Chapter 2. Deployment configuration
This chapter describes how to configure different aspects of the supported deployments using custom resources:
- Kafka clusters
- Kafka Connect clusters
- Kafka Connect clusters with Source2Image support
- Kafka MirrorMaker
- Kafka Bridge
- Cruise Control
Labels applied to a custom resource are also applied to the OpenShift resources comprising Kafka MirrorMaker. This provides a convenient mechanism for resources to be labeled as required.
2.1. Kafka cluster configuration
This section describes how to configure a Kafka deployment in your AMQ Streams cluster. A Kafka cluster is deployed with a ZooKeeper cluster. The deployment can also include the Topic Operator and User Operator, which manage Kafka topics and users.
You configure Kafka using the Kafka resource. Configuration options are also available for ZooKeeper and the Entity Operator within the Kafka resource. The Entity Operator comprises the Topic Operator and User Operator.
The full schema of the Kafka resource is described in the Section 13.2.1, “Kafka schema reference”.
Listener configuration
You configure listeners for connecting clients to Kafka brokers. For more information on configuring listeners for connecting brokers, see Listener configuration.
Authorizing access to Kafka
You can configure your Kafka cluster to allow or decline actions executed by users. For more information on securing access to Kafka brokers, see Managing access to Kafka.
Managing TLS certificates
When deploying Kafka, the Cluster Operator automatically sets up and renews TLS certificates to enable encryption and authentication within your cluster. If required, you can manually renew the cluster and client CA certificates before their renewal period ends. You can also replace the keys used by the cluster and client CA certificates. For more information, see Renewing CA certificates manually and Replacing private keys.
Additional resources
- For more information about Apache Kafka, see the Apache Kafka website.
2.1.1. Configuring Kafka
Use the properties of the Kafka resource to configure your Kafka deployment.
As well as configuring Kafka, you can add configuration for ZooKeeper and the AMQ Streams Operators. Common configuration properties, such as logging and healthchecks, are configured independently for each component.
This procedure shows only some of the possible configuration options, but those that are particularly important include:
- Resource requests (CPU / Memory)
- JVM options for maximum and minimum memory allocation
- Listeners (and authentication of clients)
- Authentication
- Storage
- Rack awareness
- Metrics
- Cruise Control for cluster rebalancing
Kafka versions
The log.message.format.version and inter.broker.protocol.version properties for the Kafka config must be the versions supported by the specified Kafka version (spec.kafka.version). The properties represent the log format version appended to messages and the version of Kafka protocol used in a Kafka cluster. Updates to these properties are required when upgrading your Kafka version. For more information, see Upgrading Kafka in the Deploying and Upgrading AMQ Streams on OpenShift guide.
Prerequisites
- An OpenShift cluster
- A running Cluster Operator
See the Deploying and Upgrading AMQ Streams on OpenShift guide for instructions on deploying a:
Procedure
Edit the
specproperties for theKafkaresource.The properties you can configure are shown in this example configuration:
apiVersion: kafka.strimzi.io/v1beta2 kind: Kafka metadata: name: my-cluster spec: kafka: replicas: 31 version: 2.8.02 logging:3 type: inline loggers: kafka.root.logger.level: "INFO" resources:4 requests: memory: 64Gi cpu: "8" limits: memory: 64Gi cpu: "12" readinessProbe:5 initialDelaySeconds: 15 timeoutSeconds: 5 livenessProbe: initialDelaySeconds: 15 timeoutSeconds: 5 jvmOptions:6 -Xms: 8192m -Xmx: 8192m image: my-org/my-image:latest7 listeners:8 - name: plain9 port: 909210 type: internal11 tls: false12 configuration: useServiceDnsDomain: true13 - name: tls port: 9093 type: internal tls: true authentication:14 type: tls - name: external15 port: 9094 type: route tls: true configuration: brokerCertChainAndKey:16 secretName: my-secret certificate: my-certificate.crt key: my-key.key authorization:17 type: simple config:18 auto.create.topics.enable: "false" offsets.topic.replication.factor: 3 transaction.state.log.replication.factor: 3 transaction.state.log.min.isr: 2 log.message.format.version: 2.8 inter.broker.protocol.version: 2.8 ssl.cipher.suites: "TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384"19 ssl.enabled.protocols: "TLSv1.2" ssl.protocol: "TLSv1.2" storage:20 type: persistent-claim21 size: 10000Gi22 rack:23 topologyKey: topology.kubernetes.io/zone metricsConfig:24 type: jmxPrometheusExporter valueFrom: configMapKeyRef:25 name: my-config-map key: my-key # ... zookeeper:26 replicas: 327 logging:28 type: inline loggers: zookeeper.root.logger: "INFO" resources: requests: memory: 8Gi cpu: "2" limits: memory: 8Gi cpu: "2" jvmOptions: -Xms: 4096m -Xmx: 4096m storage: type: persistent-claim size: 1000Gi metricsConfig: # ... entityOperator:29 tlsSidecar:30 resources: requests: cpu: 200m memory: 64Mi limits: cpu: 500m memory: 128Mi topicOperator: watchedNamespace: my-topic-namespace reconciliationIntervalSeconds: 60 logging:31 type: inline loggers: rootLogger.level: "INFO" resources: requests: memory: 512Mi cpu: "1" limits: memory: 512Mi cpu: "1" userOperator: watchedNamespace: my-topic-namespace reconciliationIntervalSeconds: 60 logging:32 type: inline loggers: rootLogger.level: INFO resources: requests: memory: 512Mi cpu: "1" limits: memory: 512Mi cpu: "1" kafkaExporter:33 # ... cruiseControl:34 # ... tlsSidecar:35 # ...- 1
- The number of replica nodes. If your cluster already has topics defined, you can scale clusters.
- 2
- Kafka version, which can be changed to a supported version by following the upgrade procedure.
- 3
- Specified Kafka loggers and log levels added directly (
inline) or indirectly (external) through a ConfigMap. A custom ConfigMap must be placed under thelog4j.propertieskey. For the Kafkakafka.root.logger.levellogger, you can set the log level to INFO, ERROR, WARN, TRACE, DEBUG, FATAL or OFF. - 4
- Requests for reservation of supported resources, currently
cpuandmemory, and limits to specify the maximum resources that can be consumed. - 5
- Healthchecks to know when to restart a container (liveness) and when a container can accept traffic (readiness).
- 6
- JVM configuration options to optimize performance for the Virtual Machine (VM) running Kafka.
- 7
- ADVANCED OPTION: Container image configuration, which is recommended only in special situations.
- 8
- Listeners configure how clients connect to the Kafka cluster via bootstrap addresses. Listeners are configured as internal or external listeners for connection from inside or outside the OpenShift cluster.
- 9
- Name to identify the listener. Must be unique within the Kafka cluster.
- 10
- Port number used by the listener inside Kafka. The port number has to be unique within a given Kafka cluster. Allowed port numbers are 9092 and higher with the exception of ports 9404 and 9999, which are already used for Prometheus and JMX. Depending on the listener type, the port number might not be the same as the port number that connects Kafka clients.
- 11
- Listener type specified as
internal, or for external listeners, asroute,loadbalancer,nodeportoringress. - 12
- Enables TLS encryption for each listener. Default is
false. TLS encryption is not required forroutelisteners. - 13
- Defines whether the fully-qualified DNS names including the cluster service suffix (usually
.cluster.local) are assigned. - 14
- Listener authentication mechanism specified as mutual TLS, SCRAM-SHA-512 or token-based OAuth 2.0.
- 15
- External listener configuration specifies how the Kafka cluster is exposed outside OpenShift, such as through a
route,loadbalancerornodeport. - 16
- Optional configuration for a Kafka listener certificate managed by an external Certificate Authority. The
brokerCertChainAndKeyspecifies aSecretthat contains a server certificate and a private key. You can configure Kafka listener certificates on any listener with enabled TLS encryption. - 17
- Authorization enables simple, OAUTH 2.0, or OPA authorization on the Kafka broker. Simple authorization uses the
AclAuthorizerKafka plugin. - 18
- The
configspecifies the broker configuration. Standard Apache Kafka configuration may be provided, restricted to those properties not managed directly by AMQ Streams. - 19
- 20
- 21
- Storage size for persistent volumes may be increased and additional volumes may be added to JBOD storage.
- 22
- Persistent storage has additional configuration options, such as a storage
idandclassfor dynamic volume provisioning. - 23
- Rack awareness is configured to spread replicas across different racks. A
topologykeymust match the label of a cluster node. - 24
- Prometheus metrics enabled. In this example, metrics are configured for the Prometheus JMX Exporter (the default metrics exporter).
- 25
- Prometheus rules for exporting metrics to a Grafana dashboard through the Prometheus JMX Exporter, which are enabled by referencing a ConfigMap containing configuration for the Prometheus JMX exporter. You can enable metrics without further configuration using a reference to a ConfigMap containing an empty file under
metricsConfig.valueFrom.configMapKeyRef.key. - 26
- ZooKeeper-specific configuration, which contains properties similar to the Kafka configuration.
- 27
- The number of ZooKeeper nodes. ZooKeeper clusters or ensembles usually run with an odd number of nodes, typically three, five, or seven. The majority of nodes must be available in order to maintain an effective quorum. If the ZooKeeper cluster loses its quorum, it will stop responding to clients and the Kafka brokers will stop working. Having a stable and highly available ZooKeeper cluster is crucial for AMQ Streams.
- 28
- Specified ZooKeeper loggers and log levels.
- 29
- Entity Operator configuration, which specifies the configuration for the Topic Operator and User Operator.
- 30
- Entity Operator TLS sidecar configuration. Entity Operator uses the TLS sidecar for secure communication with ZooKeeper.
- 31
- Specified Topic Operator loggers and log levels. This example uses
inlinelogging. - 32
- Specified User Operator loggers and log levels.
- 33
- Kafka Exporter configuration. Kafka Exporter is an optional component for extracting metrics data from Kafka brokers, in particular consumer lag data.
- 34
- Optional configuration for Cruise Control, which is used to rebalance the Kafka cluster.
- 35
- Cruise Control TLS sidecar configuration. Cruise Control uses the TLS sidecar for secure communication with ZooKeeper.
Create or update the resource:
oc apply -f KAFKA-CONFIG-FILE
2.1.2. Configuring the Entity Operator
The Entity Operator is responsible for managing Kafka-related entities in a running Kafka cluster.
The Entity Operator comprises the:
- Topic Operator to manage Kafka topics
- User Operator to manage Kafka users
Through Kafka resource configuration, the Cluster Operator can deploy the Entity Operator, including one or both operators, when deploying a Kafka cluster.
When deployed, the Entity Operator contains the operators according to the deployment configuration.
The operators are automatically configured to manage the topics and users of the Kafka cluster.
2.1.2.1. Entity Operator configuration properties
Use the entityOperator property in Kafka.spec to configure the Entity Operator.
The entityOperator property supports several sub-properties:
-
tlsSidecar -
topicOperator -
userOperator -
template
The tlsSidecar property contains the configuration of the TLS sidecar container, which is used to communicate with ZooKeeper.
The template property contains the configuration of the Entity Operator pod, such as labels, annotations, affinity, and tolerations. For more information on configuring templates, see Section 2.6, “Customizing OpenShift resources”.
The topicOperator property contains the configuration of the Topic Operator. When this option is missing, the Entity Operator is deployed without the Topic Operator.
The userOperator property contains the configuration of the User Operator. When this option is missing, the Entity Operator is deployed without the User Operator.
For more information on the properties used to configure the Entity Operator, see the EntityUserOperatorSpec schema reference.
Example of basic configuration enabling both operators
apiVersion: kafka.strimzi.io/v1beta2
kind: Kafka
metadata:
name: my-cluster
spec:
kafka:
# ...
zookeeper:
# ...
entityOperator:
topicOperator: {}
userOperator: {}
If an empty object ({}) is used for the topicOperator and userOperator, all properties use their default values.
When both topicOperator and userOperator properties are missing, the Entity Operator is not deployed.
2.1.2.2. Topic Operator configuration properties
Topic Operator deployment can be configured using additional options inside the topicOperator object. The following properties are supported:
watchedNamespace-
The OpenShift namespace in which the topic operator watches for
KafkaTopics. Default is the namespace where the Kafka cluster is deployed. reconciliationIntervalSeconds-
The interval between periodic reconciliations in seconds. Default
120. zookeeperSessionTimeoutSeconds-
The ZooKeeper session timeout in seconds. Default
18. topicMetadataMaxAttempts-
The number of attempts at getting topic metadata from Kafka. The time between each attempt is defined as an exponential back-off. Consider increasing this value when topic creation might take more time due to the number of partitions or replicas. Default
6. image-
The
imageproperty can be used to configure the container image which will be used. For more details about configuring custom container images, see Section 13.1.6, “image”. resources-
The
resourcesproperty configures the amount of resources allocated to the Topic Operator. For more details about resource request and limit configuration, see Section 13.1.5, “resources”. logging-
The
loggingproperty configures the logging of the Topic Operator. For more details, see Section 13.2.45.1, “logging”.
Example Topic Operator configuration
apiVersion: kafka.strimzi.io/v1beta2
kind: Kafka
metadata:
name: my-cluster
spec:
kafka:
# ...
zookeeper:
# ...
entityOperator:
# ...
topicOperator:
watchedNamespace: my-topic-namespace
reconciliationIntervalSeconds: 60
# ...2.1.2.3. User Operator configuration properties
User Operator deployment can be configured using additional options inside the userOperator object. The following properties are supported:
watchedNamespace-
The OpenShift namespace in which the user operator watches for
KafkaUsers. Default is the namespace where the Kafka cluster is deployed. reconciliationIntervalSeconds-
The interval between periodic reconciliations in seconds. Default
120. zookeeperSessionTimeoutSeconds-
The ZooKeeper session timeout in seconds. Default
18. image-
The
imageproperty can be used to configure the container image which will be used. For more details about configuring custom container images, see Section 13.1.6, “image”. resources-
The
resourcesproperty configures the amount of resources allocated to the User Operator. For more details about resource request and limit configuration, see Section 13.1.5, “resources”. logging-
The
loggingproperty configures the logging of the User Operator. For more details, see Section 13.2.45.1, “logging”. secretPrefix-
The
secretPrefixproperty adds a prefix to the name of all Secrets created from the KafkaUser resource. For example,STRIMZI_SECRET_PREFIX=kafka-would prefix all Secret names withkafka-. So a KafkaUser namedmy-userwould create a Secret namedkafka-my-user.
Example User Operator configuration
apiVersion: kafka.strimzi.io/v1beta2
kind: Kafka
metadata:
name: my-cluster
spec:
kafka:
# ...
zookeeper:
# ...
entityOperator:
# ...
userOperator:
watchedNamespace: my-user-namespace
reconciliationIntervalSeconds: 60
# ...2.1.3. Kafka and ZooKeeper storage types
As stateful applications, Kafka and ZooKeeper need to store data on disk. AMQ Streams supports three storage types for this data:
- Ephemeral
- Persistent
- JBOD storage
JBOD storage is supported only for Kafka, not for ZooKeeper.
When configuring a Kafka resource, you can specify the type of storage used by the Kafka broker and its corresponding ZooKeeper node. You configure the storage type using the storage property in the following resources:
-
Kafka.spec.kafka -
Kafka.spec.zookeeper
The storage type is configured in the type field.
The storage type cannot be changed after a Kafka cluster is deployed.
Additional resources
- For more information about ephemeral storage, see ephemeral storage schema reference.
- For more information about persistent storage, see persistent storage schema reference.
- For more information about JBOD storage, see JBOD schema reference.
-
For more information about the schema for
Kafka, seeKafkaschema reference.
2.1.3.1. Data storage considerations
An efficient data storage infrastructure is essential to the optimal performance of AMQ Streams.
Block storage is required. File storage, such as NFS, does not work with Kafka.
Choose from one of the following options for your block storage:
- Cloud-based block storage solutions, such as Amazon Elastic Block Store (EBS)
- Local persistent volumes
- Storage Area Network (SAN) volumes accessed by a protocol such as Fibre Channel or iSCSI
AMQ Streams does not require OpenShift raw block volumes.
2.1.3.1.1. File systems
It is recommended that you configure your storage system to use the XFS file system. AMQ Streams is also compatible with the ext4 file system, but this might require additional configuration for best results.
2.1.3.1.2. Apache Kafka and ZooKeeper storage
Use separate disks for Apache Kafka and ZooKeeper.
Three types of data storage are supported:
- Ephemeral (Recommended for development only)
- Persistent
- JBOD (Just a Bunch of Disks, suitable for Kafka only)
For more information, see Kafka and ZooKeeper storage.
Solid-state drives (SSDs), though not essential, can improve the performance of Kafka in large clusters where data is sent to and received from multiple topics asynchronously. SSDs are particularly effective with ZooKeeper, which requires fast, low latency data access.
You do not need to provision replicated storage because Kafka and ZooKeeper both have built-in data replication.
2.1.3.2. Ephemeral storage
Ephemeral storage uses emptyDir volumes to store data. To use ephemeral storage, set the type field to ephemeral.
emptyDir volumes are not persistent and the data stored in them is lost when the pod is restarted. After the new pod is started, it must recover all data from the other nodes of the cluster. Ephemeral storage is not suitable for use with single-node ZooKeeper clusters or for Kafka topics with a replication factor of 1. This configuration will cause data loss.
An example of Ephemeral storage
apiVersion: kafka.strimzi.io/v1beta2
kind: Kafka
metadata:
name: my-cluster
spec:
kafka:
# ...
storage:
type: ephemeral
# ...
zookeeper:
# ...
storage:
type: ephemeral
# ...2.1.3.2.1. Log directories
The ephemeral volume is used by the Kafka brokers as log directories mounted into the following path:
/var/lib/kafka/data/kafka-logIDX
Where IDX is the Kafka broker pod index. For example /var/lib/kafka/data/kafka-log0.
2.1.3.3. Persistent storage
Persistent storage uses Persistent Volume Claims to provision persistent volumes for storing data. Persistent Volume Claims can be used to provision volumes of many different types, depending on the Storage Class which will provision the volume. The data types which can be used with persistent volume claims include many types of SAN storage as well as Local persistent volumes.
To use persistent storage, the type has to be set to persistent-claim. Persistent storage supports additional configuration options:
id(optional)-
Storage identification number. This option is mandatory for storage volumes defined in a JBOD storage declaration. Default is
0. size(required)- Defines the size of the persistent volume claim, for example, "1000Gi".
class(optional)- The OpenShift Storage Class to use for dynamic volume provisioning.
selector(optional)- Allows selecting a specific persistent volume to use. It contains key:value pairs representing labels for selecting such a volume.
deleteClaim(optional)-
Boolean value which specifies if the Persistent Volume Claim has to be deleted when the cluster is undeployed. Default is
false.
Increasing the size of persistent volumes in an existing AMQ Streams cluster is only supported in OpenShift versions that support persistent volume resizing. The persistent volume to be resized must use a storage class that supports volume expansion. For other versions of OpenShift and storage classes which do not support volume expansion, you must decide the necessary storage size before deploying the cluster. Decreasing the size of existing persistent volumes is not possible.
Example fragment of persistent storage configuration with 1000Gi size
# ...
storage:
type: persistent-claim
size: 1000Gi
# ...The following example demonstrates the use of a storage class.
Example fragment of persistent storage configuration with specific Storage Class
# ...
storage:
type: persistent-claim
size: 1Gi
class: my-storage-class
# ...
Finally, a selector can be used to select a specific labeled persistent volume to provide needed features such as an SSD.
Example fragment of persistent storage configuration with selector
# ...
storage:
type: persistent-claim
size: 1Gi
selector:
hdd-type: ssd
deleteClaim: true
# ...2.1.3.3.1. Storage class overrides
You can specify a different storage class for one or more Kafka brokers or ZooKeeper nodes, instead of using the default storage class. This is useful if, for example, storage classes are restricted to different availability zones or data centers. You can use the overrides field for this purpose.
In this example, the default storage class is named my-storage-class:
Example AMQ Streams cluster using storage class overrides
apiVersion: kafka.strimzi.io/v1beta2
kind: Kafka
metadata:
labels:
app: my-cluster
name: my-cluster
namespace: myproject
spec:
# ...
kafka:
replicas: 3
storage:
deleteClaim: true
size: 100Gi
type: persistent-claim
class: my-storage-class
overrides:
- broker: 0
class: my-storage-class-zone-1a
- broker: 1
class: my-storage-class-zone-1b
- broker: 2
class: my-storage-class-zone-1c
# ...
zookeeper:
replicas: 3
storage:
deleteClaim: true
size: 100Gi
type: persistent-claim
class: my-storage-class
overrides:
- broker: 0
class: my-storage-class-zone-1a
- broker: 1
class: my-storage-class-zone-1b
- broker: 2
class: my-storage-class-zone-1c
# ...
As a result of the configured overrides property, the volumes use the following storage classes:
-
The persistent volumes of ZooKeeper node 0 will use
my-storage-class-zone-1a. -
The persistent volumes of ZooKeeper node 1 will use
my-storage-class-zone-1b. -
The persistent volumes of ZooKeeepr node 2 will use
my-storage-class-zone-1c. -
The persistent volumes of Kafka broker 0 will use
my-storage-class-zone-1a. -
The persistent volumes of Kafka broker 1 will use
my-storage-class-zone-1b. -
The persistent volumes of Kafka broker 2 will use
my-storage-class-zone-1c.
The overrides property is currently used only to override storage class configurations. Overriding other storage configuration fields is not currently supported. Other fields from the storage configuration are currently not supported.
2.1.3.3.2. Persistent Volume Claim naming
When persistent storage is used, it creates Persistent Volume Claims with the following names:
data-cluster-name-kafka-idx-
Persistent Volume Claim for the volume used for storing data for the Kafka broker pod
idx. data-cluster-name-zookeeper-idx-
Persistent Volume Claim for the volume used for storing data for the ZooKeeper node pod
idx.
2.1.3.3.3. Log directories
The persistent volume is used by the Kafka brokers as log directories mounted into the following path:
/var/lib/kafka/data/kafka-logIDX
Where IDX is the Kafka broker pod index. For example /var/lib/kafka/data/kafka-log0.
2.1.3.4. Resizing persistent volumes
You can provision increased storage capacity by increasing the size of the persistent volumes used by an existing AMQ Streams cluster. Resizing persistent volumes is supported in clusters that use either a single persistent volume or multiple persistent volumes in a JBOD storage configuration.
You can increase but not decrease the size of persistent volumes. Decreasing the size of persistent volumes is not currently supported in OpenShift.
Prerequisites
- An OpenShift cluster with support for volume resizing.
- The Cluster Operator is running.
- A Kafka cluster using persistent volumes created using a storage class that supports volume expansion.
Procedure
In a
Kafkaresource, increase the size of the persistent volume allocated to the Kafka cluster, the ZooKeeper cluster, or both.-
To increase the volume size allocated to the Kafka cluster, edit the
spec.kafka.storageproperty. To increase the volume size allocated to the ZooKeeper cluster, edit the
spec.zookeeper.storageproperty.For example, to increase the volume size from
1000Gito2000Gi:apiVersion: kafka.strimzi.io/v1beta2 kind: Kafka metadata: name: my-cluster spec: kafka: # ... storage: type: persistent-claim size: 2000Gi class: my-storage-class # ... zookeeper: # ...
-
To increase the volume size allocated to the Kafka cluster, edit the
Create or update the resource:
oc apply -f KAFKA-CONFIG-FILEOpenShift increases the capacity of the selected persistent volumes in response to a request from the Cluster Operator. When the resizing is complete, the Cluster Operator restarts all pods that use the resized persistent volumes. This happens automatically.
Additional resources
For more information about resizing persistent volumes in OpenShift, see Resizing Persistent Volumes using Kubernetes.
2.1.3.5. JBOD storage overview
You can configure AMQ Streams to use JBOD, a data storage configuration of multiple disks or volumes. JBOD is one approach to providing increased data storage for Kafka brokers. It can also improve performance.
A JBOD configuration is described by one or more volumes, each of which can be either ephemeral or persistent. The rules and constraints for JBOD volume declarations are the same as those for ephemeral and persistent storage. For example, you cannot decrease the size of a persistent storage volume after it has been provisioned, or you cannot change the value of sizeLimit when type=ephemeral.
2.1.3.5.1. JBOD configuration
To use JBOD with AMQ Streams, the storage type must be set to jbod. The volumes property allows you to describe the disks that make up your JBOD storage array or configuration. The following fragment shows an example JBOD configuration:
# ...
storage:
type: jbod
volumes:
- id: 0
type: persistent-claim
size: 100Gi
deleteClaim: false
- id: 1
type: persistent-claim
size: 100Gi
deleteClaim: false
# ...The ids cannot be changed once the JBOD volumes are created.
Users can add or remove volumes from the JBOD configuration.
2.1.3.5.2. JBOD and Persistent Volume Claims
When persistent storage is used to declare JBOD volumes, the naming scheme of the resulting Persistent Volume Claims is as follows:
data-id-cluster-name-kafka-idx-
Where
idis the ID of the volume used for storing data for Kafka broker podidx.
2.1.3.5.3. Log directories
The JBOD volumes will be used by the Kafka brokers as log directories mounted into the following path:
/var/lib/kafka/data-id/kafka-log_idx_-
Where
idis the ID of the volume used for storing data for Kafka broker podidx. For example/var/lib/kafka/data-0/kafka-log0.
2.1.3.6. Adding volumes to JBOD storage
This procedure describes how to add volumes to a Kafka cluster configured to use JBOD storage. It cannot be applied to Kafka clusters configured to use any other storage type.
When adding a new volume under an id which was already used in the past and removed, you have to make sure that the previously used PersistentVolumeClaims have been deleted.
Prerequisites
- An OpenShift cluster
- A running Cluster Operator
- A Kafka cluster with JBOD storage
Procedure
Edit the
spec.kafka.storage.volumesproperty in theKafkaresource. Add the new volumes to thevolumesarray. For example, add the new volume with id2:apiVersion: kafka.strimzi.io/v1beta2 kind: Kafka metadata: name: my-cluster spec: kafka: # ... storage: type: jbod volumes: - id: 0 type: persistent-claim size: 100Gi deleteClaim: false - id: 1 type: persistent-claim size: 100Gi deleteClaim: false - id: 2 type: persistent-claim size: 100Gi deleteClaim: false # ... zookeeper: # ...Create or update the resource:
oc apply -f KAFKA-CONFIG-FILE- Create new topics or reassign existing partitions to the new disks.
Additional resources
For more information about reassigning topics, see Section 2.1.4.2, “Partition reassignment”.
2.1.3.7. Removing volumes from JBOD storage
This procedure describes how to remove volumes from Kafka cluster configured to use JBOD storage. It cannot be applied to Kafka clusters configured to use any other storage type. The JBOD storage always has to contain at least one volume.
To avoid data loss, you have to move all partitions before removing the volumes.
Prerequisites
- An OpenShift cluster
- A running Cluster Operator
- A Kafka cluster with JBOD storage with two or more volumes
Procedure
- Reassign all partitions from the disks which are you going to remove. Any data in partitions still assigned to the disks which are going to be removed might be lost.
Edit the
spec.kafka.storage.volumesproperty in theKafkaresource. Remove one or more volumes from thevolumesarray. For example, remove the volumes with ids1and2:apiVersion: kafka.strimzi.io/v1beta2 kind: Kafka metadata: name: my-cluster spec: kafka: # ... storage: type: jbod volumes: - id: 0 type: persistent-claim size: 100Gi deleteClaim: false # ... zookeeper: # ...Create or update the resource:
oc apply -f KAFKA-CONFIG-FILE
Additional resources
For more information about reassigning topics, see Section 2.1.4.2, “Partition reassignment”.
2.1.4. Scaling clusters
2.1.4.1. Scaling Kafka clusters
2.1.4.1.1. Adding brokers to a cluster
The primary way of increasing throughput for a topic is to increase the number of partitions for that topic. That works because the extra partitions allow the load of the topic to be shared between the different brokers in the cluster. However, in situations where every broker is constrained by a particular resource (typically I/O) using more partitions will not result in increased throughput. Instead, you need to add brokers to the cluster.
When you add an extra broker to the cluster, Kafka does not assign any partitions to it automatically. You must decide which partitions to move from the existing brokers to the new broker.
Once the partitions have been redistributed between all the brokers, the resource utilization of each broker should be reduced.
2.1.4.1.2. Removing brokers from a cluster
Because AMQ Streams uses StatefulSets to manage broker pods, you cannot remove any pod from the cluster. You can only remove one or more of the highest numbered pods from the cluster. For example, in a cluster of 12 brokers the pods are named cluster-name-kafka-0 up to cluster-name-kafka-11. If you decide to scale down by one broker, the cluster-name-kafka-11 will be removed.
Before you remove a broker from a cluster, ensure that it is not assigned to any partitions. You should also decide which of the remaining brokers will be responsible for each of the partitions on the broker being decommissioned. Once the broker has no assigned partitions, you can scale the cluster down safely.
2.1.4.2. Partition reassignment
The Topic Operator does not currently support reassigning replicas to different brokers, so it is necessary to connect directly to broker pods to reassign replicas to brokers.
Within a broker pod, the kafka-reassign-partitions.sh utility allows you to reassign partitions to different brokers.
It has three different modes:
--generate- Takes a set of topics and brokers and generates a reassignment JSON file which will result in the partitions of those topics being assigned to those brokers. Because this operates on whole topics, it cannot be used when you only want to reassign some partitions of some topics.
--execute- Takes a reassignment JSON file and applies it to the partitions and brokers in the cluster. Brokers that gain partitions as a result become followers of the partition leader. For a given partition, once the new broker has caught up and joined the ISR (in-sync replicas) the old broker will stop being a follower and will delete its replica.
--verify-
Using the same reassignment JSON file as the
--executestep,--verifychecks whether all the partitions in the file have been moved to their intended brokers. If the reassignment is complete, --verify also removes any throttles that are in effect. Unless removed, throttles will continue to affect the cluster even after the reassignment has finished.
It is only possible to have one reassignment running in a cluster at any given time, and it is not possible to cancel a running reassignment. If you need to cancel a reassignment, wait for it to complete and then perform another reassignment to revert the effects of the first reassignment. The kafka-reassign-partitions.sh will print the reassignment JSON for this reversion as part of its output. Very large reassignments should be broken down into a number of smaller reassignments in case there is a need to stop in-progress reassignment.
2.1.4.2.1. Reassignment JSON file
The reassignment JSON file has a specific structure:
{
"version": 1,
"partitions": [
<PartitionObjects>
]
}Where <PartitionObjects> is a comma-separated list of objects like:
{
"topic": <TopicName>,
"partition": <Partition>,
"replicas": [ <AssignedBrokerIds> ]
}
Although Kafka also supports a "log_dirs" property this should not be used in AMQ Streams.
The following is an example reassignment JSON file that assigns partition 4 of topic topic-a to brokers 2, 4 and 7, and partition 2 of topic topic-b to brokers 1, 5 and 7:
{
"version": 1,
"partitions": [
{
"topic": "topic-a",
"partition": 4,
"replicas": [2,4,7]
},
{
"topic": "topic-b",
"partition": 2,
"replicas": [1,5,7]
}
]
}Partitions not included in the JSON are not changed.
2.1.4.2.2. Reassigning partitions between JBOD volumes
When using JBOD storage in your Kafka cluster, you can choose to reassign the partitions between specific volumes and their log directories (each volume has a single log directory). To reassign a partition to a specific volume, add the log_dirs option to <PartitionObjects> in the reassignment JSON file.
{
"topic": <TopicName>,
"partition": <Partition>,
"replicas": [ <AssignedBrokerIds> ],
"log_dirs": [ <AssignedLogDirs> ]
}
The log_dirs object should contain the same number of log directories as the number of replicas specified in the replicas object. The value should be either an absolute path to the log directory, or the any keyword.
For example:
{
"topic": "topic-a",
"partition": 4,
"replicas": [2,4,7].
"log_dirs": [ "/var/lib/kafka/data-0/kafka-log2", "/var/lib/kafka/data-0/kafka-log4", "/var/lib/kafka/data-0/kafka-log7" ]
}2.1.4.3. Generating reassignment JSON files
This procedure describes how to generate a reassignment JSON file that reassigns all the partitions for a given set of topics using the kafka-reassign-partitions.sh tool.
Prerequisites
- A running Cluster Operator
-
A
Kafkaresource - A set of topics to reassign the partitions of
Procedure
Prepare a JSON file named
topics.jsonthat lists the topics to move. It must have the following structure:{ "version": 1, "topics": [ <TopicObjects> ] }where <TopicObjects> is a comma-separated list of objects like:
{ "topic": <TopicName> }For example if you want to reassign all the partitions of
topic-aandtopic-b, you would need to prepare atopics.jsonfile like this:{ "version": 1, "topics": [ { "topic": "topic-a"}, { "topic": "topic-b"} ] }Copy the
topics.jsonfile to one of the broker pods:cat topics.json | oc exec -c kafka <BrokerPod> -i -- \ /bin/bash -c \ 'cat > /tmp/topics.json'Use the
kafka-reassign-partitions.shcommand to generate the reassignment JSON.oc exec <BrokerPod> -c kafka -it -- \ bin/kafka-reassign-partitions.sh --bootstrap-server localhost:9092 \ --topics-to-move-json-file /tmp/topics.json \ --broker-list <BrokerList> \ --generateFor example, to move all the partitions of
topic-aandtopic-bto brokers4and7oc exec <BrokerPod> -c kafka -it -- \ bin/kafka-reassign-partitions.sh --bootstrap-server localhost:9092 \ --topics-to-move-json-file /tmp/topics.json \ --broker-list 4,7 \ --generate
2.1.4.4. Creating reassignment JSON files manually
You can manually create the reassignment JSON file if you want to move specific partitions.
2.1.4.5. Reassignment throttles
Partition reassignment can be a slow process because it involves transferring large amounts of data between brokers. To avoid a detrimental impact on clients, you can throttle the reassignment process. This might cause the reassignment to take longer to complete.
- If the throttle is too low then the newly assigned brokers will not be able to keep up with records being published and the reassignment will never complete.
- If the throttle is too high then clients will be impacted.
For example, for producers, this could manifest as higher than normal latency waiting for acknowledgement. For consumers, this could manifest as a drop in throughput caused by higher latency between polls.
2.1.4.6. Scaling up a Kafka cluster
This procedure describes how to increase the number of brokers in a Kafka cluster.
Prerequisites
- An existing Kafka cluster.
-
A reassignment JSON file named
reassignment.jsonthat describes how partitions should be reassigned to brokers in the enlarged cluster.
Procedure
-
Add as many new brokers as you need by increasing the
Kafka.spec.kafka.replicasconfiguration option. - Verify that the new broker pods have started.
Copy the
reassignment.jsonfile to the broker pod on which you will later execute the commands:cat reassignment.json | \ oc exec broker-pod -c kafka -i -- /bin/bash -c \ 'cat > /tmp/reassignment.json'For example:
cat reassignment.json | \ oc exec my-cluster-kafka-0 -c kafka -i -- /bin/bash -c \ 'cat > /tmp/reassignment.json'Execute the partition reassignment using the
kafka-reassign-partitions.shcommand line tool from the same broker pod.oc exec broker-pod -c kafka -it -- \ bin/kafka-reassign-partitions.sh --bootstrap-server localhost:9092 \ --reassignment-json-file /tmp/reassignment.json \ --executeIf you are going to throttle replication you can also pass the
--throttleoption with an inter-broker throttled rate in bytes per second. For example:oc exec my-cluster-kafka-0 -c kafka -it -- \ bin/kafka-reassign-partitions.sh --bootstrap-server localhost:9092 \ --reassignment-json-file /tmp/reassignment.json \ --throttle 5000000 \ --executeThis command will print out two reassignment JSON objects. The first records the current assignment for the partitions being moved. You should save this to a local file (not a file in the pod) in case you need to revert the reassignment later on. The second JSON object is the target reassignment you have passed in your reassignment JSON file.
If you need to change the throttle during reassignment you can use the same command line with a different throttled rate. For example:
oc exec my-cluster-kafka-0 -c kafka -it -- \ bin/kafka-reassign-partitions.sh --bootstrap-server localhost:9092 \ --reassignment-json-file /tmp/reassignment.json \ --throttle 10000000 \ --executePeriodically verify whether the reassignment has completed using the
kafka-reassign-partitions.shcommand line tool from any of the broker pods. This is the same command as the previous step but with the--verifyoption instead of the--executeoption.oc exec broker-pod -c kafka -it -- \ bin/kafka-reassign-partitions.sh --bootstrap-server localhost:9092 \ --reassignment-json-file /tmp/reassignment.json \ --verifyFor example,
oc exec my-cluster-kafka-0 -c kafka -it -- \ bin/kafka-reassign-partitions.sh --bootstrap-server localhost:9092 \ --reassignment-json-file /tmp/reassignment.json \ --verify-
The reassignment has finished when the
--verifycommand reports each of the partitions being moved as completed successfully. This final--verifywill also have the effect of removing any reassignment throttles. You can now delete the revert file if you saved the JSON for reverting the assignment to their original brokers.
2.1.4.7. Scaling down a Kafka cluster
This procedure describes how to decrease the number of brokers in a Kafka cluster.
Prerequisites
- An existing Kafka cluster.
-
A reassignment JSON file named
reassignment.jsondescribing how partitions should be reassigned to brokers in the cluster once the broker(s) in the highest numberedPod(s)have been removed.
Procedure
Copy the
reassignment.jsonfile to the broker pod on which you will later execute the commands:cat reassignment.json | \ oc exec broker-pod -c kafka -i -- /bin/bash -c \ 'cat > /tmp/reassignment.json'For example:
cat reassignment.json | \ oc exec my-cluster-kafka-0 -c kafka -i -- /bin/bash -c \ 'cat > /tmp/reassignment.json'Execute the partition reassignment using the
kafka-reassign-partitions.shcommand line tool from the same broker pod.oc exec broker-pod -c kafka -it -- \ bin/kafka-reassign-partitions.sh --bootstrap-server localhost:9092 \ --reassignment-json-file /tmp/reassignment.json \ --executeIf you are going to throttle replication you can also pass the
--throttleoption with an inter-broker throttled rate in bytes per second. For example:oc exec my-cluster-kafka-0 -c kafka -it -- \ bin/kafka-reassign-partitions.sh --bootstrap-server localhost:9092 \ --reassignment-json-file /tmp/reassignment.json \ --throttle 5000000 \ --executeThis command will print out two reassignment JSON objects. The first records the current assignment for the partitions being moved. You should save this to a local file (not a file in the pod) in case you need to revert the reassignment later on. The second JSON object is the target reassignment you have passed in your reassignment JSON file.
If you need to change the throttle during reassignment you can use the same command line with a different throttled rate. For example:
oc exec my-cluster-kafka-0 -c kafka -it -- \ bin/kafka-reassign-partitions.sh --bootstrap-server localhost:9092 \ --reassignment-json-file /tmp/reassignment.json \ --throttle 10000000 \ --executePeriodically verify whether the reassignment has completed using the
kafka-reassign-partitions.shcommand line tool from any of the broker pods. This is the same command as the previous step but with the--verifyoption instead of the--executeoption.oc exec broker-pod -c kafka -it -- \ bin/kafka-reassign-partitions.sh --bootstrap-server localhost:9092 \ --reassignment-json-file /tmp/reassignment.json \ --verifyFor example,
oc exec my-cluster-kafka-0 -c kafka -it -- \ bin/kafka-reassign-partitions.sh --bootstrap-server localhost:9092 \ --reassignment-json-file /tmp/reassignment.json \ --verify-
The reassignment has finished when the
--verifycommand reports each of the partitions being moved as completed successfully. This final--verifywill also have the effect of removing any reassignment throttles. You can now delete the revert file if you saved the JSON for reverting the assignment to their original brokers. Once all the partition reassignments have finished, the broker(s) being removed should not have responsibility for any of the partitions in the cluster. You can verify this by checking that the broker’s data log directory does not contain any live partition logs. If the log directory on the broker contains a directory that does not match the extended regular expression
\.[a-z0-9]-delete$then the broker still has live partitions and it should not be stopped.You can check this by executing the command:
oc exec my-cluster-kafka-0 -c kafka -it -- \ /bin/bash -c \ "ls -l /var/lib/kafka/kafka-log_<N>_ | grep -E '^d' | grep -vE '[a-zA-Z0-9.-]+\.[a-z0-9]+-delete$'"where N is the number of the
Pod(s)being deleted.If the above command prints any output then the broker still has live partitions. In this case, either the reassignment has not finished, or the reassignment JSON file was incorrect.
-
Once you have confirmed that the broker has no live partitions you can edit the
Kafka.spec.kafka.replicasof yourKafkaresource, which will scale down theStatefulSet, deleting the highest numbered brokerPod(s).
2.1.5. Maintenance time windows for rolling updates
Maintenance time windows allow you to schedule certain rolling updates of your Kafka and ZooKeeper clusters to start at a convenient time.
2.1.5.1. Maintenance time windows overview
In most cases, the Cluster Operator only updates your Kafka or ZooKeeper clusters in response to changes to the corresponding Kafka resource. This enables you to plan when to apply changes to a Kafka resource to minimize the impact on Kafka client applications.
However, some updates to your Kafka and ZooKeeper clusters can happen without any corresponding change to the Kafka resource. For example, the Cluster Operator will need to perform a rolling restart if a CA (Certificate Authority) certificate that it manages is close to expiry.
While a rolling restart of the pods should not affect availability of the service (assuming correct broker and topic configurations), it could affect performance of the Kafka client applications. Maintenance time windows allow you to schedule such spontaneous rolling updates of your Kafka and ZooKeeper clusters to start at a convenient time. If maintenance time windows are not configured for a cluster then it is possible that such spontaneous rolling updates will happen at an inconvenient time, such as during a predictable period of high load.
2.1.5.2. Maintenance time window definition
You configure maintenance time windows by entering an array of strings in the Kafka.spec.maintenanceTimeWindows property. Each string is a cron expression interpreted as being in UTC (Coordinated Universal Time, which for practical purposes is the same as Greenwich Mean Time).
The following example configures a single maintenance time window that starts at midnight and ends at 01:59am (UTC), on Sundays, Mondays, Tuesdays, Wednesdays, and Thursdays:
# ...
maintenanceTimeWindows:
- "* * 0-1 ? * SUN,MON,TUE,WED,THU *"
# ...
In practice, maintenance windows should be set in conjunction with the Kafka.spec.clusterCa.renewalDays and Kafka.spec.clientsCa.renewalDays properties of the Kafka resource, to ensure that the necessary CA certificate renewal can be completed in the configured maintenance time windows.
AMQ Streams does not schedule maintenance operations exactly according to the given windows. Instead, for each reconciliation, it checks whether a maintenance window is currently "open". This means that the start of maintenance operations within a given time window can be delayed by up to the Cluster Operator reconciliation interval. Maintenance time windows must therefore be at least this long.
Additional resources
- For more information about the Cluster Operator configuration, see Section 5.1.1, “Cluster Operator configuration”.
2.1.5.3. Configuring a maintenance time window
You can configure a maintenance time window for rolling updates triggered by supported processes.
Prerequisites
- An OpenShift cluster.
- The Cluster Operator is running.
Procedure
Add or edit the
maintenanceTimeWindowsproperty in theKafkaresource. For example to allow maintenance between 0800 and 1059 and between 1400 and 1559 you would set themaintenanceTimeWindowsas shown below:apiVersion: kafka.strimzi.io/v1beta2 kind: Kafka metadata: name: my-cluster spec: kafka: # ... zookeeper: # ... maintenanceTimeWindows: - "* * 8-10 * * ?" - "* * 14-15 * * ?"Create or update the resource:
oc apply -f KAFKA-CONFIG-FILE
Additional resources
Performing rolling updates:
2.1.6. Connecting to ZooKeeper from a terminal
Most Kafka CLI tools can connect directly to Kafka, so under normal circumstances you should not need to connect to ZooKeeper. ZooKeeper services are secured with encryption and authentication and are not intended to be used by external applications that are not part of AMQ Streams.
However, if you want to use Kafka CLI tools that require a connection to ZooKeeper, you can use a terminal inside a ZooKeeper container and connect to localhost:12181 as the ZooKeeper address.
Prerequisites
- An OpenShift cluster is available.
- A Kafka cluster is running.
- The Cluster Operator is running.
Procedure
Open the terminal using the OpenShift console or run the
execcommand from your CLI.For example:
oc exec -ti my-cluster-zookeeper-0 -- bin/kafka-topics.sh --list --zookeeper localhost:12181Be sure to use
localhost:12181.You can now run Kafka commands to ZooKeeper.
2.1.7. Deleting Kafka nodes manually
This procedure describes how to delete an existing Kafka node by using an OpenShift annotation. Deleting a Kafka node consists of deleting both the Pod on which the Kafka broker is running and the related PersistentVolumeClaim (if the cluster was deployed with persistent storage). After deletion, the Pod and its related PersistentVolumeClaim are recreated automatically.
Deleting a PersistentVolumeClaim can cause permanent data loss. The following procedure should only be performed if you have encountered storage issues.
Prerequisites
See the Deploying and Upgrading AMQ Streams on OpenShift guide for instructions on running a:
Procedure
Find the name of the
Podthat you want to delete.For example, if the cluster is named cluster-name, the pods are named cluster-name-kafka-index, where index starts at zero and ends at the total number of replicas.
Annotate the
Podresource in OpenShift.Use
oc annotate:oc annotate pod cluster-name-kafka-index strimzi.io/delete-pod-and-pvc=true- Wait for the next reconciliation, when the annotated pod with the underlying persistent volume claim will be deleted and then recreated.
2.1.8. Deleting ZooKeeper nodes manually
This procedure describes how to delete an existing ZooKeeper node by using an OpenShift annotation. Deleting a ZooKeeper node consists of deleting both the Pod on which ZooKeeper is running and the related PersistentVolumeClaim (if the cluster was deployed with persistent storage). After deletion, the Pod and its related PersistentVolumeClaim are recreated automatically.
Deleting a PersistentVolumeClaim can cause permanent data loss. The following procedure should only be performed if you have encountered storage issues.
Prerequisites
See the Deploying and Upgrading AMQ Streams on OpenShift guide for instructions on running a:
Procedure
Find the name of the
Podthat you want to delete.For example, if the cluster is named cluster-name, the pods are named cluster-name-zookeeper-index, where index starts at zero and ends at the total number of replicas.
Annotate the
Podresource in OpenShift.Use
oc annotate:oc annotate pod cluster-name-zookeeper-index strimzi.io/delete-pod-and-pvc=true- Wait for the next reconciliation, when the annotated pod with the underlying persistent volume claim will be deleted and then recreated.
2.1.9. List of Kafka cluster resources
The following resources are created by the Cluster Operator in the OpenShift cluster:
Shared resources
cluster-name-cluster-ca- Secret with the Cluster CA private key used to encrypt the cluster communication.
cluster-name-cluster-ca-cert- Secret with the Cluster CA public key. This key can be used to verify the identity of the Kafka brokers.
cluster-name-clients-ca- Secret with the Clients CA private key used to sign user certificates
cluster-name-clients-ca-cert- Secret with the Clients CA public key. This key can be used to verify the identity of the Kafka users.
cluster-name-cluster-operator-certs- Secret with Cluster operators keys for communication with Kafka and ZooKeeper.
Zookeeper nodes
cluster-name-zookeeper- StatefulSet which is in charge of managing the ZooKeeper node pods.
cluster-name-zookeeper-idx- Pods created by the Zookeeper StatefulSet.
cluster-name-zookeeper-nodes- Headless Service needed to have DNS resolve the ZooKeeper pods IP addresses directly.
cluster-name-zookeeper-client- Service used by Kafka brokers to connect to ZooKeeper nodes as clients.
cluster-name-zookeeper-config- ConfigMap that contains the ZooKeeper ancillary configuration, and is mounted as a volume by the ZooKeeper node pods.
cluster-name-zookeeper-nodes- Secret with ZooKeeper node keys.
cluster-name-zookeeper- Service account used by the Zookeeper nodes.
cluster-name-zookeeper- Pod Disruption Budget configured for the ZooKeeper nodes.
cluster-name-network-policy-zookeeper- Network policy managing access to the ZooKeeper services.
data-cluster-name-zookeeper-idx-
Persistent Volume Claim for the volume used for storing data for the ZooKeeper node pod
idx. This resource will be created only if persistent storage is selected for provisioning persistent volumes to store data.
Kafka brokers
cluster-name-kafka- StatefulSet which is in charge of managing the Kafka broker pods.
cluster-name-kafka-idx- Pods created by the Kafka StatefulSet.
cluster-name-kafka-brokers- Service needed to have DNS resolve the Kafka broker pods IP addresses directly.
cluster-name-kafka-bootstrap- Service can be used as bootstrap servers for Kafka clients connecting from within the OpenShift cluster.
cluster-name-kafka-external-bootstrap-
Bootstrap service for clients connecting from outside the OpenShift cluster. This resource is created only when an external listener is enabled. The old service name will be used for backwards compatibility when the listener name is
externaland port is9094. cluster-name-kafka-pod-id-
Service used to route traffic from outside the OpenShift cluster to individual pods. This resource is created only when an external listener is enabled. The old service name will be used for backwards compatibility when the listener name is
externaland port is9094. cluster-name-kafka-external-bootstrap-
Bootstrap route for clients connecting from outside the OpenShift cluster. This resource is created only when an external listener is enabled and set to type
route. The old route name will be used for backwards compatibility when the listener name isexternaland port is9094. cluster-name-kafka-pod-id-
Route for traffic from outside the OpenShift cluster to individual pods. This resource is created only when an external listener is enabled and set to type
route. The old route name will be used for backwards compatibility when the listener name isexternaland port is9094. cluster-name-kafka-listener-name-bootstrap- Bootstrap service for clients connecting from outside the OpenShift cluster. This resource is created only when an external listener is enabled. The new service name will be used for all other external listeners.
cluster-name-kafka-listener-name-pod-id- Service used to route traffic from outside the OpenShift cluster to individual pods. This resource is created only when an external listener is enabled. The new service name will be used for all other external listeners.
cluster-name-kafka-listener-name-bootstrap-
Bootstrap route for clients connecting from outside the OpenShift cluster. This resource is created only when an external listener is enabled and set to type
route. The new route name will be used for all other external listeners. cluster-name-kafka-listener-name-pod-id-
Route for traffic from outside the OpenShift cluster to individual pods. This resource is created only when an external listener is enabled and set to type
route. The new route name will be used for all other external listeners. cluster-name-kafka-config- ConfigMap which contains the Kafka ancillary configuration and is mounted as a volume by the Kafka broker pods.
cluster-name-kafka-brokers- Secret with Kafka broker keys.
cluster-name-kafka- Service account used by the Kafka brokers.
cluster-name-kafka- Pod Disruption Budget configured for the Kafka brokers.
cluster-name-network-policy-kafka- Network policy managing access to the Kafka services.
strimzi-namespace-name-cluster-name-kafka-init- Cluster role binding used by the Kafka brokers.
cluster-name-jmx- Secret with JMX username and password used to secure the Kafka broker port. This resource is created only when JMX is enabled in Kafka.
data-cluster-name-kafka-idx-
Persistent Volume Claim for the volume used for storing data for the Kafka broker pod
idx. This resource is created only if persistent storage is selected for provisioning persistent volumes to store data. data-id-cluster-name-kafka-idx-
Persistent Volume Claim for the volume
idused for storing data for the Kafka broker podidx. This resource is created only if persistent storage is selected for JBOD volumes when provisioning persistent volumes to store data.
Entity Operator
These resources are only created if the Entity Operator is deployed using the Cluster Operator.
cluster-name-entity-operator- Deployment with Topic and User Operators.
cluster-name-entity-operator-random-string- Pod created by the Entity Operator deployment.
cluster-name-entity-topic-operator-config- ConfigMap with ancillary configuration for Topic Operators.
cluster-name-entity-user-operator-config- ConfigMap with ancillary configuration for User Operators.
cluster-name-entity-operator-certs- Secret with Entity Operator keys for communication with Kafka and ZooKeeper.
cluster-name-entity-operator- Service account used by the Entity Operator.
strimzi-cluster-name-entity-topic-operator- Role binding used by the Entity Topic Operator.
strimzi-cluster-name-entity-user-operator- Role binding used by the Entity User Operator.
Kafka Exporter
These resources are only created if the Kafka Exporter is deployed using the Cluster Operator.
cluster-name-kafka-exporter- Deployment with Kafka Exporter.
cluster-name-kafka-exporter-random-string- Pod created by the Kafka Exporter deployment.
cluster-name-kafka-exporter- Service used to collect consumer lag metrics.
cluster-name-kafka-exporter- Service account used by the Kafka Exporter.
Cruise Control
These resources are only created if Cruise Control was deployed using the Cluster Operator.
cluster-name-cruise-control- Deployment with Cruise Control.
cluster-name-cruise-control-random-string- Pod created by the Cruise Control deployment.
cluster-name-cruise-control-config- ConfigMap that contains the Cruise Control ancillary configuration, and is mounted as a volume by the Cruise Control pods.
cluster-name-cruise-control-certs- Secret with Cruise Control keys for communication with Kafka and ZooKeeper.
cluster-name-cruise-control- Service used to communicate with Cruise Control.
cluster-name-cruise-control- Service account used by Cruise Control.
cluster-name-network-policy-cruise-control- Network policy managing access to the Cruise Control service.
2.2. Kafka Connect/S2I cluster configuration
This section describes how to configure a Kafka Connect or Kafka Connect with Source-to-Image (S2I) deployment in your AMQ Streams cluster.
Kafka Connect is an integration toolkit for streaming data between Kafka brokers and other systems using connector plugins. Kafka Connect provides a framework for integrating Kafka with an external data source or target, such as a database, for import or export of data using connectors. Connectors are plugins that provide the connection configuration needed.
If you are using Kafka Connect, you configure either the KafkaConnect or the KafkaConnectS2I resource. Use the KafkaConnectS2I resource if you are using the Source-to-Image (S2I) framework to deploy Kafka Connect.
-
The full schema of the
KafkaConnectresource is described in Section 13.2.59, “KafkaConnectschema reference”. -
The full schema of the
KafkaConnectS2Iresource is described in Section 13.2.84, “KafkaConnectS2Ischema reference”.
With the introduction of build configuration to the KafkaConnect resource, AMQ Streams can now automatically build a container image with the connector plugins you require for your data connections. As a result, support for Kafka Connect with Source-to-Image (S2I) is deprecated and will be removed after AMQ Streams 1.8. To prepare for this change, you can migrate Kafka Connect S2I instances to Kafka Connect instances.
Additional resources
2.2.1. Configuring Kafka Connect
Use Kafka Connect to set up external data connections to your Kafka cluster.
Use the properties of the KafkaConnect or KafkaConnectS2I resource to configure your Kafka Connect deployment. The example shown in this procedure is for the KafkaConnect resource, but the properties are the same for the KafkaConnectS2I resource.
Kafka connector configuration
KafkaConnector resources allow you to create and manage connector instances for Kafka Connect in an OpenShift-native way.
In your Kafka Connect configuration, you enable KafkaConnectors for a Kafka Connect cluster by adding the strimzi.io/use-connector-resources annotation. You can also add a build configuration so that AMQ Streams automatically builds a container image with the connector plugins you require for your data connections. External configuration for Kafka Connect connectors is specified through the externalConfiguration property.
To manage connectors, you can use the Kafka Connect REST API, or use KafkaConnector custom resources. KafkaConnector resources must be deployed to the same namespace as the Kafka Connect cluster they link to. For more information on using these methods to create, reconfigure, or delete connectors, see Creating and managing connectors in the Deploying and Upgrading AMQ Streams on OpenShift guide.
Connector configuration is passed to Kafka Connect as part of an HTTP request and stored within Kafka itself. ConfigMaps and Secrets are standard OpenShift resources used for storing configurations and confidential data. You can use ConfigMaps and Secrets to configure certain elements of a connector. You can then reference the configuration values in HTTP REST commands, which keeps the configuration separate and more secure, if needed. This method applies especially to confidential data, such as usernames, passwords, or certificates.
Prerequisites
- An OpenShift cluster
- A running Cluster Operator
See the Deploying and Upgrading AMQ Streams on OpenShift guide for instructions on running a:
Procedure
Edit the
specproperties for theKafkaConnectorKafkaConnectS2Iresource.The properties you can configure are shown in this example configuration:
apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaConnect1 metadata: name: my-connect-cluster annotations: strimzi.io/use-connector-resources: "true"2 spec: replicas: 33 authentication:4 type: tls certificateAndKey: certificate: source.crt key: source.key secretName: my-user-source bootstrapServers: my-cluster-kafka-bootstrap:90925 tls:6 trustedCertificates: - secretName: my-cluster-cluster-cert certificate: ca.crt - secretName: my-cluster-cluster-cert certificate: ca2.crt config:7 group.id: my-connect-cluster offset.storage.topic: my-connect-cluster-offsets config.storage.topic: my-connect-cluster-configs status.storage.topic: my-connect-cluster-status key.converter: org.apache.kafka.connect.json.JsonConverter value.converter: org.apache.kafka.connect.json.JsonConverter key.converter.schemas.enable: true value.converter.schemas.enable: true config.storage.replication.factor: 3 offset.storage.replication.factor: 3 status.storage.replication.factor: 3 build:8 output:9 type: docker image: my-registry.io/my-org/my-connect-cluster:latest pushSecret: my-registry-credentials plugins:10 - name: debezium-postgres-connector artifacts: - type: tgz url: https://repo1.maven.org/maven2/io/debezium/debezium-connector-postgres/1.3.1.Final/debezium-connector-postgres-1.3.1.Final-plugin.tar.gz sha512sum: 962a12151bdf9a5a30627eebac739955a4fd95a08d373b86bdcea2b4d0c27dd6e1edd5cb548045e115e33a9e69b1b2a352bee24df035a0447cb820077af00c03 - name: camel-telegram artifacts: - type: tgz url: https://repo.maven.apache.org/maven2/org/apache/camel/kafkaconnector/camel-telegram-kafka-connector/0.7.0/camel-telegram-kafka-connector-0.7.0-package.tar.gz sha512sum: a9b1ac63e3284bea7836d7d24d84208c49cdf5600070e6bd1535de654f6920b74ad950d51733e8020bf4187870699819f54ef5859c7846ee4081507f48873479 externalConfiguration:11 env: - name: AWS_ACCESS_KEY_ID valueFrom: secretKeyRef: name: aws-creds key: awsAccessKey - name: AWS_SECRET_ACCESS_KEY valueFrom: secretKeyRef: name: aws-creds key: awsSecretAccessKey resources:12 requests: cpu: "1" memory: 2Gi limits: cpu: "2" memory: 2Gi logging:13 type: inline loggers: log4j.rootLogger: "INFO" readinessProbe:14 initialDelaySeconds: 15 timeoutSeconds: 5 livenessProbe: initialDelaySeconds: 15 timeoutSeconds: 5 metricsConfig:15 type: jmxPrometheusExporter valueFrom: configMapKeyRef: name: my-config-map key: my-key jvmOptions:16 "-Xmx": "1g" "-Xms": "1g" image: my-org/my-image:latest17 rack: topologyKey: topology.kubernetes.io/zone18 template:19 pod: affinity: podAntiAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: application operator: In values: - postgresql - mongodb topologyKey: "kubernetes.io/hostname" connectContainer:20 env: - name: JAEGER_SERVICE_NAME value: my-jaeger-service - name: JAEGER_AGENT_HOST value: jaeger-agent-name - name: JAEGER_AGENT_PORT value: "6831"- 1
- Use
KafkaConnectorKafkaConnectS2I, as required. - 2
- Enables KafkaConnectors for the Kafka Connect cluster.
- 3
- 4
- Authentication for the Kafka Connect cluster, using the TLS mechanism, as shown here, using OAuth bearer tokens, or a SASL-based SCRAM-SHA-512 or PLAIN mechanism. By default, Kafka Connect connects to Kafka brokers using a plain text connection.
- 5
- Bootstrap server for connection to the Kafka Connect cluster.
- 6
- TLS encryption with key names under which TLS certificates are stored in X.509 format for the cluster. If certificates are stored in the same secret, it can be listed multiple times.
- 7
- Kafka Connect configuration of workers (not connectors). Standard Apache Kafka configuration may be provided, restricted to those properties not managed directly by AMQ Streams.
- 8
- Build configuration properties for building a container image with connector plugins automatically.
- 9
- (Required) Configuration of the container registry where new images are pushed.
- 10
- (Required) List of connector plugins and their artifacts to add to the new container image. Each plugin must be configured with at least one
artifact. - 11
- External configuration for Kafka connectors using environment variables, as shown here, or volumes. You can also use the Kubernetes Configuration Provider to load configuration values from external sources.
- 12
- Requests for reservation of supported resources, currently
cpuandmemory, and limits to specify the maximum resources that can be consumed. - 13
- Specified Kafka Connect loggers and log levels added directly (
inline) or indirectly (external) through a ConfigMap. A custom ConfigMap must be placed under thelog4j.propertiesorlog4j2.propertieskey. For the Kafka Connectlog4j.rootLoggerlogger, you can set the log level to INFO, ERROR, WARN, TRACE, DEBUG, FATAL or OFF. - 14
- Healthchecks to know when to restart a container (liveness) and when a container can accept traffic (readiness).
- 15
- Prometheus metrics, which are enabled by referencing a ConfigMap containing configuration for the Prometheus JMX exporter in this example. You can enable metrics without further configuration using a reference to a ConfigMap containing an empty file under
metricsConfig.valueFrom.configMapKeyRef.key. - 16
- JVM configuration options to optimize performance for the Virtual Machine (VM) running Kafka Connect.
- 17
- ADVANCED OPTION: Container image configuration, which is recommended only in special situations.
- 18
- Rack awareness is configured to spread replicas across different racks. A
topologykeymust match the label of a cluster node. - 19
- Template customization. Here a pod is scheduled with anti-affinity, so the pod is not scheduled on nodes with the same hostname.
- 20
- Environment variables are also set for distributed tracing using Jaeger.
Create or update the resource:
oc apply -f KAFKA-CONNECT-CONFIG-FILE- If authorization is enabled for Kafka Connect, configure Kafka Connect users to enable access to the Kafka Connect consumer group and topics.
2.2.2. Kafka Connect configuration for multiple instances
If you are running multiple instances of Kafka Connect, you have to change the default configuration of the following config properties:
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaConnect
metadata:
name: my-connect
spec:
# ...
config:
group.id: connect-cluster
offset.storage.topic: connect-cluster-offsets
config.storage.topic: connect-cluster-configs
status.storage.topic: connect-cluster-status
# ...
# ...
Values for the three topics must be the same for all Kafka Connect instances with the same group.id.
Unless you change the default settings, each Kafka Connect instance connecting to the same Kafka cluster is deployed with the same values. What happens, in effect, is all instances are coupled to run in a cluster and use the same topics.
If multiple Kafka Connect clusters try to use the same topics, Kafka Connect will not work as expected and generate errors.
If you wish to run multiple Kafka Connect instances, change the values of these properties for each instance.
2.2.3. Configuring Kafka Connect user authorization
This procedure describes how to authorize user access to Kafka Connect.
When any type of authorization is being used in Kafka, a Kafka Connect user requires read/write access rights to the consumer group and the internal topics of Kafka Connect.
The properties for the consumer group and internal topics are automatically configured by AMQ Streams, or they can be specified explicitly in the spec of the KafkaConnect or KafkaConnectS2I resource.
Example configuration properties in the KafkaConnect resource
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaConnect
metadata:
name: my-connect
spec:
# ...
config:
group.id: my-connect-cluster
offset.storage.topic: my-connect-cluster-offsets
config.storage.topic: my-connect-cluster-configs
status.storage.topic: my-connect-cluster-status
# ...
# ...
This procedure shows how access is provided when simple authorization is being used.
Simple authorization uses ACL rules, handled by the Kafka AclAuthorizer plugin, to provide the right level of access. For more information on configuring a KafkaUser resource to use simple authorization, see the AclRule schema reference.
The default values for the consumer group and topics will differ when running multiple instances.
Prerequisites
- An OpenShift cluster
- A running Cluster Operator
Procedure
Edit the
authorizationproperty in theKafkaUserresource to provide access rights to the user.In the following example, access rights are configured for the Kafka Connect topics and consumer group using
literalname values:Expand Property Name offset.storage.topicconnect-cluster-offsetsstatus.storage.topicconnect-cluster-statusconfig.storage.topicconnect-cluster-configsgroupconnect-clusterapiVersion: kafka.strimzi.io/v1beta2 kind: KafkaUser metadata: name: my-user labels: strimzi.io/cluster: my-cluster spec: # ... authorization: type: simple acls: # access to offset.storage.topic - resource: type: topic name: connect-cluster-offsets patternType: literal operation: Write host: "*" - resource: type: topic name: connect-cluster-offsets patternType: literal operation: Create host: "*" - resource: type: topic name: connect-cluster-offsets patternType: literal operation: Describe host: "*" - resource: type: topic name: connect-cluster-offsets patternType: literal operation: Read host: "*" # access to status.storage.topic - resource: type: topic name: connect-cluster-status patternType: literal operation: Write host: "*" - resource: type: topic name: connect-cluster-status patternType: literal operation: Create host: "*" - resource: type: topic name: connect-cluster-status patternType: literal operation: Describe host: "*" - resource: type: topic name: connect-cluster-status patternType: literal operation: Read host: "*" # access to config.storage.topic - resource: type: topic name: connect-cluster-configs patternType: literal operation: Write host: "*" - resource: type: topic name: connect-cluster-configs patternType: literal operation: Create host: "*" - resource: type: topic name: connect-cluster-configs patternType: literal operation: Describe host: "*" - resource: type: topic name: connect-cluster-configs patternType: literal operation: Read host: "*" # consumer group - resource: type: group name: connect-cluster patternType: literal operation: Read host: "*"Create or update the resource.
oc apply -f KAFKA-USER-CONFIG-FILE
2.2.4. Performing a restart of a Kafka connector
This procedure describes how to manually trigger a restart of a Kafka connector by using an OpenShift annotation.
Prerequisites
- The Cluster Operator is running.
Procedure
Find the name of the
KafkaConnectorcustom resource that controls the Kafka connector you want to restart:oc get KafkaConnectorTo restart the connector, annotate the
KafkaConnectorresource in OpenShift. For example, usingoc annotate:oc annotate KafkaConnector KAFKACONNECTOR-NAME strimzi.io/restart=trueWait for the next reconciliation to occur (every two minutes by default).
The Kafka connector is restarted, as long as the annotation was detected by the reconciliation process. When Kafka Connect accepts the restart request, the annotation is removed from the
KafkaConnectorcustom resource.
Additional resources
- Creating and managing connectors in the Deploying and Upgrading guide.
2.2.5. Performing a restart of a Kafka connector task
This procedure describes how to manually trigger a restart of a Kafka connector task by using an OpenShift annotation.
Prerequisites
- The Cluster Operator is running.
Procedure
Find the name of the
KafkaConnectorcustom resource that controls the Kafka connector task you want to restart:oc get KafkaConnectorFind the ID of the task to be restarted from the
KafkaConnectorcustom resource. Task IDs are non-negative integers, starting from 0.oc describe KafkaConnector KAFKACONNECTOR-NAMETo restart the connector task, annotate the
KafkaConnectorresource in OpenShift. For example, usingoc annotateto restart task 0:oc annotate KafkaConnector KAFKACONNECTOR-NAME strimzi.io/restart-task=0Wait for the next reconciliation to occur (every two minutes by default).
The Kafka connector task is restarted, as long as the annotation was detected by the reconciliation process. When Kafka Connect accepts the restart request, the annotation is removed from the
KafkaConnectorcustom resource.
Additional resources
- Creating and managing connectors in the Deploying and Upgrading guide.
2.2.6. Migrating from Kafka Connect with S2I to Kafka Connect
Support for Kafka Connect with S2I and the KafkaConnectS2I resource is deprecated. This follows the introduction of build configuration properties to the KafkaConnect resource, which are used to build a container image with the connector plugins you require for your data connections automatically.
This procedure describes how to migrate your Kafka Connect with S2I instance to a standard Kafka Connect instance. To do this, you configure a new KafkaConnect custom resource to replace the KafkaConnectS2I resource, which is then deleted.
The migration process involves downtime from the moment the KafkaConnectS2I instance is deleted until the new KafkaConnect instance has been successfully deployed. During this time, connectors will not be running and processing data. However, after the changeover they should continue from the point at which they stopped.
Prerequisites
-
Kafka Connect with S2I is deployed using a
KafkaConnectS2Iconfiguration - Kafka Connect with S2I is using an image with connectors added using an S2I build
-
Sink and source connector instances were created using
KafkaConnectorresources or the Kafka Connect REST API
Procedure
-
Create a new
KafkaConnectcustom resource using the same name as the name used for theKafkaconnectS2Iresource. -
Copy the
KafkaConnectS2Iresource properties to theKafkaConnectresource. If specified, make sure you use the same
spec.configproperties:-
group.id -
offset.storage.topic -
config.storage.topic status.storage.topicIf these properties are not specified, defaults are used. In which case, leave them out of the
KafkaConnectresource configuration as well.
Now add configuration specific to the
KafkaConnectresource to the new resource.-
Add
buildconfiguration to configure all the connectors and other libraries you want to add to the Kafka Connect deployment.NoteAlternatively, you can build a new image with connectors manually, and specify it using the
.spec.imageproperty.Delete the old
KafkaConnectS2Iresource:oc delete -f MY-KAFKA-CONNECT-S2I-CONFIG-FILEReplace MY-KAFKA-CONNECT-S2I-CONFIG-FILE with the name of the file containing your
KafkaConnectS2Iresource configuration.Alternatively, you can specify the name of the resource:
oc delete kafkaconnects2i MY-KAFKA-CONNECT-S2IReplace MY-KAFKA-CONNECT-S2I with the name of the
KafkaConnectS2Iresource.Wait until the Kafka Connect with S2I deployment and pods are deleted.
WarningNo other resources must be deleted.
Deploy the new
KafkaConnectresource:oc apply -f MY-KAFKA-CONNECT-CONFIG-FILEReplace MY-KAFKA-CONNECT-CONFIG-FILE with the name of the file containing your new
KafkaConnectresource configuration.Wait until the new image is built, the deployment is created, and the pods have started.
If you are using
KafkaConnectorresources for managing Kafka Connect connectors, check that all expected connectors are present and are running:oc get kctr --selector strimzi.io/cluster=MY-KAFKA-CONNECT-CLUSTER -o nameReplace MY-KAFKA-CONNECT-CLUSTER with the name of your Kafka Connect cluster.
Connectors automatically recover through Kafka Connect storage. Even if you are using the Kafka Connect REST API to manage them, you should not need to recreate them manually.
2.2.7. List of Kafka Connect cluster resources
The following resources are created by the Cluster Operator in the OpenShift cluster:
- connect-cluster-name-connect
- Deployment which is in charge to create the Kafka Connect worker node pods.
- connect-cluster-name-connect-api
- Service which exposes the REST interface for managing the Kafka Connect cluster.
- connect-cluster-name-config
- ConfigMap which contains the Kafka Connect ancillary configuration and is mounted as a volume by the Kafka broker pods.
- connect-cluster-name-connect
- Pod Disruption Budget configured for the Kafka Connect worker nodes.
2.2.8. List of Kafka Connect (S2I) cluster resources
The following resources are created by the Cluster Operator in the OpenShift cluster:
- connect-cluster-name-connect-source
- ImageStream which is used as the base image for the newly-built Docker images.
- connect-cluster-name-connect
- BuildConfig which is responsible for building the new Kafka Connect Docker images.
- connect-cluster-name-connect
- ImageStream where the newly built Docker images will be pushed.
- connect-cluster-name-connect
- DeploymentConfig which is in charge of creating the Kafka Connect worker node pods.
- connect-cluster-name-connect-api
- Service which exposes the REST interface for managing the Kafka Connect cluster.
- connect-cluster-name-config
- ConfigMap which contains the Kafka Connect ancillary configuration and is mounted as a volume by the Kafka broker pods.
- connect-cluster-name-connect
- Pod Disruption Budget configured for the Kafka Connect worker nodes.
2.2.9. Integrating with Debezium for change data capture
Red Hat Debezium is a distributed change data capture platform. It captures row-level changes in databases, creates change event records, and streams the records to Kafka topics. Debezium is built on Apache Kafka. You can deploy and integrate Debezium with AMQ Streams. Following a deployment of AMQ Streams, you deploy Debezium as a connector configuration through Kafka Connect. Debezium passes change event records to AMQ Streams on OpenShift. Applications can read these change event streams and access the change events in the order in which they occurred.
Debezium has multiple uses, including:
- Data replication
- Updating caches and search indexes
- Simplifying monolithic applications
- Data integration
- Enabling streaming queries
To capture database changes, deploy Kafka Connect with a Debezium database connector . You configure a KafkaConnector resource to define the connector instance.
For more information on deploying Debezium with AMQ Streams, refer to the product documentation. The Debezium documentation includes a Getting Started with Debezium guide that guides you through the process of setting up the services and connector required to view change event records for database updates.
2.3. Kafka MirrorMaker cluster configuration
This chapter describes how to configure a Kafka MirrorMaker deployment in your AMQ Streams cluster to replicate data between Kafka clusters.
You can use AMQ Streams with MirrorMaker or MirrorMaker 2.0. MirrorMaker 2.0 is the latest version, and offers a more efficient way to mirror data between Kafka clusters.
If you are using MirrorMaker, you configure the KafkaMirrorMaker resource.
The following procedure shows how the resource is configured:
The full schema of the KafkaMirrorMaker resource is described in the KafkaMirrorMaker schema reference.
2.3.1. Configuring Kafka MirrorMaker
Use the properties of the KafkaMirrorMaker resource to configure your Kafka MirrorMaker deployment.
You can configure access control for producers and consumers using TLS or SASL authentication. This procedure shows a configuration that uses TLS encryption and authentication on the consumer and producer side.
Prerequisites
See the Deploying and Upgrading AMQ Streams on OpenShift guide for instructions on running a:
- Source and target Kafka clusters must be available
Procedure
Edit the
specproperties for theKafkaMirrorMakerresource.The properties you can configure are shown in this example configuration:
apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaMirrorMaker metadata: name: my-mirror-maker spec: replicas: 31 consumer: bootstrapServers: my-source-cluster-kafka-bootstrap:90922 groupId: "my-group"3 numStreams: 24 offsetCommitInterval: 1200005 tls:6 trustedCertificates: - secretName: my-source-cluster-ca-cert certificate: ca.crt authentication:7 type: tls certificateAndKey: secretName: my-source-secret certificate: public.crt key: private.key config:8 max.poll.records: 100 receive.buffer.bytes: 32768 ssl.cipher.suites: "TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384"9 ssl.enabled.protocols: "TLSv1.2" ssl.protocol: "TLSv1.2" ssl.endpoint.identification.algorithm: HTTPS10 producer: bootstrapServers: my-target-cluster-kafka-bootstrap:9092 abortOnSendFailure: false11 tls: trustedCertificates: - secretName: my-target-cluster-ca-cert certificate: ca.crt authentication: type: tls certificateAndKey: secretName: my-target-secret certificate: public.crt key: private.key config: compression.type: gzip batch.size: 8192 ssl.cipher.suites: "TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384"12 ssl.enabled.protocols: "TLSv1.2" ssl.protocol: "TLSv1.2" ssl.endpoint.identification.algorithm: HTTPS13 include: "my-topic|other-topic"14 resources:15 requests: cpu: "1" memory: 2Gi limits: cpu: "2" memory: 2Gi logging:16 type: inline loggers: mirrormaker.root.logger: "INFO" readinessProbe:17 initialDelaySeconds: 15 timeoutSeconds: 5 livenessProbe: initialDelaySeconds: 15 timeoutSeconds: 5 metricsConfig:18 type: jmxPrometheusExporter valueFrom: configMapKeyRef: name: my-config-map key: my-key jvmOptions:19 "-Xmx": "1g" "-Xms": "1g" image: my-org/my-image:latest20 template:21 pod: affinity: podAntiAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: application operator: In values: - postgresql - mongodb topologyKey: "kubernetes.io/hostname" connectContainer:22 env: - name: JAEGER_SERVICE_NAME value: my-jaeger-service - name: JAEGER_AGENT_HOST value: jaeger-agent-name - name: JAEGER_AGENT_PORT value: "6831" tracing:23 type: jaeger- 1
- 2
- Bootstrap servers for consumer and producer.
- 3
- 4
- 5
- 6
- TLS encryption with key names under which TLS certificates are stored in X.509 format for consumer or producer. If certificates are stored in the same secret, it can be listed multiple times.
- 7
- Authentication for consumer or producer, using the TLS mechanism, as shown here, using OAuth bearer tokens, or a SASL-based SCRAM-SHA-512 or PLAIN mechanism.
- 8
- 9
- SSL properties for external listeners to run with a specific cipher suite for a TLS version.
- 10
- Hostname verification is enabled by setting to
HTTPS. An empty string disables the verification. - 11
- If the
abortOnSendFailureproperty is set totrue, Kafka MirrorMaker will exit and the container will restart following a send failure for a message. - 12
- SSL properties for external listeners to run with a specific cipher suite for a TLS version.
- 13
- Hostname verification is enabled by setting to
HTTPS. An empty string disables the verification. - 14
- A included topics mirrored from source to target Kafka cluster.
- 15
- Requests for reservation of supported resources, currently
cpuandmemory, and limits to specify the maximum resources that can be consumed. - 16
- Specified loggers and log levels added directly (
inline) or indirectly (external) through a ConfigMap. A custom ConfigMap must be placed under thelog4j.propertiesorlog4j2.propertieskey. MirrorMaker has a single logger calledmirrormaker.root.logger. You can set the log level to INFO, ERROR, WARN, TRACE, DEBUG, FATAL or OFF. - 17
- Healthchecks to know when to restart a container (liveness) and when a container can accept traffic (readiness).
- 18
- Prometheus metrics, which are enabled by referencing a ConfigMap containing configuration for the Prometheus JMX exporter in this example. You can enable metrics without further configuration using a reference to a ConfigMap containing an empty file under
metricsConfig.valueFrom.configMapKeyRef.key. - 19
- JVM configuration options to optimize performance for the Virtual Machine (VM) running Kafka MirrorMaker.
- 20
- ADVANCED OPTION: Container image configuration, which is recommended only in special situations.
- 21
- Template customization. Here a pod is scheduled with anti-affinity, so the pod is not scheduled on nodes with the same hostname.
- 22
- Environment variables are also set for distributed tracing using Jaeger.
- 23
WarningWith the
abortOnSendFailureproperty set tofalse, the producer attempts to send the next message in a topic. The original message might be lost, as there is no attempt to resend a failed message.Create or update the resource:
oc apply -f <your-file>
2.3.2. List of Kafka MirrorMaker cluster resources
The following resources are created by the Cluster Operator in the OpenShift cluster:
- <mirror-maker-name>-mirror-maker
- Deployment which is responsible for creating the Kafka MirrorMaker pods.
- <mirror-maker-name>-config
- ConfigMap which contains ancillary configuration for the Kafka MirrorMaker, and is mounted as a volume by the Kafka broker pods.
- <mirror-maker-name>-mirror-maker
- Pod Disruption Budget configured for the Kafka MirrorMaker worker nodes.
2.4. Kafka MirrorMaker 2.0 cluster configuration
This section describes how to configure a Kafka MirrorMaker 2.0 deployment in your AMQ Streams cluster.
MirrorMaker 2.0 is used to replicate data between two or more active Kafka clusters, within or across data centers.
Data replication across clusters supports scenarios that require:
- Recovery of data in the event of a system failure
- Aggregation of data for analysis
- Restriction of data access to a specific cluster
- Provision of data at a specific location to improve latency
If you are using MirrorMaker 2.0, you configure the KafkaMirrorMaker2 resource.
MirrorMaker 2.0 introduces an entirely new way of replicating data between clusters.
As a result, the resource configuration differs from the previous version of MirrorMaker. If you choose to use MirrorMaker 2.0, there is currently no legacy support, so any resources must be manually converted into the new format.
How MirrorMaker 2.0 replicates data is described here:
The following procedure shows how the resource is configured for MirrorMaker 2.0:
The full schema of the KafkaMirrorMaker2 resource is described in the KafkaMirrorMaker2 schema reference.
2.4.1. MirrorMaker 2.0 data replication
MirrorMaker 2.0 consumes messages from a source Kafka cluster and writes them to a target Kafka cluster.
MirrorMaker 2.0 uses:
- Source cluster configuration to consume data from the source cluster
- Target cluster configuration to output data to the target cluster
MirrorMaker 2.0 is based on the Kafka Connect framework, connectors managing the transfer of data between clusters. A MirrorMaker 2.0 MirrorSourceConnector replicates topics from a source cluster to a target cluster.
The process of mirroring data from one cluster to another cluster is asynchronous. The recommended pattern is for messages to be produced locally alongside the source Kafka cluster, then consumed remotely close to the target Kafka cluster.
MirrorMaker 2.0 can be used with more than one source cluster.
Figure 2.1. Replication across two clusters
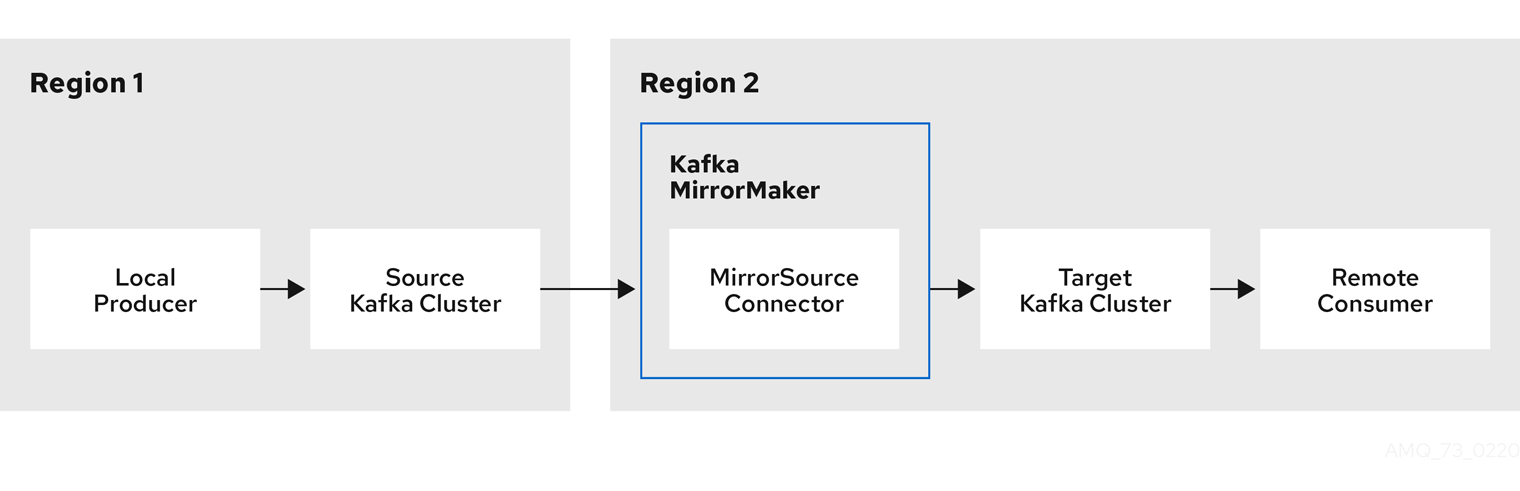
By default, a check for new topics in the source cluster is made every 10 minutes. You can change the frequency by adding refresh.topics.interval.seconds to the source connector configuration. However, increasing the frequency of the operation might affect overall performance.
2.4.2. Cluster configuration
You can use MirrorMaker 2.0 in active/passive or active/active cluster configurations.
- In an active/active configuration, both clusters are active and provide the same data simultaneously, which is useful if you want to make the same data available locally in different geographical locations.
- In an active/passive configuration, the data from an active cluster is replicated in a passive cluster, which remains on standby, for example, for data recovery in the event of system failure.
The expectation is that producers and consumers connect to active clusters only.
A MirrorMaker 2.0 cluster is required at each target destination.
2.4.2.1. Bidirectional replication (active/active)
The MirrorMaker 2.0 architecture supports bidirectional replication in an active/active cluster configuration.
Each cluster replicates the data of the other cluster using the concept of source and remote topics. As the same topics are stored in each cluster, remote topics are automatically renamed by MirrorMaker 2.0 to represent the source cluster. The name of the originating cluster is prepended to the name of the topic.
Figure 2.2. Topic renaming
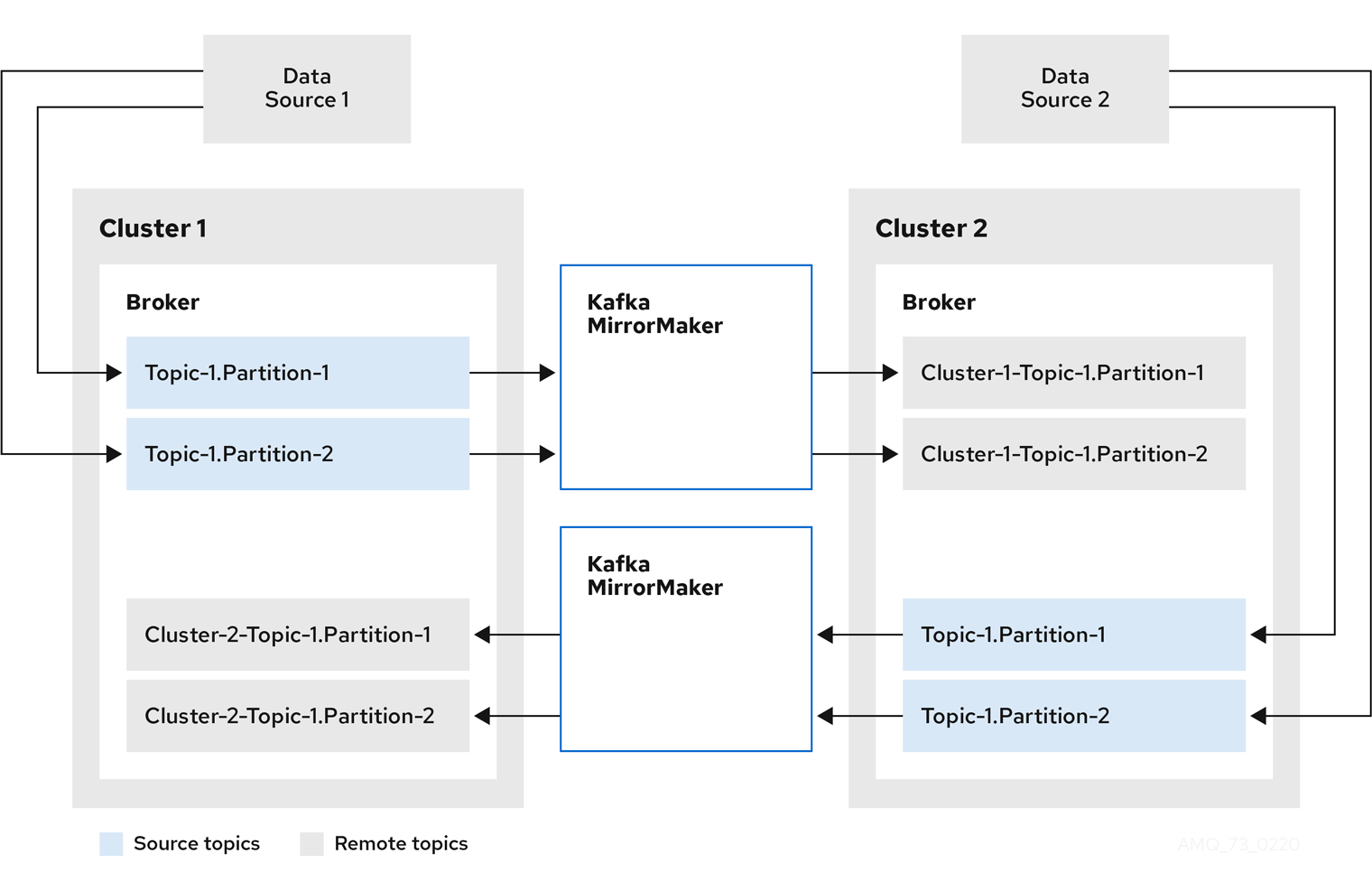
By flagging the originating cluster, topics are not replicated back to that cluster.
The concept of replication through remote topics is useful when configuring an architecture that requires data aggregation. Consumers can subscribe to source and remote topics within the same cluster, without the need for a separate aggregation cluster.
2.4.2.2. Unidirectional replication (active/passive)
The MirrorMaker 2.0 architecture supports unidirectional replication in an active/passive cluster configuration.
You can use an active/passive cluster configuration to make backups or migrate data to another cluster. In this situation, you might not want automatic renaming of remote topics.
You can override automatic renaming by adding IdentityReplicationPolicy to the source connector configuration. With this configuration applied, topics retain their original names.
2.4.2.3. Topic configuration synchronization
Topic configuration is automatically synchronized between source and target clusters. By synchronizing configuration properties, the need for rebalancing is reduced.
2.4.2.4. Data integrity
MirrorMaker 2.0 monitors source topics and propagates any configuration changes to remote topics, checking for and creating missing partitions. Only MirrorMaker 2.0 can write to remote topics.
2.4.2.5. Offset tracking
MirrorMaker 2.0 tracks offsets for consumer groups using internal topics.
- The offset sync topic maps the source and target offsets for replicated topic partitions from record metadata
- The checkpoint topic maps the last committed offset in the source and target cluster for replicated topic partitions in each consumer group
Offsets for the checkpoint topic are tracked at predetermined intervals through configuration. Both topics enable replication to be fully restored from the correct offset position on failover.
MirrorMaker 2.0 uses its MirrorCheckpointConnector to emit checkpoints for offset tracking.
2.4.2.6. Synchronizing consumer group offsets
The __consumer_offsets topic stores information on committed offsets, for each consumer group. Offset synchronization periodically transfers the consumer offsets for the consumer groups of a source cluster into the consumer offsets topic of a target cluster.
Offset synchronization is particularly useful in an active/passive configuration. If the active cluster goes down, consumer applications can switch to the passive (standby) cluster and pick up from the last transferred offset position.
To use topic offset synchronization:
-
Enable the synchronization by adding
sync.group.offsets.enabledto the checkpoint connector configuration, and setting the property totrue. Synchronization is disabled by default. -
Add the
IdentityReplicationPolicyto the source and checkpoint connector configuration so that topics in the target cluster retain their original names.
For topic offset synchronization to work, consumer groups in the target cluster cannot use the same ids as groups in the source cluster.
If enabled, the synchronization of offsets from the source cluster is made periodically. You can change the frequency by adding sync.group.offsets.interval.seconds and emit.checkpoints.interval.seconds to the checkpoint connector configuration. The properties specify the frequency in seconds that the consumer group offsets are synchronized, and the frequency of checkpoints emitted for offset tracking. The default for both properties is 60 seconds. You can also change the frequency of checks for new consumer groups using the refresh.groups.interval.seconds property, which is performed every 10 minutes by default.
Because the synchronization is time-based, any switchover by consumers to a passive cluster will likely result in some duplication of messages.
2.4.2.7. Connectivity checks
A heartbeat internal topic checks connectivity between clusters.
The heartbeat topic is replicated from the source cluster.
Target clusters use the topic to check:
- The connector managing connectivity between clusters is running
- The source cluster is available
MirrorMaker 2.0 uses its MirrorHeartbeatConnector to emit heartbeats that perform these checks.
2.4.3. ACL rules synchronization
ACL access to remote topics is possible if you are not using the User Operator.
If AclAuthorizer is being used, without the User Operator, ACL rules that manage access to brokers also apply to remote topics. Users that can read a source topic can read its remote equivalent.
OAuth 2.0 authorization does not support access to remote topics in this way.
2.4.4. Synchronizing data between Kafka clusters using MirrorMaker 2.0
Use MirrorMaker 2.0 to synchronize data between Kafka clusters through configuration.
The configuration must specify:
- Each Kafka cluster
- Connection information for each cluster, including TLS authentication
The replication flow and direction
- Cluster to cluster
- Topic to topic
Use the properties of the KafkaMirrorMaker2 resource to configure your Kafka MirrorMaker 2.0 deployment.
The previous version of MirrorMaker continues to be supported. If you wish to use the resources configured for the previous version, they must be updated to the format supported by MirrorMaker 2.0.
MirrorMaker 2.0 provides default configuration values for properties such as replication factors. A minimal configuration, with defaults left unchanged, would be something like this example:
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaMirrorMaker2
metadata:
name: my-mirror-maker2
spec:
version: 2.8.0
connectCluster: "my-cluster-target"
clusters:
- alias: "my-cluster-source"
bootstrapServers: my-cluster-source-kafka-bootstrap:9092
- alias: "my-cluster-target"
bootstrapServers: my-cluster-target-kafka-bootstrap:9092
mirrors:
- sourceCluster: "my-cluster-source"
targetCluster: "my-cluster-target"
sourceConnector: {}You can configure access control for source and target clusters using TLS or SASL authentication. This procedure shows a configuration that uses TLS encryption and authentication for the source and target cluster.
Prerequisites
See the Deploying and Upgrading AMQ Streams on OpenShift guide for instructions on running a:
- Source and target Kafka clusters must be available
Procedure
Edit the
specproperties for theKafkaMirrorMaker2resource.The properties you can configure are shown in this example configuration:
apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaMirrorMaker2 metadata: name: my-mirror-maker2 spec: version: 2.8.01 replicas: 32 connectCluster: "my-cluster-target"3 clusters:4 - alias: "my-cluster-source"5 authentication:6 certificateAndKey: certificate: source.crt key: source.key secretName: my-user-source type: tls bootstrapServers: my-cluster-source-kafka-bootstrap:90927 tls:8 trustedCertificates: - certificate: ca.crt secretName: my-cluster-source-cluster-ca-cert - alias: "my-cluster-target"9 authentication:10 certificateAndKey: certificate: target.crt key: target.key secretName: my-user-target type: tls bootstrapServers: my-cluster-target-kafka-bootstrap:909211 config:12 config.storage.replication.factor: 1 offset.storage.replication.factor: 1 status.storage.replication.factor: 1 ssl.cipher.suites: "TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384"13 ssl.enabled.protocols: "TLSv1.2" ssl.protocol: "TLSv1.2" ssl.endpoint.identification.algorithm: HTTPS14 tls:15 trustedCertificates: - certificate: ca.crt secretName: my-cluster-target-cluster-ca-cert mirrors:16 - sourceCluster: "my-cluster-source"17 targetCluster: "my-cluster-target"18 sourceConnector:19 tasksMax: 1020 config: replication.factor: 121 offset-syncs.topic.replication.factor: 122 sync.topic.acls.enabled: "false"23 refresh.topics.interval.seconds: 6024 replication.policy.separator: ""25 replication.policy.class: "io.strimzi.kafka.connect.mirror.IdentityReplicationPolicy"26 heartbeatConnector:27 config: heartbeats.topic.replication.factor: 128 checkpointConnector:29 config: checkpoints.topic.replication.factor: 130 refresh.groups.interval.seconds: 60031 sync.group.offsets.enabled: true32 sync.group.offsets.interval.seconds: 6033 emit.checkpoints.interval.seconds: 6034 replication.policy.class: "io.strimzi.kafka.connect.mirror.IdentityReplicationPolicy" topicsPattern: ".*"35 groupsPattern: "group1|group2|group3"36 resources:37 requests: cpu: "1" memory: 2Gi limits: cpu: "2" memory: 2Gi logging:38 type: inline loggers: connect.root.logger.level: "INFO" readinessProbe:39 initialDelaySeconds: 15 timeoutSeconds: 5 livenessProbe: initialDelaySeconds: 15 timeoutSeconds: 5 jvmOptions:40 "-Xmx": "1g" "-Xms": "1g" image: my-org/my-image:latest41 template:42 pod: affinity: podAntiAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: application operator: In values: - postgresql - mongodb topologyKey: "kubernetes.io/hostname" connectContainer:43 env: - name: JAEGER_SERVICE_NAME value: my-jaeger-service - name: JAEGER_AGENT_HOST value: jaeger-agent-name - name: JAEGER_AGENT_PORT value: "6831" tracing: type: jaeger44 externalConfiguration:45 env: - name: AWS_ACCESS_KEY_ID valueFrom: secretKeyRef: name: aws-creds key: awsAccessKey - name: AWS_SECRET_ACCESS_KEY valueFrom: secretKeyRef: name: aws-creds key: awsSecretAccessKey- 1
- The Kafka Connect and Mirror Maker 2.0 version, which will always be the same.
- 2
- 3
- Kafka cluster alias for Kafka Connect, which must specify the target Kafka cluster. The Kafka cluster is used by Kafka Connect for its internal topics.
- 4
- Specification for the Kafka clusters being synchronized.
- 5
- Cluster alias for the source Kafka cluster.
- 6
- Authentication for the source cluster, using the TLS mechanism, as shown here, using OAuth bearer tokens, or a SASL-based SCRAM-SHA-512 or PLAIN mechanism.
- 7
- Bootstrap server for connection to the source Kafka cluster.
- 8
- TLS encryption with key names under which TLS certificates are stored in X.509 format for the source Kafka cluster. If certificates are stored in the same secret, it can be listed multiple times.
- 9
- Cluster alias for the target Kafka cluster.
- 10
- Authentication for the target Kafka cluster is configured in the same way as for the source Kafka cluster.
- 11
- Bootstrap server for connection to the target Kafka cluster.
- 12
- Kafka Connect configuration. Standard Apache Kafka configuration may be provided, restricted to those properties not managed directly by AMQ Streams.
- 13
- SSL properties for external listeners to run with a specific cipher suite for a TLS version.
- 14
- Hostname verification is enabled by setting to
HTTPS. An empty string disables the verification. - 15
- TLS encryption for the target Kafka cluster is configured in the same way as for the source Kafka cluster.
- 16
- 17
- Cluster alias for the source cluster used by the MirrorMaker 2.0 connectors.
- 18
- Cluster alias for the target cluster used by the MirrorMaker 2.0 connectors.
- 19
- Configuration for the
MirrorSourceConnectorthat creates remote topics. Theconfigoverrides the default configuration options. - 20
- The maximum number of tasks that the connector may create. Tasks handle the data replication and run in parallel. If the infrastructure supports the processing overhead, increasing this value can improve throughput. Kafka Connect distributes the tasks between members of the cluster. If there are more tasks than workers, workers are assigned multiple tasks. For sink connectors, aim to have one task for each topic partition consumed. For source connectors, the number of tasks that can run in parallel may also depend on the external system. The connector creates fewer than the maximum number of tasks if it cannot achieve the parallelism.
- 21
- Replication factor for mirrored topics created at the target cluster.
- 22
- Replication factor for the
MirrorSourceConnectoroffset-syncsinternal topic that maps the offsets of the source and target clusters. - 23
- When ACL rules synchronization is enabled, ACLs are applied to synchronized topics. The default is
true. - 24
- Optional setting to change the frequency of checks for new topics. The default is for a check every 10 minutes.
- 25
- Defines the separator used for the renaming of remote topics.
- 26
- Adds a policy that overrides the automatic renaming of remote topics. Instead of prepending the name with the name of the source cluster, the topic retains its original name. This optional setting is useful for active/passive backups and data migration. To configure topic offset synchronization, this property must also be set for the
checkpointConnector.config. - 27
- Configuration for the
MirrorHeartbeatConnectorthat performs connectivity checks. Theconfigoverrides the default configuration options. - 28
- Replication factor for the heartbeat topic created at the target cluster.
- 29
- Configuration for the
MirrorCheckpointConnectorthat tracks offsets. Theconfigoverrides the default configuration options. - 30
- Replication factor for the checkpoints topic created at the target cluster.
- 31
- Optional setting to change the frequency of checks for new consumer groups. The default is for a check every 10 minutes.
- 32
- Optional setting to synchronize consumer group offsets, which is useful for recovery in an active/passive configuration. Synchronization is not enabled by default.
- 33
- If the synchronization of consumer group offsets is enabled, you can adjust the frequency of the synchronization.
- 34
- Adjusts the frequency of checks for offset tracking. If you change the frequency of offset synchronization, you might also need to adjust the frequency of these checks.
- 35
- Topic replication from the source cluster defined as regular expression patterns. Here we request all topics.
- 36
- Consumer group replication from the source cluster defined as regular expression patterns. Here we request three consumer groups by name. You can use comma-separated lists.
- 37
- Requests for reservation of supported resources, currently
cpuandmemory, and limits to specify the maximum resources that can be consumed. - 38
- Specified Kafka Connect loggers and log levels added directly (
inline) or indirectly (external) through a ConfigMap. A custom ConfigMap must be placed under thelog4j.propertiesorlog4j2.propertieskey. For the Kafka Connectlog4j.rootLoggerlogger, you can set the log level to INFO, ERROR, WARN, TRACE, DEBUG, FATAL or OFF. - 39
- Healthchecks to know when to restart a container (liveness) and when a container can accept traffic (readiness).
- 40
- JVM configuration options to optimize performance for the Virtual Machine (VM) running Kafka MirrorMaker.
- 41
- ADVANCED OPTION: Container image configuration, which is recommended only in special situations.
- 42
- Template customization. Here a pod is scheduled with anti-affinity, so the pod is not scheduled on nodes with the same hostname.
- 43
- Environment variables are also set for distributed tracing using Jaeger.
- 44
- 45
- External configuration for an OpenShift Secret mounted to Kafka MirrorMaker as an environment variable. You can also use the Kubernetes Configuration Provider to load configuration values from external sources.
Create or update the resource:
oc apply -f MIRRORMAKER-CONFIGURATION-FILE
2.4.5. Performing a restart of a Kafka MirrorMaker 2.0 connector
This procedure describes how to manually trigger a restart of a Kafka MirrorMaker 2.0 connector by using an OpenShift annotation.
Prerequisites
- The Cluster Operator is running.
Procedure
Find the name of the
KafkaMirrorMaker2custom resource that controls the Kafka MirrorMaker 2.0 connector you want to restart:oc get KafkaMirrorMaker2Find the name of the Kafka MirrorMaker 2.0 connector to be restarted from the
KafkaMirrorMaker2custom resource.oc describe KafkaMirrorMaker2 KAFKAMIRRORMAKER-2-NAMETo restart the connector, annotate the
KafkaMirrorMaker2resource in OpenShift. In this example,oc annotaterestarts a connector namedmy-source->my-target.MirrorSourceConnector:oc annotate KafkaMirrorMaker2 KAFKAMIRRORMAKER-2-NAME "strimzi.io/restart-connector=my-source->my-target.MirrorSourceConnector"Wait for the next reconciliation to occur (every two minutes by default).
The Kafka MirrorMaker 2.0 connector is restarted, as long as the annotation was detected by the reconciliation process. When the restart request is accepted, the annotation is removed from the
KafkaMirrorMaker2custom resource.
Additional resources
2.4.6. Performing a restart of a Kafka MirrorMaker 2.0 connector task
This procedure describes how to manually trigger a restart of a Kafka MirrorMaker 2.0 connector task by using an OpenShift annotation.
Prerequisites
- The Cluster Operator is running.
Procedure
Find the name of the
KafkaMirrorMaker2custom resource that controls the Kafka MirrorMaker 2.0 connector you want to restart:oc get KafkaMirrorMaker2Find the name of the Kafka MirrorMaker 2.0 connector and the ID of the task to be restarted from the
KafkaMirrorMaker2custom resource. Task IDs are non-negative integers, starting from 0.oc describe KafkaMirrorMaker2 KAFKAMIRRORMAKER-2-NAMETo restart the connector task, annotate the
KafkaMirrorMaker2resource in OpenShift. In this example,oc annotaterestarts task 0 of a connector namedmy-source->my-target.MirrorSourceConnector:oc annotate KafkaMirrorMaker2 KAFKAMIRRORMAKER-2-NAME "strimzi.io/restart-connector-task=my-source->my-target.MirrorSourceConnector:0"Wait for the next reconciliation to occur (every two minutes by default).
The Kafka MirrorMaker 2.0 connector task is restarted, as long as the annotation was detected by the reconciliation process. When the restart task request is accepted, the annotation is removed from the
KafkaMirrorMaker2custom resource.
Additional resources
2.5. Kafka Bridge cluster configuration
This section describes how to configure a Kafka Bridge deployment in your AMQ Streams cluster.
Kafka Bridge provides an API for integrating HTTP-based clients with a Kafka cluster.
If you are using the Kafka Bridge, you configure the KafkaBridge resource.
The full schema of the KafkaBridge resource is described in Section 13.2.110, “KafkaBridge schema reference”.
2.5.1. Configuring the Kafka Bridge
Use the Kafka Bridge to make HTTP-based requests to the Kafka cluster.
Use the properties of the KafkaBridge resource to configure your Kafka Bridge deployment.
In order to prevent issues arising when client consumer requests are processed by different Kafka Bridge instances, address-based routing must be employed to ensure that requests are routed to the right Kafka Bridge instance. Additionally, each independent Kafka Bridge instance must have a replica. A Kafka Bridge instance has its own state which is not shared with another instances.
Prerequisites
- An OpenShift cluster
- A running Cluster Operator
See the Deploying and Upgrading AMQ Streams on OpenShift guide for instructions on running a:
Procedure
Edit the
specproperties for theKafkaBridgeresource.The properties you can configure are shown in this example configuration:
apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaBridge metadata: name: my-bridge spec: replicas: 31 bootstrapServers: my-cluster-kafka-bootstrap:90922 tls:3 trustedCertificates: - secretName: my-cluster-cluster-cert certificate: ca.crt - secretName: my-cluster-cluster-cert certificate: ca2.crt authentication:4 type: tls certificateAndKey: secretName: my-secret certificate: public.crt key: private.key http:5 port: 8080 cors:6 allowedOrigins: "https://strimzi.io" allowedMethods: "GET,POST,PUT,DELETE,OPTIONS,PATCH" consumer:7 config: auto.offset.reset: earliest producer:8 config: delivery.timeout.ms: 300000 resources:9 requests: cpu: "1" memory: 2Gi limits: cpu: "2" memory: 2Gi logging:10 type: inline loggers: logger.bridge.level: "INFO" # enabling DEBUG just for send operation logger.send.name: "http.openapi.operation.send" logger.send.level: "DEBUG" jvmOptions:11 "-Xmx": "1g" "-Xms": "1g" readinessProbe:12 initialDelaySeconds: 15 timeoutSeconds: 5 livenessProbe: initialDelaySeconds: 15 timeoutSeconds: 5 image: my-org/my-image:latest13 template:14 pod: affinity: podAntiAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: application operator: In values: - postgresql - mongodb topologyKey: "kubernetes.io/hostname" bridgeContainer:15 env: - name: JAEGER_SERVICE_NAME value: my-jaeger-service - name: JAEGER_AGENT_HOST value: jaeger-agent-name - name: JAEGER_AGENT_PORT value: "6831"- 1
- 2
- Bootstrap server for connection to the target Kafka cluster.
- 3
- TLS encryption with key names under which TLS certificates are stored in X.509 format for the source Kafka cluster. If certificates are stored in the same secret, it can be listed multiple times.
- 4
- Authentication for the Kafka Bridge cluster, using the TLS mechanism, as shown here, using OAuth bearer tokens, or a SASL-based SCRAM-SHA-512 or PLAIN mechanism. By default, the Kafka Bridge connects to Kafka brokers without authentication.
- 5
- HTTP access to Kafka brokers.
- 6
- CORS access specifying selected resources and access methods. Additional HTTP headers in requests describe the origins that are permitted access to the Kafka cluster.
- 7
- Consumer configuration options.
- 8
- Producer configuration options.
- 9
- Requests for reservation of supported resources, currently
cpuandmemory, and limits to specify the maximum resources that can be consumed. - 10
- Specified Kafka Bridge loggers and log levels added directly (
inline) or indirectly (external) through a ConfigMap. A custom ConfigMap must be placed under thelog4j.propertiesorlog4j2.propertieskey. For the Kafka Bridge loggers, you can set the log level to INFO, ERROR, WARN, TRACE, DEBUG, FATAL or OFF. - 11
- JVM configuration options to optimize performance for the Virtual Machine (VM) running the Kafka Bridge.
- 12
- Healthchecks to know when to restart a container (liveness) and when a container can accept traffic (readiness).
- 13
- ADVANCED OPTION: Container image configuration, which is recommended only in special situations.
- 14
- Template customization. Here a pod is scheduled with anti-affinity, so the pod is not scheduled on nodes with the same hostname.
- 15
- Environment variables are also set for distributed tracing using Jaeger.
Create or update the resource:
oc apply -f KAFKA-BRIDGE-CONFIG-FILE
2.5.2. List of Kafka Bridge cluster resources
The following resources are created by the Cluster Operator in the OpenShift cluster:
- bridge-cluster-name-bridge
- Deployment which is in charge to create the Kafka Bridge worker node pods.
- bridge-cluster-name-bridge-service
- Service which exposes the REST interface of the Kafka Bridge cluster.
- bridge-cluster-name-bridge-config
- ConfigMap which contains the Kafka Bridge ancillary configuration and is mounted as a volume by the Kafka broker pods.
- bridge-cluster-name-bridge
- Pod Disruption Budget configured for the Kafka Bridge worker nodes.
2.6. Customizing OpenShift resources
AMQ Streams creates several OpenShift resources, such as Deployments, StatefulSets, Pods, and Services, which are managed by AMQ Streams operators. Only the operator that is responsible for managing a particular OpenShift resource can change that resource. If you try to manually change an operator-managed OpenShift resource, the operator will revert your changes back.
However, changing an operator-managed OpenShift resource can be useful if you want to perform certain tasks, such as:
-
Adding custom labels or annotations that control how
Podsare treated by Istio or other services -
Managing how
Loadbalancer-type Services are created by the cluster
You can make such changes using the template property in the AMQ Streams custom resources. The template property is supported in the following resources. The API reference provides more details about the customizable fields.
Kafka.spec.kafka-
See Section 13.2.32, “
KafkaClusterTemplateschema reference” Kafka.spec.zookeeper-
See Section 13.2.43, “
ZookeeperClusterTemplateschema reference” Kafka.spec.entityOperator-
See Section 13.2.48, “
EntityOperatorTemplateschema reference” Kafka.spec.kafkaExporter-
See Section 13.2.54, “
KafkaExporterTemplateschema reference” Kafka.spec.cruiseControl-
See Section 13.2.51, “
CruiseControlTemplateschema reference” KafkaConnect.spec-
See Section 13.2.68, “
KafkaConnectTemplateschema reference” KafkaConnectS2I.spec-
See Section 13.2.68, “
KafkaConnectTemplateschema reference” KafkaMirrorMaker.spec-
See Section 13.2.108, “
KafkaMirrorMakerTemplateschema reference” KafkaMirrorMaker2.spec-
See Section 13.2.68, “
KafkaConnectTemplateschema reference” KafkaBridge.spec-
See Section 13.2.118, “
KafkaBridgeTemplateschema reference” KafkaUser.spec-
See Section 13.2.101, “
KafkaUserTemplateschema reference”
In the following example, the template property is used to modify the labels in a Kafka broker’s StatefulSet:
Example template customization
apiVersion: kafka.strimzi.io/v1beta2
kind: Kafka
metadata:
name: my-cluster
labels:
app: my-cluster
spec:
kafka:
# ...
template:
statefulset:
metadata:
labels:
mylabel: myvalue
# ...2.6.1. Customizing the image pull policy
AMQ Streams allows you to customize the image pull policy for containers in all pods deployed by the Cluster Operator. The image pull policy is configured using the environment variable STRIMZI_IMAGE_PULL_POLICY in the Cluster Operator deployment. The STRIMZI_IMAGE_PULL_POLICY environment variable can be set to three different values:
Always- Container images are pulled from the registry every time the pod is started or restarted.
IfNotPresent- Container images are pulled from the registry only when they were not pulled before.
Never- Container images are never pulled from the registry.
The image pull policy can be currently customized only for all Kafka, Kafka Connect, and Kafka MirrorMaker clusters at once. Changing the policy will result in a rolling update of all your Kafka, Kafka Connect, and Kafka MirrorMaker clusters.
Additional resources
- For more information about Cluster Operator configuration, see Section 5.1, “Using the Cluster Operator”.
- For more information about Image Pull Policies, see Disruptions.
2.7. Configuring pod scheduling
When two applications are scheduled to the same OpenShift node, both applications might use the same resources like disk I/O and impact performance. That can lead to performance degradation. Scheduling Kafka pods in a way that avoids sharing nodes with other critical workloads, using the right nodes or dedicated a set of nodes only for Kafka are the best ways how to avoid such problems.
2.7.1. Specifying affinity, tolerations, and topology spread constraints
Use affinity, tolerations and topology spread constraints to schedule the pods of kafka resources onto nodes. Affinity, tolerations and topology spread constraints are configured using the affinity, tolerations, and topologySpreadConstraint properties in following resources:
-
Kafka.spec.kafka.template.pod -
Kafka.spec.zookeeper.template.pod -
Kafka.spec.entityOperator.template.pod -
KafkaConnect.spec.template.pod -
KafkaConnectS2I.spec.template.pod -
KafkaBridge.spec.template.pod -
KafkaMirrorMaker.spec.template.pod -
KafkaMirrorMaker2.spec.template.pod
The format of the affinity, tolerations, and topologySpreadConstraint properties follows the OpenShift specification. The affinity configuration can include different types of affinity:
- Pod affinity and anti-affinity
- Node affinity
On OpenShift 1.16 and 1.17, the support for topologySpreadConstraint is disabled by default. In order to use topologySpreadConstraint, you have to enable the EvenPodsSpread feature gate in Kubernetes API server and scheduler.
Additional resources
2.7.1.1. Use pod anti-affinity to avoid critical applications sharing nodes
Use pod anti-affinity to ensure that critical applications are never scheduled on the same disk. When running a Kafka cluster, it is recommended to use pod anti-affinity to ensure that the Kafka brokers do not share nodes with other workloads, such as databases.
2.7.1.2. Use node affinity to schedule workloads onto specific nodes
The OpenShift cluster usually consists of many different types of worker nodes. Some are optimized for CPU heavy workloads, some for memory, while other might be optimized for storage (fast local SSDs) or network. Using different nodes helps to optimize both costs and performance. To achieve the best possible performance, it is important to allow scheduling of AMQ Streams components to use the right nodes.
OpenShift uses node affinity to schedule workloads onto specific nodes. Node affinity allows you to create a scheduling constraint for the node on which the pod will be scheduled. The constraint is specified as a label selector. You can specify the label using either the built-in node label like beta.kubernetes.io/instance-type or custom labels to select the right node.
2.7.1.3. Use node affinity and tolerations for dedicated nodes
Use taints to create dedicated nodes, then schedule Kafka pods on the dedicated nodes by configuring node affinity and tolerations.
Cluster administrators can mark selected OpenShift nodes as tainted. Nodes with taints are excluded from regular scheduling and normal pods will not be scheduled to run on them. Only services which can tolerate the taint set on the node can be scheduled on it. The only other services running on such nodes will be system services such as log collectors or software defined networks.
Running Kafka and its components on dedicated nodes can have many advantages. There will be no other applications running on the same nodes which could cause disturbance or consume the resources needed for Kafka. That can lead to improved performance and stability.
2.7.2. Configuring pod anti-affinity to schedule each Kafka broker on a different worker node
Many Kafka brokers or ZooKeeper nodes can run on the same OpenShift worker node. If the worker node fails, they will all become unavailable at the same time. To improve reliability, you can use podAntiAffinity configuration to schedule each Kafka broker or ZooKeeper node on a different OpenShift worker node.
Prerequisites
- An OpenShift cluster
- A running Cluster Operator
Procedure
Edit the
affinityproperty in the resource specifying the cluster deployment. To make sure that no worker nodes are shared by Kafka brokers or ZooKeeper nodes, use thestrimzi.io/namelabel. Set thetopologyKeytokubernetes.io/hostnameto specify that the selected pods are not scheduled on nodes with the same hostname. This will still allow the same worker node to be shared by a single Kafka broker and a single ZooKeeper node. For example:apiVersion: kafka.strimzi.io/v1beta2 kind: Kafka spec: kafka: # ... template: pod: affinity: podAntiAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: strimzi.io/name operator: In values: - CLUSTER-NAME-kafka topologyKey: "kubernetes.io/hostname" # ... zookeeper: # ... template: pod: affinity: podAntiAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: strimzi.io/name operator: In values: - CLUSTER-NAME-zookeeper topologyKey: "kubernetes.io/hostname" # ...Where
CLUSTER-NAMEis the name of your Kafka custom resource.If you even want to make sure that a Kafka broker and ZooKeeper node do not share the same worker node, use the
strimzi.io/clusterlabel. For example:apiVersion: kafka.strimzi.io/v1beta2 kind: Kafka spec: kafka: # ... template: pod: affinity: podAntiAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: strimzi.io/cluster operator: In values: - CLUSTER-NAME topologyKey: "kubernetes.io/hostname" # ... zookeeper: # ... template: pod: affinity: podAntiAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: strimzi.io/cluster operator: In values: - CLUSTER-NAME topologyKey: "kubernetes.io/hostname" # ...Where
CLUSTER-NAMEis the name of your Kafka custom resource.Create or update the resource.
oc apply -f KAFKA-CONFIG-FILE
2.7.3. Configuring pod anti-affinity in Kafka components
Pod anti-affinity configuration helps with the stability and performance of Kafka brokers. By using podAntiAffinity, OpenShift will not schedule Kafka brokers on the same nodes as other workloads. Typically, you want to avoid Kafka running on the same worker node as other network or storage intensive applications such as databases, storage or other messaging platforms.
Prerequisites
- An OpenShift cluster
- A running Cluster Operator
Procedure
Edit the
affinityproperty in the resource specifying the cluster deployment. Use labels to specify the pods which should not be scheduled on the same nodes. ThetopologyKeyshould be set tokubernetes.io/hostnameto specify that the selected pods should not be scheduled on nodes with the same hostname. For example:apiVersion: kafka.strimzi.io/v1beta2 kind: Kafka spec: kafka: # ... template: pod: affinity: podAntiAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: application operator: In values: - postgresql - mongodb topologyKey: "kubernetes.io/hostname" # ... zookeeper: # ...Create or update the resource.
This can be done using
oc apply:oc apply -f KAFKA-CONFIG-FILE
2.7.4. Configuring node affinity in Kafka components
Prerequisites
- An OpenShift cluster
- A running Cluster Operator
Procedure
Label the nodes where AMQ Streams components should be scheduled.
This can be done using
oc label:oc label node NAME-OF-NODE node-type=fast-networkAlternatively, some of the existing labels might be reused.
Edit the
affinityproperty in the resource specifying the cluster deployment. For example:apiVersion: kafka.strimzi.io/v1beta2 kind: Kafka spec: kafka: # ... template: pod: affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: node-type operator: In values: - fast-network # ... zookeeper: # ...Create or update the resource.
This can be done using
oc apply:oc apply -f KAFKA-CONFIG-FILE
2.7.5. Setting up dedicated nodes and scheduling pods on them
Prerequisites
- An OpenShift cluster
- A running Cluster Operator
Procedure
- Select the nodes which should be used as dedicated.
- Make sure there are no workloads scheduled on these nodes.
Set the taints on the selected nodes:
This can be done using
oc adm taint:oc adm taint node NAME-OF-NODE dedicated=Kafka:NoScheduleAdditionally, add a label to the selected nodes as well.
This can be done using
oc label:oc label node NAME-OF-NODE dedicated=KafkaEdit the
affinityandtolerationsproperties in the resource specifying the cluster deployment.For example:
apiVersion: kafka.strimzi.io/v1beta2 kind: Kafka spec: kafka: # ... template: pod: tolerations: - key: "dedicated" operator: "Equal" value: "Kafka" effect: "NoSchedule" affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: dedicated operator: In values: - Kafka # ... zookeeper: # ...Create or update the resource.
This can be done using
oc apply:oc apply -f KAFKA-CONFIG-FILE
2.8. Logging configuration
Configure logging levels in the custom resources of Kafka components and AMQ Streams Operators. You can specify the logging levels directly in the spec.logging property of the custom resource. Or you can define the logging properties in a ConfigMap that’s referenced in the custom resource using the configMapKeyRef property.
The advantages of using a ConfigMap are that the logging properties are maintained in one place and are accessible to more than one resource. You can also reuse the ConfigMap for more than one resource. If you are using a ConfigMap to specify loggers for AMQ Streams Operators, you can also append the logging specification to add filters.
You specify a logging type in your logging specification:
-
inlinewhen specifying logging levels directly -
externalwhen referencing a ConfigMap
Example inline logging configuration
spec:
# ...
logging:
type: inline
loggers:
kafka.root.logger.level: "INFO"Example external logging configuration
spec:
# ...
logging:
type: external
valueFrom:
configMapKeyRef:
name: my-config-map
key: my-config-map-key
Values for the name and key of the ConfigMap are mandatory. Default logging is used if the name or key is not set.
Operator logging
2.8.1. Creating a ConfigMap for logging
To use a ConfigMap to define logging properties, you create the ConfigMap and then reference it as part of the logging definition in the spec of a resource.
The ConfigMap must contain the appropriate logging configuration.
-
log4j.propertiesfor Kafka components, ZooKeeper, and the Kafka Bridge -
log4j2.propertiesfor the Topic Operator and User Operator
The configuration must be placed under these properties.
In this procedure a ConfigMap defines a root logger for a Kafka resource.
Procedure
Create the ConfigMap.
You can create the ConfigMap as a YAML file or from a properties file.
ConfigMap example with a root logger definition for Kafka:
kind: ConfigMap apiVersion: v1 metadata: name: logging-configmap data: log4j.properties: kafka.root.logger.level="INFO"If you are using a properties file, specify the file at the command line:
oc create configmap logging-configmap --from-file=log4j.propertiesThe properties file defines the logging configuration:
# Define the logger kafka.root.logger.level="INFO" # ...Define external logging in the
specof the resource, setting thelogging.valueFrom.configMapKeyRef.nameto the name of the ConfigMap andlogging.valueFrom.configMapKeyRef.keyto the key in this ConfigMap.spec: # ... logging: type: external valueFrom: configMapKeyRef: name: logging-configmap key: log4j.propertiesCreate or update the resource.
oc apply -f KAFKA-CONFIG-FILE
2.8.2. Adding logging filters to Operators
If you are using a ConfigMap to configure the (log4j2) logging levels for AMQ Streams Operators, you can also define logging filters to limit what’s returned in the log.
Logging filters are useful when you have a large number of logging messages. Suppose you set the log level for the logger as DEBUG (rootLogger.level="DEBUG"). Logging filters reduce the number of logs returned for the logger at that level, so you can focus on a specific resource. When the filter is set, only log messages matching the filter are logged.
Filters use markers to specify what to include in the log. You specify a kind, namespace and name for the marker. For example, if a Kafka cluster is failing, you can isolate the logs by specifying the kind as Kafka, and use the namespace and name of the failing cluster.
This example shows a marker filter for a Kafka cluster named my-kafka-cluster.
Basic logging filter configuration
rootLogger.level="INFO"
appender.console.filter.filter1.type=MarkerFilter
appender.console.filter.filter1.onMatch=ACCEPT
appender.console.filter.filter1.onMismatch=DENY
appender.console.filter.filter1.marker=Kafka(my-namespace/my-kafka-cluster) You can create one or more filters. Here, the log is filtered for two Kafka clusters.
Multiple logging filter configuration
appender.console.filter.filter1.type=MarkerFilter
appender.console.filter.filter1.onMatch=ACCEPT
appender.console.filter.filter1.onMismatch=DENY
appender.console.filter.filter1.marker=Kafka(my-namespace/my-kafka-cluster-1)
appender.console.filter.filter2.type=MarkerFilter
appender.console.filter.filter2.onMatch=ACCEPT
appender.console.filter.filter2.onMismatch=DENY
appender.console.filter.filter2.marker=Kafka(my-namespace/my-kafka-cluster-2)Adding filters to the Cluster Operator
To add filters to the Cluster Operator, update its logging ConfigMap YAML file (install/cluster-operator/050-ConfigMap-strimzi-cluster-operator.yaml).
Procedure
Update the
050-ConfigMap-strimzi-cluster-operator.yamlfile to add the filter properties to the ConfigMap.In this example, the filter properties return logs only for the
my-kafka-clusterKafka cluster:kind: ConfigMap apiVersion: v1 metadata: name: strimzi-cluster-operator data: log4j2.properties: #... appender.console.filter.filter1.type=MarkerFilter appender.console.filter.filter1.onMatch=ACCEPT appender.console.filter.filter1.onMismatch=DENY appender.console.filter.filter1.marker=Kafka(my-namespace/my-kafka-cluster)Alternatively, edit the
ConfigMapdirectly:oc edit configmap strimzi-cluster-operatorIf you updated the YAML file instead of editing the
ConfigMapdirectly, apply the changes by deploying the ConfigMap:oc create -f install/cluster-operator/050-ConfigMap-strimzi-cluster-operator.yaml
Adding filters to the Topic Operator or User Operator
To add filters to the Topic Operator or User Operator, create or edit a logging ConfigMap.
In this procedure a logging ConfigMap is created with filters for the Topic Operator. The same approach is used for the User Operator.
Procedure
Create the ConfigMap.
You can create the ConfigMap as a YAML file or from a properties file.
In this example, the filter properties return logs only for the
my-topictopic:kind: ConfigMap apiVersion: v1 metadata: name: logging-configmap data: log4j2.properties: rootLogger.level="INFO" appender.console.filter.filter1.type=MarkerFilter appender.console.filter.filter1.onMatch=ACCEPT appender.console.filter.filter1.onMismatch=DENY appender.console.filter.filter1.marker=KafkaTopic(my-namespace/my-topic)If you are using a properties file, specify the file at the command line:
oc create configmap logging-configmap --from-file=log4j2.propertiesThe properties file defines the logging configuration:
# Define the logger rootLogger.level="INFO" # Set the filters appender.console.filter.filter1.type=MarkerFilter appender.console.filter.filter1.onMatch=ACCEPT appender.console.filter.filter1.onMismatch=DENY appender.console.filter.filter1.marker=KafkaTopic(my-namespace/my-topic) # ...Define external logging in the
specof the resource, setting thelogging.valueFrom.configMapKeyRef.nameto the name of the ConfigMap andlogging.valueFrom.configMapKeyRef.keyto the key in this ConfigMap.For the Topic Operator, logging is specified in the
topicOperatorconfiguration of theKafkaresource.spec: # ... entityOperator: topicOperator: logging: type: external valueFrom: configMapKeyRef: name: logging-configmap key: log4j2.properties- Apply the changes by deploying the Cluster Operator:
create -f install/cluster-operator -n my-cluster-operator-namespace2.9. Loading configuration values from external sources
Use the Kubernetes Configuration Provider plugin to load configuration data from external sources. Load data from OpenShift Secrets or ConfigMaps.
Suppose you have a Secret that’s managed outside the Kafka namespace, or outside the Kafka cluster. The provider allows you to reference the values of the Secret in your configuration without extracting the files. You just need to tell the provider what Secret to use and provide access rights. The provider loads the data without needing to restart the Kafka component, even when using a new Secret or ConfigMap. This capability avoids disruption when a Kafka Connect instance hosts multiple connectors.
The provider operates independently of AMQ Streams. You can use it to load configuration data for all Kafka components, including producers and consumers. Use it, for example, to provide the credentials for Kafka Connect connector configuration.
In this procedure, an external ConfigMap provides configuration properties for a connector.
OpenShift Configuration Provider can’t use mounted files. For example, it can’t load values that need the location of a truststore or keystore. Instead, you can mount ConfigMaps or Secrets into a Kafka Connect pod as environment variables or volumes. You add configuration using the externalConfiguration property in KafkaConnect.spec. You don’t need to set up access rights with this approach. However, Kafka Connect will need a restart when using a new Secret or ConfigMap for a connector. This will cause disruption to all the Kafka Connect instance’s connectors.
Prerequisites
- An OpenShift cluster is available.
- A Kafka cluster is running.
- The Cluster Operator is running.
Procedure
Create a ConfigMap or Secret that contains the configuration properties.
In this example, a ConfigMap named
my-connector-configurationcontains connector properties:Example ConfigMap with connector properties
apiVersion: v1 kind: ConfigMap metadata: name: my-connector-configuration data: option1: value1 option2: value2Specify the OpenShift Configuration Provider in the Kafka Connect configuration.
The specification shown here can support loading values from Secrets and ConfigMaps.
Example external volumes set to values from a ConfigMap
apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaConnect metadata: name: my-connect annotations: strimzi.io/use-connector-resources: "true" spec: # ... config: # ... config.providers: secrets,configmaps1 config.providers.secrets.class: io.strimzi.kafka.KubernetesSecretConfigProvider2 config.providers.configmaps.class: io.strimzi.kafka.KubernetesConfigMapConfigProvider3 # ...- 1
- The alias for the configuration provider is used to define other configuration parameters. The provider parameters use the alias from
config.providers, taking the formconfig.providers.${alias}.class. - 2
KubernetesSecretConfigProviderprovides values from Secrets.- 3
KubernetesConfigMapConfigProviderprovides values from ConfigMaps.
Create or update the resource to enable the provider.
oc apply -f KAFKA-CONNECT-CONFIG-FILECreate a role that permits access to the values in the external ConfigMap.
Example role to access values from a ConfigMap
apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: connector-configuration-role rules: - apiGroups: [""] resources: ["configmaps"] resourceNames: ["my-connector-configuration"] verbs: ["get"] # ...The rule gives the role permission to access the
my-connector-configurationConfigMap.Create a role binding to permit access to the namespace that contains the ConfigMap.
Example role binding to access the namespace that contains the ConfigMap
apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: connector-configuration-role-binding subjects: - kind: ServiceAccount name: my-connect-connect namespace: my-project roleRef: kind: Role name: connector-configuration-role apiGroup: rbac.authorization.k8s.io # ...The role binding gives the role permission to access the
my-projectnamespace.The service account must be the same one used by the Kafka Connect deployment. The service account name format is CLUSTER_NAME-connect, where CLUSTER_NAME is the name of the
KafkaConnectcustom resource.Reference the ConfigMap in the connector configuration.
Example connector configuration referencing the ConfigMap
apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaConnector metadata: name: my-connector labels: strimzi.io/cluster: my-connect spec: # ... config: option: ${configmaps:my-project/my-connector-configuration:option1} # ... # ...Placeholders for the property values in the ConfigMap are referenced in the connector configuration. The placeholder structure is
configmaps:PATH-AND-FILE-NAME:PROPERTY.KubernetesConfigMapConfigProviderreads and extracts the option1 property value from the external ConfigMap.