Chapter 5. Monitoring Ceph Clusters Running in Containers with the Red Hat Ceph Storage Dashboard
The Red Hat Ceph Storage Dashboard provides a monitoring dashboard to visualize the state of a Ceph Storage Cluster. Also, the Red Hat Ceph Storage Dashboard architecture provides a framework for additional modules to add functionality to the storage cluster.
- To learn about the Dashboard, see Section 5.1, “The Red Hat Ceph Storage Dashboard”.
- To install the Dashboard, see Section 5.2, “Installing the Red Hat Ceph Storage Dashboard”.
- To access the Dashboard, see Section 5.3, “Accessing the Red Hat Ceph Storage Dashboard”.
- To change the default password after installing the Dashboard, see Section 5.4, “Changing the default Red Hat Ceph Storage dashboard password”.
- To learn about the Prometheus plugin, see Section 5.5, “The Prometheus plugin for Red Hat Ceph Storage”.
- To learn about the Red Hat Ceph Storage Dashboard alerts and how to configure them, see Section 5.6, “The Red Hat Ceph Storage Dashboard alerts”.
Prerequisites
- A Red Hat Ceph Storage cluster running in containers
5.1. The Red Hat Ceph Storage Dashboard
The Red Hat Ceph Storage Dashboard provides a monitoring dashboard for Ceph clusters to visualize the storage cluster state. The dashboard is accessible from a web browser and provides a number of metrics and graphs about the state of the cluster, Monitors, OSDs, Pools, or the network.
With the previous releases of Red Hat Ceph Storage, monitoring data was sourced through a collectd plugin, which sent the data to an instance of the Graphite monitoring utility. Starting with Red Hat Ceph Storage 3.3, monitoring data is sourced directly from the ceph-mgr daemon, using the ceph-mgr Prometheus plugin.
The introduction of Prometheus as the monitoring data source simplifies deployment and operational management of the Red Hat Ceph Storage Dashboard solution, along with reducing the overall hardware requirements. By sourcing the Ceph monitoring data directly, the Red Hat Ceph Storage Dashboard solution is better able to support Ceph clusters deployed in containers.
With this change in architecture, there is no migration path for monitoring data from Red Hat Ceph Storage 2.x and 3.0 to Red Hat Ceph Storage 3.3.
The Red Hat Ceph Storage Dashboard uses the following utilities:
- The Ansible automation application for deployment.
-
The embedded Prometheus
ceph-mgrplugin. -
The Prometheus
node-exporterdaemon, running on each node of the storage cluster. - The Grafana platform to provide a user interface and alerting.
The Red Hat Ceph Storage Dashboard supports the following features:
- General Features
- Support for Red Hat Ceph Storage 3.1 and higher
- SELinux support
- Support for FileStore and BlueStore OSD back ends
- Support for encrypted and non-encrypted OSDs
- Support for Monitor, OSD, the Ceph Object Gateway, and iSCSI roles
- Initial support for the Metadata Servers (MDS)
- Drill down and dashboard links
- 15 second granularity
- Support for Hard Disk Drives (HDD), Solid-state Drives (SSD), Non-volatile Memory Express (NVMe) interface, and Intel® Cache Acceleration Software (Intel® CAS)
- Node Metrics
- CPU and RAM usage
- Network load
- Configurable Alerts
- Out-of-Band (OOB) alerts and triggers
- Notification channel is automatically defined during the installation
The Ceph Health Summary dashboard created by default
See the Red Hat Ceph Storage Dashboard Alerts section for details.
- Cluster Summary
- OSD configuration summary
- OSD FileStore and BlueStore summary
- Cluster versions breakdown by role
- Disk size summary
- Host size by capacity and disk count
- Placement Groups (PGs) status breakdown
- Pool counts
- Device class summary, HDD vs. SSD
- Cluster Details
-
Cluster flags status (
noout,nodown, and others) -
OSD or Ceph Object Gateway hosts
upanddownstatus - Per pool capacity usage
- Raw capacity utilization
- Indicators for active scrub and recovery processes
- Growth tracking and forecast (raw capacity)
-
Information about OSDs that are
downornear full, including the OSD host and disk - Distribution of PGs per OSD
- OSDs by PG counts, highlighting the over or under utilized OSDs
-
Cluster flags status (
- OSD Performance
- Information about I/O operations per second (IOPS) and throughput by pool
- OSD performance indicators
- Disk statistics per OSD
- Cluster wide disk throughput
- Read/write ratio (client IOPS)
- Disk utilization heat map
- Network load by Ceph role
- The Ceph Object Gateway Details
- Aggregated load view
- Per host latency and throughput
- Workload breakdown by HTTP operations
- The Ceph iSCSI Gateway Details
- Aggregated views
- Configuration
- Performance
- Per Gateway resource utilization
- Per client load and configuration
- Per Ceph Block Device image performance
5.2. Installing the Red Hat Ceph Storage Dashboard
The Red Hat Ceph Storage Dashboard provides a visual dashboard to monitor various metrics in a running Ceph Storage Cluster.
For information on upgrading the Red Hat Ceph Storage Dashboard see Upgrading Red Hat Ceph Storage Dashboard in the Installation Guide for Red Hat Enterprise Linux.
Prerequisites
- A Ceph Storage cluster running in containers deployed with the Ansible automation application.
The storage cluster nodes use Red Hat Enterprise Linux 7.
For details, see Section 1.1.1, “Registering Red Hat Ceph Storage Nodes to the CDN and Attaching Subscriptions”.
- A separate node, the Red Hat Ceph Storage Dashboard node, for receiving data from the cluster nodes and providing the Red Hat Ceph Storage Dashboard.
Prepare the Red Hat Ceph Storage Dashboard node:
- Register the system with the Red Hat Content Delivery Network (CDN), attach subscriptions, and enable Red Hat Enterprise Linux repositories. For details, see Section 1.1.1, “Registering Red Hat Ceph Storage Nodes to the CDN and Attaching Subscriptions”.
Enable the Tools repository on all nodes.
For details, see the Enabling the Red Hat Ceph Storage Repositories section in the Red Hat Ceph Storage 3 Installation Guide for Red Hat Enterprise Linux.
If using a firewall, then ensure that the following TCP ports are open:
Expand Table 5.1. TCP Port Requirements Port Use Where? 3000Grafana
The Red Hat Ceph Storage Dashboard node.
9090Basic Prometheus graphs
The Red Hat Ceph Storage Dashboard node.
9100Prometheus'
node-exporterdaemonAll storage cluster nodes.
9283Gathering Ceph data
All
ceph-mgrnodes.9287Ceph iSCSI gateway data
All Ceph iSCSI gateway nodes.
For more details see the Using Firewalls chapter in the Security Guide for Red Hat Enterprise Linux 7.
Procedure
Run the following commands on the Ansible administration node as the root user.
Install the
cephmetrics-ansiblepackage.[root@admin ~]# yum install cephmetrics-ansibleUsing the Ceph Ansible inventory as a base, add the Red Hat Ceph Storage Dashboard node under the
[ceph-grafana]section of the Ansible inventory file, by default located at/etc/ansible/hosts.[ceph-grafana] $HOST_NAMEReplace:
-
$HOST_NAMEwith the name of the Red Hat Ceph Storage Dashboard node
For example:
[ceph-grafana] node0-
Change to the
/usr/share/cephmetrics-ansible/directory.[root@admin ~]# cd /usr/share/cephmetrics-ansibleRun the Ansible playbook.
[root@admin cephmetrics-ansible]# ansible-playbook -v playbook.ymlImportantEvery time you update the cluster configuration, for example, you add or remove a MON or OSD node, you must re-run the
cephmetricsAnsible playbook.NoteThe
cephmetricsAnsible playbook does the following actions:-
Updates the
ceph-mgrinstance to enable the prometheus plugin and opens TCP port 9283. Deploys the Prometheus
node-exporterdaemon to each node in the storage cluster.- Opens TCP port 9100.
-
Starts the
node-exporterdaemon.
Deploys Grafana and Prometheus containers under Docker/systemd on the Red Hat Ceph Storage Dashboard node.
- Prometheus is configured to gather data from the ceph-mgr nodes and the node-exporters running on each ceph host
- Opens TCP port 3000.
- The dashboards, themes and user accounts are all created in Grafana.
- Outputs the URL of Grafana for the administrator.
-
Updates the
5.3. Accessing the Red Hat Ceph Storage Dashboard
Accessing the Red Hat Ceph Storage Dashboard gives you access to the web-based management tool for administrating Red Hat Ceph Storage clusters.
Prerequisites
- Install the Red Hat Ceph Storage Dashboard.
- Ensure that NTP is synchronizing clocks properly because a time lag can occur among the Ceph Storage Dashboard node, cluster nodes, and a browser when the nodes are not properly synced. See the Configuring the Network Time Protocol for Red Hat Ceph Storage section in the Red Hat Ceph Storage 3 Installation Guide for Red Hat Enterprise Linux or Ubuntu.
Procedure
Enter the following URL to a web browser:
http://$HOST_NAME:3000Replace:
-
$HOST_NAMEwith the name of the Red Hat Ceph Storage Dashboard node
For example:
http://cephmetrics:3000-
Enter the password for the
adminuser. If you did not set the password during the installation, useadmin, which is the default password.Once logged in, you are automatically placed on the Ceph At a Glance dashboard. The Ceph At a Glance dashboard provides a high-level overviews of capacity, performance, and node-level performance information.
Example
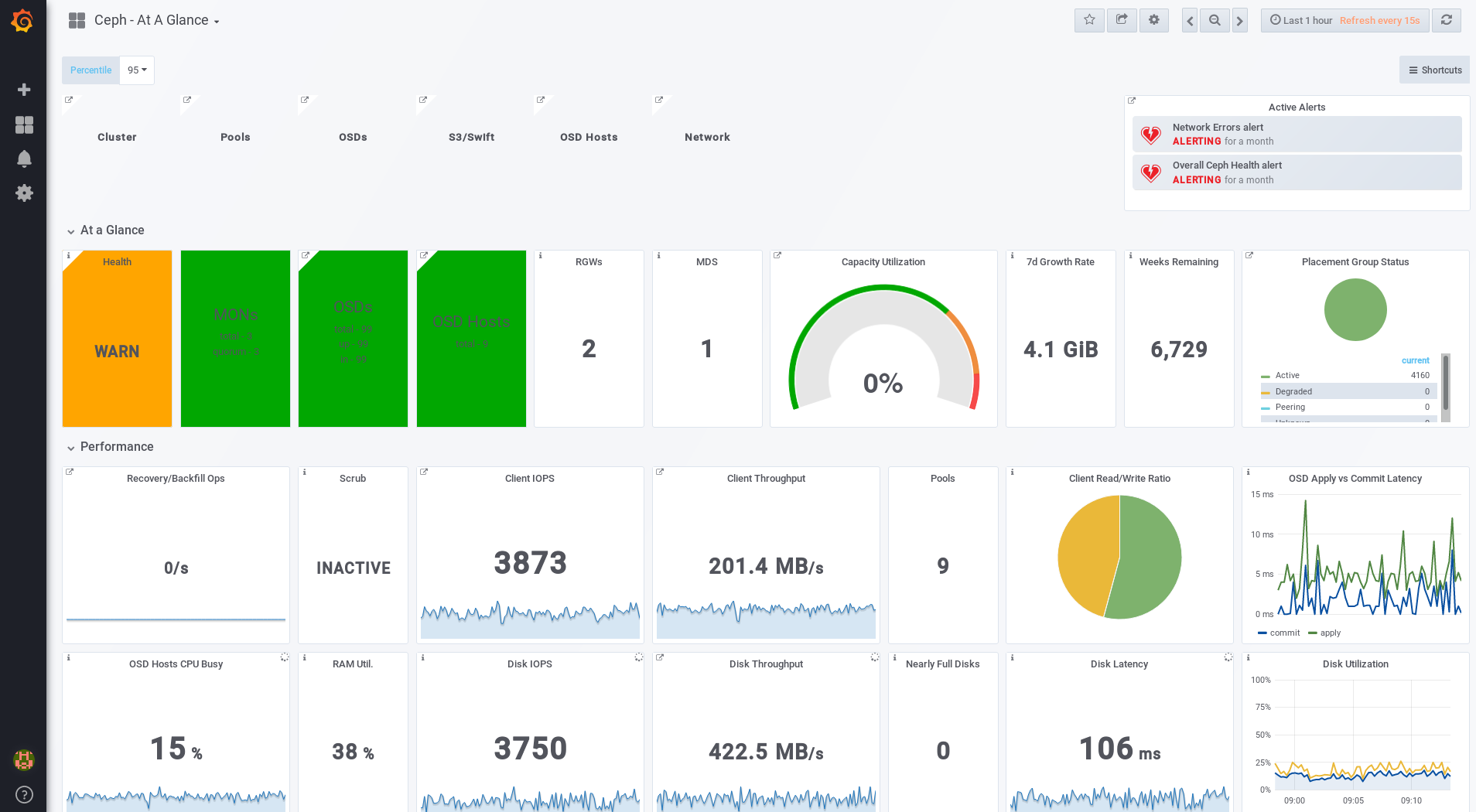
Additional Resources
- See the Changing the Default Red Hat Ceph Storage Dashboard Password section in the Red Hat Ceph Storage Administration Guide.
5.4. Changing the default Red Hat Ceph Storage dashboard password
The default user name and password for accessing the Red Hat Ceph Storage Dashboard is set to admin and admin. For security reasons, you might want to change the password after the installation.
To prevent the password from resetting to the default value, update the custom password in the /usr/share/cephmetrics-ansible/group_vars/all.yml file.
Prerequisites
Procedure
- Click the Grafana icon in the upper-left corner.
-
Hover over the user name you want to modify the password for. In this case
admin. -
Click
Profile. -
Click
Change Password. -
Enter the new password twice and click
Change Password.
Additional Resource
- If you forgot the password, follow the Reset admin password procedure on the Grafana web pages.
5.5. The Prometheus plugin for Red Hat Ceph Storage
As a storage administrator, you can gather performance data, export that data using the Prometheus plugin module for the Red Hat Ceph Storage Dashboard, and then perform queries on this data. The Prometheus module allows ceph-mgr to expose Ceph related state and performance data to a Prometheus server.
5.5.1. Prerequisites
- Running Red Hat Ceph Storage 3.1 or higher.
- Installation of the Red Hat Ceph Storage Dashboard.
5.5.2. The Prometheus plugin
The Prometheus plugin provides an exporter to pass on Ceph performance counters from the collection point in ceph-mgr. The Red Hat Ceph Storage Dashboard receives MMgrReport messages from all MgrClient processes, such as Ceph Monitors and OSDs. A circular buffer of the last number of samples contains the performance counter schema data and the actual counter data. This plugin creates an HTTP endpoint and retrieves the latest sample of every counter when polled. The HTTP path and query parameters are ignored; all extant counters for all reporting entities are returned in a text exposition format.
Additional Resources
- See the Prometheus documentation for more details on the text exposition format.
5.5.3. Managing the Prometheus environment
To monitor a Ceph storage cluster with Prometheus you can configure and enable the Prometheus exporter so the metadata information about the Ceph storage cluster can be collected.
Prerequisites
- A running Red Hat Ceph Storage 3.1 cluster
- Installation of the Red Hat Ceph Storage Dashboard
Procedure
As the
rootuser, open and edit the/etc/prometheus/prometheus.ymlfile.Under the
globalsection, set thescrape_intervalandevaluation_intervaloptions to 15 seconds.Example
global: scrape_interval: 15s evaluation_interval: 15sUnder the
scrape_configssection, add thehonor_labels: trueoption, and edit thetargets, andinstanceoptions for each of theceph-mgrnodes.Example
scrape_configs: - job_name: 'node' honor_labels: true static_configs: - targets: [ 'node1.example.com:9100' ] labels: instance: "node1.example.com" - targets: ['node2.example.com:9100'] labels: instance: "node2.example.com"NoteUsing the
honor_labelsoption enables Ceph to output properly-labelled data relating to any node in the Ceph storage cluster. This allows Ceph to export the properinstancelabel without Prometheus overwriting it.To add a new node, simply add the
targets, andinstanceoptions in the following format:Example
- targets: [ 'new-node.example.com:9100' ] labels: instance: "new-node"NoteThe
instancelabel has to match what appears in Ceph’s OSD metadatainstancefield, which is the short host name of the node. This helps to correlate Ceph stats with the node’s stats.
Add Ceph targets to the
/etc/prometheus/ceph_targets.ymlfile in the following format.Example
[ { "targets": [ "cephnode1.example.com:9283" ], "labels": {} } ]Enable the Prometheus module:
# ceph mgr module enable prometheus
5.5.4. Working with the Prometheus data and queries
The statistic names are exactly as Ceph names them, with illegal characters translated to underscores, and ceph_ prefixed to all names. All Ceph daemon statistics have a ceph_daemon label that identifies the type and ID of the daemon they come from, for example: osd.123. Some statistics can come from different types of daemons, so when querying you will want to filter on Ceph daemons starting with osd to avoid mixing in the Ceph Monitor and RocksDB stats. The global Ceph storage cluster statistics have labels appropriate to what they report on. For example, metrics relating to pools have a pool_id label. The long running averages that represent the histograms from core Ceph are represented by a pair of sum and count performance metrics.
The following example queries can be used in the Prometheus expression browser:
Show the physical disk utilization of an OSD
(irate(node_disk_io_time_ms[1m]) /10) and on(device,instance) ceph_disk_occupation{ceph_daemon="osd.1"}Show the physical IOPS of an OSD as seen from the operating system
irate(node_disk_reads_completed[1m]) + irate(node_disk_writes_completed[1m]) and on (device, instance) ceph_disk_occupation{ceph_daemon="osd.1"}Pool and OSD metadata series
Special data series are output to enable the displaying and the querying on certain metadata fields. Pools have a ceph_pool_metadata field, for example:
ceph_pool_metadata{pool_id="2",name="cephfs_metadata_a"} 1.0
OSDs have a ceph_osd_metadata field, for example:
ceph_osd_metadata{cluster_addr="172.21.9.34:6802/19096",device_class="ssd",ceph_daemon="osd.0",public_addr="172.21.9.34:6801/19096",weight="1.0"} 1.0Correlating drive statistics with node_exporter
The Prometheus output from Ceph is designed to be used in conjunction with the generic node monitoring from the Prometheus node exporter. Correlation of Ceph OSD statistics with the generic node monitoring drive statistics, special data series are output, for example:
ceph_disk_occupation{ceph_daemon="osd.0",device="sdd", exported_instance="node1"}
To get disk statistics by an OSD ID, use either the and operator or the asterisk (*) operator in the Prometheus query. All metadata metrics have the value of 1 so they act neutral with asterisk operator. Using asterisk operator allows to use group_left and group_right grouping modifiers, so that the resulting metric has additional labels from one side of the query. For example:
rate(node_disk_bytes_written[30s]) and on (device,instance) ceph_disk_occupation{ceph_daemon="osd.0"}Using label_replace
The label_replace function can add a label to, or alter a label of, a metric within a query. To correlate an OSD and its disks write rate, the following query can be used:
label_replace(rate(node_disk_bytes_written[30s]), "exported_instance", "$1", "instance", "(.*):.*") and on (device,exported_instance) ceph_disk_occupation{ceph_daemon="osd.0"}Additional Resources
- See Prometheus querying basics for more information on constructing queries.
-
See Prometheus'
label_replacedocumentation for more information.
5.5.5. Using the Prometheus expression browser
Use the builtin Prometheus expression browser to run queries against the collected data.
Prerequisites
- A running Red Hat Ceph Storage 3.1 cluster
- Installation of the Red Hat Ceph Storage Dashboard
Procedure
Enter the URL for the Prometh the web browser:
http://$DASHBOARD_SEVER_NAME:9090/graphReplace…
-
$DASHBOARD_SEVER_NAMEwith the name of the Red Hat Ceph Storage Dashboard server.
-
Click on Graph, then type in or paste the query into the query window and press the Execute button.
- View the results in the console window.
- Click on Graph to view the rendered data.
Additional Resources
- See the Prometheus expression browser documentation on the Prometheus web site for more information.
5.5.6. Additional Resources
5.6. The Red Hat Ceph Storage Dashboard alerts
This section includes information about alerting in the Red Hat Ceph Storage Dashboard.
- To learn about the Red Hat Ceph Storage Dashboard alerts, see Section 5.6.2, “About Alerts”.
- To view the alerts, see Section 5.6.3, “Accessing the Alert Status dashboard”.
- To configure the notification target, see Section 5.6.4, “Configuring the Notification Target”.
- To change the default alerts or add new ones, see Section 5.6.5, “Changing the Default Alerts and Adding New Ones”.
5.6.1. Prerequisites
5.6.2. About Alerts
The Red Hat Ceph Storage Dashboard supports alerting mechanism that is provided by the Grafana platform. You can configure the dashboard to send you a notification when a metric that you are interested in reaches certain value. Such metrics are in the Alert Status dashboard.
By default, Alert Status already includes certain metrics, such as Overall Ceph Health, OSDs Down, or Pool Capacity. You can add metrics that you are interested in to this dashboard or change their trigger values.
Here is a list of the pre-defined alerts that are included with Red Hat Ceph Storage Dashboard:
- Overall Ceph Health
- Disks Near Full (>85%)
- OSD Down
- OSD Host Down
- PG’s Stuck Inactive
- OSD Host Less - Free Capacity Check
- OSD’s With High Response Times
- Network Errors
- Pool Capacity High
- Monitors Down
- Overall Cluster Capacity Low
- OSDs With High PG Count
5.6.3. Accessing the Alert Status dashboard
Certain Red Hat Ceph Storage Dashboard alerts are configured by default in the Alert Status dashboard. This section shows two ways to access it.
Procedure
To access the dashboard:
- In the main At the Glance dashboard, click the Active Alerts panel in the upper-right corner.
Or..
- Click the dashboard menu from in the upper-left corner next to the Grafana icon. Select Alert Status.
5.6.4. Configuring the Notification Target
A notification channel called cephmetrics is automatically created during installation. All preconfigured alerts reference the cephmetrics channel but before you can receive the alerts, complete the notification channel definition by selecting the desired notification type. The Grafana platform supports a number of different notification types including email, Slack, and PagerDuty.
Procedure
- To configure the notification channel, follow the instructions in the Alert Notifications section on the Grafana web page.
5.6.5. Changing the Default Alerts and Adding New Ones
This section explains how to change the trigger value on already configured alerts and how to add new alerts to the Alert Status dashboard.
Procedure
To change the trigger value on alerts or to add new alerts, follow the Alerting Engine & Rules Guide on the Grafana web pages.
ImportantTo prevent overriding custom alerts, the Alert Status dashboard will not be updated when upgrading the Red Hat Ceph Storage Dashboard packages when you change the trigger values or add new alerts.
Additional Resources
- The Grafana web page