文件系统指南
配置和挂载 Ceph 文件系统
摘要
第 1 章 Ceph 文件系统简介
作为存储管理员,您可以了解管理 Ceph 文件系统 (CephFS) 环境的功能、系统组件和限制。
1.1. Ceph 文件系统的功能和增强
Ceph 文件系统 (CephFS) 是兼容 POSIX 标准的文件系统,在 Ceph 的分布式对象存储基础上构建,称为 RADOS(可靠的自主分布式对象存储)。CephFS 提供对 Red Hat Ceph Storage 集群的文件访问,并尽可能使用 POSIX 语义。例如,与 NFS 等其他常见网络文件系统相比,CephFS 在客户端之间保持强大的缓存一致性。目标是让使用文件系统的进程的行为与位于同一主机上的进程在不同的主机上的行为相同。但在某些情况下,CephFS 会偏离严格的 POSIX 语义。
Ceph 文件系统具有以下功能和增强功能:
- 可扩展性
- Ceph 文件系统具有高度可扩展性,因为元数据服务器水平扩展,并且直接客户端对各个 OSD 节点进行读写操作。
- 共享文件系统
- Ceph 文件系统是一种共享文件系统,因此多个客户端可以同时处理同一文件系统。
- 高可用性
- Ceph 文件系统提供 Ceph 元数据服务器 (MDS) 的集群。一个处于活动状态,另一些处于待机模式。如果活动的 MDS 意外终止,其中一个备用 MDS 就会变为活跃状态。因此,客户端挂载会继续处理服务器故障。此行为使 Ceph 文件系统高度可用。另外,您可以配置多个活跃的元数据服务器。
- 可配置文件和目录
- Ceph 文件系统允许用户配置文件和目录布局,以跨对象使用多个池、池命名空间和文件分条模式。
- POSIX 访问控制列表 (ACL)
-
Ceph 文件系统支持 POSIX 访问控制列表 (ACL)。默认启用 ACL,将 Ceph 文件系统挂载为带有内核版本
kernel-3.10.0-327.18.2.el7或更新版本的内核客户端。若要将 ACL 与挂载为 FUSE 客户端的 Ceph 文件系统搭配使用,您必须启用它们。 - 客户端配额
- Ceph 文件系统支持在系统中的任何目录上设置配额。配额可以限制目录层次结构中该点下存储的字节数或文件数量。CephFS 客户端配额默认为启用。
- 调整大小
- Ceph 文件系统大小仅由为数据池提供服务的 OSD 容量绑定。若要增加容量,可添加更多 OSD 到 CephFS 数据池中。若要减小容量,可使用客户端配额或池配额。
- 快照
- Ceph 文件系统支持只读快照,但不支持可写克隆。
- POSIX 文件系统操作
Ceph 文件系统支持标准和一致的 POSIX 文件系统操作,包括以下访问模式:
- 通过 Linux 页面缓存进行缓冲的写入操作。
- 通过 Linux 页面缓存的缓存读取操作.
- 绕过页面缓存,直接 I/O 异步或同步读/写操作。
- 内存映射的 I/O.
其它资源
- 请参阅安装指南中的安装 Metadata 服务器部分来安装 Ceph Metadata 服务器。
- 请参阅文件系统指南中的部署 Ceph 文件系统一节 ,以创建 Ceph 文件系统。
1.2. Ceph 文件系统组件
Ceph 文件系统有两个主要组件:
- 客户端
-
CephFS 客户端代表使用 CephFS 的应用执行 I/O 操作,如用于 FUSE 客户端的
ceph-fuse,kcephfs用于内核客户端。CephFS 客户端向活跃的元数据服务器发送元数据请求。为返回,CephFS 客户端了解文件元数据,可以安全地开始缓存元数据和文件数据。 - 元数据服务器 (MDS)
MDS 执行以下操作:
- 为 CephFS 客户端提供元数据。
- 管理与 Ceph 文件系统中存储的文件相关的元数据。
- 协调对共享 Red Hat Ceph Storage 的访问。
- 缓存热元数据,以减少对后备元数据池存储的请求。
- 管理 CephFS 客户端的缓存,以维护缓存一致性。
- 在活动 MDS 之间复制热元数据.
- 将元数据变异到压缩日志,并定期刷新到后备元数据池。
-
CephFS 要求至少运行一个元数据服务器守护进程 (
ceph-mds)。
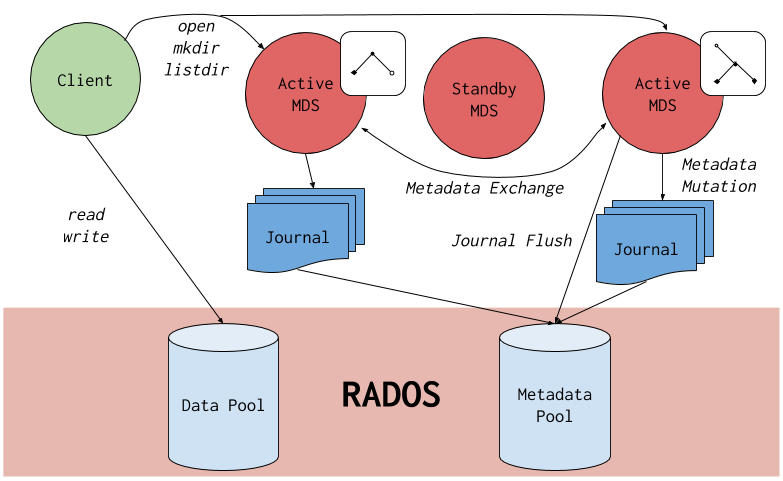
下图显示了 Ceph 文件系统的组件层。

底层代表底层核心存储集群组件:
-
存储 Ceph 文件系统数据和元数据的 Ceph OSD (
ceph-osd)。 -
用于管理 Ceph 文件系统元数据的 Ceph 元数据服务器 (
ceph-mds)。 -
Ceph 监控器 (
ceph-mon),用于管理 cluster map 的主副本。
Ceph 存储协议层代表 Ceph 原生 librados 库,用于与核心存储集群交互。
CephFS 库层包含 CephFS libcephfs 库,它位于 librados 基础上,代表 Ceph 文件系统。
顶层代表两种类型的 Ceph 客户端,它们可以访问 Ceph 文件系统。
下图显示了 Ceph 文件系统组件如何相互交互的更多详细信息。
其它资源
- 请参阅 Red Hat Ceph Storage 安装指南中的安装 Metadata 服务器部分来安装 Ceph Metadata 服务器。
- 请参阅 Red Hat Ceph Storage File System Guide 中的 Ceph 文件系统部署一节,以创建 Ceph 文件系统。
1.3. Ceph 文件系统和 SELinux
从 Red Hat Enterprise Linux 8.3 和 Red Hat Ceph Storage 4.2 开始,支持在 Ceph 文件系统 (CephFS) 环境中使用 Security-Enhanced Linux (SELinux)。现在,您可以使用 CephFS 设置任何 SELinux 文件类型,以及对各个文件分配特定的 SELinux 类型。这一支持适用于 Ceph 文件系统元数据服务器 (MDS)、用户空间 (FUSE) 客户端中的 CephFS 文件系统,以及 CephFS 内核客户端。
其它资源
- 有关 SELinux 的更多信息,请参阅在 Red Hat Enterprise Linux 8 中使用 SELinux 指南。
1.4. Ceph 文件系统限制和 POSIX 标准
默认情况下,在一个 Red Hat Ceph Storage 集群上创建多个 Ceph 文件系统是禁用的。尝试创建额外的 Ceph 文件系统失败并显示以下错误消息:
Error EINVAL: Creation of multiple filesystems is disabled.虽然在技术上可行,但红帽不支持在一个 Red Hat Ceph Storage 存储集群中拥有多个 Ceph 文件系统。这样做可能会导致 MDS 或 CephFS 客户端节点意外终止。
Ceph 文件系统通过以下方式偏离严格的 POSIX 语义:
-
如果客户端尝试编写文件失败,写入操作不一定是原子的。也就是说,客户端可能会在使用带有 8MB 缓冲区的
O_SYNC标志打开的文件上调用write()系统调用,然后意外终止写入操作,只能部分应用写入操作。几乎所有文件系统(甚至本地文件系统)都有此行为。 - 在同时发生写操作的情况下,超过对象边界的写入操作不一定是原子的。例如,写入器 A 写入 "aa|aa" 和 writer B 同时写入 "bb|bb",其中 "|" 是对象边界,编写 "aa|bb" 而不是正确的 "aa|aa" 或 "bb|bb"。
-
POSIX 包含
telldir()和searchdir()系统调用,允许您获取当前目录偏移并返回该偏移。由于 CephFS 可能会随时对目录进行碎片整理,因此难以为目录返回稳定的整数偏移。因此,调用searchdir()系统调用到非零偏移通常可以正常工作,但不保证这样做。调用seekdir()以偏移 0 将始终正常工作。这等同于rewinddir()系统调用。 -
稀疏文件传播错误地传播到
stat()系统调用的st_blocks字段。CephFS 不会显式跟踪已分配或写入的文件部分,因为st_blocks字段始终由按块大小划分的法定文件大小填充。此行为可导致du等实用程序过量使用的空间。 -
当
mmap()系统调用将文件映射到多个主机上的内存时,写入操作不会被一致的传播到其他主机的缓存中。也就是说,如果页面缓存在主机 A 上,然后在主机 B 上更新,则主机 A 页面不会被统一无效。 -
CephFS 客户端提供隐藏的
.snap目录,用于访问、创建、删除和重命名快照。虽然该目录不包括在readdir()系统调用中,但尝试创建同名文件或目录的任何进程都会返回错误。此隐藏目录的名称可以在挂载时通过-o snapdirname=.<new_name>选项或使用client_snapdir配置选项来更改。
其它资源
- 请参阅 Red Hat Ceph Storage 安装指南中的安装 Metadata 服务器部分来安装 Ceph Metadata 服务器。
- 请参阅 Red Hat Ceph Storage File System Guide 中的 Ceph 文件系统部署一节,以创建 Ceph 文件系统。
1.5. 其它资源
- 如需了解更多详细信息,请参阅 Red Hat Ceph Storage 安装指南中的安装元数据服务器 部分。
- 如果要将 NFS Ganesha 用作使用 Red Hat OpenStack Platform 的 Ceph 文件系统的接口,请参阅通过NFS 部署共享文件系统服务中的 CephFS 使用 NFS-Ganesha 部署一节,以了解如何通过 NFS 部署此类环境的说明。
第 2 章 Ceph 文件系统元数据服务器
作为存储管理员,您可以了解 Ceph 文件系统 (CephFS) 元数据服务器 (MDS) 的不同状态,以及了解 CephFS MDS 划分机制、配置 MDS 备用守护进程和缓存大小限制。了解这些概念可以让您为存储环境配置 MDS 守护进程。
2.1. 先决条件
- 一个运行良好、健康的 Red Hat Ceph Storage 集群。
-
安装 Ceph 元数据服务器守护进程 (
ceph-mds)。
2.2. 元数据服务器守护进程状态
元数据服务器 (MDS) 守护进程在两个状态下运作:
- active SAS-small 管理 Ceph 文件系统中存储的文件和目录的元数据。
- standby SAS- SASserves 作为备份,并在活跃的 MDS 守护进程变得无响应时处于活动状态。
默认情况下,Ceph 文件系统仅使用一个活跃的 MDS 守护进程。但是,具有许多客户端的系统得益于多个活跃的 MDS 守护进程。
您可以将文件系统配置为使用多个活跃 MDS 守护进程,以便您可以扩展更大工作负载的元数据性能。当元数据负载模式发生变化时,活跃的 MDS 守护进程会动态共享元数据工作负载。请注意,具有多个活跃 MDS 守护进程的系统仍需要备用 MDS 守护进程才能保持高可用性。
当活跃 MDS 守护进程出现故障时会发生什么情况
当活跃的 MDS 变得不响应时,Ceph monitor 守护进程会等待与 mds_beacon_grace 选项中指定的值相等的秒数。如果在指定的时间段过后活跃的 MDS 仍然不响应,Ceph 监控器会将 MDS 守护进程标记为 laggy。其中一个备用守护进程会变为活动状态,具体取决于配置。
若要更改 mds_beacon_grace 的值,可添加此选项到 Ceph 配置文件并指定新值。
2.3. 元数据服务器排名
每一 Ceph 文件系统 (CephFS) 具有多个等级,默认为一,从零开始。
等级定义在多个元数据服务器 (MDS) 守护进程之间共享元数据工作负载的方式。等级数是一次可以处于活跃状态的最大 MDS 守护进程数。每个 MDS 守护进程处理分配给该等级的 CephFS 元数据子集。
每个 MDS 守护进程最初启动且没有等级。Ceph 监控器将排名分配到 守护进程。MDS 守护进程一次只能有一个排名。后台程序仅在停止时丢失等级。
max_mds 设置控制将创建等级数。
只有备用守护进程可用于接受新等级时,CephFS 中实际的排名数量才会增加。
等级状态
等级可以是:
- Up - 分配给 MDS 守护进程的排名。
- Failed - 与任何 MDS 守护进程无关的等级。
-
Damaged - 损坏的等级;其元数据被损坏或缺失。在操作器修复问题之前,损坏的等级不会分配到任何 MDS 守护进程,并对损坏的等级使用
ceph mds repaired的命令。
2.4. 元数据服务器缓存大小限制
您可以通过以下方法限制 Ceph 文件系统 (CephFS) 元数据服务器 (MDS) 缓存的大小:
内存限制 :使用
mds_cache_memory_limit选项。红帽建议为mds_cache_memory_limit设置 8 GB 到 64 GB 的值。设置更多缓存可能会导致恢复问题。这个限制是使用 MDS 所需最大内存用量的大约 66%。重要红帽建议使用内存限制而不是内节点计数限制。
-
索引节点计数 :使用
mds_cache_size选项.默认情况下,禁用按索引节点计数限制 MDS 缓存。
另外,您还可以为 MDS 操作使用 mds_cache_reservation 选项来指定缓存保留。缓存保留是内存或索引节点限制的百分比,默认设置为 5%。此参数的目的是让 MDS 为其缓存保留额外内存,以便使用新的元数据操作。因此,MDS 通常应在内存限制下运行,因为它会从客户端重新调用旧状态,从而在其缓存中丢弃未使用的元数据。
在所有情况下,mds_cache_reservation 选项替换 ds_health_cache_threshold 选项,但 MDS 节点会向 Ceph monitor 发送健康警报,表示缓存太大。默认情况下,mds_health_cache_threshold 是最大缓存大小的 150%。
请注意,缓存限制不是硬限制。CephFS 客户端或 MDS 或 MDS 中潜在的错误行为或行为不当可能会导致 MDS 超过其缓存大小。mds_health_cache_threshold 选项配置存储集群健康警告消息,以便操作员可以调查 MDS 无法缩小其缓存的原因。
其它资源
- 如需更多信息,请参阅 Red Hat Ceph Storage File System Guide 的 Metadata Server daemon configuration reference 章节。
2.5. 配置多个活跃的元数据服务器守护进程
配置多个活动元数据服务器 (MDS) 守护进程,以缩放大型系统的元数据性能。
不要将所有备用 MDS 守护进程转换为活跃的 MDS 守护进程。Ceph 文件系统 (CephFS) 至少需要一个备用 MDS 守护进程才能保持高可用性。
如果配置了多个活跃的 MDS 守护进程,当前不支持清理过程。
先决条件
- MDS 节点上的 Ceph 管理功能.
流程
将
max_mds参数设置为所需的活跃 MDS 守护进程数:语法
ceph fs set NAME max_mds NUMBER示例
[root@mon ~]# ceph fs set cephfs max_mds 2本例将名为
cephfs的 CephFS 中的活跃 MDS 守护进程数量增加到两个。注意仅当有备用 MDS 守护进程可以取用新等级时,Ceph 才会增加 CephFS 中的实际排名数量。
验证活跃 MDS 守护进程的数量:
语法
ceph fs status NAME示例
[root@mon ~]# ceph fs status cephfs cephfs - 0 clients ====== +------+--------+-------+---------------+-------+-------+ | Rank | State | MDS | Activity | dns | inos | +------+--------+-------+---------------+-------+-------+ | 0 | active | node1 | Reqs: 0 /s | 10 | 12 | | 1 | active | node2 | Reqs: 0 /s | 10 | 12 | +------+--------+-------+---------------+-------+-------+ +-----------------+----------+-------+-------+ | Pool | type | used | avail | +-----------------+----------+-------+-------+ | cephfs_metadata | metadata | 4638 | 26.7G | | cephfs_data | data | 0 | 26.7G | +-----------------+----------+-------+-------+ +-------------+ | Standby MDS | +-------------+ | node3 | +-------------+
其它资源
- 如需了解更多详细信息,请参阅 Red Hat Ceph Storage File System Guide 中的 Metadata Server daemons states 章节。
- 如需了解更多详细信息,请参阅 Red Hat Ceph Storage File System Guide 中的 Decreasing the Number of Active MDS Daemons 部分。
- 如需了解更多详细信息,请参阅 Red Hat Ceph Storage Administration Guide 中的 Managing Ceph users 章节。
2.6. 配置待机守护进程数量
每个 Ceph 文件系统 (CephFS) 可以指定被视为健康状态所需的待机守护进程数量。这个数字还包括等待排序失败的待机重播守护进程。
先决条件
- 用户访问 Ceph 监控节点.
流程
为特定 CephFS 设置预期的待机守护进程数量:
语法
ceph fs set FS_NAME standby_count_wanted NUMBER注意将 NUMBER 设置为零可禁用守护进程健康检查。
示例
[root@mon]# ceph fs set cephfs standby_count_wanted 2这个示例将预期的备用守护进程数设置为 2。
2.7. 配置待机重播元数据服务器
通过添加待机重播元数据服务器 (MDS) 守护进程来配置各个 Ceph 文件系统 (CephFS)。如果活跃 MDS 不可用,可以缩短故障切换时间。
这个特定的待机重播守护进程跟踪活跃 MDS 的元数据日志。待机重播守护进程仅供同一排名相同的活跃 MDS 使用,不可用于其他等级。
如果使用 standby-replay,则每个活跃 MDS 都必须具有待机守护进程。
先决条件
- 用户访问 Ceph 监控节点.
流程
设置特定 CephFS 的待机重播:
语法
ceph fs set FS_NAME allow_standby_replay 1示例
[root@mon]# ceph fs set cephfs allow_standby_replay 1在本例中,布尔值为
1,它允许将 standby-replay 守护进程分配到活动的 Ceph MDS 守护进程。注意将
allow_standby_replay布尔值设置回0仅可防止分配新的 standby-replay 守护进程。要停止正在运行的守护进程,请使用ceph mds fail命令将其标记为failed。
其它资源
- 详情请参阅 Red Hat Ceph Storage File System Guide 中的 Using the ceph mds fail command 章节。
2.8. 减少活跃元数据服务器守护进程数量
如何减少活动 Ceph 文件系统 (CephFS) 元数据服务器 (MDS) 守护进程的数量。
先决条件
-
要删除的等级必须首先处于活跃状态,这意味着您必须具有与
max_mds参数指定的 MDS 守护进程数量相同的 MDS 守护进程数。
流程
设置由
max_mds参数指定的相同 MDS 守护进程数:语法
ceph fs status NAME示例
[root@mon ~]# ceph fs status cephfs cephfs - 0 clients +------+--------+-------+---------------+-------+-------+ | Rank | State | MDS | Activity | dns | inos | +------+--------+-------+---------------+-------+-------+ | 0 | active | node1 | Reqs: 0 /s | 10 | 12 | | 1 | active | node2 | Reqs: 0 /s | 10 | 12 | +------+--------+-------+---------------+-------+-------+ +-----------------+----------+-------+-------+ | Pool | type | used | avail | +-----------------+----------+-------+-------+ | cephfs_metadata | metadata | 4638 | 26.7G | | cephfs_data | data | 0 | 26.7G | +-----------------+----------+-------+-------+ +-------------+ | Standby MDS | +-------------+ | node3 | +-------------+在具有管理功能的节点中,将
max_mds参数改为所需的活跃 MDS 守护进程数:语法
ceph fs set NAME max_mds NUMBER示例
[root@mon ~]# ceph fs set cephfs max_mds 1-
通过观察 Ceph 文件系统状态,等待存储集群稳定到新的
max_mds值。 验证活跃 MDS 守护进程的数量:
语法
ceph fs status NAME示例
[root@mon ~]# ceph fs status cephfs cephfs - 0 clients +------+--------+-------+---------------+-------+-------+ | Rank | State | MDS | Activity | dns | inos | +------+--------+-------+---------------+-------+-------+ | 0 | active | node1 | Reqs: 0 /s | 10 | 12 | +------+--------+-------+---------------+-------+-------+ +-----------------+----------+-------+-------+ | Pool | type | used | avail | +-----------------+----------+-------+-------+ | cephfs_metadata | metadata | 4638 | 26.7G | | cephfs_data | data | 0 | 26.7G | +-----------------+----------+-------+-------+ +-------------+ | Standby MDS | +-------------+ | node3 | | node2 | +-------------+
其它资源
- 如需了解更多详细信息,请参阅 Red Hat Ceph Storage File System Guide 中的 Metadata Server daemons states 章节。
- 如需更多信息,请参阅 Red Hat Ceph Storage 文件系统指南中的配置多个活跃元数据服务器守护进程 部分。
2.9. 其它资源
- 如需了解更多详细信息,请参阅 Red Hat Ceph Storage 安装指南中的安装元数据服务器 部分。
- 有关安装 Red Hat Ceph Storage 集群的详细信息,请参阅 Red Hat Ceph Storage Installation Guide。
第 3 章 Ceph 文件系统的部署
作为存储管理员,您可以在存储环境中部署 Ceph 文件系统 (CephFS),并让客户端挂载这些 Ceph 文件系统来满足存储需求。
基本上,部署工作流有三个步骤:
- 在 Ceph 监控节点上创建 Ceph 文件系统。
- 创建具有适当功能的 Ceph 客户端用户,并在将要挂载 Ceph 文件系统的节点上提供客户端密钥。
- 使用内核客户端或用户空间 (FUSE) 客户端中的文件系统,将 CephFS 挂载到专用节点上。
3.1. 先决条件
- 一个运行良好、健康的 Red Hat Ceph Storage 集群。
-
安装和配置 Ceph 元数据服务器守护进程 (
ceph-mds)。
3.2. 布局、配额、快照和网络限制
这些用户功能可以帮助您根据所需的要求限制对 Ceph 文件系统 (CephFS) 的访问。
除 rw 外,所有用户能力标志都必须按字母顺序指定。
布局和配额
使用布局或配额时,除了 rw 功能外,客户端还需要 p 标志。设置 p 标志会限制由特殊扩展属性(带有 ceph. 前缀)设置的所有属性。另外,这限制了设置这些字段的其他方法,如 openc 操作使用布局。
示例
client.0
key: AQAz7EVWygILFRAAdIcuJ10opU/JKyfFmxhuaw==
caps: [mds] allow rwp
caps: [mon] allow r
caps: [osd] allow rw tag cephfs data=cephfs_a
client.1
key: AQAz7EVWygILFRAAdIcuJ11opU/JKyfFmxhuaw==
caps: [mds] allow rw
caps: [mon] allow r
caps: [osd] allow rw tag cephfs data=cephfs_a
在本例中,client.0 可以修改文件系统 cephfs_a 上的布局和配额,但 client.1 无法修改。
快照
在创建或删除快照时,除了 rw 功能外,客户端还需要 s 标志。当能力字符串还包含 p 标志时,s 标志必须出现在它后面。
示例
client.0
key: AQAz7EVWygILFRAAdIcuJ10opU/JKyfFmxhuaw==
caps: [mds] allow rw, allow rws path=/temp
caps: [mon] allow r
caps: [osd] allow rw tag cephfs data=cephfs_a
在本例中,client.0 可以在文件系统 cephfs_a 的 temp 目录中创建或删除快照。
Network
限制从特定网络连接的客户端.
示例
client.0
key: AQAz7EVWygILFRAAdIcuJ10opU/JKyfFmxhuaw==
caps: [mds] allow r network 10.0.0.0/8, allow rw path=/bar network 10.0.0.0/8
caps: [mon] allow r network 10.0.0.0/8
caps: [osd] allow rw tag cephfs data=cephfs_a network 10.0.0.0/8
可选的网络和前缀长度为 CIDR 表示法,例如 10.3.0.0/16。
其它资源
- 如需了解有关设置 Ceph 用户功能的详细信息,请参阅 Red Hat Ceph Storage File System Guide 中的Creating client users for a Ceph File System 部分。
3.3. 创建 Ceph 文件系统
您可以在 Ceph 监控节点上创建 Ceph 文件系统 (CephFS)。
默认情况下,每个 Ceph 存储集群只能创建一个 CephFS。
先决条件
- 一个运行良好、健康的 Red Hat Ceph Storage 集群。
-
安装和配置 Ceph 元数据服务器守护进程 (
ceph-mds)。 - Ceph 监控节点的根级别访问权限。
流程
创建两个池,一个用于存储数据,另一个用于存储元数据:
语法
ceph osd pool create NAME _PG_NUM示例
[root@mon ~]# ceph osd pool create cephfs_data 64 [root@mon ~]# ceph osd pool create cephfs_metadata 64通常,元数据池可以从比较保守的 PG 数量开始,因为它的对象通常比数据池少得多。如果需要,可以增加 PG 数量。推荐的元数据池大小范围从 64 个 PG 到 512 PG。数据池的大小与您文件系统中预期的文件的编号和大小成比例。
重要对于元数据池,请考虑使用:
- 更高的复制级别,因为对此池的任何数据丢失都可能会导致整个文件系统无法访问。
- 延迟较低的存储(如 Solid-State Drive(SSD)磁盘),因为这会直接影响客户端上观察到的文件系统操作延迟。
创建 CephFS:
语法
ceph fs new NAME METADATA_POOL DATA_POOL示例
[root@mon ~]# ceph fs new cephfs cephfs_metadata cephfs_data验证一个或多个 MDS 是否根据您的配置进入活跃状态。
语法
ceph fs status NAME示例
[root@mon ~]# ceph fs status cephfs cephfs - 0 clients ====== +------+--------+-------+---------------+-------+-------+ | Rank | State | MDS | Activity | dns | inos | +------+--------+-------+---------------+-------+-------+ | 0 | active | node1 | Reqs: 0 /s | 10 | 12 | +------+--------+-------+---------------+-------+-------+ +-----------------+----------+-------+-------+ | Pool | type | used | avail | +-----------------+----------+-------+-------+ | cephfs_metadata | metadata | 4638 | 26.7G | | cephfs_data | data | 0 | 26.7G | +-----------------+----------+-------+-------+ +-------------+ | Standby MDS | +-------------+ | node3 | | node2 | +-------------+----
其它资源
- 详情请参阅 Red Hat Ceph Storage 安装指南中的启用 Red Hat Ceph Storage 存储库一节。
- 如需了解更多详细信息,请参见 Red Hat Ceph Storage 策略指南中的 池 一章。
- 有关 Ceph 文件系统限制的更多详细信息,请参见 Red Hat Ceph Storage File System Guide 中 的The Ceph File System 部分。
- 有关安装 Red Hat Ceph Storage 集群的详细信息,请参阅 Red Hat Ceph Storage Installation Guide。
- 如需了解更多详细信息,请参阅 Red Hat Ceph Storage 安装指南中的安装元数据服务器 部分。
3.4. 使用纠删代码创建 Ceph 文件系统(技术预览)
默认情况下,Ceph 将复制池用于数据池。如果需要,您还可以添加额外的纠删代码数据池。与由复制池支持的 Ceph 文件系统相比,由纠删代码池支持的 Ceph 文件系统 (CephFS) 使用较少的总存储。尽管纠删代码池使用较少的总存储,它们也使用的内存和处理器资源要多于复制池。
使用纠删代码池的 Ceph 文件系统是一项技术预览功能。技术预览功能不包括在红帽生产服务级别协议(SLA)中,且其功能可能并不完善。因此,红帽不建议在生产环境中使用它们。这些技术预览功能可以使用户提早试用新的功能,并有机会在开发阶段提供反馈意见。如需了解更多详细信息,请参阅红帽技术预览功能的支持范围。
对于生产环境,红帽建议使用复制池作为默认数据池。
先决条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
- 正在运行的 CephFS 环境。
- 使用 BlueStore OSD 的池。
- 对 Ceph 监控节点的用户级别访问权限。
流程
为 CephFS 元数据创建复制元数据池:
语法
ceph osd pool create METADATA_POOL PG_NUM示例
[root@mon ~]# ceph osd pool create cephfs-metadata 64本例创建名为
cephfs-metadata且具有 64 个 PG 的池。为 CephFS 创建默认复制数据池:
语法
ceph osd pool create DATA_POOL PG_NUM示例
[root@mon ~]# ceph osd pool create cephfs-data 64本例创建名为
cephfs-data的复制池,具有 64 个 PG。为 CephFS 创建纠删代码数据池:
语法
ceph osd pool create DATA_POOL PG_NUM erasure示例
[root@mon ~]# ceph osd pool create cephfs-data-ec 64 erasure本例创建一个名为
cephfs-data-ec的纠删代码池,该池具有 64 个 PG。在纠删代码池中启用覆盖:
语法
ceph osd pool set DATA_POOL allow_ec_overwrites true示例
[root@mon ~]# ceph osd pool set cephfs-data-ec allow_ec_overwrites true本例启用对名为
cephfs-data-ec的纠删代码池进行覆盖。将纠删代码的数据池添加到 CephFS 元数据服务器 (MDS):
语法
ceph fs add_data_pool cephfs-ec DATA_POOL示例
[root@mon ~]# ceph fs add_data_pool cephfs-ec cephfs-data-ec(可选)验证添加了数据池:
[root@mon ~]# ceph fs ls
创建 CephFS:
语法
ceph fs new cephfs METADATA_POOL DATA_POOL示例
[root@mon ~]# ceph fs new cephfs cephfs-metadata cephfs-data重要不建议将纠删代码池用于默认数据池。
使用纠删代码创建 CephFS:
语法
ceph fs new cephfs-ec METADATA_POOL DATA_POOL示例
[root@mon ~]# ceph fs new cephfs-ec cephfs-metadata cephfs-data-ec验证一个或多个 Ceph FS 元数据服务器 (MDS) 是否进入活跃状态:
语法
ceph fs status FS_EC示例
[root@mon ~]# ceph fs status cephfs-ec cephfs-ec - 0 clients ====== +------+--------+-------+---------------+-------+-------+ | Rank | State | MDS | Activity | dns | inos | +------+--------+-------+---------------+-------+-------+ | 0 | active | node1 | Reqs: 0 /s | 10 | 12 | +------+--------+-------+---------------+-------+-------+ +-----------------+----------+-------+-------+ | Pool | type | used | avail | +-----------------+----------+-------+-------+ | cephfs-metadata | metadata | 4638 | 26.7G | | cephfs-data | data | 0 | 26.7G | | cephfs-data-ec | data | 0 | 26.7G | +-----------------+----------+-------+-------+ +-------------+ | Standby MDS | +-------------+ | node3 | | node2 | +-------------+要将新的纠删代码数据池添加到现有文件系统,请执行以下操作:
为 CephFS 创建纠删代码数据池:
语法
ceph osd pool create DATA_POOL PG_NUM erasure示例
[root@mon ~]# ceph osd pool create cephfs-data-ec1 64 erasure在纠删代码池中启用覆盖:
语法
ceph osd pool set DATA_POOL allow_ec_overwrites true示例
[root@mon ~]# ceph osd pool set cephfs-data-ec1 allow_ec_overwrites true将纠删代码的数据池添加到 CephFS 元数据服务器 (MDS):
语法
ceph fs add_data_pool cephfs-ec DATA_POOL示例
[root@mon ~]# ceph fs add_data_pool cephfs-ec cephfs-data-ec1
使用纠删代码创建 CephFS:
语法
ceph fs new cephfs-ec METADATA_POOL DATA_POOL示例
[root@mon ~]# ceph fs new cephfs-ec cephfs-metadata cephfs-data-ec1
其它资源
- 有关 CephFS MDS 的更多信息,请参见 Red Hat Ceph Storage File System Guide 中的 The Ceph File System Metadata Server 章节。
- 如需了解更多详细信息,请参阅 Red Hat Ceph Storage 安装指南中的安装元数据服务器部分。
- 如需更多信息,请参阅 Red Hat Ceph Storage Storage Strategies Guide 中的 Erasure-Coded Pools 部分。
- 如需更多信息,请参阅 Red Hat Ceph Storage Storage Strategies Guide 中的 Erasure-Coded Pools 部分。
3.5. 为 Ceph 文件系统创建客户端用户
Red Hat Ceph Storage 使用 cephx 进行身份验证,这在默认情况下是启用的。若要将 cephx 与 Ceph 文件系统搭配使用,请在 Ceph 监控节点上创建具有正确授权功能的用户,并在将要挂载 Ceph 文件系统的节点上提供其密钥。
先决条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
- 安装和配置 Ceph 元数据服务器守护进程 (ceph-mds)。
- Ceph 监控节点的根级别访问权限。
- Ceph 客户端节点的根级别访问权限。
流程
在 Ceph 监控节点上,创建一个客户端用户:
语法
ceph fs authorize FILE_SYSTEM_NAME client.CLIENT_NAME /DIRECTORY CAPABILITY [/DIRECTORY CAPABILITY] ...将客户端限制为仅在文件系统
cephfs_a的temp目录中写入:示例
[root@mon ~]# ceph fs authorize cephfs_a client.1 / r /temp rw client.1 key: AQBSdFhcGZFUDRAAcKhG9Cl2HPiDMMRv4DC43A== caps: [mds] allow r, allow rw path=/temp caps: [mon] allow r caps: [osd] allow rw tag cephfs data=cephfs_a要将客户端完全限制到
temp目录,请删除根 (/) 目录:示例
[root@mon ~]# ceph fs authorize cephfs_a client.1 /temp rw
注意提供
all或星号作为文件系统名称将授予对每个文件系统的访问权限。通常,需要对星号加上引号以避免它在 shell 中被错误使用。验证创建的密钥:
语法
ceph auth get client.ID示例
[root@mon ~]# ceph auth get client.1将密钥环复制到客户端。
在 Ceph 监控节点上,将密钥环导出到文件中:
语法
ceph auth get client.ID -o ceph.client.ID.keyring示例
[root@mon ~]# ceph auth get client.1 -o ceph.client.1.keyring exported keyring for client.1将 Ceph 监控节点的客户端密钥环复制到客户端节点上的
/etc/ceph/目录中:语法
scp root@MONITOR_NODE_NAME:/root/ceph.client.1.keyring /etc/ceph/使用 Ceph 监控节点名称或 IP 替换 _MONITOR_NODE_NAME_。
示例
[root@client ~]# scp root@mon:/root/ceph.client.1.keyring /etc/ceph/ceph.client.1.keyring
为密钥环文件设置适当的权限:
语法
chmod 644 KEYRING示例
[root@client ~]# chmod 644 /etc/ceph/ceph.client.1.keyring
其它资源
- 如需了解更多详细信息,请参见 Red Hat Ceph Storage 管理指南中的 用户管理一章。
3.6. 将 Ceph 文件系统挂载为内核客户端
您可以将 Ceph 文件系统 (CephFS) 挂载为内核客户端,也可以手动挂载或在系统引导时自动挂载。
除了 Red Hat Enterprise Linux 外,还允许在其他 Linux 发行版上运行的客户端,但不受支持。如果在 CephFS 元数据服务器或存储群集的其他部分使用这些客户端,红帽会解决这些问题。如果发现原因在客户端,则该问题必须由 Linux 发行版的内核供应商解决。
先决条件
- 对基于 Linux 的客户端节点的根级别访问权限.
- 对 Ceph 监控节点的用户级别访问权限。
- 现有的 Ceph 文件系统.
流程
配置客户端节点,以使用 Ceph 存储群集。
启用 Red Hat Ceph Storage 4 Tools 存储库:
Red Hat Enterprise Linux 7
[root@client ~]# subscription-manager repos --enable=rhel-7-server-rhceph-4-tools-rpmsRed Hat Enterprise Linux 8
[root@client ~]# subscription-manager repos --enable=rhceph-4-tools-for-rhel-8-x86_64-rpms安装
ceph-common软件包:Red Hat Enterprise Linux 7
[root@client ~]# yum install ceph-commonRed Hat Enterprise Linux 8
[root@client ~]# dnf install ceph-common将 Ceph 客户端密钥环从 Ceph 监控节点复制到客户端节点:
语法
scp root@MONITOR_NODE_NAME:/etc/ceph/KEYRING_FILE /etc/ceph/将 MONITOR_NODE_NAME 替换为 Ceph Monitor 主机名或 IP 地址。
示例
[root@client ~]# scp root@192.168.0.1:/etc/ceph/ceph.client.1.keyring /etc/ceph/将 Ceph 配置文件从 Ceph 监控节点复制到客户端节点:
语法
scp root@MONITOR_NODE_NAME:/etc/ceph/ceph.conf /etc/ceph/ceph.conf将 MONITOR_NODE_NAME 替换为 Ceph Monitor 主机名或 IP 地址。
示例
[root@client ~]# scp root@192.168.0.1:/etc/ceph/ceph.conf /etc/ceph/ceph.conf为配置文件设置适当的权限:
[root@client ~]# chmod 644 /etc/ceph/ceph.conf
在客户端节点上创建挂载目录:
语法
mkdir -p MOUNT_POINT示例
[root@client]# mkdir -p /mnt/cephfs挂载 Ceph 文件系统.要指定多个 Ceph 监控地址,在
mount命令中使用逗号将它们分隔,指定挂载点,并设置客户端名称:注意自 Red Hat Ceph Storage 4.1 起,
mount.ceph可以直接读取密钥环文件。因此,不再需要一个 secret 文件。只需使用name=CLIENT_ID指定客户端 ID,mount.ceph将找到正确的密钥环文件。语法
mount -t ceph MONITOR-1_NAME:6789,MONITOR-2_NAME:6789,MONITOR-3_NAME:6789:/ MOUNT_POINT -o name=CLIENT_ID示例
[root@client ~]# mount -t ceph mon1:6789,mon2:6789,mon3:6789:/ /mnt/cephfs -o name=1注意您可以配置 DNS 服务器,以便单个主机名解析为多个 IP 地址。然后,您可以将该单一主机名与
mount命令配合使用,而不必提供逗号分隔的列表。注意您还可以将 monitor 主机名替换为字符串
:/和mount.ceph将读取 Ceph 配置文件,以确定要连接的 monitor。验证文件系统是否已成功挂载:
语法
stat -f MOUNT_POINT示例
[root@client ~]# stat -f /mnt/cephfs
其它资源
-
请参阅
mount(8)手册页。 - 如需了解有关创建 Ceph 用户的更多详细信息,请参见 Red Hat Ceph Storage Administration Guide 中的 Ceph user management 部分。
- 详情请参阅 Red Hat Ceph Storage File System Guide 中的 Creating a Ceph File System 部分。
3.7. 将 Ceph 文件系统挂载为 FUSE 客户端
您可以将 Ceph 文件系统 (CephFS) 作为文件系统挂载到 User Space (FUSE) 客户端中,也可以手动在系统引导时自动挂载。
先决条件
- 对基于 Linux 的客户端节点的根级别访问权限.
- 对 Ceph 监控节点的用户级别访问权限。
- 现有的 Ceph 文件系统.
流程
配置客户端节点,以使用 Ceph 存储群集。
启用 Red Hat Ceph Storage 4 Tools 存储库:
Red Hat Enterprise Linux 7
[root@client ~]# subscription-manager repos --enable=rhel-7-server-rhceph-4-tools-rpmsRed Hat Enterprise Linux 8
[root@client ~]# subscription-manager repos --enable=rhceph-4-tools-for-rhel-8-x86_64-rpms安装
ceph-fuse软件包:Red Hat Enterprise Linux 7
[root@client ~]# yum install ceph-fuseRed Hat Enterprise Linux 8
[root@client ~]# dnf install ceph-fuse将 Ceph 客户端密钥环从 Ceph 监控节点复制到客户端节点:
语法
scp root@MONITOR_NODE_NAME:/etc/ceph/KEYRING_FILE /etc/ceph/将 MONITOR_NODE_NAME 替换为 Ceph Monitor 主机名或 IP 地址。
示例
[root@client ~]# scp root@192.168.0.1:/etc/ceph/ceph.client.1.keyring /etc/ceph/将 Ceph 配置文件从 Ceph 监控节点复制到客户端节点:
语法
scp root@MONITOR_NODE_NAME:/etc/ceph/ceph.conf /etc/ceph/ceph.conf将 MONITOR_NODE_NAME 替换为 Ceph Monitor 主机名或 IP 地址。
示例
[root@client ~]# scp root@192.168.0.1:/etc/ceph/ceph.conf /etc/ceph/ceph.conf为配置文件设置适当的权限:
[root@client ~]# chmod 644 /etc/ceph/ceph.conf- 选择 自动 或 手动 挂载.
手动挂载
在客户端节点上,为挂载点创建一个目录:
语法
mkdir PATH_TO_MOUNT_POINT示例
[root@client ~]# mkdir /mnt/mycephfs注意如果您将
path选项与 MDS 功能一起使用,则挂载点必须在pat中指定的范围内。使用
ceph-fuse实用程序挂载 Ceph 文件系统。语法
ceph-fuse -n client.CLIENT_ID MOUNT_POINT示例
[root@client ~]# ceph-fuse -n client.1 /mnt/mycephfs注意如果您不使用用户密钥环的默认名称和位置,即
/etc/ceph/ceph.client.CLIENT_ID.keyring,则使用--keyring选项指定用户密钥环的路径,例如:示例
[root@client ~]# ceph-fuse -n client.1 --keyring=/etc/ceph/client.1.keyring /mnt/mycephfs注意使用
-r选项指示客户端将该路径视为其根路径:语法
ceph-fuse -n client.CLIENT_ID MOUNT_POINT -r PATH示例
[root@client ~]# ceph-fuse -n client.1 /mnt/cephfs -r /home/cephfs验证文件系统是否已成功挂载:
语法
stat -f MOUNT_POINT示例
[user@client ~]$ stat -f /mnt/cephfs
自动挂载
在客户端节点上,为挂载点创建一个目录:
语法
mkdir PATH_TO_MOUNT_POINT示例
[root@client ~]# mkdir /mnt/mycephfs注意如果您将
path选项与 MDS 功能一起使用,则挂载点必须在pat中指定的范围内。编辑
/etc/fstab文件,如下所示:语法
#DEVICE PATH TYPE OPTIONS DUMP FSCK HOST_NAME:_PORT_, MOUNT_POINT fuse.ceph ceph.id=CLIENT_ID, 0 0 HOST_NAME:_PORT_, ceph.client_mountpoint=/VOL/SUB_VOL_GROUP/SUB_VOL/UID_SUB_VOL, HOST_NAME:_PORT_:/ [ADDITIONAL_OPTIONS]第一列 设置 Ceph monitor 主机名和端口号。
第二列 设置挂载点
第三列为 CephFS 设置文件系统类型,本例中为
fuse.ceph。第四列 设置各种选项,如分别使用
name和secretfile选项的用户名和机密文件。您还可以使用ceph.client_mountpoint选项设置特定的卷、子卷组和子卷。设置_netdev选项,以确保在网络子系统启动后挂载文件系统,以防止挂起和网络问题。如果您不需要访问时间信息,则设置noatime选项可提高性能。将第五个和第六个列设为零。
示例
#DEVICE PATH TYPE OPTIONS DUMP FSCK mon1:6789, /mnt/cephfs fuse.ceph ceph.id=1, 0 0 mon2:6789, ceph.client_mountpoint=/my_vol/my_sub_vol_group/my_sub_vol/0, mon3:6789:/ _netdev,defaultsCeph 文件系统将挂载到下一次系统启动时。
其它资源
-
ceph-fuse(8)手册页。 - 如需了解有关创建 Ceph 用户的更多详细信息,请参见 Red Hat Ceph Storage Administration Guide 中的 Ceph user management 部分。
- 详情请参阅 Red Hat Ceph Storage File System Guide 中的 Creating a Ceph File System 部分。
3.8. 其它资源
- 详情请查看 第 3.3 节 “创建 Ceph 文件系统”。
- 详情请查看 第 3.5 节 “为 Ceph 文件系统创建客户端用户”。
- 详情请查看 第 3.6 节 “将 Ceph 文件系统挂载为内核客户端”。
- 详情请查看 第 3.7 节 “将 Ceph 文件系统挂载为 FUSE 客户端”。
- 有关安装 CephFS 元数据服务器的详细信息,请参阅 Red Hat Ceph Storage Installation Guide。
- 有关配置 CephFS 元数据服务器守护进程的详情,请查看 第 2 章 Ceph 文件系统元数据服务器。
第 4 章 Ceph 文件系统管理
作为存储管理员,您可以执行常见的 Ceph 文件系统 (CephFS) 管理任务,例如:
- 要将目录映射到特定 MDS 等级,请参阅 第 4.4 节 “将目录树映射到元数据服务器守护进程等级”。
- 要取消目录与 MDS 等级的关联,请参阅 第 4.5 节 “与元数据服务器守护进程解除目录树的关联”。
- 要使用文件和目录布局,请参阅 第 4.8 节 “使用文件和目录”。
- 要添加新数据池,请参阅 第 4.6 节 “添加数据池”。
- 要使用配额,请参阅 第 4.7 节 “使用 Ceph 文件系统配额”。
- 要使用命令行界面删除 Ceph 文件系统,请参阅 第 4.12 节 “使用命令行界面删除 Ceph 文件系统”。
- 要使用 Ansible 删除 Ceph 文件系统,请参阅 第 4.13 节 “使用 Ansible 删除 Ceph 文件系统”。
- 要设置最低客户端版本,请参阅 第 4.14 节 “设置最低客户端版本”。
-
要使用
ceph mds fail命令,请参阅 第 4.15 节 “使用ceph mds fail命令”。
4.1. 先决条件
- 一个运行良好、健康的 Red Hat Ceph Storage 集群。
-
安装和配置 Ceph 元数据服务器守护进程 (
ceph-mds)。 - 创建并挂载 Ceph 文件系统。
4.2. 卸载挂载为内核客户端的 Ceph 文件系统
如何卸载挂载为内核客户端的 Ceph 文件系统。
先决条件
- 对执行挂载的节点的根级别访问权限。
流程
卸载挂载为内核客户端的 Ceph 文件系统:
语法
umount MOUNT_POINT示例
[root@client ~]# umount /mnt/cephfs
其它资源
-
umount(8)手册页
4.3. 卸载挂载为 FUSE 客户端的 Ceph 文件系统
卸载作为文件系统挂载到用户空间 (FUSE) 客户端中的 Ceph 文件系统。
先决条件
- 对 FUSE 客户端节点的根级别访问权限。
流程
卸载挂载在 FUSE 中的 Ceph 文件系统:
语法
fusermount -u MOUNT_POINT示例
[root@client ~]# fusermount -u /mnt/cephfs
其它资源
-
ceph-fuse(8)手册页
4.4. 将目录树映射到元数据服务器守护进程等级
要将目录及其子目录映射到特定的活动元数据服务器 (MDS) 排名,以使其元数据仅由持有该等级的 MDS 守护进程管理。这种方法允许您将应用程序负载或限制用户元数据请求的影响均匀分布到整个存储集群。
内部均衡已经动态分散应用程序负载。因此,仅将目录树映射到某些精心选择的应用的排名上。
另外,当目录映射到等级时,平衡器无法分割它。因此,映射目录中的大量操作可能会过载等级和管理它的 MDS 守护进程。
先决条件
- 至少两个活跃的 MDS 守护进程。
- 用户访问 CephFS 客户端节点。
-
使用挂载的 Ceph 文件系统,验证 CephFS 客户端节点上已安装了
attr软件包。
流程
将
p标志添加到 Ceph 用户的功能中:语法
ceph fs authorize FILE_SYSTEM_NAME client.CLIENT_NAME /DIRECTORY CAPABILITY [/DIRECTORY CAPABILITY] ...示例
[user@client ~]$ ceph fs authorize cephfs_a client.1 /temp rwp client.1 key: AQBSdFhcGZFUDRAAcKhG9Cl2HPiDMMRv4DC43A== caps: [mds] allow r, allow rwp path=/temp caps: [mon] allow r caps: [osd] allow rw tag cephfs data=cephfs_a在目录中设置
ceph.dir.pin扩展属性:语法
setfattr -n ceph.dir.pin -v RANK DIRECTORY示例
[user@client ~]$ setfattr -n ceph.dir.pin -v 2 /temp这个示例分配
/temp目录及其所有子目录来等级 2。
其它资源
-
有关
p标志的详情,请参见 Red Hat Ceph Storage File System Guide 中的 Layout, quota, snapshot, and network restrictions 部分。 - 如需了解更多详细信息,请参阅 Red Hat Ceph Storage File System Guide 中的 Disassociating directory trees from Metadata Server daemon ranks 部分。
- 如需更多信息,请参阅 Red Hat Ceph Storage 文件系统指南中的配置多个活跃元数据服务器守护进程 部分。
4.5. 与元数据服务器守护进程解除目录树的关联
将目录与特定的活动元数据服务器 (MDS) 解除关联。
先决条件
- 用户访问 Ceph 文件系统 (CephFS) 客户端节点.
-
确保在客户端节点上安装了
attr软件包并带有一个挂载的 CephFS。
流程
在目录中将
ceph.dir.pin扩展属性设置为 -1:语法
setfattr -n ceph.dir.pin -v -1 DIRECTORY示例
[user@client ~]$ serfattr -n ceph.dir.pin -v -1 /home/ceph-user注意任何单独映射的
/home/ceph-user/子目录均不受影响。
其它资源
- 如需了解更多详细信息,请参阅 Red Hat Ceph Storage 文件系统指南中的映射目录类别到 MDS 等级小节。
4.6. 添加数据池
Ceph 文件系统 (CephFS) 支持添加多个池来存储数据。这对以下情况非常有用:
- 在减少的冗余池中存储日志数据
- 在 SSD 或 NVMe 池中存储用户主目录
- 基本数据分隔。
在 Ceph 文件系统中使用另一个数据池之前,您必须添加它,如本节所述。
默认情况下,CephFS 使用创建期间指定的初始数据池来存储文件数据。要使用辅助数据池,还必须配置文件系统层次结构的一部分,以使用文件和目录布局将该池中或选择性地存储在该池的命名空间内存储文件数据。
先决条件
- Ceph 监控节点的根级别访问权限.
流程
创建新数据池:
语法
ceph osd pool create POOL_NAME PG_NUMBER替换:
-
POOL_NAME,池的名称。 -
PG_NUMBER,PG 数量。
示例
[root@mon ~]# ceph osd pool create cephfs_data_ssd 64 pool 'cephfs_data_ssd' created-
在元数据服务器控制下添加新创建的池:
语法
ceph fs add_data_pool FS_NAME POOL_NAME替换:
-
FS_NAME,文件系统的名称. -
POOL_NAME,池的名称。
例如:
[root@mon ~]# ceph fs add_data_pool cephfs cephfs_data_ssd added data pool 6 to fsmap-
验证池是否已成功添加:
示例
[root@mon ~]# ceph fs ls name: cephfs, metadata pool: cephfs_metadata, data pools: [cephfs_data cephfs_data_ssd]-
如果使用
cephx身份验证,请确保客户端可以访问新的池。
其它资源
- 有关详细信息,请参阅使用文件和目录面板。
- 详情请参阅 创建 Ceph 文件系统客户端用户。
4.7. 使用 Ceph 文件系统配额
作为存储管理员,您可以查看、设置和删除文件系统中任何目录的配额。您可以在 目录中对字节数或文件数施加配额限制。
4.7.1. 先决条件
-
确保已安装了
attr软件包。
4.7.2. Ceph 文件系统配额
Ceph 文件系统 (CephFS) 配额允许您限制存储在目录结构中的字节数或文件数。
限制
- CephFS 配额依赖于客户端挂载文件系统,从而在达到配置的限制时停止写入数据。但是,仅使用配额并不能阻止对立的、不受信任的客户端填充文件系统。
- 当向文件系统写入数据的进程达到配置的限制后,在数据量达到配额限制和进程停止写入数据之间相隔短暂的时间。时间段通常以秒为单位测量。但是,在该时间内,进程会继续写入数据。进程写入的额外数据量取决于进程停止前经过的时间量。
-
在以前的版本中,配额只支持用户空间 FUSE 客户端。对于 Linux 内核版本 4.17 或更高版本,CephFS 内核客户端支持针对 Ceph 模拟或更新集群的配额。Red Hat Enterprise Linux 8 和 Red Hat Ceph Storage 4 分别满足了这些版本要求。用户空间 FUSE 客户端可用于较旧、较新的操作系统和集群版本。FUSE 客户端由
ceph-fuse软件包提供。 -
在使用基于路径的访问限制时,请确保在限制客户端的目录或嵌套在它下的目录上配置配额。如果客户端的访问权限受限于基于 MDS 能力的特定路径,并且配额是在客户端无法访问的上级目录中配置的,则客户端不会强制实施配额。例如,如果客户端无法访问
/home/目录,且在/home/上配置了配额,客户端就无法强制设置目录/home/user/目录的配额。 - 已删除或更改的快照文件数据不会计算配额数。
4.7.3. 查看配额
使用 getfattr 命令和 ceph.quota 扩展属性来查看目录的配额设置。
如果属性出现在目录索引节点中,则该目录具有配置的配额。如果索引节点中未显示这些属性,则该目录没有设置配额,尽管其父目录可能已配置了配额。如果扩展属性的值为 0,则不设置配额。
先决条件
-
确保已安装了
attr软件包。
流程
查看 CephFS 配额:
使用字节限制配额:
语法
getfattr -n ceph.quota.max_bytes DIRECTORY示例
[root@fs ~]# getfattr -n ceph.quota.max_bytes /cephfs/使用 file-limit 配额:
语法
getfattr -n ceph.quota.max_files DIRECTORY示例
[root@fs ~]# getfattr -n ceph.quota.max_files /cephfs/
其它资源
-
如需更多信息,请参阅
getfattr(1)手册页。
4.7.4. 设置配额
本节介绍如何使用 setfattr 命令和 ceph.quota 扩展属性为目录设置配额。
先决条件
-
确保已安装了
attr软件包。
流程
设置 CephFS 配额的步骤:
使用字节限制配额:
语法
setfattr -n ceph.quota.max_bytes -v 100000000 /some/dir示例
[root@fs ~]# setfattr -n ceph.quota.max_bytes -v 100000000 /cephfs/在本例中,100000000 字节等于 100 MB。
使用 file-limit 配额:
语法
setfattr -n ceph.quota.max_files -v 10000 /some/dir示例
[root@fs ~]# setfattr -n ceph.quota.max_files -v 10000 /cephfs/在本例中,10000 等于 10,000 个文件。
其它资源
-
如需更多信息,请参阅
setfattr(1)手册页。
4.7.5. 删除配额
本节介绍如何使用 setfattr 命令和 ceph.quota 扩展属性从目录中移除配额。
先决条件
-
确保已安装了
attr软件包。
流程
移除 CephFS 配额:
使用字节限制配额:
语法
setfattr -n ceph.quota.max_bytes -v 0 DIRECTORY示例
[root@fs ~]# setfattr -n ceph.quota.max_bytes -v 0 /cephfs/使用 file-limit 配额:
语法
setfattr -n ceph.quota.max_files -v 0 DIRECTORY示例
[root@fs ~]# setfattr -n ceph.quota.max_files -v 0 /cephfs/
其它资源
-
如需更多信息,请参阅
setfattr(1)手册页。
4.7.6. 其它资源
-
如需更多信息,请参阅
getfattr(1)手册页。 -
如需更多信息,请参阅
setfattr(1)手册页。
4.8. 使用文件和目录
作为存储管理员,您可以控制文件或目录数据如何映射到对象。
本节描述了如何:
4.8.1. 先决条件
-
安装
attr软件包。
4.8.2. 文件和目录布局概述
本节介绍 Ceph 文件系统上下文中的文件和目录布局。
文件或目录的布局控制其内容如何映射到 Ceph RADOS 对象。目录布局主要用于为该目录中的新文件设置继承布局。
要查看和设置文件或目录布局,请使用虚拟扩展属性或扩展文件属性 (xattrs)。布局属性的名称取决于文件是常规文件还是目录:
-
常规文件布局属性称为
ceph.file.layout。 -
目录布局属性称为
ceph.dir.layout。
File and Directory Layout 字段 列出了您可以在文件和目录上设置的可用布局字段。
布局继承
在创建文件时,文件会继承其父目录的布局。但是,随后对父目录布局的更改不会影响子级。如果目录没有设置任何布局,文件将使用目录结构中的布局从最接近的目录继承布局。
其它资源
- 详情请查看 Layouts Inheritance。
4.8.3. 设置文件和目录布局字段
使用 setfattr 命令设置文件或目录上的布局字段。
当您修改文件的布局字段时,该文件必须为空,否则会出现错误。
先决条件
- 节点的根级别访问权限。
流程
修改文件或目录中的布局字段:
语法
setfattr -n ceph.TYPE.layout.FIELD -v VALUE PATH替换:
-
TYPE,
file或dir。 - FIELD,字段的名称。
- VALUE,字段的新值 。
- 带有到文件或目录路径的 PATH。
示例
[root@fs ~]# setfattr -n ceph.file.layout.stripe_unit -v 1048576 test-
TYPE,
其它资源
- 如需了解更多详细信息,请参见 Red Hat Ceph Storage 的文件和目录布局概述部分中的表格。
-
请参阅
setfattr(1)手册页。
4.8.4. 查看文件和目录布局字段
要使用 getfattr 命令查看文件或目录的布局字段:
先决条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
- 对存储集群中所有节点的根级别访问权限。
流程
以单一字符串形式查看文件或目录中的布局字段:
语法
getfattr -n ceph.TYPE.layout PATH- 替换
- 带有到文件或目录路径的 PATH。
-
TYPE,
file或dir。
示例
[root@mon ~] getfattr -n ceph.dir.layout /home/test ceph.dir.layout="stripe_unit=4194304 stripe_count=2 object_size=4194304 pool=cephfs_data"
在设置目录之前,该目录不具有明确的布局。因此,尝试在没有首先设置的情况下查看布局会失败,因为没有更改。
其它资源
-
getfattr(1)手册页面。 - 有关更多信息,请参阅 Red Hat Ceph Storage 文件系统指南中的设置文件和目录布局字段 部分。
4.8.5. 查看单个布局字段
使用 getfattr 命令查看文件或目录的个别布局字段。
先决条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
- 对存储集群中所有节点的根级别访问权限。
流程
查看文件或目录中的单个布局字段:
语法
getfattr -n ceph.TYPE.layout.FIELD _PATH- 替换
-
TYPE,
file或dir。 - FIELD,字段的名称。
- 带有到文件或目录路径的 PATH。
-
TYPE,
示例
[root@mon ~] getfattr -n ceph.file.layout.pool test ceph.file.layout.pool="cephfs_data"注意pool字段中的池按照名称来指示。不过,新建的池可以通过 ID 来指示。
其它资源
-
getfattr(1)手册页面。 - 如需更多信息,请参阅文件和目录布局字段。
4.8.6. 删除目录布局
使用 setfattr 命令从目录中移除布局。
设置文件布局时,您无法更改或删除该文件。
先决条件
- 具有布局的目录。
流程
从目录中删除布局:
语法
setfattr -x ceph.dir.layout DIRECTORY_PATH示例
[user@client ~]$ setfattr -x ceph.dir.layout /home/cephfs删除
pool_namespace字段:语法
setfattr -x ceph.dir.layout.pool_namespace DIRECTORY_PATH示例
[user@client ~]$ setfattr -x ceph.dir.layout.pool_namespace /home/cephfs注意pool_namespace字段是唯一可以单独删除的字段。
其它资源
-
setfattr(1)手册页
4.9. Ceph 文件系统快照注意事项
作为存储管理员,您可以了解管理 Ceph 文件系统(CephFS)快照的数据结构、系统组件和注意事项。
快照在创建时会创建文件系统的不可变视图。您可以在任何目录中创建快照,并且覆盖该目录下文件系统中的所有数据。
4.9.1. 为 Ceph 文件系统存储快照元数据
快照目录条目的存储及其内节点位于快照时位于的目录的一部分。所有目录条目都包括其有效的第一个和最后一个 snapid。
4.9.2. Ceph 文件系统快照写入
Ceph 快照依赖于客户端,以帮助确定哪些操作应用到快照,并将快照数据和元数据返回至 OSD 和 MDS 集群。处理快照回写的过程是涉及的过程,因为快照适用于文件层次结构的子树,并且可以随时创建快照。
属于同一组快照的文件层次结构部分由单个 SnapRealm 指代。每个快照都适用于嵌套在目录下的子目录,并将文件层次结构分成多个"realms",其中 realm 包含的所有文件共享同一组快照。
Ceph 元数据服务器(MDS)通过为每个内节点提供功能(cap)来控制对内节点元数据和文件数据的客户端访问。在快照创建过程中,客户端在内节点上获取脏元数据,它们有能力描述该文件在该时间的状态。当客户端收到 ClientSnap 消息时,它会更新本地 SnapRealm 及其到特定内节点的链接,并为内节点生成 CapSnap。功能回写出 ,如果脏数据存在,则 CapSnap 用于在快照清除 OSD 前阻止新数据写入。
CapSnap
MDS 生成快照存在的目录条目,作为清除它们的日常进程的一部分。MDS 将目录条目保留在内存中固定有未完成的 CapSnap 数据,直到写回进程清除它们。
4.9.3. Ceph 文件系统快照和硬链接
Ceph 将具有多个硬链接的内节点移动到 dummy 全局 SnapRealm。这个 dummy SnapRealm 涵盖了文件系统中的所有快照。任何新快照都会保留内节点的数据。保留的数据涵盖了任何索引节点链接上的快照。
4.9.4. 为 Ceph 文件系统更新快照
更新快照的过程与删除快照的过程类似。
如果您从其父 SnapRealm 中删除内节点,如果 SnapRealm 不存在,Ceph 会为重命名的内节点生成一个新的 SnapRealm。Ceph 将原始父 SnapRealm 上有效的快照 ID 保存到新 SnapRealm 的 past_parent_snaps 数据结构,然后遵循与创建快照类似的进程。
4.9.5. Ceph 文件系统快照和多个文件系统
快照已知无法与多个文件系统正常工作。
如果您有多个文件系统与命名空间共享一个 Ceph 池,则快照将冲突,并删除一个快照会导致共享同一 Ceph 池的其他快照缺少文件数据。
4.9.6. Ceph 文件系统快照数据结构
Ceph 文件系统(CephFS)使用以下快照数据结构来有效地存储数据:
SnapRealm-
每当您在文件层次结构中的新点创建快照时,都会创建一个
SnapRealm,或者在将快照的索引节点移出其父快照快照时创建。单个SnapRealm代表文件层次结构的部分,它们属于同一组快照。SnapRealm包括了一个作为快照一部分的sr_t_srnode和inodes_with_caps。 sr_t-
sr_t是磁盘快照元数据。它包含序列计数器、时间戳以及关联的快照 ID 列表和past_parent_snaps。 SnapServer-
SnapServer管理快照 ID 分配、快照删除,以及维护文件系统中累积快照的列表。文件系统只有一个SnapServer实例。 SnapContextSnapContext由快照序列 ID(snapid)和当前为对象定义的所有快照 ID 组成。发生写入操作时,Ceph 客户端会提供SnapContext,以指定对象存在的快照集合。为生成SnapContext列表,Ceph 会将与SnapRealm关联的 snapids 和past_parent_snaps数据结构中的所有有效的 snapids 合并。文件数据通过 RADOS 自我管理的快照存储。在自我管理的快照中,客户端必须为每个写入提供当前的
SnapContext。在向 Ceph OSD 写入文件数据时,客户端要小心地使用正确的SnapContext。SnapClient缓存有效快照过滤掉过时的 snapids。SnapClient-
SnapClient用于与SnapServer和缓存累积快照在本地通信。每个元数据服务器(MDS)等级都有一个SnapClient实例。
4.10. 管理 Ceph 文件系统快照
作为存储管理员,您可以获取 Ceph 文件系统(CephFS)目录的时间点快照。CephFS 快照是异步的,您可以选择进行哪个目录快照创建。
4.10.1. 先决条件
- 正在运行的、健康的 Red Hat Ceph Storage 集群。
- 部署 Ceph 文件系统.
4.10.2. Ceph 文件系统快照
Ceph 文件系统(CephFS)快照创建 Ceph 文件系统的不可变时点视图。CephFS 快照是异步的,并保存在 CephFS 目录中一个名为 .snap 的特殊隐藏目录中。您可以为 Ceph 文件系统中的任何目录指定快照创建。在指定目录时,快照还包含其下的所有子目录。
每个 Ceph 元数据服务器(MDS)集群独立分配 snap 标识符。对共享一个池的多个 Ceph 文件系统使用快照会导致快照冲突,并导致缺少文件数据。
4.10.3. 为 Ceph 文件系统启用快照
新的 Ceph 文件系统会默认启用快照功能,但您必须在现有的 Ceph 文件系统上手动启用此功能。
先决条件
- 正在运行的、健康的 Red Hat Ceph Storage 集群。
- 部署 Ceph 文件系统.
- 对 Ceph 元数据服务器(MDS)节点的根级访问。
流程
对于现有的 Ceph 文件系统,启用快照功能:
语法
ceph fs set FILE_SYSTEM_NAME allow_new_snaps true示例
[root@mds ~]# ceph fs set cephfs allow_new_snaps true enabled new snapshots
4.10.4. 为 Ceph 文件系统创建快照
您可以通过创建快照来创建 Ceph 文件系统的不可变、时间点视图。快照使用位于快照的目录中的隐藏目录。这个目录的名称默认为 .snap。
先决条件
- 正在运行的、健康的 Red Hat Ceph Storage 集群。
- 部署 Ceph 文件系统.
- 对 Ceph 元数据服务器(MDS)节点的根级访问。
流程
若要创建快照,请在
.snap目录内创建一个新的子目录。快照名称是新子目录名称。语法
mkdir NEW_DIRECTORY_PATH示例
[root@mds cephfs]# mkdir .snap/new-snaps本例在 Ceph 文件系统上创建
new-snaps子目录,该子目录挂载到/mnt/cephfs上,并通知 Ceph 元数据服务器(MDS)开始进行快照。
验证
列出新快照目录:
语法
ls -l .snap/new-snaps子目录显示在.snap目录下。
4.10.5. 删除 Ceph 文件系统的快照
您可以通过在 .snap 目录中删除对应的目录来删除快照。
先决条件
- 正在运行的、健康的 Red Hat Ceph Storage 集群。
- 部署 Ceph 文件系统.
- 在 Ceph 文件系统上创建快照。
- 对 Ceph 元数据服务器(MDS)节点的根级访问。
流程
要删除快照,请删除对应的目录:
语法
rmdir DIRECTORY_PATH示例
[root@mds cephfs]# rmdir .snap/new-snaps这个示例删除挂载到
/mnt/cephfs上的 Ceph 文件系统上的new-snaps子目录。
与常规目录不同,rmdir 命令也会成功,即使目录不为空,您不需要使用递归 rm 命令。
尝试删除可能包含底层快照的根级快照将失败。
4.10.6. 为 Ceph 文件系统恢复快照
您可以从快照恢复文件,或者完全恢复 Ceph 文件系统(CephFS)的完整快照。
先决条件
- 一个运行良好、健康的 Red Hat Ceph Storage 集群。
- 部署 Ceph 文件系统.
- 对 Ceph 元数据服务器(MDS)节点的根级访问。
流程
要从快照中恢复文件,将其从快照目录复制到常规树中:
语法
cp -a .snap/SNAP_DIRECTORY/FILENAME示例
[root@mds dir1]# cp .snap/new-snaps/file1 .这个示例将
file1恢复到当前目录。您还可以从
.snap目录树中完全恢复快照。使用所需快照中的副本替换当前条目:语法
[root@mds dir1]# rm -rf * [root@mds dir1]# cp -a .snap/SNAP_DIRECTORY/* .示例
[root@mds dir1]# rm -rf * [root@mds dir1]# cp -a .snap/new-snaps/* .这个示例删除
dir1下的所有文件和目录,并将文件从new-snaps快照恢复到当前目录dir1。
4.11. 关闭 Ceph 文件系统集群
您可以通过设置 down 标志 true 来关闭 Ceph 文件系统 (CephFS) 集群。执行此操作将通过清空日志到元数据池并停止所有客户端 I/O,正常关闭元数据服务器 (MDS) 守护进程。
您还可以快速关闭 CephFS 集群来测试文件系统的删除,并使元数据服务器 (MDS) 守护进程停机,例如练习灾难恢复方案。这样做可设置 jointable 标志,以防止 MDS 备用守护进程激活文件系统。
先决条件
- 用户访问 Ceph 监控节点.
流程
将 CephFS 集群标记为 down:
语法
ceph fs set FS_NAME down true示例
[root@mon]# ceph fs set cephfs down true使用 CephFS 集群备份:
语法
ceph fs set FS_NAME down false示例
[root@mon]# ceph fs set cephfs down false
或者
快速关闭 CephFS 集群:
语法
ceph fs fail FS_NAME示例
[root@mon]# ceph fs fail cephfs
4.12. 使用命令行界面删除 Ceph 文件系统
您可以使用命令行界面删除 Ceph 文件系统(CephFS)。在进行此操作前,请考虑备份所有数据并验证所有客户端是否已在本地卸载该文件系统。
此操作具有破坏性,将使 Ceph 文件系统上存储的数据永久无法访问。
先决条件
- 备份数据。
- 所有客户端都已卸载 Ceph 文件系统(CephFS)。
- Ceph 监控节点的根级别访问权限.
流程
显示 CephFS 状态以确定 MDS 等级。
语法
ceph fs status示例
[root@mon ~]# ceph fs status cephfs - 0 clients ====== +------+--------+----------------+---------------+-------+-------+ | Rank | State | MDS | Activity | dns | inos | +------+--------+----------------+---------------+-------+-------+ | 0 | active | cluster1-node6 | Reqs: 0 /s | 10 | 13 | +------+--------+----------------+---------------+-------+-------+ +-----------------+----------+-------+-------+ | Pool | type | used | avail | +-----------------+----------+-------+-------+ | cephfs_metadata | metadata | 2688k | 15.0G | | cephfs_data | data | 0 | 15.0G | +-----------------+----------+-------+-------+ +----------------+ | Standby MDS | +----------------+ | cluster1-node5 | +----------------+在上例中,排名是 0。
将 CephFS 标记为 down:
语法
ceph fs set FS_NAME down true将 FS_NAME 替换为您要删除的 CephFS 的名称。
示例
[root@mon]# ceph fs set cephfs down true marked down显示 CephFS 的状态以确定它已停止:
语法
ceph fs status示例
[root@mon ~]# ceph fs status cephfs - 0 clients ====== +------+----------+----------------+----------+-------+-------+ | Rank | State | MDS | Activity | dns | inos | +------+----------+----------------+----------+-------+-------+ | 0 | stopping | cluster1-node6 | | 10 | 12 | +------+----------+----------------+----------+-------+-------+ +-----------------+----------+-------+-------+ | Pool | type | used | avail | +-----------------+----------+-------+-------+ | cephfs_metadata | metadata | 2688k | 15.0G | | cephfs_data | data | 0 | 15.0G | +-----------------+----------+-------+-------+ +----------------+ | Standby MDS | +----------------+ | cluster1-node5 | +----------------+在一段时间后,MDS 不再列出:
示例
[root@mon ~]# ceph fs status cephfs - 0 clients ====== +------+-------+-----+----------+-----+------+ | Rank | State | MDS | Activity | dns | inos | +------+-------+-----+----------+-----+------+ +------+-------+-----+----------+-----+------+ +-----------------+----------+-------+-------+ | Pool | type | used | avail | +-----------------+----------+-------+-------+ | cephfs_metadata | metadata | 2688k | 15.0G | | cephfs_data | data | 0 | 15.0G | +-----------------+----------+-------+-------+ +----------------+ | Standby MDS | +----------------+ | cluster1-node5 | +----------------+失败在第 1 步的状态中显示的所有 MDS 等级:
语法
ceph mds fail RANK将 RANK 替换为 MDS 守护进程的等级失败。
示例
[root@mon]# ceph mds fail 0移除 CephFS:
语法
ceph fs rm FS_NAME --yes-i-really-mean-it将 FS_NAME 替换为您要删除的 Ceph 文件系统的名称。
示例
[root@mon]# ceph fs rm cephfs --yes-i-really-mean-it验证文件系统是否已删除:
语法
ceph fs ls示例
[root@mon ~]# ceph fs ls No filesystems enabled可选:删除 CephFS 使用的池。
在 Ceph 监控节点上,列出池:
语法
ceph osd pool ls示例
[root@mon ~]# ceph osd pool ls rbd cephfs_data cephfs_metadata在示例输出中,
cephfs_metadata和cephfs_data是 CephFS 使用的池。删除元数据池:
语法
ceph osd pool delete CEPH_METADATA_POOL CEPH_METADATA_POOL --yes-i-really-really-mean-it通过包含池名称两次,将 CEPH_METADATA_POOL 替换为用于元数据存储的池 CephFS。
示例
[root@mon ~]# ceph osd pool delete cephfs_metadata cephfs_metadata --yes-i-really-really-mean-it pool 'cephfs_metadata' removed删除数据池:
语法
ceph osd pool delete CEPH_DATA_POOL CEPH_DATA_POOL --yes-i-really-really-mean-it通过包含池名称两次,将 CEPH_DATA_POOL 替换为用于数据存储的池 CephFS。
示例
[root@mon ~]# ceph osd pool delete cephfs_data cephfs_data --yes-i-really-really-mean-it pool 'cephfs_data' removed
4.13. 使用 Ansible 删除 Ceph 文件系统
您可以使用 ceph-ansible 删除 Ceph 文件系统(CephFS)。在进行此操作前,请考虑备份所有数据并验证所有客户端是否已在本地卸载该文件系统。
此操作具有破坏性,将使 Ceph 文件系统上存储的数据永久无法访问。
先决条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
- 数据的良好备份。
- 所有客户端都已卸载 Ceph 文件系统。
- 访问 Ansible 管理节点.
- Ceph 监控节点的根级别访问权限.
流程
进入
/usr/share/ceph-ansible/目录:[admin@admin ~]$ cd /usr/share/ceph-ansible通过查看 Ansible 清单文件中的
[mds]部分来识别 Ceph 元数据服务器(MDS)节点。在 Ansible 管理节点上,打开/usr/share/ceph-ansible/hosts:示例
[mdss] cluster1-node5 cluster1-node6在示例中,
cluster1-node5和cluster1-node6是 MDS 节点。将
max_mds参数设置为1:语法
ceph fs set NAME max_mds NUMBER示例
[root@mon ~]# ceph fs set cephfs max_mds 1运行
shrink-mds.ymlplaybook,指定要删除的元数据服务器(MDS):语法
ansible-playbook infrastructure-playbooks/shrink-mds.yml -e mds_to_kill=MDS_NODE -i hosts将 MDS_NODE 替换为您要删除的元数据服务器节点。Ansible playbook 将询问您是否要缩小集群。键入
yes,然后按 enter 键。示例
[admin@admin ceph-ansible]$ ansible-playbook infrastructure-playbooks/shrink-mds.yml -e mds_to_kill=cluster1-node6 -i hosts可选:重复任何额外 MDS 节点的进程:
语法
ansible-playbook infrastructure-playbooks/shrink-mds.yml -e mds_to_kill=MDS_NODE -i hosts将 MDS_NODE 替换为您要删除的元数据服务器节点。Ansible playbook 将询问您是否要缩小集群。键入
yes,然后按 enter 键。示例
[admin@admin ceph-ansible]$ ansible-playbook infrastructure-playbooks/shrink-mds.yml -e mds_to_kill=cluster1-node5 -i hosts检查 CephFS 的状态:
语法
ceph fs status示例
[root@mon ~]# ceph fs status cephfs - 0 clients ====== +------+--------+----------------+---------------+-------+-------+ | Rank | State | MDS | Activity | dns | inos | +------+--------+----------------+---------------+-------+-------+ | 0 | failed | cluster1-node6 | Reqs: 0 /s | 10 | 13 | +------+--------+----------------+---------------+-------+-------+ +-----------------+----------+-------+-------+ | Pool | type | used | avail | +-----------------+----------+-------+-------+ | cephfs_metadata | metadata | 2688k | 15.0G | | cephfs_data | data | 0 | 15.0G | +-----------------+----------+-------+-------+ +----------------+ | Standby MDS | +----------------+ | cluster1-node5 | +----------------+从 Ansible 清单文件中删除
[mdss]部分及其节点,以便它们不会重新置备为以后在site.yml或site-container.ymlplaybook 上运行的元数据服务器。打开以编辑 Ansible 清单文件/usr/share/ceph-ansible/hosts:示例
[mdss] cluster1-node5 cluster1-node6删除
[mdss]部分及其下所有节点。移除 CephFS:
语法
ceph fs rm FS_NAME --yes-i-really-mean-it将 FS_NAME 替换为您要删除的 Ceph 文件系统的名称。
示例
[root@mon]# ceph fs rm cephfs --yes-i-really-mean-it可选:删除 CephFS 使用的池。
在 Ceph 监控节点上,列出池:
语法
ceph osd pool ls查找 CephFS 使用的池。
示例
[root@mon ~]# ceph osd pool ls rbd cephfs_data cephfs_metadata在示例输出中,
cephfs_metadata和cephfs_data是 CephFS 使用的池。删除元数据池:
语法
ceph osd pool delete CEPH_METADATA_POOL CEPH_METADATA_POOL --yes-i-really-really-mean-it通过包含池名称两次,将 CEPH_METADATA_POOL 替换为用于元数据存储的池 CephFS。
示例
[root@mon ~]# ceph osd pool delete cephfs_metadata cephfs_metadata --yes-i-really-really-mean-it pool 'cephfs_metadata' removed删除数据池:
语法
ceph osd pool delete CEPH_DATA_POOL CEPH_DATA_POOL --yes-i-really-really-mean-it通过包含池名称两次,将 CEPH_METADATA_POOL 替换为用于元数据存储的池 CephFS。
示例
[root@mon ~]# ceph osd pool delete cephfs_data cephfs_data --yes-i-really-really-mean-it pool 'cephfs_data' removed验证池不再存在:
示例
[root@mon ~]# ceph osd pool ls rbdcephfs_metadata和cephfs_data池不再被列出。
4.14. 设置最低客户端版本
您可以设置第三方客户端必须运行的 Ceph 的最低版本,才能连接到 Red Hat Ceph Storage 文件系统 (CephFS)。设置 min_compat_client 参数,以防止旧客户端挂载文件系统。CephFS 也将自动驱除当前连接的客户端,这些客户端使用的版本早于 min_compat_client 设置的版本。
此设置的理由是防止可能包含错误或功能兼容性不完整的旧客户端连接到集群并破坏其他客户端。例如,一些较旧版本的 CephFS 客户端可能无法正确发布功能,并导致其他客户端请求被缓慢处理。
min_compat_client 的值基于上游 Ceph 版本。红帽建议第三方客户端使用与 Red Hat Ceph Storage 集群相同的主要上游版本。下表列出了上游版本和对应的 Red Hat Ceph Storage 版本。
| 值 | 上游 Ceph 版本 | Red Hat Ceph Storage 版本 |
|---|---|---|
| luminous | 12.2 | Red Hat Ceph Storage 3 |
| mimic | 13.2 | 不适用 |
| nautilus | 14.2 | Red Hat Ceph Storage 4 |
如果使用 Red Hat Enterprise Linux 7,请不要将 min_compat_client 设置为 luminous 的更新版本,因为 Red Hat Enterprise Linux 7 被视为简洁的客户端,如果您使用更新的版本,CephFS 不允许它访问挂载点。
先决条件
- 部署了 Ceph 文件系统的 Red Hat Ceph Storage 集群
流程
设置最低客户端版本:
ceph fs set name min_compat_client release使用 Ceph 文件系统的名称替换 name,并将 release 替换为最低客户端版本。例如,将客户端限制为至少使用
cephfsCeph 文件系统上的nautilus上游版本:$ ceph fs set cephfs min_compat_client nautilus有关可用值的完整列表以及它们如何与 Red Hat Ceph Storage 版本对应,请参阅 表 4.1 “
min_compat_client值”。
4.15. 使用 ceph mds fail 命令
使用 ceph mds fail 命令:
-
将 MDS 守护进程标记为失败。如果守护进程活跃,且有合适的备用守护进程可用,如果在禁用
standby-replay配置后待机守护进程处于活动状态,则使用这个命令会强制切换到待机守护进程。通过禁用standby-replay守护进程,这会防止分配新的standby-replay守护进程。 - 重新启动正在运行的 MDS 守护进程。如果后台程序处于活动状态且有合适的备用后台程序可用,"失败"后台程序将变为备用后台程序。
先决条件
- 安装和配置 Ceph MDS 守护进程.
流程
守护进程失败:
语法
ceph mds fail MDS_NAME其中 MDS_NAME 是
standby-replayMDS 节点的名称。示例
[root@mds ~]# ceph mds fail example01注意您可以从
ceph fs status命令找到 Ceph MDS 名称。
其它资源
- 如需了解更多详细信息,请参阅 Red Hat Ceph Storage File System Guide 中的 Decreasing the Number of Active MDS Daemons 部分。
- 请参阅 Red Hat Ceph Storage 文件系统指南中的配置静态元数据服务器守护进程。
- 请参阅 Red Hat Ceph Storage 文件系统指南中的元数据服务器配置说明。
4.16. Ceph 文件系统客户端驱除
当 Ceph 文件系统 (CephFS) 客户端不响应或行为不当时,可能需要强制终止或驱逐它访问 CephFS。驱除 CephFS 客户端会阻止它进一步与元数据服务器 (MDS) 守护进程和 Ceph OSD 守护进程通信。如果 CephFS 客户端在驱除时将 I/O 缓冲到 CephFS,则任何未清空的数据都将丢失。CephFS 客户端驱除过程适用于所有客户端类型:FUSE 挂载、内核挂载、NFS 网关,以及使用 libcephfs API 库的任何进程。
如果 CephFS 客户端无法及时与 MDS 守护进程通信或手动通信,您可以自动驱除 CephFS 客户端。
自动客户端驱除
这些场景导致自动 CephFS 客户端驱除:
-
如果 CephFS 客户端在默认的 300 秒内未与活动 MDS 守护进程通信,或者与
session_autoclose选项所设置的 MDS 守护进程通信。 -
如果设置了
mds_cap_revoke_eviction_timeout选项,并且 CephFS 客户端没有在设定的秒数内响应最大撤销的消息。默认情况下禁用mds_cap_revoke_eviction_timeout选项。 -
在 MDS 启动或故障转移期间,MDS 守护进程经过一个重新连接阶段,等待所有 CephFS 客户端连接到新的 MDS 守护进程。如果有任何 CephFS 客户端无法在默认时间窗内重新连接 45 秒,或由
mds_reconnect_timeout选项设置。
其它资源
- 如需了解更多详细信息,请参阅 Red Hat Ceph Storage File System Guide 中的 Manually evicting a Ceph File System client 部分。
4.17. 将 Ceph 文件系统客户端列入黑名单
Ceph 文件系统客户端列入黑名单是默认启用的。当您向单个元数据服务器 (MDS) 守护进程发送驱除命令时,它会将黑名单传播到其他 MDS 守护进程。这是为了防止 CephFS 客户端访问任何数据对象,因此需要更新其他 CephFS 客户端,并且使用最新的 Ceph OSD map(包含黑名单的客户端条目)更新 MDS 守护进程。
在更新 Ceph OSD map 时,使用内部"osdmap epoch 障碍"机制。障碍的目的是验证接受功能的 CephFS 客户端具有足够最新的 Ceph OSD map,然后分配任何允许访问同一 RADOS 对象的功能,以免对已取消的操作(如 ENOSPC 或来自驱除的客户端列入黑名单)争用。
如果您由于节点缓慢或网络不可靠而频繁遇到 CephFS 客户端驱除,并且您无法修复底层问题,则您可以要求 MDS 不太严格。可以通过丢弃 MDS 会话来响应缓慢的 CephFS 客户端,但允许 CephFS 客户端重新打开会话并继续与 Ceph OSD 交互。通过将 mds_session_blacklist_on_timeout 和 mds_session_blacklist_on_evict 选项设置为 false 来启用此模式。
禁用黑名单后,被驱除的 CephFS 客户端仅对您向其发送 命令的 MDS 守护进程产生影响。在具有多个活跃 MDS 守护进程的系统上,您需要向每个活跃的守护进程发送驱除命令。
4.18. 手动驱除 Ceph 文件系统客户端
如果客户端的行为不当,且您无法访问客户端节点,或者客户端出现故障,并且您不希望等待客户端会话超时,您可能希望手动驱除 Ceph 文件系统 (CephFS) 客户端。
先决条件
- 用户访问 Ceph 监控节点.
流程
查看客户端列表:
语法
ceph tell DAEMON_NAME client ls示例
[root@mon]# ceph tell mds.0 client ls [ { "id": 4305, "num_leases": 0, "num_caps": 3, "state": "open", "replay_requests": 0, "completed_requests": 0, "reconnecting": false, "inst": "client.4305 172.21.9.34:0/422650892", "client_metadata": { "ceph_sha1": "ae81e49d369875ac8b569ff3e3c456a31b8f3af5", "ceph_version": "ceph version 12.0.0-1934-gae81e49 (ae81e49d369875ac8b569ff3e3c456a31b8f3af5)", "entity_id": "0", "hostname": "senta04", "mount_point": "/tmp/tmpcMpF1b/mnt.0", "pid": "29377", "root": "/" } } ]驱除指定的 CephFS 客户端:
语法
ceph tell DAEMON_NAME client evict id=ID_NUMBER示例
[root@mon]# ceph tell mds.0 client evict id=4305
4.19. 从黑名单中删除 Ceph 文件系统客户端
在某些情况下,允许之前列入黑名单的 Ceph 文件系统 (CephFS) 客户端重新连接到存储集群非常有用。
从黑名单中删除 CephFS 客户端会使数据完整性面临风险,也无法保证完全正常运行的 CephFS 客户端。在驱除后重新获取完全健康的 CephFS 客户端的最佳方法是卸载 CephFS 客户端并执行全新的挂载。如果其他 CephFS 客户端正在访问列入黑名单的 CephFS 客户端正在执行缓冲的 I/O 的文件,可能会导致数据崩溃。
先决条件
- 用户访问 Ceph 监控节点.
流程
查看黑名单:
示例
[root@mon]# ceph osd blacklist ls listed 1 entries 127.0.0.1:0/3710147553 2020-03-19 11:32:24.716146从黑名单中删除 CephFS 客户端:
语法
ceph osd blacklist rm CLIENT_NAME_OR_IP_ADDR示例
[root@mon]# ceph osd blacklist rm 127.0.0.1:0/3710147553 un-blacklisting 127.0.0.1:0/3710147553若要让基于 FUSE 的 CephFS 客户端在从黑名单中移除时自动重新连接,可以选择性地将它们自动重新连接。在 FUSE 客户端中,将以下选项设置为
true:client_reconnect_stale = true
4.20. 其它资源
- 详情请查看 第 3 章 Ceph 文件系统的部署。
- 详情请查看 Red Hat Ceph Storage 安装指南。
- 详情请参阅 Red Hat Ceph Storage File System Guide 中的 Configuring Metadata Server Daemons。
第 5 章 管理 Ceph 文件系统卷、子卷和子卷组
作为存储管理员,您可以使用红帽的 Ceph Container Storage Interface (CSI) 管理 Ceph 文件系统 (CephFS) 导出。这也允许您通过具有可与之交互的通用命令行界面来使用 OpenStack 文件系统服务 (Manila) 等其他服务。Ceph 管理器守护进程 (ceph-mgr) 的 volumes 模块实施导出 Ceph 文件系统 (CephFS) 的功能。
Ceph Manager volumes 模块实施以下文件系统导出抽象:
- CephFS 卷
- CephFS 子卷组
- CephFS 子卷
本章论述了如何使用:
5.1. Ceph 文件系统卷
作为存储管理员,您可以创建、列出和删除 Ceph 文件系统 (CephFS) 卷。CephFS 卷是 Ceph 文件系统的抽象。
本节描述了如何:
5.1.1. 创建文件系统卷
Ceph 管理器的编排器模块为 Ceph 文件系统 (CephFS) 创建一个元数据服务器 (MDS)。本节介绍如何创建 CephFS 卷。
这将创建 Ceph 文件系统,以及数据和元数据池。
先决条件
- 部署的 Ceph 文件系统正常工作的 Red Hat Ceph Storage 存储群集。
- 至少对 Ceph 监控器具有读取访问权限。
- Ceph 管理器节点上的读写功能。
流程
创建 CephFS 卷:
语法
ceph fs volume create VOLUME_NAME示例
[root@mon ~]# ceph fs volume create cephfs
5.1.2. 列出文件系统卷
本节介绍列出 Ceph 文件系统 (CephFS) 卷的步骤。
先决条件
- 部署的 Ceph 文件系统正常工作的 Red Hat Ceph Storage 存储群集。
- 至少对 Ceph 监控器具有读取访问权限。
- Ceph 管理器节点上的读写功能。
- CephFS 卷。
流程
列出 CephFS 卷:
示例
[root@mon ~]# ceph fs volume ls
5.1.3. 删除文件系统卷
Ceph 管理器的编排器模块移除 Ceph 文件系统 (CephFS) 的元数据服务器 (MDS)。本节介绍如何删除 Ceph 文件系统 (CephFS) 卷。
先决条件
- 部署的 Ceph 文件系统正常工作的 Red Hat Ceph Storage 存储群集。
- 至少对 Ceph 监控器具有读取访问权限。
- Ceph 管理器节点上的读写功能。
- CephFS 卷。
流程
移除 CephFS 卷:
语法
ceph fs volume rm VOLUME_NAME [--yes-i-really-mean-it]示例
[root@mon ~]# ceph fs volume rm cephfs --yes-i-really-mean-it
5.2. Ceph 文件系统子卷
作为存储管理员,您可以创建、列出、获取绝对路径、获取元数据,以及移除 Ceph 文件系统 (CephFS) 子卷。
您还可以为 CephFS 子卷授权 Ceph 客户端用户。此外,您也可以创建、列出和删除这些子卷的快照。CephFS 子卷是独立 Ceph 文件系统目录树的抽象。
本节描述了如何:
5.2.1. 创建文件系统子卷
这部分论述了如何创建 Ceph 文件系统 (CephFS) 子卷。
在创建子卷时,您可以指定其子卷组、数据池布局、uid、gid、八进制数字文件模式和大小(以字节为单位)。可以通过指定'--namespace-isolated' 选项,在单独的 RADOS 命名空间中创建子卷。默认情况下,子卷在默认子卷组中创建,使用八进制文件模式 '755'、子卷组的 uid、子卷组 gid、其父目录的数据池布局和无大小限制。
先决条件
- 部署的 Ceph 文件系统正常工作的 Red Hat Ceph Storage 存储群集。
- 至少对 Ceph 监控器具有读取访问权限。
- Ceph 管理器节点上的读写功能。
流程
创建 CephFS 子卷:
语法
ceph fs subvolume create VOLUME_NAME SUBVOLUME_NAME [--size SIZE_IN_BYTES --group_name SUBVOLUME_GROUP_NAME --pool_layout DATA_POOL_NAME --uid _UID --gid GID --mode OCTAL_MODE] [--namespace-isolated]示例
[root@mon ~]# ceph fs subvolume create cephfs sub0 --group_name subgroup0 --namespace-isolated即使子卷已存在,命令也会成功。
5.2.2. 列出文件系统子卷
本节介绍列出 Ceph 文件系统 (CephFS) 子卷的步骤。
先决条件
- 部署的 Ceph 文件系统正常工作的 Red Hat Ceph Storage 存储群集。
- 至少对 Ceph 监控器具有读取访问权限。
- Ceph 管理器节点上的读写功能。
- CephFS 子卷。
流程
列出 CephFS 子卷:
语法
ceph fs subvolume ls VOLUME_NAME [--group_name SUBVOLUME_GROUP_NAME]示例
[root@mon ~]# ceph fs subvolume ls cephfs --group_name subgroup0
5.2.3. 为文件系统子卷授权 Ceph 客户端用户
Red Hat Ceph Storage 集群使用 cephx 进行身份验证,这默认是启用的。要将 cephx 与 Ceph 文件系统(CephFS)子卷搭配使用,请在 Ceph 监控节点上创建具有正确授权功能的用户,并在挂载 Ceph 文件系统的节点中提供其密钥。您可以使用 authorize 命令授权用户访问 CephFS 子卷。
先决条件
- 部署的 CephFS 正常工作的 Red Hat Ceph Storage 集群。
- 至少对 Ceph 监控器具有读取访问权限。
- Ceph 管理器节点上的读写功能。
- 创建了一个 CephFS 卷。
流程
创建 CephFS 子卷:
语法
ceph fs subvolume create VOLUME_NAME SUBVOLUME_NAME [--size SIZE_IN_BYTES --group_name SUBVOLUME_GROUP_NAME --pool_layout DATA_POOL_NAME --uid _UID --gid GID --mode OCTAL_MODE] [--namespace-isolated]示例
[root@mon ~]# ceph fs subvolume create cephfs sub0 --group_name subgroup0 --namespace-isolated即使子卷已存在,命令也会成功。
授权 Ceph 客户端用户,对 CephFS 子卷具有读取或写入访问权限:
语法
ceph fs subvolume authorize VOLUME_NAME SUBVOLUME_NAME AUTH_ID [--group_name=GROUP_NAME] [--access_level=ACCESS_LEVEL]ACCESS_LEVEL可以是r或rw,AUTH_ID是 Ceph 客户端用户,它是一个字符串。示例
[root@mon ~]# ceph fs subvolume authorize cephfs sub0 guest --group_name=subgroup0 --access_level=rw在本例中,"client.guest"被授权访问子卷组
subgroup0中的子卷sub0。
5.2.4. 为文件系统子卷验证 Ceph 客户端用户
您可以使用 deauthorize 命令取消授权用户访问 Ceph 文件系统(CephFS)子卷。
先决条件
- 部署的 Ceph 文件系统正常工作的 Red Hat Ceph Storage 存储群集。
- 至少对 Ceph 监控器具有读取访问权限。
- Ceph 管理器节点上的读写功能。
- 已创建 CephFS 卷和子卷。
- Ceph 客户端用户有权访问 CephFS 子卷。
流程
取消授权 Ceph 客户端用户对 CephFS 子卷的访问权限:
语法
ceph fs subvolume deauthorize VOLUME_NAME SUBVOLUME_NAME AUTH_ID [--group_name=GROUP_NAME]AUTH_ID是 Ceph 客户端用户,它是一个字符串。示例
[root@mon ~]# ceph fs subvolume deauthorize cephfs sub0 guest --group_name=subgroup0在本例中,"client.guest"被取消授权访问子卷组
subgroup0中的子卷sub0。
5.2.5. 列出用于文件系统子卷的 Ceph 客户端用户
您可以使用 authorized_list 命令列出用户对 Ceph 文件系统(CephFS)子卷的访问。
先决条件
- 部署的 Ceph 文件系统正常工作的 Red Hat Ceph Storage 存储群集。
- 至少对 Ceph 监控器具有读取访问权限。
- Ceph 管理器节点上的读写功能。
- 已创建 CephFS 卷和子卷。
- Ceph 客户端用户有权访问 CephFS 子卷。
流程
列出 Ceph 客户端用户对 CephFS 子卷的访问权限:
语法
ceph fs subvolume authorized_list VOLUME_NAME SUBVOLUME_NAME [--group_name=GROUP_NAME]示例
[root@mon ~]# ceph fs subvolume authorized_list cephfs sub0 --group_name=subgroup0 [ { "guest": "rw" } ]
5.2.6. 从文件系统子卷驱除 Ceph 客户端用户
您可以使用基于 _AUTH_ID 和挂载的子卷,使用 evict 命令从 Ceph 文件系统(CephFS)子卷驱除 Ceph 客户端用户。
先决条件
- 部署的 Ceph 文件系统正常工作的 Red Hat Ceph Storage 存储群集。
- 至少对 Ceph 监控器具有读取访问权限。
- Ceph 管理器节点上的读写功能。
- 已创建 CephFS 卷和子卷。
- Ceph 客户端用户有权访问 CephFS 子卷。
流程
从 CephFS 子卷驱除 Ceph 客户端用户:
语法
ceph fs subvolume evict VOLUME_NAME SUBVOLUME_NAME AUTH_ID [--group_name=GROUP_NAME]AUTH_ID是 Ceph 客户端用户,它是一个字符串。示例
[root@mon ~]# ceph fs subvolume evict cephfs sub0 guest --group_name=subgroup0在本例中,'client.guest' 会从子卷组
subgroup0中驱除。
5.2.7. 重新定义文件系统子卷大小
本节介绍调整 Ceph 文件系统 (CephFS) 子卷大小的步骤。
ceph fs subvolume resize 命令使用 new_size 指定的大小来调整子卷配额的大小。--no_shrink 标志可防止子卷缩小到子卷的当前使用大小下方。通过将 new_size 设置为 inf 或 infinite 来将子卷重新设置为一个无限的大小。
先决条件
- 部署的 Ceph 文件系统正常工作的 Red Hat Ceph Storage 存储群集。
- 至少对 Ceph 监控器具有读取访问权限。
- Ceph 管理器节点上的读写功能。
- CephFS 子卷。
流程
重新定义 CephFS 子卷大小:
语法
ceph fs subvolume resize VOLUME_NAME SUBVOLUME_NAME_ NEW_SIZE [--group_name SUBVOLUME_GROUP_NAME] [--no_shrink]示例
[root@mon ~]# ceph fs subvolume resize cephfs sub0 1024000000 --group_name subgroup0 --no_shrink
5.2.8. 获取文件系统子卷的绝对路径
本节介绍如何获取 Ceph 文件系统 (CephFS) 子卷的绝对路径。
先决条件
- 部署的 Ceph 文件系统正常工作的 Red Hat Ceph Storage 存储群集。
- 至少对 Ceph 监控器具有读取访问权限。
- Ceph 管理器节点上的读写功能。
- CephFS 子卷。
流程
获取 CephFS 子卷的绝对路径:
语法
ceph fs subvolume getpath VOLUME_NAME SUBVOLUME_NAME [--group_name SUBVOLUME_GROUP_NAME]示例
[root@mon ~]# ceph fs subvolume getpath cephfs sub0 --group_name subgroup0 /volumes/subgroup0/sub0/c10cc8b8-851d-477f-99f2-1139d944f691
5.2.9. 获取文件系统子卷的元数据
本节介绍如何获取 Ceph 文件系统 (CephFS) 子卷的元数据。
先决条件
- 部署的 Ceph 文件系统正常工作的 Red Hat Ceph Storage 存储群集。
- 至少对 Ceph 监控器具有读取访问权限。
- Ceph 管理器节点上的读写功能。
- CephFS 子卷。
流程
获取 CephFS 子卷的元数据:
语法
ceph fs subvolume info VOLUME_NAME SUBVOLUME_NAME [--group_name SUBVOLUME_GROUP_NAME]示例
[root@mon ~]# ceph fs subvolume info cephfs sub0 --group_name subgroup0输出示例
{ "atime": "2020-09-08 09:27:15", "bytes_pcent": "undefined", "bytes_quota": "infinite", "bytes_used": 0, "created_at": "2020-09-08 09:27:15", "ctime": "2020-09-08 09:27:15", "data_pool": "cephfs_data", "features": [ "snapshot-clone", "snapshot-autoprotect", "snapshot-retention" ], "gid": 0, "mode": 16877, "mon_addrs": [ "10.8.128.22:6789", "10.8.128.23:6789", "10.8.128.24:6789" ], "mtime": "2020-09-08 09:27:15", "path": "/volumes/subgroup0/sub0/6d01a68a-e981-4ebe-84ca-96b660879173", "pool_namespace": "", "state": "complete", "type": "subvolume", "uid": 0 }
输出格式是 json,包含以下字段:
- atime :访问子卷路径的时间,格式为 "YYYY-MM-DD HH:MM:SS"。
- mtime :修改子卷路径的时间,格式为"YYYY-MM-DD HH:MM:SS"。
- ctime :更改子卷路径的时间,格式为 "YYYY-MM-DD HH:MM:SS"。
- UID :子卷路径的 uid。
- GID :子卷路径的 gid。
- mode :子卷路径的模式。
- mon_addrs :监控地址列表。
- bytes_pcent :如果设置了配额,则以百分比为单位使用的配额,否则会显示"undefined"。
- bytes_quota :如果设置了配额,则配额大小以字节为单位,否则会显示"infinite"。
- bytes_used :子卷的当前使用大小(以字节为单位)。
- created_at :创建子卷的时间,格式为 "YYYY-MM-DD HH:MM:SS"。
- data_pool :子卷所属的数据池。
- path :子卷的绝对路径。
- type:子卷类型指示它是克隆还是子卷。
- pool_namespace :子卷的 RADOS 命名空间。
- features: 子卷支持的功能,如 snapshot-clone"、"snapshot-autoprotect" 或 "snapshot-retention"。
- State :子卷的当前状态,如 "complete" 或 "snapshot-retained"
5.2.10. 创建文件系统子卷的快照
本节介绍如何创建 Ceph 文件系统 (CephFS) 子卷的快照。
先决条件
- 部署的 Ceph 文件系统正常工作的 Red Hat Ceph Storage 存储群集。
- 至少对 Ceph 监控器具有读取访问权限。
- Ceph 管理器节点上的读写功能。
- CephFS 子卷。
-
除了读取 (
r) 和写入 (w) 功能外,客户端还需要文件系统的目录路径上的s标志。
流程
验证目录中是否设置了
s标记:语法
ceph auth get CLIENT_NAME示例
client.0 key: AQAz7EVWygILFRAAdIcuJ12opU/JKyfFmxhuaw== caps: [mds] allow rw, allow rws path=/bar1 caps: [mon] allow r caps: [osd] allow rw tag cephfs data=cephfs_a2 创建 Ceph 文件系统子卷的快照:
语法
ceph fs subvolume snapshot create VOLUME_NAME _SUBVOLUME_NAME _SNAP_NAME [--group_name GROUP_NAME]示例
[root@mon ~]# ceph fs subvolume snapshot create cephfs sub0 snap0 --group_name subgroup0
5.2.11. 从快照克隆子卷
可以通过克隆子卷快照来创建子卷。这是一个异步操作,涉及将快照中的数据复制到子卷。
先决条件
- 部署的 Ceph 文件系统正常工作的 Red Hat Ceph Storage 存储群集。
- 至少对 Ceph 监控器具有读取访问权限。
- Ceph 管理器节点上的读写功能。
要创建或删除快照,除了读写功能外,客户端还需要文件系统中目录路径上的
s标志。语法
CLIENT_NAME key: AQAz7EVWygILFRAAdIcuJ12opU/JKyfFmxhuaw== caps: [mds] allow rw, allow rws path=DIRECTORY_PATH caps: [mon] allow r caps: [osd] allow rw tag cephfs data=DIRECTORY_NAME在以下示例中,
client.0可以在文件系统cephfs_a的bar目录中创建或删除快照。示例
client.0 key: AQAz7EVWygILFRAAdIcuJ12opU/JKyfFmxhuaw== caps: [mds] allow rw, allow rws path=/bar caps: [mon] allow r caps: [osd] allow rw tag cephfs data=cephfs_a
流程
创建 Ceph 文件系统 (CephFS) 卷:
语法
ceph fs volume create VOLUME_NAME示例
[root@mon ~]# ceph fs volume create cephfs这将创建 CephFS 文件系统、其数据和元数据池。
创建子卷组。默认情况下,使用八进制文件模式 '755' 创建子卷组,以及其父目录的数据池布局。
语法
ceph fs subvolumegroup create VOLUME_NAME GROUP_NAME [--pool_layout DATA_POOL_NAME --uid UID --gid GID --mode OCTAL_MODE]示例
[root@mon ~]# ceph fs subvolumegroup create cephfs subgroup0创建子卷。默认情况下,子卷在默认子卷组中创建,使用八进制文件模式 '755'、子卷组的 uid、子卷组 gid、其父目录的数据池布局和无大小限制。
语法
ceph fs subvolume create VOLUME_NAME SUBVOLUME_NAME [--size SIZE_IN_BYTES --group_name SUBVOLUME_GROUP_NAME --pool_layout DATA_POOL_NAME --uid _UID --gid GID --mode OCTAL_MODE]示例
[root@mon ~]# ceph fs subvolume create cephfs sub0 --group_name subgroup0创建子卷的快照:
语法
ceph fs subvolume snapshot create VOLUME_NAME _SUBVOLUME_NAME SNAP_NAME [--group_name SUBVOLUME_GROUP_NAME]示例
[root@mon ~]# ceph fs subvolume snapshot create cephfs sub0 snap0 --group_name subgroup0启动克隆操作:
注意默认情况下,克隆的子卷会在默认组中创建。
如果源子卷和目标克隆位于默认组中,请运行以下命令:
语法
ceph fs subvolume snapshot clone VOLUME_NAME SUBVOLUME_NAME SNAP_NAME TARGET_SUBVOLUME_NAME示例
[root@mon ~]# ceph fs subvolume snapshot clone cephfs sub0 snap0 clone0如果源子卷位于非默认组中,请使用以下命令指定源子卷组:
语法
ceph fs subvolume snapshot clone VOLUME_NAME SUBVOLUME_NAME SNAP_NAME TARGET_SUBVOLUME_NAME --group_name SUBVOLUME_GROUP_NAME示例
[root@mon ~]# ceph fs subvolume snapshot clone cephfs sub0 snap0 clone0 --group_name subgroup0如果目标克隆到非默认组中,请使用以下命令指定目标组:
语法
ceph fs subvolume snapshot clone VOLUME_NAME SUBVOLUME_NAME SNAP_NAME TARGET_SUBVOLUME_NAME --target_group_name _SUBVOLUME_GROUP_NAME示例
[root@mon ~]# ceph fs subvolume snapshot clone cephfs sub0 snap0 clone0 --target_group_name subgroup1
检查克隆操作的状态:
语法
ceph fs clone status VOLUME_NAME CLONE_NAME [--group_name TARGET_GROUP_NAME]示例
[root@mon ~]# ceph fs clone status cephfs clone0 --group_name subgroup1 { "status": { "state": "complete" } }
其它资源
- 如需了解更多详细信息,请参阅 Red Hat Ceph Storage Administration Guide 中的 Managing Ceph users 章节。
5.2.12. 列出文件系统子卷的快照
本节提供列出 Ceph 文件系统 (CephFS) 子卷快照的步骤。
先决条件
- 部署的 Ceph 文件系统正常工作的 Red Hat Ceph Storage 存储群集。
- 至少对 Ceph 监控器具有读取访问权限。
- Ceph 管理器节点上的读写功能。
- CephFS 子卷。
- 子卷的快照。
流程
列出 CephFS 子卷的快照:
语法
ceph fs subvolume snapshot ls VOLUME_NAME SUBVOLUME_NAME [--group_name SUBVOLUME_GROUP_NAME]示例
[root@mon ~]# ceph fs subvolume snapshot ls cephfs sub0 --group_name subgroup0
5.2.13. 获取文件系统子卷快照的元数据
本节提供获取 Ceph 文件系统 (CephFS) 子卷快照元数据的步骤。
先决条件
- 部署的 CephFS 正常工作的 Red Hat Ceph Storage 集群。
- 至少对 Ceph 监控器具有读取访问权限。
- Ceph 管理器节点上的读写功能。
- CephFS 子卷。
- 子卷的快照。
流程
获取 CephFS 子卷的快照元数据:
语法
ceph fs subvolume snapshot info VOLUME_NAME SUBVOLUME_NAME SNAP_NAME [--group_name SUBVOLUME_GROUP_NAME]示例
[root@mon ~]# ceph fs subvolume snapshot info cephfs sub0 snap0 --group_name subgroup0输出示例
{ "created_at": "2021-09-08 06:18:47.330682", "data_pool": "cephfs_data", "has_pending_clones": "no", "size": 0 }
输出格式为 json,包含以下字段:
- created_at :创建快照的时间,格式为 "YYYY-MM-DD HH:MM:SS:ffff"。
- data_pool :快照所属的数据池。
- has_pending_clones: "yes" 如果快照克隆正在进行中,否则为"no"。
- size :快照大小,以字节为单位.
5.2.14. 删除文件系统子卷
本节介绍删除 Ceph 文件系统 (CephFS) 子卷的步骤。
ceph fs subvolume rm 命令会在两个步骤中删除子卷及其内容。首先,它会将子卷移到回收文件夹中,然后异步清除其内容。
可以使用 --retain-snapshots 选项删除子卷的现有快照。如果保留快照,则所有不涉及保留快照的操作的子卷将被视为空。保留的快照可用作克隆源来重新创建子卷,或克隆到较新的子卷。
先决条件
- 部署的 Ceph 文件系统正常工作的 Red Hat Ceph Storage 存储群集。
- 至少对 Ceph 监控器具有读取访问权限。
- Ceph 管理器节点上的读写功能。
- CephFS 子卷。
流程
删除 CephFS 子卷:
语法
ceph fs subvolume rm VOLUME_NAME SUBVOLUME_NAME [--group_name SUBVOLUME_GROUP_NAME] [--force] [--retain-snapshots]示例
[root@mon ~]# ceph fs subvolume rm cephfs sub0 --group_name subgroup0 --retain snapshots从保留的快照重新创建子卷:
语法
ceph fs subvolume snapshot clone VOLUME_NAME DELETED_SUBVOLUME RETAINED_SNAPSHOT NEW_SUBVOLUME --group_name SUBVOLUME_GROUP_NAME --target_group_name SUBVOLUME_TARGET_GROUP_NAME*NEW_SUBVOLUME - 可以是之前删除的同一子卷,也可以克隆到新子卷中。
示例
ceph fs subvolume snapshot clone cephfs sub0 snap0 sub1 --group_name subgroup0 --target_group_name subgroup0
5.2.15. 删除文件系统子卷的快照
本节提供删除 Ceph 文件系统 (CephFS) 子卷组快照的步骤。
使用 --force 标志时,命令可以成功,否则如果快照不存在,则会失败。
先决条件
- 部署的 Ceph 文件系统正常工作的 Red Hat Ceph Storage 存储群集。
- 至少对 Ceph 监控器具有读取访问权限。
- Ceph 管理器节点上的读写功能。
- Ceph 文件系统卷.
- 子卷组的快照。
流程
移除 CephFS 子卷的快照:
语法
ceph fs subvolume snapshot rm VOLUME_NAME SUBVOLUME_NAME _SNAP_NAME [--group_name GROUP_NAME --force]示例
[root@mon ~]# ceph fs subvolume snapshot rm cephfs sub0 snap0 --group_name subgroup0 --force
5.3. Ceph 文件系统子卷组
作为存储管理员,您可以创建、列出、获取绝对路径,以及删除 Ceph 文件系统 (CephFS) 子卷组。此外,您也可以创建、列出和删除这些子卷组的快照。CephFS 子卷组是目录级别的抽象,对一组子卷的影响策略(如文件布局)。
本节描述了如何:
5.3.1. 创建文件系统子卷组
这部分论述了如何创建 Ceph 文件系统 (CephFS) 子卷组。
在创建子卷组时,您可以在八进制数中指定其数据池布局、uid、gid 和文件模式。默认情况下,使用八进制文件模式 '755'、uid '0'、gid '0' 和其父目录的数据池布局创建子卷组。
先决条件
- 部署的 Ceph 文件系统正常工作的 Red Hat Ceph Storage 存储群集。
- 至少对 Ceph 监控器具有读取访问权限。
- Ceph 管理器节点上的读写功能。
流程
创建 CephFS 子卷组:
语法
ceph fs subvolumegroup create VOLUME_NAME GROUP_NAME [--pool_layout DATA_POOL_NAME --uid UID --gid GID --mode OCTAL_MODE]示例
[root@mon ~]# ceph fs subvolumegroup create cephfs subgroup0即使子卷组已存在,命令也会成功。
5.3.2. 列出文件系统子卷组
本节介绍列出 Ceph 文件系统 (CephFS) 子卷组的步骤。
先决条件
- 部署的 Ceph 文件系统正常工作的 Red Hat Ceph Storage 存储群集。
- 至少对 Ceph 监控器具有读取访问权限。
- Ceph 管理器节点上的读写功能。
- CephFS 子卷组。
流程
列出 CephFS 子卷组:
语法
ceph fs subvolumegroup ls VOLUME_NAME示例
[root@mon ~]# ceph fs subvolumegroup ls cephfs
5.3.3. 获取文件系统子卷组的绝对路径
本节介绍如何获取 Ceph 文件系统 (CephFS) 子卷组的绝对路径。
先决条件
- 部署的 Ceph 文件系统正常工作的 Red Hat Ceph Storage 存储群集。
- 至少对 Ceph 监控器具有读取访问权限。
- Ceph 管理器节点上的读写功能。
- CephFS 子卷组。
流程
获取 CephFS 子卷组的绝对路径:
语法
ceph fs subvolumegroup getpath VOLUME_NAME GROUP_NAME示例
[root@mon ~]# ceph fs subvolumegroup getpath cephfs subgroup0 /volumes/subgroup0
5.3.4. 为文件系统子卷组创建快照
本节介绍如何创建 Ceph 文件系统 (CephFS) 子卷组的快照。
先决条件
- 部署的 Ceph 文件系统正常工作的 Red Hat Ceph Storage 存储群集。
- 至少对 Ceph 监控器具有读取访问权限。
- Ceph 管理器节点上的读写功能。
- CephFS 子卷组。
-
除了读取 (
r) 和写入 (w) 功能外,客户端还需要文件系统的目录路径上的s标志。
流程
验证目录中是否设置了
s标记:语法
ceph auth get CLIENT_NAME示例
client.0 key: AQAz7EVWygILFRAAdIcuJ12opU/JKyfFmxhuaw== caps: [mds] allow rw, allow rws path=/bar1 caps: [mon] allow r caps: [osd] allow rw tag cephfs data=cephfs_a2 创建 CephFS 子卷组的快照:
语法
ceph fs subvolumegroup snapshot create VOLUME_NAME _GROUP_NAME SNAP_NAME示例
[root@mon ~]# ceph fs subvolumegroup snapshot create cephfs subgroup0 snap0命令隐式快照子卷组下的所有子卷。
5.3.5. 列出文件系统子卷组的快照
本节提供列出 Ceph 文件系统 (CephFS) 子卷组快照的步骤。
先决条件
- 部署的 Ceph 文件系统正常工作的 Red Hat Ceph Storage 存储群集。
- 至少对 Ceph 监控器具有读取访问权限。
- Ceph 管理器节点上的读写功能。
- CephFS 子卷组。
- 子卷组的快照。
流程
列出 CephFS 子卷组的快照:
语法
ceph fs subvolumegroup snapshot ls VOLUME_NAME GROUP_NAME示例
[root@mon ~]# ceph fs subvolumegroup snapshot ls cephfs subgroup0
5.3.6. 删除文件系统子卷组的快照
本节提供删除 Ceph 文件系统 (CephFS) 子卷组快照的步骤。
使用 --force 标志时,命令可以成功,否则如果快照不存在,则会失败。
先决条件
- 部署的 Ceph 文件系统正常工作的 Red Hat Ceph Storage 存储群集。
- 至少对 Ceph 监控器具有读取访问权限。
- Ceph 管理器节点上的读写功能。
- Ceph 文件系统卷.
- 子卷组的快照。
流程
移除 CephFS 子卷组的快照:
语法
ceph fs subvolumegroup snapshot rm VOLUME_NAME GROUP_NAME SNAP_NAME [--force]示例
[root@mon ~]# ceph fs subvolumegroup snapshot rm cephfs subgroup0 snap0 --force
5.3.7. 删除文件系统子卷组
本节介绍如何删除 Ceph 文件系统 (CephFS) 子卷组。
如果子卷组未为空或不存在,则移除子卷组会失败。--force 标志允许删除不存在的子卷组。
先决条件
- 部署的 Ceph 文件系统正常工作的 Red Hat Ceph Storage 存储群集。
- 至少对 Ceph 监控器具有读取访问权限。
- Ceph 管理器节点上的读写功能。
- CephFS 子卷组。
流程
删除 CephFS 子卷组:
语法
ceph fs subvolumegroup rm VOLUME_NAME GROUP_NAME [--force]示例
[root@mon ~]# ceph fs subvolumegroup rm cephfs subgroup0 --force
5.4. 其它资源
- 如需了解更多详细信息,请参阅 Red Hat Ceph Storage Administration Guide 中的 Managing Ceph users 章节。
附录 A. Ceph 文件系统的健康状况消息
集群健康检查
Ceph 监控守护进程生成健康消息,以响应元数据服务器(MDS)的某些状态。以下是健康信息及其解释列表:
- MDS 排名 <ranks> 失败
- 目前没有将一个或多个 MDS 等级分配给任何 MDS 守护进程。在合适的替代守护进程启动后,存储集群才会恢复。
- MDS 排名 <ranks> 已损坏
- 一个或多个 MDS 级别对其存储元数据造成严重损坏,在修复元数据之前,无法重新开始。
- MDS 集群被降级
-
当前没有启动和运行 MDS 等级,客户端可能会暂停元数据 I/O,直到此情况解决为止。这包括等级失败或损坏,包括 MDS 上运行但未处于
活动状态的等级,例如,排名在重播状态。 - MDS <names> 滞后
-
MDS 守护进程应当会以
mds_beacon_interval选项指定的间隔向 monitor 发送 beacon 消息,默认为 4 秒。如果 MDS 守护进程无法在它们mds_beacon_grace选项指定的时间内发送消息,则默认为 15 秒。Ceph 监控器将 MDS 守护进程标记为滞后,并自动将其替换为待机守护进程(如果有可用)。
守护进程报告的健康检查
MDS 守护进程可以识别各种不需要的条件,并在 ceph status 命令的输出中返回它们。这些条件具有人类可读的消息,也具有唯一代码,从 MDS_HEALTH 开始,显示在 JSON 输出中。下面列出了守护进程消息、它们的代码和说明。
- "Behind on trimming…"
Code: MDS_HEALTH_TRIM
CephFS 维护一个划分为日志段的元数据日志。日志的长度(按分段数)由
mds_log_max_segments设置控制。当片段数超过该设置时,MDS 开始写回元数据,以便可以删除 (trim) 最旧的片段。如果这个过程太慢,或者软件错误正在防止修剪,则会出现这个健康信息。出现此消息的阈值是将网段数量为mds_log_max_segments的两倍。- "Client <name> failing to respond to capability release"
Code: MDS_HEALTH_CLIENT_LATE_RELEASE, MDS_HEALTH_CLIENT_LATE_RELEASE_MANY
CephFS 客户端由 MDS 发布。这些能力像锁定一样工作。有时,例如当另一个客户端需要访问权限时,MDS 会请求客户端释放其功能。如果客户端不响应,它可能无法立即这样做,或者根本无法这样做。如果客户端需要的时间超过其
mds_revoke_cap_timeout选项(默认为 60 秒)所指定的时间,将显示此消息。- "Client <name> failing to respond to cache pressure"
Code: MDS_HEALTH_CLIENT_RECALL, MDS_HEALTH_CLIENT_RECALL_MANY
客户端维护元数据缓存。客户端缓存中的项目(如索引节点)也固定在 MDS 缓存中。当 MDS 需要缩小其缓存以保持在自己的缓存大小限制内时,MDS 会将消息发送到客户端,以缩小其缓存。如果客户端不响应,它可以阻止 MDS 正确保持其缓存大小,并且 MDS 最终可能会耗尽内存并意外终止。如果客户端需要的时间超过其
mds_recall_state_timeout选项(默认为 60 秒)所指定的时间,将显示此消息。详情请参阅了解 MDS 缓存大小限制。- "Client name failing to advance its oldest client/flush tid"
Code: MDS_HEALTH_CLIENT_OLDEST_TID, MDS_HEALTH_CLIENT_OLDEST_TID_MANY
用于客户端和 MDS 服务器之间通信的 CephFS 协议使用名为 oldest tid 的字段来通知 MDS 完全完成哪些客户端请求,以便 MDS 可以忘记它们。如果一个不响应的客户端未能推进此字段,可能会阻止 MDS 正确清理客户端请求使用的资源。如果客户端的请求数超过
max_completed_requests选项(默认为 100000)指定的数量(默认为 100000),则会出现在 MDS 侧完成但还没有在客户端 最旧的 tid 值中考虑的请求数。- "Metadata damage detected"
Code: MDS_HEALTH_DAMAGE
从元数据池中读取时会出现元数据损坏或缺失的问题。此消息表示损坏已完全隔离,使 MDS 能够继续运行,尽管客户端访问损坏的子树会返回 I/O 错误。使用
damage ls管理 socket 命令查看损坏的详细信息。一旦遇到损坏,就会发出此消息。- "MDS in read-only mode"
Code: MDS_HEALTH_READ_ONLY
MDS 已进入只读模式,并将
EROFS错误代码返回尝试修改任何元数据的客户端操作。MDS 进入只读模式:- 如果在写入元数据池时遇到写入错误。
-
如果管理员强制 MDS 使用
force_readonly管理 socket 命令进入只读模式。
- "<N> slow requests are blocked"
Code: MDS_HEALTH_SLOW_REQUEST
一个或多个客户端请求尚未立即完成,这表示 MDS 运行缓慢或遇到漏洞。使用
ops管理 socket 命令列出出色的元数据操作。如果任何客户端请求的时间超过其mds_op_complaint_time选项(默认为 30 秒)指定的值,则会出现此消息。- "Too many inodes in cache"
- Code: MDS_HEALTH_CACHE_OVERSIZED
MDS 无法修剪其缓存,以遵守管理员设置的限制。如果 MDS 缓存太大,守护进程可能会耗尽可用内存并意外终止。默认情况下,如果 MDS 缓存大小大于其限制的 50%,则会出现此消息。
其它资源
- 如需了解更多详细信息,请参阅 Red Hat Ceph Storage File System Guide 中的 Metadata Server cache size limits 章节。
附录 B. 元数据服务器守护进程配置参考
请参考列表命令,它们可用于元数据服务器 (MDS) 守护进程配置。
- mon_force_standby_active
- 描述
-
如果设置为
true,请监控在待机重播模式中强制 MDS 处于活动状态。在 Ceph 配置文件的[mon]或[global]部分下设置。 - 类型
- 布尔值
- 默认
-
true
- max_mds
- 描述
-
集群创建过程中活跃 MDS 守护进程的数量。在 Ceph 配置文件的
[mon]或[global]部分下设置。 - 类型
- 32 位整数
- 默认
-
1
- mds_cache_memory_limit
- 描述
-
内存限制 MDS 为其缓存强制执行的 MDS。红帽建议使用这个参数而不是它们
mds cache size参数。 - 类型
- 64 位 Unsigned 整数
- 默认
-
1073741824
- mds_cache_reservation
- 描述
- 维护 MDS 缓存的缓存保留、内存或索引节点。该值是配置的最大缓存的百分比。MDS 开始转换为保留时,它会重新调用客户端状态,直到其缓存大小缩小来恢复保留为止。
- 类型
- 浮点值
- 默认
-
0.05
- mds_cache_size
- 描述
-
要缓存的索引节点数。值 0 表示无限数字。红帽建议使用它们
mds_cache_memory_limit来限制 MDS 缓存使用的内存量。 - 类型
- 32 位整数
- 默认
-
0
- mds_cache_mid
- 描述
- 从顶部的缓存 LRU 中新项目的插入点。
- 类型
- 浮点值
- 默认
-
0.7
- mds_dir_commit_ratio
- 描述
- 部分的目录包含 Ceph 提交之前使用完整更新(而非部分更新)的错误信息。
- 类型
- 浮点值
- 默认
-
0.5
- mds_dir_max_commit_size
- 描述
- Ceph 将目录更新前的最大目录大小(以 MB 为单位)将目录分成较小的事务。
- 类型
- 32 位整数
- 默认
-
90
- mds_decay_halflife
- 描述
- MDS 缓存温度的半寿命。
- 类型
- 浮点值
- 默认
-
5
- mds_beacon_interval
- 描述
- 发送到 monitor 的 beacon 消息的频率(以秒为单位)。
- 类型
- 浮点值
- 默认
-
4
- mds_beacon_grace
- 描述
-
Ceph 声明 MDS
滞后的时间间隔 ,并且可能替换它。 - 类型
- 浮点值
- 默认
-
15
- mds_blacklist_interval
- 描述
- OSD map 中失败 MDS 守护进程的黑名单持续时间。
- 类型
- 浮点值
- 默认
-
24.0*60.0
- mds_session_timeout
- 描述
- Ceph 超出功能和租用前客户端不活跃的时间间隔,以秒为单位。
- 类型
- 浮点值
- 默认
-
60
- mds_session_autoclose
- 描述
-
Ceph 关闭
滞后客户端会话前的时间间隔(以秒为单位)。 - 类型
- 浮点值
- 默认
-
300
- mds_reconnect_timeout
- 描述
- 在 MDS 重启期间等待客户端重新连接的时间间隔(以秒为单位)。
- 类型
- 浮点值
- 默认
-
45
- mds_tick_interval
- 描述
- MDS 执行内部定期任务的频率。
- 类型
- 浮点值
- 默认
-
5
- mds_dirstat_min_interval
- 描述
- 尝试将递归统计信息传播到树上的最小间隔(以秒为单位)。
- 类型
- 浮点值
- 默认
-
1
- mds_scatter_nudge_interval
- 描述
- 目录统计数据更改的速度传播。
- 类型
- 浮点值
- 默认
-
5
- mds_client_prealloc_inos
- 描述
- 每个客户端会话预分配的索引节点编号.
- 类型
- 32 位整数
- 默认
-
1000
- mds_early_reply
- 描述
- 确定 MDS 是否允许客户端在提交到日志之前查看请求结果。
- 类型
- 布尔值
- 默认
-
true
- mds_use_tmap
- 描述
-
使用
trivialmap进行目录更新。 - 类型
- 布尔值
- 默认
-
true
- mds_default_dir_hash
- 描述
- 用于跨目录片段的散列文件的功能。
- 类型
- 32 位整数
- 默认
-
2,是rjenkins
- mds_log
- 描述
-
如果 MDS 应记录元数据更新,则设置为
true。禁用仅进行基准测试。 - 类型
- 布尔值
- 默认
-
true
- mds_log_skip_corrupt_events
- 描述
- 决定 MDS 是否尝试在日志重播期间跳过损坏的日志事件。
- 类型
- 布尔值
- 默认
-
false
- mds_log_max_events
- 描述
-
Ceph 启动修剪前日志中的最大事件。设置为
-1以禁用限制。 - 类型
- 32 位整数
- 默认
-
-1
- mds_log_max_segments
- 描述
-
Ceph 启动修剪之前的日志中的最大网段或对象数量。设置为
-1以禁用限制。 - 类型
- 32 位整数
- 默认
-
30
- mds_log_max_expiring
- 描述
- 并行过期的最大片段数。
- 类型
- 32 位整数
- 默认
-
20
- mds_log_eopen_size
- 描述
-
EOpen事件中索引节点的最大数量. - 类型
- 32 位整数
- 默认
-
100
- mds_bal_sample_interval
- 描述
- 决定在做出碎片决策时,对目录温度进行抽样的频率。
- 类型
- 浮点值
- 默认
-
3
- mds_bal_replicate_threshold
- 描述
- Ceph 尝试将元数据复制到其他节点前的最大温度。
- 类型
- 浮点值
- 默认
-
8000
- mds_bal_unreplicate_threshold
- 描述
- Ceph 停止将元数据复制到其他节点前的最小温度。
- 类型
- 浮点值
- 默认
-
0
- mds_bal_frag
- 描述
- 决定 MDS 片段目录是否。
- 类型
- 布尔值
- 默认
-
false
- mds_bal_split_size
- 描述
- MDS 将目录片段分割为更小的位前的最大目录大小。根目录的默认片段大小限制为 10000。
- 类型
- 32 位整数
- 默认
-
10000
- mds_bal_split_rd
- 描述
- Ceph 分割目录片段之前的最大目录读取温度。
- 类型
- 浮点值
- 默认
-
25000
- mds_bal_split_wr
- 描述
- Ceph 分割目录片段之前的最大目录写入温度。
- 类型
- 浮点值
- 默认
-
10000
- mds_bal_split_bits
- 描述
- 用于分割目录片段的位数。
- 类型
- 32 位整数
- 默认
-
3
- mds_bal_merge_size
- 描述
- Ceph 尝试合并相邻目录片段前的最小目录大小。
- 类型
- 32 位整数
- 默认
-
50
- mds_bal_merge_rd
- 描述
- Ceph 合并相邻目录片段之前读取的最小温度。
- 类型
- 浮点值
- 默认
-
1000
- mds_bal_merge_wr
- 描述
- Ceph 合并相邻目录片段之前,最小写入温度。
- 类型
- 浮点值
- 默认
-
1000
- mds_bal_interval
- 描述
- MDS 节点之间工作负载交换的频率(以秒为单位)。
- 类型
- 32 位整数
- 默认
-
10
- mds_bal_fragment_interval
- 描述
- 调整目录碎片的频率(以秒为单位)。
- 类型
- 32 位整数
- 默认
-
5
- mds_bal_idle_threshold
- 描述
- Ceph 将子树迁移到其父树前的最小温度。
- 类型
- 浮点值
- 默认
-
0
- mds_bal_max
- 描述
- Ceph 停止前要运行均衡器的迭代数量。仅用于测试目的。
- 类型
- 32 位整数
- 默认
-
-1
- mds_bal_max_until
- 描述
- Ceph 停止前运行平衡的秒数。仅用于测试目的。
- 类型
- 32 位整数
- 默认
-
-1
- mds_bal_mode
- 描述
计算 MDS 负载的方法:
-
1= 混合。 -
2= 请求率和延迟。 -
3= CPU 负载。
-
- 类型
- 32 位整数
- 默认
-
0
- mds_bal_min_rebalance
- 描述
- Ceph 迁移前的最小子树温度。
- 类型
- 浮点值
- 默认
-
0.1
- mds_bal_min_start
- 描述
- Ceph 搜索子树前的最小子树温度。
- 类型
- 浮点值
- 默认
-
0.2
- mds_bal_need_min
- 描述
- 要接受的目标子树大小的最小部分。
- 类型
- 浮点值
- 默认
-
0.8
- mds_bal_need_max
- 描述
- 要接受的目标子树大小的最大部分。
- 类型
- 浮点值
- 默认
-
1.2
- mds_bal_midchunk
- 描述
- Ceph 迁移任何大于目标子树大小的子树。
- 类型
- 浮点值
- 默认
-
0.3
- mds_bal_minchunk
- 描述
- Ceph 会忽略小于目标子树大小的这一部分的任何子树。
- 类型
- 浮点值
- 默认
-
0.001
- mds_bal_target_removal_min
- 描述
- Ceph 从 MDS 映射中删除旧 MDS 目标前的最小负载均衡器迭代数量。
- 类型
- 32 位整数
- 默认
-
5
- mds_bal_target_removal_max
- 描述
- Ceph 从 MDS map 移除旧 MDS 目标前的最大均衡迭代数量。
- 类型
- 32 位整数
- 默认
-
10
- mds_replay_interval
- 描述
-
当
hot standby处于standby-replay模式时,日志的拉取间隔。 - 类型
- 浮点值
- 默认
-
1
- mds_shutdown_check
- 描述
- MDS 关闭期间轮询缓存的时间间隔。
- 类型
- 32 位整数
- 默认
-
0
- mds_thrash_exports
- 描述
- Ceph 在节点之间随机导出子树。仅用于测试目的。
- 类型
- 32 位整数
- 默认
-
0
- mds_thrash_fragments
- 描述
- Ceph 随机分割或合并目录。
- 类型
- 32 位整数
- 默认
-
0
- mds_dump_cache_on_map
- 描述
- Ceph 将 MDS 缓存内容转储到每个 MDS 映射上的一个文件。
- 类型
- 布尔值
- 默认
-
false
- mds_dump_cache_after_rejoin
- 描述
- Ceph 在恢复期间重新加入缓存后,将 MDS 缓存内容转储到文件。
- 类型
- 布尔值
- 默认
-
false
- mds_verify_scatter
- 描述
-
Ceph 声称各种 scatter/gather invariants 是
true。仅供开发人员使用。 - 类型
- 布尔值
- 默认
-
false
- mds_debug_scatterstat
- 描述
-
Ceph 声称各种递归统计在变量中是
true。仅供开发人员使用。 - 类型
- 布尔值
- 默认
-
false
- mds_debug_frag
- 描述
- Ceph 在方便时验证目录碎片不变量。仅供开发人员使用。
- 类型
- 布尔值
- 默认
-
false
- mds_debug_auth_pins
- 描述
- debug 身份验证固定变量。仅供开发人员使用。
- 类型
- 布尔值
- 默认
-
false
- mds_debug_subtrees
- 描述
- 调试子树变量.仅供开发人员使用。
- 类型
- 布尔值
- 默认
-
false
- mds_kill_mdstable_at
- 描述
- Ceph 在 MDS 表代码中注入 MDS 故障。仅供开发人员使用。
- 类型
- 32 位整数
- 默认
-
0
- mds_kill_export_at
- 描述
- Ceph 在子树导出代码中注入 MDS 故障。仅供开发人员使用。
- 类型
- 32 位整数
- 默认
-
0
- mds_kill_import_at
- 描述
- Ceph 在子树导入代码中注入 MDS 失败。仅供开发人员使用。
- 类型
- 32 位整数
- 默认
-
0
- mds_kill_link_at
- 描述
- Ceph 在硬链接代码中注入 MDS 故障。仅供开发人员使用。
- 类型
- 32 位整数
- 默认
-
0
- mds_kill_rename_at
- 描述
- Ceph 在重命名代码中注入 MDS 故障。仅供开发人员使用。
- 类型
- 32 位整数
- 默认
-
0
- mds_wipe_sessions
- 描述
- Ceph 会在启动时删除所有客户端会话。仅用于测试目的。
- 类型
- 布尔值
- 默认
-
0
- mds_wipe_ino_prealloc
- 描述
- Ceph 删除启动时索引节点预分配元数据.仅用于测试目的。
- 类型
- 布尔值
- 默认
-
0
- mds_skip_ino
- 描述
- 启动时要跳过的索引节点编号数。仅用于测试目的。
- 类型
- 32 位整数
- 默认
-
0
- mds_standby_for_name
- 描述
- MDS 守护进程对此设置中指定的名称的另一个 MDS 守护进程是备用的。
- 类型
- 字符串
- 默认
- N/A
- mds_standby_for_rank
- 描述
- MDS 守护进程的实例是这个等级的另一个 MDS 守护进程实例的备用实例。
- 类型
- 32 位整数
- 默认
-
-1
- mds_standby_replay
- 描述
-
确定 MDS 守护进程是否在用作
hot standby时轮询和重播活动 MDS 的日志。 - 类型
- 布尔值
- 默认
-
false
附录 C. Journaler 配置参考
可用于日志记录器配置的列表命令的引用。
- journaler_write_head_interval
- 描述
- 更新 journal head 对象的频率。
- 类型
- 整数
- 必需
- 否
- 默认
-
15
- journaler_prefetch_periods
- 描述
- 在日志重播上提前读取多少条带周期.
- 类型
- 整数
- 必需
- 否
- 默认
-
10
- journal_prezero_periods
- 描述
- 写入位置前要达到零的条带周期数。
- 类型
- 整数
- 必需
- 否
- 默认
-
10
- journaler_batch_interval
- 描述
- 人为地发生最大额外延迟(以秒为单位)。
- 类型
- 双
- 必需
- 否
- 默认
-
.001
- journaler_batch_max
- 描述
- 将延迟刷新的最大字节数。
- 类型
- 64-bit Unsigned 整数
- 必需
- 否
- 默认
-
0
附录 D. Ceph 文件系统客户端配置参考
本节列出了 Ceph 文件系统 (CephFS) FUSE 客户端的配置选项。在 Ceph 配置文件 [client] 部分下设置它们。
- client_acl_type
- 描述
-
设置 ACL 类型。目前,只有可能的值是
posix_acl启用 POSIX ACL 或空字符串。这个选项只有在fuse_default_permissions设为false时才会生效。 - 类型
- 字符串
- 默认
-
""(无 ACL 强制)
- client_cache_mid
- 描述
- 设置客户端缓存中点。中点将最早使用的列表分成一个热和温列表。
- 类型
- 浮点值
- 默认
-
0.75
- client_cache size
- 描述
- 设置客户端保留在元数据缓存中的索引节点数。
- 类型
- 整数
- 默认
-
16384(16 MB)
- client_caps_release_delay
- 描述
- 以秒为单位设置能力发行版本之间的延时。此延迟设置客户端等待多少秒以释放在另一个用户空间操作需要能力时不再需要的功能。
- 类型
- 整数
- 默认
-
5(秒)
- client_debug_force_sync_read
- 描述
-
如果设为
true,客户端直接从 OSD 读取数据,而不使用本地页面缓存。 - 类型
- 布尔值
- 默认
-
false
- client_dirsize_rbytes
- 描述
-
如果设置为
true,则使用目录的递归大小(即,所有子目录总数)。 - 类型
- 布尔值
- 默认
-
true
- client_max_inline_size
- 描述
-
设置存储在文件索引节点中的最大内联数据大小,而不是存储在 RADOS 中的单独数据对象中。只有在 MDS 映射中设置了
inline_data标志时,才会应用此设置。 - 类型
- 整数
- 默认
-
4096
- client_metadata
- 描述
- 发送到每个 MDS 的客户端元数据的逗号分隔字符串,以及自动生成的版本、主机名和其他元数据。
- 类型
- 字符串
- 默认
-
""(无其他元数据)
- client_mount_gid
- 描述
- 设置 CephFS 挂载的组 ID。
- 类型
- 整数
- 默认
-
-1
- client_mount_timeout
- 描述
- 设置 CephFS 挂载的超时时间(以秒为单位)。
- 类型
- 浮点值
- 默认
-
300.0
- client_mount_uid
- 描述
- 设置 CephFS 挂载的用户 ID。
- 类型
- 整数
- 默认
-
-1
- client_mountpoint
- 描述
-
ceph-fuse命令的-r选项的替代选择。 - 类型
- 字符串
- 默认
-
/
- client_oc
- 描述
- 启用对象缓存。
- 类型
- 布尔值
- 默认
-
true
- client_oc_max_dirty
- 描述
- 在对象缓存中设置最大脏字节数。
- 类型
- 整数
- 默认
-
104857600(100MB)
- client_oc_max_dirty_age
- 描述
- 在回写前,设置对象缓存中脏数据的最长期限(以秒为单位)。
- 类型
- 浮点值
- 默认
-
5.0(秒)
- client_oc_max_objects
- 描述
- 在对象缓存中设置对象的最大数量。
- 类型
- 整数
- 默认
-
1000
- client_oc_size
- 描述
- 设置客户端缓存的字节数据数。
- 类型
- 整数
- 默认
-
209715200(200 MB)
- client_oc_target_dirty
- 描述
- 设置脏数据的目标大小。红帽建议保持这个数字低。
- 类型
- 整数
- 默认
-
8388608(8MB)
- client_permissions
- 描述
- 检查所有 I/O 操作的客户端权限。
- 类型
- 布尔值
- 默认
-
true
- client_quota_df
- 描述
-
报告
statfs操作的根目录配额。 - 类型
- 布尔值
- 默认
-
true
- client_readahead_max_bytes
- 描述
-
设置内核提前读取的最大字节数,以用于将来的读取操作。被
client_readahead_max_periods设置覆盖。 - 类型
- 整数
- 默认
-
0(unlimited)
- client_readahead_max_periods
- 描述
-
设置内核提前读取的文件布局句点数(对象大小 * 条带的数量)。覆盖
client_readahead_max_bytes设置。 - 类型
- 整数
- 默认
-
4
- client_readahead_min
- 描述
- 设置内核提前读取的最小数量字节。
- 类型
- 整数
- 默认
-
131072(128KB)
- client_snapdir
- 描述
- 设置快照目录名称。
- 类型
- 字符串
- 默认
-
".snap"
- client_tick_interval
- 描述
- 以能力续订和其他 upkeep 间隔设置间隔(以秒为单位)。
- 类型
- 浮点值
- 默认
-
1.0
- client_use_random_mds
- 描述
- 为每个请求选择随机 MDS。
- 类型
- 布尔值
- 默认
-
false
- fuse_default_permissions
- 描述
-
当设置为
false时,ceph-fuse实用程序检查执行自己的权限检查,而不依赖于 FUSE 中的权限实施。将其设置为 false 并与client acl type=posix_acl选项一起使用,以启用 POSIX ACL。 - 类型
- 布尔值
- 默认
-
true
这些选项为内部选项。此处仅列出它们以填写选项列表。
- client_debug_getattr_caps
- 描述
- 检查 MDS 的回复是否包含所需的功能。
- 类型
- 布尔值
- 默认
-
false
- client_debug_inject_tick_delay
- 描述
- 在客户端勾号之间添加人为延迟。
- 类型
- 整数
- 默认
-
0
- client_inject_fixed_oldest_tid
- 描述, 类型
- 布尔值
- 默认
-
false
- client_inject_release_failure
- 描述, 类型
- 布尔值
- 默认
-
false
- client_trace
- 描述
-
所有文件操作的追踪文件路径。输出由 Ceph 复合客户端使用。详情请查看
ceph-syn(8)手册页。 - 类型
- 字符串
- 默认
-
""(禁用)