Chapter 1. Data Grid deployment models and use cases
Data Grid offers flexible deployment models that support a variety of use cases.
- Drastically improve performance of Red Hat Build of Quarkus, Red Hat JBoss EAP, and Spring applications.
- Ensure service availability and continuity.
- Lower operational costs.
1.1. Data Grid deployment models
Data Grid has two deployment models for caches, remote and embedded. Both deployment models allow applications to access data with significantly lower latency for read operations and higher throughput for write operations in comparison with traditional database systems.
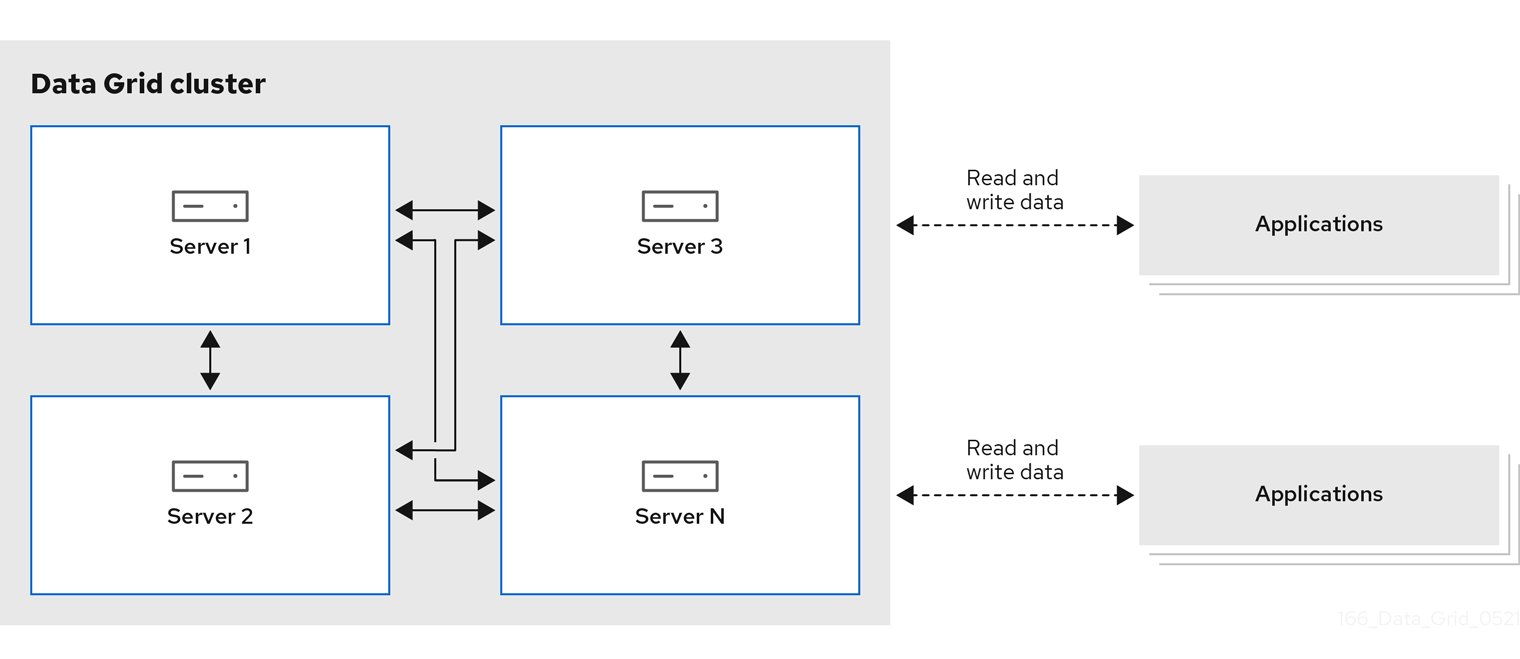
- Remote caches
- Data Grid Server nodes run in a dedicated Java Virtual Machine (JVM). Clients access remote caches using either Hot Rod, a binary TCP protocol, or REST over HTTP.
- Embedded caches
- Data Grid runs in the same JVM as your Java application, meaning that data is stored in the memory space where code is executed.
Red Hat recommends a server/client architecture for the majority of deployments. Time to deployment is much faster with remote caches because the data layer is separated from business logic. Data Grid Server also provides monitoring and observability and other built-in capabilities to help you lower development costs.
Near-caching
Near-caching capabilities allow remote clients to store data locally, which means read-intensive applications do not need to traverse the network with each call. Near-caching significantly increases speed of read operations and achieves the same performance as an embedded cache.
Figure 1.1. Remote cache deployment model
1.1.1. Platforms and automation tooling
Achieving the desired quality of service means providing Data Grid with optimal CPU and RAM resources. Too few resources downgrades Data Grid performance while using excessive amounts of host resources can quickly increase costs.
While you benchmark and tune Data Grid clusters to find the right allocation of CPU or RAM, you should also consider which host platform provides the right kind of automation tooling to scale clusters and manage resources efficiently.
Bare metal or virtual machine
Couple RHEL, or Microsoft Windows, with Red Hat Ansible to manage Data Grid configuration and poll services to ensure availability and achieve optimal resource usage.
The Ansible collection for Data Grid, available from the Automation Hub, automates cluster installation and includes options for Keycloak integration and cross-site replication.
OpenShift
Take advantage of Kubernetes orchestration to automatically provision pods, impose limits on resources, and automatically scale Data Grid clusters to meet workload demands.
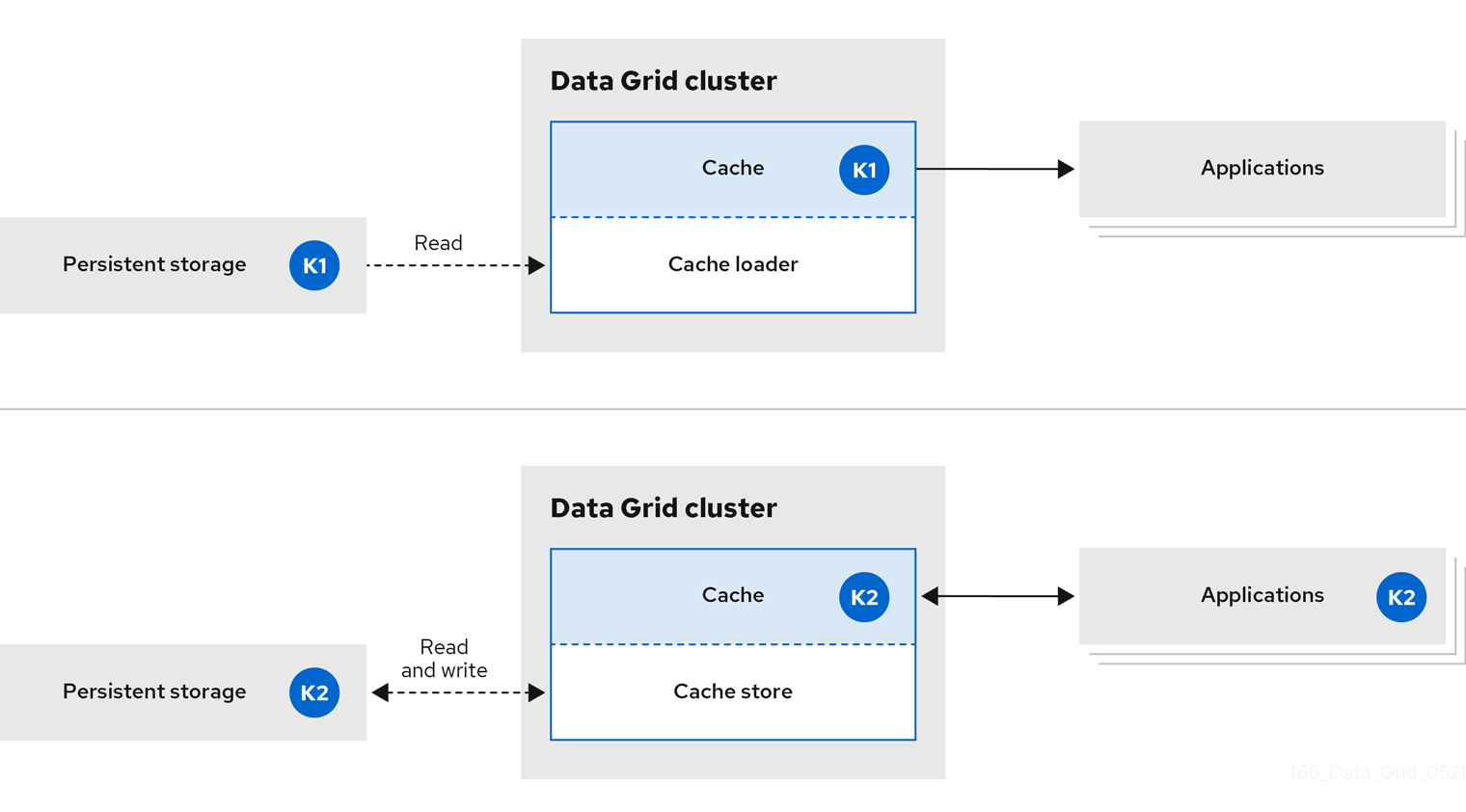
1.2. In-line caching
Data Grid handles all application requests for data that resides in persistent storage.
With in-line caches, Data Grid uses cache loaders and cache stores to operate on data in persistent storage.
- Cache loaders provide read-only access to persistent storage.
- Cache stores provide read and write access to persistent storage.
Figure 1.2. In-line caches
1.3. Side caching
Data Grid stores data that applications retrieve from persistent storage, which reduces the number of read operations to persistent storage and increases response times for subsequent reads.
Figure 1.3. Side caches
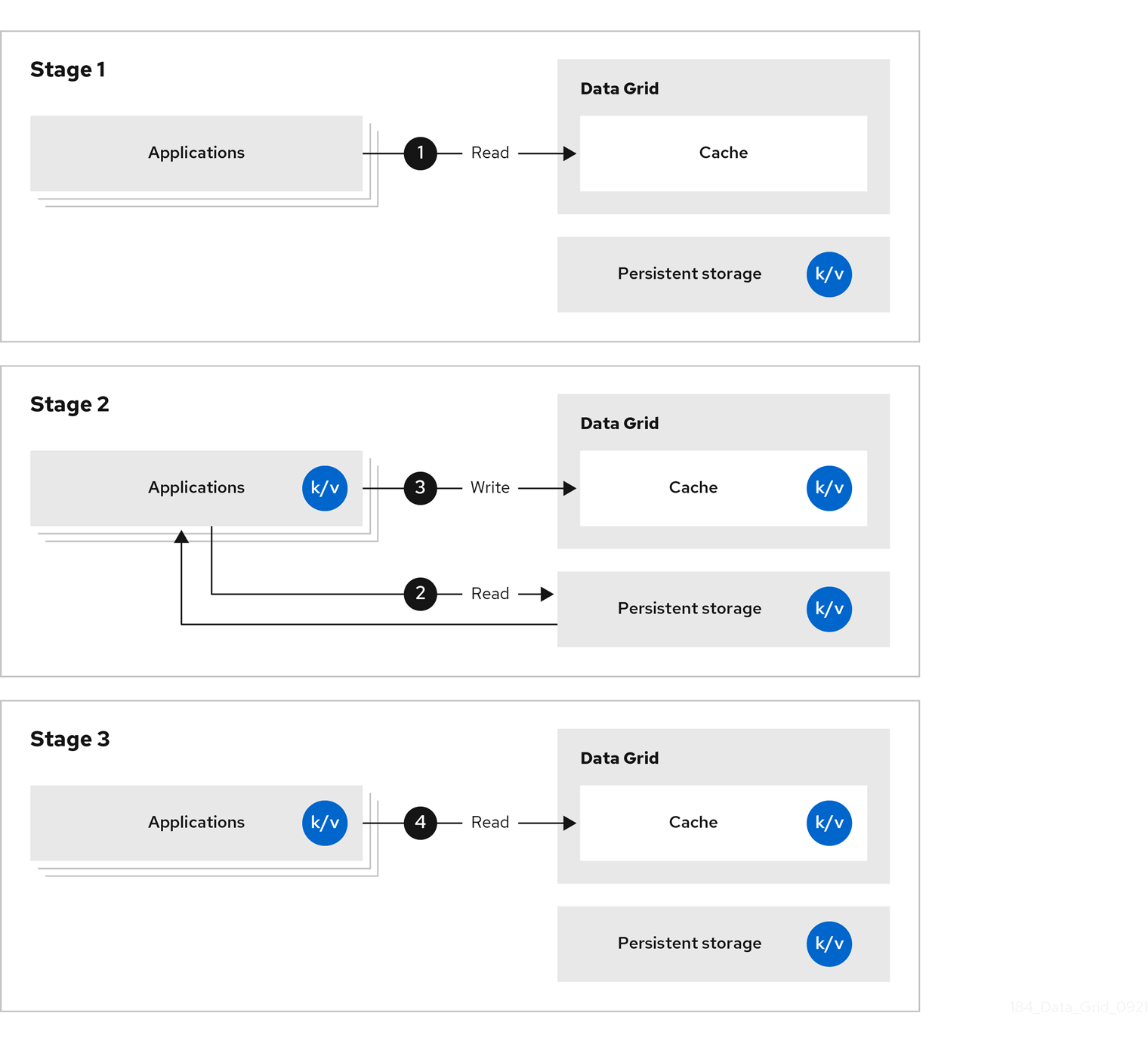
With side caches, applications control how data is added to Data Grid clusters from persistent storage. When an application requests an entry, the following occurs:
- The read request goes to Data Grid.
- If the entry is not in the cache, the application requests it from persistent storage.
- The application puts the entry in the cache.
- The application retrieves the entry from Data Grid on the next read.
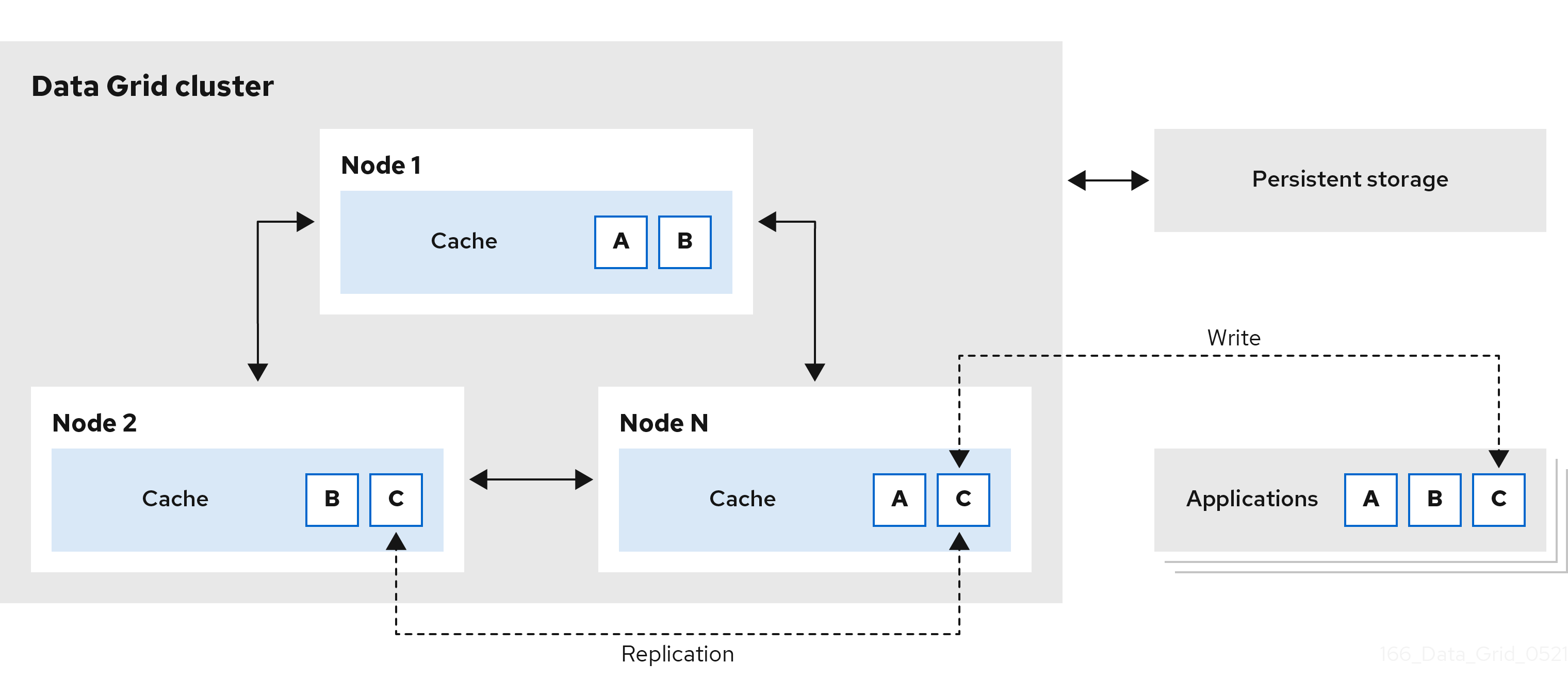
1.4. Distributed memory
Data Grid uses consistent hashing techniques to store a fixed number of copies of each entry in the cache across the cluster. Distributed caches allow you to scale the data layer linearly, increasing capacity as nodes join.
Distributed caches add redundancy to Data Grid clusters to provide fault tolerance and durability guarantees. Data Grid deployments typically configure integration with persistent storage to preserve cluster state for graceful shutdowns and restore from backup.
Figure 1.4. Distributed caches
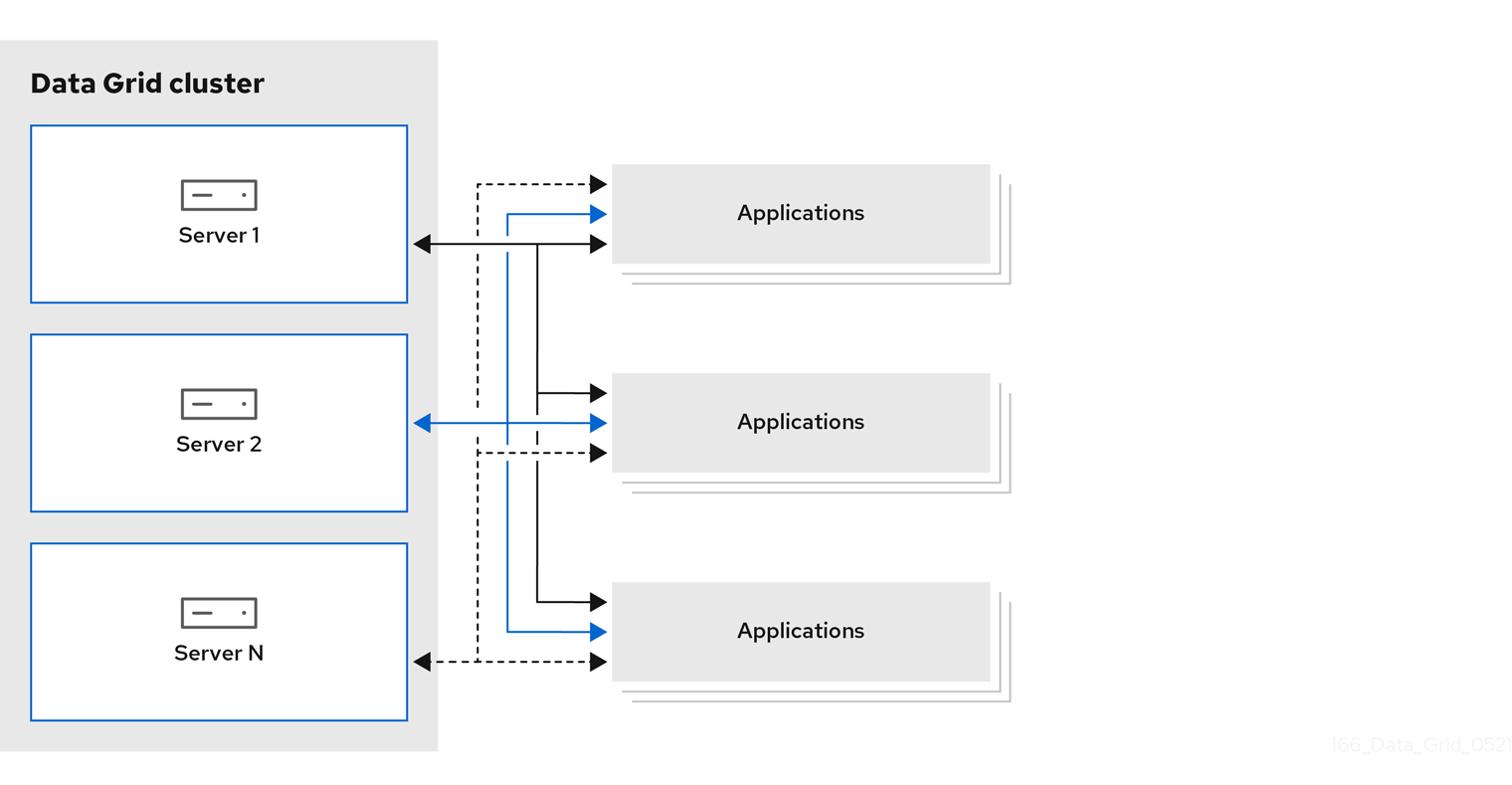
1.5. Session externalization
Data Grid can provide external caches for applications built on Red Hat Build of Quarkus, Red Hat JBoss EAP, Red Hat JBoss Web Server, and Spring. These external caches store HTTP sessions and other data independently of the application layer.
Externalizing sessions to Data Grid gives you the following benefits:
- Elasticity
- Eliminate the need for rebalancing operations when scaling applications.
- Smaller memory footprints
- Storing session data in external caches reduces overall memory requirements for applications.
Figure 1.5. Session externalization
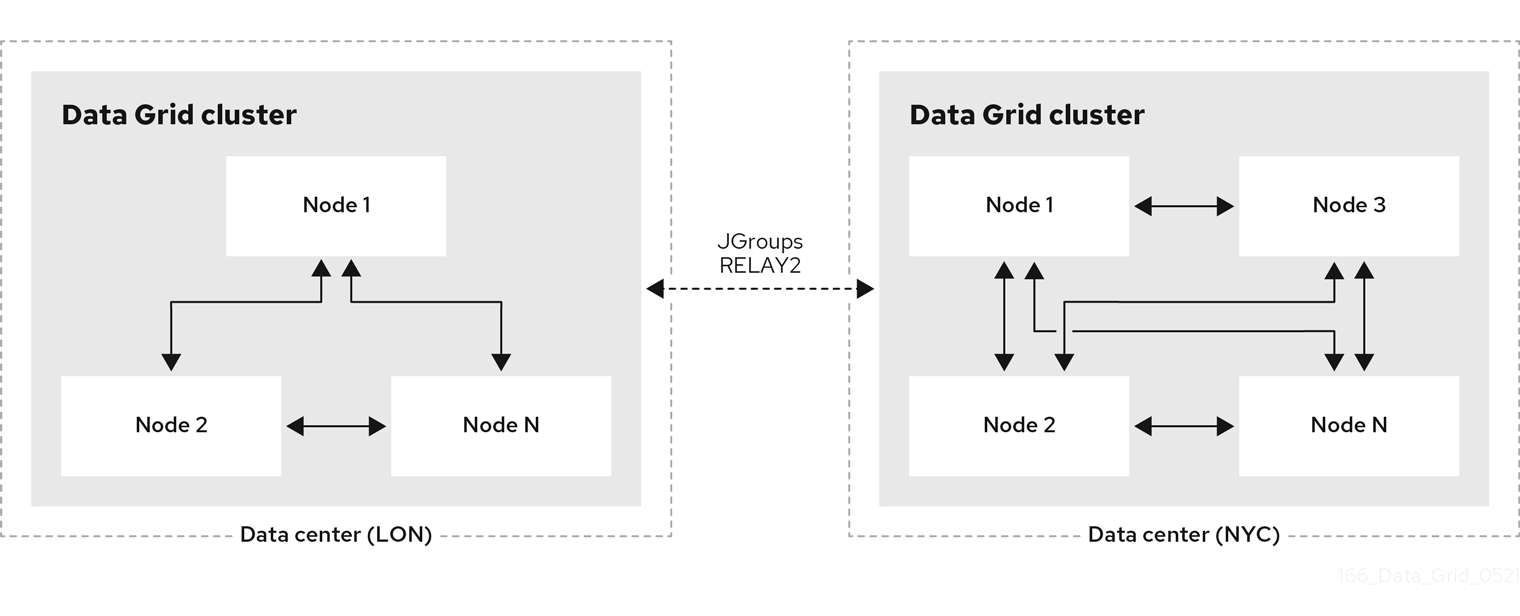
1.6. Cross-site replication
Data Grid can back up data between clusters running in geographically dispersed data centers and across different cloud providers. Cross-site replication provides Data Grid with a global cluster view and:
- Guarantees service continuity in the event of outages or disasters.
- Presents client applications with a single point of access to data in globally distributed caches.
Figure 1.6. Cross-site replication