部署规划和大小指南
规划和大小数据网格部署
摘要
Red Hat Data Grid
Data Grid 是一个高性能分布式内存数据存储。
- 无架构数据结构
- 将不同对象存储为键值对的灵活性。
- 基于网格的数据存储
- 旨在在集群中分发和复制数据。
- 弹性扩展
- 动态调整节点数量,以便在不中断服务的情况下满足需求。
- 数据互操作性
- 从不同端点在网格中存储、检索和查询数据。
Data Grid 文档
红帽客户门户网站中提供了 Data Grid 的文档。
Data Grid 下载
访问 红帽客户门户上的 Data Grid 软件下载。
您必须有一个红帽帐户才能访问和下载数据中心软件。
使开源包含更多
红帽致力于替换我们的代码、文档和 Web 属性中存在问题的语言。我们从这四个术语开始:master、slave、黑名单和白名单。由于此项工作十分艰巨,这些更改将在即将推出的几个发行版本中逐步实施。详情请查看 CTO Chris Wright 的信息。
第 1 章 Data Grid 部署模型和用例
Data Grid 提供灵活的部署模型,支持各种用例。
- 大大提高了 Red Hat Build of Quarkus、Red Hat JBoss EAP 和 Spring 应用程序的性能。
- 确保服务可用性和连续性。
- 较低的操作成本。
1.1. Data Grid 部署模型
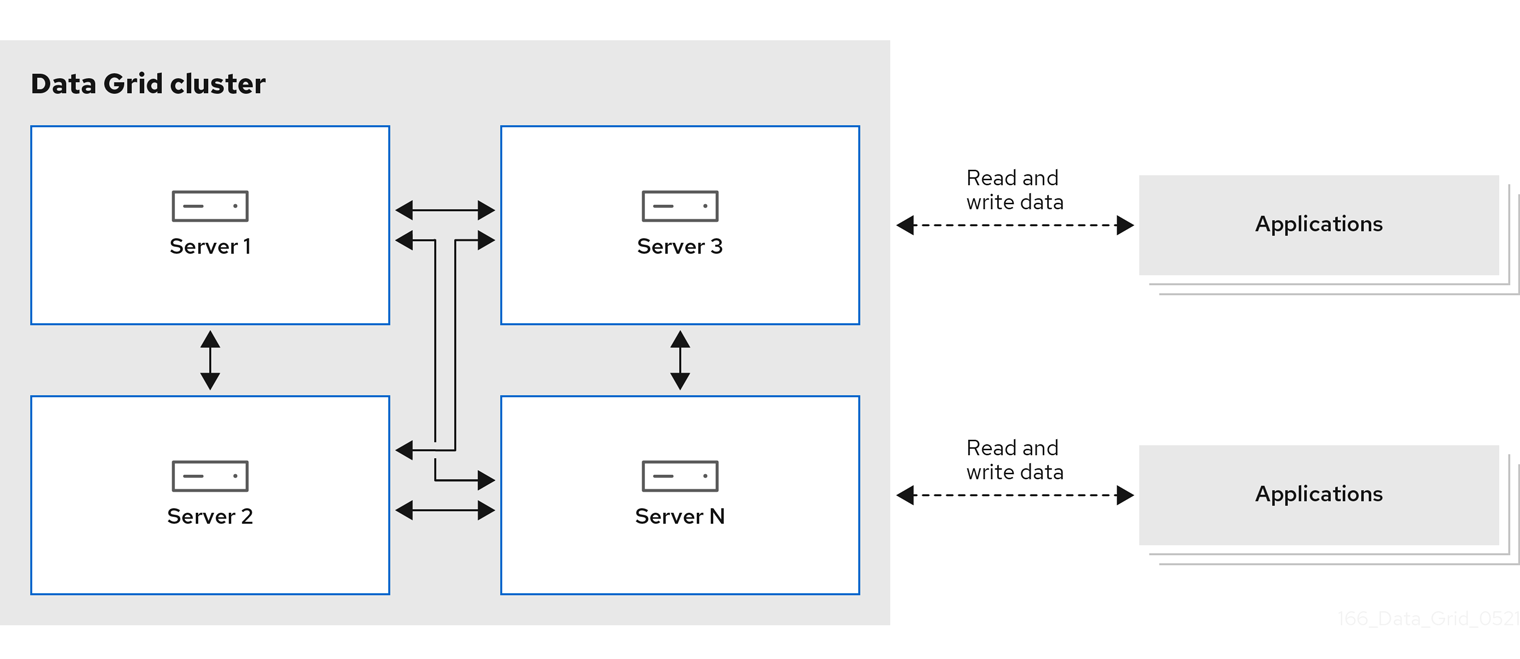
Data Grid 有两个用于缓存、远程和嵌入式部署模型。与传统数据库系统相比,两个部署模型都允许应用程序访问数据,以实现读取操作和更高的吞吐量。
- 远程缓存
- Data Grid Server 节点在专用 Java 虚拟机(JVM)中运行。客户端使用 Hot Rod、二进制 TCP 协议或 HTTP 的 REST 访问远程缓存。
- 嵌入式缓存
- Data Grid 在与 Java 应用程序相同的 JVM 中运行,这意味着数据存储在执行代码的内存空间中。
红帽建议大多数部署的服务器/客户端架构。远程缓存可更快地部署时间,因为数据层与业务逻辑分开。Data Grid Server 还提供监控和可观察性和其他内置功能,以帮助您降低开发成本。
接近缓存
接近缓存功能允许远程客户端在本地存储数据,这意味着读取密集型应用程序不需要遍历每个调用的网络。接近缓存可显著提高读操作速度,并获得与嵌入式缓存相同的性能。
图 1.1. 远程缓存部署模型
1.1.1. 平台和自动化工具
实现所需的服务质量意味着为数据平面提供最佳 CPU 和 RAM 资源。资源会降低数据网格性能,同时使用大量主机资源可以快速增加成本。
虽然您对 Data Grid 集群进行基准测试并调整数据网格集群以查找正确的 CPU 或 RAM 分配,但您应该考虑哪个主机平台提供正确类型的自动化工具来有效地扩展集群和管理资源。
裸机或虚拟机
通过 Red Hat Ansible 和 Microsoft Windows 合并 RHEL 或 Microsoft Windows,以管理数据中心配置和轮询服务,以确保可用性和获得最佳资源使用量。
Automation Hub 提供的 Data Grid 的 Ansible 集合 自动化集群安装,并包含 Keycloak 集成和跨站点复制的选项。
OpenShift
利用 Kubernetes 编配来自动置备 pod,对资源实施限制,并自动扩展 Data Grid 集群来满足工作负载需求。
1.2. 在线缓存
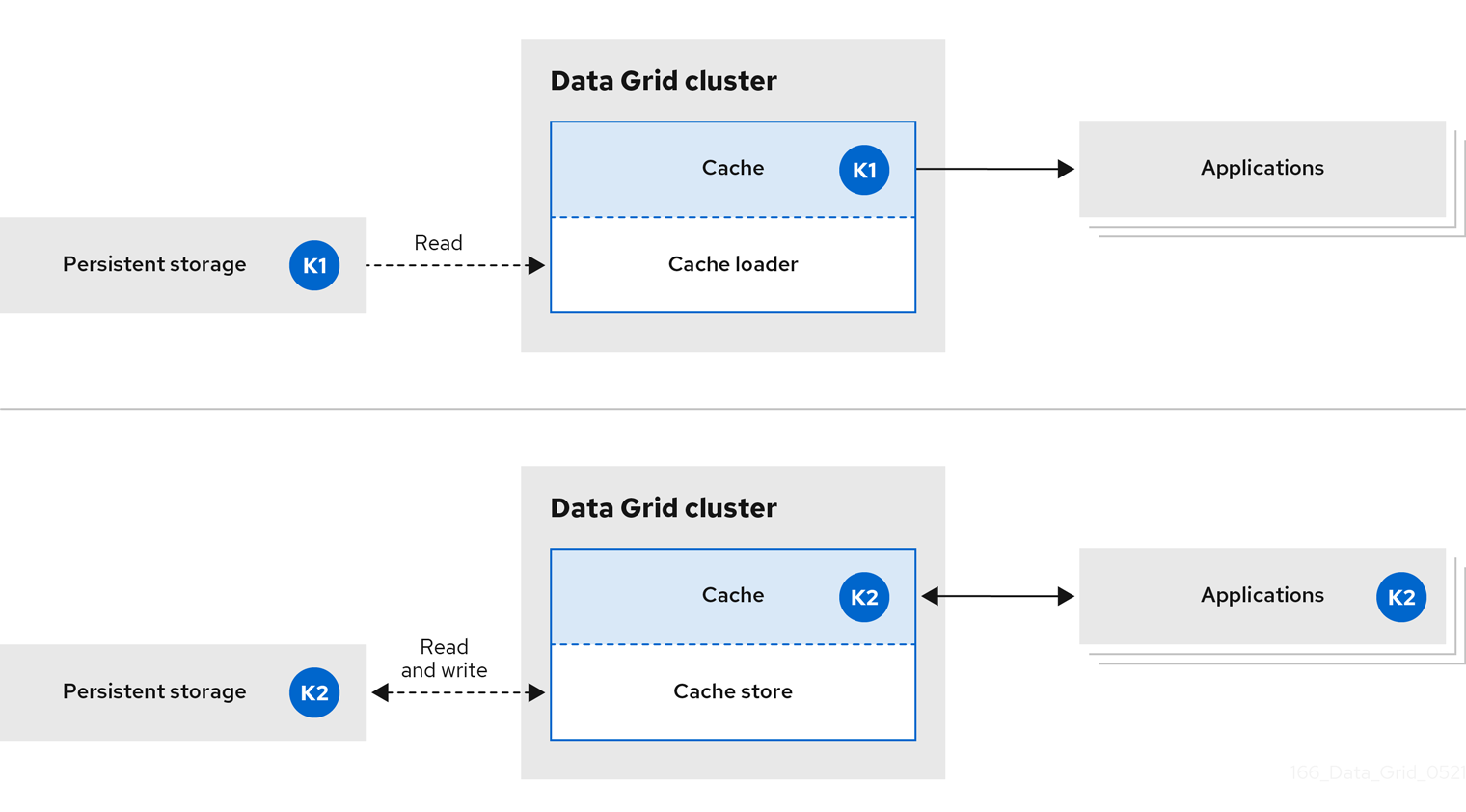
Data Grid 处理驻留在持久性存储中的数据的所有应用程序请求。
通过 in-line 缓存,Data Grid 使用缓存加载程序和缓存存储来对持久性存储中的数据进行操作。
- 缓存加载程序提供对持久性存储的只读访问。
- 缓存存储提供对持久性存储的读写访问权限。
图 1.2. 在线缓存
1.3. 侧缓存
Data Grid 存储应用程序从持久性存储检索的数据,这可以减少对持久性存储的读取操作数量,并提高后续读取的响应时间。
图 1.3. 侧缓存
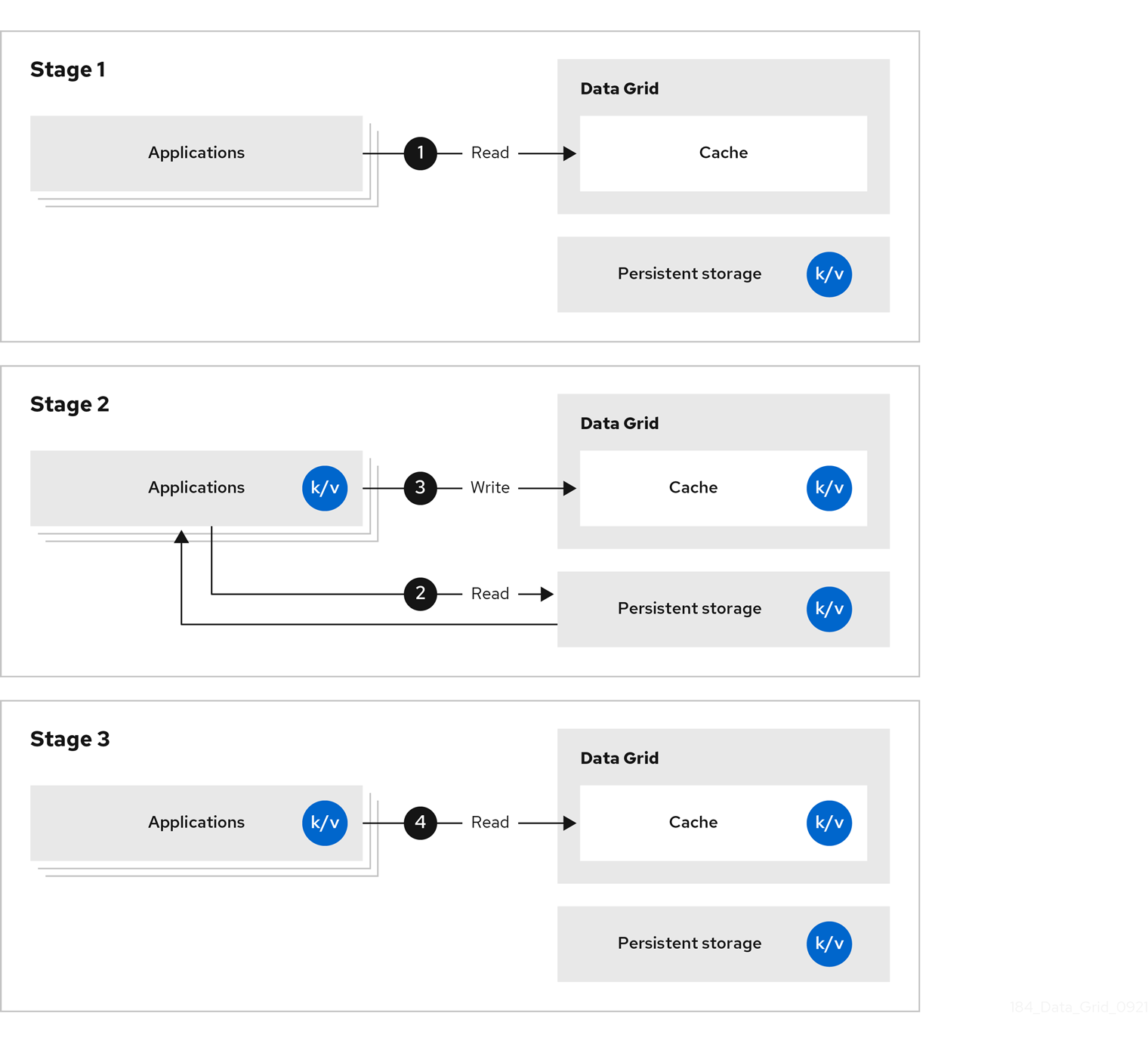
通过侧缓存,应用程序控制如何在持久性存储的 Data Grid 集群中添加数据。当应用程序请求条目时,会出现以下情况:
- 读取请求进入 Data Grid。
- 如果条目不在缓存中,应用程序会从持久性存储请求它。
- 应用程序将条目放在缓存中。
- 应用程序在下次读取时从 Data Grid 检索条目。
1.4. 分布式内存
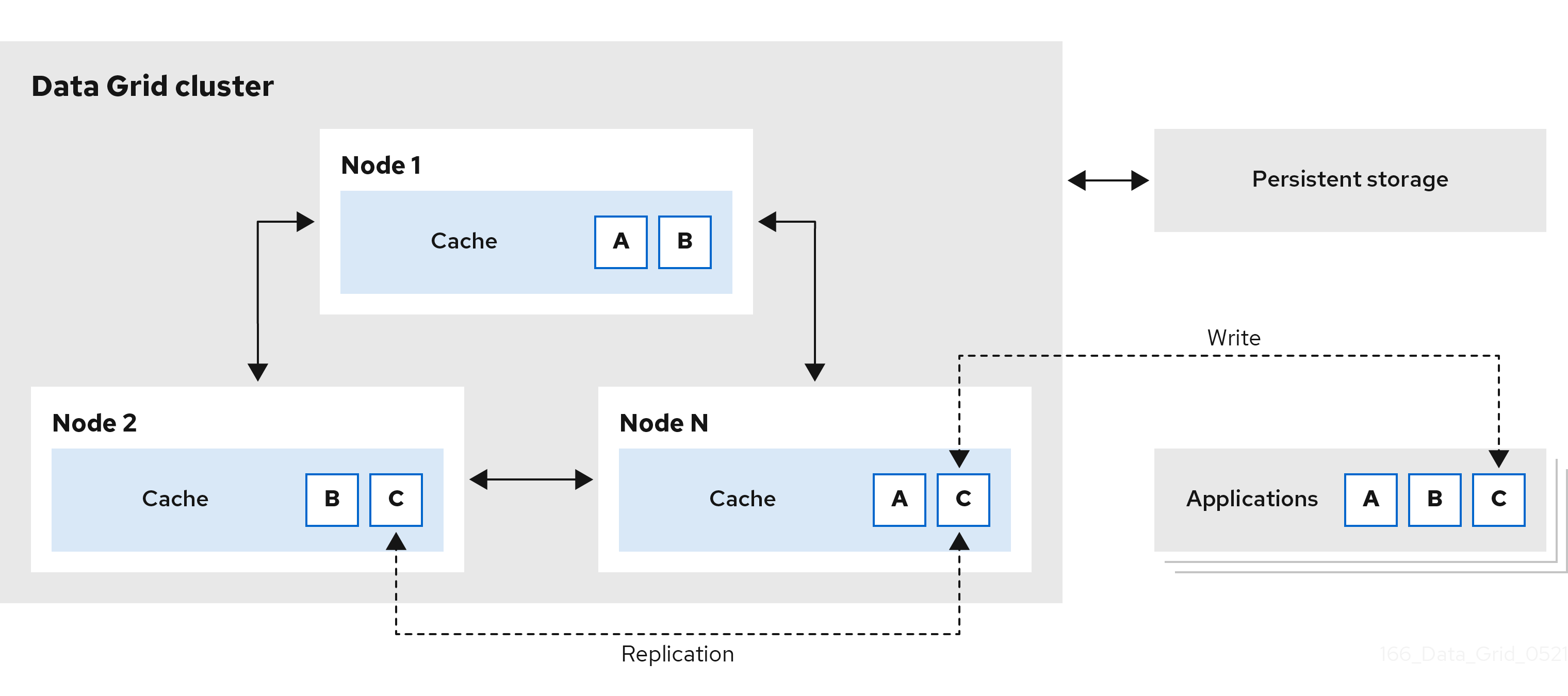
Data Grid 使用一致的哈希技术将每个条目的固定副本数存储在集群中的缓存中。分布式缓存允许您线性扩展数据层,在节点加入时增加容量。
分布式缓存为 Data Grid 集群添加冗余功能,以提供容错和持久性保证。Data Grid 部署通常会配置与持久性存储的集成,以保持集群状态,以便安全关闭并从备份中恢复。
图 1.4. 分布式缓存
1.5. 会话外部化
数据科学家可以为红帽构建的 Quarkus、Red Hat JBoss EAP、Red Hat JBoss Web Server 和 Spring 构建的应用程序提供外部缓存。这些外部缓存独立于应用层存储 HTTP 会话和其他数据。
将会话外部化到 Data Grid 为您提供了以下优点:
- 法国
- 无需在扩展应用程序时重新平衡操作。
- 内存占用较小
- 将会话数据存储在外部缓存中可减少应用程序的总内存要求。
图 1.5. 会话外部化

1.6. 跨站点复制
数据中心可以在地理分散数据中心和跨不同云供应商中运行的集群间备份数据。跨站点复制为 Data Grid 提供了一个全局集群视图,并:
- 在停机或灾难时保证服务连续性。
- 为客户端应用程序提供对全局分布式缓存中数据的单一访问点。
图 1.6. 跨站点复制
第 2 章 Data Grid 部署规划
要获得为您的 Data Grid 部署获得最佳性能,您应该执行以下操作:
- 计算数据集的大小。
- 确定哪种类型的集群缓存模式最适合您的用例和要求。
- 了解数据中心功能的性能权衡和注意事项,以提供容错和一致性保证。
2.1. 性能指标注意事项
Data Grid 包括许多可配置的组合,用于决定涵盖所有用例的性能指标的单一公式。
Data Grid 性能考虑和调优指南 文档的目的是提供有关用例和架构的详细信息,可帮助您确定数据网格部署的要求。
另外,请考虑以下适用于 Data Grid 的以下相关因素:
- 云环境中的可用 CPU 和内存资源
- 并行使用的缓存
- get, put, query balancing
- 峰值负载和吞吐量限制
- 对数据集的查询限制
- 每个缓存的条目数
- 缓存条目的大小
根据不同组合和未知外部因素的数量,提供满足所有 Data Grid 用例的性能计算。如果前面列出的任何因素都不同,则无法将一个性能测试与另一个测试进行比较。
您可以使用 Data Grid CLI 运行基本性能测试,该测试收集有限的性能指标。您可以自定义性能测试,以便测试结果可能会满足您的需要。测试结果提供基准指标,可帮助您确定数据网格缓存要求的设置和资源。
测量您当前的设置的性能,并检查它们是否满足您的要求。如果没有满足您的需求,请优化设置,然后重新衡量其性能。
2.2. 如何计算数据集的大小
规划 Data Grid 部署涉及计算您的数据集的大小,然后处理正确的节点数以及保存数据集的 RAM 数量。
您可以使用此公式估算数据集的总大小:
Data set size = Number of entries * (Average key size + Average value size + Memory overhead)使用远程缓存时,您需要以其 marshalled 格式计算密钥大小和值大小。
分布式缓存中的数据集大小
分布式缓存需要一些额外的计算来确定数据集的大小。
在正常操作条件中,分布式缓存为每个键/值条目存储多个副本,它们等于您配置的 所有者数。在集群重新平衡操作过程中,一些条目具有额外的副本,因此您应该计算 所有者数 + 1 以允许该场景。
您可以使用以下公式来调整分布式缓存的数据集大小的估算:
Distributed data set size = Data set size * (Number of owners + 1)计算分布式缓存的可用内存
分布式缓存允许您通过添加更多节点或增加每个节点的可用内存来增加数据集大小。
Distributed data set size <= Available memory per node * Minimum number of nodes为节点丢失容错调整
即使计划在集群中拥有固定数量的节点,您也应考虑所有还没有所有节点都处于集群中的所有节点的事实。分布式缓存容许 所有者数量 - 1 个节点而不丢失数据,因此除了适合数据集的最小节点数外,您还可以分配许多额外的节点。
Planned nodes = Minimum number of nodes + Number of owners - 1
Distributed data set size <= Available memory per node * (Planned nodes - Number of owners + 1)例如,您将计划存储 100万个大小为 10KB 的条目,每个条目的大小为 10KB,并为每个条目配置三个所有者。如果您计划为集群中的每个节点分配 4GB RAM,您可以使用以下公式来确定数据集所需的节点数量:
Data set size = 1_000_000 * 10KB = 10GB
Distributed data set size = (3 + 1) * 10GB = 40GB
40GB <= 4GB * Minimum number of nodes
Minimum number of nodes >= 40GB / 4GB = 10
Planned nodes = 10 + 3 - 1 = 122.2.1. 内存开销
内存开销是数据中心用来存储条目的额外内存。内存开销大约估计内存开销为 200 字节,在 JVM 堆内存中每个条目都有 200 字节,每个条目在内存不足中。然而,无法确定精确的内存开销,因为数据中心添加的开销取决于几个因素。例如,将数据容器与驱除绑定会导致 Data Grid 使用额外的内存来跟踪条目。同样,配置过期时间会为每个条目添加时间戳元数据。
查找任何确切的内存开销的唯一方法涉及 JVM 堆转储分析。JVM 堆转储并不为存储在内存不足中的条目提供信息,但内存开销比 JVM 堆内存要低得多。
额外内存用量
除了 Data Grid 为每个条目实施的内存开销外,重新平衡和索引等进程会增加总体内存用量。当节点加入并保留一些额外容量时,重新平衡集群操作,以防止在集群成员间复制条目时出现数据丢失。
2.2.2. JVM 堆空间分配
确定用于数据网格部署所需的内存卷,以便您有足够的数据存储容量来满足您的需求。
与设置垃圾回收(GC)时间相结合分配大内存堆大小可能会影响 Data Grid 部署的性能:
- 如果 JVM 只处理一个线程,GC 可能会阻断线程并降低 JVM 的性能。GC 可能会在部署之前运行。这个异步行为可能会导致大型 GC 暂停。
- 如果 CPU 资源较低,GC 与部署同步运行,则 GC 可能需要更频繁地运行可能会降低部署的性能。
下表概述了为数据存储分配 JVM 堆空间的两个示例。这些示例代表了部署集群的安全估算。
| 仅缓存操作,如读取、写入和删除操作。 | 为数据存储分配 50% 的 JVM 堆空间 |
| 缓存操作和数据处理,如查询和缓存事件监听程序。 | 为数据存储分配 33% JVM 堆空间 |
根据数据存储的模式更改和使用,您可能会考虑为 JVM 堆空间设置不同的百分比,而不是任何推荐的安全估算。
在启动 Data Grid 部署前,请考虑设置安全估算。启动部署后,检查 JVM 的性能和堆空间的 occupancy。当 JVM 的数据使用和吞吐量显著提高时,您可能需要重新调整 JVM 堆空间。
安全的估计是根据假设以下常见操作在 JVM 中运行而计算的。这个列表并不完整,您可以使用执行其他操作的目的设置这些安全估算之一。
- Data Grid 以序列化形式将对象转换为键值对。Data Grid 为缓存和持久性存储添加对。
- Data Grid 从远程连接加密和解密缓存到客户端。
- Data Grid 执行常规缓存查询以收集数据。
- 数据网格以战略方式将数据划分为段,以确保在集群间有效地分布数据,即使在状态传输操作期间也是如此。
- GC 执行更频繁的垃圾回收,因为 JVM 为 GC 操作分配了大量内存。
- GC 动态管理和监控 JVM 堆空间中的数据对象,以确保安全地删除未使用的对象。
为数据存储分配 JVM 堆空间时,以及确定 Data Grid 部署的内存和 CPU 要求时,请考虑以下因素:
- 集群缓存模式。
段数。
- 例如,少量的片段可能会影响服务器在节点间分发数据的方式。
- 读取或写入操作。
重新平衡要求。
- 例如,大量线程可能会在状态传输过程中快速并行运行,但每个线程操作可能会使用更多内存。
- 扩展集群。
- 同步或异步复制。
大多数需要高 CPU 资源的 Data Grid 操作包括重新平衡节点,在 pod 重启后运行索引查询,以及执行 GC 操作。
离线存储
Data Grid 使用对象的 JVM 堆表示来处理缓存上的读写操作,或者执行其他操作,如状态传输操作。您必须始终为 Data Grid 分配一些 JVM 堆空间,即使您将条目存储在非堆内存中。
与在 JVM 堆空间中存储的数据存储相比,Data Grid 使用的 JVM 堆内存卷要小得多。off-heap 存储的 JVM 堆内存要求使用与存储条目数相同的并发操作数进行扩展。
Data Grid 使用拓扑缓存为客户端提供集群视图。
如果您从 Data Grid 集群中收到任何 OutOfMemoryError 异常,请考虑以下选项:
- 禁用状态传输操作,如果节点加入或离开集群,可能会导致数据丢失。
- 通过以密钥大小和节点和网段的数量来重新计算 JVM 堆空间。
- 使用更多节点更好地管理集群的内存消耗。
- 使用一个节点,因为这可能会使用较少的内存。但是,如果要将集群扩展到其原始大小,请考虑其影响。
2.3. 集群缓存模式
您可以将集群的 Data Grid 缓存配置为复制或分发。
- 分布式缓存
- 通过在集群中为每个条目创建较少的副本来最大化容量。
- 复制缓存
- 通过在集群中的每个节点上创建所有条目的副本来提供冗余。
Read:Writes
考虑您的应用程序是否执行更多写操作还是更多读取操作。通常,分布式缓存为写入提供了最佳性能,而复制缓存为读取提供最佳性能。
要将 k1 放置到具有三个所有者的三个节点的分布式缓存中,Data Grid 将 k1 写入 k1 两次。复制缓存中的同一操作意味着 Data Grid 写入 k1 三次。每个写入复制缓存的额外网络流量数量等于集群中的节点数量。在 10 个节点的集群中复制缓存会导致对写入的流量增加十倍。您可以使用带有多播进行集群传输的 UDP 堆栈来最小化流量。
若要从复制缓存获取 k1,每个节点都可以在本地执行读取操作。但是,若要从分布式缓存获取 k1,处理该操作的节点可能需要从集群中的不同节点检索密钥,这会导致额外的网络跃点并增加读操作完成的时间。
客户端智能和接近缓存
Data Grid 使用一致的哈希技术使 Hot Rod 客户端拓扑感知并避免额外的网络跃点,这意味着读取操作对分布式缓存的性能相同,因为它们对复制缓存具有同样的性能。
热 Rod 客户端也可以使用接近缓存功能在本地内存中保持频繁访问的条目,并避免重复读取。
分布式缓存是大多数数据平面服务器部署的最佳选择。您可以获得读写操作的最佳性能,以及集群扩展的参与。
数据保证
由于每个节点包含所有条目,复制缓存比分布式缓存提供更多数据丢失。在三个节点的集群上,两个节点可能会崩溃,且不会丢失复制缓存中的数据。
在这种情况下,具有两个所有者的分布式缓存将会丢失数据。为了避免使用分布式缓存进行数据丢失,您可以通过以编程方式为每个条目配置更多 所有者 来增加集群中的副本数量。
在节点失败时重新平衡操作
在节点失败后重新平衡操作可能会影响性能和容量。当节点离开集群时,Data Grid 会在剩余成员内复制缓存条目,以恢复配置的拥有者数。此重新平衡操作是临时的,但增加的集群流量会对性能造成负面影响。性能下降越大,节点会保留更多。当太多节点离开时,集群中保留的节点可能没有足够的容量来在内存中保留所有数据。
集群扩展
Data Grid 集群随着工作负载需求水平扩展,以便更有效地使用计算资源,如 CPU 和内存。要充分利用这种技术的最大优势,您应该考虑如何扩展节点或缩减节点会影响缓存容量。
对于复制缓存,每个节点都加入集群时,它会收到数据集的完整副本。将所有条目复制到每个节点会增加节点加入和强制实施总体容量限制所需的时间。复制缓存永远不会超过主机可用的内存量。例如,如果数据集的大小为 10 GB,则每个节点必须至少有 10 GB 可用内存。
对于分布式缓存,添加更多节点会增加容量,因为集群中的每个成员都只存储数据的子集。要存储 10 GB 的数据,如果所有者数量为 2,则可以有 8 个节点最多 5 GB 可用内存,而无需考虑内存开销。加入集群的每个额外节点会将分布式缓存的容量增加到 5 GB。
分布式缓存的容量不会与底层主机可用的内存量绑定。
同步或异步复制
当主所有者向备份节点发送复制请求时,数据科学家可以同步或异步通信。
| 复制模式 | 影响性能 |
|---|---|
| 同步 | 同步复制有助于保持数据一致,但为集群流量增加延迟,从而减少缓存写入吞吐量。 |
| 异步 | 异步复制可减少延迟并增加写入操作的速度,但会导致数据不一致,并对数据丢失提供较低的保证。 |
通过同步复制,当复制请求在备份节点上完成时,Data Grid 会通知原始节点。如果复制请求因为集群拓扑更改而失败,则数据中心会重试操作。当复制请求因为其他错误而失败时,Data Grid 会抛出客户端应用程序的异常。
使用异步复制时,数据平面不会为复制请求提供任何确认。这对应用程序的影响相同,因为所有请求都成功。但是,在 Data Grid 集群中,主所有者具有正确的条目,Data Grid 会在以后将其复制到备份节点。如果主所有者崩溃,则备份节点可能没有条目的副本,或者它们可能没有日期副本。
集群拓扑更改还可能会导致数据与异步复制不一致。例如,假设有一个具有多个主所有者的 Data Grid 集群。由于网络错误或某些其他问题,一个或多个主所有者会意外保留集群,因此 Data Grid 更新哪些节点是片段的主所有者。当发生这种情况时,一些节点理论上可能会使用旧的集群拓扑和一些节点来使用更新的拓扑。通过异步通信,这可能会导致一个短的时间,Data Grid 处理来自之前拓扑的复制请求,并从写入操作中应用旧的值。但是,Data Grid 可以快速检测节点崩溃和更新集群拓扑更改,因为这种情况不会影响许多写入操作。
使用异步复制不能保证写入吞吐量,因为异步复制会将节点可以随时处理的备份写入数量限制为可能发送的发送者数(通过 JGroups 每发送者排序)。同步复制允许节点同时处理更多传入的写入操作,在某些配置中,单个操作需要更长的时间完成,从而为您提供更高的吞吐量。
当节点向复制条目发送多个请求时,JGroups 会一次向集群中的其他节点发送消息,这会导致每个原始节点只有一个复制请求。这意味着 Data Grid 节点可以与其他写入操作并行处理,每个写入操作对集群中的每个节点进行写入操作。
Data Grid 在集群传输层中使用 JGroups 流控制协议来处理备份节点的复制请求。如果未确认的复制请求数超过流控制阈值,则使用 max_credits 属性(默认为4MB)设置,则原始节点上阻止写操作。这适用于同步和异步复制。
片段数
Data Grid 将数据分成网段,以在集群间平均分配数据。即使部分分布也会避免过载单个节点,并使集群重新平衡操作效率更高。
默认情况下,数据中心会为每个集群创建 256 个哈希空间片段。对于每个集群最多 20 个节点的部署,这个片段是理想的选择,不应更改。
对于每个集群有超过 20 个节点的部署,增加片段数量会增加数据的粒度,以便 Data Grid 可以更有效地在集群中分发它。使用以下公式来计算您应该配置的片段数量:
Number of segments = 20 * Number of nodes例如,对于 30 个节点的集群,您应该配置 600 个片段。为较大的集群添加更多片段通常是一个很好的想法,但此公式应让您了解正确的部署数字。
更改片段数据网格创建的数量需要完全重启集群。如果您使用持久性存储,您可能还需要使用 StoreMigrator 工具更改片段数量,具体取决于缓存存储实施。
更改片段数量还可能导致数据崩溃,因此您应该根据从基准测试和性能监控收集的指标谨慎,并谨慎操作。
Data Grid 始终在内存中的片段数据。当您配置缓存存储时,Data Grid 并不总是在持久性存储中分段数据。
它依赖于缓存存储实施,但尽可能为缓存存储启用分段。在迭代持久性存储中的数据时,分段缓存存储可提高数据中心性能。例如,对于基于 RocksDB 和 JDBC 字符串的缓存存储,分段可减少数据中心从数据库检索的对象数量。
2.4. 管理过时的数据的策略
如果 Data Grid 不是数据的主要来源,嵌入式和远程缓存会按性质过时。在规划、基准测试和调优您的数据平面部署时,为您的应用程序选择适当的缓存过时性。
选择一个级别,供您最好使用可用 RAM,并避免缓存丢失。如果 Data Grid 没有在内存中的条目,则在应用程序发送读取和写入请求时调用主存储。
缓存丢失会增加读取和写入的延迟,但在很多情况下,对主存储的调用比 Data Grid 的性能损失要高得多。其中一个例子是将相关数据库管理系统(RDBMS)卸载到 Data Grid 集群。以这种方式部署数据中心可显著降低运行传统数据库的财务成本,从而在缓存中容忍更高级别的过时的条目。
借助 Data Grid,您可以为条目配置最大空闲和生命周期值,以保持可接受的缓存过时级别。
- 过期
- 控制数据平面将条目保留在缓存中的时间,并在集群间生效。
较高的过期值意味着条目保留在内存中,这会增加读取操作返回过时值的可能性。较低过期值表示缓存中存在较少的过时的值,但缓存丢失的可能性更大。
为了过期,Data Grid 会从现有的线程池中创建一个获取者。线程的主要性能考虑是配置过期运行之间的正确间隔。较短的间隔执行更频繁的过期时间,但使用更多线程。
另外,对于最大闲置过期,您可以控制 Data Grid 如何在集群中更新时间戳元数据。Data Grid 发送 touch 命令,以在节点间同步或异步协调最大空闲过期时间。通过同步复制,您可以根据您首选的一致性还是速度选择"同步"或"同步"触点命令。
2.5. 使用驱除进行 JVM 内存管理
RAM 是一个昂贵的资源,通常限制在可用性中。Data Grid 可让您通过从内存中删除条目来管理内存用量,为经常使用的数据赋予优先级。
- 驱除
- 控制 Data Grid 保留在内存中的数据量,并对每个节点生效。
驱除范围 Data Grid 缓存:
- 条目总数,最大计数。
- JVM 内存量,最大大小。
Data Grid 根据每个节点驱除条目。因为不是所有节点都驱除同一条目,所以您应该将驱除与持久性存储搭配使用,以避免数据不一致。
驱除的性能影响来自额外的处理,当缓存的大小达到配置的阈值时,需要计算这些数据网格。
驱除也会减慢读取操作的速度。例如,如果读取操作从缓存存储中检索条目,Data Grid 会将该条目置于内存中,然后驱除另一个条目。如果使用传递,此驱除过程可能包括将新被驱除的条目写入缓存存储。发生这种情况时,读取操作不会返回值,直到驱除过程完成为止。
2.6. JVM 堆和非堆内存
默认情况下,Data Grid 将缓存条目存储在 JVM 堆内存中。您可以将 Data Grid 配置为使用下游存储,这意味着您的数据在受管 JVM 内存空间外占用原生内存。
下图显示了运行 Data Grid 的 JVM 进程的内存空间的简化:
图 2.1. JVM 内存空间

JVM 堆内存
堆被分为您和旧的生成,可帮助在内存中保留引用的 Java 对象和其他应用程序数据。GC 进程从无法访问的对象回收空间,并在您的生成内存池中更频繁地运行。
当 Data Grid 将缓存条目存储在 JVM 堆内存中时,GC 运行可能需要更长时间才能完成,因为开始将数据添加到缓存中。因为 GC 是一个密集型进程,所以更长且更频繁的运行可能会降低应用程序性能。
离线内存
脱机内存是 JVM 内存管理之外的原生可用内存。JVM 内存空间 图显示包含类元数据并从原生内存分配的 Metaspace 内存池。图也代表了包含 Data Grid 缓存条目的原生内存部分。
离线内存:
- 每个条目使用较少的内存。
- 通过避免 Garbage Collector (GC)运行来提高整体 JVM 性能。
但是,一个缺点是 JVM 堆转储不显示存储在非堆内存中的条目。
2.6.1. 离线数据存储
当您向离线缓存中添加条目时,Data Grid 会动态为您的数据分配原生内存。
Data Grid 将每个密钥的序列化 字节[] 哈希散列到与标准 Java HashMap 类似的存储桶中。bucket 包括数据中心用来查找存储在非堆内存中的条目的地址指针。
虽然数据平面将缓存条目存储在原生内存中,但运行时操作需要这些对象的 JVM 堆表示。例如,cache.get () 操作会在返回前将对象读取为堆内存。同样,状态传输操作会在堆内存中保存对象的子集。
对象相等
Data Grid 使用每个对象的 serialized byte[] 表示(而非对象实例)决定非堆存储中的 Java 对象的相等性。
数据一致性
Data Grid 使用一组锁定来保护堆的地址空间。锁定数量是内核数的两倍,然后舍入到最接近的 2 的指数。这样可确保 ReadWriteLock 实例甚至分发,以防止写入操作阻止读操作。
2.7. 持久性存储
配置数据仓库以与持久数据源交互可严重影响性能。这个性能损失来自于,传统数据源比内存缓存要慢得多。当调用超出 JVM 时,读取和写入操作总是需要更长的时间。但是,根据您使用缓存存储的方式,数据网格性能降低会降低性能降低,从而提高了内存数据在访问持久性存储中的数据。
使用持久性存储配置 Data Grid 部署也提供了其他好处,例如允许您为安全集群关闭保留状态。您还可以将缓存中的数据溢出到持久性存储,并获得超过内存中可用容量。例如,您可以总有十千个条目,同时只在内存中保留 200万个条目。
Data Grid 添加键/值对,以便以 write-through 模式或 write-behind 模式缓存和持久性存储。由于这些写入模式对性能有不同影响,所以您必须在规划 Data Grid 部署时考虑它们。
| 编写模式 | 影响性能 |
|---|---|
| write-through | Data Grid 同时将数据写入缓存和持久性存储,这会提高一致性并避免可能导致节点故障的数据丢失。
直写模式外,同步写入会增加延迟并降低吞吐量。 |
| write-behind | Data Grid 同步将数据写入缓存,然后将修改添加到队列中,以便异步对持久性存储的写入进行,这可以降低一致性,但降低了写入操作的延迟。 当缓存存储无法处理写入操作数量时,Data Grid 会延迟新的写入操作,直到待处理的写入操作的数量低于配置的修改队列大小,方式与直写队列大小类似。如果存储通常足够快,但在缓存写入突发过程中发生延迟,您可以增加修改队列大小,使其包含突发并缩短延迟。 |
passivation
启用传递配置 Data Grid 仅在从内存中驱除条目时将条目写入持久性存储。传递也意味着激活。对键执行读取或写入会导致该密钥回到内存中,并将它从持久性存储中删除。在激活过程中从持久性存储中删除密钥不会阻止读取或写入操作,但它会增加外部存储的负载。
传递和激活可能会导致数据平面为缓存中给定条目执行多个持久性存储调用。例如,如果内存中没有可用条目,Data Grid 会将它回到内存中,这是一个读取操作,以及将其从持久性存储中删除的 delete 操作。另外,如果缓存达到大小限制,Data Grid 会执行另一个写入操作来传递新被驱除的条目。
使用数据预加载缓存
可能会影响 Data Grid 集群性能的持久性存储的另一个方面是预加载缓存。当 Data Grid 集群启动时,此功能填充您的缓存,以便它们是"warm",并可直接处理读取和写入。预加载缓存可能会减慢 Data Grid 集群启动速度,如果持久性存储中的数据量大于可用 RAM 量,则会导致内存不足异常。
2.8. 集群安全性
保护您的数据并防止网络入侵是部署规划最重要的方面之一。敏感的客户详情会泄漏到开放互联网或数据被破坏,从而使黑客公开机密信息对业务造成影响。
考虑到这一点,您需要一个强大的安全策略来验证用户和加密网络通信。但是您的数据中心部署性能是多少?在规划过程中,您应该如何处理这些注意事项?
身份验证
验证用户凭证的性能成本取决于机制和协议。数据中心通过 Hot Rod 验证一次用户一次的凭证,同时可能对每个通过 HTTP 的请求进行请求。
| SASL 机制 | HTTP 机制 | 性能影响 |
|---|---|---|
|
|
|
虽然 |
|
|
|
对于 Hot Rod 和 HTTP 请求,
对于 Hot Rod 端点, |
|
|
| Kerberos 服务器密钥分发中心(KDC),为用户处理身份验证和签发令牌。数据中心的性能从独立系统处理用户身份验证操作的事实中受益。但是,这些机制可以根据 KDC 服务本身的性能造成网络瓶颈。 |
|
|
| 联邦身份提供程序,实施 OAuth 标准,为 Data Grid 用户发出临时访问令牌。用户使用身份服务进行身份验证,而不是直接向 Data Grid 进行身份验证,而是将访问令牌作为请求标头传递。与直接处理身份验证相比,Data Grid 的性能损失较低来验证用户访问令牌。与 KDC 类似,实际性能影响取决于身份提供程序本身的服务质量。 |
|
|
| 您可以向 Data Grid 服务器提供信任存储,以便它通过比较客户端与信任存储中存在的证书来验证入站连接。 如果信任存储只包含签名证书(通常是证书颁发机构(CA)),则任何提供 CA 签名的证书的客户端都可以连接到 Data Grid。这提供了较低的安全性,并容易受到 MITM 攻击,但比验证每个客户端的公共证书要快。 如果信任存储还包含除签名证书外的所有客户端证书,则只有存在信任存储中签名的证书的客户端才可以连接到 Data Grid。在这种情况下,Data Grid 将客户端提供的证书中的常用通用名称(CN)与信任存储进行比较,同时验证证书是否已签名,从而增加更多开销。 |
加密
加密集群传输安全,因为它在节点间传递,并防止您的数据平面部署不受 MITM 攻击的影响。当加入集群时,节点会执行 TLS/SSL 握手,该集群会牺牲性能损失,并通过额外的往返增加延迟。但是,在每个节点建立连接后,它会永久保持连接,假设连接永不处于闲置状态。
对于远程缓存,Data Grid 服务器也可以加密与客户端的网络通信。在性能方面,客户端和远程缓存之间的 TLS/SSL 连接的影响是相同的。必要安全连接需要更长的时间,需要一些额外的工作,但一旦连接从加密建立延迟时,对数据平面性能没有问题。
除了使用 TLSv1.3 外,对加密的性能丢失的唯一方法是配置数据平面运行的 JVM。例如,使用 OpenSSL 库而不是标准 Java 加密可以更有效地处理结果,从而更快地获得 20%。
授权
基于角色的访问控制(RBAC)可让您限制对数据的操作,为部署提供额外的安全性。RBAC 是实现最小特权策略的最佳方法,供用户访问在 Data Grid 集群中分发的数据。Data Grid 用户必须有足够的级别授权来读取、创建、修改或从缓存中删除数据。
添加另一个安全层来保护您的数据始终会牺牲性能成本。授权为操作添加一些延迟,因为数据科学家会在允许用户操作数据前针对访问控制列表(ACL)验证每个延迟。但是,对授权性能的整体影响要低于加密,因此可以受益于通常平衡的成本。
2.9. 客户端监听程序
每当 Data Grid 集群中添加、删除或修改数据时,客户端监听器都会提供通知。
例如,每当温度在给定位置更改时,以下实现会触发事件:
@ClientListener
public class TemperatureChangesListener {
private String location;
TemperatureChangesListener(String location) {
this.location = location;
}
@ClientCacheEntryCreated
public void created(ClientCacheEntryCreatedEvent event) {
if(event.getKey().equals(location)) {
cache.getAsync(location)
.whenComplete((temperature, ex) ->
System.out.printf(">> Location %s Temperature %s", location, temperature));
}
}
}在 Data Grid 集群中添加监听程序会为您的部署添加性能注意事项。
对于嵌入式缓存,监听器使用与 Data Grid 相同的 CPU 内核。接收许多事件并使用大量 CPU 来处理这些事件的监听程序可减少 Data Grid 可用的 CPU,并减慢所有其他操作的速度。
对于远程缓存,Data Grid 服务器使用内部进程来触发客户端通知。Data Grid Server 将事件从主所有者节点发送到注册监听程序的节点,然后再将其发送到客户端。Data Grid Server 还包含一个后端机制,在客户端监听器处理事件过慢时延迟写操作,以延迟写操作。
过滤监听程序事件
如果每个写入操作调用监听程序,Data Grid 可以生成大量事件,在集群内和外部客户端创建网络流量。它都取决于每个监听器注册多少个客户端、它们触发的事件类型以及您的 Data Grid 集群上的数据变化。
作为远程缓存的示例,如果您有十个客户端注册了 10 个事件,则 Data Grid Server 会在网络间发送 100 个事件。
您可以使用自定义过滤器为 Data Grid Server 提供自定义过滤器,以减少到客户端的流量。过滤器允许 Data Grid Server 先处理事件,并确定是否将它们转发到客户端。
持续查询和监听程序
持续查询允许您接收匹配条目的事件,并提供部署客户端监听程序和过滤监听程序事件的替代选择。课程查询具有额外的处理成本,但如果您已经使用持续查询而不是客户端侦听器进行索引和执行查询,则需要考虑这些处理成本。
2.10. 索引和查询缓存
查询数据平面缓存可让您分析和过滤数据以获得实时分析。例如,一个在线游戏,其中播放者以某种方式相互竞争。如果要在任何时间点上使用前十个播放器实现领导板,您可以创建一个查询来查找哪个播放者在任意时间点上具有最多点,并将结果限制为最多 10 个,如下所示:
QueryFactory queryFactory = Search.getQueryFactory(playersScores);
Query topTenQuery = queryFactory
.create("from com.redhat.PlayerScore ORDER BY p.score DESC, p.timestamp ASC")
.maxResults(10);
List<PlayerScore> topTen = topTenQuery.execute().list();前面的示例演示了使用查询的好处,因为它可让您找到与可能数百万缓存条目相关的条件的十个条目。
但是,在性能影响方面,您应该考虑索引操作与查询操作所带来的权衡。将 Data Grid 配置为索引缓存可更快地进行查询。如果没有索引,查询必须滚动缓存中的所有数据,根据类型和数据数量,按 magnitude 的顺序减慢结果。
在启用索引时,对写入的性能有可测量的丢失。但是,由于一些小心的计划,并对要索引的内容有很好的了解,您可以避免影响最差。
最有效的方法是将 Data Grid 配置为仅索引您需要的字段。无论您存储 Plain Old Java 对象(POJO)还是使用 Protobuf 模式,您注解的更多字段都会花费更长的字段来构建索引。如果您有一个含有五个字段的 POJO,但您只需要查询这两个字段,请不要将 Data Grid 配置为索引您不需要的三个字段。
Data Grid 为您提供了几个选项来调优索引操作。例如,Data Grid 存储索引与数据不同,请将索引保存到磁盘而不是内存。每当添加、修改或删除条目时,使用索引写入器将索引与缓存保持与缓存同步。如果您启用索引,然后观察到较慢的写入,并考虑索引会导致性能丢失,您可以在写入磁盘前将索引保留在内存缓冲区中,以便更长的时间。这会更快地进行索引操作,并有助于降低写入吞吐量,但会消耗更多内存。对于大多数部署,但默认索引配置都适合,且不会减慢写入速度。
在某些情况下,可能不对缓存进行索引,比如对于需要查询不经常查询的写密集型缓存,且不需要产生毫秒。它都取决于您要实现的功能。更快的查询意味着更快的读取速度,但会牺牲索引的较慢的写入成本。
2.10.1. 持续查询和数据平面性能
持续查询为应用程序提供恒定的更新流,生成大量事件。Data Grid 会临时为它生成的每个事件分配内存,这可能会导致内存压力,并可能导致 OutOfMemoryError 异常,特别是远程缓存。因此,您应该仔细设计您的持续查询以避免任何性能影响。
Data Grid 强烈建议您将持续查询的范围限制为您需要的最小信息量。要达到此目的,您可以使用 projections 和 predicates。例如,以下语句只提供有关与条件匹配而不是整个条目的字段子集的结果:
SELECT field1, field2 FROM Entity WHERE x AND y
确保您创建的每个 ContinuousQueryListener 都可以快速处理所有接收的事件,而不阻断线程。要达到此目的,您应该避免任何不必要的生成事件的缓存操作。
2.11. 数据一致性
驻留在分布式系统上的数据容易受到临时网络中断、系统故障或简单人为错误造成的错误。这些外部因素不可控制,但可能会对数据的质量造成严重后果。数据崩溃的影响从较低的客户参与到昂贵的系统协调,这会导致服务不可用。
数据中心可以执行 ACID (绿色、一致、隔离、持久)事务,以确保缓存状态一致。
事务是数据中心以单一操作形式进行的一系列操作。事务中的所有写入操作都成功完成,或者它们都失败。这样,事务会以一致的方式修改缓存状态,提供读取和写入的历史记录,或者根本不修改缓存状态。
启用事务的主要性能问题是在具有更加一致的数据集和增加延迟来降低写入吞吐量的延迟之间平衡。
使用事务写入锁定
配置错误的锁定模式可能会对事务的性能造成负面影响。正确的锁定模式取决于您的 Data Grid 部署是否有高或低的密钥竞争率。
对于争用率较低的工作负载,其中两个或多个事务可能无法同时写入同一密钥,因此最佳锁定可提供最佳性能。
Data Grid 在事务提交前在密钥上获取写入锁定。如果密钥争用,获取锁定所需的时间可能会延迟提交。另外,如果 Data Grid 检测到冲突的写入,它会回滚事务,应用程序必须重试它,增加延迟。
对于具有高竞争率的工作负载,pessimistic locking 可提供最佳性能。
当应用程序访问它们以确保其他事务都不可修改密钥时,数据科学家在密钥上获取写入锁定。事务提交在单个阶段完成,因为密钥已经被锁定。通过多个关键事务进行模拟锁定会导致 Data Grid 锁定密钥更长的时间,这可以降低写入吞吐量。
读取隔离
除使用 REPEATABLE_READ 锁定外,隔离级别不会影响数据中心性能考虑。在这个版本中,Data Grid 会检查写入 skews 以检测冲突,这可能会导致较长的事务提交阶段。Data Grid 还使用版本元数据来检测冲突的写入操作,这可能会增加每个条目的内存量,并为集群生成额外的网络流量。
事务恢复和分区处理
如果网络因为分区或其他问题而不稳定,Data Grid 可将事务标记为"in-doubt"。当发生这种情况时,它会保留它获取的写入锁定,直到网络稳定,并且集群返回到健康的操作状态。在某些情况下,系统管理员可能需要手动完成任何"in-doubt"事务。
2.12. 网络分区和降级的集群
Data Grid 集群可能会遇到脑裂情况,其中集群中的节点子集相互隔离,节点之间的通信也会被取消加入。当发生这种情况时,在次要分区中的 Data Grid 缓存进入 DEGRADED 模式,同时大多数分区中的缓存仍然可用。
垃圾回收(GC)暂停是网络分区的最常见原因。当 GC 暂停节点时,Data Grid 集群可以在脑裂网络中启动操作。
通过使用 OpenJDK 的 Shenandoah 实现,而不是处理网络分区,而是尝试通过控制 JVM 堆使用情况来避免 GC 暂停。
CAP theorem 和分区处理策略
CAP theorem 代表分布式、键/值数据存储的限制,如 Data Grid。当发生网络分区事件时,您必须选择一致性或可用性,同时 Data Grid 修复分区并解决任何冲突的条目。
- 可用性
- 允许读取和写入操作。
- 一致性
- 拒绝读写操作。
数据中心还可以允许读取,同时将集群重新连接在一起。此策略是通过允许应用程序访问(潜在的)数据来拒绝对条目和可用性的写入来实现一致性选项。
删除分区
作为加入集群并返回到正常操作过程的一部分,Data Grid 会根据合并策略解析冲突条目。
默认情况下,Data Grid 不会尝试解决合并冲突,这意味着集群很快返回到健康状态,且除正常的集群重新平衡外,性能不会牺牲。然而,在这种情况下,缓存中的数据更有可能不一致。
如果您配置合并策略,则 Data Grid 需要更长的时间来修复分区。配置合并策略会导致 Data Grid 从每个缓存中检索条目的每个版本,然后解决以下冲突:
|
| Data Grid 找到集群中大多数节点上存在的值并应用它,这可从日期值中恢复。 |
|
| Data Grid 应用集群中找到的第一个非空值,该值可以从日期值中恢复。 |
|
| Data Grid 会删除任何具有冲突值的条目。 |
2.12.1. 垃圾回收和分区处理
长时间垃圾回收(GC)时间可以增加数据中心检测网络分区所需的时间。在某些情况下,GC 可能会导致 Data Grid 超过对分割的最大时间。
另外,当在分割后合并分区时,Data Grid 会尝试确认集群中存在所有节点。因为没有超时或上限适用于节点的响应时间,所以合并集群视图的操作可能会延迟。这可能会导致网络问题以及 GC 时间。
GC 通过分区处理可能会影响性能的另一个场景是,GC 挂起 JVM,从而导致一个或多个节点离开集群。当发生这种情况时,在 GC 完成后暂停节点会恢复,节点可能会没有日期或冲突的集群拓扑。
如果配置了合并策略,Data Grid 会在合并节点前尝试解决冲突。但是,只有在节点具有不兼容的哈希时才使用合并策略。如果每个片段至少有一个通用所有者,则两个一致的哈希是兼容的,或者至少有一个片段的通用所有者。
当节点具有旧的但兼容且一致的哈希时,Data Grid 会忽略过时的集群拓扑,且不会尝试解决冲突。例如,如果因为垃圾回收(GC)造成集群中的一个节点被暂停,集群中的其他节点会从一致的哈希值中删除,并将其替换为新的所有者节点。如果 numOwners > 1,旧的一致的哈希和新的一致的哈希为每个键都有一个通用所有者,从而使它们兼容,并允许数据仓库跳过冲突解析过程。
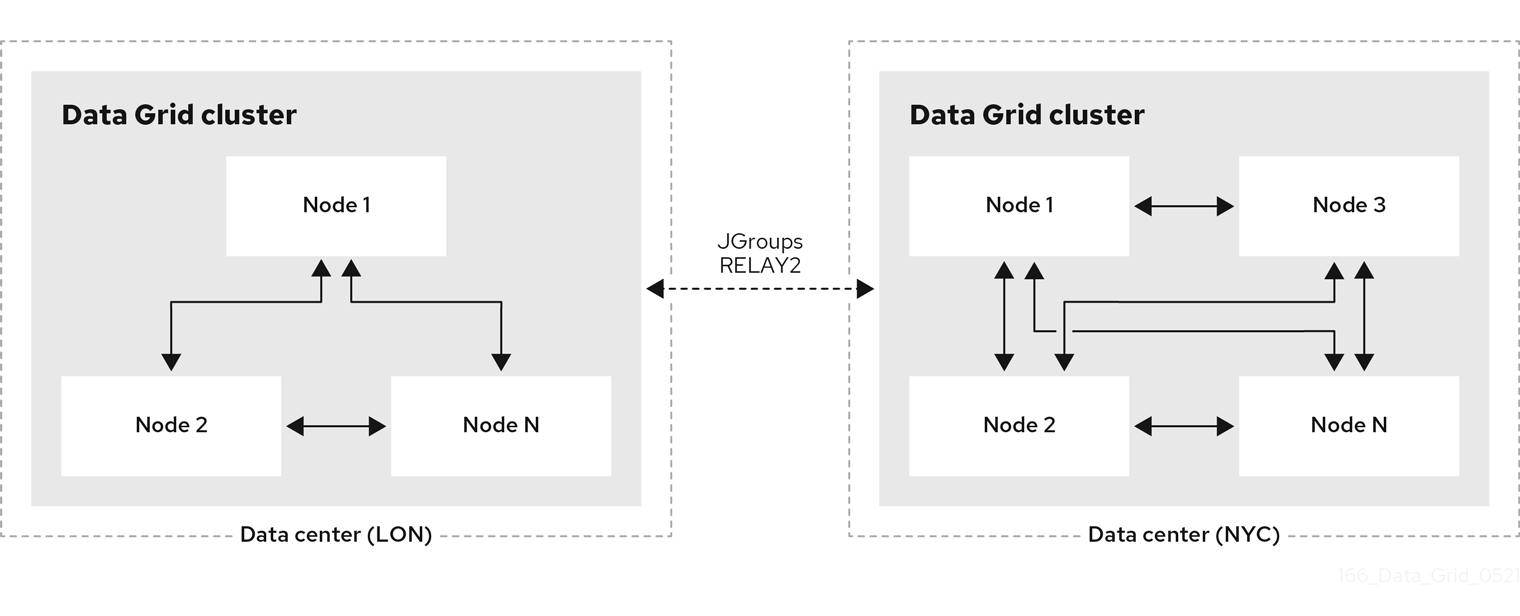
2.13. 集群备份和恢复
执行跨站点复制的数据中心集群通常会"匿名"整个 CPU 和内存分配。当您考虑跨站点复制的大小时,主要问题是集群间的状态传输操作的影响。
例如,NYC 中的 Data Grid 集群离线,客户端切换到 LON 中的 Data Grid 集群。当 NYC 中的集群重新上线时,状态传输是从 LON 到 NYC。此操作可防止客户端的过时的读取,但对集群接收状态传输的性能损失。
您可以在集群中分发状态传输操作所需的处理增加。但是,状态传输操作的性能影响完全取决于环境和因素,如数据集的类型和大小。
Active/Active 部署的冲突解析
当多个站点处理客户端请求时,Data Grid 会检测与并发写入操作冲突,称为 Active/Active 站点配置。
以下示例演示了并发写入如何为 LON 和 NYC 数据中心中运行的 Data Grid 集群产生冲突条目:
LON NYC
k1=(n/a) 0,0 0,0
k1=2 1,0 --> 1,0 k1=2
k1=3 1,1 <-- 1,1 k1=3
k1=5 2,1 1,2 k1=8
--> 2,1 (conflict)
(conflict) 1,2 <--
在 Active/Active 站点配置中,您不应该使用同步备份策略,因为并发写入会导致死锁并丢失数据。借助异步备份策略(policy=async),数据科学家为您提供了处理并发写入的跨站点合并策略。
就性能而言,Data Grid 用来解决冲突的合并策略需要额外的计算,但通常不会造成显著的损失。例如,默认的跨站点合并策略使用字典比较或"字符串比较",这需要几纳秒才能完成。
Data Grid 还为跨站点合并策略提供了一个 XSiteEntryMergePolicy SPI。如果您确实将 Data Grid 配置为解决与自定义实现冲突,您应该始终监控性能以监管任何负面影响。
XSiteEntryMergePolicy SPI 调用非阻塞线程池中的所有合并策略。如果您实现了阻塞自定义合并策略,它可能会耗尽线程池。
您应该将复杂或阻止策略委派给不同的线程,并且您的实施应返回当合并策略在其他线程中执行时完成的 CompletionStage。
2.14. 代码执行和数据处理
分布式缓存的一个优点是,您可以利用每个主机的计算资源更有效地执行大型数据处理。通过在 Data Grid 上直接执行您的处理逻辑,您可以将工作负载分散到多个 JVM 实例中。您的代码也在数据存储数据的相同内存空间中运行,这意味着您可以更快地迭代条目。
对于您的 Data Grid 部署的性能影响,这完全取决于您的代码执行。更复杂的处理操作具有更高的性能降低,因此您应该通过仔细规划在 Data Grid 集群中运行的任何代码。首先测试您的代码并在较小的样本数据集上执行多个执行。收集了一些指标后,您可以开始识别优化,并了解您正在运行的代码的性能影响。
一个确定的是,长时间运行的进程可能会开始对正常读写操作造成负面影响。因此,您必须随着时间的推移监控部署并持续评估性能。
嵌入式缓存
借助嵌入式缓存,Data Grid 提供了两个 API,可让您在与数据相同的内存空间中执行代码。
ClusterExecutorAPI- 可让您通过缓存管理器执行任何操作,包括迭代一个或多个缓存的条目,并根据 Data Grid 节点处理。
CacheStreamAPI- 可让您对集合执行操作,并根据数据进行处理。
如果要在单一节点、一组节点或特定地区中的所有节点上运行操作,那么您应该使用集群执行。如果要运行一个可保证整个数据集的正确结果的操作,则使用分布式流更为有效的选项。
集群执行
ClusterExecutor clusterExecutor = cacheManager.executor();
clusterExecutor.singleNodeSubmission().filterTargets(policy);
for (int i = 0; i < invocations; ++i) {
clusterExecutor.submitConsumer((cacheManager) -> {
TransportConfiguration tc =
cacheManager.getCacheManagerConfiguration().transport();
return tc.siteId() + tc.rackId() + tc.machineId();
}, triConsumer).get(10, TimeUnit.SECONDS);
}CacheStream
Map<Object, String> jbossValues =
cache.entrySet().stream()
.filter(e -> e.getValue().contains("JBoss"))
.collect(Collectors.toMap(Map.Entry::getKey, Map.Entry::getValue));远程缓存
对于远程缓存,Data Grid 提供了一个 ServerTask API,可让您通过 Hot Rod 调用 execute () 方法或使用 Data Grid 命令行界面(CLI)以编程方式注册自定义 Java 实现。您只能在一个 Data Grid 服务器实例或集群中的所有服务器实例上执行任务。
2.15. 客户端流量
当调整远程 Data Grid 集群的大小时,您需要计算条目的数量和大小,同时计算客户端流量的数量。Data Grid 需要足够的 RAM 来存储您的数据和 CPU,以便及时处理客户端读取和写入请求。
有很多不同的因素会影响延迟并确定响应时间。例如,键/值对的大小会影响远程缓存的响应时间。影响远程缓存性能的其他因素包括集群接收的每秒请求数、客户端数量以及对写操作的读取操作比率。
第 3 章 OpenShift 的基准测试数据
对于在 OpenShift 上运行的 Data Grid 集群,红帽建议使用 Hyperfoil 来测量性能。Hyperfoil 是一个基准测试框架,它为分布式服务提供准确的性能结果。
3.1. 基准测试数据网格
设置并配置部署后,开始基准测试您的 Data Grid 集群以分析和衡量性能。基准测试显示存在限制的位置,以便您可以调整您的环境并调整您的数据中心配置以获得最佳性能,这意味着达到最低延迟和最高吞吐量。
值得注意,最佳性能是一个持续的过程,而不是最终目标。当您的基准测试显示您的 Data Grid 部署达到所需的性能水平时,您无法期望这些结果被修复或始终有效。
3.2. 安装 Hyperfoil
通过创建一个 operator 订阅并下载包含命令行界面(CLI)的 Hyperfoil 发行版本,在 Red Hat OpenShift 上设置 Hyperfoil。
流程
通过 OpenShift Web 控制台中的 OperatorHub 创建 Hyperfoil Operator 订阅。
注意Hyperfoil Operator 作为一个 Community Operator 提供。
红帽没有认证 Hyperfoil Operator,它不与 Data Grid 结合使用。安装 Hyperfoil Operator 时,会提示您输入确认有关社区版本的警告,然后才能继续。
- 从 Hyperfoil 发行页下载最新的 Hyperfoil 版本。
3.3. 创建 Hyperfoil Controller
在 Red Hat OpenShift 上实例化 Hyperfoil Controller,以便您可以使用 Hyperfoil 命令行界面(CLI)上传并运行基准测试测试。
先决条件
- 创建 Hyperfoil Operator 订阅。
流程
定义
hyperfoil-controller.yaml。$ cat > hyperfoil-controller.yaml<<EOF apiVersion: hyperfoil.io/v1alpha2 kind: Hyperfoil metadata: name: hyperfoil spec: version: latest EOF应用 Hyperfoil Controller。
$ oc apply -f hyperfoil-controller.yaml检索连接到 Hyperfoil CLI 的路由。
$ oc get routes NAME HOST/PORT hyperfoil hyperfoil-benchmark.apps.example.net
3.4. 运行 Hyperfoil 基准
使用 Hyperfoil 运行基准测试测试,以收集 Data Grid 集群的性能数据。
先决条件
- 创建 Hyperfoil Operator 订阅。
- 在 Red Hat OpenShift 上实例化 Hyperfoil Controller。
流程
创建基准测试。
$ cat > hyperfoil-benchmark.yaml<<EOF name: hotrod-benchmark hotrod: # Replace <USERNAME>:<PASSWORD> with your Data Grid credentials. # Replace <SERVICE_HOSTNAME>:<PORT> with the host name and port for Data Grid. - uri: hotrod://<USERNAME>:<PASSWORD>@<SERVICE_HOSTNAME>:<PORT> caches: # Replace <CACHE-NAME> with the name of your Data Grid cache. - <CACHE-NAME> agents: agent-1: agent-2: agent-3: agent-4: agent-5: phases: - rampupPut: increasingRate: duration: 10s initialUsersPerSec: 100 targetUsersPerSec: 200 maxSessions: 300 scenario: &put - putData: - randomInt: cacheKey <- 1 .. 40000 - randomUUID: cacheValue - hotrodRequest: # Replace <CACHE-NAME> with the name of your Data Grid cache. put: <CACHE-NAME> key: key-${cacheKey} value: value-${cacheValue} - rampupGet: increasingRate: duration: 10s initialUsersPerSec: 100 targetUsersPerSec: 200 maxSessions: 300 scenario: &get - getData: - randomInt: cacheKey <- 1 .. 40000 - randomUUID: cacheValue - hotrodRequest: # Replace <CACHE-NAME> with the name of your Data Grid cache. put: <CACHE-NAME> key: key-${cacheKey} value: value-${cacheValue} - doPut: constantRate: startAfter: rampupPut duration: 5m usersPerSec: 10000 maxSessions: 11000 scenario: *put - doGet: constantRate: startAfter: rampupGet duration: 5m usersPerSec: 40000 maxSessions: 41000 scenario: *get EOF- 在任何浏览器中打开路由来访问 Hyperfoil CLI。
上传基准测试测试。
运行
upload命令。[hyperfoil]$ upload- 点 Select baseline file,然后导航到文件系统上的基准测试测试并上传它。
运行基准测试测试。
[hyperfoil]$ run hotrod-benchmark获取基准测试测试的结果。
[hyperfoil]$ stats
3.5. Hyperfoil 基准结果
Hyperfoil 使用 stats 命令以表格式显示基准测试的结果。
[hyperfoil]$ stats
Total stats from run <run_id>
PHASE METRIC THROUGHPUT REQUESTS MEAN p50 p90 p99 p99.9 p99.99 TIMEOUTS ERRORS BLOCKED| 列 | 描述 | 值 |
|---|---|---|
| PHASE |
对于每个运行,Hyperfoil 以两个阶段向 Data Grid 集群发出 |
|
| 指标 |
在运行的两个阶段,Hperfoil 会为每个 |
|
| 吞吐量 | 捕获每秒请求数。 | Number |
| REQUESTS | 捕获运行期间每个阶段的操作总数。 | Number |
| MEAN |
捕获 |
以毫秒为单位的时间( |
| p50 | 记录完成 50 个请求所需的时间。 |
以毫秒为单位的时间( |
| p90 | 记录完成 90 个请求所需的时间。 |
以毫秒为单位的时间( |
| p99 | 记录完成 99 个请求所需的时间。 |
以毫秒为单位的时间( |
| p99.9 | 记录 99.9 请求完成所需的时间。 |
以毫秒为单位的时间( |
| p99.99 | 记录 99.99 请求完成所需的时间。 |
以毫秒为单位的时间( |
| 超时 | 捕获运行期间操作所发生的超时总数。 | Number |
| 错误 | 捕获运行期间发生的错误总数。 | Number |
| BLOCKED | 捕获被阻止或无法完成的操作总数。 | Number |