha256:69d1292f64a2b67227c5592c1a7d499c7d00376e498634ff8e1946bc9ccdddfe이미지 태그 및 다이제스트에 대한 자세한 내용은 이미지 스트림의 이미지 참조를 참조하십시오.
각 YAML 파일에 다음 명령을 입력하여 각
clusterImageSets를 생성합니다.oc create -f <clusterImageSet_FILE>clusterImageSet_FILE을 클러스터 이미지 세트 파일의 이름으로 교체합니다. 예를 들면 다음과 같습니다.oc create -f img4.11.9-x86_64.yaml추가할 각 리소스에 대해 이 명령을 실행하면 사용 가능한 릴리스 이미지 목록을 사용할 수 있습니다.
-
또는 클러스터 콘솔 생성에 이미지 URL을 직접 붙여넣을 수 있습니다. 이미지 URL을 추가하면 새
clusterImageSets가 없는 경우 생성됩니다. - 클러스터를 생성할 때 콘솔에서 현재 사용 가능한 릴리스 이미지 목록을 확인합니다.
1.5.3. 호스트 인벤토리 소개
호스트 인벤토리 관리 및 온-프레미스 클러스터 설치는 다중 클러스터 엔진 Operator 중앙 인프라 관리 기능을 사용하여 사용할 수 있습니다. 중앙 인프라 관리는 허브 클러스터에서 Operator로 지원 설치 관리자 (인프라 운영자라고도 함)를 실행합니다.
콘솔을 사용하여 온프레미스 OpenShift Container Platform 클러스터를 생성하는 데 사용할 수 있는 베어 메탈 또는 가상 머신 풀인 호스트 인벤토리를 생성할 수 있습니다. 이러한 클러스터는 컨트롤 플레인 전용 머신 또는 컨트롤 플레인의 전용 머신이 있는 독립 실행형 클러스터일 수 있습니다. 여기서 컨트롤 플레인은 허브 클러스터에서 Pod로 실행됩니다. ../../html-single/clusters#hosted-control-planes-intro
ZTP(ZTP)를 사용하여 콘솔, API 또는 GitOps를 사용하여 독립 실행형 클러스터를 설치할 수 있습니다. ZTP에 대한 자세한 내용은 Red Hat OpenShift Container Platform 설명서의 연결이 끊긴 환경에 GitOps ZTP 설치를 참조하십시오.
시스템은 Discovery Image로 부팅한 후 호스트 인벤토리를 결합합니다. Discovery Image는 다음이 포함된 Red Hat CoreOS 라이브 이미지입니다.
- 검색, 검증 및 설치 작업을 수행하는 에이전트입니다.
- 해당하는 경우 엔드포인트, 토큰, 정적 네트워크 구성을 포함하여 허브 클러스터에서 서비스에 연결하는 데 필요한 구성입니다.
일반적으로 공통 속성 세트를 공유하는 호스트 세트인 각 인프라 환경에 대해 단일 검색 이미지가 있습니다. InfraEnv 사용자 정의 리소스 정의는 이 인프라 환경 및 관련 Discovery Image를 나타냅니다. 사용되는 이미지는 선택한 운영 체제 버전을 결정하는 OpenShift Container Platform 버전을 기반으로 합니다.
호스트가 부팅되고 에이전트가 서비스에 연결되면 서비스는 해당 호스트를 나타내는 허브 클러스터에 새 Agent 사용자 정의 리소스를 생성합니다. 에이전트 리소스는 호스트 인벤토리를 구성합니다.
나중에 OpenShift 노드로 인벤토리에 호스트를 설치할 수 있습니다. 에이전트는 필요한 구성과 함께 운영 체제를 디스크에 쓰고 호스트를 재부팅합니다.
참고: Red Hat Advanced Cluster Management 2.9 이상 및 중앙 인프라 관리는 Nutanix 가상 머신을 생성하여 추가 구성이 필요한 AgentClusterInstall 을 사용하여 Nutanix 플랫폼을 지원합니다. 자세한 내용은 지원 설치 관리자 설명서의 선택적: Nutanix에 설치를 참조하십시오.
호스트 인벤토리 및 중앙 인프라 관리에 대해 자세히 알아보려면 계속 읽으십시오.
1.5.3.1. 중앙 인프라 관리 서비스 활성화
중앙 인프라 관리 서비스는 다중 클러스터 엔진 Operator와 함께 제공되며 OpenShift Container Platform 클러스터를 배포합니다. 허브 클러스터에서 MultiClusterHub Operator를 활성화하면 중앙 인프라 관리는 자동으로 배포되지만 서비스를 수동으로 활성화해야 합니다.
1.5.3.1.1. 사전 요구 사항
중앙 인프라 관리 서비스를 활성화하기 전에 다음 사전 요구 사항을 참조하십시오.
- 지원되는 Red Hat Advanced Cluster Management for Kubernetes 버전이 있는 OpenShift Container Platform 4.13 이상에 배포된 허브 클러스터가 있어야 합니다.
- 허브 클러스터(연결됨)에 대한 인터넷 액세스 또는 환경 생성에 필요한 이미지를 검색하기 위해 인터넷에 연결되어 있는 내부 또는 미러 레지스트리에 대한 연결이 필요합니다.
- 베어 메탈 프로비저닝에 필요한 포트를 열어야 합니다. OpenShift Container Platform 설명서에서 필요한 포트 활성화를 참조하십시오.
- 베어 메탈 호스트 사용자 정의 리소스 정의가 필요합니다.
- OpenShift Container Platform 풀 시크릿 이 필요합니다. 자세한 내용은 이미지 풀 시크릿 사용을 참조하십시오.
- 구성된 기본 스토리지 클래스가 필요합니다.
- 연결이 끊긴 환경의 경우 OpenShift Container Platform 설명서에서 네트워크 맨 엣지에서 클러스터에 대한 절차를 완료합니다.
1.5.3.1.2. 베어 메탈 호스트 사용자 정의 리소스 정의 생성
중앙 인프라 관리 서비스를 활성화하기 전에 베어 메탈 호스트 사용자 정의 리소스 정의가 필요합니다.
다음 명령을 실행하여 베어 메탈 호스트 사용자 정의 리소스 정의가 있는지 확인합니다.
oc get crd baremetalhosts.metal3.io- 베어 메탈 호스트 사용자 정의 리소스 정의가 있는 경우 출력에 리소스가 생성된 날짜가 표시됩니다.
리소스가 없는 경우 다음과 유사한 오류가 표시됩니다.
Error from server (NotFound): customresourcedefinitions.apiextensions.k8s.io "baremetalhosts.metal3.io" not found
베어 메탈 호스트 사용자 정의 리소스 정의가 없는 경우 metal3.io_baremetalhosts.yaml 파일을 다운로드하고 다음 명령을 실행하여 리소스를 생성하여 콘텐츠를 적용합니다.
oc apply -f
1.5.3.1.3. 프로비저닝 리소스 생성 또는 수정
중앙 인프라 관리 서비스를 활성화하려면 프로비저닝 리소스가 필요합니다.
다음 명령을 실행하여
프로비저닝리소스가 있는지 확인합니다.oc get provisioning-
프로비저닝 리소스가 이미 있는 경우
프로비저닝리소스 를 계속 수정합니다. -
프로비저닝리소스가 없는 경우 리소스를 찾을 수 없음오류가 표시됩니다.프로비저닝리소스 생성을 계속합니다.
-
프로비저닝 리소스가 이미 있는 경우
1.5.3.1.3.1. 프로비저닝 리소스 수정
프로비저닝 리소스가 이미 있는 경우 hub 클러스터가 다음 플랫폼 중 하나에 설치된 경우 리소스를 수정해야 합니다.
- 베어 메탈
- Red Hat OpenStack Platform
- VMware vSphere
-
사용자 프로비저닝 인프라(UPI) 방법 및 플랫폼은
None입니다.
허브 클러스터가 다른 플랫폼에 설치된 경우 연결이 끊긴 환경에서 중앙 인프라 관리 활성화 또는 연결된 환경에서 중앙 인프라 관리 활성화에서 계속 진행하십시오.
다음 명령을 실행하여 Bare Metal Operator가 모든 네임스페이스를 조사할 수 있도록
프로비저닝리소스를 수정합니다.oc patch provisioning provisioning-configuration --type merge -p '{"spec":{"watchAllNamespaces": true }}'
1.5.3.1.3.2. 프로비저닝 리소스 생성
프로비저닝 리소스가 없는 경우 다음 단계를 완료합니다.
다음 YAML 콘텐츠를 추가하여
프로비저닝리소스를 생성합니다.apiVersion: metal3.io/v1alpha1 kind: Provisioning metadata: name: provisioning-configuration spec: provisioningNetwork: "Disabled" watchAllNamespaces: true다음 명령을 실행하여 콘텐츠를 적용합니다.
oc apply -f
1.5.3.1.4. 연결이 끊긴 환경에서 중앙 인프라 관리 활성화
연결이 끊긴 환경에서 중앙 인프라 관리를 활성화하려면 다음 단계를 완료합니다.
인프라 Operator와 동일한 네임스페이스에
ConfigMap을 생성하여 미러 레지스트리의ca-bundle.crt및registries.conf값을 지정합니다. 파일ConfigMap은 다음 예와 유사할 수 있습니다.apiVersion: v1 kind: ConfigMap metadata: name: <mirror-config> namespace: multicluster-engine labels: app: assisted-service data: ca-bundle.crt: | <certificate-content> registries.conf: | unqualified-search-registries = ["registry.access.redhat.com", "docker.io"] [[registry]] prefix = "" location = "registry.redhat.io/multicluster-engine" mirror-by-digest-only = true [[registry.mirror]] location = "mirror.registry.com:5000/multicluster-engine"참고: 다이제스트를 사용하여 릴리스 이미지가 지정되므로
mirror-by-digest-only를true로 설정해야 합니다.unqualified-search-registries목록의 레지스트리는PUBLIC_CONTAINER_REGISTRIES환경 변수의 인증 무시 목록에 자동으로 추가됩니다. 관리 클러스터의 풀 시크릿을 검증할 때 지정된 레지스트리는 인증이 필요하지 않습니다.-
모든
osImage요청과 함께 보낼 헤더 및 쿼리 매개변수를 나타내는 키 쌍을 작성합니다. 두 매개변수가 모두 필요하지 않은 경우 헤더 또는 쿼리 매개변수에만 대한 키 쌍을 작성합니다.
중요: 헤더 및 쿼리 매개변수는 HTTPS를 사용하는 경우에만 암호화됩니다. 보안 문제를 방지하려면 HTTPS를 사용해야 합니다.
headers라는 파일을 생성하고 다음 예제와 유사한 콘텐츠를 추가합니다.{ "Authorization": "Basic xyz" }query_params라는 파일을 생성하고 다음 예와 유사한 콘텐츠를 추가합니다.{ "api_key": "myexampleapikey", }다음 명령을 실행하여 생성한 매개변수 파일에서 시크릿을 생성합니다. 하나의 매개변수 파일만 생성한 경우 생성하지 않은 파일의 인수를 제거합니다.
oc create secret generic -n multicluster-engine os-images-http-auth --from-file=./query_params --from-file=./headers자체 서명 또는 타사 CA 인증서와 함께 HTTPS
osImages를 사용하려면image-service-additional-caConfigMap에 인증서를 추가합니다. 인증서를 생성하려면 다음 명령을 실행합니다.oc -n multicluster-engine create configmap image-service-additional-ca --from-file=tls.crtagent_service_config.yaml파일에 다음 YAML 콘텐츠를 저장하여AgentServiceConfig사용자 지정 리소스를 생성합니다.apiVersion: agent-install.openshift.io/v1beta1 kind: AgentServiceConfig metadata: name: agent spec: databaseStorage: accessModes: - ReadWriteOnce resources: requests: storage: <db_volume_size> filesystemStorage: accessModes: - ReadWriteOnce resources: requests: storage: <fs_volume_size> mirrorRegistryRef: name: <mirror_config>1 unauthenticatedRegistries: - <unauthenticated_registry>2 imageStorage: accessModes: - ReadWriteOnce resources: requests: storage: <img_volume_size>3 OSImageAdditionalParamsRef: name: os-images-http-auth OSImageCACertRef: name: image-service-additional-ca osImages: - openshiftVersion: "<ocp_version>"4 version: "<ocp_release_version>"5 url: "<iso_url>"6 cpuArchitecture: "x86_64"- 1 1
mirror_config를 미러 레지스트리 구성 세부 정보가 포함된ConfigMap의 이름으로 교체합니다.- 2
- 인증이 필요하지 않은 미러 레지스트리를 사용하는 경우 선택적
unauthenticated_registry매개변수를 포함합니다. 이 목록의 항목은 검증되지 않았거나 풀 시크릿에 항목이 있어야 합니다. - 3
img_volume_size를imageStorage필드의 볼륨 크기로 바꿉니다(예: 운영 체제 이미지당10Gi). 최소 값은10Gi이지만 권장 값은 최소50Gi입니다. 이 값은 클러스터 이미지에 할당된 스토리지 양을 지정합니다. 실행 중인 Red Hat Enterprise Linux CoreOS의 각 인스턴스에 대해 1GB의 이미지 스토리지를 허용해야 합니다. Red Hat Enterprise Linux CoreOS 클러스터 및 인스턴스가 많은 경우 더 높은 값을 사용해야 할 수 있습니다.- 4
ocp_version을 설치할 OpenShift Container Platform 버전으로 교체합니다(예:4.13).- 5
ocp_release_version을 특정 설치 버전 (예:49.83.202103251640-0)으로 바꿉니다.- 6
iso_url을 ISO URL로 바꿉니다(예:https://mirror.openshift.com/pub/openshift-v4/x86_64/dependencies/rhcos/4.13/4.13.3/rhcos-4.13.3-x86_64-live.x86_64.iso). 다른 값은 4.12.3 종속 항목에서 찾을 수 있습니다.
자체 서명 또는 타사 CA 인증서가 있는 HTTPS osImages 를 사용하는 경우 OSImageCACertRef 사양의 인증서를 참조하십시오.
중요: AgentServiceConfig 사용자 정의 리소스의 spec.osImages 릴리스를 버전 4.13 이상인 경우 클러스터를 생성할 때 사용하는 OpenShift Container Platform 릴리스 이미지는 버전 4.13 이상이어야 합니다. 버전 4.13 이상용 Red Hat Enterprise Linux CoreOS 이미지는 버전 4.13 이전의 이미지와 호환되지 않습니다.
assisted-service 및 assisted-image-service 배포를 확인하고 Pod가 준비되어 실행 중인지 확인하여 중앙 인프라 관리 서비스가 정상인지 확인할 수 있습니다.
1.5.3.1.5. 연결된 환경에서 중앙 인프라 관리 활성화
연결된 환경에서 중앙 인프라 관리를 활성화하려면 agent_service_config.yaml 파일에 다음 YAML 콘텐츠를 저장하여 AgentServiceConfig 사용자 지정 리소스를 생성합니다.
apiVersion: agent-install.openshift.io/v1beta1
kind: AgentServiceConfig
metadata:
name: agent
spec:
databaseStorage:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: <db_volume_size>
filesystemStorage:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: <fs_volume_size>
imageStorage:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: <img_volume_size> - 1
db_volume_size를databaseStorage필드의 볼륨 크기(예:10Gi)로 바꿉니다. 이 값은 클러스터의 데이터베이스 테이블 및 데이터베이스 뷰와 같은 파일을 저장하기 위해 할당된 스토리지 양을 지정합니다. 필요한 최소 값은1Gi입니다. 클러스터가 여러 개인 경우 더 높은 값을 사용해야 할 수 있습니다.- 2
fs_volume_size를filesystemStorage필드의 볼륨 크기로 바꿉니다(예: 클러스터당200M, 지원되는 OpenShift Container Platform 버전당2-3Gi). 필요한 최소 값은1Gi이지만 권장 값은100Gi이상이어야 합니다. 이 값은 클러스터의 로그, 매니페스트 및kubeconfig파일을 저장하기 위해 할당된 스토리지 양을 지정합니다. 클러스터가 여러 개인 경우 더 높은 값을 사용해야 할 수 있습니다.- 3
img_volume_size를imageStorage필드의 볼륨 크기로 바꿉니다(예: 운영 체제 이미지당10Gi). 최소 값은10Gi이지만 권장 값은 최소50Gi입니다. 이 값은 클러스터 이미지에 할당된 스토리지 양을 지정합니다. 실행 중인 Red Hat Enterprise Linux CoreOS의 각 인스턴스에 대해 1GB의 이미지 스토리지를 허용해야 합니다. Red Hat Enterprise Linux CoreOS 클러스터 및 인스턴스가 많은 경우 더 높은 값을 사용해야 할 수 있습니다.
중앙 인프라 관리 서비스가 구성되어 있습니다. assisted-service 및 assisted-image-service 배포를 확인하고 Pod가 준비되고 실행 중인지 확인하여 정상 상태인지 확인할 수 있습니다.
1.5.3.1.6. 추가 리소스
- 제로 터치 프로비저닝에 대한 자세한 내용은 OpenShift Container Platform 설명서 의 네트워크 맨 위에 있는 클러스터를 참조하십시오.
- 이미지 풀 시크릿 사용을참조하십시오.
1.5.3.2. Amazon Web Services에서 중앙 인프라 관리 활성화
Amazon Web Services에서 Hub 클러스터를 실행하고 중앙 인프라 관리 서비스를 활성화하려면 중앙 인프라 관리 서비스를 활성화한 후 다음 단계를 완료합니다.
hub 클러스터에 로그인했는지 확인하고 다음 명령을 실행하여
assisted-image-service에 구성된 고유한 도메인을 찾습니다.oc get routes --all-namespaces | grep assisted-image-service도메인은 다음 예와 유사할 수 있습니다.
assisted-image-service-multicluster-engine.apps.<yourdomain>.comhub 클러스터에 로그인했는지 확인하고
NLBtype매개변수를 사용하여 고유한 도메인으로 새IngressController를 생성합니다. 다음 예제를 참조하십시오.apiVersion: operator.openshift.io/v1 kind: IngressController metadata: name: ingress-controller-with-nlb namespace: openshift-ingress-operator spec: domain: nlb-apps.<domain>.com routeSelector: matchLabels: router-type: nlb endpointPublishingStrategy: type: LoadBalancerService loadBalancer: scope: External providerParameters: type: AWS aws: type: NLB-
nlb-apps.<매개변수에 <domain>.com에서 <yourdomain>을 <yourdomain>으로 교체하여IngressController의 domainyourdomain>을 추가합니다. 다음 명령을 실행하여 새
IngressController를 적용합니다.oc apply -f ingresscontroller.yaml다음 단계를 완료하여 새
IngressController의spec.domain매개변수 값이 기존IngressController와 충돌하지 않는지 확인합니다.다음 명령을 실행하여 모든
IngressController를 나열합니다.oc get ingresscontroller -n openshift-ingress-operator방금 생성한
ingress-controller-with-nlb를 제외하고 각IngressController에서 다음 명령을 실행합니다.oc edit ingresscontroller <name> -n openshift-ingress-operatorspec.domain보고서가 없는 경우nlb-apps.<domain>.com을 제외한 클러스터에 노출된 모든 경로와 일치하는 기본 도메인을 추가합니다.spec.domain보고서가 제공된 경우nlb-apps.<domain>.com경로가 지정된 범위에서 제외되었는지 확인합니다.
다음 명령을 실행하여
nlb-apps위치를 사용하도록assisted-image-service경로를 편집합니다.oc edit route assisted-image-service -n <namespace>기본 네임스페이스는 다중 클러스터 엔진 Operator를 설치한 위치입니다.
assisted-image-service경로에 다음 행을 추가합니다.metadata: labels: router-type: nlb name: assisted-image-serviceassisted-image-service경로에서spec.host의 URL 값을 찾습니다. URL은 다음 예와 유사할 수 있습니다.assisted-image-service-multicluster-engine.apps.<yourdomain>.com-
새
IngressController에 구성된 도메인과 일치하도록 URL의 앱을nlb-로 교체합니다.apps Amazon Web Services에서 중앙 인프라 관리 서비스가 활성화되어 있는지 확인하려면 다음 명령을 실행하여 Pod가 정상 상태인지 확인합니다.
oc get pods -n multicluster-engine | grep assist-
새 호스트 인벤토리를 생성하고 다운로드 URL이 새
nlb-appsURL을 사용하는지 확인합니다.
1.5.3.3. 콘솔을 사용하여 호스트 인벤토리 생성
호스트 인벤토리(인프라 환경)를 생성하여 OpenShift Container Platform 클러스터를 설치할 수 있는 물리적 또는 가상 머신을 검색할 수 있습니다.
1.5.3.3.1. 사전 요구 사항
- 중앙 인프라 관리 서비스를 활성화해야 합니다. 자세한 내용은 중앙 인프라 관리 서비스 활성화를 참조하십시오.
1.5.3.3.2. 호스트 인벤토리 생성
콘솔을 사용하여 호스트 인벤토리를 생성하려면 다음 단계를 완료합니다.
- 콘솔에서 인프라 > 호스트 인벤토리 로 이동하여 인프라 환경 생성 을 클릭합니다.
호스트 인벤토리 설정에 다음 정보를 추가합니다.
-
이름: 인프라 환경의 고유 이름입니다. 콘솔을 사용하여 인프라 환경을 생성하면 선택한 이름으로
InfraEnv리소스의 새 네임스페이스도 생성됩니다. 명령줄 인터페이스를 사용하여InfraEnv리소스를 생성하고 콘솔에서 리소스를 모니터링하려면 네임스페이스와InfraEnv에 동일한 이름을 사용합니다. - 네트워크 유형: 인프라 환경에 추가하는 호스트가 DHCP 또는 정적 네트워킹을 사용하는지 여부를 지정합니다. 정적 네트워킹 구성에는 추가 단계가 필요합니다.
- Location: 호스트의 지리적 위치를 지정합니다. 지리적 위치는 호스트가 있는 데이터 센터를 정의하는 데 사용할 수 있습니다.
- labels: 이 인프라 환경에서 검색된 호스트에 레이블을 추가할 수 있는 선택적 필드입니다. 지정된 위치가 레이블 목록에 자동으로 추가됩니다.
- 인프라 공급자 인증 정보: 인프라 공급자 인증 정보를 선택하면 풀 시크릿 및 SSH 공개 키 필드가 인증 정보에 자동으로 채워집니다. 자세한 내용은 온-프레미스 환경에 대한 인증 정보 만들기 를 참조하십시오.
- 풀 시크릿: OpenShift Container Platform 리소스에 액세스할 수 있는 OpenShift Container Platform 풀 시크릿 입니다. 인프라 공급자 인증 정보를 선택한 경우 이 필드가 자동으로 채워집니다.
-
SSH 공개 키: 호스트와의 보안 통신을 활성화하는 SSH 키입니다. 문제 해결을 위해 호스트에 연결하는 데 사용할 수 있습니다. 클러스터를 설치한 후에는 더 이상 SSH 키를 사용하여 호스트에 연결할 수 없습니다. 키는 일반적으로
id_rsa.pub파일에 있습니다. 기본 파일 경로는~/.ssh/id_rsa.pub입니다. SSH 공개 키 값이 포함된 인프라 공급자 인증 정보를 선택한 경우 이 필드가 자동으로 채워집니다. 호스트에 프록시 설정을 활성화하려면 활성화할 설정을 선택하고 다음 정보를 입력합니다.
- HTTP 프록시 URL: HTTP 요청에 대한 프록시의 URL입니다.
- HTTPS 프록시 URL: HTTP 요청에 대한 프록시의 URL입니다. URL은 HTTP로 시작해야 합니다. HTTPS는 지원되지 않습니다. 값을 지정하지 않으면 HTTP 프록시 URL이 기본적으로 HTTP 및 HTTPS 연결에 사용됩니다.
-
프록시 도메인 없음: 프록시를 사용하지 않으려는 쉼표로 구분된 도메인 목록입니다. 마침표(
.)로 도메인 이름을 시작하여 해당 도메인에 있는 모든 하위 도메인을 포함합니다. 모든 대상에 대해 프록시를 바이패스하려면 별표(*)를 추가합니다.
- 선택적으로 NTP 풀 또는 서버의 쉼표로 구분된 IP 또는 도메인 이름 목록을 제공하여 고유한 NTP(Network Time Protocol) 소스를 추가합니다.
-
이름: 인프라 환경의 고유 이름입니다. 콘솔을 사용하여 인프라 환경을 생성하면 선택한 이름으로
콘솔에서 사용할 수 없는 고급 구성 옵션이 필요한 경우 명령줄 인터페이스를 사용하여 호스트 인벤토리 생성을 계속합니다.
고급 구성 옵션이 필요하지 않은 경우 정적 네트워킹을 구성하여 계속해서 인프라 환경에 호스트를 추가할 수 있습니다.
1.5.3.3.3. 호스트 인벤토리에 액세스
호스트 인벤토리에 액세스하려면 콘솔에서 인프라 > 호스트 인벤토리 를 선택합니다. 목록에서 인프라 환경을 선택하여 세부 정보 및 호스트를 확인합니다.
1.5.3.3.4. 추가 리소스
- 중앙 인프라 관리 서비스 활성화를참조하십시오.
- 온-프레미스 환경에 대한 인증 정보 생성을 참조하십시오.
- 명령줄 인터페이스를 사용하여 호스트 인벤토리 생성을참조하십시오.
베어 메탈에서 호스팅된 컨트롤 플레인을 구성하는 프로세스의 일부로 이 절차를 완료한 경우 다음 절차를 완료하는 것입니다.
1.5.3.4. 명령줄 인터페이스를 사용하여 호스트 인벤토리 생성
호스트 인벤토리(인프라 환경)를 생성하여 OpenShift Container Platform 클러스터를 설치할 수 있는 물리적 또는 가상 머신을 검색할 수 있습니다. 자동화된 배포 또는 다음 고급 구성 옵션에는 콘솔 대신 명령줄 인터페이스를 사용합니다.
- 검색된 호스트를 기존 클러스터 정의에 자동으로 바인딩
- Discovery Image의 ignition 구성 덮어쓰기
- iPXE 동작 제어
- Discovery Image의 커널 인수 수정
- 검색 단계에서 호스트가 신뢰할 수 있는 추가 인증서 전달
- 최신 버전의 기본 옵션이 아닌 테스트를 위해 부팅할 Red Hat CoreOS 버전을 선택합니다.
1.5.3.4.1. 사전 요구 사항
- 중앙 인프라 관리 서비스를 활성화해야 합니다. 자세한 내용은 중앙 인프라 관리 서비스 활성화를 참조하십시오.
1.5.3.4.2. 호스트 인벤토리 생성
명령줄 인터페이스를 사용하여 호스트 인벤토리(인프라 환경)를 생성하려면 다음 단계를 완료합니다.
다음 명령을 실행하여 허브 클러스터에 로그인합니다.
oc login리소스의 네임스페이스를 생성합니다.
namespace.yaml파일을 생성하고 다음 콘텐츠를 추가합니다.apiVersion: v1 kind: Namespace metadata: name: <your_namespace>1 - 1
- 네임스페이스에서 동일한 이름을 사용하여 콘솔에서 인벤토리를 모니터링합니다.
다음 명령을 실행하여 YAML 콘텐츠를 적용합니다.
oc apply -f namespace.yaml
OpenShift Container Platform 풀 보안이 포함된
Secret사용자 정의 리소스를 생성합니다.pull-secret.yaml파일을 생성하고 다음 콘텐츠를 추가합니다.apiVersion: v1 kind: Secret type: kubernetes.io/dockerconfigjson metadata: name: pull-secret1 namespace: <your_namespace> stringData: .dockerconfigjson: <your_pull_secret>2 다음 명령을 실행하여 YAML 콘텐츠를 적용합니다.
oc apply -f pull-secret.yaml
인프라 환경을 생성합니다.
infra-env.yaml파일을 생성하고 다음 콘텐츠를 추가합니다. 필요한 경우 값을 바꿉니다.apiVersion: agent-install.openshift.io/v1beta1 kind: InfraEnv metadata: name: myinfraenv namespace: <your_namespace> spec: proxy: httpProxy: <http://user:password@ipaddr:port> httpsProxy: <http://user:password@ipaddr:port> noProxy: additionalNTPSources: sshAuthorizedKey: pullSecretRef: name: <name> agentLabels: <key>: <value> nmStateConfigLabelSelector: matchLabels: <key>: <value> clusterRef: name: <cluster_name> namespace: <project_name> ignitionConfigOverride: '{"ignition": {"version": "3.1.0"}, …}' cpuArchitecture: x86_64 ipxeScriptType: DiscoveryImageAlways kernelArguments: - operation: append value: audit=0 additionalTrustBundle: <bundle> osImageVersion: <version>
| 필드 | 선택 사항 또는 필수 | 설명 |
|---|---|---|
|
| 선택 사항 |
|
|
| 선택 사항 |
HTTP 요청에 대한 프록시의 URL입니다. URL은 |
|
| 선택 사항 |
HTTP 요청에 대한 프록시의 URL입니다. URL은 |
|
| 선택 사항 | 프록시를 사용하지 않으려는 쉼표로 구분된 도메인 및 CIDR 목록입니다. |
|
| 선택 사항 | 모든 호스트에 추가할 NTP(Network Time Protocol) 소스(hostname 또는 IP) 목록입니다. DHCP와 같은 다른 옵션을 사용하여 구성된 NTP 소스에 추가됩니다. |
|
| 선택 사항 | 검색 단계에서 디버깅에 사용할 수 있도록 모든 호스트에 추가된 SSH 공개 키입니다. 검색 단계는 호스트가 검색 이미지를 부팅하는 단계입니다. |
|
| 필수 항목 | 풀 보안이 포함된 Kubernetes 시크릿의 이름입니다. |
|
| 선택 사항 |
|
|
| 선택 사항 |
호스트의 고정 IP, 브리지 및 본딩과 같은 고급 네트워크 구성을 통합합니다. 호스트 네트워크 구성은 선택한 라벨을 사용하여 하나 이상의 |
|
| 선택 사항 |
독립 실행형 온-프레미스 클러스터를 설명하는 기존 |
|
| 선택 사항 |
Red Hat CoreOS 라이브 이미지의 ignition 구성(예: 파일 추가)을 수정합니다. 필요한 경우에만 |
|
| 선택 사항 | 지원되는 CPU 아키텍처(x86_64, aarch64, ppc64le 또는 s390x) 중 하나를 선택합니다. 기본값은 x86_64입니다. |
|
| 선택 사항 |
|
|
| 선택 사항 |
Discovery Image가 부팅될 때 에 대한 커널 인수를 수정할 수 있습니다. |
|
| 선택 사항 |
PEM 인코딩 X.509 인증서 번들, 일반적으로 호스트가 다시 암호화하는 MITTM(man-in-the-middle) 프록시가 있는 네트워크에 있거나 호스트가 컨테이너 이미지 레지스트리와 같은 다른 목적으로 인증서를 신뢰해야 하는 경우 필요합니다. |
|
| 선택 사항 |
|
다음 명령을 실행하여 YAML 콘텐츠를 적용합니다.
oc apply -f infra-env.yaml호스트 인벤토리가 생성되었는지 확인하려면 다음 명령을 사용하여 상태를 확인합니다.
oc describe infraenv myinfraenv -n <your_namespace>
다음 주요 속성 목록을 참조하십시오.
-
conditions: 이미지가 성공적으로 생성되었는지를 나타내는 표준 Kubernetes 상태입니다. -
isoDownloadURL: Discovery Image를 다운로드할 URL입니다. -
createdTime: 이미지가 마지막으로 생성된 시간입니다.InfraEnv를 수정하는 경우 새 이미지를 다운로드하기 전에 타임스탬프가 업데이트되었는지 확인합니다.
참고: InfraEnv 리소스를 수정하는 경우, createdTime 속성을 확인하여 InfraEnv 에서 새 Discovery Image를 생성했는지 확인합니다. 이미 호스트를 부팅한 경우 최신 Discovery Image를 사용하여 다시 부팅합니다.
필요한 경우 정적 네트워킹을 구성하고 인프라 환경에 호스트를 추가할 수 있습니다.
1.5.3.4.3. 추가 리소스
- 중앙 인프라 관리 서비스 활성화를 참조하십시오.
1.5.3.5. 인프라 환경에 대한 고급 네트워킹 구성
단일 인터페이스에서 DHCP 이외의 네트워킹이 필요한 호스트의 경우 고급 네트워킹을 구성해야 합니다. 필수 구성에는 하나 이상의 호스트에 대한 네트워킹을 설명하는 NMStateConfig 리소스의 인스턴스 생성이 포함됩니다.
각 NMStateConfig 리소스에는 InfraEnv 리소스의 nmStateConfigLabelSelector 와 일치하는 레이블이 포함되어야 합니다. nmStateConfigLabelSelector 에 대한 자세한 내용은 명령줄 인터페이스를 사용하여 호스트 인벤토리 생성 을 참조하십시오.
Discovery Image에는 참조된 모든 NMStateConfig 리소스에 정의된 네트워크 구성이 포함되어 있습니다. 부팅 후 각 호스트는 각 구성을 네트워크 인터페이스와 비교하고 적절한 구성을 적용합니다.
1.5.3.5.1. 사전 요구 사항
- 중앙 인프라 관리 서비스를 활성화해야 합니다.
- 호스트 인벤토리를 생성해야 합니다.
1.5.3.5.2. 명령줄 인터페이스를 사용하여 고급 네트워킹 구성
명령줄 인터페이스를 사용하여 인프라 환경에 대한 고급 네트워킹을 구성하려면 다음 단계를 완료합니다.
nmstateconfig.yaml이라는 파일을 생성하고 다음 템플릿과 유사한 콘텐츠를 추가합니다. 필요한 경우 값을 바꿉니다.apiVersion: agent-install.openshift.io/v1beta1 kind: NMStateConfig metadata: name: mynmstateconfig namespace: <your-infraenv-namespace> labels: some-key: <some-value> spec: config: interfaces: - name: eth0 type: ethernet state: up mac-address: 02:00:00:80:12:14 ipv4: enabled: true address: - ip: 192.168.111.30 prefix-length: 24 dhcp: false - name: eth1 type: ethernet state: up mac-address: 02:00:00:80:12:15 ipv4: enabled: true address: - ip: 192.168.140.30 prefix-length: 24 dhcp: false dns-resolver: config: server: - 192.168.126.1 routes: config: - destination: 0.0.0.0/0 next-hop-address: 192.168.111.1 next-hop-interface: eth1 table-id: 254 - destination: 0.0.0.0/0 next-hop-address: 192.168.140.1 next-hop-interface: eth1 table-id: 254 interfaces: - name: "eth0" macAddress: "02:00:00:80:12:14" - name: "eth1" macAddress: "02:00:00:80:12:15"
| 필드 | 선택 사항 또는 필수 | 설명 |
|---|---|---|
|
| 필수 항목 | 구성 중인 호스트 또는 호스트와 관련된 이름을 사용합니다. |
|
| 필수 항목 |
네임스페이스는 |
|
| 필수 항목 |
|
|
| 선택 사항 |
|
|
| 선택 사항 |
지정된 |
참고: 이미지 서비스는 InfraEnv 속성을 업데이트하거나 레이블 선택기와 일치하는 NMStateConfig 리소스를 변경할 때 새 이미지를 자동으로 생성합니다. 리소스를 생성한 후 InfraEnv NMStateConfig 리소스를 추가하는 경우 InfraEnv에서 InfraEnv 에서 createdTime 속성을 확인하여 새 Discovery Image를 생성해야 합니다. 이미 호스트를 부팅한 경우 최신 Discovery Image를 사용하여 다시 부팅합니다.
다음 명령을 실행하여 YAML 콘텐츠를 적용합니다.
oc apply -f nmstateconfig.yaml
1.5.3.5.3. 추가 리소스
- 명령줄 인터페이스를 사용하여 호스트 인벤토리 생성을참조하십시오.
- 선언 네트워크 API참조
1.5.3.6. Discovery Image를 사용하여 호스트 인벤토리에 호스트 추가
호스트 인벤토리(인프라 환경)를 생성한 후 호스트를 검색하여 인벤토리에 추가할 수 있습니다. 인벤토리에 호스트를 추가하려면 ISO를 다운로드하여 각 서버에 연결할 방법을 선택합니다. 예를 들어 가상 미디어를 사용하거나 USB 드라이브에 ISO를 작성하여 ISO를 다운로드할 수 있습니다.
중요: 설치에 실패하지 않도록 설치 프로세스 중에 장치에 Discovery ISO 미디어를 계속 연결하고 각 호스트를 한 번에 부팅하도록 설정합니다.
1.5.3.6.1. 사전 요구 사항
- 중앙 인프라 관리 서비스를 활성화해야 합니다. 자세한 내용은 중앙 인프라 관리 서비스 활성화를 참조하십시오.
- 호스트 인벤토리를 생성해야 합니다. 자세한 내용은 콘솔을 사용하여 호스트 인벤토리 생성 을 참조하십시오.
1.5.3.6.2. 콘솔을 사용하여 호스트 추가
다음 단계를 완료하여 ISO를 다운로드합니다.
- 콘솔에서 Infrastructure > Host inventory 를 선택합니다.
- 목록에서 인프라 환경을 선택합니다.
- 호스트 추가를 클릭하고 Discovery ISO 사용을 선택합니다.
이제 ISO를 다운로드할 URL이 표시됩니다. 부팅된 호스트가 호스트 인벤토리 테이블에 나타납니다. 호스트가 표시되는 데 몇 분이 걸릴 수 있습니다. 각 호스트를 사용하려면 먼저 승인해야 합니다. 작업을 클릭하고 승인을 선택하여 인벤토리 테이블에서 호스트를 선택할 수 있습니다.
1.5.3.6.3. 명령줄 인터페이스를 사용하여 호스트 추가
InfraEnv 리소스의 상태에서 isoDownloadURL 속성에서 ISO를 다운로드하는 URL을 볼 수 있습니다. InfraEnv 리소스에 대한 자세한 내용은 명령줄 인터페이스를 사용하여 호스트 인벤토리 생성을 참조하십시오.
부팅된 각 호스트는 동일한 네임스페이스에 에이전트 리소스를 생성합니다. 각 호스트를 사용하려면 먼저 승인해야 합니다.
1.5.3.6.4. 추가 리소스
- 중앙 인프라 관리 서비스 활성화를참조하십시오.
- 콘솔을 사용하여 호스트 인벤토리 생성을참조하십시오.
- 명령줄 인터페이스를 사용하여 호스트 인벤토리 생성을참조하십시오.
1.5.3.7. 호스트 인벤토리에 베어 메탈 호스트 자동 추가
호스트 인벤토리(인프라 환경)를 생성한 후 호스트를 검색하여 인벤토리에 추가할 수 있습니다. 베어 메탈 Operator가 각 베어 메탈 호스트의 BMC(Baseboard Management Controller)와 각 호스트에 대해 BareMetalHost 리소스 및 관련 BMC 시크릿을 생성하여 인프라 환경의 검색 이미지 부팅을 자동화할 수 있습니다. 자동화는 인프라 환경을 참조하는 BareMetalHost 의 레이블로 설정됩니다.
자동화는 다음 작업을 수행합니다.
- 인프라 환경에서 표시하는 Discovery Image를 사용하여 각 베어 메탈 호스트 부팅
- 인프라 환경 또는 관련 네트워크 구성이 업데이트되는 경우 각 호스트를 최신 검색 이미지로 재부팅
-
검색 시 각
에이전트리소스를 해당BareMetalHost리소스와 연결합니다. -
호스트 이름, 역할 및 설치 디스크와 같은
BareMetalHost의 정보를 기반으로에이전트리소스 속성 업데이트 -
클러스터 노드로 사용할
에이전트승인
1.5.3.7.1. 사전 요구 사항
- 중앙 인프라 관리 서비스를 활성화해야 합니다.
- 호스트 인벤토리를 생성해야 합니다.
1.5.3.7.2. 콘솔을 사용하여 베어 메탈 호스트 추가
콘솔을 사용하여 호스트 인벤토리에 베어 메탈 호스트를 자동으로 추가하려면 다음 단계를 완료합니다.
- 콘솔에서 Infrastructure > Host inventory 를 선택합니다.
- 목록에서 인프라 환경을 선택합니다.
- 호스트 추가를 클릭하고 BMC 양식으로 를 선택합니다.
- 필요한 정보를 추가하고 생성 을 클릭합니다.
BMC 주소 지정에 대한 자세한 내용은 추가 리소스 섹션의 BMC 주소 지정을 참조하십시오.
1.5.3.7.3. 명령줄 인터페이스를 사용하여 베어 메탈 호스트 추가
명령줄 인터페이스를 사용하여 호스트 인벤토리에 베어 메탈 호스트를 자동으로 추가하려면 다음 단계를 완료합니다.
다음 YAML 콘텐츠를 적용하고 필요한 경우 값을 교체하여 BMC 시크릿을 생성합니다.
apiVersion: v1 kind: Secret metadata: name: <bmc-secret-name> namespace: <your_infraenv_namespace>1 type: Opaque data: username: <username> password: <password>- 1
- 네임스페이스는
InfraEnv의 네임스페이스와 동일해야 합니다.
다음 YAML 콘텐츠를 적용하고 필요한 경우 값을 교체하여 베어 메탈 호스트를 생성합니다.
apiVersion: metal3.io/v1alpha1 kind: BareMetalHost metadata: name: <bmh-name> namespace: <your-infraenv-namespace>1 annotations: inspect.metal3.io: disabled bmac.agent-install.openshift.io/hostname: <hostname>2 bmac.agent-install.openshift.io/role: <role>3 labels: infraenvs.agent-install.openshift.io: <your-infraenv>4 spec: online: true automatedCleaningMode: disabled5 bootMACAddress: <your-mac-address>6 bmc: address: <machine-address>7 credentialsName: <bmc-secret-name>8 rootDeviceHints: deviceName: /dev/sda9 - 1
- 네임스페이스는
InfraEnv의 네임스페이스와 동일해야 합니다. - 2
- 선택 사항: 호스트 이름으로 바꿉니다.
- 3
- 선택 사항: 가능한 값은
master또는worker입니다. - 4
- 이름은
InfrEnv의 이름과 일치해야 하며 동일한 네임스페이스에 있어야 합니다. - 5
- 값을 설정하지 않으면
메타데이터값이 자동으로 사용됩니다. - 6
- MAC 주소가 호스트 인터페이스 중 하나의 MAC 주소와 일치하는지 확인합니다.
- 7
- BMC 주소를 사용합니다. 자세한 내용은 추가 리소스 섹션의 대역 외 관리 IP 주소에 대한 포트 액세스 및 BMC 주소 지정을 참조하십시오.
- 8
credentialsName값이 생성한 BMC 시크릿의 이름과 일치하는지 확인합니다.- 9
- 선택 사항: 설치 디스크를 선택합니다. 사용 가능한 루트 장치 팁은 BareMetalHost 사양 을 참조하십시오. 호스트를 검색 이미지로 부팅하고 해당
에이전트리소스가 생성되면 이 팁에 따라 설치 디스크가 설정됩니다.
호스트를 켜면 이미지가 다운로드되기 시작합니다. 이 작업은 몇 분 정도 걸릴 수 있습니다. 호스트가 검색되면 에이전트 사용자 지정 리소스가 자동으로 생성됩니다.
1.5.3.7.4. 통합 흐름 비활성화
통합 흐름은 기본적으로 활성화되어 있습니다. 호스트가 나타나지 않으면 통합 흐름을 일시적으로 비활성화해야 할 수 있습니다. 통합 흐름을 비활성화하려면 다음 단계를 완료합니다.
허브 클러스터에 다음 구성 맵을 생성합니다.
apiVersion: v1 kind: ConfigMap metadata: name: my-assisted-service-config namespace: multicluster-engine data: ALLOW_CONVERGED_FLOW: "false"참고:
ALLOW_CONVERGED_FLOW를"false"로 설정하면 Ironic Python 에이전트에서 활성화한 모든 기능도 비활성화합니다.다음 명령을 실행하여 구성 맵을 적용합니다.
oc annotate --overwrite AgentServiceConfig agent unsupported.agent-install.openshift.io/assisted-service-configmap=my-assisted-service-config
1.5.3.7.5. 명령줄 인터페이스를 사용하여 관리형 클러스터 노드 제거
관리형 클러스터에서 관리형 클러스터 노드를 제거하려면 OpenShift Container Platform 버전 4.13 이상을 실행 중인 허브 클러스터가 필요합니다. 노드를 부팅하는 데 필요한 정적 네트워킹 구성을 사용할 수 있어야 합니다. 에이전트 및 베어 메탈 호스트를 삭제할 때 NMStateConfig 리소스를 삭제하지 마십시오.
1.5.3.7.5.1. 베어 메탈 호스트를 사용하여 관리형 클러스터 노드 제거
허브 클러스터에 베어 메탈 호스트가 있고 관리 클러스터에서 관리 클러스터 노드를 제거하려면 다음 단계를 완료합니다.
삭제하려는 노드의
BareMetalHost리소스에 다음 주석을 추가합니다.bmac.agent-install.openshift.io/remove-agent-and-node-on-delete: true다음 명령을 실행하여
BareMetalHost리소스를 삭제합니다. <bmh-name>을BareMetalHost의 이름으로 바꿉니다.oc delete bmh <bmh-name>
1.5.3.7.5.2. 베어 메탈 호스트 없이 관리형 클러스터 노드 제거
hub 클러스터에 베어 메탈 호스트가 없고 관리 클러스터에서 관리 클러스터 노드를 제거하려면 OpenShift Container Platform 설명서의 노드 삭제 지침을 따르십시오.
1.5.3.7.6. 추가 리소스
- 제로 터치 프로비저닝에 대한 자세한 내용은 OpenShift Container Platform 설명서 의 네트워크 맨 위에 있는 클러스터를 참조하십시오.
- 베어 메탈 호스트 사용에 필요한 포트에 대한 자세한 내용은 OpenShift Container Platform 설명서 의 대역 외 관리 IP 주소에 대한 포트 액세스를 참조하십시오.
- 루트 장치 팁에 대한 자세한 내용은 OpenShift Container Platform 설명서 의 BareMetalHost 사양 을 참조하십시오.
- 이미지 풀 시크릿 사용을참조하십시오.
- 온-프레미스 환경에 대한 인증 정보 생성을 참조하십시오.
- 컴퓨팅 머신 스케일링에 대한 자세한 내용은 OpenShift Container Platform 설명서에서 컴퓨팅 머신 세트 수동 스케일링을 참조하십시오.
- 통합 흐름에 대한 자세한 내용은 배포 후 보류 중 상태의 관리형 클러스터를 참조하십시오.
- BMC 형식 주소 지정에 대한 자세한 내용은 OpenShift Container Platform 설명서의 BMC 주소 지정을 참조하십시오.
1.5.3.8. 호스트 인벤토리 관리
콘솔을 사용하거나 명령줄 인터페이스를 사용하여 호스트 인벤토리를 관리하고 기존 호스트를 편집하고 Agent 리소스를 편집할 수 있습니다.
1.5.3.8.1. 콘솔을 사용하여 호스트 인벤토리 관리
Discovery ISO로 성공적으로 부팅한 각 호스트는 호스트 인벤토리에 행으로 표시됩니다. 콘솔을 사용하여 호스트를 편집하고 관리할 수 있습니다. 호스트를 수동으로 부팅하고 베어 메탈 Operator 자동화를 사용하지 않는 경우 콘솔에서 호스트를 승인해야 사용할 수 있습니다. OpenShift 노드로 설치할 준비가 된 호스트의 상태는 Available 입니다.
1.5.3.8.2. 명령줄 인터페이스를 사용하여 호스트 인벤토리 관리
에이전트 리소스는 각 호스트를 나타냅니다. 에이전트 리소스에서 다음 속성을 설정할 수 있습니다.
clusterDeploymentName이 속성을 클러스터에 노드로 설치하려는 경우 사용할
ClusterDeployment의 네임스페이스 및 이름으로 설정합니다.선택 사항:
role클러스터에서 호스트의 역할을 설정합니다. 가능한 값은
master,worker,auto-assign입니다. 기본값은auto-assign입니다.hostname호스트의 호스트 이름을 설정합니다. 호스트에 유효한 호스트 이름이 자동으로 할당되는 경우(예: DHCP 사용) 선택 사항입니다.
승인됨호스트를 OpenShift 노드로 설치할 수 있는지 여부를 나타냅니다. 이 속성은 기본값이
False인 부울입니다. 호스트를 수동으로 부팅하고 베어 메탈 Operator 자동화를 사용하지 않는 경우 호스트를 설치하기 전에 이 속성을True로 설정해야 합니다.installation_disk_id선택한 설치 디스크의 ID가 호스트의 인벤토리에 표시됩니다.
installerArgs호스트의 coreos-installer 인수에 대한 덮어쓰기가 포함된 JSON 형식의 문자열입니다. 이 속성을 사용하여 커널 인수를 수정할 수 있습니다. 다음 예제 구문을 참조하십시오.
["--append-karg", "ip=192.0.2.2::192.0.2.254:255.255.255.0:core0.example.com:enp1s0:none", "--save-partindex", "4"]ignitionConfigOverrides호스트의 ignition 구성에 대한 덮어쓰기가 포함된 JSON 형식의 문자열입니다. 이 속성을 사용하여 ignition을 사용하여 호스트에 파일을 추가할 수 있습니다. 다음 예제 구문을 참조하십시오.
{"ignition": "version": "3.1.0"}, "storage": {"files": [{"path": "/tmp/example", "contents": {"source": "data:text/plain;base64,aGVscGltdHJhcHBlZGluYXN3YWdnZXJzcGVj"}}]}}nodeLabels호스트를 설치한 후 노드에 적용되는 라벨 목록입니다.
에이전트 리소스의 상태에 는 다음과 같은 속성이 있습니다.
role클러스터에서 호스트의 역할을 설정합니다. 이전에
Agent리소스에서역할을설정하면 값이상태에표시됩니다.인벤토리호스트에서 실행 중인 에이전트가 검색하는 호스트 속성을 포함합니다.
진행 상황호스트 설치 진행 중입니다.
ntpSources호스트의 구성된 NTP(Network Time Protocol) 소스입니다.
conditionsTrue또는False값과 함께 다음 표준 Kubernetes 조건을 포함합니다.-
SpecSynced: 지정된 모든 속성이 성공적으로 적용되면
True입니다.false오류가 발생하면 false입니다. -
connected: 설치 서비스에 대한 에이전트 연결이 중단되지 않으면
True입니다. 에이전트가 잠시 후에 설치 서비스에 도달하지 않은 경우false입니다. -
RequirementsMet: 호스트가 설치를 시작할 준비가 되면
True입니다. -
validated: 모든 호스트 검증이 통과하면
True입니다. -
installed: 호스트가 OpenShift 노드로 설치된 경우
True입니다. -
Bound: 호스트가 클러스터에 바인딩된 경우
True입니다. -
cleanup:
Agentresouce를 삭제하라는 요청이 실패하면False입니다.
-
SpecSynced: 지정된 모든 속성이 성공적으로 적용되면
debugInfo설치 로그 및 이벤트를 다운로드하기 위한 URL이 포함되어 있습니다.
validationsInfo설치에 성공했는지 확인하기 위해 호스트가 검색된 후 에이전트가 실행되는 검증에 대한 정보가 포함되어 있습니다. 값이
False인 경우 문제를 해결합니다.installation_disk_id선택한 설치 디스크의 ID가 호스트의 인벤토리에 표시됩니다.
1.5.3.8.3. 추가 리소스
- 호스트 인벤토리 액세스를참조하십시오.
- coreos-installer 설치참조
1.5.4. 클러스터 생성
다중 클러스터 엔진 Operator를 사용하여 클라우드 공급자 간에 Red Hat OpenShift Container Platform 클러스터를 생성하는 방법을 알아봅니다.
다중 클러스터 엔진 Operator는 OpenShift Container Platform과 함께 제공되는 Hive Operator를 사용하여 온프레미스 클러스터 및 호스팅 컨트롤 플레인을 제외한 모든 공급자의 클러스터를 프로비저닝합니다. 온프레미스 클러스터를 프로비저닝할 때 다중 클러스터 엔진 Operator는 OpenShift Container Platform과 함께 제공되는 중앙 인프라 관리 및 지원 설치 관리자 기능을 사용합니다. 호스팅된 컨트롤 플레인의 호스트 클러스터는 HyperShift Operator를 사용하여 프로비저닝됩니다.
- 클러스터 생성 중 추가 매니페스트 구성
- Amazon Web Services에서 클러스터 생성
- Amazon Web Services GovCloud에서 클러스터 생성
- Microsoft Azure에 클러스터 생성
- Google Cloud Platform에서 클러스터 생성
- VMware vSphere에서 클러스터 생성
- Red Hat OpenStack Platform에서 클러스터 생성
- Red Hat Virtualization에서 클러스터 생성 (더 이상 사용되지 않음)
- 온-프레미스 환경에서 클러스터 생성
- AgentClusterInstall 프록시 구성
- 호스팅된 컨트롤 플레인
1.5.4.1. CLI를 사용하여 클러스터 생성
Kubernetes Operator용 멀티 클러스터 엔진은 내부 Hive 구성 요소를 사용하여 Red Hat OpenShift Container Platform 클러스터를 생성합니다. 클러스터 생성 방법을 알아보려면 다음 정보를 참조하십시오.
1.5.4.1.1. 사전 요구 사항
클러스터를 생성하기 전에 clusterImageSets 리포지토리를 복제하여 hub 클러스터에 적용해야 합니다. 다음 단계를 참조하십시오.
다음 명령을 실행하여 복제하지만
2.x를 2.5로 바꿉니다.git clone https://github.com/stolostron/acm-hive-openshift-releases.git cd acm-hive-openshift-releases git checkout origin/backplane-<2.x>다음 명령을 실행하여 hub 클러스터에 적용합니다.
find clusterImageSets/fast -type d -exec oc apply -f {} \; 2> /dev/null
클러스터를 생성할 때 Red Hat OpenShift Container Platform 릴리스 이미지를 선택합니다.
참고: Nutanix 플랫폼을 사용하는 경우 ClusterImageSet 리소스의 releaseImage 에 x86_64 아키텍처를 사용하고 표시되는 라벨 값을 'true' 로 설정해야 합니다. 다음 예제를 참조하십시오.
apiVersion: hive.openshift.io/v1
kind: ClusterImageSet
metadata:
labels:
channel: stable
visible: 'true'
name: img4.x.47-x86-64-appsub
spec:
releaseImage: quay.io/openshift-release-dev/ocp-release:4.x.47-x86_641.5.4.1.2. ClusterDeployment을 사용하여 클러스터 생성
ClusterDeployment 은 클러스터의 라이프사이클을 제어하는 데 사용되는 Hive 사용자 정의 리소스입니다.
Hive 사용 설명서에 따라 ClusterDeployment 사용자 정의 리소스를 생성하고 개별 클러스터를 생성합니다.
1.5.4.1.3. ClusterPool로 클러스터 생성
ClusterPool 은 여러 클러스터를 생성하는 데 사용되는 Hive 사용자 정의 리소스이기도 합니다.
Cluster Pools 문서에 따라 Hive ClusterPool API로 클러스터를 생성합니다.
1.5.4.2. 클러스터 생성 중 추가 매니페스트 구성
클러스터를 생성하는 설치 프로세스 중에 추가 Kubernetes 리소스 매니페스트를 구성할 수 있습니다. 이는 네트워킹 구성 또는 로드 밸런서 설정과 같은 시나리오에 대한 추가 매니페스트를 구성해야 하는 경우 도움이 될 수 있습니다.
클러스터를 생성하기 전에 추가 리소스 매니페스트가 포함된 ConfigMap 을 지정하는 ClusterDeployment 리소스에 대한 참조를 추가해야 합니다.
참고: ClusterDeployment 리소스 및 ConfigMap 은 동일한 네임스페이스에 있어야 합니다. 다음 예제에서는 콘텐츠 표시 방법을 보여줍니다.
리소스 매니페스트가 있는 ConfigMap
다른
ConfigMap리소스가 포함된 매니페스트가 포함된ConfigMap입니다. 리소스 매니페스트ConfigMap은data.<resource_name>\.yaml 패턴에 추가된 리소스구성으로 여러 키를 포함할 수 있습니다.kind: ConfigMap apiVersion: v1 metadata: name: <my-baremetal-cluster-install-manifests> namespace: <mynamespace> data: 99_metal3-config.yaml: | kind: ConfigMap apiVersion: v1 metadata: name: metal3-config namespace: openshift-machine-api data: http_port: "6180" provisioning_interface: "enp1s0" provisioning_ip: "172.00.0.3/24" dhcp_range: "172.00.0.10,172.00.0.100" deploy_kernel_url: "http://172.00.0.3:6180/images/ironic-python-agent.kernel" deploy_ramdisk_url: "http://172.00.0.3:6180/images/ironic-python-agent.initramfs" ironic_endpoint: "http://172.00.0.3:6385/v1/" ironic_inspector_endpoint: "http://172.00.0.3:5150/v1/" cache_url: "http://192.168.111.1/images" rhcos_image_url: "https://releases-art-rhcos.svc.ci.openshift.org/art/storage/releases/rhcos-4.3/43.81.201911192044.0/x86_64/rhcos-43.81.201911192044.0-openstack.x86_64.qcow2.gz"리소스 매니페스트
ConfigMap을 참조하는 ClusterDeployment리소스 매니페스트
ConfigMap은spec.provisioning.manifestsConfigMapRef에서 참조됩니다.apiVersion: hive.openshift.io/v1 kind: ClusterDeployment metadata: name: <my-baremetal-cluster> namespace: <mynamespace> annotations: hive.openshift.io/try-install-once: "true" spec: baseDomain: test.example.com clusterName: <my-baremetal-cluster> controlPlaneConfig: servingCertificates: {} platform: baremetal: libvirtSSHPrivateKeySecretRef: name: provisioning-host-ssh-private-key provisioning: installConfigSecretRef: name: <my-baremetal-cluster-install-config> sshPrivateKeySecretRef: name: <my-baremetal-hosts-ssh-private-key> manifestsConfigMapRef: name: <my-baremetal-cluster-install-manifests> imageSetRef: name: <my-clusterimageset> sshKnownHosts: - "10.1.8.90 ecdsa-sha2-nistp256 AAAAE2VjZHNhLXvVVVKUYVkuyvkuygkuyTCYTytfkufTYAAAAIbmlzdHAyNTYAAABBBKWjJRzeUVuZs4yxSy4eu45xiANFIIbwE3e1aPzGD58x/NX7Yf+S8eFKq4RrsfSaK2hVJyJjvVIhUsU9z2sBJP8=" pullSecretRef: name: <my-baremetal-cluster-pull-secret>
1.5.4.3. Amazon Web Services에서 클러스터 생성
다중 클러스터 엔진 Operator 콘솔을 사용하여 AWS(Amazon Web Services)에서 Red Hat OpenShift Container Platform 클러스터를 생성할 수 있습니다.
클러스터를 생성할 때 생성 프로세스는 OpenShift Container Platform 설치 프로그램을 Hive 리소스와 함께 사용합니다. 이 절차를 완료한 후 클러스터 생성에 대한 질문이 있는 경우 OpenShift Container Platform 설명서에서 AWS에 설치 프로세스를 참조하십시오.
1.5.4.3.1. 사전 요구 사항
AWS에서 클러스터를 생성하기 전에 다음 사전 요구 사항을 참조하십시오.
- 배포된 허브 클러스터가 있어야 합니다.
- AWS 인증 정보가 필요합니다. 자세한 내용은 Amazon Web Services의 인증 정보 생성을 참조하십시오.
- AWS에 구성된 도메인이 필요합니다. 도메인 구성 방법에 대한 지침은 AWS 계정 구성을 참조하십시오.
- 사용자 이름, 암호, 액세스 키 ID 및 시크릿 액세스 키가 포함된 AWS(Amazon Web Services) 로그인 인증 정보가 있어야 합니다. 보안 인증 정보 이해 및 가져오기를 참조하십시오.
OpenShift Container Platform 이미지 풀 시크릿이 있어야 합니다. 이미지 풀 시크릿 사용을 참조하십시오.
참고: 클라우드 공급자의 클라우드 공급자 액세스 키를 변경하는 경우 콘솔에서 클라우드 공급자에 대한 해당 인증 정보도 수동으로 업데이트해야 합니다. 이는 관리 클러스터가 호스팅되는 클라우드 공급자에서 인증 정보가 만료되고 관리 클러스터를 삭제하려고 할 때 필요합니다.
1.5.4.3.2. AWS 클러스터 생성
AWS 클러스터 생성에 대한 다음 중요한 정보를 참조하십시오.
-
정보를 검토하고 선택적으로 클러스터를 생성하기 전에 사용자 지정할 때 YAML: On 을 선택하여 패널의
install-config.yaml파일 콘텐츠를 볼 수 있습니다. 업데이트가 있는 경우 사용자 지정 설정으로 YAML 파일을 편집할 수 있습니다. - 클러스터를 생성할 때 컨트롤러는 클러스터 및 리소스에 대한 네임스페이스를 생성합니다. 해당 네임스페이스에 해당 클러스터 인스턴스의 리소스만 포함해야 합니다.
- 클러스터를 삭제하면 네임스페이스와 모든 리소스가 삭제됩니다.
-
기존 클러스터 세트에 클러스터를 추가하려면 클러스터에 추가하려면 클러스터에 대한 올바른 권한이 있어야 합니다. 클러스터를 생성할 때
cluster-admin권한이 없는 경우clusterset-admin권한이 있는 클러스터 세트를 선택해야 합니다. -
지정된 클러스터 세트에 대한 올바른 권한이 없는 경우 클러스터 생성에 실패합니다. 선택할 클러스터 설정 옵션이 없는 경우 클러스터 세트에
clusterset-admin권한을 제공하려면 클러스터 관리자에게 문의하십시오. -
모든 관리 클러스터는 관리 클러스터 세트와 연결되어 있어야 합니다.
ManagedClusterSet에 관리 클러스터를 할당하지 않으면기본관리 클러스터 세트에 자동으로 추가됩니다. - AWS 계정으로 구성한 선택한 인증 정보와 연결된 기본 DNS 도메인이 이미 있는 경우 해당 값이 필드에 채워집니다. 값을 덮어 쓰기하여 변경할 수 있습니다. 이 이름은 클러스터의 호스트 이름에 사용됩니다.
- 릴리스 이미지는 클러스터를 생성하는 데 사용되는 OpenShift Container Platform 이미지의 버전을 식별합니다. 사용 가능한 이미지 목록에서 이미지를 선택합니다. 사용하려는 이미지를 사용할 수 없는 경우 사용하려는 이미지의 URL을 입력할 수 있습니다.
노드 풀에는 컨트롤 플레인 풀과 작업자 풀이 포함됩니다. 컨트롤 플레인 노드는 클러스터 활동 관리를 공유합니다. 정보에는 다음 필드가 포함됩니다.
- region: 노드 풀을 원하는 리전을 지정합니다.
- CPU 아키텍처: 관리 클러스터의 아키텍처 유형이 허브 클러스터의 아키텍처와 동일하지 않으면 풀에 있는 시스템의 명령 집합 아키텍처 값을 입력합니다. 유효한 값은 amd64,ppc64le,s390x 및 arm64 입니다.
- zones: 컨트롤 플레인 풀을 실행할 위치를 지정합니다. 더 분산된 컨트롤 플레인 노드 그룹에 대해 리전 내에서 여러 영역을 선택할 수 있습니다. 더 가까운 영역은 더 빠른 성능을 제공할 수 있지만 더 멀리 있는 영역이 더 분산될 수 있습니다.
- 인스턴스 유형: 컨트롤 플레인 노드의 인스턴스 유형을 지정합니다. 인스턴스 유형 및 크기를 생성한 후 변경할 수 있습니다.
- 루트 스토리지: 클러스터에 할당할 루트 스토리지 크기를 지정합니다.
작업자 풀에 0개 이상의 작업자 노드를 생성하여 클러스터의 컨테이너 워크로드를 실행할 수 있습니다. 이는 단일 작업자 풀에 있거나 여러 작업자 풀에 분산될 수 있습니다. 제로 작업자 노드가 지정되면 컨트롤 플레인 노드도 작업자 노드로 작동합니다. 선택적 정보에는 다음 필드가 포함됩니다.
- zones: 작업자 풀을 실행할 위치를 지정합니다. 더 분산된 노드 그룹에 대해 리전 내에서 여러 영역을 선택할 수 있습니다. 더 가까운 영역은 더 빠른 성능을 제공할 수 있지만 더 멀리 있는 영역이 더 분산될 수 있습니다.
- 인스턴스 유형: 작업자 풀의 인스턴스 유형을 지정합니다. 인스턴스 유형 및 크기를 생성한 후 변경할 수 있습니다.
- 노드 수: 작업자 풀의 노드 수를 지정합니다. 이 설정은 작업자 풀을 정의할 때 필요합니다.
- 루트 스토리지: 작업자 풀에 할당된 루트 스토리지의 양을 지정합니다. 이 설정은 작업자 풀을 정의할 때 필요합니다.
- 클러스터에 네트워킹 세부 정보가 필요하며 IPv6를 사용하려면 여러 네트워크가 필요합니다. 네트워크 추가를 클릭하여 추가 네트워크를 추가할 수 있습니다.
인증 정보에 제공된 프록시 정보는 프록시 필드에 자동으로 추가됩니다. 정보를 그대로 사용하거나, 덮어쓰거나 프록시를 활성화하려면 정보를 추가할 수 있습니다. 다음 목록에는 프록시를 생성하는 데 필요한 정보가 포함되어 있습니다.
-
HTTP 프록시:
HTTP트래픽의 프록시로 사용해야 하는 URL을 지정합니다. -
HTTPS 프록시:
HTTPS트래픽에 사용해야 하는 보안 프록시 URL을 지정합니다. 값을 제공하지 않으면 HTTP 및HTTPS모두에HTTP프록시 URL -
프록시 사이트 없음: 프록시를 바이패스해야 하는 쉼표로 구분된 사이트 목록입니다. 마침표로 도메인 이름을 시작합니다
.를 해당 도메인에 있는 모든 하위 도메인을 포함합니다. 모든 대상에 대해 프록시를 바이패스하려면 별표*를 추가합니다. - 추가 신뢰 번들: HTTPS 연결을 프록시하는 데 필요한 하나 이상의 추가 CA 인증서입니다.
-
HTTP 프록시:
1.5.4.3.3. 콘솔을 사용하여 클러스터 생성
새 클러스터를 생성하려면 다음 절차를 참조하십시오. 대신 가져올 기존 클러스터가 있는 경우 클러스터 가져오기 를 참조하십시오.
참고: 클러스터를 가져오기 위해 클러스터 세부 정보가 제공된 oc 명령을 실행할 필요가 없습니다. 클러스터를 생성할 때 다중 클러스터 엔진 Operator 관리 아래에 자동으로 구성됩니다.
- Infrastructure > Clusters 로 이동합니다.
- 클러스터 페이지에서 다음을 수행합니다. 클러스터 > 클러스터 생성 을 클릭하고 콘솔의 단계를 완료합니다.
- 선택 사항: 콘솔에서 정보를 입력할 때 콘텐츠 업데이트를 보려면 YAML 을 선택합니다.
인증 정보를 생성해야 하는 경우 자세한 내용은 Amazon Web Services에 대한 인증 정보 생성 을 참조하십시오.
클러스터 이름은 클러스터의 호스트 이름에 사용됩니다.
Kubernetes용 Red Hat Advanced Cluster Management를 사용하고 관리 클러스터 klusterlet을 특정 노드에서 실행하도록 구성하려면 선택 사항: 필요한 단계를 위해 특정 노드에서 실행되도록 klusterlet 구성 을 참조하십시오.
1.5.4.3.4. 추가 리소스
- AWS 개인 구성 정보는 AWS GovCloud 클러스터를 생성할 때 사용됩니다. 해당 환경에서 클러스터 생성에 대한 정보는 Amazon Web Services GovCloud 에서 클러스터 생성을 참조하십시오.
- 자세한 내용은 AWS 계정 구성을 참조하십시오.
- 릴리스 이미지에 대한 자세한 내용은 릴리스 이미지 릴리스를 참조하십시오.
- AWS General purpose instances 와 같은 클라우드 공급자 사이트를 방문하여 지원되는 즉시 유형에 대한 자세한 내용을 확인하십시오.
1.5.4.4. Amazon Web Services GovCloud에서 클러스터 생성
콘솔을 사용하여 AWS(Amazon Web Services) 또는 AWS GovCloud에 Red Hat OpenShift Container Platform 클러스터를 생성할 수 있습니다. 다음 절차에서는 AWS GovCloud에 클러스터를 생성하는 방법을 설명합니다. AWS 에서 클러스터를 생성하는 방법은 Amazon Web Services 에서 클러스터 생성을 참조하십시오.
AWS GovCloud는 정부 문서를 클라우드에 저장하는 데 필요한 추가 요구 사항을 충족하는 클라우드 서비스를 제공합니다. AWS GovCloud에서 클러스터를 생성할 때 환경을 준비하려면 추가 단계를 완료해야 합니다.
클러스터를 생성할 때 생성 프로세스는 OpenShift Container Platform 설치 프로그램을 Hive 리소스와 함께 사용합니다. 이 절차를 완료한 후 클러스터 생성에 대한 질문이 있는 경우 OpenShift Container Platform 설명서의 정부 리전에 AWS의 클러스터 설치를 참조하십시오. 다음 섹션에서는 AWS GovCloud에 클러스터를 생성하는 단계를 제공합니다.
1.5.4.4.1. 사전 요구 사항
AWS GovCloud 클러스터를 생성하기 전에 다음 사전 요구 사항이 있어야합니다.
- 사용자 이름, 암호, 액세스 키 ID 및 시크릿 액세스 키가 포함된 AWS 로그인 인증 정보가 있어야 합니다. 보안 인증 정보 이해 및 가져오기를 참조하십시오.
- AWS 인증 정보가 필요합니다. 자세한 내용은 Amazon Web Services의 인증 정보 생성을 참조하십시오.
- AWS에 구성된 도메인이 필요합니다. 도메인 구성 방법에 대한 지침은 AWS 계정 구성을 참조하십시오.
- OpenShift Container Platform 이미지 풀 시크릿이 있어야 합니다. 이미지 풀 시크릿 사용을 참조하십시오.
- 허브 클러스터용 기존 Red Hat OpenShift Container Platform 클러스터가 있는 Amazon VPC(Virtual Private Cloud)가 있어야 합니다. 이 VPC는 관리 클러스터 리소스 또는 관리형 클러스터 서비스 엔드 포인트에 사용되는 VPC와 달라야 합니다.
- 관리 클러스터 리소스가 배포되는 VPC가 필요합니다. 허브 클러스터 또는 관리 클러스터 서비스 엔드 포인트에 사용되는 VPC와 같을 수 없습니다.
- 관리 클러스터 서비스 엔드 포인트를 제공하는 VPC가 하나 이상 필요합니다. Hub 클러스터 또는 관리 클러스터 리소스에 사용되는 VPC와 같을 수 없습니다.
- CIDR(Classless Inter-Domain Routing)으로 지정된 VPC의 IP 주소가 겹치지 않는지 확인합니다.
-
Hive 네임스페이스 내에서 인증 정보를 참조하는
HiveConfig사용자 정의 리소스가 필요합니다. 이 사용자 정의 리소스는 관리형 클러스터 서비스 엔드포인트에 대해 생성한 VPC에 리소스를 생성할 수 있어야 합니다.
참고: 클라우드 공급자의 클라우드 공급자 액세스 키를 변경하는 경우 다중 클러스터 엔진 Operator 콘솔에서 클라우드 공급자에 대한 해당 인증 정보도 수동으로 업데이트해야 합니다. 이는 관리 클러스터가 호스팅되는 클라우드 공급자에서 인증 정보가 만료되고 관리 클러스터를 삭제하려고 할 때 필요합니다.
1.5.4.4.2. AWS GovCloud에 배포하도록 Hive 구성
AWS GovCloud에서 클러스터를 생성하는 것은 표준 AWS에서 클러스터를 생성하는 것과 거의 동일하지만 AWS GovCloud에서 클러스터에 대한 AWS PrivateLink를 준비하기 위해 몇 가지 추가 단계를 완료해야 합니다.
1.5.4.4.2.1. 리소스 및 엔드포인트에 대한 VPC 생성
사전 요구 사항에 나열된 대로 허브 클러스터가 포함된 VPC 외에도 두 개의 VPC가 필요합니다. VPC를 생성하기 위한 특정 단계는 Amazon Web Services 설명서에서 VPC 생성을 참조하십시오.
- 프라이빗 서브넷을 사용하여 관리형 클러스터의 VPC를 생성합니다.
- 프라이빗 서브넷을 사용하여 관리형 클러스터 서비스 엔드 포인트에 대해 VPC를 하나 이상 생성합니다. 리전의 각 VPC에는 255개의 VPC 끝점이 있으므로 해당 리전에서 255개 이상의 클러스터를 지원하려면 여러 VPC가 필요합니다.
각 VPC에 대해 해당 리전의 지원되는 모든 가용성 영역에 서브넷을 생성합니다. 각 서브넷에는 컨트롤러 요구 사항으로 인해 최소 255개의 사용 가능한 IP 주소가 있어야 합니다.
다음 예제에서는
us-gov-east-1리전에 6개의 가용성 영역이 있는 VPC의 서브넷을 구조화하는 방법을 보여줍니다.vpc-1 (us-gov-east-1) : 10.0.0.0/20 subnet-11 (us-gov-east-1a): 10.0.0.0/23 subnet-12 (us-gov-east-1b): 10.0.2.0/23 subnet-13 (us-gov-east-1c): 10.0.4.0/23 subnet-12 (us-gov-east-1d): 10.0.8.0/23 subnet-12 (us-gov-east-1e): 10.0.10.0/23 subnet-12 (us-gov-east-1f): 10.0.12.0/2vpc-2 (us-gov-east-1) : 10.0.16.0/20 subnet-21 (us-gov-east-1a): 10.0.16.0/23 subnet-22 (us-gov-east-1b): 10.0.18.0/23 subnet-23 (us-gov-east-1c): 10.0.20.0/23 subnet-24 (us-gov-east-1d): 10.0.22.0/23 subnet-25 (us-gov-east-1e): 10.0.24.0/23 subnet-26 (us-gov-east-1f): 10.0.28.0/23- 모든 허브 환경(hub 클러스터 VPC)이 피어링, 전송 게이트웨이를 사용하는 VPC 끝점에 대해 생성한 VPC에 대한 네트워크 연결이 있고 모든 DNS 설정이 활성화되어 있는지 확인합니다.
- AWS GovCloud 연결에 필요한 AWS PrivateLink의 DNS 설정을 확인하는 데 필요한 VPC 목록을 수집합니다. 여기에는 최소한 구성 중인 다중 클러스터 엔진 Operator 인스턴스의 VPC가 포함되며, 다양한 Hive 컨트롤러가 존재하는 모든 VPC 목록을 포함할 수 있습니다.
1.5.4.4.2.2. VPC 끝점의 보안 그룹 구성
AWS의 각 VPC 끝점에는 끝점에 대한 액세스를 제어하기 위해 연결된 보안 그룹이 있습니다. Hive는 VPC 끝점을 생성할 때 보안 그룹을 지정하지 않습니다. VPC의 기본 보안 그룹은 VPC 끝점에 연결되어 있습니다. VPC의 기본 보안 그룹에는 Hive 설치 프로그램 Pod에서 VPC 엔드 포인트가 생성되는 트래픽을 허용하기 위한 규칙이 있어야 합니다. 자세한 내용은 AWS 문서의 엔드 포인트 정책을 사용하여 VPC 끝점에 대한 액세스 제어를 참조하십시오.
예를 들어 Hive가 hive-vpc(10.1.0.0/16) 에서 실행되는 경우 VPC의 기본 보안 그룹에는 10.1.0.0/16 에서 수신할 수 있는 VPC 끝점이 생성되는 규칙이 있어야 합니다.
1.5.4.4.2.3. AWS PrivateLink에 대한 권한 설정
AWS PrivateLink를 구성하려면 여러 인증 정보가 필요합니다. 이러한 인증 정보에 필요한 권한은 인증 정보 유형에 따라 다릅니다.
ClusterDeployment의 인증 정보에는 다음 권한이 필요합니다.
ec2:CreateVpcEndpointServiceConfiguration ec2:DescribeVpcEndpointServiceConfigurations ec2:ModifyVpcEndpointServiceConfiguration ec2:DescribeVpcEndpointServicePermissions ec2:ModifyVpcEndpointServicePermissions ec2:DeleteVpcEndpointServiceConfigurations끝점 VPC 계정
.spec.awsPrivateLink.credentialsSecretRef에 대한 HiveConfig의 인증 정보에는 다음 권한이 필요합니다.ec2:DescribeVpcEndpointServices ec2:DescribeVpcEndpoints ec2:CreateVpcEndpoint ec2:CreateTags ec2:DescribeNetworkInterfaces ec2:DescribeVPCs ec2:DeleteVpcEndpoints route53:CreateHostedZone route53:GetHostedZone route53:ListHostedZonesByVPC route53:AssociateVPCWithHostedZone route53:DisassociateVPCFromHostedZone route53:CreateVPCAssociationAuthorization route53:DeleteVPCAssociationAuthorization route53:ListResourceRecordSets route53:ChangeResourceRecordSets route53:DeleteHostedZoneVPC를 프라이빗 호스팅 영역(
.spec.awsPrivateLink.associatedVPCs[$idx].credentialsSecretRef)에 연결하기 위해HiveConfig사용자 정의 리소스에 지정된 인증 정보입니다. VPC가 있는 계정에는 다음 권한이 필요합니다.route53:AssociateVPCWithHostedZone route53:DisassociateVPCFromHostedZone ec2:DescribeVPCs
hub 클러스터의 Hive 네임스페이스에 인증 정보 시크릿이 있는지 확인합니다.
HiveConfig 사용자 정의 리소스는 제공된 특정 VPC에서 리소스를 생성할 수 있는 권한이 있는 Hive 네임스페이스 내의 인증 정보를 참조해야 합니다. AWS GovCloud에서 AWS 클러스터를 프로비저닝하기 위해 사용 중인 인증 정보가 Hive 네임스페이스에 이미 있는 경우 다른 인증서를 생성할 필요가 없습니다. AWS GovCloud에서 AWS 클러스터를 프로비저닝하기 위해 사용 중인 인증 정보가 Hive 네임스페이스에 없는 경우 현재 인증 정보를 교체하거나 Hive 네임스페이스에서 추가 인증 정보를 생성할 수 있습니다.
HiveConfig 사용자 정의 리소스에는 다음 콘텐츠를 포함해야 합니다.
- 지정된 VPC의 리소스를 프로비저닝하는 데 필요한 권한이 있는 AWS GovCloud 인증 정보입니다.
OpenShift Container Platform 클러스터 설치용 VPC 주소와 관리형 클러스터의 서비스 끝점입니다.
모범 사례: OpenShift Container Platform 클러스터 설치 및 서비스 끝점에 다른 VPC를 사용합니다.
다음 예제에서는 인증 정보 콘텐츠를 보여줍니다.
spec:
awsPrivateLink:
## The list of inventory of VPCs that can be used to create VPC
## endpoints by the controller.
endpointVPCInventory:
- region: us-east-1
vpcID: vpc-1
subnets:
- availabilityZone: us-east-1a
subnetID: subnet-11
- availabilityZone: us-east-1b
subnetID: subnet-12
- availabilityZone: us-east-1c
subnetID: subnet-13
- availabilityZone: us-east-1d
subnetID: subnet-14
- availabilityZone: us-east-1e
subnetID: subnet-15
- availabilityZone: us-east-1f
subnetID: subnet-16
- region: us-east-1
vpcID: vpc-2
subnets:
- availabilityZone: us-east-1a
subnetID: subnet-21
- availabilityZone: us-east-1b
subnetID: subnet-22
- availabilityZone: us-east-1c
subnetID: subnet-23
- availabilityZone: us-east-1d
subnetID: subnet-24
- availabilityZone: us-east-1e
subnetID: subnet-25
- availabilityZone: us-east-1f
subnetID: subnet-26
## The credentialsSecretRef points to a secret with permissions to create.
## The resources in the account where the inventory of VPCs exist.
credentialsSecretRef:
name: <hub-account-credentials-secret-name>
## A list of VPC where various mce clusters exists.
associatedVPCs:
- region: region-mce1
vpcID: vpc-mce1
credentialsSecretRef:
name: <credentials-that-have-access-to-account-where-MCE1-VPC-exists>
- region: region-mce2
vpcID: vpc-mce2
credentialsSecretRef:
name: <credentials-that-have-access-to-account-where-MCE2-VPC-exists>
AWS PrivateLink가 endpointVPC인벤토리 목록에서 지원되는 모든 리전의 VPC 를 포함할 수 있습니다. 컨트롤러는 ClusterDeployment의 요구 사항을 충족하는 VPC를 선택합니다.
자세한 내용은 Hive 설명서를 참조하십시오.
1.5.4.4.3. 콘솔을 사용하여 클러스터 생성
콘솔에서 클러스터를 생성하려면 Infrastructure > Clusters > Create cluster > Standalone 로 이동하여 콘솔의 단계를 완료합니다.
참고: 이 절차는 클러스터를 생성하기 위한 것입니다. 가져올 기존 클러스터가 있는 경우 해당 단계에 대한 클러스터 가져오기 를 참조하십시오.
선택한 인증 정보는 AWS GovCloud 클러스터를 생성하는 경우 AWS GovCloud 리전의 리소스에 액세스할 수 있어야 합니다. 클러스터를 배포하는 데 필요한 권한이 있는 경우 Hive 네임스페이스에 이미 있는 AWS GovCloud 시크릿을 사용할 수 있습니다. 기존 인증 정보가 콘솔에 표시됩니다. 인증 정보를 생성해야 하는 경우 자세한 내용은 Amazon Web Services에 대한 인증 정보 생성 을 참조하십시오.
클러스터 이름은 클러스터의 호스트 이름에 사용됩니다.
중요: 클러스터를 생성할 때 컨트롤러는 클러스터 및 해당 리소스에 대한 네임스페이스를 생성합니다. 해당 네임스페이스에 해당 클러스터 인스턴스의 리소스만 포함해야 합니다. 클러스터를 삭제하면 네임스페이스와 모든 리소스가 삭제됩니다.
팁: 콘솔에서 정보를 입력할 때 콘텐츠 업데이트를 보려면 YAML 을 선택합니다.
기존 클러스터 세트에 클러스터를 추가하려면 클러스터에 추가하려면 클러스터에 대한 올바른 권한이 있어야 합니다. 클러스터를 생성할 때 cluster-admin 권한이 없는 경우 clusterset-admin 권한이 있는 클러스터 세트를 선택해야 합니다. 지정된 클러스터 세트에 대한 올바른 권한이 없는 경우 클러스터 생성에 실패합니다. 선택할 클러스터 설정 옵션이 없는 경우 클러스터 세트에 clusterset-admin 권한을 제공하려면 클러스터 관리자에게 문의하십시오.
모든 관리 클러스터는 관리 클러스터 세트와 연결되어 있어야 합니다. ManagedClusterSet 에 관리 클러스터를 할당하지 않으면 기본 관리 클러스터 세트에 자동으로 추가됩니다.
AWS 또는 AWS GovCloud 계정으로 구성한 선택한 인증 정보와 연결된 기본 DNS 도메인이 이미 있는 경우 해당 값이 필드에 채워집니다. 값을 덮어 쓰기하여 변경할 수 있습니다. 이 이름은 클러스터의 호스트 이름에 사용됩니다. 자세한 내용은 AWS 계정 구성을 참조하십시오.
릴리스 이미지는 클러스터를 생성하는 데 사용되는 OpenShift Container Platform 이미지의 버전을 식별합니다. 사용하려는 버전을 사용할 수 있는 경우 이미지 목록에서 이미지를 선택할 수 있습니다. 사용하려는 이미지가 표준 이미지가 아닌 경우 사용하려는 이미지의 URL을 입력할 수 있습니다. 릴리스 이미지에 대한 자세한 내용은 릴리스 이미지 릴리스를 참조하십시오.
노드 풀에는 컨트롤 플레인 풀과 작업자 풀이 포함됩니다. 컨트롤 플레인 노드는 클러스터 활동 관리를 공유합니다. 정보에는 다음 필드가 포함됩니다.
-
region: 클러스터 리소스를 생성하는 리전입니다. AWS GovCloud 공급자에 클러스터를 생성하는 경우 노드 풀의 AWS GovCloud 리전을 포함해야 합니다. 예를 들면
us-gov-west-1입니다. - CPU 아키텍처: 관리 클러스터의 아키텍처 유형이 허브 클러스터의 아키텍처와 동일하지 않으면 풀에 있는 시스템의 명령 집합 아키텍처 값을 입력합니다. 유효한 값은 amd64,ppc64le,s390x 및 arm64 입니다.
- zones: 컨트롤 플레인 풀을 실행할 위치를 지정합니다. 더 분산된 컨트롤 플레인 노드 그룹에 대해 리전 내에서 여러 영역을 선택할 수 있습니다. 더 가까운 영역은 더 빠른 성능을 제공할 수 있지만 더 멀리 있는 영역이 더 분산될 수 있습니다.
- 인스턴스 유형: 이전에 지정한 CPU 아키텍처와 동일해야 하는 컨트롤 플레인 노드의 인스턴스 유형을 지정합니다. 인스턴스 유형 및 크기를 생성한 후 변경할 수 있습니다.
- 루트 스토리지: 클러스터에 할당할 루트 스토리지 크기를 지정합니다.
작업자 풀에 0개 이상의 작업자 노드를 생성하여 클러스터의 컨테이너 워크로드를 실행할 수 있습니다. 단일 작업자 풀에 있거나 여러 작업자 풀에 배포할 수 있습니다. 제로 작업자 노드가 지정되면 컨트롤 플레인 노드도 작업자 노드로 작동합니다. 선택적 정보에는 다음 필드가 포함됩니다.
- 풀 이름: 풀에 고유한 이름을 제공합니다.
- zones: 작업자 풀을 실행할 위치를 지정합니다. 더 분산된 노드 그룹에 대해 리전 내에서 여러 영역을 선택할 수 있습니다. 더 가까운 영역은 더 빠른 성능을 제공할 수 있지만 더 멀리 있는 영역이 더 분산될 수 있습니다.
- 인스턴스 유형: 작업자 풀의 인스턴스 유형을 지정합니다. 인스턴스 유형 및 크기를 생성한 후 변경할 수 있습니다.
- 노드 수: 작업자 풀의 노드 수를 지정합니다. 이 설정은 작업자 풀을 정의할 때 필요합니다.
- 루트 스토리지: 작업자 풀에 할당된 루트 스토리지의 양을 지정합니다. 이 설정은 작업자 풀을 정의할 때 필요합니다.
클러스터에 네트워킹 세부 정보가 필요하며 IPv6를 사용하려면 여러 네트워크가 필요합니다. AWS GovCloud 클러스터의 경우 Machine CIDR 필드에 Hive VPC의 주소 블록 값을 입력합니다. 네트워크 추가를 클릭하여 추가 네트워크를 추가할 수 있습니다.
인증 정보에 제공된 프록시 정보는 프록시 필드에 자동으로 추가됩니다. 정보를 그대로 사용하거나, 덮어쓰거나 프록시를 활성화하려면 정보를 추가할 수 있습니다. 다음 목록에는 프록시를 생성하는 데 필요한 정보가 포함되어 있습니다.
-
HTTP 프록시 URL:
HTTP트래픽의 프록시로 사용해야 하는 URL을 지정합니다. -
HTTPS 프록시 URL:
HTTPS트래픽에 사용해야 하는 보안 프록시 URL을 지정합니다. 값을 제공하지 않으면 HTTP 및HTTPS모두에HTTP프록시 URL -
프록시 도메인 없음: 프록시를 바이패스해야 하는 쉼표로 구분된 도메인 목록입니다. 마침표로 도메인 이름을 시작합니다
.를 해당 도메인에 있는 모든 하위 도메인을 포함합니다. 모든 대상에 대해 프록시를 바이패스하려면 별표*를 추가합니다. - 추가 신뢰 번들: HTTPS 연결을 프록시하는 데 필요한 하나 이상의 추가 CA 인증서입니다.
AWS GovCloud 클러스터를 생성하거나 프라이빗 환경을 사용하는 경우 AMI ID 및 서브넷 값을 사용하여 AWS 개인 구성 페이지의 필드를 완료합니다. ClusterDeployment.yaml 파일에서 spec:platform:aws:privateLink:enabled 값이 true 로 설정되어 있는지 확인합니다. 이 값은 개인 구성 사용을 선택할 때 자동으로 설정됩니다.
정보를 검토하고 선택적으로 클러스터를 생성하기 전에 사용자 지정할 때 YAML: On 을 선택하여 패널의 install-config.yaml 파일 콘텐츠를 볼 수 있습니다. 업데이트가 있는 경우 사용자 지정 설정으로 YAML 파일을 편집할 수 있습니다.
참고: 클러스터를 가져오기 위해 클러스터 세부 정보가 제공된 oc 명령을 실행할 필요가 없습니다. 클러스터를 생성할 때 Kubernetes 운영자를 위한 다중 클러스터 엔진 관리 아래에 자동으로 구성됩니다.
Kubernetes용 Red Hat Advanced Cluster Management를 사용하고 관리 클러스터 klusterlet을 특정 노드에서 실행하도록 구성하려면 선택 사항: 필요한 단계를 위해 특정 노드에서 실행되도록 klusterlet 구성 을 참조하십시오.
클러스터에 액세스하는 방법에 대한 지침은 클러스터 액세스를 계속합니다.
1.5.4.5. Microsoft Azure에 클러스터 생성
다중 클러스터 엔진 Operator 콘솔을 사용하여 Microsoft Azure 또는 Microsoft Azure Government에 Red Hat OpenShift Container Platform 클러스터를 배포할 수 있습니다.
클러스터를 생성할 때 생성 프로세스는 OpenShift Container Platform 설치 프로그램을 Hive 리소스와 함께 사용합니다. 이 절차를 완료한 후 클러스터 생성에 대한 질문이 있는 경우 OpenShift Container Platform 설명서의 Azure에 프로세스에 대한 자세한 내용은 설치를 참조하십시오.
1.5.4.5.1. 사전 요구 사항
Azure에서 클러스터를 생성하기 전에 다음 사전 요구 사항을 참조하십시오.
- 배포된 허브 클러스터가 있어야 합니다.
- Azure 인증 정보가 필요합니다. 자세한 내용은 Microsoft Azure에 대한 인증 정보 생성 을 참조하십시오.
- Azure 또는 Azure Government에 구성된 도메인이 필요합니다. 도메인 구성 방법에 대한 지침은 Azure 클라우드 서비스의 사용자 정의 도메인 이름 구성을 참조하십시오.
- 사용자 이름과 암호를 포함하는 Azure 로그인 인증 정보가 필요합니다. Microsoft Azure Portal 을 참조하십시오.
-
clientId,clientSecret,tenantId를 포함하는 Azure 서비스 주체가 필요합니다. azure.microsoft.com 을 참조하십시오. - OpenShift Container Platform 이미지 풀 시크릿이 필요합니다. 이미지 풀 시크릿 사용을 참조하십시오.
참고: 클라우드 공급자의 클라우드 공급자 액세스 키를 변경하는 경우 다중 클러스터 엔진 Operator 콘솔에서 클라우드 공급자에 대한 해당 인증 정보도 수동으로 업데이트해야 합니다. 이는 관리 클러스터가 호스팅되는 클라우드 공급자에서 인증 정보가 만료되고 관리 클러스터를 삭제하려고 할 때 필요합니다.
1.5.4.5.2. 콘솔을 사용하여 클러스터 생성
다중 클러스터 엔진 Operator 콘솔에서 클러스터를 생성하려면 Infrastructure > Clusters 로 이동합니다. 클러스터 페이지에서 클러스터 생성 을 클릭하고 콘솔의 단계를 완료합니다.
참고: 이 절차는 클러스터를 생성하기 위한 것입니다. 가져올 기존 클러스터가 있는 경우 해당 단계에 대한 클러스터 가져오기 를 참조하십시오.
인증 정보를 생성해야 하는 경우 자세한 내용은 Microsoft Azure에 대한 인증 정보 생성 을 참조하십시오.
클러스터 이름은 클러스터의 호스트 이름에 사용됩니다.
중요: 클러스터를 생성할 때 컨트롤러는 클러스터 및 해당 리소스에 대한 네임스페이스를 생성합니다. 해당 네임스페이스에 해당 클러스터 인스턴스의 리소스만 포함해야 합니다. 클러스터를 삭제하면 네임스페이스와 모든 리소스가 삭제됩니다.
팁: 콘솔에서 정보를 입력할 때 콘텐츠 업데이트를 보려면 YAML 을 선택합니다.
기존 클러스터 세트에 클러스터를 추가하려면 클러스터에 추가하려면 클러스터에 대한 올바른 권한이 있어야 합니다. 클러스터를 생성할 때 cluster-admin 권한이 없는 경우 clusterset-admin 권한이 있는 클러스터 세트를 선택해야 합니다. 지정된 클러스터 세트에 대한 올바른 권한이 없는 경우 클러스터 생성에 실패합니다. 선택할 클러스터 설정 옵션이 없는 경우 클러스터 세트에 clusterset-admin 권한을 제공하려면 클러스터 관리자에게 문의하십시오.
모든 관리 클러스터는 관리 클러스터 세트와 연결되어 있어야 합니다. ManagedClusterSet 에 관리 클러스터를 할당하지 않으면 기본 관리 클러스터 세트에 자동으로 추가됩니다.
Azure 계정에 대해 구성한 선택한 인증 정보와 연결된 기본 DNS 도메인이 이미 있는 경우 해당 값이 해당 필드에 채워집니다. 값을 덮어 쓰기하여 변경할 수 있습니다. 자세한 내용은 Azure 클라우드 서비스의 사용자 정의 도메인 이름 구성 을 참조하십시오. 이 이름은 클러스터의 호스트 이름에 사용됩니다.
릴리스 이미지는 클러스터를 생성하는 데 사용되는 OpenShift Container Platform 이미지의 버전을 식별합니다. 사용하려는 버전을 사용할 수 있는 경우 이미지 목록에서 이미지를 선택할 수 있습니다. 사용하려는 이미지가 표준 이미지가 아닌 경우 사용하려는 이미지의 URL을 입력할 수 있습니다. 릴리스 이미지에 대한 자세한 내용은 릴리스 이미지 릴리스를 참조하십시오.
노드 풀에는 컨트롤 플레인 풀과 작업자 풀이 포함됩니다. 컨트롤 플레인 노드는 클러스터 활동 관리를 공유합니다. 정보에는 다음과 같은 선택적 필드가 포함됩니다.
- region: 노드 풀을 실행할 리전을 지정합니다. 더 분산된 컨트롤 플레인 노드 그룹에 대해 리전 내에서 여러 영역을 선택할 수 있습니다. 더 가까운 영역은 더 빠른 성능을 제공할 수 있지만 더 멀리 있는 영역이 더 분산될 수 있습니다.
- CPU 아키텍처: 관리 클러스터의 아키텍처 유형이 허브 클러스터의 아키텍처와 동일하지 않으면 풀에 있는 시스템의 명령 집합 아키텍처 값을 입력합니다. 유효한 값은 amd64,ppc64le,s390x 및 arm64 입니다.
클러스터를 생성한 후 컨트롤 플레인 풀의 인스턴스 유형 및 크기 및 루트 스토리지 할당(필수)을 변경할 수 있습니다.
작업자 풀에서 하나 이상의 작업자 노드를 생성하여 클러스터의 컨테이너 워크로드를 실행할 수 있습니다. 단일 작업자 풀에 있거나 여러 작업자 풀에 배포할 수 있습니다. 제로 작업자 노드가 지정되면 컨트롤 플레인 노드도 작업자 노드로 작동합니다. 정보에는 다음 필드가 포함됩니다.
- zones: 작업자 풀을 실행할 위치를 지정합니다. 더 분산된 노드 그룹에 대해 리전 내에서 여러 영역을 선택할 수 있습니다. 더 가까운 영역은 더 빠른 성능을 제공할 수 있지만 더 멀리 있는 영역이 더 분산될 수 있습니다.
- 인스턴스 유형: 인스턴스 유형을 만든 후 인스턴스의 유형과 크기를 변경할 수 있습니다.
네트워크 추가를 클릭하여 추가 네트워크를 추가할 수 있습니다. IPv6 주소를 사용하는 경우 두 개 이상의 네트워크가 있어야 합니다.
인증 정보에 제공된 프록시 정보는 프록시 필드에 자동으로 추가됩니다. 정보를 그대로 사용하거나, 덮어쓰거나 프록시를 활성화하려면 정보를 추가할 수 있습니다. 다음 목록에는 프록시를 생성하는 데 필요한 정보가 포함되어 있습니다.
-
HTTP 프록시:
HTTP트래픽의 프록시로 사용해야 하는 URL입니다. -
HTTPS 프록시:
HTTPS트래픽에 사용해야 하는 보안 프록시 URL입니다. 값을 제공하지 않으면 HTTP 및HTTPS모두에HTTP프록시 URL -
프록시 없음: 프록시를 바이패스해야 하는 쉼표로 구분된 도메인 목록입니다. 마침표로 도메인 이름을 시작합니다
.를 해당 도메인에 있는 모든 하위 도메인을 포함합니다. 모든 대상에 대해 프록시를 바이패스하려면 별표*를 추가합니다. - 추가 신뢰 번들: HTTPS 연결을 프록시하는 데 필요한 하나 이상의 추가 CA 인증서입니다.
정보를 검토하고 선택적으로 클러스터를 생성하기 전에 사용자 지정할 때 YAML 스위치를 클릭하여 패널의 install-config.yaml 파일 콘텐츠를 볼 수 있습니다. 업데이트가 있는 경우 사용자 지정 설정으로 YAML 파일을 편집할 수 있습니다.
Kubernetes용 Red Hat Advanced Cluster Management를 사용하고 관리 클러스터 klusterlet을 특정 노드에서 실행하도록 구성하려면 선택 사항: 필요한 단계를 위해 특정 노드에서 실행되도록 klusterlet 구성 을 참조하십시오.
참고: 클러스터를 가져오기 위해 클러스터 세부 정보가 제공된 oc 명령을 실행할 필요가 없습니다. 클러스터를 생성할 때 다중 클러스터 엔진 Operator 관리 아래에 자동으로 구성됩니다.
클러스터에 액세스하는 방법에 대한 지침은 클러스터 액세스를 계속합니다.
1.5.4.6. Google Cloud Platform에서 클러스터 생성
GCP(Google Cloud Platform)에 Red Hat OpenShift Container Platform 클러스터를 생성하려면 절차를 따르십시오. GCP에 대한 자세한 내용은 Google Cloud Platform 을 참조하십시오.
클러스터를 생성할 때 생성 프로세스는 OpenShift Container Platform 설치 프로그램을 Hive 리소스와 함께 사용합니다. 이 절차를 완료한 후 클러스터 생성에 대한 질문이 있는 경우 OpenShift Container Platform 설명서의 GCP에 프로세스에 대한 자세한 내용은 설치를 참조하십시오.
1.5.4.6.1. 사전 요구 사항
GCP에서 클러스터를 생성하기 전에 다음 사전 요구 사항을 참조하십시오.
- 배포된 허브 클러스터가 있어야 합니다.
- GCP 인증 정보가 있어야 합니다. 자세한 내용은 Google Cloud Platform의 인증 정보 생성을 참조하십시오.
- GCP에 구성된 도메인이 있어야 합니다. 도메인 구성 방법에 대한 지침은 사용자 정의 도메인 설정을 참조하십시오.
- 사용자 이름과 암호가 포함된 GCP 로그인 인증 정보가 필요합니다.
- OpenShift Container Platform 이미지 풀 시크릿이 있어야 합니다. 이미지 풀 시크릿 사용을 참조하십시오.
참고: 클라우드 공급자의 클라우드 공급자 액세스 키를 변경하는 경우 다중 클러스터 엔진 Operator 콘솔에서 클라우드 공급자에 대한 해당 인증 정보도 수동으로 업데이트해야 합니다. 이는 관리 클러스터가 호스팅되는 클라우드 공급자에서 인증 정보가 만료되고 관리 클러스터를 삭제하려고 할 때 필요합니다.
1.5.4.6.2. 콘솔을 사용하여 클러스터 생성
다중 클러스터 엔진 Operator 콘솔에서 클러스터를 생성하려면 Infrastructure > Clusters 로 이동합니다. 클러스터 페이지에서 클러스터 생성 을 클릭하고 콘솔의 단계를 완료합니다.
참고: 이 절차는 클러스터를 생성하기 위한 것입니다. 가져올 기존 클러스터가 있는 경우 해당 단계에 대한 클러스터 가져오기 를 참조하십시오.
인증 정보를 생성해야 하는 경우 자세한 내용은 Google Cloud Platform의 인증 정보 생성 을 참조하십시오.
클러스터 이름은 클러스터의 호스트 이름에 사용됩니다. GCP 클러스터 이름 지정에 적용되는 몇 가지 제한 사항이 있습니다. 이러한 제한에는 goog 로 이름을 시작하거나 이름에 Google 과 유사한 문자 및 숫자 그룹이 포함되어 있지 않습니다. 전체 제한 목록은 버킷 이름 지정 지침을 참조하십시오.
중요: 클러스터를 생성할 때 컨트롤러는 클러스터 및 해당 리소스에 대한 네임스페이스를 생성합니다. 해당 네임스페이스에 해당 클러스터 인스턴스의 리소스만 포함해야 합니다. 클러스터를 삭제하면 네임스페이스와 모든 리소스가 삭제됩니다.
팁: 콘솔에서 정보를 입력할 때 콘텐츠 업데이트를 보려면 YAML 을 선택합니다.
기존 클러스터 세트에 클러스터를 추가하려면 클러스터에 추가하려면 클러스터에 대한 올바른 권한이 있어야 합니다. 클러스터를 생성할 때 cluster-admin 권한이 없는 경우 clusterset-admin 권한이 있는 클러스터 세트를 선택해야 합니다. 지정된 클러스터 세트에 대한 올바른 권한이 없는 경우 클러스터 생성에 실패합니다. 선택할 클러스터 설정 옵션이 없는 경우 클러스터 세트에 clusterset-admin 권한을 제공하려면 클러스터 관리자에게 문의하십시오.
모든 관리 클러스터는 관리 클러스터 세트와 연결되어 있어야 합니다. ManagedClusterSet 에 관리 클러스터를 할당하지 않으면 기본 관리 클러스터 세트에 자동으로 추가됩니다.
GCP 계정에 대해 선택한 인증 정보와 연결된 기본 DNS 도메인이 이미 있는 경우 해당 값이 필드에 채워집니다. 값을 덮어 쓰기하여 변경할 수 있습니다. 자세한 내용은 사용자 정의 도메인 설정을 참조하십시오. 이 이름은 클러스터의 호스트 이름에 사용됩니다.
릴리스 이미지는 클러스터를 생성하는 데 사용되는 OpenShift Container Platform 이미지의 버전을 식별합니다. 사용하려는 버전을 사용할 수 있는 경우 이미지 목록에서 이미지를 선택할 수 있습니다. 사용하려는 이미지가 표준 이미지가 아닌 경우 사용하려는 이미지의 URL을 입력할 수 있습니다. 릴리스 이미지에 대한 자세한 내용은 릴리스 이미지 릴리스를 참조하십시오.
노드 풀에는 컨트롤 플레인 풀과 작업자 풀이 포함됩니다. 컨트롤 플레인 노드는 클러스터 활동 관리를 공유합니다. 정보에는 다음 필드가 포함됩니다.
- region: 컨트롤 플레인 풀을 실행할 리전을 지정합니다. 가까운 리전은 더 빠른 성능을 제공할 수 있지만 더 멀리 있는 영역이 더 분산될 수 있습니다.
- CPU 아키텍처: 관리 클러스터의 아키텍처 유형이 허브 클러스터의 아키텍처와 동일하지 않으면 풀에 있는 시스템의 명령 집합 아키텍처 값을 입력합니다. 유효한 값은 amd64,ppc64le,s390x 및 arm64 입니다.
컨트롤 플레인 풀의 인스턴스 유형을 지정할 수 있습니다. 인스턴스 유형 및 크기를 생성한 후 변경할 수 있습니다.
작업자 풀에서 하나 이상의 작업자 노드를 생성하여 클러스터의 컨테이너 워크로드를 실행할 수 있습니다. 단일 작업자 풀에 있거나 여러 작업자 풀에 배포할 수 있습니다. 제로 작업자 노드가 지정되면 컨트롤 플레인 노드도 작업자 노드로 작동합니다. 정보에는 다음 필드가 포함됩니다.
- 인스턴스 유형: 인스턴스 유형을 만든 후 인스턴스의 유형과 크기를 변경할 수 있습니다.
- 노드 수: 이 설정은 작업자 풀을 정의할 때 필요합니다.
네트워킹 세부 정보가 필요하며 IPv6 주소를 사용하려면 여러 네트워크가 필요합니다. 네트워크 추가를 클릭하여 추가 네트워크를 추가할 수 있습니다.
인증 정보에 제공된 프록시 정보는 프록시 필드에 자동으로 추가됩니다. 정보를 그대로 사용하거나, 덮어쓰거나 프록시를 활성화하려면 정보를 추가할 수 있습니다. 다음 목록에는 프록시를 생성하는 데 필요한 정보가 포함되어 있습니다.
-
HTTP 프록시:
HTTP트래픽의 프록시로 사용해야 하는 URL입니다. -
HTTPS 프록시:
HTTPS트래픽에 사용해야 하는 보안 프록시 URL입니다. 값을 제공하지 않으면 HTTP 및HTTPS모두에HTTP프록시 URL -
프록시 사이트 없음: 프록시를 바이패스해야 하는 쉼표로 구분된 사이트 목록입니다. 마침표로 도메인 이름을 시작합니다
.를 해당 도메인에 있는 모든 하위 도메인을 포함합니다. 모든 대상에 대해 프록시를 바이패스하려면 별표*를 추가합니다. - 추가 신뢰 번들: HTTPS 연결을 프록시하는 데 필요한 하나 이상의 추가 CA 인증서입니다.
정보를 검토하고 선택적으로 클러스터를 생성하기 전에 사용자 지정할 때 YAML: On 을 선택하여 패널의 install-config.yaml 파일 콘텐츠를 볼 수 있습니다. 업데이트가 있는 경우 사용자 지정 설정으로 YAML 파일을 편집할 수 있습니다.
Kubernetes용 Red Hat Advanced Cluster Management를 사용하고 관리 클러스터 klusterlet을 특정 노드에서 실행하도록 구성하려면 선택 사항: 필요한 단계를 위해 특정 노드에서 실행되도록 klusterlet 구성 을 참조하십시오.
참고: 클러스터를 가져오기 위해 클러스터 세부 정보가 제공된 oc 명령을 실행할 필요가 없습니다. 클러스터를 생성할 때 다중 클러스터 엔진 Operator 관리 아래에 자동으로 구성됩니다.
클러스터에 액세스하는 방법에 대한 지침은 클러스터 액세스를 계속합니다.
1.5.4.7. VMware vSphere에서 클러스터 생성
다중 클러스터 엔진 Operator 콘솔을 사용하여 VMware vSphere에 Red Hat OpenShift Container Platform 클러스터를 배포할 수 있습니다.
클러스터를 생성할 때 생성 프로세스는 OpenShift Container Platform 설치 프로그램을 Hive 리소스와 함께 사용합니다. 이 절차를 완료한 후 클러스터 생성에 대한 질문이 있는 경우 OpenShift Container Platform 설명서의 vSphere에 프로세스에 대한 자세한 내용은 설치를 참조하십시오.
1.5.4.7.1. 사전 요구 사항
vSphere에서 클러스터를 생성하기 전에 다음 사전 요구 사항을 참조하십시오.
- OpenShift Container Platform 버전 4.13 이상에 배포된 허브 클러스터가 있어야 합니다.
- vSphere 인증 정보가 필요합니다. 자세한 내용은 VMware vSphere의 인증 정보 생성 을 참조하십시오.
- OpenShift Container Platform 이미지 풀 시크릿이 필요합니다. 이미지 풀 시크릿 사용을 참조하십시오.
배포 중인 VMware 인스턴스에 대한 다음 정보가 있어야 합니다.
- API 및 Ingress 인스턴스에 필요한 고정 IP 주소
DNS 레코드:
다음 API 기본 도메인은 정적 API VIP를 가리켜야 합니다.
api.<cluster_name>.<base_domain>다음 애플리케이션 기본 도메인은 Ingress VIP의 고정 IP 주소를 가리켜야 합니다.
*.apps.<cluster_name>.<base_domain>
1.5.4.7.2. 콘솔을 사용하여 클러스터 생성
다중 클러스터 엔진 Operator 콘솔에서 클러스터를 생성하려면 Infrastructure > Clusters 로 이동합니다. 클러스터 페이지에서 클러스터 생성 을 클릭하고 콘솔의 단계를 완료합니다.
참고: 이 절차는 클러스터를 생성하기 위한 것입니다. 가져올 기존 클러스터가 있는 경우 해당 단계에 대한 클러스터 가져오기 를 참조하십시오.
인증 정보를 생성해야 하는 경우 인증 정보 생성에 대한 자세한 내용은 VMware vSphere의 인증 정보 생성 을 참조하십시오.
클러스터 이름은 클러스터의 호스트 이름에 사용됩니다.
중요: 클러스터를 생성할 때 컨트롤러는 클러스터 및 해당 리소스에 대한 네임스페이스를 생성합니다. 해당 네임스페이스에 해당 클러스터 인스턴스의 리소스만 포함해야 합니다. 클러스터를 삭제하면 네임스페이스와 모든 리소스가 삭제됩니다.
팁: 콘솔에서 정보를 입력할 때 콘텐츠 업데이트를 보려면 YAML 을 선택합니다.
기존 클러스터 세트에 클러스터를 추가하려면 클러스터에 추가하려면 클러스터에 대한 올바른 권한이 있어야 합니다. 클러스터를 생성할 때 cluster-admin 권한이 없는 경우 clusterset-admin 권한이 있는 클러스터 세트를 선택해야 합니다. 지정된 클러스터 세트에 대한 올바른 권한이 없는 경우 클러스터 생성에 실패합니다. 선택할 클러스터 설정 옵션이 없는 경우 클러스터 세트에 clusterset-admin 권한을 제공하려면 클러스터 관리자에게 문의하십시오.
모든 관리 클러스터는 관리 클러스터 세트와 연결되어 있어야 합니다. ManagedClusterSet 에 관리 클러스터를 할당하지 않으면 기본 관리 클러스터 세트에 자동으로 추가됩니다.
vSphere 계정에 대해 구성한 선택한 인증 정보와 연결된 기본 도메인이 이미 있는 경우 해당 값이 필드에 채워집니다. 값을 덮어 쓰기하여 변경할 수 있습니다. 자세한 내용은 사용자 지정으로 vSphere에 클러스터 설치를 참조하십시오. 이 값은 사전 요구 사항 섹션에 나열된 DNS 레코드를 생성하는 데 사용한 이름과 일치해야 합니다. 이 이름은 클러스터의 호스트 이름에 사용됩니다.
릴리스 이미지는 클러스터를 생성하는 데 사용되는 OpenShift Container Platform 이미지의 버전을 식별합니다. 사용하려는 버전을 사용할 수 있는 경우 이미지 목록에서 이미지를 선택할 수 있습니다. 사용하려는 이미지가 표준 이미지가 아닌 경우 사용하려는 이미지의 URL을 입력할 수 있습니다. 릴리스 이미지에 대한 자세한 내용은 릴리스 이미지 릴리스를 참조하십시오.
참고: OpenShift Container Platform 버전 4.13 이상의 릴리스 이미지가 지원됩니다.
노드 풀에는 컨트롤 플레인 풀과 작업자 풀이 포함됩니다. 컨트롤 플레인 노드는 클러스터 활동 관리를 공유합니다. 정보에는 CPU 아키텍처 필드가 포함됩니다. 다음 필드 설명을 표시합니다.
- CPU 아키텍처: 관리 클러스터의 아키텍처 유형이 허브 클러스터의 아키텍처와 동일하지 않으면 풀에 있는 시스템의 명령 집합 아키텍처 값을 입력합니다. 유효한 값은 amd64,ppc64le,s390x 및 arm64 입니다.
작업자 풀에서 하나 이상의 작업자 노드를 생성하여 클러스터의 컨테이너 워크로드를 실행할 수 있습니다. 단일 작업자 풀에 있거나 여러 작업자 풀에 배포할 수 있습니다. 제로 작업자 노드가 지정되면 컨트롤 플레인 노드도 작업자 노드로 작동합니다. 정보에는 소켓당 코어,CPU,Memory_min MiB, _Disk 크기 (GiB) 및 노드 수가 포함됩니다.
네트워킹 정보가 필요합니다. IPv6를 사용하려면 여러 네트워크가 필요합니다. 필수 네트워킹 정보 중 일부는 다음 필드를 포함합니다.
- vSphere 네트워크 이름: VMware vSphere 네트워크 이름을 지정합니다.
API VIP: 내부 API 통신에 사용할 IP 주소를 지정합니다.
참고: 이 값은 사전 요구 사항 섹션에 나열된 DNS 레코드를 생성하는 데 사용한 이름과 일치해야 합니다. 제공되지 않는 경우
api.가 올바르게 확인되도록 DNS를 사전 구성해야 합니다.Ingress VIP: 인그레스 트래픽에 사용할 IP 주소를 지정합니다.
참고: 이 값은 사전 요구 사항 섹션에 나열된 DNS 레코드를 생성하는 데 사용한 이름과 일치해야 합니다. 제공되지 않는 경우
test.apps.가 올바르게 확인되도록 DNS를 사전 구성해야 합니다.
네트워크 추가를 클릭하여 추가 네트워크를 추가할 수 있습니다. IPv6 주소를 사용하는 경우 두 개 이상의 네트워크가 있어야 합니다.
인증 정보에 제공된 프록시 정보는 프록시 필드에 자동으로 추가됩니다. 정보를 그대로 사용하거나, 덮어쓰거나 프록시를 활성화하려면 정보를 추가할 수 있습니다. 다음 목록에는 프록시를 생성하는 데 필요한 정보가 포함되어 있습니다.
-
HTTP 프록시:
HTTP트래픽의 프록시로 사용해야 하는 URL을 지정합니다. -
HTTPS 프록시:
HTTPS트래픽에 사용해야 하는 보안 프록시 URL을 지정합니다. 값을 제공하지 않으면 HTTP 및HTTPS모두에HTTP프록시 URL -
프록시 사이트 없음: 프록시를 바이패스해야 하는 쉼표로 구분된 사이트 목록을 제공합니다. 마침표로 도메인 이름을 시작합니다
.를 해당 도메인에 있는 모든 하위 도메인을 포함합니다. 모든 대상에 대해 프록시를 바이패스하려면 별표*를 추가합니다. - 추가 신뢰 번들: HTTPS 연결을 프록시하는 데 필요한 하나 이상의 추가 CA 인증서입니다.
Disconnected installation 을 클릭하여 연결이 끊긴 설치를 정의합니다. VMware vSphere 공급자 및 연결이 끊긴 설치를 사용하여 클러스터를 생성할 때 미러 레지스트리에 액세스하는 데 인증서가 필요한 경우 인증 정보를 구성할 때 구성 섹션의 추가 신뢰 번들 필드에 또는 클러스터를 생성할 때 연결 해제된 설치 섹션에 입력해야 합니다.
자동화 템플릿 추가를 클릭하여 템플릿을 생성할 수 있습니다.
정보를 검토하고 선택적으로 클러스터를 생성하기 전에 사용자 지정할 때 YAML 스위치를 클릭하여 패널의 install-config.yaml 파일 콘텐츠를 볼 수 있습니다. 업데이트가 있는 경우 사용자 지정 설정으로 YAML 파일을 편집할 수 있습니다.
Kubernetes용 Red Hat Advanced Cluster Management를 사용하고 관리 클러스터 klusterlet을 특정 노드에서 실행하도록 구성하려면 선택 사항: 필요한 단계를 위해 특정 노드에서 실행되도록 klusterlet 구성 을 참조하십시오.
참고: 클러스터를 가져오기 위해 클러스터 세부 정보가 제공된 oc 명령을 실행할 필요가 없습니다. 클러스터를 생성할 때 다중 클러스터 엔진 Operator 관리 아래에 자동으로 구성됩니다.
클러스터에 액세스하는 방법에 대한 지침은 클러스터 액세스를 계속합니다.
1.5.4.8. Red Hat OpenStack Platform에서 클러스터 생성
다중 클러스터 엔진 Operator 콘솔을 사용하여 Red Hat OpenStack Platform에 Red Hat OpenShift Container Platform 클러스터를 배포할 수 있습니다.
클러스터를 생성할 때 생성 프로세스는 OpenShift Container Platform 설치 프로그램을 Hive 리소스와 함께 사용합니다. 이 절차를 완료한 후 클러스터 생성에 대한 질문이 있는 경우 OpenShift Container Platform 설명서의 OpenStack에 프로세스에 대한 자세한 내용은 설치를 참조하십시오.
1.5.4.8.1. 사전 요구 사항
Red Hat OpenStack Platform에서 클러스터를 생성하기 전에 다음 사전 요구 사항을 참조하십시오.
- OpenShift Container Platform 버전 4.6 이상에 배포된 허브 클러스터가 있어야 합니다.
- Red Hat OpenStack Platform 인증 정보가 있어야 합니다. 자세한 내용은 Red Hat OpenStack Platform의 인증 정보 생성을 참조하십시오.
- OpenShift Container Platform 이미지 풀 시크릿이 필요합니다. 이미지 풀 시크릿 사용을 참조하십시오.
배포 중인 Red Hat OpenStack Platform 인스턴스에 대한 다음 정보가 필요합니다.
-
컨트롤 플레인 및 작업자 인스턴스의 플레이버 이름(예:
m1.xlarge) - 유동 IP 주소를 제공하는 외부 네트워크의 네트워크 이름
- API 및 수신 인스턴스에 필요한 유동 IP 주소
DNS 레코드:
다음 API 기본 도메인은 API의 유동 IP 주소를 가리켜야 합니다.
api.<cluster_name>.<base_domain>다음 애플리케이션 기본 도메인은 ingress:app-name의 유동 IP 주소를 가리켜야 합니다.
*.apps.<cluster_name>.<base_domain>
-
컨트롤 플레인 및 작업자 인스턴스의 플레이버 이름(예:
1.5.4.8.2. 콘솔을 사용하여 클러스터 생성
다중 클러스터 엔진 Operator 콘솔에서 클러스터를 생성하려면 Infrastructure > Clusters 로 이동합니다. 클러스터 페이지에서 클러스터 생성 을 클릭하고 콘솔의 단계를 완료합니다.
참고: 이 절차는 클러스터를 생성하기 위한 것입니다. 가져올 기존 클러스터가 있는 경우 해당 단계에 대한 클러스터 가져오기 를 참조하십시오.
인증 정보를 생성해야 하는 경우 자세한 내용은 Red Hat OpenStack Platform의 인증 정보 생성 을 참조하십시오.
클러스터 이름은 클러스터의 호스트 이름에 사용됩니다. 이름에는 15자 미만이 포함되어야 합니다. 이 값은 인증 정보 사전 요구 사항 섹션에 나열된 DNS 레코드를 생성하는 데 사용한 이름과 일치해야 합니다.
중요: 클러스터를 생성할 때 컨트롤러는 클러스터 및 해당 리소스에 대한 네임스페이스를 생성합니다. 해당 네임스페이스에 해당 클러스터 인스턴스의 리소스만 포함해야 합니다. 클러스터를 삭제하면 네임스페이스와 모든 리소스가 삭제됩니다.
팁: 콘솔에서 정보를 입력할 때 콘텐츠 업데이트를 보려면 YAML 을 선택합니다.
기존 클러스터 세트에 클러스터를 추가하려면 클러스터에 추가하려면 클러스터에 대한 올바른 권한이 있어야 합니다. 클러스터를 생성할 때 cluster-admin 권한이 없는 경우 clusterset-admin 권한이 있는 클러스터 세트를 선택해야 합니다. 지정된 클러스터 세트에 대한 올바른 권한이 없는 경우 클러스터 생성에 실패합니다. 선택할 클러스터 설정 옵션이 없는 경우 클러스터 세트에 clusterset-admin 권한을 제공하려면 클러스터 관리자에게 문의하십시오.
모든 관리 클러스터는 관리 클러스터 세트와 연결되어 있어야 합니다. ManagedClusterSet 에 관리 클러스터를 할당하지 않으면 기본 관리 클러스터 세트에 자동으로 추가됩니다.
Red Hat OpenStack Platform 계정에 대해 구성한 선택한 인증 정보와 연결된 기본 DNS 도메인이 이미 있는 경우 해당 값이 필드에 채워집니다. 값을 덮어 쓰기하여 변경할 수 있습니다. 자세한 내용은 Red Hat OpenStack Platform 설명서의 도메인 관리를 참조하십시오. 이 이름은 클러스터의 호스트 이름에 사용됩니다.
릴리스 이미지는 클러스터를 생성하는 데 사용되는 OpenShift Container Platform 이미지의 버전을 식별합니다. 사용하려는 버전을 사용할 수 있는 경우 이미지 목록에서 이미지를 선택할 수 있습니다. 사용하려는 이미지가 표준 이미지가 아닌 경우 사용하려는 이미지의 URL을 입력할 수 있습니다. 릴리스 이미지에 대한 자세한 내용은 릴리스 이미지 릴리스를 참조하십시오. OpenShift Container Platform 버전 4.6.x 이상의 릴리스 이미지만 지원됩니다.
노드 풀에는 컨트롤 플레인 풀과 작업자 풀이 포함됩니다. 컨트롤 플레인 노드는 클러스터 활동 관리를 공유합니다. 관리 클러스터의 아키텍처 유형이 허브 클러스터의 아키텍처와 동일하지 않은 경우 풀에 있는 시스템의 명령 집합 아키텍처 값을 입력합니다. 유효한 값은 amd64,ppc64le,s390x 및 arm64 입니다.
컨트롤 플레인 풀에 인스턴스 유형을 추가해야 하지만 생성된 후 인스턴스의 유형과 크기를 변경할 수 있습니다.
작업자 풀에서 하나 이상의 작업자 노드를 생성하여 클러스터의 컨테이너 워크로드를 실행할 수 있습니다. 단일 작업자 풀에 있거나 여러 작업자 풀에 배포할 수 있습니다. 제로 작업자 노드가 지정되면 컨트롤 플레인 노드도 작업자 노드로 작동합니다. 정보에는 다음 필드가 포함됩니다.
- 인스턴스 유형: 인스턴스 유형을 만든 후 인스턴스의 유형과 크기를 변경할 수 있습니다.
- 노드 수: 작업자 풀의 노드 수를 지정합니다. 이 설정은 작업자 풀을 정의할 때 필요합니다.
클러스터에 네트워킹 세부 정보가 필요합니다. IPv4 네트워크에 대해 하나 이상의 네트워크에 대한 값을 제공해야 합니다. IPv6 네트워크의 경우 둘 이상의 네트워크를 정의해야 합니다.
네트워크 추가를 클릭하여 추가 네트워크를 추가할 수 있습니다. IPv6 주소를 사용하는 경우 두 개 이상의 네트워크가 있어야 합니다.
인증 정보에 제공된 프록시 정보는 프록시 필드에 자동으로 추가됩니다. 정보를 그대로 사용하거나, 덮어쓰거나 프록시를 활성화하려면 정보를 추가할 수 있습니다. 다음 목록에는 프록시를 생성하는 데 필요한 정보가 포함되어 있습니다.
-
HTTP 프록시:
HTTP트래픽의 프록시로 사용해야 하는 URL을 지정합니다. -
HTTPS 프록시:
HTTPS트래픽에 사용해야 하는 보안 프록시 URL입니다. 값을 제공하지 않으면 HTTP 및HTTPS모두에HTTP프록시 -
프록시 없음: 프록시를 바이패스해야 하는 쉼표로 구분된 사이트 목록을 정의합니다. 마침표로 도메인 이름을 시작합니다
.를 해당 도메인에 있는 모든 하위 도메인을 포함합니다. 모든 대상에 대해 프록시를 바이패스하려면 별표*를 추가합니다. - 추가 신뢰 번들: HTTPS 연결을 프록시하는 데 필요한 하나 이상의 추가 CA 인증서입니다.
연결 해제된 설치를 클릭하여 연결 해제된 설치 이미지를 정의할 수 있습니다. Red Hat OpenStack Platform 공급자 및 연결이 끊긴 설치를 사용하여 클러스터를 생성할 때 인증서가 미러 레지스트리에 액세스해야 하는 경우, 클러스터를 생성할 때 연결 해제된 설치 구성 섹션의 추가 신뢰 번들 필드에 입력해야 합니다.
정보를 검토하고 선택적으로 클러스터를 생성하기 전에 사용자 지정할 때 YAML 스위치를 클릭하여 패널의 install-config.yaml 파일 콘텐츠를 볼 수 있습니다. 업데이트가 있는 경우 사용자 지정 설정으로 YAML 파일을 편집할 수 있습니다.
내부 CA(인증 기관)를 사용하는 클러스터를 생성할 때 다음 단계를 완료하여 클러스터의 YAML 파일을 사용자 지정해야 합니다.
검토 단계에서 YAML 스위치를 사용하여 CA 인증서 번들로 목록 상단에
Secret오브젝트를 삽입합니다. 참고: Red Hat OpenStack Platform 환경에서 여러 기관에서 서명한 인증서를 사용하여 서비스를 제공하는 경우 번들에 필요한 모든 엔드포인트를 검증하기 위해 인증서가 포함되어야 합니다.ocp3이라는 클러스터 추가는 다음 예와 유사합니다.apiVersion: v1 kind: Secret type: Opaque metadata: name: ocp3-openstack-trust namespace: ocp3 stringData: ca.crt: | -----BEGIN CERTIFICATE----- <Base64 certificate contents here> -----END CERTIFICATE----- -----BEGIN CERTIFICATE----- <Base64 certificate contents here> -----END CERTIFICATE----Hive
ClusterDeployment오브젝트를 수정하여 다음 예와 유사하게spec.platform.openstack에서certificatesSecretRef값을 지정합니다.platform: openstack: certificatesSecretRef: name: ocp3-openstack-trust credentialsSecretRef: name: ocp3-openstack-creds cloud: openstack이전 예제에서는
clouds.yaml파일의 클라우드 이름이openstack이라고 가정합니다.
Kubernetes용 Red Hat Advanced Cluster Management를 사용하고 관리 클러스터 klusterlet을 특정 노드에서 실행하도록 구성하려면 선택 사항: 필요한 단계를 위해 특정 노드에서 실행되도록 klusterlet 구성 을 참조하십시오.
참고: 클러스터를 가져오기 위해 클러스터 세부 정보가 제공된 oc 명령을 실행할 필요가 없습니다. 클러스터를 생성할 때 다중 클러스터 엔진 Operator 관리 아래에 자동으로 구성됩니다.
클러스터에 액세스하는 방법에 대한 지침은 클러스터 액세스를 계속합니다.
1.5.4.9. Red Hat Virtualization에서 클러스터 생성 (더 이상 사용되지 않음)
더 이상 사용되지 않음: Red Hat Virtualization 인증 정보 및 클러스터 생성 기능은 더 이상 사용되지 않으며 더 이상 지원되지 않습니다.
다중 클러스터 엔진 Operator 콘솔을 사용하여 Red Hat Virtualization에서 Red Hat OpenShift Container Platform 클러스터를 생성할 수 있습니다.
클러스터를 생성할 때 생성 프로세스는 OpenShift Container Platform 설치 프로그램을 Hive 리소스와 함께 사용합니다. 이 절차를 완료한 후 클러스터 생성에 대한 질문이 있는 경우 OpenShift Container Platform 설명서에서 RHV에 설치 프로세스를 참조하십시오.
1.5.4.9.1. 사전 요구 사항
Red Hat Virtualization에서 클러스터를 생성하기 전에 다음 사전 요구 사항(더 이상 사용되지 않음)을 참조하십시오.
- 배포된 허브 클러스터가 있어야 합니다.
- Red Hat Virtualization 인증 정보가 필요합니다. 자세한 내용은 Red Hat Virtualization에 대한 인증 정보 생성 을 참조하십시오.
- oVirt Engine 가상 머신에 대해 구성된 도메인 및 가상 머신 프록시가 필요합니다. 도메인 구성 방법에 대한 지침은 Red Hat OpenShift Container Platform 설명서에서 RHV 에 설치를 참조하십시오.
- Red Hat 고객 포털 사용자 이름과 암호를 포함하는 Red Hat Virtualization 로그인 인증 정보가 있어야 합니다.
- OpenShift Container Platform 이미지 풀 시크릿이 필요합니다. Pull secret 페이지에서 풀 시크릿을 다운로드할 수 있습니다. 가져오기 보안에 대한 자세한 내용은 이미지 풀 시크릿 사용을 참조하십시오.
참고: 클라우드 공급자의 클라우드 공급자 액세스 키를 변경하는 경우 다중 클러스터 엔진 Operator 콘솔에서 클라우드 공급자에 대한 해당 인증 정보도 수동으로 업데이트해야 합니다. 이는 관리 클러스터가 호스팅되는 클라우드 공급자에서 인증 정보가 만료되고 관리 클러스터를 삭제하려고 할 때 필요합니다.
다음 DNS 레코드가 필요합니다.
다음 API 기본 도메인은 정적 API VIP를 가리켜야 합니다.
api.<cluster_name>.<base_domain>다음 애플리케이션 기본 도메인은 Ingress VIP의 고정 IP 주소를 가리켜야 합니다.
*.apps.<cluster_name>.<base_domain>
1.5.4.9.2. 콘솔을 사용하여 클러스터 생성
다중 클러스터 엔진 Operator 콘솔에서 클러스터를 생성하려면 Infrastructure > Clusters 로 이동합니다. 클러스터 페이지에서 클러스터 생성 을 클릭하고 콘솔의 단계를 완료합니다.
참고: 이 절차는 클러스터를 생성하기 위한 것입니다. 가져올 기존 클러스터가 있는 경우 해당 단계에 대한 클러스터 가져오기 를 참조하십시오.
인증 정보를 생성해야 하는 경우 자세한 내용은 Red Hat Virtualization에 대한 인증 정보 생성 을 참조하십시오.
클러스터 이름은 클러스터의 호스트 이름에 사용됩니다.
중요: 클러스터를 생성할 때 컨트롤러는 클러스터 및 해당 리소스에 대한 네임스페이스를 생성합니다. 해당 네임스페이스에 해당 클러스터 인스턴스의 리소스만 포함해야 합니다. 클러스터를 삭제하면 네임스페이스와 모든 리소스가 삭제됩니다.
팁: 콘솔에서 정보를 입력할 때 콘텐츠 업데이트를 보려면 YAML 을 선택합니다.
기존 클러스터 세트에 클러스터를 추가하려면 클러스터에 추가하려면 클러스터에 대한 올바른 권한이 있어야 합니다. 클러스터를 생성할 때 cluster-admin 권한이 없는 경우 clusterset-admin 권한이 있는 클러스터 세트를 선택해야 합니다. 지정된 클러스터 세트에 대한 올바른 권한이 없는 경우 클러스터 생성에 실패합니다. 선택할 클러스터 설정 옵션이 없는 경우 클러스터 세트에 clusterset-admin 권한을 제공하려면 클러스터 관리자에게 문의하십시오.
모든 관리 클러스터는 관리 클러스터 세트와 연결되어 있어야 합니다. ManagedClusterSet 에 관리 클러스터를 할당하지 않으면 기본 관리 클러스터 세트에 자동으로 추가됩니다.
Red Hat Virtualization 계정에 대해 구성한 선택한 인증 정보와 연결된 기본 DNS 도메인이 이미 있는 경우 해당 필드에 해당 값이 채워집니다. 값을 덮어쓰고 변경할 수 있습니다.
릴리스 이미지는 클러스터를 생성하는 데 사용되는 OpenShift Container Platform 이미지의 버전을 식별합니다. 사용하려는 버전을 사용할 수 있는 경우 이미지 목록에서 이미지를 선택할 수 있습니다. 사용하려는 이미지가 표준 이미지가 아닌 경우 사용하려는 이미지의 URL을 입력할 수 있습니다. 릴리스 이미지에 대한 자세한 내용은 릴리스 이미지 릴리스를 참조하십시오.
노드 풀에 대한 정보에는 컨트롤 플레인 풀의 코어, 소켓, 메모리 및 디스크 크기 수가 포함됩니다. 세 개의 컨트롤 플레인 노드는 클러스터 활동 관리를 공유합니다. 정보에는 Architecture 필드가 포함됩니다. 다음 필드 설명을 표시합니다.
- CPU 아키텍처: 관리 클러스터의 아키텍처 유형이 허브 클러스터의 아키텍처와 동일하지 않으면 풀에 있는 시스템의 명령 집합 아키텍처 값을 입력합니다. 유효한 값은 amd64,ppc64le,s390x 및 arm64 입니다.
작업자 풀 정보에는 작업자 풀에 대한 풀 이름, 코어 수, 메모리 할당, 디스크 크기 할당, 노드 수가 필요합니다. 작업자 풀 내의 작업자 노드는 단일 작업자 풀에 있거나 여러 작업자 풀에 분산될 수 있습니다.
사전 구성된 oVirt 환경에서 다음 네트워킹 세부 정보가 필요합니다.
- ovirt 네트워크 이름
- vNIC 프로파일 ID: 가상 네트워크 인터페이스 카드 프로필 ID를 지정합니다.
API VIP: 내부 API 통신에 사용할 IP 주소를 지정합니다.
참고: 이 값은 사전 요구 사항 섹션에 나열된 DNS 레코드를 생성하는 데 사용한 이름과 일치해야 합니다. 제공되지 않는 경우
api.가 올바르게 확인되도록 DNS를 사전 구성해야 합니다.Ingress VIP: 인그레스 트래픽에 사용할 IP 주소를 지정합니다.
참고: 이 값은 사전 요구 사항 섹션에 나열된 DNS 레코드를 생성하는 데 사용한 이름과 일치해야 합니다. 제공되지 않는 경우
test.apps.가 올바르게 확인되도록 DNS를 사전 구성해야 합니다.-
네트워크 유형: 기본값은
OpenShiftSDN입니다. OVNKubernetes는 IPv6 사용에 필요한 설정입니다. -
클러스터 네트워크 CIDR: Pod IP 주소에 사용할 수 있는 여러 IP 주소 목록입니다. 이 블록은 다른 네트워크 블록과 겹치지 않아야 합니다. 기본값은
10.128.0.0/14입니다. -
네트워크 호스트 접두사: 각 노드의 서브넷 접두사 길이를 설정합니다. 기본값은
23입니다. -
서비스 네트워크 CIDR: 서비스에 대한 IP 주소 블록을 제공합니다. 이 블록은 다른 네트워크 블록과 겹치지 않아야 합니다. 기본값은
172.30.0.0/16입니다. 머신 CIDR: OpenShift Container Platform 호스트에서 사용하는 IP 주소 블록을 제공합니다. 이 블록은 다른 네트워크 블록과 겹치지 않아야 합니다. 기본값은
10.0.0.0/16입니다.네트워크 추가를 클릭하여 추가 네트워크를 추가할 수 있습니다. IPv6 주소를 사용하는 경우 두 개 이상의 네트워크가 있어야 합니다.
인증 정보에 제공된 프록시 정보는 프록시 필드에 자동으로 추가됩니다. 정보를 그대로 사용하거나, 덮어쓰거나 프록시를 활성화하려면 정보를 추가할 수 있습니다. 다음 목록에는 프록시를 생성하는 데 필요한 정보가 포함되어 있습니다.
-
HTTP 프록시:
HTTP트래픽의 프록시로 사용해야 하는 URL을 지정합니다. -
HTTPS 프록시:
HTTPS트래픽에 사용해야 하는 보안 프록시 URL을 지정합니다. 값을 제공하지 않으면 HTTP 및HTTPS모두에HTTP프록시 URL -
프록시 사이트 없음: 프록시를 바이패스해야 하는 쉼표로 구분된 사이트 목록을 제공합니다. 마침표로 도메인 이름을 시작합니다
.를 해당 도메인에 있는 모든 하위 도메인을 포함합니다. 모든 대상에 대해 프록시를 바이패스하려면 별표*를 추가합니다. - 추가 신뢰 번들: HTTPS 연결을 프록시하는 데 필요한 하나 이상의 추가 CA 인증서입니다.
정보를 검토하고 선택적으로 클러스터를 생성하기 전에 사용자 지정할 때 YAML 스위치를 클릭하여 패널의 install-config.yaml 파일 콘텐츠를 볼 수 있습니다. 업데이트가 있는 경우 사용자 지정 설정으로 YAML 파일을 편집할 수 있습니다.
Kubernetes용 Red Hat Advanced Cluster Management를 사용하고 관리 클러스터 klusterlet을 특정 노드에서 실행하도록 구성하려면 선택 사항: 필요한 단계를 위해 특정 노드에서 실행되도록 klusterlet 구성 을 참조하십시오.
참고: 클러스터를 가져오기 위해 클러스터 세부 정보가 제공된 oc 명령을 실행할 필요가 없습니다. 클러스터를 생성할 때 다중 클러스터 엔진 Operator 관리 아래에 자동으로 구성됩니다.
클러스터에 액세스하는 방법에 대한 지침은 클러스터 액세스를 계속합니다.
1.5.4.10. 온-프레미스 환경에서 클러스터 생성
콘솔을 사용하여 온프레미스 Red Hat OpenShift Container Platform 클러스터를 생성할 수 있습니다. 클러스터는 VMware vSphere, Red Hat OpenStack, Red Hat Virtualization Platform (더 이상 사용되지 않음), Nutanix 또는 베어 메탈 환경에서 단일 노드 클러스터, 다중 노드 클러스터, 컴팩트 3 노드 클러스터일 수 있습니다.
플랫폼 값이 platform=none 으로 설정되어 있으므로 클러스터를 설치하는 플랫폼과의 통합은 없습니다. 단일 노드 OpenShift 클러스터에는 컨트롤 플레인 서비스와 사용자 워크로드를 호스팅하는 단일 노드만 포함됩니다. 이 구성은 클러스터의 리소스 공간을 최소화하려는 경우 유용할 수 있습니다.
Red Hat OpenShift Container Platform에서 사용할 수 있는 기능인 제로 터치 프로비저닝 기능을 사용하여 에지 리소스에 여러 개의 단일 노드 OpenShift 클러스터를 프로비저닝할 수도 있습니다. 제로 터치 프로비저닝에 대한 자세한 내용은 OpenShift Container Platform 설명서 의 네트워크 맨 위 엣지의 클러스터를 참조하십시오.
1.5.4.10.1. 사전 요구 사항
온-프레미스 환경에서 클러스터를 생성하기 전에 다음 사전 요구 사항을 참조하십시오.
- OpenShift Container Platform 버전 4.13 이상에 배포된 허브 클러스터가 있어야 합니다.
- 구성된 호스트의 호스트 인벤토리를 사용하여 구성된 인프라 환경이 필요합니다.
- 허브 클러스터(연결됨)에 대한 인터넷 액세스 권한이 있거나 클러스터를 생성하는 데 필요한 이미지를 검색하려면 인터넷에 연결되어 있는 내부 또는 미러 레지스트리에 대한 연결이 있어야 합니다.
- 구성된 온-프레미스 인증 정보가 필요합니다.
- OpenShift Container Platform 이미지 풀 시크릿이 필요합니다. 이미지 풀 시크릿 사용을 참조하십시오.
다음 DNS 레코드가 필요합니다.
다음 API 기본 도메인은 정적 API VIP를 가리켜야 합니다.
api.<cluster_name>.<base_domain>다음 애플리케이션 기본 도메인은 Ingress VIP의 고정 IP 주소를 가리켜야 합니다.
*.apps.<cluster_name>.<base_domain>
1.5.4.10.2. 콘솔을 사용하여 클러스터 생성
콘솔에서 클러스터를 생성하려면 다음 단계를 완료합니다.
- Infrastructure > Clusters 로 이동합니다.
- 클러스터 페이지에서 클러스터 생성 을 클릭하고 콘솔의 단계를 완료합니다.
- 클러스터 유형으로 Host inventory 를 선택합니다.
지원되는 설치에 다음 옵션을 사용할 수 있습니다.
- 기존 호스트 사용: 기존 호스트 인벤토리에 있는 호스트 목록에서 호스트를 선택합니다.
- 새 호스트 검색: 기존 인프라 환경에 없는 호스트를 검색합니다. 이미 인프라 환경에 있는 호스트를 사용하는 대신 자체 호스트를 검색합니다.
인증 정보를 생성해야 하는 경우 자세한 내용은 온-프레미스 환경에 대한 인증 정보 만들기 를 참조하십시오.
클러스터 이름은 클러스터의 호스트 이름에 사용됩니다.
중요: 클러스터를 생성할 때 컨트롤러는 클러스터 및 해당 리소스에 대한 네임스페이스를 생성합니다. 해당 네임스페이스에 해당 클러스터 인스턴스의 리소스만 포함해야 합니다. 클러스터를 삭제하면 네임스페이스와 모든 리소스가 삭제됩니다.
참고: 콘솔에서 정보를 입력할 때 콘텐츠 업데이트를 보려면 YAML 을 선택합니다.
기존 클러스터 세트에 클러스터를 추가하려면 클러스터에 추가하려면 클러스터에 대한 올바른 권한이 있어야 합니다. 클러스터를 생성할 때 cluster-admin 권한이 없는 경우 clusterset-admin 권한이 있는 클러스터 세트를 선택해야 합니다. 지정된 클러스터 세트에 대한 올바른 권한이 없는 경우 클러스터 생성에 실패합니다. 선택할 클러스터 설정 옵션이 없는 경우 클러스터 세트에 clusterset-admin 권한을 제공하려면 클러스터 관리자에게 문의하십시오.
모든 관리 클러스터는 관리 클러스터 세트와 연결되어 있어야 합니다. ManagedClusterSet 에 관리 클러스터를 할당하지 않으면 기본 관리 클러스터 세트에 자동으로 추가됩니다.
공급자 계정에 대해 구성한 선택한 인증 정보와 연결된 기본 DNS 도메인이 이미 있는 경우 해당 값이 해당 필드에 채워집니다. 값을 덮어 쓰기하여 변경할 수 있지만 클러스터를 생성한 후에는 이 설정을 변경할 수 없습니다. 공급자의 기본 도메인은 Red Hat OpenShift Container Platform 클러스터 구성 요소에 대한 경로를 생성하는 데 사용됩니다. 클러스터 공급자의 DNS에서 SOA(시작 기관) 레코드로 구성됩니다.
OpenShift 버전은 클러스터를 생성하는 데 사용되는 OpenShift Container Platform 이미지의 버전을 식별합니다. 사용하려는 버전을 사용할 수 있는 경우 이미지 목록에서 이미지를 선택할 수 있습니다. 사용하려는 이미지가 표준 이미지가 아닌 경우 사용하려는 이미지의 URL을 입력할 수 있습니다. 자세한 내용은 릴리스 이미지를 참조하십시오.
지원되는 OpenShift Container Platform 버전을 선택하면 Install single-node OpenShift 를 선택하는 옵션이 표시됩니다. 단일 노드 OpenShift 클러스터에는 컨트롤 플레인 서비스와 사용자 워크로드를 호스팅하는 단일 노드가 포함되어 있습니다. 생성된 후 단일 노드 OpenShift 클러스터에 노드를 추가하는 방법에 대한 자세한 내용은 인프라 환경으로 호스트 스케일링을 참조하십시오.
클러스터가 단일 노드 OpenShift 클러스터로 전환하려면 단일 노드 OpenShift 옵션을 선택합니다. 다음 단계를 완료하여 단일 노드 OpenShift 클러스터에 작업자를 추가할 수 있습니다.
- 콘솔에서 Infrastructure > Clusters 로 이동하여 생성 또는 액세스하려는 클러스터의 이름을 선택합니다.
- 작업 > 호스트 추가를 선택하여 추가 작업자를 추가합니다.
참고: 단일 노드 OpenShift 컨트롤 플레인에는 8개의 CPU 코어가 필요하지만 다중 노드 컨트롤 플레인 클러스터의 컨트롤 플레인 노드는 4개의 CPU 코어만 필요합니다.
클러스터를 검토하고 저장하면 클러스터가 초안 클러스터로 저장됩니다. 클러스터 페이지에서 클러스터 이름을 선택하여 생성 프로세스를 종료하고 나중에 프로세스를 완료할 수 있습니다.
기존 호스트를 사용하는 경우 호스트를 직접 선택할지 아니면 자동으로 선택하려는 경우 선택합니다. 호스트 수는 선택한 노드 수를 기반으로 합니다. 예를 들어 단일 노드 OpenShift 클러스터에는 하나의 호스트만 필요하지만 표준 3-노드 클러스터에는 3개의 호스트가 필요합니다.
이 클러스터의 요구 사항을 충족하는 사용 가능한 호스트의 위치는 호스트 위치 목록에 표시됩니다. 호스트 배포 및 고가용성 구성을 위해 여러 위치를 선택합니다.
기존 인프라 환경이 없는 새 호스트를 검색하는 경우 Discovery Image를 사용하여 호스트 인벤토리에 호스트 추가 단계를 완료합니다.
호스트가 바인딩되고 검증이 통과되면 다음 IP 주소를 추가하여 클러스터의 네트워킹 정보를 완료합니다.
API VIP: 내부 API 통신에 사용할 IP 주소를 지정합니다.
참고: 이 값은 사전 요구 사항 섹션에 나열된 DNS 레코드를 생성하는 데 사용한 이름과 일치해야 합니다. 제공되지 않는 경우
api.가 올바르게 확인되도록 DNS를 사전 구성해야 합니다.Ingress VIP: 인그레스 트래픽에 사용할 IP 주소를 지정합니다.
참고: 이 값은 사전 요구 사항 섹션에 나열된 DNS 레코드를 생성하는 데 사용한 이름과 일치해야 합니다. 제공되지 않는 경우
test.apps.가 올바르게 확인되도록 DNS를 사전 구성해야 합니다.
Kubernetes용 Red Hat Advanced Cluster Management를 사용하고 관리 클러스터 klusterlet을 특정 노드에서 실행하도록 구성하려면 선택 사항: 필요한 단계를 위해 특정 노드에서 실행되도록 klusterlet 구성 을 참조하십시오.
클러스터 탐색 페이지에서 설치 상태를 볼 수 있습니다.
클러스터에 액세스하는 방법에 대한 지침은 클러스터 액세스를 계속합니다.
1.5.4.10.3. 명령줄을 사용하여 클러스터 생성
중앙 인프라 관리 구성 요소 내에서 지원 설치 프로그램 기능을 사용하여 콘솔 없이 클러스터를 생성할 수도 있습니다. 이 절차를 완료하면 생성된 검색 이미지에서 호스트를 부팅할 수 있습니다. 절차 순서는 일반적으로 중요하지 않지만 필요한 순서가 있을 때 표시됩니다.
1.5.4.10.3.1. 네임스페이스 생성
리소스에 대한 네임스페이스가 필요합니다. 공유 네임스페이스의 모든 리소스를 유지하는 것이 더 편리합니다. 이 예제에서는 네임스페이스 이름에 sample-namespace 를 사용하지만 assisted-installer 를 제외한 모든 이름을 사용할 수 있습니다. 다음 파일을 생성하고 적용하여 네임스페이스를 생성합니다.
apiVersion: v1
kind: Namespace
metadata:
name: sample-namespace1.5.4.10.3.2. 네임스페이스에 풀 시크릿 추가
다음 사용자 정의 리소스를 생성하고 적용하여 네임스페이스에 풀 시크릿 을 추가합니다.
apiVersion: v1
kind: Secret
type: kubernetes.io/dockerconfigjson
metadata:
name: <pull-secret>
namespace: sample-namespace
stringData:
.dockerconfigjson: 'your-pull-secret-json' - 1
- 풀 시크릿의 콘텐츠를 추가합니다. 예를 들어
cloud.openshift.com,quay.io또는registry.redhat.io인증이 포함될 수 있습니다.
1.5.4.10.3.3. ClusterImageSet 생성
다음 사용자 정의 리소스를 생성하고 적용하여 클러스터의 OpenShift Container Platform 버전을 지정하는 CustomImageSet 을 생성합니다.
apiVersion: hive.openshift.io/v1
kind: ClusterImageSet
metadata:
name: openshift-v4.13.0
spec:
releaseImage: quay.io/openshift-release-dev/ocp-release:4.13.0-rc.0-x86_64
참고: hub 클러스터와 다른 아키텍처가 있는 관리 클러스터를 설치하는 경우 다중 아키텍처 ClusterImageSet 을 생성해야 합니다. 자세한 내용은 다른 아키텍처에 클러스터를 배포할 릴리스 이미지 생성을 참조하십시오.
1.5.4.10.3.4. ClusterDeployment 사용자 정의 리소스 생성
ClusterDeployment 사용자 정의 리소스 정의는 클러스터의 라이프사이클을 제어하는 API입니다. 클러스터 매개변수를 정의하는 spec.ClusterInstallRef 설정에서 AgentClusterInstall 사용자 정의 리소스를 참조합니다.
다음 예제를 기반으로 ClusterDeployment 사용자 정의 리소스를 생성하고 적용합니다.
apiVersion: hive.openshift.io/v1
kind: ClusterDeployment
metadata:
name: single-node
namespace: demo-worker4
spec:
baseDomain: hive.example.com
clusterInstallRef:
group: extensions.hive.openshift.io
kind: AgentClusterInstall
name: test-agent-cluster-install
version: v1beta1
clusterName: test-cluster
controlPlaneConfig:
servingCertificates: {}
platform:
agentBareMetal:
agentSelector:
matchLabels:
location: internal
pullSecretRef:
name: <pull-secret> 1.5.4.10.3.5. AgentClusterInstall 사용자 정의 리소스 생성
AgentClusterInstall 사용자 정의 리소스에서 클러스터에 대한 많은 요구 사항을 지정할 수 있습니다. 예를 들어 클러스터 네트워크 설정, 플랫폼, 컨트롤 플레인 수 및 작업자 노드를 지정할 수 있습니다.
다음 예와 유사한 사용자 정의 리소스를 생성하고 추가합니다.
apiVersion: extensions.hive.openshift.io/v1beta1
kind: AgentClusterInstall
metadata:
name: test-agent-cluster-install
namespace: demo-worker4
spec:
platformType: BareMetal
clusterDeploymentRef:
name: single-node
imageSetRef:
name: openshift-v4.13.0
networking:
clusterNetwork:
- cidr: 10.128.0.0/14
hostPrefix: 23
machineNetwork:
- cidr: 192.168.111.0/24
serviceNetwork:
- 172.30.0.0/16
provisionRequirements:
controlPlaneAgents: 1
sshPublicKey: ssh-rsa <your-public-key-here> - 1
- 클러스터가 생성되는 환경의 플랫폼 유형을 지정합니다. 유효한 값은
BareMetal,None,VSphere,Nutanix또는External입니다. - 2
ClusterDeployment리소스에 사용한 것과 동일한 이름을 사용합니다.- 3
- Generate a
ClusterImageSet에서 생성한 ClusterImageSet을 사용합니다. - 4
- SSH 공개 키를 지정하여 호스트를 설치한 후 액세스할 수 있습니다.
1.5.4.10.3.6. 선택 사항: NMStateConfig 사용자 정의 리소스 생성
NMStateConfig 사용자 지정 리소스는 정적 IP 주소와 같은 호스트 수준 네트워크 구성이 있는 경우에만 필요합니다. 이 사용자 정의 리소스를 포함하는 경우 InfraEnv 사용자 정의 리소스를 생성하기 전에 이 단계를 완료해야 합니다. NMStateConfig 는 InfraEnv 사용자 정의 리소스의 spec.nmStateConfigLabelSelector 값으로 참조합니다.
다음 예와 유사한 NMStateConfig 사용자 지정 리소스를 생성하고 적용합니다. 필요한 경우 값을 바꿉니다.
apiVersion: agent-install.openshift.io/v1beta1
kind: NMStateConfig
metadata:
name: <mynmstateconfig>
namespace: <demo-worker4>
labels:
demo-nmstate-label: <value>
spec:
config:
interfaces:
- name: eth0
type: ethernet
state: up
mac-address: 02:00:00:80:12:14
ipv4:
enabled: true
address:
- ip: 192.168.111.30
prefix-length: 24
dhcp: false
- name: eth1
type: ethernet
state: up
mac-address: 02:00:00:80:12:15
ipv4:
enabled: true
address:
- ip: 192.168.140.30
prefix-length: 24
dhcp: false
dns-resolver:
config:
server:
- 192.168.126.1
routes:
config:
- destination: 0.0.0.0/0
next-hop-address: 192.168.111.1
next-hop-interface: eth1
table-id: 254
- destination: 0.0.0.0/0
next-hop-address: 192.168.140.1
next-hop-interface: eth1
table-id: 254
interfaces:
- name: "eth0"
macAddress: "02:00:00:80:12:14"
- name: "eth1"
macAddress: "02:00:00:80:12:15"
참고: demo-nmstate-label 레이블 이름과 값을 InfraEnv 리소스 spec.nmStateConfigLabelSelector.matchLabels 필드에 포함해야 합니다.
1.5.4.10.3.7. InfraEnv 사용자 정의 리소스 생성
InfraEnv 사용자 지정 리소스는 검색 ISO를 생성하는 구성을 제공합니다. 이 사용자 정의 리소스 내에서 프록시 설정, ignition 덮어쓰기 및 NMState 레이블의 값을 식별합니다. 이 사용자 정의 리소스의 spec.nmStateConfigLabelSelector 값은 NMStateConfig 사용자 지정 리소스를 참조합니다.
참고: optional NMStateConfig 사용자 지정 리소스를 포함하려는 경우 InfraEnv 사용자 정의 리소스에서 참조해야 합니다. NMStateConfig 사용자 지정 리소스를 생성하기 전에 InfraEnv 사용자 지정 리소스를 생성하는 경우 InfraEnv 사용자 정의 리소스를 편집하여 NMStateConfig 사용자 지정 리소스를 참조하고 참조가 추가된 후 ISO를 다운로드합니다.
다음 사용자 정의 리소스를 생성하고 적용합니다.
apiVersion: agent-install.openshift.io/v1beta1
kind: InfraEnv
metadata:
name: myinfraenv
namespace: demo-worker4
spec:
clusterRef:
name: single-node
namespace: demo-worker4
pullSecretRef:
name: pull-secret
sshAuthorizedKey: <your_public_key_here>
nmStateConfigLabelSelector:
matchLabels:
demo-nmstate-label: value
proxy:
httpProxy: http://USERNAME:PASSWORD@proxy.example.com:PORT
httpsProxy: https://USERNAME:PASSWORD@proxy.example.com:PORT
noProxy: .example.com,172.22.0.0/24,10.10.0.0/24- 1
- ClusterDeployment 만들기 에서
clusterDeployment리소스 이름을 바꿉니다. - 2
1.5.4.10.3.7.1. InfraEnv 필드 테이블
| 필드 | 선택 사항 또는 필수 | 설명 |
|---|---|---|
|
| 선택 사항 | 검색 ISO 이미지에서 부팅될 때 호스트에 액세스할 수 있는 SSH 공개 키를 지정할 수 있습니다. |
|
| 선택 사항 |
호스트의 고정 IP, 브리지 및 본딩과 같은 고급 네트워크 구성을 통합합니다. 호스트 네트워크 구성은 선택한 라벨을 사용하여 하나 이상의 |
|
| 선택 사항 | proxy 섹션에서 검색하는 동안 호스트에 필요한 프록시 설정을 지정할 수 있습니다. |
참고: IPv6로 프로비저닝할 때 noProxy 설정에서 CIDR 주소 블록을 정의할 수 없습니다. 각 주소를 별도로 정의해야 합니다.
1.5.4.10.3.8. 검색 이미지에서 호스트 부팅
나머지 단계에서는 이전 절차의 결과 검색 ISO 이미지에서 호스트를 부팅하는 방법을 설명합니다.
다음 명령을 실행하여 네임스페이스에서 검색 이미지를 다운로드합니다.
curl --insecure -o image.iso $(kubectl -n sample-namespace get infraenvs.agent-install.openshift.io myinfraenv -o=jsonpath="{.status.isoDownloadURL}")- 검색 이미지를 가상 미디어, USB 드라이브 또는 다른 스토리지 위치로 이동하고 다운로드한 검색 이미지에서 호스트를 부팅합니다.
에이전트리소스는 자동으로 생성됩니다. 클러스터에 등록되어 있으며 검색 이미지에서 부팅되는 호스트를 나타냅니다.Agent사용자 정의 리소스를 승인하고 다음 명령을 실행하여 설치를 시작합니다.oc -n sample-namespace patch agents.agent-install.openshift.io 07e80ea9-200c-4f82-aff4-4932acb773d4 -p '{"spec":{"approved":true}}' --type merge에이전트 이름 및 UUID를 값으로 바꿉니다.
이전 명령의 출력에
APPROVED매개변수에true값이 포함된 대상 클러스터의 항목이 포함될 때 승인되었는지 확인할 수 있습니다.
1.5.4.10.4. 추가 리소스
- CLI를 사용하여 Nutanix 플랫폼에서 클러스터를 생성할 때 필요한 추가 단계는 Red Hat OpenShift Container Platform 설명서 의 API 및 Nutanix 후 설치 구성으로 Nutanix에 호스트 추가 를 참조하십시오.
- 제로 터치 프로비저닝에 대한 자세한 내용은 OpenShift Container Platform 설명서 의 네트워크 맨 위에 있는 클러스터를 참조하십시오.
- 이미지 풀 시크릿 사용을참조하십시오.
- 온-프레미스 환경에 대한 인증 정보 생성을 참조하십시오.
- 릴리스 이미지참조
- Discovery Image를 사용하여 호스트 인벤토리에 호스트 추가를참조하십시오.
1.5.4.11. 프록시 환경에서 클러스터 생성
허브 클러스터가 프록시 서버를 통해 연결된 경우 Red Hat OpenShift Container Platform 클러스터를 생성할 수 있습니다. 클러스터 생성이 성공하려면 다음 상황 중 하나가 true여야 합니다.
- 다중 클러스터 엔진 Operator는 프록시를 사용하여 인터넷에 대한 관리 클러스터 액세스 권한이 있는 관리형 클러스터와의 개인 네트워크 연결이 있습니다.
- 관리 클러스터는 인프라 공급자에 있지만 방화벽 포트를 사용하면 관리 클러스터에서 허브 클러스터로 통신할 수 있습니다.
프록시로 구성된 클러스터를 생성하려면 다음 단계를 완료합니다.
Secret에 저장된
install-configYAML에 다음 정보를 추가하여 hub 클러스터에서cluster-wide-proxy설정을 구성합니다.apiVersion: v1 kind: Proxy baseDomain: <domain> proxy: httpProxy: http://<username>:<password>@<proxy.example.com>:<port> httpsProxy: https://<username>:<password>@<proxy.example.com>:<port> noProxy: <wildcard-of-domain>,<provisioning-network/CIDR>,<BMC-address-range/CIDR>username을 프록시 서버의 사용자 이름으로 바꿉니다.프록시 서버에 액세스하려면
password를 암호로 바꿉니다.proxy.example.com을 프록시 서버의 경로로 바꿉니다.port를 프록시 서버로 통신 포트로 교체합니다.wildcard-of-domain을 프록시를 바이패스해야 하는 도메인의 항목으로 교체합니다.CIDR 표기법에서
provisioning-network/CIDR를 provisioning 네트워크의 IP 주소 및 할당된 IP 주소 수로 바꿉니다.CIDR 표기법에서
BMC-address-range/CIDR를 BMC 주소 및 주소 수로 바꿉니다.이전 값을 추가한 후 설정이 클러스터에 적용됩니다.
- 클러스터 생성 절차를 완료하여 클러스터를 프로비저닝합니다. 공급자 를 선택하려면 클러스터 생성 을 참조하십시오.
참고: 클러스터를 배포할 때 install-config YAML만 사용할 수 있습니다. 클러스터를 배포한 후 install-config YAML에 대한 새 변경 사항이 적용되지 않습니다. 배포 후 구성을 업데이트하려면 정책을 사용해야 합니다. 자세한 내용은 Pod 정책을 참조하십시오.
1.5.4.11.1. 추가 리소스
- 공급자를 선택하려면 클러스터 생성 을 참조하십시오.
- 클러스터를 배포한 후 구성을 변경하는 방법을 알아보려면 Pod 정책을 참조하십시오.
- 자세한 내용은 클러스터 라이프사이클 소개 를 참조하십시오.
- 프록시 환경에서 클러스터 생성으로 돌아갑니다.
1.5.4.12. AgentClusterInstall 프록시 구성
AgentClusterInstall 프록시 필드는 설치 중에 프록시 설정을 결정하고 생성된 클러스터에서 클러스터 전체 프록시 리소스를 생성하는 데 사용됩니다.
1.5.4.12.1. AgentClusterInstall구성
AgentClusterInstall 프록시를 구성하려면 AgentClusterInstall 리소스에 프록시 설정을 추가합니다. httpProxy,httpsProxy, noProxy:를 사용하여 다음 YAML 샘플을 참조하십시오.
apiVersion: extensions.hive.openshift.io/v1beta1
kind: AgentClusterInstall
spec:
proxy:
httpProxy: http://<username>:<password>@<proxy.example.com>:<port>
httpsProxy: https://<username>:<password>@<proxy.example.com>:<port>
noProxy: <wildcard-of-domain>,<provisioning-network/CIDR>,<BMC-address-range/CIDR> - 1
httpProxy는 HTTP 요청에 대한 프록시의 URL입니다. 사용자 이름 및 암호 값을 프록시 서버의 인증 정보로 바꿉니다.proxy.example.com을 프록시 서버의 경로로 바꿉니다.- 2
httpsProxy는 HTTPS 요청의 프록시 URL입니다. 값을 자격 증명으로 바꿉니다.port를 프록시 서버로 통신 포트로 교체합니다.- 3
noProxy는 프록시를 사용하지 않아야 하는 쉼표로 구분된 도메인 및 CIDR 목록입니다.wildcard-of-domain을 프록시를 바이패스해야 하는 도메인의 항목으로 교체합니다. CIDR 표기법에서provisioning-network/CIDR를 provisioning 네트워크의 IP 주소 및 할당된 IP 주소 수로 바꿉니다. CIDR 표기법에서BMC-address-range/CIDR를 BMC 주소 및 주소 수로 바꿉니다.
1.5.5. 클러스터 가져오기
다른 Kubernetes 클라우드 공급자에서 클러스터를 가져올 수 있습니다. 가져오기 후 대상 클러스터는 다중 클러스터 엔진 Operator 허브 클러스터의 관리 클러스터가 됩니다. 별도로 지정하지 않는 한 일반적으로 hub 클러스터 및 대상 관리 클러스터에 액세스할 수 있는 가져오기 작업을 완료할 수 있습니다.
허브 클러스터는 다른 허브 클러스터를 관리할 수 없지만 자체적으로 관리할 수 있습니다. 허브 클러스터는 자동으로 가져와 자체 관리하도록 구성됩니다. 허브 클러스터를 수동으로 가져올 필요가 없습니다.
허브 클러스터를 제거하고 다시 가져오려고 하는 경우 ManagedCluster 리소스에 local-cluster:true 레이블을 추가해야 합니다.
다음 주제를 읽고 클러스터를 관리할 수 있도록 클러스터 가져오기에 대해 자세히 알아보십시오.
필수 사용자 유형 또는 액세스 수준: 클러스터 관리자
1.5.5.1. 콘솔을 사용하여 관리 클러스터 가져오기
Kubernetes Operator용 다중 클러스터 엔진을 설치한 후 관리할 클러스터를 가져올 준비가 된 것입니다. 다음 주제를 계속 읽으십시오. 콘솔을 사용하여 관리 클러스터를 가져오는 방법에 대해 알아봅니다.
1.5.5.1.1. 사전 요구 사항
- 배포된 허브 클러스터입니다. 베어 메탈 클러스터를 가져오는 경우 hub 클러스터를 Red Hat OpenShift Container Platform 버전 4.13 이상에 설치해야 합니다.
- 관리할 클러스터입니다.
-
base64명령줄 툴입니다. -
OpenShift Container Platform에서 생성하지 않은 클러스터를 가져오는 경우 정의된
multiclusterhub.spec.imagePullSecret입니다. 이 시크릿은 Kubernetes Operator의 다중 클러스터 엔진을 설치할 때 생성될 수 있습니다. 이 보안을 정의하는 방법에 대한 자세한 내용은 사용자 정의 이미지 가져오기 보안을 참조하십시오.
필수 사용자 유형 또는 액세스 수준: 클러스터 관리자
1.5.5.1.2. 새 풀 시크릿 생성
새 풀 시크릿을 생성해야 하는 경우 다음 단계를 완료합니다.
- cloud.redhat.com 에서 Kubernetes 풀 시크릿을 다운로드합니다.
- 허브 클러스터의 네임스페이스에 풀 시크릿을 추가합니다.
다음 명령을 실행하여
open-cluster-management네임스페이스에 새 시크릿을 생성합니다.oc create secret generic pull-secret -n <open-cluster-management> --from-file=.dockerconfigjson=<path-to-pull-secret> --type=kubernetes.io/dockerconfigjsonopen-cluster-management를 hub 클러스터의 네임스페이스 이름으로 교체합니다. hub 클러스터의 기본 네임스페이스는open-cluster-management입니다.path-to-pull-secret을 다운로드한 풀 시크릿 경로로 교체합니다.시크릿을 가져올 때 관리 클러스터에 자동으로 복사됩니다.
-
이전에 설치한 에이전트가 가져올 클러스터에서 삭제되었는지 확인합니다. 오류를 방지하려면
open-cluster-management-agent및open-cluster-management-agent-addon네임스페이스를 제거해야 합니다. Red Hat OpenShift Dedicated 환경에서 가져오려면 다음 노트를 참조하십시오.
- Red Hat OpenShift Dedicated 환경에 hub 클러스터가 배포되어 있어야 합니다.
-
Red Hat OpenShift Dedicated의 기본 권한은 dedicated-admin이지만 네임스페이스를 생성할 수 있는 모든 권한이 포함되지는 않습니다. 다중 클러스터 엔진 Operator를 사용하여 클러스터를 가져오고 관리하려면
cluster-admin권한이 있어야 합니다.
-
이전에 설치한 에이전트가 가져올 클러스터에서 삭제되었는지 확인합니다. 오류를 방지하려면
1.5.5.1.3. 클러스터 가져오기
사용 가능한 각 클라우드 공급자에 대해 콘솔에서 기존 클러스터를 가져올 수 있습니다.
참고: 허브 클러스터는 다른 허브 클러스터를 관리할 수 없습니다. 허브 클러스터는 자동으로 자체적으로 가져오기 및 관리하도록 설정되어 있으므로 자체적으로 관리하기 위해 허브 클러스터를 수동으로 가져올 필요가 없습니다.
기본적으로 네임스페이스는 클러스터 이름과 네임스페이스에 사용되지만 변경할 수 있습니다.
중요: 클러스터를 생성할 때 컨트롤러는 클러스터 및 해당 리소스에 대한 네임스페이스를 생성합니다. 해당 네임스페이스에 해당 클러스터 인스턴스의 리소스만 포함해야 합니다. 클러스터를 삭제하면 네임스페이스와 모든 리소스가 삭제됩니다.
모든 관리 클러스터는 관리 클러스터 세트와 연결되어 있어야 합니다. ManagedClusterSet 에 관리 클러스터를 할당하지 않으면 클러스터가 기본 관리 클러스터 세트에 자동으로 추가됩니다.
다른 클러스터 세트에 클러스터를 추가하려면 클러스터 세트에 clusterset-admin 권한이 있어야 합니다. 클러스터를 가져올 때 cluster-admin 권한이 없는 경우 clusterset-admin 권한이 있는 클러스터 세트를 선택해야 합니다. 지정된 클러스터 세트에 대한 올바른 권한이 없는 경우 클러스터 가져오기에 실패합니다. 클러스터에서 선택할 수 있는 옵션이 없는 경우 클러스터 세트에 clusterset-admin 권한을 제공하려면 클러스터 관리자에게 문의하십시오.
OpenShift Container Platform Dedicated 클러스터를 가져오고 vendor=OpenShiftDedicated 의 레이블을 추가하여 공급 업체를 지정하지 않거나 vendor=auto-detect 에 대한 레이블을 추가하면 managed-by=platform 레이블이 클러스터에 자동으로 추가됩니다. 이 추가된 레이블을 사용하여 OpenShift Container Platform Dedicated 클러스터로 클러스터를 식별하고 OpenShift Container Platform Dedicated 클러스터를 그룹으로 검색할 수 있습니다.
다음 표에서는 클러스터를 가져오는 방법을 지정하는 가져오기 모드에 사용할 수 있는 옵션을 제공합니다.
| 수동으로 가져오기 명령 실행 | Red Hat Ansible Automation Platform 템플릿을 포함하여 콘솔에 정보를 작성하고 제출한 후 대상 클러스터에서 제공된 명령을 실행하여 클러스터를 가져옵니다. OpenShift Container Platform Dedicated 환경에서 클러스터를 가져오고 수동으로 가져오기 명령을 실행하는 경우 콘솔에 정보를 제공하기 전에 OpenShift Container Platform Dedicated 환경에서 가져오기 실행 명령 실행 단계를 수동으로 완료합니다. |
| 기존 클러스터의 서버 URL 및 API 토큰을 입력합니다. | 가져오려는 클러스터의 서버 URL 및 API 토큰을 제공합니다. 클러스터를 업그레이드할 때 실행할 Red Hat Ansible Automation Platform 템플릿을 지정할 수 있습니다. |
|
|
가져오려는 클러스터의 |
참고: Ansible Automation Platform 작업을 생성하고 실행하려면 OperatorHub에서 Red Hat Ansible Automation Platform Resource Operator가 설치되어 있어야 합니다.
클러스터 API 주소를 구성하려면 선택 사항: 클러스터 API 주소 구성을 참조하십시오.
관리 클러스터 klusterlet을 특정 노드에서 실행하도록 구성하려면 선택 사항: 특정 노드에서 실행되도록 klusterlet 구성을 참조하십시오.
1.5.5.1.3.1. OpenShift Container Platform Dedicated 환경에서 수동으로 가져오기 명령 실행
참고: Klusterlet OLM Operator 및 다음 단계는 더 이상 사용되지 않습니다.
OpenShift Container Platform Dedicated 환경에서 클러스터를 가져오고 가져오기 명령을 수동으로 실행하는 경우 몇 가지 추가 단계를 완료해야 합니다.
- 가져올 클러스터의 OpenShift Container Platform 콘솔에 로그인합니다.
-
가져오려는 클러스터에
open-cluster-management-agent및open-cluster-management네임스페이스 또는 프로젝트를 생성합니다. - OpenShift Container Platform 카탈로그에서 klusterlet Operator를 찾습니다.
open-cluster-management네임스페이스 또는 생성한 프로젝트에 klusterlet Operator를 설치합니다.중요:
open-cluster-management-agent네임스페이스에 Operator를 설치하지 마십시오.다음 단계를 완료하여 가져오기 명령에서 부트스트랩 시크릿을 추출합니다.
-
import-command라는 이름의 파일에 가져오기 명령을 붙여 넣습니다. 다음 명령을 실행하여 내용을 새 파일에 삽입합니다.
cat import-command | awk '{split($0,a,"&&"); print a[3]}' | awk '{split($0,a,"|"); print a[1]}' | sed -e "s/^ echo //" | base64 -d-
출력에서
bootstrap-hub-kubeconfig라는 이름으로 시크릿을 찾아 복사합니다. -
관리 클러스터의
open-cluster-management-agent네임스페이스에 보안을 적용합니다. 설치된 Operator에 예제를 사용하여 klusterlet 리소스를 생성합니다.
clusterName값을 가져오기 중에 설정한 클러스터 이름과 동일한 이름으로 변경합니다.참고:
관리 클러스터리소스가 허브에 성공적으로 등록되면 설치된 두 개의 klusterlet Operator가 있습니다. 하나의 klusterlet Operator는open-cluster-management네임스페이스에 있으며 다른 하나는open-cluster-management-agent네임스페이스에 있습니다. 여러 Operator가 있으면 klusterlet의 기능에는 영향을 미치지 않습니다.
-
- 클러스터 > 클러스터 가져오기 를 선택한 후 콘솔에 정보를 제공합니다.
1.5.5.1.3.2. 선택사항: 클러스터 API 주소 구성
oc get managedcluster 명령을 실행할 때 표에 표시되는 URL을 구성하여 클러스터 세부 정보 페이지에 있는 클러스터 API 주소를 선택적으로 구성하려면 다음 단계를 완료합니다.
-
cluster-admin권한이 있는 ID를 사용하여 허브 클러스터에 로그인합니다. -
대상 관리 클러스터에 대한
kubeconfig파일을 구성합니다. 다음 명령을 실행하여 가져오는 클러스터의 관리 클러스터 항목을 편집하고
cluster-name을 관리 클러스터의 이름으로 교체합니다.oc edit managedcluster <cluster-name>다음 예와 같이
ManagedClusterClientConfigs섹션을 YAML 파일의ManagedCluster사양에 추가합니다.spec: hubAcceptsClient: true managedClusterClientConfigs: - url: <https://api.new-managed.dev.redhat.com>1 - 1
- URL 값을 가져오는 관리 클러스터에 대한 외부 액세스를 제공하는 URL로 바꿉니다.
1.5.5.1.3.3. 선택 사항: 특정 노드에서 실행되도록 klusterlet 구성
관리 클러스터에 대한 nodeSelector 및 허용 오차 주석을 구성하여 관리 클러스터 klusterlet을 실행할 노드를 지정할 수 있습니다. 다음 설정을 구성하려면 다음 단계를 완료합니다.
- 콘솔의 클러스터 페이지에서 업데이트할 관리 클러스터를 선택합니다.
YAML 스위치를
On으로 설정하여 YAML 콘텐츠를 확인합니다.참고: YAML 편집기는 클러스터를 가져오거나 생성하는 경우에만 사용할 수 있습니다. 가져오기 또는 생성 후 관리형 클러스터 YAML 정의를 편집하려면 OpenShift Container Platform 명령줄 인터페이스 또는 Red Hat Advanced Cluster Management 검색 기능을 사용해야 합니다.
-
관리 클러스터 YAML 정의에
nodeSelector주석을 추가합니다. 이 주석의 키는open-cluster-management/nodeSelector입니다. 이 주석의 값은 JSON 형식의 문자열 맵입니다. 관리 클러스터 YAML 정의에
허용 오차항목을 추가합니다. 이 주석의 키는open-cluster-management/tolerations입니다. 이 주석의 값은 JSON 형식의 허용 오차 목록을 나타냅니다. 결과 YAML은 다음 예와 유사할 수 있습니다.apiVersion: cluster.open-cluster-management.io/v1 kind: ManagedCluster metadata: annotations: open-cluster-management/nodeSelector: '{"dedicated":"acm"}' open-cluster-management/tolerations: '[{"key":"dedicated","operator":"Equal","value":"acm","effect":"NoSchedule"}]'
KlusterletConfig 를 사용하여 관리 클러스터에 대한 nodeSelector 및 허용 오차 를 구성할 수도 있습니다. 다음 설정을 구성하려면 다음 단계를 완료합니다.
참고: KlusterletConfig 를 사용하는 경우 관리 클러스터는 관리 클러스터 주석의 설정 대신 KlusterletConfig 설정의 구성을 사용합니다.
다음 샘플 YAML 콘텐츠를 적용합니다. 필요한 경우 값을 바꿉니다.
apiVersion: config.open-cluster-management.io/v1alpha1 kind: KlusterletConfig metadata: name: <klusterletconfigName> spec: nodePlacement: nodeSelector: dedicated: acm tolerations: - key: dedicated operator: Equal value: acm effect: NoSchedule-
agent.open-cluster-management.io/klusterlet-config: '<klusterletconfigName> 주석을 관리 클러스터에 추가하고 <klusterletconfigName>을KlusterletConfig의 이름으로 교체합니다.
1.5.5.1.4. 가져온 클러스터 제거
가져온 클러스터와 관리 클러스터에서 생성된 open-cluster-management-agent-addon 을 제거하려면 다음 절차를 완료합니다.
클러스터 페이지에서 Actions > Detach cluster 를 클릭하여 관리에서 클러스터를 제거합니다.
참고: local-cluster 라는 허브 클러스터를 분리하려고 하면 disableHubSelfManagement 의 기본 설정은 false 입니다. 이 설정으로 인해 허브 클러스터가 분리될 때 자체적으로 다시 가져와서 자체적으로 관리되고 MultiClusterHub 컨트롤러를 조정합니다. hub 클러스터에서 분리 프로세스를 완료하고 다시 가져오는 데 몇 시간이 걸릴 수 있습니다. 프로세스가 완료될 때까지 기다리지 않고 허브 클러스터를 다시 가져오려면 다음 명령을 실행하여 multiclusterhub-operator Pod를 재시작하고 더 빨리 다시 가져올 수 있습니다.
oc delete po -n open-cluster-management `oc get pod -n open-cluster-management | grep multiclusterhub-operator| cut -d' ' -f1`
disableHubSelfManagement 값을 true 로 변경하여 hub 클러스터의 값을 자동으로 가져오지 않도록 할 수 있습니다. 자세한 내용은 disableHubSelfManagement 주제를 참조하십시오.
1.5.5.1.4.1. 추가 리소스
- 사용자 정의 이미지 가져오기 보안을 정의하는 방법에 대한 자세한 내용은 사용자 정의 이미지 가져오기 보안을 참조하십시오.
- disableHubSelfManagement 주제를 참조하십시오.
1.5.5.2. CLI를 사용하여 관리 클러스터 가져오기
Kubernetes Operator용 다중 클러스터 엔진을 설치한 후 Red Hat OpenShift Container Platform CLI를 사용하여 클러스터를 가져오고 관리할 수 있습니다. 자동 가져오기 보안을 사용하거나 수동 명령을 사용하여 CLI로 관리 클러스터를 가져오는 방법을 알아보려면 다음 주제를 계속 읽으십시오.
중요: 허브 클러스터는 다른 허브 클러스터를 관리할 수 없습니다. 허브 클러스터는 로컬 클러스터로 자동으로 가져오기 및 관리하도록 설정됩니다. 자체적으로 관리하기 위해 허브 클러스터를 수동으로 가져올 필요는 없습니다. 허브 클러스터를 제거하고 다시 가져오려고 하는 경우 local-cluster:true 레이블을 추가해야 합니다.
1.5.5.2.1. 사전 요구 사항
- 배포된 허브 클러스터입니다. 베어 메탈 클러스터를 가져오는 경우 hub 클러스터를 OpenShift Container Platform 버전 4.13 이상에 설치해야 합니다.
- 관리할 별도의 클러스터입니다.
-
OpenShift Container Platform CLI 버전 4.13 이상에서
oc명령을 실행합니다. OpenShift Container Platform CLI 설치 및 구성에 대한 정보는 OpenShift CLI 시작하기 를 참조하십시오. -
OpenShift Container Platform에서 생성하지 않은 클러스터를 가져오는 경우 정의된
multiclusterhub.spec.imagePullSecret입니다. 이 시크릿은 Kubernetes Operator의 다중 클러스터 엔진을 설치할 때 생성될 수 있습니다. 이 보안을 정의하는 방법에 대한 자세한 내용은 사용자 정의 이미지 가져오기 보안을 참조하십시오.
1.5.5.2.2. 지원되는 아키텍처
- Linux (x86_64, s390x, ppc64le)
- macOS
1.5.5.2.3. 클러스터 가져오기 준비
CLI를 사용하여 관리 클러스터를 가져오기 전에 다음 단계를 완료해야 합니다.
다음 명령을 실행하여 허브 클러스터에 로그인합니다.
oc login허브 클러스터에서 다음 명령을 실행하여 프로젝트와 네임스페이스를 생성합니다. <
cluster_name>에 정의된 클러스터 이름은 YAML 파일 및 명령에서 클러스터 네임스페이스로도 사용됩니다.oc new-project <cluster_name>중요:
cluster.open-cluster-management.io/managedCluster레이블이 관리 클러스터 네임스페이스에 자동으로 추가되고 제거됩니다. 관리 클러스터 네임스페이스에서 수동으로 추가하거나 제거하지 마십시오.다음 예제 콘텐츠를 사용하여
managed-cluster.yaml이라는 파일을 생성합니다.apiVersion: cluster.open-cluster-management.io/v1 kind: ManagedCluster metadata: name: <cluster_name> labels: cloud: auto-detect vendor: auto-detect spec: hubAcceptsClient: true클라우드및벤더의 값이자동 감지로 설정된 경우 Red Hat Advanced Cluster Management는 가져오는 클러스터에서 클라우드 및 벤더 유형을 자동으로 감지합니다. 선택적으로자동 감지값을 클러스터의 클라우드 및 벤더 값으로 교체할 수 있습니다. 다음 예제를 참조하십시오.cloud: Amazon vendor: OpenShift다음 명령을 실행하여
ManagedCluster리소스에 YAML 파일을 적용합니다.oc apply -f managed-cluster.yaml
1.5.5.2.4. 자동 가져오기 보안을 사용하여 클러스터 가져오기
자동 가져오기 보안을 사용하여 관리 클러스터를 가져오려면 클러스터의 kubeconfig 파일 또는 클러스터의 kube API 서버 및 토큰 쌍에 대한 참조가 포함된 시크릿을 생성해야 합니다. 자동 가져오기 보안을 사용하여 클러스터를 가져오려면 다음 단계를 완료합니다.
-
가져올 관리 클러스터의
kubeconfig파일 또는 kube API 서버 및 토큰을 검색합니다.kubeconfig파일 또는 kube API 서버 및 토큰을 찾을 위치를 알아보려면 Kubernetes 클러스터에 대한 설명서를 참조하십시오. ${CLUSTER_NAME} 네임스페이스에
auto-import-secret.yaml파일을 생성합니다.다음 템플릿과 유사한 콘텐츠를 사용하여
auto-import-secret.yaml이라는 YAML 파일을 생성합니다.apiVersion: v1 kind: Secret metadata: name: auto-import-secret namespace: <cluster_name> stringData: autoImportRetry: "5" # If you are using the kubeconfig file, add the following value for the kubeconfig file # that has the current context set to the cluster to import: kubeconfig: |- <kubeconfig_file> # If you are using the token/server pair, add the following two values instead of # the kubeconfig file: token: <Token to access the cluster> server: <cluster_api_url> type: Opaque다음 명령을 실행하여 <cluster_name> 네임스페이스에 YAML 파일을 적용합니다.
oc apply -f auto-import-secret.yaml참고: 기본적으로 자동 가져오기 보안은 한 번 사용되며 가져오기 프로세스가 완료되면 삭제됩니다. 자동 가져오기 보안을 유지하려면
managedcluster-import-controller.open-cluster-management.io/keeping-auto-import-secret을 시크릿에 추가합니다. 다음 명령을 실행하여 추가할 수 있습니다.oc -n <cluster_name> annotate secrets auto-import-secret managedcluster-import-controller.open-cluster-management.io/keeping-auto-import-secret=""
가져온 클러스터에 대한
JOINED및AVAILABLE상태를 확인합니다. hub 클러스터에서 다음 명령을 실행합니다.oc get managedcluster <cluster_name>클러스터에서 다음 명령을 실행하여 관리 클러스터에 로그인합니다.
oc login다음 명령을 실행하여 가져오기 중인 클러스터에서 Pod 상태를 확인할 수 있습니다.
oc get pod -n open-cluster-management-agent
1.5.5.2.5. 수동으로 클러스터 가져오기
중요: 가져오기 명령에는 가져온 각 관리 클러스터에 복사되는 풀 시크릿 정보가 포함되어 있습니다. 가져온 클러스터에 액세스할 수 있는 사용자는 풀 시크릿 정보도 볼 수 있습니다.
관리 클러스터를 수동으로 가져오려면 다음 단계를 완료합니다.
다음 명령을 실행하여 허브 클러스터에서 가져오기 컨트롤러에서 생성한
klusterlet-crd.yaml파일을 가져옵니다.oc get secret <cluster_name>-import -n <cluster_name> -o jsonpath={.data.crds\\.yaml} | base64 --decode > klusterlet-crd.yaml다음 명령을 실행하여 허브 클러스터의 가져오기 컨트롤러에서 생성한
import.yaml파일을 가져옵니다.oc get secret <cluster_name>-import -n <cluster_name> -o jsonpath={.data.import\\.yaml} | base64 --decode > import.yaml가져올 클러스터에서 다음 단계를 진행합니다.
다음 명령을 입력하여 가져오는 관리 클러스터에 로그인합니다.
oc login다음 명령을 실행하여 1단계에서 생성한
klusterlet-crd.yaml을 적용합니다.oc apply -f klusterlet-crd.yaml다음 명령을 실행하여 이전에 생성한
import.yaml파일을 적용합니다.oc apply -f import.yamlhub 클러스터에서 다음 명령을 실행하여 가져오는 관리 클러스터에 대한
JOINED및AVAILABLE상태를 확인할 수 있습니다.oc get managedcluster <cluster_name>
1.5.5.2.6. klusterlet 애드온 가져오기
KlusterletAddonConfig klusterlet 애드온 구성을 구현하여 관리 클러스터에서 다른 애드온을 활성화합니다. 다음 단계를 완료하여 구성 파일을 생성하고 적용합니다.
다음 예와 유사한 YAML 파일을 생성합니다.
apiVersion: agent.open-cluster-management.io/v1 kind: KlusterletAddonConfig metadata: name: <cluster_name> namespace: <cluster_name> spec: applicationManager: enabled: true certPolicyController: enabled: true iamPolicyController: enabled: true policyController: enabled: true searchCollector: enabled: true-
파일을
klusterlet-addon-config.yaml로 저장합니다. 다음 명령을 실행하여 YAML을 적용합니다.
oc apply -f klusterlet-addon-config.yaml추가 기능은 가져오는 관리 클러스터 상태가
AVAILABLE이면 설치됩니다.다음 명령을 실행하여 가져오는 클러스터에서 애드온의 Pod 상태를 확인할 수 있습니다.
oc get pod -n open-cluster-management-agent-addon
1.5.5.2.7. 명령줄 인터페이스를 사용하여 가져온 클러스터 제거
명령줄 인터페이스를 사용하여 관리 클러스터를 제거하려면 다음 명령을 실행합니다.
oc delete managedcluster <cluster_name>
& lt;cluster_name >을 클러스터 이름으로 바꿉니다.
1.5.5.3. 에이전트 등록을 사용하여 관리 클러스터 가져오기
Kubernetes Operator용 다중 클러스터 엔진을 설치한 후 에이전트 등록 끝점을 사용하여 클러스터를 가져오고 관리할 수 있습니다. 에이전트 등록 끝점을 사용하여 관리 클러스터를 가져오는 방법을 알아보려면 다음 주제를 계속 읽으십시오.
1.5.5.3.1. 사전 요구 사항
- 배포된 허브 클러스터입니다. 베어 메탈 클러스터를 가져오는 경우 hub 클러스터를 OpenShift Container Platform 버전 4.13 이상에 설치해야 합니다.
- 관리할 클러스터입니다.
-
base64명령줄 툴입니다. OpenShift Container Platform에서 생성하지 않은 클러스터를 가져오는 경우 정의된
multiclusterhub.spec.imagePullSecret입니다. 이 시크릿은 Kubernetes Operator의 다중 클러스터 엔진을 설치할 때 생성될 수 있습니다. 이 보안을 정의하는 방법에 대한 자세한 내용은 사용자 정의 이미지 가져오기 보안을 참조하십시오.새 보안을 생성해야 하는 경우 새 풀 시크릿 생성 을 참조하십시오.
1.5.5.3.2. 지원되는 아키텍처
- Linux (x86_64, s390x, ppc64le)
- macOS
1.5.5.3.3. 클러스터 가져오기
에이전트 등록 끝점을 사용하여 관리 클러스터를 가져오려면 다음 단계를 완료합니다.
hub 클러스터에서 다음 명령을 실행하여 에이전트 등록 서버 URL을 가져옵니다.
export agent_registration_host=$(oc get route -n multicluster-engine agent-registration -o=jsonpath="{.spec.host}")참고: 허브 클러스터가 클러스터 전체 프록시를 사용하는 경우 관리 클러스터가 액세스할 수 있는 URL을 사용하고 있는지 확인합니다.
다음 명령을 실행하여 cacert를 가져옵니다.
oc get configmap -n kube-system kube-root-ca.crt -o=jsonpath="{.data['ca\.crt']}" > ca.crt_참고:
kube-root-ca발행 엔드포인트를 사용하지 않는 경우kube-root-caCA 대신 공용agent-registrationAPI 끝점 CA를 사용합니다.다음 YAML 콘텐츠를 적용하여 에이전트 등록용 토큰을 가져옵니다.
apiVersion: v1 kind: ServiceAccount metadata: name: managed-cluster-import-agent-registration-sa namespace: multicluster-engine --- apiVersion: v1 kind: Secret type: kubernetes.io/service-account-token metadata: name: managed-cluster-import-agent-registration-sa-token namespace: multicluster-engine annotations: kubernetes.io/service-account.name: "managed-cluster-import-agent-registration-sa" --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: managedcluster-import-controller-agent-registration-client rules: - nonResourceURLs: ["/agent-registration/*"] verbs: ["get"] --- kind: ClusterRoleBinding apiVersion: rbac.authorization.k8s.io/v1 metadata: name: managed-cluster-import-agent-registration roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: managedcluster-import-controller-agent-registration-client subjects: - kind: ServiceAccount name: managed-cluster-import-agent-registration-sa namespace: multicluster-engine다음 명령을 실행하여 토큰을 내보냅니다.
export token=$(oc get secret -n multicluster-engine managed-cluster-import-agent-registration-sa-token -o=jsonpath='{.data.token}' | base64 -d)자동 승인을 활성화하고 다음 명령을 실행하여 콘텐츠를
cluster-manager에 패치합니다.oc patch clustermanager cluster-manager --type=merge -p '{"spec":{"registrationConfiguration":{"featureGates":[ {"feature": "ManagedClusterAutoApproval", "mode": "Enable"}], "autoApproveUsers":["system:serviceaccount:multicluster-engine:agent-registration-bootstrap"]}}}'참고: 자동 승인을 비활성화하고 관리 클러스터에서 인증서 서명 요청을 수동으로 승인할 수도 있습니다.
관리 클러스터로 전환하고 다음 명령을 실행하여 cacert를 가져옵니다.
curl --cacert ca.crt -H "Authorization: Bearer $token" https://$agent_registration_host/agent-registration/crds/v1 | oc apply -f -다음 명령을 실행하여 관리 클러스터를 hub 클러스터로 가져옵니다.
&
lt;clusterName>을 클러스터 이름으로 바꿉니다.선택 사항: &
lt;klusterletconfigName>을 KlusterletConfig의 이름으로 바꿉니다.curl --cacert ca.crt -H "Authorization: Bearer $token" https://$agent_registration_host/agent-registration/manifests/<clusterName>?klusterletconfig=<klusterletconfigName> | oc apply -f -
1.5.5.4. 온프레미스 Red Hat OpenShift Container Platform 클러스터 수동 가져오기
Kubernetes Operator용 다중 클러스터 엔진을 설치한 후 관리할 클러스터를 가져올 준비가 된 것입니다. 추가 노드를 추가할 수 있도록 기존 OpenShift Container Platform 클러스터를 가져올 수 있습니다. 다중 클러스터 엔진 Operator를 설치할 때 허브 클러스터가 자동으로 가져오기 때문에 다음 절차를 완료하지 않고도 허브 클러스터에 노드를 추가할 수 있습니다. 자세한 내용을 보려면 다음 항목을 계속 읽으십시오.
1.5.5.4.1. 사전 요구 사항
- 중앙 인프라 관리 서비스를 활성화합니다.
1.5.5.4.2. 클러스터 가져오기
정적 네트워크 또는 베어 메탈 호스트 없이 수동으로 OpenShift Container Platform 클러스터를 가져오려면 다음 단계를 완료하고 노드 추가를 준비합니다.
다음 YAML 콘텐츠를 적용하여 가져올 OpenShift Container Platform 클러스터의 네임스페이스를 생성합니다.
apiVersion: v1 kind: Namespace metadata: name: managed-cluster다음 YAML 콘텐츠를 적용하여 가져오는 OpenShift Container Platform 클러스터와 일치하는 ClusterImageSet이 있는지 확인합니다.
apiVersion: hive.openshift.io/v1 kind: ClusterImageSet metadata: name: openshift-v4.11.18 spec: releaseImage: quay.io/openshift-release-dev/ocp-release@sha256:22e149142517dfccb47be828f012659b1ccf71d26620e6f62468c264a7ce7863다음 YAML 콘텐츠를 적용하여 이미지에 액세스할 풀 시크릿을 추가합니다.
apiVersion: v1 kind: Secret type: kubernetes.io/dockerconfigjson metadata: name: pull-secret namespace: managed-cluster stringData: .dockerconfigjson: <pull-secret-json>1 - 1
- <pull-secret-json>을 풀 시크릿 JSON으로 바꿉니다.
OpenShift Container Platform 클러스터에서 hub 클러스터에
kubeconfig를 복사합니다.다음 명령을 실행하여 OpenShift Container Platform 클러스터에서
kubeconfig를 가져옵니다.kubeconfig를 가져오는 클러스터로 설정되어 있는지 확인합니다.oc get secret -n openshift-kube-apiserver node-kubeconfigs -ojson | jq '.data["lb-ext.kubeconfig"]' --raw-output | base64 -d > /tmp/kubeconfig.some-other-cluster참고: 사용자 정의 도메인을 통해 클러스터 API에 액세스하는 경우 먼저
certificate-authority-data필드에 사용자 정의 인증서를 추가하고 사용자 정의 도메인과 일치하도록server필드를 변경하여 이kubeconfig를 편집해야 합니다.다음 명령을 실행하여
kubeconfig를 hub 클러스터에 복사합니다.kubeconfig가 hub 클러스터로 설정되어 있는지 확인합니다.oc -n managed-cluster create secret generic some-other-cluster-admin-kubeconfig --from-file=kubeconfig=/tmp/kubeconfig.some-other-cluster
다음 YAML 콘텐츠를 적용하여
AgentClusterInstall사용자 지정 리소스를 생성합니다. 필요한 경우 값을 바꿉니다.apiVersion: extensions.hive.openshift.io/v1beta1 kind: AgentClusterInstall metadata: name: <your-cluster-name>1 namespace: <managed-cluster> spec: networking: userManagedNetworking: true clusterDeploymentRef: name: <your-cluster> imageSetRef: name: openshift-v4.11.18 provisionRequirements: controlPlaneAgents:2 sshPublicKey: <"">3 다음 YAML 콘텐츠를 적용하여
ClusterDeployment을 생성합니다. 필요한 경우 값을 바꿉니다.apiVersion: hive.openshift.io/v1 kind: ClusterDeployment metadata: name: <your-cluster-name>1 namespace: managed-cluster spec: baseDomain: <redhat.com>2 installed: <true>3 clusterMetadata: adminKubeconfigSecretRef: name: <your-cluster-name-admin-kubeconfig>4 clusterID: <"">5 infraID: <"">6 clusterInstallRef: group: extensions.hive.openshift.io kind: AgentClusterInstall name: your-cluster-name-install version: v1beta1 clusterName: your-cluster-name platform: agentBareMetal: pullSecretRef: name: pull-secretInfraEnv사용자 지정 리소스를 추가하여 다음 YAML 콘텐츠를 적용하여 클러스터에 추가할 새 호스트를 검색합니다. 필요한 경우 값을 바꿉니다.참고: 고정 IP 주소를 사용하지 않는 경우 다음 예제에 추가 구성이 필요할 수 있습니다.
apiVersion: agent-install.openshift.io/v1beta1 kind: InfraEnv metadata: name: your-infraenv namespace: managed-cluster spec: clusterRef: name: your-cluster-name namespace: managed-cluster pullSecretRef: name: pull-secret sshAuthorizedKey: ""
| 필드 | 선택 사항 또는 필수 | 설명 |
|---|---|---|
|
| 선택 사항 |
late binding을 사용하는 경우 |
|
| 선택 사항 |
선택적 |
가져오기에 성공하면 ISO 파일을 다운로드할 URL이 표시됩니다. 다음 명령을 실행하여 ISO 파일을 다운로드하여 <url>을 표시되는 URL로 바꿉니다.
참고: 베어 메탈 호스트를 사용하여 호스트 검색을 자동화할 수 있습니다.
oc get infraenv -n managed-cluster some-other-infraenv -ojson | jq ".status.<url>" --raw-output | xargs curl -k -o /storage0/isos/some-other.iso-
선택 사항: OpenShift Container Platform 클러스터에서 정책과 같은 Red Hat 고급 클러스터 관리 기능을 사용하려면
ManagedCluster리소스를 생성합니다.ManagedCluster리소스의 이름이ClusterDeplpoyment리소스의 이름과 일치하는지 확인합니다.ManagedCluster리소스가 없으면 콘솔에서 클러스터 상태가분리됩니다.
1.5.5.5. 가져오기를 위해 관리 클러스터에서 이미지 레지스트리 지정
가져오는 관리 클러스터에서 이미지 레지스트리를 재정의해야 할 수 있습니다. ManagedClusterImageRegistry 사용자 정의 리소스 정의를 생성하여 이 작업을 수행할 수 있습니다.
ManagedClusterImageRegistry 사용자 정의 리소스 정의는 네임스페이스 범위 리소스입니다.
ManagedClusterImageRegistry 사용자 정의 리소스 정의는 배치를 선택할 수 있도록 관리 클러스터 세트를 지정하지만 사용자 정의 이미지 레지스트리의 다른 이미지가 필요합니다. 관리 클러스터가 새 이미지로 업데이트되면 식별을 위해 각 관리 클러스터에 다음 레이블이 추가됩니다. open-cluster-management.io/image-registry=<namespace>.<managedClusterImageRegistryName > .
다음 예제는 ManagedClusterImageRegistry 사용자 정의 리소스 정의를 보여줍니다.
apiVersion: imageregistry.open-cluster-management.io/v1alpha1
kind: ManagedClusterImageRegistry
metadata:
name: <imageRegistryName>
namespace: <namespace>
spec:
placementRef:
group: cluster.open-cluster-management.io
resource: placements
name: <placementName>
pullSecret:
name: <pullSecretName>
registries:
- mirror: <mirrored-image-registry-address>
source: <image-registry-address>
- mirror: <mirrored-image-registry-address>
source: <image-registry-address>- 1
- 을 관리 클러스터 세트를 선택하는 동일한 네임스페이스에서 배치 이름으로 바꿉니다.
- 2
- 을 사용자 정의 이미지 레지스트리에서 이미지를 가져오는 데 사용되는 풀 시크릿의 이름으로 바꿉니다.
- 3
- 각
소스및미러레지스트리의 값을 나열합니다.mirrored-image-registry-address및image-registry-address를 레지스트리의 각미러및소스값 값으로 바꿉니다.-
예 1:
registry.redhat.io/rhacm2라는 소스 이미지 레지스트리를localhost:5000/rhacm2로 교체하고registry.redhat.io/multicluster-engine을localhost:5000/multicluster-engine으로 교체하려면 다음 예제를 사용합니다.
-
예 1:
registries:
- mirror: localhost:5000/rhacm2/
source: registry.redhat.io/rhacm2
- mirror: localhost:5000/multicluster-engine
source: registry.redhat.io/multicluster-engine예 2: 소스 이미지
registry.redhat.io/rhacm2/registration-rhel8-operator를localhost:5000/rhacm2-registration-rhel8-operator로 교체하려면 다음 예제를 사용합니다.registries: - mirror: localhost:5000/rhacm2-registration-rhel8-operator source: registry.redhat.io/rhacm2/registration-rhel8-operator
중요: 에이전트 등록을 사용하여 관리 클러스터를 가져오는 경우 이미지 레지스트리가 포함된 KlusterletConfig 를 생성해야 합니다. 다음 예제를 참조하십시오. 필요한 경우 값을 바꿉니다.
apiVersion: config.open-cluster-management.io/v1alpha1
kind: KlusterletConfig
metadata:
name: <klusterletconfigName>
spec:
pullSecret:
namespace: <pullSecretNamespace>
name: <pullSecretName>
registries:
- mirror: <mirrored-image-registry-address>
source: <image-registry-address>
- mirror: <mirrored-image-registry-address>
source: <image-registry-address>자세한 내용은 에이전트 등록 끝점을 사용하여 관리 클러스터 가져오기 를 참조하십시오.
1.5.5.5.1. ManagedClusterImageRegistry가 있는 클러스터 가져오기
ManagedClusterImageRegistry 사용자 정의 리소스 정의로 사용자 지정된 클러스터를 가져오려면 다음 단계를 완료합니다.
클러스터를 가져올 네임스페이스에 풀 시크릿을 생성합니다. 이러한 단계의 경우 네임스페이스는
myNamespace입니다.$ kubectl create secret docker-registry myPullSecret \ --docker-server=<your-registry-server> \ --docker-username=<my-name> \ --docker-password=<my-password>생성한 네임스페이스에 배치를 생성합니다.
apiVersion: cluster.open-cluster-management.io/v1beta1 kind: Placement metadata: name: myPlacement namespace: myNamespace spec: clusterSets: - myClusterSet tolerations: - key: "cluster.open-cluster-management.io/unreachable" operator: Exists참고: 배치에서 클러스터를 선택할 수 있으려면
연결할 수 없는허용 오차가 필요합니다.ManagedClusterSet리소스를 생성하여 네임스페이스에 바인딩합니다.apiVersion: cluster.open-cluster-management.io/v1beta2 kind: ManagedClusterSet metadata: name: myClusterSet --- apiVersion: cluster.open-cluster-management.io/v1beta2 kind: ManagedClusterSetBinding metadata: name: myClusterSet namespace: myNamespace spec: clusterSet: myClusterSet네임스페이스에
ManagedClusterImageRegistry사용자 정의 리소스 정의를 생성합니다.apiVersion: imageregistry.open-cluster-management.io/v1alpha1 kind: ManagedClusterImageRegistry metadata: name: myImageRegistry namespace: myNamespace spec: placementRef: group: cluster.open-cluster-management.io resource: placements name: myPlacement pullSecret: name: myPullSecret registry: myRegistryAddress- 콘솔에서 관리 클러스터를 가져와서 관리 클러스터 세트에 추가합니다.
-
open-cluster-management.io/image-registry=myNamespace.myImageRegistry레이블이 관리 클러스터에 추가된 후 관리 클러스터에서 가져오기 명령을 복사하여 실행합니다.
1.5.6. 클러스터에 액세스
생성 및 관리되는 Red Hat OpenShift Container Platform 클러스터에 액세스하려면 다음 단계를 완료하십시오.
- 콘솔에서 Infrastructure > Clusters 로 이동하여 생성 또는 액세스하려는 클러스터의 이름을 선택합니다.
Reveal 인증 정보를 선택하여 클러스터의 사용자 이름 및 암호를 확인합니다. 클러스터에 로그인할 때 사용할 값을 확인합니다.
참고: 가져온 클러스터에는 Reveal credentials 옵션을 사용할 수 없습니다.
- Console URL 을 선택하여 클러스터에 연결합니다.
- 3단계에서 찾은 사용자 ID 및 암호를 사용하여 클러스터에 로그인합니다.
1.5.7. 관리형 클러스터 확장
생성한 클러스터의 경우 가상 머신 크기 및 노드 수와 같은 관리형 클러스터 사양을 사용자 지정하고 조정할 수 있습니다. 클러스터 배포를 위해 설치 관리자 프로비저닝 인프라를 사용하는 경우 다음 옵션을 참조하십시오.
클러스터 배포를 위해 중앙 인프라 관리를 사용하는 경우 다음 옵션을 참조하십시오.
1.5.7.1. MachinePool로 스케일링
다중 클러스터 엔진 Operator로 프로비저닝하는 클러스터의 경우 MachinePool 리소스가 자동으로 생성됩니다. MachinePool 을 사용하여 가상 머신 크기 및 노드 수와 같은 관리형 클러스터 사양을 추가로 사용자 지정하고 크기를 조정할 수 있습니다.
-
베어 메탈 클러스터에서는
MachinePool리소스 사용이 지원되지 않습니다. -
MachinePool리소스는 hub 클러스터의 Kubernetes 리소스로, 관리 클러스터에서MachineSet리소스를 함께 그룹화합니다. -
MachinePool리소스는 영역 구성, 인스턴스 유형 및 루트 스토리지를 포함하여 머신 리소스 세트를 균일하게 구성합니다. -
MachinePool을 사용하면 원하는 수의 노드를 수동으로 구성하거나 관리 클러스터에서 노드 자동 스케일링을 구성할 수 있습니다.
1.5.7.1.1. 자동 스케일링 구성
자동 스케일링을 구성하면 트래픽이 낮을 때 축소하여 리소스 비용을 낮추고 리소스 수요가 많을 때 리소스가 충분한지 확인하기 위해 확장 가능한 클러스터의 유연성을 제공합니다.
콘솔을 사용하여
MachinePool리소스에서 자동 스케일링을 활성화하려면 다음 단계를 완료합니다.- 탐색에서 Infrastructure > Clusters 를 선택합니다.
- 대상 클러스터의 이름을 클릭하고 머신 풀 탭을 선택합니다.
- 머신 풀 페이지의 대상 머신 풀의 옵션 메뉴에서 자동 스케일링 사용을 선택합니다.
최소 및 최대 머신 세트 복제본 수를 선택합니다. 머신 세트 복제본은 클러스터의 노드에 직접 매핑됩니다.
크기 조정을 클릭한 후 콘솔을 반영하는 데 몇 분이 걸릴 수 있습니다. 머신 풀 알림에서 머신 풀 보기를 클릭하여 스케일링 작업의 상태를 볼 수 있습니다.
명령줄을 사용하여
MachinePool리소스에서 자동 스케일링을 활성화하려면 다음 단계를 완료합니다.다음 명령을 입력하여 머신 풀 목록을 보고
managed-cluster-namespace를 대상 관리 클러스터의 네임스페이스로 교체합니다.oc get machinepools -n <managed-cluster-namespace>다음 명령을 입력하여 머신 풀의 YAML 파일을 편집합니다.
oc edit machinepool <MachinePool-resource-name> -n <managed-cluster-namespace>-
MachinePool-resource-name을MachinePool리소스의 이름으로 바꿉니다. -
managed-cluster-namespace를 관리 클러스터의 네임스페이스 이름으로 교체합니다.
-
-
YAML 파일에서
spec.replicas필드를 삭제합니다. -
spec.autoscaling.minReplicas설정 및spec.autoscaling.maxReplicas필드를 리소스 YAML에 추가합니다. -
minReplicas설정에 최소 복제본 수를 추가합니다. -
maxReplicas설정에 최대 복제본 수를 추가합니다. - 파일을 저장하여 변경 사항을 제출합니다.
1.5.7.1.2. 자동 스케일링 비활성화
콘솔 또는 명령줄을 사용하여 자동 스케일링을 비활성화할 수 있습니다.
콘솔을 사용하여 자동 스케일링을 비활성화하려면 다음 단계를 완료합니다.
- 탐색에서 Infrastructure > Clusters 를 선택합니다.
- 대상 클러스터의 이름을 클릭하고 머신 풀 탭을 선택합니다.
- 시스템 풀 페이지의 대상 시스템 풀의 옵션 메뉴에서 자동 스케일링 비활성화 를 선택합니다.
원하는 머신 세트 복제본 수를 선택합니다. 머신 세트 복제본은 클러스터의 노드와 직접 매핑됩니다.
스케일 을 클릭하면 콘솔에 표시되는 데 몇 분이 걸릴 수 있습니다. 머신 풀 탭의 알림에서 머신 보기를 클릭하여 스케일링 상태를 볼 수 있습니다.
명령줄을 사용하여 자동 스케일링을 비활성화하려면 다음 단계를 완료합니다.
다음 명령을 입력하여 머신 풀 목록을 확인합니다.
oc get machinepools -n <managed-cluster-namespace>managed-cluster-namespace를 대상 관리 클러스터의 네임스페이스로 교체합니다.다음 명령을 입력하여 머신 풀의 YAML 파일을 편집합니다.
oc edit machinepool <name-of-MachinePool-resource> -n <namespace-of-managed-cluster>name-of-MachinePool-resource를MachinePool리소스의 이름으로 교체합니다.namespace-of-managed-cluster를 관리 클러스터의 네임스페이스 이름으로 교체합니다.-
YAML 파일에서
spec.autoscaling필드를 삭제합니다. -
spec.replicas필드를 리소스 YAML에 추가합니다. -
replicas설정에 복제본 수를 추가합니다. - 파일을 저장하여 변경 사항을 제출합니다.
1.5.7.1.3. 수동 스케일링 활성화
콘솔과 명령줄에서 수동으로 확장할 수 있습니다.
1.5.7.1.3.1. 콘솔을 사용하여 수동 스케일링 활성화
콘솔을 사용하여 MachinePool 리소스를 확장하려면 다음 단계를 완료합니다.
-
MachinePool이 활성화된 경우 자동 스케일링을 비활성화합니다. 이전 단계를 참조하십시오. - 콘솔에서 인프라 > 클러스터를 클릭합니다.
- 대상 클러스터의 이름을 클릭하고 머신 풀 탭을 선택합니다.
- 머신 풀 페이지의 대상 머신 풀 의 옵션 메뉴에서 머신 풀 스케일링을 선택합니다.
- 원하는 머신 세트 복제본 수를 선택합니다. 머신 세트 복제본은 클러스터의 노드와 직접 매핑됩니다. 크기 조정을 클릭한 후 콘솔을 반영하는 데 몇 분이 걸릴 수 있습니다. 머신 풀 탭 알림에서 머신 보기를 클릭하여 스케일링 작업의 상태를 볼 수 있습니다.
1.5.7.1.3.2. 명령줄을 사용하여 수동 스케일링 활성화
명령줄을 사용하여 MachinePool 리소스를 확장하려면 다음 단계를 완료합니다.
다음 명령을 입력하여 머신 풀 목록을 보고 <
managed-cluster-namespace>를 대상 관리 클러스터 네임스페이스의 네임스페이스로 교체합니다.oc get machinepools -n <managed-cluster-namespace>다음 명령을 입력하여 머신 풀의 YAML 파일을 편집합니다.
oc edit machinepool <MachinePool-resource-name> -n <managed-cluster-namespace>-
MachinePool-resource-name을MachinePool리소스의 이름으로 바꿉니다. -
managed-cluster-namespace를 관리 클러스터의 네임스페이스 이름으로 교체합니다.
-
-
YAML 파일에서
spec.autoscaling필드를 삭제합니다. -
YAML 파일의
spec.replicas필드를 원하는 복제본 수로 수정합니다. - 파일을 저장하여 변경 사항을 제출합니다.
1.5.7.2. OpenShift Container Platform 클러스터에 작업자 노드 추가
중앙 인프라 관리를 사용하는 경우 추가 프로덕션 환경 노드를 추가하여 OpenShift Container Platform 클러스터를 사용자 지정할 수 있습니다.
필수 액세스: 관리자
1.5.7.2.1. 사전 요구 사항
관리 클러스터 API를 신뢰하는 데 필요한 새 CA 인증서가 있어야 합니다.
1.5.7.2.2. 유효한 kubeconfig생성
프로덕션 환경 작업자 노드를 OpenShift Container Platform 클러스터에 추가하기 전에 유효한 kubeconfig 가 있는지 확인해야 합니다.
관리 클러스터의 API 인증서가 변경되면 다음 단계를 완료하여 kubeconfig 를 새 CA 인증서로 업데이트합니다.
다음 명령을 실행하여
clusterDeployment의kubeconfig가 유효한지 확인합니다. <kubeconfig_name>을 현재kubeconfig이름으로 바꾸고 <cluster_name>을 클러스터 이름으로 바꿉니다.export <kubeconfig_name>=$(oc get cd $<cluster_name> -o "jsonpath={.spec.clusterMetadata.adminKubeconfigSecretRef.name}") oc extract secret/$<kubeconfig_name> --keys=kubeconfig --to=- > original-kubeconfig oc --kubeconfig=original-kubeconfig get node다음 오류 메시지가 표시되면
kubeconfig시크릿을 업데이트해야 합니다. 오류 메시지가 표시되지 않으면 계속 작업자 노드 추가:Unable to connect to the server: tls: failed to verify certificate: x509: certificate signed by unknown authoritykubeconfigcertificate-authority-data필드에서base64로 인코딩된 인증서 번들을 가져오고 다음 명령을 실행하여 디코딩합니다.echo <base64 encoded blob> | base64 --decode > decoded-existing-certs.pem원본 파일을 복사하여 업데이트된
kubeconfig파일을 생성합니다. 다음 명령을 실행하고 <new_kubeconfig_name>을 새kubeconfig파일의 이름으로 바꿉니다.cp original-kubeconfig <new_kubeconfig_name>다음 명령을 실행하여 디코딩된 pem에 새 인증서를 추가합니다.
cat decoded-existing-certs.pem new-ca-certificate.pem | openssl base64 -A-
이전 명령의
base64출력을 텍스트 편집기를 사용하여 새kubeconfig파일의certificate-authority-data키 값으로 추가합니다. 새
kubeconfig로 API를 쿼리하여 새kubeconfig가 유효한지 확인합니다. 다음 명령을 실행합니다. <new_kubeconfig_name>을 새kubeconfig파일의 이름으로 바꿉니다.KUBECONFIG=<new_kubeconfig_name> oc get nodes성공적인 출력이 표시되면
kubeconfig가 유효합니다.다음 명령을 실행하여 Red Hat Advanced Cluster Management Hub 클러스터에서
kubeconfig시크릿을 업데이트합니다. <new_kubeconfig_name>을 새kubeconfig파일의 이름으로 바꿉니다.oc patch secret $original-kubeconfig --type='json' -p="[{'op': 'replace', 'path': '/data/kubeconfig', 'value': '$(openssl base64 -A -in <new_kubeconfig_name>)'},{'op': 'replace', 'path': '/data/raw-kubeconfig', 'value': '$(openssl base64 -A -in <new_kubeconfig_name>)'}]"
1.5.7.2.3. 작업자 노드 추가
유효한 kubeconfig 가 있는 경우 다음 단계를 완료하여 OpenShift Container Platform 클러스터에 프로덕션 환경 작업자 노드를 추가합니다.
이전에 다운로드한 ISO에서 작업자 노드로 사용할 시스템을 부팅합니다.
참고: 작업자 노드가 OpenShift Container Platform 작업자 노드의 요구 사항을 충족하는지 확인합니다.
다음 명령을 실행한 후 에이전트가 등록할 때까지 기다립니다.
watch -n 5 "oc get agent -n managed-cluster"에이전트 등록이 성공하면 에이전트가 나열됩니다. 설치를 위한 에이전트를 승인합니다. 이 작업은 몇 분 정도 걸릴 수 있습니다.
참고: 에이전트가 나열되지 않은 경우 Ctrl 및 C를 눌러
watch명령을 종료한 다음 작업자 노드에 로그인하여 문제를 해결합니다.늦은 바인딩을 사용하는 경우 다음 명령을 실행하여 보류 중인 바인딩되지 않은 에이전트를 OpenShift Container Platform 클러스터와 연결합니다. late binding을 사용하지 않는 경우 5 단계로 건너뜁니다.
oc get agent -n managed-cluster -ojson | jq -r '.items[] | select(.spec.approved==false) |select(.spec.clusterDeploymentName==null) | .metadata.name'| xargs oc -n managed-cluster patch -p '{"spec":{"clusterDeploymentName":{"name":"some-other-cluster","namespace":"managed-cluster"}}}' --type merge agent다음 명령을 실행하여 설치 대기 중인 에이전트를 승인합니다.
oc get agent -n managed-cluster -ojson | jq -r '.items[] | select(.spec.approved==false) | .metadata.name'| xargs oc -n managed-cluster patch -p '{"spec":{"approved":true}}' --type merge agent
작업자 노드의 설치를 기다립니다. 작업자 노드 설치가 완료되면 작업자 노드는 가입 프로세스를 시작하기 위해 작업자 노드에 CSR(인증서 서명 요청)과 함께 관리 클러스터에 연결합니다. CSR이 자동으로 서명됩니다.
1.5.7.3. 관리 클러스터에 컨트롤 플레인 노드 추가
정상 또는 비정상적인 관리 클러스터에 컨트롤 플레인 노드를 추가하여 실패한 컨트롤 플레인을 교체할 수 있습니다.
필수 액세스: 관리자
1.5.7.3.1. 정상 관리형 클러스터에 컨트롤 플레인 노드 추가
정상 관리 클러스터에 컨트롤 플레인 노드를 추가하려면 다음 단계를 완료합니다.
- 새 컨트롤 플레인 노드의 OpenShift Container Platform 클러스터에 작업자 노드 추가 단계를 완료합니다.
Discovery ISO를 사용하여 노드를 추가하는 경우 에이전트를 승인하기 전에 에이전트를
master로 설정합니다. 다음 명령을 실행합니다.oc patch agent <AGENT-NAME> -p '{"spec":{"role": "master"}}' --type=merge참고: CSR은 자동으로 승인되지 않습니다.
BareMetalHostBareMetalHost주석에 다음 행을 추가합니다.bmac.agent-install.openshift.io/role: master- OpenShift Container Platform 설명서의 지원 설치 관리자에서 정상 클러스터에 기본 컨트롤 플레인 노드 설치 단계를 따르십시오.
1.5.7.3.2. 비정상 관리형 클러스터에 컨트롤 플레인 노드 추가
비정상적인 관리 클러스터에 컨트롤 플레인 노드를 추가하려면 다음 단계를 완료합니다.
- 비정상 컨트롤 플레인 노드의 에이전트를 제거합니다.
- 배포에 제로터치 프로비저닝 흐름을 사용한 경우 베어 메탈 호스트를 제거합니다.
- 새 컨트롤 플레인 노드의 OpenShift Container Platform 클러스터에 작업자 노드 추가 단계를 완료합니다.
다음 명령을 실행하여 에이전트를 승인하기 전에 에이전트를
master로 설정합니다.oc patch agent <AGENT-NAME> -p '{"spec":{"role": "master"}}' --type=merge참고: CSR은 자동으로 승인되지 않습니다.
- OpenShift Container Platform 설명서의 지원 설치 관리자의 비정상 클러스터에 기본 컨트롤 플레인 노드 설치 단계를 따르십시오.
1.5.8. 생성된 클러스터 완화
리소스를 절약하기 위해 다중 클러스터 엔진 Operator를 사용하여 생성된 클러스터를 구성할 수 있습니다. 하이버네이션 클러스터의 경우 실행 중인 리소스보다 리소스가 훨씬 적기 때문에 클러스터를 하이버네이트 상태로 전환하여 공급자 비용을 줄일 수 있습니다. 이 기능은 다음 환경에서 다중 클러스터 엔진 Operator가 생성한 클러스터에만 적용됩니다.
- Amazon Web Services
- Microsoft Azure
- Google Cloud Platform
1.5.8.1. 콘솔을 사용하여 클러스터 Hibernate
콘솔을 사용하여 다중 클러스터 엔진 Operator가 생성한 클러스터를 hibernate하려면 다음 단계를 완료하십시오.
- 탐색 메뉴에서 Infrastructure > Clusters 를 선택합니다. Manage clusters 탭이 선택되어 있는지 확인합니다.
- 클러스터의 옵션 메뉴에서 Hibernate 클러스터를 선택합니다. 참고: Hibernate 클러스터 옵션을 사용할 수 없는 경우 클러스터를 최대로 설정할 수 없습니다. 이는 클러스터를 가져오고 다중 클러스터 엔진 Operator에 의해 생성되지 않을 때 발생할 수 있습니다.
프로세스가 완료되면 Clusters 페이지의 클러스터 상태는 Hibernating 입니다.
팁: 클러스터 페이지에서 hibernate를 선택하고 작업 > Hibernate 클러스터를 선택하여 여러 클러스터를 구성할 수 있습니다.
선택한 클러스터가 손상되고 있습니다.
1.5.8.2. CLI를 사용하여 클러스터 Hibernate
CLI를 사용하여 다중 클러스터 엔진 Operator가 생성한 클러스터를 hibernate하려면 다음 단계를 완료하십시오.
다음 명령을 입력하여 hibernate로 클러스터 설정을 편집합니다.
oc edit clusterdeployment <name-of-cluster> -n <namespace-of-cluster>name-of-cluster를 hibernate할 클러스터 이름으로 교체합니다.hibernate로
namespace-of-cluster를 클러스터의 네임스페이스로 바꿉니다.-
spec.powerState의 값을Hibernating로 변경합니다. 다음 명령을 입력하여 클러스터 상태를 확인합니다.
oc get clusterdeployment <name-of-cluster> -n <namespace-of-cluster> -o yamlname-of-cluster를 hibernate할 클러스터 이름으로 교체합니다.hibernate로
namespace-of-cluster를 클러스터의 네임스페이스로 바꿉니다.클러스터 완화 프로세스가 완료되면 클러스터 유형 값은
type=Hibernating입니다.
선택한 클러스터가 손상되고 있습니다.
1.5.8.3. 콘솔을 사용하여 하이버네이트 클러스터의 정상적인 작동 다시 시작
콘솔을 사용하여 하이버네이트 클러스터의 정상적인 작업을 다시 시작하려면 다음 단계를 완료하십시오.
- 탐색 메뉴에서 Infrastructure > Clusters 를 선택합니다. Manage clusters 탭이 선택되어 있는지 확인합니다.
- 재개할 클러스터의 옵션 메뉴에서 Resume 클러스터를 선택합니다.
프로세스가 완료되면 클러스터 페이지의 클러스터 상태는 Ready 입니다.
팁: 클러스터 페이지에서 다시 시작하려는 클러스터를 선택하고 작업 > 클러스터 재배치를 선택하여 여러 클러스터를 재개할 수 있습니다.
선택한 클러스터가 정상적인 작업을 다시 시작합니다.
1.5.8.4. CLI를 사용하여 하이버네이트 클러스터의 정상적인 작동 다시 시작
CLI를 사용하여 하이버네이트 클러스터의 정상적인 작업을 다시 시작하려면 다음 단계를 완료하십시오.
다음 명령을 입력하여 클러스터 설정을 편집합니다.
oc edit clusterdeployment <name-of-cluster> -n <namespace-of-cluster>name-of-cluster를 hibernate할 클러스터 이름으로 교체합니다.hibernate로
namespace-of-cluster를 클러스터의 네임스페이스로 바꿉니다.-
spec.powerState의 값을Running으로 변경합니다. 다음 명령을 입력하여 클러스터 상태를 확인합니다.
oc get clusterdeployment <name-of-cluster> -n <namespace-of-cluster> -o yamlname-of-cluster를 hibernate할 클러스터 이름으로 교체합니다.hibernate로
namespace-of-cluster를 클러스터의 네임스페이스로 바꿉니다.클러스터 재시작 프로세스가 완료되면 클러스터 유형 값은
type=Running입니다.
선택한 클러스터가 정상적인 작업을 다시 시작합니다.
1.5.9. 클러스터 업그레이드
다중 클러스터 엔진 Operator로 관리하려는 Red Hat OpenShift Container Platform 클러스터를 생성한 후 다중 클러스터 엔진 Operator 콘솔을 사용하여 해당 클러스터를 관리 클러스터가 사용하는 버전 채널에서 사용 가능한 최신 마이너 버전으로 업그레이드할 수 있습니다.
연결된 환경에서는 콘솔에서 업그레이드가 필요한 각 클러스터에 대해 제공되는 알림으로 업데이트가 자동으로 식별됩니다.
참고:
주요 버전으로 업그레이드하려면 해당 버전으로 업그레이드하기 위한 모든 사전 요구 사항을 충족해야 합니다. 콘솔을 사용하여 클러스터를 업그레이드하기 전에 관리 클러스터에서 버전 채널을 업데이트해야 합니다.
관리 클러스터에서 버전 채널을 업데이트하면 다중 클러스터 엔진 Operator 콘솔에 업그레이드에 사용 가능한 최신 버전이 표시됩니다.
이 업그레이드 방법은 Ready 상태인 OpenShift Container Platform 관리 클러스터에서만 작동합니다.
중요: 다중 클러스터 엔진 Operator 콘솔을 사용하여 Red Hat OpenShift Dedicated에서 Red Hat OpenShift Kubernetes Service 관리 클러스터 또는 OpenShift Container Platform 관리 클러스터를 업그레이드할 수 없습니다.
연결된 환경에서 클러스터를 업그레이드하려면 다음 단계를 완료합니다.
- 탐색 메뉴에서 Infrastructure > Clusters 로 이동합니다. 업그레이드를 사용할 수 있는 경우 배포 버전 열에 표시됩니다.
- 업그레이드할 클러스터를 Ready 상태로 선택합니다. 클러스터는 콘솔을 사용하여 업그레이드하려면 OpenShift Container Platform 클러스터여야 합니다.
- 업그레이드 를 선택합니다.
- 각 클러스터의 새 버전을 선택합니다.
- 업그레이드 를 선택합니다.
클러스터 업그레이드에 실패하면 Operator는 일반적으로 업그레이드를 몇 번 재시도하고 중지한 후 실패한 구성 요소의 상태를 보고합니다. 경우에 따라 업그레이드 프로세스가 프로세스를 완료하려는 시도를 계속 순환합니다. 업그레이드 실패 후 클러스터를 이전 버전으로 롤백하는 것은 지원되지 않습니다. 클러스터 업그레이드에 실패하는 경우 Red Hat 지원에 문의하십시오.
1.5.9.1. 채널 선택
콘솔을 사용하여 OpenShift Container Platform에서 클러스터 업그레이드 채널을 선택할 수 있습니다. 채널을 선택하면 에라타 버전 및 릴리스 버전 둘 다에 사용할 수 있는 클러스터 업그레이드에 대해 자동으로 알립니다.
클러스터의 채널을 선택하려면 다음 단계를 완료하십시오.
- 탐색에서 Infrastructure > Clusters 를 선택합니다.
- 클러스터 세부 정보 페이지를 보려면 변경할 클러스터 이름을 선택합니다. 클러스터에 다른 채널을 사용할 수 있는 경우 채널 필드에 편집 아이콘이 표시됩니다.
- 편집 아이콘을 클릭하여 필드의 설정을 수정합니다.
- 새 채널 필드에서 채널을 선택합니다.
사용 가능한 채널 업데이트에 대한 알림은 클러스터의 클러스터 세부 정보 페이지에서 확인할 수 있습니다.
1.5.9.2. 연결이 끊긴 클러스터 업그레이드
멀티 클러스터 엔진 Operator와 함께 Red Hat OpenShift Update Service를 사용하여 연결이 끊긴 환경에서 클러스터를 업그레이드할 수 있습니다.
보안 문제로 인해 클러스터가 인터넷에 직접 연결되지 않는 경우도 있습니다. 이로 인해 업그레이드할 수 있는 시기와 이러한 업그레이드를 처리하는 방법을 알기가 어렵습니다. OpenShift Update Service를 구성하는 것이 도움이 될 수 있습니다.
OpenShift Update Service는 연결이 끊긴 환경에서 사용 가능한 관리 클러스터 버전을 모니터링하고 연결이 끊긴 환경에서 클러스터를 업그레이드하는 데 사용할 수 있도록 하는 별도의 Operator 및 피연산자입니다. OpenShift Update Service가 구성되면 다음 작업을 수행할 수 있습니다.
- 연결이 끊긴 클러스터에 대한 업그레이드를 사용할 수 있는 시기를 모니터링합니다.
- 그래프 데이터 파일을 사용하여 업그레이드하기 위해 로컬 사이트로 미러링되는 업데이트를 확인합니다.
- 콘솔을 사용하여 클러스터에 업그레이드를 사용할 수 있음을 알립니다.
다음 주제에서는 연결이 끊긴 클러스터를 업그레이드하는 절차를 설명합니다.
1.5.9.2.1. 사전 요구 사항
OpenShift Update Service를 사용하여 연결이 끊긴 클러스터를 업그레이드하려면 다음 사전 요구 사항이 있어야 합니다.
제한된 OLM이 구성된 Red Hat OpenShift Container Platform 버전 4.13 이상에서 실행 중인 배포된 허브 클러스터입니다. 제한된 OLM 을 구성하는 방법에 대한 자세한 내용은 제한된 네트워크에서 Operator Lifecycle Manager 사용을 참조하십시오.
참고: 제한된 OLM을 구성할 때 카탈로그 소스 이미지를 기록합니다.
- hub 클러스터에서 관리하는 OpenShift Container Platform 클러스터
클러스터 이미지를 미러링할 수 있는 로컬 저장소에 대한 인증 정보에 액세스합니다. 이 리포지토리를 생성하는 방법에 대한 자세한 내용은 Disconnected installation mirroring 에서 참조하십시오.
참고: 업그레이드할 현재 버전의 클러스터의 이미지를 미러링된 이미지 중 하나로 항상 사용할 수 있어야 합니다. 업그레이드에 실패하면 업그레이드 시도 시 클러스터가 클러스터 버전으로 되돌아갑니다.
1.5.9.2.2. 연결이 끊긴 미러 레지스트리 준비
업그레이드할 이미지와 로컬 미러 레지스트리로 업그레이드할 현재 이미지를 모두 미러링해야 합니다. 이미지를 미러링하려면 다음 단계를 완료합니다.
다음 예제와 유사한 콘텐츠가 포함된 스크립트 파일을 생성합니다.
UPSTREAM_REGISTRY=quay.io PRODUCT_REPO=openshift-release-dev RELEASE_NAME=ocp-release OCP_RELEASE=4.12.2-x86_64 LOCAL_REGISTRY=$(hostname):5000 LOCAL_SECRET_JSON=/path/to/pull/secret1 oc adm -a ${LOCAL_SECRET_JSON} release mirror \ --from=${UPSTREAM_REGISTRY}/${PRODUCT_REPO}/${RELEASE_NAME}:${OCP_RELEASE} \ --to=${LOCAL_REGISTRY}/ocp4 \ --to-release-image=${LOCAL_REGISTRY}/ocp4/release:${OCP_RELEASE}- 1
/path/to/pull/secret을 OpenShift Container Platform 풀 시크릿의 경로로 바꿉니다.
스크립트를 실행하여 이미지를 미러링하고, 설정을 구성하고, 릴리스 이미지와 릴리스 콘텐츠를 분리합니다.
ImageContentSourcePolicy를 생성할 때 이 스크립트의 마지막 줄의 출력을 사용할 수 있습니다.
1.5.9.2.3. OpenShift Update Service용 Operator 배포
OpenShift Container Platform 환경에서 OpenShift Update Service용 Operator를 배포하려면 다음 단계를 완료하십시오.
- hub 클러스터에서 OpenShift Container Platform Operator 허브에 액세스합니다.
-
Red Hat OpenShift Update Service Operator를 선택하여 Operator를 배포합니다. 필요한 경우 기본값을 업데이트합니다. Operator 배포는openshift-cincinnati라는 새 프로젝트를 생성합니다. Operator 설치가 완료될 때까지 기다립니다.
OpenShift Container Platform 명령줄에
oc get pods명령을 입력하여 설치 상태를 확인할 수 있습니다. Operator가running상태인지 확인합니다.
1.5.9.2.4. 그래프 데이터 init 컨테이너 빌드
OpenShift Update Service는 그래프 데이터 정보를 사용하여 사용 가능한 업그레이드를 결정합니다. 연결된 환경에서 OpenShift Update Service는 Cincinnati 그래프 데이터 GitHub 리포지토리에서 직접 업그레이드할 수 있는 그래프 데이터 정보를 가져옵니다. 연결이 끊긴 환경을 구성하기 때문에 init 컨테이너 를 사용하여 로컬 리포지토리에서 그래프 데이터를 사용할 수 있도록 설정해야 합니다. 그래프 데이터 init 컨테이너 를 생성하려면 다음 단계를 완료합니다.
다음 명령을 입력하여 그래프 데이터 Git 리포지토리를 복제합니다.
git clone https://github.com/openshift/cincinnati-graph-data그래프 데이터
init에 대한 정보가 포함된 파일을 생성합니다. 이 샘플 Dockerfile 은cincinnati-operatorGitHub 리포지토리에서 찾을 수 있습니다. 파일의 내용은 다음 샘플에 표시됩니다.FROM registry.access.redhat.com/ubi8/ubi:8.11 RUN curl -L -o cincinnati-graph-data.tar.gz https://github.com/openshift/cincinnati-graph-data/archive/master.tar.gz2 RUN mkdir -p /var/lib/cincinnati/graph-data/3 CMD exec /bin/bash -c "tar xvzf cincinnati-graph-data.tar.gz -C /var/lib/ cincinnati/graph-data/ --strip-components=1"4 이 예제에서는 다음을 수행합니다.
다음 명령을 실행하여
그래프 데이터 init 컨테이너를 빌드합니다.podman build -f <path_to_Dockerfile> -t <${DISCONNECTED_REGISTRY}/cincinnati/cincinnati-graph-data-container>:latest1 2 podman push <${DISCONNECTED_REGISTRY}/cincinnati/cincinnati-graph-data-container><2>:latest --authfile=</path/to/pull_secret>.json3 참고:
podman이 설치되어 있지 않은 경우 명령의podman을docker로 교체할 수도 있습니다.
1.5.9.2.5. 미러링된 레지스트리에 대한 인증서 구성
미러링된 OpenShift Container Platform 릴리스 이미지를 저장하기 위해 보안 외부 컨테이너 레지스트리를 사용하는 경우 OpenShift Update Service는 업그레이드 그래프를 빌드하기 위해 이 레지스트리에 액세스해야 합니다. OpenShift Update Service Pod에서 작동하도록 CA 인증서를 구성하려면 다음 단계를 완료합니다.
image.config.openshift.io에 있는 OpenShift Container Platform 외부 레지스트리 API를 찾습니다. 외부 레지스트리 CA 인증서가 저장되는 위치입니다.자세한 내용은 OpenShift Container Platform 설명서에서 이미지 레지스트리 액세스에 대한 추가 신뢰 저장소 구성 을 참조하십시오.
-
openshift-config네임스페이스에 ConfigMap을 생성합니다. updateservice-registry키 아래에 CA 인증서를 추가합니다. OpenShift Update Service는 이 설정을 사용하여 인증서를 찾습니다.apiVersion: v1 kind: ConfigMap metadata: name: trusted-ca data: updateservice-registry: | -----BEGIN CERTIFICATE----- ... -----END CERTIFICATE-----image.config.openshift.ioAPI에서클러스터리소스를 편집하여additionalTrustedCA필드를 생성한 ConfigMap의 이름으로 설정합니다.oc patch image.config.openshift.io cluster -p '{"spec":{"additionalTrustedCA":{"name":"trusted-ca"}}}' --type mergetrusted-ca를 새 ConfigMap의 경로로 교체합니다.
OpenShift Update Service Operator는 openshift-config 네임스페이스에서 생성한 image.config.openshift.io API 및 openshift-config 네임스페이스에서 생성한 ConfigMap을 모니터링한 다음 CA 인증서가 변경된 경우 배포를 다시 시작합니다.
1.5.9.2.6. OpenShift Update Service 인스턴스 배포
허브 클러스터에 OpenShift Update Service 인스턴스 배포를 완료하면 클러스터 업그레이드의 이미지를 미러링하고 연결이 끊긴 관리 클러스터에서 사용할 수 있는 이 인스턴스가 있습니다. 인스턴스를 배포하려면 다음 단계를 완료합니다.
openshift-cincinnati인 Operator의 기본 네임스페이스를 사용하지 않으려면 OpenShift Update Service 인스턴스에 대한 네임스페이스를 생성합니다.- OpenShift Container Platform 허브 클러스터 콘솔 탐색 메뉴에서 관리 > 네임스페이스 를 선택합니다.
- 네임스페이스 생성을 선택합니다.
- 네임스페이스의 이름과 네임스페이스에 대한 기타 정보를 추가합니다.
- 생성 을 선택하여 네임스페이스를 생성합니다.
- OpenShift Container Platform 콘솔의 설치된 Operator 섹션에서 Red Hat OpenShift Update Service Operator 를 선택합니다.
- 메뉴에서 Create Instance 를 선택합니다.
OpenShift Update Service 인스턴스에서 콘텐츠를 붙여넣습니다. YAML 인스턴스는 다음 매니페스트와 유사할 수 있습니다.
apiVersion: cincinnati.openshift.io/v1beta2 kind: Cincinnati metadata: name: openshift-update-service-instance namespace: openshift-cincinnati spec: registry: <registry_host_name>:<port>1 replicas: 1 repository: ${LOCAL_REGISTRY}/ocp4/release graphDataImage: '<host_name>:<port>/cincinnati-graph-data-container'2 - 만들기 를 선택하여 인스턴스를 만듭니다.
-
hub 클러스터 CLI에서
oc get pods명령을 입력하여 인스턴스 생성 상태를 확인합니다. 다소 시간이 걸릴 수 있지만 명령 결과에 인스턴스 및 Operator가 실행 중임을 표시하는 경우 프로세스가 완료됩니다.
1.5.9.2.7. 기본 레지스트리 덮어쓰기 (선택 사항)
참고: 이 섹션의 단계는 릴리스를 미러링된 레지스트리로 미러링한 경우에만 적용됩니다.
OpenShift Container Platform에는 업그레이드 패키지를 찾는 위치를 지정하는 기본 이미지 레지스트리 값이 있습니다. 연결이 끊긴 환경에서는 덮어쓰기를 생성하여 릴리스 이미지를 미러링한 로컬 이미지 레지스트리의 경로로 해당 값을 교체할 수 있습니다.
기본 레지스트리를 덮어쓰려면 다음 단계를 완료합니다.
다음 콘텐츠와 유사한
mirror.yaml이라는 YAML 파일을 생성합니다.apiVersion: operator.openshift.io/v1alpha1 kind: ImageContentSourcePolicy metadata: name: <your-local-mirror-name>1 spec: repositoryDigestMirrors: - mirrors: - <your-registry>2 source: registry.redhat.io참고:
oc adm release mirror명령을 입력하여 로컬 미러의 경로를 찾을 수 있습니다.관리 클러스터의 명령줄을 사용하여 다음 명령을 실행하여 기본 레지스트리를 재정의합니다.
oc apply -f mirror.yaml
1.5.9.2.8. 연결이 끊긴 카탈로그 소스 배포
관리 클러스터에서 모든 기본 카탈로그 소스를 비활성화하고 새 카탈로그 소스를 생성합니다. 기본 위치를 연결된 위치에서 연결이 끊긴 로컬 레지스트리로 변경하려면 다음 단계를 완료합니다.
다음 콘텐츠와 유사한
source.yaml이라는 YAML 파일을 생성합니다.apiVersion: config.openshift.io/v1 kind: OperatorHub metadata: name: cluster spec: disableAllDefaultSources: true --- apiVersion: operators.coreos.com/v1alpha1 kind: CatalogSource metadata: name: my-operator-catalog namespace: openshift-marketplace spec: sourceType: grpc image: '<registry_host_name>:<port>/olm/redhat-operators:v1'1 displayName: My Operator Catalog publisher: grpc- 1
spec.image값을 로컬 제한된 카탈로그 소스 이미지의 경로로 바꿉니다.
관리 클러스터의 명령줄에서 다음 명령을 실행하여 카탈로그 소스를 변경합니다.
oc apply -f source.yaml
1.5.9.2.9. 관리 클러스터 매개변수 변경
관리 클러스터에서 ClusterVersion 리소스 정보를 업데이트하여 업그레이드를 검색하는 위치에서 기본 위치를 변경합니다.
관리형 클러스터에서 다음 명령을 입력하여
ClusterVersion업스트림 매개변수가 현재 기본 공용 OpenShift Update Service 피연산자인지 확인합니다.oc get clusterversion -o yaml반환된 콘텐츠는 다음 내용과 유사할 수 있습니다.
apiVersion: v1 items: - apiVersion: config.openshift.io/v1 kind: ClusterVersion [..] spec: channel: stable-4.13 upstream: https://api.openshift.com/api/upgrades_info/v1/graph허브 클러스터에서 다음 명령을 입력하여 OpenShift Update Service 피연산자의 경로 URL을 식별합니다.
oc get routes이후 단계에서 반환된 값을 기록해 둡니다.
관리 클러스터의 명령줄에서 다음 명령을 입력하여
ClusterVersion리소스를 편집합니다.oc edit clusterversion versionspec.channel값을 새 버전으로 바꿉니다.spec.upstream값을 hub 클러스터 OpenShift Update Service 피연산자의 경로로 바꿉니다. 다음 단계를 완료하여 피연산자의 경로를 확인할 수 있습니다.hub 클러스터에서 다음 명령을 실행합니다.
oc get routes -A-
Cincinnati의 경로를
찾으십시오. 피연산자가HOST/PORT필드의 값인 경로입니다.
관리 클러스터의 명령줄에서 다음 명령을 입력하여
ClusterVersion의 upstream 매개변수가 로컬 허브 클러스터 OpenShift Update Service URL로 업데이트되었는지 확인합니다.oc get clusterversion -o yaml결과는 다음 콘텐츠와 유사합니다.
apiVersion: v1 items: - apiVersion: config.openshift.io/v1 kind: ClusterVersion [..] spec: channel: stable-4.13 upstream: https://<hub-cincinnati-uri>/api/upgrades_info/v1/graph
1.5.9.2.10. 사용 가능한 업그레이드 보기
클러스터 페이지에서 클러스터 의 배포 버전은 연결이 끊긴 레지스트리에 업그레이드가 있는 경우 사용 가능한 업그레이드가 있음을 나타냅니다. 클러스터를 선택하고 Actions 메뉴에서 Upgrade Cluster를 선택하여 사용 가능한 업그레이드를 볼 수 있습니다. 선택적 업그레이드 경로를 사용할 수 있는 경우 사용 가능한 업그레이드가 나열됩니다.
참고: 현재 버전이 로컬 이미지 저장소에 미러링되지 않은 경우 사용 가능한 업그레이드 버전이 표시되지 않습니다.
1.5.9.2.11. 채널 선택
콘솔을 사용하여 OpenShift Container Platform 버전 4.6 이상에서 클러스터 업그레이드 채널을 선택할 수 있습니다. 이러한 버전은 미러 레지스트리에서 사용할 수 있어야 합니다. 채널 선택 단계를 완료하여 업그레이드 채널을 지정합니다.
1.5.9.2.12. 클러스터 업그레이드
연결이 끊긴 레지스트리를 구성한 후 다중 클러스터 엔진 Operator 및 OpenShift Update Service는 연결이 끊긴 레지스트리를 사용하여 업그레이드를 사용할 수 있는지 확인합니다. 사용 가능한 업그레이드가 표시되지 않는 경우 클러스터의 현재 수준의 릴리스 이미지와 로컬 저장소에 미러링된 하나 이상의 이후 수준이 있는지 확인합니다. 현재 클러스터 버전의 릴리스 이미지를 사용할 수 없는 경우 업그레이드를 사용할 수 없습니다.
클러스터 페이지에서 클러스터 의 배포 버전은 연결이 끊긴 레지스트리에 업그레이드가 있는 경우 사용 가능한 업그레이드가 있음을 나타냅니다. 사용 가능한 업그레이드를 클릭하고 업그레이드 버전을 선택하여 이미지를 업그레이드할 수 있습니다.
관리 클러스터가 선택한 버전으로 업데이트되었습니다.
클러스터 업그레이드에 실패하면 Operator는 일반적으로 업그레이드를 몇 번 재시도하고 중지한 후 실패한 구성 요소의 상태를 보고합니다. 경우에 따라 업그레이드 프로세스가 프로세스를 완료하려는 시도를 계속 순환합니다. 업그레이드 실패 후 클러스터를 이전 버전으로 롤백하는 것은 지원되지 않습니다. 클러스터 업그레이드에 실패하는 경우 Red Hat 지원에 문의하십시오.
1.5.10. 클러스터 프록시 애드온 사용
일부 환경에서는 관리 클러스터가 방화벽 뒤에 있으며 hub 클러스터에서 직접 액세스할 수 없습니다. 액세스 권한을 얻기 위해 관리 클러스터의 kube-apiserver 에 액세스하여 보다 안전한 연결을 제공하기 위해 프록시 애드온을 설정할 수 있습니다.
중요: 허브 클러스터에 클러스터 전체 프록시 구성이 없어야 합니다.
필요한 액세스: 편집기
허브 클러스터 및 관리 클러스터에 대한 클러스터 프록시 애드온을 구성하려면 다음 단계를 완료하십시오.
다음 단계를 완료하여 관리 클러스터
kube-apiserver에 액세스하도록kubeconfig파일을 구성합니다.관리 클러스터에 유효한 액세스 토큰을 제공합니다.
참고: 서비스 계정의 해당 토큰을 사용할 수 있습니다. 기본 네임스페이스에 있는 기본 서비스 계정을 사용할 수도 있습니다.
다음 명령을 실행하여 관리 클러스터의
kubeconfig파일을 내보냅니다.export KUBECONFIG=<managed-cluster-kubeconfig>다음 명령을 실행하여 포드에 액세스할 수 있는 서비스 계정에 역할을 추가합니다.
oc create role -n default test-role --verb=list,get --resource=pods oc create rolebinding -n default test-rolebinding --serviceaccount=default:default --role=test-role다음 명령을 실행하여 서비스 계정 토큰의 시크릿을 찾습니다.
oc get secret -n default | grep <default-token>default-token을 시크릿 이름으로 교체합니다.다음 명령을 실행하여 토큰을 복사합니다.
export MANAGED_CLUSTER_TOKEN=$(kubectl -n default get secret <default-token> -o jsonpath={.data.token} | base64 -d)default-token을 시크릿 이름으로 교체합니다.
Red Hat Advanced Cluster Management Hub 클러스터에서
kubeconfig파일을 구성합니다.다음 명령을 실행하여 허브 클러스터에서 현재
kubeconfig파일을 내보냅니다.oc config view --minify --raw=true > cluster-proxy.kubeconfig편집기로
서버파일을 수정합니다. 이 예에서는sed를 사용할 때 명령을 사용합니다. OSX를 사용하는 경우alias sed=gsed를 실행합니다.export TARGET_MANAGED_CLUSTER=<managed-cluster-name> export NEW_SERVER=https://$(oc get route -n multicluster-engine cluster-proxy-addon-user -o=jsonpath='{.spec.host}')/$TARGET_MANAGED_CLUSTER sed -i'' -e '/server:/c\ server: '"$NEW_SERVER"'' cluster-proxy.kubeconfig export CADATA=$(oc get configmap -n openshift-service-ca kube-root-ca.crt -o=go-template='{{index .data "ca.crt"}}' | base64) sed -i'' -e '/certificate-authority-data:/c\ certificate-authority-data: '"$CADATA"'' cluster-proxy.kubeconfig다음 명령을 입력하여 원래 사용자 인증 정보를 삭제합니다.
sed -i'' -e '/client-certificate-data/d' cluster-proxy.kubeconfig sed -i'' -e '/client-key-data/d' cluster-proxy.kubeconfig sed -i'' -e '/token/d' cluster-proxy.kubeconfig서비스 계정의 토큰을 추가합니다.
sed -i'' -e '$a\ token: '"$MANAGED_CLUSTER_TOKEN"'' cluster-proxy.kubeconfig
다음 명령을 실행하여 대상 관리 클러스터의 대상 네임스페이스에 있는 모든 Pod를 나열합니다.
oc get pods --kubeconfig=cluster-proxy.kubeconfig -n <default>default네임스페이스를 사용하려는 네임스페이스로 바꿉니다.관리 클러스터에서 다른 서비스에 액세스합니다. 이 기능은 관리 클러스터가 Red Hat OpenShift Container Platform 클러스터인 경우 사용할 수 있습니다. 서비스는
service-serving-certificate를 사용하여 서버 인증서를 생성해야 합니다.관리 클러스터에서 다음 서비스 계정 토큰을 사용합니다.
export PROMETHEUS_TOKEN=$(kubectl get secret -n openshift-monitoring $(kubectl get serviceaccount -n openshift-monitoring prometheus-k8s -o=jsonpath='{.secrets[0].name}') -o=jsonpath='{.data.token}' | base64 -d)hub 클러스터에서 다음 명령을 실행하여 인증 기관을 파일로 변환합니다.
oc get configmap kube-root-ca.crt -o=jsonpath='{.data.ca\.crt}' > hub-ca.crt
다음 명령을 사용하여 관리 클러스터의 Prometheus 지표를 가져옵니다.
export SERVICE_NAMESPACE=openshift-monitoring export SERVICE_NAME=prometheus-k8s export SERVICE_PORT=9091 export SERVICE_PATH="api/v1/query?query=machine_cpu_sockets" curl --cacert hub-ca.crt $NEW_SERVER/api/v1/namespaces/$SERVICE_NAMESPACE/services/$SERVICE_NAME:$SERVICE_PORT/proxy-service/$SERVICE_PATH -H "Authorization: Bearer $PROMETHEUS_TOKEN"
1.5.10.1. 클러스터 프록시 애드온의 프록시 설정 구성
관리 클러스터가 HTTP 및 HTTPS 프록시 서버를 통해 hub 클러스터와 통신할 수 있도록 클러스터 프록시 애드온의 프록시 설정을 구성할 수 있습니다. 클러스터 프록시 애드온 에이전트가 프록시 서버를 통해 hub 클러스터에 액세스해야 하는 경우 프록시 설정을 구성해야 할 수 있습니다.
클러스터 프록시 애드온에 대한 프록시 설정을 구성하려면 다음 단계를 완료합니다.
hub 클러스터에
AddOnDeploymentConfig리소스를 생성하고spec.proxyConfig매개변수를 추가합니다. 다음 예제를 참조하십시오.apiVersion: addon.open-cluster-management.io/v1alpha1 kind: AddOnDeploymentConfig metadata: name: <name>1 namespace: <namespace>2 spec: agentInstallNamespace: open-cluster-managment-agent-addon proxyConfig: httpsProxy: "http://<username>:<password>@<ip>:<port>"3 noProxy: ".cluster.local,.svc,172.30.0.1"4 caBundle: <value>5 생성한
AddOnDeploymentConfig리소스를 참조하여ManagedClusterAddOn리소스를 업데이트합니다. 다음 예제를 참조하십시오.apiVersion: addon.open-cluster-management.io/v1alpha1 kind: ManagedClusterAddOn metadata: name: cluster-proxy namespace: <namespace>1 spec: installNamespace: open-cluster-managment-addon configs: group: addon.open-cluster-management.io resource: AddonDeploymentConfig name: <name>2 namespace: <namespace>3
1.5.11. 관리 클러스터에서 실행되도록 Ansible Automation Platform 작업 구성
멀티 클러스터 엔진 Operator는 Red Hat Ansible Automation Platform과 통합되어 클러스터를 생성하거나 업그레이드하기 전이나 후에 발생하는 prehook 및 posthook Ansible 작업 인스턴스를 생성할 수 있습니다. 클러스터 제거를 위한 prehook 및 posthook 작업을 구성하고 클러스터 확장 작업은 지원되지 않습니다.
필수 액세스: 클러스터 관리자
1.5.11.1. 사전 요구 사항
클러스터에서 자동화 템플릿을 실행하려면 다음 사전 요구 사항을 충족해야 합니다.
- OpenShift Container Platform 4.13 이상
- Ansible Automation Platform Resource Operator를 설치하여 Ansible 작업을 Git 서브스크립션의 라이프사이클에 연결합니다. 자동화 템플릿을 사용하여 Ansible Automation Platform 작업을 시작할 때 최상의 결과를 얻으려면 Ansible Automation Platform 작업 템플릿이 실행될 때 멱등이어야 합니다. OpenShift Container Platform OperatorHub 에서 Ansible Automation Platform Resource Operator를 찾을 수 있습니다.
1.5.11.2. 콘솔을 사용하여 클러스터에서 실행되도록 자동화 템플릿 구성
클러스터를 생성할 때, 클러스터를 가져올 때 또는 클러스터를 생성한 후 클러스터에 사용할 자동화 템플릿을 지정할 수 있습니다.
클러스터를 생성하거나 가져올 때 템플릿을 지정하려면 자동화 단계에서 클러스터에 적용할 Ansible 템플릿을 선택합니다. 자동화 템플릿이 없는 경우 자동화 템플릿 추가 를 클릭하여 하나를 생성합니다.
클러스터를 생성한 후 템플릿을 지정하려면 기존 클러스터의 작업 메뉴에서 자동화 템플릿 업데이트를 클릭합니다. 업데이트 자동화 템플릿 옵션을 사용하여 기존 자동화 템플릿을 업데이트할 수도 있습니다.
1.5.11.3. 자동화 템플릿 생성
클러스터 설치 또는 업그레이드를 사용하여 Ansible 작업을 시작하려면 작업을 실행할 시기를 지정하는 자동화 템플릿을 생성해야 합니다. 클러스터 설치 또는 업그레이드 전후에 실행되도록 구성할 수 있습니다.
템플릿을 생성하는 동안 Ansible 템플릿 실행에 대한 세부 정보를 지정하려면 콘솔의 단계를 완료합니다.
- 탐색에서 Infrastructure > Automation 을 선택합니다.
상황에 적합한 경로를 선택합니다.
- 새 템플릿을 생성하려면 Ansible 템플릿 생성 을 클릭하고 3단계를 계속합니다.
- 기존 템플릿을 수정하려면 수정할 템플릿의 옵션 메뉴에서 템플릿 편집을 클릭하고 5단계를 계속합니다.
- 소문자 영숫자 또는 하이픈(-)을 포함하는 템플릿의 고유한 이름을 입력합니다.
- 새 템플릿에 사용할 인증 정보를 선택합니다.
인증 정보를 선택한 후 모든 작업에 사용할 Ansible 인벤토리를 선택할 수 있습니다. Ansible 인증 정보를 Ansible 템플릿에 연결하려면 다음 단계를 완료합니다.
- 탐색에서 자동화 를 선택합니다. 인증 정보에 연결되지 않은 템플릿 목록에 있는 템플릿에는 템플릿을 기존 인증 정보에 연결하는 데 사용할 수 있는 인증 정보에 대한 링크가 포함되어 있습니다. 템플릿과 동일한 네임스페이스에 있는 인증 정보만 표시됩니다.
- 선택할 수 있는 인증 정보가 없거나 기존 인증 정보를 사용하지 않으려면 연결할 템플릿의 옵션 메뉴에서 템플릿 편집을 선택합니다.
- 인증 정보 추가 를 클릭하고 인증 정보를 생성해야 하는 경우 Ansible Automation Platform에 대한 인증 정보 생성 절차를 완료합니다.
- 템플릿과 동일한 네임스페이스에 인증 정보를 생성한 후 템플릿을 편집할 때 Ansible Automation Platform 인증 정보 필드에서 인증 정보를 선택합니다.
- 클러스터가 설치되기 전에 Ansible 작업을 시작하려면 사전 설치 자동화 템플릿 섹션에서 자동화 템플릿 추가 를 선택합니다.
표시되는 모달의
작업 템플릿또는워크플로 작업 템플릿중에서 선택합니다.job_tags,skip_tags, 워크플로우 유형을 추가할 수도 있습니다.-
Extra variables 필드를 사용하여
key=value쌍의 형태로AnsibleJob리소스에 데이터를 전달합니다. -
특수 키
cluster_deployment및install_config는 추가 변수로 자동으로 전달됩니다. 클러스터에 대한 일반 정보와 클러스터 설치 구성에 대한 세부 정보가 포함되어 있습니다.
-
Extra variables 필드를 사용하여
- 클러스터 설치 또는 업그레이드에 추가할 prehook 및 posthook Ansible 작업의 이름을 선택합니다.
- 필요한 경우 Ansible 작업을 끌어 순서를 변경합니다.
-
클러스터를 설치한 후 시작하려는 모든 자동화 템플릿, 업그레이드 후 자동화 템플릿 섹션, 업그레이드 전 자동화 템플릿 섹션, 업그레이드 후 자동화 템플릿 섹션에 대해 5 - 7단계를 반복합니다. 클러스터를 업그레이드할 때
Extra variables필드를 사용하여key=value쌍 형식으로AnsibleJob리소스에 데이터를 전달할 수 있습니다.cluster_deployment및install_config특수 키 외에도cluster_info특수 키는ManagedClusterInfo리소스의 데이터를 포함하는 추가 변수로 자동으로 전달됩니다.
Ansible 템플릿은 지정된 작업이 발생할 때 이 템플릿을 지정하는 클러스터에서 실행되도록 구성되어 있습니다.
1.5.11.4. Ansible 작업의 상태 보기
실행 중인 Ansible 작업의 상태를 확인하여 시작된 후 성공적으로 실행 중인지 확인할 수 있습니다. 실행 중인 Ansible 작업의 현재 상태를 보려면 다음 단계를 완료합니다.
- 메뉴에서 Infrastructure > Clusters를 선택하여 Clusters 페이지에 액세스합니다.
- 세부 정보를 보려면 클러스터 이름을 선택합니다.
클러스터 정보에서 Ansible 작업의 마지막 실행 상태를 확인합니다. 항목은 다음 상태 중 하나를 표시합니다.
-
설치 prehook 또는 posthook 작업이 실패하면 클러스터 상태가
Failed를 표시합니다. - 업그레이드 prehook 또는 posthook 작업이 실패하면 업그레이드에 실패한 배포 필드에 경고가 표시됩니다.
-
설치 prehook 또는 posthook 작업이 실패하면 클러스터 상태가
1.5.11.5. 실패한 Ansible 작업 다시 실행
클러스터 prehook 또는 posthook가 실패한 경우 클러스터 페이지에서 업그레이드를 재시도할 수 있습니다.
시간을 절약하기 위해 클러스터 자동화 템플릿의 일부인 실패한 Ansible posthook만 실행할 수도 있습니다. 전체 업그레이드를 재시도하지 않고 posthooks만 다시 실행하려면 다음 단계를 완료합니다.
ClusterCurator리소스의 루트에 다음 내용을 추가하여 설치 posthook를 다시 실행합니다.operation: retryPosthook: installPosthookClusterCurator리소스의 루트에 다음 콘텐츠를 추가하여 업그레이드 posthook를 다시 실행합니다.operation: retryPosthook: upgradePosthook
콘텐츠를 추가한 후 Ansible posthook를 실행하기 위해 새 작업이 생성됩니다.
1.5.11.6. 모든 작업에 사용할 Ansible 인벤토리 지정
ClusterCurator 리소스를 사용하여 모든 작업에 사용할 Ansible 인벤토리를 지정할 수 있습니다. 다음 예제를 참조하십시오. channel 및 desiredUpdate 를 ClusterCurator 의 올바른 값으로 바꿉니다.
apiVersion: cluster.open-cluster-management.io/v1beta1
kind: ClusterCurator
metadata:
name: test-inno
namespace: test-inno
spec:
desiredCuration: upgrade
destroy: {}
install: {}
scale: {}
upgrade:
channel: stable-4.13
desiredUpdate: 4.13.1
monitorTimeout: 150
posthook:
- extra_vars: {}
clusterName: test-inno
type: post_check
name: ACM Upgrade Checks
prehook:
- extra_vars: {}
clusterName: test-inno
type: pre_check
name: ACM Upgrade Checks
towerAuthSecret: awx
inventory: Demo Inventory참고: 예제 리소스를 사용하려면 인벤토리가 이미 Ansible에 있어야 합니다.
콘솔에서 사용 가능한 Ansible 인벤토리 목록을 확인하여 인벤토리가 생성되었는지 확인할 수 있습니다.
1.5.12. 호스팅된 클러스터에서 실행되도록 Ansible Automation Platform 작업 구성
Red Hat Ansible Automation Platform은 멀티 클러스터 엔진 Operator와 통합되어 호스트 클러스터를 생성하거나 업데이트하기 전이나 후에 발생하는 prehook 및 posthook Ansible Automation Platform 작업 인스턴스를 생성할 수 있습니다.
필수 액세스: 클러스터 관리자
1.5.12.1. 사전 요구 사항
클러스터에서 자동화 템플릿을 실행하려면 다음 사전 요구 사항을 충족해야 합니다.
- OpenShift Container Platform 4.14 이상
- Ansible Automation Platform Resource Operator를 설치하여 Ansible Automation Platform 작업을 Git 서브스크립션 라이프사이클에 연결합니다. 자동화 템플릿을 사용하여 Ansible Automation Platform 작업을 시작할 때 Ansible Automation Platform 작업 템플릿이 실행될 때 멱등인지 확인합니다. OpenShift Container Platform OperatorHub 에서 Ansible Automation Platform Resource Operator를 찾을 수 있습니다.
1.5.12.2. 호스트된 클러스터 설치를 위해 Ansible Automation Platform 작업 실행
호스트 클러스터를 설치하는 Ansible Automation Platform 작업을 시작하려면 다음 단계를 완료합니다.
pausedUntil: true필드를 포함하여HostedCluster및NodePool리소스를 생성합니다.hcp create cluster명령줄 interface 명령을 사용하는 경우--pausedUntil: true플래그를 지정할 수 있습니다.다음 예제를 참조하십시오.
apiVersion: hypershift.openshift.io/v1beta1 kind: HostedCluster metadata: name: my-cluster namespace: clusters spec: pausedUntil: 'true' ...apiVersion: hypershift.openshift.io/v1beta1 kind: NodePool metadata: name: my-cluster-us-east-2 namespace: clusters spec: pausedUntil: 'true' ...HostedCluster리소스와 동일한 이름 및HostedCluster리소스와 동일한 네임스페이스에ClusterCurator리소스를 생성합니다. 다음 예제를 참조하십시오.apiVersion: cluster.open-cluster-management.io/v1beta1 kind: ClusterCurator metadata: name: my-cluster namespace: clusters labels: open-cluster-management: curator spec: desiredCuration: install install: jobMonitorTimeout: 5 prehook: - name: Demo Job Template extra_vars: variable1: something-interesting variable2: 2 - name: Demo Job Template posthook: - name: Demo Job Template towerAuthSecret: toweraccessAnsible Automation Platform Tower에 인증이 필요한 경우 시크릿 리소스를 생성합니다. 다음 예제를 참조하십시오.
apiVersion: v1 kind: Secret metadata: name: toweraccess namespace: clusters stringData: host: https://my-tower-domain.io token: ANSIBLE_TOKEN_FOR_admin
1.5.12.3. 호스트된 클러스터를 업데이트하기 위해 Ansible Automation Platform 작업 실행
호스트 클러스터를 업데이트하는 Ansible Automation Platform 작업을 실행하려면 업데이트할 호스팅 클러스터의 ClusterCurator 리소스를 편집합니다. 다음 예제를 참조하십시오.
apiVersion: cluster.open-cluster-management.io/v1beta1
kind: ClusterCurator
metadata:
name: my-cluster
namespace: clusters
labels:
open-cluster-management: curator
spec:
desiredCuration: upgrade
upgrade:
desiredUpdate: 4.14.1
monitorTimeout: 120
prehook:
- name: Demo Job Template
extra_vars:
variable1: something-interesting
variable2: 2
- name: Demo Job Template
posthook:
- name: Demo Job Template
towerAuthSecret: toweraccess- 1
- 지원되는 버전에 대한 자세한 내용은 호스팅 컨트롤 플레인 을 참조하십시오.
참고: 호스팅된 클러스터를 이러한 방식으로 업데이트할 때 호스팅된 컨트롤 플레인과 노드 풀을 동일한 버전으로 업데이트합니다. 호스팅된 컨트롤 플레인 및 노드 풀을 다른 버전으로 업데이트할 수 없습니다.
1.5.12.4. 호스트된 클러스터를 삭제하기 위해 Ansible Automation Platform 작업 실행
호스팅된 클러스터를 삭제하는 Ansible Automation Platform 작업을 실행하려면 삭제하려는 호스팅 클러스터의 ClusterCurator 리소스를 편집합니다. 다음 예제를 참조하십시오.
apiVersion: cluster.open-cluster-management.io/v1beta1
kind: ClusterCurator
metadata:
name: my-cluster
namespace: clusters
labels:
open-cluster-management: curator
spec:
desiredCuration: destroy
destroy:
jobMonitorTimeout: 5
prehook:
- name: Demo Job Template
extra_vars:
variable1: something-interesting
variable2: 2
- name: Demo Job Template
posthook:
- name: Demo Job Template
towerAuthSecret: toweraccess참고: AWS에서 호스팅 클러스터를 삭제하는 것은 지원되지 않습니다.
1.5.12.5. 추가 리소스
-
호스트된 컨트롤 플레인 명령줄 인터페이스
hcp에 대한 자세한 내용은 호스팅된 컨트롤 플레인 명령줄 인터페이스 설치를 참조하십시오. - 지원되는 버전을 포함하여 호스팅된 클러스터에 대한 자세한 내용은 호스팅 컨트롤 플레인 을 참조하십시오.
1.5.13. ClusterClaims
ClusterClaim 은 관리 클러스터의 클러스터 범위 CRD(사용자 정의 리소스 정의)입니다. ClusterClaim은 관리 클러스터가 요구하는 정보를 나타냅니다. ClusterClaim을 사용하여 대상 클러스터에서 리소스의 배치를 해제할 수 있습니다.
다음 예제는 YAML 파일에서 식별되는 ClusterClaim을 보여줍니다.
apiVersion: cluster.open-cluster-management.io/v1alpha1
kind: ClusterClaim
metadata:
name: id.openshift.io
spec:
value: 95f91f25-d7a2-4fc3-9237-2ef633d8451c다음 표는 다중 클러스터 엔진 운영자가 관리하는 클러스터에 있을 수 있는 정의된 ClusterClaims를 보여줍니다.
| 클레임 이름 | 예약됨 | 변경 가능 | 설명 |
|---|---|---|---|
|
| true | false | 업스트림 제안에 정의된 ClusterID |
|
| true | true | Kubernetes 버전 |
|
| true | false | AWS, GCE, Equinix Metal과 같이 관리형 클러스터가 실행되고 있는 플랫폼 |
|
| true | false | OpenShift, Cryostathos, EKS 및 GKE와 같은 제품 이름 |
|
| false | false | OpenShift Container Platform 클러스터에서만 사용할 수 있는 OpenShift Container Platform 외부 ID |
|
| false | true | OpenShift Container Platform 클러스터에서만 사용할 수 있는 관리 콘솔의 URL |
|
| false | true | OpenShift Container Platform 클러스터에서만 사용할 수 있는 OpenShift Container Platform 버전 |
관리 클러스터에서 이전 클레임 중 삭제 또는 업데이트되는 경우 이전 클레임이 자동으로 복원되거나 이전 버전으로 롤백됩니다.
관리되는 클러스터가 허브에 가입하면 관리 클러스터에서 생성된 ClusterClaims가 허브의 ManagedCluster 리소스의 상태와 동기화됩니다. ClusterClaims가 있는 관리형 클러스터는 다음 예와 유사할 수 있습니다.
apiVersion: cluster.open-cluster-management.io/v1
kind: ManagedCluster
metadata:
labels:
cloud: Amazon
clusterID: 95f91f25-d7a2-4fc3-9237-2ef633d8451c
installer.name: multiclusterhub
installer.namespace: open-cluster-management
name: cluster1
vendor: OpenShift
name: cluster1
spec:
hubAcceptsClient: true
leaseDurationSeconds: 60
status:
allocatable:
cpu: '15'
memory: 65257Mi
capacity:
cpu: '18'
memory: 72001Mi
clusterClaims:
- name: id.k8s.io
value: cluster1
- name: kubeversion.open-cluster-management.io
value: v1.18.3+6c42de8
- name: platform.open-cluster-management.io
value: AWS
- name: product.open-cluster-management.io
value: OpenShift
- name: id.openshift.io
value: 95f91f25-d7a2-4fc3-9237-2ef633d8451c
- name: consoleurl.openshift.io
value: 'https://console-openshift-console.apps.xxxx.dev04.red-chesterfield.com'
- name: version.openshift.io
value: '4.13'
conditions:
- lastTransitionTime: '2020-10-26T07:08:49Z'
message: Accepted by hub cluster admin
reason: HubClusterAdminAccepted
status: 'True'
type: HubAcceptedManagedCluster
- lastTransitionTime: '2020-10-26T07:09:18Z'
message: Managed cluster joined
reason: ManagedClusterJoined
status: 'True'
type: ManagedClusterJoined
- lastTransitionTime: '2020-10-30T07:20:20Z'
message: Managed cluster is available
reason: ManagedClusterAvailable
status: 'True'
type: ManagedClusterConditionAvailable
version:
kubernetes: v1.18.3+6c42de81.5.13.1. 기존 클러스터 클레임 나열
kubectl 명령을 사용하여 관리 클러스터에 적용되는 ClusterClaim을 나열할 수 있습니다. 이는 ClusterClaim을 오류 메시지와 비교하려는 경우에 유용합니다.
참고: 리소스 clusterclaims.cluster.open-cluster-management.io 에 대한 목록 권한이 있는지 확인합니다.
다음 명령을 실행하여 관리 클러스터에 있는 기존 ClusterClaim을 모두 나열합니다.
kubectl get clusterclaims.cluster.open-cluster-management.io1.5.13.2. 사용자 정의 클러스터 클레임 생성
관리 클러스터에서 사용자 지정 이름으로 ClusterClaims를 생성하면 쉽게 식별할 수 있습니다. 사용자 정의 클러스터 클레임은 hub 클러스터에서 ManagedCluster 리소스의 상태와 동기화됩니다. 다음 콘텐츠는 사용자 지정 ClusterClaim 에 대한 정의의 예를 보여줍니다.
apiVersion: cluster.open-cluster-management.io/v1alpha1
kind: ClusterClaim
metadata:
name: <custom_claim_name>
spec:
value: <custom_claim_value>
spec.value 필드의 최대 길이는 1024입니다. ClusterClaim을 생성하려면 리소스 clusterclaims.cluster.open-cluster-management.io 에 대한 생성 권한이 필요합니다.
1.5.14. ManagedClusterSets
ManagedClusterSet 은 관리 클러스터 그룹입니다. 관리되는 클러스터 세트는 모든 관리 클러스터에 대한 액세스를 관리하는 데 도움이 될 수 있습니다. ManagedClusterSetBinding 리소스를 생성하여 ManagedClusterSet 리소스를 네임스페이스에 바인딩할 수도 있습니다.
각 클러스터는 관리 클러스터 세트의 멤버여야 합니다. 허브 클러스터를 설치하면 ManagedClusterSet 리소스가 기본 이라는 리소스가 생성됩니다. 관리 클러스터 세트에 할당되지 않은 모든 클러스터는 기본 관리 클러스터 세트에 자동으로 할당됩니다. 기본 관리 클러스터 세트를 삭제하거나 업데이트할 수 없습니다.
관리 클러스터 세트를 생성하고 관리하는 방법에 대한 자세한 내용은 계속 읽으십시오.
1.5.14.1. ManagedClusterSet생성
관리 클러스터 세트에서 관리 클러스터를 그룹화하여 관리 클러스터에서 사용자 액세스를 제한할 수 있습니다.
필수 액세스: 클러스터 관리자
ManagedClusterSet 은 클러스터 범위 리소스이므로 ManagedClusterSet 을 생성하는 클러스터에 대한 클러스터 관리 권한이 있어야 합니다. 관리되는 클러스터는 둘 이상의 ManagedClusterSet 에 포함될 수 없습니다. 다중 클러스터 엔진 Operator 콘솔 또는 CLI에서 관리 클러스터 세트를 생성할 수 있습니다.
참고: 관리형 클러스터 세트에 추가되지 않은 클러스터 풀은 기본 ManagedClusterSet 리소스에 추가되지 않습니다. 클러스터 풀에서 클러스터를 요청하면 기본 ManagedClusterSet 에 클러스터가 추가됩니다.
관리형 클러스터를 생성하면 쉽게 관리할 수 있도록 다음이 자동으로 생성됩니다.
-
global이라는ManagedClusterSet입니다. -
open-cluster-management-global-set이라는 네임스페이스입니다. 글로벌ManagedClusterSet을open-cluster-management-네임스페이스에 바인딩하기 위해 global라는global-setManagedClusterSetBinding입니다.중요:
글로벌관리 클러스터 세트를 삭제, 업데이트 또는 편집할 수 없습니다.글로벌관리 클러스터 세트에는 모든 관리 클러스터가 포함됩니다. 다음 예제를 참조하십시오.apiVersion: cluster.open-cluster-management.io/v1beta2 kind: ManagedClusterSetBinding metadata: name: global namespace: open-cluster-management-global-set spec: clusterSet: global
1.5.14.1.1. CLI를 사용하여 ManagedClusterSet 생성
CLI를 사용하여 설정된 관리 클러스터의 다음 정의를 YAML 파일에 추가하여 관리 클러스터 세트를 생성합니다.
apiVersion: cluster.open-cluster-management.io/v1beta2
kind: ManagedClusterSet
metadata:
name: <cluster_set>
& lt;cluster_set >을 관리되는 클러스터 세트의 이름으로 바꿉니다.
1.5.14.1.2. ManagedClusterSet에 클러스터 추가
ManagedClusterSet 을 생성한 후 콘솔의 지침에 따라 또는 CLI를 사용하여 설정된 관리 클러스터에 클러스터를 추가할 수 있습니다.
1.5.14.1.3. CLI를 사용하여 ManagedClusterSet 에 클러스터 추가
CLI를 사용하여 설정된 관리 클러스터에 클러스터를 추가하려면 다음 단계를 완료합니다.
managedclustersets/join의 가상 하위 리소스에서 생성할 수 있는 RBACClusterRole항목이 있는지 확인합니다.참고: 이 권한이 없으면
ManagedClusterSet에 관리 클러스터를 할당할 수 없습니다. 이 항목이 없는 경우 YAML 파일에 추가합니다. 다음 예제를 참조하십시오.kind: ClusterRole apiVersion: rbac.authorization.k8s.io/v1 metadata: name: clusterrole1 rules: - apiGroups: ["cluster.open-cluster-management.io"] resources: ["managedclustersets/join"] resourceNames: ["<cluster_set>"] verbs: ["create"]&
lt;cluster_set>을ManagedClusterSet의 이름으로 바꿉니다.참고:
ManagedClusterSet에서 다른 클러스터로 관리되는 클러스터를 이동하는 경우 두 관리 클러스터 세트 모두에서 사용 가능한 권한이 있어야 합니다.YAML 파일에서 관리 클러스터의 정의를 찾습니다. 다음 예제 정의를 참조하십시오.
apiVersion: cluster.open-cluster-management.io/v1 kind: ManagedCluster metadata: name: <cluster_name> spec: hubAcceptsClient: truecluster.open-cluster-management.io/clusterset매개변수를 추가하고ManagedClusterSet의 이름을 지정합니다. 다음 예제를 참조하십시오.apiVersion: cluster.open-cluster-management.io/v1 kind: ManagedCluster metadata: name: <cluster_name> labels: cluster.open-cluster-management.io/clusterset: <cluster_set> spec: hubAcceptsClient: true
1.5.14.2. ManagedClusterSet에 RBAC 권한 할당
허브 클러스터에서 구성된 ID 공급자가 제공하는 클러스터 세트에 사용자 또는 그룹을 할당할 수 있습니다.
필수 액세스: 클러스터 관리자
ManagedClusterSet API RBAC 권한 수준은 다음 표를 참조하십시오.
| 클러스터 세트 | 액세스 권한 | 권한 생성 |
|---|---|---|
|
| 관리 클러스터 세트에 할당된 모든 클러스터 및 클러스터 풀 리소스에 대한 전체 액세스 권한. | 클러스터 생성, 클러스터 가져오기 및 클러스터 풀을 생성할 수 있는 권한 권한을 생성할 때 관리 클러스터 세트에 할당해야 합니다. |
|
|
| 클러스터 생성, 클러스터 가져오기 또는 클러스터 풀을 생성할 수 있는 권한이 없습니다. |
|
| 관리 클러스터 세트에 할당된 모든 클러스터 및 클러스터 풀 리소스에 대한 권한만 읽습니다. | 클러스터 생성, 클러스터 가져오기 또는 클러스터 풀을 생성할 수 있는 권한이 없습니다. |
참고: 글로벌 클러스터 세트에 대한 클러스터 세트 관리자 권한을 적용할 수 없습니다.
콘솔에서 관리 클러스터 세트에 사용자 또는 그룹을 할당하려면 다음 단계를 완료합니다.
- OpenShift Container Platform 콘솔에서 Infrastructure > Clusters 로 이동합니다.
- Cluster sets 탭을 선택합니다.
- 대상 클러스터 세트를 선택합니다.
- 액세스 관리 탭을 선택합니다.
- 사용자 또는 그룹 추가를 선택합니다.
- 액세스를 제공할 사용자 또는 그룹을 검색하고 선택합니다.
- 선택한 사용자 또는 사용자 그룹에 제공할 Cluster set admin 또는 Cluster set view 역할을 선택합니다. 자세한 내용은 다중 클러스터 엔진 Operator 역할 기반 액세스 제어 의 역할 개요 를 참조하십시오.
- 추가 를 선택하여 변경 사항을 제출합니다.
사용자 또는 그룹이 테이블에 표시됩니다. 모든 관리 클러스터 세트 리소스에 대한 권한 할당을 사용자 또는 그룹으로 전파하는 데 몇 초가 걸릴 수 있습니다.
배치 정보는 ManagedCusterSets 에서 ManagedCluster필터링 을 참조하십시오.
1.5.14.3. ManagedClusterSetBinding 리소스 생성
ManagedClusterSetBinding 리소스는 ManagedClusterSet 리소스를 네임스페이스에 바인딩합니다. 동일한 네임스페이스에서 생성된 애플리케이션 및 정책은 바인딩된 관리 클러스터 세트 리소스에 포함된 클러스터에만 액세스할 수 있습니다.
네임스페이스에 대한 액세스 권한은 해당 네임스페이스에 바인딩된 관리형 클러스터 세트에 자동으로 적용됩니다. 해당 네임스페이스에 대한 액세스 권한이 있는 경우 해당 네임스페이스에 바인딩된 모든 관리 클러스터 세트에 액세스할 수 있는 권한이 자동으로 부여됩니다. 관리 클러스터 세트에 액세스할 수 있는 권한만 있는 경우 네임스페이스의 다른 관리 클러스터 세트에 액세스할 수 있는 권한이 자동으로 없습니다.
콘솔 또는 명령줄을 사용하여 관리 클러스터 세트 바인딩을 생성할 수 있습니다.
1.5.14.3.1. 콘솔을 사용하여 ManagedClusterSetBinding 생성
콘솔을 사용하여 ManagedClusterSetBinding 을 생성하려면 다음 단계를 완료합니다.
- OpenShift Container Platform 콘솔에서 Infrastructure > Clusters 로 이동하여 Cluster set 탭을 선택합니다.
- 바인딩을 생성할 클러스터 세트의 이름을 선택합니다.
- 작업 > 네임스페이스 바인딩 편집 으로 이동합니다.
- 네임스페이스 바인딩 편집 페이지의 드롭다운 메뉴에서 클러스터 세트를 바인딩할 네임스페이스를 선택합니다.
1.5.14.3.2. CLI를 사용하여 ManagedClusterSetBinding 생성
CLI를 사용하여 ManagedClusterSetBinding 을 생성하려면 다음 단계를 완료합니다.
YAML 파일에
ManagedClusterSetBinding리소스를 생성합니다.참고: 관리형 클러스터 세트 바인딩을 생성할 때 관리 클러스터 세트 바인딩의 이름은 바인딩할 관리 클러스터 세트의 이름과 일치해야 합니다.
ManagedClusterSetBinding리소스는 다음 정보와 유사할 수 있습니다.apiVersion: cluster.open-cluster-management.io/v1beta2 kind: ManagedClusterSetBinding metadata: namespace: <namespace> name: <cluster_name> spec: clusterSet: <cluster_set>대상 관리 클러스터 세트에 대한 바인딩 권한이 있는지 확인합니다. 사용자가 <
cluster_set>에 바인딩할 수 있는 규칙이 포함된ClusterRole리소스의 다음 예제를 봅니다.apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: <clusterrole> rules: - apiGroups: ["cluster.open-cluster-management.io"] resources: ["managedclustersets/bind"] resourceNames: ["<cluster_set>"] verbs: ["create"]
1.5.14.4. 테인트 및 톨러레이션을 사용하여 관리형 클러스터 배치
테인트 및 허용 오차를 사용하여 관리 클러스터 또는 관리형 클러스터 세트의 배치를 제어할 수 있습니다. 테인트 및 허용 오차는 관리 클러스터가 특정 배치에 대해 선택되지 않도록 하는 방법을 제공합니다. 이 제어는 특정 관리 클러스터가 일부 배치에 포함되지 않도록 하려는 경우 유용할 수 있습니다. 관리 클러스터에 테인트를 추가하고 배치에 허용 오차를 추가할 수 있습니다. 테인트 및 허용 오차가 일치하지 않으면 해당 배치에 대해 관리 클러스터가 선택되지 않습니다.
1.5.14.4.1. 관리 클러스터에 테인트 추가
테인트는 관리 클러스터의 속성에 지정되며, 배치에서 관리 클러스터 또는 관리 클러스터 세트를 거절할 수 있습니다. 다음 예와 유사한 명령을 입력하여 관리 클러스터에 테인트를 추가할 수 있습니다.
oc taint ManagedCluster <managed_cluster_name> key=value:NoSelect테인트의 사양에는 다음 필드가 포함됩니다.
-
필수 키 - 클러스터에 적용되는 taint 키입니다. 이 값은 해당 배치에 추가되는 기준을 충족하기 위해 관리 클러스터의 허용 오차 값과 일치해야 합니다. 이 값을 확인할 수 있습니다. 예를 들어 이 값은
bar또는foo.example.com/bar일 수 있습니다. -
선택적 값 - taint 키의 taint 값입니다. 이 값은 해당 배치에 추가되는 기준을 충족하기 위해 관리 클러스터의 허용 오차 값과 일치해야 합니다. 예를 들어 이 값은
값이될 수 있습니다. 필수 효과 - 테인트를 허용하지 않는 배치에 대한 테인트의 효과 또는 테인트 및 배치 허용 오차가 일치하지 않을 때 발생하는 상황입니다. effect 값은 다음 값 중 하나여야 합니다.
-
NoSelect- 배치는 이 테인트를 허용하지 않는 한 클러스터를 선택할 수 없습니다. 테인트를 설정하기 전에 배치에서 클러스터를 선택한 경우 배치 결정에 따라 클러스터가 제거됩니다. -
NoSelectIfNew- 스케줄러에서 새 클러스터인 경우 클러스터를 선택할 수 없습니다. 배치는 테인트를 허용하고 이미 클러스터 결정에 클러스터가 있는 경우에만 클러스터를 선택할 수 있습니다.
-
-
필수
TimeAdded- 테인트가 추가된 시간입니다. 이 값은 자동으로 설정됩니다.
1.5.14.4.2. 관리 클러스터의 상태를 반영하기 위해 기본 제공 테인트 식별
관리 클러스터에 액세스할 수 없는 경우 클러스터를 배치에 추가하지 않아도 됩니다. 다음 테인트는 액세스할 수 없는 관리형 클러스터에 자동으로 추가됩니다.
cluster.open-cluster-management.io/unavailable- 클러스터 상태가False인ManagedClusterConditionAvailable조건이 있는 경우 이 테인트가 관리 클러스터에 추가됩니다. 테인트에는 사용할 수 없는 클러스터가 예약되지 않도록NoSelect및 빈 값이 적용됩니다. 이 테인트의 예는 다음 콘텐츠에 제공됩니다.apiVersion: cluster.open-cluster-management.io/v1 kind: ManagedCluster metadata: name: cluster1 spec: hubAcceptsClient: true taints: - effect: NoSelect key: cluster.open-cluster-management.io/unavailable timeAdded: '2022-02-21T08:11:54Z'cluster.open-cluster-management.io/unreachable-ManagedClusterConditionAvailable조건 상태가 알 수 없거나 조건이없는경우 이 테인트가 관리 클러스터에 추가됩니다. 테인트는 연결할 수 없는 클러스터가 예약되지 않도록NoSelect및 빈 값이 적용됩니다. 이 테인트의 예는 다음 콘텐츠에 제공됩니다.apiVersion: cluster.open-cluster-management.io/v1 kind: ManagedCluster metadata: name: cluster1 spec: hubAcceptsClient: true taints: - effect: NoSelect key: cluster.open-cluster-management.io/unreachable timeAdded: '2022-02-21T08:11:06Z'
1.5.14.4.3. 배치에 허용 오차 추가
허용 오차는 배치에 적용되며 배치의 허용 오차와 일치하는 테인트가 없는 관리 클러스터를 복구할 수 있습니다. 허용 오차 사양에는 다음 필드가 포함됩니다.
- 선택적 키 - 키가 taint 키와 일치하여 배치를 허용합니다.
- 선택적 값 - 허용 오차의 값은 배치를 허용하기 위해 허용 오차의 값과 일치해야 합니다.
선택적 Operator - Operator는 키와 값 간의 관계를 나타냅니다. 유효한 연산자
는동일하며존재합니다. 기본값은동일합니다. 허용 오차는 키가 동일할 때 테인트와 일치하며 효과가 동일하며 Operator는 다음 값 중 하나입니다.-
동일한 - 연산자는
동일하고테인트 및 톨러레이션에서 값이 동일합니다. -
exists- 값은 와일드카드이므로 배치에서 특정 카테고리의 모든 테인트를 허용할 수 있습니다.
-
동일한 - 연산자는
-
선택적 Effect - 일치시킬 테인트 효과입니다. 비워 두면 모든 테인트 효과와 일치합니다. 지정된 경우 허용되는 값은
NoSelect또는NoSelectIfNew입니다. -
optional TolerationSeconds - 관리되는 클러스터를 새 배치로 이동하기 전에 허용 오차에서 테인트를 허용하는 시간(초)입니다. effect 값이
NoSelect또는PreferNoSelect가 아닌 경우 이 필드는 무시됩니다. 기본값은nil이며, 이는 시간 제한이 없음을 나타냅니다.TolerationSeconds계산 시작 시간은 클러스터 예약 시간 또는TolerationSeconds값이 추가되는 대신 테인트의TimeAdded값으로 자동으로 나열됩니다.
다음 예제에서는 테인트가 있는 클러스터를 허용하는 허용 오차를 구성하는 방법을 보여줍니다.
이 예는 관리 클러스터의 테인트입니다.
apiVersion: cluster.open-cluster-management.io/v1 kind: ManagedCluster metadata: name: cluster1 spec: hubAcceptsClient: true taints: - effect: NoSelect key: gpu value: "true" timeAdded: '2022-02-21T08:11:06Z'테인트를 허용할 수 있는 배치에 대한 허용 오차
apiVersion: cluster.open-cluster-management.io/v1beta1 kind: Placement metadata: name: placement1 namespace: default spec: tolerations: - key: gpu value: "true" operator: Equal허용 오차 예제를 정의하면
key: gpu및value: "true"가 일치하기 때문에 배치로cluster1을 선택할 수 있었습니다.
참고: 관리형 클러스터는 테인트에 대한 허용 오차가 포함된 배치에 배치되지 않습니다. 다른 배치에 동일한 허용 오차가 포함된 경우 관리 클러스터가 해당 배치 중 하나에 배치될 수 있습니다.
1.5.14.4.4. 임시 허용 오차 지정
TolerationSeconds 의 값은 허용 오차에서 테인트를 허용하는 기간을 지정합니다. 이 임시 허용 오차는 관리 클러스터가 오프라인 상태일 때 유용할 수 있으며 이 클러스터에 배포된 애플리케이션을 허용 시간 동안 다른 관리 클러스터로 전송할 수 있습니다.
예를 들어 다음 테인트가 있는 관리 클러스터에 연결할 수 없습니다.
apiVersion: cluster.open-cluster-management.io/v1
kind: ManagedCluster
metadata:
name: cluster1
spec:
hubAcceptsClient: true
taints:
- effect: NoSelect
key: cluster.open-cluster-management.io/unreachable
timeAdded: '2022-02-21T08:11:06Z'
다음 예제에서와 같이 TolerationSeconds 의 값으로 배치를 정의하는 경우 워크로드는 5분 후에 사용 가능한 다른 관리 클러스터로 전송합니다.
apiVersion: cluster.open-cluster-management.io/v1beta1
kind: Placement
metadata:
name: demo4
namespace: demo1
spec:
tolerations:
- key: cluster.open-cluster-management.io/unreachable
operator: Exists
tolerationSeconds: 300관리형 클러스터에 5분 동안 연결할 수 없는 경우 애플리케이션이 다른 관리 클러스터로 이동됩니다.
1.5.14.5. ManagedClusterSet에서 관리 클러스터 제거
관리 클러스터 세트에서 관리 클러스터를 제거하여 다른 관리 클러스터 세트로 이동하거나 세트의 관리 설정에서 제거할 수 있습니다. 콘솔 또는 CLI를 사용하여 설정된 관리 클러스터에서 관리 클러스터를 제거할 수 있습니다.
참고:
-
모든 관리 클러스터는 관리 클러스터 세트에 할당되어야 합니다. ManagedClusterSet에서 관리 클러스터를 제거하고 다른
ManagedClusterSet기본관리 클러스터 세트에 자동으로 추가됩니다. -
관리 클러스터에 Submariner 애드온이 설치된 경우
ManagedClusterSet에서 관리 클러스터를 제거하기 전에 애드온을 제거해야 합니다.
1.5.14.5.1. 콘솔을 사용하여 ManagedClusterSet에서 클러스터 제거
콘솔을 사용하여 설정된 관리 클러스터에서 클러스터를 제거하려면 다음 단계를 완료합니다.
- Infrastructure > Clusters 를 클릭하고 Cluster sets 탭이 선택되어 있는지 확인합니다.
- 관리 클러스터 세트에서 제거할 클러스터 세트의 이름을 선택하여 클러스터 세트 세부 정보를 확인합니다.
- 작업 > 리소스 할당 관리를 선택합니다.
리소스 할당 관리 페이지에서 클러스터 세트에서 제거할 리소스의 확인란을 제거합니다.
이 단계에서는 이미 클러스터 세트의 멤버인 리소스를 제거합니다. 관리 클러스터의 세부 정보를 확인하여 리소스가 이미 설정된 클러스터의 멤버인지 확인할 수 있습니다.
참고: 하나의 관리형 클러스터에서 다른 관리 클러스터로 관리되는 클러스터를 이동하는 경우 두 관리 클러스터 세트에 대해 필요한 RBAC 권한이 있어야 합니다.
1.5.14.5.2. CLI를 사용하여 ManagedClusterSet에서 클러스터 제거
명령줄을 사용하여 관리 클러스터 세트에서 클러스터를 제거하려면 다음 단계를 완료합니다.
다음 명령을 실행하여 관리 클러스터 세트의 관리 클러스터 목록을 표시합니다.
oc get managedclusters -l cluster.open-cluster-management.io/clusterset=<cluster_set>cluster_set을 관리 클러스터 세트의 이름으로 교체합니다.- 제거할 클러스터의 항목을 찾습니다.
제거하려는 클러스터의 YAML 항목에서 레이블을 제거합니다. 라벨 예제를 보려면 다음 코드를 참조하십시오.
labels: cluster.open-cluster-management.io/clusterset: clusterset1
참고: 한 클러스터에서 다른 클러스터로 관리되는 클러스터를 이동하는 경우 두 관리 클러스터 세트에 대해 필요한 RBAC 권한이 있어야 합니다.
1.5.15. 배치
배치 리소스는 배치 네임스페이스에 바인딩된 ManagedClusterSets 에서 집합을 선택하는 규칙을 정의하는 네임스페이스 범위 리소스입니다.
ManagedCluster Sets
필수 액세스: 클러스터 관리자, 클러스터 세트 관리자
배치 사용 방법에 대해 자세히 알아보려면 계속 읽으십시오.
1.5.15.1. 배치 개요
관리 클러스터의 배치 작동 방법에 대한 다음 정보를 참조하십시오.
-
Kubernetes 클러스터는 hub 클러스터에 클러스터 범위의
ManagedCluster로 등록됩니다. -
ManagedCluster는클러스터 범위의ManagedClusterSets로 구성됩니다. -
ManagedClusterSets는 워크로드 네임스페이스에 바인딩됩니다. -
네임스페이스 범위의 배치는 잠재적인
ManagedClusters의 작업 세트를 선택하는 ManagedClusterSet -
배치는
labelSelector및claimSelector를 사용하여ManagedClusterSets의ManagedClusters를 필터링합니다. -
ManagedCluster의배치는 테인트 및 허용 오차를 사용하여 제어할 수 있습니다. - 배치는 요구 사항에 따라 클러스터 순위를 정하고 클러스터의 하위 집합을 선택합니다.
참고:
-
해당 네임스페이스에서
ManagedClusterSet을 생성하여 하나 이상의ManagedClusterSet을 네임스페이스에 바인딩해야 합니다. -
managedclustersets/bind의 가상 하위 리소스에서CREATE에 대한 역할 기반 액세스 권한이 있어야 합니다.
1.5.15.1.1. 추가 리소스
- 자세한 내용은 테인트 및 허용 오차 사용을 참조하십시오.
- API에 대한 자세한 내용은 배치 API를 참조하십시오.
- 배치를 사용하여 Selecting ManagedClusters 로 돌아갑니다.
1.5.15.2. ManagedClusterSets에서 ManagedClusters 필터링
labelSelector 또는 claimSelector 를 사용하여 필터링할 ManagedCluster 를 선택할 수 있습니다. 두 필터를 사용하는 방법을 알아보려면 다음 예제를 참조하십시오.
다음 예에서
labelSelector는 레이블vendor가 있는 클러스터만 일치합니다. OpenShift :apiVersion: cluster.open-cluster-management.io/v1beta1 kind: Placement metadata: name: placement namespace: ns1 spec: predicates: - requiredClusterSelector: labelSelector: matchLabels: vendor: OpenShift다음 예에서
claimSelector는region.open-cluster-management.io가us-west-1인 클러스터와 일치합니다.apiVersion: cluster.open-cluster-management.io/v1beta1 kind: Placement metadata: name: placement namespace: ns1 spec: predicates: - requiredClusterSelector: claimSelector: matchExpressions: - key: region.open-cluster-management.io operator: In values: - us-west-1clusterSets매개변수를 사용하여 특정 클러스터 세트의ManagedClusters를 필터링할 수도 있습니다. 다음 예에서claimSelector는clusterset1및clusterset2를 설정하는 클러스터와만 일치합니다.apiVersion: cluster.open-cluster-management.io/v1beta1 kind: Placement metadata: name: placement namespace: ns1 spec: clusterSets: - clusterset1 - clusterset2 predicates: - requiredClusterSelector: claimSelector: matchExpressions: - key: region.open-cluster-management.io operator: In values: - us-west-1
numberOf Cluster 수를 선택할 수도 있습니다. 다음 예제를 참조하십시오.
Clusters 매개변수를 사용하여 필터링할 Managed
apiVersion: cluster.open-cluster-management.io/v1beta1
kind: Placement
metadata:
name: placement
namespace: ns1
spec:
numberOfClusters: 3
predicates:
- requiredClusterSelector:
labelSelector:
matchLabels:
vendor: OpenShift
claimSelector:
matchExpressions:
- key: region.open-cluster-management.io
operator: In
values:
- us-west-1- 1
- 선택할
ManagedCluster 수를지정합니다. 이전 예제는3으로 설정됩니다.
1.5.15.2.1. 배치로 허용 오차 를 정의하여 ManagedCluster 필터링
일치하는 테인트를 사용하여 ManagedCluster를 필터링하는 방법을 알아보려면 다음 예제를 참조하십시오.
기본적으로 배치는 다음 예에서
cluster1을 선택할 수 없습니다.apiVersion: cluster.open-cluster-management.io/v1 kind: ManagedCluster metadata: name: cluster1 spec: hubAcceptsClient: true taints: - effect: NoSelect key: gpu value: "true" timeAdded: '2022-02-21T08:11:06Z'cluster1을 선택하려면 허용 오차를 정의해야 합니다. 다음 예제를 참조하십시오.apiVersion: cluster.open-cluster-management.io/v1beta1 kind: Placement metadata: name: placement namespace: ns1 spec: tolerations: - key: gpu value: "true" operator: Equal
tolerationSeconds 매개변수를 사용하여 지정된 시간 동안 테인트가 일치하는 ManagedClusters 를 선택할 수도 있습니다. tolerationSeconds 는 허용 오차가 테인트에 바인딩된 기간을 정의합니다. tolerationSeconds 는 지정된 기간 후에 다른 관리 클러스터로 오프라인으로 이동하는 클러스터에 배포된 애플리케이션을 자동으로 전송할 수 있습니다.
다음 예제를 확인하여 tolerationSeconds 를 사용하는 방법을 알아봅니다.
다음 예에서는 관리 클러스터에 연결할 수 없습니다.
apiVersion: cluster.open-cluster-management.io/v1 kind: ManagedCluster metadata: name: cluster1 spec: hubAcceptsClient: true taints: - effect: NoSelect key: cluster.open-cluster-management.io/unreachable timeAdded: '2022-02-21T08:11:06Z'tolerationSeconds를 사용하여 배치를 정의하면 워크로드가 사용 가능한 다른 관리 클러스터로 전송됩니다. 다음 예제를 참조하십시오.apiVersion: cluster.open-cluster-management.io/v1beta1 kind: Placement metadata: name: placement namespace: ns1 spec: tolerations: - key: cluster.open-cluster-management.io/unreachable operator: Exists tolerationSeconds: 3001 - 1
- 워크로드를 전송할 시간(초)을 지정합니다.
1.5.15.2.2. 배치로 prioritizerPolicy 를 정의하여 ManagedClusters 우선순위 지정
배치와 함께 prioritizerPolicy 매개변수를 사용하여 ManagedCluster의 우선 순위를 지정하는 방법을 알아보려면 다음 예제를 확인합니다.
다음 예제에서는 가장 큰 할당 가능 메모리가 있는 클러스터를 선택합니다.
참고: Kubernetes Node Allocatable, 'allocatable'은 각 클러스터의 Pod에 사용할 수 있는 컴퓨팅 리소스의 양으로 정의됩니다.
apiVersion: cluster.open-cluster-management.io/v1beta1 kind: Placement metadata: name: placement namespace: ns1 spec: numberOfClusters: 1 prioritizerPolicy: configurations: - scoreCoordinate: builtIn: ResourceAllocatableMemory다음 예제에서는 가장 큰 할당 가능 CPU 및 메모리가 있는 클러스터를 선택하고 리소스 변경에 대한 배치를 수행합니다.
apiVersion: cluster.open-cluster-management.io/v1beta1 kind: Placement metadata: name: placement namespace: ns1 spec: numberOfClusters: 1 prioritizerPolicy: configurations: - scoreCoordinate: builtIn: ResourceAllocatableCPU weight: 2 - scoreCoordinate: builtIn: ResourceAllocatableMemory weight: 2다음 예제에서는
addOn이 가장 큰 CPU 비율을 가진 두 클러스터를 선택하고 배치 결정을 고정합니다.apiVersion: cluster.open-cluster-management.io/v1beta1 kind: Placement metadata: name: placement namespace: ns1 spec: numberOfClusters: 2 prioritizerPolicy: mode: Exact configurations: - scoreCoordinate: builtIn: Steady weight: 3 - scoreCoordinate: type: AddOn addOn: resourceName: default scoreName: cpuratio
1.5.15.2.3. 애드온 상태를 기반으로 ManagedCluster 필터링
배포된 애드온의 상태에 따라 배치의 관리 클러스터를 선택할 수 있습니다. 예를 들어 관리 클러스터에서 활성화된 특정 애드온이 있는 경우에만 배치에 대해 관리형 클러스터를 선택할 수 있습니다.
배치를 생성할 때 애드온 레이블과 해당 상태를 지정할 수 있습니다. 관리형 클러스터에서 추가 기능이 활성화된 경우 ManagedCluster 리소스에서 레이블이 자동으로 생성됩니다. 추가 기능이 비활성화되면 레이블이 자동으로 제거됩니다.
각 애드온은 feature.open-cluster-management.io/addon-<addon_name>=<status_of_addon > 형식의 레이블로 표시됩니다.
addon_name 을 선택한 관리 클러스터에서 활성화할 애드온의 이름으로 교체합니다.
status_of_addon 을 관리 클러스터를 선택하는 경우 애드온에 포함할 상태로 바꿉니다.
status_of_addon:에 대해 가능한 값의 다음 표를 참조하십시오.
| 현재의 | 설명 |
|---|---|
|
| 애드온이 활성화되어 있고 사용할 수 있습니다. |
|
| 애드온이 활성화되어 있지만 리스가 지속적으로 업데이트되지는 않습니다. |
|
| 애드온이 활성화되어 있지만 리스를 찾을 수 없습니다. 이는 관리 클러스터가 오프라인 상태일 때도 발생할 수 있습니다. |
예를 들어 사용 가능한 application-manager 애드온은 다음을 읽는 관리 클러스터의 레이블로 표시됩니다.
feature.open-cluster-management.io/addon-application-manager: available애드온 및 해당 상태를 기반으로 배치를 생성하는 방법을 알아보려면 다음 예제를 참조하십시오.
다음 배치 예제에는
application-manager가 활성화된 모든 관리 클러스터가 포함됩니다.apiVersion: cluster.open-cluster-management.io/v1beta1 kind: Placement metadata: name: placement1 namespace: ns1 spec: predicates: - requiredClusterSelector: labelSelector: matchExpressions: - key: feature.open-cluster-management.io/addon-application-manager operator: Exists다음 배치 예제에서는
사용 가능한상태로application-manager가 활성화된 모든 관리 클러스터를 포함합니다.apiVersion: cluster.open-cluster-management.io/v1beta1 kind: Placement metadata: name: placement2 namespace: ns1 spec: predicates: - requiredClusterSelector: labelSelector: matchLabels: "feature.open-cluster-management.io/addon-application-manager": "available"다음 배치 예제에는
application-manager가 비활성화된 모든 관리 클러스터가 포함됩니다.apiVersion: cluster.open-cluster-management.io/v1beta1 kind: Placement metadata: name: placement3 namespace: ns1 spec: predicates: - requiredClusterSelector: labelSelector: matchExpressions: - key: feature.open-cluster-management.io/addon-application-manager operator: DoesNotExist
1.5.15.2.4. 추가 리소스
- 자세한 내용은 Node Allocatable 을 참조하십시오.
- 다른 주제의 배치를 사용하여 Selecting ManagedClusters로 돌아갑니다.
1.5.15.3. PlacementDecision s 를 사용하여 선택한 ManagedCluster확인
클러스터에서 선택한 ManagedCluster 를 나타내기 위해 cluster.open-cluster-management.io/placement={placement_name} 레이블이 있는 하나 이상의 PlacementDecision 종류가 생성됩니다.
ManagedCluster 를 선택하고 PlacementDecision 에 추가하면 이 배치를 사용하는 구성 요소가 이 ManagedCluster 에 워크로드를 적용할 수 있습니다. ManagedCluster 가 더 이상 선택되지 않고 PlacementDecision 에서 제거된 후 이 ManagedCluster 에 적용되는 워크로드가 제거됩니다. API에 대한 자세한 내용은 PlacementDecisions API 를 참조하십시오.
다음 PlacementDecision 예제를 참조하십시오.
apiVersion: cluster.open-cluster-management.io/v1beta1
kind: PlacementDecision
metadata:
labels:
cluster.open-cluster-management.io/placement: placement1
name: placement1-kbc7q
namespace: ns1
ownerReferences:
- apiVersion: cluster.open-cluster-management.io/v1beta1
blockOwnerDeletion: true
controller: true
kind: Placement
name: placement1
uid: 05441cf6-2543-4ecc-8389-1079b42fe63e
status:
decisions:
- clusterName: cluster1
reason: ''
- clusterName: cluster2
reason: ''
- clusterName: cluster3
reason: ''1.5.15.3.1. 추가 리소스
- 자세한 내용은 PlacementDecisions API 를 참조하십시오.
1.5.16. 클러스터 풀 관리 (기술 프리뷰)
클러스터 풀은 온디맨드 및 대규모로 구성된 Red Hat OpenShift Container Platform 클러스터에 빠르고 비용 효율적으로 액세스할 수 있습니다. 클러스터 풀은 필요한 경우 요청할 수 있는 Amazon Web Services, Google Cloud Platform 또는 Microsoft Azure에 구성 가능하고 확장 가능한 수의 OpenShift Container Platform 클러스터를 프로비저닝합니다. 개발, 연속 통합 및 프로덕션 시나리오를 위해 클러스터 환경을 제공하거나 교체할 때 특히 유용합니다. 즉시 클레임할 수 있도록 계속 실행할 클러스터를 지정할 수 있으며 나머지 클러스터는 몇 분 내에 다시 시작하고 클레임할 수 있도록 하이버네이트 상태로 유지됩니다.
ClusterClaim 리소스는 클러스터 풀에서 클러스터를 확인하는 데 사용됩니다. 클러스터 클레임이 생성되면 풀에 실행 중인 클러스터를 할당합니다. 실행 중인 클러스터를 사용할 수 없는 경우 클러스터를 제공하기 위해 하이버네이트 클러스터가 다시 시작되거나 새 클러스터가 프로비저닝됩니다. 클러스터 풀은 자동으로 새 클러스터를 생성하고 하이버네이터레이션 클러스터를 재개하여 풀에서 사용 가능한 클러스터의 지정된 크기와 수를 유지합니다.
클러스터 풀을 생성하는 절차는 클러스터를 생성하는 절차와 유사합니다. 클러스터 풀의 클러스터는 즉시 사용할 수 있도록 생성되지 않습니다.
1.5.16.1. 클러스터 풀 생성
클러스터 풀을 생성하는 절차는 클러스터를 생성하는 절차와 유사합니다. 클러스터 풀의 클러스터는 즉시 사용할 수 있도록 생성되지 않습니다.
필요한 액세스: 관리자
1.5.16.1.1. 사전 요구 사항
클러스터 풀을 생성하기 전에 다음 사전 요구 사항을 참조하십시오.
- 다중 클러스터 엔진 Operator 허브 클러스터를 배포해야 합니다.
- 공급자 환경에서 Kubernetes 클러스터를 생성할 수 있도록 다중 클러스터 엔진 Operator 허브 클러스터에 대한 인터넷 액세스가 필요합니다.
- AWS, GCP 또는 Microsoft Azure 공급자 인증 정보가 필요합니다. 자세한 내용은 인증 정보 관리 개요 를 참조하십시오.
- 공급자 환경에 구성된 도메인이 필요합니다. 도메인 구성 방법에 대한 지침은 공급자 설명서를 참조하십시오.
- 공급자 로그인 인증 정보가 필요합니다.
- OpenShift Container Platform 이미지 풀 시크릿이 필요합니다. 이미지 풀 시크릿 사용을 참조하십시오.
참고: 이 절차를 사용하여 클러스터 풀을 추가하면 풀에서 클러스터를 요청할 때 multicluster 엔진 Operator가 관리할 클러스터를 자동으로 가져옵니다. 클러스터 클레임을 사용하여 관리를 위해 클레임된 클러스터를 자동으로 가져오지 않는 클러스터 풀을 생성하려면 clusterClaim 리소스에 다음 주석을 추가합니다.
kind: ClusterClaim
metadata:
annotations:
cluster.open-cluster-management.io/createmanagedcluster: "false" - 1
"false"라는 단어가 문자열임을 나타내기 위해 따옴표로 묶어야 합니다.
1.5.16.1.2. 클러스터 풀을 생성합니다.
클러스터 풀을 생성하려면 탐색 메뉴에서 Infrastructure > Clusters 를 선택합니다. 클러스터 풀 탭에는 액세스할 수 있는 클러스터 풀이 나열됩니다. 클러스터 풀 생성 을 선택하고 콘솔의 단계를 완료합니다.
클러스터 풀에 사용할 인프라 인증 정보가 없는 경우 인증 정보 추가 를 선택하여 생성할 수 있습니다.
목록에서 기존 네임스페이스를 선택하거나 새로 생성할 새 네임스페이스를 입력할 수 있습니다. 클러스터 풀이 클러스터와 동일한 네임스페이스에 있을 필요는 없습니다.
클러스터 풀의 RBAC 역할이 기존 클러스터 세트의 역할 할당을 공유하도록 하려면 클러스터 세트 이름을 선택할 수 있습니다. 클러스터 풀의 클러스터 세트는 클러스터 풀을 생성할 때만 설정할 수 있습니다. 클러스터 풀을 생성한 후에는 클러스터 풀 또는 클러스터 풀의 클러스터에 대한 클러스터 세트 연결을 변경할 수 없습니다. 클러스터 풀에서 요청하는 클러스터는 클러스터 풀과 동일한 클러스터 세트에 자동으로 추가됩니다.
참고: 클러스터 관리자 권한이 없는 경우 클러스터 세트를 선택해야 합니다. 이 경우 클러스터 세트 생성 요청은 클러스터 세트 이름을 포함하지 않는 경우 금지 오류와 함께 거부됩니다. 선택할 수 있는 클러스터 세트가 없는 경우 클러스터 관리자에게 문의하여 클러스터 세트를 생성하고 clusterset 관리자 권한을 부여합니다.
클러스터 풀 크기는 클러스터 풀에서 프로비저닝할 클러스터 수를 지정하는 반면, 클러스터 풀 실행 수는 풀이 계속 실행 중인 클러스터 수를 지정하고 즉시 사용할 준비가 된 클러스터 수를 지정합니다.
절차는 클러스터를 생성하는 절차와 매우 유사합니다.
공급자에 필요한 정보에 대한 자세한 내용은 다음 정보를 참조하십시오.
1.5.16.2. 클러스터 풀에서 클러스터 클레임
ClusterClaim 리소스는 클러스터 풀에서 클러스터를 확인하는 데 사용됩니다. 클러스터가 실행되고 클러스터 풀에서 준비되면 클레임이 완료됩니다. 클러스터 풀은 클러스터 풀에 지정된 요구 사항을 유지하기 위해 클러스터 풀에 실행 중인 새 및 hibernated 클러스터를 자동으로 생성합니다.
참고: 클러스터 풀에서 클레임된 클러스터가 더 이상 필요하지 않고 삭제되면 리소스가 삭제됩니다. 클러스터가 클러스터 풀로 반환되지 않습니다.
필요한 액세스: 관리자
1.5.16.2.1. 사전 요구 사항
클러스터 풀에서 클러스터를 요청하기 전에 다음을 사용할 수 있어야 합니다.
사용 가능한 클러스터가 있거나 없는 클러스터 풀입니다. 클러스터 풀에 사용 가능한 클러스터가 있는 경우 사용 가능한 클러스터가 클레임됩니다. 클러스터 풀에 사용 가능한 클러스터가 없으면 클레임을 충족하기 위해 클러스터가 생성됩니다. 클러스터 풀을 생성하는 방법에 대한 자세한 내용은 클러스터 풀 생성 을 참조하십시오.
1.5.16.2.2. 클러스터 풀에서 클러스터 클레임
클러스터 클레임을 생성할 때 클러스터 풀에서 새 클러스터를 요청합니다. 클러스터를 사용할 수 있을 때 풀에서 클러스터를 확인합니다. 자동 가져오기를 비활성화하지 않는 한 클레임된 클러스터는 관리 클러스터 중 하나로 자동으로 가져옵니다.
클러스터를 클레임하려면 다음 단계를 완료합니다.
- 탐색 메뉴에서 Infrastructure > Clusters 를 클릭하고 Cluster pools 탭을 선택합니다.
- 클러스터에서 요청할 클러스터 풀의 이름을 찾아 Claim 클러스터 를 선택합니다.
클러스터를 사용할 수 있는 경우 클레임되고 Managed 클러스터 탭에 즉시 표시됩니다. 사용 가능한 클러스터가 없는 경우 hibernated 클러스터를 다시 시작하거나 새 클러스터를 프로비저닝하는 데 몇 분이 걸릴 수 있습니다. 이 시간 동안 클레임 상태가 보류 중입니다. 클러스터 풀을 확장하여 보류 중인 클레임을 보거나 삭제합니다.
클레임된 클러스터는 클러스터 풀에 있는 시점과 연결된 클러스터 세트의 멤버로 유지됩니다. 클레임할 때 클레임된 클러스터의 클러스터 세트를 변경할 수 없습니다.
참고: 클라우드 공급자 인증 정보의 풀 시크릿, SSH 키 또는 기본 도메인에 대한 변경 사항은 원래 인증 정보를 사용하여 이미 프로비저닝되었으므로 클러스터 풀에서 클레임한 기존 클러스터에는 반영되지 않습니다. 콘솔을 사용하여 클러스터 풀 정보를 편집할 수 없지만 CLI 인터페이스를 사용하여 정보를 업데이트하여 업데이트할 수 있습니다. 업데이트된 정보가 포함된 인증 정보를 사용하여 새 클러스터 풀을 생성할 수도 있습니다. 새 풀에서 생성된 클러스터는 새 인증 정보에 제공된 설정을 사용합니다.
1.5.16.3. 클러스터 풀 릴리스 이미지 업데이트
클러스터 풀의 클러스터가 잠시 중단된 상태로 유지되는 경우 클러스터의 Red Hat OpenShift Container Platform 릴리스 이미지가 백 수준이 될 수 있습니다. 이 경우 클러스터 풀에 있는 클러스터의 릴리스 이미지 버전을 업그레이드할 수 있습니다.
필요한 액세스: 편집
클러스터 풀의 클러스터의 OpenShift Container Platform 릴리스 이미지를 업데이트하려면 다음 단계를 완료합니다.
참고: 이 절차에서는 클러스터 풀에 이미 클레임된 클러스터 풀에서 클러스터를 업데이트하지 않습니다. 이 절차를 완료한 후 릴리스 이미지에 대한 업데이트는 클러스터 풀과 관련된 다음 클러스터에만 적용됩니다.
- 이 절차를 사용하여 릴리스 이미지를 업데이트한 후 클러스터 풀에서 생성한 클러스터입니다.
- 클러스터 풀에서 하이버팅되는 클러스터입니다. 이전 릴리스 이미지가 있는 기존의 중단된 클러스터가 제거되고 새 릴리스 이미지가 있는 새 클러스터가 해당 클러스터를 대체합니다.
- 탐색 메뉴에서 인프라 > 클러스터를 클릭합니다.
- Cluster Pool 탭을 선택합니다.
- Cluster Pool 표에서 업데이트할 클러스터 풀의 이름을 찾습니다.
- 표에서 클러스터 풀 의 옵션 메뉴를 클릭하고 릴리스 이미지 업데이트를 선택합니다.
- 이 클러스터 풀에서 향후 클러스터 생성에 사용할 새 릴리스 이미지를 선택합니다.
클러스터 풀 릴리스 이미지가 업데이트되었습니다.
팁: 각 클러스터 풀의 상자를 선택하고 Actions 메뉴를 사용하여 선택한 클러스터 풀의 릴리스 이미지를 업데이트하여 여러 클러스터 풀의 릴리스 이미지를 업데이트할 수 있습니다.
1.5.16.4. 클러스터 풀 스케일링 (기술 프리뷰)
클러스터 풀 크기의 클러스터 수를 늘리거나 줄여 클러스터 풀의 클러스터 수를 변경할 수 있습니다.
필수 액세스: 클러스터 관리자
클러스터 풀의 클러스터 수를 변경하려면 다음 단계를 완료합니다.
- 탐색 메뉴에서 인프라 > 클러스터를 클릭합니다.
- Cluster Pool 탭을 선택합니다.
- 변경할 클러스터 풀의 옵션 메뉴에서 클러스터 풀 스케일링을 선택합니다.
- 풀 크기 값을 변경합니다.
- 선택적으로 실행 중인 클러스터 수를 업데이트하여 요청 시 즉시 사용 가능한 클러스터 수를 늘리거나 줄일 수 있습니다.
클러스터 풀은 새 값을 반영하도록 확장됩니다.
1.5.16.5. 클러스터 풀 삭제
클러스터 풀을 생성하고 더 이상 필요하지 않은 경우 클러스터 풀을 제거할 수 있습니다.
중요: 클러스터 클레임이 없는 클러스터 풀만 제거할 수 있습니다.
필수 액세스: 클러스터 관리자
클러스터 풀을 삭제하려면 다음 단계를 완료합니다.
- 탐색 메뉴에서 인프라 > 클러스터를 클릭합니다.
- Cluster Pool 탭을 선택합니다.
삭제할 클러스터 풀의 옵션 메뉴에서 확인 상자에
confirm를 입력하고 Destroy 를 선택합니다.참고:
- 클러스터 풀에 클러스터 클레임이 있는 경우 Destroy 버튼이 비활성화됩니다.
- 클러스터 풀이 포함된 네임스페이스는 삭제되지 않습니다. 이러한 클러스터의 클러스터 클레임 리소스가 동일한 네임스페이스에 생성되므로 네임스페이스를 삭제하면 클러스터 풀에서 클레임된 클러스터가 제거됩니다.
팁: 각 클러스터 풀의 상자를 선택하고 Actions 메뉴를 사용하여 선택한 클러스터 풀을 제거하여 한 가지 작업으로 여러 클러스터 풀을 제거할 수 있습니다.
1.5.17. ManagedServiceAccount 애드온 활성화
다중 클러스터 엔진 Operator 버전 2.5 이상을 설치하면 ManagedServiceAccount 애드온이 기본적으로 활성화됩니다. 허브 클러스터를 다중 클러스터 엔진 Operator 버전 2.4에서 업그레이드하고 업그레이드하기 전에 ManagedServiceAccount 애드온을 활성화하지 않은 경우 수동으로 추가 기능을 활성화해야 합니다.
ManagedServiceAccount 를 사용하면 관리 클러스터에서 서비스 계정을 생성하거나 삭제할 수 있습니다.
필요한 액세스: 편집기
hub 클러스터의 < managed_cluster > 네임스페이스에 ManagedServiceAccount 사용자 정의 리소스가 생성되면 관리 클러스터에 ServiceAccount 가 생성됩니다.
TokenRequest 는 관리형 클러스터의 Kubernetes API 서버에 대한 ServiceAccount 를 사용하여 수행됩니다. 그런 다음 토큰은 hub 클러스터의 < target_managed_cluster> 네임스페이스의 Secret 에 저장됩니다.
참고: 토큰이 만료되고 순환될 수 있습니다. 토큰 요청에 대한 자세한 내용은 TokenRequest 를 참조하십시오.
1.5.17.1. 사전 요구 사항
- Red Hat OpenShift Container Platform 버전 4.13 이상을 환경에 배포해야 하며 CLI(명령줄 인터페이스)를 사용하여 로그인해야 합니다.
- 다중 클러스터 엔진 Operator가 설치되어 있어야 합니다.
1.5.17.2. ManagedServiceAccount 활성화
허브 클러스터 및 관리 클러스터에 대한 ManagedServiceAccount 애드온을 활성화하려면 다음 단계를 완료하십시오.
-
허브 클러스터에서
ManagedServiceAccount애드온을 활성화합니다. 자세한 내용은 고급 구성 을 참조하십시오. ManagedServiceAccount애드온을 배포하고 대상 관리 클러스터에 적용합니다. 다음 YAML 파일을 생성하고target_managed_cluster를Managed-ServiceAccount애드온을 적용하는 관리 클러스터의 이름으로 바꿉니다.apiVersion: addon.open-cluster-management.io/v1alpha1 kind: ManagedClusterAddOn metadata: name: managed-serviceaccount namespace: <target_managed_cluster> spec: installNamespace: open-cluster-management-agent-addon다음 명령을 실행하여 파일을 적용합니다.
oc apply -f -이제 관리 클러스터에 대해
ManagedServiceAccount플러그인을 활성화했습니다.ManagedServiceAccount를 구성하려면 다음 단계를 참조하십시오.다음 YAML 소스를 사용하여
ManagedServiceAccount사용자 정의 리소스를 생성합니다.apiVersion: authentication.open-cluster-management.io/v1alpha1 kind: ManagedServiceAccount metadata: name: <managedserviceaccount_name> namespace: <target_managed_cluster> spec: rotation: {}-
managed_serviceaccount_name을ManagedServiceAccount의 이름으로 교체합니다. -
target_managed_cluster를ManagedServiceAccount를 적용하는 관리 클러스터의 이름으로 교체합니다.
-
확인하려면
ManagedServiceAccount오브젝트 상태에서tokenSecretRef속성을 확인하여 시크릿 이름과 네임스페이스를 찾습니다. 계정 및 클러스터 이름을 사용하여 다음 명령을 실행합니다.oc get managedserviceaccount <managed_serviceaccount_name> -n <target_managed_cluster> -o yaml관리 클러스터에서 생성된
ServiceAccount에 연결된 검색된 토큰이 포함된 보안을 확인합니다.다음 명령을 실행합니다.oc get secret <managed_serviceaccount_name> -n <target_managed_cluster> -o yaml
1.5.18. 클러스터 라이프사이클 고급 구성
설치 중 또는 설치 후 일부 클러스터 설정을 구성할 수 있습니다.
1.5.18.1. API 서버 인증서 사용자 정의
관리형 클러스터는 OpenShift Kube API 서버 외부 로드 밸런서와의 상호 연결을 통해 hub 클러스터와 통신합니다. OpenShift Container Platform을 설치할 때 기본 OpenShift Kube API 서버 인증서는 내부 Red Hat OpenShift Container Platform 클러스터 인증 기관(CA)에서 발급합니다. 필요한 경우 인증서를 추가하거나 변경할 수 있습니다.
API 서버 인증서를 변경하면 관리 클러스터와 허브 클러스터 간의 통신에 영향을 미칠 수 있습니다. 제품을 설치하기 전에 이름이 지정된 인증서를 추가하면 관리 클러스터를 오프라인 상태로 둘 수 있는 문제를 방지할 수 있습니다.
다음 목록에는 인증서를 업데이트해야 하는 몇 가지 예가 포함되어 있습니다.
외부 로드 밸런서의 기본 API 서버 인증서를 자체 인증서로 교체하려고 합니다. OpenShift Container Platform 설명서에서 API 서버 인증서 추가 의 지침에 따라 호스트 이름
api.<cluster_name>.<base_domain>이 포함된 이름이 지정된 인증서를 추가하여 외부 로드 밸런서의 기본 API 서버 인증서를 교체할 수 있습니다. 인증서를 교체하면 관리 클러스터 중 일부가 오프라인 상태로 이동할 수 있습니다. 인증서를 업그레이드한 후 클러스터가 오프라인 상태인 경우 인증서 변경 후 가져온 클러스터 문제 해결 지침에 따라 문제를 해결합니다.참고: 제품을 설치하기 전에 이름이 지정된 인증서를 추가하면 클러스터가 오프라인 상태로 전환되지 않습니다.
외부 로드 밸런서에 대해 이름이 지정된 인증서가 만료되어 이를 교체해야 합니다. 이전 인증서와 새 인증서가 중간 인증서 수에도 불구하고 동일한 루트 CA 인증서를 공유하는 경우 OpenShift Container Platform 설명서의 API 서버 인증서 추가 지침에 따라 새 인증서에 대한 새 시크릿을 생성할 수 있습니다. 그런 다음 호스트 이름
api.<cluster_name>.<base_domain>에 대한 제공 인증서 참조를APIServer사용자 정의 리소스의 새 시크릿으로 업데이트합니다. 그렇지 않으면 이전 및 새 인증서에 다른 루트 CA 인증서가 있는 경우 다음 단계를 완료하여 인증서를 교체합니다.다음 예와 유사한
APIServer사용자 정의 리소스를 찾습니다.apiVersion: config.openshift.io/v1 kind: APIServer metadata: name: cluster spec: audit: profile: Default servingCerts: namedCertificates: - names: - api.mycluster.example.com servingCertificate: name: old-cert-secret다음 명령을 실행하여 기존 및 새 인증서의 콘텐츠가 포함된
openshift-config네임스페이스에 새 보안을 생성합니다.이전 인증서를 새 인증서로 복사합니다.
cp old.crt combined.crt새 인증서의 내용을 이전 인증서의 사본에 추가합니다.
cat new.crt >> combined.crt결합된 인증서를 적용하여 보안을 생성합니다.
oc create secret tls combined-certs-secret --cert=combined.crt --key=old.key -n openshift-config
APIServer리소스를 업데이트하여servingCertificate로 결합된 인증서를 참조합니다.apiVersion: config.openshift.io/v1 kind: APIServer metadata: name: cluster spec: audit: profile: Default servingCerts: namedCertificates: - names: - api.mycluster.example.com servingCertificate: name: combined-cert-secret- 약 15분 후에 새 인증서와 이전 인증서가 모두 포함된 CA 번들이 관리형 클러스터로 전파됩니다.
다음 명령을 입력하여 새 인증서 정보만 포함된
openshift-config네임스페이스에new-cert-secret이라는 다른 보안을 생성합니다.oc create secret tls new-cert-secret --cert=new.crt --key=new.key -n openshift-config {code}new-cert-secret을 참조하도록servingCertificate의 이름을 변경하여APIServer리소스를 업데이트합니다. 리소스는 다음 예와 유사할 수 있습니다.apiVersion: config.openshift.io/v1 kind: APIServer metadata: name: cluster spec: audit: profile: Default servingCerts: namedCertificates: - names: - api.mycluster.example.com servingCertificate: name: new-cert-secret약 15분 후에 이전 인증서가 CA 번들에서 제거되고 변경 사항이 관리 클러스터에 자동으로 전파됩니다.
참고: 관리 클러스터는 호스트 이름 api.<cluster_name>.<base_domain >을 사용하여 hub 클러스터에 액세스해야 합니다. 다른 호스트 이름으로 구성된 이름이 지정된 인증서를 사용할 수 없습니다.
1.5.18.2. 허브 클러스터와 관리 클러스터 간의 프록시 구성
Kubernetes Operator 허브 클러스터의 다중 클러스터 엔진에 관리 클러스터를 등록하려면 관리 클러스터를 다중 클러스터 엔진 Operator 허브 클러스터로 전송해야 합니다. 관리되는 클러스터가 다중 클러스터 엔진 Operator 허브 클러스터에 직접 연결할 수 없는 경우가 있습니다. 이 경우 관리 클러스터의 통신이 HTTP 또는 HTTPS 프록시 서버를 통해 다중 클러스터 엔진 Operator 허브 클러스터에 액세스할 수 있도록 프록시 설정을 구성합니다.
예를 들어 다중 클러스터 엔진 Operator 허브 클러스터는 퍼블릭 클라우드에 있으며 관리 클러스터는 방화벽 뒤의 프라이빗 클라우드 환경에 있습니다. 프라이빗 클라우드에서의 통신은 HTTP 또는 HTTPS 프록시 서버를 통해서만 진행할 수 있습니다.
1.5.18.2.1. 사전 요구 사항
- HTTP 터널을 지원하는 HTTP 또는 HTTPS 프록시 서버가 실행되고 있습니다. 예를 들어 HTTP 연결 방법입니다.
- HTTP 또는 HTTPS 프록시 서버에 연결할 수 있는 조작된 클러스터가 있으며 프록시 서버는 다중 클러스터 엔진 operator hub 클러스터에 액세스할 수 있습니다.
hub 클러스터와 관리 클러스터 간의 프록시 설정을 구성하려면 다음 단계를 완료합니다.
프록시 설정을 사용하여
KlusterConfig리소스를 생성합니다.HTTP 프록시를 사용하여 다음 구성을 참조하십시오.
apiVersion: config.open-cluster-management.io/v1alpha1 kind: KlusterletConfig metadata: name: http-proxy spec: hubKubeAPIServerProxyConfig: httpProxy: "http://<username>:<password>@<ip>:<port>"HTTPS 프록시를 사용하여 다음 구성을 참조하십시오.
apiVersion: config.open-cluster-management.io/v1alpha1 kind: KlusterletConfig metadata: name: https-proxy spec: hubKubeAPIServerProxyConfig: httpsProxy: "https://<username>:<password>@<ip>:<port>" caBundle: <user-ca-bundle>참고: HTTPS 프록시 서버가 구성된 경우 CA 인증서가 필요합니다. HTTP 프록시와 HTTPS 프록시가 모두 지정된 경우 HTTPS 프록시가 사용됩니다.
관리 클러스터를 생성할 때
KlusterletConfig리소스를 참조하는 주석을 추가하여KlusterletConfig리소스를 선택합니다. 다음 예제를 참조하십시오.apiVersion: cluster.open-cluster-management.io/v1 kind: ManagedCluster metadata: annotations: agent.open-cluster-management.io/klusterlet-config: <klusterlet-config-name> name:<managed-cluster-name> spec: hubAcceptsClient: true leaseDurationSeconds: 60참고: 다중 클러스터 엔진 Operator 콘솔에서 작동할 때
ManagedCluster리소스에 주석을 추가하려면 YAML 보기를 전환해야 할 수 있습니다.
1.5.18.2.2. 허브 클러스터와 관리 클러스터 간의 프록시 비활성화
개발이 변경되면 HTTP 또는 HTTPS 프록시를 비활성화해야 할 수 있습니다.
-
ManagedCluster리소스로 이동합니다. -
agent.open-cluster-management.io/klusterlet-config주석을 제거합니다.
1.5.18.2.3. 선택 사항: 특정 노드에서 실행되도록 klusterlet 구성
Red Hat Advanced Cluster Management for Kubernetes를 사용하여 클러스터를 생성할 때 관리 클러스터에 대한 nodeSelector 및 허용 오차 주석을 구성하여 관리 대상 클러스터 klusterlet을 실행할 노드를 지정할 수 있습니다. 다음 설정을 구성하려면 다음 단계를 완료합니다.
- 콘솔의 클러스터 페이지에서 업데이트할 관리 클러스터를 선택합니다.
YAML 스위치를
On으로 설정하여 YAML 콘텐츠를 확인합니다.참고: YAML 편집기는 클러스터를 가져오거나 생성하는 경우에만 사용할 수 있습니다. 가져오기 또는 생성 후 관리형 클러스터 YAML 정의를 편집하려면 OpenShift Container Platform 명령줄 인터페이스 또는 Red Hat Advanced Cluster Management 검색 기능을 사용해야 합니다.
-
관리 클러스터 YAML 정의에
nodeSelector주석을 추가합니다. 이 주석의 키는open-cluster-management/nodeSelector입니다. 이 주석의 값은 JSON 형식의 문자열 맵입니다. 관리 클러스터 YAML 정의에
허용 오차항목을 추가합니다. 이 주석의 키는open-cluster-management/tolerations입니다. 이 주석의 값은 JSON 형식의 허용 오차 목록을 나타냅니다. 결과 YAML은 다음 예와 유사할 수 있습니다.apiVersion: cluster.open-cluster-management.io/v1 kind: ManagedCluster metadata: annotations: open-cluster-management/nodeSelector: '{"dedicated":"acm"}' open-cluster-management/tolerations: '[{"key":"dedicated","operator":"Equal","value":"acm","effect":"NoSchedule"}]'
1.5.18.3. 관리 클러스터를 가져올 때 hub 클러스터 API 서버의 서버 URL 및 CA 번들 사용자 정의 (기술 프리뷰)
관리 클러스터와 허브 클러스터 사이에 중간 구성 요소가 있는 경우 다중 클러스터 엔진 Operator 허브 클러스터에 관리 클러스터를 등록하지 못할 수 있습니다. 중간 구성 요소의 예로는 가상 IP, 로드 밸런서, 역방향 프록시 또는 API 게이트웨이가 포함됩니다. 중간 구성 요소가 있는 경우 관리 클러스터를 가져올 때 hub 클러스터 API 서버에 사용자 정의 서버 URL 및 CA 번들을 사용해야 합니다.
1.5.18.3.1. 사전 요구 사항
- hub 클러스터 API 서버가 관리 클러스터에 액세스할 수 있도록 중간 구성 요소를 구성해야 합니다.
중간 구성 요소가 관리 클러스터와 허브 클러스터 API 서버 간의 SSL 연결을 종료하는 경우 SSL 연결을 브리지하고 원래 요청의 인증 정보를 hub 클러스터 API 서버의 백엔드로 전달해야 합니다. Kubernetes API 서버의 사용자 유휴 기능을 사용하여 SSL 연결을 브리지할 수 있습니다.
중간 구성 요소는 원래 요청에서 클라이언트 인증서를 추출하고 인증서 제목의 CN(Common Name) 및 조직(O)을 가장 헤더로 추가한 다음 수정된 가장 요청을 허브 클러스터 API 서버의 백엔드로 전달합니다.
참고: SSL 연결을 브리지하는 경우 클러스터 프록시 애드온이 작동하지 않습니다.
1.5.18.3.2. 서버 URL 및 허브 클러스터 CA 번들 사용자 정의
관리 클러스터를 가져올 때 사용자 정의 허브 API 서버 URL 및 CA 번들을 사용하려면 다음 단계를 완료하십시오.
사용자 정의 허브 클러스터 API 서버 URL 및 CA 번들을 사용하여
KlusterConfig리소스를 생성합니다. 다음 예제를 참조하십시오.apiVersion: config.open-cluster-management.io/v1alpha1 kind: KlusterletConfig metadata: name:1 spec: hubKubeAPIServerURL: "https://api.example.com:6443"2 hubKubeAPIServerCABundle: "LS0tLS1CRU...LS0tCg=="3 리소스를 참조하는 주석을 추가하여 관리 클러스터를 생성할 때
KlusterletConfig리소스를 선택합니다. 다음 예제를 참조하십시오.apiVersion: cluster.open-cluster-management.io/v1 kind: ManagedCluster metadata: annotations: agent.open-cluster-management.io/klusterlet-config:1 name:2 spec: hubAcceptsClient: true leaseDurationSeconds: 60
참고: 콘솔을 사용하는 경우 YAML 보기를 활성화하여 ManagedCluster 리소스에 주석을 추가해야 할 수 있습니다.
1.5.18.4. 추가 리소스
1.5.19. 관리에서 클러스터 제거
다중 클러스터 엔진 Operator를 사용하여 생성된 관리에서 OpenShift Container Platform 클러스터를 제거하면 이를 분리 하거나 제거할 수 있습니다. 클러스터를 분리하면 관리에서 제거되지만 완전히 삭제되지는 않습니다. 관리하려는 경우 다시 가져올 수 있습니다. 이는 클러스터가 Ready 상태에 있는 경우에만 옵션입니다.
다음 절차에서는 다음 상황 중 하나로 관리에서 클러스터를 제거합니다.
- 클러스터를 이미 삭제하고 Red Hat Advanced Cluster Management에서 삭제된 클러스터를 제거하려고 합니다.
- 관리에서 클러스터를 제거하려고 하지만 클러스터를 삭제하지 않았습니다.
중요:
- 클러스터를 삭제하면 관리에서 이를 제거하고 클러스터의 구성 요소를 삭제합니다.
관리 클러스터를 분리하거나 삭제하면 관련 네임스페이스가 자동으로 삭제됩니다. 이 네임스페이스에 사용자 정의 리소스를 배치하지 마십시오.
1.5.19.1. 콘솔을 사용하여 클러스터 제거
탐색 메뉴에서 Infrastructure > Clusters 로 이동하여 관리에서 제거하려는 클러스터 옆에 있는 옵션 메뉴에서 Destroy cluster 또는 Detach 클러스터를 선택합니다.
팁: 분리 또는 삭제하려는 클러스터의 확인란을 선택하고 Detach 또는 Destroy 를 선택하여 여러 클러스터를 분리하거나 제거할 수 있습니다.
참고: local-cluster 라는 허브 클러스터를 관리하는 동안 허브 클러스터를 분리하려고 하면 disableHubSelfManagement 의 기본 설정이 false 인지 확인합니다. 이 설정으로 인해 허브 클러스터가 분리될 때 다시 가져와서 자체적으로 관리하며 MultiClusterHub 컨트롤러를 조정합니다. hub 클러스터에서 분리 프로세스를 완료하고 다시 가져오는 데 몇 시간이 걸릴 수 있습니다.
프로세스가 완료될 때까지 기다리지 않고 허브 클러스터를 다시 가져오려면 다음 명령을 입력하여 multiclusterhub-operator Pod를 재시작하고 더 빠르게 다시 가져올 수 있습니다.
oc delete po -n open-cluster-management `oc get pod -n open-cluster-management | grep multiclusterhub-operator| cut -d' ' -f1`
온라인 연결 중 설치에 설명된 대로 disableHubSelfManagement 값을 true 로 변경하여 Hub 클러스터의 값을 자동으로 가져오지 않도록 할 수 있습니다.
1.5.19.2. 명령줄을 사용하여 클러스터 제거
hub 클러스터의 명령줄을 사용하여 관리 클러스터를 분리하려면 다음 명령을 실행합니다.
oc delete managedcluster $CLUSTER_NAME분리 후 관리되는 클러스터를 삭제하려면 다음 명령을 실행합니다.
oc delete clusterdeployment <CLUSTER_NAME> -n $CLUSTER_NAME참고:
-
관리 클러스터를 제거하지 않으려면
ClusterDeployment사용자 정의 리소스에서spec.preserveOnDelete매개변수를true로 설정합니다. disableHubSelfManagement의 기본 설정은false입니다.false'setting을 사용하면 'local-cluster 라고도 하는 hub클러스터가 분리될 때 자체 가져오기 및 관리되고MultiClusterHub컨트롤러를 조정합니다.연결 해제 및 다시 가져오기 프로세스는 허브 클러스터를 완료하는 데 몇 시간이 걸릴 수 있습니다. 프로세스가 완료될 때까지 기다리지 않고 허브 클러스터를 다시 가져오려면 다음 명령을 입력하여
multiclusterhub-operatorPod를 재시작하고 더 빨리 다시 가져올 수 있습니다.oc delete po -n open-cluster-management `oc get pod -n open-cluster-management | grep multiclusterhub-operator| cut -d' ' -f1`disableHubSelfManagement값을true로 변경하여 hub 클러스터의 값을 자동으로 가져오지 않도록 할 수 있습니다. 온라인으로 연결하는 동안 설치를 참조하십시오.
1.5.19.3. 클러스터를 제거한 후 나머지 리소스 제거
관리 클러스터에 제거된 리소스가 남아 있는 경우 나머지 구성 요소를 모두 제거하는 데 필요한 추가 단계가 있습니다. 이러한 추가 단계가 필요한 경우 다음 예제가 포함됩니다.
-
관리되는 클러스터는 완전히 생성되기 전에 분리되었으며
klusterlet과 같은 구성 요소는 관리 클러스터에 남아 있습니다. - 클러스터를 관리하고 있는 허브는 관리 클러스터를 분리하기 전에 손실되거나 삭제되었으며 허브에서 관리 클러스터를 분리할 방법이 없습니다.
- 관리형 클러스터는 분리될 때 온라인 상태가 아닙니다.
이러한 상황 중 하나가 관리형 클러스터의 분리에 적용되는 경우 관리 클러스터에서 제거할 수 없는 몇 가지 리소스가 있습니다. 관리 클러스터를 분리하려면 다음 단계를 완료합니다.
-
oc명령줄 인터페이스가 구성되어 있는지 확인합니다. 관리 클러스터에
KUBECONFIG가 구성되어 있는지 확인합니다.oc get ns | grep open-cluster-management-agent를 실행하면 두 개의 네임스페이스가 표시됩니다.open-cluster-management-agent Active 10m open-cluster-management-agent-addon Active 10m다음 명령을 사용하여
klusterlet사용자 정의 리소스를 제거합니다.oc get klusterlet | grep klusterlet | awk '{print $1}' | xargs oc patch klusterlet --type=merge -p '{"metadata":{"finalizers": []}}'다음 명령을 실행하여 나머지 리소스를 제거합니다.
oc delete namespaces open-cluster-management-agent open-cluster-management-agent-addon --wait=false oc get crds | grep open-cluster-management.io | awk '{print $1}' | xargs oc delete crds --wait=false oc get crds | grep open-cluster-management.io | awk '{print $1}' | xargs oc patch crds --type=merge -p '{"metadata":{"finalizers": []}}'다음 명령을 실행하여 네임스페이스와 열려 있는 모든 클러스터 관리
crds가 모두 제거되었는지 확인합니다.oc get crds | grep open-cluster-management.io | awk '{print $1}' oc get ns | grep open-cluster-management-agent
1.5.19.4. 클러스터를 제거한 후 etcd 데이터베이스 조각 모음
많은 관리 클러스터가 있으면 hub 클러스터의 etcd 데이터베이스 크기에 영향을 미칠 수 있습니다. OpenShift Container Platform 4.8에서는 관리 클러스터를 삭제하면 허브 클러스터의 etcd 데이터베이스가 크기가 자동으로 줄어들지 않습니다. 일부 시나리오에서는 etcd 데이터베이스를 공간이 부족할 수 있습니다. etcdserver: mvcc: 데이터베이스 공간 초과 오류가 표시됩니다. 이 오류를 수정하려면 데이터베이스 기록을 압축하고 etcd 데이터베이스를 조각 모음하여 etcd 데이터베이스 크기를 줄입니다.
참고: OpenShift Container Platform 버전 4.9 이상의 경우 etcd Operator는 자동으로 디스크를 조각 모음하고 etcd 기록을 압축합니다. 수동 조작이 필요하지 않습니다. 다음 절차는 OpenShift Container Platform 버전 4.8 및 이전 버전의 절차입니다.
다음 절차를 완료하여 기록을 압축하고 hub 클러스터에서 etcd 데이터베이스를 조각 모음합니다.
etcd
1.5.19.4.1. 사전 요구 사항
-
OpenShift CLI(
oc)를 설치합니다. -
cluster-admin권한이 있는 사용자로 로그인합니다.
1.5.19.4.2. 프로세스
etcd기록을 압축합니다.etcd멤버에 대한 원격 쉘 세션을 엽니다. 예를 들면 다음과 같습니다.$ oc rsh -n openshift-etcd etcd-control-plane-0.example.com etcdctl endpoint status --cluster -w table다음 명령을 실행하여
etcd기록을 압축합니다.sh-4.4#etcdctl compact $(etcdctl endpoint status --write-out="json" | egrep -o '"revision":[0-9]*' | egrep -o '[0-9]*' -m1)출력 예
$ compacted revision 158774421
-
etcd데이터베이스를 조각 모음하고etcd데이터 분리에 설명된 대로NOSPACE경고를 지웁니다.
1.6. Discovery 서비스 도입
OpenShift Cluster Manager 에서 사용할 수 있는 OpenShift 4 클러스터를 검색할 수 있습니다. 검색 후 관리할 클러스터를 가져올 수 있습니다. Discovery 서비스는 백엔드 및 콘솔 사용에 Discover Operator를 사용합니다.
OpenShift Cluster Manager 인증 정보가 있어야 합니다. 인증 정보를 생성해야 하는 경우 Red Hat OpenShift Cluster Manager의 인증 정보 생성 을 참조하십시오.
필요한 액세스: 관리자
1.6.1. 콘솔을 사용하여 Discovery 구성
제품 콘솔을 사용하여 Discovery를 활성화합니다.
필수 액세스: 인증 정보가 생성된 네임스페이스에 대한 액세스입니다.
1.6.1.1. 사전 요구 사항
- 인증 정보가 필요합니다. OpenShift Cluster Manager 에 연결할 Red Hat OpenShift Cluster Manager의 인증 정보 생성 을 참조하십시오.
1.6.1.2. Discovery 구성
콘솔을 통해 클러스터를 찾도록 Discovery를 구성합니다. 별도의 인증 정보를 사용하여 여러 DiscoveryConfig 리소스를 생성할 수 있습니다. 콘솔의 지침을 따르십시오.
1.6.1.3. 검색된 클러스터 보기
인증 정보를 설정하고 가져올 클러스터를 검색한 후 콘솔에서 해당 정보를 볼 수 있습니다.
- Clusters > Discovered Cluster를 클릭합니다.
다음 정보로 채워진 테이블을 확인합니다.
- name 은 OpenShift Cluster Manager에 지정된 표시 이름입니다. 클러스터에 표시 이름이 없으면 클러스터 콘솔 URL을 기반으로 생성된 이름이 표시됩니다. OpenShift Cluster Manager에서 콘솔 URL이 없거나 수동으로 수정된 경우 클러스터 외부 ID가 표시됩니다.
- 네임스페이스 는 인증 정보 및 검색된 클러스터를 생성한 네임스페이스입니다.
- type 은 검색된 클러스터 Red Hat OpenShift 유형입니다.
- 배포 버전은 검색된 클러스터 Red Hat OpenShift 버전입니다.
- 인프라 공급자는 검색된 클러스터의 클라우드 공급자입니다.
- 마지막 활성 은 검색된 클러스터가 마지막으로 활성화된 시간입니다.
- 검색된 클러스터가 생성 될 때 생성됩니다.
- 검색된 클러스터가 검색된 시기를 검색합니다.
- 또한 표에서 모든 정보를 검색할 수 있습니다. 예를 들어 특정 네임스페이스에 있는 Discovered 클러스터 만 표시하려면 해당 네임스페이스를 검색합니다.
- 이제 클러스터 가져오기를 클릭하여 관리 클러스터를 생성할 수 있습니다. 검색된 클러스터 가져오기 를 참조하십시오.
1.6.1.4. 검색된 클러스터 가져오기
클러스터를 검색한 후 콘솔의 Discovered clusters 탭에 표시되는 클러스터를 가져올 수 있습니다.
1.6.1.5. 사전 요구 사항
Discovery를 구성하는 데 사용된 네임스페이스에 대한 액세스 권한이 필요합니다.
1.6.1.6. 검색된 클러스터 가져오기
- 기존 클러스터 페이지로 이동하여 Discovered clusters 탭을 클릭합니다.
- Discovered clusters 테이블에서 가져올 클러스터를 찾습니다.
- 옵션 메뉴에서 클러스터 가져오기 를 선택합니다.
- 검색된 클러스터의 경우 문서를 사용하여 수동으로 가져오거나 클러스터 가져오기를 자동으로 선택할 수 있습니다.
- 인증 정보 또는 Kubeconfig 파일을 사용하여 자동으로 가져오려면 콘텐츠를 복사하여 붙여넣습니다.
- 가져오기 를 클릭합니다.
1.6.2. CLI를 사용하여 Discovery 활성화
CLI를 사용하여 검색을 활성화하여 Red Hat OpenShift Cluster Manager에서 사용할 수 있는 클러스터를 찾습니다.
필요한 액세스: 관리자
1.6.2.1. 사전 요구 사항
- Red Hat OpenShift Cluster Manager에 연결할 인증 정보를 생성합니다.
1.6.2.2. 검색 설정 및 프로세스
참고: DiscoveryConfig 라는 이름은 discovery 이고 선택한 인증 정보와 동일한 네임스페이스에서 생성해야 합니다. 다음 DiscoveryConfig 샘플을 참조하십시오.
apiVersion: discovery.open-cluster-management.io/v1
kind: DiscoveryConfig
metadata:
name: discovery
namespace: <NAMESPACE_NAME>
spec:
credential: <SECRET_NAME>
filters:
lastActive: 7
openshiftVersions:
- "4.13"-
SECRET_NAME을 이전에 설정한 인증 정보로 교체합니다. -
NAMESPACE_NAME을SECRET_NAME의 네임스페이스로 바꿉니다. -
검색할 클러스터의 마지막 활동 이후 최대 시간을 입력합니다. 예를 들어
lastActive: 7에서는 지난 7일 동안 활성 상태인 클러스터가 검색됩니다. -
Red Hat OpenShift 클러스터 버전을 입력하여 문자열 목록으로 검색합니다. 참고:
openshiftVersions목록의 모든 항목은 OpenShift 주 및 마이너 버전을 지정합니다. 예를 들어"4.11"을 지정하면 OpenShift 버전4.11의 모든 패치 릴리스(예:4.11.1, 4.11.2)가포함됩니다.
1.6.2.3. 검색된 클러스터 보기
oc get discoveredclusters -n <namespace >를 실행하여 검색된 클러스터를 확인합니다. 여기서 namespace 는 검색 인증 정보가 존재하는 네임스페이스입니다.
1.6.2.3.1. DiscoveredClusters
오브젝트는 검색 컨트롤러에서 생성합니다. 이러한 DiscoveredClusters 는 DiscoveryConfig 검색된clusters.discovery.open-cluster-management.io API에 지정된 필터 및 자격 증명을 사용하여 OpenShift Cluster Manager에 있는 클러스터를 나타냅니다. name 값은 클러스터 외부 ID입니다.
apiVersion: discovery.open-cluster-management.io/v1
kind: DiscoveredCluster
metadata:
name: fd51aafa-95a8-41f7-a992-6fb95eed3c8e
namespace: <NAMESPACE_NAME>
spec:
activity_timestamp: "2021-04-19T21:06:14Z"
cloudProvider: vsphere
console: https://console-openshift-console.apps.qe1-vmware-pkt.dev02.red-chesterfield.com
creation_timestamp: "2021-04-19T16:29:53Z"
credential:
apiVersion: v1
kind: Secret
name: <SECRET_NAME>
namespace: <NAMESPACE_NAME>
display_name: qe1-vmware-pkt.dev02.red-chesterfield.com
name: fd51aafa-95a8-41f7-a992-6fb95eed3c8e
openshiftVersion: 4.13
status: Stale1.7. 호스팅된 컨트롤 플레인
다중 클러스터 엔진 Operator 클러스터 관리를 사용하면 독립 실행형 또는 호스팅된 컨트롤 플레인이라는 두 가지 컨트롤 플레인 구성을 사용하여 OpenShift Container Platform 클러스터를 배포할 수 있습니다. 독립 실행형 구성은 전용 가상 머신 또는 물리적 머신을 사용하여 OpenShift Container Platform 컨트롤 플레인을 호스팅합니다. OpenShift Container Platform의 호스팅된 컨트롤 플레인을 사용하면 각 컨트롤 플레인의 전용 물리적 머신 없이도 호스팅 클러스터에서 컨트롤 플레인을 Pod로 생성합니다.
OpenShift Container Platform의 호스팅된 컨트롤 플레인은 베어 메탈 및 Red Hat OpenShift Virtualization에서 사용할 수 있으며 AWS(Amazon Web Services)의 기술 프리뷰 기능으로 사용할 수 있습니다. OpenShift Container Platform 버전 4.14에서 컨트롤 플레인을 호스팅할 수 있습니다. 호스트된 컨트롤 플레인 기능은 기본적으로 활성화되어 있습니다.
1.7.1. 요구사항
다음 표는 각 플랫폼에 지원되는 OpenShift Container Platform 버전을 나타냅니다. 표에서 Cryostat OpenShift Container Platform 버전은 다중 클러스터 엔진 Operator가 활성화된 OpenShift Container Platform 버전을 나타냅니다.
| 플랫폼 | OpenShift Container Platform 버전 호스팅 | 호스팅된 OpenShift Container Platform 버전 |
| 베어 메탈 | 4.14 - 4.15 | 4.14 - 4.15 (only) |
| Red Hat OpenShift Virtualization | 4.14 - 4.15 | 4.14 - 4.15 (only) |
| AWS (기술 프리뷰) | 4.11 - 4.15 | 4.14 - 4.15 (only) |
참고: 호스팅된 컨트롤 플레인의 동일한 플랫폼에서 허브 클러스터 및 작업자를 실행합니다.
컨트롤 플레인은 단일 네임스페이스에 포함되어 있고 호스팅된 컨트롤 플레인 클러스터와 연결된 Pod로 실행됩니다. OpenShift Container Platform은 이러한 유형의 호스팅 클러스터를 생성할 때 컨트롤 플레인과 독립적인 작업자 노드를 생성합니다.
프록시를 사용하고 Pod에서 Kubernetes API 서버로 전송되는 경우 기본 Kubernetes API 서버 주소인 172.20.0.1을 no_proxy 목록에 추가합니다.
호스팅된 컨트롤 플레인 클러스터는 다음과 같은 몇 가지 이점을 제공합니다.
- 전용 컨트롤 플레인 노드를 호스팅할 필요가 없어 비용 절감
- 컨트롤 플레인과 워크로드를 분리하여 격리를 개선하고 변경이 필요할 수 있는 구성 오류를 줄입니다.
- 컨트롤 플레인 노드 부트스트랩에 대한 요구 사항을 제거하여 클러스터 생성 시간을 줄입니다.
- 턴 키 배포 또는 완전히 사용자 지정된 OpenShift Container Platform 프로비저닝 지원
호스팅된 컨트롤 플레인을 사용하려면 다음 문서로 시작합니다.
그런 다음 사용할 플랫폼과 관련된 설명서를 참조하십시오.
- AWS에서 호스팅된 컨트롤 플레인 클러스터 구성 (기술 프리뷰)
- 베어 메탈에서 호스팅된 컨트롤 플레인 클러스터 구성
- IBM Power 컴퓨팅 노드의 호스팅 컨트롤 플레인을 생성하도록 64비트 x86 OpenShift Container Platform 클러스터에서 호스팅 클러스터 구성 (기술 프리뷰)
-
IBM Z 컴퓨팅 노드의
x86베어 메탈에서 호스팅 클러스터 구성 (기술 프리뷰) - OpenShift Virtualization에서 호스트된 컨트롤 플레인 클러스터 관리
- 연결이 끊긴 환경에서 호스트된 컨트롤 플레인 구성
- 호스트 제어 기능 비활성화
노드 풀에 대한 추가 네트워크, 보장된 CPU 및 VM 스케줄링을 구성하려면 다음 문서를 참조하십시오.
호스팅된 컨트롤 플레인에 대한 추가 리소스는 다음 OpenShift Container Platform 설명서를 참조하십시오.
1.7.2. 호스팅된 컨트롤 플레인 크기 조정 지침
호스트 클러스터 워크로드 및 작업자 노드 수를 포함한 많은 요인은 특정 컨트롤 플레인 노드 내에 적합한 호스트 클러스터 수에 영향을 미칩니다. 이 크기 조정 가이드를 사용하여 호스트된 클러스터 용량 계획에 도움이 됩니다. 이 가이드에서는 고가용성 호스팅 컨트롤 플레인 토폴로지를 가정합니다. 로드 기반 크기 조정 예제는 베어 메탈 클러스터에서 측정되었습니다. 클라우드 기반 인스턴스에는 메모리 크기와 같은 제한 요소가 다를 수 있습니다. 고가용성 호스팅 컨트롤 플레인 토폴로지에 대한 자세한 내용은 호스팅 된 클러스터 워크로드 배포를 참조하십시오.
다음 리소스 사용률 크기 조정을 재정의하고 메트릭 서비스 모니터링을 비활성화할 수 있습니다. 자세한 내용은 추가 리소스 섹션의 리소스 사용률 덮어쓰기 섹션을 참조하십시오.
OpenShift Container Platform 버전 4.12.9 이상에서 테스트된 다음 고가용성 호스팅 컨트롤 플레인 요구 사항을 참조하십시오.
- 78 Pod
- etcd의 경우 3GiB PV
- 최소 vCPU: 약 5.5코어
- 최소 메모리: 약 19GiB
1.7.2.1. Pod 제한
각 노드의 maxPods 설정은 컨트롤 플레인 노드에 들어갈 수 있는 호스트 클러스터 수에 영향을 미칩니다. 모든 control-plane 노드에서 maxPods 값을 기록하는 것이 중요합니다. 고가용성 호스팅 컨트롤 플레인마다 약 75개의 Pod를 계획합니다.
베어 메탈 노드의 경우 기본 maxPods 설정 250는 제한 요소가 될 수 있습니다. 이는 머신에 많은 리소스가 부족하더라도 Pod 요구 사항을 충족하는 각 노드에 대해 약 3개의 호스팅 컨트롤 플레인이 적합하기 때문입니다. KubeletConfig 값을 구성하여 maxPods 값을 500으로 설정하면 호스트된 컨트롤 플레인 밀도가 증가할 수 있으므로 추가 컴퓨팅 리소스를 활용할 수 있습니다. 자세한 내용은 OpenShift Container Platform 설명서 의 노드당 최대 Pod 수 구성 을 참조하십시오.
1.7.2.2. 요청 기반 리소스 제한
클러스터에서 호스팅할 수 있는 최대 호스팅 컨트롤 플레인 수는 Pod의 호스팅된 컨트롤 플레인 CPU 및 메모리 요청을 기반으로 계산됩니다.
고가용성 호스트 컨트롤 플레인은 5개의 vCPU 및 18GB 메모리를 요청하는 78 Pod로 구성됩니다. 이러한 기준 번호는 클러스터 작업자 노드 리소스 용량과 비교하여 호스팅되는 컨트롤 플레인의 최대 수를 추정합니다.
1.7.2.3. 로드 기반 제한
클러스터에서 호스팅할 수 있는 최대 호스팅 컨트롤 플레인 수는 일부 워크로드가 호스팅된 컨트롤 플레인 Kubernetes API 서버에 배치될 때 호스팅된 컨트롤 플레인 CPU 및 메모리 사용률을 기반으로 계산됩니다.
다음 방법은 워크로드가 증가할 때 호스팅된 컨트롤 플레인 리소스 사용률을 측정하는 데 사용됩니다.
- KubeVirt 플랫폼을 사용하는 동안 각각 8 vCPU 및 32GiB를 사용하는 9개의 작업자가 있는 호스트 클러스터
다음 정의에 따라 API 컨트롤 플레인 과부하에 중점을 두도록 구성된 워크로드 테스트 프로필입니다.
- 각 네임스페이스에 대해 생성된 오브젝트로, 총 네임스페이스 100개까지 확장
- 연속 오브젝트 삭제 및 생성에 대한 추가 API 과부하
- 워크로드 쿼리-초당 (QPS) 및 Burst 설정은 클라이언트 측 제한을 제거하기 위해 높은 설정
로드가 1000개의 QPS로 증가하면 호스트된 컨트롤 플레인 리소스 사용률이 9개의 vCPU 및 2.5GB 메모리로 증가합니다.
일반적인 크기 조정을 위해 중간 호스트 클러스터 로드인 1000 QPS API 속도와 호스트 클러스터 로드가 많은 2000 QPS API를 고려하십시오.
참고: 이 테스트는 예상되는 API 로드에 따라 컴퓨팅 리소스 사용률을 늘리는 추정 요소를 제공합니다. 정확한 사용률 비율은 클러스터 워크로드의 유형 및 속도에 따라 다를 수 있습니다.
| 호스트된 컨트롤 플레인 리소스 사용률 스케일링 | vCPU | 메모리(GiB) |
|---|---|---|
| 로드가 없는 리소스 사용률 | 2.9 | 11.1 |
| 1000 QPS 사용 리소스 | 9.0 | 2.5 |
로드가 1000개의 QPS로 증가하면 호스트된 컨트롤 플레인 리소스 사용률이 9개의 vCPU 및 2.5GB 메모리로 증가합니다.
일반적인 크기 조정을 위해 1000개의 QPS API 속도가 중간 호스트 클러스터 로드이고 2000 QPS API를 호스트하는 클러스터 로드가 높은 것으로 간주합니다.
다음 예제에서는 워크로드 및 API 속도 정의에 대한 호스팅된 컨트롤 플레인 리소스 스케일링을 보여줍니다.
| QPS(API 속도) | vCPU 사용 | 메모리 사용량(GiB) |
|---|---|---|
| 낮은 부하 (50 QPS 미만) | 2.9 | 11.1 |
| 중간 로드 (1000 QPS) | 11.9 | 13.6 |
| 높은 부하 (2000 QPS) | 20.9 | 16.1 |
호스트된 컨트롤 플레인 크기 조정은 API 활동, etcd 활동 또는 둘 다로 인해 발생하는 컨트롤 플레인 로드 및 워크로드에 관한 것입니다. 데이터베이스 실행과 같은 데이터 플레인 로드에 중점을 둔 호스팅된 Pod 워크로드는 API 비율이 높지 않을 수 있습니다.
1.7.2.4. 크기 조정 계산 예
이 예제에서는 다음 시나리오에 대한 크기 조정 지침을 제공합니다.
-
hypershift.openshift.io/control-plane노드로 레이블이 지정된 베어 메탈 작업자 세 개 -
maxPods값이 500으로 설정 - 예상되는 API 속도는 로드 기반 제한에 따라 중간 또는 약 1000입니다.
| 제한 설명 | 서버 1 | 서버 2 |
|---|---|---|
| 작업자 노드의 vCPU 수 | 64 | 128 |
| 작업자 노드의 메모리(GiB) | 128 | 256 |
| 작업자당 최대 Pod 수 | 500 | 500 |
| 컨트롤 플레인을 호스팅하는 데 사용되는 작업자 수 | 3 | 3 |
| 최대 QPS 대상 속도(초당 API 요청) | 1000 | 1000 |
| 작업자 노드 크기 및 API 속도를 기반으로 계산된 값 | 서버 1 | 서버 2 | 계산 노트 |
| vCPU 요청을 기반으로 작업자당 최대 호스트 컨트롤 플레인 | 12.8 | 25.6 | 호스트된 컨트롤 플레인당 총 vCPU 요청 수 5개 |
| vCPU 사용을 기반으로 작업자당 최대 호스트 컨트롤 플레인 | 5.4 | 10.7 | vCPUS Cryostat (2.9 측정 유휴 vCPU 사용량 + (QPS 대상 비율 Cryostat 1000) × 9.0 QPS 증가당 vCPU 사용량 측정) |
| 메모리 요청을 기반으로 작업자당 최대 호스트 컨트롤 플레인 | 7.1 | 14.2 | 작업자 메모리 GiB Cryostat 18GiB의 호스트된 컨트롤 플레인당 총 메모리 요청 |
| 메모리 사용량을 기반으로 작업자당 최대 호스트된 컨트롤 플레인 | 9.4 | 18.8 | 작업자 메모리 GiB Cryostat (1.1 측정 유휴 메모리 사용량 + (QPS 대상 비율 Cryostat 1000) × 2.5는 1000 QPS 증가당 메모리 사용량 측정) |
| 노드 Pod 제한에 따라 작업자당 최대 호스트 컨트롤 플레인 | 6.7 | 6.7 |
호스팅된 컨트롤 플레인당 500 |
| 이전에 언급된 최소 최대값 | 5.4 | 6.7 | |
| vCPU 제한 요소 |
| ||
| 관리 클러스터 내의 최대 호스트 컨트롤 플레인 수 | 16 | 20 | 이전에 언급된 최소 최대 × 3 개의 컨트롤 플레인 작업자 |
| 이름 | 설명 |
|
| 클러스터가 고가용성 호스팅 컨트롤 플레인 리소스 요청을 기반으로 호스팅할 수 있는 최대 호스트 컨트롤 플레인 수입니다. |
|
| 모든 호스팅 컨트롤 플레인이 클러스터 Kube API 서버에 약 50 QPS를 생성하는 경우 클러스터에서 호스팅할 수 있는 호스트 컨트롤 플레인의 최대 최대 수입니다. |
|
| 모든 호스팅된 컨트롤 플레인이 클러스터 Kube API 서버에 약 1000개의 QPS를 생성하는 경우 클러스터에서 호스팅할 수 있는 호스트 컨트롤 플레인의 최대 최대 수입니다. |
|
| 모든 호스팅된 컨트롤 플레인이 약 2000 QPS를 클러스터 Kube API 서버로 만드는 경우 클러스터에서 호스팅할 수 있는 호스팅되는 컨트롤 플레인의 최대 수입니다. |
|
| 클러스터에서 호스트된 컨트롤 플레인의 기존 평균 QPS를 기반으로 호스팅할 수 있는 최대 호스트 컨트롤 플레인 수입니다. 활성 호스트 컨트롤 플레인이 없는 경우 낮은 QPS를 기대할 수 있습니다. |
1.7.2.5. 추가 리소스
1.7.3. 리소스 사용률 측정 덮어쓰기
리소스 사용률에 대한 기준 측정 세트는 모든 클러스터에서 다를 수 있습니다. 자세한 내용은 호스팅된 컨트롤 플레인 크기 조정 지침을 참조하십시오.
클러스터 워크로드의 유형 및 속도에 따라 리소스 사용률 측정을 덮어쓸 수 있습니다. 다음 단계를 완료합니다.
다음 명령을 실행하여
ConfigMap리소스를 생성합니다.oc create -f <your-config-map-file.yaml><
your-config-map-file.yaml>을hcp-sizing-baseline구성 맵이 포함된 YAML 파일의 이름으로 바꿉니다.local-cluster네임스페이스에hcp-sizing-baseline구성 맵을 생성하여 덮어쓸 측정값을 지정합니다. 구성 맵은 다음 YAML 파일과 유사할 수 있습니다.kind: ConfigMap apiVersion: v1 metadata: name: hcp-sizing-baseline namespace: local-cluster data: incrementalCPUUsagePer1KQPS: "9.0" memoryRequestPerHCP: "18" minimumQPSPerHCP: "50.0"다음 명령을 실행하여
hypershift-addon-agent배포를 삭제하여hypershift-addon-agentPod를 다시 시작합니다.oc delete deployment hypershift-addon-agent -n open-cluster-management-agent-addonhypershift-addon-agentPod 로그를 관찰합니다. 다음 명령을 실행하여 재정의된 측정이 구성 맵에서 업데이트되었는지 확인합니다.oc logs hypershift-addon-agent -n open-cluster-management-agent-addon로그는 다음 출력과 유사할 수 있습니다.
2024-01-05T19:41:05.392Z INFO agent.agent-reconciler agent/agent.go:793 setting cpuRequestPerHCP to 5 2024-01-05T19:41:05.392Z INFO agent.agent-reconciler agent/agent.go:802 setting memoryRequestPerHCP to 18 2024-01-05T19:53:54.070Z INFO agent.agent-reconciler agent/hcp_capacity_calculation.go:141 The worker nodes have 12.000000 vCPUs 2024-01-05T19:53:54.070Z INFO agent.agent-reconciler agent/hcp_capacity_calculation.go:142 The worker nodes have 49.173369 GB memoryhcp-sizing-baseline구성 맵에서 재정의된 측정이 제대로 업데이트되지 않으면hypershift-addon-agentPod 로그에 다음 오류 메시지가 표시될 수 있습니다.2024-01-05T19:53:54.052Z ERROR agent.agent-reconciler agent/agent.go:788 failed to get configmap from the hub. Setting the HCP sizing baseline with default values. {"error": "configmaps \"hcp-sizing-baseline\" not found"}
1.7.3.1. 메트릭 서비스 모니터링 비활성화
하이퍼shift-addon 관리 클러스터 애드온을 활성화한 후 기본적으로 메트릭 서비스 모니터링이 구성되므로 OpenShift Container Platform 모니터링에서 hypershift-addon 에서 메트릭을 수집할 수 있습니다. 다음 단계를 완료하여 메트릭 서비스 모니터링을 비활성화할 수 있습니다.
다음 명령을 실행하여 허브 클러스터에 로그인합니다.
oc login다음 명령을 실행하여 편집할
hypershift-addon-deploy-config배포 구성 사양을 엽니다.oc edit addondeploymentconfig hypershift-addon-deploy-config -n multicluster-engine다음 예와 같이
disableMetrics=true사용자 지정 변수를 사양에 추가합니다.apiVersion: addon.open-cluster-management.io/v1alpha1 kind: AddOnDeploymentConfig metadata: name: hypershift-addon-deploy-config namespace: multicluster-engine spec: customizedVariables: - name: hcMaxNumber value: "80" - name: hcThresholdNumber value: "60" - name: disableMetrics value: "true"-
변경 사항을 저장합니다.
disableMetrics=true사용자 지정 변수는 신규 및 기존hypershift-addon관리 클러스터 애드온에 대한 메트릭 서비스 모니터링 구성을 비활성화합니다.
1.7.3.2. 추가 리소스
1.7.4. 호스팅된 컨트롤 플레인 명령줄 인터페이스 설치
다음 단계를 완료하여 호스팅된 컨트롤 플레인 명령줄 인터페이스 hcp 를 설치할 수 있습니다.
- OpenShift Container Platform 콘솔에서 도움말 아이콘 > 명령줄 툴 을 클릭합니다.
- 플랫폼에 대한 hcp CLI 다운로드를 클릭합니다.
다음 명령을 실행하여 다운로드한 아카이브의 압축을 풉니다.
tar xvzf hcp.tar.gz다음 명령을 실행하여 바이너리 파일을 실행 가능하게 만듭니다.
chmod +x hcp다음 명령을 실행하여 바이너리 파일을 경로의 디렉터리로 이동합니다.
sudo mv hcp /usr/local/bin/.
이제 hcp create cluster 명령을 사용하여 호스팅 클러스터를 생성하고 관리할 수 있습니다. 사용 가능한 매개변수를 나열하려면 다음 명령을 입력합니다.
hcp create cluster <platform> --help - 1
- 지원되는 플랫폼은
aws,agent,kubevirt입니다.
1.7.4.1. CLI를 사용하여 호스팅된 컨트롤 플레인 명령줄 인터페이스 설치
다음 단계를 완료하여 CLI를 사용하여 호스팅되는 컨트롤 플레인 명령줄 인터페이스 hcp 를 설치할 수 있습니다.
다음 명령을 실행하여
hcp바이너리를 다운로드하려면 URL을 가져옵니다.oc get ConsoleCLIDownload hcp-cli-download -o json | jq -r ".spec"다음 명령을 실행하여
hcp바이너리를 다운로드합니다.wget <hcp_cli_download_url>1 - 1
hcp_cli_download_url을 이전 단계에서 얻은 URL로 바꿉니다.
다음 명령을 실행하여 다운로드한 아카이브의 압축을 풉니다.
tar xvzf hcp.tar.gz다음 명령을 실행하여 바이너리 파일을 실행 가능하게 만듭니다.
chmod +x hcp다음 명령을 실행하여 바이너리 파일을 경로의 디렉터리로 이동합니다.
sudo mv hcp /usr/local/bin/.
1.7.4.2. 콘텐츠 게이트웨이를 사용하여 호스팅된 컨트롤 플레인 명령줄 인터페이스 설치
콘텐츠 게이트웨이를 사용하여 호스팅되는 컨트롤 플레인 명령줄 인터페이스 hcp 를 설치할 수 있습니다. 다음 단계를 완료합니다.
-
콘텐츠 게이트웨이로 이동하여
hcp바이너리를 다운로드합니다. 다음 명령을 실행하여 다운로드한 아카이브의 압축을 풉니다.
tar xvzf hcp.tar.gz다음 명령을 실행하여 바이너리 파일을 실행 가능하게 만듭니다.
chmod +x hcp다음 명령을 실행하여 바이너리 파일을 경로의 디렉터리로 이동합니다.
sudo mv hcp /usr/local/bin/.
이제 hcp create cluster 명령을 사용하여 호스팅 클러스터를 생성하고 관리할 수 있습니다. 사용 가능한 매개변수를 나열하려면 다음 명령을 입력합니다.
hcp create cluster <platform> --help - 1
- 지원되는 플랫폼은
aws,agent,kubevirt입니다.
1.7.5. 호스트된 클러스터 워크로드 배포
OpenShift Container Platform의 호스팅 컨트롤 플레인을 시작하기 전에 노드에 라벨을 지정하여 호스팅된 클러스터 Pod를 인프라 노드에 예약해야 합니다.
노드 라벨링은 다음 기능을 보장합니다.
-
고가용성 및 적절한 워크로드 배포. 예를 들어 OpenShift Container Platform 서브스크립션에 컨트롤 플레인 워크로드 수가 발생하지 않도록
node-role.kubernetes.io/infra레이블을 설정할 수 있습니다. - 컨트롤 플레인 워크로드를 관리 클러스터의 다른 워크로드와 분리합니다.
중요: 워크로드에 관리 클러스터를 사용하지 마십시오. 컨트롤 플레인이 실행되는 노드에서 워크로드가 실행되지 않아야 합니다.
1.7.5.1. 관리 클러스터 노드의 라벨 및 테인트
관리 클러스터 관리자는 관리 클러스터 노드에서 다음 레이블 및 테인트를 사용하여 컨트롤 플레인 워크로드를 예약합니다.
-
Hypershift.openshift.io/control-plane: true: 이 레이블과 테인트를 사용하여 호스트된 컨트롤 플레인 워크로드를 실행하는 노드를 전용으로 사용합니다.true를 설정하면 컨트롤 플레인 노드를 다른 구성 요소와 공유하지 않습니다. -
Hypershift.openshift.io/cluster: <hosted-control-plane-namespace>: 노드를 단일 호스트 클러스터에 전용으로 설정하려면 이 레이블과 테인트를 사용합니다.
control-plane Pod를 호스팅하는 노드에 다음 레이블을 적용합니다.
-
node-role.kubernetes.io/infra: 서브스크립션에 컨트롤 플레인 워크로드 수가 발생하지 않도록 이 라벨을 사용합니다. -
topology.kubernetes.io/zone: 관리 클러스터 노드에서 이 레이블을 사용하여 장애 도메인에서 고가용성 클러스터를 배포합니다. 영역은 위치, 랙 이름 또는 영역이 설정된 노드의 호스트 이름이 될 수 있습니다.
각 랙을 관리 클러스터 노드의 가용성 영역으로 사용하려면 다음 명령을 입력합니다.
+
oc label node/<management_node1_name> node/<management_node2_name> topology.kubernetes.io/zone=<rack_name>
호스팅된 클러스터의 Pod에는 허용 오차가 있으며 스케줄러는 선호도 규칙을 사용하여 스케줄링합니다. 스케줄러는 hypershift.openshift.io/control-plane 및 hypershift.openshift.io/cluster: <hosted_control_plane_namespace > 로 레이블이 지정된 노드에 Pod 예약에 우선순위를 지정합니다.
ControllerAvailabilityPolicy 옵션의 경우 호스팅된 컨트롤 플레인 명령줄 인터페이스인 hcp, deploy의 기본값인 HighlyAvailable 을 사용합니다. 이 옵션을 사용하면 topology.kubernetes.io/zone 을 토폴로지 키로 설정하여 다양한 장애 도메인에서 호스트된 클러스터 내에서 각 배포에 대한 Pod를 예약할 수 있습니다. 고가용성이 아닌 컨트롤 플레인은 지원되지 않습니다.
1.7.5.2. 호스팅된 클러스터의 노드 레이블
중요: 호스팅된 컨트롤 플레인을 배포하기 전에 노드에 라벨을 추가해야 합니다.
호스팅 클러스터에서 실행되는 Pod를 인프라 노드에 예약하려면 HostedCluster CR(사용자 정의 리소스)에 role.kubernetes.io/infra: "" 라벨을 추가합니다. 다음 예제를 참조하십시오.
spec:
nodeSelector:
role.kubernetes.io/infra: ""1.7.5.3. 우선순위 클래스
기본 제공 우선순위 클래스 4개가 호스트된 클러스터 Pod의 우선 순위 및 선점에 영향을 미칩니다. 다음과 같은 순서로 관리 클러스터에 Pod를 생성할 수 있습니다.
-
Hypershift-operator: HyperShift Operator Pod -
Hypershift-etcd: etcd 용 Pod -
Hypershift-api-critical: API 호출 및 리소스 승인에 필요한 Pod입니다. 이 우선순위 클래스에는kube-apiserver, 집계 API 서버 및 웹 후크와 같은 Pod가 포함됩니다. -
Hypershift-control-plane: API-critical는 아니지만 클러스터 버전 Operator와 같이 높은 우선 순위가 필요한 컨트롤 플레인의 Pod입니다.
1.7.5.4. 추가 리소스
호스팅된 컨트롤 플레인에 대한 자세한 내용은 다음 항목을 참조하십시오.
1.7.6. AWS에서 호스팅된 컨트롤 플레인 클러스터 구성 (기술 프리뷰)
호스팅된 컨트롤 플레인을 구성하려면 호스팅 클러스터와 호스팅 클러스터가 필요합니다. hypershift-addon 관리 클러스터 애드온을 사용하여 기존 관리 클러스터에 HyperShift Operator를 배포하면 해당 클러스터를 호스팅 클러스터로 활성화하고 호스팅 클러스터를 생성할 수 있습니다. 다중 클러스터 엔진 Operator 2.5 및 Red Hat Advanced Cluster Management 2.10 허브 클러스터의 로컬 클러스터 관리 클러스터에 대해 관리 클러스터 애드온은 기본적으로 활성화되어 있습니다.
하이퍼shift- addon
호스팅 클러스터는 호스팅 클러스터에서 호스팅되 는 API 끝점 및 컨트롤 플레인이 있는 OpenShift Container Platform 클러스터입니다. 호스트된 클러스터에는 컨트롤 플레인과 해당 데이터 플레인이 포함됩니다. 다중 클러스터 엔진 Operator 콘솔 또는 호스팅된 컨트롤 플레인 명령줄 인터페이스인 hcp 를 사용하여 호스트된 클러스터를 생성할 수 있습니다. 호스팅된 클러스터는 관리 클러스터로 자동으로 가져옵니다. 이 자동 가져오기 기능을 비활성화하려면 호스팅된 클러스터를 멀티 클러스터 엔진 Operator로 자동 가져오기 비활성화 를 참조하십시오.
중요:
- 각 호스트 클러스터에는 클러스터 전체 이름이 있어야 합니다. 호스트된 클러스터 이름은 다중 클러스터 엔진 운영자가 이를 관리하기 위해 기존 관리 클러스터와 같을 수 없습니다.
-
클러스터를 호스팅
클러스터이름으로 사용하지 마십시오. - 호스팅된 컨트롤 플레인의 동일한 플랫폼에서 허브 클러스터 및 작업자를 실행합니다.
- 호스트된 클러스터는 다중 클러스터 엔진 Operator 관리 클러스터의 네임스페이스에서 생성할 수 없습니다.
1.7.6.1. 사전 요구 사항
호스팅 클러스터를 구성하려면 다음 사전 요구 사항이 있어야 합니다.
- Kubernetes Operator 2.5 이상용 멀티 클러스터 엔진은 OpenShift Container Platform 클러스터에 설치되어 있습니다. Red Hat Advanced Cluster Management를 설치할 때 다중 클러스터 엔진 Operator가 자동으로 설치됩니다. 멀티 클러스터 엔진 Operator는 OpenShift Container Platform OperatorHub의 Operator로 Red Hat Advanced Cluster Management 없이 설치할 수도 있습니다.
다중 클러스터 엔진 Operator에는 하나 이상의 관리형 OpenShift Container Platform 클러스터가 있어야 합니다.
로컬 클러스터는 멀티 클러스터 엔진 Operator 2.5 이상에서 자동으로 가져옵니다.local-cluster에 대한 자세한 내용은 고급 구성 을 참조하십시오. 다음 명령을 실행하여 허브 클러스터의 상태를 확인할 수 있습니다.oc get managedclusters local-cluster- AWS 명령줄 인터페이스
- 호스팅된 컨트롤 플레인 명령줄 인터페이스
호스팅된 컨트롤 플레인에 대한 추가 리소스는 다음 문서를 참조하십시오.
- 호스팅된 컨트롤 플레인 기능을 비활성화하거나 이미 비활성화한 경우 호스팅된 컨트롤 플레인 기능 활성화 또는 비활성화를 참조하십시오.
- Red Hat Ansible Automation Platform 작업을 실행하여 호스트된 클러스터를 관리하려면 호스팅된 클러스터에서 실행되도록 Ansible Automation Platform 작업 구성 을 참조하십시오.
- SR-IOV Operator를 배포하려면 호스팅된 컨트롤 플레인을 위한 SR-IOV Operator 배포를 참조하십시오.
1.7.6.2. Amazon Web Services S3 버킷 및 S3 OIDC 시크릿 생성
AWS에서 호스팅 클러스터를 생성하고 관리하려면 다음 단계를 완료합니다.
클러스터의 호스트 OIDC 검색 문서에 대한 공용 액세스 권한이 있는 S3 버킷을 생성합니다.
us-east-1 리전에 버킷을 생성하려면 다음 코드를 입력합니다.
aws s3api create-bucket --bucket <your-bucket-name> aws s3api delete-public-access-block --bucket <your-bucket-name> echo '{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": "*", "Action": "s3:GetObject", "Resource": "arn:aws:s3:::<your-bucket-name>/*" } ] }' | envsubst > policy.json aws s3api put-bucket-policy --bucket <your-bucket-name> --policy file://policy.json- us-east-1 리전 이외의 리전에서 버킷을 생성하려면 다음 코드를 입력합니다.
aws s3api create-bucket --bucket <your-bucket-name> \ --create-bucket-configuration LocationConstraint=<region> \ --region <region> aws s3api delete-public-access-block --bucket <your-bucket-name> echo '{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": "*", "Action": "s3:GetObject", "Resource": "arn:aws:s3:::<your-bucket-name>/*" } ] }' | envsubst > policy.json aws s3api put-bucket-policy --bucket <your-bucket-name> --policy file://policy.json-
HyperShift Operator에 대해
hypershift-operator-oidc-provider-s3-credentials라는 OIDC S3 시크릿을 생성합니다. -
로컬 클러스터네임스페이스에 시크릿을 저장합니다. 다음 표를 참조하여 보안에 다음 필드가 포함되어 있는지 확인합니다.
Expand 필드 이름 설명 bucket호스팅된 클러스터에 대한 호스트 OIDC 검색 문서에 대한 공용 액세스 권한이 있는 S3 버킷이 포함되어 있습니다.
credentials버킷에 액세스할 수 있는
기본프로필의 자격 증명이 포함된 파일에 대한 참조입니다. 기본적으로 HyperShift는기본프로필만 사용하여버킷을 작동합니다.regionS3 버킷의 리전을 지정합니다.
다음 예제에서는 샘플 AWS 시크릿 템플릿을 보여줍니다.
oc create secret generic hypershift-operator-oidc-provider-s3-credentials --from-file=credentials=<path>/.aws/credentials --from-literal=bucket=<s3-bucket-for-hypershift> --from-literal=region=<region> -n local-cluster참고: 시크릿에 대한 재해 복구 백업은 자동으로 활성화되지 않습니다. 다음 명령을 실행하여 재해 복구를 위해
hypershift-operator-oidc-provider-s3-credentials시크릿을 백업할 수 있는 레이블을 추가합니다.oc label secret hypershift-operator-oidc-provider-s3-credentials -n local-cluster cluster.open-cluster-management.io/backup=true
1.7.6.3. 라우팅 가능한 퍼블릭 영역 생성
게스트 클러스터의 애플리케이션에 액세스하려면 퍼블릭 영역을 라우팅할 수 있어야 합니다. 퍼블릭 영역이 있는 경우 이 단계를 건너뜁니다. 그렇지 않으면 퍼블릭 영역이 기존 기능에 영향을 미칩니다.
다음 명령을 실행하여 클러스터 DNS 레코드에 대한 퍼블릭 영역을 생성합니다.
aws route53 create-hosted-zone --name <your-basedomain> --caller-reference $(whoami)-$(date --rfc-3339=date)
your-basedomain 을 기본 도메인으로 교체합니다(예: www.example.com ).
1.7.6.4. 외부 DNS 활성화
컨트롤 플레인과 데이터 플레인은 호스팅된 컨트롤 플레인에서 분리되어 있습니다. 다음 두 개의 독립적인 영역에서 DNS를 구성할 수 있습니다.
-
호스트 클러스터 내의 워크로드에 대한 Ingress(예:
*.apps.service-consumer-domain.com) -
서비스 공급자 도메인을 통한 API 또는 OAUTH 끝점과 같은 관리 클러스터 내의 서비스 끝점에 대한 Ingress:
*.service-provider-domain.com
hostedCluster.spec.dns 의 입력은 호스팅 클러스터 내의 워크로드에 대한 수신을 관리합니다. hostedCluster.spec.services.servicePublishingStrategy.route.hostname 의 입력은 관리 클러스터 내의 서비스 끝점에 대한 수신을 관리합니다.
외부 DNS는 LoadBalancer 또는 Route 의 게시 유형을 지정하고 해당 게시 유형의 호스트 이름을 제공하는 호스팅 클러스터 서비스에 대한 이름 레코드를 생성합니다. Private 또는 PublicAndPrivate 엔드포인트 액세스 유형이 있는 호스팅 클러스터의 경우 APIServer 및 OAuth 서비스만 호스트 이름을 지원합니다. 프라이빗 호스트 클러스터의 경우 DNS 레코드는 VPC의 VPC(Virtual Private Cloud) 끝점의 프라이빗 IP 주소로 확인됩니다.
호스팅된 컨트롤 플레인은 다음 서비스를 노출합니다.
-
apiserver -
OAuthServer -
Konnectivity -
Ignition -
OVNSbDb -
OIDC
HostedCluster 사양에서 servicePublishingStrategy 필드를 사용하여 이러한 서비스를 노출할 수 있습니다. 기본적으로 LoadBalancer 및 Route 유형의 servicePublishingStrategy 에서는 다음 방법 중 하나로 서비스를 게시할 수 있습니다.
-
LoadBalancer유형의서비스상태에 있는 로드 밸런서의 호스트 이름 사용 -
Route리소스의status.host필드 사용
그러나 관리 서비스 컨텍스트에 호스팅된 컨트롤 플레인을 배포할 때 이러한 방법은 기본 관리 클러스터의 ingress 하위 도메인과 관리 클러스터 라이프사이클 및 재해 복구에 대한 제한 옵션을 노출할 수 있습니다.
LoadBalancer 및 Route 게시 유형에 DNS indirection이 계층화된 경우 관리형 서비스 운영자는 서비스 수준 도메인을 사용하여 모든 공용 호스팅 클러스터 서비스를 게시할 수 있습니다. 이 아키텍처를 사용하면 DNS 이름을 새 LoadBalancer 또는 경로에 다시 매핑할 수 있으며 관리 클러스터의 인그레스 도메인을 노출하지 않습니다. 호스팅된 컨트롤 플레인은 외부 DNS를 사용하여 해당 간접 계층을 달성합니다.
관리 클러스터의 hypershift 네임스페이스에 HyperShift Operator와 함께 external-dns 를 배포할 수 있습니다. 외부 DNS는 external-dns.alpha.kubernetes.io/hostname 주석이 있는 서비스 또는 경로를 감시합니다. 해당 주석은 레코드 또는 경로 (예: CNAME 레코드)와 같은 서비스를 가리키는 DNS 레코드를 생성하는 데 사용됩니다.
클라우드 환경에서만 외부 DNS를 사용할 수 있습니다. 다른 환경의 경우 DNS 및 서비스를 수동으로 구성해야 합니다.
외부 DNS에 대한 자세한 내용은 외부 DNS 를 참조하십시오.
1.7.6.4.1. 사전 요구 사항
호스팅된 컨트롤 플레인에 대한 외부 DNS를 설정하려면 먼저 다음 사전 요구 사항을 충족해야 합니다.
- 외부 공용 도메인을 생성했습니다.
- AWS Route53 관리 콘솔에 액세스할 수 있습니다.
1.7.6.4.2. 호스팅된 컨트롤 플레인의 외부 DNS 설정
서비스 수준 DNS(외부 DNS)를 사용하여 호스팅된 컨트롤 플레인 클러스터를 프로비저닝하려면 다음 단계를 완료합니다.
-
HyperShift Operator에 대한 AWS 인증 정보 시크릿을 생성하고
local-cluster네임스페이스에서hypershift-operator-external-dns-credentials이름을 지정합니다. 다음 표를 참조하여 보안에 필수 필드가 있는지 확인합니다.
Expand 필드 이름 설명 선택 사항 또는 필수 provider서비스 수준 DNS 영역을 관리하는 DNS 공급자입니다.
필수 항목
domain-filter서비스 수준 도메인입니다.
필수 항목
credentials모든 외부 DNS 유형을 지원하는 자격 증명 파일입니다.
AWS 키를 사용할 때 선택 사항
aws-access-key-id인증 정보 액세스 키 ID입니다.
AWS DNS 서비스를 사용할 때 선택 사항
aws-secret-access-key인증 정보 액세스 키 시크릿입니다.
AWS DNS 서비스를 사용할 때 선택 사항
다음 예제에서는 샘플
hypershift-operator-external-dns-credentials시크릿 템플릿을 보여줍니다.oc create secret generic hypershift-operator-external-dns-credentials --from-literal=provider=aws --from-literal=domain-filter=<domain_name> --from-file=credentials=<path_to_aws_credentials_file> -n local-cluster참고: 시크릿에 대한 재해 복구 백업은 자동으로 활성화되지 않습니다. 재해 복구를 위해 시크릿을 백업하려면 다음 명령을 입력하여
hypershift-operator-external-dns-credentials를 추가합니다.oc label secret hypershift-operator-external-dns-credentials -n local-cluster cluster.open-cluster-management.io/backup=""
1.7.6.4.3. 퍼블릭 DNS 호스팅 영역 생성
외부 DNS Operator는 퍼블릭 DNS 호스팅 영역을 사용하여 퍼블릭 호스팅 클러스터를 생성합니다.
퍼블릭 DNS 호스팅 영역을 생성하여 외부 DNS 도메인 필터로 사용할 수 있습니다. AWS Route 53 관리 콘솔에서 다음 단계를 완료합니다.
- Route 53 관리 콘솔에서 호스팅 영역 생성을 클릭합니다.
- 호스팅 영역 구성 페이지에서 도메인 이름을 입력하고 게시 호스팅 영역이 유형으로 선택되어 있는지 확인하고 호스트 영역 생성 을 클릭합니다.
- 영역이 생성되면 레코드 탭에서 Value/Route 트래픽의 값을 열로 기록해 둡니다.
- 기본 도메인에서 NS 레코드를 생성하여 DNS 요청을 위임된 영역으로 리디렉션합니다. 값 필드에 이전 단계에서 기록한 값을 입력합니다.
- 레코드 생성을 클릭합니다.
새 하위 영역에 테스트 항목을 생성하고 다음 예와 같이
dig명령으로 테스트하여 DNS 호스팅 영역이 작동하는지 확인합니다.dig +short test.user-dest-public.aws.kerberos.com 192.168.1.1LoadBalancer및Route서비스의 호스트 이름을 설정하는 호스팅 클러스터를 생성하려면 다음 명령을 입력합니다.hcp create cluster aws --name=<hosted_cluster_name> --endpoint-access=PublicAndPrivate --external-dns-domain=<public_hosted_zone> ...&
lt;public_hosted_zone>을 생성한 공개 호스팅 영역으로 바꿉니다.
이 예에서는 호스팅된 클러스터에 대한 결과 서비스 블록을 보여줍니다.
platform:
aws:
endpointAccess: PublicAndPrivate
...
services:
- service: APIServer
servicePublishingStrategy:
route:
hostname: api-example.service-provider-domain.com
type: Route
- service: OAuthServer
servicePublishingStrategy:
route:
hostname: oauth-example.service-provider-domain.com
type: Route
- service: Konnectivity
servicePublishingStrategy:
type: Route
- service: Ignition
servicePublishingStrategy:
type: Route
Control Plane Operator는 Services 및 Routes 리소스를 생성하고 external-dns.alpha.kubernetes.io/hostname 주석으로 주석을 추가합니다. 서비스 및 경로 의 경우 컨트롤 플레인 Operator는 서비스 끝점의 servicePublishingStrategy 필드에 있는 hostname 매개변수 값을 사용합니다. DNS 레코드를 만들려면 external-dns 배포와 같은 메커니즘을 사용할 수 있습니다.
공용 서비스에 대해서만 서비스 수준 DNS를 간접으로 구성할 수 있습니다. hypershift.local 프라이빗 영역을 사용하므로 프라이빗 서비스의 호스트 이름을 설정할 수 없습니다.
다음 표에서는 서비스 및 엔드포인트 조합에 대한 호스트 이름을 설정하는 것이 유효한 경우를 설명합니다.
| Service | 퍼블릭 | PublicAndPrivate | 프라이빗 |
|---|---|---|---|
|
| Y | Y | N |
|
| Y | Y | N |
|
| Y | N | N |
|
| Y | N | N |
1.7.6.4.4. 명령줄 인터페이스 및 외부 DNS를 사용하여 클러스터 배포
PublicAndPrivate 또는 Public publishing 전략을 사용하여 호스팅 클러스터를 생성하려면 관리 클러스터에 다음과 같은 아티팩트가 구성되어 있어야 합니다.
- 퍼블릭 DNS 호스팅 영역
- 외부 DNS Operator
- The HyperShift Operator
명령줄 인터페이스를 사용하여 호스트된 클러스터를 배포하려면 다음 단계를 완료합니다.
관리 클러스터에 액세스하려면 다음 명령을 입력합니다.
export KUBECONFIG=<path_to_management_cluster_kubeconfig>다음 명령을 입력하여 External DNS Operator가 실행 중인지 확인합니다.
oc get pod -n hypershift -lapp=external-dns다음 예제 출력을 참조하십시오.
NAME READY STATUS RESTARTS AGE external-dns-7c89788c69-rn8gp 1/1 Running 0 40s외부 DNS를 사용하여 호스팅된 클러스터를 생성하려면 다음 명령을 입력합니다.
hypershift create cluster aws \ --aws-creds <path_to_aws_credentials_file> \1 --instance-type <instance_type> \2 --region <region> \3 --auto-repair \ --generate-ssh \ --name <hosted_cluster_name> \4 --namespace clusters \ --base-domain <service_consumer_domain> \5 --node-pool-replicas <node_replica_count> \6 --pull-secret <path_to_your_pull_secret> \7 --release-image quay.io/openshift-release-dev/ocp-release:<ocp_release_image> \8 --external-dns-domain=<service_provider_domain> \9 --endpoint-access=PublicAndPrivate10 - 1
- AWS 인증 정보 파일의 경로를 지정합니다(예:
/user/name/.aws/credentials). - 2
- 인스턴스 유형을 지정합니다(예:
m6i.xlarge). - 3
- AWS 리전을 지정합니다(예:
us-east-1). - 4
- 호스팅된 클러스터 이름을 지정합니다(예:
my-external-aws). - 5
- 서비스 소비자가 소유한 공개 호스팅 영역을 지정합니다(예:
service-consumer-domain.com). - 6
- 노드 복제본 수를 지정합니다(예: 2).
- 7
- 풀 시크릿 파일의 경로를 지정합니다.
- 8
- 사용하려는 지원되는 OpenShift Container Platform 버전을 지정합니다(예:
4.14.0-x86_64). - 9
- 서비스 공급자가 소유한 공개 호스팅 영역을 지정합니다(예:
service-provider-domain.com). - 10
- 을
PublicAndPrivate로 설정합니다. 공용 또는PublicAndPrivate
1.7.6.5. AWS PrivateLink 활성화
PrivateLink를 사용하여 AWS 플랫폼에서 호스팅된 컨트롤 플레인 클러스터를 프로비저닝하려면 다음 단계를 완료하십시오.
-
HyperShift Operator에 대한 AWS 인증 정보 시크릿을 생성하고
hypershift-operator-private-link-credentials로 이름을 지정합니다. 보안은 호스팅 클러스터로 사용되는 관리 클러스터의 네임스페이스인 관리형 클러스터 네임스페이스에 있어야 합니다.local-cluster를 사용한 경우local-cluster네임스페이스에 시크릿을 생성합니다. 다음 표를 참조하여 보안에 필수 필드가 포함되어 있는지 확인합니다.
Expand 필드 이름
설명
선택 사항 또는 필수
regionPrivate Link에서 사용할 수 있는 리전
필수 항목
aws-access-key-id인증 정보 액세스 키 ID입니다.
필수 항목
aws-secret-access-key인증 정보 액세스 키 시크릿입니다.
필수 항목
다음 예제에서는 샘플
hypershift-operator-private-link-credentials시크릿 템플릿을 보여줍니다.oc create secret generic hypershift-operator-private-link-credentials --from-literal=aws-access-key-id=<aws-access-key-id> --from-literal=aws-secret-access-key=<aws-secret-access-key> --from-literal=region=<region> -n local-cluster참고: 시크릿에 대한 재해 복구 백업은 자동으로 활성화되지 않습니다. 다음 명령을 실행하여 재해 복구를 위해
hypershift-operator-private-link-credentials시크릿을 백업할 수 있는 레이블을 추가합니다.oc label secret hypershift-operator-private-link-credentials -n local-cluster cluster.open-cluster-management.io/backup=""
1.7.6.6. 호스트된 클러스터의 재해 복구
호스트된 컨트롤 플레인은 다중 클러스터 엔진 Operator 허브 클러스터에서 실행됩니다. 데이터 플레인은 선택한 별도의 플랫폼에서 실행됩니다. 재해에서 다중 클러스터 엔진 Operator 허브 클러스터를 복구할 때 호스트된 컨트롤 플레인을 복구해야 할 수도 있습니다.
호스팅된 컨트롤 플레인 클러스터를 백업하고 다른 클러스터에 복원하는 방법을 알아보려면 AWS 리전 내의 호스트 클러스터 재해 를 참조하십시오.
중요: 호스팅 클러스터의 재해 복구는 AWS에서만 사용할 수 있습니다.
1.7.6.7. AWS에 호스팅된 클러스터 배포
호스팅된 컨트롤 플레인 명령줄 인터페이스인 hcp 를 설정하고 local-cluster 를 호스팅 클러스터로 설정한 후 다음 단계를 완료하여 AWS에 호스팅 클러스터를 배포할 수 있습니다. 프라이빗 호스팅 클러스터를 배포하려면 AWS에 개인 호스팅 클러스터 배포를 참조하십시오.
각 변수에 대한 설명을 보려면 다음 명령을 실행합니다.
hcp create cluster aws --help- hub 클러스터에 로그인되어 있는지 확인합니다.
다음 명령을 실행하여 호스트된 클러스터를 생성합니다.
hcp create cluster aws \ --name <hosted_cluster_name> \1 --infra-id <infra_id> \2 --base-domain <basedomain> \3 --aws-creds <path_to_aws_creds> \4 --pull-secret <path_to_pull_secret> \5 --region <region> \6 --generate-ssh \ --node-pool-replicas <node_pool_replica_count> \7 --namespace <hosted_cluster_namespace>8
- 1
- 호스팅된 클러스터의 이름을 지정합니다(
예: ). <hosted_cluster_name> 및 <infra_id>에 동일한 값이 있는지 확인합니다. 그러지 않으면 Kubernetes Operator 콘솔의 다중 클러스터 엔진에 클러스터가 올바르게 표시되지 않을 수 있습니다. - 2
- 인프라 이름을 지정합니다(예:
clc-name-hs1). - 3
- 기본 도메인을 지정합니다(예:
dev09.red-chesterfield.com). - 4
- AWS 인증 정보 파일의 경로를 지정합니다(예:
/user/name/.aws/credentials). - 5
- 풀 시크릿의 경로를 지정합니다(예:
/user/name/pullsecret). - 6
- AWS 리전 이름을 지정합니다(예:
us-east-1). - 7
- 노드 풀 복제본 수를 지정합니다(예:
2). - 8
- 호스팅된 클러스터 네임스페이스를 지정합니다(예:
클러스터).참고: 기본적으로 모든
HostedCluster및NodePool사용자 정의 리소스는클러스터네임스페이스에 생성됩니다.--namespace <namespace> 매개변수를 지정하면 선택한 네임스페이스에HostedCluster및NodePool사용자 정의 리소스가 생성됩니다.다음 명령을 실행하여 호스팅 클러스터의 상태를 확인할 수 있습니다.
oc get hostedclusters -n <hosted_cluster_namespace>- 다음 명령을 실행하여 노드 풀을 확인할 수 있습니다.
oc get nodepools --namespace <hosted_cluster_namespace>
1.7.6.8. AWS의 여러 영역에서 호스팅 클러스터 생성
다음 명령을 입력하여 퍼블릭 영역의 기본 도메인을 지정하여 클러스터를 생성합니다.
hcp create cluster aws \
--name <hosted-cluster-name> \
--node-pool-replicas=<node-pool-replica-count> \
--base-domain <basedomain> \
--pull-secret <path-to-pull-secret> \
--aws-creds <path-to-aws-credentials> \
--region <region> \
--zones <zones> 지정된 각 영역에 대해 다음 인프라가 생성됩니다.
- 퍼블릭 서브넷
- 프라이빗 서브넷
- NAT 게이트웨이
- 프라이빗 경로 테이블(공용 경로 테이블은 퍼블릭 서브넷에서 공유됨)
각 영역에 대해 하나의 NodePool 리소스가 생성됩니다. 노드 풀 이름은 영역 이름으로 접미사가 지정됩니다. 영역의 프라이빗 서브넷은 spec.platform.aws.subnet.id 에 설정됩니다.
1.7.6.8.1. AWS에서 호스팅 클러스터를 생성하기 위한 인증 정보 제공
hcp create cluster aws 명령을 사용하여 호스팅 클러스터를 생성할 때 클러스터에 대한 인프라 리소스를 생성할 수 있는 권한이 있는 AWS 계정 인증 정보를 제공해야 합니다. 인프라 리소스의 예로는 VPC, 서브넷 및 NAT 게이트웨이가 있습니다. --aws-creds 플래그를 사용하거나 다중 클러스터 엔진 Operator의 AWS 클라우드 공급자 시크릿을 사용하여 AWS 인증 정보를 제공할 수 있습니다.
1.7.6.8.1.1. --aws-creds 플래그를 사용하여 인증 정보 제공
--aws-creds 플래그를 사용하여 인증 정보를 제공하는 경우 해당 플래그를 AWS 인증 정보 파일 경로의 값과 함께 사용합니다.
다음 예제를 참조하십시오.
hcp create cluster aws \
--name <hosted-cluster-name> \
--node-pool-replicas=<node-pool-replica-count> \
--base-domain <basedomain> \
--pull-secret <path-to-pull-secret> \
--aws-creds <path-to-aws-credentials> \
--region <region> 1.7.6.8.1.2. AWS 클라우드 공급자 시크릿을 사용하여 인증 정보 제공
시크릿에는 SSH 키, 풀 시크릿, 기본 도메인, AWS 인증 정보가 포함되어 있습니다. 따라서 hcp create cluster aws 명령을 --secret-creds 플래그와 함께 사용하여 AWS 인증 정보를 제공할 수 있습니다. 다음 예제를 참조하십시오.
hcp create cluster aws \
--name <hosted-cluster-name> \
--region <region> \
--namespace <hosted-cluster-namespace> \
--secret-creds <my-aws-cred>
이 시크릿을 사용하면 다음 플래그는 선택 사항이 됩니다. --secret-creds 플래그를 사용하여 이러한 플래그를 지정하면 이러한 플래그가 클라우드 공급자 시크릿의 값보다 우선합니다.
-
--aws-creds -
--base-domain -
--pull-secret -
--ssh-key
- {mce-shortF} 콘솔을 사용하여 시크릿을 생성하려면 탐색 메뉴에서 인증 정보를 선택하고 콘솔의 인증 정보 생성 단계를 따릅니다.
명령줄에서 보안을 생성하려면 다음 명령을 입력합니다.
$ oc create secret generic <my-secret> -n <namespace> --from-literal=baseDomain=<your-basedomain> --from-literal=aws_access_key_id=<your-aws-access-key> --from-literal=aws_secret_access_key=<your-aws-secret-key> --from-literal=pullSecret='{"auths":{"cloud.openshift.com":{"auth":"<auth>", "email":"<your-email>"}, "quay.io":{"auth":"<auth>", "email":"<your-email>"} } }' --from-literal=ssh-publickey=<your-ssh-publickey> --from-literal=ssh-privatekey=<your-ssh-privatekey>시크릿의 형식은 다음과 같습니다.
apiVersion: v1 metadata: name: my-aws-cred1 namespace: clusters2 type: Opaque kind: Secret stringData: ssh-publickey: # Value ssh-privatekey: # Value pullSecret: # Value, required baseDomain: # Value, required aws_secret_access_key: # Value, required aws_access_key_id: # Value, required
1.7.6.8.2. 추가 리소스
호스팅된 클러스터에 AWS EBS(Elastic File Service) CSI Driver Operator를 설치하는 방법은 보안 토큰 서비스를 사용하여 AWS EFS CSI Driver Operator 구성 을 참조하십시오.
1.7.6.9. ARM64 OpenShift Container Platform 클러스터에서 호스팅된 컨트롤 플레인 활성화 (기술 프리뷰)
관리 클러스터 환경의 OpenShift Container Platform ARM64 데이터 플레인과 함께 ARM64 호스팅 컨트롤 플레인을 사용할 수 있습니다. 이 기능은 AWS의 호스팅 컨트롤 플레인에서만 사용할 수 있습니다.
1.7.6.9.1. 사전 요구 사항
64비트 ARM 인프라에 설치된 OpenShift Container Platform 클러스터가 있어야 합니다. 자세한 내용은 Create an OpenShift Cluster: AWS (ARM) 를 참조하십시오.
1.7.6.9.2. ARM64 OpenShift Container Platform 클러스터에서 호스팅 클러스터 실행
ARM64 OpenShift Container Platform 클러스터에서 호스팅 클러스터를 실행하려면 다음 단계를 완료합니다.
다중 아키텍처 릴리스 이미지로 기본 릴리스 이미지를 덮어쓰는 호스팅 클러스터를 생성합니다.
예를 들어 호스팅된 컨트롤 플레인 명령줄 인터페이스를 통해
hcp를 입력하고 클러스터 이름, 노드 풀 복제본, 기본 도메인, 풀 시크릿, AWS 인증 정보 및 리전을 정보로 교체합니다.hcp create cluster aws \ --name $CLUSTER_NAME \ --node-pool-replicas=$NODEPOOL_REPLICAS \ --base-domain $BASE_DOMAIN \ --pull-secret $PULL_SECRET \ --aws-creds $AWS_CREDS \ --region $REGION \ --release-image quay.io/openshift-release-dev/ocp-release:4.13.0-rc.0-multi이 예제에서는
--node-pool-replicas플래그를 통해 기본NodePool오브젝트를 추가합니다.호스팅된 클러스터에 64비트 x_86
NodePool오브젝트를 추가합니다.예를 들어 호스팅된 컨트롤 플레인 명령줄 인터페이스를 통해
hcp를 입력하여 클러스터 이름, 노드 풀 이름 및 노드 풀 복제본을 정보로 교체합니다.hcp create nodepool aws \ --cluster-name $CLUSTER_NAME \ --name $NODEPOOL_NAME \ --node-count=$NODEPOOL_REPLICAS
1.7.6.9.3. AWS 호스팅 클러스터에서 ARM NodePool 오브젝트 생성
동일한 호스팅 컨트롤 플레인에서 64비트 ARM 및 AMD64에서 애플리케이션 워크로드(NodePool 오브젝트)를 예약할 수 있습니다. 이렇게 하려면 NodePool 사양에 arch 필드를 정의하여 NodePool 오브젝트에 필요한 프로세서 아키텍처를 설정합니다. arch 필드에 유효한 값은 다음과 같습니다.
-
arm64 -
amd64
arch 필드의 값을 지정하지 않으면 기본적으로 amd64 값이 사용됩니다.
AWS의 호스팅 클러스터에서 ARM NodePool 오브젝트를 생성하려면 다음 단계를 완료합니다.
HostedCluster사용자 정의 리소스에 사용할 다중 아키텍처 이미지가 있는지 확인합니다. https://multi.ocp.releases.ci.openshift.org/ 에서 다중 아키텍처 야간 이미지에 액세스할 수 있습니다.다중 아키텍처 이미지는 다음 예와 유사합니다.
% oc image info quay.io/openshift-release-dev/ocp-release-nightly@sha256:9b992c71f77501678c091e3dc77c7be066816562efe3d352be18128b8e8fce94 -a ~/pull-secrets.json error: the image is a manifest list and contains multiple images - use --filter-by-os to select from: OS DIGEST linux/amd64 sha256:c9dc4d07788ebc384a3d399a0e17f80b62a282b2513062a13ea702a811794a60 linux/ppc64le sha256:c59c99d6ff1fe7b85790e24166cfc448a3c2ac3ef3422fce3c7259e48d2c9aab linux/s390x sha256:07fcd16d5bee95196479b1e6b5b3b8064dd5359dac75e3d81f0bd4be6b8fe208 linux/arm64 sha256:1d93a6beccc83e2a4c56ecfc37e921fe73d8964247c1a3ec34c4d66f175d9b3d호스팅된 컨트롤 플레인 명령줄 인터페이스
hcp에 다음 명령을 입력하여NodePool오브젝트를 렌더링합니다.hcp create nodepool aws --cluster-name $CLUSTER_NAME --name $ARM64_NODEPOOL_NAME --node-count=$NODEPOOL_REPLICAS --render > arm_nodepool_spec.yml이 명령은 다음 예와 같이
NodePool오브젝트의 CPU 아키텍처를 지정하는 YAML 파일을 생성합니다.apiVersion: hypershift.openshift.io/v1beta1 kind: NodePool metadata: creationTimestamp: null name: hypershift-arm-us-east-1a namespace: clusters spec: arch: amd64 clusterName: hypershift-arm management: autoRepair: false upgradeType: Replace nodeDrainTimeout: 0s platform: aws: instanceProfile: hypershift-arm-2m289-worker instanceType: m5.large rootVolume: size: 120 type: gp3 securityGroups: - id: sg-064ea63968d258493 subnet: id: subnet-02c74cf1cf1e7413f type: AWS release: image: quay.io/openshift-release-dev/ocp-release-nightly@sha256:390a33cebc940912a201a35ca03927ae5b058fbdae9626f7f4679786cab4fb1c replicas: 3 status: replicas: 0다음 명령을 입력하여 YAML 파일에서
arch및instanceType값을 수정합니다. 명령에서 ARM 인스턴스 유형은m6g.large이지만 모든 ARM 인스턴스 유형이 작동합니다.sed 's/arch: amd64/arch: arm64/g; s/instanceType: m5.large/instanceType: m6g.large/g' arm_nodepool_spec.yml > temp.yml && mv temp.yml arm_nodepool_spec.yml다음 명령을 입력하여 렌더링된 YAML 파일을 호스팅 클러스터에 적용합니다.
oc apply -f arm_nodepool_spec.yml
1.7.6.10. 호스트된 클러스터에 액세스
리소스에서 직접 kubeconfig 파일 및 kubeadmin 자격 증명을 가져오거나 hcp 명령줄 인터페이스를 사용하여 kubeconfig 파일을 생성하여 호스팅된 클러스터에 액세스할 수 있습니다.
리소스에서 직접
kubeconfig파일 및 인증 정보를 가져와서 호스팅되는 클러스터에 액세스하려면 호스팅된 컨트롤 플레인 클러스터의 액세스 시크릿을 숙지해야 합니다. 보안은 호스팅된 클러스터(호스팅) 네임스페이스에 저장됩니다. 호스팅된 클러스터(호스팅) 네임스페이스에는 호스팅된 클러스터 리소스가 포함되어 있으며 호스팅된 컨트롤 플레인 네임스페이스는 호스팅된 컨트롤 플레인이 실행되는 위치입니다.보안 이름 형식은 다음과 같습니다.
-
kubeconfig시크릿: <hosted-cluster-namespace>-<name>-admin-kubeconfig(clusters-hypershift-demo-admin-kubeconfig) kubeadmin암호 시크릿: <hosted-cluster-namespace>-<name>-kubeadmin-password(clusters-hypershift-demo-kubeadmin-password)kubeconfig시크릿에는 Base64로 인코딩된kubeconfig필드가 포함되어 있으며 다음 명령과 함께 사용할 파일에 디코딩하고 저장할 수 있습니다.oc --kubeconfig <hosted-cluster-name>.kubeconfig get nodes
kubeadmin암호 시크릿도 Base64로 인코딩됩니다. 이를 디코딩하고 암호를 사용하여 호스팅된 클러스터의 API 서버 또는 콘솔에 로그인할 수 있습니다.-
hcpCLI를 사용하여kubeconfig파일을 생성하여 호스팅된 클러스터에 액세스하려면 다음 단계를 수행합니다.다음 명령을 입력하여
kubeconfig파일을 생성합니다.hcp create kubeconfig --namespace <hosted-cluster-namespace> --name <hosted-cluster-name> > <hosted-cluster-name>.kubeconfigkubeconfig파일을 저장한 후 다음 예제 명령을 입력하여 호스팅된 클러스터에 액세스할 수 있습니다.oc --kubeconfig <hosted-cluster-name>.kubeconfig get nodes
1.7.6.10.1. 추가 리소스
호스팅된 클러스터에 액세스한 후 노드 풀을 확장하거나 호스팅된 클러스터에 대한 노드 자동 확장을 활성화할 수 있습니다. 자세한 내용은 다음 항목을 참조하십시오.
호스팅된 클러스터에 대한 노드 튜닝을 구성하려면 다음 항목을 참조하십시오.
1.7.6.11. AWS에 프라이빗 호스팅 클러스터 배포 (기술 프리뷰)
호스팅된 컨트롤 플레인 명령줄 인터페이스, hcp 를 설정하고 local-cluster 를 호스팅 클러스터로 설정한 후 호스팅 클러스터 또는 AWS에 개인 호스팅 클러스터를 배포할 수 있습니다. AWS에 공용 호스팅 클러스터를 배포하려면 AWS에 호스팅된 클러스터 배포를 참조하십시오.
기본적으로 호스팅되는 컨트롤 플레인 게스트 클러스터는 퍼블릭 DNS 및 관리 클러스터의 기본 라우터를 통해 공개적으로 액세스할 수 있습니다.
AWS의 프라이빗 클러스터의 경우 게스트 클러스터와의 모든 통신은 AWS PrivateLink를 통해 수행됩니다. AWS에서 프라이빗 클러스터 지원을 위해 호스팅되는 컨트롤 플레인을 구성하려면 다음 단계를 따르십시오.
중요: 모든 리전에서 퍼블릭 클러스터를 생성할 수 있지만 --aws-private-region 에서 지정하는 리전에서만 프라이빗 클러스터를 생성할 수 있습니다.
1.7.6.11.1. 사전 요구 사항
AWS용 프라이빗 호스팅 클러스터를 활성화하려면 먼저 AWS PrivateLink를 활성화해야 합니다. 자세한 내용은 AWS PrivateLink 활성화를 참조하십시오.
1.7.6.11.2. AWS에서 개인 호스트 클러스터 생성
다음 명령을 입력하여 개인 클러스터 IAM 정책 문서를 생성합니다.
cat << EOF >> policy.json { "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "ec2:CreateVpcEndpointServiceConfiguration", "ec2:DescribeVpcEndpointServiceConfigurations", "ec2:DeleteVpcEndpointServiceConfigurations", "ec2:DescribeVpcEndpointServicePermissions", "ec2:ModifyVpcEndpointServicePermissions", "ec2:CreateTags", "elasticloadbalancing:DescribeLoadBalancers" ], "Resource": "\*" } ] }다음 명령을 입력하여 AWS에서 IAM 정책을 생성합니다.
aws iam create-policy --policy-name=hypershift-operator-policy --policy-document=file://policy.json다음 명령을 입력하여
hypershift-operatorIAM 사용자를 생성합니다.aws iam create-user --user-name=hypershift-operator이 명령을 입력하여
hypershift-operator사용자에게 정책을 연결하고 <policy-arn>을 생성한 정책의 ARN으로 교체합니다.aws iam attach-user-policy --user-name=hypershift-operator --policy-arn=<policy-arn>다음 명령을 입력하여 사용자의 IAM 액세스 키를 생성합니다.
aws iam create-access-key --user-name=hypershift-operator다음 명령을 입력하여 개인 호스팅 클러스터를 생성하고 필요에 따라 변수를 값으로 교체합니다.
hcp create cluster aws \ --name <hosted-cluster-name> \1 --node-pool-replicas=<node-pool-replica-count> \2 --base-domain <basedomain> \3 --pull-secret <path-to-pull-secret> \4 --aws-creds <path-to-aws-credentials> \5 --region <region> \6 --endpoint-access Private7 클러스터의 API 끝점은 프라이빗 DNS 영역을 통해 액세스할 수 있습니다.
-
api.<hosted-cluster-name>.hypershift.local -
*.apps.<hosted-cluster-name>.hypershift.local
-
1.7.6.11.3. AWS에서 프라이빗 호스팅 클러스터에 액세스
bastion 인스턴스를 사용하여 프라이빗 클러스터에 액세스할 수 있습니다.
다음 명령을 입력하여 bastion 인스턴스를 시작합니다.
hypershift create bastion aws --aws-creds=<aws-creds> --infra-id=<infra-id> --region=<region> --ssh-key-file=<ssh-key>&
lt;ssh-key>를 SSH 공개 키 파일로 교체하여 bastion에 연결합니다. SSH 공개 키 파일의 기본 위치는~/.ssh/id_rsa.pub입니다. <aws-creds>를 AWS 인증 정보 파일의 경로로 바꿉니다(예:/user/name/.aws/credentials).
참고: 하이퍼shift CLI를 다운로드할 수 없습니다. 다음 명령을 사용하여 hypershift 네임스페이스에 있는 HyperShift Operator Pod를 사용하여 압축을 풉니다. & lt;hypershift-operator-pod-name >을 HyperShift Operator Pod 이름으로 교체합니다.
oc project hypershift
oc rsync <hypershift-operator-pod-name>:/usr/bin/hypershift-no-cgo .
mv hypershift-no-cgo hypershift다음 명령을 입력하여 클러스터 노드 풀에서 노드의 개인 IP를 찾습니다.
aws ec2 describe-instances --filter="Name=tag:kubernetes.io/cluster/<infra-id>,Values=owned" | jq '.Reservations[] | .Instances[] | select(.PublicDnsName=="") | .PrivateIpAddress'다음 명령을 입력하여 노드에 복사할 수 있는 클러스터의
kubeconfig파일을 생성합니다.hcp create kubeconfig > <cluster-kubeconfig>다음 명령을 입력하여
create bastion명령에서 출력된 IP를 사용하여 bastion을 통해 노드 중 하나에 SSH를 입력합니다.ssh -o ProxyCommand="ssh ec2-user@<bastion-ip> -W %h:%p" core@<node-ip>SSH 쉘에서 다음 명령을 입력하여
kubeconfig파일 콘텐츠를 노드의 파일에 복사합니다.mv <path-to-kubeconfig-file> <new-file-name>다음 명령을 입력하여 kubeconfig 파일을 내보냅니다.
export KUBECONFIG=<path-to-kubeconfig-file>다음 명령을 입력하여 게스트 클러스터 상태를 확인합니다.
oc get clusteroperators clusterversion
1.7.6.11.4. 추가 리소스
AWS에 공용 호스트 클러스터를 배포하는 방법에 대한 자세한 내용은 AWS에 호스트 클러스터 배포를 참조하십시오.
1.7.6.12. 호스팅된 컨트롤 플레인에 대한 AWS 인프라 및 IAM 권한 관리 (기술 프리뷰)
AWS에서 Red Hat OpenShift Container Platform에 호스팅되는 컨트롤 플레인을 사용하는 경우 인프라 요구 사항은 설정에 따라 다릅니다.
1.7.6.12.1. 사전 요구 사항
호스팅된 컨트롤 플레인 클러스터를 생성하려면 먼저 호스팅 컨트롤 플레인을 구성해야 합니다. 자세한 내용은 AWS에서 호스팅되는 컨트롤 플레인 클러스터 구성 (기술 프리뷰) 을 참조하십시오.
1.7.6.12.2. AWS 인프라 요구사항
AWS에서 호스팅되는 컨트롤 플레인을 사용하는 경우 인프라 요구 사항은 다음 카테고리에 적합합니다.
- 임의의 AWS 계정에서 HyperShift Operator에 대한 사전 요구 사항 및 관리되지 않는 인프라
- 호스트 클러스터 AWS 계정에서 사전 요구 사항 및 관리되지 않는 인프라
- 관리 AWS 계정에서 호스팅되는 컨트롤 플레인 관리 인프라
- 호스트 클러스터 AWS 계정에서 호스팅된 컨트롤 플레인 관리 인프라
- 호스트 클러스터 AWS 계정의 Kubernetes 관리 인프라
Prerequired 는 호스팅된 컨트롤 플레인이 제대로 작동하려면 AWS 인프라가 필요하다는 것을 의미합니다. Unmanaged 는 Operator 또는 컨트롤러가 사용자를 위한 인프라를 생성하지 않음을 의미합니다. 다음 섹션에는 AWS 리소스 생성에 대한 세부 정보가 포함되어 있습니다.
1.7.6.12.2.1. 임의의 AWS 계정에서 HyperShift Operator에 대한 사전 요구 사항 및 관리되지 않는 인프라
임의의 AWS 계정은 호스팅된 컨트롤 플레인 서비스 공급자에 따라 다릅니다.
자체 관리형 호스팅 컨트롤 플레인에서 클러스터 서비스 공급자는 AWS 계정을 제어합니다. 클러스터 서비스 공급자는 클러스터 컨트롤 플레인을 호스팅하고 가동 시간을 담당하는 관리자입니다. 관리형 호스팅 컨트롤 플레인에서 AWS 계정은 Red Hat에 속합니다.
HyperShift Operator에 대한 사전 필수 및 관리되지 않는 인프라에서 다음 인프라 요구 사항이 관리 클러스터 AWS 계정에 적용됩니다.
S3 버킷 1개
- OpenID Connect(OIDC)
Route 53 호스팅 영역
- 호스팅된 클러스터의 프라이빗 및 공용 항목을 호스트하는 도메인
1.7.6.12.2.2. 호스트 클러스터 AWS 계정에서 사전 요구 사항 및 관리되지 않는 인프라
호스트 클러스터 AWS 계정에서 인프라가 사전 필수적이고 관리되지 않는 경우 모든 액세스 모드에 대한 인프라 요구 사항은 다음과 같습니다.
- VPC 1개
- DHCP 옵션 1개
두 개의 서브넷
- 내부 데이터 플레인 서브넷인 프라이빗 서브넷
- 데이터 플레인에서 인터넷에 액세스할 수 있는 공용 서브넷
- 하나의 인터넷 게이트웨이
- 탄력적 IP 1개
- NAT 게이트웨이 1개
- 하나의 보안 그룹(작업자 노드)
- 두 개의 경로 테이블(개인 1개 및 공용)
- 두 개의 Route 53 호스팅 영역
다음 항목에 대한 할당량이 충분합니다.
- 퍼블릭 호스팅 클러스터를 위한 하나의 Ingress 서비스 로드 밸런서
- 프라이빗 호스팅 클러스터용 프라이빗 링크 끝점 1개
참고: 개인 링크 네트워킹이 작동하려면 호스팅 클러스터 AWS 계정의 끝점 영역이 관리 클러스터 AWS 계정의 서비스 끝점에 의해 해결되는 인스턴스의 영역과 일치해야 합니다. AWS에서 영역 이름은 us-east-2b 와 같은 별칭이며, 다른 계정의 동일한 영역에 매핑되지는 않습니다. 결과적으로 개인 링크가 작동하려면 관리 클러스터에 해당 리전의 모든 영역에 서브넷 또는 작업자가 있어야 합니다.
1.7.6.12.2.3. 관리 AWS 계정에서 호스팅되는 컨트롤 플레인 관리 인프라
관리 AWS 계정의 호스팅된 컨트롤 플레인에서 인프라를 관리하는 경우 클러스터의 퍼블릭, 프라이빗 또는 조합 여부에 따라 인프라 요구 사항이 다릅니다.
퍼블릭 클러스터가 있는 계정의 경우 인프라 요구 사항은 다음과 같습니다.
네트워크 로드 밸런서: 로드 밸런서 Kube API 서버
- Kubernetes에서 보안 그룹을 생성합니다.
volumes
- etcd의 경우 (고용도에 따라 1개 또는 3개)
- OVN-Kube의 경우
프라이빗 클러스터가 있는 계정의 경우 인프라 요구 사항은 다음과 같습니다.
- 네트워크 로드 밸런서: 로드 밸런서 개인 라우터
- 엔드포인트 서비스(개인 링크)
퍼블릭 및 프라이빗 클러스터가 있는 계정의 경우 인프라 요구 사항은 다음과 같습니다.
- 네트워크 로드 밸런서: 로드 밸런서 공용 라우터
- 네트워크 로드 밸런서: 로드 밸런서 개인 라우터
- 엔드포인트 서비스(개인 링크)
volumes:
- etcd의 경우 (고용도에 따라 1개 또는 3개)
- OVN-Kube의 경우
1.7.6.12.2.4. 호스트 클러스터 AWS 계정에서 호스팅된 컨트롤 플레인 관리 인프라
호스팅된 클러스터 AWS 계정의 호스팅된 컨트롤 플레인에서 인프라를 관리하는 경우 클러스터의 퍼블릭, 프라이빗 또는 조합에 따라 인프라 요구 사항이 다릅니다.
퍼블릭 클러스터가 있는 계정의 경우 인프라 요구 사항은 다음과 같습니다.
-
노드 풀에는
Role및RolePolicy가 정의된 EC2 인스턴스가 있어야 합니다.
프라이빗 클러스터가 있는 계정의 경우 인프라 요구 사항은 다음과 같습니다.
- 각 가용성 영역에 대해 하나의 개인 링크 끝점
- 노드 풀용 EC2 인스턴스
퍼블릭 및 프라이빗 클러스터가 있는 계정의 경우 인프라 요구 사항은 다음과 같습니다.
- 각 가용성 영역에 대해 하나의 개인 링크 끝점
- 노드 풀용 EC2 인스턴스
1.7.6.12.2.5. 호스트 클러스터 AWS 계정의 Kubernetes 관리 인프라
Kubernetes가 호스팅 클러스터 AWS 계정에서 인프라를 관리하는 경우 인프라 요구 사항은 다음과 같습니다.
- 기본 Ingress의 네트워크 로드 밸런서
- 레지스트리의 S3 버킷
1.7.6.12.3. IAM(Identity and Access Management) 권한
호스트된 컨트롤 플레인의 컨텍스트에서 소비자는 ARM(Amazon Resource Name) 역할을 생성합니다. 소비자 는 권한 파일을 생성하기 위한 자동화된 프로세스입니다. 소비자는 명령줄 인터페이스 또는 OpenShift Cluster Manager일 수 있습니다. 호스팅된 컨트롤 플레인은 최소 권한 구성 요소의 원칙을 준수하기 위해 세분성을 활성화하려고 합니다. 즉, 모든 구성 요소가 자체 역할을 사용하여 AWS 오브젝트를 작동하거나 생성하며 역할이 제품이 정상적으로 작동하는 데 필요한 항목으로 제한됩니다.
명령줄 인터페이스에서 ARN 역할을 생성할 수 있는 방법의 예는 "AWS 인프라 및 IAM 리소스 생성"을 참조하십시오.
호스트된 클러스터는 ARN 역할을 입력으로 수신하고 소비자는 각 구성 요소에 대한 AWS 권한 구성을 생성합니다. 결과적으로 구성 요소는 STS 및 사전 구성된 OIDC IDP를 통해 인증할 수 있습니다.
다음 역할은 컨트롤 플레인에서 실행되고 데이터 플레인에서 작동하는 호스팅된 컨트롤 플레인의 일부 구성 요소에서 소비됩니다.
-
controlPlaneOperatorARN -
imageRegistryARN -
ingressARN -
kubeCloudControllerARN -
nodePoolManagementARN -
storageARN -
networkARN
다음 예제는 호스팅된 클러스터의 IAM 역할에 대한 참조를 보여줍니다.
...
endpointAccess: Public
region: us-east-2
resourceTags:
- key: kubernetes.io/cluster/example-cluster-bz4j5
value: owned
rolesRef:
controlPlaneOperatorARN: arn:aws:iam::820196288204:role/example-cluster-bz4j5-control-plane-operator
imageRegistryARN: arn:aws:iam::820196288204:role/example-cluster-bz4j5-openshift-image-registry
ingressARN: arn:aws:iam::820196288204:role/example-cluster-bz4j5-openshift-ingress
kubeCloudControllerARN: arn:aws:iam::820196288204:role/example-cluster-bz4j5-cloud-controller
networkARN: arn:aws:iam::820196288204:role/example-cluster-bz4j5-cloud-network-config-controller
nodePoolManagementARN: arn:aws:iam::820196288204:role/example-cluster-bz4j5-node-pool
storageARN: arn:aws:iam::820196288204:role/example-cluster-bz4j5-aws-ebs-csi-driver-controller
type: AWS
...컨트롤 플레인에서 사용하는 역할은 다음 예에 표시됩니다.
ingressARN{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "elasticloadbalancing:DescribeLoadBalancers", "tag:GetResources", "route53:ListHostedZones" ], "Resource": "\*" }, { "Effect": "Allow", "Action": [ "route53:ChangeResourceRecordSets" ], "Resource": [ "arn:aws:route53:::PUBLIC_ZONE_ID", "arn:aws:route53:::PRIVATE_ZONE_ID" ] } ] }imageRegistryARN{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "s3:CreateBucket", "s3:DeleteBucket", "s3:PutBucketTagging", "s3:GetBucketTagging", "s3:PutBucketPublicAccessBlock", "s3:GetBucketPublicAccessBlock", "s3:PutEncryptionConfiguration", "s3:GetEncryptionConfiguration", "s3:PutLifecycleConfiguration", "s3:GetLifecycleConfiguration", "s3:GetBucketLocation", "s3:ListBucket", "s3:GetObject", "s3:PutObject", "s3:DeleteObject", "s3:ListBucketMultipartUploads", "s3:AbortMultipartUpload", "s3:ListMultipartUploadParts" ], "Resource": "\*" } ] }storageARN{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "ec2:AttachVolume", "ec2:CreateSnapshot", "ec2:CreateTags", "ec2:CreateVolume", "ec2:DeleteSnapshot", "ec2:DeleteTags", "ec2:DeleteVolume", "ec2:DescribeInstances", "ec2:DescribeSnapshots", "ec2:DescribeTags", "ec2:DescribeVolumes", "ec2:DescribeVolumesModifications", "ec2:DetachVolume", "ec2:ModifyVolume" ], "Resource": "\*" } ] }networkARN{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "ec2:DescribeInstances", "ec2:DescribeInstanceStatus", "ec2:DescribeInstanceTypes", "ec2:UnassignPrivateIpAddresses", "ec2:AssignPrivateIpAddresses", "ec2:UnassignIpv6Addresses", "ec2:AssignIpv6Addresses", "ec2:DescribeSubnets", "ec2:DescribeNetworkInterfaces" ], "Resource": "\*" } ] }kubeCloudControllerARN{ "Version": "2012-10-17", "Statement": [ { "Action": [ "ec2:DescribeInstances", "ec2:DescribeImages", "ec2:DescribeRegions", "ec2:DescribeRouteTables", "ec2:DescribeSecurityGroups", "ec2:DescribeSubnets", "ec2:DescribeVolumes", "ec2:CreateSecurityGroup", "ec2:CreateTags", "ec2:CreateVolume", "ec2:ModifyInstanceAttribute", "ec2:ModifyVolume", "ec2:AttachVolume", "ec2:AuthorizeSecurityGroupIngress", "ec2:CreateRoute", "ec2:DeleteRoute", "ec2:DeleteSecurityGroup", "ec2:DeleteVolume", "ec2:DetachVolume", "ec2:RevokeSecurityGroupIngress", "ec2:DescribeVpcs", "elasticloadbalancing:AddTags", "elasticloadbalancing:AttachLoadBalancerToSubnets", "elasticloadbalancing:ApplySecurityGroupsToLoadBalancer", "elasticloadbalancing:CreateLoadBalancer", "elasticloadbalancing:CreateLoadBalancerPolicy", "elasticloadbalancing:CreateLoadBalancerListeners", "elasticloadbalancing:ConfigureHealthCheck", "elasticloadbalancing:DeleteLoadBalancer", "elasticloadbalancing:DeleteLoadBalancerListeners", "elasticloadbalancing:DescribeLoadBalancers", "elasticloadbalancing:DescribeLoadBalancerAttributes", "elasticloadbalancing:DetachLoadBalancerFromSubnets", "elasticloadbalancing:DeregisterInstancesFromLoadBalancer", "elasticloadbalancing:ModifyLoadBalancerAttributes", "elasticloadbalancing:RegisterInstancesWithLoadBalancer", "elasticloadbalancing:SetLoadBalancerPoliciesForBackendServer", "elasticloadbalancing:AddTags", "elasticloadbalancing:CreateListener", "elasticloadbalancing:CreateTargetGroup", "elasticloadbalancing:DeleteListener", "elasticloadbalancing:DeleteTargetGroup", "elasticloadbalancing:DescribeListeners", "elasticloadbalancing:DescribeLoadBalancerPolicies", "elasticloadbalancing:DescribeTargetGroups", "elasticloadbalancing:DescribeTargetHealth", "elasticloadbalancing:ModifyListener", "elasticloadbalancing:ModifyTargetGroup", "elasticloadbalancing:RegisterTargets", "elasticloadbalancing:SetLoadBalancerPoliciesOfListener", "iam:CreateServiceLinkedRole", "kms:DescribeKey" ], "Resource": [ "\*" ], "Effect": "Allow" } ] }nodePoolManagementARN{ "Version": "2012-10-17", "Statement": [ { "Action": [ "ec2:AllocateAddress", "ec2:AssociateRouteTable", "ec2:AttachInternetGateway", "ec2:AuthorizeSecurityGroupIngress", "ec2:CreateInternetGateway", "ec2:CreateNatGateway", "ec2:CreateRoute", "ec2:CreateRouteTable", "ec2:CreateSecurityGroup", "ec2:CreateSubnet", "ec2:CreateTags", "ec2:DeleteInternetGateway", "ec2:DeleteNatGateway", "ec2:DeleteRouteTable", "ec2:DeleteSecurityGroup", "ec2:DeleteSubnet", "ec2:DeleteTags", "ec2:DescribeAccountAttributes", "ec2:DescribeAddresses", "ec2:DescribeAvailabilityZones", "ec2:DescribeImages", "ec2:DescribeInstances", "ec2:DescribeInternetGateways", "ec2:DescribeNatGateways", "ec2:DescribeNetworkInterfaces", "ec2:DescribeNetworkInterfaceAttribute", "ec2:DescribeRouteTables", "ec2:DescribeSecurityGroups", "ec2:DescribeSubnets", "ec2:DescribeVpcs", "ec2:DescribeVpcAttribute", "ec2:DescribeVolumes", "ec2:DetachInternetGateway", "ec2:DisassociateRouteTable", "ec2:DisassociateAddress", "ec2:ModifyInstanceAttribute", "ec2:ModifyNetworkInterfaceAttribute", "ec2:ModifySubnetAttribute", "ec2:ReleaseAddress", "ec2:RevokeSecurityGroupIngress", "ec2:RunInstances", "ec2:TerminateInstances", "tag:GetResources", "ec2:CreateLaunchTemplate", "ec2:CreateLaunchTemplateVersion", "ec2:DescribeLaunchTemplates", "ec2:DescribeLaunchTemplateVersions", "ec2:DeleteLaunchTemplate", "ec2:DeleteLaunchTemplateVersions" ], "Resource": [ "\*" ], "Effect": "Allow" }, { "Condition": { "StringLike": { "iam:AWSServiceName": "elasticloadbalancing.amazonaws.com" } }, "Action": [ "iam:CreateServiceLinkedRole" ], "Resource": [ "arn:*:iam::*:role/aws-service-role/elasticloadbalancing.amazonaws.com/AWSServiceRoleForElasticLoadBalancing" ], "Effect": "Allow" }, { "Action": [ "iam:PassRole" ], "Resource": [ "arn:*:iam::*:role/*-worker-role" ], "Effect": "Allow" } ] }controlPlaneOperatorARN{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "ec2:CreateVpcEndpoint", "ec2:DescribeVpcEndpoints", "ec2:ModifyVpcEndpoint", "ec2:DeleteVpcEndpoints", "ec2:CreateTags", "route53:ListHostedZones" ], "Resource": "\*" }, { "Effect": "Allow", "Action": [ "route53:ChangeResourceRecordSets", "route53:ListResourceRecordSets" ], "Resource": "arn:aws:route53:::%s" } ] }
1.7.6.12.4. AWS 인프라 및 IAM 리소스를 별도로 생성
기본적으로 hcp create cluster aws 명령은 호스팅된 클러스터를 사용하여 클라우드 인프라를 생성하여 적용합니다. hcp create cluster aws 명령을 사용하여 클러스터를 생성하거나 적용하기 전에 수정할 수 있도록 클라우드 인프라 부분을 별도로 생성할 수 있습니다.
클라우드 인프라 부분을 별도로 생성하려면 AWS 인프라를 생성하고 AWS Identity and Access(IAM) 리소스를 생성하고 클러스터를 생성해야 합니다.
1.7.6.12.4.1. AWS 인프라 생성
AWS 인프라를 생성하려면 다음 명령을 입력합니다.
hypershift create infra aws --name CLUSTER_NAME \
--aws-creds AWS_CREDENTIALS_FILE \
--base-domain BASEDOMAIN \
--infra-id INFRA_ID \
--region REGION \
--output-file OUTPUT_INFRA_FILE - 1
CLUSTER_NAME을 생성 중인 호스팅 클러스터의 이름으로 바꿉니다. 이 값은 클러스터의 Route 53 개인 호스팅 영역을 생성하는 데 사용됩니다.- 2
AWS_CREDENTIALS_FILE을 VPC, 서브넷, NAT 게이트웨이와 같은 클러스터의 인프라 리소스를 생성할 수 있는 권한이 있는 AWS 인증 정보 파일의 이름으로 교체합니다. 이 값은 작업자가 있는 게스트 클러스터의 AWS 계정에 해당해야 합니다.- 3
BASEDOMAIN을 호스팅된 클러스터 Ingress에 사용할 기본 도메인의 이름으로 교체합니다. 이 값은 레코드를 생성할 수 있는 Route 53 공용 영역에 해당해야 합니다.- 4
- 태그를 사용하여 인프라를 식별하는 고유한 이름으로
INFRA_ID를 바꿉니다. 이 값은 Kubernetes의 클라우드 컨트롤러 관리자와 클러스터 API 관리자가 클러스터의 인프라를 식별하는 데 사용됩니다. 일반적으로 이 값은 접미사가 추가된 클러스터 이름(CLUSTER_NAME)입니다. - 5
REGION을 클러스터 인프라를 생성할 리전으로 교체합니다.- 6
OUTPUT_INFRA_FILE을 인프라 ID를 JSON 형식으로 저장하려는 파일 이름으로 바꿉니다. 이 파일을hcp create cluster aws명령에 대한 입력으로 사용하여HostedCluster및NodePoolresouces의 필드를 채울 수 있습니다.
참고: 하이퍼shift CLI를 다운로드할 수 없습니다. 다음 명령을 사용하여 hypershift 네임스페이스에 있는 HyperShift Operator Pod를 사용하여 압축을 풉니다. & lt;hypershift-operator-pod-name >을 HyperShift Operator Pod 이름으로 교체합니다.
+
oc project hypershift
oc rsync <hypershift-operator-pod-name>:/usr/bin/hypershift-no-cgo .
mv hypershift-no-cgo hypershift명령을 입력하면 다음 리소스가 생성됩니다.
- VPC 1개
- DHCP 옵션 1개
- 프라이빗 서브넷 1개
- 퍼블릭 서브넷 1개
- 하나의 인터넷 게이트웨이
- NAT 게이트웨이 1개
- 작업자 노드에 대한 하나의 보안 그룹
- 두 개의 경로 테이블: 1개의 개인 및 공용 테이블
- 두 개의 개인 호스팅 영역: 클러스터 Ingress용 1개와 프라이빗 클러스터를 생성하는 경우 PrivateLink용 1개
이러한 모든 리소스에는 kubernetes.io/cluster/INFRA_ID=owned 태그가 포함됩니다. 여기서 INFRA_ID 는 명령에서 지정한 값입니다.
1.7.6.12.4.2. AWS IAM 리소스 생성
AWS IAM 리소스를 생성하려면 다음 명령을 입력합니다.
hypershift create iam aws --infra-id INFRA_ID \
--aws-creds AWS_CREDENTIALS_FILE \
--oidc-storage-provider-s3-bucket-name OIDC_BUCKET_NAME \
--oidc-storage-provider-s3-region OIDC_BUCKET_REGION \
--region REGION \
--public-zone-id PUBLIC_ZONE_ID \
--private-zone-id PRIVATE_ZONE_ID \
--local-zone-id LOCAL_ZONE_ID \
--output-file OUTPUT_IAM_FILE - 1
INFRA_ID를create infra aws명령에 지정한 것과 동일한 ID로 바꿉니다. 이 값은 호스팅된 클러스터와 연결된 IAM 리소스를 식별합니다.- 2
AWS_CREDENTIALS_FILE을 역할과 같은 IAM 리소스를 생성할 수 있는 권한이 있는 AWS 인증 정보 파일의 이름으로 교체합니다. 이 파일은 인프라를 생성하기 위해 지정한 자격 증명 파일과 같을 필요는 없지만 동일한 AWS 계정에 해당되어야 합니다.- 3
OIDC_BUCKET_NAME을 OIDC 문서를 저장하는 버킷 이름으로 바꿉니다. 이 버킷은 호스팅된 컨트롤 플레인을 설치하기 위한 사전 요구 사항으로 생성되었습니다. 버킷의 이름은 이 명령으로 생성된 OIDC 공급자의 URL을 구성하는 데 사용됩니다.- 4
OIDC_BUCKET_REGION을 OIDC 버킷이 있는 리전으로 교체합니다.- 5
REGION을 클러스터 인프라가 있는 리전으로 교체합니다. 이 값은 호스팅된 클러스터에 속하는 시스템의 작업자 인스턴스 프로필을 생성하는 데 사용됩니다.- 6
PUBLIC_ZONE_ID를 게스트 클러스터의 공용 영역 ID로 바꿉니다. 이 값은 Ingress Operator에 대한 정책을 생성하는 데 사용됩니다.create infra aws명령으로 생성된OUTPUT_INFRA_FILE에서 이 값을 찾을 수 있습니다.- 7
PRIVATE_ZONE_ID를 게스트 클러스터의 프라이빗 영역 ID로 바꿉니다. 이 값은 Ingress Operator에 대한 정책을 생성하는 데 사용됩니다.create infra aws명령으로 생성된OUTPUT_INFRA_FILE에서 이 값을 찾을 수 있습니다.- 8
LOCAL_ZONE_ID를 프라이빗 클러스터를 생성할 때 게스트 클러스터의 로컬 영역 ID로 바꿉니다. 이 값은 PrivateLink 끝점에 대한 레코드를 관리할 수 있도록 Control Plane Operator에 대한 정책을 생성하는 데 사용됩니다.create infra aws명령으로 생성된OUTPUT_INFRA_FILE에서 이 값을 찾을 수 있습니다.- 9
OUTPUT_IAM_FILE을 IAM 리소스의 ID를 JSON 형식으로 저장하려는 파일 이름으로 바꿉니다. 그런 다음 이 파일을hcp create cluster aws명령에 대한 입력으로 사용하여HostedCluster및NodePool리소스의 필드를 채울 수 있습니다.
명령을 입력하면 다음 리소스가 생성됩니다.
- STS 인증을 활성화하는 데 필요한 OIDC 공급자 1개
- Kubernetes 컨트롤러 관리자, 클러스터 API 공급자 및 레지스트리와 같이 공급자와 상호 작용하는 모든 구성 요소에 대해 별도의 7가지 역할
- 클러스터의 모든 작업자 인스턴스에 할당된 프로필인 인스턴스 프로필 1개
1.7.6.12.4.3. 클러스터 생성
클러스터를 생성하려면 다음 명령을 입력합니다.
hcp create cluster aws \
--infra-id INFRA_ID \
--name CLUSTER_NAME \
--aws-creds AWS_CREDENTIALS \
--pull-secret PULL_SECRET_FILE \
--generate-ssh \
--node-pool-replicas 3- 1
INFRA_ID를create infra aws명령에 지정한 것과 동일한 ID로 바꿉니다. 이 값은 호스팅된 클러스터와 연결된 IAM 리소스를 식별합니다.- 2
CLUSTER_NAME을create infra aws명령에 지정한 것과 동일한 이름으로 바꿉니다.- 3
AWS_CREDENTIALS를create infra aws명령에 지정한 것과 동일한 값으로 바꿉니다.- 4
PULL_SECRET_FILE을 유효한 OpenShift Container Platform 풀 시크릿이 포함된 파일 이름으로 교체합니다.- 5
--generate-ssh플래그는 선택 사항이지만 작업자에게 SSH를 사용해야 하는 경우 포함할 수 있습니다. SSH 키는 사용자를 위해 생성되며 호스팅된 클러스터와 동일한 네임스페이스에 시크릿으로 저장됩니다.
명령에 --render 플래그를 추가하고 클러스터에 적용하기 전에 리소스를 편집할 수 있는 파일로 출력을 리디렉션할 수도 있습니다.
명령을 실행하면 다음 리소스가 클러스터에 적용됩니다.
- 네임스페이스
- 풀 시크릿이 있는 시크릿
-
HostedCluster -
A
NodePool - 컨트롤 플레인 구성 요소에 대한 세 가지 AWS STS 시크릿
-
--generate-ssh플래그를 지정한 경우 SSH 키 시크릿 1개
1.7.6.13. AWS에서 호스트된 클러스터 삭제
호스트 클러스터 및 관리 클러스터 리소스를 삭제하려면 다음 단계를 완료합니다.
다음 명령을 실행하여 다중 클러스터 엔진 Operator에서 관리되는 클러스터 리소스를 삭제합니다.
oc delete managedcluster <managed_cluster_name>여기서
<managed_cluster_name>은 관리 클러스터의 이름입니다.다음 명령을 실행하여 호스팅된 클러스터 및 해당 백엔드 리소스를 삭제합니다.
hcp destroy cluster aws --name <hosted_cluster_name> --infra-id <infra_id> --aws-creds <path_to_aws_creds> --base-domain <basedomain>필요한 경우 이름을 바꿉니다.
1.7.7. 베어 메탈에서 호스팅된 컨트롤 플레인 클러스터 구성
호스팅 클러스터로 작동하도록 클러스터를 구성하여 호스팅 컨트롤 플레인을 배포할 수 있습니다. 호스팅 클러스터는 컨트롤 플레인이 호스팅되는 OpenShift Container Platform 클러스터입니다. 호스팅 클러스터를 관리 클러스터라고도 합니다.
참고: 관리 클러스터는 관리 클러스터와 동일하지 않습니다. 관리형 클러스터는 hub 클러스터가 관리하는 클러스터입니다.
호스트된 컨트롤 플레인 기능은 기본적으로 활성화되어 있습니다.
다중 클러스터 엔진 Operator 2.5는 관리하는 허브 클러스터인 기본 로컬 클러스터와 허브 클러스터를 호스팅 클러스터로만 지원합니다. Red Hat Advanced Cluster Management 2.10에서 로컬 클러스터라고도 하는 관리 허브 클러스터를 호스팅 클러스터로 사용할 수 있습니다.
호스팅 클러스터는 호스팅 클러스터에서 호스팅되 는 API 끝점 및 컨트롤 플레인이 있는 OpenShift Container Platform 클러스터입니다. 호스트된 클러스터에는 컨트롤 플레인과 해당 데이터 플레인이 포함됩니다. 다중 클러스터 엔진 Operator 콘솔 또는 호스팅된 컨트롤 플레인 명령줄 인터페이스인 hcp 를 사용하여 호스트된 클러스터를 생성할 수 있습니다. 호스팅된 클러스터는 관리 클러스터로 자동으로 가져옵니다. 이 자동 가져오기 기능을 비활성화하려면 호스팅된 클러스터를 멀티 클러스터 엔진 Operator로 자동 가져오기 비활성화 를 참조하십시오.
중요:
- 호스팅된 컨트롤 플레인의 동일한 플랫폼에서 허브 클러스터 및 작업자를 실행합니다.
- 각 호스트 클러스터에는 클러스터 전체 이름이 있어야 합니다. 호스트된 클러스터 이름은 다중 클러스터 엔진 운영자가 이를 관리하기 위해 기존 관리 클러스터와 같을 수 없습니다.
-
클러스터를 호스팅
클러스터이름으로 사용하지 마십시오. - 호스트된 클러스터는 다중 클러스터 엔진 Operator 관리 클러스터의 네임스페이스에서 생성할 수 없습니다.
- 베어 메탈에서 호스팅되는 컨트롤 플레인을 프로비저닝하려면 에이전트 플랫폼을 사용할 수 있습니다. 에이전트 플랫폼은 중앙 인프라 관리 서비스를 사용하여 호스트된 클러스터에 작업자 노드를 추가합니다. 중앙 인프라 관리 서비스에 대한 소개는 중앙 인프라 관리 서비스 활성화를 참조하십시오.
-
모든 베어 메탈 호스트에는 중앙 인프라 관리에서 제공하는 Discovery Image ISO가 포함된 수동 부팅이 필요합니다. 수동으로 또는
Cluster-Baremetal-Operator를 사용하여 호스트를 시작할 수 있습니다. 각 호스트가 시작되면 에이전트 프로세스를 실행하여 호스트 세부 정보를 검색하고 설치를 완료합니다.에이전트사용자 정의 리소스는 각 호스트를 나타냅니다. - 에이전트 플랫폼으로 호스팅된 클러스터를 생성하면 HyperShift가 호스팅된 컨트롤 플레인 네임스페이스에 에이전트 클러스터 API 공급자를 설치합니다.
- 노드 풀로 복제본을 확장하면 머신이 생성됩니다. 모든 머신에 대해 클러스터 API 공급자는 노드 풀 사양에 지정된 요구 사항을 충족하는 에이전트를 찾아 설치합니다. 에이전트의 상태 및 조건을 확인하여 에이전트 설치를 모니터링할 수 있습니다.
- 노드 풀을 축소하면 에이전트가 해당 클러스터에서 바인딩되지 않습니다. 에이전트를 재사용하려면 먼저 Discovery 이미지를 사용하여 다시 시작해야 합니다.
- 호스트된 컨트롤 플레인에 대한 스토리지를 구성할 때 권장 etcd 사례를 고려하십시오. 대기 시간 요구 사항을 충족하는지 확인하려면 각 컨트롤 플레인 노드에서 실행되는 모든 호스팅 컨트롤 플레인 etcd 인스턴스에 빠른 스토리지 장치를 전용으로 지정합니다. LVM 스토리지를 사용하여 호스팅된 etcd pod의 로컬 스토리지 클래스를 구성할 수 있습니다. 자세한 내용은 OpenShift Container Platform 설명서의 논리 볼륨 관리자 스토리지를 사용하여 etcd 권장 사례 및 영구 스토리지를 참조하십시오.
1.7.7.1. 사전 요구 사항
호스팅 클러스터를 구성하려면 다음 사전 요구 사항이 있어야 합니다.
- Kubernetes Operator 2.2 이상용 멀티 클러스터 엔진이 OpenShift Container Platform 클러스터에 설치되어 있어야 합니다. Red Hat Advanced Cluster Management를 설치할 때 다중 클러스터 엔진 Operator가 자동으로 설치됩니다. Red Hat Advanced Cluster Management 없이 OpenShift Container Platform OperatorHub의 Operator로 다중 클러스터 엔진 Operator를 설치할 수도 있습니다.
다중 클러스터 엔진 Operator에는 하나 이상의 관리형 OpenShift Container Platform 클러스터가 있어야 합니다.
local-cluster는 다중 클러스터 엔진 Operator 2.2 이상에서 자동으로 가져옵니다.local-cluster에 대한 자세한 내용은 고급 구성 을 참조하십시오. 다음 명령을 실행하여 허브 클러스터의 상태를 확인할 수 있습니다.oc get managedclusters local-cluster-
관리 클러스터의 베어 메탈 호스트에
topology.kubernetes.io/zone레이블을 추가해야 합니다. 그렇지 않으면 호스팅되는 모든 컨트롤 플레인 Pod가 단일 노드에 예약되므로 단일 장애 지점이 발생합니다. - 중앙 인프라 관리를 활성화해야 합니다. 자세한 내용은 중앙 인프라 관리 서비스 활성화를 참조하십시오.
- 호스팅된 컨트롤 플레인 명령줄 인터페이스를 설치해야 합니다.
-
호스팅된 클러스터 API 엔드포인트에 연결하는 프록시 구성이 있는 허브 클러스터의 경우 모든 호스팅 클러스터 API 끝점을 프록시 오브젝트의
no필드에 추가합니다. 자세한 내용은 클러스터 전체 프록시 구성을 참조하십시오.Proxy
1.7.7.2. 베어 메탈 방화벽, 포트 및 서비스 요구 사항
포트가 관리 클러스터, 컨트롤 플레인 및 호스팅 클러스터 간에 통신할 수 있도록 방화벽, 포트 및 서비스 요구 사항을 충족해야 합니다.
참고: 서비스는 기본 포트에서 실행됩니다. 그러나 NodePort 게시 전략을 사용하는 경우 서비스는 NodePort 서비스에서 할당한 포트에서 실행됩니다.
방화벽 규칙, 보안 그룹 또는 기타 액세스 제어를 사용하여 필요한 소스만 액세스를 제한합니다. 필요한 경우 포트를 공개적으로 노출하지 마십시오. 프로덕션 배포의 경우 로드 밸런서를 사용하여 단일 IP 주소를 통한 액세스를 단순화합니다.
호스팅된 컨트롤 플레인은 베어 메탈에 다음 서비스를 노출합니다.
apiserver-
APIServer서비스는 기본적으로 포트 6443에서 실행되며 컨트롤 플레인 구성 요소 간 통신을 위해 수신 액세스가 필요합니다. - MetalLB 로드 밸런싱을 사용하는 경우 로드 밸런서 IP 주소에 사용되는 IP 범위에 대한 수신 액세스를 허용합니다.
-
OAuthServer-
OAuthServer서비스는 경로 및 수신을 사용하여 서비스를 노출할 때 기본적으로 포트 443에서 실행됩니다. -
NodePort게시 전략을 사용하는 경우OAuthServer서비스에 방화벽 규칙을 사용합니다.
-
Konnectivity-
Konnectivity서비스는 경로 및 Ingress를 사용하여 서비스를 노출할 때 기본적으로 포트 443에서 실행됩니다. -
호스팅된 클러스터에서 양방향 통신을 허용하도록 역방향 터널을 설정하는
Konnectivity에이전트에는 포트 6443의 클러스터 API 서버 주소에 대한 송신 액세스가 필요합니다. 해당 송신 액세스를 사용하면 에이전트가APIServer서비스에 도달할 수 있습니다. - 클러스터 API 서버 주소가 내부 IP 주소인 경우 워크로드 서브넷에서 포트 6443의 IP 주소로 액세스를 허용합니다.
- 주소가 외부 IP 주소인 경우 6443 포트에서 노드에서 해당 외부 IP 주소로 송신을 허용합니다.
-
Ignition-
Ignition서비스는 경로 및 수신을 사용하여 서비스를 노출할 때 기본적으로 포트 443에서 실행됩니다. -
NodePort게시 전략을 사용하는 경우Ignition서비스에 방화벽 규칙을 사용합니다.
-
베어 메탈에는 다음 서비스가 필요하지 않습니다.
-
OVNSbDb -
OIDC
1.7.7.3. 베어 메탈 인프라 요구 사항
에이전트 플랫폼은 인프라를 생성하지 않지만 인프라에 대한 다음과 같은 요구 사항이 있습니다.
- 에이전트: 에이전트 는 검색 이미지로 부팅되고 OpenShift Container Platform 노드로 프로비저닝할 준비가 된 호스트를 나타냅니다.
- DNS: API 및 수신 끝점은 라우팅할 수 있어야 합니다.
베어 메탈의 호스팅 컨트롤 플레인에 대한 추가 리소스는 다음 문서를 참조하십시오.
- etcd 및 LVM 스토리지 권장 사항에 대한 자세한 내용은 권장 etcd 사례 및 논리 볼륨 관리자 스토리지를 사용하여 영구 스토리지를 참조하십시오.
- 연결이 끊긴 환경에서 베어 메탈에 호스팅된 컨트롤 플레인을 구성하려면 연결이 끊긴 환경에서 호스팅된 컨트롤 플레인 구성을 참조하십시오.
- 호스팅된 컨트롤 플레인 기능을 비활성화하거나 이미 비활성화한 경우 호스팅된 컨트롤 플레인 기능 활성화 또는 비활성화를 참조하십시오.
- Red Hat Ansible Automation Platform 작업을 실행하여 호스트된 클러스터를 관리하려면 호스팅된 클러스터에서 실행되도록 Ansible Automation Platform 작업 구성 을 참조하십시오.
- SR-IOV Operator를 배포하려면 호스팅된 컨트롤 플레인을 위한 SR-IOV Operator 배포를 참조하십시오.
- 자동 가져오기 기능을 비활성화하려면 호스팅된 클러스터를 멀티 클러스터 엔진 Operator로 자동 가져오기 비활성화 를 참조하십시오.
1.7.7.4. 베어 메탈에서 DNS 구성
호스팅된 클러스터의 API 서버는 NodePort 서비스로 노출됩니다. API Server에 연결할 수 있는 대상을 가리키는 api.${HOSTED_CLUSTER_NAME}.${BASEDOMAIN} 에 대한 DNS 항목이 있어야 합니다.
DNS 항목은 호스팅된 컨트롤 플레인을 실행하는 관리형 클러스터의 노드 중 하나를 가리키는 레코드만큼 단순할 수 있습니다. 이 항목은 들어오는 트래픽을 인그레스 포드로 리디렉션하기 위해 배포된 로드 밸런서를 가리킬 수도 있습니다.
다음 예제 DNS 구성을 참조하십시오.
api.example.krnl.es. IN A 192.168.122.20 api.example.krnl.es. IN A 192.168.122.21 api.example.krnl.es. IN A 192.168.122.22 api-int.example.krnl.es. IN A 192.168.122.20 api-int.example.krnl.es. IN A 192.168.122.21 api-int.example.krnl.es. IN A 192.168.122.22 `*`.apps.example.krnl.es. IN A 192.168.122.23IPv6 네트워크에서 연결이 끊긴 환경에 대한 DNS를 구성하는 경우 다음 예제 DNS 구성을 참조하십시오.
api.example.krnl.es. IN A 2620:52:0:1306::5 api.example.krnl.es. IN A 2620:52:0:1306::6 api.example.krnl.es. IN A 2620:52:0:1306::7 api-int.example.krnl.es. IN A 2620:52:0:1306::5 api-int.example.krnl.es. IN A 2620:52:0:1306::6 api-int.example.krnl.es. IN A 2620:52:0:1306::7 `*`.apps.example.krnl.es. IN A 2620:52:0:1306::10듀얼 스택 네트워크에서 연결이 끊긴 환경에 대해 DNS를 구성하는 경우 IPv4 및 IPv6 모두에 대한 DNS 항목을 포함해야 합니다. 다음 예제 DNS 구성을 참조하십시오.
host-record=api-int.hub-dual.dns.base.domain.name,192.168.126.10 host-record=api.hub-dual.dns.base.domain.name,192.168.126.10 address=/apps.hub-dual.dns.base.domain.name/192.168.126.11 dhcp-host=aa:aa:aa:aa:10:01,ocp-master-0,192.168.126.20 dhcp-host=aa:aa:aa:aa:10:02,ocp-master-1,192.168.126.21 dhcp-host=aa:aa:aa:aa:10:03,ocp-master-2,192.168.126.22 dhcp-host=aa:aa:aa:aa:10:06,ocp-installer,192.168.126.25 dhcp-host=aa:aa:aa:aa:10:07,ocp-bootstrap,192.168.126.26 host-record=api-int.hub-dual.dns.base.domain.name,2620:52:0:1306::2 host-record=api.hub-dual.dns.base.domain.name,2620:52:0:1306::2 address=/apps.hub-dual.dns.base.domain.name/2620:52:0:1306::3 dhcp-host=aa:aa:aa:aa:10:01,ocp-master-0,[2620:52:0:1306::5] dhcp-host=aa:aa:aa:aa:10:02,ocp-master-1,[2620:52:0:1306::6] dhcp-host=aa:aa:aa:aa:10:03,ocp-master-2,[2620:52:0:1306::7] dhcp-host=aa:aa:aa:aa:10:06,ocp-installer,[2620:52:0:1306::8] dhcp-host=aa:aa:aa:aa:10:07,ocp-bootstrap,[2620:52:0:1306::9]
다음으로 베어 메탈에서 호스팅된 컨트롤 플레인에 대한 호스트 인벤토리를 생성합니다.
1.7.7.5. 베어 메탈에서 호스트 클러스터 생성
베어 메탈에서 호스팅 클러스터를 생성하거나 가져올 수 있습니다. 호스트 클러스터를 가져오는 방법은 호스팅 클러스터 가져오기를 참조하십시오.
다음 명령을 입력하여 호스팅된 컨트롤 플레인 네임스페이스를 생성합니다.
oc create ns <hosted_cluster_namespace>-<hosted_cluster_name><
;hosted_cluster_namespace>를 호스팅된 클러스터 네임스페이스 이름(예: 클러스터 )으로바꿉니다. <hosted_cluster_name>을 호스트된 클러스터 이름으로 교체합니다.클러스터에 대해 기본 스토리지 클래스가 구성되어 있는지 확인합니다. 그러지 않으면 보류 중인 PVC가 표시될 수 있습니다. 다음 명령을 실행합니다.
hcp create cluster agent \ --name=<hosted_cluster_name> \1 --pull-secret=<path_to_pull_secret> \2 --agent-namespace=<hosted_control_plane_namespace> \3 --base-domain=<basedomain> \4 --api-server-address=api.<hosted_cluster_name>.<basedomain> \ --etcd-storage-class=<etcd_storage_class> \5 --ssh-key <path_to_ssh_public_key> \6 --namespace <hosted_cluster_namespace> \7 --control-plane-availability-policy SingleReplica \ --release-image=quay.io/openshift-release-dev/ocp-release:<ocp_release_image>8 - 1
- 호스팅된 클러스터의 이름을 지정합니다(
예: ). - 2
- 풀 시크릿의 경로를 지정합니다(예:
/user/name/pullsecret). - 3
- 호스팅된 컨트롤 플레인 네임스페이스를 지정합니다(예: cluster
-example).oc get agent -n <hosted_control_plane_namespace> 명령을 사용하여 이 네임스페이스에서 에이전트를 사용할 수 있는지 확인합니다. - 4
- 기본 도메인을 지정합니다(예:
krnl.es). - 5
- etcd 스토리지 클래스 이름을 지정합니다(예:
lvm-storageclass). - 6
- SSH 공개 키의 경로를 지정합니다. 기본 파일 경로는
~/.ssh/id_rsa.pub입니다. - 7
- 호스팅된 클러스터 네임스페이스를 지정합니다.
- 8
- 사용하려는 지원되는 OpenShift Container Platform 버전을 지정합니다(예:
4.14.0-x86_64). 연결이 끊긴 환경을 사용하는 경우 <ocp_release_image>를 다이제스트 이미지로 교체합니다. OpenShift Container Platform 릴리스 이미지 다이제스트를 추출하려면 OpenShift Container Platform 릴리스 이미지 다이제스트 추출을 참조하십시오.
잠시 후 다음 명령을 입력하여 호스팅된 컨트롤 플레인 pod가 실행 중인지 확인합니다.
oc -n <hosted_control_plane_namespace> get pods다음 예제 출력을 참조하십시오.
NAME READY STATUS RESTARTS AGE capi-provider-7dcf5fc4c4-nr9sq 1/1 Running 0 4m32s catalog-operator-6cd867cc7-phb2q 2/2 Running 0 2m50s certified-operators-catalog-884c756c4-zdt64 1/1 Running 0 2m51s cluster-api-f75d86f8c-56wfz 1/1 Running 0 4m32s
1.7.7.5.1. 콘솔을 사용하여 베어 메탈에서 호스트 클러스터 생성
- OpenShift Container Platform 웹 콘솔을 열고 관리자 인증 정보를 입력하여 로그인합니다. 콘솔을 여는 방법은 OpenShift Container Platform 설명서 의 웹 콘솔 액세스를 참조하십시오.
- 콘솔 헤더에서 모든 클러스터 가 선택되어 있는지 확인합니다.
- Infrastructure > Clusters를 클릭합니다.
Create cluster > Host inventory > Hosted control Plane 을 클릭합니다.
클러스터 생성 페이지가 표시됩니다.
클러스터 생성 페이지에서 프롬프트에 따라 클러스터, 노드 풀, 네트워킹 및 자동화에 대한 세부 정보를 입력합니다.
참고: 클러스터에 대한 세부 정보를 입력하면 다음 팁이 유용할 수 있습니다.
- 사전 정의된 값을 사용하여 콘솔에서 필드를 자동으로 채우려면 호스트 인벤토리 인증 정보를 생성할 수 있습니다. 자세한 내용은 온-프레미스 환경에 대한 인증 정보 만들기 를 참조하십시오.
- 클러스터 세부 정보 페이지에서 풀 시크릿은 OpenShift Container Platform 리소스에 액세스하는 데 사용하는 OpenShift Container Platform 풀 시크릿입니다. 호스트 인벤토리 인증 정보를 선택한 경우 가져오기 보안이 자동으로 채워집니다.
- 노드 풀 페이지에서 네임스페이스에는 노드 풀의 호스트가 포함되어 있습니다. 콘솔을 사용하여 호스트 인벤토리를 생성한 경우 콘솔은 전용 네임스페이스를 생성합니다.
-
네트워킹 페이지에서 API 서버 게시 전략을 선택합니다. 호스팅된 클러스터의 API 서버는 기존 로드 밸런서를 사용하거나
NodePort유형의 서비스로 노출될 수 있습니다. API 서버에 도달할 수 있는 대상을 가리키는api.${HOSTED_CLUSTER_NAME}.${BASEDOMAIN}설정에 대한 DNS 항목이 있어야 합니다. 이 항목은 관리 클러스터의 노드 중 하나를 가리키는 레코드이거나 수신 트래픽을 Ingress pod로 리디렉션하는 로드 밸런서를 가리키는 레코드일 수 있습니다.
항목을 검토하고 생성 을 클릭합니다.
호스팅된 클러스터 보기가 표시됩니다.
- Hosted 클러스터 보기에서 호스팅된 클러스터의 배포를 모니터링합니다.
- 호스팅된 클러스터에 대한 정보가 표시되지 않는 경우 모든 클러스터가 선택되어 있는지 확인한 다음 클러스터 이름을 클릭합니다.
- 컨트롤 플레인 구성 요소가 준비될 때까지 기다립니다. 이 프로세스는 몇 분 정도 걸릴 수 있습니다.
- 노드 풀 상태를 보려면 NodePool 섹션으로 스크롤합니다. 노드를 설치하는 프로세스에는 약 10분이 걸립니다. 노드를 클릭하여 노드가 호스팅된 클러스터에 참여하고 있는지 확인할 수도 있습니다.
1.7.7.5.2. 미러 레지스트리를 사용하여 베어 메탈에서 호스팅 클러스터 생성
미러 레지스트리를 사용하여 hcp create cluster 명령에 --image-content-sources 플래그를 지정하여 베어 메탈에 호스팅 클러스터를 생성할 수 있습니다. 다음 단계를 완료합니다.
YAML 파일을 생성하여 ICSP(Image Content Source Policies)를 정의합니다. 다음 예제를 참조하십시오.
- mirrors: - brew.registry.redhat.io source: registry.redhat.io - mirrors: - brew.registry.redhat.io source: registry.stage.redhat.io - mirrors: - brew.registry.redhat.io source: registry-proxy.engineering.redhat.com-
파일을
icsp.yaml로 저장합니다. 이 파일에는 미러 레지스트리가 포함되어 있습니다. 미러 레지스트리를 사용하여 호스팅된 클러스터를 생성하려면 다음 명령을 실행합니다.
hcp create cluster agent \ --name=<hosted_cluster_name> \1 --pull-secret=<path_to_pull_secret> \2 --agent-namespace=<hosted_control_plane_namespace> \3 --base-domain=<basedomain> \4 --api-server-address=api.<hosted_cluster_name>.<basedomain> \ --image-content-sources icsp.yaml \5 --ssh-key <path_to_ssh_key> \6 --namespace <hosted_cluster_namespace> \7 --release-image=quay.io/openshift-release-dev/ocp-release:<ocp_release_image>8 - 1
- 호스팅된 클러스터의 이름을 지정합니다(
예: ). - 2
- 풀 시크릿의 경로를 지정합니다(예:
/user/name/pullsecret). - 3
- 호스팅된 컨트롤 플레인 네임스페이스를 지정합니다(예: cluster
-example).oc get agent -n <hosted-control-plane-namespace> 명령을 사용하여 이 네임스페이스에서 에이전트를 사용할 수 있는지 확인합니다. - 4
- 기본 도메인을 지정합니다(예:
krnl.es). - 5
- ICSP 및 미러 레지스트리를 정의하는
icsp.yaml파일을 지정합니다. - 6
- SSH 공개 키의 경로를 지정합니다. 기본 파일 경로는
~/.ssh/id_rsa.pub입니다. - 7
- 호스팅된 클러스터 네임스페이스를 지정합니다.
- 8
- 사용하려는 지원되는 OpenShift Container Platform 버전을 지정합니다(예:
4.14.0-x86_64). 연결이 끊긴 환경을 사용하는 경우 <ocp_release_image>를 다이제스트 이미지로 교체합니다. OpenShift Container Platform 릴리스 이미지 다이제스트를 추출하려면 OpenShift Container Platform 릴리스 이미지 다이제스트 추출을 참조하십시오.
1.7.7.5.3. 추가 리소스
- 콘솔을 사용하여 호스팅된 클러스터를 만들 때 재사용할 수 있는 인증 정보를 생성하려면 온프레미스 환경에 대한 인증 정보 생성 을 참조하십시오.
- 호스트 클러스터를 가져오려면 호스팅된 컨트롤 플레인 클러스터 수동 가져오기를 참조하십시오.
- 호스트된 클러스터에 액세스하려면 호스팅 된 클러스터 액세스를 참조하십시오.
- Discovery Image를 사용하여 호스트 인벤토리에 호스트를 추가하려면 Discovery Image 를 사용하여 호스트 인벤토리에 호스트 추가를 참조하십시오.
- OpenShift Container Platform 릴리스 이미지 다이제스트를 추출하려면 OpenShift Container Platform 릴리스 이미지 다이제스트 추출을 참조하십시오.
1.7.7.6. 호스트된 클러스터 생성 확인
배포 프로세스가 완료되면 호스트 클러스터가 성공적으로 생성되었는지 확인할 수 있습니다. 호스팅된 클러스터를 생성한 후 몇 분 후에 다음 단계를 수행합니다.
extract 명령을 입력하여 새 호스팅 클러스터에 대한 kubeconfig를 가져옵니다.
oc extract -n <hosted-control-plane-namespace> secret/admin-kubeconfig --to=- > kubeconfig-<hosted-cluster-name>kubeconfig를 사용하여 호스팅된 클러스터의 클러스터 Operator를 확인합니다. 다음 명령을 실행합니다.
oc get co --kubeconfig=kubeconfig-<hosted-cluster-name>다음 예제 출력을 참조하십시오.
NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE MESSAGE console 4.10.26 True False False 2m38s dns 4.10.26 True False False 2m52s image-registry 4.10.26 True False False 2m8s ingress 4.10.26 True False False 22m다음 명령을 입력하여 호스팅 클러스터에서 실행 중인 Pod를 볼 수도 있습니다.
oc get pods -A --kubeconfig=kubeconfig-<hosted-cluster-name>다음 예제 출력을 참조하십시오.
NAMESPACE NAME READY STATUS RESTARTS AGE kube-system konnectivity-agent-khlqv 0/1 Running 0 3m52s openshift-cluster-node-tuning-operator tuned-dhw5p 1/1 Running 0 109s openshift-cluster-storage-operator cluster-storage-operator-5f784969f5-vwzgz 1/1 Running 1 (113s ago) 20m openshift-cluster-storage-operator csi-snapshot-controller-6b7687b7d9-7nrfw 1/1 Running 0 3m8s openshift-console console-5cbf6c7969-6gk6z 1/1 Running 0 119s openshift-console downloads-7bcd756565-6wj5j 1/1 Running 0 4m3s openshift-dns-operator dns-operator-77d755cd8c-xjfbn 2/2 Running 0 21m openshift-dns dns-default-kfqnh 2/2 Running 0 113s
1.7.7.7. 호스트 클러스터의 NodePool 오브젝트 스케일링
호스팅된 클러스터에 노드를 추가하여 NodePool 오브젝트를 확장할 수 있습니다.
NodePool오브젝트를 두 개의 노드로 확장합니다.oc -n <hosted-cluster-namespace> scale nodepool <nodepool-name> --replicas 2Cluster API 에이전트 공급자는 호스트 클러스터에 할당된 두 개의 에이전트를 임의로 선택합니다. 이러한 에이전트는 다른 상태를 통과하고 마지막으로 호스팅된 클러스터에 OpenShift Container Platform 노드로 참여합니다. 에이전트는 다음 순서로 상태를 통과합니다.
-
바인딩 -
검색 -
insufficient -
설치 -
install-in-progress -
add-to-existing-cluster
-
다음 명령을 실행합니다.
oc -n <hosted-control-plane-namespace> get agent다음 예제 출력을 참조하십시오.
NAME CLUSTER APPROVED ROLE STAGE 4dac1ab2-7dd5-4894-a220-6a3473b67ee6 hypercluster1 true auto-assign d9198891-39f4-4930-a679-65fb142b108b true auto-assign da503cf1-a347-44f2-875c-4960ddb04091 hypercluster1 true auto-assign다음 명령을 실행합니다.
oc -n <hosted-control-plane-namespace> get agent -o jsonpath='{range .items[*]}BMH: {@.metadata.labels.agent-install\.openshift\.io/bmh} Agent: {@.metadata.name} State: {@.status.debugInfo.state}{"\n"}{end}'다음 예제 출력을 참조하십시오.
BMH: ocp-worker-2 Agent: 4dac1ab2-7dd5-4894-a220-6a3473b67ee6 State: binding BMH: ocp-worker-0 Agent: d9198891-39f4-4930-a679-65fb142b108b State: known-unbound BMH: ocp-worker-1 Agent: da503cf1-a347-44f2-875c-4960ddb04091 State: insufficientextract 명령을 입력하여 새 호스팅 클러스터에 대한 kubeconfig를 가져옵니다.
oc extract -n <hosted-cluster-namespace> secret/<hosted-cluster-name>-admin-kubeconfig --to=- > kubeconfig-<hosted-cluster-name>에이전트가
add-to-existing-cluster상태에 도달한 후 다음 명령을 입력하여 호스팅된 클러스터에 OpenShift Container Platform 노드를 볼 수 있는지 확인합니다.oc --kubeconfig kubeconfig-<hosted-cluster-name> get nodes다음 예제 출력을 참조하십시오.
NAME STATUS ROLES AGE VERSION ocp-worker-1 Ready worker 5m41s v1.24.0+3882f8f ocp-worker-2 Ready worker 6m3s v1.24.0+3882f8f클러스터 Operator는 노드에 워크로드를 추가하여 조정하기 시작합니다.
다음 명령을 입력하여
NodePool오브젝트를 확장할 때 두 개의 머신이 생성되었는지 확인합니다.oc -n <hosted-control-plane-namespace> get machines다음 예제 출력을 참조하십시오.
NAME CLUSTER NODENAME PROVIDERID PHASE AGE VERSION hypercluster1-c96b6f675-m5vch hypercluster1-b2qhl ocp-worker-1 agent://da503cf1-a347-44f2-875c-4960ddb04091 Running 15m 4.13z hypercluster1-c96b6f675-tl42p hypercluster1-b2qhl ocp-worker-2 agent://4dac1ab2-7dd5-4894-a220-6a3473b67ee6 Running 15m 4.13zclusterversion조정 프로세스는 결국 Ingress 및 Console 클러스터 Operator만 누락된 지점에 도달합니다.다음 명령을 실행합니다.
oc --kubeconfig kubeconfig-<hosted-cluster-name> get clusterversion,co다음 예제 출력을 참조하십시오.
NAME VERSION AVAILABLE PROGRESSING SINCE STATUS clusterversion.config.openshift.io/version False True 40m Unable to apply 4.13z: the cluster operator console has not yet successfully rolled out NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE MESSAGE clusteroperator.config.openshift.io/console 4.12z False False False 11m RouteHealthAvailable: failed to GET route (https://console-openshift-console.apps.hypercluster1.domain.com): Get "https://console-openshift-console.apps.hypercluster1.domain.com": dial tcp 10.19.3.29:443: connect: connection refused clusteroperator.config.openshift.io/csi-snapshot-controller 4.12z True False False 10m clusteroperator.config.openshift.io/dns 4.12z True False False 9m16s
1.7.7.7.1. 노드 풀 추가
이름, 복제본 수 및 에이전트 라벨 선택기와 같은 추가 정보를 지정하여 호스팅된 클러스터에 대한 노드 풀을 생성할 수 있습니다.
노드 풀을 생성하려면 다음 정보를 입력합니다.
export NODEPOOL_NAME=${CLUSTER_NAME}-extra-cpu export WORKER_COUNT="2" hcp create nodepool agent \ --cluster-name $CLUSTER_NAME \ --name $NODEPOOL_NAME \ --node-count $WORKER_COUNT \ --agentLabelSelector '{"matchLabels": {"size": "medium"}}'1 - 1
--agentLabelSelector는 선택 사항입니다. 노드 풀은"size" : "medium"라벨이 있는 에이전트를 사용합니다.
cluster 네임스페이스에
nodepool리소스를 나열하여 노드 풀의상태를확인합니다.oc get nodepools --namespace clusters다음 명령을 입력하여
admin-kubeconfig시크릿을 추출합니다.oc extract -n <hosted-control-plane-namespace> secret/admin-kubeconfig --to=./hostedcluster-secrets --confirm다음 예제 출력을 참조하십시오.
hostedcluster-secrets/kubeconfig잠시 후 다음 명령을 입력하여 노드 풀의 상태를 확인할 수 있습니다.
oc --kubeconfig ./hostedcluster-secrets get nodes다음 명령을 입력하여 사용 가능한 노드 풀 수가 예상 노드 풀 수와 일치하는지 확인합니다.
oc get nodepools --namespace clusters
1.7.7.7.2. 추가 리소스
- 데이터 플레인을 0으로 축소하려면 데이터 플레인을 0으로 축소합니다.
1.7.7.8. 베어 메탈의 호스트 클러스터에서 수신 처리
모든 OpenShift Container Platform 클러스터에는 일반적으로 연결된 외부 DNS 레코드가 있는 기본 애플리케이션 Ingress 컨트롤러가 있습니다. 예를 들어 기본 도메인 krnl.es 를 사용하여 example 이라는 호스팅 클러스터를 생성하는 경우 와일드카드 도메인 *.apps.example.krnl.es 를 라우팅할 수 있을 것으로 예상할 수 있습니다.
*.apps 도메인의 로드 밸런서 및 와일드카드 DNS 레코드를 설정하려면 게스트 클러스터에서 다음 작업을 수행합니다.
MetalLB Operator의 구성이 포함된 YAML 파일을 생성하여 MetalLB를 배포합니다.
apiVersion: v1 kind: Namespace metadata: name: metallb labels: openshift.io/cluster-monitoring: "true" annotations: workload.openshift.io/allowed: management --- apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: name: metallb-operator-operatorgroup namespace: metallb --- apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: metallb-operator namespace: metallb spec: channel: "stable" name: metallb-operator source: redhat-operators sourceNamespace: openshift-marketplace-
파일을
metallb-operator-config.yaml로 저장합니다. 다음 명령을 입력하여 구성을 적용합니다.
oc apply -f metallb-operator-config.yamlOperator가 실행되면 MetalLB 인스턴스를 생성합니다.
MetalLB 인스턴스의 구성이 포함된 YAML 파일을 생성합니다.
apiVersion: metallb.io/v1beta1 kind: MetalLB metadata: name: metallb namespace: metallb-
파일을
metallb-instance-config.yaml로 저장합니다. - 다음 명령을 입력하여 MetalLB 인스턴스를 생성합니다.
oc apply -f metallb-instance-config.yaml다음 두 리소스를 생성하여 MetalLB Operator를 구성합니다.
-
단일 IP 주소가 있는
IPAddressPool리소스. 이 IP 주소는 클러스터 노드에서 사용하는 네트워크와 동일한 서브넷에 있어야 합니다. 로드 밸런서 IP 주소를
IPAddressPool리소스에서 BGP 프로토콜을 통해 제공하는BGPAdvertisement리소스입니다.- 구성을 포함할 YAML 파일을 생성합니다.
apiVersion: metallb.io/v1beta1 kind: IPAddressPool metadata: name: <ip_address_pool_name>1 namespace: metallb spec: protocol: layer2 autoAssign: false addresses: - <ingress_ip>-<ingress_ip>2 --- apiVersion: metallb.io/v1beta1 kind: BGPAdvertisement metadata: name: <bgp_advertisement_name>3 namespace: metallb spec: ipAddressPools: - <ip_address_pool_name>4 -
단일 IP 주소가 있는
- 1 4
IPAddressPool리소스 이름을 지정합니다.- 2
- 환경의 IP 주소를 지정합니다(예:
192.168.122.23). - 3
BGPAdvertisement리소스 이름을 지정합니다.-
파일을
ipaddresspool-bgpadvertisement-config.yaml로 저장합니다. 다음 명령을 입력하여 리소스를 생성합니다.
oc apply -f ipaddresspool-bgpadvertisement-config.yaml-
LoadBalancer유형의 서비스를 생성한 후 MetalLB는 서비스에 대한 외부 IP 주소를 추가합니다.
-
metallb-loadbalancer-service.yaml이라는 YAML 파일을 생성하여 Ingress 트래픽을 Ingress 배포로 라우팅하는 새 로드 밸런서 서비스를 구성합니다.kind: Service apiVersion: v1 metadata: annotations: metallb.universe.tf/address-pool: ingress-public-ip name: metallb-ingress namespace: openshift-ingress spec: ports: - name: http protocol: TCP port: 80 targetPort: 80 - name: https protocol: TCP port: 443 targetPort: 443 selector: ingresscontroller.operator.openshift.io/deployment-ingresscontroller: default type: LoadBalancer-
metallb-loadbalancer-service.yaml파일을 저장합니다. 다음 명령을 입력하여 YAML 구성을 적용합니다.
oc apply -f metallb-loadbalancer-service.yaml다음 명령을 입력하여 OpenShift Container Platform 콘솔에 연결합니다.
curl -kI https://console-openshift-console.apps.example.krnl.es HTTP/1.1 200 OKclusterversion및clusteroperator값을 확인하여 모든 항목이 실행 중인지 확인합니다. 다음 명령을 실행합니다.oc --kubeconfig <hosted_cluster_name>.kubeconfig get clusterversion,co다음 예제 출력을 참조하십시오.
NAME VERSION AVAILABLE PROGRESSING SINCE STATUS clusterversion.config.openshift.io/version 4.x.y True False 3m32s Cluster version is 4.x.y NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE MESSAGE clusteroperator.config.openshift.io/console 4.x.y True False False 3m50s clusteroperator.config.openshift.io/ingress 4.x.y True False False 53m+
4.x.y를 사용하려는 지원되는 OpenShift Container Platform 버전으로 교체합니다(예:4.14.0-x86_64).-
파일을
1.7.7.8.1. 추가 리소스
- MetalLB에 대한 자세한 내용은 OpenShift Container Platform 설명서 의 MetalLB 및 MetalLB Operator 정보를 참조하십시오.
1.7.7.9. 호스트 클러스터의 노드 자동 확장 활성화
호스팅된 클러스터에 용량이 더 필요하고 예비 에이전트를 사용할 수 있는 경우 자동 확장을 활성화하여 새 작업자 노드를 설치할 수 있습니다.
자동 확장을 활성화하려면 다음 명령을 입력합니다.
oc -n <hosted-cluster-namespace> patch nodepool <hosted-cluster-name> --type=json -p '[{"op": "remove", "path": "/spec/replicas"},{"op":"add", "path": "/spec/autoScaling", "value": { "max": 5, "min": 2 }}]'
참고: 이 예에서 최소 노드 수는 2이고 최대값은 5입니다. 추가할 수 있는 최대 노드 수는 플랫폼에 바인딩될 수 있습니다. 예를 들어 에이전트 플랫폼을 사용하는 경우 사용 가능한 에이전트 수에 따라 최대 노드 수가 바인딩됩니다.
새 노드가 필요한 워크로드를 생성합니다.
다음 예제를 사용하여 워크로드 구성이 포함된 YAML 파일을 생성합니다.
apiVersion: apps/v1 kind: Deployment metadata: creationTimestamp: null labels: app: reversewords name: reversewords namespace: default spec: replicas: 40 selector: matchLabels: app: reversewords strategy: {} template: metadata: creationTimestamp: null labels: app: reversewords spec: containers: - image: quay.io/mavazque/reversewords:latest name: reversewords resources: requests: memory: 2Gi status: {}-
파일을
workload-config.yaml로 저장합니다. - 다음 명령을 입력하여 YAML을 적용합니다.
oc apply -f workload-config.yaml다음 명령을 입력하여
admin-kubeconfig시크릿을 추출합니다.oc extract -n <hosted-cluster-namespace> secret/<hosted-cluster-name>-admin-kubeconfig --to=./hostedcluster-secrets --confirm다음 예제 출력을 참조하십시오.
hostedcluster-secrets/kubeconfig다음 명령을 입력하여 새 노드가
Ready상태에 있는지 확인할 수 있습니다.oc --kubeconfig ./hostedcluster-secrets get nodes노드를 제거하려면 다음 명령을 입력하여 워크로드를 삭제합니다.
oc --kubeconfig ./hostedcluster-secrets -n default delete deployment reversewords추가 용량을 요구하지 않고 몇 분 정도 경과할 때까지 기다립니다. 에이전트 플랫폼에서 에이전트는 해제되어 재사용될 수 있습니다. 다음 명령을 입력하여 노드가 제거되었는지 확인할 수 있습니다.
oc --kubeconfig ./hostedcluster-secrets get nodes
1.7.7.9.1. 호스트 클러스터의 노드 자동 확장 비활성화
노드 자동 확장을 비활성화하려면 다음 명령을 입력합니다.
oc -n <hosted-cluster-namespace> patch nodepool <hosted-cluster-name> --type=json -p '[\{"op":"remove", "path": "/spec/autoScaling"}, \{"op": "add", "path": "/spec/replicas", "value": <specify-value-to-scale-replicas>]'
이 명령은 YAML 파일에서 "spec.autoScaling" 을 제거하고 "spec.replicas" 를 추가하고 지정한 정수 값에 "spec.replicas" 를 설정합니다.
1.7.7.10. 베어 메탈에서 호스트 클러스터 삭제
콘솔을 사용하여 베어 메탈 호스팅 클러스터를 제거할 수 있습니다. 베어 메탈에서 호스트된 클러스터를 삭제하려면 다음 단계를 완료합니다.
- 콘솔에서 Infrastructure > Clusters 로 이동합니다.
- 클러스터 페이지에서 삭제할 클러스터를 선택합니다.
- 작업 메뉴에서 클러스터 삭제 를 선택하여 클러스터를 제거합니다.
1.7.7.10.1. 명령줄을 사용하여 베어 메탈에서 호스트 클러스터 제거
호스트 클러스터를 삭제하려면 다음 단계를 완료합니다.
다음 명령을 실행하여 호스팅된 클러스터 및 해당 백엔드 리소스를 삭제합니다.
hcp destroy cluster agent --name <hosted_cluster_name>&
lt;hosted_cluster_name>을 호스트된 클러스터 이름으로 바꿉니다.
1.7.8. 베어 메탈이 아닌 에이전트를 사용하여 호스팅되는 컨트롤 플레인 클러스터 구성 (기술 프리뷰)
호스팅 클러스터로 작동하도록 클러스터를 구성하여 호스팅 컨트롤 플레인을 배포할 수 있습니다. 호스팅 클러스터는 컨트롤 플레인이 호스팅되는 OpenShift Container Platform 클러스터입니다. 호스팅 클러스터를 관리 클러스터라고도 합니다.
참고: 관리 클러스터는 관리 클러스터와 동일하지 않습니다. 관리형 클러스터는 hub 클러스터가 관리하는 클러스터입니다.
호스트된 컨트롤 플레인 기능은 기본적으로 활성화되어 있습니다.
다중 클러스터 엔진 Operator 2.5는 관리하는 허브 클러스터인 기본 로컬 클러스터와 허브 클러스터를 호스팅 클러스터로만 지원합니다. Red Hat Advanced Cluster Management 2.10에서 로컬 클러스터라고도 하는 관리 허브 클러스터를 호스팅 클러스터로 사용할 수 있습니다.
호스팅 클러스터는 호스팅 클러스터에서 호스팅되 는 API 끝점 및 컨트롤 플레인이 있는 OpenShift Container Platform 클러스터입니다. 호스트된 클러스터에는 컨트롤 플레인과 해당 데이터 플레인이 포함됩니다. 다중 클러스터 엔진 Operator 콘솔 또는 호스팅된 컨트롤 플레인 명령줄 인터페이스인 hcp 를 사용하여 호스트된 클러스터를 생성할 수 있습니다. 호스팅된 클러스터는 관리 클러스터로 자동으로 가져옵니다. 이 자동 가져오기 기능을 비활성화하려면 호스팅된 클러스터를 멀티 클러스터 엔진 Operator로 자동 가져오기 비활성화 를 참조하십시오.
중요:
- 각 호스트 클러스터에는 클러스터 전체 이름이 있어야 합니다. 호스트된 클러스터 이름은 다중 클러스터 엔진 운영자가 이를 관리하기 위해 기존 관리 클러스터와 같을 수 없습니다.
-
클러스터를 호스팅
클러스터이름으로 사용하지 마십시오. - 호스팅된 컨트롤 플레인의 동일한 플랫폼에서 허브 클러스터 및 작업자를 실행합니다.
- 호스트된 클러스터는 다중 클러스터 엔진 Operator 관리 클러스터의 네임스페이스에서 생성할 수 없습니다.
- 에이전트 플랫폼을 사용하여 에이전트 시스템을 호스트된 클러스터에 작업자 노드로 추가할 수 있습니다. 에이전트 머신은 Discovery Image로 부팅되고 OpenShift Container Platform 노드로 프로비저닝할 준비가 된 호스트를 나타냅니다. 에이전트 플랫폼은 중앙 인프라 관리 서비스의 일부입니다. 자세한 내용은 중앙 인프라 관리 서비스 활성화를 참조하십시오.
- 베어 메탈이 아닌 모든 호스트는 중앙 인프라 관리에서 제공하는 Discovery Image ISO로 수동 부팅이 필요합니다.
- 에이전트 플랫폼으로 호스팅된 클러스터를 생성하면 HyperShift가 호스팅된 컨트롤 플레인 네임스페이스에 에이전트 클러스터 API 공급자를 설치합니다.
- 노드 풀을 확장하면 모든 복제본에 대해 머신이 생성됩니다. 모든 머신에 대해 Cluster API 공급자는 승인된 에이전트를 찾아 설치하며, 검증을 통과하고, 현재 사용되지 않으며, 노드 풀 사양에 지정된 요구 사항을 충족합니다. 에이전트의 상태 및 조건을 확인하여 에이전트 설치를 모니터링할 수 있습니다.
- 노드 풀을 축소하면 에이전트가 해당 클러스터에서 바인딩되지 않습니다. 에이전트를 재사용하려면 먼저 Discovery 이미지를 사용하여 다시 시작해야 합니다.
- 호스트된 컨트롤 플레인에 대한 스토리지를 구성할 때 권장 etcd 사례를 고려하십시오. 대기 시간 요구 사항을 충족하는지 확인하려면 각 컨트롤 플레인 노드에서 실행되는 모든 호스팅 컨트롤 플레인 etcd 인스턴스에 빠른 스토리지 장치를 전용으로 지정합니다. LVM 스토리지를 사용하여 호스팅된 etcd pod의 로컬 스토리지 클래스를 구성할 수 있습니다. 자세한 내용은 OpenShift Container Platform 설명서의 논리 볼륨 관리자 스토리지를 사용하여 etcd 권장 사례 및 영구 스토리지를 참조하십시오.
1.7.8.1. 사전 요구 사항
호스팅 클러스터를 구성하려면 다음 사전 요구 사항이 있어야 합니다.
- Kubernetes Operator 2.5 이상용 멀티 클러스터 엔진이 OpenShift Container Platform 클러스터에 설치되어 있어야 합니다. Red Hat Advanced Cluster Management를 설치할 때 다중 클러스터 엔진 Operator가 자동으로 설치됩니다. Red Hat Advanced Cluster Management 없이 OpenShift Container Platform OperatorHub의 Operator로 다중 클러스터 엔진 Operator를 설치할 수도 있습니다.
다중 클러스터 엔진 Operator에는 하나 이상의 관리형 OpenShift Container Platform 클러스터가 있어야 합니다.
local-cluster가 자동으로 가져옵니다.local-cluster에 대한 자세한 내용은 고급 구성 을 참조하십시오. 다음 명령을 실행하여 허브 클러스터의 상태를 확인할 수 있습니다.oc get managedclusters local-cluster- 중앙 인프라 관리를 활성화해야 합니다. 자세한 내용은 중앙 인프라 관리 서비스 활성화를 참조하십시오.
- 호스팅된 컨트롤 플레인 명령줄 인터페이스를 설치해야 합니다.
1.7.8.2. 베어 메탈이 아닌 에이전트 시스템에 대한 방화벽 및 포트 요구 사항
포트가 관리 클러스터, 컨트롤 플레인 및 호스팅 클러스터 간에 통신할 수 있도록 방화벽 및 포트 요구 사항을 충족하는지 확인합니다.
kube-apiserver서비스는 기본적으로 포트 6443에서 실행되며 컨트롤 플레인 구성 요소 간의 통신을 위해 수신 액세스가 필요합니다.-
NodePort게시 전략을 사용하는 경우kube-apiserver서비스에 할당된 노드 포트가 노출되어 있는지 확인합니다. - MetalLB 로드 밸런싱을 사용하는 경우 로드 밸런서 IP 주소에 사용되는 IP 범위에 대한 수신 액세스를 허용합니다.
-
-
NodePort게시 전략을 사용하는 경우ignition-server및Oauth-server설정에 방화벽 규칙을 사용합니다. 호스팅된 클러스터에서 양방향 통신을 허용하도록 역방향 터널을 설정하는
konnectivity에이전트에는 포트 6443의 클러스터 API 서버 주소에 대한 송신 액세스가 필요합니다. 이 송신 액세스를 사용하면 에이전트가kube-apiserver서비스에 도달할 수 있습니다.- 클러스터 API 서버 주소가 내부 IP 주소인 경우 워크로드 서브넷에서 포트 6443의 IP 주소로 액세스를 허용합니다.
- 주소가 외부 IP 주소인 경우 6443 포트에서 노드에서 해당 외부 IP 주소로 송신을 허용합니다.
- 기본 6443 포트를 변경하는 경우 해당 변경 사항을 반영하도록 규칙을 조정합니다.
- 클러스터에서 실행되는 워크로드에 필요한 모든 포트를 열어야 합니다.
- 방화벽 규칙, 보안 그룹 또는 기타 액세스 제어를 사용하여 필요한 소스만 액세스를 제한합니다. 필요한 경우 포트를 공개적으로 노출하지 마십시오.
- 프로덕션 배포의 경우 로드 밸런서를 사용하여 단일 IP 주소를 통한 액세스를 단순화합니다.
1.7.8.3. 베어 메탈이 아닌 에이전트 머신에 대한 인프라 요구 사항
에이전트 플랫폼은 인프라를 생성하지 않지만 인프라에 대한 다음과 같은 요구 사항이 있습니다.
- 에이전트: 에이전트 는 검색 이미지로 부팅되고 OpenShift Container Platform 노드로 프로비저닝할 준비가 된 호스트를 나타냅니다.
- DNS: API 및 수신 끝점은 라우팅할 수 있어야 합니다.
1.7.8.4. 베어 메탈이 아닌 에이전트 머신에서 DNS 구성
호스팅된 클러스터의 API 서버는 NodePort 서비스로 노출됩니다. API Server에 연결할 수 있는 대상을 가리키는 api.<hosted-cluster-name>.<basedomain >에 대한 DNS 항목이 있어야 합니다.
DNS 항목은 호스팅된 컨트롤 플레인을 실행하는 관리형 클러스터의 노드 중 하나를 가리키는 레코드만큼 단순할 수 있습니다. 이 항목은 들어오는 트래픽을 인그레스 포드로 리디렉션하기 위해 배포된 로드 밸런서를 가리킬 수도 있습니다.
다음 예제 DNS 구성을 참조하십시오.
api-int.example.krnl.es. IN A 192.168.122.22 `*`.apps.example.krnl.es. IN A 192.168.122.23IPv6 네트워크에서 연결이 끊긴 환경에 대한 DNS를 구성하는 경우 다음 예제 DNS 구성을 참조하십시오.
api-int.example.krnl.es. IN A 2620:52:0:1306::7 `*`.apps.example.krnl.es. IN A 2620:52:0:1306::10듀얼 스택 네트워크에서 연결이 끊긴 환경에 대해 DNS를 구성하는 경우 IPv4 및 IPv6 모두에 대한 DNS 항목을 포함해야 합니다. 다음 예제 DNS 구성을 참조하십시오.
host-record=api-int.hub-dual.dns.base.domain.name,2620:52:0:1306::2 address=/apps.hub-dual.dns.base.domain.name/2620:52:0:1306::3 dhcp-host=aa:aa:aa:aa:10:01,ocp-master-0,[2620:52:0:1306::5]
1.7.8.5. 베어 메탈이 아닌 에이전트 머신에서 호스트 클러스터 생성
호스트 클러스터를 생성하거나 가져올 수 있습니다. 호스트 클러스터를 가져오는 방법은 호스팅 클러스터 가져오기를 참조하십시오.
다음 명령을 입력하여 호스팅된 컨트롤 플레인 네임스페이스를 생성합니다.
oc create ns <hosted-cluster-namespace>-<hosted-cluster-name><
;hosted-cluster-namespace>를 호스팅된 클러스터 네임스페이스 이름(예: 클러스터 )으로바꿉니다. <hosted-cluster-name>을 호스트된 클러스터 이름으로 교체합니다.클러스터에 대해 기본 스토리지 클래스가 구성되어 있는지 확인합니다. 그러지 않으면 보류 중인 PVC로 종료될 수 있습니다. 다음 명령을 입력하여 예제 변수를 정보로 교체합니다.
hcp create cluster agent \ --name=<hosted-cluster-name> \1 --pull-secret=<path-to-pull-secret> \2 --agent-namespace=<hosted-control-plane-namespace> \3 --base-domain=<basedomain> \4 --api-server-address=api.<hosted-cluster-name>.<basedomain> \ --etcd-storage-class=<etcd-storage-class> \5 --ssh-key <path-to-ssh-key> \6 --namespace <hosted-cluster-namespace> \7 --control-plane-availability-policy SingleReplica \ --release-image=quay.io/openshift-release-dev/ocp-release:<ocp-release>8 - 1
- 호스팅된 클러스터의 이름을 지정합니다(
예: ). - 2
- 풀 시크릿의 경로를 지정합니다(예:
/user/name/pullsecret). - 3
- 호스팅된 컨트롤 플레인 네임스페이스를 지정합니다(예: cluster
-example).oc get agent -n <hosted-control-plane-namespace> 명령을 사용하여 이 네임스페이스에서 에이전트를 사용할 수 있는지 확인합니다. - 4
- 기본 도메인을 지정합니다(예:
krnl.es). - 5
- etcd 스토리지 클래스 이름을 지정합니다(예:
lvm-storageclass). - 6
- SSH 공개 키의 경로를 지정합니다. 기본 파일 경로는
~/.ssh/id_rsa.pub입니다. - 7
- 호스팅된 클러스터 네임스페이스를 지정합니다.
- 8
- 사용하려는 지원되는 OpenShift Container Platform 버전을 지정합니다(예:
4.14.0-x86_64).
잠시 후 다음 명령을 입력하여 호스팅된 컨트롤 플레인 pod가 실행 중인지 확인합니다.
oc -n <hosted-control-plane-namespace> get pods다음 예제 출력을 참조하십시오.
NAME READY STATUS RESTARTS AGE catalog-operator-6cd867cc7-phb2q 2/2 Running 0 2m50s control-plane-operator-f6b4c8465-4k5dh 1/1 Running 0 4m32s
1.7.8.5.1. 콘솔을 사용하여 베어 메탈이 아닌 에이전트 머신에서 호스트 클러스터 생성
- OpenShift Container Platform 웹 콘솔을 열고 관리자 인증 정보를 입력하여 로그인합니다. 콘솔을 여는 방법은 OpenShift Container Platform 설명서 의 웹 콘솔 액세스를 참조하십시오.
- 콘솔 헤더에서 모든 클러스터 가 선택되어 있는지 확인합니다.
- Infrastructure > Clusters를 클릭합니다.
Create cluster Host inventory > Hosted control Plane 을 클릭합니다.
클러스터 생성 페이지가 표시됩니다.
클러스터 생성 페이지에서 프롬프트에 따라 클러스터, 노드 풀, 네트워킹 및 자동화에 대한 세부 정보를 입력합니다.
참고: 클러스터에 대한 세부 정보를 입력하면 다음 팁이 유용할 수 있습니다.
- 사전 정의된 값을 사용하여 콘솔에서 필드를 자동으로 채우려면 호스트 인벤토리 인증 정보를 생성할 수 있습니다. 자세한 내용은 온-프레미스 환경에 대한 인증 정보 만들기 를 참조하십시오.
- 클러스터 세부 정보 페이지에서 풀 시크릿은 OpenShift Container Platform 리소스에 액세스하는 데 사용하는 OpenShift Container Platform 풀 시크릿입니다. 호스트 인벤토리 인증 정보를 선택한 경우 가져오기 보안이 자동으로 채워집니다.
- 노드 풀 페이지에서 네임스페이스에는 노드 풀의 호스트가 포함되어 있습니다. 콘솔을 사용하여 호스트 인벤토리를 생성한 경우 콘솔은 전용 네임스페이스를 생성합니다.
-
네트워킹 페이지에서 API 서버 게시 전략을 선택합니다. 호스팅된 클러스터의 API 서버는 기존 로드 밸런서를 사용하거나
NodePort유형의 서비스로 노출될 수 있습니다. API 서버에 도달할 수 있는 대상을 가리키는api.${HOSTED_CLUSTER_NAME}.${BASEDOMAIN}설정에 대한 DNS 항목이 있어야 합니다. 이 항목은 관리 클러스터의 노드 중 하나를 가리키는 레코드이거나 수신 트래픽을 Ingress pod로 리디렉션하는 로드 밸런서를 가리키는 레코드일 수 있습니다.
항목을 검토하고 생성 을 클릭합니다.
호스팅된 클러스터 보기가 표시됩니다.
- Hosted 클러스터 보기에서 호스팅된 클러스터의 배포를 모니터링합니다. 호스팅된 클러스터에 대한 정보가 표시되지 않는 경우 모든 클러스터가 선택되어 있는지 확인하고 클러스터 이름을 클릭합니다. 컨트롤 플레인 구성 요소가 준비될 때까지 기다립니다. 이 프로세스는 몇 분 정도 걸릴 수 있습니다.
- 노드 풀 상태를 보려면 NodePool 섹션으로 스크롤합니다. 노드를 설치하는 프로세스에는 약 10분이 걸립니다. 노드를 클릭하여 노드가 호스팅된 클러스터에 참여하고 있는지 확인할 수도 있습니다.
1.7.8.5.2. 추가 리소스
- 콘솔을 사용하여 호스팅된 클러스터를 만들 때 재사용할 수 있는 인증 정보를 생성하려면 온프레미스 환경에 대한 인증 정보 생성 을 참조하십시오.
- 호스트 클러스터를 가져오려면 호스팅된 컨트롤 플레인 클러스터 수동 가져오기를 참조하십시오.
- 호스트된 클러스터에 액세스하려면 호스팅 된 클러스터 액세스를 참조하십시오.
- Discovery Image를 사용하여 호스트 인벤토리에 호스트를 추가하려면 Discovery Image 를 사용하여 호스트 인벤토리에 호스트 추가를 참조하십시오.
1.7.8.6. 호스트된 클러스터 생성 확인
배포 프로세스가 완료되면 호스트 클러스터가 성공적으로 생성되었는지 확인할 수 있습니다. 호스팅된 클러스터를 생성한 후 몇 분 후에 다음 단계를 수행합니다.
extract 명령을 입력하여 새 호스팅 클러스터에 대한 kubeconfig를 가져옵니다.
oc extract -n <hosted-cluster-namespace> secret/<hosted-cluster-name>-admin-kubeconfig --to=- > kubeconfig-<hosted-cluster-name>kubeconfig를 사용하여 호스팅된 클러스터의 클러스터 Operator를 확인합니다. 다음 명령을 실행합니다.
oc get co --kubeconfig=kubeconfig-<hosted_cluster_name>다음 예제 출력을 참조하십시오.
NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE MESSAGE console 4.10.26 True False False 2m38s csi-snapshot-controller 4.10.26 True False False 4m3s dns 4.10.26 True False False 2m52s다음 명령을 입력하여 호스팅 클러스터에서 실행 중인 Pod를 볼 수도 있습니다.
oc get pods -A --kubeconfig=kubeconfig-<hosted-cluster-name>다음 예제 출력을 참조하십시오.
NAMESPACE NAME READY STATUS RESTARTS AGE kube-system konnectivity-agent-khlqv 0/1 Running 0 3m52s openshift-cluster-samples-operator cluster-samples-operator-6b5bcb9dff-kpnbc 2/2 Running 0 20m openshift-monitoring alertmanager-main-0 6/6 Running 0 100s openshift-monitoring openshift-state-metrics-677b9fb74f-qqp6g 3/3 Running 0 104s
1.7.8.7. 호스트 클러스터의 NodePool 오브젝트 스케일링
NodePool 오브젝트를 스케일링하여 호스팅 클러스터에 노드를 추가합니다.
NodePool오브젝트를 두 개의 노드로 확장합니다.oc -n <hosted-cluster-namespace> scale nodepool <nodepool-name> --replicas 2Cluster API 에이전트 공급자는 호스트 클러스터에 할당된 두 개의 에이전트를 임의로 선택합니다. 이러한 에이전트는 다른 상태를 통과하고 마지막으로 호스팅된 클러스터에 OpenShift Container Platform 노드로 참여합니다. 에이전트는 다음 순서로 상태를 통과합니다.
-
바인딩 -
검색 -
insufficient -
설치 -
install-in-progress -
add-to-existing-cluster
-
다음 명령을 실행합니다.
oc -n <hosted-control-plane-namespace> get agent다음 예제 출력을 참조하십시오.
NAME CLUSTER APPROVED ROLE STAGE 4dac1ab2-7dd5-4894-a220-6a3473b67ee6 hypercluster1 true auto-assign다음 명령을 실행합니다.
oc -n <hosted-control-plane-namespace> get agent -o jsonpath='{range .items[*]}BMH: {@.metadata.labels.agent-install\.openshift\.io/bmh} Agent: {@.metadata.name} State: {@.status.debugInfo.state}{"\n"}{end}'다음 예제 출력을 참조하십시오.
BMH: ocp-worker-2 Agent: 4dac1ab2-7dd5-4894-a220-6a3473b67ee6 State: binding BMH: ocp-worker-1 Agent: da503cf1-a347-44f2-875c-4960ddb04091 State: insufficientextract 명령을 입력하여 새 호스팅 클러스터에 대한 kubeconfig를 가져옵니다.
oc extract -n <hosted-cluster-namespace> secret/<hosted-cluster-name>-admin-kubeconfig --to=- > kubeconfig-<hosted-cluster-name>에이전트가
add-to-existing-cluster상태에 도달한 후 다음 명령을 입력하여 호스팅된 클러스터에 OpenShift Container Platform 노드를 볼 수 있는지 확인합니다.oc --kubeconfig kubeconfig-<hosted-cluster-name> get nodes다음 예제 출력을 참조하십시오.
NAME STATUS ROLES AGE VERSION ocp-worker-1 Ready worker 5m41s v1.24.0+3882f8f클러스터 Operator는 노드에 워크로드를 추가하여 조정하기 시작합니다.
다음 명령을 입력하여
NodePool오브젝트를 확장할 때 두 개의 머신이 생성되었는지 확인합니다.oc -n <hosted-control-plane-namespace> get machines다음 예제 출력을 참조하십시오.
NAME CLUSTER NODENAME PROVIDERID PHASE AGE VERSION hypercluster1-c96b6f675-m5vch hypercluster1-b2qhl ocp-worker-1 agent://da503cf1-a347-44f2-875c-4960ddb04091 Running 15m 4.13zclusterversion조정 프로세스는 결국 Ingress 및 Console 클러스터 Operator만 누락된 지점에 도달합니다.다음 명령을 실행합니다.
oc --kubeconfig kubeconfig-<hosted-cluster-name> get clusterversion,co다음 예제 출력을 참조하십시오.
NAME VERSION AVAILABLE PROGRESSING SINCE STATUS clusterversion.config.openshift.io/version False True 40m Unable to apply 4.13z: the cluster operator console has not yet successfully rolled out NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE MESSAGE clusteroperator.config.openshift.io/console 4.13z False False False 11m RouteHealthAvailable: failed to GET route (https://console-openshift-console.apps.hypercluster1.domain.com): Get "https://console-openshift-console.apps.hypercluster1.domain.com": dial tcp 10.19.3.29:443: connect: connection refused clusteroperator.config.openshift.io/csi-snapshot-controller 4.13z True False False 10m clusteroperator.config.openshift.io/dns 4.13z True False False 9m16s
1.7.8.7.1. 노드 풀 추가
이름, 복제본 수 및 에이전트 라벨 선택기와 같은 추가 정보를 지정하여 호스팅된 클러스터에 대한 노드 풀을 생성할 수 있습니다.
노드 풀을 생성하려면 다음 정보를 입력합니다.
export NODEPOOL_NAME=${CLUSTER_NAME}-extra-cpu export WORKER_COUNT="2" hcp create nodepool agent \ --cluster-name $CLUSTER_NAME \ --name $NODEPOOL_NAME \ --node-count $WORKER_COUNT \ --agentLabelSelector '{"matchLabels": {"size": "medium"}}'1 - 1
--agentLabelSelector는 선택 사항입니다. 노드 풀은"size" : "medium"라벨이 있는 에이전트를 사용합니다.
cluster 네임스페이스에
nodepool리소스를 나열하여 노드 풀의상태를확인합니다.oc get nodepools --namespace clusters다음 명령을 입력하여
admin-kubeconfig시크릿을 추출합니다.oc extract -n <hosted-cluster-namespace> secret/<hosted-cluster-name>-admin-kubeconfig --to=./hostedcluster-secrets --confirm다음 예제 출력을 참조하십시오.
hostedcluster-secrets/kubeconfig잠시 후 다음 명령을 입력하여 노드 풀의 상태를 확인할 수 있습니다.
oc --kubeconfig ./hostedcluster-secrets get nodes다음 명령을 입력하여 사용 가능한 노드 풀 수가 예상되는 노드 풀 수와 일치하는지 확인합니다.
oc get nodepools --namespace clusters
1.7.8.7.2. 추가 리소스
- 데이터 플레인을 0으로 축소하려면 데이터 플레인을 0으로 축소합니다.
1.7.8.8. 베어 메탈이 아닌 에이전트 머신의 호스트 클러스터에서 수신 처리
모든 OpenShift Container Platform 클러스터에는 일반적으로 연결된 외부 DNS 레코드가 있는 기본 애플리케이션 Ingress 컨트롤러가 있습니다. 예를 들어 기본 도메인 krnl.es 를 사용하여 example 이라는 호스팅 클러스터를 생성하는 경우 와일드카드 도메인 *.apps.example.krnl.es 를 라우팅할 수 있을 것으로 예상할 수 있습니다.
*.apps 도메인의 로드 밸런서 및 와일드카드 DNS 레코드를 설정하려면 게스트 클러스터에서 다음 작업을 수행합니다.
MetalLB Operator의 구성이 포함된 YAML 파일을 생성하여 MetalLB를 배포합니다.
apiVersion: v1 kind: Namespace metadata: name: metallb labels: openshift.io/cluster-monitoring: "true" annotations: workload.openshift.io/allowed: management --- apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: name: metallb-operator-operatorgroup namespace: metallb --- apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: metallb-operator namespace: metallb spec: channel: "stable" name: metallb-operator source: redhat-operators sourceNamespace: openshift-marketplace-
파일을
metallb-operator-config.yaml로 저장합니다. 다음 명령을 입력하여 구성을 적용합니다.
oc apply -f metallb-operator-config.yamlOperator가 실행되면 MetalLB 인스턴스를 생성합니다.
MetalLB 인스턴스의 구성이 포함된 YAML 파일을 생성합니다.
apiVersion: metallb.io/v1beta1 kind: MetalLB metadata: name: metallb namespace: metallb-
파일을
metallb-instance-config.yaml로 저장합니다. - 다음 명령을 입력하여 MetalLB 인스턴스를 생성합니다.
oc apply -f metallb-instance-config.yaml다음 두 리소스를 생성하여 MetalLB Operator를 구성합니다.
-
단일 IP 주소가 있는
IPAddressPool리소스. 이 IP 주소는 클러스터 노드에서 사용하는 네트워크와 동일한 서브넷에 있어야 합니다. 로드 밸런서 IP 주소를
IPAddressPool리소스에서 BGP 프로토콜을 통해 제공하는BGPAdvertisement리소스입니다.- 구성을 포함할 YAML 파일을 생성합니다.
apiVersion: metallb.io/v1beta1 kind: IPAddressPool metadata: name: <ip_address_pool_name>1 namespace: metallb spec: protocol: layer2 autoAssign: false addresses: - <ingress_ip>-<ingress_ip>2 --- apiVersion: metallb.io/v1beta1 kind: BGPAdvertisement metadata: name: <bgp_advertisement_name>3 namespace: metallb spec: ipAddressPools: - <ip_address_pool_name>4 -
단일 IP 주소가 있는
- 1 4
IPAddressPool리소스 이름을 지정합니다.- 2
- 환경의 IP 주소를 지정합니다(예:
192.168.122.23). - 3
BGPAdvertisement리소스 이름을 지정합니다.-
파일을
ipaddresspool-bgpadvertisement-config.yaml로 저장합니다. 다음 명령을 입력하여 리소스를 생성합니다.
oc apply -f ipaddresspool-bgpadvertisement-config.yaml-
LoadBalancer유형의 서비스를 생성한 후 MetalLB는 서비스에 대한 외부 IP 주소를 추가합니다.
-
metallb-loadbalancer-service.yaml이라는 YAML 파일을 생성하여 Ingress 트래픽을 Ingress 배포로 라우팅하는 새 로드 밸런서 서비스를 구성합니다.kind: Service apiVersion: v1 metadata: annotations: metallb.universe.tf/address-pool: ingress-public-ip name: metallb-ingress namespace: openshift-ingress spec: ports: - name: http protocol: TCP port: 80 targetPort: 80 - name: https protocol: TCP port: 443 targetPort: 443 selector: ingresscontroller.operator.openshift.io/deployment-ingresscontroller: default type: LoadBalancer-
파일을
metallb-loadbalancer-service.yaml로 저장합니다. 다음 명령을 입력하여 YAML 구성을 적용합니다.
oc apply -f metallb-loadbalancer-service.yaml다음 명령을 입력하여 OpenShift Container Platform 콘솔에 연결합니다.
curl -kI https://console-openshift-console.apps.example.krnl.es HTTP/1.1 200 OKclusterversion및clusteroperator값을 확인하여 모든 항목이 실행 중인지 확인합니다. 다음 명령을 실행합니다.oc --kubeconfig <hosted_cluster_name>.kubeconfig get clusterversion,co다음 예제 출력을 참조하십시오.
NAME VERSION AVAILABLE PROGRESSING SINCE STATUS clusterversion.config.openshift.io/version 4.x.y True False 3m32s Cluster version is 4.x.y NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE MESSAGE clusteroperator.config.openshift.io/console 4.x.y True False False 3m50s clusteroperator.config.openshift.io/ingress 4.x.y True False False 53m+
4.x.y를 사용하려는 지원되는 OpenShift Container Platform 버전으로 교체합니다(예:4.14.0-x86_64).-
파일을
1.7.8.8.1. 추가 리소스
- MetalLB에 대한 자세한 내용은 OpenShift Container Platform 설명서 의 MetalLB 및 MetalLB Operator 정보를 참조하십시오.
1.7.8.9. 호스트 클러스터의 노드 자동 확장 활성화
호스팅된 클러스터에 용량이 더 필요하고 예비 에이전트를 사용할 수 있는 경우 자동 확장을 활성화하여 새 작업자 노드를 설치할 수 있습니다.
자동 확장을 활성화하려면 다음 명령을 입력합니다. 이 예에서 최소 노드 수는 2이고 최대값은 5입니다. 추가할 수 있는 최대 노드 수는 플랫폼에 바인딩될 수 있습니다. 예를 들어 에이전트 플랫폼을 사용하는 경우 사용 가능한 에이전트 수에 따라 최대 노드 수가 바인딩됩니다.
oc -n <hosted-cluster-namespace> patch nodepool <hosted-cluster-name> --type=json -p '[{"op": "remove", "path": "/spec/replicas"},{"op":"add", "path": "/spec/autoScaling", "value": { "max": 5, "min": 2 }}]'새 노드가 필요한 워크로드를 생성합니다.
다음 예제에서 를 사용하여 워크로드 구성이 포함된 YAML 파일을 생성합니다.
apiVersion: apps/v1 kind: Deployment metadata: creationTimestamp: null labels: app: reversewords name: reversewords namespace: default spec: replicas: 40 selector: matchLabels: app: reversewords strategy: {} template: metadata: creationTimestamp: null labels: app: reversewords spec: containers: - image: quay.io/mavazque/reversewords:latest name: reversewords resources: requests: memory: 2Gi status: {}-
파일을
workload-config.yaml로 저장합니다. - 다음 명령을 입력하여 YAML을 적용합니다.
oc apply -f workload-config.yaml다음 명령을 입력하여
admin-kubeconfig시크릿을 추출합니다.oc extract -n <hosted-cluster-namespace> secret/<hosted-cluster-name>admin-kubeconfig --to=./hostedcluster-secrets --confirm다음 예제 출력을 참조하십시오.
hostedcluster-secrets/kubeconfig다음 명령을 입력하여 새 노드가
Ready상태에 있는지 확인할 수 있습니다.oc --kubeconfig <hosted-cluster-name>.kubeconfig get nodes노드를 제거하려면 다음 명령을 입력하여 워크로드를 삭제합니다.
oc --kubeconfig <hosted-cluster-name>.kubeconfig -n default delete deployment reversewords추가 용량을 요구하지 않고 몇 분 정도 경과할 때까지 기다립니다. 에이전트 플랫폼에서 에이전트는 해제되어 재사용될 수 있습니다. 다음 명령을 입력하여 노드가 제거되었는지 확인할 수 있습니다.
oc --kubeconfig <hosted-cluster-name>.kubeconfig get nodes
1.7.8.9.1. 호스트 클러스터의 노드 자동 확장 비활성화
노드 자동 확장을 비활성화하려면 다음 명령을 입력합니다.
oc -n <hosted-cluster-namespace> patch nodepool <hosted-cluster-name> --type=json -p '[\{"op":"remove", "path": "/spec/autoScaling"}, \{"op": "add", "path": "/spec/replicas", "value": <specify-value-to-scale-replicas>]'
이 명령은 YAML 파일에서 "spec.autoScaling" 을 제거하고 "spec.replicas" 를 추가하고 지정한 정수 값에 "spec.replicas" 를 설정합니다.
1.7.8.10. 베어 메탈이 아닌 에이전트 머신에서 호스트 클러스터 제거
콘솔을 사용하여 베어 메탈이 아닌 호스팅 클러스터를 제거할 수 있습니다. 베어 메탈이 아닌 에이전트 머신에서 호스트된 클러스터를 제거하려면 다음 단계를 완료합니다.
- 콘솔에서 Infrastructure > Clusters 로 이동합니다.
- 클러스터 페이지에서 삭제할 클러스터를 선택합니다.
- 작업 메뉴에서 클러스터 삭제 를 선택하여 클러스터를 제거합니다.
1.7.8.10.1. 명령줄을 사용하여 베어 메탈이 아닌 에이전트 머신에서 호스트 클러스터 제거
호스트 클러스터를 삭제하려면 다음 단계를 완료합니다.
다음 명령을 실행하여 호스팅된 클러스터 및 해당 백엔드 리소스를 삭제합니다.
hcp destroy cluster agent --name <hosted_cluster_name>&
lt;hosted_cluster_name>을 호스트된 클러스터 이름으로 바꿉니다.
기술 프리뷰: IBM Power (ppc64le) 컴퓨팅 노드의 경우 64비트 x86 베어 메탈에서 호스팅 클러스터를 구성하는 것은 제한적으로 지원됩니다.
호스팅 클러스터로 작동하도록 클러스터를 구성하여 호스팅 컨트롤 플레인을 배포할 수 있습니다. 호스팅 클러스터는 컨트롤 플레인이 호스팅되는 OpenShift Container Platform 클러스터입니다. 호스팅 클러스터를 관리 클러스터라고도 합니다.
참고: 관리 클러스터는 관리 클러스터가 아닙니다. 관리형 클러스터는 hub 클러스터가 관리하는 클러스터입니다.
다중 클러스터 엔진 Operator 2.5는 관리하는 허브 클러스터인 기본 로컬 클러스터와 허브 클러스터를 호스팅 클러스터로만 지원합니다.
중요:
- 베어 메탈에서 호스팅되는 컨트롤 플레인을 프로비저닝하려면 에이전트 플랫폼을 사용할 수 있습니다. 에이전트 플랫폼은 중앙 인프라 관리 서비스를 사용하여 호스트된 클러스터에 작업자 노드를 추가합니다. 중앙 인프라 관리 서비스에 대한 도입은 호스트 인벤토리 생성을 참조하십시오.
- 각 IBM Power 시스템 호스트는 중앙 인프라 관리에서 제공하는 검색 이미지를 사용하여 시작해야 합니다. 각 호스트가 시작되면 에이전트 프로세스를 실행하여 호스트의 세부 정보를 검색하고 설치를 완료합니다. 에이전트 사용자 정의 리소스는 각 호스트를 나타냅니다.
- 에이전트 플랫폼으로 호스팅된 클러스터를 생성하면 HyperShift가 호스팅된 컨트롤 플레인 네임스페이스에 에이전트 클러스터 API 공급자를 설치합니다.
- 노드 풀을 확장하면 머신이 생성됩니다. Cluster API 공급자는 승인된 에이전트를 찾고 현재 검증이 사용되지 않으며, 노드 풀 사양에 지정된 요구 사항을 충족합니다. 에이전트의 상태 및 조건을 확인하여 에이전트 설치를 모니터링할 수 있습니다.
- 노드 풀을 축소하면 에이전트가 해당 클러스터에서 바인딩되지 않습니다. 클러스터를 재사용하려면 먼저 검색 이미지를 사용하여 노드 수를 업데이트하여 클러스터를 다시 시작해야 합니다.
1.7.9.1. 사전 요구 사항
호스팅 클러스터를 구성하려면 다음 사전 요구 사항이 있어야 합니다.
- Kubernetes Operator 2.5 이상용 다중 클러스터 엔진이 OpenShift Container Platform 클러스터에 설치되어 있어야 합니다. Red Hat Advanced Cluster Management를 설치할 때 다중 클러스터 엔진 Operator가 자동으로 설치됩니다. Red Hat Advanced Cluster Management 없이 OpenShift Container Platform OperatorHub의 Operator로 다중 클러스터 엔진 Operator를 설치할 수도 있습니다.
다중 클러스터 엔진 Operator에는 하나 이상의 관리형 OpenShift Container Platform 클러스터가 있어야 합니다.
로컬 클러스터는 멀티 클러스터 엔진 Operator 2.5 이상에서 자동으로 가져옵니다.local-cluster에 대한 자세한 내용은 고급 구성 을 참조하십시오. 다음 명령을 실행하여 허브 클러스터의 상태를 확인할 수 있습니다.oc get managedclusters local-cluster- HyperShift Operator를 실행하려면 작업자 노드가 3개 이상인 호스팅 클러스터가 필요합니다.
- 중앙 인프라 관리 서비스를 활성화해야 합니다. 자세한 내용은 중앙 인프라 관리 서비스 활성화를 참조하십시오.
- 호스팅된 컨트롤 플레인 명령줄 인터페이스를 설치해야 합니다. 호스팅된 컨트롤 플레인 명령줄 인터페이스 설치를 참조하십시오.
1.7.9.2. IBM Power 인프라 요구사항
에이전트 플랫폼은 인프라를 생성하지 않지만 인프라에는 다음이 필요합니다.
- 에이전트: 에이전트 는 검색 이미지로 부팅되고 OpenShift Container Platform 노드로 프로비저닝할 준비가 된 호스트를 나타냅니다.
- DNS: API 및 수신 끝점은 라우팅할 수 있어야 합니다.
1.7.9.3. IBM Power 구성 문서
사전 요구 사항을 충족한 후 베어 메탈에서 호스팅된 컨트롤 플레인을 구성하려면 다음 주제를 참조하십시오.
1.7.9.4. InfraEnv 리소스에 에이전트 추가
라이브 ISO로 시작하도록 시스템을 수동으로 구성하여 에이전트를 추가할 수 있습니다.
-
라이브 ISO를 다운로드하여 호스트를 시작하는 데 사용합니다(베어 메탈 또는 VM). 라이브 ISO의 URL은
InfraEnv리소스에서status.isoDownloadURL필드에 있습니다. 시작 시 호스트는 지원 서비스와 통신하고InfraEnv리소스와 동일한 네임스페이스에 에이전트로 등록합니다. 에이전트 및 일부 속성을 나열하려면 다음 명령을 입력합니다.
oc -n <hosted-control-plane-namespace> get agents다음 예제 출력을 참조하십시오.
NAME CLUSTER APPROVED ROLE STAGE 86f7ac75-4fc4-4b36-8130-40fa12602218 auto-assign e57a637f-745b-496e-971d-1abbf03341ba auto-assign각 에이전트가 생성되면 선택적으로 사양에
installation_disk_id및hostname을 설정하고 다음 명령을 입력하여 에이전트를 승인할 수 있습니다.oc -n <hosted-control-plane-namespace> patch agent 86f7ac75-4fc4-4b36-8130-40fa12602218 -p '{"spec":{"installation_disk_id":"/dev/sda","approved":true,"hostname":"worker-0.example.krnl.es"}}' --type merge oc -n <hosted-control-plane-namespace> patch agent 23d0c614-2caa-43f5-b7d3-0b3564688baa -p '{"spec":{"installation_disk_id":"/dev/sda","approved":true,"hostname":"worker-1.example.krnl.es"}}' --type merge에이전트가 사용되도록 승인되었는지 확인하려면 다음 명령을 입력하고 출력을 확인합니다.
oc -n <hosted-control-plane-namespace> get agents다음 예제 출력을 참조하십시오.
NAME CLUSTER APPROVED ROLE STAGE 86f7ac75-4fc4-4b36-8130-40fa12602218 true auto-assign e57a637f-745b-496e-971d-1abbf03341ba true auto-assign
1.7.9.5. IBM Power에서 호스팅된 컨트롤 플레인을 위한 DNS 구성
호스팅된 클러스터의 API 서버가 노출됩니다. API 서버에 연결할 수 있는 대상을 가리키는 api.<hosted-cluster-name>.<base-domain > 항목에 대한 DNS 항목이 있어야 합니다.
DNS 항목은 호스팅된 컨트롤 플레인을 실행하는 관리형 클러스터의 노드 중 하나를 가리키는 레코드만큼 단순할 수 있습니다.
이 항목은 들어오는 트래픽을 인그레스 포드로 리디렉션하기 위해 배포된 로드 밸런서를 가리킬 수도 있습니다.
다음 DNS 구성 예제를 참조하십시오.
$ cat /var/named/<example.krnl.es.zone>다음 예제 출력을 참조하십시오.
$ TTL 900
@ IN SOA bastion.example.krnl.es.com. hostmaster.example.krnl.es.com. (
2019062002
1D 1H 1W 3H )
IN NS bastion.example.krnl.es.com.
;
;
api IN A 1xx.2x.2xx.1xx
api-int IN A 1xx.2x.2xx.1xx
;
;
*.apps.<hosted-cluster-name>.<basedomain> IN A 1xx.2x.2xx.1xx
;
;EOF- 1
- 레코드는 호스팅된 컨트롤 플레인의 수신 및 송신 트래픽을 처리하는 API 로드 밸런서의 IP 주소를 나타냅니다.
IBM Power의 경우 에이전트의 IP 주소에 해당하는 IP 주소를 추가합니다.
compute-0 IN A 1xx.2x.2xx.1yy
compute-1 IN A 1xx.2x.2xx.1yy1.7.9.6. IBM Power 컴퓨팅 노드의 64비트 x86 베어 메탈에서 호스팅된 컨트롤 플레인에 대한 InfraEnv 리소스 생성
InfraEnv 는 라이브 ISO를 시작하는 호스트가 에이전트로 참여할 수 있는 환경입니다. 이 경우 에이전트는 호스팅된 컨트롤 플레인과 동일한 네임스페이스에 생성됩니다.
InfraEnv 리소스를 생성하려면 다음 단계를 완료합니다.
구성을 포함할 YAML 파일을 생성합니다. 다음 예제를 참조하십시오.
apiVersion: agent-install.openshift.io/v1beta1 kind: InfraEnv metadata: name: <hosted-cluster-name> namespace: <hosted-control-plane-namespace> spec: cpuArchitecture: ppc64le pullSecretRef: name: pull-secret sshAuthorizedKey: <ssh-public-key>-
파일을
infraenv-config.yaml로 저장합니다. 다음 명령을 입력하여 구성을 적용합니다.
oc apply -f infraenv-config.yamlIBM Power 머신이 에이전트로 결합할 수 있는 라이브 ISO를 다운로드하는 URL을 가져오려면 다음 명령을 입력합니다.
oc -n <hosted-control-plane-namespace> get InfraEnv <hosted-cluster-name> -o json
1.7.9.7. IBM Power에서 호스팅된 클러스터의 NodePool 오브젝트 확장
NodePool 오브젝트는 호스팅된 클러스터를 생성할 때 생성됩니다. NodePool 오브젝트를 스케일링하면 호스팅된 컨트롤 플레인에 더 많은 컴퓨팅 노드를 추가할 수 있습니다.
다음 명령을 실행하여
NodePool오브젝트를 두 개의 노드로 확장합니다.oc -n <clusters_namespace> scale nodepool <nodepool_name> --replicas 2Cluster API 에이전트 공급자는 호스트 클러스터에 할당된 두 개의 에이전트를 임의로 선택합니다. 이러한 에이전트는 다른 상태를 통과하고 마지막으로 호스팅된 클러스터에 OpenShift Container Platform 노드로 참여합니다. 에이전트는 다음 순서로 전환 단계를 통과합니다.
-
바인딩 -
검색 -
insufficient -
설치 -
install-in-progress -
add-to-existing-cluster
-
다음 명령을 실행하여 특정 확장 에이전트의 상태를 확인합니다.
oc -n <hosted_control_plane_namespace> get agent -o jsonpath='{range .items[*]}BMH: {@.metadata.labels.agent-install\.openshift\.io/bmh} Agent: {@.metadata.name} State: {@.status.debugInfo.state}{"\n"}{end}'다음 출력을 참조하십시오.
BMH: Agent: 50c23cda-cedc-9bbd-bcf1-9b3a5c75804d State: known-unbound BMH: Agent: 5e498cd3-542c-e54f-0c58-ed43e28b568a State: insufficient다음 명령을 실행하여 전환 단계를 확인합니다.
oc -n <hosted_control_plane_namespace> get agent다음 출력을 참조하십시오.
NAME CLUSTER APPROVED ROLE STAGE 50c23cda-cedc-9bbd-bcf1-9b3a5c75804d hosted-forwarder true auto-assign 5e498cd3-542c-e54f-0c58-ed43e28b568a true auto-assign da503cf1-a347-44f2-875c-4960ddb04091 hosted-forwarder true auto-assign다음 명령을 실행하여 호스팅된 클러스터에 액세스할
kubeconfig파일을 생성합니다.hcp create kubeconfig --namespace <clusters_namespace> --name <hosted_cluster_namespace> > <hosted_cluster_name>.kubeconfig에이전트가
add-to-existing-cluster상태에 도달한 후 다음 명령을 입력하여 OpenShift Container Platform 노드를 볼 수 있는지 확인합니다.oc --kubeconfig <hosted_cluster_name>.kubeconfig get nodes다음 출력을 참조하십시오.
NAME STATUS ROLES AGE VERSION worker-zvm-0.hostedn.example.com Ready worker 5m41s v1.24.0+3882f8f worker-zvm-1.hostedn.example.com Ready worker 6m3s v1.24.0+3882f8f다음 명령을 입력하여
NodePool오브젝트를 확장할 때 두 개의 머신이 생성되었는지 확인합니다.oc -n <hosted_control_plane_namespace> get machine.cluster.x-k8s.io다음 출력을 참조하십시오.
NAME CLUSTER NODENAME PROVIDERID PHASE AGE VERSION hosted-forwarder-79558597ff-5tbqp hosted-forwarder-crqq5 worker-zvm-0.hostedn.example.com agent://50c23cda-cedc-9bbd-bcf1-9b3a5c75804d Running 41h 4.15.0 hosted-forwarder-79558597ff-lfjfk hosted-forwarder-crqq5 worker-zvm-1.hostedn.example.com agent://5e498cd3-542c-e54f-0c58-ed43e28b568a Running 41h 4.15.0다음 명령을 실행하여 클러스터 버전 및 클러스터 Operator 상태를 확인합니다.
oc --kubeconfig <hosted_cluster_name>.kubeconfig get clusterversion다음 출력을 참조하십시오.
NAME VERSION AVAILABLE PROGRESSING SINCE STATUS clusterversion.config.openshift.io/version 4.15.0 True False 40h Cluster version is 4.15.0다음 명령을 실행하여 클러스터 Operator 상태를 확인합니다.
oc --kubeconfig <hosted_cluster_name>.kubeconfig get clusteroperators
클러스터의 각 구성 요소에 대해 출력에는 NAME,VERSION,AVAILABLE,PROGRESSING,DEGRADED,SINCE, MESSAGE.
출력 예제는 OpenShift Container Platform 설명서의 Initial Operator 구성 섹션을 참조하십시오.
1.7.9.7.1. 추가 리소스
- 데이터 플레인을 0으로 축소하려면 데이터 플레인을 0으로 축소합니다.
1.7.10. IBM Z 컴퓨팅 노드의 x86 베어 메탈에서 호스팅 클러스터 구성 (기술 프리뷰)
기술 프리뷰: IBM Z(s390x) 컴퓨팅 노드의 x86 베어 메탈에서 호스팅 클러스터를 구성하는 것은 제한된 지원이 포함된 기술 프리뷰 상태에 있습니다.
호스팅 클러스터로 작동하도록 클러스터를 구성하여 호스팅 컨트롤 플레인을 배포할 수 있습니다. 호스팅 클러스터는 컨트롤 플레인이 호스팅되는 OpenShift Container Platform 클러스터입니다. 호스팅 클러스터를 관리 클러스터라고도 합니다.
참고: 관리 클러스터는 관리 클러스터가 아닙니다. 관리형 클러스터는 hub 클러스터가 관리하는 클러스터입니다.
hypershift 애드온을 사용하여 해당 클러스터에 HyperShift Operator를 배포하여 관리 클러스터를 호스팅 클러스터로 변환할 수 있습니다. 그런 다음 호스팅된 클러스터를 생성할 수 있습니다.
다중 클러스터 엔진 Operator 2.5는 관리하는 허브 클러스터인 기본 로컬 클러스터와 허브 클러스터를 호스팅 클러스터로만 지원합니다.
중요:
- 베어 메탈에서 호스팅되는 컨트롤 플레인을 프로비저닝하려면 에이전트 플랫폼을 사용할 수 있습니다. 에이전트 플랫폼은 중앙 인프라 관리 서비스를 사용하여 호스트된 클러스터에 작업자 노드를 추가합니다. 중앙 인프라 관리 서비스에 대한 소개는 Kube API - 시작하기 가이드를 참조하십시오.
- 각 IBM Z 시스템 호스트는 중앙 인프라 관리에서 제공하는 PXE 이미지로 시작해야 합니다. 각 호스트가 시작되면 에이전트 프로세스를 실행하여 호스트의 세부 정보를 검색하고 설치를 완료합니다. 에이전트 사용자 정의 리소스는 각 호스트를 나타냅니다.
- 에이전트 플랫폼을 사용하여 호스팅된 클러스터를 생성하면 HyperShift Operator가 호스팅된 컨트롤 플레인 네임스페이스에 에이전트 클러스터 API 공급자를 설치합니다.
- 노드 풀을 확장하면 머신이 생성됩니다. Cluster API 공급자는 승인된 에이전트를 찾고 현재 검증이 사용되지 않으며, 노드 풀 사양에 지정된 요구 사항을 충족합니다. 에이전트의 상태 및 조건을 확인하여 에이전트 설치를 모니터링할 수 있습니다.
- 노드 풀을 축소하면 에이전트가 해당 클러스터에서 바인딩되지 않습니다. 클러스터를 재사용하기 전에 PXE 이미지를 사용하여 노드 수를 업데이트하여 클러스터를 부팅해야 합니다.
1.7.10.1. 사전 요구 사항
- Kubernetes Operator 버전 2.5 이상용 다중 클러스터 엔진은 OpenShift Container Platform 클러스터에 설치해야 합니다. Red Hat Advanced Cluster Management를 설치할 때 다중 클러스터 엔진 Operator가 자동으로 설치됩니다. Red Hat Advanced Cluster Management 없이 OpenShift Container Platform OperatorHub의 Operator로 다중 클러스터 엔진 Operator를 설치할 수도 있습니다.
다중 클러스터 엔진 Operator에는 하나 이상의 관리형 OpenShift Container Platform 클러스터가 있어야 합니다.
로컬 클러스터는 멀티 클러스터 엔진 Operator 2.5 이상에서 자동으로 가져옵니다.local-cluster에 대한 자세한 내용은 고급 구성 을 참조하십시오. 다음 명령을 실행하여 허브 클러스터의 상태를 확인할 수 있습니다.oc get managedclusters local-cluster- HyperShift Operator를 실행하려면 작업자 노드가 3개 이상 있는 호스팅 클러스터가 필요합니다.
- 중앙 인프라 관리 서비스를 활성화해야 합니다. 자세한 내용은 중앙 인프라 관리 서비스 활성화를 참조하십시오.
- 호스팅된 컨트롤 플레인 명령줄 인터페이스를 설치해야 합니다. 호스팅된 컨트롤 플레인 명령줄 인터페이스 설치를 참조하십시오.
1.7.10.2. IBM Z 인프라 요구사항
에이전트 플랫폼은 인프라를 생성하지 않지만 인프라에는 다음이 필요합니다.
- 에이전트: 에이전트 는 검색 이미지 또는 PXE 이미지로 부팅되고 OpenShift Container Platform 노드로 프로비저닝할 준비가 된 호스트를 나타냅니다.
- DNS: API 및 Ingress 끝점은 라우팅할 수 있어야 합니다.
호스트된 컨트롤 플레인 기능은 기본적으로 활성화되어 있습니다. 기능을 비활성화하고 수동으로 활성화하거나 기능을 비활성화해야 하는 경우 호스팅된 컨트롤 플레인 기능 활성화 또는 비활성화를 참조하십시오.
1.7.10.3. IBM Z 구성 문서
사전 요구 사항을 충족한 후 베어 메탈에서 호스팅된 컨트롤 플레인을 구성하려면 다음 주제를 참조하십시오.
1.7.10.4. InfraEnv 리소스에 IBM Z 에이전트 추가 (기술 프리뷰)
IBM Z 환경에 에이전트를 추가하려면 이 섹션에 자세히 설명된 추가 단계가 필요합니다.
참고: 달리 명시되지 않는 한, 다음 절차는 IBM Z 및 IBM LinuxONE의 z/VM 및 RHEL KVM 설치에 모두 적용됩니다.
1.7.10.4.1. KVM을 사용하여 IBM Z용 에이전트 추가
IBM Z with KVM의 경우 다음 명령을 실행하여 InfraEnv 리소스에서 다운로드한 PXE 이미지로 IBM Z 환경을 시작합니다. 에이전트가 생성되면 호스트는 지원 서비스와 통신하고 관리 클러스터의 InfraEnv 리소스와 동일한 네임스페이스에 등록합니다.
virt-install \
--name "<vm_name>" \
--autostart \
--ram=16384 \
--cpu host \
--vcpus=4 \
--location "<path_to_kernel_initrd_image>,kernel=kernel.img,initrd=initrd.img" \
--disk <qcow_image_path> \
--network network:macvtap-net,mac=<mac_address> \
--graphics none \
--noautoconsole \
--wait=-1 \
--extra-args "rd.neednet=1 nameserver=<nameserver> coreos.live.rootfs_url=http://<http_server>/rootfs.img random.trust_cpu=on rd.luks.options=discard ignition.firstboot ignition.platform.id=metal console=tty1 console=ttyS1,115200n8 coreos.inst.persistent-kargs=console=tty1 console=ttyS1,115200n8"
ISO 부팅의 경우 InfraEnv 리소스에서 ISO를 다운로드하고 다음 명령을 실행하여 노드를 부팅합니다.
virt-install \
--name "<vm_name>" \
--autostart \
--memory=16384 \
--cpu host \
--vcpus=4 \
--network network:macvtap-net,mac=<mac_address> \
--cdrom "<path_to_image.iso>" \
--disk <qcow_image_path> \
--graphics none \
--noautoconsole \
--os-variant <os_version> \
--wait=-1 \1.7.10.4.2. z/VM을 사용하여 IBM용 에이전트 추가
참고: z/VM 게스트에 고정 IP를 사용하려면 두 번째 부팅 시 IP 매개 변수가 유지되도록 z/VM 에이전트에 대한 NMStateConfig 특성을 구성해야 합니다.
InfraEnv 리소스에서 다운로드한 PXE 이미지로 IBM Z 환경을 시작하려면 다음 단계를 완료합니다. 에이전트가 생성되면 호스트는 지원 서비스와 통신하고 관리 클러스터의 InfraEnv 리소스와 동일한 네임스페이스에 등록합니다.
매개 변수 파일을 업데이트하여
rootfs_url,network_adaptor및disk_type값을 추가합니다.다음 예제 매개변수 파일을 참조하십시오.
rd.neednet=1 \ console=ttysclp0 \ coreos.live.rootfs_url=<rootfs_url> \ ip=<IP_guest_vm>::<nameserver>:255.255.255.0::<network_adaptor>:none \ nameserver=<nameserver> \ zfcp.allow_lun_scan=0 \1 rd.znet=qeth,<network_adaptor_range>,layer2=1 \ rd.<disk_type>=<storage> random.trust_cpu=on \2 rd.luks.options=discard \ ignition.firstboot ignition.platform.id=metal \ console=tty1 console=ttyS1,115200n8 \ coreos.inst.persistent-kargs="console=tty1 console=ttyS1,115200n8다음 명령을 실행하여
initrd, 커널 이미지 및 매개변수 파일을 게스트 VM으로 이동합니다.vmur pun -r -u -N kernel.img $INSTALLERKERNELLOCATION/<image name>vmur pun -r -u -N generic.parm $PARMFILELOCATION/paramfilenamevmur pun -r -u -N initrd.img $INSTALLERINITRAMFSLOCATION/<image name>게스트 VM 콘솔에서 다음 명령을 실행합니다.
cp ipl c에이전트 및 해당 속성을 나열하려면 다음 명령을 입력합니다.
oc -n <hosted_control_plane_namespace> get agents다음 예제 출력을 참조하십시오.
NAME CLUSTER APPROVED ROLE STAGE 50c23cda-cedc-9bbd-bcf1-9b3a5c75804d auto-assign 5e498cd3-542c-e54f-0c58-ed43e28b568a auto-assign다음 명령을 실행하여 에이전트를 승인합니다. 선택 사항: 사양에서 에이전트 ID <
installation_disk_id> 및 <hostname>을 설정할 수 있습니다.oc -n <hosted_control_plane_namespace> patch agent 50c23cda-cedc-9bbd-bcf1-9b3a5c75804d -p '{"spec":{"installation_disk_id":"/dev/sda","approved":true,"hostname":"worker-zvm-0.hostedn.example.com"}}' --type merge다음 명령을 실행하여 에이전트가 승인되었는지 확인합니다.
oc -n <hosted_control_plane_namespace> get agents다음 예제 출력을 참조하십시오.
NAME CLUSTER APPROVED ROLE STAGE 50c23cda-cedc-9bbd-bcf1-9b3a5c75804d true auto-assign 5e498cd3-542c-e54f-0c58-ed43e28b568a true auto-assign
1.7.10.5. IBM Z를 사용하여 호스팅된 컨트롤 플레인의 DNS 구성
호스팅된 클러스터의 API 서버는 'NodePort' 서비스로 노출됩니다. API 서버에 연결할 수 있는 대상을 가리키는 api.<hosted-cluster-name>.<base-domain >에 대한 DNS 항목이 있어야 합니다.
DNS 항목은 호스팅된 컨트롤 플레인을 실행하는 관리형 클러스터의 노드 중 하나를 가리키는 레코드만큼 단순할 수 있습니다.
이 항목은 들어오는 트래픽을 Ingress Pod로 리디렉션하기 위해 배포된 로드 밸런서를 가리킬 수도 있습니다.
다음 DNS 구성 예제를 참조하십시오.
$ cat /var/named/<example.krnl.es.zone>다음 예제 출력을 참조하십시오.
$ TTL 900
@ IN SOA bastion.example.krnl.es.com. hostmaster.example.krnl.es.com. (
2019062002
1D 1H 1W 3H )
IN NS bastion.example.krnl.es.com.
;
;
api IN A 1xx.2x.2xx.1xx
api-int IN A 1xx.2x.2xx.1xx
;
;
*.apps IN A 1xx.2x.2xx.1xx
;
;EOF- 1
- 레코드는 호스팅된 컨트롤 플레인의 수신 및 송신 트래픽을 처리하는 API 로드 밸런서의 IP 주소를 나타냅니다.
IBM z/VM의 경우 에이전트의 IP 주소에 해당하는 IP 주소를 추가합니다.
compute-0 IN A 1xx.2x.2xx.1yy
compute-1 IN A 1xx.2x.2xx.1yy1.7.10.6. IBM Z 컴퓨팅 노드의 x86 베어 메탈에서 호스팅된 컨트롤 플레인에 대한 InfraEnv 리소스 생성
InfraEnv 는 PXE 이미지로 부팅되는 호스트가 에이전트로 참여할 수 있는 환경입니다. 이 경우 에이전트는 호스팅된 컨트롤 플레인과 동일한 네임스페이스에 생성됩니다.
InfraEnv 리소스를 생성하려면 다음 절차를 참조하십시오.
구성을 포함할 YAML 파일을 생성합니다. 다음 예제를 참조하십시오.
apiVersion: agent-install.openshift.io/v1beta1 kind: InfraEnv metadata: name: <hosted-cluster-name> namespace: <hosted-control-plane-namespace> spec: cpuArchitecture: s390x pullSecretRef: name: pull-secret sshAuthorizedKey: <ssh-public-key>-
파일을
infraenv-config.yaml로 저장합니다. 다음 명령을 입력하여 구성을 적용합니다.
oc apply -f infraenv-config.yamlIBM Z 머신이 에이전트로 결합할 수 있는
initrd.img,kernel.img,rootfs.img와 같은 PXE 이미지를 다운로드하여 URL을 가져오려면 다음 명령을 입력합니다.oc -n <hosted-control-plane-namespace> get InfraEnv <hosted-cluster-name> -o json
1.7.10.7. IBM Z에서 호스팅된 클러스터의 NodePool 오브젝트 확장
NodePool 오브젝트는 호스팅된 클러스터를 생성할 때 생성됩니다. NodePool 오브젝트를 스케일링하면 호스팅된 컨트롤 플레인에 더 많은 컴퓨팅 노드를 추가할 수 있습니다.
다음 명령을 실행하여
NodePool오브젝트를 두 개의 노드로 확장합니다.oc -n <clusters_namespace> scale nodepool <nodepool_name> --replicas 2Cluster API 에이전트 공급자는 호스트 클러스터에 할당된 두 개의 에이전트를 임의로 선택합니다. 이러한 에이전트는 다른 상태를 통과하고 마지막으로 호스팅된 클러스터에 OpenShift Container Platform 노드로 참여합니다. 에이전트는 다음 순서로 전환 단계를 통과합니다.
-
바인딩 -
검색 -
insufficient -
설치 -
install-in-progress -
add-to-existing-cluster
-
다음 명령을 실행하여 특정 확장 에이전트의 상태를 확인합니다.
oc -n <hosted_control_plane_namespace> get agent -o jsonpath='{range .items[*]}BMH: {@.metadata.labels.agent-install\.openshift\.io/bmh} Agent: {@.metadata.name} State: {@.status.debugInfo.state}{"\n"}{end}'다음 출력을 참조하십시오.
BMH: Agent: 50c23cda-cedc-9bbd-bcf1-9b3a5c75804d State: known-unbound BMH: Agent: 5e498cd3-542c-e54f-0c58-ed43e28b568a State: insufficient다음 명령을 실행하여 전환 단계를 확인합니다.
oc -n <hosted_control_plane_namespace> get agent다음 출력을 참조하십시오.
NAME CLUSTER APPROVED ROLE STAGE 50c23cda-cedc-9bbd-bcf1-9b3a5c75804d hosted-forwarder true auto-assign 5e498cd3-542c-e54f-0c58-ed43e28b568a true auto-assign da503cf1-a347-44f2-875c-4960ddb04091 hosted-forwarder true auto-assign다음 명령을 실행하여 호스팅된 클러스터에 액세스할
kubeconfig파일을 생성합니다.hcp create kubeconfig --namespace <clusters_namespace> --name <hosted_cluster_namespace> > <hosted_cluster_name>.kubeconfig에이전트가
add-to-existing-cluster상태에 도달한 후 다음 명령을 입력하여 OpenShift Container Platform 노드를 볼 수 있는지 확인합니다.oc --kubeconfig <hosted_cluster_name>.kubeconfig get nodes다음 출력을 참조하십시오.
NAME STATUS ROLES AGE VERSION worker-zvm-0.hostedn.example.com Ready worker 5m41s v1.24.0+3882f8f worker-zvm-1.hostedn.example.com Ready worker 6m3s v1.24.0+3882f8f클러스터 Operator는 노드에 워크로드를 추가하여 조정하기 시작합니다.
다음 명령을 입력하여
NodePool오브젝트를 확장할 때 두 개의 머신이 생성되었는지 확인합니다.oc -n <hosted_control_plane_namespace> get machine.cluster.x-k8s.io다음 출력을 참조하십시오.
NAME CLUSTER NODENAME PROVIDERID PHASE AGE VERSION hosted-forwarder-79558597ff-5tbqp hosted-forwarder-crqq5 worker-zvm-0.hostedn.example.com agent://50c23cda-cedc-9bbd-bcf1-9b3a5c75804d Running 41h 4.15.0 hosted-forwarder-79558597ff-lfjfk hosted-forwarder-crqq5 worker-zvm-1.hostedn.example.com agent://5e498cd3-542c-e54f-0c58-ed43e28b568a Running 41h 4.15.0다음 명령을 실행하여 클러스터 버전을 확인합니다.
oc --kubeconfig <hosted_cluster_name>.kubeconfig get clusterversion,co다음 출력을 참조하십시오.
NAME VERSION AVAILABLE PROGRESSING SINCE STATUS clusterversion.config.openshift.io/version 4.15.0-ec.2 True False 40h Cluster version is 4.15.0-ec.2다음 명령을 실행하여 클러스터 Operator 상태를 확인합니다.
oc --kubeconfig <hosted_cluster_name>.kubeconfig get clusteroperators
클러스터의 각 구성 요소에 대해 출력에는 NAME,VERSION,AVAILABLE,PROGRESSING,DEGRADED,SINCE, MESSAGE.
출력 예제는 OpenShift Container Platform 설명서의 Initial Operator 구성 섹션을 참조하십시오.
1.7.10.7.1. 추가 리소스
- 데이터 플레인을 0으로 축소하려면 데이터 플레인을 0으로 축소합니다.
1.7.11. OpenShift Virtualization에서 호스트된 컨트롤 플레인 클러스터 관리
호스팅된 컨트롤 플레인 및 Red Hat OpenShift Virtualization을 사용하면 KubeVirt 가상 머신에서 호스팅하는 작업자 노드로 OpenShift Container Platform 클러스터를 생성할 수 있습니다. OpenShift Virtualization에서 호스팅되는 컨트롤 플레인은 다음과 같은 몇 가지 이점을 제공합니다.
- 동일한 기본 베어 메탈 인프라에서 호스트된 컨트롤 플레인 및 호스팅된 클러스터를 패키징하여 리소스 사용량 개선
- 강력한 격리를 제공하기 위해 호스팅되는 컨트롤 플레인과 호스팅 클러스터를 분리
- 베어 메탈 노드 부트스트랩 프로세스를 제거하여 클러스터 프로비저닝 시간 단축
- 동일한 기본 OpenShift Container Platform 클러스터에서 많은 릴리스 관리
호스트된 컨트롤 플레인 기능은 기본적으로 활성화되어 있습니다.
호스팅된 컨트롤 플레인 명령줄 인터페이스 hcp 를 사용하여 OpenShift Container Platform 호스팅 클러스터를 생성할 수 있습니다. 호스팅된 클러스터는 관리 클러스터로 자동으로 가져옵니다. 이 자동 가져오기 기능을 비활성화하려면 호스팅된 클러스터를 멀티 클러스터 엔진 Operator로 자동 가져오기 비활성화 를 참조하십시오.
중요:
- 호스팅된 컨트롤 플레인의 동일한 플랫폼에서 허브 클러스터 및 작업자를 실행합니다.
- 각 호스트 클러스터에는 클러스터 전체 이름이 있어야 합니다. 호스트된 클러스터 이름은 다중 클러스터 엔진 운영자가 이를 관리하기 위해 기존 관리 클러스터와 같을 수 없습니다.
-
클러스터를 호스팅
클러스터이름으로 사용하지 마십시오. - 호스트된 클러스터는 다중 클러스터 엔진 Operator 관리 클러스터의 네임스페이스에서 생성할 수 없습니다.
- 호스트된 컨트롤 플레인에 대한 스토리지를 구성할 때 권장 etcd 사례를 고려하십시오. 대기 시간 요구 사항을 충족하는지 확인하려면 각 컨트롤 플레인 노드에서 실행되는 모든 호스팅 컨트롤 플레인 etcd 인스턴스에 빠른 스토리지 장치를 전용으로 지정합니다. LVM 스토리지를 사용하여 호스팅된 etcd pod의 로컬 스토리지 클래스를 구성할 수 있습니다. 자세한 내용은 OpenShift Container Platform 설명서의 논리 볼륨 관리자 스토리지를 사용하여 etcd 권장 사례 및 영구 스토리지를 참조하십시오.
1.7.11.1. 사전 요구 사항
OpenShift Virtualization에서 OpenShift Container Platform 클러스터를 생성하려면 다음 사전 요구 사항을 충족해야 합니다.
-
KUBECONFIG환경 변수에 지정된 OpenShift Container Platform 클러스터 버전 4.14 이상에 대한 관리자 액세스 권한이 필요합니다. OpenShift Container Platform 호스팅 클러스터에는 다음 DNS에 표시된 대로 와일드카드 DNS 경로가 활성화되어 있어야 합니다.
oc patch ingresscontroller -n openshift-ingress-operator default --type=json -p '[{ "op": "add", "path": "/spec/routeAdmission", "value": {wildcardPolicy: "WildcardsAllowed"}}]'- OpenShift Container Platform 호스팅 클러스터에는 OpenShift Virtualization, 버전 4.14 이상이 설치되어 있어야 합니다. 자세한 내용은 웹 콘솔을 사용하여 OpenShift Virtualization 설치를 참조하십시오.
- OpenShift Container Platform 호스팅 클러스터는 OVNKubernetes를 기본 Pod 네트워크 CNI로 구성해야합니다.
OpenShift Container Platform 호스팅 클러스터에는 기본 스토리지 클래스가 있어야 합니다. 자세한 내용은 설치 후 스토리지 구성 을 참조하십시오. 다음 예제에서는 기본 스토리지 클래스를 설정하는 방법을 보여줍니다.
oc patch storageclass ocs-storagecluster-ceph-rbd -p '{"metadata": {"annotations":{"storageclass.kubernetes.io/is-default-class":"true"}}}'-
quay.io/openshift-release-dev리포지토리에 유효한 풀 시크릿 파일이 필요합니다. 자세한 내용은 사용자 프로비저닝 인프라가 있는 모든 x86_64 플랫폼에 OpenShift 설치를 참조하십시오. - 호스팅된 컨트롤 플레인 명령줄 인터페이스를 설치해야 합니다.
- 클러스터를 프로비저닝하려면 먼저 로드 밸런서를 구성해야 합니다. 자세한 내용은 선택 사항: MetalLB 구성을 참조하십시오.
- 최적의 네트워크 성능을 위해서는 KubeVirt 가상 머신을 호스팅하는 OpenShift Container Platform 클러스터에서 네트워크 최대 전송 단위(MTU)를 9000 이상으로 사용하십시오. 더 낮은 MTU 설정을 사용하는 경우 호스트된 Pod의 네트워크 대기 시간과 처리량이 영향을 받습니다. MTU가 9000 이상인 경우에만 노드 풀에서 멀티 큐를 활성화합니다.
다중 클러스터 엔진 Operator에는 하나 이상의 관리형 OpenShift Container Platform 클러스터가 있어야 합니다.
local-cluster가 자동으로 가져옵니다.local-cluster에 대한 자세한 내용은 고급 구성 을 참조하십시오. 다음 명령을 실행하여 허브 클러스터의 상태를 확인할 수 있습니다.oc get managedclusters local-cluster
1.7.11.2. 방화벽 및 포트 요구 사항
포트가 관리 클러스터, 컨트롤 플레인 및 호스팅 클러스터 간에 통신할 수 있도록 방화벽 및 포트 요구 사항을 충족하는지 확인합니다.
kube-apiserver서비스는 기본적으로 포트 6443에서 실행되며 컨트롤 플레인 구성 요소 간의 통신을 위해 수신 액세스가 필요합니다.-
NodePort게시 전략을 사용하는 경우kube-apiserver서비스에 할당된 노드 포트가 노출되어 있는지 확인합니다. - MetalLB 로드 밸런싱을 사용하는 경우 로드 밸런서 IP 주소에 사용되는 IP 범위에 대한 수신 액세스를 허용합니다.
-
-
NodePort게시 전략을 사용하는 경우ignition-server및Oauth-server설정에 방화벽 규칙을 사용합니다. 호스팅된 클러스터에서 양방향 통신을 허용하도록 역방향 터널을 설정하는
konnectivity에이전트에는 포트 6443의 클러스터 API 서버 주소에 대한 송신 액세스가 필요합니다. 이 송신 액세스를 사용하면 에이전트가kube-apiserver서비스에 도달할 수 있습니다.- 클러스터 API 서버 주소가 내부 IP 주소인 경우 워크로드 서브넷에서 포트 6443의 IP 주소로 액세스를 허용합니다.
- 주소가 외부 IP 주소인 경우 6443 포트에서 노드에서 해당 외부 IP 주소로 송신을 허용합니다.
- 기본 6443 포트를 변경하는 경우 해당 변경 사항을 반영하도록 규칙을 조정합니다.
- 클러스터에서 실행되는 워크로드에 필요한 모든 포트를 열어야 합니다.
- 방화벽 규칙, 보안 그룹 또는 기타 액세스 제어를 사용하여 필요한 소스만 액세스를 제한합니다. 필요한 경우 포트를 공개적으로 노출하지 마십시오.
- 프로덕션 배포의 경우 로드 밸런서를 사용하여 단일 IP 주소를 통한 액세스를 단순화합니다.
Red Hat OpenShift Virtualization의 호스팅 컨트롤 플레인에 대한 추가 리소스는 다음 문서를 참조하십시오.
- etcd 및 LVM 스토리지 권장 사항에 대한 자세한 내용은 권장 etcd 사례 및 논리 볼륨 관리자 스토리지를 사용하여 영구 스토리지를 참조하십시오.
- 연결이 끊긴 환경에서 Red Hat OpenShift Virtualization에서 호스팅되는 컨트롤 플레인을 구성하려면 연결이 끊긴 환경에서 호스팅된 컨트롤 플레인 구성을 참조하십시오.
- 호스팅된 컨트롤 플레인 기능을 비활성화하거나 이미 비활성화한 경우 호스팅된 컨트롤 플레인 기능 활성화 또는 비활성화를 참조하십시오.
- Red Hat Ansible Automation Platform 작업을 실행하여 호스트된 클러스터를 관리하려면 호스팅된 클러스터에서 실행되도록 Ansible Automation Platform 작업 구성 을 참조하십시오.
1.7.11.3. KubeVirt 플랫폼을 사용하여 호스트 클러스터 생성
OpenShift Container Platform 4.14 이상에서는 KubeVirt로 클러스터를 생성하여 외부 인프라로 생성할 수 있습니다. KubeVirt를 사용하여 생성하는 프로세스에 대해 자세히 알아보십시오.
1.7.11.3.1. 호스트 클러스터 생성
호스팅된 클러스터를 생성하려면 호스팅된 컨트롤 플레인 명령줄 인터페이스인
hcp:을 사용합니다.hcp create cluster kubevirt \ --name <hosted-cluster-name> \1 --node-pool-replicas <worker-count> \2 --pull-secret <path-to-pull-secret> \3 --memory <value-for-memory> \4 --cores <value-for-cpu> \5 --etcd-storage-class=<etcd-storage-class>6 참고:
--release-image플래그를 사용하여 특정 OpenShift Container Platform 릴리스와 함께 호스팅 클러스터를 설정할 수 있습니다.--node-pool-replicas플래그에 따라 두 개의 가상 머신 작업자 복제본이 있는 클러스터에 대한 기본 노드 풀이 생성됩니다.잠시 후 다음 명령을 입력하여 호스팅된 컨트롤 플레인 포드가 실행 중인지 확인합니다.
oc -n clusters-<hosted-cluster-name> get pods다음 예제 출력을 참조하십시오.
NAME READY STATUS RESTARTS AGE capi-provider-5cc7b74f47-n5gkr 1/1 Running 0 3m catalog-operator-5f799567b7-fd6jw 2/2 Running 0 69s certified-operators-catalog-784b9899f9-mrp6p 1/1 Running 0 66s cluster-api-6bbc867966-l4dwl 1/1 Running 0 66s . . . redhat-operators-catalog-9d5fd4d44-z8qqk 1/1 Running 0 66sKubeVirt 가상 머신에서 지원하는 작업자 노드가 있는 호스팅된 클러스터는 일반적으로 완전히 프로비저닝되는 데 10-15분이 걸립니다.
호스트 클러스터의 상태를 확인하려면 다음 명령을 입력하여 해당
HostedCluster리소스를 참조하십시오.oc get --namespace clusters hostedclusters완전히 프로비저닝된
HostedCluster오브젝트를 설명하는 다음 예제 출력을 참조하십시오.NAMESPACE NAME VERSION KUBECONFIG PROGRESS AVAILABLE PROGRESSING MESSAGE clusters example 4.x.0 example-admin-kubeconfig Completed True False The hosted control plane is available4.x.0을 사용하려는 지원되는 OpenShift Container Platform 버전으로 교체합니다.- 호스트 클러스터 액세스 지침에 따라 호스팅된 클러스터에 액세스 합니다.
1.7.11.3.2. 외부 인프라를 사용하여 호스트된 클러스터 생성
기본적으로 HyperShift Operator는 동일한 클러스터 내에서 호스팅되는 클러스터의 컨트롤 플레인 Pod와 KubeVirt 작업자 VM을 모두 호스팅합니다. 외부 인프라 기능을 사용하면 작업자 노드 VM을 컨트롤 플레인 Pod와 별도의 클러스터에 배치할 수 있습니다.
- 관리 클러스터 는 HyperShift Operator를 실행하고 호스팅된 클러스터의 컨트롤 플레인 Pod를 호스팅하는 OpenShift Container Platform 클러스터입니다.
- 인프라 클러스터 는 호스팅된 클러스터의 KubeVirt 작업자 VM을 실행하는 OpenShift Container Platform 클러스터입니다.
- 기본적으로 관리 클러스터는 VM을 호스팅하는 인프라 클러스터 역할을 합니다. 그러나 외부 인프라의 경우 관리 및 인프라 클러스터는 다릅니다.
1.7.11.3.2.1. 외부 인프라의 사전 요구 사항
- KubeVirt 노드를 호스팅하려면 외부 인프라 클러스터에 네임스페이스가 있어야 합니다.
-
외부 인프라 클러스터에 대한
kubeconfig파일이 있어야 합니다.
1.7.11.3.2.2. hcp 명령줄 인터페이스를 사용하여 호스트 클러스터 생성
hcp 명령줄 인터페이스를 사용하여 호스트된 클러스터를 생성할 수 있습니다.
인프라 클러스터에 KubeVirt 작업자 VM을 배치하려면 다음 예와 같이
--infra-kubeconfig-file및--infra-namespace인수를 사용합니다.hcp create cluster kubevirt \ --name <hosted-cluster-name> \1 --node-pool-replicas <worker-count> \2 --pull-secret <path-to-pull-secret> \3 --memory <value-for-memory> \4 --cores <value-for-cpu> \5 --infra-namespace=<hosted-cluster-namespace>-<hosted-cluster-name> \6 --infra-kubeconfig-file=<path-to-external-infra-kubeconfig>7 해당 명령을 입력하면 컨트롤 플레인 Pod가 HyperShift Operator가 실행되는 관리 클러스터에서 호스팅되고 KubeVirt VM은 별도의 인프라 클러스터에서 호스팅됩니다.
- 호스트 클러스터 액세스 지침에 따라 호스팅된 클러스터에 액세스 합니다.
1.7.11.3.3. 콘솔을 사용하여 호스트 클러스터 생성
콘솔을 사용하여 KubeVirt 플랫폼으로 호스팅된 클러스터를 생성하려면 다음 단계를 완료하십시오.
- OpenShift Container Platform 웹 콘솔을 열고 관리자 인증 정보를 입력하여 로그인합니다. 콘솔을 여는 방법은 OpenShift Container Platform 설명서 의 웹 콘솔 액세스를 참조하십시오.
- 콘솔 헤더에서 모든 클러스터 가 선택되어 있는지 확인합니다.
- Infrastructure > Clusters를 클릭합니다.
- Create cluster > Red Hat OpenShift Virtualization > Hosted를 클릭합니다.
클러스터 생성 페이지에서 프롬프트에 따라 클러스터 및 노드 풀에 대한 세부 정보를 입력합니다.
참고:
- 사전 정의된 값을 사용하여 콘솔에서 필드를 자동으로 채우려면 Red Hat OpenShift Virtualization 인증 정보를 생성할 수 있습니다. 자세한 내용은 온-프레미스 환경에 대한 인증 정보 만들기 를 참조하십시오.
- 클러스터 세부 정보 페이지에서 풀 시크릿은 OpenShift Container Platform 리소스에 액세스하는 데 사용하는 OpenShift Container Platform 풀 시크릿입니다. Red Hat OpenShift Virtualization 인증 정보를 선택한 경우 풀 시크릿이 자동으로 채워집니다.
항목을 검토하고 생성 을 클릭합니다.
호스팅된 클러스터 보기가 표시됩니다.
- Hosted 클러스터 보기에서 호스팅된 클러스터의 배포를 모니터링합니다. 호스팅된 클러스터에 대한 정보가 표시되지 않는 경우 모든 클러스터가 선택되어 있는지 확인하고 클러스터 이름을 클릭합니다.
- 컨트롤 플레인 구성 요소가 준비될 때까지 기다립니다. 이 프로세스는 몇 분 정도 걸릴 수 있습니다.
- 노드 풀 상태를 보려면 NodePool 섹션으로 스크롤합니다. 노드를 설치하는 프로세스에는 약 10분이 걸립니다. 노드를 클릭하여 노드가 호스팅된 클러스터에 참여하고 있는지 확인할 수도 있습니다.
1.7.11.3.4. 추가 리소스
- 콘솔을 사용하여 호스팅된 클러스터를 만들 때 재사용할 수 있는 인증 정보를 생성하려면 온프레미스 환경에 대한 인증 정보 생성 을 참조하십시오.
- 호스트된 클러스터에 액세스하려면 호스팅 된 클러스터 액세스를 참조하십시오.
1.7.11.4. 기본 수신 및 DNS 동작
모든 OpenShift Container Platform 클러스터에는 기본 애플리케이션 Ingress 컨트롤러가 포함되어 있으며, 이와 연결된 와일드카드 DNS 레코드가 있어야 합니다. 기본적으로 HyperShift KubeVirt 공급자를 사용하여 생성된 호스팅 클러스터는 KubeVirt 가상 머신이 실행되는 OpenShift Container Platform 클러스터의 하위 도메인이 자동으로 됩니다.
예를 들어 OpenShift Container Platform 클러스터에 다음과 같은 기본 인그레스 DNS 항목이 있을 수 있습니다.
*.apps.mgmt-cluster.example.com
결과적으로 guest 라는 이름의 KubeVirt 호스팅 클러스터에는 다음과 같은 기본 수신이 있습니다.
*.apps.guest.apps.mgmt-cluster.example.com기본 인그레스 DNS가 제대로 작동하려면 KubeVirt 가상 머신을 호스팅하는 클러스터에서 와일드카드 DNS 경로를 허용해야 합니다. 다음 명령을 입력하여 이 동작을 구성할 수 있습니다.
oc patch ingresscontroller -n openshift-ingress-operator default --type=json -p '[{ "op": "add", "path": "/spec/routeAdmission", "value": {wildcardPolicy: "WildcardsAllowed"}}]'참고: 기본 호스팅 클러스터 수신을 사용하는 경우 포트 443을 통한 HTTPS 트래픽으로 제한됩니다. 포트 80을 통한 일반 HTTP 트래픽이 거부됩니다. 이 제한은 기본 수신 동작에만 적용됩니다.
1.7.11.4.1. 수신 및 DNS 동작 사용자 정의
기본 수신 및 DNS 동작을 사용하지 않으려면 생성 시 KubeVirt 호스팅 클러스터를 고유 기본 도메인으로 구성할 수 있습니다. 이 옵션을 사용하려면 생성 중에 수동 구성 단계가 필요하며 클러스터 생성, 로드 밸런서 생성 및 와일드카드 DNS 구성의 세 가지 주요 단계가 포함됩니다.
1.7.11.4.1.1. 기본 도메인을 지정하는 호스팅된 클러스터 배포
기본 도메인을 지정하는 호스팅 클러스터를 생성하려면 다음 명령을 입력합니다.
hcp create cluster kubevirt \ --name <hosted-cluster-name> \1 --node-pool-replicas <worker-count> \2 --pull-secret <path-to-pull-secret> \3 --memory <value-for-memory> \4 --cores <value-for-cpu> \5 --base-domain <basedomain>6
결과적으로 호스팅된 클러스터에는 클러스터 이름과 기본 도메인(예: .apps.example.hypershift.lab )에 대해 구성된 수신 와일드카드가 있습니다. 호스트 클러스터는 부분 상태로 유지됩니다. 고유 기본 도메인을 사용하여 호스팅 클러스터를 생성한 후 필요한 DNS 레코드 및 로드 밸런서를 구성해야 합니다.
다음 명령을 입력하여 호스팅 클러스터의 상태를 확인합니다.
oc get --namespace clusters hostedclusters다음 예제 출력을 참조하십시오.
NAME VERSION KUBECONFIG PROGRESS AVAILABLE PROGRESSING MESSAGE example example-admin-kubeconfig Partial True False The hosted control plane is available다음 명령을 입력하여 클러스터에 액세스합니다.
hcp create kubeconfig --name <hosted-cluster-name> > <hosted-cluster-name>-kubeconfigoc --kubeconfig <hosted-cluster-name>-kubeconfig get co다음 예제 출력을 참조하십시오.
NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE MESSAGE console 4.x.0 False False False 30m RouteHealthAvailable: failed to GET route (https://console-openshift-console.apps.example.hypershift.lab): Get "https://console-openshift-console.apps.example.hypershift.lab": dial tcp: lookup console-openshift-console.apps.example.hypershift.lab on 172.31.0.10:53: no such host ingress 4.x.0 True False True 28m The "default" ingress controller reports Degraded=True: DegradedConditions: One or more other status conditions indicate a degraded state: CanaryChecksSucceeding=False (CanaryChecksRepetitiveFailures: Canary route checks for the default ingress controller are failing)4.x.0을 사용하려는 지원되는 OpenShift Container Platform 버전으로 교체합니다.다음 단계에서는 출력의 오류를 수정합니다.
참고: 호스팅 클러스터가 베어 메탈에 있는 경우 로드 밸런서 서비스를 설정하려면 MetalLB가 필요할 수 있습니다. 자세한 내용은 선택 사항: MetalLB 구성을 참조하십시오.
1.7.11.4.1.2. 로드 밸런서 설정
Ingress 트래픽을 KubeVirt VM으로 라우팅하고 로드 밸런서 IP 주소에 와일드카드 DNS 항목을 할당하는 로드 밸런서 서비스를 설정합니다.
호스팅된 클러스터 인그레스를 노출하는
NodePort서비스가 이미 존재합니다. 노드 포트를 내보내고 해당 포트를 대상으로 하는 로드 밸런서 서비스를 생성할 수 있습니다.다음 명령을 입력하여 HTTP 노드 포트를 가져옵니다.
oc --kubeconfig <hosted-cluster-name>-kubeconfig get services -n openshift-ingress router-nodeport-default -o jsonpath='{.spec.ports[?(@.name=="http")].nodePort}'다음 단계에서 사용할 HTTP 노드 포트 값을 확인합니다.
다음 명령을 입력하여 HTTPS 노드 포트를 가져옵니다.
oc --kubeconfig <hosted-cluster-name>-kubeconfig get services -n openshift-ingress router-nodeport-default -o jsonpath='{.spec.ports[?(@.name=="https")].nodePort}'
다음 단계에서 사용할 HTTPS 노드 포트 값을 확인합니다.
다음 명령을 입력하여 로드 밸런서 서비스를 생성합니다.
oc apply -f - apiVersion: v1 kind: Service metadata: labels: app: <hosted-cluster-name> name: <hosted-cluster-name>-apps namespace: clusters-<hosted-cluster-name> spec: ports: - name: https-443 port: 443 protocol: TCP targetPort: <https-node-port>1 - name: http-80 port: 80 protocol: TCP targetPort: <http-node-port>2 selector: kubevirt.io: virt-launcher type: LoadBalancer
1.7.11.4.1.3. 와일드카드 DNS 설정
로드 밸런서 서비스의 외부 IP를 참조하는 와일드카드 DNS 레코드 또는 CNAME을 설정합니다.
다음 명령을 입력하여 외부 IP 주소를 가져옵니다.
oc -n clusters-<hosted-cluster-name> get service <hosted-cluster-name>-apps -o jsonpath='{.status.loadBalancer.ingress[0].ip}'다음 예제 출력을 참조하십시오.
192.168.20.30외부 IP 주소를 참조하는 와일드카드 DNS 항목을 구성합니다. 다음 예제 DNS 항목을 확인합니다.
*.apps.<hosted-cluster-name\>.<base-domain\>.DNS 항목은 클러스터 내부 및 외부에서 라우팅할 수 있어야 합니다. 다음 DNS 확인 예를 참조하십시오.
dig +short test.apps.example.hypershift.lab 192.168.20.30다음 명령을 입력하여 호스팅 클러스터 상태가
Partial에서Completed로 이동했는지 확인합니다.oc get --namespace clusters hostedclusters다음 예제 출력을 참조하십시오.
NAME VERSION KUBECONFIG PROGRESS AVAILABLE PROGRESSING MESSAGE example 4.x.0 example-admin-kubeconfig Completed True False The hosted control plane is available4.x.0을 사용하려는 지원되는 OpenShift Container Platform 버전으로 교체합니다.
1.7.11.4.1.4. 추가 리소스
- OpenShift Virtualization에서 호스트된 컨트롤 플레인 클러스터 관리
- 선택사항: MetalLB 구성
- 이 항목의 시작 부분에서 기본 인그레스 및 DNS 동작 으로 돌아갑니다.
1.7.11.5. 선택사항: MetalLB 구성
MetalLB를 구성하기 전에 MetalLB Operator를 설치해야 합니다. 자세한 내용은 OpenShift Container Platform 설명서에서 MetalLB Operator 설치를 참조하십시오.
게스트 클러스터에서 MetalLB를 구성하려면 다음 단계를 수행합니다.
다음 샘플 YAML 콘텐츠를
configure-metallb.yaml파일에 저장하여MetalLB리소스를 생성합니다.apiVersion: metallb.io/v1beta1 kind: MetalLB metadata: name: metallb namespace: metallb-system다음 명령을 입력하여 YAML 콘텐츠를 적용합니다.
oc apply -f configure-metallb.yaml다음 예제 출력을 참조하십시오.
metallb.metallb.io/metallb createdcreate-ip-address-pool.yaml파일에 다음 샘플 YAML 콘텐츠를 저장하여IPAddressPool리소스를 만듭니다.apiVersion: metallb.io/v1beta1 kind: IPAddressPool metadata: name: metallb namespace: metallb-system spec: addresses: - 192.168.216.32-192.168.216.1221 - 1
- 노드 네트워크 내에서 사용 가능한 IP 주소 범위를 사용하여 주소 풀을 생성합니다. IP 주소 범위를 네트워크에서 사용 가능한 IP 주소의 사용되지 않는 풀로 바꿉니다.
다음 명령을 입력하여 YAML 콘텐츠를 적용합니다.
oc apply -f create-ip-address-pool.yaml다음 예제 출력을 참조하십시오.
ipaddresspool.metallb.io/metallb createdl2advertisement.yaml파일에 다음 샘플 YAML 콘텐츠를 저장하여L2Advertisement리소스를 생성합니다.apiVersion: metallb.io/v1beta1 kind: L2Advertisement metadata: name: l2advertisement namespace: metallb-system spec: ipAddressPools: - metallb다음 명령을 입력하여 YAML 콘텐츠를 적용합니다.
oc apply -f l2advertisement.yaml다음 예제 출력을 참조하십시오.
l2advertisement.metallb.io/metallb created
1.7.11.5.1. 추가 리소스
- MetalLB에 대한 자세한 내용은 MetalLB Operator 설치를 참조하십시오.
1.7.11.6. 노드 풀에 대한 추가 네트워크, 보장된 CPU 및 VM 스케줄링 구성
노드 풀에 대한 추가 네트워크를 구성해야 하는 경우 가상 머신(VM)에 대한 보장된 CPU 액세스를 요청하거나 KubeVirt VM의 스케줄링을 관리해야 하는 경우 다음 절차를 참조하십시오.
1.7.11.6.1. 노드 풀에 여러 네트워크 추가
기본적으로 노드 풀에서 생성한 노드는 Pod 네트워크에 연결됩니다. Multus 및 NetworkAttachmentDefinitions를 사용하여 추가 네트워크를 노드에 연결할 수 있습니다.
노드에 여러 네트워크를 추가하려면 다음 명령을 실행하여 --additional-network 인수를 사용합니다.
hcp create cluster kubevirt \
--name <hosted_cluster_name> \
--node-pool-replicas <worker_node_count> \
--pull-secret <path_to_pull_secret> \
--memory <memory> \
--cores <cpu> \
--additional-network name:<namespace/name> \
–-additional-network name:<namespace/name>1.7.11.6.2. 보장된 CPU 리소스 요청
기본적으로 KubeVirt VM은 노드의 다른 워크로드와 해당 CPU를 공유할 수 있습니다. 이는 VM의 성능에 영향을 미칠 수 있습니다. 성능에 미치는 영향을 방지하기 위해 VM에 대해 보장된 CPU 액세스를 요청할 수 있습니다.
보장된 CPU 리소스를 요청하려면 다음 명령을 실행하여 --qos-class 인수를 Guaranteed 로 설정합니다.
hcp create cluster kubevirt \
--name <hosted_cluster_name> \
--node-pool-replicas <worker_node_count> \
--pull-secret <path_to_pull_secret> \
--memory <memory> \
--cores <cpu> \
--qos-class Guaranteed 1.7.11.6.3. 노드 세트에서 KubeVirt VM 예약
기본적으로 노드 풀에서 생성한 KubeVirt VM은 사용 가능한 모든 노드에 예약됩니다. VM을 실행하는 데 충분한 용량이 있는 특정 노드 세트에서 KubeVirt VM을 예약할 수 있습니다.
특정 노드 세트의 노드 풀 내에서 KubeVirt VM을 예약하려면 다음 명령을 실행하여 --vm-node-selector 인수를 사용합니다.
hcp create cluster kubevirt \
--name <hosted_cluster_name> \
--node-pool-replicas <worker_node_count> \
--pull-secret <path_to_pull_secret> \
--memory <memory> \
--cores <cpu> \
--vm-node-selector <label_key>=<label_value>,<label_key>=<label_value> 1.7.11.7. 노드 풀 확장
oc scale명령을 사용하여 노드 풀을 수동으로 확장할 수 있습니다.NODEPOOL_NAME=${CLUSTER_NAME}-work NODEPOOL_REPLICAS=5 oc scale nodepool/$NODEPOOL_NAME --namespace clusters --replicas=$NODEPOOL_REPLICAS잠시 후 다음 명령을 입력하여 노드 풀의 상태를 확인합니다.
oc --kubeconfig $CLUSTER_NAME-kubeconfig get nodes다음 예제 출력을 참조하십시오.
NAME STATUS ROLES AGE VERSION example-9jvnf Ready worker 97s v1.27.4+18eadca example-n6prw Ready worker 116m v1.27.4+18eadca example-nc6g4 Ready worker 117m v1.27.4+18eadca example-thp29 Ready worker 4m17s v1.27.4+18eadca example-twxns Ready worker 88s v1.27.4+18eadca
1.7.11.7.1. 노드 풀 추가
이름, 복제본 수 및 메모리 및 CPU 요구 사항과 같은 추가 정보를 지정하여 호스팅된 클러스터에 대한 노드 풀을 생성할 수 있습니다.
노드 풀을 생성하려면 다음 정보를 입력합니다. 이 예에서 노드 풀에는 VM에 더 많은 CPU가 할당됩니다.
export NODEPOOL_NAME=${CLUSTER_NAME}-extra-cpu export WORKER_COUNT="2" export MEM="6Gi" export CPU="4" export DISK="16" hcp create nodepool kubevirt \ --cluster-name $CLUSTER_NAME \ --name $NODEPOOL_NAME \ --node-count $WORKER_COUNT \ --memory $MEM \ --cores $CPU \ --root-volume-size $DISKcluster 네임스페이스에
nodepool리소스를 나열하여 노드 풀의상태를확인합니다.oc get nodepools --namespace clusters다음 예제 출력을 참조하십시오.
NAME CLUSTER DESIRED NODES CURRENT NODES AUTOSCALING AUTOREPAIR VERSION UPDATINGVERSION UPDATINGCONFIG MESSAGE example example 5 5 False False 4.x.0 example-extra-cpu example 2 False False True True Minimum availability requires 2 replicas, current 0 available4.x.0을 사용하려는 지원되는 OpenShift Container Platform 버전으로 교체합니다.잠시 후 다음 명령을 입력하여 노드 풀의 상태를 확인할 수 있습니다.
oc --kubeconfig $CLUSTER_NAME-kubeconfig get nodes다음 예제 출력을 참조하십시오.
NAME STATUS ROLES AGE VERSION example-9jvnf Ready worker 97s v1.27.4+18eadca example-n6prw Ready worker 116m v1.27.4+18eadca example-nc6g4 Ready worker 117m v1.27.4+18eadca example-thp29 Ready worker 4m17s v1.27.4+18eadca example-twxns Ready worker 88s v1.27.4+18eadca example-extra-cpu-zh9l5 Ready worker 2m6s v1.27.4+18eadca example-extra-cpu-zr8mj Ready worker 102s v1.27.4+18eadca다음 명령을 입력하여 노드 풀이 예상되는 상태에 있는지 확인합니다.
oc get nodepools --namespace clusters다음 예제 출력을 참조하십시오.
NAME CLUSTER DESIRED NODES CURRENT NODES AUTOSCALING AUTOREPAIR VERSION UPDATINGVERSION UPDATINGCONFIG MESSAGE example example 5 5 False False 4.x.0 example-extra-cpu example 2 2 False False 4.x.04.x.0을 사용하려는 지원되는 OpenShift Container Platform 버전으로 교체합니다.
1.7.11.7.1.1. 추가 리소스
- OpenShift Virtualization에서 호스트된 컨트롤 플레인 클러스터 관리
- 이 항목의 시작 부분으로 돌아가서 노드 풀 확장.
- 데이터 플레인을 0으로 축소하려면 데이터 플레인을 0으로 축소합니다.
1.7.11.8. OpenShift Virtualization에서 호스트된 클러스터 생성 확인
호스팅 클러스터가 성공적으로 생성되었는지 확인하려면 다음 단계를 완료합니다.
다음 명령을 입력하여
HostedCluster리소스가완료된상태로 전환되었는지 확인합니다.oc get --namespace clusters hostedclusters ${CLUSTER_NAME}다음 예제 출력을 참조하십시오.
NAMESPACE NAME VERSION KUBECONFIG PROGRESS AVAILABLE PROGRESSING MESSAGE clusters example 4.12.2 example-admin-kubeconfig Completed True False The hosted control plane is available다음 명령을 입력하여 호스팅 클러스터의 모든 클러스터 운영자가 온라인 상태인지 확인합니다.
hcp create kubeconfig --name $CLUSTER_NAME > $CLUSTER_NAME-kubeconfigoc get co --kubeconfig=$CLUSTER_NAME-kubeconfig다음 예제 출력을 참조하십시오.
NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE MESSAGE console 4.12.2 True False False 2m38s csi-snapshot-controller 4.12.2 True False False 4m3s dns 4.12.2 True False False 2m52s image-registry 4.12.2 True False False 2m8s ingress 4.12.2 True False False 22m kube-apiserver 4.12.2 True False False 23m kube-controller-manager 4.12.2 True False False 23m kube-scheduler 4.12.2 True False False 23m kube-storage-version-migrator 4.12.2 True False False 4m52s monitoring 4.12.2 True False False 69s network 4.12.2 True False False 4m3s node-tuning 4.12.2 True False False 2m22s openshift-apiserver 4.12.2 True False False 23m openshift-controller-manager 4.12.2 True False False 23m openshift-samples 4.12.2 True False False 2m15s operator-lifecycle-manager 4.12.2 True False False 22m operator-lifecycle-manager-catalog 4.12.2 True False False 23m operator-lifecycle-manager-packageserver 4.12.2 True False False 23m service-ca 4.12.2 True False False 4m41s storage 4.12.2 True False False 4m43s
1.7.11.9. OpenShift Virtualization에서 호스팅된 컨트롤 플레인을 위한 스토리지 구성
고급 구성이 제공되지 않으면 KubeVirt 가상 머신(VM) 이미지, KubeVirt CSI 매핑 및 etcd 볼륨에 기본 스토리지 클래스가 사용됩니다.
1.7.11.9.1. KubeVirt CSI 스토리지 클래스 매핑
kubevirt CSI를 사용하면 ReadWriteMany 액세스 모드가 있는 모든 인프라 스토리지 클래스를 호스트된 클러스터에 노출할 수 있습니다. --infra-storage-class-mapping 인수를 사용하여 클러스터 생성 중에 클러스터 스토리지 클래스를 호스팅하도록 인프라 클러스터 스토리지 클래스의 매핑을 구성할 수 있습니다.
인프라 스토리지 클래스를 호스팅 스토리지 클래스에 매핑하려면 다음 예제를 참조하십시오.
hcp create cluster kubevirt \
--name <hosted-cluster-name> \
--node-pool-replicas <worker-count> \
--pull-secret <path-to-pull-secret> \
--memory <value-for-memory> \
--cores <value-for-cpu> \
--infra-storage-class-mapping=<storage-class>/<hosted-storage-class> \ - 1
- 호스팅된 클러스터의 이름을 지정합니다(
예: ). - 2
- 작업자 수를 지정합니다(예: 2).
- 3
- 풀 시크릿의 경로를 지정합니다(예:
/user/name/pullsecret). - 4
- 메모리 값을 지정합니다(예:
6Gi). - 5
- CPU 값을 지정합니다(예:
2). - 6
- <
storage-class>를 인프라 스토리지 클래스 이름으로 바꾸고 <hosted-storage-class>를 호스팅된 클러스터 스토리지 클래스 이름으로 바꿉니다.create명령에서--infra-storage-class-mapping인수를 여러 번 사용할 수 있습니다.
호스팅된 클러스터를 생성하면 인프라 스토리지 클래스가 호스팅된 클러스터 내에서 표시됩니다. 이러한 스토리지 클래스 중 하나를 사용하는 호스트 클러스터 내에서 PVC를 생성하면 KubeVirt CSI는 클러스터 생성 중에 구성한 인프라 스토리지 클래스 매핑을 사용하여 해당 볼륨을 프로비저닝합니다.
참고: KubeVirt CSI는 RWX( ReadWriteMany ) 액세스를 수행할 수 있는 인프라 스토리지 클래스만 매핑을 지원합니다.
1.7.11.9.2. KubeVirt VM 루트 볼륨 구성
클러스터 생성 시 --root-volume-storage-class 인수를 사용하여 KubeVirt VM 루트 볼륨을 호스팅하는 데 사용되는 스토리지 클래스를 구성할 수 있습니다.
KubeVirt VM의 사용자 정의 스토리지 클래스 및 볼륨 크기를 설정하려면 다음 예제를 참조하십시오.
hcp create cluster kubevirt \
--name <hosted-cluster-name> \
--node-pool-replicas <worker-count> \
--pull-secret <path-to-pull-secret> \
--memory <value-for-memory> \
--cores <value-for-cpu> \
--root-volume-storage-class <root-volume-storage-class> \
--root-volume-size <volume-size>
결과적으로 ocs-storagecluster-ceph-rdb 스토리지 클래스에서 호스팅하는 PVC에서 호스팅되는 VM이 있는 호스팅 클러스터입니다.
1.7.11.9.3. KubeVirt VM 이미지 캐싱 활성화
kubevirt 이미지 캐싱은 클러스터 시작 시간과 스토리지 사용률을 모두 최적화하는 데 사용할 수 있는 고급 기능입니다. 이 기능을 사용하려면 스마트 복제 및 ReadWriteMany 액세스 모드가 가능한 스토리지 클래스를 사용해야 합니다. 스마트 복제에 대한 자세한 내용은 스마트 복제 를 사용하여 데이터 볼륨 복제를 참조하십시오.
이미지 캐싱은 다음과 같이 작동합니다.
- VM 이미지는 호스팅된 클러스터와 연결된 PVC로 가져옵니다.
- 해당 PVC의 고유한 복제본은 클러스터에 작업자 노드로 추가되는 모든 KubeVirt VM에 대해 생성됩니다.
이미지 캐싱은 단일 이미지 가져오기만 요구하여 VM 시작 시간을 줄입니다. 스토리지 클래스가 COW(Copy-On-Write) 복제를 지원하는 경우 전체 클러스터 스토리지 사용량을 추가로 줄일 수 있습니다.
이미지 캐싱을 활성화하려면 클러스터 생성 중에 다음 예와 같이 --root-volume-cache-strategy=PVC 인수를 사용합니다.
hcp create cluster kubevirt \
--name <hosted-cluster-name> \
--node-pool-replicas <worker-count> \
--pull-secret <path-to-pull-secret> \
--memory <value-for-memory> \
--cores <value-for-cpu> \
--root-volume-cache-strategy=PVC 1.7.11.9.4. etcd 스토리지 구성
클러스터 생성 시 --etcd-storage-class 인수를 사용하여 etcd 데이터를 호스팅하는 데 사용되는 스토리지 클래스를 구성할 수 있습니다.
etcd의 스토리지 클래스를 구성하려면 다음 예제를 참조하십시오.
hcp create cluster kubevirt \
--name <hosted-cluster-name> \
--node-pool-replicas <worker-count> \
--pull-secret <path-to-pull-secret> \
--memory <value-for-memory> \
--cores <value-for-cpu> \
--etcd-storage-class=<etcd-storage-class-name> 1.7.11.9.4.1. 추가 리소스
1.7.11.10. OpenShift Virtualization에서 호스트된 클러스터 삭제
호스트 클러스터 및 관리 클러스터 리소스를 삭제하려면 다음 단계를 완료합니다.
다음 명령을 실행하여 다중 클러스터 엔진 Operator에서 관리되는 클러스터 리소스를 삭제합니다.
oc delete managedcluster <managed_cluster_name>여기서
<managed_cluster_name>은 관리 클러스터의 이름입니다.다음 명령을 실행하여 호스팅된 클러스터 및 해당 백엔드 리소스를 삭제합니다.
hcp destroy cluster kubevirt --name <hosted_cluster_name><
;hosted_cluster_name>을 호스트된 클러스터 이름으로 교체합니다.
1.7.12. 연결이 끊긴 환경에서 호스트된 컨트롤 플레인 구성
연결이 끊긴 환경은 인터넷에 연결되어 있지 않으며 호스팅된 컨트롤 플레인을 기반으로 사용하는 OpenShift Container Platform 클러스터입니다.
기술 프리뷰: IPv4 또는 IPv6 네트워크를 사용하여 베어 메탈 플랫폼의 연결이 끊긴 환경에 호스팅된 컨트롤 플레인을 배포할 수 있습니다. 또한 연결이 끊긴 환경의 호스팅 컨트롤 플레인은 듀얼 스택 네트워크에서 기술 프리뷰 기능으로 사용할 수 있습니다. Red Hat OpenShift Virtualization 플랫폼을 사용하는 경우 연결이 끊긴 환경에서 호스팅되는 컨트롤 플레인을 기술 프리뷰 기능으로만 사용할 수 있습니다.
1.7.12.1. 연결이 끊긴 환경 아키텍처
에이전트 플랫폼을 사용하여 베어 메탈에서 호스팅되는 컨트롤 플레인을 프로비저닝할 수 있습니다. 에이전트 플랫폼은 중앙 인프라 관리 서비스를 사용하여 호스트된 클러스터에 작업자 노드를 추가합니다. 중앙 인프라 관리 서비스에 대한 소개는 중앙 인프라 관리 서비스 활성화를 참조하십시오.
연결이 끊긴 환경의 다음 아키텍처 다이어그램을 참조하십시오.
- 연결이 끊긴 배포가 작동하는지 확인하기 위해 TLS 지원, 웹 서버 및 DNS를 사용하여 레지스트리 인증서 배포를 포함한 인프라 서비스를 구성합니다.
openshift-config네임스페이스에 구성 맵을 생성합니다. 구성 맵의 내용은 레지스트리 CA 인증서입니다. 구성 맵의 data 필드에는 다음 키와 값이 포함되어야 합니다.-
키: <
registry_dns_domain_name>..<port> (예:registry.hypershiftdomain.lab..5000:). 포트를 지정할 때 레지스트리 DNS 도메인 이름 뒤에..를 배치해야 합니다. - value: 인증서 콘텐츠
구성 맵 생성에 대한 자세한 내용은 IPv4 네트워크의 TLS 인증서 구성을 참조하십시오.
-
키: <
-
images.config.openshift.ioCR(사용자 정의 리소스)에name: registry-config의 값을 사용하여additionalTrustedCA필드를 추가합니다. multicluster-engine네임스페이스에 구성 맵을 생성합니다. 다음 샘플 구성을 참조하십시오.apiVersion: v1 kind: ConfigMap metadata: name: custom-registries namespace: multicluster-engine labels: app: assisted-service data: ca-bundle.crt: |1 -----BEGIN CERTIFICATE----- ... ... ... -----END CERTIFICATE----- registries.conf: |2 unqualified-search-registries = ["registry.access.redhat.com", "docker.io"] [[registry]] prefix = "" location = "registry.redhat.io/openshift4" mirror-by-digest-only = true [[registry.mirror]] location = "registry.ocp-edge-cluster-0.qe.lab.redhat.com:5000/openshift4" [[registry]] prefix = "" location = "registry.redhat.io/rhacm2" mirror-by-digest-only = true ... ...
- 1
- 레지스트리의 CA 인증서를 포함합니다.
- 2
RAW형식의registries.conf파일 콘텐츠를 포함합니다.-
다중 클러스터 엔진 Operator 네임스페이스에서 Agent 및
hypershift-addon애드온을 둘 다 활성화하는multiclusterengineCR을 생성합니다. 다중 클러스터 엔진 Operator 네임스페이스에는 연결이 끊긴 배포에서 동작을 수정하려면 구성 맵이 포함되어야 합니다. 네임스페이스에는multicluster-engine,assisted-service,hypershift-addon-managerPod도 포함되어 있습니다. 다음 구성 요소에 대한 오브젝트를 생성하여 호스팅된 클러스터를 배포합니다.
- 보안: 시크릿에는 풀 시크릿, SSH 키 및 etcd 암호화 키가 포함됩니다.
- 구성 맵: 구성 맵에는 프라이빗 레지스트리의 CA 인증서가 포함되어 있습니다.
-
HostedCluster:HostedCluster리소스는 호스팅된 클러스터에 대한 구성을 정의합니다. -
NodePool:NodePool리소스는 데이터 플레인에 사용할 머신을 참조하는 노드 풀을 식별합니다.
-
호스팅된 클러스터 오브젝트를 생성한 후 HyperShift Operator는
HostedControlPlane네임스페이스에 컨트롤 플레인 Pod를 생성합니다.HostedControlPlane네임스페이스는 에이전트, 베어 메탈 호스트 및InfraEnv리소스와 같은 구성 요소도 호스팅합니다. -
InfraEnv리소스를 만듭니다. ISO 이미지를 생성한 후 베어 메탈 호스트와 BMC(Baseboard Management Controller) 인증 정보가 포함된 시크릿을 생성합니다. -
openshift-machine-api네임스페이스의 Metal3 Operator는 새 베어 메탈 호스트를 검사합니다. -
Metal3 Operator는
LiveISO및RootFS값을 사용하여 BMC를 연결하고 시작합니다. 다중 클러스터 엔진 Operator 네임스페이스의AgentServiceConfigCR을 통해LiveISO및RootFS값을 지정할 수 있습니다. -
HostedCluster리소스의 작업자 노드가 시작되면 에이전트 컨테이너가 시작됩니다. -
NodePool리소스를HostedCluster리소스의 작업자 노드 수로 스케일링합니다. - 배포 프로세스가 완료될 때까지 기다립니다.
-
다중 클러스터 엔진 Operator 네임스페이스에서 Agent 및
1.7.12.2. 사전 요구 사항
연결이 끊긴 환경에서 호스팅되는 컨트롤 플레인을 구성하려면 다음 사전 요구 사항을 충족해야 합니다.
- cpu: 제공된 CPU 수에 따라 동시에 실행할 수 있는 호스트 클러스터 수가 결정됩니다. 일반적으로 노드 3개당 각 노드에 16개의 CPU를 사용합니다. 최소 개발의 경우 노드 3개에 각 노드에 12개의 CPU를 사용할 수 있습니다.
- memory: 호스트할 수 있는 호스트 클러스터 수에 영향을 미칩니다. 각 노드에 48GB의 RAM을 사용합니다. 최소한의 개발의 경우 18GB의 RAM이면 충분합니다.
스토리지: 다중 클러스터 엔진 Operator에 SSD 스토리지를 사용합니다.
- 관리 클러스터: 250GB.
- 레지스트리: 필요한 레지스트리 스토리지는 호스팅되는 릴리스, 운영자 및 이미지 수에 따라 다릅니다. 500GB가 필요할 수 있으며, 호스트 클러스터를 호스팅하는 디스크와 별도로 필요할 수 있습니다.
- 웹 서버: 필요한 웹 서버 스토리지는 호스팅되는 ISO 및 이미지 수에 따라 다릅니다. 500GB가 필요할 수 있습니다.
프로덕션: 프로덕션 환경의 경우 관리 클러스터, 레지스트리 및 웹 서버를 다른 디스크에서 분리합니다. 프로덕션에 대한 다음 예제 구성을 참조하십시오.
- 레지스트리: 2TB
- 관리 클러스터: 500GB
- 웹 서버: 2TB
1.7.12.3. OpenShift Container Platform 릴리스 이미지 다이제스트 추출
태그된 이미지를 사용하여 OpenShift Container Platform 릴리스 이미지 다이제스트를 추출할 수 있습니다. 다음 단계를 완료합니다.
다음 명령을 실행하여 이미지 다이제스트를 가져옵니다.
oc adm release info <tagged_openshift_release_image> | grep "Pull From"<
tagged_openshift_release_image>를 지원되는 OpenShift Container Platform 버전에 대한 태그된 이미지로 바꿉니다(예:quay.io/openshift-release-dev/ocp-release:4.14.0-x8_64).다음 예제 출력을 참조하십시오.
Pull From: quay.io/openshift-release-dev/ocp-release@sha256:69d1292f64a2b67227c5592c1a7d499c7d00376e498634ff8e1946bc9ccdddfe이미지 태그 및 다이제스트에 대한 자세한 내용은 OpenShift Container Platform 설명서의 이미지 스트림 참조 에서 참조하십시오.
1.7.12.3.1. 추가 리소스
1.7.12.4. 연결이 끊긴 환경에서 사용자 워크로드 모니터링
하이퍼shift-addon 관리 클러스터 애드온은 HyperShift Operator에서 --enable-uwm-telemetry-remote-write 옵션을 활성화합니다. 이 옵션을 활성화하면 사용자 워크로드 모니터링이 활성화되고 컨트롤 플레인에서 Telemetry 메트릭을 원격으로 작성할 수 있습니다.
인터넷에 연결되지 않은 OpenShift Container Platform 클러스터에 다중 클러스터 엔진 Operator를 설치한 경우 다음 명령을 입력하여 HyperShift Operator의 사용자 워크로드 모니터링 기능을 실행하려고 하면 오류와 함께 기능이 실패합니다.
oc get events -n hypershift오류는 다음과 같을 수 있습니다.
LAST SEEN TYPE REASON OBJECT MESSAGE
4m46s Warning ReconcileError deployment/operator Failed to ensure UWM telemetry remote write: cannot get telemeter client secret: Secret "telemeter-client" not found
이 오류를 방지하려면 local-cluster 네임스페이스에 구성 맵을 생성하여 사용자 워크로드 모니터링 옵션을 비활성화해야 합니다. 애드온을 활성화하기 전이나 후에 구성 맵을 생성할 수 있습니다. 애드온 에이전트는 HyperShift Operator를 재구성합니다.
다음 구성 맵을 생성합니다.
kind: ConfigMap
apiVersion: v1
metadata:
name: hypershift-operator-install-flags
namespace: local-cluster
data:
installFlagsToAdd: ""
installFlagsToRemove: "--enable-uwm-telemetry-remote-write"1.7.12.4.1. 호스트된 컨트롤 플레인 기능의 상태 확인
호스트된 컨트롤 플레인 기능은 기본적으로 활성화되어 있습니다.
기능이 비활성화되고 이를 활성화하려면 다음 명령을 입력합니다.
multiclusterengine을 다중 클러스터 엔진 Operator 인스턴스의 이름으로 교체합니다.oc patch mce <multiclusterengine> --type=merge -p '{"spec":{"overrides":{"components":[{"name":"hypershift","enabled": true}]}}}'기능을 활성화하면
hypershift-addon관리 클러스터 애드온이로컬 클러스터 관리 클러스터에설치되고 애드온 에이전트는 다중 클러스터 엔진 Operator 허브 클러스터에 HyperShift Operator를 설치합니다.다음 명령을 입력하여
hypershift-addon관리 클러스터 애드온이 설치되었는지 확인합니다.oc get managedclusteraddons -n local-cluster hypershift-addon결과 출력을 확인합니다.
NAME AVAILABLE DEGRADED PROGRESSING hypershift-addon True False이 프로세스 중에 시간 초과를 방지하려면 다음 명령을 입력합니다.
oc wait --for=condition=Degraded=True managedclusteraddons/hypershift-addon -n local-cluster --timeout=5moc wait --for=condition=Available=True managedclusteraddons/hypershift-addon -n local-cluster --timeout=5m프로세스가 완료되면
hypershift-addon관리 클러스터 애드온 및 HyperShift Operator가 설치되고로컬 클러스터관리 클러스터를 호스팅 및 관리할 수 있습니다.
1.7.12.4.2. 인프라 노드에서 실행되도록 하이퍼shift-addon 관리 클러스터 애드온 구성
기본적으로 hypershift-addon 관리 클러스터 애드온에 노드 배치 기본 설정은 지정되지 않습니다. 인프라 노드에서 애드온을 실행하는 것이 좋습니다. 이렇게 하면 서브스크립션 수와 별도의 유지 관리 및 관리 작업에 대해 청구 비용이 발생하지 않도록 할 수 있습니다.
- hub 클러스터에 로그인합니다.
다음 명령을 입력하여 편집할
hypershift-addon-deploy-config배포 구성 사양을 엽니다.oc edit addondeploymentconfig hypershift-addon-deploy-config -n multicluster-engine다음 예와 같이
nodePlacement필드를 사양에 추가합니다.apiVersion: addon.open-cluster-management.io/v1alpha1 kind: AddOnDeploymentConfig metadata: name: hypershift-addon-deploy-config namespace: multicluster-engine spec: nodePlacement: nodeSelector: node-role.kubernetes.io/infra: "" tolerations: - effect: NoSchedule key: node-role.kubernetes.io/infra operator: Exists-
변경 사항을 저장합니다.
하이퍼shift-addon관리 클러스터 애드온은 신규 및 기존 관리 클러스터를 위해 인프라 노드에 배포됩니다.
1.7.12.5. IPv4를 사용하여 연결이 끊긴 환경에서 호스트된 컨트롤 플레인 구성
IPv4 네트워크를 사용하여 연결이 끊긴 환경에서 호스팅된 컨트롤 플레인을 구성할 수 있습니다. IPv4 범위에는 IPv6 또는 듀얼 스택 설정보다 적은 수의 외부 구성 요소가 필요합니다.
IPv4 네트워크에서 호스팅 컨트롤 플레인을 구성하려면 다음 단계를 검토하십시오.
- IPv4 네트워크에 대한 하이퍼바이저 구성
- IPv4 네트워크에 대한 DNS 구성
- IPv4 네트워크의 레지스트리 배포
- IPv4 네트워크의 관리 클러스터 설정
- IPv4 네트워크에 대한 웹 서버 구성
- IPv4 네트워크의 이미지 미러링 구성
- IPv4 네트워크용 다중 클러스터 엔진 Operator 배포
- IPv4 네트워크에 대한 TLS 인증서 구성
- IPv4 네트워크용 호스트 클러스터 배포
- IPv4 네트워크에 대한 배포 완료
1.7.12.5.1. IPv4 네트워크에 대한 하이퍼바이저 구성
다음 정보는 가상 머신 환경에만 적용됩니다.
1.7.12.5.1.1. 가상 OpenShift Container Platform 클러스터용 패키지 액세스 및 배포
가상 OpenShift Container Platform 관리 클러스터를 배포하려면 다음 명령을 입력하여 필요한 패키지에 액세스합니다.
sudo dnf install dnsmasq radvd vim golang podman bind-utils net-tools httpd-tools tree htop strace tmux -y다음 명령을 입력하여 Podman 서비스를 활성화하고 시작합니다.
systemctl enable --now podmankcli를 사용하여 OpenShift Container Platform 관리 클러스터 및 기타 가상 구성 요소를 배포하려면 다음 명령을 입력하여 하이퍼바이저를 설치 및 구성합니다.sudo yum -y install libvirt libvirt-daemon-driver-qemu qemu-kvmsudo usermod -aG qemu,libvirt $(id -un)sudo newgrp libvirtsudo systemctl enable --now libvirtdsudo dnf -y copr enable karmab/kclisudo dnf -y install kclisudo kcli create pool -p /var/lib/libvirt/images defaultkcli create host kvm -H 127.0.0.1 localsudo setfacl -m u:$(id -un):rwx /var/lib/libvirt/imageskcli create network -c 192.168.122.0/24 default
1.7.12.5.1.2. 네트워크 관리자 디스패처 활성화
네트워크 관리자 디스패처를 활성화하여 가상 머신이 필요한 도메인, 경로 및 레지스트리를 확인할 수 있는지 확인합니다. 네트워크 관리자 디스패처를 활성화하려면
/etc/NetworkManager/dispatcher.d/디렉터리에서 다음 콘텐츠가 포함된forcedns라는 스크립트를 생성하여 환경에 맞게 값을 교체하십시오.#!/bin/bash export IP="192.168.126.1"1 export BASE_RESOLV_CONF="/run/NetworkManager/resolv.conf" if ! [[ `grep -q "$IP" /etc/resolv.conf` ]]; then export TMP_FILE=$(mktemp /etc/forcedns_resolv.conf.XXXXXX) cp $BASE_RESOLV_CONF $TMP_FILE chmod --reference=$BASE_RESOLV_CONF $TMP_FILE sed -i -e "s/dns.base.domain.name//" -e "s/search /& dns.base.domain.name /" -e "0,/nameserver/s/nameserver/& $IP\n&/" $TMP_FILE2 mv $TMP_FILE /etc/resolv.conf fi echo "ok"파일을 생성한 후 다음 명령을 입력하여 권한을 추가합니다.
chmod 755 /etc/NetworkManager/dispatcher.d/forcedns-
스크립트를 실행하고 출력이
ok를 반환하는지 확인합니다.
1.7.12.5.1.3. BMC 액세스 구성
가상 머신의 BMC(Baseboard Management Controller)를 시뮬레이션하도록
ksushy를 구성합니다. 다음 명령을 입력합니다.sudo dnf install python3-pyOpenSSL.noarch python3-cherrypy -ykcli create sushy-service --ssl --port 9000sudo systemctl daemon-reloadsystemctl enable --now ksushy다음 명령을 입력하여 서비스가 올바르게 작동하는지 테스트합니다.
systemctl status ksushy
1.7.12.5.1.4. 연결을 허용하도록 하이퍼바이저 시스템 구성
개발 환경에서 작업하는 경우 환경 내에서 다양한 가상 네트워크를 통한 다양한 유형의 연결을 허용하도록 하이퍼바이저 시스템을 구성합니다.
참고: 프로덕션 환경에서 작업하는 경우 firewalld 서비스에 대한 적절한 규칙을 설정하고 안전한 환경을 유지 관리하도록 SELinux 정책을 구성해야 합니다.
SELinux의 경우 다음 명령을 입력합니다.
sed -i s/^SELINUX=.*$/SELINUX=permissive/ /etc/selinux/config; setenforce 0firewalld의 경우 다음 명령을 입력합니다.systemctl disable --now firewalldlibvirtd의 경우 다음 명령을 입력합니다.systemctl restart libvirtdsystemctl enable --now libvirtd
다음으로 환경에 맞게 DNS를 구성합니다.
1.7.12.5.1.5. 추가 리소스
-
kcli에 대한 자세한 내용은 공식 kcli 설명서 를 참조하십시오.
1.7.12.5.2. IPv4 네트워크에 대한 DNS 구성
이 단계는 가상 및 베어 메탈 환경 모두에서 연결이 끊긴 환경과 연결된 환경 모두에 필요합니다. 가상 환경과 베어 메탈 환경 간의 주요 차이점은 리소스를 구성하는 위치에 있습니다. 베어 메탈 환경에서는 dnsmasq 와 같은 경량 솔루션이 아닌 바인딩과 같은 솔루션을 사용합니다.
- 가상 환경에서 IPv4 네트워크에 대한 DNS를 구성하려면 기본 인그레스 및 DNS 동작을 참조하십시오.
- 베어 메탈에서 IPv4 네트워크의 DNS를 구성하려면 베어 메탈 에서 DNS 구성을 참조하십시오.
다음으로 레지스트리를 배포합니다.
1.7.12.5.3. IPv4 네트워크의 레지스트리 배포
개발 환경의 경우 Podman 컨테이너를 사용하여 소규모 자체 호스팅 레지스트리를 배포합니다. 프로덕션 환경의 경우 Red Hat Quay, Nexus 또는 Artifactory와 같은 엔터프라이즈 호스팅 레지스트리를 사용합니다.
Podman을 사용하여 작은 레지스트리를 배포하려면 다음 단계를 완료합니다.
권한 있는 사용자로
${HOME}디렉터리에 액세스하고 다음 스크립트를 생성합니다.#!/usr/bin/env bash set -euo pipefail PRIMARY_NIC=$(ls -1 /sys/class/net | grep -v podman | head -1) export PATH=/root/bin:$PATH export PULL_SECRET="/root/baremetal/hub/openshift_pull.json"1 if [[ ! -f $PULL_SECRET ]];then echo "Pull Secret not found, exiting..." exit 1 fi dnf -y install podman httpd httpd-tools jq skopeo libseccomp-devel export IP=$(ip -o addr show $PRIMARY_NIC | head -1 | awk '{print $4}' | cut -d'/' -f1) REGISTRY_NAME=registry.$(hostname --long) REGISTRY_USER=dummy REGISTRY_PASSWORD=dummy KEY=$(echo -n $REGISTRY_USER:$REGISTRY_PASSWORD | base64) echo "{\"auths\": {\"$REGISTRY_NAME:5000\": {\"auth\": \"$KEY\", \"email\": \"sample-email@domain.ltd\"}}}" > /root/disconnected_pull.json mv ${PULL_SECRET} /root/openshift_pull.json.old jq ".auths += {\"$REGISTRY_NAME:5000\": {\"auth\": \"$KEY\",\"email\": \"sample-email@domain.ltd\"}}" < /root/openshift_pull.json.old > $PULL_SECRET mkdir -p /opt/registry/{auth,certs,data,conf} cat <<EOF > /opt/registry/conf/config.yml version: 0.1 log: fields: service: registry storage: cache: blobdescriptor: inmemory filesystem: rootdirectory: /var/lib/registry delete: enabled: true http: addr: :5000 headers: X-Content-Type-Options: [nosniff] health: storagedriver: enabled: true interval: 10s threshold: 3 compatibility: schema1: enabled: true EOF openssl req -newkey rsa:4096 -nodes -sha256 -keyout /opt/registry/certs/domain.key -x509 -days 3650 -out /opt/registry/certs/domain.crt -subj "/C=US/ST=Madrid/L=San Bernardo/O=Karmalabs/OU=Guitar/CN=$REGISTRY_NAME" -addext "subjectAltName=DNS:$REGISTRY_NAME" cp /opt/registry/certs/domain.crt /etc/pki/ca-trust/source/anchors/ update-ca-trust extract htpasswd -bBc /opt/registry/auth/htpasswd $REGISTRY_USER $REGISTRY_PASSWORD podman create --name registry --net host --security-opt label=disable --replace -v /opt/registry/data:/var/lib/registry:z -v /opt/registry/auth:/auth:z -v /opt/registry/conf/config.yml:/etc/docker/registry/config.yml -e "REGISTRY_AUTH=htpasswd" -e "REGISTRY_AUTH_HTPASSWD_REALM=Registry" -e "REGISTRY_HTTP_SECRET=ALongRandomSecretForRegistry" -e REGISTRY_AUTH_HTPASSWD_PATH=/auth/htpasswd -v /opt/registry/certs:/certs:z -e REGISTRY_HTTP_TLS_CERTIFICATE=/certs/domain.crt -e REGISTRY_HTTP_TLS_KEY=/certs/domain.key docker.io/library/registry:latest [ "$?" == "0" ] || !! systemctl enable --now registry- 1
PULL_SECRET위치를 설정에 적합한 위치로 교체합니다.
스크립트 파일 이름을
registry.sh로 지정하고 저장합니다. 스크립트를 실행하면 다음 정보를 가져옵니다.- 하이퍼바이저 호스트 이름을 기반으로 하는 레지스트리 이름
- 필요한 인증 정보 및 사용자 액세스 세부 정보
다음과 같이 실행 플래그를 추가하여 권한을 조정합니다.
chmod u+x ${HOME}/registry.sh매개변수 없이 스크립트를 실행하려면 다음 명령을 입력합니다.
${HOME}/registry.sh스크립트가 서버를 시작합니다.
스크립트는 관리 목적으로
systemd서비스를 사용합니다. 스크립트를 관리해야 하는 경우 다음 명령을 사용할 수 있습니다.systemctl statussystemctl startsystemctl stop
레지스트리의 루트 폴더는 /opt/registry 디렉터리에 있으며 다음 하위 디렉터리가 포함되어 있습니다.
-
인증서에는TLS 인증서가 포함되어 있습니다. -
auth에는 인증 정보가 포함됩니다. -
데이터에는 레지스트리 이미지가 포함되어 있습니다. -
conf에는 레지스트리 구성이 포함되어 있습니다.
1.7.12.5.4. IPv4 네트워크의 관리 클러스터 설정
OpenShift Container Platform 관리 클러스터를 설정하려면 dev-scripts를 사용하거나 가상 머신을 기반으로 하는 경우 kcli 툴을 사용할 수 있습니다. 다음 지침은 kcli 툴에 따라 다릅니다.
하이퍼바이저에서 적절한 네트워크를 사용할 준비가 되었는지 확인합니다. 네트워크는 관리 및 호스팅 클러스터를 모두 호스팅합니다. 다음
kcli명령을 입력합니다.kcli create network -c 192.168.125.0/24 -P dhcp=false -P dns=false --domain dns.base.domain.name ipv4다음과 같습니다.
-
-c는 네트워크의 CIDR을 지정합니다. -
-P dhcp=false는 DHCP를 비활성화하도록 네트워크를 구성하며, 구성한dnsmasq에서 처리합니다. -
-P dns=false는 DNS를 비활성화하도록 네트워크를 구성하며, 구성한dnsmasq에서도 처리합니다. -
--domain은 검색할 도메인을 설정합니다. -
DNS.base.domain.name은 DNS 기본 도메인 이름입니다. -
ipv4는 생성 중인 네트워크의 이름입니다.
-
네트워크가 생성되면 다음 출력을 검토합니다.
[root@hypershiftbm ~]# kcli list network Listing Networks... +---------+--------+---------------------+-------+------------------+------+ | Network | Type | Cidr | Dhcp | Domain | Mode | +---------+--------+---------------------+-------+------------------+------+ | default | routed | 192.168.122.0/24 | True | default | nat | | ipv4 | routed | 192.168.125.0/24 | False | dns.base.domain.name | nat | | ipv6 | routed | 2620:52:0:1306::/64 | False | dns.base.domain.name | nat | +---------+--------+---------------------+-------+------------------+------+[root@hypershiftbm ~]# kcli info network ipv4 Providing information about network ipv4... cidr: 192.168.125.0/24 dhcp: false domain: dns.base.domain.name mode: nat plan: kvirt type: routedOpenShift Container Platform 관리 클러스터를 배포할 수 있도록 풀 시크릿 및
kcli계획 파일이 있는지 확인합니다.-
풀 시크릿이
kcli계획과 동일한 폴더에 있고 풀 시크릿 파일의 이름이openshift_pull.json인지 확인합니다. mgmt-compact-hub-ipv4.yaml파일에서 OpenShift Container Platform 정의가 포함된kcli계획을 추가합니다. 해당 환경과 일치하도록 파일 콘텐츠를 업데이트해야 합니다.plan: hub-ipv4 force: true version: nightly tag: "4.x.y-x86_64"1 cluster: "hub-ipv4" domain: dns.base.domain.name api_ip: 192.168.125.10 ingress_ip: 192.168.125.11 disconnected_url: registry.dns.base.domain.name:5000 disconnected_update: true disconnected_user: dummy disconnected_password: dummy disconnected_operators_version: v4.14 disconnected_operators: - name: metallb-operator - name: lvms-operator channels: - name: stable-4.13 disconnected_extra_images: - quay.io/user-name/trbsht:latest - quay.io/user-name/hypershift:BMSelfManage-v4.14-rc-v3 - registry.redhat.io/openshift4/ose-kube-rbac-proxy:v4.10 dualstack: false disk_size: 200 extra_disks: [200] memory: 48000 numcpus: 16 ctlplanes: 3 workers: 0 manifests: extra-manifests metal3: true network: ipv4 users_dev: developer users_devpassword: developer users_admin: admin users_adminpassword: admin metallb_pool: ipv4-virtual-network metallb_ranges: - 192.168.125.150-192.168.125.190 metallb_autoassign: true apps: - users - lvms-operator - metallb-operator vmrules: - hub-bootstrap: nets: - name: ipv4 mac: aa:aa:aa:aa:02:10 - hub-ctlplane-0: nets: - name: ipv4 mac: aa:aa:aa:aa:02:01 - hub-ctlplane-1: nets: - name: ipv4 mac: aa:aa:aa:aa:02:02 - hub-ctlplane-2: nets: - name: ipv4 mac: aa:aa:aa:aa:02:03
- 1
4.x.y를 사용하려는 지원되는 OpenShift Container Platform 버전으로 교체합니다.
-
풀 시크릿이
관리 클러스터를 프로비저닝하려면 다음 명령을 입력합니다.
kcli create cluster openshift --pf mgmt-compact-hub-ipv4.yaml
1.7.12.5.4.1. 추가 리소스
-
kcli계획 파일의 매개변수에 대한 자세한 내용은 공식kcli문서의 parameters.yml 만들기 를 참조하십시오.
1.7.12.5.5. IPv4 네트워크에 대한 웹 서버 구성
호스트 클러스터로 배포 중인 OpenShift Container Platform 릴리스와 연결된 RHCOS(Red Hat Enterprise Linux CoreOS) 이미지를 호스팅하도록 추가 웹 서버를 구성해야 합니다.
웹 서버를 구성하려면 다음 단계를 완료합니다.
다음 명령을 입력하여 사용할 OpenShift Container Platform 릴리스에서
openshift-install바이너리를 추출합니다.oc adm -a ${LOCAL_SECRET_JSON} release extract --command=openshift-install "${LOCAL_REGISTRY}/${LOCAL_REPOSITORY}:${OCP_RELEASE}-${ARCHITECTURE}"다음 스크립트를 실행합니다. 이 스크립트는
/opt/srv디렉터리에 폴더를 생성합니다. 폴더에는 작업자 노드를 프로비저닝하는 RHCOS 이미지가 포함되어 있습니다.#!/bin/bash WEBSRV_FOLDER=/opt/srv ROOTFS_IMG_URL="$(./openshift-install coreos print-stream-json | jq -r '.architectures.x86_64.artifacts.metal.formats.pxe.rootfs.location')"1 LIVE_ISO_URL="$(./openshift-install coreos print-stream-json | jq -r '.architectures.x86_64.artifacts.metal.formats.iso.disk.location')"2 mkdir -p ${WEBSRV_FOLDER}/images curl -Lk ${ROOTFS_IMG_URL} -o ${WEBSRV_FOLDER}/images/${ROOTFS_IMG_URL##*/} curl -Lk ${LIVE_ISO_URL} -o ${WEBSRV_FOLDER}/images/${LIVE_ISO_URL##*/} chmod -R 755 ${WEBSRV_FOLDER}/* ## Run Webserver podman ps --noheading | grep -q websrv-ai if [[ $? == 0 ]];then echo "Launching Registry pod..." /usr/bin/podman run --name websrv-ai --net host -v /opt/srv:/usr/local/apache2/htdocs:z quay.io/alosadag/httpd:p8080 fi
다운로드가 완료되면 컨테이너가 실행되어 웹 서버에서 이미지를 호스팅합니다. 컨테이너는 공식 HTTPd 이미지의 변형을 사용하여 IPv6 네트워크에서도 작업할 수 있습니다.
1.7.12.5.6. IPv4 네트워크의 이미지 미러링 구성
이미지 미러링은 registry.redhat.com 또는 quay.io 와 같은 외부 레지스트리에서 이미지를 가져와서 프라이빗 레지스트리에 저장하는 프로세스입니다.
1.7.12.5.6.1. 미러링 프로세스 완료
참고: 레지스트리 서버가 실행된 후 미러링 프로세스를 시작합니다.
다음 절차에서는 ImageSetConfiguration 오브젝트를 사용하는 바이너리인 oc-mirror 툴이 사용됩니다. 파일에서 다음 정보를 지정할 수 있습니다.
-
미러링할 OpenShift Container Platform 버전입니다. 버전은
quay.io에 있습니다. - 미러링할 추가 Operator입니다. 패키지를 개별적으로 선택합니다.
- 리포지토리에 추가할 추가 이미지입니다.
이미지 미러링을 구성하려면 다음 단계를 완료합니다.
-
이미지를 푸시하려는 프라이빗 레지스트리와 미러링할 레지스트리를 사용하여
${HOME}/.docker/config.json파일이 업데이트되었는지 확인합니다. 다음 예제를 사용하여 미러링에 사용할
ImageSetConfiguration오브젝트를 만듭니다. 환경에 맞게 필요에 따라 값을 바꿉니다.apiVersion: mirror.openshift.io/v1alpha2 kind: ImageSetConfiguration storageConfig: registry: imageURL: registry.dns.base.domain.name:5000/openshift/release/metadata:latest1 mirror: platform: channels: - name: candidate-4.14 minVersion: 4.x.y-x86_642 maxVersion: 4.x.y-x86_64 type: ocp graph: true additionalImages: - name: quay.io/karmab/origin-keepalived-ipfailover:latest - name: quay.io/karmab/kubectl:latest - name: quay.io/karmab/haproxy:latest - name: quay.io/karmab/mdns-publisher:latest - name: quay.io/karmab/origin-coredns:latest - name: quay.io/karmab/curl:latest - name: quay.io/karmab/kcli:latest - name: quay.io/user-name/trbsht:latest - name: quay.io/user-name/hypershift:BMSelfManage-v4.14-rc-v3 - name: registry.redhat.io/openshift4/ose-kube-rbac-proxy:v4.10 operators: - catalog: registry.redhat.io/redhat/redhat-operator-index:v4.14 packages: - name: lvms-operator - name: local-storage-operator - name: odf-csi-addons-operator - name: odf-operator - name: mcg-operator - name: ocs-operator - name: metallb-operator - name: kubevirt-hyperconverged다음 명령을 입력하여 미러링 프로세스를 시작합니다.
oc-mirror --source-skip-tls --config imagesetconfig.yaml docker://${REGISTRY}미러링 프로세스가 완료되면 호스트 클러스터에 적용할 ICSP 및 카탈로그 소스가 포함된
oc-mirror-workspace/results-XXXXXX/라는 새 폴더가 있습니다.oc adm release mirror명령을 사용하여 OpenShift Container Platform의 Nightly 또는 CI 버전을 미러링합니다. 다음 명령을 실행합니다.REGISTRY=registry.$(hostname --long):5000 oc adm release mirror \ --from=registry.ci.openshift.org/ocp/release:4.x.y-x86_64 \ --to=${REGISTRY}/openshift/release \ --to-release-image=${REGISTRY}/openshift/release-images:4.x.y-x86_644.x.y를 사용하려는 지원되는 OpenShift Container Platform 버전으로 교체합니다.- 연결이 끊긴 네트워크에 설치 단계에 따라 최신 다중 클러스터 엔진 Operator 이미지를 미러링합니다.
1.7.12.5.6.2. 관리 클러스터에 오브젝트 적용
미러링 프로세스가 완료되면 관리 클러스터에 두 개의 오브젝트를 적용해야 합니다.
- Image Content Source Policies (ICSP) 또는 Image Digest 미러 세트(IDMS)
- 카탈로그 소스
oc-mirror 툴을 사용하는 경우 출력 아티팩트는 oc-mirror-workspace/results-XXXXXX/ 이라는 폴더에 있습니다.
ICSP 또는 IDMS는 노드를 재시작하지 않고 각 노드에서 kubelet을 다시 시작하는 MachineConfig 변경 사항을 시작합니다. 노드가 READY 로 표시되면 새로 생성된 카탈로그 소스를 적용해야 합니다.
카탈로그 소스는 카탈로그 이미지 다운로드 및 처리와 같은 openshift-marketplace Operator에서 작업을 시작하여 해당 이미지에 포함된 모든 PackageManifest 를 검색합니다.
새 소스를 확인하려면 새
CatalogSource를 소스로 사용하여 다음 명령을 실행합니다.oc get packagemanifest아티팩트를 적용하려면 다음 단계를 완료합니다.
다음 명령을 입력하여 ICSP(ICSP) 또는 IDMS 아티팩트를 생성합니다.
oc apply -f oc-mirror-workspace/results-XXXXXX/imageContentSourcePolicy.yaml- 노드가 준비될 때까지 기다린 다음 다음 명령을 입력합니다.
oc apply -f catalogSource-XXXXXXXX-index.yamlOLM 카탈로그를 미러링하고 미러를 가리키도록 uchd 클러스터를 구성합니다.
관리(기본값) OLMCatalogPlacement 모드를 사용하면 관리 클러스터의 ICSP에서 재정의 정보를 사용하여 OLM 카탈로그에 사용되는 이미지 스트림이 자동으로 수정되지 않습니다.-
원래 이름 및 태그를 사용하여 OLM 카탈로그가 내부 레지스트리에 올바르게 미러링된 경우
hypershift.openshift.io/olm-catalogs-is-registry-overrides주석을HostedCluster리소스에 추가합니다. 형식은"sr1=dr1,sr2=dr2"입니다. 여기서 소스 레지스트리 문자열은 키이고 대상 레지스트리는 값입니다. OLM 카탈로그 이미지 스트림 메커니즘을 바이패스하려면
HostedCluster리소스에서 다음 4개의 주석을 사용하여 OLM Operator 카탈로그에 사용할 4개의 이미지의 주소를 직접 지정합니다.-
hypershift.openshift.io/certified-operators-catalog-image -
hypershift.openshift.io/community-operators-catalog-image -
hypershift.openshift.io/redhat-marketplace-catalog-image -
hypershift.openshift.io/redhat-operators-catalog-image
이 경우 이미지 스트림이 생성되지 않으며 Operator 업데이트를 가져오려면 내부 미러가 새로 고쳐질 때 주석 값을 업데이트해야 합니다.
-
참고: 재정의 메커니즘이 필요한 경우 4개의 기본 카탈로그 소스에 대한 4개의 값이 모두 필요합니다.
-
원래 이름 및 태그를 사용하여 OLM 카탈로그가 내부 레지스트리에 올바르게 미러링된 경우
1.7.12.5.6.3. 추가 리소스
- 가상 환경에서 작업하는 경우 미러링을 구성한 후 OpenShift Virtualization에서 호스팅되는 컨트롤 플레인의 사전 요구 사항을 충족해야 합니다.
- Nightly 또는 CI 버전의 OpenShift Container Platform 미러링에 대한 자세한 내용은 oc-mirror 플러그인을 사용하여 연결이 끊긴 설치의 이미지 미러링을 참조하십시오.
1.7.12.5.7. IPv4 네트워크용 다중 클러스터 엔진 Operator 배포
다중 클러스터 엔진 Operator는 공급업체에 클러스터를 배포하는 데 중요한 역할을 합니다. Red Hat Advanced Cluster Management를 이미 설치한 경우 자동으로 설치되므로 다중 클러스터 엔진 Operator를 설치할 필요가 없습니다.
다중 클러스터 엔진 Operator가 설치되어 있지 않은 경우 다음 문서를 검토하여 사전 요구 사항 및 설치 단계를 이해하십시오.
1.7.12.5.7.1. AgentServiceConfig 리소스 배포
AgentServiceConfig 사용자 지정 리소스는 다중 클러스터 엔진 Operator의 일부인 지원 서비스 애드온의 필수 구성 요소입니다. 베어 메탈 클러스터 배포를 담당합니다. 애드온이 활성화되면 AgentServiceConfig 리소스를 배포하여 애드온을 구성합니다.
AgentServiceConfig 리소스를 구성하는 것 외에도 연결이 끊긴 환경에서 다중 클러스터 엔진 Operator가 제대로 작동하는지 확인하기 위해 추가 구성 맵을 포함해야 합니다.
배포를 사용자 지정하는 연결이 끊긴 세부 정보가 포함된 다음 구성 맵을 추가하여 사용자 정의 레지스트리를 구성합니다.
--- apiVersion: v1 kind: ConfigMap metadata: name: custom-registries namespace: multicluster-engine labels: app: assisted-service data: ca-bundle.crt: | -----BEGIN CERTIFICATE----- -----END CERTIFICATE----- registries.conf: | unqualified-search-registries = ["registry.access.redhat.com", "docker.io"] [[registry]] prefix = "" location = "registry.redhat.io/openshift4" mirror-by-digest-only = true [[registry.mirror]] location = "registry.dns.base.domain.name:5000/openshift4"1 [[registry]] prefix = "" location = "registry.redhat.io/rhacm2" mirror-by-digest-only = true ... ...- 1
dns.base.domain.name을 DNS 기본 도메인 이름으로 교체합니다.
오브젝트에는 다음 두 개의 필드가 있습니다.
- 사용자 정의 CA: 이 필드에는 배포의 다양한 프로세스에 로드되는 CA(인증 기관)가 포함되어 있습니다.
-
Registry:
Registries.conf필드에는 원래 소스 레지스트리가 아닌 미러 레지스트리에서 사용해야 하는 이미지 및 네임스페이스에 대한 정보가 포함되어 있습니다.
다음 예와 같이
AssistedServiceConfig오브젝트를 추가하여 Assisted Service를 구성합니다.--- apiVersion: agent-install.openshift.io/v1beta1 kind: AgentServiceConfig metadata: annotations: unsupported.agent-install.openshift.io/assisted-service-configmap: assisted-service-config1 name: agent namespace: multicluster-engine spec: mirrorRegistryRef: name: custom-registries2 databaseStorage: storageClassName: lvms-vg1 accessModes: - ReadWriteOnce resources: requests: storage: 10Gi filesystemStorage: storageClassName: lvms-vg1 accessModes: - ReadWriteOnce resources: requests: storage: 20Gi osImages:3 - cpuArchitecture: x86_64 openshiftVersion: "4.14" rootFSUrl: http://registry.dns.base.domain.name:8080/images/rhcos-414.92.202308281054-0-live-rootfs.x86_64.img4 url: http://registry.dns.base.domain.name:8080/images/rhcos-414.92.202308281054-0-live.x86_64.iso version: 414.92.202308281054-0- 1
metadata.annotations["unsupported.agent-install.openshift.io/assisted-service-configmap"]주석은 Operator가 동작을 사용자 정의하는 데 사용하는 구성 맵 이름을 참조합니다.- 2
spec.mirrorRegistryRef.name주석은 Assisted Service Operator가 사용하는 연결이 끊긴 레지스트리 정보가 포함된 구성 맵을 가리킵니다. 이 구성 맵은 배포 프로세스 중에 해당 리소스를 추가합니다.- 3
spec.osImages필드에는 이 Operator에서 배포할 수 있는 다양한 버전이 포함되어 있습니다. 이 필드는 필수입니다. 이 예제에서는 이미RootFS및LiveISO파일을 다운로드했다고 가정합니다.- 4
rootFSUrl및url필드에서dns.base.domain.name을 DNS 기본 도메인 이름으로 교체합니다.
해당 오브젝트를 단일 파일에 연결하고 관리 클러스터에 적용하여 모든 오브젝트를 배포합니다. 이렇게 하려면 다음 명령을 입력합니다.
oc apply -f agentServiceConfig.yaml이 명령은 이 예제 출력에 표시된 대로 두 개의 Pod를 트리거합니다.
assisted-image-service-0 1/1 Running 2 11d1 assisted-service-668b49548-9m7xw 2/2 Running 5 11d2
1.7.12.5.8. IPv4 네트워크에 대한 TLS 인증서 구성
연결이 끊긴 환경에서 호스팅된 컨트롤 플레인을 구성하는 프로세스에 여러 TLS 인증서가 포함됩니다. 관리 클러스터에 CA(인증 기관)를 추가하려면 OpenShift Container Platform 컨트롤 플레인 및 작업자 노드에서 다음 파일의 내용을 수정해야 합니다.
-
/etc/pki/ca-trust/extracted/pem/ -
/etc/pki/ca-trust/source/anchors -
/etc/pki/tls/certs/
관리 클러스터에 CA를 추가하려면 다음 단계를 완료합니다.
-
공식 OpenShift Container Platform 설명서에서 CA 번들 업데이트 단계를 완료합니다. 이 방법은 CA를 OpenShift Container Platform 노드에 배포하는
image-registry-operator를 사용하는 것입니다. 해당 방법이 상황에 적용되지 않는 경우 관리 클러스터의
openshift-config네임스페이스에user-ca-bundle이라는 구성 맵이 포함되어 있는지 확인합니다.네임스페이스에 해당 구성 맵이 포함된 경우 다음 명령을 입력합니다.
## REGISTRY_CERT_PATH=<PATH/TO/YOUR/CERTIFICATE/FILE> export REGISTRY_CERT_PATH=/opt/registry/certs/domain.crt oc create configmap user-ca-bundle -n openshift-config --from-file=ca-bundle.crt=${REGISTRY_CERT_PATH}네임스페이스에 해당 구성 맵이 포함되지 않은 경우 다음 명령을 입력합니다.
## REGISTRY_CERT_PATH=<PATH/TO/YOUR/CERTIFICATE/FILE> export REGISTRY_CERT_PATH=/opt/registry/certs/domain.crt export TMP_FILE=$(mktemp) oc get cm -n openshift-config user-ca-bundle -ojsonpath='{.data.ca-bundle\.crt}' > ${TMP_FILE} echo >> ${TMP_FILE} echo \#registry.$(hostname --long) >> ${TMP_FILE} cat ${REGISTRY_CERT_PATH} >> ${TMP_FILE} oc create configmap user-ca-bundle -n openshift-config --from-file=ca-bundle.crt=${TMP_FILE} --dry-run=client -o yaml | kubectl apply -f -
1.7.12.5.9. IPv4 네트워크용 호스트 클러스터 배포
호스팅 클러스터는 관리 클러스터에서 호스팅되는 컨트롤 플레인 및 API 끝점이 있는 OpenShift Container Platform 클러스터입니다. 호스트된 클러스터에는 컨트롤 플레인과 해당 데이터 플레인이 포함됩니다.
Red Hat Advanced Cluster Management에서 콘솔을 사용하여 호스트 클러스터를 생성할 수 있지만 다음 절차에서는 관련 아티팩트를 수정하는 데 더 유연하게 사용할 수 있는 매니페스트를 사용합니다.
1.7.12.5.9.1. 호스트된 클러스터 오브젝트 배포
이 절차의 목적을 위해 다음 값이 사용됩니다.
-
HostedCluster 이름:
hosted-ipv4 -
HostedCluster 네임스페이스:
클러스터 -
disconnected:
true -
네트워크 스택:
IPv4
일반적으로 HyperShift Operator는 HostedControlPlane 네임스페이스를 생성합니다. 그러나 이 경우 HyperShift Operator가 HostedCluster 오브젝트를 조정하기 전에 모든 오브젝트를 포함해야 합니다. 그러면 Operator가 조정 프로세스를 시작하면 모든 오브젝트를 찾을 수 있습니다.
네임스페이스에 대한 다음 정보를 사용하여 YAML 파일을 생성합니다.
--- apiVersion: v1 kind: Namespace metadata: creationTimestamp: null name: clusters-hosted-ipv4 spec: {} status: {} --- apiVersion: v1 kind: Namespace metadata: creationTimestamp: null name: clusters spec: {} status: {}HostedCluster배포에 포함할 구성 맵 및 시크릿에 대한 다음 정보를 사용하여 YAML 파일을 생성합니다.--- apiVersion: v1 data: ca-bundle.crt: | -----BEGIN CERTIFICATE----- -----END CERTIFICATE----- kind: ConfigMap metadata: name: user-ca-bundle namespace: clusters --- apiVersion: v1 data: .dockerconfigjson: xxxxxxxxx kind: Secret metadata: creationTimestamp: null name: hosted-ipv4-pull-secret namespace: clusters --- apiVersion: v1 kind: Secret metadata: name: sshkey-cluster-hosted-ipv4 namespace: clusters stringData: id_rsa.pub: ssh-rsa xxxxxxxxx --- apiVersion: v1 data: key: nTPtVBEt03owkrKhIdmSW8jrWRxU57KO/fnZa8oaG0Y= kind: Secret metadata: creationTimestamp: null name: hosted-ipv4-etcd-encryption-key namespace: clusters type: Opaque지원 서비스 에이전트가 호스팅된 컨트롤 플레인과 동일한
HostedControlPlane네임스페이스에 있을 수 있고 클러스터 API에서 계속 관리할 수 있도록 RBAC 역할이 포함된 YAML 파일을 생성합니다.apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: creationTimestamp: null name: capi-provider-role namespace: clusters-hosted-ipv4 rules: - apiGroups: - agent-install.openshift.io resources: - agents verbs: - '*'필요에 따라 값을 교체하여
HostedCluster오브젝트에 대한 정보를 사용하여 YAML 파일을 생성합니다.apiVersion: hypershift.openshift.io/v1beta1 kind: HostedCluster metadata: name: hosted-ipv4 namespace: clusters spec: additionalTrustBundle: name: "user-ca-bundle" olmCatalogPlacement: guest imageContentSources:1 - source: quay.io/openshift-release-dev/ocp-v4.0-art-dev mirrors: - registry.dns.base.domain.name:5000/openshift/release - source: quay.io/openshift-release-dev/ocp-release mirrors: - registry.dns.base.domain.name:5000/openshift/release-images - mirrors: ... ... autoscaling: {} controllerAvailabilityPolicy: SingleReplica dns: baseDomain: dns.base.domain.name etcd: managed: storage: persistentVolume: size: 8Gi restoreSnapshotURL: null type: PersistentVolume managementType: Managed fips: false networking: clusterNetwork: - cidr: 10.132.0.0/14 networkType: OVNKubernetes serviceNetwork: - cidr: 172.31.0.0/16 platform: agent: agentNamespace: clusters-hosted-ipv4 type: Agent pullSecret: name: hosted-ipv4-pull-secret release: image: registry.dns.base.domain.name:5000/openshift/release-images:4.x.y-x86_64 secretEncryption: aescbc: activeKey: name: hosted-ipv4-etcd-encryption-key type: aescbc services: - service: APIServer servicePublishingStrategy: nodePort: address: api.hosted-ipv4.dns.base.domain.name type: NodePort - service: OAuthServer servicePublishingStrategy: nodePort: address: api.hosted-ipv4.dns.base.domain.name type: NodePort - service: OIDC servicePublishingStrategy: nodePort: address: api.hosted-ipv4.dns.base.domain.name type: NodePort - service: Konnectivity servicePublishingStrategy: nodePort: address: api.hosted-ipv4.dns.base.domain.name type: NodePort - service: Ignition servicePublishingStrategy: nodePort: address: api.hosted-ipv4.dns.base.domain.name type: NodePort sshKey: name: sshkey-cluster-hosted-ipv4 status: controlPlaneEndpoint: host: "" port: 0여기서
dns.base.domain.name은 DNS 기본 도메인 이름이며4.x.y는 사용하려는 지원되는 OpenShift Container Platform 버전입니다.- 1
imageContentSources섹션에는 호스팅된 클러스터 내의 사용자 워크로드에 대한 미러 참조가 포함되어 있습니다.
OpenShift Container Platform 릴리스의 HyperShift Operator 릴리스를 가리키는
HostedCluster오브젝트에 주석을 추가합니다.다음 명령을 입력하여 이미지 페이로드를 가져옵니다.
oc adm release info registry.dns.base.domain.name:5000/openshift-release-dev/ocp-release:4.x.y-x86_64 | grep hypershift여기서
dns.base.domain.name은 DNS 기본 도메인 이름이며4.x.y는 사용하려는 지원되는 OpenShift Container Platform 버전입니다.다음 출력을 참조하십시오.
hypershift sha256:31149e3e5f8c5e5b5b100ff2d89975cf5f7a73801b2c06c639bf6648766117f8OpenShift Container Platform 이미지 네임스페이스를 사용하여 다음 명령을 입력하여 다이제스트를 확인합니다.
podman pull registry.dns.base.domain.name:5000/openshift-release-dev/ocp-v4.0-art-dev@sha256:31149e3e5f8c5e5b5b100ff2d89975cf5f7a73801b2c06c639bf6648766117f8여기서
dns.base.domain.name은 DNS 기본 도메인 이름입니다.다음 출력을 참조하십시오.
podman pull registry.dns.base.domain.name:5000/openshift/release@sha256:31149e3e5f8c5e5b5b100ff2d89975cf5f7a73801b2c06c639bf6648766117f8 Trying to pull registry.dns.base.domain.name:5000/openshift/release@sha256:31149e3e5f8c5e5b5b100ff2d89975cf5f7a73801b2c06c639bf6648766117f8... Getting image source signatures Copying blob d8190195889e skipped: already exists Copying blob c71d2589fba7 skipped: already exists Copying blob d4dc6e74b6ce skipped: already exists Copying blob 97da74cc6d8f skipped: already exists Copying blob b70007a560c9 done Copying config 3a62961e6e done Writing manifest to image destination Storing signatures 3a62961e6ed6edab46d5ec8429ff1f41d6bb68de51271f037c6cb8941a007fde
참고:
HostedCluster오브젝트에 설정된 릴리스 이미지는 태그가 아닌 다이제스트를 사용해야 합니다. 예를 들어quay.io/openshift-release-dev/ocp-release@sha256:e3ba11bd1e5e8ea5a0b36a75791c90f29afb0fdbe4125be4e48f69c76a5c.YAML 파일에 정의된 모든 오브젝트를 파일에 연결하고 관리 클러스터에 적용하여 해당 오브젝트를 생성합니다. 이렇게 하려면 다음 명령을 입력합니다.
oc apply -f 01-4.14-hosted_cluster-nodeport.yaml호스트된 컨트롤 플레인의 출력을 참조하십시오.
NAME READY STATUS RESTARTS AGE capi-provider-5b57dbd6d5-pxlqc 1/1 Running 0 3m57s catalog-operator-9694884dd-m7zzv 2/2 Running 0 93s cluster-api-f98b9467c-9hfrq 1/1 Running 0 3m57s cluster-autoscaler-d7f95dd5-d8m5d 1/1 Running 0 93s cluster-image-registry-operator-5ff5944b4b-648ht 1/2 Running 0 93s cluster-network-operator-77b896ddc-wpkq8 1/1 Running 0 94s cluster-node-tuning-operator-84956cd484-4hfgf 1/1 Running 0 94s cluster-policy-controller-5fd8595d97-rhbwf 1/1 Running 0 95s cluster-storage-operator-54dcf584b5-xrnts 1/1 Running 0 93s cluster-version-operator-9c554b999-l22s7 1/1 Running 0 95s control-plane-operator-6fdc9c569-t7hr4 1/1 Running 0 3m57s csi-snapshot-controller-785c6dc77c-8ljmr 1/1 Running 0 77s csi-snapshot-controller-operator-7c6674bc5b-d9dtp 1/1 Running 0 93s csi-snapshot-webhook-5b8584875f-2492j 1/1 Running 0 77s dns-operator-6874b577f-9tc6b 1/1 Running 0 94s etcd-0 3/3 Running 0 3m39s hosted-cluster-config-operator-f5cf5c464-4nmbh 1/1 Running 0 93s ignition-server-6b689748fc-zdqzk 1/1 Running 0 95s ignition-server-proxy-54d4bb9b9b-6zkg7 1/1 Running 0 95s ingress-operator-6548dc758b-f9gtg 1/2 Running 0 94s konnectivity-agent-7767cdc6f5-tw782 1/1 Running 0 95s kube-apiserver-7b5799b6c8-9f5bp 4/4 Running 0 3m7s kube-controller-manager-5465bc4dd6-zpdlk 1/1 Running 0 44s kube-scheduler-5dd5f78b94-bbbck 1/1 Running 0 2m36s machine-approver-846c69f56-jxvfr 1/1 Running 0 92s oauth-openshift-79c7bf44bf-j975g 2/2 Running 0 62s olm-operator-767f9584c-4lcl2 2/2 Running 0 93s openshift-apiserver-5d469778c6-pl8tj 3/3 Running 0 2m36s openshift-controller-manager-6475fdff58-hl4f7 1/1 Running 0 95s openshift-oauth-apiserver-dbbc5cc5f-98574 2/2 Running 0 95s openshift-route-controller-manager-5f6997b48f-s9vdc 1/1 Running 0 95s packageserver-67c87d4d4f-kl7qh 2/2 Running 0 93s호스트 클러스터의 출력을 참조하십시오.
NAMESPACE NAME VERSION KUBECONFIG PROGRESS AVAILABLE PROGRESSING MESSAGE clusters hosted-ipv4 hosted-admin-kubeconfig Partial True False The hosted control plane is available
다음으로 NodePool 오브젝트를 생성합니다.
1.7.12.5.9.2. 호스트된 클러스터에 대한 NodePool 오브젝트 생성
NodePool 은 호스팅된 클러스터와 연결된 확장 가능한 작업자 노드 집합입니다. NodePool 머신 아키텍처는 특정 풀 내에서 일관되게 유지되며 컨트롤 플레인의 머신 아키텍처와 독립적입니다.
NodePool오브젝트에 대한 다음 정보를 사용하여 YAML 파일을 생성하여 필요에 따라 값을 바꿉니다.apiVersion: hypershift.openshift.io/v1beta1 kind: NodePool metadata: creationTimestamp: null name: hosted-ipv4 namespace: clusters spec: arch: amd64 clusterName: hosted-ipv4 management: autoRepair: false1 upgradeType: InPlace2 nodeDrainTimeout: 0s platform: type: Agent release: image: registry.dns.base.domain.name:5000/openshift/release-images:4.x.y-x86_643 replicas: 0 status: replicas: 04 - 1
- 노드가 제거되면 노드가 다시 생성되지 않기 때문에
autoRepair필드가false로 설정됩니다. - 2
upgradeType은 업그레이드 중에 동일한 베어 메탈 노드가 재사용됨을 나타내는InPlace로 설정됩니다.- 3
- 이
NodePool에 포함된 모든 노드는 다음 OpenShift Container Platform 버전4.x.y-x86_64를 기반으로 합니다.dns.base.domain.name을 DNS 기본 도메인 이름으로 바꾸고4.x.y를 사용하려는 지원되는 OpenShift Container Platform 버전으로 바꿉니다. - 4
- 필요한 경우 스케일링할 수 있도록
replicas값은0으로 설정됩니다. 모든 단계가 완료될 때까지NodePool복제본을 0으로 유지하는 것이 중요합니다.
다음 명령을 입력하여
NodePool오브젝트를 생성합니다.oc apply -f 02-nodepool.yaml출력을 참조하십시오.
NAMESPACE NAME CLUSTER DESIRED NODES CURRENT NODES AUTOSCALING AUTOREPAIR VERSION UPDATINGVERSION UPDATINGCONFIG MESSAGE clusters hosted-ipv4 hosted 0 False False 4.x.y-x86_644.x.y를 사용하려는 지원되는 OpenShift Container Platform 버전으로 교체합니다.
다음으로 InfraEnv 리소스를 생성합니다.
1.7.12.5.9.3. 호스트된 클러스터에 대한 InfraEnv 리소스 생성
InfraEnv 리소스는 pullSecretRef 및 sshAuthorizedKey 와 같은 필수 세부 정보를 포함하는 지원 서비스 오브젝트입니다. 이러한 세부 사항은 호스팅된 클러스터에 대해 사용자 지정된 RHCOS(Red Hat Enterprise Linux CoreOS) 부팅 이미지를 생성하는 데 사용됩니다.
필요에 따라 값을 교체하여
InfraEnv리소스에 대한 다음 정보를 사용하여 YAML 파일을 생성합니다.--- apiVersion: agent-install.openshift.io/v1beta1 kind: InfraEnv metadata: name: hosted-ipv4 namespace: clusters-hosted-ipv4 spec: pullSecretRef:1 name: pull-secret sshAuthorizedKey: ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABgQDk7ICaUE+/k4zTpxLk4+xFdHi4ZuDi5qjeF52afsNkw0w/glILHhwpL5gnp5WkRuL8GwJuZ1VqLC9EKrdmegn4MrmUlq7WTsP0VFOZFBfq2XRUxo1wrRdor2z0Bbh93ytR+ZsDbbLlGngXaMa0Vbt+z74FqlcajbHTZ6zBmTpBVq5RHtDPgKITdpE1fongp7+ZXQNBlkaavaqv8bnyrP4BWahLP4iO9/xJF9lQYboYwEEDzmnKLMW1VtCE6nJzEgWCufACTbxpNS7GvKtoHT/OVzw8ArEXhZXQUS1UY8zKsX2iXwmyhw5Sj6YboA8WICs4z+TrFP89LmxXY0j6536TQFyRz1iB4WWvCbH5n6W+ABV2e8ssJB1AmEy8QYNwpJQJNpSxzoKBjI73XxvPYYC/IjPFMySwZqrSZCkJYqQ023ySkaQxWZT7in4KeMu7eS2tC+Kn4deJ7KwwUycx8n6RHMeD8Qg9flTHCv3gmab8JKZJqN3hW1D378JuvmIX4V0=2 다음 명령을 입력하여
InfraEnv리소스를 생성합니다.oc apply -f 03-infraenv.yaml다음 출력을 참조하십시오.
NAMESPACE NAME ISO CREATED AT clusters-hosted-ipv4 hosted 2023-09-11T15:14:10Z
다음으로 작업자 노드를 생성합니다.
1.7.12.5.9.4. 호스트된 클러스터의 작업자 노드 생성
베어 메탈 플랫폼에서 작업하는 경우 작업자 노드를 생성하는 것은 BareMetalHost 의 세부 정보가 올바르게 구성되었는지 확인하는 데 중요합니다.
가상 머신으로 작업하는 경우 다음 단계를 완료하여 Metal3 Operator에서 사용하는 빈 작업자 노드를 생성할 수 있습니다. 이렇게 하려면 kcli 를 사용합니다.
이것이 작업자 노드 생성을 처음 시도하지 않은 경우 먼저 이전 설정을 삭제해야 합니다. 이렇게 하려면 다음 명령을 입력하여 계획을 삭제합니다.
kcli delete plan hosted-ipv4-
계획을 삭제할지 여부를 확인하라는 메시지가 표시되면
y를 입력합니다. - 계획이 삭제되었음을 알리는 메시지가 표시되는지 확인합니다.
-
계획을 삭제할지 여부를 확인하라는 메시지가 표시되면
다음 명령을 입력하여 가상 머신을 생성합니다.
kcli create vm -P start=False -P uefi_legacy=true -P plan=hosted-ipv4 -P memory=8192 -P numcpus=16 -P disks=[200,200] -P nets=["{\"name\": \"ipv4\", \"mac\": \"aa:aa:aa:aa:02:11\"}"] -P uuid=aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaa0211 -P name=hosted-ipv4-worker0kcli create vm -P start=False -P uefi_legacy=true -P plan=hosted-ipv4 -P memory=8192 -P numcpus=16 -P disks=[200,200] -P nets=["{\"name\": \"ipv4\", \"mac\": \"aa:aa:aa:aa:02:12\"}"] -P uuid=aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaa0212 -P name=hosted-ipv4-worker1kcli create vm -P start=False -P uefi_legacy=true -P plan=hosted-ipv4 -P memory=8192 -P numcpus=16 -P disks=[200,200] -P nets=["{\"name\": \"ipv4\", \"mac\": \"aa:aa:aa:aa:02:13\"}"] -P uuid=aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaa0213 -P name=hosted-ipv4-worker2systemctl restart ksushy다음과 같습니다.
-
start=False는 VM(가상 머신)이 생성 시 자동으로 시작되지 않음을 의미합니다. -
uefi_legacy=true는 UEFI 레거시 부팅을 사용하여 이전 UEFI 구현과의 호환성을 보장합니다. -
plan=hosted-dual은 시스템 그룹을 클러스터로 식별하는 계획 이름을 나타냅니다. -
memory=8192및numcpus=16은 RAM 및 CPU를 포함하여 VM의 리소스를 지정하는 매개변수입니다. -
disks=[200,200]은 VM에 씬 프로비저닝된 두 개의 디스크를 생성 중임을 나타냅니다. -
nets=[{"name": "dual", "mac": "aa:aa:aa:aa:aa:aa:02:13"}]은 연결할 네트워크 이름과 기본 인터페이스의 MAC 주소를 포함한 네트워크 세부 정보입니다. -
ksushy를 다시 시작하여ksushy툴을 다시 시작하여 추가한 VM을 감지합니다.
-
결과 출력을 확인합니다.
+---------------------+--------+-------------------+----------------------------------------------------+-------------+---------+ | Name | Status | Ip | Source | Plan | Profile | +---------------------+--------+-------------------+----------------------------------------------------+-------------+---------+ | hosted-worker0 | down | | | hosted-ipv4 | kvirt | | hosted-worker1 | down | | | hosted-ipv4 | kvirt | | hosted-worker2 | down | | | hosted-ipv4 | kvirt | +---------------------+--------+-------------------+----------------------------------------------------+-------------+---------+
다음으로 호스팅된 클러스터에 대한 베어 메탈 호스트를 생성합니다.
1.7.12.5.9.5. 호스트 클러스터를 위한 베어 메탈 호스트 생성
베어 메탈 호스트 는 Metal3 Operator가 식별할 수 있도록 물리적 및 논리 세부 정보를 포함하는 openshift-machine-api 오브젝트입니다. 이러한 세부 사항은 에이전트 라고 하는 기타 지원 서비스 오브젝트와 연결됩니다.
중요: 베어 메탈 호스트 및 대상 노드를 생성하기 전에 가상 머신을 생성해야 합니다.
베어 메탈 호스트를 생성하려면 다음 단계를 완료합니다.
다음 정보를 사용하여 YAML 파일을 생성합니다.
참고: 베어 메탈 호스트 인증 정보를 보유하는 시크릿이 하나 이상 있으므로 각 작업자 노드에 대해 두 개 이상의 오브젝트를 생성해야 합니다.
--- apiVersion: v1 kind: Secret metadata: name: hosted-ipv4-worker0-bmc-secret namespace: clusters-hosted-ipv4 data: password: YWRtaW4= username: YWRtaW4= type: Opaque --- apiVersion: metal3.io/v1alpha1 kind: BareMetalHost metadata: name: hosted-ipv4-worker0 namespace: clusters-hosted-ipv4 labels: infraenvs.agent-install.openshift.io: hosted-ipv41 annotations: inspect.metal3.io: disabled bmac.agent-install.openshift.io/hostname: hosted-ipv4-worker02 spec: automatedCleaningMode: disabled3 bmc: disableCertificateVerification: true4 address: redfish-virtualmedia://[192.168.125.1]:9000/redfish/v1/Systems/local/hosted-ipv4-worker05 credentialsName: hosted-ipv4-worker0-bmc-secret6 bootMACAddress: aa:aa:aa:aa:02:117 online: true8 - 1
infraenvs.agent-install.openshift.io는 지원 설치 프로그램과BareMetalHost오브젝트 간의 링크 역할을 합니다.- 2
- B
MAC.agent-install.openshift.io/hostname은 배포 중에 채택된 노드 이름을 나타냅니다. - 3
automatedCleaningMode를 사용하면 Metal3 Operator에 의해 노드가 지워지지 않습니다.- 4
- 클라이언트에서 인증서 유효성 검사를 바이패스하려면
disableCertificateVerification이true로 설정됩니다. - 5
address는 작업자 노드의 BMC(Baseboard Management Controller) 주소를 나타냅니다.- 6
credentialsName은 사용자 및 암호 인증 정보가 저장된 시크릿을 가리킵니다.- 7
bootMACAddress는 노드가 시작되는 인터페이스 MACAddress를 나타냅니다.- 8
online은BareMetalHost개체가 생성된 후 노드의 상태를 정의합니다.
다음 명령을 입력하여
BareMetalHost오브젝트를 배포합니다.oc apply -f 04-bmh.yaml프로세스 중에 다음 출력을 볼 수 있습니다.
이 출력은 프로세스가 노드에 연결을 시도 중임을 나타냅니다.
NAMESPACE NAME STATE CONSUMER ONLINE ERROR AGE clusters-hosted hosted-worker0 registering true 2s clusters-hosted hosted-worker1 registering true 2s clusters-hosted hosted-worker2 registering true 2s이 출력은 노드가 시작됨을 나타냅니다.
NAMESPACE NAME STATE CONSUMER ONLINE ERROR AGE clusters-hosted hosted-worker0 provisioning true 16s clusters-hosted hosted-worker1 provisioning true 16s clusters-hosted hosted-worker2 provisioning true 16s- 이 출력은 노드가 성공적으로 시작되었음을 나타냅니다.
NAMESPACE NAME STATE CONSUMER ONLINE ERROR AGE clusters-hosted hosted-worker0 provisioned true 67s clusters-hosted hosted-worker1 provisioned true 67s clusters-hosted hosted-worker2 provisioned true 67s노드가 시작된 후 다음 예와 같이 네임스페이스의 에이전트를 확인합니다.
NAMESPACE NAME CLUSTER APPROVED ROLE STAGE clusters-hosted aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaa0411 true auto-assign clusters-hosted aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaa0412 true auto-assign clusters-hosted aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaa0413 true auto-assign에이전트는 설치에 사용할 수 있는 노드를 나타냅니다. 호스트 클러스터에 노드를 할당하려면 노드 풀을 확장합니다.
1.7.12.5.9.6. 노드 풀 확장
베어 메탈 호스트를 생성한 후 해당 상태가 Registering 에서 Provisioning (프로비저닝)으로 변경됨. 노드는 에이전트의 LiveISO 및 에이전트 라는 기본 Pod로 시작합니다. 해당 에이전트는 OpenShift Container Platform 페이로드를 설치하기 위해 Assisted Service Operator에서 지침을 받습니다.
노드 풀을 확장하려면 다음 명령을 입력합니다.
oc -n clusters scale nodepool hosted-ipv4 --replicas 3확장 프로세스가 완료되면 에이전트가 호스팅된 클러스터에 할당되어 있습니다.
NAMESPACE NAME CLUSTER APPROVED ROLE STAGE clusters-hosted aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaa0411 hosted true auto-assign clusters-hosted aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaa0412 hosted true auto-assign clusters-hosted aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaa0413 hosted true auto-assign또한 노드 풀 복제본이 설정되어 있습니다.
NAMESPACE NAME CLUSTER DESIRED NODES CURRENT NODES AUTOSCALING AUTOREPAIR VERSION UPDATINGVERSION UPDATINGCONFIG MESSAGE clusters hosted hosted 3 False False 4.x.y-x86_64 Minimum availability requires 3 replicas, current 0 available4.x.y를 사용하려는 지원되는 OpenShift Container Platform 버전으로 교체합니다.- 노드가 클러스터에 참여할 때까지 기다립니다. 프로세스 중에 에이전트는 단계 및 상태에 대한 업데이트를 제공합니다.
다음으로 호스트 클러스터의 배포를 모니터링합니다.
1.7.12.5.10. IPv4 네트워크의 호스트 클러스터 배포 완료
컨트롤 플레인과 데이터 플레인의 두 가지 관점에서 호스팅 클러스터 배포를 모니터링할 수 있습니다.
1.7.12.5.10.1. 컨트롤 플레인 모니터링
호스팅 클러스터를 배포하는 동안 다음 명령을 입력하여 컨트롤 플레인을 모니터링할 수 있습니다.
export KUBECONFIG=/root/.kcli/clusters/hub-ipv4/auth/kubeconfigwatch "oc get pod -n hypershift;echo;echo;oc get pod -n clusters-hosted-ipv4;echo;echo;oc get bmh -A;echo;echo;oc get agent -A;echo;echo;oc get infraenv -A;echo;echo;oc get hostedcluster -A;echo;echo;oc get nodepool -A;echo;echo;"이러한 명령은 다음 아티팩트에 대한 정보를 제공합니다.
- The HyperShift Operator
-
HostedControlPlanePod - 베어 메탈 호스트
- 에이전트
-
InfraEnv리소스 -
HostedCluster및NodePool리소스
1.7.12.5.10.2. 데이터 플레인 모니터링
배포 프로세스 중에 Operator가 진행 중인 방식을 모니터링하려면 다음 명령을 입력합니다.
oc get secret -n clusters-hosted-ipv4 admin-kubeconfig -o jsonpath='{.data.kubeconfig}' |base64 -d > /root/hc_admin_kubeconfig.yamlexport KUBECONFIG=/root/hc_admin_kubeconfig.yamlwatch "oc get clusterversion,nodes,co"이러한 명령은 다음 아티팩트에 대한 정보를 제공합니다.
- 클러스터 버전
- 특히 노드가 클러스터에 참여하는지 여부에 대한 노드
- 클러스터 Operator
1.7.12.6. IPv6 네트워크에서 호스트된 컨트롤 플레인 구성
IPv6 네트워크 구성은 현재 연결이 끊긴 것으로 지정됩니다. 이러한 지정의 주요 이유는 원격 레지스트리가 IPv6에서 작동하지 않기 때문입니다.
IPv6 네트워크에서 호스팅된 컨트롤 플레인을 구성하려면 다음 단계를 검토하십시오.
- IPv6 네트워크에 대한 하이퍼바이저 구성
- IPv6 네트워크에 대한 DNS 구성
- IPv6 네트워크의 레지스트리 배포
- IPv6 네트워크의 관리 클러스터 설정
- IPv6 네트워크에 대한 웹 서버 구성
- IPv6 네트워크에 대한 이미지 미러링 구성
- IPv6 네트워크용 다중 클러스터 엔진 Operator 배포
- IPv6 네트워크에 대한 TLS 인증서 구성
- IPv6 네트워크에 대해 호스트된 클러스터 배포
- IPv6 네트워크에 대한 배포 완료
1.7.12.6.1. IPv6 네트워크에 대한 하이퍼바이저 구성
다음 정보는 가상 머신 환경에만 적용됩니다.
1.7.12.6.1.1. 가상 OpenShift Container Platform 클러스터용 패키지 액세스 및 배포
가상 OpenShift Container Platform 관리 클러스터를 배포하려면 다음 명령을 입력하여 필요한 패키지에 액세스합니다.
sudo dnf install dnsmasq radvd vim golang podman bind-utils net-tools httpd-tools tree htop strace tmux -y다음 명령을 입력하여 Podman 서비스를 활성화하고 시작합니다.
systemctl enable --now podmankcli를 사용하여 OpenShift Container Platform 관리 클러스터 및 기타 가상 구성 요소를 배포하려면 다음 명령을 입력하여 하이퍼바이저를 설치 및 구성합니다.sudo yum -y install libvirt libvirt-daemon-driver-qemu qemu-kvmsudo usermod -aG qemu,libvirt $(id -un)sudo newgrp libvirtsudo systemctl enable --now libvirtdsudo dnf -y copr enable karmab/kclisudo dnf -y install kclisudo kcli create pool -p /var/lib/libvirt/images defaultkcli create host kvm -H 127.0.0.1 localsudo setfacl -m u:$(id -un):rwx /var/lib/libvirt/imageskcli create network -c 192.168.122.0/24 default
1.7.12.6.1.2. 네트워크 관리자 디스패처 활성화
네트워크 관리자 디스패처를 활성화하여 가상 머신이 필요한 도메인, 경로 및 레지스트리를 확인할 수 있는지 확인합니다. 네트워크 관리자 디스패처를 활성화하려면
/etc/NetworkManager/dispatcher.d/디렉터리에서 다음 콘텐츠가 포함된forcedns라는 스크립트를 생성하여 환경에 맞게 값을 교체하십시오.#!/bin/bash export IP="2620:52:0:1306::1"1 export BASE_RESOLV_CONF="/run/NetworkManager/resolv.conf" if ! [[ `grep -q "$IP" /etc/resolv.conf` ]]; then export TMP_FILE=$(mktemp /etc/forcedns_resolv.conf.XXXXXX) cp $BASE_RESOLV_CONF $TMP_FILE chmod --reference=$BASE_RESOLV_CONF $TMP_FILE sed -i -e "s/dns.base.domain.name//" -e "s/search /& dns.base.domain.name /" -e "0,/nameserver/s/nameserver/& $IP\n&/" $TMP_FILE2 mv $TMP_FILE /etc/resolv.conf fi echo "ok"파일을 생성한 후 다음 명령을 입력하여 권한을 추가합니다.
chmod 755 /etc/NetworkManager/dispatcher.d/forcedns-
스크립트를 실행하고 출력이
ok를 반환하는지 확인합니다.
1.7.12.6.1.3. BMC 액세스 구성
가상 머신의 BMC(Baseboard Management Controller)를 시뮬레이션하도록
ksushy를 구성합니다. 다음 명령을 입력합니다.sudo dnf install python3-pyOpenSSL.noarch python3-cherrypy -ykcli create sushy-service --ssl --ipv6 --port 9000sudo systemctl daemon-reloadsystemctl enable --now ksushy다음 명령을 입력하여 서비스가 올바르게 작동하는지 테스트합니다.
systemctl status ksushy
1.7.12.6.1.4. 연결을 허용하도록 하이퍼바이저 시스템 구성
개발 환경에서 작업하는 경우 환경 내에서 다양한 가상 네트워크를 통한 다양한 유형의 연결을 허용하도록 하이퍼바이저 시스템을 구성합니다.
참고: 프로덕션 환경에서 작업하는 경우 firewalld 서비스에 대한 적절한 규칙을 설정하고 안전한 환경을 유지 관리하도록 SELinux 정책을 구성해야 합니다.
SELinux의 경우 다음 명령을 입력합니다.
sed -i s/^SELINUX=.*$/SELINUX=permissive/ /etc/selinux/config; setenforce 0firewalld의 경우 다음 명령을 입력합니다.systemctl disable --now firewalldlibvirtd의 경우 다음 명령을 입력합니다.systemctl restart libvirtdsystemctl enable --now libvirtd
다음으로 환경에 맞게 DNS를 구성합니다.
1.7.12.6.1.5. 추가 리소스
-
kcli에 대한 자세한 내용은 공식 kcli 설명서 를 참조하십시오.
1.7.12.6.2. IPv6 네트워크에 대한 DNS 구성
이 단계는 가상 및 베어 메탈 환경 모두에서 연결이 끊긴 환경과 연결된 환경 모두에 필요합니다. 가상 환경과 베어 메탈 환경 간의 주요 차이점은 리소스를 구성하는 위치에 있습니다. 베어 메탈 환경에서는 dnsmasq 와 같은 경량 솔루션이 아닌 바인딩과 같은 솔루션을 사용합니다.
- 가상 환경에서 IPv6 네트워크에 대한 DNS를 구성하려면 기본 인그레스 및 DNS 동작을 참조하십시오.
- 베어 메탈에서 IPv6 네트워크의 DNS를 구성하려면 베어 메탈 에서 DNS 구성을 참조하십시오.
다음으로 레지스트리를 배포합니다.
1.7.12.6.3. IPv6 네트워크의 레지스트리 배포
개발 환경의 경우 Podman 컨테이너를 사용하여 소규모 자체 호스팅 레지스트리를 배포합니다. 프로덕션 환경의 경우 Red Hat Quay, Nexus 또는 Artifactory와 같은 엔터프라이즈 호스팅 레지스트리를 사용합니다.
Podman을 사용하여 작은 레지스트리를 배포하려면 다음 단계를 완료합니다.
권한 있는 사용자로
${HOME}디렉터리에 액세스하고 다음 스크립트를 생성합니다.#!/usr/bin/env bash set -euo pipefail PRIMARY_NIC=$(ls -1 /sys/class/net | grep -v podman | head -1) export PATH=/root/bin:$PATH export PULL_SECRET="/root/baremetal/hub/openshift_pull.json"1 if [[ ! -f $PULL_SECRET ]];then echo "Pull Secret not found, exiting..." exit 1 fi dnf -y install podman httpd httpd-tools jq skopeo libseccomp-devel export IP=$(ip -o addr show $PRIMARY_NIC | head -1 | awk '{print $4}' | cut -d'/' -f1) REGISTRY_NAME=registry.$(hostname --long) REGISTRY_USER=dummy REGISTRY_PASSWORD=dummy KEY=$(echo -n $REGISTRY_USER:$REGISTRY_PASSWORD | base64) echo "{\"auths\": {\"$REGISTRY_NAME:5000\": {\"auth\": \"$KEY\", \"email\": \"sample-email@domain.ltd\"}}}" > /root/disconnected_pull.json mv ${PULL_SECRET} /root/openshift_pull.json.old jq ".auths += {\"$REGISTRY_NAME:5000\": {\"auth\": \"$KEY\",\"email\": \"sample-email@domain.ltd\"}}" < /root/openshift_pull.json.old > $PULL_SECRET mkdir -p /opt/registry/{auth,certs,data,conf} cat <<EOF > /opt/registry/conf/config.yml version: 0.1 log: fields: service: registry storage: cache: blobdescriptor: inmemory filesystem: rootdirectory: /var/lib/registry delete: enabled: true http: addr: :5000 headers: X-Content-Type-Options: [nosniff] health: storagedriver: enabled: true interval: 10s threshold: 3 compatibility: schema1: enabled: true EOF openssl req -newkey rsa:4096 -nodes -sha256 -keyout /opt/registry/certs/domain.key -x509 -days 3650 -out /opt/registry/certs/domain.crt -subj "/C=US/ST=Madrid/L=San Bernardo/O=Karmalabs/OU=Guitar/CN=$REGISTRY_NAME" -addext "subjectAltName=DNS:$REGISTRY_NAME" cp /opt/registry/certs/domain.crt /etc/pki/ca-trust/source/anchors/ update-ca-trust extract htpasswd -bBc /opt/registry/auth/htpasswd $REGISTRY_USER $REGISTRY_PASSWORD podman create --name registry --net host --security-opt label=disable --replace -v /opt/registry/data:/var/lib/registry:z -v /opt/registry/auth:/auth:z -v /opt/registry/conf/config.yml:/etc/docker/registry/config.yml -e "REGISTRY_AUTH=htpasswd" -e "REGISTRY_AUTH_HTPASSWD_REALM=Registry" -e "REGISTRY_HTTP_SECRET=ALongRandomSecretForRegistry" -e REGISTRY_AUTH_HTPASSWD_PATH=/auth/htpasswd -v /opt/registry/certs:/certs:z -e REGISTRY_HTTP_TLS_CERTIFICATE=/certs/domain.crt -e REGISTRY_HTTP_TLS_KEY=/certs/domain.key docker.io/library/registry:latest [ "$?" == "0" ] || !! systemctl enable --now registry- 1
PULL_SECRET위치를 설정에 적합한 위치로 교체합니다.
스크립트 파일 이름을
registry.sh로 지정하고 저장합니다. 스크립트를 실행하면 다음 정보를 가져옵니다.- 하이퍼바이저 호스트 이름을 기반으로 하는 레지스트리 이름
- 필요한 인증 정보 및 사용자 액세스 세부 정보
다음과 같이 실행 플래그를 추가하여 권한을 조정합니다.
chmod u+x ${HOME}/registry.sh매개변수 없이 스크립트를 실행하려면 다음 명령을 입력합니다.
${HOME}/registry.sh스크립트가 서버를 시작합니다.
스크립트는 관리 목적으로
systemd서비스를 사용합니다. 스크립트를 관리해야 하는 경우 다음 명령을 사용할 수 있습니다.systemctl statussystemctl startsystemctl stop
레지스트리의 루트 폴더는 /opt/registry 디렉터리에 있으며 다음 하위 디렉터리가 포함되어 있습니다.
-
인증서에는TLS 인증서가 포함되어 있습니다. -
auth에는 인증 정보가 포함됩니다. -
데이터에는 레지스트리 이미지가 포함되어 있습니다. -
conf에는 레지스트리 구성이 포함되어 있습니다.
1.7.12.6.4. IPv6 네트워크의 관리 클러스터 설정
OpenShift Container Platform 관리 클러스터를 설정하려면 dev-scripts를 사용하거나 가상 머신을 기반으로 하는 경우 kcli 툴을 사용할 수 있습니다. 다음 지침은 kcli 툴에 따라 다릅니다.
하이퍼바이저에서 적절한 네트워크를 사용할 준비가 되었는지 확인합니다. 네트워크는 관리 및 호스팅 클러스터를 모두 호스팅합니다. 다음
kcli명령을 입력합니다.kcli create network -c 2620:52:0:1305::0/64 -P dhcp=false -P dns=false --domain dns.base.domain.name --nodhcp ipv6다음과 같습니다.
-
-c는 네트워크의 CIDR을 지정합니다. -
-P dhcp=false는 DHCP를 비활성화하도록 네트워크를 구성하며, 구성한dnsmasq에서 처리합니다. -
-P dns=false는 DNS를 비활성화하도록 네트워크를 구성하며, 구성한dnsmasq에서도 처리합니다. -
--domain은 검색할 도메인을 설정합니다. -
DNS.base.domain.name은 DNS 기본 도메인 이름입니다. -
ipv6는 생성 중인 네트워크의 이름입니다.
-
네트워크가 생성되면 다음 출력을 검토합니다.
[root@hypershiftbm ~]# kcli list network Listing Networks... +---------+--------+---------------------+-------+------------------+------+ | Network | Type | Cidr | Dhcp | Domain | Mode | +---------+--------+---------------------+-------+------------------+------+ | default | routed | 192.168.122.0/24 | True | default | nat | | ipv4 | routed | 192.168.125.0/24 | False | dns.base.domain.name | nat | | ipv4 | routed | 2620:52:0:1305::/64 | False | dns.base.domain.name | nat | +---------+--------+---------------------+-------+------------------+------+[root@hypershiftbm ~]# kcli info network ipv6 Providing information about network ipv6... cidr: 2620:52:0:1305::/64 dhcp: false domain: dns.base.domain.name mode: nat plan: kvirt type: routedOpenShift Container Platform 관리 클러스터를 배포할 수 있도록 풀 시크릿 및
kcli계획 파일이 있는지 확인합니다.-
풀 시크릿이
kcli계획과 동일한 폴더에 있고 풀 시크릿 파일의 이름이openshift_pull.json인지 확인합니다. -
mgmt-compact-hub-ipv6.yaml파일에서 OpenShift Container Platform 정의가 포함된kcli계획을 추가합니다. 해당 환경과 일치하도록 파일 콘텐츠를 업데이트해야 합니다.
plan: hub-ipv6 force: true version: nightly tag: "4.x.y-x86_64" cluster: "hub-ipv6" ipv6: true domain: dns.base.domain.name api_ip: 2620:52:0:1305::2 ingress_ip: 2620:52:0:1305::3 disconnected_url: registry.dns.base.domain.name:5000 disconnected_update: true disconnected_user: dummy disconnected_password: dummy disconnected_operators_version: v4.14 disconnected_operators: - name: metallb-operator - name: lvms-operator channels: - name: stable-4.13 disconnected_extra_images: - quay.io/user-name/trbsht:latest - quay.io/user-name/hypershift:BMSelfManage-v4.14-rc-v3 - registry.redhat.io/openshift4/ose-kube-rbac-proxy:v4.10 dualstack: false disk_size: 200 extra_disks: [200] memory: 48000 numcpus: 16 ctlplanes: 3 workers: 0 manifests: extra-manifests metal3: true network: ipv6 users_dev: developer users_devpassword: developer users_admin: admin users_adminpassword: admin metallb_pool: ipv6-virtual-network metallb_ranges: - 2620:52:0:1305::150-2620:52:0:1305::190 metallb_autoassign: true apps: - users - lvms-operator - metallb-operator vmrules: - hub-bootstrap: nets: - name: ipv6 mac: aa:aa:aa:aa:03:10 - hub-ctlplane-0: nets: - name: ipv6 mac: aa:aa:aa:aa:03:01 - hub-ctlplane-1: nets: - name: ipv6 mac: aa:aa:aa:aa:03:02 - hub-ctlplane-2: nets: - name: ipv6 mac: aa:aa:aa:aa:03:03-
풀 시크릿이
관리 클러스터를 프로비저닝하려면 다음 명령을 입력합니다.
kcli create cluster openshift --pf mgmt-compact-hub-ipv6.yaml
1.7.12.6.4.1. 추가 리소스
-
kcli계획 파일의 매개변수에 대한 자세한 내용은 공식kcli문서의 parameters.yml 만들기 를 참조하십시오.
1.7.12.6.5. IPv6 네트워크에 대한 웹 서버 구성
호스트 클러스터로 배포 중인 OpenShift Container Platform 릴리스와 연결된 RHCOS(Red Hat Enterprise Linux CoreOS) 이미지를 호스팅하도록 추가 웹 서버를 구성해야 합니다.
웹 서버를 구성하려면 다음 단계를 완료합니다.
다음 명령을 입력하여 사용할 OpenShift Container Platform 릴리스에서
openshift-install바이너리를 추출합니다.oc adm -a ${LOCAL_SECRET_JSON} release extract --command=openshift-install "${LOCAL_REGISTRY}/${LOCAL_REPOSITORY}:${OCP_RELEASE}-${ARCHITECTURE}"다음 스크립트를 실행합니다. 이 스크립트는
/opt/srv디렉터리에 폴더를 생성합니다. 폴더에는 작업자 노드를 프로비저닝하는 RHCOS 이미지가 포함되어 있습니다.#!/bin/bash WEBSRV_FOLDER=/opt/srv ROOTFS_IMG_URL="$(./openshift-install coreos print-stream-json | jq -r '.architectures.x86_64.artifacts.metal.formats.pxe.rootfs.location')"1 LIVE_ISO_URL="$(./openshift-install coreos print-stream-json | jq -r '.architectures.x86_64.artifacts.metal.formats.iso.disk.location')"2 mkdir -p ${WEBSRV_FOLDER}/images curl -Lk ${ROOTFS_IMG_URL} -o ${WEBSRV_FOLDER}/images/${ROOTFS_IMG_URL##*/} curl -Lk ${LIVE_ISO_URL} -o ${WEBSRV_FOLDER}/images/${LIVE_ISO_URL##*/} chmod -R 755 ${WEBSRV_FOLDER}/* ## Run Webserver podman ps --noheading | grep -q websrv-ai if [[ $? == 0 ]];then echo "Launching Registry pod..." /usr/bin/podman run --name websrv-ai --net host -v /opt/srv:/usr/local/apache2/htdocs:z quay.io/alosadag/httpd:p8080 fi
다운로드가 완료되면 컨테이너가 실행되어 웹 서버에서 이미지를 호스팅합니다. 컨테이너는 공식 HTTPd 이미지의 변형을 사용하여 IPv6 네트워크에서도 작업할 수 있습니다.
1.7.12.6.6. IPv6 네트워크에 대한 이미지 미러링 구성
이미지 미러링은 registry.redhat.com 또는 quay.io 와 같은 외부 레지스트리에서 이미지를 가져와서 프라이빗 레지스트리에 저장하는 프로세스입니다.
1.7.12.6.6.1. 미러링 프로세스 완료
참고: 레지스트리 서버가 실행된 후 미러링 프로세스를 시작합니다.
다음 절차에서는 ImageSetConfiguration 오브젝트를 사용하는 바이너리인 oc-mirror 툴이 사용됩니다. 파일에서 다음 정보를 지정할 수 있습니다.
-
미러링할 OpenShift Container Platform 버전입니다. 버전은
quay.io에 있습니다. - 미러링할 추가 Operator입니다. 패키지를 개별적으로 선택합니다.
- 리포지토리에 추가할 추가 이미지입니다.
이미지 미러링을 구성하려면 다음 단계를 완료합니다.
-
이미지를 푸시하려는 프라이빗 레지스트리와 미러링할 레지스트리를 사용하여
${HOME}/.docker/config.json파일이 업데이트되었는지 확인합니다. 다음 예제를 사용하여 미러링에 사용할
ImageSetConfiguration오브젝트를 만듭니다. 환경에 맞게 필요에 따라 값을 바꿉니다.apiVersion: mirror.openshift.io/v1alpha2 kind: ImageSetConfiguration storageConfig: registry: imageURL: registry.dns.base.domain.name:5000/openshift/release/metadata:latest1 mirror: platform: channels: - name: candidate-4.14 minVersion: 4.x.y-x86_64 maxVersion: 4.x.y-x86_64 type: ocp graph: true additionalImages: - name: quay.io/karmab/origin-keepalived-ipfailover:latest - name: quay.io/karmab/kubectl:latest - name: quay.io/karmab/haproxy:latest - name: quay.io/karmab/mdns-publisher:latest - name: quay.io/karmab/origin-coredns:latest - name: quay.io/karmab/curl:latest - name: quay.io/karmab/kcli:latest - name: quay.io/user-name/trbsht:latest - name: quay.io/user-name/hypershift:BMSelfManage-v4.14-rc-v3 - name: registry.redhat.io/openshift4/ose-kube-rbac-proxy:v4.10 operators: - catalog: registry.redhat.io/redhat/redhat-operator-index:v4.14 packages: - name: lvms-operator - name: local-storage-operator - name: odf-csi-addons-operator - name: odf-operator - name: mcg-operator - name: ocs-operator - name: metallb-operator- 1
dns.base.domain.name을 DNS 기본 도메인 이름으로 바꾸고4.x.y를 사용하려는 지원되는 OpenShift Container Platform 버전으로 바꿉니다.
다음 명령을 입력하여 미러링 프로세스를 시작합니다.
oc-mirror --source-skip-tls --config imagesetconfig.yaml docker://${REGISTRY}미러링 프로세스가 완료되면 호스트 클러스터에 적용할 ICSP 및 카탈로그 소스가 포함된
oc-mirror-workspace/results-XXXXXX/라는 새 폴더가 있습니다.oc adm release mirror명령을 사용하여 OpenShift Container Platform의 Nightly 또는 CI 버전을 미러링합니다. 다음 명령을 실행합니다.REGISTRY=registry.$(hostname --long):5000 oc adm release mirror \ --from=registry.ci.openshift.org/ocp/release:4.x.y-x86_64 \ --to=${REGISTRY}/openshift/release \ --to-release-image=${REGISTRY}/openshift/release-images:4.x.y-x86_644.x.y를 사용하려는 지원되는 OpenShift Container Platform 버전으로 교체합니다.- 연결이 끊긴 네트워크에 설치 단계에 따라 최신 다중 클러스터 엔진 Operator 이미지를 미러링합니다.
1.7.12.6.6.2. 관리 클러스터에 오브젝트 적용
미러링 프로세스가 완료되면 관리 클러스터에 두 개의 오브젝트를 적용해야 합니다.
- Image Content Source Policies (ICSP) 또는 Image Digest 미러 세트(IDMS)
- 카탈로그 소스
oc-mirror 툴을 사용하는 경우 출력 아티팩트는 oc-mirror-workspace/results-XXXXXX/ 이라는 폴더에 있습니다.
ICSP 또는 IDMS는 노드를 재시작하지 않고 각 노드에서 kubelet을 다시 시작하는 MachineConfig 변경 사항을 시작합니다. 노드가 READY 로 표시되면 새로 생성된 카탈로그 소스를 적용해야 합니다.
카탈로그 소스는 카탈로그 이미지 다운로드 및 처리와 같은 openshift-marketplace Operator에서 작업을 시작하여 해당 이미지에 포함된 모든 PackageManifest 를 검색합니다.
새 소스를 확인하려면 새
CatalogSource를 소스로 사용하여 다음 명령을 실행합니다.oc get packagemanifest아티팩트를 적용하려면 다음 단계를 완료합니다.
다음 명령을 입력하여 ICSP 또는 IDMS 아티팩트를 생성합니다.
oc apply -f oc-mirror-workspace/results-XXXXXX/imageContentSourcePolicy.yaml- 노드가 준비될 때까지 기다린 다음 다음 명령을 입력합니다.
oc apply -f catalogSource-XXXXXXXX-index.yaml
1.7.12.6.6.3. 추가 리소스
- 가상 환경에서 작업하는 경우 미러링을 구성한 후 OpenShift Virtualization에서 호스팅되는 컨트롤 플레인의 사전 요구 사항을 충족해야 합니다.
- Nightly 또는 CI 버전의 OpenShift Container Platform 미러링에 대한 자세한 내용은 oc-mirror 플러그인을 사용하여 연결이 끊긴 설치의 이미지 미러링을 참조하십시오.
1.7.12.6.7. IPv6 네트워크용 다중 클러스터 엔진 Operator 배포
다중 클러스터 엔진 Operator는 공급업체에 클러스터를 배포하는 데 중요한 역할을 합니다. Red Hat Advanced Cluster Management를 이미 설치한 경우 자동으로 설치되므로 다중 클러스터 엔진 Operator를 설치할 필요가 없습니다.
다중 클러스터 엔진 Operator가 설치되어 있지 않은 경우 다음 문서를 검토하여 사전 요구 사항 및 설치 단계를 이해하십시오.
1.7.12.6.7.1. AgentServiceConfig 리소스 배포
AgentServiceConfig 사용자 지정 리소스는 다중 클러스터 엔진 Operator의 일부인 지원 서비스 애드온의 필수 구성 요소입니다. 베어 메탈 클러스터 배포를 담당합니다. 애드온이 활성화되면 AgentServiceConfig 리소스를 배포하여 애드온을 구성합니다.
AgentServiceConfig 리소스를 구성하는 것 외에도 연결이 끊긴 환경에서 다중 클러스터 엔진 Operator가 제대로 작동하는지 확인하기 위해 추가 구성 맵을 포함해야 합니다.
배포를 사용자 지정하는 연결이 끊긴 세부 정보가 포함된 다음 구성 맵을 추가하여 사용자 정의 레지스트리를 구성합니다.
--- apiVersion: v1 kind: ConfigMap metadata: name: custom-registries namespace: multicluster-engine labels: app: assisted-service data: ca-bundle.crt: | -----BEGIN CERTIFICATE----- -----END CERTIFICATE----- registries.conf: | unqualified-search-registries = ["registry.access.redhat.com", "docker.io"] [[registry]] prefix = "" location = "registry.redhat.io/openshift4" mirror-by-digest-only = true [[registry.mirror]] location = "registry.dns.base.domain.name:5000/openshift4"1 [[registry]] prefix = "" location = "registry.redhat.io/rhacm2" mirror-by-digest-only = true ... ...- 1
dns.base.domain.name을 DNS 기본 도메인 이름으로 교체합니다.
오브젝트에는 다음 두 개의 필드가 있습니다.
- 사용자 정의 CA: 이 필드에는 배포의 다양한 프로세스에 로드되는 CA(인증 기관)가 포함되어 있습니다.
-
Registry:
Registries.conf필드에는 원래 소스 레지스트리가 아닌 미러 레지스트리에서 사용해야 하는 이미지 및 네임스페이스에 대한 정보가 포함되어 있습니다.
다음 예와 같이
AssistedServiceConfig오브젝트를 추가하여 Assisted Service를 구성합니다.--- apiVersion: agent-install.openshift.io/v1beta1 kind: AgentServiceConfig metadata: annotations: unsupported.agent-install.openshift.io/assisted-service-configmap: assisted-service-config1 name: agent namespace: multicluster-engine spec: mirrorRegistryRef: name: custom-registries2 databaseStorage: storageClassName: lvms-vg1 accessModes: - ReadWriteOnce resources: requests: storage: 10Gi filesystemStorage: storageClassName: lvms-vg1 accessModes: - ReadWriteOnce resources: requests: storage: 20Gi osImages:3 - cpuArchitecture: x86_64 openshiftVersion: "4.14" rootFSUrl: http://registry.dns.base.domain.name:8080/images/rhcos-414.92.202308281054-0-live-rootfs.x86_64.img4 url: http://registry.dns.base.domain.name:8080/images/rhcos-414.92.202308281054-0-live.x86_64.iso version: 414.92.202308281054-0- 1
metadata.annotations["unsupported.agent-install.openshift.io/assisted-service-configmap"]주석은 Operator가 동작을 사용자 정의하는 데 사용하는 구성 맵 이름을 참조합니다.- 2
spec.mirrorRegistryRef.name주석은 Assisted Service Operator가 사용하는 연결이 끊긴 레지스트리 정보가 포함된 구성 맵을 가리킵니다. 이 구성 맵은 배포 프로세스 중에 해당 리소스를 추가합니다.- 3
spec.osImages필드에는 이 Operator에서 배포할 수 있는 다양한 버전이 포함되어 있습니다. 이 필드는 필수입니다. 이 예제에서는 이미RootFS및LiveISO파일을 다운로드했다고 가정합니다.- 4
rootFSUrl및url필드에서dns.base.domain.name을 DNS 기본 도메인 이름으로 교체합니다.
해당 오브젝트를 단일 파일에 연결하고 관리 클러스터에 적용하여 모든 오브젝트를 배포합니다. 이렇게 하려면 다음 명령을 입력합니다.
oc apply -f agentServiceConfig.yaml이 명령은 이 예제 출력에 표시된 대로 두 개의 Pod를 트리거합니다.
assisted-image-service-0 1/1 Running 2 11d1 assisted-service-668b49548-9m7xw 2/2 Running 5 11d2
1.7.12.6.8. IPv6 네트워크에 대한 TLS 인증서 구성
연결이 끊긴 환경에서 호스팅된 컨트롤 플레인을 구성하는 프로세스에 여러 TLS 인증서가 포함됩니다. 관리 클러스터에 CA(인증 기관)를 추가하려면 OpenShift Container Platform 컨트롤 플레인 및 작업자 노드에서 다음 파일의 내용을 수정해야 합니다.
-
/etc/pki/ca-trust/extracted/pem/ -
/etc/pki/ca-trust/source/anchors -
/etc/pki/tls/certs/
관리 클러스터에 CA를 추가하려면 다음 단계를 완료합니다.
-
공식 OpenShift Container Platform 설명서에서 CA 번들 업데이트 단계를 완료합니다. 이 방법은 CA를 OpenShift Container Platform 노드에 배포하는
image-registry-operator를 사용하는 것입니다. 해당 방법이 상황에 적용되지 않는 경우 관리 클러스터의
openshift-config네임스페이스에user-ca-bundle이라는 구성 맵이 포함되어 있는지 확인합니다.네임스페이스에 해당 구성 맵이 포함된 경우 다음 명령을 입력합니다.
## REGISTRY_CERT_PATH=<PATH/TO/YOUR/CERTIFICATE/FILE> export REGISTRY_CERT_PATH=/opt/registry/certs/domain.crt oc create configmap user-ca-bundle -n openshift-config --from-file=ca-bundle.crt=${REGISTRY_CERT_PATH}네임스페이스에 해당 구성 맵이 포함되지 않은 경우 다음 명령을 입력합니다.
## REGISTRY_CERT_PATH=<PATH/TO/YOUR/CERTIFICATE/FILE> export REGISTRY_CERT_PATH=/opt/registry/certs/domain.crt export TMP_FILE=$(mktemp) oc get cm -n openshift-config user-ca-bundle -ojsonpath='{.data.ca-bundle\.crt}' > ${TMP_FILE} echo >> ${TMP_FILE} echo \#registry.$(hostname --long) >> ${TMP_FILE} cat ${REGISTRY_CERT_PATH} >> ${TMP_FILE} oc create configmap user-ca-bundle -n openshift-config --from-file=ca-bundle.crt=${TMP_FILE} --dry-run=client -o yaml | kubectl apply -f -
1.7.12.6.9. IPv6 네트워크에 대해 호스트된 클러스터 배포
호스팅 클러스터는 관리 클러스터에서 호스팅되는 컨트롤 플레인 및 API 끝점이 있는 OpenShift Container Platform 클러스터입니다. 호스트된 클러스터에는 컨트롤 플레인과 해당 데이터 플레인이 포함됩니다.
Red Hat Advanced Cluster Management에서 콘솔을 사용하여 호스트 클러스터를 생성할 수 있지만 다음 절차에서는 관련 아티팩트를 수정하는 데 더 유연하게 사용할 수 있는 매니페스트를 사용합니다.
1.7.12.6.9.1. 호스트된 클러스터 오브젝트 배포
이 절차의 목적을 위해 다음 값이 사용됩니다.
-
HostedCluster 이름:
hosted-ipv6 -
HostedCluster 네임스페이스:
클러스터 -
disconnected:
true -
네트워크 스택:
IPv6
일반적으로 HyperShift Operator는 HostedControlPlane 네임스페이스를 생성합니다. 그러나 이 경우 HyperShift Operator가 HostedCluster 오브젝트를 조정하기 전에 모든 오브젝트를 포함해야 합니다. 그러면 Operator가 조정 프로세스를 시작하면 모든 오브젝트를 찾을 수 있습니다.
네임스페이스에 대한 다음 정보를 사용하여 YAML 파일을 생성합니다.
--- apiVersion: v1 kind: Namespace metadata: creationTimestamp: null name: clusters-hosted-ipv6 spec: {} status: {} --- apiVersion: v1 kind: Namespace metadata: creationTimestamp: null name: clusters spec: {} status: {}HostedCluster배포에 포함할 구성 맵 및 시크릿에 대한 다음 정보를 사용하여 YAML 파일을 생성합니다.--- apiVersion: v1 data: ca-bundle.crt: | -----BEGIN CERTIFICATE----- -----END CERTIFICATE----- kind: ConfigMap metadata: name: user-ca-bundle namespace: clusters --- apiVersion: v1 data: .dockerconfigjson: xxxxxxxxx kind: Secret metadata: creationTimestamp: null name: hosted-ipv6-pull-secret namespace: clusters --- apiVersion: v1 kind: Secret metadata: name: sshkey-cluster-hosted-ipv6 namespace: clusters stringData: id_rsa.pub: ssh-rsa xxxxxxxxx --- apiVersion: v1 data: key: nTPtVBEt03owkrKhIdmSW8jrWRxU57KO/fnZa8oaG0Y= kind: Secret metadata: creationTimestamp: null name: hosted-ipv6-etcd-encryption-key namespace: clusters type: Opaque지원 서비스 에이전트가 호스팅된 컨트롤 플레인과 동일한
HostedControlPlane네임스페이스에 있을 수 있고 클러스터 API에서 계속 관리할 수 있도록 RBAC 역할이 포함된 YAML 파일을 생성합니다.apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: creationTimestamp: null name: capi-provider-role namespace: clusters-hosted-ipv6 rules: - apiGroups: - agent-install.openshift.io resources: - agents verbs: - '*'필요에 따라 값을 교체하여
HostedCluster오브젝트에 대한 정보를 사용하여 YAML 파일을 생성합니다.apiVersion: hypershift.openshift.io/v1beta1 kind: HostedCluster metadata: name: hosted-ipv6 namespace: clusters annotations: hypershift.openshift.io/control-plane-operator-image: registry.ocp-edge-cluster-0.qe.lab.redhat.com:5005/openshift/release@sha256:31149e3e5f8c5e5b5b100ff2d89975cf5f7a73801b2c06c639bf6648766117f8 spec: additionalTrustBundle: name: "user-ca-bundle" olmCatalogPlacement: guest imageContentSources:1 - source: quay.io/openshift-release-dev/ocp-v4.0-art-dev mirrors: - registry.dns.base.domain.name:5000/openshift/release - source: quay.io/openshift-release-dev/ocp-release mirrors: - registry.dns.base.domain.name:5000/openshift/release-images - mirrors: ... ... autoscaling: {} controllerAvailabilityPolicy: SingleReplica dns: baseDomain: dns.base.domain.name etcd: managed: storage: persistentVolume: size: 8Gi restoreSnapshotURL: null type: PersistentVolume managementType: Managed fips: false networking: clusterNetwork: - cidr: 10.132.0.0/14 networkType: OVNKubernetes serviceNetwork: - cidr: 172.31.0.0/16 platform: agent: agentNamespace: clusters-hosted-ipv6 type: Agent pullSecret: name: hosted-ipv6-pull-secret release: image: registry.dns.base.domain.name:5000/openshift/release-images:4.x.y-x86_64 secretEncryption: aescbc: activeKey: name: hosted-ipv6-etcd-encryption-key type: aescbc services: - service: APIServer servicePublishingStrategy: nodePort: address: api.hosted-ipv6.dns.base.domain.name type: NodePort - service: OAuthServer servicePublishingStrategy: nodePort: address: api.hosted-ipv6.dns.base.domain.name type: NodePort - service: OIDC servicePublishingStrategy: nodePort: address: api.hosted-ipv6.dns.base.domain.name type: NodePort - service: Konnectivity servicePublishingStrategy: nodePort: address: api.hosted-ipv6.dns.base.domain.name type: NodePort - service: Ignition servicePublishingStrategy: nodePort: address: api.hosted-ipv6.dns.base.domain.name type: NodePort sshKey: name: sshkey-cluster-hosted-ipv6 status: controlPlaneEndpoint: host: "" port: 0여기서
dns.base.domain.name은 DNS 기본 도메인 이름이며4.x.y는 사용하려는 지원되는 OpenShift Container Platform 버전입니다.- 1
imageContentSources섹션에는 호스팅된 클러스터 내의 사용자 워크로드에 대한 미러 참조가 포함되어 있습니다.
OpenShift Container Platform 릴리스의 HyperShift Operator 릴리스를 가리키는
HostedCluster오브젝트에 주석을 추가합니다.다음 명령을 입력하여 이미지 페이로드를 가져옵니다.
oc adm release info registry.dns.base.domain.name:5000/openshift-release-dev/ocp-release:4.x.y-x86_64 | grep hypershift여기서
dns.base.domain.name은 DNS 기본 도메인 이름이며4.x.y는 사용하려는 지원되는 OpenShift Container Platform 버전입니다.다음 출력을 참조하십시오.
hypershift sha256:31149e3e5f8c5e5b5b100ff2d89975cf5f7a73801b2c06c639bf6648766117f8OpenShift Container Platform 이미지 네임스페이스를 사용하여 다음 명령을 입력하여 다이제스트를 확인합니다.
podman pull registry.dns.base.domain.name:5000/openshift-release-dev/ocp-v4.0-art-dev@sha256:31149e3e5f8c5e5b5b100ff2d89975cf5f7a73801b2c06c639bf6648766117f8여기서
dns.base.domain.name은 DNS 기본 도메인 이름입니다.다음 출력을 참조하십시오.
podman pull registry.dns.base.domain.name:5000/openshift/release@sha256:31149e3e5f8c5e5b5b100ff2d89975cf5f7a73801b2c06c639bf6648766117f8 Trying to pull registry.dns.base.domain.name:5000/openshift/release@sha256:31149e3e5f8c5e5b5b100ff2d89975cf5f7a73801b2c06c639bf6648766117f8... Getting image source signatures Copying blob d8190195889e skipped: already exists Copying blob c71d2589fba7 skipped: already exists Copying blob d4dc6e74b6ce skipped: already exists Copying blob 97da74cc6d8f skipped: already exists Copying blob b70007a560c9 done Copying config 3a62961e6e done Writing manifest to image destination Storing signatures 3a62961e6ed6edab46d5ec8429ff1f41d6bb68de51271f037c6cb8941a007fde
참고:
HostedCluster오브젝트에 설정된 릴리스 이미지는 태그가 아닌 다이제스트를 사용해야 합니다. 예를 들어quay.io/openshift-release-dev/ocp-release@sha256:e3ba11bd1e5e8ea5a0b36a75791c90f29afb0fdbe4125be4e48f69c76a5c.YAML 파일에 정의된 모든 오브젝트를 파일에 연결하고 관리 클러스터에 적용하여 해당 오브젝트를 생성합니다. 이렇게 하려면 다음 명령을 입력합니다.
oc apply -f 01-4.14-hosted_cluster-nodeport.yaml호스트된 컨트롤 플레인의 출력을 참조하십시오.
NAME READY STATUS RESTARTS AGE capi-provider-5b57dbd6d5-pxlqc 1/1 Running 0 3m57s catalog-operator-9694884dd-m7zzv 2/2 Running 0 93s cluster-api-f98b9467c-9hfrq 1/1 Running 0 3m57s cluster-autoscaler-d7f95dd5-d8m5d 1/1 Running 0 93s cluster-image-registry-operator-5ff5944b4b-648ht 1/2 Running 0 93s cluster-network-operator-77b896ddc-wpkq8 1/1 Running 0 94s cluster-node-tuning-operator-84956cd484-4hfgf 1/1 Running 0 94s cluster-policy-controller-5fd8595d97-rhbwf 1/1 Running 0 95s cluster-storage-operator-54dcf584b5-xrnts 1/1 Running 0 93s cluster-version-operator-9c554b999-l22s7 1/1 Running 0 95s control-plane-operator-6fdc9c569-t7hr4 1/1 Running 0 3m57s csi-snapshot-controller-785c6dc77c-8ljmr 1/1 Running 0 77s csi-snapshot-controller-operator-7c6674bc5b-d9dtp 1/1 Running 0 93s csi-snapshot-webhook-5b8584875f-2492j 1/1 Running 0 77s dns-operator-6874b577f-9tc6b 1/1 Running 0 94s etcd-0 3/3 Running 0 3m39s hosted-cluster-config-operator-f5cf5c464-4nmbh 1/1 Running 0 93s ignition-server-6b689748fc-zdqzk 1/1 Running 0 95s ignition-server-proxy-54d4bb9b9b-6zkg7 1/1 Running 0 95s ingress-operator-6548dc758b-f9gtg 1/2 Running 0 94s konnectivity-agent-7767cdc6f5-tw782 1/1 Running 0 95s kube-apiserver-7b5799b6c8-9f5bp 4/4 Running 0 3m7s kube-controller-manager-5465bc4dd6-zpdlk 1/1 Running 0 44s kube-scheduler-5dd5f78b94-bbbck 1/1 Running 0 2m36s machine-approver-846c69f56-jxvfr 1/1 Running 0 92s oauth-openshift-79c7bf44bf-j975g 2/2 Running 0 62s olm-operator-767f9584c-4lcl2 2/2 Running 0 93s openshift-apiserver-5d469778c6-pl8tj 3/3 Running 0 2m36s openshift-controller-manager-6475fdff58-hl4f7 1/1 Running 0 95s openshift-oauth-apiserver-dbbc5cc5f-98574 2/2 Running 0 95s openshift-route-controller-manager-5f6997b48f-s9vdc 1/1 Running 0 95s packageserver-67c87d4d4f-kl7qh 2/2 Running 0 93s호스트 클러스터의 출력을 참조하십시오.
NAMESPACE NAME VERSION KUBECONFIG PROGRESS AVAILABLE PROGRESSING MESSAGE clusters hosted-ipv6 hosted-admin-kubeconfig Partial True False The hosted control plane is available
다음으로 NodePool 오브젝트를 생성합니다.
1.7.12.6.9.2. 호스트된 클러스터에 대한 NodePool 오브젝트 생성
NodePool 은 호스팅된 클러스터와 연결된 확장 가능한 작업자 노드 집합입니다. NodePool 머신 아키텍처는 특정 풀 내에서 일관되게 유지되며 컨트롤 플레인의 머신 아키텍처와 독립적입니다.
NodePool오브젝트에 대한 다음 정보를 사용하여 YAML 파일을 생성하여 필요에 따라 값을 바꿉니다.apiVersion: hypershift.openshift.io/v1beta1 kind: NodePool metadata: creationTimestamp: null name: hosted-ipv6 namespace: clusters spec: arch: amd64 clusterName: hosted-ipv6 management: autoRepair: false1 upgradeType: InPlace2 nodeDrainTimeout: 0s platform: type: Agent release: image: registry.dns.base.domain.name:5000/openshift/release-images:4.x.y-x86_643 replicas: 0 status: replicas: 04 - 1
- 노드가 제거되면 노드가 다시 생성되지 않기 때문에
autoRepair필드가false로 설정됩니다. - 2
upgradeType은 업그레이드 중에 동일한 베어 메탈 노드가 재사용됨을 나타내는InPlace로 설정됩니다.- 3
- 이
NodePool에 포함된 모든 노드는 다음 OpenShift Container Platform 버전4.x.y-x86_64를 기반으로 합니다.dns.base.domain.name을 DNS 기본 도메인 이름으로 바꾸고4.x.y를 사용하려는 지원되는 OpenShift Container Platform 버전으로 바꿉니다. - 4
- 필요한 경우 스케일링할 수 있도록
replicas값은0으로 설정됩니다. 모든 단계가 완료될 때까지NodePool복제본을 0으로 유지하는 것이 중요합니다.
다음 명령을 입력하여
NodePool오브젝트를 생성합니다.oc apply -f 02-nodepool.yaml출력을 참조하십시오.
NAMESPACE NAME CLUSTER DESIRED NODES CURRENT NODES AUTOSCALING AUTOREPAIR VERSION UPDATINGVERSION UPDATINGCONFIG MESSAGE clusters hosted-ipv6 hosted 0 False False 4.x.y-x86_64
다음으로 InfraEnv 리소스를 생성합니다.
1.7.12.6.9.3. 호스트된 클러스터에 대한 InfraEnv 리소스 생성
InfraEnv 리소스는 pullSecretRef 및 sshAuthorizedKey 와 같은 필수 세부 정보를 포함하는 지원 서비스 오브젝트입니다. 이러한 세부 사항은 호스팅된 클러스터에 대해 사용자 지정된 RHCOS(Red Hat Enterprise Linux CoreOS) 부팅 이미지를 생성하는 데 사용됩니다.
필요에 따라 값을 교체하여
InfraEnv리소스에 대한 다음 정보를 사용하여 YAML 파일을 생성합니다.--- apiVersion: agent-install.openshift.io/v1beta1 kind: InfraEnv metadata: name: hosted-ipv6 namespace: clusters-hosted-ipv6 spec: pullSecretRef:1 name: pull-secret sshAuthorizedKey: ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABgQDk7ICaUE+/k4zTpxLk4+xFdHi4ZuDi5qjeF52afsNkw0w/glILHhwpL5gnp5WkRuL8GwJuZ1VqLC9EKrdmegn4MrmUlq7WTsP0VFOZFBfq2XRUxo1wrRdor2z0Bbh93ytR+ZsDbbLlGngXaMa0Vbt+z74FqlcajbHTZ6zBmTpBVq5RHtDPgKITdpE1fongp7+ZXQNBlkaavaqv8bnyrP4BWahLP4iO9/xJF9lQYboYwEEDzmnKLMW1VtCE6nJzEgWCufACTbxpNS7GvKtoHT/OVzw8ArEXhZXQUS1UY8zKsX2iXwmyhw5Sj6YboA8WICs4z+TrFP89LmxXY0j6536TQFyRz1iB4WWvCbH5n6W+ABV2e8ssJB1AmEy8QYNwpJQJNpSxzoKBjI73XxvPYYC/IjPFMySwZqrSZCkJYqQ023ySkaQxWZT7in4KeMu7eS2tC+Kn4deJ7KwwUycx8n6RHMeD8Qg9flTHCv3gmab8JKZJqN3hW1D378JuvmIX4V0=2 다음 명령을 입력하여
InfraEnv리소스를 생성합니다.oc apply -f 03-infraenv.yaml다음 출력을 참조하십시오.
NAMESPACE NAME ISO CREATED AT clusters-hosted-ipv6 hosted 2023-09-11T15:14:10Z
다음으로 작업자 노드를 생성합니다.
1.7.12.6.9.4. 호스트된 클러스터의 작업자 노드 생성
베어 메탈 플랫폼에서 작업하는 경우 작업자 노드를 생성하는 것은 BareMetalHost 의 세부 정보가 올바르게 구성되었는지 확인하는 데 중요합니다.
가상 머신으로 작업하는 경우 다음 단계를 완료하여 Metal3 Operator에서 사용하는 빈 작업자 노드를 생성할 수 있습니다. 이렇게 하려면 kcli 툴을 사용합니다.
이것이 작업자 노드 생성을 처음 시도하지 않은 경우 먼저 이전 설정을 삭제해야 합니다. 이렇게 하려면 다음 명령을 입력하여 계획을 삭제합니다.
kcli delete plan hosted-ipv6-
계획을 삭제할지 여부를 확인하라는 메시지가 표시되면
y를 입력합니다. - 계획이 삭제되었음을 알리는 메시지가 표시되는지 확인합니다.
-
계획을 삭제할지 여부를 확인하라는 메시지가 표시되면
다음 명령을 입력하여 가상 머신을 생성합니다.
kcli create vm -P start=False -P uefi_legacy=true -P plan=hosted-ipv6 -P memory=8192 -P numcpus=16 -P disks=[200,200] -P nets=["{\"name\": \"ipv6\", \"mac\": \"aa:aa:aa:aa:02:11\"}"] -P uuid=aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaa0211 -P name=hosted-ipv6-worker0kcli create vm -P start=False -P uefi_legacy=true -P plan=hosted-ipv6 -P memory=8192 -P numcpus=16 -P disks=[200,200] -P nets=["{\"name\": \"ipv6\", \"mac\": \"aa:aa:aa:aa:02:12\"}"] -P uuid=aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaa0212 -P name=hosted-ipv6-worker1kcli create vm -P start=False -P uefi_legacy=true -P plan=hosted-ipv6 -P memory=8192 -P numcpus=16 -P disks=[200,200] -P nets=["{\"name\": \"ipv6\", \"mac\": \"aa:aa:aa:aa:02:13\"}"] -P uuid=aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaa0213 -P name=hosted-ipv6-worker2systemctl restart ksushy다음과 같습니다.
-
start=False는 VM(가상 머신)이 생성 시 자동으로 시작되지 않음을 의미합니다. -
uefi_legacy=true는 UEFI 레거시 부팅을 사용하여 이전 UEFI 구현과의 호환성을 보장합니다. -
plan=hosted-dual은 시스템 그룹을 클러스터로 식별하는 계획 이름을 나타냅니다. -
memory=8192및numcpus=16은 RAM 및 CPU를 포함하여 VM의 리소스를 지정하는 매개변수입니다. -
disks=[200,200]은 VM에 씬 프로비저닝된 두 개의 디스크를 생성 중임을 나타냅니다. -
nets=[{"name": "dual", "mac": "aa:aa:aa:aa:aa:aa:02:13"}]은 연결할 네트워크 이름과 기본 인터페이스의 MAC 주소를 포함한 네트워크 세부 정보입니다. -
ksushy를 다시 시작하여ksushy툴을 다시 시작하여 추가한 VM을 감지합니다.
-
결과 출력을 확인합니다.
+---------------------+--------+-------------------+----------------------------------------------------+-------------+---------+ | Name | Status | Ip | Source | Plan | Profile | +---------------------+--------+-------------------+----------------------------------------------------+-------------+---------+ | hosted-worker0 | down | | | hosted-ipv6 | kvirt | | hosted-worker1 | down | | | hosted-ipv6 | kvirt | | hosted-worker2 | down | | | hosted-ipv6 | kvirt | +---------------------+--------+-------------------+----------------------------------------------------+-------------+---------+
다음으로 호스팅된 클러스터에 대한 베어 메탈 호스트를 생성합니다.
1.7.12.6.9.5. 호스트 클러스터를 위한 베어 메탈 호스트 생성
베어 메탈 호스트 는 Metal3 Operator가 식별할 수 있도록 물리적 및 논리 세부 정보를 포함하는 openshift-machine-api 오브젝트입니다. 이러한 세부 사항은 에이전트 라고 하는 기타 지원 서비스 오브젝트와 연결됩니다.
중요: 베어 메탈 호스트 및 대상 노드를 생성하기 전에 가상 머신을 생성해야 합니다.
베어 메탈 호스트를 생성하려면 다음 단계를 완료합니다.
다음 정보를 사용하여 YAML 파일을 생성합니다.
참고: 베어 메탈 호스트 인증 정보를 보유하는 시크릿이 하나 이상 있으므로 각 작업자 노드에 대해 두 개 이상의 오브젝트를 생성해야 합니다.
--- apiVersion: v1 kind: Secret metadata: name: hosted-ipv6-worker0-bmc-secret namespace: clusters-hosted-ipv6 data: password: YWRtaW4= username: YWRtaW4= type: Opaque --- apiVersion: metal3.io/v1alpha1 kind: BareMetalHost metadata: name: hosted-ipv6-worker0 namespace: clusters-hosted-ipv6 labels: infraenvs.agent-install.openshift.io: hosted-ipv61 annotations: inspect.metal3.io: disabled bmac.agent-install.openshift.io/hostname: hosted-ipv6-worker02 spec: automatedCleaningMode: disabled3 bmc: disableCertificateVerification: true4 address: redfish-virtualmedia://[192.168.125.1]:9000/redfish/v1/Systems/local/hosted-ipv6-worker05 credentialsName: hosted-ipv6-worker0-bmc-secret6 bootMACAddress: aa:aa:aa:aa:03:117 online: true8 - 1
infraenvs.agent-install.openshift.io는 지원 설치 프로그램과BareMetalHost오브젝트 간의 링크 역할을 합니다.- 2
- B
MAC.agent-install.openshift.io/hostname은 배포 중에 채택된 노드 이름을 나타냅니다. - 3
automatedCleaningMode를 사용하면 Metal3 Operator에 의해 노드가 지워지지 않습니다.- 4
- 클라이언트에서 인증서 유효성 검사를 바이패스하려면
disableCertificateVerification이true로 설정됩니다. - 5
address는 작업자 노드의 BMC(Baseboard Management Controller) 주소를 나타냅니다.- 6
credentialsName은 사용자 및 암호 인증 정보가 저장된 시크릿을 가리킵니다.- 7
bootMACAddress는 노드가 시작되는 인터페이스 MAC 주소를 나타냅니다.- 8
online은BareMetalHost개체가 생성된 후 노드의 상태를 정의합니다.
다음 명령을 입력하여
BareMetalHost오브젝트를 배포합니다.oc apply -f 04-bmh.yaml프로세스 중에 다음 출력을 볼 수 있습니다.
이 출력은 프로세스가 노드에 연결을 시도 중임을 나타냅니다.
NAMESPACE NAME STATE CONSUMER ONLINE ERROR AGE clusters-hosted hosted-worker0 registering true 2s clusters-hosted hosted-worker1 registering true 2s clusters-hosted hosted-worker2 registering true 2s이 출력은 노드가 시작됨을 나타냅니다.
NAMESPACE NAME STATE CONSUMER ONLINE ERROR AGE clusters-hosted hosted-worker0 provisioning true 16s clusters-hosted hosted-worker1 provisioning true 16s clusters-hosted hosted-worker2 provisioning true 16s- 이 출력은 노드가 성공적으로 시작되었음을 나타냅니다.
NAMESPACE NAME STATE CONSUMER ONLINE ERROR AGE clusters-hosted hosted-worker0 provisioned true 67s clusters-hosted hosted-worker1 provisioned true 67s clusters-hosted hosted-worker2 provisioned true 67s노드가 시작된 후 다음 예와 같이 네임스페이스의 에이전트를 확인합니다.
NAMESPACE NAME CLUSTER APPROVED ROLE STAGE clusters-hosted aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaa0411 true auto-assign clusters-hosted aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaa0412 true auto-assign clusters-hosted aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaa0413 true auto-assign에이전트는 설치에 사용할 수 있는 노드를 나타냅니다. 호스트 클러스터에 노드를 할당하려면 노드 풀을 확장합니다.
1.7.12.6.9.6. 노드 풀 확장
베어 메탈 호스트를 생성한 후 해당 상태가 Registering 에서 Provisioning (프로비저닝)으로 변경됨. 노드는 에이전트의 LiveISO 및 에이전트 라는 기본 Pod로 시작합니다. 해당 에이전트는 OpenShift Container Platform 페이로드를 설치하기 위해 Assisted Service Operator에서 지침을 받습니다.
노드 풀을 확장하려면 다음 명령을 입력합니다.
oc -n clusters scale nodepool hosted-ipv6 --replicas 3확장 프로세스가 완료되면 에이전트가 호스팅된 클러스터에 할당되어 있습니다.
NAMESPACE NAME CLUSTER APPROVED ROLE STAGE clusters-hosted aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaa0211 hosted true auto-assign clusters-hosted aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaa0212 hosted true auto-assign clusters-hosted aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaa0213 hosted true auto-assign또한 노드 풀 복제본이 설정되어 있습니다.
NAMESPACE NAME CLUSTER DESIRED NODES CURRENT NODES AUTOSCALING AUTOREPAIR VERSION UPDATINGVERSION UPDATINGCONFIG MESSAGE clusters hosted hosted 3 False False 4.x.y-x86_64 Minimum availability requires 3 replicas, current 0 available- 노드가 클러스터에 참여할 때까지 기다립니다. 프로세스 중에 에이전트는 단계 및 상태에 대한 업데이트를 제공합니다.
다음으로 호스트 클러스터의 배포를 모니터링합니다.
1.7.12.6.10. IPv6 네트워크의 호스트 클러스터 배포 완료
컨트롤 플레인과 데이터 플레인의 두 가지 관점에서 호스팅 클러스터 배포를 모니터링할 수 있습니다.
1.7.12.6.10.1. 컨트롤 플레인 모니터링
호스팅 클러스터를 배포하는 동안 다음 명령을 입력하여 컨트롤 플레인을 모니터링할 수 있습니다.
export KUBECONFIG=/root/.kcli/clusters/hub-ipv4/auth/kubeconfigwatch "oc get pod -n hypershift;echo;echo;oc get pod -n clusters-hosted-ipv4;echo;echo;oc get bmh -A;echo;echo;oc get agent -A;echo;echo;oc get infraenv -A;echo;echo;oc get hostedcluster -A;echo;echo;oc get nodepool -A;echo;echo;"이러한 명령은 다음 아티팩트에 대한 정보를 제공합니다.
- The HyperShift Operator
-
HostedControlPlanePod - 베어 메탈 호스트
- 에이전트
-
InfraEnv리소스 -
HostedCluster및NodePool리소스
1.7.12.6.10.2. 데이터 플레인 모니터링
배포 프로세스 중에 Operator가 진행 중인 방식을 모니터링하려면 다음 명령을 입력합니다.
oc get secret -n clusters-hosted-ipv4 admin-kubeconfig -o jsonpath='{.data.kubeconfig}' |base64 -d > /root/hc_admin_kubeconfig.yamlexport KUBECONFIG=/root/hc_admin_kubeconfig.yamlwatch "oc get clusterversion,nodes,co"이러한 명령은 다음 아티팩트에 대한 정보를 제공합니다.
- 클러스터 버전
- 특히 노드가 클러스터에 참여하는지 여부에 대한 노드
- 클러스터 Operator
1.7.12.7. 듀얼 스택 네트워크에서 호스팅된 컨트롤 플레인 구성 (기술 프리뷰)
호스팅된 컨트롤 플레인의 컨텍스트에서 연결이 끊긴 환경은 인터넷에 연결되지 않고 호스팅된 컨트롤 플레인을 기반으로 사용하는 OpenShift Container Platform 클러스터입니다. 원격 레지스트리가 IPv6에서 작동하지 않기 때문에 연결이 끊긴 환경에서만 이중 스택 네트워크에서 호스팅되는 컨트롤 플레인을 구성할 수 있습니다.
듀얼 스택 네트워크에서 호스팅된 컨트롤 플레인을 구성하려면 다음 단계를 검토하십시오.
- 듀얼 스택 네트워크에 대한 하이퍼바이저 구성
- 듀얼 스택 네트워크에 대한 DNS 구성
- 듀얼 스택 네트워크의 레지스트리 배포
- 듀얼 스택 네트워크에 대한 관리 클러스터 설정
- 듀얼 스택 네트워크에 대한 웹 서버 구성
- 듀얼 스택 네트워크의 이미지 미러링 구성
- 듀얼 스택 네트워크용 다중 클러스터 엔진 Operator 배포
- 듀얼 스택 네트워크에 대한 TLS 인증서 구성
- 듀얼 스택 네트워크용 호스트 클러스터 배포
- 듀얼 스택 네트워크의 배포 완료
1.7.12.7.1. 듀얼 스택 네트워크에 대한 하이퍼바이저 구성
다음 정보는 가상 머신 환경에만 적용됩니다.
1.7.12.7.1.1. 가상 OpenShift Container Platform 클러스터용 패키지 액세스 및 배포
가상 OpenShift Container Platform 관리 클러스터를 배포하려면 다음 명령을 입력하여 필요한 패키지에 액세스합니다.
sudo dnf install dnsmasq radvd vim golang podman bind-utils net-tools httpd-tools tree htop strace tmux -y다음 명령을 입력하여 Podman 서비스를 활성화하고 시작합니다.
systemctl enable --now podmankcli를 사용하여 OpenShift Container Platform 관리 클러스터 및 기타 가상 구성 요소를 배포하려면 다음 명령을 입력하여 하이퍼바이저를 설치 및 구성합니다.sudo yum -y install libvirt libvirt-daemon-driver-qemu qemu-kvmsudo usermod -aG qemu,libvirt $(id -un)sudo newgrp libvirtsudo systemctl enable --now libvirtdsudo dnf -y copr enable karmab/kclisudo dnf -y install kclisudo kcli create pool -p /var/lib/libvirt/images defaultkcli create host kvm -H 127.0.0.1 localsudo setfacl -m u:$(id -un):rwx /var/lib/libvirt/imageskcli create network -c 192.168.122.0/24 default
1.7.12.7.1.2. 네트워크 관리자 디스패처 활성화
네트워크 관리자 디스패처를 활성화하여 가상 머신이 필요한 도메인, 경로 및 레지스트리를 확인할 수 있는지 확인합니다. 네트워크 관리자 디스패처를 활성화하려면
/etc/NetworkManager/dispatcher.d/디렉터리에서 다음 콘텐츠가 포함된forcedns라는 스크립트를 생성하여 환경에 맞게 값을 교체하십시오.#!/bin/bash export IP="192.168.126.1"1 export BASE_RESOLV_CONF="/run/NetworkManager/resolv.conf" if ! [[ `grep -q "$IP" /etc/resolv.conf` ]]; then export TMP_FILE=$(mktemp /etc/forcedns_resolv.conf.XXXXXX) cp $BASE_RESOLV_CONF $TMP_FILE chmod --reference=$BASE_RESOLV_CONF $TMP_FILE sed -i -e "s/dns.base.domain.name//" -e "s/search /& dns.base.domain.name /" -e "0,/nameserver/s/nameserver/& $IP\n&/" $TMP_FILE2 mv $TMP_FILE /etc/resolv.conf fi echo "ok"파일을 생성한 후 다음 명령을 입력하여 권한을 추가합니다.
chmod 755 /etc/NetworkManager/dispatcher.d/forcedns-
스크립트를 실행하고 출력이
ok를 반환하는지 확인합니다.
1.7.12.7.1.3. BMC 액세스 구성
가상 머신의 BMC(Baseboard Management Controller)를 시뮬레이션하도록
ksushy를 구성합니다. 다음 명령을 입력합니다.sudo dnf install python3-pyOpenSSL.noarch python3-cherrypy -ykcli create sushy-service --ssl --ipv6 --port 9000sudo systemctl daemon-reloadsystemctl enable --now ksushy다음 명령을 입력하여 서비스가 올바르게 작동하는지 테스트합니다.
systemctl status ksushy
1.7.12.7.1.4. 연결을 허용하도록 하이퍼바이저 시스템 구성
개발 환경에서 작업하는 경우 환경 내에서 다양한 가상 네트워크를 통한 다양한 유형의 연결을 허용하도록 하이퍼바이저 시스템을 구성합니다.
참고: 프로덕션 환경에서 작업하는 경우 firewalld 서비스에 대한 적절한 규칙을 설정하고 안전한 환경을 유지 관리하도록 SELinux 정책을 구성해야 합니다.
SELinux의 경우 다음 명령을 입력합니다.
sed -i s/^SELINUX=.*$/SELINUX=permissive/ /etc/selinux/config; setenforce 0firewalld의 경우 다음 명령을 입력합니다.systemctl disable --now firewalldlibvirtd의 경우 다음 명령을 입력합니다.systemctl restart libvirtdsystemctl enable --now libvirtd
다음으로 환경에 맞게 DNS를 구성합니다.
1.7.12.7.1.5. 추가 리소스
-
kcli에 대한 자세한 내용은 공식 kcli 설명서 를 참조하십시오.
1.7.12.7.2. 듀얼 스택 네트워크에 대한 DNS 구성
가상 및 베어 메탈 환경 모두에서 연결이 끊긴 환경과 연결된 환경 모두에 대해 DNS를 구성해야 합니다. 가상 환경과 베어 메탈 환경 간의 주요 차이점은 리소스를 구성하는 위치에 있습니다. 비가상 환경에서 dnsmasq 와 같은 경량 솔루션을 사용하는 대신 바인딩과 같은 솔루션을 사용하십시오.
- 가상 환경에서 듀얼 스택 네트워크에 대한 DNS를 구성하려면 기본 인그레스 및 DNS 동작을 참조하십시오.
- 베어 메탈에서 듀얼 스택 네트워크의 DNS를 구성하려면 베어 메탈 에서 DNS 구성을 참조하십시오.
다음으로 레지스트리를 배포합니다.
1.7.12.7.3. 듀얼 스택 네트워크의 레지스트리 배포
개발 환경의 경우 Podman 컨테이너를 사용하여 소규모 자체 호스팅 레지스트리를 배포합니다. 프로덕션 환경의 경우 Red Hat Quay, Nexus 또는 Artifactory와 같은 엔터프라이즈 호스팅 레지스트리를 배포합니다.
Podman을 사용하여 작은 레지스트리를 배포하려면 다음 단계를 완료합니다.
권한 있는 사용자로
${HOME}디렉터리에 액세스하고 다음 스크립트를 생성합니다.#!/usr/bin/env bash set -euo pipefail PRIMARY_NIC=$(ls -1 /sys/class/net | grep -v podman | head -1) export PATH=/root/bin:$PATH export PULL_SECRET="/root/baremetal/hub/openshift_pull.json"1 if [[ ! -f $PULL_SECRET ]];then echo "Pull Secret not found, exiting..." exit 1 fi dnf -y install podman httpd httpd-tools jq skopeo libseccomp-devel export IP=$(ip -o addr show $PRIMARY_NIC | head -1 | awk '{print $4}' | cut -d'/' -f1) REGISTRY_NAME=registry.$(hostname --long) REGISTRY_USER=dummy REGISTRY_PASSWORD=dummy KEY=$(echo -n $REGISTRY_USER:$REGISTRY_PASSWORD | base64) echo "{\"auths\": {\"$REGISTRY_NAME:5000\": {\"auth\": \"$KEY\", \"email\": \"sample-email@domain.ltd\"}}}" > /root/disconnected_pull.json mv ${PULL_SECRET} /root/openshift_pull.json.old jq ".auths += {\"$REGISTRY_NAME:5000\": {\"auth\": \"$KEY\",\"email\": \"sample-email@domain.ltd\"}}" < /root/openshift_pull.json.old > $PULL_SECRET mkdir -p /opt/registry/{auth,certs,data,conf} cat <<EOF > /opt/registry/conf/config.yml version: 0.1 log: fields: service: registry storage: cache: blobdescriptor: inmemory filesystem: rootdirectory: /var/lib/registry delete: enabled: true http: addr: :5000 headers: X-Content-Type-Options: [nosniff] health: storagedriver: enabled: true interval: 10s threshold: 3 compatibility: schema1: enabled: true EOF openssl req -newkey rsa:4096 -nodes -sha256 -keyout /opt/registry/certs/domain.key -x509 -days 3650 -out /opt/registry/certs/domain.crt -subj "/C=US/ST=Madrid/L=San Bernardo/O=Karmalabs/OU=Guitar/CN=$REGISTRY_NAME" -addext "subjectAltName=DNS:$REGISTRY_NAME" cp /opt/registry/certs/domain.crt /etc/pki/ca-trust/source/anchors/ update-ca-trust extract htpasswd -bBc /opt/registry/auth/htpasswd $REGISTRY_USER $REGISTRY_PASSWORD podman create --name registry --net host --security-opt label=disable --replace -v /opt/registry/data:/var/lib/registry:z -v /opt/registry/auth:/auth:z -v /opt/registry/conf/config.yml:/etc/docker/registry/config.yml -e "REGISTRY_AUTH=htpasswd" -e "REGISTRY_AUTH_HTPASSWD_REALM=Registry" -e "REGISTRY_HTTP_SECRET=ALongRandomSecretForRegistry" -e REGISTRY_AUTH_HTPASSWD_PATH=/auth/htpasswd -v /opt/registry/certs:/certs:z -e REGISTRY_HTTP_TLS_CERTIFICATE=/certs/domain.crt -e REGISTRY_HTTP_TLS_KEY=/certs/domain.key docker.io/library/registry:latest [ "$?" == "0" ] || !! systemctl enable --now registry- 1
PULL_SECRET위치를 설정에 적합한 위치로 교체합니다.
스크립트 파일 이름을
registry.sh로 지정하고 저장합니다. 스크립트를 실행하면 다음 정보를 가져옵니다.- 하이퍼바이저 호스트 이름을 기반으로 하는 레지스트리 이름
- 필요한 인증 정보 및 사용자 액세스 세부 정보
다음과 같이 실행 플래그를 추가하여 권한을 조정합니다.
chmod u+x ${HOME}/registry.sh매개변수 없이 스크립트를 실행하려면 다음 명령을 입력합니다.
${HOME}/registry.sh스크립트가 서버를 시작합니다.
스크립트는 관리 목적으로
systemd서비스를 사용합니다. 스크립트를 관리해야 하는 경우 다음 명령을 사용할 수 있습니다.systemctl statussystemctl startsystemctl stop
레지스트리의 루트 폴더는 /opt/registry 디렉터리에 있으며 다음 하위 디렉터리가 포함되어 있습니다.
-
인증서에는TLS 인증서가 포함되어 있습니다. -
auth에는 인증 정보가 포함됩니다. -
데이터에는 레지스트리 이미지가 포함되어 있습니다. -
conf에는 레지스트리 구성이 포함되어 있습니다.
1.7.12.7.4. 듀얼 스택 네트워크의 관리 클러스터 설정
OpenShift Container Platform 관리 클러스터를 설정하려면 dev-scripts를 사용하거나 가상 머신을 기반으로 하는 경우 kcli 툴을 사용할 수 있습니다. 다음 지침은 kcli 툴에 따라 다릅니다.
하이퍼바이저에서 적절한 네트워크를 사용할 준비가 되었는지 확인합니다. 네트워크는 관리 및 호스팅 클러스터를 모두 호스팅합니다. 다음
kcli명령을 입력합니다.kcli create network -c 192.168.126.0/24 -P dhcp=false -P dns=false -d 2620:52:0:1306::0/64 --domain dns.base.domain.name --nodhcp dual다음과 같습니다.
-
-c는 네트워크의 CIDR을 지정합니다. -
-P dhcp=false는 DHCP를 비활성화하도록 네트워크를 구성하며, 구성한dnsmasq에서 처리합니다. -
-P dns=false는 DNS를 비활성화하도록 네트워크를 구성하며, 구성한dnsmasq에서도 처리합니다. -
--domain은 검색할 도메인을 설정합니다. -
DNS.base.domain.name은 DNS 기본 도메인 이름입니다. -
Dual은 생성 중인 네트워크의 이름입니다.
-
네트워크가 생성되면 다음 출력을 검토합니다.
[root@hypershiftbm ~]# kcli list network Listing Networks... +---------+--------+---------------------+-------+------------------+------+ | Network | Type | Cidr | Dhcp | Domain | Mode | +---------+--------+---------------------+-------+------------------+------+ | default | routed | 192.168.122.0/24 | True | default | nat | | ipv4 | routed | 2620:52:0:1306::/64 | False | dns.base.domain.name | nat | | ipv4 | routed | 192.168.125.0/24 | False | dns.base.domain.name | nat | | ipv6 | routed | 2620:52:0:1305::/64 | False | dns.base.domain.name | nat | +---------+--------+---------------------+-------+------------------+------+[root@hypershiftbm ~]# kcli info network ipv6 Providing information about network ipv6... cidr: 2620:52:0:1306::/64 dhcp: false domain: dns.base.domain.name mode: nat plan: kvirt type: routedOpenShift Container Platform 관리 클러스터를 배포할 수 있도록 풀 시크릿 및
kcli계획 파일이 있는지 확인합니다.-
풀 시크릿이
kcli계획과 동일한 폴더에 있고 풀 시크릿 파일의 이름이openshift_pull.json인지 확인합니다. mgmt-compact-hub-dual.yaml파일에서 OpenShift Container Platform 정의가 포함된kcli계획을 추가합니다. 해당 환경과 일치하도록 파일 콘텐츠를 업데이트해야 합니다.plan: hub-dual force: true version: stable tag: "4.x.y-x86_64"1 cluster: "hub-dual" dualstack: true domain: dns.base.domain.name api_ip: 192.168.126.10 ingress_ip: 192.168.126.11 service_networks: - 172.30.0.0/16 - fd02::/112 cluster_networks: - 10.132.0.0/14 - fd01::/48 disconnected_url: registry.dns.base.domain.name:5000 disconnected_update: true disconnected_user: dummy disconnected_password: dummy disconnected_operators_version: v4.14 disconnected_operators: - name: metallb-operator - name: lvms-operator channels: - name: stable-4.13 disconnected_extra_images: - quay.io/user-name/trbsht:latest - quay.io/user-name/hypershift:BMSelfManage-v4.14-rc-v3 - registry.redhat.io/openshift4/ose-kube-rbac-proxy:v4.10 dualstack: true disk_size: 200 extra_disks: [200] memory: 48000 numcpus: 16 ctlplanes: 3 workers: 0 manifests: extra-manifests metal3: true network: dual users_dev: developer users_devpassword: developer users_admin: admin users_adminpassword: admin metallb_pool: dual-virtual-network metallb_ranges: - 192.168.126.150-192.168.126.190 metallb_autoassign: true apps: - users - lvms-operator - metallb-operator vmrules: - hub-bootstrap: nets: - name: ipv6 mac: aa:aa:aa:aa:10:07 - hub-ctlplane-0: nets: - name: ipv6 mac: aa:aa:aa:aa:10:01 - hub-ctlplane-1: nets: - name: ipv6 mac: aa:aa:aa:aa:10:02 - hub-ctlplane-2: nets: - name: ipv6 mac: aa:aa:aa:aa:10:03
- 1
4.x.y를 사용하려는 지원되는 OpenShift Container Platform 버전으로 교체합니다.
-
풀 시크릿이
관리 클러스터를 프로비저닝하려면 다음 명령을 입력합니다.
kcli create cluster openshift --pf mgmt-compact-hub-dual.yaml
다음으로 웹 서버를 구성합니다.
1.7.12.7.4.1. 추가 리소스
-
kcli계획 파일의 매개변수에 대한 자세한 내용은 공식kcli문서의 parameters.yml 만들기 를 참조하십시오.
1.7.12.7.5. 듀얼 스택 네트워크에 대한 웹 서버 구성
호스트 클러스터로 배포 중인 OpenShift Container Platform 릴리스와 연결된 RHCOS(Red Hat Enterprise Linux CoreOS) 이미지를 호스팅하도록 추가 웹 서버를 구성해야 합니다.
웹 서버를 구성하려면 다음 단계를 완료합니다.
다음 명령을 입력하여 사용할 OpenShift Container Platform 릴리스에서
openshift-install바이너리를 추출합니다.oc adm -a ${LOCAL_SECRET_JSON} release extract --command=openshift-install "${LOCAL_REGISTRY}/${LOCAL_REPOSITORY}:${OCP_RELEASE}-${ARCHITECTURE}"다음 스크립트를 실행합니다. 이 스크립트는
/opt/srv디렉터리에 폴더를 생성합니다. 폴더에는 작업자 노드를 프로비저닝하는 RHCOS 이미지가 포함되어 있습니다.#!/bin/bash WEBSRV_FOLDER=/opt/srv ROOTFS_IMG_URL="$(./openshift-install coreos print-stream-json | jq -r '.architectures.x86_64.artifacts.metal.formats.pxe.rootfs.location')"1 LIVE_ISO_URL="$(./openshift-install coreos print-stream-json | jq -r '.architectures.x86_64.artifacts.metal.formats.iso.disk.location')"2 mkdir -p ${WEBSRV_FOLDER}/images curl -Lk ${ROOTFS_IMG_URL} -o ${WEBSRV_FOLDER}/images/${ROOTFS_IMG_URL##*/} curl -Lk ${LIVE_ISO_URL} -o ${WEBSRV_FOLDER}/images/${LIVE_ISO_URL##*/} chmod -R 755 ${WEBSRV_FOLDER}/* ## Run Webserver podman ps --noheading | grep -q websrv-ai if [[ $? == 0 ]];then echo "Launching Registry pod..." /usr/bin/podman run --name websrv-ai --net host -v /opt/srv:/usr/local/apache2/htdocs:z quay.io/alosadag/httpd:p8080 fi
다운로드가 완료되면 컨테이너가 실행되어 웹 서버에서 이미지를 호스팅합니다. 컨테이너는 공식 HTTPd 이미지의 변형을 사용하여 IPv6 네트워크에서도 작업할 수 있습니다.
1.7.12.7.6. 듀얼 스택 네트워크의 이미지 미러링 구성
이미지 미러링은 registry.redhat.com 또는 quay.io 와 같은 외부 레지스트리에서 이미지를 가져와서 프라이빗 레지스트리에 저장하는 프로세스입니다.
1.7.12.7.6.1. 미러링 프로세스 완료
참고: 레지스트리 서버가 실행된 후 미러링 프로세스를 시작합니다.
다음 절차에서는 ImageSetConfiguration 오브젝트를 사용하는 바이너리인 oc-mirror 툴이 사용됩니다. 파일에서 다음 정보를 지정할 수 있습니다.
-
미러링할 OpenShift Container Platform 버전입니다. 버전은
quay.io에 있습니다. - 미러링할 추가 Operator입니다. 패키지를 개별적으로 선택합니다.
- 리포지토리에 추가할 추가 이미지입니다.
이미지 미러링을 구성하려면 다음 단계를 완료합니다.
-
이미지를 푸시하려는 프라이빗 레지스트리와 미러링할 레지스트리를 사용하여
${HOME}/.docker/config.json파일이 업데이트되었는지 확인합니다. 다음 예제를 사용하여 미러링에 사용할
ImageSetConfiguration오브젝트를 만듭니다. 환경에 맞게 필요에 따라 값을 바꿉니다.apiVersion: mirror.openshift.io/v1alpha2 kind: ImageSetConfiguration storageConfig: registry: imageURL: registry.dns.base.domain.name:5000/openshift/release/metadata:latest mirror: platform: channels: - name: candidate-4.14 minVersion: 4.x.y-x86_641 maxVersion: 4.x.y-x86_64 type: ocp graph: true additionalImages: - name: quay.io/karmab/origin-keepalived-ipfailover:latest - name: quay.io/karmab/kubectl:latest - name: quay.io/karmab/haproxy:latest - name: quay.io/karmab/mdns-publisher:latest - name: quay.io/karmab/origin-coredns:latest - name: quay.io/karmab/curl:latest - name: quay.io/karmab/kcli:latest - name: quay.io/user-name/trbsht:latest - name: quay.io/user-name/hypershift:BMSelfManage-v4.14-rc-v3 - name: registry.redhat.io/openshift4/ose-kube-rbac-proxy:v4.10 operators: - catalog: registry.redhat.io/redhat/redhat-operator-index:v4.14 packages: - name: lvms-operator - name: local-storage-operator - name: odf-csi-addons-operator - name: odf-operator - name: mcg-operator - name: ocs-operator - name: metallb-operator- 1
4.x.y를 사용하려는 지원되는 OpenShift Container Platform 버전으로 교체합니다.
다음 명령을 입력하여 미러링 프로세스를 시작합니다.
oc-mirror --source-skip-tls --config imagesetconfig.yaml docker://${REGISTRY}미러링 프로세스가 완료되면 호스트 클러스터에 적용할 ICSP 및 카탈로그 소스가 포함된
oc-mirror-workspace/results-XXXXXX/라는 새 폴더가 있습니다.oc adm release mirror명령을 사용하여 OpenShift Container Platform의 Nightly 또는 CI 버전을 미러링합니다. 다음 명령을 실행합니다.REGISTRY=registry.$(hostname --long):5000 oc adm release mirror \ --from=registry.ci.openshift.org/ocp/release:4.x.y-x86_64 \ --to=${REGISTRY}/openshift/release \ --to-release-image=${REGISTRY}/openshift/release-images:registry.dns.base.domain.name:5000/openshift/release-images:4.x.y-x86_644.x.y를 사용하려는 지원되는 OpenShift Container Platform 버전으로 교체합니다.- 연결이 끊긴 네트워크에 설치 단계에 따라 최신 다중 클러스터 엔진 Operator 이미지를 미러링합니다.
1.7.12.7.6.2. 관리 클러스터에 오브젝트 적용
미러링 프로세스가 완료되면 관리 클러스터에 두 개의 오브젝트를 적용해야 합니다.
- Image Content Source Policies (ICSP) 또는 Image Digest 미러 세트(IDMS)
- 카탈로그 소스
oc-mirror 툴을 사용하는 경우 출력 아티팩트는 oc-mirror-workspace/results-XXXXXX/ 이라는 폴더에 있습니다.
ICSP 또는 IDMS는 노드를 재시작하지 않고 각 노드에서 kubelet을 다시 시작하는 MachineConfig 변경 사항을 시작합니다. 노드가 READY 로 표시되면 새로 생성된 카탈로그 소스를 적용해야 합니다.
카탈로그 소스는 카탈로그 이미지 다운로드 및 처리와 같은 openshift-marketplace Operator에서 작업을 시작하여 해당 이미지에 포함된 모든 PackageManifest 를 검색합니다.
새 소스를 확인하려면 새
CatalogSource를 소스로 사용하여 다음 명령을 실행합니다.oc get packagemanifest아티팩트를 적용하려면 다음 단계를 완료합니다.
다음 명령을 입력하여 ICSP 또는 IDMS 아티팩트를 생성합니다.
oc apply -f oc-mirror-workspace/results-XXXXXX/imageContentSourcePolicy.yaml- 노드가 준비될 때까지 기다린 다음 다음 명령을 입력합니다.
oc apply -f catalogSource-XXXXXXXX-index.yaml
다음으로 다중 클러스터 엔진 Operator를 배포합니다.
1.7.12.7.6.3. 추가 리소스
- 가상 환경에서 작업하는 경우 미러링을 구성한 후 OpenShift Virtualization에서 호스팅되는 컨트롤 플레인의 사전 요구 사항을 충족해야 합니다.
- Nightly 또는 CI 버전의 OpenShift Container Platform 미러링에 대한 자세한 내용은 oc-mirror 플러그인을 사용하여 연결이 끊긴 설치의 이미지 미러링을 참조하십시오.
1.7.12.7.7. 듀얼 스택 네트워크용 다중 클러스터 엔진 Operator 배포
다중 클러스터 엔진 Operator는 공급업체에 클러스터를 배포하는 데 중요한 역할을 합니다. Red Hat Advanced Cluster Management를 이미 설치한 경우 자동으로 설치되므로 다중 클러스터 엔진 Operator를 설치할 필요가 없습니다.
다중 클러스터 엔진 Operator가 설치되어 있지 않은 경우 다음 문서를 검토하여 사전 요구 사항 및 설치 단계를 이해하십시오.
1.7.12.7.7.1. AgentServiceConfig 리소스 배포
AgentServiceConfig 사용자 지정 리소스는 다중 클러스터 엔진 Operator의 일부인 지원 서비스 애드온의 필수 구성 요소입니다. 베어 메탈 클러스터 배포를 담당합니다. 애드온이 활성화되면 AgentServiceConfig 리소스를 배포하여 애드온을 구성합니다.
AgentServiceConfig 리소스를 구성하는 것 외에도 연결이 끊긴 환경에서 다중 클러스터 엔진 Operator가 제대로 작동하는지 확인하기 위해 추가 구성 맵을 포함해야 합니다.
배포를 사용자 지정하는 연결이 끊긴 세부 정보가 포함된 다음 구성 맵을 추가하여 사용자 정의 레지스트리를 구성합니다.
--- apiVersion: v1 kind: ConfigMap metadata: name: custom-registries namespace: multicluster-engine labels: app: assisted-service data: ca-bundle.crt: | -----BEGIN CERTIFICATE----- -----END CERTIFICATE----- registries.conf: | unqualified-search-registries = ["registry.access.redhat.com", "docker.io"] [[registry]] prefix = "" location = "registry.redhat.io/openshift4" mirror-by-digest-only = true [[registry.mirror]] location = "registry.dns.base.domain.name:5000/openshift4"1 [[registry]] prefix = "" location = "registry.redhat.io/rhacm2" mirror-by-digest-only = true ... ...- 1
dns.base.domain.name을 DNS 기본 도메인 이름으로 교체합니다.
오브젝트에는 다음 두 개의 필드가 있습니다.
- 사용자 정의 CA: 이 필드에는 배포의 다양한 프로세스에 로드되는 CA(인증 기관)가 포함되어 있습니다.
-
Registry:
Registries.conf필드에는 원래 소스 레지스트리가 아닌 미러 레지스트리에서 사용해야 하는 이미지 및 네임스페이스에 대한 정보가 포함되어 있습니다.
다음 예와 같이
AssistedServiceConfig오브젝트를 추가하여 Assisted Service를 구성합니다.--- apiVersion: agent-install.openshift.io/v1beta1 kind: AgentServiceConfig metadata: annotations: unsupported.agent-install.openshift.io/assisted-service-configmap: assisted-service-config1 name: agent namespace: multicluster-engine spec: mirrorRegistryRef: name: custom-registries2 databaseStorage: storageClassName: lvms-vg1 accessModes: - ReadWriteOnce resources: requests: storage: 10Gi filesystemStorage: storageClassName: lvms-vg1 accessModes: - ReadWriteOnce resources: requests: storage: 20Gi osImages:3 - cpuArchitecture: x86_64 openshiftVersion: "4.14" rootFSUrl: http://registry.dns.base.domain.name:8080/images/rhcos-414.92.202308281054-0-live-rootfs.x86_64.img4 url: http://registry.dns.base.domain.name:8080/images/rhcos-414.92.202308281054-0-live.x86_64.iso version: 414.92.202308281054-0- 1
metadata.annotations["unsupported.agent-install.openshift.io/assisted-service-configmap"]주석은 Operator가 동작을 사용자 정의하는 데 사용하는 구성 맵 이름을 참조합니다.- 2
spec.mirrorRegistryRef.name주석은 Assisted Service Operator가 사용하는 연결이 끊긴 레지스트리 정보가 포함된 구성 맵을 가리킵니다. 이 구성 맵은 배포 프로세스 중에 해당 리소스를 추가합니다.- 3
spec.osImages필드에는 이 Operator에서 배포할 수 있는 다양한 버전이 포함되어 있습니다. 이 필드는 필수입니다. 이 예제에서는 이미RootFS및LiveISO파일을 다운로드했다고 가정합니다.- 4
rootFSUrl및url필드에서dns.base.domain.name을 DNS 기본 도메인 이름으로 교체합니다.
해당 오브젝트를 단일 파일에 연결하고 관리 클러스터에 적용하여 모든 오브젝트를 배포합니다. 이렇게 하려면 다음 명령을 입력합니다.
oc apply -f agentServiceConfig.yaml이 명령은 이 예제 출력에 표시된 대로 두 개의 Pod를 트리거합니다.
assisted-image-service-0 1/1 Running 2 11d1 assisted-service-668b49548-9m7xw 2/2 Running 5 11d2
1.7.12.7.8. 듀얼 스택 네트워크에 대한 TLS 인증서 구성
연결이 끊긴 환경에서 호스팅된 컨트롤 플레인을 구성하는 프로세스에 여러 TLS 인증서가 포함됩니다. 관리 클러스터에 CA(인증 기관)를 추가하려면 OpenShift Container Platform 컨트롤 플레인 및 작업자 노드에서 다음 파일의 내용을 수정해야 합니다.
-
/etc/pki/ca-trust/extracted/pem/ -
/etc/pki/ca-trust/source/anchors -
/etc/pki/tls/certs/
관리 클러스터에 CA를 추가하려면 다음 단계를 완료합니다.
-
공식 OpenShift Container Platform 설명서에서 CA 번들 업데이트 단계를 완료합니다. 이 방법은 CA를 OpenShift Container Platform 노드에 배포하는
image-registry-operator를 사용하는 것입니다. 해당 방법이 상황에 적용되지 않는 경우 관리 클러스터의
openshift-config네임스페이스에user-ca-bundle이라는 구성 맵이 포함되어 있는지 확인합니다.네임스페이스에 해당 구성 맵이 포함된 경우 다음 명령을 입력합니다.
## REGISTRY_CERT_PATH=<PATH/TO/YOUR/CERTIFICATE/FILE> export REGISTRY_CERT_PATH=/opt/registry/certs/domain.crt oc create configmap user-ca-bundle -n openshift-config --from-file=ca-bundle.crt=${REGISTRY_CERT_PATH}네임스페이스에 해당 구성 맵이 포함되지 않은 경우 다음 명령을 입력합니다.
## REGISTRY_CERT_PATH=<PATH/TO/YOUR/CERTIFICATE/FILE> export REGISTRY_CERT_PATH=/opt/registry/certs/domain.crt export TMP_FILE=$(mktemp) oc get cm -n openshift-config user-ca-bundle -ojsonpath='{.data.ca-bundle\.crt}' > ${TMP_FILE} echo >> ${TMP_FILE} echo \#registry.$(hostname --long) >> ${TMP_FILE} cat ${REGISTRY_CERT_PATH} >> ${TMP_FILE} oc create configmap user-ca-bundle -n openshift-config --from-file=ca-bundle.crt=${TMP_FILE} --dry-run=client -o yaml | kubectl apply -f -
1.7.12.7.9. 듀얼 스택 네트워크에 대해 호스트된 클러스터 배포
호스팅 클러스터는 관리 클러스터에서 호스팅되는 컨트롤 플레인 및 API 끝점이 있는 OpenShift Container Platform 클러스터입니다. 호스트된 클러스터에는 컨트롤 플레인과 해당 데이터 플레인이 포함됩니다.
Red Hat Advanced Cluster Management에서 콘솔을 사용하여 호스트 클러스터를 생성할 수 있지만 다음 절차에서는 관련 아티팩트를 수정하는 데 더 유연하게 사용할 수 있는 매니페스트를 사용합니다.
1.7.12.7.9.1. 호스트된 클러스터 오브젝트 배포
이 절차의 목적을 위해 다음 값이 사용됩니다.
-
HostedCluster 이름:
hosted-dual -
HostedCluster 네임스페이스:
클러스터 -
disconnected:
true -
네트워크 스택:
듀얼
일반적으로 HyperShift Operator는 HostedControlPlane 네임스페이스를 생성합니다. 그러나 이 경우 HyperShift Operator가 HostedCluster 오브젝트를 조정하기 전에 모든 오브젝트를 포함해야 합니다. 그러면 Operator가 조정 프로세스를 시작하면 모든 오브젝트를 찾을 수 있습니다.
네임스페이스에 대한 다음 정보를 사용하여 YAML 파일을 생성합니다.
--- apiVersion: v1 kind: Namespace metadata: creationTimestamp: null name: clusters-hosted-dual spec: {} status: {} --- apiVersion: v1 kind: Namespace metadata: creationTimestamp: null name: clusters spec: {} status: {}HostedCluster배포에 포함할 구성 맵 및 시크릿에 대한 다음 정보를 사용하여 YAML 파일을 생성합니다.--- apiVersion: v1 data: ca-bundle.crt: | -----BEGIN CERTIFICATE----- -----END CERTIFICATE----- kind: ConfigMap metadata: name: user-ca-bundle namespace: clusters --- apiVersion: v1 data: .dockerconfigjson: xxxxxxxxx kind: Secret metadata: creationTimestamp: null name: hosted-dual-pull-secret namespace: clusters --- apiVersion: v1 kind: Secret metadata: name: sshkey-cluster-hosted-dual namespace: clusters stringData: id_rsa.pub: ssh-rsa xxxxxxxxx --- apiVersion: v1 data: key: nTPtVBEt03owkrKhIdmSW8jrWRxU57KO/fnZa8oaG0Y= kind: Secret metadata: creationTimestamp: null name: hosted-dual-etcd-encryption-key namespace: clusters type: Opaque지원 서비스 에이전트가 호스팅된 컨트롤 플레인과 동일한
HostedControlPlane네임스페이스에 있을 수 있고 클러스터 API에서 계속 관리할 수 있도록 RBAC 역할이 포함된 YAML 파일을 생성합니다.apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: creationTimestamp: null name: capi-provider-role namespace: clusters-hosted-dual rules: - apiGroups: - agent-install.openshift.io resources: - agents verbs: - '*'필요에 따라 값을 교체하여
HostedCluster오브젝트에 대한 정보를 사용하여 YAML 파일을 생성합니다.apiVersion: hypershift.openshift.io/v1beta1 kind: HostedCluster metadata: name: hosted-dual namespace: clusters spec: additionalTrustBundle: name: "user-ca-bundle" olmCatalogPlacement: guest imageContentSources:1 - source: quay.io/openshift-release-dev/ocp-v4.0-art-dev mirrors: - registry.dns.base.domain.name:5000/openshift/release2 - source: quay.io/openshift-release-dev/ocp-release mirrors: - registry.dns.base.domain.name:5000/openshift/release-images - mirrors: ... ... autoscaling: {} controllerAvailabilityPolicy: SingleReplica dns: baseDomain: dns.base.domain.name etcd: managed: storage: persistentVolume: size: 8Gi restoreSnapshotURL: null type: PersistentVolume managementType: Managed fips: false networking: clusterNetwork: - cidr: 10.132.0.0/14 - cidr: fd01::/48 networkType: OVNKubernetes serviceNetwork: - cidr: 172.31.0.0/16 - cidr: fd02::/112 platform: agent: agentNamespace: clusters-hosted-dual type: Agent pullSecret: name: hosted-dual-pull-secret release: image: registry.dns.base.domain.name:5000/openshift/release-images:4.x.y-x86_643 secretEncryption: aescbc: activeKey: name: hosted-dual-etcd-encryption-key type: aescbc services: - service: APIServer servicePublishingStrategy: nodePort: address: api.hosted-dual.dns.base.domain.name type: NodePort - service: OAuthServer servicePublishingStrategy: nodePort: address: api.hosted-dual.dns.base.domain.name type: NodePort - service: OIDC servicePublishingStrategy: nodePort: address: api.hosted-dual.dns.base.domain.name type: NodePort - service: Konnectivity servicePublishingStrategy: nodePort: address: api.hosted-dual.dns.base.domain.name type: NodePort - service: Ignition servicePublishingStrategy: nodePort: address: api.hosted-dual.dns.base.domain.name type: NodePort sshKey: name: sshkey-cluster-hosted-dual status: controlPlaneEndpoint: host: "" port: 0OpenShift Container Platform 릴리스의 HyperShift Operator 릴리스를 가리키는
HostedCluster오브젝트에 주석을 추가합니다.다음 명령을 입력하여 이미지 페이로드를 가져옵니다.
oc adm release info registry.dns.base.domain.name:5000/openshift-release-dev/ocp-release:4.x.y-x86_64 | grep hypershift여기서
dns.base.domain.name은 DNS 기본 도메인 이름이며4.x.y는 사용하려는 지원되는 OpenShift Container Platform 버전입니다.다음 출력을 참조하십시오.
hypershift sha256:31149e3e5f8c5e5b5b100ff2d89975cf5f7a73801b2c06c639bf6648766117f8OpenShift Container Platform 이미지 네임스페이스를 사용하여 다음 명령을 입력하여 다이제스트를 확인합니다.
podman pull registry.dns.base.domain.name:5000/openshift-release-dev/ocp-v4.0-art-dev@sha256:31149e3e5f8c5e5b5b100ff2d89975cf5f7a73801b2c06c639bf6648766117f8여기서
dns.base.domain.name은 DNS 기본 도메인 이름입니다.다음 출력을 참조하십시오.
podman pull registry.dns.base.domain.name:5000/openshift/release@sha256:31149e3e5f8c5e5b5b100ff2d89975cf5f7a73801b2c06c639bf6648766117f8 Trying to pull registry.dns.base.domain.name:5000/openshift/release@sha256:31149e3e5f8c5e5b5b100ff2d89975cf5f7a73801b2c06c639bf6648766117f8... Getting image source signatures Copying blob d8190195889e skipped: already exists Copying blob c71d2589fba7 skipped: already exists Copying blob d4dc6e74b6ce skipped: already exists Copying blob 97da74cc6d8f skipped: already exists Copying blob b70007a560c9 done Copying config 3a62961e6e done Writing manifest to image destination Storing signatures 3a62961e6ed6edab46d5ec8429ff1f41d6bb68de51271f037c6cb8941a007fde
참고:
HostedCluster오브젝트에 설정된 릴리스 이미지는 태그가 아닌 다이제스트를 사용해야 합니다. 예를 들어quay.io/openshift-release-dev/ocp-release@sha256:e3ba11bd1e5e8ea5a0b36a75791c90f29afb0fdbe4125be4e48f69c76a5c.YAML 파일에 정의된 모든 오브젝트를 파일에 연결하고 관리 클러스터에 적용하여 해당 오브젝트를 생성합니다. 이렇게 하려면 다음 명령을 입력합니다.
oc apply -f 01-4.14-hosted_cluster-nodeport.yaml호스트된 컨트롤 플레인의 출력을 참조하십시오.
NAME READY STATUS RESTARTS AGE capi-provider-5b57dbd6d5-pxlqc 1/1 Running 0 3m57s catalog-operator-9694884dd-m7zzv 2/2 Running 0 93s cluster-api-f98b9467c-9hfrq 1/1 Running 0 3m57s cluster-autoscaler-d7f95dd5-d8m5d 1/1 Running 0 93s cluster-image-registry-operator-5ff5944b4b-648ht 1/2 Running 0 93s cluster-network-operator-77b896ddc-wpkq8 1/1 Running 0 94s cluster-node-tuning-operator-84956cd484-4hfgf 1/1 Running 0 94s cluster-policy-controller-5fd8595d97-rhbwf 1/1 Running 0 95s cluster-storage-operator-54dcf584b5-xrnts 1/1 Running 0 93s cluster-version-operator-9c554b999-l22s7 1/1 Running 0 95s control-plane-operator-6fdc9c569-t7hr4 1/1 Running 0 3m57s csi-snapshot-controller-785c6dc77c-8ljmr 1/1 Running 0 77s csi-snapshot-controller-operator-7c6674bc5b-d9dtp 1/1 Running 0 93s csi-snapshot-webhook-5b8584875f-2492j 1/1 Running 0 77s dns-operator-6874b577f-9tc6b 1/1 Running 0 94s etcd-0 3/3 Running 0 3m39s hosted-cluster-config-operator-f5cf5c464-4nmbh 1/1 Running 0 93s ignition-server-6b689748fc-zdqzk 1/1 Running 0 95s ignition-server-proxy-54d4bb9b9b-6zkg7 1/1 Running 0 95s ingress-operator-6548dc758b-f9gtg 1/2 Running 0 94s konnectivity-agent-7767cdc6f5-tw782 1/1 Running 0 95s kube-apiserver-7b5799b6c8-9f5bp 4/4 Running 0 3m7s kube-controller-manager-5465bc4dd6-zpdlk 1/1 Running 0 44s kube-scheduler-5dd5f78b94-bbbck 1/1 Running 0 2m36s machine-approver-846c69f56-jxvfr 1/1 Running 0 92s oauth-openshift-79c7bf44bf-j975g 2/2 Running 0 62s olm-operator-767f9584c-4lcl2 2/2 Running 0 93s openshift-apiserver-5d469778c6-pl8tj 3/3 Running 0 2m36s openshift-controller-manager-6475fdff58-hl4f7 1/1 Running 0 95s openshift-oauth-apiserver-dbbc5cc5f-98574 2/2 Running 0 95s openshift-route-controller-manager-5f6997b48f-s9vdc 1/1 Running 0 95s packageserver-67c87d4d4f-kl7qh 2/2 Running 0 93s호스트 클러스터의 출력을 참조하십시오.
NAMESPACE NAME VERSION KUBECONFIG PROGRESS AVAILABLE PROGRESSING MESSAGE clusters hosted-dual hosted-admin-kubeconfig Partial True False The hosted control plane is available
다음으로 NodePool 오브젝트를 생성합니다.
1.7.12.7.9.2. 호스트된 클러스터에 대한 NodePool 오브젝트 생성
NodePool 은 호스팅된 클러스터와 연결된 확장 가능한 작업자 노드 집합입니다. NodePool 머신 아키텍처는 특정 풀 내에서 일관되게 유지되며 컨트롤 플레인의 머신 아키텍처와 독립적입니다.
NodePool오브젝트에 대한 다음 정보를 사용하여 YAML 파일을 생성하여 필요에 따라 값을 바꿉니다.apiVersion: hypershift.openshift.io/v1beta1 kind: NodePool metadata: creationTimestamp: null name: hosted-dual namespace: clusters spec: arch: amd64 clusterName: hosted-dual management: autoRepair: false1 upgradeType: InPlace2 nodeDrainTimeout: 0s platform: type: Agent release: image: registry.dns.base.domain.name:5000/openshift/release-images:4.x.y-x86_643 replicas: 0 status: replicas: 04 - 1
- 노드가 제거되면 노드가 다시 생성되지 않기 때문에
autoRepair필드가false로 설정됩니다. - 2
upgradeType은 업그레이드 중에 동일한 베어 메탈 노드가 재사용됨을 나타내는InPlace로 설정됩니다.- 3
- 이
NodePool에 포함된 모든 노드는 다음 OpenShift Container Platform 버전4.x.y-x86_64를 기반으로 합니다.dns.base.domain.name값을 DNS 기본 도메인 이름으로 바꾸고4.x.y값을 사용하려는 지원되는 OpenShift Container Platform 버전으로 바꿉니다. - 4
- 필요한 경우 스케일링할 수 있도록
replicas값은0으로 설정됩니다. 모든 단계가 완료될 때까지NodePool복제본을 0으로 유지하는 것이 중요합니다.
다음 명령을 입력하여
NodePool오브젝트를 생성합니다.oc apply -f 02-nodepool.yaml출력을 참조하십시오.
NAMESPACE NAME CLUSTER DESIRED NODES CURRENT NODES AUTOSCALING AUTOREPAIR VERSION UPDATINGVERSION UPDATINGCONFIG MESSAGE clusters hosted-dual hosted 0 False False 4.x.y-x86_64
다음으로 InfraEnv 리소스를 생성합니다.
1.7.12.7.9.3. 호스트된 클러스터에 대한 InfraEnv 리소스 생성
InfraEnv 리소스는 pullSecretRef 및 sshAuthorizedKey 와 같은 필수 세부 정보를 포함하는 지원 서비스 오브젝트입니다. 이러한 세부 사항은 호스팅된 클러스터에 대해 사용자 지정된 RHCOS(Red Hat Enterprise Linux CoreOS) 부팅 이미지를 생성하는 데 사용됩니다.
필요에 따라 값을 교체하여
InfraEnv리소스에 대한 다음 정보를 사용하여 YAML 파일을 생성합니다.--- apiVersion: agent-install.openshift.io/v1beta1 kind: InfraEnv metadata: name: hosted-dual namespace: clusters-hosted-dual spec: pullSecretRef:1 name: pull-secret sshAuthorizedKey: ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABgQDk7ICaUE+/k4zTpxLk4+xFdHi4ZuDi5qjeF52afsNkw0w/glILHhwpL5gnp5WkRuL8GwJuZ1VqLC9EKrdmegn4MrmUlq7WTsP0VFOZFBfq2XRUxo1wrRdor2z0Bbh93ytR+ZsDbbLlGngXaMa0Vbt+z74FqlcajbHTZ6zBmTpBVq5RHtDPgKITdpE1fongp7+ZXQNBlkaavaqv8bnyrP4BWahLP4iO9/xJF9lQYboYwEEDzmnKLMW1VtCE6nJzEgWCufACTbxpNS7GvKtoHT/OVzw8ArEXhZXQUS1UY8zKsX2iXwmyhw5Sj6YboA8WICs4z+TrFP89LmxXY0j6536TQFyRz1iB4WWvCbH5n6W+ABV2e8ssJB1AmEy8QYNwpJQJNpSxzoKBjI73XxvPYYC/IjPFMySwZqrSZCkJYqQ023ySkaQxWZT7in4KeMu7eS2tC+Kn4deJ7KwwUycx8n6RHMeD8Qg9flTHCv3gmab8JKZJqN3hW1D378JuvmIX4V0=2 다음 명령을 입력하여
InfraEnv리소스를 생성합니다.oc apply -f 03-infraenv.yaml다음 출력을 참조하십시오.
NAMESPACE NAME ISO CREATED AT clusters-hosted-dual hosted 2023-09-11T15:14:10Z
다음으로 작업자 노드를 생성합니다.
1.7.12.7.9.4. 호스트된 클러스터의 작업자 노드 생성
베어 메탈 플랫폼에서 작업하는 경우 작업자 노드를 생성하는 것은 BareMetalHost 의 세부 정보가 올바르게 구성되었는지 확인하는 데 중요합니다.
가상 머신으로 작업하는 경우 다음 단계를 완료하여 Metal3 Operator에서 사용할 빈 작업자 노드를 생성할 수 있습니다. 이렇게 하려면 kcli 툴을 사용합니다.
이것이 작업자 노드 생성을 처음 시도하지 않은 경우 먼저 이전 설정을 삭제해야 합니다. 이렇게 하려면 다음 명령을 입력하여 계획을 삭제합니다.
kcli delete plan hosted-dual-
계획을 삭제할지 여부를 확인하라는 메시지가 표시되면
y를 입력합니다. - 계획이 삭제되었음을 알리는 메시지가 표시되는지 확인합니다.
-
계획을 삭제할지 여부를 확인하라는 메시지가 표시되면
다음 명령을 입력하여 가상 머신을 생성합니다.
kcli create vm -P start=False -P uefi_legacy=true -P plan=hosted-dual -P memory=8192 -P numcpus=16 -P disks=[200,200] -P nets=["{\"name\": \"dual\", \"mac\": \"aa:aa:aa:aa:11:01\"}"] -P uuid=aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaa1101 -P name=hosted-dual-worker0kcli create vm -P start=False -P uefi_legacy=true -P plan=hosted-dual -P memory=8192 -P numcpus=16 -P disks=[200,200] -P nets=["{\"name\": \"dual\", \"mac\": \"aa:aa:aa:aa:11:02\"}"] -P uuid=aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaa1102 -P name=hosted-dual-worker1kcli create vm -P start=False -P uefi_legacy=true -P plan=hosted-dual -P memory=8192 -P numcpus=16 -P disks=[200,200] -P nets=["{\"name\": \"dual\", \"mac\": \"aa:aa:aa:aa:11:03\"}"] -P uuid=aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaa1103 -P name=hosted-dual-worker2systemctl restart ksushy다음과 같습니다.
-
start=False는 VM(가상 머신)이 생성 시 자동으로 시작되지 않음을 의미합니다. -
uefi_legacy=true는 UEFI 레거시 부팅을 사용하여 이전 UEFI 구현과의 호환성을 보장합니다. -
plan=hosted-dual은 시스템 그룹을 클러스터로 식별하는 계획 이름을 나타냅니다. -
memory=8192및numcpus=16은 RAM 및 CPU를 포함하여 VM의 리소스를 지정하는 매개변수입니다. -
disks=[200,200]은 VM에 씬 프로비저닝된 두 개의 디스크를 생성 중임을 나타냅니다. -
nets=[{"name": "dual", "mac": "aa:aa:aa:aa:aa:aa:02:13"}]은 연결할 네트워크 이름과 기본 인터페이스의 MAC 주소를 포함한 네트워크 세부 정보입니다. -
ksushy를 다시 시작하여ksushy툴을 다시 시작하여 추가한 VM을 감지합니다.
-
결과 출력을 확인합니다.
+---------------------+--------+-------------------+----------------------------------------------------+-------------+---------+ | Name | Status | Ip | Source | Plan | Profile | +---------------------+--------+-------------------+----------------------------------------------------+-------------+---------+ | hosted-worker0 | down | | | hosted-dual | kvirt | | hosted-worker1 | down | | | hosted-dual | kvirt | | hosted-worker2 | down | | | hosted-dual | kvirt | +---------------------+--------+-------------------+----------------------------------------------------+-------------+---------+
다음으로 호스팅된 클러스터에 대한 베어 메탈 호스트를 생성합니다.
1.7.12.7.9.5. 호스트 클러스터를 위한 베어 메탈 호스트 생성
베어 메탈 호스트 는 Metal3 Operator가 식별할 수 있도록 물리적 및 논리 세부 정보를 포함하는 openshift-machine-api 오브젝트입니다. 이러한 세부 사항은 에이전트 라고 하는 기타 지원 서비스 오브젝트와 연결됩니다.
중요: 베어 메탈 호스트 및 대상 노드를 생성하기 전에 가상 머신을 생성해야 합니다.
베어 메탈 호스트를 생성하려면 다음 단계를 완료합니다.
다음 정보를 사용하여 YAML 파일을 생성합니다.
참고: 베어 메탈 호스트 인증 정보를 보유하는 시크릿이 하나 이상 있으므로 각 작업자 노드에 대해 두 개 이상의 오브젝트를 생성해야 합니다.
--- apiVersion: v1 kind: Secret metadata: name: hosted-dual-worker0-bmc-secret namespace: clusters-hosted-dual data: password: YWRtaW4= username: YWRtaW4= type: Opaque --- apiVersion: metal3.io/v1alpha1 kind: BareMetalHost metadata: name: hosted-dual-worker0 namespace: clusters-hosted-dual labels: infraenvs.agent-install.openshift.io: hosted-dual1 annotations: inspect.metal3.io: disabled bmac.agent-install.openshift.io/hostname: hosted-dual-worker02 spec: automatedCleaningMode: disabled3 bmc: disableCertificateVerification: true4 address: redfish-virtualmedia://[192.168.126.1]:9000/redfish/v1/Systems/local/hosted-dual-worker05 credentialsName: hosted-dual-worker0-bmc-secret6 bootMACAddress: aa:aa:aa:aa:02:117 online: true8 - 1
infraenvs.agent-install.openshift.io는 지원 설치 프로그램과BareMetalHost오브젝트 간의 링크 역할을 합니다.- 2
- B
MAC.agent-install.openshift.io/hostname은 배포 중에 채택된 노드 이름을 나타냅니다. - 3
automatedCleaningMode를 사용하면 Metal3 Operator에 의해 노드가 지워지지 않습니다.- 4
- 클라이언트에서 인증서 유효성 검사를 바이패스하려면
disableCertificateVerification이true로 설정됩니다. - 5
address는 작업자 노드의 BMC(Baseboard Management Controller) 주소를 나타냅니다.- 6
credentialsName은 사용자 및 암호 인증 정보가 저장된 시크릿을 가리킵니다.- 7
bootMACAddress는 노드가 시작되는 인터페이스 MAC 주소를 나타냅니다.- 8
online은BareMetalHost개체가 생성된 후 노드의 상태를 정의합니다.
다음 명령을 입력하여
BareMetalHost오브젝트를 배포합니다.oc apply -f 04-bmh.yaml프로세스 중에 다음 출력을 볼 수 있습니다.
이 출력은 프로세스가 노드에 연결을 시도 중임을 나타냅니다.
NAMESPACE NAME STATE CONSUMER ONLINE ERROR AGE clusters-hosted hosted-worker0 registering true 2s clusters-hosted hosted-worker1 registering true 2s clusters-hosted hosted-worker2 registering true 2s이 출력은 노드가 시작됨을 나타냅니다.
NAMESPACE NAME STATE CONSUMER ONLINE ERROR AGE clusters-hosted hosted-worker0 provisioning true 16s clusters-hosted hosted-worker1 provisioning true 16s clusters-hosted hosted-worker2 provisioning true 16s- 이 출력은 노드가 성공적으로 시작되었음을 나타냅니다.
NAMESPACE NAME STATE CONSUMER ONLINE ERROR AGE clusters-hosted hosted-worker0 provisioned true 67s clusters-hosted hosted-worker1 provisioned true 67s clusters-hosted hosted-worker2 provisioned true 67s노드가 시작된 후 다음 예와 같이 네임스페이스의 에이전트를 확인합니다.
NAMESPACE NAME CLUSTER APPROVED ROLE STAGE clusters-hosted aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaa0411 true auto-assign clusters-hosted aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaa0412 true auto-assign clusters-hosted aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaa0413 true auto-assign에이전트는 설치에 사용할 수 있는 노드를 나타냅니다. 호스트 클러스터에 노드를 할당하려면 노드 풀을 확장합니다.
1.7.12.7.9.6. 노드 풀 확장
베어 메탈 호스트를 생성한 후 해당 상태가 Registering 에서 Provisioning (프로비저닝)으로 변경됨. 노드는 에이전트의 LiveISO 및 에이전트 라는 기본 Pod로 시작합니다. 해당 에이전트는 OpenShift Container Platform 페이로드를 설치하기 위해 Assisted Service Operator에서 지침을 받습니다.
노드 풀을 확장하려면 다음 명령을 입력합니다.
oc -n clusters scale nodepool hosted-dual --replicas 3확장 프로세스가 완료되면 에이전트가 호스팅된 클러스터에 할당되어 있습니다.
NAMESPACE NAME CLUSTER APPROVED ROLE STAGE clusters-hosted aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaa0411 hosted true auto-assign clusters-hosted aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaa0412 hosted true auto-assign clusters-hosted aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaa0413 hosted true auto-assign또한 노드 풀 복제본이 설정되어 있습니다.
NAMESPACE NAME CLUSTER DESIRED NODES CURRENT NODES AUTOSCALING AUTOREPAIR VERSION UPDATINGVERSION UPDATINGCONFIG MESSAGE clusters hosted hosted 3 False False 4.x.y-x86_64 Minimum availability requires 3 replicas, current 0 available4.x.y를 사용하려는 지원되는 OpenShift Container Platform 버전으로 교체합니다.- 노드가 클러스터에 참여할 때까지 기다립니다. 프로세스 중에 에이전트는 단계 및 상태에 대한 업데이트를 제공합니다.
다음으로 호스트 클러스터의 배포를 모니터링합니다.
1.7.12.7.10. 듀얼 스택 네트워크에 대해 호스트된 클러스터 배포 완료
컨트롤 플레인과 데이터 플레인의 두 가지 관점에서 호스팅 클러스터 배포를 모니터링할 수 있습니다.
1.7.12.7.10.1. 컨트롤 플레인을 사용하여 호스트된 클러스터 배포 모니터링
컨트롤 플레인을 사용하여 호스팅된 클러스터 배포를 모니터링할 수 있습니다.
다음 명령을 입력하여 호스팅 클러스터
kubeconfig파일을 내보냅니다.export KUBECONFIG=<path_to_hosted_cluster_kubeconfig>다음 명령을 입력하여 호스팅된 클러스터 배포 진행 상황을 관찰합니다.
watch "oc get pod -n hypershift;echo;echo;oc get pod -n <hosted_control_plane_namespace>;echo;echo;oc get bmh -A;echo;echo;oc get agent -A;echo;echo;oc get infraenv -A;echo;echo;oc get hostedcluster -A;echo;echo;oc get nodepool -A;echo;echo;"
이 명령은 다음 아티팩트에 대한 정보를 제공합니다.
- The HyperShift Operator
-
HostedControlPlanePod - 베어 메탈 호스트
- 에이전트
-
InfraEnv리소스 -
HostedCluster및NodePool리소스
1.7.12.7.10.2. 데이터 플레인을 사용하여 호스트된 클러스터 배포 모니터링
데이터 플레인을 사용하여 호스트 클러스터 배포 프로세스 중에 Operator가 진행 중인 방식을 모니터링할 수 있습니다.
다음 명령을 입력하여 호스팅된 클러스터에 대한
kubeconfig파일을 생성합니다.hcp create kubeconfig --name <hosted_cluster_name> --namespace <hosted_cluster_namespace>다음 명령을 입력하여 호스팅 클러스터
kubeconfig파일을 내보냅니다.export KUBECONFIG=<path_to_hosted_cluster_kubeconfig>다음 명령을 입력하여 클러스터 버전, 노드 및 클러스터 Operator의 상태를 확인합니다.
watch "oc get clusterversion,nodes,co"
1.7.13. 수동으로 호스팅된 컨트롤 플레인 클러스터 가져오기
호스팅된 컨트롤 플레인을 사용할 수 있게 되면 호스팅된 클러스터는 멀티 클러스터 엔진 Operator로 자동으로 가져옵니다. 호스트 클러스터를 수동으로 가져오려면 다음 단계를 완료합니다.
- 콘솔에서 Infrastructure > Clusters 를 클릭하고 가져올 호스팅 클러스터를 선택합니다.
호스팅 클러스터 가져오기 를 클릭합니다.
참고: 검색된 호스트 클러스터의 경우 콘솔에서 가져올 수도 있지만 클러스터는 업그레이드 가능한 상태여야 합니다. 호스팅된 컨트롤 플레인을 사용할 수 없기 때문에 호스팅된 클러스터가 업그레이드 가능한 상태가 아닌 경우 클러스터의 가져오기가 비활성화됩니다. 가져오기 를 클릭하여 프로세스를 시작합니다. 클러스터가 업데이트를 수신하는 동안 상태가
Importing된 다음Ready로 변경됩니다.
1.7.13.1. AWS에서 호스팅된 컨트롤 플레인 클러스터를 수동으로 가져오기
다음 단계를 완료하여 명령줄 인터페이스를 사용하여 AWS에서 호스팅되는 컨트롤 플레인 클러스터를 가져올 수도 있습니다.
다음 샘플 YAML 파일을 사용하여
ManagedCluster리소스를 생성합니다.apiVersion: cluster.open-cluster-management.io/v1 kind: ManagedCluster metadata: annotations: import.open-cluster-management.io/hosting-cluster-name: local-cluster import.open-cluster-management.io/klusterlet-deploy-mode: Hosted open-cluster-management/created-via: hypershift labels: cloud: auto-detect cluster.open-cluster-management.io/clusterset: default name: <cluster_name> vendor: OpenShift name: <cluster_name> spec: hubAcceptsClient: true leaseDurationSeconds: 60&
lt;cluster_name>을 호스트된 클러스터 이름으로 바꿉니다.다음 명령을 실행하여 리소스를 적용합니다.
oc apply -f <file_name><file_name>을 이전 단계에서 생성한 YAML 파일 이름으로 바꿉니다.
다음 샘플 YAML 파일을 사용하여
KlusterletAddonConfig리소스를 생성합니다. 이는 Red Hat Advanced Cluster Management에만 적용됩니다. 다중 클러스터 엔진 Operator만 설치한 경우 다음 단계를 건너뜁니다.apiVersion: agent.open-cluster-management.io/v1 kind: KlusterletAddonConfig metadata: name: <cluster_name> namespace: <cluster_name> spec: clusterName: <cluster_name> clusterNamespace: <cluster_name> clusterLabels: cloud: auto-detect vendor: auto-detect applicationManager: enabled: true certPolicyController: enabled: true iamPolicyController: enabled: true policyController: enabled: true searchCollector: enabled: false&
lt;cluster_name>을 호스트된 클러스터 이름으로 바꿉니다.다음 명령을 실행하여 리소스를 적용합니다.
oc apply -f <file_name><file_name>을 이전 단계에서 생성한 YAML 파일 이름으로 바꿉니다.
가져오기 프로세스가 완료되면 콘솔에 호스팅된 클러스터가 표시됩니다. 다음 명령을 실행하여 호스팅 클러스터의 상태를 확인할 수도 있습니다.
oc get managedcluster <cluster_name>
1.7.13.2. 추가 리소스
- 호스트 클러스터의 자동 가져오기를 비활성화하는 방법은 호스트 클러스터의 자동 가져오기 비활성화를 참조하십시오.
1.7.13.3. 호스트 클러스터 자동 가져오기를 다중 클러스터 엔진 Operator로 비활성화
컨트롤 플레인을 사용할 수 있게 되면 호스팅된 클러스터를 자동으로 다중 클러스터 엔진 Operator로 가져와서 호스트된 클러스터의 자동 가져오기를 비활성화할 수 있습니다.
자동 가져오기를 비활성화하더라도 이전에 가져온 호스팅 클러스터는 영향을 받지 않습니다. 다중 클러스터 엔진 Operator 2.5로 업그레이드하고 자동 가져오기가 활성화되면 컨트롤 플레인을 사용할 수 있는 경우 가져오지 않은 모든 호스팅 클러스터를 자동으로 가져옵니다.
참고: Red Hat Advanced Cluster Management가 설치된 경우 모든 Red Hat Advanced Cluster Management 애드온도 활성화됩니다.
자동 가져오기가 비활성화되면 새로 생성된 호스팅 클러스터만 자동으로 가져오지 않습니다. 이미 가져온 호스트 클러스터는 영향을 받지 않습니다. 콘솔을 사용하거나 ManagedCluster 및 KlusterletAddonConfig 사용자 정의 리소스를 생성하여 클러스터를 수동으로 가져올 수 있습니다.
호스트 클러스터의 자동 가져오기를 비활성화하려면 다음 단계를 완료합니다.
다중 클러스터 엔진 Operator 허브 클러스터에서
AddonDeploymentConfig리소스를 열어multicluster-engine네임스페이스에서hypershift-addon-deploy-config사양을 편집합니다. 다음 명령을 실행합니다.oc edit addondeploymentconfig hypershift-addon-deploy-config -n multicluster-enginespec.customizedVariables섹션에서 다음 예와 같이 값이"true"인autoImportDisabled변수를 추가합니다.apiVersion: addon.open-cluster-management.io/v1alpha1 kind: AddOnDeploymentConfig metadata: name: hypershift-addon-deploy-config namespace: multicluster-engine spec: customizedVariables: - name: autoImportDisabled value: "true"-
자동 가져오기를 다시 활성화하려면
autoImportDisabled변수 값을"false"로 설정하거나AddonDeploymentConfig리소스에서 변수를 제거합니다.
1.7.13.3.1. 추가 리소스
호스트 클러스터를 수동으로 가져오는 방법은 호스팅된 컨트롤 플레인 클러스터 수동 가져오기를 참조하십시오.
1.7.14. 호스팅된 컨트롤 플레인 기능 활성화 또는 비활성화
호스팅된 컨트롤 플레인 기능 및 hypershift-addon 관리 클러스터 애드온은 기본적으로 활성화되어 있습니다. 기능을 비활성화하거나 비활성화한 후 수동으로 활성화하려면 다음 절차를 참조하십시오.
1.7.14.1. 수동으로 호스트된 컨트롤 플레인 기능 활성화
다음 명령을 실행하여 기능을 활성화할 수 있습니다.
oc patch mce multiclusterengine --type=merge -p '{"spec":{"overrides":{"components":[{"name":"hypershift","enabled": true}]}}}'1 - 1
- 기본
MultiClusterEngine리소스 인스턴스 이름은multiclusterengine이지만 다음 명령을 실행하여 클러스터에서MultiClusterEngine이름을 가져올 수 있습니다.$ oc get mce.
다음 명령을 실행하여
MultiClusterEngine사용자 정의 리소스에서hypershift및hypershift-local-hosting기능이 활성화되어 있는지 확인합니다.oc get mce multiclusterengine -o yaml1 - 1
- 기본
MultiClusterEngine리소스 인스턴스 이름은multiclusterengine이지만 다음 명령을 실행하여 클러스터에서MultiClusterEngine이름을 가져올 수 있습니다.$ oc get mce.
출력은 다음 예와 유사합니다.
apiVersion: multicluster.openshift.io/v1 kind: MultiClusterEngine metadata: name: multiclusterengine spec: overrides: components: - name: hypershift enabled: true - name: hypershift-local-hosting enabled: true
1.7.14.1.1. local-cluster의 하이퍼shift-addon 관리 클러스터 애드온 수동 활성화
호스팅된 컨트롤 플레인 기능을 활성화하면 하이퍼shift-addon 관리 클러스터 애드온이 자동으로 활성화됩니다. hypershift-addon 관리 클러스터 애드온을 수동으로 활성화해야 하는 경우 hypershift-addon 을 사용하여 local-cluster 에 HyperShift Operator를 설치하려면 다음 단계를 완료합니다.
다음 예제와 유사한 파일을 생성하여
ManagedClusterAddonHyperShift 애드온을 생성합니다.apiVersion: addon.open-cluster-management.io/v1alpha1 kind: ManagedClusterAddOn metadata: name: hypershift-addon namespace: local-cluster spec: installNamespace: open-cluster-management-agent-addon다음 명령을 실행하여 파일을 적용합니다.
oc apply -f <filename>filename을 생성한 파일의 이름으로 바꿉니다.다음 명령을 실행하여
hypershift-addon이 설치되었는지 확인합니다.oc get managedclusteraddons -n local-cluster hypershift-addon애드온이 설치된 경우 출력은 다음 예와 유사합니다.
NAME AVAILABLE DEGRADED PROGRESSING hypershift-addon True
HyperShift 애드온이 설치되고 호스팅 클러스터를 사용하여 호스팅 클러스터를 생성하고 관리할 수 있습니다.
1.7.14.2. 호스트된 컨트롤 플레인 기능 비활성화
HyperShift Operator를 설치 제거하고 호스팅된 컨트롤 플레인을 비활성화할 수 있습니다. 호스팅된 컨트롤 플레인 클러스터 기능을 비활성화할 때 호스트된 컨트롤 플레인 클러스터 관리 항목에 설명된 대로 멀티 클러스터 엔진 Operator에서 호스팅 클러스터 및 관리 클러스터 리소스를 제거해야 합니다.
1.7.14.2.1. HyperShift Operator 설치 제거
HyperShift Operator를 설치 제거하고 local-cluster 에서 hypershift-addon 을 비활성화하려면 다음 단계를 완료하십시오.
다음 명령을 실행하여 호스트 클러스터가 실행되고 있지 않은지 확인합니다.
oc get hostedcluster -A중요: 호스트 클러스터가 실행 중인 경우
hypershift-addon이 비활성화된 경우에도 HyperShift Operator가 제거되지 않습니다.다음 명령을 실행하여
hypershift-addon을 비활성화합니다.oc patch mce multiclusterengine --type=merge -p '{"spec":{"overrides":{"components":[{"name":"hypershift-local-hosting","enabled": false}]}}}'1 - 1
- 기본
MultiClusterEngine리소스 인스턴스 이름은multiclusterengine이지만 다음 명령을 실행하여 클러스터에서MultiClusterEngine이름을 가져올 수 있습니다.$ oc get mce.
참고:
hypershift-addon을 비활성화한 후 다중 클러스터 엔진 Operator 콘솔에서local-cluster의hypershift-addon을 비활성화할 수도 있습니다.
1.7.14.2.2. 호스트된 컨트롤 플레인 기능 비활성화
먼저 호스팅된 컨트롤 플레인 기능을 비활성화하기 전에 HyperShift Operator를 설치 제거해야 합니다. 다음 명령을 실행하여 호스팅된 컨트롤 플레인 기능을 비활성화합니다.
oc patch mce multiclusterengine --type=merge -p '{"spec":{"overrides":{"components":[{"name":"hypershift","enabled": false}]}}}' - 1
- 기본
MultiClusterEngine리소스 인스턴스 이름은multiclusterengine이지만 다음 명령을 실행하여 클러스터에서MultiClusterEngine이름을 가져올 수 있습니다.$ oc get mce.
다음 명령을 실행하여 hypershift 및 hypershift-local-hosting 기능이 MultiClusterEngine 사용자 정의 리소스에서 비활성화되어 있는지 확인할 수 있습니다.
oc get mce multiclusterengine -o yaml - 1
- 기본
MultiClusterEngine리소스 인스턴스 이름은multiclusterengine이지만 다음 명령을 실행하여 클러스터에서MultiClusterEngine이름을 가져올 수 있습니다.$ oc get mce.
hypershift 및 hypershift-local-hosting 에 enabled: flags가 false 로 설정된 다음 예제를 참조하십시오.
apiVersion: multicluster.openshift.io/v1
kind: MultiClusterEngine
metadata:
name: multiclusterengine
spec:
overrides:
components:
- name: hypershift
enabled: false
- name: hypershift-local-hosting
enabled: false1.7.14.3. 추가 리소스
1.8. API
다중 클러스터 엔진 Operator를 사용하여 클러스터 라이프사이클 관리를 위해 다음 API에 액세스할 수 있습니다. 사용자 필수 액세스: 역할이 할당된 작업만 수행할 수 있습니다.
참고: 통합 콘솔에서 모든 API에 액세스할 수도 있습니다. local-cluster 보기에서 Home > API Explorer 로 이동하여 API 그룹을 살펴봅니다.
자세한 내용은 다음 리소스 각각에 대한 API 설명서를 참조하십시오.
1.8.1. 클러스터 API
1.8.1.1. 개요
이 문서는 Kubernetes Operator용 다중 클러스터 엔진용 클러스터 리소스에 대한 것입니다. 클러스터 리소스에는 생성, 쿼리, 삭제 및 업데이트의 네 가지 요청이 있습니다.
1.8.1.1.1. URI 스키마
BasePath : /kubernetes/apis
Schemes : HTTPS
1.8.1.1.2. 태그
- cluster.open-cluster-management.io : 클러스터 생성 및 관리
1.8.1.2. 경로
1.8.1.2.1. 모든 클러스터 쿼리
GET /cluster.open-cluster-management.io/v1/managedclusters1.8.1.2.1.1. 설명
자세한 내용은 클러스터를 쿼리합니다.
1.8.1.2.1.2. 매개 변수
| 유형 | 이름 | 설명 | 스키마 |
|---|---|---|---|
| 헤더 |
COOKIE | 권한 부여: Bearer {ACCESS_TOKEN}; ACCESS_TOKEN은 사용자 액세스 토큰입니다. | string |
1.8.1.2.1.3. 응답
| HTTP 코드 | 설명 | 스키마 |
|---|---|---|
| 200 | 성공 | 콘텐츠 없음 |
| 403 | 액세스 금지 | 콘텐츠 없음 |
| 404 | 리소스를 찾을 수 없음 | 콘텐츠 없음 |
| 500 | 내부 서비스 오류 | 콘텐츠 없음 |
| 503 | 서비스를 사용할 수 없음 | 콘텐츠 없음 |
1.8.1.2.1.4. 사용
-
cluster/yaml
1.8.1.2.1.5. 태그
- cluster.open-cluster-management.io
1.8.1.2.2. 클러스터 생성
POST /cluster.open-cluster-management.io/v1/managedclusters1.8.1.2.2.1. 설명
클러스터 생성
1.8.1.2.2.2. 매개 변수
| 유형 | 이름 | 설명 | 스키마 |
|---|---|---|---|
| 헤더 |
COOKIE | 권한 부여: Bearer {ACCESS_TOKEN}; ACCESS_TOKEN은 사용자 액세스 토큰입니다. | string |
| 본문 |
본문 | 생성할 클러스터를 설명하는 매개변수입니다. |
1.8.1.2.2.3. 응답
| HTTP 코드 | 설명 | 스키마 |
|---|---|---|
| 200 | 성공 | 콘텐츠 없음 |
| 403 | 액세스 금지 | 콘텐츠 없음 |
| 404 | 리소스를 찾을 수 없음 | 콘텐츠 없음 |
| 500 | 내부 서비스 오류 | 콘텐츠 없음 |
| 503 | 서비스를 사용할 수 없음 | 콘텐츠 없음 |
1.8.1.2.2.4. 사용
-
cluster/yaml
1.8.1.2.2.5. 태그
- cluster.open-cluster-management.io
1.8.1.2.2.6. HTTP 요청의 예
1.8.1.2.2.6.1. 요청 본문
{
"apiVersion" : "cluster.open-cluster-management.io/v1",
"kind" : "ManagedCluster",
"metadata" : {
"labels" : {
"vendor" : "OpenShift"
},
"name" : "cluster1"
},
"spec": {
"hubAcceptsClient": true,
"managedClusterClientConfigs": [
{
"caBundle": "test",
"url": "https://test.com"
}
]
},
"status" : { }
}1.8.1.2.3. 단일 클러스터 쿼리
GET /cluster.open-cluster-management.io/v1/managedclusters/{cluster_name}1.8.1.2.3.1. 설명
자세한 내용은 단일 클러스터를 쿼리합니다.
1.8.1.2.3.2. 매개 변수
| 유형 | 이름 | 설명 | 스키마 |
|---|---|---|---|
| 헤더 |
COOKIE | 권한 부여: Bearer {ACCESS_TOKEN}; ACCESS_TOKEN은 사용자 액세스 토큰입니다. | string |
| 경로 |
cluster_name | 쿼리할 클러스터의 이름입니다. | string |
1.8.1.2.3.3. 응답
| HTTP 코드 | 설명 | 스키마 |
|---|---|---|
| 200 | 성공 | 콘텐츠 없음 |
| 403 | 액세스 금지 | 콘텐츠 없음 |
| 404 | 리소스를 찾을 수 없음 | 콘텐츠 없음 |
| 500 | 내부 서비스 오류 | 콘텐츠 없음 |
| 503 | 서비스를 사용할 수 없음 | 콘텐츠 없음 |
1.8.1.2.3.4. 태그
- cluster.open-cluster-management.io
1.8.1.2.4. 클러스터 삭제
DELETE /cluster.open-cluster-management.io/v1/managedclusters/{cluster_name}1.8.1.2.4.1. 설명
단일 클러스터 삭제
1.8.1.2.4.2. 매개 변수
| 유형 | 이름 | 설명 | 스키마 |
|---|---|---|---|
| 헤더 |
COOKIE | 권한 부여: Bearer {ACCESS_TOKEN}; ACCESS_TOKEN은 사용자 액세스 토큰입니다. | string |
| 경로 |
cluster_name | 삭제할 클러스터의 이름입니다. | string |
1.8.1.2.4.3. 응답
| HTTP 코드 | 설명 | 스키마 |
|---|---|---|
| 200 | 성공 | 콘텐츠 없음 |
| 403 | 액세스 금지 | 콘텐츠 없음 |
| 404 | 리소스를 찾을 수 없음 | 콘텐츠 없음 |
| 500 | 내부 서비스 오류 | 콘텐츠 없음 |
| 503 | 서비스를 사용할 수 없음 | 콘텐츠 없음 |
1.8.1.2.4.4. 태그
- cluster.open-cluster-management.io
1.8.1.3. 정의
1.8.1.3.1. Cluster
| 이름 | 스키마 |
|---|---|
|
apiVersion | string |
|
종류 | string |
|
메타데이터 | object |
|
사양 |
spec
| 이름 | 스키마 |
|---|---|
|
hubAcceptsClient | bool |
|
managedClusterClientConfigs | < managedClusterClientConfigs > array |
|
leaseDurationSeconds | 정수(int32) |
managedClusterClientConfigs
| 이름 | 설명 | 스키마 |
|---|---|---|
|
URL | string | |
|
cabundle | 패턴 : | 문자열(바이트) |
1.8.2. Clustersets API (v1beta2)
1.8.2.1. 개요
이 문서는 Kubernetes Operator용 다중 클러스터 엔진용 Clusterset 리소스에 대한 것입니다. Clusterset 리소스에는 생성, 쿼리, 삭제 및 업데이트의 네 가지 요청이 있습니다.
1.8.2.1.1. URI 스키마
BasePath : /kubernetes/apis
Schemes : HTTPS
1.8.2.1.2. 태그
- cluster.open-cluster-management.io : Clustersets 생성 및 관리
1.8.2.2. 경로
1.8.2.2.1. 모든 clustersets 쿼리
GET /cluster.open-cluster-management.io/v1beta2/managedclustersets1.8.2.2.1.1. 설명
자세한 내용은 Clustersets를 쿼리합니다.
1.8.2.2.1.2. 매개 변수
| 유형 | 이름 | 설명 | 스키마 |
|---|---|---|---|
| 헤더 |
COOKIE | 권한 부여: Bearer {ACCESS_TOKEN}; ACCESS_TOKEN은 사용자 액세스 토큰입니다. | string |
1.8.2.2.1.3. 응답
| HTTP 코드 | 설명 | 스키마 |
|---|---|---|
| 200 | 성공 | 콘텐츠 없음 |
| 403 | 액세스 금지 | 콘텐츠 없음 |
| 404 | 리소스를 찾을 수 없음 | 콘텐츠 없음 |
| 500 | 내부 서비스 오류 | 콘텐츠 없음 |
| 503 | 서비스를 사용할 수 없음 | 콘텐츠 없음 |
1.8.2.2.1.4. 사용
-
clusterset/yaml
1.8.2.2.1.5. 태그
- cluster.open-cluster-management.io
1.8.2.2.2. clusterset 생성
POST /cluster.open-cluster-management.io/v1beta2/managedclustersets1.8.2.2.2.1. 설명
클러스터 세트를 생성합니다.
1.8.2.2.2.2. 매개 변수
| 유형 | 이름 | 설명 | 스키마 |
|---|---|---|---|
| 헤더 |
COOKIE | 권한 부여: Bearer {ACCESS_TOKEN}; ACCESS_TOKEN은 사용자 액세스 토큰입니다. | string |
| 본문 |
본문 | 생성할 clusterset을 설명하는 매개변수입니다. |
1.8.2.2.2.3. 응답
| HTTP 코드 | 설명 | 스키마 |
|---|---|---|
| 200 | 성공 | 콘텐츠 없음 |
| 403 | 액세스 금지 | 콘텐츠 없음 |
| 404 | 리소스를 찾을 수 없음 | 콘텐츠 없음 |
| 500 | 내부 서비스 오류 | 콘텐츠 없음 |
| 503 | 서비스를 사용할 수 없음 | 콘텐츠 없음 |
1.8.2.2.2.4. 사용
-
clusterset/yaml
1.8.2.2.2.5. 태그
- cluster.open-cluster-management.io
1.8.2.2.2.6. HTTP 요청의 예
1.8.2.2.2.6.1. 요청 본문
{
"apiVersion" : "cluster.open-cluster-management.io/v1beta2",
"kind" : "ManagedClusterSet",
"metadata" : {
"name" : "clusterset1"
},
"spec": { },
"status" : { }
}1.8.2.2.3. 단일 클러스터 세트 쿼리
GET /cluster.open-cluster-management.io/v1beta2/managedclustersets/{clusterset_name}1.8.2.2.3.1. 설명
자세한 내용은 단일 클러스터 세트를 쿼리합니다.
1.8.2.2.3.2. 매개 변수
| 유형 | 이름 | 설명 | 스키마 |
|---|---|---|---|
| 헤더 |
COOKIE | 권한 부여: Bearer {ACCESS_TOKEN}; ACCESS_TOKEN은 사용자 액세스 토큰입니다. | string |
| 경로 |
clusterset_name | 쿼리할 클러스터 세트의 이름입니다. | string |
1.8.2.2.3.3. 응답
| HTTP 코드 | 설명 | 스키마 |
|---|---|---|
| 200 | 성공 | 콘텐츠 없음 |
| 403 | 액세스 금지 | 콘텐츠 없음 |
| 404 | 리소스를 찾을 수 없음 | 콘텐츠 없음 |
| 500 | 내부 서비스 오류 | 콘텐츠 없음 |
| 503 | 서비스를 사용할 수 없음 | 콘텐츠 없음 |
1.8.2.2.3.4. 태그
- cluster.open-cluster-management.io
1.8.2.2.4. clusterset 삭제
DELETE /cluster.open-cluster-management.io/v1beta2/managedclustersets/{clusterset_name}1.8.2.2.4.1. 설명
단일 클러스터 세트를 삭제합니다.
1.8.2.2.4.2. 매개 변수
| 유형 | 이름 | 설명 | 스키마 |
|---|---|---|---|
| 헤더 |
COOKIE | 권한 부여: Bearer {ACCESS_TOKEN}; ACCESS_TOKEN은 사용자 액세스 토큰입니다. | string |
| 경로 |
clusterset_name | 삭제할 클러스터 세트의 이름입니다. | string |
1.8.2.2.4.3. 응답
| HTTP 코드 | 설명 | 스키마 |
|---|---|---|
| 200 | 성공 | 콘텐츠 없음 |
| 403 | 액세스 금지 | 콘텐츠 없음 |
| 404 | 리소스를 찾을 수 없음 | 콘텐츠 없음 |
| 500 | 내부 서비스 오류 | 콘텐츠 없음 |
| 503 | 서비스를 사용할 수 없음 | 콘텐츠 없음 |
1.8.2.2.4.4. 태그
- cluster.open-cluster-management.io
1.8.2.3. 정의
1.8.2.3.1. clusterset
| 이름 | 스키마 |
|---|---|
|
apiVersion | string |
|
종류 | string |
|
메타데이터 | object |
1.8.3. Clustersetbindings API (v1beta2)
1.8.3.1. 개요
이 문서는 Kubernetes용 다중 클러스터 엔진의 clustersetbinding 리소스를 위한 것입니다. Clustersetbinding 리소스에는 생성, 쿼리, 삭제 및 업데이트의 네 가지 요청이 있습니다.
1.8.3.1.1. URI 스키마
BasePath : /kubernetes/apis
Schemes : HTTPS
1.8.3.1.2. 태그
- cluster.open-cluster-management.io : clustersetbindings 생성 및 관리
1.8.3.2. 경로
1.8.3.2.1. 모든 clustersetbindings 쿼리
GET /cluster.open-cluster-management.io/v1beta2/namespaces/{namespace}/managedclustersetbindings1.8.3.2.1.1. 설명
자세한 내용은 clustersetbindings를 쿼리합니다.
1.8.3.2.1.2. 매개 변수
| 유형 | 이름 | 설명 | 스키마 |
|---|---|---|---|
| 헤더 |
COOKIE | 권한 부여: Bearer {ACCESS_TOKEN}; ACCESS_TOKEN은 사용자 액세스 토큰입니다. | string |
| 경로 |
네임스페이스 | 사용할 네임스페이스(예: default)입니다. | string |
1.8.3.2.1.3. 응답
| HTTP 코드 | 설명 | 스키마 |
|---|---|---|
| 200 | 성공 | 콘텐츠 없음 |
| 403 | 액세스 금지 | 콘텐츠 없음 |
| 404 | 리소스를 찾을 수 없음 | 콘텐츠 없음 |
| 500 | 내부 서비스 오류 | 콘텐츠 없음 |
| 503 | 서비스를 사용할 수 없음 | 콘텐츠 없음 |
1.8.3.2.1.4. 사용
-
clustersetbinding/yaml
1.8.3.2.1.5. 태그
- cluster.open-cluster-management.io
1.8.3.2.2. clustersetbinding 생성
POST /cluster.open-cluster-management.io/v1beta2/namespaces/{namespace}/managedclustersetbindings1.8.3.2.2.1. 설명
clustersetbinding을 생성합니다.
1.8.3.2.2.2. 매개 변수
| 유형 | 이름 | 설명 | 스키마 |
|---|---|---|---|
| 헤더 |
COOKIE | 권한 부여: Bearer {ACCESS_TOKEN}; ACCESS_TOKEN은 사용자 액세스 토큰입니다. | string |
| 경로 |
네임스페이스 | 사용할 네임스페이스(예: default)입니다. | string |
| 본문 |
본문 | 생성할 clustersetbinding을 설명하는 매개변수입니다. |
1.8.3.2.2.3. 응답
| HTTP 코드 | 설명 | 스키마 |
|---|---|---|
| 200 | 성공 | 콘텐츠 없음 |
| 403 | 액세스 금지 | 콘텐츠 없음 |
| 404 | 리소스를 찾을 수 없음 | 콘텐츠 없음 |
| 500 | 내부 서비스 오류 | 콘텐츠 없음 |
| 503 | 서비스를 사용할 수 없음 | 콘텐츠 없음 |
1.8.3.2.2.4. 사용
-
clustersetbinding/yaml
1.8.3.2.2.5. 태그
- cluster.open-cluster-management.io
1.8.3.2.2.6. HTTP 요청의 예
1.8.3.2.2.6.1. 요청 본문
{
"apiVersion" : "cluster.open-cluster-management.io/v1",
"kind" : "ManagedClusterSetBinding",
"metadata" : {
"name" : "clusterset1",
"namespace" : "ns1"
},
"spec": {
"clusterSet": "clusterset1"
},
"status" : { }
}1.8.3.2.3. 단일 clustersetbinding 쿼리
GET /cluster.open-cluster-management.io/v1beta2/namespaces/{namespace}/managedclustersetbindings/{clustersetbinding_name}1.8.3.2.3.1. 설명
자세한 내용은 단일 clustersetbinding을 쿼리합니다.
1.8.3.2.3.2. 매개 변수
| 유형 | 이름 | 설명 | 스키마 |
|---|---|---|---|
| 헤더 |
COOKIE | 권한 부여: Bearer {ACCESS_TOKEN}; ACCESS_TOKEN은 사용자 액세스 토큰입니다. | string |
| 경로 |
네임스페이스 | 사용할 네임스페이스(예: default)입니다. | string |
| 경로 |
clustersetbinding_name | 쿼리할 clustersetbinding의 이름입니다. | string |
1.8.3.2.3.3. 응답
| HTTP 코드 | 설명 | 스키마 |
|---|---|---|
| 200 | 성공 | 콘텐츠 없음 |
| 403 | 액세스 금지 | 콘텐츠 없음 |
| 404 | 리소스를 찾을 수 없음 | 콘텐츠 없음 |
| 500 | 내부 서비스 오류 | 콘텐츠 없음 |
| 503 | 서비스를 사용할 수 없음 | 콘텐츠 없음 |
1.8.3.2.3.4. 태그
- cluster.open-cluster-management.io
1.8.3.2.4. clustersetbinding 삭제
DELETE /cluster.open-cluster-management.io/v1beta2/managedclustersetbindings/{clustersetbinding_name}1.8.3.2.4.1. 설명
단일 clustersetbinding을 삭제합니다.
1.8.3.2.4.2. 매개 변수
| 유형 | 이름 | 설명 | 스키마 |
|---|---|---|---|
| 헤더 |
COOKIE | 권한 부여: Bearer {ACCESS_TOKEN}; ACCESS_TOKEN은 사용자 액세스 토큰입니다. | string |
| 경로 |
네임스페이스 | 사용할 네임스페이스(예: default)입니다. | string |
| 경로 |
clustersetbinding_name | 삭제할 clustersetbinding의 이름입니다. | string |
1.8.3.2.4.3. 응답
| HTTP 코드 | 설명 | 스키마 |
|---|---|---|
| 200 | 성공 | 콘텐츠 없음 |
| 403 | 액세스 금지 | 콘텐츠 없음 |
| 404 | 리소스를 찾을 수 없음 | 콘텐츠 없음 |
| 500 | 내부 서비스 오류 | 콘텐츠 없음 |
| 503 | 서비스를 사용할 수 없음 | 콘텐츠 없음 |
1.8.3.2.4.4. 태그
- cluster.open-cluster-management.io
1.8.3.3. 정의
1.8.3.3.1. Clustersetbinding
| 이름 | 스키마 |
|---|---|
|
apiVersion | string |
|
종류 | string |
|
메타데이터 | object |
|
사양 |
spec
| 이름 | 스키마 |
|---|---|
|
clusterSet | string |
1.8.4. Clusterview API(v1alpha1)
1.8.4.1. 개요
이 문서는 Kubernetes용 다중 클러스터 엔진의 clusterview 리소스에 대한 것입니다. clusterview 리소스는 액세스할 수 있는 관리 클러스터 및 관리 클러스터 세트 목록을 볼 수 있는 CLI 명령을 제공합니다. 가능한 세 가지 요청은 list, get, watch입니다.
1.8.4.1.1. URI 스키마
BasePath : /kubernetes/apis
Schemes : HTTPS
1.8.4.1.2. 태그
- clusterview.open-cluster-management.io : ID가 액세스할 수 있는 관리 클러스터 목록을 확인합니다.
1.8.4.2. 경로
1.8.4.2.1. 관리 클러스터 가져오기
GET /managedclusters.clusterview.open-cluster-management.io1.8.4.2.1.1. 설명
액세스할 수 있는 관리 클러스터 목록을 확인합니다.
1.8.4.2.1.2. 매개 변수
| 유형 | 이름 | 설명 | 스키마 |
|---|---|---|---|
| 헤더 |
COOKIE | 권한 부여: Bearer {ACCESS_TOKEN}; ACCESS_TOKEN은 사용자 액세스 토큰입니다. | string |
1.8.4.2.1.3. 응답
| HTTP 코드 | 설명 | 스키마 |
|---|---|---|
| 200 | 성공 | 콘텐츠 없음 |
| 403 | 액세스 금지 | 콘텐츠 없음 |
| 404 | 리소스를 찾을 수 없음 | 콘텐츠 없음 |
| 500 | 내부 서비스 오류 | 콘텐츠 없음 |
| 503 | 서비스를 사용할 수 없음 | 콘텐츠 없음 |
1.8.4.2.1.4. 사용
-
managedcluster/yaml
1.8.4.2.1.5. 태그
- clusterview.open-cluster-management.io
1.8.4.2.2. 관리 클러스터 나열
LIST /managedclusters.clusterview.open-cluster-management.io1.8.4.2.2.1. 설명
액세스할 수 있는 관리 클러스터 목록을 확인합니다.
1.8.4.2.2.2. 매개 변수
| 유형 | 이름 | 설명 | 스키마 |
|---|---|---|---|
| 헤더 |
COOKIE | 권한 부여: Bearer {ACCESS_TOKEN}; ACCESS_TOKEN은 사용자 액세스 토큰입니다. | string |
| 본문 |
본문 | 관리 클러스터를 나열할 사용자 ID의 이름입니다. | string |
1.8.4.2.2.3. 응답
| HTTP 코드 | 설명 | 스키마 |
|---|---|---|
| 200 | 성공 | 콘텐츠 없음 |
| 403 | 액세스 금지 | 콘텐츠 없음 |
| 404 | 리소스를 찾을 수 없음 | 콘텐츠 없음 |
| 500 | 내부 서비스 오류 | 콘텐츠 없음 |
| 503 | 서비스를 사용할 수 없음 | 콘텐츠 없음 |
1.8.4.2.2.4. 사용
-
managedcluster/yaml
1.8.4.2.2.5. 태그
- clusterview.open-cluster-management.io
1.8.4.2.2.6. HTTP 요청의 예
1.8.4.2.2.6.1. 요청 본문
{
"apiVersion" : "clusterview.open-cluster-management.io/v1alpha1",
"kind" : "ClusterView",
"metadata" : {
"name" : "<user_ID>"
},
"spec": { },
"status" : { }
}1.8.4.2.3. 관리 클러스터 세트 모니터링
WATCH /managedclusters.clusterview.open-cluster-management.io1.8.4.2.3.1. 설명
액세스할 수 있는 관리형 클러스터를 확인합니다.
1.8.4.2.3.2. 매개 변수
| 유형 | 이름 | 설명 | 스키마 |
|---|---|---|---|
| 헤더 |
COOKIE | 권한 부여: Bearer {ACCESS_TOKEN}; ACCESS_TOKEN은 사용자 액세스 토큰입니다. | string |
| 경로 |
clusterview_name | 조사할 사용자 ID의 이름입니다. | string |
1.8.4.2.3.3. 응답
| HTTP 코드 | 설명 | 스키마 |
|---|---|---|
| 200 | 성공 | 콘텐츠 없음 |
| 403 | 액세스 금지 | 콘텐츠 없음 |
| 404 | 리소스를 찾을 수 없음 | 콘텐츠 없음 |
| 500 | 내부 서비스 오류 | 콘텐츠 없음 |
| 503 | 서비스를 사용할 수 없음 | 콘텐츠 없음 |
1.8.4.2.4. 관리되는 클러스터 세트를 나열합니다.
GET /managedclustersets.clusterview.open-cluster-management.io1.8.4.2.4.1. 설명
액세스할 수 있는 관리 클러스터를 나열합니다.
1.8.4.2.4.2. 매개 변수
| 유형 | 이름 | 설명 | 스키마 |
|---|---|---|---|
| 헤더 |
COOKIE | 권한 부여: Bearer {ACCESS_TOKEN}; ACCESS_TOKEN은 사용자 액세스 토큰입니다. | string |
| 경로 |
clusterview_name | 조사할 사용자 ID의 이름입니다. | string |
1.8.4.2.4.3. 응답
| HTTP 코드 | 설명 | 스키마 |
|---|---|---|
| 200 | 성공 | 콘텐츠 없음 |
| 403 | 액세스 금지 | 콘텐츠 없음 |
| 404 | 리소스를 찾을 수 없음 | 콘텐츠 없음 |
| 500 | 내부 서비스 오류 | 콘텐츠 없음 |
| 503 | 서비스를 사용할 수 없음 | 콘텐츠 없음 |
1.8.4.2.5. 관리되는 클러스터 세트를 나열합니다.
LIST /managedclustersets.clusterview.open-cluster-management.io1.8.4.2.5.1. 설명
액세스할 수 있는 관리 클러스터를 나열합니다.
1.8.4.2.5.2. 매개 변수
| 유형 | 이름 | 설명 | 스키마 |
|---|---|---|---|
| 헤더 |
COOKIE | 권한 부여: Bearer {ACCESS_TOKEN}; ACCESS_TOKEN은 사용자 액세스 토큰입니다. | string |
| 경로 |
clusterview_name | 조사할 사용자 ID의 이름입니다. | string |
1.8.4.2.5.3. 응답
| HTTP 코드 | 설명 | 스키마 |
|---|---|---|
| 200 | 성공 | 콘텐츠 없음 |
| 403 | 액세스 금지 | 콘텐츠 없음 |
| 404 | 리소스를 찾을 수 없음 | 콘텐츠 없음 |
| 500 | 내부 서비스 오류 | 콘텐츠 없음 |
| 503 | 서비스를 사용할 수 없음 | 콘텐츠 없음 |
1.8.4.2.6. 관리되는 클러스터 세트를 확인합니다.
WATCH /managedclustersets.clusterview.open-cluster-management.io1.8.4.2.6.1. 설명
액세스할 수 있는 관리형 클러스터를 확인합니다.
1.8.4.2.6.2. 매개 변수
| 유형 | 이름 | 설명 | 스키마 |
|---|---|---|---|
| 헤더 |
COOKIE | 권한 부여: Bearer {ACCESS_TOKEN}; ACCESS_TOKEN은 사용자 액세스 토큰입니다. | string |
| 경로 |
clusterview_name | 조사할 사용자 ID의 이름입니다. | string |
1.8.4.2.6.3. 응답
| HTTP 코드 | 설명 | 스키마 |
|---|---|---|
| 200 | 성공 | 콘텐츠 없음 |
| 403 | 액세스 금지 | 콘텐츠 없음 |
| 404 | 리소스를 찾을 수 없음 | 콘텐츠 없음 |
| 500 | 내부 서비스 오류 | 콘텐츠 없음 |
| 503 | 서비스를 사용할 수 없음 | 콘텐츠 없음 |
1.8.5. ManagedServiceAccount API (v1alpha1) (더 이상 사용되지 않음)
1.8.5.1. 개요
이 문서는 다중 클러스터 엔진 Operator의 ManagedServiceAccount 리소스에 대한 것입니다. ManagedServiceAccount 리소스에는 생성, 쿼리, 삭제 및 업데이트의 네 가지 요청이 있습니다.
deprecated: v1alpha1 API는 더 이상 사용되지 않습니다. 최상의 결과를 얻으려면 대신 v1beta1 을 사용하십시오.
1.8.5.1.1. URI 스키마
BasePath : /kubernetes/apis
Schemes : HTTPS
1.8.5.1.2. 태그
-
managedserviceaccounts.authentication.open-cluster-management.io:ManagedServiceAccounts생성 및 관리
1.8.5.2. 경로
1.8.5.2.1. ManagedServiceAccount 생성
POST /authentication.open-cluster-management.io/v1beta1/managedserviceaccounts1.8.5.2.1.1. 설명
ManagedServiceAccount 를 생성합니다.
1.8.5.2.1.2. 매개 변수
| 유형 | 이름 | 설명 | 스키마 |
|---|---|---|---|
| 헤더 |
COOKIE | 권한 부여: Bearer {ACCESS_TOKEN}; ACCESS_TOKEN은 사용자 액세스 토큰입니다. | string |
| 본문 |
본문 | 생성할 ManagedServiceAccount를 설명하는 매개변수입니다. | ManagedServiceAccount |
1.8.5.2.1.3. 응답
| HTTP 코드 | 설명 | 스키마 |
|---|---|---|
| 200 | 성공 | 콘텐츠 없음 |
| 403 | 액세스 금지 | 콘텐츠 없음 |
| 404 | 리소스를 찾을 수 없음 | 콘텐츠 없음 |
| 500 | 내부 서비스 오류 | 콘텐츠 없음 |
| 503 | 서비스를 사용할 수 없음 | 콘텐츠 없음 |
1.8.5.2.1.4. 사용
-
managedserviceaccount/yaml
1.8.5.2.1.5. 태그
- managedserviceaccounts.authentication.open-cluster-management.io
1.8.5.2.1.5.1. 요청 본문
apiVersion: apiextensions.k8s.io/v1
kind: CustomResourceDefinition
metadata:
annotations:
controller-gen.kubebuilder.io/version: v0.14.0
name: managedserviceaccounts.authentication.open-cluster-management.io
spec:
group: authentication.open-cluster-management.io
names:
kind: ManagedServiceAccount
listKind: ManagedServiceAccountList
plural: managedserviceaccounts
singular: managedserviceaccount
scope: Namespaced
versions:
- deprecated: true
deprecationWarning: authentication.open-cluster-management.io/v1alpha1 ManagedServiceAccount
is deprecated; use authentication.open-cluster-management.io/v1beta1 ManagedServiceAccount;
version v1alpha1 will be removed in the next release
name: v1alpha1
schema:
openAPIV3Schema:
description: ManagedServiceAccount is the Schema for the managedserviceaccounts
API
properties:
apiVersion:
description: |-
APIVersion defines the versioned schema of this representation of an object.
Servers should convert recognized schemas to the latest internal value, and
may reject unrecognized values.
More info: https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#resources
type: string
kind:
description: |-
Kind is a string value representing the REST resource this object represents.
Servers may infer this from the endpoint the client submits requests to.
Cannot be updated.
In CamelCase.
More info: https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#types-kinds
type: string
metadata:
type: object
spec:
description: ManagedServiceAccountSpec defines the desired state of ManagedServiceAccount
properties:
rotation:
description: Rotation is the policy for rotation the credentials.
properties:
enabled:
default: true
description: |-
Enabled prescribes whether the ServiceAccount token will
be rotated from the upstream
type: boolean
validity:
default: 8640h0m0s
description: Validity is the duration for which the signed ServiceAccount
token is valid.
type: string
type: object
ttlSecondsAfterCreation:
description: |-
ttlSecondsAfterCreation limits the lifetime of a ManagedServiceAccount.
If the ttlSecondsAfterCreation field is set, the ManagedServiceAccount will be
automatically deleted regardless of the ManagedServiceAccount's status.
When the ManagedServiceAccount is deleted, its lifecycle guarantees
(e.g. finalizers) will be honored. If this field is unset, the ManagedServiceAccount
won't be automatically deleted. If this field is set to zero, the
ManagedServiceAccount becomes eligible for deletion immediately after its creation.
In order to use ttlSecondsAfterCreation, the EphemeralIdentity feature gate must be enabled.
exclusiveMinimum: true
format: int32
minimum: 0
type: integer
required:
- rotation
type: object
status:
description: ManagedServiceAccountStatus defines the observed state of
ManagedServiceAccount
properties:
conditions:
description: Conditions is the condition list.
items:
description: "Condition contains details for one aspect of the current
state of this API Resource.\n---\nThis struct is intended for
direct use as an array at the field path .status.conditions. For
example,\n\n\n\ttype FooStatus struct{\n\t // Represents the
observations of a foo's current state.\n\t // Known .status.conditions.type
are: \"Available\", \"Progressing\", and \"Degraded\"\n\t //
+patchMergeKey=type\n\t // +patchStrategy=merge\n\t // +listType=map\n\t
\ // +listMapKey=type\n\t Conditions []metav1.Condition `json:\"conditions,omitempty\"
patchStrategy:\"merge\" patchMergeKey:\"type\" protobuf:\"bytes,1,rep,name=conditions\"`\n\n\n\t
\ // other fields\n\t}"
properties:
lastTransitionTime:
description: |-
lastTransitionTime is the last time the condition transitioned from one status to another.
This should be when the underlying condition changed. If that is not known, then using the time when the API field changed is acceptable.
format: date-time
type: string
message:
description: |-
message is a human readable message indicating details about the transition.
This may be an empty string.
maxLength: 32768
type: string
observedGeneration:
description: |-
observedGeneration represents the .metadata.generation that the condition was set based upon.
For instance, if .metadata.generation is currently 12, but the .status.conditions[x].observedGeneration is 9, the condition is out of date
with respect to the current state of the instance.
format: int64
minimum: 0
type: integer
reason:
description: |-
reason contains a programmatic identifier indicating the reason for the condition's last transition.
Producers of specific condition types may define expected values and meanings for this field,
and whether the values are considered a guaranteed API.
The value should be a CamelCase string.
This field may not be empty.
maxLength: 1024
minLength: 1
pattern: ^[A-Za-z]([A-Za-z0-9_,:]*[A-Za-z0-9_])?$
type: string
status:
description: status of the condition, one of True, False, Unknown.
enum:
- "True"
- "False"
- Unknown
type: string
type:
description: |-
type of condition in CamelCase or in foo.example.com/CamelCase.
---
Many .condition.type values are consistent across resources like Available, but because arbitrary conditions can be
useful (see .node.status.conditions), the ability to deconflict is important.
The regex it matches is (dns1123SubdomainFmt/)?(qualifiedNameFmt)
maxLength: 316
pattern: ^([a-z0-9]([-a-z0-9]*[a-z0-9])?(\.[a-z0-9]([-a-z0-9]*[a-z0-9])?)*/)?(([A-Za-z0-9][-A-Za-z0-9_.]*)?[A-Za-z0-9])$
type: string
required:
- lastTransitionTime
- message
- reason
- status
- type
type: object
type: array
expirationTimestamp:
description: ExpirationTimestamp is the time when the token will expire.
format: date-time
type: string
tokenSecretRef:
description: |-
TokenSecretRef is a reference to the corresponding ServiceAccount's Secret, which stores
the CA certficate and token from the managed cluster.
properties:
lastRefreshTimestamp:
description: |-
LastRefreshTimestamp is the timestamp indicating when the token in the Secret
is refreshed.
format: date-time
type: string
name:
description: Name is the name of the referenced secret.
type: string
required:
- lastRefreshTimestamp
- name
type: object
type: object
type: object
served: true
storage: false
subresources:
status: {}
- name: v1beta1
schema:
openAPIV3Schema:
description: ManagedServiceAccount is the Schema for the managedserviceaccounts
API
properties:
apiVersion:
description: |-
APIVersion defines the versioned schema of this representation of an object.
Servers should convert recognized schemas to the latest internal value, and
may reject unrecognized values.
More info: https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#resources
type: string
kind:
description: |-
Kind is a string value representing the REST resource this object represents.
Servers may infer this from the endpoint the client submits requests to.
Cannot be updated.
In CamelCase.
More info: https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#types-kinds
type: string
metadata:
type: object
spec:
description: ManagedServiceAccountSpec defines the desired state of ManagedServiceAccount
properties:
rotation:
description: Rotation is the policy for rotation the credentials.
properties:
enabled:
default: true
description: |-
Enabled prescribes whether the ServiceAccount token will be rotated before it expires.
Deprecated: All ServiceAccount tokens will be rotated before they expire regardless of this field.
type: boolean
validity:
default: 8640h0m0s
description: Validity is the duration of validity for requesting
the signed ServiceAccount token.
type: string
type: object
ttlSecondsAfterCreation:
description: |-
ttlSecondsAfterCreation limits the lifetime of a ManagedServiceAccount.
If the ttlSecondsAfterCreation field is set, the ManagedServiceAccount will be
automatically deleted regardless of the ManagedServiceAccount's status.
When the ManagedServiceAccount is deleted, its lifecycle guarantees
(e.g. finalizers) will be honored. If this field is unset, the ManagedServiceAccount
won't be automatically deleted. If this field is set to zero, the
ManagedServiceAccount becomes eligible for deletion immediately after its creation.
In order to use ttlSecondsAfterCreation, the EphemeralIdentity feature gate must be enabled.
exclusiveMinimum: true
format: int32
minimum: 0
type: integer
required:
- rotation
type: object
status:
description: ManagedServiceAccountStatus defines the observed state of
ManagedServiceAccount
properties:
conditions:
description: Conditions is the condition list.
items:
description: "Condition contains details for one aspect of the current
state of this API Resource.\n---\nThis struct is intended for
direct use as an array at the field path .status.conditions. For
example,\n\n\n\ttype FooStatus struct{\n\t // Represents the
observations of a foo's current state.\n\t // Known .status.conditions.type
are: \"Available\", \"Progressing\", and \"Degraded\"\n\t //
+patchMergeKey=type\n\t // +patchStrategy=merge\n\t // +listType=map\n\t
\ // +listMapKey=type\n\t Conditions []metav1.Condition `json:\"conditions,omitempty\"
patchStrategy:\"merge\" patchMergeKey:\"type\" protobuf:\"bytes,1,rep,name=conditions\"`\n\n\n\t
\ // other fields\n\t}"
properties:
lastTransitionTime:
description: |-
lastTransitionTime is the last time the condition transitioned from one status to another.
This should be when the underlying condition changed. If that is not known, then using the time when the API field changed is acceptable.
format: date-time
type: string
message:
description: |-
message is a human readable message indicating details about the transition.
This may be an empty string.
maxLength: 32768
type: string
observedGeneration:
description: |-
observedGeneration represents the .metadata.generation that the condition was set based upon.
For instance, if .metadata.generation is currently 12, but the .status.conditions[x].observedGeneration is 9, the condition is out of date
with respect to the current state of the instance.
format: int64
minimum: 0
type: integer
reason:
description: |-
reason contains a programmatic identifier indicating the reason for the condition's last transition.
Producers of specific condition types may define expected values and meanings for this field,
and whether the values are considered a guaranteed API.
The value should be a CamelCase string.
This field may not be empty.
maxLength: 1024
minLength: 1
pattern: ^[A-Za-z]([A-Za-z0-9_,:]*[A-Za-z0-9_])?$
type: string
status:
description: status of the condition, one of True, False, Unknown.
enum:
- "True"
- "False"
- Unknown
type: string
type:
description: |-
type of condition in CamelCase or in foo.example.com/CamelCase.
---
Many .condition.type values are consistent across resources like Available, but because arbitrary conditions can be
useful (see .node.status.conditions), the ability to deconflict is important.
The regex it matches is (dns1123SubdomainFmt/)?(qualifiedNameFmt)
maxLength: 316
pattern: ^([a-z0-9]([-a-z0-9]*[a-z0-9])?(\.[a-z0-9]([-a-z0-9]*[a-z0-9])?)*/)?(([A-Za-z0-9][-A-Za-z0-9_.]*)?[A-Za-z0-9])$
type: string
required:
- lastTransitionTime
- message
- reason
- status
- type
type: object
type: array
expirationTimestamp:
description: ExpirationTimestamp is the time when the token will expire.
format: date-time
type: string
tokenSecretRef:
description: |-
TokenSecretRef is a reference to the corresponding ServiceAccount's Secret, which stores
the CA certficate and token from the managed cluster.
properties:
lastRefreshTimestamp:
description: |-
LastRefreshTimestamp is the timestamp indicating when the token in the Secret
is refreshed.
format: date-time
type: string
name:
description: Name is the name of the referenced secret.
type: string
required:
- lastRefreshTimestamp
- name
type: object
type: object
type: object
served: true
storage: true
subresources:
status: {}1.8.5.2.2. 단일 ManagedServiceAccount 쿼리
GET /authentication.open-cluster-management.io/v1beta1/namespaces/{namespace}/managedserviceaccounts/{managedserviceaccount_name}1.8.5.2.2.1. 설명
자세한 내용은 단일 ManagedServiceAccount 를 쿼리합니다.
1.8.5.2.2.2. 매개 변수
| 유형 | 이름 | 설명 | 스키마 |
|---|---|---|---|
| 헤더 |
COOKIE | 권한 부여: Bearer {ACCESS_TOKEN}; ACCESS_TOKEN은 사용자 액세스 토큰입니다. | string |
| 경로 |
managedserviceaccount_name |
쿼리할 | string |
1.8.5.2.2.3. 응답
| HTTP 코드 | 설명 | 스키마 |
|---|---|---|
| 200 | 성공 | 콘텐츠 없음 |
| 403 | 액세스 금지 | 콘텐츠 없음 |
| 404 | 리소스를 찾을 수 없음 | 콘텐츠 없음 |
| 500 | 내부 서비스 오류 | 콘텐츠 없음 |
| 503 | 서비스를 사용할 수 없음 | 콘텐츠 없음 |
1.8.5.2.2.4. 태그
- managedserviceaccounts.authentication.open-cluster-management.io
1.8.5.2.3. ManagedServiceAccount삭제
DELETE /authentication.open-cluster-management.io/v1beta1/namespaces/{namespace}/managedserviceaccounts/{managedserviceaccount_name}1.8.5.2.3.1. 설명
단일 ManagedServiceAccount 를 삭제합니다.
1.8.5.2.3.2. 매개 변수
| 유형 | 이름 | 설명 | 스키마 |
|---|---|---|---|
| 헤더 |
COOKIE | 권한 부여: Bearer {ACCESS_TOKEN}; ACCESS_TOKEN은 사용자 액세스 토큰입니다. | string |
| 경로 |
managedserviceaccount_name |
삭제할 | string |
1.8.5.2.3.3. 응답
| HTTP 코드 | 설명 | 스키마 |
|---|---|---|
| 200 | 성공 | 콘텐츠 없음 |
| 403 | 액세스 금지 | 콘텐츠 없음 |
| 404 | 리소스를 찾을 수 없음 | 콘텐츠 없음 |
| 500 | 내부 서비스 오류 | 콘텐츠 없음 |
| 503 | 서비스를 사용할 수 없음 | 콘텐츠 없음 |
1.8.5.2.3.4. 태그
- managedserviceaccounts.authentication.open-cluster-management.io
1.8.5.3. 정의
1.8.5.3.1. ManagedServiceAccount
| 이름 | 설명 | 스키마 |
|---|---|---|
|
apiVersion |
| string |
|
종류 | REST 리소스를 나타내는 문자열 값입니다. | string |
|
메타데이터 |
| object |
|
사양 |
|
1.8.6. MultiClusterEngine API (v1alpha1)
1.8.6.1. 개요
이 문서는 Kubernetes용 다중 클러스터 엔진의 MultiClusterEngine 리소스에 대한 것입니다. MultiClusterEngine 리소스에는 생성, 쿼리, 삭제 및 업데이트의 네 가지 가능한 요청이 있습니다.
1.8.6.1.1. URI 스키마
BasePath : /kubernetes/apis
Schemes : HTTPS
1.8.6.1.2. 태그
- multiclusterengines.multicluster.openshift.io : MultiClusterEngines 생성 및 관리
1.8.6.2. 경로
1.8.6.2.1. MultiClusterEngine 생성
POST /apis/multicluster.openshift.io/v1alpha1/multiclusterengines1.8.6.2.1.1. 설명
MultiClusterEngine을 생성합니다.
1.8.6.2.1.2. 매개 변수
| 유형 | 이름 | 설명 | 스키마 |
|---|---|---|---|
| 헤더 |
COOKIE | 권한 부여: Bearer {ACCESS_TOKEN}; ACCESS_TOKEN은 사용자 액세스 토큰입니다. | string |
| 본문 |
본문 | 생성할 MultiClusterEngine을 설명하는 매개변수입니다. | MultiClusterEngine |
1.8.6.2.1.3. 응답
| HTTP 코드 | 설명 | 스키마 |
|---|---|---|
| 200 | 성공 | 콘텐츠 없음 |
| 403 | 액세스 금지 | 콘텐츠 없음 |
| 404 | 리소스를 찾을 수 없음 | 콘텐츠 없음 |
| 500 | 내부 서비스 오류 | 콘텐츠 없음 |
| 503 | 서비스를 사용할 수 없음 | 콘텐츠 없음 |
1.8.6.2.1.4. 사용
-
MultiClusterEngines/yaml
1.8.6.2.1.5. 태그
- multiclusterengines.multicluster.openshift.io
1.8.6.2.1.5.1. 요청 본문
{
"apiVersion": "apiextensions.k8s.io/v1",
"kind": "CustomResourceDefinition",
"metadata": {
"annotations": {
"controller-gen.kubebuilder.io/version": "v0.4.1"
},
"creationTimestamp": null,
"name": "multiclusterengines.multicluster.openshift.io"
},
"spec": {
"group": "multicluster.openshift.io",
"names": {
"kind": "MultiClusterEngine",
"listKind": "MultiClusterEngineList",
"plural": "multiclusterengines",
"shortNames": [
"mce"
],
"singular": "multiclusterengine"
},
"scope": "Cluster",
"versions": [
{
"additionalPrinterColumns": [
{
"description": "The overall state of the MultiClusterEngine",
"jsonPath": ".status.phase",
"name": "Status",
"type": "string"
},
{
"jsonPath": ".metadata.creationTimestamp",
"name": "Age",
"type": "date"
}
],
"name": "v1alpha1",
"schema": {
"openAPIV3Schema": {
"description": "MultiClusterEngine is the Schema for the multiclusterengines\nAPI",
"properties": {
"apiVersion": {
"description": "APIVersion defines the versioned schema of this representation\nof an object. Servers should convert recognized schemas to the latest\ninternal value, and may reject unrecognized values. More info: https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#resources",
"type": "string"
},
"kind": {
"description": "Kind is a string value representing the REST resource this\nobject represents. Servers may infer this from the endpoint the client\nsubmits requests to. Cannot be updated. In CamelCase. More info: https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#types-kinds",
"type": "string"
},
"metadata": {
"type": "object"
},
"spec": {
"description": "MultiClusterEngineSpec defines the desired state of MultiClusterEngine",
"properties": {
"imagePullSecret": {
"description": "Override pull secret for accessing MultiClusterEngine\noperand and endpoint images",
"type": "string"
},
"nodeSelector": {
"additionalProperties": {
"type": "string"
},
"description": "Set the nodeselectors",
"type": "object"
},
"targetNamespace": {
"description": "Location where MCE resources will be placed",
"type": "string"
},
"tolerations": {
"description": "Tolerations causes all components to tolerate any taints.",
"items": {
"description": "The pod this Toleration is attached to tolerates any\ntaint that matches the triple <key,value,effect> using the matching\noperator <operator>.",
"properties": {
"effect": {
"description": "Effect indicates the taint effect to match. Empty\nmeans match all taint effects. When specified, allowed values\nare NoSchedule, PreferNoSchedule and NoExecute.",
"type": "string"
},
"key": {
"description": "Key is the taint key that the toleration applies\nto. Empty means match all taint keys. If the key is empty,\noperator must be Exists; this combination means to match all\nvalues and all keys.",
"type": "string"
},
"operator": {
"description": "Operator represents a key's relationship to the\nvalue. Valid operators are Exists and Equal. Defaults to Equal.\nExists is equivalent to wildcard for value, so that a pod\ncan tolerate all taints of a particular category.",
"type": "string"
},
"tolerationSeconds": {
"description": "TolerationSeconds represents the period of time\nthe toleration (which must be of effect NoExecute, otherwise\nthis field is ignored) tolerates the taint. By default, it\nis not set, which means tolerate the taint forever (do not\nevict). Zero and negative values will be treated as 0 (evict\nimmediately) by the system.",
"format": "int64",
"type": "integer"
},
"value": {
"description": "Value is the taint value the toleration matches\nto. If the operator is Exists, the value should be empty,\notherwise just a regular string.",
"type": "string"
}
},
"type": "object"
},
"type": "array"
}
},
"type": "object"
},
"status": {
"description": "MultiClusterEngineStatus defines the observed state of MultiClusterEngine",
"properties": {
"components": {
"items": {
"description": "ComponentCondition contains condition information for\ntracked components",
"properties": {
"kind": {
"description": "The resource kind this condition represents",
"type": "string"
},
"lastTransitionTime": {
"description": "LastTransitionTime is the last time the condition\nchanged from one status to another.",
"format": "date-time",
"type": "string"
},
"message": {
"description": "Message is a human-readable message indicating\ndetails about the last status change.",
"type": "string"
},
"name": {
"description": "The component name",
"type": "string"
},
"reason": {
"description": "Reason is a (brief) reason for the condition's\nlast status change.",
"type": "string"
},
"status": {
"description": "Status is the status of the condition. One of True,\nFalse, Unknown.",
"type": "string"
},
"type": {
"description": "Type is the type of the cluster condition.",
"type": "string"
}
},
"type": "object"
},
"type": "array"
},
"conditions": {
"items": {
"properties": {
"lastTransitionTime": {
"description": "LastTransitionTime is the last time the condition\nchanged from one status to another.",
"format": "date-time",
"type": "string"
},
"lastUpdateTime": {
"description": "The last time this condition was updated.",
"format": "date-time",
"type": "string"
},
"message": {
"description": "Message is a human-readable message indicating\ndetails about the last status change.",
"type": "string"
},
"reason": {
"description": "Reason is a (brief) reason for the condition's\nlast status change.",
"type": "string"
},
"status": {
"description": "Status is the status of the condition. One of True,\nFalse, Unknown.",
"type": "string"
},
"type": {
"description": "Type is the type of the cluster condition.",
"type": "string"
}
},
"type": "object"
},
"type": "array"
},
"phase": {
"description": "Latest observed overall state",
"type": "string"
}
},
"type": "object"
}
},
"type": "object"
}
},
"served": true,
"storage": true,
"subresources": {
"status": {}
}
}
]
},
"status": {
"acceptedNames": {
"kind": "",
"plural": ""
},
"conditions": [],
"storedVersions": []
}
}1.8.6.2.2. 모든 MultiClusterEngines 쿼리
GET /apis/multicluster.openshift.io/v1alpha1/multiclusterengines1.8.6.2.2.1. 설명
자세한 내용은 다중 클러스터 엔진을 쿼리합니다.
1.8.6.2.2.2. 매개 변수
| 유형 | 이름 | 설명 | 스키마 |
|---|---|---|---|
| 헤더 |
COOKIE | 권한 부여: Bearer {ACCESS_TOKEN}; ACCESS_TOKEN은 사용자 액세스 토큰입니다. | string |
1.8.6.2.2.3. 응답
| HTTP 코드 | 설명 | 스키마 |
|---|---|---|
| 200 | 성공 | 콘텐츠 없음 |
| 403 | 액세스 금지 | 콘텐츠 없음 |
| 404 | 리소스를 찾을 수 없음 | 콘텐츠 없음 |
| 500 | 내부 서비스 오류 | 콘텐츠 없음 |
| 503 | 서비스를 사용할 수 없음 | 콘텐츠 없음 |
1.8.6.2.2.4. 사용
-
operator/yaml
1.8.6.2.2.5. 태그
- multiclusterengines.multicluster.openshift.io
1.8.6.2.3. MultiClusterEngine Operator 삭제
DELETE /apis/multicluster.openshift.io/v1alpha1/multiclusterengines/{name}1.8.6.2.3.1. 매개 변수
| 유형 | 이름 | 설명 | 스키마 |
|---|---|---|---|
| 헤더 |
COOKIE | 권한 부여: Bearer {ACCESS_TOKEN}; ACCESS_TOKEN은 사용자 액세스 토큰입니다. | string |
| 경로 |
이름 | 삭제할 다중 클러스터 엔진의 이름입니다. | string |
1.8.6.2.3.2. 응답
| HTTP 코드 | 설명 | 스키마 |
|---|---|---|
| 200 | 성공 | 콘텐츠 없음 |
| 403 | 액세스 금지 | 콘텐츠 없음 |
| 404 | 리소스를 찾을 수 없음 | 콘텐츠 없음 |
| 500 | 내부 서비스 오류 | 콘텐츠 없음 |
| 503 | 서비스를 사용할 수 없음 | 콘텐츠 없음 |
1.8.6.2.3.3. 태그
- multiclusterengines.multicluster.openshift.io
1.8.6.3. 정의
1.8.6.3.1. MultiClusterEngine
| 이름 | 설명 | 스키마 |
|---|---|---|
|
apiVersion | MultiClusterEngines의 버전이 지정된 스키마입니다. | string |
|
종류 | REST 리소스를 나타내는 문자열 값입니다. | string |
|
메타데이터 | 리소스를 정의하는 규칙을 설명합니다. | object |
|
사양 | MultiClusterEngineSpec은 원하는 MultiClusterEngine 상태를 정의합니다. | 사양 목록을참조하십시오. |
1.8.6.3.2. 사양 목록
| 이름 | 설명 | 스키마 |
|---|---|---|
|
nodeSelector | 노드 선택기를 설정합니다. | map[string]string |
|
imagePullSecret | MultiClusterEngine 피연산자 및 끝점 이미지에 액세스하기 위해 풀 시크릿을 재정의합니다. | string |
|
허용 오차 | 허용 오차를 사용하면 모든 구성 요소가 모든 테인트를 허용합니다. | []corev1.Toleration |
|
targetNamespace | MCE 리소스가 배치되는 위치입니다. | string |
1.8.7. 배치 API(v1beta1)
1.8.7.1. 개요
이 문서는 Kubernetes용 다중 클러스터 엔진의 배치 리소스에 대한 것입니다. 배치 리소스에는 생성, 쿼리, 삭제 및 업데이트의 네 가지 요청이 있습니다.
1.8.7.1.1. URI 스키마
BasePath : /kubernetes/apis
Schemes : HTTPS
1.8.7.1.2. 태그
- cluster.open-cluster-management.io : 배치 생성 및 관리
1.8.7.2. 경로
1.8.7.2.1. 모든 배치 쿼리
GET /cluster.open-cluster-management.io/v1beta1/namespaces/{namespace}/placements1.8.7.2.1.1. 설명
자세한 내용은 배치를 쿼리합니다.
1.8.7.2.1.2. 매개 변수
| 유형 | 이름 | 설명 | 스키마 |
|---|---|---|---|
| 헤더 |
COOKIE | 권한 부여: Bearer {ACCESS_TOKEN}; ACCESS_TOKEN은 사용자 액세스 토큰입니다. | string |
1.8.7.2.1.3. 응답
| HTTP 코드 | 설명 | 스키마 |
|---|---|---|
| 200 | 성공 | 콘텐츠 없음 |
| 403 | 액세스 금지 | 콘텐츠 없음 |
| 404 | 리소스를 찾을 수 없음 | 콘텐츠 없음 |
| 500 | 내부 서비스 오류 | 콘텐츠 없음 |
| 503 | 서비스를 사용할 수 없음 | 콘텐츠 없음 |
1.8.7.2.1.4. 사용
-
placement/yaml
1.8.7.2.1.5. 태그
- cluster.open-cluster-management.io
1.8.7.2.2. 배치 생성
POST /cluster.open-cluster-management.io/v1beta1/namespaces/{namespace}/placements1.8.7.2.2.1. 설명
배치를 생성합니다.
1.8.7.2.2.2. 매개 변수
| 유형 | 이름 | 설명 | 스키마 |
|---|---|---|---|
| 헤더 |
COOKIE | 권한 부여: Bearer {ACCESS_TOKEN}; ACCESS_TOKEN은 사용자 액세스 토큰입니다. | string |
| 본문 |
본문 | 생성할 배치를 설명하는 매개변수입니다. |
1.8.7.2.2.3. 응답
| HTTP 코드 | 설명 | 스키마 |
|---|---|---|
| 200 | 성공 | 콘텐츠 없음 |
| 403 | 액세스 금지 | 콘텐츠 없음 |
| 404 | 리소스를 찾을 수 없음 | 콘텐츠 없음 |
| 500 | 내부 서비스 오류 | 콘텐츠 없음 |
| 503 | 서비스를 사용할 수 없음 | 콘텐츠 없음 |
1.8.7.2.2.4. 사용
-
placement/yaml
1.8.7.2.2.5. 태그
- cluster.open-cluster-management.io
1.8.7.2.2.6. HTTP 요청의 예
1.8.7.2.2.6.1. 요청 본문
{
"apiVersion" : "cluster.open-cluster-management.io/v1beta1",
"kind" : "Placement",
"metadata" : {
"name" : "placement1",
"namespace": "ns1"
},
"spec": {
"predicates": [
{
"requiredClusterSelector": {
"labelSelector": {
"matchLabels": {
"vendor": "OpenShift"
}
}
}
}
]
},
"status" : { }
}1.8.7.2.3. 단일 배치 쿼리
GET /cluster.open-cluster-management.io/v1beta1/namespaces/{namespace}/placements/{placement_name}1.8.7.2.3.1. 설명
자세한 내용은 단일 배치를 쿼리합니다.
1.8.7.2.3.2. 매개 변수
| 유형 | 이름 | 설명 | 스키마 |
|---|---|---|---|
| 헤더 |
COOKIE | 권한 부여: Bearer {ACCESS_TOKEN}; ACCESS_TOKEN은 사용자 액세스 토큰입니다. | string |
| 경로 |
placement_name | 쿼리할 배치의 이름입니다. | string |
1.8.7.2.3.3. 응답
| HTTP 코드 | 설명 | 스키마 |
|---|---|---|
| 200 | 성공 | 콘텐츠 없음 |
| 403 | 액세스 금지 | 콘텐츠 없음 |
| 404 | 리소스를 찾을 수 없음 | 콘텐츠 없음 |
| 500 | 내부 서비스 오류 | 콘텐츠 없음 |
| 503 | 서비스를 사용할 수 없음 | 콘텐츠 없음 |
1.8.7.2.3.4. 태그
- cluster.open-cluster-management.io
1.8.7.2.4. 배치 삭제
DELETE /cluster.open-cluster-management.io/v1beta1/namespaces/{namespace}/placements/{placement_name}1.8.7.2.4.1. 설명
단일 배치를 삭제합니다.
1.8.7.2.4.2. 매개 변수
| 유형 | 이름 | 설명 | 스키마 |
|---|---|---|---|
| 헤더 |
COOKIE | 권한 부여: Bearer {ACCESS_TOKEN}; ACCESS_TOKEN은 사용자 액세스 토큰입니다. | string |
| 경로 |
placement_name | 삭제할 배치의 이름입니다. | string |
1.8.7.2.4.3. 응답
| HTTP 코드 | 설명 | 스키마 |
|---|---|---|
| 200 | 성공 | 콘텐츠 없음 |
| 403 | 액세스 금지 | 콘텐츠 없음 |
| 404 | 리소스를 찾을 수 없음 | 콘텐츠 없음 |
| 500 | 내부 서비스 오류 | 콘텐츠 없음 |
| 503 | 서비스를 사용할 수 없음 | 콘텐츠 없음 |
1.8.7.2.4.4. 태그
- cluster.open-cluster-management.io
1.8.7.3. 정의
1.8.7.3.1. 배치
| 이름 | 설명 | 스키마 |
|---|---|---|
|
apiVersion | 배치의 버전이 지정된 스키마입니다. | string |
|
종류 | REST 리소스를 나타내는 문자열 값입니다. | string |
|
메타데이터 | 배치의 메타 데이터입니다. | object |
|
사양 | 배치 사양입니다. |
spec
| 이름 | 설명 | 스키마 |
|---|---|---|
|
ClusterSets | ManagedClusters가 선택된 ManagedClusterSet의 서브 세트입니다. 비어 있는 경우 Placement 네임스페이스에 바인딩된 ManagedClusterSets에서 ManagedClusters가 선택됩니다. 그렇지 않으면 ManagedClusters가 이 하위 집합의 교차점에서 선택되며 ManagedClusterSets는 배치 네임스페이스에 바인딩됩니다. | 문자열 배열 |
|
numberOfClusters | 선택할 ManagedCluster 수입니다. | 정수(int32) |
|
서술자 | ManagedClusters를 선택하는 클러스터 서술자의 하위 집합입니다. 조건부 논리는 또는 입니다. |
clusterPredicate
| 이름 | 설명 | 스키마 |
|---|---|---|
|
requiredClusterSelector | 레이블 및 클러스터 클레임이 있는 ManagedClusters를 선택하는 클러스터 선택기입니다. |
clusterSelector
| 이름 | 설명 | 스키마 |
|---|---|---|
|
labelSelector | 라벨별 ManagedClusters 선택기입니다. | object |
|
claimSelector | 클레임에 의한 ManagedCluster의 선택기입니다. |
clusterClaimSelector
| 이름 | 설명 | 스키마 |
|---|---|---|
|
matchExpressions | 클러스터 클레임 선택기 요구 사항의 하위 집합입니다. 조건부 논리는 AND 입니다. | < object > array |
1.8.8. PlacementDecisions API (v1beta1)
1.8.8.1. 개요
이 문서는 Kubernetes용 다중 클러스터 엔진의 PlacementDecision 리소스에 대한 것입니다. PlacementDecision 리소스에는 생성, 쿼리, 삭제 및 업데이트의 네 가지 가능한 요청이 있습니다.
1.8.8.1.1. URI 스키마
BasePath : /kubernetes/apis
Schemes : HTTPS
1.8.8.1.2. 태그
- cluster.open-cluster-management.io : PlacementDecisions를 생성 및 관리합니다.
1.8.8.2. 경로
1.8.8.2.1. 모든 PlacementDecisions 쿼리
GET /cluster.open-cluster-management.io/v1beta1/namespaces/{namespace}/placementdecisions1.8.8.2.1.1. 설명
자세한 내용은 PlacementDecisions를 쿼리합니다.
1.8.8.2.1.2. 매개 변수
| 유형 | 이름 | 설명 | 스키마 |
|---|---|---|---|
| 헤더 |
COOKIE | 권한 부여: Bearer {ACCESS_TOKEN}; ACCESS_TOKEN은 사용자 액세스 토큰입니다. | string |
1.8.8.2.1.3. 응답
| HTTP 코드 | 설명 | 스키마 |
|---|---|---|
| 200 | 성공 | 콘텐츠 없음 |
| 403 | 액세스 금지 | 콘텐츠 없음 |
| 404 | 리소스를 찾을 수 없음 | 콘텐츠 없음 |
| 500 | 내부 서비스 오류 | 콘텐츠 없음 |
| 503 | 서비스를 사용할 수 없음 | 콘텐츠 없음 |
1.8.8.2.1.4. 사용
-
placementdecision/yaml
1.8.8.2.1.5. 태그
- cluster.open-cluster-management.io
1.8.8.2.2. PlacementDecision 생성
POST /cluster.open-cluster-management.io/v1beta1/namespaces/{namespace}/placementdecisions1.8.8.2.2.1. 설명
PlacementDecision을 생성합니다.
1.8.8.2.2.2. 매개 변수
| 유형 | 이름 | 설명 | 스키마 |
|---|---|---|---|
| 헤더 |
COOKIE | 권한 부여: Bearer {ACCESS_TOKEN}; ACCESS_TOKEN은 사용자 액세스 토큰입니다. | string |
| 본문 |
본문 | 생성할 PlacementDecision을 설명하는 매개변수입니다. |
1.8.8.2.2.3. 응답
| HTTP 코드 | 설명 | 스키마 |
|---|---|---|
| 200 | 성공 | 콘텐츠 없음 |
| 403 | 액세스 금지 | 콘텐츠 없음 |
| 404 | 리소스를 찾을 수 없음 | 콘텐츠 없음 |
| 500 | 내부 서비스 오류 | 콘텐츠 없음 |
| 503 | 서비스를 사용할 수 없음 | 콘텐츠 없음 |
1.8.8.2.2.4. 사용
-
placementdecision/yaml
1.8.8.2.2.5. 태그
- cluster.open-cluster-management.io
1.8.8.2.2.6. HTTP 요청의 예
1.8.8.2.2.6.1. 요청 본문
{
"apiVersion" : "cluster.open-cluster-management.io/v1beta1",
"kind" : "PlacementDecision",
"metadata" : {
"labels" : {
"cluster.open-cluster-management.io/placement" : "placement1"
},
"name" : "placement1-decision1",
"namespace": "ns1"
},
"status" : { }
}1.8.8.2.3. 단일 PlacementDecision 쿼리
GET /cluster.open-cluster-management.io/v1beta1/namespaces/{namespace}/placementdecisions/{placementdecision_name}1.8.8.2.3.1. 설명
자세한 내용은 단일 PlacementDecision을 쿼리합니다.
1.8.8.2.3.2. 매개 변수
| 유형 | 이름 | 설명 | 스키마 |
|---|---|---|---|
| 헤더 |
COOKIE | 권한 부여: Bearer {ACCESS_TOKEN}; ACCESS_TOKEN은 사용자 액세스 토큰입니다. | string |
| 경로 |
placementdecision_name | 쿼리할 PlacementDecision의 이름입니다. | string |
1.8.8.2.3.3. 응답
| HTTP 코드 | 설명 | 스키마 |
|---|---|---|
| 200 | 성공 | 콘텐츠 없음 |
| 403 | 액세스 금지 | 콘텐츠 없음 |
| 404 | 리소스를 찾을 수 없음 | 콘텐츠 없음 |
| 500 | 내부 서비스 오류 | 콘텐츠 없음 |
| 503 | 서비스를 사용할 수 없음 | 콘텐츠 없음 |
1.8.8.2.3.4. 태그
- cluster.open-cluster-management.io
1.8.8.2.4. PlacementDecision 삭제
DELETE /cluster.open-cluster-management.io/v1beta1/namespaces/{namespace}/placementdecisions/{placementdecision_name}1.8.8.2.4.1. 설명
단일 PlacementDecision을 삭제합니다.
1.8.8.2.4.2. 매개 변수
| 유형 | 이름 | 설명 | 스키마 |
|---|---|---|---|
| 헤더 |
COOKIE | 권한 부여: Bearer {ACCESS_TOKEN}; ACCESS_TOKEN은 사용자 액세스 토큰입니다. | string |
| 경로 |
placementdecision_name | 삭제할 PlacementDecision의 이름입니다. | string |
1.8.8.2.4.3. 응답
| HTTP 코드 | 설명 | 스키마 |
|---|---|---|
| 200 | 성공 | 콘텐츠 없음 |
| 403 | 액세스 금지 | 콘텐츠 없음 |
| 404 | 리소스를 찾을 수 없음 | 콘텐츠 없음 |
| 500 | 내부 서비스 오류 | 콘텐츠 없음 |
| 503 | 서비스를 사용할 수 없음 | 콘텐츠 없음 |
1.8.8.2.4.4. 태그
- cluster.open-cluster-management.io
1.8.8.3. 정의
1.8.8.3.1. PlacementDecision
| 이름 | 설명 | 스키마 |
|---|---|---|
|
apiVersion | PlacementDecision의 버전이 지정된 스키마입니다. | string |
|
종류 | REST 리소스를 나타내는 문자열 값입니다. | string |
|
메타데이터 | PlacementDecision의 메타 데이터입니다. | object |
1.9. 문제 해결
문제 해결 가이드를 사용하기 전에 oc adm must-gather 명령을 실행하여 세부 정보, 로그 및 디버깅 문제 단계를 수행할 수 있습니다. 자세한 내용은 must-gather 명령 실행을 참조하십시오.
또한 역할 기반 액세스를 확인합니다. 자세한 내용은 다중 클러스터 엔진 운영자 역할 기반 액세스 제어를 참조하십시오.
1.9.1. 문서화된 문제 해결
다중 클러스터 엔진 Operator의 문제 해결 주제 목록을 확인합니다.
설치:
설치 작업의 기본 문서를 보려면 다중 클러스터 엔진 Operator 설치 및 업그레이드를 참조하십시오.
클러스터 관리:
클러스터 관리에 대한 주요 문서를 보려면 클러스터 라이프사이클 소개를 참조하십시오.
- 기존 클러스터에 Day-two 노드 추가 문제 해결 실패
- 오프라인 클러스터 문제 해결
- 관리형 클러스터 가져오기 실패 문제 해결
- 알 수 없는 권한 오류로 클러스터 다시 가져오기 실패
- 가져오기 보류 중 상태의 클러스터 문제 해결
- 인증서 변경 후 가져온 클러스터 오프라인 문제 해결
- 클러스터 상태가 오프라인에서 사용 가능으로 변경 문제 해결
- VMware vSphere에서 클러스터 생성 문제 해결
- 보류 중 또는 실패 상태의 콘솔에서 클러스터 문제 해결
- OpenShift Container Platform 버전 3.11 클러스터 가져오기 실패 문제 해결
- 성능이 저하된 조건으로 Klusterlet 문제 해결
- 클러스터를 삭제한 후에도 네임스페이스가 남아 있음
- 클러스터를 가져올 때 auto-import-secret-exists 오류
- 배치 생성 후 누락된 PlacementDecision 문제 해결
- Dell 하드웨어에서 베어 메탈 호스트의 검색 실패 문제 해결
- 최소 ISO 부팅 실패 문제 해결
-
호스팅된 컨트롤 플레인 클러스터를 사용하여 ROSA에
설치중인 설치 상태 문제 해결 -
호스트된 컨트롤 플레인 클러스터가
있는ROSA에서 모든 관리 클러스터의 알 수 없음
1.9.2. must-gather 명령을 실행하여 문제 해결
문제 해결을 시작하려면 사용자가 must-gather 명령을 실행하여 문제를 디버깅하는 데 필요한 문제 해결 시나리오에 대해 확인한 다음 명령 사용을 시작하는 절차를 참조하십시오.
필수 액세스: 클러스터 관리자
1.9.2.1. must-gather 시나리오
시나리오 1: 문서화된 문제 해결 섹션을 사용하여 문제에 대한 해결 방법이 문서화되어 있는지 확인합니다. 이 가이드는 제품의 주요 기능에 의해 구성됩니다.
이 시나리오에서는 가이드가 설명서에 있는지 확인합니다.
-
시나리오 2: 해결 단계에 문제가 문서화되지 않은 경우
must-gather명령을 실행하고 출력을 사용하여 문제를 디버깅합니다. -
시나리오 3:
must-gather명령의 출력을 사용하여 문제를 디버깅할 수 없는 경우 Red Hat 지원과 출력을 공유하십시오.
1.9.2.2. must-gather 절차
must-gather 명령을 사용하려면 다음 절차를 참조하십시오.
-
must-gather명령에 대해 알아보고 OpenShift Container Platform 설명서에서 클러스터에 대한 데이터 수집에 필요한 사전 요구 사항을 설치합니다. 클러스터에 로그인합니다. 일반적인 사용 사례의 경우 엔진 클러스터에 로그인하는 동안
must-gather를 실행해야 합니다.참고: 관리 클러스터를 확인하려면
cluster-scoped-resources디렉터리에 있는gather-managed.log파일을 찾습니다.<your-directory>/cluster-scoped-resources/gather-managed.log>JOINED 및 AVAILABLE 열에
True가 설정되지 않은 관리형 클러스터를 확인합니다.True상태와 연결되지 않은 클러스터에서must-gather명령을 실행할 수 있습니다.- 데이터 및 디렉터리 수집에 사용되는 Kubernetes 이미지에 대한 다중 클러스터 엔진을 추가합니다. 다음 명령을 실행합니다.
oc adm must-gather --image=registry.redhat.io/multicluster-engine/must-gather-rhel9:v2.5 --dest-dir=<directory>지정된 디렉터리로 이동하여 다음 수준에서 구성된 출력을 확인합니다.
-
두 개의 피어 수준:
cluster-scoped-resources및namespaceresources. - 각 하위 수준: 클러스터 범위 및 네임스페이스 범위 리소스 모두에 대한 사용자 정의 리소스 정의에 대한 API 그룹입니다.
-
유형별로 정렬된 YAML 파일 각의 다음 수준 .
-
두 개의 피어 수준:
1.9.2.3. 연결이 끊긴 환경의 must-gather
연결이 끊긴 환경에서 must-gather 명령을 실행하려면 다음 단계를 완료합니다.
- 연결이 끊긴 환경에서 Red Hat Operator 카탈로그 이미지를 미러 레지스트리에 미러링합니다. 자세한 내용은 연결이 끊긴 네트워크에 설치를 참조하십시오.
-
다음 명령을 실행하여 미러 레지스트리에서 이미지를 참조하는 로그를 추출합니다.
sha256을 현재 이미지로 교체합니다.
REGISTRY=registry.example.com:5000
IMAGE=$REGISTRY/multicluster-engine/must-gather-rhel9@sha256:ff9f37eb400dc1f7d07a9b6f2da9064992934b69847d17f59e385783c071b9d8>
oc adm must-gather --image=$IMAGE --dest-dir=./data1.9.2.4. 호스트 클러스터의 must-gather
호스팅된 컨트롤 플레인 클러스터에 문제가 발생하는 경우 must-gather 명령을 실행하여 문제 해결을 위한 정보를 수집할 수 있습니다.
필수 액세스: 클러스터 관리
1.9.2.4.1. 호스팅된 클러스터의 must-gather 명령 정보
must-gather 명령은 관리 클러스터 및 호스팅 클러스터에 대한 출력을 생성합니다. 수집되는 데이터에 대해 자세히 알아보십시오.
다음 데이터는 다중 클러스터 엔진 Operator 허브 클러스터에서 수집됩니다.
- 클러스터 범위 리소스: 이러한 리소스는 관리 클러스터의 노드 정의입니다.
-
hypershift-dump압축 파일: 이 파일은 다른 사용자와 콘텐츠를 공유해야 하는 경우에 유용합니다. - 네임스페이스 리소스: 이러한 리소스에는 구성 맵, 서비스, 이벤트 및 로그와 같은 관련 네임스페이스의 모든 오브젝트가 포함됩니다.
- 네트워크 로그: 이 로그에는 OVN northbound 및 southbound 데이터베이스와 각각에 대한 상태가 포함됩니다.
- 호스트 클러스터: 이 수준의 출력에는 호스팅된 클러스터 내부의 모든 리소스가 포함됩니다.
다음 데이터는 호스팅 클러스터에서 수집됩니다.
- 클러스터 범위 리소스: 이러한 리소스에는 노드 및 CRD와 같은 모든 클러스터 전체 오브젝트가 포함됩니다.
- 네임스페이스 리소스: 이러한 리소스에는 구성 맵, 서비스, 이벤트 및 로그와 같은 관련 네임스페이스의 모든 오브젝트가 포함됩니다.
출력에 클러스터의 보안 오브젝트가 포함되어 있지 않지만 시크릿 이름에 대한 참조를 포함할 수 있습니다.
1.9.2.4.2. 사전 요구 사항
must-gather 명령을 실행하여 정보를 수집하려면 다음 사전 요구 사항을 충족해야 합니다.
-
kubeconfig파일이 로드되고 다중 클러스터 엔진 Operator 허브 클러스터를 가리키는지 확인해야 합니다. -
HostedCluster리소스의 name 값과 사용자 정의 리소스가 배포된 네임스페이스가 있어야 합니다.
1.9.2.4.3. 호스트된 클러스터에 대한 must-gather 명령 입력
must-gather 명령에서 정보를 수집하려면 다음 프로세스를 참조하십시오.
호스트된 클러스터에 대한 정보를 수집하려면 다음 명령을 입력합니다. &
lt;v2.x>를 사용 중인 버전으로 바꿉니다.oc adm must-gather --image=registry.redhat.io/multicluster-engine/must-gather-rhel9:<v2.x> /usr/bin/gather hosted-cluster-namespace=HOSTEDCLUSTERNAMESPACE hosted-cluster-name=HOSTEDCLUSTERNAMEhosted-cluster-namespace=HOSTEDCLUSTERNAMESPACE매개변수는 선택 사항입니다. 매개변수를 포함하지 않으면 호스트된 클러스터가 기본 네임스페이스인 클러스터인 것처럼 명령이실행됩니다.명령의 결과를 압축 파일에 저장하려면 동일한 명령을 실행하고 선택 사항인
--dest-dir=NAME매개 변수를 추가합니다.NAME을 결과를 저장할 디렉터리의 이름으로 바꿉니다. <v2.x>를 사용 중인 버전으로 바꿉니다. 선택적 매개변수를 사용하여 다음 명령을 참조하십시오.oc adm must-gather --image=registry.redhat.io/multicluster-engine/must-gather-rhel9:<v2.x> /usr/bin/gather hosted-cluster-namespace=HOSTEDCLUSTERNAMESPACE hosted-cluster-name=HOSTEDCLUSTERNAME --dest-dir=NAME ; tar -cvzf NAME.tgz NAME
1.9.2.4.4. 연결이 끊긴 환경에서 must-gather 명령 입력
연결이 끊긴 환경에서 must-gather 명령을 실행하려면 다음 단계를 완료합니다.
- 연결이 끊긴 환경에서 Red Hat Operator 카탈로그 이미지를 미러 레지스트리에 미러링합니다. 자세한 내용은 연결이 끊긴 네트워크에 설치를 참조하십시오.
다음 명령을 실행하여 미러 레지스트리에서 이미지를 참조하는 로그를 추출합니다.
REGISTRY=registry.example.com:5000 IMAGE=$REGISTRY/multicluster-engine/must-gather-rhel8@sha256:ff9f37eb400dc1f7d07a9b6f2da9064992934b69847d17f59e385783c071b9d8 oc adm must-gather --image=$IMAGE /usr/bin/gather hosted-cluster-namespace=HOSTEDCLUSTERNAMESPACE hosted-cluster-name=HOSTEDCLUSTERNAME --dest-dir=./data
1.9.2.4.5. 추가 리소스
- 호스트된 컨트롤 플레인 문제 해결에 대한 자세한 내용은 OpenShift Container Platform 설명서의 호스트된 컨트롤 플레인 문제 해결을 참조하십시오.
1.9.3. 문제 해결: 보류 중인 사용자 작업과 함께 기존 클러스터에 Day-two 노드 추가 실패
설치 중에 Zero Touch 프로비저닝 또는 호스트 인벤토리를 사용하여 Kubernetes Operator에 대해 다중 클러스터 엔진에 의해 생성된 기존 클러스터에 노드를 추가하거나 축소할 수 없습니다. 설치 프로세스는 검색 단계에서 올바르게 작동하지만 설치 단계에서는 실패합니다.
네트워크 구성이 실패합니다. 통합 콘솔의 hub 클러스터에서 Pending 사용자 작업이 표시됩니다. 설명에서 재부팅 단계에서 실패하는 것을 확인할 수 있습니다.
설치 호스트에서 실행 중인 에이전트에서 정보를 보고할 수 없기 때문에 실패에 대한 오류 메시지는 매우 정확하지 않습니다.
1.9.3.1. 증상: 2 일 작업자를 위한 설치 실패
Discover 단계 후에는 호스트가 재부팅되어 설치를 계속하지만 네트워크를 구성할 수 없습니다. 다음 증상 및 메시지를 확인합니다.
통합 콘솔의 hub 클러스터에서 추가 노드에서
Pending사용자 작업을 확인하고재부팅 표시기를사용합니다.This host is pending user action. Host timed out when pulling ignition. Check the host console... RebootingRed Hat OpenShift Container Platform 구성 관리 클러스터에서 기존 클러스터
의 MachineConfig를 확인합니다.MachineConfigs중 하나가 다음 디렉토리에 파일을 생성하는지 확인합니다.-
/sysroot/etc/NetworkManager/system-connections/ -
/sysroot/etc/sysconfig/network-scripts/
-
-
설치 호스트의 터미널에서 다음 메시지가 실패하는 호스트를 확인합니다.
journalctl을 사용하여 로그 메시지를 볼 수 있습니다.
info: networking config is defined in the real root
info: will not attempt to propagate initramfs networking로그에 마지막 메시지가 표시되면 이전에 Symptom 에 나열된 폴더에 기존 네트워크 구성이 이미 발견되었기 때문에 네트워킹 구성이 전파되지 않습니다.
1.9.3.2. 문제 해결: 노드 병합 네트워크 구성 다시 생성
설치 중에 적절한 네트워크 구성을 사용하려면 다음 작업을 수행합니다.
- 허브 클러스터에서 노드를 삭제합니다.
- 이전 프로세스를 반복하여 동일한 방식으로 노드를 설치합니다.
다음 주석을 사용하여 노드의
BareMetalHost오브젝트를 생성합니다."bmac.agent-install.openshift.io/installer-args": "[\"--append-karg\", \"coreos.force_persist_ip\"]"
노드가 설치를 시작합니다. 검색 단계 후 노드는 기존 클러스터의 변경 사항과 초기 구성 간의 네트워크 구성을 병합합니다.
1.9.4. 에이전트 플랫폼에서 호스트된 컨트롤 플레인 클러스터 삭제 실패 문제 해결
에이전트 플랫폼에서 호스팅된 컨트롤 플레인 클러스터를 삭제하면 일반적으로 모든 백엔드 리소스가 삭제됩니다. 머신 리소스가 올바르게 삭제되지 않으면 클러스터 삭제에 실패합니다. 이 경우 나머지 시스템 리소스를 수동으로 제거해야 합니다.
1.9.4.1. 증상: 호스트된 컨트롤 플레인 클러스터를 제거할 때 오류가 발생합니다.
에이전트 플랫폼에서 호스트된 컨트롤 플레인 클러스터를 제거하려고 하면 다음과 같은 오류와 함께 hcp destroy 명령이 실패합니다.
+
2024-02-22T09:56:19-05:00 ERROR HostedCluster deletion failed {"namespace": "clusters", "name": "hosted-0", "error": "context deadline exceeded"}
2024-02-22T09:56:19-05:00 ERROR Failed to destroy cluster {"error": "context deadline exceeded"}1.9.4.2. 문제 해결: 나머지 머신 리소스를 수동으로 제거
에이전트 플랫폼에서 호스트된 컨트롤 플레인 클러스터를 성공적으로 제거하려면 다음 단계를 완료합니다.
다음 명령을 실행하여 <
hosted_cluster_namespace>를 호스팅된 클러스터 네임스페이스이름으로 교체하여 나머지 머신 리소스 목록을 확인합니다.oc get machine -n <hosted_cluster_namespace>다음 예제 출력을 참조하십시오.
NAMESPACE NAME CLUSTER NODENAME PROVIDERID PHASE AGE VERSION clusters-hosted-0 hosted-0-9gg8b hosted-0-nhdbp Deleting 10h 4.15.0-rc.8다음 명령을 실행하여 머신 리소스에 연결된
machine.cluster.x-k8s.io종료자를 제거합니다.oc edit machines -n <hosted_cluster_namespace>다음 명령을 실행하여 터미널에
No resources found메시지가 표시되는지 확인합니다.oc get agentmachine -n <hosted_cluster_namespace>다음 명령을 실행하여 에이전트 플랫폼에서 호스팅된 컨트롤 플레인 클러스터를 제거합니다.
hcp destroy cluster agent --name <cluster_name>&
lt;cluster_name>을 클러스터 이름으로 바꿉니다.
1.9.5. 설치 또는 보류 중인 설치 상태 문제 해결
다중 클러스터 엔진 Operator를 설치할 때 MultiClusterEngine 은 Installing 단계에 남아 있거나 여러 Pod가 Pending 상태를 유지합니다.
1.9.5.1. 증상: 보류 중 상태 발생
MultiClusterEngine을 설치한 후 10분 이상 전달되었으며 리소스의 MultiClusterEngine status.components 필드에서 하나 이상의 구성 요소가 ProgressDeadlineExceeded. 클러스터의 리소스 제약 조건이 문제가 될 수 있습니다.
MultiClusterEngine 이 설치된 네임스페이스에서 Pod를 확인합니다. 다음과 유사한 상태로 보류 중이 표시될 수 있습니다.
reason: Unschedulable
message: '0/6 nodes are available: 3 Insufficient cpu, 3 node(s) had taint {node-role.kubernetes.io/master:
}, that the pod didn't tolerate.'이 경우 제품을 실행하기 위해 작업자 노드 리소스가 클러스터에 충분하지 않습니다.
1.9.5.2. 문제 해결: 작업자 노드 크기 조정
이 문제가 있는 경우 더 큰 작업자 노드로 클러스터를 업데이트해야 합니다. 클러스터 크기 지정에 대한 지침은 클러스터 크기 조정을 참조하십시오.
1.9.6. 설치 실패 문제 해결
다중 클러스터 엔진 Operator를 다시 설치할 때 Pod가 시작되지 않습니다.
1.9.6.1. 증상: 재설치 실패
다중 클러스터 엔진 Operator를 설치한 후 Pod가 시작되지 않는 경우 이전 멀티 클러스터 엔진 Operator의 항목이 제거될 때 올바르게 제거되지 않았기 때문에 종종 Pod가 시작되지 않습니다.
이 경우 설치 프로세스를 완료한 후 Pod가 시작되지 않습니다.
1.9.6.2. 문제 해결: 설치 실패
이 문제가 있는 경우 다음 단계를 완료합니다.
- 설치 제거 프로세스를 실행하여 설치 제거의 단계에 따라 현재 구성 요소를 제거합니다. ???
- Helm 설치 지침에 따라 Helm CLI 바이너리 버전 3.2.0 이상을 설치합니다. https://helm.sh/docs/intro/install/
-
Red Hat OpenShift Container Platform CLI가
oc명령을 실행하도록 구성되어 있는지 확인합니다.oc명령 구성에 대한 자세한 내용은 OpenShift Container Platform 설명서에서 OpenShift CLI 시작하기 를 참조하십시오. 다음 스크립트를 파일에 복사합니다.
#!/bin/bash MCE_NAMESPACE=<namespace> oc delete multiclusterengine --all oc delete apiservice v1.admission.cluster.open-cluster-management.io v1.admission.work.open-cluster-management.io oc delete crd discoveredclusters.discovery.open-cluster-management.io discoveryconfigs.discovery.open-cluster-management.io oc delete mutatingwebhookconfiguration ocm-mutating-webhook managedclustermutators.admission.cluster.open-cluster-management.io oc delete validatingwebhookconfiguration ocm-validating-webhook oc delete ns $MCE_NAMESPACE스크립트에서
<namespace>를 다중 클러스터 엔진 Operator가 설치된 네임스페이스의 이름으로 바꿉니다. 네임스페이스가 정리 및 삭제되므로 올바른 네임스페이스를 지정해야 합니다.- 스크립트를 실행하여 이전 설치에서 아티팩트를 제거합니다.
- 설치를 실행합니다. 온라인으로 연결하는 동안 설치를 참조하십시오.
1.9.7. 오프라인 클러스터 문제 해결
오프라인 상태를 표시하는 클러스터에는 몇 가지 일반적인 원인이 있습니다.
1.9.7.1. 증상: 클러스터 상태가 오프라인 상태
클러스터 생성 절차를 완료한 후에는 Red Hat Advanced Cluster Management 콘솔에서 액세스할 수 없으며 오프라인 상태가 표시됩니다.
1.9.7.2. 문제 해결: 클러스터 상태가 오프라인 상태입니다.
관리 클러스터를 사용할 수 있는지 확인합니다. Red Hat Advanced Cluster Management 콘솔의 Clusters 영역에서 확인할 수 있습니다.
사용할 수 없는 경우 관리 클러스터를 다시 시작하십시오.
관리 클러스터 상태가 여전히 오프라인 상태인 경우 다음 단계를 완료합니다.
-
hub 클러스터에서
oc get managedcluster <cluster_name> -o yaml명령을 실행합니다. <cluster_name>을 클러스터 이름으로 바꿉니다. -
status.conditions섹션을 찾습니다. -
ManagedClusterConditionAvailable 유형의메시지를 확인하고 모든 문제를 해결합니다.
-
hub 클러스터에서
1.9.8. 관리형 클러스터 가져오기 실패 문제 해결
클러스터 가져오기에 실패하면 클러스터 가져오기에 실패한 이유를 확인하기 위해 수행할 수 있는 몇 가지 단계가 있습니다.
1.9.8.1. 증상: 가져온 클러스터를 사용할 수 없음
클러스터 가져오기 절차를 완료한 후에는 콘솔에서 액세스할 수 없습니다.
1.9.8.2. 문제 해결: 가져온 클러스터를 사용할 수 없음
가져오기를 시도한 후에는 가져온 클러스터를 사용할 수 없는 몇 가지 이유가 있을 수 있습니다. 클러스터 가져오기에 실패하면 가져오기에 실패한 이유를 찾을 때까지 다음 단계를 완료합니다.
hub 클러스터에서 다음 명령을 실행하여 가져오기 컨트롤러가 실행 중인지 확인합니다.
kubectl -n multicluster-engine get pods -l app=managedcluster-import-controller-v2실행 중인 Pod 두 개가 표시되어야 합니다. Pod 중 하나가 실행 중이 아닌 경우 다음 명령을 실행하여 로그를 확인하여 이유를 확인합니다.
kubectl -n multicluster-engine logs -l app=managedcluster-import-controller-v2 --tail=-1hub 클러스터에서 다음 명령을 실행하여 가져오기 컨트롤러에서 관리 클러스터 가져오기 보안이 성공적으로 생성되었는지 확인합니다.
kubectl -n <managed_cluster_name> get secrets <managed_cluster_name>-import가져오기 보안이 없는 경우 다음 명령을 실행하여 가져오기 컨트롤러의 로그 항목을 보고 생성되지 않은 이유를 확인합니다.
kubectl -n multicluster-engine logs -l app=managedcluster-import-controller-v2 --tail=-1 | grep importconfig-controller허브 클러스터에서 관리 클러스터가
로컬클러스터이고 Hive에서 프로비저닝하거나 자동 가져오기 시크릿이 있는 경우 다음 명령을 실행하여 관리 클러스터의 가져오기 상태를 확인합니다.kubectl get managedcluster <managed_cluster_name> -o=jsonpath='{range .status.conditions[*]}{.type}{"\t"}{.status}{"\t"}{.message}{"\n"}{end}' | grep ManagedClusterImportSucceededManagedClusterImportSucceeded조건이true가 아닌 경우 명령의 결과는 실패 이유를 나타냅니다.- 성능이 저하된 상태에 대해 관리 클러스터의 Klusterlet 상태를 확인합니다. Klusterlet의 성능이 저하된 이유를 찾으려면 성능이 저하된 Klusterlet 문제 해결을 참조하십시오.
1.9.9. 알 수 없는 권한 오류로 클러스터 다시 가져오기 실패
관리 클러스터를 다중 클러스터 엔진 Operator 허브 클러스터로 다시 가져올 때 문제가 발생하는 경우 절차를 수행하여 문제를 해결합니다.
1.9.9.1. 증상: 알 수 없는 권한 오류로 클러스터 가져오기 실패
다중 클러스터 엔진 Operator를 사용하여 OpenShift Container Platform 클러스터를 프로비저닝한 후 OpenShift Container Platform 클러스터에 API 서버 인증서를 변경하거나 API 서버 인증서를 추가할 때 알 수 없는 기관에서 서명한 x509: 인증서로 클러스터를 다시 가져올 수 있습니다.
1.9.9.2. 문제 식별: 알 수 없는 권한 오류로 인해 클러스터를 다시 가져오지 못했습니다
관리 클러스터를 다시 가져오지 못한 후 다음 명령을 실행하여 다중 클러스터 엔진 Operator 허브 클러스터에서 가져오기 컨트롤러 로그를 가져옵니다.
kubectl -n multicluster-engine logs -l app=managedcluster-import-controller-v2 -f다음 오류 로그가 표시되면 관리 클러스터 API 서버 인증서가 변경될 수 있습니다.
ERROR Reconciler error {"controller": "clusterdeployment-controller", "object": {"name":"awscluster1","namespace": "awscluster1", "name": "awscluster1", "reconcileID": "reconcileID": "a2cccf24-2547-4e26-f258a6710", "a2cccf24-2547-4e26-f258a6710", "error": "awscluster1"}
관리형 클러스터 API 서버 인증서가 변경되었는지 확인하려면 다음 단계를 완료합니다.
다음 명령을 실행하여
your-managed-cluster-name을 관리 클러스터 이름으로 교체하여 관리 클러스터 이름을 지정합니다.cluster_name=<your-managed-cluster-name>다음 명령을 실행하여 관리형 클러스터
kubeconfig시크릿 이름을 가져옵니다.kubeconfig_secret_name=$(oc -n ${cluster_name} get clusterdeployments ${cluster_name} -ojsonpath='{.spec.clusterMetadata.adminKubeconfigSecretRef.name}')다음 명령을 실행하여
kubeconfig를 새 파일로 내보냅니다.oc -n ${cluster_name} get secret ${kubeconfig_secret_name} -ojsonpath={.data.kubeconfig} | base64 -d > kubeconfig.oldexport KUBECONFIG=kubeconfig.old다음 명령을 실행하여
kubeconfig를 사용하여 관리 클러스터에서 네임스페이스를 가져옵니다.oc get ns
다음 메시지와 유사한 오류가 발생하면 클러스터 API 서버 ceritificates가 변경되었으며 kubeconfig 파일이 유효하지 않습니다.
서버에 연결할 수 없음: x509: 알 수 없는 기관에서 서명한 인증서
1.9.9.3. 문제 해결: 알 수 없는 권한 오류로 인해 클러스터를 다시 가져오지 못했습니다
관리 클러스터 관리자는 관리 클러스터에 유효한 새 kubeconfig 파일을 생성해야 합니다.
새 kubeconfig 를 생성한 후 다음 단계를 완료하여 관리 클러스터의 새 kubeconfig 를 업데이트합니다.
다음 명령을 실행하여
kubeconfig파일 경로와 클러스터 이름을 설정합니다. <path_to_kubeconfig>를 새kubeconfig파일의 경로로 바꿉니다. <managed_cluster_name>을 관리 클러스터 이름으로 바꿉니다.cluster_name=<managed_cluster_name> kubeconfig_file=<path_to_kubeconfig>다음 명령을 실행하여 새
kubeconfig를 인코딩합니다.kubeconfig=$(cat ${kubeconfig_file} | base64 -w0)참고: macOS에서 다음 명령을 실행합니다.
kubeconfig=$(cat ${kubeconfig_file} | base64)다음 명령을 실행하여
kubeconfigjson 패치를 정의합니다.kubeconfig_patch="[\{\"op\":\"replace\", \"path\":\"/data/kubeconfig\", \"value\":\"${kubeconfig}\"}, \{\"op\":\"replace\", \"path\":\"/data/raw-kubeconfig\", \"value\":\"${kubeconfig}\"}]"다음 명령을 실행하여 관리 클러스터에서 관리자
kubeconfig시크릿 이름을 검색합니다.kubeconfig_secret_name=$(oc -n ${cluster_name} get clusterdeployments ${cluster_name} -ojsonpath='{.spec.clusterMetadata.adminKubeconfigSecretRef.name}')다음 명령을 실행하여 관리자
kubeconfig시크릿을 새kubeconfig로 패치합니다.oc -n ${cluster_name} patch secrets ${kubeconfig_secret_name} --type='json' -p="${kubeconfig_patch}"
1.9.10. 가져오기 보류 중 상태의 클러스터 문제 해결
클러스터 콘솔에서 보류 중 가져오기 가 계속되는 경우 절차에 따라 문제를 해결합니다.
1.9.10.1. 증상: 가져오기 상태가 보류 중인 클러스터
Red Hat Advanced Cluster Management 콘솔을 사용하여 클러스터를 가져온 후 클러스터에 Pending import 상태로 콘솔에 표시됩니다.
1.9.10.2. 문제 확인: 가져오기 보류 중인 클러스터
관리 클러스터에서 다음 명령을 실행하여 문제가 있는 Kubernetes Pod 이름을 확인합니다.
kubectl get pod -n open-cluster-management-agent | grep klusterlet-registration-agent관리 클러스터에서 다음 명령을 실행하여 오류의 로그 항목을 찾습니다.
kubectl logs <registration_agent_pod> -n open-cluster-management-agentregistration_agent_pod 를 1단계에서 확인한 포드 이름으로 교체합니다.
-
반환된 결과에 네트워킹 연결 문제가 있음을 나타내는 텍스트를 검색합니다. 예제에는
이러한 호스트가 없습니다.
1.9.10.3. 문제 해결: 가져오기 보류 중인 클러스터
hub 클러스터에 다음 명령을 입력하여 문제가 있는 포트 번호를 검색합니다.
oc get infrastructure cluster -o yaml | grep apiServerURL관리 클러스터의 호스트 이름을 확인할 수 있고 호스트와 포트에 대한 아웃바운드 연결이 발생하는지 확인합니다.
관리 클러스터에서 통신을 설정할 수 없는 경우 클러스터 가져오기가 완료되지 않습니다. 관리 클러스터의 클러스터 상태는 가져오기 보류 중입니다.
1.9.11. 인증서 변경 후 가져온 클러스터 오프라인 문제 해결
사용자 정의 apiserver 인증서 설치가 지원되지만 인증서 정보를 변경하기 전에 가져온 하나 이상의 클러스터의 상태가 오프라인 상태가 될 수 있습니다.
1.9.11.1. 증상: 인증서 변경 후 오프라인 클러스터
인증서 보안 업데이트 절차를 완료한 후 온라인 상태의 클러스터 중 하나 이상이 이제 콘솔에 오프라인 상태를 표시합니다.
1.9.11.2. 문제 식별: 인증서 변경 후 오프라인 클러스터
사용자 정의 API 서버 인증서에 대한 정보를 업데이트한 후 새 인증서가 이제 오프라인 상태가 되기 전에 가져온 클러스터입니다.
인증서가 문제가 있음을 나타내는 오류는 오프라인 관리 클러스터의 open-cluster-management-agent 네임스페이스에 있는 Pod 로그에서 확인할 수 있습니다. 다음 예제는 로그에 표시되는 오류와 유사합니다.
다음 work-agent 로그를 참조하십시오.
E0917 03:04:05.874759 1 manifestwork_controller.go:179] Reconcile work test-1-klusterlet-addon-workmgr fails with err: Failed to update work status with err Get "https://api.aaa-ocp.dev02.location.com:6443/apis/cluster.management.io/v1/namespaces/test-1/manifestworks/test-1-klusterlet-addon-workmgr": x509: certificate signed by unknown authority
E0917 03:04:05.874887 1 base_controller.go:231] "ManifestWorkAgent" controller failed to sync "test-1-klusterlet-addon-workmgr", err: Failed to update work status with err Get "api.aaa-ocp.dev02.location.com:6443/apis/cluster.management.io/v1/namespaces/test-1/manifestworks/test-1-klusterlet-addon-workmgr": x509: certificate signed by unknown authority
E0917 03:04:37.245859 1 reflector.go:127] k8s.io/client-go@v0.19.0/tools/cache/reflector.go:156: Failed to watch *v1.ManifestWork: failed to list *v1.ManifestWork: Get "api.aaa-ocp.dev02.location.com:6443/apis/cluster.management.io/v1/namespaces/test-1/manifestworks?resourceVersion=607424": x509: certificate signed by unknown authority
다음 registration-agent 로그를 참조하십시오.
I0917 02:27:41.525026 1 event.go:282] Event(v1.ObjectReference{Kind:"Namespace", Namespace:"open-cluster-management-agent", Name:"open-cluster-management-agent", UID:"", APIVersion:"v1", ResourceVersion:"", FieldPath:""}): type: 'Normal' reason: 'ManagedClusterAvailableConditionUpdated' update managed cluster "test-1" available condition to "True", due to "Managed cluster is available"
E0917 02:58:26.315984 1 reflector.go:127] k8s.io/client-go@v0.19.0/tools/cache/reflector.go:156: Failed to watch *v1beta1.CertificateSigningRequest: Get "https://api.aaa-ocp.dev02.location.com:6443/apis/cluster.management.io/v1/managedclusters?allowWatchBookmarks=true&fieldSelector=metadata.name%3Dtest-1&resourceVersion=607408&timeout=9m33s&timeoutSeconds=573&watch=true"": x509: certificate signed by unknown authority
E0917 02:58:26.598343 1 reflector.go:127] k8s.io/client-go@v0.19.0/tools/cache/reflector.go:156: Failed to watch *v1.ManagedCluster: Get "https://api.aaa-ocp.dev02.location.com:6443/apis/cluster.management.io/v1/managedclusters?allowWatchBookmarks=true&fieldSelector=metadata.name%3Dtest-1&resourceVersion=607408&timeout=9m33s&timeoutSeconds=573&watch=true": x509: certificate signed by unknown authority
E0917 02:58:27.613963 1 reflector.go:127] k8s.io/client-go@v0.19.0/tools/cache/reflector.go:156: Failed to watch *v1.ManagedCluster: failed to list *v1.ManagedCluster: Get "https://api.aaa-ocp.dev02.location.com:6443/apis/cluster.management.io/v1/managedclusters?allowWatchBookmarks=true&fieldSelector=metadata.name%3Dtest-1&resourceVersion=607408&timeout=9m33s&timeoutSeconds=573&watch=true"": x509: certificate signed by unknown authority1.9.11.3. 문제 해결: 인증서 변경 후 오프라인 클러스터
관리 클러스터가 로컬 클러스터이거나 관리되는 클러스터 가 다중 클러스터 엔진 Operator에 의해 생성된 경우 관리 클러스터를 복구하기 위해 10분 이상 기다려야 합니다.
관리 클러스터를 즉시 복구하려면 hub 클러스터에서 관리 클러스터 가져오기 보안을 삭제하고 다중 클러스터 엔진 Operator를 사용하여 복구할 수 있습니다. 다음 명령을 실행합니다.
oc delete secret -n <cluster_name> <cluster_name>-import
& lt;cluster_name >을 복구하려는 관리 클러스터의 이름으로 바꿉니다.
다중 클러스터 엔진 Operator를 사용하여 가져온 관리 클러스터를 복구하려면 다음 단계를 완료하십시오. 관리 클러스터를 다시 가져옵니다.
hub 클러스터에서 다음 명령을 실행하여 관리 클러스터 가져오기 보안을 다시 생성합니다.
oc delete secret -n <cluster_name> <cluster_name>-import&
lt;cluster_name>을 가져올 관리 클러스터의 이름으로 바꿉니다.허브 클러스터에서 다음 명령을 실행하여 관리 클러스터 가져오기 보안을 YAML 파일에 노출합니다.
oc get secret -n <cluster_name> <cluster_name>-import -ojsonpath='{.data.import\.yaml}' | base64 --decode > import.yaml&
lt;cluster_name>을 가져올 관리 클러스터의 이름으로 바꿉니다.관리 클러스터에서 다음 명령을 실행하여
import.yaml파일을 적용합니다.oc apply -f import.yaml
참고: 이전 단계에서는 hub 클러스터에서 관리 클러스터를 분리하지 않습니다. 이 단계에서는 새 인증서 정보를 포함하여 관리 클러스터의 현재 설정으로 필요한 매니페스트를 업데이트합니다.
1.9.12. 클러스터 상태가 오프라인에서 사용 가능으로 변경 문제 해결
관리 클러스터의 상태는 환경 또는 클러스터를 수동으로 변경하지 않고 오프라인에서 사용 가능한 상태로 변경됩니다.
1.9.12.1. 증상: 클러스터 상태가 오프라인에서 사용 가능으로 변경
관리 클러스터를 허브 클러스터에 연결하는 네트워크가 불안정한 경우 허브 클러스터 사이클에 의해 오프라인 과 사용 가능 으로 보고되는 관리 클러스터의 상태가 불안정합니다.
1.9.12.2. 문제 해결: 클러스터 상태가 오프라인에서 사용 가능으로 변경
이 문제를 해결하려면 다음 단계를 완료하십시오.
다음 명령을 입력하여 hub 클러스터에서
ManagedCluster사양을 편집합니다.oc edit managedcluster <cluster-name>cluster-name 을 관리 클러스터의 이름으로 바꿉니다.
-
ManagedCluster사양에서leaseDurationSeconds값을 늘립니다. 기본값은 5분이지만 네트워크 문제와의 연결을 유지하기에 충분한 시간이 아닐 수 있습니다. 리스에 더 많은 시간을 지정합니다. 예를 들어 설정을 20분으로 늘릴 수 있습니다.
1.9.13. VMware vSphere에서 클러스터 생성 문제 해결
VMware vSphere에서 Red Hat OpenShift Container Platform 클러스터를 생성할 때 문제가 발생하는 경우 다음 문제 해결 정보를 참조하여 문제가 해결되었는지 확인하십시오.
참고: VMware vSphere에서 클러스터 생성 프로세스가 실패하면 로그를 볼 수 있는 링크가 활성화되어 있지 않을 수 있습니다. 이 경우 hive-controllers Pod의 로그를 확인하여 문제를 식별할 수 있습니다. hive-controllers 로그는 hive 네임스페이스에 있습니다.
1.9.13.1. 인증서 IP SAN 오류와 함께 관리되는 클러스터 생성 실패
1.9.13.1.1. 증상: 관리형 클러스터 생성이 인증서 IP SAN 오류로 인해 실패합니다.
VMware vSphere에서 새 Red Hat OpenShift Container Platform 클러스터를 생성한 후 클러스터에 인증서 IP SAN 오류를 나타내는 오류 메시지와 함께 실패합니다.
1.9.13.1.2. 문제 식별: 관리형 클러스터 생성이 인증서 IP SAN 오류로 인해 실패합니다.
관리 클러스터의 배포가 실패하고 배포 로그에 다음 오류를 반환합니다.
time="2020-08-07T15:27:55Z" level=error msg="Error: error setting up new vSphere SOAP client: Post https://147.1.1.1/sdk: x509: cannot validate certificate for xx.xx.xx.xx because it doesn't contain any IP SANs"
time="2020-08-07T15:27:55Z" level=error1.9.13.1.3. 문제 해결: 인증서 IP SAN 오류로 관리되는 클러스터 생성에 실패합니다.
자격 증명의 IP 주소 대신 VMware vCenter 서버 정규화된 호스트 이름을 사용합니다. VMware vCenter CA 인증서를 업데이트하여 IP SAN을 포함할 수도 있습니다.
1.9.13.2. 알 수 없는 인증 기관으로 관리 클러스터 생성 실패
1.9.13.2.1. 증상: 관리형 클러스터 생성이 알 수 없는 인증 기관으로 인해 실패함
VMware vSphere에서 새 Red Hat OpenShift Container Platform 클러스터를 생성하면 인증서가 알 수 없는 기관에서 서명했기 때문에 클러스터가 실패합니다.
1.9.13.2.2. 문제 식별: Managed cluster creation fails with unknown certificate authority
관리 클러스터의 배포가 실패하고 배포 로그에 다음 오류를 반환합니다.
Error: error setting up new vSphere SOAP client: Post https://vspherehost.com/sdk: x509: certificate signed by unknown authority"1.9.13.2.3. 문제 해결: 알 수 없는 인증 기관을 사용하면 관리형 클러스터 생성이 실패합니다.
인증 정보를 생성할 때 인증 기관에서 올바른 인증서를 입력했는지 확인합니다.
1.9.13.3. 만료된 인증서로 관리되는 클러스터 생성 실패
1.9.13.3.1. 증상: 만료된 인증서로 관리 클러스터 생성에 실패합니다.
VMware vSphere에서 새 Red Hat OpenShift Container Platform 클러스터를 생성한 후 인증서가 만료되거나 유효하지 않기 때문에 클러스터가 실패합니다.
1.9.13.3.2. 문제 식별: 만료된 인증서로 관리 클러스터 생성이 실패합니다.
관리 클러스터의 배포가 실패하고 배포 로그에 다음 오류를 반환합니다.
x509: certificate has expired or is not yet valid1.9.13.3.3. 문제 해결: 만료된 인증서로 관리 클러스터 생성이 실패합니다.
ESXi 호스트의 시간이 동기화되었는지 확인합니다.
1.9.13.4. 관리 클러스터 생성에 실패하여 태그 지정 권한이 충분하지 않음
1.9.13.4.1. 증상: 관리형 클러스터 생성이 실패하고 태그 지정 권한이 충분하지 않음
VMware vSphere에서 새 Red Hat OpenShift Container Platform 클러스터를 생성한 후 태그 지정을 사용할 수 있는 권한이 부족하기 때문에 클러스터가 실패합니다.
1.9.13.4.2. 문제 식별: 관리형 클러스터 생성이 실패하여 태그 지정 권한이 부족하지 않습니다.
관리 클러스터의 배포가 실패하고 배포 로그에 다음 오류를 반환합니다.
time="2020-08-07T19:41:58Z" level=debug msg="vsphere_tag_category.category: Creating..."
time="2020-08-07T19:41:58Z" level=error
time="2020-08-07T19:41:58Z" level=error msg="Error: could not create category: POST https://vspherehost.com/rest/com/vmware/cis/tagging/category: 403 Forbidden"
time="2020-08-07T19:41:58Z" level=error
time="2020-08-07T19:41:58Z" level=error msg=" on ../tmp/openshift-install-436877649/main.tf line 54, in resource \"vsphere_tag_category\" \"category\":"
time="2020-08-07T19:41:58Z" level=error msg=" 54: resource \"vsphere_tag_category\" \"category\" {"1.9.13.4.3. 문제 해결: 태그 지정에 대한 권한이 부족하여 관리되는 클러스터 생성이 실패합니다.
VMware vCenter 필수 계정 권한이 올바른지 확인합니다. 자세한 내용은 이미지 레지스트리 를 참조하십시오.
1.9.13.5. 관리 클러스터 생성이 유효하지 않은 dnsVIP와 함께 실패합니다.
1.9.13.5.1. 증상: 관리형 클러스터 생성이 유효하지 않은 dnsVIP와 함께 실패합니다.
VMware vSphere에서 새 Red Hat OpenShift Container Platform 클러스터를 생성한 후 잘못된 dnsVIP가 있으므로 클러스터가 실패합니다.
1.9.13.5.2. 문제 식별: Managed 클러스터 생성이 유효하지 않은 dnsVIP와 함께 실패합니다.
VMware vSphere를 사용하여 새 관리 클러스터를 배포하려고 할 때 다음 메시지가 표시되면 VMware 설치 관리자 프로비저닝 인프라(IPI)를 지원하지 않는 이전 OpenShift Container Platform 릴리스 이미지가 있기 때문입니다.
failed to fetch Master Machines: failed to load asset \\\"Install Config\\\": invalid \\\"install-config.yaml\\\" file: platform.vsphere.dnsVIP: Invalid value: \\\"\\\": \\\"\\\" is not a valid IP1.9.13.5.3. 문제 해결: 잘못된 dnsVIP와 함께 관리 클러스터 생성이 실패합니다.
VMware 설치 관리자 프로비저닝 인프라를 지원하는 이후 버전의 OpenShift Container Platform에서 릴리스 이미지를 선택합니다.
1.9.13.6. 관리형 클러스터 생성이 잘못된 네트워크 유형과 함께 실패합니다.
1.9.13.6.1. 증상: 관리형 클러스터 생성이 잘못된 네트워크 유형과 함께 실패합니다.
VMware vSphere에서 새 Red Hat OpenShift Container Platform 클러스터를 생성한 후 잘못된 네트워크 유형이 지정되어 있으므로 클러스터가 실패합니다.
1.9.13.6.2. 문제 식별: Managed cluster creation fails with incorrect network type
VMware vSphere를 사용하여 새 관리 클러스터를 배포하려고 할 때 다음 메시지가 표시되면 VMware Installer Provisioned Infrastructure (IPI)를 지원하지 않는 이전 OpenShift Container Platform 이미지가 있기 때문입니다.
time="2020-08-11T14:31:38-04:00" level=debug msg="vsphereprivate_import_ova.import: Creating..."
time="2020-08-11T14:31:39-04:00" level=error
time="2020-08-11T14:31:39-04:00" level=error msg="Error: rpc error: code = Unavailable desc = transport is closing"
time="2020-08-11T14:31:39-04:00" level=error
time="2020-08-11T14:31:39-04:00" level=error
time="2020-08-11T14:31:39-04:00" level=fatal msg="failed to fetch Cluster: failed to generate asset \"Cluster\": failed to create cluster: failed to apply Terraform: failed to complete the change"1.9.13.6.3. 문제 해결: 관리형 클러스터 생성이 잘못된 네트워크 유형으로 인해 실패합니다.
지정된 VMware 클러스터에 유효한 VMware vSphere 네트워크 유형을 선택합니다.
1.9.13.7. 디스크 처리 디스크 변경 오류와 함께 관리되는 클러스터 생성 실패
1.9.13.7.1. 증상: 오류 처리 디스크 변경으로 인해 VMware vSphere 관리 클러스터 추가 실패
VMware vSphere에서 새 Red Hat OpenShift Container Platform 클러스터를 생성한 후 디스크 변경 사항을 처리할 때 오류가 있기 때문에 클러스터가 실패합니다.
1.9.13.7.2. 문제 식별: 오류 처리 디스크 변경으로 인해 VMware vSphere 관리 클러스터를 추가할 수 없습니다
다음과 유사한 메시지가 로그에 표시됩니다.
ERROR
ERROR Error: error reconfiguring virtual machine: error processing disk changes post-clone: disk.0: ServerFaultCode: NoPermission: RESOURCE (vm-71:2000), ACTION (queryAssociatedProfile): RESOURCE (vm-71), ACTION (PolicyIDByVirtualDisk)1.9.13.7.3. 문제 해결: 오류 처리 디스크 변경으로 인해 VMware vSphere 관리 클러스터를 추가할 수 없습니다
VMware vSphere 클라이언트를 사용하여 프로파일 중심 스토리지 권한에 대한 모든 권한을 사용자에게 부여합니다.
1.9.14. 보류 중 또는 실패 상태의 콘솔에서 클러스터 문제 해결
생성한 클러스터의 콘솔에서 Pending 상태 또는 실패 상태를 모니터링하는 경우 절차를 수행하여 문제를 해결합니다.
1.9.14.1. 증상: 보류 중이거나 실패한 콘솔의 클러스터
콘솔을 사용하여 새 클러스터를 생성하면 Pending 상태 이상으로 클러스터가 진행되지 않거나 Failed 상태가 표시됩니다.
1.9.14.2. 문제 식별: 보류 중이거나 실패한 콘솔의 클러스터
클러스터에 Failed 상태가 표시되면 클러스터의 세부 정보 페이지로 이동하여 제공된 로그 링크를 따릅니다. 로그를 찾을 수 없거나 클러스터에 Pending 상태가 표시되면 다음 절차를 계속 실행하여 로그를 확인합니다.
절차 1
허브 클러스터에서 다음 명령을 실행하여 새 클러스터의 네임스페이스에 생성된 Kubernetes Pod의 이름을 확인합니다.
oc get pod -n <new_cluster_name>new_cluster_name을 생성한 클러스터 이름으로 교체합니다.이름에
provision문자열이 포함된 Pod가 나열되지 않은 경우 Procedure 2를 계속합니다. 제목에프로비저닝이 있는 Pod가 있는 경우 허브 클러스터에서 다음 명령을 실행하여 해당 Pod의 로그를 확인합니다.oc logs <new_cluster_name_provision_pod_name> -n <new_cluster_name> -c hivenew_cluster_name_provision_pod_name을 생성한 클러스터 이름 및 프로비저닝이 포함된 포드 이름으로 교체합니다.- 문제의 원인을 설명할 수 있는 로그에서 오류를 검색합니다.
절차 2
이름이
provision인 Pod가 없는 경우 프로세스 초기에 문제가 발생했습니다. 로그를 보려면 다음 절차를 완료합니다.hub 클러스터에서 다음 명령을 실행합니다.
oc describe clusterdeployments -n <new_cluster_name>new_cluster_name을 생성한 클러스터 이름으로 교체합니다. 클러스터 설치 로그에 대한 자세한 내용은 Red Hat OpenShift 설명서의 설치 로그 수집을 참조하십시오.- 리소스의 Status.Conditions.Message 및 Status.Conditions.Reason 항목에서 문제에 대한 추가 정보가 있는지 확인하십시오.
1.9.14.3. 문제 해결: 보류 중이거나 실패한 콘솔의 클러스터
로그에서 오류를 확인한 후 클러스터를 제거하고 다시 생성하기 전에 오류를 해결하는 방법을 확인합니다.
다음 예제에서는 지원되지 않는 영역을 선택할 때 발생할 수 있는 로그 오류와 이를 해결하는 데 필요한 작업을 제공합니다.
No subnets provided for zones클러스터를 생성할 때 지원되지 않는 리전 내에서 하나 이상의 영역을 선택했습니다. 클러스터를 재생성하여 문제를 해결할 때 다음 작업 중 하나를 완료합니다.
- 지역 내에서 다른 영역을 선택합니다.
- 다른 영역이 나열된 경우 지원을 제공하지 않는 영역을 생략합니다.
- 클러스터의 다른 리전을 선택합니다.
로그에서 문제를 확인한 후 클러스터를 제거하고 다시 생성합니다.
클러스터 생성에 대한 자세한 내용은 클러스터 생성 소개 를 참조하십시오.
1.9.15. OpenShift Container Platform 버전 3.11 클러스터 가져오기 실패 문제 해결
1.9.15.1. 증상: OpenShift Container Platform 버전 3.11 클러스터 가져오기 실패
Red Hat OpenShift Container Platform 버전 3.11 클러스터를 가져오려고 하면 다음 콘텐츠와 유사한 로그 메시지와 함께 가져오기가 실패합니다.
customresourcedefinition.apiextensions.k8s.io/klusterlets.operator.open-cluster-management.io configured
clusterrole.rbac.authorization.k8s.io/klusterlet configured
clusterrole.rbac.authorization.k8s.io/open-cluster-management:klusterlet-admin-aggregate-clusterrole configured
clusterrolebinding.rbac.authorization.k8s.io/klusterlet configured
namespace/open-cluster-management-agent configured
secret/open-cluster-management-image-pull-credentials unchanged
serviceaccount/klusterlet configured
deployment.apps/klusterlet unchanged
klusterlet.operator.open-cluster-management.io/klusterlet configured
Error from server (BadRequest): error when creating "STDIN": Secret in version "v1" cannot be handled as a Secret:
v1.Secret.ObjectMeta:
v1.ObjectMeta.TypeMeta: Kind: Data: decode base64: illegal base64 data at input byte 1313, error found in #10 byte of ...|dhruy45="},"kind":"|..., bigger context ...|tye56u56u568yuo7i67i67i67o556574i"},"kind":"Secret","metadata":{"annotations":{"kube|...1.9.15.2. 문제 식별: OpenShift Container Platform 버전 3.11 클러스터 가져오기 실패
이는 설치된 kubectl 명령줄 툴이 1.11 이하이기 때문에 발생하는 경우가 많습니다. 다음 명령을 실행하여 실행 중인 kubectl 명령줄 툴 버전을 확인합니다.
kubectl version반환된 데이터에 버전 1.11 또는 이전 버전이 나열된 경우 문제 해결 방법 중 하나를 완료하십시오: OpenShift Container Platform 버전 3.11 클러스터 가져오기 실패.
1.9.15.3. 문제 해결: OpenShift Container Platform 버전 3.11 클러스터 가져오기 실패
다음 절차 중 하나를 완료하여 이 문제를 해결할 수 있습니다.
kubectl명령줄 툴의 최신 버전을 설치합니다.-
Kubernetes 문서에서 Install and Set Up
kubectl툴의 최신 버전을 다운로드합니다. -
kubectl툴을 업그레이드한 후 클러스터를 다시 가져옵니다.
-
Kubernetes 문서에서 Install and Set Up
import 명령이 포함된 파일을 실행합니다.
- CLI를 사용하여 관리 클러스터 가져오기 절차를 시작합니다.
-
클러스터를 가져오는 명령을 생성할 때 해당 명령을
import.yaml이라는 YAML 파일에 복사합니다. 다음 명령을 실행하여 파일에서 클러스터를 다시 가져옵니다.
oc apply -f import.yaml
1.9.16. 성능이 저하된 조건으로 Klusterlet 문제 해결
Klusterlet 성능이 저하된 조건은 관리 클러스터에서 Klusterlet 에이전트의 상태를 진단하는 데 도움이 될 수 있습니다. Klusterlet이 성능 저하된 상태에 있는 경우 관리 클러스터의 Klusterlet 에이전트에 문제를 해결해야 하는 오류가 있을 수 있습니다. Klusterlet degraded conditions that are set to True 를 참조하십시오.
1.9.16.1. 증상: Klusterlet은 성능 저하 상태에 있습니다.
관리 클러스터에 Klusterlet을 배포한 후 KlusterletRegistrationDegraded 또는 KlusterletWorkDegraded 상태가 True 로 표시됩니다.
1.9.16.2. 문제 식별: Klusterlet은 성능 저하된 상태에 있습니다.
관리 클러스터에서 다음 명령을 실행하여 Klusterlet 상태를 확인합니다.
kubectl get klusterlets klusterlet -oyaml-
KlusterletRegistrationDegraded또는KlusterletWorkDegraded를 선택하여 조건이True로 설정되어 있는지 확인합니다. 나열된 모든 성능이 저하된 조건에 대한 문제를 복구합니다.
1.9.16.3. 문제 해결: Klusterlet은 성능 저하 상태에 있습니다.
다음 성능 저하 상태의 목록과 이러한 문제를 해결하는 방법을 참조하십시오.
-
상태가 True 이고 조건 이유가 있는
KlusterletRegistrationDegraded조건이 BootStrapSecretMissing 인 경우open-cluster-management-agent네임스페이스에 부트스트랩 시크릿을 생성해야 합니다. -
KlusterletRegistrationDegraded조건이 True 로 표시되고 조건 이유가 BootstrapSecretError 또는 BootstrapSecretUnauthorized 이면 현재 부트스트랩 보안이 유효하지 않습니다. 현재 부트스트랩 시크릿을 삭제하고open-cluster-management-agent네임스페이스에 유효한 부트스트랩 시크릿을 다시 생성합니다. -
KlusterletRegistrationDegraded및KlusterletWorkDegraded가 True 로 표시되고 조건 이유가 HubKubeConfigSecretMissing 인 경우 Klusterlet을 삭제하고 다시 생성합니다. -
KlusterletRegistrationDegraded및KlusterletWorkDegraded가 True 로 표시되고 조건 이유가 ClusterNameMissing,KubeConfig Mising ,HubConfigSecretError, 또는 HubConfigSecretUnauthorized,open-cluster-management-agent네임스페이스에서 hub cluster kubeconfig 시크릿을 삭제합니다. 등록 에이전트는 다시 부팅되어 새 hub 클러스터 kubeconfig 시크릿을 가져옵니다. -
KlusterletRegistrationDegraded가 True 를 표시하고 조건 이유가 GetRegistrationDeploymentFailed 또는 UnavailableRegistrationPod 인 경우 상태 메시지를 확인하여 문제 세부 정보를 가져오고 해결하려고 할 수 있습니다. -
KlusterletWorkDegraded에 True 가 표시되고 조건 이유가 GetWorkDeploymentFailed 또는 UnavailableWorkPod 인 경우 상태 메시지를 확인하여 문제 세부 정보를 가져오고 해결하려고 할 수 있습니다.
1.9.17. 클러스터를 삭제한 후에도 네임스페이스가 남아 있음
관리 클러스터를 제거하면 일반적으로 네임스페이스가 클러스터 제거 프로세스의 일부로 제거됩니다. 드문 경우지만 네임스페이스에 일부 아티팩트가 남아 있습니다. 이 경우 네임스페이스를 수동으로 제거해야 합니다.
1.9.17.1. 증상: 클러스터를 삭제한 후에도 네임스페이스가 유지됩니다.
관리 클러스터를 제거한 후 네임스페이스는 제거되지 않습니다.
1.9.17.2. 문제 해결: 클러스터를 삭제한 후에도 네임스페이스가 남아 있습니다.
네임스페이스를 수동으로 제거하려면 다음 단계를 완료합니다.
다음 명령을 실행하여 <cluster_name> 네임스페이스에 남아 있는 리소스 목록을 생성합니다.
oc api-resources --verbs=list --namespaced -o name | grep -E '^secrets|^serviceaccounts|^managedclusteraddons|^roles|^rolebindings|^manifestworks|^leases|^managedclusterinfo|^appliedmanifestworks'|^clusteroauths' | xargs -n 1 oc get --show-kind --ignore-not-found -n <cluster_name>cluster_name을 제거하려는 클러스터의 네임스페이스 이름으로 교체합니다.다음 명령을 입력하여 목록을 편집하여
Delete상태가 없는 목록에서 식별된 각 리소스를 삭제합니다.oc edit <resource_kind> <resource_name> -n <namespace>resource_kind를 리소스 종류로 바꿉니다.resource_name을 리소스 이름으로 교체합니다.namespace를 리소스의 네임스페이스 이름으로 교체합니다.-
메타데이터에서
종료자속성을 찾습니다. -
vi 편집기
dd명령을 사용하여 Kubernetes가 아닌 종료자를 삭제합니다. -
목록을 저장하고
:wq명령을 입력하여vi편집기를 종료합니다. 다음 명령을 입력하여 네임스페이스를 삭제합니다.
oc delete ns <cluster-name>cluster-name을 삭제하려는 네임스페이스 이름으로 교체합니다.
1.9.18. 클러스터를 가져올 때 auto-import-secret-exists 오류
자동 가져오기 보안이라는 오류 메시지와 함께 클러스터 가져오기가 실패합니다.
1.9.18.1. 증상: 클러스터를 가져올 때 자동 가져오기 보안 오류가 발생했습니다
관리를 위해 하이브 클러스터를 가져올 때 자동 가져오기 보안 오류가 이미 표시됩니다.
1.9.18.2. 문제 해결: 클러스터를 가져올 때 Auto-import-secret-exists 오류
이 문제는 이전에 관리한 클러스터를 가져오려고 할 때 발생합니다. 이 경우 클러스터를 다시 가져오려고 할 때 보안이 충돌합니다.
이 문제를 해결하려면 다음 단계를 완료하십시오.
기존
auto-import-secret을 수동으로 삭제하려면 hub 클러스터에서 다음 명령을 실행합니다.oc delete secret auto-import-secret -n <cluster-namespace>cluster-namespace를 클러스터의 네임스페이스로 바꿉니다.- 클러스터 가져오기 소개의 절차를 사용하여 클러스터를 다시 가져옵니다.
1.9.19. 배치 생성 후 누락된 PlacementDecision 문제 해결
배치를 생성한 후 이 생성되지 않는 경우 절차에 따라 문제를 해결합니다.
Placement Descision
1.9.19.1. 증상: 배치 생성 후 Placement 중단
배치를 생성하면 이 자동으로 생성되지 않습니다.
Placement Descision
1.9.19.2. 문제 해결: 배치 생성 후 placementDecision 해제
이 문제를 해결하려면 다음 단계를 완료합니다.
다음 명령을 실행하여
배치조건을 확인합니다.kubectl describe placement <placement-name>placement-name을배치이름으로 교체합니다.출력은 다음 예와 유사할 수 있습니다.
Name: demo-placement Namespace: default Labels: <none> Annotations: <none> API Version: cluster.open-cluster-management.io/v1beta1 Kind: Placement Status: Conditions: Last Transition Time: 2022-09-30T07:39:45Z Message: Placement configurations check pass Reason: Succeedconfigured Status: False Type: PlacementMisconfigured Last Transition Time: 2022-09-30T07:39:45Z Message: No valid ManagedClusterSetBindings found in placement namespace Reason: NoManagedClusterSetBindings Status: False Type: PlacementSatisfied Number Of Selected Clusters: 0PlacementMisconfigured및PlacementSatisfied:의 상태에 대한 출력을 확인합니다.-
PlacementMisconfiguredStatus가 true이면 배치에 구성 오류가 발생합니다. 구성 오류 및 해결 방법에 대한 자세한 내용은 포함된 메시지를 확인하십시오. -
PlacementSatisfiedStatus가 false인 경우 관리 클러스터가 배치를 충족하지 않습니다. 자세한 내용과 오류 해결 방법에 대해서는 포함된 메시지를 확인하십시오. 이전 예에서는 placement 네임스페이스에ManagedClusterSetBindings가 없습니다.
-
이벤트에서 각 클러스터의 점수를 확인하여 점수가 낮은 일부 클러스터가 선택되지 않은 이유를 확인할 수 있습니다.
출력은 다음 예와 유사할 수 있습니다.Name: demo-placement Namespace: default Labels: <none> Annotations: <none> API Version: cluster.open-cluster-management.io/v1beta1 Kind: Placement Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal DecisionCreate 2m10s placementController Decision demo-placement-decision-1 is created with placement demo-placement in namespace default Normal DecisionUpdate 2m10s placementController Decision demo-placement-decision-1 is updated with placement demo-placement in namespace default Normal ScoreUpdate 2m10s placementController cluster1:0 cluster2:100 cluster3:200 Normal DecisionUpdate 3s placementController Decision demo-placement-decision-1 is updated with placement demo-placement in namespace default Normal ScoreUpdate 3s placementController cluster1:200 cluster2:145 cluster3:189 cluster4:200참고: 배치 컨트롤러는 점수를 할당하고 각 필터링된
ManagedCluster에 대한 이벤트를 생성합니다. 배치 컨트롤러는 클러스터 점수가 변경될 때 새 이벤트를 생성합니다.
1.9.20. Dell 하드웨어에서 베어 메탈 호스트의 검색 실패 문제 해결
Dell 하드웨어에서 베어 메탈 호스트를 검색하지 못하면 IDRAC(Integrated Dell Remote Access Controller)가 알려지지 않은 인증 기관의 인증서를 허용하지 않도록 구성됩니다.
1.9.20.1. 증상: Dell 하드웨어에서 베어 메탈 호스트의 검색 실패
베이스 보드 관리 컨트롤러를 사용하여 베어 메탈 호스트를 검색하는 절차를 완료하면 다음과 유사한 오류 메시지가 표시됩니다.
ProvisioningError 51s metal3-baremetal-controller Image provisioning failed: Deploy step deploy.deploy failed with BadRequestError: HTTP POST https://<bmc_address>/redfish/v1/Managers/iDRAC.Embedded.1/VirtualMedia/CD/Actions/VirtualMedia.InsertMedia returned code 400. Base.1.8.GeneralError: A general error has occurred. See ExtendedInfo for more information Extended information: [
{"Message": "Unable to mount remote share https://<ironic_address>/redfish/boot-<uuid>.iso.", 'MessageArgs': ["https://<ironic_address>/redfish/boot-<uuid>.iso"], "MessageArgs@odata.count": 1, "MessageId": "IDRAC.2.5.RAC0720", "RelatedProperties": ["#/Image"], "RelatedProperties@odata.count": 1, "Resolution": "Retry the operation.", "Severity": "Informational"}
]1.9.20.2. 문제 해결: Dell 하드웨어에서 베어 메탈 호스트의 검색 실패
iDRAC는 알 수 없는 인증 기관의 인증서를 수락하지 않도록 구성되어 있습니다.
이 문제를 바이패스하려면 다음 단계를 완료하여 호스트 iDRAC의 베이스 보드 관리 컨트롤러에서 인증서 확인을 비활성화합니다.
- iDRAC 콘솔에서 구성 > 가상 미디어 > 원격 파일 공유로 이동합니다.
-
Expired 또는 잘못된 인증서 작업 의 값을
Yes로 변경합니다.
1.9.21. 최소 ISO 부팅 실패 문제 해결
최소한의 ISO를 부팅하려고 할 때 문제가 발생할 수 있습니다.
1.9.21.1. 증상: 최소 ISO 부팅 실패
부팅 화면에서 호스트가 루트 파일 시스템 이미지를 다운로드하지 못했음을 보여줍니다.
1.9.21.2. 문제 해결: 최소 ISO 부팅 실패
문제 해결 방법을 알아보려면 OpenShift Container Platform 설명서의 지원 설치 관리자에서 최소한의 ISO 부팅 실패 문제 해결을 참조하십시오.
1.9.22. Red Hat OpenShift Virtualization에서 호스트된 클러스터 문제 해결
Red Hat OpenShift Virtualization에서 호스트된 클러스터의 문제를 해결할 때 최상위 HostedCluster 및 NodePool 리소스로 시작한 다음 근본 원인을 찾을 때까지 스택을 축소합니다. 다음 단계는 일반적인 문제의 근본 원인을 찾는 데 도움이 될 수 있습니다.
1.9.22.1. 증상: HostedCluster 리소스가 부분적인 상태로 유지됨
HostedCluster 리소스가 보류 중이므로 호스트 컨트롤 플레인이 완전히 온라인 상태가 아닙니다.
1.9.22.1.1. 문제 확인: 사전 요구 사항, 리소스 조건 및 노드 및 Operator 상태 확인
- Red Hat OpenShift Virtualization에서 호스트된 클러스터의 모든 사전 요구 사항을 충족하는지 확인
-
진행을 방지하는 검증 오류는
HostedCluster및NodePool리소스의 조건을 확인합니다. 호스팅 클러스터의
kubeconfig파일을 사용하여 호스트 클러스터의 상태를 검사합니다.-
oc get clusteroperators명령의 출력을 보고 보류 중인 클러스터 Operator를 확인합니다. -
oc get nodes명령의 출력을 보고 작업자 노드가 준비되었는지 확인합니다.
-
1.9.22.2. 증상: 작업자 노드가 등록되지 않음
호스팅된 컨트롤 플레인에 등록된 작업자 노드가 없으므로 호스팅된 컨트롤 플레인이 완전히 온라인 상태가 아닙니다.
1.9.22.2.1. 문제 식별: 호스팅된 컨트롤 플레인의 다양한 부분의 상태 확인
-
문제가 발생할 수 있음을 나타내는 실패의
HostedCluster및NodePool조건을 확인합니다. 다음 명령을 입력하여
NodePool리소스의 KubeVirt 작업자 노드 VM(가상 머신) 상태를 확인합니다.oc get vm -n <namespace>VM이 프로비저닝 상태에 있는 경우 다음 명령을 입력하여 가져오기 Pod가 완료되지 않은 이유에 대한 이해를 위해 VM 네임스페이스 내에서 CDI 가져오기 Pod를 확인합니다.
oc get pods -n <namespace> | grep "import"VM이 시작 상태에 있는 경우 다음 명령을 입력하여 virt-launcher Pod의 상태를 확인합니다.
oc get pods -n <namespace> -l kubevirt.io=virt-launchervirt-launcher Pod가 보류 중 상태인 경우 Pod가 예약되지 않은 이유를 조사합니다. 예를 들어 virt-launcher Pod를 실행하는 데 리소스가 부족할 수 있습니다.
- VM이 실행 중이지만 작업자 노드로 등록되지 않은 경우 웹 콘솔을 사용하여 영향을 받는 VM 중 하나에 대한 VNC 액세스를 얻습니다. VNC 출력은 Ignition 구성이 적용되었는지 여부를 나타냅니다. VM이 시작 시 호스팅된 컨트롤 플레인 ignition 서버에 액세스할 수 없는 경우 VM을 올바르게 프로비저닝할 수 없습니다.
- Ignition 구성이 적용되지만 VM이 여전히 노드로 등록되지 않은 경우 문제 식별을 참조하십시오. 시작 중에 VM 콘솔 로그에 액세스하는 방법을 알아보려면 VM 콘솔 로그에 액세스합니다.
1.9.22.3. 증상: 작업자 노드는 NotReady 상태에 있습니다.
클러스터 생성 중에 네트워킹 스택이 롤아웃되는 동안 노드가 일시적으로 NotReady 상태로 들어갑니다. 이 과정의 일부는 정상입니다. 그러나 프로세스의 이 부분이 15분 이상 걸리는 경우 문제가 발생할 수 있습니다.
1.9.22.3.1. 문제 식별: 노드 오브젝트 및 Pod
다음 명령을 입력하여 노드 오브젝트의 조건을 확인하고 노드가 준비되지 않은 이유를 확인합니다.
oc get nodes -o yaml다음 명령을 입력하여 클러스터 내에서 실패한 Pod를 찾습니다.
oc get pods -A --field-selector=status.phase!=Running,status,phase!=Succeeded
1.9.22.4. 증상: Ingress 및 콘솔 클러스터 Operator는 온라인 상태가 아닙니다.
Ingress 및 콘솔 클러스터 Operator가 온라인 상태가 아니므로 호스팅 컨트롤 플레인이 완전히 온라인 상태가 아닙니다.
1.9.22.4.1. 문제 식별: 와일드카드 DNS 경로 및 로드 밸런서 확인
클러스터에서 기본 Ingress 동작을 사용하는 경우 다음 명령을 입력하여 가상 머신(VM)이 호스팅되는 OpenShift Container Platform 클러스터에서 와일드카드 DNS 경로가 활성화되어 있는지 확인합니다.
oc patch ingresscontroller -n openshift-ingress-operator default --type=json -p '[{ "op": "add", "path": "/spec/routeAdmission", "value": {wildcardPolicy: "WildcardsAllowed"}}]'호스팅된 컨트롤 플레인에 사용자 정의 기본 도메인을 사용하는 경우 다음 단계를 완료합니다.
- 로드 밸런서가 VM pod를 올바르게 대상으로 지정 중인지 확인합니다.
- 와일드카드 DNS 항목이 로드 밸런서 IP를 대상으로 하는지 확인합니다.
1.9.22.5. 증상: 호스팅된 클러스터의 로드 밸런서 서비스를 사용할 수 없음
로드 밸런서 서비스를 사용할 수 없기 때문에 호스팅 컨트롤 플레인이 완전히 온라인 상태가 되지 않습니다.
1.9.22.5.1. 문제 식별: 이벤트, 세부 정보 및 kccm Pod 확인
- 호스팅된 클러스터 내에서 로드 밸런서 서비스와 연결된 이벤트 및 세부 정보를 찾습니다.
기본적으로 호스팅된 클러스터의 로드 밸런서는 호스팅된 컨트롤 플레인 네임스페이스 내의 kubevirt-cloud-controller-manager에 의해 처리됩니다. kccm pod가 온라인 상태인지 확인하고 오류 또는 경고에 대한 로그를 확인합니다. 호스팅된 컨트롤 플레인 네임스페이스에서 kccm Pod를 식별하려면 다음 명령을 입력합니다.
oc get pods -n <hosted-control-plane-namespace> -l app=cloud-controller-manager
1.9.22.6. 증상: 호스팅된 클러스터 PVC를 사용할 수 없음
호스트 클러스터의 PVC(영구 볼륨 클레임)를 사용할 수 없기 때문에 호스팅된 컨트롤 플레인이 완전히 온라인 상태가 아닙니다.
1.9.22.6.1. 문제 식별: PVC 이벤트 및 세부 정보 및 구성 요소 로그 확인
- PVC와 연결된 이벤트 및 세부 정보를 찾아 발생하는 오류를 파악합니다.
PVC가 Pod에 연결하지 못하는 경우 호스트 클러스터 내에서 kubevirt-csi-node 데몬 세트 구성 요소의 로그를 확인하여 문제를 추가로 조사합니다. 각 노드의 kubevirt-csi-node Pod를 식별하려면 다음 명령을 입력합니다.
oc get pods -n openshift-cluster-csi-drivers -o wide -l app=kubevirt-csi-driverPVC가 PV(영구 볼륨)에 바인딩할 수 없는 경우 호스팅된 컨트롤 플레인 네임스페이스 내에서 kubevirt-csi-controller 구성 요소의 로그를 확인합니다. 호스팅된 컨트롤 플레인 네임스페이스 내에서 kubevirt-csi-controller Pod를 식별하려면 다음 명령을 입력합니다.
oc get pods -n <hcp namespace> -l app=kubevirt-csi-driver
1.9.22.7. 증상: VM 노드가 클러스터에 올바르게 참여하지 않음
VM 노드가 클러스터에 올바르게 참여하지 않기 때문에 호스팅된 컨트롤 플레인이 완전히 온라인 상태가 아닙니다.
1.9.22.7.1. 문제 확인: VM 콘솔 로그에 액세스
VM 콘솔 로그에 액세스하려면 OpenShift Virtualization Hosted Control Plane 클러스터의 VM 부분에 대한 직렬 콘솔 로그를 가져오는 방법의 단계를 완료합니다.
1.9.22.8. 문제 해결: 베어 메탈이 아닌 클러스터를 늦은 바인딩 풀로 반환
BareMetalHosts 없이 늦은 바인딩 관리 클러스터를 사용하는 경우 늦은 바인딩 클러스터를 제거하고 노드를 Discovery ISO로 반환하려면 추가 수동 단계를 완료해야 합니다.
1.9.22.8.1. 증상: 베어 메탈이 아닌 클러스터를 늦은 바인딩 풀로 반환
BareMetalHosts 가 없는 최신 바인딩 관리 클러스터의 경우 클러스터 정보를 제거해도 모든 노드를 Discovery ISO로 자동으로 반환하지는 않습니다.
1.9.22.8.2. 문제 해결: 베어 메탈이 아닌 클러스터를 늦은 바인딩 풀로 반환
늦은 바인딩으로 베어 메탈이 아닌 노드를 바인딩 해제하려면 다음 단계를 완료하십시오.
- 클러스터 정보를 제거합니다. 자세한 내용은 관리에서 클러스터 제거를 참조하십시오.
- 루트 디스크를 정리합니다.
- Discovery ISO를 사용하여 수동으로 재부팅합니다.
1.9.22.9. 호스팅된 컨트롤 플레인 클러스터를 사용하여 ROSA에 설치 중인 설치 상태 문제 해결
호스팅된 컨트롤 플레인 클러스터가 있는 AWS(ROSA)에 Kubernetes Operator를 위한 다중 클러스터 엔진을 설치할 때 다중 클러스터 엔진 Operator는 설치 단계에서 중단되고 local-cluster 는 알 수 없는 상태로 유지됩니다.
1.9.22.9.1. 증상: 호스팅된 컨트롤 플레인 클러스터가 있는 ROSA에 설치 중 상태로 유지됨
local-cluster 는 다중 클러스터 엔진 Operator를 설치한 후 10분 동안 알 수 없는 상태로 유지됩니다. klusterlet-agent Pod가 hub 클러스터의 open-cluster-management-agent 네임스페이스에 로그인하면 다음과 같은 오류 메시지가 표시됩니다.
E0809 18:45:29.450874 1 reflector.go:147] k8s.io/client-go@v0.29.4/tools/cache/reflector.go:229: Failed to watch *v1.CertificateSigningRequest: failed to list *v1.CertificateSigningRequest: Get "https://api.xxx.openshiftapps.com:443/apis/certificates.k8s.io/v1/certificatesigningrequests?limit=500&resourceVersion=0": tls: failed to verify certificate: x509: certificate signed by unknown authority1.9.22.9.2. 문제 해결: 호스팅된 컨트롤 플레인 클러스터의 ROSA에 설치 중이 중단됨
이 문제를 해결하려면 다음 단계를 완료하여 ISRG Root X1 인증서를 klusterlet CA 번들에 추가합니다.
다음 명령을 실행하여 루트 CA 인증서를 다운로드하여 인코딩합니다.
curl -s https://letsencrypt.org/certs/isrgrootx1.pem | base64 | tr -d "\n"KlusterletConfig리소스를 생성하고 인코딩된 CA 인증서를spec매개변수 섹션에 추가합니다. 다음 예제를 참조하십시오.apiVersion: config.open-cluster-management.io/v1alpha1 kind: KlusterletConfig metadata: name: isrg-root-x1-ca spec: hubKubeAPIServerCABundle: "<your_ca_certificate>"hub 클러스터에서 다음 명령을 실행하여 리소스를 적용합니다.
oc apply -f <filename>hub 클러스터에서 다음 명령을 실행하여 관리 클러스터에 주석을 답니다.
oc annotate --overwrite managedcluster local-cluster agent.open-cluster-management.io/klusterlet-config='isrg-root-x1-ca'local-cluster상태가 1분 내에 복구되지 않으면 hub 클러스터에서 다음 명령을 실행하여import.yaml파일을 내보내고 디코딩합니다.oc get secret local-cluster-import -n local-cluster -o jsonpath={.data.import/.yaml} | base64 --decode > import.yamlhub 클러스터에서 다음 명령을 실행하여 파일을 적용합니다.
oc apply -f import.yaml-
새 클러스터 전용의 경우
ManagedCluster리소스에 다음 주석을 추가합니다.
annotations:
agent.open-cluster-management.io/klusterlet-config: isrg-root-x1-ca1.9.22.10. 호스트된 컨트롤 플레인 클러스터가 있는 ROSA에서 모든 관리 클러스터의 알 수 없음
호스팅된 컨트롤 플레인 클러스터가 있는 AWS(Red Hat OpenShift Service on AWS)에서 모든 관리 클러스터의 상태가 알 수 없음 으로 전환될 수 있습니다.
1.9.22.10.1. 증상: 호스팅된 컨트롤 플레인 클러스터 가 있는 ROSA에서 모든 관리 클러스터를 알 수 없음
ROSA 호스트 클러스터의 모든 관리 클러스터의 상태는 갑자기 알 수 없게 됩니다. klusterlet-agent Pod가 관리 클러스터의 open-cluster-management-agent 네임스페이스에 로그인하면 다음과 같은 오류 메시지가 표시됩니다.
E0809 18:45:29.450874 1 reflector.go:147] k8s.io/client-go@v0.29.4/tools/cache/reflector.go:229: Failed to watch *v1.CertificateSigningRequest: failed to list *v1.CertificateSigningRequest: Get "https://api.xxx.openshiftapps.com:443/apis/certificates.k8s.io/v1/certificatesigningrequests?limit=500&resourceVersion=0": tls: failed to verify certificate: x509: certificate signed by unknown authority1.9.22.10.2. 문제 해결: 호스팅된 컨트롤 플레인 클러스터가 있는 ROSA에서 모든 관리 클러스터를 알 수 없음
이 문제를 해결하려면 다음 단계를 완료하여 ISRG Root X1 인증서를 klusterlet CA 번들에 추가합니다.
다음 명령을 실행하여 루트 CA 인증서를 다운로드하여 인코딩합니다.
curl -s https://letsencrypt.org/certs/isrgrootx1.pem | base64 | tr -d "\n"KlusterletConfig리소스를 생성하고 인코딩된 CA 인증서를spec매개변수 섹션에 추가합니다. 다음 예제를 참조하십시오.apiVersion: config.open-cluster-management.io/v1alpha1 kind: KlusterletConfig metadata: name: isrg-root-x1-ca spec: hubKubeAPIServerCABundle: "<your_ca_certificate>"hub 클러스터에서 다음 명령을 실행하여 리소스를 적용합니다.
oc apply -f <filename>hub 클러스터에서 다음 명령을 실행하여 관리 클러스터에 주석을 답니다. 필요한 경우 값을 바꿉니다.
oc annotate --overwrite managedcluster <cluster_name> agent.open-cluster-management.io/klusterlet-config='isrg-root-x1-ca'일부 관리 클러스터의 상태가 복구될 수 있습니다.
Unknown상태로 남아 있는 관리 클러스터의 경우 hub 클러스터에서 다음 명령을 실행하여import.yaml파일을 내보내고 디코딩합니다. 필요한 경우 값을 바꿉니다.oc get secret <cluster_name>-import -n <cluster_name> -o jsonpath={.data.import/.yaml} | base64 --decode > <cluster_name>-import.yaml관리 클러스터에서 다음 명령을 실행하여 파일을 적용합니다. 필요한 경우 값을 바꿉니다.
oc apply -f <cluster_name>-import.yaml-
새로운 Red Hat Advanced Cluster Management for Kubernetes Hub 클러스터의 경우
ManagedCluster리소스에 다음 주석을 추가합니다.
annotations:
agent.open-cluster-management.io/klusterlet-config: isrg-root-x1-ca1.9.23. 베어 메탈에서 호스트 클러스터 문제 해결
베어 메탈에서 호스트된 클러스터를 해결할 때 다음 단계를 수행하여 일반적인 문제의 근본 원인을 알아보십시오.
1.9.23.1. 증상: 베어 메탈의 호스트된 컨트롤 플레인에 노드를 추가하지 못했습니다
지원 설치 관리자를 사용하여 프로비저닝된 노드로 호스팅되는 컨트롤 플레인 클러스터를 확장할 때 호스트는 포트 22642가 포함된 URL로 Ignition을 가져오지 못합니다. 해당 URL은 호스팅된 컨트롤 플레인에서 유효하지 않으며 클러스터에 문제가 있음을 나타냅니다.
1.9.23.2. 문제 식별: 노드가 베어 메탈의 호스팅된 컨트롤 플레인에 추가되지 않음
문제를 확인하려면 assisted-service 로그를 검토합니다.
oc logs -n multicluster-engine <assisted_service_pod_name>1 - 1
- 지원 서비스 Pod 이름을 지정합니다.
로그에서 다음 예와 유사한 오류를 찾습니다.
error="failed to get pull secret for update: invalid pull secret data in secret pull-secret"pull secret must contain auth for \"registry.redhat.io\"
1.9.23.3. 문제 해결: 베어 메탈의 호스팅된 컨트롤 플레인에 노드를 추가하지 못했습니다.
- 이 문제를 해결하려면 네임스페이스에 가져오기 보안 추가의 지침을 따르십시오.