Chapter 3. Ceph Monitor configuration
As a storage administrator, you can use the default configuration values for the Ceph Monitor or customize them according to the intended workload.
3.1. Prerequisites
- Installation of the Red Hat Ceph Storage software.
3.2. Ceph Monitor configuration
Understanding how to configure a Ceph Monitor is an important part of building a reliable Red Hat Ceph Storage cluster. All storage clusters have at least one monitor. A Ceph Monitor configuration usually remains fairly consistent, but you can add, remove or replace a Ceph Monitor in a storage cluster.
Ceph monitors maintain a "master copy" of the cluster map. That means a Ceph client can determine the location of all Ceph monitors and Ceph OSDs just by connecting to one Ceph monitor and retrieving a current cluster map.
Before Ceph clients can read from or write to Ceph OSDs, they must connect to a Ceph Monitor first. With a current copy of the cluster map and the CRUSH algorithm, a Ceph client can compute the location for any object. The abilityto compute object locations allows a Ceph client to talk directly to Ceph OSDs, which is a very important aspect of Ceph’s high scalability and performance.
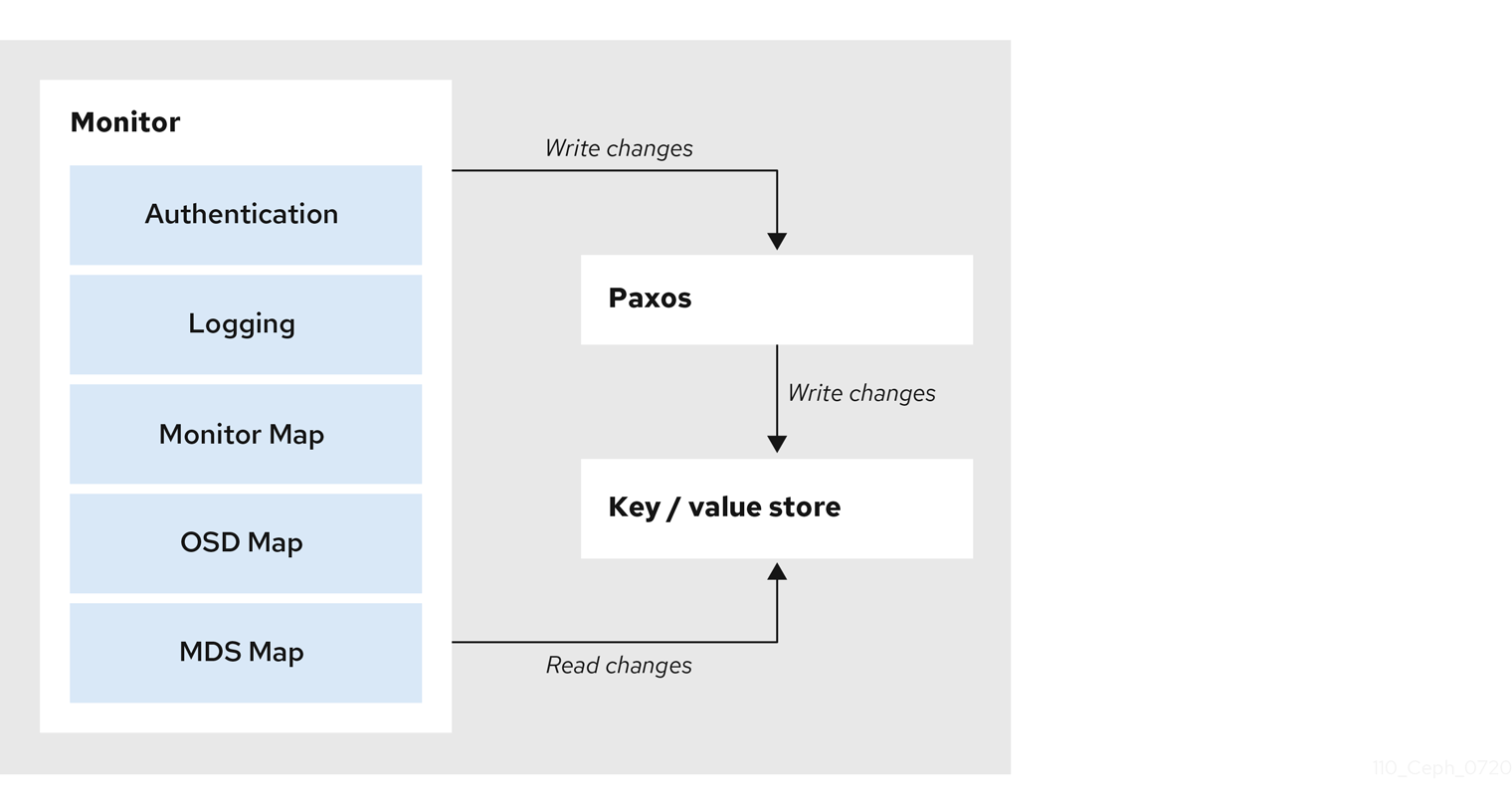
The primary role of the Ceph Monitor is to maintain a master copy of the cluster map. Ceph Monitors also provide authentication and logging services. Ceph Monitors write all changes in the monitor services to a single Paxos instance, and Paxos writes the changes to a key-value store for strong consistency. Ceph Monitors can query the most recent version of the cluster map during synchronization operations. Ceph Monitors leverage the key-value store’s snapshots and iterators, using the rocksdb database, to perform store-wide synchronization.
3.3. Ceph cluster maps
The cluster map is a composite of maps, including the monitor map, the OSD map, and the placement group map. The cluster map tracks a number of important events:
-
Which processes are
inthe Red Hat Ceph Storage cluster. -
Which processes that are
inthe Red Hat Ceph Storage cluster areupand running ordown. -
Whether, the placement groups are
activeorinactive, andcleanor in some other state. other details that reflect the current state of the cluster such as:
- the total amount of storage space or
- the amount of storage used.
When there is a significant change in the state of the cluster for example, a Ceph OSD goes down, a placement group falls into a degraded state, and so on. The cluster map gets updated to reflect the current state of the cluster. Additionally, the Ceph monitor also maintains a history of the prior states of the cluster. The monitor map, OSD map, and placement group map each maintain a history of their map versions. Each version is called an epoch.
When operating the Red Hat Ceph Storage cluster, keeping track of these states is an important part of the cluster administration.
3.4. Ceph Monitor quorum
A cluster will run sufficiently with a single monitor. However, a single monitor is a single-point-of-failure. To ensure high availability in a production Ceph storage cluster, run Ceph with multiple monitors so that the failure of a single monitor will not cause a failure of the entire storage cluster.
When a Ceph storage cluster runs multiple Ceph Monitors for high availability, Ceph Monitors use the Paxos algorithm to establish consensus about the master cluster map. A consensus requires a majority of monitors running to establish a quorum for consensus about the cluster map. For example, 1; 2 out of 3; 3 out of 5; 4 out of 6; and so on.
Red Hat recommends running a production Red Hat Ceph Storage cluster with at least three Ceph Monitors to ensure high availability. When you run multiple monitors, you can specify the initial monitors that must be members of the storage cluster in order to establish a quorum. This may reduce the time it takes for the storage cluster to come online.
[mon]
mon_initial_members = a,b,c
A majority of the monitors in the storage cluster must be able to reach each other in order to establish a quorum. You can decrease the initial number of monitors to establish a quorum with the mon_initial_members option.
3.5. Ceph Monitor consistency
When you add monitor settings to the Ceph configuration file, you need to be aware of some of the architectural aspects of Ceph Monitors. Ceph imposes strict consistency requirements for a Ceph Monitor when discovering another Ceph Monitor within the cluster. Whereas, Ceph clients and other Ceph daemons use the Ceph configuration file to discover monitors, monitors discover each other using the monitor map (monmap), not the Ceph configuration file.
A Ceph Monitor always refers to the local copy of the monitor map when discovering other Ceph Monitors in the Red Hat Ceph Storage cluster. Using the monitor map instead of the Ceph configuration file avoids errors that could break the cluster. For example, typos in the Ceph configuration file when specifying a monitor address or port. Since monitors use monitor maps for discovery and they share monitor maps with clients and other Ceph daemons, the monitor map provides monitors with a strict guarantee that their consensus is valid.
Strict consistency when applying updates to the monitor maps
As with any other updates on the Ceph Monitor, changes to the monitor map always run through a distributed consensus algorithm called Paxos. The Ceph Monitors must agree on each update to the monitor map, such as adding or removing a Ceph Monitor, to ensure that each monitor in the quorum has the same version of the monitor map. Updates to the monitor map are incremental so that Ceph Monitors have the latest agreed upon version, and a set of previous versions.
Maintaining history
Maintaining a history enables a Ceph Monitor that has an older version of the monitor map to catch up with the current state of the Red Hat Ceph Storage cluster.
If Ceph Monitors discovered each other through the Ceph configuration file instead of through the monitor map, it would introduce additional risks because the Ceph configuration files are not updated and distributed automatically. Ceph Monitors might inadvertently use an older Ceph configuration file, fail to recognize a Ceph Monitor, fall out of a quorum, or develop a situation where Paxos is not able to determine the current state of the system accurately.
3.6. Bootstrap the Ceph Monitor
In most configuration and deployment cases, tools that deploy Ceph such as Ansible might help bootstrap the Ceph monitors by generating a monitor map for you.
A Ceph monitor requires a few explicit settings:
-
File System ID: The
fsidis the unique identifier for your object store. Since you can run multiple storage clusters on the same hardware, you must specify the unique ID of the object store when bootstrapping a monitor. Using deployment tools, such as Ansible will generate a file system identifier, but you can specify thefsidmanually too. -
Monitor ID: A monitor ID is a unique ID assigned to each monitor within the cluster. It is an alphanumeric value, and by convention the identifier usually follows an alphabetical increment. For example,
a,b, and so on. This can be set in the Ceph configuration file. For example,[mon.a],[mon.b], and so on, by a deployment tool, or using thecephcommand. - Keys: The monitor must have secret keys.
3.7. Ceph Monitor section in the configuration file
To apply configuration settings to the entire cluster, enter the configuration settings under the [global] section. To apply configuration settings to all monitors in the cluster, enter the configuration settings under the [mon] section. To apply configuration settings to specific monitors, specify the monitor instance.
Example
[mon.a]
By convention, monitor instance names use alpha notation.
[global]
[mon]
[mon.a]
[mon.b]
[mon.c]3.8. Minimum configuration for a Ceph Monitor
The bare minimum monitor settings for a Ceph monitor in the Ceph configuration file includes a host name for each monitor if it is not configured for DNS and the monitor address. You can configure these under [mon] or under the entry for a specific monitor.
[mon]
mon_host = hostname1,hostname2,hostname3
mon_addr = 10.0.0.10:6789,10.0.0.11:6789,10.0.0.12:6789,10.0.0.10:3300,10.0.0.11:3300,10.0.0.12:3300Or
[mon.a]
host = hostname1
mon_addr = 10.0.0.10:6789, 10.0.0.10:3300
This minimum configuration for monitors assumes that a deployment tool generates the fsid and the mon. key for you.
Once you deploy a Ceph cluster, do not change the IP address of the monitors.
To configure the Ceph cluster for DNS lookup, set the mon_dns_srv_name setting in the Ceph configuration file.
Once set, configure the DNS. Create records either IPv4 (A) or IPv6 (AAAA) for the monitors in the DNS zone.
Example
#IPv4
mon1.example.com. A 192.168.0.1
mon2.example.com. A 192.168.0.2
mon3.example.com. A 192.168.0.3
#IPv6
mon1.example.com. AAAA 2001:db8::100
mon2.example.com. AAAA 2001:db8::200
mon3.example.com. AAAA 2001:db8::300
Where: example.com is the DNS search domain.
Then, create the SRV TCP records with the name mon_dns_srv_name configuration setting pointing to the three Monitors. The following example uses the default ceph-mon value.
Example
_ceph-mon._tcp.example.com. 60 IN SRV 10 60 6789 mon1.example.com.
_ceph-mon._tcp.example.com. 60 IN SRV 10 60 6789 mon2.example.com.
_ceph-mon._tcp.example.com. 60 IN SRV 10 60 6789 mon3.example.com.
_ceph-mon._tcp.example.com. 60 IN SRV 10 60 3300 mon1.example.com.
_ceph-mon._tcp.example.com. 60 IN SRV 10 60 3300 mon2.example.com.
_ceph-mon._tcp.example.com. 60 IN SRV 10 60 3300 mon3.example.com.
Monitors run on port 6789 and 3300 by default, and their priority and weight are all set to 10 and 60 respectively in the foregoing example.
3.9. Unique identifier for Ceph
Each Red Hat Ceph Storage cluster has a unique identifier (fsid). If specified, it usually appears under the [global] section of the configuration file. Deployment tools usually generate the fsid and store it in the monitor map, so the value may not appear in a configuration file. The fsid makes it possible to run daemons for multiple clusters on the same hardware.
Do not set this value if you use a deployment tool that does it for you.
3.10. Ceph Monitor data store
Ceph provides a default path where Ceph monitors store data.
Red Hat recommends running Ceph monitors on separate hosts and drives from Ceph OSDs for optimal performance in a production Red Hat Ceph Storage cluster.
Ceph monitors call the fsync() function often, which can interfere with Ceph OSD workloads.
Ceph monitors store their data as key-value pairs. Using a data store prevents recovering Ceph monitors from running corrupted versions through Paxos, and it enables multiple modification operations in one single atomic batch, among other advantages.
Red Hat does not recommend changing the default data location. If you modify the default location, make it uniform across Ceph monitors by setting it in the [mon] section of the configuration file.
Disks that store the monitor database need to be encrypted, for more information see LUKS disk encryption.
3.11. Ceph storage capacity
When a Red Hat Ceph Storage cluster gets close to its maximum capacity (specified by the mon_osd_full_ratio parameter), Ceph prevents you from writing to Ceph OSDs as a safety measure to prevent data loss. Therefore, letting a production Red Hat Ceph Storage cluster approach its full ratio is not a good practice, because it sacrifices high availability. The default full ratio is .95, or 95% of capacity. This a very aggressive setting for a test cluster with a small number of OSDs.
When monitoring a cluster, be alert to warnings related to the nearfull ratio. This means that a failure of some OSDs could result in a temporary service disruption if one or more OSDs fails. Consider adding more OSDs to increase storage capacity.
A common scenario for test clusters involves a system administrator removing a Ceph OSD from the Red Hat Ceph Storage cluster to watch the cluster re-balance. Then, removing another Ceph OSD, and so on until the Red Hat Ceph Storage cluster eventually reaches the full ratio and locks up.
Red Hat recommends a bit of capacity planning even with a test cluster. Planning enables you to gauge how much spare capacity you will need in order to maintain high availability.
Ideally, you want to plan for a series of Ceph OSD failures where the cluster can recover to an active + clean state without replacing those Ceph OSDs immediately. You can run a cluster in an active + degraded state, but this is not ideal for normal operating conditions.
The following diagram depicts a simplistic Red Hat Ceph Storage cluster containing 33 Ceph Nodes with one Ceph OSD per host, each Ceph OSD Daemon reading from and writing to a 3TB drive. So this exemplary Red Hat Ceph Storage cluster has a maximum actual capacity of 99TB. With a mon osd full ratio of 0.95, if the Red Hat Ceph Storage cluster falls to 5 TB of remaining capacity, the cluster will not allow Ceph clients to read and write data. So the Red Hat Ceph Storage cluster’s operating capacity is 95 TB, not 99 TB.

It is normal in such a cluster for one or two OSDs to fail. A less frequent but reasonable scenario involves a rack’s router or power supply failing, which brings down multiple OSDs simultaneously for example, OSDs 7-12. In such a scenario, you should still strive for a cluster that can remain operational and achieve an active + clean state, even if that means adding a few hosts with additional OSDs in short order. If your capacity utilization is too high, you might not lose data, but you could still sacrifice data availability while resolving an outage within a failure domain if capacity utilization of the cluster exceeds the full ratio. For this reason, Red Hat recommends at least some rough capacity planning.
Identify two numbers for your cluster:
- the number of OSDs
- the total capacity of the cluster
To determine the mean average capacity of an OSD within a cluster, divide the total capacity of the cluster by the number of OSDs in the cluster. Consider multiplying that number by the number of OSDs you expect to fail simultaneously during normal operations (a relatively small number). Finally, multiply the capacity of the cluster by the full ratio to arrive at a maximum operating capacity. Then, subtract the number of amount of data from the OSDs you expect to fail to arrive at a reasonable full ratio. Repeat the foregoing process with a higher number of OSD failures (for example, a rack of OSDs) to arrive at a reasonable number for a near full ratio.
3.12. Ceph heartbeat
Ceph monitors know about the cluster by requiring reports from each OSD, and by receiving reports from OSDs about the status of their neighboring OSDs. Ceph provides reasonable default settings for interaction between monitor and OSD, however, you can modify them as needed.
3.13. Ceph Monitor synchronization role
When you run a production cluster with multiple monitors which is recommended, each monitor checks to see if a neighboring monitor has a more recent version of the cluster map. For example, a map in a neighboring monitor with one or more epoch numbers higher than the most current epoch in the map of the instant monitor. Periodically, one monitor in the cluster might fall behind the other monitors to the point where it must leave the quorum, synchronize to retrieve the most current information about the cluster, and then rejoin the quorum.
Synchronization roles
For the purposes of synchronization, monitors can assume one of three roles:
- Leader: The Leader is the first monitor to achieve the most recent Paxos version of the cluster map.
- Provider: The Provider is a monitor that has the most recent version of the cluster map, but was not the first to achieve the most recent version.
- Requester: The Requester is a monitor that has fallen behind the leader and must synchronize in order to retrieve the most recent information about the cluster before it can rejoin the quorum.
These roles enable a leader to delegate synchronization duties to a provider, which prevents synchronization requests from overloading the leader and improving performance. In the following diagram, the requester has learned that it has fallen behind the other monitors. The requester asks the leader to synchronize, and the leader tells the requester to synchronize with a provider.
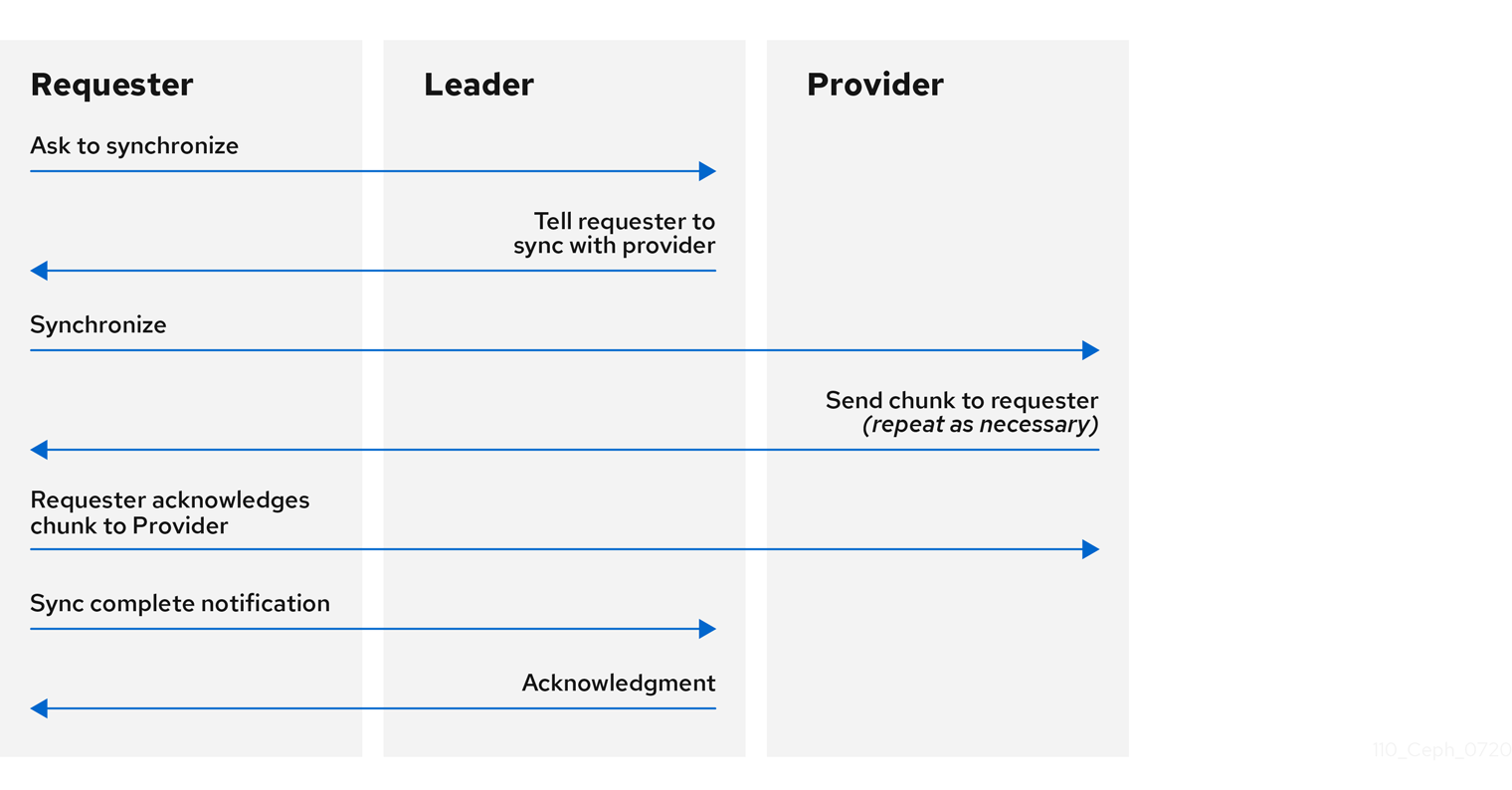
Monitor synchronization
Synchronization always occurs when a new monitor joins the cluster. During runtime operations, monitors can receive updates to the cluster map at different times. This means the leader and provider roles may migrate from one monitor to another. If this happens while synchronizing for example, a provider falls behind the leader, the provider can terminate synchronization with a requester.
Once synchronization is complete, Ceph requires trimming across the cluster. Trimming requires that the placement groups are active + clean.
3.14. Ceph time synchronization
Ceph daemons pass critical messages to each other, which must be processed before daemons reach a timeout threshold. If the clocks in Ceph monitors are not synchronized, it can lead to a number of anomalies.
For example:
- Daemons ignoring received messages such as outdated timestamps.
- Timeouts triggered too soon or late when a message was not received in time.
Install NTP on the Ceph monitor hosts to ensure that the monitor cluster operates with synchronized clocks.
Clock drift may still be noticeable with NTP even though the discrepancy is not yet harmful. Ceph clock drift and clock skew warnings can get triggered even though NTP maintains a reasonable level of synchronization. Increasing your clock drift may be tolerable under such circumstances. However, a number of factors such as workload, network latency, configuring overrides to default timeouts and other synchronization options that can influence the level of acceptable clock drift without compromising Paxos guarantees.
Additional Resources
- See section on Ceph time synchronization for more details.
3.15. Additional Resources
- See all the Red Hat Ceph Storage Monitor configuration options in Appendix C for specific option descriptions and usage.