Chapter 1. High level overview of Debezium
Debezium is a set of distributed services that capture changes in your databases. Your applications can consume and respond to those changes. Debezium captures each row-level change in each database table in a change event record and streams these records to Kafka topics. Applications read these streams, which provide the change event records in the same order in which they were generated.
More details are in the following sections:
1.1. Debezium Features
Debezium is a set of source connectors for Apache Kafka Connect. Each connector ingests changes from a different database by using that database’s features for change data capture (CDC). Unlike other approaches, such as polling or dual writes, log-based CDC as implemented by Debezium:
- Ensures that all data changes are captured.
- Produces change events with a very low delay while avoiding increased CPU usage required for frequent polling. For example, for MySQL or PostgreSQL, the delay is in the millisecond range.
- Requires no changes to your data model, such as a "Last Updated" column.
- Can capture deletes.
- Can capture old record state and additional metadata such as transaction ID and causing query, depending on the database’s capabilities and configuration.
Five Advantages of Log-Based Change Data Capture is a blog post that provides more details.
Debezium connectors capture data changes with a range of related capabilities and options:
- Snapshots: optionally, an initial snapshot of a database’s current state can be taken if a connector is started and not all logs still exist. Typically, this is the case when the database has been running for some time and has discarded transaction logs that are no longer needed for transaction recovery or replication. There are different modes for performing snapshots, including support for incremental snapshots, which can be triggered at connector runtime. For more details, see the documentation for the connector that you are using.
- Filters: you can configure the set of captured schemas, tables and columns with include/exclude list filters.
- Masking: the values from specific columns can be masked, for example, when they contain sensitive data.
- Monitoring: most connectors can be monitored by using JMX.
- Ready-to-use single message transformations (SMTs) for message routing, filtering, event flattening, and more. For more information about the SMTs that Debezium provides, see Applying transformations to modify messages exchanged with Apache Kafka.
The documentation for each connector provides details about the connectors features and configuration options.
1.2. Description of Debezium architecture
You deploy Debezium by means of Apache Kafka Connect. Kafka Connect is a framework and runtime for implementing and operating:
- Source connectors such as Debezium that send records into Kafka
- Sink connectors that propagate records from Kafka topics to other systems
The following image shows the architecture of a change data capture pipeline based on Debezium:
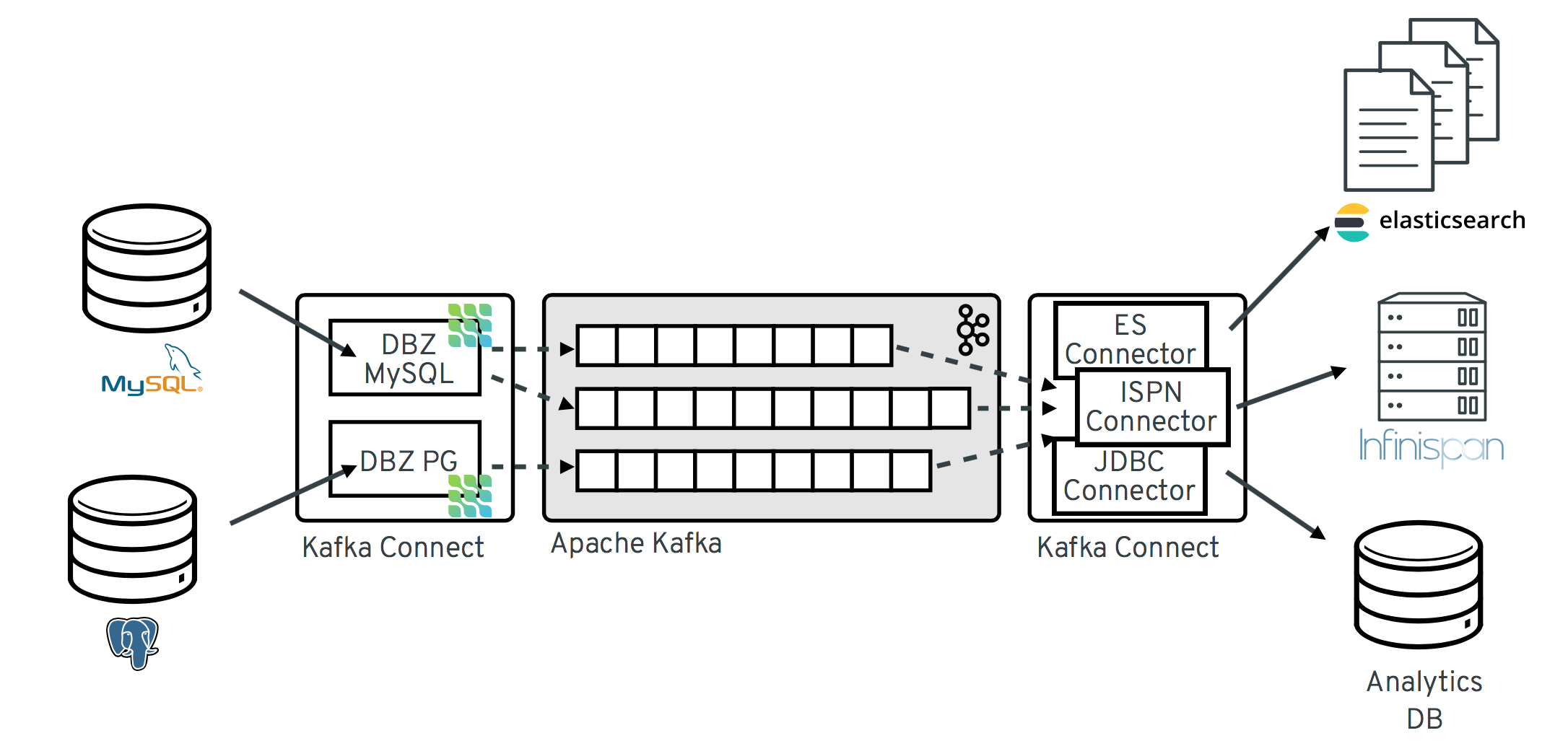
As shown in the image, the Debezium connectors for MySQL and PostgresSQL are deployed to capture changes to these two types of databases. Each Debezium connector establishes a connection to its source database:
-
The MySQL connector uses a client library for accessing the
binlog. - The PostgreSQL connector reads from a logical replication stream.
Kafka Connect operates as a separate service besides the Kafka broker.
By default, changes from one database table are written to a Kafka topic whose name corresponds to the table name. If needed, you can adjust the destination topic name by configuring Debezium’s topic routing transformation. For example, you can:
- Route records to a topic whose name is different from the table’s name
- Stream change event records for multiple tables into a single topic
After change event records are in Apache Kafka, different connectors in the Kafka Connect ecosystem can stream the records to other systems and databases such as Elasticsearch, data warehouses and analytics systems, or caches such as Infinispan. Depending on the chosen sink connector, you might need to configure the Debezium new record state extraction transformation. This Kafka Connect SMT propagates the after structure from a Debezium change event to the sink connector. The modified change event record replaces the original, more verbose record that is propagated by default.
Debezium Server
You can also deploy Debezium by using the Debezium Server. The Debezium server is a configurable, ready-to-use application that streams change events from a source database to a variety of messaging infrastructures.
Debezium Server is Developer Preview software only. Developer Preview software is not supported by Red Hat in any way and is not functionally complete or production-ready. Do not use Developer Preview software for production or business-critical workloads. Developer Preview software provides early access to upcoming product software in advance of its possible inclusion in a Red Hat product offering. Customers can use this software to test functionality and provide feedback during the development process. This software might not have any documentation, is subject to change or removal at any time, and has received limited testing. Red Hat might provide ways to submit feedback on Developer Preview software without an associated SLA.
For more information about the support scope of Red Hat Developer Preview software, see Developer Preview Support Scope.
The following image shows the architecture of a change data capture pipeline that uses the Debezium Server:
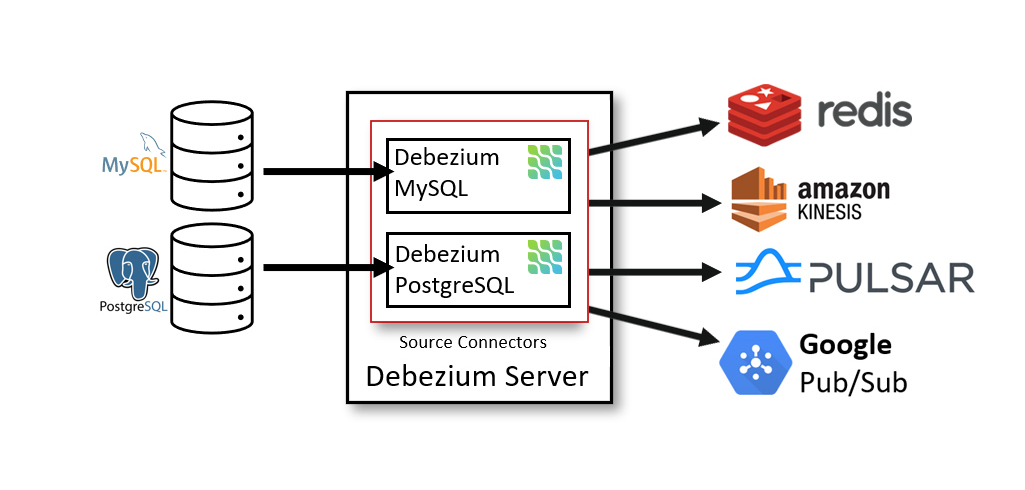
You can configure Debezium server to use one of the Debezium source connectors to capture changes from a source database. Change events can be serialized to different formats like JSON or Apache Avro and then will be sent to one of a variety of messaging infrastructures such as Apache Kafka or Redis Streams.