规划部署
部署 Red Hat OpenShift Data Foundation 4.12 时的重要注意事项
摘要
使开源包含更多
红帽致力于替换我们的代码、文档和 Web 属性中存在问题的语言。我们从这四个术语开始:master、slave、黑名单和白名单。由于此项工作十分艰巨,这些更改将在即将推出的几个发行版本中逐步实施。详情请查看 CTO Chris Wright 的信息。
对红帽文档提供反馈
我们感谢您对文档提供反馈信息。请告诉我们如何让它更好。提供反馈:
关于特定内容的简单评论:
- 请确定您使用 Multi-page HTML 格式查看文档。另外,确定 Feedback 按钮出现在文档页的右上方。
- 用鼠标指针高亮显示您想评论的文本部分。
- 点在高亮文本上弹出的 Add Feedback。
- 按照显示的步骤操作。
要提交更复杂的反馈,请创建一个 Bugzilla ticket:
- 进入 Bugzilla 网站。
- 在 Component 部分中,选择 文档。
- 在 Description 中输入您要提供的信息。包括文档相关部分的链接。
- 点 Submit Bug。
第 1 章 OpenShift Data Foundation 介绍
Red Hat OpenShift Data Foundation 是 Red Hat OpenShift Container Platform 的云存储和数据服务的高度集成集合。它作为 Red Hat OpenShift Container Platform Service Catalog 的一部分提供,它作为一个 operator 提供,以便于简单部署和管理。
Red Hat OpenShift Data Foundation 服务主要通过代表以下组件的存储类提供给应用程序:
- 块存储设备,主要服务于数据库工作负载。示例包括 Red Hat OpenShift Container Platform 日志记录和监控,以及 PostgreSQL。
- 共享和分布式文件系统,主要服务于软件开发、消息传递和数据聚合工作负载。示例包括 Jenkins 构建源和工件、Wordpress 上传的内容、Red Hat OpenShift Container Platform registry,以及使用 JBoss AMQ 的消息传递。
- 多云对象存储,具有一个轻量级 S3 API 端点,可以从多个云对象存储中提取存储和检索数据。
- 在内部对象存储中,具有一个稳定的 S3 API 端点,可扩展到数十拍字节(PB)和数十亿个对象的环境,主要面向数据密集型应用。例如,使用 Spark、Pacesto、Red Hat AMQ Streams (Kafka) 等应用程序,以及 TensorFlow 和 Pytorch 等机器学习框架。
不支持在 CephFS 持久性卷上运行 PostgresSQL 工作负载,建议使用 RADOS 块设备 (RBD) 卷。如需更多信息,请参阅知识库文章解决方案 ODF 数据库工作负载必须不使用 CephFS PV/PVC。
Red Hat OpenShift Data Foundation 版本 4.x 由一组软件项目组成,包括:
- Ceph,提供块存储、共享分布式文件系统以及内部对象存储
- Ceph CSI,用于管理持久性卷和声明的调配和生命周期
- NooBaa 提供多云对象网关
- OpenShift Data Foundation、Rook-Ceph 和 NooBaa 操作器,用于初始化和管理 OpenShift Data Foundation 服务。
第 2 章 OpenShift Data Foundation 基础架构
Red Hat OpenShift Data Foundation 为 Red Hat OpenShift Container Platform 提供服务,也可以从Red Hat OpenShift Container Platform 内部运行。
图 2.1. Red Hat OpenShift Data Foundation 架构
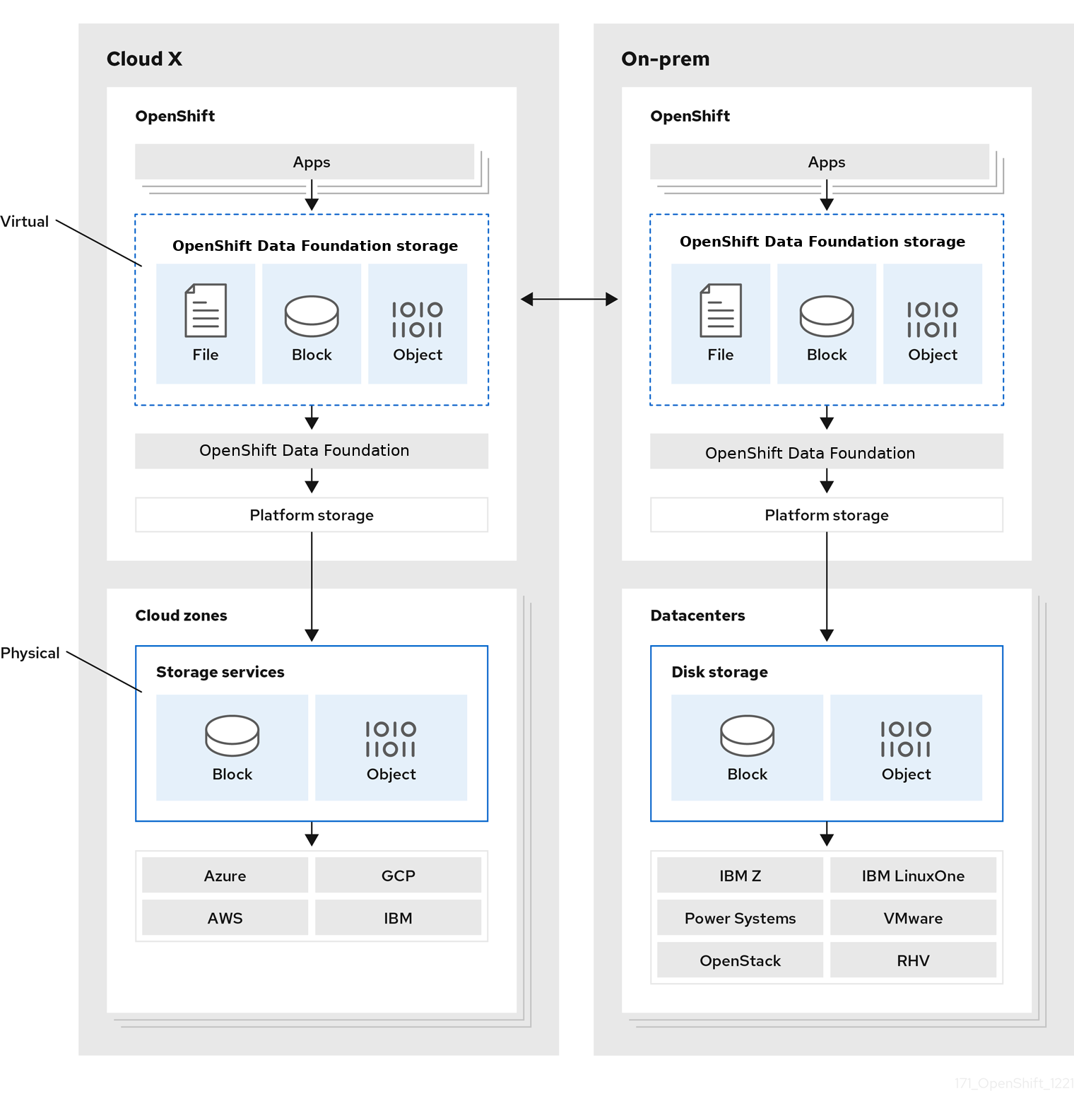
Red Hat OpenShift Data Foundation 支持部署到在安装程序置备的基础架构或用户置备的基础架构上部署的 Red Hat OpenShift Container Platform 集群中。
有关这两种方法的详情,请参阅 OpenShift Container Platform - 安装过程。
如需了解更多有关 Red Hat OpenShift Data Foundation 和 Red Hat OpenShift Container Platform 组件互操作性的信息,请参阅 Red Hat OpenShift Data Foundation 支持性和互操作性检查器。
如需有关 OpenShift Container Platform 架构和生命周期的信息,请参阅 OpenShift Container Platform 架构。
对于 IBM Power,请参阅 OpenShift Container Platform - 安装过程。
2.1. 关于 Operator
Red Hat OpenShift Data Foundation 由三个主要操作器(operator)组成,它们协调管理任务和自定义资源,以便您可以轻松自动化任务和资源特征。管理员定义集群的所需最终状态,OpenShift Data Foundation 通过最少的管理员干预来确保集群处于该状态,或接近该状态。
OpenShift Data Foundation operator(操作器)
使用特定测试的方法在其他 Operator 上绘制并强制实施受支持的 Red Hat OpenShift Data Foundation 部署的建议和要求。rook-ceph 和 noobaa operator 提供了打包了这些资源的存储集群资源。
Rook-ceph operator
此 operator 自动打包、部署、管理、升级和扩展持久存储和文件、块和对象服务。它为所有环境创建块和文件存储类,并在内部环境中创建针对它的对象存储类和服务对象存储桶声明(Object Bucket Claims (OBCs))。
此外,对于内部模式集群,它提供 Ceph 集群资源,它管理部署和服务,如下所示:
- 对象存储守护进程 (OSD)
- 监视器 (MON)
- 经理 (MGR)
- 元数据服务器 (MDS)
- 仅限内部 RADOS 对象网关 (RGW)
多云对象网关 operator
此 operator 自动打包、部署、管理、升级和扩展多云对象网关对象(MCG)服务。它创建一个对象存储类,以及 OBCs 提出的服务。
另外,它还提供 NooBaa 集群资源,用于管理 NooBaa core、数据库和端点的部署和服务。
2.2. 存储集群部署方法
日益增加的运营模式列表表明,灵活性是 Red Hat OpenShift Data Foundation 的核心原则。本节将为您提供信息,帮助您为您的环境选择最合适的方法。
Red Hat OpenShift Data Foundation 可以完全在 OpenShift Container Platform 中部署(内部方法),或者从 OpenShift Container Platform 外部运行的集群(外部方法)提供服务。
2.2.1. 内部方法
在 Red Hat OpenShift Container Platform 中完全部署 Red Hat OpenShift Data Foundation 具有基于 Operator 的部署和管理优势。图形用户界面(GUI)中的内部附加设备方法可用于使用本地存储 operator 和本地存储设备以内部模式部署 Red Hat OpenShift Data Foundation。
简化部署和管理是在 OpenShift Container Platform 内部运行 OpenShift Data Foundation 服务的关键。当 Red Hat OpenShift Data Foundation 完全在 Red Hat OpenShift Container Platform 中运行时,可以使用两种不同的部署模式:
- Simple(简单)
- Optimized(优化)
简单部署
Red Hat OpenShift Data Foundation 服务与应用程序共同运行。Red Hat OpenShift Container Platform 中的 Operator 管理这些应用程序。
简单的部署最适用于以下情况。
- 存储要求不明确。
- Red Hat OpenShift Data Foundation 服务与应用程序共同运行。
- 创建一个有特定大小的端点实例(例如在裸机上)比较困难。
为了让 Red Hat OpenShift Data Foundation 与应用程序共同运行,它们必须具有动态附加本地存储设备或可移植存储设备(如 EC2 上的 EBS 卷或 VMware 上的 vSphere 虚拟磁盘)或由 PowerVC 动态置备的 SAN 卷。
PowerVC 动态置备 SAN 卷。
优化的部署
Red Hat OpenShift Data Foundation 服务在专用的基础架构节点上运行。Red Hat OpenShift Container Platform 管理这些基础架构节点。
优化的方法最适合以下情况,
- 存储要求很明确。
- Red Hat OpenShift Data Foundation 服务在专用的基础架构节点上运行。
- 创建特定大小的节点实例很容易,例如在云、虚拟化环境中。
2.2.2. 外部方法
Red Hat OpenShift Data Foundation 将 OpenShift Container Platform 集群外运行的 Red Hat Ceph Storage 服务作为存储类公开。
在以下情况下最适合使用外部方法,
- 存储要求非常显著(超过 600 个存储设备)
- 多个 OpenShift Container Platform 集群需要消耗来自通用外部集群的存储服务。
- 其他团队,如站点可靠性工程 (SRE) 团队、存储团队等,需要管理提供存储服务的外部集群。可能已存在。
2.3. 节点类型
节点运行容器运行时和服务,以确保容器正在运行,并且维护容器集之间的网络通信和隔离。在 OpenShift Data Foundation 中,有三种类型的节点。
| 节点类型 | 描述 |
|---|---|
| Master | 这些节点运行公开 Kubernetes API、观察和调度新创建的 pod、维护节点健康和数量,以及控制与底层云供应商的交互的进程。 |
| Infrastructure (Infra) | Infra 节点运行集群级别的基础架构服务,如日志记录、指标、registry 和路由。这些在 OpenShift Container Platform 集群中是可选的。为了将 OpenShift Data Foundation 工作负载与应用程序分离,请确保在虚拟化和云环境中使用 infra 节点作为 OpenShift Data Foundation。
要创建 Infra 节点,您可以置备标记为 |
| Worker | Worker 节点也称为应用节点,因为它们运行应用。 当 OpenShift Data Foundation 以内部模式部署时,您需要包含 3 个 worker 节点的最小集群。确保节点分散在 3 种不同的机架或可用性区域,以确保可用性。为了使 OpenShift Data Foundation 在 worker 节点上运行,您需要将本地存储设备或可移植的存储设备动态附加到 worker 节点。 当 OpenShift Data Foundation 以外部模式部署时,它会在多个节点上运行。这允许 Kubernetes 在故障时重新调度到可用节点上。 |
OpenShift Data Foundation 需要与 OpenShift Container Platform 相同的订阅数。但是,如果 OpenShift Data Foundation 在 infra 节点上运行,OpenShift 不需要 OpenShift Container Platform 订阅用于这些节点。因此,OpenShift Data Foundation control plane 不需要额外的 OpenShift Container Platform 和 OpenShift Data Foundation 订阅。如需更多信息,请参阅 第 6 章 订阅。
第 3 章 内部存储服务
Red Hat OpenShift Data Foundation 服务可在内部被在以下基础架构上运行的 Red Hat OpenShift Container Platform 使用:
- Amazon Web Services (AWS)
- 裸机
- VMware vSphere
- Microsoft Azure
- Google Cloud [技术预览]
- Red Hat Virtualization 4.4.x 或更高版本(安装程序置备的基础架构)
- Red Hat OpenStack 13 或更高版本 (安装程序置备的基础架构)[技术预览]
- IBM Power
- IBM Z 和 LinuxONE
创建内部集群资源将导致内部置备 OpenShift Data Foundation 基础服务,并为应用程序提供额外的存储类。
第 4 章 外部存储服务
Red Hat OpenShift Data Foundation 可以使用 IBM FlashSystems,或者从外部 Red Hat Ceph Storage 集群提供服务,以便通过在以下平台上运行的 OpenShift Container Platform 集群使用:
- VMware vSphere
- 裸机
- Red Hat OpenStack Platform(技术预览)
- IBM Power
- IBM Z 基础架构
OpenShift Data Foundation operator 会创建和管理服务,以满足对外部服务的持久性卷声明(PV)和对象存储桶声明(OBC)。外部集群可以为 OpenShift Container Platform 上运行的应用程序提供块、文件和对象存储类。Operator 不会部署或管理外部集群。
第 5 章 安全考虑
5.1. FIPS-140-2
Federal Information Processing Standard Publication 140-2 (FIPS-140-2) 是定义使用加密模块的一系列安全要求的标准。这个标准受到美国政府机构和承包商的强制要求,在其他国际和行业特定的标准中也会引用该标准。
Red Hat OpenShift Data Foundation 现在使用 FIPS 验证的加密模块。Red Hat Enterprise Linux OS/CoreOS(RHCOS)提供这些模块。
目前,Cryptographic Module Validation Program (CMVP) 用于处理加密模块。您可以在modules in Process List 中查看这些模块的状态。有关最新信息,请参阅红帽知识库解决方案 RHEL 内核加密组件。
在安装 OpenShift Data Foundation 前,在 OpenShift Container Platform 上启用 FIPS 模式。OpenShift Container Platform 必须在 RHCOS 节点上运行,因为该功能不支持在 Red Hat Enterprise Linux 7(RHEL 7)上部署 OpenShift Data Foundation。
如需更多信息,请参阅 OpenShift Container Platform 文档中的安装指南的在 FIPS 模式下安装集群和对 FIPS 加密的支持部分。
5.2. 代理环境
代理环境是一个生产环境,它拒绝直接访问互联网并提供可用的 HTTP 或 HTTPS 代理。Red Hat Openshift Container Platform 被配置为使用代理,方法是修改现有集群的代理对象,或在新集群的 install-config.yaml 文件中配置代理设置。
当已根据配置集群范围的代理的内容配置了 OpenShift Container Platform,则红帽支持在代理环境中部署 OpenShift Data Foundation。
5.3. 数据加密选项
加密可让您对数据进行编码,使其在没有所需的加密密钥的情况下无法读取。通过这种机制,当物理性安全被破坏的情况下,您的数据所在的物理介质丢失时,可以保护您的数据的安全性。每个PV 加密也提供同一 OpenShift Container Platform 集群内其他命名空间的访问保护。当数据写入到磁盘时,数据会被加密,并在从磁盘读取数据时对其进行解密。使用加密的数据可能会对性能产生较小的影响。
只有使用 Red Hat OpenShift Data Foundation 4.6 或更高版本部署的新集群才支持加密。没有使用外部密钥管理系统 (KMS) 的现有加密集群无法迁移为使用外部 KMS。
以前,HashiCorp Vault 是唯一支持集群范围的 KMS 和持久性卷加密的 KMS。在 OpenShift Data Foundation 4.7.0 和 4.7.1 中,只支持 HashiCorp Vault Key/Value (KV) secret engine API,支持版本 1。从 OpenShift Data Foundation 4.7.2 开始,支持 HashiCorp Vault KV secret engine API、版本 1 和 2。从 OpenShift Data Foundation 4.12 开始,Thales CipherTrust Manager 已被作为额外支持的 KMS 被引进。
- KMS 是 StorageClass 加密所必需的,对于集群范围的加密,它是可选的。
- 首先,存储类加密需要一个有效的 Red Hat OpenShift Data Foundation Advanced 订阅。如需更多信息,请参阅 OpenShift Data Foundation 订阅中的知识库文章。
红帽与技术合作伙伴合作,将本文档作为为客户提供服务。但是,红帽不为 Hashicorp 产品提供支持。有关此产品的技术协助,请联系 Hashicorp。
5.3.1. 集群范围的加密
Red Hat OpenShift Data Foundation 支持存储集群中所有磁盘和多云对象网关操作的集群范围加密 (encryption-at-rest)。OpenShift Data Foundation 使用基于 Linux 统一密钥系统 (LUKS) 版本 2 的加密,其密钥大小为 512 位,以及 aes-xts-plain64 密码,其中每个设备都有不同的加密密钥。密钥使用 Kubernetes secret 或外部 KMS 存储。两种方法都是互斥的,您不能在方法之间迁移。
对于块存储和文件存储,默认会禁用加密。您可以在部署时为集群启用加密。MultiCloud 对象网关默认支持加密。如需更多信息,请参阅部署指南。
集群范围内的加密在没有 Key Management System (KMS) 的 OpenShift Data Foundation 4.6 中被支持。从 OpenShift Data Foundation 4.7 开始,使用和不使用 HashiCorp Vault KMS 都被支持。从 OpenShift Data Foundation 4.12 开始,使用和不使用 HashiCorp Vault KMS 和 Thales CipherTrust Manager KMS 都被支持。
需要有效的 Red Hat OpenShift Data Foundation 高级订阅。要了解 OpenShift Data Foundation 订阅如何工作,请参阅与 OpenShift Data Foundation 订阅相关的知识库文章。
使用 HashiCorp Vault KMS 进行集群范围内的加密提供了两种身份验证方法:
- 令牌 :此方法允许使用 vault 令牌进行身份验证。在 openshift-storage 命名空间中创建包含 vault 令牌的 kubernetes secret,用于身份验证。如果选择了这个验证方法,那么管理员必须提供 vault 中后端路径(其中存储了加密密钥)的 vault 令牌。
Kubernetes :此方法允许使用服务账户(serviceaccounts)通过 vault 进行身份验证。如果选择了这种身份验证方法,那么管理员必须提供 Vault 中配置的角色的名称,从而提供对后端路径的访问,然后存储了加密密钥。然后,此角色的值会添加到
ocs-kms-connection-details配置映射中。此方法可从 OpenShift Data Foundation 4.10 中提供。目前,HashiCorp Vault 是唯一受支持的 KMS。在 OpenShift Data Foundation 4.7.0 和 4.7.1 中,只支持 HashiCorp Vault KV secret 引擎,API 版本 1。从 OpenShift Data Foundation 4.7.2 开始,支持 HashiCorp Vault KV secret engine API、版本 1 和 2。
除了 HashiCorp Vault KMS,IBM Cloud 平台上的 OpenShift Data Foundation 现在还支持 Hyper Protect Crypto Services(HPCS)Key Management Services(KMS)作为加密解决方案。
红帽与技术合作伙伴合作,将本文档作为为客户提供服务。但是,红帽不为 Hashicorp 产品提供支持。有关此产品的技术协助,请联系 Hashicorp。
5.3.2. 存储类加密
您可以使用外部密钥管理系统 (KMS) 使用存储类加密来加密持久性卷(仅限块)来存储设备加密密钥。永久卷加密仅可用于 RADOS 块设备 (RBD) 持久卷。请参阅如何使用持久性卷加密创建存储类。
存储类加密在使用 HashiCorp Vault KMS 的 OpenShift Data Foundation 4.7 或更高版本中被支持。存储类加密在使用 HashiCorp Vault KMS 和 Thales CipherTrust Manager KMS 的 OpenShift Data Foundation 4.12 或更高版本中被支持。
需要有效的 Red Hat OpenShift Data Foundation 高级订阅。要了解 OpenShift Data Foundation 订阅如何工作,请参阅与 OpenShift Data Foundation 订阅相关的知识库文章。
5.3.3. CipherTrust manager
Red Hat OpenShift Data Foundation 版本 4.12 引入了 Thales CipherTrust Manager 作为部署的附加密钥管理系统 (KMS) 供应商。Thales CipherTrust Manager 提供了中央化的密钥生命周期管理功能。CipherTrust Manager 支持密钥管理互操作性协议(KMIP),它启用了密钥管理系统之间的通信。
CipherTrust Manager 在部署期间被启用。
5.4. Transit 中的加密
您需要启用 IPsec,以便 OVN-Kubernetes Container Network Interface (CNI) 集群网络中的节点之间的所有网络流量都通过加密的隧道进行传输。
默认情况下禁用 IPsec。您可以在安装集群前或安装集群之后启用它。如果您需要在集群安装后启用 IPsec,您必须首先将集群 MTU 大小调整为考虑 IPsec ESP IP 标头的开销。
有关如何配置 IPsec 加密的更多信息,请参阅 OpenShift Container Platform 文档中的配置网络指南的 IPsec 加密。
第 6 章 订阅
6.1. 订阅服务
Red Hat OpenShift Data Foundation 订阅基于"内核对",与 Red Hat OpenShift Container Platform 类似的。Red Hat OpenShift Data Foundation 2 核订阅基于 OpenShift Container Platform 运行的系统中 CPU 的逻辑内核数量。
与 OpenShift Container Platform 一样:
- OpenShift Data FoundationOpenShift 订阅可以被叠加,以覆盖更大的主机。
- 内核可以根据需要在多个虚拟机 (VM) 间进行分配。例如,十个 2 核订阅将提供 20 个内核,对于 IBM Power 的 2 核订阅(SMT 级别 为 8),提供 2 个内核或 16 个 vCPU,可在任意数量的虚拟机中使用。
- OpenShift Data Foundation 订阅提供高级或标准支持。
6.2. 灾难恢复订阅要求
Red Hat OpenShift Data Foundation 支持的灾难恢复功能需要满足以下所有先决条件,才能成功实施灾难恢复解决方案:
- 有效的 Red Hat OpenShift Data Foundation 高级授权
- 有效的 Red Hat Advanced Cluster Management for Kubernetes 订阅
任何包含 PV(包括作为源或目标)的 PV 的 Red Hat OpenShift Data Foundation 集群都需要 OpenShift Data Foundation 高级授权。此订阅应该在源和目标集群上处于活跃状态。
要了解 OpenShift Data Foundation 订阅如何工作,请参阅与 OpenShift Data Foundation 订阅相关的知识库文章。
6.3. 内核与 vCPU 和超线程
判断特定系统是否消耗一个或多个内核目前取决于该系统是否可用超线程。超线程只是 Intel CPU 的一项功能。访问红帽客户门户,以确定特定系统是否支持超线程。
对于启用了超线程的系统,一个超线程等于一个可见的系统内核,内核的计算是 2 个内核到 4 个 vCPU 的比率。因此,2 核订阅涵盖超线程系统中的 4 个 vCPU。一个大型虚拟机 (VM) 可能具有 8 个 vCPU,相当于 4 个订阅内核。当订阅以 2 核作为单位时,您将需要两个 2 核订阅来满足 4 个内核或 8 个 vCPU。
如果没有启用超线程,并且每个可见的系统内核直接与底层物理内核关联,内核的计算为 2 个内核到 2 个 vCPU 的比率。
6.3.1. 用于 IBM Power 的内核数和并发多线程(SMT)
确定特定系统是否消耗一个或多个内核目前取决于配置的并发多线程级别 (SMT)。IBM Power 为每个内核提供并发多线程级别 1、2、4 或 8,每个内核对应于下表中的 vCPU 数量。
| SMT 级别 | SMT=1 | SMT=2 | SMT=4 | SMT=8 |
|---|---|---|---|---|
| 1 个内核 | # vCPUs=1 | # vCPUs=2 | # vCPUs=4 | # vCPUs=8 |
| 2 个内核 | # vCPUs=2 | # vCPUs=4 | # vCPUs=8 | # vCPUs=16 |
| 4 个内核 | # vCPUs=4 | # vCPUs=8 | # vCPUs=16 | # vCPUs=32 |
对于配置 SMT 的系统,用于订阅所需的内核数取决于 SMT 级别。因此,2 核订阅对于 SMT 级别 1 是 2 个 vCPU、对于 SMT 级别 2 是 4 个 vCPU,对于 SMT 级别 4 是 8 个 vCPU,对于 SMT 级别 8 是 16 个 vCPU,如上表所示。一个大型虚拟机 (VM) 可能有 16 个 vCPU,在 SMT 级别 8 中,需要一个 2 核订阅。计算方法是 vCPU 的数量除以 SMT 级别(对于 SMT-8,16 个 vCPU / 8 = 2)。当订阅以 2 核为单位时,您将需要一个 2 核订阅来满足这 2 个内核或 16 个 vCPU。
6.4. 分割内核
需要奇数内核的系统需要消耗整个 2 核订阅。例如,对于被计算为只需要 1 个内核的系统,在注册和订阅后,它会消耗一个整个的 2 核订阅。
当一个使用超线程、具有 2 个 vCPU 的虚拟机 (VM),其计算的 vCPU 为 1 个时,则需要一个完整的 2 核订阅;一个 2 核订阅不能在两个使用超线程的带有 2 个 vCPU 的虚拟机间分割。如需更多信息,请参阅内核、 vCPU 以及超线程的比较部分。
建议对虚拟实例进行大小调整,以便它们需要偶数数量的内核。
6.5. 订阅要求
Red Hat OpenShift Data Foundation 组件可以在 OpenShift Container Platform worker 或基础架构节点上运行,您可以将 Red Hat CoreOS (RHCOS) 或 Red Hat Enterprise Linux (RHEL) 8.4 用作主机操作系统。RHEL 7 现已弃用。每个 OpenShift Container Platform 订阅的内核都需要 OpenShift Data Foundation 订阅,比率为 1:1。
当使用基础架构节点时,即使 OpenShift worker 节点不需要任何 OpenShift Container Platform 或 OpenShift Data Foundation 订阅,为所有 worker 节点内核订阅 OpenShift Data Foundation 的这条规则也需要被满足。您可以使用标签来说明节点是 worker 还是基础架构节点。
如需更多信息,请参阅管理和分配存储资源指南中的如何将专用 worker 节点用于 Red Hat OpenShift Data Foundation 章节。
第 7 章 基础架构要求
7.1. 平台要求
Red Hat OpenShift Data Foundation 4.12 只在 OpenShift Container Platform 版本 4.12 及其以后的次版本中被支持。
以前版本的 Red Hat OpenShift Data Foundation 的程序错误修正将会作为程序错误修复版本发布。详情请参阅 Red Hat OpenShift Container Platform 生命周期政策。
有关外部集群订阅要求,请参阅红帽知识库解决方案 OpenShift Data Foundation 订阅指南。
有关支持的平台版本的完整列表,请参阅 Red Hat OpenShift Data Foundation Supportability and Interoperability Checker。
7.1.1. Amazon EC2
只支持内部 Red Hat OpenShift Data Foundation 集群。
内部集群必须满足存储设备要求,并且具有通过 aws-ebs 置备程序提供 EBS 存储的存储类。
OpenShift Data Foundation 支持由 Amazon Web Services (AWS) 提供的 gp2-csi 和 gp3-csi 驱动程序。这些驱动程序提供更好的存储扩展功能,并减少了每月的价格点 (gp3-csi)。现在,您可以在选择存储类时选择新驱动程序。如果需要高吞吐量,建议在部署 OpenShift Data Foundation 时使用 gp3-csi。
7.1.2. 裸机
支持内部集群和使用外部集群。
内部集群必须满足存储设备要求,并且具有通过 Local Storage Operator 提供本地 SSD(NVMe/SATA/SAS、SAN)的存储类。
7.1.3. VMware vSphere
支持内部集群和使用外部集群。
推荐的版本:
- vSphere 6.7、更新 2 或更高版本
- vSphere 7.0 或更高版本。
如需了解更多详细信息,请参阅 VMware vSphere 基础架构要求。
如果 VMware ESXi 不将设备识别为闪存设备,请将其标记为闪存设备。在 Red Hat OpenShift Data Foundation 部署之前,请参考将设备标记为闪存。
另外,内部集群必须满足存储设备要求,并具有提供存储类的存储类。
- VSAN 或 VMFS 数据存储通过 vsphere-volume 置备程序
- VMDK、RDM 或 DirectPath 存储设备通过 Local Storage Operator。
7.1.4. Microsoft Azure
只支持内部 Red Hat OpenShift Data Foundation 集群。
内部集群必须满足 存储设备要求,并且具有通过 azure-disk 置备程序提供的存储类。
7.1.5. Google Cloud [技术预览]
只支持内部 Red Hat OpenShift Data Foundation 集群。
内部集群必须满足存储设备要求,并且具有通过 gce-pd 置备程序提供 GCE Persistent Disk 的存储类。
7.1.6. Red Hat Virtualization Platform
只支持内部 Red Hat OpenShift Data Foundation 集群。
内部集群必须满足存储设备要求,并且具有通过 Local Storage Operator 提供本地 SSD(NVMe/SATA/SAS、SAN)的存储类。
7.1.7. Red Hat OpenStack Platform [技术预览]
支持内部 Red Hat OpenShift Data Foundation 集群和使用外部集群。
内部集群必须满足存储设备要求,并具有通过 Cinder 置备程序提供标准磁盘的存储类。
7.1.8. IBM Power
支持内部 Red Hat OpenShift Data Foundation 集群和使用外部集群。
内部集群必须满足存储设备要求,并且具有通过 Local Storage Operator 提供本地 SSD(NVMe/SATA/SAS、SAN)的存储类。
7.1.9. IBM Z 和 LinuxONE
支持内部 Red Hat OpenShift Data Foundation 集群。此外,也支持在 x86 上运行的 Ceph 的外部模式。
内部集群必须满足存储设备要求,并且具有通过 Local Storage Operator 提供本地 SSD(NVMe/SATA/SAS、SAN)的存储类。
7.2. 外部模式要求
7.2.1. Red Hat Ceph Storage
要以外部模式检查 Red Hat Ceph Storage (RHCS) 与 Red Hat OpenShift Data Foundation 的支持性和互操作性,请转至 lab Red Hat OpenShift Data Foundation 支持性和互操作性检查器。
-
选择 Service Type 为
ODF as Self-Managed Service。 - 从下拉菜单中选择适当的 Version。
- 在 Versions 选项卡中,点 支持的 RHCS 兼容性选项卡。
有关如何安装 RHCS 集群的说明,请参阅安装指南。
7.2.2. IBM FlashSystem
要将 IBM FlashSystem 用作其他供应商上的可插拔外部存储,您需要先部署它,然后才能部署 OpenShift Data Foundation,这会使用 IBM FlashSystem 存储类作为后备存储。
有关最新支持的 FlashSystem 存储系统和版本,请参阅 ODF FlashSystem 驱动程序文档。
有关如何部署 OpenShift Data Foundation 的说明,请参阅 为外部 IBM FlashSystem 存储创建 OpenShift Data Foundation。
7.3. 资源要求
Red Hat OpenShift Data Foundation 服务由一组初始的基础服务组成,并可使用附加设备集进行扩展。所有这些 Red Hat OpenShift Data Foundation 服务 pod 都由 OpenShift Container Platform 节点上的 kubernetes 进行调度。以三个节点(每个故障域中一个节点)来扩展集群是满足 pod 放置规则的一种简单方法。
这些要求仅与 OpenShift Data Foundation 服务相关,与这些节点上运行的其他服务、operator 或工作负载无关。
| 部署模式 | 基础服务 | 附加设备集 |
|---|---|---|
| 内部 |
|
|
| 外部 |
| Not applicable |
示例:对于内部模式中带有单个设备集的 3 个节点集群,至少需要 3 x 10 = 30 个 CPU 单元。
有关设计 Red Hat OpenShift Data Foundation 集群的其他指导,请参阅 ODF 大小工具。
CPU 单元
在本节中,1 个 CPU 单元映射到 Kubernetes 的 1 个 CPU 单元的概念。
- 1 个 CPU 单元相当于 1 个非超线程 CPU 内核。
- 2 个 CPU 单元相当于 1 个超线程 CPU 内核。
- Red Hat OpenShift Data Foundation 基于内核的订阅总是成对提供(2 内核)。
| 部署模式 | 基础服务 |
|---|---|
| 内部 |
|
| 外部 |
|
示例:对于内部附加设备模式中的 3 个节点集群,至少需要 48(3 x 16)个 CPU 单元,3 x 64 = 192 GB 内存。
7.3.1. IBM Z 和 LinuxONE 基础架构的资源要求
Red Hat OpenShift Data Foundation 服务由一组初始的基础服务组成,并可使用附加设备集进行扩展。
所有这些 Red Hat OpenShift Data Foundation 服务 pod 都由 OpenShift Container Platform 节点上的 kubernetes 调度。以三个节点(每个故障域中一个节点)来扩展集群是满足 pod 放置规则的一种简单方法。
| 部署模式 | 基础服务 | 附加设备集 | IBM Z 和 LinuxONE 最低硬件要求 |
|---|---|---|---|
| 内部 |
|
| 1 个 IFL |
| 外部 |
| Not applicable | Not applicable |
- CPU
- 是系统管理程序、IBM z/VM、内核虚拟机(KVM)或两者中定义的虚拟内核数。
- IFL(Linux 集成设施)
- 是 IBM Z 和 LinuxONE 的物理核心。
最低系统环境
- 要运行带有 1 逻辑分区(LPAR)的最小群集,需要在 6 IFL 之上再添加一个 IFL。OpenShift 容器平台使用这些 IFL。
7.3.2. 最低部署资源要求
当不符合标准部署资源要求时,将使用最低配置部署 OpenShift Data Foundation 集群。
这些要求仅与 OpenShift Data Foundation 服务相关,与这些节点上运行的其他服务、operator 或工作负载无关。
| 部署模式 | 基础服务 |
|---|---|
| 内部 |
|
如果要添加额外的设备集,我们建议将最小部署转换为标准部署。
7.3.3. 紧凑部署资源要求
Red Hat OpenShift Data Foundation 可以安装到三节点 OpenShift 紧凑裸机集群中,所有工作负载都在三个强大的 master 节点上运行。没有 worker 或存储节点。
这些要求仅与 OpenShift Data Foundation 服务相关,与这些节点上运行的其他服务、operator 或工作负载无关。
| 部署模式 | 基础服务 | 附加设备集 |
|---|---|---|
| 内部 |
|
|
要在紧凑的裸机集群中配置 OpenShift Container Platform,请参阅部署配置三节点集群和为 Edge 部署提供三节点架构。
7.3.4. 仅使用 MCG 部署的资源要求
仅使用 Multicloud Object Gateway(MCG)组件部署的 OpenShift Data Foundation 集群在部署时提供了灵活性,有助于减少资源消耗。
| 部署模式 | Core | 数据库(DB) | 端点 |
|---|---|---|---|
| 内部 |
|
|
注意 默认自动扩展介于 1 到 2 之间。 |
7.3.5. 使用网络文件系统的资源要求
随着 Red Hat OpenShift Data Foundation 版本 4.12 的发布,您可以使用 Network File System(NFS)创建导出,然后可以作为技术预览从 OpenShift 集群访问。如果您计划使用这个功能,NFS 服务会消耗 3 个 CPU 和 8Gi 内存。NFS 是可选的,并默认禁用。
NFS 卷可以通过两种方式访问:
- 集群内:被 Openshift 集群内的应用程序 pod 使用。
- 集群外:来自 Openshift 集群之外。
有关 NFS 功能的更多信息,请参阅使用 NFS 创建导出
NFS 是一个技术预览功能。技术预览功能不受红帽产品服务等级协议(SLA)支持,且功能可能并不完整。红帽不推荐在生产环境中使用它们。这些技术预览功能可以使用户提早试用新的功能,并有机会在开发阶段提供反馈意见。
如需更多信息,请参阅技术预览功能支持范围。
7.4. Pod 放置规则
Kubernetes 根据声明性放置规则负责 pod 放置。内部集群的 Red Hat OpenShift Data Foundation 基础服务放置规则总结如下:
-
节点使用
cluster.ocs.openshift.io/openshift-storage密钥标记 - 如果不存在,节点将被排序为伪故障域
- 需要高可用性的组件分散在故障域中
- 每个故障域中必须可以访问存储设备
这会产生以下要求:至少有三个节点,并且节点于三个不同的机架或区域故障域中(如果预先存在的拓扑标签 )。
对于额外的设备集,在三个故障域中必须有一个存储设备和消耗它的 pod 的充足资源。可以使用手动放置规则覆盖默认放置规则,但这种方法通常仅适用于裸机部署。
7.5. 存储设备要求
使用本节了解在规划内部模式部署和升级时可以考虑的不同存储容量要求。我们通常建议每个节点 9 个设备或更少。本建议可确保节点保持低于云供应商动态存储设备附加限制,以及限制使用本地存储设备的节点故障后恢复时间。以三个节点(每个故障域中一个节点)来扩展集群是满足 pod 放置规则的一种简单方法。
存储节点应至少有两个磁盘,一个用于操作系统,其余磁盘用于 OpenShift Data Foundation 组件。
您只能根据安装时所选的容量递增来扩展存储容量。
7.5.1. 动态存储设备
Red Hat OpenShift Data Foundation 允许选择 0.5 TiB、2 TiB 或 4 TiB 容量作为动态存储设备大小的请求大小。可以每个节点运行的动态存储设备数量取决于节点大小、底层置备程序限制和资源要求。
7.5.2. 本地存储设备
对于本地存储部署,可以使用 4 TiB 或更少的磁盘大小,并且所有磁盘的大小和类型都应相同。可以每个节点运行的本地存储设备数量取决于节点大小和资源要求。以三个节点(每个故障域中一个节点)来扩展集群是满足 pod 放置规则的一种简单方法。
不支持磁盘分区。
7.5.3. 容量规划
始终确保可用的存储容量保持领先于消费。如果可用存储容量已完全用尽,则需要更多的干预,而不是仅仅添加容量、删除或迁移内容。
当集群存储容量达到总容量的 75%(接近满)和 85%(满)时,会发出容量警报。始终及时处理容量警告的信息,并定期检查您的存储以确保您不会耗尽存储空间。达到 75% (接近满) 时,释放一些空间或扩展集群。当出现 85%(满)警报时,这表示您已完全耗尽存储空间,并且无法使用标准命令释放空间。如果出现这种情况,请联系红帽客户支持。
下表显示了带有动态存储设备的 Red Hat OpenShift Data Foundation 节点配置示例。
| 存储设备大小 | 每个节点的存储设备 | 总容量 | 可用的存储容量 |
|---|---|---|---|
| 0.5 TiB | 1 | 1.5 TiB | 0.5 TiB |
| 2 TiB | 1 | 6 TiB | 2 TiB |
| 4 TiB | 1 | 12 TiB | 4 TiB |
| 存储设备大小 (D) | 每个节点的存储设备 (M) | 总容量 (D * M * N) | 可用的存储容量 (D*M*N/3) |
|---|---|---|---|
| 0.5 TiB | 3 | 45 TiB | 15 TiB |
| 2 TiB | 6 | 360 TiB | 120 TiB |
| 4 TiB | 9 | 1080 TiB | 360 TiB |
7.6. 网络要求
使用本节了解规划部署时的不同网络注意事项。
7.6.1. IPv6 支持
Red Hat OpenShift Data Foundation 版本 4.12 引入了对 IPv6 的支持。IPv6 只在单一堆栈中被支持,且不能与 IPv4 一起使用。当在 Openshift Container Platform 中打开 IPv6 时,IPv6 是 OpenShift Data Foundation 中的默认行为。
7.7. 多网络插件 (Multus) 支持 [技术预览]
默认情况下,Red Hat OpenShift Data Foundation 被配置为使用 Red Hat OpenShift Software Defined Network(SDN)。在这个默认配置中,SDN 会传输以下类型的流量:
- Pod 到 pod 流量
- Pod 到 OpenShift Data Foundation 的流量,称为 OpenShift Data Foundation 公共网络流量
- OpenShift Data Foundation 复制和重新平衡,称为 OpenShift Data Foundation 集群网络流量
但是,OpenShift Data Foundation 4.8 及更新的版本支持作为技术预览使用 Multus 通过隔离不同类型的网络流量来提高安全性和性能。
Multus 支持是一个技术预览功能,它只受支持并在裸机和 VMWare 部署中测试。技术预览功能不受红帽产品服务等级协议(SLA)支持,且功能可能并不完整。红帽不推荐在生产环境中使用它们。这些技术预览功能可以使用户提早试用新的功能,并有机会在开发阶段提供反馈意见。
如需更多信息,请参阅技术预览功能支持范围。
7.7.1. 了解多网络
在 Kubernetes 中,容器联网由实现了 Container Network Interface (CNI) 的网络插件负责。
OpenShift Container Platform 使用 Multus CNI 插件来实现对 CNI 插件的链接。在集群安装过程中,您要配置 default pod 网络。默认网络处理集群中的所有一般网络流量。您可以基于可用的 CNI 插件定义额外网络,并将一个或多个这种网络附加到 pod。您可以根据需要为集群定义多个额外网络。这可让您灵活地配置提供交换或路由等网络功能的 pod。
7.7.1.1. 额外网络使用场景
您可以在需要网络隔离的情况下使用额外网络,包括分离数据平面与控制平面。隔离网络流量对以下性能和安全性原因很有用:
- 性能
- 您可以在两个不同的平面上发送流量,以管理每个平面上流量的多少。
- 安全性
- 您可以将敏感的流量发送到专为安全考虑而管理的网络平面,也可隔离不能在租户或客户间共享的私密数据。
集群中的所有 pod 仍然使用集群范围的默认网络,以维持整个集群中的连通性。每个 pod 都有一个 eth0 接口,附加到集群范围的 pod 网络。您可以使用 oc exec -it <pod_name> -- ip a 命令来查看 pod 的接口。如果您添加使用 Multus CNI 的额外网络接口,则名称为 net1、net2、…、netN。
要将额外网络接口附加到 pod,您必须创建配置来定义接口的附加方式。您可以使用 NetworkAttachmentDefinition 自定义资源(CR)来指定各个接口。各个 CR 中的 CNI 配置定义如何创建该接口。
7.7.2. 使用 Multus 隔离存储流量
要使用 Multus,在部署 OpenShift Data Foundation 集群前,您必须创建稍后要附加到集群的网络附加定义(NAD)。如需更多信息,请参阅:
使用 Multus 时,根据您的硬件设置或 VMWare 实例网络设置,可以进行以下配置:
具有双网络接口的节点建议配置
隔离的存储流量
- 为 OpenShift SDN 配置一个接口(pod 到 pod 流量)
- 为所有 OpenShift Data Foundation 流量配置一个接口
具有三倍网络接口的节点建议配置
完整流量隔离
- 为 OpenShift SDN 配置一个接口(pod 到 pod 流量)
- 为所有容器集配置一个接口到 OpenShift Data Foundation 流量(OpenShift Data Foundation 公共流量)
- 为所有 OpenShift Data Foundation 复制和重新平衡流量(OpenShift Data Foundation 集群流量)配置一个接口
7.7.3. Multus 配置的建议网络配置和要求
如果您决定利用 Multus 配置,必须满足以下先决条件:
- 用于部署 OpenShift Data Foundation 的所有节点必须具有相同的网络接口配置,才能保证完全正常工作的 Multus 配置。所有节点上的网络接口名称必须相同,并连接到 Multus 公共网络和 Multus 集群网络的相同底层交换机制。
- 用于部署使用 OpenShift Data Foundation 进行持久性存储的应用程序的所有节点必须具有相同的网络接口配置,以确保完全正常工作的 Multus 配置。两个接口之一必须与在存储节点上配置 Multus 公共网络的接口名称相同。所有工作程序网络接口必须连接到与存储节点的 Multus 公共网络相同的底层交换机制。
双网络接口隔离配置模式示例:
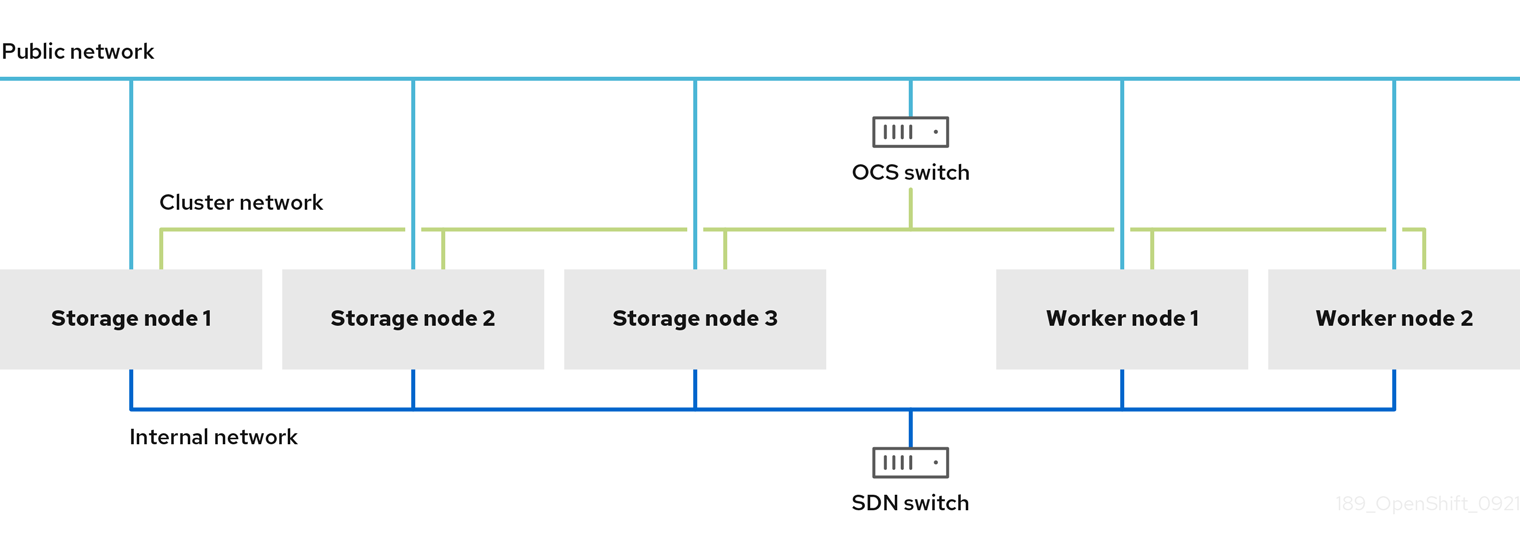
三网络接口完整隔离的配置模式示例:
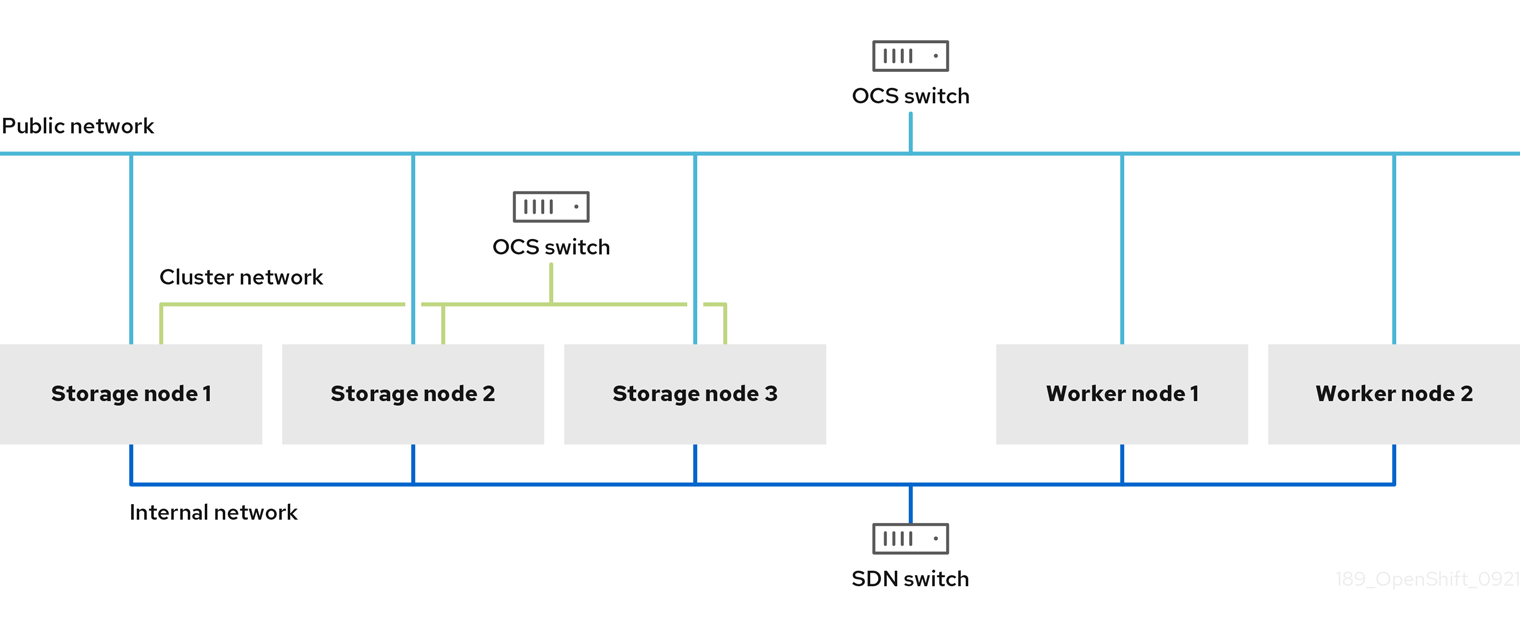
只有运行 OpenShift Data Foundation OSD 的存储节点需要访问通过 Multus 配置的 OpenShift Data Foundation 集群网络。
如需了解配置基于裸机的 Multus 配置所需的步骤,请参阅创建 Multus 网络。
如需了解在 VMware 上配置 Multus 配置所需的步骤,请参阅创建 Multus 网络。
第 8 章 Disaster Recovery
灾难恢复 (DR) 有助于机构在出现中断或紧急情况时恢复业务关键功能或正常操作。OpenShift Data Foundation 为有状态应用程序提供高可用性(HA)和 DR 解决方案,它们被广泛分为两个宽泛:
- Metro-DR:单一区域和跨数据中心保护,无数据丢失。
- Region-DR:跨区域保护,减少潜在的数据丢失 [技术预览]
Red Hat Advanced Cluster Management (RHACM) 2.7 的 OpenShift Data Foundation Metro-DR 功能现已正式发布。
Block 和 Files 的 Regional-DR 解决方案作为技术预览提供,并受技术预览支持限制。
8.1. Metro-DR
Metro-DR 由 Red Hat Advanced Cluster Management for Kubernetes(RHACM)、Red Hat Ceph Storage 和 OpenShift Data Foundation 组件组成,以便在 OpenShift Container Platform 集群中提供应用程序和数据移动性。
这个版本的 Metro-DR 功能在分散的网站之间提供卷持久数据和元数据复制。在公有云中,它们类似于防止可用性区域失败。Metro-DR 可确保在数据中心出现问题时保持业务的连续性,并不会造成数据丢失。此解决方案对 Red Hat Advanced Cluster Management(RHACM)和 OpenShift Data Foundation 高级 SKU 和相关捆绑包授权。
先决条件
Red Hat OpenShift Data Foundation 支持的灾难恢复功能需要满足以下所有先决条件,才能成功实施灾难恢复解决方案:
- 有效的 Red Hat OpenShift Data Foundation 高级授权
- 有效的 Red Hat Advanced Cluster Management for Kubernetes 订阅
要了解 OpenShift Data Foundation 订阅如何工作,请参阅与 OpenShift Data Foundation 订阅相关的知识库文章。
有关详细信息要求,请参阅 Metro-DR 要求,Red Hat Ceph Storage 的部署要求具有随机和 RHACM 要求。
8.2. Region-DR [技术预览]
region-DR 由 Red Hat Advanced Cluster Management for Kubernetes(RHACM)和 OpenShift Data Foundation 组件组成,以便在 OpenShift Container Platform 集群中提供应用程序和数据移动性。它以同步数据复制为基础,因此可能会存在潜在的数据丢失,但可为一组广泛的故障提供保护。
Red Hat OpenShift Data Foundation 由 Ceph 作为存储供应商支持,其生命周期由 Rook 管理,并增强了它的功能:
- 启用池以进行镜像。
- 在 RBD 池中自动镜像镜像。
- 提供 csi-addons 以管理每个持久性卷声明镜像。
此 Regional-DR 发行版本支持在不同的地区和数据中心中部署的多集群配置。例如,两个受管集群位于两个不同的区域或数据中心之间的双向复制。此解决方案对 Red Hat Advanced Cluster Management(RHACM)和 OpenShift Data Foundation 高级 SKU 和相关捆绑包授权。
先决条件
Red Hat OpenShift Data Foundation 支持的灾难恢复功能需要满足以下所有先决条件,才能成功实施灾难恢复解决方案:
- 有效的 Red Hat OpenShift Data Foundation 高级授权
- 有效的 Red Hat Advanced Cluster Management for Kubernetes 订阅
要了解 OpenShift Data Foundation 订阅如何工作,请参阅与 OpenShift Data Foundation 订阅相关的知识库文章。
有关详细要求,请参阅 Regional-DR 要求 和 RHACM 要求。
使用 Advanced Cluster Management 为 Regional-DR 配置 OpenShift 数据基础是一项技术预览功能,并受技术预览支持限制。技术预览功能不受红帽产品服务等级协议(SLA)支持,且功能可能并不完整。红帽不推荐在生产环境中使用它们。这些技术预览功能可以使用户提早试用新的功能,并有机会在开发阶段提供反馈意见。
如需更多信息,请参阅技术预览功能支持范围。
第 9 章 断开连接的环境
断开连接的环境是一个网络受限网络,Operator Lifecycle Manager (OLM) 无法访问需要互联网连接的默认 Operator Hub 和镜像 registry。
红帽支持在受限网络中安装 OpenShift Container Platform 的断开连接的环境中部署 OpenShift Data Foundation。
要在断开连接的环境中安装 OpenShift Data Foundation,请参阅 OpenShift Container Platform 文档中的 Operator 指南的在受限网络中使用 Operator Lifecycle Manager 部分。
在受限网络环境中安装 OpenShift Data Foundation 时,请将自定义网络时间协议 (NTP) 配置应用到节点,因为默认情况下,OpenShift Container Platform 中会假设互联网连接,chronyd 被配置为使用 *.rhel.pool.ntp.org 服务器。
如需更多信息,请参阅 OpenShift Container Platform 文档中的安装指南的配置 chrony 时间服务部分,以及红帽知识库解决方案 A newly deployed OCS 4 cluster status shows as "Degraded", Why?。
Red Hat OpenShift Data Foundation 版本 4.12 引入了用于断开连接的环境部署的基于 Agent 的安装程序。基于 Agent 的安装程序允许您使用镜像 registry 进行断开连接的安装。如需更多信息,请参阅准备使用基于代理的安装程序进行安装。
OpenShift Data Foundation 的集群日志记录
在修剪 redhat-operator 索引镜像时,请为 OpenShift Data Foundation 部署包含以下软件包列表:
-
ocs-operator -
odf-operator -
mcg-operator -
odf-csi-addons-operator -
odr-cluster-operator -
odr-hub-operator 可选:
local-storage-operator只适用于本地存储部署。
可选:
odf-multicluster-orchestrator只适用于区域灾难恢复(Regional-DR)配置。
将 CatalogSource 命名为 redhat-operators。
第 10 章 IBM Power 和 IBM Z 基础架构支持的功能和不支持的功能
| 功能 | IBM Power | IBM Z 基础架构 |
|---|---|---|
| 紧凑部署 | 不支持 | 不支持 |
| 动态存储设备 | 不支持 | 支持 |
| 扩展的集群 - Arbiter | 支持 | 不支持 |
| Federal Information Processing Standard Publication (FIPS) | 支持 | 不支持 |
| 查看池压缩指标的功能 | 支持 | 不支持 |
| 多云对象网关(MCG)端点 pod 的自动化扩展 | 支持 | 不支持 |
| 控制过量置备的警报 | 支持 | 不支持 |
| Ceph monitor 空间不足时的警报 | 支持 | 不支持 |
| 部署独立多云对象网关组件 | 支持 | 不支持 |
| 扩展 OpenShift Data Foundation 控制平面,允许可插拔外部存储,如 IBM Flashsystem | 不支持 | 不支持 |
| IPV6 支持 | 不支持 | 不支持 |
| Multus | 不支持 | 不支持 |
| multicloud Object Gateway (MCG)存储桶复制 | 支持 | 不支持 |
| 对象数据的配额支持 | 支持 | 不支持 |
| 最小部署 | 不支持 | 不支持 |
| 使用 Red Hat Advanced Cluster Management(RHACM)的 Region-Disaster Recovery(Regional-DR) | 支持 | 不支持 |
| 使用 RHACM 的 Metro-Disaster Recovery(Metro-DR) | 支持 | 不支持 |
| 用于 Radio 访问网络的单一节点解决方案(RAN) | 不支持 | 不支持 |
| 支持网络文件系统 (NFS) 服务 | 支持 | 不支持 |
| 更改 Multicloud Object Gateway (MCG) 帐户凭证 | 支持 | 不支持 |
| Red Hat Advanced Cluster Management 控制台中的多集群监控 | 支持 | 不支持 |
| 在 Multicloud Object Gateway 生命周期中删除过期的对象 | 支持 | 不支持 |
第 11 章 后续步骤
要开始部署 OpenShift Data Foundation,您可以使用 OpenShift Container Platform 中的内部模式,或使用外部模式从 OpenShift Container Platform 外运行的集群提供可用服务。
根据您的要求,请转至相应的部署指南。
内部模式
- 使用 Amazon Web 服务部署 OpenShift Data Foundation
- 使用裸机部署 OpenShift Data Foundation
- 使用 VMWare vSphere 部署 OpenShift Data Foundation
- 使用 Microsoft Azure 部署 OpenShift Data Foundation
- 使用 Google Cloud 部署 OpenShift Data Foundation [技术预览]
- 使用 Red Hat OpenStack Platform 部署 OpenShift Data Foundation [技术预览]
- 使用 Red Hat Virtualization Platform 部署 OpenShift Data Foundation
- 在 IBM Power 上部署 OpenShift Data Foundation
- 在 IBM Z 基础架构上部署 OpenShift Data Foundation