通过 NFS 部署共享文件系统服务
了解、使用并管理在 Red Hat OpenStack Platform 中的通过 NFS 实现的带有 CephFS 的 Shared File Systems 服务
摘要
使开源包含更多
红帽致力于替换我们的代码、文档和 Web 属性中存在问题的语言。我们从这四个术语开始:master、slave、黑名单和白名单。由于此项工作十分艰巨,这些更改将在即将推出的几个发行版本中逐步实施。详情请查看 CTO Chris Wright 的信息。
对红帽文档提供反馈
我们感谢您对文档提供反馈信息。与我们分享您的成功秘诀。
使用直接文档反馈(DDF)功能
使用 添加反馈 DDF 功能,用于特定句子、段落或代码块上的直接注释。
- 以 Multi-page HTML 格式查看文档。
- 请确定您看到文档右上角的 反馈 按钮。
- 用鼠标指针高亮显示您想评论的文本部分。
- 点 添加反馈。
- 在添加反馈项中输入您的意见。
- 可选:添加您的电子邮件地址,以便文档团队可以联系您以讨论您的问题。
- 点 Submit。
第 1 章 通过 NFS 使用 CephFS 的共享文件系统服务
通过 NFS 使用共享文件系统服务(manila)和 Ceph 文件系统(CephFS),您可以使用同一个 Ceph 集群用于块存储和对象存储,以通过 NFS 协议提供文件共享。有关更多信息,请参阅存储指南中的共享文件系统服务。
有关 Red Hat OpenStack Platform 文档的完整套件,请参阅 Red Hat OpenStack Platform 文档。
对于 RHOSP 16.0 和更高版本,带有 CephFS through NFS 的 Red Hat OpenStack Platform(RHOSP)共享文件系统服务支持与 Red Hat Ceph Storage 版本 4.1 或更高版本搭配使用。有关如何确定系统上安装的 Ceph Storage 版本的更多信息,请参阅 Red Hat Ceph Storage 发行版本以及对应的 Ceph 软件包版本。
CephFS 是 Ceph 的高可扩展、开源分布式文件系统组件,它是一个统一的分布式存储平台。Ceph 使用可靠的自主分布式对象存储(RADOS)实施对象、块和文件存储。CephFS 是兼容 POSIX 的,提供对 Ceph 存储集群的文件访问。
您可以使用共享文件系统服务在 CephFS 中创建共享,并通过 NFS-Ganesha 的 NFS 4.1 访问它们。NFS-Ganesha 控制对共享的访问,并通过 NFS 4.1 协议将它们导出到客户端。共享文件系统服务管理 Red Hat OpenStack Platform (RHOSP) 中这些共享的生命周期。当云管理员将服务配置为通过 NFS 来使用 CephFS 时,这些文件共享会来自 CephFS 集群,但会使用您所熟悉的 NFS 共享方式创建和访问。
有关更多信息,请参阅存储指南中的共享文件系统服务。
1.1. Ceph 文件系统架构
Ceph 文件系统(CephFS)是一种分布式文件系统,您可以使用 NFS v4 协议(支持)或 CephFS 原生驱动程序与 NFS-Ganesha 一起使用。
1.1.1. 原生CephFS 带有原生驱动程序
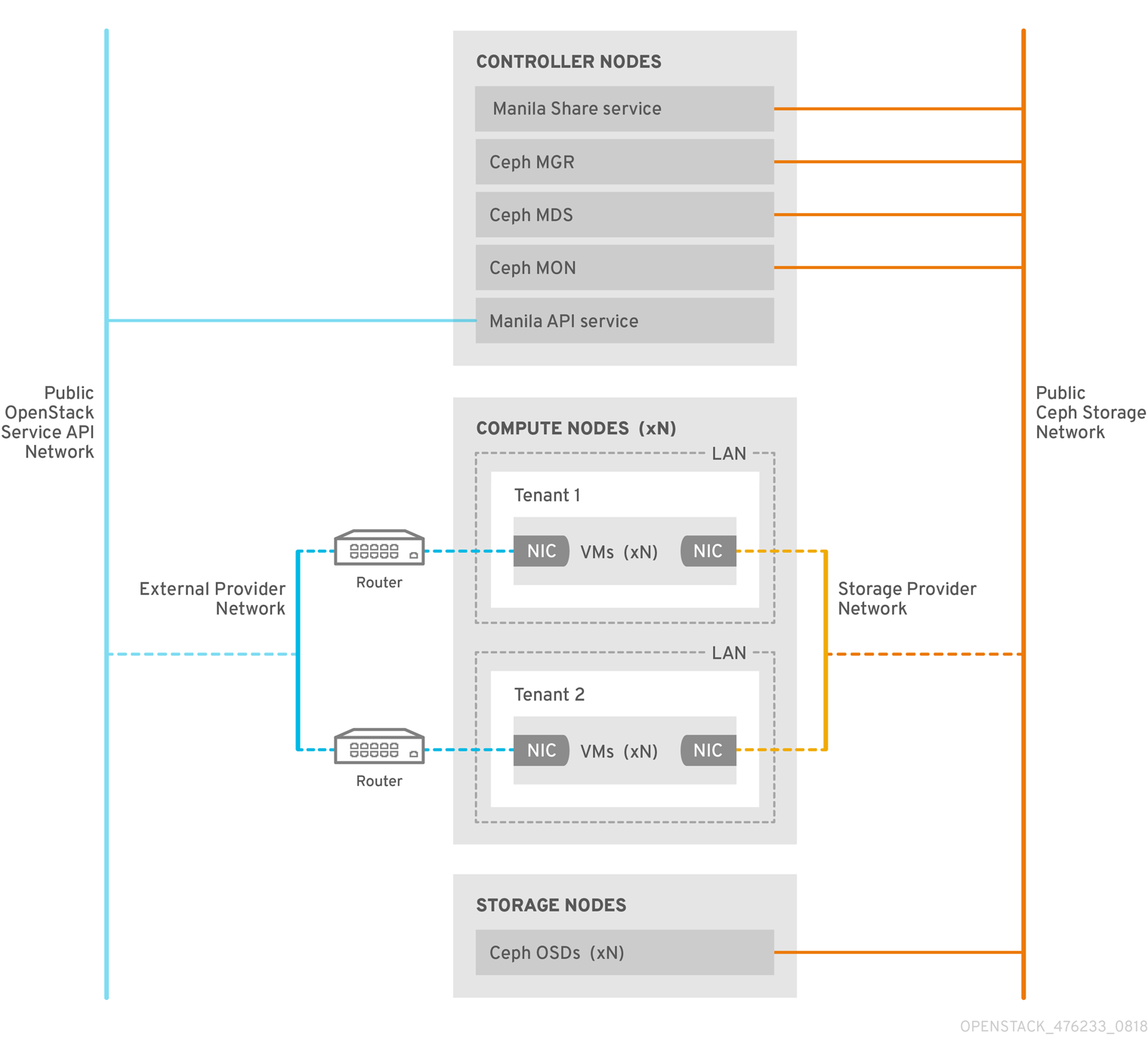
CephFS 原生驱动程序将 OpenStack 共享文件系统服务(manila)和 Red Hat Ceph Storage 结合。使用 Red Hat OpenStack(RHOSP)director 时,Controller 节点托管 Ceph 守护进程,如管理器、元数据服务器(MDS),以及监控(MON)和共享文件系统服务。
Compute 节点可以托管一个或多个项目。项目(以前称为租户)在以下图形中由白色框表示,包含用户管理的虚拟机,由灰色框表示,并带有两个 NIC。若要访问 ceph 和 manila 守护进程项目,可通过公共 Ceph 存储网络连接到守护进程。在这个网络上,您可以访问 Ceph Object Storage Daemon(OSD)提供的存储节点上的数据。在项目引导时托管的实例 (VM) 带有两个 NIC:一个用于存储提供商网络,第二个则专用于外部提供商网络。
存储提供商网络将项目上运行的虚拟机连接到公共 Ceph 存储网络。Ceph 公共网络提供 Ceph 对象存储节点、元数据服务器(MDS)和控制器节点的后端访问。
通过利用原生驱动程序,CephFS 依赖于与客户端和服务器协作来强制实施配额,保证项目隔离和安全性。具有原生驱动程序的 CephFS 可在具有信任最终用户的环境中正常工作。此配置要求在用户控制下运行软件,才能正常工作。
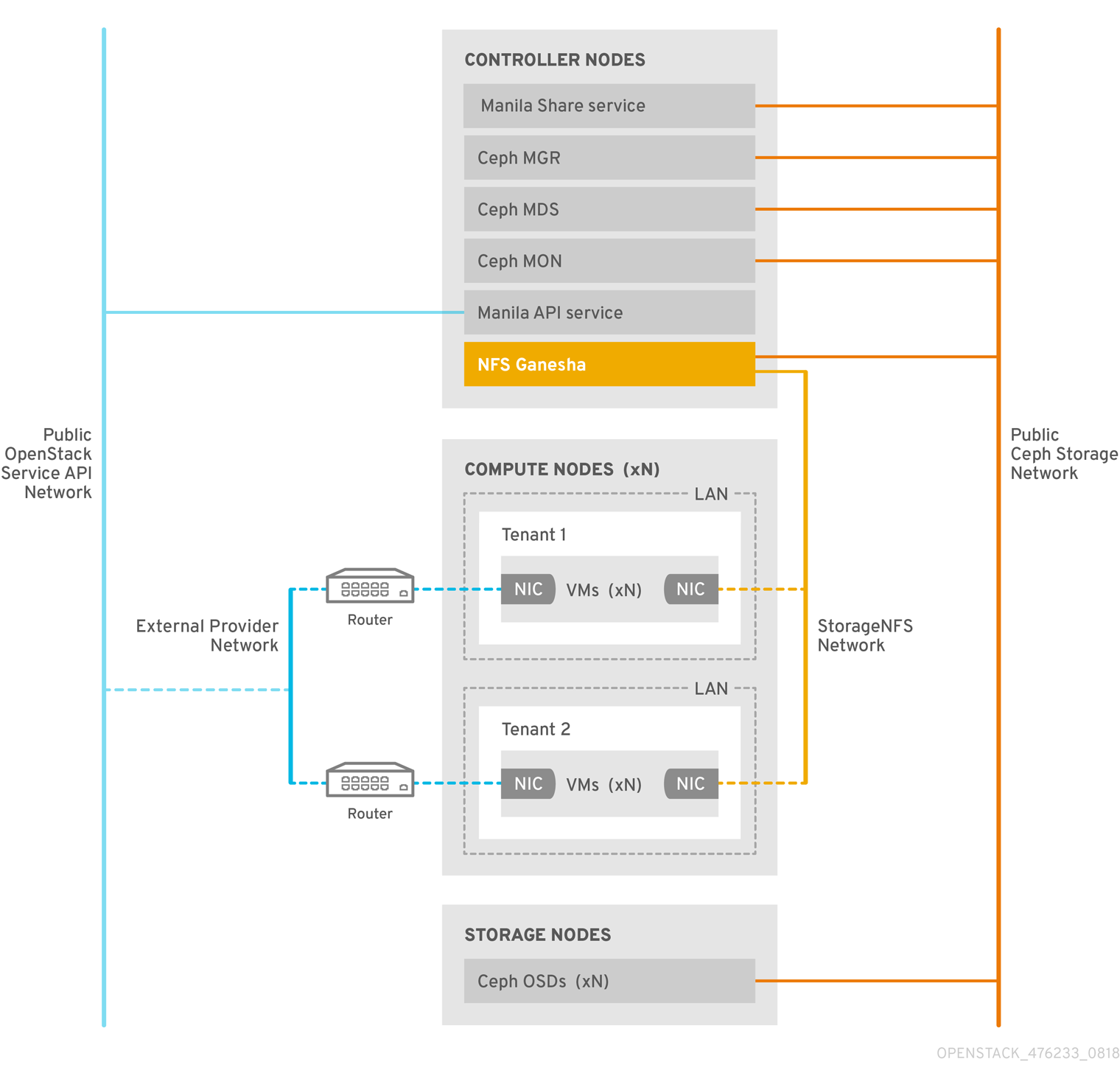
1.1.2. CephFS through NFS
共享文件系统服务(manila)中的 NFS 后端由 Ceph 元数据代理(MDS)、通过 NFS 网关(NFS-Ganesha)和 Ceph 集群服务组件组成的 CephFS。共享文件系统服务 CephFS NFS 驱动程序使用 NFS-Ganesha 网关来提供 CephFS 共享的 NFSv4 协议访问。Ceph MDS 服务将文件系统的目录和文件名称映射到存储在 RADOS 集群中的对象。NFS 网关可以提供与 Ceph 等不同存储后端的 NFS 文件共享。NFS-Ganesha 服务通过 Ceph 服务在 Controller 节点上运行。
实例使用至少两个 NIC 引导:一个 NIC 连接到项目路由器,第二个 NIC 连接到 StorageNFS 网络,后者直接连接到 NFS-Ganesha 网关。实例使用 NFS 协议挂载共享。Ceph OSD 节点上托管的 CephFS 共享通过 NFS 网关提供。
NFS-Ganesha 通过防止用户实例直接访问 MDS 和其他 Ceph 服务来提高安全性。实例无法直接访问 Ceph 守护进程。
ce-client-access-CephFS-architect']
1.1.2.1. Ceph 服务和客户端访问
除了 monitor、OSD、RGW 和 manager 服务在使用 Ceph 提供对象和块存储时,需要 Ceph 元数据服务(MDS)和 NFS-Ganesha 服务作为使用 NFS 协议的原生 CephFS 的网关时。对于面向用户的对象存储,也会部署 RGW 服务。网关运行 CephFS 客户端来访问 Ceph 公共网络,并由管理员而不是最终用户进行控制。
NFS-Ganesha 在自己的容器中运行,它们同时连接到 Ceph 公共网络和新的隔离网络 StorageNFS。Red Hat OpenStack Platform(RHOSP)director 的可组合网络功能会部署这个网络,并将其连接到 Controller 节点。作为云管理员,您可以将网络配置为 Networking(neutron)提供商网络。
NFS-Ganesha 通过 Ceph 公共网络访问 CephFS,并使用 StorageNFS 网络上的地址来绑定其 NFS 服务。
要访问 NFS 共享,请置备用户 VM、Compute(nova)实例,以及一个连接到存储 NFS 网络的额外 NIC。CephFS 共享的导出位置显示为标准 NFS IP:<path> 元组,它们使用 StorageNFS 网络上的 NFS-Ganesha 服务器 VIP。网络使用用户虚拟机的 IP 地址对 NFS 共享执行访问控制。
网络(neutron)安全组阻止属于项目 1 的用户虚拟机访问通过 StorageNFS 属于项目 2 的用户虚拟机。项目共享相同的 CephFS 文件系统,但实施项目数据路径分离,因为用户虚拟机只能访问导出树下的文件:/path/to/share1/…., /path/to/share2/….
1.1.2.2. 通过 NFS 容错使用 CephFS 的共享文件系统服务
当 Red Hat OpenStack Platform(RHOSP)director 启动 Ceph 服务守护进程时,它们管理自己的高可用性(HA)状态。通常情况下,这些守护进程会有多个实例在运行。相反,在这个发行版本中,一个 NFS-Ganesha 实例一次只能提供文件共享。
为避免通过 NFS 共享进行 CephFS 数据路径中的单点故障,NFS-Ganesha 在由 Pacemaker-Corosync 集群管理的主动被动配置中运行在 RHOSP Controller 节点上运行。NFS-Ganesha 使用虚拟服务 IP 地址来跨 Controller 节点充当虚拟服务。
如果一个 Controller 节点失败或者特定 Controller 节点上的服务失败,且无法在那个节点上恢复,Pacemaker-Corosync 会使用同一虚拟 IP 地址在不同的 Controller 节点上启动新的 NFS-Ganesha 实例。保留现有客户端挂载,因为它们使用虚拟 IP 地址进行共享导出位置。
失败后,使用默认 NFS mount-option 设置和 NFS 4.1 或更高版本,并重置 TCP 连接和客户端重新连接。I/O 操作在故障切换过程中临时停止响应,但它们不会失败。应用程序 I/O 也停止响应,但在故障转移完成后恢复。
新的连接、新锁定状态等,直到服务器在达到 90 秒的宽限期后才会被拒绝,直到服务器等待客户端回收其锁定。如果所有客户端都回收其锁定,NFS-Ganesha 保留了客户端列表并提前退出宽限期。
宽限期的默认值为 90 秒。要更改这个值,请编辑 NFSv4 Grace_Period 配置选项。
第 2 章 CephFS through NFS 安装
2.1. 带有 NFS-Ganesha 部署的 CephFS
在 Red Hat OpenStack Platform(RHOSP)环境中通过 NFS 安装的典型 Ceph 文件系统(CephFS)包括以下配置:
- 运行容器化 Ceph 元数据服务器(MDS)、Ceph 监控器(MON)、manila 和 NFS-Ganesha 服务的 OpenStack 控制器节点。其中一些服务可以在同一节点上共存,或者可以有一个或多个专用节点。
- Ceph 存储集群,具有在 Ceph 存储节点上运行的容器化对象存储守护进程(OSD)。
- 隔离存储NFS 网络,从项目提供对 NFS 共享调配的 NFS-Ganesha 服务的访问。
通过 NFS 使用 CephFS 的共享文件系统服务(manila)完全支持通过 Manila CSI 与 Red Hat OpenShift Container Platform 提供服务共享。这个解决方案不适用于大规模部署。有关重要建议,请参阅 https://access.redhat.com/articles/6667651。
共享文件系统服务(manila)提供 API,允许项目请求文件系统共享,由驱动程序模块实现。Red Hat CephFS 的驱动 manila.share.drivers.cephfs.driver.CephFSDriver 代码您可以将共享文件系统服务用作 CephFS 后端。RHOSP director 配置驱动程序来部署 NFS-Ganesha 网关,以便 CephFS 共享通过 NFS 4.1 协议提供。
使用 RHOSP director 使用 overcloud 上的 CephFS 后端部署共享文件系统服务,director 会自动创建 heat 模板中定义的必要存储网络。有关网络规划的更多信息,请参阅 Director 安装和使用 指南中的 Overcloud 网络。
虽然您可以通过编辑其节点 /etc/manila/manila.conf 文件手动配置共享文件系统服务,但 RHOSP director 可以在将来的 overcloud 更新中覆盖任何设置。配置共享文件系统服务后端的建议方法是通过 director。
支持通过 NFS 将 CephFS 添加到外部部署的 Ceph 集群(不是由 Red Hat OpenStack Platform(RHOSP)director 配置)。目前,可以在 director 中定义一个 CephFS 后端。如需更多信息,请参阅 Integrating an Overcloud with an Existing Red Hat Ceph Storage Cluster 指南中的 Integrate with an existing Ceph Storage cluster。
2.1.1. 要求
从 Red Hat OpenStack Platform 版本(RHOSP)13 开始完全支持 CephFS。RHOSP 16.0 通过 NFS 与 CephFS 的 RHOSP 共享文件系统服务支持与 Red Hat Ceph Storage 版本 4.1 或更高版本搭配使用。有关如何确定系统上安装的 Ceph Storage 版本的更多信息,请参阅 Red Hat Ceph Storage 发行版本以及对应的 Ceph 软件包版本。
先决条件
- 您可以在 Controller 节点上安装共享文件系统服务,因为是默认行为。
- 您可以在 Controller 节点的 Pacemaker 集群上安装 NFS-Ganesha 网关服务。
- 您仅配置 CephFS 后端的一个实例,以使用共享文件系统服务。您可以将其他非 CephFS 后端用于单个 CephFS 后端。
- 您可以使用 RHOSP director 为存储流量创建额外的网络(StorageNFS)。
2.1.3. 隔离 CephFS through NFS 使用的网络
CephFS through NFS 对 CephFS 使用额外的隔离网络 StorageNFS。部署此网络以便用户可在该网络上通过 NFS 挂载共享,而无需访问为基础架构流量保留的存储或存储管理网络。
有关隔离网络的更多信息,请参阅 Director 安装和使用指南中的基本网络隔离。
要安装 CephFS through NFS,完成以下步骤:
- 安装 ceph-ansible 软件包。请查看 第 2.2.1 节 “安装 ceph-ansible 软件包”
-
生成自定义角色文件,
role_data.yaml和network_data.yaml文件。请查看 第 2.2.1.1 节 “生成自定义角色文件” -
使用带有自定义角色和环境的
openstack overcloud deploy命令,部署 Ceph、共享文件系统服务(manila)和 CephFS。请查看 第 2.2.2 节 “部署更新的环境” - 配置 isolated StorageNFS 网络并创建默认共享类型。请查看 第 2.2.3 节 “完成部署后配置”
示例在 Red Hat Platform (RHOSP)环境中使用标准 stack 用户。
作为 RHOSP 安装或环境更新的一部分执行任务。
2.2.1. 安装 ceph-ansible 软件包
安装要在 undercloud 节点上安装的 ceph-ansible 软件包,以部署容器化 Ceph。
流程
-
以
stack用户身份登录 undercloud 节点。 安装 ceph-ansible 软件包:
[stack@undercloud-0 ~]$ sudo dnf install -y ceph-ansible [stack@undercloud-0 ~]$ sudo dnf list ceph-ansible ... Installed Packages ceph-ansible.noarch 4.0.23-1.el8cp @rhelosp-ceph-4-tools
2.2.1.1. 生成自定义角色文件
ControllerStorageNFS 自定义角色配置隔离的 StorageNFS 网络。此角色类似于默认的 Controller.yaml 角色文件,它添加了 StorageNFS 网络和 CephNfs 服务,由 OS::TripleO::Services:CephNfs 命令指示。
[stack@undercloud ~]$ cd /usr/share/openstack-tripleo-heat-templates/roles
[stack@undercloud roles]$ diff Controller.yaml ControllerStorageNfs.yaml
16a17
> - StorageNFS
50a45
> - OS::TripleO::Services::CephNfs
如需有关 openstack overcloud roles generate 命令的更多信息,请参阅高级 Overcloud 自定义指南中的角色。
openstack overcloud roles generate 命令创建一个自定义 roles_data.yaml 文件,包括 -o 指定的服务。在以下示例中,创建的 roles_data.yaml 文件具有 ControllerStorageNfs、Compute 和 CephStorage 的服务。
如果您有一个现有的 roles_data.yaml 文件,请修改该文件以将 ControllerStorageNfs、Compute 和 CephStorage 服务添加到配置文件中。有关更多信息,请参阅高级 Overcloud 自定义指南中的角色。
流程
-
以
stack用户身份登录 undercloud 节点, 使用
openstack overcloud roles generate命令创建roles_data.yaml文件:[stack@undercloud ~]$ openstack overcloud roles generate --roles-path /usr/share/openstack-tripleo-heat-templates/roles -o /home/stack/roles_data.yaml ControllerStorageNfs Compute CephStorage
2.2.2. 部署更新的环境
当您准备好部署环境时,请使用 openstack overcloud deploy 命令以及使用 NFS-Ganesha 运行 CephFS 所需的自定义虚拟环境和角色。
overcloud 部署命令除其它所需选项外,还具有以下选项:
| 操作 | 选项 | 附加信息 |
|---|---|---|
|
使用 |
| |
|
添加上一节中的 |
| |
|
使用 |
| Deploying an Overcloud with Containerized Red Hat Ceph 指南中的 Initiating Overcloud Deployment。 |
|
使用 |
| Deploying an Overcloud with Containerized Red Hat Ceph 指南中的 Initiating Overcloud Deployment。 |
| 通过 NFS 后端使用 CephFS 部署共享文件系统服务(manila)服务。使用 director 配置 NFS-Ganesha。 |
|
下例演示了一个 openstack overcloud deploy 命令,带有选项通过 NFS-Ganesha、Ceph 集群、Ceph MDS 和隔离的 StorageNFS 网络部署 CephFS:
[stack@undercloud ~]$ openstack overcloud deploy \
--templates /usr/share/openstack-tripleo-heat-templates \
-n /usr/share/openstack-tripleo-heat-templates/network_data_ganesha.yaml \
-r /home/stack/roles_data.yaml \
-e /home/stack/containers-default-parameters.yaml \
-e /usr/share/openstack-tripleo-heat-templates/environments/network-isolation.yaml \
-e /home/stack/network-environment.yaml \
-e/usr/share/openstack-tripleo-heat-templates/environments/ceph-ansible/ceph-ansible.yaml \
-e /usr/share/openstack-tripleo-heat-templates/environments/ceph-ansible/ceph-mds.yaml \
-e /usr/share/openstack-tripleo-heat-templates/environments/manila-cephfsganesha-config.yaml
有关 openstack overcloud deploy 命令的更多信息,请参阅 Director 安装和使用 指南中的 部署命令。
2.2.2.1. StorageNFS 和 network_data_ganesha.yaml 文件
使用可组合网络定义自定义网络并将其分配到任何角色。您可以使用 network_data_ganesha.yaml 文件配置 StorageNFS 可组合网络,而不使用标准 network_data.yaml 文件。这两个角色都位于 /usr/share/openstack-tripleo-heat-templates 目录中。
network_data_ganesha.yaml 文件包含一个额外部分,用于定义隔离的 StorageNFS 网络。虽然大多数安装都可以的默认设置,但您必须编辑 YAML 文件以添加网络设置,包括 VLAN ID、子网和其他设置。
name: StorageNFS
enabled: true
vip: true
name_lower: storage_nfs
vlan: 70
ip_subnet: '172.17.0.0/20'
allocation_pools: [{'start': '172.17.0.4', 'end': '172.17.0.250'}]
ipv6_subnet: 'fd00:fd00:fd00:7000::/64'
ipv6_allocation_pools: [{'start': 'fd00:fd00:fd00:7000::4', 'end': 'fd00:fd00:fd00:7000::fffe'}]有关可组合网络的更多信息,请参阅高级 Overcloud 自定义指南中的使用可组合网络。
2.2.2.2. CephFS 后端环境文件
用于定义 CephFS 后端 manila-cephfsganesha-config.yaml 的集成式环境文件位于 /usr/share/openstack-tripleo-heat-templates/environments/ 中。
manila-cephfsganesha-config.yaml 环境文件包含与部署共享文件系统服务(manila)相关的设置。后端默认设置可用于大多数环境。以下示例显示了 director 在部署共享文件系统服务过程中使用的默认值:
[stack@undercloud ~]$ cat /usr/share/openstack-tripleo-heat-templates/environments/manila-cephfsganesha-config.yaml
# A Heat environment file which can be used to enable a
# a Manila CephFS-NFS driver backend.
resource_registry:
OS::TripleO::Services::ManilaApi: ../deployment/manila/manila-api-container-puppet.yaml
OS::TripleO::Services::ManilaScheduler: ../deployment/manila/manila-scheduler-container-puppet.yaml
# Only manila-share is pacemaker managed:
OS::TripleO::Services::ManilaShare: ../deployment/manila/manila-share-pacemaker-puppet.yaml
OS::TripleO::Services::ManilaBackendCephFs: ../deployment/manila/manila-backend-cephfs.yaml
# ceph-nfs (ganesha) service is installed and configured by ceph-ansible
# but it's still managed by pacemaker
OS::TripleO::Services::CephNfs: ../deployment/ceph-ansible/ceph-nfs.yaml
parameter_defaults:
ManilaCephFSBackendName: cephfs
ManilaCephFSDriverHandlesShareServers: false
ManilaCephFSCephFSAuthId: 'manila'
ManilaCephFSCephFSEnableSnapshots: false
# manila cephfs driver supports either native cephfs backend - 'CEPHFS'
# (users mount shares directly from ceph cluster), or nfs-ganesha backend -
# 'NFS' (users mount shares through nfs-ganesha server)
ManilaCephFSCephFSProtocolHelperType: 'NFS'
parameter_defaults 标头表示配置的开头。在此部分中,您可以编辑设置来覆盖 resource_registry 中设置的默认值。这包括 OS::Tripleo::Services::Services::ManilaBackendCephFs 设置的值,它为 CephFS 后端设置默认值。
- 1
ManilaCephFSBackendName设置 CephFS 后端的 manila 配置名称。在这种情况下,默认后端名称为cephfs。- 2
ManilaCephFSDriverHandlesShareServers控制共享服务器的生命周期。当设置为false时,驱动程序不会处理生命周期。这是唯一支持的选项。- 3
ManilaCephFSCephFSAuthId定义了 director 为manila服务访问 Ceph 集群而创建的 Ceph 身份验证 ID。- 4
ManilaCephFSEnableSnapshots控制快照激活。false值表示没有启用快照。当前不支持这个功能。
有关环境文件的更多信息,请参阅 Director 安装和使用指南中的环境文件。
2.2.3. 完成部署后配置
在创建 NFS 共享、授予用户访问权限和挂载 NFS 共享之前,您必须完成两个部署后配置任务。
- 将网络服务(neutron)StorageNFS 网络映射到隔离的数据中心存储 NFS 网络。
- 创建默认共享类型。
完成这些步骤后,租户计算实例可以创建、允许访问和挂载 NFS 共享。
2.2.3.1. 创建存储提供商网络
将新隔离存储NFS 网络映射到网络(neutron)提供商网络。Compute 虚拟机附加到网络,以访问由 NFS-Ganesha 网关提供的共享导出位置。
有关使用共享文件系统服务的网络安全性 ,请参阅安全和强化指南中的强化共享文件系统服务。
流程
openstack network create 命令定义 StorageNFS neutron 网络的配置。
在 undercloud 节点上输入以下命令:
[stack@undercloud ~]$ source ~/overcloudrc在 undercloud 节点上,创建 StorageNFS 网络:
(overcloud) [stack@undercloud-0 ~]$ openstack network create StorageNFS --share --provider-network-type vlan --provider-physical-network datacentre --provider-segment 70您可以使用以下选项输入这个命令:
-
对于
--provider-physical-network选项,使用默认值datacentre,除非您通过 tripleo-heat-templates 中的 NeutronBridgeMappings 为 br-isolated 网桥设置了另一个标签。 -
对于
--provider-segment选项,在 heat 模板中为 StorageNFS 隔离网络设置的 VLAN 值/usr/share/openstack-tripleo-heat-templates/network_data_ganesha.yaml。此值为 70,除非部署者修改了隔离的网络定义。 -
对于
--provider-network-type选项,请使用值vlan。
-
对于
2.2.3.2. 配置共享供应商 StorageNFS 网络
在 neutron-shared 提供商网络上创建对应的 StorageNFSSubnet。确保子网与 network_data.yml 文件中的 storage_nfs 网络定义相同,并确保 StorageNFS 子网的分配范围不会重叠。不需要网关,因为 StorageNFS 子网专用于提供 NFS 共享。
先决条件
- 分配池的开头和结束 IP 范围。
- 子网 IP 范围。
第 3 章 通过 NFS 部署验证 CephFS 是否成功
当您通过 NFS 部署 CephFS 作为共享文件系统服务(manila)的后端时,您将以下新元素添加到 overcloud 环境中:
- StorageNFS 网络
- 控制器上的 Ceph MDS 服务
- 控制器上的 NFS-Ganesha 服务
有关使用 CephFS through NFS 的共享文件系统服务的更多信息,请参阅存储指南中的共享文件系统服务。
作为云管理员,您必须通过 NFS 环境验证 CephFS 的稳定性,然后才能供服务用户使用。
3.1. 验证隔离存储NFS 网络的创建
network_data_ganesha.yaml 文件用于将 CephFS 作为共享文件系统服务后端部署,以创建 StorageNFS VLAN。完成以下步骤以验证隔离存储NFS 网络是否存在。
前提条件
- 完成 第 2 章 CephFS through NFS 安装 中的步骤
流程
- 登录 overcloud 中的一个控制器。
输入以下命令检查连接的网络,并验证
network_data_ganesha.yaml中设置的 VLAN 存在:$ ip a 15: vlan310: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UNKNOWN group default qlen 1000 link/ether 32:80:cf:0e:11:ca brd ff:ff:ff:ff:ff:ff inet 172.16.4.4/24 brd 172.16.4.255 scope global vlan310 valid_lft forever preferred_lft forever inet 172.16.4.7/32 brd 172.16.4.255 scope global vlan310 valid_lft forever preferred_lft forever inet6 fe80::3080:cfff:fe0e:11ca/64 scope link valid_lft forever preferred_lft forever
3.2. 验证 Ceph MDS 服务
使用 systemctl status 命令验证 Ceph MDS 服务状态。
流程
在所有 Controller 节点上输入以下命令来检查 MDS 容器的状态:
$ systemctl status ceph-mds<@CONTROLLER-HOST>例如:
$ systemctl status ceph-mds@controller-0.service
ceph-mds@controller-0.service - Ceph MDS
Loaded: loaded (/etc/systemd/system/ceph-mds@.service; enabled; vendor preset: disabled)
Active: active (running) since Tue 2018-09-18 20:11:53 UTC; 6 days ago
Main PID: 65066 (conmon)
Tasks: 16 (limit: 204320)
Memory: 38.2M
CGroup: /system.slice/system-ceph\x2dmds.slice/ceph-mds@controller-0.service
└─60921 /usr/bin/podman run --rm --net=host --memory=32000m --cpus=4 -v
/var/lib/ceph:/var/lib/ceph:z -v /etc/ceph:/etc/ceph:z -v
/var/run/ceph:/var/run/ceph:z -v /etc/localtime:/etc/localtime:ro>3.3. 验证 Ceph 集群状态
完成以下步骤以验证 Ceph 集群状态。
流程
- 登录到活跃的 Controller 节点。
使用以下命令:
$ sudo ceph -s cluster: id: 3369e280-7578-11e8-8ef3-801844eeec7c health: HEALTH_OK services: mon: 3 daemons, quorum overcloud-controller-1,overcloud-controller-2,overcloud-controller-0 mgr: overcloud-controller-1(active), standbys: overcloud-controller-2, overcloud-controller-0 mds: cephfs-1/1/1 up {0=overcloud-controller-0=up:active}, 2 up:standby osd: 6 osds: 6 up, 6 in- 结果
- 有一个活跃 MDS,备用上有两个 MDS。
要更详细地检查 Ceph 文件系统的状态,请输入以下命令,并将
<cephfs>替换为 Ceph 文件系统的名称:$ sudo ceph fs ls name: cephfs, metadata pool: manila_metadata, data pools: [manila_data]
3.5. 验证 manila-api 服务确认调度程序和共享服务
完成以下步骤以确认 manila-api 服务确认调度程序和共享服务。
流程
- 登录 undercloud。
使用以下命令:
$ source /home/stack/overcloudrc输入以下命令确认启用了
manila-scheduler和manila-share:$ manila service-list | Id | Binary | Host | Zone | Status | State | Updated_at | | 2 | manila-scheduler | hostgroup | nova | enabled | up | 2018-08-08T04:15:03.000000 | | 5 | manila-share | hostgroup@cephfs | nova | enabled | up | 2018-08-08T04:15:03.000000 |