Dieser Inhalt ist in der von Ihnen ausgewählten Sprache nicht verfügbar.
Chapter 7. Configuring Data Grid to handle network partitions
Data Grid clusters can split into network partitions in which subsets of nodes become isolated from each other. This condition results in loss of availability or consistency for clustered caches. Data Grid automatically detects crashed nodes and resolves conflicts to merge caches back together.
7.1. Split clusters and network partitions
Network partitions are the result of error conditions in the running environment, such as when a network router crashes. When a cluster splits into partitions, nodes create a JGroups cluster view that includes only the nodes in that partition. This condition means that nodes in one partition can operate independently of nodes in the other partition.
Detecting a split
To automatically detect network partitions, Data Grid uses the FD_ALL protocol in the default JGroups stack to determine when nodes leave the cluster abruptly.
Data Grid cannot detect what causes nodes to leave abruptly. This can happen not only when there is a network failure but also for other reasons, such as when Garbage Collection (GC) pauses the JVM.
Data Grid suspects that nodes have crashed after the following number of milliseconds:
FD_ALL[2|3].timeout + FD_ALL[2|3].interval + VERIFY_SUSPECT[2].timeout + GMS.view_ack_collection_timeoutWhen it detects that the cluster is split into network partitions, Data Grid uses a strategy for handling cache operations. Depending on your application requirements Data Grid can:
- Allow read and/or write operations for availability
- Deny read and write operations for consistency
Merging partitions together
To fix a split cluster, Data Grid merges the partitions back together. During the merge, Data Grid uses the .equals() method for values of cache entries to determine if any conflicts exist. To resolve any conflicts between replicas it finds on partitions, Data Grid uses a merge policy that you can configure.
7.1.1. Data consistency in a split cluster
Network outages or errors that cause Data Grid clusters to split into partitions can result in data loss or consistency issues regardless of any handling strategy or merge policy.
Between the split and detection
If a write operation takes place on a node that is in a minor partition when a split occurs, and before Data Grid detects the split, that value is lost when Data Grid transfers state to that minor partition during the merge.
In the event that all partitions are in the DEGRADED mode that value is not lost because no state transfer occurs but the entry can have an inconsistent value. For transactional caches write operations that are in progress when the split occurs can be committed on some nodes and rolled back on other nodes, which also results in inconsistent values.
During the split and the time that Data Grid detects it, it is possible to get stale reads from a cache in a minor partition that has not yet entered DEGRADED mode.
During the merge
When Data Grid starts removing partitions nodes reconnect to the cluster with a series of merge events. Before this merge process completes it is possible that write operations on transactional caches succeed on some nodes but not others, which can potentially result in stale reads until the entries are updated.
7.2. Cache availability and degraded mode
To preserve data consistency, Data Grid can put caches into DEGRADED mode if you configure them to use either the DENY_READ_WRITES or ALLOW_READS partition handling strategy.
Data Grid puts caches in a partition into DEGRADED mode when the following conditions are true:
-
At least one segment has lost all owners.
This happens when a number of nodes equal to or greater than the number of owners for a distributed cache have left the cluster. -
There is not a majority of nodes in the partition.
A majority of nodes is any number greater than half the total number of nodes in the cluster from the most recent stable topology, which was the last time a cluster rebalancing operation completed successfully.
When caches are in DEGRADED mode, Data Grid:
- Allows read and write operations only if all replicas of an entry reside in the same partition.
Denies read and write operations and throws an
AvailabilityExceptionif the partition does not include all replicas of an entry.NoteWith the
ALLOW_READSstrategy, Data Grid allows read operations on caches inDEGRADEDmode.
DEGRADED mode guarantees consistency by ensuring that write operations do not take place for the same key in different partitions. Additionally DEGRADED mode prevents stale read operations that happen when a key is updated in one partition but read in another partition.
If all partitions are in DEGRADED mode then the cache becomes available again after merge only if the cluster contains a majority of nodes from the most recent stable topology and there is at least one replica of each entry. When the cluster has at least one replica of each entry, no keys are lost and Data Grid can create new replicas based on the number of owners during cluster rebalancing.
In some cases a cache in one partition can remain available while entering DEGRADED mode in another partition. When this happens the available partition continues cache operations as normal and Data Grid attempts to rebalance data across those nodes. To merge the cache together Data Grid always transfers state from the available partition to the partition in DEGRADED mode.
7.2.1. Degraded cache recovery example
This topic illustrates how Data Grid recovers from split clusters with caches that use the DENY_READ_WRITES partition handling strategy.
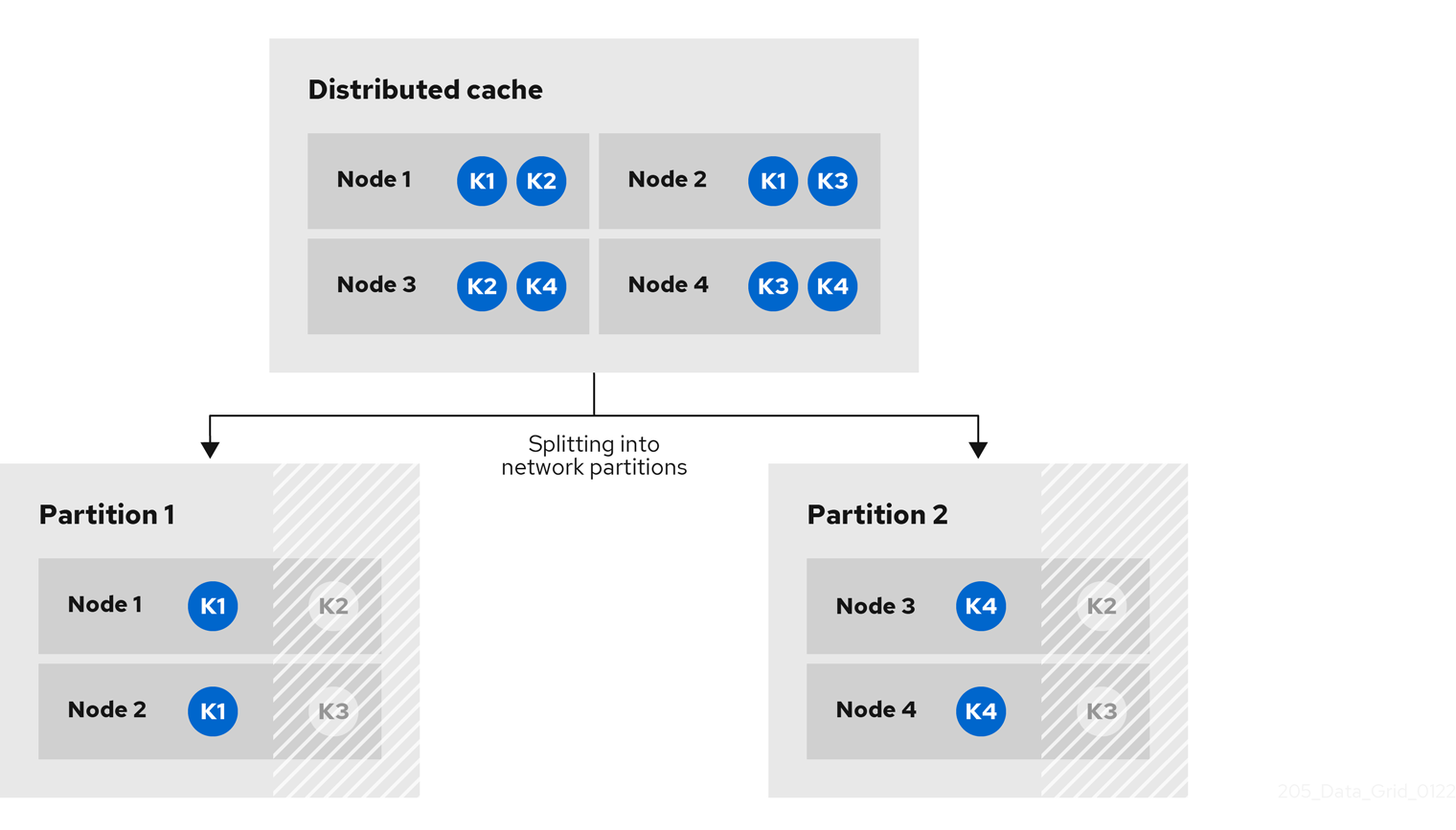
As an example, a Data Grid cluster has four nodes and includes a distributed cache with two replicas for each entry (owners=2). There are four entries in the cache, k1, k2, k3 and k4.
With the DENY_READ_WRITES strategy, if the cluster splits into partitions, Data Grid allows cache operations only if all replicas of an entry are in the same partition.
In the following diagram, while the cache is split into partitions, Data Grid allows read and write operations for k1 on partition 1 and k4 on partition 2. Because there is only one replica for k2 and k3 on either partition 1 or partition 2, Data Grid denies read and write operations for those entries.
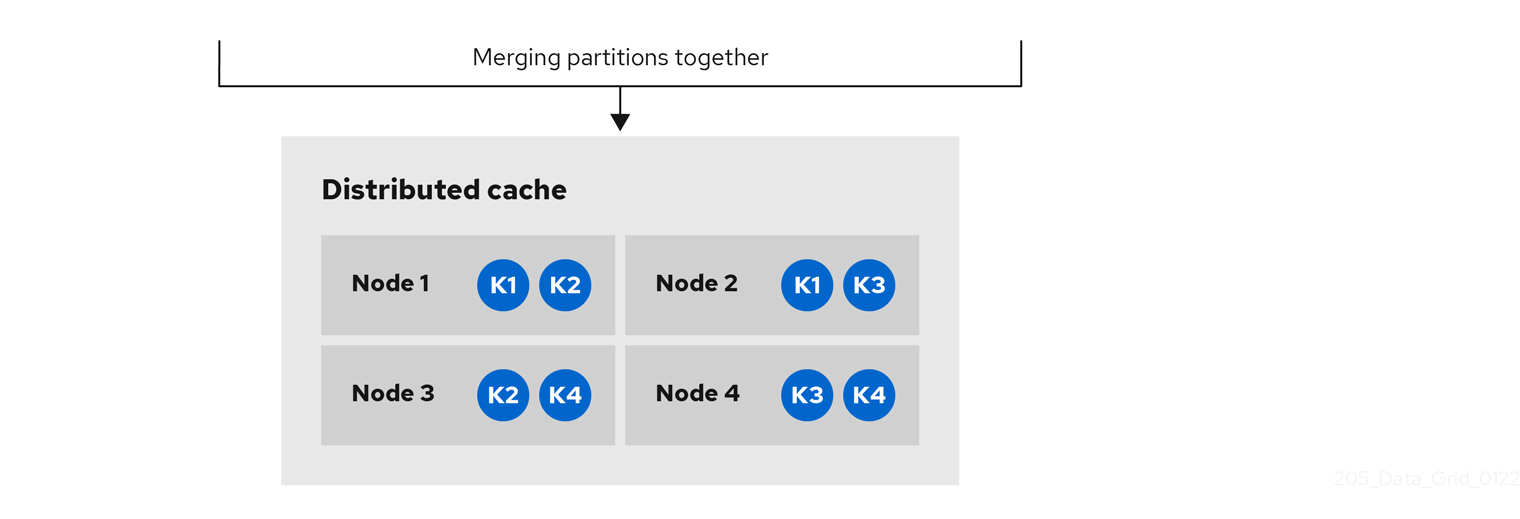
When network conditions allow the nodes to re-join the same cluster view, Data Grid merges the partitions without state transfer and restores normal cache operations.
7.2.2. Verifying cache availability during network partitions
Determine if caches on Data Grid clusters are in AVAILABLE mode or DEGRADED mode during a network partition.
When Data Grid clusters split into partitions, nodes in those partitions can enter DEGRADED mode to guarantee data consistency. In DEGRADED mode clusters do not allow cache operations resulting in loss of availability.
Procedure
Verify availability of clustered caches in network partitions in one of the following ways:
-
Check Data Grid logs for
ISPN100011messages that indicate if the cluster is available or if at least one cache is inDEGRADEDmode. Get the availability of remote caches through the Data Grid Console or with the REST API.
- Open the Data Grid Console in any browser, select the Data Container tab, and then locate the availability status in the Health column.
Retrieve cache health from the REST API.
GET /rest/v2/container/health
-
Programmatically retrieve the availability of embedded caches with the
getAvailability()method in theAdvancedCacheAPI.
7.2.3. Making caches available
Make caches available for read and write operations by forcing them out of DEGRADED mode.
You should force clusters out of DEGRADED mode only if your deployment can tolerate data loss and inconsistency.
Procedure
Make caches available in one of the following ways:
- Open the Data Grid Console and select the Make available option.
Change the availability of remote caches with the REST API.
POST /rest/v2/caches/<cacheName>?action=set-availability&availability=AVAILABLEProgrammatically change the availability of embedded caches with the
AdvancedCacheAPI.AdvancedCache ac = cache.getAdvancedCache(); // Retrieve cache availability boolean available = ac.getAvailability() == AvailabilityMode.AVAILABLE; // Make the cache available if (!available) { ac.setAvailability(AvailabilityMode.AVAILABLE); }
7.3. Configuring partition handling
Configure Data Grid to use a partition handling strategy and merge policy so it can resolve split clusters when network issues occur. By default Data Grid uses a strategy that provides availability at the cost of lowering consistency guarantees for your data. When a cluster splits due to a network partition clients can continue to perform read and write operations on caches.
If you require consistency over availability, you can configure Data Grid to deny read and write operations while the cluster is split into partitions. Alternatively you can allow read operations and deny write operations. You can also specify custom merge policy implementations that configure Data Grid to resolve splits with custom logic tailored to your requirements.
Prerequisites
Have a Data Grid cluster where you can create either a replicated or distributed cache.
NotePartition handling configuration applies only to replicated and distributed caches.
Procedure
- Open your Data Grid configuration for editing.
-
Add partition handling configuration to your cache with either the
partition-handlingelement orpartitionHandling()method. Specify a strategy for Data Grid to use when the cluster splits into partitions with the
when-splitattribute orwhenSplit()method.The default partition handling strategy is
ALLOW_READ_WRITESso caches remain availabile. If your use case requires data consistency over cache availability, specify theDENY_READ_WRITESstrategy.Specify a policy that Data Grid uses to resolve conflicting entries when merging partitions with the
merge-policyattribute ormergePolicy()method.By default Data Grid does not resolve conflicts on merge.
- Save the changes to your Data Grid configuration.
Partition handling configuration
XML
<distributed-cache>
<partition-handling when-split="DENY_READ_WRITES"
merge-policy="PREFERRED_ALWAYS"/>
</distributed-cache>JSON
{
"distributed-cache": {
"partition-handling" : {
"when-split": "DENY_READ_WRITES",
"merge-policy": "PREFERRED_ALWAYS"
}
}
}YAML
distributedCache:
partitionHandling:
whenSplit: DENY_READ_WRITES
mergePolicy: PREFERRED_ALWAYSConfigurationBuilder
ConfigurationBuilder builder = new ConfigurationBuilder();
builder.clustering().cacheMode(CacheMode.DIST_SYNC)
.partitionHandling()
.whenSplit(PartitionHandling.DENY_READ_WRITES)
.mergePolicy(MergePolicy.PREFERRED_NON_NULL);7.4. Partition handling strategies
Partition handling strategies control if Data Grid allows read and write operations when a cluster is split. The strategy you configure determines whether you get cache availability or data consistency.
| Strategy | Description | Availability or consistency |
|---|---|---|
|
| Data Grid allows read and write operations on caches while a cluster is split into network partitions. Nodes in each partition remain available and function independently of each other. This is the default partition handling strategy. | Availability |
|
| Data Grid allows read and write operations only if all replicas of an entry are in the partition. If a partition does not include all replicas of an entry, Data Grid prevents cache operations for that entry. | Consistency |
|
| Data Grid allows read operations for entries and prevents write operations unless the partition includes all replicas of an entry. | Consistency with read availability |
7.5. Merge policies
Merge policies control how Data Grid resolves conflicts between replicas when bringing cluster partitions together. You can use one of the merge policies that Data Grid provides or you can create a custom implementation of the EntryMergePolicy API.
| Merge policy | Description | Considerations |
|---|---|---|
|
| Data Grid does not resolve conflicts when merging split clusters. This is the default merge policy. | Nodes drop segments for which they are not the primary owner, which can result in data loss. |
|
| Data Grid finds the value that exists on the majority of nodes in the cluster and uses it to resolve conflicts. | Data Grid could use stale values to resolve conflicts. Even if an entry is available the majority of nodes, the last update could happen on the minority partition. |
|
| Data Grid uses the first non-null value that it finds on the cluster to resolve conflicts. | Data Grid could restore deleted entries. |
|
| Data Grid removes any conflicting entries from the cache. | Results in loss of any entries that have different values when merging split clusters. |
7.6. Configuring custom merge policies
Configure Data Grid to use custom implementations of the EntryMergePolicy API when handling network partitions.
Prerequisites
Implement the
EntryMergePolicyAPI.public class CustomMergePolicy implements EntryMergePolicy<String, String> { @Override public CacheEntry<String, String> merge(CacheEntry<String, String> preferredEntry, List<CacheEntry<String, String>> otherEntries) { // Decide which entry resolves the conflict return the_solved_CacheEntry; }
Procedure
Deploy your merge policy implementation to Data Grid Server if you use remote caches.
Package your classes as a JAR file that includes a
META-INF/services/org.infinispan.conflict.EntryMergePolicyfile that contains the fully qualified class name of your merge policy.# List implementations of EntryMergePolicy with the full qualified class name org.example.CustomMergePolicyAdd the JAR file to the
server/libdirectory.TipUse the
installcommand with the Data Grid Command Line Interface (CLI) to download the JAR to theserver/libdirectory.
- Open your Data Grid configuration for editing.
Configure cache encoding with the
encodingelement orencoding()method as appropriate.For remote caches, if you use only object metadata for comparison when merging entries then you can use
application/x-protostreamas the media type. In this case Data Grid returns entries to theEntryMergePolicyasbyte[].If you require the object itself when merging conflicts then you should configure caches with the
application/x-java-objectmedia type. In this case you must deploy the relevant ProtoStream marshallers to Data Grid Server so it can performbyte[]to object transformations if clients use Protobuf encoding.-
Specify your custom merge policy with the
merge-policyattribute ormergePolicy()method as part of the partition handling configuration. - Save your changes.
Custom merge policy configuration
XML
<distributed-cache name="mycache">
<partition-handling when-split="DENY_READ_WRITES"
merge-policy="org.example.CustomMergePolicy"/>
</distributed-cache>JSON
{
"distributed-cache": {
"partition-handling" : {
"when-split": "DENY_READ_WRITES",
"merge-policy": "org.example.CustomMergePolicy"
}
}
}YAML
distributedCache:
partitionHandling:
whenSplit: DENY_READ_WRITES
mergePolicy: org.example.CustomMergePolicyConfigurationBuilder
ConfigurationBuilder builder = new ConfigurationBuilder();
builder.clustering().cacheMode(CacheMode.DIST_SYNC)
.partitionHandling()
.whenSplit(PartitionHandling.DENY_READ_WRITES)
.mergePolicy(new CustomMergePolicy());7.7. Manually merging partitions in embedded caches
Detect and resolve conflicting entries to manually merge embedded caches after network partitions occur.
Procedure
Retrieve the
ConflictManagerfrom theEmbeddedCacheManagerto detect and resolve conflicting entries in a cache, as in the following example:EmbeddedCacheManager manager = new DefaultCacheManager("example-config.xml"); Cache<Integer, String> cache = manager.getCache("testCache"); ConflictManager<Integer, String> crm = ConflictManagerFactory.get(cache.getAdvancedCache()); // Get all versions of a key Map<Address, InternalCacheValue<String>> versions = crm.getAllVersions(1); // Process conflicts stream and perform some operation on the cache Stream<Map<Address, CacheEntry<Integer, String>>> conflicts = crm.getConflicts(); conflicts.forEach(map -> { CacheEntry<Integer, String> entry = map.values().iterator().next(); Object conflictKey = entry.getKey(); cache.remove(conflictKey); }); // Detect and then resolve conflicts using the configured EntryMergePolicy crm.resolveConflicts(); // Detect and then resolve conflicts using the passed EntryMergePolicy instance crm.resolveConflicts((preferredEntry, otherEntries) -> preferredEntry);
Although the ConflictManager::getConflicts stream is processed per entry, the underlying spliterator lazily loads cache entries on a per segment basis.