Chapter 3. Introduction to CRUSH
The CRUSH map for your storage cluster describes your device locations within CRUSH hierarchies and a ruleset for each hierarchy that determines how Ceph will store data.
The CRUSH map contains at least one hierarchy of nodes and leaves. The nodes of a hierarchy—called "buckets" in Ceph—are any aggregation of storage locations (e.g., rows, racks, chassis, hosts, etc.) as defined by their type. Each leaf of the hierarchy consists essentially of one of the storage devices in the list of storage devices (note: storage devices or OSDs are added to the CRUSH map when you add an OSD to the cluster). A leaf is always contained in one node or "bucket." A CRUSH map also has a list of rules that tell CRUSH how it should store and retrieve data.
The CRUSH algorithm distributes data objects among storage devices according to a per-device weight value, approximating a uniform probability distribution. CRUSH distributes objects and their replicas (or coding chunks) according to the hierarchical cluster map you define. Your CRUSH map represents the available storage devices and the logical buckets that contain them for the ruleset, and by extension each pool that uses the ruleset.
To map placement groups to OSDs across failure domains or performance domains, a CRUSH map defines a hierarchical list of bucket types (i.e., under types in the generated CRUSH map). The purpose of creating a bucket hierarchy is to segregate the leaf nodes by their failure domains and/or performance domains. Failure domains include hosts, chassis, racks, power distribution units, pods, rows, rooms and data centers. Performance domains include failure domains and OSDs of a particular configuration (e.g., SSDs, SAS drives with SSD journals, SATA drives), etc.
With the exception of the leaf nodes representing OSDs, the rest of the hierarchy is arbitrary, and you may define it according to your own needs if the default types don’t suit your requirements. We recommend adapting your CRUSH map bucket types to your organization’s hardware naming conventions and using instance names that reflect the physical hardware names. Your naming practice can make it easier to administer the cluster and troubleshoot problems when an OSD and/or other hardware malfunctions and the administrator needs remote or physical access to the host or other hardware.
In the following example, the bucket hierarchy has four leaf buckets (osd 1-4), two node buckets (host 1-2) and one rack node (rack 1).
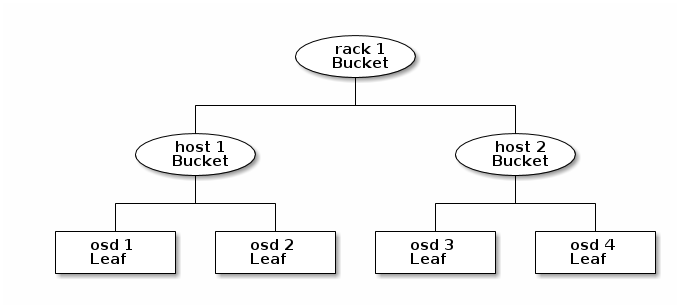
Since leaf nodes reflect storage devices declared under the devices list at the beginning of the CRUSH map, you do not need to declare them as bucket instances. The second lowest bucket type in your hierarchy usually aggregates the devices (i.e., it’s usually the computer containing the storage media, and uses whatever term you prefer to describe it, such as "node", "computer", "server," "host", "machine", etc.). In high density environments, it is increasingly common to see multiple hosts/nodes per card and per chassis. You should account for card and chassis failure too—e.g., the need to pull a card or chassis if a node fails may result in bringing down numerous hosts/nodes and their OSDs.
When declaring a bucket instance, you must specify its type, give it a unique name (string), assign it a unique ID expressed as a negative integer (optional), specify a weight relative to the total capacity/capability of its item(s), specify the bucket algorithm (usually straw), and the hash (usually 0, reflecting hash algorithm rjenkins1). A bucket may have one or more items. The items may consist of node buckets or leaves. Items may have a weight that reflects the relative weight of the item.
3.1. Dynamic Data Placement
Ceph Clients and Ceph OSDs both use the CRUSH map and the CRUSH algorithm.
- Ceph Clients: By distributing CRUSH maps to Ceph clients, CRUSH empowers Ceph clients to communicate with OSDs directly. This means that Ceph clients avoid a centralized object look-up table that could act as a single point of failure, a performance bottleneck, a connection limitation at a centralized look-up server and a physical limit to the storage cluster’s scalability.
- Ceph OSDs: By distributing CRUSH maps to Ceph OSDs, Ceph empowers OSDs to handle replication, backfilling and recovery. This means that the Ceph OSDs handle storage of object replicas (or coding chunks) on behalf of the Ceph client. It also means that Ceph OSDs know enough about the cluster to re-balance the cluster (backfilling) and recover from failures dynamically.
3.2. Failure Domains
Having multiple object replicas (or M coding chunks) may help prevent data loss, but it isn’t sufficient to address high availability. By reflecting the underlying physical organization of the Ceph Storage Cluster, CRUSH can model—and thereby address—potential sources of correlated device failures. By encoding the cluster’s topology into the cluster map, CRUSH placement policies can separate object replicas (or coding chunks) across different failure domains while still maintaining the desired pseudo-random distribution. For example, to address the possibility of concurrent failures, it may be desirable to ensure that data replicas (or coding chunks) are on devices using different shelves, racks, power supplies, controllers, and/or physical locations. This helps to prevent data loss and allows you to operate a cluster in a degraded state.
3.3. Performance Domains
Ceph can support multiple hierarchies to separate one type of hardware performance profile (e.g., SSDs) from another type of hardware performance profile (e.g., hard drives, hard drives with SSD journals, etc.). Performance domains—hierarchies that take the performance profile of the underlying hardware into consideration—are increasingly popular due to the need to support different performance characteristics. Operationally, these are just CRUSH maps with more than one root type bucket. Use case examples include:
- VMs: Ceph hosts that serve as a back end to cloud platforms like OpenStack, CloudStack, ProxMox or OpenNebula tend to use the most stable and performant filesystem (i.e., XFS) on SAS drives with a partitioned high performance SSD for journaling, because XFS doesn’t journal and write simultaneously. To maintain a consistent performance profile, such use cases should aggregate similar hardware in a CRUSH hierarchy.
- Object Storage: Ceph hosts that serve as an object storage back end for S3 and Swift interfaces may take advantage of less expensive storage media such as SATA drives that may not be suitable for VMs—reducing the cost per gigabyte for object storage, while separating more economical storage hosts from more performant ones intended for storing volumes and images on cloud platforms. HTTP tends to be the bottleneck in object storage systems.
- Cold Storage: Systems designed for cold storage (infrequently accessed data, or data retrieval with relaxed performance requirements) may take advantage of less expensive storage media and erasure coding. However, erasure coding may require a bit of additional RAM and CPU, and thus differ in RAM and CPU requirements from a host used for object storage or VMs.
-
SSD-backed Pools: SSDs are expensive, but they provide significant advantages over hard drives. SSDs have no seek time and they provide high total throughput. In addition to using SSDs for journaling, you can create SSD-backed pools in Ceph. Common use cases include cache-tiering or high performance SSD pools (e.g., mapping the
.rgw.buckets.indexpool for the Ceph Object Gateway to SSDs instead of SATA drives). Even in cache tiering scenarios, you can take advantage of less expensive SSDs that have relatively poor write performance if your intended use is for read-only cache tiers, whereas such hardware might prove unsuitable for writeback cache tiers that require fast sequential writes.