实例和镜像指南
管理实例、镜像、卷和容器
摘要
序言
Red Hat Enterprise Linux OpenStack Platform(RHEL OpenStack Platform)提供了一个在 Red Hat Enterprise Linux 上构建私有或公共 IaaS (Infrastructure-as-a-Service,基础设施即服务)云服务的平台。它为部署使用云技术的计算环境提供了扩展性和容错性。
本指南讨论了与创建和管理镜像(image)、实例(instance)、卷(volume,也被称为云硬盘)和容器(container)相关的内容。同时,它还包括了为实例配置存储,以及为 RHEL OpenStack Platform 配置 NFS 后端的信息。
您可以通过 OpenStack dashboard 或命令行客户端来对云进行管理。多数操作都可以通过这两种方法中的任一方法完成,而一些高级的操作只能通过命令行来完成。
如需完整的 RHEL OpenStack Platform 文档,请访问 Red Hat Enterprise Linux OpenStack Platform Documentation
第 1 章 镜像服务
本章介绍了在 RHEL OpenStack Platform 中管理镜像和存储所需的步骤。
虚拟机镜像(image)就是一个包括安装了可引导操作系统的虚拟磁盘的文件。虚拟机镜像可以有不同的格式,以下是 RHEL OpenStack Platform 支持的格式:
-
RAW- 没有进行结构化的磁盘镜像格式。 -
QCOW2- QEMU 仿真程序支持的磁盘格式。 -
ISO- 保存在一个二进制文件中的、包括磁盘每个扇区中的数据的数据备份。 -
AKI- Amazon Kernel Image。 -
AMI- Amazon Machine Image。 -
ARI- Amazon RAMDisk Image。 -
VDI- VirtualBox 虚拟机监控程序和 QEMU 仿真程序支持的磁盘格式。 -
VHD- VMWare、VirtualBox 以及其它系统的虚拟机监控程序支持的通用磁盘格式。 -
VMDK- 一些通用虚拟机监控程序支持的磁盘格式。
因为 ISO 包括了已安装了操作系统的可引导文件系统,所以我们通常不认为 ISO 是一个虚拟机镜像格式。但是,您可以向处理其它虚拟机镜像文件一样处理 ISO。
为了下载红帽官方的 Red Hat Enterprise Linux 云镜像,您需要一个有效的 Red Hat Enterprise Linux 订阅:
1.1. 镜像服务:新功能
RHEL OpenStack Platform 7 发行版本中的镜像服务包括以下新功能:
镜像转换 - 在导入镜像时调用任务 API 对镜像进行转换(在 Kilo 中只支持 qcow/raw 格式的转换)。
作为镜像导入流程的一部分,一个插件提供了对镜像进行转换的功能。这个插件可以根据用户的配置被启用或被禁用。因此,用户需要指定用于进行部署的首选镜像格式。
镜像服务(Image service)在接收到特定格式镜像的数据后会把这些数据保存在一个临时的存储中。然后,会触发转换插件来把这些数据转换为目标格式,并把转换后的数据保存在最终的存储位置中。当整个过程完成后,临时存储的镜像数据会被删除。因此,上传的原始镜像数据不会被镜像服务保留。
注意镜像转换的过程只会在导入(import)一个镜像时才会被触发。在上传(upload)一个镜像时不会触发镜像的转换。例如:
$ glance --os-image-api-version 2 task-create --type import --input '{"import_from_format": "qcow2", "import_from": "http://127.0.0.1:8000/test.qcow2", "image_properties": {"disk_format": "qcow2", "container_format": "bare"}}'镜像內省(Image Introspection) - 每种格式的镜像本身都会包括一组元数据。
例如,一个
vmdk包括以下参数:$ head -20 so-disk.vmdk # Disk DescriptorFile version=1 CID=d5a0bce5 parentCID=ffffffff createType="streamOptimized" # Extent description RDONLY 209714 SPARSE "generated-stream.vmdk" # The Disk Data Base #DDB ddb.adapterType = "buslogic" ddb.geometry.cylinders = "102" ddb.geometry.heads = "64" ddb.geometry.sectors = "32" ddb.virtualHWVersion = "4"通过对 vmdk 进行內省,您可以方便地知道 disk_type 是 streamOptimized,adapter_type 是 buslogic。通过在镜像服务中对这些元数据进行提取,管理员不再需要了解所有元数据(除非需要覆盖其中的一些数据)。这些元数据参数对镜像的使用者非常有用。例如,在 Compute 节点中,对一个 streamOptimized 磁盘进行实例化的过程和对 flat 磁盘进行实例化的过程完全不同。现在,您可以在导入镜像的过程中,通过调用任务 API 进行镜像內省。
注意在 Kilo 中,您只能內省 virtual_size 元数据参数。
1.2. 管理镜像
OpenStack Image 服务 (glance) 提供了磁盘和服务器镜像的发现(discovery)、注册(registration)和分发(delivery)功能。您可以对服务器镜像进行复制或进行快照,然后进行保存。存储的镜像可以作为模板来快速设置并运行一个新服务器。
1.2.1. 创建镜像
本节介绍了使用 Red Hat Enterprise Linux 6 和 Red Hat Enterprise Linux 7 ISO 文件手工创建 OpenStack 兼容的 .qcow2 格式镜像。
1.2.1.1. 在 RHEL OpenStack Platform 中使用 KVM Guest 镜像
您可以使用一个已经准备就绪的 RHEL KVM guest qcow2 镜像(可以从 RHEL 7 KVM Guest Image 或 RHEL 6.6 KVM Guest Image 获得)。这些镜像被配置为使用 cloud-init,并需要使用 ec2 兼容的元数据服务来提供 SSH 密钥。
对于 KVM guest 镜像:
-
这个镜像中的
root帐号被禁用,但是,可以通过sudo来使用一个名为cloud-user的特殊用户。 -
这个镜像服务没有
root密码设置。
root 密码在 /etc/shadow 中被锁定(在第 2 项中加了 !!)。
对于一个 OpenStack 实例,我们推荐用户通过 OpenStack dashboard 或命令行产生一个 ssh 密钥对,并使用它们进行 SSH 公共验证来作为实例的 root 用户。
在启动实例时,公共密钥会被植入。您可以使用在创建密钥对时下载的私人密钥进行验证。
如果您不想使用密钥对,您可以使用在为一个实例添加一个 admin 密码一节中介绍的过程创建 admin 密码。
如果您需要创建一个自定义的 Red Hat Enterprise Linux 镜像,请参阅创建一个 Red Hat Enterprise Linux 7 镜像或创建一个 Red Hat Enterprise Linux 6 镜像。
1.2.1.2. 创建自定义的 Red Hat Enterprise Linux 镜像
先决条件:
- 使用一个运行 Linux 的主机创建镜像。它可以是任何可以安装并运行 Linux 软件包的机器。
-
libvirt 和 virt-manager(运行
yum groupinstall -y @virtualization)。这会安装创建一个 guest 操作系统所需的所有软件包。 -
Libguestfs 工具程序(运行
yum install -y libguestfs-tools-c)。这会安装一组用来访问和修改虚拟机镜像的工具程序。 - 一个 Red Hat Enterprise Linux 7 ISO 文件(RHEL 7.0 Binary DVD 或 RHEL 6.6 Binary DVD)。
-
一个用来修改
kickstart文件的文本编辑程序。
在以下的过程中,所有带有 [user@host]# 提示符的命令都需要在您的主机系统上运行。
1.2.1.2.1. 创建一个 Red Hat Enterprise Linux 7 镜像
本节介绍了使用 Red Hat Enterprise Linux 7 ISO 文件手工创建 OpenStack 兼容的 .qcow2 格式镜像的步骤。
使用
virt-install开始进行安装:[user@host]# qemu-img create -f qcow2 rhel7.qcow2 8G [user@host]# virt-install --virt-type kvm --name rhel7 --ram 2048 \ --cdrom /tmp/rhel-server-7.0-x86_64-dvd.iso \ --disk rhel7.qcow2,format=qcow2 \ --network=bridge:virbr0 --graphics vnc,listen=0.0.0.0 \ --noautoconsole --os-type=linux --os-variant=rhel7启动一个实例并开始安装过程。
注意如果实例没有自动启动,运行以下命令:
[user@host]# virt-viewer rhel7按以下内容设置虚拟机:
-
At the initial Installer boot menu, choose the Install Red Hat Enterprise Linux 7.0 option.
- 选择适当的 Language 和 Keyboard 选项。
-
When prompted about which type of devices your installation uses, choose Auto-detected installation media.
-
When prompted about which type of installation destination, choose Local Standard Disks.
 For other storage options, choose Automatically configure partitioning.
For other storage options, choose Automatically configure partitioning.
- 对于软件,选择 Minimal Install。
-
对于网络和主机名,为您的设备选择
eth0作为网络,并输入设备的 hostname。默认的主机名是localhost.localdomain。 -
Choose the
rootpassword. The installation process completes and the Complete! screen appears.
The installation process completes and the Complete! screen appears.
-
At the initial Installer boot menu, choose the Install Red Hat Enterprise Linux 7.0 option.
- 安装完成后,重启实例并以 root 用户身份登录。
更新
/etc/sysconfig/network-scripts/ifcfg-eth0文件,使它只包括以下内容:TYPE=Ethernet DEVICE=eth0 ONBOOT=yes BOOTPROTO=dhcp NM_CONTROLLED=no- 重启机器。
在 Content Delivery Network 中注册机器:
# subscription-manager register在提示时输入您的用户门户网站(Customer Portal)的用户名和密码:
Username: admin@example.com Password:找到包括所需频道的权利池:
# subscription-manager list --available | grep -A8 "Red Hat Enterprise Linux Server"使用在上一步所获得的权利池 ID 来把
Red Hat Enterprise Linux Server的权利附加到系统上:# subscription-manager attach --pool=pool_id启用所需的频道:
# subscription-manager repos --enable=rhel-7-server-rpms对于 RHEL OpenStack Platform 7,所需的频道是
rhel-7-server-openstack-7.0-rpms和rhel-7-server-rh-common-rpms。注意如需更多相关信息,请参阅 Installation Reference 中的 "Subscribe to the Required Channels"。
更新系统。
# yum -y update安装
cloud-init软件包。# yum install -y cloud-utils-growpart cloud-init编辑
/etc/cloud/cloud.cfg配置文件,在cloud_init_modules下添加以下内容:- resolv-conf当实例第一次引导时,
resolv-conf选项会自动配置resolv.conf。这个文件包括了与实例相关的信息,如nameservers、domain和其它选项。把以下行添加到
/etc/sysconfig/network以避免访问 EC2 元数据服务时出现问题。NOZEROCONF=yes为了确保控制台的信息出现在 dashboard 的
日志标签页中,以及nova console-log输出中,把以下的引导选项添加到/etc/default/grub文件中:GRUB_CMDLINE_LINUX_DEFAULT="console=tty0 console=ttyS0,115200n8"运行以下命令:
# grub2-mkconfig -o /boot/grub2/grub.cfg这会输出以下结果:
Generating grub configuration file ... Found linux image: /boot/vmlinuz-3.10.0-229.7.2.el7.x86_64 Found initrd image: /boot/initramfs-3.10.0-229.7.2.el7.x86_64.img Found linux image: /boot/vmlinuz-3.10.0-121.el7.x86_64 Found initrd image: /boot/initramfs-3.10.0-121.el7.x86_64.img Found linux image: /boot/vmlinuz-0-rescue-b82a3044fb384a3f9aeacf883474428b Found initrd image: /boot/initramfs-0-rescue-b82a3044fb384a3f9aeacf883474428b.img done取消注册虚拟机。这样可以避免通过对创建的镜像进行克隆所产生的镜像都有相同的订阅请求。
# subscription-manager repos --disable=* # subscription-manager unregister # yum clean all关闭实例:
# poweroff使用
virt-sysprep命令重置并清理镜像,从而可以避免在创建实例时出现问题:[user@host]# virt-sysprep -d rhel7使用
virt-sparsify命令减少镜像的大小。这个命令会把磁盘镜像中的所有空闲空间转换为主机的空闲空间:[user@host]# virt-sparsify --compress /tmp/rhel7.qcow2 rhel7-cloud.qcow2这会在运行此命令的地方创建一个新的
rhel7-cloud.qcow2文件。
rhel7-cloud.qcow2 镜像文件可以被上传到 Image 服务。如需了解使用 dashboard 把镜像文件上传到 OpenStack 部署中的信息,请参阅上传镜像。
1.2.1.2.2. 创建 Red Hat Enterprise Linux 6 镜像
本节介绍了使用 Red Hat Enterprise Linux 6 ISO 文件手工创建 OpenStack 兼容的 .qcow2 格式镜像的步骤。
使用
virt-install开始进行安装:[user@host]# qemu-img create -f qcow2 rhel6.qcow2 4G [user@host]# virt-install --connect=qemu:///system --network=bridge:virbr0 \ --name=rhel6.6 --os-type linux --os-variant rhel6 \ --disk path=rhel6.qcow2,format=qcow2,size=10,cache=none \ --ram 4096 --vcpus=2 --check-cpu --accelerate \ --hvm --cdrom=rhel-server-6.6-x86_64-dvd.iso启动一个实例并开始安装过程。
注意如果实例没有自动启动,运行以下命令:
[user@host]# virt-viewer rhel6按以下内容设置虚拟机:
At the initial Installer boot menu, choose the Install or upgrade an existing system option.
 Step through the installation prompts. Accept the defaults.
Step through the installation prompts. Accept the defaults.
安装的过程会检查磁盘并进行一个介质检查操作。当检查成功完成后,会弹出磁盘。
- 选择适当的 Language 和 Keyboard 选项。
-
When prompted about which type of devices your installation uses, choose Basic Storage Devices.

-
为主机选择一个 hostname。默认的主机名是
localhost.localdomain。 -
设置 timezone 和
root密码。 -
Based on the space on the disk, choose the type of installation.
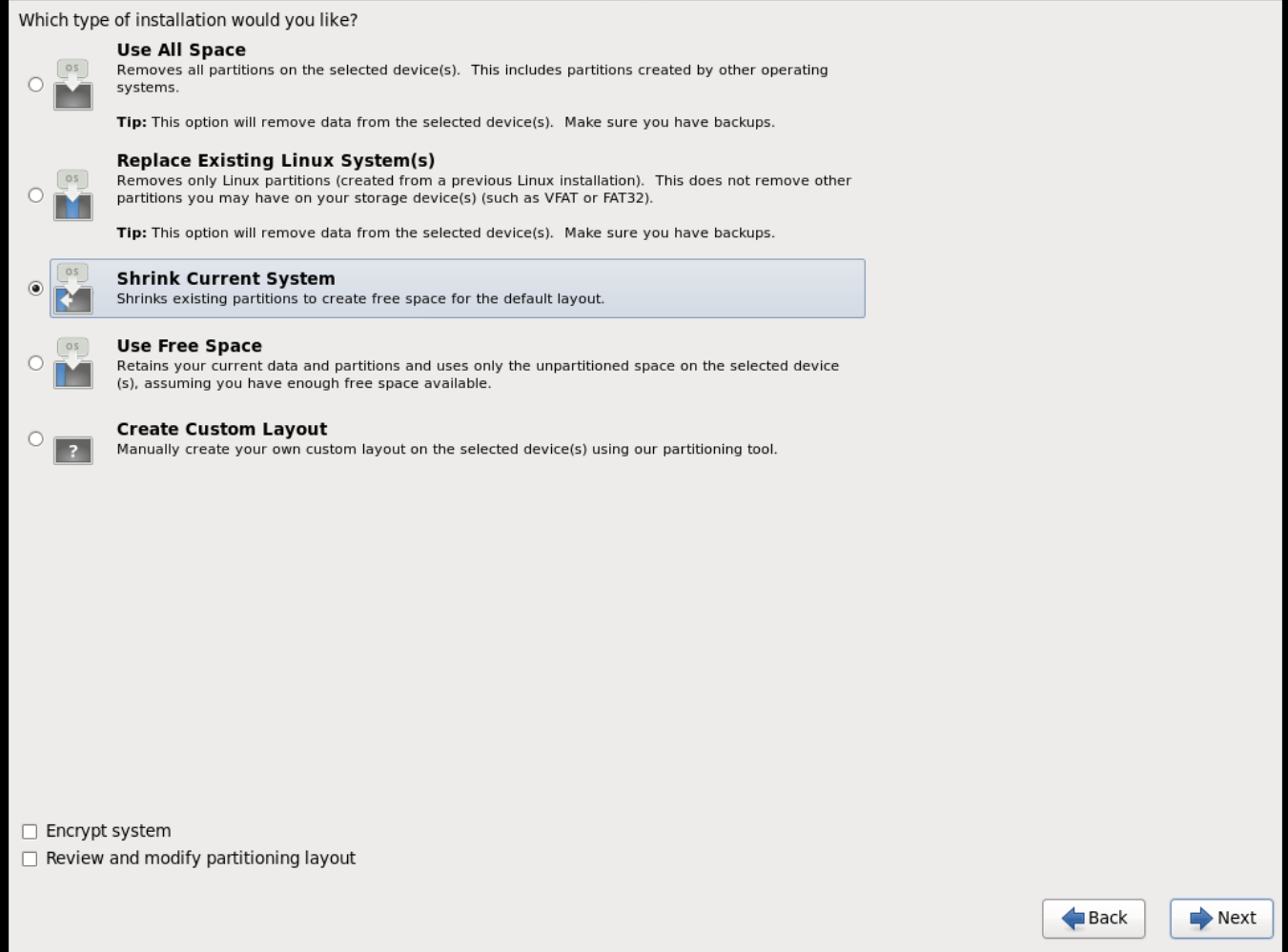
-
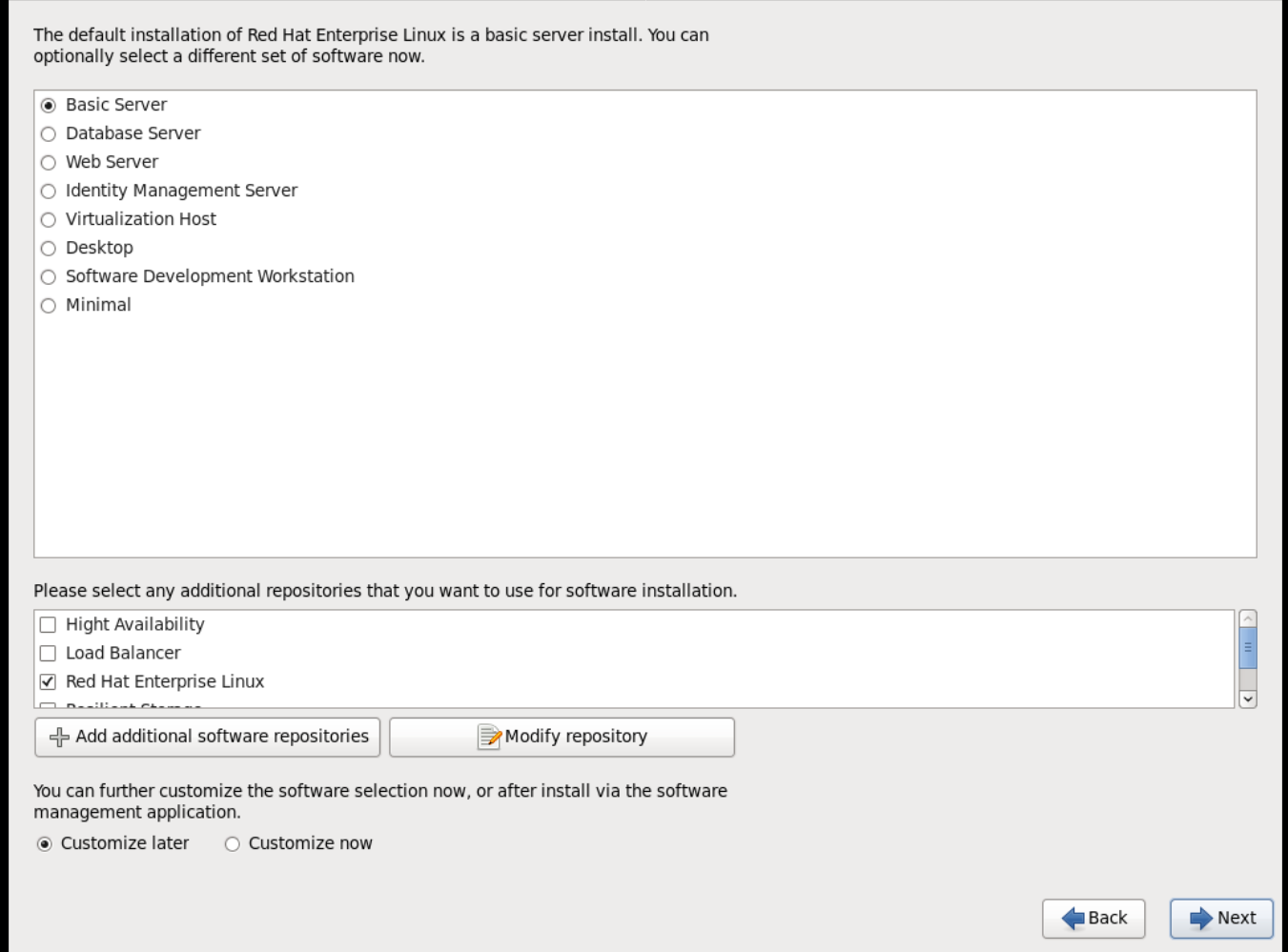
Choose the Basic Server install, which installs an SSH server.
- 安装过程完成,Congratulations, your Red Hat Enterprise Linux installation is complete 界面会出现。
-
重启实例,并以
root用户登录。 更新
/etc/sysconfig/network-scripts/ifcfg-eth0文件,使它只包括以下内容:TYPE=Ethernet DEVICE=eth0 ONBOOT=yes BOOTPROTO=dhcp NM_CONTROLLED=no- 重启机器。
在 Content Delivery Network 中注册机器:
# subscription-manager register在提示时输入您的用户门户网站(Customer Portal)的用户名和密码:
Username: admin@example.com Password:找到包括所需频道的权利池:
# subscription-manager list --available | grep -A8 "Red Hat Enterprise Linux Server"使用在上一步所获得的权利池 ID 来把
Red Hat Enterprise Linux Server的权利附加到系统上:# subscription-manager attach --pool=pool_id启用所需的频道:
# subscription-manager repos --enable=rhel-6-server-rpms对于 RHEL OpenStack Platform 7,所需的频道是
rhel-7-server-openstack-7.0-rpms和rhel-6-server-rh-common-rpms。注意如需更多相关信息,请参阅 Installation Reference 中的 "Subscribe to the Required Channels"。
更新系统。
# yum -y update安装
cloud-init软件包。# yum install -y cloud-utils-growpart cloud-init编辑
/etc/cloud/cloud.cfg配置文件,在cloud_init_modules下添加以下内容:- resolv-conf当实例第一次引导时,
resolv-conf选项会自动配置resolv.conf。这个文件包括了与实例相关的信息,如nameservers、domain和其它选项。为了防止网络出现问题,创建
/etc/udev/rules.d/75-persistent-net-generator.rules文件。# echo "#" > /etc/udev/rules.d/75-persistent-net-generator.rules这会避免创建
/etc/udev/rules.d/70-persistent-net.rules文件。如果创建了/etc/udev/rules.d/70-persistent-net.rules文件,当从快照引导时,网络可能无法正常工作(网络接口被创建为 "eth1",而不是 "eth0"。IP 地址也没有被分配)。把以下行添加到
/etc/sysconfig/network以避免访问 EC2 元数据服务时出现问题。NOZEROCONF=yes为了确保控制台的信息出现在 dashboard 的
日志标签页中,以及nova console-log输出中,把以下的引导选项添加到/etc/grub.conf中:console=tty0 console=ttyS0,115200n8取消注册虚拟机。这样可以避免通过对创建的镜像进行克隆所产生的镜像都有相同的订阅请求。
# subscription-manager repos --disable=* # subscription-manager unregister # yum clean all关闭实例:
# poweroff使用
virt-sysprep命令重置并清理镜像,从而可以避免在创建实例时出现问题:[user@host]# virt-sysprep -d rhel6.6使用
virt-sparsify命令减少镜像的大小。这个命令会把磁盘镜像中的所有空闲空间转换为主机的空闲空间:[user@host]# virt-sparsify - -compress rhel6.qcow2 rhel6-cloud.qcow2这会在运行此命令的地方创建一个新的
rhel6-cloud.qcow2文件。注意根据应用到这个实例的 flavor 中的磁盘空间设置,您需要手工调整实例分区的大小。
rhel6-cloud.qcow2 镜像文件可以被上传到 Image 服务。如需了解使用 dashboard 把镜像文件上传到 OpenStack 部署中的信息,请参阅上传镜像。
1.2.2. 上传镜像
- 在 dashboard 中,选择项目 > Compute > 镜像。
- 点创建镜像。
- 输入相关的值后点创建镜像。
| 项 | 备注 |
|---|---|
|
名称 |
镜像的名称。在一个项目中,不同镜像的名称需要是唯一的。 |
|
描述 |
对镜像的简单描述。 |
|
镜像源 |
镜像源:镜像地址或镜像文件。根据您的选择,以下项会被显示。 |
|
镜像地址或镜像文件 |
|
|
格式 |
镜像格式(例如 qcow2)。 |
|
构架 |
镜像架构。例如,使用 i686 作为 32 位架构;或使用 x86_64 作为 64 位架构。 |
|
最小磁盘 (GB) |
引导镜像所需的最小磁盘大小。如果没有指定,默认值是 0(没有最小磁盘大小的限制)。 |
|
最低内存 (MB) |
引导镜像所需的最低内存大小。如果没有指定,默认值是 0(没有最低内存大小的限制)。 |
|
公有 |
如果选择这个选项,这个镜像对所有可以访问这个项目的用户有效。 |
|
受保护的 |
如果选择了这个选项,只有具有特定权限的用户可以删除这个镜像。 |
另外,您也可以使用带有 property 选项的 glance image-create 命令创建镜像。在这个命令的命令行中可以使用多个值(请参阅镜像配置参数)。
1.2.3. 更新镜像
- 在 dashboard 中,选择项目 > Compute > 镜像。
从下拉菜单中选编辑镜像。
注意编辑镜像选项只在以
admin用户登录时才有效。当以demo用户登录时,有效的选项是启动云主机和创建云硬盘。- 更新相关的值后点更新镜像。您可以编辑以下值:名称、描述、内核 ID、ramdisk ID、架构、格式、最小磁盘、最低内存、公共、受保护的。
- 点下拉菜单并选更新元数据选项。
- 通过把左面栏中的项添加到右面栏来指定元数据。左面的栏中包括了在 Image Service Metadata Catalog 中定义的元数据。如果需要添加您自己选择的关键字的元数据,选其它,然后点保存。
另外,您也可以使用带有 property 选项的 glance image-update 命令创建镜像。在这个命令的命令行中可以使用多个值(请参阅镜像配置参数)。
1.2.4. 删除镜像
- 在 dashboard 中,选择项目 > Compute > 镜像。
- 选择需要删除的镜像后点删除镜像。
第 2 章 配置 OpenStack Compute 存储
本节介绍了 OpenStack Compute(nova)中的镜像后端存储的架构,以及基本的配置选项。
2.1. 架构概述
在 Red Hat Enterprise Linux OpenStack Platform 中,OpenStack Compute 服务使用 KVM hypervisor 来执行计算负载。libvirt 驱动被用来处理和 KVM 间的所有交流,并启用对虚拟机的创建功能。
Compute 服务需要考虑两类 libvirt 存储:
- 基础镜像(base image):Image 服务镜像的一个缓存的、具有特定格式的副本。
-
实例磁盘(Instance disk):由
libvirt创建作为虚拟机实例的后端。实例磁盘可以存储在 Compute 的临时存储(使用libvirt),也可以存储在一个具有持久性的存储中(如使用 Block Storage)。
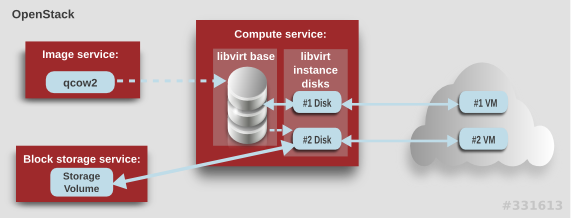
Compute 服务创建虚拟机实例的步骤是:
-
缓存 Image 服务的后端镜像作为
libvirt的基础。 - 把基础镜像转换为 raw 格式(如果被配置)。
- 调整基础镜像的大小来匹配虚拟机 flavor 的规范。
- 使用基础镜像创建 libvirt 实例磁盘。
在上面的图中,#1 实例磁盘使用临时存储;#2 磁盘使用块存储卷。
2.2. 配置
用来处理 libvirt 基础镜像和实例磁盘的 Compute 配置(参数在 /etc/nova/nova.conf 文件中定义)会决定环境的性能和安全性。
| 项 | 参数 | 描述 | 默认 |
|---|---|---|---|
|
[DEFAULT] |
|
是否把
把基础镜像转换为 raw 格式会比 hypervisor 直接使用镜像(例如,一个 qcow2 镜像)需要更多空间。如果您的系统有较慢的 I/O 或空间比较小,您可以把它设置为 'false',这样可以通过提高数据压缩/解压操作对 CPU 的要求来换取对输入带宽要求最小化的目的。
raw 基础镜像需要和 |
|
|
[DEFAULT] |
|
|
true |
|
[DEFAULT] |
|
即使没有使用 CoW 实例磁盘,每个虚拟机所获得的数据副本也是稀疏的,因此,虚拟机可能会在运行时出现 ENOSPC 错误。通过在实例磁盘镜像中运行 |
none |
|
[DEFAULT] |
|
是否启用通过访问块设备上的基础镜像来直接调整基础镜像的功能(布尔值)。使用较旧版本的 因为这个参数会启用直接挂载镜像的功能,而这个功能通常会因为安全性的原因被禁用,所以它在默认情况下没有被启用。 |
|
|
[DEFAULT] |
|
一个新临时卷的默认格式。它的值可能是: |
|
|
[DEFAULT] |
|
在连续两次运行镜像缓存管理器(image cache manager)间需要等待的秒数,这会影响到 libvirt compute 节点的基础缓存。在这段间隔时间内会自动删除不再使用的缓存镜像(请参阅 |
|
|
[DEFAULT] |
|
是否启动自动删除不使用的基础镜像的功能(每 |
|
|
[DEFAULT] |
|
在从 |
|
|
[ |
|
为 |
|
第 3 章 虚拟机实例
OpenStack Compute 是一个中心组件,它根据需要提供虚拟机。Compute 会通过 Identity 服务进行用户验证;使用 Image 服务来获得镜像(用来启动实例);使用 dashboard 服务作为用户和管理界面。
RHEL OpenStack Platform 可以使您方便地管理云中的实例。Compute 服务会创建、调度并管理实例,并使其它 OpenStack 组件可以使用这个功能。本章介绍了相关的操作,以及添加组件(如密钥对、安全组、主机集合、flavor)的信息。实例(instance) 在 OpenStack 中被用来代表虚拟机实例。
3.1. 管理实例
在创建实例前,您需要确保其它 OpenStack 组件(例如网络、密钥对、作为引导源的镜像或卷)已为实例准备好。
本节讨论了添加这些组件的步骤,以及创建和管理实例的内容。管理实例包括更新实例、登录到实例、查看实例是如何被使用的、调整实例的大小以及删除实例。
3.1.1. 添加组件
按照以下小节中介绍的内容创建网络、密钥对以及上传镜像或卷源的内容。当创建实例时需要这些元素,而它们在默认的情况下不会被自动提供。同时,您还需要创建一个新的安装组来提供对用户的 SSH 访问。
- 在 dashboard 中选择项目。
- 选择网络 > 网络,确定已经存在了一个新实例可以加入的私人网络。如需了解创建网络的信息,请参阅 Networking Guide 的 Add a Network 一节(Red Hat Enterprise Linux OpenStack Platform)。
- 选择Compute > 访问 & 安全 > 密钥对,确定已经存在了一个密钥对(如需了解创建密钥对的信息,请参阅 第 3.2.1.1 节 “创建一个密钥对”)。
确定您有一个可以作为引导源的镜像或云硬盘:
- 要查看引导源镜像,选择镜像标签页(如需了解创建镜像的信息,请参阅 第 1.2.1 节 “创建镜像”)。
- 要查看引导源云硬盘,选择云硬盘标签页(如需了解创建云硬盘的信息,请参阅 第 4.1.1 节 “创建云硬盘”)。
- 选择 Compute > 访问 & 安全 > 安全组,确定您已经创建了一个安全组规则(如需了解创建安全组的信息,请参阅 Users and Identity Management Guide 中的 Project Security Management(Red Hat Enterprise Linux OpenStack Platform)。
3.1.2. 创建实例
- 在 dashboard 中选择项目 > Compute > 实例。
- 点启动云主机。
- 输入所需的信息(带有 '* '标记的项是必需的)后点运行。
| 标签页 | 项 | 备注 |
|---|---|---|
|
详情 |
可用域 |
域(zone)就是可以放置您的实例的、包括云资源的逻辑组。如果您不能确定您的选择,使用默认域(如需了解更多信息,请参阅 第 3.4 节 “管理主机集合”)。 |
|
云主机名称 |
实例的名称。 | |
|
云主机类型 |
云主机类型决定了实例可以获得什么资源(例如,内存)。如需了解更多与云主机类型相关的信息,请参阅 第 3.3 节 “管理 flavor”。 | |
|
云主机启动源 |
根据所做的选择,新的项会被显示用来选择启动源:
| |
|
访问和安全 |
密钥对 |
指定的密钥对会被植入到实例中,并在使用 SSH 远程访问实例时使用它们。通常情况下,每个项目都会创建一个密钥对。 |
|
安全组 |
安全组包括了一组防火墙规则用来过滤并处理实例的网络数据(如需了解创建安全组的信息,请参阅 Users and Identity Management Guide 中的 Project Security Management(Red Hat Enterprise Linux OpenStack Platform)。 | |
|
Networking |
已选择的网络 |
您需要最少指定一个网络。一般情况下,实例会被分配一个私有网络,然后会获得一个浮动 IP 地址用于外部连接。 |
|
创建后 |
定制脚本源 |
您可以提供一组命令或一个脚本文件,当实例被引导后运行它们。例如,使用它们来设置实例的主机名 ,或设置一个用户密码。如果选择了 '直接输入',您可以在 '脚本数据项' 中直接输入您的命令;如果使用其它选项,则指定您的脚本文件。 注意 任何以 '#cloud-config' 开始的脚本都会被解析为使用 cloud-config 语法(如需了解与此语法相关的信息,请参阅 http://cloudinit.readthedocs.org/en/latest/topics/examples.html)。 |
|
高级选项 |
磁盘分区 |
在默认情况下,实例只包括一个分区,并可以根据需要自动调整它的大小。但是,您也可以选择手工配置您自己的分区。 |
|
配置驱动器 |
如果选择了这个选项,OpenStack 把元数据写到一个只读的配置驱动器中,在引导时会被附加到实例中(而不是加入到 Compute 的元数据服务中)。在实例被引导后,您可以挂载这个驱动器来查看其中的内容(您可以为实例提供文件)。 |
3.1.4. 重新调整实例的大小
要调整一个实例的大小(内存或 CPU 的数量),您需要为这个实例选择一个适当的新 flavor(有时也被称为“云主机类型”)。如果您需要增加它的大小,则需要保证包括它的主机有足够的空间。
设置每个主机来使用 SSH 密钥进行身份验证,从而使 Compute 可以使用 SSH 来在主机间移动磁盘(例如,compute 节点可以共享相同的 SSH 密钥)。
如需了解更多与设置 SSH 密钥验证相关的信息,请参阅 Migrating Instances Guide 中的 Configure SSH Tunneling Between Nodes(Red Hat Enterprise Linux OpenStack Platform)。
在
/etc/nova/nova.conf文件中设置以下参数来允许在原始主机上重新调整大小:[DEFAULT] allow_resize_to_same_host = True- 在 dashboard 中选择项目 > Compute > 实例。
- 点主机的操作箭头,选调整云主机大小。
- 在新的云主机类型项中选择一个新 flavor。
如果您需要在启动实例时手工对它进行分区(构建时间会比较快):
- 选择高级选项。
- 在磁盘分区项中选择手工。
- 点重新调整大小。
3.1.5. 连接到一个实例
本节介绍了通过 dashboard 或命令行接口访问一个实例控制台的方法。您也可以直接连接到实例的串口来进行故障排除(在网络连接失败时也可以使用这个方法)。
3.1.5.1. 使用 Dashboard 访问实例的控制台
您可以在 dashboard 中使用控制台(console)直接连接到您的实例。
- 在 dashboard 中选择 Compute > 实例。
-
Click the instance’s More button and select Console.

- 使用镜像的用户名和密码进行登录(例如,一个 CirrOS 镜像使用 cirros/cubswin:))。
3.1.5.2. 直接连接到一个 VNC 控制台
您可以使用 nova get-vnc-console 命令所返回的 URL 来直接访问一个实例的 VNC 控制台。
- 浏览器
要获得一个浏览器 URL,使用:
$ nova get-vnc-console INSTANCE_ID novnc- Java 客户端
要获得一个 Java-client URL,使用:
$ nova get-vnc-console INSTANCE_ID xvpvnc
nova-xvpvncviewer 提供了一个 Java 客户端的简单示例。要下载客户端,运行:
# git clone https://github.com/cloudbuilders/nova-xvpvncviewer
# cd nova-xvpvncviewer/viewer
# make使用实例的 Java-client URL 来运行 viewer:
# java -jar VncViewer.jar _URL_提供这个工具的目的只是方便用户的使用,红帽并不正式支持它。
3.1.5.3. 直接连接到一个串行控制台
您可以使用一个 websocket 客户端来直接访问实例的串口。串口连接通常被作为故障排除工具使用(例如,在网络配置失败时,也可以通过它来访问实例)。要获得一个正在运行的实例 URL,运行以下命令:
$ nova get-serial-console INSTANCE_IDnovaconsole 提供了一个 websocket 客户端的简单示例。要下载客户端,运行:
# git clone https://github.com/larsks/novaconsole/
# cd novaconsole使用实例的串口 URL 运行客户端:
# python console-client-poll.py提供这个工具的目的只是方便用户的使用,红帽并不正式支持它。
但是,根据所进行的安装,管理员可能会需要首先设置 nova-serialproxy 服务。这个代理服务是一个 websocket 代理,它提供了连接到 OpenStack Compute 串口的功能。
3.1.5.3.1. 安装并配置 nova-serialproxy
安装
nova-serialproxy服务:# yum install openstack-nova-serialproxy更新
/etc/nova/nova.conf文件中的serial_console部分:启用
nova-serialproxy服务:$ openstack-config --set /etc/nova/nova.conf serial_console enabled true指定用来创建由
nova get-serial-console命令提供的 URLS 的字符串。$ openstack-config --set /etc/nova/nova.conf serial_console base_url ws://PUBLIC_IP:6083/其中的
PUBLIC_IP是运行nova-serialproxy服务的主机的公共 IP 地址。指定实例串口控制台监听的 IP 地址(字符串)。
$ openstack-config --set /etc/nova/nova.conf serial_console listen 0.0.0.0指定需要连接的 proxy client 的地址(字符串)。
$ openstack-config --set /etc/nova/nova.conf serial_console proxyclient_address ws://HOST_IP:6083/其中的
HOST_IP是您的 Compute 主机的 IP 地址。例如,对于一个启用了nova-serialproxy服务的配置会和以下类似:[serial_console] enabled=true base_url=ws://192.0.2.0:6083/ listen=0.0.0.0 proxyclient_address=192.0.2.3
重启 Compute 服务:
# openstack-service restart nova启动
nova-serialproxy服务:# systemctl enable openstack-nova-serialproxy # systemctl start openstack-nova-serialproxy- 重启所有正在运行的实例,从而使它们可以监听正确的网络套接字。
打开防火墙的串行控制器端口连接。串口的端口范围通过
/etc/nova/nova.conf中的[serial_console]`port_range 进行设置。在默认情况下,它的范围是10000:20000。更新 iptables:# iptables -I INPUT 1 -p tcp --dport 10000:20000 -j ACCEPT
3.1.6. 查看实例的使用
使用情况的统计数据可以基于:
每个项目
要查看每个项目的使用情况,选项目 > Compute > 概况。所有项目实例的使用数据会被显示。
您可以通过指定时间范围并点提交来查看特定时间段内的使用情况数据。
每个虚拟机管理器
如果以管理员的身份进行登录,您也可以查看所有项目的信息。点管理员 > 系统,选择其中的一个标签页。例如,资源使用情况标签页中提供了特定时间段中的使用情况数据报告。您也可以点虚拟机管理器来查看您当前的 vCPU、内存或磁盘的使用情况统计数据。
注意vCPU 使用情况的值(y 中的 x)反映了所有虚拟机的总 vCPU 数(x)和虚拟机管理器的内核数量(y)。
3.1.7. 删除实例
- 在 dashboard 中选择项目 > Compute > 实例,然后选择您的实例。
- 点终止云主机。
删除一个实例的操作并不会删除附加到它上面的卷,您需要单独删除它们(请参阅 第 4.1.4 节 “删除卷”)。
3.2. 管理实例安全
您可以通过为实例分配正确的安全组(设置防火墙规则)和密钥对(启用 SSH 用户访问)来管理对它的访问。另外,还可以为实例分配一个浮动 IP 地址,使它可以被外部网络访问。以下介绍了创建和管理密钥对、安全组、浮动 IP 地址以及使用 SSH 登录到一个实例的信息,以及为实例添加一个 admin 密码的方法。
如需了解更多与管理安全组相关的信息,请参阅 Users and Identity Management Guide 中的 Project Security Management(Red Hat Enterprise Linux OpenStack Platform)。
3.2.1. 管理密钥对
密钥对提供了到实例的 SSH 访问能力。每次创建一个密钥对时,它的证书都会被下载到本地系统,从而可以分发给用户。通常情况下,每个项目都会创建一个密钥对(可以在多个实例中使用)。
您也可以为 OpenStack 导入一个已经存在的密钥对。
3.2.1.1. 创建一个密钥对
- 在 dashboard 中,选项目 > Compute > 访问 & 安全。
- 在密钥对标签页中点创建密钥对。
- 在密钥对名称项中输入一个名称,点创建密钥对。
当密钥对被创建后,一个密钥对文件会通过浏览器自动下载。您需要保存这个文件用于以后的连接。对于使用命令行的 SSH 连接,您可以使用以下命令把这个文件加载到 SSH:
# ssh-add ~/.ssh/os-key.pem3.2.1.2. 导入一个密钥对
- 在 dashboard 中,选项目 > Compute > 访问 & 安全。
- 在密钥对标签页中点导入密钥对。
- 在密钥对名称项中输入一个名称,把您的公共密钥复制/粘贴到公共密钥项中。
- 点导入密钥对。
3.2.1.3. 删除密钥对
- 在 dashboard 中,选项目 > Compute > 访问 & 安全。
- 在密钥对标签页中点相应密钥的删除密钥对按钮。
3.2.2. 创建安全组
安全组就是一组 IP 过滤器规则,它可以分配给项目实例,用来设置对实例的网络访问。安全组是与项目相关联的,项目成员可以编辑安全组的默认设置,并可以向其添加新规则。
- 在 dashboard 中,选项目标签页,点 Compute > 访问 & 安全。
- 在安全组标签页中,点 + 创建安全组。
- 为安全组提供一个名称和描述,点创建安全组。
如需了解更多与管理项目安全的信息,请参阅 Users and Identity Management Guide 中的 Project Security Management(Red Hat Enterprise Linux OpenStack Platform)。
3.2.3. 创建、分配和释放浮动 IP 地址
在默认情况下,实例会在首次创建时被分配一个内部 IP 地址。但是,您可以通过创建和分配一个浮动 IP 地址(外部地址)来使它可以通过公共网络进行访问。无论实例处于什么状态,您都可以修改与实例相关联的 IP 地址。
每个项目的可用浮动 IP 地址资源都是有限的(在默认情况下,是 50 个地址),因此您需要在某个 IP 地址不再被使用时释放它,从而使它可以被重复使用。浮动 IP 地址只能从一个存在的浮动 IP 地址池中分配。如需了解更多相关信息,请参阅 Networking Guide 中的 Create Floating IP Pools(Red Hat Enterprise Linux OpenStack Platform)。
3.2.3.1. 为项目分配一个浮动 IP 地址
- 在 dashboard 中,选项目 > Compute > 访问 & 安全。
- 在浮动 IP 标签页中,点分配 IP 给项目。
- 在资源池中选择用来分配 IP 地址的网络。
- 点分配 IP。
3.2.3.2. 分配一个浮动 IP
- 在 dashboard 中,选项目 > Compute > 访问 & 安全。
- 在浮动 IP 标签页中,点相关地址的关联按钮。
在 IP 地址项中选择要分配的地址。
注意如果没有可用的地址,您可以点
+按钮创建一个新地址。- 在待连接的端口项中选择要被关联的实例。一个实例只能和一个浮动 IP 地址相关联。
- 点关联。
3.2.3.3. 释放浮动 IP
- 在 dashboard 中,选项目 > Compute > 访问 & 安全。
- 在浮动 IP 标签页中,点地址的菜单箭头(在关联/取消关联按钮旁)。
- 选择释放浮动 IP。
3.2.4. 登录到实例
先决条件:
- 确保实例的安全组中有一个 SSH 规则。请参阅 Users and Identity Management Guide 中的 Project Security Management(Red Hat Enterprise Linux OpenStack Platform)。
- 确保实例有一个与之关联的浮动 IP 地址(外部地址)。请参阅 创建、分配和释放浮动 IP 地址。
- 获得实例的密钥对证书。当密钥对被创建时,这个证书会被下载。如果您没有自己创建密钥对,请联系您的系统管理员(如需更多相关信息,请参阅 第 3.2.1 节 “管理密钥对”)。
首先把密钥对文件加入到 SSH,然后使用它:
修改所产生的密钥对证书的访问权限。
$ chmod 600 os-key.pem检查
ssh-agent是否已运行:# ps -ef | grep ssh-agent如果还没有运行,使用以下命令运行它:
# eval `ssh-agent`在您的本地机器上,把密钥对证书加载到 SSH。例如:
$ ssh-add ~/.ssh/os-key.pem- 现在,您可以 SSH 到镜像文件。
以下是使用 cloud-user 用户 SSH 到 Red Hat Enterprise Linux 虚拟机镜像的示例:
$ ssh cloud-user@192.0.2.24您也可以直接使用证书。例如:
$ ssh -i /myDir/os-key.pem cloud-user@192.0.2.243.2.5. 为实例添加一个 admin 密码
您可以使用以下方法为一个实例添加一个 admin(root)密码。
在
/etc/openstack-dashboard/local_settings文件中,把change_set_password参数的值设为True。can_set_password: True在
/etc/nova/nova.conf文件中,把inject_password参数的值设为True。inject_password=true重启 Compute 服务。
# service nova-compute restart
当使用 nova boot 命令启动一个新实例时,命令的输出中会显示一个 adminPass 参数。您可以使用它作为 root 用户的密码登录到这个实例。
Compute 服务会覆盖 /etc/shadow 文件中的 root 用户的密码。它同时也会为 KVM 客户机镜像激活 root 账户。如需了解更多与使用 KVM 客户机镜像相关的信息,请参阅 第 1.2.1.1 节 “在 RHEL OpenStack Platform 中使用 KVM Guest 镜像”
您也可以使用 dashboard 设置一个自定义密码。在把 can_set_password 参数的值设为 true 后运行以下命令:
# systemctl restart httpd.service
新添加的 admin 密码项如下所示:

这些项可以在启动或重建一个实例时使用。
3.3. 管理 flavor
每个创建的实例都会被分配一个 flavor(资源模板),它定义了实例的大小和容量。Flavor 也可以指定二级临时存储(secondary ephemeral storage)、交换磁盘、元数据来限制资源使用或对特定项目的访问(默认的 flavor 都没有定义这些额外的属性)。flavor 在 Red Hat Enterprise OpenStack Platform 中有时也被称为“云主机类型”。
| 名称 | vCPU | RAM | Root 磁盘大小 |
|---|---|---|---|
|
m1.tiny |
1 |
512 MB |
1 GB |
|
m1.small |
1 |
2048 MB |
20 GB |
|
m1.medium |
2 |
4096 MB |
40 GB |
|
m1.large |
4 |
8192 MB |
80 GB |
|
m1.xlarge |
8 |
16384 MB |
160 GB |
多数最终用户都可以使用这些默认的 flavor。但是,您可能会需要创建并管理特殊的 flavor。例如,您可能需要:
- 根据所使用的硬件修改默认的内存和能力。
- 添加元数据来为实例强制一个特定的 I/O 速率,或匹配一个主机集合(host aggregate)。
使用镜像属性设置的行为会覆盖使用 flavors 设置的行为。如需了解更多信息,请参阅 第 1.2 节 “管理镜像”。
3.3.1. 更新配置权限
在默认情况下,只有管理员可以创建 flavor 或查看完整的 flavor 列表(选择 "管理员 > 系统 > 云主机类型")。要允许所有用户配置 flavor,在 /etc/nova/policy.json 文件(nova-api 服务器)中指定以下内容:
"compute_extension:flavormanage": "",
3.3.2. 创建 flavor
- 使用一个 admin 用户,在 dashboard 中选择管理员 > 系统 > 云主机类型。
点创建云主机类型, 指定以下项:
Expand 标签页 项 描述 主机类型信息
名称
唯一的名字。
ID
唯一的 ID。默认值
auto会自动产生一个 UUID4 值,但是您可以手工指定一个整数或 UUID4 值。VCPU
虚拟 CPU 的数量
RAM (MB)
内存(以 MB 为单位)
根磁盘 (GB)
临时磁盘的大小(以 GB 为单位)。要使用镜像本身的大小,把它设为
0。当 Instance Boot Source=Boot from Volume 时这个磁盘不被使用。临时磁盘 (GB)
二级临时磁盘的大小(以 GB 为单位)。
Swap 磁盘 (MB)
交换磁盘的大小(以 MB 为单位)
云主机类型访问
选择的项目
可以使用这个云主机类型的项目。如果没有选择项目,所有项目都可以访问(
Public=Yes)。- 点创建云主机类型。
3.3.3. 更新常规属性
- 使用一个 admin 用户,在 dashboard 中选择管理员 > 系统 > 云主机类型。
- 点 flavor 的 编辑云主机类型按钮。
- 更新相关的值并点保存。
3.3.4. 更新云主机类型的元数据
除了常规属性外,您还可以为云主机类型添加元数据(extra_specs),它可以更精细地定义实例的使用情况。例如,您可以设置允许使用的最大带宽。
- 预定义的关键字决定了硬件支持或配额。它受您所使用的虚拟机管理器(hypervisor)的限制(对于 libvirt,请参阅 表 3.2 “Libvirt 元数据”)。
-
预定义的关键字和用户定义的关键字都可以决定实例的调度。例如,您可以设置
SpecialComp=True,任何使用这个云主机类型的实例都将只能在元数据中带有相同关键字和值的主机集合中运行。如需了解更多相关信息,请参阅 第 3.4 节 “管理主机集合”。
3.3.4.1. 查看元数据
- 使用一个 admin 用户,在 dashboard 中选择管理员 > 系统 > 云主机类型。
-
点云主机类型的 Metadata 链接(
Yes或No)。当前所有的值都在右面的 Existing Metadata 项中列出。
3.3.4.2. 添加元数据
您可以使用一个关键字/值数据对来指定云主机类型的元数据。
- 使用一个 admin 用户,在 dashboard 中选择管理员 > 系统 > 云主机类型。
-
点云主机类型的 Metadata 链接(
Yes或No)。当前所有的值都在右面的 Existing Metadata 项中列出。 - 在可用的元数据中,点其它项,选择您需要添加的关键字(请参阅 表 3.2 “Libvirt 元数据”)。
- 点 + 按钮;您现在可以看到新的关键字出现在已存在的元数据项中。
在右面项中输入关键字的值。
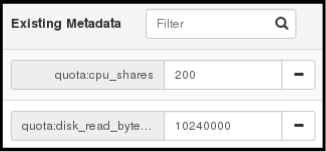
- 当输入完“关键字/值”数据对后,点保存。
| 键 | 描述 |
|---|---|
|
hw:action |
用来配置每个实例的支持限制。有效值包括:
例如: |
|
hw:NUMA_def |
定义 NUMA 的拓扑。当 flavor 中的 RAM 和 vCPU 的分配值比 compute 主机中的 NUMA 节点大时,通过定义 NUMA 拓扑可以使主机更好地利用 NUMA,并提高客户机 OS 的性能。flavor 中定义的 NUMA 设置会覆盖镜像中的设置。有效的定义包括:
注意 如果 numa_cpu 或 numa_mem.N 的值比实际有效的值大,则会出现一个异常错误。 示例(带有 8 个 vCPU 和 4GB 内存的实例):
调度程序会查找带有 2 个 NUMA 节点的主机,它需要可以在一个节点上运行 6 个 CPU 和 3 GB 内存,在另一个节点上运行 2 个 CPU 和 1 GB 内存。如果某个主机只有一个 NUMA 节点,它可以运行 8 个 CPU 和 4 GB 内存,这个主机不会被认为是一个有效的匹配。无论 numa_mempolicy 是如何设置的,相同的逻辑都适用于调度程序。 |
|
hw:watchdog_action |
当实例出现故障时,可以使用实例的 watchdog 设备触发一个操作。有效的操作是:
例如: |
|
hw_rng:action |
通过使用镜像属性把一个随机数生成器设备添加到镜像中(请参阅 RHEL OpenStack Platform 文档的 "Command-Line Interface Reference" 部分中的 hw_rng_model 内容)。 如果添加了设备,有效的操作将包括:
例如: |
|
hw_video:ram_max_mb |
视频设备允许使用的最大内存数量(以 MB 为单位)。
例如: |
|
quota:option |
对实例的限制。有效选项包括:
例如: |
3.4. 管理主机集合
为了性能和管理的目的,一个单一的 Compute 部署可以被分成不同的逻辑组。OpenStack 会使用以下的相关术语:
主机集合(Host aggregate) - 一个主机集合就是 OpenStack 部署中的一个逻辑组,它包括了一组 Compute 主机,以及相关的元数据。一个主机可以属于多个主机集合。只有系统管理员可以查看或创建主机集合。
一个主机集合的元数据通常被用来为 Compute 调度器(scheduler)提供信息(如为一部分主机限制特定的云主机类型或镜像)。当在一个主机集合中指定了元数据,只有那些在云主机类型中指定了相同元数据的实例才可以使用其中的主机。
系统管理员可以通过主机集合实现负载均衡、强制物理隔离(或冗余)、对带有相同属性的服务器进行分组或分离不同的硬件系统。当您创建一个集合时,需要指定一个域名(zone name),它会作为最终用户可以看到的这个集合的名称。
可用域(Availability zone) - 可用域就是最终用户可以看到的主机集合。最终用户无法看到这个域是由哪些主机组成的,也无法看到这个域的元数据,而只能看到域的名称。
系统管理员可以设置包括特定计算能力的域,或位于特定区域中的域,最终用户将可以使用这些配置的域。
3.4.1. 启用主机集合调度
在默认情况下,主机集合元数据不会被用来过滤实例的使用情况,您需要更新 Compute 的调度配置来启用元数据:
-
编辑
/etc/nova/nova.conf文件(您需要具有 root 或 nova 用户的权限)。 确定
scheduler_default_filters参数包括:AggregateInstanceExtraSpecsFilter(对于主机集合元数据)。例如:scheduler_default_filters=AggregateInstanceExtraSpecsFilter,RetryFilter,RamFilter,ComputeFilter,ComputeCapabilitiesFilter,ImagePropertiesFilter,CoreFilterAvailabilityZoneFilter在启动一个实例时的有效域主机的规格。例如:scheduler_default_filters=AvailabilityZoneFilter,RetryFilter,RamFilter,ComputeFilter,ComputeCapabilitiesFilter,ImagePropertiesFilter,CoreFilter
- 保存配置文件。
3.4.2. 查看可用域或主机集合
使用一个 admin 用户,在 dashboard 中选择管理员 > 系统 > 主机集合。当前所有定义的集合会在主机集合项中列出,所有域会在可用域项中列出。
3.4.3. 添加一个主机集合
- 使用一个 admin 用户,在 dashboard 中选择管理员 > 系统 > 主机集合。当前所有定义的集合会在主机集合项中列出。
- 点创建主机集合。
- 在名称项中指定集合的名称,最终用户将会在可用域项中看到这个名称。
- 点在集合中管理主机。
- 点相应主机的 + 图标来选择主机。
- 点创建主机集合。
3.4.4. 更新一个主机集合
- 使用一个 admin 用户,在 dashboard 中选择管理员 > 系统 > 主机集合。当前所有定义的集合会在主机集合项中列出。
更新实例的名称或可用域:
- 点集群的编辑主机集群按钮。
- 更新名称或可用域的值,点保存。
更新实例的分配的主机:
- 在操作项中选集合的箭头图标。
- 点管理主机。
- 点主机的 + 或 - 图标来修改主机的分配。
- 完成后点保存。
更新实例的元数据:
- 在操作项中选集合的箭头图标。
- 点更新元数据按钮。所有当前值都在右面的存在的元数据项中列出。
- 在可用的元数据中点其它项,输入您要添加的关键字。您可以使用预定义的关键字(请参阅 表 3.3 “主机集合元数据”)或添加您自己的关键字(只在实例的 flavor 中设置了相同关键字时才有效)。
点 + 按钮;您现在可以看到新的关键字出现在已存在的元数据项中。
注意点 - 图标删除一个关键字。
点保存。
Expand 表 3.3. 主机集合元数据 键 描述 cpu_allocation_ratio设置虚拟 CPU 对物理 CPU 的分配比率。这取决于为 Compute 调度设置的
AggregateCoreFilter过滤。disk_allocation_ratio设置虚拟磁盘对物理磁盘的分配比率。这取决于为 Compute 调度设置的
AggregateDiskFilter过滤。filter_tenant_id如果指定,集合只包括这个租户(项目)的主机。这取决于为 Compute 调度设置的
AggregateMultiTenancyIsolation过滤。ram_allocation_ratio设置虚拟内存对物理内存的分配比率。这取决于为 Compute 调度设置的
AggregateRamFilter过滤。
3.4.5. 删除一个主机集群
- 使用一个 admin 用户,在 dashboard 中选择管理员 > 系统 > 主机集合。当前所有定义的集合会在主机集合项中列出。
从集群中删除所有分配的主机:
- 在操作项中选集合的箭头图标。
- 点管理主机。
- 点主机的 - 图标删除主机。
- 完成后点保存。
- 在操作项中选集合的箭头图标。
- 点删除主机集合。
3.5. 调度主机和 Cell
Compute 调度服务决定了一个实例要被放置在哪个 cell 或主机(或主机集合)中。作为一个管理员,您可以设置调度的决定过程。例如,您可以把实例调度到特定组中的主机,或具有特定 RAM 的主机中。
您可以配置以下组件:
- Filters(过滤器) - 决定可以放置实例的初始主机范围(请参阅 第 3.5.1 节 “配置调度过滤器”)。
- Weights(权重) - 通过过滤程序后的主机再根据权重系统来进行优先级排列。具有最高权重值的主机有最高的优先级(请参阅 第 3.5.2 节 “配置调度权重”)。
-
Scheduler service(调度程序服务) - 在调度程序所在主机的
/etc/nova/nova.conf文件中包括了以下配置选项,它决定了调度程序如何执行它的任务、处理权重和过滤。主机和 cell 都有调度程序。如需了解这些选项的完整列表,请参阅 "Configuration Reference" (RHEL OpenStack Platform Documentation)。
在下图中,主机 1 和主机 3 都通过了过滤程序。主机 1 具有最高的权重,因此在调度过程中有最高优先级。

3.5.1. 配置调度过滤器
您可以使用 scheduler_default_filters 选项(/etc/nova/nova.conf 文件)来定义调度程序(scheduler)使用的过滤器(您需要具有 root 或 nova 用户的权限)。过滤器可以被添加或删除。
默认情况下,以下过滤器被配置并在调度程序中运行:
scheduler_default_filters=RetryFilter,AvailabilityZoneFilter,RamFilter,ComputeFilter,ComputeCapabilitiesFilter,ImagePropertiesFilter,ServerGroupAntiAffinityFilter,ServerGroupAffinityFilter一些过滤器会使用通过命令中的参数传递给实例的信息:
-
nova boot命令,请参阅 RHEL OpenStack Platform Documentation 中的 "Command-Line Interface Reference"。 - 实例的 flavor(参阅 第 3.3.4 节 “更新云主机类型的元数据”)
- 实例的镜像(参阅 附录 A, 镜像配置参数)。
下表列出了可用的过滤器
| 过滤器 | 描述 |
|---|---|
|
AggregateCoreFilter |
使用 host-aggregate 元数据关键字 cpu_allocation_ratio 过滤掉超过过度分配(over-commit)比率(虚拟 CPU 和物理 CPU 分配的比率)的主机,它只在为实例指定了主机集合(host aggregate)的情况下有效。 |
|
如果没有设置这个值,过滤器会使用 /etc/nova/nova.conf 文件中的 cpu_allocation_ratio 的值。它的默认值是 | |
|
AggregateDiskFilter |
使用 host-aggregate 元数据关键字 disk_allocation_ratio 过滤掉超过过度分配(over-commit)比率(虚拟磁盘和物理磁盘分配的比率)的主机,它只在为实例指定了主机集合(host aggregate)的情况下有效。 |
|
如果没有设置这个值,过滤器会使用 /etc/nova/nova.conf 文件中的 disk_allocation_ratio 的值。它的默认值是 | |
|
AggregateImagePropertiesIsolation |
只通过那些元数据和实例镜像的元数据匹配的主机集合中的主机,它只在为实例指定了主机集合的情况下有效。如需了解更多相关信息,请参阅 第 1.2.1 节 “创建镜像”。 |
|
AggregateInstanceExtraSpecsFilter |
主机集合中的元数据必须与主机的 flavor 元数据相匹配。如需了解更多相关信息,请参阅 第 3.3.4 节 “更新云主机类型的元数据”。 |
|
AggregateMultiTenancyIsolation |
指定了 filter_tenant_id 的主机只能包括所指定租户(项目)中的实例。 注意 租户仍然可以在其它主机上放置实例。 |
|
AggregateRamFilter |
使用 host-aggregate 元数据关键字 ram_allocation_ratio 过滤掉超过过度分配(over-commit)比率(虚拟内存和物理内存分配的比率)的主机,它只在为实例指定了主机集合(host aggregate)的情况下有效。 |
|
如果没有设置这个值,过滤器会使用 /etc/nova/nova.conf 文件中的 ram_allocation_ratio 的值。它的默认值是 | |
|
AllHostsFilter |
通过所有有效的主机(但不禁用其它过滤器)。 |
|
AvailabilityZoneFilter |
过滤器使用实例指定的可用域。 |
|
ComputeCapabilitiesFilter |
确定 Compute 元数据被正确读取。 |
|
ComputeFilter |
通过所有可以正常工作并被启用的主机。 |
|
CoreFilter |
使用 |
|
DifferentHostFilter |
在一个和指定主机不同的主机上创建实例。使用 |
|
DiskFilter |
使用 |
|
ImagePropertiesFilter |
只通过匹配实例镜像属性的主机。如需了解更多信息,请参阅 第 1.2.1 节 “创建镜像”。 |
|
IsolatedHostsFilter |
只通过运行独立镜像(在 |
|
JsonFilter |
接受并使用实例的自定义 JSON 过滤器:
|
|
这个过滤器通过
| |
|
MetricFilter |
过滤掉带有无效指标数据的过滤器。 |
|
NUMATopologyFilter |
根据主机的 NUMA 拓扑过滤主机。如果实例没有定义拓扑,所有主机都可以被使用。这个过滤程序会尝试匹配带有完全相同的 NUMA 拓扑的主机。这个过滤器还会查看每个 NUMA 节点的标准过度订阅(over-subscription)的限制,并根据它为 compute 主机提供限制。 |
|
RamFilter |
使用 |
|
RetryFilter |
过滤掉调度失败的主机。它只在 scheduler_max_attempts 大于 0 的情况下有效( |
|
SameHostFilter |
通过一个或多个指定的主机。使用 |
|
ServerGroupAffinityFilter |
只通过一个特定服务器组中的主机:
|
|
ServerGroupAntiAffinityFilter |
只通过还没有包括任何实例的服务器组中的主机:
|
|
SimpleCIDRAffinityFilter |
只通过特定 IP 子网范围内(由实例的 cidr 和
|
3.5.2. 配置调度权重
cell 和主机可以被加上权重来进行调度,具有最大权重的主机或 cell 将会在经过过滤后被选择。所有的权重器都具有一个乘数(multiplier),它会在规格化节点权重后被应用。一个节点的权重以以下方法计算:
w1_multiplier * norm(w1) + w2_multiplier * norm(w2) + ...
您可以在调度程序主机的 /etc/nova/nova.conf 文件中配置权重选项(需要有 root 或 nova 的用户权限)。
3.5.2.1. 为主机配置权重选项
您可以在 [DEFAULT] scheduler_weight_classes 选项中定义调度程序需要使用的主机权重器:
-
nova.scheduler.weights.ram- 主机可用内存的权重。 -
nova.scheduler.weights.metrics- 主机指标数据(metrics)的权重。 -
nova.scheduler.weights.all_weighers- 使用所有主机权重器(默认)。
| 权重器 | 选项 | 描述 |
|---|---|---|
|
所有 |
[DEFAULT] scheduler_host_subset_size |
定义所选主机的子集合的大小(整数),它的值必须不小于 |
|
metrics |
[metrics] required |
指定当 [metrics]
|
|
metrics |
[metrics] |
当 [metrics] |
|
metrics |
[metrics] |
权重 metric 使用的乘数。在默认情况下, |
|
metrics |
[metrics] |
指定 metric 以及它们权重的比率,它是一个使用逗号分隔的
例如: |
|
ram |
[DEFAULT] |
RAM 的乘数(浮点值)。在默认情况下是 |
3.5.2.2. 为 cell 配置权重选项
您可以使用 [cells] scheduler_weight_classes 选项(在 /etc/nova/nova.conf 文件中)来定义调度器使用的 cell 权重程序。您需要具有 root 或 nova 用户权限。
有效的权重程序是:
-
nova.cells.weights.all_weighers- 使用所有 cell 权重程序(默认)。 -
nova.cells.weights.mute_child- 对一个子 cell 是否已经有一段时间没有发送容量或容量进行权重。 -
nova.cells.weights.ram_by_instance_type- 对 cell 的有效 RAM 进行权重。 nova.cells.weights.weight_offset- 评估一个 cell 的权重 offset.注意在
`nova-manage cell create命令中使用 --woffset 选项可以指定一个 cell 的权重 offset。
| 权重程序 | 选项 | 描述 |
|---|---|---|
|
|
[cells] |
已经沉默了一段时间的主机的乘数(multiplier)。它需要是一个负的浮点数,默认值是 |
|
|
[cells] |
沉默主机的权重值。它的值需要是负的浮点数,默认值是 |
|
|
[cells] |
权重 RAM 的乘数。它的值需要是一个浮点数,默认值是 |
|
|
[cells] |
权重 cell 的乘数(浮点值)。允许实例通过把它的权重偏移(weight offset)设置为 |
3.6. 撤离实例
如果您需要把一个实例从一个有故障或已停止运行的 compute 节点上移到同一个环境中的其它主机服务器上时,可以使用 nova evacuate 命令对实例进行撤离(evacuate)。
- 撤离的操作只有在实例的磁盘在共享存储上,或实例的磁盘是块存储卷时才有效。因为在其它情况下,磁盘无法被新 compute 节点访问。
-
实例只有在它所在的服务器停止运行的情况下才可以被撤离;如果服务器没有被关闭,
evacuate命令会运行失败。
如果您有一个可以正常工作的 compute 节点,您需要:
-
对实例进行一个静态复制(实例没有处于运行状态)作为备份;或把实例复制到其它环境中。使用
nova image-create创建一个快照(请参阅 Migrate a Static Instance)。 -
把一个静态(没有运行的)实例移到相同环境中的另外一个主机(不需要共享存储),使用
nova migrate(请参阅 Migrate a Static Instance)。 -
把一个动态(正在运行的)实例移到相同环境中的另外一个主机,使用
nova live-migration命令(请参阅 Migrate a Live (running) Instance)。
3.6.1. 撤离一个实例
使用以下命令撤离一个实例:
# nova evacuate [--password pass] [--on-shared-storage] instance_name [target_host]其中:
-
--password- 撤离实例的 admin 密码(如果指定了--on-shared-storage,则无法使用)。如果没有指定密码,一个随机密码会被产生,并在撤离操作完成后被输出。 -
--on-shared-storage- 指定所有实例文件都在共享存储中。 -
instance_name- 要撤离的实例名称。 target_host- 实例撤离到的主机;如果您没有指定这个主机,Compute 调度会为您选择一个主机。您可以使用以下命令找到可能的主机:# nova host-list | grep compute例如:
# nova evacuate myDemoInstance Compute2_OnEL7.myDomain
-
3.6.2. 撤离所有实例
使用以下命令在一个特定主机上撤离所有实例:
# nova host-evacuate instance_name [--target target_host] [--on-shared-storage] source_host其中:
--target- 实例撤离到的主机;如果您没有指定这个主机,Compute 调度会为您选择一个主机。您可以使用以下命令找到可能的主机:# nova host-list | grep compute-
--on-shared-storage- 指定所有实例文件都在共享存储中。 source_host- 被撤离的主机名。例如:
# nova host-evacuate --target Compute2_OnEL7.localdomain myDemoHost.localdomain
第 4 章 管理卷(云硬盘)
卷就是一个块存储设备,它为 OpenStack 实例提供持久性的存储。在 Red Hat Enterprise OpenStack Platform 中,卷有时也被称为云硬盘。
4.1. 基本云硬盘(Volume)的使用和配置
以下介绍了对最终用户的云硬盘进行基本管理的方法
4.1.1. 创建云硬盘
- 在 dashboard 中选择项目 > Compute > 云硬盘。
点创建云硬盘,编辑以下项:
Expand 项 描述 云硬盘名称
云硬盘的名称
描述
对云硬盘的描述信息(可选)
类型
卷类型(可选)。请参阅 第 4.2.3 节 “使用云硬盘类型进行云硬盘分组设置”。
如果您有多个块存储后端,您可以在这里选择一个后端。请参阅 第 4.1.2 节 “为创建的云硬盘指定后端”。
大小(GB)
卷的大小(以 GB 为单位)
可用域
可用域(逻辑服务器组)和主机集合(host aggregate)是在 OpenStack 中进行资源聚合的常用方法。可用域在安装的过程中被定义。如需了解更多与可用域和主机集合相关的信息,请参阅 第 3.4 节 “管理主机集合”。
指定云硬盘源:
Expand 源 描述 没有源,空白云硬盘
云硬盘为空,不包括文件系统和分区表。
快照
使用一个存在的快照作为云硬盘的源。如果您选择这个选项,一个“使用快照作为源”的列表会被显示,您可以从这个列表中选择一个快照。如需了解更多与云硬盘快照相关的信息,请参阅 第 4.1.8 节 “创建、克隆或删除云硬盘快照”。
镜像
使用一个存在的镜像作为云硬盘源。如果您选择这个选项,一个“使用镜像作为源”的列表会出现,您可以从这个列表中选择一个镜像。
卷
使用一个存在的云硬盘作为云硬盘源。如果您选择这个选项,一个“将云硬盘作为源”的列表会出现,您可以从这个列表中选择一个云硬盘。
- 点创建云硬盘。云硬盘被创建后,它的名字会出现在云硬盘列表中。
4.1.2. 为创建的云硬盘指定后端
您可以配置 Block Storage 服务来使用多个后端。例如,配置 OpenStack 使用 NFS 后端介绍了如果配置 Block Storage 服务来使用一个 NFS 共享和默认后端的方法。
在创建多个 Block Storage 后端时,您还需要为每个后端创建一个云硬盘类型。然后,您可以使用这个类型来指定创建的云硬盘使用哪个后端。如需了解更多相关信息,请参阅 第 4.2.3 节 “使用云硬盘类型进行云硬盘分组设置”。
在创建云硬盘时通过在“类型”下拉列表中选择云硬盘类型来为它指定后端(请参阅 第 4.1.1 节 “创建云硬盘”)。
如果您在创建云硬盘时没有指定后端,Block Storage 服务会自动选择一个。默认情况下,它会选择有最大可用空间的设备作为后端。您也可以配置 Block Storage 服务在所有可用后端中随机进行选择。如需了解更多相关信息,请参阅 第 4.2.6 节 “配置如何在多后端间分配卷”。
4.1.3. 编辑一个云硬盘的名称或描述信息
- 在 dashboard 中选择项目 > Compute > 云硬盘。
- 按云硬盘的编辑云硬盘按钮。
- 根据需要修改云硬盘的名称和描述。
- 点编辑云硬盘保存您的改变。
要创建一个加密的卷,首先需要一个可以提供卷加密功能的卷类型。另外,Compute 和 Block Storage 服务都需要被配置为使用相同的静态密钥。如需了解更详细的信息,请参阅 第 4.2.5 节 “使用静态密钥加密卷”。
4.1.4. 删除卷
- 在 dashboard 中选择项目 > Compute > 云硬盘。
- 在云硬盘列表中,选择要删除的云硬盘。
- 点删除云硬盘。
当一个云硬盘(卷)存在快照时,这个云硬盘将无法被删除。如需了解删除快照的信息,请参阅 第 4.1.8 节 “创建、克隆或删除云硬盘快照”。
4.1.5. 为实例附加或取消附加一个云硬盘
实例可以使用一个云硬盘来进行持久保存。一个云硬盘同时只能附加到一个实例。如需了解更多与实例相关的信息,请参阅 第 3.1 节 “管理实例”。
4.1.5.1. 为实例挂载一个云硬盘
- 在 dashboard 中选择项目 > Compute > 云硬盘。
- 选择云硬盘的编辑挂载操作。如果这个云硬盘还没有挂载到一个实例,“挂载到云主机”下拉列表会被显示。
- 在挂载到云主机列表中选择需要挂载这个云硬盘的云主机。
- 点挂载云硬盘。
4.1.5.2. 从实例上断开一个云硬盘
- 在 dashboard 中选择项目 > Compute > 云硬盘。
- 选择云硬盘的管理挂载操作。如果这个云硬盘已被挂载到一个实例,实例的名称会出现在挂载项中。
- 点端口云硬盘。
4.1.6. 把云硬盘设为只读
您可以把一个云硬盘设置为允许多个用户对它进行访问,但不能对它的内容进行编辑。使用以下命令把云硬盘设置为只读:
# cinder readonly-mode-update VOLUME true
使用目标云硬盘的 ID 替换 VOLUME。
如果需要把只读云硬盘设为可读写,运行以下命令:
# cinder readonly-mode-update VOLUME true4.1.7. 改变一个云硬盘的所有者
为了改变云硬盘的所有者,您需要进行一个"云硬盘传送(volume transfer)"操作。云硬盘传送操作由云硬盘的当前所有者发起,当云硬盘的新所有者接受了这个操作,云硬盘传送操作就完成了。
4.1.7.1. 通过命令行进行云硬盘传送
- 以云硬盘当前所有者身份登录。
列出有效的云硬盘:
# cinder list启动云硬盘操作:
# cinder transfer-create VOLUME其中的
VOLUME是云硬盘的名称或ID。例如:+------------+--------------------------------------+ | Property | Value | +------------+--------------------------------------+ | auth_key | f03bf51ce7ead189 | | created_at | 2014-12-08T03:46:31.884066 | | id | 3f5dc551-c675-4205-a13a-d30f88527490 | | name | None | | volume_id | bcf7d015-4843-464c-880d-7376851ca728 | +------------+--------------------------------------+cinder transfer-create命令清除了云硬盘的所有者设置,并为所有者转换的过程创建了一个id和auth_key。其它用户可以使用这些值接受所有者转换请求,并成为这个云硬盘的新所有者。新用户现在可以接受成为云硬盘的新所有者。用户需要从命令行登录并运行:
# cinder transfer-accept TRANSFERID TRANSFERKEY其中,
TRANSFERID和TRANSFERKEY分别是cinder transfer-create命令返回的id和auth_key的值。例如:# cinder transfer-accept 3f5dc551-c675-4205-a13a-d30f88527490 f03bf51ce7ead189
您可以使用以下命令查看所有有效的云硬盘转移:
# cinder transfer-list4.1.7.2. 通过 Dashboard 进行云硬盘传送
通过 Dashboard 进行云硬盘传送
- 使用云硬盘(卷)所有者的身份在 dashboard 中选择项目 > 云硬盘。
- 在要进行传送的云硬盘的操作栏中选创建传送。
在创建传送对话框中,输入传送的名称,点新增存储卷迁移。
云硬盘传送操作会被创建,在存储卷迁移界面中包括了需要发送到接收项目的
传送号和认证密钥信息。注意认证密钥信息只会出现在存储卷迁移界面中。如果您丢失了这个信息,则需要取消这个存储卷迁移,并创建一个新的迁移来产生一个新的认证密钥。
关闭存储卷迁移界面返回卷列表。
卷的状态会变为
awaiting-transfer,直到接收项目接受了这个转移操作
通过 dashboard 接受一个存储卷转移
- 使用接收项目所有者的身份在 dashboard 中选择项目 > 云硬盘。
- 点接受转移。
在接受存储卷转移对话框中,输入从存储卷当前所有者那里获得的
转移号和认证密钥,点接受存储卷转移。这个存储卷现在会出现在活跃项目的云硬盘列表中。
4.1.8. 创建、克隆或删除云硬盘快照
您可以通过创建一个云硬盘快照来保存一个云硬盘在某个时间点上的状态。然后,可以使用这个快照来克隆新的云硬盘。
为一个已经挂载到某个实例上的云硬盘创建快照可能会破坏快照的数据。如需了解如何把云硬盘从实例上断开,请参阅 第 4.1.5.2 节 “从实例上断开一个云硬盘”。
卷备份和快照有所不同。备份会保存包括在卷中的数据,而快照会保存一个卷在某个时间点上的状态。另外,当一个卷带有快照时,这个卷将无法被删除。卷备份的目的是防止数据丢失,而快照的目的是用于克隆。
因为这个原因,快照后端通常会和存储卷后端在一起,从而可以在进行克隆时最小化延迟的影响。相反的,在一个企业级的环境中,备份存储库通常会存在于不同的位置(例如,在不同的节点上、不同的物理存储上,甚至不同的地理位置)。这可以在存储卷后台被破坏时,备份数据不会受到影响。
如需了解更多与云硬盘备份相关的信息,请参阅 第 4.2.1 节 “备份和恢复一个云硬盘”。
创建云硬盘快照:
- 在 dashboard 中选择项目 > Compute > 云硬盘。
- 选择目标云硬盘的创建快照操作。
- 为快照输入一个快照名,点创建云硬盘快照。云硬盘快照标签也会显示所有快照。
当一个快照出现在云硬盘快照表中,您就可以使用它来克隆新云硬盘。点快照的创建云硬盘来克隆云硬盘。如需了解更多相关信息,请参阅 第 4.1.1 节 “创建云硬盘”。
要删除一个快照,选择删除云硬盘快照操作。
如果您的 OpenStack 部署使用 Red Hat Ceph 后端,请参阅 第 4.1.8.1 节 “Red Hat Ceph 后端中保护的快照和未保护的快照” 来获取更多相关信息。
4.1.8.1. Red Hat Ceph 后端中保护的快照和未保护的快照
当使用 Red Hat Ceph 作为 OpenStack 部署的后端时,可以把快照在后端设置为受保护的。在 OpenStack 中进行删除受保护的快照操作(通过 dashboard 或使用 cinder snapshot-delete 命令)将会失败。
如果需要删除受保护的快照,您需要先在 Red Hat Ceph 后端把快照设置为未保护,然后,就可以使用一般的方法在 OpenStack 中删除这个快照。
如需了解相关信息,请参阅 Protecting a Snapshot 和 Unprotecting a Snapshot。
4.1.9. 把一个云硬盘上传到 Image 服务
您可以把一个存在的云硬盘作为一个镜像直接上传到 Image 服务:
- 在 dashboard 中选择项目 > Compute > 云硬盘。
- 选择目标云硬盘的上传到镜像操作。
- 为云硬盘提供一个镜像名称,并从磁盘格式列表中选择一个值。
- 点上传。QEMU 磁盘镜像工具程序会使用您所提供的名称上传您所选择格式的镜像。
要查看上传的镜像,选项目 > Compute > 镜像。新的镜像会出现在镜像列表中。如需了解更多关于使用和配置镜像的信息,请参阅 第 1.2 节 “管理镜像”。
4.2. 高级卷配置
以下介绍了如何进行高级的卷管理。这些操作需要管理权限。
4.2.1. 备份和恢复一个云硬盘
云硬盘备份就是一个可以持久保存的云硬盘内容的副本。云硬盘备份通常被创建为项存储,在默认情况下,通过 Object Storage 服务进行管理。您也可以为您的备份设置不同的存储技术,OpenStack 支持 Ceph、GlusterFS 和 NFS 作为替代的存储后端。
当创建云硬盘备份时,所有备份的元数据被保存在 Block Storage 服务的数据库中。当 cinder 使用备份进行数据恢复时会使用这个元数据。因此,如果数据库已经被破坏,您在恢复云硬盘备份前需要首先恢复 Block Storage 服务的数据库。
如果您只希望配置云硬盘的一部分来使它可以在数据库被破坏的情况下仍然可以工作,您也可以导出备份的元数据。导出元数据后,您就可以在需要时把元数据重新导入到 Block Storage 数据库中。然后,就可以正常地恢复云硬盘。
卷备份和快照有所不同。备份会保存包括在卷中的数据,而快照会保存一个卷在某个时间点上的状态。另外,当一个卷带有快照时,这个卷将无法被删除。卷备份的目的是防止数据丢失,而快照的目的是用于克隆。
因为这个原因,快照后端通常会和存储卷后端在一起,从而可以在进行克隆时最小化延迟的影响。相反的,在一个企业级的环境中,备份存储库通常会存在于不同的位置(例如,在不同的节点上、不同的物理存储上,甚至不同的地理位置)。这可以在存储卷后台被破坏时,备份数据不会受到影响。
如需了解更多与云硬盘快照相关的信息,请参阅 第 4.1.8 节 “创建、克隆或删除云硬盘快照”。
4.2.1.1. 创建一个完全云硬盘备份
使用 cinder backup-create 命令可以对云硬盘进行备份。在默认情况下,这个命令会对云硬盘创建一个完全备份。如果这个云硬盘已经存在了备份,则可以创建一个增量备份(请参阅 第 4.2.1.2 节 “创建一个增量云硬盘备份”)。
您可以对您有访问权限的云硬盘进行备份。这意味着,有管理权限的用户可以备份任何云硬盘(无论这些云硬盘的所有者是谁)。如需了解更详细的信息,请参阅 第 4.2.1.1.1 节 “以 Admin 身份创建云硬盘备份”。
查看需要备份的云硬盘的
ID或Display Name:# cinder list备份云硬盘:
# cinder backup-create VOLUME使用要备份的云硬盘的
ID或Display Name替换 VOLUME。例如:+-----------+--------------------------------------+ | Property | Value | +-----------+--------------------------------------+ | id | e9d15fc7-eeae-4ca4-aa72-d52536dc551d | | name | None | | volume_id | 5f75430a-abff-4cc7-b74e-f808234fa6c5 | +-----------+--------------------------------------+注意备份的
volume_id会和被备份的源云硬盘的ID相同。运行以下命令检查云硬盘备份是否已经成功完成:
# cinder backup-list当备份项的
Status为available时,意味着云硬盘备份已完成。
现在,您还可以导出并保存云硬盘备份的元数据。这将使您可以在 Block Storage 数据库被破坏的情况下仍然可以恢复云硬盘的备份。运行以下命令:
# cinder --os-volume-api-version 2 backup-export BACKUPID其中的 BACKUPID 是云硬盘备份的 ID 或名称。例如:
+----------------+------------------------------------------+
| Property | Value |
+----------------+------------------------------------------+
| backup_service | cinder.backup.drivers.swift |
| backup_url | eyJzdGF0dXMiOiAiYXZhaWxhYmxlIiwgIm9iam...|
| | ...4NS02ZmY4MzBhZWYwNWUiLCAic2l6ZSI6IDF9 |
+----------------+------------------------------------------+
云硬盘备份的元数据包括 backup_service 和 backup_url 的值。
4.2.1.1.1. 以 Admin 身份创建云硬盘备份
具有管理权限的用户(例如默认的 admin 用户)可以备份 OpenStack 管理的任何云硬盘。当 admin 用户备份一个所有者是非 admin 用户的云硬盘时,在默认情况下,所做的备份对云硬盘的所有者不可见。
作为一个 admin 用户,您可以创建一个云硬盘的备份,并且使这个备份对特定的租户有效。运行以下命令:
# cinder --os-auth-url KEYSTONEURL --os-tenant-name TENANTNAME --os-username USERNAME --os-password PASSWD backup-create VOLUME其中:
- TENANTNAME 是可以访问这个备份的租户的名称。
- USERNAME 和 PASSWD 是 TENANTNAME 内的一个用户的 username/password 信息
- VOLUME 是您需要备份的云硬盘的名称或 ID。
- KEYSTONEURL 是 Identity 服务的 URL 端点(通常是 http://IP:5000/v2,其中的 IP 是 Identity 服务主机的 IP 地址)。
在进行这个操作时,备份的大小会占用 TENANTNAME 的配额,而不会占用 admin 的配额。
4.2.1.2. 创建一个增量云硬盘备份
在默认情况下,cinder backup-create 命令会对云硬盘创建一个完全备份。如果这个云硬盘已经存在了备份,则可以创建一个增量备份。
因为云硬盘的数据可能会随着使用时间的增加变得非常大,因此定期进行完全备份会消耗大量资源。而增量备份只记录从上一次备份(完全备份或增量备份)以来数据的变化,这样就可以定期记录云硬盘上数据的所有变化,同时最小化对资源的消耗。
使用 --incremental 选项创建一个增量备份:
# cinder backup-create VOLUME --incremental
使用要备份的云硬盘的 ID 或 Display Name 替换 VOLUME。
当存在增量备份时,不能删除相关的完全备份。例如,当一个完全备份有多个增量备份时,您只能删除最后一个增量备份。
增量备份在 NFS 和 Object Storage 备份存储库中被完全支持。Ceph 备份存储库也支持增量备份,但只针对于存储在 Ceph 后端的存储卷。
4.2.1.3. 当 Block Storage 数据库损坏时恢复云硬盘
Block Storage 数据库包括了云硬盘备份服务(openstack-cinder-backup)所需的元数据,因此一般情况下,Block Storage 数据库损坏时将无法恢复一个云硬盘备份。元数据包括 backup_service 和 backup_url 的值,您可以在创建备份后导出它们(第 4.2.1.1 节 “创建一个完全云硬盘备份”)。
如果您已经导出并保存了元数据,就可以在需要时把它导入到一个新的 Block Storage 数据库,这样就可以对云硬盘备份进行恢复。
使用带有管理员权限的用户运行:
# cinder --os-volume-api-version 2 backup-import backup_service backup_url其中的 backup_service 和 backup_url 包括在您导出的元数据中。例如,使用 第 4.2.1.1 节 “创建一个完全云硬盘备份” 导出的元数据:
# cinder --os-volume-api-version 2 backup-import cinder.backup.drivers.swift eyJzdGF0dXMi...c2l6ZSI6IDF9 +----------+--------------------------------------+ | Property | Value | +----------+--------------------------------------+ | id | 77951e2f-4aff-4365-8c64-f833802eaa43 | | name | None | +----------+--------------------------------------+- 在元数据被导入到 Block Storage 服务数据库后,您就可以象一般情况一样恢复云硬盘(请参阅 第 4.2.1.4 节 “从备份恢复一个云硬盘”)。
4.2.1.4. 从备份恢复一个云硬盘
找到您需要使用的云硬盘备份的
ID:# cinder backup-listVolume ID需要和您要恢复的云硬盘的 ID 相匹配。恢复云硬盘备份:
# cinder backup-restore BACKUP_ID其中的 BACKUP_ID 是您要使用的云硬盘备份的 ID。
如果您不再需要一个备份,运行以下命令删除它:
# cinder backup-delete BACKUP_ID
4.2.1.5. 查看和修改租户的备份配额
和多数租户存储配额(云硬盘数量、云硬盘存储、快照等)不同,备份的配额当前还无法通过 dashboard 进行修改。
当前,备份配额只能通过命令行进行修改(使用 cinder quota-update 命令)。
使用以下命令查看某个特定租户(TENANTNAME)的存储配额:
# cinder quota-show TENANTNAME运行以下命令更新一个特定租户可以创建的最大备份数量(MAXNUM):
# cinder quota-update --backups MAXNUM TENANTNAME运行以下命令更新一个特定租户可以创建的所有备份的总量(MAXGB):
# cinder quota-update --backup-gigabytes MAXGB TENANTNAME运行以下命令查看一个特定租户的存储配额的使用情况:
# cinder quota-usage TENANTNAME4.2.1.6. 通过 Dashboard 启用云硬盘备份管理功能
现在,您可以通过 dashboard 创建、查看、删除和恢复云硬盘备份。使用项目 > Compute > 云硬盘 > 云硬盘备份标签页可以进行这些操作。
在默认情况下,云硬盘备份标签页没有被启用,您需要根据以下步骤配置 dashboard 来启用它:
-
打开
/etc/openstack-dashboard/local_settings文件。 找到以下设置:
OPENSTACK_CINDER_FEATURES = { 'enable_backup': False, }把这个设置改为:
OPENSTACK_CINDER_FEATURES = { 'enable_backup': True, }通过重启
httpd服务来重启 dashboard:# systemctl restart httpd.service
4.2.1.7. 设置一个 NFS 共享作为备份存储库
在默认情况下,Block Storage 服务使用 Object Storage 服务作为备份的存储库。您可以使用以下方法,把 Block Storage 服务配置为使用一个存在的 NFS 共享作为备份存储库:
- 使用一个带有管理权限的用户登录到提供备份服务(openstack-cinder-backup)的节点上。
把 Block Storage 服务配置为使用 NFS 备份驱动(
cinder.backup.drivers.nfs):# openstack-config --set /etc/cinder/cinder.conf DEFAULT backup_driver cinder.backup.drivers.nfs设置您需要作为备份存储库使用的 NFS 共享:
# openstack-config --set /etc/cinder/cinder.conf DEFAULT backup_share NFSHOST:PATH其中:
- NFSHOST 是 NFS 服务器的 IP 地址或主机名。
- PATH 是 NFS 共享在 NFSHOST 上的绝对路径。
运行以下命令可以为 NFS 共享设置可选的挂载配置:
# openstack-config --set /etc/cinder/cinder.conf DEFAULT backup_mount_options NFSMOUNTOPTS其中,NFSMOUNTOPTS 是由逗号分隔的 NFS 挂载选项(例如,
rw,sync)。如需了解更多相关信息,请参阅 nfs 和 mount 的 man 页。重启 Block Storage 备份服务来使所做的改变生效:
# systemctl restart openstack-cinder-backup.service
4.2.1.7.1. 设置不同的备份文件大小
备份服务会使用一个最大的备份文件大小设置来限制备份文件的大小,当云硬盘备份的实际大小超过这个值时,备份会被分为多个文件。备份文件大小的默认值是 1.8GB。
运行以下命令可以修改备份文件大小的设置:
# openstack-config --set /etc/cinder/cinder.conf DEFAULT backup_file_size SIZE使用您实际需要的值替换 SIZE(以字节为单位)。重启 Block Storage 备份服务使所做的修改生效:
# systemctl restart openstack-cinder-backup.service4.2.2. 迁移卷
只有管理员可以迁移卷。迁移卷时卷不能被使用,也不能有任何快照。
以一个管理员用户的身份,列出所有有效的卷:
# cinder list列出有效的后端(主机)和它们相关的可用域:
# cinder-manage host list初始迁移的过程:
# cinder migrate VOLUME BACKEND其中:
-
VOLUME是要迁移卷的ID。 -
BACKEND是卷要被迁移到的后端。
-
查看迁移卷的当前状态:
# cinder show VOLUME例如:
# cinder show 45a85c3c-3715-484d-ab5d-745da0e0bd5a +---------------------------------------+------------------+ | Property | Value | +---------------------------------------+------------------+ | ... | ... | | os-vol-host-attr:host | server1 | | os-vol-mig-status-attr:migstat | None | | ... | ... | +---------------------------------------+------------------+
在迁移过程中,请关注以下属性:
- os-vol-host-attr:host
- 卷当前的后台。当迁移完成后,它的值会变为目标后台(BACKEND 的值)。
- os-vol-mig-status-attr:migstat
-
迁移的状态。当它的值为
None时说明迁移没有在进行。
4.2.3. 使用云硬盘类型进行云硬盘分组设置
OpenStack 允许您创建云硬盘类型,并在创建一个云硬盘时应用云硬盘类型中包括的设置(第 4.1.1 节 “创建云硬盘”)。例如,您可以设置:
- 是否对云硬盘进行加密(第 4.2.5.2 节 “配置云硬盘类型加密”)
- 云硬盘所使用的后端(第 4.1.2 节 “为创建的云硬盘指定后端”)
- Quality-of-Service (QoS) 规格
使用“键-值”对来与云硬盘类型进行关联的设置被称为特别设定(Extra Specs)。当您在创建云硬盘时指定一个云硬盘类型,Block Storage 调度器会应用这些使用“键/值”对指定的设置。您可以为同一个云硬盘类型关联多个“键/值”对。
云硬盘类型可以为不同用户提供不同级别的存储级别。通过使用“键/值”对为云硬盘类型关联相关的设置,您可以为不同的云硬盘类型指定不同的存储级别。然后,您就可以在创建云硬盘时通过指定云硬盘类型来为云硬盘指定相应的存储级别。
被支持的特别设定会根据卷驱动的不同而有所不同。请参考您的卷驱动的相关文档来获得详细信息。
4.2.3.1. 创建并配置一个云硬盘类型
- 使用一个 admin 用户,在 dashboard 中选择管理员 > 云硬盘 > 云硬盘类型。
- 点创建云硬盘类型。
- 在名称项中输入云硬盘类型的名称。
- 点创建云硬盘类型。新类型会出现在云硬盘类型项中。
- 选择云硬盘类型的查看特别设定操作。
- 点创建,设置键和值。所指定的键/值对必须有效,否则在创建云硬盘时指定云硬盘类型会出现错误。
- 点创建。相关联的设置(“键/值”对)会出现在特别设定列表中。
在默认情况下,所有的云硬盘类型对于所有 OpenStack 租户都有效。如果您创建的云硬盘类型需要对租户访问进行限制时,则需要使用 CLI 进行设置。如需了解相关信息,请参阅 第 4.2.3.4 节 “创建和配置私有云硬盘类型”。
您也可以为云硬盘类型关联一个 QOS 规格。如需了解详细信息,请参阅 第 4.2.4.2 节 “为云硬盘类型关联一个 QOS 规格”。
4.2.3.2. 编辑一个云硬盘类型
- 使用一个 admin 用户,在 dashboard 中选择管理员 > 云硬盘 > 云硬盘类型。
- 在云硬盘类型项中,选择云硬盘类型的查看特定设置操作。
在卷扩展规格属性列表中,您可以:
- 为云硬盘类型添加新设置。点创建,指定需要和这个云硬盘类型相关联的“键/值”对。
- 编辑一个存在的设置。选择编辑操作。
- 删除已存在的设置。点删除额外规格按钮。
4.2.3.3. 删除一个云硬盘类型
要删除一个云硬盘类型,在云硬盘类型列表中选择相应的云硬盘并点删除云硬盘类型。
4.2.3.4. 创建和配置私有云硬盘类型
在默认情况下,所有的云硬盘类型对于所有 OpenStack 租户都有效。您可以在创建云硬盘类型的过程中修改这个设置,把所创建的云硬盘类型设置为私有(把它的 Is_Public 标记设置为 False)。
通过设置私有云硬盘类型,可以限制对特定云硬盘类型的访问。一般情况下,某些设置(例如,需要进行测试的新后端或超高性能配置)应该只可以被特定租户使用。
运行以下命令创建一个私有云硬盘类型:
# cinder --os-volume-api-version 2 type-create --is-public false _VTYPE_+ 使用私有云硬盘类型的名称替换 VTYPE。
在默认情况下,私有云硬盘类型只能被它的创建者访问。admin 用户可以使用以下命令找到并查看私有云硬盘类型:
# cinder --os-volume-api-version 2 type-list --all这个命令会列出公共云硬盘类型和私有云硬盘类型,并列出它们的名称和 ID。您需要使用云硬盘类型的 ID 对它们进行访问。
分配私有云硬盘类型的访问权限是在租户一级进行的。运行以下命令可以为一个租户分配访问一个私有云硬盘类型的权限:
# cinder --os-volume-api-version 2 type-access-add --volume-type _VTYPEID_ --project-id _TENANTID_其中:
- VTYPEID 是私有云硬盘类型的 ID。
- TENANTID 是被分配可以访问 VTYPEID 权限的项目/租户 ID。
运行以下命令可以查看哪些租户可以访问某个私有云硬盘类型:
# cinder --os-volume-api-version 2 type-access-list --volume-type _VTYPE_运行以下命令可以把一个租户从一个私有云硬盘的访问列表中删除:
# cinder --os-volume-api-version 2 type-access-remove --volume-type _VTYPE_ --project-id _TENANTID_在默认情况下,只有具有管理权限的用户才可以创建、查看或配置私有云硬盘类型的访问权限。
4.2.4. 使用服务质量规格
您可以把多个性能设置包括在一个服务质量规格( Quality-of-Service specification,简称 QOS Specs)中,这样,就可以为不同类型的用户提供相应服务质量的性能。
和卷类型相似,性能设置通过一个“关键字/值”数据对来映射到规格。服务质量规格和卷类型的不同之处在于:
服务质量规格被用来实现性能设置,包括对磁盘读/写的限制。不同的存储驱动会支持不同性能设置。
如需了解您的后端所支持的 QOS 规格,请参阅您的后端设备的卷驱动文档。
- 卷类型会直接应用到卷,而 QOS 规格会与卷类型相关联。在创建卷时,指定卷类型的同时也会应用和这个卷类型相关联的 QOS 规格中定义的性能设置。
4.2.4.1. 创建并配置一个 QOS 规格
作为管理员,您可以通过 QOS 规格列表创建并配置 QOS 规格。您可以为同一个 QOS 规格管理多个“键/值”对。
- 使用一个 admin 用户,在 dashboard 中选择管理员 > 云硬盘 > 云硬盘类型。
- 在 QOS 规格项中点创建 QOS 规格。
- 为 QOS 规格 输入一个名称。
在消费者项中指定 QOS 规格在哪里被强制执行:
Expand 表 4.1. 消费者类型 类型 描述 back-endQOS 规格需要应用到 Block Storage 后端。
front-endQOS 规格需要应用到 Compute。
bothQOS 规格将应用到 Block Storage 和 Compute。
- 点创建。新创建的 QOS 规格应该出现在 QOS 规格列表中。
- 在 QOS 规格列表中,选择新规格的管理规格操作。
- 点创建,设置键和值。所指定的键/值对必须有效,否则在创建云硬盘时,指定和这个 QOS 规格相关联的云硬盘类型时会出现错误。
- 点创建。相关联的设置(“键/值”对)会出现在键值对列表中。
4.2.4.2. 为云硬盘类型关联一个 QOS 规格
作为一个管理员,您可以使用云硬盘类型列表为一个存在的卷类型关联 QOS 规格。
- 使用一个 admin 用户,在 dashboard 中选择管理员 > 云硬盘 > 云硬盘类型。
- 在云硬盘类型项中,选择云硬盘类型的管理 QOS 规格关联操作。
- 从要关联的 QOS 规格下拉列表中选择一个 QOS 规格。
- 点关联。所选的 QOS 规格将会出现在被编辑的云硬盘类型的已关联 QOS 规格栏中。
4.2.4.3. 为云硬盘类型取消关联一个 QOS 规格
- 使用一个 admin 用户,在 dashboard 中选择管理员 > 云硬盘 > 云硬盘类型。
- 在云硬盘类型项中,选择云硬盘类型的管理 QOS 规格关联操作。
- 从要关联的 QOS 规格列表中选择 None。
- 点关联。所选的 QOS 规格将会不会出现在被编辑的云硬盘类型的已关联 QOS 规格栏中。
4.2.5. 使用静态密钥加密卷
对卷进行加密可以在卷后台的安全性被破坏时为数据提供基本的安全保护。被加密卷的内容只有在使用一个特定密钥时才可以被读写;Compute 和 Block Storage 服务都需要被配置为使用相同的密钥来使实例可以使用加密的卷。以下介绍了如何配置 OpenStack 部署来使用一个密钥来加密卷。
4.2.5.1. 创建一个静态密钥
实现基本卷加密的第一步是设置一个静态密钥(static key)。这个密钥需要是一个十六进制的字符串,并被 Block Storage 卷服务(openstack-cinder-volume)和所有 Compute 服务(openstack-nova-compute)使用。要设置这两个服务使用这个密钥,在它们的相关配置文件中的 [keymgr] 项中使用这个密钥作为 fixed_key 的值。
-
通过命令行,以
root身份登录到包括openstack-cinder-volume的节点。 设置静态密钥:
# openstack-config --set /etc/cinder/cinder.conf keymgr fixed_key HEX_KEY把
HEX_KEY替换为一个 16 位的十六进制密钥值(例如0000000000000000000000000000000000000000000000000000000000000000)。重启 Block Storage 卷服务:
# openstack-service restart cinder-volume登录到包括
openstack-nova-compute的节点,设置相同的静态密钥:# openstack-config --set /etc/nova/nova.conf keymgr fixed_key HEX_KEY注意如果您有多个 Compute 节点(多个节点都包括
openstack-nova-compute),您需要在每个节点的/etc/nova/nova.conf中设置相同的静态密钥。重启 Compute 服务:
# openstack-service restart nova-compute注意同样,如果您在多个 Compute 节点上设置了静态密钥,您需要在每个节点上都重启
openstack-nova-compute服务。
到目前为止,Compute 和 Block Storage 卷服务都可以使用相同的静态密钥对卷进行加密和解密。新的实例将可以使用经过静态密钥(HEX_KEY)加密的卷。
4.2.5.2. 配置云硬盘类型加密
为了使用 第 4.2.5.1 节 “创建一个静态密钥” 创建的静态密钥对云硬盘进行加密,您需要一个加密的云硬盘类型。配置一个加密的云硬盘类型包括设置 provider class、cipher 和 key_size。运行以下命令:
# cinder encryption-type-create --cipher aes-xts-plain64 --key_size BITSIZE --control_location front-end VOLTYPE nova.volume.encryptors.luks.LuksEncryptor其中:
-
BITSIZE是密钥的大小(例如,512代表 512 位的密钥)。 -
VOLTYPE是您需要加密的云硬盘类型的名称。
这个命令设置了 nova.volume.encryptors.luks.LuksEncryptor provider class 和 aes-xts-plain64 cipher。在这个发行版本中,云硬盘加密只支持这个 class/cipher 配置。
在您创建了一个加密的云硬盘类型后,您就可以在创建加密云硬盘时自动使用它。在创建云硬盘窗口中的类型下拉菜单中选择需要的加密云硬盘类型(请参阅 第 4.1 节 “基本云硬盘(Volume)的使用和配置”)。
4.2.6. 配置如何在多后端间分配卷
如果 Block Storage 服务被配置为使用多后端,您可以使用配置的云硬盘类型来指定卷可以在哪里创建。如需更详细的信息,请参阅 第 4.1.2 节 “为创建的云硬盘指定后端”。
如果在创建云硬盘的过程中没有进行指定,Block Storage 服务会自动选择一个后端。Block Storage 把第一个定义的后端作为默认的后端,在这个后端还有空间时,它会被使用。如果第一个后端没有可用的空间,Block Storage 会把第 2 个后端设置为默认后端。以此类推。
如果这无法满足您的要求,则可以使用过滤调度程序来控制 Block Storage 如何选择后端。调度程序会根据不同的过滤规则选择适当的后端,例如:
- AvailabilityZoneFilter
- 过滤掉不符合所需卷的可用域要求的后端。
- CapacityFilter
- 只选择有足够空间的后端来保存云硬盘
- CapabilitiesFilter
- 只选择可以支持卷中的所有指定设置的后端
按照以下步骤配置过滤器:
启用
FilterScheduler。# openstack-config --set /etc/cinder/cinder.conf DEFAULT scheduler_driver cinder.scheduler.filter_scheduler.FilterScheduler设置哪个过滤器应该被激活:
# openstack-config --set /etc/cinder/cinder.conf DEFAULT scheduler_default_filters AvailabilityZoneFilter,CapacityFilter,CapabilitiesFilter配置调度程序如何选择适当的后端。如果您需要调度程序:
总选择具有最多可用空间的后端,运行:
# openstack-config --set /etc/cinder/cinder.conf DEFAULT scheduler_default_weighers AllocatedCapacityWeigher # openstack-config --set /etc/cinder/cinder.conf DEFAULT allocated_capacity_weight_multiplier -1.0在适当后端中随机选择,运行:
# openstack-config --set /etc/cinder/cinder.conf DEFAULT scheduler_default_weighers ChanceWeigher
重启 Block Storage 调度程序来使您的改变生效:
# openstack-service restart openstack-cinder-scheduler
第 5 章 管理容器
OpenStack Object Storage (swift) 使用容器(container)来保存它的对象(数据),容器和一个文件系统的目录相似,只是不能进行嵌套。它为用户提供了一个存储无结构数据的方法。例如,对象可以包括图形、文本文件或镜像。存储的对象没有被加密,也不被压缩。
为了更好地组织数据,可以使用虚拟文件夹(pseudo-folder)。虚拟文件夹是包括对象的逻辑设备,并可以进行嵌套。例如,您可以在存储照片的容器中创建一个 Images 文件夹;在存储视频的容器中创建一个 Media 文件夹。
您可以在每个项目中创建一个或多个容器,在每个容器中创建一个或多个对象或虚拟文件夹。
5.1. 创建一个容器
- 在 dashboard 中选择项目 > 对象存储 > 容器。
- 点创建容器。
指定容器名,在容器访问项中选择以下值之一:
Expand 类型 描述 Private限制当前的项目只能被某个用户访问。
Public允许 API 访问所有具有公共 URL 的容器。但是在 dashboard 中,项目用户无法看到其它项目的公共容器和数据。
- 点创建容器。
5.2. 为容器创建虚拟文件夹
- 在 dashboard 中选择项目 > 对象存储 > 容器。
- 点您需要添加虚拟文件夹的容器名称。
- 点创建虚拟文件夹。
- 在虚拟文件夹名称项中输入名称,点创建。
5.3. 上传一个对象
如果您没有上传一个实际的文件,对象仍然会被创建(作为一个占位符),它可以在以后被用来上传文件。
- 在 dashboard 中选择项目 > 对象存储 > 容器。
- 点放置上传对象的容器的名称;如果容器中存在虚拟文件夹,您可以点它的名称。
- 找到您的文件,点上传对象。
在对象名项中输入一个名称:
- 虚拟文件夹的名称可以使用 /(如 Images/myImage.jpg)。如果指定的文件夹不存在,在对象上传时会被自动创建。
- 如果您使用的名称不是唯一的(同名的对象已经存在),它会覆盖以前同名对象的内容。
- 点上传对象。
5.4. 复制一个对象
- 在 dashboard 中选择项目 > 对象存储 > 容器。
- 点对象容器或文件夹的名称来显示对象。
- 点上传对象。
- 找到需要复制的文件,在菜单中选复制。
指定下列值:
Expand 项 描述 目标容器
新对象的目标容器。
路径
目标容器中的虚拟文件夹;如果文件夹不存在,会创建它。
目标对象名
新对象的名称。如果这个名称不是唯一的(同名的对象已经存在),它会覆盖以前同名对象的内容。
- 点复制对象。
5.5. 删除对象
- 在 dashboard 中选择项目 > 对象存储 > 容器。
- 找到对象,在菜单中选择删除对象。
- 点删除对象来确认删除操作。
5.6. 删除容器
- 在 dashboard 中选择项目 > 对象存储 > 容器。
- 在容器项中找到需要删除的容器,确认其中的对象都已经被删除(请参阅 第 5.5 节 “删除对象”)。
- 在容器的菜单中选择删除容器。
- 点删除容器来确认删除操作。
第 6 章 配置 OpenStack 使用 NFS 后端
本章介绍了如何配置 OpenStack 卷服务(openstack-cinder-volume)来使用一个存在的 NFS 服务器作为一个额外的后端。另外,本章还介绍了如何创建一个云硬盘类型,从而可以在创建云硬盘时使用它来设置 NFS 共享作为后端。
先决条件:
- 要作为后端的 NFS 共享已被正确配置。
- 提供 OpenStack 卷服务的节点有到 NFS 共享的读/写访问权限。
-
具有运行 OpenStack 卷服务的系统的
root访问权限。
基于的假设:
- 您的 OpenStack 环境不是通过 Red Hat Enterprise Linux OpenStack Platform Installer 进行部署的。
-
您的 OpenStack Block Storage 服务使用默认的后端(通过 Packstack 部署的、名为
lvm的后端)。
6.1. 配置 SELinux
当客户端启用了 SELinux 时,如果需要从这个客户端访问一个实例上的 NFS 卷,则需要启用 virt_use_nfs 布尔值。以 root 身份运行以下命令来启用这个布尔值(并使它在重启后仍然有效):
# setsebool -P virt_use_nfs on在需要访问实例上的 NFS 共享的所有客户端主机上运行这个命令(包括所有 Compute 节点)。
6.3. 创建一个新的后端定义
在默认情况下,Packstack 在 /etc/cinder/cinder.conf 中为 LVM 定义一个后端:
[lvm]
iscsi_helper=lioadm
volume_group=cinder-volumes
iscsi_ip_address=
volume_driver=cinder.volume.drivers.lvm.LVMISCSIDriver
volume_backend_name=lvm
在 /etc/cinder/cinder.conf 中定义了一个 NFS 共享后,可以按照以下步骤为它配置一个额外的后端:
-
以
root身份登录到运行 OpenStack 卷服务的节点上。 为 NFS 后端创建一个新定义,把卷服务设置为使用定义了 NFS 共享的文件(
/etc/cinder/nfs_share):# openstack-config --set /etc/cinder/cinder.conf nfs nfs_shares_config /etc/cinder/nfs_shares在这里,我们使用
nfsbackend作为一个定义的名称。配置卷服务使用 NFS 卷驱动(名为
cinder.volume.drivers.nfs.NfsDriver):# openstack-config --set /etc/cinder/cinder.conf nfs volume_driver cinder.volume.drivers.nfs.NfsDriver为 NFS 后端定义一个卷后端名(在以下命令中是
nfs):# openstack-config --set /etc/cinder/cinder.conf nfs volume_backend_name nfsbackend在 nfs_mount_options 配置关键字中添加需要的挂载选项(
MOUNTOPTIONS):# openstack-config --set /etc/cinder/cinder.conf nfs nfs_mount_options _MOUNTOPTIONS_
现在,以下项应该出现在 /etc/cinder/cinder.conf 中:
[nfs]
nfs_shares_config = /etc/cinder/nfs_shares
volume_driver = cinder.volume.drivers.nfs.NfsDriver
volume_backend_name = nfsbackend
nfs_mount_options =
现在,您可以启用 NFS 后端(使用 /etc/cinder/cinder.conf 中的 enabled_backends 配置关键字)。Packstack 创建的默认后端应该已在这里列出:
enabled_backends=lvm在这个列表中添加新的 NFS 后端定义:
enabled_backends=lvm,nfs当 NFS 后端被启用后,重启 OpenStack 卷服务:
# openstack-service restart cinder-volume6.4. 为 NFS 后端创建一个云硬盘类型
现在,新创建的 NFS 后端已经有效,但在创建新的云硬盘时还不能使用。为了使新的云硬盘可以使用这个 NFS 后端,您需要首先为它创建一个云硬盘类型。
查看存在的云硬盘类型。在默认情况下,使用 lvm 后端的云硬盘类型应该已经存在(名为 iscsi):
+--------------------------------------+-------+ | ID | Name | +--------------------------------------+-------+ | f8d31dc8-a20e-410c-81bf-6b0a971c61a0 | iscsi | +--------------------------------------+-------+为 NFS 后端创建一个新的、名为
nfstype的云硬盘类型:# cinder type-create nfstype使用后端的名称(
nfsbackend)把nfstype云硬盘类型配置为使用 NFS 后端:# cinder type-key nfstype set volume_backend_name=nfsbackend检查新创建的云硬盘类型被正确创建并配置:
+--------------------------------------+---------+ | ID | Name | +--------------------------------------+---------+ | bbff44b5-52b1-43d6-beb4-83aa2d20bc59 | nfstype | | f8d31dc8-a20e-410c-81bf-6b0a971c61a0 | iscsi | +--------------------------------------+---------+ +-----------------------+-------+---------------------------------------+ | ID | Name | extra_specs | +-----------------------+-------+---------------------------------------+ |bbff44b5-~-83aa2d20bc59|nfstype|{u'volume_backend_name': u'nfsbackend'}| |f8d31dc8-~-6b0a971c61a0| iscsi | {u'volume_backend_name': u'lvm'} | +-----------------------+-------+---------------------------------------+
您可以通过 dashboard 创建并配置云硬盘类型。如需了解更多信息,请参阅 第 4.2.3 节 “使用云硬盘类型进行云硬盘分组设置”。
6.5. 测试新的 NFS 后端
为了测试新的 NFS 后端,在创建一个名为 nfsvolume 的云硬盘时调用云硬盘类型 nfstype:
+---------------------+--------------------------------------+
| Property | Value |
+---------------------+--------------------------------------+
| attachments | [] |
| availability_zone | nova |
| bootable | false |
| created_at | 2015-01-06T05:14:09.271114 |
| display_description | None |
| display_name | nfsvolume |
| encrypted | False |
| id | 0cd7ac45-622a-47b0-9503-7025bbedc8ed |
| metadata | {} |
| size | 1 |
| snapshot_id | None |
| source_volid | None |
| status | creating |
| volume_type | nfstype |
+---------------------+--------------------------------------+当云硬盘被成功创建后,在 NFS 服务器上检查 NFS 共享。一个相应的云硬盘(它的名字中包括新创建云硬盘的 ID)应该在那里出现:
drwxrwxrwx. 2 root root 4.0K Jan 6 15:14 .
drwxr-xr-x. 18 root root 4.0K Jan 5 04:03 ..
-rw-rw-rw-. 1 nfsnobody nfsnobody 1.0G Jan 6 15:14+ +volume-0cd7ac45-622a-47b0-9503-7025bbedc8ed第 7 章 配置带有 NUMA 的 CPU 固定(CPU Pinning)
本章介绍了与 NUMA 拓扑相关的信息,以及如何在支持 NUMA 的系统上配置 OpenStack 环境。在这类设置中,虚拟机实例被固定到专用的 CPU 内核,从而可以通过更加智能的调度来提高客户机的性能。
如需了解 NUMA 的背景信息,请参阅 What is NUMA and how does it work on Linux ?。如需了解使用 libvirt 对 NUMA 进行性能调优的信息,请参阅 Virtualization Tuning and Optimization Guide。
7.1. Compute 节点的配置
虽然具体的配置取决于您的主机系统的 NUMA 拓扑,但是,您必须为主机进程在所有 NUMA 节点上保留一些 CPU 内核,并让剩余的 CPU 内核处理客户虚拟机实例。例如,有 8 个 CPU 内核平均分布在 2 个 NUMA 节点上,它的结构可以和以下类似:
NUMA 拓扑示例
┌─────────────────┬─────────────────┬─────────────────┐
│ │ Node 0 │ Node 1 │
├─────────────────┼────────┬────────┼────────┬────────┤
│ Host processes │ Core 0 │ Core 1 │ Core 4 │ Core 5 │
├─────────────────┼────────┼────────┼────────┼────────┤
│ Guest processes │ Core 2 │ Core 3 │ Core 6 │ Core 7 │
└─────────────────┴────────┴────────┴────────┴────────┘为了决定为主机进程保留的内核数量,需要在特定工作负载的情况下对主机性能进行观察。
配置 Compute 节点包括以下几个步骤:
把
/etc/nova/nova.conf文件中的vcpu_pin_set选项设置成为客户系统进程保留的 CPU 内核列表。对于上面的示例,您可以进行以下设置:vcpu_pin_set=2,3,6,7把相同文件中的
reserved_host_memory_mb选项设置成为主机进程保留的 RAM 的数量。如果您需要保留 512 MB 内存,配置如下:reserved_host_memory_mb=512运行以下命令在 Compute 节点上重启 Compute 服务:
systemctl restart openstack-nova-compute.service在引导选项中,使用 isolcpus 并加上 CPU 列表。这可以把主机进程限制为只能访问列出的 CPU 内核。对于以上的示例,您可以运行:
grubby --update-kernel=ALL --args="isolcpus=2,3,6,7"更新引导记录使这个改变生效:
grub2-install /dev/device使用包括引导记录的设备名替换 device,这个设备名通常是 sda。
- 重启系统。
7.2. 调度程序配置
在运行 OpenStack Compute Scheduler 的每个系统上编辑
/etc/nova/nova.conf文件。找到scheduler_default_filters选项,如果它被注释掉,取消它的注释,在过滤器列表中加入AggregateInstanceExtraSpecFilter和NUMATopologyFilter。这个行的内容应该和以下类似:scheduler_default_filters=RetryFilter,AvailabilityZoneFilter,RamFilter, ComputeFilter,ComputeCapabilitiesFilter,ImagePropertiesFilter,CoreFilter, NUMATopologyFilter,AggregateInstanceExtraSpecsFilter重启 openstack-nova-scheduler 服务:
systemctl restart openstack-nova-scheduler.service
7.3. 集合(Aggregate)和 Flavor 配置
为了把您的 OpenStack 环境中的虚拟机固定在特定资源上运行,在一个系统的 Compute 命令行接口中执行以下步骤:
加载
admin身份信息:source ~/keystonerc_admin创建一个可以接收固定请求的主机集合:
nova aggregate-create name使用适当的名称(如 performance 或 cpu_pinning)替换 name。
编辑集合的元数据来启用固定功能:
nova aggregate-set-metadata 1 pinned=true在这个命令中,数字 1 匹配在前一步中创建的集合 ID。
为其它主机创建一个集合:
nova aggregate-create name使用适当的名称(如 normal)替换 name。
为这个集合编辑元数据:
nova aggregate-set-metadata 2 pinned=false其中,使用的数字是 2,这是因为它在 1(第一个集合的 ID)之后。
修改存在的 flavors 设置:
for i in $(nova flavor-list | cut -f 2 -d ' ' | grep -o '[0-9]*'); do nova flavor-key $i set "aggregate_instance_extra_specs:pinned"="false"; done为可以接收固定请求的主机创建一个 flavor:
nova flavor-create name ID RAM disk vCPUs使用适当的名称(如 m1.small.performance 或 pinned.small)替换 name;使用新 flavor 的 ID 替换 ID(如果您有 5 个标准的 flavor,使用
6;如果您需要nova来产生 UUID,使用auto);使用需要的内存数量(以 MB 为单位)替换 RAM;使用需要的磁盘大小(以 GB 为单位)替换 disk;使用需要保留的虚拟 CPU 数量替换 vCPUs。把 flavor 的
hw:cpu_policy设置为dedicated,这将启用 CPU 固定功能:nova flavor-key ID set hw:cpu_policy=dedicated使用在前一步中创建的 flavor 的 ID 替换 ID。
把
aggregate_instance_extra_specs:pinned设置为 true,从而确保基于这个 flavor 的实例在它们的元数据中有这个设置:nova flavor-key ID set aggregate_instance_extra_specs:pinned=true使用 flavor 的 ID 替换 ID。
为新的集合添加以下主机:
nova aggregate-add-host ID_1 host_1使用第一个("performance"/"pinning")集合的 ID 替换 ID_1;把 host_1 替换为需要被加入到这个集合中的主机名。
nova aggregate-add-host ID_2 host_2使用第 2 个("normal")集合的 ID 替换 ID_2;把 host_2 替换为需要被加入到这个集合中的主机名。
运行以下命令使用新 flavor 引导一个实例:
nova boot --image image --flavor flavor server_name
把 image 替换为保存的 VM 镜像名(请参阅 nova image-list);把 flavor 替换为实际的 flavor 名(m1.small.performance、pinned.small 或任何您使用的名称);把 server_name 替换为新服务器的名称。
为了检查新服务器被正确配置,运行以下命令,在输出中检查 OS-EXT-SRV-ATTR:hypervisor_hostname 的值:
nova show server_name附录 A. 镜像配置参数
在 glance image-update 和 glance image-create 命令中,property 选项可以使用以下关键字.
$ glance image-update IMG-UUID --property architecture=x86_64通过镜像属性进行的配置会覆盖通过 flavor 进行的配置。如需了解更多信息,请参阅 Manage Flavors。
| 针对于 | 键 | 描述 | 支持的值 | 所有 |
|---|---|---|---|---|
|
architecture |
hypervisor 支持的 CPU 架构。例如, |
|
所有 |
hypervisor_type |
|
hypervisor 的类型。 |
|
所有 |
instance_uuid |
对于快照镜像,这个值就是创建这个镜像的服务器的 UUID。 |
|
有效的服务器 UUID |
所有 |
kernel_id |
在引导一个 AMI 镜像时,作为内核使用的、存储于Image 服务中的镜像 ID。 |
有效的镜像 ID |
|
所有 |
os_distro |
操作系统的通用名称(使用小写)。请使用 libosinfo project 中定义的名称。在这个项中只指定可以被识别的名称,过时的名称同时被列在这里来帮助您找到可识别的名称。 |
|
所有 |
|
os_version |
发行厂商指定的操作系统版本。 |
版本号(例如,"11.10") |
所有 |
ramdisk_id |
|
在引导一个 AMI 镜像时,作为 ramdisk 使用的、存储于Image 服务中的镜像 ID。 |
有效的镜像 ID |
所有 |
vm_mode |
虚拟机模式。它代表了为虚拟机使用的主机/客户机 ABI(application binary interface)。 |
|
|
libvirt API 驱动 |
hw_disk_bus |
指定附加到磁盘设备的磁盘控制器类型。 |
|
|
libvirt API 驱动 |
hw_numa_nodes |
对实例有效的 NUMA 节点的数量(不会覆盖 flavor 的定义)。 |
整数。关于 NUMA 拓扑定义的详情,请参阅添加元数据中关于 hw:NUMA_def 关键字的介绍。 |
libvirt API 驱动 |
|
hw_numa_mempolicy |
NUMA 内存分配策略(不会覆盖 flavor 的定义)。 |
strict - 强制实例的内存分配来自于和它绑定的 NUMA 节点(如果设置了 numa_nodes,这是默认值)。preferred - 内核可以使用其它节点。当 'hw:numa_nodes' 被设置为 '1' 时会有用。 |
libvirt API 驱动 |
hw_numa_cpus.0 |
|
vCPU N-M 到 NUMA 节点 0 的映射(不会覆盖 flavor 的定义)。 |
用逗号隔开的整数列表 |
libvirt API 驱动 |
hw_numa_cpus.1 |
vCPU N-M 到 NUMA 节点 1 的映射(不会覆盖 flavor 的定义)。 |
|
用逗号隔开的整数列表 |
libvirt API 驱动 |
hw_numa_mem.0 |
把 N GB 内存映射到 NUMA 节点 0(不会覆盖 flavor 的定义)。 |
整数 |
|
libvirt API 驱动 |
hw_numa_mem.1 |
把 N GB 内存映射到 NUMA 节点 1(不会覆盖 flavor 的定义)。 |
整数 |
libvirt API 驱动 |
|
hw_qemu_guest_agent |
guest agent 支持。如果设为 |
|
libvirt API 驱动 |
hw_rng_model |
|
为镜像实例添加的一个随机数生成器。云管理员可以通过配置实例的 flavor 来启用并控制设备的行为。在默认情况下:
* The generator device is disabled. * /dev/random is used as the default entropy source. To specify a physical HW RNG device, use the following option in the nova.conf file: |
|
libvirt API 驱动 |
hw_scsi_model |
启用 VirtIO SCSI(virtio-scsi)来为 compute 实例提供块设备访问。在默认情况下,实例使用 VirtIO Block(virtio-blk)。VirtIO SCSI 是一个半虚拟化的 SCSI 控制器设备,它可以提供更高的可扩展性和性能,并支持高级 SCSI 硬件。 |
|
|
libvirt API 驱动 |
hw_video_model |
使用的视频驱动 |
|
|
libvirt API 驱动 |
hw_video_ram |
视频影像的最大内存数量。它只有当 |
整数(以 MB 为单位,如 '64') |
libvirt API 驱动 |
|
hw_watchdog_action |
启用一个虚拟硬件 watchdog 设备,它会在服务器停止工作时执行指定的任务。watchdog 使用 i6300esb 设备(仿真一个 PCI Intel 6300ESB)。如果 |
|
libvirt API 驱动 |
os_command_line |
|
libvirt 驱动使用的内核命令行(替代默认值)。对于 Linux Containers(LXC),这个值被用作初始化参数。这个关键字只对 Amazon 内核、ramdisk 和机器镜像(aki、ari 和 ami)有效。 |
libvirt API 驱动和 VMware API 驱动 |
hw_vif_model |
指定要使用的虚拟网络接口设备的型号。 | |
|
有效值取决于配置的 hypervisor。 * KVM and QEMU: e1000, ne2k_pci, pcnet, rtl8139, and virtio. * VMware: e1000, e1000e, VirtualE1000, VirtualE1000e, VirtualPCNet32, VirtualSriovEthernetCard, and VirtualVmxnet. * Xen: e1000, netfront, ne2k_pci, pcnet, and rtl8139. |
VMware API 驱动 |
vmware_adaptertype |
hypervisor 使用的虚拟 SCSI 或 IDE 控制器。 |
|
|
VMware API 驱动 |
vmware_ostype |
一个 VMware GuestID,它描述了安装在镜像中的操作系统。当创建虚拟机时,这个值被传递给 hypervisor。如果没有指定,这个关键字的值被默认设为 |
请参阅 thinkvirt.com。 |
VMware API 驱动 |
|
vmware_image_version |
当前没有使用。 |
|
XenAPI 驱动 |
auto_disk_config |
|
如果设为 true,磁盘的 root 分区会在实例引导前自动重新调整它的大小。这个值只在 Compute 服务使用一个带有 XenAPI 启动的、基于 Xen 的 hypervisor 时有效。Compute 服务只在镜像中包括一个分区,而且分区是 |
|
XenAPI 驱动 |
os_type |
在镜像中安装的操作系统。XenAPI 驱动中所包括的逻辑代码会根据镜像的 |