此内容没有您所选择的语言版本。
Chapter 5. High availability
5.1. High availability overview
The term high availability refers to a system that is capable of remaining operational, even when part of that system fails or is taken offline. With Broker on OCP, specifically, HA refers to both maintaining the availability of brokers and the integrity of the messaging data if a broker fails.
In an HA configuration on AMQ Broker on OpenShift Container Platform, you run multiple instances of a broker pod simultaneously. Each individual broker pod writes its message data to a persistent volume (PVs), which logically define the storage volumes in the system. If a broker pod fails or is taken offline, the message data stored in that PV is redistributed to an alternative available broker, which then stores it in its own PV.
Figure 5.1. StatefulSet working normally
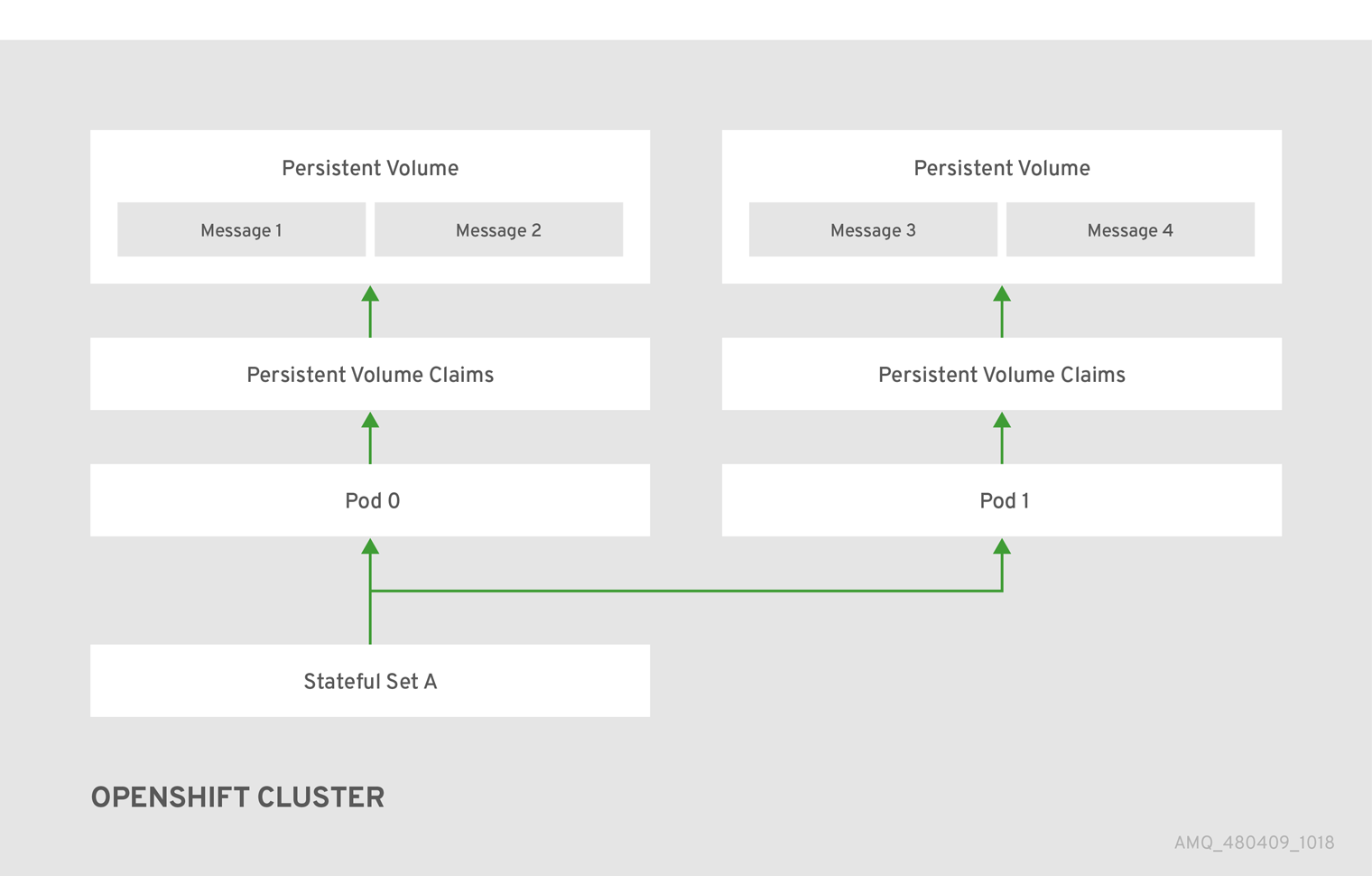
When you take a broker pod offline, the StatefulSet is scaled down and you must manage what happens to the message data in the unattached PV. To migrate the messages held in the PV associated with the now-offline pod, you use the scaledown controller. The process of migrating message data in this fashion is sometimes referred to as pod draining.
5.2. Message migration
5.2.1. Message migration overview
Message migration is how you ensure the integrity of messaging data when a broker in a clustered deployment shuts down due to failure or intentional scaledown of the deployment. Message migration, which uses a method called Pod draining, refers to the removal and redistribution of "orphaned" messages from the persistent volume used by the broker to store messaging data. With message migration enabled, the scaledown controller, which is part of the AMQ Broker Operator, detects shutdown of any broker Pods in your deployment. The scaledown controller starts a dedicated drainer Pod for each broker Pod that is shut down, to prepare for message migration. Each drainer Pod connects to one of the remaining live broker Pods in the cluster and migrates messages over to that live broker Pod. After migration is complete, each drainer Pod shuts down. Persistent volumes previously used by running brokers are returned to a "Released" state.
The scaledown controller within the AMQ Broker Operator can operate only within a single OpenShift project. The controller cannot migrate messages between brokers in separate projects.
If you scale a broker deployment down to 0 (zero), message migration does not occur, since there is no running broker Pod to which the messaging data can be migrated. However, if you scale a deployment down to zero brokers and then back up to only some of the brokers that were in the original deployment, drainer Pods are started for the brokers that remain shut down.
5.2.1.1. How does message migration work?
When you enable message migration in a broker deployment created using the AMQ Broker Operator, a scaledown controller is started by the Operator within the same project namespace as the broker Pods.
The scaledown controller registers itself and listens for Kubernetes events that are related to persistent volume claims (PVCs) in the project namespace.
The scaledown controller checks for PVCs that have been orphaned by looking at the ordinal on the volume claim. The ordinal on the volume claim is compared to the ordinal on the existing broker Pods, which are part of the StatefulSet in the project namespace.
If the ordinal on the volume claim is greater than the ordinal on the existing broker Pods, then the Pod at that ordinal has been terminated and the data must be migrated to another broker.
When these conditions are met, a drainer Pod is started. The drainer Pod runs the broker and executes the message migration. Then, the drainer Pod identifies an alternative broker Pod to which the orphaned PVC messages can be migrated.
There must be at least one broker Pod still running in your deployment for message migration to occur.
Figure 5.2. The scaledown controller registers itself, deletes the PVC, and redistributes messages on the persistent volume.
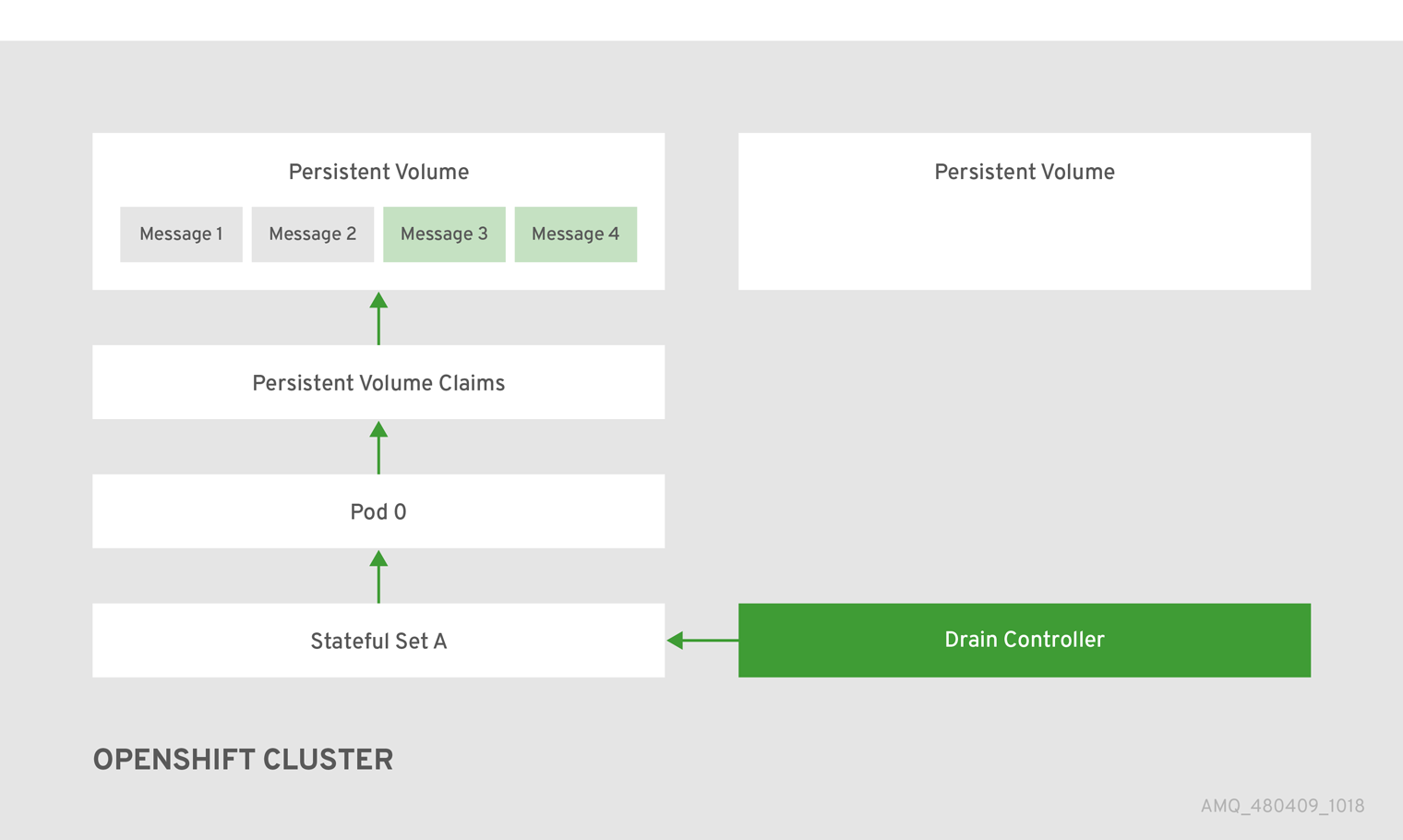
After the messages are successfully migrated to an operational broker Pod, the drainer Pod shuts down and the scaledown controller removes the orphaned PVC. The persistent volume is returned to a "Released" state.
Additional resources
- For an example of message migration when you scale down a broker deployment, see Migrating Messages Upon Scaledown.