Chapter 1. Observability service introduction
The observability component is a service you can use to understand the health and utilization of clusters across your fleet. By default, multicluster observability operator is enabled during the installation of Red Hat Advanced Cluster Management.
Read the following documentation for more details about the observability component:
1.1. Observability architecture
The multiclusterhub-operator enables the multicluster-observability-operator pod by default. You must configure the multicluster-observability-operator pod.
When you enable the service, the observability-endpoint-operator is automatically deployed to each imported or created cluster. This controller collects the data from Red Hat OpenShift Container Platform Prometheus, then sends it to the Red Hat Advanced Cluster Management hub cluster. If the hub cluster imports itself is self-managed and imports itself as the local-cluster, observability is also enabled on it and metrics are collected from the hub cluster. As a reminder, when the hub cluster is self-managed the disableHubSelfManagement parameter is set to false.
The following diagram shows the components of observability:
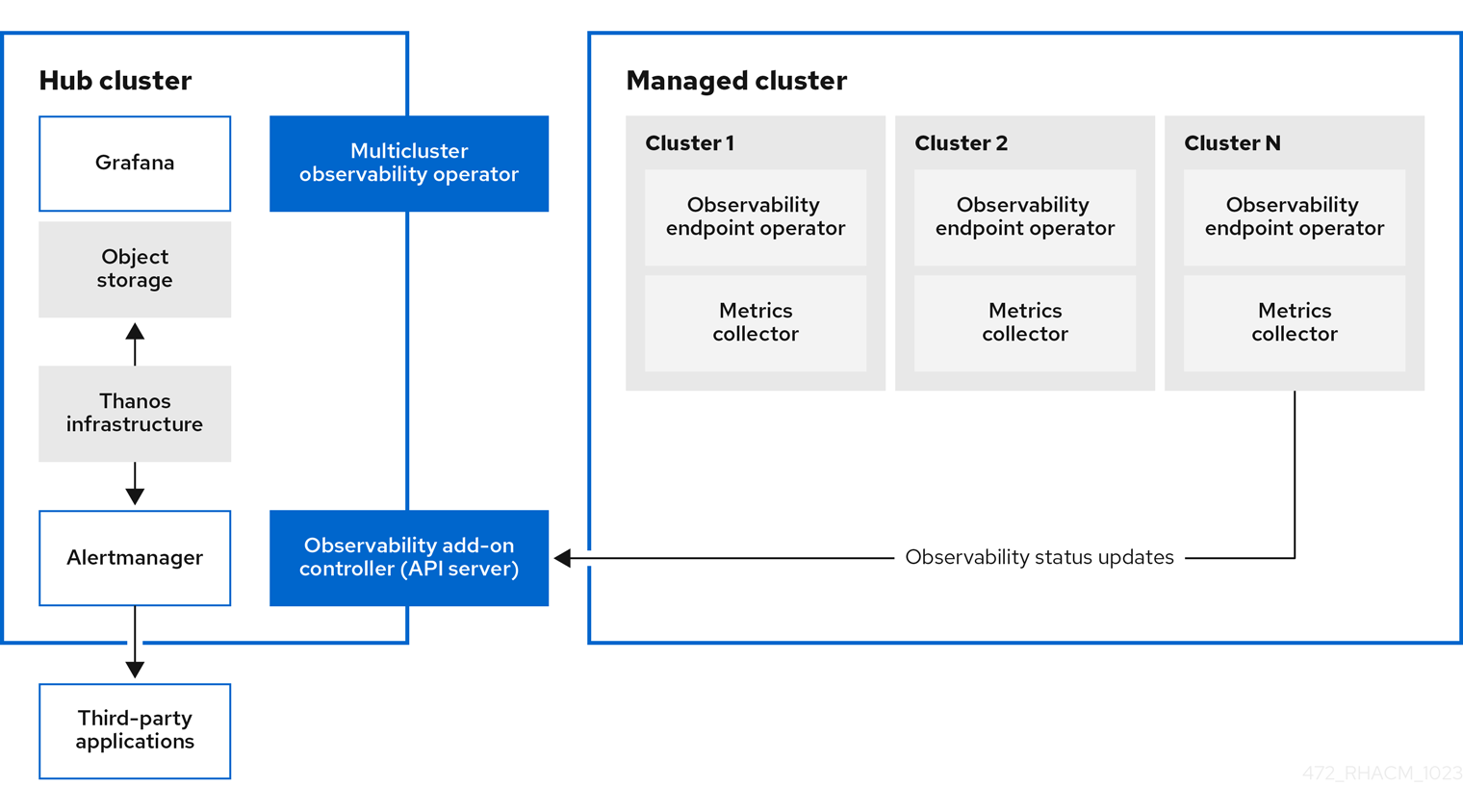
The components of the observability architecture include the following items:
-
The multicluster hub operator, also known as the
multiclusterhub-operatorpod, deploys themulticluster-observability-operatorpod. It sends hub cluster data to your managed clusters. - The observability add-on controller is the API server that automatically updates the log of the managed cluster.
The Thanos infrastructure includes the Thanos Compactor, which is deployed by the
multicluster-observability-operatorpod. The Thanos Compactor ensures that queries are performing well by using the retention configuration, and compaction of the data in storage.To help identify when the Thanos Compactor is experiencing issues, use the four default alerts that are monitoring its health. Read the following table of default alerts:
Expand Table 1.1. Table of default Thanos alerts Alert Severity Description ACMThanosCompactHaltedcritical
An alert is sent when the compactor stops.
ACMThanosCompactHighCompactionFailureswarning
An alert is sent when the compaction failure rate is greater than 5 percent.
ACMThanosCompactBucketHighOperationFailureswarning
An alert is sent when the bucket operation failure rate is greater than 5%.
ACMThanosCompactHasNotRunwarning
An alert is sent when the compactor has not uploaded anything in last 24 hours.
- The observability component deploys an instance of Grafana to enable data visualization with dashboards (static) or data exploration. Red Hat Advanced Cluster Management supports version 8.5.20 of Grafana. You can also design your Grafana dashboard. For more information, see Designing your Grafana dashboard.
- The Prometheus Alertmanager enables alerts to be forwarded with third-party applications. You can customize the observability service by creating custom recording rules or alerting rules. Red Hat Advanced Cluster Management supports version 0.25 of Prometheus Alertmanager.
1.1.1. Persistent stores used in the observability service
Important: Do not use the local storage operator or a storage class that uses local volumes for persistent storage. You can lose data if the pod relaunched on a different node after a restart. When this happens, the pod can no longer access the local storage on the node. Be sure that you can access the persistent volumes of the receive and rules pods to avoid data loss.
When you install Red Hat Advanced Cluster Management the following persistent volumes (PV) must be created so that Persistent Volume Claims (PVC) can attach to it automatically. As a reminder, you must define a storage class in the MultiClusterObservability custom resource when there is no default storage class specified or you want to use a non-default storage class to host the PVs. It is recommended to use Block Storage, similar to what Prometheus uses. Also each replica of alertmanager, thanos-compactor, thanos-ruler, thanos-receive-default and thanos-store-shard must have its own PV. View the following table:
| Persistent volume name | Purpose |
| alertmanager |
Alertmanager stores the |
| thanos-compact | The compactor needs local disk space to store intermediate data for its processing, as well as bucket state cache. The required space depends on the size of the underlying blocks. The compactor must have enough space to download all of the source blocks, then build the compacted blocks on the disk. On-disk data is safe to delete between restarts and should be the first attempt to get crash-looping compactors unstuck. However, it is recommended to give the compactor persistent disks in order to effectively use bucket state cache in between restarts. |
| thanos-rule |
The thanos ruler evaluates Prometheus recording and alerting rules against a chosen query API by issuing queries at a fixed interval. Rule results are written back to the disk in the Prometheus 2.0 storage format. The amount of hours or days of data retained in this stateful set was fixed in the API version |
| thanos-receive-default |
Thanos receiver accepts incoming data (Prometheus remote-write requests) and writes these into a local instance of the Prometheus TSDB. Periodically (every 2 hours), TSDB blocks are uploaded to the object storage for long term storage and compaction. The amount of hours or days of data retained in this stateful set, which acts a local cache was fixed in API Version |
| thanos-store-shard | It acts primarily as an API gateway and therefore does not need a significant amount of local disk space. It joins a Thanos cluster on startup and advertises the data it can access. It keeps a small amount of information about all remote blocks on local disk and keeps it in sync with the bucket. This data is generally safe to delete across restarts at the cost of increased startup times. |
Note: The time series historical data is stored in object stores. Thanos uses object storage as the primary storage for metrics and metadata related to them. For more details about the object storage and downsampling, see Enabling observability service.
1.1.2. Additional resources
1.2. Observability configuration
Continue reading to understand what metrics can be collected with the observability compnent, and for information about the observability pod capacity.
1.2.1. Metric types
By default, OpenShift Container Platform sends metrics to Red Hat using the Telemetry service. The acm_managed_cluster_info is available with Red Hat Advanced Cluster Management and is included with telemetry, but is not displayed on the Red Hat Advanced Cluster Management Observe environments overview dashboard.
View the following table of metric types that are supported by the framework:
| Metric name | Metric type | Labels/tags | Status |
|---|---|---|---|
|
| Gauge |
| Stable |
|
| Histogram | None | Stable. Read Governance metric for more details. |
|
| Histogram | None | Stable. Refer to Governance metric for more details. |
|
| Histogram | None | Stable. Read Governance metric for more details. |
|
| Gauge |
| Stable. Review Governance metric for more details. |
|
| Gauge |
| Stable. Read Managing insight _PolicyReports_ for more details. |
|
| Counter | None | Stable. See the Search components section in the Searching in the console introduction documentation. |
|
| Histogram | None | Stable. See the Search components section in the Searching in the console introduction documentation. |
|
| Histogram | None | Stable. See the Search components section in the Searching in the console introduction documentation. |
|
| Counter | None | Stable. See the Search components section in the Searching in the console introduction documentation. |
|
| Histogram | None | Stable. See the Search components section in the Searching in the console introduction documentation. |
|
| Gauge | None | Stable. See the Search components section in the Searching in the console introduction documentation. |
|
| Histogram | None | Stable. See the Search components section in the Searching in the console introduction documentation. |
1.2.2. Observability pod capacity requests
Observability components require 2701mCPU and 11972Mi memory to install the observability service. The following table is a list of the pod capacity requests for five managed clusters with observability-addons enabled:
| Deployment or StatefulSet | Container name | CPU (mCPU) | Memory (Mi) | Replicas | Pod total CPU | Pod total memory |
|---|---|---|---|---|---|---|
| observability-alertmanager | alertmanager | 4 | 200 | 3 | 12 | 600 |
| config-reloader | 4 | 25 | 3 | 12 | 75 | |
| alertmanager-proxy | 1 | 20 | 3 | 3 | 60 | |
| observability-grafana | grafana | 4 | 100 | 2 | 8 | 200 |
| grafana-dashboard-loader | 4 | 50 | 2 | 8 | 100 | |
| observability-observatorium-api | observatorium-api | 20 | 128 | 2 | 40 | 256 |
| observability-observatorium-operator | observatorium-operator | 100 | 100 | 1 | 10 | 50 |
| observability-rbac-query-proxy | rbac-query-proxy | 20 | 100 | 2 | 40 | 200 |
| oauth-proxy | 1 | 20 | 2 | 2 | 40 | |
| observability-thanos-compact | thanos-compact | 100 | 512 | 1 | 100 | 512 |
| observability-thanos-query | thanos-query | 300 | 1024 | 2 | 600 | 2048 |
| observability-thanos-query-frontend | thanos-query-frontend | 100 | 256 | 2 | 200 | 512 |
| observability-thanos-query-frontend-memcached | memcached | 45 | 128 | 3 | 135 | 384 |
| exporter | 5 | 50 | 3 | 15 | 150 | |
| observability-thanos-receive-controller | thanos-receive-controller | 4 | 32 | 1 | 4 | 32 |
| observability-thanos-receive-default | thanos-receive | 300 | 512 | 3 | 900 | 1536 |
| observability-thanos-rule | thanos-rule | 50 | 512 | 3 | 150 | 1536 |
| configmap-reloader | 4 | 25 | 3 | 12 | 75 | |
| observability-thanos-store-memcached | memcached | 45 | 128 | 3 | 135 | 384 |
| exporter | 5 | 50 | 3 | 15 | 150 | |
| observability-thanos-store-shard | thanos-store | 100 | 1024 | 3 | 300 | 3072 |
1.2.3. Additional resources
- For more information about enabling observability, read Enabling the observability service.
- Read Customizing observability to learn how to configure the observability service, view metrics and other data.
- Read Using Grafana dashboards.
- Learn from the OpenShift Container Platform documentation what types of metrics are collected and sent using telemetry. See Information collected by Telemetry for information.
- Refer to Governance metric for details.
- Read Managing insight PolicyReports.
- Refer to Prometheus recording rules.
- Also refer to Prometheus alerting rules.
- Return to Observability service introduction.