部署指南
使开源更具 Incsive
前言
1. 目录服务器概述
- 多supplier 复制 - 为读写操作提供高度可用的目录服务。多层复制可与简单级联复制结合使用,以提供高度灵活且可扩展的复制环境。
- 链和引用 - 通过在单个服务器上存储目录的完整逻辑视图,并透明地在大量目录服务器上维护数据,从而增加该目录的威力。
- 角色和服务类 - 提供灵活的机制,用于在条目之间动态分组和共享属性。
- 有效的访问控制机制 - 提供对宏的支持,大大减少了目录中使用的访问控制声明数量,并提高访问控制评估的可扩展性。
- 通过绑定 DN 来实现资源限制 - 根据客户端的绑定 DN 控制分配给搜索操作的服务器资源量。
- 多数据库 - 提供划分目录数据的简单方法,以简化在目录服务中的复制和锁实施。
- 密码策略和帐户锁定 - 定义一组规则,规定了管理目录服务器中如何管理密码和用户帐户的规则。
- TLS 通过网络提供安全身份验证和通信,使用 Mozilla Network Security Services (NSS) 库进行加密。
- LDAP 服务器 - LDAP v3 兼容网络守护进程。
- Web 控制台 - 图形化管理控制台,用于减少设置和维护目录服务的努力。
- SNMP 代理 - 可使用简单网络管理协议(SNMP)监控目录服务器。
第 1 章 目录服务简介
1.1. 关于目录服务
- 物理设备(如组织内打印机)的信息,,如位置、彩色还是黑白、制造商、购买日期和序列号。
- 公共员工信息,如姓名、电子邮件地址和部门。
- 员工的个人信息,如工资、政府身份证明的标识号、主页地址、电话号码和工资级别。
- 合同或帐户信息,如客户端名称、最终交付日期、投标信息、合同号和项目日期。
1.1.1. 关于全局目录服务
1.1.2. 关于 LDAP
1.2. Directory 服务器简介
- 核心目录服务器 LDAP 服务器、LDAP v3 兼容网络守护进程(ns-slapd)以及所有相关插件、用于管理服务器及其数据库的命令行工具,及其配置和模式文件。有关命令行工具的更多信息,请参阅 红帽目录服务器配置、命令和文件参考。
- 管理服务器,一种控制访问 LDAP 服务器的不同门户的 Web 服务器。有关管理服务器的更多信息,请参阅 红帽目录服务器管理指南。
- Web 控制台是一种图形化管理控制台,用于减少设置和维护目录服务的努力。有关 Web 控制台的更多信息,请参阅 红帽目录服务器管理指南。
- SNMP 代理使用简单网络管理协议 (SNMP) 监控目录服务器。有关 SNMP 监控的更多信息,请参阅 红帽目录服务器管理指南。
1.2.1. 服务器前端概述
1.2.2. 服务器端概述
1.2.3. 基本目录树概述
图 1.1. 默认目录服务器目录树的布局

- cn=config,包含服务器内部配置信息的子树。
- cn=monitor,包含目录服务器服务器和数据库监控统计信息的子树。
- cn=schema,包含服务器中当前载入的 schema 元素的子树。
- user_suffix,设置 Directory 服务器时创建的默认用户数据库的后缀。后缀的名称在服务器创建时由用户定义;关联的数据库的名称为 userRoot。可以通过设置时导入 LDIF 文件或条目来填充该数据库。user_suffix 后缀经常具有
dc命名约定,如 dc=example,dc=com。另一个常见的 naming 属性是o属性,用于整个组织,如 o=example.com。
图 1.2. 扩展 Example Corp 的 Directory 树.

1.3. 目录服务器数据存储
1.3.1. 关于目录条目
givenname 和 telephoneNumber 属性。分配给这些属性的值提供了条目所代表的人的名称和电话号码。
1.3.1.1. 对目录尝试执行查询
1.3.2. 分发目录数据
1.4. 目录设计概述
1.4.1. 设计过程概述
- 目录包含诸如用户名、电话号码和组详情等数据。本章分析机构中各种数据源,并了解它们的相互关系。它描述了可以在目录中存储的数据类型和其他要执行的任务,以设计目录服务器的内容。
- 目录旨在支持一个或多个启用了目录的应用程序。这些应用对存储在 目录中的数据的要求,如文件格式。目录架构决定了 目录中存储的数据的特征。目录服务器附带的标准架构在本章中引入,并介绍了如何定制架构的模式和提示,以维护一致性模式。
- 除了确定目录服务器中要包含哪些信息外,还需要确定如何组织和使用这些信息。本章介绍了目录树,并概述数据层次结构的设计。也提供了示例目录树设计。
- 拓扑设计意味着目录树如何划分到多个物理目录服务器以及这些服务器如何与另一个服务器进行通信。设计的一般原则是,使用多个数据库,并使用一个有效的机制将分布式数据连接在一起。目录本身如何跟踪分布式数据的信息将在本章中阐述。
- 使用复制时,多个目录服务器维护相同的目录数据,以提高性能并提供容错功能。本章论述了复制如何工作,即可以复制哪些数据类型、通用复制方案以及构建高可用性目录服务的提示。
- 红帽目录服务器中存储的信息可以通过与 Microsoft Active Directory 数据库中存储的信息同步,从而更好地与混合平台基础架构集成。本章论述了同步工作方式、什么数据可以同步,数据类型以及在目录数中的位置以适合于同步。
- 最后,计划如何保护目录中的数据并设计服务的其他方面,以满足用户和应用程序的安全要求。本章论述了常见的安全威胁、安全方法概述、分析安全需求过程中涉及的步骤,以及设计访问控制和保护目录数据完整性的建议。
1.4.2. 部署目录
- 所需资源的估算
- 计划需要完成的内容,以及时间
- 一组用于衡量部署是否成功的条件
1.5. 其他常规目录资源
- RFC 2849:LDAP 数据交换格式(LDIF)技术规格, http://www.ietf.org/rfc/rfc2849.txt
- RFC 2251:轻量级目录访问协议(v3), http://www.ietf.org/rfc/rfc2251.txt
- 了解和部署 LDAP 目录服务.T. Howes, M. Smith, G. am, Macmillan Technical Publishing, 1999.
第 2 章 规划目录数据
2.1. 目录数据简介
- 它比写入更频繁。
- 这涉及到多个人或组。例如,许多人和应用程序都需要员工的名称或打印机的物理位置的信息。
- 它将从多个物理位置访问。
2.1.1. 目录中包含的信息
- 联系信息,如电话号码、物理地址和电子邮件地址。
- 描述性信息,如员工号码、工作标题、经理或管理员识别以及与作业相关的兴趣。
- 组织联系信息,如电话号码、物理地址、管理员标识和业务描述。
- 设备信息,如打印机物理位置、打印机类型以及打印机每分钟可以打印的页数。
- 有关公司交易合作伙伴、客户以及客户的联系和账单信息。
- 合同信息,如客户姓名、到期日期、工作说明和定价信息。
- 个人的软件首选项或软件配置信息。
- 资源站点,如指向 Web 服务器或特定文件或应用程序的文件系统。
- 合同或客户端帐户详情
- 工资数据
- 物理设备信息
- 主页联系信息
- 企业内不同站点的办公室联系信息
2.1.2. 从目录中排除的信息
2.2. 定义目录需求
- 现在应该把什么放置到目录中?
- 部署目录可解决哪些即时问题?
- 使用启用目录的应用程序的即时需求是什么?
- 在不久的将来,哪些信息会添加到目录中?例如,企业可能会使用目前不支持 LDAP 且在几个月内启用 LDAP 的核算软件包。识别 LDAP 兼容应用程序使用的数据,并在可行时计划将数据迁移到目录中。
- 将来可以将哪些信息保存在目录中?例如,托管公司可能使未来的客户与当前客户不同的数据要求,比如需要存储镜像或介质文件。虽然对未来的预测比较困难,但这可能会为您带来意外的好处。至少,这种计划有助于识别尚未考虑的数据源。
2.3. 执行站点问卷调查
- 识别使用目录的应用程序。确定跨企业部署的目录应用程序及其数据需求。
- 识别数据源。调查企业并识别数据来源,如 Active Directory、其他 LDAP 服务器、PBX 系统、人工资源数据库和电子邮件系统。
- 对目录需要包含的数据进行定性。确定目录中应包括哪些对象(例如,人员或组)以及这些对象在目录中要维护哪些属性(如用户名和密码)。
- 确定要提供的服务级别。决定目录数据可用如何成为客户端应用程序,并相应地设计架构。要如何复制数据,以及将链策略配置为连接存储在远程服务器上的数据,从而如何影响复制数据。有关复制的信息,请参阅 第 7 章 设计复制过程,有关链的信息,请参阅 第 6.1 节 “拓扑概述”。
- 识别数据供应商.数据供应商包含目录数据的主源。此数据可能会镜像到其他服务器,以进行负载平衡和恢复。对于每个数据,确定其数据的来源。
- 确定数据所有权。对于每个数据,确定负责确保数据最新状态的人员。
- 确定数据访问。如果数据从其他来源导入,为批量导入和增量更新制订相关策略。作为此策略的一部分,尝试在单个位置管理数据,并且限制可以更改数据的应用程序数量。另外,限制写入任何给定数据的人员数量。较小的组可确保数据完整性,同时减少管理开销。
- 记录网站调查。
2.3.1. 确定使用目录的应用程序
- 目录浏览器应用程序,如在线笔记本电脑。确定用户需要哪些信息(如电子邮件地址、电话号码和员工名称),并将其包含在目录中。
- 电子邮件应用程序,特别是电子邮件服务器.所有电子邮件服务器都需要在目录中提供电子邮件地址、用户名和一些路由信息。其他系统可能还需要更高级的信息,如存储用户的邮箱数据、假期通知信息和协议信息(例如,IMAP 和 POP)等在磁盘中的位置。
- 启用目录的人工资源应用程序.这需要更多个人信息,如政府身份标识号、家地址、家电话号码、出生日期、短文和职务。
- Microsoft Active Directory.通过 Windows User Sync,Windows 目录服务可以集成以与 Directory Server 配合使用。这两个目录都可以存储用户信息(用户名和密码、电子邮件地址、电话号码)和组信息(成员)。在现有 Windows 服务器部署后(反之亦然),使目录服务器数据可以平稳同步。
| Application(应用程序) | 数据类别 | data |
|---|---|---|
| 电话 | 人员 | 名称、电子邮件地址、电话号码、用户 ID、密码、部门号码、经理、邮件停止. |
| Web 服务器 | 人员、组 | 用户 ID、密码、组名称、组成员、组所有者。 |
| 日历服务器 | 人员、会议室 | 名称、用户 ID、已用数字、会议室名称。 |
- 各种传统应用程序和用户所需的数据
- 传统应用程序与 LDAP 目录通信的功能
2.3.2. 识别数据源
- 识别提供信息的机构。找到管理企业信息的所有组织。通常,这包括信息服务、人类资源、注册和会计部门。
- 识别作为信息源的工具和流程。某些信息的常见来源包括网络操作系统(Windows、Novell Netware、UNIX NIS)、电子邮件系统、安全系统、PBX(交换)系统和人类资源应用程序。
- 确定对数据进行中央化如何影响数据管理。集中式数据管理可能需要新的工具和新流程。对于一些机构,中央化可能需要增加员工,而对于其他一些机构,则可能会减少员工。
| 数据源 | 数据类别 | data |
|---|---|---|
| 人员资源数据库 | 人员 | 名称、地址、电话号码、部门号码、经理。 |
| 电子邮件系统 | 人员、组 | 名称、电子邮件地址、用户 ID、密码、电子邮件首选项. |
| 设施系统 | 设施 | 构建名称、指纹、现有数字、访问代码。 |
2.3.3. 为目录数据定性
- 格式
- 大小
- 各种应用程序中发生次数
- 数据所有者
- 与其它目录数据的关系
| data | 格式 | 大小 | 所有者 | 相关 |
|---|---|---|---|---|
| 员工名称 | 文本字符串 | 128 个字符 | 人员资源 | 用户条目 |
| 传真号 | 电话号码 | 14 个数字 | 设施 | 用户条目 |
| 电子邮件地址 | 文本 | 多个字符 | IS 部门 | 用户条目 |
2.3.4. 确定的服务质量等级
2.3.5. 考虑数据供应商
- 在目录服务器间复制
- Directory 服务器和 Active Directory 之间的同步
- 用于访问目录服务器数据的独立客户端应用程序
- 管理目录以及不使用目录的所有应用程序中的数据。维护多个数据供应商不需要自定义脚本在目录和其他应用程序中移动数据。但是,如果数据在一个位置更改,则人员必须在所有其他站点上进行更改。在目录中维护供应商数据以及所有不使用目录的应用程序都可能会导致数据在整个企业中无同步(这是应该阻止的目录是什么)。
- 在目录以外的一些应用程序中管理数据,然后编写脚本、程序或网关来将该数据导入到目录中。在非目录应用程序中管理数据时,如果两个应用程序已经用于管理数据,并且目录将仅用于查找(例如,在线企业电话书)。
2.3.6. 确定数据所有权
- 允许任何人对该目录的只读访问,但一组小的目录内容管理器除外。
- 允许个人用户自己管理某些战略性信息子集。此信息子集可能包括他们的密码、描述自身及其在机构内的角色信息、其自主权许可证的数量以及联系信息,如电话号码或办公室号码。
- 允许个人经理写入该人员信息的一些战略性子集,如联系信息或职位。
- 允许机构管理员创建和管理该组织的条目。这种方法允许组织管理员作为目录内容管理器运行。
- 创建赋予用户读取或写入访问权限组的角色。例如,可以为人工资源、财务或核算创建角色。允许这些角色具有读取访问权限、写入访问权限或这两个角色对组需要的数据具有读访问权限。这可包括工资信息、政府标识号以及主页电话号码和地址。有关角色和分组条目的更多信息,请参阅 第 4.3 节 “分组目录条目”。
2.3.7. 确定数据访问
- 数据是否匿名读取?LDAP 协议支持匿名访问,并允许轻松查找常见信息,如办公室站点、电子邮件地址和业务电话号码。但是,匿名访问可让任何人访问目录访问通用信息。因此,请小心使用匿名访问。
- 数据是否可以跨企业广泛读取?可以设置访问控制,使客户端必须登录(或绑定到)目录才能读取特定信息。与匿名访问不同,这种形式的访问控制可确保只有机构的成员可以查看目录信息。它还捕获目录访问日志中的登录信息,因此有记录谁访问信息。有关访问控制的更多信息,请参阅 第 9.7 节 “设计访问控制”。
- 是否存在一组需要读取数据的人员或应用程序的可识别组?对数据具有写入权限的用户通常需要读访问权限(具有密码的写入访问权限除外)。还可能有特定于特定组织或项目组的数据。识别这些访问权限需要有助于确定哪些组、角色和访问控制。有关组和主机的详情,请参考 第 4 章 设计目录树。有关访问控制的详情请参考 第 9.7 节 “设计访问控制”。
2.4. 记录网站调查
| 数据名称 | 所有者 | 供应商服务器/应用程序 | 自助读取/写 | 全局读 | HR Writable | IS Writable |
|---|---|---|---|---|---|---|
| 员工名称 | HR | PeopleSoft | 只读 | 是(匿名) | 是 | 是 |
| 用户密码 | IS | Directory US-1 | 读/写 | 否 | 否 | 是 |
| 主页电话号码 | HR | PeopleSoft | 读/写 | 否 | 是 | 否 |
| 员工位置 | IS | Directory US-1 | 只读 | 是(必须登录) | 否 | 是 |
| 办公室电话号码 | 设施 | 电话交换机 | 只读 | 是(匿名) | 否 | 否 |
- Owner。人类资源拥有此信息,因此负责更新和更改。
- Supplier Server/Application。PeopleSoft 应用程序管理员工名称信息。
- Self Read/Write。个人可以读取自己的名称,但不能对它进行写(或更改)。
- Global Read。员工名称可以被有权访问该目录的任何人匿名读取。
- HR Writable.人员资源组成员可能会更改、添加和删除目录中的员工名称。
- IS 可写.information services 组的成员可在 目录中更改、添加和删除员工名称。
2.5. 重复站点问卷调查
第 3 章 设计目录架构
3.1. 模式设计过程概述
- 选择预定义的架构元素以满足尽可能多的数据需求。
- 扩展标准目录服务器架构,以定义新的元素以满足其他剩余需求。
- 规划架构维护。
3.2. 标准架构
3.2.1. 模式格式
objectclasses: ( 2.5.6.6 NAME 'person' DESC 'Standard Person Object Class' SUP top
MUST (objectclass $ sn $ cn) MAY (description $ seeAlso $ telephoneNumber $ userPassword)
X-ORIGIN 'RFC 2252' )objectclass,sn, 和 cn),以及允许的属性(描述、seeAlso、telephoneNumber 和 userPassword)。
3.2.2. 标准属性
commonName (cn)。因此,名为 Babs Jensen 的人员的条目具有 attribute-data 对 cn: Babs Jensen。
dn: uid=bjensen,ou=people,dc=example,dc=com objectClass: top objectClass: person objectClass: organizationalPerson objectClass: inetOrgPerson cn: Babs Jensen sn: Jensen givenName: Babs givenName: Barbara mail: bjensen@example.com
givenName 属性显示两次,每次都有一个唯一值。
- 唯一的名称。
- 属性的对象标识符(OID)。
- 属性的文本描述。
- 属性语法的 OID。
- 指示 属性是单值还是多值,无论属性是否适用于目录自己的用途、属性的来源,以及与 属性关联的任何其他匹配规则。
cn 属性定义出现在 schema 中,如下所示:
attributetypes: ( 2.5.4.3 NAME 'cn' DESC 'commonName Standard Attribute'
SYNTAX 1.3.6.1.4.1.1466.115.121.1.15 )3.2.3. 标准对象类
- 唯一的名称。
- 为 对象命名的对象标识符 (OID)。
- 一组强制属性。
- 组允许(或可选)属性。
objectclasses: ( 2.5.6.6 NAME 'person' DESC 'Standard Person Object Class' SUP top
MUST (objectclass $ sn $ cn) MAY (description $ seeAlso $ telephoneNumber $ userPassword)
X-ORIGIN 'RFC 2252' )3.3. 将数据映射到默认架构
3.3.1. 查看默认目录架构
/usr/share/dirsrv/schema/ 目录中。
00core.ldif 文件中找到。早期版本的目录所使用的配置模式可在 50ns-directory.ldif 文件中找到。
3.3.2. 将数据与架构元素匹配
- 确定数据描述的对象类型。选择一个最能与站点调查中描述的数据匹配的对象。有时,一个数据可以描述多个对象。确定在目录 schema 中是否需要记录区别。例如,电话号码可以描述员工的电话号码和会议室的电话号码。确定这些不同类型的数据是否需要被视为目录架构中不同的对象。
- 从默认架构中选择一个类似的对象类。最好使用通用对象类,如组、人员和机构。
- 从匹配的对象类选择类似的属性。从匹配对象类中选择一个属性,它们最适合站点调查中标识的数据片段。
- 识别来自站点调查的不匹配数据。如果有一些数据与默认目录架构定义的对象类和属性不匹配,请自定义 schema。如需更多信息,请参阅 第 3.4 节 “自定义架构”。
| data | 所有者 | 对象类 | 属性 |
|---|---|---|---|
| 员工名称 | HR | 个人 | cn (commonName) |
| 用户密码 | IS | 个人 | userPassword |
| 主页电话号码 | HR | inetOrgPerson | homePhone |
| 员工位置 | IS | inetOrgPerson | localityName |
| 办公室电话号码 | 设施 | 个人 | telephoneNumber |
cn 或 commonName 属性来描述个人的完整名称。此属性为包含员工名称数据的最佳匹配。
userPassword 属性则列在 person 对象类的允许属性中。
homePhone 属性,它适用于包含员工的主页电话号码。
3.4. 自定义架构
- 使架构尽可能简单。
- 尽可能重复使用现有的 schema 元素。
- 尽可能减少为每个对象类定义的必要属性数量。
- 不要为相同目的(数据)定义多个对象类或属性。
- 不要修改属性或对象类的任何现有定义。
99user.ldif 文件中定义。每个实例在 /etc/dirsrv/slapd-instance_name/schema/ 目录中维护自己的 99user.ldif 文件。也可以创建自定义模式文件,并将架构动态重新加载到服务器中。
3.4.1. 当扩展架构时
3.4.2. 获取和分配对象标识符
- 从互联网编号分配机构(IANA)或国家组织获取 OID。在某些国家/地区,公司已分配给他们的 OID。如果您的组织还没有 OID,可以从 IANA 获取。有关更多信息,请访问 IANA 网站 http://www.iana.org/cgi-bin/enterprise.pl。
- 创建 OID registry 以跟踪 OID 分配。OID registry 是目录 schema 中使用的 OID 和描述的列表。这样可确保不使用 OID 用于多个目的。然后使用 schema 发布 OID 注册表。
- 在 OID 树中创建分支以容纳 schema 元素。在 OID 分支或目录 schema 下至少创建两个分支,将 OID.1 用于属性,OID.2 用于对象类。要定义自定义匹配规则或控制,请根据需要添加新分支(例如OID.3)。
3.4.3. 命名属性和对象类
3.4.4. 定义新对象类的策略
- 创建多个新对象类,每个对象类结构对应一个属性。
- 创建一个对象类,它支持为目录创建的所有自定义属性。这种对象类的方法是将它定义为辅助对象类。
exampleDateOfBirth、examplePreferredOS、exampleBuildingFloor 和 exampleViceP 常处。简单的解决方案是创建多个对象类,允许其中的一些部分属性。
- 一个对象类( examplePerson )被创建,并允许
exampleDateOfBirth和examplePreferredOS。examplePerson 的父项是 inetOrgPerson。 - 第二个对象类 exampleOrganization 允许
exampleBuildingFloor和exampleViceP常常。exampleOrganization 的父是 机构 对象类。
objectclasses: ( 2.16.840.1.117370.999.1.2.3 NAME 'examplePerson' DESC 'Example Person Object Class'
SUP inetorgPerson MAY (exampleDateOfBirth $ examplePreferredOS) )
objectclasses: ( 2.16.840.1.117370.999.1.2.4 NAME 'exampleOrganization' DESC 'Organization Object Class'
SUP organization MAY (exampleBuildingFloor $ exampleVicePresident) )objectclasses: (2.16.840.1.117370.999.1.2.5 NAME 'exampleEntry' DESC 'Standard Entry Object Class' SUP top
AUXILIARY MAY (exampleDateOfBirth $ examplePreferredOS $ exampleBuildingFloor $ exampleVicePresident) )- 多个对象类会导致更多架构元素来创建和维护。通常,元素数量较小且需要较少的维护。但是,如果架构中增加了两个或多个对象类,那么使用单个对象类可能更易于使用。
- 多个对象类需要更小心、更严格的数据设计。严格数据设计强制注意用于放置每个数据的对象类结构,这可能很有帮助或繁琐。
- 当数据被应用到多个对象类(如人员和资产条目)时,单一对象类简化了数据设计。例如,可以在 person 和 group 条目上设置自定义
preferredOS属性。单个对象类可以在这两类条目上允许此属性。 - 避免新对象类的必要属性。指定
require而不是允许新对象类中的属性,可能会导致 schema 不灵活。在创建新对象类时,请使用allow而不是需要尽可能多的内容。定义新对象类后,决定其允许和需要哪些属性,以及它继承属性的对象类。
3.4.5. 定义新属性的策略
dateOfBirth,并在新的辅助对象类 examplePerson 中设置为允许的属性。
attributetypes: ( dateofbirth-oid NAME 'dateofbirth' DESC 'For employee birthdays'
SYNTAX 1.3.6.1.4.1.1466.115.121.1.15 X-ORIGIN 'Example defined')
objectclasses: ( 2.16.840.1.117370.999.1.2.3 NAME 'examplePerson' DESC 'Example Person Object Class'
SUP inetorgPerson MAY (exampleDateOfBirth $ cn) X-ORIGIN 'Example defined')3.4.6. 删除架构元素
3.4.7. 创建自定义架构文件
99user.ldif 文件外,管理员还可以为 Directory 服务器创建自定义架构文件。这些架构文件保存特定于组织的新自定义属性和对象类。新的模式文件应位于 schema 目录中,/etc/dirsrv/slapd-instance_name/schema/。
99user.ldif,或者服务器可能会遇到问题。
- 手动将这些自定义模式文件复制到实例的 schema 目录
/etc/dirsrv/slapd-instance/schema。要载入架构,请通过运行 schema-reload.pl 脚本来动态重新加载模式。 - 使用 LDAP 客户端(如 Web 控制台或 ldapmodify )修改服务器上的 schema。
- 如果服务器被复制,则允许复制过程将架构信息复制到每个使用者服务器。通过复制,所有复制模式元素都复制到消费者服务器的
99user.ldif文件中。要将架构保留在自定义模式文件中,如90example_schema.ldif,必须手动将文件复制到消费者服务器。复制不会复制架构文件。
99user.ldif 文件中。目录无法跟踪存储架构定义的位置。在消费者的 99user.ldif 文件中存储架构元素不会产生问题,只要该架构仅在供应商服务器上维护。
99user.ldif 文件中。在 99user.ldif 文件中进行了更改可能会导致架构管理困难,因为一些属性将出现在消费者上的两个独立模式文件中,一次在从供应商复制的原始自定义模式文件中,并在复制后再次出现在 99user.ldif 文件中。
3.4.8. 自定义架构最佳实践
3.4.8.1. 命名架构文件
[00-99]yourName.ldif
99user.ldif。这可让目录服务器通过 LDAP 工具和 Web 控制台写入 99user.ldif。
99user.ldif 文件包含 X-ORIGIN 值为 'user defined' 的属性;但是,目录服务器将所有"用户定义的"模式元素写入最高命名的文件,然后按字母顺序排列。如果存在一个名为 99zzz.ldif 的模式文件,下一次更新 schema 时(通过 LDAP 命令行工具或 Web 控制台)所有带有 X-ORIGIN 的值为 'user defined' 的属性都会写入 99zzz.ldif。结果是两个包含重复信息的 LDIF 文件,而 99zz.ldif 文件中的一些信息可能会被清除。
3.4.8.2. 使用"用户定义的"作为 Origin
60example.ldif),因为当通过 LDAP 添加模式时,目录服务器在内部使用 'user defined'。在自定义架构文件中,使用更多描述性,如 'Example Corp. defined'。
99user.ldif 中,请使用 'user defined' 作为 X-ORIGIN 的值。如果设置了不同的 X-ORIGIN 值,则服务器可能会覆盖它。
99user.ldif 文件中的模式定义不会被 Directory 服务器从文件中删除。目录服务器不会删除它们,因为它依赖于值 'user defined' 的 X-ORIGIN 来告知它哪些元素应驻留在 99user.ldif 文件中。
attributetypes: ( exampleContact-oid NAME 'exampleContact' DESC 'Example Corporate contact' SYNTAX 1.3.6.1.4.1.1466.115.121.1.15 X-ORIGIN 'Example defined')
attributetypes: ( exampleContact-oid NAME 'exampleContact'
DESC 'Example Corporate contact'
SYNTAX 1.3.6.1.4.1.1466.115.121.1.15
X-ORIGIN ('Example defined' 'user defined') )3.4.8.3. 在对象类前定义属性
3.4.8.4. 在单个文件中定义架构
- 请注意每个架构文件中包括哪些 schema 元素。
- 在命名和更新模式文件中要小心。通过 LDAP 工具编辑模式元素时,更改会自动写入最后一个文件(通常)。大多数架构更改,然后写入默认文件
99user.ldif,而不是自定义架构文件,如60example.ldif。另外,99user.ldif中的架构元素会覆盖其他架构文件中的重复元素。 - 将所有架构定义添加到
99user.ldif文件。这在通过 Web 控制台管理模式时很有用。
3.5. 维护一致性架构
- 使用 schema 检查来确保属性和对象类符合 schema 规则。
- 使用语法验证,以确保属性值与所需属性语法匹配。
- 选择并应用一致的数据格式。
3.5.1. Schema 检查
cn)和 surname (sn)属性。也就是说,创建条目时必须设置这些属性的值。另外,还有可在条目上使用的属性列表,包括 telephoneNumber、uid、streetAddress 和 userPassword 等描述性属性。
3.5.2. 语法验证
telephoneNumber 属性实际具有其值的有效电话号码。
3.5.2.1. 语法验证概述
3.5.2.2. 语法验证和其他目录服务器操作
数据库加密
对于普通的 LDAP 操作,属性仅在值写入数据库之前加密。这意味着,加密会在验证属性语法后进行。
-E 标志完成这些导出和导入操作,这允许导入操作正常进行。但是,如果加密数据库在没有使用 -E 标志(不支持)的情况下导出,那么会创建一个带有加密值的 LDIF。当导入此 LDIF 后,无法验证加密的属性,则会记录警告,并在导入的条目中跳过属性验证。
同步
对于 Windows Active Directory 条目和 Red Hat Directory Server 条目中的属性,允许或拒绝语法存在区别。在这种情况下,Active Directory 值无法正确同步,因为语法验证会在 Directory Server 条目中强制实施 RFC 标准。
复制
如果 Directory Server 11.0 实例是一个将更改复制到消费者的供应商,则使用语法验证没有问题。但是,如果复制中的供应商是旧版本的目录服务器或已禁用语法验证,则 11.0 消费者上不应使用语法验证,因为目录服务器 11.0 使用者可能会拒绝供应商允许的属性值。
3.5.3. 选择一致性数据格式
- ITU-T 建议 E.123.国家和国际电话号码表示法。
- ITU-T 建议 E.163.国际电话服务的数字计划。例如,美国电话号码格式化为 +1 555 222 1717。
postalAddress 属性需要一个以多行字符串形式的属性值,该形式使用美元符号($)作为行分隔符。正确格式化的目录条目如下:
postalAddress: 1206 Directory Drive$Pleasant View, MN$34200
3.5.4. 维护复制架构
- 不要修改只读副本中的 schema。在只读副本中修改 schema 在 schema 中引入了不一致的问题,并导致复制失败。
- 不要创建具有相同名称的属性,它们使用不同的语法。如果在读写副本中创建属性,其名称与供应商副本上的属性相同,但与供应商的属性不同,复制将失败。
3.6. 其他架构资源
- RFC 2251:轻量级目录访问协议(v3), http://www.ietf.org/rfc/rfc2251.txt
- RFC 2252: LDAPv3 属性语法定义, http://www.ietf.org/rfc/rfc2252.txt
- X.500 用户架构的 RFC 2256: Summary for with LDAPv3, http://www.ietf.org/rfc/rfc2256.txt
- Internet 工程任务组(IETF) http://www.ietf.org/
- 了解和部署 LDAP 目录服务.T. Howes, M. Smith, G. am, Macmillan Technical Publishing, 1999.
第 4 章 设计目录树
4.1. Directory Tree 简介
- 简化的目录数据维护。
- 创建复制策略和访问控制的灵活性。
- 支持使用目录服务的应用程序。
- 目录用户的简化目录导航。
4.2. 设计目录树
- 选择包含数据的后缀。
- 确定数据条目之间的分层关系。
- 命名目录树层次结构中的条目。
4.2.1. 选择 Suffix
4.2.1.1. 后缀命名
- 全局唯一。
- 静态,因此很少会在发生改变的情况下。
- 简而言之,这样,在屏幕上更轻松地阅读条目。
- 易于输入并记住。
dc 属性通过将域名拆分到其组件部分来代表后缀。
dc定义域名的组件。c包含代表国家名称的双位代码,由 ISO 定义。l标识条目所在的数目、城市或其他地理位置,或者与该条目相关联。st识别条目所在的状态或省去。o标识条目所属组织的名称。
4.2.1.2. 命名多个 Suffixes
图 4.1. 在数据库中包含多个目录树

4.2.2. 创建目录树结构
4.2.2.1. 对目录进行分支
- 将树分支,仅代表企业中最大的组织细分。所有这些分支点应限制在部门(如公司信息服务、客户支持、销售与工程)。确保用于分支目录树的部门具有稳定的;如果企业经常重新组织,则不执行此类分支。
- 对分支点使用功能或通用名称而不是实际的机构名称。名称更改。虽然子树可以重命名,但它是具有许多子条目的大型后缀的很长和资源密集型过程。使用代表机构功能的通用名称(例如,使用 Engineering 而不是 Widget Research 和 Development)使得在机构或项目更改后需要重命名子树的几率要小。
- 如果有多个机构执行类似的功能,请尝试为该功能创建单个分支点,而不是基于划分行进行分支。例如,即使有多个营销机构,每个营销机构都负责特定的产品行,请创建一个 ou=Marketing 子树。然后,所有营销条目都属于该树。
Enterprise 环境中的分支
如果目录树结构基于可能更改的信息,可以避免名称更改。例如,对树中的对象类型而非组织,对对象类型的结构为基础。这有助于避免在组织单元之间影响一个条目,这需要修改可分辨名称 (DN),这是代价昂贵的操作。
- ou=people
- ou=groups
- ou=services
图 4.2. Environment Directory 树示例
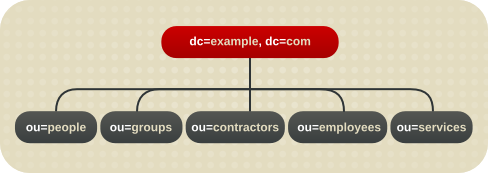
主机环境中的分支
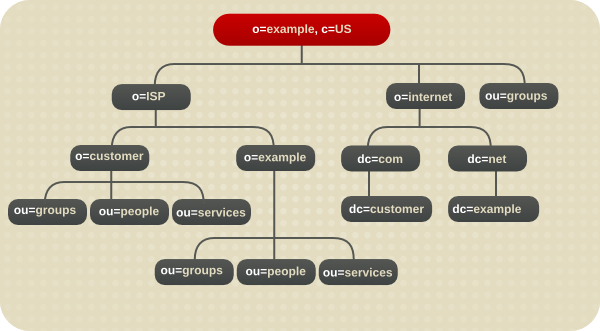
对于托管环境,创建一个树,其中包含对象类 组织 (o)的两个条目,以及对象类 organizationalUnit (ou)下的一个条目。例如,ISP 分支其目录示例,如下所示。
图 4.3. 主机目录树示例

4.2.2.2. 识别分支点
图 4.4. 示例 Corp 的 Directory 树。
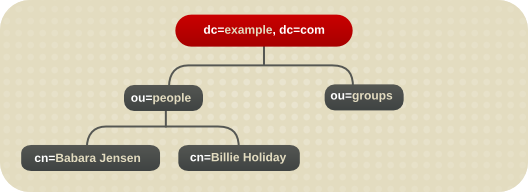
图 4.5. 示例 ISP 的目录树

- 保持一致。如果区分名称 (DN) 格式在目录树中不一致,则一些 LDAP 客户端应用程序可能会混淆。也就是说,如果
l属于目录树的一个部分的ou,请确保在目录服务的所有其他部分的l从属为ou。 - 尝试只使用传统属性(在 第 4.2.2.2 节 “识别分支点”中显示)。使用传统属性会增加保留与第三方 LDAP 客户端应用程序的兼容性的可能性。使用传统属性还意味着它们对默认目录架构所知,这有助于为分支 DN 构建条目。
| 属性 | 定义 |
|---|---|
dc | 域名的一个元素,如 dc=example ;这经常在对中指定,甚至更长,具体取决于域,如 dc=example,dc=com 或 dc=mtv,dc=example,dc=com。 |
c | 国家/地区名称。 |
o | 机构名称。此属性通常用于代表一个大的分部分支,如公司部门、学术线(人类、科学)、子公司,或者企业内的其他主要分支,如 第 4.2.1.1 节 “后缀命名”。 |
ou | 组织单元。此属性通常用来代表比组织较小的部门分支。组织单元一般与上述机构从属。 |
st | 状态或省名称。 |
l 或 locality | 本地性,如城市、国家、办公室或设备名称。 |
4.2.2.3. 复制注意事项
图 4.6. 示例公司的 Directory 树的初始分支。
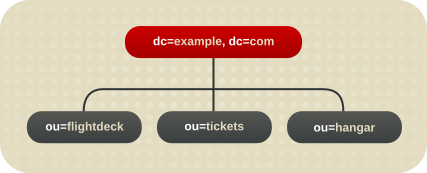
图 4.7. 为示例公司扩展分支.

图 4.8. 示例 ISP 的目录分支
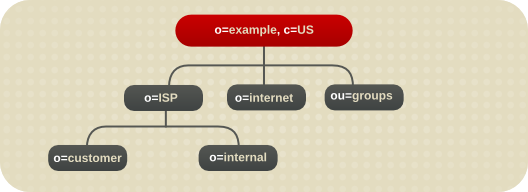
图 4.9. 用于示例 ISP 的扩展分支
4.2.2.4. 访问控制注意事项
4.2.3. 命名条目
- 为命名选择的属性应不太可能改变。
- 该名称在目录中必须是唯一的。唯一名称可确保 DN 在 目录中最多可以看到一个条目。
l 来代表一个机构,或者 c 代表组织单元。
4.2.3.1. 命名角色条目
commonName 或 cn 属性来命名其个人条目。也就是说,名为 Babs Jensen 的个人可能具有可区分名称 cn=Babs Jensen,dc=example,dc=com 的条目。
cn 以外的某些属性的 person 条目。考虑使用以下属性之一:
uid使用uid属性指定个人的一些唯一值。可能包括用户登录 ID 或员工号码。托管环境中的订阅者应该由uid属性识别。mailmail属性包含个人的电子邮件地址,该地址始终是唯一的。这个选项可能会导致包含重复属性值(如 mail=bjensen@example.com,dc=example,dc=com)的 awkward DNs,因此仅在没有与uid属性一起使用的其他唯一值时才使用这个选项。例如,如果企业没有为临时或合同员工分配员工数量或用户 ID,则使用mail属性而不是uid属性。employeeNumber对于 inetOrgPerson 对象类的员工,请考虑使用人员分配的属性值,如employeeNumber。
uid 和 cn 属性使用人类可读的名称。
在托管环境中为 Person 条目的注意事项
如果一个人是服务的订阅者,则条目应该是对象类 inetUser,条目应包含 uid 属性。在客户子树中,属性必须是唯一的。
将 Person Entries 放置到 DIT 中
以下是将人员条目放入目录树的一些准则:
- 企业中的人员应位于组织条目下的目录树中。
- 对托管机构的订阅者需要低于托管机构的 ou=people 分支。
4.2.3.2. 命名组条目
- 静态组 显式定义是成员。groupOfNames 或 groupOfUniqueNames 对象类包含命名组成员的值。静态组适合具有几个成员的组,如目录管理员组。静态组不适用于具有数千个成员的组。静态组条目必须包含 uniqueMember 属性值,因为 uniqueMember 是 groupOfUniqueNames 对象的强制属性。此对象类需要
cn属性,它可用于组成组条目的 DN。 - 动态组 使用一个代表搜索过滤器和子树的组的条目。与过滤器匹配的条目是组的成员。
- 角色 统一了静态和动态组概念。如需更多信息,请参阅 第 4.3 节 “分组目录条目”。
4.2.3.3. 命名机构条目
organization (o)属性作为 naming 属性。
4.2.3.4. 命名其他 Entries 的 Kind
cn 属性(如果可能)。然后,为命名组条目,将其命名为 cn=administrators,dc=example,dc=com 等内容。
commonName 属性。反之,使用条目对象类支持的属性。
4.2.4. 重命名条目和子树
例 4.1. building Entry DNs
dc=example,dc=com => root suffix
ou=People,dc=example,dc=com => org unit
st=California,ou=People,dc=example,dc=com => state/province
l=Mountain View,st=California,ou=People,dc=example,dc=com => city
ou=Engineering,l=Mountain View,st=California,ou=People,dc=example,dc=com => org unit
uid=jsmith,ou=Engineering,l=Mountain View,st=California,ou=People,dc=example,dc=com => leaf entry图 4.10. Leaf Entry 的 modrdn Operations

图 4.11. 子树条目的 modrdn 操作

newsuperior 属性,它将条目从一个父项移到另一个父项。
图 4.12. 对一个新父项的 modrdn 操作

entryrdn.db 索引中。每个条目都由其自己的键(一个 self-link)标识,然后是一个子键来标识其父项( 父链接)和任何子项。这是一个层次结构目录树的格式,它将父项和子项视为条目的属性,每个条目都由唯一 ID 及其 RDN 描述,而不是完整的 DN 进行标识。
numeric_id:RDN => self link
ID: #; RDN: "rdn"; NRDN: normalized_rdn
P#:RDN => parent link
ID: #; RDN: "rdn"; NRDN: normalized_rdn
C#:RDN => child link
ID: #; RDN: "rdn"; NRDN: normalized_rdn4:ou=people ID: 4; RDN: "ou=People"; NRDN: "ou=people" P4:ou=people ID: 1; RDN: "dc=example,dc=com"; NRDN: "dc=example,dc=com" C4:ou=people ID: 10; RDN: "uid=jsmith"; NRDN: "uid=jsmith"
- 您无法重命名 root 后缀。
- 子树重命名操作对复制的影响最少。复制协议会应用于整个数据库,而不是数据库中的子树,因此子树重命名操作不需要重新配置复制协议。子树重命名操作之后的所有名称都会正常进行复制。
- 重命名子树 可能需要 重新配置任何同步协议。同步协议在后缀或子树级别上设置,因此重命名子树可能会破坏同步。
- 重命名子树 要求 手动重新配置子树级 ACI,以及为子树子条目设置的任何条目级 ACI。
- 您可以将子树重命名为子树,但您无法删除子树。
- 尝试更改子树的组件,如从
ou移到dc,可能会因为 schema 违反而失败。例如,organizationalUnit 对象类需要ou属性。如果该属性作为重命名子树的一部分被删除,则操作将失败。
4.3. 分组目录条目
- 使用组
- 使用角色
4.3.1. 关于组
- 静态组 有有限且定义的成员列表,这些成员被手动添加到组条目中。
- 动态组使用过滤器来识别哪些条目是组的成员,因此当与组过滤器更改的条目时,组成员资格将不断改变。
4.3.1.1. 列出用户条目中的组成员资格
memberOf 属性,其名称为组的名称。
memberOf 属性中的用户条目中。用户所属的每个组的名称列为 memberOf 属性。这些 memberOf 属性的值由 Directory 服务器管理。
memberOf 属性更新用户条目,因为插件无法确定它们之间的关系。
memberOfAllBackends 属性配置为搜索所有配置的数据库。
memberofgroupattr,可以将 MemberOf 插件的单一实例配置为识别多个成员属性,以便 MemberOf 插件可以管理多种类型的组。
4.3.1.2. 自动添加新条目到组
图 4.13. 正则表达式条件

4.3.2. 关于角色
- 明确列出角色成员。查看角色将显示该角色的完整列表。角色本身可以查询以检查成员资格(无法通过动态组)。
- 显示条目所属角色。因为角色成员资格由条目上的属性决定,只需查看条目即可显示它所属的所有角色。这和组的 memberOf 属性类似,只需要启用或配置插件实例才能正常工作。它是自动的。
- 分配适当的角色。角色成员资格通过条目(entry)进行分配,而不是通过角色分配,因此单个步骤中可以通过编辑条目轻松地分配和移除用户所属的角色。
- 受管角色 具有明确的 enumerated 列表。
- 根据 每个条目包含的属性(在 LDAP 过滤器中指定),过滤 过滤角色将条目分配给角色。与过滤器匹配的条目拥有角色。
- 嵌套角色是包含其他角色的角色。
nsAccountLock 属性设置为 true。
nsAccountLock 设置为 true。可以有多个嵌套角色层,并在嵌套的任意点上激活嵌套角色,则会在它下面的所有角色和用户中激活。
4.3.3. 确定角色和组之间的选择
nsRole 操作属性来检查角色成员资格;此多值属性标识条目所属的每个角色。从客户端应用程序视图中,检查成员资格的方法统一并在服务器端执行。
memberOf strikes a nice 平衡,使客户端使用且对服务器进行计算效率。
memberOf 属性。客户端可以在组条目上运行单个搜索,以获取其所有成员的列表,或者在用户条目上搜索单个搜索来获取它所属的所有组的完整列表。
memberOf (user)属性都存储在数据库中,因此不需要额外的处理来搜索,从而使从客户端搜索非常高效。
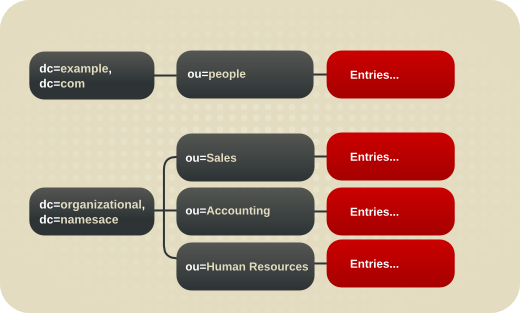
4.4. 虚拟目录信息树视图
4.4.1. 关于虚拟 DIT 视图
- 分层目录信息树。
- 扁平目录信息树。
图 4.14. Flat 和组织的 DIT 示例
nsviewfilter)。在添加了附加属性后,与 view 过滤器匹配的条目会立即填充视图。目标条目只 出现在 视图中,它们真正的位置不会改变。虚拟 DIT 视图的行为与子树或一级搜索的普通 DIT 的行为可以通过返回预期的结果来执行。
图 4.15. 使用视图组合 DIT
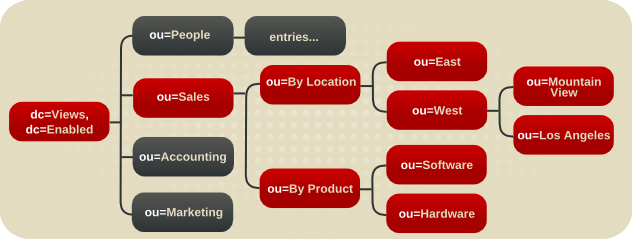
图 4.16. 带有虚拟 DIT 视图层次结构的 DIT

- sub-tree ou=People 包含实际 条目 A 和 Entry B 条目。
- sub-tree ou=Location Views 是一个视图层次结构。
- leaf nodes ou=Sunnyvale 和 ou=Mountain View 各自包含一个属性
nsviewfilter,它描述了视图。这些是叶节点,因为它们不包含实际条目。但是,当客户端应用程序搜索这些视图时,它会在 ou=Sunnyvale 下找到 Entry A,并在 ou=Mountain View 下找到条目 B。这个虚拟搜索空间由所有上级视图的nsviewfilter属性描述。从视图中进行的搜索会返回虚拟搜索空间和实际搜索空间中的条目。这可让视图层次结构作为传统 DIT 工作,或者将传统的 DIT 更改为 view 层次结构。
4.4.2. 使用虚拟 DIT 视图的好处
- 视图有助于将扁平命名空间用于条目,因为虚拟 DIT 视图提供了类似于传统层次结构提供的导航和管理器性支持。另外,每当对 DIT 进行更改时,条目从不需要移动;只有虚拟 DIT 视图层次结构变化。由于这些层次结构不包含实际条目,因此简单且快速修改。
- 在部署计划期间超额,使用虚拟 DIT 视图的灾难性较低。如果在第一个实例中没有正确开发层次结构,可以在不中断服务的情况下轻松、快速地更改。
- 查看层次结构可在几分钟内完全修订,结果会立即实现,从而显著降低目录维护成本。对虚拟 DIT 层次结构的更改会立即实现。发生组织更改时,可以快速创建一个新的虚拟 DIT 视图。新的虚拟 DIT 视图可以与旧视图同时存在,从而促进了更逐步更改自身以及使用这些条目的应用程序。因为目录中的一个机构更改不是全权操作,所以可以在一段时间内完成,无需服务中断。
- 通过使用多个虚拟 DIT 视图进行导航和管理,可以更灵活地使用目录服务。通过虚拟 DIT 视图提供的功能,组织可以使用旧方法和新方法组织目录数据,而无需在 DIT 的特定点上放置条目。
- 虚拟 DIT 视图层次结构可以作为某种可用的查询来创建,以方便检索常见必要信息。
- 视图在工作实践中提升灵活性并降低目录用户创建复杂搜索过滤器的要求,使用它们原本不需要知道的属性名称和值。能够灵活地查看和查询目录信息,让最终用户和应用程序能够更直观地找到他们通过分层导航功能所需的内容。
4.4.3. 虚拟 DIT 视图示例
dn: ou=Location Views,dc=example,dc=com objectclass: top objectclass: organizationalUnit objectclass: nsView ou: Location Views description: views categorized by location dn: ou=Sunnyvale,ou=Location Views,dc=example,dc=com objectclass: top objectclass: organizationalUnit objectclass: nsView ou: Sunnyvale nsViewFilter: (l=Sunnyvale) description: views categorized by location dn: ou=Santa Clara,ou=Location Views,dc=example,dc=com objectclass: top objectclass: organizationalUnit objectclass: nsView ou: Santa Clara nsViewFilter: (l=Santa Clara) description: views categorized by location dn: ou=Cupertino,ou=Location Views,dc=example,dc=com objectclass: top objectclass: organizationalUnit objectclass: nsView ou: Cupertino nsViewFilter: (l=Cupertino) description: views categorized by location
nsfilter 属性添加到 ou=Location Views,dc=example,dc=com,其过滤器值 (objectclass=organizationalperson)。
4.4.4. 查看和其他目录功能
4.4.5. 虚拟视图对性能的影响
4.4.6. 与现有应用程序兼容
- 使用目标条目的 DN 来导航 DIT 的应用程序。这种类型的应用程序会发现,它正在导航出条目物理存在的层次结构,而不是找到该条目的视图层次结构。这样做的原因是,通过更改条目的 DN 以符合视图的层次结构,不会尝试忽略条目的真正位置。这由设计 - 如果条目的真正位置进行解包,例如依赖 DN 来识别唯一条目的应用程序时,许多应用程序都无法正常工作。这种对 DN 的超额导航是客户端应用程序的一个不常见的技术,但却没有人为无法按预期工作的那些客户端。
- 使用
numSubordinates操作属性的应用程序来确定节点下存在多少个条目。对于视图中的节点,这目前只有那些存在于实际搜索空间中的条目数,忽略虚拟搜索空间。因此,应用程序可能无法使用搜索来评估视图。
4.5. 目录树设计示例
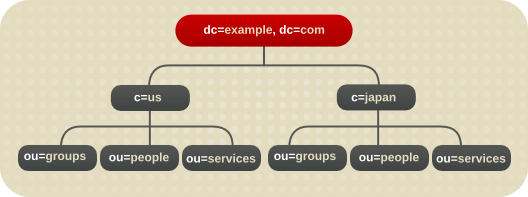
4.5.1. 国际企业的目录树
c 属性可以代表每个国家分支:
图 4.17. 使用 c Attribute 来代表不同的计数器
l 属性来代表不同的国家:
图 4.18. 使用 l Attribute 来代表不同的计数器

4.5.2. ISP 的目录树
图 4.19. 示例 ISP 的目录树
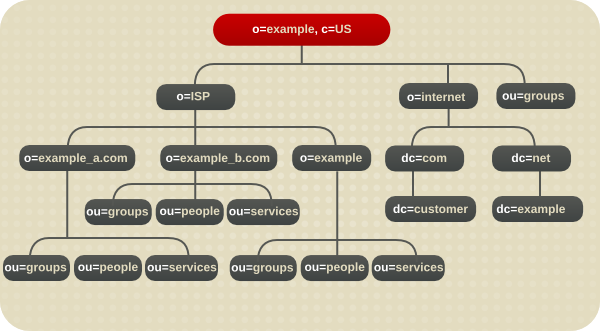
4.6. 其他目录树资源
第 5 章 定义动态属性值
5.1. 受管属性简介
- 属性唯一要求子树或数据库中的特定属性的每个实例都有唯一的值。每当创建条目或修改属性时,都会强制实施。
- 服务类将一个条目用作模板; 每当该属性值更改时,CoS 范围内的所有其他条目都会在其条目上自动具有相同的属性。(受 CoS 影响的条目通过定义条目来标识。)
- 当创建定义的范围的另一个条目时,受管条目会根据定义的模板创建一个条目。有时,特别是与外部客户端集成时,可能需要自动创建和管理条目对。受管条目定义第二个条目的模板,并提供自动更新的机制。
- 链接的属性遵循一个条目中的属性中的 DN 值,并将预先确定的属性(具有指向原始条目的值)到引用的条目。因此,如果条目 A 列出条目 B 作为直接报告,则可以自动更新条目 B,使其包含
manager属性,并将条目 A 作为指定的管理器。 - 分布式数字分配 会自动为条目分配唯一标识号。这对 GID 或 UID 号分配有用,这在组织内必须是唯一的。
- 条目是如何相关?条目之间有哪些常见属性?是否存在哪些属性必须代表条目间的连接?
- 数据的原始源可能被维护,在哪里以及位置(在什么条目中)?此信息更新的频率以及数据更改时影响多少条目?
- 这些条目使用哪些架构元素以及这些属性的语法是什么?
- 插件如何处理分布式目录配置,如复制或同步?
5.2. 关于属性唯一性
- 它可以检查指定子树中的每个条目。例如,如果某个公司是 example.com,则托管 example_a.com 和 example_b.com 的目录,当一个条目(如 uid=jdoe,ou=people,o=example_a,dc=example,dc=com )中被添加,唯一性需要只在 o=example_a,dc=example,dc=com 子树中强制执行。这可以通过在属性唯一标识符配置中明确列出子树的 DN。
- 指定与更新条目 DN 中的条目相关的对象类,并对它下的所有条目执行唯一性检查。这个选项在托管环境中很有用。例如,当添加诸如 uid=jdoe,ou=people, o=example_a,dc=example,dc=com 等条目时,在 o=example_a,dc=example,dc=example,dc=com 子树中显式列出此子树时,通过指示 标记对象类。如果标记对象类设置为 机构,则唯一性检查算法会在 DN 中查找具有此对象类(o=example_a)的条目,并对它下的所有条目执行检查。另外,只有在更新的条目包含指定对象类时,才能检查唯一性。例如,只有在更新的条目包含 objectclass=inetorgperson 时,才能执行检查。
uid 属性提供属性唯一插件的默认实例。此插件实例确保提供给 uid 属性的值在 root 后缀中是唯一的(与 userRoot 数据库对应的后缀)。
- 执行唯一性检查的属性是 naming 属性。
- 在这两个供应商服务器上都启用了属性唯一插件。
5.3. 关于服务类
facsimileTelephoneNumber。传统上,修改传真号需要单独更新每个项,这可能会是一个非常大型的任务,并可能造成没有全部更改的风险。使用 CoS 时,可以动态生成属性值。facsimileTelephoneNumber 属性存储在一个位置,每个条目都从该位置检索其 fax number 属性。对于应用程序,这些属性看起来像所有其他属性一样,尽管实际存储在条目本身上。
- 条目的 DN(目录树中的不同部分可能包含不同的 CoS)。
- 通过该条目存储的服务类属性值。缺少 service class 属性可以表示特定的默认 CoS。
- 存储在 CoS 模板条目中的属性值。每个 CoS 模板条目提供特定 CoS 的属性值。
- 条目的对象类。只有条目包含对象类时,才会生成 COS 属性值,允许启用架构检查时属性;否则,将生成所有属性值。
- 存储在目录树中某个特定条目的属性。
cosAttribute 参数)。
5.3.1. 关于 Pointer CoS
图 5.1. Pointer CoS 示例
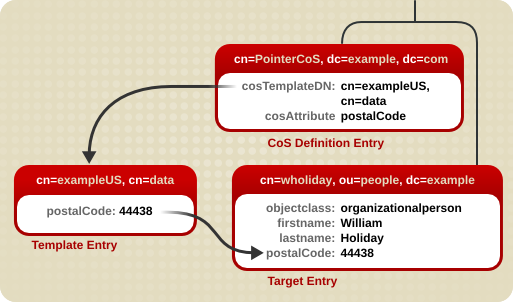
postalCode 属性时,Directory 服务器都会返回模板条目 cn=exampleUS,cn=data 中可用值。
5.3.2. 关于Indirect CoS
图 5.2. Indirect CoS 示例
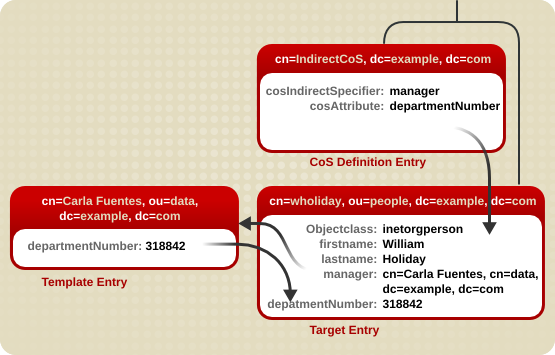
manager 属性的间接指定符。William 的经理是 Carla Fuentes,因此 manager 属性包含模板条目的 DN 的指针 cn=Carla Fuentes,ou=people,dc=example,dc=com。模板条目依次提供 departmentNumber 属性值 318842。
5.3.3. 关于经典 CoS
图 5.3. Classic CoS 示例
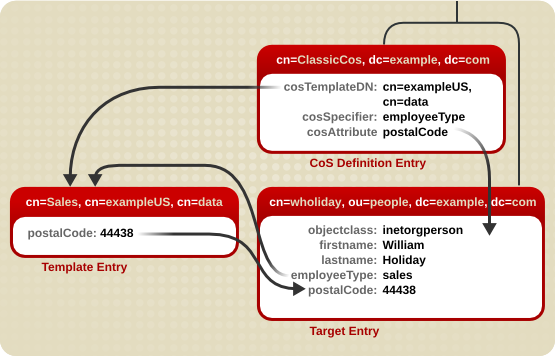
cosSpecifier 属性指定 employeeType 属性。此属性与模板 DN 相结合,将模板条目标识为 cn=sales,cn=exampleUS,cn=data。然后,模板条目为目标条目提供 postalCode 属性的值。
5.4. 关于受管条目
- 用于标识原始条目的搜索条件(使用搜索范围和搜索过滤器)
- 在其中创建受管条目(新条目位置)的子树
- 用于受管条目的模板条目
图 5.4. 定义受管条目
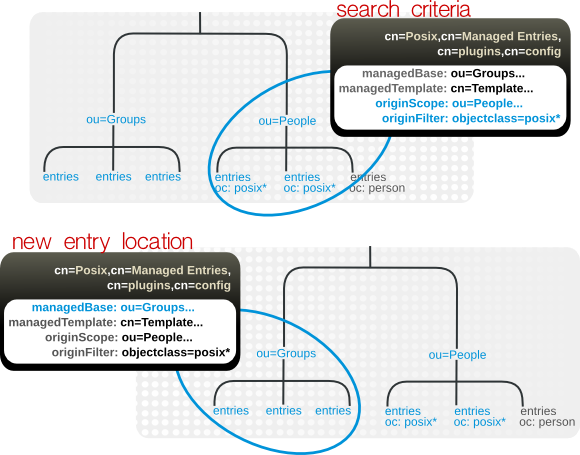
dn: cn=Posix User-Group,cn=Managed Entries,cn=plugins,cn=config objectclass: extensibleObject cn: Posix User-Group originScope: ou=people,dc=example,dc=com originFilter: objectclass=posixAccount managedBase: ou=groups,dc=example,dc=com managedTemplate: cn=Posix User-Group Template,ou=Templates,dc=example,dc=com
5.4.1. 为受管条目定义模板
dn: cn=Posix User-Group Template,ou=Templates,dc=example,dc=com objectclass: mepTemplateEntry cn: Posix User-Group Template mepRDNAttr: cn mepStaticAttr: objectclass: posixGroup mepMappedAttr: cn: $uid Group mepMappedAttr: gidNumber: $gidNumber mepMappedAttr: memberUid: $uid
图 5.5. 受管条目、模板和原始条目

5.4.2. Managed Entries 插件的 entry Attributes Written
dn: uid=jsmith,ou=people,dc=example,dc=com objectclass: mepOriginEntry objectclass: posixAccount ... sn: Smith mail: jsmith@example.com mepManagedEntry: cn=jsmith Posix Group,ou=groups,dc=example,dc=com
dn: cn=jsmith Posix Group,ou=groups,dc=example,dc=com objectclass: mepManagedEntry objectclass: posixGroup ... mepManagedBy: uid=jsmith,ou=people,dc=example,dc=com
5.4.3. Managed Entries 插件和目录服务器操作
- 添加。对于每个添加操作,服务器会检查新条目是否在任何 Managed Entries 插件实例范围内。如果满足原始条目的条件,则创建受管条目和受管条目相关的属性将添加到 origin 和 managed 条目中。
- 修改。如果修改了原始条目,它会触发插件来更新受管条目。但是,更改 模板 条目不会自动更新受管条目。对模板条目的任何更改都不会反映在受管条目中,直到下次修改原始条目后。在受管条目中映射的受管属性无法手动修改,只有通过 Managed Entry 插件进行修改。受管条目中的其他属性(包括由 Managed Entry 插件添加的静态属性)可以手动修改。
- 删除。如果删除了 origin 条目,则 Managed Entries 插件也会删除与该条目关联的任何受管条目。对可以删除的条目有一些限制。
- 如果模板条目当前由插件实例定义引用,则无法删除它。
- 除了 Managed Entries 插件外,无法删除受管条目。
- 重命名。如果重命名了原始条目,则插件会更新对应的受管条目。如果条目从插件范围 移出,则删除受管条目;而如果某个条目 移至 插件范围,它将被视为 add 操作,并且创建新的受管条目。与删除操作一样,可以重命名或移动条目受到限制。
- 无法将配置定义条目从 Managed Entries 插件容器条目中移出。如果删除了该条目,则该插件实例将处于激活状态。
- 如果条目 移至 Managed Entries 插件容器条目,则它将被验证并视为活跃的配置定义。
- 如果模板条目目前由插件实例定义引用,则无法重命名或移动。
- 除了 Managed Entries 插件外,无法重命名或移动受管条目。
- 复制。复制更新不会启动 Managed Entries 插件操作。如果插件范围中某个条目的添加或修改操作被复制到另一个副本,则该操作不会触发副本上的 Managed Entries 插件实例来创建或更新条目。要复制受管条目的更新的唯一方法是将最终受管条目复制到副本。
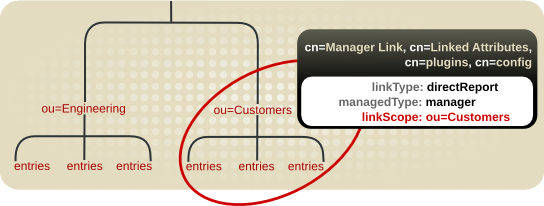
5.5. 关于链接属性
成员 的属性中列出其成员。在用户所属的组的用户条目中,可以指示其中的一个问题;这在 memberOf 属性中设置。memberOf 属性是通过 MemberOf 插件的 managed 属性。该插件轮询每个组条目,以针对其各自成员属性的更改。每当从组中添加或删除组成员时,对应的用户条目都会使用更改的 memberOf 属性进行更新。这样,成员 (和其他成员属性)和 memberOf 属性 链接。
linkType)和一个属性,由插件(managedType)自动维护。
图 5.6. 基本链接属性配置

图 5.7. 限制链接的属性插件到特定子树
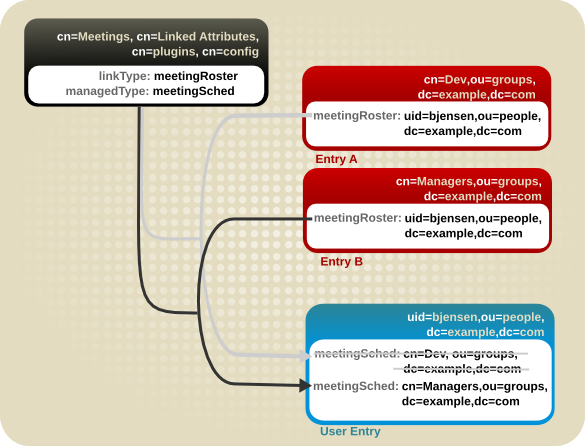
5.5.1. 链接属性的 schema 要求
图 5.8. 错误:使用单值链接的属性
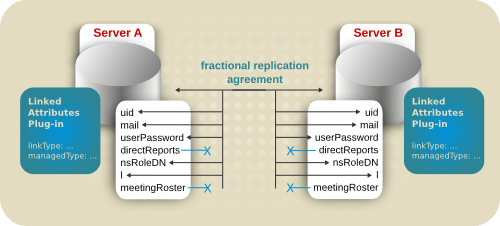
5.5.2. 使用带有复制的链接属性
图 5.9. 链接属性和复制
5.6. 关于动态分配唯一数量值
uidNumber 和 gidNumber。目录服务器可使用分布式 Numeric Assignment(DNA)插件为指定属性自动生成和提供唯一数字。
5.6.1. 目录服务器管理唯一数字的方式
- 从单一唯一数字范围内分配给单个属性类型的单个数字。
- 对于一个条目,分配给两个属性的唯一数字相同。
- 分配了两个不同的属性,与相同范围的唯一数字不同。
employeeID 时,务必要为每个员工条目分配一个唯一的 employeeID。
uidNumber 和 gidNumber 分配给 posixAccount 条目时,可将 DNA 插件配置为为这两个属性分配相同的数字。
5.6.2. 使用 DNA 分配值到属性
uidNumber 属性。如果 uidNumber 属性由 DNA 插件管理,并且添加用户条目时没有过滤器范围内的 uidNumber 属性,那么服务器会检查新条目,查看它需要 managed uidNumber 属性,并使用自动分配的值添加属性。
ldapmodify-a-D "cn=Directory Manager" -W -p 389 -h server.example.com -x dn: uid=jsmith,ou=people,dc=example,dc=com objectClass: top objectClass: personobjectClass: posixAccountuid: jsmith cn: John Smith ....
uidNumber 和 gidNumber 都分配相同的唯一数字到 posixAccount 条目,DNA 插件将为这两个属性分配相同的数字。为此,请将两个受管属性传递给修改操作,指定数量。例如:
ldapmodify-a-D "cn=Directory Manager" -W -p 389 -h server.example.com -x dn: uid=jsmith,ou=people,dc=example,dc=com objectClass: top objectClass: person objectClass: posixAccount uid: jsmith cn: John SmithuidNumber: magicgidNumber: magic....
5.6.3. 使用带有复制的 DNA 插件
- DNA 插件的受管范围
- 保存服务器可用范围信息的共享配置条目
dn: dnaHostname=ldap1.example.com+dnaPortNum=389,cn=Account UIDs,ou=Ranges,dc=example,dc=com objectClass: extensibleObject objectClass: top dnahostname: ldap1.example.com dnaPortNum: 389 dnaSecurePortNum: 636 dnaRemainingValues: 1000
第 6 章 设计目录拓扑
6.1. 拓扑概述
- 获得启用目录的应用程序的最佳性能。
- 提高目录服务的可用性。
- 改进目录服务的管理。
6.2. 分发目录数据
6.2.1. 关于使用多个数据库

图 6.1. 在独立的数据库中保存后缀数据

图 6.2. 在独立的服务器间划分后缀数据库

6.2.2. 关于 Suffixes
图 6.3. 示例公司的目录树.

图 6.4. 跨多个数据库进行目录树读取

图 6.5. 分布式目录树的后缀

使用多个 Root Suffixes
目录服务可以包含多个根后缀。例如,名为"Example"的 ISP 可以托管几个网站,一个用于 example_a.com,一个用于 example_b.com。ISP 将创建两个 root 后缀,一个用于 o=example_a.com 命名上下文,另一个对应于 o=example_b.com 命名上下文。
图 6.6. 带有多个 Root Suffixes 的目录树

6.3. 关于知识库参考
- 引用 - 服务器将一类信息返回到客户端应用,指示客户端应用程序需要联系另一个服务器来满足该请求。
- 链 - 服务器代表客户端应用程序联系其他服务器,并在操作完成后将结果返回给客户端应用程序。
6.3.1. 使用引用
- 默认引用 - 当客户端应用程序显示服务器没有匹配后缀的 DN 时,目录会返回默认引用。默认引用存储在服务器的配置文件中。可以为 Directory Server 设置一个默认引用,每个数据库都有一个默认的引用。每个数据库的默认引用是通过后缀配置信息进行的。当禁用数据库的后缀时,将目录服务配置为将默认引用返回到向该后缀发出的客户端请求。有关后缀的详情,请参考 第 6.2.2 节 “关于 Suffixes”。有关配置后缀的详情,请参考 Red Hat Directory Server Administration Guide 。
- 智能引用 - 智能引用存储在目录服务本身内的条目上。智能引用指向目录服务器,其了解其 DN 与包含智能引用的条目的 DN 匹配。
6.3.1.1. LDAP 推荐结构
- 要联系的服务器的主机名。
- 配置为侦听 LDAP 请求的服务器上的端口号。
- 基本 DN(用于搜索操作)或目标 DN(用于添加、删除和修改操作)。
ldap://europe.example.com:389/ou=people, l=europe,dc=example,dc=com
6.3.1.2. 关于默认引用
uid=bjensen,ou=people,dc=example,dc=com
nsslapd-referral 属性设置。目录中每个数据库的默认引用由配置中的数据库条目中的 nsslapd-referral 属性设置。这些属性值存储在 dse.ldif 文件中。
6.3.1.3. 智能引用
- 不同服务器上包含的同一命名空间。
- 本地服务器上的不同命名空间。
- 同一服务器上的不同命名空间。
图 6.7. 使用智能引用重定向请求

图 6.8. 将查询重定向到不同的服务器和客户端
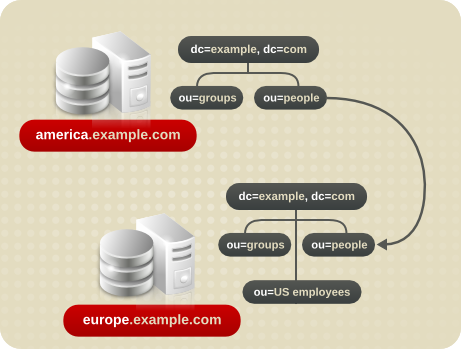
图 6.9. 将一个命名空间中的 Query 重定向到 Same 服务器上的Another Namespace

6.3.1.4. 设计智能清单的提示
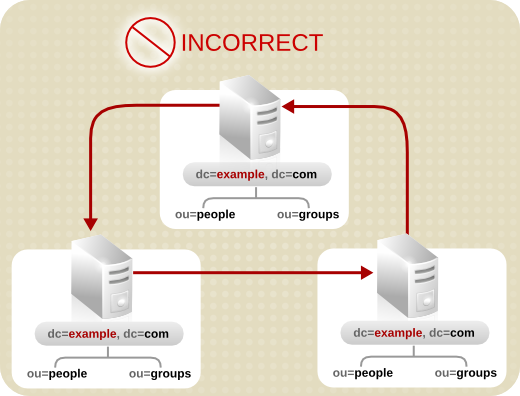
- 简化设计。使用复杂的 Web 部署目录服务会导致管理困难。过度使用智能引用也可以导致循环引用模式。例如,一个引用指向 LDAP URL,该 URL 又指向另一个 LDAP URL,以此类推,直到链中的参考位置返回原始服务器。下面是以下说明:
图 6.10. Circular 推荐模式
- 重定向位于主要分支点.限制引用使用,以便在目录树的后缀级别处理重定向。智能引用将 leaf(non-branch)条目的查找请求重定向到不同的服务器和 DN。因此,它会临时使用 smart 引用作为别名机制,从而导致出现一种复杂而困难的方法来保护目录结构。将引用限制为目录树的后缀或主要分支点,限制了必须管理的引用数量,从而减少了目录的管理开销。
- 考虑安全性影响。访问控制不可跨越引用。即使源自该请求的服务器允许访问条目,智能引用时也向其他服务器发送客户端请求,但客户端应用可能无法被允许访问。此外,客户端的凭据需要在服务器上可用,上面提到了客户端进行客户端身份验证。
6.3.2. 使用链

- 不允许访问远程数据。由于数据库链接可以解决客户端请求,因此数据分布在客户端中完全隐藏。
- 动态管理。可在整个系统一直供客户端应用程序使用时,在系统中添加或删除目录服务的一部分。数据库链接可以临时返回引用到应用程序,直到在目录服务中重新分发条目。这也可以通过后缀本身实现,它可以返回引用而不是将客户端应用程序转发到数据库。
- 访问控制.数据库链接模拟客户端应用,为远程服务器提供适当的授权身份。当不需要访问控制评估时,可以在远程服务器上禁用用户模仿。有关配置数据库链接的更多信息,请参阅 红帽目录服务器管理指南。
6.3.3. 在引用和链之间决定
6.3.3.1. 使用差异
6.3.3.2. 评估访问控制
使用引用执行搜索请求
下图显示了使用参考到服务器的客户端请求:
图 6.11. 使用引用将客户端请求发送到服务器
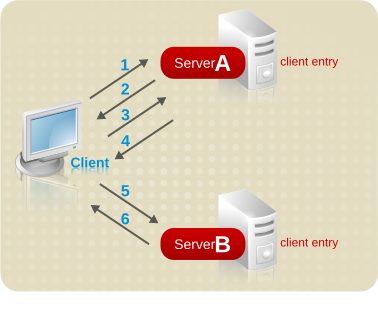
- 客户端应用首先与服务器 A 绑定。
- server A 包含一个用于提供用户名和密码的客户端的条目,因此它会返回一个 bind 接受消息。为使推荐工作,客户端条目必须在 server A 上显示。
- 客户端应用将操作请求发送到服务器 A。
- 但是,Server A 不包含请求的信息。相反,服务器 A 会向客户端应用程序返回一个引用,指示它联系服务器 B。
- 然后,客户端应用程序会向 Server B 发送绑定请求。要成功绑定,服务器 B 还必须包含客户端应用程序的条目。
- 绑定成功,客户端应用程序现在可以将其搜索操作重新提交到 Server B。
使用链执行搜索请求
使用链解决跨服务器复制客户端条目的问题。在链的系统上,搜索请求会多次转发,直到有响应为止。
图 6.12. 使用链将客户端请求发送到服务器
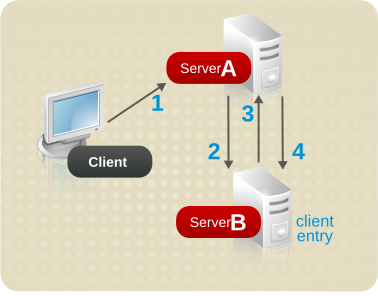
- 客户端应用与服务器 A 绑定,服务器 A 会尝试确认用户名和密码是否正确。
- 服务器 A 不包含与客户端应用程序对应的条目。相反,它包含一个到 Server B 的数据库链接,其中包含客户端的实际条目。服务器 A 将绑定请求发送到服务器 B。
- 服务器 B 将接受响应发送到服务器 A。
- 然后,服务器 A 使用数据库链接处理客户端应用的请求。数据库链接联系位于 Server B 上的远程数据存储,以处理搜索操作。
图 6.13. 使用不同服务器验证客户端和检索数据

- 客户端应用与服务器 A 绑定,服务器 A 会尝试确认用户名和密码是否正确。
- 服务器 A 不包含与客户端应用程序对应的条目。相反,它包含一个到 Server B 的数据库链接,其中包含客户端的实际条目。服务器 A 将绑定请求发送到服务器 B。
- 服务器 B 将接受响应发送到服务器 A。
- 然后,服务器 A 使用另一个数据库链接处理客户端应用的请求。数据库链接联系位于 Server C 上的远程数据存储,以处理搜索操作。
不支持的访问控制
数据库链接不支持以下访问控制:
- 当用户条目位于其他服务器上时,不支持访问用户条目的内容。这包括基于组、过滤器和角色的访问控制。
- 可能会拒绝基于客户端 IP 地址或 DNS 域的控制。这是因为数据库链接在联系远程服务器时模拟客户端。如果远程数据库包含基于 IP 的访问控制,它会使用数据库链接的域而不是原始客户端域来评估它们。
6.4. 使用索引来提升数据库性能
cn.db 的文件包含通用 name 属性的所有索引。
6.4.1. 目录索引类型概述
- presence index - 列出具有特定属性的条目,如
uid。 - equality index - 列出包含特定属性值的条目,如 cn=Babs Jensen。
- 大约索引 - 允许近似(或"类似于"的")搜索。例如,条目可能包含 cn=Babs L. Jensen 的属性值。大约搜索将返回针对 cn~=Babs Jensen、cn~=Babs 和 cn~=Jensen 进行搜索的值。注意大约索引要求使用 ASCII 字符以英文写入名称。
- substring index - 允许搜索条目内的子字符串。例如,搜索 cncategoriesderson 将匹配包含此字符串的通用名称(如 Bill Anderson、Norma Henderson 和 netobserv Sanderson)。
- 国际索引 - 提高了搜索在国际目录中信息的性能。通过将区域设置(internationalization OID)与要索引的属性关联,将索引配置为应用匹配的规则。
- 浏览索引或虚拟列表视图(VLV)索引 - 提高了 web 控制台中条目的显示性能。可以在目录树中的任何分支中创建 浏览索引,以提高显示性能。
6.4.2. 评估索引的成本
- 索引会增加修改条目所需的时间。维护的索引越长,目录服务需要更新数据库所需的时间。
- 索引文件使用磁盘空间。使用更多属性进行索引,会创建更多文件。如果包含长字符串的属性有大约和子字符串的索引,则这些文件可能会快速增长。
- 索引文件使用内存。要更有效地运行,目录服务会将尽可能多的索引文件放在内存中。根据数据库缓存大小,索引文件使用池中可用的内存。大量索引文件需要更大的数据库缓存。
- 创建索引文件需要一些时间。虽然索引文件在搜索过程中节省时间,但维护不必要的索引会浪费时间。请确保仅使用目录服务维护客户端应用程序所需的文件。
第 7 章 设计复制过程
7.1. 复制简介
- 容错和故障转移 - 通过将目录树复制到多个服务器,即使硬件、软件或网络问题也提供了目录服务,即使是硬件、软件或网络问题也会阻止目录客户端应用程序访问特定的目录服务器。客户端被称为另一个目录服务器进行读写操作。注意写入故障切换只能在多层次复制的情况下实现。
- 负载平衡 - 在服务器间复制目录树可减少对任何给定计算机的访问负载,从而改进了服务器响应时间。
- 更高的性能和减少响应时间 - 在用户接近的位置复制目录条目可显著改进了目录响应时间。
- 本地数据管理 - 复制允许本地拥有和管理信息,同时与整个企业的其他目录服务器共享。
7.1.1. 复制概念
- 要复制哪些信息。
- 哪些服务器拥有该信息的主副本,或 读写副本。
- 哪些服务器拥有该信息的只读副本,或 只读副本。
- 当只读副本收到更新请求时,应该会出现什么情况,即它应该引用该请求的服务器。
7.1.1.1. 复制单元
7.1.1.2. 读写和只读副本
7.1.1.3. 供应商和消费者
- 对于 multi-supplier replication,供应商可以将供应商和消费者用作同一读写副本的用户。更多信息请参阅 第 7.2.2 节 “Multi-Supplier Replication”。
供应商
对于任何特定副本,供应商服务器必须:
- 响应从目录客户端读取请求和更新请求。
- 维护副本的状态信息和 changelog。
- 启动到消费者服务器的复制。
消费者
消费者服务器必须:
- 响应读取请求。
- 请参阅对副本的供应商服务器更新请求。
Hub 厂商
在级联复制的特殊情况下,hub 供应商必须:
- 响应读取请求。
- 请参阅对副本的供应商服务器更新请求。
- 启动到消费者服务器的复制。
7.1.1.4. 复制和更改日志
nsslapd-changelogmaxage 或 nsslapd-changelogmaxentries。这些属性会修剪旧的 changelogs,以合理的更改日志大小。
7.1.1.5. 复制协议
- 要复制的数据库。
- 将数据推送到的使用者服务器。
- 复制发生的时间。
- 供应商服务器必须使用的 DN 来绑定(称为 供应商绑定 DN)。
- 连接的保护方式(TLS、启动 TLS、客户端验证、SASL 或简单身份验证)。
- 任何不会被复制的属性(请参阅 第 7.3.2 节 “使用 Fractional Replication 复制复制所选属性”)。
7.1.2. 数据一致性
- 服务器之间有可靠、高速连接。
- 目录服务服务的客户端请求主要是搜索、读取和写入和比较操作,以及相对较少的更新操作。
- 可用网络连接不可靠或间歇性。
- 目录服务服务的客户端请求主要更新操作。
- 需要降低通信成本。
- 在供应商间传播更新操作时会有一个延迟。
- 提供服务更新操作的供应商不会等待第二个供应商在向客户端返回"成功"消息前进行验证。
7.2. 常见复制场景
7.2.1. 单层复制
图 7.1. 单层复制

7.2.2. Multi-Supplier Replication
图 7.2. 简化多层次复制配置
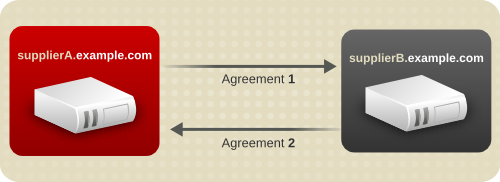
图 7.3. 在简单多Supplier 环境中复制流量
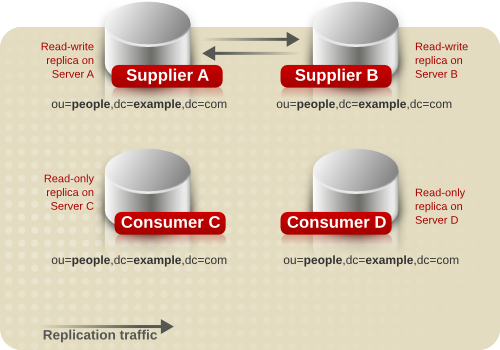
图 7.4. 多层复制配置 A

图 7.5. 配置 B

- 存在多少个供应商
- 其地理位置
- 供应商将用于更新其他位置的服务器的路径
- 不同供应商的拓扑、目录树和模式
- 网络质量
- 服务器负载和性能
- 目录数据所需的更新间隔
7.2.3. cascading Replication
图 7.6. cascading Replication Scenario
图 7.7. 复制流量和更改日志

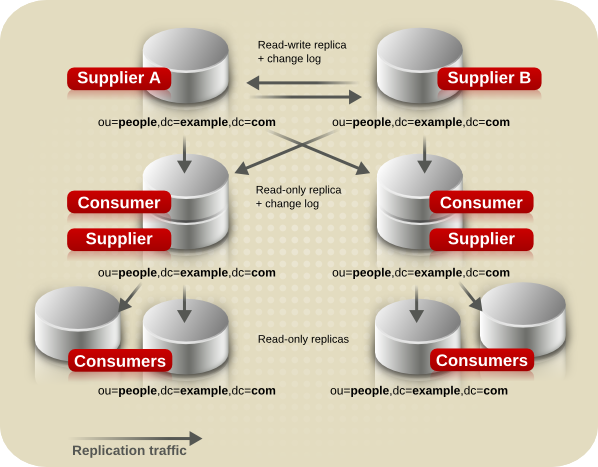
7.2.4. 混合环境
图 7.8. 合并多路和捕获复制
7.3. 定义复制策略
- 评估网络、流量负载和资源对目录服务的资源要求。
- 如果不同位置或部分不同的用户有多个用户,或者一些服务器不安全,则使用部分 复制 来排除敏感或 seldom-modified 信息,以在不损害敏感信息的情况下维持数据完整性。如需更多信息,请参阅 第 7.3.2 节 “使用 Fractional Replication 复制复制所选属性”。
- 如果网络在地理区域扩展,则多个站点有多个目录服务器,本地数据供应商通过多层次复制连接了本地数据供应商。如需更多信息,请参阅 第 7.3.5 节 “跨 Wide-Area 网络复制”。
- 如果高可用性是主要关注的,请在单一站点上创建一个包含多个目录服务器的数据中心。单supplier 复制提供了读取失败,而 multi-supplier 复制则提供了 write-failover。如需更多信息,请参阅 第 7.3.6 节 “使用复制进行高可用性”。
- 如果本地可用性是主要关注,请使用复制将数据分布到位于全球本地办事处的目录服务器。所有信息的一个主要副本可以在单一位置(如公司总部)维护,或者每个本地站点都可以管理与其相关的 DIT 部分。如需更多信息,请参阅 第 7.3.7 节 “使用 Replication 进行本地可用性”。
- 在所有情况下,平衡由目录服务器提供服务的请求负载,并避免网络拥塞。如需更多信息,请参阅 第 7.3.8 节 “使用 Replication 进行负载均衡”。
7.3.1. 执行复制调查
- LAN 和 WAN 的质量可以连接不同的构建或远程站点以及可用带宽的数量。
- 用户的物理位置、每个站点中的用户数量及其使用模式;这就是他们打算如何使用目录服务。
- 访问目录服务的应用程序数量以及读取、搜索的相对百分比,以及比较操作与写入操作。
- 如果消息传递服务器使用 目录,请找出它处理的每个电子邮件消息所执行的操作数量。依赖于目录服务的其他产品通常是身份验证应用程序或子目录应用程序等产品。对于每个,确定目录服务中执行的操作的类型和频率。
- 存储在目录服务中的条目的数量和大小。
7.3.2. 使用 Fractional Replication 复制复制所选属性
- 如果消费者服务器使用较慢的网络进行连接,但不经常更改的属性或更大属性,如
jpegPhoto会导致网络流量减少。 - 如果使用者服务器放置在不受信任的网络中,例如公共互联网,不包括敏感属性,如电话数字,即使服务器的访问控制措施被破坏或机器被攻击者破坏,也不再提供任何级别的保护。
7.3.3. 复制资源要求
- 磁盘用量 - 在供应商服务器中,更改日志在每个更新操作后写入。接收许多更新操作的供应商服务器可能会遇到更多磁盘用量。注意每个供应商服务器都使用单一的 changelog。如果供应商包含多个复制的数据库,则更改日志会更频繁使用,磁盘使用量越高。
- 服务器线程 - 每个复制协议使用一个服务器线程。因此,客户端应用程序可用的线程数量会减少,可能会影响客户端应用程序的服务器性能。
- 文件描述符 - 服务器可用的文件描述符数量会减少更改日志(一个文件描述符)和每个复制协议(每个协议一个文件描述符)。
7.3.4. 管理多容量复制所需的磁盘空间
nsslapd-changelogmaxage设置更改日志中条目可以达到的最长期限;一旦一个条目比这个限制旧,它会被删除。这样会使更改日志无限期地增大。nsslapd-changelogmaxentries设置 changelog 中允许的最大条目数。与nsslapd-changelogmaxage一样,这也会修剪更改日志,但要小心设置。这必须足够大,以允许一组完整的目录信息或多层次复制可能无法正常工作。
nsDS5ReplicaPurgeDelay设置 tombstone (删除)条目和状态信息的最大期限。一旦 tombstone 或 state information 条目早于这个年龄,就可以删除它。这与nsslapd-changelogmaxage属性不同,其中nsDS5ReplicaPurgeDelay值仅适用于 tombstone 和状态信息条目;nsslapd-changelogmaxage适用于 changelog 中的每个条目,包括目录修改。nsDS5ReplicaTombstonePurgeInterval设置服务器运行清除操作的频率。在这个间隔里,Directory 服务器会运行内部操作来清理 changelog 中的 tombstone 和 state 条目。确保最长期限超过复制更新调度的最长期限,或者多层次复制可能无法正确更新副本。
7.3.5. 跨 Wide-Area 网络复制
- 如果跨公共网络(如互联网)执行复制,则强烈建议使用 TLS。这种保护措施可防止停止复制流量。
- 对网络使用 T-1 或更快互联网连接。
- 在创建用于跨域网络复制的协议时,请避免在服务器间持续同步。复制流量可能会消耗大量带宽,并减慢整个网络和互联网连接的速度。
- 初始化消费者时,不会立即初始化消费者;相反,使用文件系统副本初始化速度要快于在线初始化或从文件初始化。有关使用文件系统副本初始化的信息,请参阅 红帽目录服务器管理指南。
7.3.6. 使用复制进行高可用性
7.3.7. 使用 Replication 进行本地可用性
- 保留数据的本地主副本。对于大型的跨国企业来说,这是一个重要的策略,需要仅维护特定国家或地区员工感兴趣的目录信息。拥有本地主副本对于任何企业来说也很重要,因为任何位于部门或机构级别控制数据的任何企业来说也很重要。
- 缓解不可靠或间歇性可用的网络连接。如果出现不可靠的 WAN,则可能会出现间歇性网络连接,如国际网络中发生。
- 要偏移定期,极高的网络负载可能会导致目录服务的性能被严重降低。在具有陈旧网络的企业中,性能可能也会受到影响,在正常的工作时间内可能会遇到这些状况。
7.3.8. 使用 Replication 进行负载均衡
- 通过将用户的搜索活动分散在多个服务器中。
- 将服务器指定给只读活动(只在供应商服务器上发生)。
- 通过将特殊服务器专用于特定的任务,如支持邮件服务器活动。
| 加载类型 | 对象(object)[a] | access/Day[b] | avg.条目大小 | Load |
|---|---|---|---|---|
| 复制 | 100万次 | 100,000 | 1KB | 100Mb/day |
| 远程查找 | 100 | 1,000 | 1KB | 1Mb/day |
[a]
对于复制,对象 指的是数据库中的条目数量。对于远程查找,它指的是访问数据库的用户数量。
[b]
对于复制,Accesses/Day 基于 10% 对需要复制的数据库的变化率。对于远程查找,它基于每日的远程用户的查询。
| ||||
7.3.8.1. 网络负载均衡示例
图 7.9. 在远程办公室管理企业子树

- 为每个办公室选择一个服务器作为本地管理数据的供应商服务器。
- 将本地管理的数据从该服务器复制到远程办公室中对应的供应商服务器。
- 将每个供应商服务器上的目录树(包括从远程办公室提供的数据)复制到至少一个本地目录服务器,以确保目录数据的可用性。对本地管理的后缀使用多supplier 复制,为接收远程服务器数据的主副本的后缀进行级联复制。

7.3.8.2. 用于提高性能的负载平衡示例
- 使用一个目录服务器,其中包含支持 100 万用户的 150 万个条目
- 每个用户每天执行十个目录查找
- 使用一个消息传递服务器,每天处理 2,500万邮件
- 消息传递服务器针对它处理的每个邮件执行五个目录查找
| 访问类型 | 类型数 | 每日访问 | 总访问数 |
|---|---|---|---|
| 用户查找 | 100万次 | 10 | 1,000 万 |
| 电子邮件查找 | 2,500 万 | 5 | 125 million |
| 组合访问 | 135 million | ||
| 总计 | 1.35億(3,125/second) |
- 在一个城市中配置两个目录服务器以处理所有写入流量。此配置假定应该对所有目录数据有单一的控制点。
- 使用这些供应商服务器复制到一个或多个 hub 供应商。目录服务服务的读取、搜索和比较应针对于消费者服务器的请求,从而释放供应商服务器来处理写入请求。
- 使用 hub 供应商将复制到整个企业的本地站点。复制到本地站点有助于平衡服务器的工作负载和 WAN,以及确保目录数据的高可用性。
- 在每个站点,至少复制一次以确保高可用性,至少用于读取操作。
- 使用 DNS sort 以确保本地用户始终找到他们可以用于目录查找的本地目录服务器。
7.3.8.3. Small 站点的 Replication 策略示例
- 整个企业都包含在一个构建中。
- 构建速度很高(每秒100 Mb/秒)和轻量使用的网络。
- 网络非常稳定,服务器硬件和操作系统平台是可靠的。
- 单一服务器可轻松处理站点的负载。
7.3.8.4. 大型站点的复制策略示例
- 企业包含在两种独立构建中。
- 构建之间有较慢的连接,这些连接在正常工作时间内非常忙。
- 在两个构建中选择一个服务器,以包含目录数据的主副本。此服务器应放在构建中,其中包含负责目录数据的主副本的最大人员数量。我们应该将这一构建视为构建 A。
- 在构建 A 中至少复制一次以实现高可用性目录数据。使用多supplier 复制配置来确保写入失败。
- 在第二个构建(Building B)中创建两个副本。
- 如果供应商和消费者服务器之间不需要关闭一致性,请调度复制,使其仅在非高峰期时间进行。
7.4. 使用带有其他目录服务器功能的复制
7.4.1. 复制和访问控制
7.4.2. 复制和目录服务器插件
- 属性唯一插件Attribute Uniqueness Plug-in validate 属性值已添加至本地条目,以确保所有值都是唯一的。但是,这个检查直接在服务器上完成,而不是从其他供应商复制。例如,Example Corp. 要求
mail属性是唯一的,但两个用户同时添加相同的mail属性到两个不同的供应商服务器。只要没有命名冲突,就没有复制冲突,但mail属性不是唯一的。 - 参考完整性插件参考完整性可以和多层次复制一同工作,只要该插件仅在多层次集中的一个供应商上启用。这样可确保仅在其中一个供应商服务器上发生引用完整性更新,并传播到其他供应商服务器。
7.4.3. 复制和数据库链接
图 7.10. 复制链的数据库

7.4.4. 模式复制
- 如果供应商和消费者的 schema 条目都相同,复制操作将继续。
- 如果供应商服务器的模式版本比消费者中存储的版本更新,则供应商服务器会将其架构复制到消费者,然后再继续数据复制。
- 如果供应商服务器的模式版本早于使用者上存储的版本,服务器可能会在复制过程中返回许多错误,因为消费者的 schema 无法支持新的数据。
99user.ldif 文件进行的更改。自定义架构文件以及对自定义架构文件所做的任何更改都不会被复制。
自定义架构
如果标准 99user.ldif 文件用于自定义模式,则这些更改将复制到所有消费者。
7.4.5. 复制和同步
第 8 章 设计同步
8.1. Windows 同步概述
- 用户和组同步.与多倍复制一样,用户和组条目将通过插件同步,默认情况下是启用的。与用于多层次复制的变更记录也用于将更新从 Directory 服务器发送到 Windows 同步对等服务器作为 LDAP 操作。服务器还针对其 Windows 服务器执行 LDAP 搜索操作,将 Windows 条目所做的更改同步到对应的目录服务器条目。
- 密码同步.此应用程序捕获 Windows 用户的密码更改,并通过 LDAPS 将这些更改转发回目录服务器。它必须安装在 Active Directory 机器上。
图 8.1. 同步过程

8.1.1. 同步协议
8.1.2. changelogs
8.2. 支持的 Active Directory 版本
8.3. 规划 Windows 同步
8.3.1. 资源要求
- 磁盘用量 - 更改日志在每个更新操作后写入。接收许多更新操作的服务器可能会看到更多磁盘用量。另外,为所有复制数据库和同步数据库维护单一的 changelog。如果供应商包含多个复制和同步的数据库,则更改日志会更频繁使用,磁盘使用量越高。
- 服务器线程 - 同步协议使用一个服务器线程。
- 文件描述符 - 服务器可用的文件描述符数量会减少更改日志(一个文件描述符)和每个复制与同步协议(每个协议一个文件描述符)。
- LAN 和 WAN 质量可以连接不同的构建或远程站点,以及可用带宽的数量。
- 目录中存储条目的数量和大小。
8.3.2. 为 Changelog 管理磁盘空间
nsslapd-changelogmaxage设置更改日志中条目可以达到的最长期限;一旦一个条目比这个限制旧,它会被删除。这样会使更改日志无限期地增大。nsslapd-changelogmaxentries设置 changelog 中允许的最大条目数。与nsslapd-changelogmaxage一样,这也会修剪更改日志,但要小心设置。这必须足够大,以便完整的目录信息或同步可能无法正常工作。
nsDS5ReplicaPurgeDelay设置 tombstone (删除)条目和状态信息的最大期限。一旦 tombstone 或 state information 条目早于这个年龄,就可以删除它。这与nsslapd-changelogmaxage属性不同,其中nsDS5ReplicaPurgeDelay值仅适用于 tombstone 和状态信息条目;nsslapd-changelogmaxage适用于 changelog 中的每个条目,包括目录修改。nsDS5ReplicaTombstonePurgeInterval设置服务器运行清除操作的频率。在这个间隔里,Directory 服务器会运行内部操作来清理 changelog 中的 tombstone 和 state 条目。确保最长期限超过复制更新调度的最长期限,或者多层次复制可能无法正确更新副本。
8.3.3. 定义连接类型
8.3.4. 考虑数据供应商
8.3.5. 确定要同步的子树
samAccount 和 Directory Server 中的 uid 属性关联。如果一个条目(基于 samAccount/uid 关系)已从同步子树中删除,同步插件请注意,因为它已被删除或移动。这是对条目不再同步的同步插件的信号。该问题是同步过程需要一些配置来确定如何处理该移动条目。同步协议中可以设置三个选项:删除对应的 Directory Server 条目,忽略更改(默认),或者取消同步条目,但保留其他内容。
8.3.6. 与复制环境交互
ou=People,dc=example,dc=com)链接到对应的 Windows 域和子树(cn=Users,dc=test,dc=com)。每个子树都只能同步到其他子树,以避免命名冲突和更改冲突。
图 8.2. 多Supplier 目录服务器 - Windows 域同步

8.3.7. 控制同步方向
oneWaySync 参数,可以创建 uni-directional 同步。此属性定义要发送更改的方向。
from Windows。在这种情况下,在常规同步更新间隔中,Directory 服务器联系 Active Directory 服务器,并发送 DirSync 控制来请求更新。但是,目录服务器不会向其发送任何更改或条目。因此,同步更新包含要发送到和更新目录服务器条目的 Active Directory 更改。
toWindows。Directory 服务器在正常更新中向 Active Directory 服务器发送条目修改,但它不包括 DirSync 控制,以便它不会从 Active Directory 端请求任何更新。
8.3.8. 控制要同步的尝试
- 在 Windows 子树中,只能将用户和组群条目同步到 Directory Server。在创建同步协议时,可以选择在创建新 Windows 用户和组条目时同步它们。如果在 上 将这些属性设置为,则现有 Windows 条目将同步到目录服务器,并在 Windows 服务器中创建的条目与 Directory Server 同步。
- 与 Active Directory 条目一样,只能同步目录服务器中的用户和组群条目。同步的条目必须具有 ntUser 或 ntGroup 对象类和所需属性;忽略所有其他条目。
8.3.9. 确定要同步的目录数据
- 目录用户和员工的联系信息,如电话号码、家和办公室地址以及电子邮件地址。
- 交易合作伙伴、客户以及客户的联系信息。
- 用户软件首选项或软件配置信息。
- 群组信息和组成员资格。只有组成员处于同步后缀中时,才会同步。不在协议范围内的组成员在两端都保持不变;也就是说,它们被列为适当目录服务上的组的成员,而是组条目中的
member属性与同步对等点同步。
8.3.10. 为用户和组群同步 POSIX 属性
ntUser 和 ntGroup 属性,它们会自动添加将其识别为 Windows 帐户,但没有通过同步 POSIX 属性(即使它们存在于 Active Directory 条目中),并且不会在 Directory Server 端添加 POSIX 属性。
uidNumber、gidNumber 和 homeDirectory)在 Active Directory 和 Directory Server 条目之间同步。但是,如果新 POSIX 条目或 POSIX 属性添加到 Directory 服务器中的现有条目中,只有 POSIX 属性才会同步到 Active Directory 对应的条目 中。POSIX 对象类(posixAccount 用于用户,posixGroup 用于组)不会添加到 Active Directory 条目。
8.3.11. 同步密码和安装密码服务
userPassword 属性)。这意味着,即使 Directory Server 用户条目与 Windows 服务器同步,用户条目在 Windows 域(在其它方面)不会激活,这些同步用户也无法登录到域,因为它们没有密码。
passwordTrackUpdateTime 的密码策略属性,它为用户密码最后一次更新记录一个单独的时间戳。这样可以更轻松地同步 Active Directory 和 Directory Server 或其他客户端之间的密码更改。
8.3.12. 定义更新策略
winSyncInterval)或设置不同的更新调度(nsDS5ReplicaUpdateSchedule)来更改此调度。
8.3.13. 编辑同步协议
8.4. Active Directory 和 Directory Server 间同步的元素
ntUniqueId包含对应 Windows 条目的objectGUID属性的值。此属性由同步进程设置,不应手动设置或修改。- 当 Windows 条目同步时,会自动设置
ntUserDeleteAccount,但必须为 Directory Server 条目手动设置。如果ntUserDeleteAccount的值为 true,则在删除 Directory Server 条目时会删除对应的 Windows 条目。 ntDomainUser对应于 Active Directory 条目的samAccountName属性。仅用户条目。- 为同步的 Windows 组自动设置
ntGroupType,但必须在同步前手动在 Directory Server 条目上设置。仅组条目。
givenName 属性与 Active Directory 中的 givenName 属性匹配。由于 Active Directory 和红帽目录服务器中定义的模式稍有不同,所以其他属性在 Active Directory 和 Red Hat Directory Server 之间映射;其中大多数是 Directory Server 中特定于 Windows 的属性。
8.4.1. 用户属性同步目录服务器和 Active Directory
| 目录服务器 | Active Directory |
|---|---|
| cn | name |
| ntUserDomainId | sAMAccountName |
| ntUserHomeDir | homeDirectory |
| ntUserScriptPath | scriptPath |
| ntUserLastLogon | lastLogon |
| ntUserLastLogoff | lastLogoff |
| ntUserAcctExpires | accountExpires |
| ntUserCodePage | codePage |
| ntUserLogonHours | logonHours |
| ntUserMaxStorage | maxStorage |
| ntUserProfile | profilePath |
| ntUserParms | userParameters |
| ntUserWorkstations | userWorkstations |
| cn | physicalDeliveryOfficeName |
| description | postOfficeBox |
| destinationIndicator | postalAddress |
| facsimileTelephoneNumber | postalCode |
| givenName | registeredAddress |
| homePhone | sn |
| homePostalAddress | st |
| Initials | street |
| l | telephoneNumber |
| teletexTerminalIdentifier | |
| manager | telexNumber |
| mobile | title |
| o | userCertificate |
| ou | x121Address |
| pager |
8.4.2. Red Hat Directory Server 和 Active Directory 之间的用户架构差异
8.4.2.1. cn Attributes 的值
cn 属性可以是 multi-valued,而 Active Directory 此属性必须只有一个值。当 Directory Server cn 属性同步时,只有一个值发送到 Active Directory peer。
cn 值添加到 Active Directory 条目,并且该值不是 Directory Server 中 cn 的值之一,则所有 Directory Server cn 值都会用单个 Active Directory 值覆盖。
cn 属性作为其命名属性,其中 Directory 服务器使用 uid。这意味着,如果 Directory Server 中编辑 cn 属性,则可能完全重命名条目。如果该 cn 更改被写入 Active Directory 条目,则该条目将被重命名,并且新命名条目将写回到目录服务器。这只有在 cn 属性同步时才会发生。如果没有同步更改,则不会重命名该条目。
8.4.2.2. 密码策略
8.4.2.3. street 和 streetAddress 的值
streetAddress 用于用户或组的 postal 地址;这是目录服务器使用 street 属性的方式。Active Directory 和 Directory 服务器使用 streetAddress 和 street 属性的方式有两个重要区别:
- 在目录服务器中,
streetAddress是street的别名。Active Directory 也具有street属性,但它是一个单独的属性,它可以保存独立值,而不是streetAddress的别名。 - Active Directory 将
streetAddress和street定义为单值属性,而目录服务器将street定义为多值属性,如 RFC 4519 中指定的。
streetAddress 和 street 属性的不同方法,在 Active Directory 和 Directory Server 中设置地址属性时,需要遵循两个规则:
- Windows Sync 将 Windows 条目中的
streetAddress映射到目录服务器中的street。为避免冲突,不应在 Active Directory 中使用street属性。 - 只有一个目录服务器
street属性值会同步到 Active Directory。如果在 Active Directory 中更改了streetAddress属性,且 Directory Server 中新值尚不存在,则 Directory Server 中的所有street属性值都会替换为新的、单一 Active Directory 值。
8.4.2.4. 对初始属性的限制
initials 属性,Active Directory 对六个字符实施最大长度约束,但 Directory 服务器没有长度限制。如果向 Directory 服务器添加了一个大于 6 个字符的 initials 属性,则该值会在与 Active Directory 条目同步时被修剪。
8.4.3. 在目录服务器和 Active Directory 之间同步组属性
| 目录服务器 | Active Directory | |||
|---|---|---|---|---|
| cn | name | |||
| ntGroupAttributes | groupAttributes | |||
| ntGroupId |
| |||
| ntGroupType | groupType |
| cn | 成员 |
| description | ou |
| l | seeAlso |
8.4.4. Red Hat Directory Server 和 Active Directory 之间的组架构差异
第 9 章 设计安全目录
9.1. 关于安全 Threats
- 未授权访问
- 未授权的篡改
- 拒绝服务
9.1.1. 未授权访问
9.1.2. 未授权的 Tampering
9.1.3. 拒绝服务
9.2. 分析安全性需求
- 如何为用户提供和应用程序,并可访问执行其作业所需的信息。
- 如何保护员工或业务方面的敏感数据。
- 如何为客户提供隐私保证。
- 如何保证信息的完整性。
9.2.1. 确定访问权限
- 尽可能多授予权限,同时仍然保护敏感数据。开放方法需要准确确定哪些数据对业务敏感或至关重要。
- 授予每个类别用户完成其作业所需的最小访问权限。限制的方法需要几乎了解用户内部的每个类别的信息需求,并且可能对机构以外各用户的信息需求。
9.2.2. 确保数据保密性和完整性
- 通过加密数据传输。
- 通过使用证书对数据传输进行签名。
9.2.3. 执行常规审计
9.2.4. Security Needs Analysis 示例
- example.com 内部信息
- 属于公司客户的信息
- 与个人订阅者相关的信息
- 向其自身目录信息提供托管公司(example_a 和 example_b)的目录管理员的访问权限。
- 为托管公司的目录信息实施访问控制策略。
- 为从其家通过 example.com 进行互联网访问的所有单独客户端实施标准访问控制策略。
- 拒绝对 example.com 的公司目录访问所有外部公司。
- 为世界授予 example.com 订阅者目录的读取访问权限。
9.3. 安全方法概述
| 安全方法 | 描述 |
|---|---|
| 身份验证 | 供一个方验证其他身份的方法。例如,客户端在 LDAP 绑定操作期间为 Directory 服务器提供密码。 |
| 密码策略 | 定义密码必须满足的条件,如年龄、长度和语法等。 |
| Encryption | 保护信息隐私。当数据被加密时,它会以仅接收者可以理解的方式进行评分。 |
| Access control | 定制授予不同目录用户的访问权限,并提供指定所需凭证或绑定属性的方法。 |
| 帐户取消激活 | 禁用用户帐户、帐户组或整个域,以便自动拒绝所有身份验证尝试。 |
| 安全连接 | 通过加密 TLS、启动 TLS 或 SASL 连接来保持信息的完整性。如果在传输过程中加密信息,则接收者可决定在传输过程中不会修改它。设置最低安全强因素,从而需要安全连接。 |
| Auditing | 确定目录的安全性是否已被破坏,一个简单的审核方法是查看由 目录维护的日志文件。 |
| SELinux | 使用 Red Hat Enterprise Linux 计算机上的安全策略来限制并控制对目录服务器文件和流程的访问。 |
9.4. 选择适当的验证方法
9.4.1. 匿名和未验证的访问
ldapsearch -x -D "cn=jsmith,ou=people,dc=example,dc=com" -b "dc=example,dc=com" "(cn=joe)"
9.4.2. 简单绑定和安全绑定
userPassword 属性的对象类。这样可确保目录识别绑定 DN 和密码。
- 用户输入唯一标识符,如用户 ID (例如 fchen)。
- LDAP 客户端应用搜索该标识符的目录,并返回相关的可分名称(如 uid=fchen,ou=people,dc=example,dc=com)。
- LDAP 客户端应用使用检索到的区分名称和用户提供的密码绑定到目录。
nsslapd-require-secure-binds 配置属性需要使用 TLS 或 Start TLS 在安全连接中进行简单的密码身份验证。这会有效地加密纯文本密码,使其不能被黑客嗅探。
nsslapd-require-secure-binds 配置属性需要通过安全连接进行简单的密码身份验证,即 TLS 或 Start TLS。此设置还支持其他安全连接,如 SASL 身份验证或基于证书的验证。
9.4.3. 基于证书的身份验证
9.4.4. 代理身份验证
ldapmodify -D "cn=Directory Manager" -W -x -D "cn=directory manager" -W -p 389 -h server.example.com -x -Y "cn=joe,dc=example,dc=com" -f mods.ldif
mods.ldif 文件中应用修改。管理器不需要提供 Joe 的密码才能进行此更改。
9.4.5. 直通身份验证
图 9.1. 简单的传递身份验证过程

图 9.2. PAM 直通身份验证过程
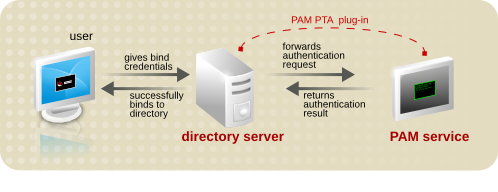
/etc/pam.d/system-auth。
9.4.6. 无密码验证
9.5. 设计帐户锁定策略
nsAccountLock 实现的。当条目包含值为 true 的 nsAccountLock 属性时,服务器会拒绝该帐户的绑定尝试。
- 帐户锁定策略可以与密码策略(第 9.6 节 “设计密码策略”)关联。当用户在指定次数后使用正确的凭证登录时,帐户会被锁定,直到管理员手动解锁它。这样可防止尝试通过重复尝试猜测用户密码来进入该目录的攻击。
- 在存在一定时间后,可以锁定帐户。这可用于控制临时用户(如 interns、学员或季节性工作者)的访问,根据帐户创建时间限制访问时间。或者,如果帐户在上一次登录时间不活动一段时间内,可以在激活用户帐户时创建帐户策略。基于时间的帐户锁定策略通过帐户策略插件来定义,该策略设定目录的全局设置。可以为不同的过期时间和类型创建多个帐户策略子条目,然后通过服务类应用到条目。
9.6. 设计密码策略
9.6.1. 密码策略的工作方式
- 整个目录。这样的策略称为 全局 密码策略。配置并启用后,该策略将应用到 目录中的所有用户,除了启用了本地密码策略的用户条目和那些启用了本地密码策略的用户条目。这可以为所有目录用户定义通用、单一密码策略。
- 目录的特定子树。这种策略称为 子树级别 或 本地密码策略。配置并启用后,策略将应用到指定子树下的所有用户。在托管环境中,为每个托管公司支持不同的密码策略,而不是对所有托管公司强制执行单个策略。
- 目录的特定用户。此类策略 称为用户级别 或 本地密码策略。配置并启用后,策略只会应用到指定用户。这可以为不同的目录用户定义不同的密码策略。例如,指定一些用户每天更改其密码,一些用户每月更改,而所有其他用户每六个月更改一次。
nsslapd-pwpolicy-local 属性。此属性充当交换机,打开和关闭精细密码策略。
ns-newpwpolicy.pl 脚本已弃用。但是,此脚本在 389-ds-base-legacy-tools 软件包中仍然可用。
图 9.3. 密码策略检查过程
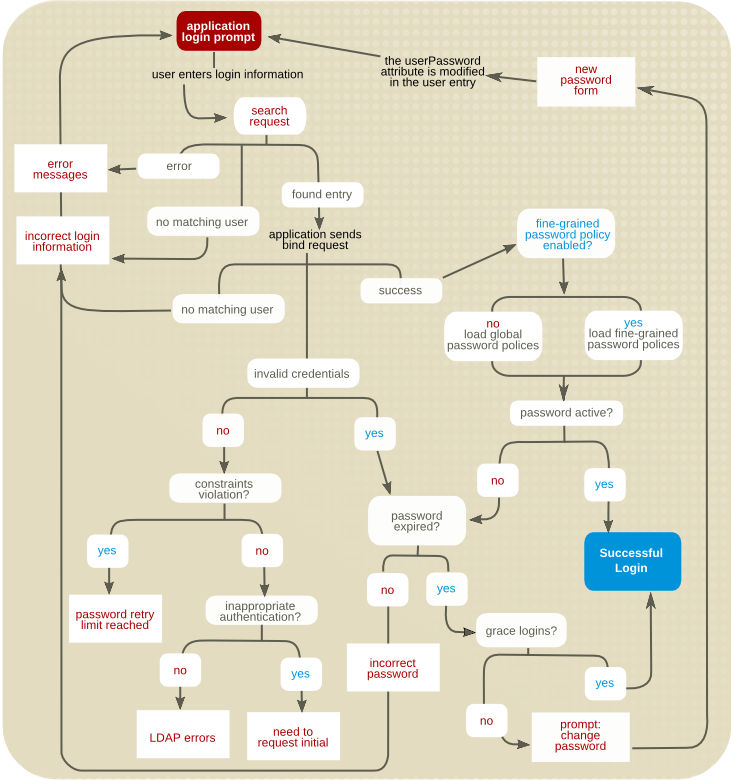
userPassword 属性(在以下部分中介绍),则密码策略检查也会在添加和修改操作过程中发生。
userPassword 的值检查两个密码策略设置:
- 激活密码最短期限策略。如果最短期限要求尚未满足,服务器会返回 constraintViolation 错误。密码更新操作失败。
- 密码历史记录策略已激活。如果
userPassword的新值位于密码历史记录中,或者它与当前密码相同,则服务器会返回 constraintViolation 错误。密码更新操作失败。
userPassword 检查密码策略的值:
- 激活密码最小长度策略。如果
userPassword的新值小于所需的最小长度,服务器会返回 constraintViolation 错误。密码更新操作失败。 - 密码语法检查策略已激活。如果
userPassword的新值与条目的另一个属性相同,服务器会返回 constraintViolation 错误。密码更新操作失败。
9.6.2. 密码策略属性
9.6.2.1. 最大故障数
passwordMaxFailure 参数中设置。
passwordLegacyPolicy 参数中启用旧行为。
9.6.2.2. 重置后更改密码
9.6.2.3. 用户定义的密码
- 它需要大量管理员的时间。
- 因为管理员指定的密码通常更难以记住,用户更有可能写出密码,从而增加发现的风险。
9.6.2.4. 密码过期
9.6.2.5. 过期警告
9.6.2.6. 宽限期登录限制
9.6.2.7. 密码语法检查
passwordCheckSyntax 属性中设置。
uid、cn、sn、gedName、gou、nou 或 mail属性中的任何值。- 密码中所需的最小字符数(
passwordMinLength) - 最小数字数,即零到 9 之间的数字(
passwordMinDigits) - 大写和小写的 ASCII 字母字符数(
passwordMinAlphas) - 最少大写 ASCII 字母字符数(
passwordMinUppers) - 最低小写 ASCII 字母数(
passwordMinLowers) - 最小特殊 ASCII 字符数,如 !@#$ (
passwordMinSpecials) - 最小 8 位字符数(
passwordMin8bit) - 可以立即重复同一字符的次数上限,如 aaabbb (
passwordMaxRepeats) - 每个密码所需的最小字符类别数;类别可以是大写或小写字母、特殊字符、数字或 8 位字符(
passwordMinCategories) - 目录服务器针对
CrackLib字典检查密码(passwordDictCheck) - 目录服务器检查密码是否包含 palindrome (
passwordPalindrome) - 目录服务器可防止设置同一类别(
passwordMaxClassChars)中连续字符的密码。 - 目录服务器可防止设置包含某些字符串的密码(
passwordBadWords) - 目录服务器可防止设置包含管理员定义属性中设置的字符串的密码(
passwordUserAttributes)
9.6.2.8. 密码长度
9.6.2.9. password Minimum Age
passwordHistory 属性一起使用时,不建议用户使用旧密码。
passwordMinAge)属性是 2 天,用户可以在单个会话中重复更改其密码。这可以防止它们通过密码历史记录加以利用,以便他们可以重复利用旧密码。
9.6.2.10. 密码历史
9.6.2.11. 密码存储
- CLEAR,这意味着没有加密。这是唯一可与 SASL Digest-MD5 一起使用的选项,因此使用 SASL 需要 CLEAR 密码存储方案。虽然目录中存储的密码可以通过使用访问控制信息 (ACI) 指令进行保护,但它仍然不是将纯文本密码存储在目录中的最佳选择。
- 安全散列算法 (SHA、SHA-256、SHA-384 和 SHA-512)。这比 SSHA 更安全。
- UNIX CRYPT 算法.这个算法提供与 UNIX 密码的兼容性。
- MD5.这个存储方案比 SSHA 不太安全,但对于需要 MD5 的传统应用程序会包括这个存储方案。
- salt 的 MD5。这个存储方案比普通 MD5 哈希更安全,但仍然比 SSHA 更安全。此存储方案不包含用于新密码,而是有助于将用户帐户从支持 salt 的 MD5 的目录中迁移。
9.6.2.12. 密码最后修改时间
passwordTrackUpdateTime 属性告知服务器最后一次为条目更新密码的时间戳。密码更改时间本身作为操作属性存储在用户条目 pwdUpdateTime 上(与 modifyTimestamp 或 lastModified 操作属性分开)。
9.6.3. 在复制环境中设计密码策略
- 在数据供应商强制密码策略。
- 在复制设置中的所有服务器上强制使用帐户锁定。
- 所有副本都发出警告密码过期。此信息保留在每台服务器上,因此,如果用户依次绑定到多个副本,则用户会多次收到相同的警告。此外,如果用户更改密码,则可能需要过些时间,将此信息过滤到副本。如果用户更改密码,然后立即重新绑定,绑定可能会失败,直到副本注册更改为止。
- 所有服务器上都应该发生相同的绑定行为,包括供应商和副本。始终在每台服务器上创建相同的密码策略配置信息。
- 在多层次环境中,帐户锁定计数器可能无法按预期工作。
9.7. 设计访问控制
- 整个目录。
- 目录的特定子树。
- 目录中特定条目。
- 一组特定条目属性。
- 任何与给定 LDAP 搜索过滤器匹配的条目。
9.7.1. 关于 ACI 格式
target (permission bind_rule)(permission bind_rule)...
9.7.1.1. 目标
targetattr 参数设置为以一个或多个属性为目标。如果没有设置 targetattr 参数,则不会作为任何属性。详情请查看 Red Hat Directory Server Administration Guide 中的对应部分。
9.7.1.2. 权限
| 权限 | 描述 |
|---|---|
| 读 | 指明目录数据是否可以读取。 |
| 写 | 指明目录数据是否可以更改或创建。此权限还允许删除目录数据,但不能删除条目本身。要删除整个条目,用户必须具有删除权限。 |
| 搜索 |
指明能否搜索目录数据。这与读取权限不同,如果作为搜索操作的一部分返回,读取允许查看目录数据。
例如,如果搜索常用名称以及个人房间编号的读取权限,则可以返回房间号码作为通用名称搜索的一部分,但空间编号本身不能用作搜索的主题。使用这个组合以防止人员搜索目录,以查看谁位于特定房间。
|
| 比较 | 指明数据是否可以用于比较操作。比较权限表示搜索功能,但搜索实际目录信息不会返回。相反,会返回一个简单的布尔值,指明比较的值是否匹配。这用于在目录身份验证过程中匹配 userPassword 属性值。 |
| 自我写入 | 仅用于组管理。这个权限可让用户在组中添加或删除自己。 |
| 添加 | 指明是否可以创建子条目。这个权限可让用户在目标条目的下面创建子条目。 |
| 删除 | 指明是否可以删除条目。这个权限可让用户删除目标条目。 |
| Proxy | 表示用户可以使用任何其他 DN( Directory Manager 除外)访问具有此 DN 权利的目录。 |
9.7.1.3. 绑定规则
- 只有绑定操作是从特定 IP 地址(IPv4 或 IPv6)或 DNS 主机名到达时。这通常用于强制从给定计算机或网络域进行所有目录更新。
- 如果个人匿名绑定。为匿名绑定设置权限也意味着,权限也适用于绑定到该目录的任何人。
- 对于成功绑定到该目录的任何人。这可在阻止匿名访问时进行常规访问。
- 只有客户端绑定为条目的直接父项时。
- 只有该人绑定了满足特定 LDAP 搜索条件的条目。
- 父.如果 bind DN 是即时父条目,则绑定规则为 true。这意味着,可以授予特定权限,允许目录分支点管理其即时子条目。
- 自我.如果 bind DN 与请求访问的条目相同,则绑定规则为 true。可以授予特定权限以允许个人更新他们自己的条目。
- 所有.对于成功绑定到该目录的任何人,绑定规则为 true。
- Anyone.对于每个人,绑定规则都为 true。这个关键字用于允许或拒绝匿名访问。
9.7.2. 设置权限
9.7.2.1. Precedence Rule
9.7.2.2. 允许或拒绝访问
uid 属性的权限。或者,以以下方式编写允许写入访问的两个访问规则:
- 创建一个规则,允许向每个属性写入特权,但
uid属性除外。此规则应适用于每个人。 - 创建一个规则,允许对
uid属性进行写入特权。此规则应仅应用于 Directory 管理员组的成员。
9.7.2.3. 当拒绝访问
- 有一个大型目录树,其中包括复杂的 ACL。为安全起见,可能需要突然拒绝对特定用户、组或物理位置的访问。不必花费时间仔细检查现有的 ACL 以了解如何适当限制允许权限,而是临时设置显式拒绝特权,直到有时间进行分析。如果 ACL 变得很复杂,对于长远来讲,使用拒绝 ACI 只会添加管理的开销。在可能的情况下,尽快取消相关的 ACL 以避免显式拒绝特权,然后简化整体访问控制方案。
- 访问控制应该基于周中的一天或一天中的一个小时。例如,所有写入活动都可以在下午 11:00 时拒绝。(2300 到周一至周一的上午 1:00.(0100).从管理的角度来看,管理一个基于时间的 ACI 更容易,其明确限制此类的基于时间的访问,而不是搜索所有 allow-for-write ACIs 并在这一时间段内限制它们的范围。
- 在委派目录管理机构到多个人员时,应限制特权。要允许一个人或一组人管理目录树的某些部分,而无需修改树的某些方面,请使用明确拒绝特权。例如,要确保 Mail Administrators 不允许对通用 name 属性的写访问,请设置可明确拒绝对常见 name 属性的写入访问权限的 ACI。
9.7.2.4. Place Access Control Rules 的位置
9.7.2.5. 使用过滤的访问控制规则
organizationalUnit 属性的 entry 的读访问权限允许设置为 marketing。
- 在每个用户的目录条目上创建一个名为
publishHomeContactInfo的属性。 - 设置一个访问控制规则,仅针对其
publishHomeContactInfo属性设为 true 的条目授予对homePhone和homePostalAddress属性的读取访问权限。使用 LDAP 搜索过滤器来表达此规则的目标。 - 允许目录用户将自己的
publishHomeContactInfo属性的值更改为 true 或 false。这样,目录用户可以决定是否公开此信息。
9.7.3. 查看 ACI:获取 Effective Rights
- 管理员可以将 get effective rights 命令用于分钟的访问控制,例如允许特定组或用户访问条目并限制其他组。例如,QA Managers 组的成员可以搜索和读取
标题和salary等属性,但只有 HR Group 成员具有修改或删除它们的权限。 - 用户可以使用 get effective rights 选项来确定他们可以在自己的个人条目上查看或修改哪些属性。例如,用户应该有权访问
homePostalAddress和cn等属性,但可能只具有对title和salary的读取访问权限。
-E 交换机执行的 ldapsearch 返回特定条目的访问控制作为正常搜索结果的一部分。以下搜索显示了用户 Ted Morris 必须对其个人条目的权限:
ldapsearch -x -p 389 -h server.example.com -D "uid=tmorris,ou=people,dc=example,dc=com" -W -b "uid=tmorris,ou=people,dc=example,dc=com" -E !1.3.6.1.4.1.42.2.27.9.5.2:dn:uid=tmorris,ou=people,dc=example,dc=com "(objectClass=*)"
version: 1
dn: uid=tmorris,ou=People,dc=example,dc=com
givenName: Ted
sn: Morris
ou: Accounting
ou: People
l: Santa Clara
manager: uid=dmiller,ou=People,dc=example,dc=com
roomNumber: 4117
mail: tmorris@example.com
facsimileTelephoneNumber: +1 408 555 5409
objectClass: top
objectClass: person
objectClass: organizationalPerson
objectClass: inetOrgPerson
uid: tmorris
cn: Ted Morris
userPassword: {SSHA}bz0uCmHZM5b357zwrCUCJs1IOHtMD6yqPyhxBA==
entryLevelRights: vadn
attributeLevelRights: givenName:rsc, sn:rsc, ou:rsc, l:rscow, manager:rsc, roomNumber:rscwo, mail:rscwo, facsimileTelephoneNumber:rscwo, objectClass:rsc, uid:rsc, cn:rsc, userPassword:woentryLevelRights 所示。他可以读取、搜索、比较、自我修改或自我删除位置(l)属性,但仅对其密码进行自我写入和自我删除权限,如 attributeLevelRights 结果所示。
userPassword 值,则以后对上述条目的有效权限搜索不会返回 userPassword 的任何有效权限,即使可以允许自助和自我删除权利。同样,如果添加了 street 属性读取、比较和搜索权利,则 street: rsc 将出现在 attributeLevelRights 结果中。
ldapsearch -x -E !1.3.6.1.4.1.42.2.27.9.5.2:dn:uid=scarter,ou=people,dc=example,dc=com "(objectclass=*)" "*"ldapsearch -x -E !1.3.6.1.4.1.42.2.27.9.5.2:dn:uid=scarter,ou=people,dc=example,dc=com "(objectclass=*)" "+"9.7.4. 使用 ACI:某些 Hint 和 Tricks
- 最小化目录中的 ACI 数量。虽然目录服务器可以评估超过 50,000 ACI,但很难管理大量 ACI 语句。大量 ACI 可让人工管理员立即决定特定客户端可用的目录对象。目录服务器使用宏最小化目录中的 ACI 数量。宏是用于在 ACI 中代表 DN 或 DN 的部分占位符。使用 宏代表 ACI 或绑定规则部分或两者的目标部分中的 DN。有关宏 ACI 的更多信息,请参阅红帽目录服务器管理指南中的" 管理访问控制"章节。
- 平衡允许和拒绝权限。虽然默认规则是拒绝对任何没有被特别授予访问权限的用户的访问,但最好使用一个命令 ACI 来减少 ACI 的数量,以便访问树的根,以及少量拒绝 ACI 条目。这种情境可避免使用多个 allow ACI 来接近leaf 条目。
- 识别任何给定 ACI 上属性的最小集合。在允许或拒绝对象中属性子集的访问时,确定最小列表是允许的属性还是拒绝的属性集合。然后,指定 ACI,以便它只需要管理最小列表。例如,person 对象类包含大量属性。要允许用户仅更新其中一个或两个属性,请编写 ACI,以便仅允许这些几个属性进行写入访问。但是,要允许用户更新除一或两个属性以外的所有属性,请创建 ACI,以便它允许对所有内容进行写入访问,但有几个命名的属性。
- 谨慎使用 LDAP 搜索过滤器。搜索过滤器不会直接命名管理访问权限的对象。因此,它们的使用可能会导致意外的结果。当目录变得更为复杂时,这尤其如此。在 ACI 中使用搜索过滤器前,使用同一过滤器运行一个 ldapsearch 操作,以明确更改的结果的含义。
- 不要在目录树的不同部分中重复 ACI。针对重叠 ACI 的保护。例如,如果目录根点上有一个 ACI,则允许组对
commonName和givenName属性的写入访问权限,而另一个 ACI 则仅允许对commonName属性执行同一组写入权限,然后考虑对 ACI 进行修改,以便只有一个控制授予组的写入访问权限。随着目录的日益复杂,意外的 ACI 的风险很快会增加。通过避免 ACI 重叠,安全性管理变得更加容易,同时可能会减少包含在目录中的 ACI 总数。 - 名称 ACI.在命名 ACI 是可选的时,为每个 ACI 提供简短的、有意义的名称有助于管理安全模型。
- 在目录中尽可能地对 ACI 进行分组。尝试将 ACI 放置限制为目录根点和主要目录分支点。对 ACI 进行分组有助于管理 ACI 的总列表,并帮助保持目录中的 ACI 总数最少。
- 避免使用双引号,例如,如果绑定 DN 不等于 cn=Joe 时拒绝写入。尽管此语法对于服务器是完全可以接受的,但它对于人类管理员来说令人困惑。
9.7.5. 将 ACI 应用到根 DN(目录管理器)
dse.ldif 文件中定义,而不是在常规用户数据库中定义,因此 ACI 目标不包括该用户。
- 基于时间的访问控制用于时间范围,如 8a.m 到 5p.m。(转至 1700)。
- day-of-week 访问控制,因此仅在明确定义的天数时允许访问
- IP 地址规则,其中只有指定的 IP 地址、域或子网被显式允许或拒绝
- 主机访问规则,其中只有指定的主机名、域名或子域被显式允许或拒绝
9.8. 加密数据库
9.9. 保护服务器连接
- 传输层安全性(TLS)为了通过网络提供安全通信,目录服务器可以在传输层安全(TLS)上使用 LDAP。TLS 可以与来自 RSA 的加密算法一起使用。为特定连接选择的加密方法是客户端应用程序和目录服务器之间的协商结果。
- 启动 TLS。目录服务器也支持启动 TLS,这是通过常规的未加密 LDAP 端口发起传输层安全(TLS)连接的方法。
- 简单身份验证和安全层(SASL)SASL 是安全框架,这意味着它设置一个系统,允许不同的机制向服务器验证用户,这取决于客户端和服务器应用程序中启用了哪些机制。它还可在客户端和服务器之间建立一个加密的会话。在目录服务器中,SASL 与 GSS-API 一起使用以启用 Kerberos 登录,并可用于几乎所有服务器到服务器连接,包括复制、链接和通过传递身份验证。(SASL 无法与 Windows 同步一起使用。)
9.10. 使用 SELinux 策略
- Directory 服务器的 dirsrv_t
- SNMP 的 dirsrv_snmp_t
图 9.4. 编辑目录服务器文件标签

- 每个实例的文件和目录都带有特定的 SELinux 上下文。( Directory Server 使用的大多数主要目录具有所有本地实例的子目录,无论多少次,一个策略都轻松应用到新实例。)
- 每个实例的端口使用特定的 SELinux 上下文标记。
- 所有目录服务器进程都在适当的域中进行限制。
- 每个域具有特定的规则,它们定义域授权了哪些操作。
- SELinux 策略中没有指定的访问权限将拒绝实例。
9.11. 其他安全资源
- 了解和部署 LDAP 目录服务.T. Howes, M. Smith, G. am, Macmillan Technical Publishing, 1999.
- SecurityFocus.com http://www.securityfocus.com
- 计算机出现响应团队(CERT)协调中心 http://www.cert.org
第 10 章 目录设计示例
10.1. 设计示例:本地企业
10.1.1. 本地企业数据设计
- Corp. 的 目录将由消息传递服务器、Web 服务器、日历服务器、人工资源应用程序和白页应用程序使用。
- 消息传递服务器对
uid、mailServerName和mailAddress等属性执行精确搜索。为提高数据库性能,example Corp. 将维护这些属性的索引,以支持通过消息传递服务器搜索。有关使用索引的详情请参考 第 6.4 节 “使用索引来提升数据库性能”。 - 空白页面应用程序会频繁搜索用户名和电话号码。因此,该目录需要能够频繁地子字符串、通配符和 fuzzy 搜索,后者返回大量结果。示例 Corp. 决定维护
cn,sn, 和givenName属性的存在、相等、大约和子字符串索引,以及telephoneNumber属性的 presence, equality, 和 substring 索引。 - 示例 Corp. 的目录维护用户和组信息,以支持整个组织内部署的基于 LDAP 服务器的 Intranet。大多数 Example Corp. 的用户和组信息将由一组目录管理员集中管理。但是,Example Corp. 还希望电子邮件信息由独立的邮件管理员组管理。
- 企业计划将来支持公钥基础架构(PKI)应用程序,如 S/MIME 电子邮件,因此需要准备好将用户的公钥证书存储在目录中。
10.1.2. 本地企业架构设计
userCertificate 和 uid (userID)属性,这两个属性都由 Example Corp. 目录支持。
exampleID 属性。此属性包含分配给每个 Example Corp. staff 的特殊员工号码。
10.1.3. 本地目录树设计
- 目录树的根是 Example Corp.'s Internet 域名:
dc=example,dc=com。 - 目录树有四个分支点:
ou=people,ou=groups,ou=roles,和ou=resources。 - 所有 Example Corp. 的人条目都在
ou=people分支下创建。人员条目是个人、organizationalPerson、inetOrgPerson 和 examplePerson 对象类的所有成员。uid属性唯一标识每个条目的 DN。例如,Example Corp. 包含 Babs Jensen (uid=bjensen)和 Emily Stanton (uid=estanton)的条目。 - 他们创建了三个角色,为示例企业中的每个部门创建一个角色:销售、营销和会计。每个人条目都包含一个 role 属性,用于标识该人员所属的部门。example Corp. 现在可以根据这些角色创建 ACI。有关角色的更多信息,请参阅 第 4.3.2 节 “关于角色”。
- 它们在
ou=groups分支下创建两个组分支。第一个组cn=administrators包含管理目录内容的目录管理员的条目。第二个组cn=messaging admin含有管理邮件帐户的邮件管理员的条目。此组对应于 messaging 服务器使用的管理员组。示例 Corp. 确保它为消息传递服务器配置的组与为 Directory 服务器创建的组不同。 - 它们在
ou=resources分支下创建两个分支,一个用于会议房间(ou=conference rooms),另一个用于办公室(ou=offices)。 - 它们创建 类服务(CoS),根据条目是否属于管理组,为
mailquota属性提供值。这个 CoS 为管理员提供了 100GB 的邮件配额,而普通示例公司。员工拥有 5GB 邮件配额。有关服务类的更多信息,请参阅 第 5.3 节 “关于服务类”。
图 10.1. 示例公司的目录树.

10.1.4. 本地 Enterprise Topology 设计
10.1.4.1. 数据库拓扑
根后缀 信息存储在第三个数据库(DB3)中。图 10.2 “Corp 的数据库拓扑.” 中演示了这一点。
图 10.2. Corp 的数据库拓扑.
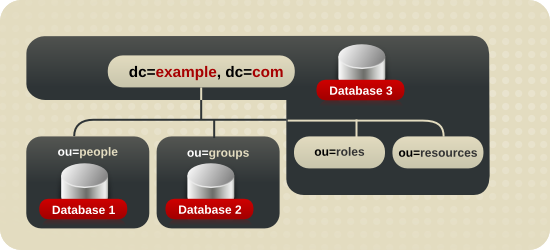
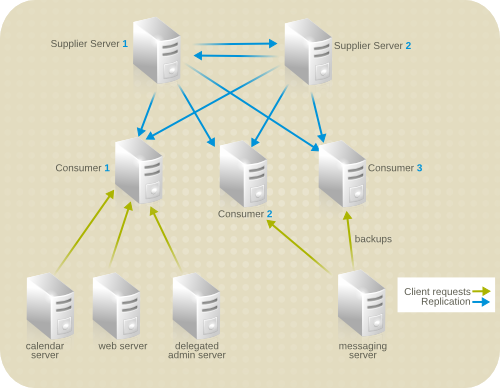
图 10.3. 示例公司的服务器拓扑.
10.1.5. 本地企业复制设计
10.1.5.1. 供应商架构
图 10.4. 企业供应商架构示例.

10.1.5.2. 供应商消费者架构
图 10.5. 企业示例供应商和消费者架构.
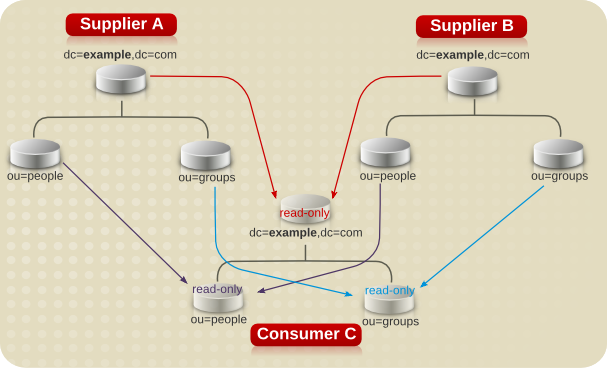
10.1.6. 本地企业安全设计
- 它们创建一个 ACI,使员工能够修改自己的条目。用户可以修改除
uid、管理器和部门属性以外的所有属性。 - 为了保护员工数据的隐私,他们会创建一个 ACI,仅允许员工及其经理查看员工的主页地址和电话号码。
- 它们在目录树的根目录处创建一个 ACI,允许两个管理员对适当的目录权限进行分组。目录管理员组需要对该目录具有完全访问权限。消息传递管理员组需要对 mailRecipient 和 mailGroup 对象类以及 mailGroup 对象类以及
mail属性的访问。示例 Corp. 还授予消息传递管理员组write、delete,并将权限添加到组子目录以创建邮件组。 - 它们在目录树的根目录处创建常规 ACI,允许匿名访问读取、搜索和比较访问。这个 ACI 拒绝对密码信息进行匿名写入访问。
- 为了防止服务器拒绝服务攻击和不当使用,它们会根据要绑定的目录客户端的
DN设置资源限值。示例 Corp. 允许匿名用户在响应搜索请求时收到 100 个条目,以响应搜索请求、消息管理用户接收 1,000 个条目,以及目录管理员获得无限个条目。有关根据绑定 DN 设置资源限值的更多信息,请参阅 红帽目录服务器管理员指南中的"用户帐户管理"一章。 - 它们会创建一个密码策略,指定密码必须至少为 8 个字符,并在 90 天后过期。有关密码策略的更多信息,请参阅 第 9.6 节 “设计密码策略”。
- 它们创建一个 ACI,为财务角色成员提供对所有付费信息的访问权限。
10.1.7. 本地企业操作决策
- 每晚备份数据库。
- 使用 SNMP 监控服务器状态。有关 SNMP 的更多信息,请参阅 红帽目录服务器管理员指南。
- 自动轮转访问和错误日志。
- 监控错误日志,以确保服务器按预期执行。
- 监控访问日志到屏幕,以查看应索引的搜索。
10.2. 设计示例:多企业及其 Extranet
10.2.1. 跨性企业数据设计
- 消息传递服务器用于为大多数 Example Corp. 站点提供电子邮件路由、交付和读取服务。企业服务器提供文档发布服务。所有服务器均在 Red Hat Enterprise Linux 7 上运行。
- 示例 Corp. 需要允许本地管理数据。例如,欧洲站点负责管理目录的欧洲分支。这也意味着,欧洲负责其数据的主副本。
- 由于 Example Corp. 的办公室的地理分布,因此目录需要每天 24 小时提供给用户和应用程序。
- 许多数据元素需要容纳多种不同语言的数据值。注意所有数据都使用 UTF-8 字符集;任何其他字符集都违反了 LDAP 标准。
- 部分供应商需要登录到示例 Corp. 的 目录,以便管理其有 Example Corp 的合同。部分供应商依赖于用于身份验证的数据元素,如名称和用户密码。
- 示例企业的合作伙伴将使用目录查找合作伙伴网络中人员的联系详情,如电子邮件地址和电话号码。
10.2.2. 跨性企业架构设计
exampleSupplierID 属性。此属性包含由 Example Corp 分配的唯一 ID。国际每个自治区部分供应商。
examplePartnerID 属性。此属性包含由 Example Corp 分配的唯一 ID。国际每个交易合作伙伴。
10.2.3. 多企业目录树设计
- 目录树的根目录是
dc=com后缀。在此后缀下,Example Corp. 创建两个分支。一个分支(dc=exampleCorp,dc=com),包含 Example Corp 的内部数据。国际.另一个分支dc=exampleNet,dc=com包含 extranet 的数据。 - intranet 的目录树(在
dc=exampleCorp,dc=com)有三个主要分支,各自对应于 Example Corp. 具有办事处的其中一个区域。这些分支使用l(本地性)属性来标识。 dc=exampleCorp,dc=com下的每个主要分支模拟 Example Corp 的原始目录树设计。在每个地区下,Example Corp. 创建一个ou=people、ou=groups、ou=roles和ou=resources分支。有关这个目录树设计的更多信息,请参阅 图 10.1 “示例公司的目录树.”。- 在
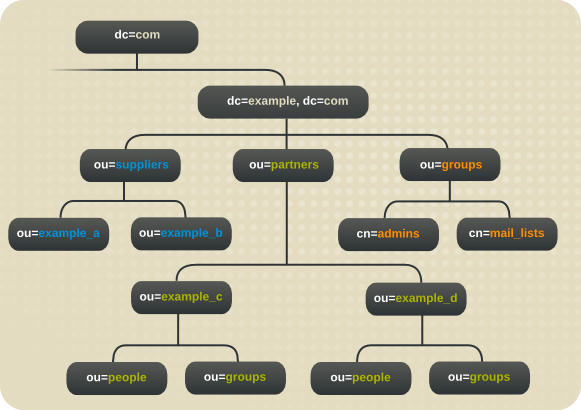
dc=exampleNet,dc=com分支下,Example Corp. 创建三个分支。供应商的一个分支(o=suppliers)、合作伙伴(o= partners)的一个分支,另一个用于组(ou=groups)。 - extranet 的
ou=groups分支包含 extranet 管理员的条目,以及用于邮件列表,供合作伙伴订阅有关 automobile 部分 manufacturing 中的最新信息。
图 10.6. 示例公司的基本目录树.国际
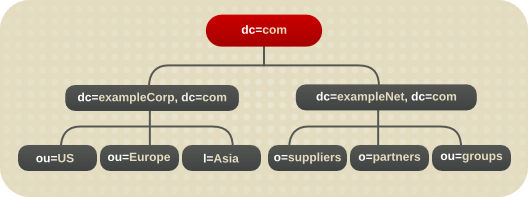
图 10.7. 示例公司的目录树.国际 Intranet
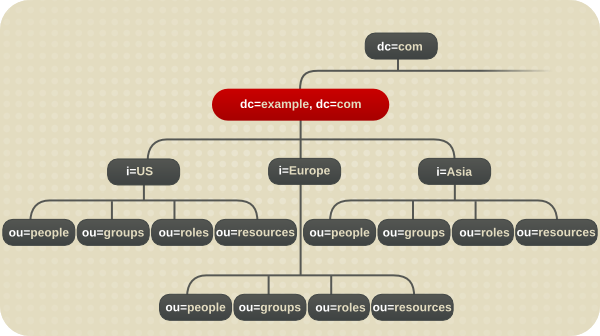
l=Asia 条目的条目会出现在 LDIF 中,如下所示:
dn: l=Asia,dc=exampleCorp,dc=com objectclass: top objectclass: locality l: Asia description: includes all sites in Asia
图 10.8. 示例公司的目录树.国际 Extranet
10.2.4. 跨性企业拓扑设计
10.2.4.1. 数据库拓扑
图 10.9. Corp 的数据库拓扑.欧洲
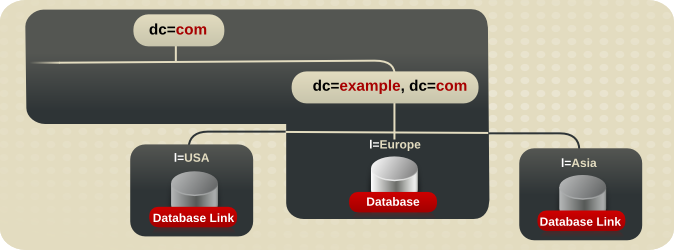
l=US 分支下数据的欧洲服务器由 Austin, Texas 的服务器上的数据库链接串联。有关数据库链接和链的详情,请参考 第 6.3.2 节 “使用链”。
dc=exampleCorp,dc=com 和 root 条目 dc=com 的数据的主副本存储在 l=Europe 数据库中。
o=suppliers 数据的主副本存储在数据库 1 (DB1)中,针对 o= partners 存储在数据库 2 (DB2)中,而 ou=groups 则存储在数据库三(DB3)中。
图 10.10. Corp 的数据库拓扑.国际 Extranet

10.2.4.2. 服务器拓扑
图 10.11. 示例公司的服务器拓扑.欧洲
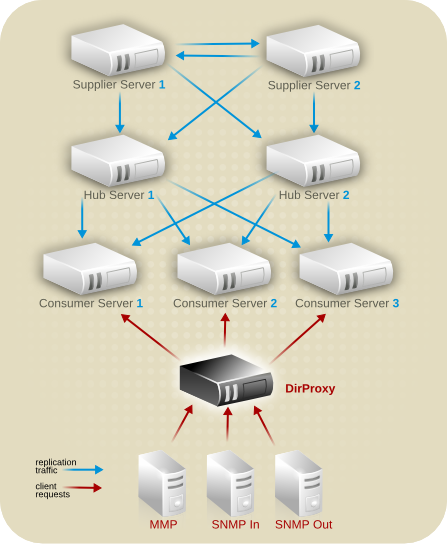
图 10.12. 示例公司的服务器拓扑.国际 Extranet

10.2.5. 跨性企业复制设计
- 数据将在本地管理。
- 网络连接质量因站点而异。
- 数据库链接将用于连接远程服务器上的数据。
- 包含数据的只读副本的 hub 服务器将用于复制数据到消费者服务器。
10.2.5.1. 供应商架构
dc=exampleCorp,dc=com 和 dc=com 信息:
图 10.13. 企业供应商架构示例.欧洲
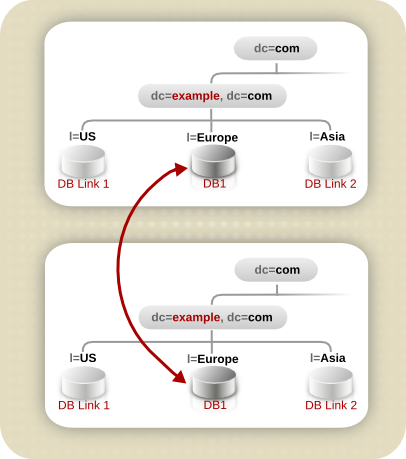
图 10.14. 示例公司的多层次复制设计.欧洲和示例公司.US
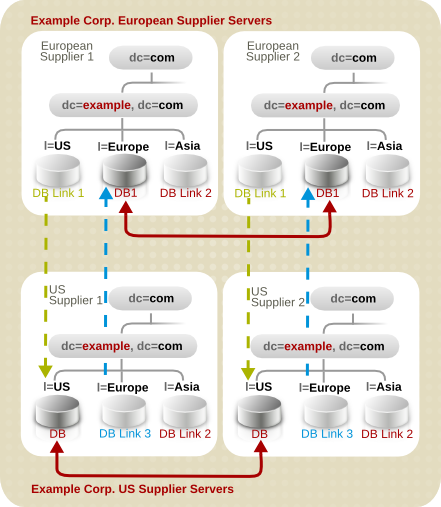
10.2.6. 跨性企业安全设计
- 示例 Corp. 将常规 ACI 添加到内部的根目录中,在每个国家/地区中创建更严格的 ACI,以及各个国家下的分支。
- Corp. 决定使用宏 ACI 来最小化目录中的 ACI 数量。示例 Corp. 使用宏代表 ACI 目标中的 DN 或绑定规则部分。当目录获得传入 LDAP 操作时,ACI 宏与 LDAP 操作目标的资源匹配。如果存在匹配项,则宏替换为目标资源的 DN 值。有关宏 ACI 的更多信息,请参阅 红帽目录服务器管理员指南。
- Corp. 决定对所有 extranet 活动使用基于证书的身份验证。当人们登录到 extranet 时,他们需要一个数字证书。目录用于存储证书。由于 目录存储了证书,因此用户可以通过查找保存在 目录中的公钥来发送加密的电子邮件。
- 示例 Corp. 创建一个 ACI,用于禁止对 extranet 的匿名访问。这样可防止 extranet 拒绝服务攻击。
- 示例 Corp. 希望更新目录数据,使其仅来自 example Corp. 托管的应用程序。这意味着,使用 extranet 的合作伙伴和供应商只能使用 Example Corp 提供的工具。将 extranet 用户限制为 Example Corp. 的首选工具允许 example Corp. 管理员使用审计日志跟踪目录的使用,并限制 Example Corp 外部的 extranet 用户可以引入的问题类型。国际.
附录 A. 目录服务器 RFC 支持
A.1. LDAPv3 功能
- 技术规范路线图(RFC 4510)
- 这是一个跟踪文档,不包含要求。
- 协议(RFC 4511)
- 支持。例外:
- RFC 4511 第 4.4.1 节.请注意 Disconnection :Directory 服务器在这种情况下终止连接。
- RFC 4511 第 4.5.1.3 节:SearchRequest.derefAliases 不支持 LDAP 别名。
- 目录信息模型(RFC 4512)
- 支持。例外:
- RFC 4512 第 2.4.2 节.结构化对象类 :目录服务器支持多个结构对象类的条目。
- RFC 4512 第 4.1.2 节:attribute Types :不支持属性类型
COLLECTIVE。
请注意,RFC 4512 启用 LDAP 服务器不支持之前列出的异常。详情请查看 RFC 4512 第 7.1 部分。服务器指南. - 验证方法和安全性机制(RFC 4513)
- 支持。
- 可辨识名称的字符串(RFC 4514)
- 支持。
- 搜索过滤器的字符串(RFC 4515)
- 支持。
- 统一资源查找器(RFC 4516)
- 支持。但是,这个 RFC 主要侧重于 LDAP 客户端。
- 语法和匹配规则(RFC 4517)
- 支持。例外:
directoryStringFirstComponentMatchintegerFirstComponentMatchobjectIdentifierFirstComponentMatchobjectIdentifierFirstComponentMatchkeywordMatchwordMatch
- 国际化的字符串准备(RFC 4518)
- 支持。
- 用户应用的模式(RFC 4519)
- 支持。
A.2. 验证方法
- 匿名 SASL 机制(RFC 4505)
- 不支持。请注意,RFC 4512 不需要
ANONYMOUSSASL 机制。但是,Directory 服务器支持 LDAP 匿名绑定。 - 外部 SASL 机制(RFC 4422)
- 支持。
- 纯 SASL 机制(RFC 4616)
- 不支持。请注意,RFC 4512 不需要
PLAINSASL 机制。但是,Directory 服务器支持 LDAP 匿名绑定。 - SecurID SASL Mechanism(RFC 2808)
- 不支持。但是,如果出现 Cyrus SASL 插件,Directory 服务器就可以使用它。
- Kerberos V5(GSSAPI)SASL 机制(RFC 4752)
- 支持。
- CRAM-MD5 SASL 机制(RFC 2195)
- 支持。
- 摘要-MD5 SASL 机制(RFC 2831)
- 支持。
- 一次性密码 SASL 机制(RFC 2444)
- 不支持。但是,如果出现 Cyrus SASL 插件,Directory 服务器就可以使用它。
A.3. X.509 证书架构和属性支持
- X.509 证书的 LDAP 架构定义(RFC 4523)
- 属性类型和对象类:支持的.
- 语法:不支持。目录服务器使用二进制和八位字节语法。
- 匹配规则:不支持。
附录 B. 修订历史记录
| 修订历史 | |||
|---|---|---|---|
| 修订 11.5-1 | Tue May 10 2022 | ||
| |||
| 修订 11.4-1 | Tue Nov 09 2021 | ||
| |||
| 修订 11.3-1 | Tue May 11 2021 | ||
| |||
| 修订 11.2-1 | Tue Nov 03 2020 | ||
| |||
| 修订 11.1-1 | Tue Apr 28 2020 | ||
| |||
| 修订历史 | |||
|---|---|---|---|
| 修订 11.0-1 | Thu Nov 21 2019 | ||
| |||