This documentation is for a release that is no longer maintained
See documentation for the latest supported version 3 or the latest supported version 4.4.5. 使用 Node Tuning Operator
了解 Node Tuning Operator,以及如何使用它通过编排 tuned 守护进程以管理节点级别的性能优化。
4.5.1. 关于 Node Tuning Operator
Node Tuning Operator 可以帮助您通过编排 tuned 守护进程来管理节点级别的性能优化。大多数高性能应用程序都需要一定程度的内核级性能优化。Node Tuning Operator 为用户提供了一个统一的、节点一级的 sysctl 管理接口,并可以根据具体用户的需要灵活地添加自定义性能优化设置。Node Tuning Operator 把为 OpenShift Container Platform 容器化的 tuned 守护进程作为一个 Kubernetes DaemonSet 进行管理。它保证了自定义性能优化设置以可被守护进程支持的格式传递到在集群中运行的所有容器化的 tuned 守护进程中。相应的守护进程会在集群的所有节点上运行,每个节点上运行一个。
在发生触发配置集更改的事件时,或通过接收和处理终止信号安全终止容器化 tuned 守护进程时,容器化 tuned 守护进程所应用的节点级设置将被回滚。
在版本 4.1 及更高版本中,OpenShift Container Platform 标准安装中包含了 Node Tuning Operator。
4.5.2. 访问 Node Tuning Operator 示例规格
使用此流程来访问 Node Tuning Operator 的示例规格。
流程
运行:
oc get Tuned/default -o yaml -n openshift-cluster-node-tuning-operator
$ oc get Tuned/default -o yaml -n openshift-cluster-node-tuning-operatorCopy to Clipboard Copied! Toggle word wrap Toggle overflow
请注意,默认 CR 应用来为 OpenShift Container Platform 平台提供标准的节点级性能优化,而任何对默认 CR 的自定义更改都会被 Operator 覆盖。若进行自定义性能优化,请创建自己的 tuned CR。新创建的 CR 将与默认 CR 合并,并基于节点/pod 标签和配置集优先级对 OpenShift Container Platform 节点应用自定义性能优化。
4.5.3. 自定义性能优化规格
Operator 的自定义资源 (CR) 包含两个主要部分。第一部分是 profile:,这是 tuned 配置集及其名称的列表。第二部分是 recommend:,用来定义配置集选择逻辑。
多个自定义调优规格可以共存,作为 Operator 命名空间中的多个 CR。Operator 会检测到是否存在新 CR 或删除了旧 CR。所有现有的自定义性能优化设置都会合并,同时更新容器化 tuned 守护进程的适当对象。
配置集数据
profile: 部分列出了 tuned 配置集及其名称。
建议的配置集
profile: 选择逻辑通过 CR 的 recommend: 部分来定义:
如果省略 <match>,则假定配置集匹配(如 true)。
<match> 是一个递归定义的可选数组,如下所示:
- label: <label_name> # node or pod label name
value: <label_value> # optional node or pod label value; if omitted, the presence of <label_name> is enough to match
type: <label_type> # optional node or pod type ("node" or "pod"); if omitted, "node" is assumed
<match> # an optional <match> array
- label: <label_name> # node or pod label name
value: <label_value> # optional node or pod label value; if omitted, the presence of <label_name> is enough to match
type: <label_type> # optional node or pod type ("node" or "pod"); if omitted, "node" is assumed
<match> # an optional <match> array
如果不省略 <match>,则所有嵌套的 <match> 部分也必须评估为 true。否则会假定 false,并且不会应用或建议具有对应 <match> 部分的配置集。因此,嵌套(子级 <match> 部分)会以逻辑 AND 运算来运作。反之,如果匹配 <match> 数组中任何一项,整个 <match> 数组评估为 true。因此,该数组以逻辑 OR 运算来运作。
示例
根据配置集优先级,以上 CR 针对容器化 tuned 守护进程转换为 recommend.conf 文件。优先级最高 (10) 的配置集是 openshift-control-plane-es,因此会首先考虑它。在给定节点上运行的容器化 tuned 守护进程会查看同一节点上是否在运行设有 tuned.openshift.io/elasticsearch 标签的 pod。如果没有,则整个 <match> 部分评估为 false。如果存在具有该标签的 pod,为了让 <match> 部分评估为 true,节点标签也需要是 node-role.kubernetes.io/master 或 node-role.kubernetes.io/infra。
如果这些标签对优先级为 10 的配置集而言匹配,则应用 openshift-control-plane-es 配置集,并且不考虑其他配置集。如果节点/pod 标签组合不匹配,则考虑优先级第二高的配置集 (openshift-control-plane)。如果容器化 tuned pod 在具有标签 node-role.kubernetes.io/master 或 node-role.kubernetes.io/infra 的节点上运行,则应用此配置集。
最后,配置集 openshift-node 的优先级最低 (30)。它没有 <match> 部分,因此始终匹配。如果给定节点上不匹配任何优先级更高的配置集,它会作为一个适用于所有节点的配置集来设置 openshift-node 配置集。
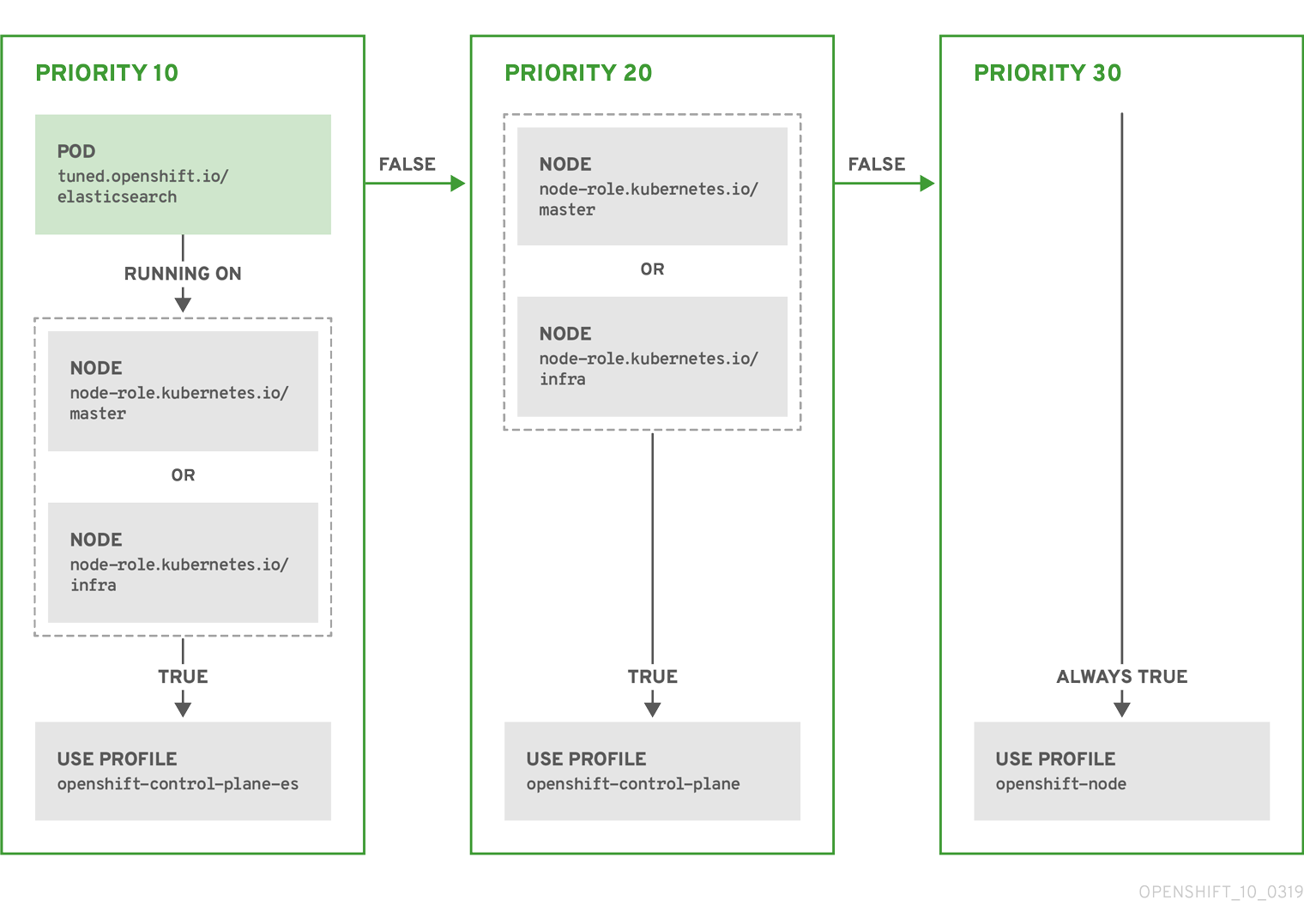
4.5.4. 在集群中设置默认配置集
以下是在集群中设置的默认配置集。
4.5.5. 支持的 Tuned 守护进程插件
在使用 Tuned CR 的 profile: 部分中定义的自定义配置集时,以下 Tuned 插件都受到支持,但 [main] 部分除外:
- audio
- cpu
- disk
- eeepc_she
- modules
- mounts
- net
- scheduler
- scsi_host
- selinux
- sysctl
- sysfs
- usb
- video
- vm
其中一些插件提供了不受支持的动态性能优化功能。以下 Tuned 插件目前还不支持:
- bootloader
- script
- systemd
如需更多信息,请参阅可用的 Tuned 插件和 Tuned 入门。