操作测量
第 1 章 操作测量简介
在 Red Hat OpenStack Platform 环境中使用遥测服务的组件,您可以跟踪物理和虚拟资源,并使用在 Gnocchi 后端上存储聚合的数据集合守护进程收集部署中 CPU 使用率和资源可用性等指标。
1.1. 了解运营测量
使用操作工具帮助您测量和维护 Red Hat OpenStack Platform 环境。这些测量工具执行以下功能:
- 可用性监控:监控 Red Hat OpenStack Platform (RHOSP)环境中的所有组件,并确定任何组件当前出现停机或无法正常工作。您还可以将系统配置为在发现问题时提醒您。
- 性能监控 :定期收集系统信息并提供一种机制,使用数据收集守护进程以各种方式存储和监控值。此守护进程存储它收集的数据,如操作系统和日志文件,或者通过网络提供数据。您可以使用从数据收集的统计信息来监控系统、查找性能瓶颈和预测将来的系统负载。
1.2. Telemetry 架构
Red Hat OpenStack Platform (RHOSP) Telemetry 为基于 OpenStack 的云提供用户级使用情况数据。您可以使用这些数据进行客户计帐、系统监控或警报。您可以配置 Telemetry 组件从现有 RHOSP 组件发送的通知中收集数据,如计算使用情况事件,或者轮询 RHOSP 基础架构资源,如 libvirt。Telemetry 将收集的数据发布到包括数据存储和消息队列的各种目标。
Telemetry 由以下组件组成:
- 数据收集 :Telemetry 使用 Ceilometer 收集指标和事件数据。更多信息请参阅 第 1.3.1 节 “Ceilometer”。
- 存储 :Telemetry 将指标数据存储在 Gnocchi 中,并将事件数据存储在 Panko 中。更多信息请参阅 第 1.4 节 “使用 Gnocchi 存储”。
- 警报服务 :Telemetry 使用 Aodh 来基于定义的规则根据 Ceilometer 收集的指标或事件数据来触发操作。
收集数据时,您可以使用第三方工具(如 Red Hat Cloudforms)来显示和分析指标数据,您可以使用警报服务 Aodh 配置事件的警报。
图 1.1. Telemetry 架构

1.3. 数据收集
Red Hat OpenStack Platform (RHOSP)支持两种类型的数据收集:
- collectd 用于基础架构监控。更多信息请参阅 第 1.3.2 节 “collectd”。
- Ceilometer 用于 OpenStack 组件级监控。更多信息请参阅 第 1.3.1 节 “Ceilometer”。
1.3.1. Ceilometer
Ceilometer 是 OpenStack 遥测服务的默认数据收集组件,能够在所有 OpenStack 核心组件中规范化和转换数据。Ceilometer 收集与 OpenStack 服务相关的计量和事件数据。用户可以根据部署配置访问收集的数据。
Ceilometer 服务使用三个代理从 Red Hat OpenStack Platform (RHOSP)组件收集数据:
-
计算代理(ceilometer-agent-compute) :在每个 Compute 节点上运行,并轮询资源利用率统计。此代理与轮询代理
ceilometer-polling与使用参数--polling namespace-compute一起运行相同。 -
中央代理(ceilometer-agent-central) :在中央管理服务器上运行,以轮询不与实例或计算节点关联的资源利用率统计。您可以启动多个代理来横向扩展服务。这与轮询代理
ceilometer-polling使用参数--polling namespace-central运行。 - 通知代理(ceilometer-agent-notification) :在中央管理服务器上运行,并使用来自消息队列的消息来构建事件和计量数据。然后将数据发布到定义的目标。默认情况下,数据被推送到 Gnocchi。这些服务使用 RHOSP 通知总线进行通信。
Ceilometer 代理使用发布者将数据发送到对应的端点,如 Gnocchi。您可以在 pipeline.yaml 文件中配置这些信息。
其他资源
- 有关发布程序的更多信息,请参阅 第 1.3.1.1 节 “publishers”。
1.3.1.1. publishers
遥测服务提供多种传输方法,用于将收集的数据转让给外部系统。此数据的使用者则不同,例如,监控系统可接受数据丢失,以及计费系统,这需要可靠的数据传输。Telemetry 提供了一种方法来减轻这两种系统类型的要求。您可以使用服务的发布组件将数据通过消息总线将数据保存到持久性存储中,或将其发送到一个或多个外部用户。个链可以包含多个发布程序。
支持以下发布程序类型:
- Gnocchi (默认) :当启用 Gnocchi 发布程序时,指标和资源信息将推送到 Gnocchi,以优化时间序列。确保您在身份服务中注册了 Gnocchi,因为 Ceilometer 通过身份服务发现确切的路径。
-
Panko:您可以在 panko 中存储 Ceilometer 的事件数据,该界面提供了一个 HTTP REST 接口,以在 Red Hat OpenStack Platform 中查询系统事件。要将数据推送到 panko,请将发布器设置为
direct://?dispatcher=panko。
1.3.1.1.1. 配置发布者参数
您可以为遥测服务内每个数据点配置多发布程序,使相同的技术计量或事件多次发布到多个目的地,每个都可能使用不同的传输方法。
流程
创建一个 YAML 文件来描述可能的发布程序参数和默认值,如
ceilometer-publisher.yaml。在parameter_defaults中插入以下参数:Copy to Clipboard Copied! Toggle word wrap Toggle overflow 部署您的定制 overcloud。部署 overcloud 的方法有两种:
在
openstack overcloud deploy命令中包含修改后的 YAML 文件,以定义发布者。在以下示例中,将 <environment-files> 替换为您要包含在部署中的其他 YAML 文件:openstack overcloud deploy --templates \ -e /home/custom/ceilometer-publisher.yaml -e <environment-files>
$ openstack overcloud deploy --templates \ -e /home/custom/ceilometer-publisher.yaml -e <environment-files>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 创建一个 YAML 文件来包括所有本地修改,例如
local_modifications.yaml。您可以使用脚本执行部署,如下例所示:Copy to Clipboard Copied! Toggle word wrap Toggle overflow
1.3.2. collectd
性能监控会定期收集系统信息,并提供一种机制,使用收集的数据代理以各种方式存储和监控值。红帽支持 collectd 守护进程作为数据收集代理。此守护进程将数据存储在时间序列数据库中。红帽支持的数据库之一称为 Gnocchi。您可以使用此存储的数据来监控系统、查找性能瓶颈和预测将来的系统负载。
其他资源
- 有关 Gnocchi 的更多信息,请参阅 第 1.4 节 “使用 Gnocchi 存储”。
- 有关 collectd 的更多信息,请参阅 第 3.1 节 “安装 collectd”。
1.4. 使用 Gnocchi 存储
Gnocchi 是开源时间序列数据库。它以非常大的规模存储指标,并提供对操作器和用户的指标和资源的访问权限。Gnocchi 使用归档策略来定义计算和要保留的聚合数;以及索引器驱动程序,以存储所有资源、归档策略和指标的索引。
1.4.1. 归档策略:存储时间序列数据库中的短期和长期数据
归档策略定义了计算的聚合以及要保留的聚合数量。Gnocchi 支持不同的聚合方法,如最小值、最大值、平均数、Nthile 和标准偏差。这些聚合会在特定时间段的时间段内计算名为 granularity 并保留的。
归档策略定义了指标的聚合方式,以及它们的存储时间。每个归档策略定义为 timespan 的点数。
例如,如果您的归档策略定义了粒度为 1 秒的 10 点策略,则时间序列存档最多保留 10 秒,各自代表一个超过 1 秒的聚合。这意味着,时间序列的最大值为上限,在最近点和旧点之间保留 10 秒的数据。
归档策略也定义使用哪些聚合方法。默认设置为参数 default_aggregation_methods,其默认值为 mean、min、max. sum、std、count。因此,根据用例,归档策略和粒度会有所不同。
其他资源
- 有关归档策略的更多信息,请参阅 规划和管理归档策略。
1.4.2. 索引器驱动程序
索引器负责存储所有资源、归档策略和指标的索引及其定义、类型和属性。它还负责将资源与指标链接。Red Hat OpenStack Platform director 默认安装 indexer 驱动程序。您需要一个数据库来索引 Gnocchi 处理的所有资源和指标。支持的驱动程序是 MySQL。
1.4.3. Gnocchi Metric-as-a-Service 术语
下表包含 Metric-as-a-Service 功能常用术语的定义。
| 术语 | 定义 |
|---|---|
| 聚合方法 | 种函数用于将多个测量结果聚合到聚合中。例如,min 聚合方法将不同测量结果的值聚合到时间范围中所有测量结果的最小值。 |
| aggregate | 根据归档策略,从多个测量结果生成的数据点元数据。聚合由时间戳和值组成。 |
| 归档策略 | 附加到指标的聚合存储策略。归档策略决定聚合在指标中保留的时长,以及如何聚合聚合(聚合方法)。 |
| granularity | 在一系列指标的聚合中两个聚合之间的时间。 |
| 测量 | API 发送到时间序列数据库的传入数据点元。测量由时间戳和值组成。 |
| 指标 | 由 UUID 标识的实体。指标可以使用名称附加到资源。指标存储其聚合的方式由与指标关联的归档策略定义。 |
| 资源 | 代表您与指标关联的任何实体。资源由唯一 ID 标识,可以包含属性。 |
| 时间序列 | 按时间排序的聚合列表。 |
| timespan | 指标保留其聚合的时间周期。它用于归档策略的上下文。 |
1.5. 显示指标数据
您可以使用以下工具显示和分析指标数据:
- Grafana :开源指标分析和视觉化套件。Grafana 最常用于可视化时间序列数据以进行基础架构和应用程序分析。
- 红帽 CloudForms :IT 部门用来控制用户自助式服务功能的基础架构管理平台,以调配、管理并确保虚拟机及私有云中的合规性。
其他资源
- 有关 Grafana 的更多信息,请参阅 第 1.5.1 节 “使用并连接 Grafana 来显示数据”。
- 有关 Red Hat Cloudforms 的更多信息,请参阅 产品文档。
1.5.1. 使用并连接 Grafana 来显示数据
您可以使用第三方软件(如 Grafana)来查看收集和存储的指标的图形化表示。
Grafana 是一个开源指标分析、监控和视觉化套件。要安装和配置 Grafana,请参阅官方 Grafana 文档。
第 2 章 规划运营测量
您监控的资源取决于您的业务需求。您可以使用 Ceilometer 或 collectd 来监控您的资源。
- 如需有关 collectd 测量的更多信息,请参阅 第 2.2 节 “collectd 测量”。
- 有关 Ceilometer 测量的更多信息,请参阅 第 2.1 节 “Ceilometer 测量”。
2.1. Ceilometer 测量
有关 Ceilometer 测量的完整列表,请参阅 https://docs.openstack.org/ceilometer/queens/admin/telemetry-measurements.html
2.2. collectd 测量
以下测量是最常用的 collectd 指标:
- disk
- interface
- load
- 内存
- 进程
- tcpconns
有关测量结果的完整列表,请参阅 collectd 指标和事件。
2.3. 监控 Gnocchi 和 Ceilometer 性能
您可以使用 openstack metric 命令管理部署的归档策略、基准测试、测量、指标和资源。
流程
在命令行中输入
openstack metric status,以监控部署中 Gnocchi 安装并检查测量的状态:Copy to Clipboard Copied! Toggle word wrap Toggle overflow
2.4. 规划数据存储
Gnocchi 存储数据点的集合,其中每个数据点都是一个聚合的。存储格式使用不同的技术进行压缩。因此,为了计算时间序列数据库的大小,您可以根据最糟糕的情况来估算大小。
流程
计算数据点数:
point 数量 = timespan / granularity
例如,如果要使用一分钟分辨率保留一个年的数据,请使用公式:
数据点数 = (365 天 24 小时 X 60 分钟)/1 分钟的数据点数 = 525600
计算时间序列数据库的大小:
字节大小 = 数据点 X 8 字节数
如果您将这个公式应用到示例,则结果为 4.1 MB:
字节大小 = 525600 点 X 8 字节 = 4204800 字节 = 4.1 MB
这个值是一个单一聚合时间序列数据库的估算存储要求。如果您的归档策略使用多个聚合方法(min、max、mean、ided、std、std 和 count),则按您使用的聚合方法数乘以该值。
其他资源
- 更多信息请参阅 第 1.4.1 节 “归档策略:存储时间序列数据库中的短期和长期数据”。
2.5. 规划和管理归档策略
归档策略定义了您如何聚合指标,以及将指标存储在时间序列数据库中的时长。归档策略定义为 timespan 的点数。
如果您的归档策略定义了粒度为 1 秒的 10 点策略,则时间序列存档最多保留 10 秒,各自代表 1 秒的聚合。这意味着,时间序列在最近点和旧点之间保留最多 10 秒的数据。归档策略也定义要使用的聚合方法。默认设置为参数 default_aggregation_methods,其中默认值设置为 mean、min、max。总、std、count.因此,根据用例,归档策略和粒度可能会有所不同。
要计划归档策略,请确定您熟悉以下概念:
- 指标.更多信息请参阅 第 2.5.1 节 “指标”。
- 测量结果。更多信息请参阅 第 2.5.2 节 “创建自定义测量结果”。
- 聚合.更多信息请参阅 第 2.5.4 节 “计算时间序列聚合的大小”。
- 指标的 worker。更多信息请参阅 第 2.5.5 节 “metricd worker”。
要创建和管理归档策略,请完成以下任务:
- 创建归档策略。更多信息请参阅 第 2.5.6 节 “创建归档策略”。
- 管理归档策略。更多信息请参阅 第 2.5.7 节 “管理归档策略”。
- 创建归档策略规则。更多信息请参阅 第 2.5.8 节 “创建归档策略规则”。
2.5.1. 指标
Gnocchi 提供名为 metric 的对象类型。指标是您可以测量的任何内容,例如,服务器的 CPU 使用量、空间温度或网络接口发送的字节数。指标具有以下属性:
- 用于标识它的 UUID
- 一个名称
- 用于存储和聚合测量结果的归档策略
其他资源
- 有关术语定义,请参阅 Gnocchi Metric-as-a-Service 术语。
2.5.1.1. 创建指标
流程
创建资源。将 <resource_name> 替换为资源名称:
openstack metric resource create <resource_name>
$ openstack metric resource create <resource_name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 创建指标。将 <resource_name> 替换为资源名称,将 <metric_name> 替换为指标的名称:
openstack metric metric create -r <resource_name> <metric_name>
$ openstack metric metric create -r <resource_name> <metric_name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 在创建指标时,归档策略属性会被修复并不可更改。您可以通过
archive_policy端点更改归档策略的定义。
2.5.2. 创建自定义测量结果
测量 API 发送到 Gnocchi 的传入数据点数。它由一个时间戳和值组成。您可以创建自己的自定义测量结果。
流程
创建自定义测量:
openstack metric measures add -m <MEASURE1> -m <MEASURE2> .. -r <RESOURCE_NAME> <METRIC_NAME>
$ openstack metric measures add -m <MEASURE1> -m <MEASURE2> .. -r <RESOURCE_NAME> <METRIC_NAME>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
2.5.3. 默认归档策略
默认情况下,Gnocc 具有以下归档策略:
低
- 5 分钟粒度超过 30 天
-
使用的聚合方法:
default_aggregation_methods - 每个指标的最大估算大小: 406 KiB
中
- 1 分钟粒度超过 7 天
- 365 天 1 小时粒度
-
使用的聚合方法:
default_aggregation_methods - 每个指标的最大估算大小:887 KiB
high
- 1 小时第二个粒度
- 1 周的 1 分钟粒度
- 1 小时粒度超过 1 年
-
使用的聚合方法:
default_aggregation_methods - 每个指标的最大预计大小:1 057 KiB
bool
- 1 年超过 1 秒的粒度
- 使用的聚合方法:最后
- 每个指标的最大优化大小:1 539 KiB
- 每个指标的最大 pessimistic 大小:277 172 KiB
2.5.4. 计算时间序列聚合的大小
Gnocchi 存储一系列数据点,其中每个点都是一个聚合的。存储格式使用不同的技术进行压缩。因此,根据最糟糕的情况,计算时间序列的大小估计是估算的,如下例所示。
流程
使用此公式计算点数:
point 数量 = timespan / granularity
例如,如果要使用一分钟分辨率保留一年的数据:
点数 = (365 天 X 24 小时 X 60 分钟)/1 分钟
点数 = 525600
要计算点大小(以字节为单位),请使用这个公式:
字节大小(以字节为单位) = 点 X 8 字节数
字节大小 = 525600 点 X 8 字节 = 4204800 字节 = 4.1 MB
这个值是一个单一聚合时间序列的估算存储要求。如果您的归档策略使用多个聚合方法 - 分钟、max、mean、sted、std、count - 按您使用的聚合方法数乘以该值。
2.5.5. metricd worker
您可以使用 metricd 守护进程来处理测量结果,创建聚合、存储测量结果,以及删除指标。metricd 守护进程负责 Gnocchi 中大多数 CPU 用量和 I/O 作业。每个指标的归档策略决定指标守护进程执行的速度。metricd 会定期检查传入的存储是否有新的测量结果。要配置每个检查之间的延迟,您可以使用 [metricd]metric_processing_delay 配置选项。
2.5.6. 创建归档策略
流程
创建归档策略。将 <archive-policy-name> 替换为策略的名称,将 <aggregation-method> 替换为聚合的方法。
openstack metric archive policy create <archive-policy-name> --definition <definition> \ --aggregation-method <aggregation-method>
# openstack metric archive policy create <archive-policy-name> --definition <definition> \ --aggregation-method <aggregation-method>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 注意<definition> 是策略定义。使用逗号分隔多个属性(、)。使用冒号(:)分隔归档策略定义的 name 和值。
2.5.7. 管理归档策略
删除归档策略:
openstack metric archive policy delete <archive-policy-name>
openstack metric archive policy delete <archive-policy-name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 查看所有归档策略:
openstack metric archive policy list
# openstack metric archive policy listCopy to Clipboard Copied! Toggle word wrap Toggle overflow 查看归档策略的详情:
openstack metric archive-policy show <archive-policy-name>
# openstack metric archive-policy show <archive-policy-name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
2.5.8. 创建归档策略规则
归档策略规则定义了指标和归档策略之间的映射。这样,用户可以预定义规则,以便基于匹配模式将归档策略分配给指标。
流程
创建归档策略规则。将 <rule-name> 替换为规则的名称,<archive-policy-name> 替换为归档策略的名称:
openstack metric archive-policy-rule create <rule-name> / --archive-policy-name <archive-policy-name>
# openstack metric archive-policy-rule create <rule-name> / --archive-policy-name <archive-policy-name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
第 3 章 安装和配置操作测量工具
您必须安装收集的数据收集代理、collectd 和时间序列数据库 Gnocchi。
3.1. 安装 collectd
安装 collectd 时,您可以配置多个 collectd 插件来适合您的环境。
流程
-
将文件
/usr/share/openstack-tripleo-heat-templates/environments/collectd-environment.yaml复制到本地目录。 打开
collectd-environment.yaml并列出您要在CollectdExtraPlugins下的插件。您还可以在ExtraConfig部分提供参数:Copy to Clipboard Copied! Toggle word wrap Toggle overflow 默认情况下,collectd 附带了
磁盘、接口、加载、内存、进程和tcpconns插件。您可以使用CollectdExtraPlugins参数添加额外的插件。您还可以使用ExtraConfig选项为 CollectdExtraPlugins 提供额外的配置信息,如下所示。这个示例添加了virt插件,并配置连接字符串和主机名格式。在
openstack overcloud deploy命令中包含修改后的 YAML 文件,以便在所有 overcloud 节点上安装 collectd 守护进程:openstack overcloud deploy --templates \/home/templates/environments/collectd.yaml \ -e /path-to-copied/collectd-environment.yaml
$ openstack overcloud deploy --templates \/home/templates/environments/collectd.yaml \ -e /path-to-copied/collectd-environment.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
其他资源
- 有关 collectd 的更多信息,请参阅 第 1.3.2 节 “collectd”。
- 要查看 collectd 插件和配置,请参阅 Service Telemetry Framework 指南中的 collectd 插件。
3.2. 安装 Gnocchi
默认情况下,在 undercloud 上不启用 Gnocchi。红帽不推荐在 undercloud 上启用 Telemetry,因为它会生成很多 undercloud 无法处理的数据,因为资源和单点故障。
默认情况下,Telemetry 和 Gnocchi 安装在控制器和 Compute 节点上。Gnocchi 的默认存储后端为 file。
您可以通过以下两种方式之一在 overcloud 上部署 Gnocchi:
- 内部.更多信息请参阅 第 3.2.1 节 “在内部部署 Gnocchi”。
- 外部.更多信息请参阅 第 3.2.2 节 “在外部部署 Gnocchi”。
3.2.1. 在内部部署 Gnocchi
默认部署为 internal。
流程
-
要部署 collectd 以向内部 Gnocchi 发送指标数据,请将
/usr/share/openstack-tripleo-heat-templates/environments/services/collectd.yaml添加到overcloud deploy命令。
其他资源
- 更多信息请参阅 第 3.1 节 “安装 collectd”。
3.2.2. 在外部部署 Gnocchi
流程
在本地目录中创建自定义 YAML 文件,如
ExternalGnocchi.yaml,并确保您包含以下详情:CollectdGnocchiServer: <IPofExternalServer> CollectdGnocchiUser: admin CollectdGnocchiAuth: basic
CollectdGnocchiServer: <IPofExternalServer> CollectdGnocchiUser: admin CollectdGnocchiAuth: basicCopy to Clipboard Copied! Toggle word wrap Toggle overflow 若要部署 Gnocchi,请将自定义 YAML 文件添加到
overcloud deploy命令中。使用<existing_overcloud_environment_files>属于现有部署一部分的环境文件列表替换。openstack overcloud deploy \ -e <existing_overcloud_environment_files> \ -e /usr/share/openstack-tripleo-heat-templates/environments/services/collectd.yaml \ -e /home/templates/environments/ExternalGnocchi.yaml \ ...
openstack overcloud deploy \ -e <existing_overcloud_environment_files> \ -e /usr/share/openstack-tripleo-heat-templates/environments/services/collectd.yaml \ -e /home/templates/environments/ExternalGnocchi.yaml \ ...Copy to Clipboard Copied! Toggle word wrap Toggle overflow 注意您可以在以下 YAML 文件中找到所有 Gnocchi 参数:
/usr/share/openstack-tripleo-heat-templates/puppet/services/metrics/collectd.yaml
3.2.3. 验证 Gnocchi 部署
流程
列出新资源和指标:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
第 4 章 管理操作测量
4.1. 根据您的部署修改环境变量
流程
-
将
/usr/share/openstack-tripleo-heat-templates/environments/gnocchi-environment.yaml文件复制到您的主目录。 修改参数以符合您的环境。您可以在 YAML 文件中修改以下主要参数:
-
GnocchiIndexerBackend:要使用的数据库索引程序后端,如
mysql。请查看 https://github.com/openstack/tripleo-heat-templates/blob/stable/queens/puppet/services/gnocchi-base.yaml#L33 -
GnocchiBackend:临时存储的类型。该值可以是
rbd、swift或file(ceph)。更多信息请参阅 https://github.com/openstack/tripleo-heat-templates/blob/stable/queens/environments/storage-environment.yaml#L29-L30 - NumberOfStorageSacks:存储黑名单的数量。更多信息请参阅 第 4.1.2 节 “sacks 的数量”。
-
GnocchiIndexerBackend:要使用的数据库索引程序后端,如
将
gnocchi-environment.yaml添加到overcloud deploy命令中,以及与您的环境和部署相关的任何其他环境文件。使用<existing_overcloud_environment_files>属于现有部署一部分的环境文件列表替换:openstack overcloud deploy \ <existing_overcloud_environment_files> \ -e ~gnocchi-environment.yaml \ ...
$ openstack overcloud deploy \ <existing_overcloud_environment_files> \ -e ~gnocchi-environment.yaml \ ...Copy to Clipboard Copied! Toggle word wrap Toggle overflow
4.1.1. 运行 metricd worker
默认情况下,gnocchi-metricd 守护进程会跨越 CPU 电源,以最大化计算指标聚合时的 CPU 使用。
流程
使用
openstack metric status命令查询 HTTP API 并检索用于指标处理的状态:openstack metric status
# openstack metric statusCopy to Clipboard Copied! Toggle word wrap Toggle overflow 命令输出显示
gnocchi-metrid守护进程的处理 backlog。只要此积压不持续增加,gnocchi-metricd就可以与要收集的指标数量保持同步。如果持续增加进程的测量结果数量,请增加gnocchi-metricd守护进程的数量。您可以在任意数量的服务器上运行任意数量的指标守护进程。
4.1.2. sacks 的数量
Gnocchi 中传入的指标数据被推送到不同的 sacks,每个 sack 被分配到一个或多个 gnocchi-metricd 守护进程进行处理。攻击的数量取决于系统捕获的活动指标。
红帽建议 sacks 的数量大于活跃 gnocchi-metricd worker 总数。
4.1.3. 更改 sack 大小
如果想收集更多指标而不是最初的预计,您可以更改 sack 大小。
推送到 Gnocchi 的测量数据被分成多个 sack 以更好地分发。传入的指标被推送到特定的 sack,每个 sack 都会被分配给一个或多个 gnocchi-metricd 守护进程进行处理。要设置 sacks 的数量,请使用系统捕获的活动指标数量。sacks 的数量应该大于活跃 gnocchi-metricd worker 的总数。
流程
要确定要设置的适当 sacks 值,请使用以下内容:
sacks value = 活跃 指标的数量/ 300
注意如果估算的指标数量是绝对最大值,请将值除以 500 个。如果活跃指标的预计数量是保守和预期增长,请将值除以容纳增长。
4.2. 监控时间序列数据库服务
HTTP API 的 /v1/status 端点返回信息,如要处理的测量结果数量(measures backlog),您可以监控这些信息。以下条件表示一个健康的系统:
-
HTTP 服务器和
gnocchi-metricd正在运行 -
HTTP 服务器和
gnocchi-metricd不会将错误消息写入到日志文件中。
流程
查看时间序列数据库的状态:
openstack metric status
# openstack metric statusCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出显示时间序列数据库的状态以及要处理的指标数量。这里的数值越好,最好是接近 0。
4.3. 备份和恢复时间序列数据库
要从意外事件中恢复,请备份索引和存储。您必须使用 PostgreSQL 或 MySQL 创建数据库转储,并使用 Ceph、Swift 或您的文件系统获取数据存储的快照或副本。
流程
- 恢复您的索引和存储备份。
- 如有必要,重新安装 Gnocchi。
- 重新启动 Gnocchi.
4.4. 查看测量结果
您可以查看特定资源的测量结果列表:
流程
使用
metric measures命令:openstack metric measures show --resource-id UUID <METER_NAME>
# openstack metric measures show --resource-id UUID <METER_NAME>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 列出一系列时间戳中特定资源的测量结果:
openstack metric measures show --aggregation mean --start <START_TIME> --stop <STOP_TIME> --resource-id UUID <METER_NAME>
# openstack metric measures show --aggregation mean --start <START_TIME> --stop <STOP_TIME> --resource-id UUID <METER_NAME>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 时间戳变量 <START_TIME> 和 <END_TIME> 使用格式 iso-dateThh:mm:ss。
4.5. 管理资源类型
您可以创建、查看和删除资源类型。默认资源类型是通用的,但您可以使用任意数量的属性创建自己的资源类型。
流程
创建新资源类型:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 查看资源类型的配置:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 删除资源类型:
openstack metric resource-type delete testResource01
$ openstack metric resource-type delete testResource01Copy to Clipboard Copied! Toggle word wrap Toggle overflow
如果资源正在使用,则无法删除资源类型。
4.6. 查看云使用量措施
流程
查看每个项目所有实例的平均内存用量:
openstack metrics measures aggregation --resource-type instance --groupby project_id -m “memoryView L3” --resource-id UUID
openstack metrics measures aggregation --resource-type instance --groupby project_id -m “memoryView L3” --resource-id UUIDCopy to Clipboard Copied! Toggle word wrap Toggle overflow
4.6.1. 启用 L3 缓存监控
如果您的 Intel 硬件和 libvirt 版本支持缓存监控技术(CMT),您可以使用 cpu_l3_cache 量表来监控实例使用的 L3 缓存量。
要监控 L3 缓存,必须具有以下参数和文件:
-
LibvirtEnabledPerfEvents参数中的 CMT。 -
gnocchi_resources.yaml文件中的cpu_l3_cache。 -
Ceilometer poll
.yaml文件中的cpu_l3_cache。
流程
-
为 Telemetry 创建一个 YAML 文件,如
ceilometer-environment.yaml。 -
在
ceilometer-environment.yaml文件中,将cmt添加到LibvirtEnabledPerfEvents参数。如需更多信息,请参阅/usr/share/openstack-triple-heat-templates/puppet/services/nova_libvirt.yaml。 使用此 YAML 文件部署 overcloud。使用
<existing_overcloud_environment_files>属于现有部署一部分的环境文件列表替换:Copy to Clipboard Copied! Toggle word wrap Toggle overflow 验证 Compute 节点上的 Gnocchi 中是否启用了
cpu_l3_cache。Copy to Clipboard Copied! Toggle word wrap Toggle overflow 注意更改容器镜像中的设置不会在重新引导后保留。
在此 Compute 节点上启动客户端实例后,监控
CMT指标:Copy to Clipboard Copied! Toggle word wrap Toggle overflow
4.7. 升级 Gnocchi
默认情况下,使用 Red Hat OpenStack Platform director 升级 Gnocchi 升级您的部署。有关升级部署的详情,请参阅升级 Red Hat OpenStack Platform。如果您使用 Red Hat OpenStack Platform 10 并希望升级到 Red Hat OpenStack Platform 13,请参阅 快进升级。
第 5 章 管理警报
您可以使用名为 aodh 的警报服务根据定义的规则根据 Ceilometer 或 Gnocchi 收集的指标数据来触发操作。
5.1. 查看现有警报
流程
列出现有的 Telemetry 警报:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 要列出分配给资源的计量,请指定资源的 UUID。例如:
openstack resource show 5e3fcbe2-7aab-475d-b42c-a440aa42e5ad
# openstack resource show 5e3fcbe2-7aab-475d-b42c-a440aa42e5adCopy to Clipboard Copied! Toggle word wrap Toggle overflow
5.2. 创建警报
您可以使用 aodh 创建在达到阈值时激活的警报。在本例中,警报激活并在单个实例的平均 CPU 利用率超过 80% 时添加一个日志条目。
流程
创建警报并使用查询来隔离实例的特定 ID (94619081-abf5-4f1f-81c7-9cedaa872403)以进行监控:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 若要编辑现有阈值警报,可使用 aodh alarm update 命令。例如,要将警报阈值增加到 75%,请使用以下命令:
openstack alarm update --name cpu_usage_high --threshold 75
# openstack alarm update --name cpu_usage_high --threshold 75Copy to Clipboard Copied! Toggle word wrap Toggle overflow
5.3. 禁用警报
流程
要禁用警报,请输入以下命令:
openstack alarm update --name cpu_usage_high --enabled=false
# openstack alarm update --name cpu_usage_high --enabled=falseCopy to Clipboard Copied! Toggle word wrap Toggle overflow
5.4. 删除警报
流程
要删除警报,请输入以下命令:
openstack alarm delete --name cpu_usage_high
# openstack alarm delete --name cpu_usage_highCopy to Clipboard Copied! Toggle word wrap Toggle overflow
5.5. 示例:监控实例的磁盘活动
以下示例演示了如何使用 aodh 警报来监控特定项目中包含的所有实例的累积磁盘活动。
流程
检查现有项目,再选择您要监控的项目的适当 UUID。本例使用
admin租户:Copy to Clipboard Copied! Toggle word wrap Toggle overflow 使用项目 UUID 创建警报,以分析
admin租户中实例生成的所有读取请求的sum ()。您可以使用--query参数进一步限制查询:Copy to Clipboard Copied! Toggle word wrap Toggle overflow
5.6. 示例:监控 CPU 使用
要监控实例的性能,可检查 Gnocchi 数据库以确定您可以监控哪些指标,如内存或 CPU 使用量。
流程
输入
openstack metric resource show命令和实例 UUID,以识别您可以监控的指标:Copy to Clipboard Copied! Toggle word wrap Toggle overflow 因此,指标值列出了您可以使用 aodh 警报监控的组件,如
cpu_util。要监控 CPU 用量,请使用
cpu_util指标:Copy to Clipboard Copied! Toggle word wrap Toggle overflow - archive_policy:定义计算 std、count、min、max、sum 和 mean 值的聚合间隔。
使用 aodh 创建查询
cpu_util的监控任务。此任务会根据您指定的设置触发事件。例如,当实例的 CPU 高峰持续时间超过 80% 时,要引发日志条目,请使用以下命令:Copy to Clipboard Copied! Toggle word wrap Toggle overflow - comparison-operator:如果 CPU 使用率大于或等于 80%,ge 运算符定义了警报触发。
- granularity:指标关联有一个归档策略,策略可以具有各种粒度。例如,每月 1 小时的 5 分钟聚合为 1 小时聚合。granularity 值必须与归档策略中描述的持续时间匹配。
- 评估-periods:在警报触发前需要传递的粒度周期数。例如,如果您将此值设置为 2,则在警报触发前,CPU 用量需要超过 80% 才能触发两个轮询周期。
[U'log://']:当您将
alarm_actions或ok_actions设置为[u'log://']时,事件会被触发或返回到普通的状态,则会记录到 aodh 日志文件。注意您可以定义在警报触发时运行的不同操作(alarm_actions),并在返回正常状态(ok_actions) (如 Webhook URL)时运行。
5.7. 查看警报历史记录
若要检查是否触发了警报,您可以查询警报历史记录。
流程
使用
openstack alarm-history show命令:Copy to Clipboard Copied! Toggle word wrap Toggle overflow
第 6 章 日志
Red Hat OpenStack Platform (RHOSP)将信息消息写入特定的日志文件中;您可以使用这些消息来故障排除和监控系统事件。
您不需要手动将单个日志文件附加到您的支持问题单中。sosreport 工具会自动收集所需日志。
6.1. OpenStack 服务的日志文件位置
每个 OpenStack 组件都有一个单独的日志记录目录,其中包含特定于正在运行的服务的文件。
6.1.1. 裸机置备(ironic)日志文件
| Service | 服务名称 | 日志路径 |
|---|---|---|
| OpenStack Ironic API | openstack-ironic-api.service | /var/log/containers/ironic/ironic-api.log |
| OpenStack Ironic Conductor | openstack-ironic-conductor.service | /var/log/containers/ironic/ironic-conductor.log |
6.1.2. Block Storage (cinder)日志文件
| Service | 服务名称 | 日志路径 |
|---|---|---|
| Block Storage API | openstack-cinder-api.service | /var/log/containers/cinder-api.log |
| 块存储备份 | openstack-cinder-backup.service | /var/log/containers/cinder/backup.log |
| 信息性信息 | cinder-manage 命令 | /var/log/containers/cinder/cinder-manage.log |
| 块存储调度程序 | openstack-cinder-scheduler.service | /var/log/containers/cinder/scheduler.log |
| 块存储卷 | openstack-cinder-volume.service | /var/log/containers/cinder/volume.log |
6.1.3. compute (nova)日志文件
| Service | 服务名称 | 日志路径 |
|---|---|---|
| OpenStack Compute API 服务 | openstack-nova-api.service | /var/log/containers/nova/nova-api.log |
| OpenStack 计算证书服务器 | openstack-nova-cert.service | /var/log/containers/nova/nova-cert.log |
| OpenStack 计算服务 | openstack-nova-compute.service | /var/log/containers/nova/nova-compute.log |
| OpenStack Compute Conductor 服务 | openstack-nova-conductor.service | /var/log/containers/nova/nova-conductor.log |
| OpenStack Compute VNC 控制台身份验证服务器 | openstack-nova-consoleauth.service | /var/log/containers/nova/nova-consoleauth.log |
| 信息性信息 | nova-manage 命令 | /var/log/containers/nova/nova-manage.log |
| OpenStack Compute NoVNC 代理服务 | openstack-nova-novncproxy.service | /var/log/containers/nova/nova-novncproxy.log |
| OpenStack 计算调度程序服务 | openstack-nova-scheduler.service | /var/log/containers/nova/nova-scheduler.log |
6.1.4. 仪表板(horizon)日志文件
| Service | 服务名称 | 日志路径 |
|---|---|---|
| 特定用户交互的日志 | 仪表板接口 | /var/log/containers/horizon/horizon.log |
Apache HTTP 服务器将多个额外的日志文件用于 Dashboard Web 界面,您可以使用网页浏览器或命令行客户端(如 keystone 和 nova)进行访问。以下日志文件有助于跟踪控制面板的使用并诊断错误:
| 用途 | 日志路径 |
|---|---|
| 所有已处理的 HTTP 请求 | /var/log/containers/httpd/horizon_access.log |
| HTTP 错误 | /var/log/containers/httpd/horizon_error.log |
| admin-role API 请求 | /var/log/containers/httpd/keystone_wsgi_admin_access.log |
| admin-role API 错误 | /var/log/containers/httpd/keystone_wsgi_admin_error.log |
| member-role API 请求 | /var/log/containers/httpd/keystone_wsgi_main_access.log |
| member-role API 错误 | /var/log/containers/httpd/keystone_wsgi_main_error.log |
另外,还有 /var/log/containers/httpd/default_error.log,它存储同一主机上运行的其他 Web 服务报告的错误。
6.1.5. 数据处理(sahara)日志文件
| Service | 服务名称 | 日志路径 |
|---|---|---|
| Sahara API Server |
openstack-sahara-all.service |
/var/log/containers/sahara/sahara-all.log |
| Sahara Engine Server | openstack-sahara-engine.service | /var/log/containers/messages |
6.1.6. 数据库即服务(trove)日志文件
| Service | 服务名称 | 日志路径 |
|---|---|---|
| OpenStack Trove API 服务 | openstack-trove-api.service | /var/log/containers/trove/trove-api.log |
| OpenStack Trove Conductor 服务 | openstack-trove-conductor.service | /var/log/containers/trove/trove-conductor.log |
| OpenStack Trove 客户机代理服务 | openstack-trove-guestagent.service | /var/log/containers/trove/logfile.txt |
| OpenStack Trove taskmanager Service | openstack-trove-taskmanager.service | /var/log/containers/trove/trove-taskmanager.log |
6.1.7. Identity Service (keystone)日志文件
| Service | 服务名称 | 日志路径 |
|---|---|---|
| OpenStack 身份服务 | openstack-keystone.service | /var/log/containers/keystone/keystone.log |
6.1.8. Image Service (glance)日志文件
| Service | 服务名称 | 日志路径 |
|---|---|---|
| OpenStack Image Service API 服务器 | openstack-glance-api.service | /var/log/containers/glance/api.log |
| OpenStack Image Service Registry 服务器 | openstack-glance-registry.service | /var/log/containers/glance/registry.log |
6.1.9. networking (neutron)日志文件
| Service | 服务名称 | 日志路径 |
|---|---|---|
| OpenStack Neutron DHCP Agent | neutron-dhcp-agent.service | /var/log/containers/neutron/dhcp-agent.log |
| OpenStack 网络层 3 代理 | neutron-l3-agent.service | /var/log/containers/neutron/l3-agent.log |
| 元数据代理服务 | neutron-metadata-agent.service | /var/log/containers/neutron/metadata-agent.log |
| 元数据命名空间代理 | 不适用 | /var/log/containers/neutron/neutron-ns-metadata-proxy-UUID.log |
| Open vSwitch 代理 | neutron-openvswitch-agent.service | /var/log/containers/neutron/openvswitch-agent.log |
| OpenStack 网络服务 | neutron-server.service | /var/log/containers/neutron/server.log |
6.1.10. Object Storage (swift)日志文件
OpenStack Object Storage 仅将日志发送到系统日志功能。
默认情况下,所有 Object Storage 日志文件都会使用 local0、local1 和 local2 syslog 工具进入 /var/log/containers/swift.log。
对象存储的日志消息分为两大类:由 REST API 服务以及后台守护进程使用它们。API 服务消息包含每个 API 请求的一个行,其方式与常见的 HTTP 服务器类似;前端(Proxy)和后端(Account、Container、Object)服务也会发布此类消息。守护进程消息的结构较少,通常包含有关执行定期任务的守护进程的人类可读信息。但是,无论对象存储的哪个部分生成消息,源身份始终位于行首。
以下是代理消息的示例:
Apr 20 15:20:34 rhev-a24c-01 proxy-server: 127.0.0.1 127.0.0.1 20/Apr/2015/19/20/34 GET /v1/AUTH_zaitcev%3Fformat%3Djson%26marker%3Dtestcont HTTP/1.0 200 - python-swiftclient-2.1.0 AUTH_tk737d6... - 2 - txc454fa8ea4844d909820a-0055355182 - 0.0162 - - 1429557634.806570053 1429557634.822791100
Apr 20 15:20:34 rhev-a24c-01 proxy-server: 127.0.0.1 127.0.0.1 20/Apr/2015/19/20/34 GET /v1/AUTH_zaitcev%3Fformat%3Djson%26marker%3Dtestcont HTTP/1.0 200 - python-swiftclient-2.1.0 AUTH_tk737d6... - 2 - txc454fa8ea4844d909820a-0055355182 - 0.0162 - - 1429557634.806570053 1429557634.822791100以下是来自后台守护进程的临时信息示例:
6.1.11. 编配(heat)日志文件
| Service | 服务名称 | 日志路径 |
|---|---|---|
| OpenStack Heat API 服务 | openstack-heat-api.service | /var/log/containers/heat/heat-api.log |
| OpenStack Heat Engine Service | openstack-heat-engine.service | /var/log/containers/heat/heat-engine.log |
| 编排服务事件 | 不适用 | /var/log/containers/heat/heat-manage.log |
6.1.13. 遥测(ceilometer)日志文件
| Service | 服务名称 | 日志路径 |
|---|---|---|
| OpenStack ceilometer 通知代理 | openstack-ceilometer-notification.service | /var/log/containers/ceilometer/agent-notification.log |
| OpenStack ceilometer 警报评估 | openstack-ceilometer-alarm-evaluator.service | /var/log/containers/ceilometer/alarm-evaluator.log |
| OpenStack ceilometer 警报通知 | openstack-ceilometer-alarm-notifier.service | /var/log/containers/ceilometer/alarm-notifier.log |
| OpenStack ceilometer API | httpd.service | /var/log/containers/ceilometer/api.log |
| 信息性信息 | MongoDB 集成 | /var/log/containers/ceilometer/ceilometer-dbsync.log |
| OpenStack ceilometer 中央代理 | openstack-ceilometer-central.service | /var/log/containers/ceilometer/central.log |
| OpenStack ceilometer 集合 | openstack-ceilometer-collector.service | /var/log/containers/ceilometer/collector.log |
| OpenStack ceilometer 计算代理 | openstack-ceilometer-compute.service | /var/log/containers/ceilometer/compute.log |
6.1.14. 支持服务的日志文件
下列服务由核心 OpenStack 组件使用,并拥有自己的日志目录和文件。
| Service | 服务名称 | 日志路径 |
|---|---|---|
| 消息代理(RabbitMQ) | rabbitmq-server.service |
/var/log/rabbitmq/rabbit@short_hostname.log |
| 数据库服务器(MariaDB) | mariadb.service | /var/log/mariadb/mariadb.log |
| 面向文档的数据库(MongoDB) | mongod.service | /var/log/mongodb/mongodb.log |
| 虚拟网络交换机(Open vSwitch) | openvswitch-nonetwork.service |
/var/log/openvswitch/ovsdb-server.log |
6.2. 集中式日志系统架构和组件
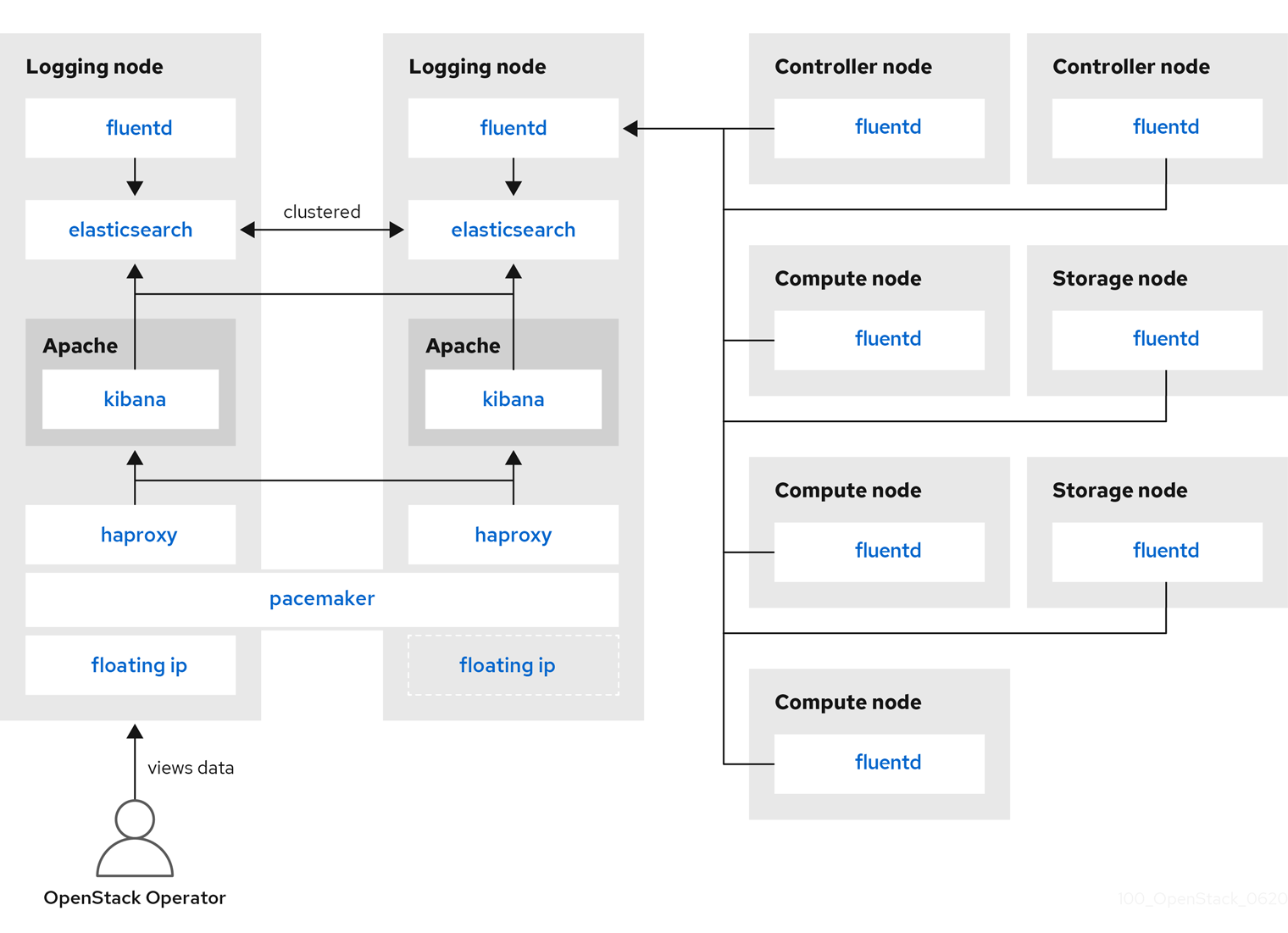
监控工具使用客户端-服务器模型以及部署到 Red Hat OpenStack Platform (RHOSP) overcloud 节点上的客户端。Fluentd 服务提供客户端集中式日志记录(CL)。所有 RHOSP 服务都生成和更新日志文件。这些日志文件记录操作、错误、警告和其他事件。在 OpenStack 等分布式环境中,将这些日志收集中央位置简化了调试和管理。集中化日志记录允许您有一个中央位置查看整个 OpenStack 环境的日志。这些日志来自操作系统,如 syslog 和 audit 日志文件、基础架构组件(如 RabbitMQ 和 MariaDB)以及 OpenStack 服务,如 Identity、Compute 等等。集中式日志记录工具链包括以下组件:
- log Collection Agent (Fluentd)
- log Relay/Transformer (Fluentd)
- 数据存储(ElasticSearch)
- API/Presentation Layer (Kibana)
Red Hat OpenStack Platform director 不会为集中式日志记录部署服务器端组件。红帽不支持服务器端组件,包括 ElasticSearch 数据库、Kibana 和 Fluentd,带有作为日志聚合器运行的插件。下图中描述了集中式日志记录组件及其交互。
蓝色中显示的项目表示红帽支持的组件。
图 6.1. Red Hat OpenStack Platform 单一 HA 部署
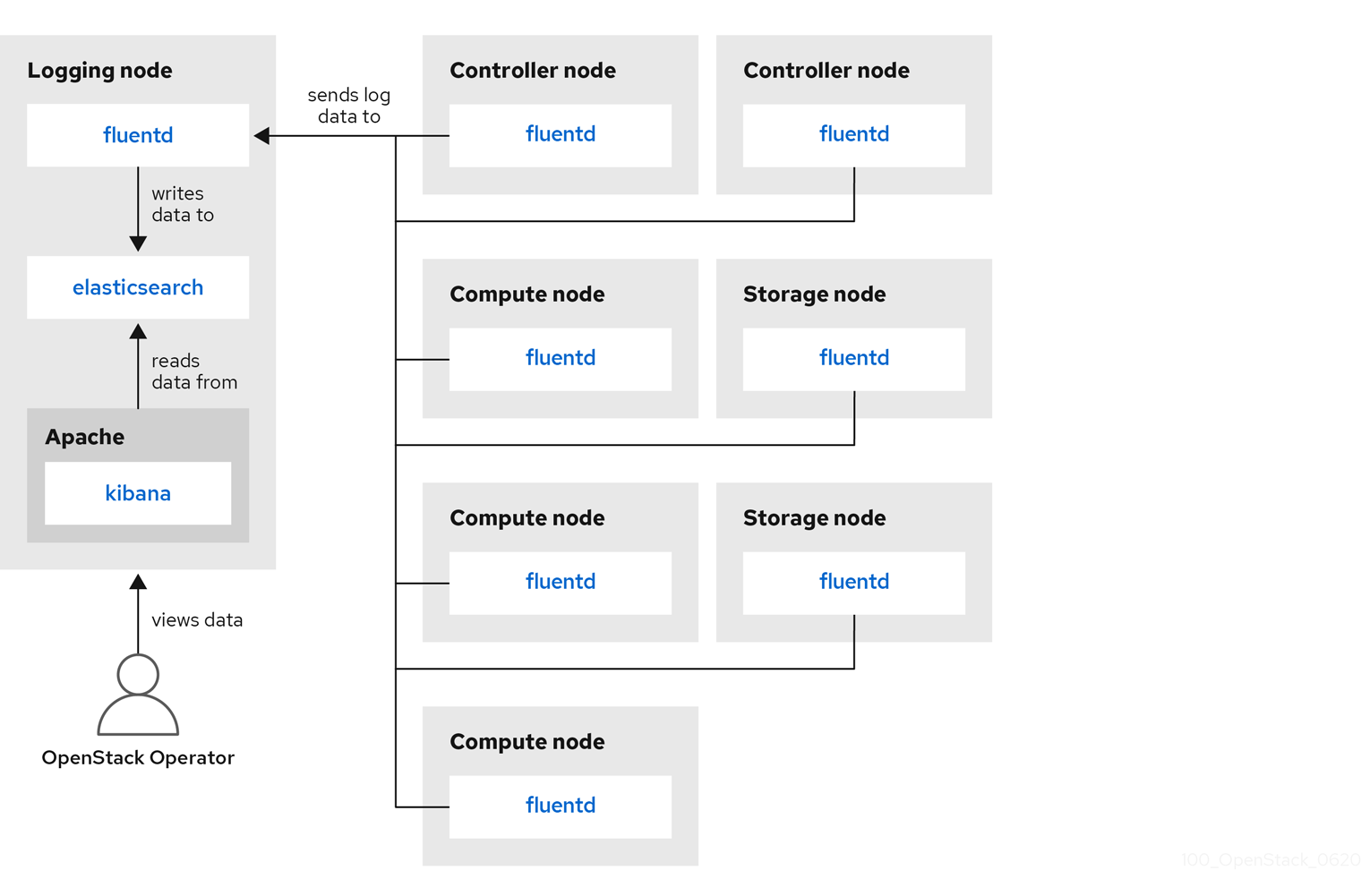
图 6.2. Red Hat OpenStack Platform 的 HA 部署
6.3. 日志服务安装概述
日志收集代理 Fluentd 收集客户端的日志,并将这些日志发送到在服务器端运行的 Fluentd 实例。此 Fluentd 实例将日志记录重定向到 Elasticsearch 以进行存储。
6.4. 在所有机器上部署 Fluentd
Fluentd 是一个日志收集代理,是集中式日志记录工具链的一部分。要在所有机器上部署 Fluentd,您必须修改 logging-environment.yaml 文件中的 LoggingServers 参数:
前提条件
- 确保在服务器端安装 Elasticsearch 和 Fluentd 转发。如需更多信息,请参阅 opstools-ansible 项目中 与客户端集成兼容的示例部署。
流程
-
将
tripleo-heat-templates/environments/logging-environment.yaml文件复制到您的主目录。 在复制的文件中,在
LoggingServers参数中创建条目以适应您的环境。以下片段是LoggingServers参数配置示例:Copy to Clipboard Copied! Toggle word wrap Toggle overflow 在
openstack overcloud deploy命令中包括修改后的环境文件,以及与您环境和部署相关的任何其他环境文件。使用<existing_overcloud_environment_files>属于现有部署一部分的环境文件列表替换:openstack overcloud deploy \ <existing_overcloud_environment_files> \ -e /home/templates/environments/logging-environment.yaml \ ...
$ openstack overcloud deploy \ <existing_overcloud_environment_files> \ -e /home/templates/environments/logging-environment.yaml \ ...Copy to Clipboard Copied! Toggle word wrap Toggle overflow S .Additional 资源
- 更多信息请参阅 第 6.5 节 “可配置的日志记录参数”。
6.5. 可配置的日志记录参数
这个表格包含您可以配置的日志记录参数的描述。您可以在 tripleo-heat-templates/puppet/services/logging/fluentd-config.yaml 文件中找到这些参数。
| 参数 | Description |
|---|---|
| LoggingDefaultFormat | 用于解析日志文件中消息的默认格式。 |
| LoggingPosFilePath |
放置 Fluentd |
| LoggingDefaultGroups |
将 Fluentd 用户添加到这些组。如果要修改组的默认列表,请覆盖此参数。使用 |
| LoggingExtraGroups |
除了 |
| LoggingDefaultFilters |
Fluentd 默认过滤器列表。此列表传递给 |
| LoggingExtraFilters |
附加 Fluentd 过滤器列表。此列表传递给 |
| LoggingUsesSSL |
布尔值表示是否使用 |
| LoggingSSLKey |
用于 Fluentd CA 证书的 PEM 编码密钥。 |
| LoggingSSLCertificate | 用于 Fluentd 的 PEM 编码 SSL CA 证书。 |
| LoggingSSLKeyPassphrase |
|
| LoggingSharedKey |
Fluentd |
| LoggingDefaultSources |
Fluentd 的默认日志源列表。覆盖此参数以禁用默认的日志记录源。使用 |
| LoggingExtraSources |
此列表与 |
6.6. 覆盖日志文件的默认路径
如果您修改默认容器和修改包含服务日志文件的路径,还必须修改默认的日志文件路径。每个可组合服务都有一个 < service_name>LoggingSource 参数。例如,对于 nova-compute 服务,参数是 NovaComputeLoggingSource。
流程
要覆盖 nova-compute 服务的默认路径,请在配置文件中添加
NovaComputeLoggingSource参数的路径。NovaComputeLoggingSource: tag: openstack.nova.compute path: /some/other/path/nova-compute.logNovaComputeLoggingSource: tag: openstack.nova.compute path: /some/other/path/nova-compute.logCopy to Clipboard Copied! Toggle word wrap Toggle overflow tag 和 path 属性是 <
service_name>LoggingSource 参数的必要元素。在每个服务上,定义标签和路径,默认派生了其余值。您可以修改特定服务的格式。这会直接传递给 Fluentd 配置。
LoggingDefaultFormat参数的默认格式为 /(?<time>\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2}.\d+) (<pid>\d+) (<priority>\S+) (<message>.*)$/使用以下语法:<service_name>LoggingSource: tag: <service_name>.tag path: <service_name>.path format: <service_name>.format<service_name>LoggingSource: tag: <service_name>.tag path: <service_name>.path format: <service_name>.formatCopy to Clipboard Copied! Toggle word wrap Toggle overflow 以下片段是一个更复杂的转换示例:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
6.7. 验证部署是否成功
要验证集中式日志记录是否已成功部署,请查看日志来了解输出是否与预期相符。您可以使用第三方视觉化软件,如 Kibana。