Dieser Inhalt ist in der von Ihnen ausgewählten Sprache nicht verfügbar.
Chapter 2. Clustered caches
You can create embedded and remote caches on Data Grid clusters that replicate data across nodes.
2.1. Replicated caches
Data Grid replicates all entries in the cache to all nodes in the cluster. Each node can perform read operations locally.
Replicated caches provide a quick and easy way to share state across a cluster, but is suitable for clusters of less than ten nodes. Because the number of replication requests scales linearly with the number of nodes in the cluster, using replicated caches with larger clusters reduces performance. However you can use UDP multicasting for replication requests to improve performance.
Each key has a primary owner, which serializes data container updates in order to provide consistency.
Figure 2.1. Replicated cache
Synchronous or asynchronous replication
-
Synchronous replication blocks the caller (e.g. on a
cache.put(key, value)) until the modifications have been replicated successfully to all the nodes in the cluster. - Asynchronous replication performs replication in the background, and write operations return immediately. Asynchronous replication is not recommended, because communication errors, or errors that happen on remote nodes are not reported to the caller.
Transactions
If transactions are enabled, write operations are not replicated through the primary owner.
With pessimistic locking, each write triggers a lock message, which is broadcast to all the nodes. During transaction commit, the originator broadcasts a one-phase prepare message and an unlock message (optional). Either the one-phase prepare or the unlock message is fire-and-forget.
With optimistic locking, the originator broadcasts a prepare message, a commit message, and an unlock message (optional). Again, either the one-phase prepare or the unlock message is fire-and-forget.
2.2. Distributed caches
Data Grid attempts to keep a fixed number of copies of any entry in the cache, configured as numOwners. This allows distributed caches to scale linearly, storing more data as nodes are added to the cluster.
As nodes join and leave the cluster, there will be times when a key has more or less than numOwners copies. In particular, if numOwners nodes leave in quick succession, some entries will be lost, so we say that a distributed cache tolerates numOwners - 1 node failures.
The number of copies represents a trade-off between performance and durability of data. The more copies you maintain, the lower performance will be, but also the lower the risk of losing data due to server or network failures.
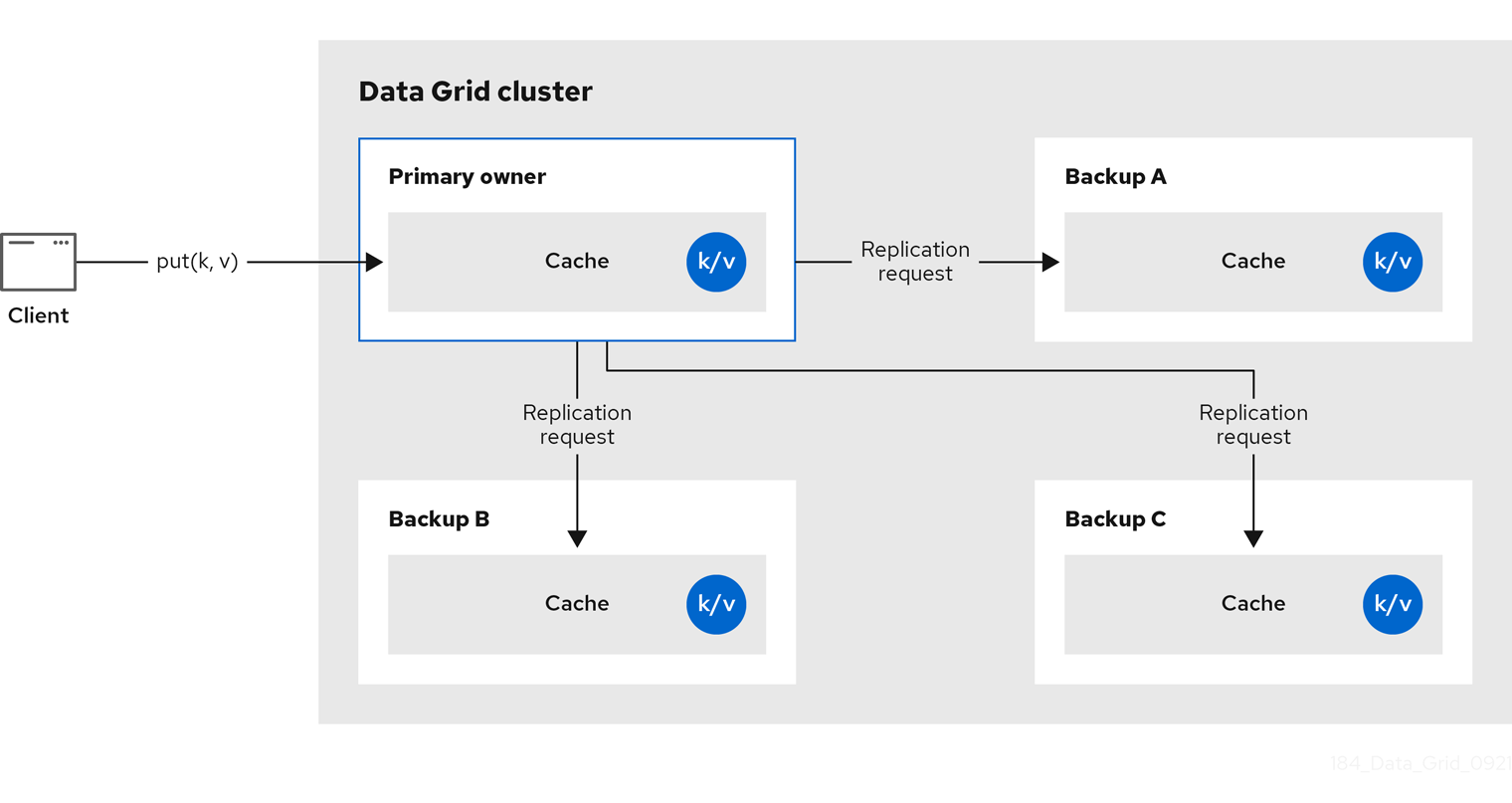
Data Grid splits the owners of a key into one primary owner, which coordinates writes to the key, and zero or more backup owners.
The following diagram shows a write operation that a client sends to a backup owner. In this case the backup node forwards the write to the primary owner, which then replicates the write to the backup.
Figure 2.2. Cluster replication

Figure 2.3. Distributed cache

Read operations
Read operations request the value from the primary owner. If the primary owner does not respond in a reasonable amount of time, Data Grid requests the value from the backup owners as well.
A read operation may require 0 messages if the key is present in the local cache, or up to 2 * numOwners messages if all the owners are slow.
Write operations
Write operations result in at most 2 * numOwners messages. One message from the originator to the primary owner and numOwners - 1 messages from the primary to the backup nodes along with the corresponding acknowledgment messages.
Cache topology changes may cause retries and additional messages for both read and write operations.
Synchronous or asynchronous replication
Asynchronous replication is not recommended because it can lose updates. In addition to losing updates, asynchronous distributed caches can also see a stale value when a thread writes to a key and then immediately reads the same key.
Transactions
Transactional distributed caches send lock/prepare/commit/unlock messages to the affected nodes only, meaning all nodes that own at least one key affected by the transaction. As an optimization, if the transaction writes to a single key and the originator is the primary owner of the key, lock messages are not replicated.
2.2.1. Read consistency
Even with synchronous replication, distributed caches are not linearizable. For transactional caches, they do not support serialization/snapshot isolation.
For example, a thread is carrying out a single put request:
cache.get(k) -> v1 cache.put(k, v2) cache.get(k) -> v2
But another thread might see the values in a different order:
cache.get(k) -> v2 cache.get(k) -> v1
The reason is that read can return the value from any owner, depending on how fast the primary owner replies. The write is not atomic across all the owners. In fact, the primary commits the update only after it receives a confirmation from the backup. While the primary is waiting for the confirmation message from the backup, reads from the backup will see the new value, but reads from the primary will see the old one.
2.2.2. Key ownership
Distributed caches split entries into a fixed number of segments and assign each segment to a list of owner nodes. Replicated caches do the same, with the exception that every node is an owner.
The first node in the list of owners is the primary owner. The other nodes in the list are backup owners. When the cache topology changes, because a node joins or leaves the cluster, the segment ownership table is broadcast to every node. This allows nodes to locate keys without making multicast requests or maintaining metadata for each key.
The numSegments property configures the number of segments available. However, the number of segments cannot change unless the cluster is restarted.
Likewise the key-to-segment mapping cannot change. Keys must always map to the same segments regardless of cluster topology changes. It is important that the key-to-segment mapping evenly distributes the number of segments allocated to each node while minimizing the number of segments that must move when the cluster topology changes.
| Consistent hash factory implementation | Description |
|---|---|
|
| Uses an algorithm based on consistent hashing. Selected by default when server hinting is disabled. This implementation always assigns keys to the same nodes in every cache as long as the cluster is symmetric. In other words, all caches run on all nodes. This implementation does have some negative points in that the load distribution is slightly uneven. It also moves more segments than strictly necessary on a join or leave. |
|
|
Equivalent to |
|
|
Achieves a more even distribution than |
|
|
Equivalent to |
|
| Used internally to implement replicated caches. You should never explicitly select this algorithm in a distributed cache. |
Hashing configuration
You can configure ConsistentHashFactory implementations, including custom ones, with embedded caches only.
XML
<distributed-cache name="distributedCache"
owners="2"
segments="100"
capacity-factor="2" />
ConfigurationBuilder
Configuration c = new ConfigurationBuilder()
.clustering()
.cacheMode(CacheMode.DIST_SYNC)
.hash()
.numOwners(2)
.numSegments(100)
.capacityFactor(2)
.build();
Additional resources
2.2.3. Capacity factors
Capacity factors allocate the number of segments based on resources available to each node in the cluster.
The capacity factor for a node applies to segments for which that node is both the primary owner and backup owner. In other words, the capacity factor specifies is the total capacity that a node has in comparison to other nodes in the cluster.
The default value is 1 which means that all nodes in the cluster have an equal capacity and Data Grid allocates the same number of segments to all nodes in the cluster.
However, if nodes have different amounts of memory available to them, you can configure the capacity factor so that the Data Grid hashing algorithm assigns each node a number of segments weighted by its capacity.
The value for the capacity factor configuration must be a positive number and can be a fraction such as 1.5. You can also configure a capacity factor of 0 but is recommended only for nodes that join the cluster temporarily and should use the zero capacity configuration instead.
2.2.3.1. Zero capacity nodes
You can configure nodes where the capacity factor is 0 for every cache, user defined caches, and internal caches. When defining a zero capacity node, the node does not hold any data.
Zero capacity node configuration
XML
<infinispan> <cache-container zero-capacity-node="true" /> </infinispan>
JSON
{
"infinispan" : {
"cache-container" : {
"zero-capacity-node" : "true"
}
}
}
YAML
infinispan:
cacheContainer:
zeroCapacityNode: "true"
ConfigurationBuilder
new GlobalConfigurationBuilder().zeroCapacityNode(true);
2.2.4. Level one (L1) caches
Data Grid nodes create local replicas when they retrieve entries from another node in the cluster. L1 caches avoid repeatedly looking up entries on primary owner nodes and adds performance.
The following diagram illustrates how L1 caches work:
Figure 2.4. L1 cache
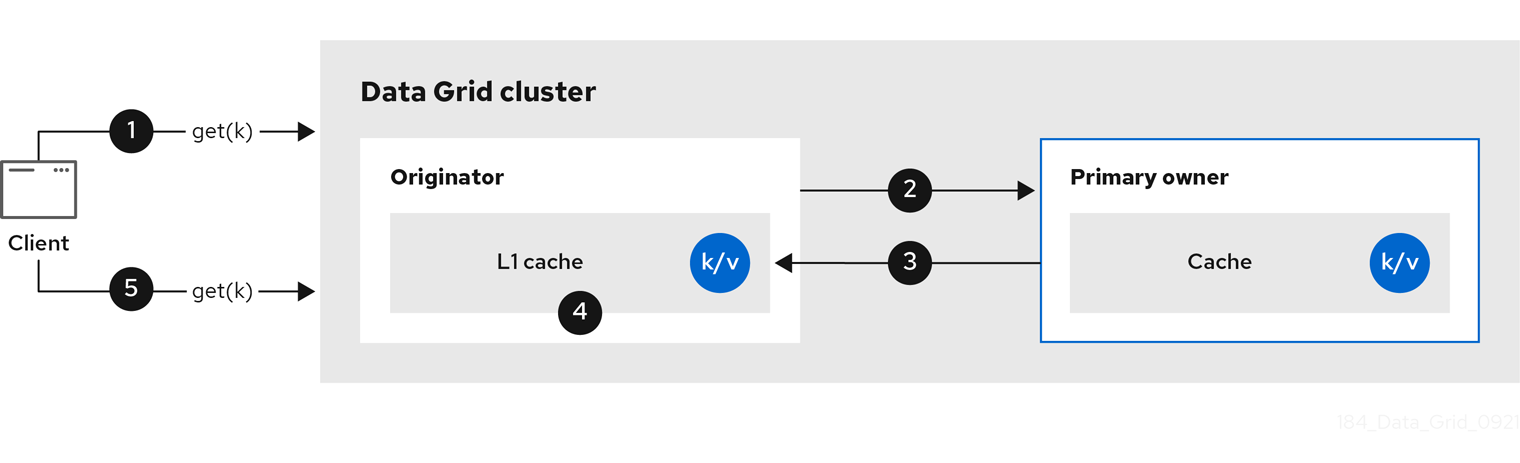
In the "L1 cache" diagram:
-
A client invokes
cache.get()to read an entry for which another node in the cluster is the primary owner. - The originator node forwards the read operation to the primary owner.
- The primary owner returns the key/value entry.
- The originator node creates a local copy.
-
Subsequent
cache.get()invocations return the local entry instead of forwarding to the primary owner.
L1 caching performance
Enabling L1 improves performance for read operations but requires primary owner nodes to broadcast invalidation messages when entries are modified. This ensures that Data Grid removes any out of date replicas across the cluster. However this also decreases performance of write operations and increases memory usage, reducing overall capacity of caches.
Data Grid evicts and expires local replicas, or L1 entries, like any other cache entry.
L1 cache configuration
XML
<distributed-cache l1-lifespan="5000"
l1-cleanup-interval="60000">
</distributed-cache>
JSON
{
"distributed-cache": {
"l1-lifespan": "5000",
"l1-cleanup-interval": "60000"
}
}
YAML
distributedCache: l1Lifespan: "5000" l1-cleanup-interval: "60000"
ConfigurationBuilder
ConfigurationBuilder builder = new ConfigurationBuilder();
builder.clustering().cacheMode(CacheMode.DIST_SYNC)
.l1()
.lifespan(5000, TimeUnit.MILLISECONDS)
.cleanupTaskFrequency(60000, TimeUnit.MILLISECONDS);
2.2.5. Server hinting
Server hinting increases availability of data in distributed caches by replicating entries across as many servers, racks, and data centers as possible.
Server hinting applies only to distributed caches.
When Data Grid distributes the copies of your data, it follows the order of precedence: site, rack, machine, and node. All of the configuration attributes are optional. For example, when you specify only the rack IDs, then Data Grid distributes the copies across different racks and nodes.
Server hinting can impact cluster rebalancing operations by moving more segments than necessary if the number of segments for the cache is too low.
An alternative for clusters in multiple data centers is cross-site replication.
Server hinting configuration
XML
<cache-container>
<transport cluster="MyCluster"
machine="LinuxServer01"
rack="Rack01"
site="US-WestCoast"/>
</cache-container>
JSON
{
"infinispan" : {
"cache-container" : {
"transport" : {
"cluster" : "MyCluster",
"machine" : "LinuxServer01",
"rack" : "Rack01",
"site" : "US-WestCoast"
}
}
}
}
YAML
cacheContainer:
transport:
cluster: "MyCluster"
machine: "LinuxServer01"
rack: "Rack01"
site: "US-WestCoast"
GlobalConfigurationBuilder
GlobalConfigurationBuilder global = GlobalConfigurationBuilder.defaultClusteredBuilder()
.transport()
.clusterName("MyCluster")
.machineId("LinuxServer01")
.rackId("Rack01")
.siteId("US-WestCoast");
Additional resources
2.2.6. Key affinity service
In a distributed cache, a key is allocated to a list of nodes with an opaque algorithm. There is no easy way to reverse the computation and generate a key that maps to a particular node. However, Data Grid can generate a sequence of (pseudo-)random keys, see what their primary owner is, and hand them out to the application when it needs a key mapping to a particular node.
Following code snippet depicts how a reference to this service can be obtained and used.
// 1. Obtain a reference to a cache
Cache cache = ...
Address address = cache.getCacheManager().getAddress();
// 2. Create the affinity service
KeyAffinityService keyAffinityService = KeyAffinityServiceFactory.newLocalKeyAffinityService(
cache,
new RndKeyGenerator(),
Executors.newSingleThreadExecutor(),
100);
// 3. Obtain a key for which the local node is the primary owner
Object localKey = keyAffinityService.getKeyForAddress(address);
// 4. Insert the key in the cache
cache.put(localKey, "yourValue");The service is started at step 2: after this point it uses the supplied Executor to generate and queue keys. At step 3, we obtain a key from the service, and at step 4 we use it.
Lifecycle
KeyAffinityService extends Lifecycle, which allows stopping and (re)starting it:
public interface Lifecycle {
void start();
void stop();
}
The service is instantiated through KeyAffinityServiceFactory. All the factory methods have an Executor parameter, that is used for asynchronous key generation (so that it won’t happen in the caller’s thread). It is the user’s responsibility to handle the shutdown of this Executor.
The KeyAffinityService, once started, needs to be explicitly stopped. This stops the background key generation and releases other held resources.
The only situation in which KeyAffinityService stops by itself is when the Cache Manager with which it was registered is shutdown.
Topology changes
When the cache topology changes, the ownership of the keys generated by the KeyAffinityService might change. The key affinity service keep tracks of these topology changes and doesn’t return keys that would currently map to a different node, but it won’t do anything about keys generated earlier.
As such, applications should treat KeyAffinityService purely as an optimization, and they should not rely on the location of a generated key for correctness.
In particular, applications should not rely on keys generated by KeyAffinityService for the same address to always be located together. Collocation of keys is only provided by the Grouping API.
2.2.7. Grouping API
Complementary to the Key affinity service, the Grouping API allows you to co-locate a group of entries on the same nodes, but without being able to select the actual nodes.
By default, the segment of a key is computed using the key’s hashCode(). If you use the Grouping API, Data Grid will compute the segment of the group and use that as the segment of the key.
When the Grouping API is in use, it is important that every node can still compute the owners of every key without contacting other nodes. For this reason, the group cannot be specified manually. The group can either be intrinsic to the entry (generated by the key class) or extrinsic (generated by an external function).
To use the Grouping API, you must enable groups.
Configuration c = new ConfigurationBuilder() .clustering().hash().groups().enabled() .build();
<distributed-cache> <groups enabled="true"/> </distributed-cache>
If you have control of the key class (you can alter the class definition, it’s not part of an unmodifiable library), then we recommend using an intrinsic group. The intrinsic group is specified by adding the @Group annotation to a method, for example:
class User {
...
String office;
...
public int hashCode() {
// Defines the hash for the key, normally used to determine location
...
}
// Override the location by specifying a group
// All keys in the same group end up with the same owners
@Group
public String getOffice() {
return office;
}
}
}
The group method must return a String
If you don’t have control over the key class, or the determination of the group is an orthogonal concern to the key class, we recommend using an extrinsic group. An extrinsic group is specified by implementing the Grouper interface.
public interface Grouper<T> {
String computeGroup(T key, String group);
Class<T> getKeyType();
}
If multiple Grouper classes are configured for the same key type, all of them will be called, receiving the value computed by the previous one. If the key class also has a @Group annotation, the first Grouper will receive the group computed by the annotated method. This allows you even greater control over the group when using an intrinsic group.
Example Grouper implementation
public class KXGrouper implements Grouper<String> {
// The pattern requires a String key, of length 2, where the first character is
// "k" and the second character is a digit. We take that digit, and perform
// modular arithmetic on it to assign it to group "0" or group "1".
private static Pattern kPattern = Pattern.compile("(^k)(<a>\\d</a>)$");
public String computeGroup(String key, String group) {
Matcher matcher = kPattern.matcher(key);
if (matcher.matches()) {
String g = Integer.parseInt(matcher.group(2)) % 2 + "";
return g;
} else {
return null;
}
}
public Class<String> getKeyType() {
return String.class;
}
}
Grouper implementations must be registered explicitly in the cache configuration. If you are configuring Data Grid programmatically:
Configuration c = new ConfigurationBuilder() .clustering().hash().groups().enabled().addGrouper(new KXGrouper()) .build();
Or, if you are using XML:
<distributed-cache>
<groups enabled="true">
<grouper class="com.example.KXGrouper" />
</groups>
</distributed-cache>Advanced API
AdvancedCache has two group-specific methods:
-
getGroup(groupName)retrieves all keys in the cache that belong to a group. -
removeGroup(groupName)removes all the keys in the cache that belong to a group.
Both methods iterate over the entire data container and store (if present), so they can be slow when a cache contains lots of small groups.
2.3. Invalidation caches
Invalidation cache mode in Data Grid is designed to optimize systems that perform high volumes of read operations to a shared permanent data store. You can use invalidation mode to reduce the number of database writes when state changes occur.
Invalidation cache mode is deprecated for Data Grid remote deployments. Use invalidation cache mode with embedded caches that are stored in shared cache stores only.
Invalidation cache mode is effective only when you have a permanent data store, such as a database, and are only using Data Grid as an optimization in a read-heavy system to prevent hitting the database for every read.
When a cache is configured for invalidation, each data change in a cache triggers a message to other caches in the cluster, informing them that their data is now stale and should be removed from memory. Invalidation messages remove stale values from other nodes' memory. The messages are very small compared to replicating the entire value, and also other caches in the cluster look up modified data in a lazy manner, only when needed. The update to the shared store is typically handled by user application code or Hibernate.
Figure 2.5. Invalidation cache
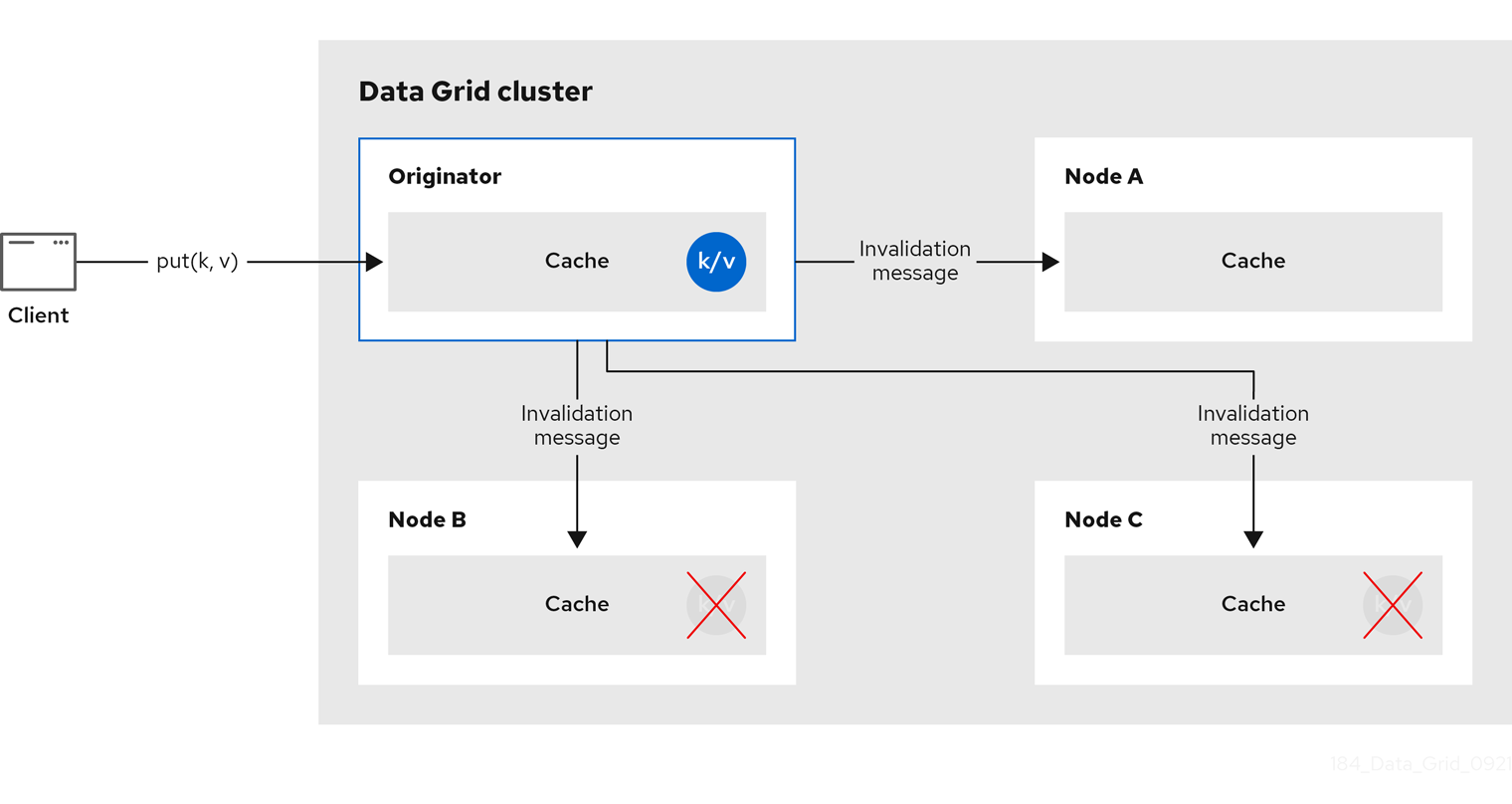
Sometimes the application reads a value from the external store and wants to write it to the local cache, without removing it from the other nodes. To do this, it must call Cache.putForExternalRead(key, value) instead of Cache.put(key, value).
Invalidation mode is suitable only for shared stores where all nodes can access the same data. Using invalidation mode without a persistent store is impractical, as updated values need to be read from a shared store for consistency across nodes.
Never use invalidation mode with a local, non-shared, cache store. The invalidation message will not remove entries in the local store, and some nodes will keep seeing the stale value.
An invalidation cache can also be configured with a special cache loader, ClusterLoader. When ClusterLoader is enabled, read operations that do not find the key on the local node will request it from all the other nodes first, and store it in memory locally. This can lead to storing stale values, so only use it if you have a high tolerance for stale values.
Synchronous or asynchronous replication
When synchronous, a write operation blocks until all nodes in the cluster have evicted the stale value. When asynchronous, the originator broadcasts invalidation messages but does not wait for responses. That means other nodes still see the stale value for a while after the write completed on the originator.
Transactions
Transactions can be used to batch the invalidation messages. Transactions acquire the key lock on the primary owner.
With pessimistic locking, each write triggers a lock message, which is broadcast to all the nodes. During transaction commit, the originator broadcasts a one-phase prepare message (optionally fire-and-forget) which invalidates all affected keys and releases the locks.
With optimistic locking, the originator broadcasts a prepare message, a commit message, and an unlock message (optional). Either the one-phase prepare or the unlock message is fire-and-forget, and the last message always releases the locks.
2.4. Scattered caches
Scattered caches are very similar to distributed caches as they allow linear scaling of the cluster. Scattered caches allow single node failure by maintaining two copies of the data (numOwners=2). Unlike distributed caches, the location of data is not fixed; while we use the same Consistent Hash algorithm to locate the primary owner, the backup copy is stored on the node that wrote the data last time. When the write originates on the primary owner, backup copy is stored on any other node (the exact location of this copy is not important).
This has the advantage of single Remote Procedure Call (RPC) for any write (distributed caches require one or two RPCs), but reads have to always target the primary owner. That results in faster writes but possibly slower reads, and therefore this mode is more suitable for write-intensive applications.
Storing multiple backup copies also results in slightly higher memory consumption. In order to remove out-of-date backup copies, invalidation messages are broadcast in the cluster, which generates some overhead. This lowers the performance of scattered caches in clusters with a large number of nodes.
When a node crashes, the primary copy may be lost. Therefore, the cluster has to reconcile the backups and find out the last written backup copy. This process results in more network traffic during state transfer.
Since the writer of data is also a backup, even if we specify machine/rack/site IDs on the transport level the cluster cannot be resilient to more than one failure on the same machine/rack/site.
You cannot use scattered caches with transactions or asynchronous replication.
The cache is configured in a similar way as the other cache modes, here is an example of declarative configuration:
<scattered-cache name="scatteredCache" />
Configuration c = new ConfigurationBuilder() .clustering().cacheMode(CacheMode.SCATTERED_SYNC) .build();
Scattered mode is not exposed in the server configuration as the server is usually accessed through the Hot Rod protocol. The protocol automatically selects primary owner for the writes and therefore the write (in distributed mode with two owner) requires single RPC inside the cluster, too. Therefore, scattered cache would not bring the performance benefit.
2.5. Asynchronous replication
All clustered cache modes can be configured to use asynchronous communications with the mode="ASYNC" attribute on the <replicated-cache/>, <distributed-cache>, or <invalidation-cache/> element.
With asynchronous communications, the originator node does not receive any acknowledgement from the other nodes about the status of the operation, so there is no way to check if it succeeded on other nodes.
We do not recommend asynchronous communications in general, as they can cause inconsistencies in the data, and the results are hard to reason about. Nevertheless, sometimes speed is more important than consistency, and the option is available for those cases.
Asynchronous API
The Asynchronous API allows you to use synchronous communications, but without blocking the user thread.
There is one caveat: The asynchronous operations do NOT preserve the program order. If a thread calls cache.putAsync(k, v1); cache.putAsync(k, v2), the final value of k may be either v1 or v2. The advantage over using asynchronous communications is that the final value can’t be v1 on one node and v2 on another.
2.5.1. Return values with asynchronous replication
Because the Cache interface extends java.util.Map, write methods like put(key, value) and remove(key) return the previous value by default.
In some cases, the return value may not be correct:
-
When using
AdvancedCache.withFlags()withFlag.IGNORE_RETURN_VALUE,Flag.SKIP_REMOTE_LOOKUP, orFlag.SKIP_CACHE_LOAD. -
When the cache is configured with
unreliable-return-values="true". - When using asynchronous communications.
- When there are multiple concurrent writes to the same key, and the cache topology changes. The topology change will make Data Grid retry the write operations, and a retried operation’s return value is not reliable.
Transactional caches return the correct previous value in cases 3 and 4. However, transactional caches also have a gotcha: in distributed mode, the read-committed isolation level is implemented as repeatable-read. That means this example of "double-checked locking" won’t work:
Cache cache = ...
TransactionManager tm = ...
tm.begin();
try {
Integer v1 = cache.get(k);
// Increment the value
Integer v2 = cache.put(k, v1 + 1);
if (Objects.equals(v1, v2) {
// success
} else {
// retry
}
} finally {
tm.commit();
}
The correct way to implement this is to use cache.getAdvancedCache().withFlags(Flag.FORCE_WRITE_LOCK).get(k).
In caches with optimistic locking, writes can also return stale previous values. Write skew checks can avoid stale previous values.
2.6. Configuring initial cluster size
Data Grid handles cluster topology changes dynamically. This means that nodes do not need to wait for other nodes to join the cluster before Data Grid initializes the caches.
If your applications require a specific number of nodes in the cluster before caches start, you can configure the initial cluster size as part of the transport.
Procedure
- Open your Data Grid configuration for editing.
-
Set the minimum number of nodes required before caches start with the
initial-cluster-sizeattribute orinitialClusterSize()method. -
Set the timeout, in milliseconds, after which the Cache Manager does not start with the
initial-cluster-timeoutattribute orinitialClusterTimeout()method. - Save and close your Data Grid configuration.
Initial cluster size configuration
XML
<infinispan>
<cache-container>
<transport initial-cluster-size="4"
initial-cluster-timeout="30000" />
</cache-container>
</infinispan>
JSON
{
"infinispan" : {
"cache-container" : {
"transport" : {
"initial-cluster-size" : "4",
"initial-cluster-timeout" : "30000"
}
}
}
}
YAML
infinispan:
cacheContainer:
transport:
initialClusterSize: "4"
initialClusterTimeout: "30000"
ConfigurationBuilder
GlobalConfiguration global = GlobalConfigurationBuilder.defaultClusteredBuilder() .transport() .initialClusterSize(4) .initialClusterTimeout(30000, TimeUnit.MILLISECONDS);