This documentation is for a release that is no longer maintained
See documentation for the latest supported version 3 or the latest supported version 4.Developer Guide
OpenShift Enterprise 3.0 Developer Reference
Abstract
- Monitor and browse projects with the web console
- Configure and utilize the CLI
- Generate configurations using templates
- Manage builds and webhooks
- Define and trigger deployments
- Integrate external services (databases, SaaS endpoints)
Chapter 1. Overview
This guide helps developers set up and configure a workstation to develop and deploy applications in an OpenShift cloud environment with a command-line interface (CLI). This guide provides detailed instructions and examples to help developers:
- Monitor and browse projects with the web console
- Configure and utilize the CLI
- Generate configurations using templates
- Manage builds and webhooks
- Define and trigger deployments
- Integrate external services (databases, SaaS endpoints)
Chapter 2. Authentication
2.1. Web Console Authentication
When accessing the web console from a browser at <master_public_addr>:8443, you are automatically redirected to a login page.
Review the browser versions and operating systems that can be used to access the web console.
You can provide your login credentials on this page to obtain a token to make API calls. After logging in, you can navigate your projects using the web console.
2.2. CLI Authentication
You can authenticate from the command line using the CLI command oc login. You can get started with the CLI by running this command without any options:
oc login
$ oc loginThe command’s interactive flow helps you establish a session to an OpenShift server with the provided credentials. If any information required to successfully log in to an OpenShift server is not provided, the command prompts for user input as required. The configuration is automatically saved and is then used for every subsequent command.
All configuration options for the oc login command, listed in the oc login --help command output, are optional. The following example shows usage with some common options:
oc login [-u=<username>] \ [-p=<password>] \ [-s=<server>] \ [-n=<project>] \ [--certificate-authority=</path/to/file.crt>|--insecure-skip-tls-verify]
$ oc login [-u=<username>] \
[-p=<password>] \
[-s=<server>] \
[-n=<project>] \
[--certificate-authority=</path/to/file.crt>|--insecure-skip-tls-verify]The following table describes these common options:
| Option | Syntax | Description |
|---|---|---|
|
|
oc login -s=<server> | Specifies the host name of the OpenShift server. If a server is provided through this flag, the command does not ask for it interactively. This flag can also be used if you already have a CLI configuration file and want to log in and switch to another server. |
|
|
oc login -u=<username> -p=<password> | Allows you to specify the credentials to log in to the OpenShift server. If user name or password are provided through these flags, the command does not ask for it interactively. These flags can also be used if you already have a configuration file with a session token established and want to log in and switch to another user name. |
|
|
oc login -u=<username> -p=<password> -n=<project> |
A global CLI option which, when used with |
|
|
oc login --certificate-authority=<path/to/file.crt> | Correctly and securely authenticates with an OpenShift server that uses HTTPS. The path to a certificate authority file must be provided. |
|
|
oc login --insecure-skip-tls-verify |
Allows interaction with an HTTPS server bypassing the server certificate checks; however, note that it is not secure. If you try to |
CLI configuration files allow you to easily manage multiple CLI profiles.
If you have access to administrator credentials but are no longer logged in as the default system user system:admin, you can log back in as this user at any time as long as the credentials are still present in your CLI configuration file. The following command logs in and switches to the default project:
oc login -u system:admin -n default
$ oc login -u system:admin -n defaultChapter 3. Projects
3.1. Overview
A project allows a community of users to organize and manage their content in isolation from other communities.
3.2. Creating a Project
If allowed by your cluster administrator, you can create a new project using the CLI or the web console.
To create a new project using the CLI:
oc new-project <project_name> \
--description="<description>" --display-name="<display_name>"
$ oc new-project <project_name> \
--description="<description>" --display-name="<display_name>"For example:
oc new-project hello-openshift \
--description="This is an example project to demonstrate OpenShift v3" \
--display-name="Hello OpenShift"
$ oc new-project hello-openshift \
--description="This is an example project to demonstrate OpenShift v3" \
--display-name="Hello OpenShift"3.3. Viewing Projects
When viewing projects, you are restricted to seeing only the projects you have access to view based on the authorization policy.
To view a list of projects:
oc get projects
$ oc get projectsYou can change from the current project to a different project for CLI operations. The specified project is then used in all subsequent operations that manipulate project-scoped content:
oc project <project_name>
$ oc project <project_name>You can also use the web console to view and change between projects. After authenticating and logging in, you are presented with a list of projects that you have access to:
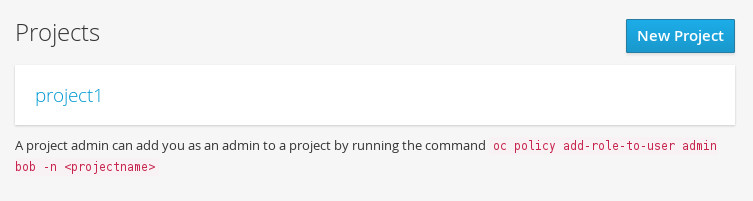
If you use the CLI to create a new project, you can then refresh the page in the browser to see the new project.
Selecting a project brings you to the project overview for that project.
3.4. Checking Project Status
The oc status command provides a high-level overview of the current project, with its components and their relationships. This command takes no argument:
oc status
$ oc status3.5. Filtering by Labels
You can filter the contents of a project page in the web console by using the labels of a resource. You can pick from a suggested label name and values, or type in your own. Multiple filters can be added. When multiple filters are applied, resources must match all of the filters to remain visible.
To filter by labels:
Select a label type:

Select one of the following:
exists
Verify that the label name exists, but ignore its value.
in
Verify that the label name exists and is equal to one of the selected values.
not in
Verify that the label name does not exist, or is not equal to any of the selected values.

If you selected in or not in, select a set of values then select Filter:

After adding filters, you can stop filtering by selecting Clear all filters or by clicking individual filters to remove them:

3.6. Deleting a Project
When you delete a project, the server updates the project status to Terminating from Active. The server then clears all content from a project that is Terminating before finally removing the project. While a project is in Terminating status, a user cannot add new content to the project.
To delete a project:
oc delete project <project_name>
$ oc delete project <project_name>Chapter 4. Service Accounts
4.1. Overview
When a person uses the command line or web console, their API token authenticates them to the OpenShift API. However, when a regular user’s credentials are not available, it is common for components to make API calls independently. For example:
- Replication controllers make API calls to create or delete pods
- Applications inside containers could make API calls for discovery purposes
- External applications could make API calls for monitoring or integration purposes
Service accounts provide a flexible way to control API access without sharing a regular user’s credentials.
4.2. Usernames and groups
Every service account has an associated username that can be granted roles, just like a regular user. The username is derived from its project and name: system:serviceaccount:<project>:<name>
For example, to add the view role to the robot service account in the top-secret project:
oc policy add-role-to-user view system:serviceaccount:top-secret:robot
$ oc policy add-role-to-user view system:serviceaccount:top-secret:robotEvery service account is also a member of two groups:
- system:serviceaccounts, which includes all service accounts in the system
- system:serviceaccounts:<project>, which includes all service accounts in the specified project
For example, to allow all service accounts in all projects to view resources in the top-secret project:
oc policy add-role-to-group view system:serviceaccounts -n top-secret
$ oc policy add-role-to-group view system:serviceaccounts -n top-secretTo allow all service accounts in the managers project to edit resources in the top-secret project:
oc policy add-role-to-group edit system:serviceaccounts:managers -n top-secret
$ oc policy add-role-to-group edit system:serviceaccounts:managers -n top-secret4.3. Default service accounts and roles
Three service accounts are automatically created in every project:
- builder is used by build pods. It is given the system:image-builder role, which allows pushing images to any image stream in the project using the internal Docker registry.
- deployer is used by deployment pods and is given the system:deployer role, which allows viewing and modifying replication controllers and pods in the project.
- default is used to run all other pods unless they specify a different service account.
All service accounts in a project are given the system:image-puller role, which allows pulling images from any image stream in the project using the internal Docker registry.
4.4. Managing service accounts
Service accounts are API objects that exist within each project. They can be created or deleted like any other API object.
4.5. Managing service account credentials
As soon as a service account is created, two secrets are automatically added to it:
- an API token
- credentials for the internal Docker registry
These can be seen by describing the service account:
The system ensures that service accounts always have an API token and internal Docker registry credentials.
The generated API token and Docker registry credentials do not expire, but they can be revoked by deleting the secret. When the secret is deleted, a new one is automatically generated to take its place.
4.6. Managing allowed secrets
In addition to providing API credentials, a pod’s service account determines which secrets the pod is allowed to use.
Pods use secrets in two ways:
- image pull secrets, providing credentials used to pull images for the pod’s containers
- mountable secrets, injecting the contents of secrets into containers as files
To allow a secret to be used as an image pull secret by a service account’s pods, run oc secrets add --for=pull serviceaccount/<serviceaccount-name> secret/<secret-name>
To allow a secret to be mounted by a service account’s pods, run oc secrets add --for=mount serviceaccount/<serviceaccount-name> secret/<secret-name>
This example creates and adds secrets to a service account:
4.7. Using a service account’s credentials inside a container
When a pod is created, it specifies a service account (or uses the default service account), and is allowed to use that service account’s API credentials and referenced secrets.
A file containing an API token for a pod’s service account is automatically mounted at /var/run/secrets/kubernetes.io/serviceaccount/token
That token can be used to make API calls as the pod’s service account. This example calls the users/~ API to get information about the user identified by the token:
4.8. Using a service account’s credentials externally
The same token can be distributed to external applications that need to authenticate to the API.
Use oc describe secret <secret-name> to view a service account’s API token:
Chapter 5. Creating New Applications
5.1. Overview
You can create a new OpenShift application using the web console or by running the oc new-app command from the CLI. OpenShift creates a new application by specifying source code, images, or templates. The new-app command looks for images on the local Docker installation (if available), in a Docker registry, or an OpenShift image stream.
If you specify source code, new-app attempts to construct a build configuration that builds your source into a new application image. It also constructs a deployment configuration that deploys that new image, and a service to provide load balanced access to the deployment that is running your image.
If you specify source code, you may need to run a build with oc start-build after the application is created.
5.2. Using the CLI
You can create a new application using the oc new-app command from the CLI.
5.2.1. Specifying Source Code
The new-app command allows you to create applications using source code from a local or remote Git repository. If only a source repository is specified, new-app tries to automatically determine the type of build strategy to use (Docker or Source), and in the case of Source type builds, an appropriate language builder image.
You can tell new-app to use a subdirectory of your source code repository by specifying a --context-dir flag. Also, when specifying a remote URL, you can specify a Git reference to use by appending #[reference] to the end of the URL.
If using a local Git repository, the repository must have an origin remote that points to a URL accessible by the OpenShift cluster.
Example 5.1. To Create an Application Using the Git Repository at the Current Directory:
oc new-app .
$ oc new-app .Example 5.2. To Create an Application Using a Remote Git Repository and a Context Subdirectory:
oc new-app https://github.com/openshift/sti-ruby.git \
--context-dir=2.0/test/puma-test-app
$ oc new-app https://github.com/openshift/sti-ruby.git \
--context-dir=2.0/test/puma-test-appExample 5.3. To Create an Application Using a Remote Git Repository with a Specific Branch Reference:
oc new-app https://github.com/openshift/ruby-hello-world.git#beta4
$ oc new-app https://github.com/openshift/ruby-hello-world.git#beta45.2.1.1. Build Strategy Detection
If new-app finds a Dockerfile in the repository, it generates a Docker build strategy. Otherwise, it generates a Source strategy. To use a specific strategy, set the --strategy flag to either source or docker.
Example 5.4. To Force new-app to Use the Docker Strategy for a Local Source Repository:
oc new-app /home/user/code/myapp --strategy=docker
$ oc new-app /home/user/code/myapp --strategy=docker5.2.1.2. Language Detection
If creating a Source build, new-app attempts to determine which language builder to use based on the presence of certain files in the root of the repository:
| Language | Files |
|---|---|
|
| Rakefile, Gemfile, config.ru |
|
| pom.xml |
|
| app.json, package.json |
|
| index.php, composer.json |
|
| requirements.txt, config.py |
|
| index.pl, cpanfile |
After a language is detected, new-app searches the OpenShift server for image stream tags that have a supports annotation matching the detected language, or an image stream that matches the name of the detected language. If a match is not found, new-app searches the Docker Hub registry for an image that matches the detected language based on name.
To override the image that new-app uses as the builder for a particular source repository, the image (either an image stream or Docker specification) can be specified along with the repository using a ~ as a separator.
Example 5.5. To Use Image Stream myproject/my-ruby to Build the Source at a Remote GitHub Repository:
oc new-app myproject/my-ruby~https://github.com/openshift/ruby-hello-world.git
$ oc new-app myproject/my-ruby~https://github.com/openshift/ruby-hello-world.gitExample 5.6. To Use Docker Image openshift/ruby-20-centos7:latest to Build Source in a Local Repository:
oc new-app openshift/ruby-20-centos7:latest~/home/user/code/my-ruby-app
$ oc new-app openshift/ruby-20-centos7:latest~/home/user/code/my-ruby-app5.2.2. Specifying an Image
The new-app command generates the necessary artifacts to deploy an existing image as an application. Images can come from image streams in the OpenShift server, images in a specific registry or Docker Hub, or images in the local Docker server.
The new-app command attempts to determine the type of image specified in the arguments passed to it. However, you can explicitly tell new-app whether the image is a Docker image (using the --docker-image argument) or an image stream (using the -i|--image argument).
If you specify an image from your local Docker repository, you must ensure that the same image is available to the OpenShift cluster nodes.
Example 5.7. To Create an Application from the DockerHub MySQL Image:
oc new-app mysql
$ oc new-app mysqlTo create an application using an image in a private registry, specify the full Docker image specification.
Example 5.8. To Create an Application from a Local Registry:
oc new-app myregistry:5000/example/myimage
$ oc new-app myregistry:5000/example/myimage
If the registry that the image comes from is not secured with SSL, cluster administrators must ensure that the Docker daemon on the OpenShift nodes is run with the --insecure-registry flag pointing to that registry. You must also tell new-app that the image comes from an insecure registry with the --insecure-registry=true flag.
To create an application from an existing image stream, specify the namespace (optional), name, and tag (optional) for the image stream.
Example 5.9. To Create an Application from an Existing Image Stream with a Specific Tag:
oc new-app my-stream:v1
$ oc new-app my-stream:v15.2.3. Specifying a Template
The new-app command can instantiate a template from a previously stored template or from a template file. To instantiate a previously stored template, specify the name of the template as an argument. For example, store a sample application template and use it to create an application.
Example 5.10. To Create an Application from a Previously Stored Template:
oc create -f examples/sample-app/application-template-stibuild.json oc new-app ruby-helloworld-sample
$ oc create -f examples/sample-app/application-template-stibuild.json
$ oc new-app ruby-helloworld-sample
To use a template in the file system directly, without first storing it in OpenShift, use the -f|--file argument or simply specify the file name as the argument to new-app.
Example 5.11. To Create an Application from a Template in a File:
oc new-app -f examples/sample-app/application-template-stibuild.json
$ oc new-app -f examples/sample-app/application-template-stibuild.json5.2.3.1. Template Parameters
When creating an application based on a template, use the -p|--param argument to set parameter values defined by the template.
Example 5.12. To Specify Template Parameters with a Template:
oc new-app ruby-helloworld-sample \
-p ADMIN_USERNAME=admin,ADMIN_PASSWORD=mypassword
$ oc new-app ruby-helloworld-sample \
-p ADMIN_USERNAME=admin,ADMIN_PASSWORD=mypassword5.2.4. Specifying Environment Variables
When generating applications from source or an image, you can use the -e|--env argument to specify environment to be passed to the application container at run time.
Example 5.13. To Set Environment Variables When Creating an Application for a Database Image:
oc new-app openshift/postgresql-92-centos7 \
-e POSTGRESQL_USER=user \
-e POSTGRESQL_DATABASE=db \
-e POSTGRESQL_PASSWORD=password
$ oc new-app openshift/postgresql-92-centos7 \
-e POSTGRESQL_USER=user \
-e POSTGRESQL_DATABASE=db \
-e POSTGRESQL_PASSWORD=password5.2.5. Specifying Labels
When generating applications from source, images, or templates, you can use the l|--label argument to add labels to objects created by new-app. This is recommended, as labels make it easy to collectively select, manipulate, and delete objects associated with the application.
Example 5.14. To Use the Label Argument to Label Objects Created by new-app:
oc new-app https://github.com/openshift/ruby-hello-world -l name=hello-world
$ oc new-app https://github.com/openshift/ruby-hello-world -l name=hello-world5.2.6. Command Output
The new-app command generates OpenShift objects that will build, deploy, and run the application being created. Normally, these objects are created in the current project using names derived from the input source repositories or the input images. However, new-app allows you to modify this behavior.
5.2.6.1. Output Without Creation
To see a dry-run of what new-app will create, you can use the -o|--output flag with a value of either yaml or json. You can then use the output to preview the objects that will be created, or redirect it to a file that you can edit and then use with oc create to create the OpenShift objects.
Example 5.15. To Output new-app Artifacts to a File, Edit Them, Then Create Them Using oc create:
oc new-app https://github.com/openshift/ruby-hello-world -o json > myapp.json vi myapp.json oc create -f myapp.json
$ oc new-app https://github.com/openshift/ruby-hello-world -o json > myapp.json
$ vi myapp.json
$ oc create -f myapp.json5.2.6.2. Object names
Objects created by new-app are normally named after the source repository or the image used to generate them. You can set the name of the objects produced by adding a --name flag to the command.
Example 5.16. To Create new-app Artifacts with a Different Name:
oc new-app https://github.com/openshift/ruby-hello-world --name=myapp
$ oc new-app https://github.com/openshift/ruby-hello-world --name=myapp5.2.6.3. Object Project or Namespace
Normally new-app creates objects in the current project. However, you can tell it to create objects in a different project that you have access to using the -n|--namespace argument.
Example 5.17. To Create new-app Artifacts in a Different Project:
oc new-app https://github.com/openshift/ruby-hello-world -n myproject
$ oc new-app https://github.com/openshift/ruby-hello-world -n myproject5.2.6.4. Artifacts Created
The set of artifacts created by new-app depends on the artifacts passed as input: source repositories, images, or templates.
| Artifact | Description |
|---|---|
|
|
A |
|
|
For |
|
|
A |
|
|
The |
| Other | Other objects can be generated when instantiating templates. |
5.2.7. Advanced: Multiple Components and Grouping
The new-app command allows creating multiple applications from source, images, or templates at once. To do this, simply specify multiple parameters to the new-app call. Labels specified in the command line apply to all objects created by the single call. Environment variables apply to all components created from source or images.
Example 5.18. To Create an Application from a Source Repository and a Docker Hub Image:
oc new-app https://github.com/openshift/ruby-hello-world mysql
$ oc new-app https://github.com/openshift/ruby-hello-world mysql
If a source code repository and a builder image are specified as separate arguments, new-app uses the builder image as the builder for the source code repository. If this is not the intent, simply specify a specific builder image for the source using the ~ separator.
5.2.7.1. Grouping Images and Source in a Single Pod
The new-app command allows deploying multiple images together in a single pod. In order to specify which images to group together, use the + separator. The --group command line argument can also be used to specify which images should be grouped together. To group the image built from a source repository with other images, specify its builder image in the group.
Example 5.19. To Deploy Two Images in a Single Pod:
oc new-app nginx+mysql
$ oc new-app nginx+mysqlExample 5.20. To Deploy an Image Built from Source and an External Image Together:
oc new-app \
ruby~https://github.com/openshift/ruby-hello-world \
mysql \
--group=ruby+mysql
$ oc new-app \
ruby~https://github.com/openshift/ruby-hello-world \
mysql \
--group=ruby+mysql5.3. Using the Web Console
You can also create applications using the web console:
While in the desired project, click Add to Project:
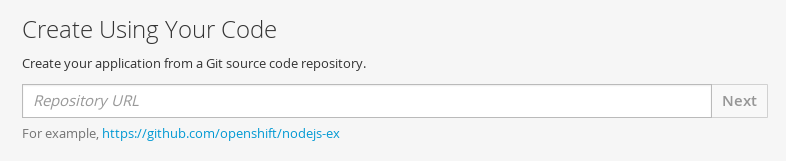
Enter the repository URL for the application to build:
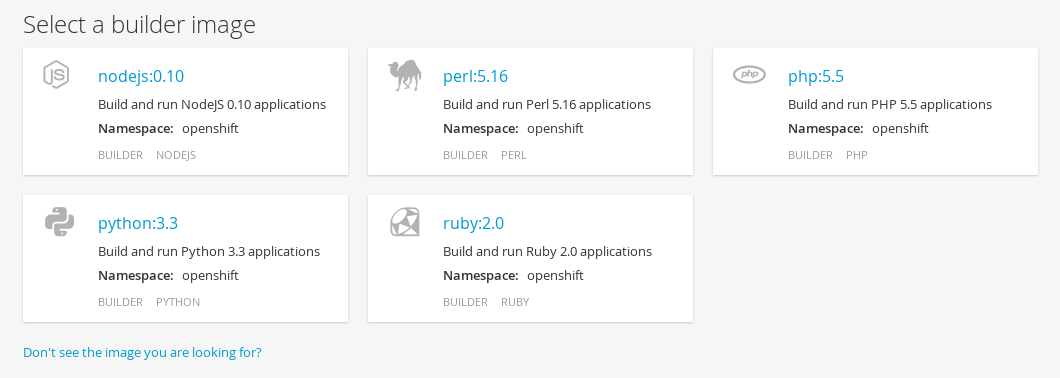
Select either a builder image from the list of images in your project, or from the global library:
 Note
NoteOnly image stream tags which have the builder tag listed in their annotations will appear in this list, as demonstrated here:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- Including builder here ensures this
ImageStreamTagwill appear in the web console as a builder.
Modify the settings in the new application screen to configure the objects to support your application:
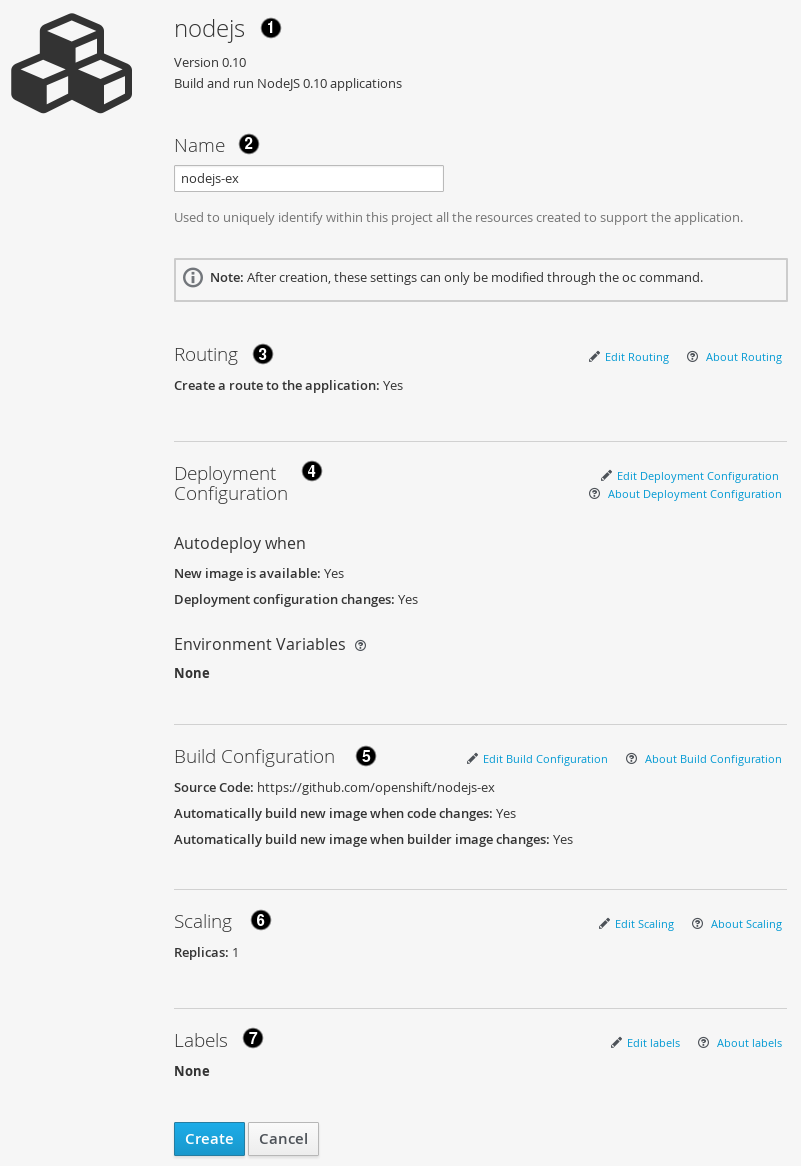
- The builder image name and description.
- The application name used for the generated OpenShift objects.
- Routing configuration section for making this application publicly accessible.
- Deployment configuration section for customizing deployment triggers and image environment variables.
- Build configuration section for customizing build triggers.
- Replica scaling section for configuring the number of running instances of the application.
- The labels to assign to all items generated for the application. You can add and edit labels for all objects here.
Chapter 6. Templates
6.1. Overview
A template describes a set of objects that can be parameterized and processed to produce a list of objects for creation by OpenShift. A template can be processed to create anything you have permission to create within a project, for example services, build configurations, and deployment configurations. A template may also define a set of labels to apply to every object defined in the template.
You can create a list of objects from a template using the CLI or, if a template has been uploaded to your project or the global template library, using the web console.
6.2. Uploading a Template
If you have a JSON or YAML file that defines a template, for example as seen in this example, you can upload the template to projects using the CLI. This saves the template to the project for repeated use by any user with appropriate access to that project. Instructions on writing your own templates are provided later in this topic.
To upload a template to your current project’s template library, pass the JSON or YAML file with the following command:
oc create -f <filename>
$ oc create -f <filename>
You can upload a template to a different project using the -n option with the name of the project:
oc create -f <filename> -n <project>
$ oc create -f <filename> -n <project>The template is now available for selection using the web console or the CLI.
6.3. Creating from Templates Using the Web Console
To create the objects from an uploaded template using the web console:
While in the desired project, click Add to Project:
Select a template from the list of templates in your project, or provided by the global template library:
Modify template parameters in the template creation screen:
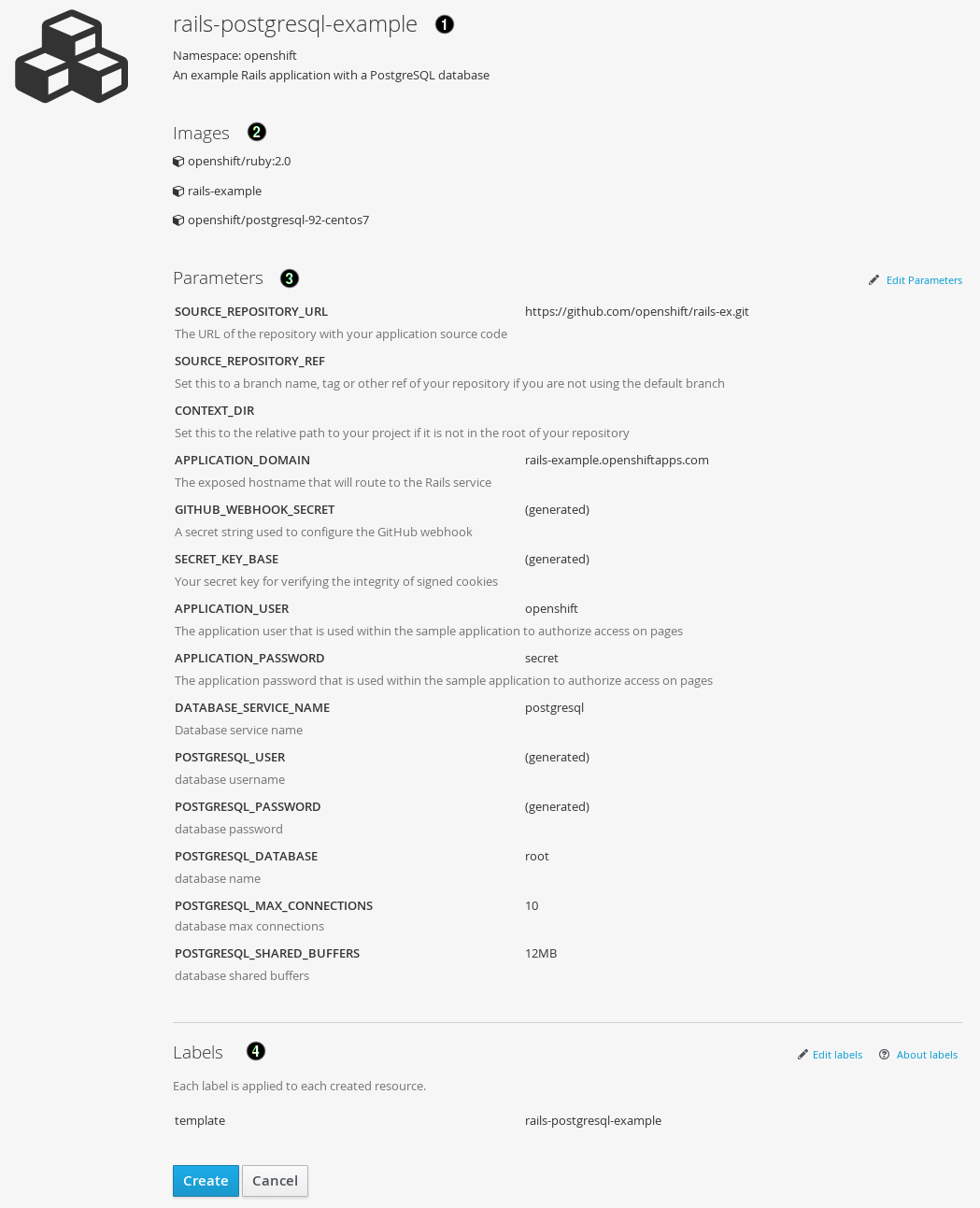
- Template name and description.
- Container images included in the template.
- Parameters defined by the template. You can edit values for parameters defined in the template here.
- Labels to assign to all items included in the template. You can add and edit labels for objects.
6.4. Creating from Templates Using the CLI
You can use the CLI to process templates and use the configuration that is generated to create objects.
6.4.1. Labels
Labels are used to manage and organize generated objects, such as pods. The labels specified in the template are applied to every object that is generated from the template.
There is also the ability to add labels in the template from the command line.
oc process -f <filename> -l name=otherLabel
$ oc process -f <filename> -l name=otherLabel6.4.2. Parameters
The list of parameters that you can override are listed in the parameters section of the template. You can list them with the CLI by using the following command and specifying the file to be used:
oc process --parameters -f <filename>
$ oc process --parameters -f <filename>Alternatively, if the template is already uploaded:
oc process --parameters -n <project> <template_name>
$ oc process --parameters -n <project> <template_name>For example, the following shows the output when listing the parameters for one of the InstantApp templates in the default openshift project:
The output identifies several parameters that are generated with a regular expression-like generator when the template is processed.
6.4.3. Generating a List of Objects
Using the CLI, you can process a file defining a template to return the list of objects to standard output:
oc process -f <filename>
$ oc process -f <filename>Alternatively, if the template has already been uploaded to the current project:
oc process <template_name>
$ oc process <template_name>
The process command also takes a list of templates you can process to a list of objects. In that case, every template will be processed and the resulting list of objects will contain objects from all templates passed to a process command:
cat <first_template> <second_template> | oc process -f -
$ cat <first_template> <second_template> | oc process -f -
You can create objects from a template by processing the template and piping the output to oc create:
oc process -f <filename> | oc create -f -
$ oc process -f <filename> | oc create -f -Alternatively, if the template has already been uploaded to the current project:
oc process <template> | oc create -f -
$ oc process <template> | oc create -f -
You can override any parameter values defined in the file by adding the -v option followed by a comma-separated list of <name>=<value> pairs. A parameter reference may appear in any text field inside the template items.
For example, in the following the POSTGRESQL_USER and POSTGRESQL_DATABASE parameters of a template are overridden to output a configuration with customized environment variables:
Example 6.1. Creating a List of Objects from a Template
oc process -f my-rails-postgresql \
-v POSTGRESQL_USER=bob,POSTGRESQL_DATABASE=mydatabase
$ oc process -f my-rails-postgresql \
-v POSTGRESQL_USER=bob,POSTGRESQL_DATABASE=mydatabase
The JSON file can either be redirected to a file or applied directly without uploading the template by piping the processed output to the oc create command:
oc process -f my-rails-postgresql \
-v POSTGRESQL_USER=bob,POSTGRESQL_DATABASE=mydatabase \
| oc create -f -
$ oc process -f my-rails-postgresql \
-v POSTGRESQL_USER=bob,POSTGRESQL_DATABASE=mydatabase \
| oc create -f -6.5. Modifying an Uploaded Template
You can edit a template that has already been uploaded to your project by using the following command:
oc edit template <template>
$ oc edit template <template>6.6. Using the InstantApp Templates
OpenShift provides a number of default InstantApp templates to make it easy to quickly get started creating a new application for different languages. Templates are provided for Rails (Ruby), Django (Python), Node.js, CakePHP (PHP), and Dancer (Perl). Your cluster administrator should have created these templates in the default, global openshift project so you have access to them. You can list the available default InstantApp templates with:
oc get templates -n openshift
$ oc get templates -n openshiftIf they are not available, direct your cluster administrator to the First Steps topic.
By default, the templates build using a public source repository on GitHub that contains the necessary application code. In order to be able to modify the source and build your own version of the application, you must:
-
Fork the repository referenced by the template’s default
SOURCE_REPOSITORY_URLparameter. -
Override the value of the
SOURCE_REPOSITORY_URLparameter when creating from the template, specifying your fork instead of the default value.
By doing this, the build configuration created by the template will now point to your fork of the application code, and you can modify the code and rebuild the application at will. A walkthrough of this process using the web console is provided in Getting Started for Developers: Web Console.
Some of the InstantApp templates define a database deployment configuration. The configuration they define uses ephemeral storage for the database content. These templates should be used for demonstration purposes only as all database data will be lost if the database pod restarts for any reason.
6.7. Writing Templates
You can define new templates to make it easy to recreate all the objects of your application. The template will define the objects it creates along with some metadata to guide the creation of those objects.
6.7.1. Description
The template description covers information that informs users what your template does and helps them find it when searching in the web console. In addition to general descriptive information, it includes a set of tags. Useful tags include the name of the language your template is related to (e.g., java, php, ruby, etc.). In addition, adding the special tag instant-app causes your template to be displayed in the list of InstantApps on the template selection page of the web console.
6.7.2. Labels
Templates can include a set of labels. These labels will be added to each object created when the template is instantiated. Defining a label in this way makes it easy for users to find and manage all the objects created from a particular template.
- 1
- A label that will be applied to all objects created from this template.
6.7.3. Parameters
Parameters allow a value to be supplied by the user or generated when the template is instantiated. This is useful for generating random passwords or allowing the user to supply a host name or other user-specific value that is required to customize the template. Parameters can be referenced by placing values in the form "${PARAMETER_NAME}" in place of any string field in the template.
- 1
- This value will be replaced with the value of the
SOURCE_REPOSITORY_URLparameter when the template is instantiated. - 2
- The name of the parameter. This value is displayed to users and used to reference the parameter within the template.
- 3
- A description of the parameter.
- 4
- A default value for the parameter which will be used if the user does not override the value when instantiating the template.
- 5
- Indicates this parameter is required, meaning the user cannot override it with an empty value. If the parameter does not provide a default or generated value, the user must supply a value.
- 6
- A parameter which has its value generated via a regular expression-like syntax.
- 7
- The input to the generator. In this case, the generator will produce a 40 character alphanumeric value including upper and lowercase characters.
6.7.4. Object List
The main portion of the template is the list of objects which will be created when the template is instantiated. This can be any valid API object, such as a BuildConfig, DeploymentConfig, Service, etc. The object will be created exactly as defined here, with any parameter values substituted in prior to creation. The definition of these objects can reference parameters defined earlier.
- 1
- The definition of a
Servicewhich will be created by this template.
If an object definition’s metadata includes a namespace field, the field will be stripped out of the definition during template instantiation. This is necessary because all objects created during instantiation are placed into the target namespace, so it would be invalid for the object to declare a different namespace.
6.7.5. Creating a Template from Existing Objects
Rather than writing an entire template from scratch, you can also export existing objects from your project in template form, and then modify the template from there by adding parameters and other customizations. To export objects in a project in template form, run:
oc export all --as-template=<template_name>
$ oc export all --as-template=<template_name>
You can also substitute a particular resource type or multiple resources instead of all. Run $ oc export -h for more examples.
Chapter 7. Builds
7.1. Overview
A build is a process of creating runnable images to be used on OpenShift. There are three build strategies:
- Source-To-Image (S2I) (description, options)
- Docker (description, options)
- Custom (description, options)
7.2. Defining a BuildConfig
A build configuration describes a single build definition and a set of triggers for when a new build should be created.
A build configuration is defined by a BuildConfig, which is a REST object that can be used in a POST to the API server to create a new instance. The following example BuildConfig results in a new build every time a Docker image tag or the source code changes:
Example 7.1. BuildConfig Object Definition
- 1
- This specification will create a new
BuildConfignamed ruby-sample-build. - 2
- You can specify a list of triggers, which cause a new build to be created.
- 3
- The
sourcesection defines the source code repository location. You can provide additional options, such assourceSecretorcontextDirhere. - 4
- The
strategysection describes the build strategy used to execute the build. You can specifySource,DockerandCustomstrategies here. This above example uses theruby-20-centos7Docker image that Source-To-Image will use for the application build. - 5
- After the Docker image is successfully built, it will be pushed into the repository described in the
outputsection.
7.3. Source-to-Image Strategy Options
The following options are specific to the S2I build strategy.
7.3.1. Force Pull
By default, if the builder image specified in the build configuration is available locally on the node, that image will be used. However, to override the local image and refresh it from the registry to which the image stream points, create a BuildConfig with the forcePull flag set to true:
- 1
- The builder image being used, where the local version on the node may not be up to date with the version in the registry to which the image stream points.
- 2
- This flag causes the local builder image to be ignored and a fresh version to be pulled from the registry to which the image stream points. Setting
forcePullto false results in the default behavior of honoring the image stored locally.
7.3.2. Incremental Builds
S2I can perform incremental builds, which means it reuses artifacts from previously-built images. To create an incremental build, create a BuildConfig with the following modification to the strategy definition:
- 1
- Specify an image that supports incremental builds. The S2I images provided by OpenShift do not implement artifact reuse, so setting
incrementalto true will have no effect on builds using those builder images. - 2
- This flag controls whether an incremental build is attempted. If the builder image does not support incremental builds, the build will still succeed, but you will get a log message stating the incremental build was not successful because of a missing save-artifacts script.
See the S2I Requirements topic for information on how to create a builder image supporting incremental builds.
7.3.3. Override Builder Image Scripts
You can override the assemble, run, and save-artifactsS2I scripts provided by the builder image in one of two ways. Either:
- Provide an assemble, run, and/or save-artifacts script in the .sti/bin directory of your application source repository, or
- Provide a URL of a directory containing the scripts as part of the strategy definition. For example:
- 1
- This path will have run, assemble, and save-artifacts appended to it. If any or all scripts are found they will be used in place of the same named script(s) provided in the image.
Files located at the scripts URL take precedence over files located in .sti/bin of the source repository. See the S2I Requirements topic and the S2I documentation for information on how S2I scripts are used.
7.3.4. Environment Variables
There are two ways to make environment variables available to the source build process and resulting image: environment files and BuildConfig environment values.
7.3.4.1. Environment Files
Source build enables you to set environment values (one per line) inside your application, by specifying them in a .sti/environment file in the source repository. The environment variables specified in this file are present during the build process and in the final Docker image. The complete list of supported environment variables is available in the documentation for each image.
If you provide a .sti/environment file in your source repository, S2I reads this file during the build. This allows customization of the build behavior as the assemble script may use these variables.
For example, if you want to disable assets compilation for your Rails application, you can add DISABLE_ASSET_COMPILATION=true in the .sti/environment file to cause assets compilation to be skipped during the build.
In addition to builds, the specified environment variables are also available in the running application itself. For example, you can add RAILS_ENV=development to the .sti/environment file to cause the Rails application to start in development mode instead of production.
7.3.4.2. BuildConfig Environment
You can add environment variables to the sourceStrategy definition of the BuildConfig. The environment variables defined there are visible during the assemble script execution and will be defined in the output image, making them also available to the run script and application code.
For example disabling assets compilation for your Rails application:
7.4. Docker Strategy Options
The following options are specific to the Docker build strategy.
7.4.1. No Cache
Docker builds normally reuse cached layers found on the host performing the build. Setting the noCache option to true forces the build to ignore cached layers and rerun all steps of the Dockerfile:
strategy:
type: "Docker"
dockerStrategy:
noCache: true
strategy:
type: "Docker"
dockerStrategy:
noCache: true7.4.2. Force Pull
By default, if the builder image specified in the build configuration is available locally on the node, that image will be used. However, to override the local image and refresh it from the registry to which the image stream points, create a BuildConfig with the forcePull flag set to true:
- 1
- This flag causes the local builder image to be ignored, and a fresh version to be pulled from the registry to which the image stream points. Setting
forcePullto false results in the default behavior of honoring the image stored locally.
7.4.3. Environment Variables
To make environment variables available to the Docker build process and resulting image, you can add environment variables to the dockerStrategy definition of the BuildConfig.
The environment variables defined there are inserted as a single ENV Dockerfile instruction right after the FROM instruction, so that it can be referenced later on within the Dockerfile.
The variables are defined during build and stay in the output image, therefore they will be present in any container that runs that image as well.
For example, defining a custom HTTP proxy to be used during build and runtime:
7.5. Custom Strategy Options
The following options are specific to the Custom build strategy.
7.5.1. Exposing the Docker Socket
In order to allow the running of Docker commands and the building of Docker images from inside the Docker container, the build container must be bound to an accessible socket. To do so, set the exposeDockerSocket option to true:
7.5.2. Secrets
In addition to secrets for source and images that can be added to all build types, custom strategies allow adding an arbitrary list of secrets to the builder pod.
Each secret can be mounted at a specific location:
7.5.3. Force Pull
By default, when setting up the build pod, the build controller checks if the image specified in the build configuration is available locally on the node. If so, that image will be used. However, to override the local image and refresh it from the registry to which the image stream points, create a BuildConfig with the forcePull flag set to true:
- 1
- This flag causes the local builder image to be ignored, and a fresh version to be pulled from the registry to which the image stream points. Setting
forcePullto false results in the default behavior of honoring the image stored locally.
7.5.4. Environment Variables
To make environment variables available to the Custom build process, you can add environment variables to the customStrategy definition of the BuildConfig.
The environment variables defined there are passed to the pod that runs the custom build.
For example, defining a custom HTTP proxy to be used during build:
7.6. Using a Proxy for Git Cloning
If your Git repository can only be accessed using a proxy, you can define the proxy to use in the source section of the BuildConfig. You can configure both a HTTP and HTTPS proxy to use. Both fields are optional.
Your source URI must use the HTTP or HTTPS protocol for this to work.
7.6.1. Using Private Repositories for Builds
Supply valid credentials to build an application from a private repository. Currently, only SSH key based authentication is supported. The repository keys are located in the $HOME/.ssh/ directory, and are named id_dsa.pub, id_ecdsa.pub, id_ed25519.pub, or id_rsa.pub by default. Generate SSH key credentials with the following command:
ssh-keygen -t rsa -C "your_email@example.com"
$ ssh-keygen -t rsa -C "your_email@example.com"For a SSH key to work in OpenShift builds, it must not have a passphrase set. When prompted for a passphrase, leave it blank.
Two files are created: the public key and a corresponding private key (one of id_dsa, id_ecdsa, id_ed25519, or id_rsa). With both of these in place, consult your source control management (SCM) system’s manual on how to upload the public key. The private key will be used to access your private repository.
A secret is used to store your keys.
Create the
secretfirst before using the SSH key to access the private repository:oc secrets new scmsecret ssh-privatekey=$HOME/.ssh/id_rsa
$ oc secrets new scmsecret ssh-privatekey=$HOME/.ssh/id_rsaCopy to Clipboard Copied! Toggle word wrap Toggle overflow Add the
secretto the builder service account. Each build is run withserviceaccount/builderrole, so you need to give it access your secret with following command:oc secrets add serviceaccount/builder secrets/sshsecret
$ oc secrets add serviceaccount/builder secrets/sshsecretCopy to Clipboard Copied! Toggle word wrap Toggle overflow Add a
sourceSecretfield into thesourcesection inside theBuildConfigand set it to the name of thesecretthat you created. In this casescmsecret:Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- The URL of private repository is usually in the form
git@example.com:<username>/<repository>.
7.7. Dockerfile Source
When the BuildConfig.spec.source.type is Dockerfile, an inline Dockerfile is used as the build input, and no additional sources can be provided.
This source type is valid when the build strategy type is Docker or Custom.
The source definition is part of the spec section in the BuildConfig:
source: type: "Dockerfile" dockerfile: "FROM centos:7\nRUN yum install -y httpd"
source:
type: "Dockerfile"
dockerfile: "FROM centos:7\nRUN yum install -y httpd" - 1
- The
dockerfilefield contains an inline Dockerfile that will be built.
7.8. Binary Source
When the BuildConfig.spec.source.type is Binary, the build will expect a binary as input, and an inline Dockerfile is optional.
The binary is generally assumed to be a tar, gzipped tar, or zip file depending on the strategy. For Docker builds, this is the build context and an optional Dockerfile may be specified to override any Dockerfile in the build context. For Source builds, this is assumed to be an archive as described above. For Source and Docker builds, if binary.asFile is set the build will receive a directory with a single file. The contextDir field may be used when an archive is provided. Custom builds will receive this binary as input on standard input (stdin).
A binary source potentially extracts content, in which case contextDir allows changing to a subdirectory within the content before the build executes.
The source definition is part of the spec section in the BuildConfig:
- 1
- The
binaryfield specifies the details of the binary source. - 2
- The
asFilefield specifies the name of a file that will be created with the binary contents. - 3
- The
contextDirfield specifies a subdirectory with the contents of a binary archive. - 4
- If the optional
dockerfilefield is provided, it should be a string containing an inline Dockerfile that potentially replaces one within the contents of the binary archive.
7.9. Image Source
Additional files can be provided to the build process via images. Input images are referenced in the same way the From and To image targets are defined. This means both docker images and image stream tags can be referenced. In conjunction with the image, you must provide one or more path pairs to indicate the path of the files/directories to copy out of the image and the destination to place them in the build context.
The source path can be any absolute path within the image specified. The destination must be a relative directory path. At build time, the image will be loaded and the indicated files/directories will be copied into the context directory of the build process. This is the same directory into which the source repository content (if any) is cloned.
Image inputs are specified in the source definition of the BuildConfig:
- 1
- An array of one or more input images and files.
- 2
- A reference to the image containing the files to be copied.
- 3
- An array of source/destination paths.
- 4
- The directory relative to the build root where the build process can access the file.
- 5
- The location of the file to be copied out of the referenced image.
- 6
- An optional secret provided if credentials are needed to access the input image.
This feature is not supported for builds using the Custom strategy.
7.10. Using Secrets During a Build
In some scenarios operations performed by the build require credentials to access dependent resources, but it is undesirable for those credentials to be available in the final application image produced by the build.
For example, you are building a NodeJS application and you set up your private mirror for NodeJS modules. In order to download modules from that private mirror, you have to supply a custom .npmrc file for the build that contains a URL, username and password. For security reasons, you do not want to expose your credentials in the application image.
While this example describes NodeJS, you can use the same approach for adding SSL certificates into the /etc/ssl/certs directory, API keys or tokens, license files, etc.
7.10.1. Defining Secrets in the BuildConfig
First, you have to create the Secret you want to use. You can do that by executing the following command:
oc secrets new secret-npmrc .npmrc=~/.npmrc
$ oc secrets new secret-npmrc .npmrc=~/.npmrc
This command will create a new Secret named secret-npmrc and store the base64 encoded content of the ~/.npmrc file in it.
Now, that you have the secret created, you can add references to secrets into the source section in the existing BuildConfig:
If you want to create a new BuildConfig and you want to include the secrets in it, you can run the following command:
oc new-build openshift/nodejs-010-centos7~https://github.com/openshift/nodejs-ex.git --build-secret secret-npmrc
$ oc new-build openshift/nodejs-010-centos7~https://github.com/openshift/nodejs-ex.git --build-secret secret-npmrc
During the build in both of these examples the .npmrc will be copied into a directory where the source code is located. In case of the OpenShift Source-To-Image builder images, this will be the image working directory which is set using the WORKDIR instruction in the Dockerfile. If you want to specify another directory, you can add a destinationDir into the secret definition:
You can also specify the destination directory when creating a new BuildConfig:
oc new-build openshift/nodejs-010-centos7~https://github.com/openshift/nodejs-ex.git --build-secret “secret-npmrc:/etc”
$ oc new-build openshift/nodejs-010-centos7~https://github.com/openshift/nodejs-ex.git --build-secret “secret-npmrc:/etc”In both cases, the .npmrc file will be added into the /etc directory of the build environment. Note that for a Docker strategy the destination directory must be a relative path.
7.10.2. Source-to-Image Strategy
When you are using a Source strategy all defined source secrets will be copied to the respective destinationDir. If you left destinationDir empty then the secrets will be placed to the working directory of the builder image. The same rule is used when a destination directory is a relative path - the secrets will be placed into the paths that are relative to the image’s working directory. The destinationDir must exist or an error will occur. No directory paths are created during the copy process.
Keep in mind that in the current implementation, files with the secrets are world-writable (have 0666 permissions) and will be truncated to size zero after execution of the assemble script. This means that the secret files will exist in the resulting image but they will be empty for security reasons.
7.10.3. Docker Strategy
When you are using a Docker strategy, you can add all defined source secrets into your Docker image using the ADD and COPY instructions in your Dockerfile. If you don’t specify the destinationDir for a secret, then the files will be copied into the same directory in which the Dockerfile is located. If you specify a relative path as destinationDir, then the secrets will be copied into that directory, relative to your Dockerfile location. This makes the secret files available to the Docker build operation as part of the context directory used during the build.
Note that for security reasons, users should always remove their secrets from the final application image. This removal should be part of the Dockerfile itself. In that case, the secrets will not be present in the container running from that image. However, the secrets will still exist in the image itself in the layer where they were added.
7.10.4. Custom Strategy
When you are using a Custom strategy, then all the defined source secrets will be available inside the builder container under /var/run/secrets/openshift.io/build directory. It is the custom build image’s responsibility to use these secrets appropriately. The Custom strategy also allows secrets to be defined as described in Secrets. There is no technical difference between existing strategy secrets and the source secrets. However, your builder image might distinguish between them and use them differently, based on your build use case. The source secrets are always mounted into /var/run/secrets/openshift.io/build directory or your builder can parse the $BUILD environment variable which includes the full Build object serialized into JSON format.
7.11. Starting a Build
Manually invoke a build using the following command:
oc start-build <BuildConfigName>
$ oc start-build <BuildConfigName>
Re-run a build using the --from-build flag:
oc start-build --from-build=<buildName>
$ oc start-build --from-build=<buildName>
Specify the --follow flag to stream the build’s logs in stdout:
oc start-build <BuildConfigName> --follow
$ oc start-build <BuildConfigName> --follow7.12. Canceling a Build
Manually cancel a build using the following command:
oc cancel-build <buildName>
$ oc cancel-build <buildName>7.13. Accessing Build Logs
To allow access to build logs, use the following command:
oc build-logs <buildName>
$ oc build-logs <buildName>Log Verbosity
To enable more verbose output, pass the BUILD_LOGLEVEL environment variable as part of the sourceStrategy or dockerStrategy in a BuildConfig:
- 1
- Adjust this value to the desired log level.
A platform administrator can set verbosity for the entire OpenShift instance by passing the --loglevel option to the openshift start command. If both --loglevel and BUILD_LOGLEVEL are specified, BUILD_LOGLEVEL takes precedence.
Available log levels for Source builds are as follows:
| Level 0 | Produces output from containers running the assemble script and all encountered errors. This is the default. |
| Level 1 | Produces basic information about the executed process. |
| Level 2 | Produces very detailed information about the executed process. |
| Level 3 | Produces very detailed information about the executed process, and a listing of the archive contents. |
| Level 4 | Currently produces the same information as level 3. |
| Level 5 | Produces everything mentioned on previous levels and additionally provides docker push messages. |
7.14. Source Code
The source code location is one of the required parameters for the BuildConfig. The build uses this location and fetches the source code that is later built. The source code location definition is part of the spec section in the BuildConfig:
- 1
- The
typefield describes which SCM is used to fetch your source code. - 2
- The
gitfield contains the URI to the remote Git repository of the source code. Optionally, specify thereffield to check out a specific Git reference. A validrefcan be a SHA1 tag or a branch name. - 3
- The
contextDirfield allows you to override the default location inside the source code repository where the build looks for the application source code. If your application exists inside a sub-directory, you can override the default location (the root folder) using this field.
7.15. Build Triggers
When defining a BuildConfig, you can define triggers to control the circumstances in which the BuildConfig should be run. The following build triggers are available:
7.15.1. Webhook Triggers
Webhook triggers allow you to trigger a new build by sending a request to the OpenShift API endpoint. You can define these triggers using GitHub webhooks or Generic webhooks.
GitHub Webhooks
GitHub webhooks handle the call made by GitHub when a repository is updated. When defining the trigger, you must specify a secret as part of the URL you supply to GitHub when configuring the webhook. The secret ensures that only you and your repository can trigger the build. The following example is a trigger definition JSON within the BuildConfig:
The payload URL is returned as the GitHub Webhook URL by the describe command (see below), and is structured as follows:
http://<openshift_api_host:port>/osapi/v1/namespaces/<namespace>/buildconfigs/<name>/webhooks/<secret>/github
http://<openshift_api_host:port>/osapi/v1/namespaces/<namespace>/buildconfigs/<name>/webhooks/<secret>/githubGeneric Webhooks
Generic webhooks can be invoked from any system capable of making a web request. As with a GitHub webhook, you must specify a secret when defining the trigger, and the caller must provide this secret to trigger the build. The following is an example trigger definition JSON within the BuildConfig:
To set up the caller, supply the calling system with the URL of the generic webhook endpoint for your build:
http://<openshift_api_host:port>/osapi/v1/namespaces/<namespace>/buildconfigs/<name>/webhooks/<secret>/generic
http://<openshift_api_host:port>/osapi/v1/namespaces/<namespace>/buildconfigs/<name>/webhooks/<secret>/genericThe endpoint can accept an optional payload with the following format:
Displaying a BuildConfig’s Webhook URLs
Use the following command to display the webhook URLs associated with a build configuration:
oc describe bc <name>
$ oc describe bc <name>If the above command does not display any webhook URLs, then no webhook trigger is defined for that build configuration.
7.15.2. Image Change Triggers
Image change triggers allow your build to be automatically invoked when a new version of an upstream image is available. For example, if a build is based on top of a RHEL image, then you can trigger that build to run any time the RHEL image changes. As a result, the application image is always running on the latest RHEL base image.
Configuring an image change trigger requires the following actions:
Define an
ImageStreamthat points to the upstream image you want to trigger on:Copy to Clipboard Copied! Toggle word wrap Toggle overflow This defines the image stream that is tied to a Docker image repository located at
<system-registry>/<namespace>/ruby-20-centos7. The<system-registry>is defined as a service with the namedocker-registryrunning in OpenShift.If an image stream is the base image for the build, set the from field in the build strategy to point to the image stream:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow In this case, the
sourceStrategydefinition is consuming thelatesttag of the image stream namedruby-20-centos7located within this namespace.Define a build with one or more triggers that point to image streams:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- An image change trigger that monitors the
ImageStreamandTagas defined by the build strategy’sfromfield. TheimageChangepart must be empty. - 2
- An image change trigger that monitors an arbitrary image stream. The
imageChangepart in this case must include afromfield that references theImageStreamTagto monitor.
When using an image change trigger for the strategy image stream, the generated build is supplied with an immutable Docker tag that points to the latest image corresponding to that tag. This new image reference will be used by the strategy when it executes for the build. For other image change triggers that do not reference the strategy image stream, a new build will be started, but the build strategy will not be updated with a unique image reference.
In the example above that has an image change trigger for the strategy, the resulting build will be:
This ensures that the triggered build uses the new image that was just pushed to the repository, and the build can be re-run any time with the same inputs.
In addition to setting the image field for all Strategy types, for custom builds, the OPENSHIFT_CUSTOM_BUILD_BASE_IMAGE environment variable is checked. If it does not exist, then it is created with the immutable image reference. If it does exist then it is updated with the immutable image reference.
If a build is triggered due to a webhook trigger or manual request, the build that is created uses the immutableid resolved from the ImageStream referenced by the Strategy. This ensures that builds are performed using consistent image tags for ease of reproduction.
Image streams that point to Docker images in v1 Docker registries only trigger a build once when the image stream tag becomes available and not on subsequent image updates. This is due to the lack of uniquely identifiable images in v1 Docker registries.
7.15.3. Configuration Change Triggers
A configuration change trigger allows a build to be automatically invoked as soon as a new BuildConfig is created. The following is an example trigger definition JSON within the BuildConfig:
{
"type": "ConfigChange"
}
{
"type": "ConfigChange"
}
Configuration change triggers currently only work when creating a new BuildConfig. In a future release, configuration change triggers will also be able to launch a build whenever a BuildConfig is updated.
7.16. Using Docker Credentials for Pushing and Pulling Images
Supply the .dockercfg file with valid Docker Registry credentials in order to push the output image into a private Docker Registry or pull the builder image from the private Docker Registry that requires authentication. For the OpenShift Docker Registry, you don’t have to do this because secrets are generated automatically for you by OpenShift.
The .dockercfg JSON file is found in your home directory by default and has the following format:
You can define multiple Docker registry entries in this file. Alternatively, you can also add authentication entries to this file by running the docker login command. The file will be created if it does not exist. Kubernetes provides secret, which are used to store your configuration and passwords.
Create the
secretfrom your local .dockercfg file:oc secrets new dockerhub ~/.dockercfg
$ oc secrets new dockerhub ~/.dockercfgCopy to Clipboard Copied! Toggle word wrap Toggle overflow This generates a JSON specification of the
secretnamed dockerhub and creates the object.Once the
secretis created, add it to the builder service account:oc secrets add serviceaccount/builder secrets/dockerhub
$ oc secrets add serviceaccount/builder secrets/dockerhubCopy to Clipboard Copied! Toggle word wrap Toggle overflow Add a
pushSecretfield into theoutputsection of theBuildConfigand set it to the name of thesecretthat you created, which in the above example is dockerhub:Copy to Clipboard Copied! Toggle word wrap Toggle overflow Pull the builder Docker image from a private Docker registry by specifying the
pullSecretfield, which is part of the build strategy definition:Copy to Clipboard Copied! Toggle word wrap Toggle overflow
Chapter 8. Deployments
8.1. Overview
A deployment in OpenShift is a replication controller based on a user defined template called a deployment configuration. Deployments are created manually or in response to triggered events.
The deployment system provides:
- A deployment configuration, which is a template for deployments.
- Triggers that drive automated deployments in response to events.
- User-customizable strategies to transition from the previous deployment to the new deployment.
- Rollbacks to a previous deployment.
- Manual replication scaling.
The deployment configuration contains a version number that is incremented each time a new deployment is created from that configuration. In addition, the cause of the last deployment is added to the configuration.
8.2. Creating a Deployment Configuration
A deployment configuration consists of the following key parts:
Deployment configurations are deploymentConfig OpenShift API resources which can be managed with the oc command like any other resource. The following is an example of a deploymentConfig resource:
- 1
- The replication controller template named
frontenddescribes a simple Ruby application. - 2
- There will be 5 replicas of
frontendby default. - 3
- A configuration change trigger causes a new deployment to be created any time the replication controller template changes.
- 4
- An image change trigger trigger causes a new deployment to be created each time a new version of the
origin-ruby-sample:latestimage repository is available. - 5
- The Rolling strategy is the default and may be omitted.
8.3. Starting a Deployment
To start a new deployment manually:
oc deploy <deployment_config> --latest
$ oc deploy <deployment_config> --latestIf there’s already a deployment in progress, the command will display a message and a new deployment will not be started.
8.4. Viewing a Deployment
To get basic information about recent deployments:
oc deploy <deployment_config>
$ oc deploy <deployment_config>This will show details about the latest and recent deployments, including any currently running deployment.
For more detailed information about a deployment configuration and the latest deployment:
oc describe dc <deployment_config>
$ oc describe dc <deployment_config>8.5. Canceling a Deployment
To cancel a running or stuck deployment:
oc deploy <deployment_config> --cancel
$ oc deploy <deployment_config> --cancelThe cancellation is a best-effort operation, and may take some time to complete. It’s possible the deployment will partially or totally complete before the cancellation is effective.
8.6. Retrying a Deployment
To retry the last failed deployment:
oc deploy <deployment_config> --retry
$ oc deploy <deployment_config> --retryIf the last deployment didn’t fail, the command will display a message and the deployment will not be retried.
Retrying a deployment restarts the deployment and does not create a new deployment version. The restarted deployment will have the same configuration it had when it failed.
8.7. Rolling Back a Deployment
Rollbacks revert an application back to a previous deployment and can be performed using the REST API or the CLI.
To rollback to the last successful deployment:
oc rollback <deployment_config>
$ oc rollback <deployment_config>The deployment configuration’s template will be reverted to match the deployment specified in the rollback command, and a new deployment will be started.
Image change triggers on the deployment configuration are disabled as part of the rollback to prevent unwanted deployments soon after the rollback is complete. To re-enable the image change triggers:
oc deploy <deployment_config> --enable-triggers
$ oc deploy <deployment_config> --enable-triggersTo roll back to a specific version:
oc rollback <deployment_config> --to-version=1
$ oc rollback <deployment_config> --to-version=1To see what the rollback would look like without performing the rollback:
oc rollback <deployment_config> --dry-run
$ oc rollback <deployment_config> --dry-run8.8. Triggers
A deployment configuration can contain triggers, which drive the creation of new deployments in response to events, both inside and outside OpenShift.
If no triggers are defined on a deployment configuration, deployments must be started manually.
8.8.1. Configuration Change Trigger
The ConfigChange trigger results in a new deployment whenever changes are detected to the replication controller template of the deployment configuration.
If a ConfigChange trigger is defined on a deployment configuration, the first deployment will be automatically created soon after the deployment configuration itself is created.
The following is an example of a ConfigChange trigger:
"triggers": [
{
"type": "ConfigChange"
}
]
"triggers": [
{
"type": "ConfigChange"
}
]8.8.2. Image Change Trigger
The ImageChange trigger results in a new deployment whenever the value of an image stream tag changes.
The following is an example of an ImageChange trigger:
- 1
- If the
automaticoption is set tofalse, the trigger is disabled.
With the above example, when the latest tag value of the origin-ruby-sample image stream changes and the new tag value differs from the current image specified in the deployment configuration’s helloworld container, a new deployment is created using the new tag value for the helloworld container.
8.9. Strategies
A deployment strategy determines the deployment process, and is defined by the deployment configuration. Each application has different requirements for availability (and other considerations) during deployments. OpenShift provides strategies to support a variety of deployment scenarios.
A deployment strategy uses readiness checks to determine if a new pod is ready for use. If a readiness check fails, the deployment is stopped.
The Rolling strategy is the default strategy used if no strategy is specified on a deployment configuration.
8.9.1. Rolling Strategy
The rolling strategy performs a rolling update and supports lifecycle hooks for injecting code into the deployment process.
The rolling deployment strategy waits for pods to pass their readiness check before scaling down old components, and does not allow pods that do not pass their readiness check within a configurable timeout.
The following is an example of the Rolling strategy:
The Rolling strategy will:
-
Execute any
prelifecycle hook. - Scale up the new deployment based on the surge configuration.
- Scale down the old deployment based on the max unavailable configuration.
- Repeat this scaling until the new deployment has reached the desired replica count and the old deployment has been scaled to zero.
-
Execute any
postlifecycle hook.
When scaling down, the Rolling strategy waits for pods to become ready so it can decide whether further scaling would affect availability. If scaled up pods never become ready, the deployment will eventually time out and result in a deployment failure.
When executing the post lifecycle hook, all failures will be ignored regardless of the failure policy specified on the hook.
The maxUnavailable parameter is the maximum number of pods that can be unavailable during the update. The maxSurge parameter is the maximum number of pods that can be scheduled above the original number of pods. Both parameters can be set to either a percentage (e.g., 10%) or an absolute value (e.g., 2). The default value for both is 25%.
These parameters allow the deployment to be tuned for availability and speed. For example:
-
maxUnavailable=0andmaxSurge=20%ensures full capacity is maintained during the update and rapid scale up. -
maxUnavailable=10%andmaxSurge=0performs an update using no extra capacity (an in-place update). -
maxUnavailable=10%andmaxSurge=10%scales up and down quickly with some potential for capacity loss.
8.9.2. Recreate Strategy
The Recreate strategy has basic rollout behavior and supports lifecycle hooks for injecting code into the deployment process.
The following is an example of the Recreate strategy:
The Recreate strategy will:
- Execute any "pre" lifecycle hook.
- Scale down the previous deployment to zero.
- Scale up the new deployment.
- Execute any "post" lifecycle hook.
During scale up, if the replica count of the deployment is greater than one, the first replica of the deployment will be validated for readiness before fully scaling up the deployment. If the validation of the first replica fails, the deployment will be considered a failure.
When executing the "post" lifecycle hook, all failures will be ignored regardless of the failure policy specified on the hook.
8.9.3. Custom Strategy
The Custom strategy allows you to provide your own deployment behavior.
The following is an example of the Custom strategy:
In the above example, the organization/strategy Docker image provides the deployment behavior. The optional command array overrides any CMD directive specified in the image’s Dockerfile. The optional environment variables provided are added to the execution environment of the strategy process.
Additionally, OpenShift provides the following environment variables to the strategy process:
| Environment Variable | Description |
|---|---|
|
| The name of the new deployment (a replication controller). |
|
| The namespace of the new deployment. |
The replica count of the new deployment will initially be zero. The responsibility of the strategy is to make the new deployment active using the logic that best serves the needs of the user.
8.10. Lifecycle Hooks
The Recreate and Rolling strategies support lifecycle hooks, which allow behavior to be injected into the deployment process at predefined points within the strategy:
The following is an example of a "pre" lifecycle hook:
"pre": {
"failurePolicy": "Abort",
"execNewPod": {}
}
"pre": {
"failurePolicy": "Abort",
"execNewPod": {}
}- 1
execNewPodis a pod-based lifecycle hook.
Every hook has a failurePolicy, which defines the action the strategy should take when a hook failure is encountered:
|
| The deployment should be considered a failure if the hook fails. |
|
| The hook execution should be retried until it succeeds. |
|
| Any hook failure should be ignored and the deployment should proceed. |
Some hook points for a strategy might support only a subset of failure policy values. For example, the Recreate and Rolling strategies do not currently support the Abort policy for a "post" deployment lifecycle hook. Consult the documentation for a given strategy for details on any restrictions regarding lifecycle hooks.
Hooks have a type-specific field that describes how to execute the hook. Currently pod-based hooks are the only supported hook type, specified by the execNewPod field.
8.10.1. Pod-based Lifecycle Hook
Pod-based lifecycle hooks execute hook code in a new pod derived from the template in a deployment configuration.
The following simplified example deployment configuration uses the Rolling strategy. Triggers and some other minor details are omitted for brevity:
In this example, the "pre" hook will be executed in a new pod using the openshift/origin-ruby-sample image from the helloworld container. The hook container command will be /usr/bin/command arg1 arg2, and the hook container will have the CUSTOM_VAR1=custom_value1 environment variable. Because the hook failure policy is Abort, the deployment will fail if the hook fails.
8.11. Deployment Resources
A deployment is completed by a pod that consumes resources (memory and cpu) on a node. By default, pods consume unbounded node resources. However, if a project specifies default container limits, then pods consume resources up to those limits. Another way to limit resource use is to specify resource limits as part of the deployment strategy. In the following example, each of resources, cpu, and memory is optional.
Deployment resources can be used with the Recreate, Rolling, or Custom deployment strategies.
8.12. Manual Scaling
In addition to rollbacks, you can exercise fine-grained control over the number of replicas by using the oc scale command. For example, the following command sets the replicas in the deployment configuration frontend to 3.
oc scale dc frontend --replicas=3
$ oc scale dc frontend --replicas=3
The number of replicas eventually propagates to the desired and current state of the deployment configured by the deployment configuration frontend.
Chapter 9. Routes
9.1. Overview
An OpenShift route exposes a service at a host name, like www.example.com, so that external clients can reach it by name.
DNS resolution for a host name is handled separately from routing; your administrator may have configured a cloud domain that will always correctly resolve to the OpenShift router, or if using an unrelated host name you may need to modify its DNS records independently to resolve to the router.
9.2. Creating Routes
Tooling for creating routes is developing. In the web console, they are displayed but there is not yet a method to create them. Using the CLI, you currently can create only an unsecured route:
oc expose service/<name> --hostname=<www.example.com>
$ oc expose service/<name> --hostname=<www.example.com>The new route inherits the name from the service unless you specify one.
Example 9.1. An Unsecured Route YAML Definition
Unsecured routes are the default configuration, and are therefore the simplest to set up. However, secured routes offer security for connections to remain private. To create a secured HTTPS route encrypted with a key and certificate (PEM-format files which you must generate and sign separately), you must edit the unsecured route to add TLS termination.
TLS is the replacement of SSL for HTTPS and other encrypted protocols.
oc edit route/<name>
$ oc edit route/<name>Example 9.2. A Secure Route Using Edge Termination
You can specify a secured route without a key and certificate, in which case the router’s default certificate will be used for TLS termination.
TLS termination in OpenShift relies on SNI for serving custom certificates. Any non-SNI traffic received on port 443 is handled with TLS termination and a default certificate, which may not match the requested host name, resulting in validation errors.
Further information on all types of TLS termination as well as path-based routing are available in the Architecture section.
Chapter 10. Integrating External Services
10.1. Overview
Many OpenShift applications use external resources, such as external databases, or an external SaaS endpoint. These external resources can be modeled as native OpenShift services, so that applications can work with them as they would any other internal service.
10.2. External MySQL Database
One of the most common types of external services is an external database. To support an external database, an application needs:
- An endpoint to communicate with.
A set of credentials and coordinates, including:
- A user name
- A passphrase
- A database name
The solution for integrating with an external database includes:
-
A
Serviceobject to represent the SaaS provider as an OpenShift service. -
One or more
Endpointsfor the service. - Environment variables in the appropriate pods containing the credentials.
The following steps outline a scenario for integrating with an external MySQL database:
Create an OpenShift service to represent your external database. This is similar to creating an internal service; the difference is in the service’s
Selectorfield.Internal OpenShift services use the
Selectorfield to associate pods with services using labels. TheEndpointsControllersystem component synchronizes the endpoints for services that specify selectors with the pods that match the selector. The service proxy and OpenShift router load-balance requests to the service amongst the service’s endpoints.Services that represent an external resource do not require associated pods. Instead, leave the
Selectorfield unset. This represents the external service, making theEndpointsControllerignore the service and allows you to specify endpoints manually:Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- The
selectorfield to leave blank.
Next, create the required endpoints for the service. This gives the service proxy and router the location to send traffic directed to the service:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- The name of the
Serviceinstance, as defined in the previous step. - 2
- Traffic to the service will be load-balanced between the supplied
Endpointsif more than one is supplied. - 3
- Endpoints IPs cannot be loopback (127.0.0.0/8), link-local (169.254.0.0/16), or link-local multicast (224.0.0.0/24).
- 4
- The
portandnamedefinition must match theportandnamevalue in the service defined in the previous step.
Now that the service and endpoints are defined, give the appropriate pods access to the credentials to use the service by setting environment variables in the appropriate containers:
External Database Environment Variables
Using an external service in your application is similar to using an internal service. Your application will be assigned environment variables for the service and the additional environment variables with the credentials described in the previous step. For example, a MySQL container receives the following environment variables:
-
EXTERNAL_MYSQL_SERVICE_SERVICE_HOST=<ip_address> -
EXTERNAL_MYSQL_SERVICE_SERVICE_PORT=<port_number> -
MYSQL_USERNAME=<mysql_username> -
MYSQL_PASSPHRASE=<mysql_passphrase> -
MYSQL_DATABASE_NAME=<mysql_database>
The application is responsible for reading the coordinates and credentials for the service from the environment and establishing a connection with the database via the service.
10.3. External SaaS Provider
A common type of external service is an external SaaS endpoint. To support an external SaaS provider, an application needs:
- An endpoint to communicate with
A set of credentials, such as:
- An API key
- A user name
- A passphrase
The following steps outline a scenario for integrating with an external SaaS provider:
Create an OpenShift service to represent the external service. This is similar to creating an internal service; however the difference is in the service’s
Selectorfield.Internal OpenShift services use the
Selectorfield to associate pods with services using labels. A system component calledEndpointsControllersynchronizes the endpoints for services that specify selectors with the pods that match the selector. The service proxy and OpenShift router load-balance requests to the service amongst the service’s endpoints.Services that represents an external resource do not require that pods be associated with it. Instead, leave the
Selectorfield unset. This makes theEndpointsControllerignore the service and allows you to specify endpoints manually:Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- The
selectorfield to leave blank.
Next, create endpoints for the service containing the information about where to send traffic directed to the service proxy and the router:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
- 1
- The name of the
Serviceinstance. - Traffic to the service is load-balanced between the
subsetssupplied here.Now that the service and endpoints are defined, give pods the credentials to use the service by setting environment variables in the appropriate containers:
External SaaS Provider Environment Variables
Similarly, when using an internal service, your application is assigned environment variables for the service and the additional environment variables with the credentials described in the above steps. In the above example, the container receives the following environment variables:
-
EXAMPLE_EXTERNAL_SERVICE_SERVICE_HOST=<ip_address> -
EXAMPLE_EXTERNAL_SERVICE_SERVICE_PORT=<port_number> -
SAAS_API_KEY=<saas_api_key> -
SAAS_USERNAME=<saas_username> -
SAAS_PASSPHRASE=<saas_passphrase>
The application reads the coordinates and credentials for the service from the environment and establishes a connection with the service.
Chapter 11. Secrets
11.1. Overview
The Secret object type provides a mechanism to hold sensitive information such as passwords, OpenShift client config files, dockercfg files, etc. Secrets decouple sensitive content from the pods that use it and can be mounted into containers using a volume plug-in or used by the system to perform actions on behalf of a pod. This topic discusses important properties of secrets and provides an overview on how developers can use them.
- 1
- The allowable format for the keys in the
datafield must meet the guidelines in the DNS_SUBDOMAIN value in the Kubernetes identifiers glossary.
11.2. Properties of Secrets
Key properties include:
- Secret data can be referenced independently from its definition.
- Secret data never comes to rest on the node. Volumes are backed by temporary file-storage facilities (tmpfs).
- Secret data can be shared within a namespace.
11.2.1. Secrets and the Pod Lifecycle
A secret must be created before the pods that depend on it.
Containers read the secret from the files. If a secret is expected to be stored in an environment variable, then you must modify the image to populate the environment variable from the file before running the main program.
Once a pod is created, its secret volumes do not change, even if the secret resource is modified. To change the secret used, the original pod must be deleted, and a new pod (perhaps with an identical PodSpec) must be created. An exception to this is when a node is rebooted and the secret data must be re-read from the API server. Updating a secret follows the same workflow as deploying a new container image. The kubectl rollingupdate command can be used.
The resourceVersion value in a secret is not specified when it is referenced. Therefore, if a secret is updated at the same time as pods are starting, then the version of the secret will be used for the pod will not be defined.
Currently, it is not possible to check the resource version of a secret object that was used when a pod was created. It is planned that pods will report this information, so that a controller could restart ones using a old resourceVersion. In the interim, do not update the data of existing secrets, but create new ones with distinct names.
11.3. Creating and Using Secrets
When creating secrets:
- Create a secret object with secret data
-
Create a pod with a volume of type
secretand a container to mount the volume - Update the pod’s service account to allow the reference to the secret.
11.3.1. Creating Secrets
To create a secret object, use the following command, where the json file is a predefined secret:
oc create -f secret.json
$ oc create -f secret.json11.3.2. Secrets in Volumes
See Examples.
11.3.3. Image Pull Secrets
See the Image Pull Secrets topic for more information.
11.4. Restrictions
Secret volume sources are validated to ensure that the specified object reference points to a Secret object. Therefore, a secret needs to be created before the pods that depend on it.
Secret API objects reside in a namespace. They can only be referenced by pods in that same namespace.
Individual secrets are limited to 1MB in size. This is to discourage the creation of large secrets that would exhaust apiserver and kubelet memory. However, creation of a number of smaller secrets could also exhaust memory.
Currently, when mounting a secret, the service account for a pod must have the secret in the list of mountable secrets. If a template contains a secret definition and pods that consume it, the pods will be rejected until the service account is updated.
11.4.1. Secret Data Keys
Secret keys must be in a DNS subdomain.
11.5. Examples
Example 11.1. YAML of a Pod Consuming Data in a Volume
Chapter 12. Image Pull Secrets
12.1. Overview
Docker registries can be secured to prevent unauthorized parties from accessing certain images. If you are using OpenShift’s integrated Docker registry and are pulling from image streams located in the same project, then your pod’s service account should already have permissions and no additional action should be required. If this is not the case, then additional configuration steps are required.
12.2. Integrated Registry Authentication and Authorization
OpenShift’s integrated Docker registry authenticates using the same tokens as the OpenShift API. To perform a docker login against the integrated registry, you can choose any user name and email, but the password must be a valid OpenShift token. In order to pull an image, the authenticated user must have get rights on the requested imagestreams/layers. In order to push an image, the authenticated user must have update rights on the requested imagestreams/layers.
By default, all service accounts in a project have rights to pull any image in the same project, and the builder service account has rights to push any image in the same project.
12.2.1. Allowing Pods to Reference Images Across Projects
When using the integrated registry, to allow pods in project-a to reference images in project-b, a service account in project-a must be bound to the system:image-puller role in project-b:
oc policy add-role-to-user \
system:image-puller system:serviceaccount:project-a:default \
--namespace=project-b
$ oc policy add-role-to-user \
system:image-puller system:serviceaccount:project-a:default \
--namespace=project-bAfter adding that role, the pods in project-a that reference the default service account will be able to pull images from project-b.
To allow access for any service account in project-a, use the group:
oc policy add-role-to-group \
system:image-puller system:serviceaccounts:project-a \
--namespace=project-b
$ oc policy add-role-to-group \
system:image-puller system:serviceaccounts:project-a \
--namespace=project-b12.3. Allowing Pods to Reference Images from Other Secured Registries
To pull a secured Docker image that is not from OpenShift’s integrated registry, you must create a dockercfg secret and add it to your service account.
If you already have a .dockercfg file for the secured registry, you can create a secret from that file by running:
oc secrets new <pull_secret_name> \
.dockercfg=<path/to/.dockercfg>
$ oc secrets new <pull_secret_name> \
.dockercfg=<path/to/.dockercfg>If you do not already have a .dockercfg file for the secured registry, you can create a secret by running:
oc secrets new-dockercfg <pull_secret_name> \
--docker-server=<registry_server> --docker-username=<user_name> \
--docker-password=<password> --docker-email=<email>
$ oc secrets new-dockercfg <pull_secret_name> \
--docker-server=<registry_server> --docker-username=<user_name> \
--docker-password=<password> --docker-email=<email>To use a secret for pulling images for pods, you must add the secret to your service account. The name of the service account in this example should match the name of the service account the pod will use; default is the default service account:
oc secrets add serviceaccount/default secrets/<pull_secret_name> --for=pull
$ oc secrets add serviceaccount/default secrets/<pull_secret_name> --for=pullTo use a secret for pushing and pulling build images, the secret must be mountable inside of a pod. You can do this by running:
oc secrets add serviceaccount/builder secrets/<pull_secret_name>
$ oc secrets add serviceaccount/builder secrets/<pull_secret_name>Chapter 13. Resource Limits
13.1. Overview
A LimitRange object enumerates the minimum and maximum resource usage values per object in a project.
13.2. Limits
A LimitRange object can enumerate the following limits for each object type and resource value that is created or modified in the project. If a usage limit is defined, and the incoming resource exceeds the allowed range, then the resource is forbidden from the project.
For some fields, in the absence of a value on the incoming resource, it is possible to apply a default value, if it is specified in the LimitRange definition.
| Type | ResourceName | Description | Default Value Supported |
|---|---|---|---|
|
|
| Minimum/maximum CPU allowed per container. | yes |
|
|
| Minimum/maximum memory allowed per container. | yes |
|
|
| Minimum/maximum CPU allowed across all containers in a pod. | no |
|
|
| Minimum/maximum memory allowed across all containers in a pod. | no |
13.3. Limit Enforcement
Once a LimitRange is created in a project, all resource create and modification requests are evaluated against each LimitRange object in the project. If the resource violates a minimum or maximum constraint enumerated, then the resource is rejected. If the resource does not set an explicit value, and if the constraint supports a default value, then the default value is applied to the resource.
For example, if the container does not express a CPU resource requirement, but the LimitRange specifies a default value for container CPU, then the default value is set to the allowed CPU usage for that container, and the minimum (if specified) is set as the minimum requested value for that container.
Example 13.1. Limit Range Object Definition
- 1
- The name of the limit range document.
- 2
- The maximum amount of memory that a pod can consume on a node across all containers.
- 3
- The maximum amount of cpu that a pod can consume on a node across all containers.
- 4
- The minimum amount of memory that a pod can consume on a node across all containers.
- 5
- The minimum amount of cpu that a pod can consume on a node across all containers.
- 6
- The maximum amount of memory that a single container in a pod can consume.
- 7
- The maximum amount of cpu that a single container in a pod can consume.
- 8
- The maximum amount of memory that a single container in a pod can consume.
- 9
- The maximum amount of cpu that a single container in a pod can consume.
- 10
- The default amount of memory that a container will request if not specified.
- 11
- The default amount of cpu that a container will request if not specified.
13.4. Creating a Limit Range
To apply a limit range to a project, create a limit range object definition on your file system to your specifications, then run:
oc create -f <limit_range_file>
$ oc create -f <limit_range_file>13.5. Viewing Limits
To view limits enforced in a project:
13.6. Deleting Limits
If you do not want to enforce limits in a project, you can remove any active limit range by name:
oc delete limits <limit_name>
$ oc delete limits <limit_name>Chapter 14. Resource Quota
14.1. Overview
A ResourceQuota object enumerates hard resource usage limits per project. It limits the total number of a particular type of object that may be created in a project, and the total amount of compute resources that may be consumed by resources in that project.
14.2. Usage Limits
The following describes the set of limits that may be enforced by a ResourceQuota.
| Resource Name | Description |
|---|---|
|
| Total cpu usage across all containers |
|
| Total memory usage across all containers |
|
| Total number of pods |
|
| Total number of replication controllers |
|
| Total number of resource quotas |
|
| Total number of services |
|
| Total number of secrets |
|
| Total number of persistent volume claims |
14.3. Quota Enforcement
After a project quota is first created, the project restricts the ability to create any new resources that may violate a quota constraint until it has calculated updated usage statistics.
Once a quota is created and usage statistics are up-to-date, the project accepts the creation of new content. When you create or modify resources, your quota usage is incremented immediately upon the request to create or modify the resource. When you delete a resource, your quota use is decremented during the next full recalculation of quota statistics for the project. When you delete resources, a configurable amount of time determines how long it takes to reduce quota usage statistics to their current observed system value.
If project modifications exceed a quota usage limit, the server denies the action, and an appropriate error message is returned to the end-user explaining the quota constraint violated, and what their currently observed usage stats are in the system.
14.4. Sample Resource Quota File
resource-quota.json
- 1
- The name of this quota document
- 2
- The total amount of memory consumed across all containers may not exceed 1Gi.
- 3
- The total number of cpu usage consumed across all containers may not exceed 20 Kubernetes compute units.
- 4
- The total number of pods in the project
- 5
- The total number of services in the project
- 6
- The total number of replication controllers in the project
- 7
- The total number of resource quota documents in the project
14.5. Create a Quota
To apply a quota to a project:
oc create -f resource-quota.json
$ oc create -f resource-quota.json14.6. View a Quota
To view usage statistics related to any hard limits defined in your quota:
14.7. Configuring the Quota Synchronization Period
When a set of resources are deleted, the synchronization timeframe of resources is determined by the resource-quota-sync-period setting in the /etc/openshift/master/master-config.yaml file. Before your quota usage is restored, you may encounter problems when attempting to reuse the resources. Change the resource-quota-sync-period setting to have the set of resources regenerate at the desired amount of time (in seconds) and for the resources to be available again:
Adjusting the regeneration time can be helpful for creating resources and determining resource usage when automation is used.
The resource-quota-sync-period setting is designed to balance system performance. Reducing the sync period can result in a heavy load on the master.
Chapter 15. Managing Volumes
15.1. Overview
Containers are not persistent by default; on restart, their contents are cleared. Volumes are mounted file systems available to pods and their containers which may be backed by a number of host-local or network attached storage endpoints.
The simplest volume type is EmptyDir, which is a temporary directory on a single machine. Administrators may also allow you to request a persistent volume that is automatically attached to your pods.
You can use the CLI command oc volume to add, update, or remove volumes and volume mounts for any object that has a pod template like replication controllers or deployment configurations. You can also list volumes in pods or any object that has a pod template.
15.2. General CLI Usage
The oc volume command uses the following general syntax:
oc volume <object_selection> <operation> <mandatory_parameters> <optional_parameters>
$ oc volume <object_selection> <operation> <mandatory_parameters> <optional_parameters>
This topic uses the form <object_type>/<name> for <object_selection> in later examples, however you can choose one of the following options:
| Syntax | Description | Example |
|---|---|---|
|
|
Selects |
|
|
|
Selects |
|
|
|
Selects resources of type |
|
|
|
Selects all resources of type |
|
|
| File name, directory, or URL to file to use to edit the resource. |
|
The <operation> can be one of --add, --remove, or --list.
Any <mandatory_parameters> or <optional_parameters> are specific to the selected operation and are discussed in later sections.
15.3. Adding Volumes
To add a volume, a volume mount, or both to pod templates:
oc volume <object_type>/<name> --add [options]
$ oc volume <object_type>/<name> --add [options]| Option | Description | Default |
|---|---|---|
|
| Name of the volume. | Automatically generated, if not specified. |
|
|
Name of the volume source. Supported values: |
|
|
|
Select containers by name. It can also take wildcard |
|
|
| Mount path inside the selected containers. | |
|
|
Host path. Mandatory parameter for | |
|
|
Name of the secret. Mandatory parameter for | |
|
|
Name of the persistent volume claim. Mandatory parameter for | |
|
|
Details of volume source as a JSON string. Recommended if the desired volume source is not supported by | |
|
|
Display the modified objects instead of updating them on the server. Supported values: | |
|
| Output the modified objects with the given version. |
|
Examples
Add a new volume source emptyDir to deployment configuration registry:
oc volume dc/registry --add
$ oc volume dc/registry --addAdd volume v1 with secret $ecret for replication controller r1 and mount inside the containers at /data:
oc volume rc/r1 --add --name=v1 --type=secret --secret-name=$ecret --mount-path=/data
$ oc volume rc/r1 --add --name=v1 --type=secret --secret-name=$ecret --mount-path=/dataAdd existing persistent volume v1 with claim name pvc1 to deployment configuration dc.json on disk, mount the volume on container c1 at /data, and update the deployment configuration on the server:
oc volume -f dc.json --add --name=v1 --type=persistentVolumeClaim \ --claim-name=pvc1 --mount-path=/data --containers=c1
$ oc volume -f dc.json --add --name=v1 --type=persistentVolumeClaim \
--claim-name=pvc1 --mount-path=/data --containers=c1Add volume v1 based on Git repository https://github.com/namespace1/project1 with revision 5125c45f9f563 for all replication controllers:
oc volume rc --all --add --name=v1 \
--source='{"gitRepo": {
"repository": "https://github.com/namespace1/project1",
"revision": "5125c45f9f563"
}}'
$ oc volume rc --all --add --name=v1 \
--source='{"gitRepo": {
"repository": "https://github.com/namespace1/project1",
"revision": "5125c45f9f563"
}}'15.4. Updating Volumes
Updating existing volumes or volume mounts is the same as adding volumes, but with the --overwrite option:
oc volume <object_type>/<name> --add --overwrite [options]
$ oc volume <object_type>/<name> --add --overwrite [options]Examples
Replace existing volume v1 for replication controller r1 with existing persistent volume claim pvc1:
oc volume rc/r1 --add --overwrite --name=v1 --type=persistentVolumeClaim --claim-name=pvc1
$ oc volume rc/r1 --add --overwrite --name=v1 --type=persistentVolumeClaim --claim-name=pvc1Change deployment configuration d1 mount point to /opt for volume v1:
oc volume dc/d1 --add --overwrite --name=v1 --mount-path=/opt
$ oc volume dc/d1 --add --overwrite --name=v1 --mount-path=/opt15.5. Removing Volumes
To remove a volume or volume mount from pod templates:
oc volume <object_type>/<name> --remove [options]
$ oc volume <object_type>/<name> --remove [options]| Option | Description | Default |
|---|---|---|
|
| Name of the volume. | |
|
|
Select containers by name. It can also take wildcard |
|
|
| Indicate that you want to remove multiple volumes at once. | |
|
|
Display the modified objects instead of updating them on the server. Supported values: | |
|
| Output the modified objects with the given version. |
|
Some examples:
Remove a volume v1 from deployment config 'd1':
oc volume dc/d1 --remove --name=v1
$ oc volume dc/d1 --remove --name=v1Unmount volume v1 from container c1 for deployment configuration d1 and remove the volume v1 if it is not referenced by any containers on d1:
oc volume dc/d1 --remove --name=v1 --containers=c1
$ oc volume dc/d1 --remove --name=v1 --containers=c1Remove all volumes for replication controller r1:
oc volume rc/r1 --remove --confirm
$ oc volume rc/r1 --remove --confirm15.6. Listing Volumes
To list volumes or volume mounts for pods or pod templates:
oc volume <object_type>/<name> --list [options]
$ oc volume <object_type>/<name> --list [options]List volume supported options:
| Option | Description | Default |
|---|---|---|
|
| Name of the volume. | |
|
|
Select containers by name. It can also take wildcard |
|
Examples
List all volumes for pod p1:
oc volume pod/p1 --list
$ oc volume pod/p1 --listList volume v1 defined on all deployment configurations:
oc volume dc --all --name=v1
$ oc volume dc --all --name=v1Chapter 16. Using Persistent Volumes
16.1. Overview
A PersistentVolume object is a storage resource in an OpenShift cluster. Storage is provisioned by an administrator by creating PersistentVolume objects from sources such as GCE Persistent Disks, AWS Elastic Block Stores (EBS), and NFS mounts.
Persistent volume plug-ins other than the supported NFS plug-in, such as AWS Elastic Block Stores (EBS), GCE Persistent Disks, GlusterFS, iSCSI, and RADOS (Ceph), are currently in Technology Preview. The Administrator Guide provides instructions on provisioning an OpenShift cluster with persistent storage using NFS.
Storage can be made available to you by laying claims to the resource. You can make a request for storage resources using a PersistentVolumeClaim object; the claim is paired with a volume that generally matches your request.
16.2. Requesting Storage
You can request storage by creating PersistentVolumeClaim objects in your projects:
Example 16.1. Persistent Volume Claim Object Definition
16.3. Volume and Claim Binding
A PersistentVolume is a specific resource. A PersistentVolumeClaim is a request for a resource with specific attributes, such as storage size. In between the two is a process that matches a claim to an available volume and binds them together. This allows the claim to be used as a volume in a pod. OpenShift finds the volume backing the claim and mounts it into the pod.
You can tell whether a claim or volume is bound by querying using the CLI:
16.4. Claims as Volumes in Pods
A PersistentVolumeClaim is used by a pod as a volume. OpenShift finds the claim with the given name in the same namespace as the pod, then uses the claim to find the corresponding volume to mount.
Example 16.2. Pod Definition with a Claim
See Kubernetes Persistent Volumes for more information.
Chapter 17. Executing Remote Commands
17.1. Overview
You can use the CLI to execute remote commands in a container. This allows you to run general Linux commands for routine operations in the container.
For security purposes, the oc exec command does not work when accessing privileged containers. See the CLI operations topic for more information.
17.2. Basic Usage
Support for remote container command execution is built into the CLI:
oc exec <pod> [-c <container>] <command> [<arg_1> ... <arg_n>]
$ oc exec <pod> [-c <container>] <command> [<arg_1> ... <arg_n>]For example:
oc exec mypod date Thu Apr 9 02:21:53 UTC 2015
$ oc exec mypod date
Thu Apr 9 02:21:53 UTC 201517.3. Protocol
Clients initiate the execution of a remote command in a container by issuing a request to the Kubernetes API server:
/proxy/minions/<node_name>/exec/<namespace>/<pod>/<container>?command=<command>
/proxy/minions/<node_name>/exec/<namespace>/<pod>/<container>?command=<command>In the above URL:
-
<node_name>is the FQDN of the node. -
<namespace>is the namespace of the target pod. -
<pod>is the name of the target pod. -
<container>is the name of the target container. -
<command>is the desired command to be executed.
For example:
/proxy/minions/node123.openshift.com/exec/myns/mypod/mycontainer?command=date
/proxy/minions/node123.openshift.com/exec/myns/mypod/mycontainer?command=dateAdditionally, the client can add parameters to the request to indicate if:
- the client should send input to the remote container’s command (stdin).
- the client’s terminal is a TTY.
- the remote container’s command should send output from stdout to the client.
- the remote container’s command should send output from stderr to the client.
After sending an exec request to the API server, the client upgrades the connection to one that supports multiplexed streams; the current implementation uses SPDY.
The client creates one stream each for stdin, stdout, and stderr. To distinguish among the streams, the client sets the streamType header on the stream to one of stdin, stdout, or stderr.
The client closes all streams, the upgraded connection, and the underlying connection when it is finished with the remote command execution request.
Administrators can see the Architecture guide for more information.
Chapter 18. Port Forwarding
18.1. Overview
You can use the CLI to forward one or more local ports to a pod. This allows you to listen on a given or random port locally, and have data forwarded to and from given ports in the pod.
18.2. Basic Usage
Support for port forwarding is built into the CLI:
oc port-forward -p <pod> [<local_port>:]<pod_port> [[<local_port>:]<pod_port> ...]
$ oc port-forward -p <pod> [<local_port>:]<pod_port> [[<local_port>:]<pod_port> ...]The CLI listens on each local port specified by the user, forwarding via the protocol described below.
Ports may be specified using the following formats:
|
| The client listens on port 5000 locally and forwards to 5000 in the pod. |
|
| The client listens on port 6000 locally and forwards to 5000 in the pod. |
|
| The client selects a free local port and forwards to 5000 in the pod. |
For example, to listen on ports 5000 and 6000 locally and forward data to and from ports 5000 and 6000 in the pod, run:
oc port-forward -p mypod 5000 6000
$ oc port-forward -p mypod 5000 6000
To listen on port 8888 locally and forward to 5000 in the pod, run:
oc port-forward -p mypod 8888:5000
$ oc port-forward -p mypod 8888:5000
To listen on a free port locally and forward to 5000 in the pod, run:
oc port-forward -p mypod :5000
$ oc port-forward -p mypod :5000Or, alternatively:
oc port-forward -p mypod 0:5000
$ oc port-forward -p mypod 0:500018.3. Protocol
Clients initiate port forwarding to a pod by issuing a request to the Kubernetes API server:
/proxy/minions/<node_name>/portForward/<namespace>/<pod>
/proxy/minions/<node_name>/portForward/<namespace>/<pod>In the above URL:
-
<node_name>is the FQDN of the node. -
<namespace>is the namespace of the target pod. -
<pod>is the name of the target pod.
For example:
/proxy/minions/node123.openshift.com/portForward/myns/mypod
/proxy/minions/node123.openshift.com/portForward/myns/mypodAfter sending a port forward request to the API server, the client upgrades the connection to one that supports multiplexed streams; the current implementation uses SPDY.
The client creates a stream with the port header containing the target port in the pod. All data written to the stream is delivered via the Kubelet to the target pod and port. Similarly, all data sent from the pod for that forwarded connection is delivered back to the same stream in the client.
The client closes all streams, the upgraded connection, and the underlying connection when it is finished with the port forwarding request.
Administrators can see the Architecture guide for more information.
Chapter 20. Application Health
20.1. Overview
In software systems, components can become unhealthy due to transient issues (such as temporary connectivity loss), configuration errors, or problems with external dependencies. OpenShift applications have a number of options to detect and handle unhealthy containers.
20.2. Container Health Checks Using Probes
A probe is a Kuberbetes action that periodically performs diagnostics on a running container. Currently, two types of probes exist, each serving a different purpose:
| Liveness Probe |
A liveness probe checks if the container in which it is configured is still running. If the liveness probe fails, the kubelet kills the container, which will be subjected to its restart policy. Set a liveness check by configuring the |
| Readiness Probe |
A readiness probe determines if a container is ready to service requests. If the readiness probe fails a container, the endpoints controller ensures the container has its IP address removed from the endpoints of all services. A readiness probe can be used to signal to the endpoints controller that even though a container is running, it should not receive any traffic from a proxy. Set a readiness check by configuring the |
Both probes can be configured in three ways:
HTTP Checks
The kubelet uses a web hook to determine the healthiness of the container. The check is deemed successful if the HTTP response code is between 200 and 399. The following is an example of a readiness check using the HTTP checks method:
Example 20.1. Readiness HTTP check
A HTTP check is ideal for applications that return HTTP status codes when completely initialized.
Container Execution Checks
The kubelet executes a command inside the container. Exiting the check with status 0 is considered a success. The following is an example of a liveness check using the container execution method:
Example 20.2. Liveness Container Execution Check
TCP Socket Checks
The kubelet attempts to open a socket to the container. The container is only considered healthy if the check can establish a connection. The following is an example of a liveness check using the TCP socket check method:
Example 20.3. Liveness TCP Socket Check
A TCP socket check is ideal for applications that do not start listening until initialization is complete.
For more information on health checks, see the Kubernetes documentation.
Chapter 21. Events
21.1. Overview
OpenShift events are modeled based on events that happen to API objects in an OpenShift cluster. Events allow OpenShift to record information about real-world events in a resource-agnostic manner. They also allow developers and administrators to consume information about system components in a unified way.
21.2. Querying events with the CLI
This section will be expanded as more information becomes available
21.3. Viewing events in the console
This section will be expanded as more information becomes available
21.4. Out-of-band interface
OpenShift administrators can consume events directly via an out-of-band interface instead of querying the API server. This can be helpful, for example, if the API server cannot be contacted by a system component in order to record events.
This section will be expanded as more information becomes available
Chapter 22. Downward API
22.1. Overview
It is common for containers to consume information about API objects. The downward API is a mechanism that allows containers to do this without coupling to OpenShift. Containers can consume information from the downward API using environment variables or a volume plug-in.
22.2. Selecting Fields
Fields within the pod are selected using the FieldRef API type. FieldRef has two fields:
| Field | Description |
|---|---|
|
| The path of the field to select, relative to the pod. |
|
|
The API version to interpret the |
Currently, there are four valid selectors in the v1 API:
| Selector | Description |
|---|---|
|
| The pod’s name. |
|
| The pod’s namespace. |
|
| The pod’s labels. |
|
| The pod’s annotations. |
The apiVersion field, if not specified, defaults to the API version of the enclosing pod template.
In the future, more information, such as resource limits for pods and information about services, will be available using the downward API.
22.3. Using Environment Variables
One mechanism for consuming the downward API is using a container’s environment variables. The EnvVar type’s valueFrom field (of type EnvVarSource) is used to specify that the variable’s value should come from a FieldRef source instead of the literal value specified by the value field. In the future, additional sources may be supported; currently the source’s fieldRef field is used to select a field from the downward API.
Only constant attributes of the pod can be consumed this way, as environment variables cannot be updated once a process is started in a way that allows the process to be notified that the value of a variable has changed. The fields supported using environment variables are:
- Pod name
- Pod namespace
For example:
Create a
pod.jsonfile:Copy to Clipboard Copied! Toggle word wrap Toggle overflow Create the pod from the
pod.jsonfile:oc create -f pod.json
$ oc create -f pod.jsonCopy to Clipboard Copied! Toggle word wrap Toggle overflow Check the container’s logs:
oc logs -p dapi-env-test-pod
$ oc logs -p dapi-env-test-podCopy to Clipboard Copied! Toggle word wrap Toggle overflow You should see
MY_POD_NAMEandMY_POD_NAMESPACEin the logs.
22.4. Using the Volume Plug-in
Another mechanism for consuming the downward API is using a volume plug-in. The downward API volume plug-in creates a volume with configured fields projected into files. The metadata field of the VolumeSource API object is used to configure this volume. The plug-in supports the following fields:
- Pod name
- Pod namespace
- Pod annotations
- Pod labels
Example 22.1. Downward API Volume Plug-in Configuration
For example:
Create a
volume-pod.jsonfile:Copy to Clipboard Copied! Toggle word wrap Toggle overflow Create the pod from the
volume-pod.jsonfile:oc create -f volume-pod.json
$ oc create -f volume-pod.jsonCopy to Clipboard Copied! Toggle word wrap Toggle overflow Check the container’s logs and verify the presence of the configured fields:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
Chapter 23. Managing Environment Variables
23.1. Overview
You can set, unset or list environment variables in pods or pod templates using the oc env command.
23.2. CLI Interface
OpenShift provides the oc env command to set or unset environment variables for objects that have a pod template, such as replication controllers or deployment configurations. It can also list environment variables in pods or any object that has a pod template.
The oc env command uses the following general syntax:
oc env <object-selection> <environment-variables> [options]
$ oc env <object-selection> <environment-variables> [options]
There are several ways to express <object-selection>.
| Syntax | Description | Example |
|---|---|---|
|
| Selects <object-name> of type <object-type>. |
|
|
| Selects <object-name> of type <object-type>. |
|
|
| Selects objects of type <object-type> that match <object-label-selector>. |
|
|
| Selects all objects of type <object-type>. |
|
|
| Look in <ref> — a filename, directory name, or URL — for the definition of the object to edit. |
|
Supported common options for set, unset or list environment variables:
| Option | Description |
|---|---|
|
|
Select containers by |
|
|
Display the changed objects in |
|
|
Output the changed objects with |
|
|
Proceed only if |
23.3. Set Environment Variables
To set environment variables in the pod templates:
oc env <object-selection> KEY_1=VAL_1 ... KEY_N=VAL_N [<set-env-options>] [<common-options>]
$ oc env <object-selection> KEY_1=VAL_1 ... KEY_N=VAL_N [<set-env-options>] [<common-options>]Set environment options:
| Option | Description |
|---|---|
|
| Set given key value pairs of environment variables. |
|
| Confirm updating existing environment variables. |
In the following example, both commands modify environment variable STORAGE in the deployment config registry. The first adds, with value /data. The second updates, with value /opt.
oc env dc/registry STORAGE=/data oc env dc/registry --overwrite STORAGE=/opt
$ oc env dc/registry STORAGE=/data
$ oc env dc/registry --overwrite STORAGE=/opt
The following example finds environment variables in the current shell whose names begin with RAILS_ and adds them to the replication controller r1 on the server:
env | grep RAILS_ | oc env rc/r1 -e -
$ env | grep RAILS_ | oc env rc/r1 -e -
The following example does not modify the replication controller defined in file rc.json. Instead, it writes a YAML object with updated environment STORAGE=/local to new file rc.yaml.
oc env -f rc.json STORAGE=/opt -o yaml > rc.yaml
$ oc env -f rc.json STORAGE=/opt -o yaml > rc.yaml23.4. Unset Environment Variables
To unset environment variables in the pod templates:
oc env <object-selection> KEY_1- ... KEY_N- [<common-options>]
$ oc env <object-selection> KEY_1- ... KEY_N- [<common-options>]
The trailing hyphen (-, U+2D) is required.
This example removes environment variables ENV1 and ENV2 from deployment config d1:
oc env dc/d1 ENV1- ENV2-
$ oc env dc/d1 ENV1- ENV2-
This removes environment variable ENV from all replication controllers:
oc env rc --all ENV-
$ oc env rc --all ENV-
This removes environment variable ENV from container c1 for replication controller r1:
oc env rc r1 --containers='c1' ENV-
$ oc env rc r1 --containers='c1' ENV-23.5. List Environment Variables
To list environment variables in pods or pod templates:
oc env <object-selection> --list [<common-options>]
$ oc env <object-selection> --list [<common-options>]
This example lists all environment variables for pod p1:
oc env pod/p1 --list
$ oc env pod/p1 --listChapter 24. Revision History: Developer Guide
24.1. Wed May 25 2016
| Affected Topic | Description of Change |
|---|---|
|
Fixed |
24.2. Thu May 19 2016
| Affected Topic | Description of Change |
|---|---|
| Updated the examples in the Defining a BuildConfig, Source Code, and Using a Proxy for Git Cloning sections to use https for GitHub access. |
24.3. Tue Apr 19 2016
| Affected Topic | Description of Change |
|---|---|
| Added a pointer to the browser requirements from the Web Console Authentication section. |
24.4. Thu Mar 17 2016
| Affected Topic | Description of Change |
|---|---|
|
In the No Cache subsection of the Docker Strategy Options section, spelled |
24.5. Mon Feb 15 2016
| Affected Topic | Description of Change |
|---|---|
| Corrected port numbers across the page and converted examples to YAML. |
24.6. Tue Jun 23 2015
OpenShift Enterprise 3.0 release.
Legal Notice
Copyright © Red Hat
OpenShift documentation is licensed under the Apache License 2.0 (https://www.apache.org/licenses/LICENSE-2.0).
Modified versions must remove all Red Hat trademarks.
Portions adapted from https://github.com/kubernetes-incubator/service-catalog/ with modifications by Red Hat.
Red Hat, Red Hat Enterprise Linux, the Red Hat logo, the Shadowman logo, JBoss, OpenShift, Fedora, the Infinity logo, and RHCE are trademarks of Red Hat, Inc., registered in the United States and other countries.
Linux® is the registered trademark of Linus Torvalds in the United States and other countries.
Java® is a registered trademark of Oracle and/or its affiliates.
XFS® is a trademark of Silicon Graphics International Corp. or its subsidiaries in the United States and/or other countries.
MySQL® is a registered trademark of MySQL AB in the United States, the European Union and other countries.
Node.js® is an official trademark of the OpenJS Foundation.
The OpenStack® Word Mark and OpenStack logo are either registered trademarks/service marks or trademarks/service marks of the OpenStack Foundation, in the United States and other countries and are used with the OpenStack Foundation’s permission. We are not affiliated with, endorsed or sponsored by the OpenStack Foundation, or the OpenStack community.
All other trademarks are the property of their respective owners.