Chapter 6. Administer
6.1. Global configuration
The OpenShift Serverless Operator manages the global configuration of a Knative installation, including propagating values from the KnativeServing and KnativeEventing custom resources to system config maps. Any updates to config maps which are applied manually are overwritten by the Operator. However, modifying the Knative custom resources allows you to set values for these config maps.
Knative has multiple config maps that are named with the prefix config-. All Knative config maps are created in the same namespace as the custom resource that they apply to. For example, if the KnativeServing custom resource is created in the knative-serving namespace, all Knative Serving config maps are also created in this namespace.
The spec.config in the Knative custom resources have one <name> entry for each config map, named config-<name>, with a value which is be used for the config map data.
6.1.1. Configuring the default channel implementation
You can use the default-ch-webhook config map to specify the default channel implementation of Knative Eventing. You can specify the default channel implementation for the entire cluster or for one or more namespaces. Currently the InMemoryChannel and KafkaChannel channel types are supported.
Prerequisites
- You have administrator permissions on OpenShift Container Platform.
- You have installed the OpenShift Serverless Operator and Knative Eventing on your cluster.
-
If you want to use Kafka channels as the default channel implementation, you must also install the
KnativeKafkaCR on your cluster.
Procedure
Modify the
KnativeEventingcustom resource to add configuration details for thedefault-ch-webhookconfig map:apiVersion: operator.knative.dev/v1alpha1 kind: KnativeEventing metadata: name: knative-eventing namespace: knative-eventing spec: config:1 default-ch-webhook:2 default-ch-config: | clusterDefault:3 apiVersion: messaging.knative.dev/v1 kind: InMemoryChannel spec: delivery: backoffDelay: PT0.5S backoffPolicy: exponential retry: 5 namespaceDefaults:4 my-namespace: apiVersion: messaging.knative.dev/v1beta1 kind: KafkaChannel spec: numPartitions: 1 replicationFactor: 1- 1
- In
spec.config, you can specify the config maps that you want to add modified configurations for. - 2
- The
default-ch-webhookconfig map can be used to specify the default channel implementation for the cluster or for one or more namespaces. - 3
- The cluster-wide default channel type configuration. In this example, the default channel implementation for the cluster is
InMemoryChannel. - 4
- The namespace-scoped default channel type configuration. In this example, the default channel implementation for the
my-namespacenamespace isKafkaChannel.
ImportantConfiguring a namespace-specific default overrides any cluster-wide settings.
6.1.2. Configuring the default broker backing channel
If you are using a channel-based broker, you can set the default backing channel type for the broker to either InMemoryChannel or KafkaChannel.
Prerequisites
- You have administrator permissions on OpenShift Container Platform.
- You have installed the OpenShift Serverless Operator and Knative Eventing on your cluster.
-
You have installed the OpenShift (
oc) CLI. -
If you want to use Kafka channels as the default backing channel type, you must also install the
KnativeKafkaCR on your cluster.
Procedure
Modify the
KnativeEventingcustom resource (CR) to add configuration details for theconfig-br-default-channelconfig map:apiVersion: operator.knative.dev/v1alpha1 kind: KnativeEventing metadata: name: knative-eventing namespace: knative-eventing spec: config:1 config-br-default-channel: channel-template-spec: | apiVersion: messaging.knative.dev/v1beta1 kind: KafkaChannel2 spec: numPartitions: 63 replicationFactor: 34 - 1
- In
spec.config, you can specify the config maps that you want to add modified configurations for. - 2
- The default backing channel type configuration. In this example, the default channel implementation for the cluster is
KafkaChannel. - 3
- The number of partitions for the Kafka channel that backs the broker.
- 4
- The replication factor for the Kafka channel that backs the broker.
Apply the updated
KnativeEventingCR:$ oc apply -f <filename>
6.1.3. Configuring the default broker class
You can use the config-br-defaults config map to specify default broker class settings for Knative Eventing. You can specify the default broker class for the entire cluster or for one or more namespaces. Currently the MTChannelBasedBroker and Kafka broker types are supported.
Prerequisites
- You have administrator permissions on OpenShift Container Platform.
- You have installed the OpenShift Serverless Operator and Knative Eventing on your cluster.
-
If you want to use Kafka broker as the default broker implementation, you must also install the
KnativeKafkaCR on your cluster.
Procedure
Modify the
KnativeEventingcustom resource to add configuration details for theconfig-br-defaultsconfig map:apiVersion: operator.knative.dev/v1alpha1 kind: KnativeEventing metadata: name: knative-eventing namespace: knative-eventing spec: defaultBrokerClass: Kafka1 config:2 config-br-defaults:3 default-br-config: | clusterDefault:4 brokerClass: Kafka apiVersion: v1 kind: ConfigMap name: kafka-broker-config5 namespace: knative-eventing6 namespaceDefaults:7 my-namespace: brokerClass: MTChannelBasedBroker apiVersion: v1 kind: ConfigMap name: config-br-default-channel8 namespace: knative-eventing9 ...- 1
- The default broker class for Knative Eventing.
- 2
- In
spec.config, you can specify the config maps that you want to add modified configurations for. - 3
- The
config-br-defaultsconfig map specifies the default settings for any broker that does not specifyspec.configsettings or a broker class. - 4
- The cluster-wide default broker class configuration. In this example, the default broker class implementation for the cluster is
Kafka. - 5
- The
kafka-broker-configconfig map specifies default settings for the Kafka broker. See "Configuring Kafka broker settings" in the "Additional resources" section. - 6
- The namespace where the
kafka-broker-configconfig map exists. - 7
- The namespace-scoped default broker class configuration. In this example, the default broker class implementation for the
my-namespacenamespace isMTChannelBasedBroker. You can specify default broker class implementations for multiple namespaces. - 8
- The
config-br-default-channelconfig map specifies the default backing channel for the broker. See "Configuring the default broker backing channel" in the "Additional resources" section. - 9
- The namespace where the
config-br-default-channelconfig map exists.
ImportantConfiguring a namespace-specific default overrides any cluster-wide settings.
6.1.4. Enabling scale-to-zero
Knative Serving provides automatic scaling, or autoscaling, for applications to match incoming demand. You can use the enable-scale-to-zero spec to enable or disable scale-to-zero globally for applications on the cluster.
Prerequisites
- You have installed OpenShift Serverless Operator and Knative Serving on your cluster.
- You have cluster administrator permissions.
- You are using the default Knative Pod Autoscaler. The scale to zero feature is not available if you are using the Kubernetes Horizontal Pod Autoscaler.
Procedure
Modify the
enable-scale-to-zerospec in theKnativeServingcustom resource (CR):Example KnativeServing CR
apiVersion: operator.knative.dev/v1alpha1 kind: KnativeServing metadata: name: knative-serving spec: config: autoscaler: enable-scale-to-zero: "false"1 - 1
- The
enable-scale-to-zerospec can be either"true"or"false". If set to true, scale-to-zero is enabled. If set to false, applications are scaled down to the configured minimum scale bound. The default value is"true".
6.1.5. Configuring the scale-to-zero grace period
Knative Serving provides automatic scaling down to zero pods for applications. You can use the scale-to-zero-grace-period spec to define an upper bound time limit that Knative waits for scale-to-zero machinery to be in place before the last replica of an application is removed.
Prerequisites
- You have installed OpenShift Serverless Operator and Knative Serving on your cluster.
- You have cluster administrator permissions.
- You are using the default Knative Pod Autoscaler. The scale to zero feature is not available if you are using the Kubernetes Horizontal Pod Autoscaler.
Procedure
Modify the
scale-to-zero-grace-periodspec in theKnativeServingcustom resource (CR):Example KnativeServing CR
apiVersion: operator.knative.dev/v1alpha1 kind: KnativeServing metadata: name: knative-serving spec: config: autoscaler: scale-to-zero-grace-period: "30s"1 - 1
- The grace period time in seconds. The default value is 30 seconds.
6.1.6. Overriding system deployment configurations
You can override the default configurations for some specific deployments by modifying the deployments spec in the KnativeServing and KnativeEventing custom resources (CRs).
6.1.6.1. Overriding Knative Serving system deployment configurations
You can override the default configurations for some specific deployments by modifying the deployments spec in the KnativeServing custom resource (CR). Currently, overriding default configuration settings is supported for the resources, replicas, labels, annotations, and nodeSelector fields.
In the following example, a KnativeServing CR overrides the webhook deployment so that:
- The deployment has specified CPU and memory resource limits.
- The deployment has 3 replicas.
-
The
example-label: labellabel is added. -
The
example-annotation: annotationannotation is added. -
The
nodeSelectorfield is set to select nodes with thedisktype: hddlabel.
The KnativeServing CR label and annotation settings override the deployment’s labels and annotations for both the deployment itself and the resulting pods.
KnativeServing CR example
apiVersion: operator.knative.dev/v1alpha1
kind: KnativeServing
metadata:
name: ks
namespace: knative-serving
spec:
high-availability:
replicas: 2
deployments:
- name: webhook
resources:
- container: webhook
requests:
cpu: 300m
memory: 60Mi
limits:
cpu: 1000m
memory: 1000Mi
replicas: 3
labels:
example-label: label
annotations:
example-annotation: annotation
nodeSelector:
disktype: hdd6.1.6.2. Overriding Knative Eventing system deployment configurations
You can override the default configurations for some specific deployments by modifying the deployments spec in the KnativeEventing custom resource (CR). Currently, overriding default configuration settings is supported for the eventing-controller, eventing-webhook, and imc-controller fields.
The replicas spec cannot override the number of replicas for deployments that use the Horizontal Pod Autoscaler (HPA), and does not work for the eventing-webhook deployment.
In the following example, a KnativeEventing CR overrides the eventing-controller deployment so that:
- The deployment has specified CPU and memory resource limits.
- The deployment has 3 replicas.
-
The
example-label: labellabel is added. -
The
example-annotation: annotationannotation is added. -
The
nodeSelectorfield is set to select nodes with thedisktype: hddlabel.
KnativeEventing CR example
apiVersion: operator.knative.dev/v1beta1
kind: KnativeEventing
metadata:
name: knative-eventing
namespace: knative-eventing
spec:
deployments:
- name: eventing-controller
resources:
- container: eventing-controller
requests:
cpu: 300m
memory: 100Mi
limits:
cpu: 1000m
memory: 250Mi
replicas: 3
labels:
example-label: label
annotations:
example-annotation: annotation
nodeSelector:
disktype: hdd
The KnativeEventing CR label and annotation settings override the deployment’s labels and annotations for both the deployment itself and the resulting pods.
6.1.7. Configuring the EmptyDir extension
emptyDir volumes are empty volumes that are created when a pod is created, and are used to provide temporary working disk space. emptyDir volumes are deleted when the pod they were created for is deleted.
The kubernetes.podspec-volumes-emptydir extension controls whether emptyDir volumes can be used with Knative Serving. To enable using emptyDir volumes, you must modify the KnativeServing custom resource (CR) to include the following YAML:
Example KnativeServing CR
apiVersion: operator.knative.dev/v1alpha1
kind: KnativeServing
metadata:
name: knative-serving
spec:
config:
features:
kubernetes.podspec-volumes-emptydir: enabled
...6.1.8. HTTPS redirection global settings
HTTPS redirection provides redirection for incoming HTTP requests. These redirected HTTP requests are encrypted. You can enable HTTPS redirection for all services on the cluster by configuring the httpProtocol spec for the KnativeServing custom resource (CR).
Example KnativeServing CR that enables HTTPS redirection
apiVersion: operator.knative.dev/v1alpha1
kind: KnativeServing
metadata:
name: knative-serving
spec:
config:
network:
httpProtocol: "redirected"
...6.1.9. Setting the URL scheme for external routes
The URL scheme of external routes defaults to HTTPS for enhanced security. This scheme is determined by the default-external-scheme key in the KnativeServing custom resource (CR) spec.
Default spec
...
spec:
config:
network:
default-external-scheme: "https"
...
You can override the default spec to use HTTP by modifying the default-external-scheme key:
HTTP override spec
...
spec:
config:
network:
default-external-scheme: "http"
...6.1.10. Setting the Kourier Gateway service type
The Kourier Gateway is exposed by default as the ClusterIP service type. This service type is determined by the service-type ingress spec in the KnativeServing custom resource (CR).
Default spec
...
spec:
ingress:
kourier:
service-type: ClusterIP
...
You can override the default service type to use a load balancer service type instead by modifying the service-type spec:
LoadBalancer override spec
...
spec:
ingress:
kourier:
service-type: LoadBalancer
...6.1.11. Enabling PVC support
Some serverless applications need permanent data storage. To achieve this, you can configure persistent volume claims (PVCs) for your Knative services.
PVC support for Knative services is a Technology Preview feature only. Technology Preview features are not supported with Red Hat production service level agreements (SLAs) and might not be functionally complete. Red Hat does not recommend using them in production. These features provide early access to upcoming product features, enabling customers to test functionality and provide feedback during the development process.
For more information about the support scope of Red Hat Technology Preview features, see https://access.redhat.com/support/offerings/techpreview/.
Procedure
To enable Knative Serving to use PVCs and write to them, modify the
KnativeServingcustom resource (CR) to include the following YAML:Enabling PVCs with write access
... spec: config: features: "kubernetes.podspec-persistent-volume-claim": enabled "kubernetes.podspec-persistent-volume-write": enabled ...-
The
kubernetes.podspec-persistent-volume-claimextension controls whether persistent volumes (PVs) can be used with Knative Serving. -
The
kubernetes.podspec-persistent-volume-writeextension controls whether PVs are available to Knative Serving with the write access.
-
The
To claim a PV, modify your service to include the PV configuration. For example, you might have a persistent volume claim with the following configuration:
NoteUse the storage class that supports the access mode that you are requesting. For example, you can use the
ocs-storagecluster-cephfsclass for theReadWriteManyaccess mode.PersistentVolumeClaim configuration
apiVersion: v1 kind: PersistentVolumeClaim metadata: name: example-pv-claim namespace: my-ns spec: accessModes: - ReadWriteMany storageClassName: ocs-storagecluster-cephfs resources: requests: storage: 1GiIn this case, to claim a PV with write access, modify your service as follows:
Knative service PVC configuration
apiVersion: serving.knative.dev/v1 kind: Service metadata: namespace: my-ns ... spec: template: spec: containers: ... volumeMounts:1 - mountPath: /data name: mydata readOnly: false volumes: - name: mydata persistentVolumeClaim:2 claimName: example-pv-claim readOnly: false3 NoteTo successfully use persistent storage in Knative services, you need additional configuration, such as the user permissions for the Knative container user.
6.1.12. Enabling init containers
Init containers are specialized containers that are run before application containers in a pod. They are generally used to implement initialization logic for an application, which may include running setup scripts or downloading required configurations. You can enable the use of init containers for Knative services by modifying the KnativeServing custom resource (CR).
Init containers for Knative services is a Technology Preview feature only. Technology Preview features are not supported with Red Hat production service level agreements (SLAs) and might not be functionally complete. Red Hat does not recommend using them in production. These features provide early access to upcoming product features, enabling customers to test functionality and provide feedback during the development process.
For more information about the support scope of Red Hat Technology Preview features, see https://access.redhat.com/support/offerings/techpreview/.
Init containers may cause longer application start-up times and should be used with caution for serverless applications, which are expected to scale up and down frequently.
Prerequisites
- You have installed OpenShift Serverless Operator and Knative Serving on your cluster.
- You have cluster administrator permissions.
Procedure
Enable the use of init containers by adding the
kubernetes.podspec-init-containersflag to theKnativeServingCR:Example KnativeServing CR
apiVersion: operator.knative.dev/v1alpha1 kind: KnativeServing metadata: name: knative-serving spec: config: features: kubernetes.podspec-init-containers: enabled ...
6.1.13. Tag-to-digest resolution
If the Knative Serving controller has access to the container registry, Knative Serving resolves image tags to a digest when you create a revision of a service. This is known as tag-to-digest resolution, and helps to provide consistency for deployments.
To give the controller access to the container registry on OpenShift Container Platform, you must create a secret and then configure controller custom certificates. You can configure controller custom certificates by modifying the controller-custom-certs spec in the KnativeServing custom resource (CR). The secret must reside in the same namespace as the KnativeServing CR.
If a secret is not included in the KnativeServing CR, this setting defaults to using public key infrastructure (PKI). When using PKI, the cluster-wide certificates are automatically injected into the Knative Serving controller by using the config-service-sa config map. The OpenShift Serverless Operator populates the config-service-sa config map with cluster-wide certificates and mounts the config map as a volume to the controller.
6.1.13.1. Configuring tag-to-digest resolution by using a secret
If the controller-custom-certs spec uses the Secret type, the secret is mounted as a secret volume. Knative components consume the secret directly, assuming that the secret has the required certificates.
Prerequisites
- You have cluster administrator permissions on OpenShift Container Platform.
- You have installed the OpenShift Serverless Operator and Knative Serving on your cluster.
Procedure
Create a secret:
Example command
$ oc -n knative-serving create secret generic custom-secret --from-file=<secret_name>.crt=<path_to_certificate>Configure the
controller-custom-certsspec in theKnativeServingcustom resource (CR) to use theSecrettype:Example KnativeServing CR
apiVersion: operator.knative.dev/v1alpha1 kind: KnativeServing metadata: name: knative-serving namespace: knative-serving spec: controller-custom-certs: name: custom-secret type: Secret
6.2. Configuring Knative Kafka
Knative Kafka provides integration options for you to use supported versions of the Apache Kafka message streaming platform with OpenShift Serverless. Kafka provides options for event source, channel, broker, and event sink capabilities.
In addition to the Knative Eventing components that are provided as part of a core OpenShift Serverless installation, cluster administrators can install the KnativeKafka custom resource (CR).
Knative Kafka is not currently supported for IBM Z and IBM Power Systems.
The KnativeKafka CR provides users with additional options, such as:
- Kafka source
- Kafka channel
- Kafka broker
- Kafka sink
6.2.1. Installing Knative Kafka
Knative Kafka provides integration options for you to use supported versions of the Apache Kafka message streaming platform with OpenShift Serverless. Knative Kafka functionality is available in an OpenShift Serverless installation if you have installed the KnativeKafka custom resource.
Prerequisites
- You have installed the OpenShift Serverless Operator and Knative Eventing on your cluster.
- You have access to a Red Hat AMQ Streams cluster.
-
Install the OpenShift CLI (
oc) if you want to use the verification steps. - You have cluster administrator permissions on OpenShift Container Platform.
- You are logged in to the OpenShift Container Platform web console.
Procedure
-
In the Administrator perspective, navigate to Operators
Installed Operators. - Check that the Project dropdown at the top of the page is set to Project: knative-eventing.
- In the list of Provided APIs for the OpenShift Serverless Operator, find the Knative Kafka box and click Create Instance.
Configure the KnativeKafka object in the Create Knative Kafka page.
ImportantTo use the Kafka channel, source, broker, or sink on your cluster, you must toggle the enabled switch for the options you want to use to true. These switches are set to false by default. Additionally, to use the Kafka channel, broker, or sink you must specify the bootstrap servers.
Example
KnativeKafkacustom resourceapiVersion: operator.serverless.openshift.io/v1alpha1 kind: KnativeKafka metadata: name: knative-kafka namespace: knative-eventing spec: channel: enabled: true1 bootstrapServers: <bootstrap_servers>2 source: enabled: true3 broker: enabled: true4 defaultConfig: bootstrapServers: <bootstrap_servers>5 numPartitions: <num_partitions>6 replicationFactor: <replication_factor>7 sink: enabled: true8 - 1
- Enables developers to use the
KafkaChannelchannel type in the cluster. - 2
- A comma-separated list of bootstrap servers from your AMQ Streams cluster.
- 3
- Enables developers to use the
KafkaSourceevent source type in the cluster. - 4
- Enables developers to use the Knative Kafka broker implementation in the cluster.
- 5
- A comma-separated list of bootstrap servers from your Red Hat AMQ Streams cluster.
- 6
- Defines the number of partitions of the Kafka topics, backed by the
Brokerobjects. The default is10. - 7
- Defines the replication factor of the Kafka topics, backed by the
Brokerobjects. The default is3. - 8
- Enables developers to use a Kafka sink in the cluster.
NoteThe
replicationFactorvalue must be less than or equal to the number of nodes of your Red Hat AMQ Streams cluster.- Using the form is recommended for simpler configurations that do not require full control of KnativeKafka object creation.
- Editing the YAML is recommended for more complex configurations that require full control of KnativeKafka object creation. You can access the YAML by clicking the Edit YAML link in the top right of the Create Knative Kafka page.
- Click Create after you have completed any of the optional configurations for Kafka. You are automatically directed to the Knative Kafka tab where knative-kafka is in the list of resources.
Verification
- Click on the knative-kafka resource in the Knative Kafka tab. You are automatically directed to the Knative Kafka Overview page.
View the list of Conditions for the resource and confirm that they have a status of True.
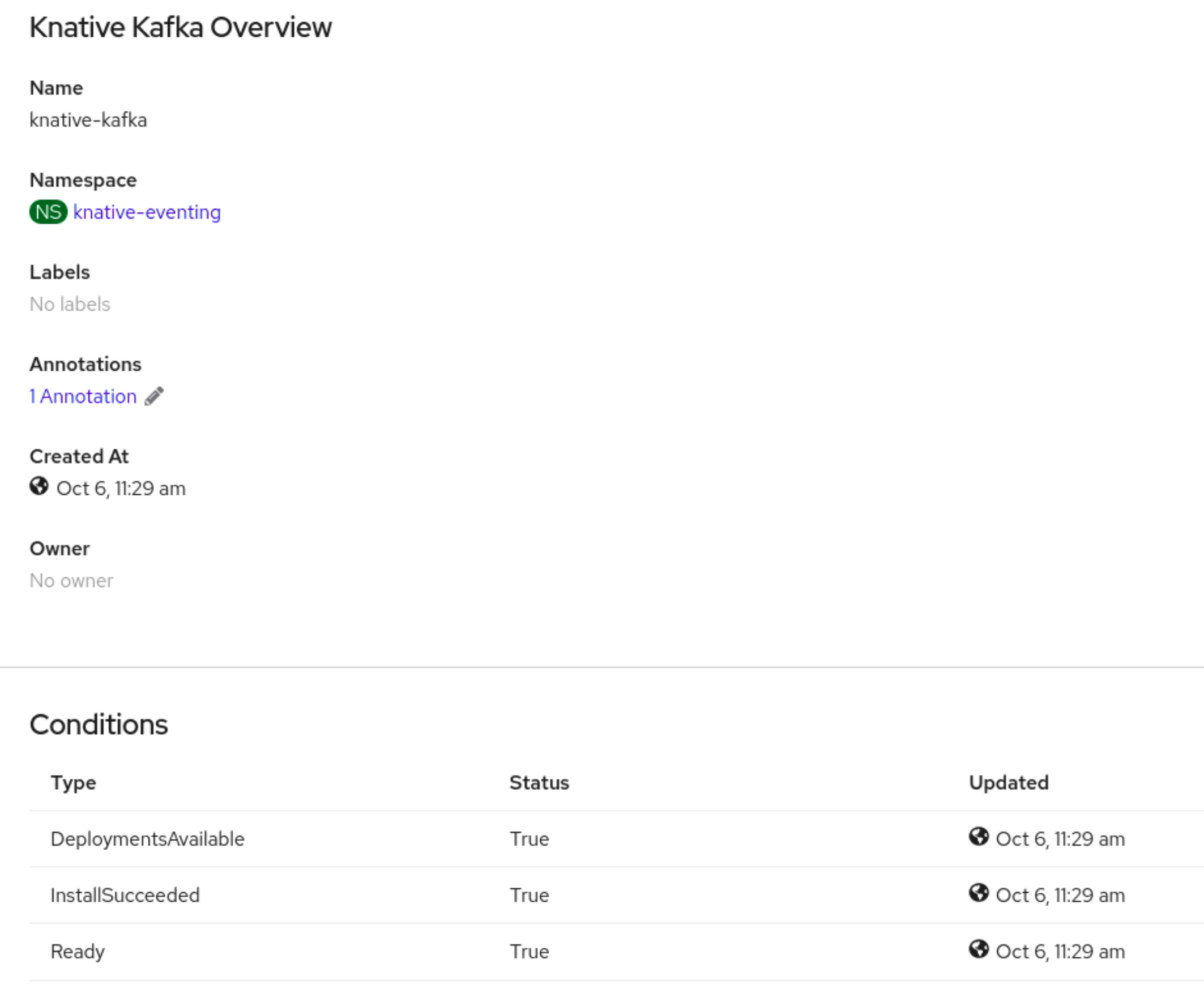
If the conditions have a status of Unknown or False, wait a few moments to refresh the page.
Check that the Knative Kafka resources have been created:
$ oc get pods -n knative-eventingExample output
NAME READY STATUS RESTARTS AGE kafka-broker-dispatcher-7769fbbcbb-xgffn 2/2 Running 0 44s kafka-broker-receiver-5fb56f7656-fhq8d 2/2 Running 0 44s kafka-channel-dispatcher-84fd6cb7f9-k2tjv 2/2 Running 0 44s kafka-channel-receiver-9b7f795d5-c76xr 2/2 Running 0 44s kafka-controller-6f95659bf6-trd6r 2/2 Running 0 44s kafka-source-dispatcher-6bf98bdfff-8bcsn 2/2 Running 0 44s kafka-webhook-eventing-68dc95d54b-825xs 2/2 Running 0 44s
6.2.2. Security configuration for Knative Kafka
Kafka clusters are generally secured by using the TLS or SASL authentication methods. You can configure a Kafka broker or channel to work against a protected Red Hat AMQ Streams cluster by using TLS or SASL.
Red Hat recommends that you enable both SASL and TLS together.
6.2.2.1. Configuring TLS authentication for Kafka brokers
Transport Layer Security (TLS) is used by Apache Kafka clients and servers to encrypt traffic between Knative and Kafka, as well as for authentication. TLS is the only supported method of traffic encryption for Knative Kafka.
Prerequisites
- You have cluster administrator permissions on OpenShift Container Platform.
-
The OpenShift Serverless Operator, Knative Eventing, and the
KnativeKafkaCR are installed on your OpenShift Container Platform cluster. - You have created a project or have access to a project with the appropriate roles and permissions to create applications and other workloads in OpenShift Container Platform.
-
You have a Kafka cluster CA certificate stored as a
.pemfile. -
You have a Kafka cluster client certificate and a key stored as
.pemfiles. -
Install the OpenShift CLI (
oc).
Procedure
Create the certificate files as a secret in the
knative-eventingnamespace:$ oc create secret -n knative-eventing generic <secret_name> \ --from-literal=protocol=SSL \ --from-file=ca.crt=caroot.pem \ --from-file=user.crt=certificate.pem \ --from-file=user.key=key.pemImportantUse the key names
ca.crt,user.crt, anduser.key. Do not change them.Edit the
KnativeKafkaCR and add a reference to your secret in thebrokerspec:apiVersion: operator.serverless.openshift.io/v1alpha1 kind: KnativeKafka metadata: namespace: knative-eventing name: knative-kafka spec: broker: enabled: true defaultConfig: authSecretName: <secret_name> ...
6.2.2.2. Configuring SASL authentication for Kafka brokers
Simple Authentication and Security Layer (SASL) is used by Apache Kafka for authentication. If you use SASL authentication on your cluster, users must provide credentials to Knative for communicating with the Kafka cluster; otherwise events cannot be produced or consumed.
Prerequisites
- You have cluster administrator permissions on OpenShift Container Platform.
-
The OpenShift Serverless Operator, Knative Eventing, and the
KnativeKafkaCR are installed on your OpenShift Container Platform cluster. - You have created a project or have access to a project with the appropriate roles and permissions to create applications and other workloads in OpenShift Container Platform.
- You have a username and password for a Kafka cluster.
-
You have chosen the SASL mechanism to use, for example,
PLAIN,SCRAM-SHA-256, orSCRAM-SHA-512. -
If TLS is enabled, you also need the
ca.crtcertificate file for the Kafka cluster. -
Install the OpenShift CLI (
oc).
Procedure
Create the certificate files as a secret in the
knative-eventingnamespace:$ oc create secret -n knative-eventing generic <secret_name> \ --from-literal=protocol=SASL_SSL \ --from-literal=sasl.mechanism=<sasl_mechanism> \ --from-file=ca.crt=caroot.pem \ --from-literal=password="SecretPassword" \ --from-literal=user="my-sasl-user"-
Use the key names
ca.crt,password, andsasl.mechanism. Do not change them. If you want to use SASL with public CA certificates, you must use the
tls.enabled=trueflag, rather than theca.crtargument, when creating the secret. For example:$ oc create secret -n <namespace> generic <kafka_auth_secret> \ --from-literal=tls.enabled=true \ --from-literal=password="SecretPassword" \ --from-literal=saslType="SCRAM-SHA-512" \ --from-literal=user="my-sasl-user"
-
Use the key names
Edit the
KnativeKafkaCR and add a reference to your secret in thebrokerspec:apiVersion: operator.serverless.openshift.io/v1alpha1 kind: KnativeKafka metadata: namespace: knative-eventing name: knative-kafka spec: broker: enabled: true defaultConfig: authSecretName: <secret_name> ...
6.2.2.3. Configuring TLS authentication for Kafka channels
Transport Layer Security (TLS) is used by Apache Kafka clients and servers to encrypt traffic between Knative and Kafka, as well as for authentication. TLS is the only supported method of traffic encryption for Knative Kafka.
Prerequisites
- You have cluster administrator permissions on OpenShift Container Platform.
-
The OpenShift Serverless Operator, Knative Eventing, and the
KnativeKafkaCR are installed on your OpenShift Container Platform cluster. - You have created a project or have access to a project with the appropriate roles and permissions to create applications and other workloads in OpenShift Container Platform.
-
You have a Kafka cluster CA certificate stored as a
.pemfile. -
You have a Kafka cluster client certificate and a key stored as
.pemfiles. -
Install the OpenShift CLI (
oc).
Procedure
Create the certificate files as secrets in your chosen namespace:
$ oc create secret -n <namespace> generic <kafka_auth_secret> \ --from-file=ca.crt=caroot.pem \ --from-file=user.crt=certificate.pem \ --from-file=user.key=key.pemImportantUse the key names
ca.crt,user.crt, anduser.key. Do not change them.Start editing the
KnativeKafkacustom resource:$ oc edit knativekafkaReference your secret and the namespace of the secret:
apiVersion: operator.serverless.openshift.io/v1alpha1 kind: KnativeKafka metadata: namespace: knative-eventing name: knative-kafka spec: channel: authSecretName: <kafka_auth_secret> authSecretNamespace: <kafka_auth_secret_namespace> bootstrapServers: <bootstrap_servers> enabled: true source: enabled: trueNoteMake sure to specify the matching port in the bootstrap server.
For example:
apiVersion: operator.serverless.openshift.io/v1alpha1 kind: KnativeKafka metadata: namespace: knative-eventing name: knative-kafka spec: channel: authSecretName: tls-user authSecretNamespace: kafka bootstrapServers: eventing-kafka-bootstrap.kafka.svc:9094 enabled: true source: enabled: true
6.2.2.4. Configuring SASL authentication for Kafka channels
Simple Authentication and Security Layer (SASL) is used by Apache Kafka for authentication. If you use SASL authentication on your cluster, users must provide credentials to Knative for communicating with the Kafka cluster; otherwise events cannot be produced or consumed.
Prerequisites
- You have cluster administrator permissions on OpenShift Container Platform.
-
The OpenShift Serverless Operator, Knative Eventing, and the
KnativeKafkaCR are installed on your OpenShift Container Platform cluster. - You have created a project or have access to a project with the appropriate roles and permissions to create applications and other workloads in OpenShift Container Platform.
- You have a username and password for a Kafka cluster.
-
You have chosen the SASL mechanism to use, for example,
PLAIN,SCRAM-SHA-256, orSCRAM-SHA-512. -
If TLS is enabled, you also need the
ca.crtcertificate file for the Kafka cluster. -
Install the OpenShift CLI (
oc).
Procedure
Create the certificate files as secrets in your chosen namespace:
$ oc create secret -n <namespace> generic <kafka_auth_secret> \ --from-file=ca.crt=caroot.pem \ --from-literal=password="SecretPassword" \ --from-literal=saslType="SCRAM-SHA-512" \ --from-literal=user="my-sasl-user"-
Use the key names
ca.crt,password, andsasl.mechanism. Do not change them. If you want to use SASL with public CA certificates, you must use the
tls.enabled=trueflag, rather than theca.crtargument, when creating the secret. For example:$ oc create secret -n <namespace> generic <kafka_auth_secret> \ --from-literal=tls.enabled=true \ --from-literal=password="SecretPassword" \ --from-literal=saslType="SCRAM-SHA-512" \ --from-literal=user="my-sasl-user"
-
Use the key names
Start editing the
KnativeKafkacustom resource:$ oc edit knativekafkaReference your secret and the namespace of the secret:
apiVersion: operator.serverless.openshift.io/v1alpha1 kind: KnativeKafka metadata: namespace: knative-eventing name: knative-kafka spec: channel: authSecretName: <kafka_auth_secret> authSecretNamespace: <kafka_auth_secret_namespace> bootstrapServers: <bootstrap_servers> enabled: true source: enabled: trueNoteMake sure to specify the matching port in the bootstrap server.
For example:
apiVersion: operator.serverless.openshift.io/v1alpha1 kind: KnativeKafka metadata: namespace: knative-eventing name: knative-kafka spec: channel: authSecretName: scram-user authSecretNamespace: kafka bootstrapServers: eventing-kafka-bootstrap.kafka.svc:9093 enabled: true source: enabled: true
6.2.2.5. Configuring SASL authentication for Kafka sources
Simple Authentication and Security Layer (SASL) is used by Apache Kafka for authentication. If you use SASL authentication on your cluster, users must provide credentials to Knative for communicating with the Kafka cluster; otherwise events cannot be produced or consumed.
Prerequisites
- You have cluster or dedicated administrator permissions on OpenShift Container Platform.
-
The OpenShift Serverless Operator, Knative Eventing, and the
KnativeKafkaCR are installed on your OpenShift Container Platform cluster. - You have created a project or have access to a project with the appropriate roles and permissions to create applications and other workloads in OpenShift Container Platform.
- You have a username and password for a Kafka cluster.
-
You have chosen the SASL mechanism to use, for example,
PLAIN,SCRAM-SHA-256, orSCRAM-SHA-512. -
If TLS is enabled, you also need the
ca.crtcertificate file for the Kafka cluster. -
You have installed the OpenShift (
oc) CLI.
Procedure
Create the certificate files as secrets in your chosen namespace:
$ oc create secret -n <namespace> generic <kafka_auth_secret> \ --from-file=ca.crt=caroot.pem \ --from-literal=password="SecretPassword" \ --from-literal=saslType="SCRAM-SHA-512" \1 --from-literal=user="my-sasl-user"- 1
- The SASL type can be
PLAIN,SCRAM-SHA-256, orSCRAM-SHA-512.
Create or modify your Kafka source so that it contains the following
specconfiguration:apiVersion: sources.knative.dev/v1beta1 kind: KafkaSource metadata: name: example-source spec: ... net: sasl: enable: true user: secretKeyRef: name: <kafka_auth_secret> key: user password: secretKeyRef: name: <kafka_auth_secret> key: password type: secretKeyRef: name: <kafka_auth_secret> key: saslType tls: enable: true caCert:1 secretKeyRef: name: <kafka_auth_secret> key: ca.crt ...- 1
- The
caCertspec is not required if you are using a public cloud Kafka service, such as Red Hat OpenShift Streams for Apache Kafka.
6.2.2.6. Configuring security for Kafka sinks
Transport Layer Security (TLS) is used by Apache Kafka clients and servers to encrypt traffic between Knative and Kafka, as well as for authentication. TLS is the only supported method of traffic encryption for Knative Kafka.
Simple Authentication and Security Layer (SASL) is used by Apache Kafka for authentication. If you use SASL authentication on your cluster, users must provide credentials to Knative for communicating with the Kafka cluster; otherwise events cannot be produced or consumed.
Prerequisites
-
The OpenShift Serverless Operator, Knative Eventing, and the
KnativeKafkacustom resources (CRs) are installed on your OpenShift Container Platform cluster. -
Kafka sink is enabled in the
KnativeKafkaCR. - You have created a project or have access to a project with the appropriate roles and permissions to create applications and other workloads in OpenShift Container Platform.
-
You have a Kafka cluster CA certificate stored as a
.pemfile. -
You have a Kafka cluster client certificate and a key stored as
.pemfiles. -
You have installed the OpenShift (
oc) CLI. -
You have chosen the SASL mechanism to use, for example,
PLAIN,SCRAM-SHA-256, orSCRAM-SHA-512.
Procedure
Create the certificate files as a secret in the same namespace as your
KafkaSinkobject:ImportantCertificates and keys must be in PEM format.
For authentication using SASL without encryption:
$ oc create secret -n <namespace> generic <secret_name> \ --from-literal=protocol=SASL_PLAINTEXT \ --from-literal=sasl.mechanism=<sasl_mechanism> \ --from-literal=user=<username> \ --from-literal=password=<password>For authentication using SASL and encryption using TLS:
$ oc create secret -n <namespace> generic <secret_name> \ --from-literal=protocol=SASL_SSL \ --from-literal=sasl.mechanism=<sasl_mechanism> \ --from-file=ca.crt=<my_caroot.pem_file_path> \1 --from-literal=user=<username> \ --from-literal=password=<password>- 1
- The
ca.crtcan be omitted to use the system’s root CA set if you are using a public cloud managed Kafka service, such as Red Hat OpenShift Streams for Apache Kafka.
For authentication and encryption using TLS:
$ oc create secret -n <namespace> generic <secret_name> \ --from-literal=protocol=SSL \ --from-file=ca.crt=<my_caroot.pem_file_path> \1 --from-file=user.crt=<my_cert.pem_file_path> \ --from-file=user.key=<my_key.pem_file_path>- 1
- The
ca.crtcan be omitted to use the system’s root CA set if you are using a public cloud managed Kafka service, such as Red Hat OpenShift Streams for Apache Kafka.
Create or modify a
KafkaSinkobject and add a reference to your secret in theauthspec:apiVersion: eventing.knative.dev/v1alpha1 kind: KafkaSink metadata: name: <sink_name> namespace: <namespace> spec: ... auth: secret: ref: name: <secret_name> ...Apply the
KafkaSinkobject:$ oc apply -f <filename>
6.2.3. Configuring Kafka broker settings
You can configure the replication factor, bootstrap servers, and the number of topic partitions for a Kafka broker, by creating a config map and referencing this config map in the Kafka Broker object.
Prerequisites
- You have cluster or dedicated administrator permissions on OpenShift Container Platform.
-
The OpenShift Serverless Operator, Knative Eventing, and the
KnativeKafkacustom resource (CR) are installed on your OpenShift Container Platform cluster. - You have created a project or have access to a project that has the appropriate roles and permissions to create applications and other workloads in OpenShift Container Platform.
-
You have installed the OpenShift CLI (
oc).
Procedure
Modify the
kafka-broker-configconfig map, or create your own config map that contains the following configuration:apiVersion: v1 kind: ConfigMap metadata: name: <config_map_name>1 namespace: <namespace>2 data: default.topic.partitions: <integer>3 default.topic.replication.factor: <integer>4 bootstrap.servers: <list_of_servers>5 - 1
- The config map name.
- 2
- The namespace where the config map exists.
- 3
- The number of topic partitions for the Kafka broker. This controls how quickly events can be sent to the broker. A higher number of partitions requires greater compute resources.
- 4
- The replication factor of topic messages. This prevents against data loss. A higher replication factor requires greater compute resources and more storage.
- 5
- A comma separated list of bootstrap servers. This can be inside or outside of the OpenShift Container Platform cluster, and is a list of Kafka clusters that the broker receives events from and sends events to.
ImportantThe
default.topic.replication.factorvalue must be less than or equal to the number of Kafka broker instances in your cluster. For example, if you only have one Kafka broker, thedefault.topic.replication.factorvalue should not be more than"1".Example Kafka broker config map
apiVersion: v1 kind: ConfigMap metadata: name: kafka-broker-config namespace: knative-eventing data: default.topic.partitions: "10" default.topic.replication.factor: "3" bootstrap.servers: "my-cluster-kafka-bootstrap.kafka:9092"Apply the config map:
$ oc apply -f <config_map_filename>Specify the config map for the Kafka
Brokerobject:Example Broker object
apiVersion: eventing.knative.dev/v1 kind: Broker metadata: name: <broker_name>1 namespace: <namespace>2 annotations: eventing.knative.dev/broker.class: Kafka3 spec: config: apiVersion: v1 kind: ConfigMap name: <config_map_name>4 namespace: <namespace>5 ...Apply the broker:
$ oc apply -f <broker_filename>
6.3. Serverless components in the Administrator perspective
If you do not want to switch to the Developer perspective in the OpenShift Container Platform web console or use the Knative (kn) CLI or YAML files, you can create Knative components by using the Administator perspective of the OpenShift Container Platform web console.
6.3.1. Creating serverless applications using the Administrator perspective
Serverless applications are created and deployed as Kubernetes services, defined by a route and a configuration, and contained in a YAML file. To deploy a serverless application using OpenShift Serverless, you must create a Knative Service object.
Example Knative Service object YAML file
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: hello
namespace: default
spec:
template:
spec:
containers:
- image: docker.io/openshift/hello-openshift
env:
- name: RESPONSE
value: "Hello Serverless!"After the service is created and the application is deployed, Knative creates an immutable revision for this version of the application. Knative also performs network programming to create a route, ingress, service, and load balancer for your application and automatically scales your pods up and down based on traffic.
Prerequisites
To create serverless applications using the Administrator perspective, ensure that you have completed the following steps.
- The OpenShift Serverless Operator and Knative Serving are installed.
- You have logged in to the web console and are in the Administrator perspective.
Procedure
-
Navigate to the Serverless
Serving page. - In the Create list, select Service.
- Manually enter YAML or JSON definitions, or by dragging and dropping a file into the editor.
- Click Create.
6.4. Integrating Service Mesh with OpenShift Serverless
The OpenShift Serverless Operator provides Kourier as the default ingress for Knative. However, you can use Service Mesh with OpenShift Serverless whether Kourier is enabled or not. Integrating with Kourier disabled allows you to configure additional networking and routing options that the Kourier ingress does not support, such as mTLS functionality.
OpenShift Serverless only supports the use of Red Hat OpenShift Service Mesh functionality that is explicitly documented in this guide, and does not support other undocumented features.
6.4.1. Prerequisites
The examples in the following procedures use the domain
example.com. The example certificate for this domain is used as a certificate authority (CA) that signs the subdomain certificate.To complete and verify these procedures in your deployment, you need either a certificate signed by a widely trusted public CA or a CA provided by your organization. Example commands must be adjusted according to your domain, subdomain, and CA.
-
You must configure the wildcard certificate to match the domain of your OpenShift Container Platform cluster. For example, if your OpenShift Container Platform console address is
https://console-openshift-console.apps.openshift.example.com, you must configure the wildcard certificate so that the domain is*.apps.openshift.example.com. For more information about configuring wildcard certificates, see the following topic about Creating a certificate to encrypt incoming external traffic. - If you want to use any domain name, including those which are not subdomains of the default OpenShift Container Platform cluster domain, you must set up domain mapping for those domains. For more information, see the OpenShift Serverless documentation about Creating a custom domain mapping.
6.4.2. Creating a certificate to encrypt incoming external traffic
By default, the Service Mesh mTLS feature only secures traffic inside of the Service Mesh itself, between the ingress gateway and individual pods that have sidecars. To encrypt traffic as it flows into the OpenShift Container Platform cluster, you must generate a certificate before you enable the OpenShift Serverless and Service Mesh integration.
Prerequisites
- You have access to an OpenShift Container Platform account with cluster administrator access.
- You have installed the OpenShift Serverless Operator and Knative Serving.
-
Install the OpenShift CLI (
oc). - You have created a project or have access to a project with the appropriate roles and permissions to create applications and other workloads in OpenShift Container Platform.
Procedure
Create a root certificate and private key that signs the certificates for your Knative services:
$ openssl req -x509 -sha256 -nodes -days 365 -newkey rsa:2048 \ -subj '/O=Example Inc./CN=example.com' \ -keyout root.key \ -out root.crtCreate a wildcard certificate:
$ openssl req -nodes -newkey rsa:2048 \ -subj "/CN=*.apps.openshift.example.com/O=Example Inc." \ -keyout wildcard.key \ -out wildcard.csrSign the wildcard certificate:
$ openssl x509 -req -days 365 -set_serial 0 \ -CA root.crt \ -CAkey root.key \ -in wildcard.csr \ -out wildcard.crtCreate a secret by using the wildcard certificate:
$ oc create -n istio-system secret tls wildcard-certs \ --key=wildcard.key \ --cert=wildcard.crtThis certificate is picked up by the gateways created when you integrate OpenShift Serverless with Service Mesh, so that the ingress gateway serves traffic with this certificate.
6.4.3. Integrating Service Mesh with OpenShift Serverless
You can integrate Service Mesh with OpenShift Serverless without using Kourier as the default ingress. To do this, do not install the Knative Serving component before completing the following procedure. There are additional steps required when creating the KnativeServing custom resource definition (CRD) to integrate Knative Serving with Service Mesh, which are not covered in the general Knative Serving installation procedure. This procedure might be useful if you want to integrate Service Mesh as the default and only ingress for your OpenShift Serverless installation.
Prerequisites
- You have access to an OpenShift Container Platform account with cluster administrator access.
- You have created a project or have access to a project with the appropriate roles and permissions to create applications and other workloads in OpenShift Container Platform.
Install the Red Hat OpenShift Service Mesh Operator and create a
ServiceMeshControlPlaneresource in theistio-systemnamespace. If you want to use mTLS functionality, you must also set thespec.security.dataPlane.mtlsfield for theServiceMeshControlPlaneresource totrue.ImportantUsing OpenShift Serverless with Service Mesh is only supported with Red Hat OpenShift Service Mesh version 2.0.5 or later.
- Install the OpenShift Serverless Operator.
-
Install the OpenShift CLI (
oc).
Procedure
Add the namespaces that you would like to integrate with Service Mesh to the
ServiceMeshMemberRollobject as members:apiVersion: maistra.io/v1 kind: ServiceMeshMemberRoll metadata: name: default namespace: istio-system spec: members:1 - knative-serving - <namespace>- 1
- A list of namespaces to be integrated with Service Mesh.
ImportantThis list of namespaces must include the
knative-servingnamespace.Apply the
ServiceMeshMemberRollresource:$ oc apply -f <filename>Create the necessary gateways so that Service Mesh can accept traffic:
Example
knative-local-gatewayobject using HTTPapiVersion: networking.istio.io/v1alpha3 kind: Gateway metadata: name: knative-ingress-gateway namespace: knative-serving spec: selector: istio: ingressgateway servers: - port: number: 443 name: https protocol: HTTPS hosts: - "*" tls: mode: SIMPLE credentialName: <wildcard_certs>1 --- apiVersion: networking.istio.io/v1alpha3 kind: Gateway metadata: name: knative-local-gateway namespace: knative-serving spec: selector: istio: ingressgateway servers: - port: number: 8081 name: http protocol: HTTP2 hosts: - "*" --- apiVersion: v1 kind: Service metadata: name: knative-local-gateway namespace: istio-system labels: experimental.istio.io/disable-gateway-port-translation: "true" spec: type: ClusterIP selector: istio: ingressgateway ports: - name: http2 port: 80 targetPort: 8081- 1
- Add the name of the secret that contains the wildcard certificate.
- 2
- The
knative-local-gatewayserves HTTP traffic. Using HTTP means that traffic coming from outside of Service Mesh, but using an internal hostname, such asexample.default.svc.cluster.local, is not encrypted. You can set up encryption for this path by creating another wildcard certificate and an additional gateway that uses a differentprotocolspec.
Example
knative-local-gatewayobject using HTTPSapiVersion: networking.istio.io/v1alpha3 kind: Gateway metadata: name: knative-local-gateway namespace: knative-serving spec: selector: istio: ingressgateway servers: - port: number: 443 name: https protocol: HTTPS hosts: - "*" tls: mode: SIMPLE credentialName: <wildcard_certs>Apply the
Gatewayresources:$ oc apply -f <filename>Install Knative Serving by creating the following
KnativeServingcustom resource definition (CRD), which also enables the Istio integration:apiVersion: operator.knative.dev/v1alpha1 kind: KnativeServing metadata: name: knative-serving namespace: knative-serving spec: ingress: istio: enabled: true1 deployments:2 - name: activator annotations: "sidecar.istio.io/inject": "true" "sidecar.istio.io/rewriteAppHTTPProbers": "true" - name: autoscaler annotations: "sidecar.istio.io/inject": "true" "sidecar.istio.io/rewriteAppHTTPProbers": "true"Apply the
KnativeServingresource:$ oc apply -f <filename>Create a Knative Service that has sidecar injection enabled and uses a pass-through route:
apiVersion: serving.knative.dev/v1 kind: Service metadata: name: <service_name> namespace: <namespace>1 annotations: serving.knative.openshift.io/enablePassthrough: "true"2 spec: template: metadata: annotations: sidecar.istio.io/inject: "true"3 sidecar.istio.io/rewriteAppHTTPProbers: "true" spec: containers: - image: <image_url>- 1
- A namespace that is part of the Service Mesh member roll.
- 2
- Instructs Knative Serving to generate an OpenShift Container Platform pass-through enabled route, so that the certificates you have generated are served through the ingress gateway directly.
- 3
- Injects Service Mesh sidecars into the Knative service pods.
Apply the
Serviceresource:$ oc apply -f <filename>
Verification
Access your serverless application by using a secure connection that is now trusted by the CA:
$ curl --cacert root.crt <service_url>Example command
$ curl --cacert root.crt https://hello-default.apps.openshift.example.comExample output
Hello Openshift!
6.4.4. Enabling Knative Serving metrics when using Service Mesh with mTLS
If Service Mesh is enabled with mTLS, metrics for Knative Serving are disabled by default, because Service Mesh prevents Prometheus from scraping metrics. This section shows how to enable Knative Serving metrics when using Service Mesh and mTLS.
Prerequisites
- You have installed the OpenShift Serverless Operator and Knative Serving on your cluster.
- You have installed Red Hat OpenShift Service Mesh with the mTLS functionality enabled.
- You have access to an OpenShift Container Platform account with cluster administrator access.
-
Install the OpenShift CLI (
oc). - You have created a project or have access to a project with the appropriate roles and permissions to create applications and other workloads in OpenShift Container Platform.
Procedure
Specify
prometheusas themetrics.backend-destinationin theobservabilityspec of the Knative Serving custom resource (CR):apiVersion: operator.knative.dev/v1beta1 kind: KnativeServing metadata: name: knative-serving spec: config: observability: metrics.backend-destination: "prometheus" ...This step prevents metrics from being disabled by default.
Apply the following network policy to allow traffic from the Prometheus namespace:
apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: name: allow-from-openshift-monitoring-ns namespace: knative-serving spec: ingress: - from: - namespaceSelector: matchLabels: name: "openshift-monitoring" podSelector: {} ...Modify and reapply the default Service Mesh control plane in the
istio-systemnamespace, so that it includes the following spec:... spec: proxy: networking: trafficControl: inbound: excludedPorts: - 8444 ...
6.4.5. Integrating Service Mesh with OpenShift Serverless when Kourier is enabled
You can use Service Mesh with OpenShift Serverless even if Kourier is already enabled. This procedure might be useful if you have already installed Knative Serving with Kourier enabled, but decide to add a Service Mesh integration later.
Prerequisites
- You have access to an OpenShift Container Platform account with cluster administrator access.
- You have created a project or have access to a project with the appropriate roles and permissions to create applications and other workloads in OpenShift Container Platform.
-
Install the OpenShift CLI (
oc). - Install the OpenShift Serverless Operator and Knative Serving on your cluster.
- Install Red Hat OpenShift Service Mesh. OpenShift Serverless with Service Mesh and Kourier is supported for use with both Red Hat OpenShift Service Mesh versions 1.x and 2.x.
Procedure
Add the namespaces that you would like to integrate with Service Mesh to the
ServiceMeshMemberRollobject as members:apiVersion: maistra.io/v1 kind: ServiceMeshMemberRoll metadata: name: default namespace: istio-system spec: members: - <namespace>1 ...- 1
- A list of namespaces to be integrated with Service Mesh.
Apply the
ServiceMeshMemberRollresource:$ oc apply -f <filename>Create a network policy that permits traffic flow from Knative system pods to Knative services:
For each namespace that you want to integrate with Service Mesh, create a
NetworkPolicyresource:apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: name: allow-from-serving-system-namespace namespace: <namespace>1 spec: ingress: - from: - namespaceSelector: matchLabels: knative.openshift.io/part-of: "openshift-serverless" podSelector: {} policyTypes: - Ingress ...- 1
- Add the namespace that you want to integrate with Service Mesh.
NoteThe
knative.openshift.io/part-of: "openshift-serverless"label was added in OpenShift Serverless 1.22.0. If you are using OpenShift Serverless 1.21.1 or earlier, add theknative.openshift.io/part-oflabel to theknative-servingandknative-serving-ingressnamespaces.Add the label to the
knative-servingnamespace:$ oc label namespace knative-serving knative.openshift.io/part-of=openshift-serverlessAdd the label to the
knative-serving-ingressnamespace:$ oc label namespace knative-serving-ingress knative.openshift.io/part-of=openshift-serverlessApply the
NetworkPolicyresource:$ oc apply -f <filename>
6.4.6. Improving memory usage by using secret filtering for Service Mesh
By default, the informers implementation for the Kubernetes client-go library fetches all resources of a particular type. This can lead to a substantial overhead when many resources are available, which can cause the Knative net-istio ingress controller to fail on large clusters due to memory leaking. However, a filtering mechanism is available for the Knative net-istio ingress controller, which enables the controller to only fetch Knative related secrets. You can enable this mechanism by adding an annotation to the KnativeServing custom resource (CR).
Prerequisites
- You have access to an OpenShift Container Platform account with cluster administrator access.
- You have created a project or have access to a project with the appropriate roles and permissions to create applications and other workloads in OpenShift Container Platform.
- Install Red Hat OpenShift Service Mesh. OpenShift Serverless with Service Mesh only is supported for use with Red Hat OpenShift Service Mesh version 2.0.5 or later.
- Install the OpenShift Serverless Operator and Knative Serving.
-
Install the OpenShift CLI (
oc).
Procedure
Add the
serverless.openshift.io/enable-secret-informer-filteringannotation to theKnativeServingCR:Example KnativeServing CR
apiVersion: operator.knative.dev/v1alpha1 kind: KnativeServing metadata: name: knative-serving namespace: knative-serving annotations: serverless.openshift.io/enable-secret-informer-filtering: "true"1 spec: ingress: istio: enabled: true deployments: - annotations: sidecar.istio.io/inject: "true" sidecar.istio.io/rewriteAppHTTPProbers: "true" name: activator - annotations: sidecar.istio.io/inject: "true" sidecar.istio.io/rewriteAppHTTPProbers: "true" name: autoscaler- 1
- Adding this annotation injects an environment variable,
ENABLE_SECRET_INFORMER_FILTERING_BY_CERT_UID=true, to thenet-istiocontroller pod.
6.5. Serverless administrator metrics
Metrics enable cluster administrators to monitor how OpenShift Serverless cluster components and workloads are performing.
You can view different metrics for OpenShift Serverless by navigating to Dashboards in the OpenShift Container Platform web console Administrator perspective.
6.5.1. Prerequisites
- See the OpenShift Container Platform documentation on Managing metrics for information about enabling metrics for your cluster.
- To view metrics for Knative components on OpenShift Container Platform, you need cluster administrator permissions, and access to the web console Administrator perspective.
If Service Mesh is enabled with mTLS, metrics for Knative Serving are disabled by default because Service Mesh prevents Prometheus from scraping metrics.
For information about resolving this issue, see Enabling Knative Serving metrics when using Service Mesh with mTLS.
Scraping the metrics does not affect autoscaling of a Knative service, because scraping requests do not go through the activator. Consequently, no scraping takes place if no pods are running.
6.5.2. Controller metrics
The following metrics are emitted by any component that implements a controller logic. These metrics show details about reconciliation operations and the work queue behavior upon which reconciliation requests are added to the work queue.
| Metric name | Description | Type | Tags | Unit |
|---|---|---|---|---|
|
| The depth of the work queue. | Gauge |
| Integer (no units) |
|
| The number of reconcile operations. | Counter |
| Integer (no units) |
|
| The latency of reconcile operations. | Histogram |
| Milliseconds |
|
| The total number of add actions handled by the work queue. | Counter |
| Integer (no units) |
|
| The length of time an item stays in the work queue before being requested. | Histogram |
| Seconds |
|
| The total number of retries that have been handled by the work queue. | Counter |
| Integer (no units) |
|
| The length of time it takes to process and item from the work queue. | Histogram |
| Seconds |
|
| The length of time that outstanding work queue items have been in progress. | Histogram |
| Seconds |
|
| The length of time that the longest outstanding work queue items has been in progress. | Histogram |
| Seconds |
6.5.3. Webhook metrics
Webhook metrics report useful information about operations. For example, if a large number of operations fail, this might indicate an issue with a user-created resource.
| Metric name | Description | Type | Tags | Unit |
|---|---|---|---|---|
|
| The number of requests that are routed to the webhook. | Counter |
| Integer (no units) |
|
| The response time for a webhook request. | Histogram |
| Milliseconds |
6.5.4. Knative Eventing metrics
Cluster administrators can view the following metrics for Knative Eventing components.
By aggregating the metrics from HTTP code, events can be separated into two categories; successful events (2xx) and failed events (5xx).
6.5.4.1. Broker ingress metrics
You can use the following metrics to debug the broker ingress, see how it is performing, and see which events are being dispatched by the ingress component.
| Metric name | Description | Type | Tags | Unit |
|---|---|---|---|---|
|
| Number of events received by a broker. | Counter |
| Integer (no units) |
|
| The time taken to dispatch an event to a channel. | Histogram |
| Milliseconds |
6.5.4.2. Broker filter metrics
You can use the following metrics to debug broker filters, see how they are performing, and see which events are being dispatched by the filters. You can also measure the latency of the filtering action on an event.
| Metric name | Description | Type | Tags | Unit |
|---|---|---|---|---|
|
| Number of events received by a broker. | Counter |
| Integer (no units) |
|
| The time taken to dispatch an event to a channel. | Histogram |
| Milliseconds |
|
| The time it takes to process an event before it is dispatched to a trigger subscriber. | Histogram |
| Milliseconds |
6.5.4.3. InMemoryChannel dispatcher metrics
You can use the following metrics to debug InMemoryChannel channels, see how they are performing, and see which events are being dispatched by the channels.
| Metric name | Description | Type | Tags | Unit |
|---|---|---|---|---|
|
|
Number of events dispatched by | Counter |
| Integer (no units) |
|
|
The time taken to dispatch an event from an | Histogram |
| Milliseconds |
6.5.4.4. Event source metrics
You can use the following metrics to verify that events have been delivered from the event source to the connected event sink.
| Metric name | Description | Type | Tags | Unit |
|---|---|---|---|---|
|
| Number of events sent by the event source. | Counter |
| Integer (no units) |
|
| Number of retried events sent by the event source after initially failing to be delivered. | Counter |
| Integer (no units) |
6.5.5. Knative Serving metrics
Cluster administrators can view the following metrics for Knative Serving components.
6.5.5.1. Activator metrics
You can use the following metrics to understand how applications respond when traffic passes through the activator.
| Metric name | Description | Type | Tags | Unit |
|---|---|---|---|---|
|
| The number of concurrent requests that are routed to the activator, or average concurrency over a reporting period. | Gauge |
| Integer (no units) |
|
| The number of requests that are routed to activator. These are requests that have been fulfilled from the activator handler. | Counter |
| Integer (no units) |
|
| The response time in milliseconds for a fulfilled, routed request. | Histogram |
| Milliseconds |
6.5.5.2. Autoscaler metrics
The autoscaler component exposes a number of metrics related to autoscaler behavior for each revision. For example, at any given time, you can monitor the targeted number of pods the autoscaler tries to allocate for a service, the average number of requests per second during the stable window, or whether the autoscaler is in panic mode if you are using the Knative pod autoscaler (KPA).
| Metric name | Description | Type | Tags | Unit |
|---|---|---|---|---|
|
| The number of pods the autoscaler tries to allocate for a service. | Gauge |
| Integer (no units) |
|
| The excess burst capacity served over the stable window. | Gauge |
| Integer (no units) |
|
| The average number of requests for each observed pod over the stable window. | Gauge |
| Integer (no units) |
|
| The average number of requests for each observed pod over the panic window. | Gauge |
| Integer (no units) |
|
| The number of concurrent requests that the autoscaler tries to send to each pod. | Gauge |
| Integer (no units) |
|
| The average number of requests-per-second for each observed pod over the stable window. | Gauge |
| Integer (no units) |
|
| The average number of requests-per-second for each observed pod over the panic window. | Gauge |
| Integer (no units) |
|
| The number of requests-per-second that the autoscaler targets for each pod. | Gauge |
| Integer (no units) |
|
|
This value is | Gauge |
| Integer (no units) |
|
| The number of pods that the autoscaler has requested from the Kubernetes cluster. | Gauge |
| Integer (no units) |
|
| The number of pods that are allocated and currently have a ready state. | Gauge |
| Integer (no units) |
|
| The number of pods that have a not ready state. | Gauge |
| Integer (no units) |
|
| The number of pods that are currently pending. | Gauge |
| Integer (no units) |
|
| The number of pods that are currently terminating. | Gauge |
| Integer (no units) |
6.5.5.3. Go runtime metrics
Each Knative Serving control plane process emits a number of Go runtime memory statistics (MemStats).
The name tag for each metric is an empty tag.
| Metric name | Description | Type | Tags | Unit |
|---|---|---|---|---|
|
|
The number of bytes of allocated heap objects. This metric is the same as | Gauge |
| Integer (no units) |
|
| The cumulative bytes allocated for heap objects. | Gauge |
| Integer (no units) |
|
| The total bytes of memory obtained from the operating system. | Gauge |
| Integer (no units) |
|
| The number of pointer lookups performed by the runtime. | Gauge |
| Integer (no units) |
|
| The cumulative count of heap objects allocated. | Gauge |
| Integer (no units) |
|
| The cumulative count of heap objects that have been freed. | Gauge |
| Integer (no units) |
|
| The number of bytes of allocated heap objects. | Gauge |
| Integer (no units) |
|
| The number of bytes of heap memory obtained from the operating system. | Gauge |
| Integer (no units) |
|
| The number of bytes in idle, unused spans. | Gauge |
| Integer (no units) |
|
| The number of bytes in spans that are currently in use. | Gauge |
| Integer (no units) |
|
| The number of bytes of physical memory returned to the operating system. | Gauge |
| Integer (no units) |
|
| The number of allocated heap objects. | Gauge |
| Integer (no units) |
|
| The number of bytes in stack spans that are currently in use. | Gauge |
| Integer (no units) |
|
| The number of bytes of stack memory obtained from the operating system. | Gauge |
| Integer (no units) |
|
|
The number of bytes of allocated | Gauge |
| Integer (no units) |
|
|
The number of bytes of memory obtained from the operating system for | Gauge |
| Integer (no units) |
|
|
The number of bytes of allocated | Gauge |
| Integer (no units) |
|
|
The number of bytes of memory obtained from the operating system for | Gauge |
| Integer (no units) |
|
| The number of bytes of memory in profiling bucket hash tables. | Gauge |
| Integer (no units) |
|
| The number of bytes of memory in garbage collection metadata. | Gauge |
| Integer (no units) |
|
| The number of bytes of memory in miscellaneous, off-heap runtime allocations. | Gauge |
| Integer (no units) |
|
| The target heap size of the next garbage collection cycle. | Gauge |
| Integer (no units) |
|
| The time that the last garbage collection was completed in Epoch or Unix time. | Gauge |
| Nanoseconds |
|
| The cumulative time in garbage collection stop-the-world pauses since the program started. | Gauge |
| Nanoseconds |
|
| The number of completed garbage collection cycles. | Gauge |
| Integer (no units) |
|
| The number of garbage collection cycles that were forced due to an application calling the garbage collection function. | Gauge |
| Integer (no units) |
|
| The fraction of the available CPU time of the program that has been used by the garbage collector since the program started. | Gauge |
| Integer (no units) |
6.6. Using metering with OpenShift Serverless
Metering is a deprecated feature. Deprecated functionality is still included in OpenShift Container Platform and continues to be supported; however, it will be removed in a future release of this product and is not recommended for new deployments.
For the most recent list of major functionality that has been deprecated or removed within OpenShift Container Platform, refer to the Deprecated and removed features section of the OpenShift Container Platform release notes.
As a cluster administrator, you can use metering to analyze what is happening in your OpenShift Serverless cluster.
For more information about metering on OpenShift Container Platform, see About metering.
Metering is not currently supported for IBM Z and IBM Power Systems.
6.6.1. Installing metering
For information about installing metering on OpenShift Container Platform, see Installing Metering.
6.6.2. Data source reports for Knative Serving metering
The following data source reports are examples of how Knative Serving can be used with OpenShift Container Platform metering.
6.6.2.1. Data source report for CPU usage in Knative Serving
This data source report provides the accumulated CPU seconds used per Knative service over the report time period.
Example YAML file
apiVersion: metering.openshift.io/v1
kind: ReportDataSource
metadata:
name: knative-service-cpu-usage
spec:
prometheusMetricsImporter:
query: >
sum
by(namespace,
label_serving_knative_dev_service,
label_serving_knative_dev_revision)
(
label_replace(rate(container_cpu_usage_seconds_total{container!="POD",container!="",pod!=""}[1m]), "pod", "$1", "pod", "(.*)")
*
on(pod, namespace)
group_left(label_serving_knative_dev_service, label_serving_knative_dev_revision)
kube_pod_labels{label_serving_knative_dev_service!=""}
)6.6.2.2. Data source report for memory usage in Knative Serving
This data source report provides the average memory consumption per Knative service over the report time period.
Example YAML file
apiVersion: metering.openshift.io/v1
kind: ReportDataSource
metadata:
name: knative-service-memory-usage
spec:
prometheusMetricsImporter:
query: >
sum
by(namespace,
label_serving_knative_dev_service,
label_serving_knative_dev_revision)
(
label_replace(container_memory_usage_bytes{container!="POD", container!="",pod!=""}, "pod", "$1", "pod", "(.*)")
*
on(pod, namespace)
group_left(label_serving_knative_dev_service, label_serving_knative_dev_revision)
kube_pod_labels{label_serving_knative_dev_service!=""}
)6.6.2.3. Applying data source reports for Knative Serving metering
You can apply data source reports by using the following command:
$ oc apply -f <data_source_report_name>.yamlExample command
$ oc apply -f knative-service-memory-usage.yaml6.6.3. Queries for Knative Serving metering
The following ReportQuery resources reference the example ReportDataSource resources provided:
Query for CPU usage in Knative Serving
apiVersion: metering.openshift.io/v1
kind: ReportQuery
metadata:
name: knative-service-cpu-usage
spec:
inputs:
- name: ReportingStart
type: time
- name: ReportingEnd
type: time
- default: knative-service-cpu-usage
name: KnativeServiceCpuUsageDataSource
type: ReportDataSource
columns:
- name: period_start
type: timestamp
unit: date
- name: period_end
type: timestamp
unit: date
- name: namespace
type: varchar
unit: kubernetes_namespace
- name: service
type: varchar
- name: data_start
type: timestamp
unit: date
- name: data_end
type: timestamp
unit: date
- name: service_cpu_seconds
type: double
unit: cpu_core_seconds
query: |
SELECT
timestamp '{| default .Report.ReportingStart .Report.Inputs.ReportingStart| prestoTimestamp |}' AS period_start,
timestamp '{| default .Report.ReportingEnd .Report.Inputs.ReportingEnd | prestoTimestamp |}' AS period_end,
labels['namespace'] as project,
labels['label_serving_knative_dev_service'] as service,
min("timestamp") as data_start,
max("timestamp") as data_end,
sum(amount * "timeprecision") AS service_cpu_seconds
FROM {| dataSourceTableName .Report.Inputs.KnativeServiceCpuUsageDataSource |}
WHERE "timestamp" >= timestamp '{| default .Report.ReportingStart .Report.Inputs.ReportingStart | prestoTimestamp |}'
AND "timestamp" < timestamp '{| default .Report.ReportingEnd .Report.Inputs.ReportingEnd | prestoTimestamp |}'
GROUP BY labels['namespace'],labels['label_serving_knative_dev_service']Query for memory usage in Knative Serving
apiVersion: metering.openshift.io/v1
kind: ReportQuery
metadata:
name: knative-service-memory-usage
spec:
inputs:
- name: ReportingStart
type: time
- name: ReportingEnd
type: time
- default: knative-service-memory-usage
name: KnativeServiceMemoryUsageDataSource
type: ReportDataSource
columns:
- name: period_start
type: timestamp
unit: date
- name: period_end
type: timestamp
unit: date
- name: namespace
type: varchar
unit: kubernetes_namespace
- name: service
type: varchar
- name: data_start
type: timestamp
unit: date
- name: data_end
type: timestamp
unit: date
- name: service_usage_memory_byte_seconds
type: double
unit: byte_seconds
query: |
SELECT
timestamp '{| default .Report.ReportingStart .Report.Inputs.ReportingStart| prestoTimestamp |}' AS period_start,
timestamp '{| default .Report.ReportingEnd .Report.Inputs.ReportingEnd | prestoTimestamp |}' AS period_end,
labels['namespace'] as project,
labels['label_serving_knative_dev_service'] as service,
min("timestamp") as data_start,
max("timestamp") as data_end,
sum(amount * "timeprecision") AS service_usage_memory_byte_seconds
FROM {| dataSourceTableName .Report.Inputs.KnativeServiceMemoryUsageDataSource |}
WHERE "timestamp" >= timestamp '{| default .Report.ReportingStart .Report.Inputs.ReportingStart | prestoTimestamp |}'
AND "timestamp" < timestamp '{| default .Report.ReportingEnd .Report.Inputs.ReportingEnd | prestoTimestamp |}'
GROUP BY labels['namespace'],labels['label_serving_knative_dev_service']6.6.3.1. Applying Queries for Knative Serving metering
Apply the
ReportQueryresource:$ oc apply -f <query_name>.yamlExample command
$ oc apply -f knative-service-memory-usage.yaml
6.6.4. Metering reports for Knative Serving
You can run metering reports against Knative Serving by creating Report resources. Before you run a report, you must modify the input parameter within the Report resource to specify the start and end dates of the reporting period.
Example Report resource
apiVersion: metering.openshift.io/v1
kind: Report
metadata:
name: knative-service-cpu-usage
spec:
reportingStart: '2019-06-01T00:00:00Z'
reportingEnd: '2019-06-30T23:59:59Z'
query: knative-service-cpu-usage
runImmediately: true6.6.4.1. Running a metering report
Run the report:
$ oc apply -f <report_name>.ymlYou can then check the report:
$ oc get reportExample output
NAME QUERY SCHEDULE RUNNING FAILED LAST REPORT TIME AGE knative-service-cpu-usage knative-service-cpu-usage Finished 2019-06-30T23:59:59Z 10h
6.7. High availability
High availability (HA) is a standard feature of Kubernetes APIs that helps to ensure that APIs stay operational if a disruption occurs. In an HA deployment, if an active controller crashes or is deleted, another controller is readily available. This controller takes over processing of the APIs that were being serviced by the controller that is now unavailable.
HA in OpenShift Serverless is available through leader election, which is enabled by default after the Knative Serving or Eventing control plane is installed. When using a leader election HA pattern, instances of controllers are already scheduled and running inside the cluster before they are required. These controller instances compete to use a shared resource, known as the leader election lock. The instance of the controller that has access to the leader election lock resource at any given time is called the leader.
6.7.1. Configuring high availability replicas for Knative Serving
High availability (HA) is available by default for the Knative Serving activator, autoscaler, autoscaler-hpa, controller, webhook, kourier-control, and kourier-gateway components, which are configured to have two replicas each by default. You can change the number of replicas for these components by modifying the spec.high-availability.replicas value in the KnativeServing custom resource (CR).
Prerequisites
- You have access to an OpenShift Container Platform cluster with cluster administrator permissions.
- The OpenShift Serverless Operator and Knative Serving are installed on your cluster.
- You have logged into the web console.
Procedure
-
In the OpenShift Container Platform web console Administrator perspective, navigate to OperatorHub
Installed Operators. -
Select the
knative-servingnamespace. - Click Knative Serving in the list of Provided APIs for the OpenShift Serverless Operator to go to the Knative Serving tab.
Click knative-serving, then go to the YAML tab in the knative-serving page.
Modify the number of replicas in the
KnativeServingCR:Example YAML
apiVersion: operator.knative.dev/v1alpha1 kind: KnativeServing metadata: name: knative-serving namespace: knative-serving spec: high-availability: replicas: 3
6.7.2. Configuring high availability replicas for Knative Eventing
High availability (HA) is available by default for the Knative Eventing eventing-controller, eventing-webhook, imc-controller, imc-dispatcher, and mt-broker-controller components, which are configured to have two replicas each by default. You can change the number of replicas for these components by modifying the spec.high-availability.replicas value in the KnativeEventing custom resource (CR).
For Knative Eventing, the mt-broker-filter and mt-broker-ingress deployments are not scaled by HA. If multiple deployments are needed, scale these components manually.
Prerequisites
- You have access to an OpenShift Container Platform cluster with cluster administrator permissions.
- The OpenShift Serverless Operator and Knative Eventing are installed on your cluster.
Procedure
-
In the OpenShift Container Platform web console Administrator perspective, navigate to OperatorHub
Installed Operators. -
Select the
knative-eventingnamespace. - Click Knative Eventing in the list of Provided APIs for the OpenShift Serverless Operator to go to the Knative Eventing tab.
Click knative-eventing, then go to the YAML tab in the knative-eventing page.
Modify the number of replicas in the
KnativeEventingCR:Example YAML
apiVersion: operator.knative.dev/v1alpha1 kind: KnativeEventing metadata: name: knative-eventing namespace: knative-eventing spec: high-availability: replicas: 3
6.7.3. Configuring high availability replicas for Knative Kafka
High availability (HA) is available by default for the Knative Kafka kafka-controller and kafka-webhook-eventing components, which are configured to have two each replicas by default. You can change the number of replicas for these components by modifying the spec.high-availability.replicas value in the KnativeKafka custom resource (CR).
Prerequisites
- You have access to an OpenShift Container Platform cluster with cluster administrator permissions.
- The OpenShift Serverless Operator and Knative Kafka are installed on your cluster.
Procedure
-
In the OpenShift Container Platform web console Administrator perspective, navigate to OperatorHub
Installed Operators. -
Select the
knative-eventingnamespace. - Click Knative Kafka in the list of Provided APIs for the OpenShift Serverless Operator to go to the Knative Kafka tab.
Click knative-kafka, then go to the YAML tab in the knative-kafka page.
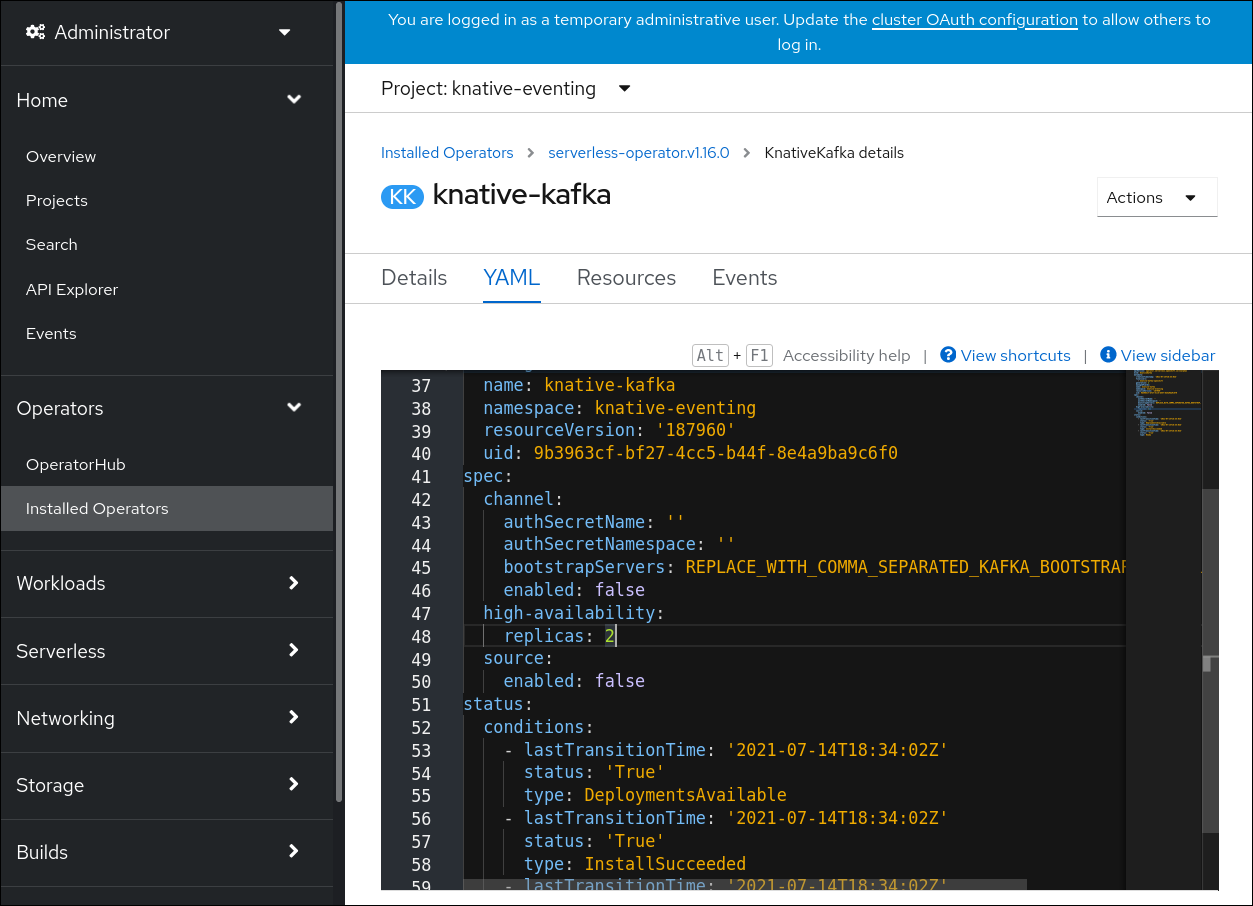
Modify the number of replicas in the
KnativeKafkaCR:Example YAML
apiVersion: operator.serverless.openshift.io/v1alpha1 kind: KnativeKafka metadata: name: knative-kafka namespace: knative-eventing spec: high-availability: replicas: 3