Accelerate enterprise software development with NVIDIA and MaaS
Optimize private app development using NVIDIA Nemotron models through Models-as-a-Service on your own multi-tenant infrastructure in Red Hat AI.
This content is authored by Red Hat experts, but has not yet been tested on every supported configuration.
Accelerate enterprise software development with NVIDIA and MaaS
Optimize private app development using NVIDIA Nemotron models through Models-as-a-Service on your own multi-tenant infrastructure in Red Hat AI.
Table of contents
Detailed description
Developing software with speed and efficiency is a competitive necessity. Developers are often overwhelmed and slowed down by repetitive code, complicated debugging and testing, and the constant need to learn new technologies. AI-powered coding assistance can help, but how do you leverage it securely and cost-effectively?
For organizations restricted by strict data privacy requirements, regulations, or specific performance needs, public AI hosted services often are not an option. As your usage expands, you also need to consider how to keep things as cost-efficient as possible. Models as a Service (MaaS) solves this by enabling centralized IT teams to host and manage private models that remote teams can consume easily and securely. This keeps proprietary data within the organization’s boundaries while providing developers access to the generative AI technology they need. By providing access to the models via API tokens, administrators can also implement specific rate limits and quotas. This approach doesn’t just simplify access and usage, it allows organizations to monitor metrics, forecast capacity and compute needs, and manage chargebacks with precision.
This quickstart demonstrates how you can easily deploy a private AI code assistant powered by NVIDIA Nemotron models and delivered through Red Hat AI's integrated Models as a Service (MaaS) offering. Developers access the assistant through OpenShift DevSpaces, a containerized cloud-native IDE included in OpenShift.
Architecture diagrams
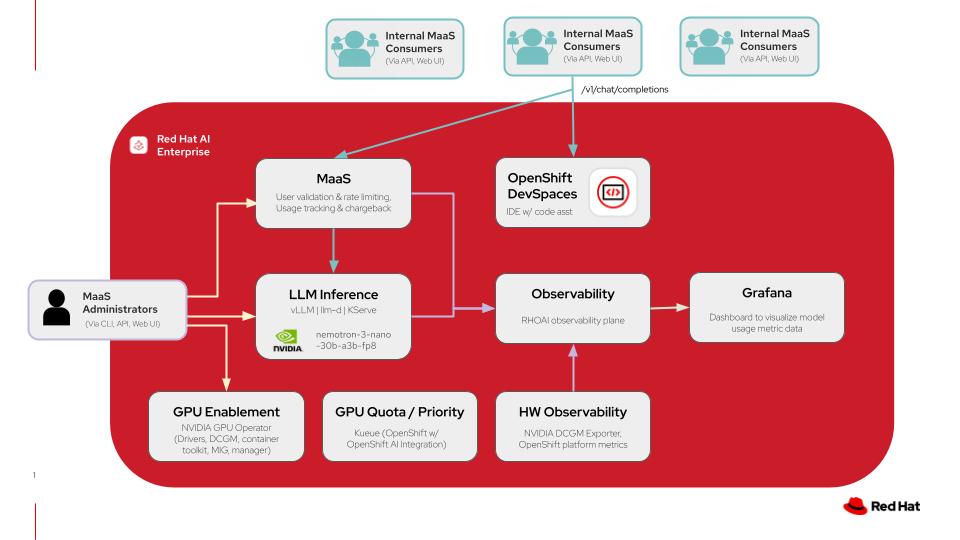
This diagram illustrates a models-as-a-service architecture on Red Hat AI including the model deployments in addition to the code assistant application with OpenShift DevSpaces. For more details click here.
{kind=link}
| Layer/Component | Technology | Purpose/Description |
|---|---|---|
| Orchestration | Red Hat AI Enterprise | Container orchestration and comprehensive AI platform |
| Inference | vLLM and llm-d | High performance inference engine for Gen AI model deployment and kubernetes-native distributed inference capabilities with llm-d |
| LLM | nemotron-3-nano-30b-a3b-fp8 | A quantized 30B-parameter hybrid Mamba-Transformer MoE model with a 1M-token context window, designed for efficient reasoning, chat, and agentic AI applications |
| Models-as-a-Service | Red Hat AI Enterprise | Integrated LLM governance layer that provides rate-limited model access with usage tracking and chargeback across teams |
| GPU Acceleration | NVIDIA GPU Operator | Enables GPUs and manages drivers, DCGM, container toolkit, and MIG capabilities for GPU acceleration |
| Development Environment | OpenShift DevSpaces | Provides IDE instances for development teams to develop and deploy all on the same cluster |
| Observability | Prometheus Operator | Monitors model inference metrics and GPU telemetry |
| Dashboard | Grafana | Metrics scraped from Prometheus are then surfaced and shown visually in custom Grafana dashboards |
Requirements
Minimum hardware requirements
- One NVIDIA GPU node with 48GB VRAM for Nemotron model
- One NVIDIA GPU node with 48GB VRAM for gpt-oss model
Note: Models in this quickstart were tested with 2 L40S GPU instances on AWS (instance type g6e.2xlarge).
Minimum software requirements
- Red Hat OpenShift 4.20
- Red Hat OpenShift AI 3.2
- Helm CLI
- OpenShift Client CLI
- Bash shell available in PATH
- sed available in PATH
Required user permissions
- Regular user permissions for usage of Models-as-a-Service enabled endpoint, access to DevSpaces workspace, and access to Grafana dashboard for viewing usage data.
- Cluster Admin access needed for any changes to model deployments or MaaS configurations.
Deploy
The following instructions will easily deploy the quickstart to your Red Hat AI environment using an auto-pilot script-based installation. This will configure the necessary prerequisites for your environment and wire everything together, removing the need for additional configuration.
Please see the advanced deployment section for details on setting up your own prerequisites and deploying the quickstart with more control.
Prerequisites
- OpenShift cluster (specific version is specified in the software requirements section)
- Optional: certificates managed for the OpenShift Router
- OpenShift cluster has GPUs available
- The NVIDIA GPU Operator is installed and configured with a ClusterPolicy to configure the driver
- You do not have other workloads or configurations in the cluster, such as:
- An identity provider deployed and configured
- Red Hat OpenShift AI installed
- Red Hat Connectivity Link deployed and configured
- Red Hat OpenShift Dev Spaces deployed
Installation Steps
- git clone quickstart repository
git clone https://github.com/rh-ai-quickstart/maas-code-assistant.git
- cd into the directory
cd maas-code-assistant
- Ensure you’re logged into your cluster as a cluster-admin user, such as
kube:adminorsystem:admin:
oc whoami
- Run all-in-one.sh. Enter passwords for the admin and user accounts when prompted.
./all-in-one.sh
Delete
To remove the core quickstart components (models, Dev Spaces workspaces, etc.) run the following:
helm uninstall maas-code-assistant
To remove the Developer Preview of MaaS, run this afterwards:
oc delete -k ./dev-preview
To clean up other dependencies, such as Red Hat Connectivity Link and OpenShift AI, follow their documented uninstallation procedures by removing their Operands first, allowing the operators to reconcile and complete removal, before uninstalling the operators themselves.
References
- vLLM: The High-Throughput and Memory-Efficient inference and serving engine for LLMs.
- llm-d: a Kubernetes-native high-performance distributed LLM inference framework.
- Red Hat OpenShift DevSpaces: a container-based, in-browser development environment offered by Red Hat that facilitates cloud-native development directly within the OpenShift ecosystem. Included within the OpenShift product offering.
- NVIDIA Nemotron: a family of open models with open weights, training data, and recipes, delivering leading efficiency and accuracy for building specialized AI agents.
- NVIDIA GPU Operator: uses the operator framework within Kubernetes to automate the management of all NVIDIA software components needed to provision GPU.
Advanced Deployment
This advanced deployment option will allow you to control the deployment of all prerequisites separately and tailor it to your specific environment.
Use this deployment path if you:
- Have a configured cluster with some or all of the prerequisites already deployed.
- Prefer a different configuration path than the defaults set in the quickstart repository installation script.
- Are using the cluster for other workloads and therefore need to customize the installation to avoid conflict with existing cluster resources.
Prerequisites
The following prerequisites are required in your environment to prevent any conflicts with the quickstart:
- Users have been configured with OpenShift OAuth, backed by OIDC or some other auth method such as htpasswd, as documented.
- OpenShift cluster and user-workload monitoring is configured, as documented.
- Grafana is deployed and managed through the Grafana Operator, in the
grafananamespace.- An example Grafana operand, with all RBAC and resources wired up to User Workload Monitoring, is available in
docs/examples/grafana.yaml. It expects that your Grafana Operator installation was
namespace scoped, and deployed to the
grafananamespace, and that your in-cluster registry is configured.
- An example Grafana operand, with all RBAC and resources wired up to User Workload Monitoring, is available in
docs/examples/grafana.yaml. It expects that your Grafana Operator installation was
namespace scoped, and deployed to the
- Red Hat OpenShift Dev Spaces is deployed,
as documented.
- A basic CheCluster resource is configured, as in steps 2 and 3 of the above.
- Red Hat OpenShift AI version 3.2.0 has been deployed from the fast-3.x channel,
as documented.
- A Data Science Cluster has been created that enables at least the Dashboard, KServe, and Llama Stack Operator components, as documented.
- Note that using Manual approval mode with the startingCSV set to
rhods-operator.3.2.0is recommended to stay on the version tested with this code base.
- Red Hat Connectivity Link has been deployed from the stable channel,
as documented.
- A
Kuadrantresource has been installed in thekuadrant-systemnamespace, as documented.
- A
- You have created the
openshift-defaultGatewayClass object for Gateway API in OpenShift, and are able to create Gateway instances using your clusters load balancer and infrastructure configuration. See the documentation for more details about Gateway API in OpenShift.
Installation Steps
- Ensure you’re logged into your cluster as a cluster-admin user:
oc whoami
oc get nodes
Install the developer preview release of Models as a Service.
Create a namespace for the developer preview:
oc create ns maas-apiRun, from the root of the cloned repository, the following and ensure the values look correct for your cluster:
./dev-preview/render.shApply the rendered developer preview overlay with the following:
oc apply -k ./dev-preview
Copy
charts/maas-code-assistant/values.yamlto edit it:
cp charts/maas-code-assistant/values.yaml environment.yaml
Edit the file and update the following sections to match your environment:
global.wildcardDomainandglobal.wildcardCertName- You can recover the proper values by running the following:
oc get ingresscontroller -n openshift-ingress-operator default -ojsonpath='{.status.domain}{"\n"}' oc get ingresscontroller -n openshift-ingress-operator default -ojsonpath='{.spec.defaultCertificate.name}{"\n"}'grafana.namespaceandgrafana.selectors- Use the Namespace of your
Grafanaresource for the Grafana Operator. - Set
selectorsto match labels on yourGrafanainstance. For example, if you get the following output:
oc get grafana grafana -n grafana -ojsonpath='{.metadata.labels}' | jq .{“app”: “grafana”}
You should setselectorstoapp: grafana.- Use the Namespace of your
If you have deployed the
openshift-defaultGatewayClass, as instructed above, configure it to not be managed by the chart by settingopenshift-ai.gatewayClass.createtofalse.
Update the
tierssection to map your desired user/tier mapping for the default MaaS tiers.- For example, if you have users named “bob,” “sue,” and “tom,” and would like them all to be in the enterprise
tier, with user “sally” in the premium tier and “frank” in the free tier, use the following value for
tiers:
tiers: free: users: - frank premium: users: - sally enterprise: users: - bob - sue - tom- For example, if you have users named “bob,” “sue,” and “tom,” and would like them all to be in the enterprise
tier, with user “sally” in the premium tier and “frank” in the free tier, use the following value for
Complete any tweaks necessary to the
modelsarray to ensure the workloads will place on your GPU-enabled nodes. This may involve changing the tolerations, adjusting the resources, adding thenodeSelectorfield to each model and configuring it with a validnodeSelectorfor the pod template, etc.Install the quickstart with helm:
helm install maas-code-assistant ./charts/maas-code-assistant -f environment.yaml
Note that, depending on your environment, the openshift-ai-inference Gateway may already be deployed in your cluster,
giving you error output such as
Error: INSTALLATION FAILED: Unable to continue with install: Gateway "openshift-ai-inference" in namespace "openshift-ingress" exists and cannot be imported into the current release.
If this is the case, update your environment.yaml to include openshift-ai.gateway.create set to false.