파일 시스템 가이드
Ceph 파일 시스템 구성 및 마운트
초록
1장. Ceph 파일 시스템 소개
스토리지 관리자는 Ceph File System(CephFS) 환경을 관리하기 위한 기능, 시스템 구성 요소 및 제한 사항에 대해 이해할 수 있습니다.
1.1. Ceph File System 기능 및 개선 사항
Ceph 파일 시스템(CephFS)은 RADOS(Reliable Autonomic Distributed Object Storage)라는 Ceph의 분산 개체 저장소 상단에 구축된 POSIX 표준과 호환되는 파일 시스템입니다. CephFS는 Red Hat Ceph Storage 클러스터에 파일 액세스를 제공하고 가능한 경우 POSIX 의미를 사용합니다. 예를 들어, NFS와 같은 다른 여러 일반적인 네트워크 파일 시스템과 달리 CephFS는 클라이언트 간에 강력한 캐시 일관성을 유지합니다. 목표는 파일 시스템을 사용하는 프로세스가 동일한 호스트에 있을 때와 다른 호스트에 있을 때 동일하게 작동하는 것입니다. 그러나 경우에 따라 CephFS는 엄격한 POSIX 의미에서 달라집니다.
Ceph 파일 시스템에는 다음과 같은 기능 및 향상된 기능이 있습니다.
- 확장성
- Ceph 파일 시스템은 메타데이터 서버의 수평 확장과 개별 OSD 노드에서 클라이언트 읽기 및 쓰기로 인해 확장성이 높습니다.
- 공유 파일 시스템
- Ceph 파일 시스템은 공유 파일 시스템이므로 여러 클라이언트가 동일한 파일 시스템에서 동시에 작업할 수 있습니다.
- 고가용성
- Ceph 파일 시스템은 Ceph 메타데이터 서버(MDS) 클러스터를 제공합니다. 하나는 활성 상태이고 다른 하나는 대기 모드입니다. 활성 MDS가 예기치 않게 종료되면 대기 MDS 중 하나가 활성화됩니다. 결과적으로 클라이언트 마운트는 서버 오류를 통해 계속 작동합니다. 이 동작은 Ceph 파일 시스템을 고가용성으로 만듭니다. 또한 여러 활성 메타데이터 서버를 구성할 수 있습니다.
- 구성 가능한 파일 및 디렉터리 레이아웃
- Ceph 파일 시스템을 사용하면 파일 및 디렉터리 레이아웃을 구성하여 여러 풀, 풀 네임스페이스 및 파일 스트라이핑 모드를 오브젝트 간에 사용할 수 있습니다.
- POSIX ACL(액세스 제어 목록)
-
Ceph 파일 시스템은 POSIX ACL(액세스 제어 목록)을 지원합니다. 커널 버전
kernel-3.10.0-327.18.2.el7이상이 있는 커널 클라이언트로 마운트된 Ceph 파일 시스템을 사용하여 기본적으로 ACL이 활성화됩니다. FUSE 클라이언트로 마운트된 Ceph File Systems에서 ACL을 사용하려면 활성화해야 합니다. - 클라이언트 할당량
- Ceph 파일 시스템은 시스템의 모든 디렉터리에서 할당량 설정을 지원합니다. 할당량은 디렉터리 계층 구조의 해당 지점 아래에 저장된 파일 수 또는 바이트 수를 제한할 수 있습니다. CephFS 클라이언트 할당량은 기본적으로 활성화되어 있습니다.
- 크기 조정
- Ceph 파일 시스템 크기는 데이터 풀을 서비스하는 OSD 용량에 의해서만 바인딩됩니다. 용량을 늘리려면 CephFS 데이터 풀에 OSD를 더 추가합니다. 용량을 줄이려면 클라이언트 할당량 또는 풀 할당량을 사용합니다.
- 스냅샷
- Ceph 파일 시스템은 읽기 전용 스냅샷을 지원하지만 쓰기 가능한 복제본은 지원하지 않습니다.
- POSIX 파일 시스템 작업
Ceph File System은 다음과 같은 액세스 패턴을 포함하여 일관된 표준 POSIX 파일 시스템 작업을 지원합니다.
- Linux 페이지 캐시를 통한 쓰기 작업.
- Linux 페이지 캐시를 통해 읽기 작업을 캐시합니다.
- 직접 I/O 비동기 또는 동기 읽기/쓰기 작업을 수행하여 페이지 캐시를 바이패스합니다.
- 메모리 매핑된 I/O.
추가 리소스
- Ceph 메타데이터 서버를 설치하기 위한 설치 가이드의 메타데이터 서버 설치 섹션을 참조하십시오.
- Ceph 파일 시스템 생성 방법은 파일 시스템 가이드의 Ceph 파일 시스템 배포 섹션을 참조하십시오.
1.2. Ceph 파일 시스템 구성 요소
Ceph 파일 시스템에는 다음과 같은 두 가지 기본 구성 요소가 있습니다.
- 클라이언트
-
CephFS 클라이언트는 커널 클라이언트용
ceph-fuse및 fcephfs와 같은 CephFS를 사용하여 애플리케이션을 대신하여 I/O 작업을 수행합니다. CephFS 클라이언트는 메타데이터 요청을 활성 메타데이터 서버로 보냅니다. 결국 CephFS 클라이언트는 파일 메타데이터를 학습하고 메타데이터 및 파일 데이터 모두를 안전하게 캐싱할 수 있습니다. - 메타데이터 서버(MDS)
MDS는 다음을 수행합니다.
- CephFS 클라이언트에 메타데이터를 제공합니다.
- Ceph 파일 시스템에 저장된 파일과 관련된 메타데이터를 관리합니다.
- 공유 Red Hat Ceph Storage 클러스터에 대한 액세스를 조정합니다.
- 백업 메타데이터 풀 저장소에 대한 요청을 줄이기 위해 hot 메타데이터를 캐시합니다.
- 캐시 일관성을 유지하기 위해 CephFS 클라이언트 캐시를 관리합니다.
- 활성 MDS 간에 핫 메타데이터를 복제합니다.
- 메타데이터 변경 작업을 백업 메타데이터 풀에 정기적으로 플러시하는 컴팩트 저널에 대해 병합합니다.
-
CephFS를 실행하려면 하나 이상의 메타데이터 서버 데몬(
ceph-mds)이 필요합니다.
아래 다이어그램은 Ceph 파일 시스템의 구성 요소 계층을 보여줍니다.
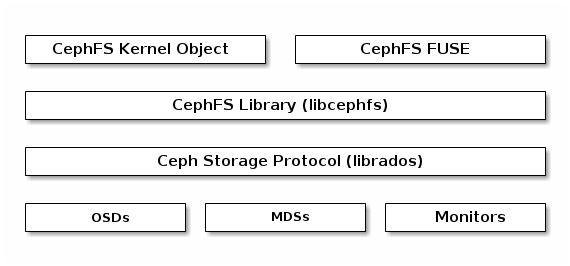
하단 계층은 기본 스토리지 클러스터 구성 요소를 나타냅니다.
-
Ceph 파일 시스템 데이터 및 메타데이터가 저장되는 Ceph OSD(
ceph-osd). -
Ceph 파일 시스템 메타데이터를 관리하는 Ceph 메타데이터 서버(
ceph-mds). -
클러스터 맵의 마스터 복사본을 관리하는 Ceph 모니터(
ceph-mon).
Ceph Storage 프로토콜 계층은 코어 스토리지 클러스터와 상호 작용하기 위한 Ceph 네이티브 librados 라이브러리를 나타냅니다.
CephFS 라이브러리 계층에는 librados 에서 작동하고 Ceph File System을 나타내는 CephFS libcephfs 라이브러리가 포함되어 있습니다.
최상위 계층은 Ceph 파일 시스템에 액세스할 수 있는 두 가지 유형의 Ceph 클라이언트를 나타냅니다.
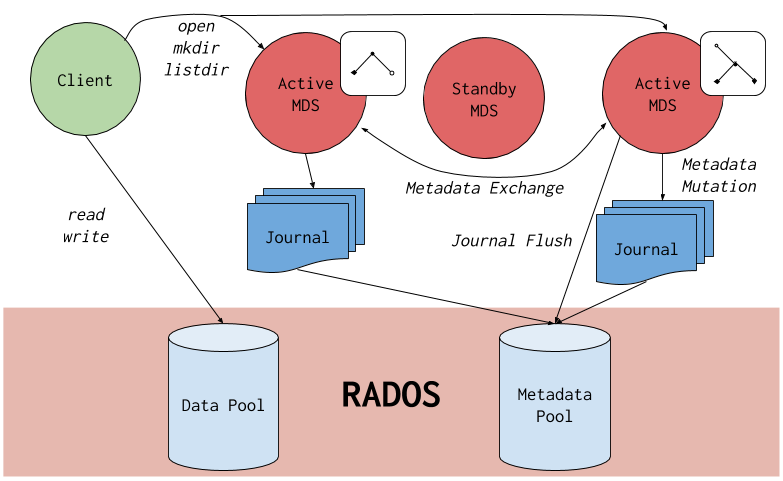
아래 다이어그램은 Ceph 파일 시스템 구성 요소가 서로 상호 작용하는 방법에 대한 자세한 내용을 보여줍니다.
추가 리소스
- Red Hat Ceph Storage 설치 가이드의 메타데이터 서버 설치 섹션을 참조하여 Ceph 메타데이터 서버 설치를 참조하십시오.
- Ceph 파일 시스템 생성 방법은 Red Hat Ceph Storage 파일 시스템 가이드의 Ceph 파일 시스템 배포 섹션을 참조하십시오.
1.3. Ceph 파일 시스템 및 SELinux
Red Hat Enterprise Linux 8.3 및 Red Hat Ceph Storage 4.2부터 Ceph File Systems(CephFS) 환경에서 SELinux(Security--02- Linux) 사용을 지원합니다. 이제 개별 파일에 특정 SELinux 유형 할당과 함께 CephFS를 사용하여 모든 SELinux 파일 유형을 설정할 수 있습니다. 이 지원은 Ceph File System Metadata Server (MDS), CephFS 파일 시스템 in User Space (FUSE) 클라이언트 및 CephFS 커널 클라이언트에 적용됩니다.
추가 리소스
1.4. Ceph File System의 제한 사항 및 POSIX 표준
하나의 Red Hat Ceph Storage 클러스터에 여러 Ceph File Systems 생성은 기본적으로 비활성화되어 있습니다. 다음 오류 메시지와 함께 추가 Ceph File System을 생성하려고 하면 실패합니다.
Error EINVAL: Creation of multiple filesystems is disabled.
Error EINVAL: Creation of multiple filesystems is disabled.기술적으로 가능하지만 Red Hat은 하나의 Red Hat Ceph Storage 클러스터에서 여러 Ceph 파일 시스템을 보유하는 것을 지원하지 않습니다. 이렇게 하면 MDS 또는 CephFS 클라이언트 노드가 예기치 않게 종료될 수 있습니다.
Ceph 파일 시스템은 다음과 같은 방법으로 엄격한 POSIX 의미와 차별화됩니다.
-
클라이언트의 파일 쓰기 시도가 실패하면 쓰기 작업이 반드시 원자성이 아닙니다. 즉 클라이언트는 8MB 버퍼와 함께
O_SYNC플래그를 사용하여 열린 파일에서write()시스템 호출을 호출할 수 있으며 예기치 않게 종료되고 쓰기 작업이 부분적으로만 적용될 수 있습니다. 거의 모든 파일 시스템, 심지어 로컬 파일 시스템도 이러한 동작을 갖습니다. - 쓰기 작업이 동시에 발생하는 경우 개체 경계를 초과하는 쓰기 작업이 반드시 atomic이 아닙니다. 예를 들어 작성자 A 는 "aa|a" 와 writer B 는 "bb|bb" 를 동시에 씁니다. 여기서 "| " 는 적절한 "aa| a" 또는 "bb|bb" 가 아닌 개체 경계입니다.
-
POSIX는 현재 디렉터리 오프셋을 가져와 다시
찾을 수 있는시스템 호출을 포함합니다. CephFS는 언제든지 디렉터리를 조각화할 수 있으므로 디렉터리의 안정적인 정수 오프셋을 반환하기 어렵습니다. 따라서 0이 아닌 오프셋에 대한telldir()및 searchdir()seekingdir()시스템 호출을 호출하면 종종 작동할 수 있지만 그렇게 하는 것은 보장되지 않습니다. 0을 오프셋하기 위해 seekingdir()을 호출하면 항상 작동합니다. 이는rewinddir()시스템 호출과 동일합니다. -
스파스 파일은
stat()시스템 호출의st_blocks필드에 잘못 전파됩니다. CephFS는st_blocks필드가 항상 블록 크기로 구분되어 있는 파일 크기의 몫으로 인해 할당되거나 작성된 파일의 일부를 명시적으로 추적하지 않습니다. 이 동작은du와 같은 유틸리티가 사용된 공간을 초과하게 합니다. -
mmap()시스템 호출이 여러 호스트의 메모리에 파일을 매핑하면 쓰기 작업이 다른 호스트의 캐시에 일관되게 전파되지 않습니다. 즉, 페이지가 호스트 A에 캐시된 다음 호스트 B에서 업데이트된 경우 호스트 A 페이지가 일관되게 무효화되지 않습니다. -
CephFS 클라이언트에는 스냅샷 액세스, 생성, 삭제, 이름 변경에 사용되는 숨겨진
.snap디렉터리가 있습니다. 이 디렉터리는readdir()시스템 호출에서 제외되지만, 동일한 이름의 파일 또는 디렉터리를 만들려고 하는 모든 프로세스는 오류를 반환합니다. 이 숨겨진 디렉터리의 이름은 마운트 시-o snapdirname=.<new_name> 옵션을 사용하거나client_snapdir구성 옵션을 사용하여 변경할 수 있습니다.
추가 리소스
- Red Hat Ceph Storage 설치 가이드의 메타데이터 서버 설치 섹션을 참조하여 Ceph 메타데이터 서버 설치를 참조하십시오.
- Ceph 파일 시스템 생성 방법은 Red Hat Ceph Storage 파일 시스템 가이드의 Ceph 파일 시스템 배포 섹션을 참조하십시오.
1.5. 추가 리소스
- 자세한 내용은 Red Hat Ceph Storage 설치 가이드의 메타데이터 서버 설치 섹션을 참조하십시오.
- NFS Ganesha를 Red Hat OpenStack Platform과 함께 Ceph 파일 시스템의 인터페이스로 사용하려면 해당 환경을 배포하는 방법에 대한 지침은 CephFS with NFS-Ganesha 배포 섹션의 CephFS 파일 시스템 서비스 배포 섹션을 참조하십시오.
2장. Ceph 파일 시스템 메타데이터 서버
스토리지 관리자는 Ceph 파일 시스템(CephFS) 메타데이터 서버(MDS)의 다양한 상태에 대해 알아볼 수 있으며 CephFS MDS 순위 메커니즘에 대한 학습과 MDSWait 데몬 구성 및 캐시 크기 제한에 대해 배울 수 있습니다. 이러한 개념을 알고 있으면 스토리지 환경에 맞게 MDS 데몬을 구성할 수 있습니다.
2.1. 사전 요구 사항
- 실행 중이고 정상적인 Red Hat Ceph Storage 클러스터.
-
Ceph Metadata Server 데몬(
ceph-mds) 설치.
2.2. 메타데이터 서버 데몬 상태
메타데이터 서버(MDS) 데몬은 다음 두 가지 상태로 작동합니다.
- 파일 및 디렉터리에 대한 메타데이터를 Ceph 파일 시스템에 저장합니다.
- Stleep-databindserves는 백업으로 예약되며 활성 MDS 데몬이 응답하지 않을 때 활성화됩니다.
기본적으로 Ceph 파일 시스템은 하나의 활성 MDS 데몬만 사용합니다. 그러나 클라이언트가 많은 시스템은 여러 활성 MDS 데몬을 활용할 수 있습니다.
대규모 워크로드에 대한 메타데이터 성능을 확장할 수 있도록 여러 활성 MDS 데몬을 사용하도록 파일 시스템을 구성할 수 있습니다. 활성 MDS 데몬은 메타데이터 로드 패턴이 변경될 때 메타데이터 워크로드를 동적으로 공유합니다. 활성 MDS 데몬이 여러 개 있는 시스템에서는 keepaly MDS 데몬을 계속 사용할 수 있어야 합니다.
Active MDS Daemon Fails의 경우 어떻게 해야 합니까?
활성 MDS가 응답하지 않는 경우 Ceph Monitor 데몬은 mds_beacon_grace 옵션에 지정된 값과 동일한 시간(초)을 기다립니다. 지정된 기간이 지난 후에도 활성 MDS가 계속 응답하지 않는 경우 Ceph Monitor는 MDS 데몬을 지연 으로 표시합니다. 설정에 따라 대기 데몬 중 하나가 활성 상태가 됩니다.
mds_beacon_grace 값을 변경하려면 이 옵션을 Ceph 구성 파일에 추가하고 새 값을 지정합니다.
2.3. metadata Server 순위
각 Ceph 파일 시스템(CephFS)에는 기본적으로 0부터 시작하는 순위 수가 많습니다.
순위는 여러 메타데이터 서버(MDS) 데몬 간에 메타데이터 워크로드를 공유하는 방법을 정의합니다. 순위 수는 한 번에 활성화할 수 있는 최대 MDS 데몬 수입니다. 각 MDS 데몬은 해당 순위에 할당된 CephFS 메타데이터의 하위 집합을 처리합니다.
각 MDS 데몬은 우선 순위없이 처음 시작됩니다. Ceph 모니터는 데몬에 순위를 할당합니다. MDS 데몬은 한 번에 하나의 순위만 유지할 수 있습니다. 데몬은 중지된 경우에만 순위가 손실됩니다.
max_mds 설정은 생성할 순위 수를 제어합니다.
CephFS의 실제 순위 수는 새 순위를 허용하는 데 사용할 수 있는 예비 데몬 경우에만 증가합니다.
순위 상태
순위는 다음과 같습니다.
- Up - MDS 데몬에 할당된 순위입니다.
- failed - MDS 데몬과 연결되어 있지 않은 순위입니다.
-
손상된 - 메타데이터가 손상되거나 누락된 순위입니다. 손상된 순위는 Operator가 문제를 해결할 때까지 MDS 데몬에 할당되지 않으며 손상된 랭크에서
ceph mds 복구명령을 사용합니다.
2.4. 메타데이터 서버 캐시 크기 제한
다음을 통해 Ceph 파일 시스템(CephFS) 메타데이터 서버(MDS) 캐시의 크기를 제한할 수 있습니다.
메모리 제한:
mds_cache_memory_limit옵션을 사용합니다. Red Hat은mds_cache_memory_limit의 경우 8GB에서 64GB 사이의 값을 권장합니다. 캐시를 더 설정하면 복구 문제가 발생할 수 있습니다. 이 제한은 MDS의 원하는 최대 메모리 사용량의 약 66%입니다.중요Red Hat은 inode 수 제한 대신 메모리 제한을 사용하는 것이 좋습니다.
-
inode count:
mds_cache_size옵션을 사용합니다. 기본적으로 MDS 캐시를 inode 개수로 제한하는 것은 비활성화되어 있습니다.
또한 MDS 작업에 mds_cache_reservation 옵션을 사용하여 캐시 예약을 지정할 수 있습니다. 캐시 예약은 메모리 또는 inode 제한의 백분율로 제한되며 기본적으로 5%로 설정됩니다. 이 매개변수의 의도는 MDS가 새 메타데이터 작업을 사용할 수 있도록 캐시의 추가 메모리 예약을 유지 관리하도록 하는 것입니다. 결과적으로 MDS는 일반적으로 캐시에서 사용되지 않는 메타데이터를 삭제하기 위해 클라이언트에서 이전 상태를 다시 호출하므로 메모리 제한 아래로 작동해야 합니다.
mds_cache_reservation 옵션은 MDS 노드가 캐시를 나타내는 Ceph Monitor에 상태 경고를 보내는 경우를 제외하고 모든 상황에서 mds_health_cache_threshold 옵션을 대체합니다. 기본적으로 mds_health_cache_threshold 는 최대 캐시 크기의 150%입니다.
캐시 제한은 하드 제한이 아닙니다. CephFS 클라이언트 또는 MDS 또는 misbehaving 애플리케이션의 잠재적인 버그로 인해 MDS가 캐시 크기를 초과할 수 있습니다. mds_health_cache_threshold 옵션은 스토리지 클러스터 상태 경고 메시지를 구성하여 MDS가 캐시를 축소할 수 없는 이유를 조사할 수 있습니다.
추가 리소스
- 자세한 내용은 Red Hat Ceph Storage 파일 시스템 가이드 의 Metadata Server 데몬 구성 참조 섹션을 참조하십시오.
2.5. 여러 활성 메타데이터 서버 데몬 구성
대규모 시스템의 메타데이터 성능을 확장하도록 여러 활성 메타데이터 서버(MDS) 데몬을 구성합니다.
대기 MDS 데몬을 활성 상태로 변환하지 마십시오. Ceph 파일 시스템(CephFS)은 고가용성 상태를 유지하기 위해 하나 이상의 대기 MDS 데몬을 필요로 합니다.
여러 활성 MDS 데몬이 구성된 경우 현재 스크럽 프로세스가 지원되지 않습니다.
사전 요구 사항
- MDS 노드의 Ceph 관리 기능.
절차
max_mds매개변수를 원하는 개수의 활성 MDS 데몬으로 설정합니다.구문
ceph fs set NAME max_mds NUMBER
ceph fs set NAME max_mds NUMBERCopy to Clipboard Copied! Toggle word wrap Toggle overflow 예제
ceph fs set cephfs max_mds 2
[root@mon ~]# ceph fs set cephfs max_mds 2Copy to Clipboard Copied! Toggle word wrap Toggle overflow 이 예에서는
cephfs라는 CephFS에서 활성 MDS 데몬 수를 두 개로 늘립니다.참고예비 MDS 데몬을 사용하여 새 순위를 사용할 수 있는 경우 Ceph에서만 CephFS에서 실제 순위 수를 늘립니다.
활성 MDS 데몬 수를 확인합니다.
구문
ceph fs status NAME
ceph fs status NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow 예제
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
추가 리소스
- 자세한 내용은 Red Hat Ceph Storage File System Guide 의 Metadata Server 데몬 을 참조하십시오.
- 자세한 내용은 Red Hat Ceph Storage 파일 시스템 가이드 의 활성 MDS 데몬 수를 줄이는 Dereasing the number of MDS Daemons 섹션을 참조하십시오.
- 자세한 내용은 Red Hat Ceph Storage 관리 가이드의 Ceph 사용자 관리 섹션을 참조하십시오.
2.6. 대기 데몬 수 구성
각 Ceph 파일 시스템(CephFS)은 정상으로 간주할 필수 대기 데몬 수를 지정할 수 있습니다. 이 번호에는 랭크 실패를 기다리는 Wait-replay 데몬도 포함되어 있습니다.
사전 요구 사항
- 사용자가 Ceph 모니터 노드에 액세스할 수 있습니다.
절차
특정 CephFS에 대해 예상되는 Wait 데몬 수를 설정합니다.
구문
ceph fs set FS_NAME standby_count_wanted NUMBER
ceph fs set FS_NAME standby_count_wanted NUMBERCopy to Clipboard Copied! Toggle word wrap Toggle overflow 참고NUMBER 를 0으로 설정하면 데몬 상태 점검이 비활성화됩니다.
예제
ceph fs set cephfs standby_count_wanted 2
[root@mon]# ceph fs set cephfs standby_count_wanted 2Copy to Clipboard Copied! Toggle word wrap Toggle overflow 이 예에서는 예상되는 Wait daemon 수를 2로 설정합니다.
2.7. Wait-replay 메타데이터 서버 구성
Wait-replay Metadata Server (MDS) 데몬을 추가하여 각 Ceph File System (CephFS)을 구성합니다. 이렇게 하면 활성 MDS를 사용할 수 없게 되는 경우 장애 조치 시간이 단축됩니다.
이 특정 Stand-replay 데몬은 활성 MDS의 메타데이터 저널을 따릅니다. edge-replay 데몬은 동일한 순위의 활성 MDS에서만 사용되며 다른 순위에서는 사용할 수 없습니다.
Wait-replay를 사용하는 경우 모든 활성 MDS에는 Wait-replay 데몬이 있어야 합니다.
사전 요구 사항
- 사용자가 Ceph 모니터 노드에 액세스할 수 있습니다.
절차
특정 CephFS에 대해 Wait-replay를 설정합니다.
구문
ceph fs set FS_NAME allow_standby_replay 1
ceph fs set FS_NAME allow_standby_replay 1Copy to Clipboard Copied! Toggle word wrap Toggle overflow 예제
ceph fs set cephfs allow_standby_replay 1
[root@mon]# ceph fs set cephfs allow_standby_replay 1Copy to Clipboard Copied! Toggle word wrap Toggle overflow 이 예제에서 부울 값은
1입니다. 이 값을 사용하면 Wait-replay 데몬을 활성 Ceph MDS 데몬에 할당할 수 있습니다.참고allow_standby_replay부울 값을0으로 다시 설정하면 새 Wait-replay 데몬이 할당되지 않습니다. 실행 중인 데몬도 중지하려면ceph mds fail명령을 사용하여실패한것으로 표시합니다.
추가 리소스
- 자세한 내용은 Red Hat Ceph Storage File System Guide 의 ceph mds fail 명령 사용 섹션을 참조하십시오.
2.8. 활성 메타데이터 서버 데몬 수 감소
How to reduce the number of active Ceph File System (CephFS) Metadata Server (MDS) 데몬의 수를 줄이는 방법
사전 요구 사항
-
제거할 순위는 먼저 활성화되어야 합니다. 즉,
max_mds매개변수에서 지정한 것과 동일한 수의 MDS 데몬이 있어야 합니다.
절차
max_mds매개변수에 지정된 대로 동일한 MDS 데몬 수를 설정합니다.구문
ceph fs status NAME
ceph fs status NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow 예제
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 관리 기능이 있는 노드에서
max_mds매개변수를 원하는 수의 활성 MDS 데몬으로 변경합니다.구문
ceph fs set NAME max_mds NUMBER
ceph fs set NAME max_mds NUMBERCopy to Clipboard Copied! Toggle word wrap Toggle overflow 예제
ceph fs set cephfs max_mds 1
[root@mon ~]# ceph fs set cephfs max_mds 1Copy to Clipboard Copied! Toggle word wrap Toggle overflow -
Ceph File System 상태를 확인하여 스토리지 클러스터가 새로운
max_mds값으로 안정화될 때까지 기다립니다. 활성 MDS 데몬 수를 확인합니다.
구문
ceph fs status NAME
ceph fs status NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow 예제
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
추가 리소스
- Red Hat Ceph Storage 파일 시스템 가이드의 Metadata Server 데몬 상태 섹션을 참조하십시오.
- Red Hat Ceph Storage 파일 시스템 가이드의 여러 활성 메타데이터 서버 데몬 구성 섹션을 참조하십시오.
2.9. 추가 리소스
- 자세한 내용은 Red Hat Ceph Storage 설치 가이드의 메타데이터 서버 설치 섹션을 참조하십시오.
- Red Hat Ceph Storage 클러스터 설치에 대한 자세한 내용은 Red Hat Ceph Storage 설치 가이드 를 참조하십시오.
3장. Ceph 파일 시스템 배포
스토리지 관리자는 Ceph 파일 시스템(CephFS)을 스토리지 환경에 배포하고 클라이언트가 해당 Ceph 파일 시스템을 마운트하여 스토리지 요구 사항을 충족할 수 있습니다.
기본적으로 배포 워크플로는 다음 세 단계로 구성됩니다.
- Ceph 모니터 노드에 Ceph 파일 시스템을 만듭니다.
- 적절한 기능을 사용하여 Ceph 클라이언트 사용자를 생성하고 Ceph 파일 시스템이 마운트될 노드에서 클라이언트 키를 사용할 수 있도록 합니다.
- 커널 클라이언트 또는 FUSE(User Space)의 파일 시스템을 사용하여 전용 노드에 CephFS를 마운트합니다.
3.1. 사전 요구 사항
- 실행 중이고 정상적인 Red Hat Ceph Storage 클러스터.
-
Ceph Metadata Server 데몬(
ceph-mds)의 설치 및 구성.
3.2. 레이아웃, 할당량, 스냅샷 및 네트워크 제한 사항
이러한 사용자 기능을 사용하면 필요한 요구 사항에 따라 Ceph 파일 시스템(CephFS)에 대한 액세스를 제한할 수 있습니다.
rw 를 제외한 모든 사용자 기능 플래그는 알파벳순으로 지정해야 합니다.
레이아웃 및 할당량
레이아웃 또는 할당량을 사용하는 경우 클라이언트에는 rw 기능 외에도 p 플래그가 필요합니다. p 플래그를 설정하면 특수 확장 속성을 통해 설정하는 모든 속성( ceph. 접두사가 있는 속성이 제한됩니다. 또한 이는 레이아웃을 사용하는 openc 작업과 같이 이러한 필드를 설정하는 다른 수단도 제한합니다.
예제
이 예에서 client.0 은 파일 시스템 cephfs_a 에서 레이아웃과 할당량을 수정할 수 있지만 client.1 은 수정할 수 없습니다.
스냅샷
스냅샷을 생성하거나 삭제할 때 클라이언트에는 rw 기능과 함께 s 플래그가 필요합니다. 기능 문자열에 p 플래그가 포함되면 s 플래그가 뒤에 표시되어야 합니다.
예제
client.0
key: AQAz7EVWygILFRAAdIcuJ10opU/JKyfFmxhuaw==
caps: [mds] allow rw, allow rws path=/temp
caps: [mon] allow r
caps: [osd] allow rw tag cephfs data=cephfs_a
client.0
key: AQAz7EVWygILFRAAdIcuJ10opU/JKyfFmxhuaw==
caps: [mds] allow rw, allow rws path=/temp
caps: [mon] allow r
caps: [osd] allow rw tag cephfs data=cephfs_a
이 예제에서 client.0 은 파일 시스템 cephfs_a 의 temp 디렉터리에서 스냅샷을 생성하거나 삭제할 수 있습니다.
네트워크
특정 네트워크에서 연결하는 클라이언트 제한.
예제
client.0 key: AQAz7EVWygILFRAAdIcuJ10opU/JKyfFmxhuaw== caps: [mds] allow r network 10.0.0.0/8, allow rw path=/bar network 10.0.0.0/8 caps: [mon] allow r network 10.0.0.0/8 caps: [osd] allow rw tag cephfs data=cephfs_a network 10.0.0.0/8
client.0
key: AQAz7EVWygILFRAAdIcuJ10opU/JKyfFmxhuaw==
caps: [mds] allow r network 10.0.0.0/8, allow rw path=/bar network 10.0.0.0/8
caps: [mon] allow r network 10.0.0.0/8
caps: [osd] allow rw tag cephfs data=cephfs_a network 10.0.0.0/8
선택적 네트워크 및 접두사 길이는 CIDR 표기법입니다(예: 10.3.0.0/16 ).
추가 리소스
3.3. Ceph 파일 시스템 생성
Ceph Monitor 노드에 Ceph 파일 시스템(CephFS)을 생성할 수 있습니다.
기본적으로 Ceph Storage 클러스터당 하나의 CephFS만 생성할 수 있습니다.
사전 요구 사항
- 실행 중이고 정상적인 Red Hat Ceph Storage 클러스터.
-
Ceph Metadata Server 데몬(
ceph-mds)의 설치 및 구성. - Ceph 모니터 노드에 대한 루트 수준 액세스.
절차
두 개의 풀, 즉 데이터를 저장하기 위한 풀과 메타데이터를 저장하기 위한 풀을 생성합니다.
구문
ceph osd pool create NAME _PG_NUM
ceph osd pool create NAME _PG_NUMCopy to Clipboard Copied! Toggle word wrap Toggle overflow 예제
ceph osd pool create cephfs_data 64 ceph osd pool create cephfs_metadata 64
[root@mon ~]# ceph osd pool create cephfs_data 64 [root@mon ~]# ceph osd pool create cephfs_metadata 64Copy to Clipboard Copied! Toggle word wrap Toggle overflow 일반적으로 메타데이터 풀은 일반적으로 데이터 풀보다 훨씬 적은 수의 배치 그룹(PG)으로 시작할 수 있습니다. 필요한 경우 PG 수를 늘릴 수 있습니다. 권장되는 메타데이터 풀 범위는 64 PG에서 512 PG까지입니다. 데이터 풀의 크기는 파일 시스템에서 예상하는 파일의 수와 크기에 비례합니다.
중요메타데이터 풀의 경우 다음을 사용합니다.
- 이 풀에 대한 데이터가 손실되어 전체 파일 시스템에 액세스할 수 없기 때문에 복제 수준이 높아집니다.
- SSD(Solid-State Drive) 디스크와 같은 대기 시간이 짧은 스토리지가 클라이언트의 파일 시스템 작업 대기 시간에 직접 영향을 미치기 때문입니다.
CephFS를 생성합니다.
구문
ceph fs new NAME METADATA_POOL DATA_POOL
ceph fs new NAME METADATA_POOL DATA_POOLCopy to Clipboard Copied! Toggle word wrap Toggle overflow 예제
ceph fs new cephfs cephfs_metadata cephfs_data
[root@mon ~]# ceph fs new cephfs cephfs_metadata cephfs_dataCopy to Clipboard Copied! Toggle word wrap Toggle overflow 하나 이상의 MDS가 구성에 따라 활성 상태로 전환되는지 확인합니다.
구문
ceph fs status NAME
ceph fs status NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow 예제
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
추가 리소스
- 자세한 내용은 Red Hat Ceph Storage 설치 가이드의 Red Hat Ceph Storage 리포지토리 활성화 섹션을 참조하십시오.
- 자세한 내용은 Red Hat Ceph Storage Storage Strategies Guide 의 풀 장을 참조하십시오.
- Ceph 파일 시스템 제한에 대한 자세한 내용은 Red Hat Ceph Storage 파일 시스템 가이드 의 Ceph 파일 시스템 섹션을 참조하십시오.
- Red Hat Ceph Storage 설치에 대한 자세한 내용은 Red Hat Ceph Storage 설치 가이드 를 참조하십시오.
- 자세한 내용은 Red Hat Ceph Storage 설치 가이드에서 메타데이터 서버 설치를 참조하십시오.
3.4. 삭제 코딩을 사용하여 Ceph 파일 시스템 생성(기술 프리뷰)
기본적으로 Ceph는 데이터 풀에 복제된 풀을 사용합니다. 필요한 경우 삭제 코딩된 데이터 풀을 추가할 수도 있습니다. 삭제된 풀의 Ceph File Systems(CephFS)는 복제된 풀에서 지원하는 Ceph 파일 시스템과 비교하여 전체적인 스토리지를 덜 사용합니다. 리플로스 코딩된 풀은 전체 스토리지를 덜 사용하지만 복제된 풀보다 더 많은 메모리 및 프로세서 리소스를 사용합니다.
rasure-coded 풀을 사용하는 Ceph 파일 시스템은 기술 프리뷰 기능입니다. 기술 프리뷰 기능은 Red Hat 프로덕션 서비스 수준 계약(SLA)에서 지원하지 않으며, 기능상 완전하지 않을 수 있어 프로덕션에 사용하지 않는 것이 좋습니다. 이러한 기능을 사용하면 향후 제품 기능을 조기에 이용할 수 있어 개발 과정에서 고객이 기능을 테스트하고 피드백을 제공할 수 있습니다. 자세한 내용은 Red Hat 기술 프리뷰 기능의 지원 범위를 참조하십시오.
프로덕션 환경의 경우 복제된 풀을 기본 데이터 풀로 사용하는 것이 좋습니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 실행 중인 CephFS 환경.
- BlueStore OSD를 사용하는 풀입니다.
- Ceph 모니터 노드에 대한 사용자 수준 액세스.
절차
CephFS 메타데이터에 대한 복제된 메타데이터 풀을 생성합니다.
구문
ceph osd pool create METADATA_POOL PG_NUM
ceph osd pool create METADATA_POOL PG_NUMCopy to Clipboard Copied! Toggle word wrap Toggle overflow 예제
ceph osd pool create cephfs-metadata 64
[root@mon ~]# ceph osd pool create cephfs-metadata 64Copy to Clipboard Copied! Toggle word wrap Toggle overflow 이 예제에서는 배치 그룹이 64개인
cephfs-metadata풀을 생성합니다.CephFS에 대한 기본 복제 데이터 풀을 생성합니다.
구문
ceph osd pool create DATA_POOL PG_NUM
ceph osd pool create DATA_POOL PG_NUMCopy to Clipboard Copied! Toggle word wrap Toggle overflow 예제
ceph osd pool create cephfs-data 64
[root@mon ~]# ceph osd pool create cephfs-data 64Copy to Clipboard Copied! Toggle word wrap Toggle overflow 이 예제에서는 64개의 배치 그룹을 사용하여
cephfs-data라는 복제된 풀을 생성합니다.CephFS에 대한 deletesure-coded 데이터 풀을 생성합니다.
구문
ceph osd pool create DATA_POOL PG_NUM erasure
ceph osd pool create DATA_POOL PG_NUM erasureCopy to Clipboard Copied! Toggle word wrap Toggle overflow 예제
ceph osd pool create cephfs-data-ec 64 erasure
[root@mon ~]# ceph osd pool create cephfs-data-ec 64 erasureCopy to Clipboard Copied! Toggle word wrap Toggle overflow 이 예제에서는 64개의 배치 그룹을 사용하여
cephfs-data-ec라는 삭제가 코딩된 풀을 생성합니다.deletesure-coded 풀에서 덮어 쓰기를 활성화합니다.
구문
ceph osd pool set DATA_POOL allow_ec_overwrites true
ceph osd pool set DATA_POOL allow_ec_overwrites trueCopy to Clipboard Copied! Toggle word wrap Toggle overflow 예제
ceph osd pool set cephfs-data-ec allow_ec_overwrites true
[root@mon ~]# ceph osd pool set cephfs-data-ec allow_ec_overwrites trueCopy to Clipboard Copied! Toggle word wrap Toggle overflow 이 예제에서는
cephfs-data-ec라는 삭제-코딩된 풀에서 덮어 쓰기를 활성화합니다.invokesure-coded 데이터 풀을 CephFS 메타데이터 서버(MDS)에 추가합니다.
구문
ceph fs add_data_pool cephfs-ec DATA_POOL
ceph fs add_data_pool cephfs-ec DATA_POOLCopy to Clipboard Copied! Toggle word wrap Toggle overflow 예제
ceph fs add_data_pool cephfs-ec cephfs-data-ec
[root@mon ~]# ceph fs add_data_pool cephfs-ec cephfs-data-ecCopy to Clipboard Copied! Toggle word wrap Toggle overflow 선택적으로 데이터 풀이 추가되었는지 확인합니다.
ceph fs ls
[root@mon ~]# ceph fs lsCopy to Clipboard Copied! Toggle word wrap Toggle overflow
CephFS를 생성합니다.
구문
ceph fs new cephfs METADATA_POOL DATA_POOL
ceph fs new cephfs METADATA_POOL DATA_POOLCopy to Clipboard Copied! Toggle word wrap Toggle overflow 예제
ceph fs new cephfs cephfs-metadata cephfs-data
[root@mon ~]# ceph fs new cephfs cephfs-metadata cephfs-dataCopy to Clipboard Copied! Toggle word wrap Toggle overflow 중요기본 데이터 풀에 deletesure-coded 풀을 사용하는 것은 권장되지 않습니다.
삭제 코딩을 사용하여 CephFS를 생성합니다.
구문
ceph fs new cephfs-ec METADATA_POOL DATA_POOL
ceph fs new cephfs-ec METADATA_POOL DATA_POOLCopy to Clipboard Copied! Toggle word wrap Toggle overflow 예제
ceph fs new cephfs-ec cephfs-metadata cephfs-data-ec
[root@mon ~]# ceph fs new cephfs-ec cephfs-metadata cephfs-data-ecCopy to Clipboard Copied! Toggle word wrap Toggle overflow 하나 이상의 Ceph FS 메타데이터 서버(MDS)가 활성 상태인지 확인합니다.
구문
ceph fs status FS_EC
ceph fs status FS_ECCopy to Clipboard Copied! Toggle word wrap Toggle overflow 예제
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 기존 파일 시스템에 새 삭제-코딩된 데이터 풀을 추가하려면 다음을 수행합니다.
CephFS에 대한 deletesure-coded 데이터 풀을 생성합니다.
구문
ceph osd pool create DATA_POOL PG_NUM erasure
ceph osd pool create DATA_POOL PG_NUM erasureCopy to Clipboard Copied! Toggle word wrap Toggle overflow 예제
ceph osd pool create cephfs-data-ec1 64 erasure
[root@mon ~]# ceph osd pool create cephfs-data-ec1 64 erasureCopy to Clipboard Copied! Toggle word wrap Toggle overflow deletesure-coded 풀에서 덮어 쓰기를 활성화합니다.
구문
ceph osd pool set DATA_POOL allow_ec_overwrites true
ceph osd pool set DATA_POOL allow_ec_overwrites trueCopy to Clipboard Copied! Toggle word wrap Toggle overflow 예제
ceph osd pool set cephfs-data-ec1 allow_ec_overwrites true
[root@mon ~]# ceph osd pool set cephfs-data-ec1 allow_ec_overwrites trueCopy to Clipboard Copied! Toggle word wrap Toggle overflow invokesure-coded 데이터 풀을 CephFS 메타데이터 서버(MDS)에 추가합니다.
구문
ceph fs add_data_pool cephfs-ec DATA_POOL
ceph fs add_data_pool cephfs-ec DATA_POOLCopy to Clipboard Copied! Toggle word wrap Toggle overflow 예제
ceph fs add_data_pool cephfs-ec cephfs-data-ec1
[root@mon ~]# ceph fs add_data_pool cephfs-ec cephfs-data-ec1Copy to Clipboard Copied! Toggle word wrap Toggle overflow
삭제 코딩을 사용하여 CephFS를 생성합니다.
구문
ceph fs new cephfs-ec METADATA_POOL DATA_POOL
ceph fs new cephfs-ec METADATA_POOL DATA_POOLCopy to Clipboard Copied! Toggle word wrap Toggle overflow 예제
ceph fs new cephfs-ec cephfs-metadata cephfs-data-ec1
[root@mon ~]# ceph fs new cephfs-ec cephfs-metadata cephfs-data-ec1Copy to Clipboard Copied! Toggle word wrap Toggle overflow
추가 리소스
- CephFS MDS에 대한 자세한 내용은 Red Hat Ceph Storage 파일 시스템 가이드의 Ceph 파일 시스템 메타데이터 서버 장을 참조하십시오.
- CephFS 설치에 대한 자세한 내용은 Red Hat Ceph Storage 설치 가이드 의 메타데이터 서버 설치 섹션을 참조하십시오.
- 자세한 내용은 Red Hat Ceph Storage Strategies Guide 의 Erasure-Coded Pools 섹션을 참조하십시오.
- 자세한 내용은 Red Hat Ceph Storage Storage Strategies Guide 의 Erasure Coding with Overwrites 섹션을 참조하십시오.
3.5. Ceph 파일 시스템의 클라이언트 사용자 생성
Red Hat Ceph Storage는 설치에 의해 기본적으로 활성화되어 있는 authentication에 RuntimeClass를 사용합니다. Ceph 파일 시스템과 함께 RuntimeClass를 사용하려면 Ceph Monitor 노드에서 올바른 권한 부여 기능이 있는 사용자를 생성하고 Ceph File System이 마운트되는 노드에서 키를 사용할 수 있도록 합니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- Ceph Metadata Server 데몬(ceph-mds)의 설치 및 구성.
- Ceph 모니터 노드에 대한 루트 수준 액세스.
- Ceph 클라이언트 노드에 대한 루트 수준 액세스.
절차
Ceph 모니터 노드에서 클라이언트 사용자를 생성합니다.
구문
ceph fs authorize FILE_SYSTEM_NAME client.CLIENT_NAME /DIRECTORY CAPABILITY [/DIRECTORY CAPABILITY] ...
ceph fs authorize FILE_SYSTEM_NAME client.CLIENT_NAME /DIRECTORY CAPABILITY [/DIRECTORY CAPABILITY] ...Copy to Clipboard Copied! Toggle word wrap Toggle overflow 클라이언트가 파일 시스템
cephfs_a의temp디렉터리만 작성하도록 제한하려면 다음을 수행합니다.예제
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 클라이언트를
temp디렉토리로 완전히 제한하려면 루트(/) 디렉토리를 제거하십시오.예제
ceph fs authorize cephfs_a client.1 /temp rw
[root@mon ~]# ceph fs authorize cephfs_a client.1 /temp rwCopy to Clipboard Copied! Toggle word wrap Toggle overflow
참고모든또는 별표를 파일 시스템 이름으로 제공하면 모든 파일 시스템에 액세스할 수 있습니다. 일반적으로 쉘에서 보호하려면 별표를 인용해야 합니다.생성된 키를 확인합니다.
구문
ceph auth get client.ID
ceph auth get client.IDCopy to Clipboard Copied! Toggle word wrap Toggle overflow 예제
ceph auth get client.1
[root@mon ~]# ceph auth get client.1Copy to Clipboard Copied! Toggle word wrap Toggle overflow 인증 키를 클라이언트에 복사합니다.
Ceph Monitor 노드에서 인증 키를 파일로 내보냅니다.
구문
ceph auth get client.ID -o ceph.client.ID.keyring
ceph auth get client.ID -o ceph.client.ID.keyringCopy to Clipboard Copied! Toggle word wrap Toggle overflow 예제
ceph auth get client.1 -o ceph.client.1.keyring exported keyring for client.1
[root@mon ~]# ceph auth get client.1 -o ceph.client.1.keyring exported keyring for client.1Copy to Clipboard Copied! Toggle word wrap Toggle overflow Ceph Monitor 노드의 클라이언트 인증 키를 클라이언트 노드의
/etc/ceph/디렉터리에 복사합니다.구문
scp root@MONITOR_NODE_NAME:/root/ceph.client.1.keyring /etc/ceph/
scp root@MONITOR_NODE_NAME:/root/ceph.client.1.keyring /etc/ceph/Copy to Clipboard Copied! Toggle word wrap Toggle overflow Ceph Monitor 노드 이름 또는 IP로 Replace_SERVICEITOR_NODE_NAME_with Ceph Monitor 노드 이름 또는 IP
예제
scp root@mon:/root/ceph.client.1.keyring /etc/ceph/ceph.client.1.keyring
[root@client ~]# scp root@mon:/root/ceph.client.1.keyring /etc/ceph/ceph.client.1.keyringCopy to Clipboard Copied! Toggle word wrap Toggle overflow
인증 키 파일에 적절한 권한을 설정합니다.
구문
chmod 644 KEYRING
chmod 644 KEYRINGCopy to Clipboard Copied! Toggle word wrap Toggle overflow 예제
chmod 644 /etc/ceph/ceph.client.1.keyring
[root@client ~]# chmod 644 /etc/ceph/ceph.client.1.keyringCopy to Clipboard Copied! Toggle word wrap Toggle overflow
추가 리소스
- 자세한 내용은 Red Hat Ceph Storage 관리 가이드의 사용자 관리 장을 참조하십시오.
3.6. Ceph 파일 시스템을 커널 클라이언트로 마운트
수동으로 또는 시스템 부팅 시 Ceph 파일 시스템(CephFS)을 커널 클라이언트로 마운트할 수 있습니다.
Red Hat Enterprise Linux 이외의 다른 Linux 배포판에서 실행되는 클라이언트는 허용되지만 지원되지 않습니다. 이러한 클라이언트를 사용할 때 CephFS 메타데이터 서버 또는 스토리지 클러스터의 다른 부분에서 문제가 발견되면 Red Hat에서 해당 문제를 해결합니다. 문제가 클라이언트 측에 있는 것으로 확인되면 Linux 배포판의 커널 벤더가 문제를 해결해야 합니다.
사전 요구 사항
- Linux 기반 클라이언트 노드에 대한 루트 수준 액세스.
- Ceph 모니터 노드에 대한 사용자 수준 액세스.
- 기존 Ceph 파일 시스템.
절차
Ceph 스토리지 클러스터를 사용하도록 클라이언트 노드를 구성합니다.
Red Hat Ceph Storage 4 툴 리포지토리를 활성화합니다.
Red Hat Enterprise Linux 7
subscription-manager repos --enable=rhel-7-server-rhceph-4-tools-rpms
[root@client ~]# subscription-manager repos --enable=rhel-7-server-rhceph-4-tools-rpmsCopy to Clipboard Copied! Toggle word wrap Toggle overflow Red Hat Enterprise Linux 8
subscription-manager repos --enable=rhceph-4-tools-for-rhel-8-x86_64-rpms
[root@client ~]# subscription-manager repos --enable=rhceph-4-tools-for-rhel-8-x86_64-rpmsCopy to Clipboard Copied! Toggle word wrap Toggle overflow ceph-common패키지를 설치합니다.Red Hat Enterprise Linux 7
yum install ceph-common
[root@client ~]# yum install ceph-commonCopy to Clipboard Copied! Toggle word wrap Toggle overflow Red Hat Enterprise Linux 8
dnf install ceph-common
[root@client ~]# dnf install ceph-commonCopy to Clipboard Copied! Toggle word wrap Toggle overflow Ceph 모니터 노드에서 클라이언트 노드에 Ceph 클라이언트 인증 키를 복사합니다.
구문
scp root@MONITOR_NODE_NAME:/etc/ceph/KEYRING_FILE /etc/ceph/
scp root@MONITOR_NODE_NAME:/etc/ceph/KEYRING_FILE /etc/ceph/Copy to Clipboard Copied! Toggle word wrap Toggle overflow MONITOR_NODE_NAME 을 Ceph Monitor 호스트 이름 또는 IP 주소로 교체합니다.
예제
scp root@192.168.0.1:/etc/ceph/ceph.client.1.keyring /etc/ceph/
[root@client ~]# scp root@192.168.0.1:/etc/ceph/ceph.client.1.keyring /etc/ceph/Copy to Clipboard Copied! Toggle word wrap Toggle overflow Ceph Monitor 노드의 Ceph 구성 파일을 클라이언트 노드로 복사합니다.
구문
scp root@MONITOR_NODE_NAME:/etc/ceph/ceph.conf /etc/ceph/ceph.conf
scp root@MONITOR_NODE_NAME:/etc/ceph/ceph.conf /etc/ceph/ceph.confCopy to Clipboard Copied! Toggle word wrap Toggle overflow MONITOR_NODE_NAME 을 Ceph Monitor 호스트 이름 또는 IP 주소로 교체합니다.
예제
scp root@192.168.0.1:/etc/ceph/ceph.conf /etc/ceph/ceph.conf
[root@client ~]# scp root@192.168.0.1:/etc/ceph/ceph.conf /etc/ceph/ceph.confCopy to Clipboard Copied! Toggle word wrap Toggle overflow 구성 파일에 적절한 권한을 설정합니다.
chmod 644 /etc/ceph/ceph.conf
[root@client ~]# chmod 644 /etc/ceph/ceph.confCopy to Clipboard Copied! Toggle word wrap Toggle overflow
클라이언트 노드에 마운트 디렉터리를 생성합니다.
구문
mkdir -p MOUNT_POINT
mkdir -p MOUNT_POINTCopy to Clipboard Copied! Toggle word wrap Toggle overflow 예제
mkdir -p /mnt/cephfs
[root@client]# mkdir -p /mnt/cephfsCopy to Clipboard Copied! Toggle word wrap Toggle overflow Ceph 파일 시스템을 마운트합니다. 여러 Ceph Monitor 주소를 지정하려면
mount명령에서 쉼표로 구분하고 마운트 지점을 지정하고 클라이언트 이름을 설정합니다.참고Red Hat Ceph Storage 4.1부터
mount.ceph는 인증 키 파일을 직접 읽을 수 있습니다. 따라서 보안 파일은 더 이상 필요하지 않습니다.name=CLIENT_ID를 사용하여 클라이언트 ID를 지정하면mount.ceph가 올바른 인증 키 파일을 찾습니다.구문
mount -t ceph MONITOR-1_NAME:6789,MONITOR-2_NAME:6789,MONITOR-3_NAME:6789:/ MOUNT_POINT -o name=CLIENT_ID
mount -t ceph MONITOR-1_NAME:6789,MONITOR-2_NAME:6789,MONITOR-3_NAME:6789:/ MOUNT_POINT -o name=CLIENT_IDCopy to Clipboard Copied! Toggle word wrap Toggle overflow 예제
mount -t ceph mon1:6789,mon2:6789,mon3:6789:/ /mnt/cephfs -o name=1
[root@client ~]# mount -t ceph mon1:6789,mon2:6789,mon3:6789:/ /mnt/cephfs -o name=1Copy to Clipboard Copied! Toggle word wrap Toggle overflow 참고단일 호스트 이름이 여러 IP 주소로 확인되도록 DNS 서버를 구성할 수 있습니다. 그런 다음 쉼표로 구분된 목록을 제공하는 대신
mount명령과 함께 단일 호스트 이름을 사용할 수 있습니다.참고모니터 호스트 이름을
:/문자열로 교체할 수도있습니다.ceph는 Ceph 구성 파일을 읽고 연결할 모니터를 결정합니다.파일 시스템이 성공적으로 마운트되었는지 확인합니다.
구문
stat -f MOUNT_POINT
stat -f MOUNT_POINTCopy to Clipboard Copied! Toggle word wrap Toggle overflow 예제
stat -f /mnt/cephfs
[root@client ~]# stat -f /mnt/cephfsCopy to Clipboard Copied! Toggle word wrap Toggle overflow
추가 리소스
-
mount(8)매뉴얼 페이지를 참조하십시오. - Ceph 사용자 생성에 대한 자세한 내용은 Red Hat Ceph Storage 관리 가이드 의 Ceph 사용자 관리 장을 참조하십시오.
- 자세한 내용은 Red Hat Ceph Storage File System 가이드의 Ceph파일 시스템 생성 섹션을 참조하십시오.
3.7. Ceph 파일 시스템을 FUSE 클라이언트로 마운트
Ceph 파일 시스템(CephFS)을 수동으로 또는 시스템 부팅 시 사용자 공간(FUSE)에서 파일 시스템으로 마운트할 수 있습니다.
사전 요구 사항
- Linux 기반 클라이언트 노드에 대한 루트 수준 액세스.
- Ceph 모니터 노드에 대한 사용자 수준 액세스.
- 기존 Ceph 파일 시스템.
절차
Ceph 스토리지 클러스터를 사용하도록 클라이언트 노드를 구성합니다.
Red Hat Ceph Storage 4 툴 리포지토리를 활성화합니다.
Red Hat Enterprise Linux 7
subscription-manager repos --enable=rhel-7-server-rhceph-4-tools-rpms
[root@client ~]# subscription-manager repos --enable=rhel-7-server-rhceph-4-tools-rpmsCopy to Clipboard Copied! Toggle word wrap Toggle overflow Red Hat Enterprise Linux 8
subscription-manager repos --enable=rhceph-4-tools-for-rhel-8-x86_64-rpms
[root@client ~]# subscription-manager repos --enable=rhceph-4-tools-for-rhel-8-x86_64-rpmsCopy to Clipboard Copied! Toggle word wrap Toggle overflow ceph-fuse패키지를 설치합니다.Red Hat Enterprise Linux 7
yum install ceph-fuse
[root@client ~]# yum install ceph-fuseCopy to Clipboard Copied! Toggle word wrap Toggle overflow Red Hat Enterprise Linux 8
dnf install ceph-fuse
[root@client ~]# dnf install ceph-fuseCopy to Clipboard Copied! Toggle word wrap Toggle overflow Ceph 모니터 노드에서 클라이언트 노드에 Ceph 클라이언트 인증 키를 복사합니다.
구문
scp root@MONITOR_NODE_NAME:/etc/ceph/KEYRING_FILE /etc/ceph/
scp root@MONITOR_NODE_NAME:/etc/ceph/KEYRING_FILE /etc/ceph/Copy to Clipboard Copied! Toggle word wrap Toggle overflow MONITOR_NODE_NAME 을 Ceph Monitor 호스트 이름 또는 IP 주소로 교체합니다.
예제
scp root@192.168.0.1:/etc/ceph/ceph.client.1.keyring /etc/ceph/
[root@client ~]# scp root@192.168.0.1:/etc/ceph/ceph.client.1.keyring /etc/ceph/Copy to Clipboard Copied! Toggle word wrap Toggle overflow Ceph Monitor 노드의 Ceph 구성 파일을 클라이언트 노드로 복사합니다.
구문
scp root@MONITOR_NODE_NAME:/etc/ceph/ceph.conf /etc/ceph/ceph.conf
scp root@MONITOR_NODE_NAME:/etc/ceph/ceph.conf /etc/ceph/ceph.confCopy to Clipboard Copied! Toggle word wrap Toggle overflow MONITOR_NODE_NAME 을 Ceph Monitor 호스트 이름 또는 IP 주소로 교체합니다.
예제
scp root@192.168.0.1:/etc/ceph/ceph.conf /etc/ceph/ceph.conf
[root@client ~]# scp root@192.168.0.1:/etc/ceph/ceph.conf /etc/ceph/ceph.confCopy to Clipboard Copied! Toggle word wrap Toggle overflow 구성 파일에 적절한 권한을 설정합니다.
chmod 644 /etc/ceph/ceph.conf
[root@client ~]# chmod 644 /etc/ceph/ceph.confCopy to Clipboard Copied! Toggle word wrap Toggle overflow - 자동 또는 수동으로 마운트를 선택합니다.
수동 마운트
클라이언트 노드에서 마운트 지점의 디렉터리를 생성합니다.
구문
mkdir PATH_TO_MOUNT_POINT
mkdir PATH_TO_MOUNT_POINTCopy to Clipboard Copied! Toggle word wrap Toggle overflow 예제
mkdir /mnt/mycephfs
[root@client ~]# mkdir /mnt/mycephfsCopy to Clipboard Copied! Toggle word wrap Toggle overflow 참고MDS 기능에
pathceph-fuse유틸리티를 사용하여 Ceph 파일 시스템을 마운트합니다.구문
ceph-fuse -n client.CLIENT_ID MOUNT_POINT
ceph-fuse -n client.CLIENT_ID MOUNT_POINTCopy to Clipboard Copied! Toggle word wrap Toggle overflow 예제
ceph-fuse -n client.1 /mnt/mycephfs
[root@client ~]# ceph-fuse -n client.1 /mnt/mycephfsCopy to Clipboard Copied! Toggle word wrap Toggle overflow 참고사용자 인증 키의 기본 이름과 위치를 사용하지 않는 경우, 즉
/etc/ceph/ceph.client.CLIENT_ID.keyring.keyring옵션을 사용하여 사용자 인증 키의 경로를 지정합니다. 예를 들면 다음과 같습니다.예제
ceph-fuse -n client.1 --keyring=/etc/ceph/client.1.keyring /mnt/mycephfs
[root@client ~]# ceph-fuse -n client.1 --keyring=/etc/ceph/client.1.keyring /mnt/mycephfsCopy to Clipboard Copied! Toggle word wrap Toggle overflow 참고-r옵션을 사용하여 클라이언트에 해당 경로를 root로 처리하도록 지시합니다.구문
ceph-fuse -n client.CLIENT_ID MOUNT_POINT -r PATH
ceph-fuse -n client.CLIENT_ID MOUNT_POINT -r PATHCopy to Clipboard Copied! Toggle word wrap Toggle overflow 예제
ceph-fuse -n client.1 /mnt/cephfs -r /home/cephfs
[root@client ~]# ceph-fuse -n client.1 /mnt/cephfs -r /home/cephfsCopy to Clipboard Copied! Toggle word wrap Toggle overflow 파일 시스템이 성공적으로 마운트되었는지 확인합니다.
구문
stat -f MOUNT_POINT
stat -f MOUNT_POINTCopy to Clipboard Copied! Toggle word wrap Toggle overflow 예제
stat -f /mnt/cephfs
[user@client ~]$ stat -f /mnt/cephfsCopy to Clipboard Copied! Toggle word wrap Toggle overflow
자동 마운트
클라이언트 노드에서 마운트 지점의 디렉터리를 생성합니다.
구문
mkdir PATH_TO_MOUNT_POINT
mkdir PATH_TO_MOUNT_POINTCopy to Clipboard Copied! Toggle word wrap Toggle overflow 예제
mkdir /mnt/mycephfs
[root@client ~]# mkdir /mnt/mycephfsCopy to Clipboard Copied! Toggle word wrap Toggle overflow 참고MDS 기능에
path다음과 같이
/etc/fstab파일을 편집합니다.구문
#DEVICE PATH TYPE OPTIONS DUMP FSCK HOST_NAME:_PORT_, MOUNT_POINT fuse.ceph ceph.id=CLIENT_ID, 0 0 HOST_NAME:_PORT_, ceph.client_mountpoint=/VOL/SUB_VOL_GROUP/SUB_VOL/UID_SUB_VOL, HOST_NAME:_PORT_:/ [ADDITIONAL_OPTIONS]
#DEVICE PATH TYPE OPTIONS DUMP FSCK HOST_NAME:_PORT_, MOUNT_POINT fuse.ceph ceph.id=CLIENT_ID, 0 0 HOST_NAME:_PORT_, ceph.client_mountpoint=/VOL/SUB_VOL_GROUP/SUB_VOL/UID_SUB_VOL, HOST_NAME:_PORT_:/ [ADDITIONAL_OPTIONS]Copy to Clipboard Copied! Toggle word wrap Toggle overflow 첫 번째 열 은 Ceph Monitor 호스트 이름과 포트 번호를 설정합니다.
두 번째 열 은 마운트 지점을 설정
세 번째 열 은 CephFS에 대한 파일 시스템 유형(이 경우
fuse.ceph)을 설정합니다.네 번째 열 은 각각 name 및
secretfile옵션을 사용하여 사용자이름및 시크릿 파일과 같은 다양한 옵션을 설정합니다.ceph.client_mountpoint옵션을 사용하여 특정 볼륨, 하위 볼륨, 하위 볼륨을 설정할 수도 있습니다. 중단 및 네트워킹 문제를 방지하기 위해 네트워킹 하위 시스템이 시작된 후 파일 시스템이 마운트되도록_netdev옵션을 설정합니다. 액세스 시간 정보가 필요하지 않은 경우noatime옵션을 설정하면 성능이 향상될 수 있습니다.다섯 번째 및 여섯 번째 열을 0으로 설정합니다.
예제
#DEVICE PATH TYPE OPTIONS DUMP FSCK mon1:6789, /mnt/cephfs fuse.ceph ceph.id=1, 0 0 mon2:6789, ceph.client_mountpoint=/my_vol/my_sub_vol_group/my_sub_vol/0, mon3:6789:/ _netdev,defaults
#DEVICE PATH TYPE OPTIONS DUMP FSCK mon1:6789, /mnt/cephfs fuse.ceph ceph.id=1, 0 0 mon2:6789, ceph.client_mountpoint=/my_vol/my_sub_vol_group/my_sub_vol/0, mon3:6789:/ _netdev,defaultsCopy to Clipboard Copied! Toggle word wrap Toggle overflow Ceph 파일 시스템은 다음 시스템 부팅 시 마운트됩니다.
추가 리소스
-
ceph-fuse(8)매뉴얼 페이지. - Ceph 사용자 생성에 대한 자세한 내용은 Red Hat Ceph Storage 관리 가이드 의 Ceph 사용자 관리 장을 참조하십시오.
- 자세한 내용은 Red Hat Ceph Storage File System 가이드의 Ceph파일 시스템 생성 섹션을 참조하십시오.
3.8. 추가 리소스
- 자세한 내용은 3.3절. “Ceph 파일 시스템 생성” 을 참조하십시오.
- 자세한 내용은 3.5절. “Ceph 파일 시스템의 클라이언트 사용자 생성” 을 참조하십시오.
- 자세한 내용은 3.6절. “Ceph 파일 시스템을 커널 클라이언트로 마운트” 을 참조하십시오.
- 자세한 내용은 3.7절. “Ceph 파일 시스템을 FUSE 클라이언트로 마운트” 을 참조하십시오.
- CephFS 메타데이터 서버 설치에 대한 자세한 내용은 Red Hat Ceph Storage 설치 가이드 를 참조하십시오.
- CephFS 메타데이터 서버 데몬 구성에 대한 자세한 내용은 2장. Ceph 파일 시스템 메타데이터 서버 을 참조하십시오.
4장. Ceph 파일 시스템 관리
스토리지 관리자는 다음과 같은 공통 Ceph File System(CephFS) 관리 작업을 수행할 수 있습니다.
- 디렉터리를 특정 MDS 순위에 매핑하려면 4.4절. “디렉터리 트리를 메타데이터 서버 데몬 순위에 매핑” 을 참조하십시오.
- MDS 순위에서 디렉터리의 연결을 끊으려면 4.5절. “Metadata Server 데몬에서 디렉터리 트리를 분산시키는 순위” 을 참조하십시오.
- 파일 및 디렉터리 레이아웃으로 작업하려면 4.8절. “파일 및 디렉터리 레이아웃 작업” 을 참조하십시오.
- 새 데이터 풀을 추가하려면 4.6절. “데이터 풀 추가” 을 참조하십시오.
- 할당량으로 작업하려면 4.7절. “Ceph 파일 시스템 할당량 작업” 을 참조하십시오.
- 명령줄 인터페이스를 사용하여 Ceph 파일 시스템을 제거하려면 4.12절. “명령줄 인터페이스를 사용하여 Ceph 파일 시스템 제거” 을 참조하십시오.
- Ansible을 사용하여 Ceph 파일 시스템을 제거하려면 4.13절. “Ansible을 사용하여 Ceph 파일 시스템 제거” 을 참조하십시오.
- 최소 클라이언트 버전을 설정하려면 4.14절. “최소 클라이언트 버전 설정” 을 참조하십시오.
-
ceph mds fail명령을 사용하려면 4.15절. “ceph mds fail명령 사용” 을 참조하십시오.
4.1. 사전 요구 사항
- 실행 중이고 정상적인 Red Hat Ceph Storage 클러스터.
-
Ceph Metadata Server 데몬(
ceph-mds)의 설치 및 구성. - Ceph 파일 시스템을 생성하고 마운트합니다.
4.2. 커널 클라이언트로 마운트된 Ceph 파일 시스템 마운트 해제
커널 클라이언트로 마운트된 Ceph 파일 시스템을 마운트 해제하는 방법
사전 요구 사항
- 마운트를 수행하는 노드에 대한 루트 수준 액세스.
절차
커널 클라이언트로 마운트된 Ceph 파일 시스템을 마운트 해제하려면 다음을 수행합니다.
구문
umount MOUNT_POINT
umount MOUNT_POINTCopy to Clipboard Copied! Toggle word wrap Toggle overflow 예제
umount /mnt/cephfs
[root@client ~]# umount /mnt/cephfsCopy to Clipboard Copied! Toggle word wrap Toggle overflow
추가 리소스
-
ArgoCD
(8)매뉴얼 페이지
4.3. FUSE 클라이언트로 마운트된 Ceph 파일 시스템 마운트 해제
FUSE(User Space) 클라이언트에서 파일 시스템으로 마운트된 Ceph 파일 시스템을 마운트 해제합니다.
사전 요구 사항
- FUSE 클라이언트 노드에 대한 루트 수준 액세스.
절차
FUSE에 마운트된 Ceph 파일 시스템을 마운트 해제하려면 다음을 수행합니다.
구문
fusermount -u MOUNT_POINT
fusermount -u MOUNT_POINTCopy to Clipboard Copied! Toggle word wrap Toggle overflow 예제
fusermount -u /mnt/cephfs
[root@client ~]# fusermount -u /mnt/cephfsCopy to Clipboard Copied! Toggle word wrap Toggle overflow
추가 리소스
-
ceph-fuse(8)매뉴얼 페이지
4.4. 디렉터리 트리를 메타데이터 서버 데몬 순위에 매핑
디렉터리 및 해당 하위 디렉터리를 특정 활성 메타데이터 서버(MDS)에 매핑하려면 해당 메타데이터가 해당 순위를 포함하는 MDS 데몬에서만 관리되도록 합니다. 이 방법을 사용하면 애플리케이션 로드를 균등하게 분배하거나 사용자 메타데이터 요청이 전체 스토리지 클러스터에 미치는 영향을 제한할 수 있습니다.
내부 밸런서는 이미 애플리케이션 로드를 동적으로 분배합니다. 따라서 신중하게 선택한 특정 애플리케이션에 대해서만 디렉터리 트리를 매핑합니다.
또한 디렉터리가 순위로 매핑되면 밸런서를 분할할 수 없습니다. 결과적으로 매핑된 디렉터리 내의 많은 수의 작업이 순위를 오버로드하고 이를 관리하는 MDS 데몬을 오버로드할 수 있습니다.
사전 요구 사항
- 두 개 이상의 활성 MDS 데몬.
- CephFS 클라이언트 노드에 대한 사용자 액세스.
-
attr패키지가 Ceph 파일 시스템이 마운트된 CephFS 클라이언트 노드에 설치되어 있는지 확인합니다.
절차
Ceph 사용자의 기능에
p플래그를 추가합니다.구문
ceph fs authorize FILE_SYSTEM_NAME client.CLIENT_NAME /DIRECTORY CAPABILITY [/DIRECTORY CAPABILITY] ...
ceph fs authorize FILE_SYSTEM_NAME client.CLIENT_NAME /DIRECTORY CAPABILITY [/DIRECTORY CAPABILITY] ...Copy to Clipboard Copied! Toggle word wrap Toggle overflow 예제
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 디렉터리에
ceph.dir.pinextended 속성을 설정합니다.구문
setfattr -n ceph.dir.pin -v RANK DIRECTORY
setfattr -n ceph.dir.pin -v RANK DIRECTORYCopy to Clipboard Copied! Toggle word wrap Toggle overflow 예제
setfattr -n ceph.dir.pin -v 2 /temp
[user@client ~]$ setfattr -n ceph.dir.pin -v 2 /tempCopy to Clipboard Copied! Toggle word wrap Toggle overflow 이 예에서는
/temp디렉토리 및 모든 하위 디렉토리를 순위 2로 할당합니다.
추가 리소스
-
p플래그에 대한 자세한 내용은 Red Hat Ceph Storage File System Guide 의 레이아웃, 할당량, 스냅샷, 네트워크 제한 섹션을 참조하십시오. - 자세한 내용은 Red Hat Ceph Storage 파일 시스템 가이드의 메타데이터 서버 데몬에서 해제 디렉터리 트리 를 참조하십시오.
- 자세한 내용은 Red Hat Ceph Storage 파일 시스템 가이드 의 여러 활성 메타데이터 서버 데몬 구성 섹션을 참조하십시오.
4.5. Metadata Server 데몬에서 디렉터리 트리를 분산시키는 순위
특정 활성 메타데이터 서버(MDS) 순위에서 디렉터리의 연결을 끊습니다.
사전 요구 사항
- Ceph 파일 시스템(CephFS) 클라이언트 노드에 대한 사용자 액세스.
-
attr패키지가 마운트된 CephFS가 있는 클라이언트 노드에 설치되어 있는지 확인합니다.
절차
디렉터리에서
ceph.dir.pinextended 속성을 -1로 설정합니다.구문
setfattr -n ceph.dir.pin -v -1 DIRECTORY
setfattr -n ceph.dir.pin -v -1 DIRECTORYCopy to Clipboard Copied! Toggle word wrap Toggle overflow 예제
serfattr -n ceph.dir.pin -v -1 /home/ceph-user
[user@client ~]$ serfattr -n ceph.dir.pin -v -1 /home/ceph-userCopy to Clipboard Copied! Toggle word wrap Toggle overflow 참고/home/ceph-user/의 별도로 매핑된 하위 디렉터리는 영향을 받지 않습니다.
추가 리소스
- 자세한 내용은 Red Hat Ceph Storage File System Guide 의 Mapping Directory Trees to MDS rankings 섹션을 참조하십시오.
4.6. 데이터 풀 추가
Ceph 파일 시스템(CephFS)은 데이터 저장에 사용할 풀을 두 개 이상 추가할 수 있도록 지원합니다. 이 기능은 다음과 같은 경우에 유용할 수 있습니다.
- 감소된 중복 풀에 로그 데이터 저장
- SSD 또는 NVMe 풀에 사용자 홈 디렉터리 저장
- 기본 데이터 분리.
Ceph 파일 시스템에서 다른 데이터 풀을 사용하기 전에 이 섹션에 설명된 대로 추가해야 합니다.
기본적으로 파일 데이터를 저장하기 위해 CephFS는 생성 중 지정된 초기 데이터 풀을 사용합니다. 보조 데이터 풀을 사용하려면 파일 시스템 계층 구조의 일부를 구성하여 해당 풀에 파일 데이터를 저장하거나 선택적으로 파일 및 디렉터리 레이아웃을 사용하여 해당 풀의 네임스페이스 내에서 저장해야 합니다.
사전 요구 사항
- Ceph Monitor 노드에 대한 루트 수준 액세스입니다.
절차
새 데이터 풀을 생성합니다.
구문
ceph osd pool create POOL_NAME PG_NUMBER
ceph osd pool create POOL_NAME PG_NUMBERCopy to Clipboard Copied! Toggle word wrap Toggle overflow 교체:
-
POOL_NAME풀에 이름을 지정합니다. -
PG_NUMBER, 배치 그룹 수(PG)
예제
ceph osd pool create cephfs_data_ssd 64 pool 'cephfs_data_ssd' created
[root@mon ~]# ceph osd pool create cephfs_data_ssd 64 pool 'cephfs_data_ssd' createdCopy to Clipboard Copied! Toggle word wrap Toggle overflow -
메타데이터 서버 제어 아래에 새로 생성된 풀을 추가합니다.
구문
ceph fs add_data_pool FS_NAME POOL_NAME
ceph fs add_data_pool FS_NAME POOL_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow 교체:
-
FS_NAME파일 시스템의 이름입니다. -
POOL_NAME풀에 이름을 지정합니다.
예제:
ceph fs add_data_pool cephfs cephfs_data_ssd added data pool 6 to fsmap
[root@mon ~]# ceph fs add_data_pool cephfs cephfs_data_ssd added data pool 6 to fsmapCopy to Clipboard Copied! Toggle word wrap Toggle overflow -
풀이 성공적으로 추가되었는지 확인합니다.
예제
ceph fs ls name: cephfs, metadata pool: cephfs_metadata, data pools: [cephfs_data cephfs_data_ssd]
[root@mon ~]# ceph fs ls name: cephfs, metadata pool: cephfs_metadata, data pools: [cephfs_data cephfs_data_ssd]Copy to Clipboard Copied! Toggle word wrap Toggle overflow -
RuntimeClass 인증을 사용하는 경우 클라이언트가 새 풀에 액세스할 수 있는지 확인합니다.
추가 리소스
- 자세한 내용은 파일 및 디렉터리 레이아웃 작업을 참조하십시오.
- 자세한 내용은 Ceph File System Client 사용자 생성을 참조하십시오.
4.7. Ceph 파일 시스템 할당량 작업
스토리지 관리자는 파일 시스템의 모든 디렉터리에서 할당량을 보고, 설정하고, 제거할 수 있습니다. 디렉터리 내의 파일 수 또는 파일 수에 할당량 제한을 배치할 수 있습니다.
4.7.1. 사전 요구 사항
-
attr패키지가 설치되어 있는지 확인합니다.
4.7.2. Ceph 파일 시스템 할당량
Ceph 파일 시스템(CephFS) 할당량을 사용하면 디렉터리 구조에 저장된 바이트 수 또는 파일 수를 제한할 수 있습니다.
제한 사항
- CephFS 할당량은 파일 시스템을 마운트하는 클라이언트 마운트에 따라 구성된 제한에 도달하면 데이터 쓰기를 중지합니다. 그러나 할당량만으로는 적대하고 신뢰할 수 없는 클라이언트가 파일 시스템을 채우지 못하도록 할 수 없습니다.
- 파일 시스템에 데이터를 쓰는 프로세스가 구성된 제한에 도달하면 데이터 양이 할당량 제한에 도달하는 시점과 프로세스가 데이터 쓰기를 중지합니다. 시간 기간은 일반적으로 10초 동안 측정됩니다. 그러나 프로세스는 해당 기간 동안 계속 데이터를 작성합니다. 프로세스에서 쓰는 추가 데이터의 양은 중지되기 전에 경과한 시간에 따라 달라집니다.
-
이전에는 사용자 공간 FUSE 클라이언트에서만 할당량을 지원했습니다. Linux 커널 버전 4.17 이상에서는 CephFS 커널 클라이언트에서 Ceph mimic 또는 최신 클러스터에 대한 할당량을 지원합니다. 이러한 버전 요구 사항은 Red Hat Enterprise Linux 8 및 Red Hat Ceph Storage 4에서 각각 충족합니다. 사용자 공간 FUSE 클라이언트는 이전 및 최신 OS 및 클러스터 버전에서 사용할 수 있습니다. FUSE 클라이언트는
ceph-fuse패키지에서 제공합니다. -
경로 기반 액세스 제한을 사용하는 경우 클라이언트가 제한된 디렉터리 또는 디렉터리 아래에 중첩된 디렉터리에 대한 할당량을 구성해야 합니다. 클라이언트가 MDS 기능을 기반으로 특정 경로에 대한 액세스를 제한하고 클라이언트가 액세스할 수 없는 NetNamespace 디렉터리에 할당량을 구성하는 경우 클라이언트는 할당량을 적용하지 않습니다. 예를 들어 클라이언트가
/home/디렉터리에 액세스할 수 없고 할당량을/home/에 구성할 수 없는 경우 클라이언트는/home/user/디렉터리에 해당 할당량을 적용할 수 없습니다. - 삭제되거나 변경된 스냅샷 파일 데이터는 할당량에 포함되지 않습니다.
4.7.3. 할당량 보기
getfattr 명령과 ceph.quota 확장된 속성을 사용하여 디렉터리의 할당량 설정을 확인합니다.
속성이 디렉터리 inode에 표시되면 해당 디렉터리에 할당량이 구성되어 있습니다. 속성이 inode에 표시되지 않으면 상위 디렉터리에 할당량이 구성되어 있을 수 있지만 디렉터리에 할당량이 설정되지 않습니다. extended 속성 값이 0이면 할당량이 설정되지 않습니다.
사전 요구 사항
-
attr패키지가 설치되어 있는지 확인합니다.
절차
CephFS 할당량을 보려면 다음을 수행합니다.
바이트 제한 할당량 사용:
구문
getfattr -n ceph.quota.max_bytes DIRECTORY
getfattr -n ceph.quota.max_bytes DIRECTORYCopy to Clipboard Copied! Toggle word wrap Toggle overflow 예제
getfattr -n ceph.quota.max_bytes /cephfs/
[root@fs ~]# getfattr -n ceph.quota.max_bytes /cephfs/Copy to Clipboard Copied! Toggle word wrap Toggle overflow file-limit 할당량 사용:
구문
getfattr -n ceph.quota.max_files DIRECTORY
getfattr -n ceph.quota.max_files DIRECTORYCopy to Clipboard Copied! Toggle word wrap Toggle overflow 예제
getfattr -n ceph.quota.max_files /cephfs/
[root@fs ~]# getfattr -n ceph.quota.max_files /cephfs/Copy to Clipboard Copied! Toggle word wrap Toggle overflow
추가 리소스
-
자세한 내용은
getfattr(1)매뉴얼 페이지를 참조하십시오.
4.7.4. 할당량 설정
이 섹션에서는 setfattr 명령과 ceph.quota 확장 속성을 사용하여 디렉토리의 할당량을 설정하는 방법을 설명합니다.
사전 요구 사항
-
attr패키지가 설치되어 있는지 확인합니다.
절차
CephFS 할당량을 설정하려면 다음을 수행합니다.
바이트 제한 할당량 사용:
구문
setfattr -n ceph.quota.max_bytes -v 100000000 /some/dir
setfattr -n ceph.quota.max_bytes -v 100000000 /some/dirCopy to Clipboard Copied! Toggle word wrap Toggle overflow 예제
setfattr -n ceph.quota.max_bytes -v 100000000 /cephfs/
[root@fs ~]# setfattr -n ceph.quota.max_bytes -v 100000000 /cephfs/Copy to Clipboard Copied! Toggle word wrap Toggle overflow 이 예에서 100000000바이트는 100MB입니다.
file-limit 할당량 사용:
구문
setfattr -n ceph.quota.max_files -v 10000 /some/dir
setfattr -n ceph.quota.max_files -v 10000 /some/dirCopy to Clipboard Copied! Toggle word wrap Toggle overflow 예제
setfattr -n ceph.quota.max_files -v 10000 /cephfs/
[root@fs ~]# setfattr -n ceph.quota.max_files -v 10000 /cephfs/Copy to Clipboard Copied! Toggle word wrap Toggle overflow 이 예에서 10000은 파일 10,000개와 동일합니다.
추가 리소스
-
자세한 내용은
setfattr(1)매뉴얼 페이지를 참조하십시오.
4.7.5. 할당량 제거
이 섹션에서는 setfattr 명령과 ceph.quota 확장 속성을 사용하여 디렉터리에서 할당량을 제거하는 방법을 설명합니다.
사전 요구 사항
-
attr패키지가 설치되어 있는지 확인합니다.
절차
CephFS 할당량을 제거하려면 다음을 수행합니다.
바이트 제한 할당량 사용:
구문
setfattr -n ceph.quota.max_bytes -v 0 DIRECTORY
setfattr -n ceph.quota.max_bytes -v 0 DIRECTORYCopy to Clipboard Copied! Toggle word wrap Toggle overflow 예제
setfattr -n ceph.quota.max_bytes -v 0 /cephfs/
[root@fs ~]# setfattr -n ceph.quota.max_bytes -v 0 /cephfs/Copy to Clipboard Copied! Toggle word wrap Toggle overflow file-limit 할당량 사용:
구문
setfattr -n ceph.quota.max_files -v 0 DIRECTORY
setfattr -n ceph.quota.max_files -v 0 DIRECTORYCopy to Clipboard Copied! Toggle word wrap Toggle overflow 예제
setfattr -n ceph.quota.max_files -v 0 /cephfs/
[root@fs ~]# setfattr -n ceph.quota.max_files -v 0 /cephfs/Copy to Clipboard Copied! Toggle word wrap Toggle overflow
추가 리소스
-
자세한 내용은
setfattr(1)매뉴얼 페이지를 참조하십시오.
4.7.6. 추가 리소스
-
자세한 내용은
getfattr(1)매뉴얼 페이지를 참조하십시오. -
자세한 내용은
setfattr(1)매뉴얼 페이지를 참조하십시오.
4.8. 파일 및 디렉터리 레이아웃 작업
스토리지 관리자는 파일 또는 디렉터리 데이터가 개체에 매핑되는 방법을 제어할 수 있습니다.
이 섹션에서는 다음을 수행하는 방법에 대해 설명합니다.
4.8.1. 사전 요구 사항
-
attr패키지 설치
4.8.2. 파일 및 디렉터리 레이아웃 개요
이 섹션에서는 Ceph 파일 시스템의 컨텍스트에 있는 파일 및 디렉터리 레이아웃을 설명합니다.
파일 또는 디렉터리의 레이아웃은 해당 콘텐츠가 Ceph RADOS 오브젝트에 매핑되는 방법을 제어합니다. 디렉터리 레이아웃은 해당 디렉터리에서 새 파일에 대해 상속된 레이아웃을 설정하는 데 주로 사용됩니다.
파일 또는 디렉터리 레이아웃을 보고 설정하려면 가상 확장 속성 또는 확장 파일 속성(xattrs)을 사용합니다. 레이아웃 속성의 이름은 파일이 일반 파일인지 디렉터리인지에 따라 달라집니다.
-
일반 파일 레이아웃 속성은
ceph.file.layout. -
디렉터리 레이아웃 속성은
ceph.dir.layout.
파일 및 디렉터리 레이아웃 필드 테이블에는 파일 및 디렉터리에 설정할 수 있는 사용 가능한 레이아웃 필드가 나열됩니다.
레이아웃 Inheritance
파일은 파일을 생성할 때 상위 디렉터리의 레이아웃을 상속합니다. 그러나 상위 디렉터리 레이아웃에 대한 후속 변경 사항은 하위 디렉터리에 영향을 미치지 않습니다. 디렉터리에 레이아웃이 설정되어 있지 않은 경우 파일은 디렉터리 구조의 레이아웃이 있는 가장 가까운 디렉터리에서 레이아웃을 상속합니다.
추가 리소스
- 자세한 내용은 레이아웃 Inheritance를 참조하십시오.
4.8.3. 파일 및 디렉터리 레이아웃 필드 설정
setfattr 명령을 사용하여 파일 또는 디렉터리에 레이아웃 필드를 설정합니다.
파일의 레이아웃 필드를 수정하면 파일이 비어 있어야 하며 그렇지 않으면 오류가 발생합니다.
사전 요구 사항
- 노드에 대한 루트 수준 액세스.
절차
파일 또는 디렉터리에서 레이아웃 필드를 수정하려면 다음을 수행합니다.
구문
setfattr -n ceph.TYPE.layout.FIELD -v VALUE PATH
setfattr -n ceph.TYPE.layout.FIELD -v VALUE PATHCopy to Clipboard Copied! Toggle word wrap Toggle overflow 교체:
-
파일 또는 디렉터리의유형. - 먼저 필드 의 이름을 입력합니다.
- 필드 의 새 값을 입력합니다.Type the new value of the field.
- 파일 또는 디렉터리의 경로를 사용하여 PATH 를 지정합니다.
예제
setfattr -n ceph.file.layout.stripe_unit -v 1048576 test
[root@fs ~]# setfattr -n ceph.file.layout.stripe_unit -v 1048576 testCopy to Clipboard Copied! Toggle word wrap Toggle overflow -
추가 리소스
- 자세한 내용은 Red Hat Ceph Storage 파일 시스템 가이드의 파일및 디렉터리 레이아웃 개요 섹션에 있는 표를 참조하십시오.
-
setfattr(1)매뉴얼 페이지를 참조하십시오.
4.8.4. 파일 및 디렉터리 레이아웃 필드 보기
getfattr 명령을 사용하여 파일 또는 디렉터리의 레이아웃 필드를 보려면 다음을 수행합니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 스토리지 클러스터의 모든 노드에 대한 루트 수준 액세스.
절차
파일 또는 디렉터리의 레이아웃 필드를 단일 문자열로 보려면 다음을 수행합니다.
구문
getfattr -n ceph.TYPE.layout PATH
getfattr -n ceph.TYPE.layout PATHCopy to Clipboard Copied! Toggle word wrap Toggle overflow - replace
- 파일 또는 디렉터리의 경로를 사용하여 PATH 를 지정합니다.
-
파일 또는 디렉터리의유형.
예제
[root@mon ~] getfattr -n ceph.dir.layout /home/test ceph.dir.layout="stripe_unit=4194304 stripe_count=2 object_size=4194304 pool=cephfs_data"
[root@mon ~] getfattr -n ceph.dir.layout /home/test ceph.dir.layout="stripe_unit=4194304 stripe_count=2 object_size=4194304 pool=cephfs_data"Copy to Clipboard Copied! Toggle word wrap Toggle overflow
디렉터리를 설정할 때까지 명시적 레이아웃이 없습니다.A directory does not have an explicit layout until you set it. 결과적으로 먼저 설정하지 않고 레이아웃을 확인하려고 하면 표시할 변경 사항이 없기 때문에 실패합니다.
추가 리소스
-
getfattr(1)매뉴얼 페이지. - 자세한 내용은 Red Hat Ceph Storage 파일 시스템 가이드의 파일 및 디렉터리 레이아웃 설정을 참조하십시오.
4.8.5. 개별 레이아웃 필드 보기
getfattr 명령을 사용하여 파일 또는 디렉토리의 개별 레이아웃 필드를 봅니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 스토리지 클러스터의 모든 노드에 대한 루트 수준 액세스.
절차
파일 또는 디렉터리에서 개별 레이아웃 필드를 보려면 다음을 수행합니다.
구문
getfattr -n ceph.TYPE.layout.FIELD _PATH
getfattr -n ceph.TYPE.layout.FIELD _PATHCopy to Clipboard Copied! Toggle word wrap Toggle overflow - replace
-
파일 또는 디렉터리의유형. - 먼저 필드 의 이름을 입력합니다.
- 파일 또는 디렉터리의 경로를 사용하여 PATH 를 지정합니다.
-
예제
[root@mon ~] getfattr -n ceph.file.layout.pool test ceph.file.layout.pool="cephfs_data"
[root@mon ~] getfattr -n ceph.file.layout.pool test ceph.file.layout.pool="cephfs_data"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 참고pool필드의 풀은 이름으로 표시됩니다. 그러나 새로 생성된 풀은 ID로 표시할 수 있습니다.
추가 리소스
-
getfattr(1)매뉴얼 페이지. - 자세한 내용은 파일 및 디렉터리 레이아웃 필드 를 참조하십시오.
4.8.6. 디렉터리 레이아웃 제거
setfattr 명령을 사용하여 디렉토리에서 레이아웃을 제거합니다.
파일 레이아웃을 설정하면 변경하거나 제거할 수 없습니다.
사전 요구 사항
- 레이아웃이 있는 디렉터리입니다.
절차
디렉토리에서 레이아웃을 제거하려면 다음을 수행합니다.
구문
setfattr -x ceph.dir.layout DIRECTORY_PATH
setfattr -x ceph.dir.layout DIRECTORY_PATHCopy to Clipboard Copied! Toggle word wrap Toggle overflow 예제
setfattr -x ceph.dir.layout /home/cephfs
[user@client ~]$ setfattr -x ceph.dir.layout /home/cephfsCopy to Clipboard Copied! Toggle word wrap Toggle overflow pool_namespace필드를 제거하려면 다음을 수행합니다.구문
setfattr -x ceph.dir.layout.pool_namespace DIRECTORY_PATH
setfattr -x ceph.dir.layout.pool_namespace DIRECTORY_PATHCopy to Clipboard Copied! Toggle word wrap Toggle overflow 예제
setfattr -x ceph.dir.layout.pool_namespace /home/cephfs
[user@client ~]$ setfattr -x ceph.dir.layout.pool_namespace /home/cephfsCopy to Clipboard Copied! Toggle word wrap Toggle overflow 참고pool_namespace필드는 별도로 제거할 수 있는 유일한 필드입니다.
추가 리소스
-
setfattr(1)매뉴얼 페이지
4.9. Ceph File System 스냅샷 고려 사항
스토리지 관리자는 Ceph File System(CephFS) 스냅샷을 관리하는 데이터 구조, 시스템 구성 요소 및 고려 사항을 이해할 수 있습니다.
스냅샷은 생성 시점의 파일 시스템의 변경 불가능한 뷰를 생성합니다. 디렉터리 내에 스냅샷을 생성할 수 있으며, 해당 디렉터리의 파일 시스템에 있는 모든 데이터를 다룹니다.
4.9.1. Ceph 파일 시스템의 스냅샷 메타데이터 저장
스냅샷 디렉터리 항목 및 해당 inode의 스토리지는 스냅샷 당시에 있는 디렉터리의 일부로 인라인으로 수행됩니다. 모든 디렉터리 항목에는 유효한 첫 번째 및 마지막 snapid 가 포함됩니다.
4.9.2. Ceph 파일 시스템 스냅샷 쓰기
Ceph 스냅샷은 클라이언트에 따라 스냅샷 및 플러시 스냅샷 데이터 및 메타데이터에 적용되는 작업을 OSD 및 MDS 클러스터로 결정하는 데 도움이 됩니다. 스냅샷 쓰기 처리는 스냅샷이 파일 계층 구조의 하위 트리에 적용되며 스냅샷 생성이 언제든지 발생할 수 있기 때문에 관련 프로세스입니다.
동일한 스냅샷 세트에 속하는 파일 계층 구조의 일부는 단일 SnapRealm 에 의해 참조됩니다. 각 스냅샷은 디렉토리 아래에 중첩된 하위 디렉터리에 적용되며, 영역에 포함된 모든 파일이 동일한 스냅샷 세트를 공유하는 여러 개의 "realms"로 파일 계층을 나눕니다.
Ceph Metadata Server(MDS)는 각 inode의 기능(caps)을 발행하여 inode 메타데이터 및 파일 데이터에 대한 클라이언트 액세스를 제어합니다. 스냅샷을 생성하는 동안 클라이언트는 해당 시점에서 파일 상태를 설명하는 기능을 사용하여 inode에서 더티 메타데이터를 확보합니다. 클라이언트가 ClientSnap 메시지를 수신하면 로컬 SnapRealm 과 해당 링크를 특정 inode에 업데이트하고 inode에 대한 capSnap 을 생성합니다. 기능 백백은 capSnap 을 플러시하고, 더티 데이터가 있는 경우 스냅 샷이 OSD에 플러시될 때까지 새 데이터 쓰기를 차단하는 데 사용됩니다.
MDS는 플러시를 위한 일상적인 프로세스의 일부로 스냅샷 관련 디렉터리 항목을 생성합니다. MDS는 쓰기 프로세스가 플러시될 때까지 메모리 및 저널에 고정되어 있는 미결제 데이터를 사용하여 디렉터리 항목을 유지합니다.
4.9.3. Ceph 파일 시스템 스냅샷 및 하드 링크
Ceph는 여러 하드 링크가 있는 inode를 더미 글로벌 SnapRealm 으로 이동합니다. 이 더미 SnapRealm 은 파일 시스템의 모든 스냅샷을 다룹니다. 새 스냅샷은 inode의 데이터를 보존합니다. 이 보존된 데이터는 inode의 모든 링크에 대한 스냅샷을 다룹니다.
4.9.4. Ceph 파일 시스템의 스냅샷 업데이트
스냅샷 업데이트 프로세스는 스냅샷을 삭제하는 프로세스와 유사합니다.
상위 SnapRealm 에서 inode를 제거하면 SnapRealm 이 아직 존재하지 않는 경우 Ceph는 이름이 변경된 inode에 대한 새 SnapRealm 을 생성합니다. Ceph는 원래 상위 SnapRealm 에 적용되는 스냅샷 ID를 새 SnapRealm 의 past_parent_snaps 데이터 구조에 저장한 다음 스냅샷을 생성하는 것과 유사한 프로세스를 따릅니다.
4.9.5. Ceph 파일 시스템 스냅샷 및 여러 파일 시스템
스냅샷은 여러 파일 시스템에서 제대로 작동하지 않는 것으로 알려져 있습니다.
네임스페이스와 단일 Ceph 풀을 공유하는 여러 파일 시스템이 있는 경우 스냅샷은 충돌하며 하나의 스냅샷을 삭제하면 동일한 Ceph 풀을 공유하는 다른 스냅샷에 필요한 파일 데이터가 누락됩니다.
4.9.6. Ceph File System 스냅샷 데이터 구조
Ceph 파일 시스템(CephFS)은 다음과 같은 스냅샷 데이터 구조를 사용하여 데이터를 효율적으로 저장합니다.
SnapRealm-
SnapRealm은 파일 계층 구조에서 새 시점에서 스냅샷을 만들 때마다 또는 스냅샷된 inode를 상위 스냅샷 외부에서 이동할 때마다 생성됩니다. 단일SnapRealm은 동일한 스냅샷 세트에 속하는 파일 계층 구조의 부분을 나타냅니다.SnapRealm에는 스냅샷의 일부인sr_t_srnode및inodes_with_caps가 포함되어 있습니다. sr_t-
sr_t는 디스크상의 스냅샷 메타데이터입니다. 여기에는 시퀀스 카운터, 타임 스탬프, 관련 스냅샷 ID 목록 및past_parent_snaps목록이 포함됩니다. SnapServer-
SnapServer는 스냅샷 ID 할당, 스냅샷 삭제 및 파일 시스템에서 누적 스냅샷 목록을 유지 관리합니다. 파일 시스템에는SnapServer인스턴스 하나만 있습니다. SnapContextSnapContext는 스냅샷 시퀀스 ID(snapid) 및 개체에 대해 현재 정의된 모든 스냅샷 ID로 구성됩니다. 쓰기 작업이 발생하면 Ceph 클라이언트에서 오브젝트에 존재하는 스냅샷 세트를 지정하는SnapContext를 제공합니다. Ceph는SnapContext목록을 생성하기 위해SnapRealm과 관련된 snapids와past_parent_snaps데이터 구조를 결합합니다.파일 데이터는 RADOS 자체 관리 스냅샷을 사용하여 저장됩니다. 자체 관리 스냅샷에서 클라이언트는 각 쓰기에서 현재
SnapContext를 제공해야 합니다. 클라이언트는 파일 데이터를 Ceph OSD에 작성할 때 올바른SnapContext를 사용해야 합니다.SnapClient의 유효 스냅샷은 오래된 snapid를 필터링합니다.SnapClient-
SnapClient는SnapServer및 캐시 누적 스냅샷과 로컬에서 통신하는 데 사용됩니다. 각 메타데이터 서버(MDS) 순위에는SnapClient인스턴스가 있습니다.
4.10. Ceph 파일 시스템 스냅샷 관리
스토리지 관리자는 Ceph 파일 시스템(CephFS) 디렉터리의 특정 시점 스냅샷을 가져올 수 있습니다. CephFS 스냅샷은 비동기적이므로 에서 생성되는 디렉터리 스냅샷 생성을 선택할 수 있습니다.
4.10.1. 사전 요구 사항
- 실행 중이고 정상적인 Red Hat Ceph Storage 클러스터입니다.
- Ceph 파일 시스템 배포.
4.10.2. Ceph 파일 시스템 스냅샷
Ceph 파일 시스템(CephFS) 스냅샷은 Ceph 파일 시스템에 대한 변경 불가능한 지정 시점 보기를 생성합니다. CephFS 스냅샷은 비동기적이며 CephFS 디렉터리( .snap )의 특수 숨겨진 디렉터리에 보관됩니다. Ceph 파일 시스템 내의 모든 디렉터리에 스냅샷 생성을 지정할 수 있습니다. 디렉터리를 지정할 때 스냅샷에는 해당 디렉터리 아래의 모든 하위 디렉터리도 포함됩니다.
각 Ceph Metadata Server (MDS) 클러스터는 스냅 식별자를 독립적으로 할당합니다. 단일 풀을 공유하는 여러 Ceph File Systems에 스냅샷을 사용하면 스냅샷 충돌이 발생하고 파일 데이터가 누락됩니다.
4.10.3. Ceph 파일 시스템의 스냅샷 활성화
새로운 Ceph File Systems는 기본적으로 스냅샷 기능을 활성화하지만 기존 Ceph 파일 시스템에서 해당 기능을 수동으로 활성화해야 합니다.
사전 요구 사항
- 실행 중이고 정상적인 Red Hat Ceph Storage 클러스터입니다.
- Ceph 파일 시스템 배포.
- Ceph 메타데이터 서버(MDS) 노드에 대한 루트 수준 액세스.
절차
기존 Ceph 파일 시스템의 경우 스냅샷 생성 기능을 활성화합니다.
구문
ceph fs set FILE_SYSTEM_NAME allow_new_snaps true
ceph fs set FILE_SYSTEM_NAME allow_new_snaps trueCopy to Clipboard Copied! Toggle word wrap Toggle overflow 예제
ceph fs set cephfs allow_new_snaps true enabled new snapshots
[root@mds ~]# ceph fs set cephfs allow_new_snaps true enabled new snapshotsCopy to Clipboard Copied! Toggle word wrap Toggle overflow
4.10.4. Ceph 파일 시스템의 스냅샷 생성
스냅샷을 생성하여 Ceph 파일 시스템의 변경 불가능한 지정 시점 보기를 생성할 수 있습니다. 스냅샷은 디렉터리에 있는 숨겨진 디렉터리를 사용하여 스냅샷을 만듭니다. 이 디렉터리의 이름은 기본적으로 .snap 입니다.
사전 요구 사항
- 실행 중이고 정상적인 Red Hat Ceph Storage 클러스터입니다.
- Ceph 파일 시스템 배포.
- Ceph 메타데이터 서버(MDS) 노드에 대한 루트 수준 액세스.
절차
스냅샷을 만들려면
.snap디렉터리 내에 새 하위 디렉터리를 만듭니다. 스냅샷 이름은 새 하위 디렉터리 이름입니다.구문
mkdir NEW_DIRECTORY_PATH
mkdir NEW_DIRECTORY_PATHCopy to Clipboard Copied! Toggle word wrap Toggle overflow 예제
mkdir .snap/new-snaps
[root@mds cephfs]# mkdir .snap/new-snapsCopy to Clipboard Copied! Toggle word wrap Toggle overflow 이 예제에서는
/mnt/cephfs에 마운트된 Ceph 파일 시스템에new-snaps하위 디렉터리를 생성하고 Ceph Metadata Server (MDS)를 알려 스냅샷을 만듭니다.
검증
새 스냅샷 디렉터리를 나열합니다.
구문
ls -l .snap/
ls -l .snap/Copy to Clipboard Copied! Toggle word wrap Toggle overflow new-snaps하위 디렉터리가.snap디렉터리에 표시됩니다.
4.10.5. Ceph 파일 시스템의 스냅샷 삭제
.snap 디렉터리에서 해당 디렉터리를 제거하여 스냅샷을 삭제할 수 있습니다.
사전 요구 사항
- 실행 중이고 정상적인 Red Hat Ceph Storage 클러스터입니다.
- Ceph 파일 시스템 배포.
- Ceph 파일 시스템에서 스냅샷 생성.
- Ceph 메타데이터 서버(MDS) 노드에 대한 루트 수준 액세스.
절차
스냅샷을 삭제하려면 해당 디렉터리를 제거하십시오.
구문
rmdir DIRECTORY_PATH
rmdir DIRECTORY_PATHCopy to Clipboard Copied! Toggle word wrap Toggle overflow 예제
rmdir .snap/new-snaps
[root@mds cephfs]# rmdir .snap/new-snapsCopy to Clipboard Copied! Toggle word wrap Toggle overflow 이 예에서는
/mnt/cephfs에 마운트된 Ceph 파일 시스템에서new-snaps하위 디렉터리를 삭제합니다.
일반 디렉터리와 반대로 디렉터리가 비어 있지 않은 경우에도 rmdir 명령이 성공하므로 재귀 rm 명령을 사용할 필요가 없습니다.
기본 스냅샷이 포함될 수 있는 루트 수준 스냅샷을 삭제하려고 하면 실패합니다.
4.10.6. Ceph 파일 시스템의 스냅샷 복원
스냅샷에서 파일을 복원하거나 Ceph 파일 시스템(CephFS)의 전체 스냅샷을 완전히 복원할 수 있습니다.
사전 요구 사항
- 실행 중이고 정상적인 Red Hat Ceph Storage 클러스터.
- Ceph 파일 시스템 배포.
- Ceph 메타데이터 서버(MDS) 노드에 대한 루트 수준 액세스.
절차
스냅샷에서 파일을 복원하려면 스냅샷 디렉터리에서 일반 트리로 파일을 복사합니다.
구문
cp -a .snap/SNAP_DIRECTORY/FILENAME
cp -a .snap/SNAP_DIRECTORY/FILENAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow 예제
cp .snap/new-snaps/file1 .
[root@mds dir1]# cp .snap/new-snaps/file1 .Copy to Clipboard Copied! Toggle word wrap Toggle overflow 이 예제에서는
file1을 현재 디렉터리로 복원합니다..snap디렉터리 트리에서 스냅샷을 완전히 복원할 수도 있습니다. 현재 항목을 원하는 스냅샷의 복사본으로 바꿉니다.구문
rm -rf * cp -a .snap/SNAP_DIRECTORY/* .
[root@mds dir1]# rm -rf * [root@mds dir1]# cp -a .snap/SNAP_DIRECTORY/* .Copy to Clipboard Copied! Toggle word wrap Toggle overflow 예제
rm -rf * cp -a .snap/new-snaps/* .
[root@mds dir1]# rm -rf * [root@mds dir1]# cp -a .snap/new-snaps/* .Copy to Clipboard Copied! Toggle word wrap Toggle overflow 이 예제에서는
dir1아래의 모든 파일과 디렉터리를 제거하고new-snaps스냅샷에서 현재 디렉터리인dir1로 파일을 복원합니다.
4.11. Ceph 파일 시스템 클러스터 삭제
간단히 다운 플래그를 설정하여 Ceph File System (CephFS) 클러스터를 중단할 수 있습니다. 이렇게 하면 메타 데이터 풀로 저널을 플러시하고 모든 클라이언트 I/O가 중지되어 메타데이터 서버(MDS) 데몬이 정상적으로 종료됩니다.
파일 시스템 삭제를 테스트하고 메타데이터 서버(MDS) 데몬을 가져오는 등의 재해 복구 시나리오를 수행하는 등의 작업을 수행하기 위해 CephFS 클러스터를 신속하게 종료할 수도 있습니다. 이렇게 하면 MDS Wait 데몬이 파일 시스템을 활성화하지 못하도록 jointable 플래그가 설정됩니다.
사전 요구 사항
- 사용자가 Ceph 모니터 노드에 액세스할 수 있습니다.
절차
CephFS 클러스터를 down으로 표시하려면 다음을 수행합니다.
구문
ceph fs set FS_NAME down true
ceph fs set FS_NAME down trueCopy to Clipboard Copied! Toggle word wrap Toggle overflow Exmaple
ceph fs set cephfs down true
[root@mon]# ceph fs set cephfs down trueCopy to Clipboard Copied! Toggle word wrap Toggle overflow CephFS 클러스터를 다시 표시하려면 다음을 수행합니다.
구문
ceph fs set FS_NAME down false
ceph fs set FS_NAME down falseCopy to Clipboard Copied! Toggle word wrap Toggle overflow Exmaple
ceph fs set cephfs down false
[root@mon]# ceph fs set cephfs down falseCopy to Clipboard Copied! Toggle word wrap Toggle overflow
또는
CephFS 클러스터를 신속하게 축소하려면 다음을 수행합니다.
구문
ceph fs fail FS_NAME
ceph fs fail FS_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow Exmaple
ceph fs fail cephfs
[root@mon]# ceph fs fail cephfsCopy to Clipboard Copied! Toggle word wrap Toggle overflow
4.12. 명령줄 인터페이스를 사용하여 Ceph 파일 시스템 제거
명령줄 인터페이스를 사용하여 Ceph 파일 시스템(CephFS)을 제거할 수 있습니다. 이 작업을 수행하기 전에 모든 데이터를 백업하고 모든 클라이언트가 파일 시스템을 로컬에서 마운트 해제했는지 확인하는 것이 좋습니다.
이 작업은 안전하지 않으며 Ceph 파일 시스템에 저장된 데이터를 영구적으로 액세스할 수 없게 됩니다.
사전 요구 사항
- 데이터를 백업합니다.
- 모든 클라이언트는 Ceph 파일 시스템(CephFS)을 마운트 해제했습니다.
- Ceph 모니터 노드에 대한 루트 수준 액세스.
절차
CephFS 상태를 표시하여 MDS 순위를 확인합니다.
구문
ceph fs status
ceph fs statusCopy to Clipboard Copied! Toggle word wrap Toggle overflow 예제
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 위의 예에서 랭크는 0 입니다.
CephFS를 down으로 표시합니다.
구문
ceph fs set FS_NAME down true
ceph fs set FS_NAME down trueCopy to Clipboard Copied! Toggle word wrap Toggle overflow FS_NAME 을 제거할 CephFS의 이름으로 교체합니다.
예제
ceph fs set cephfs down true marked down
[root@mon]# ceph fs set cephfs down true marked downCopy to Clipboard Copied! Toggle word wrap Toggle overflow CephFS의 상태를 표시하여 중지되었는지 확인합니다.
구문
ceph fs status
ceph fs statusCopy to Clipboard Copied! Toggle word wrap Toggle overflow 예제
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 잠시 후 MDS가 더 이상 나열되지 않습니다.
예제
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 단계 1의 상태에 표시된 모든 MDS 순위를 검색합니다.
구문
ceph mds fail RANK
ceph mds fail RANKCopy to Clipboard Copied! Toggle word wrap Toggle overflow RANK 를 실패할 MDS 데몬 순위로 교체합니다.
예제
ceph mds fail 0
[root@mon]# ceph mds fail 0Copy to Clipboard Copied! Toggle word wrap Toggle overflow CephFS를 제거합니다.
구문
ceph fs rm FS_NAME --yes-i-really-mean-it
ceph fs rm FS_NAME --yes-i-really-mean-itCopy to Clipboard Copied! Toggle word wrap Toggle overflow FS_NAME 을 제거할 Ceph 파일 시스템의 이름으로 바꿉니다.
예제
ceph fs rm cephfs --yes-i-really-mean-it
[root@mon]# ceph fs rm cephfs --yes-i-really-mean-itCopy to Clipboard Copied! Toggle word wrap Toggle overflow 파일 시스템이 제거되었는지 확인합니다.
구문
ceph fs ls
ceph fs lsCopy to Clipboard Copied! Toggle word wrap Toggle overflow 예제
ceph fs ls No filesystems enabled
[root@mon ~]# ceph fs ls No filesystems enabledCopy to Clipboard Copied! Toggle word wrap Toggle overflow 선택 사항: CephFS에서 사용한 풀을 제거합니다.
Ceph Monitor 노드에서 풀을 나열합니다.
구문
ceph osd pool ls
ceph osd pool lsCopy to Clipboard Copied! Toggle word wrap Toggle overflow 예제
ceph osd pool ls rbd cephfs_data cephfs_metadata
[root@mon ~]# ceph osd pool ls rbd cephfs_data cephfs_metadataCopy to Clipboard Copied! Toggle word wrap Toggle overflow 예제 출력에서
cephfs_metadata및cephfs_data는 CephFS에서 사용하는 풀입니다.메타데이터 풀을 제거합니다.
구문
ceph osd pool delete CEPH_METADATA_POOL CEPH_METADATA_POOL --yes-i-really-really-mean-it
ceph osd pool delete CEPH_METADATA_POOL CEPH_METADATA_POOL --yes-i-really-really-mean-itCopy to Clipboard Copied! Toggle word wrap Toggle overflow CEPH_METADATA_POOL 을 풀 이름을 두 번 포함하여 메타데이터 스토리지에 사용되는 풀 CephFS로 교체합니다.
예제
ceph osd pool delete cephfs_metadata cephfs_metadata --yes-i-really-really-mean-it pool 'cephfs_metadata' removed
[root@mon ~]# ceph osd pool delete cephfs_metadata cephfs_metadata --yes-i-really-really-mean-it pool 'cephfs_metadata' removedCopy to Clipboard Copied! Toggle word wrap Toggle overflow 데이터 풀을 제거합니다.
구문
ceph osd pool delete CEPH_DATA_POOL CEPH_DATA_POOL --yes-i-really-really-mean-it
ceph osd pool delete CEPH_DATA_POOL CEPH_DATA_POOL --yes-i-really-really-mean-itCopy to Clipboard Copied! Toggle word wrap Toggle overflow CEPH_DATA_POOL 을 풀 이름을 두 번 포함하여 데이터 스토리지에 사용되는 풀 CephFS로 교체합니다.
예제
ceph osd pool delete cephfs_data cephfs_data --yes-i-really-really-mean-it pool 'cephfs_data' removed
[root@mon ~]# ceph osd pool delete cephfs_data cephfs_data --yes-i-really-really-mean-it pool 'cephfs_data' removedCopy to Clipboard Copied! Toggle word wrap Toggle overflow
4.13. Ansible을 사용하여 Ceph 파일 시스템 제거
ceph-ansible 을 사용하여 Ceph 파일 시스템(CephFS)을 제거할 수 있습니다. 이 작업을 수행하기 전에 모든 데이터를 백업하고 모든 클라이언트가 파일 시스템을 로컬에서 마운트 해제했는지 확인하는 것이 좋습니다.
이 작업은 안전하지 않으며 Ceph 파일 시스템에 저장된 데이터를 영구적으로 액세스할 수 없게 됩니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 데이터의 좋은 백업입니다.
- 모든 클라이언트는 Ceph 파일 시스템을 마운트 해제했습니다.
- Ansible 관리 노드에 액세스합니다.
- Ceph 모니터 노드에 대한 루트 수준 액세스.
절차
/usr/share/ceph-ansible/디렉터리로 이동합니다.cd /usr/share/ceph-ansible
[admin@admin ~]$ cd /usr/share/ceph-ansibleCopy to Clipboard Copied! Toggle word wrap Toggle overflow Ansible 인벤토리 파일에서
[mds]섹션을 검토하여 Ceph Metadata Server(MDS) 노드를 식별합니다. Ansible 관리 노드에서/usr/share/ceph-ansible/hosts를 엽니다.예제
[mdss] cluster1-node5 cluster1-node6
[mdss] cluster1-node5 cluster1-node6Copy to Clipboard Copied! Toggle word wrap Toggle overflow 예에서는
cluster1-node5및cluster1-node6은 MDS 노드입니다.max_mds매개변수를1로 설정합니다.구문
ceph fs set NAME max_mds NUMBER
ceph fs set NAME max_mds NUMBERCopy to Clipboard Copied! Toggle word wrap Toggle overflow 예제
ceph fs set cephfs max_mds 1
[root@mon ~]# ceph fs set cephfs max_mds 1Copy to Clipboard Copied! Toggle word wrap Toggle overflow 제거할 메타데이터 서버(MDS)를 지정하여
shrink-mds.yml플레이북을 실행합니다.구문
ansible-playbook infrastructure-playbooks/shrink-mds.yml -e mds_to_kill=MDS_NODE -i hosts
ansible-playbook infrastructure-playbooks/shrink-mds.yml -e mds_to_kill=MDS_NODE -i hostsCopy to Clipboard Copied! Toggle word wrap Toggle overflow MDS_NODE 를 삭제하려는 메타데이터 서버 노드로 바꿉니다. Ansible Playbook은 클러스터를 축소할지 묻는 메시지를 표시합니다.
yes를 입력하고 Enter 키를 누릅니다.예제
ansible-playbook infrastructure-playbooks/shrink-mds.yml -e mds_to_kill=cluster1-node6 -i hosts
[admin@admin ceph-ansible]$ ansible-playbook infrastructure-playbooks/shrink-mds.yml -e mds_to_kill=cluster1-node6 -i hostsCopy to Clipboard Copied! Toggle word wrap Toggle overflow 선택 사항: 추가 MDS 노드의 프로세스를 반복합니다.
구문
ansible-playbook infrastructure-playbooks/shrink-mds.yml -e mds_to_kill=MDS_NODE -i hosts
ansible-playbook infrastructure-playbooks/shrink-mds.yml -e mds_to_kill=MDS_NODE -i hostsCopy to Clipboard Copied! Toggle word wrap Toggle overflow MDS_NODE 를 삭제하려는 메타데이터 서버 노드로 바꿉니다. Ansible Playbook은 클러스터를 축소할지 묻는 메시지를 표시합니다.
yes를 입력하고 Enter 키를 누릅니다.예제
ansible-playbook infrastructure-playbooks/shrink-mds.yml -e mds_to_kill=cluster1-node5 -i hosts
[admin@admin ceph-ansible]$ ansible-playbook infrastructure-playbooks/shrink-mds.yml -e mds_to_kill=cluster1-node5 -i hostsCopy to Clipboard Copied! Toggle word wrap Toggle overflow CephFS의 상태를 확인합니다.
구문
ceph fs status
ceph fs statusCopy to Clipboard Copied! Toggle word wrap Toggle overflow 예제
Copy to Clipboard Copied! Toggle word wrap Toggle overflow [mds]섹션과 Ansible 인벤토리 파일에서 해당 노드를 제거하여 나중에site.yml또는site-container.yml플레이북의 메타데이터 서버로 다시 프로비저닝되지 않습니다. Ansible 인벤토리 파일/usr/share/ceph-ansible/hosts를 편집하기 위해 을 엽니다.예제
[mdss] cluster1-node5 cluster1-node6
[mdss] cluster1-node5 cluster1-node6Copy to Clipboard Copied! Toggle word wrap Toggle overflow [mds]섹션과 해당 섹션 아래의 모든 노드를 제거합니다.CephFS를 제거합니다.
구문
ceph fs rm FS_NAME --yes-i-really-mean-it
ceph fs rm FS_NAME --yes-i-really-mean-itCopy to Clipboard Copied! Toggle word wrap Toggle overflow FS_NAME 을 제거할 Ceph 파일 시스템의 이름으로 바꿉니다.
예제
ceph fs rm cephfs --yes-i-really-mean-it
[root@mon]# ceph fs rm cephfs --yes-i-really-mean-itCopy to Clipboard Copied! Toggle word wrap Toggle overflow 선택 사항: CephFS에서 사용한 풀을 제거합니다.
Ceph Monitor 노드에서 풀을 나열합니다.
구문
ceph osd pool ls
ceph osd pool lsCopy to Clipboard Copied! Toggle word wrap Toggle overflow CephFS에서 사용한 풀을 찾습니다.
예제
ceph osd pool ls rbd cephfs_data cephfs_metadata
[root@mon ~]# ceph osd pool ls rbd cephfs_data cephfs_metadataCopy to Clipboard Copied! Toggle word wrap Toggle overflow 예제 출력에서
cephfs_metadata및cephfs_data는 CephFS에서 사용하는 풀입니다.메타데이터 풀을 제거합니다.
구문
ceph osd pool delete CEPH_METADATA_POOL CEPH_METADATA_POOL --yes-i-really-really-mean-it
ceph osd pool delete CEPH_METADATA_POOL CEPH_METADATA_POOL --yes-i-really-really-mean-itCopy to Clipboard Copied! Toggle word wrap Toggle overflow CEPH_METADATA_POOL 을 풀 이름을 두 번 포함하여 메타데이터 스토리지에 사용되는 풀 CephFS로 교체합니다.
예제
ceph osd pool delete cephfs_metadata cephfs_metadata --yes-i-really-really-mean-it pool 'cephfs_metadata' removed
[root@mon ~]# ceph osd pool delete cephfs_metadata cephfs_metadata --yes-i-really-really-mean-it pool 'cephfs_metadata' removedCopy to Clipboard Copied! Toggle word wrap Toggle overflow 데이터 풀을 제거합니다.
구문
ceph osd pool delete CEPH_DATA_POOL CEPH_DATA_POOL --yes-i-really-really-mean-it
ceph osd pool delete CEPH_DATA_POOL CEPH_DATA_POOL --yes-i-really-really-mean-itCopy to Clipboard Copied! Toggle word wrap Toggle overflow CEPH_METADATA_POOL 을 풀 이름을 두 번 포함하여 메타데이터 스토리지에 사용되는 풀 CephFS로 교체합니다.
예제
ceph osd pool delete cephfs_data cephfs_data --yes-i-really-really-mean-it pool 'cephfs_data' removed
[root@mon ~]# ceph osd pool delete cephfs_data cephfs_data --yes-i-really-really-mean-it pool 'cephfs_data' removedCopy to Clipboard Copied! Toggle word wrap Toggle overflow 풀이 더 이상 존재하지 않는지 확인합니다.
예제
ceph osd pool ls rbd
[root@mon ~]# ceph osd pool ls rbdCopy to Clipboard Copied! Toggle word wrap Toggle overflow cephfs_metadata및cephfs_data풀은 더 이상 나열되지 않습니다.
4.14. 최소 클라이언트 버전 설정
Red Hat Ceph Storage Ceph File System(CephFS)에 연결하려면 타사 클라이언트를 실행해야 하는 최소 버전의 Ceph를 설정할 수 있습니다. 이전 클라이언트가 파일 시스템을 마운트하지 못하도록 min_compat_client 매개변수를 설정합니다. CephFS는 min_compat_client 로 설정된 버전보다 이전 버전을 사용하는 현재 연결된 클라이언트를 자동으로 제거합니다.
이 설정의 논리는 버그가 포함되거나 불완전한 기능 호환성이 클러스터에 연결하여 다른 클라이언트를 방해할 수 있는 이전 클라이언트를 방지하기 위한 것입니다. 예를 들어 일부 이전 버전의 CephFS 클라이언트는 기능을 제대로 릴리스하지 않고 다른 클라이언트 요청이 느리게 처리될 수 있습니다.
min_compat_client 값은 업스트림 Ceph 버전을 기반으로 합니다. 타사 클라이언트는 Red Hat Ceph Storage 클러스터를 기반으로 하는 것과 동일한 주요 업스트림 버전을 사용하는 것이 좋습니다. 업스트림 버전 및 해당 Red Hat Ceph Storage 버전을 보려면 다음 표를 참조하십시오.
| 값 | 업스트림 Ceph 버전 | Red Hat Ceph Storage 버전 |
|---|---|---|
| luminous | 12.2 | Red Hat Ceph Storage 3 |
| mimic | 13.2 | 해당 없음 |
| nautilus | 14.2 | Red Hat Ceph Storage 4 |
Red Hat Enterprise Linux 7을 사용하는 경우 Red Hat Enterprise Linux 7이 고급 클라이언트로 간주되고 이후 버전을 사용하는 경우 CephFS에서 마운트 지점에 액세스할 수 없기 때문에 min_compat_client 를 최신 버전 대신 설정하지 마십시오.
사전 요구 사항
- Ceph 파일 시스템이 배포된 작동 중인 Red Hat Ceph Storage 클러스터
절차
최소 클라이언트 버전을 설정합니다.
ceph fs set name min_compat_client release
ceph fs set name min_compat_client releaseCopy to Clipboard Copied! Toggle word wrap Toggle overflow name 을 Ceph File System의 이름으로 바꾸고 릴리스를 최소 클라이언트 버전으로 변경합니다. 예를 들어,
cephfsCeph 파일 시스템에서nautilus업스트림 버전을 최소로 사용하도록 클라이언트를 제한하려면 다음을 수행합니다.ceph fs set cephfs min_compat_client nautilus
$ ceph fs set cephfs min_compat_client nautilusCopy to Clipboard Copied! Toggle word wrap Toggle overflow 사용 가능한 값의 전체 목록과 Red Hat Ceph Storage 버전에 해당하는 방법은 표 4.1. “
min_compat_clientvalues” 에서 참조하십시오.
4.15. ceph mds fail 명령 사용
ceph mds fail 명령을 사용하여 다음을 수행합니다.
-
MDS 데몬을 실패로 표시합니다. 데몬이 활성 상태이고 적절한 Wait 데몬을 사용할 수 있고, Wait
-replay구성을 비활성화한 후 Wait daemon이 활성화된 경우 이 명령을 사용하여 대기 데몬으로 장애 조치를 강제 적용합니다. Wait-replay데몬을 비활성화하면 새 Wait-replay데몬이 할당되지 않습니다. - 실행 중인 MDS 데몬을 다시 시작합니다. 데몬이 활성 상태이고 적절한 Wait 데몬을 사용할 수 있는 경우 "실패한" 데몬을 사용할 수 있습니다.
사전 요구 사항
- Ceph MDS 데몬의 설치 및 구성.
절차
데몬에 실패하면 다음을 수행합니다.
구문
ceph mds fail MDS_NAME
ceph mds fail MDS_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow 여기서 MDS_NAME 은 Wait
-replayMDS 노드의 이름입니다.예제
ceph mds fail example01
[root@mds ~]# ceph mds fail example01Copy to Clipboard Copied! Toggle word wrap Toggle overflow 참고Ceph MDS 이름은
ceph fs status명령에서 찾을 수 있습니다.
추가 리소스
- Red Hat Ceph Storage 파일 시스템 가이드 의 활성 MDS 데몬 12개를 참조하십시오.
- Red Hat Ceph Storage 파일 시스템 가이드의 Configuring Standby Metadata Server Daemons 를 참조하십시오.
- Red Hat Ceph Storage 파일 시스템 가이드 의 메타데이터 서버 구성에서의 순위 설명을 참조하십시오.
4.16. Ceph 파일 시스템 클라이언트 제거
Ceph 파일 시스템(CephFS) 클라이언트가 응답하지 않거나 오류가 발생하는 경우 CephFS에 액세스하지 못하도록 강제로 종료하거나 제거해야 할 수 있습니다. CephFS 클라이언트를 제거하면 메타데이터 서버(MDS) 데몬 및 Ceph OSD 데몬과 더 이상 통신할 수 없습니다. 제거 시 CephFS 클라이언트가 CephFS에 I/O를 버퍼링하는 경우 영향을 받지 않은 데이터가 손실됩니다. CephFS 클라이언트 제거 프로세스는 FUSE 마운트, 커널 마운트, NFS 게이트웨이 및 libcephfs API 라이브러리를 사용하는 모든 프로세스의 모든 클라이언트 유형에 적용됩니다.
MDS 데몬과 즉시 통신하지 못하거나 수동으로 CephFS 클라이언트를 제거할 수 있습니다.
자동 클라이언트 제거
이러한 시나리오에서는 자동 CephFS 클라이언트 제거가 발생합니다.
-
CephFS 클라이언트가 기본 300초 동안 활성 MDS 데몬과 통신하지 않은 경우 또는
session_autoclose옵션에 의해 설정된 경우 -
mds_cap_revoke_eviction_timeout옵션이 설정되어 있고 CephFS 클라이언트가 설정된 시간(초) 동안 제한 취소 메시지에 응답하지 않았습니다.mds_cap_revoke_eviction_timeout옵션은 기본적으로 비활성화되어 있습니다. -
MDS 시작 또는 페일오버 중에 MDS 데몬은 모든 CephFS 클라이언트가 새 MDS 데몬에 연결할 때까지 대기 중인 다시 연결 단계를 수행합니다. CephFS 클라이언트가 기본 시간 45초 내에 다시 연결하지 못하거나
mds_reconnect_timeout옵션에 의해 설정된 경우.
추가 리소스
- 자세한 내용은 Red Hat Ceph Storage 파일 시스템 가이드의 Ceph 파일 시스템클라이언트 수동 제거 섹션을 참조하십시오.
4.17. Ceph 파일 시스템 클라이언트 블랙리스트
Ceph 파일 시스템 클라이언트 블랙리스트 기능은 기본적으로 활성화되어 있습니다. 단일 메타데이터 서버(MDS) 데몬으로 eviction 명령을 보내면 블랙리스트를 다른 MDS 데몬으로 전달합니다. 이는 CephFS 클라이언트가 데이터 오브젝트에 액세스하지 못하도록 하기 위한 것이므로 블랙리스트된 클라이언트 항목이 포함된 최신 Ceph OSD 맵을 사용하여 다른 CephFS 클라이언트 및 MDS 데몬을 업데이트해야 합니다.
Ceph OSD 맵을 업데이트할 때 내부 "osdmap epoch barrier" 메커니즘이 사용됩니다. 장벽은 ENOSPC 또는 차단된 클라이언트가 제거에서와 같은 취소된 작업과 경쟁하지 않도록 동일한 RADOS 오브젝트에 액세스할 수 있는 기능을 할당하기 전에 기능을 수신하는 CephFS 클라이언트를 확인하는 것입니다.
노드 또는 신뢰할 수 없는 네트워크로 인해 CephFS 클라이언트 제거 빈도가 자주 발생하고 기본 문제를 해결할 수 없는 경우 MDS를 덜 엄격하게 요청할 수 있습니다. MDS 세션을 간단히 삭제하여 느린 CephFS 클라이언트에 응답할 수 있지만 CephFS 클라이언트가 세션을 다시 열고 Ceph OSD에 계속 연결할 수 있습니다. mds_session_blacklist_on_timeout 및 mds_session_blacklist_on_on_evict 옵션을 false 로 설정하면 이 모드를 사용할 수 있습니다.
블랙리스트를 사용하면 제거된 CephFS 클라이언트가 명령을 보낼 MDS 데몬에만 영향을 미칩니다. 활성 MDS 데몬이 여러 개 있는 시스템에서는 eviction 명령을 각 활성 데몬에 보내야 합니다.
4.18. Ceph 파일 시스템 클라이언트 수동 제거
Ceph 파일 시스템(CephFS) 클라이언트를 수동으로 제거할 수 있습니다. 클라이언트가 잘못 작동하고 클라이언트 노드에 액세스할 수 없는 경우 클라이언트 세션이 시간 초과될 때까지 기다리지 않습니다.
사전 요구 사항
- 사용자가 Ceph 모니터 노드에 액세스할 수 있습니다.
절차
클라이언트 목록을 검토합니다.
구문
ceph tell DAEMON_NAME client ls
ceph tell DAEMON_NAME client lsCopy to Clipboard Copied! Toggle word wrap Toggle overflow Exmaple
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 지정된 CephFS 클라이언트를 제거합니다.
구문
ceph tell DAEMON_NAME client evict id=ID_NUMBER
ceph tell DAEMON_NAME client evict id=ID_NUMBERCopy to Clipboard Copied! Toggle word wrap Toggle overflow Exmaple
ceph tell mds.0 client evict id=4305
[root@mon]# ceph tell mds.0 client evict id=4305Copy to Clipboard Copied! Toggle word wrap Toggle overflow
4.19. 블랙리스트에서 Ceph 파일 시스템 클라이언트 제거
이전 블랙리스트로 지정된 Ceph 파일 시스템(CephFS) 클라이언트가 스토리지 클러스터에 다시 연결할 수 있는 경우 유용할 수 있습니다.
블랙리스트에서 CephFS 클라이언트를 제거하면 데이터 무결성을 위험에 빠뜨리며, 결과적으로 정상적이고 기능적인 CephFS 클라이언트를 보장하지 않습니다. 제거 후 완전히 정상 CephFS 클라이언트를 다시 가져오는 가장 좋은 방법은 CephFS 클라이언트를 마운트 해제하고 새로 마운트하는 것입니다. 다른 CephFS 클라이언트가 블랙리스트로 지정된 CephFS 클라이언트가 버퍼링된 I/O를 수행한 파일에 액세스하는 경우 데이터 손상이 발생할 수 있습니다.
사전 요구 사항
- 사용자가 Ceph 모니터 노드에 액세스할 수 있습니다.
절차
블랙리스트를 확인합니다.
Exmaple
ceph osd blacklist ls listed 1 entries 127.0.0.1:0/3710147553 2020-03-19 11:32:24.716146
[root@mon]# ceph osd blacklist ls listed 1 entries 127.0.0.1:0/3710147553 2020-03-19 11:32:24.716146Copy to Clipboard Copied! Toggle word wrap Toggle overflow 블랙리스트에서 CephFS 클라이언트를 제거합니다.
구문
ceph osd blacklist rm CLIENT_NAME_OR_IP_ADDR
ceph osd blacklist rm CLIENT_NAME_OR_IP_ADDRCopy to Clipboard Copied! Toggle word wrap Toggle overflow Exmaple
ceph osd blacklist rm 127.0.0.1:0/3710147553 un-blacklisting 127.0.0.1:0/3710147553
[root@mon]# ceph osd blacklist rm 127.0.0.1:0/3710147553 un-blacklisting 127.0.0.1:0/3710147553Copy to Clipboard Copied! Toggle word wrap Toggle overflow 필요한 경우 FUSE 기반 CephFS 클라이언트가 블랙리스트에서 제거할 때 자동으로 다시 연결을 시도합니다. FUSE 클라이언트에서 다음 옵션을
true로 설정합니다.client_reconnect_stale = true
client_reconnect_stale = trueCopy to Clipboard Copied! Toggle word wrap Toggle overflow
4.20. 추가 리소스
- 자세한 내용은 3장. Ceph 파일 시스템 배포의 내용을 참조하십시오.
- 자세한 내용은 Red Hat Ceph Storage 설치 가이드를 참조하십시오.
- 자세한 내용은 Red Hat Ceph Storage 파일 시스템 가이드 의 메타데이터 서버 데몬 구성을 참조하십시오.
5장. Ceph File System 볼륨, 하위 볼륨, 하위 볼륨 그룹 관리
스토리지 관리자는 Red Hat의 Ceph Container Storage Interface(CSI)를 사용하여 Ceph 파일 시스템(CephFS) 내보내기를 관리할 수 있습니다. 또한 와 상호 작용할 수 있는 공통 명령줄 인터페이스를 통해 OpenStack의 파일 시스템 서비스(Manila)와 같은 다른 서비스도 사용할 수 있습니다. Ceph Manager 데몬(ceph-mgr)의 volumes 모듈은 CephFS(CephFS)를 내보내는 기능을 구현합니다.
Ceph Manager volumes 모듈은 다음 파일 시스템 내보내기 추상화를 구현합니다.
- CephFS 볼륨
- CephFS 하위 볼륨 그룹
- CephFS 하위 볼륨
이 장에서는 다음을 수행하는 방법을 설명합니다.
5.1. Ceph 파일 시스템 볼륨
스토리지 관리자는 Ceph 파일 시스템(CephFS) 볼륨을 생성, 나열 및 제거할 수 있습니다. CephFS 볼륨은 Ceph 파일 시스템에 대한 추상화입니다.
이 섹션에서는 다음을 수행하는 방법에 대해 설명합니다.
5.1.1. 파일 시스템 볼륨 생성
Ceph Manager의 오케스트레이터 모듈은 Ceph 파일 시스템(CephFS)에 대한 메타 데이터 서버(MDS)를 생성합니다. 이 섹션에서는 CephFS 볼륨 생성 방법에 대해 설명합니다.
이렇게 하면 Ceph 파일 시스템이 데이터 및 메타데이터 풀과 함께 생성됩니다.
사전 요구 사항
- Ceph 파일 시스템이 배포된 작동 중인 Red Hat Ceph Storage 클러스터.
- Ceph 모니터에서 최소 읽기 액세스 권한입니다.
- Ceph Manager 노드의 읽기 및 쓰기 기능.
절차
CephFS 볼륨을 생성합니다.
구문
ceph fs volume create VOLUME_NAME
ceph fs volume create VOLUME_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow 예제
ceph fs volume create cephfs
[root@mon ~]# ceph fs volume create cephfsCopy to Clipboard Copied! Toggle word wrap Toggle overflow
5.1.2. 파일 시스템 볼륨 나열
이 섹션에서는 Ceph 파일 시스템(CephFS) 볼륨을 나열하는 단계에 대해 설명합니다.
사전 요구 사항
- Ceph 파일 시스템이 배포된 작동 중인 Red Hat Ceph Storage 클러스터.
- Ceph 모니터에서 최소 읽기 액세스 권한입니다.
- Ceph Manager 노드의 읽기 및 쓰기 기능.
- CephFS 볼륨.
절차
CephFS 볼륨을 나열합니다.
예제
ceph fs volume ls
[root@mon ~]# ceph fs volume lsCopy to Clipboard Copied! Toggle word wrap Toggle overflow
5.1.3. 파일 시스템 볼륨 제거
Ceph Manager의 오케스트레이터 모듈은 Ceph 파일 시스템(CephFS)의 메타 데이터 서버(MDS)를 제거합니다. 이 섹션에서는 Ceph 파일 시스템(CephFS) 볼륨을 제거하는 방법을 보여줍니다.
사전 요구 사항
- Ceph 파일 시스템이 배포된 작동 중인 Red Hat Ceph Storage 클러스터.
- Ceph 모니터에서 최소 읽기 액세스 권한입니다.
- Ceph Manager 노드의 읽기 및 쓰기 기능.
- CephFS 볼륨.
절차
CephFS 볼륨을 제거합니다.
구문
ceph fs volume rm VOLUME_NAME [--yes-i-really-mean-it]
ceph fs volume rm VOLUME_NAME [--yes-i-really-mean-it]Copy to Clipboard Copied! Toggle word wrap Toggle overflow 예제
ceph fs volume rm cephfs --yes-i-really-mean-it
[root@mon ~]# ceph fs volume rm cephfs --yes-i-really-mean-itCopy to Clipboard Copied! Toggle word wrap Toggle overflow
5.2. Ceph 파일 시스템 하위 볼륨
스토리지 관리자는 Ceph File System(CephFS) 하위 볼륨을 생성, 나열, 절대 경로 가져오기, 메타데이터 가져오기 및 제거할 수 있습니다.
CephFS 하위 볼륨에 대해 Ceph 클라이언트 사용자에게 권한을 부여할 수도 있습니다. 또한 이러한 하위 볼륨의 스냅샷을 생성, 나열 및 제거할 수도 있습니다. CephFS 하위 볼륨은 독립 Ceph 파일 시스템 디렉터리 트리에 대한 추상화입니다.
이 섹션에서는 다음을 수행하는 방법에 대해 설명합니다.
- 파일 시스템 하위 볼륨을 생성합니다.
- 파일 시스템 하위 볼륨 나열.
- 파일 시스템 하위 볼륨에 대한 Ceph 클라이언트 사용자 인증.
- 파일 시스템 하위 볼륨에 대해 Ceph 클라이언트 사용자 분리.
- 파일 시스템 하위 볼륨의 Ceph 클라이언트 사용자 나열.
- 파일 시스템 하위 볼륨에서 Ceph 클라이언트 사용자 제거.
- 파일 시스템 하위 볼륨 크기 조정.
- 파일 시스템 하위 볼륨의 절대 경로를 가져옵니다.
- 파일 시스템 하위 볼륨의 메타데이터 가져오기.
- 파일 시스템 하위 볼륨의 스냅샷을 생성합니다.
- 파일 시스템 하위 볼륨의 스냅샷을 나열합니다.
- 파일 시스템 하위 볼륨의 스냅샷의 메타데이터 가져오기.
- 파일 시스템 하위 볼륨을 제거합니다.
- 파일 시스템 하위 볼륨의 스냅샷을 제거합니다.
5.2.1. 파일 시스템 하위 볼륨 생성
이 섹션에서는 Ceph 파일 시스템(CephFS) 하위 볼륨을 생성하는 방법을 설명합니다.
하위 볼륨을 생성할 때 하위 볼륨 그룹, 데이터 풀 레이아웃, uid, gid, 파일 모드를 8진수 숫자로 지정하고 바이트 단위로 크기를 지정할 수 있습니다. '-namespace-isolated' 옵션을 지정하여 하위 볼륨을 별도의 RADOS 네임스페이스에 생성할 수 있습니다. 기본적으로 하위 볼륨은 기본 하위 볼륨 그룹 내에 생성되며 8진수 파일 모드 '755', subvolume 그룹의 uid, subvolume 그룹의 gid, 상위 디렉터리의 데이터 풀 레이아웃 및 크기 제한은 없습니다.
사전 요구 사항
- Ceph 파일 시스템이 배포된 작동 중인 Red Hat Ceph Storage 클러스터.
- Ceph 모니터에서 최소 읽기 액세스 권한입니다.
- Ceph Manager 노드의 읽기 및 쓰기 기능.
절차
CephFS 하위 볼륨을 생성합니다.
구문
ceph fs subvolume create VOLUME_NAME SUBVOLUME_NAME [--size SIZE_IN_BYTES --group_name SUBVOLUME_GROUP_NAME --pool_layout DATA_POOL_NAME --uid _UID --gid GID --mode OCTAL_MODE] [--namespace-isolated]
ceph fs subvolume create VOLUME_NAME SUBVOLUME_NAME [--size SIZE_IN_BYTES --group_name SUBVOLUME_GROUP_NAME --pool_layout DATA_POOL_NAME --uid _UID --gid GID --mode OCTAL_MODE] [--namespace-isolated]Copy to Clipboard Copied! Toggle word wrap Toggle overflow 예제
ceph fs subvolume create cephfs sub0 --group_name subgroup0 --namespace-isolated
[root@mon ~]# ceph fs subvolume create cephfs sub0 --group_name subgroup0 --namespace-isolatedCopy to Clipboard Copied! Toggle word wrap Toggle overflow 하위 볼륨이 이미 존재하는 경우에도 명령이 성공합니다.
5.2.2. 파일 시스템 하위 볼륨 나열
이 섹션에서는 Ceph 파일 시스템(CephFS) 하위 볼륨을 나열하는 단계에 대해 설명합니다.
사전 요구 사항
- Ceph 파일 시스템이 배포된 작동 중인 Red Hat Ceph Storage 클러스터.
- Ceph 모니터에서 최소 읽기 액세스 권한입니다.
- Ceph Manager 노드의 읽기 및 쓰기 기능.
- CephFS 하위 볼륨.
절차
CephFS 하위 볼륨을 나열합니다.
구문
ceph fs subvolume ls VOLUME_NAME [--group_name SUBVOLUME_GROUP_NAME]
ceph fs subvolume ls VOLUME_NAME [--group_name SUBVOLUME_GROUP_NAME]Copy to Clipboard Copied! Toggle word wrap Toggle overflow 예제
ceph fs subvolume ls cephfs --group_name subgroup0
[root@mon ~]# ceph fs subvolume ls cephfs --group_name subgroup0Copy to Clipboard Copied! Toggle word wrap Toggle overflow
5.2.3. 파일 시스템 하위 볼륨에 대한 Ceph 클라이언트 사용자 인증
Red Hat Ceph Storage 클러스터에서는 설치에 의해 활성화되는 authentication에 RuntimeClass를 사용합니다. Ceph 파일 시스템(CephFS) 하위 볼륨과 함께 RuntimeClass를 사용하려면 Ceph Monitor 노드에서 올바른 권한 부여 기능을 가진 사용자를 생성하고 Ceph 파일 시스템이 마운트된 노드에서 키를 사용할 수 있도록 합니다. authorize 명령을 사용하여 CephFS 하위 볼륨에 액세스하도록 사용자에게 권한을 부여할 수 있습니다.
사전 요구 사항
- CephFS가 배포된 상태에서 작동하는 Red Hat Ceph Storage 클러스터.
- Ceph 모니터에서 최소 읽기 액세스 권한입니다.
- Ceph Manager 노드의 읽기 및 쓰기 기능.
- 생성된 CephFS 볼륨입니다.
절차
CephFS 하위 볼륨을 생성합니다.
구문
ceph fs subvolume create VOLUME_NAME SUBVOLUME_NAME [--size SIZE_IN_BYTES --group_name SUBVOLUME_GROUP_NAME --pool_layout DATA_POOL_NAME --uid _UID --gid GID --mode OCTAL_MODE] [--namespace-isolated]
ceph fs subvolume create VOLUME_NAME SUBVOLUME_NAME [--size SIZE_IN_BYTES --group_name SUBVOLUME_GROUP_NAME --pool_layout DATA_POOL_NAME --uid _UID --gid GID --mode OCTAL_MODE] [--namespace-isolated]Copy to Clipboard Copied! Toggle word wrap Toggle overflow 예제
ceph fs subvolume create cephfs sub0 --group_name subgroup0 --namespace-isolated
[root@mon ~]# ceph fs subvolume create cephfs sub0 --group_name subgroup0 --namespace-isolatedCopy to Clipboard Copied! Toggle word wrap Toggle overflow 하위 볼륨이 이미 존재하는 경우에도 명령이 성공합니다.
CephFS 하위 볼륨에 대한 읽기 또는 쓰기 액세스 권한을 사용하여 Ceph 클라이언트 사용자를 인증합니다.
구문
ceph fs subvolume authorize VOLUME_NAME SUBVOLUME_NAME AUTH_ID [--group_name=GROUP_NAME] [--access_level=ACCESS_LEVEL]
ceph fs subvolume authorize VOLUME_NAME SUBVOLUME_NAME AUTH_ID [--group_name=GROUP_NAME] [--access_level=ACCESS_LEVEL]Copy to Clipboard Copied! Toggle word wrap Toggle overflow ACCESS_LEVEL은r또는rw일 수 있으며AUTH_ID는 문자열인 Ceph 클라이언트 사용자입니다.예제
ceph fs subvolume authorize cephfs sub0 guest --group_name=subgroup0 --access_level=rw
[root@mon ~]# ceph fs subvolume authorize cephfs sub0 guest --group_name=subgroup0 --access_level=rwCopy to Clipboard Copied! Toggle word wrap Toggle overflow 이 예에서 'client.guest'는 하위 볼륨 그룹
subgroup0의subvolume 하위0에 액세스할 수 있는 권한이 있습니다.
5.2.4. 파일 시스템 하위 볼륨을 위한 Ceph 클라이언트 사용자 분리
deauthorize 명령을 사용하여 Ceph 파일 시스템(CephFS) 하위 볼륨에 액세스하도록 사용자의 인증을 해제할 수 있습니다.
사전 요구 사항
- Ceph 파일 시스템이 배포된 작동 중인 Red Hat Ceph Storage 클러스터.
- Ceph 모니터에서 최소 읽기 액세스 권한입니다.
- Ceph Manager 노드의 읽기 및 쓰기 기능.
- 생성된 CephFS 볼륨 및 하위 볼륨입니다.
- CephFS 하위 볼륨에 액세스할 권한이 있는 Ceph 클라이언트 사용자.
절차
Ceph 클라이언트 사용자의 CephFS 하위 볼륨에 대한 액세스의 인증을 해제합니다.
구문
ceph fs subvolume deauthorize VOLUME_NAME SUBVOLUME_NAME AUTH_ID [--group_name=GROUP_NAME]
ceph fs subvolume deauthorize VOLUME_NAME SUBVOLUME_NAME AUTH_ID [--group_name=GROUP_NAME]Copy to Clipboard Copied! Toggle word wrap Toggle overflow AUTH_ID는 문자열인 Ceph 클라이언트 사용자입니다.예제
ceph fs subvolume deauthorize cephfs sub0 guest --group_name=subgroup0
[root@mon ~]# ceph fs subvolume deauthorize cephfs sub0 guest --group_name=subgroup0Copy to Clipboard Copied! Toggle word wrap Toggle overflow 이 예에서 'client.guest'는 subvolume 그룹
subgroup0의subvolume 하위0에 액세스할 수 없습니다.
5.2.5. 파일 시스템 하위 볼륨의 Ceph 클라이언트 사용자 나열
authorized_list 명령을 사용하여 Ceph 파일 시스템(CephFS) 하위 볼륨에 대한 사용자 액세스를 나열할 수 있습니다.
사전 요구 사항
- Ceph 파일 시스템이 배포된 작동 중인 Red Hat Ceph Storage 클러스터.
- Ceph 모니터에서 최소 읽기 액세스 권한입니다.
- Ceph Manager 노드의 읽기 및 쓰기 기능.
- 생성된 CephFS 볼륨 및 하위 볼륨입니다.
- CephFS 하위 볼륨에 액세스할 권한이 있는 Ceph 클라이언트 사용자.
절차
Ceph 클라이언트 사용자의 CephFS 하위 볼륨에 대한 액세스를 나열합니다.
구문
ceph fs subvolume authorized_list VOLUME_NAME SUBVOLUME_NAME [--group_name=GROUP_NAME]
ceph fs subvolume authorized_list VOLUME_NAME SUBVOLUME_NAME [--group_name=GROUP_NAME]Copy to Clipboard Copied! Toggle word wrap Toggle overflow 예제
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
5.2.6. 파일 시스템 하위 볼륨에서 Ceph 클라이언트 사용자 제거
_AUTH_ID 및 마운트된 하위 볼륨을 기반으로 remove 명령을 사용하여 Ceph 파일 시스템(CephFS) 하위 볼륨에서 Ceph 클라이언트 사용자를 제거할 수 있습니다.
사전 요구 사항
- Ceph 파일 시스템이 배포된 작동 중인 Red Hat Ceph Storage 클러스터.
- Ceph 모니터에서 최소 읽기 액세스 권한입니다.
- Ceph Manager 노드의 읽기 및 쓰기 기능.
- 생성된 CephFS 볼륨 및 하위 볼륨입니다.
- CephFS 하위 볼륨에 액세스할 권한이 있는 Ceph 클라이언트 사용자.
절차
CephFS 하위 볼륨에서 Ceph 클라이언트 사용자를 제거합니다.
구문
ceph fs subvolume evict VOLUME_NAME SUBVOLUME_NAME AUTH_ID [--group_name=GROUP_NAME]
ceph fs subvolume evict VOLUME_NAME SUBVOLUME_NAME AUTH_ID [--group_name=GROUP_NAME]Copy to Clipboard Copied! Toggle word wrap Toggle overflow AUTH_ID는 문자열인 Ceph 클라이언트 사용자입니다.예제
ceph fs subvolume evict cephfs sub0 guest --group_name=subgroup0
[root@mon ~]# ceph fs subvolume evict cephfs sub0 guest --group_name=subgroup0Copy to Clipboard Copied! Toggle word wrap Toggle overflow 이 예에서 'client.guest'는 subvolumegroup
하위 그룹에서 제거됩니다.
5.2.7. 파일 시스템 하위 볼륨 크기 조정
이 섹션에서는 Ceph 파일 시스템(CephFS) 하위 볼륨의 크기를 조정하는 단계를 설명합니다.
ceph fs 하위 볼륨 크기 조정 명령은 new_size 에서 지정한 크기를 사용하여 하위 볼륨 할당량의 크기를 조정합니다. --no_shrink 플래그를 사용하면 하위 볼륨이 현재 사용된 하위 볼륨 크기보다 축소되지 않습니다. subvolume을 new_size 로 inf 또는 infinite 를 전달하여 무한한 크기로 조정할 수 있습니다.
사전 요구 사항
- Ceph 파일 시스템이 배포된 작동 중인 Red Hat Ceph Storage 클러스터.
- Ceph 모니터에서 최소 읽기 액세스 권한입니다.
- Ceph Manager 노드의 읽기 및 쓰기 기능.
- CephFS 하위 볼륨.
절차
CephFS 하위 볼륨의 크기를 조정합니다.
구문
ceph fs subvolume resize VOLUME_NAME SUBVOLUME_NAME_ NEW_SIZE [--group_name SUBVOLUME_GROUP_NAME] [--no_shrink]
ceph fs subvolume resize VOLUME_NAME SUBVOLUME_NAME_ NEW_SIZE [--group_name SUBVOLUME_GROUP_NAME] [--no_shrink]Copy to Clipboard Copied! Toggle word wrap Toggle overflow 예제
ceph fs subvolume resize cephfs sub0 1024000000 --group_name subgroup0 --no_shrink
[root@mon ~]# ceph fs subvolume resize cephfs sub0 1024000000 --group_name subgroup0 --no_shrinkCopy to Clipboard Copied! Toggle word wrap Toggle overflow
5.2.8. 파일 시스템 하위 볼륨의 절대 경로 가져오기
이 섹션에서는 Ceph 파일 시스템(CephFS) 하위 볼륨의 절대 경로를 가져오는 방법을 보여줍니다.
사전 요구 사항
- Ceph 파일 시스템이 배포된 작동 중인 Red Hat Ceph Storage 클러스터.
- Ceph 모니터에서 최소 읽기 액세스 권한입니다.
- Ceph Manager 노드의 읽기 및 쓰기 기능.
- CephFS 하위 볼륨.
절차
CephFS 하위 볼륨의 절대 경로를 가져옵니다.
구문
ceph fs subvolume getpath VOLUME_NAME SUBVOLUME_NAME [--group_name SUBVOLUME_GROUP_NAME]
ceph fs subvolume getpath VOLUME_NAME SUBVOLUME_NAME [--group_name SUBVOLUME_GROUP_NAME]Copy to Clipboard Copied! Toggle word wrap Toggle overflow 예제
ceph fs subvolume getpath cephfs sub0 --group_name subgroup0 /volumes/subgroup0/sub0/c10cc8b8-851d-477f-99f2-1139d944f691
[root@mon ~]# ceph fs subvolume getpath cephfs sub0 --group_name subgroup0 /volumes/subgroup0/sub0/c10cc8b8-851d-477f-99f2-1139d944f691Copy to Clipboard Copied! Toggle word wrap Toggle overflow
5.2.9. 파일 시스템 하위 볼륨의 메타데이터 가져오기
이 섹션에서는 Ceph 파일 시스템(CephFS) 하위 볼륨의 메타데이터를 가져오는 방법을 보여줍니다.
사전 요구 사항
- Ceph 파일 시스템이 배포된 작동 중인 Red Hat Ceph Storage 클러스터.
- Ceph 모니터에서 최소 읽기 액세스 권한입니다.
- Ceph Manager 노드의 읽기 및 쓰기 기능.
- CephFS 하위 볼륨.
절차
CephFS 하위 볼륨의 메타데이터를 가져옵니다.
구문
ceph fs subvolume info VOLUME_NAME SUBVOLUME_NAME [--group_name SUBVOLUME_GROUP_NAME]
ceph fs subvolume info VOLUME_NAME SUBVOLUME_NAME [--group_name SUBVOLUME_GROUP_NAME]Copy to Clipboard Copied! Toggle word wrap Toggle overflow 예제
ceph fs subvolume info cephfs sub0 --group_name subgroup0
[root@mon ~]# ceph fs subvolume info cephfs sub0 --group_name subgroup0Copy to Clipboard Copied! Toggle word wrap Toggle overflow 출력 예
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
출력 형식은 json이며 다음 필드를 포함합니다.
- Atime: "YYYY-MM-DD HH:MM:SS" 형식의 하위 볼륨 경로의 액세스 시간입니다.
- mtime: "YYYY-MM-DD HH:MM:SS" 형식의 하위 볼륨 경로의 수정 시간입니다.
- ctime: "YYYY-MM-DD HH:MM:SS" 형식의 하위 볼륨 경로 변경
- UID: 하위 볼륨 경로의 기본값입니다.
- GID: subvolume 경로를 gid합니다.
- mode: 하위 볼륨 경로의 모드입니다.
- mon_addrs: 모니터 주소 목록입니다.
- bytes_pcent: 할당량이 설정된 경우 백분율로 사용된 할당량은 "정의되지 않음"으로 표시됩니다.
- bytes_quota: 할당량이 설정된 경우 할당량 크기(바이트)는 바이트이며, 그렇지 않으면 "infinite"가 표시됩니다.
- bytes_used: 현재 사용된 하위 볼륨의 크기(바이트)
- created_at: "YYYY-MM-DD HH:MM:SS" 형식으로 하위 볼륨을 생성합니다.
- data_pool: 하위 볼륨이 속한 데이터 풀입니다.
- path: 하위 볼륨의 절대 경로입니다.
- Type: subvolume은 clone 또는 subvolume인지 여부를 나타냅니다.
- pool_namespace: subvolume의 RADOS 네임스페이스입니다.
- features: , "snapshot-clone", "snapshot-autoprotect" 또는 "snapshot-retention"과 같은 하위 볼륨에서 지원하는 기능입니다.
- State: "완전" 또는 "snapshot-retained"와 같은 하위 볼륨의 현재 상태입니다.
5.2.10. 파일 시스템 하위 볼륨의 스냅샷 생성
이 섹션에서는 Ceph 파일 시스템(CephFS) 하위 볼륨의 스냅샷을 생성하는 방법을 보여줍니다.
사전 요구 사항
- Ceph 파일 시스템이 배포된 작동 중인 Red Hat Ceph Storage 클러스터.
- Ceph 모니터에서 최소 읽기 액세스 권한입니다.
- Ceph Manager 노드의 읽기 및 쓰기 기능.
- CephFS 하위 볼륨.
-
클라이언트에는 읽기(
r) 및 쓰기(w) 기능 외에도 파일 시스템 내의 디렉터리 경로에s플래그가 필요합니다.
절차
s플래그가 디렉터리에 설정되어 있는지 확인합니다.구문
ceph auth get CLIENT_NAME
ceph auth get CLIENT_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow 예제
client.0 key: AQAz7EVWygILFRAAdIcuJ12opU/JKyfFmxhuaw== caps: [mds] allow rw, allow rws path=/bar caps: [mon] allow r caps: [osd] allow rw tag cephfs data=cephfs_aclient.0 key: AQAz7EVWygILFRAAdIcuJ12opU/JKyfFmxhuaw== caps: [mds] allow rw, allow rws path=/bar1 caps: [mon] allow r caps: [osd] allow rw tag cephfs data=cephfs_a2 Copy to Clipboard Copied! Toggle word wrap Toggle overflow Ceph 파일 시스템 하위 볼륨의 스냅샷을 생성합니다.
구문
ceph fs subvolume snapshot create VOLUME_NAME _SUBVOLUME_NAME _SNAP_NAME [--group_name GROUP_NAME]
ceph fs subvolume snapshot create VOLUME_NAME _SUBVOLUME_NAME _SNAP_NAME [--group_name GROUP_NAME]Copy to Clipboard Copied! Toggle word wrap Toggle overflow 예제
ceph fs subvolume snapshot create cephfs sub0 snap0 --group_name subgroup0
[root@mon ~]# ceph fs subvolume snapshot create cephfs sub0 snap0 --group_name subgroup0Copy to Clipboard Copied! Toggle word wrap Toggle overflow
5.2.11. 스냅샷에서 하위 볼륨 복제
하위 볼륨은 하위 볼륨 스냅샷을 복제하여 생성할 수 있습니다. 스냅샷의 데이터를 하위 볼륨으로 복사하는 비동기 작업입니다.
사전 요구 사항
- Ceph 파일 시스템이 배포된 작동 중인 Red Hat Ceph Storage 클러스터.
- Ceph 모니터에서 최소 읽기 액세스 권한입니다.
- Ceph Manager 노드의 읽기 및 쓰기 기능.
스냅샷을 생성하거나 삭제하려면 읽기 및 쓰기 기능 외에도 클라이언트에는 파일 시스템 내의 디렉터리 경로에
s플래그가 필요합니다.구문
CLIENT_NAME key: AQAz7EVWygILFRAAdIcuJ12opU/JKyfFmxhuaw== caps: [mds] allow rw, allow rws path=DIRECTORY_PATH caps: [mon] allow r caps: [osd] allow rw tag cephfs data=DIRECTORY_NAMECLIENT_NAME key: AQAz7EVWygILFRAAdIcuJ12opU/JKyfFmxhuaw== caps: [mds] allow rw, allow rws path=DIRECTORY_PATH caps: [mon] allow r caps: [osd] allow rw tag cephfs data=DIRECTORY_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow 다음 예제에서
client.0은 파일 시스템cephfs_a의bar디렉터리에서 스냅샷을 생성하거나 삭제할 수 있습니다.예제
client.0 key: AQAz7EVWygILFRAAdIcuJ12opU/JKyfFmxhuaw== caps: [mds] allow rw, allow rws path=/bar caps: [mon] allow r caps: [osd] allow rw tag cephfs data=cephfs_aclient.0 key: AQAz7EVWygILFRAAdIcuJ12opU/JKyfFmxhuaw== caps: [mds] allow rw, allow rws path=/bar caps: [mon] allow r caps: [osd] allow rw tag cephfs data=cephfs_aCopy to Clipboard Copied! Toggle word wrap Toggle overflow
절차
Ceph 파일 시스템(CephFS) 볼륨을 생성합니다.
구문
ceph fs volume create VOLUME_NAME
ceph fs volume create VOLUME_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow 예제
ceph fs volume create cephfs
[root@mon ~]# ceph fs volume create cephfsCopy to Clipboard Copied! Toggle word wrap Toggle overflow 이렇게 하면 CephFS 파일 시스템, 해당 데이터 및 메타데이터 풀이 생성됩니다.
하위 볼륨 그룹을 생성합니다. 기본적으로 하위 볼륨 그룹은 8진수 파일 모드 '755' 및 상위 디렉터리의 데이터 풀 레이아웃으로 생성됩니다.
구문
ceph fs subvolumegroup create VOLUME_NAME GROUP_NAME [--pool_layout DATA_POOL_NAME --uid UID --gid GID --mode OCTAL_MODE]
ceph fs subvolumegroup create VOLUME_NAME GROUP_NAME [--pool_layout DATA_POOL_NAME --uid UID --gid GID --mode OCTAL_MODE]Copy to Clipboard Copied! Toggle word wrap Toggle overflow 예제
ceph fs subvolumegroup create cephfs subgroup0
[root@mon ~]# ceph fs subvolumegroup create cephfs subgroup0Copy to Clipboard Copied! Toggle word wrap Toggle overflow 하위 볼륨을 생성합니다. 기본적으로 하위 볼륨은 기본 하위 볼륨 그룹 내에 생성되며 8진수 파일 모드 '755', subvolume 그룹의 uid, subvolume 그룹의 gid, 상위 디렉터리의 데이터 풀 레이아웃 및 크기 제한은 없습니다.
구문
ceph fs subvolume create VOLUME_NAME SUBVOLUME_NAME [--size SIZE_IN_BYTES --group_name SUBVOLUME_GROUP_NAME --pool_layout DATA_POOL_NAME --uid _UID --gid GID --mode OCTAL_MODE]
ceph fs subvolume create VOLUME_NAME SUBVOLUME_NAME [--size SIZE_IN_BYTES --group_name SUBVOLUME_GROUP_NAME --pool_layout DATA_POOL_NAME --uid _UID --gid GID --mode OCTAL_MODE]Copy to Clipboard Copied! Toggle word wrap Toggle overflow 예제
ceph fs subvolume create cephfs sub0 --group_name subgroup0
[root@mon ~]# ceph fs subvolume create cephfs sub0 --group_name subgroup0Copy to Clipboard Copied! Toggle word wrap Toggle overflow 하위 볼륨의 스냅샷을 생성합니다.
구문
ceph fs subvolume snapshot create VOLUME_NAME _SUBVOLUME_NAME SNAP_NAME [--group_name SUBVOLUME_GROUP_NAME]
ceph fs subvolume snapshot create VOLUME_NAME _SUBVOLUME_NAME SNAP_NAME [--group_name SUBVOLUME_GROUP_NAME]Copy to Clipboard Copied! Toggle word wrap Toggle overflow 예제
ceph fs subvolume snapshot create cephfs sub0 snap0 --group_name subgroup0
[root@mon ~]# ceph fs subvolume snapshot create cephfs sub0 snap0 --group_name subgroup0Copy to Clipboard Copied! Toggle word wrap Toggle overflow 복제 작업을 시작합니다.
참고기본적으로 복제된 하위 볼륨은 기본 그룹에 생성됩니다.
소스 하위 볼륨 및 대상 복제가 기본 그룹에 있는 경우 다음 명령을 실행합니다.
구문
ceph fs subvolume snapshot clone VOLUME_NAME SUBVOLUME_NAME SNAP_NAME TARGET_SUBVOLUME_NAME
ceph fs subvolume snapshot clone VOLUME_NAME SUBVOLUME_NAME SNAP_NAME TARGET_SUBVOLUME_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow 예제
ceph fs subvolume snapshot clone cephfs sub0 snap0 clone0
[root@mon ~]# ceph fs subvolume snapshot clone cephfs sub0 snap0 clone0Copy to Clipboard Copied! Toggle word wrap Toggle overflow source 하위 볼륨이 기본값이 아닌 그룹에 있는 경우 다음 명령에서 source 하위 볼륨 그룹을 지정합니다.
구문
ceph fs subvolume snapshot clone VOLUME_NAME SUBVOLUME_NAME SNAP_NAME TARGET_SUBVOLUME_NAME --group_name SUBVOLUME_GROUP_NAME
ceph fs subvolume snapshot clone VOLUME_NAME SUBVOLUME_NAME SNAP_NAME TARGET_SUBVOLUME_NAME --group_name SUBVOLUME_GROUP_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow 예제
ceph fs subvolume snapshot clone cephfs sub0 snap0 clone0 --group_name subgroup0
[root@mon ~]# ceph fs subvolume snapshot clone cephfs sub0 snap0 clone0 --group_name subgroup0Copy to Clipboard Copied! Toggle word wrap Toggle overflow 대상 복제가 기본값이 아닌 그룹에 있는 경우 다음 명령에서 대상 그룹을 지정합니다.
구문
ceph fs subvolume snapshot clone VOLUME_NAME SUBVOLUME_NAME SNAP_NAME TARGET_SUBVOLUME_NAME --target_group_name _SUBVOLUME_GROUP_NAME
ceph fs subvolume snapshot clone VOLUME_NAME SUBVOLUME_NAME SNAP_NAME TARGET_SUBVOLUME_NAME --target_group_name _SUBVOLUME_GROUP_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow 예제
ceph fs subvolume snapshot clone cephfs sub0 snap0 clone0 --target_group_name subgroup1
[root@mon ~]# ceph fs subvolume snapshot clone cephfs sub0 snap0 clone0 --target_group_name subgroup1Copy to Clipboard Copied! Toggle word wrap Toggle overflow
복제 작업의 상태를 확인합니다.
구문
ceph fs clone status VOLUME_NAME CLONE_NAME [--group_name TARGET_GROUP_NAME]
ceph fs clone status VOLUME_NAME CLONE_NAME [--group_name TARGET_GROUP_NAME]Copy to Clipboard Copied! Toggle word wrap Toggle overflow 예제
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
추가 리소스
- Red Hat Ceph Storage 관리 가이드의 Ceph 사용자 관리 섹션을 참조하십시오.
5.2.12. 파일 시스템 하위 볼륨의 스냅샷 나열
이 섹션에서는 Ceph 파일 시스템(CephFS) 하위 볼륨의 스냅샷을 나열하는 단계를 제공합니다.
사전 요구 사항
- Ceph 파일 시스템이 배포된 작동 중인 Red Hat Ceph Storage 클러스터.
- Ceph 모니터에서 최소 읽기 액세스 권한입니다.
- Ceph Manager 노드의 읽기 및 쓰기 기능.
- CephFS 하위 볼륨.
- 하위 볼륨의 스냅샷입니다.
절차
CephFS 하위 볼륨의 스냅샷을 나열합니다.
구문
ceph fs subvolume snapshot ls VOLUME_NAME SUBVOLUME_NAME [--group_name SUBVOLUME_GROUP_NAME]
ceph fs subvolume snapshot ls VOLUME_NAME SUBVOLUME_NAME [--group_name SUBVOLUME_GROUP_NAME]Copy to Clipboard Copied! Toggle word wrap Toggle overflow 예제
ceph fs subvolume snapshot ls cephfs sub0 --group_name subgroup0
[root@mon ~]# ceph fs subvolume snapshot ls cephfs sub0 --group_name subgroup0Copy to Clipboard Copied! Toggle word wrap Toggle overflow
5.2.13. 파일 시스템 하위 볼륨의 스냅샷의 메타데이터 가져오기
이 섹션에서는 Ceph 파일 시스템(CephFS) 하위 볼륨의 스냅샷의 메타데이터를 가져오는 단계를 제공합니다.
사전 요구 사항
- CephFS가 배포된 상태에서 작동하는 Red Hat Ceph Storage 클러스터.
- Ceph 모니터에서 최소 읽기 액세스 권한입니다.
- Ceph Manager 노드의 읽기 및 쓰기 기능.
- CephFS 하위 볼륨.
- 하위 볼륨의 스냅샷입니다.
절차
CephFS 하위 볼륨의 스냅샷 메타데이터를 가져옵니다.
구문
ceph fs subvolume snapshot info VOLUME_NAME SUBVOLUME_NAME SNAP_NAME [--group_name SUBVOLUME_GROUP_NAME]
ceph fs subvolume snapshot info VOLUME_NAME SUBVOLUME_NAME SNAP_NAME [--group_name SUBVOLUME_GROUP_NAME]Copy to Clipboard Copied! Toggle word wrap Toggle overflow 예제
ceph fs subvolume snapshot info cephfs sub0 snap0 --group_name subgroup0
[root@mon ~]# ceph fs subvolume snapshot info cephfs sub0 snap0 --group_name subgroup0Copy to Clipboard Copied! Toggle word wrap Toggle overflow 출력 예
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
출력 형식은 json이며 다음 필드를 포함합니다.
- created_at: "YYYY-MM-DD HH:MM:SS:ffffff" 형식으로 스냅샷을 생성할 때입니다.
- data_pool: 스냅샷이 속하는 데이터 풀입니다.
- has_pending_clones: "yes"는 스냅샷 복제본이 진행 중인 경우 "no"입니다.
- size: 스냅샷 크기(바이트)입니다.
5.2.14. 파일 시스템 하위 볼륨 제거
이 섹션에서는 Ceph 파일 시스템(CephFS) 하위 볼륨을 제거하는 단계를 설명합니다.
ceph fs subvolume rm 명령은 subvolume과 해당 콘텐츠를 두 단계로 제거합니다. 먼저 하위 볼륨을 Keycloak 폴더로 이동한 다음 해당 콘텐츠를 비동기적으로 제거합니다.
subvolume은 --retain-snapshots 옵션을 사용하여 하위 볼륨의 기존 스냅샷을 유지할 수 있습니다. 스냅샷이 유지되는 경우 보존 스냅샷을 포함하지 않는 모든 작업에 대해 하위 볼륨이 비어 있는 것으로 간주됩니다. 보존 스냅샷은 하위 볼륨을 재생성하거나 최신 하위 볼륨에 복제하는 복제본 소스로 사용할 수 있습니다.
사전 요구 사항
- Ceph 파일 시스템이 배포된 작동 중인 Red Hat Ceph Storage 클러스터.
- Ceph 모니터에서 최소 읽기 액세스 권한입니다.
- Ceph Manager 노드의 읽기 및 쓰기 기능.
- CephFS 하위 볼륨.
절차
CephFS 하위 볼륨을 제거합니다.
구문
ceph fs subvolume rm VOLUME_NAME SUBVOLUME_NAME [--group_name SUBVOLUME_GROUP_NAME] [--force] [--retain-snapshots]
ceph fs subvolume rm VOLUME_NAME SUBVOLUME_NAME [--group_name SUBVOLUME_GROUP_NAME] [--force] [--retain-snapshots]Copy to Clipboard Copied! Toggle word wrap Toggle overflow 예제
ceph fs subvolume rm cephfs sub0 --group_name subgroup0 --retain snapshots
[root@mon ~]# ceph fs subvolume rm cephfs sub0 --group_name subgroup0 --retain snapshotsCopy to Clipboard Copied! Toggle word wrap Toggle overflow 보존 스냅샷에서 하위 볼륨을 재생성하려면 다음을 수행합니다.
구문
ceph fs subvolume snapshot clone VOLUME_NAME DELETED_SUBVOLUME RETAINED_SNAPSHOT NEW_SUBVOLUME --group_name SUBVOLUME_GROUP_NAME --target_group_name SUBVOLUME_TARGET_GROUP_NAME
ceph fs subvolume snapshot clone VOLUME_NAME DELETED_SUBVOLUME RETAINED_SNAPSHOT NEW_SUBVOLUME --group_name SUBVOLUME_GROUP_NAME --target_group_name SUBVOLUME_TARGET_GROUP_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow *NEW_SUB tekton - 이전에 삭제된 하위 볼륨과 동일한 하위 볼륨이거나 새 하위 볼륨에 복제할 수 있습니다.
예제
ceph fs subvolume snapshot clone cephfs sub0 snap0 sub1 --group_name subgroup0 --target_group_name subgroup0
ceph fs subvolume snapshot clone cephfs sub0 snap0 sub1 --group_name subgroup0 --target_group_name subgroup0Copy to Clipboard Copied! Toggle word wrap Toggle overflow
5.2.15. 파일 시스템 하위 볼륨의 스냅샷 제거
이 섹션에서는 Ceph 파일 시스템(CephFS) 하위 볼륨의 스냅샷을 제거하는 단계를 제공합니다.
--force 플래그를 사용하면 스냅샷이 없는 경우 명령이 성공하게 됩니다.
사전 요구 사항
- Ceph 파일 시스템이 배포된 작동 중인 Red Hat Ceph Storage 클러스터.
- Ceph 모니터에서 최소 읽기 액세스 권한입니다.
- Ceph Manager 노드의 읽기 및 쓰기 기능.
- Ceph 파일 시스템 볼륨.
- subvolume 그룹의 스냅샷입니다.
절차
CephFS 하위 볼륨의 스냅샷을 제거합니다.
구문
ceph fs subvolume snapshot rm VOLUME_NAME SUBVOLUME_NAME _SNAP_NAME [--group_name GROUP_NAME --force]
ceph fs subvolume snapshot rm VOLUME_NAME SUBVOLUME_NAME _SNAP_NAME [--group_name GROUP_NAME --force]Copy to Clipboard Copied! Toggle word wrap Toggle overflow 예제
ceph fs subvolume snapshot rm cephfs sub0 snap0 --group_name subgroup0 --force
[root@mon ~]# ceph fs subvolume snapshot rm cephfs sub0 snap0 --group_name subgroup0 --forceCopy to Clipboard Copied! Toggle word wrap Toggle overflow
5.3. Ceph 파일 시스템 하위 볼륨 그룹
스토리지 관리자는 Ceph 파일 시스템(CephFS) 하위 볼륨 그룹을 생성, 나열, 가져오기, 제거할 수 있습니다. 또한 이러한 하위 볼륨의 스냅샷을 생성, 나열 및 제거할 수도 있습니다. CephFS 하위 볼륨 그룹은 일련의 하위 볼륨에서 정책(예: 파일 레이아웃)에 영향을 주는 디렉터리 수준에서 추상화됩니다.
이 섹션에서는 다음을 수행하는 방법에 대해 설명합니다.
5.3.1. 파일 시스템 하위 볼륨 그룹 생성
이 섹션에서는 Ceph 파일 시스템(CephFS) 하위 볼륨 그룹을 생성하는 방법을 설명합니다.
하위 볼륨 그룹을 생성할 때 8진수 숫자로 데이터 풀 레이아웃, uid, gid 및 파일 모드를 지정할 수 있습니다. 기본적으로 하위 볼륨 그룹은 8진수 파일 모드 '755', uid '0', gid '0' 및 상위 디렉터리의 데이터 풀 레이아웃으로 생성됩니다.
사전 요구 사항
- Ceph 파일 시스템이 배포된 작동 중인 Red Hat Ceph Storage 클러스터.
- Ceph 모니터에서 최소 읽기 액세스 권한입니다.
- Ceph Manager 노드의 읽기 및 쓰기 기능.
절차
CephFS 하위 볼륨 그룹을 생성합니다.
구문
ceph fs subvolumegroup create VOLUME_NAME GROUP_NAME [--pool_layout DATA_POOL_NAME --uid UID --gid GID --mode OCTAL_MODE]
ceph fs subvolumegroup create VOLUME_NAME GROUP_NAME [--pool_layout DATA_POOL_NAME --uid UID --gid GID --mode OCTAL_MODE]Copy to Clipboard Copied! Toggle word wrap Toggle overflow 예제
ceph fs subvolumegroup create cephfs subgroup0
[root@mon ~]# ceph fs subvolumegroup create cephfs subgroup0Copy to Clipboard Copied! Toggle word wrap Toggle overflow 하위 볼륨이 이미 존재하는 경우에도 명령이 성공합니다.
5.3.2. 파일 시스템 하위 볼륨 그룹 나열
이 섹션에서는 Ceph 파일 시스템(CephFS) 하위 볼륨 그룹을 나열하는 단계에 대해 설명합니다.
사전 요구 사항
- Ceph 파일 시스템이 배포된 작동 중인 Red Hat Ceph Storage 클러스터.
- Ceph 모니터에서 최소 읽기 액세스 권한입니다.
- Ceph Manager 노드의 읽기 및 쓰기 기능.
- CephFS 하위 볼륨 그룹.
절차
CephFS 하위 볼륨 그룹을 나열합니다.
구문
ceph fs subvolumegroup ls VOLUME_NAME
ceph fs subvolumegroup ls VOLUME_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow 예제
ceph fs subvolumegroup ls cephfs
[root@mon ~]# ceph fs subvolumegroup ls cephfsCopy to Clipboard Copied! Toggle word wrap Toggle overflow
5.3.3. 파일 시스템 하위 볼륨의 절대 경로 가져오기
이 섹션에서는 Ceph 파일 시스템(CephFS) 하위 볼륨의 절대 경로를 가져오는 방법을 보여줍니다.
사전 요구 사항
- Ceph 파일 시스템이 배포된 작동 중인 Red Hat Ceph Storage 클러스터.
- Ceph 모니터에서 최소 읽기 액세스 권한입니다.
- Ceph Manager 노드의 읽기 및 쓰기 기능.
- CephFS 하위 볼륨 그룹.
절차
CephFS 하위 볼륨 그룹의 절대 경로를 가져옵니다.
구문
ceph fs subvolumegroup getpath VOLUME_NAME GROUP_NAME
ceph fs subvolumegroup getpath VOLUME_NAME GROUP_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow 예제
ceph fs subvolumegroup getpath cephfs subgroup0 /volumes/subgroup0
[root@mon ~]# ceph fs subvolumegroup getpath cephfs subgroup0 /volumes/subgroup0Copy to Clipboard Copied! Toggle word wrap Toggle overflow
5.3.4. 파일 시스템 하위 볼륨 그룹의 스냅샷 생성
이 섹션에서는 Ceph 파일 시스템(CephFS) 하위 볼륨 그룹의 스냅샷을 생성하는 방법을 보여줍니다.
사전 요구 사항
- Ceph 파일 시스템이 배포된 작동 중인 Red Hat Ceph Storage 클러스터.
- Ceph 모니터에서 최소 읽기 액세스 권한입니다.
- Ceph Manager 노드의 읽기 및 쓰기 기능.
- CephFS 하위 볼륨 그룹.
-
클라이언트에는 읽기(
r) 및 쓰기(w) 기능 외에도 파일 시스템 내의 디렉터리 경로에s플래그가 필요합니다.
절차
s플래그가 디렉터리에 설정되어 있는지 확인합니다.구문
ceph auth get CLIENT_NAME
ceph auth get CLIENT_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow 예제
client.0 key: AQAz7EVWygILFRAAdIcuJ12opU/JKyfFmxhuaw== caps: [mds] allow rw, allow rws path=/bar caps: [mon] allow r caps: [osd] allow rw tag cephfs data=cephfs_aclient.0 key: AQAz7EVWygILFRAAdIcuJ12opU/JKyfFmxhuaw== caps: [mds] allow rw, allow rws path=/bar1 caps: [mon] allow r caps: [osd] allow rw tag cephfs data=cephfs_a2 Copy to Clipboard Copied! Toggle word wrap Toggle overflow CephFS 하위 볼륨 그룹의 스냅샷을 생성합니다.
구문
ceph fs subvolumegroup snapshot create VOLUME_NAME _GROUP_NAME SNAP_NAME
ceph fs subvolumegroup snapshot create VOLUME_NAME _GROUP_NAME SNAP_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow 예제
ceph fs subvolumegroup snapshot create cephfs subgroup0 snap0
[root@mon ~]# ceph fs subvolumegroup snapshot create cephfs subgroup0 snap0Copy to Clipboard Copied! Toggle word wrap Toggle overflow 이 명령은 subvolume 그룹의 모든 하위 볼륨을 암시적으로 스냅샷합니다.
5.3.5. 파일 시스템 하위 볼륨의 스냅샷 나열
이 섹션에서는 Ceph 파일 시스템(CephFS) 하위 볼륨의 스냅샷을 나열하는 단계를 제공합니다.
사전 요구 사항
- Ceph 파일 시스템이 배포된 작동 중인 Red Hat Ceph Storage 클러스터.
- Ceph 모니터에서 최소 읽기 액세스 권한입니다.
- Ceph Manager 노드의 읽기 및 쓰기 기능.
- CephFS 하위 볼륨 그룹.
- subvolume 그룹의 스냅샷입니다.
절차
CephFS 하위 볼륨의 스냅샷을 나열합니다.
구문
ceph fs subvolumegroup snapshot ls VOLUME_NAME GROUP_NAME
ceph fs subvolumegroup snapshot ls VOLUME_NAME GROUP_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow 예제
ceph fs subvolumegroup snapshot ls cephfs subgroup0
[root@mon ~]# ceph fs subvolumegroup snapshot ls cephfs subgroup0Copy to Clipboard Copied! Toggle word wrap Toggle overflow
5.3.6. 파일 시스템 하위 볼륨의 스냅샷 제거
이 섹션에서는 Ceph 파일 시스템(CephFS) 하위 볼륨의 스냅샷을 제거하는 단계를 제공합니다.
--force 플래그를 사용하면 스냅샷이 없는 경우 명령이 성공하게 됩니다.
사전 요구 사항
- Ceph 파일 시스템이 배포된 작동 중인 Red Hat Ceph Storage 클러스터.
- Ceph 모니터에서 최소 읽기 액세스 권한입니다.
- Ceph Manager 노드의 읽기 및 쓰기 기능.
- Ceph 파일 시스템 볼륨.
- subvolume 그룹의 스냅샷입니다.
절차
CephFS 하위 볼륨 그룹의 스냅샷을 제거합니다.
구문
ceph fs subvolumegroup snapshot rm VOLUME_NAME GROUP_NAME SNAP_NAME [--force]
ceph fs subvolumegroup snapshot rm VOLUME_NAME GROUP_NAME SNAP_NAME [--force]Copy to Clipboard Copied! Toggle word wrap Toggle overflow 예제
ceph fs subvolumegroup snapshot rm cephfs subgroup0 snap0 --force
[root@mon ~]# ceph fs subvolumegroup snapshot rm cephfs subgroup0 snap0 --forceCopy to Clipboard Copied! Toggle word wrap Toggle overflow
5.3.7. 파일 시스템 하위 볼륨 그룹 제거
이 섹션에서는 Ceph 파일 시스템(CephFS) 하위 볼륨 그룹을 제거하는 방법을 보여줍니다.
하위 볼륨 그룹이 비어 있지 않거나 존재하지 않는 경우 실패합니다. --force 플래그를 사용하면 존재하지 않는 하위 볼륨을 제거할 수 있습니다.
사전 요구 사항
- Ceph 파일 시스템이 배포된 작동 중인 Red Hat Ceph Storage 클러스터.
- Ceph 모니터에서 최소 읽기 액세스 권한입니다.
- Ceph Manager 노드의 읽기 및 쓰기 기능.
- CephFS 하위 볼륨 그룹.
절차
CephFS 하위 볼륨 그룹을 제거합니다.
구문
ceph fs subvolumegroup rm VOLUME_NAME GROUP_NAME [--force]
ceph fs subvolumegroup rm VOLUME_NAME GROUP_NAME [--force]Copy to Clipboard Copied! Toggle word wrap Toggle overflow 예제
ceph fs subvolumegroup rm cephfs subgroup0 --force
[root@mon ~]# ceph fs subvolumegroup rm cephfs subgroup0 --forceCopy to Clipboard Copied! Toggle word wrap Toggle overflow
5.4. 추가 리소스
- Red Hat Ceph Storage 관리 가이드의 Ceph 사용자 관리 섹션을 참조하십시오.
부록 A. Ceph 파일 시스템의 상태 메시지
클러스터 상태 점검
Ceph Monitor 데몬은 메타데이터 서버(MDS)의 특정 상태에 대한 응답으로 상태 메시지를 생성합니다. 다음은 상태 메시지 목록 및 설명입니다.
- MDS rank(s) <ranks>가 실패했습니다.
- 하나 이상의 MDS 순위는 현재 MDS 데몬에 할당되지 않습니다. 적절한 교체 데몬이 시작될 때까지 스토리지 클러스터가 복구되지 않습니다.
- MDS rank(s) <ranks>가 손상되었습니다.
- 하나 이상의 MDS 순위는 저장된 메타데이터에 심각한 손상을 초래했으며, 메타데이터를 복구할 때까지 다시 시작할 수 없습니다.
- MDS 클러스터 성능이 저하됨
-
하나 이상의 MDS 순위가 현재 실행되고 있지 않으므로 이러한 상황이 해결될 때까지 클라이언트는 메타데이터 I/O를 일시 정지할 수 있습니다. 이는 실패 또는 손상된 순위를 포함하며 MDS에서 실행 중이지만
활성상태가 아닌 재생 상태의 순위 (예:재생상태의 순위)를 포함합니다. - MDS <names>은 Laggy입니다.
-
MDS 데몬은
mds_beacon_interval옵션에 지정된 간격에 따라 비컨대 메시지를 모니터에 전송하도록 되어 있으며 기본값은 4초입니다. MDS 데몬이mds_beacon_grace옵션에 지정된 시간 내에 메시지를 보내지 못하면 기본값은 15초입니다. Ceph 모니터는 MDS 데몬을laggy로 표시하고 사용 가능한 경우 해당 데몬으로 자동으로 대체합니다.
데몬 보고 상태 점검
MDS 데몬은 다양한 원치 않는 조건을 식별하고 ceph status 명령의 출력에 반환할 수 있습니다. 이러한 조건에는 사람이 읽을 수 있는 메시지가 있으며 JSON 출력에 표시되는 고유 코드가 MDS_HEALTH 입니다. 다음은 데몬 메시지 목록, 코드 및 설명입니다.
- "Thimming…에 유의하십시오.
코드: MDS_HEALTH_TRIM
CephFS에서는 로그 세그먼트로 구분된 메타데이터 저널을 유지 관리합니다. 저널의 길이( 세그먼트 수)는
mds_log_max_segments설정으로 제어합니다. 세그먼트 수가 해당 설정을 초과하면 MDS에서 메타데이터 쓰기를 시작하여 가장 오래된 세그먼트를 제거합니다. 이 프로세스가 너무 느리거나 소프트웨어 버그가 트리밍을 방지하는 경우 이 상태 메시지가 나타납니다. 표시할 이 메시지의 임계값은 이중mds_log_max_segments가 되는 세그먼트 수에 대한 임계값입니다.- "client <name>이 기능 릴리스에 응답하지 않음"
Code: MDS_HEALTH_CLIENT_LATE_RELEASE, MDS_HEALTH_CLIENT_LATE_RELEASE_MANY
CephFS 클라이언트는 MDS에서 기능을 발행합니다. 기능은 잠금과 같이 작동합니다. 예를 들어 다른 클라이언트에 액세스가 필요한 경우 MDS에서 클라이언트가 기능을 해제하도록 요청합니다. 클라이언트가 응답하지 않는 경우 즉시 수행하지 못하거나 전혀 그렇게하지 못할 수 있습니다. 이 메시지는 클라이언트가
mds_revoke_cap_timeout옵션(기본값은 60초)에서 지정한 시간보다 준수하는 데 시간이 오래 걸리는 경우 표시됩니다.- "client <name>이 캐시 부족에 응답하지 않음"
Code: MDS_HEALTH_CLIENT_RECALL, MDS_HEALTH_CLIENT_RECALL_MANY
클라이언트에서 메타데이터 캐시를 유지합니다. 클라이언트 캐시의 inode와 같은 항목도 MDS 캐시에 고정되어 있습니다. 자체 캐시 크기 제한 내에 유지하기 위해 MDS를 축소해야 하는 경우 MDS는 캐시를 축소하여 클라이언트에 메시지를 보냅니다. 클라이언트가 응답하지 않는 경우 MDS가 캐시 크기 내에 제대로 유지되지 않도록 할 수 있으며 MDS가 메모리가 부족하여 예기치 않게 종료될 수 있습니다. 이 메시지는 클라이언트가
mds_recall_state_timeout옵션(기본값은 60초)에서 지정한 시간보다 준수하는 데 더 많은 시간이 걸리는 경우 표시됩니다. 자세한 내용은 MDS 캐시 크기 제한 이해를 참조하십시오.- "클라이언트 이름이 가장 오래된 클라이언트/플루시 트id를 진행하지 못했습니다."
Code: MDS_HEALTH_CLIENT_OLDEST_TID, MDS_HEALTH_CLIENT_OLDEST_TID_MANY
클라이언트와 MDS 서버 간의 통신을 위한 CephFS 프로토콜은 가장 오래된 Tid라는 필드를 사용하여 MDS에서 MDS를 완전히 완료하여 MDS에서 잊어 버릴 수 있도록 합니다. 응답하지 않는 클라이언트가 이 필드를 진행하지 못하면 MDS에서 클라이언트 요청에 사용하는 리소스를 올바르게 정리하지 못할 수 있습니다. 이 메시지는 클라이언트가 MDS 측에서 완료되었지만 클라이언트의 가장 오래된 tid 값에 대해 아직 고려하지 않은
max_completed_requests옵션(기본값은 100000)에서 지정한 수보다 많은 요청을 보유하는 경우 나타납니다.- "metadata damage detected"
코드: MDS_HEALTH_DAMAGE
메타데이터 풀에서 읽을 때 손상되거나 누락된 메타데이터가 발생했습니다. 이 메시지는 MDS가 계속 작동할 수 있도록 손상이 충분히 분리되었음을 나타냅니다. 클라이언트가 손상된 하위 트리 반환 I/O 오류에 액세스하더라도 해당 손상이 계속 작동됨을 나타냅니다.
damage lsadministration socket 명령을 사용하여 손상에 대한 세부 정보를 확인합니다. 이 메시지는 손상이 발생하는 즉시 나타납니다.- "MDS in read-only mode"
코드: MDS_HEALTH_READ_ONLY
MDS가 읽기 전용 모드로 입력되었으며, 메타데이터를 수정하려는 클라이언트 작업에
EROFS오류 코드를 반환합니다. MDS가 읽기 전용 모드로 들어갑니다.- 메타데이터 풀에 쓰는 동안 쓰기 오류가 발생하면.
-
관리자가
force_readonly관리 소켓 명령을 사용하여 MDS가 읽기 전용 모드로 전환하도록 강제 적용하는 경우.
- "<N> 느린 요청이 차단되어 있습니다.
코드: MDS_HEALTH_SLOW_REQUEST
MDS가 매우 느리게 실행 중이거나 버그가 있음을 나타내는 하나 이상의 클라이언트 요청이 즉시 완료되지 않았습니다. controlPlane
관리소켓 명령을 사용하여 미해결 메타데이터 작업을 나열합니다. 이 메시지는 모든 클라이언트 요청이mds_op_complaint_time옵션(기본값은 30초)에서 지정한 값보다 더 많은 시간을 소비한 경우에 나타납니다.- " cache의 많은 inode"
- 코드: MDS_HEALTH_CACHE_OVERSIZED
MDS는 관리자가 설정한 제한을 준수하기 위해 캐시를 트리밍하지 못했습니다. MDS 캐시가 너무 크면 데몬에서 사용 가능한 메모리를 소비하고 예기치 않게 종료될 수 있습니다. 기본적으로 MDS 캐시 크기가 제한보다 50% 큰 경우 이 메시지가 표시됩니다.
추가 리소스
- 자세한 내용은 Red Hat Ceph Storage 파일 시스템 가이드 의 Metadata Server 캐시 크기 제한 섹션을 참조하십시오.
부록 B. metadata Server 데몬 구성 참조
메타데이터 서버(MDS) 데몬 구성에 사용할 수 있는 목록 명령을 참조하십시오.
- mon_force_standby_active
- 설명
-
true로 설정하면 모니터가 대기 재생 모드의 MDS가 활성화되도록 합니다. Ceph 구성 파일의[mon]또는[global]섹션에 설정합니다. - 유형
- 부울
- 기본값
-
true
- max_mds
- 설명
-
클러스터 생성 중 활성 MDS 데몬 수입니다. Ceph 구성 파일의
[mon]또는[global]섹션에 설정합니다. - 유형
- 32비트 정수
- 기본값
-
1
- mds_cache_memory_limit
- 설명
-
MDS가 캐시에 적용하는 메모리 제한입니다. Red Hat은
mds 캐시 크기매개변수 대신 이 매개변수를 사용하는 것이 좋습니다. - 유형
- 64비트 Integer 서명되지 않음
- 기본값
-
1073741824
- mds_cache_reservation
- 설명
- MDS 캐시를 유지하기 위한 캐시 예약, 메모리 또는 inode입니다. 값은 구성된 최대 캐시의 백분율입니다. MDS가 예약 대기를 시작하면 캐시 크기가 축소되어 예약을 복원할 때까지 클라이언트 상태를 호출합니다.
- 유형
- 부동 값
- 기본값
-
0.05
- mds_cache_size
- 설명
-
캐시할 inode 수입니다. 값 0은 무제한 수를 나타냅니다. Red Hat은
mds_cache_memory_limit를 사용하여 MDS 캐시에서 사용하는 메모리 양을 제한하는 것이 좋습니다. - 유형
- 32비트 정수
- 기본값
-
0
- mds_cache_mid
- 설명
- 맨 위 캐시 LRU의 새 항목에 대한 삽입 지점.
- 유형
- 부동 값
- 기본값
-
0.7
- mds_dir_commit_ratio
- 설명
- 디렉터리의 일부에는 부분적인 업데이트가 아니라 Ceph가 전체 업데이트를 사용하여 커밋하기 전에 잘못된 정보가 포함되어 있습니다.
- 유형
- 부동 값
- 기본값
-
0.5
- mds_dir_max_commit_size
- 설명
- Ceph가 디렉터리를 작은 트랜잭션으로 제거하기 전에 디렉터리 업데이트의 최대 크기(MB)입니다.
- 유형
- 32비트 정수
- 기본값
-
90
- mds_decay_halflife
- 설명
- MDS 캐시 온도의 반감입니다.
- 유형
- 부동 값
- 기본값
-
5
- mds_beacon_interval
- 설명
- 비컨 메시지의 빈도(초)는 모니터로 전송됩니다.
- 유형
- 부동 값
- 기본값
-
4
- mds_beacon_grace
- 설명
-
Ceph가 MDS 지연을 선언하고
, 대체될 수 있습니다. - 유형
- 부동 값
- 기본값
-
15
- mds_blacklist_interval
- 설명
- OSD 맵에서 실패한 MDS 데몬의 블랙리스트 기간입니다.
- 유형
- 부동 값
- 기본값
-
24.0*60.0
- mds_session_timeout
- 설명
- Ceph가 기능 및 리스를 제한하기 전에 클라이언트 비활성 간격(초)입니다.
- 유형
- 부동 값
- 기본값
-
60
- mds_session_autoclose
- 설명
-
Ceph가 지연 클라이언트 세션을 종료하기 전 간격
(초)입니다. - 유형
- 부동 값
- 기본값
-
300
- mds_reconnect_timeout
- 설명
- MDS를 다시 시작하는 동안 클라이언트가 다시 연결될 때까지 대기하는 간격(초)입니다.
- 유형
- 부동 값
- 기본값
-
45
- mds_tick_interval
- 설명
- MDS가 내부 주기적 작업을 얼마나 자주 수행하는가.
- 유형
- 부동 값
- 기본값
-
5
- mds_dirstat_min_interval
- 설명
- 재귀 통계를 사용하지 않도록 하는 최소 간격(초)입니다.
- 유형
- 부동 값
- 기본값
-
1
- mds_scatter_nudge_interval
- 설명
- 디렉토리 통계의 변경 사항이 얼마나 빠르게 전파되는지.
- 유형
- 부동 값
- 기본값
-
5
- mds_client_prealloc_inos
- 설명
- 클라이언트 세션당 사전 할당하기 위한 inode 번호 수입니다.
- 유형
- 32비트 정수
- 기본값
-
1000
- mds_early_reply
- 설명
- MDS에서 클라이언트가 저널에 커밋하기 전에 요청 결과를 확인할 수 있는지 여부를 결정합니다.
- 유형
- 부울
- 기본값
-
true
- mds_use_tmap
- 설명
-
디렉터리 업데이트에
trivialmap을 사용합니다. - 유형
- 부울
- 기본값
-
true
- mds_default_dir_hash
- 설명
- 디렉토리 조각에서 파일을 해시하는 데 사용할 함수입니다.
- 유형
- 32비트 정수
- 기본값
-
2, 즉rjenkins
- mds_log
- 설명
-
MDS가 저널 메타데이터 업데이트가 필요한 경우
true로 설정합니다. 벤치마킹을 위해서만 비활성화합니다. - 유형
- 부울
- 기본값
-
true
- mds_log_skip_corrupt_events
- 설명
- 저널 재생 중에 MDS가 손상된 저널 이벤트를 건너뛰는지 여부를 결정합니다.
- 유형
- 부울
- 기본값
-
false
- mds_log_max_events
- 설명
-
Ceph 이전의 저널의 최대 이벤트는 트리밍을 시작합니다. 제한을 비활성화하려면
-1로 설정합니다. - 유형
- 32비트 정수
- 기본값
-
-1
- mds_log_max_segments
- 설명
-
Ceph가 트리밍을 시작하기 전 저널에서 최대 세그먼트 또는 오브젝트 수입니다. 제한을 비활성화하려면
-1로 설정합니다. - 유형
- 32비트 정수
- 기본값
-
30
- mds_log_max_expiring
- 설명
- 병렬로 만료할 최대 세그먼트 수입니다.
- 유형
- 32비트 정수
- 기본값
-
20
- mds_log_eopen_size
- 설명
-
EOpen이벤트의 최대 inode 수입니다. - 유형
- 32비트 정수
- 기본값
-
100
- mds_bal_sample_interval
- 설명
- 조각화 결정을 내릴 때 디렉터리 온도를 샘플링하는 빈도가 결정됩니다.
- 유형
- 부동 값
- 기본값
-
3
- mds_bal_replicate_threshold
- 설명
- Ceph가 메타데이터를 다른 노드에 복제하기 전의 최대 온도입니다.
- 유형
- 부동 값
- 기본값
-
8000
- mds_bal_unreplicate_threshold
- 설명
- Ceph가 다른 노드에 메타데이터 복제를 중지하기 전의 최소 온도입니다.
- 유형
- 부동 값
- 기본값
-
0
- mds_bal_frag
- 설명
- MDS 조각의 디렉터리를 결정합니다.
- 유형
- 부울
- 기본값
-
false
- mds_bal_split_size
- 설명
- MDS가 디렉터리를 작은 비트로 분할하기 전에 최대 디렉터리 크기입니다. 루트 디렉터리의 기본 조각 크기 제한은 10000입니다.
- 유형
- 32비트 정수
- 기본값
-
10000
- mds_bal_split_rd
- 설명
- Ceph가 디렉토리 조각을 분할하기 전에 최대 디렉터리 읽기 온도입니다.
- 유형
- 부동 값
- 기본값
-
25000
- mds_bal_split_wr
- 설명
- Ceph가 디렉토리 조각을 분할하기 전의 최대 디렉터리 쓰기 온도입니다.
- 유형
- 부동 값
- 기본값
-
10000
- mds_bal_split_bits
- 설명
- 디렉터리 조각을 분할할 비트 수입니다.
- 유형
- 32비트 정수
- 기본값
-
3
- mds_bal_merge_size
- 설명
- Ceph가 인접한 디렉터리 내용을 병합하기 전의 최소 디렉터리 크기입니다.
- 유형
- 32비트 정수
- 기본값
-
50
- mds_bal_merge_rd
- 설명
- Ceph가 인접한 디렉토리 조각을 병합하기 전의 최소 읽기 온도입니다.
- 유형
- 부동 값
- 기본값
-
1000
- mds_bal_merge_wr
- 설명
- Ceph가 인접한 디렉토리 조각을 병합하기 전의 최소 쓰기 온도입니다.
- 유형
- 부동 값
- 기본값
-
1000
- mds_bal_interval
- 설명
- MDS 노드 간 워크로드 교환 빈도(초)입니다.
- 유형
- 32비트 정수
- 기본값
-
10
- mds_bal_fragment_interval
- 설명
- 디렉터리 조각화 조정의 빈도(초)입니다.
- 유형
- 32비트 정수
- 기본값
-
5
- mds_bal_idle_threshold
- 설명
- Ceph가 하위 트리를 상위로 다시 마이그레이션하기 전의 최소 온도입니다.
- 유형
- 부동 값
- 기본값
-
0
- mds_bal_max
- 설명
- Ceph가 중지되기 전에 밸런서를 실행하는 반복 횟수입니다. 테스트 목적으로만 사용됩니다.
- 유형
- 32비트 정수
- 기본값
-
-1
- mds_bal_max_until
- 설명
- Ceph가 중지되기 전에 밸런서를 실행하는 시간(초)입니다. 테스트 목적으로만 사용됩니다.
- 유형
- 32비트 정수
- 기본값
-
-1
- mds_bal_mode
- 설명
MDS 로드를 계산하는 방법입니다.
-
1= Hybrid. -
2= 요청 속도 및 대기 시간. -
3= CPU 부하.
-
- 유형
- 32비트 정수
- 기본값
-
0
- mds_bal_min_rebalance
- 설명
- Ceph가 마이그레이션되기 전의 최소 하위 트리 온도입니다.
- 유형
- 부동 값
- 기본값
-
0.1
- mds_bal_min_start
- 설명
- Ceph가 하위 트리를 검색하기 전의 최소 하위 트리 온도입니다.
- 유형
- 부동 값
- 기본값
-
0.2
- mds_bal_need_min
- 설명
- 허용할 대상 하위 트리 크기의 최소 비율입니다.
- 유형
- 부동 값
- 기본값
-
0.8
- mds_bal_need_max
- 설명
- 허용할 대상 하위 트리의 최대 비율입니다.
- 유형
- 부동 값
- 기본값
-
1.2
- mds_bal_midchunk
- 설명
- Ceph는 대상 하위 트리 크기의 이 부분보다 큰 모든 하위 트리를 마이그레이션합니다.
- 유형
- 부동 값
- 기본값
-
0.3
- mds_bal_minchunk
- 설명
- Ceph는 대상 하위 트리 크기의 이 부분보다 작은 하위 트리를 무시합니다.
- 유형
- 부동 값
- 기본값
-
0.001
- mds_bal_target_removal_min
- 설명
- Ceph가 MDS 맵에서 이전 MDS 대상을 제거하기 전에 최소 밸런서 수입니다.
- 유형
- 32비트 정수
- 기본값
-
5
- mds_bal_target_removal_max
- 설명
- Ceph가 MDS 맵에서 이전 MDS 대상을 제거하기 전에 최대 밸런서 수입니다.
- 유형
- 32비트 정수
- 기본값
-
10
- mds_replay_interval
- 설명
-
핫 대기 상태의.대기 모드에 있을때 저널 폴링 간격입니다 - 유형
- 부동 값
- 기본값
-
1
- mds_shutdown_check
- 설명
- MDS를 종료하는 동안 캐시를 폴링하는 간격입니다.
- 유형
- 32비트 정수
- 기본값
-
0
- mds_thrash_exports
- 설명
- Ceph는 노드 간 하위 트리를 임의로 내보냅니다. 테스트 목적으로만 사용됩니다.
- 유형
- 32비트 정수
- 기본값
-
0
- mds_thrash_fragments
- 설명
- Ceph는 디렉터리를 임의로 조각하거나 병합합니다.
- 유형
- 32비트 정수
- 기본값
-
0
- mds_dump_cache_on_map
- 설명
- Ceph는 MDS 캐시 콘텐츠를 각 MDS 맵의 파일에 덤프합니다.
- 유형
- 부울
- 기본값
-
false
- mds_dump_cache_after_rejoin
- 설명
- 복구 중에 캐시에 다시 참여한 후 Ceph에서 MDS 캐시 콘텐츠를 파일에 덤프합니다.
- 유형
- 부울
- 기본값
-
false
- mds_verify_scatter
- 설명
-
Ceph는 다양한 distributed/gather invariants가
true라고 가정합니다. 개발자 전용입니다. - 유형
- 부울
- 기본값
-
false
- mds_debug_scatterstat
- 설명
-
Ceph는 다양한 재귀 통계가
true라고 가정합니다. 개발자 전용입니다. - 유형
- 부울
- 기본값
-
false
- mds_debug_frag
- 설명
- 편리한 경우 Ceph에서 디렉터리 조각화의 변형을 확인합니다. 개발자 전용입니다.
- 유형
- 부울
- 기본값
-
false
- mds_debug_auth_pins
- 설명
- 디버그 인증 핀의 변형(invariants)입니다. 개발자 전용입니다.
- 유형
- 부울
- 기본값
-
false
- mds_debug_subtrees
- 설명
- 하위 트리의 변형 디버깅. 개발자 전용입니다.
- 유형
- 부울
- 기본값
-
false
- mds_kill_mdstable_at
- 설명
- Ceph에서 MDS 테이블 코드에 MDS 오류를 삽입합니다. 개발자 전용입니다.
- 유형
- 32비트 정수
- 기본값
-
0
- mds_kill_export_at
- 설명
- Ceph는 하위 트리 내보내기 코드에 MDS 오류를 삽입합니다. 개발자 전용입니다.
- 유형
- 32비트 정수
- 기본값
-
0
- mds_kill_import_at
- 설명
- Ceph는 하위 트리 가져오기 코드에 MDS 오류를 삽입합니다. 개발자 전용입니다.
- 유형
- 32비트 정수
- 기본값
-
0
- mds_kill_link_at
- 설명
- Ceph는 하드 링크 코드에 MDS 오류를 삽입합니다. 개발자 전용입니다.
- 유형
- 32비트 정수
- 기본값
-
0
- mds_kill_rename_at
- 설명
- Ceph는 이름 변경 코드에 MDS 오류를 삽입합니다. 개발자 전용입니다.
- 유형
- 32비트 정수
- 기본값
-
0
- mds_wipe_sessions
- 설명
- Ceph는 시작 시 모든 클라이언트 세션을 삭제합니다. 테스트 목적으로만 사용됩니다.
- 유형
- 부울
- 기본값
-
0
- mds_wipe_ino_prealloc
- 설명
- Ceph deletea inode 사전 할당 메타데이터는 시작 시입니다. 테스트 목적으로만 사용됩니다.
- 유형
- 부울
- 기본값
-
0
- mds_skip_ino
- 설명
- 시작 시 건너뛸 inode 번호 수입니다. 테스트 목적으로만 사용됩니다.
- 유형
- 32비트 정수
- 기본값
-
0
- mds_standby_for_name
- 설명
- MDS 데몬은 이 설정에 지정된 이름의 다른 MDS 데몬에 대한 internal입니다.
- 유형
- 문자열
- 기본값
- 해당 없음
- mds_standby_for_rank
- 설명
- MDS 데몬 인스턴스는 이 순위의 다른 MDS 데몬 인스턴스에 대한 대기 모드입니다.
- 유형
- 32비트 정수
- 기본값
-
-1
- mds_standby_replay
- 설명
-
MDS 데몬이
핫 대기상태로 사용될 때 활성 MDS의 로그를 폴링하고 재생하는지 여부를 결정합니다. - 유형
- 부울
- 기본값
-
false
부록 C. journaler 구성 참조
저널러 구성에 사용할 수 있는 목록 명령의 참조입니다.
- journaler_write_head_interval
- 설명
- 저널 헤드 오브젝트를 업데이트하는 빈도입니다.
- 유형
- 정수
- 필수 항목
- 없음
- 기본값
-
15
- journaler_prefetch_periods
- 설명
- 저널 재생에서 미리 읽을 스트라이프 기간 수입니다.
- 유형
- 정수
- 필수 항목
- 없음
- 기본값
-
10
- journal_prezero_periods
- 설명
- 쓰기 위치 앞에 0까지의 스트라이프 기간 수입니다.
- 유형
- 정수
- 필수 항목
- 없음
- 기본값
-
10
- journaler_batch_interval
- 설명
- 인위적으로 발생하도록 최대 추가 대기 시간(초)입니다.
- 유형
- double
- 필수 항목
- 없음
- 기본값
-
.001
- journaler_batch_max
- 설명
- 플러시 지연이 지연되는 최대 바이트 수입니다.
- 유형
- 64비트 서명되지 않은 Integer
- 필수 항목
- 없음
- 기본값
-
0
부록 D. Ceph File System 클라이언트 구성 참조
이 섹션에는 Ceph 파일 시스템(CephFS) FUSE 클라이언트의 구성 옵션이 나열되어 있습니다. [client] 섹션의 Ceph 구성 파일에 설정합니다.
- client_acl_type
- 설명
-
ACL 유형을 설정합니다. 현재는 POSIX ACL 또는 빈 문자열을 활성화하기 위한
posix_acl값만 사용할 수 있습니다. 이 옵션은fuse_default_permissions가false로 설정된 경우에만 적용됩니다. - 유형
- 문자열
- 기본값
-
""( ACL 적용 없음)
- client_cache_mid
- 설명
- 클라이언트 캐시 중간 지점을 설정합니다. 중간 포인트는 최근에 사용한 목록을 핫 및 웜 목록으로 분할합니다.
- 유형
- 부동 값
- 기본값
-
0.75
- client_cache size
- 설명
- 클라이언트가 메타데이터 캐시에 보관하는 inode 수를 설정합니다.
- 유형
- 정수
- 기본값
-
16384(16MB)
- client_caps_release_delay
- 설명
- 기능 릴리스 간 지연 시간을 초 단위로 설정합니다. 지연은 클라이언트가 다른 사용자 공간 작업에 필요한 기능이 더 이상 필요하지 않은 기능을 해제하기 위해 대기하는 시간(초)을 설정합니다.
- 유형
- 정수
- 기본값
-
5(초)
- client_debug_force_sync_read
- 설명
-
true로 설정하면 클라이언트는 로컬 페이지 캐시를 사용하는 대신 OSD에서 직접 데이터를 읽습니다. - 유형
- 부울
- 기본값
-
false
- client_dirsize_rbytes
- 설명
-
true로 설정하는 경우 디렉터리의 재귀 크기(즉, 모든 하위 항목 총)를 사용합니다. - 유형
- 부울
- 기본값
-
true
- client_max_inline_size
- 설명
-
RADOS의 별도의 데이터 오브젝트가 아닌 파일 inode에 저장된 인라인 데이터의 최대 크기를 설정합니다. 이 설정은
inline_data플래그가 MDS 맵에 설정된 경우에만 적용됩니다. - 유형
- 정수
- 기본값
-
4096
- client_metadata
- 설명
- 자동으로 생성된 버전, 호스트 이름 및 기타 메타데이터 외에도 각 MDS로 전송된 클라이언트 메타데이터의 쉼표로 구분된 문자열입니다.
- 유형
- 문자열
- 기본값
-
""(추가 메타데이터 없음)
- client_mount_gid
- 설명
- CephFS 마운트의 그룹 ID를 설정합니다.
- 유형
- 정수
- 기본값
-
-1
- client_mount_timeout
- 설명
- CephFS 마운트의 시간 초과를 초 단위로 설정합니다.
- 유형
- 부동 값
- 기본값
-
300.0
- client_mount_uid
- 설명
- CephFS 마운트의 사용자 ID를 설정합니다.
- 유형
- 정수
- 기본값
-
-1
- client_mountpoint
- 설명
-
ceph-fuse명령의-r옵션 대안. - 유형
- 문자열
- 기본값
-
/
- client_oc
- 설명
- 개체 캐싱을 활성화합니다.
- 유형
- 부울
- 기본값
-
true
- client_oc_max_dirty
- 설명
- 오브젝트 캐시에서 최대 더티 바이트 수를 설정합니다.
- 유형
- 정수
- 기본값
-
104857600(100MB)
- client_oc_max_dirty_age
- 설명
- 쓰기 전에 오브젝트 캐시에 있는 최대 더티 데이터의 최대 기간(초)을 설정합니다.
- 유형
- 부동 값
- 기본값
-
5.0(초)
- client_oc_max_objects
- 설명
- 오브젝트 캐시의 최대 오브젝트 수를 설정합니다.
- 유형
- 정수
- 기본값
-
1000
- client_oc_size
- 설명
- 클라이언트 캐시의 데이터 바이트 수를 설정합니다.
- 유형
- 정수
- 기본값
-
209715200(200 MB)
- client_oc_target_dirty
- 설명
- 더티 데이터의 대상 크기를 설정합니다. Red Hat은 이 수치를 낮게 유지할 것을 권장합니다.
- 유형
- 정수
- 기본값
-
8388608(8MB)
- client_permissions
- 설명
- 모든 I/O 작업에 대한 클라이언트 권한을 확인합니다.
- 유형
- 부울
- 기본값
-
true
- client_quota_df
- 설명
-
statfs작업에 대한 루트 디렉터리 할당량을 보고합니다. - 유형
- 부울
- 기본값
-
true
- client_readahead_max_bytes
- 설명
-
향후 읽기 작업에 대해 커널이 미리 읽은 최대 바이트 수를 설정합니다.
client_readahead_max_periods설정에 의해 재정의되었습니다. - 유형
- 정수
- 기본값
-
0(무제한)
- client_readahead_max_periods
- 설명
-
커널이 미리 읽는 파일 레이아웃 기간(오브젝트 크기 * 스트라이프 수) 수를 설정합니다.
client_readahead_max_bytes설정을 덮어씁니다. - 유형
- 정수
- 기본값
-
4
- client_readahead_min
- 설명
- 커널이 미리 읽는 최소 수 바이트 수를 설정합니다.
- 유형
- 정수
- 기본값
-
131072(128KB)
- client_snapdir
- 설명
- 스냅샷 디렉터리 이름을 설정합니다.
- 유형
- 문자열
- 기본값
-
".snap"
- client_tick_interval
- 설명
- 기능 갱신과 기타 확장 유지 사이의 간격(초)을 설정합니다.
- 유형
- 부동 값
- 기본값
-
1.0
- client_use_random_mds
- 설명
- 각 요청에 대해 임의의 MDS를 선택합니다.
- 유형
- 부울
- 기본값
-
false
- fuse_default_permissions
- 설명
-
false로 설정하면ceph-fuse유틸리티 검사에서 FUSE의 권한 적용을 사용하는 대신 자체 권한 검사를 수행합니다. POSIX ACL을 활성화하려면client acl type=posix_acl옵션과 함께 false로 설정합니다. - 유형
- 부울
- 기본값
-
true
이러한 옵션은 내부 전용입니다. 이 목록은 옵션 목록을 완료하기 위해서만 나열됩니다.
- client_debug_getattr_caps
- 설명
- MDS의 응답에 필요한 기능이 포함되어 있는지 확인합니다.
- 유형
- 부울
- 기본값
-
false
- client_debug_inject_tick_delay
- 설명
- 클라이언트 진드 사이에 인위적인 지연을 추가합니다.
- 유형
- 정수
- 기본값
-
0
- client_inject_fixed_oldest_tid
- 설명, 유형
- 부울
- 기본값
-
false
- client_inject_release_failure
- 설명, 유형
- 부울
- 기본값
-
false
- client_trace
- 설명
-
모든 파일 작업에 대한 추적 파일의 경로입니다. 출력은 Ceph 합성 클라이언트에서 사용하도록 설계되었습니다. 자세한 내용은
ceph-syn(8)매뉴얼 페이지를 참조하십시오. - 유형
- 문자열
- 기본값
-
""(비활성화)