Dieser Inhalt ist in der von Ihnen ausgewählten Sprache nicht verfügbar.
Chapter 3. Ceph Object Gateway and the S3 API
As a developer, you can use a RESTful application programming interface (API) that is compatible with the Amazon S3 data access model. You can manage the buckets and objects stored in a Red Hat Ceph Storage cluster through the Ceph Object Gateway.
Prerequisites
- A running Red Hat Ceph Storage cluster.
- A RESTful client.
3.1. S3 limitations
The following limitations should be used with caution. There are implications related to your hardware selections, so you should always discuss these requirements with your Red Hat account team.
-
Maximum object size when using Amazon S3: Individual Amazon S3 objects can range in size from a minimum of 0B to a maximum of 5TB. The largest object that can be uploaded in a single
PUTis 5GB. For objects larger than 100MB, you should consider using the Multipart Upload capability. - Maximum metadata size when using Amazon S3: There is no defined limit on the total size of user metadata that can be applied to an object, but a single HTTP request is limited to 16,000 bytes.
- The amount of data overhead Red Hat Ceph Storage cluster produces to store S3 objects and metadata: The estimate here is 200-300 bytes plus the length of the object name. Versioned objects consume additional space proportional to the number of versions. Also, transient overhead is produced during multi-part upload and other transactional updates, but these overheads are recovered during garbage collection.
Additional Resources
- See the Red Hat Ceph Storage Developer Guide for details on the unsupported header fields.
3.2. Accessing the Ceph Object Gateway with the S3 API
As a developer, you must configure access to the Ceph Object Gateway and the Secure Token Service (STS) before you can start using the Amazon S3 API.
Prerequisites
- A running Red Hat Ceph Storage cluster.
- A running Ceph Object Gateway.
- A RESTful client.
3.2.1. S3 authentication
Requests to the Ceph Object Gateway can be either authenticated or unauthenticated. Ceph Object Gateway assumes unauthenticated requests are sent by an anonymous user. Ceph Object Gateway supports canned ACLs.
For most use cases, clients use existing open source libraries like the Amazon SDK’s AmazonS3Client for Java, and Python Boto. With open source libraries you simply pass in the access key and secret key and the library builds the request header and authentication signature for you. However, you can create requests and sign them too.
Authenticating a request requires including an access key and a base 64-encoded hash-based Message Authentication Code (HMAC) in the request before it is sent to the Ceph Object Gateway server. Ceph Object Gateway uses an S3-compatible authentication approach.
Example
HTTP/1.1
PUT /buckets/bucket/object.mpeg
Host: cname.domain.com
Date: Mon, 2 Jan 2012 00:01:01 +0000
Content-Encoding: mpeg
Content-Length: 9999999
Authorization: AWS ACCESS_KEY:HASH_OF_HEADER_AND_SECRET
In the above example, replace ACCESS_KEY with the value for the access key ID followed by a colon (:). Replace HASH_OF_HEADER_AND_SECRET with a hash of a canonicalized header string and the secret corresponding to the access key ID.
Generate hash of header string and secret
To generate the hash of the header string and secret:
- Get the value of the header string.
- Normalize the request header string into canonical form.
- Generate an HMAC using a SHA-1 hashing algorithm.
-
Encode the
hmacresult as base-64.
Normalize header
To normalize the header into canonical form:
-
Get all
content-headers. -
Remove all
content-headers except forcontent-typeandcontent-md5. -
Ensure the
content-header names are lowercase. -
Sort the
content-headers lexicographically. -
Ensure you have a
Dateheader AND ensure the specified date uses GMT and not an offset. -
Get all headers beginning with
x-amz-. -
Ensure that the
x-amz-headers are all lowercase. -
Sort the
x-amz-headers lexicographically. - Combine multiple instances of the same field name into a single field and separate the field values with a comma.
- Replace white space and line breaks in header values with a single space.
- Remove white space before and after colons.
- Append a new line after each header.
- Merge the headers back into the request header.
Replace the HASH_OF_HEADER_AND_SECRET with the base-64 encoded HMAC string.
Additional Resources
- For additional details, consult the Signing and Authenticating REST Requests section of Amazon Simple Storage Service documentation.
3.2.2. S3-server-side encryption
The Ceph Object Gateway supports server-side encryption of uploaded objects for the S3 application programming interface (API). Server-side encryption means that the S3 client sends data over HTTP in its unencrypted form, and the Ceph Object Gateway stores that data in the Red Hat Ceph Storage cluster in encrypted form.
Red Hat does NOT support S3 object encryption of Static Large Object (SLO) or Dynamic Large Object (DLO).
To use encryption, client requests MUST send requests over an SSL connection. Red Hat does not support S3 encryption from a client unless the Ceph Object Gateway uses SSL. However, for testing purposes, administrators can disable SSL during testing by setting the rgw_crypt_require_ssl configuration setting to false at runtime, using the ceph config set client.rgw command, and then restarting the Ceph Object Gateway instance.
In a production environment, it might not be possible to send encrypted requests over SSL. In such a case, send requests using HTTP with server-side encryption.
For information about how to configure HTTP with server-side encryption, see the Additional Resources section below.
There are two options for the management of encryption keys:
Customer-provided Keys
When using customer-provided keys, the S3 client passes an encryption key along with each request to read or write encrypted data. It is the customer’s responsibility to manage those keys. Customers must remember which key the Ceph Object Gateway used to encrypt each object.
Ceph Object Gateway implements the customer-provided key behavior in the S3 API according to the Amazon SSE-C specification.
Since the customer handles the key management and the S3 client passes keys to the Ceph Object Gateway, the Ceph Object Gateway requires no special configuration to support this encryption mode.
Key Management Service
When using a key management service, the secure key management service stores the keys and the Ceph Object Gateway retrieves them on demand to serve requests to encrypt or decrypt data.
Ceph Object Gateway implements the key management service behavior in the S3 API according to the Amazon SSE-KMS specification.
Currently, the only tested key management implementations are HashiCorp Vault, and OpenStack Barbican. However, OpenStack Barbican is a Technology Preview and is not supported for use in production systems.
Additional Resources
3.2.3. S3 access control lists
Ceph Object Gateway supports S3-compatible Access Control Lists (ACL) functionality. An ACL is a list of access grants that specify which operations a user can perform on a bucket or on an object. Each grant has a different meaning when applied to a bucket versus applied to an object:
| Permission | Bucket | Object |
|---|---|---|
|
| Grantee can list the objects in the bucket. | Grantee can read the object. |
|
| Grantee can write or delete objects in the bucket. | N/A |
|
| Grantee can read bucket ACL. | Grantee can read the object ACL. |
|
| Grantee can write bucket ACL. | Grantee can write to the object ACL. |
|
| Grantee has full permissions for object in the bucket. | Grantee can read or write to the object ACL. |
3.2.4. Preparing access to the Ceph Object Gateway using S3
You have to follow some pre-requisites on the Ceph Object Gateway node before attempting to access the gateway server.
Prerequisites
- Installation of the Ceph Object Gateway software.
- Root-level access to the Ceph Object Gateway node.
Procedure
As
root, open port8080on the firewall:[root@rgw ~]# firewall-cmd --zone=public --add-port=8080/tcp --permanent [root@rgw ~]# firewall-cmd --reloadAdd a wildcard to the DNS server that you are using for the gateway as mentioned in the Object Gateway Configuration and Administration Guide.
You can also set up the gateway node for local DNS caching. To do so, execute the following steps:
As
root, install and setupdnsmasq:[root@rgw ~]# yum install dnsmasq [root@rgw ~]# echo "address=/.FQDN_OF_GATEWAY_NODE/IP_OF_GATEWAY_NODE" | tee --append /etc/dnsmasq.conf [root@rgw ~]# systemctl start dnsmasq [root@rgw ~]# systemctl enable dnsmasqReplace
IP_OF_GATEWAY_NODEandFQDN_OF_GATEWAY_NODEwith the IP address and FQDN of the gateway node.As
root, stop NetworkManager:[root@rgw ~]# systemctl stop NetworkManager [root@rgw ~]# systemctl disable NetworkManagerAs
root, set the gateway server’s IP as the nameserver:[root@rgw ~]# echo "DNS1=IP_OF_GATEWAY_NODE" | tee --append /etc/sysconfig/network-scripts/ifcfg-eth0 [root@rgw ~]# echo "IP_OF_GATEWAY_NODE FQDN_OF_GATEWAY_NODE" | tee --append /etc/hosts [root@rgw ~]# systemctl restart network [root@rgw ~]# systemctl enable network [root@rgw ~]# systemctl restart dnsmasqReplace
IP_OF_GATEWAY_NODEandFQDN_OF_GATEWAY_NODEwith the IP address and FQDN of the gateway node.Verify subdomain requests:
[user@rgw ~]$ ping mybucket.FQDN_OF_GATEWAY_NODEReplace
FQDN_OF_GATEWAY_NODEwith the FQDN of the gateway node.WarningSetting up the gateway server for local DNS caching is for testing purposes only. You won’t be able to access the outside network after doing this. It is strongly recommended to use a proper DNS server for the Red Hat Ceph Storage cluster and gateway node.
-
Create the
radosgwuser forS3access carefully as mentioned in the Object Gateway Configuration and Administration Guide and copy the generatedaccess_keyandsecret_key. You will need these keys forS3access and subsequent bucket management tasks.
3.2.5. Accessing the Ceph Object Gateway using Ruby AWS S3
You can use Ruby programming language along with aws-s3 gem for S3 access. Execute the steps mentioned below on the node used for accessing the Ceph Object Gateway server with Ruby AWS::S3.
Prerequisites
- User-level access to Ceph Object Gateway.
- Root-level access to the node accessing the Ceph Object Gateway.
- Internet access.
Procedure
Install the
rubypackage:[root@dev ~]# yum install rubyNoteThe above command will install
rubyand its essential dependencies likerubygemsandruby-libs. If somehow the command does not install all the dependencies, install them separately.Install the
aws-s3Ruby package:[root@dev ~]# gem install aws-s3Create a project directory:
[user@dev ~]$ mkdir ruby_aws_s3 [user@dev ~]$ cd ruby_aws_s3Create the connection file:
[user@dev ~]$ vim conn.rbPaste the following contents into the
conn.rbfile:Syntax
#!/usr/bin/env ruby require 'aws/s3' require 'resolv-replace' AWS::S3::Base.establish_connection!( :server => 'FQDN_OF_GATEWAY_NODE', :port => '8080', :access_key_id => 'MY_ACCESS_KEY', :secret_access_key => 'MY_SECRET_KEY' )Replace
FQDN_OF_GATEWAY_NODEwith the FQDN of the Ceph Object Gateway node. ReplaceMY_ACCESS_KEYandMY_SECRET_KEYwith theaccess_keyandsecret_keythat were generated when you created theradosgwuser forS3access as mentioned in the Red Hat Ceph Storage Object Gateway Configuration and Administration Guide.Example
#!/usr/bin/env ruby require 'aws/s3' require 'resolv-replace' AWS::S3::Base.establish_connection!( :server => 'testclient.englab.pnq.redhat.com', :port => '8080', :access_key_id => '98J4R9P22P5CDL65HKP8', :secret_access_key => '6C+jcaP0dp0+FZfrRNgyGA9EzRy25pURldwje049' )Save the file and exit the editor.
Make the file executable:
[user@dev ~]$ chmod +x conn.rbRun the file:
[user@dev ~]$ ./conn.rb | echo $?If you have provided the values correctly in the file, the output of the command will be
0.Create a new file for creating a bucket:
[user@dev ~]$ vim create_bucket.rbPaste the following contents into the file:
#!/usr/bin/env ruby load 'conn.rb' AWS::S3::Bucket.create('my-new-bucket1')Save the file and exit the editor.
Make the file executable:
[user@dev ~]$ chmod +x create_bucket.rbRun the file:
[user@dev ~]$ ./create_bucket.rbIf the output of the command is
trueit would mean that bucketmy-new-bucket1was created successfully.Create a new file for listing owned buckets:
[user@dev ~]$ vim list_owned_buckets.rbPaste the following content into the file:
#!/usr/bin/env ruby load 'conn.rb' AWS::S3::Service.buckets.each do |bucket| puts "{bucket.name}\t{bucket.creation_date}" endSave the file and exit the editor.
Make the file executable:
[user@dev ~]$ chmod +x list_owned_buckets.rbRun the file:
[user@dev ~]$ ./list_owned_buckets.rbThe output should look something like this:
my-new-bucket1 2020-01-21 10:33:19 UTCCreate a new file for creating an object:
[user@dev ~]$ vim create_object.rbPaste the following contents into the file:
#!/usr/bin/env ruby load 'conn.rb' AWS::S3::S3Object.store( 'hello.txt', 'Hello World!', 'my-new-bucket1', :content_type => 'text/plain' )Save the file and exit the editor.
Make the file executable:
[user@dev ~]$ chmod +x create_object.rbRun the file:
[user@dev ~]$ ./create_object.rbThis will create a file
hello.txtwith the stringHello World!.Create a new file for listing a bucket’s content:
[user@dev ~]$ vim list_bucket_content.rbPaste the following content into the file:
#!/usr/bin/env ruby load 'conn.rb' new_bucket = AWS::S3::Bucket.find('my-new-bucket1') new_bucket.each do |object| puts "{object.key}\t{object.about['content-length']}\t{object.about['last-modified']}" endSave the file and exit the editor.
Make the file executable.
[user@dev ~]$ chmod +x list_bucket_content.rbRun the file:
[user@dev ~]$ ./list_bucket_content.rbThe output will look something like this:
hello.txt 12 Fri, 22 Jan 2020 15:54:52 GMTCreate a new file for deleting an empty bucket:
[user@dev ~]$ vim del_empty_bucket.rbPaste the following contents into the file:
#!/usr/bin/env ruby load 'conn.rb' AWS::S3::Bucket.delete('my-new-bucket1')Save the file and exit the editor.
Make the file executable:
[user@dev ~]$ chmod +x del_empty_bucket.rbRun the file:
[user@dev ~]$ ./del_empty_bucket.rb | echo $?If the bucket is successfully deleted, the command will return
0as output.NoteEdit the
create_bucket.rbfile to create empty buckets, for example,my-new-bucket4,my-new-bucket5. Next, edit the above-mentioneddel_empty_bucket.rbfile accordingly before trying to delete empty buckets.Create a new file for deleting non-empty buckets:
[user@dev ~]$ vim del_non_empty_bucket.rbPaste the following contents into the file:
#!/usr/bin/env ruby load 'conn.rb' AWS::S3::Bucket.delete('my-new-bucket1', :force => true)Save the file and exit the editor.
Make the file executable:
[user@dev ~]$ chmod +x del_non_empty_bucket.rbRun the file:
[user@dev ~]$ ./del_non_empty_bucket.rb | echo $?If the bucket is successfully deleted, the command will return
0as output.Create a new file for deleting an object:
[user@dev ~]$ vim delete_object.rbPaste the following contents into the file:
#!/usr/bin/env ruby load 'conn.rb' AWS::S3::S3Object.delete('hello.txt', 'my-new-bucket1')Save the file and exit the editor.
Make the file executable:
[user@dev ~]$ chmod +x delete_object.rbRun the file:
[user@dev ~]$ ./delete_object.rbThis will delete the object
hello.txt.
3.2.6. Accessing the Ceph Object Gateway using Ruby AWS SDK
You can use the Ruby programming language along with aws-sdk gem for S3 access. Execute the steps mentioned below on the node used for accessing the Ceph Object Gateway server with Ruby AWS::SDK.
Prerequisites
- User-level access to Ceph Object Gateway.
- Root-level access to the node accessing the Ceph Object Gateway.
- Internet access.
Procedure
Install the
rubypackage:[root@dev ~]# yum install rubyNoteThe above command will install
rubyand its essential dependencies likerubygemsandruby-libs. If somehow the command does not install all the dependencies, install them separately.Install the
aws-sdkRuby package:[root@dev ~]# gem install aws-sdkCreate a project directory:
[user@dev ~]$ mkdir ruby_aws_sdk [user@dev ~]$ cd ruby_aws_sdkCreate the connection file:
[user@dev ~]$ vim conn.rbPaste the following contents into the
conn.rbfile:Syntax
#!/usr/bin/env ruby require 'aws-sdk' require 'resolv-replace' Aws.config.update( endpoint: 'http://FQDN_OF_GATEWAY_NODE:8080', access_key_id: 'MY_ACCESS_KEY', secret_access_key: 'MY_SECRET_KEY', force_path_style: true, region: 'us-east-1' )Replace
FQDN_OF_GATEWAY_NODEwith the FQDN of the Ceph Object Gateway node. ReplaceMY_ACCESS_KEYandMY_SECRET_KEYwith theaccess_keyandsecret_keythat were generated when you created theradosgwuser forS3access as mentioned in the Red Hat Ceph Storage Object Gateway Configuration and Administration Guide.Example
#!/usr/bin/env ruby require 'aws-sdk' require 'resolv-replace' Aws.config.update( endpoint: 'http://testclient.englab.pnq.redhat.com:8080', access_key_id: '98J4R9P22P5CDL65HKP8', secret_access_key: '6C+jcaP0dp0+FZfrRNgyGA9EzRy25pURldwje049', force_path_style: true, region: 'us-east-1' )Save the file and exit the editor.
Make the file executable:
[user@dev ~]$ chmod +x conn.rbRun the file:
[user@dev ~]$ ./conn.rb | echo $?If you have provided the values correctly in the file, the output of the command will be
0.Create a new file for creating a bucket:
[user@dev ~]$ vim create_bucket.rbPaste the following contents into the file:
Syntax
#!/usr/bin/env ruby load 'conn.rb' s3_client = Aws::S3::Client.new s3_client.create_bucket(bucket: 'my-new-bucket2')Save the file and exit the editor.
Make the file executable:
[user@dev ~]$ chmod +x create_bucket.rbRun the file:
[user@dev ~]$ ./create_bucket.rbIf the output of the command is
true, this means that bucketmy-new-bucket2was created successfully.Create a new file for listing owned buckets:
[user@dev ~]$ vim list_owned_buckets.rbPaste the following content into the file:
#!/usr/bin/env ruby load 'conn.rb' s3_client = Aws::S3::Client.new s3_client.list_buckets.buckets.each do |bucket| puts "{bucket.name}\t{bucket.creation_date}" endSave the file and exit the editor.
Make the file executable:
[user@dev ~]$ chmod +x list_owned_buckets.rbRun the file:
[user@dev ~]$ ./list_owned_buckets.rbThe output should look something like this:
my-new-bucket2 2020-01-21 10:33:19 UTCCreate a new file for creating an object:
[user@dev ~]$ vim create_object.rbPaste the following contents into the file:
#!/usr/bin/env ruby load 'conn.rb' s3_client = Aws::S3::Client.new s3_client.put_object( key: 'hello.txt', body: 'Hello World!', bucket: 'my-new-bucket2', content_type: 'text/plain' )Save the file and exit the editor.
Make the file executable:
[user@dev ~]$ chmod +x create_object.rbRun the file:
[user@dev ~]$ ./create_object.rbThis will create a file
hello.txtwith the stringHello World!.Create a new file for listing a bucket’s content:
[user@dev ~]$ vim list_bucket_content.rbPaste the following content into the file:
#!/usr/bin/env ruby load 'conn.rb' s3_client = Aws::S3::Client.new s3_client.list_objects(bucket: 'my-new-bucket2').contents.each do |object| puts "{object.key}\t{object.size}" endSave the file and exit the editor.
Make the file executable.
[user@dev ~]$ chmod +x list_bucket_content.rbRun the file:
[user@dev ~]$ ./list_bucket_content.rbThe output will look something like this:
hello.txt 12 Fri, 22 Jan 2020 15:54:52 GMTCreate a new file for deleting an empty bucket:
[user@dev ~]$ vim del_empty_bucket.rbPaste the following contents into the file:
#!/usr/bin/env ruby load 'conn.rb' s3_client = Aws::S3::Client.new s3_client.delete_bucket(bucket: 'my-new-bucket2')Save the file and exit the editor.
Make the file executable:
[user@dev ~]$ chmod +x del_empty_bucket.rbRun the file:
[user@dev ~]$ ./del_empty_bucket.rb | echo $?If the bucket is successfully deleted, the command will return
0as output.NoteEdit the
create_bucket.rbfile to create empty buckets, for example,my-new-bucket6,my-new-bucket7. Next, edit the above-mentioneddel_empty_bucket.rbfile accordingly before trying to delete empty buckets.Create a new file for deleting a non-empty bucket:
[user@dev ~]$ vim del_non_empty_bucket.rbPaste the following contents into the file:
#!/usr/bin/env ruby load 'conn.rb' s3_client = Aws::S3::Client.new Aws::S3::Bucket.new('my-new-bucket2', client: s3_client).clear! s3_client.delete_bucket(bucket: 'my-new-bucket2')Save the file and exit the editor.
Make the file executable:
[user@dev ~]$ chmod +x del_non_empty_bucket.rbRun the file:
[user@dev ~]$ ./del_non_empty_bucket.rb | echo $?If the bucket is successfully deleted, the command will return
0as output.Create a new file for deleting an object:
[user@dev ~]$ vim delete_object.rbPaste the following contents into the file:
#!/usr/bin/env ruby load 'conn.rb' s3_client = Aws::S3::Client.new s3_client.delete_object(key: 'hello.txt', bucket: 'my-new-bucket2')Save the file and exit the editor.
Make the file executable:
[user@dev ~]$ chmod +x delete_object.rbRun the file:
[user@dev ~]$ ./delete_object.rbThis will delete the object
hello.txt.
3.2.7. Accessing the Ceph Object Gateway using PHP
You can use PHP scripts for S3 access. This procedure provides some example PHP scripts to do various tasks, such as deleting a bucket or an object.
The examples given below are tested against php v5.4.16 and aws-sdk v2.8.24.
Prerequisites
- Root-level access to a development workstation.
- Internet access.
Procedure
Install the
phppackage:[root@dev ~]# yum install php-
Download the zip archive of
aws-sdkfor PHP and extract it. Create a project directory:
[user@dev ~]$ mkdir php_s3 [user@dev ~]$ cd php_s3Copy the extracted
awsdirectory to the project directory. For example:[user@dev ~]$ cp -r ~/Downloads/aws/ ~/php_s3/Create the connection file:
[user@dev ~]$ vim conn.phpPaste the following contents in the
conn.phpfile:Syntax
<?php define('AWS_KEY', 'MY_ACCESS_KEY'); define('AWS_SECRET_KEY', 'MY_SECRET_KEY'); define('HOST', 'FQDN_OF_GATEWAY_NODE'); define('PORT', '8080'); // require the AWS SDK for php library require '/PATH_TO_AWS/aws-autoloader.php'; use Aws\S3\S3Client; // Establish connection with host using S3 Client client = S3Client::factory(array( 'base_url' => HOST, 'port' => PORT, 'key' => AWS_KEY, 'secret' => AWS_SECRET_KEY )); ?>Replace
FQDN_OF_GATEWAY_NODEwith the FQDN of the gateway node. ReplaceMY_ACCESS_KEYandMY_SECRET_KEYwith theaccess_keyandsecret_keythat were generated when creating theradosgwuser forS3access as mentioned in the Red Hat Ceph Storage Object Gateway Configuration and Administration Guide. ReplacePATH_TO_AWSwith the absolute path to the extractedawsdirectory that you copied to thephpproject directory.Save the file and exit the editor.
Run the file:
[user@dev ~]$ php -f conn.php | echo $?If you have provided the values correctly in the file, the output of the command will be
0.Create a new file for creating a bucket:
[user@dev ~]$ vim create_bucket.phpPaste the following contents into the new file:
Syntax
<?php include 'conn.php'; client->createBucket(array('Bucket' => 'my-new-bucket3')); ?>Save the file and exit the editor.
Run the file:
[user@dev ~]$ php -f create_bucket.phpCreate a new file for listing owned buckets:
[user@dev ~]$ vim list_owned_buckets.phpPaste the following content into the file:
Syntax
<?php include 'conn.php'; blist = client->listBuckets(); echo "Buckets belonging to " . blist['Owner']['ID'] . ":\n"; foreach (blist['Buckets'] as b) { echo "{b['Name']}\t{b['CreationDate']}\n"; } ?>Save the file and exit the editor.
Run the file:
[user@dev ~]$ php -f list_owned_buckets.phpThe output should look similar to this:
my-new-bucket3 2020-01-21 10:33:19 UTCCreate an object by first creating a source file named
hello.txt:[user@dev ~]$ echo "Hello World!" > hello.txtCreate a new php file:
[user@dev ~]$ vim create_object.phpPaste the following contents into the file:
Syntax
<?php include 'conn.php'; key = 'hello.txt'; source_file = './hello.txt'; acl = 'private'; bucket = 'my-new-bucket3'; client->upload(bucket, key, fopen(source_file, 'r'), acl); ?>Save the file and exit the editor.
Run the file:
[user@dev ~]$ php -f create_object.phpThis will create the object
hello.txtin bucketmy-new-bucket3.Create a new file for listing a bucket’s content:
[user@dev ~]$ vim list_bucket_content.phpPaste the following content into the file:
Syntax
<?php include 'conn.php'; o_iter = client->getIterator('ListObjects', array( 'Bucket' => 'my-new-bucket3' )); foreach (o_iter as o) { echo "{o['Key']}\t{o['Size']}\t{o['LastModified']}\n"; } ?>Save the file and exit the editor.
Run the file:
[user@dev ~]$ php -f list_bucket_content.phpThe output will look similar to this:
hello.txt 12 Fri, 22 Jan 2020 15:54:52 GMTCreate a new file for deleting an empty bucket:
[user@dev ~]$ vim del_empty_bucket.phpPaste the following contents into the file:
Syntax
<?php include 'conn.php'; client->deleteBucket(array('Bucket' => 'my-new-bucket3')); ?>Save the file and exit the editor.
Run the file:
[user@dev ~]$ php -f del_empty_bucket.php | echo $?If the bucket is successfully deleted, the command will return
0as output.NoteEdit the
create_bucket.phpfile to create empty buckets, for example,my-new-bucket4,my-new-bucket5. Next, edit the above-mentioneddel_empty_bucket.phpfile accordingly before trying to delete empty buckets.ImportantDeleting a non-empty bucket is currently not supported in PHP 2 and newer versions of
aws-sdk.Create a new file for deleting an object:
[user@dev ~]$ vim delete_object.phpPaste the following contents into the file:
Syntax
<?php include 'conn.php'; client->deleteObject(array( 'Bucket' => 'my-new-bucket3', 'Key' => 'hello.txt', )); ?>Save the file and exit the editor.
Run the file:
[user@dev ~]$ php -f delete_object.phpThis will delete the object
hello.txt.
3.2.8. Secure Token Service
The Amazon Web Services' Secure Token Service (STS) returns a set of temporary security credentials for authenticating users.
Red Hat Ceph Storage Object Gateway supports a subset of Amazon STS application programming interfaces (APIs) for identity and access management (IAM).
Users first authenticate against STS and receive a short-lived S3 access key and secret key that can be used in subsequent requests.
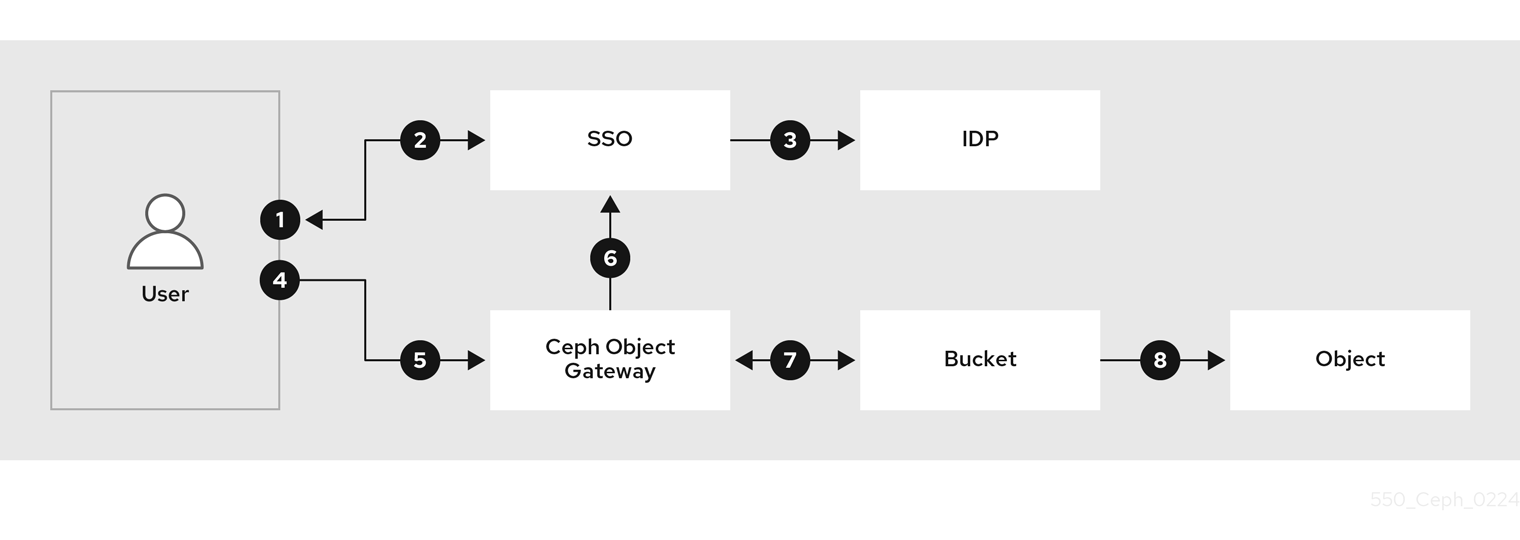
Red Hat Ceph Storage can authenticate S3 users by integrating with a Single Sign-On by configuring an OIDC provider. This feature enables Object Storage users to authenticate against an enterprise identity provider rather than the local Ceph Object Gateway database. For instance, if the SSO is connected to an enterprise IDP in the backend, Object Storage users can use their enterprise credentials to authenticate and get access to the Ceph Object Gateway S3 endpoint.
By using STS along with the IAM role policy feature, you can create finely tuned authorization policies to control access to your data. This enables you to implement either a Role-Based Access Control (RBAC) or Attribute-Based Access Control (ABAC) authorization model for your object storage data, giving you complete control over who can access the data.
Simplifies workflow to access S3 resources with STS
- The user wants access S3 resources in Red Hat Ceph Storage.
- The user needs to authenticate against the SSO provider.
- The SSO provider is federated with an IDP and checks if the user credentials are valid, the user gets authenticated and the SSO provides a Token to the user.
- Using the Token provided by the SSO, the user accesses the Ceph Object Gateway STS endpoint, asking to assume an IAM role that provides the user with access to S3 resources.
- The Red Hat Ceph Storage gateway receives the user token and asks the SSO to validate the token.
- Once the SSO validates the token, the user is allowed to assume the role. Through STS, the user is with temporary access and secret keys that give the user access to the S3 resources.
- Depending on the policies attached to the IAM role the user has assumed, the user can access a set of S3 resources.
- For example, read for bucket A and write to bucket B.
Additional Resources
- Amazon Web Services Secure Token Service welcome page.
- See the Configuring and using STS Lite with Keystone section of the Red Hat Ceph Storage Developer Guide for details on STS Lite and Keystone.
- See the Working around the limitations of using STS Lite with Keystone section of the Red Hat Ceph Storage Developer Guide for details on the limitations of STS Lite and Keystone.
3.2.8.1. The Secure Token Service application programming interfaces
The Ceph Object Gateway implements the following Secure Token Service (STS) application programming interfaces (APIs):
AssumeRole
This API returns a set of temporary credentials for cross-account access. These temporary credentials allow for both, permission policies attached with Role and policies attached with AssumeRole API. The RoleArn and the RoleSessionName request parameters are required, but the other request parameters are optional.
RoleArn- Description
- The role to assume for the Amazon Resource Name (ARN) with a length of 20 to 2048 characters.
- Type
- String
- Required
- Yes
RoleSessionName- Description
-
Identifying the role session name to assume. The role session name can uniquely identify a session when different principals or different reasons assume a role. This parameter’s value has a length of 2 to 64 characters. The
=,,,.,@, and-characters are allowed, but no spaces allowed. - Type
- String
- Required
- Yes
Policy- Description
- An identity and access management policy (IAM) in a JSON format for use in an inline session. This parameter’s value has a length of 1 to 2048 characters.
- Type
- String
- Required
- No
DurationSeconds- Description
-
The duration of the session in seconds, with a minimum value of
900seconds to a maximum value of43200seconds. The default value is3600seconds. - Type
- Integer
- Required
- No
ExternalId- Description
- When assuming a role for another account, provide the unique external identifier if available. This parameter’s value has a length of 2 to 1224 characters.
- Type
- String
- Required
- No
SerialNumber- Description
- A user’s identification number from their associated multi-factor authentication (MFA) device. The parameter’s value can be the serial number of a hardware device or a virtual device, with a length of 9 to 256 characters.
- Type
- String
- Required
- No
TokenCode- Description
- The value generated from the multi-factor authentication (MFA) device, if the trust policy requires MFA. If an MFA device is required, and if this parameter’s value is empty or expired, then AssumeRole call returns an "access denied" error message. This parameter’s value has a fixed length of 6 characters.
- Type
- String
- Required
- No
AssumeRoleWithWebIdentity
This API returns a set of temporary credentials for users who have been authenticated by an application, such as OpenID Connect or OAuth 2.0 Identity Provider. The RoleArn and the RoleSessionName request parameters are required, but the other request parameters are optional.
RoleArn- Description
- The role to assume for the Amazon Resource Name (ARN) with a length of 20 to 2048 characters.
- Type
- String
- Required
- Yes
RoleSessionName- Description
-
Identifying the role session name to assume. The role session name can uniquely identify a session when different principals or different reasons assume a role. This parameter’s value has a length of 2 to 64 characters. The
=,,,.,@, and-characters are allowed, but no spaces are allowed. - Type
- String
- Required
- Yes
Policy- Description
- An identity and access management policy (IAM) in a JSON format for use in an inline session. This parameter’s value has a length of 1 to 2048 characters.
- Type
- String
- Required
- No
DurationSeconds- Description
-
The duration of the session in seconds, with a minimum value of
900seconds to a maximum value of43200seconds. The default value is3600seconds. - Type
- Integer
- Required
- No
ProviderId- Description
- The fully qualified host component of the domain name from the identity provider. This parameter’s value is only valid for OAuth 2.0 access tokens, with a length of 4 to 2048 characters.
- Type
- String
- Required
- No
WebIdentityToken- Description
- The OpenID Connect identity token or OAuth 2.0 access token provided from an identity provider. This parameter’s value has a length of 4 to 2048 characters.
- Type
- String
- Required
- No
Additional Resources
- See the Examples using the Secure Token Service APIs section of the Red Hat Ceph Storage Developer Guide for more details.
- Amazon Web Services Security Token Service, the AssumeRole action.
- Amazon Web Services Security Token Service, the AssumeRoleWithWebIdentity action.
3.2.8.2. Configuring the Secure Token Service
Configure the Secure Token Service (STS) for use with the Ceph Object Gateway by setting the rgw_sts_key, and rgw_s3_auth_use_sts options.
The S3 and STS APIs co-exist in the same namespace, and both can be accessed from the same endpoint in the Ceph Object Gateway.
Prerequisites
- A running Red Hat Ceph Storage cluster.
- A running Ceph Object Gateway.
- Root-level access to a Ceph Manager node.
Procedure
Set the following configuration options for the Ceph Object Gateway client:
Syntax
ceph config set RGW_CLIENT_NAME rgw_sts_key STS_KEY ceph config set RGW_CLIENT_NAME rgw_s3_auth_use_sts trueThe
rgw_sts_keyis the STS key for encrypting or decrypting the session token and is exactly 16 hex characters.ImportantThe STS key needs to be alphanumeric.
Example
[root@mgr ~]# ceph config set client.rgw rgw_sts_key 7f8fd8dd4700mnop [root@mgr ~]# ceph config set client.rgw rgw_s3_auth_use_sts trueRestart the Ceph Object Gateway for the added key to take effect.
NoteUse the output from the
ceph orch pscommand, under theNAMEcolumn, to get the SERVICE_TYPE.ID information.To restart the Ceph Object Gateway on an individual node in the storage cluster:
Syntax
systemctl restart ceph-CLUSTER_ID@SERVICE_TYPE.ID.serviceExample
[root@host01 ~]# systemctl restart ceph-c4b34c6f-8365-11ba-dc31-529020a7702d@rgw.realm.zone.host01.gwasto.serviceTo restart the Ceph Object Gateways on all nodes in the storage cluster:
Syntax
ceph orch restart SERVICE_TYPEExample
[ceph: root@host01 /]# ceph orch restart rgw
Additional Resources
- See Secure Token Service application programming interfaces section in the Red Hat Ceph Storage Developer Guide for more details on the STS APIs.
- See the The basics of Ceph configuration chapter in the Red Hat Ceph Storage Configuration Guide for more details on using the Ceph configuration database.
3.2.8.3. Creating a user for an OpenID Connect provider
To establish trust between the Ceph Object Gateway and the OpenID Connect Provider create a user entity and a role trust policy.
Prerequisites
- User-level access to the Ceph Object Gateway node.
- Secure Token Service configured.
Procedure
Create a new Ceph user:
Syntax
radosgw-admin --uid USER_NAME --display-name "DISPLAY_NAME" --access_key USER_NAME --secret SECRET user createExample
[user@rgw ~]$ radosgw-admin --uid TESTER --display-name "TestUser" --access_key TESTER --secret test123 user createConfigure the Ceph user capabilities:
Syntax
radosgw-admin caps add --uid="USER_NAME" --caps="oidc-provider=*"Example
[user@rgw ~]$ radosgw-admin caps add --uid="TESTER" --caps="oidc-provider=*"Add a condition to the role trust policy using the Secure Token Service (STS) API:
Syntax
"{\"Version\":\"2020-01-17\",\"Statement\":[{\"Effect\":\"Allow\",\"Principal\":{\"Federated\":[\"arn:aws:iam:::oidc-provider/IDP_URL\"]},\"Action\":[\"sts:AssumeRoleWithWebIdentity\"],\"Condition\":{\"StringEquals\":{\"IDP_URL:app_id\":\"AUD_FIELD\"\}\}\}\]\}"ImportantThe
app_idin the syntax example above must match theAUD_FIELDfield of the incoming token.
Additional Resources
- See the Obtaining the Root CA Thumbprint for an OpenID Connect Identity Provider article on Amazon’s website.
- See the Secure Token Service application programming interfaces section in the Red Hat Ceph Storage Developer Guide for more details on the STS APIs.
- See the Examples using the Secure Token Service APIs section of the Red Hat Ceph Storage Developer Guide for more details.
3.2.8.4. Obtaining a thumbprint of an OpenID Connect provider
Get the OpenID Connect provider’s (IDP) configuration document.
Any SSO that follows the OIDC protocol standards is expected to work with the Ceph Object Gateway. Red Hat has tested with the following SSO providers:
- Red Hat Single Sing-on
- Keycloak
Prerequisites
-
Installation of the
opensslandcurlpackages.
Procedure
Get the configuration document from the IDP’s URL:
Syntax
curl -k -v \ -X GET \ -H "Content-Type: application/x-www-form-urlencoded" \ "IDP_URL:8000/CONTEXT/realms/REALM/.well-known/openid-configuration" \ | jq .Example
[user@client ~]$ curl -k -v \ -X GET \ -H "Content-Type: application/x-www-form-urlencoded" \ "http://www.example.com:8000/auth/realms/quickstart/.well-known/openid-configuration" \ | jq .Get the IDP certificate:
Syntax
curl -k -v \ -X GET \ -H "Content-Type: application/x-www-form-urlencoded" \ "IDP_URL/CONTEXT/realms/REALM/protocol/openid-connect/certs" \ | jq .Example
[user@client ~]$ curl -k -v \ -X GET \ -H "Content-Type: application/x-www-form-urlencoded" \ "http://www.example.com/auth/realms/quickstart/protocol/openid-connect/certs" \ | jq .NoteThe
x5ccert can be available on the/certspath or in the/jwkspath depending on the SSO provider.Copy the result of the "x5c" response from the previous command and paste it into the
certificate.crtfile. Include—–BEGIN CERTIFICATE—–at the beginning and—–END CERTIFICATE—–at the end.Example
-----BEGIN CERTIFICATE----- MIIDYjCCAkqgAwIBAgIEEEd2CDANBgkqhkiG9w0BAQsFADBzMQkwBwYDVQQGEwAxCTAHBgNVBAgTADEJMAcGA1UEBxMAMQkwBwYDVQQKEwAxCTAHBgNVBAsTADE6MDgGA1UEAxMxYXV0aHN2Yy1pbmxpbmVtZmEuZGV2LnZlcmlmeS5pYm1jbG91ZHNlY3VyaXR5LmNvbTAeFw0yMTA3MDUxMzU2MzZaFw0zMTA3MDMxMzU2MzZaMHMxCTAHBgNVBAYTADEJMAcGA1UECBMAMQkwBwYDVQQHEwAxCTAHBgNVBAoTADEJMAcGA1UECxMAMTowOAYDVQQDEzFhdXRoc3ZjLWlubGluZW1mYS5kZXYudmVyaWZ5LmlibWNsb3Vkc2VjdXJpdHkuY29tMIIBIjANBgkqhkiG9w0BAQEFAAOCAQ8AMIIBCgKCAQEAphyu3HaAZ14JH/EXetZxtNnerNuqcnfxcmLhBz9SsTlFD59ta+BOVlRnK5SdYEqO3ws2iGEzTvC55rczF+hDVHFZEBJLVLQe8ABmi22RAtG1P0dA/Bq8ReFxpOFVWJUBc31QM+ummW0T4yw44wQJI51LZTMz7PznB0ScpObxKe+frFKd1TCMXPlWOSzmTeFYKzR83Fg9hsnz7Y8SKGxi+RoBbTLT+ektfWpR7O+oWZIf4INe1VYJRxZvn+qWcwI5uMRCtQkiMknc3Rj6Eupiqq6FlAjDs0p//EzsHAlW244jMYnHCGq0UP3oE7vViLJyiOmZw7J3rvs3m9mOQiPLoQIDAQABMA0GCSqGSIb3DQEBCwUAA4IBAQCeVqAzSh7Tp8LgaTIFUuRbdjBAKXC9Nw3+pRBHoiUTdhqO3ualyGih9m/js/clb8Vq/39zl0VPeaslWl2NNX9zaK7xo+ckVIOY3ucCaTC04ZUn1KzZu/7azlN0C5XSWg/CfXgU2P3BeMNzc1UNY1BASGyWn2lEplIVWKLaDZpNdSyyGyaoQAIBdzxeNCyzDfPCa2oSO8WH1czmFiNPqR5kdknHI96CmsQdi+DT4jwzVsYgrLfcHXmiWyIAb883hR3Pobp+Bsw7LUnxebQ5ewccjYmrJzOk5Wb5FpXBhaJH1B3AEd6RGalRUyc/zUKdvEy0nIRMDS9x2BP3NVvZSADD -----END CERTIFICATE-----Get the certificate thumbprint:
Syntax
openssl x509 -in CERT_FILE -fingerprint -nooutExample
[user@client ~]$ openssl x509 -in certificate.crt -fingerprint -noout SHA1 Fingerprint=F7:D7:B3:51:5D:D0:D3:19:DD:21:9A:43:A9:EA:72:7A:D6:06:52:87- Remove all the colons from the SHA1 fingerprint and use this as the input for creating the IDP entity in the IAM request.
Additional Resources
- See the Obtaining the Root CA Thumbprint for an OpenID Connect Identity Provider article on Amazon’s website.
- See the Secure Token Service application programming interfaces section in the Red Hat Ceph Storage Developer Guide for more details on the STS APIs.
- See the Examples using the Secure Token Service APIs section of the Red Hat Ceph Storage Developer Guide for more details.
3.2.8.5. Registering the OpenID Connect provider
Register the OpenID Connect provider’s (IDP) configuration document.
Prerequisites
-
Installation of the
opensslandcurlpackages. - Secure Token Service configured.
- User created for an OIDC provider.
- Thumbprint of an OIDC obtained.
Procedure
Extract URL from the token.
Example
[root@host01 ~]# bash check_token_isv.sh | jq .iss "https://keycloak-sso.apps.ocp.example.com/auth/realms/ceph"Register the OIDC provider with Ceph Object Gateway.
Example
[root@host01 ~]# aws --endpoint https://cephproxy1.example.com:8443 iam create-open-id-connect-provider --url https://keycloak-sso.apps.ocp.example.com/auth/realms/ceph --thumbprint-list 00E9CFD697E0B16DD13C86B0FFDC29957E5D24DFVerify that the OIDC provider is added to the Ceph Object Gateway.
Example
[root@host01 ~]# aws --endpoint https://cephproxy1.example.com:8443 iam list-open-id-connect-providers { "OpenIDConnectProviderList": [ { "Arn": "arn:aws:iam:::oidc-provider/keycloak-sso.apps.ocp.example.com/auth/realms/ceph" } ] }
3.2.8.6. Creating IAM roles and policies
Create IAM roles and policies.
Prerequisites
-
Installation of the
opensslandcurlpackages. - Secure Token Service configured.
- User created for an OIDC provider.
- Thumbprint of an OIDC obtained.
- The OIDC provider in Ceph Object Gateway registered.
Procedure
Retrieve and validate JWT token.
Example
[root@host01 ~]# curl -k -q -L -X POST "https://keycloak-sso.apps.example.com/auth/realms/ceph/protocol/openid-connect/ token" \ -H 'Content-Type: application/x-www-form-urlencoded' \ --data-urlencode 'client_id=ceph' \ --data-urlencode 'grant_type=password' \ --data-urlencode 'client_secret=XXXXXXXXXXXXXXXXXXXXXXX' \ --data-urlencode 'scope=openid' \ --data-urlencode "username=SSOUSERNAME" \ --data-urlencode "password=SSOPASSWORD"Verify the token.
Example
[root@host01 ~]# cat check_token.sh USERNAME=$1 PASSWORD=$2 KC_CLIENT="ceph" KC_CLIENT_SECRET="7sQXqyMSzHIeMcSALoKaljB6sNIBDRjU" KC_ACCESS_TOKEN="$(./get_web_token.sh $USERNAME $PASSWORD | jq -r '.access_token')" KC_SERVER="https://keycloak-sso.apps.ocp.stg.local" KC_CONTEXT="auth" KC_REALM="ceph" curl -k -s -q \ -X POST \ -u "$KC_CLIENT:$KC_CLIENT_SECRET" \ -d "token=$KC_ACCESS_TOKEN" \ "$KC_SERVER/$KC_CONTEXT/realms/$KC_REALM/protocol/openid-connect/token/introspect" | jq . [root@host01 ~]# ./check_token.sh s3admin passw0rd | jq .sub "ceph"In this example, the jq filter is used by the subfield in the token and is set to ceph.
Create a JSON file with role properties. Set
StatementtoAllowand theActionasAssumeRoleWithWebIdentity. Allow access to any user with the JWT token that matches the condition withsub:ceph.Example
[root@host01 ~]# cat role-rgwadmins.json { "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Federated": [ "arn:aws:iam:::oidc-provider/keycloak-sso.apps.example.com/auth/realms/ceph" ] }, "Action": [ "sts:AssumeRoleWithWebIdentity" ], "Condition": { "StringLike": { "keycloak-sso.apps.example.com/auth/realms/ceph:sub":"ceph" } } } ] }Create a Ceph Object Gateway role using the JSON file.
Example
[root@host01 ~]# radosgw-admin role create --role-name rgwadmins \ --assume-role-policy-doc=$(jq -rc . /root/role-rgwadmins.json)
.
3.2.8.7. Accessing S3 resources
Verify the Assume Role with STS credentials to access S3 resources.
Prerequisites
-
Installation of the
opensslandcurlpackages. - Secure Token Service configured.
- User created for an OIDC provider.
- Thumbprint of an OIDC obtained.
- The OIDC provider in Ceph Object Gateway registered.
- IAM roles and policies created
Procedure
Following is an example of assume Role with STS to get temporary access and secret key to access S3 resources.
[roo@host01 ~]# cat test-assume-role.sh #!/bin/bash export AWS_CA_BUNDLE="/etc/pki/ca-trust/source/anchors/cert.pem" unset AWS_ACCESS_KEY_ID unset AWS_SECRET_ACCESS_KEY unset AWS_SESSION_TOKEN KC_ACCESS_TOKEN=$(curl -k -q -L -X POST "https://keycloak-sso.apps.ocp.example.com/auth/realms/ceph/protocol/openid-connect/ token" \ -H 'Content-Type: application/x-www-form-urlencoded' \ --data-urlencode 'client_id=ceph' \ --data-urlencode 'grant_type=password' \ --data-urlencode 'client_secret=XXXXXXXXXXXXXXXXXXXXXXX' \ --data-urlencode 'scope=openid' \ --data-urlencode "<varname>SSOUSERNAME</varname>" \ --data-urlencode "<varname>SSOPASSWORD</varname>" | jq -r .access_token) echo ${KC_ACCESS_TOKEN} IDM_ASSUME_ROLE_CREDS=$(aws sts assume-role-with-web-identity --role-arn "arn:aws:iam:::role/$3" --role-session-name testbr --endpoint=https://cephproxy1.example.com:8443 --web-identity-token="$KC_ACCESS_TOKEN") echo "aws sts assume-role-with-web-identity --role-arn "arn:aws:iam:::role/$3" --role-session-name testb --endpoint=https://cephproxy1.example.com:8443 --web-identity-token="$KC_ACCESS_TOKEN"" echo $IDM_ASSUME_ROLE_CREDS export AWS_ACCESS_KEY_ID=$(echo $IDM_ASSUME_ROLE_CREDS | jq -r .Credentials.AccessKeyId) export AWS_SECRET_ACCESS_KEY=$(echo $IDM_ASSUME_ROLE_CREDS | jq -r .Credentials.SecretAccessKey) export AWS_SESSION_TOKEN=$(echo $IDM_ASSUME_ROLE_CREDS | jq -r .Credentials.SessionToken)Run the script.
Example
[root@host01 ~]# source ./test-assume-role.sh s3admin passw0rd rgwadmins [root@host01 ~]# aws s3 mb s3://testbucket [root@host01 ~]# aws s3 ls
3.2.9. Configuring and using STS Lite with Keystone (Technology Preview)
The Amazon Secure Token Service (STS) and S3 APIs co-exist in the same namespace. The STS options can be configured in conjunction with the Keystone options.
Both S3 and STS APIs can be accessed using the same endpoint in Ceph Object Gateway.
Prerequisites
- Red Hat Ceph Storage 5.0 or higher.
- A running Ceph Object Gateway.
- Installation of the Boto Python module, version 3 or higher.
- Root-level access to a Ceph Manager node.
- User-level access to an OpenStack node.
Procedure
Set the following configuration options for the Ceph Object Gateway client:
Syntax
ceph config set RGW_CLIENT_NAME rgw_sts_key STS_KEY ceph config set RGW_CLIENT_NAME rgw_s3_auth_use_sts trueThe
rgw_sts_keyis the STS key for encrypting or decrypting the session token and is exactly 16 hex characters.ImportantThe STS key needs to be alphanumeric.
Example
[root@mgr ~]# ceph config set client.rgw rgw_sts_key 7f8fd8dd4700mnop [root@mgr ~]# ceph config set client.rgw rgw_s3_auth_use_sts trueGenerate the EC2 credentials on the OpenStack node:
Example
[user@osp ~]$ openstack ec2 credentials create +------------+--------------------------------------------------------+ | Field | Value | +------------+--------------------------------------------------------+ | access | b924dfc87d454d15896691182fdeb0ef | | links | {u'self': u'http://192.168.0.15/identity/v3/users/ | | | 40a7140e424f493d8165abc652dc731c/credentials/ | | | OS-EC2/b924dfc87d454d15896691182fdeb0ef'} | | project_id | c703801dccaf4a0aaa39bec8c481e25a | | secret | 6a2142613c504c42a94ba2b82147dc28 | | trust_id | None | | user_id | 40a7140e424f493d8165abc652dc731c | +------------+--------------------------------------------------------+Use the generated credentials to get back a set of temporary security credentials using GetSessionToken API:
Example
import boto3 access_key = b924dfc87d454d15896691182fdeb0ef secret_key = 6a2142613c504c42a94ba2b82147dc28 client = boto3.client('sts', aws_access_key_id=access_key, aws_secret_access_key=secret_key, endpoint_url=https://www.example.com/rgw, region_name='', ) response = client.get_session_token( DurationSeconds=43200 )Obtaining the temporary credentials can be used for making S3 calls:
Example
s3client = boto3.client('s3', aws_access_key_id = response['Credentials']['AccessKeyId'], aws_secret_access_key = response['Credentials']['SecretAccessKey'], aws_session_token = response['Credentials']['SessionToken'], endpoint_url=https://www.example.com/s3, region_name='') bucket = s3client.create_bucket(Bucket='my-new-shiny-bucket') response = s3client.list_buckets() for bucket in response["Buckets"]: print "{name}\t{created}".format( name = bucket['Name'], created = bucket['CreationDate'], )Create a new S3Access role and configure a policy.
Assign a user with administrative CAPS:
Syntax
radosgw-admin caps add --uid="USER" --caps="roles=*"Example
[root@mgr ~]# radosgw-admin caps add --uid="gwadmin" --caps="roles=*"Create the S3Access role:
Syntax
radosgw-admin role create --role-name=ROLE_NAME --path=PATH --assume-role-policy-doc=TRUST_POLICY_DOCExample
[root@mgr ~]# radosgw-admin role create --role-name=S3Access --path=/application_abc/component_xyz/ --assume-role-policy-doc=\{\"Version\":\"2012-10-17\",\"Statement\":\[\{\"Effect\":\"Allow\",\"Principal\":\{\"AWS\":\[\"arn:aws:iam:::user/TESTER\"\]\},\"Action\":\[\"sts:AssumeRole\"\]\}\]\}Attach a permission policy to the S3Access role:
Syntax
radosgw-admin role-policy put --role-name=ROLE_NAME --policy-name=POLICY_NAME --policy-doc=PERMISSION_POLICY_DOCExample
[root@mgr ~]# radosgw-admin role-policy put --role-name=S3Access --policy-name=Policy --policy-doc=\{\"Version\":\"2012-10-17\",\"Statement\":\[\{\"Effect\":\"Allow\",\"Action\":\[\"s3:*\"\],\"Resource\":\"arn:aws:s3:::example_bucket\"\}\]\}-
Now another user can assume the role of the
gwadminuser. For example, thegwuseruser can assume the permissions of thegwadminuser. Make a note of the assuming user’s
access_keyandsecret_keyvalues.Example
[root@mgr ~]# radosgw-admin user info --uid=gwuser | grep -A1 access_key
Use the AssumeRole API call, providing the
access_keyandsecret_keyvalues from the assuming user:Example
import boto3 access_key = 11BS02LGFB6AL6H1ADMW secret_key = vzCEkuryfn060dfee4fgQPqFrncKEIkh3ZcdOANY client = boto3.client('sts', aws_access_key_id=access_key, aws_secret_access_key=secret_key, endpoint_url=https://www.example.com/rgw, region_name='', ) response = client.assume_role( RoleArn='arn:aws:iam:::role/application_abc/component_xyz/S3Access', RoleSessionName='Bob', DurationSeconds=3600 )ImportantThe AssumeRole API requires the S3Access role.
Additional Resources
- See the Test S3 Access section in the Red Hat Ceph Storage Object Gateway Guide for more information on installing the Boto Python module.
- See the Create a User section in the Red Hat Ceph Storage Object Gateway Guide for more information.
3.2.10. Working around the limitations of using STS Lite with Keystone (Technology Preview)
A limitation with Keystone is that it does not supports Secure Token Service (STS) requests. Another limitation is the payload hash is not included with the request. To work around these two limitations the Boto authentication code must be modified.
Prerequisites
- A running Red Hat Ceph Storage cluster, version 5.0 or higher.
- A running Ceph Object Gateway.
- Installation of Boto Python module, version 3 or higher.
Procedure
Open and edit Boto’s
auth.pyfile.Add the following four lines to the code block:
class SigV4Auth(BaseSigner): """ Sign a request with Signature V4. """ REQUIRES_REGION = True def __init__(self, credentials, service_name, region_name): self.credentials = credentials # We initialize these value here so the unit tests can have # valid values. But these will get overriden in ``add_auth`` # later for real requests. self._region_name = region_name if service_name == 'sts':1 self._service_name = 's3'2 else:3 self._service_name = service_name4 Add the following two lines to the code block:
def _modify_request_before_signing(self, request): if 'Authorization' in request.headers: del request.headers['Authorization'] self._set_necessary_date_headers(request) if self.credentials.token: if 'X-Amz-Security-Token' in request.headers: del request.headers['X-Amz-Security-Token'] request.headers['X-Amz-Security-Token'] = self.credentials.token if not request.context.get('payload_signing_enabled', True): if 'X-Amz-Content-SHA256' in request.headers: del request.headers['X-Amz-Content-SHA256'] request.headers['X-Amz-Content-SHA256'] = UNSIGNED_PAYLOAD1 else:2 request.headers['X-Amz-Content-SHA256'] = self.payload(request)
Additional Resources
- See the Test S3 Access section in the Red Hat Ceph Storage Object Gateway Guide for more information on installing the Boto Python module.
3.3. S3 bucket operations
As a developer, you can perform bucket operations with the Amazon S3 application programming interface (API) through the Ceph Object Gateway.
The following table list the Amazon S3 functional operations for buckets, along with the function’s support status.
| Feature | Status | Notes |
|---|---|---|
| Supported | ||
| Supported | Different set of canned ACLs. | |
| Supported | ||
| Supported | ||
| Supported | ||
| Supported | ||
| Supported | ||
| Supported | ||
| Partially Supported |
| |
| Partially Supported |
| |
| Supported | ||
| Supported | ||
| Supported | ||
| Supported | ||
| Supported | ||
| Supported | ||
| Supported | Different set of canned ACLs | |
| Supported | Different set of canned ACLs | |
| Supported | ||
| Supported | ||
| Supported | ||
| Supported | ||
| Supported | ||
| Supported | ||
| Partially Supported | ||
| Supported | ||
| Supported | ||
| Supported | ||
| Supported | ||
| Supported | ||
| Supported |
Prerequisites
- A running Red Hat Ceph Storage cluster.
- A RESTful client.
3.3.1. S3 create bucket notifications
Create bucket notifications at the bucket level. The notification configuration has the Red Hat Ceph Storage Object Gateway S3 events, ObjectCreated, ObjectRemoved, and ObjectLifecycle:Expiration. These need to be published and the destination to send the bucket notifications. Bucket notifications are S3 operations.
To create a bucket notification for s3:objectCreate, s3:objectRemove and s3:ObjectLifecycle:Expiration events, use PUT:
Example
client.put_bucket_notification_configuration(
Bucket=bucket_name,
NotificationConfiguration={
'TopicConfigurations': [
{
'Id': notification_name,
'TopicArn': topic_arn,
'Events': ['s3:ObjectCreated:*', 's3:ObjectRemoved:*', 's3:ObjectLifecycle:Expiration:*']
}]})
Red Hat supports ObjectCreate events, such as put, post, multipartUpload, and copy. Red Hat also supports ObjectRemove events, such as object_delete and s3_multi_object_delete.
Request Entities
NotificationConfiguration- Description
-
list of
TopicConfigurationentities. - Type
- Container
- Required
- Yes
TopicConfiguration- Description
-
Id,Topic, andlistof Event entities. - Type
- Container
- Required
- Yes
id- Description
- Name of the notification.
- Type
- String
- Required
- Yes
Topic- Description
Topic Amazon Resource Name(ARN)
NoteThe topic must be created beforehand.
- Type
- String
- Required
- Yes
Event- Description
- List of supported events. Multiple event entities can be used. If omitted, all events are handled.
- Type
- String
- Required
- No
Filter- Description
-
S3Key,S3MetadataandS3Tagsentities. - Type
- Container
- Required
- No
S3Key- Description
-
A list of
FilterRuleentities, for filtering based on the object key. At most, 3 entities may be in the list, for exampleNamewould beprefix,suffix, orregex. All filter rules in the list must match for the filter to match. - Type
- Container
- Required
- No
S3Metadata- Description
-
A list of
FilterRuleentities, for filtering based on object metadata. All filter rules in the list must match the metadata defined on the object. However, the object still matches if it has other metadata entries not listed in the filter. - Type
- Container
- Required
- No
S3Tags- Description
-
A list of
FilterRuleentities, for filtering based on object tags. All filter rules in the list must match the tags defined on the object. However, the object still matches if it has other tags not listed in the filter. - Type
- Container
- Required
- No
S3Key.FilterRule- Description
-
NameandValueentities. Name is :prefix,suffix, orregex. TheValuewould hold the key prefix, key suffix, or a regular expression for matching the key, accordingly. - Type
- Container
- Required
- Yes
S3Metadata.FilterRule- Description
-
NameandValueentities. Name is the name of the metadata attribute for examplex-amz-meta-xxx. The value is the expected value for this attribute. - Type
- Container
- Required
- Yes
S3Tags.FilterRule- Description
-
NameandValueentities. Name is the tag key, and the value is the tag value. - Type
- Container
- Required
- Yes
HTTP response
400- Status Code
-
MalformedXML - Description
- The XML is not well-formed.
400- Status Code
-
InvalidArgument - Description
- Missing Id or missing or invalid topic ARN or invalid event.
404- Status Code
-
NoSuchBucket - Description
- The bucket does not exist.
404- Status Code
-
NoSuchKey - Description
- The topic does not exist.
3.3.2. S3 get bucket notifications
Get a specific notification or list all the notifications configured on a bucket.
Syntax
Get /BUCKET?notification=NOTIFICATION_ID HTTP/1.1
Host: cname.domain.com
Date: date
Authorization: AWS ACCESS_KEY:HASH_OF_HEADER_AND_SECRETExample
Get /testbucket?notification=testnotificationID HTTP/1.1
Host: cname.domain.com
Date: date
Authorization: AWS ACCESS_KEY:HASH_OF_HEADER_AND_SECRETExample Response
<NotificationConfiguration xmlns="http://s3.amazonaws.com/doc/2006-03-01/">
<TopicConfiguration>
<Id></Id>
<Topic></Topic>
<Event></Event>
<Filter>
<S3Key>
<FilterRule>
<Name></Name>
<Value></Value>
</FilterRule>
</S3Key>
<S3Metadata>
<FilterRule>
<Name></Name>
<Value></Value>
</FilterRule>
</S3Metadata>
<S3Tags>
<FilterRule>
<Name></Name>
<Value></Value>
</FilterRule>
</S3Tags>
</Filter>
</TopicConfiguration>
</NotificationConfiguration>
The notification subresource returns the bucket notification configuration or an empty NotificationConfiguration element. The caller must be the bucket owner.
Request Entities
notification-id- Description
- Name of the notification. All notifications are listed if the ID is not provided.
- Type
- String
NotificationConfiguration- Description
-
list of
TopicConfigurationentities. - Type
- Container
- Required
- Yes
TopicConfiguration- Description
-
Id,Topic, andlistof Event entities. - Type
- Container
- Required
- Yes
id- Description
- Name of the notification.
- Type
- String
- Required
- Yes
Topic- Description
Topic Amazon Resource Name(ARN)
NoteThe topic must be created beforehand.
- Type
- String
- Required
- Yes
Event- Description
- Handled event. Multiple event entities may exist.
- Type
- String
- Required
- Yes
Filter- Description
- The filters for the specified configuration.
- Type
- Container
- Required
- No
HTTP response
404- Status Code
-
NoSuchBucket - Description
- The bucket does not exist.
404- Status Code
-
NoSuchKey - Description
- The notification does not exist if it has been provided.
3.3.3. S3 delete bucket notifications
Delete a specific or all notifications from a bucket.
Notification deletion is an extension to the S3 notification API. Any defined notifications on a bucket are deleted when the bucket is deleted. Deleting an unknown notification for example double delete, is not considered an error.
To delete a specific or all notifications use DELETE:
Syntax
DELETE /BUCKET?notification=NOTIFICATION_ID HTTP/1.1Example
DELETE /testbucket?notification=testnotificationID HTTP/1.1Request Entities
notification-id- Description
- Name of the notification. All notifications on the bucket are deleted if the notification ID is not provided.
- Type
- String
HTTP response
404- Status Code
-
NoSuchBucket - Description
- The bucket does not exist.
3.3.4. Accessing bucket host names
There are two different modes of accessing the buckets. The first, and preferred method identifies the bucket as the top-level directory in the URI.
Example
GET /mybucket HTTP/1.1
Host: cname.domain.comThe second method identifies the bucket via a virtual bucket host name.
Example
GET / HTTP/1.1
Host: mybucket.cname.domain.comRed Hat prefers the first method, because the second method requires expensive domain certification and DNS wild cards.
3.3.5. S3 list buckets
GET / returns a list of buckets created by the user making the request. GET / only returns buckets created by an authenticated user. You cannot make an anonymous request.
Syntax
GET / HTTP/1.1
Host: cname.domain.com
Authorization: AWS ACCESS_KEY:HASH_OF_HEADER_AND_SECRETResponse Entities
Buckets- Description
- Container for list of buckets.
- Type
- Container
Bucket- Description
- Container for bucket information.
- Type
- Container
Name- Description
- Bucket name.
- Type
- String
CreationDate- Description
- UTC time when the bucket was created.
- Type
- Date
ListAllMyBucketsResult- Description
- A container for the result.
- Type
- Container
Owner- Description
-
A container for the bucket owner’s
IDandDisplayName. - Type
- Container
ID- Description
- The bucket owner’s ID.
- Type
- String
DisplayName- Description
- The bucket owner’s display name.
- Type
- String
3.3.6. S3 return a list of bucket objects
Returns a list of bucket objects.
Syntax
GET /BUCKET?max-keys=25 HTTP/1.1
Host: cname.domain.comParameters
prefix- Description
- Only returns objects that contain the specified prefix.
- Type
- String
delimiter- Description
- The delimiter between the prefix and the rest of the object name.
- Type
- String
marker- Description
- A beginning index for the list of objects returned.
- Type
- String
max-keys- Description
- The maximum number of keys to return. Default is 1000.
- Type
- Integer
HTTP Response
200- Status Code
-
OK - Description
- Buckets retrieved.
GET /BUCKET returns a container for buckets with the following fields:
Bucket Response Entities
ListBucketResult- Description
- The container for the list of objects.
- Type
- Entity
Name- Description
- The name of the bucket whose contents will be returned.
- Type
- String
Prefix- Description
- A prefix for the object keys.
- Type
- String
Marker- Description
- A beginning index for the list of objects returned.
- Type
- String
MaxKeys- Description
- The maximum number of keys returned.
- Type
- Integer
Delimiter- Description
-
If set, objects with the same prefix will appear in the
CommonPrefixeslist. - Type
- String
IsTruncated- Description
-
If
true, only a subset of the bucket’s contents were returned. - Type
- Boolean
CommonPrefixes- Description
- If multiple objects contain the same prefix, they will appear in this list.
- Type
- Container
The ListBucketResult contains objects, where each object is within a Contents container.
Object Response Entities
Contents- Description
- A container for the object.
- Type
- Object
Key- Description
- The object’s key.
- Type
- String
LastModified- Description
- The object’s last-modified date and time.
- Type
- Date
ETag- Description
- An MD-5 hash of the object. Etag is an entity tag.
- Type
- String
Size- Description
- The object’s size.
- Type
- Integer
StorageClass- Description
-
Should always return
STANDARD. - Type
- String
3.3.7. S3 create a new bucket
Creates a new bucket. To create a bucket, you must have a user ID and a valid AWS Access Key ID to authenticate requests. You can not create buckets as an anonymous user.
Constraints
In general, bucket names should follow domain name constraints.
- Bucket names must be unique.
- Bucket names cannot be formatted as IP address.
- Bucket names can be between 3 and 63 characters long.
- Bucket names must not contain uppercase characters or underscores.
- Bucket names must start with a lowercase letter or number.
- Bucket names can contain a dash (-).
- Bucket names must be a series of one or more labels. Adjacent labels are separated by a single period (.). Bucket names can contain lowercase letters, numbers, and hyphens. Each label must start and end with a lowercase letter or a number.
The above constraints are relaxed if rgw_relaxed_s3_bucket_names is set to true. The bucket names must still be unique, cannot be formatted as IP address, and can contain letters, numbers, periods, dashes, and underscores of up to 255 characters long.
Syntax
PUT /BUCKET HTTP/1.1
Host: cname.domain.com
x-amz-acl: public-read-write
Authorization: AWS ACCESS_KEY:HASH_OF_HEADER_AND_SECRETParameters
x-amz-acl- Description
- Canned ACLs.
- Valid Values
-
private,public-read,public-read-write,authenticated-read - Required
- No
HTTP Response
If the bucket name is unique, within constraints, and unused, the operation will succeed. If a bucket with the same name already exists and the user is the bucket owner, the operation will succeed. If the bucket name is already in use, the operation will fail.
409- Status Code
-
BucketAlreadyExists - Description
- Bucket already exists under different user’s ownership.
3.3.8. S3 put bucket website
The put bucket website API sets the configuration of the website that is specified in the website subresource. To configure a bucket as a website, the website subresource can be added on the bucket.
Put operation requires S3:PutBucketWebsite permission. By default, only the bucket owner can configure the website attached to a bucket.
Syntax
PUT /BUCKET?website-configuration=HTTP/1.1Example
PUT /testbucket?website-configuration=HTTP/1.13.3.9. S3 get bucket website
The get bucket website API retrieves the configuration of the website that is specified in the website subresource.
Get operation requires the S3:GetBucketWebsite permission. By default, only the bucket owner can read the bucket website configuration.
Syntax
GET /BUCKET?website-configuration=HTTP/1.1Example
GET /testbucket?website-configuration=HTTP/1.13.3.10. S3 delete bucket website
The delete bucket website API removes the website configuration for a bucket.
Syntax
DELETE /BUCKET?website-configuration=HTTP/1.1Example
DELETE /testbucket?website-configuration=HTTP/1.13.3.11. S3 put bucket replication
The put bucket replication API configures replication configuration for a bucket or replaces an existing one.
Syntax
PUT /BUCKET?replication HTTP/1.1Example
PUT /testbucket?replication HTTP/1.13.3.12. S3 get bucket replication
The get bucket replication API returns the replication configuration of a bucket.
Syntax
GET /BUCKET?replication HTTP/1.1Example
GET /testbucket?replication HTTP/1.13.3.13. S3 delete bucket replication
The delete bucket replication API deletes the replication configuration from a bucket.
Syntax
DELETE /BUCKET?replication HTTP/1.1Example
DELETE /testbucket?replication HTTP/1.13.3.14. S3 delete a bucket
Deletes a bucket. You can reuse bucket names following a successful bucket removal.
Syntax
DELETE /BUCKET HTTP/1.1
Host: cname.domain.com
Authorization: AWS ACCESS_KEY:HASH_OF_HEADER_AND_SECRETHTTP Response
204- Status Code
-
No Content - Description
- Bucket removed.
3.3.15. S3 bucket lifecycle
You can use a bucket lifecycle configuration to manage your objects so they are stored effectively throughout their lifetime. The S3 API in the Ceph Object Gateway supports a subset of the AWS bucket lifecycle actions:
-
Expiration: This defines the lifespan of objects within a bucket. It takes the number of days the object should live or expiration date, at which point Ceph Object Gateway will delete the object. If the bucket doesn’t enable versioning, Ceph Object Gateway will delete the object permanently. If the bucket enables versioning, Ceph Object Gateway will create a delete marker for the current version, and then delete the current version. -
NoncurrentVersionExpiration: This defines the lifespan of noncurrent object versions within a bucket. To use this feature, you must enable bucket versioning. It takes the number of days a noncurrent object should live, at which point Ceph Object Gateway will delete the noncurrent object. -
NewerNoncurrentVersions: Specifies how many noncurrent object versions to retain. You can specify up to 100 noncurrent versions to retain. If the specified number to retain is more than 100, additional noncurrent versions are deleted. -
AbortIncompleteMultipartUpload: This defines the number of days an incomplete multipart upload should live before it is aborted. -
BlockPublicPolicy reject: This action is for public access block. It calls PUT access point policy and PUT bucket policy that are made through the access point if the specified policy (for either the access point or the underlying bucket) allows public access. The Amazon S3 Block Public Access feature is available in Red Hat Ceph Storage 5.x/ Ceph Pacific versions. It provides settings for access points, buckets, and accounts to help you manage public access to Amazon S3 resources. By default, new buckets, access points, and objects do not allow public access. However, you can modify bucket policies, access point policies, or object permissions to allow public access. S3 Block Public Access settings override these policies and permissions so that you can limit public access to these resources.
The lifecycle configuration contains one or more rules using the <Rule> element.
Example
<LifecycleConfiguration>
<Rule>
<Prefix/>
<Status>Enabled</Status>
<Expiration>
<Days>10</Days>
</Expiration>
</Rule>
</LifecycleConfiguration>
A lifecycle rule can apply to all or a subset of objects in a bucket based on the <Filter> element that you specify in the lifecycle rule. You can specify a filter in several ways:
- Key prefixes
- Object tags
- Both key prefix and one or more object tags
Key prefixes
You can apply a lifecycle rule to a subset of objects based on the key name prefix. For example, specifying <keypre/> would apply to objects that begin with keypre/:
<LifecycleConfiguration>
<Rule>
<Status>Enabled</Status>
<Filter>
<Prefix>keypre/</Prefix>
</Filter>
</Rule>
</LifecycleConfiguration>You can also apply different lifecycle rules to objects with different key prefixes:
<LifecycleConfiguration>
<Rule>
<Status>Enabled</Status>
<Filter>
<Prefix>keypre/</Prefix>
</Filter>
</Rule>
<Rule>
<Status>Enabled</Status>
<Filter>
<Prefix>mypre/</Prefix>
</Filter>
</Rule>
</LifecycleConfiguration>Object tags
You can apply a lifecycle rule to only objects with a specific tag using the <Key> and <Value> elements:
<LifecycleConfiguration>
<Rule>
<Status>Enabled</Status>
<Filter>
<Tag>
<Key>key</Key>
<Value>value</Value>
</Tag>
</Filter>
</Rule>
</LifecycleConfiguration>Both prefix and one or more tags
In a lifecycle rule, you can specify a filter based on both the key prefix and one or more tags. They must be wrapped in the <And> element. A filter can have only one prefix, and zero or more tags:
<LifecycleConfiguration>
<Rule>
<Status>Enabled</Status>
<Filter>
<And>
<Prefix>key-prefix</Prefix>
<Tag>
<Key>key1</Key>
<Value>value1</Value>
</Tag>
<Tag>
<Key>key2</Key>
<Value>value2</Value>
</Tag>
...
</And>
</Filter>
</Rule>
</LifecycleConfiguration>Additional Resources
- See the S3 GET bucket lifecycle section in the Red Hat Ceph Storage Developer Guide for details on getting a bucket lifecycle.
- See the S3 create or replace a bucket lifecycle section in the Red Hat Ceph Storage Developer Guide for details on creating a bucket lifecycle.
- See the S3 delete a bucket lifecycle secton in the Red Hat Ceph Storage Developer Guide for details on deleting a bucket lifecycle.
3.3.16. S3 GET bucket lifecycle
To get a bucket lifecycle, use GET and specify a destination bucket.
Syntax
GET /BUCKET?lifecycle HTTP/1.1
Host: cname.domain.com
Authorization: AWS ACCESS_KEY:HASH_OF_HEADER_AND_SECRETRequest Headers
See the S3 common request headers in Appendix B for more information about common request headers.
Response
The response contains the bucket lifecycle and its elements.
3.3.17. S3 create or replace a bucket lifecycle
To create or replace a bucket lifecycle, use PUT and specify a destination bucket and a lifecycle configuration. The Ceph Object Gateway only supports a subset of the S3 lifecycle functionality.
Syntax
PUT /BUCKET?lifecycle HTTP/1.1
Host: cname.domain.com
Authorization: AWS ACCESS_KEY:HASH_OF_HEADER_AND_SECRET
<LifecycleConfiguration>
<Rule>
<Expiration>
<Days>10</Days>
</Expiration>
</Rule>
...
<Rule>
</Rule>
</LifecycleConfiguration>Request Headers
content-md5- Description
- A base64 encoded MD-5 hash of the message
- Valid Values
- String No defaults or constraints.
- Required
- No
Additional Resources
- See the S3 common request headers section in Appendix B of the Red Hat Ceph Storage Developer Guide for more information on Amazon S3 common request headers.
- See the S3 bucket lifecycles section of the Red Hat Ceph Storage Developer Guide for more information on Amazon S3 bucket lifecycles.
3.3.18. S3 delete a bucket lifecycle
To delete a bucket lifecycle, use DELETE and specify a destination bucket.
Syntax
DELETE /BUCKET?lifecycle HTTP/1.1
Host: cname.domain.com
Authorization: AWS ACCESS_KEY:HASH_OF_HEADER_AND_SECRETRequest Headers
The request does not contain any special elements.
Response
The response returns common response status.
Additional Resources
- See the S3 common request headers section in Appendix B of the Red Hat Ceph Storage Developer Guide for more information on Amazon S3 common request headers.
- See the S3 common response status codes section in Appendix C of Red Hat Ceph Storage Developer Guide for more information on Amazon S3 common response status codes.
3.3.19. S3 get bucket location
Retrieves the bucket’s zone group. The user needs to be the bucket owner to call this. A bucket can be constrained to a zone group by providing LocationConstraint during a PUT request.
Add the location subresource to the bucket resource as shown below.
Syntax
GET /BUCKET?location HTTP/1.1
Host: cname.domain.com
Authorization: AWS ACCESS_KEY:HASH_OF_HEADER_AND_SECRETResponse Entities
LocationConstraint- Description
- The zone group where bucket resides, an empty string for default zone group.
- Type
- String
3.3.20. S3 get bucket versioning
Retrieves the versioning state of a bucket. The user needs to be the bucket owner to call this.
Add the versioning subresource to the bucket resource as shown below.
Syntax
GET /BUCKET?versioning HTTP/1.1
Host: cname.domain.com
Authorization: AWS ACCESS_KEY:HASH_OF_HEADER_AND_SECRET3.3.21. S3 put bucket versioning
This subresource set the versioning state of an existing bucket. The user needs to be the bucket owner to set the versioning state. If the versioning state has never been set on a bucket, then it has no versioning state. Doing a GET versioning request does not return a versioning state value.
Setting the bucket versioning state:
Enabled: Enables versioning for the objects in the bucket. All objects added to the bucket receive a unique version ID. Suspended: Disables versioning for the objects in the bucket. All objects added to the bucket receive the version ID null.
Syntax
PUT /BUCKET?versioning HTTP/1.1Example
PUT /testbucket?versioning HTTP/1.1Bucket Request Entities
VersioningConfiguration- Description
- A container for the request.
- Type
- Container
Status- Description
- Sets the versioning state of the bucket. Valid Values: Suspended/Enabled
- Type
- String
3.3.22. S3 get bucket access control lists
Retrieves the bucket access control list. The user needs to be the bucket owner or to have been granted READ_ACP permission on the bucket.
Add the acl subresource to the bucket request as shown below.
Syntax
GET /BUCKET?acl HTTP/1.1
Host: cname.domain.com
Authorization: AWS ACCESS_KEY:HASH_OF_HEADER_AND_SECRETResponse Entities
AccessControlPolicy- Description
- A container for the response.
- Type
- Container
AccessControlList- Description
- A container for the ACL information.
- Type
- Container
Owner- Description
-
A container for the bucket owner’s
IDandDisplayName. - Type
- Container
ID- Description
- The bucket owner’s ID.
- Type
- String
DisplayName- Description
- The bucket owner’s display name.
- Type
- String
Grant- Description
-
A container for
GranteeandPermission. - Type
- Container
Grantee- Description
-
A container for the
DisplayNameandIDof the user receiving a grant of permission. - Type
- Container
Permission- Description
-
The permission given to the
Granteebucket. - Type
- String
3.3.23. S3 put bucket Access Control Lists
Sets an access control to an existing bucket. The user needs to be the bucket owner or to have been granted WRITE_ACP permission on the bucket.
Add the acl subresource to the bucket request as shown below.
Syntax
PUT /BUCKET?acl HTTP/1.1Request Entities
S3 list multipart uploads
AccessControlList- Description
- A container for the ACL information.
- Type
- Container
Owner- Description
-
A container for the bucket owner’s
IDandDisplayName. - Type
- Container
ID- Description
- The bucket owner’s ID.
- Type
- String
DisplayName- Description
- The bucket owner’s display name.
- Type
- String
Grant- Description
-
A container for
GranteeandPermission. - Type
- Container
Grantee- Description
-
A container for the
DisplayNameandIDof the user receiving a grant of permission. - Type
- Container
Permission- Description
-
The permission given to the
Granteebucket. - Type
- String
3.3.24. S3 get bucket cors
Retrieves the cors configuration information set for the bucket. The user needs to be the bucket owner or to have been granted READ_ACP permission on the bucket.
Add the cors subresource to the bucket request as shown below.
Syntax
GET /BUCKET?cors HTTP/1.1
Host: cname.domain.com
Authorization: AWS ACCESS_KEY:HASH_OF_HEADER_AND_SECRET3.3.25. S3 put bucket cors
Sets the cors configuration for the bucket. The user needs to be the bucket owner or to have been granted READ_ACP permission on the bucket.
Add the cors subresource to the bucket request as shown below.
Syntax
PUT /BUCKET?cors HTTP/1.1
Host: cname.domain.com
Authorization: AWS ACCESS_KEY:HASH_OF_HEADER_AND_SECRET3.3.26. S3 delete a bucket cors
Deletes the cors configuration information set for the bucket. The user needs to be the bucket owner or to have been granted READ_ACP permission on the bucket.
Add the cors subresource to the bucket request as shown below.
Syntax
DELETE /BUCKET?cors HTTP/1.1
Host: cname.domain.com
Authorization: AWS ACCESS_KEY:HASH_OF_HEADER_AND_SECRET3.3.27. S3 list bucket object versions
Returns a list of metadata about all the version of objects within a bucket. Requires READ access to the bucket.
Add the versions subresource to the bucket request as shown below.
Syntax
GET /BUCKET?versions HTTP/1.1
Host: cname.domain.com
Authorization: AWS ACCESS_KEY:HASH_OF_HEADER_AND_SECRET
You can specify parameters for GET /BUCKET?versions, but none of them are required.
Parameters
prefix- Description
- Returns in-progress uploads whose keys contain the specified prefix.
- Type
- String
delimiter- Description
- The delimiter between the prefix and the rest of the object name.
- Type
- String
key-marker- Description
- The beginning marker for the list of uploads.
- Type
- String
max-keys- Description
- The maximum number of in-progress uploads. The default is 1000.
- Type
- Integer
version-id-marker- Description
- Specifies the object version to begin the list.
- Type
- String
Response Entities
KeyMarker- Description
-
The key marker specified by the
key-markerrequest parameter, if any. - Type
- String
NextKeyMarker- Description
-
The key marker to use in a subsequent request if
IsTruncatedistrue. - Type
- String
NextUploadIdMarker- Description
-
The upload ID marker to use in a subsequent request if
IsTruncatedistrue. - Type
- String
IsTruncated- Description
-
If
true, only a subset of the bucket’s upload contents were returned. - Type
- Boolean
Size- Description
- The size of the uploaded part.
- Type
- Integer
DisplayName- Description
- The owner’s display name.
- Type
- String
ID- Description
- The owner’s ID.
- Type
- String
Owner- Description
-
A container for the
IDandDisplayNameof the user who owns the object. - Type
- Container
StorageClass- Description
-
The method used to store the resulting object.
STANDARDorREDUCED_REDUNDANCY - Type
- String
Version- Description
- Container for the version information.
- Type
- Container
versionId- Description
- Version ID of an object.
- Type
- String
versionIdMarker- Description
- The last version of the key in a truncated response.
- Type
- String
3.3.28. S3 head bucket
Calls HEAD on a bucket to determine if it exists and if the caller has access permissions. Returns 200 OK if the bucket exists and the caller has permissions; 404 Not Found if the bucket does not exist; and, 403 Forbidden if the bucket exists but the caller does not have access permissions.
Syntax
HEAD /BUCKET HTTP/1.1
Host: cname.domain.com
Date: date
Authorization: AWS ACCESS_KEY:HASH_OF_HEADER_AND_SECRET3.3.29. S3 list multipart uploads
GET /?uploads returns a list of the current in-progress multipart uploads, that is, the application initiates a multipart upload, but the service hasn’t completed all the uploads yet.
Syntax
GET /BUCKET?uploads HTTP/1.1
You can specify parameters for GET /BUCKET?uploads, but none of them are required.
Parameters
prefix- Description
- Returns in-progress uploads whose keys contain the specified prefix.
- Type
- String
delimiter- Description
- The delimiter between the prefix and the rest of the object name.
- Type
- String
key-marker- Description
- The beginning marker for the list of uploads.
- Type
- String
max-keys- Description
- The maximum number of in-progress uploads. The default is 1000.
- Type
- Integer
max-uploads- Description
- The maximum number of multipart uploads. The range is from 1-1000. The default is 1000.
- Type
- Integer
version-id-marker- Description
-
Ignored if
key-markerisn’t specified. Specifies theIDof the first upload to list in lexicographical order at or following theID. - Type
- String
Response Entities
ListMultipartUploadsResult- Description
- A container for the results.
- Type
- Container
ListMultipartUploadsResult.Prefix- Description
-
The prefix specified by the
prefixrequest parameter, if any. - Type
- String
Bucket- Description
- The bucket that will receive the bucket contents.
- Type
- String
KeyMarker- Description
-
The key marker specified by the
key-markerrequest parameter, if any. - Type
- String
UploadIdMarker- Description
-
The marker specified by the
upload-id-markerrequest parameter, if any. - Type
- String
NextKeyMarker- Description
-
The key marker to use in a subsequent request if
IsTruncatedistrue. - Type
- String
NextUploadIdMarker- Description
-
The upload ID marker to use in a subsequent request if
IsTruncatedistrue. - Type
- String
MaxUploads- Description
-
The max uploads specified by the
max-uploadsrequest parameter. - Type
- Integer
Delimiter- Description
-
If set, objects with the same prefix will appear in the
CommonPrefixeslist. - Type
- String
IsTruncated- Description
-
If
true, only a subset of the bucket’s upload contents were returned. - Type
- Boolean
Upload- Description
-
A container for
Key,UploadId,InitiatorOwner,StorageClass, andInitiatedelements. - Type
- Container
Key- Description
- The key of the object once the multipart upload is complete.
- Type
- String
UploadId- Description
-
The
IDthat identifies the multipart upload. - Type
- String
Initiator- Description
-
Contains the
IDandDisplayNameof the user who initiated the upload. - Type
- Container
DisplayName- Description
- The initiator’s display name.
- Type
- String
ID- Description
- The initiator’s ID.
- Type
- String
Owner- Description
-
A container for the
IDandDisplayNameof the user who owns the uploaded object. - Type
- Container
StorageClass- Description
-
The method used to store the resulting object.
STANDARDorREDUCED_REDUNDANCY - Type
- String
Initiated- Description
- The date and time the user initiated the upload.
- Type
- Date
CommonPrefixes- Description
- If multiple objects contain the same prefix, they will appear in this list.
- Type
- Container
CommonPrefixes.Prefix- Description
-
The substring of the key after the prefix as defined by the
prefixrequest parameter. - Type
- String
3.3.30. S3 bucket policies
The Ceph Object Gateway supports a subset of the Amazon S3 policy language applied to buckets.
Creation and Removal
Ceph Object Gateway manages S3 Bucket policies through standard S3 operations rather than using the radosgw-admin CLI tool.
Administrators may use the s3cmd command to set or delete a policy.
Example
$ cat > examplepol
{
"Version": "2012-10-17",
"Statement": [{
"Effect": "Allow",
"Principal": {"AWS": ["arn:aws:iam::usfolks:user/fred"]},
"Action": "s3:PutObjectAcl",
"Resource": [
"arn:aws:s3:::happybucket/*"
]
}]
}
$ s3cmd setpolicy examplepol s3://happybucket
$ s3cmd delpolicy s3://happybucketLimitations
Ceph Object Gateway only supports the following S3 actions:
-
s3:AbortMultipartUpload -
s3:CreateBucket -
s3:DeleteBucketPolicy -
s3:DeleteBucket -
s3:DeleteBucketWebsite -
s3:DeleteBucketReplication -
s3:DeleteReplicationConfiguration -
s3:DeleteObject -
s3:DeleteObjectVersion -
s3:GetBucketAcl -
s3:GetBucketCORS -
s3:GetBucketLocation -
s3:GetBucketPolicy -
s3:GetBucketRequestPayment -
s3:GetBucketVersioning -
s3:GetBucketWebsite -
s3:GetBucketReplication -
s3:GetReplicationConfiguration -
s3:GetLifecycleConfiguration -
s3:GetObjectAcl -
s3:GetObject -
s3:GetObjectTorrent -
s3:GetObjectVersionAcl -
s3:GetObjectVersion -
s3:GetObjectVersionTorrent -
s3:ListAllMyBuckets -
s3:ListBucketMultiPartUploads -
s3:ListBucket -
s3:ListBucketVersions -
s3:ListMultipartUploadParts -
s3:PutBucketAcl -
s3:PutBucketCORS -
s3:PutBucketPolicy -
s3:PutBucketRequestPayment -
s3:PutBucketVersioning -
s3:PutBucketWebsite -
s3:PutBucketReplication -
s3:PutReplicationConfiguration -
s3:PutLifecycleConfiguration -
s3:PutObjectAcl -
s3:PutObject -
s3:PutObjectVersionAcl
Ceph Object Gateway does not support setting policies on users, groups, or roles.
The Ceph Object Gateway uses the RGW tenant identifier in place of the Amazon twelve-digit account ID. Ceph Object Gateway administrators who want to use policies between Amazon Web Service (AWS) S3 and Ceph Object Gateway S3 will have to use the Amazon account ID as the tenant ID when creating users.
With AWS S3, all tenants share a single namespace. By contrast, Ceph Object Gateway gives every tenant its own namespace of buckets. At present, Ceph Object Gateway clients trying to access a bucket belonging to another tenant MUST address it as tenant:bucket in the S3 request.
In the AWS, a bucket policy can grant access to another account, and that account owner can then grant access to individual users with user permissions. Since Ceph Object Gateway does not yet support user, role, and group permissions, account owners will need to grant access directly to individual users.
Granting an entire account access to a bucket grants access to ALL users in that account.
Bucket policies do NOT support string interpolation.
Ceph Object Gateway supports the following condition keys:
-
aws:CurrentTime -
aws:EpochTime -
aws:PrincipalType -
aws:Referer -
aws:SecureTransport -
aws:SourceIp -
aws:UserAgent -
aws:username
Ceph Object Gateway ONLY supports the following condition keys for the ListBucket action:
-
s3:prefix -
s3:delimiter -
s3:max-keys
Impact on Swift
Ceph Object Gateway provides no functionality to set bucket policies under the Swift API. However, bucket policies that are set with the S3 API govern Swift and S3 operations.
Ceph Object Gateway matches Swift credentials against principals that are specified in a policy.
3.3.31. S3 get the request payment configuration on a bucket
Uses the requestPayment subresource to return the request payment configuration of a bucket. The user needs to be the bucket owner or to have been granted READ_ACP permission on the bucket.
Add the requestPayment subresource to the bucket request as shown below.
Syntax
GET /BUCKET?requestPayment HTTP/1.1
Host: cname.domain.com
Authorization: AWS ACCESS_KEY:HASH_OF_HEADER_AND_SECRET3.3.32. S3 set the request payment configuration on a bucket
Uses the requestPayment subresource to set the request payment configuration of a bucket. By default, the bucket owner pays for downloads from the bucket. This configuration parameter enables the bucket owner to specify that the person requesting the download will be charged for the request and the data download from the bucket.
Add the requestPayment subresource to the bucket request as shown below.
Syntax
PUT /BUCKET?requestPayment HTTP/1.1
Host: cname.domain.comRequest Entities
Payer- Description
- Specifies who pays for the download and request fees.
- Type
- Enum
RequestPaymentConfiguration- Description
-
A container for
Payer. - Type
- Container
3.3.33. Multi-tenant bucket operations
When a client application accesses buckets, it always operates with the credentials of a particular user. In Red Hat Ceph Storage cluster, every user belongs to a tenant. Consequently, every bucket operation has an implicit tenant in its context if no tenant is specified explicitly. Thus multi-tenancy is completely backward compatible with previous releases, as long as the referred buckets and referring user belong to the same tenant.
Extensions employed to specify an explicit tenant differ according to the protocol and authentication system used.
In the following example, a colon character separates tenant and bucket. Thus a sample URL would be:
https://rgw.domain.com/tenant:bucketBy contrast, a simple Python example separates the tenant and bucket in the bucket method itself:
Example
from boto.s3.connection import S3Connection, OrdinaryCallingFormat
c = S3Connection(
aws_access_key_id="TESTER",
aws_secret_access_key="test123",
host="rgw.domain.com",
calling_format = OrdinaryCallingFormat()
)
bucket = c.get_bucket("tenant:bucket")
It’s not possible to use S3-style subdomains using multi-tenancy, since host names cannot contain colons or any other separators that are not already valid in bucket names. Using a period creates an ambiguous syntax. Therefore, the bucket-in-URL-path format has to be used with multi-tenancy.
Additional Resources
- See the Multi Tenancy section under User Management in the Red Hat Ceph Storage Object Gateway Guide for additional details.
3.3.34. S3 Block Public Access
You can use the S3 Block Public Access feature to set buckets and users to help you manage public access to Red Hat Ceph Storage object storage S3 resources.
Using this feature, bucket policies, access point policies, and object permissions can be overridden to allow public access. By default, new buckets, access points, and objects do not allow public access.
The S3 API in the Ceph Object Gateway supports a subset of the AWS public access settings:
BlockPublicPolicy: This defines the setting to allow users to manage access point and bucket policies. This setting does not allow the users to publicly share the bucket or the objects it contains. Existing access point and bucket policies are not affected by enabling this setting. Setting this option toTRUEcauses the S3:- To reject calls to PUT Bucket policy.
- To reject calls to PUT access point policy for all of the bucket’s same-account access points.
Apply this setting at the user level so that users cannot alter a specific bucket’s block public access setting.
The TRUE setting only works if the specified policy allows public access.
-
RestrictPublicBuckets: This defines the setting to restrict access to a bucket or access point with public policy. The restriction applies to only AWS service principals and authorized users within the bucket owner’s account and access point owner’s account. This blocks cross-account access to the access point or bucket, except for the cases specified, while still allowing users within the account to manage the access points or buckets. Enabling this setting does not affect existing access point or bucket policies. It only defines that Amazon S3 blocks public and cross-account access derived from any public access point or bucket policy, including non-public delegation to specific accounts.
Access control lists (ACLs) are not currently supported by Red Hat Ceph Storage.
Bucket policies are assumed to be public unless defined otherwise. To block public access a bucket policy must give access only to fixed values for one or more of the following:
A fixed value does not contain a wildcard (*) or an AWS Identity and Access Management Policy Variable.
- An AWS principal, user, role, or service principal
-
A set of Classless Inter-Domain Routings (CIDRs), using
aws:SourceIp -
aws:SourceArn -
aws:SourceVpc -
aws:SourceVpce -
aws:SourceOwner -
aws:SourceAccount -
s3:x-amz-server-side-encryption-aws-kms-key-id -
aws:userid, outside the patternAROLEID:* s3:DataAccessPointArnNoteWhen used in a bucket policy, this value can contain a wildcard for the access point name without rendering the policy public, as long as the account ID is fixed.
-
s3:DataAccessPointPointAccount
The following example policy is considered public.
Example
{
"Principal": "*",
"Resource": "*",
"Action": "s3:PutObject",
"Effect": "Allow",
"Condition": { "StringLike": {"aws:SourceVpc": "vpc-*"}}
}To make a policy non-public, include any of the condition keys with a fixed value.
Example
{
"Principal": "*",
"Resource": "*",
"Action": "s3:PutObject",
"Effect": "Allow",
"Condition": {"StringEquals": {"aws:SourceVpc": "vpc-91237329"}}
}Additional Resources
- See the S3 GET `PublicAccessBlock` section in the Red Hat Ceph Storage Developer Guide for details on getting a PublicAccessBlock.
- See the S3 PUT `PublicAccessBlock` section in the Red Hat Ceph Storage Developer Guide for details on creating or modifying a PublicAccessBlock.
- See the S3 Delete `PublicAccessBlock` section in the Red Hat Ceph Storage Developer Guide for details on deleting a PublicAccessBlock.
- See the S3 bucket policies section in the Red Hat Ceph Storage Developer Guide for details on bucket policies.
- See the Blocking public access to your Amazon S3 storage section of Amazon Simple Storage Service (S3) documentation.
3.3.35. S3 GET PublicAccessBlock
To get the S3 Block Public Access feature configured, use GET and specify a destination AWS account.
Syntax
GET /v20180820/configuration/publicAccessBlock HTTP/1.1
Host: cname.domain.com
x-amz-account-id: _ACCOUNTID_Request Headers
See the S3 common request headers in Appendix B for more information about common request headers.
Response
The response is an HTTP 200 response and is returned in XML format.
3.3.36. S3 PUT PublicAccessBlock
Use this to create or modify the PublicAccessBlock configuration for an S3 bucket.
To use this operation, you must have the s3:PutBucketPublicAccessBlock permission.
If the PublicAccessBlock configuration is different between the bucket and the account, Amazon S3 uses the most restrictive combination of the bucket-level and account-level settings.
Syntax
PUT /?publicAccessBlock HTTP/1.1
Host: Bucket.s3.amazonaws.com
Content-MD5: ContentMD5
x-amz-sdk-checksum-algorithm: ChecksumAlgorithm
x-amz-expected-bucket-owner: ExpectedBucketOwner
<?xml version="1.0" encoding="UTF-8"?>
<PublicAccessBlockConfiguration xmlns="http://s3.amazonaws.com/doc/2006-03-01/">
<BlockPublicAcls>boolean</BlockPublicAcls>
<IgnorePublicAcls>boolean</IgnorePublicAcls>
<BlockPublicPolicy>boolean</BlockPublicPolicy>
<RestrictPublicBuckets>boolean</RestrictPublicBuckets>
</PublicAccessBlockConfiguration>Request Headers
See the S3 common request headers in Appendix B for more information about common request headers.
Response
The response is an HTTP 200 response and is returned with an empty HTTP body.
3.3.37. S3 delete PublicAccessBlock
Use this to delete the PublicAccessBlock configuration for an S3 bucket.
Syntax
DELETE /v20180820/configuration/publicAccessBlock HTTP/1.1
Host: s3-control.amazonaws.com
x-amz-account-id: AccountIdRequest Headers
See the S3 common request headers in Appendix B for more information about common request headers.
Response
The response is an HTTP 200 response and is returned with an empty HTTP body.
3.4. S3 object operations
As a developer, you can perform object operations with the Amazon S3 application programming interface (API) through the Ceph Object Gateway.
The following table list the Amazon S3 functional operations for objects, along with the function’s support status.
| Feature | Status |
|---|---|
| Supported | |
| Supported | |
| Supported | |
| Supported | |
| Supported | |
| Supported | |
| Supported | |
| Supported | |
| Supported | |
| Supported | |
| Supported | |
| Supported | |
| Supported | |
| Supported | |
| Supported | |
| Supported | |
| Supported | |
| Supported | |
| Supported | |
| Supported | |
| Supported | |
| Supported | |
| Supported | |
| Supported | |
| Supported | |
| Multi-Tenancy | Supported |
Prerequisites
- A running Red Hat Ceph Storage cluster.
- A RESTful client.
3.4.1. S3 get an object from a bucket
Retrieves an object from a bucket:
Syntax
GET /BUCKET/OBJECT HTTP/1.1
Add the versionId subresource to retrieve a particular version of the object:
Syntax
GET /BUCKET/OBJECT?versionId=VERSION_ID HTTP/1.1Request Headers
partNumber- Description
-
Part number of the object being read. This enables a ranged
GETrequest for the specified part. Using this request is useful for downloading just a part of an object. - Valid Values
- A positive integer between 1 and 10,000.
- Required
- No
range- Description
The range of the object to retrieve.
NoteMultiple ranges of data per GET request are not supported.
- Valid Values
- Range:bytes=beginbyte-endbyte
- Required
- No
if-modified-since- Description
- Gets only if modified since the timestamp.
- Valid Values
- Timestamp
- Required
- No
if-unmodified-since- Description
- Gets only if not modified since the timestamp.
- Valid Values
- Timestamp
- Required
- No
if-match- Description
- Gets only if object ETag matches ETag.
- Valid Values
- Entity Tag
- Required
- No
if-none-match- Description
- Gets only if object ETag does not match ETag.
- Valid Values
- Entity Tag
- Required
- No
Sytnax with request headers
GET /BUCKET/OBJECT?partNumber=PARTNUMBER&versionId=VersionId HTTP/1.1
Host: Bucket.s3.amazonaws.com
If-Match: IfMatch
If-Modified-Since: IfModifiedSince
If-None-Match: IfNoneMatch
If-Unmodified-Since: IfUnmodifiedSince
Range: RangeResponse Headers
Content-Range- Description
- Data range, will only be returned if the range header field was specified in the request.
x-amz-version-id- Description
- Returns the version ID or null.
3.4.2. S3 get information on an object
Returns information about an object. This request will return the same header information as with the Get Object request, but will include the metadata only, not the object data payload.
Retrieves the current version of the object:
Syntax
HEAD /BUCKET/OBJECT HTTP/1.1
Add the versionId subresource to retrieve info for a particular version:
Syntax
HEAD /BUCKET/OBJECT?versionId=VERSION_ID HTTP/1.1Request Headers
range- Description
- The range of the object to retrieve.
- Valid Values
- Range:bytes=beginbyte-endbyte
- Required
- No
if-modified-since- Description
- Gets only if modified since the timestamp.
- Valid Values
- Timestamp
- Required
- No
if-match- Description
- Gets only if object ETag matches ETag.
- Valid Values
- Entity Tag
- Required
- No
if-none-match- Description
- Gets only if object ETag matches ETag.
- Valid Values
- Entity Tag
- Required
- No
Response Headers
x-amz-version-id- Description
- Returns the version ID or null.
3.4.3. S3 put object lock
The put object lock API places a lock configuration on the selected bucket. With object lock, you can store objects using a Write-Once-Read-Many (WORM) model. Object lock ensures an object is not deleted or overwritten, for a fixed amount of time or indefinitely. The rule specified in the object lock configuration is applied by default to every new object placed in the selected bucket.
Enable the object lock when creating a bucket otherwise, the operation fails.
Syntax
PUT /BUCKET?object-lock HTTP/1.1Example
PUT /testbucket?object-lock HTTP/1.1Request Entities
ObjectLockConfiguration- Description
- A container for the request.
- Type
- Container
- Required
- Yes
ObjectLockEnabled- Description
- Indicates whether this bucket has an object lock configuration enabled.
- Type
- String
- Required
- Yes
Rule- Description
- The object lock rule in place for the specified bucket.
- Type
- Container
- Required
- No
DefaultRetention- Description
- The default retention period applied to new objects placed in the specified bucket.
- Type
- Container
- Required
- No
Mode- Description
- The default object lock retention mode. Valid values: GOVERNANCE/COMPLIANCE.
- Type
- Container
- Required
- Yes
Days- Description
- The number of days specified for the default retention period.
- Type
- Integer
- Required
- No
Years- Description
- The number of years specified for the default retention period.
- Type
- Integer
- Required
- No
HTTP Response
400- Status Code
-
MalformedXML - Description
- The XML is not well-formed.
409- Status Code
-
InvalidBucketState - Description
- The bucket object lock is not enabled.
3.4.4. S3 get object lock
The get object lock API retrieves the lock configuration for a bucket.
Syntax
GET /BUCKET?object-lock HTTP/1.1Example
GET /testbucket?object-lock HTTP/1.1Response Entities
ObjectLockConfiguration- Description
- A container for the request.
- Type
- Container
- Required
- Yes
ObjectLockEnabled- Description
- Indicates whether this bucket has an object lock configuration enabled.
- Type
- String
- Required
- Yes
Rule- Description
- The object lock rule is in place for the specified bucket.
- Type
- Container
- Required
- No
DefaultRetention- Description
- The default retention period applied to new objects placed in the specified bucket.
- Type
- Container
- Required
- No
Mode- Description
- The default object lock retention mode. Valid values: GOVERNANCE/COMPLIANCE.
- Type
- Container
- Required
- Yes
Days- Description
- The number of days specified for the default retention period.
- Type
- Integer
- Required
- No
Years- Description
- The number of years specified for the default retention period.
- Type
- Integer
- Required
- No
3.4.5. S3 put object legal hold
The put object legal hold API applies a legal hold configuration to the selected object. With a legal hold in place, you cannot overwrite or delete an object version. A legal hold does not have an associated retention period and remains in place until you explicitly remove it.
Syntax
PUT /BUCKET/OBJECT?legal-hold&versionId= HTTP/1.1Example
PUT /testbucket/testobject?legal-hold&versionId= HTTP/1.1
The versionId subresource retrieves a particular version of the object.
Request Entities
LegalHold- Description
- A container for the request.
- Type
- Container
- Required
- Yes
Status- Description
- Indicates whether the specified object has a legal hold in place. Valid values: ON/OFF
- Type
- String
- Required
- Yes
3.4.6. S3 get object legal hold
The get object legal hold API retrieves an object’s current legal hold status.
Syntax
GET /BUCKET/OBJECT?legal-hold&versionId= HTTP/1.1Example
GET /testbucket/testobject?legal-hold&versionId= HTTP/1.1
The versionId subresource retrieves a particular version of the object.
Response Entities
LegalHold- Description
- A container for the request.
- Type
- Container
- Required
- Yes
Status- Description
- Indicates whether the specified object has a legal hold in place. Valid values: ON/OFF
- Type
- String
- Required
- Yes
3.4.7. S3 put object retention
The put object retention API places an object retention configuration on an object. A retention period protects an object version for a fixed amount of time. There are two modes: GOVERNANCE and COMPLIANCE. These two retention modes apply different levels of protection to your objects.
During this period, your object is Write-Once-Read-Many-protected (WORM-protected) and cannot be overwritten or deleted.
Syntax
PUT /BUCKET/OBJECT?retention&versionId= HTTP/1.1Example
PUT /testbucket/testobject?retention&versionId= HTTP/1.1
The versionId sub-resource retrieves a particular version of the object.
Request Entities
Retention- Description
- A container for the request.
- Type
- Container
- Required
- Yes
Mode- Description
- Retention mode for the specified object. Valid values: GOVERNANCE, COMPLIANCE.
- Type
- String
- Required
- Yes
RetainUntilDate- Description
- Retention date.
- Format
- 2020-01-05T00:00:00.000Z
- Type
- Timestamp
- Required
- Yes
3.4.8. S3 get object retention
The get object retention API retrieves an object retention configuration on an object.
Syntax
GET /BUCKET/OBJECT?retention&versionId= HTTP/1.1Example
GET /testbucket/testobject?retention&versionId= HTTP/1.1
The versionId subresource retrieves a particular version of the object.
Response Entities
Retention- Description
- A container for the request.
- Type
- Container
- Required
- Yes
Mode- Description
- Retention mode for the specified object. Valid values: GOVERNANCE/COMPLIANCE
- Type
- String
- Required
- Yes
RetainUntilDate- Description
- Retention date. Format: 2020-01-05T00:00:00.000Z
- Type
- Timestamp
- Required
- Yes
3.4.9. S3 put object tagging
The put object tagging API associates tags with an object. A tag is a key-value pair. To put tags of any other version, use the versionId query parameter. You must have permission to perform the s3:PutObjectTagging action. By default, the bucket owner has this permission and can grant this permission to others.
Syntax
PUT /BUCKET/OBJECT?tagging&versionId= HTTP/1.1Example
PUT /testbucket/testobject?tagging&versionId= HTTP/1.1Request Entities
Tagging- Description
- A container for the request.
- Type
- Container
- Required
- Yes
TagSet- Description
- A collection of a set of tags.
- Type
- String
- Required
- Yes
3.4.10. S3 get object tagging
The get object tagging API returns the tag of an object. By default, the GET operation returns information on the current version of an object.
For a versioned bucket, you can have multiple versions of an object in your bucket. To retrieve tags of any other version, add the versionId query parameter in the request.
Syntax
GET /BUCKET/OBJECT?tagging&versionId= HTTP/1.1Example
GET /testbucket/testobject?tagging&versionId= HTTP/1.13.4.11. S3 delete object tagging
The delete object tagging API removes the entire tag set from the specified object. You must have permission to perform the s3:DeleteObjectTagging action, to use this operation.
To delete tags of a specific object version, add the versionId query parameter in the request.
Syntax
DELETE /BUCKET/OBJECT?tagging&versionId= HTTP/1.1Example
DELETE /testbucket/testobject?tagging&versionId= HTTP/1.13.4.12. S3 add an object to a bucket
Adds an object to a bucket. You must have write permissions on the bucket to perform this operation.
Syntax
PUT /BUCKET/OBJECT HTTP/1.1Request Headers
content-md5- Description
- A base64 encoded MD-5 hash of the message.
- Valid Values
- A string. No defaults or constraints.
- Required
- No
content-type- Description
- A standard MIME type.
- Valid Values
-
Any MIME type. Default:
binary/octet-stream. - Required
- No
x-amz-meta-<…>*- Description
- User metadata. Stored with the object.
- Valid Values
- A string up to 8kb. No defaults.
- Required
- No
x-amz-acl- Description
- A canned ACL.
- Valid Values
-
private,public-read,public-read-write,authenticated-read - Required
- No
Response Headers
x-amz-version-id- Description
- Returns the version ID or null.
3.4.13. S3 delete an object
Removes an object. Requires WRITE permission set on the containing bucket.
Deletes an object. If object versioning is on, it creates a marker.
Syntax
DELETE /BUCKET/OBJECT HTTP/1.1
To delete an object when versioning is on, you must specify the versionId subresource and the version of the object to delete.
DELETE /BUCKET/OBJECT?versionId=VERSION_ID HTTP/1.13.4.14. S3 delete multiple objects
This API call deletes multiple objects from a bucket.
Syntax
POST /BUCKET/OBJECT?delete HTTP/1.13.4.15. S3 get an object’s Access Control List (ACL)
Returns the ACL for the current version of the object:
Syntax
GET /BUCKET/OBJECT?acl HTTP/1.1
Add the versionId subresource to retrieve the ACL for a particular version:
Syntax
GET /BUCKET/OBJECT?versionId=VERSION_ID&acl HTTP/1.1Response Headers
x-amz-version-id- Description
- Returns the version ID or null.
Response Entities
AccessControlPolicy- Description
- A container for the response.
- Type
- Container
AccessControlList- Description
- A container for the ACL information.
- Type
- Container
Owner- Description
-
A container for the bucket owner’s
IDandDisplayName. - Type
- Container
ID- Description
- The bucket owner’s ID.
- Type
- String
DisplayName- Description
- The bucket owner’s display name.
- Type
- String
Grant- Description
-
A container for
GranteeandPermission. - Type
- Container
Grantee- Description
-
A container for the
DisplayNameandIDof the user receiving a grant of permission. - Type
- Container
Permission- Description
-
The permission given to the
Granteebucket. - Type
- String
3.4.16. S3 set an object’s Access Control List (ACL)
Sets an object ACL for the current version of the object.
Syntax
PUT /BUCKET/OBJECT?aclRequest Entities
AccessControlPolicy- Description
- A container for the response.
- Type
- Container
AccessControlList- Description
- A container for the ACL information.
- Type
- Container
Owner- Description
-
A container for the bucket owner’s
IDandDisplayName. - Type
- Container
ID- Description
- The bucket owner’s ID.
- Type
- String
DisplayName- Description
- The bucket owner’s display name.
- Type
- String
Grant- Description
-
A container for
GranteeandPermission. - Type
- Container
Grantee- Description
-
A container for the
DisplayNameandIDof the user receiving a grant of permission. - Type
- Container
Permission- Description
-
The permission given to the
Granteebucket. - Type
- String
3.4.17. S3 copy an object
To copy an object, use PUT and specify a destination bucket and the object name.
Syntax
PUT /DEST_BUCKET/DEST_OBJECT HTTP/1.1
x-amz-copy-source: SOURCE_BUCKET/SOURCE_OBJECTRequest Headers
x-amz-copy-source- Description
- The source bucket name + object name.
- Valid Values
-
BUCKET/OBJECT - Required
- Yes
x-amz-acl- Description
- A canned ACL.
- Valid Values
-
private,public-read,public-read-write,authenticated-read - Required
- No
x-amz-copy-if-modified-since- Description
- Copies only if modified since the timestamp.
- Valid Values
- Timestamp
- Required
- No
x-amz-copy-if-unmodified-since- Description
- Copies only if unmodified since the timestamp.
- Valid Values
- Timestamp
- Required
- No
x-amz-copy-if-match- Description
- Copies only if object ETag matches ETag.
- Valid Values
- Entity Tag
- Required
- No
x-amz-copy-if-none-match- Description
- Copies only if object ETag matches ETag.
- Valid Values
- Entity Tag
- Required
- No
Response Entities
CopyObjectResult- Description
- A container for the response elements.
- Type
- Container
LastModified- Description
- The last modified date of the source object.
- Type
- Date
Etag- Description
- The ETag of the new object.
- Type
- String
3.4.18. S3 add an object to a bucket using HTML forms
Adds an object to a bucket using HTML forms. You must have write permissions on the bucket to perform this operation.
Syntax
POST /BUCKET/OBJECT HTTP/1.13.4.19. S3 determine options for a request
A preflight request to determine if an actual request can be sent with the specific origin, HTTP method, and headers.
Syntax
OPTIONS /OBJECT HTTP/1.13.4.20. S3 initiate a multipart upload
Initiates a multi-part upload process. Returns a UploadId, which you can specify when adding additional parts, listing parts, and completing or abandoning a multi-part upload.
Syntax
POST /BUCKET/OBJECT?uploadsRequest Headers
content-md5- Description
- A base64 encoded MD-5 hash of the message.
- Valid Values
- A string. No defaults or constraints.
- Required
- No
content-type- Description
- A standard MIME type.
- Valid Values
-
Any MIME type. Default:
binary/octet-stream - Required
- No
x-amz-meta-<…>- Description
- User metadata. Stored with the object.
- Valid Values
- A string up to 8kb. No defaults.
- Required
- No
x-amz-acl- Description
- A canned ACL.
- Valid Values
-
private,public-read,public-read-write,authenticated-read - Required
- No
Response Entities
InitiatedMultipartUploadsResult- Description
- A container for the results.
- Type
- Container
Bucket- Description
- The bucket that will receive the object contents.
- Type
- String
Key- Description
-
The key specified by the
keyrequest parameter, if any. - Type
- String
UploadId- Description
-
The ID specified by the
upload-idrequest parameter identifying the multipart upload, if any. - Type
- String
3.4.21. S3 add a part to a multipart upload
Adds a part to a multi-part upload.
Specify the uploadId subresource and the upload ID to add a part to a multi-part upload:
Syntax
PUT /BUCKET/OBJECT?partNumber=&uploadId=UPLOAD_ID HTTP/1.1The following HTTP response might be returned:
HTTP Response
404- Status Code
-
NoSuchUpload - Description
- Specified upload-id does not match any initiated upload on this object.
3.4.22. S3 list the parts of a multipart upload
Specify the uploadId subresource and the upload ID to list the parts of a multi-part upload:
Syntax
GET /BUCKET/OBJECT?uploadId=UPLOAD_ID HTTP/1.1Response Entities
InitiatedMultipartUploadsResult- Description
- A container for the results.
- Type
- Container
Bucket- Description
- The bucket that will receive the object contents.
- Type
- String
Key- Description
-
The key specified by the
keyrequest parameter, if any. - Type
- String
UploadId- Description
-
The ID specified by the
upload-idrequest parameter identifying the multipart upload, if any. - Type
- String
Initiator- Description
-
Contains the
IDandDisplayNameof the user who initiated the upload. - Type
- Container
ID- Description
- The initiator’s ID.
- Type
- String
DisplayName- Description
- The initiator’s display name.
- Type
- String
Owner- Description
-
A container for the
IDandDisplayNameof the user who owns the uploaded object. - Type
- Container
StorageClass- Description
-
The method used to store the resulting object.
STANDARDorREDUCED_REDUNDANCY - Type
- String
PartNumberMarker- Description
-
The part marker to use in a subsequent request if
IsTruncatedistrue. Precedes the list. - Type
- String
NextPartNumberMarker- Description
-
The next part marker to use in a subsequent request if
IsTruncatedistrue. The end of the list. - Type
- String
IsTruncated- Description
-
If
true, only a subset of the object’s upload contents were returned. - Type
- Boolean
Part- Description
-
A container for
Key,Part,InitiatorOwner,StorageClass, andInitiatedelements. - Type
- Container
PartNumber- Description
-
A container for
Key,Part,InitiatorOwner,StorageClass, andInitiatedelements. - Type
- Integer
ETag- Description
- The part’s entity tag.
- Type
- String
Size- Description
- The size of the uploaded part.
- Type
- Integer
3.4.23. S3 assemble the uploaded parts
Assembles uploaded parts and creates a new object, thereby completing a multipart upload.
Specify the uploadId subresource and the upload ID to complete a multi-part upload:
Syntax
POST /BUCKET/OBJECT?uploadId=UPLOAD_ID HTTP/1.1Request Entities
CompleteMultipartUpload- Description
- A container consisting of one or more parts.
- Type
- Container
- Required
- Yes
Part- Description
-
A container for the
PartNumberandETag. - Type
- Container
- Required
- Yes
PartNumber- Description
- The identifier of the part.
- Type
- Integer
- Required
- Yes
ETag- Description
- The part’s entity tag.
- Type
- String
- Required
- Yes
Response Entities
CompleteMultipartUploadResult- Description
- A container for the response.
- Type
- Container
Location- Description
- The resource identifier (path) of the new object.
- Type
- URI
bucket- Description
- The name of the bucket that contains the new object.
- Type
- String
Key- Description
- The object’s key.
- Type
- String
ETag- Description
- The entity tag of the new object.
- Type
- String
3.4.24. S3 copy a multipart upload
Uploads a part by copying data from an existing object as data source.
Specify the uploadId subresource and the upload ID to perform a multi-part upload copy:
Syntax
PUT /BUCKET/OBJECT?partNumber=PartNumber&uploadId=UPLOAD_ID HTTP/1.1
Host: cname.domain.com
Authorization: AWS ACCESS_KEY:HASH_OF_HEADER_AND_SECRETRequest Headers
x-amz-copy-source- Description
- The source bucket name and object name.
- Valid Values
- BUCKET/OBJECT
- Required
- Yes
x-amz-copy-source-range- Description
- The range of bytes to copy from the source object.
- Valid Values
-
Range:
bytes=first-last, where the first and last are the zero-based byte offsets to copy. For example,bytes=0-9indicates that you want to copy the first ten bytes of the source. - Required
- No
Response Entities
CopyPartResult- Description
- A container for all response elements.
- Type
- Container
ETag- Description
- Returns the ETag of the new part.
- Type
- String
LastModified- Description
- Returns the date the part was last modified.
- Type
- String
Additional Resources
- For more information about this feature, see the Amazon S3 site.
3.4.25. S3 abort a multipart upload
Aborts a multipart upload.
Specify the uploadId subresource and the upload ID to abort a multi-part upload:
Syntax
DELETE /BUCKET/OBJECT?uploadId=UPLOAD_ID HTTP/1.13.4.26. S3 Hadoop interoperability
For data analytics applications that require Hadoop Distributed File System (HDFS) access, the Ceph Object Gateway can be accessed using the Apache S3A connector for Hadoop. The S3A connector is an open-source tool that presents S3 compatible object storage as an HDFS file system with HDFS file system read and write semantics to the applications while data is stored in the Ceph Object Gateway.
Ceph Object Gateway is fully compatible with the S3A connector that ships with Hadoop 2.7.3.
3.5. S3 select operations
As a developer, you can run S3 select to accelerate throughput. Users can run S3 select queries directly without a mediator.
There are three S3 select workflow - CSV, Apache Parquet (Parquet), and JSON that provide S3 select operations with CSV, Parquet, and JSON objects:
- A CSV file stores tabular data in plain text format. Each line of the file is a data record.
- Parquet is an open source, column-oriented data file format designed for efficient data storage and retrieval. It provides highly efficient data compression and encoding schemes with enhanced performance to handle complex data in bulk. Parquet enables the S3 select-engine to skip columns and chunks, thereby reducing IOPS dramatically (contrary to CSV and JSON format).
- JSON is a format structure. The S3 select engine enables the use of SQL statements on top of the JSON format input data using the JSON reader, enabling the scanning of highly nested and complex JSON formatted data.
For example, a CSV, Parquet, or JSON S3 object with several gigabytes of data allows the user to extract a single column which is filtered by another column using the following query:
Example
select customerid from s3Object where age>30 and age<65;Currently, the S3 object must retrieve data from the Ceph OSD through the Ceph Object Gateway before filtering and extracting data. There is improved performance when the object is large and the query is more specific. The Parquet format can be processed more efficiently than CSV.
Prerequisites
- A running Red Hat Ceph Storage cluster.
- A RESTful client.
- A S3 user created with user access.
3.5.1. S3 select content from an object
The select object content API filters the content of an object through the structured query language (SQL). See the Metadata collected by inventory section in the AWS Systems Manager User Guide for an example of the description of what should reside in the inventory object. The inventory content impacts the type of queries that should be run against that inventory. The number of SQL statements that potentially could provide essential information is large, but S3 select is an SQL-like utility and therefore, some operators are not supported, such as group-by and join.
For CSV only, you must specify the data serialization format as comma-separated values of the object to retrieve the specified content. Parquet has no delimiter because it is in binary format. Amazon Web Services (AWS) command-line interface (CLI) select object content uses the CSV or Parquet format to parse object data into records and returns only the records specified in the query.
You must specify the data serialization format for the response. You must have s3:GetObject permission for this operation.
-
The
InputSerializationelement describes the format of the data in the object that is being queried. Objects can be in CSV or Parquet format. -
The
OutputSerializationelement is part of the AWS-CLI user client and describes how the output data is formatted. Ceph has implemented the server client for AWS-CLI and therefore, provides the same output according toOutputSerializationwhich currently is CSV only. -
The format of the
InputSerializationdoes not need to match the format of theOutputSerialization. So, for example, you can specify Parquet in theInputSerializationand CSV in theOutputSerialization.
Syntax
POST /BUCKET/KEY?select&select-type=2 HTTP/1.1\r\nExample
POST /testbucket/sample1csv?select&select-type=2 HTTP/1.1\r\n
POST /testbucket/sample1parquet?select&select-type=2 HTTP/1.1\r\nRequest entities
Bucket- Description
- The bucket to select object content from.
- Type
- String
- Required
- Yes
Key- Description
- The object key.
- Length Constraints
- Minimum length of 1.
- Type
- String
- Required
- Yes
SelectObjectContentRequest- Description
- Root level tag for the select object content request parameters.
- Type
- String
- Required
- Yes
Expression- Description
- The expression that is used to query the object.
- Type
- String
- Required
- Yes
ExpressionType- Description
- The type of the provided expression for example SQL.
- Type
- String
- Valid Values
- SQL
- Required
- Yes
InputSerialization- Description
- Describes the format of the data in the object that is being queried.
- Type
- String
- Required
- Yes
OutputSerialization- Description
- Format of data returned in comma separator and new-line.
- Type
- String
- Required
- Yes
Response entities
If the action is successful, the service sends back HTTP 200 response. Data is returned in XML format by the service:
Payload- Description
- Root level tag for the payload parameters.
- Type
- String
- Required
- Yes
Records- Description
- The records event.
- Type
- Base64-encoded binary data object
- Required
- No
Stats- Description
- The stats event.
- Type
- Long
- Required
- No
The Ceph Object Gateway supports the following response:
Example
{:event-type,records} {:content-type,application/octet-stream} {:message-type,event}Syntax (for CSV)
aws --endpoint-URL http://localhost:80 s3api select-object-content
--bucket BUCKET_NAME
--expression-type 'SQL'
--input-serialization
'{"CSV": {"FieldDelimiter": "," , "QuoteCharacter": "\"" , "RecordDelimiter" : "\n" , "QuoteEscapeCharacter" : "\\" , "FileHeaderInfo": "USE" }, "CompressionType": "NONE"}'
--output-serialization '{"CSV": {}}'
--key OBJECT_NAME.csv
--expression "select count(0) from s3object where int(_1)<10;" output.csvExample (for CSV)
aws --endpoint-url http://localhost:80 s3api select-object-content
--bucket testbucket
--expression-type 'SQL'
--input-serialization
'{"CSV": {"FieldDelimiter": "," , "QuoteCharacter": "\"" , "RecordDelimiter" : "\n" , "QuoteEscapeCharacter" : "\\" , "FileHeaderInfo": "USE" }, "CompressionType": "NONE"}'
--output-serialization '{"CSV": {}}'
--key testobject.csv
--expression "select count(0) from s3object where int(_1)<10;" output.csvSyntax (for Parquet)
aws --endpoint-url http://localhost:80 s3api select-object-content
--bucket BUCKET_NAME
--expression-type 'SQL'
--input-serialization
'{"Parquet": {}, {"CompressionType": "NONE"}'
--output-serialization '{"CSV": {}}'
--key OBJECT_NAME.parquet
--expression "select count(0) from s3object where int(_1)<10;" output.csvExample (for Parquet)
aws --endpoint-url http://localhost:80 s3api select-object-content
--bucket testbucket
--expression-type 'SQL'
--input-serialization
'{"Parquet": {}, {"CompressionType": "NONE"}'
--output-serialization '{"CSV": {}}'
--key testobject.parquet
--expression "select count(0) from s3object where int(_1)<10;" output.csvSyntax (for JSON)
aws --endpoint-URL http://localhost:80 s3api select-object-content
--bucket BUCKET_NAME
--expression-type 'SQL'
--input-serialization
'{"JSON": {"CompressionType": "NONE"}'
--output-serialization '{"CSV": {}}}'
--key OBJECT_NAME.json
--expression "select count(0) from s3object where int(_1)<10;" output.csvExample (for JSON)
aws --endpoint-url http://localhost:80 s3api select-object-content
--bucket testbucket
--expression-type 'SQL'
--input-serialization
'{"JSON": {"CompressionType": "NONE"}'
--output-serialization '{"CSV": {}}}'
--key testobject.json
--expression "select count(0) from s3object where int(_1)<10;" output.csvExample (for BOTO3)
import pprint
import boto3
from botocore.exceptions import ClientError
def run_s3select(bucket,key,query,column_delim=",",row_delim="\n",quot_char='"',esc_char='\\',csv_header_info="NONE"):
s3 = boto3.client('s3',
endpoint_url=endpoint,
aws_access_key_id=access_key,
region_name=region_name,
aws_secret_access_key=secret_key)
result = ""
try:
r = s3.select_object_content(
Bucket=bucket,
Key=key,
ExpressionType='SQL',
InputSerialization = {"CSV": {"RecordDelimiter" : row_delim, "FieldDelimiter" : column_delim,"QuoteEscapeCharacter": esc_char, "QuoteCharacter": quot_char, "FileHeaderInfo": csv_header_info}, "CompressionType": "NONE"},
OutputSerialization = {"CSV": {}},
Expression=query,
RequestProgress = {"Enabled": progress})
except ClientError as c:
result += str(c)
return result
for event in r['Payload']:
if 'Records' in event:
result = ""
records = event['Records']['Payload'].decode('utf-8')
result += records
if 'Progress' in event:
print("progress")
pprint.pprint(event['Progress'],width=1)
if 'Stats' in event:
print("Stats")
pprint.pprint(event['Stats'],width=1)
if 'End' in event:
print("End")
pprint.pprint(event['End'],width=1)
return result
run_s3select(
"my_bucket",
"my_csv_object",
"select int(_1) as a1, int(_2) as a2 , (a1+a2) as a3 from s3object where a3>100 and a3<300;")Supported features
Currently, only part of the AWS s3 select command is supported:
3.5.2. S3 supported select functions
S3 select supports the following functions: .Timestamp
- to_timestamp(string)
- Description
- Converts string to timestamp basic type. In the string format, any missing 'time' value is populated with zero; for missing month and day value, 1 is the default value. 'Timezone' is in format +/-HH:mm or Z , where the letter 'Z' indicates Coordinated Universal Time (UTC). Value of timezone can range between - 12:00 and +14:00.
- Supported
Currently it can convert the following string formats into timestamp:
- YYYY-MM-DDTHH:mm:ss.SSSSSS+/-HH:mm
- YYYY-MM-DDTHH:mm:ss.SSSSSSZ
- YYYY-MM-DDTHH:mm:ss+/-HH:mm
- YYYY-MM-DDTHH:mm:ssZ
- YYYY-MM-DDTHH:mm+/-HH:mm
- YYYY-MM-DDTHH:mmZ
- YYYY-MM-DDT
- YYYYT
- to_string(timestamp, format_pattern)
- Description
- Returns a string representation of the input timestamp in the given input string format.
- Parameters
| Format | Example | Description |
|---|---|---|
| yy | 69 | 2-year digit. |
| y | 1969 | 4-year digit. |
| yyyy | 1969 | Zero-padded 4-digit year. |
| M | 1 | Month of the year. |
| MM | 01 | Zero-padded month of the year. |
| MMM | Jan | Abbreviated month of the year name. |
| MMMM | January | full month of the year name. |
| MMMMM | J |
Month of the year first letter. Not valid for use with the |
| d | 2 | Day of the month (1-31). |
| dd | 02 | Zero-padded day of the month (01-31). |
| a | AM | AM or PM of day. |
| h | 3 | Hour of the day (1-12). |
| hh | 03 | Zero-padded hour of day (01-12). |
| H | 3 | Hour of the day (0-23). |
| HH | 03 | Zero-padded hour of the day (00-23). |
| m | 4 | Minute of the hour (0-59). |
| mm | 04 | Zero-padded minute of the hour (00-59). |
| s | 5 | Second of the minute (0-59). |
| ss | 05 | Zero-padded second of the minute (00-59). |
| S | 1 | Fraction of the second (precision: 0.1, range: 0.0-0.9). |
| SS | 12 | Fraction of the second (precision: 0.01, range: 0.0-0.99). |
| SSS | 123 | Fraction of the second (precision: 0.01, range: 0.0-0.999). |
| SSSS | 1234 | Fraction of the second (precision: 0.001, range: 0.0-0.9999). |
| SSSSSS | 123456 | Fraction of the second (maximum precision: 1 nanosecond, range: 0.0-0.999999). |
| n | 60000000 | Nano of second. |
| X | +07 or Z | Offset in hours or “Z” if the offset is 0. |
| XX or XXXX | +0700 or Z | Offset in hours and minutes or “Z” if the offset is 0. |
| XXX or XXXXX | +07:00 or Z | Offset in hours and minutes or “Z” if the offset is 0. |
| x | 7 | Offset in hours. |
| xx or xxxx | 700 | Offset in hours and minutes. |
| xxx or xxxxx | +07:00 | Offset in hours and minutes. |
- extract(date-part from timestamp)
- Description
- Returns integer according to date-part extract from input timestamp.
- Supported
- year, month, week, day, hour, minute, second, timezone_hour, timezone_minute.
- date_add(date-part ,integer,timestamp)
- Description
- Returns timestamp, a calculation based on the results of input timestamp and date-part.
- Supported
- year, month, day, hour, minute, second.
- date_diff(date-part,timestamp,timestamp)
- Description
- Return an integer, a calculated result of the difference between two timestamps according to date-part.
- Supported
- year, month, day, hour, minute, second.
- utcnow()
- Description
- Return timestamp of current time.
Aggregation
- count()
- Description
- Returns integers based on the number of rows that match a condition if there is one.
- sum(expression)
- Description
- Returns a summary of expression on each row that matches a condition if there is one.
- avg(expression)
- Description
- Returns an average expression on each row that matches a condition if there is one.
- max(expression)
- Description
- Returns the maximal result for all expressions that match a condition if there is one.
- min(expression)
- Description
- Returns the minimal result for all expressions that match a condition if there is one.
String
- substring (string,from,for)
- Description
- Returns a string extract from the input string according to from, for inputs.
- Char_length
- Description
- Returns a number of characters in string. Character_length also does the same.
- trim([[leading | trailing | both remove_chars] from] string )
- Description
- Trims leading/trailing (or both) characters from the target string. The default value is a blank character.
- Upper\lower
- Description
- Converts characters into uppercase or lowercase.
NULL
The NULL value is missing or unknown that is NULL can not produce a value on any arithmetic operations. The same applies to arithmetic comparison, any comparison to NULL is NULL that is unknown.
| A is NULL | Result(NULL=UNKNOWN) |
|---|---|
| Not A |
|
| A or False |
|
| A or True |
|
| A or A |
|
| A and False |
|
| A and True |
|
| A and A |
|
3.5.3. S3 alias programming construct
Alias programming construct is an essential part of the s3 select language because it enables better programming with objects that contain many columns or complex queries. When a statement with alias construct is parsed, it replaces the alias with a reference to the right projection column and on query execution, the reference is evaluated like any other expression. Alias maintains result-cache that is if an alias is used more than once, the same expression is not evaluated and the same result is returned because the result from the cache is used. Currently, Red Hat supports the column alias.
Example
select int(_1) as a1, int(_2) as a2 , (a1+a2) as a3 from s3object where a3>100 and a3<300;")3.5.4. S3 parsing explained
The S3 select engine has parsers for all three file formats - CSV, Parquet, and JSON which separate the commands into more processable components, which are then attached to tags that define each component.
3.5.4.1. S3 CSV parsing
The CSV definitions with input serialization uses these default values:
-
Use
{\n}`for row-delimiter. -
Use
{“}for quote. -
Use
{\}for escape characters.
The csv-header-info is parsed upon USE appearing in the AWS-CLI; this is the first row in the input object containing the schema. Currently, output serialization and compression-type is not supported. The S3 select engine has a CSV parser which parses S3-objects:
- Each row ends with a row-delimiter.
- The field-separator separates the adjacent columns.
-
The successive field separator defines the
NULLcolumn. - The quote-character overrides the field-separator; that is, the field separator is any character between the quotes.
- The escape character disables any special character except the row delimiter.
The following are examples of CSV parsing rules:
| Feature | Description | Input (Tokens) |
|---|---|---|
|
| Successive field delimiter |
|
|
| The quote character overrides the field delimiter. |
|
|
| The escape character overrides the meta-character. |
A container for the object owner’s |
|
| There is no closed quote; row delimiter is the closing line. |
|
|
| FileHeaderInfo tag | USE value means each token on the first line is the column-name; IGNORE value means to skip the first line. |
3.5.4.2. S3 Parquet parsing
Apache Parquet is an open-source, columnar data file format designed for efficient data storage and retrieval.
The S3 select engine’s Parquet parser parses S3-objects as follows:
Example
4-byte magic number "PAR1"
<Column 1 Chunk 1 + Column Metadata>
<Column 2 Chunk 1 + Column Metadata>
...
<Column N Chunk 1 + Column Metadata>
<Column 1 Chunk 2 + Column Metadata>
<Column 2 Chunk 2 + Column Metadata>
...
<Column N Chunk 2 + Column Metadata>
...
<Column 1 Chunk M + Column Metadata>
<Column 2 Chunk M + Column Metadata>
...
<Column N Chunk M + Column Metadata>
File Metadata
4-byte length in bytes of file metadata
4-byte magic number "PAR1"- In the above example, there are N columns in this table, split into M row groups. The file metadata contains the locations of all the column metadata start locations.
- Metadata is written after the data to allow for single pass writing.
- All the column chunks can be found in the file metadata which should later be read sequentially.
- The format is explicitly designed to separate the metadata from the data. This allows splitting columns into multiple files, as well as having a single metadata file reference multiple parquet files.
3.5.4.3. S3 JSON parsing
JSON document enables nesting values within objects or arrays without limitations. When querying a specific value in a JSON document in the S3 select engine, the location of the value is specified through a path in the SELECT statement.
The generic structure of a JSON document does not have a row and column structure like CSV and Parquet. Instead, it is the SQL statement itself that defines the rows and columns when querying a JSON document.
The S3 select engine’s JSON parser parses S3-objects as follows:
-
The
FROMclause in theSELECTstatement defines the row boundaries. - A row in a JSON document is similar to how the row delimiter is used to define rows for CSV objects, and how row groups are used to define rows for Parquet objects
Consider the following example:
Example
{ "firstName": "Joe", "lastName": "Jackson", "gender": "male", "age": "twenty" }, { "firstName": "Joe_2", "lastName": "Jackson_2", "gender": "male", "age": 21 }, "phoneNumbers": [ { "type": "home1", "number": "734928_1","addr": 11 }, { "type": "home2", "number": "734928_2","addr": 22 } ], "key_after_array": "XXX", "description" : { "main_desc" : "value_1", "second_desc" : "value_2" } # the from-clause define a single row. # _1 points to root object level. # _1.age appears twice in Documnet-row, the last value is used for the operation. query = "select _1.firstname,_1.key_after_array,_1.age+4,_1.description.main_desc,_1.description.second_desc from s3object[*].aa.bb.cc;"; expected_result = Joe_2,XXX,25,value_1,value_2-
The statement instructs the reader to search for the path
aa.bb.ccand defines the row boundaries based on the occurrence of this path. -
A row begins when the reader encounters the path, and it ends when the reader exits the innermost part of the path, which in this case is the object
cc.
-
The statement instructs the reader to search for the path
3.5.5. Integrating Ceph Object Gateway with Trino
Integrate the Ceph Object Gateway with Trino, an important utility that enables the user to run SQL queries 9x faster on S3 objects.
Following are some benefits of using Trino:
- Trino is a complete SQL engine.
- Pushes down S3 select requests wherein the Trino engine identifies part of the SQL statement that is cost effective to run on the server-side.
- uses the optimization rules of Ceph/S3select to enhance performance.
- Leverages Red Hat Ceph Storage scalability and divides the original object into multiple equal parts, performs S3 select requests, and merges the request.
If the s3select syntax does not work while querying through trino, use the SQL syntax.
Prerequisites
- A running Red Hat Ceph Storage cluster with Ceph Object Gateway installed.
- Docker or Podman installed.
- Buckets created.
- Objects are uploaded.
Procedure
Deploy Trino and hive.
Example
[cephuser@host01 ~]$ git clone https://github.com/ceph/s3select.git [cephuser@host01 ~]$ cd s3selectModify the
hms_trino.yamlfile with S3 endpoint, access key, and secret key.Example
[cephuser@host01 s3select]$ cat container/trino/hms_trino.yaml version: '3' services: hms: image: galsl/hms:dev container_name: hms environment: # S3_ENDPOINT the CEPH/RGW end-point-url - S3_ENDPOINT=http://rgw_ip:port - S3_ACCESS_KEY=abc - S3_SECRET_KEY=abc # the container starts with booting the hive metastore command: sh -c '. ~/.bashrc; start_hive_metastore' ports: - 9083:9083 networks: - trino_hms trino: image: trinodb/trino:405 container_name: trino volumes: # the trino directory contains the necessary configuration - ./trino:/etc/trino ports: - 8080:8080 networks: - trino_hms networks: trino_hmModify the
hive.propertiesfile with S3 endpoint, access key, and secret key.Example
[cephuser@host01 s3select]$ cat container/trino/trino/catalog/hive.properties connector.name=hive hive.metastore.uri=thrift://hms:9083 #hive.metastore.warehouse.dir=s3a://hive/ hive.allow-drop-table=true hive.allow-rename-table=true hive.allow-add-column=true hive.allow-drop-column=true hive.allow-rename-column=true hive.non-managed-table-writes-enabled=true hive.s3select-pushdown.enabled=true hive.s3.aws-access-key=abc hive.s3.aws-secret-key=abc # should modify per s3-endpoint-url hive.s3.endpoint=http://rgw_ip:port #hive.s3.max-connections=1 #hive.s3select-pushdown.max-connections=1 hive.s3.connect-timeout=100s hive.s3.socket-timeout=100s hive.max-splits-per-second=10000 hive.max-split-size=128MBStart a Trino container to integrate Ceph Object Gateway.
Example
[cephuser@host01 s3select]$ sudo docker compose -f ./container/trino/hms_trino.yaml up -dVerify integration.
Example
[cephuser@host01 s3select]$ sudo docker exec -it trino /bin/bash trino@66f753905e82:/$ trino trino> create schema hive.csvbkt1schema; trino> create table hive.csvbkt1schema.polariondatacsv(c1 varchar,c2 varchar, c3 varchar, c4 varchar, c5 varchar, c6 varchar, c7 varchar, c8 varchar, c9 varchar) WITH ( external_location = 's3a://csvbkt1/',format = 'CSV'); trino> select * from hive.csvbkt1schema.polariondatacsv;NoteThe external location must point to the bucket name or a directory, and not the end of a file.