Architecture
An overview of the architecture for OpenShift Container Platform 4.1
Abstract
Chapter 1. OpenShift Container Platform architecture
1.1. Introduction to OpenShift Container Platform
OpenShift Container Platform is a platform for developing and running containerized applications. It is designed to allow applications and the data centers that support them to expand from just a few machines and applications to thousands of machines that serve millions of clients.
With its foundation in Kubernetes, OpenShift Container Platform incorporates the same technology that serves as the engine for massive telecommunications, streaming video, gaming, banking and other applications. Its implementation in open Red Hat technologies lets you extend your containerized applications beyond a single cloud to on-premise and multi-cloud environments.
1.1.1. About Kubernetes
Although container images and the containers that run from them are the primary building blocks for modern application development, to run them at scale requires a reliable and flexible distribution system. Kubernetes is the defacto standard for orchestrating containers.
Kubernetes is an open source container orchestration engine for automating deployment, scaling, and management of containerized applications. The general concept of Kubernetes is fairly simple:
- Start with one or more worker nodes to run the container workloads.
- Manage the deployment of those workloads from one or more master nodes.
- Wrap containers in a deployment unit called a Pod. Using Pods provides extra metadata with the container and offers the ability to group several containers in a single deployment entity.
- Create special kinds of assets. For example, services are represented by a set of Pods and a policy that defines how they are accessed. This policy allows containers to connect to the services that they need even if they do not have the specific IP addresses for the services. Replication controllers are another special asset that indicates how many Pod Replicas are required to run at a time. You can use this capability to automatically scale your application to adapt to its current demand.
In only a few years, Kubernetes has seen massive cloud and on-premise adoption. The open source development model allows many people to extend Kubernetes by implementing different technologies for components such as networking, storage, and authentication.
1.1.2. The benefits of containerized applications
Using containerized applications offers many advantages over using traditional deployment methods. Where applications were once expected to be installed on operating systems that included all their dependencies, containers let an application carry their dependencies with them. Creating containerized applications offers many benefits.
1.1.2.1. Operating system benefits
Containers use small, dedicated Linux operating systems without a kernel. Their file system, networking, cgroups, process tables, and namespaces are separate from the host Linux system, but the containers can integrate with the hosts seamlessly when necessary. Being based on Linux allows containers to use all the advantages that come with the open source development model of rapid innovation.
Because each container uses a dedicated operating system, you can deploy applications that require conflicting software dependencies on the same host. Each container carries its own dependent software and manages its own interfaces, such as networking and file systems, so applications never need to compete for those assets.
1.1.2.2. Deployment and scaling benefits
If you employ rolling upgrades between major releases of your application, you can continuously improve your applications without downtime and still maintain compatibility with the current release.
You can also deploy and test a new version of an application alongside the existing version. Deploy the new application version in addition to the current version. If the container passes your tests, simply deploy more new containers and remove the old ones.
Since all the software dependencies for an application are resolved within the container itself, you can use a generic operating system on each host in your data center. You do not need to configure a specific operating system for each application host. When your data center needs more capacity, you can deploy another generic host system.
Similarly, scaling containerized applications is simple. OpenShift Container Platform offers a simple, standard way of scaling any containerized service. For example, if you build applications as a set of microservices rather than large, monolithic applications, you can scale the individual microservices individually to meet demand. This capability allows you to scale only the required services instead of the entire application, which can allow you to meet application demands while using minimal resources.
1.1.3. OpenShift Container Platform overview
OpenShift Container Platform provides enterprise-ready enhancements to Kubernetes, including the following enhancements:
- Hybrid cloud deployments. You can deploy OpenShift Container Platform clusters to variety of public cloud platforms or in your data center.
- Integrated Red Hat technology. Major components in OpenShift Container Platform come from Red Hat Enterprise Linux and related Red Hat technologies. OpenShift Container Platform benefits from the intense testing and certification initiatives for Red Hat’s enterprise quality software.
- Open source development model. Development is completed in the open, and the source code is available from public software repositories. The open collaboration fosters rapid innovation and development.
Although Kubernetes excels at managing your applications, it does not specify or manage platform-level requirements or deployment processes. Powerful and flexible platform management tools and processes are important benefits that OpenShift Container Platform 4.1 offers. The following sections describe some unique features and benefits of OpenShift Container Platform.
1.1.3.1. Custom operating system
OpenShift Container Platform uses Red Hat Enterprise Linux CoreOS (RHCOS), a new container-oriented operating system that combines some of the best features and functions of the CoreOS and Red Hat Atomic Host operating systems. RHCOS is specifically designed for running containerized applications from OpenShift Container Platform and works with new tools to provide fast installation, Operator-based management, and simplified upgrades.
RHCOS includes:
- Ignition, which is a firstboot system configuration for initially bringing up and configuring OpenShift Container Platform nodes.
- cri-o, a Kubernetes native container runtime implementation that integrates closely with the operating system to deliver an efficient and optimized Kubernetes experience.
- Kubelet, the primary node agent for Kubernetes that is responsible for launching and monitoring containers.
In OpenShift Container Platform 4.1, you must use RHCOS for all control plane machines, but you can use Red Hat Enterprise Linux (RHEL) as the operating system for compute machines, which are also known as worker machines. If you choose to use RHEL workers, you must perform more system maintenance than if you use RHCOS for all of the cluster machines.
1.1.3.2. Simplified installation and update process
With OpenShift Container Platform 4.1, if you have an account with the right permissions, you can deploy a production cluster in supported clouds by running a single command and providing a few values. You can also customize your cloud installation or install your cluster in your data center if you use a supported platform.
For clusters that use RHCOS for all machines, updating, or upgrading, OpenShift Container Platform is a simple, highly-automated process. Because OpenShift Container Platform completely controls the systems and services that run on each machine, including the operating system itself, from a central control plane, upgrades are designed to become automatic events. If your cluster contains RHEL worker machines, the control plane benefits from the streamlined update process, but you must perform more tasks to upgrade the RHEL machines.
1.1.3.3. Other key features
Operators are both the fundamental unit of the OpenShift Container Platform 4.1 code base and a convenient way to deploy applications and software components for your applications to use. By using Operators as the platform foundation, OpenShift Container Platform replace manual upgrades of operating systems and control plane applications. OpenShift Container Platform Operators such as the Cluster Version Operator and Machine Config Operator allow simplified, cluster-wide management of those critical components.
Operator Lifecycle Manager (OLM) and the OperatorHub provide facilities for storing and distributing Operators to people developing and deploying applications.
CRI-O Container Engine is the streamlined container engine that is is developed in tandem with Kubernetes releases and provides facilities for running, stopping, and restarting containers. It fully replaces the Docker Container Engine in OpenShift Container Platform 4.1.
The Red Hat Quay Container Registry is a Quay.io container registry that serves most of the container images and Operators to OpenShift Container Platform clusters. Quay.io is a public registry version of Red Hat Quay that stores millions of images and tags.
Other enhancements to Kubernetes in OpenShift Container Platform include improvements in software defined networking (SDN), authentication, log aggregation, monitoring, and routing. OpenShift Container Platform also offers a comprehensive web console and the custom OpenShift CLI (oc) interface.
1.1.3.4. OpenShift Container Platform lifecycle
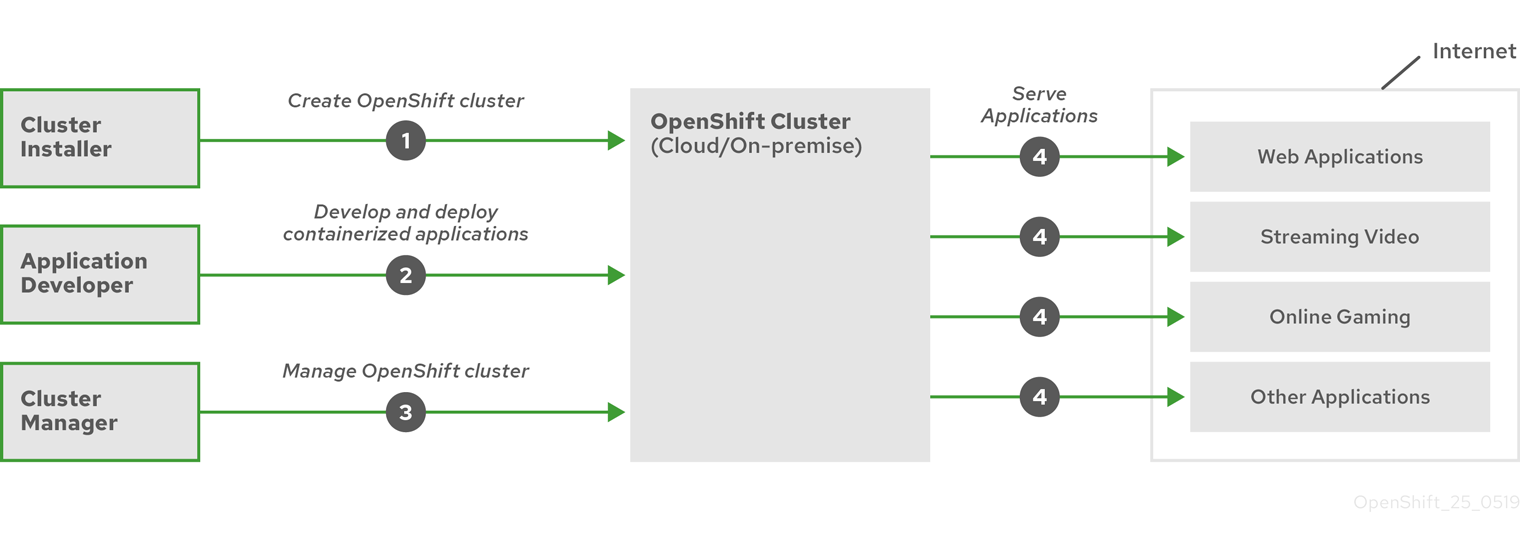
The following figure illustrates the basic OpenShift Container Platform lifecycle:
- Creating an OpenShift Container Platform cluster
- Managing the cluster
- Developing and deploying applications
- Scaling up applications
Figure 1.1. High level OpenShift Container Platform overview
1.1.3.5. OpenShift Container Platform 3 and 4
With OpenShift Container Platform 4.1, the core story remains unchanged: OpenShift Container Platform offers your developers a set of tools to evolve their applications under operational oversight and using Kubernetes to provide application infrastructure. The key change to OpenShift Container Platform 4.1 is that the infrastructure and its management are flexible, automated, and self-managing.
A major difference between OpenShift Container Platform 3 and OpenShift Container Platform 4.1 is that OpenShift Container Platform 4.1 uses Operators as both the fundamental unit of the product and an option for easily deploying and managing utilities that your apps use.
1.1.4. Internet and Telemetry access for OpenShift Container Platform
In OpenShift Container Platform 4.1, Telemetry is the component that provides metrics about cluster health and the success of updates. To perform subscription management, including legally entitling your purchase from Red Hat, you must use the Telemetry service and access the Red Hat OpenShift Cluster Manager page.
Because there is no disconnected subscription management, you cannot both opt out of sending data back to Red Hat and entitle your purchase. Support for disconnected subscription management might be added in future releases of OpenShift Container Platform
Your machines must have direct internet access to install the cluster.
You must have internet access to:
- Access the Infrastructure Provider page on the Red Hat OpenShift Cluster Manager site to download the installation program
- Access Quay.io to obtain the packages that are required to install your cluster
- Obtain the packages that are required to perform cluster updates
- Access Red Hat’s software as a service page to perform subscription management
Chapter 2. Installation and update
2.1. OpenShift Container Platform installation overview
The OpenShift Container Platform installation program offers you flexibility. You can use the installation program to deploy a cluster on infrastructure that the installation program provisions and the cluster maintains or deploy a cluster on infrastructure that you prepare and maintain.
OpenShift Container Platform requires all machines, including the computer that you run the installation process on, to have direct internet access to pull images for platform containers and provide telemetry data to Red Hat.
You cannot specify a proxy server for OpenShift Container Platform.
These two basic types of OpenShift Container Platform clusters are frequently called installer-provisioned infrastructure clusters and user-provisioned infrastructure clusters.
Both types of clusters have the following characteristics:
- Highly available infrastructure with no single points of failure is available by default
- Administrators maintain control over what updates are applied and when
You use the same installation program to deploy both types of clusters. The main assets generated by the installation program are the Ignition config files for the bootstrap, master, and worker machines. With these three configurations and correctly configured infrastructure, you can start an OpenShift Container Platform cluster.
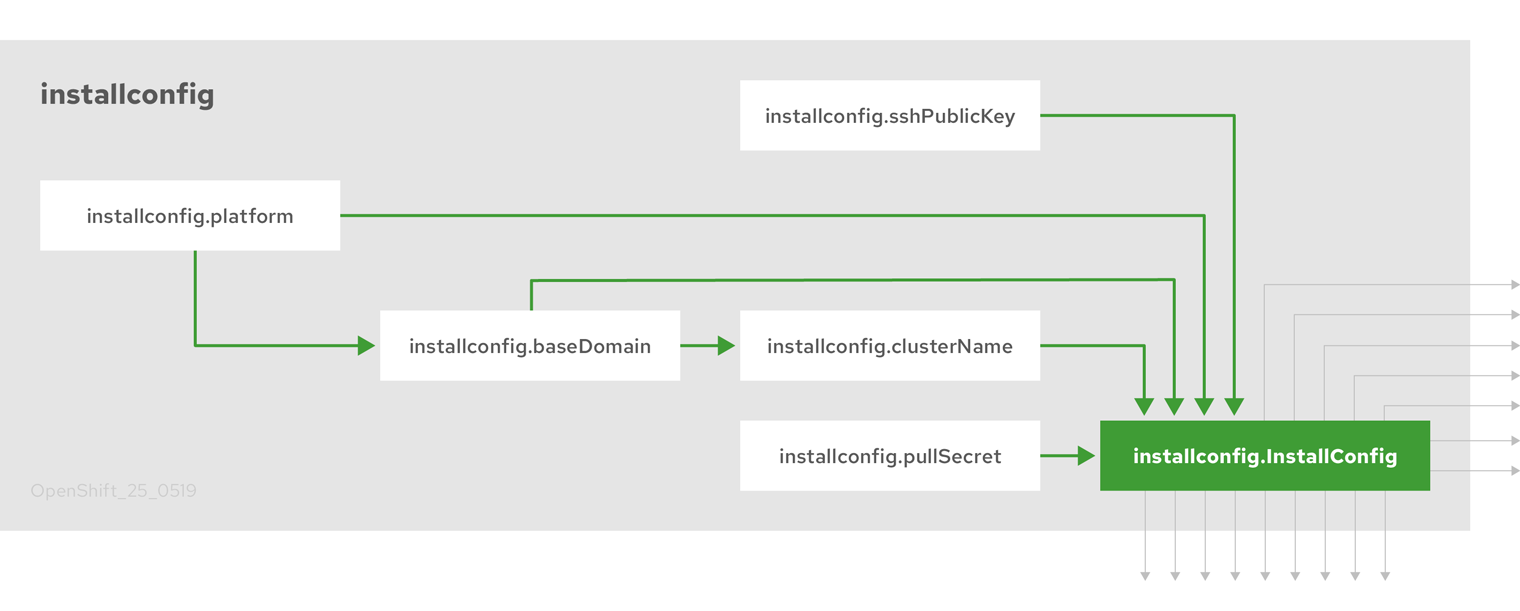
The OpenShift Container Platform installation program uses a set of targets and dependencies to manage cluster installation. The installation program has a set of targets that it must achieve, and each target has a set of dependencies. Because each target is only concerned with its own dependencies, the installation program can act to achieve multiple targets in parallel. The ultimate target is a running cluster. By meeting dependencies instead of running commands, the installation program is able to recognize and use existing components instead of running the commands to create them again.
The following diagram shows a subset of the installation targets and dependencies:
Figure 2.1. OpenShift Container Platform installation targets and dependencies
After installation, each cluster machine uses Red Hat Enterprise Linux CoreOS (RHCOS) as the operating system. RHCOS is the immutable container host version of Red Hat Enterprise Linux (RHEL) and features a RHEL kernel with SELinux enabled by default. It includes the kubelet, which is the Kubernetes node agent, and the CRI-O container runtime, which is optimized for Kubernetes.
Every control plane machine in an OpenShift Container Platform 4.1 cluster must use RHCOS, which includes a critical first-boot provisioning tool called Ignition. This tool enables the cluster to configure the machines. Operating system updates are delivered as an Atomic OSTree repository that is embedded in a container image that is rolled out across the cluster by an Operator. Actual operating system changes are made in-place on each machine as an atomic operation by using rpm-ostree. Together, these technologies enable OpenShift Container Platform to manage the operating system like it manages any other application on the cluster, via in-place upgrades that keep the entire platform up-to-date. These in-place updates can reduce the burden on operations teams.
If you use RHCOS as the operating system for all cluster machines, the cluster manages all aspects of its components and machines, including the operating system. Because of this, only the installation program and the Machine Config Operator can change machines. The installation program uses Ignition config files to set the exact state of each machine, and the Machine Config Operator completes more changes to the machines, such as the application of new certificates or keys, after installation.
2.1.1. Available platforms
In OpenShift Container Platform 4.1, you can install a cluster that uses installer-provisioned infrastructure on only Amazon Web Services (AWS).
In OpenShift Container Platform 4.1, you can install a cluster that uses user-provisioned infrastructure on the following platforms:
- AWS
- VMware vSphere
- Bare metal
The OpenShift Container Platform 4.x Tested Integrations page contains details about integration testing for different platforms.
2.1.2. Installation process
When you install an OpenShift Container Platform cluster, you download the installation program from the appropriate Infrastructure Provider page on the Red Hat OpenShift Cluster Manager site. This site manages:
- REST API for accounts
- Registry tokens, which are the pull secrets that you use to obtain the required components
- Cluster registration, which associates the cluster identity to your Red Hat account to facilitate the gathering of usage metrics
In OpenShift Container Platform 4.1, the installation program is a Go binary file that performs a series of file transformations on a set of assets. The way you interact with the installation program differs depending on your installation type.
- For clusters with installer-provisioned infrastructure, you delegate the infrastructure bootstrapping and provisioning to the installation program instead of doing it yourself. The installation program creates all of the networking, machines, and operating systems that are required to support the cluster.
- If you provision and manage the infrastructure for your cluster, you must provide all of the cluster infrastructure and resources, including the bootstrap machine, networking, load balancing, storage, and individual cluster machines. You cannot use the advanced machine management and scaling capabilities that an installer-provisioned infrastructure cluster offers.
You use three sets of files during installation: an installation configuration file that is named install-config.yaml, Kubernetes manifests, and Ignition config files for your machine types.
It is possible to modify Kubernetes and the Ignition config files that control the underlying RHCOS operating system during installation. However, no validation is available to confirm the suitability of any modifications that you make to these objects. If you modify these objects, you might render your cluster non-functional. Because of this risk, modifying Kubernetes and Ignition config files is not supported unless you are following documented procedures or are instructed to do so by Red Hat support.
The installation configuration file is transformed into Kubernetes manifests, and then the manifests are wrapped into Ignition config files. The installation program uses these Ignition config files to create the cluster.
The installation configuration files are all pruned when you run the installation program, so be sure to back up all configuration files that you want to use again.
You cannot modify the parameters that you set during installation, but you can modify many cluster attributes after installation.
The installation process with installer-provisioned infrastructure
In version 4.1, you can install an OpenShift Container Platform cluster that uses installer-provisioned infrastructure on only Amazon Web Services (AWS).
The default installation type uses installer-provisioned infrastructure on AWS. By default, the installation program acts as an installation wizard, prompting you for values that it cannot determine on its own and providing reasonable default values for the remaining parameters. You can also customize the installation process to support advanced infrastructure scenarios. The installation program provisions the underlying infrastructure for the cluster.
You can install either a standard cluster or a customized cluster. With a standard cluster, you provide minimum details that are required to install the cluster. With a customized cluster, you can specify more details about the platform, such as the number of machines that the control plane uses, the type of virtual machine that the cluster deploys, or the CIDR range for the Kubernetes service network.
If possible, use this feature to avoid having to provision and maintain the cluster infrastructure. In all other environments, you use the installation program to generate the assets that you require to provision your cluster infrastructure.
With installer-provisioned infrastructure clusters, OpenShift Container Platform manages all aspects of the cluster, including the operating system itself. Each machine boots with a configuration that references resources hosted in the cluster that it joins. This configuration allows the cluster to manage itself as updates are applied.
The installation process with user-provisioned infrastructure
You can also install OpenShift Container Platform on infrastructure that you provide. You use the installation program to generate the assets that you require to provision the cluster infrastructure, create the cluster infrastructure, and then deploy the cluster to the infrastructure that you provided.
If you do not use infrastructure that the installation program provisioned, you must manage and maintain the cluster resources yourself, including:
- The control plane and compute machines that make up the cluster
- Load balancers
- Cluster networking, including the DNS records and required subnets
- Storage for the cluster infrastructure and applications
If your cluster uses user-provisioned infrastructure, you have the option of adding RHEL worker machines to your cluster.
Installation process details
Because each machine in the cluster requires information about the cluster when it is provisioned, OpenShift Container Platform uses a temporary bootstrap machine during initial configuration to provide the required information to the permanent control plane. It boots by using an Ignition config file that describes how to create the cluster. The bootstrap machine creates the master machines that make up the control plane. The control plane machines then create the compute machines, which are also known as worker machines. The following figure illustrates this process:
Figure 2.2. Creating the bootstrap, master, and worker machines
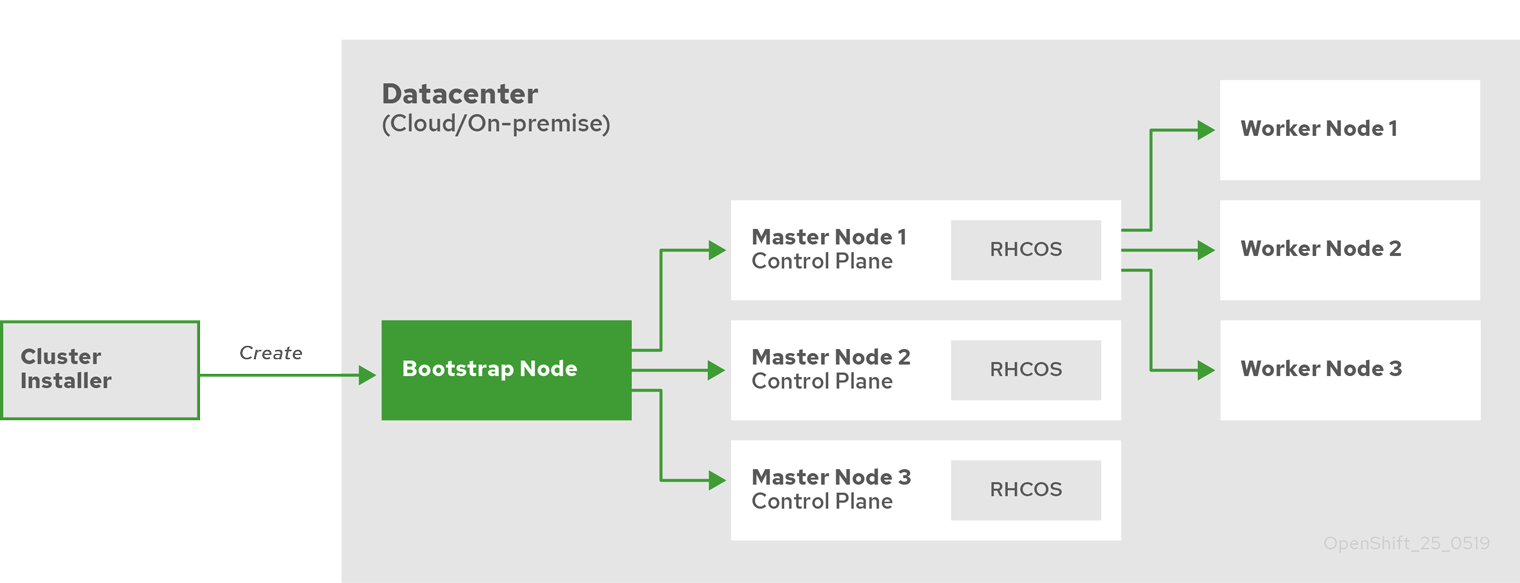
After the cluster machines initialize, the bootstrap machine is destroyed. All clusters use the bootstrap process to initialize the cluster, but if you provision the infrastructure for your cluster, you must complete many of the steps manually.
The Ignition config files that the installation program generates contain certificates that expire after 24 hours. You must complete your cluster installation and keep the cluster running for 24 hours in a non-degraded state to ensure that the first certificate rotation has finished.
Bootstrapping a cluster involves the following steps:
- The bootstrap machine boots and starts hosting the remote resources required for the master machines to boot. (Requires manual intervention if you provision the infrastructure)
- The master machines fetch the remote resources from the bootstrap machine and finish booting. (Requires manual intervention if you provision the infrastructure)
- The master machines use the bootstrap machine to form an etcd cluster.
- The bootstrap machine starts a temporary Kubernetes control plane using the new etcd cluster.
- The temporary control plane schedules the production control plane to the master machines.
- The temporary control plane shuts down and passes control to the production control plane.
- The bootstrap machine injects OpenShift Container Platform components into the production control plane.
- The installation program shuts down the bootstrap machine. (Requires manual intervention if you provision the infrastructure)
- The control plane sets up the worker nodes.
- The control plane installs additional services in the form of a set of Operators.
The result of this bootstrapping process is a fully running OpenShift Container Platform cluster. The cluster then downloads and configures remaining components needed for the day-to-day operation, including the creation of worker machines in supported environments.
Installation process details
Installation scope
The scope of the OpenShift Container Platform installation program is intentionally narrow. It is designed for simplicity and ensured success. You can complete many more configuration tasks after installation completes.
2.2. About the OpenShift Container Platform update service
The OpenShift Container Platform update service is the hosted service that provides over-the-air updates to both OpenShift Container Platform and Red Hat Enterprise Linux CoreOS (RHCOS). It provides a graph, or diagram that contain vertices and the edges that connect them, of component Operators. The edges in the graph show which versions you can safely update to, and the vertices are update payloads that specify the intended state of the managed cluster components.
The Cluster Version Operator (CVO) in your cluster checks with the OpenShift Container Platform update service to see the valid updates and update paths based on current component versions and information in the graph. When you request an update, the OpenShift Container Platform CVO uses the release image for that update to upgrade your cluster. The release artifacts are hosted in Quay as container images.
To allow the OpenShift Container Platform update service to provide only compatible updates, a release verification pipeline exists to drive automation. Each release artifact is verified for compatibility with supported cloud platforms and system architectures as well as other component packages. After the pipeline confirms the suitability of a release, the OpenShift Container Platform update service notifies you that it is available.
During continuous update mode, two controllers run. One continuously updates the payload manifests, applies them to the cluster, and outputs the status of the controlled rollout of the Operators, whether they are available, upgrading, or failed. The second controller polls the OpenShift Container Platform update service to determine if updates are available.
Reverting your cluster to a previous version, or a rollback, is not supported. Only upgrading to a newer version is supported.
Chapter 3. The OpenShift Container Platform control plane
3.1. Understanding the OpenShift Container Platform control plane
The control plane, which is composed of master machines, manages the OpenShift Container Platform cluster. The control plane machines manage workloads on the compute machines, which are also known as worker machines. The cluster itself manages all upgrades to the machines by the actions of the Cluster Version Operator, the Machine Config Operator, and set of individual Operators.
3.1.1. Machine roles in OpenShift Container Platform
OpenShift Container Platform assigns hosts different roles. These roles define the function of the machine within the cluster. The cluster contains definitions for the standard master and worker role types.
The cluster also contains the definition for the bootstrap role. Because the bootstrap machine is used only during cluster installation, its function is explained in the cluster installation documentation.
3.1.1.1. Cluster workers
In a Kubernetes cluster, the worker nodes are where the actual workloads requested by Kubernetes users run and are managed. The worker nodes advertise their capacity and the scheduler, which is part of the master services, determines on which nodes to start containers and Pods. Important services run on each worker node, including CRI-O, which is the container engine, Kubelet, which is the service that accepts and fulfills requests for running and stopping container workloads, and a service proxy, which manages communication for pods across workers.
In OpenShift Container Platform, MachineSets control the worker machines. Machines with the worker role drive compute workloads that are governed by a specific machine pool that autoscales them. Because OpenShift Container Platform has the capacity to support multiple machine types, the worker machines are classed as compute machines. In this release, the terms "worker machine" and "compute machine" are used interchangeably because the only default type of compute machine is the worker machine. In future versions of OpenShift Container Platform, different types of compute machines, such as infrastructure machines, might be used by default.
3.1.1.2. Cluster masters
In a Kubernetes cluster, the master nodes run services that are required to control the Kubernetes cluster. In OpenShift Container Platform, the master machines are the control plane. They contain more than just the Kubernetes services for managing the OpenShift Container Platform cluster. Because all of the machines with the control plane role are master machines, the terms master and control plane are used interchangeably to describe them. Instead of being grouped into a MachineSet, master machines are defined by a series of standalone machine API resources. Extra controls apply to master machines to prevent you from deleting all master machines and breaking your cluster.
Use three master nodes. Although you can theoretically use any number of master nodes, the number is constrained by etcd quorum due to master static Pods and etcd static Pods working on the same hosts.
Services that fall under the Kubernetes category on the master include the API server, etcd, controller manager server, and HAProxy services.
| Component | Description |
|---|---|
| API Server | The Kubernetes API server validates and configures the data for Pods, Services, and replication controllers. It also provides a focal point for cluster’s shared state. |
| etcd | etcd stores the persistent master state while other components watch etcd for changes to bring themselves into the specified state. |
| Controller Manager Server | The Controller Manager Server watches etcd for changes to objects such as replication, namespace, and serviceaccount controller objects, and then uses the API to enforce the specified state. Several such processes create a cluster with one active leader at a time. |
Some of these services on the master machines run as systemd services, while others run as static Pods.
Systemd services are appropriate for services that you need to always come up on that particular system shortly after it starts. For master machines, those include sshd, which allows remote login. It also includes services such as:
- The CRI-O container engine (crio), which runs and manages the containers. OpenShift Container Platform 4.1 uses CRI-O instead of the Docker Container Engine.
- Kubelet (kubelet), which accepts requests for managing containers on the machine from master services.
CRI-O and Kubelet must run directly on the host as systemd services because they need to be running before you can run other containers.
3.1.2. Operators in OpenShift Container Platform
In OpenShift Container Platform, Operators are the preferred method of packaging, deploying, and managing services on the control plane. They also provide advantages to applications that users run. Operators integrate with Kubernetes APIs and CLI tools such as kubectl and oc commands. They provide the means of watching over an application, performing health checks, managing over-the-air updates, and ensuring that the applications remain in your specified state.
Because CRI-O and the Kubelet run on every node, almost every other cluster function can be managed on the control plane by using Operators. Operators are among the most important components of OpenShift Container Platform 4.1. Components that are added to the control plane by using Operators include critical networking and credential services.
The Operator that manages the other Operators in an OpenShift Container Platform cluster is the Cluster Version Operator.
OpenShift Container Platform 4.1 uses different classes of Operators to perform cluster operations and run services on the cluster for your applications to use.
3.1.2.1. Platform Operators in OpenShift Container Platform
In OpenShift Container Platform 4.1, all cluster functions are divided into a series of platform Operators. Platform Operators manage a particular area of cluster functionality, such as cluster-wide application logging, management of the Kubernetes control plane, or the machine provisioning system.
Each Operator provides you with a simple API for determining cluster functionality. The Operator hides the details of managing the lifecycle of that component. Operators can manage a single component or tens of components, but the end goal is always to reduce operational burden by automating common actions. Operators also offer a more granular configuration experience. You configure each component by modifying the API that the Operator exposes instead of modifying a global configuration file.
3.1.2.2. Operators managed by OLM
The Cluster Operator Lifecycle Management (OLM) component manages Operators that are available for use in applications. It does not manage the Operators that comprise OpenShift Container Platform. OLM is a framework that manages Kubernetes-native applications as Operators. Instead of managing Kubernetes manifests, it manages Kubernetes Operators. OLM manages two classes of Operators, Red Hat Operators and certified Operators.
Some Red Hat Operators drive the cluster functions, like the scheduler and problem detectors. Others are provided for you to manage yourself and use in your applications, like etcd. OpenShift Container Platform also offers certified Operators, which the community built and maintains. These certified Operators provide an API layer to traditional applications so you can manage the application through Kubernetes constructs.
3.1.2.3. About the OpenShift Container Platform update service
The OpenShift Container Platform update service is the hosted service that provides over-the-air updates to both OpenShift Container Platform and Red Hat Enterprise Linux CoreOS (RHCOS). It provides a graph, or diagram that contain vertices and the edges that connect them, of component Operators. The edges in the graph show which versions you can safely update to, and the vertices are update payloads that specify the intended state of the managed cluster components.
The Cluster Version Operator (CVO) in your cluster checks with the OpenShift Container Platform update service to see the valid updates and update paths based on current component versions and information in the graph. When you request an update, the OpenShift Container Platform CVO uses the release image for that update to upgrade your cluster. The release artifacts are hosted in Quay as container images.
To allow the OpenShift Container Platform update service to provide only compatible updates, a release verification pipeline exists to drive automation. Each release artifact is verified for compatibility with supported cloud platforms and system architectures as well as other component packages. After the pipeline confirms the suitability of a release, the OpenShift Container Platform update service notifies you that it is available.
During continuous update mode, two controllers run. One continuously updates the payload manifests, applies them to the cluster, and outputs the status of the controlled rollout of the Operators, whether they are available, upgrading, or failed. The second controller polls the OpenShift Container Platform update service to determine if updates are available.
Reverting your cluster to a previous version, or a rollback, is not supported. Only upgrading to a newer version is supported.
3.1.2.4. Understanding the Machine Config Operator
OpenShift Container Platform 4.1 integrates both operating system and cluster management. Because the cluster manages its own updates, including updates to Red Hat Enterprise Linux CoreOS (RHCOS) on cluster nodes, OpenShift Container Platform provides an opinionated lifecycle management experience that simplifies the orchestration of node upgrades.
OpenShift Container Platform employs three DaemonSets and controllers to simplify node management. These DaemonSets orchestrate operating system updates and configuration changes to the hosts by using standard Kubernetes-style constructs. They include:
-
The
machine-config-controller, which coordinates machine upgrades from the control plane. It monitors all of the cluster nodes and orchestrates their configuration updates. -
The
machine-config-daemonDaemonSet, which runs on each node in the cluster and updates a machine to configuration defined by MachineConfig as instructed by the MachineConfigController. When the node sees a change, it drains off its pods, applies the update, and reboots. These changes come in the form of Ignition configuration files that apply the specified machine configuration and control kubelet configuration. The update itself is delivered in a container. This process is key to the success of managing OpenShift Container Platform and RHCOS updates together. -
The
machine-config-serverDaemonSet, which provides the Ignition config files to master nodes as they join the cluster.
The machine configuration is a subset of the Ignition configuration. The machine-config-daemon reads the machine configuration to see if it needs to do an OSTree update or if it must apply a series of systemd kubelet file changes, configuration changes, or other changes to the operating system or OpenShift Container Platform configuration.
When you perform node management operations, you create or modify a KubeletConfig Custom Resource (CR).
Chapter 4. Understanding OpenShift Container Platform development
To fully leverage the capability of containers when developing and running enterprise-quality applications, ensure your environment is supported by tools that allow containers to be:
- Created as discrete microservices that can be connected to other containerized, and non-containerized, services. For example, you might want to join your application with a database or attach a monitoring application to it.
- Resilient, so if a server crashes or needs to go down for maintenance or to be decommissioned, containers can start on another machine.
- Automated to pick up code changes automatically and then start and deploy new versions of themselves.
- Scaled up, or replicated, to have more instances serving clients as demand increases and then spun down to fewer instances as demand declines.
- Run in different ways, depending on the type of application. For example, one application might run once a month to produce a report and then exit. Another application might need to run constantly and be highly available to clients.
- Managed so you can watch the state of your application and react when something goes wrong.
Containers’ widespread acceptance, and the resulting requirements for tools and methods to make them enterprise-ready, resulted in many options for them.
The rest of this section explains options for assets you can create when you build and deploy containerized Kubernetes applications in OpenShift Container Platform. It also describes which approaches you might use for different kinds of applications and development requirements.
4.1. About developing containerized applications
You can approach application development with containers in many ways, and different approaches might be more appropriate for different situations. To illustrate some of this variety, the series of approaches that is presented starts with developing a single container and ultimately deploys that container as a mission-critical application for a large enterprise. These approaches show different tools, formats, and methods that you can employ with containerized application development. This topic describes:
- Building a simple container and storing it in a registry
- Creating a Kubernetes manifest and saving it to a Git repository
- Making an Operator to share your application with others
4.2. Building a simple container
You have an idea for an application and you want to containerize it.
First you require a tool for building a container, like buildah or docker, and a file that describes what goes in your container, which is typically a Dockerfile.
Next, you require a location to push the resulting container image so you can pull it to run anywhere you want it to run. This location is a container registry.
Some examples of each of these components are installed by default on most Linux operating systems, except for the Dockerfile, which you provide yourself.
The following diagram displays the process of building and pushing an image:
Figure 4.1. Create a simple containerized application and push it to a registry
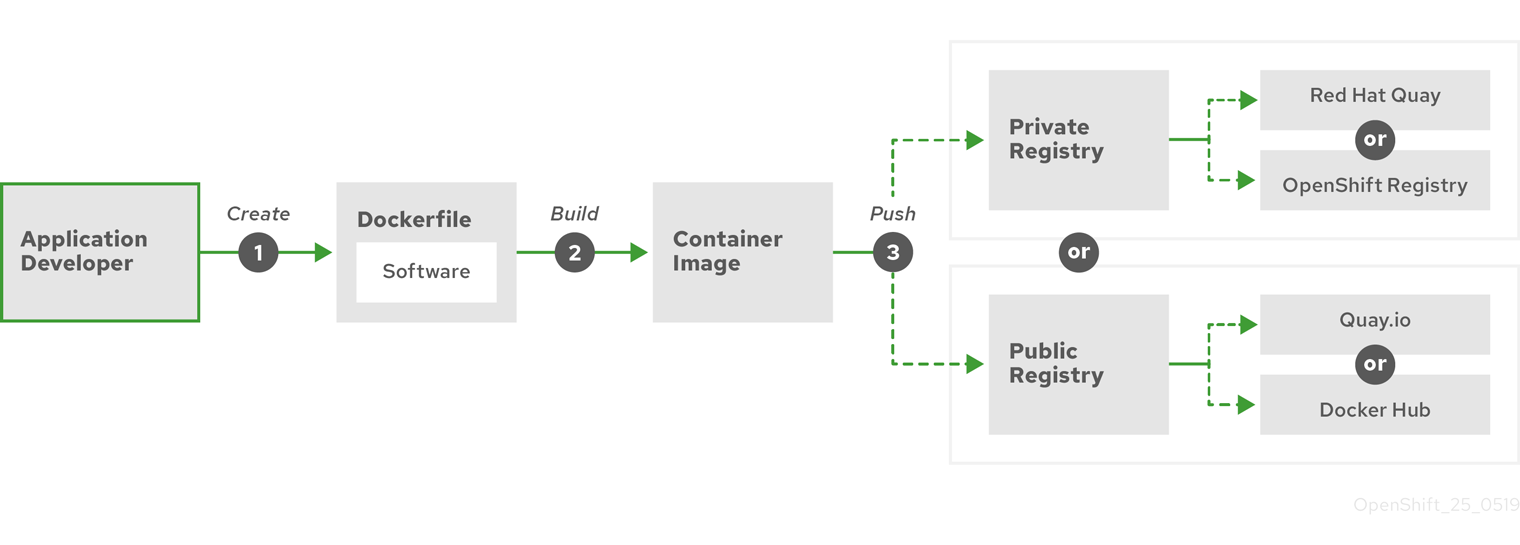
If you use a computer that runs Red Hat Enterprise Linux (RHEL) as the operating system, the process of creating a containerized application requires the following steps:
- Install container build tools: RHEL contains a set of tools that includes podman, buildah, and skopeo that you use to build and manage containers.
-
Create a Dockerfile to combine base image and software: Information about building your container goes into a file that is named
Dockerfile. In that file, you identify the base image you build from, the software packages you install, and the software you copy into the container. You also identify parameter values like network ports that you expose outside the container and volumes that you mount inside the container. Put your Dockerfile and the software you want to containerized in a directory on your RHEL system. -
Run buildah or docker build: Run the
buildah build-using-dockerfileor thedocker buildcommand to pull you chosen base image to the local system and creates a container image that is stored locally. You can also build container without a Dockerfile by using buildah. -
Tag and push to a registry: Add a tag to your new container image that identifies the location of the registry in which you want to store and share your container. Then push that image to the registry by running the
podman pushordocker pushcommand. -
Pull and run the image: From any system that has a container client tool, such as podman or docker, run a command that identifies your new image. For example, run the
podman run <image_name>ordocker run <image_name>command. Here<image_name>is the name of your new container image, which resemblesquay.io/myrepo/myapp:latest. The registry might require credentials to push and pull images.
For more details on the process of building container images, pushing them to registries, and running them, see Custom image builds with Buildah.
4.2.1. Container build tool options
While the Docker Container Engine and docker command are popular tools to work with containers, with RHEL and many other Linux systems, you can instead choose a different set of container tools that includes podman, skopeo, and buildah. You can still use Docker Container Engine tools to create containers that will run in OpenShift Container Platform and any other container platform.
Building and managing containers with buildah, podman, and skopeo results in industry standard container images that include features tuned specifically for ultimately deploying those containers in OpenShift Container Platform or other Kubernetes environments. These tools are daemonless and can be run without root privileges, so there is less overhead in running them.
When you ultimately run your containers in OpenShift Container Platform, you use the CRI-O container engine. CRI-O runs on every worker and master machine in an OpenShift Container Platform cluster, but CRI-O is not yet supported as a standalone runtime outside of OpenShift Container Platform.
4.2.2. Base image options
The base image you choose to build your application on contains a set of software that resembles a Linux system to your application. When you build your own image, your software is placed into that file system and sees that file system as though it were looking at its operating system. Choosing this base image has major impact on how secure, efficient and upgradeable your container is in the future.
Red Hat provides a new set of base images referred to as Red Hat Universal Base Images (UBI). These images are based on Red Hat Enterprise Linux and are similar to base images that Red Hat has offered in the past, with one major difference: they are freely redistributable without a Red Hat subscription. As a result, you can build your application on UBI images without having to worry about how they are shared or the need to create different images for different environments.
These UBI images have standard, init, and minimal versions. You can also use the Red Hat Software Collections images as a foundation for applications that rely on specific runtime environments such as Node.js, Perl, or Python. Special versions of some of these runtime base images referred to as Source-to-image (S2I) images. With S2I images, you can insert your code into a base image environment that is ready to run that code.
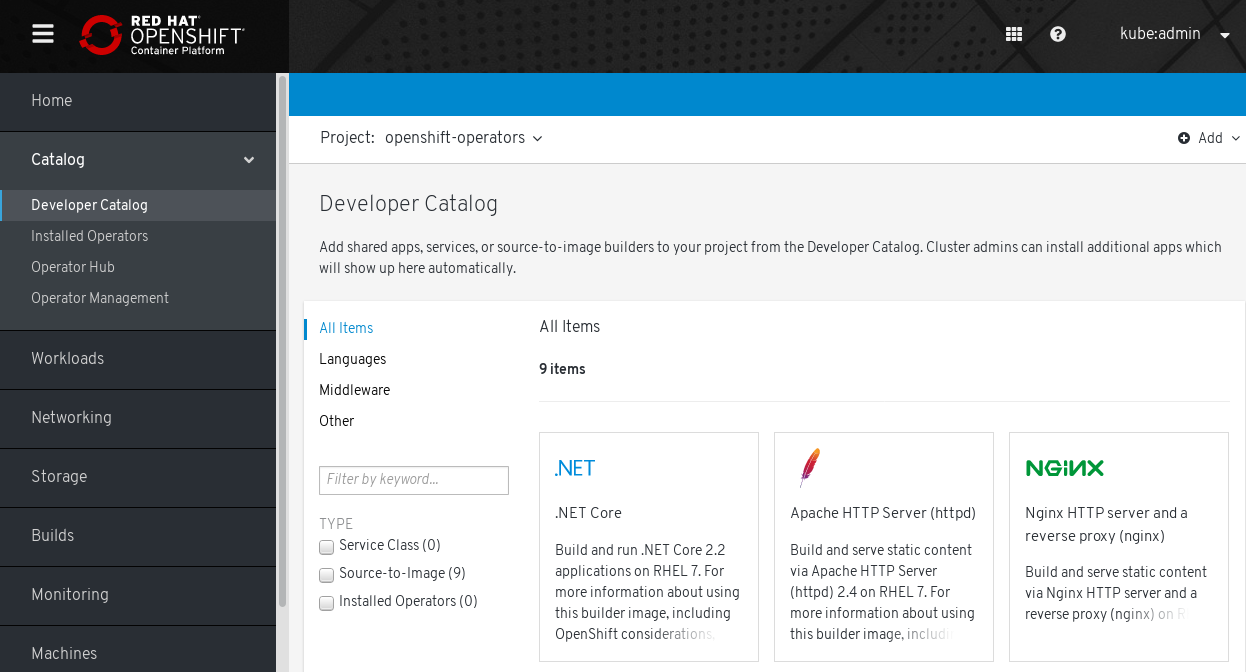
S2I images are available for you to use directly from the OpenShift Container Platform web UI by selecting Catalog → Developer Catalog, as shown in the following figure:
Figure 4.2. Choose S2I base images for apps that need specific runtimes
4.2.3. Registry options
Container Registries are where you store container images so you can share them with others and make them available to the platform where they ultimately run. You can select large, public container registries that offer free accounts or a premium version that offer more storage and special features. You can also install your own registry that can be exclusive to your organization or selectively shared with others.
To get Red Hat images and certified partner images, you can draw from the Red Hat Registry. The Red Hat Registry is represented by two locations: registry.access.redhat.com, which is unauthenticated and deprecated, and registry.redhat.io, which requires authentication. You can learn about the Red Hat and partner images in the Red Hat Registry from the Red Hat Container Catalog. Besides listing Red Hat container images, it also shows extensive information about the contents and quality of those images, including health scores that are based on applied security updates.
Large, public registries include Docker Hub and Quay.io. The Quay.io registry is owned and managed by Red Hat. Many of the components used in OpenShift Container Platform are stored in Quay.io, including container images and the Operators that are used to deploy OpenShift Container Platform itself. Quay.io also offers the means of storing other types of content, including Helm Charts.
If you want your own, private container registry, OpenShift Container Platform itself includes a private container registry that is installed with OpenShift Container Platform and runs on its cluster. Red Hat also offers a private version of the Quay.io registry called Red Hat Quay. Red Hat Quay includes geo replication, Git build triggers, Clair image scanning, and many other features.
All of the registries mentioned here can require credentials to download images from those registries. Some of those credentials are presented on a cluster-wide basis from OpenShift Container Platform, while other credentials can be assigned to individuals.
4.3. Creating a Kubernetes Manifest for OpenShift Container Platform
While the container image is the basic building block for a containerized application, more information is required to manage and deploy that application in a Kubernetes environment such as OpenShift Container Platform. The typical next steps after you create an image are to:
- Understand the different resources you work with in Kubernetes manifests
- Make some decisions about what kind of an application you are running
- Gather supporting components
- Create a manifest and store that manifest in a Git repository so you can store it in a source versioning system, audit it, track it, promote and deploy it to the next environment, roll it back to earlier versions, if necessary, and share it with others
4.3.1. About Kubernetes Pods and services
While the container image is the basic unit with docker, the basic units that Kubernetes works with are called Pods. Pods represent the next step in building out an application. A Pod can contain one or more than one container. The key is that the Pod is the single unit that you deploy, scale, and manage.
Scalability and namespaces are probably the main items to consider when determining what goes in a Pod. For ease of deployment, you might want to deploy a container in a Pod and include its own logging and monitoring container in the Pod. Later, when you run the Pod and need to scale up an additional instance, those other containers are scaled up with it. For namespaces, containers in a Pod share the same network interfaces, shared storage volumes, and resource limitations, such as memory and CPU, which makes it easier to manage the contents of the Pod as a single unit. Containers in a Pod can also communicate with each other by using standard inter-process communications, such as System V semaphores or POSIX shared memory.
While individual Pods represent a scalable unit in Kubernetes, a service provides a means of grouping together a set of Pods to create a complete, stable application that can complete tasks such as load balancing. A service is also more permanent than a Pod because the service remains available from the same IP address until you delete it. When the service is in use, it is requested by name and the OpenShift Container Platform cluster resolves that name into the IP addresses and ports where you can reach the Pods that compose the service.
By their nature, containerized applications are separated from the operating systems where they run and, by extension, their users. Part of your Kubernetes manifest describes how to expose the application to internal and external networks by defining network policies that allow fine-grained control over communication with your containerized applications. To connect incoming requests for HTTP, HTTPS, and other services from outside your cluster to services inside your cluster, you can use an Ingress resource.
If your container requires on-disk storage instead of database storage, which might be provided through a service, you can add volumes to your manifests to make that storage available to your Pods. You can configure the manifests to create persistent volumes (PVs) or dynamically create volumes that are added to your Pod definitions.
After you define a group of Pods that compose your application, you can define those Pods in deployments and deploymentconfigs.
4.3.2. Application types
Next, consider how your application type influences how to run it.
Kubernetes defines different types of workloads that are appropriate for different kinds of applications. To determine the appropriate workload for your application, consider if the application is:
- Meant to run to completion and be done. An example is an application that starts up to produce a report and exits when the report is complete. The application might not run again then for a month. Suitable OpenShift Container Platform objects for these types of applications include Jobs and CronJob objects.
- Expected to run continuously. For long-running applications, you can write a Deployment or a DeploymentConfig.
- Required to be highly available. If your application requires high availability, then you want to size your deployment to have more than one instance. A Deployment or DeploymentConfig can incorporate a ReplicaSet for that type of application. With ReplicaSets, Pods run across multiple nodes to make sure the application is always available, even if a worker goes down.
- Need to run on every node. Some types of Kubernetes applications are intended to run in the cluster itself on every master or worker node. DNS and monitoring applications are examples of applications that need to run continuously on every node. You can run this type of application as a DaemonSet. You can also run a DaemonSet on a subset of nodes, based on node labels.
- Require life-cycle management. When you want to hand off your application so that others can use it, consider creating an Operator. Operators let you build in intelligence, so it can handle things like backups and upgrades automatically. Coupled with the Operator Lifecycle Manager (OLM), cluster managers can expose Operators to selected namespaces so that users in the cluster can run them.
-
Have identity or numbering requirements. An application might have identity requirements or numbering requirements. For example, you might be required to run exactly three instances of the application and to name the instances
0,1, and2. A StatefulSet is suitable for this application. StatefulSets are most useful for applications that require independent storage, such as databases and zookeeper clusters.
4.3.3. Available supporting components
The application you write might need supporting components, like a database or a logging component. To fulfill that need, you might be able to obtain the required component from the following Catalogs that are available in the OpenShift Container Platform web console:
- OperatorHub, which is available in each OpenShift Container Platform 4.1 cluster. The OperatorHub makes Operators available from Red Hat, certified Red Hat partners, and community members to the cluster operator. The cluster operator can make those Operators available in all or selected namespaces in the cluster, so developers can launch them and configure them with their applications.
- Service Catalog, which offers alternatives to Operators. While deploying Operators is the preferred method of getting packaged applications in OpenShift Container Platform, there are some reasons why you might want to use the Service Catalog to get supporting applications for your own application. You might want to use the Service Catalog if you are an existing OpenShift Container Platform 3 customer and are invested in Service Catalog applications or if you already have a Cloud Foundry environment from which you are interested in consuming brokers from other ecosystems.
- Templates, which are useful for a one-off type of application, where the lifecycle of a component is not important after it is installed. A template provides an easy way to get started developing a Kubernetes application with minimal overhead. A template can be a list of resource definitions, which could be deployments, services, routes, or other objects. If you want to change names or resources, you can set these values as parameters in the template. The Template Service Broker Operator is a service broker that you can use to instantiate your own templates. You can also install templates directly from the command line.
You can configure the supporting Operators, Service Catalog applications, and templates to the specific needs of your development team and then make them available in the namespaces in which your developers work. Many people add shared templates to the openshift namespace because it is accessible from all other namespaces.
4.3.4. Applying the manifest
Kubernetes manifests let you create a more complete picture of the components that make up your Kubernetes applications. You write these manifests as YAML files and deploy them by applying them to the cluster, for example, by running the oc apply command.
4.3.5. Next steps
At this point, consider ways to automate your container development process. Ideally, you have some sort of CI pipeline that builds the images and pushes them to a registry. In particular, a GitOps pipeline integrates your container development with the Git repositories that you use to store the software that is required to build your applications.
The workflow to this point might look like:
-
Day 1: You write some YAML. You then run the
oc applycommand to apply that YAML to the cluster and test that it works. - Day 2: You put your YAML container configuration file into your own Git repository. From there, people who want to install that app, or help you improve it, can pull down the YAML and apply it to their cluster to run the app.
- Day 3: Consider writing an Operator for your application.
4.4. Develop for Operators
Packaging and deploying your application as an Operator might be preferred if you make your application available for others to run. As noted earlier, Operators add a lifecycle component to your application that acknowledges that the job of running an application is not complete as soon as it is installed.
When you create an application as an Operator, you can build in your own knowledge of how to run and maintain the application. You can build in features for upgrading the application, backing it up, scaling it, or keeping track of its state. If you configure the application correctly, maintenance tasks, like updating the Operator, can happen automatically and invisibly to the Operator’s users.
An example of a useful Operator is one that is set up to automatically back up data at particular times. Having an Operator manage an application’s backup at set times can save a system administrator from remembering to do it.
Any application maintenance that has traditionally been completed manually, like backing up data or rotating certificates, can be completed automatically with an Operator.
Chapter 5. Red Hat Enterprise Linux CoreOS (RHCOS)
5.1. About RHCOS
Red Hat Enterprise Linux CoreOS (RHCOS) represents the next generation of single-purpose container operating system technology. Created by the same development teams that created Red Hat Enterprise Linux Atomic Host and CoreOS Container Linux, RHCOS combines the quality standards of Red Hat Enterprise Linux (RHEL) with the automated, remote upgrade features from Container Linux.
RHCOS is supported only as a component of OpenShift Container Platform 4.1 for all OpenShift Container Platform machines. RHCOS is the only supported operating system for OpenShift Container Platform control plane, or master, machines. While RHCOS is the default operating system for all cluster machines, you can create compute machines, which are also known as worker machines, that use RHEL as their operating system.
If you install your cluster on infrastructure that the cluster provisions, RHCOS images are downloaded to the target platform during installation, and suitable Ignition config files, which control the RHCOS configuration, are used to deploy the machines. If you install your cluster on infrastructure that you manage, you must follow the installation documentation to obtain the RHCOS images, generate Ignition config files, and use the Ignition config files to provision your machines.
5.1.1. Key RHCOS features
The following list describes key features of the RHCOS operating system:
The underlying operating system consists primarily of RHEL components. The same quality, security, and control measures that support RHEL also support RHCOS. For example, RHCOS software is in RPM packages, and each RHCOS system starts up with a RHEL kernel and a set of services that are managed by the systemd init system.
Although it contains RHEL components, RHCOS is designed to be managed more tightly than a default RHEL installation. Management is performed remotely from the OpenShift Container Platform cluster. When you set up your RHCOS machines, you can modify only a few system settings. This controlled immutability allows OpenShift Container Platform to store the latest state of RHCOS systems in the cluster so it is always able to create additional machines and perform updates based on the latest RHCOS configurations.
Although RHCOS contains features for running the OCI- and libcontainer-formatted containers that Docker requires, it incorporates the CRI-O container engine instead of the Docker container engine. By focusing on features needed by Kubernetes platforms, such as OpenShift Container Platform, CRI-O can offer specific compatibility with different Kubernetes versions. CRI-O also offers a smaller footprint and reduced attack surface than is possible with container engines that offer a larger feature set. At the moment, CRI-O is only available as a container engine within OpenShift Container Platform clusters.
For tasks such as building, copying, and otherwise managing containers, RHCOS replaces the Docker CLI tool with a compatible set of container tools. The podman CLI tool supports many container runtime features, such as running, starting, stopping, listing, and removing containers and container images. The skopeo CLI tool can copy, authenticate, and sign images. You can use the crictl CLI tool to work with containers and pods from the CRI-O container engine. While direct use of these tools in RHCOS is discouraged, you can use them for debugging purposes.
RHCOS features transactional upgrades using the rpm-ostree system. Updates are delivered via container images and are part of the OpenShift update process. When deployed, the container image is pulled, extracted, and written to disk, then the bootloader is modified to boot into the new version. The machine will reboot into the update in a rolling manner to ensure cluster capacity is minimally impacted.
For RHCOS systems, the layout of the rpm-ostree file system has the following characteristics:
-
/usris where the operating system binaries and libraries are stored and is read-only. We do not support altering this. -
/etc,/boot,/varare writable on the system but only intended to be altered by the Machine Config Operator. -
/var/lib/containersis the graph storage location for storing container images.
In OpenShift Container Platform, the Machine Config Operator handles operating system upgrades. Instead of upgrading individual packages, as is done with yum upgrades, rpm-ostree delivers upgrades of the OS as an atomic unit. The new OS deployment is staged during upgrades and goes into effect on the next reboot. If something goes wrong with the upgrade, a single rollback and reboot returns the system to the previous state. RHCOS upgrades in OpenShift Container Platform are performed during cluster updates.
5.1.2. Configuring RHCOS in OpenShift Container Platform
For OpenShift Container Platform, RHCOS images are set up initially with a feature called Ignition, which runs only on the system’s first boot. After first boot, RHCOS systems are managed by the Machine Config Operator (MCO) that runs in the OpenShift Container Platform cluster.
Because RHCOS systems in OpenShift Container Platform are designed to be fully managed from the OpenShift Container Platform cluster, directly logging in to a RHCOS machine is discouraged. Limited direct access to RHCOS machines in an OpenShift Container Platform cluster can be completed for debugging purposes.
5.1.3. About Ignition
Ignition is the utility that is used by RHCOS to manipulate disks during initial configuration. It completes common disk tasks, including partitioning disks, formatting partitions, writing files, and configuring users. On first boot, Ignition reads its configuration from the installation media or the location that you specify and applies the configuration to the machines.
Whether you are installing your cluster or adding machines to it, Ignition always performs the initial configuration of the OpenShift Container Platform cluster machines. Most of the actual system setup happens on each machine itself. For each machine, Ignition takes the RHCOS image and boots the RHCOS kernel. Options on the kernel command line, identify the type of deployment and the location of the Ignition-enabled initial Ram Disk (initramfs).
OpenShift Container Platform uses Ignition version 2 and Ignition config version 2.3
5.1.3.1. How Ignition works
To create machines by using Ignition, you need Ignition config files. The OpenShift Container Platform installation program creates the Ignition config files that you need to deploy your cluster. These files are based on the information that you provide to the installation program directly or through an install-config.yaml file.
The way that Ignition configures machines is similar to how tools like cloud-init or Linux Anaconda kickstart configure systems, but with some important differences:
- Ignition runs from an initial RAM disk that is separate from the system you are installing to. Because of that, Ignition can repartition disks, set up file systems, and perform other changes to the machine’s permanent file system. In contrast, cloud-init runs as part of a machine’s init system when the system boots, so making foundational changes to things like disk partitions cannot be done as easily. With cloud-init, it is also difficult to reconfigure the boot process while you are in the middle of the node’s boot process.
- Ignition is meant to initialize systems, not change existing systems. After a machine initializes and the kernel is running from the installed system, the Machine Config Operator from the OpenShift Container Platform cluster completes all future machine configuration.
- Instead of completing a defined set of actions, Ignition implements a declarative configuration. It checks that all partitions, files, services, and other items are in place before the new machine starts. It then makes the changes, like copying files to disk that are necessary for the new machine to meet the specified configuration.
- After Ignition finishes configuring a machine, the kernel keeps running but discards the initial RAM disk and pivots to the installed system on disk. All of the new system services and other features start without requiring a system reboot.
- Because Ignition confirms that all new machines meet the declared configuration, you cannot have a partially-configured machine. If a machine’s setup fails, the initialization process does not finish, and Ignition does not start the new machine. Your cluster will never contain partially-configured machines. If Ignition cannot complete, the machine is not added to the cluster. You must add a new machine instead. This behavior prevents the difficult case of debugging a machine when the results of a failed configuration task are not known until something that depended on it fails at a later date.
- If there is a problem with an Ignition config that causes the setup of a machine to fail, Ignition will not try to use the same config to set up another machine. For example, a failure could result from an Ignition config made up of a parent and child config that both want to create the same file. A failure in such a case would prevent that Ignition config from being used again to set up an other machines, until the problem is resolved.
- If you have multiple Ignition config files, you get a union of that set of configs. Because Ignition is declarative, conflicts between the configs could cause Ignition to fail to set up the machine. The order of information in those files doesn’t matter. Ignition will sort and implement each setting in ways that make the most sense. For example, if a file needs a directory several levels deep, if another file needs a directory along that path, the later file is created first. Ignition sorts and creates all files, directories, and links by depth.
- Because Ignition can start with a completely empty hard disk, it can do something cloud-init can’t do: set up systems on bare metal from scratch (using features such as PXE boot). In the bare metal case, the Ignition config is injected into the boot partition so Ignition can find it and configure the system correctly.
5.1.3.2. The Ignition sequence
The Ignition process for an RHCOS machine in an OpenShift Container Platform cluster involves the following steps:
- The machine gets its Ignition config file. Master machines get their Ignition config files from the bootstrap machine, and worker machines get Ignition config files from a master.
- Ignition creates disk partitions, file systems, directories, and links on the machine. It supports RAID arrays but does not support LVM volumes
-
Ignition mounts the root of the permanent file system to the
/sysrootdirectory in the initramfs and starts working in that/sysrootdirectory. - Ignition configures all defined file systems and sets them up to mount appropriately at runtime.
-
Ignition runs
systemdtemporary files to populate required files in the/vardirectory. - Ignition runs the Ignition config files to set up users, systemd unit files, and other configuration files.
- Ignition unmounts all components in the permanent system that were mounted in the initramfs.
- Ignition starts up new machine’s init process which, in turn, starts up all other services on the machine that run during system boot.
The machine is then ready to join the cluster and does not require a reboot.
5.2. Viewing Ignition configuration files
To see the Ignition config file used to deploy the bootstrap machine, run the following command:
$ openshift-install create ignition-configs --dir $HOME/testconfig
After you answer a few questions, the bootstrap.ign, master.ign, and worker.ign files appear in the directory you entered.
To see the contents of the bootstrap.ign file, pipe it through the jq filter. Here’s a snippet from that file:
$ cat $HOME/testconfig/bootstrap.ign | jq
\\{
"ignition": \\{
"config": \\{},
…
"storage": \\{
"files": [
\\{
"filesystem": "root",
"path": "/etc/motd",
"user": \\{
"name": "root"
},
"append": true,
"contents": \\{
"source": "data:text/plain;charset=utf-8;base64,VGhpcyBpcyB0aGUgYm9vdHN0cmFwIG5vZGU7IGl0IHdpbGwgYmUgZGVzdHJveWVkIHdoZW4gdGhlIG1hc3RlciBpcyBmdWxseSB1cC4KClRoZSBwcmltYXJ5IHNlcnZpY2UgaXMgImJvb3RrdWJlLnNlcnZpY2UiLiBUbyB3YXRjaCBpdHMgc3RhdHVzLCBydW4gZS5nLgoKICBqb3VybmFsY3RsIC1iIC1mIC11IGJvb3RrdWJlLnNlcnZpY2UK",
To decode the contents of a file listed in the bootstrap.ign file, pipe the base64-encoded data string representing the contents of that file to the base64 -d command. Here’s an example using the contents of the /etc/motd file added to the bootstrap machine from the output shown above:
$ echo VGhpcyBpcyB0aGUgYm9vdHN0cmFwIG5vZGU7IGl0IHdpbGwgYmUgZGVzdHJveWVkIHdoZW4gdGhlIG1hc3RlciBpcyBmdWxseSB1cC4KClRoZSBwcmltYXJ5IHNlcnZpY2UgaXMgImJvb3RrdWJlLnNlcnZpY2UiLiBUbyB3YXRjaCBpdHMgc3RhdHVzLCBydW4gZS5nLgoKICBqb3VybmFsY3RsIC1iIC1mIC11IGJvb3RrdWJlLnNlcnZpY2UK | base64 -dThis is the bootstrap machine; it will be destroyed when the master is fully up.
The primary service is "bootkube.service". To watch its status, run, e.g.:
journalctl -b -f -u bootkube.service
Repeat those commands on the master.ign and worker.ign files to see the source of Ignition config files for each of those machine types. You should see a line like the following for the worker.ign, identifying how it gets its Ignition config from the bootstrap machine:
"source": "https://api.myign.develcluster.example.com:22623/config/worker",
Here are a few things you can learn from the bootstrap.ign file:
- Format: The format of the file is defined in the Ignition config spec. Files of the same format are used later by the MCO to merge changes into a machine’s configuration.
-
Contents: Because the bootstrap machine serves the Ignition configs for other machines, both master and worker machine Ignition config information is stored in the
bootstrap.ign, along with the bootstrap machine’s configuration. - Size: The file is more than 1300 lines long, with path to various types of resources.
- The content of each file that will be copied to the machine is actually encoded into data URLs, which tends to make the content a bit clumsy to read. (Use the jq and base64 commands shown previously to make the content more readable.)
- Configuration: The different sections of the Ignition config file are generally meant to contain files that are just dropped into a machine’s file system, rather than commands to modify existing files. For example, instead of having a section on NFS that configures that service, you would just add an NFS configuration file, which would then be started by the init process when the system comes up.
- users: A user named core is created, with your ssh key assigned to that user. This allows you to log in to the cluster with that user name and your credentials.
-
storage: The storage section identifies files that are added to each machine. A few notable files include
/root/.docker/config.json(which provides credentials your cluster needs to pull from container image registries) and a bunch of manifest files in/opt/openshift/manifeststhat are used to configure your cluster. - systemd: The systemd section holds content used to create systemd unit files. Those files are used to start up services at boot time, as well as manage those services on running systems.
- Primitives: Ignition also exposes low-level primitives that other tools can build on.
5.3. Changing Ignition Configs after installation
Machine Config Pools manage a cluster of nodes and their corresponding Machine Configs. Machine Configs contain configuration information for a cluster. To list all Machine Config Pools that are known:
$ oc get machineconfigpools
NAME CONFIG UPDATED UPDATING DEGRADED
master master-1638c1aea398413bb918e76632f20799 False False False
worker worker-2feef4f8288936489a5a832ca8efe953 False False FalseTo list all Machine Configs:
$ oc get machineconfig
NAME GENERATEDBYCONTROLLER IGNITIONVERSION CREATED OSIMAGEURL
00-master 4.0.0-0.150.0.0-dirty 2.2.0 16m
00-master-ssh 4.0.0-0.150.0.0-dirty 16m
00-worker 4.0.0-0.150.0.0-dirty 2.2.0 16m
00-worker-ssh 4.0.0-0.150.0.0-dirty 16m
01-master-kubelet 4.0.0-0.150.0.0-dirty 2.2.0 16m
01-worker-kubelet 4.0.0-0.150.0.0-dirty 2.2.0 16m
master-1638c1aea398413bb918e76632f20799 4.0.0-0.150.0.0-dirty 2.2.0 16m
worker-2feef4f8288936489a5a832ca8efe953 4.0.0-0.150.0.0-dirty 2.2.0 16mThe Machine Config Operator acts somewhat differently than Ignition when it comes to applying these machineconfigs. The machineconfigs are read in order (from 00* to 99*). Labels inside the machineconfigs identify the type of node each is for (master or worker). If the same file appears in multiple machineconfig files, the last one wins. So, for example, any file that appears in a 99* file would replace the same file that appeared in a 00* file. The input machineconfig objects are unioned into a "rendered" machineconfig object, which will be used as a target by the operator and is the value you can see in the machineconfigpool.
To see what files are being managed from a machineconfig, look for “Path:” inside a particular machineconfig. For example:
$ oc describe machineconfigs 01-worker-container-runtime | grep Path:
Path: /etc/containers/registries.conf
Path: /etc/containers/storage.conf
Path: /etc/crio/crio.conf
If you wanted to change a setting in one of those files, for example to change pids_limit to 1500 (pids_limit = 1500) inside the crio.conf file, you could create a new machineconfig containing only the file you want to change.
Be sure to give the machineconfig a later name (such as 10-worker-container-runtime). Keep in mind that the content of each file is in URL-style data. Then apply the new machineconfig to the cluster.
Legal Notice
Copyright © Red Hat
OpenShift documentation is licensed under the Apache License 2.0 (https://www.apache.org/licenses/LICENSE-2.0).
Modified versions must remove all Red Hat trademarks.
Portions adapted from https://github.com/kubernetes-incubator/service-catalog/ with modifications by Red Hat.
Red Hat, Red Hat Enterprise Linux, the Red Hat logo, the Shadowman logo, JBoss, OpenShift, Fedora, the Infinity logo, and RHCE are trademarks of Red Hat, Inc., registered in the United States and other countries.
Linux® is the registered trademark of Linus Torvalds in the United States and other countries.
Java® is a registered trademark of Oracle and/or its affiliates.
XFS® is a trademark of Silicon Graphics International Corp. or its subsidiaries in the United States and/or other countries.
MySQL® is a registered trademark of MySQL AB in the United States, the European Union and other countries.
Node.js® is an official trademark of the OpenJS Foundation.
The OpenStack® Word Mark and OpenStack logo are either registered trademarks/service marks or trademarks/service marks of the OpenStack Foundation, in the United States and other countries and are used with the OpenStack Foundation’s permission. We are not affiliated with, endorsed or sponsored by the OpenStack Foundation, or the OpenStack community.
All other trademarks are the property of their respective owners.