Hibernate Search Reference Guide
for use with JBoss Enterprise Application Platform 5 Common Criteria Certification
Edition 5.1.0
Copyright © 2011 Red Hat, Inc
Abstract
Preface
Chapter 1. Getting started
1.1. System Requirements
| Java Runtime | A JDK or JRE version 5 or greater. You can download a Java Runtime for Windows/Linux/Solaris here. |
| Hibernate Search | hibernate-search.jar and all runtime dependencies from the lib directory of the Hibernate Search distribution. Please refer to README.txt in the lib directory to understand which dependencies are required. |
| Hibernate Core | This instructions have been tested against Hibernate 3.3.x. You will need hibernate-core.jar and its transitive dependencies from the lib directory of the distribution. Refer to README.txt in the lib directory of the distribution to determine the minimum runtime requirements. |
| Hibernate Annotations | Even though Hibernate Search can be used without Hibernate Annotations the following instructions will use them for basic entity configuration (@Entity, @Id, @OneToMany,...). This part of the configuration could also be expressed in xml or code. However, Hibernate Search itself has its own set of annotations (@Indexed, @DocumentId, @Field,...) for which there exists so far no alternative configuration. The tutorial is tested against version 3.4.x of Hibernate Annotations. |
1.2. Using Maven
pom.xml or settings.xml:
Example 1.1. Adding the JBoss maven repository to settings.xml
<repository> <id>repository.jboss.org</id> <name>JBoss Maven Repository</name> <url>http://repository.jboss.org/maven2</url> <layout>default</layout> </repository>
Example 1.2. Maven dependencies for Hibernate Search
<dependency> <groupId>org.hibernate</groupId> <artifactId>hibernate-search</artifactId> <version>3.1.0.GA</version> </dependency> <dependency> <groupId>org.hibernate</groupId> <artifactId>hibernate-annotations</artifactId> <version>3.4.0.GA</version> </dependency> <dependency> <groupId>org.hibernate</groupId> <artifactId>hibernate-entitymanager</artifactId> <version>3.4.0.GA</version> </dependency> <dependency> <groupId>org.apache.solr</groupId> <artifactId>solr-common</artifactId> <version>1.3.0</version> </dependency> <dependency> <groupId>org.apache.solr</groupId> <artifactId>solr-core</artifactId> <version>1.3.0</version> </dependency> <dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-snowball</artifactId> <version>2.4.0</version> </dependency>
lucene-snowball dependency is needed if you want to utililze Lucene's snowball stemmer.
1.3. Configuration
hibernate.properties or hibernate.cfg.xml. If you are using Hibernate via JPA you can also add the properties to persistence.xml. The good news is that for standard use most properties offer a sensible default. An example persistence.xml configuration could look like this:
Example 1.3. Basic configuration options to be added to hibernate.propertieshibernate.cfg.xmlpersistence.xml
... <property name="hibernate.search.default.directory_provider" value="org.hibernate.search.store.FSDirectoryProvider"/> <property name="hibernate.search.default.indexBase" value="/var/lucene/indexes"/> ...
DirectoryProvider to use. This can be achieved by setting the hibernate.search.default.directory_provider property. Apache Lucene has the notion of a Directory to store the index files. Hibernate Search handles the initialization and configuration of a Lucene Directory instance via a DirectoryProvider. In this tutorial we will use a subclass of DirectoryProvider called FSDirectoryProvider. This will give us the ability to physically inspect the Lucene indexes created by Hibernate Search (eg via Luke). Once you have a working configuration you can start experimenting with other directory providers (see Section 3.1, “Directory configuration”). Next to the directory provider you also have to specify the default root directory for all indexes via hibernate.search.default.indexBase.
example.Book and example.Author and you want to add free text search capabilities to your application in order to search the books contained in your database.
Example 1.4. Example entities Book and Author before adding Hibernate Search specific annotatons
package example;
...
@Entity
public class Book {
@Id
@GeneratedValue
private Integer id;
private String title;
private String subtitle;
@ManyToMany
private Set<Author> authors = new HashSet<Author>();
private Date publicationDate;
public Book() {
}
// standard getters/setters follow here
...
}
package example;
...
@Entity
public class Author {
@Id
@GeneratedValue
private Integer id;
private String name;
public Author() {
}
// standard getters/setters follow here
...
}
Book and Author class. The first annotation @Indexed marks Book as indexable. By design Hibernate Search needs to store an untokenized id in the index to ensure index unicity for a given entity. @DocumentId marks the property to use for this purpose and is in most cases the same as the database primary key. In fact since the 3.1.0 release of Hibernate Search @DocumentId is optional in the case where an @Id annotation exists.
title and subtitle and annotate both with @Field. The parameter index=Index.TOKENIZED will ensure that the text will be tokenized using the default Lucene analyzer. Usually, tokenizing means chunking a sentence into individual words and potentially excluding common words like 'a' or 'the'. We will talk more about analyzers a little later on. The second parameter we specify within @Field, store=Store.NO, ensures that the actual data will not be stored in the index. Whether this data is stored in the index or not has nothing to do with the ability to search for it. From Lucene's perspective it is not necessary to keep the data once the index is created. The benefit of storing it is the ability to retrieve it via projections (Section 5.1.2.5, “Projection”).
Store.NO - is recommended since it returns managed objects whereas projections only return object arrays.
Book class. Another annotation we have not yet discussed is @DateBridge. This annotation is one of the built-in field bridges in Hibernate Search. The Lucene index is purely string based. For this reason Hibernate Search must convert the data types of the indexed fields to strings and vice versa. A range of predefined bridges are provided, including the DateBridge which will convert a java.util.Date into a String with the specified resolution. For more details see Section 4.2, “Property/Field Bridge”.
@IndexedEmbedded. This annotation is used to index associated entities (@ManyToMany, @*ToOne and @Embedded) as part of the owning entity. This is needed since a Lucene index document is a flat data structure which does not know anything about object relations. To ensure that the authors' name wil be searchable you have to make sure that the names are indexed as part of the book itself. On top of @IndexedEmbedded you will also have to mark all fields of the associated entity you want to have included in the index with @Indexed. For more dedails see Section 4.1.3, “Embedded and associated objects”.
Example 1.5. Example entities after adding Hibernate Search annotations
package example; ... @Entity @Indexed public class Book { @Id @GeneratedValue @DocumentId private Integer id; @Field(index=Index.TOKENIZED, store=Store.NO) private String title; @Field(index=Index.TOKENIZED, store=Store.NO) private String subtitle; @IndexedEmbedded @ManyToMany private Set<Author> authors = new HashSet<Author>(); @Field(index = Index.UN_TOKENIZED, store = Store.YES) @DateBridge(resolution = Resolution.DAY) private Date publicationDate; public Book() { } // standard getters/setters follow here ... }
package example;
...
@Entity
public class Author {
@Id
@GeneratedValue
private Integer id;
@Field(index=Index.TOKENIZED, store=Store.NO)
private String name;
public Author() {
}
// standard getters/setters follow here
...
}
1.4. Indexing
Example 1.6. Using Hibernate Session to index data
FullTextSession fullTextSession = Search.getFullTextSession(session);
Transaction tx = fullTextSession.beginTransaction();
List books = session.createQuery("from Book as book").list();
for (Book book : books) {
fullTextSession.index(book);
}
tx.commit(); //index is written at commit time
Example 1.7. Using JPA to index data
EntityManager em = entityManagerFactory.createEntityManager();
FullTextEntityManager fullTextEntityManager = Search.getFullTextEntityManager(em);
em.getTransaction().begin();
List books = em.createQuery("select book from Book as book").getResultList();
for (Book book : books) {
fullTextEntityManager.index(book);
}
em.getTransaction().commit();
em.close();
/var/lucene/indexes/example.Book. Go ahead an inspect this index with Luke. It will help you to understand how Hibernate Search works.
1.5. Searching
Books.
Example 1.8. Using Hibernate Session to create and execute a search
FullTextSession fullTextSession = Search.getFullTextSession(session);
Transaction tx = fullTextSession.beginTransaction();
// create native Lucene query
String[] fields = new String[]{"title", "subtitle", "authors.name", "publicationDate"};
MultiFieldQueryParser parser = new MultiFieldQueryParser(fields, new StandardAnalyzer());
org.apache.lucene.search.Query query = parser.parse( "Java rocks!" );
// wrap Lucene query in a org.hibernate.Query
org.hibernate.Query hibQuery = fullTextSession.createFullTextQuery(query, Book.class);
// execute search
List result = hibQuery.list();
tx.commit();
session.close();
Example 1.9. Using JPA to create and execute a search
EntityManager em = entityManagerFactory.createEntityManager();
FullTextEntityManager fullTextEntityManager =
org.hibernate.search.jpa.Search.getFullTextEntityManager(em);
em.getTransaction().begin();
// create native Lucene query
String[] fields = new String[]{"title", "subtitle", "authors.name", "publicationDate"};
MultiFieldQueryParser parser = new MultiFieldQueryParser(fields, new StandardAnalyzer());
org.apache.lucene.search.Query query = parser.parse( "Java rocks!" );
// wrap Lucene query in a javax.persistence.Query
javax.persistence.Query persistenceQuery = fullTextEntityManager.createFullTextQuery(query, Book.class);
// execute search
List result = persistenceQuery.getResultList();
em.getTransaction().commit();
em.close();
1.6. Analyzer
- Setting the
hibernate.search.analyzerproperty in the configuration file. The specified class will then be the default analyzer. - Setting the
@Analyzer - Setting the
@annotation at the field level.Analyzer
@Analyzer annotation one can either specify the fully qualified classname of the analyzer to use or one can refer to an analyzer definition defined by the @AnalyzerDef annotation. In the latter case the Solr analyzer framework with its factories approach is utilized. To find out more about the factory classes available you can either browse the Solr JavaDoc or read the corresponding section on the Solr Wiki. Note that depending on the chosen factory class additional libraries on top of the Solr dependencies might be required. For example, the PhoneticFilterFactory depends on commons-codec.
StandardTokenizerFactory is used followed by two filter factories, LowerCaseFilterFactory and SnowballPorterFilterFactory. The standard tokenizer splits words at punctuation characters and hyphens while keeping email addresses and internet hostnames intact. It is a good general purpose tokenizer. The lowercase filter lowercases the letters in each token whereas the snowball filter finally applies language specific stemming.
Example 1.10. Using @AnalyzerDef and the Solr framework to define and use an analyzer
package example; ... @Entity @Indexed @AnalyzerDef(name = "customanalyzer", tokenizer = @TokenizerDef(factory = StandardTokenizerFactory.class), filters = { @TokenFilterDef(factory = LowerCaseFilterFactory.class), @TokenFilterDef(factory = SnowballPorterFilterFactory.class, params = { @Parameter(name = "language", value = "English") }) }) public class Book { @Id @GeneratedValue @DocumentId private Integer id; @Field(index=Index.TOKENIZED, store=Store.NO) @Analyzer(definition = "customanalyzer") private String title; @Field(index=Index.TOKENIZED, store=Store.NO) @Analyzer(definition = "customanalyzer") private String subtitle; @IndexedEmbedded @ManyToMany private Set<Author> authors = new HashSet<Author>(); @Field(index = Index.UN_TOKENIZED, store = Store.YES) @DateBridge(resolution = Resolution.DAY) private Date publicationDate; public Book() { } // standard getters/setters follow here ... }
1.7. What's next
Example 1.11. Using the maven achetype to create tutorial sources
mvn archetype:create \
-DarchetypeGroupId=org.hibernate \
-DarchetypeArtifactId=hibernate-search-quickstart \
-DarchetypeVersion=3.1.0.GA \
-DgroupId=my.company -DartifactId=quickstartChapter 2. Architecture
2.1. Overview
DirectoryProviders. A directory provider will manage a given Lucene Directory type. You can configure directory providers to adjust the directory target (see Section 3.1, “Directory configuration”).
FullTextSession is built on top of the Hibernate Session. so that the application code can use the unified org.hibernate.Query or javax.persistence.Query APIs exactly the way a HQL, JPA-QL or native queries would do.
- Performance: Lucene indexing works better when operation are executed in batch.
- ACIDity: The work executed has the same scoping as the one executed by the database transaction and is executed if and only if the transaction is committed. This is not ACID in the strict sense of it, but ACID behavior is rarely useful for full text search indexes since they can be rebuilt from the source at any time.
Note
2.2. Back end
2.2.1. Back end types
2.2.1.1. Lucene
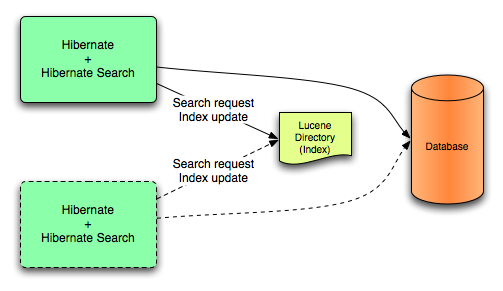
2.2.1.2. JMS

Note
hibernate-dev@lists.jboss.org.
2.2.2. Work execution
2.2.2.1. Synchronous
2.2.2.2. Asynchronous
2.3. Reader strategy
2.3.1. Shared
IndexReader, for a given Lucene index, across multiple queries and threads provided that the IndexReader is still up-to-date. If the IndexReader is not up-to-date, a new one is opened and provided. Each IndexReader is made of several SegmentReaders. This strategy only reopens segments that have been modified or created after last opening and shares the already loaded segments from the previous instance. This strategy is the default.
shared.
2.3.2. Not-shared
IndexReader is opened. This strategy is not the most efficient since opening and warming up an IndexReader can be a relatively expensive operation.
not-shared.
2.3.3. Custom
org.hibernate.search.reader.ReaderProvider. The implementation must be thread safe.
Chapter 3. Configuration
3.1. Directory configuration
Directory to store the index files. The Directory implementation can be customized, but Lucene comes bundled with a file system (FSDirectoryProvider) and an in memory (RAMDirectoryProvider) implementation. DirectoryProviders are the Hibernate Search abstraction around a Lucene Directory and handle the configuration and the initialization of the underlying Lucene resources. Table 3.1, “List of built-in Directory Providers” shows the list of the directory providers bundled with Hibernate Search.
| Class | Description | Properties |
|---|---|---|
| org.hibernate.search.store.RAMDirectoryProvider | Memory based directory, the directory will be uniquely identified (in the same deployment unit) by the @Indexed.index element | none |
| org.hibernate.search.store.FSDirectoryProvider | File system based directory. The directory used will be <indexBase>/< indexName > | indexBase : Base directory
indexName: override @Indexed.index (useful for sharded indexes)
locking_strategy : optional, see Section 3.9, “LockFactory configuration”
|
| org.hibernate.search.store.FSMasterDirectoryProvider |
File system based directory. Like FSDirectoryProvider. It also copies the index to a source directory (aka copy directory) on a regular basis.
The recommended value for the refresh period is (at least) 50% higher than the time to copy the information (default 3600 seconds - 60 minutes).
Note that the copy is based on an incremental copy mechanism reducing the average copy time.
DirectoryProvider typically used on the master node in a JMS back end cluster.
The
buffer_size_on_copy optimum depends on your operating system and available RAM; most people reported good results using values between 16 and 64MB.
| indexBase: Base directory
indexName: override @Indexed.index (useful for sharded indexes)
sourceBase: Source (copy) base directory.
source: Source directory suffix (default to @Indexed.index). The actual source directory name being <sourceBase>/<source>
refresh: refresh period in second (the copy will take place every refresh seconds).
buffer_size_on_copy: The amount of MegaBytes to move in a single low level copy instruction; defaults to 16MB.
locking_strategy : optional, see Section 3.9, “LockFactory configuration”
|
| org.hibernate.search.store.FSSlaveDirectoryProvider |
File system based directory. Like FSDirectoryProvider, but retrieves a master version (source) on a regular basis. To avoid locking and inconsistent search results, 2 local copies are kept.
The recommended value for the refresh period is (at least) 50% higher than the time to copy the information (default 3600 seconds - 60 minutes).
Note that the copy is based on an incremental copy mechanism reducing the average copy time.
DirectoryProvider typically used on slave nodes using a JMS back end.
The
buffer_size_on_copy optimum depends on your operating system and available RAM; most people reported good results using values between 16 and 64MB.
| indexBase: Base directory
indexName: override @Indexed.index (useful for sharded indexes)
sourceBase: Source (copy) base directory.
source: Source directory suffix (default to @Indexed.index). The actual source directory name being <sourceBase>/<source>
refresh: refresh period in second (the copy will take place every refresh seconds).
buffer_size_on_copy: The amount of MegaBytes to move in a single low level copy instruction; defaults to 16MB.
locking_strategy : optional, see Section 3.9, “LockFactory configuration”
|
org.hibernate.store.DirectoryProvider interface.
hibernate.search.indexname . Default properties inherited to all indexes can be defined using the prefix hibernate.search.default.
hibernate.search.indexname.directory_provider
Example 3.1. Configuring directory providers
hibernate.search.default.directory_provider org.hibernate.search.store.FSDirectoryProvider hibernate.search.default.indexBase=/usr/lucene/indexes hibernate.search.Rules.directory_provider org.hibernate.search.store.RAMDirectoryProvider
Example 3.2. Specifying the index name using the index parameter of @Indexed
@Indexed(index="Status")
public class Status { ... }
@Indexed(index="Rules")
public class Rule { ... }/usr/lucene/indexes/Status where the Status entities will be indexed, and use an in memory directory named Rules where Rule entities will be indexed.
DirectoryProvider, you can utilize this configuration mechanism as well.
3.2. Sharding indexes
IndexShardingStrategy. By default, no sharding strategy is enabled, unless the number of shards is configured. To configure the number of shards use the following property
Example 3.3. Enabling index sharding by specifying nbr_of_shards for a specific index
hibernate.search.<indexName>.sharding_strategy.nbr_of_shards 5
IndexShardingStrategy and by setting the following property
Example 3.4. Specifying a custom sharding strategy
hibernate.search.<indexName>.sharding_strategy my.shardingstrategy.Implementation
<indexName>.0 to <indexName>.4. In other words, each shard has the name of it's owning index followed by . (dot) and its index number.
Example 3.5. Configuring the sharding configuration for an example entity Animal
hibernate.search.default.indexBase /usr/lucene/indexes hibernate.search.Animal.sharding_strategy.nbr_of_shards 5 hibernate.search.Animal.directory_provider org.hibernate.search.store.FSDirectoryProvider hibernate.search.Animal.0.indexName Animal00 hibernate.search.Animal.3.indexBase /usr/lucene/sharded hibernate.search.Animal.3.indexName Animal03
FSDirectoryProvider instances and the directory where each subindex is stored is as followed:
- for subindex 0: /usr/lucene/indexes/Animal00 (shared indexBase but overridden indexName)
- for subindex 1: /usr/lucene/indexes/Animal.1 (shared indexBase, default indexName)
- for subindex 2: /usr/lucene/indexes/Animal.2 (shared indexBase, default indexName)
- for subindex 3: /usr/lucene/shared/Animal03 (overridden indexBase, overridden indexName)
- for subindex 4: /usr/lucene/indexes/Animal.4 (shared indexBase, default indexName)
3.3. Sharing indexes (two entities into the same directory)
Note
- Configuring the underlying directory providers to point to the same physical index directory. In practice, you set the property
hibernate.search.[fully qualified entity name].indexNameto the same value. As an example let’s use the same index (directory) for theFurnitureandAnimalentity. We just setindexNamefor both entities to for example “Animal”. Both entities will then be stored in the Animal directoryhibernate.search.org.hibernate.search.test.shards.Furniture.indexName = Aninal hibernate.search.org.hibernate.search.test.shards.Animal.indexName = Aninal - Setting the
@Indexedannotation’sindexattribute of the entities you want to merge to the same value. If we again wanted allFurnitureinstances to be indexed in theAnimalindex along with all instances ofAnimalwe would specify@Indexed(index=”Animal”)on bothAnimalandFurnitureclasses.
3.4. Worker configuration
| Property | Description |
hibernate.search.worker.backend | Out of the box support for the Apache Lucene back end and the JMS back end. Default to lucene. Supports also jms. |
hibernate.search.worker.execution | Supports synchronous and asynchrounous execution. Default to . Supports also async. |
hibernate.search.worker.thread_pool.size | Defines the number of threads in the pool. useful only for asynchrounous execution. Default to 1. |
hibernate.search.worker.buffer_queue.max | Defines the maximal number of work queue if the thread poll is starved. Useful only for asynchrounous execution. Default to infinite. If the limit is reached, the work is done by the main thread. |
hibernate.search.worker.jndi.* | Defines the JNDI properties to initiate the InitialContext (if needed). JNDI is only used by the JMS back end. |
hibernate.search.worker.jms.connection_factory | Mandatory for the JMS back end. Defines the JNDI name to lookup the JMS connection factory from (/ConnectionFactory by default in JBoss AS) |
hibernate.search.worker.jms.queue | Mandatory for the JMS back end. Defines the JNDI name to lookup the JMS queue from. The queue will be used to post work messages. |
3.5. JMS Master/Slave configuration
3.5.1. Slave nodes
Example 3.6. JMS Slave configuration
### slave configuration ## DirectoryProvider # (remote) master location hibernate.search.default.sourceBase = /mnt/mastervolume/lucenedirs/mastercopy # local copy location hibernate.search.default.indexBase = /Users/prod/lucenedirs # refresh every half hour hibernate.search.default.refresh = 1800 # appropriate directory provider hibernate.search.default.directory_provider = org.hibernate.search.store.FSSlaveDirectoryProvider ## Backend configuration hibernate.search.worker.backend = jms hibernate.search.worker.jms.connection_factory = /ConnectionFactory hibernate.search.worker.jms.queue = queue/hibernatesearch #optional jndi configuration (check your JMS provider for more information) ## Optional asynchronous execution strategy # hibernate.search.worker.execution = async # hibernate.search.worker.thread_pool.size = 2 # hibernate.search.worker.buffer_queue.max = 50
3.5.2. Master node
Example 3.7. JMS Master configuration
### master configuration ## DirectoryProvider # (remote) master location where information is copied to hibernate.search.default.sourceBase = /mnt/mastervolume/lucenedirs/mastercopy # local master location hibernate.search.default.indexBase = /Users/prod/lucenedirs # refresh every half hour hibernate.search.default.refresh = 1800 # appropriate directory provider hibernate.search.default.directory_provider = org.hibernate.search.store.FSMasterDirectoryProvider ## Backend configuration #Backend is the default lucene one
Example 3.8. Message Driven Bean processing the indexing queue
@MessageDriven(activationConfig = {
@ActivationConfigProperty(propertyName="destinationType", propertyValue="javax.jms.Queue"),
@ActivationConfigProperty(propertyName="destination", propertyValue="queue/hibernatesearch"),
@ActivationConfigProperty(propertyName="DLQMaxResent", propertyValue="1")
} )
public class MDBSearchController extends AbstractJMSHibernateSearchController implements MessageListener {
@PersistenceContext EntityManager em;
//method retrieving the appropriate session
protected Session getSession() {
return (Session) em.getDelegate();
}
//potentially close the session opened in #getSession(), not needed here
protected void cleanSessionIfNeeded(Session session)
}
}getSession() and cleanSessionIfNeeded(), please check AbstractJMSHibernateSearchController's javadoc.
3.6. Reader strategy configuration
shared: share index readers across several queries. This strategy is the most efficient.not-shared: create an index reader for each individual query
shared. This can be adjusted:
hibernate.search.reader.strategy = not-shared
not-shared strategy.
hibernate.search.reader.strategy = my.corp.myapp.CustomReaderProvider
my.corp.myapp.CustomReaderProvider is the custom strategy implementation.
3.7. Enabling Hibernate Search and automatic indexing
3.7.1. Enabling Hibernate Search
hibernate.search.autoregister_listeners to false. Note that there is no performance penalty when the listeners are enabled even though no entities are indexed.
FullTextIndexEventListener for the following six Hibernate events.
Example 3.9. Explicitly enabling Hibernate Search by configuring the FullTextIndexEventListener
<hibernate-configuration>
<session-factory>
...
<event type="post-update"/>
<listener class="org.hibernate.search.event.FullTextIndexEventListener"/>
</event>
<event type="post-insert"/>
<listener class="org.hibernate.search.event.FullTextIndexEventListener"/>
</event>
<event type="post-delete"/>
<listener class="org.hibernate.search.event.FullTextIndexEventListener"/>
</event>
<event type="post-collection-recreate"/>
<listener class="org.hibernate.search.event.FullTextIndexEventListener"/>
</event>
<event type="post-collection-remove"/>
<listener class="org.hibernate.search.event.FullTextIndexEventListener"/>
</event>
<event type="post-collection-update"/>
<listener class="org.hibernate.search.event.FullTextIndexEventListener"/>
</event>
</session-factory>
</hibernate-configuration>3.7.2. Automatic indexing
hibernate.search.indexing_strategy manual
Note
3.8. Tuning Lucene indexing performance
IndexWriter such as mergeFactor, maxMergeDocs and maxBufferedDocs. You can specify these parameters either as default values applying for all indexes, on a per index basis, or even per shard.
transaction keyword:
hibernate.search.[default|<indexname>].indexwriter.transaction.<parameter_name>When indexing occurs via
FullTextSession.index() (see Chapter 6, Manual indexing), the used properties are those grouped under the batch keyword:
hibernate.search.[default|<indexname>].indexwriter.batch.<parameter_name>
.batch property is explicitly set, the value will default to the .transaction property. If no value is set for a .batch value in a specific shard configuration, Hibernate Search will look at the index section, then at the default section and after that it will look for a .transaction in the same order:
hibernate.search.Animals.2.indexwriter.transaction.max_merge_docs 10 hibernate.search.Animals.2.indexwriter.transaction.merge_factor 20 hibernate.search.default.indexwriter.batch.max_merge_docs 100This configuration will result in these settings applied to the second shard of Animals index:
transaction.max_merge_docs= 10batch.max_merge_docs= 100transaction.merge_factor= 20batch.merge_factor= 20
2.4. For more information about Lucene indexing performances, please refer to the Lucene documentation.
| Property | Description | Default Value |
|---|---|---|
hibernate.search.[default|<indexname>].indexwriter.[transaction|batch].max_buffered_delete_terms |
Determines the minimal number of delete terms required before the buffered in-memory delete terms are applied and flushed. If there are documents buffered in memory at the time, they are merged and a new segment is created.
| Disabled (flushes by RAM usage) |
hibernate.search.[default|<indexname>].indexwriter.[transaction|batch].max_buffered_docs |
Controls the amount of documents buffered in memory during indexing. The bigger the more RAM is consumed.
| Disabled (flushes by RAM usage) |
hibernate.search.[default|<indexname>].indexwriter.[transaction|batch].max_field_length |
The maximum number of terms that will be indexed for a single field. This limits the amount of memory required for indexing so that very large data will not crash the indexing process by running out of memory. This setting refers to the number of running terms, not to the number of different terms.
This silently truncates large documents, excluding from the index all terms that occur further in the document. If you know your source documents are large, be sure to set this value high enough to accomodate the expected size. If you set it to Integer.MAX_VALUE, then the only limit is your memory, but you should anticipate an OutOfMemoryError.
If setting this value in
batch differently than in transaction you may get different data (and results) in your index depending on the indexing mode.
| 10000 |
hibernate.search.[default|<indexname>].indexwriter.[transaction|batch].max_merge_docs |
Defines the largest number of documents allowed in a segment. Larger values are best for batched indexing and speedier searches. Small values are best for transaction indexing.
| Unlimited (Integer.MAX_VALUE) |
hibernate.search.[default|<indexname>].indexwriter.[transaction|batch].merge_factor |
Controls segment merge frequency and size.
Determines how often segment indices are merged when insertion occurs. With smaller values, less RAM is used while indexing, and searches on unoptimized indices are faster, but indexing speed is slower. With larger values, more RAM is used during indexing, and while searches on unoptimized indices are slower, indexing is faster. Thus larger values (> 10) are best for batch index creation, and smaller values (< 10) for indices that are interactively maintained. The value must no be lower than 2.
| 10 |
hibernate.search.[default|<indexname>].indexwriter.[transaction|batch].ram_buffer_size |
Controls the amount of RAM in MB dedicated to document buffers. When used together max_buffered_docs a flush occurs for whichever event happens first.
Generally for faster indexing performance it's best to flush by RAM usage instead of document count and use as large a RAM buffer as you can.
| 16 MB |
hibernate.search.[default|<indexname>].indexwriter.[transaction|batch].term_index_interval |
Expert: Set the interval between indexed terms.
Large values cause less memory to be used by IndexReader, but slow random-access to terms. Small values cause more memory to be used by an IndexReader, and speed random-access to terms. See Lucene documentation for more details.
| 128 |
hibernate.search.[default|<indexname>].indexwriter.[transaction|batch].use_compound_file | The advantage of using the compound file format is that less file descriptors are used. The disadvantage is that indexing takes more time and temporary disk space. You can set this parameter to false in an attempt to improve the indexing time, but you could run out of file descriptors if mergeFactor is also large.
Boolean parameter, use "
true" or "false". The default value for this option is true.
| true |
3.9. LockFactory configuration
hibernate.search.<index>.locking_strategy option to one of simple, native, single or none, or set it to the fully qualified name of an implementation of org.hibernate.search.store.LockFactoryFactory; Implementing this interface you can provide a custom org.apache.lucene.store.LockFactory.
| name | Class | Description |
|---|---|---|
| simple | org.apache.lucene.store.SimpleFSLockFactory |
Safe implementation based on Java's File API, it marks the usage of the index by creating a marker file.
If for some reason you had to kill your application, you will need to remove this file before restarting it.
This is the default implementation for
FSDirectoryProvider,FSMasterDirectoryProvider and FSSlaveDirectoryProvider.
|
| native | org.apache.lucene.store.NativeFSLockFactory |
As does
simple this also marks the usage of the index by creating a marker file, but this one is using native OS file locks so that even if your application crashes the locks will be cleaned up.
This implementation has known problems on NFS.
|
| single | org.apache.lucene.store.SingleInstanceLockFactory |
This LockFactory doesn't use a file marker but is a Java object lock held in memory; therefore it's possible to use it only when you are sure the index is not going to be shared by any other process.
This is the default implementation for
RAMDirectoryProvider.
|
| none | org.apache.lucene.store.NoLockFactory |
All changes to this index are not coordinated by any lock; test your application carefully and make sure you know what it means.
|
hibernate.search.default.locking_strategy simple hibernate.search.Animals.locking_strategy native hibernate.search.Books.locking_strategy org.custom.components.MyLockingFactory
Chapter 4. Mapping entities to the index structure
4.1. Mapping an entity
4.1.1. Basic mapping
@Indexed (all entities not annotated with @Indexed will be ignored by the indexing process):
Example 4.1. Making a class indexable using the @Indexed annotation
@Entity
@Indexed(index="indexes/essays")
public class Essay {
...
}index attribute tells Hibernate what the Lucene directory name is (usually a directory on your file system). It is recommended to define a base directory for all Lucene indexes using the hibernate.search.default.indexBase property in your configuration file. Alternatively you can specify a base directory per indexed entity by specifying hibernate.search.<index>.indexBase, where <index> is the fully qualified classname of the indexed entity. Each entity instance will be represented by a Lucene Document inside the given index (aka Directory).
@Field does declare a property as indexed. When indexing an element to a Lucene document you can specify how it is indexed:
name: describe under which name, the property should be stored in the Lucene Document. The default value is the property name (following the JavaBeans convention)store: describe whether or not the property is stored in the Lucene index. You can store the valueStore.YES(comsuming more space in the index but allowing projection, see Section 5.1.2.5, “Projection” for more information), store it in a compressed wayStore.COMPRESS(this does consume more CPU), or avoid any storageStore.NO(this is the default value). When a property is stored, you can retrieve its original value from the Lucene Document. This is not related to whether the element is indexed or not.- index: describe how the element is indexed and the type of information store. The different values are
Index.NO(no indexing, ie cannot be found by a query),Index.TOKENIZED(use an analyzer to process the property),Index.UN_TOKENISED(no analyzer pre processing),Index.NO_NORM(do not store the normalization data). The default value isTOKENIZED. - termVector: describes collections of term-frequency pairs. This attribute enables term vectors being stored during indexing so they are available within documents. The default value is TermVector.NO.The different values of this attribute are:
Value Definition TermVector.YES Store the term vectors of each document. This produces two synchronized arrays, one contains document terms and the other contains the term's frequency. TermVector.NO Do not store term vectors. TermVector.WITH_OFFSETS Store the term vector and token offset information. This is the same as TermVector.YES plus it contains the starting and ending offset position information for the terms. TermVector.WITH_POSITIONS Store the term vector and token position information. This is the same as TermVector.YES plus it contains the ordinal positions of each occurrence of a term in a document. TermVector.WITH_POSITIONS_OFFSETS Store the term vector, token position and offset information. This is a combination of the YES, WITH_OFFSETS and WITH_POSITIONS.
Note
@DocumentId annotation. If you are using Hibernate Annotations and you have specified @Id you can omit @DocumentId. The chosen entity id will also be used as document id.
Example 4.2. Adding @DocumentId ad @Field annotations to an indexed entity
@Entity
@Indexed(index="indexes/essays")
public class Essay {
...
@Id
@DocumentId
public Long getId() { return id; }
@Field(name="Abstract", index=Index.TOKENIZED, store=Store.YES)
public String getSummary() { return summary; }
@Lob
@Field(index=Index.TOKENIZED)
public String getText() { return text; }
}@DocumentId ad @Field annotations to an indexed entity” define an index with three fields: id , Abstract and text . Note that by default the field name is decapitalized, following the JavaBean specification
4.1.2. Mapping properties multiple times
UN_TOKENIZED. If one wants to search by words in this property and still sort it, one need to index it twice - once tokenized and once untokenized. @Fields allows to achieve this goal.
Example 4.3. Using @Fields to map a property multiple times
@Entity
@Indexed(index = "Book" )
public class Book {
@Fields( {
@Field(index = Index.TOKENIZED),
@Field(name = "summary_forSort", index = Index.UN_TOKENIZED, store = Store.YES)
} )
public String getSummary() {
return summary;
}
...
}summary is indexed twice; once as summary in a tokenized way, and once as summary_forSort in an untokenized way. @Field supports 2 attributes useful when @Fields is used:
- analyzer: defines a @Analyzer annotation per field rather than per property
- bridge: defines a @FieldBridge annotation per field rather than per property
4.1.3. Embedded and associated objects
address.city:Atlanta).
Example 4.4. Using @IndexedEmbedded to index associations
@Entity
@Indexed
public class Place {
@Id
@GeneratedValue
@DocumentId
private Long id;
@Field( index = Index.TOKENIZED )
private String name;
@OneToOne( cascade = { CascadeType.PERSIST, CascadeType.REMOVE } )
@IndexedEmbedded
private Address address;
....
}
@Entity
public class Address {
@Id
@GeneratedValue
private Long id;
@Field(index=Index.TOKENIZED)
private String street;
@Field(index=Index.TOKENIZED)
private String city;
@ContainedIn
@OneToMany(mappedBy="address")
private Set<Place> places;
...
}Place index. The Place index documents will also contain the fields address.id, address.street, and address.city which you will be able to query. This is enabled by the @IndexedEmbedded annotation.
@IndexedEmbedded technique, Hibernate Search needs to be aware of any change in the Place object and any change in the Address object to keep the index up to date. To make sure the Place Lucene document is updated when it's Address changes, you need to mark the other side of the birirectional relationship with @ContainedIn.
@ContainedIn is only useful on associations pointing to entities as opposed to embedded (collection of) objects.
Example 4.5. Nested usage of @IndexedEmbedded and @ContainedIn
@Entity
@Indexed
public class Place {
@Id
@GeneratedValue
@DocumentId
private Long id;
@Field( index = Index.TOKENIZED )
private String name;
@OneToOne( cascade = { CascadeType.PERSIST, CascadeType.REMOVE } )
@IndexedEmbedded
private Address address;
....
}
@Entity
public class Address {
@Id
@GeneratedValue
private Long id;
@Field(index=Index.TOKENIZED)
private String street;
@Field(index=Index.TOKENIZED)
private String city;
@IndexedEmbedded(depth = 1, prefix = "ownedBy_")
private Owner ownedBy;
@ContainedIn
@OneToMany(mappedBy="address")
private Set<Place> places;
...
}
@Embeddable
public class Owner {
@Field(index = Index.TOKENIZED)
private String name;
...
}@*ToMany, @*ToOne and @Embedded attribute can be annotated with @IndexedEmbedded. The attributes of the associated class will then be added to the main entity index. In the previous example, the index will contain the following fields
- id
- name
- address.street
- address.city
- addess.ownedBy_name
propertyName., following the traditional object navigation convention. You can override it using the prefix attribute as it is shown on the ownedBy property.
Note
depth property is necessary when the object graph contains a cyclic dependency of classes (not instances). For example, if Owner points to Place. Hibernate Search will stop including Indexed embedded atttributes after reaching the expected depth (or the object graph boundaries are reached). A class having a self reference is an example of cyclic dependency. In our example, because depth is set to 1, any @IndexedEmbedded attribute in Owner (if any) will be ignored.
@IndexedEmbedded for object associations allows you to express queries such as:
- Return places where name contains JBoss and where address city is Atlanta. In Lucene query this would be
+name:jboss +address.city:atlanta
- Return places where name contains JBoss and where owner's name contain Joe. In Lucene query this would be
+name:jboss +address.orderBy_name:joe
Note
@Indexed
@ContainedIn (as seen in the previous example). If not, Hibernate Search has no way to update the root index when the associated entity is updated (in our example, a Place index document has to be updated when the associated Address instance is updated).
@IndexedEmbedded is not the object type targeted by Hibernate and Hibernate Search. This is especially the case when interfaces are used in lieu of their implementation. For this reason you can override the object type targeted by Hibernate Search using the targetElement parameter.
Example 4.6. Using the targetElement property of @IndexedEmbedded
@Entity
@Indexed
public class Address {
@Id
@GeneratedValue
@DocumentId
private Long id;
@Field(index= Index.TOKENIZED)
private String street;
@IndexedEmbedded(depth = 1, prefix = "ownedBy_", targetElement = Owner.class)
@Target(Owner.class)
private Person ownedBy;
...
}
@Embeddable
public class Owner implements Person { ... }4.1.4. Boost factor
@Boost at the @Field, method or class level.
Example 4.7. Using different ways of increasing the weight of an indexed element using a boost factor
@Entity @Indexed(index="indexes/essays") @Boost(1.7f) public class Essay { ... @Id @DocumentId public Long getId() { return id; } @Field(name="Abstract", index=Index.TOKENIZED, store=Store.YES, boost=@Boost(2f)) @Boost(1.5f) public String getSummary() { return summary; } @Lob @Field(index=Index.TOKENIZED, boost=@Boost(1.2f)) public String getText() { return text; } @Field public String getISBN() { return isbn; } }
Essay's probability to reach the top of the search list will be multiplied by 1.7. The summary field will be 3.0 (2 * 1.5 - @Field.boost and @Boost on a property are cumulative) more important than the isbn field. The text field will be 1.2 times more important than the isbn field. Note that this explanation in strictest terms is actually wrong, but it is simple and close enough to reality for all practical purposes. Please check the Lucene documentation or the excellent Lucene In Action from Otis Gospodnetic and Erik Hatcher.
4.1.5. Dynamic boost factor
@Boost annotation used in Section 4.1.4, “Boost factor” defines a static boost factor which is is independent of the state of of the indexed entity at runtime. However, there are usecases in which the boost factor may depends on the actual state of the entity. In this case you can use the @DynamicBoost annotation together with an accompanying custom BoostStrategy.
Example 4.8. Dynamic boost example
public enum PersonType {
NORMAL,
VIP
}
@Entity
@Indexed
@DynamicBoost(impl = VIPBoostStrategy.class)
public class Person {
private PersonType type;
// ....
}
public class VIPBoostStrategy implements BoostStrategy {
public float defineBoost(Object value) {
Person person = ( Person ) value;
if ( person.getType().equals( PersonType.VIP ) ) {
return 2.0f;
}
else {
return 1.0f;
}
}
}VIPBoostStrategy as implementation of the BoostStrategy interface to be used at indexing time. You can place the @DynamicBoost either at class or field level. Depending on the placement of the annotation either the whole entity is passed to the defineBoost method or just the annotated field/property value. It's up to you to cast the passed object to the correct type. In the example all indexed values of a VIP person would be double as important as the values of a normal person.
Note
BoostStrategy implementation must define a public no-arg constructor.
@Boost and @DynamicBoost annotations in your entity. All defined boost factors are cummulative as described in Section 4.1.4, “Boost factor”.
4.1.6. Analyzer
hibernate.search.analyzer property. The default value for this property is org.apache.lucene.analysis.standard.StandardAnalyzer.
Example 4.9. Different ways of specifying an analyzer
@Entity @Indexed @Analyzer(impl = EntityAnalyzer.class) public class MyEntity { @Id @GeneratedValue @DocumentId private Integer id; @Field(index = Index.TOKENIZED) private String name; @Field(index = Index.TOKENIZED) @Analyzer(impl = PropertyAnalyzer.class) private String summary; @Field(index = Index.TOKENIZED, analyzer = @Analyzer(impl = FieldAnalyzer.class) private String body; ... }
EntityAnalyzer is used to index all tokenized properties (eg. name), except summary and body which are indexed with PropertyAnalyzer and FieldAnalyzer respectively.
Important
4.1.6.1. Analyzer definitions
@Analyzer declarations. An analyzer definition is composed of:
- a name: the unique string used to refer to the definition
- a tokenizer: responsible for tokenizing the input stream into individual words
- a list of filters: each filter is responsible to remove, modify or sometimes even add words into the stream provided by the tokenizer
Tokenizer starts the analysis process by turning the character input into tokens which are then further processed by the TokenFilters. Hibernate Search supports this infrastructure by utilizing the Solr analyzer framework. Make sure to add solr-core.jar and solr-common.jar to your classpath to use analyzer definitions. In case you also want to utilizing a snowball stemmer also include the lucene-snowball.jar. Other Solr analyzers might depend on more libraries. For example, the PhoneticFilterFactory depends on commons-codec. Your distribution of Hibernate Search provides these dependecies in its lib directory.
Example 4.10. @AnalyzerDef and the Solr framework
@AnalyzerDef(name="customanalyzer",
tokenizer = @TokenizerDef(factory = StandardTokenizerFactory.class),
filters = {
@TokenFilterDef(factory = ISOLatin1AccentFilterFactory.class),
@TokenFilterDef(factory = LowerCaseFilterFactory.class),
@TokenFilterDef(factory = StopFilterFactory.class, params = {
@Parameter(name="words", value= "org/hibernate/search/test/analyzer/solr/stoplist.properties" ),
@Parameter(name="ignoreCase", value="true")
})
})
public class Team {
...
}Warning
@AnalyzerDef annotation. Make sure to think twice about this order.
@Analyzer declaration using the definition name rather than declaring an implementation class.
Example 4.11. Referencing an analyzer by name
@Entity
@Indexed
@AnalyzerDef(name="customanalyzer", ... )
public class Team {
@Id
@DocumentId
@GeneratedValue
private Integer id;
@Field
private String name;
@Field
private String location;
@Field @Analyzer(definition = "customanalyzer")
private String description;
}@AnalyzerDef are available by their name in the SearchFactory.
Analyzer analyzer = fullTextSession.getSearchFactory().getAnalyzer("customanalyzer");4.1.6.2. Available analyzers
| Factory | Description | parameters |
|---|---|---|
| StandardTokenizerFactory | Use the Lucene StandardTokenizer | none |
| HTMLStripStandardTokenizerFactory | Remove HTML tags, keep the text and pass it to a StandardTokenizer | none |
| Factory | Description | parameters |
|---|---|---|
| StandardFilterFactory | Remove dots from acronyms and 's from words | none |
| LowerCaseFilterFactory | Lowercase words | none |
| StopFilterFactory | remove words (tokens) matching a list of stop words | words: points to a resource file containing the stop words
ignoreCase: true if
case should be ignore when comparing stop words, false otherwise
|
| SnowballPorterFilterFactory | Reduces a word to it's root in a given language. (eg. protect, protects, protection share the same root). Using such a filter allows searches matching related words. | language: Danish, Dutch, English, Finnish, French, German, Italian, Norwegian, Portuguese, Russian, Spanish, Swedish
|
| ISOLatin1AccentFilterFactory | remove accents for languages like French | none |
org.apache.solr.analysis.TokenizerFactory and org.apache.solr.analysis.TokenFilterFactory in your IDE to see the implementations available.
4.1.6.3. Analyzer discriminator (experimental)
BlogEntry class for example the analyzer could depend on the language property of the entry. Depending on this property the correct language specific stemmer should be chosen to index the actual text.
AnalyzerDiscriminator annotation. The following example demonstrates the usage of this annotation:
Example 4.12. Usage of @AnalyzerDiscriminator in order to select an analyzer depending on the entity state
@Entity
@Indexed
@AnalyzerDefs({
@AnalyzerDef(name = "en",
tokenizer = @TokenizerDef(factory = StandardTokenizerFactory.class),
filters = {
@TokenFilterDef(factory = LowerCaseFilterFactory.class),
@TokenFilterDef(factory = EnglishPorterFilterFactory.class
)
}),
@AnalyzerDef(name = "de",
tokenizer = @TokenizerDef(factory = StandardTokenizerFactory.class),
filters = {
@TokenFilterDef(factory = LowerCaseFilterFactory.class),
@TokenFilterDef(factory = GermanStemFilterFactory.class)
})
})
public class BlogEntry {
@Id
@GeneratedValue
@DocumentId
private Integer id;
@Field
@AnalyzerDiscriminator(impl = LanguageDiscriminator.class)
private String language;
@Field
private String text;
private Set<BlogEntry> references;
// standard getter/setter
...
}public class LanguageDiscriminator implements Discriminator {
public String getAnanyzerDefinitionName(Object value, Object entity, String field) {
if ( value == null || !( entity instanceof Article ) ) {
return null;
}
return (String) value;
}
}@AnalyzerDiscriminator is that all analyzers which are going to be used are predefined via @AnalyzerDef definitions. If this is the case one can place the @AnalyzerDiscriminator annotation either on the class or on a specific property of the entity for which to dynamically select an analyzer. Via the impl parameter of the AnalyzerDiscriminator you specify a concrete implementation of the Discriminator interface. It is up to you to provide an implementation for this interface. The only method you have to implement is getAnanyzerDefinitionName() which gets called for each field added to the Lucene document. The entity which is getting indexed is also passed to the interface method. The value parameter is only set if the AnalyzerDiscriminator is placed on property level instead of class level. In this case the value represents the current value of this property.
Discriminator interface has to return the name of an existing analyzer definition if the analyzer should be set dynamically or null if the default analyzer should not be overridden. The given example assumes that the language paramter is either 'de' or 'en' which matches the specified names in the @AnalyzerDefs.
Note
@AnalyzerDiscriminator is currently still experimental and the API might still change. We are hoping for some feedback from the community about the usefulness and usability of this feature.
4.1.6.4. Retrieving an analyzer
Note
Example 4.13. Using the scoped analyzer when building a full-text query
org.apache.lucene.queryParser.QueryParser parser = new QueryParser(
"title",
fullTextSession.getSearchFactory().getAnalyzer( Song.class )
);
org.apache.lucene.search.Query luceneQuery =
parser.parse( "title:sky Or title_stemmed:diamond" );
org.hibernate.Query fullTextQuery =
fullTextSession.createFullTextQuery( luceneQuery, Song.class );
List result = fullTextQuery.list(); //return a list of managed objectstitle and a stemming analyzer is used in the field title_stemmed. By using the analyzer provided by the search factory, the query uses the appropriate analyzer depending on the field targeted.
searchFactory.getAnalyzer(String).
4.2. Property/Field Bridge
@Field have to be indexed in a String form. For most of your properties, Hibernate Search does the translation job for you thanks to a built-in set of bridges. In some cases, though you need a more fine grain control over the translation process.
4.2.1. Built-in bridges
- null
- null elements are not indexed. Lucene does not support null elements and this does not make much sense either.
- java.lang.String
- String are indexed as is
- short, Short, integer, Integer, long, Long, float, Float, double, Double, BigInteger, BigDecimal
- Numbers are converted in their String representation. Note that numbers cannot be compared by Lucene (ie used in ranged queries) out of the box: they have to be padded
Note
Using a Range query is debatable and has drawbacks, an alternative approach is to use a Filter query which will filter the result query to the appropriate range.Hibernate Search will support a padding mechanism - java.util.Date
- Dates are stored as yyyyMMddHHmmssSSS in GMT time (200611072203012 for Nov 7th of 2006 4:03PM and 12ms EST). You shouldn't really bother with the internal format. What is important is that when using a DateRange Query, you should know that the dates have to be expressed in GMT time.Usually, storing the date up to the milisecond is not necessary.
@DateBridgedefines the appropriate resolution you are willing to store in the index (@DateBridge(resolution=Resolution.DAY)@Entity @Indexed public class Meeting { @Field(index=Index.UN_TOKENIZED) @DateBridge(resolution=Resolution.MINUTE) private Date date; ...Warning
A Date whose resolution is lower thanMILLISECONDcannot be a@DocumentId - java.net.URI, java.net.URL
- URI and URL are converted to their string representation
- java.lang.Class
- Class are converted to their fully qualified class name. The thread context classloader is used when the class is rehydrated
4.2.2. Custom Bridge
4.2.2.1. StringBridge
Object to String bridge. To do so you need to implements the org.hibernate.search.bridge.StringBridge interface. All implementations have to be thread-safe as they are used concurrently.
Example 4.14. Implementing your own StringBridge
/** * Padding Integer bridge. * All numbers will be padded with 0 to match 5 digits * * @author Emmanuel Bernard */ public class PaddedIntegerBridge implements StringBridge { private int PADDING = 5; public String objectToString(Object object) { String rawInteger = ( (Integer) object ).toString(); if (rawInteger.length() > PADDING) throw new IllegalArgumentException( "Try to pad on a number too big" ); StringBuilder paddedInteger = new StringBuilder( ); for ( int padIndex = rawInteger.length() ; padIndex < PADDING ; padIndex++ ) { paddedInteger.append('0'); } return paddedInteger.append( rawInteger ).toString(); } }
@FieldBridge annotation
@FieldBridge(impl = PaddedIntegerBridge.class)
private Integer length;ParameterizedBridge interface, and the parameters are passed through the @FieldBridge annotation.
Example 4.15. Passing parameters to your bridge implementation
public class PaddedIntegerBridge implements StringBridge, ParameterizedBridge { public static String PADDING_PROPERTY = "padding"; private int padding = 5; //default public void setParameterValues(Map parameters) { Object padding = parameters.get( PADDING_PROPERTY ); if (padding != null) this.padding = (Integer) padding; } public String objectToString(Object object) { String rawInteger = ( (Integer) object ).toString(); if (rawInteger.length() > padding) throw new IllegalArgumentException( "Try to pad on a number too big" ); StringBuilder paddedInteger = new StringBuilder( ); for ( int padIndex = rawInteger.length() ; padIndex < padding ; padIndex++ ) { paddedInteger.append('0'); } return paddedInteger.append( rawInteger ).toString(); } } //property @FieldBridge(impl = PaddedIntegerBridge.class, params = @Parameter(name="padding", value="10") ) private Integer length;
ParameterizedBridge interface can be implemented by StringBridge , TwoWayStringBridge , FieldBridge implementations.
@DocumentId ), you need to use a slightly extended version of StringBridge named TwoWayStringBridge. Hibernate Search needs to read the string representation of the identifier and generate the object out of it. There is not difference in the way the @FieldBridge annotation is used.
Example 4.16. Implementing a TwoWayStringBridge which can for example be used for id properties
public class PaddedIntegerBridge implements TwoWayStringBridge, ParameterizedBridge {
public static String PADDING_PROPERTY = "padding";
private int padding = 5; //default
public void setParameterValues(Map parameters) {
Object padding = parameters.get( PADDING_PROPERTY );
if (padding != null) this.padding = (Integer) padding;
}
public String objectToString(Object object) {
String rawInteger = ( (Integer) object ).toString();
if (rawInteger.length() > padding)
throw new IllegalArgumentException( "Try to pad on a number too big" );
StringBuilder paddedInteger = new StringBuilder( );
for ( int padIndex = rawInteger.length() ; padIndex < padding ; padIndex++ ) {
paddedInteger.append('0');
}
return paddedInteger.append( rawInteger ).toString();
}
public Object stringToObject(String stringValue) {
return new Integer(stringValue);
}
}
//id property
@DocumentId
@FieldBridge(impl = PaddedIntegerBridge.class,
params = @Parameter(name="padding", value="10")
private Integer id;
4.2.2.2. FieldBridge
FieldBridge. This interface gives you a property value and let you map it the way you want in your Lucene Document.The interface is very similar in its concept to the Hibernate UserType's.
Example 4.17. Implementing the FieldBridge interface in order to a given property into multiple document fields
/**
* Store the date in 3 different fields - year, month, day - to ease Range Query per
* year, month or day (eg get all the elements of December for the last 5 years).
*
* @author Emmanuel Bernard
*/
public class DateSplitBridge implements FieldBridge {
private final static TimeZone GMT = TimeZone.getTimeZone("GMT");
public void set(String name, Object value, Document document, LuceneOptions luceneOptions) {
Date date = (Date) value;
Calendar cal = GregorianCalendar.getInstance(GMT);
cal.setTime(date);
int year = cal.get(Calendar.YEAR);
int month = cal.get(Calendar.MONTH) + 1;
int day = cal.get(Calendar.DAY_OF_MONTH);
// set year
Field field = new Field(name + ".year", String.valueOf(year),
luceneOptions.getStore(), luceneOptions.getIndex(),
luceneOptions.getTermVector());
field.setBoost(luceneOptions.getBoost());
document.add(field);
// set month and pad it if needed
field = new Field(name + ".month", month < 10 ? "0" : ""
+ String.valueOf(month), luceneOptions.getStore(),
luceneOptions.getIndex(), luceneOptions.getTermVector());
field.setBoost(luceneOptions.getBoost());
document.add(field);
// set day and pad it if needed
field = new Field(name + ".day", day < 10 ? "0" : ""
+ String.valueOf(day), luceneOptions.getStore(),
luceneOptions.getIndex(), luceneOptions.getTermVector());
field.setBoost(luceneOptions.getBoost());
document.add(field);
}
}
//property
@FieldBridge(impl = DateSplitBridge.class)
private Date date;4.2.2.3. ClassBridge
@ClassBridge and @ClassBridge annotations can be defined at the class level (as opposed to the property level). In this case the custom field bridge implementation receives the entity instance as the value parameter instead of a particular property. Though not shown in this example, @ClassBridge supports the termVector attribute discussed in section Section 4.1.1, “Basic mapping”.
Example 4.18. Implementing a class bridge
@Entity @Indexed @ClassBridge(name="branchnetwork", index=Index.TOKENIZED, store=Store.YES, impl = CatFieldsClassBridge.class, params = @Parameter( name="sepChar", value=" " ) ) public class Department { private int id; private String network; private String branchHead; private String branch; private Integer maxEmployees; ... } public class CatFieldsClassBridge implements FieldBridge, ParameterizedBridge { private String sepChar; public void setParameterValues(Map parameters) { this.sepChar = (String) parameters.get( "sepChar" ); } public void set(String name, Object value, Document document, LuceneOptions luceneOptions) { // In this particular class the name of the new field was passed // from the name field of the ClassBridge Annotation. This is not // a requirement. It just works that way in this instance. The // actual name could be supplied by hard coding it below. Department dep = (Department) value; String fieldValue1 = dep.getBranch(); if ( fieldValue1 == null ) { fieldValue1 = ""; } String fieldValue2 = dep.getNetwork(); if ( fieldValue2 == null ) { fieldValue2 = ""; } String fieldValue = fieldValue1 + sepChar + fieldValue2; Field field = new Field( name, fieldValue, luceneOptions.getStore(), luceneOptions.getIndex(), luceneOptions.getTermVector() ); field.setBoost( luceneOptions.getBoost() ); document.add( field ); } }
CatFieldsClassBridge is applied to the department instance, the field bridge then concatenate both branch and network and index the concatenation.
4.3. Providing your own id
Warning
4.3.1. The ProvidedId annotation
Example 4.19. Providing your own id
@ProvidedId (bridge = org.my.own.package.MyCustomBridge)
@Indexed
public class MyClass{
@Field
String MyString;
...
}Chapter 5. Querying
- Creating a
FullTextSession - Creating a Lucene query
- Wrapping the Lucene query using a
org.hibernate.Query - Executing the search by calling for example
list()orscroll()
FullTextSession . This Search specfic session wraps a regular org.hibernate.Session to provide query and indexing capabilities.
Example 5.1. Creating a FullTextSession
Session session = sessionFactory.openSession(); ... FullTextSession fullTextSession = Search.getFullTextSession(session);
Example 5.2. Creating a Lucene query
org.apache.lucene.queryParser.QueryParser parser =
new QueryParser("title", new StopAnalyzer() );
org.apache.lucene.search.Query luceneQuery = parser.parse( "summary:Festina Or brand:Seiko" );
org.hibernate.Query fullTextQuery = fullTextSession.createFullTextQuery( luceneQuery );
List result = fullTextQuery.list(); //return a list of managed objectsorg.hibernate.Query, which means you are in the same paradigm as the other Hibernate query facilities (HQL, Native or Criteria). The regular list() , uniqueResult(), iterate() and scroll() methods can be used.
Example 5.3. Creating a Search query using the JPA API
EntityManager em = entityManagerFactory.createEntityManager();
FullTextEntityManager fullTextEntityManager =
org.hibernate.hibernate.search.jpa.Search.getFullTextEntityManager(em);
...
org.apache.lucene.queryParser.QueryParser parser =
new QueryParser("title", new StopAnalyzer() );
org.apache.lucene.search.Query luceneQuery = parser.parse( "summary:Festina Or brand:Seiko" );
javax.persistence.Query fullTextQuery = fullTextEntityManager.createFullTextQuery( luceneQuery );
List result = fullTextQuery.getResultList(); //return a list of managed objectsFullTextQuery is retrieved.
5.1. Building queries
org.hibernate.Query as your primary query manipulation API.
5.1.1. Building a Lucene query
5.1.2. Building a Hibernate Search query
5.1.2.1. Generality
Example 5.4. Wrapping a Lucene query into a Hibernate Query
FullTextSession fullTextSession = Search.getFullTextSession( session ); org.hibernate.Query fullTextQuery = fullTextSession.createFullTextQuery( luceneQuery );
Example 5.5. Filtering the search result by entity type
org.hibernate.Query fullTextQuery = fullTextSession.createFullTextQuery( luceneQuery, Customer.class ); // or fullTextQuery = fullTextSession.createFullTextQuery( luceneQuery, Item.class, Actor.class );
Customers, the second returns matching Actors and Items. The type restriction is fully polymorphic which means that if there are two indexed subclasses Salesman and Customer of the baseclass Person, it is possible to just specify Person.class in order to filter on result types.
5.1.2.2. Pagination
Example 5.6. Defining pagination for a search query
org.hibernate.Query fullTextQuery = fullTextSession.createFullTextQuery( luceneQuery, Customer.class ); fullTextQuery.setFirstResult(15); //start from the 15th element fullTextQuery.setMaxResults(10); //return 10 elements
Note
fulltextQuery.getResultSize()
5.1.2.3. Sorting
Example 5.7. Specifying a Lucene Sort in order to sort the results
org.hibernate.search.FullTextQuery query = s.createFullTextQuery( query, Book.class );
org.apache.lucene.search.Sort sort = new Sort(new SortField("title"));
query.setSort(sort);
List results = query.list();FullTextQuery interface which is a sub interface of org.hibernate.Query. Be aware that fields used for sorting must not be tokenized.
5.1.2.4. Fetching strategy
Example 5.8. Specifying FetchMode on a query
Criteria criteria = s.createCriteria( Book.class ).setFetchMode( "authors", FetchMode.JOIN ); s.createFullTextQuery( luceneQuery ).setCriteriaQuery( criteria );
setCriteriaQuery if more than one entity type is expected to be returned.
5.1.2.5. Projection
Example 5.9. Using projection instead of returning the full domain object
org.hibernate.search.FullTextQuery query = s.createFullTextQuery( luceneQuery, Book.class );
query.setProjection( "id", "summary", "body", "mainAuthor.name" );
List results = query.list();
Object[] firstResult = (Object[]) results.get(0);
Integer id = (Integer) firstResult[0];
String summary = (String) firstResult[1];
String body = (String) firstResult[2];
String authorName = (String) firstResult[3];Object[]. Projections avoid a potential database round trip (useful if the query response time is critical), but has some constraints:
- the properties projected must be stored in the index (
@Field(store=Store.YES)), which increase the index size - the properties projected must use a
FieldBridgeimplementingorg.hibernate.search.bridge.TwoWayFieldBridgeororg.hibernate.search.bridge.TwoWayStringBridge, the latter being the simpler version. All Hibernate Search built-in types are two-way. - you can only project simple properties of the indexed entity or its embedded associations. This means you cannot project a whole embedded entity.
- projection does not work on collections or maps which are indexed via
@IndexedEmbedded
Example 5.10. Using projection in order to retrieve meta data
org.hibernate.search.FullTextQuery query = s.createFullTextQuery( luceneQuery, Book.class );
query.setProjection( FullTextQuery.SCORE, FullTextQuery.THIS, "mainAuthor.name" );
List results = query.list();
Object[] firstResult = (Object[]) results.get(0);
float score = (Float) firstResult[0];
Book book = (Book) firstResult[1];
String authorName = (String) firstResult[2];- FullTextQuery.THIS: returns the intialized and managed entity (as a non projected query would have done).
- FullTextQuery.DOCUMENT: returns the Lucene Document related to the object projected.
- FullTextQuery.OBJECT_CLASS: returns the class of the indexded entity.
- FullTextQuery.SCORE: returns the document score in the query. Scores are handy to compare one result against an other for a given query but are useless when comparing the result of different queries.
- FullTextQuery.ID: the id property value of the projected object.
- FullTextQuery.DOCUMENT_ID: the Lucene document id. Careful, Lucene document id can change overtime between two different IndexReader opening (this feature is experimental).
- FullTextQuery.EXPLANATION: returns the Lucene Explanation object for the matching object/document in the given query. Do not use if you retrieve a lot of data. Running explanation typically is as costly as running the whole Lucene query per matching element. Make sure you use projection!
5.2. Retrieving the results
list(), uniqueResult(), iterate(), scroll().
5.2.1. Performance considerations
list() or uniqueResult() are recommended. list() work best if the entity batch-size is set up properly. Note that Hibernate Search has to process all Lucene Hits elements (within the pagination) when using list() , uniqueResult() and iterate().
scroll() is more appropriate. Don't forget to close the ScrollableResults object when you're done, since it keeps Lucene resources. If you expect to use scroll, but wish to load objects in batch, you can use query.setFetchSize(). When an object is accessed, and if not already loaded, Hibernate Search will load the next fetchSize objects in one pass.
5.2.2. Result size
- for the Google-like feature 1-10 of about 888,000,000
- to implement a fast pagination navigation
- to implement a multi step search engine (adding approximation if the restricted query return no or not enough results)
Example 5.11. Determining the result size of a query
org.hibernate.search.FullTextQuery query = s.createFullTextQuery( luceneQuery, Book.class ); assert 3245 == query.getResultSize(); //return the number of matching books without loading a single one org.hibernate.search.FullTextQuery query = s.createFullTextQuery( luceneQuery, Book.class ); query.setMaxResults(10); List results = query.list(); assert 3245 == query.getResultSize(); //return the total number of matching books regardless of pagination
Note
5.2.3. ResultTransformer
ResultTransformer operation post query to match the targeted data structure:
Example 5.12. Using ResultTransformer in conjuncton with projections
org.hibernate.search.FullTextQuery query = s.createFullTextQuery( luceneQuery, Book.class );
query.setProjection( "title", "mainAuthor.name" );
query.setResultTransformer( new AliasToBeanResultTransformer( BookView.class ) );
List<BookView> results = (List<BookView>) query.list();
for(BookView view : results) {
log.info( "Book: " + view.getTitle() + ", " + view.getAuthor() );
}ResultTransformer implementations can be found in the Hibernate Core codebase.
5.2.4. Understanding results
Explanation object for a given result (in a given query). This class is considered fairly advanced to Lucene users but can provide a good understanding of the scoring of an object. You have two ways to access the Explanation object for a given result:
- Use the
fullTextQuery.explain(int)method - Use projection
FullTextQuery.DOCUMENT_ID constant.
Warning
Explanation object using the FullTextQuery.EXPLANATION constant.
Example 5.13. Retrieving the Lucene Explanation object using projection
FullTextQuery ftQuery = s.createFullTextQuery( luceneQuery, Dvd.class )
.setProjection( FullTextQuery.DOCUMENT_ID, FullTextQuery.EXPLANATION, FullTextQuery.THIS );
@SuppressWarnings("unchecked") List<Object[]> results = ftQuery.list();
for (Object[] result : results) {
Explanation e = (Explanation) result[1];
System.out.println( e.toString() );
}5.3. Filters
- security
- temporal data (eg. view only last month's data)
- population filter (eg. search limited to a given category)
- and many more
Example 5.14. Enabling fulltext filters for a given query
fullTextQuery = s.createFullTextQuery( query, Driver.class );
fullTextQuery.enableFullTextFilter("bestDriver");
fullTextQuery.enableFullTextFilter("security").setParameter( "login", "andre" );
fullTextQuery.list(); //returns only best drivers where andre has credentials@FullTextFilterDef annotation. This annotation can be on any @Indexed entity regardless of the query the filter is later applied to. This implies that filter definitions are global and their names must be unique. A SearchException is thrown in case two different @FullTextFilterDef annotations with the same name are defined. Each named filter has to specify its actual filter implementation.
Example 5.15. Defining and implementing a Filter
@Entity
@Indexed
@FullTextFilterDefs( {
@FullTextFilterDef(name = "bestDriver", impl = BestDriversFilter.class),
@FullTextFilterDef(name = "security", impl = SecurityFilterFactory.class)
})
public class Driver { ... }public class BestDriversFilter extends org.apache.lucene.search.Filter {
public DocIdSet getDocIdSet(IndexReader reader) throws IOException {
OpenBitSet bitSet = new OpenBitSet( reader.maxDoc() );
TermDocs termDocs = reader.termDocs( new Term( "score", "5" ) );
while ( termDocs.next() ) {
bitSet.set( termDocs.doc() );
}
return bitSet;
}
}BestDriversFilter is an example of a simple Lucene filter which reduces the result set to drivers whose score is 5. In this example the specified filter implements the org.apache.lucene.search.Filter directly and contains a no-arg constructor.
Example 5.16. Creating a filter using the factory pattern
@Entity
@Indexed
@FullTextFilterDef(name = "bestDriver", impl = BestDriversFilterFactory.class)
public class Driver { ... }
public class BestDriversFilterFactory {
@Factory
public Filter getFilter() {
//some additional steps to cache the filter results per IndexReader
Filter bestDriversFilter = new BestDriversFilter();
return new CachingWrapperFilter(bestDriversFilter);
}
}@Factory annotated method and use it to build the filter instance. The factory must have a no-arg constructor. For people familiar with JBoss Seam, this is similar to the component factory pattern, but the annotation is different!
Example 5.17. Passing parameters to a defined filter
fullTextQuery = s.createFullTextQuery( query, Driver.class );
fullTextQuery.enableFullTextFilter("security").setParameter( "level", 5 );Example 5.18. Using paramters in the actual filter implementation
public class SecurityFilterFactory {
private Integer level;
/**
* injected parameter
*/
public void setLevel(Integer level) {
this.level = level;
}
@Key public FilterKey getKey() {
StandardFilterKey key = new StandardFilterKey();
key.addParameter( level );
return key;
}
@Factory
public Filter getFilter() {
Query query = new TermQuery( new Term("level", level.toString() ) );
return new CachingWrapperFilter( new QueryWrapperFilter(query) );
}
}@Key returning a FilterKey object. The returned object has a special contract: the key object must implement equals() / hashcode() so that 2 keys are equal if and only if the given Filter types are the same and the set of parameters are the same. In other words, 2 filter keys are equal if and only if the filters from which the keys are generated can be interchanged. The key object is used as a key in the cache mechanism.
@Key methods are needed only if:
- you enabled the filter caching system (enabled by default)
- your filter has parameters
StandardFilterKey implementation will be good enough. It delegates the equals() / hashcode() implementation to each of the parameters equals and hashcode methods.
SoftReferences when needed. Once the limit of the hard reference cache is reached addtional filters are cached as SoftReferences. To adjust the size of the hard reference cache, use hibernate.search.filter.cache_strategy.size (defaults to 128). For advance use of filter caching, you can implement your own FilterCachingStrategy. The classname is defined by hibernate.search.filter.cache_strategy.
IndexReader around a CachingWrapperFilter. The wrapper will cache the DocIdSet returned from the getDocIdSet(IndexReader reader) method to avoid expensive recomputation. It is important to mention that the computed DocIdSet is only cachable for the same IndexReader instance, because the reader effectively represents the state of the index at the moment it was opened. The document list cannot change within an opened IndexReader. A different/new IndexReader instance, however, works potentially on a different set of Documents (either from a different index or simply because the index has changed), hence the cached DocIdSet has to be recomputed.
cache flag of @FullTextFilterDef is set to FilterCacheModeType.INSTANCE_AND_DOCIDSETRESULTS which will automatically cache the filter instance as well as wrap the specified filter around a Hibernate specific implementation of CachingWrapperFilter (org.hibernate.search.filter.CachingWrapperFilter). In contrast to Lucene's version of this class SoftReferences are used together with a hard reference count (see dicussion about filter cache). The hard reference count can be adjusted using hibernate.search.filter.cache_docidresults.size (defaults to 5). The wrapping behaviour can be controlled using the @FullTextFilterDef.cache parameter. There are three differerent values for this parameter:
| Value | Definition |
|---|---|
| FilterCacheModeType.NONE | No filter instance and no result is cached by Hibernate Search. For every filter call, a new filter instance is created. This setting might be useful for rapidly changing data sets or heavily memory constrained environments. |
| FilterCacheModeType.INSTANCE_ONLY | The filter instance is cached and reused across concurrent Filter.getDocIdSet() calls. DocIdSet results are not cached. This setting is useful when a filter uses its own specific caching mechanism or the filter results change dynamically due to application specific events making DocIdSet caching in both cases unnecessary. |
| FilterCacheModeType.INSTANCE_AND_DOCIDSETRESULTS | Both the filter instance and the DocIdSet results are cached. This is the default value. |
- the system does not update the targeted entity index often (in other words, the IndexReader is reused a lot)
- the Filter's DocIdSet is expensive to compute (compared to the time spent to execute the query)
5.4. Optimizing the query process
- the Lucene query itself: read the literature on this subject
- the number of object loaded: use pagination (always ;-) ) or index projection (if needed)
- the way Hibernate Search interacts with the Lucene readers: defines the appropriate Section 2.3, “Reader strategy”.
5.5. Native Lucene Queries
Chapter 6. Manual indexing
6.1. Indexing
FullTextSession.index() allows you to do so.
Example 6.1. Indexing an entity via FullTextSession.index()
FullTextSession fullTextSession = Search.getFullTextSession(session);
Transaction tx = fullTextSession.beginTransaction();
for (Customer customer : customers) {
fullTextSession.index(customer);
}
tx.commit(); //index are written at commit timeOutOfMemoryException. To avoid this exception, you can use fullTextSession.flushToIndexes(). Every time fullTextSession.flushToIndexes() is called (or if the transaction is committed), the batch queue is processed (freeing memory) applying all index changes. Be aware that once flushed changes cannot be rolled back.
Note
hibernate.search.worker.batch_size has been deprecated in favor of this explicit API which provides better control
hibernate.search.[default|<indexname>].indexwriter.[batch|transaction].max_buffered_docshibernate.search.[default|<indexname>].indexwriter.[batch|transaction].max_field_lengthhibernate.search.[default|<indexname>].indexwriter.[batch|transaction].max_merge_docshibernate.search.[default|<indexname>].indexwriter.[batch|transaction].merge_factorhibernate.search.[default|<indexname>].indexwriter.[batch|transaction].ram_buffer_sizehibernate.search.[default|<indexname>].indexwriter.[batch|transaction].term_index_interval
Example 6.2. Efficiently indexing a given class (useful for index (re)initialization)
fullTextSession.setFlushMode(FlushMode.MANUAL);
fullTextSession.setCacheMode(CacheMode.IGNORE);
transaction = fullTextSession.beginTransaction();
//Scrollable results will avoid loading too many objects in memory
ScrollableResults results = fullTextSession.createCriteria( Email.class )
.setFetchSize(BATCH_SIZE)
.scroll( ScrollMode.FORWARD_ONLY );
int index = 0;
while( results.next() ) {
index++;
fullTextSession.index( results.get(0) ); //index each element
if (index % BATCH_SIZE == 0) {
fullTextSession.flushToIndexes(); //apply changes to indexes
fullTextSession.clear(); //clear since the queue is processed
}
}
transaction.commit();6.2. Purging
FullTextSession.
Example 6.3. Purging a specific instance of an entity from the index
FullTextSession fullTextSession = Search.getFullTextSession(session);
Transaction tx = fullTextSession.beginTransaction();
for (Customer customer : customers) {
fullTextSession.purge( Customer.class, customer.getId() );
}
tx.commit(); //index are written at commit timepurgeAll method. This operation remove all entities of the type passed as a parameter as well as all its subtypes.
Example 6.4. Purging all instances of an entity from the index
FullTextSession fullTextSession = Search.getFullTextSession(session);
Transaction tx = fullTextSession.beginTransaction();
fullTextSession.purgeAll( Customer.class );
//optionally optimize the index
//fullTextSession.getSearchFactory().optimize( Customer.class );
tx.commit(); //index are written at commit timeNote
index, purge and purgeAll are available on FullTextEntityManager as well.
Chapter 7. Index Optimization
- on an idle system or when the searches are less frequent
- after a lot of index modifications
7.1. Automatic optimization
- a certain amount of operations (insertion, deletion)
- or a certain amout of transactions
Example 7.1. Defining automatic optimization parameters
hibernate.search.default.optimizer.operation_limit.max = 1000 hibernate.search.default.optimizer.transaction_limit.max = 100 hibernate.search.Animal.optimizer.transaction_limit.max = 50
Animal index as soon as either:
- the number of additions and deletions reaches 1000
- the number of transactions reaches 50 (
hibernate.search.Animal.optimizer.transaction_limit.maxhaving priority overhibernate.search.default.optimizer.transaction_limit.max)
7.2. Manual optimization
SearchFactory:
Example 7.2. Programmatic index optimization
FullTextSession fullTextSession = Search.getFullTextSession(regularSession); SearchFactory searchFactory = fullTextSession.getSearchFactory(); searchFactory.optimize(Order.class); // or searchFactory.optimize();
Orders; the second, optimizes all indexes.
Note
searchFactory.optimize() has no effect on a JMS backend. You must apply the optimize operation on the Master node.
7.3. Adjusting optimization
hibernate.search.[default|<indexname>].indexwriter.[batch|transaction].max_buffered_docshibernate.search.[default|<indexname>].indexwriter.[batch|transaction].max_field_lengthhibernate.search.[default|<indexname>].indexwriter.[batch|transaction].max_merge_docshibernate.search.[default|<indexname>].indexwriter.[batch|transaction].merge_factorhibernate.search.[default|<indexname>].indexwriter.[batch|transaction].ram_buffer_sizehibernate.search.[default|<indexname>].indexwriter.[batch|transaction].term_index_interval
Chapter 8. Advanced features
8.1. SearchFactory
SearchFactory object keeps track of the underlying Lucene resources for Hibernate Search, it's also a convenient way to access Lucene natively. The SearchFactory can be accessed from a FullTextSession:
Example 8.1. Accessing the SearchFactory
FullTextSession fullTextSession = Search.getFullTextSession(regularSession); SearchFactory searchFactory = fullTextSession.getSearchFactory();
8.2. Accessing a Lucene Directory
SearchFactory keeps track of the DirectoryProviders per indexed class. One directory provider can be shared amongst several indexed classes if the classes share the same underlying index directory. While usually not the case, a given entity can have several DirectoryProviders if the index is sharded (see Section 3.2, “Sharding indexes”).
Example 8.2. Accessing the Lucene Directory
DirectoryProvider[] provider = searchFactory.getDirectoryProviders(Order.class); org.apache.lucene.store.Directory directory = provider[0].getDirectory();
Orders information. Note that the obtained Lucene directory must not be closed (this is Hibernate Search responsibility).
8.3. Using an IndexReader
IndexReader. Hibernate Search caches all index readers to maximize performance. Your code can access this cached resources, but you have to follow some "good citizen" rules.
Example 8.3. Accesing an IndexReader
DirectoryProvider orderProvider = searchFactory.getDirectoryProviders(Order.class)[0];
DirectoryProvider clientProvider = searchFactory.getDirectoryProviders(Client.class)[0];
ReaderProvider readerProvider = searchFactory.getReaderProvider();
IndexReader reader = readerProvider.openReader(orderProvider, clientProvider);
try {
//do read-only operations on the reader
}
finally {
readerProvider.closeReader(reader);
}IndexReader is shared amongst several clients, you must adhere to the following rules:
- Never call indexReader.close(), but always call readerProvider.closeReader(reader), preferably in a finally block.
- Don't use this
IndexReaderfor modification operations (you would get an exception). If you want to use a read/write index reader, open one from the Lucene Directory object.
IndexReaders will make most queries more efficient.
8.4. Customizing Lucene's scoring formula
org.apache.lucene.search.Similarity. The abstract methods defined in this class match the factors of the follownig formula calculating the score of query q for document d:
| Factor | Description |
|---|---|
| tf(t ind) | Term frequency factor for the term (t) in the document (d). |
| idf(t) | Inverse document frequency of the term. |
| coord(q,d) | Score factor based on how many of the query terms are found in the specified document. |
| queryNorm(q) | Normalizing factor used to make scores between queries comparable. |
| t.getBoost() | Field boost. |
| norm(t,d) | Encapsulates a few (indexing time) boost and length factors. |
Similarity's Javadocs for more information.
Similarity implementation using the property hibernate.search.similarity. The default value is org.apache.lucene.search.DefaultSimilarity. Additionally you can override the default similarity on class level using the @Similarity annotation.
@Entity
@Indexed
@Similarity(impl = DummySimilarity.class)
public class Book {
...
}
As an exmaple, let's assume it is not important how often a term appears in a document. Documents with a single occurrence of the term should be scored the same as documents with multiple occurrences. In this case your custom implementation of the method tf(float freq) should return 1.0.
Appendix A. Revision History
| Revision History | ||||
|---|---|---|---|---|
| Revision 5.1.0-110.33.400 | 2013-10-31 | |||
| ||||
| Revision 5.1.0-110.33 | July 24 2012 | |||
| ||||
| Revision 5.1-0 | Wed Sep 15 2010 | |||
| ||||