块设备指南
管理、创建、配置和使用 Red Hat Ceph Storage 块设备
摘要
第 1 章 Ceph 块设备简介
块是具有一定长度的一组字节序列,例如 512 字节的数据块。将多个块组合到一个文件中,可用作您可以从中读取和写入的存储设备。基于块的存储接口是使用旋转介质存储数据的最常见的方式,例如:
- 硬盘驱动器
- CD/DVD 磁盘
- 软盘
- 传统的 9 轨磁带
因为块设备的广泛使用,虚拟块设备成为与 Red Hat Ceph Storage 等海量数据存储系统交互的理想候选者。
Ceph 块设备是精简调配、可调整大小的,并在 Ceph 存储集群中的多个对象存储设备 (OSD) 上存储数据分条。Ceph 块设备也称为可靠的自主分布式对象存储 (RADOS) 块设备(RBD)。Ceph 块设备利用 RADOS 功能,例如:
- 快照
- 复制
- 数据一致性
Ceph 块设备利用 librbd 库与 OSD 交互。
Ceph 块设备为内核虚拟机 (KVM)(如快速仿真器(QEMU))和基于云的计算系统(如 OpenStack)提供高性能,它们依赖于 libvirt 和 QEMU 实用程序与 Ceph 块设备集成。您可以使用同一个存储集群同时运行 Ceph 对象网关和 Ceph 块设备。
若要使用 Ceph 块设备,您需要有权访问正在运行的 Ceph 存储集群。详情请参阅 Red Hat Ceph Storage 指南中的安装 Red Hat Ceph Storage 集群。
第 2 章 Ceph 块设备命令
作为存储管理员,熟悉 Ceph 的块设备命令可帮助您有效管理 Red Hat Ceph Storage 集群。您可以创建和管理块设备池和镜像,以及启用和禁用 Ceph 块设备的各种功能。
2.1. 先决条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
2.2. 显示命令帮助
显示命令行界面中的命令和子命令在线帮助。
-h 选项仍然显示所有可用命令的帮助信息。
先决条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
- 客户端节点的根级别访问权限。
流程
使用
rbd help命令显示特定rbd命令及其子命令的帮助信息:语法
rbd help COMMAND SUBCOMMAND显示
snap list命令的帮助信息:[root@rbd-client ~]# rbd help snap list
2.3. 创建块设备池
在使用块设备客户端之前,请确保已启用并初始化 rbd 的池。
您必须先创建一个池,然后才能将它指定为来源。
先决条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
- 客户端节点的根级别访问权限。
流程
要创建
rbd池,请执行以下操作:语法
ceph osd pool create POOL_NAME PG_NUM ceph osd pool application enable POOL_NAME rbd rbd pool init -p POOL_NAME示例
[root@rbd-client ~]# ceph osd pool create example 128 [root@rbd-client ~]# ceph osd pool application enable example rbd [root@rbd-client ~]# rbd pool init -p example
其它资源
- 如需了解更多详细信息,请参见 Red Hat Ceph Storage 策略指南中的 池 一章。
2.4. 创建块设备镜像
在添加块设备到节点之前,在 Ceph 存储集群中为其创建镜像。
先决条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
- 客户端节点的根级别访问权限。
流程
要创建块设备镜像,请执行以下命令:
语法
rbd create IMAGE_NAME --size MEGABYTES --pool POOL_NAME示例
[root@rbd-client ~]# rbd create data --size 1024 --pool stack本例创建一个名为
data的 1 GB 镜像,该镜像将信息存储在名为stack的池中。注意在创建镜像之前,确保池存在。
其它资源
- 如需了解更多详细信息,请参阅 Red Hat Ceph Storage 块设备指南中的创建块设备池部分。
2.5. 列出块设备镜像
列出块设备镜像。
先决条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
- 客户端节点的根级别访问权限。
流程
若要列出
rbd池中的块设备,可执行下列命令(rbd是默认的池名称):[root@rbd-client ~]# rbd ls要列出特定池中的块设备,请执行以下命令,但将
POOL_NAME替换为池的名称:语法
rbd ls POOL_NAME示例
[root@rbd-client ~]# rbd ls swimmingpool
2.6. 检索块设备镜像信息
检索块设备镜像上的信息。
先决条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
- 客户端节点的根级别访问权限。
流程
要从特定镜像检索信息,请执行以下操作,但将
IMAGE_NAME替换为镜像的名称:语法
rbd --image IMAGE_NAME info示例
[root@rbd-client ~]# rbd --image foo info要从池中的镜像检索信息,请执行以下命令,但将
IMAGE_NAME替换为镜像的名称,并将POOL_NAME替换为池的名称:语法
rbd --image IMAGE_NAME -p POOL_NAME info示例
[root@rbd-client ~]# rbd --image bar -p swimmingpool info
2.7. 重新定义块设备镜像大小
Ceph 块设备镜像是精简配置。在开始将数据保存到其中之前,它们不会实际使用任何物理存储。但是,它们具有您通过 --size 选项设置的最大容量。
先决条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
- 客户端节点的根级别访问权限。
流程
增加或减少 Ceph 块设备镜像的最大大小:
语法
[root@rbd-client ~]# rbd resize --image IMAGE_NAME --size SIZE
2.8. 删除块设备镜像
删除块设备镜像。
先决条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
- 客户端节点的根级别访问权限。
流程
要删除块设备,请执行以下操作,但将
IMAGE_NAME替换为您要删除的镜像的名称:语法
rbd rm IMAGE_NAME示例
[root@rbd-client ~]# rbd rm foo要从池中移除块设备,请执行以下操作,但将
IMAGE_NAME替换为要删除的镜像名称,并将POOL_NAME替换为池的名称:语法
rbd rm IMAGE_NAME -p POOL_NAME示例
[root@rbd-client ~]# rbd rm bar -p swimmingpool
2.9. 使用 trash 命令管理块设备镜像
RADOS 块设备 (RBD) 镜像可以使用 rbd trash 命令移到回收站中。
这个命令提供了广泛的选项,例如:
- 从回收站中删除镜像。
- 从回收站中列出镜像.
- 防止从回收站中删除镜像。
- 从回收站中删除镜像.
- 从回收站中恢复镜像
- 从回收站中恢复镜像并对其进行重命名。
- 从回收站中清除过期的镜像。
- 调度从回收站中清除。
先决条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
- 客户端节点的根级别访问权限。
流程
将镜像移动到回收站:
语法
rbd trash mv POOL_NAME/IMAGE_NAME示例
[root@rbd-client ~]# rbd trash mv mypool/myimage镜像处于回收站中后,将分配一个唯一镜像 ID。
注意如果需要使用任何回收选项,则在指定镜像时需要此镜像 ID。
列出回收站中的镜像:
语法
rbd trash ls POOL_NAME示例
[root@rbd-client ~]# rbd trash ls mypool 1558a57fa43b rename_image唯一的 IMAGE_ID
1558a57fa43b可用于任何垃圾选项。将镜像移动到回收站中,并提提从回收站中删除镜像:
语法
rbd trash mv POOL_NAME/IMAGE_NAME --expires-at "EXPIRATION_TIME"EXPIRATION_TIME 可以是秒数、小时、日期、时间为"HH:MM:SS"或"tomorrow"。
示例
[root@rbd-client ~]# rbd trash mv mypool/myimage --expires-at "60 seconds"在本例中,
myimage被移到 trash。但是,在 60 秒前,您无法从回收中删除它。从回收站中恢复镜像:
语法
rbd trash restore POOL_NAME/IMAGE_ID示例
[root@rbd-client ~]# rbd trash restore mypool/14502ff9ee4d从回收站中删除镜像:
语法
rbd trash rm POOL_NAME/IMAGE_ID [--force]示例
[root@rbd-client ~]# rbd trash rm mypool/14502ff9ee4d Removing image: 100% complete...done.如果镜像延迟删除,则不能将其从回收站中删除,直到过期为止。您收到以下出错信息:
示例
Deferment time has not expired, please use --force if you really want to remove the image Removing image: 0% complete...failed. 2021-12-02 06:37:49.573 7fb5d237a500 -1 librbd::api::Trash: remove: error: deferment time has not expired.重要从回收站中删除镜像后,便无法恢复。
重命名镜像,然后从回收站中恢复:
语法
rbd trash restore POOL_NAME/IMAGE_ID --image NEW_IMAGE_NAME示例
[root@rbd-client ~]# rbd trash restore mypool/14502ff9ee4d --image test_image从回收站中删除过期的镜像:
语法
rbd trash purge POOL_NAME示例
[root@rbd-client ~]# rbd trash purge mypool在本例中,从
mypool遍历的所有镜像都会被移除。
2.10. 启用和禁用镜像功能
您可以在现有镜像上启用或禁用镜像功能,如 fast-diff、exclusive-lock、object-map 或 journaling。
deep flatten 功能只能在现有的镜像上禁用,而不能启用。要使用 deep flatten 功能,需要在创建镜像时启用它。
先决条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
- 客户端节点的根级别访问权限。
流程
要启用某一功能,请执行以下操作:
语法
rbd feature enable POOL_NAME/IMAGE_NAME FEATURE_NAME在
data池中的image1镜像上启用exclusive-lock功能:示例
[root@rbd-client ~]# rbd feature enable data/image1 exclusive-lock重要如果启用了
fast-diff和object-map功能,则重建对象映射:+ 语法
rbd object-map rebuild POOL_NAME/IMAGE_NAME
要禁用某一功能,请执行以下操作:
语法
rbd feature disable POOL_NAME/IMAGE_NAME FEATURE_NAME在
data池中禁用image2镜像的fast-diff功能:示例
[root@rbd-client ~]# rbd feature disable data/image2 fast-diff
2.11. 使用镜像元数据
Ceph 支持以键值对的形式添加自定义镜像元数据添。这些键值对没有严格的格式限制。
此外,通过使用元数据,您可以为特定镜像设置 RADOS 块设备 (RBD) 配置参数。
使用 rbd image-meta 命令处理元数据。
先决条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
- 客户端节点的根级别访问权限。
流程
设置新的元数据键值对:
语法
rbd image-meta set POOL_NAME/IMAGE_NAME KEY VALUE示例
[root@rbd-client ~]# rbd image-meta set data/dataset last_update 2016-06-06本例将
last_update键设置为data池中dataset镜像的2016-06-06值。删除元数据键值对:
语法
rbd image-meta remove POOL_NAME/IMAGE_NAME KEY示例
[root@rbd-client ~]# rbd image-meta remove data/dataset last_update本例从
data池中的dataset镜像中删除last_update键值对。查看一个键的值:
语法
rbd image-meta get POOL_NAME/IMAGE_NAME KEY示例
[root@rbd-client ~]# rbd image-meta get data/dataset last_update这个示例查看
last_update键的值。显示镜像中的所有元数据:
语法
rbd image-meta list POOL_NAME/IMAGE_NAME示例
[root@rbd-client ~]# rbd data/dataset image-meta list本例列出了为
data池中dataset镜像设置的元数据。覆盖特定镜像的 Ceph 配置文件中设置的 RBD 镜像配置设置:
语法
rbd config image set POOL_NAME/IMAGE_NAME PARAMETER VALUE示例
[root@rbd-client ~]# rbd config image set data/dataset rbd_cache false本例为
data池中的dataset镜像禁用 RBD 缓存。
其它资源
- 如需了解可能配置选项列表,请参阅 Red Hat Ceph Storage 块设备指南中的块设备常规选项部分。
2.12. 在池之间移动镜像
您可以在同一集群内的不同池之间移动 RADOS 块设备 (RBD) 镜像。迁移可以在复制池之间、纠删代码池之间,或者在复制池和纠删代码池之间迁移。
在此过程中,源镜像会复制到具有所有快照历史记录的目标镜像,也可选择性地复制到源镜像的父镜像中,以帮助保留稀疏性。源镜像是只读的,目标镜像是可写的。目标镜像在迁移过程中链接到源镜像。
您可以在使用新目标镜像时安全地在后台运行此过程。但是,在准备步骤前停止使用目标镜像的所有客户端,以确保更新使用该镜像的客户端以指向新的目标镜像。
krbd 内核模块目前不支持实时迁移。
先决条件
- 停止所有使用该源镜像的客户端。
- 客户端节点的根级别访问权限。
流程
通过创建跨链接源和目标镜像的新目标镜像准备迁移:
语法
rbd migration prepare SOURCE_IMAGE TARGET_IMAGE替换:
- SOURCE_IMAGE,带有要移动的镜像的名称。使用 POOL/IMAGE_NAME 格式。
- TARGET_IMAGE,带有新镜像的名称。使用 POOL/IMAGE_NAME 格式。
示例
[root@rbd-client ~]# rbd migration prepare data/source stack/target验证新目标镜像的状态,这应该为
prepared:语法
rbd status TARGET_IMAGE示例
[root@rbd-client ~]# rbd status stack/target Watchers: none Migration: source: data/source (5e2cba2f62e) destination: stack/target (5e2ed95ed806) state: prepared- (可选)使用新目标镜像名称重新启动客户端。
将源镜像复制到目标镜像:
语法
rbd migration execute TARGET_IMAGE示例
[root@rbd-client ~]# rbd migration execute stack/target确保迁移已完成:
示例
[root@rbd-client ~]# rbd status stack/target Watchers: watcher=1.2.3.4:0/3695551461 client.123 cookie=123 Migration: source: data/source (5e2cba2f62e) destination: stack/target (5e2ed95ed806) state: executed通过删除源镜像和目标镜像之间的跨链接来提交迁移,这也会移除源镜像:
语法
rbd migration commit TARGET_IMAGE示例
[root@rbd-client ~]# rbd migration commit stack/target如果源镜像是一个或多个克隆的父镜像,请在确保克隆镜像不在使用后使用
--force选项:示例
[root@rbd-client ~]# rbd migration commit stack/target --force- 如果您在准备步骤后没有重新启动客户端,请使用新目标镜像名称重启客户端。
2.13. rbdmap 服务
systemd 单元文件 rbdmap.service 包含在 ceph-common 软件包中。rbdmap.service 单元执行 rbdmap shell 脚本。
此脚本自动为一个或多个 RBD 镜像自动映射和取消 map RADOS 块设备 (RBD)。脚本可以随时手动运行,但典型的用例是在引导时自动挂载 RBD 镜像,并在关机时卸载。脚本采用单个参数,可以是 map (用于挂载)或 unmap(卸载)RBD 镜像。脚本解析配置文件,默认为 /etc/ceph/rbdmap,但可使用名为 RBDMAPFILE 的环境变量来覆盖。配置文件的每一行对应于 RBD 镜像。
配置文件格式的格式如下:
IMAGE_SPEC RBD_OPTS
其中 IMAGE_SPEC 指定 POOL_NAME / IMAGE_NAME,或仅使用 IMAGE_NAME,在这种情况下,POOL_NAME 默认为 rbd。RBD_OPTS 是要传递到底层 rbd map 命令的选项列表。这些参数及其值应指定为用逗号分开的字符串:
OPT1=VAL1,OPT2=VAL2,…,OPT_N=VAL_N
这将导致脚本发出类似如下的 rbd map 命令:
rbd map POOLNAME/IMAGE_NAME --OPT1 VAL1 --OPT2 VAL2
对于包含逗号或相等符号的选项和值,可以使用简单的符号来防止替换它们。
成功后,rbd map 操作会将镜像映射到 /dev/rbdX 设备,此时会触发一个 udev 规则来创建一个友好的设备名称 symlink,如 /dev/rbd/POOL_NAME/IMAGE_NAME 指向实际映射的设备。要成功挂载或卸载,友好的设备名称必须在 /etc/fstab 文件中具有对应的条目。为 RBD 镜像编写 /etc/fstab 条目时,最好指定 noauto 或 nofail 挂载选项。这可防止 init 系统在设备存在前尝试过早挂载该设备。
2.14. 配置 rbdmap 服务
要在引导时或关机时自动映射和挂载或取消 map 和卸载 RADOS 块设备 (RBD)。
先决条件
- 对执行挂载的节点的根级别访问权限。
-
安装
ceph-common软件包.
流程
-
打开并编辑
/etc/ceph/rbdmap配置文件。 将 RBD 镜像或镜像添加到配置文件中:
示例
foo/bar1 id=admin,keyring=/etc/ceph/ceph.client.admin.keyring foo/bar2 id=admin,keyring=/etc/ceph/ceph.client.admin.keyring,options='lock_on_read,queue_depth=1024'- 保存对配置文件的更改。
启用 RBD 映射服务:
示例
[root@client ~]# systemctl enable rbdmap.service
2.15. 使用命令行界面监控 Ceph 块设备的性能
自 Red Hat Ceph Storage 4.1 开始,在 Ceph OSD 和管理器组件中集成了性能指标收集框架。此框架提供了一种内置方法,用于生成和处理构建其他 Ceph 块设备性能监控解决方案的性能指标。
新的 Ceph 管理器模块rbd_support 在启用时聚合性能指标。rbd 命令具有两个新操作:iotop 和 iostat。
这些操作的初始使用可能需要大约 30 秒时间来填充数据字段。
先决条件
- 对 Ceph 监控节点的用户级别访问权限.
流程
启用
rbd_supportCeph Manager 模块:示例
[user@mon ~]$ ceph mgr module enable rbd_support显示"iotop"的镜像格式:
示例
[user@mon ~]$ rbd perf image iotop注意可以使用右箭头键对 write ops、read-ops、write-bytes、read-latency 和 read-latency 列进行动态排序。
显示镜像的"iostat"样式:
示例
[user@mon ~]$ rbd perf image iostat注意此命令的输出可以是 JSON 或 XML 格式,然后使用其他命令行工具进行排序。
2.16. 其它资源
-
有关映射和取消映射块设备的详情,请查看 第 3 章
rbd内核模块。
第 3 章 rbd 内核模块
作为存储管理员,您可以通过 rbd 内核模块访问 Ceph 块设备。您可以映射和取消映射块设备,并显示这些映射。此外,您可以通过 rbd 内核模块获取镜像列表。
用户可以使用 Red Hat Enterprise Linux (RHEL) 以外的 Linux 发行版本中的内核客户端,但并不被支持。如果在存储集群中使用这些内核客户端时发现问题,红帽会解决这些问题,但是如果发现根本原因在内核客户端一侧,则软件供应商必须解决这个问题。
3.1. 先决条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
3.2. 创建 Ceph 块设备并从 Linux 内核模块客户端使用它
作为存储管理员,您可以在 Red Hat Ceph Storage 控制面板中为 Linux 内核模块客户端创建 Ceph 块设备。作为系统管理员,您可以使用命令行将该块设备映射到 Linux 客户端,并进行分区、格式化和挂载。之后,您可以为其读取和写入文件。
先决条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
- 一个 Red Hat Enterprise Linux 客户端。
3.2.1. 使用控制面板为 Linux 内核模块客户端创建 Ceph 块设备
您可以通过仅启用其所需的功能,使用控制面板 Web 界面为 Linux 内核模块客户端创建专用的 Ceph 块设备。
先决条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
流程
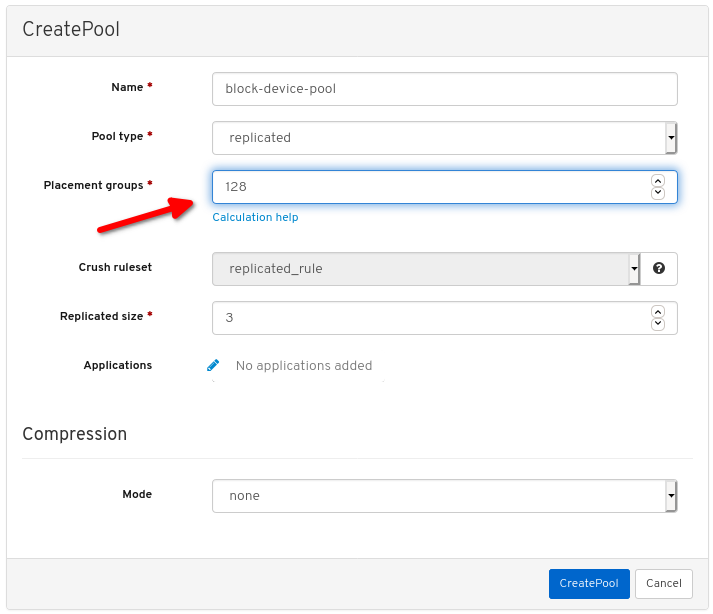
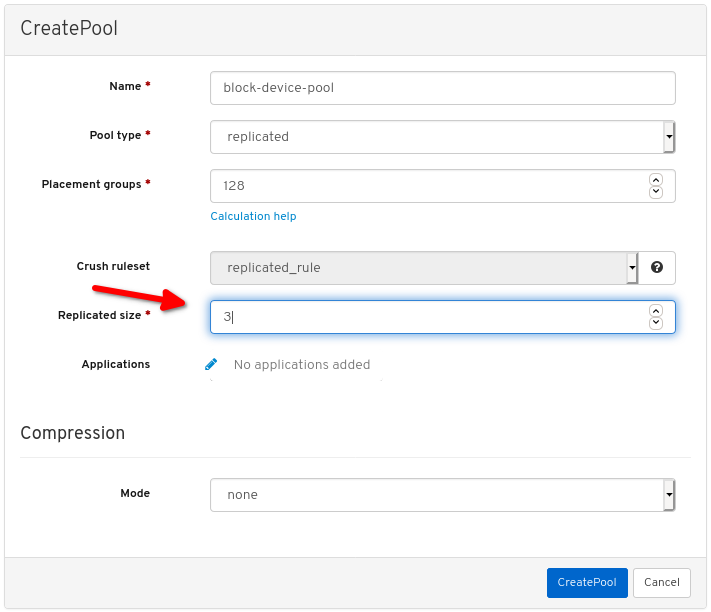
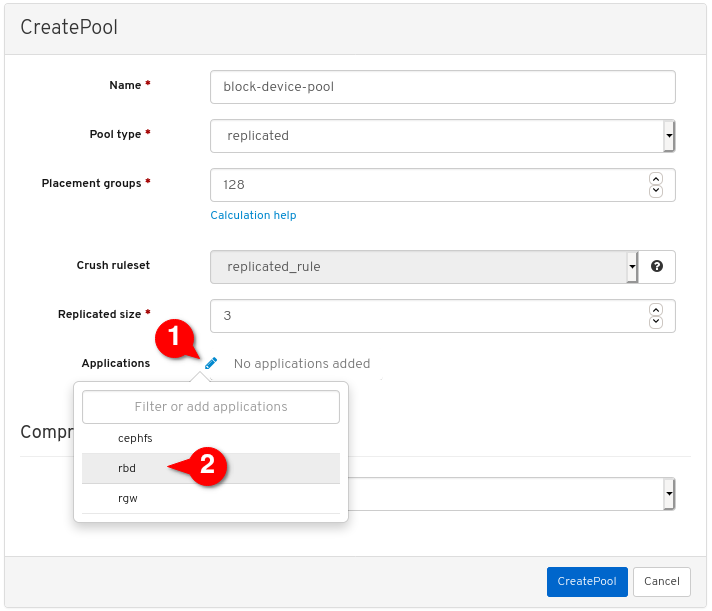
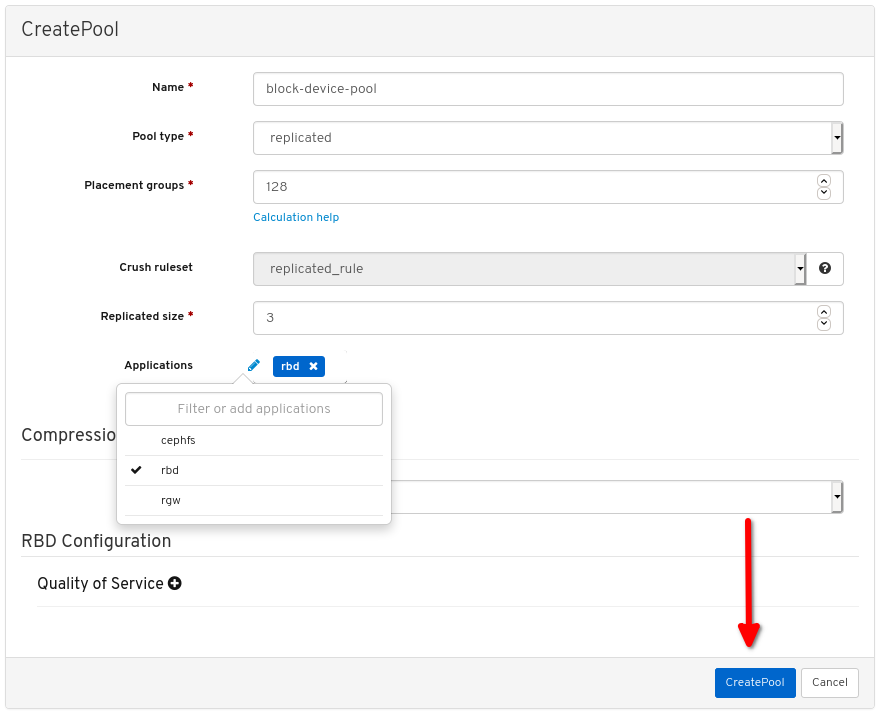

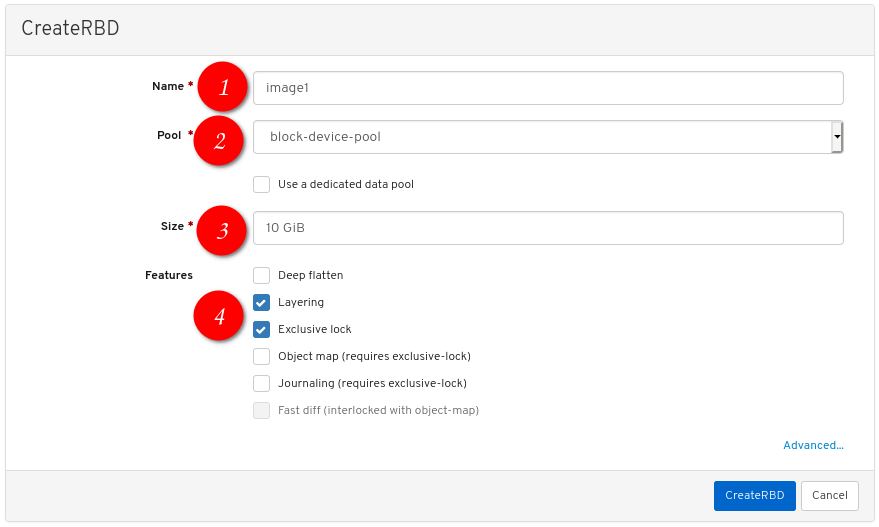
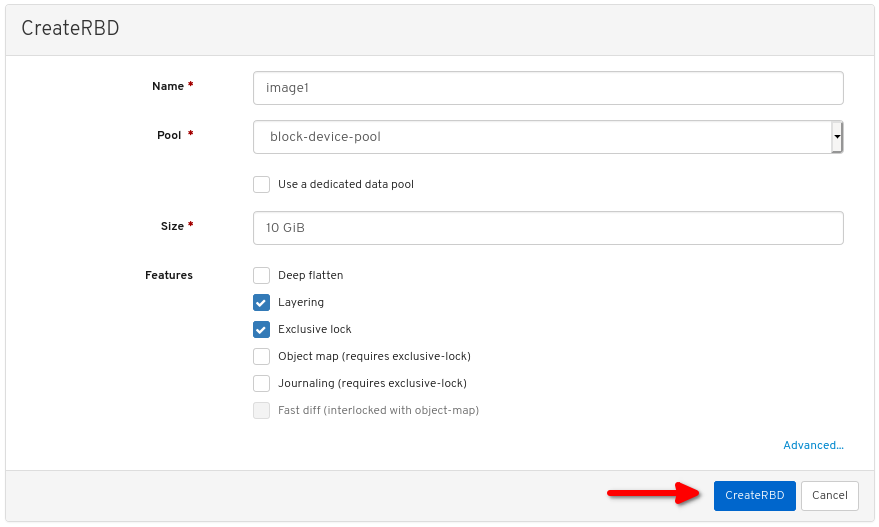
其它资源
- 如需更多信息,请参阅使用命令行映射并在 Linux 中挂载 Ceph 块设备。
- 如需更多信息,请参阅控制面板指南。
3.2.2. 使用命令行映射并挂载 Ceph 块设备到 Linux 上
您可以使用 Linux rbd 内核模块从 Red Hat Enterprise Linux 客户端映射 Ceph 块设备。映射之后,您可以对其进行分区、格式化和挂载,以便您可以将文件写入到其中。
先决条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
- 为 Linux 内核模块客户端创建了 Ceph 块设备。
- 一个 Red Hat Enterprise Linux 客户端。
流程
在 Red Hat Enterprise Linux 客户端节点上,启用 Red Hat Ceph Storage 4 Tools 存储库:
Red Hat Enterprise Linux 7
[root@client1 ~]# subscription-manager repos --enable=rhel-7-server-rhceph-4-tools-rpmsRed Hat Enterprise Linux 8
[root@client1 ~]# subscription-manager repos --enable=rhceph-4-tools-for-rhel-8-x86_64-rpms安装
ceph-commonRPM 软件包:Red Hat Enterprise Linux 7
[root@client1 ~]# yum install ceph-commonRed Hat Enterprise Linux 8
[root@client1 ~]# dnf install ceph-common将 Ceph 配置文件从 monitor 节点复制到客户端节点:
scp root@MONITOR_NODE:/etc/ceph/ceph.conf /etc/ceph/ceph.conf示例
[root@client1 ~]# scp root@cluster1-node2:/etc/ceph/ceph.conf /etc/ceph/ceph.conf root@192.168.0.32's password: ceph.conf 100% 497 724.9KB/s 00:00将密钥文件从 monitor 节点复制到客户端节点:
scp root@MONITOR_NODE:/etc/ceph/ceph.client.admin.keyring /etc/ceph/ceph.client.admin.keyring示例
[root@client1 ~]# scp root@cluster1-node2:/etc/ceph/ceph.client.admin.keyring /etc/ceph/ceph.client.admin.keyring root@192.168.0.32's password: ceph.client.admin.keyring 100% 151 265.0KB/s 00:00映射镜像:
rbd map --pool POOL_NAME IMAGE_NAME --id admin示例
[root@client1 ~]# rbd map --pool block-device-pool image1 --id admin /dev/rbd0 [root@client1 ~]#在块设备中创建分区表:
parted /dev/MAPPED_BLOCK_DEVICE mklabel msdos示例
[root@client1 ~]# parted /dev/rbd0 mklabel msdos Information: You may need to update /etc/fstab.为 XFS 文件系统创建分区:
parted /dev/MAPPED_BLOCK_DEVICE mkpart primary xfs 0% 100%示例
[root@client1 ~]# parted /dev/rbd0 mkpart primary xfs 0% 100% Information: You may need to update /etc/fstab.格式化分区:
mkfs.xfs /dev/MAPPED_BLOCK_DEVICE_WITH_PARTITION_NUMBER示例
[root@client1 ~]# mkfs.xfs /dev/rbd0p1 meta-data=/dev/rbd0p1 isize=512 agcount=16, agsize=163824 blks = sectsz=512 attr=2, projid32bit=1 = crc=1 finobt=1, sparse=1, rmapbt=0 = reflink=1 data = bsize=4096 blocks=2621184, imaxpct=25 = sunit=16 swidth=16 blks naming =version 2 bsize=4096 ascii-ci=0, ftype=1 log =internal log bsize=4096 blocks=2560, version=2 = sectsz=512 sunit=16 blks, lazy-count=1 realtime =none extsz=4096 blocks=0, rtextents=0创建要挂载新文件系统的目录:
mkdir PATH_TO_DIRECTORY示例
[root@client1 ~]# mkdir /mnt/ceph挂载文件系统:
mount /dev/MAPPED_BLOCK_DEVICE_WITH_PARTITION_NUMBER PATH_TO_DIRECTORY示例
[root@client1 ~]# mount /dev/rbd0p1 /mnt/ceph/验证文件系统是否已挂载并显示正确的大小:
df -h PATH_TO_DIRECTORY示例
[root@client1 ~]# df -h /mnt/ceph/ Filesystem Size Used Avail Use% Mounted on /dev/rbd0p1 10G 105M 9.9G 2% /mnt/ceph
其它资源
- 如需更多信息,请参阅使用仪表板为 Linux 内核模块客户端创建 Ceph 块设备。
- 如需更多信息,请参阅为 Red Hat Enterprise Linux 8 管理文件系统。
- 如需更多信息,请参阅 Red Hat Enterprise Linux 7 的存储管理指南。
3.3. 获取镜像列表
获取 Ceph 块设备镜像的列表。
先决条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
- 节点的根级别访问权限。
流程
要挂载块设备镜像,首先返回镜像列表:
[root@rbd-client ~]# rbd list
3.4. 映射块设备
使用 rbd 将镜像名称映射到内核模块。您必须指定镜像名称、池名称和用户名。RBD 将加载 RBD 内核模块(如果尚未加载)。
先决条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
- 节点的根级别访问权限。
流程
将镜像名称映射到内核模块:
语法
rbd device map POOL_NAME/IMAGE_NAME --id USER_NAME示例
[root@rbd-client ~]# rbd device map rbd/myimage --id admin在使用
cephx身份验证时,通过密钥环或包含 secret 的文件指定 secret:语法
[root@rbd-client ~]# rbd device map POOL_NAME/IMAGE_NAME --id USER_NAME --keyring PATH_TO_KEYRING或
[root@rbd-client ~]# rbd device map POOL_NAME/IMAGE_NAME --id USER_NAME --keyfile PATH_TO_FILE
3.5. 显示映射的块设备
您可以使用 rbd 命令显示哪些块设备镜像映射到内核模块。
先决条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
- 节点的根级别访问权限。
流程
显示映射的块设备:
[root@rbd-client ~]# rbd device list
3.6. 取消映射块设备
您可以使用 unmap 选项并提供设备名称,通过 rbd 命令取消 map 块设备镜像。
先决条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
- 节点的根级别访问权限。
流程
取消映射块设备镜像:
语法
rbd device unmap /dev/rbd/POOL_NAME/IMAGE_NAME示例
[root@rbd-client ~]# rbd device unmap /dev/rbd/rbd/foo
3.7. 分隔同一池中的独立命名空间中的镜像
当直接在不使用更高级别的系统(如 OpenStack 或 OpenShift Container Storage)的情况下直接使用 Ceph 块设备时,无法限制用户对特定块设备镜像的访问。与 CephX 功能相结合时,用户可以限制为特定的池命名空间来限制对镜像的访问。
您可以使用 RADOS 命名空间(一个新的身份级别)来识别对象,以在池中客户端之间提供隔离。例如,客户端只能对特定命名空间具有完全权限。这样,每个租户都可行使用不同的 RADOS 客户端,对于很多不同租户访问自己的块设备镜像,这尤其有用。
您可以在同一池中的独立命名空间中隔离块设备镜像。
先决条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
- 将所有内核升级到 4x,并在所有客户端上升级到 librbd 和 librados。
- 对 monitor 和客户端节点的 root 级别访问。
流程
创建
rbd池:语法
ceph osd pool create POOL_NAME PG_NUM示例
[root@mon ~]# ceph osd pool create mypool 100 pool 'mypool' created将
rbd池与 RBD 应用关联:语法
ceph osd pool application enable POOL_NAME rbd示例
[root@mon ~]# ceph osd pool application enable mypool rbd enabled application 'rbd' on pool 'mypool'使用 RBD 应用初始化池:
语法
rbd pool init -p POOL_NAME示例
[root@mon ~]# rbd pool init -p mypool创建两个命名空间:
语法
rbd namespace create --namespace NAMESPACE示例
[root@mon ~]# rbd namespace create --namespace namespace1 [root@mon ~]# rbd namespace create --namespace namespace2 [root@mon ~]# rbd namespace ls --format=json [{"name":"namespace2"},{"name":"namespace1"}]为两个用户提供命名空间的访问权限:
语法
ceph auth get-or-create client.USER_NAME mon 'profile rbd' osd 'profile rbd pool=rbd namespace=NAMESPACE' -o /etc/ceph/client.USER_NAME.keyring示例
[root@mon ~]# ceph auth get-or-create client.testuser mon 'profile rbd' osd 'profile rbd pool=rbd namespace=namespace1' -o /etc/ceph/client.testuser.keyring [root@mon ~]# ceph auth get-or-create client.newuser mon 'profile rbd' osd 'profile rbd pool=rbd namespace=namespace2' -o /etc/ceph/client.newuser.keyring获取客户端的密钥:
语法
ceph auth get client.USER_NAME示例
[root@mon ~]# ceph auth get client.testuser [client.testuser] key = AQDMp61hBf5UKRAAgjQ2In0Z3uwAase7mrlKnQ== caps mon = "profile rbd" caps osd = "profile rbd pool=rbd namespace=namespace1" exported keyring for client.testuser [root@mon ~]# ceph auth get client.newuser [client.newuser] key = AQDfp61hVfLFHRAA7D80ogmZl80ROY+AUG4A+Q== caps mon = "profile rbd" caps osd = "profile rbd pool=rbd namespace=namespace2" exported keyring for client.newuser创建块设备镜像,并使用池中的预定义命名空间:
语法
rbd create --namespace NAMESPACE IMAGE_NAME --size SIZE_IN_GB示例
[root@mon ~]# rbd create --namespace namespace1 image01 --size 1G [root@mon ~]# rbd create --namespace namespace2 image02 --size 1G可选:获取命名空间和关联的镜像详情:
语法
rbd --namespace NAMESPACE ls --long示例
[root@mon ~]# rbd --namespace namespace1 ls --long NAME SIZE PARENT FMT PROT LOCK image01 1 GiB 2 [root@mon ~]# rbd --namespace namespace2 ls --long NAME SIZE PARENT FMT PROT LOCK image02 1 GiB 2将 Ceph 配置文件从 Ceph 监控节点复制到客户端节点:
scp /etc/ceph/ceph.conf root@CLIENT_NODE:/etc/ceph/示例
[root@mon ~]# scp /etc/ceph/ceph.conf root@host02:/etc/ceph/ root@host02's password: ceph.conf 100% 497 724.9KB/s 00:00将 Ceph 监控节点的 admin keyring 复制到客户端节点:
语法
scp /etc/ceph/ceph.client.admin.keyring root@CLIENT_NODE:/etc/ceph示例
[root@mon ~]# scp /etc/ceph/ceph.client.admin.keyring root@host02:/etc/ceph/ root@host02's password: ceph.client.admin.keyring 100% 151 265.0KB/s 00:00将用户的密钥环从 Ceph 监控节点复制到客户端节点:
语法
scp /etc/ceph/ceph.client.USER_NAME.keyring root@CLIENT_NODE:/etc/ceph/示例
[root@mon ~]# scp /etc/ceph/client.newuser.keyring root@host02:/etc/ceph/ [root@mon ~]# scp /etc/ceph/client.testuser.keyring root@host02:/etc/ceph/映射块设备镜像:
语法
rbd map --name NAMESPACE IMAGE_NAME -n client.USER_NAME --keyring /etc/ceph/client.USER_NAME.keyring示例
[root@mon ~]# rbd map --namespace namespace1 image01 -n client.testuser --keyring=/etc/ceph/client.testuser.keyring /dev/rbd0 [root@mon ~]# rbd map --namespace namespace2 image02 -n client.newuser --keyring=/etc/ceph/client.newuser.keyring /dev/rbd1这不允许访问同一池中的其他命名空间中的用户。
示例
[root@mon ~]# rbd map --namespace namespace2 image02 -n client.testuser --keyring=/etc/ceph/client.testuser.keyring rbd: warning: image already mapped as /dev/rbd1 rbd: sysfs write failed rbd: error asserting namespace: (1) Operation not permitted In some cases useful info is found in syslog - try "dmesg | tail". 2021-12-06 02:49:08.106 7f8d4fde2500 -1 librbd::api::Namespace: exists: error asserting namespace: (1) Operation not permitted rbd: map failed: (1) Operation not permitted [root@mon ~]# rbd map --namespace namespace1 image01 -n client.newuser --keyring=/etc/ceph/client.newuser.keyring rbd: warning: image already mapped as /dev/rbd0 rbd: sysfs write failed rbd: error asserting namespace: (1) Operation not permitted In some cases useful info is found in syslog - try "dmesg | tail". 2021-12-03 12:16:24.011 7fcad776a040 -1 librbd::api::Namespace: exists: error asserting namespace: (1) Operation not permitted rbd: map failed: (1) Operation not permitted验证设备:
示例
[root@mon ~]# rbd showmapped id pool namespace image snap device 0 rbd namespace1 image01 - /dev/rbd0 1 rbd namespace2 image02 - /dev/rbd1
第 4 章 快照管理
作为存储管理员,熟悉 Ceph 的快照功能可帮助您管理存储在 Red Hat Ceph Storage 集群中的镜像的快照和克隆。
4.1. 先决条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
4.2. Ceph 块设备快照
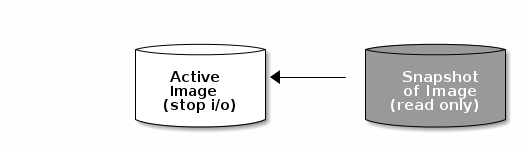
快照是镜像在特定时间点上状态的只读副本。Ceph 块设备的其中一个高级功能是您可以创建镜像的快照来保留镜像状态的历史记录。Ceph 也支持快照分层,允许您快速轻松地克隆镜像,例如虚拟机镜像。Ceph 支持利用 rbd 命令和许多更高级别的接口进行块设备快照,包括 QEMU、libvirt、OpenStack 和 CloudStack。
如果在有 I/O 操作时进行快照,则快照可能无法获取镜像的准确或最新的数据,并且快照可能需要克隆到一个信的、可以挂载的映像。红帽建议在进行快照前,停止 I/O。如果镜像包含文件系统,则执行快照之前文件系统必须处于一致状态。您可以使用 fsfreeze 命令停止 I/O。对于虚拟机,qemu-guest-agent 可用于在创建快照时自动冻结文件系统。
其它资源
-
详情请查看
fsfreeze(8)手册页。
4.3. Ceph 用户和密钥环
启用 cephx 后,您必须指定用户名或 ID,以及包含用户对应密钥的密钥环的路径。
cephx 默认启用。
您还可以添加 CEPH_ARGS 环境变量以避免重新输入以下参数:
语法
rbd --id USER_ID --keyring=/path/to/secret [commands]
rbd --name USERNAME --keyring=/path/to/secret [commands]示例
[root@rbd-client ~]# rbd --id admin --keyring=/etc/ceph/ceph.keyring [commands]
[root@rbd-client ~]# rbd --name client.admin --keyring=/etc/ceph/ceph.keyring [commands]
将用户和 secret 添加到 CEPH_ARGS 环境变量,以便您无需每次输入它们。
4.4. 创建块设备快照
创建 Ceph 块设备的快照。
先决条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
- 节点的根级别访问权限。
流程
指定
snap create选项、池名称和镜像名称:语法
rbd --pool POOL_NAME snap create --snap SNAP_NAME IMAGE_NAME rbd snap create POOL_NAME/IMAGE_NAME@SNAP_NAME示例
[root@rbd-client ~]# rbd --pool rbd snap create --snap snapname foo [root@rbd-client ~]# rbd snap create rbd/foo@snapname
4.5. 列出块设备快照
列出块设备快照。
先决条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
- 节点的根级别访问权限。
流程
指定池名称和镜像名称:
语法
rbd --pool POOL_NAME snap ls IMAGE_NAME rbd snap ls POOL_NAME/IMAGE_NAME示例
[root@rbd-client ~]# rbd --pool rbd snap ls foo [root@rbd-client ~]# rbd snap ls rbd/foo
4.6. 回滚块设备快照
回滚块设备快照。
将镜像回滚到快照意味着使用快照中的数据覆盖镜像的当前版本。执行回滚所需的时间会随着镜像大小的增加而增加。从快照克隆快于将镜像回滚到照要,这是返回到预先存在状态的首选方法。
先决条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
- 节点的根级别访问权限。
流程
指定
snap rollback选项、池名称、镜像名称和快照名称:语法
rbd --pool POOL_NAME snap rollback --snap SNAP_NAME IMAGE_NAME rbd snap rollback POOL_NAME/IMAGE_NAME@SNAP_NAME示例
[root@rbd-client ~]# rbd --pool rbd snap rollback --snap snapname foo [root@rbd-client ~]# rbd snap rollback rbd/foo@snapname
4.7. 删除块设备快照
删除 Ceph 块设备的快照。
先决条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
- 节点的根级别访问权限。
流程
指定
snap rm选项、池名称、镜像名称和快照名称:语法
rbd --pool POOL_NAME snap rm --snap SNAP_NAME IMAGE_NAME rbd snap rm POOL_NAME-/IMAGE_NAME@SNAP_NAME示例
[root@rbd-client ~]# rbd --pool rbd snap rm --snap snapname foo [root@rbd-client ~]# rbd snap rm rbd/foo@snapname
如果镜像具有任何克隆,克隆的镜像会保留对父镜像快照的引用。要删除父镜像快照,您必须首先扁平化子镜像。
Ceph OSD 守护进程异步删除数据,因此删除快照不会立即释放磁盘空间。
其它资源
- 详情请参阅 Red Hat Ceph Storage 块设备指南中的扁平化克隆镜像。
4.8. 清除块设备快照
清除块设备快照。
先决条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
- 节点的根级别访问权限。
流程
指定
snap purge选项和镜像名称:语法
rbd --pool POOL_NAME snap purge IMAGE_NAME rbd snap purge POOL_NAME/IMAGE_NAME示例
[root@rbd-client ~]# rbd --pool rbd snap purge foo [root@rbd-client ~]# rbd snap purge rbd/foo
4.9. 重命名块设备快照
重新命名块设备快照。
先决条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
- 节点的根级别访问权限。
流程
重新命名快照:
语法
rbd snap rename POOL_NAME/IMAGE_NAME@ORIGINAL_SNAPSHOT_NAME POOL_NAME/IMAGE_NAME@NEW_SNAPSHOT_NAME示例
[root@rbd-client ~]# rbd snap rename data/dataset@snap1 data/dataset@snap2这会将
data池上dataset镜像的snap1快照重命名为snap2。-
执行
rbd help snap rename命令,以显示重命名快照的更多详细信息。
4.10. Ceph 块设备分层
Ceph 支持创建许多块设备快照的写时复制 (COW) 或读时复制 (COR) 克隆。快照分层使得 Ceph 块设备客户端能够非常快速地创建镜像。例如,您可以使用写入它的 Linux 虚拟机创建块设备镜像。然后,对镜像执行快照,保护快照,并创建所需数量的克隆。快照是只读的,因此克隆快照可以简化语义-使快速创建克隆成为可能。
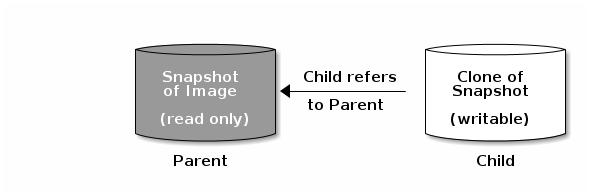
术语 父项(parent)和子项(child)表示 Ceph 块设备快照、父项,以及从快照子级克隆的对应映像。这些术语对于以下命令行用法非常重要。
每个克隆的镜像(子镜像)存储对其父镜像的引用,这使得克隆的镜像能够打开父快照并读取它。当克隆扁平化时,当快照中的信息完全复制到克隆时,会删除此引用。
快照克隆的行为与任何其他 Ceph 块设备镜像完全相同。您可以读取、写入、克隆和调整克隆的镜像大小。克隆的镜像没有特殊限制。但是,快照的克隆会指向快照,因此在克隆快照前,必须会对其进行保护。
快照的克隆可以是写时复制 (COW) 或读时复制 (COR) 克隆。在必须显式启用读取时复制 (COR) 时,始终为克隆启用写时复制 (COW)。当数据写入到克隆中的未分配对象时,写时复制 (COW) 将数据从父项复制到克隆。当父进程从克隆中未分配的对象读取时,从父进程复制数据到克隆。如果克隆中尚不存在对象,则仅从父项读取数据。RADOS 块设备将大型镜像分成多个对象。默认值为 4 MB,所有写时复制 (COW) 和写时复制 (COR) 操作都发生在完整的对象上,这会将 1 字节写入到克隆,如果之前的 COW/COR 操作的克隆中目标对象尚不存在,则会导致从父对象读取 4 MB 对象并写入克隆。
是否启用读取时复制 (COR),任何通过从克隆读取底层对象无法满足的读取都将重新路由到父对象。由于父项实际上没有限制,这意味着您可以对一个克隆进行克隆,因此,在找到对象或您到达基础父镜像时,这个重新路由将继续进行。如果启用了读取时复制 (COR),克隆中任何未直接满足的读取会导致从父项读取完整的对象并将该数据写入克隆,以便克隆本身可以满足相同的扩展读取,而无需从父级读取。
这基本上是一个按需、按对象扁平化的操作。当克隆位于与它的父级(位于另一个地理位置)的父级(位于其他地理位置)的高延迟连接中时,这特别有用。读时复制 (COR) 可降低读分化延迟。前几次读取具有较高的延迟,因为它将导致从父进程读取额外的数据,例如,您从克隆中读取 1 字节,但现在 4 MB 必须从父级读取并写入克隆,但将来的所有读取都将从克隆本身提供。
要从快照创建写时复制 (COR) 克隆,您必须通过在 ceph.conf 文件的 [global] 或 [client] 部分添加 rbd_clone_copy_on_read = true 来显式启用此功能。
其它资源
-
有关
扁平化的更多信息,请参阅 Red Hat Ceph Storage Block Gudie 中的扁平克隆镜像部分。
4.11. 保护块设备快照
克隆访问父快照。如果用户意外删除父快照,则所有克隆都会中断。为防止数据丢失,必须默认保护快照,然后才能克隆快照。
先决条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
- 节点的根级别访问权限。
流程
在以下 命令中指定
POOL_NAME、IMAGE_NAME和SNAP_SHOT_NAME:语法
rbd --pool POOL_NAME snap protect --image IMAGE_NAME --snap SNAPSHOT_NAME rbd snap protect POOL_NAME/IMAGE_NAME@SNAPSHOT_NAME示例
[root@rbd-client ~]# rbd --pool rbd snap protect --image my-image --snap my-snapshot [root@rbd-client ~]# rbd snap protect rbd/my-image@my-snapshot注意您无法删除受保护的快照。
4.12. 克隆块设备快照
克隆块设备快照,以在同一个池或其他池中创建快照的读取或写入子镜像。一种用例是将只读镜像和快照维护为一个池中的模板,然后在另一个池中维护可写克隆。
默认情况下,您必须先保护快照,然后才能克隆快照。为避免在克隆快照前对其进行保护,请设置 ceph osd set-require-min-compat-clientimic。您也可以将其设置为比模拟更高的版本。
先决条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
- 节点的根级别访问权限。
流程
要克隆快照,您需要指定父池、快照、子池和镜像名称:
语法
rbd --pool POOL_NAME --image PARENT_IMAGE --snap SNAP_NAME --dest-pool POOL_NAME --dest CHILD_IMAGE_NAME rbd clone POOL_NAME/PARENT_IMAGE@SNAP_NAME POOL_NAME/CHILD_IMAGE_NAME示例
[root@rbd-client ~]# rbd --pool rbd --image my-image --snap my-snapshot --dest-pool rbd --dest new-image [root@rbd-client ~]# rbd clone rbd/my-image@my-snapshot rbd/new-image
4.13. 取消保护块设备快照
您必须先取消保护快照,然后才能删除快照。此外,您不得删除从克隆引用的快照。您必须扁平化快照的每个克隆,然后才能删除快照。
先决条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
- 节点的根级别访问权限。
流程
运行以下命令:
语法
rbd --pool POOL_NAME snap unprotect --image IMAGE_NAME --snap SNAPSHOT_NAME rbd snap unprotect POOL_NAME/IMAGE_NAME@SNAPSHOT_NAME示例
[root@rbd-client ~]# rbd --pool rbd snap unprotect --image my-image --snap my-snapshot [root@rbd-client ~]# rbd snap unprotect rbd/my-image@my-snapshot
4.14. 列出快照的子项
列出快照的子项。
先决条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
- 节点的根级别访问权限。
流程
要列出快照的子项,请执行以下操作:
语法
rbd --pool POOL_NAME children --image IMAGE_NAME --snap SNAP_NAME rbd children POOL_NAME/IMAGE_NAME@SNAPSHOT_NAME示例
rbd --pool rbd children --image my-image --snap my-snapshot rbd children rbd/my-image@my-snapshot
4.15. 扁平化克隆的镜像
克隆的镜像保留对父快照的引用。当您从子克隆删除引用到父快照时,您有效地通过将信息从快照复制到克隆来"扁平化"镜像。随着快照大小的增加,扁平化克隆所需的时间会增加。由于扁平化的镜像包含快照的所有信息,因此扁平化的镜像将占用比分层克隆更多的存储空间。
如果镜像上启用 深度扁平化(deep flatten)功能,则默认情况下镜像克隆与其父级解除关联。
先决条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
- 节点的根级别访问权限。
流程
要删除与子镜像关联的父镜像快照,您必须首先扁平化子镜像:
语法
rbd --pool POOL_NAME flatten --image IMAGE_NAME rbd flatten POOL_NAME/IMAGE_NAME示例
[root@rbd-client ~]# rbd --pool rbd flatten --image my-image [root@rbd-client ~]# rbd flatten rbd/my-image
第 5 章 镜像 Ceph 块设备
作为存储管理员,您可以通过镜像 Red Hat Ceph Storage 集群之间的数据镜像,为 Ceph 块设备添加另一层冗余。了解和使用 Ceph 块设备镜像功能可帮助您防止数据丢失,如站点故障。镜像 Ceph 块设备有两种配置,单向镜像或双向镜像,您可以在池和单个镜像上配置镜像功能。
5.1. 先决条件
- 至少运行两个健康的 Red Hat Ceph Storage 集群。
- 两个存储集群之间的网络连接。
- 为每个 Red Hat Ceph Storage 集群访问 Ceph 客户端节点。
5.2. Ceph 块设备镜像
RADOS 块设备 (RBD) 镜像是在两个或多个 Ceph 存储集群之间异步复制 Ceph 块设备镜像的过程。通过在不同的地理位置查找 Ceph 存储集群,RBD 镜像功能可帮助您从站点灾难中恢复。基于日志的 Ceph 块设备镜像可确保镜像所有更改的时间点一致性副本,包括读取和写入、块设备调整大小、快照、克隆和扁平化。
RBD 镜像使用专用锁定和日志记录功能,按照镜像发生的顺序记录对镜像的所有修改。这样可确保镜像的崩溃一致性镜像可用。
支持镜像块设备镜像的主要和次要池的 CRUSH 层次结构必须具有相同的容量和性能特性,并且必须具有足够的带宽才能确保镜像无延迟。例如,如果您的主存储集群中有 X MB/s 平均写入吞吐量,则网络必须支持连接至次要站点的 N * X 吞吐量,以及 Y% 用于镜像 N 镜像的安全因子。
rbd-mirror 守护进程负责通过从远程主镜像拉取更改,将镜像从一个 Ceph 存储集群同步到另一个 Ceph 存储集群,并将这些更改写入本地的非主镜像。rbd-mirror 守护进程可以在单个 Ceph 存储集群上运行,实现单向镜像功能,也可以在两个 Ceph 存储集群上运行,以实现参与镜像关系的双向镜像。
要使 RBD 镜像工作(可使用单向复制或双向复制),进行几个假设:
- 两个存储集群中都存在一个名称相同的池。
- 池包含您要镜像的启用了日志的镜像。
在单向或双向复制中,rbd-mirror 的每个实例必须能够同时连接其他 Ceph 存储集群。此外,两个数据中心站点之间网络必须具有足够的带宽才能处理镜像。
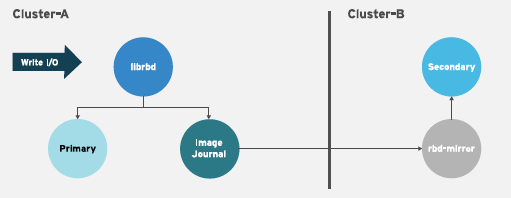
单向复制(One-way Replication)
单向镜像意味着一个存储集群中的主要镜像或镜像池会被复制到次要存储集群。单向镜像还支持复制到多个次要存储集群。
在辅助存储群集上,镜像是非主要复制;即 Ceph 客户端无法写入镜像。当数据从主存储集群镜像到次要存储集群时,rbd-mirror 只在次要存储集群上运行。
为了进行单向镜像工作,应进行几项假设:
- 您有两个 Ceph 存储集群,希望将镜像从主存储集群复制到辅助存储集群。
-
辅助存储集群附加有运行
rbd-mirror守护进程的 Ceph 客户端节点。rbd-mirror守护进程将连接到主存储集群,将镜像同步到次要存储集群。
双向复制(Two-way Replication)
双向复制在主集群中添加一个 rbd-mirror 守护进程,使得镜像可以在集群上降级并提升到次要集群中。然后可以对次要群集上的镜像进行更改,然后按照相反方向(从次要到主要)进行复制。两个集群都必须运行 rbd-mirror,才能在任一集群上提升和降级镜像。目前,仅在两个站点间支持双向复制。
要进行双向镜像工作,请进行几项假设:
- 您有两个存储集群,希望在它们之间以任一方向复制镜像。
-
两个存储集群都附加了一个客户端节点,它们运行
rbd-mirror守护进程。次要存储集群上运行的rbd-mirror守护进程将连接到主存储集群,将镜像同步到次要存储集群,而主存储集群上运行的rbd-mirror守护进程将连接到次要存储集群,将镜像同步到主要位置。

自 Red Hat Ceph Storage 4 起,支持在一个集群中运行多个活跃的 rbd-mirror 守护进程。
镜像模式
镜像以每个池为基础配置,带有镜像对等存储集群。Ceph 支持两种镜像模式,具体取决于池中镜像的类型。
- 池模式
- 启用了日志记录功能的池中的所有镜像都会被镜像(mirror)。
- 镜像模式
- 只有池中的特定镜像子集才会被镜像(mirror)。您必须为每个镜像单独启用镜像功能。
镜像状态
镜像是否可以修改取决于其状态:
- 可以修改处于主要状态的镜像。
- 处于非主要状态的镜像无法修改。
镜像在镜像上首次启用镜像时自动提升为主版本。升级可能发生:
- 通过在池模式中启用镜像来隐式执行镜像。
- 通过启用特定镜像的镜像来显式启用。
可以降级主镜像并提升非主镜像。
其它资源
- 如需了解更多详细信息,请参阅 Red Hat Ceph Storage 块设备指南中的镜像提升和降级小节。
5.3. 使用 Ansible 配置单向镜像
此流程使用 ceph-ansible,在称为 site-a 的主存储集群上配置镜像的单向复制,到名为 site-b 的辅助存储集群。在以下示例中,data 是包含要镜像的镜像的池名称。
先决条件
- 两个正在运行的 Red Hat Ceph Storage 集群。
- Ceph 客户端节点.
- 两个集群中都存在具有相同名称的池。
- 池中的镜像必须为基于日志的镜像启用 exclusive-lock 和日志记录。
使用单向复制时,您可以镜像到多个次要存储集群。
流程
在镜像源自的集群中,在镜像上启用 exclusive-lock 和 journaling 功能。
对于新镜像,使用
--image-feature选项:语法
rbd create IMAGE_NAME --size MEGABYTES --pool POOL_NAME --image-feature FEATURE[,FEATURE]示例
[root@rbd-client ~]# rbd create image1 --size 1024 --pool data --image-feature exclusive-lock,journaling对于现有镜像,请使用
rbd feature enable命令:语法
rbd feature enable POOL_NAME/IMAGE_NAME FEATURE_NAME示例
[root@rbd-client ~]# rbd feature enable data/image1 exclusive-lock,journaling要默认在所有新镜像上启用专用锁定和日志记录功能,请在 Ceph 配置文件中添加以下设置:
rbd_default_features = 125
在
site-a集群中,完成以下步骤:在 monitor 节点上,创建
rbd-mirror守护进程将用于连接集群的用户。这个示例创建一个site-a用户,并将密钥输出到名为site-a.client.site-a.keyring的文件中:语法
ceph auth get-or-create client.CLUSTER_NAME mon 'profile rbd' osd 'profile rbd pool=data' -o /etc/ceph/CLUSTER_NAME.client.USER_NAME.keyring示例
[root@mon ~]# ceph auth get-or-create client.site-a mon 'profile rbd' osd 'profile rbd pool=data' -o /etc/ceph/site-a.client.site-a.keyring-
将 Ceph 配置文件和新创建的密钥文件从 monitor 节点复制到
site-b监控器和客户端节点。 -
将 Ceph 配置文件从
ceph.conf重命名为 CLUSTER-NAME.conf。在这些示例中,该文件是/etc/ceph/site-a.conf。
在
site-b集群中,完成以下步骤:-
在 Ansible 管理节点上,在 Ansible 清单文件中添加
[rbdmirrors]组。通常的清单文件为/etc/ansible/hosts。 在
[rbdmirrors]组下,添加将在其上运行rbd-mirror守护进程的site-b客户端节点的名称。守护进程将从site-a拉取镜像更改到site-b。[rbdmirrors] ceph-client进入
/usr/share/ceph-ansible/目录:[root@admin ~]# cd /usr/share/ceph-ansible通过将 group_vars/rbdmirrors.yml.
sample 复制到.yml 来创建新的group_vars/rbdmirrors.ymlrbdmirrors.yml文件:[root@admin ceph-ansible]# cp group_vars/rbdmirrors.yml.sample group_vars/rbdmirrors.yml-
打开
group_vars/rbdmirrors.yml文件进行编辑。 将
ceph_rbd_mirror_configure设置为true。将ceph_rbd_mirror_pool设置为您要在其中镜像镜像的池。在这些示例中,data是池的名称。ceph_rbd_mirror_configure: true ceph_rbd_mirror_pool: "data"默认情况下,
ceph-ansible使用池模式配置镜像功能,它会镜像池中的所有镜像。启用镜像(mirror)镜像(mirror)的镜像模式。要启用镜像模式,将ceph_rbd_mirror_mode设置为image:ceph_rbd_mirror_mode: imagerbd-mirror将从中拉取的集群设置名称。在这些示例中,其他集群是site-a。ceph_rbd_mirror_remote_cluster: "site-a"在 Ansible 管理节点上,使用
ceph_rbd_mirror_remote_user设置密钥的用户名。使用您在创建密钥时使用的相同名称。在这些示例中,该用户命名为client.site-a。ceph_rbd_mirror_remote_user: "client.site-a"以 ceph-ansible 用户身份,运行 Ansible playbook:
裸机部署:
[user@admin ceph-ansible]$ ansible-playbook site.yml --limit rbdmirrors -i hosts容器部署:
[ansible@admin ceph-ansible]$ ansible-playbook site-container.yml --limit rbdmirrors -i hosts
-
在 Ansible 管理节点上,在 Ansible 清单文件中添加
在
site-a和site-b集群中明确启用镜像的镜像:语法
基于日志的镜像:
rbd mirror image enable POOL/IMAGE基于快照的镜像:
rbd mirror image enable POOL/IMAGE snapshot示例
[root@mon ~]# rbd mirror image enable data/image1 [root@mon ~]# rbd mirror image enable data/image1 snapshot注意每当您想要将新镜像镜像到对等集群时,请重复此步骤。
验证镜像状态。从
site-b集群的 Ceph 监控节点运行以下命令:示例
基于日志的镜像:
[root@mon ~]# rbd mirror image status data/image1 image1: global_id: 7d486c3f-d5a1-4bee-ae53-6c4f1e0c8eac state: up+replaying1 description: replaying, master_position=[object_number=3, tag_tid=1, entry_tid=3], mirror_position=[object_number=3, tag_tid=1, entry_tid=3], entries_behind_master=0 last_update: 2019-04-22 13:19:27基于快照的镜像:
[root@mon ~]# rbd mirror image status data/image1 image1: global_id: 06acc9e6-a63d-4aa1-bd0d-4f3a79b0ae33 state: up+replaying1 description: replaying, {"bytes_per_second":0.0,"bytes_per_snapshot":0.0,"local_snapshot_timestamp":1642689843,"remote_snapshot_timestamp":1642689843,"replay_state":"idle"} service: admin on ceph-rbd2-vasi-43-5hwia4-node2 last_update: 2022-01-20 12:41:57注意根据站点之间的连接,镜像可能需要很长时间才能同步镜像。
5.4. 使用 Ansible 配置双向镜像
此流程使用 ceph-ansible 来配置双向复制,以便镜像可以按照称为 site-a 和 site-b 的两个集群之间的任一方向进行镜像。在以下示例中,data 是包含要镜像的镜像的池名称。
双向镜像不允许对任一集群中的同一镜像同时写入。镜像在一个集群中被提升并降级到另一个集群中。根据自己的状态,它们将从一个方向或另一个方向进行镜像。
先决条件
- 两个正在运行的 Red Hat Ceph Storage 集群。
- 每个集群都有一个客户端节点。
- 两个集群中都存在具有相同名称的池。
- 池中的镜像必须为基于日志的镜像启用 exclusive-lock 和日志记录。
流程
在镜像源自的集群中,在镜像上启用 exclusive-lock 和 journaling 功能。
对于新镜像,使用
--image-feature选项:语法
rbd create IMAGE_NAME --size MEGABYTES --pool POOL_NAME --image-feature FEATURE[,FEATURE]示例
[root@rbd-client ~]# rbd create image1 --size 1024 --pool data --image-feature exclusive-lock,journaling对于现有镜像,请使用
rbd feature enable命令:语法
rbd feature enable POOL_NAME/IMAGE_NAME FEATURE_NAME示例
[root@rbd-client ~]# rbd feature enable data/image1 exclusive-lock,journaling要默认在所有新镜像上启用专用锁定和日志记录功能,请在 Ceph 配置文件中添加以下设置:
rbd_default_features = 125
在
site-a集群中,完成以下步骤:在 monitor 节点上,创建
rbd-mirror守护进程将用来连接到集群的用户。该示例创建了一个site-a用户,并将密钥输出到名为site-a.client.site-a.keyring的文件,Ceph 配置文件为/etc/ceph/site-a.conf。语法
ceph auth get-or-create client.PRIMARY_CLUSTER_NAME mon 'profile rbd' osd 'profile rbd pool=data' -o /etc/ceph/PRIMARY_CLUSTER_NAME.client.USER_NAME.keyring -c /etc/ceph/PRIMARY_CLUSTER_NAME.conf示例
[root@mon ~]# ceph auth get-or-create client.site-a mon 'profile rbd' osd 'profile rbd pool=data' -o /etc/ceph/site-a.client.site-a.keyring -c /etc/ceph/site-a.conf将密钥环复制到
site-b集群。将 文件复制到rbd-daemon将在其上运行的site-b集群中的客户端节点。将文件保存到/etc/ceph/site-a.client.site-a.keyring:语法
scp /etc/ceph/PRIMARY_CLUSTER_NAME.client.USER_NAME.keyring root@SECONDARY_CLIENT_NODE_NAME:/etc/ceph/PRIMARY_CLUSTER_NAME.client.USER_NAME.keyring示例
[root@mon ~]# scp /etc/ceph/site-a.client.site-a.keyring root@client.site-b:/etc/ceph/site-a.client.site-a.keyring将 Ceph 配置文件从 monitor 节点复制到
site-b监控节点和客户端节点。本例中的 Ceph 配置文件为/etc/ceph/site-a.conf。语法
scp /etc/ceph/PRIMARY_CLUSTER_NAME.conf root@SECONDARY_MONITOR_NODE_NAME:/etc/ceph/PRIMARY_CLUSTER_NAME.conf scp /etc/ceph/PRIMARY_CLUSTER_NAME.conf user@SECONDARY_CLIENT_NODE_NAME:/etc/ceph/PRIMARY_CLUSTER_NAME.conf示例
[root@mon ~]# scp /etc/ceph/site-a.conf root@mon.site-b:/etc/ceph/site-a.conf [root@mon ~]# scp /etc/ceph/site-a.conf user@client.site-b:/etc/ceph/site-a.conf
在
site-b集群中,完成以下步骤:-
配置从
site-a到site-b的镜像功能。在 Ansible 管理节点上,在 Ansible 清单文件中添加[rbdmirrors]组,通常为/usr/share/ceph-ansible/hosts。 在
[rbdmirrors]组下,添加rbd-mirror守护进程将要运行的site-b客户端节点的名称。此守护进程拉取从site-a到site-b的镜像更改。示例
[rbdmirrors] client.site-b进入
/usr/share/ceph-ansible/目录:[root@admin ~]$ cd /usr/share/ceph-ansible通过将 group_vars/rbdmirrors.yml.
sample 复制到.yml 来创建新的group_vars/rbdmirrors.ymlrbdmirrors.yml文件:[root@admin ceph-ansible]# cp group_vars/rbdmirrors.yml.sample group_vars/rbdmirrors.yml-
打开并编辑
group_vars/rbdmirrors.yml文件。 将
ceph_rbd_mirror_configure设置为true,并将ceph_rbd_mirror_pool设置为您要在其中镜像镜像的池。在这些示例中,data是池的名称。ceph_rbd_mirror_configure: true ceph_rbd_mirror_pool: "data"默认情况下,
ceph-ansible使用池模式配置镜像功能,它会镜像池中的所有镜像。启用镜像(mirror)镜像(mirror)的镜像模式。要启用镜像模式,将ceph_rbd_mirror_mode设置为image:ceph_rbd_mirror_mode: image在
group_vars/mirrors 的名称。在这些示例中,其他集群是rbdmirrors.yml文件中,为集群设置 rbd-site-a。ceph_rbd_mirror_remote_cluster: "site-a"在 Ansible 管理节点上,使用
group设置密钥的用户名。使用您在创建密钥时使用的相同名称。在这些示例中,该用户命名为_vars/rbdmirrors.yml文件中的 ceph_rbd_mirror_userclient.site-a。ceph_rbd_mirror_remote_user: "client.site-a"以 ansible 用户身份,运行 Ansible playbook:
裸机部署:
[user@admin ceph-ansible]$ ansible-playbook site.yml --limit rbdmirrors -i hosts容器部署:
[user@admin ceph-ansible]$ ansible-playbook site-container.yml --limit rbdmirrors -i hosts
-
配置从
验证镜像状态。从
site-b集群的 Ceph 监控节点运行以下命令:示例
基于日志的镜像:
[root@mon ~]# rbd mirror image status data/image1 image1: global_id: 7d486c3f-d5a1-4bee-ae53-6c4f1e0c8eac state: up+replaying1 description: replaying, master_position=[object_number=3, tag_tid=1, entry_tid=3], mirror_position=[object_number=3, tag_tid=1, entry_tid=3], entries_behind_master=0 last_update: 2021-04-22 13:19:27基于快照的镜像:
[root@mon ~]# rbd mirror image status data/image1 image1: global_id: 06acc9e6-a63d-4aa1-bd0d-4f3a79b0ae33 state: up+replaying1 description: replaying, {"bytes_per_second":0.0,"bytes_per_snapshot":0.0,"local_snapshot_timestamp":1642689843,"remote_snapshot_timestamp":1642689843,"replay_state":"idle"} service: admin on ceph-rbd2-vasi-43-5hwia4-node2 last_update: 2022-01-20 12:41:57注意根据站点之间的连接,镜像可能需要很长时间才能同步镜像。
在
site-b集群中,完成以下步骤。步骤大体上是相同的:在 monitor 节点上,创建
rbd-mirror守护进程将用来连接到集群的用户。该示例创建了一个site-b用户,并将密钥输出到名为site-b.client.site-b.keyring的文件,Ceph 配置文件为/etc/ceph/site-b.conf。语法
ceph auth get-or-create client.SECONDARY_CLUSTER_NAME mon 'profile rbd' osd 'profile rbd pool=data' -o /etc/ceph/SECONDARY_CLUSTER_NAME.client.USER_NAME.keyring -c /etc/ceph/SECONDARY_CLUSTER_NAME.conf示例
[root@mon ~]# ceph auth get-or-create client.site-b mon 'profile rbd' osd 'profile rbd pool=data' -o /etc/ceph/site-b.client.site-b.keyring -c /etc/ceph/site-b.conf将密钥环复制到
site-a集群。将文件复制到rbd-daemon将运行于的site-a集群中的客户端节点。将文件保存到/etc/ceph/site-b.client.site-b.keyring:语法
scp /etc/ceph/SECONDARY_CLUSTER_NAME.client.USER_NAME.keyring root@PRIMARY_CLIENT_NODE_NAME:/etc/ceph/SECONDARY_CLUSTER_NAME.client.USER_NAME.keyring示例
[root@mon ~]# scp /etc/ceph/site-b.client.site-b.keyring root@client.site-a:/etc/ceph/site-b.client.site-b.keyring将 Ceph 配置文件从 monitor 节点复制到
site-amonitor 节点和客户端节点。本例中的 Ceph 配置文件为/etc/ceph/site-b.conf。语法
scp /etc/ceph/SECONDARY_CLUSTER_NAME.conf root@PRIMARY_MONITOR_NODE_NAME:/etc/ceph/SECONDARY_CLUSTER_NAME.conf scp /etc/ceph/SECONDARY_CLUSTER_NAME.conf user@PRIMARY_CLIENT_NODE_NAME:/etc/ceph/SECONDARY_CLUSTER_NAME.conf示例
[root@mon ~]# scp /etc/ceph/site-b.conf root@mon.site-a:/etc/ceph/site-b.conf [root@mon ~]# scp /etc/ceph/site-b.conf user@client.site-a:/etc/ceph/site-b.conf
在
site-a集群中,完成以下步骤:-
配置从
site-b到site-a的镜像。在 Ansible 管理节点上,在 Ansible 清单文件中添加[rbdmirrors]组,通常为/usr/share/ceph-ansible/hosts。 在
[rbdmirrors]组下,添加rbd-mirror守护进程将要在其中运行的site-a客户端节点的名称。此守护进程拉取从site-b到site-a的镜像更改。示例
[rbdmirrors] client.site-a进入
/usr/share/ceph-ansible/目录:[root@admin ~]# cd /usr/share/ceph-ansible通过将 group_vars/rbdmirrors.yml.
sample 复制到.yml 来创建新的group_vars/rbdmirrors.ymlrbdmirrors.yml文件:[root@admin ceph-ansible]# cp group_vars/rbdmirrors.yml.sample group_vars/rbdmirrors.yml-
打开并编辑
group_vars/rbdmirrors.yml文件。 将
ceph_rbd_mirror_configure设置为true,并将ceph_rbd_mirror_pool设置为您要在其中镜像镜像的池。在这些示例中,data是池的名称。ceph_rbd_mirror_configure: true ceph_rbd_mirror_pool: "data"默认情况下,
ceph-ansible使用池模式配置镜像功能,它会镜像池中的所有镜像。启用镜像(mirror)镜像(mirror)的镜像模式。要启用镜像模式,将ceph_rbd_mirror_mode设置为image:ceph_rbd_mirror_mode: image在 Ansible 管理节点上,在
group_vars/rbdmirrors.yml文件中为rbd-mirror的集群设置一个名称。按照示例所示,其他集群名为site-b。ceph_rbd_mirror_remote_cluster: "site-b"在 Ansible 管理节点上,使用
group设置密钥的用户名。在这些示例中,该用户命名为_vars/rbdmirrors.yml文件中的 ceph_rbd_mirror_userclient.site-b。ceph_rbd_mirror_remote_user: "client.site-b"在管理节点上以 Ansible 用户身份,运行 Ansible playbook:
裸机部署:
[user@admin ceph-ansible]$ ansible-playbook site.yml --limit rbdmirrors -i hosts容器部署:
[user@admin ceph-ansible]$ ansible-playbook site-container.yml --limit rbdmirrors -i hosts
-
配置从
在
site-a和site-b集群中明确启用镜像的镜像:语法
基于日志的镜像:
rbd mirror image enable POOL/IMAGE基于快照的镜像:
rbd mirror image enable POOL/IMAGE snapshot示例
[root@mon ~]# rbd mirror image enable data/image1 [root@mon ~]# rbd mirror image enable data/image1 snapshot注意每当您想要将新镜像镜像到对等集群时,请重复此步骤。
验证镜像状态。在
site-a集群中的客户端节点中运行以下命令:示例
基于日志的镜像:
[root@mon ~]# rbd mirror image status data/image1 image1: global_id: 08027096-d267-47f8-b52e-59de1353a034 state: up+stopped1 description: local image is primary last_update: 2021-04-16 15:45:31基于快照的镜像:
[root@mon ~]# rbd mirror image status data/image1 image1: global_id: 47fd1aae-5f19-4193-a5df-562b5c644ea7 state: up+stopped1 description: local image is primary service: admin on ceph-rbd1-vasi-43-5hwia4-node2 last_update: 2022-01-20 12:42:54 peer_sites: name: rbd-mirror.site-b state: up+replaying description: replaying, {"bytes_per_second":0.0,"bytes_per_snapshot":0.0,"local_snapshot_timestamp":1642693094,"remote_snapshot_timestamp":1642693094,"replay_state":"idle"} last_update: 2022-01-20 12:42:59 snapshots: 5 .mirror.primary.47fd1aae-5f19-4193-a5df-562b5c644ea7.dda146c6-5f21-4e75-ba93-660f6e57e301 (peer_uuids:[bfd09289-c9c9-40c8-b2d3-ead9b6a99a45])
5.5. 使用命令行界面配置单向镜像
此流程配置池从主存储集群到辅助存储集群的单向复制。
使用单向复制时,您可以镜像到多个次要存储集群。
本节中的示例通过将主镜像作为 site-a 引用主存储集群和您将要复制镜像的辅助存储集群作为 site-b 来区分两个存储集群。这些示例中使用的池名称称为 data。
先决条件
- 至少两个健康状态并运行 Red Hat Ceph Storage 集群。
- 对每个存储集群的 Ceph 客户端节点的根级别访问权限。
- 具有管理员级别功能的 CephX 用户。
- 池中的镜像必须为基于日志的镜像启用 exclusive-lock 和日志记录。
流程
在连接到
site-b存储集群的客户端节点上安装rbd-mirror软件包:Red Hat Enterprise Linux 7
[root@rbd-client ~]# yum install rbd-mirrorRed Hat Enterprise Linux 8
[root@rbd-client ~]# dnf install rbd-mirror注意软件包由 Red Hat Ceph Storage 工具存储库提供。
在镜像上启用 exclusive-lock 和 loging 功能。
对于新镜像,使用
--image-feature选项:语法
rbd create IMAGE_NAME --size MEGABYTES --pool POOL_NAME --image-feature FEATURE [,FEATURE]示例
[root@rbd-client ~]# rbd create image1 --size 1024 --pool data --image-feature exclusive-lock,journaling对于现有镜像,请使用
rbd feature enable命令:语法
rbd feature enable POOL_NAME/IMAGE_NAME FEATURE [,FEATURE]示例
[root@rbd-client ~]# rbd feature enable data/image1 exclusive-lock,journaling要默认在所有新镜像上启用专用锁定和日志记录功能,请在 Ceph 配置文件中添加以下设置:
rbd_default_features = 125
选择镜像模式,可以是池或镜像模式。
重要使用镜像模式进行基于快照的镜像功能。
启用 池模式 :
语法
rbd mirror pool enable POOL_NAME MODE示例
[root@rbd-client ~]# rbd mirror pool enable data pool这个示例启用对名为
data的完整池进行镜像。启用 镜像模式 :
语法
rbd mirror pool enable POOL_NAME MODE示例
[root@rbd-client ~]# rbd mirror pool enable data image这个示例在名为
data的池上启用镜像模式镜像。验证镜像是否已成功启用:
语法
rbd mirror pool info POOL_NAME示例
[root@rbd-client ~]# rbd mirror pool info data Mode: image Site Name: 94cbd9ca-7f9a-441a-ad4b-52a33f9b7148 Peer Sites: none
在
site-a集群中,完成以下步骤:在 Ceph 客户端节点上,创建一个用户:
语法
ceph auth get-or-create client.PRIMARY_CLUSTER_NAME mon 'profile rbd-mirror' osd 'profile rbd' -o /etc/ceph/ceph.PRIMARY_CLUSTER_NAME.keyring示例
[root@rbd-client-site-a ~]# ceph auth get-or-create client.rbd-mirror.site-a mon 'profile rbd-mirror' osd 'profile rbd' -o /etc/ceph/ceph.client.rbd-mirror.site-a.keyring将密钥环复制到
site-b集群:语法
scp /etc/ceph/ceph.PRIMARY_CLUSTER_NAME.keyring root@SECONDARY_CLUSTER:_PATH_示例
[root@rbd-client-site-a ~]# scp /etc/ceph/ceph.client.rbd-mirror.site-a.keyring root@rbd-client-site-b:/etc/ceph/在 Ceph 客户端节点上,引导存储集群对等点。
将存储集群对点注册到池:
语法
rbd mirror pool peer bootstrap create --site-name LOCAL_SITE_NAME POOL_NAME > PATH_TO_BOOTSTRAP_TOKEN示例
[root@rbd-client-site-a ~]# rbd mirror pool peer bootstrap create --site-name rbd-mirror.site-a data > /root/bootstrap_token_rbd-mirror.site-a注意此示例 bootstrap 命令创建
client.rbd-mirror-peerCeph 用户。将 bootstrap 令牌文件复制到
site-b存储集群。语法
scp PATH_TO_BOOTSTRAP_TOKEN root@SECONDARY_CLUSTER:/root/示例
[root@rbd-client-site-a ~]# scp /root/bootstrap_token_site-a root@ceph-rbd2:/root/
在
site-b集群中,完成以下步骤:在客户端节点上,创建用户:
语法
ceph auth get-or-create client.SECONDARY_CLUSTER_NAME mon 'profile rbd-mirror' osd 'profile rbd' -o /etc/ceph/ceph.SECONDARY_CLUSTER_NAME.keyring示例
[root@rbd-client-site-b ~]# ceph auth get-or-create client.rbd-mirror.site-b mon 'profile rbd-mirror' osd 'profile rbd' -o /etc/ceph/ceph.client.rbd-mirror.site-b.keyring将密钥环复制到
站点(Ceph 客户端节点)中:语法
scp /etc/ceph/ceph.SECONDARY_CLUSTER_NAME.keyring root@PRIMARY_CLUSTER:_PATH_示例
[root@rbd-client-site-b ~]# scp /etc/ceph/ceph.client.rbd-mirror.site-b.keyring root@rbd-client-site-a:/etc/ceph/导入 bootstrap 令牌:
语法
rbd mirror pool peer bootstrap import --site-name LOCAL_SITE_NAME --direction rx-only POOL_NAME PATH_TO_BOOTSTRAP_TOKEN示例
[root@rbd-client-site-b ~]# rbd mirror pool peer bootstrap import --site-name rbd-mirror.site-b --direction rx-only data /root/bootstrap_token_rbd-mirror.site-a注意对于单向 RBD 镜像功能,您必须使用
--direction rx-only参数,因为在引导对等时双向镜像是默认设置。在客户端节点上启用并启动
rbd-mirror守护进程:语法
systemctl enable ceph-rbd-mirror.target systemctl enable ceph-rbd-mirror@rbd-mirror.CLIENT_ID systemctl start ceph-rbd-mirror@rbd-mirror.CLIENT_ID将
CLIENT_ID替换为前面创建的 Ceph 用户。示例
[root@rbd-client-site-b ~]# systemctl enable ceph-rbd-mirror.target [root@rbd-client-site-b ~]# systemctl enable ceph-rbd-mirror@rbd-mirror.site-a [root@rbd-client-site-b ~]# systemctl start ceph-rbd-mirror@rbd-mirror.site-a
重要每个
rbd-mirror守护进程必须具有唯一的客户端 ID。要验证镜像状态,请从
site-a和site-b集群中的 Ceph Monitor 节点运行以下命令:语法
rbd mirror image status POOL_NAME/IMAGE_NAME示例
基于日志的镜像:
[root@mon-site-a ~]# rbd mirror image status data/image1 image1: global_id: 08027096-d267-47f8-b52e-59de1353a034 state: up+stopped1 description: local image is primary last_update: 2021-04-22 13:45:31基于快照的镜像:
[root@mon-site-a ~]# rbd mirror image status data/image1 image1: global_id: 47fd1aae-5f19-4193-a5df-562b5c644ea7 state: up+stopped1 description: local image is primary service: admin on ceph-rbd1-vasi-43-5hwia4-node2 last_update: 2022-01-20 12:42:54 peer_sites: name: rbd-mirror.site-b state: up+replaying description: replaying, {"bytes_per_second":0.0,"bytes_per_snapshot":0.0,"local_snapshot_timestamp":1642693094,"remote_snapshot_timestamp":1642693094,"replay_state":"idle"} last_update: 2022-01-20 12:42:59 snapshots: 5 .mirror.primary.47fd1aae-5f19-4193-a5df-562b5c644ea7.dda146c6-5f21-4e75-ba93-660f6e57e301 (peer_uuids:[bfd09289-c9c9-40c8-b2d3-ead9b6a99a45])示例
基于日志的镜像:
[root@mon-site-b ~]# rbd mirror image status data/image1 image1: global_id: 7d486c3f-d5a1-4bee-ae53-6c4f1e0c8eac state: up+replaying1 description: replaying, master_position=[object_number=3, tag_tid=1, entry_tid=3], mirror_position=[object_number=3, tag_tid=1, entry_tid=3], entries_behind_master=0 last_update: 2021-04-22 14:19:27基于快照的镜像:
[root@mon-site-b ~]# rbd mirror image status data/image1 image1: global_id: 06acc9e6-a63d-4aa1-bd0d-4f3a79b0ae33 state: up+replaying1 description: replaying, {"bytes_per_second":0.0,"bytes_per_snapshot":0.0,"local_snapshot_timestamp":1642689843,"remote_snapshot_timestamp":1642689843,"replay_state":"idle"} service: admin on ceph-rbd2-vasi-43-5hwia4-node2 last_update: 2022-01-20 12:41:57注意根据站点之间的连接,镜像可能需要很长时间才能同步镜像。
其它资源
- 如需了解更多详细信息,请参阅 Red Hat Ceph Storage 块设备指南中的 Ceph 块设备镜像部分。
- 有关 Ceph 用户的更多详细信息,请参见 Red Hat Ceph Storage 管理指南中的用户管理一节。
5.6. 使用命令行界面配置双向镜像
此流程配置主存储集群和辅助存储集群之间的池的双向复制。
使用双向复制时,您只能在两个存储集群之间镜像。
本节中的示例通过将主镜像作为 site-a 引用主存储集群和您将要复制镜像的辅助存储集群作为 site-b 来区分两个存储集群。这些示例中使用的池名称称为 data。
先决条件
- 至少两个健康状态并运行 Red Hat Ceph Storage 集群。
- 对每个存储集群的 Ceph 客户端节点的根级别访问权限。
- 具有管理员级别功能的 CephX 用户。
- 池中的镜像必须为基于日志的镜像启用 exclusive-lock 和日志记录。
流程
在连接到
site-a存储集群的客户端节点上,以及连接到site-b存储集群的客户端节点上安装rbd-mirror软件包:Red Hat Enterprise Linux 7
[root@rbd-client ~]# yum install rbd-mirrorRed Hat Enterprise Linux 8
[root@rbd-client ~]# dnf install rbd-mirror注意软件包由 Red Hat Ceph Storage 工具存储库提供。
在镜像上启用 exclusive-lock 和 loging 功能。
对于新镜像,使用
--image-feature选项:语法
rbd create IMAGE_NAME --size MEGABYTES --pool POOL_NAME --image-feature FEATURE [,FEATURE]示例
[root@rbd-client ~]# rbd create image1 --size 1024 --pool data --image-feature exclusive-lock,journaling对于现有镜像,请使用
rbd feature enable命令:语法
rbd feature enable POOL_NAME/IMAGE_NAME FEATURE [,FEATURE]示例
[root@rbd-client ~]# rbd feature enable data/image1 exclusive-lock,journaling要默认在所有新镜像上启用专用锁定和日志记录功能,请在 Ceph 配置文件中添加以下设置:
rbd_default_features = 125
选择镜像模式,可以是池或镜像模式。
重要使用镜像模式进行基于快照的镜像功能。
启用 池模式 :
语法
rbd mirror pool enable POOL_NAME MODE示例
[root@rbd-client ~]# rbd mirror pool enable data pool这个示例启用对名为
data的完整池进行镜像。启用 镜像模式 :
语法
rbd mirror pool enable POOL_NAME MODE示例
[root@rbd-client ~]# rbd mirror pool enable data image这个示例在名为
data的池上启用镜像模式镜像。验证镜像是否已成功启用:
语法
rbd mirror pool info POOL_NAME示例
[root@rbd-client ~]# rbd mirror pool info data Mode: image Site Name: 94cbd9ca-7f9a-441a-ad4b-52a33f9b7148 Peer Sites: none
在
site-a集群中,完成以下步骤:在 Ceph 客户端节点上,创建一个用户:
语法
ceph auth get-or-create client.PRIMARY_CLUSTER_NAME mon 'profile rbd-mirror' osd 'profile rbd' -o /etc/ceph/ceph.PRIMARY_CLUSTER_NAME.keyring示例
[root@rbd-client-site-a ~]# ceph auth get-or-create client.rbd-mirror.site-a mon 'profile rbd-mirror' osd 'profile rbd' -o /etc/ceph/ceph.client.rbd-mirror.site-a.keyring将密钥环复制到
site-b集群:语法
scp /etc/ceph/ceph.PRIMARY_CLUSTER_NAME.keyring root@SECONDARY_CLUSTER:_PATH_示例
[root@rbd-client-site-a ~]# scp /etc/ceph/ceph.client.rbd-mirror.site-a.keyring root@rbd-client-site-b:/etc/ceph/在 Ceph 客户端节点上,引导存储集群对等点。
将存储集群对点注册到池:
语法
rbd mirror pool peer bootstrap create --site-name LOCAL_SITE_NAME POOL_NAME > PATH_TO_BOOTSTRAP_TOKEN示例
[root@rbd-client-site-a ~]# rbd mirror pool peer bootstrap create --site-name rbd-mirror.site-a data > /root/bootstrap_token_rbd-mirror.site-a注意此示例 bootstrap 命令创建
client.rbd-mirror-peerCeph 用户。将 bootstrap 令牌文件复制到
site-b存储集群。语法
scp PATH_TO_BOOTSTRAP_TOKEN root@SECONDARY_CLUSTER:/root/示例
[root@rbd-client-site-a ~]# scp /root/bootstrap_token_site-a root@ceph-rbd2:/root/
在
site-b集群中,完成以下步骤:在客户端节点上,创建用户:
语法
ceph auth get-or-create client.SECONDARY_CLUSTER_NAME mon 'profile rbd-mirror' osd 'profile rbd' -o /etc/ceph/ceph.SECONDARY_CLUSTER_NAME.keyring示例
[root@rbd-client-site-b ~]# ceph auth get-or-create client.rbd-mirror.site-b mon 'profile rbd-mirror' osd 'profile rbd' -o /etc/ceph/ceph.client.rbd-mirror.site-b.keyring将密钥环复制到
站点(Ceph 客户端节点)中:语法
scp /etc/ceph/ceph.SECONDARY_CLUSTER_NAME.keyring root@PRIMARY_CLUSTER:_PATH_示例
[root@rbd-client-site-b ~]# scp /etc/ceph/ceph.client.rbd-mirror.site-b.keyring root@rbd-client-site-a:/etc/ceph/导入 bootstrap 令牌:
语法
rbd mirror pool peer bootstrap import --site-name LOCAL_SITE_NAME --direction rx-tx POOL_NAME PATH_TO_BOOTSTRAP_TOKEN示例
[root@rbd-client-site-b ~]# rbd mirror pool peer bootstrap import --site-name rbd-mirror.site-b --direction rx-tx data /root/bootstrap_token_rbd-mirror.site-a注意--direction参数是可选的,因为在 bootstrapping peers 时双向镜像是默认设置。
在主客户端和次要客户端节点上启用并启动
rbd-mirror守护进程:语法
systemctl enable ceph-rbd-mirror.target systemctl enable ceph-rbd-mirror@rbd-mirror.CLIENT_ID systemctl start ceph-rbd-mirror@rbd-mirror.CLIENT_ID将
CLIENT_ID替换为前面创建的 Ceph 用户。示例
[root@rbd-client-site-a ~]# systemctl enable ceph-rbd-mirror.target [root@rbd-client-site-a ~]# systemctl enable ceph-rbd-mirror@rbd-mirror.site-a [root@rbd-client-site-a ~]# systemctl start ceph-rbd-mirror@rbd-mirror.site-a [root@rbd-client-site-a ~]# systemctl enable ceph-rbd-mirror@rbd-mirror.site-b [root@rbd-client-site-a ~]# systemctl start ceph-rbd-mirror@rbd-mirror.site-b在上例中,用户在主集群
site-a中被启用示例
[root@rbd-client-site-b ~]# systemctl enable ceph-rbd-mirror.target [root@rbd-client-site-b ~]# systemctl enable ceph-rbd-mirror@rbd-mirror.site-a [root@rbd-client-site-b ~]# systemctl start ceph-rbd-mirror@rbd-mirror.site-a [root@rbd-client-site-b ~]# systemctl enable ceph-rbd-mirror@rbd-mirror.site-b [root@rbd-client-site-b ~]# systemctl start ceph-rbd-mirror@rbd-mirror.site-b在上例中,用户在第二个集群
site-b中启用重要每个
rbd-mirror守护进程必须具有唯一的客户端 ID。要验证镜像状态,请从
site-a和site-b集群中的 Ceph Monitor 节点运行以下命令:语法
rbd mirror image status POOL_NAME/IMAGE_NAME示例
基于日志的镜像:
[root@mon-site-a ~]# rbd mirror image status data/image1 image1: global_id: 08027096-d267-47f8-b52e-59de1353a034 state: up+stopped1 description: local image is primary last_update: 2021-04-22 13:45:31基于快照的镜像:
[root@mon-site-a ~]# rbd mirror image status data/image1 image1: global_id: 47fd1aae-5f19-4193-a5df-562b5c644ea7 state: up+stopped1 description: local image is primary service: admin on ceph-rbd1-vasi-43-5hwia4-node2 last_update: 2022-01-20 12:42:54 peer_sites: name: rbd-mirror.site-b state: up+replaying description: replaying, {"bytes_per_second":0.0,"bytes_per_snapshot":0.0,"local_snapshot_timestamp":1642693094,"remote_snapshot_timestamp":1642693094,"replay_state":"idle"} last_update: 2022-01-20 12:42:59 snapshots: 5 .mirror.primary.47fd1aae-5f19-4193-a5df-562b5c644ea7.dda146c6-5f21-4e75-ba93-660f6e57e301 (peer_uuids:[bfd09289-c9c9-40c8-b2d3-ead9b6a99a45])示例
基于日志的镜像:
[root@mon-site-b ~]# rbd mirror image status data/image1 image1: global_id: 7d486c3f-d5a1-4bee-ae53-6c4f1e0c8eac state: up+replaying1 description: replaying, master_position=[object_number=3, tag_tid=1, entry_tid=3], mirror_position=[object_number=3, tag_tid=1, entry_tid=3], entries_behind_master=0 last_update: 2021-04-22 14:19:27基于快照的镜像:
[root@mon-site-b ~]# rbd mirror image status data/image1 image1: global_id: 06acc9e6-a63d-4aa1-bd0d-4f3a79b0ae33 state: up+replaying1 description: replaying, {"bytes_per_second":0.0,"bytes_per_snapshot":0.0,"local_snapshot_timestamp":1642689843,"remote_snapshot_timestamp":1642689843,"replay_state":"idle"} service: admin on ceph-rbd2-vasi-43-5hwia4-node2 last_update: 2022-01-20 12:41:57注意根据站点之间的连接,镜像可能需要很长时间才能同步镜像。
其它资源
- 如需了解更多详细信息,请参阅 Red Hat Ceph Storage 块设备指南中的 Ceph 块设备镜像部分。
- 有关 Ceph 用户的更多详细信息,请参见 Red Hat Ceph Storage 管理指南中的用户管理一节。
5.7. 镜像 Ceph 块设备的管理
作为存储管理员,您可以执行各种任务来帮助您管理 Ceph 块设备镜像环境。您可以执行以下任务:
- 查看有关存储群集对等点的信息.
- 添加或删除对等存储群集。
- 获取池或镜像的镜像状态。
- 启用对池或镜像的镜像。
- 禁用对池或镜像的镜像。
- 延迟块设备复制。
- 提升和降级镜像。
5.7.1. 先决条件
- 至少运行两个健康的 Red Hat Ceph Storage 集群。
- 对 Ceph 客户端节点的根级别访问权限。
- 单向或双向 Ceph 块设备镜像关系。
5.7.2. 查看有关同级的信息
查看有关存储集群对等点的信息。
先决条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
- 节点的根级别访问权限。
流程
查看对等点的信息:
语法
rbd mirror pool info POOL_NAME示例
[root@rbd-client ~]# rbd mirror pool info data Mode: pool Site Name: site-a Peer Sites: UUID: 950ddadf-f995-47b7-9416-b9bb233f66e3 Name: site-b Mirror UUID: 4696cd9d-1466-4f98-a97a-3748b6b722b3 Direction: rx-tx Client: client.site-b
5.7.3. 启用对池的镜像
在两个对等集群中运行以下命令,在池上启用镜像功能。
先决条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
- 节点的根级别访问权限。
流程
在池上启用镜像:
语法
rbd mirror pool enable POOL_NAME MODE示例
[root@rbd-client ~]# rbd mirror pool enable data pool这个示例启用对名为
data的完整池进行镜像。示例
[root@rbd-client ~]# rbd mirror pool enable data image这个示例在名为
data的池上启用镜像模式镜像。
其它资源
- 详情请参阅 Red Hat Ceph Storage 块设备指南中的镜像 Ceph 块设备一节。
5.7.4. 禁用对池的镜像
在禁用镜像前,删除对等集群。
当您禁用对池的镜像时,您还会在池中在镜像模式中单独启用镜像的镜像禁用它。
先决条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
- 节点的根级别访问权限。
流程
在池上禁用镜像:
语法
rbd mirror pool disable POOL_NAME示例
[root@rbd-client ~]# rbd mirror pool disable data此示例禁用名为
data的池的镜像。
5.7.5. 启用镜像镜像
在两个对等存储集群中,以镜像模式对整个池启用镜像功能。
先决条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
- 节点的根级别访问权限。
流程
为池中的特定镜像启用镜像功能:
语法
rbd mirror image enable POOL_NAME/IMAGE_NAME示例
[root@rbd-client ~]# rbd mirror image enable data/image2本例启用对
data池中的image2镜像启用镜像。
其它资源
- 详情请参阅 Red Hat Ceph Storage Block Device 指南 中的 对池启用镜像部分。
5.7.6. 禁用镜像镜像
禁用镜像的镜像。
先决条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
- 节点的根级别访问权限。
流程
禁用特定镜像的镜像:
语法
rbd mirror image disable POOL_NAME/IMAGE_NAME示例
[root@rbd-client ~]# rbd mirror image disable data/image2本例禁用
data池中image2镜像的镜像。
5.7.7. 镜像提升和降级
提升或降级镜像。
不要强制提升仍在同步的非主镜像,因为镜像在提升后无效。
先决条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
- 节点的根级别访问权限。
流程
将镜像降级为非主要镜像:
语法
rbd mirror image demote POOL_NAME/IMAGE_NAME示例
[root@rbd-client ~]# rbd mirror image demote data/image2本例降级
data池中的image2镜像。将镜像提升为主要步骤:
语法
rbd mirror image promote POOL_NAME/IMAGE_NAME示例
[root@rbd-client ~]# rbd mirror image promote data/image2本例提升了
data池中的image2。根据您使用的镜像类型,请参阅通过单向镜像从灾难中恢复,或者通过双向镜像从灾难中恢复。
使用
--force选项强制提升非主镜像:语法
rbd mirror image promote --force POOL_NAME/IMAGE_NAME示例
[root@rbd-client ~]# rbd mirror image promote --force data/image2当降级无法传播到对等 Ceph 存储群集时,请使用强制提升。例如,由于集群失败或通信中断。
其它资源
- 有关详细信息,请参阅 Red Hat Ceph Storage 块设备指南中的故障切换部分。
5.7.8. 镜像重新同步
重新同步镜像.如果两个对等集群之间状态不一致,rbd-mirror 守护进程不会尝试镜像导致不一致的镜像。
先决条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
- 节点的根级别访问权限。
流程
请求主镜像重新同步:
语法
rbd mirror image resync POOL_NAME/IMAGE_NAME示例
[root@rbd-client ~]# rbd mirror image resync data/image2这个示例请求在
data池中重新同步image2。
其它资源
- 要因为灾难而需要从不一致的状态中恢复,请参阅通过单向镜像从灾难中恢复,或者通过双向镜像从灾难中恢复。
5.7.9. 添加存储集群对等集群
为 rbd-mirror 守护进程添加一个存储集群 peer,以发现其对等存储集群。例如,要将 site-a 存储集群添加为 site-b 存储集群的对等点,然后从 site-b 存储集群中的客户端节点按照以下步骤操作。
先决条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
- 节点的根级别访问权限。
流程
将 peer 注册到池:
语法
rbd --cluster CLUSTER_NAME mirror pool peer add POOL_NAME PEER_CLIENT_NAME@PEER_CLUSTER_NAME -n CLIENT_NAME示例
[root@rbd-client ~]# rbd --cluster site-b mirror pool peer add data client.site-a@site-a -n client.site-b
5.7.10. 删除存储集群 peer
通过指定对等 UUID 来删除存储群集 peer。
先决条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
- 节点的根级别访问权限。
流程
指定池名称和同级通用唯一标识符 (UUID)。
语法
rbd mirror pool peer remove POOL_NAME PEER_UUID示例
[root@rbd-client ~]# rbd mirror pool peer remove data 7e90b4ce-e36d-4f07-8cbc-42050896825d提示若要查看对等 UUID,可使用
rbd mirror pool info命令。
5.7.11. 获取池的镜像状态
获取池的镜像状态。
先决条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
- 节点的根级别访问权限。
流程
获取镜像池概述:
语法
rbd mirror pool status POOL_NAME示例
[root@rbd-client ~]# rbd mirror pool status data health: OK images: 1 total提示要输出池中每个镜像的状态详情,请使用
--verbose选项。
5.7.12. 获取单个镜像的镜像状态
获取镜像的镜像状态。
先决条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
- 节点的根级别访问权限。
流程
获取已镜像镜像的状态:
语法
rbd mirror image status POOL_NAME/IMAGE_NAME示例
[root@rbd-client ~]# rbd mirror image status data/image2 image2: global_id: 703c4082-100d-44be-a54a-52e6052435a5 state: up+replaying description: replaying, master_position=[object_number=0, tag_tid=3, entry_tid=0], mirror_position=[object_number=0, tag_tid=3, entry_tid=0], entries_behind_master=0 last_update: 2019-04-23 13:39:15本例获取
data池中image2镜像的状态。
5.7.13. 延迟块设备复制
无论您使用的是单向复制还是双向复制,您都可以延迟 RADOS 块设备 (RBD) 镜像镜像之间的复制。如果您要在复制到次要镜像之前恢复对主镜像的更改,则可能需要实施延迟复制。
为实施延迟复制,目标存储集群内的 rbd-mirror 守护进程应设置 rbd_mirroring_replay_delay = MINIMUM_DELAY_IN_SECONDS 配置选项。此设置可以在 rbd-mirror 守护进程使用的 ceph.conf 文件中全局应用,也可以在单个镜像基础上应用。
先决条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
- 节点的根级别访问权限。
流程
要使用特定镜像的延迟复制,在主镜像上运行以下
rbdCLI 命令:语法
rbd image-meta set POOL_NAME/IMAGE_NAME conf_rbd_mirroring_replay_delay MINIMUM_DELAY_IN_SECONDS示例
[root@rbd-client ~]# rbd image-meta set vms/vm-1 conf_rbd_mirroring_replay_delay 600本例在
vms池中设置镜像vm-1的最小复制延迟 10 分钟。
5.7.14. 异步更新和 Ceph 块设备镜像
使用带有异步更新的 Ceph 块设备镜像来更新存储集群时,请遵循 Red Hat Ceph Storage 安装指南中的更新说明。完成更新后,重新启动 Ceph 块设备实例。
在重启实例时不需要按照一定顺序进行。红帽建议重启实例,使其指向主镜像池,然后实例指向镜像池。
5.7.15. 创建镜像 mirror-snapshot
在使用基于快照的镜像功能时,创建镜像 mirror-snapshot,以镜像 RBD 镜像已更改的内容。
先决条件
- 至少运行两个健康的 Red Hat Ceph Storage 集群。
- 对 Red Hat Ceph Storage 集群的 Ceph 客户端节点的根级别访问权限。
- 具有管理员级别功能的 CephX 用户。
- 访问创建快照镜像的 Red Hat Ceph Storage 集群。
默认情况下,每个镜像只能创建 3 个镜像 mirror-snapshot。如果达到限制,则最新镜像 mirror-snapshot 会自动被删除。如果需要,可以通过 rbd_mirroring_max_mirroring_snapshots 配置覆盖限制。镜像 mirror-snapshot 会在镜像被删除或禁用镜像时自动删除。
流程
创建 image-mirror 快照:
语法
rbd --cluster CLUSTER_NAME mirror image snapshot POOL_NAME/IMAGE_NAME示例
root@rbd-client ~]# rbd --cluster site-a mirror image snapshot data/image1
其它资源
- 详情请参阅 Red Hat Ceph Storage 块设备指南中的镜像 Ceph 块设备一节。
5.7.16. 调度 mirror-snapshot
在定义 mirror-snapshot 调度时,可以自动创建 mirror-snapshots。mirror-snapshot 可以按池或镜像级别进行全局调度。可以在任何级别上定义多个 mirror-snapshot 调度,但只有与单个镜像的镜像匹配的最具体的快照调度才会运行。
其它资源
- 详情请参阅 Red Hat Ceph Storage 块设备指南中的镜像 Ceph 块设备一节。
5.7.17. 创建 mirror-snapshot 调度
创建 mirror-snapshot 调度。
先决条件
- 至少运行两个健康的 Red Hat Ceph Storage 集群。
- 对 Red Hat Ceph Storage 集群的 Ceph 客户端节点的根级别访问权限。
- 具有管理员级别功能的 CephX 用户。
- 访问创建快照镜像的 Red Hat Ceph Storage 集群。
流程
创建 mirror-snapshot 调度:
语法
rbd mirror snapshot schedule add --pool POOL_NAME --image IMAGE_NAME INTERVAL START_TIME间隔可以分别使用 d、h 或 m 后缀以天、小时或分钟为单位指定。可选的 START_TIME 可以使用 ISO 8601 时间格式指定。
示例
在镜像级别调度:
[root@rbd-client ~]# rbd mirror snapshot schedule add --pool data --image image1 6h在池级别调度:
[root@rbd-client ~]# rbd mirror snapshot schedule add --pool data 24h 14:00:00-05:00按全局级别调度:
[root@rbd-client ~]# rbd mirror snapshot schedule add 48h
其它资源
- 详情请参阅 Red Hat Ceph Storage 块设备指南中的镜像 Ceph 块设备一节。
5.7.18. 列出特定级别的所有快照计划
列出特定级别的所有快照计划。
先决条件
- 至少运行两个健康的 Red Hat Ceph Storage 集群。
- 对 Red Hat Ceph Storage 集群的 Ceph 客户端节点的根级别访问权限。
- 具有管理员级别功能的 CephX 用户。
- 访问创建快照镜像的 Red Hat Ceph Storage 集群。
流程
使用可选池或镜像名称列出特定全局、池或镜像级别的所有快照调度:
语法
rbd --cluster site-a mirror snapshot schedule ls --pool POOL_NAME --recursive此外,还可指定
`--recursive选项来列出指定级别的所有调度,如下所示:示例
[root@rbd-client ~]# rbd --cluster site-a mirror snapshot schedule ls --pool data --recursive POOL NAMESPACE IMAGE SCHEDULE data - - every 1d starting at 14:00:00-05:00 data - image1 every 6h
其它资源
- 详情请参阅 Red Hat Ceph Storage 块设备指南中的镜像 Ceph 块设备一节。
5.7.19. 删除 mirror-snapshot 调度
删除 mirror-snapshot 调度。
先决条件
- 至少运行两个健康的 Red Hat Ceph Storage 集群。
- 对 Red Hat Ceph Storage 集群的 Ceph 客户端节点的根级别访问权限。
- 具有管理员级别功能的 CephX 用户。
- 访问创建快照镜像的 Red Hat Ceph Storage 集群。
流程
删除 mirror-snapshot 调度:
语法
rbd --cluster CLUSTER_NAME mirror snapshot schedule remove POOL_NAME/IMAGE_NAME INTERVAL START_TIME间隔可以分别使用 d、h 和 m 后缀来以天数、小时或分钟为单位指定。可选的 START_TIME 可以使用 ISO 8601 时间格式指定。
示例
[root@rbd-client ~]# rbd --cluster site-a mirror snapshot schedule remove data/image1 6h示例
[root@rbd-client ~]# rbd --cluster site-a mirror snapshot schedule remove data/image1 24h 14:00:00-05:00
其它资源
- 详情请参阅 Red Hat Ceph Storage 块设备指南中的镜像 Ceph 块设备一节。
5.7.20. 查看要创建的下一个快照的状态
查看要为基于快照的镜像 RBD 镜像创建下一快照的状态。
先决条件
- 至少运行两个健康的 Red Hat Ceph Storage 集群。
- 对 Red Hat Ceph Storage 集群的 Ceph 客户端节点的根级别访问权限。
- 具有管理员级别功能的 CephX 用户。
- 访问创建快照镜像的 Red Hat Ceph Storage 集群。
流程
查看要创建的下一个快照的状态:
语法
rbd --cluster site-a mirror snapshot schedule status POOL_NAME/IMAGE_NAME示例
[root@rbd-client ~]# rbd --cluster site-a mirror snapshot schedule status SCHEDULE TIME IMAGE 2020-02-26 18:00:00 data/image1
其它资源
- 详情请参阅 Red Hat Ceph Storage 块设备指南中的镜像 Ceph 块设备一节。
5.8. 从灾难中恢复
作为存储管理员,您可以通过了解如何从配置了镜像功能的另一个存储集群恢复数据,为最终的硬件故障做好准备。
在示例中,主存储集群称为 site-a,辅助存储集群称为 site-b。此外,存储集群还拥有一个含有两个镜像,image1 和 image2 的 data 池。
5.8.1. 先决条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
- 配置了单向或双向镜像。
5.8.2. 灾难恢复
在两个或多个 Red Hat Ceph Storage 集群间异步复制块数据可减少停机时间,并防止发生重大数据中心故障时出现数据丢失。这些故障具有广泛的影响,也称为 大刀片,并且可能源自对电网和危险性的影响。
客户数据需要在这些情况下受到保护。卷必须遵循一致性和效率,并在恢复点目标 (RPO) 和恢复时间目标 (RTO) 目标内进行复制。此解决方案称为广域网灾难恢复 (WAN-DR)。
在这种情况下,很难恢复主系统和数据中心。恢复的最快速方法是将应用程序故障转移到备用的 Red Hat Ceph Storage 集群(灾难恢复站点),并使集群能够运行最新可用数据副本。用于从这些故障场景中恢复的解决方案由应用程序指导:
- 恢复点目标 (RPO):在最坏的情况下,应用程序允许的数据丢失的数量。
- 恢复时间目标(RTO) :使用最新可用数据副本使应用程序重新上线所需的时间。
其它资源
- 详情请参阅 Red Hat Ceph Storage 块设备指南中的镜像 Ceph 块设备一节。
- 请参阅 Red Hat Ceph Storage 数据安全和硬化指南中的加密传输部分,以了解更多有关通过加密状态通过线路传输数据的信息。
5.8.3. 使用单向镜像从灾难中恢复
要使用单向镜像功能,可以从灾难中恢复,请使用以下步骤:它们显示在主集群终止后如何切换到次集群,以及如何恢复故障。关闭可以按照一定顺序进行,也可以不按照一定顺序进行。
单向镜像支持多个次要站点。如果使用额外的次集群,请选择一个二级集群来切换到它。在故障恢复期间从同一集群进行同步。
5.8.4. 使用双向镜像从灾难中恢复
要使用双向镜像功能,可以从灾难中恢复,请使用以下步骤:它们演示了如何在主集群终止后切换到次要集群中的镜像数据,以及如何故障恢复。关闭可以按照一定顺序进行,也可以不按照一定顺序进行。
其它资源
- 有关演示、提升和重新同步镜像的详情,请参阅 Red Hat Ceph Storage Block Device Guide 中的配置镜像部分。
5.8.5. 有序关闭后故障转移
正常关闭后故障转移到次存储集群。
先决条件
- 至少两个正在运行的 Red Hat Ceph Storage 集群。
- 节点的根级别访问权限。
- 使用单向镜像配置的池镜像或镜像镜像。
流程
- 停止使用主镜像的所有客户端。此步骤取决于哪些客户端使用该镜像。例如,从使用该镜像的任何 OpenStack 实例分离卷。
在
site-a集群中的监控节点中运行以下命令来降级位于site-a集群中的主镜像:语法
rbd mirror image demote POOL_NAME/IMAGE_NAME示例
[root@rbd-client ~]# rbd mirror image demote data/image1 [root@rbd-client ~]# rbd mirror image demote data/image2在
site-b集群中的监控节点中运行以下命令来提升位于site-b集群中的非主镜像:语法
rbd mirror image promote POOL_NAME/IMAGE_NAME示例
[root@rbd-client ~]# rbd mirror image promote data/image1 [root@rbd-client ~]# rbd mirror image promote data/image2经过一段时间后,检查
site-b集群中监控节点中的镜像状态。它们应当显示up+stopped状态,并列为主要状态:[root@rbd-client ~]# rbd mirror image status data/image1 image1: global_id: 08027096-d267-47f8-b52e-59de1353a034 state: up+stopped description: local image is primary last_update: 2019-04-17 16:04:37 [root@rbd-client ~]# rbd mirror image status data/image2 image2: global_id: 596f41bc-874b-4cd4-aefe-4929578cc834 state: up+stopped description: local image is primary last_update: 2019-04-17 16:04:37- 恢复对镜像的访问。此步骤取决于哪些客户端使用该镜像。
其它资源
- 请参阅 Red Hat OpenStack Platform 指南中的块存储和卷章节。
5.8.6. 非有序关闭后故障转移
非有序关闭后故障转移到次要存储集群。
先决条件
- 至少两个正在运行的 Red Hat Ceph Storage 集群。
- 节点的根级别访问权限。
- 使用单向镜像配置的池镜像或镜像镜像。
流程
- 验证主存储集群是否已关闭。
- 停止使用主镜像的所有客户端。此步骤取决于哪些客户端使用该镜像。例如,从使用该镜像的任何 OpenStack 实例分离卷。
从
site-b存储集群中的 Ceph 监控节点提升非主镜像。使用--force选项,因为降级无法传播到site-a存储集群:语法
rbd mirror image promote --force POOL_NAME/IMAGE_NAME示例
[root@rbd-client ~]# rbd mirror image promote --force data/image1 [root@rbd-client ~]# rbd mirror image promote --force data/image2检查
site-b存储集群中 Ceph 监控节点的镜像状态。它们应当显示up+stopping_replay状态,描述应显示force promoted:示例
[root@rbd-client ~]# rbd mirror image status data/image1 image1: global_id: 08027096-d267-47f8-b52e-59de1353a034 state: up+stopping_replay description: force promoted last_update: 2019-04-17 13:25:06 [root@rbd-client ~]# rbd mirror image status data/image2 image2: global_id: 596f41bc-874b-4cd4-aefe-4929578cc834 state: up+stopping_replay description: force promoted last_update: 2019-04-17 13:25:06
其它资源
- 请参阅 Red Hat OpenStack Platform 指南中的块存储和卷章节。
5.8.7. 准备故障恢复
如果两个存储集群最初只配置为单向镜像,为了避免故障,请配置主存储集群以进行镜像,以便按照相反方向复制镜像。
先决条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
- 节点的根级别访问权限。
流程
在
site-a存储集群的客户端节点上,安装rbd-mirror软件包:[root@rbd-client ~]# yum install rbd-mirror注意软件包由 Red Hat Ceph Storage 工具存储库提供。
在
site-a存储集群的客户端节点上,通过在/etc/sysconfig/ceph文件中添加CLUSTER选项来指定存储集群名称:CLUSTER=site-b将
site-bCeph 配置文件和密钥环文件从site-bCeph Monitor 节点复制到site-aCeph monitor 和客户端节点:语法
scp /etc/ceph/ceph.conf USER@SITE_A_MON_NODE_NAME:/etc/ceph/site-b.conf scp /etc/ceph/site-b.client.site-b.keyring root@SITE_A_MON_NODE_NAME:/etc/ceph/ scp /etc/ceph/ceph.conf user@SITE_A_CLIENT_NODE_NAME:/etc/ceph/site-b.conf scp /etc/ceph/site-b.client.site-b.keyring user@SITE_A_CLIENT_NODE_NAME:/etc/ceph/注意使用
scp命令从site-bCeph 监控节点传输 Ceph 配置文件到site-aCeph monitor 节点,将该文件重命名为site-a.conf。密钥环文件名保持不变。将
site-aCeph Monitor 节点的site-akeyring 文件复制到site-a客户端节点:语法
scp /etc/ceph/site-a.client.site-a.keyring <user>@SITE_A_CLIENT_HOST_NAME:/etc/ceph/在
site-a客户端节点上启用并启动rbd-mirror守护进程:语法
systemctl enable ceph-rbd-mirror.target systemctl enable ceph-rbd-mirror@CLIENT_ID systemctl start ceph-rbd-mirror@CLIENT_ID将
CLIENT_ID更改为rbd-mirror守护进程将使用的 Ceph 存储集群用户。用户必须具有对存储集群的适当cephx访问权限。示例
[root@rbd-client ~]# systemctl enable ceph-rbd-mirror.target [root@rbd-client ~]# systemctl enable ceph-rbd-mirror@site-a [root@rbd-client ~]# systemctl start ceph-rbd-mirror@site-a在
site-a集群的客户端节点中,将site-b集群添加为对等集群:示例
[root@rbd-client ~]# rbd --cluster site-a mirror pool peer add data client.site-b@site-b -n client.site-a如果您使用多个次要存储集群,则必须添加选择故障转移到的次要存储集群,并从中恢复故障。
在
site-a存储集群中的监控节点中,验证site-b存储集群是否已成功添加为对等集群:语法
rbd mirror pool info POOL_NAME示例
[root@rbd-client ~]# rbd mirror pool info data Mode: image Site Name: site-a Peer Sites: UUID: 950ddadf-f995-47b7-9416-b9bb233f66e3 Name: site-b Mirror UUID: 4696cd9d-1466-4f98-a97a-3748b6b722b3 Direction: rx-tx Client: client.site-b
其它资源
- 如需更多信息,请参见 Red Hat Ceph Storage 管理指南中的用户管理一章。
5.8.7.1. 返回主存储集群失败
当以前的主存储集群恢复时,失败回主存储集群。
先决条件
- 至少两个正在运行的 Red Hat Ceph Storage 集群。
- 节点的根级别访问权限。
- 使用单向镜像配置的池镜像或镜像镜像。
流程
再次检查
site-b集群中监控节点的镜像状态。它们应该显示up-stopped状态,描述应该会指出local image is primary:示例
[root@rbd-client ~]# rbd mirror image status data/image1 image1: global_id: 08027096-d267-47f8-b52e-59de1353a034 state: up+stopped description: local image is primary last_update: 2019-04-22 17:37:48 [root@rbd-client ~]# rbd mirror image status data/image2 image2: global_id: 08027096-d267-47f8-b52e-59de1353a034 state: up+stopped description: local image is primary last_update: 2019-04-22 17:38:18从
site-a存储集群的 Ceph 监控节点确定镜像是否仍然是主镜像:语法
rbd info POOL_NAME/IMAGE_NAME示例
[root@rbd-client ~]# rbd info data/image1 [root@rbd-client ~]# rbd info data/image2在命令的输出中,查找
mirroring primary: true或mirroring primary: false以确定状态。从
site-a存储集群中的 Ceph monitor 节点运行以下命令来降级列为主要镜像:语法
rbd mirror image demote POOL_NAME/IMAGE_NAME示例
[root@rbd-client ~]# rbd mirror image demote data/image1如果未按顺序关闭,则仅重新同步镜像。在
site-a存储集群中的监控节点上运行以下命令,以重新同步从site-b到site-a的镜像:语法
rbd mirror image resync POOL_NAME/IMAGE_NAME示例
[root@rbd-client ~]# rbd mirror image resync data/image1 Flagged image for resync from primary [root@rbd-client ~]# rbd mirror image resync data/image2 Flagged image for resync from primary一段时间后,通过验证镜像是否处于
up+replaying状态确保完成镜像重新同步。通过在site-a存储集群中的监控节点中运行以下命令来检查其状态:语法
rbd mirror image status POOL_NAME/IMAGE_NAME示例
[root@rbd-client ~]# rbd mirror image status data/image1 [root@rbd-client ~]# rbd mirror image status data/image2在
site-b存储集群中的 Ceph monitor 节点上运行以下命令来降级site-b存储集群中的镜像:语法
rbd mirror image demote POOL_NAME/IMAGE_NAME示例
[root@rbd-client ~]# rbd mirror image demote data/image1 [root@rbd-client ~]# rbd mirror image demote data/image2注意如果有多个次要存储集群,则只需要从提升它的次要存储集群完成。
在
site-a存储集群中的 Ceph monitor 节点中运行以下命令来提升位于site-a存储集群中的以前主镜像:语法
rbd mirror image promote POOL_NAME/IMAGE_NAME示例
[root@rbd-client ~]# rbd mirror image promote data/image1 [root@rbd-client ~]# rbd mirror image promote data/image2检查
site-a存储集群中 Ceph 监控节点的镜像状态。它们应当显示up+stopped状态,描述应该为local image is primary:语法
rbd mirror image status POOL_NAME/IMAGE_NAME示例
[root@rbd-client ~]# rbd mirror image status data/image1 image1: global_id: 08027096-d267-47f8-b52e-59de1353a034 state: up+stopped description: local image is primary last_update: 2019-04-22 11:14:51 [root@rbd-client ~]# rbd mirror image status data/image2 image2: global_id: 596f41bc-874b-4cd4-aefe-4929578cc834 state: up+stopped description: local image is primary last_update: 2019-04-22 11:14:51
5.8.8. 删除双向镜像
恢复失败后,您可以移除双向镜像功能,并禁用 Ceph 块设备镜像服务。
先决条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
- 节点的根级别访问权限。
流程
将
site-b存储集群作为对等集群从site-a存储集群中删除:示例
[root@rbd-client ~]# rbd mirror pool peer remove data client.remote@remote --cluster local [root@rbd-client ~]# rbd --cluster site-a mirror pool peer remove data client.site-b@site-b -n client.site-a在
site-a客户端中停止并禁用rbd-mirror守护进程:语法
systemctl stop ceph-rbd-mirror@CLIENT_ID systemctl disable ceph-rbd-mirror@CLIENT_ID systemctl disable ceph-rbd-mirror.target示例
[root@rbd-client ~]# systemctl stop ceph-rbd-mirror@site-a [root@rbd-client ~]# systemctl disable ceph-rbd-mirror@site-a [root@rbd-client ~]# systemctl disable ceph-rbd-mirror.target
第 6 章 使用 Ceph 块设备 Python 模块
rbd python 模块提供对 Ceph 块设备镜像的类文件访问。要使用此内置工具,请导入 rbd 和 rados Python 模块。
先决条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
- 节点的根级别访问权限。
流程
连接到 RADOS 并打开 IO 上下文:
cluster = rados.Rados(conffile='my_ceph.conf') cluster.connect() ioctx = cluster.open_ioctx('mypool')实例化一个
:class:rbd.RBD对象,用于创建镜像:rbd_inst = rbd.RBD() size = 4 * 1024**3 # 4 GiB rbd_inst.create(ioctx, 'myimage', size)要在镜像上执行 I/O,请实例化一个
:class:rbd.Image对象:image = rbd.Image(ioctx, 'myimage') data = 'foo' * 200 image.write(data, 0)这会将"foo"写入镜像的前 600 字节。请注意,数据不能是
:type:unicode-librbd不知道如何处理比:c:type:char更宽的字符。关闭镜像、IO 上下文和与 RADOS 的连接:
image.close() ioctx.close() cluster.shutdown()为了安全起见,每个调用都必须位于单独的
:finally中 :import rados import rbd cluster = rados.Rados(conffile='my_ceph_conf') try: ioctx = cluster.open_ioctx('my_pool') try: rbd_inst = rbd.RBD() size = 4 * 1024**3 # 4 GiB rbd_inst.create(ioctx, 'myimage', size) image = rbd.Image(ioctx, 'myimage') try: data = 'foo' * 200 image.write(data, 0) finally: image.close() finally: ioctx.close() finally: cluster.shutdown()这可能会有问题,Rados、Ioctx 和 Image 类可以用作自动关闭或关闭的上下文管理器。使用它们作为上下文管理器时,上述示例如下:
with rados.Rados(conffile='my_ceph.conf') as cluster: with cluster.open_ioctx('mypool') as ioctx: rbd_inst = rbd.RBD() size = 4 * 1024**3 # 4 GiB rbd_inst.create(ioctx, 'myimage', size) with rbd.Image(ioctx, 'myimage') as image: data = 'foo' * 200 image.write(data, 0)
第 7 章 Ceph iSCSI 网关(有限可用性)
作为存储管理员,您可以为 Red Hat Ceph Storage 集群安装和配置 iSCSI 网关。利用 Ceph 的 iSCSI 网关,您可以有效地运行完全集成的块存储基础架构,其具备传统存储区域网络 (SAN) 的所有功能和好处。
该技术是有限可用性。如需更多信息,请参阅 已弃用的功能 章节。
不支持 SCSI 持久保留。如果使用集群感知文件系统或不依赖 SCSI 持久保留的集群软件,则支持将多个 iSCSI 启动器映射到 RBD 镜像。例如,支持使用 ATS 的 VMware vSphere 环境,但不支持使用 Microsoft 的集群服务器 (MSCS)。
7.1. Ceph iSCSI 网关简介
通常,对 Ceph 存储集群的块级访问仅限于 QEMU 和 librbd,这是在 OpenStack 环境中采用的关键推动因素。Ceph 存储群集的块级别访问现在可以利用 iSCSI 标准来提供数据存储。
iSCSI 网关将 Red Hat Ceph Storage 与 iSCSI 标准集成,以提供高可用性 (HA) iSCSI 目标,将 RADOS 块设备 (RBD) 镜像导出为 SCSI 磁盘。iSCSI 协议允许客户端(称为启动器)通过 TCP/IP 网络发送 SCSI 命令到 SCSI 存储设备(称为目标)。这允许异构客户端(如 Microsoft Windows)访问 Red Hat Ceph Storage 集群。
图 7.1. Ceph iSCSI 网关 HA 设计
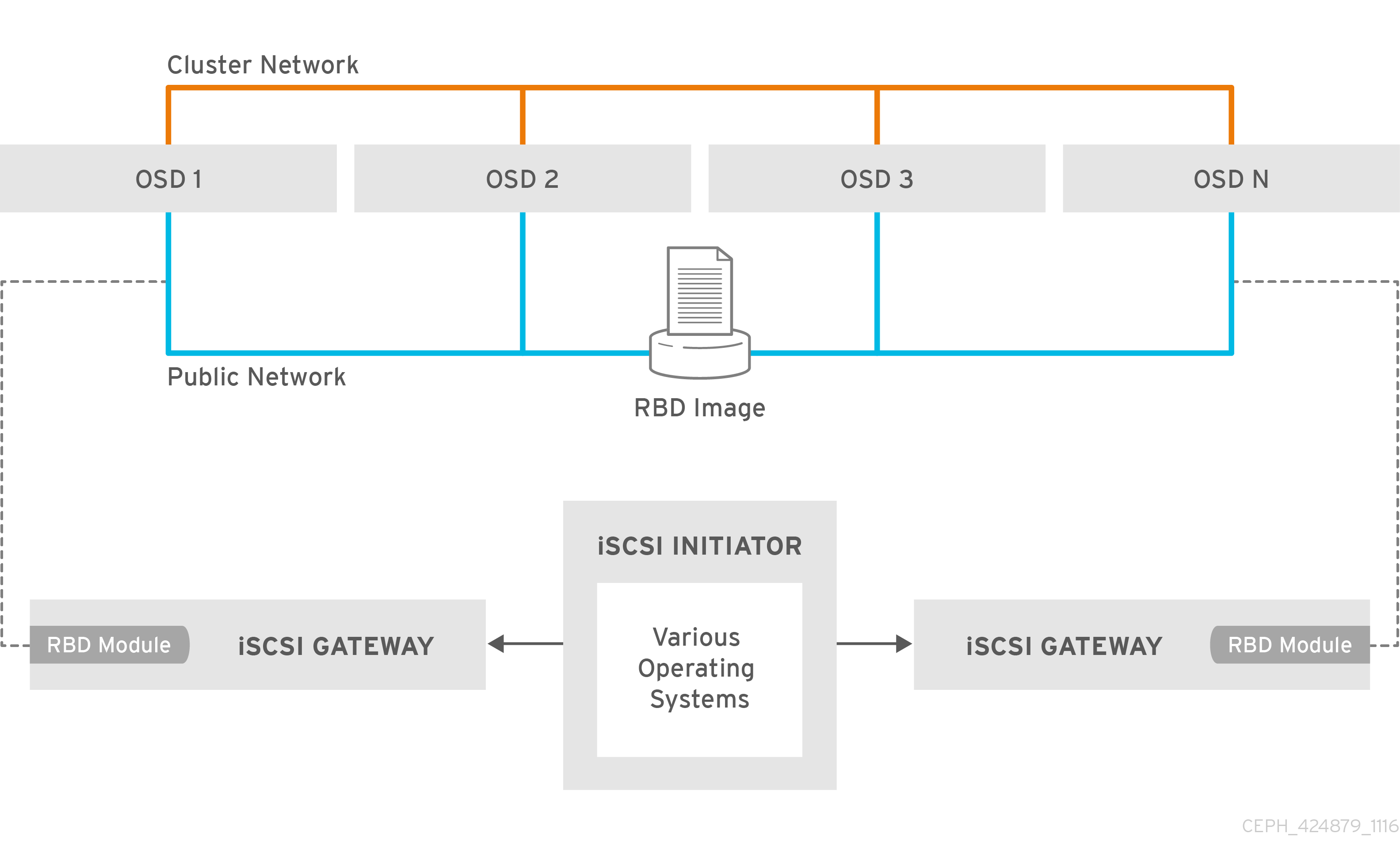
7.2. iSCSI 目标的要求
Red Hat Ceph Storage 高可用性 (HA) iSCSI 网关解决方案对用于检测故障 OSD 的网关节点、内存容量和定时器设置数量的要求。
所需节点数
至少安装两个 iSCSI 网关节点。要提高弹性和 I/O 处理,可以最多安装四个 iSCSI 网关节点。
内存要求
RBD 镜像的内存占用量可能会增大到较大的大小。iSCSI 网关节点上映射的每个 RBD 镜像使用大约 90 MB 内存。确保 iSCSI 网关节点有足够的内存来支持每个映射的 RBD 镜像。
检测关闭 OSD
Ceph 监控器或 OSD 没有特定的 iSCSI 网关选项,但务必要降低检测故障 OSD 的默认计时器,以减少启动器超时的可能性。按照 Lowering 定时器设置以检测下线的 OSD 中的说明操作,以减少启动器超时的可能性。
其它资源
- 如需更多信息,请参阅 Red Hat Ceph Storage 硬件选择指南 。
7.3. 安装 iSCSI 网关
作为存储管理员,您必须先安装必要的软件包,然后才能利用 Ceph iSCSI 网关的优势。您可以使用 Ansible 部署工具或 命令行界面 来安装 Ceph iSCSI 网关。
每个 iSCSI 网关运行 Linux I/O 目标内核子系统 (LIO) 以提供 iSCSI 协议支持。LIO 利用用户空间透传 (TCMU) 与 Ceph librbd 库交互,将 RBD 镜像公开给 iSCSI 客户端。利用 Ceph iSCSI 网关,您可以有效地运行完全集成的块存储基础架构,其具备传统存储区域网络 (SAN) 的所有功能和好处。
7.3.1. 先决条件
- Red Hat Enterprise Linux 8 或 7.7 或更高版本。
- 正在运行的 Red Hat Ceph Storage 4 或更高版本集群。
7.3.2. 使用 Ansible 安装 Ceph iSCSI 网关
使用 Ansible 实用程序安装软件包,并为 Ceph iSCSI 网关设置守护进程。
先决条件
-
安装了
ceph-ansible软件包的 Ansible 管理节点。
流程
- 在 iSCSI 网关节点上,启用 Red Hat Ceph Storage 4 工具存储库。详情请参阅 Red Hat Ceph Storage 安装指南中的启用 Red Hat Ceph Storage 存储库一节。
在 Ansible 管理节点上,在
/etc/ansible/hosts文件中为 gateway 组添加一个条目。如果您将 iSCSI 网关与 OSD 节点并置,请将 OSD 节点添加到[iscsigws]部分中。[iscsigws] ceph-igw-1 ceph-igw-2-
Ansible 将文件放置在
/usr/share/ceph-ansible/group_vars/目录中,名为iscsigws.yml.sample。创建iscsigws.yml.sample文件的副本,名为iscsigws.yml。 -
打开
iscsigws.yml文件进行编辑。 取消注释
trusted_ip_list选项,并使用 IPv4 或 IPv6 地址相应地更新值。示例
使用 IPv4 地址 10.172.19.21 和 10.172.19.22 添加两个网关,以配置
trusted_ip_list:trusted_ip_list: 10.172.19.21,10.172.19.22(可选)查看 iSCSI 网关变量部分中的 Ansible 变量和描述,并根据需要更新
iscsigws.yml。警告网关配置更改一次仅受一个网关的支持。尝试通过多个网关同时运行更改可能会导致配置不稳定和不一致。
警告在使用
ansible-playbook命令时,Ansible 安装ceph-iscsi软件包,创建和更新/etc/ceph/iscsi-gateway.cfg文件,具体取决于group_vars/iscsigws.yml文件中的设置。如果您之前已经使用命令行界面安装了ceph-iscsi软件包(如 Installing the iSCSI gateway using the command-line interface 所述),请将现存的设置从iscsi-gateway.cfg文件复制到group_vars/iscsigws.yml文件。在 Ansible 管理节点上,执行 Ansible playbook。
裸机部署:
[admin@ansible ~]$ cd /usr/share/ceph-ansible [admin@ansible ceph-ansible]$ ansible-playbook site.yml -i hosts容器部署:
[admin@ansible ~]$ cd /usr/share/ceph-ansible [admin@ansible ceph-ansible]$ ansible-playbook site-container.yml -i hosts警告在独立 iSCSI 网关节点上,验证是否已启用正确的 Red Hat Ceph Storage 4 软件存储库。如果它们不可用,Ansible 可能会安装不正确的软件包。
若要创建目标、LUN 和客户端,可使用
gwcli实用程序或 Red Hat Ceph Storage 仪表板。重要不要使用
targetcli实用程序来更改配置,这会导致以下问题: ALUA 配置错误和路径故障转移问题。可能会导致数据损坏,跨 iSCSI 网关进行不匹配的配置,并且 WWN 信息不匹配,从而导致客户端路径问题。
其它资源
-
请参阅 Sample
iscsigws.yml文件 来查看完整的示例文件。 - 使用命令行界面配置 iSCSI 目标
- 创建 iSCSI 目标
7.3.3. 使用命令行界面安装 Ceph iSCSI 网关
Ceph iSCSI 网关是 iSCSI 目标节点,也是 Ceph 客户端节点。Ceph iSCSI 网关可以是单机节点,也可以并置在 Ceph 对象存储磁盘(OSD)节点上。完成以下步骤,安装 Ceph iSCSI 网关。
先决条件
- Red Hat Enterprise Linux 8 或 7.7 及更新的版本
- Red Hat Ceph Storage 4 集群或更新版本
在存储集群的所有 Ceph 监控节点上,以
root用户身份重启ceph-mon服务:语法
systemctl restart ceph-mon@MONITOR_HOST_NAME示例
[root@mon ~]# systemctl restart ceph-mon@monitor1-
如果 Ceph iSCSI 网关不在 OSD 节点上并置,请将位于
/etc/ceph/目录下的 Ceph 配置文件从存储集群中正在运行的 Ceph 节点复制到所有 iSCSI 网关节点。Ceph 配置文件必须存在于/etc/ceph/的 iSCSI 网关节点上。 - 在所有 Ceph iSCSI 网关节点上,启用 Ceph Tools 存储库。详情请参阅安装指南中的启用 Red Hat Ceph Storage 存储库一节。
- 在所有 Ceph iSCSI 网关节点上,安装和配置 Ceph 命令行界面。详情请参阅 Red Hat Ceph Storage 4 安装指南中的安装 Ceph 命令行界面一章。
- 如果需要,在所有 Ceph iSCSI 节点上的防火墙上打开 TCP 端口 3260 和 5000。
- 新建或使用现有的 RADOS 块设备 (RBD)。
流程
在所有 Ceph iSCSI 网关节点上,安装
ceph-iscsi和tcmu-runner软件包:[root@iscsigw ~]# yum install ceph-iscsi tcmu-runner重要如果这些软件包以前的版本存在,请在安装更新的版本前将其删除。您必须从 Red Hat Ceph Storage 存储库安装这些较新版本。
(可选)在所有 Ceph iSCSI 网关节点上,根据需要安装和配置 OpenSSL 实用程序。
安装
openssl软件包:[root@iscsigw ~]# yum install openssl在主 iSCSI 网关节点上,创建一个目录来存放 SSL 密钥:
[root@iscsigw ~]# mkdir ~/ssl-keys [root@iscsigw ~]# cd ~/ssl-keys在主 iSCSI 网关节点上,创建证书和密钥文件。出现提示时,输入环境信息。
[root@iscsigw ~]# openssl req -newkey rsa:2048 -nodes -keyout iscsi-gateway.key -x509 -days 365 -out iscsi-gateway.crt在主 iSCSI 网关节点上,创建一个 PEM 文件:
[root@iscsigw ~]# cat iscsi-gateway.crt iscsi-gateway.key > iscsi-gateway.pem在主 iSCSI 网关节点上,创建一个公钥:
[root@iscsigw ~]# openssl x509 -inform pem -in iscsi-gateway.pem -pubkey -noout > iscsi-gateway-pub.key-
从主 iSCSI 网关节点,将
iscsi-gateway.crt、iscsi-gateway.pem、iscsi-gateway-pub.key和iscsi-gateway.key文件复制到其他 iSCSI 网关节点上的/etc/ceph/目录中。
在 Ceph iSCSI 网关节点上创建配置文件,然后将它复制到所有 iSCSI 网关节点。
在
/etc/ceph/目录中创建一个名为iscsi-gateway.cfg的文件:[root@iscsigw ~]# touch /etc/ceph/iscsi-gateway.cfg编辑
iscsi-gateway.cfg文件并添加以下几行:语法
[config] cluster_name = CLUSTER_NAME gateway_keyring = CLIENT_KEYRING api_secure = false trusted_ip_list = IP_ADDR,IP_ADDR示例
[config] cluster_name = ceph gateway_keyring = ceph.client.admin.keyring api_secure = false trusted_ip_list = 192.168.0.10,192.168.0.11-
将
iscsi-gateway.cfg文件复制到所有 iSCSI 网关节点。请注意,该文件在所有 iSCSI 网关节点上必须相同。
在所有 Ceph iSCSI 网关节点上,启用并启动 API 服务:
[root@iscsigw ~]# systemctl enable rbd-target-api [root@iscsigw ~]# systemctl start rbd-target-api [root@iscsigw ~]# systemctl enable rbd-target-gw [root@iscsigw ~]# systemctl start rbd-target-gw- 接下来,配置目标、LUN 和客户端。详情请参阅使用命令行界面配置 iSCSI 目标 部分。
其它资源
- 有关选项的更多详细信息,请参阅 iSCSI 网关变量 部分。
- 创建 iSCSI 目标
7.3.4. 其它资源
- 有关 Ceph iSCSI 网关 Anisble 变量的更多信息,请参阅 附录 B, iSCSI 网关变量。
7.4. 配置 iSCSI 目标
作为存储管理员,您可以使用 gwcli 命令行实用程序 配置 目标、LUN 和客户端。您还可以使用 gwcli reconfigure 子命令来优化 iSCSI 目标的性能。
红帽不支持管理由 Ceph iSCSI 网关工具(如 gwcli 和 ceph-ansible)导出的 Ceph 块设备镜像。此外,使用 rbd 命令重命名或删除 Ceph iSCSI 网关导出的 RBD 镜像可能会导致存储集群不稳定。
7.4.1. 先决条件
- 安装 Ceph iSCSI 网关软件。
7.4.2. 使用命令行界面配置 iSCSI 目标
Ceph iSCSI 网关是 iSCSI 目标节点,也是 Ceph 客户端节点。在独立节点上配置 Ceph iSCSI 网关,或者将它与 Ceph 对象存储设备 (OSD) 节点共存。
除非在本文档中指定,或者红帽支持指示您这样做,否则不要使用 gwcli reconfigure 子命令来调整其他选项。
先决条件
- 安装 Ceph iSCSI 网关软件。
流程
启动 iSCSI 网关命令行界面:
[root@iscsigw ~]# gwcli使用 IPv4 或 IPv6 地址创建 iSCSI 网关:
语法
>/iscsi-targets create iqn.2003-01.com.redhat.iscsi-gw:_target_name_ > goto gateways > create ISCSI_GW_NAME IP_ADDR_OF_GW > create ISCSI_GW_NAME IP_ADDR_OF_GW示例
>/iscsi-targets create iqn.2003-01.com.redhat.iscsi-gw:ceph-igw > goto gateways > create ceph-gw-1 10.172.19.21 > create ceph-gw-2 10.172.19.22注意您不能混合使用 IPv4 和 IPv6 地址。
添加 Ceph 块设备:
语法
> cd /disks >/disks/ create POOL_NAME image=IMAGE_NAME size=IMAGE_SIZE_m|g|t示例
> cd /disks >/disks/ create rbd image=disk_1 size=50g注意不要在池或镜像名称中使用任何句点(
.)。创建客户端:
语法
> goto hosts > create iqn.1994-05.com.redhat:_client_name_ > auth use username=USER_NAME password=PASSWORD示例
> goto hosts > create iqn.1994-05.com.redhat:rh7-client > auth username=iscsiuser1 password=temp12345678重要红帽不支持混合客户端,如有些启用了 Challenge Handshake Authentication Protocol (CHAP),另外一些禁用了一些 CHAP。所有客户端都必须启用 CHAP,或者禁用 CHAP。默认的行为是仅通过其启动器名称验证启动器。
如果启动器无法登录到目标,某些启动器可能无法正确配置 CHAP 身份验证,例如:
o- hosts ................................ [Hosts: 2: Auth: MISCONFIG]在
主机级别使用以下命令重置所有 CHAP 身份验证:/> goto hosts /iscsi-target...csi-igw/hosts> auth nochap ok ok /iscsi-target...csi-igw/hosts> ls o- hosts ................................ [Hosts: 2: Auth: None] o- iqn.2005-03.com.ceph:esx ........... [Auth: None, Disks: 4(310G)] o- iqn.1994-05.com.redhat:rh7-client .. [Auth: None, Disks: 0(0.00Y)]向客户端添加磁盘:
语法
>/iscsi-target..eph-igw/hosts > cd iqn.1994-05.com.redhat:_CLIENT_NAME_ > disk add POOL_NAME/IMAGE_NAME示例
>/iscsi-target..eph-igw/hosts > cd iqn.1994-05.com.redhat:rh7-client > disk add rbd/disk_1若要确认 API 在正确使用 SSL,请搜索位于
/var/log/rbd-target-api.log或/var/log/rbd-target/rbd-target-api.log(对于https) 的rbd-target-api日志文件,例如:Aug 01 17:27:42 test-node.example.com python[1879]: * Running on https://0.0.0.0:5000/验证 Ceph ISCSI 网关是否正常工作:
/> goto gateways /iscsi-target...-igw/gateways> ls o- gateways ............................ [Up: 2/2, Portals: 2] o- ceph-gw-1 ........................ [ 10.172.19.21 (UP)] o- ceph-gw-2 ........................ [ 10.172.19.22 (UP)]如果状态为
UNKNOWN,请检查网络问题和任何错误配置。如果使用防火墙,请验证是否打开适当的 TCP 端口。验证 iSCSI 网关是否列在trusted_ip_list选项中。验证rbd-target-api服务是否在 iSCSI 网关节点上运行。另外,还可重新配置
max_data_area_mb选项:语法
>/disks/ reconfigure POOL_NAME/IMAGE_NAME max_data_area_mb NEW_BUFFER_SIZE示例
>/disks/ reconfigure rbd/disk_1 max_data_area_mb 64注意max_data_area_mb选项控制每个镜像可用于在 iSCSI 目标和 Ceph 集群之间传递 SCSI 命令数据的内存量(以兆字节为单位)。如果这个值太小,可能会导致过量队列完全重试,这将影响性能。如果该值太大,则可能会导致一个磁盘使用过多的系统内存,这可能会导致其他子系统的分配失败。max_data_area_mb选项的默认值为8。- 配置 iSCSI 启动器.
其它资源
- 详情请参阅安装 iSCSI 网关。
- 如需更多信息,请参阅配置 iSCSI initiator 部分。
7.4.3. 优化 iSCSI 目标的性能
有许多设置控制 iSCSI 目标如何通过网络传输数据。这些设置可用于优化 iSCSI 网关的性能。
只有在由红帽支持团队指示或根据本文档中指定的要求时才更改这些设置。
gwcli reconfigure 子命令可控制用于优化 iSCSI 网关性能的设置。
影响 iSCSI 目标性能的设置
-
max_data_area_mb -
cmdsn_depth -
immediate_data -
initial_r2t -
max_outstanding_r2t -
first_burst_length -
max_burst_length -
max_recv_data_segment_length -
max_xmit_data_segment_length
其它资源
-
有关
max_data_area_mb的信息,包括演示如何使用gwcli reconfigure的示例,位于使用命令行接口配置 iSCSI 目标一节中。
7.4.4. 降低检测下线 OSD 的计时器设置
有时,需要降低检测下线 OSD 的定时器设置。例如,在将 Red Hat Ceph Storage 用作 iSCSI 网关时,您可以通过降低检测下线 OSD 的计时器设置来降低启动器超时的可能性。
先决条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
- 访问 Ansible 管理节点.
流程
将 Ansible 配置为使用新的计时器设置。
在 Ansible 管理节点上,在
group_vars/all.yml文件中添加ceph_conf_overrides部分,如下所示,或编辑任何现有的ceph_conf_overrides部分:ceph_conf_overrides: osd: osd_client_watch_timeout: 15 osd_heartbeat_grace: 20 osd_heartbeat_interval: 5在 Ansible playbook 运行时,上面的设置将添加到 OSD 节点上的
ceph.conf配置文件中。进入
ceph-ansible目录:[admin@ansible ~]$ cd /usr/share/ceph-ansible使用 Ansible 更新
ceph.conf文件,并在所有 OSD 节点上重新启动 OSD 守护进程。在 Ansible admin 节点上运行以下命令:裸机 部署
[admin@ansible ceph-ansible]$ ansible-playbook site.yml --limit osds容器 部署
[admin@ansible ceph-ansible]$ ansible-playbook site-container.yml --limit osds -i hosts
验证定时器设置与
ceph_conf_overrides中设置的相同:语法
ceph daemon osd.OSD_ID config get osd_client_watch_timeout ceph daemon osd.OSD_ID config get osd_heartbeat_grace ceph daemon osd.OSD_ID config get osd_heartbeat_interval示例
[root@osd ~]# ceph daemon osd.0 config get osd_client_watch_timeout { "osd_client_watch_timeout": "15" } [root@osd ~]# ceph daemon osd.0 config get osd_heartbeat_grace { "osd_heartbeat_grace": "20" } [root@osd ~]# ceph daemon osd.0 config get osd_heartbeat_interval { "osd_heartbeat_interval": "5" }可选:如果无法立即重新启动 OSD 守护进程,您可以从 Ceph 监控节点进行在线更新,或者直接更新所有 Ceph OSD 节点。在您能够重新启动 OSD 守护进程后,如上所述,使用 Ansible 将新的计时器设置添加到
ceph.conf中,以便在重启后保留设置。从 Ceph 监控节点在线更新 OSD 计时器设置:
语法
ceph tell osd.OSD_ID injectargs '--osd_client_watch_timeout 15' ceph tell osd.OSD_ID injectargs '--osd_heartbeat_grace 20' ceph tell osd.OSD_ID injectargs '--osd_heartbeat_interval 5'示例
[root@mon ~]# ceph tell osd.0 injectargs '--osd_client_watch_timeout 15' [root@mon ~]# ceph tell osd.0 injectargs '--osd_heartbeat_grace 20' [root@mon ~]# ceph tell osd.0 injectargs '--osd_heartbeat_interval 5'从 Ceph OSD 节点在线更新 OSD 计时器设置:
语法
ceph daemon osd.OSD_ID config set osd_client_watch_timeout 15 ceph daemon osd.OSD_ID config set osd_heartbeat_grace 20 ceph daemon osd.OSD_ID config set osd_heartbeat_interval 5示例
[root@osd ~]# ceph daemon osd.0 config set osd_client_watch_timeout 15 [root@osd ~]# ceph daemon osd.0 config set osd_heartbeat_grace 20 [root@osd ~]# ceph daemon osd.0 config set osd_heartbeat_interval 5
其它资源
- 有关将红帽 Ceph 存储用作 iSCSI 网关的更多信息,请参阅 Red Hat Ceph Storage 块设备指南中的 Ceph iSCSI 网关。
7.4.5. 使用命令行界面配置 iSCSI 主机组
Ceph iSCSI 网关可以配置主机组,以管理共享同一磁盘配置的多个服务器。iSCSI 主机组创建主机以及该组中每一主机有权访问的磁盘的逻辑分组。
将磁盘设备共享到多个主机必须使用群集感知型文件系统。
先决条件
- 安装 Ceph iSCSI 网关软件。
- 对 Ceph iSCSI 网关节点的 root 级别访问权限。
流程
启动 iSCSI 网关命令行界面:
[root@iscsigw ~]# gwcli创建新主机组:
语法
cd iscsi-targets/ cd IQN/host-groups create group_name=GROUP_NAME示例
/> cd iscsi-targets/ /iscsi-targets> cd iqn.2003-01.com.redhat.iscsi-gw:ceph-igw/host-groups/ /iscsi-target.../host-groups> create group_name=igw_grp01在主机组中添加主机:
语法
cd GROUP_NAME host add client_iqn=CLIENT_IQN示例
> cd igw_grp01 /iscsi-target.../host-groups/igw_grp01> host add client_iqn=iqn.1994-05.com.redhat:rh8-client重复此步骤,将其他主机添加到组中。
在主机组中添加磁盘:
语法
cd /disks/ /disks> create pool=POOL image=IMAGE_NAME size=SIZE cd /IQN/host-groups/GROUP_NAME disk add POOL/IMAGE_NAME示例
> cd /disks/ /disks> create pool=rbd image=rbdimage size=1G /> cd iscsi-targets/iqn.2003-01.com.redhat.iscsi-gw:ceph-igw/host-groups/igw_grp01/ /iscsi-target...s/igw_grp01> disk add rbd/rbdimage重复此步骤,向该组添加其他磁盘。
7.4.6. 其它资源
- 有关使用 Red Hat Ceph Storage 仪表板配置 iSCSI 目标的详情,请参阅 Red Hat Ceph Storage 仪表板指南中的创建 iSCSI 目标部分。
7.5. 配置 iSCSI 启动器
您可以配置 iSCSI 启动器,以连接到以下平台上的 Ceph iSCSI 网关:
7.5.1. 为 Red Hat Enterprise Linux 配置 iSCSI 启动器
先决条件
- Red Hat Enterprise Linux 7.7 或更高版本。
-
必须安装了软件包
iscsi-initiator-utils-6.2.0.873-35或更新的版本。 -
必须安装
package device-mapper-multipath-0.4.9-99或更新版本。
流程
安装 iSCSI 启动器和多路径工具:
[root@rhel ~]# yum install iscsi-initiator-utils [root@rhel ~]# yum install device-mapper-multipath-
通过编辑
/etc/iscsi/initiatorname.iscsi文件来设置启动器名称。请注意,启动器名称必须与使用gwcli命令在初始设置期间使用的启动器名称匹配。 配置多路径 I/O.
创建默认
/etc/multipath.conf文件并启用multipathd服务:[root@rhel ~]# mpathconf --enable --with_multipathd y更新
/etc/multipath.conf文件,如下所示:devices { device { vendor "LIO-ORG" product "TCMU device" hardware_handler "1 alua" path_grouping_policy "failover" path_selector "queue-length 0" failback 60 path_checker tur prio alua prio_args exclusive_pref_bit fast_io_fail_tmo 25 no_path_retry queue } }重启
multipathd服务:[root@rhel ~]# systemctl reload multipathd
设置 CHAP 和 iSCSI 发现和登录。
通过相应地更新
/etc/iscsi/iscsid.conf文件来提供 CHAP 用户名和密码,例如:node.session.auth.authmethod = CHAP node.session.auth.username = user node.session.auth.password = password发现目标门户:
语法
iscsiadm -m discovery -t st -p IP_ADDR登录到目标:
语法
iscsiadm -m node -T TARGET -l
查看多路径 I/O 配置。
multipathd守护进程根据multipath.conf文件中的设置自动设置设备。使用
multipath命令显示故障切换配置中的设备设置,以及每个路径的优先级组,例如:示例
[root@rhel ~]# multipath -ll mpathbt (360014059ca317516a69465c883a29603) dm-1 LIO-ORG,TCMU device size=1.0G features='0' hwhandler='1 alua' wp=rw |-+- policy='queue-length 0' prio=50 status=active | `- 28:0:0:1 sde 8:64 active ready running `-+- policy='queue-length 0' prio=10 status=enabled `- 29:0:0:1 sdc 8:32 active ready runningmultipath -ll输出的prio值指示 ALUA 状态,其中prio=50表示它是在 ALUA Active-Optimized 状态下拥有 iSCSI 网关的路径,prio=10表示它是一个 Active-non-Optimized 路径。status字段指示正在使用的路径,其中active表示当前使用的路径,enabled表示在active失败时的故障转移路径。要将设备名称(例如
multipath -ll输出中的sde)与 iSCSI 网关匹配:示例
[root@rhel ~]# iscsiadm -m session -P 3Persistent Portal值是分配给 iSCSI 网关的 IP 地址,列在gwcli实用程序中。
7.5.2. 为 Red Hat Virtualization 配置 iSCSI 启动程序
先决条件
- Red Hat Virtualization 4.1
- 在所有 Red Hat Virtualization 节点上配置了 MPIO 设备
-
iscsi-initiator-utils-6.2.0.873-35软件包或更新版本 -
device-mapper-multipath-0.4.9-99软件包或更新版本
流程
配置多路径 I/O.
更新
/etc/multipath/conf.d/DEVICE_NAME.conf文件,如下所示:devices { device { vendor "LIO-ORG" product "TCMU device" hardware_handler "1 alua" path_grouping_policy "failover" path_selector "queue-length 0" failback 60 path_checker tur prio alua prio_args exclusive_pref_bit fast_io_fail_tmo 25 no_path_retry queue } }重启
multipathd服务:[root@rhv ~]# systemctl reload multipathd
- 单击 Storage 资源选项卡,以列出现有的存储域。
- 单击 New Domain 按钮打开 New Domain 窗口。
- 输入新存储域的名称。
- 使用 Data Center 下拉菜单选择数据中心。
- 使用下拉菜单选择 Domain Function 和 Storage Type。与所选域功能不兼容的存储域类型不可用。
- 在 Use Host 字段中选择一个活动主机。如果这不是数据中心中的第一个数据域,您必须选择数据中心的 SPM 主机。
当选择 iSCSI 作为存储类型时,新建域 窗口会自动显示已知带有未使用的 LUN 的目标。如果没有列出您要添加存储的目标,您可以使用目标发现来找到目标,否则继续下一步。
- 单击 Discover Targets 以启用目标发现选项。发现目标并登录后,新建域 窗口将自动显示环境未使用的目标。请注意,环境外部的 LUN 也会显示。您可以使用 发现目标 选项在多个目标或同一 LUN 的多个路径中添加 LUN。
- 在 Address 字段中输入 iSCSI 主机的完全限定域名或 IP 地址。
-
在 Port 字段中输入在浏览目标时,用于连接到主机的端口。默认值为
3260。 - 如果使用 Challenge Handshake Authentication Protocol (CHAP) 来保护存储,请选中 User Authentication 复选框。输入 CHAP 用户名 和 CHAP 密码。
- 单击 Discover 按钮。
从发现结果中选择要使用的目标,然后单击 登录 按钮。或者,单击 Login All 以登录所有发现的目标。
重要如果需要多个路径访问,请确保通过所有必要的路径发现并登录到目标。目前不支持修改存储域以添加其他路径。
- 单击所需目标旁边的 + 按钮。这将展开条目并显示与目标连接的所有未使用的 LUN。
- 选中您正在使用的每个 LUN 的复选框,以创建存储域。
另外,您还可以配置高级参数。
- 单击 Advanced Parameters。
- 在 Warning Low Space Indicator 字段中输入一个百分比值。如果存储域中的可用空间低于这个百分比,则会向用户显示警告消息并记录日志。
- 在 Critical Space Action Blocker 字段中输入一个 GB 值。如果存储域中可用的可用空间低于此值,则会向用户和记录错误消息显示,并且任何占用空间的新操作(即便是临时使用)都会被阻止。
-
选中 Wipe After Delete 复选框以启用
wipe after delete选项。您可以在创建域后编辑此选项,但这样做不会改变已存在磁盘的wipe after delete属性。 - 选中 Discard After Delete 复选框,以在删除后启用丢弃选项。您可以在创建域后编辑这个选项。此选项仅适用于块存储域。
- 单击 确定 以创建存储域并关闭该窗口。
7.5.3. 为 Microsoft Windows 配置 iSCSI 启动器
先决条件
- Microsoft Windows Server 2016
流程
安装 iSCSI 启动器并配置发现和设置。
- 安装 iSCSI 启动器驱动程序和 MPIO 工具。
- 启动 MPIO 程序,单击 Discover Multi-Paths 选项卡,选中 iSCSI 设备添加支持框,然后单击 Add。
- 重启 MPIO 程序。
在 iSCSI 启动器属性窗口中,在发现选项卡
 中添加一个目标门户。输入 Ceph iSCSI 网关的 IP 地址或 DNS 名称
中添加一个目标门户。输入 Ceph iSCSI 网关的 IP 地址或 DNS 名称
 和端口
和端口
 :
:
在 Targets 选项卡
中,选择目标并点击 Connect
:

在 Connect To Target 窗口中,选择 启用多路径选项
,然后点击 高级 按钮
:

在 Connect using 部分下,选择一个 目标门户 IP
。选择 Enable CHAP login on
并从 Ceph iSCSI 客户端凭证部分输入 Name 和 Target secret 值
,然后单击 OK  :
:
 重要
重要Windows Server 2016 不接受小于 12 字节的 CHAP secret。
- 为设置 iSCSI 网关时定义的每个目标门户重复前面的两个步骤。
如果启动器名称与初始设置期间使用的启动器名称不同,请重命名启动器名称。在配置选项卡中的 iSCSI 启动器属性 窗口中,单击更改按钮
来重命名启动器名称。
设置
多路径I/O。在 PowerShell 中,使用PDORemovePeriod命令设置 MPIO 负载平衡策略和mpclaim命令来设置负载平衡策略。iSCSI 启动器工具配置剩余的选项。注意红帽建议将
PDORemovePeriod选项从 PowerShell 增加到 120 秒。您可能需要根据应用调整此值。当所有路径都关闭且 120 秒过期时,操作系统将启动 I/O 请求失败。Set-MPIOSetting -NewPDORemovePeriod 120设置故障切换策略
mpclaim.exe -l -m 1验证故障转移策略
mpclaim -s -m MSDSM-wide Load Balance Policy: Fail Over Only使用 iSCSI 启动器工具
从 Targets 选项卡点击 Devices… 按钮
:

在 Devices 窗口中选择一个磁盘
并点击 MPIO… 按钮
:
Device Details 窗口显示到每个目标门户的路径。负载均衡策略 Fail Over Only 必须被选择。

查看 PowerShell 中的
多路径配置:mpclaim -s -d MPIO_DISK_ID将 MPIO_DISK_ID 替换为适当的磁盘标识符。
注意存在一个 Active/Optimized 路径,它是拥有 LUN 的 iSCSI 网关节点的路径,其他 iSCSI 网关节点有一个 Active/未优化路径。

(可选)调整设置。考虑使用以下 registry 设置:
Windows 磁盘超时
键
HKEY_LOCAL_MACHINE\System\CurrentControlSet\Services\Disk值
TimeOutValue = 65Microsoft iSCSI Initiator Driver
键
HKEY_LOCAL_MACHINE\\SYSTEM\CurrentControlSet\Control\Class\{4D36E97B-E325-11CE-BFC1-08002BE10318}\<Instance_Number>\Parameters值
LinkDownTime = 25 SRBTimeoutDelta = 15
7.5.4. 为 VMware ESXi 配置 iSCSI 启动器
先决条件
- 有关支持的 VMware ESXi 版本,请查看客户门户网站知识库文章 iSCSI 网关(IGW) 部分。
- 访问 VMware 主机客户端.
-
根对 VMware ESXi 主机的访问权限,以执行
esxcli命令。
流程
禁用
HardwareAcceleratedMove(XCOPY):> esxcli system settings advanced set --int-value 0 --option /DataMover/HardwareAcceleratedMove启用 iSCSI 软件。在导航窗格中,单击 Storage
。选择 适配器选项卡
。点击 配置 iSCSI
:
验证名称和别名中的启动器名称
。
如果使用
gwcli在初始设置期间创建客户端时使用的启动器名称与使用 VMware ESX 主机的启动器名称不同,请使用以下esxcli命令。获取 iSCSI 软件的适配器名称:
> esxcli iscsi adapter list > Adapter Driver State UID Description > ------- --------- ------ ------------- ---------------------- > vmhba64 iscsi_vmk online iscsi.vmhba64 iSCSI Software Adapter设置 initiator 名称:
语法
> esxcli iscsi adapter set -A ADAPTOR_NAME -n INITIATOR_NAME示例
> esxcli iscsi adapter set -A vmhba64 -n iqn.1994-05.com.redhat:rh7-client
配置 CHAP。展开 CHAP 身份验证 部分
。选择"不使用 CHAP,除非目标需要"
。输入初始设置中使用的 CHAP Name 和 Secret
凭证。验证 Mutual CHAP 验证部分
是否选择了 "Do not use CHAP"。
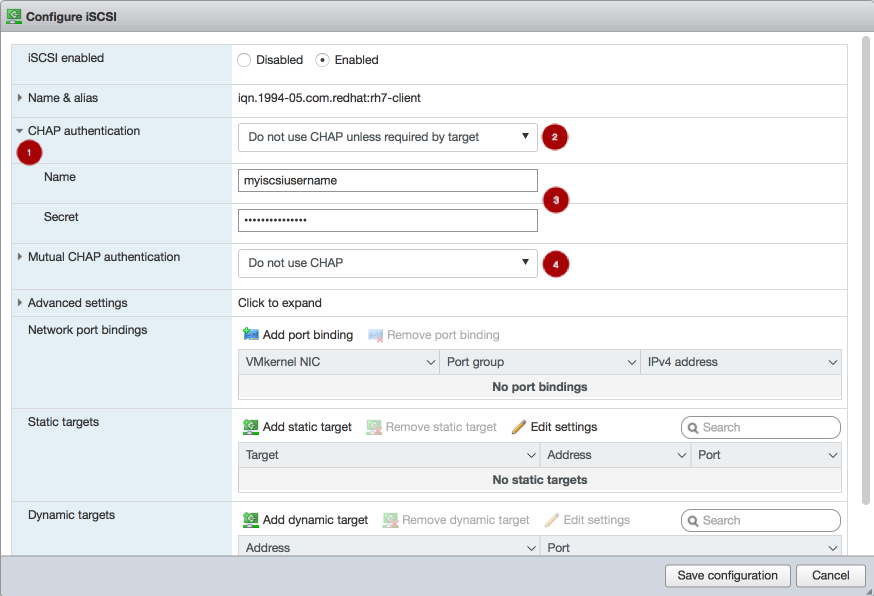 警告
警告由于 VMware Host 客户端中的一个错误,最初不会使用 CHAP 设置。在 Ceph iSCSI 网关节点上,内核日志包括以下错误来指示此错误:
> kernel: CHAP user or password not set for Initiator ACL > kernel: Security negotiation failed. > kernel: iSCSI Login negotiation failed.要临时解决这个问题,请使用
esxcli命令配置 CHAP 设置。authname参数是 vSphere Web 客户端中的 Name :> esxcli iscsi adapter auth chap set --direction=uni --authname=myiscsiusername --secret=myiscsipassword --level=discouraged -A vmhba64配置 iSCSI 设置。扩展 高级设置
。将 RecoveryTimeout 值设置为 25
。

设置发现地址。在 Dynamic target 部分中
,点 Add dynamic target
。在 地址
下,为其中一个 Ceph iSCSI 网关添加 IP 地址。只需要添加一个 IP 地址。最后,单击 保存配置 按钮
。在主界面的 Devices 选项卡中,您将看到 RBD 镜像。
 注意
注意LUN 是自动配置的,使用 ALUA SATP 和 MRU PSP。不要使用其他 SATP 和 PSP。您可以通过
esxcli命令验证:语法
esxcli storage nmp path list -d eui.DEVICE_ID使用适当的设备标识符替换 DEVICE_ID。
验证多路径设置是否正确。
列出设备:
示例
> esxcli storage nmp device list | grep iSCSI Device Display Name: LIO-ORG iSCSI Disk (naa.6001405f8d087846e7b4f0e9e3acd44b) Device Display Name: LIO-ORG iSCSI Disk (naa.6001405057360ba9b4c434daa3c6770c)从上一步中获取 Ceph iSCSI 磁盘的多路径信息:
示例
> esxcli storage nmp path list -d naa.6001405f8d087846e7b4f0e9e3acd44b iqn.2005-03.com.ceph:esx1-00023d000001,iqn.2003-01.com.redhat.iscsi-gw:iscsi-igw,t,1-naa.6001405f8d087846e7b4f0e9e3acd44b Runtime Name: vmhba64:C0:T0:L0 Device: naa.6001405f8d087846e7b4f0e9e3acd44b Device Display Name: LIO-ORG iSCSI Disk (naa.6001405f8d087846e7b4f0e9e3acd44b) Group State: active Array Priority: 0 Storage Array Type Path Config: {TPG_id=1,TPG_state=AO,RTP_id=1,RTP_health=UP} Path Selection Policy Path Config: {current path; rank: 0} iqn.2005-03.com.ceph:esx1-00023d000002,iqn.2003-01.com.redhat.iscsi-gw:iscsi-igw,t,2-naa.6001405f8d087846e7b4f0e9e3acd44b Runtime Name: vmhba64:C1:T0:L0 Device: naa.6001405f8d087846e7b4f0e9e3acd44b Device Display Name: LIO-ORG iSCSI Disk (naa.6001405f8d087846e7b4f0e9e3acd44b) Group State: active unoptimized Array Priority: 0 Storage Array Type Path Config: {TPG_id=2,TPG_state=ANO,RTP_id=2,RTP_health=UP} Path Selection Policy Path Config: {non-current path; rank: 0}在示例输出中,每个路径都有一个带有以下部分的 iSCSI 或 SCSI 名称:
Initiator name =
iqn.2005-03.com.ceph:esx1ISID =00023d000002Target name =iqn.2003-01.com.redhat.iscsi-gw:iscsi-igwTarget port group =2Device id =naa.6001405f8d087846e7b4f0e9e3acd44bactive的Group State值表示这是到 iSCSI 网关的 Active-Optimized 路径。gwcli命令列出active作为 iSCSI 网关所有者。如果active路径进入dead状态,则其余路径具有unoptimized的Group State值,并且是故障转移路径。
匹配其各自 iSCSI 网关的所有路径:
示例
> esxcli iscsi session connection list vmhba64,iqn.2003-01.com.redhat.iscsi-gw:iscsi-igw,00023d000001,0 Adapter: vmhba64 Target: iqn.2003-01.com.redhat.iscsi-gw:iscsi-igw ISID: 00023d000001 CID: 0 DataDigest: NONE HeaderDigest: NONE IFMarker: false IFMarkerInterval: 0 MaxRecvDataSegmentLength: 131072 MaxTransmitDataSegmentLength: 262144 OFMarker: false OFMarkerInterval: 0 ConnectionAddress: 10.172.19.21 RemoteAddress: 10.172.19.21 LocalAddress: 10.172.19.11 SessionCreateTime: 08/16/18 04:20:06 ConnectionCreateTime: 08/16/18 04:20:06 ConnectionStartTime: 08/16/18 04:30:45 State: logged_in vmhba64,iqn.2003-01.com.redhat.iscsi-gw:iscsi-igw,00023d000002,0 Adapter: vmhba64 Target: iqn.2003-01.com.redhat.iscsi-gw:iscsi-igw ISID: 00023d000002 CID: 0 DataDigest: NONE HeaderDigest: NONE IFMarker: false IFMarkerInterval: 0 MaxRecvDataSegmentLength: 131072 MaxTransmitDataSegmentLength: 262144 OFMarker: false OFMarkerInterval: 0 ConnectionAddress: 10.172.19.22 RemoteAddress: 10.172.19.22 LocalAddress: 10.172.19.12 SessionCreateTime: 08/16/18 04:20:06 ConnectionCreateTime: 08/16/18 04:20:06 ConnectionStartTime: 08/16/18 04:30:41 State: logged_in将路径名称与
ISID值匹配,RemoteAddress值是自有 iSCSI 网关的 IP 地址。
7.6. 管理 iSCSI 服务
ceph-iscsi 软件包将安装配置管理逻辑,以及 rbd-target-gw 和 rbd-target-api systemd 服务。
rbd-target-api 服务在启动时恢复 Linux iSCSI 目标状态,并从诸如 gwcli 和 Red Hat Ceph Storage 仪表板的工具响应 ceph-iscsi REST API 调用。rbd-target-gw 服务使用 Prometheus 插件提供指标数据。
rbd-target-api 服务假定这是 Linux 内核目标层的唯一用户。使用 rbd-target-api 时,不要使用 targetcli 软件包安装的 target 服务。Ansible 在 Ceph iSCSI 网关安装期间自动禁用 targetcli 目标服务。
流程
启动服务:
# systemctl start rbd-target-api # systemctl start rbd-target-gw重启服务:
# systemctl restart rbd-target-api # systemctl restart rbd-target-gw重新载入服务:
# systemctl reload rbd-target-api # systemctl reload rbd-target-gwreload请求会强制rbd-target-api重新读取配置,并将它应用到当前运行的环境。这通常不需要,因为更改是从 Ansible 并行部署到所有 iSCSI 网关节点。停止服务:
# systemctl stop rbd-target-api # systemctl stop rbd-target-gwstop请求关闭网关的门户接口,丢弃与客户端的连接,并从内核中擦除当前的 Linux iSCSI 目标配置。这会将 iSCSI 网关返回到干净的状态。当客户端断开连接时,活跃 I/O 通过客户端多路径重新调度到其他 iSCSI 网关。
7.7. 添加更多 iSCSI 网关
作为存储管理员,您可以使用 gwcli 命令行工具或 Red Hat Ceph Storage 仪表板将初始两个 iSCSI 网关扩展到四个 iSCSI 网关。添加更多 iSCSI 网关在使用负载平衡和故障转移选项时为您提供更大的灵活性,同时提供更多冗余。
7.7.1. 先决条件
- 正在运行的 Red Hat Ceph Storage 4 集群
- 备用节点或现有 OSD 节点
-
root权限
7.7.2. 使用 Ansible 添加更多 iSCSI 网关
您可以使用 Ansible 自动化实用程序添加更多 iSCSI 网关。此流程将两个 iSCSI 网关的默认安装扩展到四个 iSCSI 网关。您可以在独立节点上配置 iSCSI 网关,也可以与现有 OSD 节点共存。
先决条件
- Red Hat Enterprise Linux 7.7 或更高版本。
- 一个正在运行的 Red Hat Ceph Storage 集群。
- 安装 iSCSI 网关软件。
-
在 Ansible 管理节点上具有
admin用户访问权限. -
在新节点上具有
root用户访问权限.
流程
在新的 iSCSI 网关节点上,启用 Red Hat Ceph Storage Tools 存储库:
Red Hat Enterprise Linux 7
[root@iscsigw ~]# subscription-manager repos --enable=rhel-7-server-rhceph-4-tools-rpmsRed Hat Enterprise Linux 8
[root@iscsigw ~]# subscription-manager repos --enable=rhceph-4-tools-for-rhel-8-x86_64-rpms安装
ceph-iscsi-config软件包:[root@iscsigw ~]# yum install ceph-iscsi-config附加到网关组的
/etc/ansible/hosts文件中的列表:示例
[iscsigws] ... ceph-igw-3 ceph-igw-4注意如果与 OSD 节点共存 iSCSI 网关,请将 OSD 节点添加到
[iscsigws]部分中。进入
ceph-ansible目录:[admin@ansible ~]$ cd /usr/share/ceph-ansible在 Ansible 管理节点上,运行适当的 Ansible playbook:
裸机部署:
[admin@ansible ceph-ansible]$ ansible-playbook site.yml -i hosts容器部署:
[admin@ansible ceph-ansible]$ ansible-playbook site-container.yml -i hosts
重要为
gateway_ip_list选项提供 IP 地址是必需的。您不能混合使用 IPv4 和 IPv6 地址。- 从 iSCSI 启动器,重新登录以使用新添加的 iSCSI 网关。
其它资源
- 有关使用 iSCSI 启动器的更多详细信息,请参阅配置 iSCSI 启动器。
- 详情请参阅 Red Hat Ceph Storage 安装指南中的启用 Red Hat Ceph Storage 存储库一节。
7.7.3. 使用 gwcli 添加更多 iSCSI 网关
您可以使用 gwcli 命令行工具添加更多 iSCSI 网关。此流程将两个 iSCSI 网关的默认扩展为四个 iSCSI 网关。
先决条件
- Red Hat Enterprise Linux 7.7 或更高版本。
- 一个正在运行的 Red Hat Ceph Storage 集群。
- 安装 iSCSI 网关软件。
-
具有
root用户对新节点或 OSD 节点的访问权限.
流程
-
如果 Ceph iSCSI 网关不在 OSD 节点上并置,请将位于
/etc/ceph/目录下的 Ceph 配置文件从存储集群中正在运行的 Ceph 节点复制到新的 iSCSI 网关节点。Ceph 配置文件必须存在于/etc/ceph/目录下的 iSCSI 网关节点上。 - 安装和配置 Ceph 命令行界面。
在新的 iSCSI 网关节点上,启用 Red Hat Ceph Storage Tools 存储库:
Red Hat Enterprise Linux 7
[root@iscsigw ~]# subscription-manager repos --enable=rhel-7-server-rhceph-4-tools-rpmsRed Hat Enterprise Linux 8
[root@iscsigw ~]# subscription-manager repos --enable=rhceph-4-tools-for-rhel-8-x86_64-rpms安装
ceph-iscsi和tcmu-runner软件包:Red Hat Enterprise Linux 7
[root@iscsigw ~]# yum install ceph-iscsi tcmu-runnerRed Hat Enterprise Linux 8
[root@iscsigw ~]# dnf install ceph-iscsi tcmu-runner如果需要,安装
openssl软件包:Red Hat Enterprise Linux 7
[root@iscsigw ~]# yum install opensslRed Hat Enterprise Linux 8
[root@iscsigw ~]# dnf install openssl
在其中一个现有 iSCSI 网关节点上,编辑
/etc/ceph/iscsi-gateway.cfg文件,并使用新 iSCSI 网关节点的新 IP 地址附加trusted_ip_list选项。例如:[config] ... trusted_ip_list = 10.172.19.21,10.172.19.22,10.172.19.23,10.172.19.24将更新的
/etc/ceph/iscsi-gateway.cfg文件复制到所有 iSCSI 网关节点。重要在所有 iSCSI 网关节点上,
iscsi-gateway.cfg文件都必须相同。-
(可选)如果使用 SSL,还可以将
~/ssl-keys/iscsi-gateway.crt、~/ssl-keys/iscsi-gateway.pem、~/ssl-keys/iscsi-gateway-pub.key和~/ssl-keys/iscsi-gateway.key文件从其中一个现有 iSCSI 网关节点复制到新 iSCSI 网关节点上的/etc/ceph/目录中。 在新的 iSCSI 网关节点上启用并启动 API 服务:
[root@iscsigw ~]# systemctl enable rbd-target-api [root@iscsigw ~]# systemctl start rbd-target-api启动 iSCSI 网关命令行界面:
[root@iscsigw ~]# gwcli使用 IPv4 或 IPv6 地址创建 iSCSI 网关:
语法
>/iscsi-target create iqn.2003-01.com.redhat.iscsi-gw:_TARGET_NAME_ > goto gateways > create ISCSI_GW_NAME IP_ADDR_OF_GW > create ISCSI_GW_NAME IP_ADDR_OF_GW示例
>/iscsi-target create iqn.2003-01.com.redhat.iscsi-gw:ceph-igw > goto gateways > create ceph-gw-3 10.172.19.23 > create ceph-gw-4 10.172.19.24重要您不能混合使用 IPv4 和 IPv6 地址。
- 从 iSCSI 启动器,重新登录以使用新添加的 iSCSI 网关。
其它资源
- 有关使用 iSCSI 启动器的更多详细信息,请参阅配置 iSCSI 启动器。
- 详情请参阅 Red Hat Ceph Storage 安装指南中的安装 Ceph 命令行界面一章。
7.8. 验证启动器是否已连接到 iSCSI 目标
安装 iSCSI 网关并配置 iSCSI 目标和启动器后,验证启动器是否已正确连接到 iSCSI 目标。
先决条件
- 安装 Ceph iSCSI 网关软件。
- 配置 iSCSI 目标。
- 配置 iSCSI 启动器.
流程
启动 iSCSI 网关命令行界面:
[root@iscsigw ~]# gwcli验证启动器是否已连接 iSCSI 目标:
/> goto hosts /iscsi-target...csi-igw/hosts> ls o- hosts .............................. [Hosts: 1: Auth: None] o- iqn.1994-05.com.redhat:rh7-client [LOGGED-IN, Auth: None, Disks: 0(0.00Y)]如果已连接,则启动器状态为
LOGGED-IN。验证 LUN 是否在 iSCSI 网关间平衡:
/> goto hosts /iscsi-target...csi-igw/hosts> ls o- hosts ................................. [Hosts: 2: Auth: None] o- iqn.2005-03.com.ceph:esx ............ [Auth: None, Disks: 4(310G)] | o- lun 0 ............................. [rbd.disk_1(100G), Owner: ceph-gw-1] | o- lun 1 ............................. [rbd.disk_2(10G), Owner: ceph-gw-2]在创建磁盘时,会根据网关映射 LUN 数量最低,将磁盘分配为 iSCSI 网关作为其
Owner。如果这个数字是均衡的,则根据循环分配来分配网关。目前,LUN 的平衡不是动态的,用户无法选择。当启动器登录到目标并且
多路径层处于优化状态时,启动器的操作系统多路径实用程序会将到Owner网关的路径报告为处于 ALUA Active-Optimized(AO)状态。多路径工具将其他路径报告为处于 ALUA Active-non-Optimized(ANO)状态。如果 AO 路径失败,则使用另一个 iSCSI 网关。故障转移网关的排序取决于启动器的
多路径层,其中通常基于首先发现的路径。
7.9. 使用 Ansible 升级 Ceph iSCSI 网关
可以使用专为滚动升级设计的 Ansible playbook 升级 Red Hat Ceph Storage iSCSI 网关。
先决条件
- 正在运行的 Ceph iSCSI 网关。
- 一个正在运行的 Red Hat Ceph Storage 集群。
- 对存储集群中所有节点的管理员级别访问权限。
您可以以管理用户或 root 身份运行升级过程。如果要以 root 身份运行它,请确保已设置 ssh 以用于 Ansible。
流程
-
验证 Ansible 清单文件 (
/etc/ansible/hosts) 中列出了正确的 iSCSI 网关节点。 运行滚动升级 playbook:
[admin@ansible ceph-ansible]$ ansible-playbook rolling_update.yml运行适当的 playbook 来完成升级:
裸机部署
[admin@ansible ceph-ansible]$ ansible-playbook site.yml --limit iscsigws -i hosts容器部署
[admin@ansible ceph-ansible]$ ansible-playbook site-container.yml --limit iscsigws -i hosts
其它资源
7.10. 使用命令行界面升级 Ceph iSCSI 网关
可以通过一次升级一个裸机 iSCSI 网关,以滚动方式升级 Red Hat Ceph Storage iSCSI 网关。
在升级和重启 Ceph OSD 时,不要升级 iSCSI 网关。等待 OSD 升级完成并且存储集群处于 active+clean 状态。
先决条件
- 正在运行的 Ceph iSCSI 网关。
- 一个正在运行的 Red Hat Ceph Storage 集群。
-
对 iSCSI 网关节点具有
root访问权限.
流程
更新 iSCSI 网关软件包:
[root@iscsigw ~]# yum update ceph-iscsi停止 iSCSI 网关守护进程:
[root@iscsigw ~]# systemctl stop rbd-target-api [root@iscsigw ~]# systemctl stop rbd-target-gw验证 iSCSI 网关守护进程是否已完全停止:
[root@iscsigw ~]# systemctl status rbd-target-gw-
如果
rbd-target-gw服务成功停止,则跳转到第 4 步。 如果
rbd-target-gw服务无法停止,请执行以下步骤:如果
targetcli软件包没有安装,请安装targetcli软件包:[root@iscsigw ~]# yum install targetcli检查现有的目标对象:
[root@iscsigw ~]# targetcli ls示例
o- / ............................................................. [...] o- backstores .................................................... [...] | o- user:rbd ..................................... [Storage Objects: 0] o- iscsi .................................................. [Targets: 0]如果
backstores和Storage Objects为空,则 iSCSI 目标已完全关闭,您可以跳过到第 4 步。如果您仍然有目标对象,请使用以下命令强制删除所有目标对象:
[root@iscsigw ~]# targetcli clearconfig confirm=True警告如果多个服务正在使用 iSCSI 目标,请在交互模式中使用
targetcli来删除这些特定对象。
-
如果
更新
tcmu-runner软件包:[root@iscsigw ~]# yum update tcmu-runner停止
tcmu-runner服务:[root@iscsigw ~]# systemctl stop tcmu-runner按照以下顺序重启 iSCSI 网关服务:
[root@iscsigw ~]# systemctl start tcmu-runner [root@iscsigw ~]# systemctl start rbd-target-gw [root@iscsigw ~]# systemctl start rbd-target-api
7.11. 监控 iSCSI 网关
Red Hat Ceph Storage 集群现在将通用指标收集 OSD 和 MGR 中的框架,以提供内置监控。指标数据在 Red Hat Ceph Storage 集群中生成,不需要访问客户端节点来提取指标。若要监控 RBD 镜像的性能,Ceph 具有内置的 MGR Prometheus exporter 模块,用于将单个 RADOS 对象指标转换为每秒输入/输出 (I/O) 操作的聚合 RBD 镜像指标、吞吐量和延迟。Ceph iSCSI 网关还为 Linux-IO(LIO)级别性能指标提供 Prometheus 导出器,支持监控和视觉化工具,如 Grafana。这些指标包括有关定义的目标门户组 (TPG) 和映射的逻辑单元号 (LUN)、每个 LUN 状态和每秒输入输出操作数(IOPS)、每个 LUN 读字节数和写入字节数的信息。默认情况下启用 Prometheus exporter。您可以使用 iscsi-gateway.cfg 中的以下选项更改默认设置:
示例
[config]
prometheus_exporter = True
prometheus_port = 9287
prometheus_host = xx.xx.xx.xxx
Ceph iSCSI 网关环境用于监控导出的 Ceph 块设备 (RBD) 镜像性能的 gwtop 工具已弃用。
7.12. 删除 iSCSI 配置
要删除 iSCSI 配置,请使用 gwcli 实用程序删除主机和磁盘,以及 Ansible purge-iscsi-gateways.yml playbook 来删除 iSCSI 目标配置。
使用 purge-iscsi-gateways.yml playbook 是针对 iSCSI 网关环境的破坏性操作。
如果 RBD 镜像有快照或克隆并且通过 Ceph iSCSI 网关导出,则尝试使用 purge-iscsi-gateways.yml 会失败。
先决条件
断开所有 iSCSI 启动器:
Red Hat Enterprise Linux 启动程序:
语法
iscsiadm -m node -T TARGET_NAME --logout使用配置的 iSCSI 目标名称替换
TARGET_NAME,例如:示例
# iscsiadm -m node -T iqn.2003-01.com.redhat.iscsi-gw:ceph-igw --logout Logging out of session [sid: 1, target: iqn.2003-01.com.redhat.iscsi-gw:iscsi-igw, portal: 10.172.19.21,3260] Logging out of session [sid: 2, target: iqn.2003-01.com.redhat.iscsi-gw:iscsi-igw, portal: 10.172.19.22,3260] Logout of [sid: 1, target: iqn.2003-01.com.redhat.iscsi-gw:iscsi-igw, portal: 10.172.19.21,3260] successful. Logout of [sid: 2, target: iqn.2003-01.com.redhat.iscsi-gw:iscsi-igw, portal: 10.172.19.22,3260] successful.Windows 启动器:
如需了解更多详细信息,请参阅 Microsoft 文档。
VMware ESXi 启动器:
如需了解更多详细信息,请参阅 VMware 文档。
流程
运行 iSCSI 网关命令行工具:
[root@iscsigw ~]# gwcli删除主机:
语法
/> cd /iscsi-target/iqn.2003-01.com.redhat.iscsi-gw:$TARGET_NAME/hosts /> /iscsi-target...TARGET_NAME/hosts> delete CLIENT_NAME使用配置的 iSCSI 目标名称替换
TARGET_NAME,并将CLIENT_NAME替换为 iSCSI initiator 名称,例如:示例
/> cd /iscsi-target/iqn.2003-01.com.redhat.iscsi-gw:ceph-igw/hosts /> /iscsi-target...eph-igw/hosts> delete iqn.1994-05.com.redhat:rh7-client删除磁盘:
语法
/> cd /disks/ /disks> delete POOL_NAME.IMAGE_NAME将
POOL_NAME替换为池的名称,将IMAGE_NAME替换为镜像的名称。示例
/> cd /disks/ /disks> delete rbd.disk_1作为 root 用户,对于 容器化部署,请确保 iSCSI 网关节点上启用了所有 Red Hat Ceph Storage 工具和存储库:
Red Hat Enterprise Linux 7
[root@admin ~]# subscription-manager repos --enable=rhel-7-server-rpms [root@admin ~]# subscription-manager repos --enable=rhel-7-server-extras-rpms [root@admin ~]# subscription-manager repos --enable=rhel-7-server-rhceph-4-tools-rpms --enable=rhel-7-server-ansible-2.9-rpmsRed Hat Enterprise Linux 8
[root@admin ~]# subscription-manager repos --enable=rhel-8-for-x86_64-baseos-rpms [root@admin ~]# subscription-manager repos --enable=rhel-8-for-x86_64-appstream-rpms [root@admin ~]# subscription-manager repos --enable=rhceph-4-tools-for-rhel-8-x86_64-rpms --enable=ansible-2.9-for-rhel-8-x86_64-rpms注意对于 裸机部署,客户端安装启用了 Ceph 工具。
在每个 iSCSI 网关节点上,安装
ceph-common和ceph-iscsi软件包:Red Hat Enterprise Linux 7
[root@admin ~]# yum install -y ceph-common [root@admin ~]# yum install -y ceph-iscsiRed Hat Enterprise Linux 8
[root@admin ~]# dnf install -y ceph-common [root@admin ~]# dnf install -y ceph-iscsi-
运行
yum history list命令,并获取ceph-iscsi安装的事务 ID。 切换到 Ansible 用户:
示例
[root@admin ~]# su ansible进入
/usr/share/ceph-ansible/目录:示例
[ansible@admin ~]# cd /usr/share/ceph-ansible以 ansible 用户身份,运行 iSCSI 网关清除 Ansible playbook:
[ansible@admin ceph-ansible]$ ansible-playbook purge-iscsi-gateways.yml在提示时输入清除类型:
lio- 在此模式下,在定义的所有 iSCSI 网关上清除 Linux iSCSI 目标配置。创建的磁盘在 Ceph 存储集群中保持不变。
all-
当选择
all时,Linux iSCSI 目标配置会与 iSCSI 网关环境中定义的 all RBD 镜像一起移除,其他不相关的 RBD 镜像不会被删除。请务必选择正确的模式,因为此操作会删除数据。
示例
[ansible@rh7-iscsi-client ceph-ansible]$ ansible-playbook purge-iscsi-gateways.yml Which configuration elements should be purged? (all, lio or abort) [abort]: all PLAY [Confirm removal of the iSCSI gateway configuration] ********************* GATHERING FACTS *************************************************************** ok: [localhost] TASK: [Exit playbook if user aborted the purge] ******************************* skipping: [localhost] TASK: [set_fact ] ************************************************************* ok: [localhost] PLAY [Removing the gateway configuration] ************************************* GATHERING FACTS *************************************************************** ok: [ceph-igw-1] ok: [ceph-igw-2] TASK: [igw_purge | purging the gateway configuration] ************************* changed: [ceph-igw-1] changed: [ceph-igw-2] TASK: [igw_purge | deleting configured rbd devices] *************************** changed: [ceph-igw-1] changed: [ceph-igw-2] PLAY RECAP ******************************************************************** ceph-igw-1 : ok=3 changed=2 unreachable=0 failed=0 ceph-igw-2 : ok=3 changed=2 unreachable=0 failed=0 localhost : ok=2 changed=0 unreachable=0 failed=0检查是否删除了活跃的容器:
Red Hat Enterprise Linux 7
[root@admin ~]# docker psRed Hat Enterprise Linux 8
[root@admin ~]# podman psCeph iSCSI 容器 ID 已移除。
可选:删除
ceph-iscsi软件包:语法
yum history undo TRANSACTION_ID示例
[root@admin ~]# yum history undo 4警告不要删除
ceph-common软件包。这会删除/etc/ceph的内容,并使该节点上的守护进程无法启动。
7.13. 其它资源
- 有关如何使用 Red Hat Ceph Storage 存储仪表板管理 iSCSI 网关的详细信息,请参阅 Red Hat Ceph Storage 4 仪表板指南中的iSCSI 功能部分。
附录 A. Ceph 块设备配置参考
作为存储管理员,您可以通过可用的各种选项,微调 Ceph 块设备的行为。您可以使用此参考来查看默认 Ceph 块设备选项和 Ceph 块设备缓存选项等内容。
A.1. 先决条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
A.2. 块设备默认选项
可以通过创建镜像来覆盖默认设置。Ceph 将创建格式为 2 的镜像,没有条带化。
- rbd_default_format
- 描述
-
如果没有指定其他格式,则使用默认格式 (
2)格式1是新镜像的原始格式,兼容所有版本的librbd和内核模块,但不支持克隆等较新的功能。从版本 3.11 开始,rbd和内核模块支持格式2(条带除外)。格式2添加了对克隆的支持,且更易于扩展,以在未来允许更多功能。 - 类型
- 整数
- 默认
-
2
- rbd_default_order
- 描述
- 如果没有指定其他顺序,默认的顺序。
- 类型
- 整数
- 默认
-
22
- rbd_default_stripe_count
- 描述
- 如果未指定任何其他条带数,默认的条带数。更改默认值需要条带 v2 功能。
- 类型
- 64-bit Unsigned 整数
- 默认
-
0
- rbd_default_stripe_unit
- 描述
-
如果未指定其他条带单元,默认条带单元。将单元从
0(即对象大小)改为其他值需要条带 v2 功能。 - 类型
- 64-bit Unsigned 整数
- 默认
-
0
- rbd_default_features
- 描述
创建块设备镜像时启用的默认功能。此设置仅适用于格式 2 镜像。设置为:
1: Layering support.分层允许您使用克隆。
2: Striping v2 support.条带化可在多个对象之间分散数据。条带有助于并行处理连续读/写工作负载。
4: Exclusive locking support.启用后,它要求客户端在进行写入前获得对象锁定。
8: Object map support.块设备是精简配置的 - 这代表仅存储实际存在的数据。对象映射支持有助于跟踪实际存在的对象(将数据存储在驱动器上)。启用对象映射支持可加快克隆或导入和导出稀疏填充镜像的 I/O 操作。
16: Fast-diff support.Fast-diff 支持取决于对象映射支持和专用锁定支持。它向对象映射中添加了另一个属性,这可以更快地生成镜像快照和快照的实际数据使用量之间的差别。
32: Deep-flatten support.深度扁平使
rbd flatten除了镜像本身外还作用于镜像的所有快照。如果没有它,镜像的快照仍会依赖于父级,因此在快照被删除之前,父级将无法删除。深度扁平化使得父级独立于克隆,即使它们有快照。64: Journaling support.日志记录会按照镜像发生的顺序记录对镜像的所有修改。这样可确保远程镜像的 crash-consistent 镜像在本地可用
启用的功能是数字设置的总和。
- 类型
- 整数
- 默认
61- 启用了分层、专用锁定、对象映射、fast-diff 和 deep-flatten重要当前的默认设置不兼容 RBD 内核驱动程序或较旧的 RBD 客户端。
- rbd_default_map_options
- 描述
-
大多数选项主要用于调试和基准测试。详情请参阅
map Options下的man rbd。 - 类型
- 字符串
- 默认
-
""
A.3. 块设备常规选项
- rbd_op_threads
- 描述
- 块设备操作线程数量。
- 类型
- 整数
- 默认
-
1
不要更改 rbd_op_threads 的默认值,因为将其设置为大于 1 的数字可能会导致数据损坏。
- rbd_op_thread_timeout
- 描述
- 块设备操作线程的超时时间(以秒为单位)。
- 类型
- 整数
- 默认
-
60
- rbd_non_blocking_aio
- 描述
-
如果为
true,Ceph 将处理来自 worker 线程的块设备异步 I/O 操作,以防止阻止。 - 类型
- 布尔值
- 默认
-
true
- rbd_concurrent_management_ops
- 描述
- 处理中并发管理操作的最大数量(例如,删除或调整镜像大小)。
- 类型
- 整数
- 默认
-
10
- rbd_request_timed_out_seconds
- 描述
- 维护请求超时前的秒数。
- 类型
- 整数
- 默认
-
30
- rbd_clone_copy_on_read
- 描述
-
当设置为
true时,会启用读时复制克隆。 - 类型
- 布尔值
- 默认
-
false
- rbd_enable_alloc_hint
- 描述
-
如果为
true,则启用分配提示,块设备将向 OSD 后端发出提示,以指示预期的大小对象。 - 类型
- 布尔值
- 默认
-
true
- rbd_skip_partial_discard
- 描述
-
如果为
true,则块设备在尝试丢弃对象内的范围时将跳过零范围。 - 类型
- 布尔值
- 默认
-
false
- rbd_tracing
- 描述
-
将这个选项设置为
true以启用 Linux Trace Toolkit Next Generation User Space Tracer (LTTng-UST) 追踪点。详情请参阅 使用 RBD Replay 功能跟踪 RADOS 块设备(RBD) 工作负载。 - 类型
- 布尔值
- 默认
-
false
- rbd_validate_pool
- 描述
-
将此选项设置为
true,以验证空池以实现 RBD 兼容性。 - 类型
- 布尔值
- 默认
-
true
- rbd_validate_names
- 描述
-
将此选项设置为
true以验证镜像规格。 - 类型
- 布尔值
- 默认
-
true
A.4. 块设备缓存选项
Ceph 块设备的用户空间实施(即 librbd )无法利用 Linux 页面缓存,因此它包含了自己的内存中缓存,称为 RBD caching(RBD 缓存)。Ceph 块设备缓存的行为与行为良好的硬盘缓存一样。当操作系统发送阻碍或清空请求时,所有脏数据都会写入 Ceph OSD。这意味着,使用回写缓存和使用功能良好的物理硬盘和正确发送清除(即 Linux 内核 2.6.32 或更高版本)的虚拟机一样安全。缓存使用最早使用 (LRU) 算法,在回写模式中,它可以联合相邻的请求来获得更好的吞吐量。
Ceph 块设备支持回写缓存。若要启用回写缓存,可将 rbd_cache = true 设置为 Ceph 配置文件的 [client] 部分。默认情况下,librbd 不执行任何缓存。写入和读取直接进入存储集群,只有数据处于所有副本的磁盘中时写入才会返回。启用缓存时,写入会立即返回,除非存在超过 rbd_cache_max_dirty 未清空字节。在这种情况下,写入会触发 write-back 并拦截,直到清空了充足的字节为止。
Ceph 块设备支持直写缓存。您可以设置缓存的大小,您可以设置从回写缓存切换到直写缓存的目标和限制。若要启用 write-through 模式,可将 rbd_cache_max_dirty 设置为 0。这意味着,只有在数据处于所有副本的磁盘上时写入才会返回,但读取可能来自缓存。缓存位于客户端上的内存中,每个 Ceph 块设备镜像都有自己的内存。由于缓存对客户端而言是本地的,如果其他人访问该镜像,则没有一致性。在 Ceph 块设备上运行其他文件系统(如 GFS 或 OCFS)将无法用于启用缓存。
默认情况下,Ceph 块设备的 Ceph 配置设置必须在 Ceph 配置文件的 [client] 部分中设置,默认为 /etc/ceph/ceph.conf。
设置包括:
- rbd_cache
- 描述
- 为 RADOS 块设备 (RBD) 启用缓存。
- 类型
- 布尔值
- 必填
- 否
- 默认
-
true
- rbd_cache_size
- 描述
- 以字节为单位的 RBD 缓存大小。
- 类型
- 64 位整数
- 必填
- 否
- 默认
-
32 MiB
- rbd_cache_max_dirty
- 描述
-
以字节为单位的
脏限制,达到时缓存将触发回写。如果为0,则使用直写缓存。 - 类型
- 64 位整数
- 必填
- 否
- 约束
-
必须小于
rbd 缓存大小。 - 默认
-
24 MiB
- rbd_cache_target_dirty
- 描述
-
缓存开始将数据写入数据存储前的
脏目标。不要阻止写入到缓存。 - 类型
- 64 位整数
- 必填
- 否
- 约束
-
必须小于
rbd cache max dirty。 - 默认
-
16 MiB
- rbd_cache_max_dirty_age
- 描述
- 在开始回写前,脏数据在缓存中的秒数。
- 类型
- 浮点值
- 必填
- 否
- 默认
-
1.0
- rbd_cache_max_dirty_object
- 描述
-
对象的脏限制 - 设为
0,用于从rbd_cache_size自动计算。 - 类型
- 整数
- 默认
-
0
- rbd_cache_block_writes_upfront
- 描述
-
如果为
true,它将在aio_write调用完成前阻止写入缓存。如果为false,它将在调用aio_completion之前阻止。 - 类型
- 布尔值
- 默认
-
false
- rbd_cache_writethrough_until_flush
- 描述
- 以直写模式开始,并在收到第一个 flush 请求后切换到回写模式。如果 rbd 上运行的虚拟机太旧而无法发送清空,如 Linux 中的 virtio 驱动程序 2.6.32 之前,启用此设置比较保守,但安全设置。
- 类型
- 布尔值
- 必填
- 否
- 默认
-
true
A.5. 块设备父级和子读选项
- rbd_balance_snap_reads
- 描述
- Ceph 通常从Primary OSD 读取对象。由于读取不可变,您可以启用此功能来平衡 Primary OSD 和副本之间的 snap 读取。
- 类型
- 布尔值
- 默认
-
false
- rbd_localize_snap_reads
- 描述
-
rbd_balance_snap_reads将随机化副本以读取快照。如果启用rbd_localize_snap_reads,块设备将查看 CRUSH map,以查找最接近或本地 OSD 以读取快照。 - 类型
- 布尔值
- 默认
-
false
- rbd_balance_parent_reads
- 描述
- Ceph 通常从Primary OSD 读取对象。由于读取不可变,您可以启用此功能来平衡 Primary OSD 和副本之间的父读取。
- 类型
- 布尔值
- 默认
-
false
- rbd_localize_parent_reads
- 描述
-
rbd_balance_parent_reads将随机化副本以读取父项。如果启用rbd_localize_parent_reads,块设备将查找 CRUSH map 来查找最接近或本地 OSD 以读取父级。 - 类型
- 布尔值
- 默认
-
true
A.6. 块设备读取预置选项
RBD 支持 read-ahead/prefetching 来优化小顺序读取。在虚拟机的情况下,这通常由客户机操作系统处理,但启动加载器可能不会产生高效的读取问题。如果禁用缓存,则会自动禁用 read-ahead。
- rbd_readahead_trigger_requests
- 描述
- 触发 read-ahead 所需的连续读取请求数。
- 类型
- 整数
- 必填
- 否
- 默认
-
10
- rbd_readahead_max_bytes
- 描述
- read-ahead 请求的最大大小.如果为零,则禁用 read-ahead。
- 类型
- 64 位整数
- 必填
- 否
- 默认
-
512 KiB
- rbd_readahead_disable_after_bytes
- 描述
- 从 RBD 镜像读取了这一字节后,对该镜像禁用 read-ahead,直到关闭为止。这允许客户机操作系统在启动后接管读头。如果为零,则启用 read-ahead。
- 类型
- 64 位整数
- 必填
- 否
- 默认
-
50 MiB
A.7. 块设备黑名单选项
- rbd_blacklist_on_break_lock
- 描述
- 是否将锁定中断的客户端列入黑名单.
- 类型
- 布尔值
- 默认
-
true
- rbd_blacklist_expire_seconds
- 描述
- OSD 默认列入黑名单的秒数 - 设置为 0。
- 类型
- 整数
- 默认
-
0
A.8. 块设备日志选项
- rbd_journal_order
- 描述
-
转换到计算日志对象最大大小的位数。该值介于
12到64之间。 - 类型
- 32-bit Unsigned 整数
- 默认
-
24
- rbd_journal_splay_width
- 描述
- 活动日志对象的数量。
- 类型
- 32-bit Unsigned 整数
- 默认
-
4
- rbd_journal_commit_age
- 描述
- 提交时间间隔(以秒为单位)。
- 类型
- 双精确浮动点数
- 默认
-
5
- rbd_journal_object_flush_interval
- 描述
- 每个日志对象每个待处理提交的最大数量。
- 类型
- 整数
- 默认
-
0
- rbd_journal_object_flush_bytes
- 描述
- 每个日志对象最多待处理字节数。
- 类型
- 整数
- 默认
-
0
- rbd_journal_object_flush_age
- 描述
- 等待提交的最大时间间隔(以秒为单位)。
- 类型
- 双精确浮动点数
- 默认
-
0
- rbd_journal_pool
- 描述
- 为日志对象指定池。
- 类型
- 字符串
- 默认
-
""
A.9. 块设备配置覆盖选项
全局级别和池级别的块设备配置覆盖选项。块设备配置的 QoS 设置仅适用于 librbd,不能用于 krbd。
全局级别
可用密钥
rbd_qos_bps_burst- 描述
- 所需的 IO 字节突发限制。
- 类型
- 整数
- 默认
-
0
rbd_qos_bps_limit- 描述
- 每秒 IO 字节数所需的限制。
- 类型
- 整数
- 默认
-
0
rbd_qos_iops_burst- 描述
- IO 操作所需的突发限制。
- 类型
- 整数
- 默认
-
0
rbd_qos_iops_limit- 描述
- 每秒所需的 IO 操作限制。
- 类型
- 整数
- 默认
-
0
rbd_qos_read_bps_burst- 描述
- 所需的读字节突发限制。
- 类型
- 整数
- 默认
-
0
rbd_qos_read_bps_limit- 描述
- 所需的每秒读取字节数限制。
- 类型
- 整数
- 默认
-
0
rbd_qos_read_iops_burst- 描述
- 所需的读操作突发限制。
- 类型
- 整数
- 默认
-
0
rbd_qos_read_iops_limit- 描述
- 每秒读取操作所需的限制。
- 类型
- 整数
- 默认
-
0
rbd_qos_write_bps_burst- 描述
- 写入字节所需的突发限制。
- 类型
- 整数
- 默认
-
0
rbd_qos_write_bps_limit- 描述
- 所需的每秒写入字节数限制。
- 类型
- 整数
- 默认
-
0
rbd_qos_write_iops_burst- 描述
- 写入操作所需的突发限制。
- 类型
- 整数
- 默认
-
0
rbd_qos_write_iops_limit- 描述
- 每秒写入操作的预期突发限制。
- 类型
- 整数
- 默认
-
0
以上键可用于以下目的:
rbd config global set CONFIG_ENTITY KEY VALUE- 描述
- 设置全局级配置覆盖。
rbd config global get CONFIG_ENTITY KEY- 描述
- 获取全局配置覆盖。
rbd config global list CONFIG_ENTITY- 描述
- 列出全局级别配置覆盖。
rbd config global remove CONFIG_ENTITY KEY- 描述
- 删除全局级配置覆盖。
池级别
rbd config pool set POOL_NAME KEY VALUE- 描述
- 设置池级配置覆盖。
rbd config pool get POOL_NAME KEY- 描述
- 获取池级配置覆盖。
rbd config pool list POOL_NAME- 描述
- 列出池级配置覆盖。
rbd config pool remove POOL_NAME KEY- 描述
- 删除池级配置覆盖。
CONFIG_ENTITY 是全局、客户端或客户端 ID。KEY 是配置键。VALUE 是配置值。POOL_NAME 是池的名称。
附录 B. iSCSI 网关变量
iSCSI 网关常规变量
seed_monitor- 用途
-
每一 iSCSI 网关需要访问 Ceph 存储集群,以进行 RADOS 和 RBD 调用。这意味着 iSCSI 网关必须定义适当的
/etc/ceph/目录。seed_monitor主机用于填充 iSCSI 网关的/etc/ceph/目录。
gateway_keyring- 用途
- 定义自定义密钥环名称。
perform_system_checks- 用途
-
这是一个布尔值,用于检查每个 iSCSI 网关上的多路径和 LVM 配置设置。至少第一次运行时必须设置为
true,以确保正确配置multipathd守护进程和 LVM。
iSCSI 网关 RBD-TARGET-API 变量
api_user- 用途
-
API 的用户名。默认值为
admin。
api_password- 用途
-
使用 API 的密码。默认值为
admin。
api_port- 用途
-
使用 API 的 TCP 端口号。默认值为
5000。
api_secure- 用途
-
值可以是
true或false。默认值为false。
loop_delay- 用途
-
控制轮询 iSCSI 管理对象所需的睡眠间隔(以秒为单位)。默认值为
1。
trusted_ip_list- 用途
- 可访问 API 的 IPv4 或 IPv6 地址列表。默认情况下,只有 iSCSI 网关节点有权访问。
附录 C. iscsigws.yml 文件示例
# Variables here are applicable to all host groups NOT roles
# This sample file generated by generate_group_vars_sample.sh
# Dummy variable to avoid error because ansible does not recognize the
# file as a good configuration file when no variable in it.
dummy:
# You can override vars by using host or group vars
###########
# GENERAL #
###########
# Whether or not to generate secure certificate to iSCSI gateway nodes
#generate_crt: False
#iscsi_conf_overrides: {}
#iscsi_pool_name: rbd
#iscsi_pool_size: "{{ osd_pool_default_size }}"
#copy_admin_key: True
##################
# RBD-TARGET-API #
##################
# Optional settings related to the CLI/API service
#api_user: admin
#api_password: admin
#api_port: 5000
#api_secure: false
#loop_delay: 1
#trusted_ip_list: 192.168.122.1
##########
# DOCKER #
##########
# Resource limitation
# For the whole list of limits you can apply see: docs.docker.com/engine/admin/resource_constraints
# Default values are based from: https://access.redhat.com/documentation/zh-cn/red_hat_ceph_storage/2/html/red_hat_ceph_storage_hardware_guide/minimum_recommendations
# These options can be passed using the 'ceph_mds_docker_extra_env' variable.
# TCMU_RUNNER resource limitation
#ceph_tcmu_runner_docker_memory_limit: "{{ ansible_memtotal_mb }}m"
#ceph_tcmu_runner_docker_cpu_limit: 1
# RBD_TARGET_GW resource limitation
#ceph_rbd_target_gw_docker_memory_limit: "{{ ansible_memtotal_mb }}m"
#ceph_rbd_target_gw_docker_cpu_limit: 1
# RBD_TARGET_API resource limitation
#ceph_rbd_target_api_docker_memory_limit: "{{ ansible_memtotal_mb }}m"
#ceph_rbd_target_api_docker_cpu_limit: 1