管理指南
管理 Red Hat Ceph Storage
摘要
第 1 章 Ceph 管理
Red Hat Ceph Storage 集群是所有 Ceph 部署的基础。部署 Red Hat Ceph Storage 集群后,相关的管理操作可以保持 Red Hat Ceph Storage 集群运行正常且处于最佳状态。
Red Hat Ceph Storage 管理指南可帮助存储管理员执行这些任务,例如:
- 如何检查我的 Red Hat Ceph Storage 集群的健康状态?
- 如何启动和停止 Red Hat Ceph Storage 集群服务?
- 如何从正在运行的 Red Hat Ceph Storage 集群中添加或删除 OSD?
- 如何为 Red Hat Ceph Storage 集群中存储的对象管理用户身份验证和访问控制?
- 我想了解如何在 Red Hat Ceph Storage 集群中使用覆盖。
- 我想监控 Red Hat Ceph Storage 集群的性能。
基本 Ceph 存储集群由两种类型的守护进程组成:
- Ceph Object Storage Device (OSD) 将数据存储在分配给 OSD 的 PG 内
- Ceph Monitor 维护集群映射的一个主(master)副本
生产系统具有三个或更多 Ceph 监控功能,以实现高可用性,一般最少 50 个 OSD 用于可接受的负载平衡、数据重新平衡和数据恢复。
第 2 章 了解 Ceph 的进程管理
作为存储管理员,您可以按裸机或容器中的类型或实例来操作各种 Ceph 守护进程。通过操作这些守护进程,您可以根据需要启动、停止和重启所有 Ceph 服务。
2.1. 先决条件
- 安装 Red Hat Ceph Storage 软件。
2.2. Ceph 进程管理
在红帽 Ceph 存储中,所有流程管理都通过 Systemd 服务完成。在每次 start, restart, 和 stop Ceph 守护进程时,必须指定守护进程类型或守护进程实例。
其它资源
- 有关使用 Systemd 的更多信息,请参阅 Red Hat Enterprise Linux 系统管理员指南中的使用 systemd 管理服务的章节。
2.3. 启动、停止和重启所有 Ceph 守护进程
以 admin 用户身份启动、停止和重启所有 Ceph 守护进程。
前提条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
-
具有对节点的
root访问权限。
流程
启动所有 Ceph 守护进程:
systemctl start ceph.target
[root@admin ~]# systemctl start ceph.targetCopy to Clipboard Copied! Toggle word wrap Toggle overflow 停止所有 Ceph 守护进程:
systemctl stop ceph.target
[root@admin ~]# systemctl stop ceph.targetCopy to Clipboard Copied! Toggle word wrap Toggle overflow 重启所有 Ceph 守护进程:
systemctl restart ceph.target
[root@admin ~]# systemctl restart ceph.targetCopy to Clipboard Copied! Toggle word wrap Toggle overflow
2.4. 按类型启动、停止和重新启动 Ceph 守护进程
若要启动、停止或重新启动特定类型的所有 Ceph 守护进程,请在运行 Ceph 守护进程的节点上按照以下步骤操作。
前提条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
-
具有对节点的
root访问权限。
流程
在 Ceph 监控 节点上:
启动:
systemctl start ceph-mon.target
[root@mon ~]# systemctl start ceph-mon.targetCopy to Clipboard Copied! Toggle word wrap Toggle overflow 停止:
systemctl stop ceph-mon.target
[root@mon ~]# systemctl stop ceph-mon.targetCopy to Clipboard Copied! Toggle word wrap Toggle overflow 重启:
systemctl restart ceph-mon.target
[root@mon ~]# systemctl restart ceph-mon.targetCopy to Clipboard Copied! Toggle word wrap Toggle overflow 在 Ceph Manager 节点上:
启动:
systemctl start ceph-mgr.target
[root@mgr ~]# systemctl start ceph-mgr.targetCopy to Clipboard Copied! Toggle word wrap Toggle overflow 停止:
systemctl stop ceph-mgr.target
[root@mgr ~]# systemctl stop ceph-mgr.targetCopy to Clipboard Copied! Toggle word wrap Toggle overflow 重启:
systemctl restart ceph-mgr.target
[root@mgr ~]# systemctl restart ceph-mgr.targetCopy to Clipboard Copied! Toggle word wrap Toggle overflow 在 Ceph OSD 节点上:
启动:
systemctl start ceph-osd.target
[root@osd ~]# systemctl start ceph-osd.targetCopy to Clipboard Copied! Toggle word wrap Toggle overflow 停止:
systemctl stop ceph-osd.target
[root@osd ~]# systemctl stop ceph-osd.targetCopy to Clipboard Copied! Toggle word wrap Toggle overflow 重启:
systemctl restart ceph-osd.target
[root@osd ~]# systemctl restart ceph-osd.targetCopy to Clipboard Copied! Toggle word wrap Toggle overflow 在 Ceph 对象网关 节点上:
启动:
systemctl start ceph-radosgw.target
[root@rgw ~]# systemctl start ceph-radosgw.targetCopy to Clipboard Copied! Toggle word wrap Toggle overflow 停止:
systemctl stop ceph-radosgw.target
[root@rgw ~]# systemctl stop ceph-radosgw.targetCopy to Clipboard Copied! Toggle word wrap Toggle overflow 重启:
systemctl restart ceph-radosgw.target
[root@rgw ~]# systemctl restart ceph-radosgw.targetCopy to Clipboard Copied! Toggle word wrap Toggle overflow
2.5. 按实例启动、停止和重新启动 Ceph 守护进程
若要通过实例启动、停止或重新启动 Ceph 守护进程,请在运行 Ceph 守护进程的节点上按照以下步骤操作。
前提条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
-
具有对节点的
root访问权限。
流程
在 Ceph 监控 节点上:
启动:
systemctl start ceph-mon@MONITOR_HOST_NAME
[root@mon ~]# systemctl start ceph-mon@MONITOR_HOST_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow 停止:
systemctl stop ceph-mon@MONITOR_HOST_NAME
[root@mon ~]# systemctl stop ceph-mon@MONITOR_HOST_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow 重启:
systemctl restart ceph-mon@MONITOR_HOST_NAME
[root@mon ~]# systemctl restart ceph-mon@MONITOR_HOST_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow 替换
-
MONITOR_HOST_NAME,名称为 Ceph Monitor 节点。
-
在 Ceph Manager 节点上:
启动:
systemctl start ceph-mgr@MANAGER_HOST_NAME
[root@mgr ~]# systemctl start ceph-mgr@MANAGER_HOST_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow 停止:
systemctl stop ceph-mgr@MANAGER_HOST_NAME
[root@mgr ~]# systemctl stop ceph-mgr@MANAGER_HOST_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow 重启:
systemctl restart ceph-mgr@MANAGER_HOST_NAME
[root@mgr ~]# systemctl restart ceph-mgr@MANAGER_HOST_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow 替换
-
MANAGER_HOST_NAME,名称为 Ceph Manager 节点。
-
在 Ceph OSD 节点上:
启动:
systemctl start ceph-osd@OSD_NUMBER
[root@osd ~]# systemctl start ceph-osd@OSD_NUMBERCopy to Clipboard Copied! Toggle word wrap Toggle overflow 停止:
systemctl stop ceph-osd@OSD_NUMBER
[root@osd ~]# systemctl stop ceph-osd@OSD_NUMBERCopy to Clipboard Copied! Toggle word wrap Toggle overflow 重启:
systemctl restart ceph-osd@OSD_NUMBER
[root@osd ~]# systemctl restart ceph-osd@OSD_NUMBERCopy to Clipboard Copied! Toggle word wrap Toggle overflow 替换
OSD_NUMBER为 Ceph OSD 的ID数。例如,当查看
ceph osd tree命令输出时,osd.0的ID为0。
在 Ceph 对象网关 节点上:
启动:
systemctl start ceph-radosgw@rgw.OBJ_GATEWAY_HOST_NAME
[root@rgw ~]# systemctl start ceph-radosgw@rgw.OBJ_GATEWAY_HOST_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow 停止:
systemctl stop ceph-radosgw@rgw.OBJ_GATEWAY_HOST_NAME
[root@rgw ~]# systemctl stop ceph-radosgw@rgw.OBJ_GATEWAY_HOST_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow 重启:
systemctl restart ceph-radosgw@rgw.OBJ_GATEWAY_HOST_NAME
[root@rgw ~]# systemctl restart ceph-radosgw@rgw.OBJ_GATEWAY_HOST_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow 替换
-
OBJ_GATEWAY_HOST_NAME,名称为 Ceph 对象网关节点。
-
2.6. 启动、停止和重启容器中运行的 Ceph 守护进程
使用 systemctl 命令启动、停止或重启容器中运行的 Ceph 守护进程。
前提条件
- 安装 Red Hat Ceph Storage 软件。
- 节点的根级别访问权限。
流程
要启动、停止或重启容器中运行的 Ceph 守护进程,请以以下格式组成的
root命令运行systemctl命令:systemctl ACTION ceph-DAEMON@ID
systemctl ACTION ceph-DAEMON@IDCopy to Clipboard Copied! Toggle word wrap Toggle overflow - 替换
-
ACTION 是要执行的操作;
start,stop, 或restart。 -
DAEMON 是守护进程;
osd、mon、mds或rgw。 ID 是其中之一:
-
运行
ceph-mon、ceph-mds或ceph-rgw守护进程的短主机名。 -
ceph-osd守护进程的 ID (如果部署)。
-
运行
例如,要重启 ID 为
osd01的ceph-osd守护进程:systemctl restart ceph-osd@osd01
[root@osd ~]# systemctl restart ceph-osd@osd01Copy to Clipboard Copied! Toggle word wrap Toggle overflow 要启动
ceph-mondemon,在ceph-monitor01主机上运行:systemctl start ceph-mon@ceph-monitor01
[root@mon ~]# systemctl start ceph-mon@ceph-monitor01Copy to Clipboard Copied! Toggle word wrap Toggle overflow 停止在
ceph-rgw01主机上运行的ceph-rgw守护进程:systemctl stop ceph-radosgw@ceph-rgw01
[root@rgw ~]# systemctl stop ceph-radosgw@ceph-rgw01Copy to Clipboard Copied! Toggle word wrap Toggle overflow -
ACTION 是要执行的操作;
验证操作是否已成功完成。
systemctl status ceph-DAEMON@ID
systemctl status ceph-DAEMON@IDCopy to Clipboard Copied! Toggle word wrap Toggle overflow 例如:
systemctl status ceph-mon@ceph-monitor01
[root@mon ~]# systemctl status ceph-mon@ceph-monitor01Copy to Clipboard Copied! Toggle word wrap Toggle overflow
其它资源
- 如需更多信息,请参阅 Red Hat Ceph Storage 管理指南中的了解 Ceph 的进程管理部分。
2.7. 查看容器中运行的 Ceph 守护进程的日志
使用容器主机中的 journald 守护进程,从容器中查看 Ceph 守护进程的日志。
前提条件
- 安装 Red Hat Ceph Storage 软件。
- 节点的根级别访问权限。
流程
要查看整个 Ceph 日志,请以以下格式组成的
root用户身份运行journalctl命令:journalctl -u ceph-DAEMON@ID
journalctl -u ceph-DAEMON@IDCopy to Clipboard Copied! Toggle word wrap Toggle overflow - 替换
-
DAEMON 是 Ceph 守护进程;
osd、mon或rgw。 ID 是其中之一:
-
运行
ceph-mon、ceph-mds或ceph-rgw守护进程的短主机名。 -
ceph-osd守护进程的 ID (如果部署)。
-
运行
例如,使用 ID
osd01查看ceph-osd守护进程的完整日志:journalctl -u ceph-osd@osd01
[root@osd ~]# journalctl -u ceph-osd@osd01Copy to Clipboard Copied! Toggle word wrap Toggle overflow -
DAEMON 是 Ceph 守护进程;
要只显示最新的日志条目,请使用
-f选项。journalctl -fu ceph-DAEMON@ID
journalctl -fu ceph-DAEMON@IDCopy to Clipboard Copied! Toggle word wrap Toggle overflow 例如,仅查看
ceph-mon守护进程最近在ceph-monitor01主机上运行的日志条目:journalctl -fu ceph-mon@ceph-monitor01
[root@mon ~]# journalctl -fu ceph-mon@ceph-monitor01Copy to Clipboard Copied! Toggle word wrap Toggle overflow
您还可以使用 sosreport 实用程序查看 journald 日志。有关 SOS 报告的详情,请查看 什么是 sosreport 以及如何在 Red Hat Enterprise Linux 中创建它? 红帽客户门户网站上的解决方案。
其它资源
-
journalctl (1)手册页。
2.8. 为容器化 Ceph 守护进程启用日志记录到文件
默认情况下,容器化 Ceph 守护进程不记录到文件。您可以使用集中式配置管理,使容器化 Ceph 守护进程能够记录到文件。
前提条件
- 安装 Red Hat Ceph Storage 软件。
- 根级别访问运行容器化守护进程的节点。
流程
进入
var/log/ceph目录:Example
cd /var/log/ceph
[root@host01 ~]# cd /var/log/cephCopy to Clipboard Copied! Toggle word wrap Toggle overflow 记录任何现有日志文件。
语法
ls -l /var/log/ceph/
ls -l /var/log/ceph/Copy to Clipboard Copied! Toggle word wrap Toggle overflow Example
ls -l /var/log/ceph/ total 396 -rw-r--r--. 1 ceph ceph 107230 Feb 5 14:42 ceph-osd.0.log -rw-r--r--. 1 ceph ceph 107230 Feb 5 14:42 ceph-osd.3.log -rw-r--r--. 1 root root 181641 Feb 5 14:42 ceph-volume.log
[root@host01 ceph]# ls -l /var/log/ceph/ total 396 -rw-r--r--. 1 ceph ceph 107230 Feb 5 14:42 ceph-osd.0.log -rw-r--r--. 1 ceph ceph 107230 Feb 5 14:42 ceph-osd.3.log -rw-r--r--. 1 root root 181641 Feb 5 14:42 ceph-volume.logCopy to Clipboard Copied! Toggle word wrap Toggle overflow 在示例中,登录 OSD.0 和 OSD.3 的文件已经启用。
获取您要启用日志记录的守护进程的容器名称:
Red Hat Enterprise Linux 7
docker ps -a
[root@host01 ceph]# docker ps -aCopy to Clipboard Copied! Toggle word wrap Toggle overflow Red Hat Enterprise Linux 8
podman ps -a
[root@host01 ceph]# podman ps -aCopy to Clipboard Copied! Toggle word wrap Toggle overflow 使用集中式配置管理,为 Ceph 守护进程启用文件日志记录。
Red Hat Enterprise Linux 7
docker exec CONTAINER_NAME ceph config set DAEMON_NAME log_to_file true
docker exec CONTAINER_NAME ceph config set DAEMON_NAME log_to_file trueCopy to Clipboard Copied! Toggle word wrap Toggle overflow Red Hat Enterprise Linux 8
podman exec CONTAINER_NAME ceph config set DAEMON_NAME log_to_file true
podman exec CONTAINER_NAME ceph config set DAEMON_NAME log_to_file trueCopy to Clipboard Copied! Toggle word wrap Toggle overflow DAEMON_NAME 由 CONTAINER_NAME 派生而来。删除
ceph-,并将守护进程和守护进程 ID 之间的连字符替换为一个句点。Red Hat Enterprise Linux 7
docker exec ceph-mon-host01 ceph config set mon.host01 log_to_file true
[root@host01 ceph]# docker exec ceph-mon-host01 ceph config set mon.host01 log_to_file trueCopy to Clipboard Copied! Toggle word wrap Toggle overflow Red Hat Enterprise Linux 8
podman exec ceph-mon-host01 ceph config set mon.host01 log_to_file true
[root@host01 ceph]# podman exec ceph-mon-host01 ceph config set mon.host01 log_to_file trueCopy to Clipboard Copied! Toggle word wrap Toggle overflow 可选:要为集群日志启用日志日志,请使用
mon_cluster_log_to_file选项:Red Hat Enterprise Linux 7
docker exec CONTAINER_NAME ceph config set DAEMON_NAME mon_cluster_log_to_file true
docker exec CONTAINER_NAME ceph config set DAEMON_NAME mon_cluster_log_to_file trueCopy to Clipboard Copied! Toggle word wrap Toggle overflow Red Hat Enterprise Linux 8
podman exec CONTAINER_NAME ceph config set DAEMON_NAME mon_cluster_log_to_file true
podman exec CONTAINER_NAME ceph config set DAEMON_NAME mon_cluster_log_to_file trueCopy to Clipboard Copied! Toggle word wrap Toggle overflow Red Hat Enterprise Linux 7
docker exec ceph-mon-host01 ceph config set mon.host01 mon_cluster_log_to_file true
[root@host01 ceph]# docker exec ceph-mon-host01 ceph config set mon.host01 mon_cluster_log_to_file trueCopy to Clipboard Copied! Toggle word wrap Toggle overflow Red Hat Enterprise Linux 8
podman exec ceph-mon-host01 ceph config set mon.host01 mon_cluster_log_to_file true
[root@host01 ceph]# podman exec ceph-mon-host01 ceph config set mon.host01 mon_cluster_log_to_file trueCopy to Clipboard Copied! Toggle word wrap Toggle overflow 验证更新的配置:
Red Hat Enterprise Linux 7
docker exec CONTAINER_NAME ceph config show-with-defaults DAEMON_NAME | grep log_to_file
docker exec CONTAINER_NAME ceph config show-with-defaults DAEMON_NAME | grep log_to_fileCopy to Clipboard Copied! Toggle word wrap Toggle overflow Red Hat Enterprise Linux 8
podman exec CONTAINER_NAME ceph config show-with-defaults DAEMON_NAME | grep log_to_file
podman exec CONTAINER_NAME ceph config show-with-defaults DAEMON_NAME | grep log_to_fileCopy to Clipboard Copied! Toggle word wrap Toggle overflow Example
podman exec ceph-mon-host01 ceph config show-with-defaults mon.host01 | grep log_to_file log_to_file true mon default[false] mon_cluster_log_to_file true mon default[false]
[root@host01 ceph]# podman exec ceph-mon-host01 ceph config show-with-defaults mon.host01 | grep log_to_file log_to_file true mon default[false] mon_cluster_log_to_file true mon default[false]Copy to Clipboard Copied! Toggle word wrap Toggle overflow 可选:重启 Ceph 守护进程:
语法
systemctl restart ceph-DAEMON@DAEMON_ID
systemctl restart ceph-DAEMON@DAEMON_IDCopy to Clipboard Copied! Toggle word wrap Toggle overflow Example
systemctl restart ceph-mon@host01
[root@host01 ceph]# systemctl restart ceph-mon@host01Copy to Clipboard Copied! Toggle word wrap Toggle overflow 验证新日志文件是否存在:
语法
ls -l /var/log/ceph/
ls -l /var/log/ceph/Copy to Clipboard Copied! Toggle word wrap Toggle overflow Example
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 创建了两个新文件,
ceph-mon.host01.log用于 monitor 守护进程和ceph.log,用于集群日志。
2.9. 收集 Ceph 守护进程的日志文件
若要收集 Ceph 守护进程的日志文件,请运行 gather-ceph-logs.yml Ansible playbook。目前,Red Hat Ceph Storage 仅支持为非容器化部署收集日志。
前提条件
- 已部署正在运行的 Red Hat Ceph Storage 集群。
- 对 Ansible 节点的管理员级访问。
流程
进入
/usr/share/ceph-ansible目录:cd /usr/share/ceph-ansible
[ansible@admin ~]# cd /usr/share/ceph-ansibleCopy to Clipboard Copied! Toggle word wrap Toggle overflow 运行 playbook:
ansible-playbook infrastructure-playbooks/gather-ceph-logs.yml -i hosts
[ansible@admin ~]# ansible-playbook infrastructure-playbooks/gather-ceph-logs.yml -i hostsCopy to Clipboard Copied! Toggle word wrap Toggle overflow - 等待在 Ansible 管理节点上收集日志。
其它资源
- 详情请查看 Red Hat Ceph Storage Administration Guide 的 Viewing log files of Ceph daemons that run in containers 部分。
2.10. 关闭并重启 Red Hat Ceph Storage 集群
按照以下步骤关闭和重新引导 Ceph 集群。
先决条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
-
具有
root访问权限。
流程
关闭 Red Hat Ceph Storage 集群
- 停止使用该集群上的 RBD 镜像和 RADOS 网关以及任何其他客户端的客户端。
-
在继续操作前,集群必须处于健康状态(
Health_OK以及所有的 PG 为active+clean)。在具有客户端密钥环的节点上运行ceph 状态,如 Ceph 监控器或 OpenStack 控制器节点,以确保集群健康。 如果使用 Ceph 文件系统(
CephFS),则必须关闭CephFS集群。缩减CephFS集群是通过将排名数量减少到1来完成,设置cluster_down标志,然后对最后的等级失败。例如:
ceph fs set FS_NAME max_mds 1 ceph mds deactivate FS_NAME:1 # rank 2 of 2 ceph status # wait for rank 1 to finish stopping ceph fs set FS_NAME cluster_down true ceph mds fail FS_NAME:0
[root@osd ~]# ceph fs set FS_NAME max_mds 1 [root@osd ~]# ceph mds deactivate FS_NAME:1 # rank 2 of 2 [root@osd ~]# ceph status # wait for rank 1 to finish stopping [root@osd ~]# ceph fs set FS_NAME cluster_down true [root@osd ~]# ceph mds fail FS_NAME:0Copy to Clipboard Copied! Toggle word wrap Toggle overflow 设置
cluster_down标志可防止待机使用失败的等级。设置
noout、norecover、norebalance、nobackfill、nodown和pause标志。在具有客户端密钥环的节点上运行以下命令:例如,Ceph Monitor 或 OpenStack 控制器节点:Copy to Clipboard Copied! Toggle word wrap Toggle overflow 逐一关闭 OSD 节点:
systemctl stop ceph-osd.target
[root@osd ~]# systemctl stop ceph-osd.targetCopy to Clipboard Copied! Toggle word wrap Toggle overflow 逐一关闭 monitor 节点:
systemctl stop ceph-mon.target
[root@mon ~]# systemctl stop ceph-mon.targetCopy to Clipboard Copied! Toggle word wrap Toggle overflow
重新引导 Red Hat Ceph Storage 集群
- 启动管理节点。
打开监控节点:
systemctl start ceph-mon.target
[root@mon ~]# systemctl start ceph-mon.targetCopy to Clipboard Copied! Toggle word wrap Toggle overflow 打开 OSD 节点:
systemctl start ceph-osd.target
[root@osd ~]# systemctl start ceph-osd.targetCopy to Clipboard Copied! Toggle word wrap Toggle overflow - 等待所有节点上线。验证所有服务都已启动,且节点之间的连接是正常的。
取消设置
noout、norecover、norebalance、nobackfill、nodown和pause标志。在具有客户端密钥环的节点上运行以下命令:例如,Ceph Monitor 或 OpenStack 控制器节点:Copy to Clipboard Copied! Toggle word wrap Toggle overflow 如果使用 Ceph 文件系统(
CephFS),则必须通过将cluster_down标志设置为false来备份CephFS集群:ceph fs set FS_NAME cluster_down false
[root@admin~]# ceph fs set FS_NAME cluster_down falseCopy to Clipboard Copied! Toggle word wrap Toggle overflow -
验证集群处于健康状态(
Health_OK和所有 PGactive+clean)。在具有客户端密钥环的节点中运行ceph status。例如,Ceph Monitor 或 OpenStack 控制器节点确保集群运行正常。
2.11. 其它资源
- 有关安装 Ceph 的更多信息,请参阅 Red Hat Ceph Storage 安装指南
第 3 章 监控 Ceph 存储集群
作为存储管理员,您可以监控 Red Hat Ceph Storage 集群的整体健康状况,以及监控 Ceph 各个组件的健康状态。
运行 Red Hat Ceph Storage 集群后,您可以开始监控存储集群,以确保 Ceph 监控器和 Ceph OSD 守护进程在高级别中运行。Ceph 存储集群客户端连接到 Ceph Monitor 并接收最新版本的存储集群映射,然后才能将数据读取和写入到存储集群中的 Ceph 池。因此,在 Ceph 客户端可以读取和写入数据之前,监控器集群必须拥有集群状态的协议。
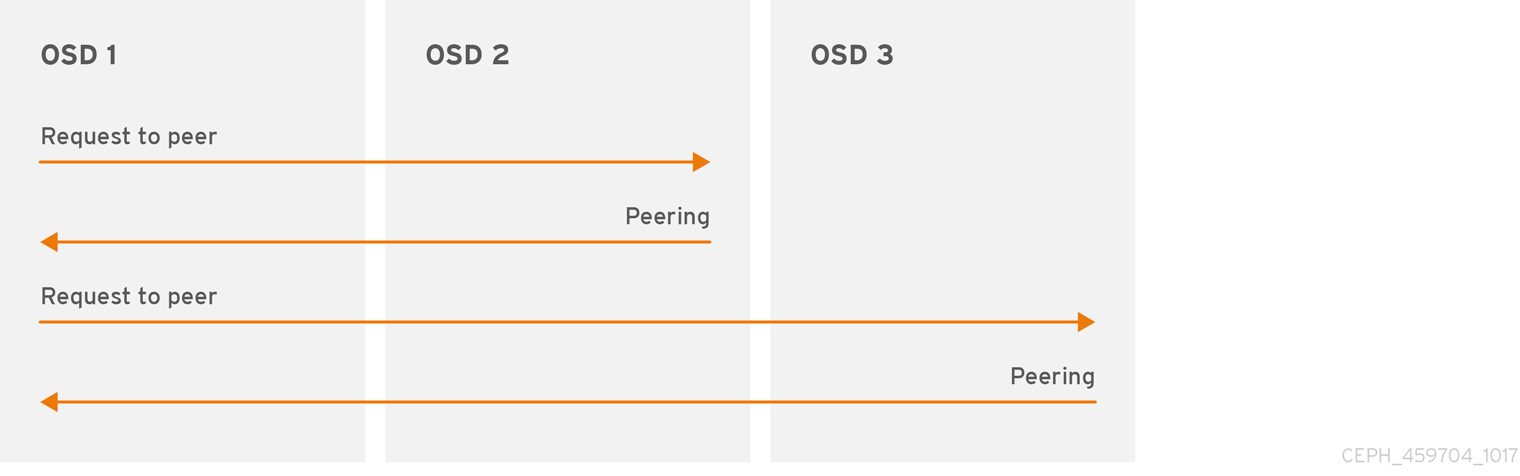
Ceph OSD 必须将主 OSD 上的放置组与次要 OSD 上的 PG 的副本进行对等(peer)。如果出现错误,则 peering 将处于 active + clean 以外的状态。
3.1. 先决条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
3.2. Ceph 存储集群的高级别监控
作为存储管理员,您可以监控 Ceph 守护进程的健康状况,以确保它们已启动并在运行。高级别监控还涉及检查存储集群容量,以确保存储集群不会超过其全满比率(full ratio)。Red Hat Ceph Storage 控制面板 是进行高级别监控的最常见方法。但是,您也可以使用命令行界面、Ceph 管理 socket 或 Ceph API 来监控存储集群。
3.2.1. 先决条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
3.2.2. 以互动方式使用 Ceph 命令行界面
您可以使用 ceph 命令行工具与 Ceph 存储集群进行交互。
先决条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
- 节点的根级别访问权限。
流程
以交互模式运行
ceph实用程序。裸机部署:
示例
ceph ceph> health ceph> status ceph> quorum_status ceph> mon_status
[root@mon ~]# ceph ceph> health ceph> status ceph> quorum_status ceph> mon_statusCopy to Clipboard Copied! Toggle word wrap Toggle overflow 容器部署:
Red Hat Enterprise Linux 7
docker exec -it ceph-mon-MONITOR_NAME /bin/bash
docker exec -it ceph-mon-MONITOR_NAME /bin/bashCopy to Clipboard Copied! Toggle word wrap Toggle overflow Red Hat Enterprise Linux 8
podman exec -it ceph-mon-MONITOR_NAME /bin/bash
podman exec -it ceph-mon-MONITOR_NAME /bin/bashCopy to Clipboard Copied! Toggle word wrap Toggle overflow - 替换
MONITOR_NAME 使用 Ceph Monitor 容器的名称,分别通过分别运行
docker ps或podman ps命令找到。Example
podman exec -it ceph-mon-mon01 /bin/bash
[root@container-host ~]# podman exec -it ceph-mon-mon01 /bin/bashCopy to Clipboard Copied! Toggle word wrap Toggle overflow 本例在
mon01上打开一个交互式终端会话,您可以在其中启动 Ceph 交互式 shell。
3.2.3. 检查存储集群健康状况
启动 Ceph 存储集群后,在开始读取或写入数据前,首先检查存储集群的健康状态。
先决条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
- 节点的根级别访问权限。
流程
您可以使用以下方法检查 Ceph 存储集群的运行状况:
ceph health
[root@mon ~]# ceph healthCopy to Clipboard Copied! Toggle word wrap Toggle overflow 如果您为配置或密钥环指定了非默认位置,您可以指定它们的位置:
ceph -c /path/to/conf -k /path/to/keyring health
[root@mon ~]# ceph -c /path/to/conf -k /path/to/keyring healthCopy to Clipboard Copied! Toggle word wrap Toggle overflow
在启动 Ceph 集群时,您可能会遇到运行状况警告,如 HEALTH_WARN XXX num placement groups stale。等待几分钟,然后再次检查。当存储集群就绪时,ceph health 应返回一个如 HEALTH_OK 的消息。此时,可以开始使用群集。
3.2.4. 监视存储集群事件
您可以使用命令行界面观察 Ceph 存储集群发生的事件。
先决条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
- 节点的根级别访问权限。
流程
要在命令行中监控集群的持续事件,请打开一个新终端,然后输入:
ceph -w
[root@mon ~]# ceph -wCopy to Clipboard Copied! Toggle word wrap Toggle overflow Ceph 将打印每个事件。例如,一个由一个 monitor 和两个 OSD 组成的小型 Ceph 集群可能会打印以下内容:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 输出提供:
- 集群 ID
- 集群健康状态
- monitor map epoch 和 monitor 仲裁的状态
- OSD map epoch 和 OSD 的状态
- 放置组映射版本
- 放置组和池的数量
- 存储的 数据数量和存储的对象数量
- 保存的数据总量
3.2.5. Ceph 如何计算数据使用量
used 值反映了使用的实际原始存储量。xxx GB / xxx GB 代表可用的存储(其中较小的数字)和总存储容量。总容量反映了在复制、克隆或快照前存储数据的大小。因此,实际存储的数据量通常会超过名义上的存储量。这是因为 Ceph 会创建数据的副本,进行克隆和快照也需要使用存储。
3.2.6. 了解存储集群用量统计
要检查集群的数据使用量和数据分布在池间,请使用 df 选项。它类似于 Linux df 命令。您可以运行 ceph df 命令或 ceph df detail 命令。
示例
ceph df detail 命令提供了更多关于其他池统计数据的详细信息,如配额对象、配额字节、压缩状态等。
示例
输出的 RAW STORAGE 部分概述了存储集群用于存储数据的存储量。
- CLASS: 所用的设备类型。
SIZE: 由存储集群管理的整体存储容量。
在上例中,如果
SIZE是 90 GiB,它是不包括复制因子(默认为三)的总大小。带有复制因子的可用的总容量为 30 GiB(90 GiB/3)。根据全满比率(默认为 0.85%),最大可用空间为 30 GiB * 0.85 = 25.5 GiBAVAIL: 存储集群中可用空间的数量。
在上例中,如果
SIZE是 90 GiB,而USED空间为 6 GiB,则AVAIL空间为 84 GiB。带有复制因素的总可用空间(默认为 84 GiB/3 = 28 GiB)USED: 存储集群中的已用空间由用户数据、内部开销或保留容量使用。
在上例中,100 MiB 是在考虑了复制因子后的总可用空间。实际可用大小为 33 MiB。
-
RAW USED :USED 以及分配给
db和walBlueStore 分区的空间的总和。 -
% RAW USED: RAW USED 的百分比 .使用这个数值以及
full ratio和near full ratio,以确保您没有消耗倒所有的存储集群容量。
输出的 POOLS 部分提供了池列表以及每个池的使用情况。本节的输出不会反映副本、克隆或快照的情况。例如,如果您存储 1 MB 的数据的对象,名义的使用量为 1 MB,但实际使用量可能为 3 MB 或更多。具体的实际使用量取决于副本的数量(例如: size = 3)、克隆和快照。
- POOL:池的名称。
- ID: 池 ID。
- STORED: 用户存储在池中的实际数据量。
- OBJECTS: 每个池存储的名义数量。
-
USED: 存储以 KB 为单位的数据数量,除非数字带有 M(megabyte)或 G(gigabytes)。它是
STORED大小 * 复制因素。 - %USED: 每个池使用的名义存储的百分比。
MAX AVAIL: 可以写入这个池的数据数量的估计值。它是在第一个 OSD 变为满之前可以使用的数据量。它考虑了 CRUSH map 中跨磁盘的项目分布数据,并使用第一个 OSD 来填充作为目标。
在上例中,
MAX AVAIL为 153.85,而不考虑复制因素,默认为三。如需 简单的复制池,请参阅知识库文章 ceph df AVAIL,以计算
MAX AVAIL的值。- QUOTA OBJECTS: 配额对象的数量。
- QUOTA BYTES: 配额对象中的字节数。
- USED COMPR: 为压缩数据分配的空间量,包括其压缩数据、分配、复制和擦除编码开销。
- UNDER COMPR: 通过压缩格式传输的数据量,以压缩形式存储有更多益处。
POOLS 部分中的数字是估算的。它们不包括副本数、快照或克隆的数量。因此,USED 和 %USED 数值的总和可能会与输出的 GLOBAL 部分中的 RAW USED 和 %RAW USED 不同。
MAX AVAIL 值是所用的复制或纠删代码的一个复杂功能,CRUSH 规则将存储映射到设备、这些设备的使用以及配置的 mon_osd_full_ratio。
3.2.7. 了解 OSD 使用统计
使用 ceph osd df 命令查看 OSD 使用率统计。
- ID: OSD 的名称。
- CLASS: OSD 使用的设备类型。
- WEIGHT: CRUSH 映射中的 OSD 权重。
- REWEIGHT: 默认的重新加权值。
- SIZE: OSD 的整体存储容量。
- USE: OSD 容量。
- DATA: 用户数据使用的 OSD 容量量。
-
OMAP: 用于存储对象映射(
omap)数据(rocksdb中存储的键值对)的bluefs存储的估算值。 -
META: 分配的
bluefs空间或在bluestore_bluefs_min参数中设置的值(取决于哪个值更大),对于内部元数据,它的值是在bluefs中分配的总空间减去预计的omap数据大小。 - AVAIL: OSD 上可用的空间量。
- %USE: OSD 使用的存储百分比
- VAR: 高于或低于平均利用率的差异。
- PGS: OSD 中的置放组数量。
- MIN/MAX VAR: 所有 OSD 的最小和最大变化。
其它资源
- 详情请参阅 Ceph 如何计算数据使用量。
- 详情请参阅 Understanding the OSD usage stats。
- 详情请查看 Red Hat Ceph Storage Storage 策略指南中的 CRUSH Weights。
3.2.8. 检查 Red Hat Ceph Storage 集群状态
您可以从命令行界面查看 Red Hat Ceph Storage 集群的状态。status 子命令或 -s 参数将显示存储集群的当前状态。
先决条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
- 节点的根级别访问权限。
流程
要检查存储集群的状态,请执行以下操作:
ceph status
[root@mon ~]# ceph statusCopy to Clipboard Copied! Toggle word wrap Toggle overflow 或者:
ceph -s
[root@mon ~]# ceph -sCopy to Clipboard Copied! Toggle word wrap Toggle overflow 在互动模式中,键入
status并按 Enter :ceph> status
[root@mon ~]# ceph> statusCopy to Clipboard Copied! Toggle word wrap Toggle overflow 例如,一个由一个 monitor 组成的 tiny Ceph 集群,两个 OSD 可以打印以下内容:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
3.2.9. 检查 Ceph Monitor 状态
如果存储集群有多个 Ceph Monitor,这是生产环境 Red Hat Ceph Storage 集群的要求,然后在启动存储集群后检查 Ceph monitor 仲裁状态,然后再执行任何读取或写入数据。
当多个 monitor 正在运行时,必须存在仲裁。
定期检查 Ceph Monitor 状态,以确保它们正在运行。如果 Ceph Monitor 存在问题,这可以防止存储集群的状态存在协议,则故障可能会阻止 Ceph 客户端读取和写入数据。
前提条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
- 节点的根级别访问权限。
流程
要显示 monitor map,请执行以下操作:
ceph mon stat
[root@mon ~]# ceph mon statCopy to Clipboard Copied! Toggle word wrap Toggle overflow 或者
ceph mon dump
[root@mon ~]# ceph mon dumpCopy to Clipboard Copied! Toggle word wrap Toggle overflow 要检查存储集群的仲裁状态,请执行以下操作:
ceph quorum_status -f json-pretty
[root@mon ~]# ceph quorum_status -f json-prettyCopy to Clipboard Copied! Toggle word wrap Toggle overflow Ceph 将返回仲裁状态。由三个监控器组成的 Red Hat Ceph Storage 集群可能会返回以下内容:
Example
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
3.2.10. 使用 Ceph 管理 socket
使用管理套接字可以通过 UNIX 套接字文件直接与给定守护进程交互。例如,这个套接字可以:
- 在运行时列出 Ceph 配置
-
在运行时直接设置配置值,而不依赖 Monitor。当 Monitor
停机时,这非常有用。 - 转储历史操作
- 转储操作优先级队列状态
- 在不重启的情况下转储操作
- 转储性能计数器
另外,在对 monitor 或 OSD 相关的问题进行故障排除时,使用 socket 很有用。
管理套接字仅在守护进程正在运行时才可用。当您正确关闭守护进程时,管理套接字会被删除。但是,如果守护进程意外终止,管理套接字可能仍然会被保留。
无论如何,如果守护进程没有运行,在尝试使用管理套接字时会返回以下错误:
Error 111: Connection Refused
Error 111: Connection Refused前提条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
- 节点的根级别访问权限。
流程
使用套接字:
语法
ceph daemon TYPE.ID COMMAND
[root@mon ~]# ceph daemon TYPE.ID COMMANDCopy to Clipboard Copied! Toggle word wrap Toggle overflow 替换:
-
使用 Ceph 守护进程类型
TYPE(mon、osd、mds)。 -
带有守护进程
ID的 ID 带有要运行的命令的
COMMAND。使用help列出给定守护进程的可用命令。Example
要查看名为
mon.0的 Ceph monitor 的 monitor 状态:ceph daemon mon.0 mon_status
[root@mon ~]# ceph daemon mon.0 mon_statusCopy to Clipboard Copied! Toggle word wrap Toggle overflow
-
使用 Ceph 守护进程类型
或者,使用其套接字文件指定 Ceph 守护进程:
ceph daemon /var/run/ceph/SOCKET_FILE COMMAND
ceph daemon /var/run/ceph/SOCKET_FILE COMMANDCopy to Clipboard Copied! Toggle word wrap Toggle overflow 查看名为
osd.2的 Ceph OSD 的状态:ceph daemon /var/run/ceph/ceph-osd.2.asok status
[root@mon ~]# ceph daemon /var/run/ceph/ceph-osd.2.asok statusCopy to Clipboard Copied! Toggle word wrap Toggle overflow 列出 Ceph 进程的所有套接字文件:
ls /var/run/ceph
[root@mon ~]# ls /var/run/cephCopy to Clipboard Copied! Toggle word wrap Toggle overflow
其它资源
- 如需更多信息,请参阅 Red Hat Ceph Storage 故障排除指南。
3.2.11. 了解 Ceph OSD 状态
OSD 的状态在集群中是,位于,或从集群 之外。它是 up 和 running、up up 或 down。如果 OSD 为 up,它可以 位于 存储集群中,其中可以读取和写入数据,或者存储集群 之外。如果 集群中有 它,并且最近从集群中 移出,Ceph 会将放置组迁移到其他 OSD。如果 OSD 超出 集群,CRUSH 不会将 PG 分配给 OSD。如果 OSD 为 down,它也应为 out。
如果 OSD 为 down 和 in,则代表有一个问题,集群也不会处于健康状态。

如果执行诸如 ceph health, ceph -s 或 ceph -w 等命令,您可能会注意到集群并不总是回显 HEALTH OK。不要 panic。对于 OSD,在几个预期情况下,集群应该不会回显 HEALTH OK :
- 还没有启动集群,它不会响应。
- 您刚启动或重启集群,但还没有就绪,因为 PG 已创建,并且 OSD 在 peering 过程中。
- 您刚添加或删除 OSD。
- 您刚刚修改 cluster map。
监控 OSD 的一个重要方面是,确保集群在启动和运行,所有 in 集群中的 OSD 都为 up 且在运行。
要查看所有 OSD 是否在运行,请执行:
ceph osd stat
[root@mon ~]# ceph osd stat或者
ceph osd dump
[root@mon ~]# ceph osd dump
结果应该提供了映射的 epoch, eNNNN, OSD 的总数, x, 多少 y 为e up,多少 z, 为 in:
eNNNN: x osds: y up, z in
eNNNN: x osds: y up, z in
如果 in 集群中的 OSD 数量超过 up 的 OSD 数量。执行以下命令来识别未运行的 ceph-osd 守护进程:
ceph osd tree
[root@mon ~]# ceph osd treeExample
通过设计良好的 CRUSH 层次结构搜索功能可以帮助您更加快速地通过确定物理位置对存储集群进行故障排除。
如果 OSD 为 down,请连接到 节点并启动它。您可以使用红帽存储控制台重启 OSD 节点,或者您可以使用命令行。
Example
systemctl start ceph-osd@OSD_ID
[root@mon ~]# systemctl start ceph-osd@OSD_ID3.2.12. 其它资源
3.3. Ceph 存储集群的低级别监控
作为存储管理员,您可以从低级角度监控 Red Hat Ceph Storage 集群的健康状态。低级监控通常涉及确保 Ceph OSD 正确对等。当发生对等错误时,放置组将处于降级状态。这种降级状态可能是许多不同的事情,如硬件故障、挂起或崩溃的 Ceph 守护进程、网络延迟或完整的站点中断。
3.3.1. 先决条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
3.3.2. 监控放置组设置
当 CRUSH 将 PG 分配给 OSD 时,它会查看池的副本数量,并将 PG 分配到 OSD,使得 PG 的每个副本分配到不同的 OSD。例如,如果池需要三个放置组副本,则 CRUSH 可以分别分配给 osd.1、 osd.2 和 osd.3。CRUSH 实际上寻求伪随机放置,该放置将考虑您在 CRUSH 映射中设置的故障域,这样您很少可以看到分配给大型集群中最接近邻居 OSD 的 PG。我们引用应当包含特定放置组副本的 OSD 集合,作为 操作集合。在某些情况下,Acting Set 中的 OSD 为 down,否则无法在放置组中对对象进行服务请求。当出现这些情况时,不会出现 panic。常见示例包括:
- 添加或删除 OSD。然后,CRUSH 将 PG 重新分配给其他 OSD,从而更改操作集合的组成,并使用"回填"过程生成数据的迁移。
-
OSD
已停机,已经重启,现在正在恢复。 -
Acting Set 中的 OSD 为
down或 unable to service requests,另一个 OSD 暂时假定其职责。
Ceph 使用 Up Set 处理客户端请求,这是实际处理请求的 OSD 集合。在大多数情况下,Up Set 和 Acting Set 几乎是相同的。当它们不是时,这可能表示 Ceph 正在迁移数据,或者 OSD 正在恢复,或者存在问题,Ceph 通常会在这样的场景中以"stuck stale"消息来回显 HEALTH WARN 状态。
前提条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
- 节点的根级别访问权限。
流程
检索放置组列表:
ceph pg dump
[root@mon ~]# ceph pg dumpCopy to Clipboard Copied! Toggle word wrap Toggle overflow 查看在 Acting Set 或一个给定放置组的 Up Set 中哪些 OSD:
ceph pg map PG_NUM
[root@mon ~]# ceph pg map PG_NUMCopy to Clipboard Copied! Toggle word wrap Toggle overflow 结果应该告诉您 osdmap epoch、
eNNN、放置组号、PG_NUM、在 Up Setup[]中的 OSD,以及操作集合acting[]中的 OSD:ceph osdmap eNNN pg PG_NUM-> up [0,1,2] acting [0,1,2]
[root@mon ~]# ceph osdmap eNNN pg PG_NUM-> up [0,1,2] acting [0,1,2]Copy to Clipboard Copied! Toggle word wrap Toggle overflow 注意如果 Up Set 和 Acting Set 没有匹配,这可能代表集群重新平衡本身或集群中的潜在问题。
3.3.3. Ceph OSD 对等
在将数据写入放置组之前,它必须处于 active 状态,且应该处于 clean 状态。若要让 Ceph 确定放置组的当前状态,PG 的 Primary OSD(活跃集中的第一个 OSD)与二级和三级 OSD 为对等,以变为放置组的当前状态建立协议。假设 PG 具有 3 个副本的池。
3.3.4. 放置组状态
如果执行诸如 ceph health, ceph -s 或 ceph -w 等命令,您可能会注意到集群并不总是回显 HEALTH OK。检查 OSD 是否在运行后,您也应检查放置组状态。您应该可以预计,在与放置组对等相关的一些情况下,集群不会反映 HEALTH OK :
- 您刚刚创建了一个池,放置组还没有对等。
- 放置组正在恢复。
- 您刚刚向集群添加一个 OSD 或从集群中移除一个 OSD。
- 您刚修改了 CRUSH map,并且已迁移了放置组。
- 在放置组的不同副本中,数据不一致。
- Ceph 清理放置组的副本。
- Ceph 没有足够存储容量来完成回填操作。
如果一个预期的情况导致 Ceph 反映了 HEALTH WARN,请不要紧张。在很多情况下,集群将自行恢复。在某些情况下,您可能需要采取措施。监控放置组的一个重要方面是确保在集群启动并运行所有放置组处于 active 状态,并且最好处于 clean 状态。
要查看所有放置组的状态,请执行:
ceph pg stat
[root@mon ~]# ceph pg stat
结果显示放置组映射版本 vNNNNNN、放置组总数 x 以及放置组数量 y 都处于特定的状态,如 active+clean :
vNNNNNN: x pgs: y active+clean; z bytes data, aa MB used, bb GB / cc GB avail
vNNNNNN: x pgs: y active+clean; z bytes data, aa MB used, bb GB / cc GB availCeph 通常会报告放置组的多个状态。
Snapshot Trimming PG States
当快照存在时,将报告两个额外的 PG 状态。
-
snaptrim:PG 目前被修剪 -
snaptrim_wait:PG 等待被修剪
输出示例:
244 active+clean+snaptrim_wait 32 active+clean+snaptrim
244 active+clean+snaptrim_wait
32 active+clean+snaptrim
除了放置组状态外,Ceph 还会回显所使用的数据量,aa(剩余存储容量),bb(放置组的总存储容量)。在一些情况下,这些数字非常重要:
-
您达到了
几乎全满比率或全满比率。 - 由于 CRUSH 配置中的一个错误,您的数据不会分散到集群中。
放置组 ID
放置组 ID 由池的号而不是名称组成,后跟一个句点 (.) 和放置组 ID(一个十六进制数字)。您可以从 ceph osd lspools 的输出中查看池编号及其名称。默认池名称为 data, metadata 和 rbd,分别与池号 0, 1 和 2 对应。完全限定的放置组 ID 的格式如下:
POOL_NUM.PG_ID
POOL_NUM.PG_ID输出示例:
0.1f
0.1f检索放置组列表:
ceph pg dump
[root@mon ~]# ceph pg dumpCopy to Clipboard Copied! Toggle word wrap Toggle overflow 以 JSON 格式格式化输出并将其保存到文件中:
ceph pg dump -o FILE_NAME --format=json
[root@mon ~]# ceph pg dump -o FILE_NAME --format=jsonCopy to Clipboard Copied! Toggle word wrap Toggle overflow 查询特定的放置组:
ceph pg POOL_NUM.PG_ID query
[root@mon ~]# ceph pg POOL_NUM.PG_ID queryCopy to Clipboard Copied! Toggle word wrap Toggle overflow JSON 格式的输出示例:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
其它资源
- 有关快照修剪设置的详情,请参阅 Red Hat Ceph Storage 4 配置指南中的 章节 Object Storage Daemon (OSD)配置选项。
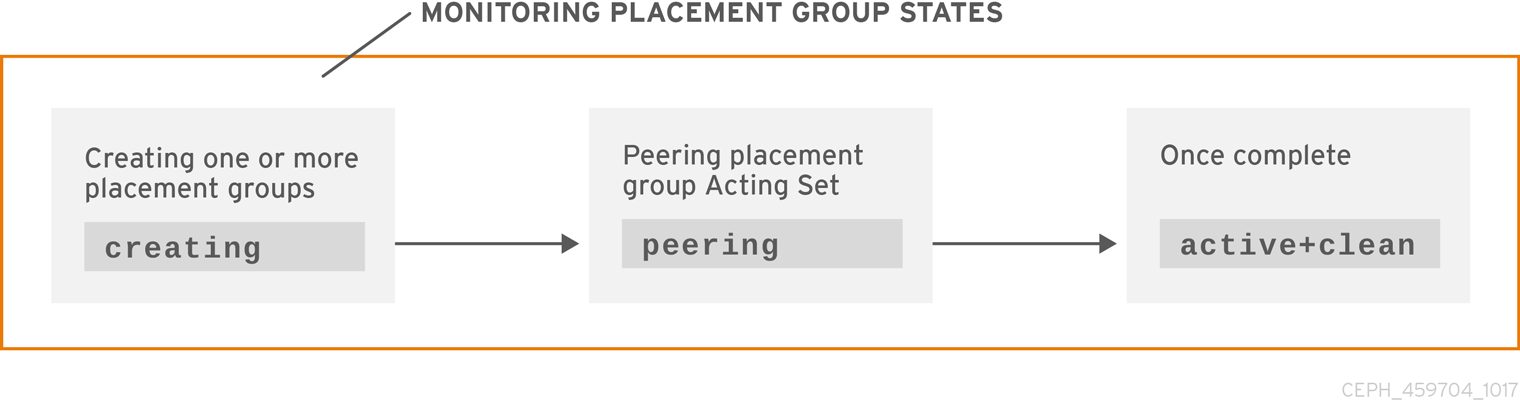
3.3.5. 放置组创建状态
在创建池时,将创建您指定的 PG 数量。Ceph 将在创建一个或多个放置组时回显 creating。创建之后,作为 PG Acting 设置一部分的 OSD 将会被对等点。对等点完成后,PG 状态应当为 active+clean,即 Ceph 客户端可以开始写入到 PG。
3.3.6. 放置组对等状态
当 Ceph 对等一个放置组时,Ceph 会将存储放置组副本的 OSD 变为与放置组中的对象和元数据的同意状态。当 Ceph 完成对等时,这意味着存储放置组的 OSD 同意该放置组的当前状态。但是,完成 peering 的进程并不表示每个副本都有最新的内容。
权威历史
Ceph 将不会确认对客户端的写操作,直到该工作集合的所有 OSD 都会保留这个写入操作。这种做法可确保,自上一次成功的对等操作,至少有一个成员具有每个确认的写操作的记录。
通过使用对每个已确认的写入操作的准确记录,Ceph 可以构建并分离 PG 的新权威历史记录。执行后,一组完全排序的操作(如果执行)会将使 OSD 的副本保持最新状态。
3.3.7. 放置组激活状态
Ceph 完成对等进程后,PG 可能会变为 active 状态。Active 状态表示放置组中的数据通常在主放置组中可用,而副本用于读取和写入操作。
3.3.8. 放置组清理状态
当放置组处于 clean 状态时,主 OSD 和副本 OSD 已成功对等,并且放置组没有预先复制。Ceph 复制 PG 中正确次数的所有对象。
3.3.9. 放置组降级状态
当客户端将对象写入 Primary OSD 时,OSD 负责将副本写入副本 OSD。在主 OSD 将对象写入存储后,PG 将会维持为 degraded 状态,直到主 OSD 收到来自副本 OSD 的 Ceph 已成功创建副本对象的确认。
PG 可以是 active+degraded 的原因是,OSD 可以处于 active 状态,尽管它还没有保存所有对象。如果 OSD 停机,Ceph 会将分配到 OSD 的每个 PG 标记为 degraded。当 OSD 重新上线时,OSD 必须再次对等。但是,如果客户端处于 active 状态,客户端仍然可以将新对象写入到一个降级的(degraded) PG。
如果 OSD 为 down 并且一直处于 degraded 状况,Ceph 可能会将 down OSD 标记为集群 out,并将 down OSD 的数据重新映射到另一个 OSD。在标记为 down 和标记为 out 之间的时间由 mon_osd_down_out_interval 控制。它被默认设置为 600 秒。
放置组也可以为 degraded,因为 Ceph 找不到一个或多个 Ceph 认为应该在放置组里的对象。虽然您无法读取或写入到未找到的对象,但您仍可以访问 degraded PG 中所有其他对象。
假设有 9 个 OSD,即副本池。如果 OSD 数量 9 停机,分配给 OSD 9 的 PG 会处于降级状态。如果 OSD 9 没有被恢复,它会退出集群,集群会重新平衡。在这种情况下,PG 被降级,然后恢复到 active 状态。
3.3.10. 放置组恢复状态
Ceph 设计为容错性,可以大规模地出现硬件和软件问题持续发展的问题。当 OSD 为 down 时,其内容可能落后于 PG 中其他副本的当前状态。当 OSD 变为 up,必须更新放置组的内容,以反映当前状态。在该时间段内,OSD 可能会处于 recovering 状态。
恢复并非始终正常,因为硬件故障可能会导致多个 OSD 的级联故障。例如,一个 rack 或 cabinet 的网络交换机可能会失败,这可能会导致大量主机机器的 OSD 不在集群的当前状态后。在错误解决后,每个 OSD 必须恢复。
Ceph 提供了多个设置,用于在新服务请求和恢复数据对象之间平衡资源争用,并将放置组恢复到当前状态。osd recovery delay start 设置允许 OSD 重新启动、重复操作,甚至在开始恢复过程前处理一些重播请求。osd recovery threads 设置限制恢复过程的线程数量,默认为一个线程。osd 恢复线程超时设置线程 超时,因为多个 OSD 可能会失败,重启和重新执行速度为 staggered 率。osd 恢复 max active 设置限制了 OSD 同时进入的恢复请求数,以防止 OSD 无法提供。osd recovery max chunk 设置限制了恢复的数据块的大小,以防止网络拥塞。
3.3.11. Back fill 状态
当新的 OSD 加入集群时,CRUSH 会将集群中的 OSD 重新分配给新添加的 OSD。强制新 OSD 接受重新分配的 PG,可立即对新 OSD 进行过度负载。使用放置组回填 OSD 使此过程在后台开始。回填完成后,新 OSD 会在请求就绪时开始提供请求。
在回填操作中,您可能会看到状态中的一个:* backfill_wait 表示回填操作处于待处理状态,但没有发生 * backfill 表示回填操作处于路上去 * backfill_too_full 表示请求回填操作,但可能会因为存储容量不足而无法完成。
当 PG 无法回填时,它可能被视为 不完整。
Ceph 提供了一些设置,用于管理与 PG 相关的负载高峰,特别是新 OSD。默认情况下,osd_max_backfills 将最大并发回填数量(来自或到一个 OSD)设置为 10。如果 OSD 接近全满比率,则 osd 回填比率 可让 OSD 拒绝回填请求,默认为 85%。如果 OSD 拒绝回填请求,osd backfill retry interval 可让 OSD 在 10 秒后重试请求。OSD 也可以设置 osd backfill scan min 和 osd backfill scan max,以管理扫描间隔(默认为 64 和 512)。
对于某些工作负载,完全避免常规恢复并使用回填会很有帮助。由于回填在后台发生,因此这允许 I/O 继续进行 OSD 中的对象。要强制回填而不是恢复,将 osd_min_pg_log_entries 设为 1,并将 osd_max_pg_log_en 则设为 2。当这个情况与您的工作负载相符,请联系您的红帽支持团队。
3.3.12. 更改恢复或回填操作的优先级
当某些放置组(PG)需要恢复和/或回填时,您可能会遇到一个情况,其中一些放置组包含比其他目的更重要的数据。使用 pg-recovery 或 pg-backfill 命令,确保具有较高优先级数据的 PG 先恢复或回填。
前提条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
- 节点的根级别访问权限。
流程
发出
pg-recovery或pg force-backfill命令,并使用较高优先级数据为 PG 指定优先级顺序:语法
ceph pg force-recovery PG1 [PG2] [PG3 ...] ceph pg force-backfill PG1 [PG2] [PG3 ...]
ceph pg force-recovery PG1 [PG2] [PG3 ...] ceph pg force-backfill PG1 [PG2] [PG3 ...]Copy to Clipboard Copied! Toggle word wrap Toggle overflow Example
ceph pg force-recovery group1 group2 ceph pg force-backfill group1 group2
[root@node]# ceph pg force-recovery group1 group2 [root@node]# ceph pg force-backfill group1 group2Copy to Clipboard Copied! Toggle word wrap Toggle overflow 此命令会导致 Red Hat Ceph Storage 在处理其他放置组(PG)之前首先对指定的放置组(PG)执行恢复或回填。发出 命令不会中断当前执行的回填或恢复操作。在当前运行的操作完成后,可以指定的 PG 尽快进行恢复或回填。
3.3.13. 在指定的放置组上更改或取消恢复或回填操作
如果您在存储集群中的特定放置组 (PG) 取消了一个高优先级的 force-recovery 或 force-backfill 操作,则这些 PG 的操作将恢复到默认的恢复或回填设置。
前提条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
- 节点的根级别访问权限。
流程
在指定的放置组上更改或取消恢复或回填操作:
语法
ceph pg cancel-force-recovery PG1 [PG2] [PG3 ...] ceph pg cancel-force-backfill PG1 [PG2] [PG3 ...]
ceph pg cancel-force-recovery PG1 [PG2] [PG3 ...] ceph pg cancel-force-backfill PG1 [PG2] [PG3 ...]Copy to Clipboard Copied! Toggle word wrap Toggle overflow Example
ceph pg cancel-force-recovery group1 group2 ceph pg cancel-force-backfill group1 group2
[root@node]# ceph pg cancel-force-recovery group1 group2 [root@node]# ceph pg cancel-force-backfill group1 group2Copy to Clipboard Copied! Toggle word wrap Toggle overflow 这会取消
force标记,并以默认顺序处理 PG。完成指定 PG 的恢复或回填操作后,处理顺序将恢复为默认值。
其它资源
- 有关 RADOS 中恢复和回填操作顺序的更多信息,请参阅 RADOS 中的 放置组恢复和回填的优先级。
3.3.14. 对池强制进行高优先级恢复或回填操作
如果池中的所有放置组都需要高优先级恢复或回填,请使用 force-recovery 或 force-backfill 选项来发起操作。
前提条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
- 节点的根级别访问权限。
流程
在指定池中所有 PG 上强制进行高优先级恢复或回填:
语法
ceph osd pool force-recovery POOL_NAME ceph osd pool force-backfill POOL_NAME
ceph osd pool force-recovery POOL_NAME ceph osd pool force-backfill POOL_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow Example
ceph osd pool force-recovery pool1 ceph osd pool force-backfill pool1
[root@node]# ceph osd pool force-recovery pool1 [root@node]# ceph osd pool force-backfill pool1Copy to Clipboard Copied! Toggle word wrap Toggle overflow 注意请谨慎使用
force-recovery和force-backfill命令。更改这些操作的优先级可能会破坏 Ceph 内部优先级计算的顺序。
3.3.15. 取消池高优先级恢复或回填操作
如果您取消了一个池中的所有放置组的高优先级的 force-recovery 或 force-backfill 操作,则该池中的 PG 的操作将恢复到默认的恢复或回填设置。
前提条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
- 节点的根级别访问权限。
流程
在指定池中所有 PG 上取消高优先级恢复或回填操作:
语法
ceph osd pool cancel-force-recovery POOL_NAME ceph osd pool cancel-force-backfill POOL_NAME
ceph osd pool cancel-force-recovery POOL_NAME ceph osd pool cancel-force-backfill POOL_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow Example
ceph osd pool cancel-force-recovery pool1 ceph osd pool cancel-force-backfill pool1
[root@node]# ceph osd pool cancel-force-recovery pool1 [root@node]# ceph osd pool cancel-force-backfill pool1Copy to Clipboard Copied! Toggle word wrap Toggle overflow
3.3.16. 为池重新排序恢复或回填操作的优先级
如果您有多个当前使用相同的底层 OSD 的池,并且部分池包含高优先级数据,您可以重新排列操作执行的顺序。使用 recovery_priority 选项,为具有更高优先级数据的池分配更高的优先级值。这些池将在优先级较低值的池之前执行,或者设置为默认优先级的池。
前提条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
- 节点的根级别访问权限。
流程
重新排列池的恢复/回填优先级:
语法
ceph osd pool set POOL_NAME recovery_priority VALUE
ceph osd pool set POOL_NAME recovery_priority VALUECopy to Clipboard Copied! Toggle word wrap Toggle overflow Example
ceph osd pool set pool1 recovery_priority 10
ceph osd pool set pool1 recovery_priority 10Copy to Clipboard Copied! Toggle word wrap Toggle overflow VALUE 设置优先级顺序。例如,如果您有 10 个池,优先级值为 10 的池首先会处理,然后处理优先级为 9 的池,以此类推。如果只有某些池具有高优先级,您可以仅为这些池设置优先级值。没有设置优先级的池按默认顺序处理。
3.3.17. RADOS 中的放置组恢复的优先级
本节介绍了 RADOS 中 PG 恢复和回填的相对优先级值。首先处理更高的值。inactive PG 接收高于活跃或降级的 PG 的优先级值。
| 操作 | 值 | 描述 |
|---|---|---|
| OSD_RECOVERY_PRIORITY_MIN | 0 | 最小恢复值 |
| OSD_BACKFILL_PRIORITY_BASE | 100 | 用于 MBackfillReserve 的基础回填优先级 |
| OSD_BACKFILL_DEGRADED_PRIORITY_BASE | 140 | 用于 MBackfillReserve 的基础回填优先级(降级 PG) |
| OSD_RECOVERY_PRIORITY_BASE | 180 | MBackfillReserve 的基本恢复优先级 |
| OSD_BACKFILL_INACTIVE_PRIORITY_BASE | 220 | 用于 MBackfillReserve 的基础回填优先级(在主动 PG 中) |
| OSD_RECOVERY_INACTIVE_PRIORITY_BASE | 220 | MRecoveryReserve 的基本恢复优先级(在主动 PG 中) |
| OSD_RECOVERY_PRIORITY_MAX | 253 | max 手动/自动为 MBackfillReserve 设置恢复优先级 |
| OSD_BACKFILL_PRIORITY_FORCED | 254 | 手动强制输入的回填优先级(以 MBackfillReserve) |
| OSD_RECOVERY_PRIORITY_FORCED | 255 | 手动强制时 MRecoveryReserve 恢复优先级 |
| OSD_DELETE_PRIORITY_NORMAL | 179 | 当 OSD 未满时,PG 的优先级删除 |
| OSD_DELETE_PRIORITY_FULLISH | 219 | 在 OSD 接近满时,PG 的优先级删除 |
| OSD_DELETE_PRIORITY_FULL | 255 | OSD 满时要删除的优先级 |
3.3.18. PG 重新映射状态
当决定服务设置放置组更改时,数据会从旧操作集迁移到新行为集。这可能需要经过一定时间后,新的 Primary OSD 才会处理服务请求。因此,可能需要旧的主系统继续服务请求,直到放置组迁移完成为止。数据迁移完成后,映射将使用新操作集合的 Primary OSD。
3.3.19. 放置组已过时状态
虽然 Ceph 使用心跳来确保主机和守护进程正在运行,ceph-osd 守护进程也会在没有及时报告统计数据的情况下变为 stuck 状态。例如,临时网络故障。默认情况下,OSD 守护进程每半秒钟报告其放置组、启动和失败统计,即 0.5,它比心跳阈值更频繁。如果放置组所采取集合的 Primary OSD 报告监控器失败,或者其他 OSD 报告了 Primary OSD down,则监视器会将 PG 标记为 stale。
当您启动存储集群时,通常会看到 stale 状态,直到对等进程完成为止。在存储集群运行一段时间后,如果放置组处于 stale 状态则代表这些放置组的主 OSD 的状态为 down 或者没有向监控器报告放置组统计信息。
3.3.20. 放置组错误替换状态
当 PG 临时映射到一个 OSD 时会有一些临时回填情况。当这个临时状态已不存在时,PG 可能仍然位于临时位置,而没有位于正确的位置。在这种情况下,它们被认为是 misplaced。这是因为实际上存在正确的额外副本数量,但一个或多个副本位于错误的地方。
例如,有 3 个 OSD:0、1,2 和所有 PG 映射到这三个。如果您添加了另一个 OSD(OSD 3),一些 PG 现在将映射到 OSD 3,而不是另一个 OSD 3。但是,在 OSD 3 回填之前,PG 有一个临时映射,允许它继续从旧映射提供 I/O。在此期间,PG 为 misplaced,因为它有一个临时映射,但不是 degraded,因为存在 3 个副本。
示例
pg 1.5: up=acting: [0,1,2] ADD_OSD_3 pg 1.5: up: [0,3,1] acting: [0,1,2]
pg 1.5: up=acting: [0,1,2]
ADD_OSD_3
pg 1.5: up: [0,3,1] acting: [0,1,2]
[0,1,2] 是一个临时映射,因此 up 与 acting 并不完全相同。PG 为 misplaced 而不是 degraded,因为 [0,1,2] 仍然是三个副本。
示例
pg 1.5: up=acting: [0,3,1]
pg 1.5: up=acting: [0,3,1]OSD 3 现在被回填,临时映射已被删除,而不是降级。
3.3.21. 放置组不完整状态
当内容不完整且对等失败(没有足够完整的 OSD 来执行恢复),PG 就会变为 incomplete 状态。
假设 OSD 1、2 和 3 是活跃的 OSD 集,它切换到 OSD 1、4 和 3,然后 osd.1 将请求一个临时活跃集包括 OSD 1、2 和 3,同时对 OSD 4 进行回填。在此期间,如果 OSD 1、2 和 3 都停机,则 osd.4 将是唯一没有完全回填所有数据的 OSD。此时,PG 会变为 incomplete,表明没有足够完整的 OSD 来执行恢复。
另外,如果没有涉及 osd.4,并且在 OSD 1、2 和 3 停机时,如果 osd.4 没有被涉及到,并且当 OSD 1、2 和 3 停机时,PG 就有可能变为 stale,这代表 mons 没有在这个 PG 上听到任何信息,因为执行集发生了变化。没有 OSD 以通知新的 OSD 的原因。
3.3.22. 找出卡住的 PG
如前所述,放置组不一定存在问题,因为它的状态不是 活动+clean。通常,当放置组卡时,Ceph 自助修复的能力可能无法工作。卡住状态包括:
- Unclean: 放置组包含不会复制所需次数的对象。它们应该正在进行恢复。
-
Inactive :放置组无法处理读取或写入,因为它们正在等待具有最新数据的 OSD 返回到
up状态。 -
Stale:放置组处于未知状态,因为托管它们的 OSD 在一段时间内未报告到监控集群,并可使用
mon osd report timeout配置。
先决条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
- 节点的根级别访问权限。
流程
要识别卡的放置组,请执行以下操作:
ceph pg dump_stuck {inactive|unclean|stale|undersized|degraded [inactive|unclean|stale|undersized|degraded...]} {<int>}ceph pg dump_stuck {inactive|unclean|stale|undersized|degraded [inactive|unclean|stale|undersized|degraded...]} {<int>}Copy to Clipboard Copied! Toggle word wrap Toggle overflow
3.3.23. 查找对象的位置
Ceph 客户端检索最新的集群映射,并且 CRUSH 算法计算如何将对象映射到放置组,然后计算如何动态将 PG 分配给 OSD。
先决条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
- 节点的根级别访问权限。
流程
要查找对象位置,您需要对象名称和池名称:
ceph osd map POOL_NAME OBJECT_NAME
ceph osd map POOL_NAME OBJECT_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow
第 4 章 覆盖 Ceph 行为
作为存储管理员,您需要了解如何对 Red Hat Ceph Storage 集群使用覆盖,以便在运行时更改 Ceph 选项。
4.1. 先决条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
4.2. 设置和取消设置 Ceph 覆盖选项
您可以设置和取消设置 Ceph 选项来覆盖 Ceph 的默认行为。
先决条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
- 节点的根级别访问权限。
流程
要覆盖 Ceph 的默认行为,请使用
ceph osd set命令和您要覆盖的行为:ceph osd set FLAG
ceph osd set FLAGCopy to Clipboard Copied! Toggle word wrap Toggle overflow 设置行为后,
ceph health将反映您为集群设定的覆盖。要覆盖 Ceph 的默认行为,请使用
ceph osd unset命令以及您想要的覆盖。ceph osd unset FLAG
ceph osd unset FLAGCopy to Clipboard Copied! Toggle word wrap Toggle overflow
| 标记 | 描述 |
|---|---|
|
|
防止 OSD 被视为在集群 |
|
|
防止 OSD 被视在集群 |
|
|
防止 OSD 被视为 |
|
|
防止 OSD 被视为 |
|
|
集群已达到其 |
|
|
Ceph 将会停止处理读和写操作,但并不会影响 OSD |
|
| Ceph 将阻止新的回填操作。 |
|
| Ceph 将阻止新的重新平衡操作。 |
|
| Ceph 将阻止新的恢复操作。 |
|
| Ceph 将阻止新的清理操作。 |
|
| Ceph 将阻止新的深度清理操作。 |
|
| Ceph 将禁用正在查找 cold/dirty 对象以清空和驱除的进程。 |
4.3. Ceph 覆盖用例
-
noin:常见与noout一起使用来解决流化 OSD 的问题。 -
noout:如果超过了mon osd report timeout,并且 OSD 没有报告给 monitor,OSD 将被标记为out。如果发生这种情况错误,可以设置noout以防止在对问题进行故障排除时阻止 OSD 标记为out。 -
noup:常见与nodown一起使用来解决流化 OSD 的问题。 -
nodown: 网络问题可能会中断 Ceph 的 'heartbeat' 进程,而 OSD 可能会为up,但仍标记为 down。您可以设置nodown来防止 OSD 在对问题进行故障排除时处于标记状态。 full:如果集群到达其full_ratio,您可以预先将集群设置为full并扩展容量。注意将集群设置为
full将阻止写操作。-
pause:如果需要在不读取和写入数据的情况下对正在运行的 Ceph 集群进行故障排除,您可以将集群设置为pause以防止客户端操作。 -
nobackfill:如果需要临时将 OSD 或节点设置为down(如升级守护进程),您可以设置nobackfill,以便 Ceph 在 OSD 为down时不会回填。 -
norecover:如果您需要替换 OSD 磁盘,并且在热交换磁盘时您不希望 PG 恢复到另一个 OSD,则可以设置norecover。这可以防止其他 OSD 将新的 PG 复制到其他 OSD。 -
noscrub和nodeep-scrubb:如果您希望防止刮除发生(例如,为了在高负载操作,如恢复、回填和重新平衡期间减少开销),您可以设置noscrub和/或nodeep-scrub以防止集群刮除 OSD。 -
notieragent:如果要阻止层代理进程查找冷对象,以刷新到后备存储层,则可以设置notieragent。
第 5 章 Ceph 用户管理
作为存储管理员,您可以通过为 Red Hat Ceph Storage 集群中的对象提供身份验证、密钥环管理和访问控制来管理 Ceph 用户基础。
5.1. 先决条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
- 访问 Ceph monitor 或 Ceph 客户端节点。
5.2. Ceph 用户管理背景
当 Ceph 在启用身份验证和授权运行时,您必须指定包含指定用户 secret 密钥的用户名和密钥环。如果未指定用户名,Ceph 将使用 client.admin 管理用户作为默认用户名。如果未指定密钥环,Ceph 将通过使用 Ceph 配置中的 密钥环 设置来查找密钥环。例如,如果您在不指定用户或密钥环的情况下执行 ceph health 命令:
ceph health
# ceph healthCeph 会解释如下命令:
ceph -n client.admin --keyring=/etc/ceph/ceph.client.admin.keyring health
# ceph -n client.admin --keyring=/etc/ceph/ceph.client.admin.keyring health
或者,您可以使用 CEPH_ARGS 环境变量以避免重新输入用户名和 secret。
无论 Ceph 客户端的类型(例如块设备、对象存储、文件系统、原生 API 或 Ceph 命令行),Ceph 都会将所有数据在池中作为对象保存。Ceph 用户必须有权访问池才能读取和写入数据。此外,管理 Ceph 用户必须具有执行 Ceph 管理命令的权限。
以下概念可帮助您理解 Ceph 用户管理。
存储集群用户
Red Hat Ceph Storage 集群的用户是个人或一个应用程序。通过创建用户,您可以控制谁可以访问存储集群、池以及这些池中的数据。
Ceph 具有用户类型的概念。对于用户管理而言,类型将始终是 客户端。Ceph 使用带有句点(.)作为分隔符的名称来标识用户,它由用户类型和用户 ID 组成。例如,TYPE.ID、client.admin 或 client.user1。用户需要键入的原因是 Ceph 监控器和 OSD 也使用 Cephx 协议,但它们并不是客户端。区分用户类型有助于区分客户端用户和其他用户精简访问控制、用户监控和可追溯性。
有时,Ceph 的用户类型似乎比较混乱,因为 Ceph 命令行允许您根据命令行使用而指定具有或没有类型的用户。如果指定了 --user 或 --id,可以省略该类型。因此,输入 user1 可以代表 client.user1。如果指定 --name 或 -n,您必须指定类型和名称,如 client.user1。作为最佳做法,红帽建议尽可能使用类型和名称。
Red Hat Ceph Storage 集群用户与 Ceph Object Gateway 用户不同。对象网关使用 Red Hat Ceph Storage 集群用户在网关守护进程和存储集群间进行通信,但网关具有自己的用户管理功能。
语法
DAEMON_TYPE 'allow CAPABILITY' [DAEMON_TYPE 'allow CAPABILITY']
DAEMON_TYPE 'allow CAPABILITY' [DAEMON_TYPE 'allow CAPABILITY']monitor Caps: Monitor 功能包括
r,w,x,allow profile CAP, 和profile rbd。示例
mon 'allow rwx` mon 'allow profile osd'
mon 'allow rwx` mon 'allow profile osd'Copy to Clipboard Copied! Toggle word wrap Toggle overflow OSD Caps: OSD 功能包括
r,w,x,class-read,class-write,profile osd,profile rbd,profile rbd-read-only。另外,OSD 功能还允许池和命名空间设置。osd 'allow CAPABILITY' [pool=POOL_NAME] [namespace=NAMESPACE_NAME]
osd 'allow CAPABILITY' [pool=POOL_NAME] [namespace=NAMESPACE_NAME]Copy to Clipboard Copied! Toggle word wrap Toggle overflow
Ceph 对象网关守护进程 (radosgw) 是 Ceph 存储集群的客户端,因此不表示 Ceph 存储集群守护进程类型。
以下条目描述了每个功能。
|
| 守护进程的以前访问设置。 |
|
| 授予用户读取访问权限。需要 monitor 来检索 CRUSH map。 |
|
| 授予用户对对象的写入访问权限。 |
|
|
为用户提供调用类方法(即读写)的能力,并在 monitor 上执行 |
|
|
授予用户调用类读取方法的能力。 |
|
|
授予用户调用类写入方法的能力。 |
|
| 授予用户对特定守护进程或池的读取、写入和执行权限,以及执行 admin 命令的能力。 |
|
| 授予用户权限以 OSD 连接到其他 OSD 或 monitor。在 OSD 上延迟,使 OSD 能够处理复制心跳流量和状态报告。 |
|
| 授予用户引导 OSD 的权限,以便在引导 OSD 时具有添加密钥的权限。 |
|
| 授予用户对 Ceph 块设备的读写访问权限。 |
|
| 授予用户对 Ceph 块设备的只读访问权限。 |
pool
池为 Ceph 客户端定义存储策略,并充当该策略的逻辑分区。
在 Ceph 部署中,创建池来支持不同类型的用例是很常见的。例如,云卷或镜像、对象存储、热存储、冷存储等等。将 Ceph 部署为 OpenStack 的后端时,典型的部署会具有卷、镜像、备份和虚拟机以及诸如 client.glance、client.cinder 等用户的池。
命名空间
池中的对象可以关联到池中命名空间的逻辑对象组。用户对池的访问可以关联到命名空间,以便用户读取和写入仅在命名空间内进行。写入到池中的一个命名空间的对象只能由有权访问该命名空间的用户访问。
目前,命名空间仅适用于在 librados 之上编写的应用。块设备和对象存储等 Ceph 客户端目前不支持此功能。
命名空间的比率是池可以根据用例来计算聚合数据的计算方法,因为每个池创建了一组映射到 OSD 的放置组。如果多个池使用相同的 CRUSH 层次结构和规则集,OSD 性能可能会随着负载增加而降级。
例如,一个池对于每个 OSD 应有大约 100 个 PG。因此,有 1000 个 OSD 的集群对于一个池有 100,000 个 PG。映射到同一 CRUSH 层次结构的每个池将在 exemplary 集群中创建另一个 100,000 个放置组。相反,将对象写入命名空间只是将命名空间与对象名称关联的对象名称与单独池的计算开销相关联。您可以使用命名空间,而不是为用户或一组用户创建单独的池。
目前仅在使用 librados 时才可用。
其它资源
- 有关配置身份验证的详细信息,请参阅 Red Hat Ceph Storage 配置指南。
5.3. 管理 Ceph 用户
作为存储管理员,您可以通过创建、修改、删除和导入用户来管理 Ceph 用户。Ceph 客户端用户可以是个人或应用程序,它们使用 Ceph 客户端与红帽 Ceph Storage 集群守护进程交互。
5.3.1. 先决条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
- 访问 Ceph monitor 或 Ceph 客户端节点。
5.3.2. 列出 Ceph 用户
您可以使用命令行界面列出存储集群中的用户。
先决条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
- 节点的根级别访问权限。
流程
要列出存储集群中的用户,请执行以下操作:
ceph auth list
[root@mon ~]# ceph auth listCopy to Clipboard Copied! Toggle word wrap Toggle overflow Ceph 将列出存储群集中的所有用户。例如,在双节点 exemplary 存储集群中,
ceph auth 列表将输出类似如下的内容:Example
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
用户使用 TYPE.ID 的形式代表,例如 osd.0 代表一个用户,类型为 osd,ID 是 0;client.admin 是一个用户,类型是 client,ID 为 admin,这是默认的 client.admin 用户。另请注意,每个条目都有一个 key: VALUE 条目,以及一个或多个 caps: 条目。
您可以将 -o FILE_NAME 选项与 ceph auth list 一起使用,以将输出保存到文件中。
5.3.3. 显示 Ceph 用户信息
您可以使用命令行界面显示 Ceph 的用户信息。
先决条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
- 节点的根级别访问权限。
流程
要检索特定用户、密钥和功能,请执行以下操作:
ceph auth export TYPE.ID
ceph auth export TYPE.IDCopy to Clipboard Copied! Toggle word wrap Toggle overflow Example
ceph auth get client.admin
[root@mon ~]# ceph auth get client.adminCopy to Clipboard Copied! Toggle word wrap Toggle overflow 您还可以将
-o FILE_NAME选项与ceph auth get搭配使用,以将输出保存到文件中。开发人员也可以执行以下操作:ceph auth export TYPE.ID
ceph auth export TYPE.IDCopy to Clipboard Copied! Toggle word wrap Toggle overflow Example
ceph auth export client.admin
[root@mon ~]# ceph auth export client.adminCopy to Clipboard Copied! Toggle word wrap Toggle overflow
auth export 命令与 auth get 相同,但也打印出内部 auid,但与最终用户无关。
5.3.4. 添加新的 Ceph 用户
添加用户的用户名,即 TYPE.ID、一个 secret 密钥和您用来创建用户的命令中包含的任何功能。
用户密钥可让用户与 Ceph 存储集群进行身份验证。用户的能力授权用户在 Ceph 监视器(mon)、Ceph OSD(osd)或 Ceph 元数据服务器(mds)上读取、写入或执行。
添加用户有几种方法:
-
ceph auth add:此命令是添加用户的规范方式。它将创建用户,并生成一个密钥并添加任何指定的功能。 -
ceph auth get-or-create:此命令通常是创建用户的最方便的方法,因为它会返回一个密钥文件,带有用户名(在括号中)和密钥。如果用户已存在,这个命令会以 keyfile 格式返回用户名和密钥。您可以使用-o FILE_NAME选项将输出保存到文件中。 -
Ceph auth get-or-create-key:这个命令是创建用户并仅返回用户密钥的便捷方式。这对只需要密钥的客户端(如libvirt)非常有用。如果用户已存在,这个命令只返回密钥。您可以使用-o FILE_NAME选项将输出保存到文件中。
在创建客户端用户时,您可以创建没有功能的用户。对于一个没有带有任何能力的用户,除进行身份验证之外没有任何用处,因为客户端无法从监控器检索 cluster map。但是,如果您想要以后使用 ceph auth caps 命令添加新的能力,则可以先创建一个没有权限的用户。
典型的用户在 Ceph OSD 上至少具有 Ceph 监视器的读取功能,以及 Ceph OSD 上的读写功能。另外,用户的 OSD 权限通常仅限于访问特定池。
ceph auth add client.john mon 'allow r' osd 'allow rw pool=liverpool' ceph auth get-or-create client.paul mon 'allow r' osd 'allow rw pool=liverpool' ceph auth get-or-create client.george mon 'allow r' osd 'allow rw pool=liverpool' -o george.keyring ceph auth get-or-create-key client.ringo mon 'allow r' osd 'allow rw pool=liverpool' -o ringo.key
[root@mon ~]# ceph auth add client.john mon 'allow r' osd 'allow rw pool=liverpool'
[root@mon ~]# ceph auth get-or-create client.paul mon 'allow r' osd 'allow rw pool=liverpool'
[root@mon ~]# ceph auth get-or-create client.george mon 'allow r' osd 'allow rw pool=liverpool' -o george.keyring
[root@mon ~]# ceph auth get-or-create-key client.ringo mon 'allow r' osd 'allow rw pool=liverpool' -o ringo.key如果您为用户提供 OSD 的功能,但没有限制特定池的访问权限,则该用户将能够访问集群中的所有池!
5.3.5. 修改 Ceph 用户
ceph auth caps 命令允许您指定用户并更改用户的能力。设置新功能将覆盖当前功能。因此,首先查看当前功能,并在您添加新功能时包括它们。
前提条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
- 节点的根级别访问权限。
流程
查看当前功能:
ceph auth get USERTYPE.USERID
ceph auth get USERTYPE.USERIDCopy to Clipboard Copied! Toggle word wrap Toggle overflow Example
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 要添加能力,请使用表单:
ceph auth caps USERTYPE.USERID DAEMON 'allow [r|w|x|*|...] [pool=POOL_NAME] [namespace=NAMESPACE_NAME]'
ceph auth caps USERTYPE.USERID DAEMON 'allow [r|w|x|*|...] [pool=POOL_NAME] [namespace=NAMESPACE_NAME]'Copy to Clipboard Copied! Toggle word wrap Toggle overflow Example
ceph auth caps client.john mon 'allow r' osd 'allow rwx pool=liverpool'
[root@mon ~]# ceph auth caps client.john mon 'allow r' osd 'allow rwx pool=liverpool'Copy to Clipboard Copied! Toggle word wrap Toggle overflow 在示例中,添加对 OSD 执行功能。
验证添加的功能:
ceph auth get _USERTYPE_._USERID_
ceph auth get _USERTYPE_._USERID_Copy to Clipboard Copied! Toggle word wrap Toggle overflow Example
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 在示例中,可以看到对 OSD 执行功能。
要删除功能,请设置您要删除的所有功能。
ceph auth caps USERTYPE.USERID DAEMON 'allow [r|w|x|*|...] [pool=POOL_NAME] [namespace=NAMESPACE_NAME]'
ceph auth caps USERTYPE.USERID DAEMON 'allow [r|w|x|*|...] [pool=POOL_NAME] [namespace=NAMESPACE_NAME]'Copy to Clipboard Copied! Toggle word wrap Toggle overflow Example
ceph auth caps client.john mon 'allow r' osd 'allow rw pool=liverpool'
[root@mon ~]# ceph auth caps client.john mon 'allow r' osd 'allow rw pool=liverpool'Copy to Clipboard Copied! Toggle word wrap Toggle overflow 在示例中,不包含在 OSD 上执行功能,因此会被删除。
验证删除的功能:
ceph auth get _USERTYPE_._USERID_
ceph auth get _USERTYPE_._USERID_Copy to Clipboard Copied! Toggle word wrap Toggle overflow Example
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 在示例中,不再列出对 OSD 执行功能。
其它资源
- 如需更多与 功能相关的信息,请参阅授权 功能。
5.3.6. 删除 Ceph 用户
您可以使用命令行界面从 Ceph 存储集群中删除用户。
先决条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
- 节点的根级别访问权限。
流程
要删除用户,请使用
ceph auth del:ceph auth del TYPE.ID
[root@mon ~]# ceph auth del TYPE.IDCopy to Clipboard Copied! Toggle word wrap Toggle overflow 其中
TYPE是客户端、osd、mon或mds之一,而ID是守护进程的用户名或 ID。
5.3.7. 输出 Ceph 用户密钥
您可以使用命令行界面显示 Ceph 用户的密钥信息。
先决条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
- 节点的根级别访问权限。
流程
要将用户的身份验证密钥打印到标准输出,请执行以下操作:
ceph auth print-key TYPE.ID
ceph auth print-key TYPE.IDCopy to Clipboard Copied! Toggle word wrap Toggle overflow 其中
TYPE是客户端、osd、mon或mds之一,而ID是守护进程的用户名或 ID。当您需要使用用户的密钥(例如
libvirt)填充客户端软件时,打印用户的密钥非常有用。mount -t ceph HOSTNAME:/MOUNT_POINT -o name=client.user,secret=ceph auth print-key client.user
mount -t ceph HOSTNAME:/MOUNT_POINT -o name=client.user,secret=ceph auth print-key client.userCopy to Clipboard Copied! Toggle word wrap Toggle overflow
5.3.8. 导入 Ceph 用户
您可以使用命令行界面导入 Ceph 用户。
前提条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
- 节点的根级别访问权限。
流程
要导入一个或多个用户,请使用
ceph auth 导入并指定密钥环:ceph auth import -i /PATH/TO/KEYRING
ceph auth import -i /PATH/TO/KEYRINGCopy to Clipboard Copied! Toggle word wrap Toggle overflow Example
ceph auth import -i /etc/ceph/ceph.keyring
[root@mon ~]# ceph auth import -i /etc/ceph/ceph.keyringCopy to Clipboard Copied! Toggle word wrap Toggle overflow
Ceph 存储集群将添加新用户、其密钥及其功能,并将更新现有用户、其密钥及其功能。
5.4. 管理 Ceph 密钥环
作为存储管理员,管理 Ceph 用户密钥对于访问 Red Hat Ceph Storage 集群非常重要。您可以创建密钥环,将用户添加到密钥环中,然后使用密钥环修改用户。
5.4.1. 前提条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
- 访问 Ceph monitor 或 Ceph 客户端节点。
5.4.2. 创建密钥环
您需要向 Ceph 客户端提供用户密钥,以便 Ceph 客户端能够检索指定用户的密钥并使用 Ceph Storage 集群进行身份验证。用于查找用户名并检索用户密钥的 Ceph 客户端访问密钥环。
ceph-authtool 工具允许您创建密钥环。
前提条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
- 节点的根级别访问权限。
流程
要创建空密钥环,请使用
--create-keyring或-C。Example
ceph-authtool --create-keyring /path/to/keyring
[root@mon ~]# ceph-authtool --create-keyring /path/to/keyringCopy to Clipboard Copied! Toggle word wrap Toggle overflow 当使用多个用户创建密钥环时,我们建议使用集群名称。例如,针对密钥环文件名的
CLUSTER_NAME.keyring'并将其保存在/etc/ceph/目录中,以便密钥环配置默认设置会获取文件名,而无需在 Ceph 配置文件的本地副本中指定该文件。通过执行以下操作来创建
ceph.keyring:ceph-authtool -C /etc/ceph/ceph.keyring
[root@mon ~]# ceph-authtool -C /etc/ceph/ceph.keyringCopy to Clipboard Copied! Toggle word wrap Toggle overflow
使用单个用户创建密钥环时,我们建议使用集群名称,用户类型和用户名,并将其保存在 /etc/ceph/ 目录中。例如,client.admin 用户的 ceph.client.admin.keyring。
要在 /etc/ceph/ 中创建密钥环,您必须以 root 用户身份执行此操作。这意味着,该文件仅针对 root 用户具有 rw 权限,这在密钥环包含管理员密钥时合适。但是,如果您打算将密钥环用于特定用户或一组用户,请确保执行 chown 或 chmod 来建立适当的密钥环所有权和访问权限。
5.4.3. 将用户添加到密钥环
当您将用户添加到 Ceph 存储集群时,您可以使用 get 过程来检索用户、密钥和功能,然后将用户保存到密钥环文件中。当您只想为每个密钥环使用一个用户时,使用 -o 选项的 Display Ceph 用户信息 过程会将输出保存为密钥环文件格式。
前提条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
- 节点的根级别访问权限。
流程
要为
client.admin用户创建密钥环,请执行以下操作:ceph auth get client.admin -o /etc/ceph/ceph.client.admin.keyring
[root@mon ~]# ceph auth get client.admin -o /etc/ceph/ceph.client.admin.keyringCopy to Clipboard Copied! Toggle word wrap Toggle overflow 请注意,我们为单个用户使用推荐的文件格式。
当您要导入用户到密钥环时,您可以使用
ceph-authtool指定目标密钥环和源密钥环。ceph-authtool /etc/ceph/ceph.keyring --import-keyring /etc/ceph/ceph.client.admin.keyring
[root@mon ~]# ceph-authtool /etc/ceph/ceph.keyring --import-keyring /etc/ceph/ceph.client.admin.keyringCopy to Clipboard Copied! Toggle word wrap Toggle overflow
5.4.4. 创建具有密钥环的 Ceph 用户
Ceph 提供了在 Red Hat Ceph Storage 集群中直接创建用户的功能。但是,您还可以直接在 Ceph 客户端密钥环中创建用户、密钥和功能。
前提条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
- 节点的根级别访问权限。
流程
将用户导入到密钥环中:
Example
ceph-authtool -n client.ringo --cap osd 'allow rwx' --cap mon 'allow rwx' /etc/ceph/ceph.keyring
[root@mon ~]# ceph-authtool -n client.ringo --cap osd 'allow rwx' --cap mon 'allow rwx' /etc/ceph/ceph.keyringCopy to Clipboard Copied! Toggle word wrap Toggle overflow 创建密钥环并同时向密钥环中添加新用户:
例如:
ceph-authtool -C /etc/ceph/ceph.keyring -n client.ringo --cap osd 'allow rwx' --cap mon 'allow rwx' --gen-key
[root@mon ~]# ceph-authtool -C /etc/ceph/ceph.keyring -n client.ringo --cap osd 'allow rwx' --cap mon 'allow rwx' --gen-keyCopy to Clipboard Copied! Toggle word wrap Toggle overflow 在忘记情景中,新用户
client.ringo只是在密钥环中。将新用户添加到 Ceph 存储集群中:
ceph auth add client.ringo -i /etc/ceph/ceph.keyring
[root@mon ~]# ceph auth add client.ringo -i /etc/ceph/ceph.keyringCopy to Clipboard Copied! Toggle word wrap Toggle overflow
其它资源
- 有关功能的更多详情,请参阅 Ceph 用户管理背景。
5.4.5. 使用密钥环修改 Ceph 用户
您可以使用命令行界面修改 Ceph 用户及其密钥环。
前提条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
- 节点的根级别访问权限。
流程
- 要修改密钥环中用户记录的功能,请指定密钥环,然后用户以及相应的功能,例如:
ceph-authtool /etc/ceph/ceph.keyring -n client.ringo --cap osd 'allow rwx' --cap mon 'allow rwx'
[root@mon ~]# ceph-authtool /etc/ceph/ceph.keyring -n client.ringo --cap osd 'allow rwx' --cap mon 'allow rwx'- 要将用户更新至 Red Hat Ceph Storage 集群,您必须将密钥环中的用户更新至 Red Hat Ceph Storage 集群中的用户条目:
ceph auth import -i /etc/ceph/ceph.keyring
[root@mon ~]# ceph auth import -i /etc/ceph/ceph.keyring
您还可以直接在存储集群中修改用户功能,将结果保存到密钥环文件中;然后,将密钥环导入到主 ceph.keyring 文件中。
其它资源
5.4.6. Ceph 用户的命令行用法
Ceph 支持以下使用用户名和 secret:
--id | --user
- 描述
-
Ceph 识别具有类型和 ID 的用户。例如,
TYPE.ID或client.admin,client.user1。id、name和-n选项允许您指定用户名的 ID 部分。例如,管理员、user1或foo。您可以使用--id指定用户,省略 类型。例如,要指定用户client.foo,请输入以下内容:
ceph --id foo --keyring /path/to/keyring health ceph --user foo --keyring /path/to/keyring health
[root@mon ~]# ceph --id foo --keyring /path/to/keyring health
[root@mon ~]# ceph --user foo --keyring /path/to/keyring health
--name | -n
- 描述
-
Ceph 识别具有类型和 ID 的用户。例如,
TYPE.ID或client.admin,client.user1。name和-n选项允许您指定完全限定的用户名。您必须使用用户 ID 指定用户类型(通常是客户端)。例如:
ceph --name client.foo --keyring /path/to/keyring health ceph -n client.foo --keyring /path/to/keyring health
[root@mon ~]# ceph --name client.foo --keyring /path/to/keyring health
[root@mon ~]# ceph -n client.foo --keyring /path/to/keyring health
--keyring
- 描述
-
包含一个或多个用户名和 secret 的密钥环路径。
--secret选项提供相同的功能,但它无法用于 Ceph RADOS 网关,网关使用--secret来另一用途。您可以使用ceph auth get-or-create检索密钥环,并将其存储在本地。这是首选的方法,因为您可以在不切换密钥环路径的情况下切换用户名。例如:
rbd map foo --pool rbd myimage --id client.foo --keyring /path/to/keyring
[root@mon ~]# rbd map foo --pool rbd myimage --id client.foo --keyring /path/to/keyring5.4.7. Ceph 用户管理限制
cephx 协议相互验证 Ceph 客户端和服务器。它并不适用于处理代表其运行的人用户或应用程序程序的身份验证。如果需要该效果来处理访问控制需求,则您必须有另一种机制,该机制可能特定于用于访问 Ceph 对象存储的前端。这种其他机制具有确保 Ceph 允许访问其对象存储的计算机上只有可接受的用户和程序能够运行的角色。
用于验证 Ceph 客户端和服务器的密钥通常存储在可信主机中具有适当权限的纯文本文件中。
在纯文本文件中存储密钥具有安全性不足,但难以避免,因为 Ceph 在后台使用的基本身份验证方法。设置 Ceph 系统应该了解这些不足的问题。
特别是任意用户计算机(特别是便携式计算机)应配置为直接与 Ceph 交互,因为这种模式需要在不安全的计算机上存储纯文本验证密钥。对机器造成破坏或获取访问权限的任何人都可以获取允许他们向 Ceph 验证自己机器的密钥。
用户不必允许潜在的不安全计算机直接访问 Ceph 对象存储,而是需要使用为目的提供足够的安全性的方法,在环境中登录可信机器。该可信计算机将为人类用户存储纯文本 Ceph 密钥。未来的 Ceph 版本可以更加全面地解决这些特定身份验证问题。
目前,没有 Ceph 身份验证协议在传输过程中为消息提供保密性。因此,线路图可以听到和理解 Ceph 中客户端和服务器之间发送的所有数据,即使他无法创建或更改它们。在 Ceph 中存储敏感数据时,应考虑加密其数据,然后再将其提供给 Ceph 系统。
例如,Ceph 对象网关提供 S3 API Serverside Encryption,它在将 Ceph Object Gateway 客户端中存储并类似地解密从 Ceph Storage 集群发送之前从 Ceph Storage 集群接收的数据加密。为确保在客户端和 Ceph 对象网关之间传输加密,Ceph 对象网关应配置为使用 SSL。
第 6 章 ceph-volume 工具
作为存储管理员,您可以使用 ceph-volume 实用程序准备、创建和激活 Ceph OSD。ceph-volume 实用程序是单一目的命令行工具,可将逻辑卷部署为 OSD。它使用插件类型框架来部署使用不同设备技术的 OSD。ceph-volume 实用程序遵循 ceph-disk 实用程序的类似工作流,用于部署 OSD,具有可预测的、可靠的准备、激活和启动 OSD 的方法。目前,ceph-volume 实用程序只支持 lvm 插件,计划以后支持其他技术。
ceph-disk 命令已弃用。
6.1. 先决条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
6.2. Ceph 卷 lvm 插件
通过使用 LVM 标签,lvm 子命令可以通过查询与 OSD 关联的设备来存储和重新发现它们,以便可以激活它们。这包括对基于 lvm 的技术(如 dm-cache )的支持。
使用 ceph-volume 时,dm-cache 的使用是透明的,并像逻辑卷一样对待 dm-cache。使用 dm-cache 时性能提升和丢失将取决于特定工作负载。通常,随机的读取和顺序的读取将以较小的块大小来提高性能。对于大的块大小,随机和顺序写入的性能会降低。
要使用 LVM 插件,在 ceph-volume 命令中添加 lvm 作为子命令:
ceph-volume lvm
[root@osd ~]# ceph-volume lvm
lvm 子命令有三个子命令,如下所示:
create 子命令将 prepare 和 activate 子命令合并到一个子命令中。
其它资源
-
如需了解更多详细信息,请参阅
create子命令 部分。
6.3. 为什么 ceph-volume 替换 ceph-disk?
以前的 Red Hat Ceph Storage 版本使用 ceph-disk 实用程序来准备、激活和创建 OSD。从 Red Hat Ceph Storage 4 开始,ceph-disk 被 ceph-volume 实用程序替代,该实用程序旨在作为 OSD 部署逻辑卷,同时在准备、激活和创建 OSD 时维护类似的 API 到 ceph-disk。
ceph-volume 的工作原理?
ceph-volume 是一个模块化工具,目前支持置备硬件设备、传统的 ceph-disk 设备和 LVM(逻辑卷管理器)设备的方法。ceph-volume lvm 命令使用 LVM 标签存储特定于 Ceph 的设备及其与 OSD 的关系信息。它使用这些标签来稍后重新发现和查询与 OSDs 关联的设备,以便它可以激活它们。它还支持基于 LVM 和 dm-cache 的技术。
ceph-volume 实用程序以透明方式使用 dm-cache,并将其视为逻辑卷。根据您要处理的特定工作负载,您可能会考虑使用 dm-cache 时的性能提升和丢失。通常,随机和顺序读取操作的性能会提高较小的块大小;而随机和顺序写入操作的性能则降低更大的块大小。使用 ceph-volume 不会导致任何明显的性能下降。
ceph-disk 实用程序已弃用。
如果这些设备仍在使用,ceph-volume simple 命令可处理旧的 ceph-disk 设备。
ceph-disk 的工作原理?
需要 ceph-disk 工具来支持许多不同类型的 init 系统,如 upstart 或 sysvinit,同时能够发现设备。因此,ceph-disk 只会专注于 GUID 分区表 (GPT) 分区。具体在 GPT GUID 中,以独特的方式标记设备,以如下方式回答问题:
-
此设备是否为
journal? - 该设备是否是加密的数据分区?
- 设备是否部分准备了吗?
为解决这些问题,ceph-disk 使用 UDEV 规则与 GUID 匹配。
使用 ceph-disk 有什么缺点?
使用 UDEV 规则调用 ceph-disk 可能会导致在 ceph-disk systemd 单元和 ceph-disk 间的相互往来。整个过程非常不可靠且消耗时间,可能会导致 OSD 在节点启动过程中根本不会出现。此外,由于 UDEV 的异步行为,很难调试甚至复制这些问题。
由于 ceph-disk 只能用于 GPT 分区,所以它不支持其他技术,如逻辑卷管理器(LVM)卷或类似的设备映射器设备。
为确保 GPT 分区能与设备发现工作流正常工作,ceph-disk 需要大量特殊的标志。此外,这些分区需要设备完全归 Ceph 所有。
6.4. 使用 ceph-volume准备 Ceph OSD
prepare 子命令准备 OSD 后端对象存储,并消耗 OSD 数据和日志的逻辑卷(LV)。它不会修改逻辑卷,但使用 LVM 添加额外的元数据标签。这些标签使卷更容易发现,它们也会将卷识别为 Ceph Storage 集群的一部分,以及存储集群中这些卷的角色。
BlueStore OSD 后端支持以下配置:
-
块设备,
block.wal设备和block.db设备 -
块设备和一个
block.wal设备 -
块设备和
block.db设备 - 单个块设备
prepare 子命令接受整个设备或分区,或者用于 块 的逻辑卷。
先决条件
- 对 OSD 节点的 root 级别访问。
- (可选)创建逻辑卷。如果您提供到物理设备的路径,子命令会将设备转换为逻辑卷。这种方法更为简单,但是您无法配置或更改创建逻辑卷的方式。
流程
准备 LVM 卷:
语法
ceph-volume lvm prepare --bluestore --data VOLUME_GROUP/LOGICAL_VOLUME
ceph-volume lvm prepare --bluestore --data VOLUME_GROUP/LOGICAL_VOLUMECopy to Clipboard Copied! Toggle word wrap Toggle overflow 示例
ceph-volume lvm prepare --bluestore --data example_vg/data_lv
[root@osd ~]# ceph-volume lvm prepare --bluestore --data example_vg/data_lvCopy to Clipboard Copied! Toggle word wrap Toggle overflow 另外,如果您要将单独的设备用于 RocksDB,请指定
--block.db和--block.wal选项:语法
ceph-volume lvm prepare --bluestore --block.db --block.wal --data VOLUME_GROUP/LOGICAL_VOLUME
ceph-volume lvm prepare --bluestore --block.db --block.wal --data VOLUME_GROUP/LOGICAL_VOLUMECopy to Clipboard Copied! Toggle word wrap Toggle overflow 示例
ceph-volume lvm prepare --bluestore --block.db --block.wal --data example_vg/data_lv
[root@osd ~]# ceph-volume lvm prepare --bluestore --block.db --block.wal --data example_vg/data_lvCopy to Clipboard Copied! Toggle word wrap Toggle overflow 另外,要加密数据,请使用
--dmcrypt标志:语法
ceph-volume lvm prepare --bluestore --dmcrypt --data VOLUME_GROUP/LOGICAL_VOLUME
ceph-volume lvm prepare --bluestore --dmcrypt --data VOLUME_GROUP/LOGICAL_VOLUMECopy to Clipboard Copied! Toggle word wrap Toggle overflow 示例
ceph-volume lvm prepare --bluestore --dmcrypt --data example_vg/data_lv
[root@osd ~]# ceph-volume lvm prepare --bluestore --dmcrypt --data example_vg/data_lvCopy to Clipboard Copied! Toggle word wrap Toggle overflow
其它资源
- 如需更多详细信息,请参阅 Red Hat Ceph Storage 管理指南中的使用 'ceph-volume' 激活 Ceph OSD。
- 如需更多详细信息,请参阅 Red Hat Ceph Storage 管理指南中的使用 'ceph-volume' 创建 Ceph OSD。
6.5. 使用 ceph-volume 激活 Ceph OSD
激活过程在引导时启用 systemd 单元,允许启用和挂载正确的 OSD 标识符及其 UUID。
先决条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
- 对 Ceph OSD 节点的 root 级别访问权限。
-
Ceph OSD 由
ceph-volume实用程序准备。
流程
从 OSD 节点获取 OSD ID 和 UUID:
ceph-volume lvm list
[root@osd ~]# ceph-volume lvm listCopy to Clipboard Copied! Toggle word wrap Toggle overflow 激活 OSD:
语法
ceph-volume lvm activate --bluestore OSD_ID OSD_UUID
ceph-volume lvm activate --bluestore OSD_ID OSD_UUIDCopy to Clipboard Copied! Toggle word wrap Toggle overflow 示例
ceph-volume lvm activate --bluestore 0 0263644D-0BF1-4D6D-BC34-28BD98AE3BC8
[root@osd ~]# ceph-volume lvm activate --bluestore 0 0263644D-0BF1-4D6D-BC34-28BD98AE3BC8Copy to Clipboard Copied! Toggle word wrap Toggle overflow 要激活为激活准备的所有 OSD,请使用
--all选项:Example
ceph-volume lvm activate --all
[root@osd ~]# ceph-volume lvm activate --allCopy to Clipboard Copied! Toggle word wrap Toggle overflow
其它资源
- 如需更多详细信息,请参阅 Red Hat Ceph Storage 管理指南中的使用 'ceph-volume' 准备 Ceph OSD。
- 如需更多详细信息,请参阅 Red Hat Ceph Storage 管理指南中的使用 'ceph-volume' 创建 Ceph OSD。
6.6. 使用 ceph-volume 创建 Ceph OSD
create 子命令调用 prepare 子命令,然后调用 activate 子命令。
先决条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
- 对 Ceph OSD 节点的 root 级别访问权限。
如果您希望对创建过程拥有更多控制,可以单独使用 prepare 和 activate 子命令来创建 OSD,而不必使用 create。您可以使用两个子命令逐步将新的 OSD 引入到存储集群中,同时避免重新平衡大量数据。这两种方法的工作方式相同,唯一的不同是使用 create 子命令会使 OSD 在完成后立即变为 up 和 in。
流程
要创建新 OSD,请执行以下操作:
语法
ceph-volume lvm create --bluestore --data VOLUME_GROUP/LOGICAL_VOLUME
ceph-volume lvm create --bluestore --data VOLUME_GROUP/LOGICAL_VOLUMECopy to Clipboard Copied! Toggle word wrap Toggle overflow 示例
ceph-volume lvm create --bluestore --data example_vg/data_lv
[root@osd ~]# ceph-volume lvm create --bluestore --data example_vg/data_lvCopy to Clipboard Copied! Toggle word wrap Toggle overflow
其它资源
- 如需更多详细信息,请参阅 Red Hat Ceph Storage 管理指南中的使用 'ceph-volume' 准备 Ceph OSD。
- 如需更多详细信息,请参阅 Red Hat Ceph Storage 管理指南中的使用 'ceph-volume' 激活 Ceph OSD。
6.7. 将批处理模式与 ceph-volume搭配使用
当提供单一设备时,batch 子命令可自动创建多个 OSD。
ceph-volume 命令根据驱动器类型决定使用创建 OSD 的最佳方法。Ceph OSD 优化取决于可用的设备:
-
如果所有设备都是传统的硬盘驱动器,
batch会为每个设备创建一个 OSD。 -
如果所有设备都是固态硬盘,则
batch会为每个设备创建两个 OSD。 -
如果混合使用传统硬盘驱动器和固态驱动器,
batch使用传统的硬盘驱动器用于数据,并在固态硬盘上创建最大可能的日志(block.db)。
batch 子命令不支持为 write-ahead-log (block.wal) 设备创建单独的逻辑卷。
先决条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
- 对 Ceph OSD 节点的 root 级别访问权限。
流程
在几个驱动器中创建 OSD:
语法
ceph-volume lvm batch --bluestore PATH_TO_DEVICE [PATH_TO_DEVICE]
ceph-volume lvm batch --bluestore PATH_TO_DEVICE [PATH_TO_DEVICE]Copy to Clipboard Copied! Toggle word wrap Toggle overflow 示例
ceph-volume lvm batch --bluestore /dev/sda /dev/sdb /dev/nvme0n1
[root@osd ~]# ceph-volume lvm batch --bluestore /dev/sda /dev/sdb /dev/nvme0n1Copy to Clipboard Copied! Toggle word wrap Toggle overflow
其它资源
- 如需更多详细信息,请参阅 Red Hat Ceph Storage 管理指南中的使用 'ceph-volume' 创建 Ceph OSD。
第 7 章 Ceph 性能基准
作为存储管理员,您可以对 Red Hat Ceph Storage 集群的基准测试性能进行基准测试。本节的目的是让 Ceph 管理员能够了解 Ceph 的原生基准工具。这些工具将深入探讨 Ceph 存储集群的运行情况。这不是 Ceph 性能基准的确定指南,也不是一个有关如何相应地调整 Ceph 的指南。
7.1. 先决条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
7.2. 性能基准
OSD(包括日志、磁盘和网络吞吐量)应具有一个用于比较的性能基准。您可以通过将基准性能数据与 Ceph 原生工具中的数据进行比较来识别潜在的调优机会。Red Hat Enterprise Linux 具有许多内置工具,以及开源社区工具的 plethora,可用于帮助完成这些任务。
其它资源
- 有关一些可用工具的详情,请查看知识库文章。
7.3. Ceph 性能基准
Ceph 包含 rados bench 命令,用于在 RADOS 存储群集上执行性能基准测试。命令将执行写入测试,以及两种类型的读测试。在测试读取和写入性能时,--no-cleanup 选项非常重要。默认情况下,rados bench 命令会删除它写入存储池的对象。保留这些对象后,可以使用两个读取测试来测量顺序读取和随机读取的性能。
在运行这些性能测试前,运行以下命令丢弃所有文件系统缓存:
echo 3 | sudo tee /proc/sys/vm/drop_caches && sudo sync
[root@mon~ ]# echo 3 | sudo tee /proc/sys/vm/drop_caches && sudo sync前提条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
- 节点的根级别访问权限。
流程
创建新存储池:
ceph osd pool create testbench 100 100
[root@osd~ ]# ceph osd pool create testbench 100 100Copy to Clipboard Copied! Toggle word wrap Toggle overflow 对新创建的存储池执行 10 秒的写入测试:
rados bench -p testbench 10 write --no-cleanup
[root@osd~ ]# rados bench -p testbench 10 write --no-cleanupCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 为存储池执行一次10 秒的连续读测试 :
# rados bench -p testbench 10 seq
[root@osd~ ]## rados bench -p testbench 10 seqCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 为存储池执行一次 10 秒的随机读取测试 :
rados bench -p testbench 10 rand
[root@osd ~]# rados bench -p testbench 10 randCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 要增加并发读取和写入的数量,请使用
-t选项,默认为 16 个线程。另外,-b参数可以调整所写入对象的大小。默认对象大小为 4 MB。安全最大对象大小为 16 MB。红帽建议将这些基准测试中的多个副本运行到不同的池。这样做显示与多个客户端的性能更改。添加
--run-name <label> 选项来控制在基准测试测试期间写入的对象名称。通过更改每个运行命令实例的--run-name标签,可以同时运行多个rados bench命令。这可防止当多个客户端试图访问同一对象时可能会出现潜在的 I/O 错误,并允许不同的客户端访问不同的对象。在尝试模拟真实工作负载时,--run-name选项也很有用。例如:rados bench -p testbench 10 write -t 4 --run-name client1
[root@osd ~]# rados bench -p testbench 10 write -t 4 --run-name client1Copy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 删除
rados bench命令创建的数据:rados -p testbench cleanup
[root@osd ~]# rados -p testbench cleanupCopy to Clipboard Copied! Toggle word wrap Toggle overflow
7.4. 基准测试 Ceph 块性能
Ceph 包含 rbd bench-write 命令,以测试对块设备测量吞吐量和延迟情况的连续写入。默认字节大小为 4096,默认 I/O 线程数为 16,默认的写入字节数为 1 GB。这些默认值可通过 --io-size, --io-threads 和 --io-total 选项分别进行修改。
先决条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
- 节点的根级别访问权限。
流程
如果还没有加载,载入
rbd内核模块:modprobe rbd
[root@mon ~]# modprobe rbdCopy to Clipboard Copied! Toggle word wrap Toggle overflow 在
testbench池中创建一个 1 GB 的rbd镜像文件:rbd create image01 --size 1024 --pool testbench
[root@mon ~]# rbd create image01 --size 1024 --pool testbenchCopy to Clipboard Copied! Toggle word wrap Toggle overflow 将镜像文件映射到设备文件中:
rbd map image01 --pool testbench --name client.admin
[root@mon ~]# rbd map image01 --pool testbench --name client.adminCopy to Clipboard Copied! Toggle word wrap Toggle overflow 在块设备中创建
ext4文件系统:mkfs.ext4 /dev/rbd/testbench/image01
[root@mon ~]# mkfs.ext4 /dev/rbd/testbench/image01Copy to Clipboard Copied! Toggle word wrap Toggle overflow 创建新目录:
mkdir /mnt/ceph-block-device
[root@mon ~]# mkdir /mnt/ceph-block-deviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow 将块设备挂载到
/mnt/ceph-block-device/下:mount /dev/rbd/testbench/image01 /mnt/ceph-block-device
[root@mon ~]# mount /dev/rbd/testbench/image01 /mnt/ceph-block-deviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow 对块设备执行写入性能测试
rbd bench --io-type write image01 --pool=testbench
[root@mon ~]# rbd bench --io-type write image01 --pool=testbenchCopy to Clipboard Copied! Toggle word wrap Toggle overflow 示例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
其它资源
-
有关
rbd命令 的更多信息,请参阅 Red Hat Ceph Storage Block Device Device Guide 中的块设备命令部分。
第 8 章 Ceph 性能计数器
作为存储管理员,您可以收集 Red Hat Ceph Storage 集群的性能指标。Ceph 性能计数器是内部基础架构指标的集合。此指标数据的集合、聚合和图表可以通过一组工具进行,并可用于性能分析。
8.1. 先决条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
8.2. 访问 Ceph 性能计数器
性能计数器可通过 Ceph 监控和 OSD 的套接字接口提供。每个对应守护进程的套接字文件默认位于 /var/run/ceph 下。性能计数器分组到集合名称中。这些集合名称代表子系统或子系统实例。
以下是 monitor 和 OSD 集合名称类别的完整列表,其中包含每个的简短描述信息:
Monitor 集合名称目录
- Cluster Metrics - 显示存储集群的信息:监控、OSD、池和 PG
-
Level Database Metrics - 显示后端
KeyValueStore数据库的信息 - Monitor Metrics - 显示常规监控信息
- Paxos Metrics - 显示集群仲裁管理的信息
- Throttle Metrics - 显示监控器节流的统计信息
OSD 集合名称目录
- Write Back Throttle Metrics - 显示写入后节流的统计是如何跟踪未清空的 IO
-
Level Database Metrics - 显示后端
KeyValueStore数据库的信息 - Objecter Metrics - 显示各种基于对象的操作的信息
- 读和写操作指标 - 显示各种读写操作的信息
- 恢复状态指标 - 显示 - 显示各种恢复状态的延迟
- OSD Throttle Metrics - 显示 OSD 节流的统计
RADOS 网关集合名称 Categories
- Object Gateway Client Metrics - 显示 GET 和 PUT 请求的统计信息
- Objecter Metrics - 显示各种基于对象的操作的信息
- Object Gateway Throttle Metrics - 显示 OSD 节流方式的统计信息
8.3. 显示 Ceph 性能计数器
ceph 守护进程 .. perf 模式 命令会输出可用的指标。每个指标都有一个关联的位字段值类型。
先决条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
- 节点的根级别访问权限。
流程
查看指标的 schema:
ceph daemon DAEMON_NAME perf schema
ceph daemon DAEMON_NAME perf schemaCopy to Clipboard Copied! Toggle word wrap Toggle overflow 注意您必须从节点运行
ceph daemon命令来运行守护进程。从 monitor
节点执行 ceph 守护进程 .. perf 模式命令:ceph daemon mon.`hostname -s` perf schema
[root@mon ~]# ceph daemon mon.`hostname -s` perf schemaCopy to Clipboard Copied! Toggle word wrap Toggle overflow Example
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 从 OSD
节点执行 ceph 守护进程 .. perf 模式命令:ceph daemon osd.0 perf schema
[root@mon ~]# ceph daemon osd.0 perf schemaCopy to Clipboard Copied! Toggle word wrap Toggle overflow Example
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
| 位 | 含义 |
|---|---|
| 1 | 浮点值 |
| 2 | 未签名的 64 位整数值 |
| 4 | 平均(Sum + Count) |
| 8 | 计数 |
每个值都将有位 1 或 2 设置来表示类型,可以是浮点或整数值。当位 4 被设置时,将有两个值可供读取,分别是 sum 和 count。当设置了第 8 位时,以前间隔的平均间隔值为总 delta 值(自上一次读取以来)除以 delta 的数量。另外,从右边的值分离会提供生命周期平均值值。通常,这用于衡量延迟、请求数和请求延迟总和。一些位的值会被合并,如 5、6 和 10。位值 5 是位 1 和位 4 的组合。这意味着平均值将是一个浮点值。位值 6 是位 2 和位 4 的组合。这意味着平均值为一个整数。位值 10 是位 2 和位 8 的组合。这意味着计数器值将是整数值。
其它资源
- 如需了解更多详细信息,请参阅 平均计数和总和。
8.4. 转储 Ceph 性能计数器
ceph daemon .. perf dump 命令会输出当前值,并将指标分组到各个子系统的集合名称下。
先决条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
- 节点的根级别访问权限。
流程
查看当前的指标数据:
ceph daemon DAEMON_NAME perf dump
# ceph daemon DAEMON_NAME perf dumpCopy to Clipboard Copied! Toggle word wrap Toggle overflow 注意您必须从节点运行
ceph daemon命令来运行守护进程。从 monitor 节点执行
ceph daemon .. perf dump命令:ceph daemon mon.`hostname -s` perf dump
# ceph daemon mon.`hostname -s` perf dumpCopy to Clipboard Copied! Toggle word wrap Toggle overflow Example
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 从 OSD 节点执行
ceph daemon .. perf dump命令:ceph daemon osd.0 perf dump
# ceph daemon osd.0 perf dumpCopy to Clipboard Copied! Toggle word wrap Toggle overflow Example
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
其它资源
- 要查看每个 monitor 指标可用的简短说明,请参阅 Ceph 监控指标表。
8.5. 平均计数和总和
所有延迟数量都有一个 bit 字段值 5。此字段包含平均计数和 sum 的浮点值。avgcount 是这个范围内的操作数,sum 是总延迟(以秒为单位)。将 sum 除以 avgcount 的值为您提供了关于每个操作的延迟理念。
其它资源
- 要查看每个可用 OSD 指标的简短描述,请参阅 Ceph OSD 表。
8.6. Ceph 监控指标
| 集合名称 | 指标名称 | 位字段值 | 简短描述 |
|---|---|---|---|
|
|
| 2 | 监控器数 |
|
| 2 | 仲裁中的 monitor 数量 | |
|
| 2 | OSD 的总数 | |
|
| 2 | 已启动的 OSD 数量 | |
|
| 2 | 集群中的 OSD 数量 | |
|
| 2 | OSD map 的当前 epoch | |
|
| 2 | 集群总容量(以字节为单位) | |
|
| 2 | 集群中的已用字节数 | |
|
| 2 | 集群中的可用字节数 | |
|
| 2 | 池数 | |
|
| 2 | 放置组总数 | |
|
| 2 | active+clean 状态的放置组数量 | |
|
| 2 | 处于活跃状态的放置组数量 | |
|
| 2 | 处于 peering 状态的放置组数量 | |
|
| 2 | 集群中的对象总数 | |
|
| 2 | 降级数量(减少副本)对象 | |
|
| 2 | 对象中错误的原位(集群位置)数 | |
|
| 2 | 未找到的对象数量 | |
|
| 2 | 所有对象的字节数 | |
|
| 2 | 启动的 MDS 数量 | |
|
| 2 | 集群中的 MDS 数量 | |
|
| 2 | 失败的 MDS 数量 | |
|
| 2 | MDS 映射的当前 epoch |
| 集合名称 | 指标名称 | 位字段值 | 简短描述 |
|---|---|---|---|
|
|
| 10 | Gets |
|
| 10 | Transactions | |
|
| 10 | Compactions | |
|
| 10 | 按范围完成 | |
|
| 10 | 在压缩队列中合并范围 | |
|
| 2 | 压缩队列长度 |
| 集合名称 | 指标名称 | 位字段值 | 简短描述 |
|---|---|---|---|
|
|
| 2 | 当前打开的 monitor 会话数量 |
|
| 10 | 创建的 monitor 会话数量 | |
|
| 10 | monitor 中的 remove_session 调用数量 | |
|
| 10 | 修剪监控会话的数量 | |
|
| 10 | 参与的 elections monitor 数量 | |
|
| 10 | 有 monitor 启动的选举数 | |
|
| 10 | 监控可享受的选举数量 | |
|
| 10 | 监控丢失的选举数量 |
| 集合名称 | 指标名称 | 位字段值 | 简短描述 |
|---|---|---|---|
|
|
| 10 | 以领导角色开始 |
|
| 10 | 以 peon 角色启动 | |
|
| 10 | 重启 | |
|
| 10 | 刷新 | |
|
| 5 | 刷新延迟 | |
|
| 10 | 启动和处理开始 | |
|
| 6 | 开始时事务中的键 | |
|
| 6 | 开始时事务中的数据 | |
|
| 5 | 开始操作的延迟 | |
|
| 10 | 提交 | |
|
| 6 | 提交时事务中的键 | |
|
| 6 | 提交时事务中的数据 | |
|
| 5 | 提交延迟 | |
|
| 10 | peon 收集 | |
|
| 6 | peon collect 时事务中的键 | |
|
| 6 | peon collect 时事务中的数据 | |
|
| 5 | peon 收集延迟 | |
|
| 10 | 在开始的和处理的 collect 中未提交的值 | |
|
| 10 | 收集超时 | |
|
| 10 | 接受超时 | |
|
| 10 | 租期确认超时 | |
|
| 10 | 租期超时 | |
|
| 10 | 在磁盘上存储共享状态 | |
|
| 6 | 存储在事务中的密钥 | |
|
| 6 | 存储在存储状态下的事务中的数据 | |
|
| 5 | 存储状态延迟 | |
|
| 10 | 状态共享 | |
|
| 6 | 共享状态的密钥 | |
|
| 6 | 处于共享状态的数据 | |
|
| 10 | 新提议号查询 | |
|
| 5 | 新的提议号获得延迟 |
| 集合名称 | 指标名称 | 位字段值 | 简短描述 |
|---|---|---|---|
|
|
| 10 | 目前可用节流 |
|
| 10 | 最大值 throttle | |
|
| 10 | Gets | |
|
| 10 | 获取数据 | |
|
| 10 | 在 get_or_fail 时被阻断 | |
|
| 10 | 在 get_or_fail 期间获得成功 | |
|
| 10 | Takes | |
|
| 10 | 获取的数据 | |
|
| 10 | Puts | |
|
| 10 | 放置数据 | |
|
| 5 | 等待延迟 |
8.7. Ceph OSD 指标
| 集合名称 | 指标名称 | 位字段值 | 简短描述 |
|---|---|---|---|
|
|
| 2 | 脏数据 |
|
| 2 | 写入数据 | |
|
| 2 | 脏操作 | |
|
| 2 | 写入操作 | |
|
| 2 | 等待写入的条目 | |
|
| 2 | 写入条目 |
| 集合名称 | 指标名称 | 位字段值 | 简短描述 |
|---|---|---|---|
|
|
| 10 | Gets |
|
| 10 | Transactions | |
|
| 10 | Compactions | |
|
| 10 | 按范围完成 | |
|
| 10 | 在压缩队列中合并范围 | |
|
| 2 | 压缩队列长度 |
| 集合名称 | 指标名称 | 位字段值 | 简短描述 |
|---|---|---|---|
|
|
| 2 | 活跃操作 |
|
| 2 | Laggy 操作 | |
|
| 10 | 发送的操作 | |
|
| 10 | 发送的数据 | |
|
| 10 | 重新发送操作 | |
|
| 10 | 提交回调 | |
|
| 10 | 操作提交 | |
|
| 10 | 操作 | |
|
| 10 | 读取操作 | |
|
| 10 | 写操作 | |
|
| 10 | Read-modify-write 操作 | |
|
| 10 | PG 操作 | |
|
| 10 | Stat 操作 | |
|
| 10 | 创建对象操作 | |
|
| 10 | 读取操作 | |
|
| 10 | 写操作 | |
|
| 10 | 编写完整对象操作 | |
|
| 10 | 附加操作 | |
|
| 10 | 将对象设置为零操作 | |
|
| 10 | 截断对象操作 | |
|
| 10 | 删除对象操作 | |
|
| 10 | 映射扩展操作 | |
|
| 10 | 稀疏读取操作 | |
|
| 10 | 克隆范围操作 | |
|
| 10 | Get xattr 操作 | |
|
| 10 | 设置 xattr 操作 | |
|
| 10 | xattr 比较操作 | |
|
| 10 | 删除 xattr 操作 | |
|
| 10 | 重置 xattr 操作 | |
|
| 10 | TMAP 更新操作 | |
|
| 10 | TMAP put 操作 | |
|
| 10 | TMAP get 操作 | |
|
| 10 | 调用(执行)操作 | |
|
| 10 | 按对象操作监视 | |
|
| 10 | 通知对象操作 | |
|
| 10 | 多操作中的扩展属性比较 | |
|
| 10 | 其他操作 | |
|
| 2 | 活跃的闲置操作 | |
|
| 10 | 发送的闲置操作 | |
|
| 10 | 重新闲置操作 | |
|
| 10 | 将 ping 发送到闲置操作 | |
|
| 2 | 活跃池操作 | |
|
| 10 | 发送池操作 | |
|
| 10 | 重组池操作 | |
|
| 2 | Active get pool stat 操作 | |
|
| 10 | 池 stat 操作发送 | |
|
| 10 | 重新设置池统计 | |
|
| 2 | statfs 操作 | |
|
| 10 | 发送的 FS stats | |
|
| 10 | 重新发送的 FS stats | |
|
| 2 | 活跃命令 | |
|
| 10 | 发送命令 | |
|
| 10 | 重新发送命令 | |
|
| 2 | OSD map epoch | |
|
| 10 | 收到的完整 OSD 映射 | |
|
| 10 | 接收的增量 OSD map | |
|
| 2 | 开放会话 | |
|
| 10 | 会话已打开 | |
|
| 10 | 会话关闭 | |
|
| 2 | Laggy OSD 会话 |
| 集合名称 | 指标名称 | 位字段值 | 简短描述 |
|---|---|---|---|
|
|
| 2 | 复制当前正在被处理的操作(主) |
|
| 10 | 客户端操作总写入大小 | |
|
| 10 | 客户端操作总读取大小 | |
|
| 5 | 客户端操作的延迟(包括队列时间) | |
|
| 5 | 客户端操作的延迟(不包括队列时间) | |
|
| 10 | 客户端读取操作 | |
|
| 10 | 读取客户端数据 | |
|
| 5 | 读取操作的延迟(包括队列时间) | |
|
| 5 | 读取操作的延迟(不包括队列时间) | |
|
| 10 | 客户端写入操作 | |
|
| 10 | 写入的客户端数据 | |
|
| 5 | 客户端写入操作可读/应用延迟 | |
|
| 5 | 写入操作的延迟(包括队列时间) | |
|
| 5 | 写入操作的延迟(不包括队列时间) | |
|
| 10 | 客户端 read-modify-write 操作 | |
|
| 10 | 客户端 read-modify-write 操作写入 | |
|
| 10 | 客户端 read-modify-write 操作读出 | |
|
| 5 | 客户端 read-modify-write 操作可读/应用延迟 | |
|
| 5 | 读写操作的延迟(包括队列时间) | |
|
| 5 | 读写操作的延迟(不包括队列时间) | |
|
| 10 | Suboperations | |
|
| 10 | Suboperations 总数 | |
|
| 5 | Suboperations 延迟 | |
|
| 10 | 复制写入 | |
|
| 10 | 复制的写入数据大小 | |
|
| 5 | 复制的写入延迟 | |
|
| 10 | Suboperations pull 请求 | |
|
| 5 | Suboperations pull 延迟 | |
|
| 10 | Suboperations push 消息 | |
|
| 10 | Suboperations 推送的大小 | |
|
| 5 | Suboperations push 延迟 | |
|
| 10 | 发送的拉取请求 | |
|
| 10 | 推送发送的消息 | |
|
| 10 | 推送的大小 | |
|
| 10 | 入站推送消息 | |
|
| 10 | 入站推送的大小 | |
|
| 10 | 开始恢复操作 | |
|
| 2 | CPU 负载 | |
|
| 2 | 分配的缓冲大小总量 | |
|
| 2 | 放置组 | |
|
| 2 | 此 osd 是主的放置组 | |
|
| 2 | 此 osd 是副本的放置组 | |
|
| 2 | 准备好从此 osd 删除 PG | |
|
| 2 | 发送给对等点的心跳(ping) | |
|
| 2 | 接收来自其中的心跳(ping)对等点 | |
|
| 10 | OSD map 消息 | |
|
| 10 | OSD map epochs | |
|
| 10 | OSD map 重复 | |
|
| 2 | OSD 大小 | |
|
| 2 | 使用的空间 | |
|
| 2 | 可用空间 | |
|
| 10 | RADOS 'copy-from' 操作 | |
|
| 10 | 等级提升 | |
|
| 10 | Tier flushes | |
|
| 10 | 失败的分层清除 | |
|
| 10 | tier flush 尝试 | |
|
| 10 | 失败的分层清除尝试 | |
|
| 10 | 等级驱除 | |
|
| 10 | Tier whiteouts | |
|
| 10 | 设定脏层标志 | |
|
| 10 | 清理脏层标志 | |
|
| 10 | Tier delays (agent waiting) | |
|
| 10 | 层代理读取 | |
|
| 10 | 分层代理唤醒 | |
|
| 10 | 代理跳过的对象 | |
|
| 10 | 分层代理清除 | |
|
| 10 | 分层代理驱除 | |
|
| 10 | 对象上下文缓存命 | |
|
| 10 | 对象上下文缓存查找 |
| 集合名称 | 指标名称 | 位字段值 | 简短描述 |
|---|---|---|---|
|
|
| 5 | 初始恢复状态延迟 |
|
| 5 | 开始恢复状态延迟 | |
|
| 5 | 重置恢复状态延迟 | |
|
| 5 | 启动恢复状态延迟 | |
|
| 5 | 主要恢复状态延迟 | |
|
| 5 | 对等恢复状态延迟 | |
|
| 5 | 回填恢复状态延迟 | |
|
| 5 | 等待远程回填保留恢复状态延迟 | |
|
| 5 | 等待本地回填保留恢复状态延迟 | |
|
| 5 | Notbackfilling 恢复状态延迟 | |
|
| 5 | 重新恢复恢复状态延迟 | |
|
| 5 | rep 等待恢复保留恢复状态延迟 | |
|
| 5 | Rep 等待回填保留的恢复状态 | |
|
| 5 | 重新恢复恢复状态延迟 | |
|
| 5 | 激活恢复状态延迟 | |
|
| 5 | 等待本地恢复状态延迟 | |
|
| 5 | 等待远程恢复保留状态延迟 | |
|
| 5 | 恢复状态延迟 | |
|
| 5 | 恢复状态延迟 | |
|
| 5 | 清理恢复状态延迟 | |
|
| 5 | 主动恢复状态延迟 | |
|
| 5 | Replicaactive 恢复状态延迟 | |
|
| 5 | stray 恢复状态延迟 | |
|
| 5 | Getinfo 恢复状态延迟 | |
|
| 5 | Getlog 恢复状态延迟 | |
|
| 5 | Waitactingchange 恢复状态延迟 | |
|
| 5 | 恢复状态延迟不完整 | |
|
| 5 | 获取恢复状态延迟 | |
|
| 5 | Waitupthru 恢复状态延迟 |
| 集合名称 | 指标名称 | 位字段值 | 简短描述 |
|---|---|---|---|
|
|
| 10 | 目前可用节流 |
|
| 10 | 最大值 throttle | |
|
| 10 | Gets | |
|
| 10 | 获取数据 | |
|
| 10 | 在 get_or_fail 时被阻断 | |
|
| 10 | 在 get_or_fail 期间获得成功 | |
|
| 10 | Takes | |
|
| 10 | 获取的数据 | |
|
| 10 | Puts | |
|
| 10 | 放置数据 | |
|
| 5 | 等待延迟 |
8.8. Ceph 对象网关指标
| 集合名称 | 指标名称 | 位字段值 | 简短描述 |
|---|---|---|---|
|
|
| 10 | Requests |
|
| 10 | 中止的请求 | |
|
| 10 | Gets | |
|
| 10 | gets 的大小 | |
|
| 5 | 获取延迟 | |
|
| 10 | Puts | |
|
| 10 | puts 的大小 | |
|
| 5 | Put 延迟 | |
|
| 2 | 队列长度 | |
|
| 2 | 活跃请求队列 | |
|
| 10 | 缓存命中 | |
|
| 10 | 缓存未命中 | |
|
| 10 | Keystone 令牌缓存命 | |
|
| 10 | Keystone 令牌缓存未命中 | |
|
| 10 | 自上次重启 Ceph 对象网关后,已停用的对象计数 |
| 集合名称 | 指标名称 | 位字段值 | 简短描述 |
|---|---|---|---|
|
|
| 2 | 活跃操作 |
|
| 2 | Laggy 操作 | |
|
| 10 | 发送的操作 | |
|
| 10 | 发送的数据 | |
|
| 10 | 重新发送操作 | |
|
| 10 | 提交回调 | |
|
| 10 | 操作提交 | |
|
| 10 | 操作 | |
|
| 10 | 读取操作 | |
|
| 10 | 写操作 | |
|
| 10 | Read-modify-write 操作 | |
|
| 10 | PG 操作 | |
|
| 10 | Stat 操作 | |
|
| 10 | 创建对象操作 | |
|
| 10 | 读取操作 | |
|
| 10 | 写操作 | |
|
| 10 | 编写完整对象操作 | |
|
| 10 | 附加操作 | |
|
| 10 | 将对象设置为零操作 | |
|
| 10 | 截断对象操作 | |
|
| 10 | 删除对象操作 | |
|
| 10 | 映射扩展操作 | |
|
| 10 | 稀疏读取操作 | |
|
| 10 | 克隆范围操作 | |
|
| 10 | Get xattr 操作 | |
|
| 10 | 设置 xattr 操作 | |
|
| 10 | xattr 比较操作 | |
|
| 10 | 删除 xattr 操作 | |
|
| 10 | 重置 xattr 操作 | |
|
| 10 | TMAP 更新操作 | |
|
| 10 | TMAP put 操作 | |
|
| 10 | TMAP get 操作 | |
|
| 10 | 调用(执行)操作 | |
|
| 10 | 按对象操作监视 | |
|
| 10 | 通知对象操作 | |
|
| 10 | 多操作中的扩展属性比较 | |
|
| 10 | 其他操作 | |
|
| 2 | 活跃的闲置操作 | |
|
| 10 | 发送的闲置操作 | |
|
| 10 | 重新闲置操作 | |
|
| 10 | 将 ping 发送到闲置操作 | |
|
| 2 | 活跃池操作 | |
|
| 10 | 发送池操作 | |
|
| 10 | 重组池操作 | |
|
| 2 | Active get pool stat 操作 | |
|
| 10 | 池 stat 操作发送 | |
|
| 10 | 重新设置池统计 | |
|
| 2 | statfs 操作 | |
|
| 10 | 发送的 FS stats | |
|
| 10 | 重新发送的 FS stats | |
|
| 2 | 活跃命令 | |
|
| 10 | 发送命令 | |
|
| 10 | 重新发送命令 | |
|
| 2 | OSD map epoch | |
|
| 10 | 收到的完整 OSD 映射 | |
|
| 10 | 接收的增量 OSD map | |
|
| 2 | 开放会话 | |
|
| 10 | 会话已打开 | |
|
| 10 | 会话关闭 | |
|
| 2 | Laggy OSD 会话 |
| 集合名称 | 指标名称 | 位字段值 | 简短描述 |
|---|---|---|---|
|
|
| 10 | 目前可用节流 |
|
| 10 | 最大值 throttle | |
|
| 10 | Gets | |
|
| 10 | 获取数据 | |
|
| 10 | 在 get_or_fail 时被阻断 | |
|
| 10 | 在 get_or_fail 期间获得成功 | |
|
| 10 | Takes | |
|
| 10 | 获取的数据 | |
|
| 10 | Puts | |
|
| 10 | 放置数据 | |
|
| 5 | 等待延迟 |
第 9 章 BlueStore
从 Red Hat Ceph Storage 4 开始,BlueStore 是 OSD 守护进程的默认对象存储。较早的对象存储 FileStore 需要在原始块设备之上创建一个文件系统。对象然后写入文件系统。BlueStore 不需要初始文件系统,因为 BlueStore 会将对象直接放在块设备上。
BlueStore 为生产环境中的 OSD 守护进程提供了高性能后端。默认情况下,BlueStore 配置为自我调整。如果您确定您的环境使用手动调优的 BlueStore 的性能更好,请联系红帽支持并共享您的配置详情,以帮助我们改进自动调整功能。红帽期待您的反馈意见并感谢您的建议。
9.1. Ceph BlueStore
以下是使用 BlueStore 的一些主要功能:
- 直接管理存储设备
- BlueStore 使用原始块设备或分区。这可避免任何抽象层的抽象层,如 XFS 等本地文件系统,这可能会限制性能或增加复杂性。
- 使用 RocksDB 进行元数据管理
- BlueStore 使用 RocksDB 的键值数据库来管理内部元数据,如从对象名称映射到磁盘上的块位置。
- 完整数据和元数据校验和
- 默认情况下,写入 BlueStore 的所有数据和元数据都受到一个或多个校验和的保护。在不验证的情况下,不会从磁盘或返回给用户读取数据或元数据。
- 高效的 copy-on-write 功能
- Ceph 块设备和 Ceph 文件系统快照依赖于在 BlueStore 中高效实施的写时复制克隆机制。这可以提高常规快照以及依赖克隆来实现高效的两阶段提交的纠删代码池的 I/O 效率。
- 没有大型的双写方式
- BlueStore 首先将任何新数据写入块设备上未分配空间,然后提交 RocksDB 事务来更新对象元数据以引用磁盘的新区域。只有写入操作低于可配置的大小阈值时,它才会回退到写出日志方案,这与 FileStore 的运行方式类似。
- 支持多设备
BlueStore 可以使用多个块设备来存储不同的数据。例如:用于数据的硬盘驱动器(HDD),用于元数据的 Solid-state Drive(SSD),即 Non-volatile Memory(NVM)或 Non-volatile random-access memory(NVRAM)或 RocksDB write-ahead 日志的持久性内存。详情请查看 Ceph BlueStore 设备。
注意ceph-disk实用程序尚未置备多个设备。若要使用多个设备,必须手动设置 OSD。- 高效的块设备使用
- 因为 BlueStore 不使用任何文件系统,所以它将尽可能减少需要清除存储设备缓存的需要。
9.2. Ceph BlueStore 设备
本节介绍 BlueStore 后端使用哪些块设备。
BlueStore 可以管理一个、两个或三个存储设备。
- 主
- WAL
- DB
在最简单的情形中,BlueStore 使用一个(主)存储设备。存储设备分为两个部分,其中包括:
- OSD 元数据 :使用 XFS 格式化的小分区,其中包含 OSD 的基本元数据。此数据目录包含 OSD 的信息,如其标识符、所属集群及其专用密钥环。
- 数据 :一个大型分区,占据由 BlueStore 直接管理的设备的其余部分,其中包含所有 OSD 数据。这个主要设备由数据目录中的块符号链接识别。
您还可以使用两个附加设备:
-
WAL(write-ahead-log)设备 :存储 BlueStore 内部日志或 write-ahead 日志的设备。它通过数据目录中的
block.wal符号链接来识别。只有在设备比主设备更快时才请考虑使用 WAL 设备。例如,当 WAL 设备使用 SSD 磁盘且主设备使用 HDD 磁盘时。 - DB 设备 :存储 BlueStore 内部元数据的设备。嵌入式 RocksDB 数据库包含尽可能多的元数据,因为它可以在 DB 设备上而不是主设备上的元数据来提高性能。如果 DB 设备已满,它开始向主设备添加元数据。只有在设备比主设备更快时才考虑使用 DB 设备。
如果您在快速设备中只有 1GB 的存储。红帽建议将其用作 WAL 设备。如果您使用更快速的设备可用,请考虑将其用作 DB 设备。BlueStore 日志始终放在最快的设备上,因此使用 DB 设备提供相同的好处,同时允许存储额外的元数据。
9.3. Ceph BlueStore 缓存
BlueStore 缓存是缓冲区的集合,具体取决于配置,可以填充数据,因为 OSD 守护进程从中读取或写入到磁盘。默认情况下,Red Hat Ceph Storage 中 BlueStore 将缓存读内容,但不进行写入。这是因为 bluestore_default_buffered_write 选项设置为 false,以避免出现与缓存驱除相关的潜在开销。
如果 bluestore_default_buffered_write 选项被设置为 true,则数据会首先写入缓冲区,然后提交到磁盘。之后,写入确认将发送到客户端,从而加快对缓存中已存在的数据的后续读取速度,直到数据被驱除为止。
对于有大量读操作的工作负载不会立即从 BlueStore 缓存中受益。完成更多阅读后,缓存会随时间增长,后续的读取将提高性能。缓存填充的速度取决于 BlueStore 块和数据库磁盘类型,以及客户端的工作负载要求。
在启用 bluestore_default_buffered_write 选项前,请联系红帽支持。
9.4. Ceph BlueStore 的大小考虑
使用 BlueStore OSD 混合传统和固态硬盘时,必须相应地调整 RocksDB 逻辑卷(block.db)。红帽建议,RocksDB 逻辑卷不要小于使用对象、文件和混合工作负载的块大小的 4%。红帽通过 RocksDB 和 OpenStack 块工作负载支持 1% 的 BlueStore 块大小。例如,如果对象工作负载的块大小为 1 TB,则至少创建 40 GB RocksDB 逻辑卷。
如果没有混合驱动器类型,则不需要单独的 RocksDB 逻辑卷。BlueStore 将自动管理 RocksDB 的大小。
BlueStore 的缓存内存用于 RocksDB、BlueStore 元数据和对象数据的键值对元数据。
除了 OSD 已消耗的内存占用空间外,BlueStore 缓存内存值也除外。
9.5. 添加 Ceph BlueStore OSD
这部分论述了如何使用 BlueStore 后端对象存储安装新的 Ceph OSD 节点。
前提条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
- 节点的根级别访问权限。
流程
添加新的 OSD 节点到 Ansible 清单文件中的
[osds]部分,默认为位于/etc/ansible/hosts。[osds] node1 node2 node3 HOST_NAME
[osds] node1 node2 node3 HOST_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow 替换:
-
HOST_NAME为 OSD 节点的名称
Example
[osds] node1 node2 node3 node4
[osds] node1 node2 node3 node4Copy to Clipboard Copied! Toggle word wrap Toggle overflow -
进入
/usr/share/ceph-ansible/目录。cd /usr/share/ceph-ansible
[user@admin ~]$ cd /usr/share/ceph-ansibleCopy to Clipboard Copied! Toggle word wrap Toggle overflow 创建
host_vars目录。[root@admin ceph-ansible] mkdir host_vars
[root@admin ceph-ansible] mkdir host_varsCopy to Clipboard Copied! Toggle word wrap Toggle overflow 在
host_vars中为新添加的 OSD 创建配置文件。[root@admin ceph-ansible] touch host_vars/HOST_NAME.yml
[root@admin ceph-ansible] touch host_vars/HOST_NAME.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 替换:
-
带有新添加 OSD 的主机名的
HOST_NAME
Example
[root@admin ceph-ansible] touch host_vars/node4.yml
[root@admin ceph-ansible] touch host_vars/node4.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow -
带有新添加 OSD 的主机名的
在新创建的文件中添加以下设置:
osd_objectstore: bluestore
osd_objectstore: bluestoreCopy to Clipboard Copied! Toggle word wrap Toggle overflow 注意要将 BlueStore 用于所有 OSD,请将
osd_objectstore:bluestore添加到group_vars/all.yml文件中。在
host_vars/HOST_NAME.yml中配置 BlueStore OSD:语法
lvm_volumes: - data: DATALV data_vg: DATAVGlvm_volumes: - data: DATALV data_vg: DATAVGCopy to Clipboard Copied! Toggle word wrap Toggle overflow 替换:
-
带有数据逻辑卷名称的
DATALV -
带有数据逻辑卷组名称的
DATAVG
Example
lvm_volumes: - data: data-lv1 data_vg: vg1lvm_volumes: - data: data-lv1 data_vg: vg1Copy to Clipboard Copied! Toggle word wrap Toggle overflow -
带有数据逻辑卷名称的
可选。如果要将
block.wal和block.db存储在专用逻辑卷中,请编辑host_vars/HOST_NAME.yml文件,如下所示:Copy to Clipboard Copied! Toggle word wrap Toggle overflow 替换:
- 带有数据逻辑卷的 DATALV
- WALLV 及应该包含 write-ahead-log 的逻辑卷
- 带有 WAL 和/或 DB 设备 LV 所在卷组的 VG
- 包含 BlueStore 内部元数据的 DBLV
Example
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 注意当使用
lvm_volumes:withosd_objectstore: bluestore时,LVM_volumesYAML 字典中必须至少包含数据。定义wal或db时,它必须同时具有 LV 名称和 VG 名称(不需要db和wal)。这允许四个组合:只包括数据、数据和 wal、数据和 Wal 和 db,或者 data 和 db。数据可以是裸设备、lv 或分区。wal和db可以是 lv 或 partition。当指定裸设备或分区ceph-volume时,会将逻辑卷放在其中。注意目前,
ceph-ansible不会创建卷组或逻辑卷。这必须在运行 Anisble playbook 之前完成。可选:您可以在
group_vars/all.yml文件中覆盖block.db默认大小:语法
ceph_conf_overrides: osd: bluestore_block_db_size: VALUEceph_conf_overrides: osd: bluestore_block_db_size: VALUECopy to Clipboard Copied! Toggle word wrap Toggle overflow Example
ceph_conf_overrides: osd: bluestore_block_db_size: 24336000000ceph_conf_overrides: osd: bluestore_block_db_size: 24336000000Copy to Clipboard Copied! Toggle word wrap Toggle overflow 注意bluestore_block_db_size的值应大于 2 GB。打开并编辑
group_vars/all.yml文件,然后取消注释osd_memory_target选项。调整 OSD 要消耗的内存数量。注意osd_memory_target选项的默认值为4000000000,即 4 GB。这个选项在内存中固定 BlueStore 缓存。重要osd_memory_target选项仅适用于 BlueStore 支持的 OSD。运行以下 Ansible playbook:
ansible-playbook site.yml
[user@admin ceph-ansible]$ ansible-playbook site.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 在 Ceph 监控节点中,验证新 OSD 是否已成功添加:
ceph osd tree
[root@mon ~]# ceph osd treeCopy to Clipboard Copied! Toggle word wrap Toggle overflow
9.6. 为小写入调优 Ceph BlueStore
在 BlueStore 中,原始分区在 bluestore_min_alloc_size 的块中分配和管理。默认情况下,蓝色store_min_alloc_size 是 64 KB ( HDD)和 4 KB 用于 SSD。当每个块中的未写入区域写入原始分区时,会用零填充。当您没有针对的工作负载正确配置大小时,这可能会导致浪费掉未使用的空间(例如,当编写小对象时)。
最佳实践是将 bluestore_min_alloc_size 设置为与最小写入匹配,以便避免写法。
例如,如果您的客户端会频繁写入 4 KB 对象,请使用 ceph-ansible 在 OSD 节点上配置以下设置:
bluestore_min_alloc_size = 4096
设置 bluestore_min_alloc_size_ssd 和 bluestore_min_alloc_size_hdd 分别特定于 SSD 和 HDD,但设置它们是必需的,因为设置 bluestore_min_alloc_size 覆盖它们。
先决条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
- 可重新置备为 OSD 节点的新服务器,或者:
- 可以重新部署的 OSD 节点。
- 如果您要重新部署现有的 Ceph OSD 节点,Ceph 监控节点的管理密钥环。
流程
可选: 如果重新部署现有的 OSD 节点,请使用
shrink-osd.ymlAnsible playbook 从集群中删除 OSD。ansible-playbook -v infrastructure-playbooks/shrink-osd.yml -e osd_to_kill=OSD_ID
ansible-playbook -v infrastructure-playbooks/shrink-osd.yml -e osd_to_kill=OSD_IDCopy to Clipboard Copied! Toggle word wrap Toggle overflow Example
ansible-playbook -v infrastructure-playbooks/shrink-osd.yml -e osd_to_kill=1
[admin@admin ceph-ansible]$ ansible-playbook -v infrastructure-playbooks/shrink-osd.yml -e osd_to_kill=1Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 如果重新部署现有的 OSD 节点,请擦除 OSD 驱动器并重新安装操作系统。
- 使用 Ansible 为 OSD 调配准备节点。准备任务示例包括启用 Red Hat Ceph Storage 存储库、添加 Ansible 用户以及启用无密码 SSH 登录。
将
bluestore_min_alloc_size添加到group_vars/all.ymlAnsible playbook 的ceph_conf_overrides部分:ceph_conf_overrides: osd: bluestore_min_alloc_size: 4096ceph_conf_overrides: osd: bluestore_min_alloc_size: 4096Copy to Clipboard Copied! Toggle word wrap Toggle overflow 如果部署新节点,请将其添加到 Ansible 清单文件中,通常为
/etc/ansible/hosts:[osds] OSD_NODE_NAME
[osds] OSD_NODE_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow Example
[osds] osd1 devices="[ '/dev/sdb' ]"
[osds] osd1 devices="[ '/dev/sdb' ]"Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 如果重新部署现有的 OSD,请将 Ceph Monitor 节点上的 admin keyring 文件复制到您要部署 OSD 的节点。
使用 Ansible 置备 OSD 节点:
ansible-playbook -v site.yml -l OSD_NODE_NAME
ansible-playbook -v site.yml -l OSD_NODE_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow Example
ansible-playbook -v site.yml -l osd1
[admin@admin ceph-ansible]$ ansible-playbook -v site.yml -l osd1Copy to Clipboard Copied! Toggle word wrap Toggle overflow playbook 完成后,使用
ceph 守护进程命令验证设置:ceph daemon OSD.ID config get bluestore_min_alloc_size
ceph daemon OSD.ID config get bluestore_min_alloc_sizeCopy to Clipboard Copied! Toggle word wrap Toggle overflow Example
ceph daemon osd.1 config get bluestore_min_alloc_size { "bluestore_min_alloc_size": "4096" }[root@osd1 ~]# ceph daemon osd.1 config get bluestore_min_alloc_size { "bluestore_min_alloc_size": "4096" }Copy to Clipboard Copied! Toggle word wrap Toggle overflow 您可以看到
bluestore_min_alloc_size设置为 4096 字节,相当于 4 KiB。
其它资源
- 如需更多信息,请参阅"Red Hat Ceph Storage 安装指南 "。
9.7. BlueStore 碎片工具
作为存储管理员,您要定期检查 BlueStore OSD 的碎片级别。您可以通过一个简单命令检查碎片级别,以便离线或在线 OSD。
9.7.1. 前提条件
- 正在运行的 Red Hat Ceph Storage 3.3 或更高版本的存储集群。
- BlueStore OSDs.
9.7.2. BlueStore 碎片工具是什么?
对于 BlueStore OSD,可用空间随时间在底层存储设备上发生碎片。有些碎片是正常的,但在出现过量碎片时会导致性能降低。
BlueStore 碎片工具在 BlueStore OSD 的碎片级别生成分数。此碎片分数指定为范围 0 到 1。分数为 0 表示没有碎片,1 分代表严重碎片。
| 分数 | 碎片挂载 |
|---|---|
| 0.0 - 0.4 | 没有或非常少的碎片。 |
| 0.4 - 0.7 | 较少且可接受的碎片。 |
| 0.7 - 0.9 | 需要考虑但安全的碎片。 |
| 0.9 - 1.0 | 严重碎片会导致性能问题。 |
如果您存在严重碎片,且需要一些有助于解决问题,请联络红帽支持。
9.7.3. 检查碎片
可以在线或离线检查 BlueStore OSD 的碎片级别。
前提条件
- 正在运行的 Red Hat Ceph Storage 3.3 或更高版本的存储集群。
- BlueStore OSDs.
在线 BlueStore 碎片得分
检查正在运行的 BlueStore OSD 进程:
简单报告:
语法
ceph daemon OSD_ID bluestore allocator score block
ceph daemon OSD_ID bluestore allocator score blockCopy to Clipboard Copied! Toggle word wrap Toggle overflow 示例
ceph daemon osd.123 bluestore allocator score block
[root@osd ~]# ceph daemon osd.123 bluestore allocator score blockCopy to Clipboard Copied! Toggle word wrap Toggle overflow 详细的报告:
语法
ceph daemon OSD_ID bluestore allocator dump block
ceph daemon OSD_ID bluestore allocator dump blockCopy to Clipboard Copied! Toggle word wrap Toggle overflow 示例
ceph daemon osd.123 bluestore allocator dump block
[root@osd ~]# ceph daemon osd.123 bluestore allocator dump blockCopy to Clipboard Copied! Toggle word wrap Toggle overflow
离线 BlueStore 碎片得分
检查非运行 BlueStore OSD 进程:
简单报告:
语法
ceph-bluestore-tool --path PATH_TO_OSD_DATA_DIRECTORY --allocator block free-score
ceph-bluestore-tool --path PATH_TO_OSD_DATA_DIRECTORY --allocator block free-scoreCopy to Clipboard Copied! Toggle word wrap Toggle overflow 示例
ceph-bluestore-tool --path /var/lib/ceph/osd/ceph-123 --allocator block free-score
[root@osd ~]# ceph-bluestore-tool --path /var/lib/ceph/osd/ceph-123 --allocator block free-scoreCopy to Clipboard Copied! Toggle word wrap Toggle overflow 详细的报告:
语法
ceph-bluestore-tool --path PATH_TO_OSD_DATA_DIRECTORY --allocator block free-dump
ceph-bluestore-tool --path PATH_TO_OSD_DATA_DIRECTORY --allocator block free-dumpCopy to Clipboard Copied! Toggle word wrap Toggle overflow 示例
ceph-bluestore-tool --path /var/lib/ceph/osd/ceph-123 --allocator block free-dump
[root@osd ~]# ceph-bluestore-tool --path /var/lib/ceph/osd/ceph-123 --allocator block free-dumpCopy to Clipboard Copied! Toggle word wrap Toggle overflow
其它资源
- 如需了解碎片分数的详细信息,请参阅 Red Hat Ceph Storage 4.1 BlueStore Fragmentation Tool。
9.8. 如何将对象存储从 FileStore 迁移到 BlueStore
作为存储管理员,您可以从传统对象存储 FileStore 迁移到新的对象存储 BlueStore。
9.8.1. 前提条件
- 一个健康且运行 Red Hat Ceph Storage 集群。
9.8.2. 从 FileStore 迁移到 BlueStore
与传统的 FileStore 相比,BlueStore 提高了性能和稳健性。单个 Red Hat Ceph Storage 集群可以包含 FileStore 和 BlueStore 设备的组合。
转换单个 OSD 无法进行,或者隔离。转换过程将依赖于存储集群的常规复制和修复过程或将 OSD 内容从旧(FileStore)设备复制到新的(BlueStore)设备的工具和策略。有两种方法可以从 FileStore 迁移到 BlueStore。
第一种方法
第一种方法是依次标记每个设备,等待数据在存储集群中复制,重新置备 OSD,并将它重新标记为"in"。这个方法的优点和缺点:
- 优点
- 简单.
- 可以在设备基础上完成。
- 不需要备用设备或节点。
- 缺点
在网络上复制数据两次。
注意一个副本到存储集群中的其他 OSD,允许您维护所需的副本数,然后将另一个副本重新复制到重新置备的 BlueStore OSD。
第二种方法
第二种方法是进行整个节点替换。您需要有一个没有数据的空节点。
有两种方法可以做到这一点:* 从不是存储集群一部分的一个新空节点开始。* 通过从存储集群中现有节点卸载数据。
- 优点
- 数据仅通过网络复制。
- 可一次性转换整个节点的 OSD。
- 可以并行转换多个节点。
- 每个节点不需要备用设备。
- 缺点
- 需要一个备用节点。
- 整个节点需要 OSD 将一次迁移数据。这可能会影响整个集群性能。
- 所有迁移的数据仍通过网络进行一个完整的跃点。
9.8.3. 使用 Ansible 从 FileStore 迁移到 BlueStore
使用 Ansible 从 FileStore 迁移到 BlueStore,将缩小并重新部署节点上的所有 OSD。在开始迁移前,Ansible playbook 会执行容量检查。然后,ceph-volume 程序重新部署 OSD。
前提条件
- 正常运行的 Red Hat Ceph Storage 4 集群。
-
用于 Ansible 应用的
ansible用户帐户。
流程
-
以
ansible用户身份登录 Ansible 管理节点。 编辑
group_vars/osd.yml文件,添加和设置以下选项:nb_retry_wait_osd_up: 50 delay_wait_osd_up: 30
nb_retry_wait_osd_up: 50 delay_wait_osd_up: 30Copy to Clipboard Copied! Toggle word wrap Toggle overflow 运行以下 Ansible playbook:
语法
ansible-playbook infrastructure-playbooks/filestore-to-bluestore.yml --limit OSD_NODE_TO_MIGRATE
ansible-playbook infrastructure-playbooks/filestore-to-bluestore.yml --limit OSD_NODE_TO_MIGRATECopy to Clipboard Copied! Toggle word wrap Toggle overflow Example
ansible-playbook infrastructure-playbooks/filestore-to-bluestore.yml --limit osd1
[ansible@admin ~]$ ansible-playbook infrastructure-playbooks/filestore-to-bluestore.yml --limit osd1Copy to Clipboard Copied! Toggle word wrap Toggle overflow 警告如果您在 Ceph 配置文件中明确设置了
osd_crush_update_on_start = False,则转换会失败。它将创建具有不同 ID 的新 OSD,并在 CRUSH 规则中写出它。另外,它无法清除旧的 OSD 数据目录。- 等待迁移完成,然后再在存储集群中的下一个 OSD 节点上启动。
9.8.4. 使用标记和替换方法从 FileStore 迁移到 BlueStore
从 FileStore 迁移到 BlueStore 最简单的方法是依次标记每个设备,等待数据在存储集群中复制,重新置备 OSD,然后再次将其标记为"in"。
前提条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
-
根访问节点。
流程
将下列变量 OSD_ID 替换为 ODS 标识号。
找到要替换的 FileStore OSD。
获取 OSD 标识号:
ceph osd tree
[root@ceph-client ~]# ceph osd treeCopy to Clipboard Copied! Toggle word wrap Toggle overflow 确定 OSD 是否使用 FileStore 还是 BlueStore:
语法
ceph osd metadata OSD_ID | grep osd_objectstore
ceph osd metadata OSD_ID | grep osd_objectstoreCopy to Clipboard Copied! Toggle word wrap Toggle overflow Example
ceph osd metadata 0 | grep osd_objectstore "osd_objectstore": "filestore",[root@ceph-client ~]# ceph osd metadata 0 | grep osd_objectstore "osd_objectstore": "filestore",Copy to Clipboard Copied! Toggle word wrap Toggle overflow 查看 FileStore 设备与 BlueStore 设备的当前计数:
ceph osd count-metadata osd_objectstore
[root@ceph-client ~]# ceph osd count-metadata osd_objectstoreCopy to Clipboard Copied! Toggle word wrap Toggle overflow
将 FileStore OSD 标记为 out:
ceph osd out OSD_ID
ceph osd out OSD_IDCopy to Clipboard Copied! Toggle word wrap Toggle overflow 等待数据从 OSD 迁出:
while ! ceph osd safe-to-destroy OSD_ID ; do sleep 60 ; done
while ! ceph osd safe-to-destroy OSD_ID ; do sleep 60 ; doneCopy to Clipboard Copied! Toggle word wrap Toggle overflow 停止 OSD:
systemctl stop ceph-osd@OSD_ID
systemctl stop ceph-osd@OSD_IDCopy to Clipboard Copied! Toggle word wrap Toggle overflow 捕获此 OSD 正在使用的设备:
mount | grep /var/lib/ceph/osd/ceph-OSD_ID
mount | grep /var/lib/ceph/osd/ceph-OSD_IDCopy to Clipboard Copied! Toggle word wrap Toggle overflow 卸载 OSD:
umount /var/lib/ceph/osd/ceph-OSD_ID
umount /var/lib/ceph/osd/ceph-OSD_IDCopy to Clipboard Copied! Toggle word wrap Toggle overflow 使用第 5 步的值作为
DEVICE销毁 OSD 数据:ceph-volume lvm zap DEVICE
ceph-volume lvm zap DEVICECopy to Clipboard Copied! Toggle word wrap Toggle overflow 重要成为 EXTREMELY CAREFUL,因为这会销毁设备的内容。在继续之前,不需要在该设备上使用这些数据,即存储集群处于健康状态。
注意如果 OSD 被加密,则卸载
osd-lockbox并在使用dmsetup 删除OSD 前删除加密。注意如果 OSD 包含逻辑卷,则在
ceph-volume lvm zap命令中使用--destroy选项。使存储集群知道 OSD 已销毁:
ceph osd destroy OSD_ID --yes-i-really-mean-it
[root@ceph-client ~]# ceph osd destroy OSD_ID --yes-i-really-mean-itCopy to Clipboard Copied! Toggle word wrap Toggle overflow 使用
DEVICE从第 5 步和相同的OSD_ID将 OSD 重新置备为 BlueStore OSD:ceph-volume lvm create --bluestore --data DEVICE --osd-id OSD_ID
[root@ceph-client ~]# ceph-volume lvm create --bluestore --data DEVICE --osd-id OSD_IDCopy to Clipboard Copied! Toggle word wrap Toggle overflow 重复此步骤。
注意只要您确保存储集群在销毁任何 OSD 之前存储集群为
HEALTH_OK,新的 BlueStore OSD 的重填操作可以与排空下一个 FileStore OSD 同时进行。如果不这样做,将降低数据的冗余,并增加风险,或者降低数据丢失。
9.8.5. 使用整个节点替换方法从 FileStore 迁移到 BlueStore
通过将每个存储的数据副本从 FileStore 迁移到 BlueStore,可以逐个节点执行。此迁移可以使用存储集群中的备用节点完成,或者有足够的可用空间从存储集群中清空整个节点,以便将其用作备用节点。理想情况下,节点必须与您要迁移的其他节点大致相同。
前提条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
-
根访问节点。 - 没有数据的空节点。
流程
-
将下面的变量
NEWNODE替换为新节点名称。 -
将以下变量
EXISTING_NODE_TO_CONVERT替换为存储集群中已存在的节点名称。 将下列变量
OSD_ID替换为 OSD 标识号。使用不在存储集群中的新节点。对于在存储集群中使用现有节点,请跳至第 3 步。
将节点添加到 CRUSH 层次结构中:
ceph osd crush add-bucket NEWNODE node
[root@mon ~]# ceph osd crush add-bucket NEWNODE nodeCopy to Clipboard Copied! Toggle word wrap Toggle overflow 重要不要将它附加到 root 用户。
安装 Ceph 软件包:
yum install ceph-osd
[root@mon ~]# yum install ceph-osdCopy to Clipboard Copied! Toggle word wrap Toggle overflow 注意将 Ceph 配置文件(默认为
/etc/ceph/ceph.conf)和密钥环复制到新节点。
- 跳至第 5 步。
如果您使用已在存储集群中已存在的节点,请使用以下命令:
ceph osd crush unlink EXISTING_NODE_TO_CONVERT default
[root@mon ~]# ceph osd crush unlink EXISTING_NODE_TO_CONVERT defaultCopy to Clipboard Copied! Toggle word wrap Toggle overflow 注意其中
default是 CRUSH map 中的即时维护器。- 跳至第 8 步。
为所有设备置备新的 BlueStore OSD:
ceph-volume lvm create --bluestore --data /dev/DEVICE
[root@mon ~]# ceph-volume lvm create --bluestore --data /dev/DEVICECopy to Clipboard Copied! Toggle word wrap Toggle overflow 验证 OSD 是否加入集群:
ceph osd tree
[root@mon ~]# ceph osd treeCopy to Clipboard Copied! Toggle word wrap Toggle overflow 您应当会在节点名称下看到新节点名称及所有 OSD,但 不得将 节点嵌套在层次结构中任何其他节点。
Example
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 将新节点交换到集群中的旧节点位置:
ceph osd crush swap-bucket NEWNODE EXISTING_NODE_TO_CONVERT
[root@mon ~]# ceph osd crush swap-bucket NEWNODE EXISTING_NODE_TO_CONVERTCopy to Clipboard Copied! Toggle word wrap Toggle overflow 此时,
EXISTING_NODE_TO_CONVERT上的所有数据都将开始迁移到NEWNODE上的 OSD。注意如果旧节点和新节点的总量不同,您可能还会看到一些数据迁移到存储集群中的其他节点,但只要节点的大小类似,这就是一个相对较小的数据。
等待数据迁移完成:
while ! ceph osd safe-to-destroy $(ceph osd ls-tree EXISTING_NODE_TO_CONVERT); do sleep 60 ; done
while ! ceph osd safe-to-destroy $(ceph osd ls-tree EXISTING_NODE_TO_CONVERT); do sleep 60 ; doneCopy to Clipboard Copied! Toggle word wrap Toggle overflow 登录到
EXISTING_NODE_TO_CONVERT,停止并卸载 now-emptyEXISTING_NODE_TO_CONVERT上的所有旧 OSD:systemctl stop ceph-osd@OSD_ID umount /var/lib/ceph/osd/ceph-OSD_ID
[root@mon ~]# systemctl stop ceph-osd@OSD_ID [root@mon ~]# umount /var/lib/ceph/osd/ceph-OSD_IDCopy to Clipboard Copied! Toggle word wrap Toggle overflow 销毁并清除旧的 OSD:
for osd in ceph osd ls-tree EXISTING_NODE_TO_CONVERT; do ceph osd purge $osd --yes-i-really-mean-it ; done
for osd in ceph osd ls-tree EXISTING_NODE_TO_CONVERT; do ceph osd purge $osd --yes-i-really-mean-it ; doneCopy to Clipboard Copied! Toggle word wrap Toggle overflow 擦除旧的 OSD 设备。这要求您确定手动擦除哪些设备。为每个设备执行以下命令:
ceph-volume lvm zap DEVICE
[root@mon ~]# ceph-volume lvm zap DEVICECopy to Clipboard Copied! Toggle word wrap Toggle overflow 重要成为 EXTREMELY CAREFUL,因为这会销毁设备的内容。在继续之前,不需要在该设备上使用这些数据,即存储集群处于健康状态。
注意如果 OSD 被加密,则卸载
osd-lockbox并在使用dmsetup 删除OSD 前删除加密。注意如果 OSD 包含逻辑卷,则在
ceph-volume lvm zap命令中使用--destroy选项。- 使用 now-empty 旧节点作为新节点,再重复这个过程。