성능 조정 가이드
Red Hat Enterprise Linux 6에서 서브시스템 처리량을 최적화
엮음 4.0
초록
1장. 개요
- 특징
- 각 서브시스템 장에서는 Red Hat Enterprise Linux 6에서 고유의 (또는 다른 방법으로 구현된) 성능 기능에 대해 설명합니다. 또한 Red Hat Enterprise Linux 5를 통해 특정 서브 시스템의 성능이 크게 개선된 Red Hat Enterprise Linux 6 업데이트에 대해서도 설명합니다.
- 분석
- 이 문서에서는 각각의 특정 서브시스템 별 성능 지표도 소개합니다. 이러한 지표의 일반적인 값은 특정 서비스의 컨텍스트에 설명되어 있어서 실제 제품 시스템에서의 중요도의 이해를 돕습니다.또한 성능 조정 가이드는 서브시스템의 성능 데이터 (즉 프로파일링)의 다른 검색 방법도 소개합니다. 여기서 보여드리는 프로파일링 도구 중 일부는 다른 곳에서 보다 자세하게 설명되어 있습니다.
- 설정
- 이 문서에서 가장 중요한 정보는 Red Hat Enterprise Linux 6의 특정 서브시스템의 성능을 조정하는 방법에 대한 지시 사항이라고 생각됩니다. 성능 조정 가이드에서는 특정 서비스에 대해 Red Hat Enterprise Linux 6 서브시스템을 세밀히 조정하는 방법에 대해 설명합니다.
1.1. 대상
- 시스템/비즈니스 분석가
- 이 문서에서는 Red Hat Enterprise Linux 6 성능 기능을 높은 수준에서 설명하고 (기본값 및 최적화되었을 때 모두에서) 특정 작업부하의 서브 시스템을 수행하는 방법에 대해 충분한 정보를 제공합니다. Red Hat Enterprise Linux 6 성능 기능에 대한 상세한 설명을 통해 잠재적 고객 및 세일즈 엔지니어는 허용 가능한 수준에서 리소스 집약적 서비스를 제공하기 위해 이 플랫폼의 적합성을 이해할 수 있게 합니다.또한 성능 조정 가이드는 가능한 각 기능에 대한 보다 상세한 문서로의 링크를 제공합니다. 세부적으로 사용자는 성능 기능을 충분히 이해하여 Red Hat Enterprise Linux 6의 배포 및 최적화에 있어서 높은 수준의 전략을 형성할 수 있습니다. 따라서 사용자는 인프라 제안을 개발 및 평가할 수 있습니다.이는 기능에 초점을 둔 문서이므로 Linux 서브 시스템과 기업 수준의 네트워크를 고도로 이해할 수 있는 사용자를 위한 것입니다.
- 시스템 관리자
- 이 문서에 나열된 절차는 RHCE [1] 기술 수준 (또는 이에 상응하는 즉 Linux 배포 및 관리경험 3-5년)을 갖는 시스템 관리자를 위한 것입니다. 성능 조정 가이드에서는 각 설정의 효과에 대해 최대한 상세하게 설명하고 있습니다. 즉 발생할 수 있는 성능 장단점을 설명하고 있습니다.성능 튜닝에 있어서 기본 기술은 서브 시스템을 분석 및 튜닝하는 방법을 알고 있는 것에 있지 않습니다. 오히려 성능 튜닝에 익숙한 시스템 관리자는 특정 목적을 위해 Red Hat Enterprise Linux 6 시스템을 최적화하고 균형을 갖게 하는 방법을 알고 있습니다. 이는 특정 서브시스템의 성능을 개선하기 위한 설정을 구현할 때 장단점 및 성능 저하에 대해서도 알고 있다는 것을 의미합니다.
1.2. 수평적 확장성
1.2.1. 병렬 컴퓨팅
1.3. 분산 시스템
- 통신
- 수평적 확장성에서는 많은 작업이 (병렬로) 동시에 실행되어야 합니다. 따라서 이러한 작업은 프로세스간 통신에서 작업을 조정해야 합니다. 또한 수평적 확장성의 플랫폼은 여러 시스템에 걸쳐 작업을 공유할 수 있어야 합니다.
- 스토리지
- 로컬 디스크를 통한 스토리지는 수평적 확장성의 요구 사항을 충족하기에 충분하지 않습니다. 일부 분산 또는 공유 형태의 스토리지는 단일 스토리지 볼륨의 용량이 새로운 스토리지 하드웨어를 추가하여 원활하게 확장할 수 있는 추상화 계층을 제공하는 것이 필요합니다.
- 관리
- 분산 컴퓨팅에서 가장 중요한 임무는 관리 계층입니다. 이러한 관리 계층은 모든 소프트웨어 및 하드웨어 구성요소를 조정하고 통신, 스토리지, 공유 리소스의 사용을 효율적으로 관리합니다.
1.3.1. 통신
- 하드웨어
- 소프트웨어
컴퓨터 간에 가장 일반적인 통신 방법은 이더넷을 사용하는 것입니다. 현재 시스템에서 GbE (Gigabit Ethernet)가 기본적으로 제공되며 대부분의 서버에는 기가바이트 이더넷 포트가 2-4개 있습니다. GbE는 우수한 대역폭 및 대기 시간을 제공합니다. 이는 현재 사용되는 대부분의 분산 시스템의 기초가 되고 있습니다. 시스템에 고속 네트워크 하드웨어가 있어도 전용 관리 인터페이스는 일반적으로 GbE를 사용합니다.
10GbE (10 Gigabit Ethernet)은 하이 엔드 및 미드 레인지 서버에서 급속히 확대하고 있습니다. 10GbE는 GbE의 10 배의 대역폭을 제공합니다. 주요 장점 중 하나는 최신 멀티 코어 프로세서와 함께 사용하면 통신과 컴퓨팅 간의 균형을 회복하는 것입니다. 단일 코어 시스템에서 GbE를 사용하는 경우와 8 코어 시스템에서 10GbE를 사용하는 것을 비교해 보면 차이를 잘 알 수 있습니다. 이 방법의 사용에서 전체적인 시스템 성능을 유지하고 통신 병목 현상을 해소하기 위해 10GbE가 특히 유용합니다.
Infiniband는 10GbE 보다 더 높은 성능을 제공합니다. 이더넷과 함께 사용되는 TCP/IP 및 UDP 네트워크 연결 이외에 Infiniband는 공유 메모리 통신을 지원합니다. 이는 Infiniband가 RDMA (remote direct memory access)를 통해 시스템 간의 작업을 가능하게 합니다.
RoCCE (RDMA over Ethernet)는 10GbE 인프라를 통해 Infiniband 스타일 통신 (RDMA 포함)을 구현합니다. 10GbE 제품의 볼륨 확대와 관련하여 비용 향상을 감안할 때 다양한 시스템 및 애플리케이션에서 RDMA 및 RoCCE 사용 증가가 예상됩니다.
1.3.2. 스토리지
- 단일 위치에서 여러 시스템이 데이터를 저장하고 있는 경우
- 여러 스토리지 어플라이언스로 구성된 스토리지 장치 (예: 볼륨)
NFS (Network File System)는 여러 대의 서버나 사용자가 TCP 또는 UDP를 통해 원격 스토리지의 동일한 인스턴스를 마운트 및 사용하는 것을 허용합니다. 일반적으로 NFS는 여러 애플리케이션에 의해 공유되는 데이터를 보유하고 있습니다. 또한 대량 데이터의 대량 저장에 적합니다.
SAN (Storage Area Networks)는 파이버 채널이나 iSCSI 프로토콜을 사용하여 스토리지에 원격 액세스를 제공합니다. 파이버 채널 인프라 (파이버 채널 호스트 버스 어댑터, 스위치, 스토리지 어레이 등)는 고성능, 높은 대역폭, 대량 스토리지를 결합합니다. SAN은 프로세스에서 스토리지를 분리함으로써 시스템 디자인의 유연성이 매우 높아집니다.
- 스토리지로의 액세스 제어
- 대량 데이터 관리
- 시스템 구축
- 데이터 백업 및 복제
- 스냅샷 만들기
- 시스템 장애 복구 지원
- 데이터 무결성 보장
- 데이터 마이그레이션
Red Hat GFS2 (Global File System 2) 파일 시스템은 몇몇 특별한 기능을 제공합니다. GFS2의 기본 기능은 동시에 읽기/쓰기 액세스, 여러 클러스터 멤버 간 공유를 포함하여 단일 파일 시스템을 제공합니다. 즉 각 클러스터 멤버는 GFS2 파일 시스템의 "디스크 상"에서 완전히 동일한 데이터를 볼 수 있습니다.
1.3.3. 통합 네트워크
FCoE로 표준 파이버 채널 명령 및 데이터 패킷은 단일 CNA (converged network card)를 통해 10GbE 물리적 인프라로 이동합니다. 표준 TCP/IP 이더넷 트래픽과 파이버 채널 스토리지 작업도 동일한 링크를 통해 이동할 수 있습니다. FCoE는 여러 논리 네트워크/스토리지 연결을 위해 하나의 물리적 네트워크 인터페이스 카드 (하나의 케이블)를 사용합니다.
- 연결 수 감소
- FCoE를 사용하면 서버로의 네트워크 연결 수를 절반으로 줄일 수 있습니다. 성능이나 가용성을 목적으로 여러 연결을 선택할 수 있지만 단일 연결은 스토리지와 네트워크 연결을 모두 제공합니다. 이는 특히 피자 박스 서버와 블레이드 서버의 경우 구성 요소의 공간이 한정되어 있기 때문에 유용할 것입니다.
- 낮은 비용
- 연결 수를 줄이면 바로 케이블, 스위치 및 기타 네트워크 장비 수가 줄어들게 됩니다. 또한 이더넷의 기록에 있어서 경제적 규모를 특징으로 합니다. 시장에서의 디바이스 수가 수백만에서 수십억으로 늘어나면 100Mb 이더넷 및 기가 바이트 이더넷 장치의 가격 하락에서 볼 수 있듯이 네트워크 비용은 현저하게 감소합니다.이와 유사하게 10GbE 사용을 채택하는 기업이 늘어남에 따라 이 가격은 더 저렴해 지게 됩니다. 또한 CNA 하드웨어가 단일 칩으로 통합되고 사용 확대는 시장에서 볼륨을 증가시키고 결과적으로 시간이 지남에 따라 가격이 대폭 하락하게 됩니다.
iSCSI (Internet SCSI)는 다른 유형의 통합된 네트워크 프로토콜로 FCoE의 대안입니다. 파이버 채널과 같이 iSCSI는 네트워크를 통해 블록 레벨 스토리지를 제공합니다. 하지만 iSCSI는 전체 관리 환경을 제공하지 않습니다. FCoE를 통한 iSCSI의 주요 장점은 iSCSI는 파이버 채널의 대부분의 기능과 유연성을 더 낮은 비용으로 제공할 수 있다는 점입니다.
2장. Red Hat Enterprise Linux 6 성능 특징
2.1. 64 비트 지원
- Huge pages 및 transparent huge pages
- NUMA (Non-Uniform Memory Access) 개선
Red Hat Enterprise Linux 6에서 huge pages의 구현으로 다른 메모리 작업 동안 메모리 사용을 효과적으로 관리할 수 있게 되었습니다. Huge pages는 표준 4 KB 페이지 크기와 비교하여 동적으로 2 MB 페이지를 이용하므로 애플리케이션은 기가바이트나 테라바이트 메모리 처리에서 충분히 확장 가능합니다.
현재 새로운 시스템의 대부분은 NUMA (Non-Uniform Memory Access)를 지원하고 있습니다. NUMA는 대규모 시스템의 하드웨어 설계 및 생성을 간소화합니다. 하지만 이는 애플리케이션 개발에 다른 복잡성을 추가합니다. 예를 들어 NUMA는 로컬 및 원격 메모리를 구현하고 여기서 원격 메모리는 로컬 메모리 보다 몇 배의 액세스 시간이 소요됩니다. 이 기능은 (다른 기능과 함께) 배포되는 운영 체제, 애플리케이션, 시스템 설정 등 많은 성능에 영향을 미칠 수 있습니다.
2.2. Ticket Spinlocks
2.3. 동적 목록 구조
2.4. 틱리스 커널
2.5. 컨트롤 그룹
- cgroup에 할당된 작업 목록
- 이러한 작업에 할당된 리소스
- CPUsets
- 메모리
- I/O
- 네트워크 (대역폭)
2.6. 스토리지 및 파일 시스템 개선 사항
Ext4는 Red Hat Enterprise Linux 6의 기본 파일 시스템입니다. 이는 EXT 파일 시스템 제품군의 4세대로 이론적으로 최대 1 엑사바이트 파일 시스템과 16TB 단일 파일을 지원합니다. Red Hat Enterprise Linux 6는 최대 16TB의 파일 시스템과 16TB의 단일 파일을 지원합니다. 더 큰 스토리지 기능 이외에 ext4에는 다음과 같은 다른 여러 새로운 기능이 포함되어 있습니다.
- 익스텐트 기반의 메타데이터
- 지연 할당
- 저널 체크섬 (Journal check-summing)
XFS는 강력하고 안정된 64 비트 저널링 파일 시스템으로 단일 호스트에서 매우 큰 파일 및 파일 시스템을 지원합니다. 이러한 파일 시스템은 SGI에 의해 개발된 것으로 매우 큰 서버 및 스토리지 어레이에서 장기간 실행된 기록이 있습니다. XFS 기능은 다음과 같습니다:
- 지연 할당
- 동적으로 할당된 inode
- 여유 공간 관리의 확장성을 위한 B 트리 인덱싱
- 온라인 조각 모음 및 파일 시스템 확장
- 정교한 메타데이터 미리 읽기 알고리즘
전형적인 BIOS는 최대 2.2TB의 디스크 크기를 지원합니다. BIOS를 사용하는 Red Hat Enterprise Linux 6 시스템은 GPT (Global Partition Table)라는 새로운 디스크 구조를 사용하여 2.2TB 이상의 디스크 크기를 지원할 수 있습니다. GPT는 데이터 디스크 용으로만 사용할 수 있으며 BIOS와 함께 부팅 드라이브 용으로는 사용할 수 없으므로 부팅 드라이브의 최대 크기는 2.2TB만 될 수 있습니다. 원래 BIOS는 IBM PC 용으로 생성되었습니다. BIOS가 최신 하드웨어에 적응할 수 있도록 진화한 반면 UEFI (Unified Extensible Firmware Interface)는 새로운 최신 하드웨어를 지원하도록 설계되어 있습니다.
중요
중요
3장. 시스템 성능 모니터링 및 분석
3.1. proc 파일 시스템
proc "파일 시스템"은 Linux 커널의 현재 상태를 나타내는 파일의 계층 구조가 들어 있는 디렉토리입니다. 이를 통해 애플리케이션 및 사용자는 시스템의 커널 보기를 할 수 있습니다.
proc 디렉토리에는 시스템의 하드웨어 및 현재 실행 중인 프로세스에 대한 정보가 들어 있습니다. 이 파일의 대부분은 읽기 전용이지만 일부 파일 (주로 /proc/sys에 있는 파일)은 커널에 설정 변경을 전달하기 위해 사용자 및 애플리케이션에 의해 조작될 수 있습니다.
proc 디렉토리에 있는 파일을 확인 및 편집에 대한 보다 자세한 내용은 http://access.redhat.com/site/documentation/Red_Hat_Enterprise_Linux/의 운용 가이드에서 참조하십시오.
3.2. GNOME 및 KDE 시스템 모니터
GNOME 시스템 모니터는 기본 시스템 정보를 표시하고 시스템 프로세스, 리소스,파일 시스템 사용량을 모니터링할 수 있습니다. Terminal에서 gnome-system-monitor 명령으로 이를 오픈하거나 메뉴를 클릭하여 > 를 선택합니다.
- 컴퓨터의 하드웨어 및 소프트웨어에 대한 기본 정보를 표시합니다.
- 활성 프로세스 및 해당 프로세스 간의 관계 뿐 만 아니라 각 프로세스에 대한 자세한 정보를 보여줍니다. 또한 표시된 프로세스를 필터링하고 이러한 프로세스에 특정 작업 (시작, 중지, 중단, 우선 순위 변경 등)을 수행할 수 있게 합니다.
- 현재 CPU 시간 사용량, 메모리, 스왑 공간 사용량, 네트워크 사용량을 표시합니다.
- 파일 시스템 유형, 마운트 지점, 메모리 사용량과 같은 각각에 대한 몇 가지 기본적인 정보와 함께 마운트된 모든 파일 시스템을 나열합니다.
KDE 시스템 가드를 통해 현재 실행되고 있는 프로세스 및 현재 시스템 로드를 모니터링할 수 있습니다. 터미널에서 ksysguard 명령으로 이를 오픈하거나 을 클릭한 후 > > 를 선택합니다.
- 기본값으로 실행 중인 모든 프로세스의 목록을 알파벳 순으로 표시합니다. 또한 총 CPU 사용량, 물리적 또는 공유 메모리 사용량, 소유자, 우선 순위 등과 같은 다른 속성에 따라 프로세스를 정렬할 수 있습니다. 가시적 결과를 필터링하거나, 특정 프로세스를 검색 또는 프로세스에서 특정 작업을 수행할 수 있습니다.
- CPU 사용량, 메모리, 스왑 공간 사용량, 네트워크 사용량의 그래픽 기록을 표시합니다. 자세한 분석 및 그래프 키를 위해 그래프에 마우스 오버합니다.
3.3. 내장된 명령행 모니터링 도구
toptop 도구는 실행 중인 시스템에서 프로세스의 동적인 실시간 뷰를 제공합니다. 이는 시스템 요약, Linux 커널에 의해 관리되는 작업 등과 같은 다양한 정보를 표시할 수 있습니다. 또한 프로세스를 조작할 수 있는 제한된 기능을 가지고 있습니다. 이러한 동작 및 표시되는 정보는 모두 설정 가능하고 설정 세부 사항은 다시 시작하기를 통해 영구적으로 만들 수 있습니다.
man top man 페이지에서 참조하십시오.
psps 도구는 활성 프로세스의 선택 그룹의 스냅샷을 찍습니다. 기본값으로 이 그룹은 현재 사용자가 소유하고 있고 동일한 터미널과 관련된 프로세스로 제한됩니다.
man ps man 페이지에서 참조하십시오.
vmstatvmstat (Virtual Memory Statistics)는 시스템의 프로세스, 메모리, 페이징, I/O 차단, 인터럽트, CPU 동작에 대한 즉각적인 보고서를 출력합니다.
man vmstat man 페이지에서 참조하십시오.
sarsar (System Activity Reporter)는 지금까지 현재의 시스템 동작에 대한 정보를 수집 및 보고합니다. 기본값 출력은 하루의 시작에서 10분 간격으로 현재의 CPU 사용률을 포함합니다:
12:00:01 AM CPU %user %nice %system %iowait %steal %idle
12:10:01 AM all 0.10 0.00 0.15 2.96 0.00 96.79
12:20:01 AM all 0.09 0.00 0.13 3.16 0.00 96.61
12:30:01 AM all 0.09 0.00 0.14 2.11 0.00 97.66
...
man sar man 페이지에서 참조하십시오.
3.4. Tuned 및 ktune
default- 기본적인 절전 프로파일입니다. 이는 가장 기본적인 절전 프로파일입니다. 디스크 및 CPU 플러그인만 활성화합니다. 이는 tuned-adm을 튜닝 해제하는 것과 동일하지 않습니다. 이 경우 tuned 및 ktune 모두는 비활성화됩니다.
latency-performance- 전형적인 지연 성능 튜닝 용 서버 프로파일입니다. 이는 tuned 및 ktune 절전 메커니즘을 비활성화합니다.
cpuspeed모드는performance로 변경됩니다. 각 장치의 I/O 엘리베이터는deadline으로 변경됩니다. 서비스의 전원 관리 품질의 경우cpu_dma_latency요구 사항 값0이 등록됩니다. throughput-performance- 전형적인 처리량 성능 튜닝 용 서버 프로파일입니다. 시스템이 엔터프라이즈급 스토리지가 없는 경우 이 프로파일이 권장됩니다. 이는
latency-performance와 동일하지만 다음과 같은 차이점이 있습니다:kernel.sched_min_granularity_ns(scheduler minimal preemption granularity)는10밀리초로 설정됩니다.kernel.sched_wakeup_granularity_ns(scheduler wake-up granularity)는15밀리초로 설정됩니다.vm.dirty_ratio(virtual machine dirty ratio)는 40%로 설정됩니다.- transparent huge pages가 활성화됩니다.
enterprise-storage- 이 프로파일은 배터리 백업 컨트롤터 캐시 보호 및 디스크 내장 캐시 관리 등 엔터프라이즈급 스토리지로 엔터프라이즈 크기 서버 설정에 권장됩니다. 이는
throughput-performance프로파일과 동일하지만 파일 시스템은barrier=0로 다시 마운트됩니다. virtual-guest- 이 프로파일은 배터리 백업 컨트롤터 캐시 보호 및 디스크 내장 캐시 관리 등 엔터프라이즈급 스토리지로 엔터프라이즈 크기 서버 설정에 권장됩니다. 이는
throughput-performance프로파일과 동일하지만 다음과 같은 차이점이 있습니다:readahead값은4x로 설정됩니다.- root/boot 파일 시스템 이외의 파일 시스템은
barrier=0으로 다시 마운트됩니다.
virtual-hostenterprise-storage프로파일에 따라virtual-host도 가상 메모리의 swappiness를 줄이고 더티 페이지의 보다 적극적인 쓰기 저장을 가능하게 합니다. 이 프로파일은 Red Hat Enterprise Linux 6.3 이상 버전에서 사용 가능하며 KVM 및 Red Hat Enterprise Virtualization 호스트를 포함하여 가상화 호스트의 프로파일에 권장됩니다.
3.5. 애플리케이션 프로파일러
3.5.1. SystemTap
3.5.2. OProfile
- 성능 모니터링 샘플이 정확하지 않을 수 있습니다 - 프로세서가 잘못된 지시 사항을 실행할 수 있기 때문에 샘플이 인터럽트를 발생시킨 지시 사항 대신 인근 지시 사항에서 기록될 수 있습니다.
- OProfile은 시스템 전역의 것으로 프로세스가 여러번 시작 및 중지될 수 있으며 여러 실행에서의 샘플이 축적 허용됩니다. 즉 이는 이전 실행에서 데이터 샘플을 삭제해야 함을 의미합니다.
- CPU 제한 프로세서의 문제를 확인하는 것에 초점을 두고 있으므로 다른 이벤트에 대해 잠금 상태에서 기다리는 동안 수면 상태에 있는 프로세스를 인식하지는 않습니다.
/usr/share/doc/oprofile-<version>에 있는 시스템의 oprofile 문서에서 참조하십시오.
3.5.3. Valgrind
man valgrind 명령을 사용하여 참조할 수 있습니다. 기타 다른 문서는 다음에서 확인하실 수 있습니다:
/usr/share/doc/valgrind-<version>/valgrind_manual.pdf/usr/share/doc/valgrind-<version>/html/index.html
3.5.4. Perf
perf stat- 이 명령은 실행된 지시 사항 및 소비된 클럭 사이클을 포함하여 일반적인 성능 이벤트의 전체 통계를 제공합니다. 옵션 플래그를 사용하여 기본 측정 이벤트 이외에 이벤트의 통계를 수집할 수 있습니다. Red Hat Enterprise Linux 6.4에서
perf stat를 사용하여 하나 이상의 지정된 컨트롤 그룹 (cgroups)에 기반하여 모니터링을 필터링할 수 있습니다. 보다 자세한 내용은man perf-statman 페이지에서 참조하십시오. perf record- 이 명령은 성능 데이터를
perf report를 사용하여 나중에 분석할 수 있는 파일에 기록합니다. 보다 자세한 내용은man perf-recordman 페이지에서 참조하십시오. perf report- 이 명령은 파일에서 성능 데이터를 읽고 기록된 데이터를 분석합니다. 보다 자세한 내용은
man perf-reportman 페이지에서 참조하십시오. perf list- 이 명령은 특정 컴퓨터에서 사용할 수 있는 이벤트를 나열합니다. 이러한 이벤트는 성능 모니터링 하드웨어 및 시스템의 소프트웨어 설정에 따라 다릅니다. 보다 자세한 내용은
man perf-listman 페이지에서 참조하십시오. perf top- 이 명령은 top 도구와 유사한 기능을 수행합니다. 실시간으로 성능 카운트 프로파일을 생성 및 표시합니다. 보다 자세한 내용은
man perf-topman 페이지에서 참조하십시오.
3.6. Red Hat Enterprise MRG
- 전원 관리, 오류 감지, 시스템 관리 인터럽트와 관련된 BIOS 매개 변수;
- 인터럽트 합병, TCP 사용과 같은 네트워크 설정;
- 파일 시스템 저널링에서 동작 저널링;
- 시스템 로깅;
- 특정 CPU 또는 CPU 범위에 의해 인터럽트와 사용자 프로세스가 처리되는지에 대한 여부;
- 스왑 공간이 사용되는지에 대한 여부;
- 메모리 부족 예외를 처리하는 방법
4장. CPU
토폴로지
스레드
인터럽트
4.1. CPU 토폴로지
4.1.1. CPU 및 NUMA 토폴로지
- 직렬 버스
- NUMA 토폴로지
- 시스템의 토폴로지는 무엇입니까?
- 현재 애플리케이션은 어디에서 실행되고 있습니까?
- 가장 가까운 메모리 뱅크는 어디에 있습니까?
4.1.2. CPU 성능 튜닝
- CPU (0-3 중 하나)는 로컬 메모리 컨트롤러로의 메모리 주소를 표시합니다.
- 메모리 컨트롤러는 메모리 주소로의 액세스를 설정합니다.
- CPU는 해당 메모리 주소에서 읽기/쓰기 작업을 수행합니다.
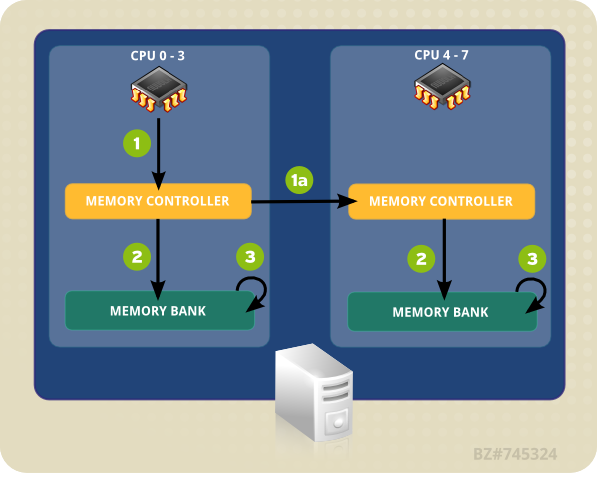
그림 4.1. NUMA 토폴로지에서 로컬 및 원격 메모리 액세스
- CPU (0-3 중 하나)는 로컬 메모리 컨트롤러에 원격 메모리 액세스를 표시합니다.
- 원격 메모리 주소의 CPU 요청은 메모리 주소가 있는 노드로의 로컬, 원격 메모리 컨트롤러에 전달됩니다.
- 원격 메모리 컨트롤러는 원격 메모리 주소로의 액세스를 설정합니다.
- CPU는 해당 원격 메모리 주소에서 읽기 또는 쓰기 작업을 수행합니다.
- 시스템의 토폴로지 (구성 요소가 연결된 방법)
- 애플리케이션을 실행하는 코어
- 가장 가까운 메모리 뱅크 위치
4.1.2.1. taskset으로 CPU 친화도 설정
0x00000001은 프로세서 0을 0x00000003은 프로세스 0 및 1을 나타냅니다.
# taskset -p mask pid# taskset mask -- program-c 옵션을 사용하여 별도의 프로세서를 콤마로 구분한 목록 또는 프로세서 범위를 제공할 수 있습니다. 예:
# taskset -c 0,5,7-9 -- myprogramman taskset man 페이지에서 참조하십시오.
4.1.2.2. numactl로 NUMA 정책 제어
numactl은 지정된 스케줄링 또는 메모리 배치 정책으로 프로세스를 실행합니다. 선택된 정책은 해당 프로세스 및 모든 자식 프로세스에 설정됩니다. numactl은 공유 메모리 세그먼트 또는 파일 용 영구 정책을 설정할 수 있고 프로세스의 CPU 친화도 및 메모리 친화도를 설정할 수 있습니다. 이는 /sys 파일 시스템을 사용하여 시스템 토폴로지를 지정합니다.
/sys 파일 시스템에는 CPU, 메모리, 주변 장치가 NUMA 상호 연결을 통해 연결된 방법에 관한 정보가 들어 있습니다. 특히 /sys/devices/system/cpu 디렉토리에는 시스템의 CPU가 각각 연결된 방법에 대한 정보가 들어 있습니다. /sys/devices/system/node 디렉토리에는 시스템의 NUMA 노드와 노드 간의 상대 거리에 대한 정보가 들어 있습니다.
--show- 현재 프로세스의 NUMA 정책 설정을 표시합니다. 이 매개 변수는 추가 매개 변수를 필요로 하지 않으며 다음과 같이 사용할 수 있습니다:
numactl --show --hardware- 시스템에서 사용 가능한 노드의 인벤토리를 표시합니다.
--membind- 지정된 노드에서 메모리만 할당합니다. 노드가 사용 중이고 이러한 노드에 있는 메모리가 충분하지 않을 경우 할당은 실패하게 됩니다. 이러한 매개 변수의 사용 방법은
numactl --membind=nodes program입니다. 여기서 nodes는 메모리를 할당하고자 하는 노드 목록이고, program은 메모리 요구 사항을 해당 노드에서 할당해야 하는 프로그램입니다. 노드 번호는 콤마로 구분된 목록, 범위, 또는 이 두 가지 조합으로 지정할 수 있습니다. 보다 자세한 내용은 numactl man 페이지인man numactl에서 참조하십시오. --cpunodebind- 지정된 노드에 속한 CPU에 있는 명령 (및 자식 프로세스)만을 실행합니다. 이 매개 변수의 사용 방법은
numactl --cpunodebind=nodes program입니다. 여기서 nodes는 지정된 프로그램 (program)이 바인딩되어야 하는 CPU의 노드 목록입니다. 노드 번호는 쉼표로 구분된 목록 또는 범위 또는 이 두가지 조합으로 지정할 수 있습니다. 보다 자세한 내용은 numactl man 페이지인man numactl에서 참조하십시오. --physcpubind- 지정된 CPU에 있는 명령 (및 자식 프로세스)만을 수행합니다. 이 매개 변수의 사용 방법은
numactl --physcpubind=cpu program입니다. 여기서 cpu는/proc/cpuinfo의 프로세서 필드에 표시된 물리적 CPU 번호를 콤마로 구분한 목록이고 program은 이러한 CPU에서만 실행해야 하는 프로그램입니다. CPU는 현재cpuset에 상대적으로 지정될 수 있습니다. 보다 자세한 내용은 numactl man 페이지인man numactl에서 참조하십시오. --localalloc- 현재 노드에 항상 할당되어야 하는 메모리를 지정합니다.
--preferred- 가능한 경우, 메모리는 지정된 노드에 할당됩니다. 메모리를 지정된 노드에 할당할 수 없는 경우 다른 노드로 대체합니다. 이 옵션은
numactl --preferred=node과 같이 하나의 노드 번호만을 사용합니다. 보다 자세한 내용은 numactl man 페이지인man numactl에서 참조하십시오.
man numa(3) man 페이지에서 참조하십시오.
4.1.3. numastat
중요
numastat, 옵션이나 매개 변수 없이)은 도구의 이전 버전과 엄격하게 호환성을 유지하고 있지만 이 명령에 추가되는 옵션이나 매개 변수는 출력 내용과 포맷 모두가 변경됨에 유의합니다.
numastat를 실행하면 각 노드에 대해 다음과 같이 이벤트 카테고리에 의해 점유된 메모리 페이지 수를 표시합니다.
numa_miss 및 numa_foreign 값이 낮으면 CPU 성능이 최적화되어 있음을 나타냅니다.
기본 추적 카테고리
- numa_hit
- 해당 노드에 할당을 시도하여 성공한 수 입니다.
- numa_miss
- 다른 노드에 할당 시도한 것으로 원래 의도된 노드에 메모리가 부족하여 해당 노드에 할당된 수입니다. 각각의
numa_miss이벤트는 해당하는numa_foreign이벤트가 다른 노드에 있습니다. - numa_foreign
- 처음에는 해당 노드에 할당 의도한 것으로 대신 다른 노드에 할당된 수입니다. 각각의
numa_foreign이벤트는 해당하는numa_miss이벤트가 다른 노드에 있습니다. - interleave_hit
- 해당 노드에 인터리브 정책 할당을 시도하여 성공한 수 입니다.
- local_node
- 해당 노드의 프로세스가 해당 노드에 있는 메모리 할당에 성공한 횟수입니다.
- other_node
- 다른 노드의 프로세스가 해당 노드에 있는 메모리를 할당한 횟수입니다.
-c- 표시된 정보 테이블을 가로로 축소합니다. 이는 NUMA 노드 수가 많은 시스템에서 유용하지만 열의 폭과 열 사이의 간격은 예측 불가능합니다. 이 옵션을 사용하면 메모리 양은 가장 가까운 메가바이트로 반올림됩니다.
-m- 노드 당 시스템 전체 메모리 사용량을 표시합니다. 이는
/proc/meminfo에 있는 정보와 유사합니다. -n- 원래 측정 단위로 메가 바이트를 사용하여 업데이트된 형식으로
numastat명령 (numa_hit, numa_miss, numa_foreign, interleave_hit, local_node, and other_node)과 동일한 정보가 표시됩니다. -p pattern- 지정된 패턴의 노드 당 메모리 정보를 표시합니다. pattern의 값이 숫자로 구성되면 numastat는 이를 숫자 프로세스 식별자로 간주합니다. 그렇지 않을 경우 numastat는 지정된 패턴의 프로세스 명령행을 검색합니다.
-p옵션 값 다음에 입력되는 명령행 인수는 필터링 추가 패턴으로 간주됩니다. 추가 패턴은 필터를 좁히는 것이 아니라 확장합니다. -s- 표시된 데이터를 내림 차순으로 정렬하므로 (
total란에 따라) 메모리 사용량이 많은 것이 먼저 나열됩니다.옵션으로 node를 지정하면 표는 node 란에 따라 정렬됩니다. 이 옵션을 사용할 때 다음과 같이 node 값은-s옵션 바로 뒤에 와야 합니다.numastat -s2옵션과 값 사이에 공백을 넣지 마십시오. -v- 자세한 정보를 표시합니다. 즉 여러 프로세스의 프로세스 정보는 각 프로세스에 대해 자세한 정보를 표시합니다.
-V- numastat 버전 정보를 표시합니다.
-z- 표시된 정보에서 제로 값을 갖는 표의 행과 열을 생략합니다. 표시 목적으로 제로로 반올림된 제로에 가까운 값은 표시된 출력에서 생략되지 않음에 유의합니다.
4.1.4. NUMA 친화도 관리 데몬 (numad)
/proc 파일 시스템에서 정보에 액세스하여 노드 당 사용 가능한 시스템 리소스를 모니터링합니다. 그 후 데몬은 충분히 정렬된 메모리와 최적의 NUMA 성능을 위한 CPU 리소스를 갖는 NUMA 노드에 중요한 프로세스를 배치합니다. 프로세스 관리의 최신 임계값은 하나의 CPU의 최소 50%와 300 MB 메모리입니다. numad는 리소스 사용량 수준을 유지하고 필요시 NUMA 노드 간 프로세스를 이동하여 할당 균형을 다시 조정합니다.
-w 옵션을 사용하는 방법에 대한 보다 자세한 내용은 man numad man 페이지에서 참조하십시오.
4.1.4.1. numad의 장점
4.1.4.2. 운영 모드
참고
- 서비스로 사용
- 실행 파일로 사용
4.1.4.2.1. numad를 서비스로 사용
# service numad start# chkconfig numad on4.1.4.2.2. numad를 실행 파일로 사용
# numad/var/log/numad.log에 기록됩니다.
# numad -S 0 -p pid-p pid- 지정된 pid를 명시적 대상 목록에 추가합니다. 지정된 프로세스는 numad 프로세스 중요도 임계값에 도달할 때 까지 관리되지 않습니다.
-S mode-S매개 변수는 프로세스 스캔 유형을 지정합니다. 다음에서 볼 수 있듯이 이를0으로 설정하면 numad 관리를 명시적으로 추가 프로세스에 한정합니다.
# numad -i 0man numad에서 참조하십시오.
4.2. CPU 스케줄링
- 실시간 정책
- SCHED_FIFO
- SCHED_RR
- 일반 정책
- SCHED_OTHER
- SCHED_BATCH
- SCHED_IDLE
4.2.1. 실시간 스케줄링 정책
SCHED_FIFO- 이 정책은 정적 우선 순위 스케줄링이라고도 합니다. 이는 각 스레드의 고정 우선 순위 (1에서 99 사이)를 정의하기 때문입니다. 이 스케줄러는 SCHED_FIFO 스레드 목록을 우선 순위 순서로 스캔하여 실행할 준비가 된 가장 우선 순위가 높은 스레드를 스케줄합니다. 이 스레드는 차단, 종료 또는 실행할 준비가 된 보다 높은 우선 순위를 갖는 스레드로 대체될 때 까지 실행됩니다.우선 순위가 가장 낮은 실시간 스레드도 비 실시간 정책 스레드 보다 먼저 스케줄됩니다. 하나의 실시간 스레드만이 존재할 경우
SCHED_FIFO우선 순위 값은 중요하지 않습니다. SCHED_RRSCHED_FIFO정책의 라운드 로빈 변형입니다.SCHED_RR스레드에는 고정 우선 순위 (1에서 99 사이)가 주어집니다. 하지만 동일한 우선 순위를 갖는 스레드는 특정 양 또는 시간 범위 내에서 라운드 로빈 스타일이 스케줄됩니다.sched_rr_get_interval(2)시스템 호출은 시간 범위 값을 반환하지만 시간 범위 길이를 사용자가 설정할 수 없습니다. 이 정책은 동일한 우선 순위로 여러 스레드를 실행해야 하는 경우 유용합니다.
SCHED_FIFO 스레드는 차단, 종료, 더 높은 우선 순위를 갖는 스레드로 대체될 때 까지 실행됩니다. 따라서 우선 순위를 99로 설정하는 것은 권장되지 않습니다. 이는 프로세스를 마이그레이션 및 워치독 스레드와 동일한 우선 순위 레벨로 배치하는 것이 됩니다. 이러한 스레드는 연산 루프에 들어갔기 때문에 이러한 스레드가 차단되면 실행 불가능하게 됩니다. 이러한 상황에서 단일 프로세서 시스템은 궁극적으로 잠금되어 버립니다.
SCHED_FIFO 정책에는 대역폭 제한 메커니즘이 포함되어 있습니다. 이는 CPU를 독점할 수 있는 실시간 작업에서 실시간 애플리케이션 프로그래머를 보호합니다. 이러한 메커니즘은 다음의 /proc 파일 시스템 매개 변수를 통해 조정할 수 있습니다:
/proc/sys/kernel/sched_rt_period_us- CPU 대역폭의 100% 가능한 시간을 마이크로초 단위로 정의합니다. ('us'는 일반 텍스트 'µs'에 가장 가까운 것에 해당됨) 기본값은 1000000µs 또는 1 초입니다.
/proc/sys/kernel/sched_rt_runtime_us- 실시간 스레드 실행에 할당할 시간을 마이크로초 단위로 정의합니다 ('us'는 일반 텍스트 'µs'에 가장 가까운 것에 해당됨). 기본 값은 950000µs 또는 0.95 초입니다.
4.2.2. 일반 스케줄링 정책
SCHED_OTHER, SCHED_BATCH, SCHED_IDLE의 3 가지가 있습니다. 하지만 SCHED_BATCH 및 SCHED_IDLE 정책은 우선 순위가 매우 낮은 작업을 대상으로 하고 있어서 성능 조정 가이드에서는 관심이 낮아지고 있습니다.
SCHED_OTHER, 또는SCHED_NORMAL- 기본 스케줄링 정책입니다. 이 정책은 CFS (Completely Fair Scheduler)를 사용하여 이 정책을 사용하는 모든 스레드에 대해 공정한 액세스 기간을 제공합니다. CFS는 각 프로세스 스레드의
niceness값에 따라 부분적으로 동적 우선 순위 목록을 설정합니다. (이 매개 변수 및/proc파일 시스템에 대한 보다 자세한 내용은 운용 가이드에서 참조하십시오.) 이는 프로세스 우선 순위를 통해 사용자에게 간접적인 제어 수준을 제공하지만 동적 우선 순위 목록은 CFS를 통해 직접적으로 변경할 수 있습니다.
4.2.3. 정책 선택
SCHED_OTHER를 사용하여 시스템이 CPU 사용을 관리하게 합니다.
SCHED_FIFO를 사용합니다. 스레드 수가 적은 경우 CPU 소켓을 고립시키고 스레드를 소켓의 코어로 이동시켜 코어에서 다른 스레드와 시간 경합을 하지 않도록 합니다.
4.3. 인터럽트 및 IRQ 튜닝
/proc/interrupts 파일은 I/O 장치 당 CPU 당 인터럽트 수를 나열합니다. 이는 IRQ 번호, 각 CPU 코어에 의해 처리되는 인터럽트 수, 인터럽트 유형, 인터럽트를 수신하도록 등록된 콤마로 구분된 드라이버 목록을 표시합니다. (보다 자세한 내용은 man 5 proc proc(5) man 페이지에서 참조하십시오.
smp_affinity가 있어 해당 IRQ의 ISR 실행을 허용하는 CPU 코어를 정의합니다. 이러한 속성은 하나 이상의 특정 CPU 코어에 인터럽트 친화도 및 애플리케이션의 스레드 친화도를 할당하여 애플리케이션의 성능을 향상시키는데 사용될 수 있습니다. 이를 통해 지정된 인터럽트와 애플리케이션 스레드 간의 캐시 라인을 공유할 수 있습니다.
/proc/irq/IRQ_NUMBER/smp_affinity 파일에 저장되어 있으며 이는 root 사용자로 수정 및 확인할 수 있습니다. 이 파일에 저장된 값은 시스템에 있는 모든 CPU 코어를 나타내는 16 진수 비트 마스크입니다.
# grep eth0 /proc/interrupts
32: 0 140 45 850264 PCI-MSI-edge eth0smp_affinity 파일을 배치하려면 IRQ 번호를 사용합니다:
# cat /proc/irq/32/smp_affinity
ff는 IRQ가 시스템에 있는 모든 CPU에서 서비스할 수 있다는 것을 의미합니다. 다음과 같이 이 값을 1로 설정하면 CPU 0 만이 이 인터럽트를 서비스할 수 있다는 것을 의미합니다:
# echo 1 >/proc/irq/32/smp_affinity
# cat /proc/irq/32/smp_affinity
1smp_affinity 값을 구분하는데 사용할 수 있습니다. 이는 32 개 이상의 코어를 갖는 시스템에 필요합니다. 예를 들어 다음의 예에서는 IRQ 40이 64 코어 시스템의 모든 코어에서 서비스되는 것을 보여줍니다:
# cat /proc/irq/40/smp_affinity
ffffffff,ffffffff# echo 0xffffffff,00000000 > /proc/irq/40/smp_affinity
# cat /proc/irq/40/smp_affinity
ffffffff,00000000참고
smp_affinity를 수정하여 하드웨어를 설정하고 인터럽트를 특정 CPU에서 실행하는 결정을 커널에서의 간섭없이 하드웨어 수준에서 수행할 수 있습니다.
4.4. Red Hat Enterprise Linux 6에서 NUMA 기능 강화
4.4.1. 베어 메탈 및 확장성 최적화
4.4.1.1. 토폴로지 인식 기능 향상
- 토폴로지 검색 강화
- 이는 운영 체제가 낮은 수준의 하드웨어 정보 (논리 CPU 및 하이퍼 스레드, 코어, 소켓, NUMA 노드, 노드 간 액세스 시간 등) 부팅 시 검색할 수 있게 하며 시스템에서 프로세스를 최적화합니다.
- 완전 공정 스케줄러 (CFS, Completely Fair Scheduler)
- 이러한 새로운 스케줄링 모드는 런타임이 유효한 프로세스 간에 동등하게 공유되고 있는지 확인합니다. 이를 토폴로지 검색과 결합하여 프로세스가 동일한 소켓에 있는 CPU로 스케줄되어 고가의 원격 메모리 액세스에 대한 필요를 방지하고 가능한 캐시 내용이 보존되는지를 확인할 수 있습니다.
mallocmalloc은 프로세스에 할당된 메모리 영역이 프로세스가 실행되고 있는 코어에 물리적으로 가능한 가깝도록 최적화되어 있습니다. 이를 통해 메모리 액세스 속도가 높아집니다.- skbuff I/O 버퍼 할당
malloc과 유사하게 이는 장치 인터럽트와 같은 I/O 작업을 처리하는 CPU에 물리적으로 가까운 메모리를 사용하도록 최적화되어 있습니다.- 장치 인터럽트 친화도
- 어떤 CPU가 어떤 인터럽트를 처리하는가에 관한 장치 드라이브에 의해 기록된 정보는 캐시 친화도를 보존하고 소켓 사이의 높은 볼륨간 소켓 통신을 제한하며, 동일한 물리적 소켓 내에 있는 CPU에 인터럽트 처리를 제한하는데 사용될 수 있습니다.
4.4.1.2. 멀티 프로세서 동기화 기능 개선
- RCU (Read-Copy-Update) 잠금
- 일반적으로 잠금의 90%는 읽기 전용 목적으로 취득됩니다. RCU 잠금은 액세스되는 데이터가 수정되지 않을 때 단독 액세스 잠금을 획득할 필요성을 제거합니다. 이러한 잠금 모드는 현재 페이지 캐시 메모리 할당에 사용됩니다. 현재 잠금은 할당 또는 할당 취소 작업에만 사용됩니다.
- CPU 당 및 소켓 당 알고리즘
- 대부분의 알고리즘은 보다 세밀한 잠금을 허용하도록 동일한 소켓에 있는 협력 CPU 간 잠금 조정을 수행하도록 업데이트되었습니다. 수많은 글로벌 스핀락 (spinlock)은 소켓 당 잠금 방법으로 대체되어 업데이트된 메모리 할당자 영역과 관련 메모리 페이지 목록은 작업 할당 또는 할당 취소 작업을 수행할 때 메모리 할당 논리가 보다 효율적으로 메모리 매핑 데이터 구조의 하위 집합을 통과할 수 있습니다.
4.4.2. 가상화 최적화
- CPU 핀 설정
- 가상 게스트가 로컬 캐시 사용을 최적화하고 고가의 소켓 간의 통신 및 원격 메모리 액세스에 대한 필요성을 제거하기 위해 특정 소켓에서 실행하도록 바인딩할 수 있습니다.
- THP (transparent hugepages)
- THP를 활성화하면 시스템은 연속적인 대량의 메모리에 대해 자동으로 NUMA 인식 메모리 할당 요청을 수행하고, 잠금 경합 및 TLB (translation lookaside buffer) 메모리 관리 작업 횟수가 감소되며, 가상화 게스트에서 최대 20% 까지 성능이 향상됩니다.
- 커널 기반 I/O 구현
- 가상 게스트의 I/O 서브시스템이 커널에 구현되어 대량의 컨텍스트 스위칭 및 동기화, 통신 오버 헤드를 방지하여 노드간 통신 및 메모리 액세스 비용이 현저하게 감소됩니다.
5장. 메모리
5.1. HugeTLB (Huge Translation Lookaside Buffer)
/usr/share/doc/kernel-doc-version/Documentation/vm/hugetlbpage.txt에서 참조하십시오.
5.2. Huge Pages 및 Transparent Huge Pages
- 하드웨어 메모리 관리 장치에서 페이지 테이블 엔트리 수를 늘림
- 페이지 크기를 확대함
5.3. 프로파일 메모리 사용에 Valgrind 사용
valgrind --tool=toolname programmemcheck, massif, cachegrind)으로 변경하고 program을 Valgrind으로 프로파일링하고자 하는 프로그램으로 변경합니다. Valgrind의 계측을 사용하면 프로그램이 평소보다 더 느리게 실행되는 원인이 될 수 있음에 유의합니다.
man valgrind 명령으로 확인하거나 다음의 위치에서 확인하실 수 있습니다:
/usr/share/doc/valgrind-version/valgrind_manual.pdf,/usr/share/doc/valgrind-version/html/index.html.
5.3.1. Memcheck로 메모리 사용량 프로파일링
--tool=memcheck를 지정하지 않고 valgrind program으로 실행될 수 있습니다. 발생해서는 안되는 메모리 액세스, 정의되지 않거나 초기화되지 않은 값의 사용, 올바르지 않게 해제된 힙 메모리, 중복 포인터, 메모리 누수와 같은 감지 및 진단이 어려운 여러 메모리 오류를 감지하고 보고합니다. Memcheck를 사용하면 프로그램은 일반적으로 실행되는 것 보다 10-30 배 느리게 실행됩니다.
/usr/share/doc/valgrind-version/valgrind_manual.pdf에 포함된 Valgrind 문서에 자세히 설명되어 있습니다.
--leak-check- 활성화할 경우 Memcheck는 클라이언트 프로그램이 완료되면 메모리 누수를 검색합니다. 기본값은
summary로 발견된 누수 수를 출력합니다. 사용 가능한 다른 값은yes및full로 모두 개별적 누수 세부 정보를 제공하며no는 메모리 누수 검사를 비활성화합니다. --undef-value-errors- 활성화할 경우 (
yes로 설정할 경우) Memcheck는 정의되지 않은 값이 사용되고 있을 때 오류를 보고합니다. 비활성화할 경우 (no로 설정할 경우) 정의되지 않은 값 오류는 보고되지 않습니다. 이는 기본값으로 활성화되어 있습니다. 이를 비활성화하면 Memcheck 속도가 약간 빨라집니다. --ignore-ranges- 적용 가능성을 검사할 때 사용자는 Memcheck가 무시해야 하는 하나 이상의 범위를 지정할 수 있습니다. 여러 범위는 다음과 같이 콤마로 구분합니다. 예:
--ignore-ranges=0xPP-0xQQ,0xRR-0xSS
/usr/share/doc/valgrind-version/valgrind_manual.pdf에 있는 문서에서 참조하십시오.
5.3.2. Cachegrind로 캐시 사용량 프로파일링
# valgrind --tool=cachegrind program- 첫 번째 레벨 지시 캐시 읽기 (또는 실행된 명령) 및 읽기 미스, 마지막 레벨 지시 캐시 읽기 미스;
- 데이터 캐시 읽기 (또는 메모리 읽기), 읽기 미스, 마지막 레벨 캐시 데이터 읽기 미스;
- 데이터 캐시 쓰기 (또는 메모리 쓰기), 쓰기 미스 및 마지막 레벨 캐시 쓰기 미스
- 실행 및 잘못 예측된 조건 분기
- 실행 및 잘못 예측된 간접 분기
cachegrind.out.pid, 여기서 pid는 Cachegrind를 실행하는 프로그램의 프로세스 ID입니다). 이러한 파일은 다음과 같이 cg_annotate 도구로 추가 처리할 수 있습니다:
# cg_annotate cachegrind.out.pid참고
# cg_diff first second--I1- 콤마로 구분하여 첫 번째 레벨 지시 캐시의 크기, 연결성, 행의 크기를 지정합니다:
--I1=size,associativity,line size. --D1- 콤마로 구분하여 첫 번째 레벨 데이터 캐시의 크기, 연결성, 행의 크기를 지정합니다:
--D1=size,associativity,line size. --LL- 콤마로 구분하여 마지막 레벨 캐시의 크기, 연결성, 행의 크기를 지정합니다:
--LL=size,associativity,line size. --cache-sim- 캐시 액세스 및 미스 카운트의 모음을 활성화 또는 비활성화합니다. 기본값은
yes(활성화)입니다.이 옵션 및--branch-sim모두를 비활성화하면 Cachegrind에는 수집할 정보가 없게 됨에 유의합니다. --branch-sim- 분기 지시 및 예측 실패 수의 모음을 활성화 또는 비활성화합니다. 이는 Cachegrind를 약 25% 느리게 할 수 있으므로 기본값은
no(비활성화)로 설정되어 있습니다.이 옵션 및--cache-sim모두를 비활성화하면 Cachegrind에는 수집할 정보가 없게 됨에 유의합니다.
/usr/share/doc/valgrind-version/valgrind_manual.pdf에 있는 문서에서 참조하십시오.
5.3.3. Massif를 사용하여 힙 및 스택 영역 프로파일링
massif를 지정합니다:
# valgrind --tool=massif programmassif.out.pid라는 파일에 기록됩니다. 여기서 pid는 지정된 program의 프로세스 ID입니다.
ms_print 명령으로 그래프화할 수 있습니다:
# ms_print massif.out.pid--heap- 힙 프로파일링을 수행할 지에 대한 여부를 지정합니다. 기본값은
yes입니다. 이 옵션을no로 설정하면 힙 프로파일링을 비활성화할 수 있습니다. --heap-admin- 힙 프로파일링을 활성화할 때 관리에 사용할 블록 당 바이트 수를 지정합니다. 기본값은 블록 당
8바이트입니다. --stacks- 스택 프로파일링을 수행할 지에 대한 여부를 지정합니다. 기본값은
no(비활성화)입니다. 스택 프로파일링을 활성화하려면 이 옵션을yes로 설정합니다. 하지만 이러한 설정으로 Massif가 현저히 느려지게 될 것임에 유의합니다. 또한 프로파일링된 프로그램이 제어하는 스택 부분의 크기를 보다 알기 쉽게 표시하기 위해 Massif는 메인 스택 크기가 시작 시 0이라고 가정하고 있다는 점에 유의합니다. --time-unit- 프로파일링에 사용되는 시간 단위를 지정합니다. 이 옵션에는 세 개의 유효한 값이 있습니다: 실행된 명령 (
i), 기본값으로 대부분의 경우 유용합니다. 실시간 (ms밀리초 단위), 특정 인스턴스에서 유용합니다. 힙 또는 스택에서 할당/할당해제된 바이트 (B), 이는 다른 시스템에서 가장 재생 가능해서 단기 실행 프로그램 및 테스트 목적으로 유용합니다. 이 옵션은ms_print로 Massif 출력을 그래프화할 때 유용합니다.
/usr/share/doc/valgrind-version/valgrind_manual.pdf에 있는 문서에서 참조하십시오.
5.4. 용량 튜닝
overcommit_memory를 일시적으로 1로 설정하려면 다음을 실행합니다:
# echo 1 > /proc/sys/vm/overcommit_memorysysctl 명령을 사용해야 합니다. 보다 자세한 내용은 http://access.redhat.com/site/documentation/Red_Hat_Enterprise_Linux/의 운용 가이드에서 참조하십시오.
튜닝 가능한 용량 관련 메모리
/proc/sys/vm/에 있습니다.
overcommit_memory- 대량 메모리 요청을 수락 또는 거부할 지에 대해 결정하는 조건을 지정합니다. 이러한 매개 변수에 대해 세 가지 사용 가능한 값이 있습니다:
0— 기본 설정입니다. 커널은 사용 가능한 메모리 양을 추정하고 잘못된 요청을 실패시켜 휴리스틱 메모리 오버커밋 처리를 수행합니다. 불행히도 메모리는 정확한 알고리즘이 아닌 휴리스틱 알고리즘을 사용하여 할당되므로 이러한 설정은 시스템에서 사용가능한 메모리가 오버로드되게 할 수 있습니다.1— 커널은 메모리 오버커밋 처리를 수행하지 않습니다. 이러한 설정에서 메모리 오버로드 가능성은 증가하므로 메모리 집약적 작업을 위한 성능입니다.2— 커널은 총 사용 가능한 스왑의 합계와overcommit_ratio에 지정된 물리적 RAM의 백분율 보다 메모리가 크거나 동일한 경우 요청을 거부합니다. 메모리 오버커밋의 위험을 줄이고자 할 경우 이 설정이 가장 적합니다.참고
이 설정은 스왑 공간이 실제 메모리보다 큰 시스템의 경우에만 권장됩니다.
overcommit_ratioovercommit_memory가2로 설정되어 있는 경우 고려해야 할 물리적 RAM의 백분율을 지정합니다. 기본값은50입니다.max_map_count- 프로세스가 사용할 수 있는 메모리 맵 영역의 최대 수를 지정합니다. 대부분의 경우 기본값으로
65530이 적절합니다. 애플리케이션에 이 파일 보다 많은 수를 매핑해야 하는 경우 이 값을 늘립니다. nr_hugepages- 커널에서 설정되는 hugepage 수를 지정합니다. 기본값은 0입니다. 시스템에 물리적으로 연속된 빈 페이지가 충분할 경우에만 hugepage를 할당 (또는 할당 해제)할 수 있습니다. 이러한 매개 변수에 의해 예약된 페이지를 다른 목적으로 사용할 수 없습니다. 보다 자세한 내용은
/usr/share/doc/kernel-doc-kernel_version/Documentation/vm/hugetlbpage.txt에 있는 설치된 문서에서 참조하십시오.
튜닝 가능한 용량 관련 커널
/proc/sys/kernel/에 있습니다.
msgmax- 메세지 큐에서 단일 메세지의 최대 크기를 바이트 단위로 지정합니다. 이 값은 큐의 크기 (
msgmnb)를 초과해서는 안됩니다. 기본값은65536입니다. msgmnb- 단일 메세지 큐의 최대 크기를 바이트 단위로 지정합니다. 기본값은
65536바이트입니다. msgmni- 메세지 큐 식별자의 최대 수를 지정합니다 (따라서 큐의 최대 수). 64 비트 아키텍처 시스템에서 기본값은
1985이고 32 비트 아키텍처에서 기본값은1736입니다. shmall- 한 번에 시스템에서 사용할 수 있는 총 공유 메모리 양을 바이트 단위로 지정합니다. 64 비트 아키텍처 시스템에서 기본값은
4294967296이며 32 비트 아키텍처에서 기본값은268435456입니다. shmmax- 커널이 허용하는 최대 공유 메모리 세그먼트를 바이트 단위로 정의합니다. 64 비트 아키텍처 시스템에서 기본값은
68719476736이고 32 비트 아키텍처의 경우 기본값은4294967295입니다. 하지만 커널은 이 보다 더 큰 값을 지원함에 유의합니다. shmmni- 시스템 전체의 공유 메모리 세그먼트의 최대 수를 지정합니다. 64 비트 및 32 비트 아키텍처에서 기본값은
4096입니다. threads-max- 시스템 전체에서 커널이 한번에 사용할 스레드 (작업)의 최대 수를 지정합니다. 기본값은 커널
max_threads값과 동일합니다. 사용되는 식은 다음과 같습니다:max_threads = mempages / (8 * THREAD_SIZE / PAGE_SIZE )threads-max의 최저 값은20입니다.
튜닝 가능한 용량 관련 파일 시스템
/proc/sys/fs/에 있습니다.
aio-max-nr- 모든 활성 비동기 I/O 컨텍스트에서 허용되는 최대 이벤트 수를 지정합니다. 기본값은
65536입니다. 이 값을 변경해도 커널 데이터 구조를 미리 할당하거나 크기 변경이 되지 않음에 유의합니다. file-max- 커널이 할당된 최대 파일 처리 개수를 나열합니다. 기본값은 커널에서
files_stat.max_files의 값과 일치하고 이는(mempages * (PAGE_SIZE / 1024)) / 10, 또는NR_FILE(Red Hat Enterprise Linux에서는 8192) 중 가장 큰 값으로 설정됩니다. 이 값이 높을 수록 사용 가능한 파일 처리 부족으로 인한 오류를 해결할 수 있습니다.
튜닝 가능한 메모리 부족 종료
/proc/sys/vm/panic_on_oom 매개 변수를 0으로 설정하면 OOM 발생 시 커널이 oom_killer 기능을 호출합니다. 일반적으로 oom_killer는 악성 프로세스를 종료하고 시스템을 유지합니다.
oom_killer 기능에 의해 강제 종료되는 프로세스의 제어 능력을 증가시킵니다. 이는 proc 파일 시스템에 있는 /proc/pid/에 있으며 여기서 pid는 프로세스 ID 번호입니다.
oom_adj- 값을
-16에서15로 지정하면 프로세스의oom_score를 결정하는데 도움이 됩니다.oom_score값이 높으면oom_killer에 의해 프로세스가 종료될 가능성이 높아집니다.oom_adj값을-17로 설정하면 프로세스의oom_killer가 비활성화됩니다.중요
조정된 프로세스에 의해 생성된 모든 프로세스는 해당 프로세스의oom_score를 상속합니다. 예를 들어,sshd프로세스가oom_killer기능에서 보호되고 있을 경우 SSH 세션에 의해 시작된 모든 프로세스도 모두 보호됩니다. 이는 OOM 발생시 시스템을 구제하기 위한oom_killer기능에 영향을 미칠 수 있습니다.
5.5. 가상 메모리 튜닝
swappiness- 0에서 100의 값으로 시스템이 스왑하는 정도를 제어합니다. 값이 높으면 시스템 성능에 우선 순위를 두고 물리적 메모리가 활성화되지 않은 경우 메모리에서 프로세스를 적극적으로 스왑합니다. 값이 낮으면 상호 작용에 우선 순위를 두고 가능한 오래동안 물리적 메모리에서 프로세스 스왑을 피하기 때문에 응답 지연을 감소시킵니다. 기본값은
60입니다. min_free_kbytes- 시스템 전체에 걸쳐 빈 공간으로 두는 최소 크기 (KB)입니다. 이 값은 각각의 낮은 메모리 영역에서 워터마크 값을 계산하는데 사용되며 그 후 그 크기에 비례하여 저장된 빈 페이지 수를 할당합니다.
주의
이 매개 변수를 설정할 때 주의하십시오. 값이 너무 낮거나 너무 높으면 시스템을 손상시킬 수 있습니다.min_free_kbytes를 너무 낮게 설정하면 시스템이 메모리 회수를 실행하지 못할 수 있습니다. 이로 인해 시스템이 중단되고 메모리 부족으로 인해 여러 프로세스가 종료될 수 있습니다.하지만 이러한 매개 변수를 너무 높은 값 (총 시스템 메모리의 5-10%)으로 설정하면 바로 시스템 메모리 부족을 초래하게 됩니다. Linux는 캐시 파일 시스템 데이터에 사용 가능한 모든 RAM을 사용하도록 설계되어 있습니다.min_free_kbytes값을 높게 설정하면 시스템이 메모리를 회수하는데 너무 많은 시간을 소모하게 됩니다. dirty_ratio- 백분율 값을 정의합니다. 더티 데이터의 Writeout은 (pdflush를 통해) 더티 데이터가 총 시스템 메모리의 이러한 퍼센트를 차지하는 때에 시작됩니다. 기본값은
20입니다. dirty_background_ratio- 백분율 값을 정의합니다. 더티 데이터의 Writeout은 (pdflush를 통해) 더티 데이터가 총 메모리의 이러한 퍼센트를 차지하는 때에 백그라운드에서 시작됩니다. 기본값은
10입니다. drop_caches- 이 값을
1,2,3중 하나로 설정하면 커널은 페이지 캐시와 슬랩 캐시의 다양한 조합을 드롭하게 됩니다.- 1
- 시스템은 모든 페이지 캐시 메모리를 비활성화하여 해제합니다.
- 2
- 시스템은 사용되지 않는 모든 슬랩 캐시 메모리를 해제합니다.
- 3
- 시스템은 모든 페이지 캐시 및 스랩 캐시 메모리를 해제합니다.
이는 비파괴적인 작업입니다. 더티 개체가 해제될 수 없으므로 이 매개 변수의 값을 설정하기 전sync를 실행하는 것이 좋습니다.중요
프로덕션 환경에서drop_caches를 사용한 메모리 해제는 권장되지 않습니다.
swappiness를 일시적으로 50으로 설정하려면 다음을 실행합니다:
# echo 50 > /proc/sys/vm/swappinesssysctl 명령을 사용해야 합니다. 보다 자세한 내용은 http://access.redhat.com/site/documentation/Red_Hat_Enterprise_Linux/의 운용 가이드에서 참조하십시오.
6장. 입/출력
6.1. 특징
- SSD (Solid state disk)가 자동으로 인식되고 이러한 장치가 수행할 수 있는 초당 높은 I/O (IOPS)의 장점을 취하도록 I/O 스케줄러의 성능이 조정됩니다.
- 삭제 지원이 커널에 추가되어 기본 스토리지에 사용되지 않는 블록 범위가 보고됩니다. 이는 SSD의 웨어 레벨링 (wear-leveling) 알고리즘에 도움이 됩니다. 또한 사용 중인 실제 스토리지 용량에 가까운 탭을 유지하여 논리 블록 프로비저닝 (스토리지 용 가상 주소 공간의 일종)을 지원하는 스토리지에 도움이 됩니다.
- Red Hat Enterprise Linux 6.1에서 파일 시스템 장애 구현이 보다 철저히 정비되어 성능이 개선되었습니다.
pdflush가 per-backing-device flusher 스레드로 대체되어 대량의 LUN 카운트 설정에서 시스템 확장성이 크게 개선되었습니다.
6.2. 분석
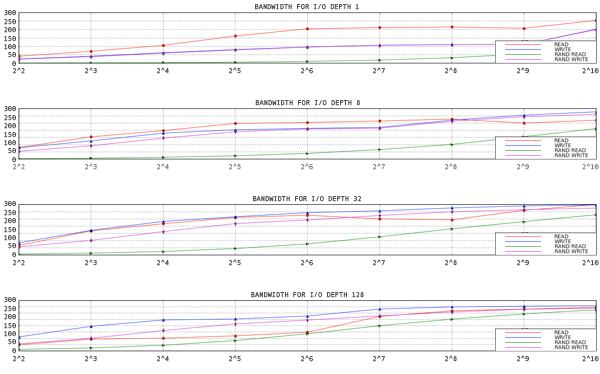
그림 6.1. 1 스레드, 1 파일 용 aio-stress 출력
- aio-stress
- iozone
- fio
6.3. 도구
si (swap in), so (swap out), bi (block in), bo (block out), wa (I/O wait time). si 및 so는 스왑 공간이 데이터 파티션 및 전체 메모리 압력 표시자와 같은 장치에 있을 때 유용합니다. si 및 bi는 읽기 작업인 반면 so 및 bo는 쓰기 작업입니다. 각 카테고리는 킬로바이트 단위로 보고됩니다. wa는 대기 시간으로 실행 큐의 어느 부분이 I/O 완료를 기다리며 차단되어 있는지를 보여줍니다.
free, buff, cache 칼럼도 눈여겨볼 만 합니다. cache 값이 bo 값과 함께 증가하고 이후에 cache가 감소하고 free가 증가하는 경우 시스템은 페이지 캐시의 비활성화 및 다시 쓰기를 실행하고 있음을 나타냅니다.
avgqu-sz)를 사용하여 스토리지 성능을 특성화할 때 생성한 그래프를 사용하여 스토리지 성능을 예상할 수 있습니다. 여기서 일부 일반화가 적용됩니다. 예를 들어, 평균 요청 크기가 4KB이고 평균 큐 크기가 1일 경우 처리량이 매우 고성능일 가능성은 낮습니다.
8,64 3 1 0.000000000 4162 Q RM 73992 + 8 [fs_mark]
8,64 3 0 0.000012707 0 m N cfq4162S / alloced
8,64 3 2 0.000013433 4162 G RM 73992 + 8 [fs_mark]
8,64 3 3 0.000015813 4162 P N [fs_mark]
8,64 3 4 0.000017347 4162 I R 73992 + 8 [fs_mark]
8,64 3 0 0.000018632 0 m N cfq4162S / insert_request
8,64 3 0 0.000019655 0 m N cfq4162S / add_to_rr
8,64 3 0 0.000021945 0 m N cfq4162S / idle=0
8,64 3 5 0.000023460 4162 U N [fs_mark] 1
8,64 3 0 0.000025761 0 m N cfq workload slice:300
8,64 3 0 0.000027137 0 m N cfq4162S / set_active wl_prio:0 wl_type:2
8,64 3 0 0.000028588 0 m N cfq4162S / fifo=(null)
8,64 3 0 0.000029468 0 m N cfq4162S / dispatch_insert
8,64 3 0 0.000031359 0 m N cfq4162S / dispatched a request
8,64 3 0 0.000032306 0 m N cfq4162S / activate rq, drv=1
8,64 3 6 0.000032735 4162 D R 73992 + 8 [fs_mark]
8,64 1 1 0.004276637 0 C R 73992 + 8 [0]Total (sde):
Reads Queued: 19, 76KiB Writes Queued: 142,183, 568,732KiB
Read Dispatches: 19, 76KiB Write Dispatches: 25,440, 568,732KiB
Reads Requeued: 0 Writes Requeued: 125
Reads Completed: 19, 76KiB Writes Completed: 25,315, 568,732KiB
Read Merges: 0, 0KiB Write Merges: 116,868, 467,472KiB
IO unplugs: 20,087 Timer unplugs: 0- Q — 블록 I/O가 대기열에 있음
- G — 요청 취득새로 대기열이된 블록 I/O는 기존 요청과 병합하기 위한 후보가 아니기 때문에 새로운 블록 레이어 요청이 할당됩니다.
- M — 블록 I/O는 기존 요청과 병합됩니다.
- I — 요청이 장치 큐에 삽입됩니다.
- D — 요청이 장치에 발급됩니다.
- C — 요청은 드라이버에 의해 완료됩니다.
- P — 블럭 장치 큐가 연결되어 요청 집계를 허용합니다.
- U — 장치 큐가 연결 해제되어 장치에 발급된 요청 집계를 허용합니다.
- Q2Q — 블록 층에 전송된 요청 사이의 시간
- Q2G — 블록 I/O가 대기 상태에서 요청이 할당될 때 가지의 시간
- G2I — 요청이 할당되는 시간 부터 장치의 큐에 넣을 때 까지의 시간
- Q2M — 블록 I/O가 대기열에 있는 시간 부터 기존 요청과 병합될 때 까지의 시간
- I2D — 요청이 장치 큐에 삽입된 시간 부터 실제로 장치에 발급될 때 가지의 시간
- M2D — 블록 I/O가 기존 요청과 병합된 시간 부터 요청이 장치 발급될 때 까지의 시간
- D2C — 장치에서 요청된 서비스 시간
- Q2C — 요청에 대해 블록 층에서 총 소요된 시간
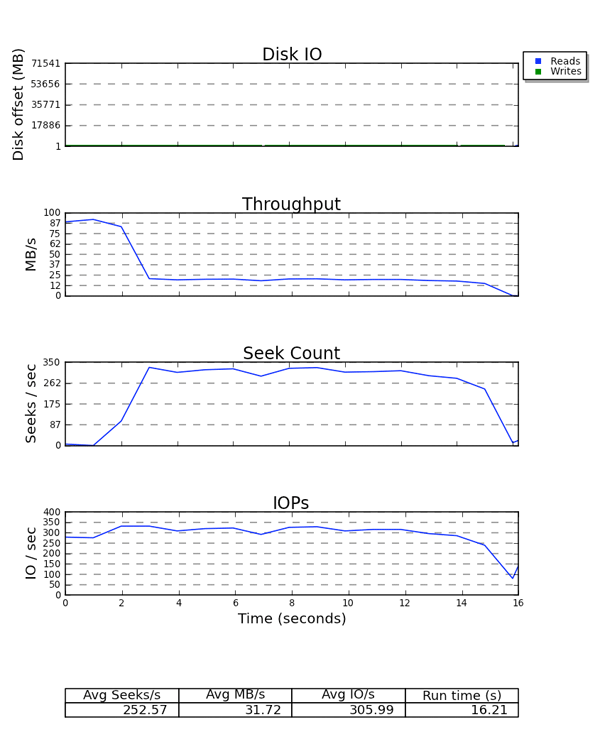
그림 6.2. seekwatcher 출력의 예
6.4. 설정
6.4.1. CFQ (Completely Fair Queuing)
ionice 명령을 사용하여 수동으로 할당하거나 ioprio_set 시스템 호출을 통해 프로그램에 할당할 수 있습니다. 기본값으로 프로세스는 최선형 스케줄링 클래스에 배치됩니다. 실시간 및 최선형 스케줄링 클래스는 각 클래스 내에서 8 개의 I/O 우선 순위로 나뉘며 우선 순위 0은 가장 높은것이고 7은 가장 낮은것이 됩니다. 실시간 스케줄링 클래스에 있는 프로세스는 최선형이나 유휴 상태에 있는 프로세스 보다 적극적으로 스케줄되기 때문에 스케줄된 실시간 I/O는 항상 최선형이나 유휴 I/O 보다 먼저 실행됩니다. 즉 실시간 우선 순위의 I/O는 최선형과 유휴 클래스 모두를 실행할 필요 없게 할 수 있습니다. 최선형 스케줄링은 기본값 스케줄링 클래스로 이 클래스에 있는 기본값 우선 순위는 4입니다. 유휴 스케줄링 클래스에 있는 프로세스는 시스템에 실행되지 않는 다른 I/O가 없는 경우에만 실행됩니다. 즉 프로세스에서 I/O가 프로세스 진행에 전혀 필요하지 않은 경우에만 프로세스의 I/O 스케줄링 클래스를 유휴로 설정하는 것은 매우 중요합니다.
/sys/block/device/queue/iosched/에 있는 동일한 이름의 파일에서 다음과 같은 매개 변수를 설정합니다:
slice_idle = 0
quantum = 64
group_idle = 1group_idle이 1로 설정된 경우에도 I/O 스톨 (백엔드 스토리지는 유휴 상태로 인해 사용 중이지 않음)의 가능성은 여전히 남아 있습니다. 하지만 이러한 스톨의 빈도는 시스템에 있는 각 큐의 유휴 상태보다 적습니다.
조정 가능한 매개 변수
back_seek_max- 뒤로 검색은 헤드의 위치 변경에 있어 앞으로 검색보다 상당한 지연을 발생시킬 수 있으므로 일반적으로 성능이 나빠집니다. 하지만 뒤로 검색 크기가 크지 않은 경우 CFQ가 여전히 이를 실행합니다. 이러한 조정 가능한 매개 변수는 I/O 스케줄러가 뒤로 검색을 허용하는 최대 거리를 KB 단위로 제어합니다. 기본값은
16KB입니다. back_seek_penalty- 뒤로 검색의 비효율성으로 인해 각각에 패널티가 연결됩니다. 패널티는 승수로 예를 들어 1024KB의 디스크 헤드 위치를 생각해 봅시다. 큐에 두 개의 요청이 있다고 가정합니다. 하나는 1008KB이고 다른 하나는 1040KB입니다. 이러한 두 요청은 현재 헤드 위치에서 등거리에 있습니다. 하지만 뒤로 검색 패널티 (기본값: 2)를 적용하면 디스크에서 나중 위치에 있는 요청은 이전 요청의 위치보다 2배 가까운 거리에 있게 됩니다. 따라서 헤드가 앞으로 이동합니다.
fifo_expire_async- 이러한 조정 가능한 매개 변수는 비동기 (버퍼링된 쓰기) 요청이 실행되지 않는 시간을 제어합니다. 만료 후 (밀리초 단위) 단일 비동기 요청은 디스패치 목록으로 이동합니다. 기본값은
250밀리초입니다. fifo_expire_sync- 이는 동기화 (읽기 및 O_DIRECT 쓰기) 요청의 fifo_expire_async 조정 가능한 매개 변수와 같습니다. 기본값은
125밀리초입니다. group_idle- 이것이 설정되면 CFQ는 cgroup에서 I/O를 실행하는 마지막 프로세스에서 유휴 상태가 됩니다. 비례 가중 I/O cgroup을 사용할 때 이를
1로 설정하고slice_idle을0으로 (일반적으로 고속 스토리지에서 실행) 설정해야 합니다. group_isolation- 그룹 분리(group isolation)가 활성화되어 있는 경우 (
1로 설정) 이는 처리량을 대가로하여 그룹 간의 분리를 강화합니다. 일반적으로 그룹 분리가 비활성화되어 있는 경우 공정성은 연속 워크로드에만 제공됩니다. 그룹 분리를 활성화하면 연속 및 임의의 워크로드 모두에 공정성을 제공합니다. 기본값은0(비활성화)입니다. 보다 자세한 내용은Documentation/cgroups/blkio-controller.txt에서 참조하십시오. low_latency- 낮은 대기 시간 (low latency)이 활성화되어 있는 경우 (
1로 설정) CFQ는 장치에서 I/O를 실행하는 각 프로세스에 대해 최대 300 밀리초의 대기 시간을 제공하려 합니다. 이는 처리량 보다 공정성을 우선으로 합니다. 낮은 대기 시간을 비활성화하면 (0으로 설정) 대상 대기 시간이 무시되고 시스템에 있는 각 프로세스는 전체 타임 슬라이스를 가져옵니다. 낮은 대기 시간은 기본값으로 활성화되어 있습니다. quantum- quantum은 CFQ가 한번에 스토리지에 전송하는 I/O 수를 제어하고 실질적으로 장치 큐 깊이를 제한합니다. 기본값으로 이는
8로 설정되어 있습니다. 스토리지는 더 깊은 큐 깊이를 지원할 수 있지만quantum을 증가시키면 대기 시간에 부정적인 영향을 미치고 특히 대량의 연속 쓰기 워크로드가 있을 경우 더욱 그러합니다. slice_async- 이러한 조정 가능한 매개 변수는 비동기 (버퍼링된 쓰기) I/O를 실행하는 각 프로세스에 할당된 타임 슬라이스를 제어합니다. 기본값으로 이는
40밀리초로 설정되어 있습니다. slice_idle- 이는 추가 요청을 기다리는 동안 CFQ가 유휴 상태가 될 시간을 지정합니다. Red Hat Enterprise Linux 6.1 및 이전 버전에서 기본값은
8밀리초입니다. Red Hat Enterprise Linux 6.2 및 이후 버전에서 기본값은0입니다. 값이 0일 경우 큐와 서비스 트리 레벨에 있는 모든 유휴 상태를 제거하므로 외부 RAID 스토리지 처리량이 향상됩니다. 하지만 이는 전체 검색 수를 증가시키기 때문에 내부의 비 RAID 스토리지 처리량을 저하시킬 수 있습니다. 비 RAID 스토리지의 경우slice_idle값을 0 보다 크게 할 것을 권장합니다. slice_sync- 이 매개 변수는 동기화 (읽기 또는 직접 쓰기) I/O를 실행하는 프로세스에 할당된 타임 슬라이스를 규정합니다. 기본값은
100밀리초입니다.
6.4.2. 데드라인 I/O 스케줄러
조정 가능한 매개 변수
fifo_batch- 이는 단일 배치에서 실행할 읽기 또는 쓰기 수를 지정합니다. 기본값은
16입니다. 이를 높은 값으로 설정하면 처리량은 향상되지만 대기 시간은 길어질 수 있습니다. front_merges- 워크로드가 전면 병합을 생성하지 않는 경우 이 매개 변수를
0으로 설정할 수 있습니다. 이 체크의 오버헤드를 측정하지 않는 한 기본 설정 (1) 그대로 두는 것이 좋습니다. read_expire- 이 매개 변수로 읽기 요청이 실행되는 시간을 밀리초 단위로 설정할 수 있습니다. 기본값은
500밀리초 (0.5초)로 설정되어 있습니다. write_expire- 이 매개 변수로 쓰기 요청이 실행되는 시간을 밀리초 단위로 설정할 수 있습니다. 기본값은
5000밀리초 (5초)로 설정되어 있습니다. writes_starved- 이 매개 변수는 단일 쓰기 배치 처리 전 처리할 수 있는 읽기 배치 수를 제어합니다. 이 값을 높게 설정할 수록 읽기가 우선이 됩니다.
6.4.3. Noop
/sys/block/sdX/queue의 튜닝 가능한 매개 변수
- add_random
- 일부 경우
/dev/random에 대한 엔트로피 풀에 기여하고 있는 I/O 이벤트의 오버헤드는 측정 가능합니다. 이러한 경우 이 값을 0로 설정하는 것이 좋습니다. max_sectors_kb- 기본값으로 디스크에 전송되는 최대 요청 크기는
512KB입니다. 이 매개 변수는 값을 늘리거나 줄일 수 있습니다. 최소 값은 논리 블록 크기에 의해 제한되고 최대 값은max_hw_sectors_kb에 의해 제한됩니다. I/O 크기가 내부 소거 블록 크기를 초과하면 성능이 악화되는 일부 SSD가 있습니다. 이러한 경우max_hw_sectors_kb를 소거 블록 크기로 줄이는 것이 좋습니다. iozone 또는 aio-stress와 같은 I/O 생성기를 사용하여 레코드 크기를512바이트에서1MB로 변경하는 것과 같이 이를 테스트할 수 있습니다. nomerges- 이 매개 변수는 주로 디버깅에 도움이 됩니다. 대부분의 워크로드는 요청 병합 (SSD와 같은 고속 스토리지에서도)에서 혜택을 받을 수 있습니다. 하지만 일부 경우 미리 읽기 또는 임의 I/O를 수행하지 않고 스토리지 백엔드에서 처리할 수 있는 IOPS 수를 알고자 하는 경우와 같이 병합을 비활성화하는 것이 좋은 경우도 있습니다.
nr_requests- 각 요청 큐에는 읽기 및 쓰기 I/O 마다 할당할 수 있는 총 요청 디스크립터 수에 제한이 있습니다. 기본값은
128이며 이는 프로세스를 수면 상태로 두기 전 한 번에 128 개의 읽기 및 128 개의 쓰기를 대기열에 둘 수 있음을 의미합니다. 수면 상태에 있는 프로세스는 요청 할당을 시도하는 다음 것으로 사용 가능한 모든 요청을 할당한 프로세스일 필요는 없습니다.대기 시간에 민감한 애플리케이션이 있는 경우, 요청 큐에서nr_requests의 값을 낮추고 스토리지의 명령큐 깊이를 낮은 (1정도로 낮은) 수치로 제한하는 것이 좋습니다. 이렇게 하면 다시 쓰기 I/O는 사용 가능한 모든 요청 디스크립터를 할당할 수 없으며 쓰기 I/O로 장치 큐를 채울 수 없습니다.nr_requests가 할당되면 I/O를 실행하는 다른 모든 프로세스가 요청을 사용할 수 있을 때 까지 대기하기 위해 수면 상태로 됩니다. 이로 인해 요청을 (하나의 프로세스가 빠르게 순차적으로 모두 소비하는 것이 아니라) 라운드 로빈 방식으로 분배하기 때문에 공정성이 유지됩니다. 이는 기본 CFQ 설정이 이러한 상황에 대해 보호하려는 것으로 데드라인 또는 noop 스케줄러 사용시에만 문제가 되는 점에 유의합니다. optimal_io_size- 상황에 따라 기초적인 스토리지가 최적의 I/O 크기를 보고합니다. 이는 최적의 I/O 크기가 스트라이프 크기로 되는 하드웨어 및 소프트웨어 RAID에서 가장 일반적인 것입니다. 값이 보고되면 애플리케이션은 가능한 최적의 I/O 크기로 조정되어 그 배수의 I/O를 실행합니다.
read_ahead_kb- 운영 체제는 애플리케이션이 파일 또는 디스크에서 데이터를 순차적으로 읽을 때 이를 감지할 수 있습니다. 이러한 경우는 지능형 미리 읽기 알고리즘을 실행하여 사용자가 요청한 데이터보다 더 많은 테이터를 디스크에서 읽습니다. 즉 사용자가 다음 데이터 블록을 읽으려고 할 때 해당 데이터가 이미 운영 체제의 페이지 캐시에 있는 것입니다. 이것의 가능한 단점은 운영 체제가 디스크에서 필요 이상의 데이터를 읽을 수 있다는 것입니다. 이로 인해 메모리 압력이 높아져 데이터가 삭제될 때 까지 데이터는 페이지 캐시의 공간을 차지하게 됩니다. 이러한 상황에서 여러 프로세스가 미리 읽기를 잘못 실행할 경우 메모리 압력이 높아질 수 있습니다.장치 매퍼 장치의 경우
read_ahead_kb값을8192와 같이 큰 값으로 하는 것이 좋습니다. 이는 장치 매퍼 장치가 여러 기초적인 장치로 구성되어 있기 때문입니다. 이 값을 매핑하려는 장치의 수를 곱한 기본값 (128KB)으로 설정하면 튜닝을 위한 좋은 출발점이 됩니다. rotational- 기존 하드 디스크는 회전 (회전 원반으로 구성)했었지만 SSD는 다릅니다. 대부분의 SSD는 이를 제대로 알리지만 이러한 플래그를 정확하게 알리지 않는 장치의 경우 회전을
0으로 수동 설정해야 합니다. 회전이 비활성화된 경우 비회전 미디어에서 검색 작업에 약간의 패널티가 있기 때문에 I/O 엘레베이터는 검색을 줄이기 위해 논리를 사용하지 않습니다. rq_affinity- I/O 완료는 I/O를 실행한 CPU와 다른 CPU에서 처리할 수 있습니다.
rq_affinity를1로 설정하면 커널은 I/O가 실행된 CPU에 완료를 전달합니다. 이는 CPU 데이터 캐싱 효과를 개선할 수 있습니다.
7장. 파일 시스템
7.1. 파일 시스템 튜닝 시 고려 사항
7.1.1. 포맷 옵션
블록 크기는 mkfs 실행 시 선택할 수 있습니다. 유효한 크기 범위는 시스템에 따라 다릅니다: 상한 범위는 호스트 시스템의 최대 페이지 크기에서 하한 범위는 사용되는 파일 시스템에 의존합니다. 기본값 블록 크기는 대부분의 사용 경우에 적합하도록 되어 있습니다.
시스템이 RAID5와 같은 스트라이프 스토리지를 사용하는 경우 mkfs 실행 시 기본적인 스토리지 지오메트리 사용으로 데이터 및 메타데이터를 정리하여 성능을 향상시킬 수 있습니다. 소프트웨어 RAID (LVM 또는 MD) 및 일부 엔터프라이즈 하드웨어 스토리지 일부의 경우 이 정보는 쿼리되어 자동으로 설정되지만 대부분의 경우 관리자가 명령행에서 mkfs를 사용하여 수동으로 지오메트리를 지정해야 합니다.
메타데이터 집약적 워크로드는 저널링 파일 시스템 (ext4 및 XFS 등)의 로그 섹션이 매우 자주 업데이트되는 것을 의미합니다. 파일 시스템에서 저널로의 탐색 시간을 최소화하려면 전용 스토리지에 저널을 배치합니다. 하지만 주요 파일 시스템보다 느리게 외부 스토리지에 저널을 배치하면 외부 스토리지 사용과 관련하여 얻을 수 있는 잠재적 이익을 무효화할 수 있다는 점에 유의합니다.
주의
mkfs 실행 시 생성됩니다. 자세한 내용은 mke2fs(8), mkfs.xfs(8), 및 mount(8) man 페이지에서 참조하십시오.
7.1.2. 마운트 옵션
쓰기 장애는 심하게 변동하는 쓰기 장애가 전원을 상실해도 해당 파일 시스템의 메타데이터가 올바르게 작성되어 영구적인 스토리지에 정렬되어 있는지 확인하는데 사용되는 커널 메커니즘입니다. 쓰기 장애를 갖는 파일 시스템은 fsync()를 통해 전송된 데이터가 정전 중에도 영구적으로 지속하게 합니다. Red Hat Enterprise Linux는 이를 지원하는 모든 하드웨어에 기본값으로 장애를 활성화합니다.
fsync()를 많이 사용하는 애플리케이션이나 여러 작은 파일을 생성 및 삭제하는 애플리케이션의 경우 그러합니다. 심하게 변동하는 쓰기 캐시가 없는 스토리지나 드물게는 정전 이후 파일 시스템 불이치 또는 데이터 손실이 허용되는 경우 nobarrier 마운트 옵션을 사용하여 장애를 비활성화할 수 있습니다. 보다 자세한 내용은 스토리지 관리 가이드에서 참조하십시오.
기존에는 파일을 읽을 때 파일의 액세스 시간 (atime)은 추가 쓰기 I/O가 포함된 inode 메타데이터에 업데이트해야 했습니다. 정확한 atime 메타데이터가 필요하지 않은 경우 noatime 옵션으로 파일 시스템을 마운트하여 이러한 메타데이터 업데이트를 제거합니다. 하지만 대부분의 경우 Red Hat Enterprise Linux 6 커널에서 기본값 관련 atime (또는 relatime) 동작으로 인해 대량의 atime 오버헤드가 없습니다. relatime 동작은 이전 atime이 수정 시간 (mtime) 또는 상태 변경 시간 (ctime) 보다 오래된 경우에만 atime을 업데이트합니다.
참고
noatime 옵션을 활성화하면 nodiratime 동작도 활성화됩니다; noatime과 nodiratime 모두를 설정할 필요는 없습니다.
미리 읽기는 데이터를 먼저 가져와 이를 페이지 캐시에 로딩하여 디스크에서가 아닌 메모리에서 먼저 사용가능하므로 파일 액세스 속도를 빠르게 합니다. 대량의 연속 I/O 스트리밍 작업과 같은 일부 워크로드는 미리 읽기 값이 높으면 효과를 얻습니다.
blockdev 명령을 사용하여 미리 읽기 값을 표시하나 편집합니다. 특정 블록 장치에 대한 현재의 미리 읽기 값을 표시하려면 다음 명령을 실행합니다:
# blockdev -getra device# blockdev -setra N deviceblockdev 명령으로 선택된 값은 재부팅 후에도 유지되지 않는다는 점에 유의합니다. 부팅 시 이 값을 설정하려면 런레벨 init.d 스크립트를 작성하는 것이 좋습니다.
7.1.3. 파일 시스템 유지 보수
배치 폐기와 온라인 폐기 작업은 파일 시스템에 의해 사용되지 않는 블록을 폐기하는 마운트된 파일 시스템의 기능입니다. 이러한 작업은 솔리드 스테이트 드라이브 및 씬 프로비저닝 스토리지 모두에 유용합니다.
fstrim 명령으로 사용자에 의해 명시적으로 실행됩니다. 이 명령은 사용자의 기준과 일치하는 파일 시스템에서 사용하지 않는 모든 블록을 폐기합니다. 두 작업 유형은 파일 시스템의 기반이 되는 블록 장치가 물리적 폐기 작업을 지원하는 한 Red Hat Enterprise Linux 6.2 및 이후 버전에서 XFS 및 ext4 파일 시스템과 사용 가능합니다. 물리적 폐기 작업은 /sys/block/device/queue/discard_max_bytes 값이 제로가 아닌 경우 지원됩니다.
-o discard 옵션 (/etc/fstab에서 또는 mount 명령의 부분으로)으로 지정되어 사용자 개입없이 실시간으로 실행됩니다. 온라인 폐기 작업은 사용됨에서 사용 해제로 전환되는 블록만을 폐기합니다. 온라인 폐기 작업은 Red Hat Enterprise Linux 6.2 이상 버전에서는 ext4 파일 시스템에서 Red Hat Enterprise Linux 6.4 이상 버전에서는 XFS 파일 시스템에서 지원됩니다.
7.1.4. 애플리케이션 유의 사항
ext4, XFS, GFS2 파일 시스템은 fallocate(2) glibc 호출을 통해 효율적인 공간의 사전 할당을 지원합니다. 쓰기 패턴으로 인해 파일이 잘못 조각화되어 읽기 성능이 저하될 경우 공간의 사전 할당은 유용한 방법이 될 수 있습니다. 사전 할당은 테이터를 공간에 작성하지 않고 디스크 공간이 파일에 할당된 것처럼 표시합니다. 사전 할당 블록에 실제 데이터가 기록될 때 까지 읽기 작업은 제로를 반환합니다.
7.2. 파일 시스템 성능 프로파일
latency-performance- 전형적인 지연 성능 튜닝 용 서버 프로파일입니다. 이는 tuned 및 ktune 절전 메커니즘을 비활성화합니다.
cpuspeed모드는performance로 변경됩니다. 각 장치의 I/O 엘리베이터는deadline으로 변경됩니다.cpu_dma_latency매개 변수는 전원 관리 서비스에 대해0값 (최소 대기 시간)으로 등록되어 가능한 범위에서 전원 관리 대기 시간을 제한합니다. throughput-performance- 전형적인 처리량 성능 튜닝 용 서버 프로파일입니다. 시스템에 엔터프라이즈급 스토리지가 없는 경우 이 프로파일이 권장됩니다. 이는
latency-performance와 동일하지만 다음과 같은 차이점이 있습니다:kernel.sched_min_granularity_ns(scheduler minimal preemption granularity)는10밀리초로 설정됩니다.kernel.sched_wakeup_granularity_ns(scheduler wake-up granularity)는15밀리초로 설정됩니다.vm.dirty_ratio(virtual machine dirty ratio)는 40%로 설정됩니다.- transparent huge pages가 활성화됩니다.
enterprise-storage- 이 프로파일은 배터리 백업 컨트롤러 캐시 보호 및 디스크 내장 캐시 관리 등 엔터프라이즈급 스토리지로 엔터프라이즈 크기 서버 설정에 권장됩니다. 이는
throughput-performance프로파일과 동일하지만 다음과 같은 차이점이 있습니다:readahead값은4x로 설정됩니다.- root/boot 파일 시스템 이외의 파일 시스템은
barrier=0으로 다시 마운트됩니다.
man tuned-adm) 또는 전원 관리 가이드 (http://access.redhat.com/site/documentation/Red_Hat_Enterprise_Linux/)에서 참조하십시오.
7.3. 파일 시스템
7.3.1. Ext4 파일 시스템
참고
대형 파일 시스템에서 mkfs.ext4 프로세스는 파일 시스템에 있는 모든 inode 테이블을 초기화하는데 시간이 오래 걸릴 수 있습니다. 이 프로세스는 -E lazy_itable_init=1 옵션으로 미룰 수 있습니다. 이 옵션을 사용하면 커널 프로세스는 파일 시스템을 마운트한 후 초기화를 계속 진행하게 됩니다. 이러한 초기화 발생 비율은 mount 명령의 -o init_itable=n 옵션으로 제어할 수 있습니다. 여기서 백그라운드 초기화 실행에 소요되는 시간은 약 1/n입니다. n의 기본값은 10입니다.
일부 애플리케이션은 기존 파일 이름을 바꾸거나 잘라내기 및 재작성 후 fsync()가 항상 제대로 작동한다고 할 수 없기 때문에 이름 바꾸기 (rename)를 통한 재배치 (replace) 작업 및 잘라내기 (truncate)를 통한 재배치 (replace) 작업 이후에 ext4는 파일의 자동 동기화를 기본값으로 설정합니다. 이 동작은 이전의 ext3 파일 시스템 동작과 일치합니다. 하지만 fsync() 작업은 시간이 걸리는 작업이므로 자동 동작이 필요없는 경우 mount 명령과 함께 -o noauto_da_alloc 옵션을 사용하여 이를 비활성화합니다. 즉 애플리케이션은 명시적으로 fsync()를 사용하여 데이터 일관성을 유지해야 합니다.
기본값으로 저널 커밋 I/O는 일반적인 I/O 보다 약간 더 높은 우선 순위가 부여되어 있습니다. 이러한 우선 순위는 mount 명령의 journal_ioprio=n 옵션을 사용하여 제어할 수 있습니다. 기본값은 3입니다. 유효한 값의 범위는 0에서 7이며 0은 가장 높은 I/O 우선 순위입니다.
mkfs 및 튜닝 옵션의 경우 mkfs.ext4(8) 및 mount(8) man 페이지 그리고 kernel-doc 패키지에 있는 Documentation/filesystems/ext4.txt 파일을 참조하십시오.
7.3.2. XFS 파일 시스템
mkfs 실행 시 XFS가 제공하는 튜닝 옵션 중 일부는 b-trees의 폭이 달라 이는 다른 서브 시스템의 확장성 특징을 변경합니다.
7.3.2.1. XFS의 기본적 튜닝
mkfs.xfs 명령은 올바른 스트라이프 장치와 하드웨어에 맞춰 폭 자체를 자동으로 구성합니다. 하드웨어 RAID를 사용하고 있는 경우 이를 수동으로 설정해야 할 수 도 있습니다.
inode64 마운트 옵션이 강력하게 권장됩니다.
logbsize 마운트 옵션이 권장됩니다. 기본값은 MAX (32 KB, 로그 스트라이프 단위)이며 최대 크기는 256 KB입니다. 대폭적인 수정이 이루어지는 파일 시스템의 경우 256 KB 값이 권장됩니다.
7.3.2.2. XFS의 고급 튜닝
XFS는 파일 시스템에 저장할 수 있는 파일 수에 임의의 제한을 부과합니다. 일반적으로 이러한 제한은 초과할 수 없도록 높게 설정됩니다. 미리 기본 제한이 충분하지 않다고 판단될 경우 mkfs.xfs 명령을 사용하여 inodes에 허용되는 파일 시스템 공간의 비율을 늘릴 수 있습니다. 파일 시스템 생성 후 파일 제한이 발생한 경우 (파일 또는 디렉토리를 생성하려고 할 때 여유 공간이 충분해도 일반적으로 ENOSPC 오류가 표시됨) xfs_growfs 명령을 사용하여 제한을 조정할 수 있습니다.
디렉토리 블록 크기는 파일 시스템의 수명 동안 고정되어 있으며 mkfs로 초기화 포맷을 제외하고는 변경할 수 없습니다. 최소 디렉토리 블록은 파일 시스템 블록 크기로 기본값은 MAX (4 KB, 파일 시스템 블록 크기) 입니다. 일반적으로 디렉토리 블록 크기를 줄일 필요가 없습니다.
다른 파일 시스템과 달리 작업이 비공유 객체에서 실행되고 있으면 XFS는 많은 유형의 할당 및 할당 해제 작업을 동시에 실행할 수 있습니다. 익스텐트 할당 또는 할당 해제는 이러한 작업이 다른 할당 그룹에서 실행되고 있는 경우 동시에 실행할 수 있습니다. 유사하게 inode의 할당 또는 할당 해제도 동시 실행 작업이 다른 할당 그룹에 영향을 미치고 있는 경우 동시에 실행할 수 있습니다.
inode에 사용 가능한 공간이 있을 경우 XFS는 직접 inode에 작은 속성을 저장할 수 있습니다. 속성이 inode에 잘 맞는 경우 다른 속성 블록을 검색하기 위한 별도의 I/O를 필요로 하지 않고 검색 및 수정할 수 있습니다. 인라인 (inode) 및 아웃 오브 라인 (out-of-line) 속성 간의 성능 차이는 아웃 오브 라인 속성이 한 자리 적을 정도로 다릅니다.
로그 크기는 지속적인 메타 데이터 수정의 달성 수준을 결정하는 주요 요인입니다. 로그 장치는 원형이기 때문에 후행 부분이 덮어쓰기되기 전 로그에 있는 모든 수정은 디스크의 실제 위치에 기록되어야 합니다. 이에는 모든 더티 메타데이터를 다시 되돌려 작성하기 위한 상당한 노력이 포함될 수 있습니다. 기본값 설정은 전체 파일 시스템 크기와 관련하여 로그 크기를 확장하기 때문에 대부분의 경우 로그 크기를 튜닝할 필요가 없습니다.
mkfs는 MD 및 DM 장치에 대해 기본값으로 이를 실행하지만 하드웨어 RAID의 경우 이를 지정해야 합니다. 이를 올바르게 설정하면 디스크에 수정 사항을 기록할 때 정렬되지 않은 I/O 및 후속하는 읽기-수정-쓰기 작업의 원인이 되는 로그 I/O의 모든 가능성을 해결합니다.
logbsize)를 늘리면 로그에 변경 사항을 기록할 수 있는 속도가 증가합니다. 기본값 로그 버퍼 크기는 MAX (32 KB, 로그 스트라이프 단위)이며 최대 크기는 256 KB입니다. 일반적으로 값이 크면 성능 속도가 빨라집니다. 하지만 fsync가 많은 워크로드에서 작은 로그 버퍼는 대형의 스트라이프 단위 조정을 사용하면 큰 버퍼 보다 현저하게 빨라집니다.
delaylog 마운트 옵션은 로그에 변경 사항 수를 줄임으로써 지속적인 메타데이터 수정 성능을 향상시킵니다. 이는 로그에 변경 사항을 작성하기 전 메모리에 있는 개별적 변경 사항을 집계하여 달성합니다. 자주 수정되는 메타데이터는 수정할 때 마다가 아닌 정기적으로 로그에 기록됩니다. 이 옵션은 더티 메타데이터를 추적하는 메모리 사용량을 늘리고 충돌이 발생하면 작업 손실의 가능성이 증가하지만 메타데이터 수정 속도와 확장성을 한 자리수 이상 개선할 수 있습니다. 데이터 및 메타데이터가 디스크에 작성되는지 확인하기 위해 fsync, fdatasync, sync를 사용할 때 이 옵션을 사용해도 데이터나 메타데이터의 무결성이 감소되지 않습니다.
7.4. 클러스터링
7.4.1. GFS 2 (Global File System 2)
- 가능한 경우
fallocate로 파일 및 디렉토리를 사전할당하여 할당 프로세스를 최적화하고 소스 페이지를 잠금할 필요가 없도록 합니다. - 여러 노드 간에 공유되는 파일 시스템의 영역을 최소화하고 노드간 캐시 무효화를 최소화하며 성능을 향상시킵니다. 예를 들어 여러 노드가 동일한 파일 시스템을 마운트해서 다른 서브 디렉토리에 액세스하면 서브 디렉토리를 다른 파일 시스템으로 이동하여 성능을 향상시킬 가능성이 높아집니다.
- 최적의 리소스 그룹 크기와 수를 선택합니다. 이는 전형적인 파일 크기와 시스템에서 사용 가능한 여유 공간에 따라 다르며 여러 노드가 리소스 그룹을 동시에 사용하려고 시도할 가능성에 영향을 미칩니다. 리소스 그룹이 너무 많으면 할당 공간이 배치되는 동안 블록 할당이 느려집니다. 반면 리소스 그룹이 너무 적으면 할당 해제 동안 잠금 경합을 일으킬 수 있습니다. 일반적으로 여러 설정을 테스트하고 워크로드에 가장 적합한 것을 지정하는 것이 가장 좋습니다.
- 클러스터 노드에서 예측되는 I/O 패턴 및 파일 시스템의 성능 요구 사항에 따라 스토리지 하드웨어를 선택합니다.
- 가능한 솔리드 스테이트 스토리지를 사용하여 검색 시간을 줄입니다.
- 워크로드에 적합한 크기의 파일 시스템을 생성하고 파일 시스템이 용량의 80%를 초과하지 않도록 합니다. 작은 파일 시스템은 크기에 비례하여 짧은 백업 시간을 가지며 파일 시스템 검사에 필요한 시간과 메모리가 적지만 워크로드에 대해 너무 작을 경우 높은 조각화가 진행될 수 있습니다.
- 메타데이터 집약적인 워크로드의 경우 또는 저널링 데이터가 사용되고 있는 경우 저널 크기를 크게 설정합니다. 이것이 더 많은 메모리를 사용하더라도 쓰기가 필요하기 전에 데이터를 저장하기 위해 더 많은 저널링 공간을 사용할 수 있으므로 성능이 향상됩니다.
- GFS2 노드에 있는 클럭이 네트워크 애플리케이션 문제를 방지하도록 동기화되어 있는지 확인합니다. NTP (Network Time Protocol) 사용을 권장합니다.
- 애플리케이션 작업에서 파일이나 디렉토리 액세스 시간이 중요하지 않은 경우 파일 시스템을
noatime및nodiratime마운트 옵션으로 마운트합니다.참고
Red Hat은 GFS2에서noatime옵션을 사용할 것을 권장합니다. - 할당량을 사용할 필요가 있는 경우 쿼터 동기화 트랜잭션의 빈도를 낮추거나 fuzzy 쿼터 동기화를 사용하여 지속적인 쿼터 파일 업데이트에서 발생하는 성능 문제를 방지합니다.
참고
Fuzzy 쿼터 계산은 사용자 및 그룹이 쿼터 제한을 약간 초과하는 것을 허용합니다. 이 문제를 최소화하기 위해 사용자 또는 그룹이 쿼터 제한에 도달하면 GFS2는 동기화 주기를 동적으로 감소시킵니다.
8장. 네트워킹
8.1. 네트워크 성능 개선
8.1.1. RPS (Receive Packet Steering)
rx 큐를 활성화하여 수신 softirq 워크로드를 여러 CPU에 분산하는 것을 허용합니다. 이는 네트워크 트래픽이 단일 NIC 하드웨어 큐에서의 병목 현상을 방지할 수 있습니다.
/sys/class/net/ethX/queues/rx-N/rps_cpus에 지정합니다. 여기서 ethX는 NIC의 해당 장치 이름 (예: eth1, eth2)으로 rx-N은 지정된 NIC 수신 큐로 대체합니다. 이렇게 하면 파일에 지정된 CPU가 ethX에 있는 큐 rx-N에서 데이터를 처리할 수 있습니다. CPU를 지정할 때 큐의 캐시 친화도 [4]를 고려합니다.
8.1.2. RFS (Receive Flow Steering)
/proc/sys/net/core/rps_sock_flow_entries- 이는 커널이 지정된 CPU 방향으로 조정할 수 있는 소켓/흐름의 최대 수를 제어합니다. 이는 시스템 전체의 공유 제한입니다.
/sys/class/net/ethX/queues/rx-N/rps_flow_cnt- 이는 NIC (
ethX)에서 커널이 특정 수신 큐 (rx-N)를 조정할 수 있는 소켓/흐름의 최대 수를 제어합니다. 모든 NIC에서 이러한 조정 가능한 매개 변수의 모든 큐마다 값의 합계는 같거나/proc/sys/net/core/rps_sock_flow_entries이하이어야 함에 유의합니다.
8.1.3. TCP thin-stream의 getsockopt 지원
getsockopt 호출이 강화되어 다음과 같은 두 가지 옵션을 지원합니다:
- TCP_THIN_DUPACK
- 이 부울 값은 하나의 dupACK 후 thin stream의 재전송 동적 트리거를 활성화합니다.
- TCP_THIN_LINEAR_TIMEOUTS
- 이 부울 값은 thin stream의 선형 시간 초과 동적 트리거를 활성화합니다.
file:///usr/share/doc/kernel-doc-version/Documentation/networking/ip-sysctl.txt에서 참조하십시오. thin-stream에 대한 보다 자세한 내용은 file:///usr/share/doc/kernel-doc-version/Documentation/networking/tcp-thin.txt에서 참조하십시오.
8.1.4. 투명 프록시 (TProxy) 지원
file:///usr/share/doc/kernel-doc-version/Documentation/networking/tproxy.txt에서 참조하십시오.
8.2. 네트워크 설정 최적화
- netstat
- 네트워크 연결, 라우팅 테이블, 인터페이스 통계, 마스커레이드 연결, 멀티캐스트 구성원을 인쇄하는 명령행 유틸리티입니다. 이는
/proc/net/파일 시스템에서 네트워킹 서브시스템에 대한 정보를 검색합니다. 이러한 파일은 다음과 같습니다:/proc/net/dev(장치 정보)/proc/net/tcp(TCP 소켓 정보)/proc/net/unix(Unix 도메인 소켓 정보)
netstat및/proc/net/에서의 관련 참조 파일에 대한 보다 자세한 내용은netstatman 페이지인man netstat에서 참조하십시오. - dropwatch
- 커널이 드롭한 패킷을 감시하는 모니터링 유틸리티입니다. 보다 자세한 내용은
dropwatchman 페이지인man dropwatch에서 참조하십시오. - ip
- 라우트, 장치, 정책 라우팅, 터널을 관리 및 모니터링하기 위한 유틸리티입니다. 보다 자세한 내용은
ipman 페이지인man ip에서 참조하십시오. - ethtool
- NIC 설정을 표시하거나 변경하기 위한 유틸리티입니다. 보다 자세한 내용은
ethtoolman 페이지인man ethtool에서 참조하십시오. - /proc/net/snmp
snmp에이전트의 IP, ICMP, TCP, UDP 관리 정보 베이스에 필요한 ASCII 데이터를 표시하는 파일입니다. 또한 이는 실시간 UDP-lite 통계도 표시합니다.
/proc/net/snmp에서 UDP 입력 오류가 증가하면 네트워크 스택은 새로운 프레임을 애플리케이션의 소켓으로 추가하려고 할 때 하나 이상의 소켓 수신 큐가 가득찼다고 나타납니다.
8.2.1. 소켓 수신 버퍼 크기
sk_stream_wait_memory.stp에 있는 분석과 같이 추가 분석할 경우 소켓 큐의 소진 비율이 너무 느리므로 애플리케이션의 소켓 큐의 정도를 증가시키는 것이 좋습니다. 이를 위해 다음 값 중 하나를 설정하여 소켓이 사용하는 수신 버퍼 크기를 늘립니다:
- rmem_default
- 소켓이 사용하는 수신 버퍼의 기본값 크기를 제어하는 커널 매개 변수입니다. 이를 설정하려면 다음 명령을 실행합니다:
sysctl -w net.core.rmem_default=NN을 원하는 버퍼 크기 (바이트 단위)로 대체합니다. 이 커널 매개 변수의 값을 지정하려면/proc/sys/net/core/rmem_default에서 확인합니다.rmem_default값은rmem_max(/proc/sys/net/core/rmem_max)를 초과하지 않도록 주의합니다. 필요한 경우rmem_max값을 늘립니다. - SO_RCVBUF
- 소켓의 수신 버퍼의 최대 크기를 바이트 단위로 제어하는 소켓 옵션입니다.
SO_RCVBUF에 대한 자세한 내용은man 7 socket의 man 페이지에서 참조하십시오.SO_RCVBUF를 설정하려면setsockopt유틸리티를 사용합니다. 현재SO_RCVBUF값은getsockopt로 검색할 수 있습니다. 이러한 두 가지 유틸리티에 대한 보다 자세한 내용은setsockoptman 페이지인man setsockopt에서 참조하십시오.
8.3. 패킷 수신 개요

그림 8.1. 네트워크 수신 경로 다이어그램
- 하드웨어 리셉션: NIC (network interface card)는 와이어에서 프레임을 수신합니다. 해당 드라이버 설정에 따라 NIC는 프레임을 내부 하드웨어 버퍼 메모리 또는 지정된 링 버퍼로 전송합니다.
- 하드 IRQ: NIC는 CPU를 인터럽트하여 넷 프레임의 존재를 주장합니다. 이는 NIC 드라이버가 인터럽트를 승인하고 소프트 IRQ 작업을 스케줄링합니다.
- 소프트 IRQ: 이 단계에서는 실제 프레임 수신 프로세스를 구현하고
softirq문맥에서 실행합니다. 즉 이 단계는 지정된 CPU에서 실행되고 있는 모든 애플리케이션을 먼저 실행하지만 하드 IRQ의 주장을 허용합니다.이 문맥에서 (하드 IRQ로 동일한 CPU에서 실행하여 잠금 오버헤드를 최소화하고 있는) 커널은 실제로 NIC 하드웨어 버퍼에서 프레임을 제거하여 네트워크 스택을 통해 처리합니다. 여기서 프레임은 대상 청취 소켓에 전송, 삭제 또는 전달됩니다.소켓에 전달되면 프레임은 소켓을 소유하는 애플리케이션에 추가됩니다. 이러한 프로세스는 NIC 하드웨어 버퍼가 프레임을 소진할 때 까지 또는 장치 무게 (device weight) (dev_weight) 까지 반복됩니다. 장치 무게에 대한 보다 자세한 내용은 8.4.1절. “NIC 하드웨어 버퍼 ”에서 참조하십시오. - 애플리케이션 수신: 애플리케이션은 프레임을 수신하고 표준 POSIX 호출 (
read,recv,recvfrom)을 통해 소유한 소켓에서 큐를 분리합니다. 이 때에 네트워크를 통해 수신된 데이터는 네트워크 스택에 더이상 존재하지 않습니다.
8.3.1. CPU/캐시 친화도
8.4. 일반적인 큐/프레임 손실 문제 해결
8.4.1. NIC 하드웨어 버퍼
softirq에 의해 배출됩니다. 큐의 상태를 확인하려면 다음과 같은 명령을 사용합니다:
ethtool -S ethXethX를 NIC의 해당 장치 이름으로 대체합니다. 이는 ethX 내에서 얼마나 많은 프레임이 드롭되었는지를 표시합니다. 드롭이 발생하는 대부분의 이유는 큐가 프레임을 저장할 버퍼 공간이 부족하기 때문입니다.
- 입력 트래픽
- 입력 트래픽을 느리게하여 큐 오버런을 방지할 수 있습니다. 이는 통합된 멀티캐스트 그룹의 수를 필터링하여 줄이고 브로드 캐스트 트래픽을 감소시켜 달성할 수 있습니다.
- 큐 길이
- 다른 방법으로 큐의 길이를 늘릴 수 있습니다. 이는 드라이버가 허용하는 최대 값 까지 지정된 큐에 있는 버퍼 수를 늘리는 것입니다. 이를 위해 다음과 같이
ethX의rx/tx링 매개변수를 편집합니다:ethtool --set-ring ethX앞서 언급한 명령에 해당rx또는tx값을 추가합니다. 보다 자세한 내용은man ethtool에서 참조하십시오. - 장치 무게
- 큐가 배출되는 속도를 높일 수 있습니다. 이를 위해 NIC의 장치 무게 (device weight)를 적절하게 조정합니다. 이 속성은
softirq컨텍스트가 CPU를 포기하고 자체 일정을 변경하기 전 NIC가 받을 수 있는 최대 프레임 수를 말합니다. 이는/proc/sys/net/core/dev_weight변수에 의해 제어됩니다.
8.4.2. 소켓 큐
softirq 컨텍스트에서 네트워크 스택으로 채워집니다. 그러면 애플리케이션은 read, recvfrom 등의 호출을 통해 해당 소켓의 큐를 배출합니다.
netstat 유틸리티를 사용합니다. Recv-Q 칼럼은 큐의 크기를 표시합니다. 일반적으로 소켓 큐에서 오버런은 NIC 하드웨어 버퍼 오버런과 같은 방법으로 관리됩니다 (예: 8.4.1절. “NIC 하드웨어 버퍼 ”).
- 입력 트래픽
- 첫 번째 옵션은 큐가 채워지는 비율을 설정하여 입력 트래픽을 느려지게 합니다. 이렇게 하려면 프레임을 필터링하거나 미리 드롭합니다. NIC의 장치 무게를 낮추어 입력 트래픽을 느려지게할 수 있습니다 [6].
- 큐 깊이
- 큐 깊이를 증가시켜 소켓 큐 오버런을 방지할 수 있습니다. 이렇게 하려면
rmem_default커널 매개 변수 또는SO_RCVBUF소켓 옵션의 값 중 하나를 늘립니다. 이에 대한 자세한 내용은 8.2절. “네트워크 설정 최적화 ”에서 참조하십시오. - 애플리케이션 호출 빈도
- 가능하면 자주 호출을 수행하는 애플리케이션을 최적화합니다. 이에는 보다 자주 POSIX 호출 (
recv,read)을 수행하기 위해 네트워크 애플리케이션을 수정 또는 재설정하는 것이 포함됩니다. 이렇게하면 애플리케이션이 더 빠르게 큐를 배출할 수 있습니다.
8.5. 멀티캐스트에 있어서 고려할 사항
softirq 컨텍스트에서 발생합니다.
softirq 컨텍스트의 실행 시간에 직접적인 영향을 미칩니다. 멀티 캐스트 그룹에 리스너를 추가하면 커널이 해당 그룹에 대해 수신된 각 프레임에 대해 추가 복사본을 작성해야 함을 의미합니다.
softirq 컨텍스트의 실행 시간이 증가하여 네트워크 카드 및 소켓 큐 모두에서 프레임 드롭이 발생합니다. softirq 런타임이 증가하면 애플리케이션은 높은 부하 시스템에서 실행하는 기회가 감소되도록 변환되므로 고용량의 멀티 캐스트 그룹을 청취하는 애플리케이션 수의 증가로 멀티 캐스트 프레임 손실 비율이 증가합니다.
/proc/sys/net/core/dev_weight를 통해 제어됩니다. 장치 무게와 조정의 의미에 대한 자세한 내용은 8.4.1절. “NIC 하드웨어 버퍼 ”에서 참조하십시오.
부록 A. 고친 과정
| 고친 과정 | |||||
|---|---|---|---|---|---|
| 고침 4.0-22.2.400 | 2013-10-31 | ||||
| |||||
| 고침 4.0-22.2 | Thu Jun 27 2013 | ||||
| |||||
| 고침 4.0-22.1 | Thu Apr 18 2013 | ||||
| |||||
| 고침 4.0-22 | Fri Feb 15 2013 | ||||
| |||||
| 고침 4.0-19 | Wed Jan 16 2013 | ||||
| |||||
| 고침 4.0-18 | Tue Nov 27 2012 | ||||
| |||||
| 고침 4.0-17 | Mon Nov 19 2012 | ||||
| |||||
| 고침 4.0-16 | Thu Nov 08 2012 | ||||
| |||||
| 고침 4.0-15 | Wed Oct 17 2012 | ||||
| |||||
| 고침 4.0-13 | Wed Oct 17 2012 | ||||
| |||||
| 고침 4.0-12 | Tue Oct 16 2012 | ||||
| |||||
| 고침 4.0-9 | Tue Oct 9 2012 | ||||
| |||||
| 고침 4.0-6 | Thu Oct 4 2012 | ||||
| |||||
| 고침 4.0-3 | Tue Sep 18 2012 | ||||
| |||||
| 고침 4.0-2 | Mon Sep 10 2012 | ||||
| |||||
| 고침 3.0-15 | Thursday March 22 2012 | ||||
| |||||
| 고침 3.0-10 | Friday March 02 2012 | ||||
| |||||
| 고침 3.0-8 | Thursday February 02 2012 | ||||
| |||||
| 고침 3.0-5 | Tuesday January 17 2012 | ||||
| |||||
| 고침 3.0-3 | Wednesday January 11 2012 | ||||
| |||||
| 고침 1.0-0 | Friday December 02 2011 | ||||
| |||||