Chapter 21. High Availability and Failover
AMQ Broker 7.0 allows brokers to be linked together as master and slave, where each master broker can have one or more slave brokers. Only master brokers actively serve client requests. After a master broker and its clients are no longer able to communicate with each other, a slave broker replaces the master, enabling the clients to reconnect and continue their work.
There are two main High Availability (HA) policies available, each deploying a different strategy to enable HA. The first, replication, synchronizes the data between master and slave brokers over the network. The second HA policy, shared store, involves the master and slave brokers sharing a location for their messaging data. A third option, live only, enables you to scale down master brokers and provides a limited amount of HA that is useful during controlled shutdowns.
It is recommended that your cluster have three or more master-slave pairs. Also, only persistent message data survives a failover. Any non persistent message data is not be available after failover. See Persisting Messages for more information about how to persist your messages.
AMQ Broker 7.0 defines two types of client failover, each of which is covered in its own section later in this chapter: automatic client failover and application-level client failover. The broker also provides 100% transparent automatic reattachment of connections to the same broker, as in the case of transient network problems, for example. This is similar to failover, except the client is reconnecting to the same broker.
During failover, if the client has consumers on any non persistent or temporary queues, those queues are automatically re-created during failover on the slave broker, since the slave broker does not have any knowledge of non persistent queues.
21.1. Using Replication for High Availability
When using replication as the HA strategy for your cluster, all data synchronization is done over the network. All persistent data received by the master broker is synchronized to the slave when the master drops from the network. A slave broker first needs to synchronize all existing data from the master broker before becoming capable of replacing it. The time it takes for this to happen depends on the amount of data to be synchronized and the connection speed.
Figure 21.1. Replicated Store for High Availability
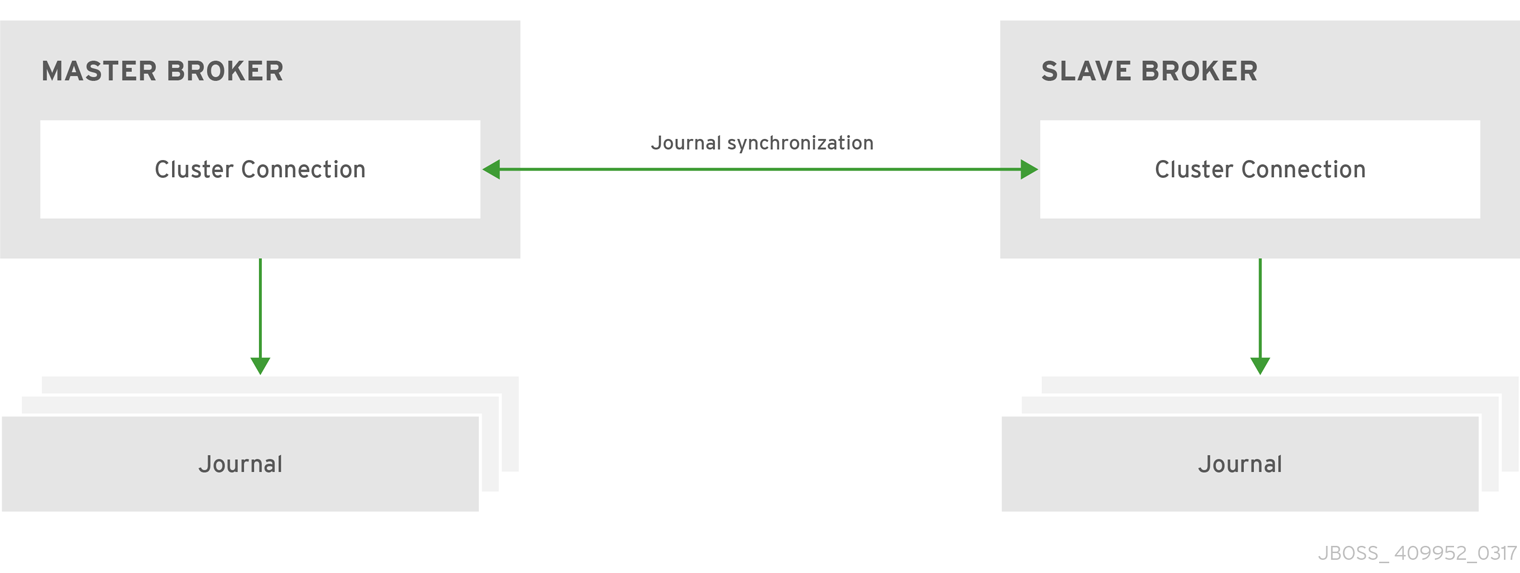
In general, synchronization occurs in parallel with current network traffic, so this does not cause any blocking on current clients. However, there is a critical moment at the end of this process where the replicating broker must complete the synchronization and ensure the backup acknowledges the completion. This synchronization blocks any journal related operations. The maximum length of time that this exchange blocks is controlled by the initial-replication-sync-timeout configuration element.
The replicating master and slave pair must be part of a cluster. The cluster connection also defines how slave brokers find the remote master brokers to pair with. See Clusters for details on how this is done, and how to configure a cluster connection.
It is recommended that your cluster have three or more master-slave pairs.
Within a cluster using data replication, there are two ways that a slave broker locates a master broker:
-
Connect to a group. A slave broker can be configured to connect only to a master broker that shares the same broker
group-name. -
Connect to any live. The behavior if
group-nameis not configured. Slave brokers are free to connect to any master broker.
The slave searches for any master broker that it is configured to connect to. It then tries to replicate with each master broker in turn until it finds a master broker that has no current slave configured. If no master broker is available it waits until the cluster topology changes and repeats the process.
The slave broker does not know whether any data it might have is up to date, so it really cannot decide to activate automatically. To activate a replicating slave broker using the data it has, the administrator must change its configuration to make it a master broker.
When the master broker stops or crashes, its replicating slave becomes active and take over its duties. Specifically, the slave becomes active when it loses connection to its master broker. This can be problematic because a connection loss might be due to a temporary network problem. In order to address this issue, the slave tries to determine whether it can connect to the other brokers in the cluster. If it can connect to more than half the brokers, it becomes active. If it can connect to fewer than half, the slave does not become active but tries to reconnect with the master. This avoids a split-brain situation.
21.1.1. Configuring Replication
You configure brokers for replication by editing their broker.xml configuration file. The default configuration values cover most use cases, making it easy to start using replication. You can also supply your own configuration for these values when needed however. The appendix includes a table of the configuration elements you can add to broker.xml when using replication HA.
Prerequisites
Master and slave brokers must form a cluster and use a cluster-connection to communicate. See Clustering for more information on cluster connections.
Procedure
Configure a cluster of brokers to use the replication HA policy by modifying the main configuration file, BROKER_INSTANCE_DIR/etc/broker.xml.
Configure the master broker to use replication for its HA policy.
<configuration> <core> ... <ha-policy> <replication> <master/> </replication> </ha-policy> ... </core> </configuration>Configure the slave brokers in the same way, but use the
slaveelement instead ofmasterto denote their role in the cluster.<configuration> <core> ... <ha-policy> <replication> <slave/> </replication> </ha-policy> ... </core> </configuration>
Related Information
- See the appendix for a table of the configuration elements available when configuring master and slave brokers for replication.
-
For working examples demonstrating replication HA see the example Maven projects located under
INSTALL_DIR/examples/features/ha.
21.1.2. Failing Back to the Master Broker
After a master broker has failed and a slave has taken over its duties, you might want to restart the master broker and have clients fail back to it.
In replication HA mode, you can configure a master broker so that at startup it searches the cluster for another broker using the same cluster node ID. If it finds one, the master attempts to synchronize its data with it. Once the data is synchronized, the master requests that the other broker shut down. The master broker then resumes its active role within the cluster.
Prerequisites
Configuring a master broker to fail back as described above requires the replication HA policy.
Procedure
To configure brokers to fail back to the original master, edit the BROKER_INSTANCE_DIR/etc/broker.xml configuration file for the master and slave brokers as follows.
Add the
check-for-live-serverelement and set its value totrueto tell this broker to check if a slave has assumed the role of master.<configuration> <core> ... <ha-policy> <replication> <master> <check-for-live-server>true</check-for-live-server> ... </master> </replication> </ha-policy> ... </core> </configuration>Add the
allow-failbackelement to the slave broker(s) and set its value totrueso that the slave fails back to the original master.<configuration> <core> ... <ha-policy> <replication> <slave> <allow-failback>true</allow-failback> ... </slave> </replication> </ha-policy> ... </core> </configuration>
Be aware that if you restart a master broker after failover has occurred, then the value for check-for-live-server must be set to true. Otherwise, the master broker restarts and process the same messages that the slave has already handled, causing duplicates.
21.1.3. Grouping Master and Slave Brokers
You can specify a group of master brokers that a slave broker can connect to. This is done by adding a group-name configuration element to BROKER_INSTANCE_DIR/etc/broker.xml. A slave broker connects only to a master broker that shares the same group-name.
As an example of using group-name, suppose you have five master brokers and six slave brokers. You could divide the brokers into two groups.
-
Master brokers
master1,master2, andmaster3use agroup-nameoffish, whilemaster4andmaster5usebird. -
Slave brokers
slave1,slave2,slave3, andslave4usefishfor theirgroup-name, andslave5andslave6usebird.
After joining the cluster, each slave with a group-name of fish searches for a master broker also assigned to fish. Since there is one slave too many, the group has one spare slave that remains un-paired. Meanwhile, each slave assigned to bird pairs with one of the master brokers in their group, master4 or master5.
Prerequisites
Grouping brokers into HA groups requires you configure the brokers to use the replication HA policy.
Procedure
Configure a cluster of brokers to form groups of master and slave brokers by modifying the main configuration file, BROKER_INSTANCE_DIR/etc/broker.xml.
Configure the master broker to use the chosen
group-nameby adding it beneath themasterconfiguration element. In the example below the master broker is assigned the group namefish.<configuration> <core> ... <ha-policy> <replication> <master> <group-name>fish</group-name> ... </master> </replication> </ha-policy> ... </core> </configuration>Configure the slave broker(s) in the same way, by adding the
group-nameelement underslave.<configuration> <core> ... <ha-policy> <replication> <slave> <group-name>fish</group-name> ... </slave> </replication> </ha-policy> ... </core> </configuration>
21.2. Using a Shared Store for High Availability
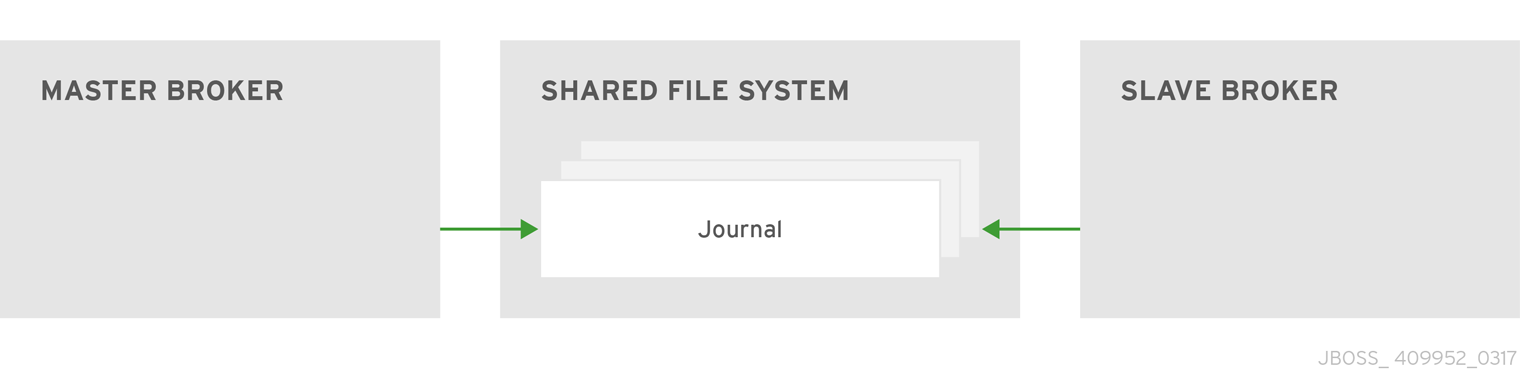
When using a shared store, both master and slave brokers share a single data directory using a shared file system. This data directory includes the paging directory, journal directory, large messages, and binding journal. A slave broker loads the persistent storage from the shared file system if the master broker disconnects from the cluster. Clients can connect to the slave broker and continue their sessions.
The advantage of shared-store high availability is that no replication occurs between the master and slave nodes. This means it does not suffer any performance penalties due to the overhead of replication during normal operation.
The disadvantage of shared store replication is that it requires a shared file system. Consequently, when the slave broker takes over, it needs to load the journal from the shared store which can take some time depending on the amount of data in the store.
This style of high availability differs from data replication in that it requires a shared file system which is accessible by both the master and slave nodes. Typically this is some kind of high performance Storage Area Network (SAN). It is not recommend you use Network Attached Storage (NAS).
Red Hat recommends that your cluster have three or more master-slave pairs.
Figure 21.2. Shared Store for High Availability
21.2.2. Failing Back to the Master Broker
After a master broker has failed and a slave has taken over its duties, you might want to restart the master broker and have clients fail back to it. When using a shared store, you only need to restart the original master broker and kill the slave broker.
Alternatively, you can set allow-failback to true on the slave configuration, which forces a slave that has become master to automatically stop.
Procedure
In each slave broker, add the
allow-failbackconfiguration element and set its value totrue, as in the example below.<configuration> <core> ... <ha-policy> <shared-store> <slave> <allow-failback>true</allow-failback> ... </slave> </shared-store> </ha-policy> ... </core> </configuration>
21.3. Colocating Slave Brokers
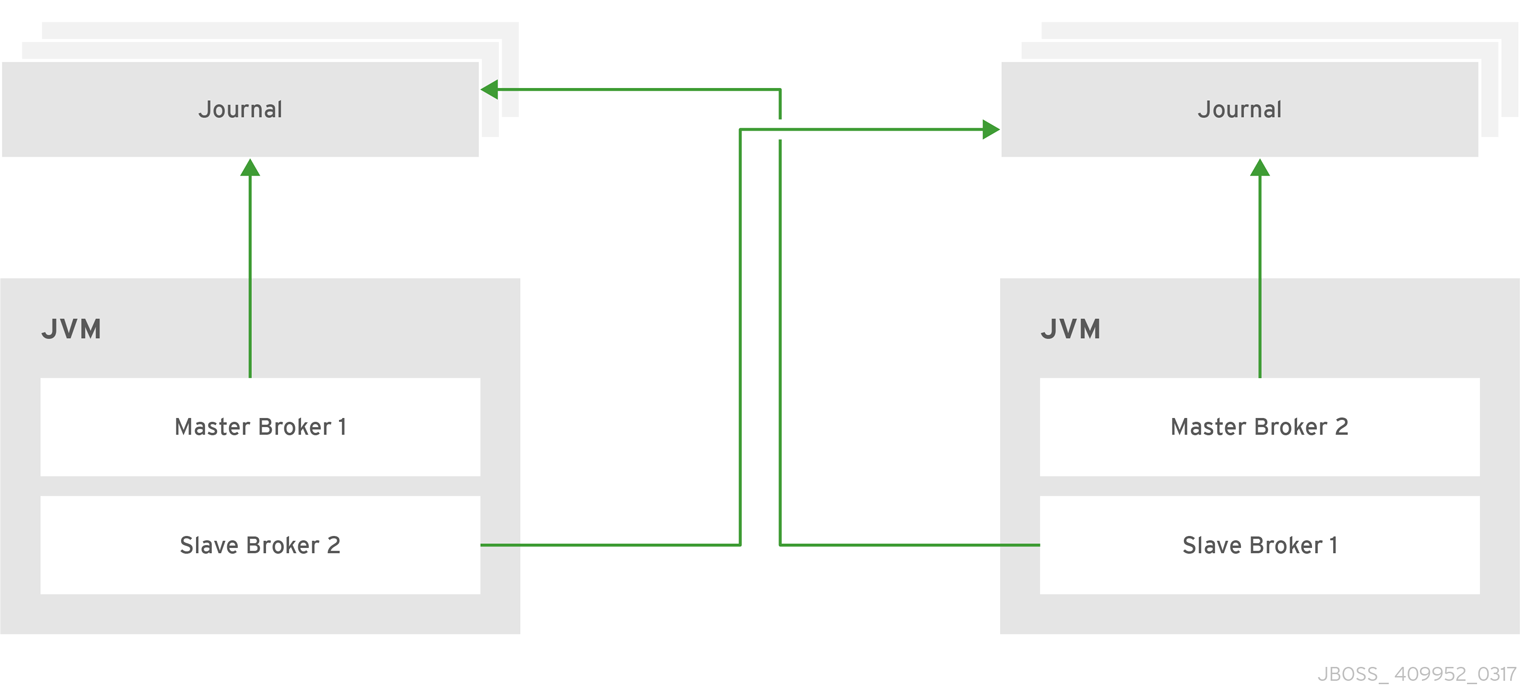
It is also possible to colocate slave brokers in the same JVM as a master broker. A master broker can be configured to request another master to start a slave broker that resides in its Java Virtual Machine. You can colocate slave brokers using either shared store or replication as your HA policy. The new slave broker inherits its configuration from the master broker creating it. The name of the slave is set to colocated_backup_n where n is the number of backups the master broker has created.
The slave inherits configuration for its connectors and acceptors from the master broker creating it. However, AMQ Broker applies a default port offset of 100 for each. For example, if the master contains configuration for a connection that uses port 61616, the first slave created uses port 61716, the second uses 61816, and so on.
For In-VM connectors and acceptors the ID has colocated_backup_n appended, where n is the slave broker number.
Directories for the journal, large messages, and paging are set according to the HA strategy you choose. If you choose shared-store, the requesting broker notifies the target broker which directories to use. If replication is chosen, directories are inherited from the creating broker and have the new backup’s name appended to them.
Figure 21.3. Co-located Master and Slave Brokers
21.3.1. Configuring Colocated Slaves
A master broker can also be configured to allow requests from backups and also how many backups a master broker can start. This way you can evenly distribute backups around the cluster. This is configured under the ha-policy element in the BROKER_INSTANCE_DIR/etc/broker.xml file.
Prerequisites
You must configure a master broker to use either replication or shared store as its HA policy.
Procedure
After choosing an HA policy, add configuration for the colocation of master and slave broker.
The example below uses each of the configuration options available and gives a description for each after the example. Some elements have a default value and therefore do not need to be explicitly added to the configuration unless you want to use your own value. Note that this example uses
replicationbut you can use ashared-storefor yourha-policyas well.<configuration> <core> ... <ha-policy> <replication> <colocated>1 <request-backup>true</request-backup>2 <max-backups>1</max-backups>3 <backup-request-retries>-1</backup-request-retries>4 <backup-request-retry-interval>5000</backup-request-retry-interval/>5 <backup-port-offset>150</backup-port-offset>6 <master> ...7 </master> <slave> ...8 </slave> </colocated> <replication> </ha-policy> </core> </configuration>- 1
- You add the
colocatedelement directly underneath the choice ofha-policy. In the example above,colocatedappears afterreplication. The rest of the configuration falls under this element. - 2
- Use
request-backupto determine whether this broker requests a slave on another broker in the cluster. The default isfalse. - 3
- Setting
backup-request-retriesdefines how many times the master broker tries to request a slave. The default is-1which means unlimited tries. - 4
- The broker waits this long before retrying a request for a slave broker. The default value for
backup-request-retry-intervalis5000, or 5 seconds. - 5
- Use
max-backupsdetermines how many backups a master broker can create. Set to0to stop this live broker from accepting backup requests from other live brokers. The default is1. - 6
- The port offset to use for the connectors and acceptors for a new slave broker. The default is
100. - 7
- The master broker is configured according to the
ha-policyyou chose,replicationorshared-store. - 8
- Like the master, the slave broker adheres to the configuration of the chosen
ha-policy.
Related Information
-
For working examples that demonstrate colocation see the colocation example Maven projects located under
INSTALL_DIR/examples/features/ha.
21.3.2. Excluding Connectors
Sometimes some of the connectors you configure are for external brokers and should be excluded from the offset. For instance, you might have a connector used by the cluster connection to do quorum voting for a replicated slave broker. Use the excludes element to identify connectors you do not want offset.
Prerequisites
You must configure a broker for colocation before modifying the configuration to exclude connectors.
Procedure
Modify
BROKER_INSTANCE_DIR/etc/broker.xmlby adding theexcludesconfiguration element, as in the example below.<configuration> <core> ... <ha-policy> <replication> <colocated> <excludes> </excludes> ... <colocated> </replication> </ha-policy> </core> </configuration>Add a
connector-refelement for each connector you want to exclude. In the example below, the connector with the nameremote-connectoris excluded from the connectors inherited by the slave.<configuration> <core> ... <ha-policy> <replication> <colocated> <excludes> <connector-ref>remote-connector</connector-ref> </excludes> ... <colocated> </replication> </ha-policy> </core> </configuration>
21.4. Scaling Down Master Brokers
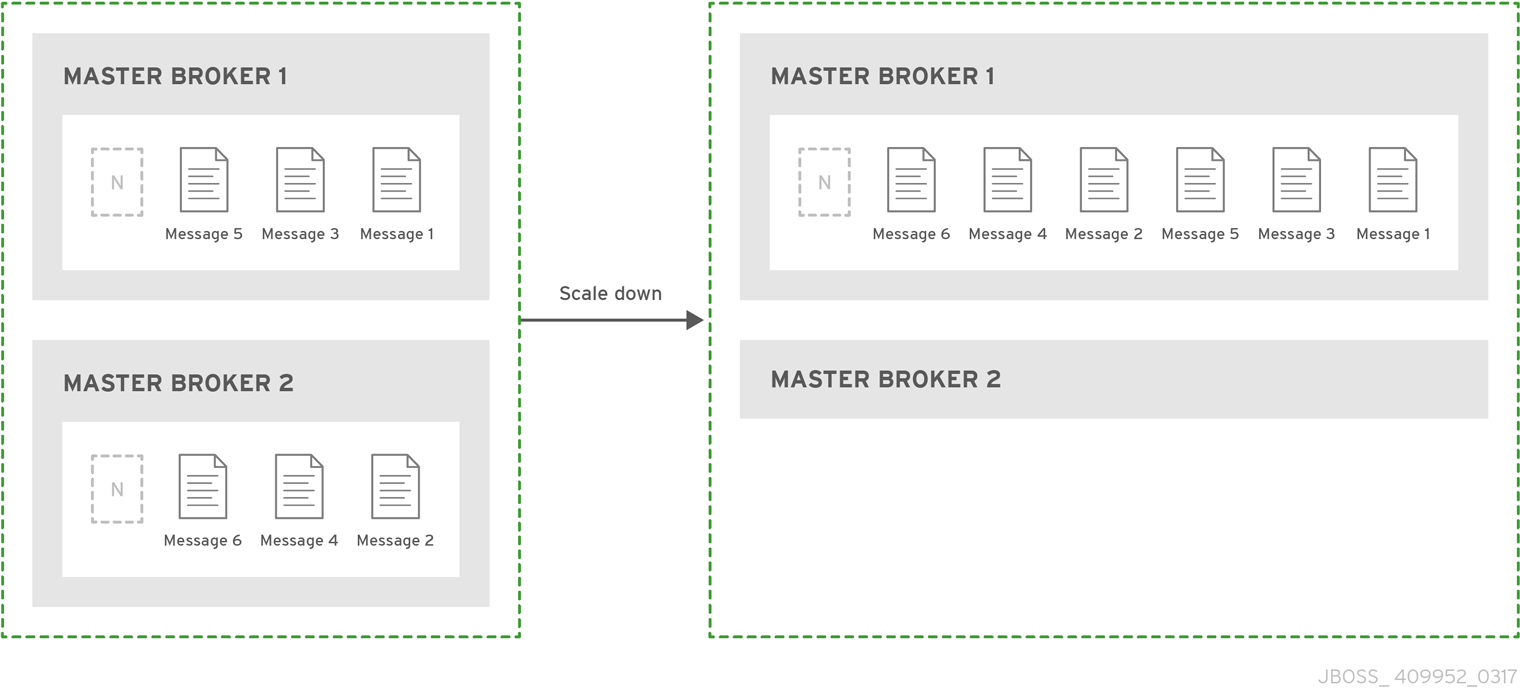
You can configure brokers to scale down as an alternative to using a replication or shared store HA policy. When configured for scale down, a master broker copies its messages and transaction state to another master broker before shutting down. The advantage of scale down is that you do not need full backups to provide some form of HA. However, scaling down handles only cases where a broker stops gracefully. It is not made to handle an unexpected failure gracefully.
Another disadvantage is that it is possible to lose message ordering when scaling down. This happens because the messages in the broker that is scaling down are appended to the end of the queues of the other broker. For example, two master brokers have ten messages distributed evenly between them. If one of the brokers scales down, the messages sent to the other broker are added to queue after the ones already there. Consequently, after Broker 2 scales down, the order of the messages in Broker 1 would be 1, 3, 5, 7, 9, 2, 4, 6, 8, 10.
When a broker is preparing to scale down, it sends a message to its clients before they are disconnected informing them which new broker is ready to process their messages. However, clients should reconnect to the new broker only after their initial broker has finished scaling down. This ensures that any state, such as queues or transactions, is available on the other broker when the client reconnects. The normal reconnect settings apply when the client is reconnecting so these should be high enough to deal with the time needed to scale down.
Figure 21.4. Scaling Down Master Brokers
21.4.1. Configuring Scaling Down Using a Specific Broker
You can configure a broker to use a specific connector to scale down. If a connector is not specified, the broker uses the first In-VM connector appearing in the configuration.
Prerequisites
Using a static list of brokers during scale down requires that you configure a connector to the broker that receives the state of the broker scaling down. See About Connectors for more information.
Procedure
Configure scale down to a specific broker by adding a
connector-refelement under the configuration for thescale-downinBROKER_INSTANCE_DIR/etc/broker.xml, as in the example below.<configuration> <core> ... <ha-policy> <live-only> <scale-down> <connectors> <connector-ref>server1-connector</connector-ref> </connectors> </scale-down> </live-only> </ha-policy> ... </core> </configuration>
Related Information
-
For a working example of scaling down using a static connector that demonstrate colocation see the
scale-downexample Maven project located underINSTALL_DIR/examples/features/ha.
21.4.2. Using Dynamic Discovery
You can use dynamic discovery when configuring the cluster for scale down. Instead of scaling down to a specific broker by using a connector, brokers instead use a discovery group and find another broker dynamically.
Prerequisites
Using dynamic discovery during scale down requires that you configure a discovery-group. See About Discovery Groups for more information.
Procedure
Configure scale down to use a discovery group by adding a
discovery-group-refelement under the configuration for thescale-downinBROKER_INSTANCE_DIR/etc/broker.xml, as in the example below. Note thatdiscovery-group-refuses the attributediscovery-group-nameto hold the name of the discovery group to use.<configuration> <core> ... <ha-policy> <live-only> <scale-down> <discovery-group-ref discovery-group-name="my-discovery-group"/> </scale-down> </live-only> </ha-policy> ... </core> </configuration>
21.4.3. Using Broker Groups
It is also possible to configure brokers to scale down only to brokers that are configured with the same group.
Procedure
Configure scale down for a group of brokers by adding a
group-nameelement, and a value for the desired group name, inBROKER_INSTANCE_DIR/etc/broker.xml.In the example below, only brokers that belong to the group
my-group-nameare scaled down.<configuration> <core> ... <ha-policy> <live-only> <scale-down> <group-name>my-group-name</group-name> </scale-down> </live-only> </ha-policy> ... </core> </configuration>
21.4.4. Using Slave Brokers
You can mix scale down with HA and use master and slave brokers. In such a configuration, a slave immediately scales down to another master broker instead of becoming active itself.
Procedure
Edit the master’s broker.xml to colocate a slave broker that is configured for scale down. Configuration using replication for its HA policy would look like the example below.
<configuration>
<core>
...
<ha-policy>
<replication>
<colocated>
<backup-request-retries>44</backup-request-retries>
<backup-request-retry-interval>33</backup-request-retry-interval>
<max-backups>3</max-backups>
<request-backup>false</request-backup>
<backup-port-offset>33</backup-port-offset>
<master>
<group-name>purple</group-name>
<check-for-live-server>true</check-for-live-server>
<cluster-name>abcdefg</cluster-name>
</master>
<slave>
<group-name>tiddles</group-name>
<max-saved-replicated-journals-size>22</max-saved-replicated-journals-size>
<cluster-name>33rrrrr</cluster-name>
<restart-backup>false</restart-backup>
<scale-down>
<!--a grouping of servers that can be scaled down to-->
<group-name>boo!</group-name>
<!--either a discovery group-->
<discovery-group-ref discovery-group-name="wahey"/>
</scale-down>
</slave>
</colocated>
</replication>
</ha-policy>
...
</core>
</configuration>21.5. Automatic Client Failover
A client can receive information about all master and slave brokers, so that in the event of a connection failure, it can reconnect to the slave broker. The slave broker then automatically re-creates any sessions and consumers that existed on each connection before failover. This feature saves you from having to hand-code manual reconnection logic in your applications.
When a session is re-created on the slave, it does not have any knowledge of messages already sent or acknowledged. Any in-flight sends or acknowledgements at the time of failover might also be lost. However, even without 100% transparent failover, it is simple to guarantee once and only once delivery, even in the case of failure, by using a combination of duplicate detection and retrying of transactions.
Clients detect connection failure when they have not received packets from the broker within a configurable period of time. See Detecting Dead Connections for more information.
You have a number of methods to configure clients to receive information about master and slave. One option is to configure clients to connect to a specific broker and then receive information about the other brokers in the cluster. See Configuring a Client to Use Static Discovery for more information. The most common way, however, is to use broker discovery. For details on how to configure broker discovery, see Configuring a Client to Use Dynamic Discovery.
Also, you can configure the client by adding parameters to the query string of the URL used to connect to the broker, as in the example below.
connectionFactory.ConnectionFactory=tcp://localhost:61616?ha=true&reconnectAttempts=3Procedure
To configure your clients for failover through the use of a query string, ensure the following components of the URL are set properly.
-
The
host:portportion of the URL should point to a master broker that is properly configured with a backup. This host and port is used only for the initial connection. Thehost:portvalue has nothing to do with the actual connection failover between a live and a backup server. In the example above,localhost:61616is used for thehost:port. (Optional) To use more than one broker as a possible initial connection, group the
host:portentries as in the following example:connectionFactory.ConnectionFactory=(tcp://host1:port,tcp://host2:port)?ha=true&reconnectAttempts=3-
Include the name-value pair
ha=trueas part of the query string to ensure the client receives information about each master and slave broker in the cluster. -
Include the name-value pair
reconnectAttempts=n, wherenis an integer greater than0. This parameter sets the number of times the client attempts to reconnect to a broker.
Failover occurs only if ha=true and reconnectAttempts is greater than 0. Also, the client must make an initial connection to the master broker in order to receive information about other brokers. If the initial connection fails, the client can only retry to establish it. See Failing Over During the Initial Connection for more information.
21.5.1. Failing Over During the Initial Connection
Because the client does not receive information about every broker until after the first connection to the HA cluster, there is a window of time where the client can connect only to the broker included in the connection URL. Therefore, if a failure happens during this initial connection, the client cannot failover to other master brokers, but can only try to re-establish the initial connection. Clients can be configured for set number of reconnection attempts. Once the number of attempts has been made an exception is thrown.
Setting the Number of Reconnection Attempts
Procedure
The examples below shows how to set the number of reconnection attempts to 3 using the Core JMS client. The default value is 0, that is, try only once.
Set the number of reconnection attempts by passing a value to
ServerLocator.setInitialConnectAttempts().ConnectionFactory cf = ActiveMQJMSClient.createConnectionFactory(...) cf.setInitialConnectAttempts(3);
Setting a Global Number of Reconnection Attempts
Alternatively, you can apply a global value for the maximum number of reconnection attempts within the broker’s configuration. The maximum is applied to all client connections.
Procedure
Edit
BROKER_INSTANCE_DIR/etc/broker.xmlby adding theinitial-connect-attemptsconfiguration element and providing a value for the time-to-live, as in the example below.<configuration> <core> ... <initial-connect-attempts>3</initial-connect-attempts>1 ... </core> </configuration>- 1
- All clients connecting to the broker are allowed a maximum of three attempts to reconnect. The default is
-1, which allows clients unlimited attempts.
21.5.2. Handling Blocking Calls During Failover
When failover occurs and the client is waiting for a response from the broker to continue its execution, the newly created session does not have any knowledge of the call that was in progress. The initial call might otherwise hang forever, waiting for a response that never comes. To prevent this, the broker is designed to unblock any blocking calls that were in progress at the time of failover by making them throw an exception. Client code can catch these exceptions and retry any operations if desired.
If the method being unblocked is a call to commit() or prepare(), the transaction is automatically rolled back and the broker throws an exception.
21.5.3. Handling Failover With Transactions
If the client session is transactional and messages have already been sent or acknowledged in the current transaction, the broker cannot be sure that those messages or their acknowledgements were lost during the failover. Consequently, the transaction is marked for rollback only. Any subsequent attempt to commit it throws an javax.jms.TransactionRolledBackException.
The caveat to this rule is when XA is used. If a two-phase commit is used and prepare() has already been called, rolling back could cause a HeuristicMixedException. Because of this, the commit throws an XAException.XA_RETRY exception, which informs the Transaction Manager it should retry the commit at some later point. If the original commit has not occurred, it still exists and can be committed. If the commit does not exist, it is assumed to have been committed, although the transaction manager might log a warning. A side effect of this exception is that any non-persistent messages are lost. To avoid such losses, always use persistent messages when using XA. This is not an issue with acknowledgements since they are flushed to the broker before prepare() is called.
It is up to the user to catch the exception and perform any client side rollback as necessary. There is no need to manually roll back the session since it was already rolled back. The user can then retry the transactional operations again on the same session.
If failover occurs when a commit call is being executed, the broker, as previously described, unblocks the call to prevent the client from waiting indefinitely, since no response has come back. In this case it is not easy for the client to determine whether the transaction commit was actually processed on the master broker before failure occurred.
To remedy this, the client can simply enable duplicate detection in the transaction, and retry the transaction operations again after the call is unblocked. If the transaction was successfully committed on the master broker before failover, then when the transaction is retried, duplicate detection ensures that any durable messages present in the transaction are ignored on the broker to prevent them from being sent more than once.
If the session is non transactional, messages or acknowledgements can be lost in the event of failover. If you want to provide once and only once delivery guarantees for non transacted sessions, enable duplicate detection and catch unblock exceptions.
21.5.4. Getting Notified of Connection Failure
JMS provides a standard mechanism for getting notified asynchronously of connection failure: java.jms.ExceptionListener.
Any ExceptionListener or SessionFailureListener instance is always called by the broker if a connection failure occurs, whether the connection was successfully failed over, reconnected, or reattached. You can find out if a reconnect or a reattach has happened by examining the failedOver flag passed in on the connectionFailed on SessionFailureListener. Alternatively, you can inspect the error code of the javax.jms.JMSException, which can be one of the following:
| Error code | Description |
|---|---|
| FAILOVER | Failover has occurred and the broker has successfully reattached or reconnected |
| DISCONNECT | No failover has occurred and the broker is disconnected |
21.6. Application-Level Failover
In some cases you might not want automatic client failover, but prefer to code your own reconnection logic in a failure handler instead. This is known as application-level failover, since the failover is handled at the application level.
To implement application-level failover when using JMS, set an ExceptionListener class on the JMS connection. The ExceptionListener is called by the broker in the event that a connection failure is detected. In your ExceptionListener, you should close your old JMS connections. You might also want to look up new connection factory instances from JNDI and create new connections.