Configuring and managing networking
Managing network interfaces, firewalls, and advanced networking features
Abstract
- You can configure bonds, VLANs, bridges, tunnels and other network types to connect the host to the network.
- You can build performance-critical firewalls for the local host and the entire network. RHEL contains packet filtering software, such as the
firewalldservice, thenftablesframework, and Express Data Path (XDP). - RHEL also supports advanced networking features, such as policy-based routing and Multipath TCP (MPTCP).
Providing feedback on Red Hat documentation
We are committed to providing high-quality documentation and value your feedback. To help us improve, you can submit suggestions or report errors through the Red Hat Jira tracking system.
Procedure
Log in to the Jira website.
If you do not have an account, select the option to create one.
- Click Create in the top navigation bar.
- Enter a descriptive title in the Summary field.
- Enter your suggestion for improvement in the Description field. Include links to the relevant parts of the documentation.
- Click Create at the bottom of the dialogue.
Chapter 1. Implementing consistent network interface naming
The udev device manager implements consistent device naming in Red Hat Enterprise Linux. The device manager supports different naming schemes and, by default, assigns fixed names based on firmware, topology, and location information.
Without consistent device naming, the Linux kernel assigns names to network interfaces by combining a fixed prefix and an index. The index increases as the kernel initializes the network devices. For example, eth0 represents the first Ethernet device being probed on start-up. If you add another network interface controller to the system, the assignment of the kernel device names is no longer fixed because, after a reboot, the devices can initialize in a different order. In that case, the kernel can name the devices differently.
To solve this problem, udev assigns consistent device names. This has the following advantages:
- Device names are stable across reboots.
- Device names stay fixed even if you add or remove hardware.
- Defective hardware can be seamlessly replaced.
- The network naming is stateless and does not require explicit configuration files.
Generally, Red Hat does not support systems where consistent device naming is disabled.
Additional resources
1.1. How the udev device manager renames network interfaces
The udev device manager processes a set of rules to implement a consistent naming scheme for network interfaces.
Order of rule files:
Optional:
/usr/lib/udev/rules.d/60-net.rulesThe
/usr/lib/udev/rules.d/60-net.rulesfile defines that the deprecated/usr/lib/udev/rename_devicehelper utility searches for theHWADDRparameter in/etc/sysconfig/network-scripts/ifcfg-*files. If the value set in the variable matches the MAC address of an interface, the helper utility renames the interface to the name set in theDEVICEparameter of theifcfgfile.If the system uses only NetworkManager connection profiles in keyfile format,
udevskips this step.Only on Dell systems:
/usr/lib/udev/rules.d/71-biosdevname.rulesThis file exists only if the
biosdevnamepackage is installed, and the rules file defines that thebiosdevnameutility renames the interface according to its naming policy, if it was not renamed in the previous step.NoteInstall and use
biosdevnameonly on Dell systems./usr/lib/udev/rules.d/75-net-description.rulesThis file defines how
udevexamines the network interface and sets the properties inudev-internal variables. These variables are then processed in the next step by the/usr/lib/udev/rules.d/80-net-setup-link.rulesfile. Some of the properties can be undefined./usr/lib/udev/rules.d/80-net-setup-link.rulesThis file calls the
net_setup_linkbuiltin of theudevservice, andudevrenames the interface based on the order of the policies in theNamePolicyparameter in the/usr/lib/systemd/network/99-default.linkfile.If none of the policies applies,
udevdoes not rename the interface.
1.2. Network interface naming policies
By default, the udev device manager uses the /usr/lib/systemd/network/99-default.link file to determine how it renames interfaces. The NamePolicy parameter in this file defines which naming policies udev applies and in what order.
Default order:
NamePolicy=kernel database onboard slot path
The following table describes the different actions of udev based on which policy matches first as specified by the NamePolicy parameter:
| Policy | Description | Example name |
|---|---|---|
| kernel |
If the kernel indicates that a device name is predictable, |
|
| database |
This policy assigns names based on mappings in the |
|
| onboard | Device names incorporate firmware or BIOS-provided index numbers for onboard devices. |
|
| slot | Device names incorporate firmware or BIOS-provided PCI Express (PCIe) hot-plug slot-index numbers. |
|
| path | Device names incorporate the physical location of the connector of the hardware. |
|
| mac | Device names incorporate the MAC address. By default, Red Hat Enterprise Linux does not use this policy, but administrators can enable it. |
|
1.3. Network interface naming schemes
The udev device manager uses certain stable interface attributes that device drivers provide to generate consistent device names.
If a new udev version changes how the service creates names for certain interfaces, Red Hat adds a new scheme version and documents the details in the systemd.net-naming-scheme(7) man page on your system. By default, Red Hat Enterprise Linux (RHEL) 8 uses the rhel-8.0 naming scheme, even if you install or update to a later minor version of RHEL.
If you want to use a scheme other than the default, you can switch the network interface naming scheme.
For further details about the naming schemes for different device types and platforms, see the systemd.net-naming-scheme(7) man page on your system.
1.4. Switching to a different network interface naming scheme
By default, (RHEL) uses the rhel-8.0 naming scheme, even if you install or update to a later minor version of RHEL. Although the default naming scheme fits in most scenarios, there might be reasons to switch to a different scheme version.
Examples when you must change the naming scheme:
- A new scheme can help to better identify a device if it adds additional attributes, such as a slot number, to an interface name.
-
An new scheme can prevent
udevfrom falling back to the kernel-assigned device names (eth*). This happens if the driver does not provide enough unique attributes for two or more interfaces to generate unique names for them.
Prerequisites
- You have access to the console of the server.
Procedure
List the network interfaces:
# ip link show 2: eno1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP mode DEFAULT group default qlen 1000 link/ether 00:00:5e:00:53:1a brd ff:ff:ff:ff:ff:ff ...Record the MAC addresses of the interfaces.
Optional: Display the
ID_NET_NAMING_SCHEMEproperty of a network interface to identify the naming scheme that RHEL currently uses:# udevadm info --query=property /sys/class/net/eno1 | grep "ID_NET_NAMING_SCHEME" ID_NET_NAMING_SCHEME=rhel-8.0Note that the property is not available on the
loloopback device.Append the
net.naming-scheme=<scheme>option to the command line of all installed kernels, for example:# grubby --update-kernel=ALL --args=net.naming-scheme=rhel-8.4Reboot the system.
# rebootBased on the MAC addresses you recorded, identify the new names of network interfaces that have changed due to the different naming scheme:
# ip link show 2: eno1np0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP mode DEFAULT group default qlen 1000 link/ether 00:00:5e:00:53:1a brd ff:ff:ff:ff:ff:ff ...After switching the scheme,
udevnames the device with the specified MAC addresseno1np0, whereas it was namedeno1before.Identify which NetworkManager connection profile uses an interface with the previous name:
# nmcli -f device,name connection show DEVICE NAME eno1 example_profile ...Set the
connection.interface-nameproperty in the connection profile to the new interface name:# nmcli connection modify example_profile connection.interface-name "eno1np0"Reactivate the connection profile:
# nmcli connection up example_profile
Verification
Identify the naming scheme that RHEL now uses by displaying the
ID_NET_NAMING_SCHEMEproperty of a network interface:# udevadm info --query=property /sys/class/net/eno1np0 | grep "ID_NET_NAMING_SCHEME" ID_NET_NAMING_SCHEME=_rhel-8.4
1.5. Determining a predictable RoCE device name on the IBM Z platform
Before you can use a udev rule or a systemd link file to rename an interface manually, you must determine a predictable device name.
On Red Hat Enterprise Linux (RHEL) 8.7 and later, the udev device manager sets names for RoCE interfaces on IBM Z as follows:
-
If the host enforces a unique identifier (UID) for a device,
udevassigns a consistent device name that is based on the UID, for exampleeno<UID_in_decimal>. If the host does not enforce a UID for a device, the behavior depends on your settings:
-
By default,
udevuses unpredictable names for the device. -
If you set the
net.naming-scheme=rhel-8.7kernel command line option,udevassigns a consistent device name that is based on the function identifier (FID) of the device, for exampleens<FID_in_decimal>.
-
By default,
Manually configure predictable device name for RoCE interfaces on IBM Z in the following cases:
Your host runs RHEL 8.6 or earlier and enforces a UID for a device, and you plan to update to RHEL 8.7 or later.
After an update to RHEL 8.7 or later,
udevuses consistent interface names. However, if you used unpredictable device names before the update, NetworkManager connection profiles still use these names and fail to activate until you update the affected profiles.- Your host runs RHEL 8.7 or later and does not enforce a UID, and you plan to upgrade to RHEL 9.
Prerequisites
- An RoCE controller is installed in the system.
-
The
sysfsutilspackage is installed.
Procedure
Display the available network devices, and note the names of the RoCE devices:
# ip link show ... 2: enP5165p0s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP mode DEFAULT group default qlen 1000 ...Display the device path in the
/sys/file system:# systool -c net -p Class = "net" Class Device = "enP5165p0s0" Class Device path = "/sys/devices/pci142d:00/142d:00:00.0/net/enP5165p0s0" Device = "142d:00:00.0" Device path = "/sys/devices/pci142d:00/142d:00:00.0"Use the path shown in the
Device pathfield in the next steps.Display the value of the
<device_path>/uid_id_uniquefile, for example:# cat /sys/devices/pci142d:00/142d:00:00.0/uid_id_uniqueThe displayed value indicates whether UID uniqueness is enforced or not, and you require this value in later steps.
Determine a unique identifier:
If UID uniqueness is enforced (
1), display the UID stored in the<device_path>/uidfile, for example:# cat /sys/devices/pci142d:00/142d:00:00.0/uidIf UID uniqueness is not enforced (
0), display the FID stored in the<device_path>/function_idfile, for example:# cat /sys/devices/pci142d:00/142d:00:00.0/function_id
The outputs of the commands display the UID and FID values in hexadecimal.
Convert the hexadecimal identifier to decimal, for example:
# printf "%d\n" 0x00001402 5122To determine the predictable device name, append the identifier in decimal format to the corresponding prefix based on whether UID uniqueness is enforced or not:
-
If UID uniqueness is enforced, append the identifier to the
enoprefix, for exampleeno5122. -
If UID uniqueness is not enforced, append the identifier to the
ensprefix, for exampleens5122.
-
If UID uniqueness is enforced, append the identifier to the
Next steps
Use one of the following methods to rename the interface to the predictable name:
1.6. Customizing the prefix for Ethernet interfaces during installation
If you do not want to use the default device-naming policy for Ethernet interfaces, you can set a custom device prefix during the Red Hat Enterprise Linux (RHEL) installation.
Red Hat supports systems with customized Ethernet prefixes only if you set the prefix during the RHEL installation. Using the prefixdevname utility on already deployed systems is not supported.
If you set a device prefix during the installation, the udev service uses the <prefix><index> format for Ethernet interfaces after the installation. For example, if you set the prefix net, the service assigns the names net0, net1, and so on to the Ethernet interfaces.
The udev service appends the index to the custom prefix, and preserves the index values of known Ethernet interfaces. If you add an interface, udev assigns an index value that is one greater than the previously-assigned index value to the new interface.
Prerequisites
- The prefix consists of ASCII characters.
- The prefix is an alphanumeric string.
- The prefix is shorter than 16 characters.
-
The prefix does not conflict with any other well-known network interface prefix, such as
eth,eno,ens, andem.
Procedure
- Boot the Red Hat Enterprise Linux installation media.
In the boot manager, follow these steps:
-
Select the
Install Red Hat Enterprise Linux <version>entry. - Press Tab to edit the entry.
-
Append
net.ifnames.prefix=<prefix>to the kernel options. - Press Enter to start the installation program.
-
Select the
- Install Red Hat Enterprise Linux.
Verification
To verify the interface names, display the network interfaces:
# ip link show ... 2: net0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP mode DEFAULT group default qlen 1000 link/ether 00:00:5e:00:53:1a brd ff:ff:ff:ff:ff:ff ...
1.7. Configuring user-defined network interface names by using udev rules
You can use udev rules to implement custom network interface names that reflect your organization’s requirements.
Procedure
Identify the network interface that you want to rename:
# ip link show ... enp1s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP mode DEFAULT group default qlen 1000 link/ether 00:00:5e:00:53:1a brd ff:ff:ff:ff:ff:ff ...Record the MAC address of the interface.
Display the device type ID of the interface:
# cat /sys/class/net/enp1s0/type 1Create the
/etc/udev/rules.d/70-persistent-net.rulesfile, and add a rule for each interface that you want to rename:SUBSYSTEM=="net",ACTION=="add",ATTR{address}=="<MAC_address>",ATTR{type}=="<device_type_id>",NAME="<new_interface_name>"ImportantUse only
70-persistent-net.rulesas a file name if you require consistent device names during the boot process. Thedracututility adds a file with this name to theinitrdimage if you regenerate the RAM disk image.For example, use the following rule to rename the interface with MAC address
00:00:5e:00:53:1atoprovider0:SUBSYSTEM=="net",ACTION=="add",ATTR{address}=="00:00:5e:00:53:1a",ATTR{type}=="1",NAME="provider0"Optional: Regenerate the
initrdRAM disk image:# dracut -fYou require this step only if you need networking capabilities in the RAM disk. For example, this is the case if the root file system is stored on a network device, such as iSCSI.
Identify which NetworkManager connection profile uses the interface that you want to rename:
# nmcli -f device,name connection show DEVICE NAME enp1s0 example_profile ...Unset the
connection.interface-nameproperty in the connection profile:# nmcli connection modify example_profile connection.interface-name ""Temporarily, configure the connection profile to match both the new and the previous interface name:
# nmcli connection modify example_profile match.interface-name "provider0 enp1s0"Reboot the system:
# rebootVerify that the device with the MAC address that you specified in the link file has been renamed to
provider0:# ip link show provider0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP mode DEFAULT group default qlen 1000 link/ether 00:00:5e:00:53:1a brd ff:ff:ff:ff:ff:ff ...Configure the connection profile to match only the new interface name:
# nmcli connection modify example_profile match.interface-name "provider0"You have now removed the old interface name from the connection profile.
Reactivate the connection profile:
# nmcli connection up example_profile
1.8. Configuring user-defined network interface names by using systemd link files
You can use systemd link files to implement custom network interface names that reflect your organization’s requirements.
Prerequisites
- You must meet one of these conditions: NetworkManager does not manage this interface, or the corresponding connection profile uses the keyfile format.
Procedure
Identify the network interface that you want to rename:
# ip link show ... enp1s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP mode DEFAULT group default qlen 1000 link/ether 00:00:5e:00:53:1a brd ff:ff:ff:ff:ff:ff ...Record the MAC address of the interface.
If it does not already exist, create the
/etc/systemd/network/directory:# mkdir -p /etc/systemd/network/For each interface that you want to rename, create a
70-*.linkfile in the/etc/systemd/network/directory with the following content:[Match] MACAddress=<MAC_address> [Link] Name=<new_interface_name>ImportantUse a file name with a
70-prefix to keep the file names consistent with theudevrules-based solution.For example, create the
/etc/systemd/network/70-provider0.linkfile with the following content to rename the interface with MAC address00:00:5e:00:53:1atoprovider0:[Match] MACAddress=00:00:5e:00:53:1a [Link] Name=provider0Optional: Regenerate the
initrdRAM disk image:# dracut -fYou require this step only if you need networking capabilities in the RAM disk. For example, this is the case if the root file system is stored on a network device, such as iSCSI.
Identify which NetworkManager connection profile uses the interface that you want to rename:
# nmcli -f device,name connection show DEVICE NAME enp1s0 example_profile ...Unset the
connection.interface-nameproperty in the connection profile:# nmcli connection modify example_profile connection.interface-name ""Temporarily, configure the connection profile to match both the new and the previous interface name:
# nmcli connection modify example_profile match.interface-name "provider0 enp1s0"Reboot the system:
# rebootVerify that the device with the MAC address that you specified in the link file has been renamed to
provider0:# ip link show provider0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP mode DEFAULT group default qlen 1000 link/ether 00:00:5e:00:53:1a brd ff:ff:ff:ff:ff:ff ...Configure the connection profile to match only the new interface name:
# nmcli connection modify example_profile match.interface-name "provider0"You have now removed the old interface name from the connection profile.
Reactivate the connection profile.
# nmcli connection up example_profile
1.9. Assigning alternative names to a network interface by using systemd link files
With alternative interface naming, the kernel can assign additional names to network interfaces. You can use these alternative names in the same way as the normal interface names in commands that require a network interface name.
Prerequisites
- You must use ASCII characters for the alternative name.
- The alternative name must be shorter than 128 characters.
Procedure
Display the network interface names and their MAC addresses:
# ip link show ... enp1s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP mode DEFAULT group default qlen 1000 link/ether 00:00:5e:00:53:1a brd ff:ff:ff:ff:ff:ff ...Record the MAC address of the interface to which you want to assign an alternative name.
If it does not already exist, create the
/etc/systemd/network/directory:# mkdir -p /etc/systemd/network/For each interface that must have an alternative name, create a copy of the
/usr/lib/systemd/network/99-default.linkfile with a unique name and.linksuffix in the/etc/systemd/network/directory, for example:# cp /usr/lib/systemd/network/99-default.link /etc/systemd/network/98-lan.linkModify the file you created in the previous step. Rewrite the
[Match]section as follows, and append theAlternativeNameentries to the[Link]section:[Match] MACAddress=<MAC_address> [Link] ... AlternativeName=<alternative_interface_name_1> AlternativeName=<alternative_interface_name_2> AlternativeName=<alternative_interface_name_n>For example, create the
/etc/systemd/network/70-altname.linkfile with the following content to assignprovideras an alternative name to the interface with MAC address00:00:5e:00:53:1a:[Match] MACAddress=00:00:5e:00:53:1a [Link] NamePolicy=kernel database onboard slot path AlternativeNamesPolicy=database onboard slot path MACAddressPolicy=persistent AlternativeName=providerRegenerate the
initrdRAM disk image:# dracut -fReboot the system:
# reboot
Verification
Use the alternative interface name. For example, display the IP address settings of the device with the alternative name
provider:# ip address show provider 2: enp1s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000 link/ether 00:00:5e:00:53:1a brd ff:ff:ff:ff:ff:ff altname provider ...
Chapter 2. Configuring an Ethernet connection
NetworkManager creates a connection profile for each Ethernet adapter that is installed in a host. By default, this profile uses DHCP for both IPv4 and IPv6 connections.
Modify this automatically-created profile or add a new one in the following cases:
- The network requires custom settings, such as a static IP address configuration.
- You require multiple profiles because the host roams among different networks.
Red Hat Enterprise Linux provides administrators different options to configure Ethernet connections. For example:
-
Use
nmclito configure connections on the command line. -
Use
nmtuito configure connections in a text-based user interface. -
Use the GNOME Settings menu or
nm-connection-editorapplication to configure connections in a graphical interface. -
Use
nmstatectlto configure connections through thenmstateAPI. - Use RHEL system roles to automate the configuration of connections on one or multiple hosts.
If you want to manually configure Ethernet connections on hosts running in the Microsoft Azure cloud, disable the cloud-init service or configure it to ignore the network settings retrieved from the cloud environment. Otherwise, cloud-init overrides on the next reboot the network settings that you have manually configured.
2.1. Configuring an Ethernet connection by using nmcli
If you connect a host to the network over Ethernet, you can manage the connection’s settings on the command line by using the nmcli utility.
Prerequisites
- A physical or virtual Ethernet Network Interface Controller (NIC) exists in the server’s configuration.
Procedure
List the NetworkManager connection profiles:
# nmcli connection show NAME UUID TYPE DEVICE Wired connection 1 a5eb6490-cc20-3668-81f8-0314a27f3f75 ethernet enp1s0By default, NetworkManager creates a profile for each NIC in the host. If you plan to connect this NIC only to a specific network, adapt the automatically-created profile. If you plan to connect this NIC to networks with different settings, create individual profiles for each network.
If you want to create an additional connection profile, enter:
# nmcli connection add con-name <connection-name> ifname <device-name> type ethernetSkip this step to modify an existing profile.
Optional: Rename the connection profile:
# nmcli connection modify "Wired connection 1" connection.id "Internal-LAN"On hosts with multiple profiles, a meaningful name makes it easier to identify the purpose of a profile.
Display the current settings of the connection profile:
# nmcli connection show Internal-LAN ... connection.interface-name: enp1s0 connection.autoconnect: yes ipv4.method: auto ipv6.method: auto ...Configure the IPv4 settings:
To use DHCP, enter:
# nmcli connection modify Internal-LAN ipv4.method autoSkip this step if
ipv4.methodis already set toauto(default).To set a static IPv4 address, network mask, default gateway, DNS servers, and search domain, enter:
# nmcli connection modify Internal-LAN ipv4.method manual ipv4.addresses 192.0.2.1/24 ipv4.gateway 192.0.2.254 ipv4.dns 192.0.2.200 ipv4.dns-search example.com
Configure the IPv6 settings:
To use stateless address autoconfiguration (SLAAC), enter:
# nmcli connection modify Internal-LAN ipv6.method autoSkip this step if
ipv6.methodis already set toauto(default).To set a static IPv6 address, network mask, default gateway, DNS servers, and search domain, enter:
# nmcli connection modify Internal-LAN ipv6.method manual ipv6.addresses 2001:db8:1::fffe/64 ipv6.gateway 2001:db8:1::fffe ipv6.dns 2001:db8:1::ffbb ipv6.dns-search example.com
To customize other settings in the profile, use the following command:
# nmcli connection modify <connection-name> <setting> <value>Enclose values with spaces or semicolons in quotes.
Activate the profile:
# nmcli connection up Internal-LAN
Verification
Display the IP settings of the NIC:
# ip address show enp1s0 2: enp1s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000 link/ether 52:54:00:17:b8:b6 brd ff:ff:ff:ff:ff:ff inet 192.0.2.1/24 brd 192.0.2.255 scope global noprefixroute enp1s0 valid_lft forever preferred_lft forever inet6 2001:db8:1::fffe/64 scope global noprefixroute valid_lft forever preferred_lft foreverDisplay the IPv4 default gateway:
# ip route show default default via 192.0.2.254 dev enp1s0 proto static metric 102Display the IPv6 default gateway:
# ip -6 route show default default via 2001:db8:1::fffe dev enp1s0 proto static metric 102 pref mediumDisplay the DNS settings:
# cat /etc/resolv.conf search example.com nameserver 192.0.2.200 nameserver 2001:db8:1::ffbbIf multiple connection profiles are active at the same time, the order of
nameserverentries depend on the DNS priority values in these profiles and the connection types.Use the
pingutility to verify that this host can send packets to other hosts:# ping <host-name-or-IP-address>
Troubleshooting
- Verify that the network cable is plugged-in to the host and a switch.
- Check whether the link failure exists only on this host or also on other hosts connected to the same switch.
- Verify that the network cable and the network interface are working as expected. Perform hardware diagnosis steps and replace defective cables and network interface cards.
- If the configuration on the disk does not match the configuration on the device, starting or restarting NetworkManager creates an in-memory connection that reflects the configuration of the device. For further details and how to avoid this problem, see the Red Hat Knowledgebase solution NetworkManager duplicates a connection after restart of NetworkManager service.
2.2. Configuring an Ethernet connection by using the nmcli interactive editor
If you connect a host to the network over Ethernet, you can manage the connection’s settings on the command line by using the nmcli utility.
Prerequisites
- A physical or virtual Ethernet Network Interface Controller (NIC) exists in the server’s configuration.
Procedure
List the NetworkManager connection profiles:
# nmcli connection show NAME UUID TYPE DEVICE Wired connection 1 a5eb6490-cc20-3668-81f8-0314a27f3f75 ethernet enp1s0By default, NetworkManager creates a profile for each NIC in the host. If you plan to connect this NIC only to a specific network, adapt the automatically-created profile. If you plan to connect this NIC to networks with different settings, create individual profiles for each network.
Start
nmcliin interactive mode:To create an additional connection profile, enter:
# nmcli connection edit type ethernet con-name "<connection-name>"To modify an existing connection profile, enter:
# nmcli connection edit con-name "<connection-name>"
Optional: Rename the connection profile:
nmcli> set connection.id Internal-LANOn hosts with multiple profiles, a meaningful name makes it easier to identify the purpose of a profile.
Do not use quotes to set an ID that contains spaces to avoid
nmclimaking the quotes part of the name. For example, to setExample Connectionas ID, enterset connection.id Example Connection.Display the current settings of the connection profile:
nmcli> print ... connection.interface-name: enp1s0 connection.autoconnect: yes ipv4.method: auto ipv6.method: auto ...If you create a new connection profile, set the network interface:
nmcli> set connection.interface-name enp1s0Configure the IPv4 settings:
To use DHCP, enter:
nmcli> set ipv4.method autoSkip this step if
ipv4.methodis already set toauto(default).To set a static IPv4 address, network mask, default gateway, DNS servers, and search domain, enter:
nmcli> ipv4.addresses 192.0.2.1/24 Do you also want to set 'ipv4.method' to 'manual'? [yes]: yes nmcli> ipv4.gateway 192.0.2.254 nmcli> ipv4.dns 192.0.2.200 nmcli> ipv4.dns-search example.com
Configure the IPv6 settings:
To use stateless address autoconfiguration (SLAAC), enter:
nmcli> set ipv6.method autoSkip this step if
ipv6.methodis already set toauto(default).To set a static IPv6 address, network mask, default gateway, DNS servers, and search domain, enter:
nmcli> ipv6.addresses 2001:db8:1::fffe/64 Do you also want to set 'ipv6.method' to 'manual'? [yes]: yes nmcli> ipv6.gateway 2001:db8:1::fffe nmcli> ipv6.dns 2001:db8:1::ffbb nmcli> ipv6.dns-search example.com
Save and activate the connection:
nmcli> save persistentLeave the interactive mode:
nmcli> quit
Verification
Display the IP settings of the NIC:
# ip address show enp1s0 2: enp1s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000 link/ether 52:54:00:17:b8:b6 brd ff:ff:ff:ff:ff:ff inet 192.0.2.1/24 brd 192.0.2.255 scope global noprefixroute enp1s0 valid_lft forever preferred_lft forever inet6 2001:db8:1::fffe/64 scope global noprefixroute valid_lft forever preferred_lft foreverDisplay the IPv4 default gateway:
# ip route show default default via 192.0.2.254 dev enp1s0 proto static metric 102Display the IPv6 default gateway:
# ip -6 route show default default via 2001:db8:1::fffe dev enp1s0 proto static metric 102 pref mediumDisplay the DNS settings:
# cat /etc/resolv.conf search example.com nameserver 192.0.2.200 nameserver 2001:db8:1::ffbbIf multiple connection profiles are active at the same time, the order of
nameserverentries depend on the DNS priority values in these profiles and the connection types.Use the
pingutility to verify that this host can send packets to other hosts:# ping <host-name-or-IP-address>
Troubleshooting
- Verify that the network cable is plugged-in to the host and a switch.
- Check whether the link failure exists only on this host or also on other hosts connected to the same switch.
- Verify that the network cable and the network interface are working as expected. Perform hardware diagnosis steps and replace defective cables and network interface cards.
- If the configuration on the disk does not match the configuration on the device, starting or restarting NetworkManager creates an in-memory connection that reflects the configuration of the device. For further details and how to avoid this problem, see the Red Hat Knowledgebase solution NetworkManager duplicates a connection after restart of NetworkManager service.
2.3. Configuring an Ethernet connection by using nmtui
If you connect a host to an Ethernet network, you can manage the connection’s settings in a text-based user interface. Use the nmtui application to create new profiles and to update existing ones on a host without a graphical interface.
In nmtui:
- Navigate by using the cursor keys.
- Press a button by selecting it and hitting Enter.
- Select and clear checkboxes by using Space.
- To return to the previous screen, use ESC.
Prerequisites
- A physical or virtual Ethernet Network Interface Controller (NIC) exists in the server’s configuration.
Procedure
If you do not know the network device name you want to use in the connection, display the available devices:
# nmcli device status DEVICE TYPE STATE CONNECTION enp1s0 ethernet unavailable -- ...Start
nmtui:# nmtui- Select Edit a connection, and press Enter.
Choose whether to add a new connection profile or to modify an existing one:
To create a new profile:
- Press Add.
- Select Ethernet from the list of network types, and press Enter.
- To modify an existing profile, select the profile from the list, and press Enter.
Optional: Update the name of the connection profile.
On hosts with multiple profiles, a meaningful name makes it easier to identify the purpose of a profile.
- If you create a new connection profile, enter the network device name into the Device field.
Depending on your environment, configure the IP address settings in the
IPv4 configurationandIPv6 configurationareas accordingly. For this, press the button next to these areas, and select:- Disabled, if this connection does not require an IP address.
- Automatic, if a DHCP server dynamically assigns an IP address to this NIC.
Manual, if the network requires static IP address settings. In this case, you must fill further fields:
- Press Show next to the protocol you want to configure to display additional fields.
Press Add next to Addresses, and enter the IP address and the subnet mask in Classless Inter-Domain Routing (CIDR) format.
If you do not specify a subnet mask, NetworkManager sets a
/32subnet mask for IPv4 addresses and/64for IPv6 addresses.- Enter the address of the default gateway.
- Press Add next to DNS servers, and enter the DNS server address.
- Press Add next to Search domains, and enter the DNS search domain.
Figure 2.1. Example of an Ethernet connection with static IP address settings
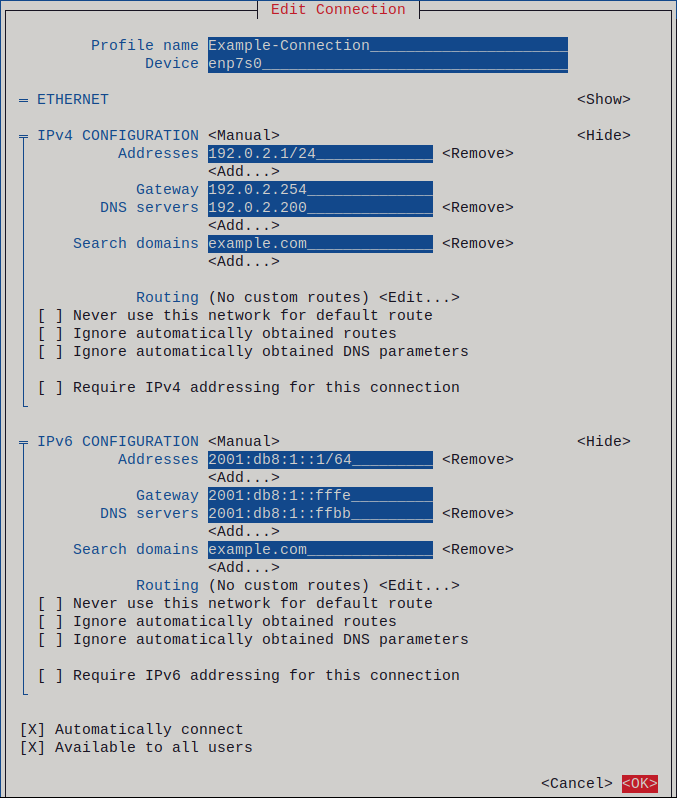
- Press OK to create and automatically activate the new connection.
- Press Back to return to the main menu.
-
Select Quit, and press Enter to close the
nmtuiapplication.
Verification
Display the IP settings of the NIC:
# ip address show enp1s0 2: enp1s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000 link/ether 52:54:00:17:b8:b6 brd ff:ff:ff:ff:ff:ff inet 192.0.2.1/24 brd 192.0.2.255 scope global noprefixroute enp1s0 valid_lft forever preferred_lft forever inet6 2001:db8:1::fffe/64 scope global noprefixroute valid_lft forever preferred_lft foreverDisplay the IPv4 default gateway:
# ip route show default default via 192.0.2.254 dev enp1s0 proto static metric 102Display the IPv6 default gateway:
# ip -6 route show default default via 2001:db8:1::fffe dev enp1s0 proto static metric 102 pref mediumDisplay the DNS settings:
# cat /etc/resolv.conf search example.com nameserver 192.0.2.200 nameserver 2001:db8:1::ffbbIf multiple connection profiles are active at the same time, the order of
nameserverentries depend on the DNS priority values in these profiles and the connection types.Use the
pingutility to verify that this host can send packets to other hosts:# ping <host-name-or-IP-address>
Troubleshooting
- Verify that the network cable is plugged-in to the host and a switch.
- Check whether the link failure exists only on this host or also on other hosts connected to the same switch.
- Verify that the network cable and the network interface are working as expected. Perform hardware diagnosis steps and replace defective cables and network interface cards.
- If the configuration on the disk does not match the configuration on the device, starting or restarting NetworkManager creates an in-memory connection that reflects the configuration of the device. For further details and how to avoid this problem, see the Red Hat Knowledgebase solution NetworkManager duplicates a connection after restart of NetworkManager service.
2.4. Configuring an Ethernet connection by using control-center
If you connect a host to the network over Ethernet, you can manage the connection’s settings with a graphical interface by using the GNOME Settings menu.
Note that control-center does not support as many configuration options as the nm-connection-editor application or the nmcli utility.
Prerequisites
- A physical or virtual Ethernet Network Interface Controller (NIC) exists in the server’s configuration.
- GNOME is installed.
Procedure
-
Press the Super key, enter
Settings, and press Enter. - Select Network in the navigation on the left.
Choose whether to add a new connection profile or to modify an existing one:
- To create a new profile, click the button next to the Ethernet entry.
- To modify an existing profile, click the gear icon next to the profile entry.
Optional: On the Identity tab, update the name of the connection profile.
On hosts with multiple profiles, a meaningful name makes it easier to identify the purpose of a profile.
Depending on your environment, configure the IP address settings on the IPv4 and IPv6 tabs accordingly:
-
To use DHCP or IPv6 stateless address autoconfiguration (SLAAC), select
Automatic (DHCP)as method (default). To set a static IP address, network mask, default gateway, DNS servers, and search domain, select
Manualas method, and fill the fields on the tabs: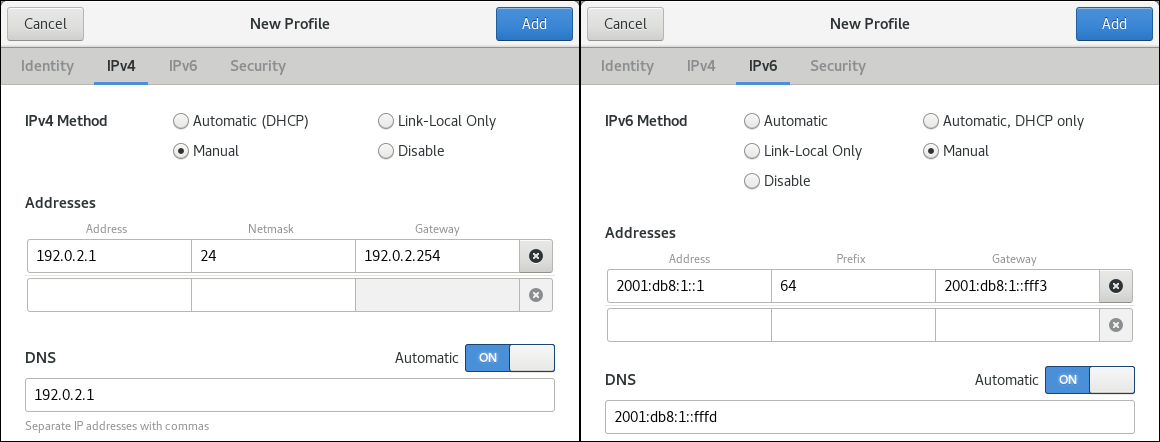
-
To use DHCP or IPv6 stateless address autoconfiguration (SLAAC), select
Depending on whether you add or modify a connection profile, click the or button to save the connection.
The GNOME
control-centerautomatically activates the connection.
Verification
Display the IP settings of the NIC:
# ip address show enp1s0 2: enp1s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000 link/ether 52:54:00:17:b8:b6 brd ff:ff:ff:ff:ff:ff inet 192.0.2.1/24 brd 192.0.2.255 scope global noprefixroute enp1s0 valid_lft forever preferred_lft forever inet6 2001:db8:1::fffe/64 scope global noprefixroute valid_lft forever preferred_lft foreverDisplay the IPv4 default gateway:
# ip route show default default via 192.0.2.254 dev enp1s0 proto static metric 102Display the IPv6 default gateway:
# ip -6 route show default default via 2001:db8:1::fffe dev enp1s0 proto static metric 102 pref mediumDisplay the DNS settings:
# cat /etc/resolv.conf search example.com nameserver 192.0.2.200 nameserver 2001:db8:1::ffbbIf multiple connection profiles are active at the same time, the order of
nameserverentries depend on the DNS priority values in these profiles and the connection types.Use the
pingutility to verify that this host can send packets to other hosts:# ping <host-name-or-IP-address>
Troubleshooting steps
- Verify that the network cable is plugged-in to the host and a switch.
- Check whether the link failure exists only on this host or also on other hosts connected to the same switch.
- Verify that the network cable and the network interface are working as expected. Perform hardware diagnosis steps and replace defective cables and network interface cards.
- If the configuration on the disk does not match the configuration on the device, starting or restarting NetworkManager creates an in-memory connection that reflects the configuration of the device. For further details and how to avoid this problem, see the Red Hat Knowledgebase solution NetworkManager duplicates a connection after restart of NetworkManager service.
2.5. Configuring an Ethernet connection by using nm-connection-editor
If you connect a host to the network over Ethernet, you can manage the connection’s settings with a graphical interface by using the nm-connection-editor application.
Prerequisites
- A physical or virtual Ethernet Network Interface Controller (NIC) exists in the server’s configuration.
- GNOME is installed.
Procedure
Open a console, and enter:
$ nm-connection-editorChoose whether to add a new connection profile or to modify an existing one:
To create a new profile:
- Click the button
- Select Ethernet as connection type, and click .
- To modify an existing profile, double-click the profile entry.
Optional: Update the name of the profile in the Connection Name field.
On hosts with multiple profiles, a meaningful name makes it easier to identify the purpose of a profile.
-
If you create a new profile, select the device on the
Ethernettab. Depending on your environment, configure the IP address settings on the IPv4 Settings and IPv6 Settings tabs accordingly:
-
To use DHCP or IPv6 stateless address autoconfiguration (SLAAC), select
Automatic (DHCP)as method (default). To set a static IP address, network mask, default gateway, DNS servers, and search domain, select
Manualas method, and fill the fields on the tabs: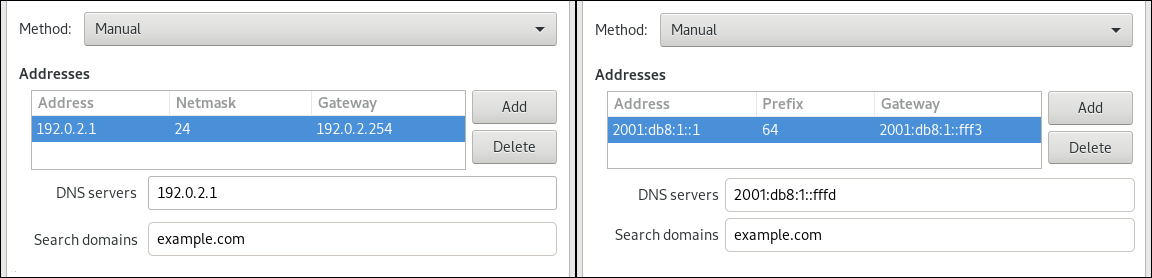
-
To use DHCP or IPv6 stateless address autoconfiguration (SLAAC), select
- Click .
- Close nm-connection-editor.
Verification
Display the IP settings of the NIC:
# ip address show enp1s0 2: enp1s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000 link/ether 52:54:00:17:b8:b6 brd ff:ff:ff:ff:ff:ff inet 192.0.2.1/24 brd 192.0.2.255 scope global noprefixroute enp1s0 valid_lft forever preferred_lft forever inet6 2001:db8:1::fffe/64 scope global noprefixroute valid_lft forever preferred_lft foreverDisplay the IPv4 default gateway:
# ip route show default default via 192.0.2.254 dev enp1s0 proto static metric 102Display the IPv6 default gateway:
# ip -6 route show default default via 2001:db8:1::fffe dev enp1s0 proto static metric 102 pref mediumDisplay the DNS settings:
# cat /etc/resolv.conf search example.com nameserver 192.0.2.200 nameserver 2001:db8:1::ffbbIf multiple connection profiles are active at the same time, the order of
nameserverentries depend on the DNS priority values in these profiles and the connection types.Use the
pingutility to verify that this host can send packets to other hosts:# ping <host-name-or-IP-address>
Troubleshooting steps
- Verify that the network cable is plugged-in to the host and a switch.
- Check whether the link failure exists only on this host or also on other hosts connected to the same switch.
- Verify that the network cable and the network interface are working as expected. Perform hardware diagnosis steps and replace defective cables and network interface cards.
- If the configuration on the disk does not match the configuration on the device, starting or restarting NetworkManager creates an in-memory connection that reflects the configuration of the device. For further details and how to avoid this problem, see the Red Hat Knowledgebase solution NetworkManager duplicates a connection after restart of NetworkManager service.
2.6. Configuring an Ethernet connection with a static IP address by using nmstatectl with an interface name
You can use the declarative Nmstate API to configure an Ethernet connection with static IP addresses, gateways, and DNS settings, and assign them to a specified interface name. Nmstate ensures that the result matches the configuration file or rolls back the changes.
Prerequisites
- A physical or virtual Ethernet Network Interface Controller (NIC) exists in the server’s configuration.
-
The
nmstatepackage is installed.
Procedure
Create a YAML file, for example
~/create-ethernet-profile.yml, with the following content:--- interfaces: - name: enp1s0 type: ethernet state: up ipv4: enabled: true address: - ip: 192.0.2.1 prefix-length: 24 dhcp: false ipv6: enabled: true address: - ip: 2001:db8:1::1 prefix-length: 64 autoconf: false dhcp: false routes: config: - destination: 0.0.0.0/0 next-hop-address: 192.0.2.254 next-hop-interface: enp1s0 - destination: ::/0 next-hop-address: 2001:db8:1::fffe next-hop-interface: enp1s0 dns-resolver: config: search: - example.com server: - 192.0.2.200 - 2001:db8:1::ffbbThese settings define an Ethernet connection profile for the
enp1s0device with the following settings:-
A static IPv4 address -
192.0.2.1with the/24subnet mask -
A static IPv6 address -
2001:db8:1::1with the/64subnet mask -
An IPv4 default gateway -
192.0.2.254 -
An IPv6 default gateway -
2001:db8:1::fffe -
An IPv4 DNS server -
192.0.2.200 -
An IPv6 DNS server -
2001:db8:1::ffbb -
A DNS search domain -
example.com
-
A static IPv4 address -
Apply the settings to the system:
# nmstatectl apply ~/create-ethernet-profile.yml
Verification
Display the current state in YAML format:
# nmstatectl show enp1s0Display the IP settings of the NIC:
# ip address show enp1s0 2: enp1s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000 link/ether 52:54:00:17:b8:b6 brd ff:ff:ff:ff:ff:ff inet 192.0.2.1/24 brd 192.0.2.255 scope global noprefixroute enp1s0 valid_lft forever preferred_lft forever inet6 2001:db8:1::fffe/64 scope global noprefixroute valid_lft forever preferred_lft foreverDisplay the IPv4 default gateway:
# ip route show default default via 192.0.2.254 dev enp1s0 proto static metric 102Display the IPv6 default gateway:
# ip -6 route show default default via 2001:db8:1::fffe dev enp1s0 proto static metric 102 pref mediumDisplay the DNS settings:
# cat /etc/resolv.conf search example.com nameserver 192.0.2.200 nameserver 2001:db8:1::ffbbIf multiple connection profiles are active at the same time, the order of
nameserverentries depend on the DNS priority values in these profiles and the connection types.Use the
pingutility to verify that this host can send packets to other hosts:# ping <host-name-or-IP-address>
2.7. Configuring an Ethernet connection with a static IP address by using the network RHEL system role with an interface name
You can use the network RHEL system role to configure an Ethernet connection with static IP addresses, gateways, and DNS settings, and assign them to a specified interface name.
To connect a Red Hat Enterprise Linux host to an Ethernet network, create a NetworkManager connection profile for the network device. By using Ansible and the network RHEL system role, you can automate this process and remotely configure connection profiles on the hosts defined in a playbook.
Typically, administrators want to reuse a playbook and not maintain individual playbooks for each host to which Ansible assigns static IP addresses. In this case, you can use variables in the playbook and maintain the settings in the inventory. As a result, you need only one playbook to dynamically assign individual settings to multiple hosts.
Prerequisites
- You have prepared the control node and the managed nodes.
-
The account you use to connect to the managed nodes has
sudopermissions for these nodes. - A physical or virtual Ethernet device exists in the server configuration.
- The managed nodes use NetworkManager to configure the network.
Procedure
Edit the
~/inventoryfile, and append the host-specific settings to the host entries:managed-node-01.example.com interface=enp1s0 ip_v4=192.0.2.1/24 ip_v6=2001:db8:1::1/64 gateway_v4=192.0.2.254 gateway_v6=2001:db8:1::fffe managed-node-02.example.com interface=enp1s0 ip_v4=192.0.2.2/24 ip_v6=2001:db8:1::2/64 gateway_v4=192.0.2.254 gateway_v6=2001:db8:1::fffeCreate a playbook file, for example,
~/playbook.yml, with the following content:--- - name: Configure the network hosts: managed-node-01.example.com,managed-node-02.example.com tasks: - name: Ethernet connection profile with static IP address settings ansible.builtin.include_role: name: redhat.rhel_system_roles.network vars: network_connections: - name: "{{ interface }}" interface_name: "{{ interface }}" type: ethernet autoconnect: yes ip: address: - "{{ ip_v4 }}" - "{{ ip_v6 }}" gateway4: "{{ gateway_v4 }}" gateway6: "{{ gateway_v6 }}" dns: - 192.0.2.200 - 2001:db8:1::ffbb dns_search: - example.com state: upThis playbook reads certain values dynamically for each host from the inventory file and uses static values in the playbook for settings which are the same for all hosts.
For details about all variables used in the playbook, see the
/usr/share/ansible/roles/rhel-system-roles.network/README.mdfile on the control node.Validate the playbook syntax:
$ ansible-playbook --syntax-check ~/playbook.ymlNote that this command only validates the syntax and does not protect against a wrong but valid configuration.
Run the playbook:
$ ansible-playbook ~/playbook.yml
Verification
Query the Ansible facts of the managed node and verify the active network settings:
# ansible managed-node-01.example.com -m ansible.builtin.setup ... "ansible_default_ipv4": { "address": "192.0.2.1", "alias": "enp1s0", "broadcast": "192.0.2.255", "gateway": "192.0.2.254", "interface": "enp1s0", "macaddress": "52:54:00:17:b8:b6", "mtu": 1500, "netmask": "255.255.255.0", "network": "192.0.2.0", "prefix": "24", "type": "ether" }, "ansible_default_ipv6": { "address": "2001:db8:1::1", "gateway": "2001:db8:1::fffe", "interface": "enp1s0", "macaddress": "52:54:00:17:b8:b6", "mtu": 1500, "prefix": "64", "scope": "global", "type": "ether" }, ... "ansible_dns": { "nameservers": [ "192.0.2.1", "2001:db8:1::ffbb" ], "search": [ "example.com" ] }, ...
2.8. Configuring an Ethernet connection with a static IP address by using the network RHEL system role with a device path
You can use the network RHEL system role to configure an Ethernet connection with static IP addresses, gateways, and DNS settings, and assign them to a device based on its path instead of its name.
To connect a Red Hat Enterprise Linux host to an Ethernet network, create a NetworkManager connection profile for the network device. By using Ansible and the network RHEL system role, you can automate this process and remotely configure connection profiles on the hosts defined in a playbook.
Prerequisites
- You have prepared the control node and the managed nodes.
-
The account you use to connect to the managed nodes has
sudopermissions for these nodes. - A physical or virtual Ethernet device exists in the server’s configuration.
- The managed nodes use NetworkManager to configure the network.
-
You know the path of the device. You can display the device path by using the
udevadm info /sys/class/net/<device_name> | grep ID_PATH=command.
Procedure
Create a playbook file, for example,
~/playbook.yml, with the following content:--- - name: Configure the network hosts: managed-node-01.example.com tasks: - name: Ethernet connection profile with static IP address settings ansible.builtin.include_role: name: redhat.rhel_system_roles.network vars: network_connections: - name: example match: path: - pci-0000:00:0[1-3].0 - '&!pci-0000:00:02.0' type: ethernet autoconnect: yes ip: address: - 192.0.2.1/24 - 2001:db8:1::1/64 gateway4: 192.0.2.254 gateway6: 2001:db8:1::fffe dns: - 192.0.2.200 - 2001:db8:1::ffbb dns_search: - example.com state: upThe settings specified in the example playbook include the following:
match-
Defines that a condition must be met in order to apply the settings. You can only use this variable with the
pathoption. path-
Defines the persistent path of a device. You can set it as a fixed path or an expression. Its value can contain modifiers and wildcards. The example applies the settings to devices that match PCI ID
0000:00:0[1-3].0, but not0000:00:02.0.
For details about all variables used in the playbook, see the
/usr/share/ansible/roles/rhel-system-roles.network/README.mdfile on the control node.Validate the playbook syntax:
$ ansible-playbook --syntax-check ~/playbook.ymlNote that this command only validates the syntax and does not protect against a wrong but valid configuration.
Run the playbook:
$ ansible-playbook ~/playbook.yml
Verification
Query the Ansible facts of the managed node and verify the active network settings:
# ansible managed-node-01.example.com -m ansible.builtin.setup ... "ansible_default_ipv4": { "address": "192.0.2.1", "alias": "enp1s0", "broadcast": "192.0.2.255", "gateway": "192.0.2.254", "interface": "enp1s0", "macaddress": "52:54:00:17:b8:b6", "mtu": 1500, "netmask": "255.255.255.0", "network": "192.0.2.0", "prefix": "24", "type": "ether" }, "ansible_default_ipv6": { "address": "2001:db8:1::1", "gateway": "2001:db8:1::fffe", "interface": "enp1s0", "macaddress": "52:54:00:17:b8:b6", "mtu": 1500, "prefix": "64", "scope": "global", "type": "ether" }, ... "ansible_dns": { "nameservers": [ "192.0.2.1", "2001:db8:1::ffbb" ], "search": [ "example.com" ] }, ...
2.9. Configuring an Ethernet connection with a dynamic IP address by using nmstatectl with an interface name
You can use the declarative Nmstate API to configure an Ethernet connection with static IP addresses, gateways, and DNS settings, and assign the configuration to a device based on its PCI address. Nmstate ensures that the result matches the configuration file or rolls back the changes.
Prerequisites
- A physical or virtual Ethernet Network Interface Controller (NIC) exists in the server’s configuration.
- A DHCP server is available in the network.
-
The
nmstatepackage is installed.
Procedure
Create a YAML file, for example
~/create-ethernet-profile.yml, with the following content:--- interfaces: - name: enp1s0 type: ethernet state: up ipv4: enabled: true auto-dns: true auto-gateway: true auto-routes: true dhcp: true ipv6: enabled: true auto-dns: true auto-gateway: true auto-routes: true autoconf: true dhcp: trueThese settings define an Ethernet connection profile for the
enp1s0device. The connection retrieves IPv4 addresses, IPv6 addresses, default gateway, routes, DNS servers, and search domains from a DHCP server and IPv6 stateless address autoconfiguration (SLAAC).Apply the settings to the system:
# nmstatectl apply ~/create-ethernet-profile.yml
Verification
Display the current state in YAML format:
# nmstatectl show enp1s0Display the IP settings of the NIC:
# ip address show enp1s0 2: enp1s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000 link/ether 52:54:00:17:b8:b6 brd ff:ff:ff:ff:ff:ff inet 192.0.2.1/24 brd 192.0.2.255 scope global noprefixroute enp1s0 valid_lft forever preferred_lft forever inet6 2001:db8:1::fffe/64 scope global noprefixroute valid_lft forever preferred_lft foreverDisplay the IPv4 default gateway:
# ip route show default default via 192.0.2.254 dev enp1s0 proto static metric 102Display the IPv6 default gateway:
# ip -6 route show default default via 2001:db8:1::fffe dev enp1s0 proto static metric 102 pref mediumDisplay the DNS settings:
# cat /etc/resolv.conf search example.com nameserver 192.0.2.200 nameserver 2001:db8:1::ffbbIf multiple connection profiles are active at the same time, the order of
nameserverentries depend on the DNS priority values in these profiles and the connection types.Use the
pingutility to verify that this host can send packets to other hosts:# ping <host-name-or-IP-address>
2.10. Configuring an Ethernet connection with a dynamic IP address by using the network RHEL system role with an interface name
You can use the network RHEL system role to configure an Ethernet connection that retrieves its IP addresses, gateways, and DNS settings from a DHCP server and IPv6 stateless address autoconfiguration (SLAAC). With this role you can assign the connection profile to the specified interface name.
To connect a Red Hat Enterprise Linux host to an Ethernet network, create a NetworkManager connection profile for the network device. By using Ansible and the network RHEL system role, you can automate this process and remotely configure connection profiles on the hosts defined in a playbook.
Prerequisites
- You have prepared the control node and the managed nodes.
-
The account you use to connect to the managed nodes has
sudopermissions for these nodes. - A physical or virtual Ethernet device exists in the servers' configuration.
- A DHCP server and SLAAC are available in the network.
- The managed nodes use the NetworkManager service to configure the network.
Procedure
Create a playbook file, for example,
~/playbook.yml, with the following content:--- - name: Configure the network hosts: managed-node-01.example.com tasks: - name: Ethernet connection profile with dynamic IP address settings ansible.builtin.include_role: name: redhat.rhel_system_roles.network vars: network_connections: - name: enp1s0 interface_name: enp1s0 type: ethernet autoconnect: yes ip: dhcp4: yes auto6: yes state: upThe settings specified in the example playbook include the following:
dhcp4: yes- Enables automatic IPv4 address assignment from DHCP, PPP, or similar services.
auto6: yes-
Enables IPv6 auto-configuration. By default, NetworkManager uses Router Advertisements. If the router announces the
managedflag, NetworkManager requests an IPv6 address and prefix from a DHCPv6 server.
For details about all variables used in the playbook, see the
/usr/share/ansible/roles/rhel-system-roles.network/README.mdfile on the control node.Validate the playbook syntax:
$ ansible-playbook --syntax-check ~/playbook.ymlNote that this command only validates the syntax and does not protect against a wrong but valid configuration.
Run the playbook:
$ ansible-playbook ~/playbook.yml
Verification
Query the Ansible facts of the managed node and verify that the interface received IP addresses and DNS settings:
# ansible managed-node-01.example.com -m ansible.builtin.setup ... "ansible_default_ipv4": { "address": "192.0.2.1", "alias": "enp1s0", "broadcast": "192.0.2.255", "gateway": "192.0.2.254", "interface": "enp1s0", "macaddress": "52:54:00:17:b8:b6", "mtu": 1500, "netmask": "255.255.255.0", "network": "192.0.2.0", "prefix": "24", "type": "ether" }, "ansible_default_ipv6": { "address": "2001:db8:1::1", "gateway": "2001:db8:1::fffe", "interface": "enp1s0", "macaddress": "52:54:00:17:b8:b6", "mtu": 1500, "prefix": "64", "scope": "global", "type": "ether" }, ... "ansible_dns": { "nameservers": [ "192.0.2.1", "2001:db8:1::ffbb" ], "search": [ "example.com" ] }, ...
2.11. Configuring an Ethernet connection with a dynamic IP address by using the network RHEL system role with a device path
By using the network RHEL system role, you can configure an Ethernet connection to retrieve its IP addresses, gateways, and DNS settings from a DHCP server and IPv6 stateless address autoconfiguration (SLAAC). The role can assign the profile by the device’s path.
To connect a Red Hat Enterprise Linux host to an Ethernet network, create a NetworkManager connection profile for the network device. By using Ansible and the network RHEL system role, you can automate this process and remotely configure connection profiles on the hosts defined in a playbook.
Prerequisites
- You have prepared the control node and the managed nodes.
-
The account you use to connect to the managed nodes has
sudopermissions for these nodes. - A physical or virtual Ethernet device exists in the server’s configuration.
- A DHCP server and SLAAC are available in the network.
- The managed hosts use NetworkManager to configure the network.
-
You know the path of the device. You can display the device path by using the
udevadm info /sys/class/net/<device_name> | grep ID_PATH=command.
Procedure
Create a playbook file, for example,
~/playbook.yml, with the following content:--- - name: Configure the network hosts: managed-node-01.example.com tasks: - name: Ethernet connection profile with dynamic IP address settings ansible.builtin.include_role: name: redhat.rhel_system_roles.network vars: network_connections: - name: example match: path: - pci-0000:00:0[1-3].0 - '&!pci-0000:00:02.0' type: ethernet autoconnect: yes ip: dhcp4: yes auto6: yes state: upThe settings specified in the example playbook include the following:
match: path-
Defines that a condition must be met in order to apply the settings. You can only use this variable with the
pathoption. path: <path_and_expressions>-
Defines the persistent path of a device. You can set it as a fixed path or an expression. Its value can contain modifiers and wildcards. The example applies the settings to devices that match PCI ID
0000:00:0[1-3].0, but not0000:00:02.0. dhcp4: yes- Enables automatic IPv4 address assignment from DHCP, PPP, or similar services.
auto6: yes-
Enables IPv6 auto-configuration. By default, NetworkManager uses Router Advertisements. If the router announces the
managedflag, NetworkManager requests an IPv6 address and prefix from a DHCPv6 server.
For details about all variables used in the playbook, see the
/usr/share/ansible/roles/rhel-system-roles.network/README.mdfile on the control node.Validate the playbook syntax:
$ ansible-playbook --syntax-check ~/playbook.ymlNote that this command only validates the syntax and does not protect against a wrong but valid configuration.
Run the playbook:
$ ansible-playbook ~/playbook.yml
Verification
Query the Ansible facts of the managed node and verify that the interface received IP addresses and DNS settings:
# ansible managed-node-01.example.com -m ansible.builtin.setup ... "ansible_default_ipv4": { "address": "192.0.2.1", "alias": "enp1s0", "broadcast": "192.0.2.255", "gateway": "192.0.2.254", "interface": "enp1s0", "macaddress": "52:54:00:17:b8:b6", "mtu": 1500, "netmask": "255.255.255.0", "network": "192.0.2.0", "prefix": "24", "type": "ether" }, "ansible_default_ipv6": { "address": "2001:db8:1::1", "gateway": "2001:db8:1::fffe", "interface": "enp1s0", "macaddress": "52:54:00:17:b8:b6", "mtu": 1500, "prefix": "64", "scope": "global", "type": "ether" }, ... "ansible_dns": { "nameservers": [ "192.0.2.1", "2001:db8:1::ffbb" ], "search": [ "example.com" ] }, ...
2.12. Configuring multiple Ethernet interfaces by using a single connection profile by interface name
NetworkManager supports using wildcards for interface names in connection profiles. With this feature, you can create a single profile for multiple Ethernet interfaces, which is useful when a host roams between Ethernet networks with dynamic IP address assignment.
Prerequisites
- Multiple physical or virtual Ethernet devices exist in the server’s configuration.
- A DHCP server is available in the network.
- No connection profile exists on the host.
Procedure
Add a connection profile that applies to all interface names starting with
enp:# nmcli connection add con-name "Wired connection 1" connection.multi-connect multiple match.interface-name enp* type ethernet
Verification
Display all settings of the single connection profile:
# nmcli connection show "Wired connection 1" connection.id: Wired connection 1 ... connection.multi-connect: 3 (multiple) match.interface-name: enp* ...3indicates that the interface can be active multiple times at a particular moment. The connection profile uses all devices that match the pattern in thematch.interface-nameparameter and, therefore, the connection profiles have the same Universally Unique Identifier (UUID).Display the status of the connections:
# nmcli connection show NAME UUID TYPE DEVICE ... Wired connection 1 6f22402e-c0cc-49cf-b702-eaf0cd5ea7d1 ethernet enp7s0 Wired connection 1 6f22402e-c0cc-49cf-b702-eaf0cd5ea7d1 ethernet enp8s0 Wired connection 1 6f22402e-c0cc-49cf-b702-eaf0cd5ea7d1 ethernet enp9s0
Chapter 4. Configuring a NIC team
Network interface controller (NIC) teaming is a method to combine or aggregate physical and virtual network interfaces to provide a logical interface with higher throughput or redundancy. NIC teaming uses a small kernel module to implement fast handling of packet flows and a user-space service for other tasks. This way, NIC teaming is an easily extensible and scalable solution for load-balancing and redundancy requirements.
Red Hat Enterprise Linux provides administrators different options to configure team devices. For example:
-
Use
nmclito configure teams connections using the command line. - Use the RHEL web console to configure team connections using a web browser.
-
Use the
nm-connection-editorapplication to configure team connections in a graphical interface.
NIC teaming is deprecated in Red Hat Enterprise Linux 9. If you plan to upgrade your server to a future version of RHEL, consider using the kernel bonding driver as an alternative.
4.1. Understanding the default behavior of controller and port interfaces
Understanding the default behavior of NetworkManager when managing bond port interfaces helps you to troubleshoot problems more effectively.
Default behavior:
- Starting the controller interface does not automatically start the port interfaces.
- Starting a port interface always starts the controller interface.
- Stopping the controller interface also stops the port interface.
- A controller without ports can start static IP connections.
- A controller without ports waits for ports when starting DHCP connections.
- A controller with a DHCP connection waiting for ports completes when you add a port with a carrier.
- A controller with a DHCP connection waiting for ports continues waiting when you add a port without a carrier.
4.2. Understanding the teamd service, runners, and link-watchers
The team service, teamd, controls one instance of the team driver. This instance of the driver adds instances of a hardware device driver to form a team of network interfaces. The team driver presents a network interface, for example team0, to the kernel.
The teamd service implements the common logic to all methods of teaming. Those functions are unique to the different load sharing and backup methods, such as round-robin, and implemented by separate units of code referred to as runners. Administrators specify runners in JavaScript Object Notation (JSON) format, and the JSON code is compiled into an instance of teamd when the instance is created. Alternatively, when using NetworkManager, you can set the runner in the team.runner parameter, and NetworkManager auto-creates the corresponding JSON code.
The following runners are available:
-
broadcast: Transmits data over all ports. -
roundrobin: Transmits data over all ports in turn. -
activebackup: Transmits data over one port while the others are kept as a backup. -
loadbalance: Transmits data over all ports with active Tx load balancing and Berkeley Packet Filter (BPF)-based Tx port selectors. -
random: Transmits data on a randomly selected port. -
lacp: Implements the 802.3ad Link Aggregation Control Protocol (LACP).
The teamd services use a link watcher to monitor the state of subordinate devices. The following link-watchers are available:
-
ethtool: Thelibteamlibrary uses theethtoolutility to watch for link state changes. This is the default link-watcher. -
arp_ping: Thelibteamlibrary uses thearp_pingutility to monitor the presence of a far-end hardware address using Address Resolution Protocol (ARP). -
nsna_ping: On IPv6 connections, thelibteamlibrary uses the Neighbor Advertisement and Neighbor Solicitation features from the IPv6 Neighbor Discovery protocol to monitor the presence of a neighbor’s interface.
Each runner can use any link watcher, with the exception of lacp. This runner can only use the ethtool link watcher.
4.3. Configuring a NIC team by using nmcli
To configure a network interface controller (NIC) team on the command line, use the nmcli utility.
NIC teaming is deprecated in Red Hat Enterprise Linux 9. If you plan to upgrade your server to a future version of RHEL, consider using the kernel bonding driver as an alternative. For details, see Configuring a network bond.
Prerequisites
-
The
teamdandNetworkManager-teampackages are installed. - Two or more physical or virtual network devices are installed on the server.
- To use Ethernet devices as ports of the team, the physical or virtual Ethernet devices must be installed on the server and connected to a switch.
To use bond, bridge, or Virtual Local Area Network (VLAN) devices as ports of the team, you can either create these devices while you create the team or you can create them in advance as described in:
Procedure
Create a team interface:
# nmcli connection add type team con-name team0 ifname team0 team.runner activebackupThis command creates a NIC team named
team0that uses theactivebackuprunner.Optional: Set a link watcher. For example, to set the
ethtoollink watcher in theteam0connection profile:# nmcli connection modify team0 team.link-watchers "name=ethtool"Link watchers support different parameters. To set parameters for a link watcher, specify them space-separated in the
nameproperty. Note that the name property must be surrounded by quotation marks. For example, to use theethtoollink watcher and set itsdelay-upparameter to2500milliseconds (2.5 seconds):# nmcli connection modify team0 team.link-watchers "name=ethtool delay-up=2500"To set multiple link watchers and each of them with specific parameters, the link watchers must be separated by a comma. The following example sets the
ethtoollink watcher with thedelay-upparameter and thearp_pinglink watcher with thesource-hostandtarget-hostparameter:# nmcli connection modify team0 team.link-watchers "name=ethtool delay-up=2, name=arp_ping source-host=192.0.2.1 target-host=192.0.2.2"Display the network interfaces, and note the names of the interfaces you want to add to the team:
# nmcli device status DEVICE TYPE STATE CONNECTION enp7s0 ethernet disconnected -- enp8s0 ethernet disconnected -- bond0 bond connected bond0 bond1 bond connected bond1 ...In this example:
-
enp7s0andenp8s0are not configured. To use these devices as ports, add connection profiles in the next step. Note that you can only use Ethernet interfaces in a team that are not assigned to any connection. -
bond0andbond1have existing connection profiles. To use these devices as ports, modify their profiles in the next step.
-
Assign the port interfaces to the team:
If the interfaces you want to assign to the team are not configured, create new connection profiles for them:
# nmcli connection add type ethernet slave-type team con-name team0-port1 ifname enp7s0 master team0 # nmcli connection add type ethernet slave--type team con-name team0-port2 ifname enp8s0 master team0These commands create profiles for
enp7s0andenp8s0, and add them to theteam0connection.To assign an existing connection profile to the team:
Set the
masterparameter of these connections toteam0:# nmcli connection modify bond0 master team0 # nmcli connection modify bond1 master team0These commands assign the existing connection profiles named
bond0andbond1to theteam0connection.Reactivate the connections:
# nmcli connection up bond0 # nmcli connection up bond1
Configure the IPv4 settings:
To set a static IPv4 address, network mask, default gateway, and DNS server to the
team0connection, enter:# nmcli connection modify team0 ipv4.addresses '192.0.2.1/24' ipv4.gateway '192.0.2.254' ipv4.dns '192.0.2.253' ipv4.dns-search 'example.com' ipv4.method manual- To use DHCP, no action is required.
- If you plan to use this team device as a port of other devices, no action is required.
Configure the IPv6 settings:
To set a static IPv6 address, network mask, default gateway, and DNS server to the
team0connection, enter:# nmcli connection modify team0 ipv6.addresses '2001:db8:1::1/64' ipv6.gateway '2001:db8:1::fffe' ipv6.dns '2001:db8:1::fffd' ipv6.dns-search 'example.com' ipv6.method manual- If you plan to use this team device as a port of other devices, no action is required.
- To use stateless address autoconfiguration (SLAAC), no action is required.
Activate the connection:
# nmcli connection up team0
Verification
Display the status of the team:
# teamdctl team0 state setup: runner: activebackup ports: enp7s0 link watches: link summary: up instance[link_watch_0]: name: ethtool link: up down count: 0 enp8s0 link watches: link summary: up instance[link_watch_0]: name: ethtool link: up down count: 0 runner: active port: enp7s0In this example, both ports are up.
4.4. Configuring a NIC team by using the RHEL web console
Use the RHEL web console to configure a network interface controller (NIC) team if you prefer to manage network settings using a web browser-based interface.
NIC teaming is deprecated in Red Hat Enterprise Linux 9. If you plan to upgrade your server to a future version of RHEL, consider using the kernel bonding driver as an alternative. For details, see Configuring a network bond.
Prerequisites
-
The
teamdandNetworkManager-teampackages are installed. - Two or more physical or virtual network devices are installed on the server.
- To use Ethernet devices as ports of the team, the physical or virtual Ethernet devices must be installed on the server and connected to a switch.
To use bond, bridge, or Virtual Local Area Network (VLAN) devices as ports of the team, create them in advance as described in:
- You have installed the RHEL 8 web console.
- You have enabled the cockpit service.
Your user account is allowed to log in to the web console.
For instructions, see Installing and enabling the web console.
Procedure
Log in to the RHEL 8 web console.
For details, see Logging in to the web console.
-
Select the
Networkingtab in the navigation on the left side of the screen. -
Click in the
Interfacessection. - Enter the name of the team device you want to create.
- Select the interfaces that should be ports of the team.
Select the runner of the team.
If you select
Load balancingor802.3ad LACP, the web console shows the additional fieldBalancer.Set the link watcher:
-
If you select
Ethtool, additionally, set a link up and link down delay. -
If you set
ARP pingorNSNA ping, additionally, set a ping interval and ping target.
-
If you select
- Click .
By default, the team uses a dynamic IP address. If you want to set a static IP address:
-
Click the name of the team in the
Interfacessection. -
Click
Editnext to the protocol you want to configure. -
Select
Manualnext toAddresses, and enter the IP address, prefix, and default gateway. -
In the
DNSsection, click the button, and enter the IP address of the DNS server. Repeat this step to set multiple DNS servers. -
In the
DNS search domainssection, click the button, and enter the search domain. -
If the interface requires static routes, configure them in the
Routessection. - Click
-
Click the name of the team in the
Verification
-
Select the
Networkingtab in the navigation on the left side of the screen, and check if there is incoming and outgoing traffic on the interface. Display the status of the team:
# teamdctl team0 state setup: runner: activebackup ports: enp7s0 link watches: link summary: up instance[link_watch_0]: name: ethtool link: up down count: 0 enp8s0 link watches: link summary: up instance[link_watch_0]: name: ethtool link: up down count: 0 runner: active port: enp7s0In this example, both ports are up.
4.5. Configuring a NIC team by using nm-connection-editor
If you use Red Hat Enterprise Linux with a graphical interface, you can configure network interface controller (NIC) teams using the nm-connection-editor application.
Note that nm-connection-editor can add only new ports to a team. To use an existing connection profile as a port, create the team using the nmcli utility as described in Configuring a NIC team by using nmcli.
NIC teaming is deprecated in Red Hat Enterprise Linux 9. If you plan to upgrade your server to a future version of RHEL, consider using the kernel bonding driver as an alternative. For details, see Configuring a network bond.
Prerequisites
-
The
teamdandNetworkManager-teampackages are installed. - Two or more physical or virtual network devices are installed on the server.
- To use Ethernet devices as ports of the team, the physical or virtual Ethernet devices must be installed on the server.
- To use team, bond, or Virtual Local Area Network (VLAN) devices as ports of the team, ensure that these devices are not already configured.
Procedure
Open a console, and enter
nm-connection-editor:$ nm-connection-editor- Click the button to add a new connection.
- Select the Team connection type, and click .
On the Team tab:
- Optional: Set the name of the team interface in the Interface name field.
Click the button to add a new connection profile for a network interface and add the profile as a port to the team.
- Select the connection type of the interface. For example, select Ethernet for a wired connection.
- Optional: Set a connection name for the port.
- If you create a connection profile for an Ethernet device, open the Ethernet tab, and select in the Device field the network interface you want to add as a port to the team. If you selected a different device type, configure it accordingly. Note that you can only use Ethernet interfaces in a team that are not assigned to any connection.
- Click .
- Repeat the previous step for each interface you want to add to the team.
Click the button to set advanced options to the team connection.
- On the Runner tab, select the runner.
- On the Link Watcher tab, set the link watcher and its optional settings.
- Click .
Configure the IP address settings on both the IPv4 Settings and IPv6 Settings tabs:
- If you plan to use this bridge device as a port of other devices, set the Method field to Disabled.
- To use DHCP, leave the Method field at its default, Automatic (DHCP).
To use static IP settings, set the Method field to Manual and fill the fields accordingly:

- Click .
-
Close
nm-connection-editor.
Verification
Display the status of the team:
# teamdctl team0 state setup: runner: activebackup ports: enp7s0 link watches: link summary: up instance[link_watch_0]: name: ethtool link: up down count: 0 enp8s0 link watches: link summary: up instance[link_watch_0]: name: ethtool link: up down count: 0 runner: active port: enp7s0
Chapter 5. Configuring VLAN tagging
A Virtual Local Area Network (VLAN) is a logical network within a physical network. The VLAN interface tags packets with the VLAN ID as they pass through the interface, and removes tags of returning packets.
You create VLAN interfaces on top of another interface, such as Ethernet, bond, or bridge devices. These interfaces are called the parent interface.
Red Hat Enterprise Linux provides administrators different options to configure VLAN devices. For example:
-
Use
nmclito configure VLAN tagging using the command line. - Use the RHEL web console to configure VLAN tagging using a web browser.
-
Use
nmtuito configure VLAN tagging in a text-based user interface. -
Use the
nm-connection-editorapplication to configure connections in a graphical interface. -
Use
nmstatectlto configure connections through the Nmstate API. - Use RHEL system roles to automate the VLAN configuration on one or multiple hosts.
5.1. Configuring VLAN tagging by using nmcli
You can configure Virtual Local Area Network (VLAN) tagging on the command line using the nmcli utility.
Prerequisites
- The interface you plan to use as a parent to the virtual VLAN interface supports VLAN tags.
If you configure the VLAN on top of a bond interface:
- The ports of the bond are up.
-
The bond is not configured with the
fail_over_mac=followoption. A VLAN virtual device cannot change its MAC address to match the parent’s new MAC address. In such a case, the traffic would still be sent with the incorrect source MAC address. -
The bond is usually not expected to get IP addresses from a DHCP server or IPv6 auto-configuration. Ensure it by setting the
ipv4.method=disableandipv6.method=ignoreoptions while creating the bond. Otherwise, if DHCP or IPv6 auto-configuration fails after some time, the interface might be brought down.
- The switch, the host is connected to, is configured to support VLAN tags. For details, see the documentation of your switch.
Procedure
Display the network interfaces:
# nmcli device status DEVICE TYPE STATE CONNECTION enp1s0 ethernet disconnected enp1s0 bridge0 bridge connected bridge0 bond0 bond connected bond0 ...Create the VLAN interface. For example, to create a VLAN interface named
vlan10that usesenp1s0as its parent interface and that tags packets with VLAN ID10, enter:# nmcli connection add type vlan con-name vlan10 ifname vlan10 vlan.parent enp1s0 vlan.id 10Note that the VLAN must be within the range from
0to4094.By default, the VLAN connection inherits the maximum transmission unit (MTU) from the parent interface. If you require a different MTU value, enter:
# nmcli connection modify vlan10 ethernet.mtu 2000Configure the IPv4 settings:
To set a static IPv4 address, network mask, default gateway, and DNS server to the
vlan10connection, enter:# nmcli connection modify vlan10 ipv4.addresses '192.0.2.1/24' ipv4.gateway '192.0.2.254' ipv4.dns '192.0.2.253' ipv4.method manual- To use DHCP, no action is required.
- If you plan to use this VLAN device as a port of other devices, no action is required.
Configure the IPv6 settings:
To set a static IPv6 address, network mask, default gateway, and DNS server to the
vlan10connection, enter:# nmcli connection modify vlan10 ipv6.addresses '2001:db8:1::1/32' ipv6.gateway '2001:db8:1::fffe' ipv6.dns '2001:db8:1::fffd' ipv6.method manual- To use stateless address autoconfiguration (SLAAC), no action is required.
- If you plan to use this VLAN device as a port of other devices, no action is required.
Activate the connection:
# nmcli connection up vlan10
Verification
Verify the settings:
# ip -d addr show vlan10 4: vlan10@enp1s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000 link/ether 52:54:00:72:2f:6e brd ff:ff:ff:ff:ff:ff promiscuity 0 vlan protocol 802.1Q id 10 <REORDER_HDR> numtxqueues 1 numrxqueues 1 gso_max_size 65536 gso_max_segs 65535 inet 192.0.2.1/24 brd 192.0.2.255 scope global noprefixroute vlan10 valid_lft forever preferred_lft forever inet6 2001:db8:1::1/32 scope global noprefixroute valid_lft forever preferred_lft forever inet6 fe80::8dd7:9030:6f8e:89e6/64 scope link noprefixroute valid_lft forever preferred_lft forever
5.2. Configuring VLAN tagging by using the RHEL web console
You can configure VLAN tagging if you prefer to manage network settings using a web browser-based interface in the RHEL web console.
Prerequisites
- The interface you plan to use as a parent to the virtual VLAN interface supports VLAN tags.
If you configure the VLAN on top of a bond interface:
- The ports of the bond are up.
-
The bond is not configured with the
fail_over_mac=followoption. A VLAN virtual device cannot change its MAC address to match the parent’s new MAC address. In such a case, the traffic would still be sent with the incorrect source MAC address. - The bond is usually not expected to get IP addresses from a DHCP server or IPv6 auto-configuration. Ensure it by disabling the IPv4 and IPv6 protocol creating the bond. Otherwise, if DHCP or IPv6 auto-configuration fails after some time, the interface might be brought down.
- The switch, the host is connected to, is configured to support VLAN tags. For details, see the documentation of your switch.
- You have installed the RHEL 8 web console.
- You have enabled the cockpit service.
Your user account is allowed to log in to the web console.
For instructions, see Installing and enabling the web console.
Procedure
Log in to the RHEL 8 web console.
For details, see Logging in to the web console.
-
Select the
Networkingtab in the navigation on the left side of the screen. -
Click in the
Interfacessection. - Select the parent device.
- Enter the VLAN ID.
- Enter the name of the VLAN device or keep the automatically-generated name.
- Click .
By default, the VLAN device uses a dynamic IP address. If you want to set a static IP address:
-
Click the name of the VLAN device in the
Interfacessection. -
Click
Editnext to the protocol you want to configure. -
Select
Manualnext toAddresses, and enter the IP address, prefix, and default gateway. -
In the
DNSsection, click the button, and enter the IP address of the DNS server. Repeat this step to set multiple DNS servers. -
In the
DNS search domainssection, click the button, and enter the search domain. -
If the interface requires static routes, configure them in the
Routessection. - Click
-
Click the name of the VLAN device in the
Verification
-
Select the
Networkingtab in the navigation on the left side of the screen, and check if there is incoming and outgoing traffic on the interface.
5.3. Configuring VLAN tagging by using nmtui
The nmtui application provides a text-based user interface for NetworkManager. You can use nmtui to configure VLAN tagging on a host without a graphical interface.
In nmtui:
- Navigate by using the cursor keys.
- Press a button by selecting it and hitting Enter.
- Select and clear checkboxes by using Space.
- To return to the previous screen, use ESC.
Prerequisites
- The interface you plan to use as a parent to the virtual VLAN interface supports VLAN tags.
If you configure the VLAN on top of a bond interface:
- The ports of the bond are up.
-
The bond is not configured with the
fail_over_mac=followoption. A VLAN virtual device cannot change its MAC address to match the parent’s new MAC address. In such a case, the traffic would still be sent with the then incorrect source MAC address. -
The bond is usually not expected to get IP addresses from a DHCP server or IPv6 auto-configuration. Ensure it by setting the
ipv4.method=disableandipv6.method=ignoreoptions while creating the bond. Otherwise, if DHCP or IPv6 auto-configuration fails after some time, the interface might be brought down.
- The switch the host is connected to is configured to support VLAN tags. For details, see the documentation of your switch.
Procedure
If you do not know the network device name on which you want configure VLAN tagging, display the available devices:
# nmcli device status DEVICE TYPE STATE CONNECTION enp1s0 ethernet unavailable -- ...Start
nmtui:# nmtui- Select Edit a connection, and press Enter.
- Press Add.
- Select VLAN from the list of network types, and press Enter.
Optional: Enter a name for the NetworkManager profile to be created.
On hosts with multiple profiles, a meaningful name makes it easier to identify the purpose of a profile.
- Enter the VLAN device name to be created into the Device field.
- Enter the name of the device on which you want to configure VLAN tagging into the Parent field.
-
Enter the VLAN ID. The ID must be within the range from
0to4094. Depending on your environment, configure the IP address settings in the IPv4 configuration and IPv6 configuration areas accordingly. For this, press the button next to these areas, and select:
-
Disabled, if this VLAN device does not require an IP address or you want to use it as a port of other devices. -
Automatic, if a DHCP server or stateless address autoconfiguration (SLAAC) dynamically assigns an IP address to the VLAN device. Manual, if the network requires static IP address settings. In this case, you must fill further fields:- Press Show next to the protocol you want to configure to display additional fields.
Press Add next to Addresses, and enter the IP address and the subnet mask in Classless Inter-Domain Routing (CIDR) format.
If you do not specify a subnet mask, NetworkManager sets a
/32subnet mask for IPv4 addresses and/64for IPv6 addresses.- Enter the address of the default gateway.
- Press Add next to DNS servers, and enter the DNS server address.
- Press Add next to Search domains, and enter the DNS search domain.
-
- Press OK to create and automatically activate the new connection.
- Press Back to return to the main menu.
-
Select Quit, and press Enter to close the
nmtuiapplication.
Verification
Verify the settings:
# ip -d addr show vlan10 4: vlan10@enp1s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000 link/ether 52:54:00:72:2f:6e brd ff:ff:ff:ff:ff:ff promiscuity 0 vlan protocol 802.1Q id 10 <REORDER_HDR> numtxqueues 1 numrxqueues 1 gso_max_size 65536 gso_max_segs 65535 inet 192.0.2.1/24 brd 192.0.2.255 scope global noprefixroute vlan10 valid_lft forever preferred_lft forever inet6 2001:db8:1::1/32 scope global noprefixroute valid_lft forever preferred_lft forever inet6 fe80::8dd7:9030:6f8e:89e6/64 scope link noprefixroute valid_lft forever preferred_lft forever
5.4. Configuring VLAN tagging by using nm-connection-editor
You can configure Virtual Local Area Network (VLAN) tagging in a graphical interface using the nm-connection-editor application.
Prerequisites
- The interface you plan to use as a parent to the virtual VLAN interface supports VLAN tags.
If you configure the VLAN on top of a bond interface:
- The ports of the bond are up.
-
The bond is not configured with the
fail_over_mac=followoption. A VLAN virtual device cannot change its MAC address to match the parent’s new MAC address. In such a case, the traffic would still be sent with the incorrect source MAC address.
- The switch, the host is connected to, is configured to support VLAN tags. For details, see the documentation of your switch.
Procedure
Open a console, and enter
nm-connection-editor:$ nm-connection-editor- Click the button to add a new connection.
- Select the VLAN connection type, and click .
On the VLAN tab:
- Select the parent interface.
- Select the VLAN id. Note that the VLAN must be within the range from 0 to 4094.
- By default, the VLAN connection inherits the maximum transmission unit (MTU) from the parent interface. If you require a different MTU value, enter:
- Optional: Set the name of the VLAN interface and further VLAN-specific options.
Configure the IP address settings on both the IPv4 Settings and IPv6 Settings tabs:
- If you plan to use this bridge device as a port of other devices, set the Method field to Disabled.
- To use DHCP, leave the Method field at its default, Automatic (DHCP).
To use static IP settings, set the Method field to Manual and fill the fields accordingly:

- Click .
-
Close
nm-connection-editor.
Verification
Verify the settings:
# ip -d addr show vlan10 4: vlan10@enp1s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000 link/ether 52:54:00:d5:e0:fb brd ff:ff:ff:ff:ff:ff promiscuity 0 vlan protocol 802.1Q id 10 <REORDER_HDR> numtxqueues 1 numrxqueues 1 gso_max_size 65536 gso_max_segs 65535 inet 192.0.2.1/24 brd 192.0.2.255 scope global noprefixroute vlan10 valid_lft forever preferred_lft forever inet6 2001:db8:1::1/32 scope global noprefixroute valid_lft forever preferred_lft forever inet6 fe80::8dd7:9030:6f8e:89e6/64 scope link noprefixroute valid_lft forever preferred_lft forever
5.5. Configuring VLAN tagging by using nmstatectl
You can use the declarative Nmstate API to configure a Virtual Local Area Network VLAN. Nmstate ensures that the result matches the configuration file or rolls back the changes.
Depending on your environment, adjust the YAML file accordingly. For example, to use different devices than Ethernet adapters in the VLAN, adapt the base-iface attribute and type attributes of the ports you use in the VLAN.
Prerequisites
- To use Ethernet devices as ports in the VLAN, the physical or virtual Ethernet devices must be installed on the server.
-
The
nmstatepackage is installed.
Procedure
Create a YAML file, for example
~/create-vlan.yml, with the following content:--- interfaces: - name: vlan10 type: vlan state: up ipv4: enabled: true address: - ip: 192.0.2.1 prefix-length: 24 dhcp: false ipv6: enabled: true address: - ip: 2001:db8:1::1 prefix-length: 64 autoconf: false dhcp: false vlan: base-iface: enp1s0 id: 10 - name: enp1s0 type: ethernet state: up routes: config: - destination: 0.0.0.0/0 next-hop-address: 192.0.2.254 next-hop-interface: vlan10 - destination: ::/0 next-hop-address: 2001:db8:1::fffe next-hop-interface: vlan10 dns-resolver: config: search: - example.com server: - 192.0.2.200 - 2001:db8:1::ffbbThese settings define a VLAN with ID 10 that uses the
enp1s0device. As the child device, the VLAN connection has the following settings:-
A static IPv4 address -
192.0.2.1with the/24subnet mask -
A static IPv6 address -
2001:db8:1::1with the/64subnet mask -
An IPv4 default gateway -
192.0.2.254 -
An IPv6 default gateway -
2001:db8:1::fffe -
An IPv4 DNS server -
192.0.2.200 -
An IPv6 DNS server -
2001:db8:1::ffbb -
A DNS search domain -
example.com
-
A static IPv4 address -
Apply the settings to the system:
# nmstatectl apply ~/create-vlan.yml
Verification
Display the status of the devices and connections:
# nmcli device status DEVICE TYPE STATE CONNECTION vlan10 vlan connected vlan10Display all settings of the connection profile:
# nmcli connection show vlan10 connection.id: vlan10 connection.uuid: 1722970f-788e-4f81-bd7d-a86bf21c9df5 connection.stable-id: -- connection.type: vlan connection.interface-name: vlan10 ...Display the connection settings in YAML format:
# nmstatectl show vlan10
5.6. Configuring VLAN tagging by using the network RHEL system role
You can use the network RHEL system role to configure VLAN tagging and, if a connection profile for the VLAN’s parent device does not exist, the role can create it as well.
If your network uses Virtual Local Area Networks (VLANs) to separate network traffic into logical networks, create a NetworkManager connection profile to configure VLAN tagging. By using Ansible and the network RHEL system role, you can automate this process and remotely configure connection profiles on the hosts defined in a playbook.
If the VLAN device requires an IP address, default gateway, and DNS settings, configure them on the VLAN device and not on the parent device.
Prerequisites
- You have prepared the control node and the managed nodes.
-
The account you use to connect to the managed nodes has
sudopermissions for these nodes.
Procedure
Create a playbook file, for example,
~/playbook.yml, with the following content:--- - name: Configure the network hosts: managed-node-01.example.com tasks: - name: VLAN connection profile with Ethernet port ansible.builtin.include_role: name: redhat.rhel_system_roles.network vars: network_connections: # Ethernet profile - name: enp1s0 type: ethernet interface_name: enp1s0 autoconnect: yes state: up ip: dhcp4: no auto6: no # VLAN profile - name: enp1s0.10 type: vlan vlan: id: 10 ip: dhcp4: yes auto6: yes parent: enp1s0 state: upThe settings specified in the example playbook include the following:
type: <profile_type>- Sets the type of the profile to create. The example playbook creates two connection profiles: One for the parent Ethernet device and one for the VLAN device.
dhcp4: <value>-
If set to
yes, automatic IPv4 address assignment from DHCP, PPP, or similar services is enabled. Disable the IP address configuration on the parent device. auto6: <value>-
If set to
yes, IPv6 auto-configuration is enabled. In this case, by default, NetworkManager uses Router Advertisements and, if the router announces themanagedflag, NetworkManager requests an IPv6 address and prefix from a DHCPv6 server. Disable the IP address configuration on the parent device. parent: <parent_device>- Sets the parent device of the VLAN connection profile. In the example, the parent is the Ethernet interface.
For details about all variables used in the playbook, see the
/usr/share/ansible/roles/rhel-system-roles.network/README.mdfile on the control node.Validate the playbook syntax:
$ ansible-playbook --syntax-check ~/playbook.ymlNote that this command only validates the syntax and does not protect against a wrong but valid configuration.
Run the playbook:
$ ansible-playbook ~/playbook.yml
Verification
Verify the VLAN settings:
# ansible managed-node-01.example.com -m command -a 'ip -d addr show enp1s0.10' managed-node-01.example.com | CHANGED | rc=0 >> 4: vlan10@enp1s0.10: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000 link/ether 52:54:00:72:2f:6e brd ff:ff:ff:ff:ff:ff promiscuity 0 vlan protocol 802.1Q id 10 <REORDER_HDR> numtxqueues 1 numrxqueues 1 gso_max_size 65536 gso_max_segs 65535 ...
Chapter 6. Configuring a network bridge
A network bridge is a link-layer device that forwards traffic between networks by using a MAC address table. For example, you can use a software bridge to connect virtual machines to the same network as the host.
A bridge requires a network device in each network the bridge should connect. When you configure a bridge, the bridge is called controller and the devices it uses ports.
You can create bridges on different types of devices, such as:
- Physical and virtual Ethernet devices
- Network bonds
- Network teams
- Virtual Local Area Network (VLAN) devices
Due to the IEEE 802.11 standard which specifies the use of 3-address frames in Wi-Fi for the efficient use of airtime, you cannot configure a bridge over Wi-Fi networks operating in Ad-Hoc or Infrastructure modes.
6.1. Configuring a network bridge by using nmcli
To configure a network bridge on the command line, use the nmcli utility.
Prerequisites
- Two or more physical or virtual network devices are installed on the server.
- To use Ethernet devices as ports of the bridge, the physical or virtual Ethernet devices must be installed on the server.
To use team, bond, or Virtual Local Area Network (VLAN) devices as ports of the bridge, you can either create these devices while you create the bridge or you can create them in advance as described in:
Procedure
Create a bridge interface:
# nmcli connection add type bridge con-name bridge0 ifname bridge0This command creates a bridge named
bridge0.Display the network interfaces, and note the names of the interfaces you want to add to the bridge:
# nmcli device status DEVICE TYPE STATE CONNECTION enp7s0 ethernet disconnected -- enp8s0 ethernet disconnected -- bond0 bond connected bond0 bond1 bond connected bond1 ...In this example:
-
enp7s0andenp8s0are not configured. To use these devices as ports, add connection profiles in the next step. -
bond0andbond1have existing connection profiles. To use these devices as ports, modify their profiles in the next step.
-
Assign the interfaces to the bridge.
If the interfaces you want to assign to the bridge are not configured, create new connection profiles for them:
# nmcli connection add type ethernet slave-type bridge con-name bridge0-port1 ifname enp7s0 master bridge0 # nmcli connection add type ethernet slave-type bridge con-name bridge0-port2 ifname enp8s0 master bridge0These commands create profiles for
enp7s0andenp8s0, and add them to thebridge0connection.If you want to assign an existing connection profile to the bridge:
Set the
masterparameter of these connections tobridge0:# nmcli connection modify bond0 master bridge0 # nmcli connection modify bond1 master bridge0These commands assign the existing connection profiles named
bond0andbond1to thebridge0connection.Reactivate the connections:
# nmcli connection up bond0 # nmcli connection up bond1
Configure the IPv4 settings:
To set a static IPv4 address, network mask, default gateway, and DNS server to the
bridge0connection, enter:# nmcli connection modify bridge0 ipv4.addresses '192.0.2.1/24' ipv4.gateway '192.0.2.254' ipv4.dns '192.0.2.253' ipv4.dns-search 'example.com' ipv4.method manual- To use DHCP, no action is required.
- If you plan to use this bridge device as a port of other devices, no action is required.
Configure the IPv6 settings:
To set a static IPv6 address, network mask, default gateway, and DNS server to the
bridge0connection, enter:# nmcli connection modify bridge0 ipv6.addresses '2001:db8:1::1/64' ipv6.gateway '2001:db8:1::fffe' ipv6.dns '2001:db8:1::fffd' ipv6.dns-search 'example.com' ipv6.method manual- To use stateless address autoconfiguration (SLAAC), no action is required.
- If you plan to use this bridge device as a port of other devices, no action is required.
Optional: Configure further properties of the bridge. For example, to set the Spanning Tree Protocol (STP) priority of
bridge0to16384, enter:# nmcli connection modify bridge0 bridge.priority '16384'By default, STP is enabled.
Activate the connection:
# nmcli connection up bridge0Verify that the ports are connected, and the
CONNECTIONcolumn displays the port’s connection name:# nmcli device DEVICE TYPE STATE CONNECTION ... enp7s0 ethernet connected bridge0-port1 enp8s0 ethernet connected bridge0-port2When you activate any port of the connection, NetworkManager also activates the bridge, but not the other ports of it. You can configure that Red Hat Enterprise Linux enables all ports automatically when the bridge is enabled:
Enable the
connection.autoconnect-slavesparameter of the bridge connection:# nmcli connection modify bridge0 connection.autoconnect-slaves 1Reactivate the bridge:
# nmcli connection up bridge0
Verification
Use the
iputility to display the link status of Ethernet devices that are ports of a specific bridge:# ip link show master bridge0 3: enp7s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel master bridge0 state UP mode DEFAULT group default qlen 1000 link/ether 52:54:00:62:61:0e brd ff:ff:ff:ff:ff:ff 4: enp8s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel master bridge0 state UP mode DEFAULT group default qlen 1000 link/ether 52:54:00:9e:f1:ce brd ff:ff:ff:ff:ff:ffUse the
bridgeutility to display the status of Ethernet devices that are ports of any bridge device:# bridge link show 3: enp7s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 master bridge0 state forwarding priority 32 cost 100 4: enp8s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 master bridge0 state listening priority 32 cost 100 5: enp9s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 master bridge1 state forwarding priority 32 cost 100 6: enp11s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 master bridge1 state blocking priority 32 cost 100 ...To display the status for a specific Ethernet device, use the
bridge link show dev <ethernet_device_name>command.
6.2. Configuring a network bridge by using the RHEL web console
Use the RHEL web console to configure a network bridge if you prefer to manage network settings using a web browser-based interface.
Prerequisites
- Two or more physical or virtual network devices are installed on the server.
- To use Ethernet devices as ports of the bridge, the physical or virtual Ethernet devices must be installed on the server.
To use team, bond, or Virtual Local Area Network (VLAN) devices as ports of the bridge, you can either create these devices while you create the bridge or you can create them in advance as described in:
- You have installed the RHEL 8 web console.
- You have enabled the cockpit service.
Your user account is allowed to log in to the web console.
For instructions, see Installing and enabling the web console.
Procedure
Log in to the RHEL 8 web console.
For details, see Logging in to the web console.
- Select the Networking tab in the navigation on the left side of the screen.
- Click in the Interfaces section.
- Enter the name of the bridge device you want to create.
- Select the interfaces that should be ports of the bridge.
- Optional: Enable the Spanning tree protocol (STP) feature to avoid bridge loops and broadcast radiation.
- Click .
By default, the bridge uses a dynamic IP address. If you want to set a static IP address:
- Click the name of the bridge in the Interfaces section.
- Click Edit next to the protocol you want to configure.
- Select Manual next to Addresses, and enter the IP address, prefix, and default gateway.
- In the DNS section, click the button, and enter the IP address of the DNS server. Repeat this step to set multiple DNS servers.
- In the DNS search domains section, click the button, and enter the search domain.
- If the interface requires static routes, configure them in the Routes section.
- Click
Verification
- Select the Networking tab in the navigation on the left side of the screen, and check if there is incoming and outgoing traffic on the interface.
6.3. Configuring a network bridge by using nmtui
The nmtui application provides a text-based user interface for NetworkManager. You can use nmtui to configure a network bridge on a host without a graphical interface.
In nmtui:
- Navigate by using the cursor keys.
- Press a button by selecting it and hitting Enter.
- Select and clear checkboxes by using Space.
- To return to the previous screen, use ESC.
Prerequisites
- Two or more physical or virtual network devices are installed on the server.
- To use Ethernet devices as ports of the bridge, the physical or virtual Ethernet devices must be installed on the server.
Procedure
If you do not know the network device names on which you want configure a network bridge, display the available devices:
# nmcli device status DEVICE TYPE STATE CONNECTION enp7s0 ethernet unavailable -- enp8s0 ethernet unavailable -- ...Start
nmtui:# nmtui-
Select
Edit a connection, and press Enter. -
Press
Add. -
Select
Bridgefrom the list of network types, and press Enter. Optional: Enter a name for the NetworkManager profile to be created.
On hosts with multiple profiles, a meaningful name makes it easier to identify the purpose of a profile.
-
Enter the bridge device name to be created into the
Devicefield. Add ports to the bridge to be created:
-
Press
Addnext to theSlaveslist. -
Select the type of the interface you want to add as a port to the bridge, for example,
Ethernet. - Optional: Enter a name for the NetworkManager profile to be created for this bridge port.
-
Enter the port’s device name into the
Devicefield. -
Press
OKto return to the window with the bridge settings. - Repeat these steps to add more ports to the bridge.
-
Press
Depending on your environment, configure the IP address settings in the
IPv4 configurationandIPv6 configurationareas accordingly. For this, press the button next to these areas, and select:-
Disabled, if the bridge does not require an IP address. -
Automatic, if a DHCP server or stateless address autoconfiguration (SLAAC) dynamically assigns an IP address to the bridge. Manual, if the network requires static IP address settings. In this case, you must fill further fields:-
Press
Shownext to the protocol you want to configure to display additional fields. Press
Addnext toAddresses, and enter the IP address and the subnet mask in Classless Inter-Domain Routing (CIDR) format.If you do not specify a subnet mask, NetworkManager sets a
/32subnet mask for IPv4 addresses and/64for IPv6 addresses.- Enter the address of the default gateway.
-
Press
Addnext toDNS servers, and enter the DNS server address. -
Press
Addnext toSearch domains, and enter the DNS search domain.
-
Press
-
-
Press
OKto create and automatically activate the new connection. -
Press
Backto return to the main menu. -
Select
Quit, and press Enter to close thenmtuiapplication.
Verification
Use the
iputility to display the link status of Ethernet devices that are ports of a specific bridge:# ip link show master bridge0 3: enp7s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel master bridge0 state UP mode DEFAULT group default qlen 1000 link/ether 52:54:00:62:61:0e brd ff:ff:ff:ff:ff:ff 4: enp8s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel master bridge0 state UP mode DEFAULT group default qlen 1000 link/ether 52:54:00:9e:f1:ce brd ff:ff:ff:ff:ff:ffUse the
bridgeutility to display the status of Ethernet devices that are ports of any bridge device:# bridge link show 3: enp7s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 master bridge0 state forwarding priority 32 cost 100 4: enp8s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 master bridge0 state listening priority 32 cost 100 ...To display the status for a specific Ethernet device, use the
bridge link show dev <ethernet_device_name>command.
6.4. Configuring a network bridge by using nm-connection-editor
If you use Red Hat Enterprise Linux with a graphical interface, you can configure network bridges using the nm-connection-editor application.
Note that nm-connection-editor can add only new ports to a bridge. To use an existing connection profile as a port, create the bridge using the nmcli utility as described in Configuring a network bridge by using nmcli.
Prerequisites
- Two or more physical or virtual network devices are installed on the server.
- To use Ethernet devices as ports of the bridge, the physical or virtual Ethernet devices must be installed on the server.
- To use team, bond, or Virtual Local Area Network (VLAN) devices as ports of the bridge, ensure that these devices are not already configured.
Procedure
Open a console, and enter
nm-connection-editor:$ nm-connection-editor- Click the button to add a new connection.
- Select the Bridge connection type, and click .
On the Bridge tab:
- Optional: Set the name of the bridge interface in the Interface name field.
Click the button to create a new connection profile for a network interface and add the profile as a port to the bridge.
- Select the connection type of the interface. For example, select Ethernet for a wired connection.
- Optional: Set a connection name for the port device.
- If you create a connection profile for an Ethernet device, open the Ethernet tab, and select in the Device field the network interface you want to add as a port to the bridge. If you selected a different device type, configure it accordingly.
- Click .
- Repeat the previous step for each interface you want to add to the bridge.
- Optional: Configure further bridge settings, such as Spanning Tree Protocol (STP) options.
Configure the IP address settings on both the IPv4 Settings and IPv6 Settings tabs:
- If you plan to use this bridge device as a port of other devices, set the Method field to Disabled.
- To use DHCP, leave the Method field at its default, Automatic (DHCP).
To use static IP settings, set the Method field to Manual and fill the fields accordingly:
- Click .
-
Close
nm-connection-editor.
Verification
Use the
iputility to display the link status of Ethernet devices that are ports of a specific bridge.# ip link show master bridge0 3: enp7s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel master bridge0 state UP mode DEFAULT group default qlen 1000 link/ether 52:54:00:62:61:0e brd ff:ff:ff:ff:ff:ff 4: enp8s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel master bridge0 state UP mode DEFAULT group default qlen 1000 link/ether 52:54:00:9e:f1:ce brd ff:ff:ff:ff:ff:ffUse the
bridgeutility to display the status of Ethernet devices that are ports in any bridge device:# bridge link show 3: enp7s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 master bridge0 state forwarding priority 32 cost 100 4: enp8s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 master bridge0 state listening priority 32 cost 100 5: enp9s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 master bridge1 state forwarding priority 32 cost 100 6: enp11s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 master bridge1 state blocking priority 32 cost 100 ...To display the status for a specific Ethernet device, use the
bridge link show dev ethernet_device_namecommand.
6.5. Configuring a network bridge by using nmstatectl
You can use the declarative Nmstate API to configure a network bridge. Nmstate ensures that the result matches the configuration file or rolls back the changes.
Depending on your environment, adjust the YAML file accordingly. For example, to use different devices than Ethernet adapters in the bridge, adapt the base-iface attribute and type attributes of the ports you use in the bridge.
Prerequisites
- Two or more physical or virtual network devices are installed on the server.
- To use Ethernet devices as ports in the bridge, the physical or virtual Ethernet devices must be installed on the server.
-
To use team, bond, or Virtual Local Area Network (VLAN) devices as ports in the bridge, set the interface name in the
portlist, and define the corresponding interfaces. -
The
nmstatepackage is installed.
Procedure
Create a YAML file, for example
~/create-bridge.yml, with the following content:--- interfaces: - name: bridge0 type: linux-bridge state: up ipv4: enabled: true address: - ip: 192.0.2.1 prefix-length: 24 dhcp: false ipv6: enabled: true address: - ip: 2001:db8:1::1 prefix-length: 64 autoconf: false dhcp: false bridge: options: stp: enabled: true port: - name: enp1s0 - name: enp7s0 - name: enp1s0 type: ethernet state: up - name: enp7s0 type: ethernet state: up routes: config: - destination: 0.0.0.0/0 next-hop-address: 192.0.2.254 next-hop-interface: bridge0 - destination: ::/0 next-hop-address: 2001:db8:1::fffe next-hop-interface: bridge0 dns-resolver: config: search: - example.com server: - 192.0.2.200 - 2001:db8:1::ffbbThese settings define a network bridge with the following settings:
-
Network interfaces in the bridge:
enp1s0andenp7s0 - Spanning Tree Protocol (STP): Enabled
-
Static IPv4 address:
192.0.2.1with the/24subnet mask -
Static IPv6 address:
2001:db8:1::1with the/64subnet mask -
IPv4 default gateway:
192.0.2.254 -
IPv6 default gateway:
2001:db8:1::fffe -
IPv4 DNS server:
192.0.2.200 -
IPv6 DNS server:
2001:db8:1::ffbb -
DNS search domain:
example.com
-
Network interfaces in the bridge:
Apply the settings to the system:
# nmstatectl apply ~/create-bridge.yml
Verification
Display the status of the devices and connections:
# nmcli device status DEVICE TYPE STATE CONNECTION bridge0 bridge connected bridge0Display all settings of the connection profile:
# nmcli connection show bridge0 connection.id: bridge0_ connection.uuid: e2cc9206-75a2-4622-89cf-1252926060a9 connection.stable-id: -- connection.type: bridge connection.interface-name: bridge0 ...Display the connection settings in YAML format:
# nmstatectl show bridge0
6.6. Configuring a network bridge by using the network RHEL system role
You can use the network RHEL system role to configure a bridge and, if a connection profile for the bridge’s parent device does not exist, the role can create it as well.
You can connect multiple networks on layer 2 of the Open Systems Interconnection (OSI) model by creating a network bridge. To configure a bridge, create a connection profile in NetworkManager. By using Ansible and the network RHEL system role, you can automate this process and remotely configure connection profiles on the hosts defined in a playbook.
If you want to assign IP addresses, gateways, and DNS settings to a bridge, configure them on the bridge and not on its ports.
Prerequisites
- You have prepared the control node and the managed nodes.
-
The account you use to connect to the managed nodes has
sudopermissions for these nodes. - Two or more physical or virtual network devices are installed on the server.
Procedure
Create a playbook file, for example,
~/playbook.yml, with the following content:--- - name: Configure the network hosts: managed-node-01.example.com tasks: - name: Bridge connection profile with two Ethernet ports ansible.builtin.include_role: name: redhat.rhel_system_roles.network vars: network_connections: # Bridge profile - name: bridge0 type: bridge interface_name: bridge0 ip: dhcp4: yes auto6: yes state: up # Port profile for the 1st Ethernet device - name: bridge0-port1 interface_name: enp7s0 type: ethernet controller: bridge0 port_type: bridge state: up # Port profile for the 2nd Ethernet device - name: bridge0-port2 interface_name: enp8s0 type: ethernet controller: bridge0 port_type: bridge state: upThe settings specified in the example playbook include the following:
type: <profile_type>- Sets the type of the profile to create. The example playbook creates three connection profiles: One for the bridge and two for the Ethernet devices.
dhcp4: yes- Enables automatic IPv4 address assignment from DHCP, PPP, or similar services.
auto6: yes-
Enables IPv6 auto-configuration. By default, NetworkManager uses Router Advertisements. If the router announces the
managedflag, NetworkManager requests an IPv6 address and prefix from a DHCPv6 server.
For details about all variables used in the playbook, see the
/usr/share/ansible/roles/rhel-system-roles.network/README.mdfile on the control node.Validate the playbook syntax:
$ ansible-playbook --syntax-check ~/playbook.ymlNote that this command only validates the syntax and does not protect against a wrong but valid configuration.
Run the playbook:
$ ansible-playbook ~/playbook.yml
Verification
Display the link status of Ethernet devices that are ports of a specific bridge:
# ansible managed-node-01.example.com -m command -a 'ip link show master bridge0' managed-node-01.example.com | CHANGED | rc=0 >> 3: enp7s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel master bridge0 state UP mode DEFAULT group default qlen 1000 link/ether 52:54:00:62:61:0e brd ff:ff:ff:ff:ff:ff 4: enp8s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel master bridge0 state UP mode DEFAULT group default qlen 1000 link/ether 52:54:00:9e:f1:ce brd ff:ff:ff:ff:ff:ffDisplay the status of Ethernet devices that are ports of any bridge device:
# ansible managed-node-01.example.com -m command -a 'bridge link show' managed-node-01.example.com | CHANGED | rc=0 >> 3: enp7s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 master bridge0 state forwarding priority 32 cost 100 4: enp8s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 master bridge0 state listening priority 32 cost 100
Chapter 7. Setting up an IPsec VPN
Configure and manage a secure Virtual Private Network (VPN) by using the Libreswan implementation of the IPsec protocol suite to create encrypted tunnels for secure data transmission over the internet.
IPsec tunnels ensure the confidentiality and integrity of data in transit. Common use cases include connecting branch offices to headquarters or providing remote users with secure access to a corporate network.
RHEL provides different options to configure Libreswan:
- Manually edit the Libreswan configuration files for granular control over advanced options.
-
Use the
vpnRHEL system role to automate the process of creating Libreswan VPN configurations.
Libreswan does not use terms such as "client" and "server". Instead, IPsec refers to endpoints as "left" and "right". This design often enables you to use the same configuration on both hosts because Libreswan dynamically determines which role to adopt. As a convention, administrators typically use "left" for the local host and "right" for the remote host.
Libreswan is the only supported VPN technology in RHEL.
IPsec relies on standardized protocols, such as Internet Key Exchange (IKE), to ensure that different systems can communicate effectively. However, in practice, minor differences in how vendors implement these standards can lead to compatibility problems. If you encounter such interoperability issues when connecting Libreswan to a third-party IPsec peer, contact Red Hat Support.
7.1. Components in an IPsec VPN
Before setting up an IPsec VPN, it is important to understand its main components: Internet Key Exchange (IKE) for authentication and negotiation, and IPsec for data encryption and transport.
IKE is the protocol two endpoints use to authenticate each other and negotiate connection rules, including encryption algorithms. Libreswan implements IKE in a daemon called pluto.
IPsec is the part of the protocol that actually encrypts and transports data according to the policy agreed upon during the IKE negotiation. The Linux kernel implements the IPsec protocol suite.
7.2. Libreswan authentication methods
Select the appropriate authentication method to establish a secure VPN connection based on your security needs and network environment.
Libreswan supports the following authentication methods:
- Pre-Shared key
- The Pre-Shared Key (PSK) method involves both endpoints by using the same secret to authenticate each other. PSKs offer simplicity and broad compatibility, making them suitable for small-scale deployments. However, managing PSKs is risky if the key is reused or not rotated frequently. To maintain security, PSKs must consist of more than 64 random characters and must meet FIPS strength requirements if your host operates in FIPS mode.
- Raw RSA key
- This method uses an RSA public and private key pair on each peer for mutual identification. Raw RSA keys provide stronger security than PSKs and are ideal for environments where a full certificate infrastructure is not required.
- X.509 certificates
- This method uses X.509 certificates issued by a trusted Certificate Authority (CA). Each peer proves its identity by using its certificate and private key, which the other peer verifies against the trusted CA. Although providing the highest level of security and scalability for large enterprises, this method is more complex as it requires deploying and maintaining a public key infrastructure (PKI).
- NULL authentication
- This method provides only encryption with no authentication between peers. Because it does not verify the identity of the remote endpoint, NULL authentication is insecure and offers no protection against man-in-the-middle attacks.
- Protection against quantum computers
- Although not a standalone authentication method, Libreswan offers Post-quantum Pre-shared Keys (PPKs) to protect modern IKEv2 connections from future attacks by quantum computers. This feature is necessary because neither the older IKEv1 protocol nor standard IKEv2 is inherently quantum-resistant on its own. A PPK adds another layer of security on top of the primary authentication method, and its security relies on using a cryptographically strong key that has been distributed securely through an external communication channel.
7.3. Installing Libreswan
Before you can set a VPN through the Libreswan IPsec/IKE implementation, you must install the corresponding packages, start the ipsec service, and allow the service in your firewall.
Prerequisites
-
The
AppStreamrepository is enabled.
Procedure
Install the
libreswanpackages:# yum install libreswanIf you are re-installing Libreswan, remove its old database files and create a new database:
# systemctl stop ipsec # rm /etc/ipsec.d/*db # ipsec initnssStart the
ipsecservice, and enable the service to be started automatically on boot:# systemctl enable ipsec --nowConfigure the firewall to allow 500 and 4500/UDP ports for the IKE, ESP, and AH protocols by adding the
ipsecservice:# firewall-cmd --add-service="ipsec" # firewall-cmd --runtime-to-permanent
7.4. Creating a host-to-host VPN
You can configure Libreswan to create a host-to-host IPsec VPN between two hosts referred to as left and right using authentication by raw RSA keys.
Prerequisites
-
Libreswan is installed and the
ipsecservice is started on each node.
Procedure
Generate a raw RSA key pair on each host:
# ipsec newhostkeyThe previous step returned the generated key’s
ckaid. Use thatckaidwith the following command on left, for example:# ipsec showhostkey --left --ckaid 2d3ea57b61c9419dfd6cf43a1eb6cb306c0e857dThe output of the previous command generated the
leftrsasigkey=line required for the configuration. Do the same on the second host (right):# ipsec showhostkey --right --ckaid a9e1f6ce9ecd3608c24e8f701318383f41798f03In the
/etc/ipsec.d/directory, create a newmy_host-to-host.conffile. Write the RSA host keys from the output of theipsec showhostkeycommands in the previous step to the new file. For example:conn mytunnel leftid=@west left=192.1.2.23 leftrsasigkey=0sAQOrlo+hOafUZDlCQmXFrje/oZm [...] W2n417C/4urYHQkCvuIQ== rightid=@east right=192.1.2.45 rightrsasigkey=0sAQO3fwC6nSSGgt64DWiYZzuHbc4 [...] D/v8t5YTQ== authby=rsasigAfter importing keys, restart the
ipsecservice:# systemctl restart ipsecLoad the connection:
# ipsec auto --add mytunnelEstablish the tunnel:
# ipsec auto --up mytunnelTo automatically start the tunnel when the
ipsecservice is started, add the following line to the connection definition:auto=start- If you use this host in a network with DHCP or Stateless Address Autoconfiguration (SLAAC), the connection can be vulnerable to being redirected. For details and mitigation steps, see Assigning a VPN connection to a dedicated routing table to prevent the connection from bypassing the tunnel.
7.5. Configuring a site-to-site VPN
To create a site-to-site IPsec VPN, by joining two networks, an IPsec tunnel between the two hosts is created. The hosts thus act as the end points, which are configured to permit traffic from one or more subnets to pass through. Therefore you can think of the host as gateways to the remote portion of the network.
The configuration of the site-to-site VPN only differs from the host-to-host VPN in that one or more networks or subnets must be specified in the configuration file.
Prerequisites
- A host-to-host VPN is already configured.
Procedure
Copy the file with the configuration of your host-to-host VPN to a new file, for example:
# cp /etc/ipsec.d/my_host-to-host.conf /etc/ipsec.d/my_site-to-site.confAdd the subnet configuration to the file created in the previous step, for example:
conn mysubnet also=mytunnel leftsubnet=192.0.1.0/24 rightsubnet=192.0.2.0/24 auto=start conn mysubnet6 also=mytunnel leftsubnet=2001:db8:0:1::/64 rightsubnet=2001:db8:0:2::/64 auto=start # the following part of the configuration file is the same for both host-to-host and site-to-site connections: conn mytunnel leftid=@west left=192.1.2.23 leftrsasigkey=0sAQOrlo+hOafUZDlCQmXFrje/oZm [...] W2n417C/4urYHQkCvuIQ== rightid=@east right=192.1.2.45 rightrsasigkey=0sAQO3fwC6nSSGgt64DWiYZzuHbc4 [...] D/v8t5YTQ== authby=rsasig- If you use this host in a network with DHCP or Stateless Address Autoconfiguration (SLAAC), the connection can be vulnerable to being redirected. For details and mitigation steps, see Assigning a VPN connection to a dedicated routing table to prevent the connection from bypassing the tunnel.
7.6. Configuring a remote access VPN
Road warriors are traveling users with mobile clients and a dynamically assigned IP address. The mobile clients authenticate using X.509 certificates.
The following example shows configuration for IKEv2, and it avoids using the IKEv1 XAUTH protocol.
On the server:
conn roadwarriors
ikev2=insist
# support (roaming) MOBIKE clients (RFC 4555)
mobike=yes
fragmentation=yes
left=1.2.3.4
# if access to the LAN is given, enable this, otherwise use 0.0.0.0/0
# leftsubnet=10.10.0.0/16
leftsubnet=0.0.0.0/0
leftcert=gw.example.com
leftid=%fromcert
leftxauthserver=yes
leftmodecfgserver=yes
right=%any
# trust our own Certificate Agency
rightca=%same
# pick an IP address pool to assign to remote users
# 100.64.0.0/16 prevents RFC1918 clashes when remote users are behind NAT
rightaddresspool=100.64.13.100-100.64.13.254
# if you want remote clients to use some local DNS zones and servers
modecfgdns="1.2.3.4, 5.6.7.8"
modecfgdomains="internal.company.com, corp"
rightxauthclient=yes
rightmodecfgclient=yes
authby=rsasig
# Optional: Run the client X.509 ID through pam to allow or deny client
# pam-authorize=yes
# load connection, do not initiate
auto=add
# kill vanished roadwarriors
dpddelay=1m
dpdtimeout=5m
dpdaction=clearOn the mobile client, the road warrior’s device, use a slight variation of the previous configuration:
conn to-vpn-server
ikev2=insist
# pick up our dynamic IP
left=%defaultroute
leftsubnet=0.0.0.0/0
leftcert=myname.example.com
leftid=%fromcert
leftmodecfgclient=yes
# right can also be a DNS hostname
right=1.2.3.4
# if access to the remote LAN is required, enable this, otherwise use 0.0.0.0/0
# rightsubnet=10.10.0.0/16
rightsubnet=0.0.0.0/0
fragmentation=yes
# trust our own Certificate Agency
rightca=%same
authby=rsasig
# allow narrowing to the server’s suggested assigned IP and remote subnet
narrowing=yes
# support (roaming) MOBIKE clients (RFC 4555)
mobike=yes
# initiate connection
auto=startIf you use this host in a network with DHCP or Stateless Address Autoconfiguration (SLAAC), the connection can be vulnerable to being redirected. For details and mitigation steps, see Assigning a VPN connection to a dedicated routing table to prevent the connection from bypassing the tunnel.
7.7. Configuring a mesh VPN
An IPsec mesh creates a fully interconnected network where every server can communicate securely and directly with every other server. This is ideal for distributed database clusters or high-availability environments that span multiple data centers or cloud providers.
The mesh VPN network can be configured in two ways:
- To require IPsec.
- To prefer IPsec but allow a fallback to clear-text communication.
Authentication between the nodes can be based on X.509 certificates or on DNS Security Extensions (DNSSEC).
You can use any regular IKEv2 authentication method for opportunistic IPsec, because these connections are regular Libreswan configurations, except for the opportunistic IPsec that is defined by right=%opportunisticgroup entry. A common authentication method is for hosts to authenticate each other based on X.509 certificates using a commonly shared certification authority (CA). Cloud deployments typically issue certificates for each node in the cloud as part of the standard procedure.
Do not use PreSharedKey (PSK) authentication because one compromised host would result in the group PSK secret being compromised as well.
You can use NULL authentication to deploy encryption between nodes without authentication, which protects only against passive attackers.
The following procedure uses X.509 certificates. You can generate these certificates by using any kind of CA management system, such as the Dogtag Certificate System. Dogtag assumes that the certificates for each node are available in the PKCS #12 format (.p12 files), which contain the private key, the node certificate, and the Root CA certificate used to validate other nodes' X.509 certificates.
Each node has an identical configuration with the exception of its X.509 certificate. This allows for adding new nodes without reconfiguring any of the existing nodes in the network. The PKCS #12 files require a "friendly name", for which we use the name "node" so that the configuration files referencing the friendly name can be identical for all nodes.
Prerequisites
-
Libreswan is installed, and the
ipsecservice is started on each node. A new NSS database is initialized.
If you already have an old NSS database, remove the old database files:
# systemctl stop ipsec # rm /etc/ipsec.d/*dbYou can initialize a new database with the following command:
# ipsec initnss
Procedure
On each node, import PKCS #12 files. This step requires the password used to generate the PKCS #12 files:
# ipsec import nodeXXX.p12Create the following three connection definitions for the
IPsec required(private),IPsec optional(private-or-clear), andNo IPsec(clear) profiles:# cat /etc/ipsec.d/mesh.conf conn clear auto=ondemand type=passthrough authby=never left=%defaultroute right=%group conn private auto=ondemand type=transport authby=rsasig failureshunt=drop negotiationshunt=drop ikev2=insist left=%defaultroute leftcert=nodeXXXX leftid=%fromcert rightid=%fromcert right=%opportunisticgroup conn private-or-clear auto=ondemand type=transport authby=rsasig failureshunt=passthrough negotiationshunt=passthrough # left left=%defaultroute leftcert=nodeXXXX leftid=%fromcert leftrsasigkey=%cert # right rightrsasigkey=%cert rightid=%fromcert right=%opportunisticgroupwhere:
auto=<option>Specifies how Libreswan handles connection initiation. Valid options:
-
ondemand: Initiates a connection automatically when the kernel receives the first packet that matches a trap XFRM policy. Use this option for opportunistic IPsec or for connections that do not need to be active continuously. -
add: Prepares the connection and accepts incoming connection requests. To initiate the connection from the local peer, use theipsec auto --upcommand. -
start: Automatically activates the connection when the Libreswan service starts.
-
leftid=%fromcertandrightid=%fromcert- Configures Libreswan to retrieve the identity from the distinguished name (DN) field of the certificate.
leftcert="<server_certificate_nickname>"- Specifies the nickname of the server’s certificate used in the NSS database.
Add the IP address of the network to the corresponding category. For example, if all nodes reside in the
10.15.0.0/16network, and all nodes must use IPsec encryption:# echo "10.15.0.0/16" >> /etc/ipsec.d/policies/privateTo allow certain nodes, for example,
10.15.34.0/24, to work with and without IPsec, add those nodes to the private-or-clear group:# echo "10.15.34.0/24" >> /etc/ipsec.d/policies/private-or-clearTo define a host, for example,
10.15.1.2, which is not capable of IPsec into the clear group, use:# echo "10.15.1.2/32" >> /etc/ipsec.d/policies/clearYou can create the files in the
/etc/ipsec.d/policiesdirectory from a template for each new node, or you can provision them by using Puppet or Ansible.Note that every node has the same list of exceptions or different traffic flow expectations. Two nodes, therefore, might not be able to communicate because one requires IPsec and the other cannot use IPsec.
Restart the node to add it to the configured mesh:
# systemctl restart ipsec- If you use this host in a network with DHCP or Stateless Address Autoconfiguration (SLAAC), the connection can be vulnerable to being redirected. For details and mitigation steps, see Assigning a VPN connection to a dedicated routing table to prevent the connection from bypassing the tunnel.
Verification
Open an IPsec tunnel by using the
pingcommand:# ping <nodeYYY>Display the NSS database with the imported certification:
# certutil -L -d sql:/etc/ipsec.d Certificate Nickname Trust Attributes SSL,S/MIME,JAR/XPI west u,u,u ca CT,,See which tunnels are open on the node:
# ipsec trafficstatus 006 #2: "private#10.15.0.0/16"[1] ...<nodeYYY>, type=ESP, add_time=1691399301, inBytes=512, outBytes=512, maxBytes=2^63B, id='C=US, ST=NC, O=Example Organization, CN=east'
7.8. Deploying a FIPS-compliant IPsec VPN
RHEL in Federal Information Processing Standard (FIPS) mode exclusively uses validated cryptographic modules, automatically disabling legacy protocols and ciphers. Enabling FIPS mode is often a requirement for federal compliance and enhances system security.
The Libreswan IPsec implementation provided by RHEL is fully FIPS-compliant. When the system is in FIPS mode, Libreswan automatically uses the certified cryptographic modules without requiring any additional configuration, regardless of whether Libreswan is installed on a new FIPS-enabled system or when FIPS mode is activated on a system with an existing Libreswan VPN.
Prerequisites
-
The
AppStreamrepository is enabled.
Procedure
Install the
libreswanpackages:# yum install libreswanIf you are re-installing Libreswan, remove its old NSS database:
# systemctl stop ipsec # rm /etc/ipsec.d/*dbStart the
ipsecservice, and enable the service to be started automatically on boot:# systemctl enable ipsec --nowConfigure the firewall to allow
500and4500UDP ports for the IKE, ESP, and AH protocols by adding theipsecservice:# firewall-cmd --add-service="ipsec" # firewall-cmd --runtime-to-permanentSwitch the system to FIPS mode:
# fips-mode-setup --enableRestart your system to allow the kernel to switch to FIPS mode:
# reboot
Verification
Confirm Libreswan is running in FIPS mode:
# ipsec whack --fipsstatus 000 FIPS mode enabledAlternatively, check entries for the
ipsecunit in thesystemdjournal:$ journalctl -u ipsec ... Jan 22 11:26:50 localhost.localdomain pluto[3076]: FIPS Product: YES Jan 22 11:26:50 localhost.localdomain pluto[3076]: FIPS Kernel: YES Jan 22 11:26:50 localhost.localdomain pluto[3076]: FIPS Mode: YESTo see the available algorithms in FIPS mode:
# ipsec pluto --selftest 2>&1 | head -11 FIPS Product: YES FIPS Kernel: YES FIPS Mode: YES NSS DB directory: sql:/etc/ipsec.d Initializing NSS Opening NSS database "sql:/etc/ipsec.d" read-only NSS initialized NSS crypto library initialized FIPS HMAC integrity support [enabled] FIPS mode enabled for pluto daemon NSS library is running in FIPS mode FIPS HMAC integrity verification self-test passedTo query disabled algorithms in FIPS mode:
# ipsec pluto --selftest 2>&1 | grep disabled Encryption algorithm CAMELLIA_CTR disabled; not FIPS compliant Encryption algorithm CAMELLIA_CBC disabled; not FIPS compliant Encryption algorithm SERPENT_CBC disabled; not FIPS compliant Encryption algorithm TWOFISH_CBC disabled; not FIPS compliant Encryption algorithm TWOFISH_SSH disabled; not FIPS compliant Encryption algorithm NULL disabled; not FIPS compliant Encryption algorithm CHACHA20_POLY1305 disabled; not FIPS compliant Hash algorithm MD5 disabled; not FIPS compliant PRF algorithm HMAC_MD5 disabled; not FIPS compliant PRF algorithm AES_XCBC disabled; not FIPS compliant Integrity algorithm HMAC_MD5_96 disabled; not FIPS compliant Integrity algorithm HMAC_SHA2_256_TRUNCBUG disabled; not FIPS compliant Integrity algorithm AES_XCBC_96 disabled; not FIPS compliant DH algorithm MODP1024 disabled; not FIPS compliant DH algorithm MODP1536 disabled; not FIPS compliant DH algorithm DH31 disabled; not FIPS compliantTo list all allowed algorithms and ciphers in FIPS mode:
# ipsec pluto --selftest 2>&1 | grep ESP | grep FIPS | sed "s/^.*FIPS//" {256,192,*128} aes_ccm, aes_ccm_c {256,192,*128} aes_ccm_b {256,192,*128} aes_ccm_a [*192] 3des {256,192,*128} aes_gcm, aes_gcm_c {256,192,*128} aes_gcm_b {256,192,*128} aes_gcm_a {256,192,*128} aesctr {256,192,*128} aes {256,192,*128} aes_gmac sha, sha1, sha1_96, hmac_sha1 sha512, sha2_512, sha2_512_256, hmac_sha2_512 sha384, sha2_384, sha2_384_192, hmac_sha2_384 sha2, sha256, sha2_256, sha2_256_128, hmac_sha2_256 aes_cmac null null, dh0 dh14 dh15 dh16 dh17 dh18 ecp_256, ecp256 ecp_384, ecp384 ecp_521, ecp521
7.9. Protecting the IPsec NSS database by a password
By default, only the root user can access the IPsec Network Security Services (NSS) database in the /etc/ipsec.d/ directory. You can additionally protect the database with a password. This is required if you run RHEL in Federal Information Processing Standard (FIPS) mode.
In the previous releases of RHEL up to version 6.6, you had to protect the IPsec NSS database with a password to meet the FIPS 140-2 requirements because the NSS cryptographic libraries were certified for the FIPS 140-2 Level 2 standard. In RHEL 8, NIST certified NSS to Level 1 of this standard, and this status does not require password protection for the database.
Prerequisites
-
The
/etc/ipsec.d/directory contains NSS database files.
Procedure
Enable password protection for the
NSSdatabase for Libreswan:# certutil -N -d sql:/etc/ipsec.d Enter Password or Pin for "NSS Certificate DB": Enter a password which will be used to encrypt your keys. The password should be at least 8 characters long, and should contain at least one non-alphabetic character. Enter new password:Create the
/etc/ipsec.d/nsspasswordfile that contains the password you have set in the previous step, for example:# cat /etc/ipsec.d/nsspassword NSS Certificate DB:_<password>_The
nsspasswordfile use the following syntax:<token_1>:<password1> <token_2>:<password2>The default NSS software token is
NSS Certificate DB. If your system is running in FIPS mode, the name of the token isNSS FIPS 140-2 Certificate DB.Depending on your scenario, either start or restart the
ipsecservice after you finish thensspasswordfile:# systemctl restart ipsec
Verification
Check that the
ipsecservice is running after you have added a non-empty password to its NSS database:# systemctl status ipsec ● ipsec.service - Internet Key Exchange (IKE) Protocol Daemon for IPsec Loaded: loaded (/usr/lib/systemd/system/ipsec.service; enabled; vendor preset: disable> Active: active (running)...Check that the
Journallog contains entries that confirm a successful initialization:# journalctl -u ipsec ... pluto[6214]: Initializing NSS using read-write database "sql:/etc/ipsec.d" pluto[6214]: NSS Password from file "/etc/ipsec.d/nsspassword" for token "NSS Certificate DB" with length 20 passed to NSS pluto[6214]: NSS crypto library initialized ...
7.10. Configuring TCP fallback for an IPsec VPN connection
Standard IPsec VPNs can fail on restrictive networks that block the UDP and Encapsulating Security Payload (ESP) protocols. To ensure connectivity in such environments, Libreswan can encapsulate all VPN traffic within a TCP connection.
Encapsulating VPN packets within TCP can reduce throughput and increase latency. For this reason, use TCP encapsulation only as a fallback option or if UDP-based connections are consistently blocked in your environment.
Prerequisites
- The IPsec connection is configured.
Procedure
Edit the
/etc/ipsec.conffile, and make the following changes in theconfig setupsection:Configure Libreswan to listen on a TCP port:
listen-tcp=yesBy default, Libreswan listens on port 4500. If you want to use a different port, enter:
tcp-remoteport=<port_number>Decide whether TCP should be used as a fallback option if UDP is not available or permanent:
As a fallback option, enter:
enable-tcp=fallback retransmit-timeout=5sBy default, Libreswan waits 60 seconds after a failed attempt to connect by using UDP before retrying the connection over TCP. Lowering the
retransmit-timeoutvalue shortens the delay, enabling the fallback protocol to initiate more quickly.As a permanent replacement for UDP, enter:
enable-tcp=yes
Restart the
ipsecservice:# systemctl restart ipsecIf you configured a TCP port other than the default 4500, open the port in the firewall:
# firewall-cmd --permanent --add-port=<tcp_port>/tcp # firewall-cmd --reload- Repeat the procedure on the peers that use this gateway.
7.11. Configuring automatic detection and usage of ESP hardware offload to accelerate an IPsec connection
Offloading Encapsulating Security Payload (ESP) to the hardware accelerates IPsec connections over Ethernet. By default, Libreswan detects and enables hardware support. In case that the feature was disabled or explicitly enabled, you can switch back to automatic detection.
Prerequisites
- The network card supports ESP hardware offload.
- The network driver supports ESP hardware offload.
- The IPsec connection is configured and works.
Procedure
-
Edit the Libreswan configuration file in the
/etc/ipsec.d/directory of the connection that should use automatic detection of ESP hardware offload support. -
Ensure the
nic-offloadparameter is not set in the connection’s settings. If you removed
nic-offload, restart theipsecservice:# systemctl restart ipsec
Verification
Display the
tx_ipsecandrx_ipseccounters of the Ethernet device the IPsec connection uses:# ethtool -S enp1s0 | grep -E "_ipsec" tx_ipsec: 10 rx_ipsec: 10Send traffic through the IPsec tunnel. For example, ping a remote IP address:
# ping -c 5 remote_ip_addressDisplay the
tx_ipsecandrx_ipseccounters of the Ethernet device again:# ethtool -S enp1s0 | grep -E "_ipsec" tx_ipsec: 15 rx_ipsec: 15If the counter values have increased, ESP hardware offload works.
7.12. Configuring ESP hardware offload on a bond to accelerate an IPsec connection
Offloading Encapsulating Security Payload (ESP) to the hardware accelerates IPsec connections. If you use a network bond for fail-over reasons, the requirements and the procedure to configure ESP hardware offload are different from those using a regular Ethernet device. For example, in this scenario, you enable the offload support on the bond, and the kernel applies the settings to the ports of the bond.
Prerequisites
-
All network cards in the bond support ESP hardware offload. Use the
ethtool -k <interface_name> | grep "esp-hw-offload"command to verify whether each bond port supports this feature. - The bond is configured and works.
-
The bond uses the
active-backupmode. The bonding driver does not support any other modes for this feature. - The IPsec connection is configured and works.
Procedure
Enable ESP hardware offload support on the network bond:
# nmcli connection modify bond0 ethtool.feature-esp-hw-offload onThis command enables ESP hardware offload support on the
bond0connection.Reactivate the
bond0connection:# nmcli connection up bond0Edit the Libreswan configuration file in the
/etc/ipsec.d/directory of the connection that should use ESP hardware offload, and append thenic-offload=yesstatement to the connection entry:conn example ... nic-offload=yesRestart the
ipsecservice:# systemctl restart ipsec
Verification
The verification methods depend on various aspects, such as the kernel version and driver. For example, certain drivers provide counters, but their names can vary. See the documentation of your network driver for details.
The following verification steps work for the ixgbe driver on Red Hat Enterprise Linux 8:
Display the active port of the bond:
# grep "Currently Active Slave" /proc/net/bonding/bond0 Currently Active Slave: enp1s0Display the
tx_ipsecandrx_ipseccounters of the active port:# ethtool -S enp1s0 | grep -E "_ipsec" tx_ipsec: 10 rx_ipsec: 10Send traffic through the IPsec tunnel. For example, ping a remote IP address:
# ping -c 5 remote_ip_addressDisplay the
tx_ipsecandrx_ipseccounters of the active port again:# ethtool -S enp1s0 | grep -E "_ipsec" tx_ipsec: 15 rx_ipsec: 15If the counter values have increased, ESP hardware offload works.
7.13. Configuring IPsec VPN connections by using RHEL system roles
Configure IPsec VPN connections to establish encrypted tunnels over untrusted networks and ensure the integrity of data in transit. By using the RHEL system roles, you can automate the setup for use cases, such as connecting branch offices to headquarters.
The vpn RHEL system role can only create VPN configurations that use pre-shared keys (PSKs) or certificates to authenticate peers to each other.
7.13.1. Configuring an IPsec host-to-host VPN with PSK authentication by using the vpn RHEL system role
A host-to-host VPN establishes an encrypted connection between two devices, allowing applications to communicate safely over an insecure network. By using the vpn RHEL system role, you can automate the process of creating IPsec host-to-host connections.
For authentication, a pre-shared key (PSK) is a straightforward method that uses a single, shared secret known only to the two peers. This approach is simple to configure and ideal for basic setups where ease of deployment is a priority. However, you must keep the key strictly confidential. An attacker with access to the key can compromise the connection.
Prerequisites
- You have prepared the control node and the managed nodes.
-
The account you use to connect to the managed nodes has
sudopermissions for these nodes.
Procedure
Create a playbook file, for example,
~/playbook.yml, with the following content:--- - name: Configuring VPN hosts: managed-node-01.example.com, managed-node-02.example.com tasks: - name: IPsec VPN with PSK authentication ansible.builtin.include_role: name: redhat.rhel_system_roles.vpn vars: vpn_connections: - hosts: managed-node-01.example.com: managed-node-02.example.com: auth_method: psk auto: start vpn_manage_firewall: true vpn_manage_selinux: trueThe settings specified in the example playbook include the following:
hosts: <list>Defines a YAML dictionary with the peers between which you want to configure a VPN. If an entry is not an Ansible managed node, you must specify its fully-qualified domain name (FQDN) or IP address in the
hostnameparameter, for example:... - hosts: ... external-host.example.com: hostname: 192.0.2.1The role configures the VPN connection on each managed node. The connections are named
<peer_A>-to-<peer_B>, for example,managed-node-01.example.com-to-managed-node-02.example.com. Note that the role cannot configure Libreswan on external (unmanaged) nodes. You must manually create the configuration on these peers.auth_method: psk-
Enables PSK authentication between the peers. The role uses
opensslon the control node to create the PSK. auto: <startup_method>-
Specifies the startup method of the connection. Valid values are
add,ondemand,start, andignore. For details, see theipsec.conf(5)man page on a system with Libreswan installed. The default value of this variable is null, which means no automatic startup operation. vpn_manage_firewall: true-
Defines that the role opens the required ports in the
firewalldservice on the managed nodes. vpn_manage_selinux: true- Defines that the role sets the required SELinux port type on the IPsec ports.
For details about all variables used in the playbook, see the
/usr/share/ansible/roles/rhel-system-roles.vpn/README.mdfile on the control node.Validate the playbook syntax:
$ ansible-playbook --syntax-check ~/playbook.ymlNote that this command only validates the syntax and does not protect against a wrong but valid configuration.
Run the playbook:
$ ansible-playbook ~/playbook.yml
Verification
Confirm that the connections are successfully started, for example:
# ansible managed-node-01.example.com -m shell -a 'ipsec trafficstatus | grep "managed-node-01.example.com-to-managed-node-02.example.com"' ... 006 #3: "managed-node-01.example.com-to-managed-node-02.example.com", type=ESP, add_time=1741857153, inBytes=38622, outBytes=324626, maxBytes=2^63B, id='@managed-node-02.example.com'Note that this command only succeeds if the VPN connection is active. If you set the
autovariable in the playbook to a value other thanstart, you might need to manually activate the connection on the managed nodes first.
Use the vpn RHEL system role to automate the process of creating an IPsec host-to-host VPN. To enhance security by minimizing the risk of control messages being intercepted or disrupted, configure separate connections for both the data traffic and the control traffic.
A host-to-host VPN establishes a direct, secure, and encrypted connection between two devices, allowing applications to communicate safely over an insecure network, such as the internet.
For authentication, a pre-shared key (PSK) is a straightforward method that uses a single, shared secret known only to the two peers. This approach is simple to configure and ideal for basic setups where ease of deployment is a priority. However, you must keep the key strictly confidential. An attacker with access to the key can compromise the connection.
Prerequisites
- You have prepared the control node and the managed nodes.
-
The account you use to connect to the managed nodes has
sudopermissions for these nodes.
Procedure
Create a playbook file, for example,
~/playbook.yml, with the following content:--- - name: Configuring VPN hosts: managed-node-01.example.com, managed-node-02.example.com tasks: - name: IPsec VPN with PSK authentication ansible.builtin.include_role: name: redhat.rhel_system_roles.vpn vars: vpn_connections: - name: control_plane_vpn hosts: managed-node-01.example.com: hostname: 203.0.113.1 # IP address for the control plane managed-node-02.example.com: hostname: 198.51.100.2 # IP address for the control plane auth_method: psk auto: start - name: data_plane_vpn hosts: managed-node-01.example.com: hostname: 10.0.0.1 # IP address for the data plane managed-node-02.example.com: hostname: 172.16.0.2 # IP address for the data plane auth_method: psk auto: start vpn_manage_firewall: true vpn_manage_selinux: trueThe settings specified in the example playbook include the following:
hosts: <list>Defines a YAML dictionary with the hosts between which you want to configure a VPN. The connections are named
<name>-<IP_address_A>-to-<IP_address_B>, for examplecontrol_plane_vpn-203.0.113.1-to-198.51.100.2.The role configures the VPN connection on each managed node. Note that the role cannot configure Libreswan on external (unmanaged) nodes. You must manually create the configuration on these hosts.
auth_method: psk-
Enables PSK authentication between the hosts. The role uses
opensslon the control node to create the pre-shared key. auto: <startup_method>-
Specifies the startup method of the connection. Valid values are
add,ondemand,start, andignore. For details, see theipsec.conf(5)man page on a system with Libreswan installed. The default value of this variable is null, which means no automatic startup operation. vpn_manage_firewall: true-
Defines that the role opens the required ports in the
firewalldservice on the managed nodes. vpn_manage_selinux: true- Defines that the role sets the required SELinux port type on the IPsec ports.
For details about all variables used in the playbook, see the
/usr/share/ansible/roles/rhel-system-roles.vpn/README.mdfile on the control node.Validate the playbook syntax:
$ ansible-playbook --syntax-check ~/playbook.ymlNote that this command only validates the syntax and does not protect against a wrong but valid configuration.
Run the playbook:
$ ansible-playbook ~/playbook.yml
Verification
Confirm that the connections are successfully started, for example:
# ansible managed-node-01.example.com -m shell -a 'ipsec trafficstatus | grep "control_plane_vpn-203.0.113.1-to-198.51.100.2"' ... 006 #3: "control_plane_vpn-203.0.113.1-to-198.51.100.2", type=ESP, add_time=1741860073, inBytes=0, outBytes=0, maxBytes=2^63B, id='198.51.100.2'Note that this command only succeeds if the VPN connection is active. If you set the
autovariable in the playbook to a value other thanstart, you might need to manually activate the connection on the managed nodes first.
7.13.3. Configuring an IPsec site-to-site VPN with PSK authentication by using the vpn RHEL system role
A site-to-site VPN establishes an encrypted tunnel between two distinct networks, seamlessly linking them across an insecure public network. By using the vpn RHEL system role, you can automate the process of creating IPsec site-to-site VPN connections.
A site-to-site VPN enables devices in a branch office to access resources at a corporate headquarters just as if they were all part of the same local network.
For authentication, a pre-shared key (PSK) is a straightforward method that uses a single, shared secret known only to the two peers. This approach is simple to configure and ideal for basic setups where ease of deployment is a priority. However, you must keep the key strictly confidential. An attacker with access to the key can compromise the connection.
Prerequisites
- You have prepared the control node and the managed nodes.
-
The account you use to connect to the managed nodes has
sudopermissions for these nodes.
Procedure
Create a playbook file, for example,
~/playbook.yml, with the following content:--- - name: Configuring VPN hosts: managed-node-01.example.com, managed-node-02.example.com tasks: - name: IPsec VPN with PSK authentication ansible.builtin.include_role: name: redhat.rhel_system_roles.vpn vars: vpn_connections: - hosts: managed-node-01.example.com: subnets: - 192.0.2.0/24 managed-node-02.example.com: subnets: - 198.51.100.0/24 - 203.0.113.0/24 auth_method: psk auto: start vpn_manage_firewall: true vpn_manage_selinux: trueThe settings specified in the example playbook include the following:
hosts: <list>Defines a YAML dictionary with the gateways between which you want to configure a VPN. If an entry is not an Ansible-managed node, you must specify its fully-qualified domain name (FQDN) or IP address in the
hostnameparameter, for example:... - hosts: ... external-host.example.com: hostname: 192.0.2.1The role configures the VPN connection on each managed node. The connections are named
<gateway_A>-to-<gateway_B>, for example,managed-node-01.example.com-to-managed-node-02.example.com. Note that the role cannot configure Libreswan on external (unmanaged) nodes. You must manually create the configuration on these peers.subnets: <yaml_list_of_subnets>- Defines subnets in classless inter-domain routing (CIDR) format that are connected through the tunnel.
auth_method: psk-
Enables PSK authentication between the peers. The role uses
opensslon the control node to create the PSK. auto: <startup_method>-
Specifies the startup method of the connection. Valid values are
add,ondemand,start, andignore. For details, see theipsec.conf(5)man page on a system with Libreswan installed. The default value of this variable is null, which means no automatic startup operation. vpn_manage_firewall: true-
Defines that the role opens the required ports in the
firewalldservice on the managed nodes. vpn_manage_selinux: true- Defines that the role sets the required SELinux port type on the IPsec ports.
For details about all variables used in the playbook, see the
/usr/share/ansible/roles/rhel-system-roles.vpn/README.mdfile on the control node.Validate the playbook syntax:
$ ansible-playbook --syntax-check ~/playbook.ymlNote that this command only validates the syntax and does not protect against a wrong but valid configuration.
Run the playbook:
$ ansible-playbook ~/playbook.yml
Verification
Confirm that the connections are successfully started, for example:
# ansible managed-node-01.example.com -m shell -a 'ipsec trafficstatus | grep "managed-node-01.example.com-to-managed-node-02.example.com"' ... 006 #3: "managed-node-01.example.com-to-managed-node-02.example.com", type=ESP, add_time=1741857153, inBytes=38622, outBytes=324626, maxBytes=2^63B, id='@managed-node-02.example.com'Note that this command only succeeds if the VPN connection is active. If you set the
autovariable in the playbook to a value other thanstart, you might need to manually activate the connection on the managed nodes first.
7.13.4. Configuring an IPsec mesh VPN with certificate-based authentication by using the vpn RHEL system role
An IPsec mesh creates a fully interconnected network where every server can communicate securely and directly with every other server. By using the vpn RHEL system role, you can automate configuring a VPN mesh with certificate-based authentication among managed nodes.
An IPsec mesh is ideal for distributed database clusters or high-availability environments that span multiple data centers or cloud providers. Establishing a direct, encrypted tunnel between each pair of servers ensures secure communication without a central bottleneck.
For authentication, using digital certificates managed by a Certificate Authority (CA) offers a highly secure and scalable solution. Each host in the mesh presents a certificate signed by a trusted CA. This method provides strong, verifiable authentication and simplifies user management. Access can be granted or revoked centrally at the CA, and Libreswan enforces this by checking each certificate against a certificate revocation list (CRL), denying access if a certificate appears on the list.
Prerequisites
- You have prepared the control node and the managed nodes.
-
The account you use to connect to the managed nodes has
sudopermissions for these nodes. You prepared a PKCS #12 file for each managed node:
Each file contains:
- The private key of the server
- The server certificate
- The CA certificate
- If required, intermediate certificates
-
The files are named
<managed_node_name_as_in_the_inventory>.p12. - The files are stored in the same directory as the playbook.
The server certificate contains the following fields:
-
Extended Key Usage (EKU) is set to
TLS Web Server Authentication. - Common Name (CN) or Subject Alternative Name (SAN) is set to the fully-qualified domain name (FQDN) of the host.
- X509v3 CRL distribution points contain URLs to Certificate Revocation Lists (CRLs).
-
Extended Key Usage (EKU) is set to
Procedure
Edit the
~/inventoryfile, and append thecert_namevariable:managed-node-01.example.com cert_name=managed-node-01.example.com managed-node-02.example.com cert_name=managed-node-02.example.com managed-node-03.example.com cert_name=managed-node-03.example.comSet the
cert_namevariable to the value of the common name (CN) field used in the certificate for each host. Typically, the CN field is set to the fully-qualified domain name (FQDN).Store your sensitive variables in an encrypted file:
Create the vault:
$ ansible-vault create ~/vault.yml New Vault password: <vault_password> Confirm New Vault password: <vault_password>After the
ansible-vault createcommand opens an editor, enter the sensitive data in the<key>: <value>format:pkcs12_pwd: <password>- Save the changes, and close the editor. Ansible encrypts the data in the vault.
Create a playbook file, for example,
~/playbook.yml, with the following content:- name: Configuring VPN hosts: managed-node-01.example.com, managed-node-02.example.com, managed-node-03.example.com vars_files: - ~/vault.yml tasks: - name: Install LibreSwan ansible.builtin.package: name: libreswan state: present - name: Identify the path to IPsec NSS database ansible.builtin.set_fact: nss_db_dir: "{{ '/etc/ipsec.d/' if ansible_distribution in ['CentOS', 'RedHat'] and ansible_distribution_major_version is version('8', '=') else '/var/lib/ipsec/nss/' }}" - name: Locate IPsec NSS database files ansible.builtin.find: paths: "{{ nss_db_dir }}" patterns: "*.db" register: db_files - name: Initialize IPsec NSS database if not initialized ansible.builtin.command: cmd: ipsec initnss when: db_files.matched == 0 - name: Copy PKCS #12 file to the managed node ansible.builtin.copy: src: "~/{{ inventory_hostname }}.p12" dest: "/etc/ipsec.d/{{ inventory_hostname }}.p12" mode: 0600 - name: Import PKCS #12 file in IPsec NSS database ansible.builtin.shell: cmd: 'pk12util -d {{ nss_db_dir }} -i /etc/ipsec.d/{{ inventory_hostname }}.p12 -W "{{ pkcs12_pwd }}"' - name: Remove PKCS #12 file ansible.builtin.file: path: "/etc/ipsec.d/{{ inventory_hostname }}.p12" state: absent - name: Opportunistic mesh IPsec VPN with certificate-based authentication ansible.builtin.include_role: name: redhat.rhel_system_roles.vpn vars: vpn_connections: - opportunistic: true auth_method: cert policies: - policy: private cidr: default - policy: private cidr: 192.0.2.0/24 - policy: clear cidr: 192.0.2.1/32 vpn_manage_firewall: true vpn_manage_selinux: trueThe settings specified in the example playbook include the following:
opportunistic: true-
Enables an opportunistic mesh among multiple hosts. The
policiesvariable defines for which subnets and hosts traffic must or can be encrypted and which of them continue using plain text connections. auth_method: cert- Enables certificate-based authentication. This requires that you specify the nickname of each managed node’s certificate in the inventory.
policies: <list_of_policies>Defines the Libreswan policies in YAML list format.
The default policy is
private-or-clear. To change it toprivate, the playbook contains an according policy for the defaultcidrentry.To prevent a loss of the SSH connection during the execution of the playbook if the Ansible control node is in the same IP subnet as the managed nodes, add a
clearpolicy for the control node’s IP address. For example, if you want the mesh to be configured for the192.0.2.0/24subnet and the control node uses the IP address192.0.2.1, you require aclearpolicy for192.0.2.1/32as shown in the playbook.For details about policies, see the
ipsec.conf(5)man page on a system with Libreswan installed.vpn_manage_firewall: true-
Defines that the role opens the required ports in the
firewalldservice on the managed nodes. vpn_manage_selinux: true- Defines that the role sets the required SELinux port type on the IPsec ports.
For details about all variables used in the playbook, see the
/usr/share/ansible/roles/rhel-system-roles.vpn/README.mdfile on the control node.Validate the playbook syntax:
$ ansible-playbook --ask-vault-pass --syntax-check ~/playbook.ymlNote that this command only validates the syntax and does not protect against a wrong but valid configuration.
Run the playbook:
$ ansible-playbook --ask-vault-pass ~/playbook.yml
Verification
On a node in the mesh, ping another node to activate the connection:
[root@managed-node-01]# ping managed-node-02.example.comConfirm that the connection is active:
[root@managed-node-01]# ipsec trafficstatus 006 #2: "private#192.0.2.0/24"[1] ...192.0.2.2, type=ESP, add_time=1741938929, inBytes=372408, outBytes=545728, maxBytes=2^63B, id='CN=managed-node-02.example.com'
7.14. Enabling legacy ciphers and algorithms in Libreswan
Enable legacy ciphers and algorithms in Libreswan for backward compatibility with other IPsec peers. This overrides the RHEL system-wide cryptographic policies which, by default, enforce strong encryption ciphers and algorithms for IPsec and Internet Key Exchange (IKE).
The RHEL system-wide cryptographic policies create a special connection called %default. This connection sets the default values for the keyexchange, esp, and ike parameters.
Prerequisites
- Libreswan is installed.
Procedure
To override the defaults set by the RHEL system-wide cryptographic policies, add the
keyexchange,esp, andikeparameters to your connection configuration and set them to the values you require. For example:conn <connection_name> ikev2=no ike=aes-sha2,aes-sha1;modp2048 esp=aes-sha2,aes-sha1 ...Restart the
ipsecservice:# systemctl restart ipsec
7.15. Troubleshooting IPsec configurations
Diagnosing IPsec configuration failures can be challenging, because issues can be caused by mismatched settings, firewall rules, and kernel-level errors. The following information provides a systematic approach to resolving common problems with IPsec VPN connections.
7.15.1. Basic connection issues
Problems with VPN connections often occur due to mismatched configurations between the endpoints.
To confirm that an IPsec connection is established, enter:
# ipsec trafficstatus
006 #8: "vpn.example.com"[1] 192.0.2.1, type=ESP, add_time=1595296930, inBytes=5999, outBytes=3231, id='@vpn.example.com', lease=198.51.100.1/32For a successful connection, the command shows an entry with the connection’s name and details. If the output is empty, the tunnel is not established.
7.15.3. Mismatched Configurations
VPN connections fail if the endpoints are not configured with matching Internet Key Exchange (IKE) versions, algorithms, IP address ranges, or pre-shared keys (PSK). If you identify a mismatch, you must align the settings on both endpoints to resolve the issue.
- Remote Peer Not Running IKE/IPsec
If the connection was refused, an ICMP error is displayed:
# ipsec auto --up vpn.example.com ... 000 "vpn.example.com"[1] 192.0.2.2 #16: ERROR: asynchronous network error report on wlp2s0 (192.0.2.2:500), complainant 198.51.100.1: Connection refused [errno 111, origin ICMP type 3 code 3 (not authenticated)]- Mismatched IKE Algorithms
The connection fails with a
NO_PROPOSAL_CHOSENnotification during the initial setup:# ipsec auto --up vpn.example.com ... 003 "vpn.example.com"[1] 193.110.157.148 #3: dropping unexpected IKE_SA_INIT message containing NO_PROPOSAL_CHOSEN notification; message payloads: N; missing payloads: SA,KE,Ni- Mismatched IPsec Algorithms
The connection fails with a
NO_PROPOSAL_CHOSENerror after the initial exchange:# ipsec auto --up vpn.example.com ... 182 "vpn.example.com"[1] 193.110.157.148 #5: STATE_PARENT_I2: sent v2I2, expected v2R2 {auth=IKEv2 cipher=AES_GCM_16_256 integ=n/a prf=HMAC_SHA2_256 group=MODP2048} 002 "vpn.example.com"[1] 193.110.157.148 #6: IKE_AUTH response contained the error notification NO_PROPOSAL_CHOSEN- Mismatched IP Address Ranges (IKEv2)
The remote peer responds with a
TS_UNACCEPTABLEerror:# ipsec auto --up vpn.example.com ... 1v2 "vpn.example.com" #1: STATE_PARENT_I2: sent v2I2, expected v2R2 {auth=IKEv2 cipher=AES_GCM_16_256 integ=n/a prf=HMAC_SHA2_512 group=MODP2048} 002 "vpn.example.com" #2: IKE_AUTH response contained the error notification TS_UNACCEPTABLE- Mismatched IP Address Ranges (IKEv1)
The connection times out during quick mode, with a message indicating the peer did not accept the proposal:
# ipsec auto --up vpn.example.com ... 031 "vpn.example.com" #2: STATE_QUICK_I1: 60 second timeout exceeded after 0 retransmits. No acceptable response to our first Quick Mode message: perhaps peer likes no proposal- Mismatched PSK (IKEv2)
The peer rejects the connection with an
AUTHENTICATION_FAILEDerror:# ipsec auto --up vpn.example.com ... 003 "vpn.example.com" #1: received Hash Payload does not match computed value 223 "vpn.example.com" #1: sending notification INVALID_HASH_INFORMATION to 192.0.2.23:500- Mismatched PSK (IKEv1)
The hash payload does not match, making the IKE message unreadable and resulting in an
INVALID_HASH_INFORMATIONerror:# ipsec auto --up vpn.example.com ... 002 "vpn.example.com" #1: IKE SA authentication request rejected by peer: AUTHENTICATION_FAILED
7.15.4. MTU issues
Diagnose intermittent IPsec connection failures caused by Maximum Transmission Unit (MTU) issues. Encryption increases packet size, leading to fragmentation and lost data when packets exceed the network’s MTU, often seen with larger data transfers.
A common symptom is that small packets, for example pings, work correctly, but larger packets, such as an SSH session, freeze after the login. To fix the problem, lower the MTU for the tunnel by adding the mtu=1400 option to the configuration file.
7.15.5. NAT conflicts
Resolve NAT conflicts that occur when an IPsec host also acts as a NAT router. Incorrect NAT application can translate source IP addresses before encryption, causing packets to be sent unencrypted over the network.
For example, if the source IP address of the packet is translated by a masquerade rule before IPsec encryption is applied, the packet’s source no longer matches the IPsec policy, and Libreswan sends it unencrypted over the network.
To solve this problem, add a firewall rule that excludes traffic between the IPsec subnets from NAT. Insert this rule at the beginning of the POSTROUTING chain to ensure it is processed before the general NAT rule.
Example 7.1. Solution by using the nftables framework
The following example uses nftables to set up a basic NAT environment that excludes traffic between the 192.0.2.0/24 and 198.51.100.0/24 subnets from address translation:
# nft add table ip nat
# nft add chain ip nat postrouting { type nat hook postrouting priority 100 \; }
# nft add rule ip nat postrouting ip saddr 192.0.2.0/24 ip daddr 198.51.100.0/24 return7.15.6. Kernel-level IPsec issues
Troubleshoot kernel-level IPsec issues when a VPN tunnel appears established but no traffic flows. In this case, inspect the kernel’s IPsec state to check if the tunnel policies and cryptographic keys were correctly installed.
This process involves checking two components:
- The Security Policy Database (SPD): The rule that instructs the kernel what traffic to encrypt.
- The Security Association Database (SAD): The keys that instruct the kernel how to encrypt that traffic.
First, check if the correct policy exists in the SPD:
# ip xfrm policy
src 192.0.2.1/32 dst 10.0.0.0/8
dir out priority 666 ptype main
tmpl src 198.51.100.13 dst 203.0.113.22
proto esp reqid 16417 mode tunnel
The output contains the policies matching your leftsubnet and rightsubnet parameters with both in and out directions. If you do not see a policy for your traffic, Libreswan failed to create the kernel rule, and traffic is not encrypted.
If the policy exists, check if it has a corresponding set of keys in the SAD:
# ip xfrm state
src 203.0.113.22 dst 198.51.100.13
proto esp spi 0xa78b3fdb reqid 16417 mode tunnel
auth-trunc hmac(sha1) 0x3763cd3b... 96
enc cbc(aes) 0xd9dba399...This command displays private cryptographic keys. Do not share this output, because attackers can use it to decrypt your VPN traffic.
If a policy exists but you see no corresponding state with the same reqid, it typically means the Internet Key Exchange (IKE) negotiation failed. The two VPN endpoints could not agree on a set of keys.
For more detailed diagnostics, use the -s option with either of the commands. This option adds traffic counters, which can help you identify if the kernel processes packets by a specific rule.
7.15.7. Kernel IPsec subsystem bugs
A defect in the kernel’s IPsec subsystem can cause it to lose sync with the IKE daemon. This can lead to discrepancies between negotiated security associations and actual IPsec policy enforcement, disrupting secure network communication.
To check for kernel-level errors, display the transform (XFRM) statistics:
# cat /proc/net/xfrm_stat
If any of the counters in the output, such as XfrmInError, show a nonzero value, it indicates a problem with the kernel subsystem. In this case, open a support case, and attach the output of the command along with the corresponding IKE logs.
7.15.8. Displaying Libreswan logs
Display Libreswan logs to diagnose and troubleshoot IPsec service events and issues. Access the journal for the ipsec service to gain insights into connection status and potential problems.
To display the journal, enter:
# journalctl -xeu ipsec
If the default logging level does not provide enough details, enable comprehensive debug logging by adding the following settings to the config setup section in the /etc/ipsec.conf file:
plutodebug=all
logfile=/var/log/pluto.log
Because debug logging can produce many entries, redirecting the messages to a dedicated log file can prevent the journald and systemd services from rate-limiting the messages.
7.16. Configuring a VPN connection with control-center
If you use Red Hat Enterprise Linux with a graphical interface, you can configure a VPN connection in the GNOME control-center.
Prerequisites
-
The
NetworkManager-libreswan-gnomepackage is installed.
Procedure
-
Press the Super key, type
Settings, and press Enter to open thecontrol-centerapplication. -
Select the
Networkentry on the left. - Click the + icon.
-
Select
VPN. Select the
Identitymenu entry to see the basic configuration options:General
Gateway- The name orIPaddress of the remote VPN gateway.Authentication
Type-
IKEv2 (Certificate)- client is authenticated by certificate. It is more secure (default). IKEv1 (XAUTH)- client is authenticated by user name and password, or a pre-shared key (PSK).The following configuration settings are available under the
Advancedsection:Figure 7.1. Advanced options of a VPN connection
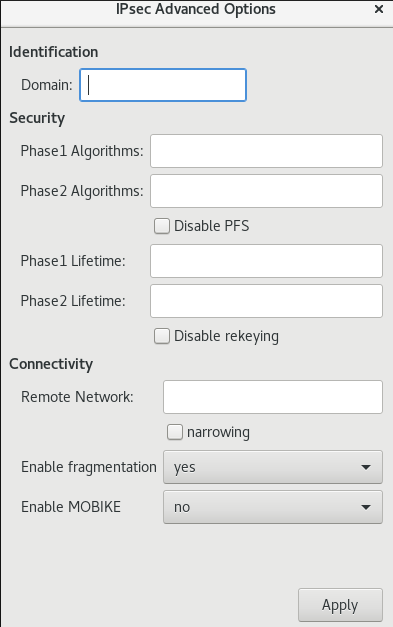 Warning
WarningWhen configuring an IPsec-based VPN connection using the
gnome-control-centerapplication, theAdvanceddialog displays the configuration, but it does not allow any changes. As a consequence, users cannot change any advanced IPsec options. Use thenm-connection-editorornmclitools instead to perform configuration of the advanced properties.Identification
Domain- If required, enter the Domain Name.Security
-
Phase1 Algorithms- corresponds to theikeLibreswan parameter - enter the algorithms to be used to authenticate and set up an encrypted channel. Phase2 Algorithms- corresponds to theespLibreswan parameter - enter the algorithms to be used for theIPsecnegotiations.Check the
Disable PFSfield to turn off Perfect Forward Secrecy (PFS) to ensure compatibility with old servers that do not support PFS.-
Phase1 Lifetime- corresponds to theikelifetimeLibreswan parameter - how long the key used to encrypt the traffic will be valid. Phase2 Lifetime- corresponds to thesalifetimeLibreswan parameter - how long a particular instance of a connection should last before expiring.Note that the encryption key should be changed from time to time for security reasons.
Remote network- corresponds to therightsubnetLibreswan parameter - the destination private remote network that should be reached through the VPN.Check the
narrowingfield to enable narrowing. Note that it is only effective in IKEv2 negotiation.-
Enable fragmentation- corresponds to thefragmentationLibreswan parameter - whether or not to allow IKE fragmentation. Valid values areyes(default) orno. -
Enable Mobike- corresponds to themobikeLibreswan parameter - whether or not to allow Mobility and Multihoming Protocol (MOBIKE, RFC 4555) to enable a connection to migrate its endpoint without needing to restart the connection from scratch. This is used on mobile devices that switch between wired, wireless, or mobile data connections. The values areno(default) oryes.
-
Select the menu entry:
IPv4 Method
-
Automatic (DHCP)- Choose this option if the network you are connecting to uses aDHCPserver to assign dynamicIPaddresses. -
Link-Local Only- Choose this option if the network you are connecting to does not have aDHCPserver and you do not want to assignIPaddresses manually. Random addresses will be assigned as per RFC 3927 with prefix169.254/16. -
Manual- Choose this option if you want to assignIPaddresses manually. Disable-IPv4is disabled for this connection.DNS
In the
DNSsection, whenAutomaticisON, switch it toOFFto enter the IP address of a DNS server you want to use separating the IPs by comma.Routes
Note that in the
Routessection, whenAutomaticisON, routes from DHCP are used, but you can also add additional static routes. WhenOFF, only static routes are used.-
Address- Enter theIPaddress of a remote network or host. -
Netmask- The netmask or prefix length of theIPaddress entered above. -
Gateway- TheIPaddress of the gateway leading to the remote network or host entered above. Metric- A network cost, a preference value to give to this route. Lower values will be preferred over higher values.Use this connection only for resources on its network
Select this check box to prevent the connection from becoming the default route. Selecting this option means that only traffic specifically destined for routes learned automatically over the connection or entered here manually is routed over the connection.
-
To configure
IPv6settings in aVPNconnection, select the menu entry:IPv6 Method
-
Automatic- Choose this option to useIPv6Stateless Address AutoConfiguration (SLAAC) to create an automatic, stateless configuration based on the hardware address and Router Advertisements (RA). -
Automatic, DHCP only- Choose this option to not use RA, but request information fromDHCPv6directly to create a stateful configuration. -
Link-Local Only- Choose this option if the network you are connecting to does not have aDHCPserver and you do not want to assignIPaddresses manually. Random addresses will be assigned as per RFC 4862 with prefixFE80::0. -
Manual- Choose this option if you want to assignIPaddresses manually. Disable-IPv6is disabled for this connection.Note that
DNS,Routes,Use this connection only for resources on its networkare common toIPv4settings.
-
-
Once you have finished editing the
VPNconnection, click the button to customize the configuration or the button to save it for the existing one. -
Switch the profile to
ONto activate theVPNconnection. - If you use this host in a network with DHCP or Stateless Address Autoconfiguration (SLAAC), the connection can be vulnerable to being redirected. For details and mitigation steps, see Assigning a VPN connection to a dedicated routing table to prevent the connection from bypassing the tunnel.
7.17. Configuring a VPN connection using nm-connection-editor
If you use Red Hat Enterprise Linux with a graphical interface, you can configure a VPN connection in the nm-connection-editor application.
Prerequisites
-
The
NetworkManager-libreswan-gnomepackage is installed. If you configure an Internet Key Exchange version 2 (IKEv2) connection:
- The certificate is imported into the IPsec network security services (NSS) database.
- The nickname of the certificate in the NSS database is known.
Procedure
Open a console, and enter:
$ nm-connection-editor- Click the button to add a new connection.
-
Select the
IPsec based VPNconnection type, and click . On the
VPNtab:Enter the host name or IP address of the VPN gateway into the
Gatewayfield, and select an authentication type. Based on the authentication type, you must enter different additional information:-
IKEv2 (Certifiate)authenticates the client by using a certificate, which is more secure. This setting requires the nickname of the certificate in the IPsec NSS database IKEv1 (XAUTH)authenticates the user by using a user name and password (pre-shared key). This setting requires that you enter the following values:- User name
- Password
- Group name
- Secret
-
If the remote server specifies a local identifier for the IKE exchange, enter the exact string in the
Remote IDfield. If the remote server runs Libreswan, this value is set in the server’sleftidparameter.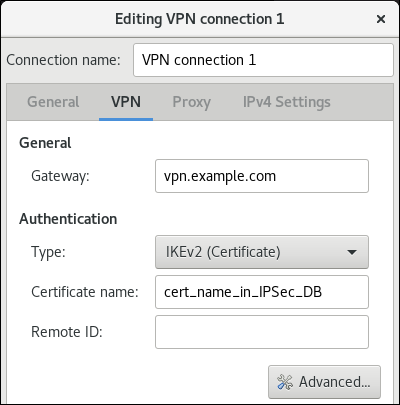
Optional: Configure additional settings by clicking the button. You can configure the following settings:
Identification
-
Domain- If required, enter the domain name.
-
Security
-
Phase1 Algorithmscorresponds to theikeLibreswan parameter. Enter the algorithms to be used to authenticate and set up an encrypted channel. Phase2 Algorithmscorresponds to theespLibreswan parameter. Enter the algorithms to be used for theIPsecnegotiations.Check the
Disable PFSfield to turn off Perfect Forward Secrecy (PFS) to ensure compatibility with old servers that do not support PFS.-
Phase1 Lifetimecorresponds to theikelifetimeLibreswan parameter. This parameter defines how long the key used to encrypt the traffic is valid. -
Phase2 Lifetimecorresponds to thesalifetimeLibreswan parameter. This parameter defines how long a security association is valid.
-
Connectivity
Remote networkcorresponds to therightsubnetLibreswan parameter and defines the destination private remote network that should be reached through the VPN.Check the
narrowingfield to enable narrowing. Note that it is only effective in the IKEv2 negotiation.-
Enable fragmentationcorresponds to thefragmentationLibreswan parameter and defines whether or not to allow IKE fragmentation. Valid values areyes(default) orno. -
Enable Mobikecorresponds to themobikeLibreswan parameter. The parameter defines whether or not to allow Mobility and Multihoming Protocol (MOBIKE) (RFC 4555) to enable a connection to migrate its endpoint without needing to restart the connection from scratch. This is used on mobile devices that switch between wired, wireless or mobile data connections. The values areno(default) oryes.
On the
IPv4 Settingstab, select the IP assignment method and, optionally, set additional static addresses, DNS servers, search domains, and routes.
- Save the connection.
-
Close
nm-connection-editor. If you use this host in a network with DHCP or Stateless Address Autoconfiguration (SLAAC), the connection can be vulnerable to being redirected. For details and mitigation steps, see Assigning a VPN connection to a dedicated routing table to prevent the connection from bypassing the tunnel.
NoteWhen you add a new connection by clicking the button, NetworkManager creates a new configuration file for that connection and then opens the same dialog that is used for editing an existing connection. The difference between these dialogs is that an existing connection profile has a Details menu entry.
7.18. Assigning a VPN connection to a dedicated routing table to prevent the connection from bypassing the tunnel
To protect your VPN connection from traffic redirection attacks, assign it to a dedicated routing table. This prevents malicious network servers from bypassing the secure tunnel and compromising data integrity.
Both a DHCP server and Stateless Address Autoconfiguration (SLAAC) can add routes to a client’s routing table. For example, a malicious DHCP server can use this feature to force a host with VPN connection to redirect traffic through a physical interface instead of the VPN tunnel. This vulnerability is also known as TunnelVision and described in the CVE-2024-3661 vulnerability article.
To mitigate this vulnerability, you can assign the VPN connection to a dedicated routing table. This prevents the DHCP configuration or SLAAC from manipulating routing decisions for network packets intended for the VPN tunnel.
Follow the steps if at least one of the conditions applies to your environment:
- At least one network interface uses DHCP or SLAAC.
- Your network does not use mechanisms, such as DHCP snooping, that prevent a rogue DHCP server.
Routing the entire traffic through the VPN prevents the host from accessing local network resources.
Prerequisites
- You use NetworkManager 1.40.16-18 or later.
Procedure
- Decide which routing table you want to use. The following steps use table 75. By default, RHEL does not use the tables 1-254, and you can use any of them.
Configure the VPN connection profile to place the VPN routes in a dedicated routing table:
# nmcli connection modify <vpn_connection_profile> ipv4.route-table 75 ipv6.route-table 75Set a low priority value for the table you used in the previous command:
# nmcli connection modify <vpn_connection_profile> ipv4.routing-rules "priority 32345 from all table 75" ipv6.routing-rules "priority 32345 from all table 75"The priority value can be any value between 1 and 32766. The lower the value, the higher the priority.
Reconnect the VPN connection:
# nmcli connection down <vpn_connection_profile> # nmcli connection up <vpn_connection_profile>
Verification
Display the IPv4 routes in table 75:
# ip route show table 75 ... 192.0.2.0/24 via 192.0.2.254 dev vpn_device proto static metric 50 default dev vpn_device proto static scope link metric 50The output confirms that both the route to the remote network and the default gateway are assigned to routing table 75 and, therefore, all traffic is routed through the tunnel. If you set
ipv4.never-default truein the VPN connection profile, a default route is not created and, therefore, not visible in this output.Display the IPv6 routes in table 75:
# ip -6 route show table 75 ... 2001:db8:1::/64 dev vpn_device proto kernel metric 50 pref medium default dev vpn_device proto static metric 50 pref mediumThe output confirms that both the route to the remote network and the default gateway are assigned to routing table 75 and, therefore, all traffic is routed through the tunnel. If you set
ipv6.never-default truein the VPN connection profile, a default route is not created and, therefore, not visible in this output.
Chapter 8. Configuring IP tunnels
Similar to a VPN, an IP tunnel directly connects two networks over a third network, such as the internet. However, not all tunnel protocols support encryption.
The routers in both networks that establish the tunnel requires at least two interfaces:
- One interface that is connected to the local network
- One interface that is connected to the network through which the tunnel is established.
To establish the tunnel, you create a virtual interface on both routers with an IP address from the remote subnet.
NetworkManager supports the following IP tunnels:
- Generic Routing Encapsulation (GRE)
- Generic Routing Encapsulation over IPv6 (IP6GRE)
- Generic Routing Encapsulation Terminal Access Point (GRETAP)
- Generic Routing Encapsulation Terminal Access Point over IPv6 (IP6GRETAP)
- IPv4 over IPv4 (IPIP)
- IPv4 over IPv6 (IPIP6)
- IPv6 over IPv6 (IP6IP6)
- Simple Internet Transition (SIT)
Depending on the type, these tunnels act either on layer 2 or 3 of the Open Systems Interconnection (OSI) model.
8.1. Configuring an IPIP tunnel to encapsulate IPv4 traffic in IPv4 packets
An IP over IP (IPIP) tunnel operates on OSI layer 3 and encapsulates IPv4 traffic in IPv4 packets.
Data sent through an IPIP tunnel is not encrypted. For security reasons, use the tunnel only for data that is already encrypted, for example, by other protocols, such as HTTPS.
Note that IPIP tunnels support only unicast packets. If you require an IPv4 tunnel that supports multicast, see Configuring a GRE tunnel to encapsulate layer-3 traffic in IPv4 packets.
For example, you can create an IPIP tunnel between two RHEL routers to connect two internal subnets over the internet as shown in the following diagram:
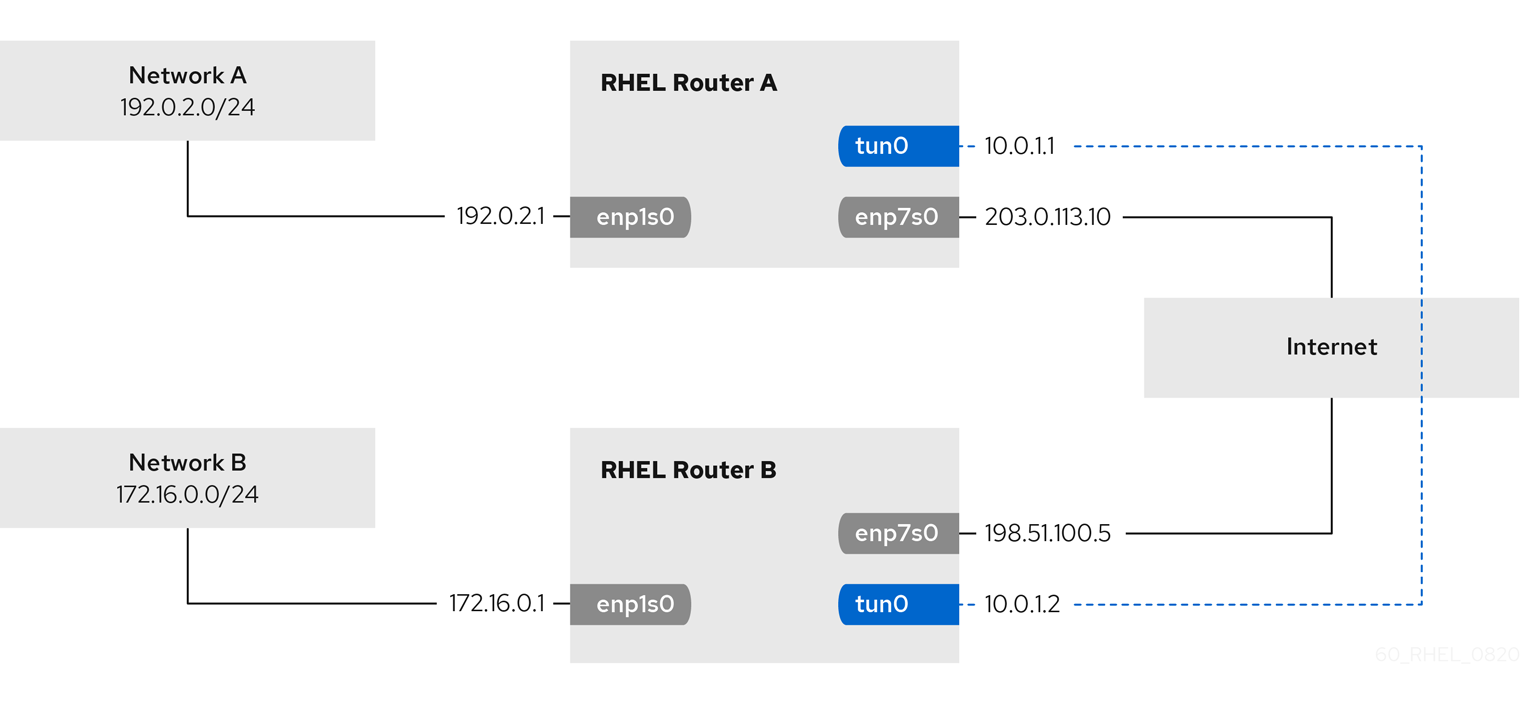
Prerequisites
- Each RHEL router has a network interface that is connected to its local subnet.
- Each RHEL router has a network interface that is connected to the internet.
- The traffic you want to send through the tunnel is IPv4 unicast.
Procedure
On the RHEL router in network A:
Create an IPIP tunnel interface named
tun0:# nmcli connection add type ip-tunnel ip-tunnel.mode ipip con-name tun0 ifname tun0 remote 198.51.100.5 local 203.0.113.10The
remoteandlocalparameters set the public IP addresses of the remote and the local routers.Set the IPv4 address to the
tun0device:# nmcli connection modify tun0 ipv4.addresses '10.0.1.1/30'Note that a
/30subnet with two usable IP addresses is sufficient for the tunnel.Configure the
tun0connection to use a manual IPv4 configuration:# nmcli connection modify tun0 ipv4.method manualAdd a static route that routes traffic to the
172.16.0.0/24network to the tunnel IP on router B:# nmcli connection modify tun0 +ipv4.routes "172.16.0.0/24 10.0.1.2"Enable the
tun0connection.# nmcli connection up tun0Enable packet forwarding:
# echo "net.ipv4.ip_forward=1" > /etc/sysctl.d/95-IPv4-forwarding.conf # sysctl -p /etc/sysctl.d/95-IPv4-forwarding.conf
On the RHEL router in network B:
Create an IPIP tunnel interface named
tun0:# nmcli connection add type ip-tunnel ip-tunnel.mode ipip con-name tun0 ifname tun0 remote 203.0.113.10 local 198.51.100.5The
remoteandlocalparameters set the public IP addresses of the remote and local routers.Set the IPv4 address to the
tun0device:# nmcli connection modify tun0 ipv4.addresses '10.0.1.2/30'Configure the
tun0connection to use a manual IPv4 configuration:# nmcli connection modify tun0 ipv4.method manualAdd a static route that routes traffic to the
192.0.2.0/24network to the tunnel IP on router A:# nmcli connection modify tun0 +ipv4.routes "192.0.2.0/24 10.0.1.1"Enable the
tun0connection.# nmcli connection up tun0Enable packet forwarding:
# echo "net.ipv4.ip_forward=1" > /etc/sysctl.d/95-IPv4-forwarding.conf # sysctl -p /etc/sysctl.d/95-IPv4-forwarding.conf
Verification
From each RHEL router, ping the IP address of the internal interface of the other router:
On Router A, ping
172.16.0.1:# ping 172.16.0.1On Router B, ping
192.0.2.1:# ping 192.0.2.1
8.2. Configuring a GRE tunnel to encapsulate layer-3 traffic in IPv4 packets
A Generic Routing Encapsulation (GRE) tunnel encapsulates layer-3 traffic in IPv4 packets. A GRE tunnel can encapsulate any layer 3 protocol with a valid Ethernet type.
Data sent through a GRE tunnel is not encrypted. For security reasons, use the tunnel only for data that is already encrypted, for example, by other protocols, such as HTTPS.
For example, you can create a GRE tunnel between two RHEL routers to connect two internal subnets over the internet as shown in the following diagram:
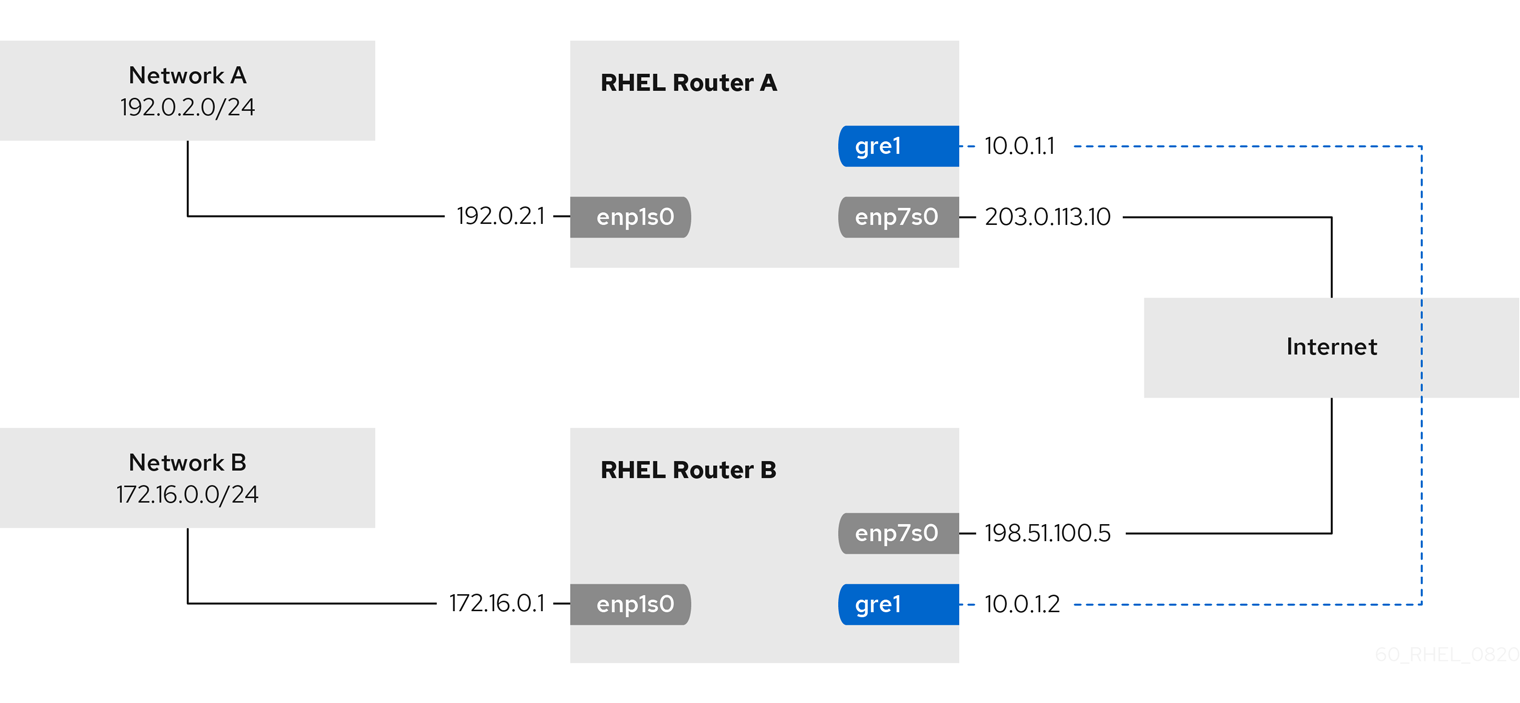
Prerequisites
- Each RHEL router has a network interface that is connected to its local subnet.
- Each RHEL router has a network interface that is connected to the internet.
Procedure
On the RHEL router in network A:
Create a GRE tunnel interface named
gre1:# nmcli connection add type ip-tunnel ip-tunnel.mode gre con-name gre1 ifname gre1 remote 198.51.100.5 local 203.0.113.10The
remoteandlocalparameters set the public IP addresses of the remote and the local routers.ImportantThe
gre0device name is reserved. Usegre1or a different name for the device.Set the IPv4 address to the
gre1device:# nmcli connection modify gre1 ipv4.addresses '10.0.1.1/30'Note that a
/30subnet with two usable IP addresses is sufficient for the tunnel.Configure the
gre1connection to use a manual IPv4 configuration:# nmcli connection modify gre1 ipv4.method manualAdd a static route that routes traffic to the
172.16.0.0/24network to the tunnel IP on router B:# nmcli connection modify gre1 +ipv4.routes "172.16.0.0/24 10.0.1.2"Enable the
gre1connection.# nmcli connection up gre1Enable packet forwarding:
# echo "net.ipv4.ip_forward=1" > /etc/sysctl.d/95-IPv4-forwarding.conf # sysctl -p /etc/sysctl.d/95-IPv4-forwarding.conf
On the RHEL router in network B:
Create a GRE tunnel interface named
gre1:# nmcli connection add type ip-tunnel ip-tunnel.mode gre con-name gre1 ifname gre1 remote 203.0.113.10 local 198.51.100.5The
remoteandlocalparameters set the public IP addresses of the remote and the local routers.Set the IPv4 address to the
gre1device:# nmcli connection modify gre1 ipv4.addresses '10.0.1.2/30'Configure the
gre1connection to use a manual IPv4 configuration:# nmcli connection modify gre1 ipv4.method manualAdd a static route that routes traffic to the
192.0.2.0/24network to the tunnel IP on router A:# nmcli connection modify gre1 +ipv4.routes "192.0.2.0/24 10.0.1.1"Enable the
gre1connection.# nmcli connection up gre1Enable packet forwarding:
# echo "net.ipv4.ip_forward=1" > /etc/sysctl.d/95-IPv4-forwarding.conf # sysctl -p /etc/sysctl.d/95-IPv4-forwarding.conf
Verification
From each RHEL router, ping the IP address of the internal interface of the other router:
On Router A, ping
172.16.0.1:# ping 172.16.0.1On Router B, ping
192.0.2.1:# ping 192.0.2.1
8.3. Configuring a GRETAP tunnel to transfer Ethernet frames over IPv4
A Generic Routing Encapsulation Terminal Access Point (GRETAP) tunnel operates on OSI level 2 and encapsulates Ethernet traffic in IPv4 packets.
Data sent through a GRETAP tunnel is not encrypted. For security reasons, establish the tunnel over a VPN or a different encrypted connection.
For example, you can create a GRETAP tunnel between two RHEL routers to connect two networks using a bridge as shown in the following diagram:
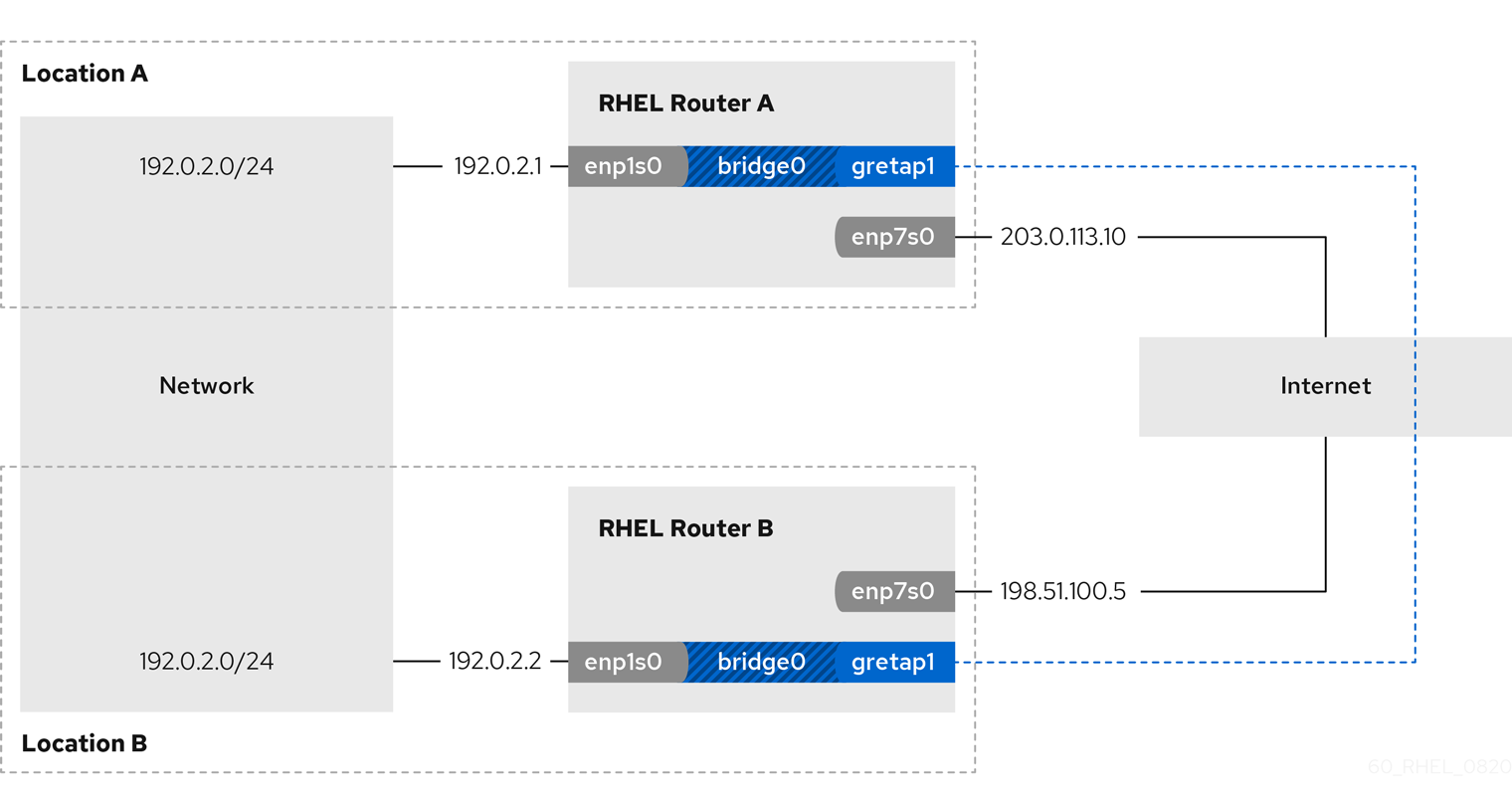
Prerequisites
- Each RHEL router has a network interface that is connected to its local network, and the interface has no IP configuration assigned.
- Each RHEL router has a network interface that is connected to the internet.
Procedure
On the RHEL router in network A:
Create a bridge interface named
bridge0:# nmcli connection add type bridge con-name bridge0 ifname bridge0Configure the IP settings of the bridge:
# nmcli connection modify bridge0 ipv4.addresses '192.0.2.1/24' # nmcli connection modify bridge0 ipv4.method manualAdd a new connection profile for the interface that is connected to local network to the bridge:
# nmcli connection add type ethernet slave-type bridge con-name bridge0-port1 ifname enp1s0 master bridge0Add a new connection profile for the GRETAP tunnel interface to the bridge:
# nmcli connection add type ip-tunnel ip-tunnel.mode gretap slave-type bridge con-name bridge0-port2 ifname gretap1 remote 198.51.100.5 local 203.0.113.10 master bridge0The
remoteandlocalparameters set the public IP addresses of the remote and the local routers.ImportantThe
gretap0device name is reserved. Usegretap1or a different name for the device.Optional: Disable the Spanning Tree Protocol (STP) if you do not need it:
# nmcli connection modify bridge0 bridge.stp noBy default, STP is enabled and causes a delay before you can use the connection.
Configure that activating the
bridge0connection automatically activates the ports of the bridge:# nmcli connection modify bridge0 connection.autoconnect-slaves 1Active the
bridge0connection:# nmcli connection up bridge0
On the RHEL router in network B:
Create a bridge interface named
bridge0:# nmcli connection add type bridge con-name bridge0 ifname bridge0Configure the IP settings of the bridge:
# nmcli connection modify bridge0 ipv4.addresses '192.0.2.2/24' # nmcli connection modify bridge0 ipv4.method manualAdd a new connection profile for the interface that is connected to local network to the bridge:
# nmcli connection add type ethernet slave-type bridge con-name bridge0-port1 ifname enp1s0 master bridge0Add a new connection profile for the GRETAP tunnel interface to the bridge:
# nmcli connection add type ip-tunnel ip-tunnel.mode gretap slave-type bridge con-name bridge0-port2 ifname gretap1 remote 203.0.113.10 local 198.51.100.5 master bridge0The
remoteandlocalparameters set the public IP addresses of the remote and the local routers.Optional: Disable the Spanning Tree Protocol (STP) if you do not need it:
# nmcli connection modify bridge0 bridge.stp noConfigure that activating the
bridge0connection automatically activates the ports of the bridge:# nmcli connection modify bridge0 connection.autoconnect-slaves 1Active the
bridge0connection:# nmcli connection up bridge0
Verification
On both routers, verify that the
enp1s0andgretap1connections are connected and that theCONNECTIONcolumn displays the connection name of the port:# nmcli device nmcli device DEVICE TYPE STATE CONNECTION ... bridge0 bridge connected bridge0 enp1s0 ethernet connected bridge0-port1 gretap1 iptunnel connected bridge0-port2From each RHEL router, ping the IP address of the internal interface of the other router:
On Router A, ping
192.0.2.2:# ping 192.0.2.2On Router B, ping
192.0.2.1:# ping 192.0.2.1
Chapter 9. Using a VXLAN to create a virtual layer-2 domain for VMs
A virtual extensible LAN (VXLAN) is a networking protocol that tunnels layer-2 traffic over an IP network using the UDP protocol. For example, certain virtual machines (VMs) that are running on different hosts can communicate over a VXLAN tunnel. The hosts can be in different subnets or even in different data centers around the world. From the perspective of the VMs, other VMs in the same VXLAN are within the same layer-2 domain:
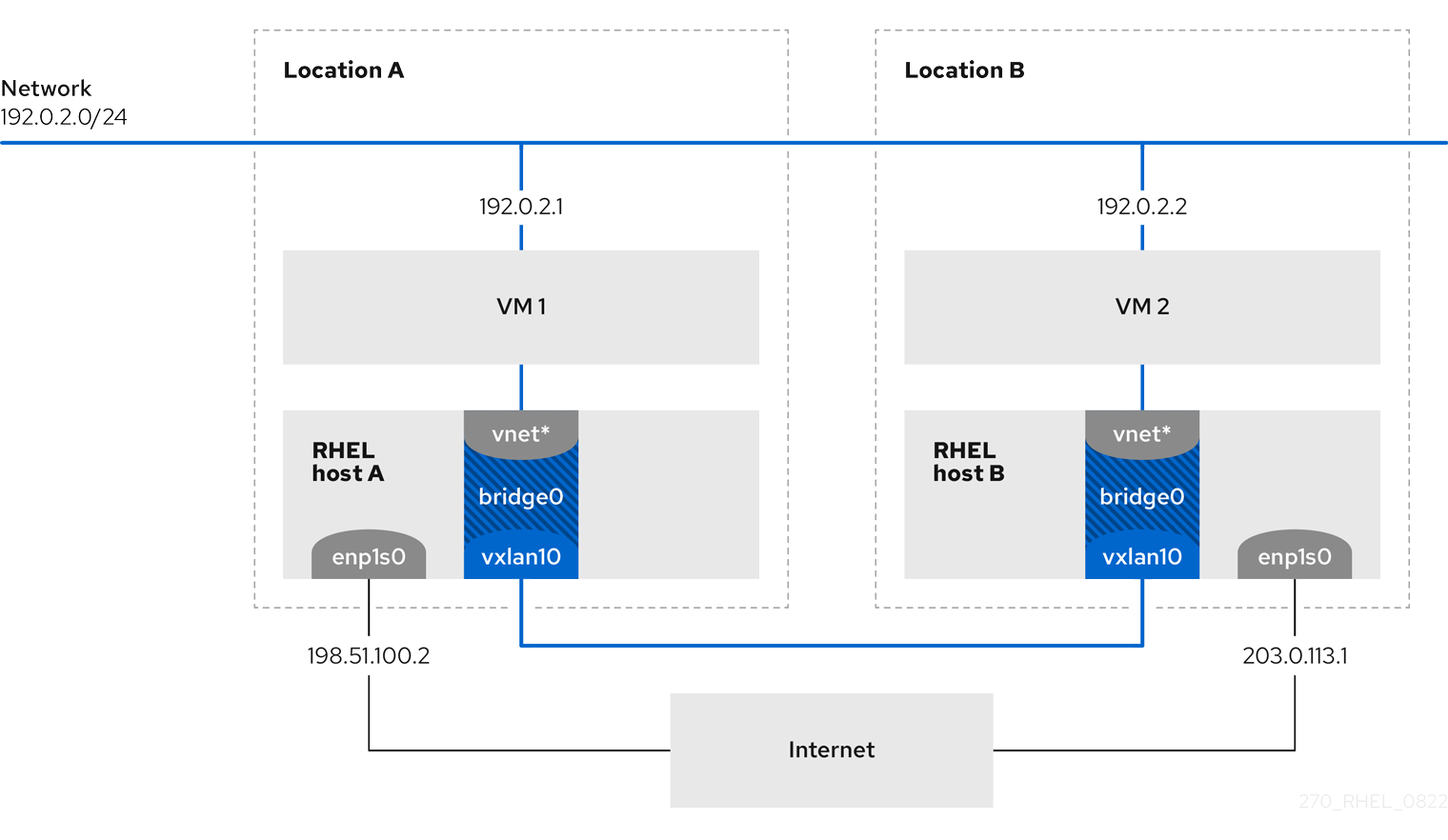
In this example, RHEL-host-A and RHEL-host-B use a bridge, br0, to connect the virtual network of a VM on each host with a VXLAN named vxlan10. Due to this configuration, the VXLAN is invisible to the VMs, and the VMs do not require any special configuration. If you later connect more VMs to the same virtual network, the VMs are automatically members of the same virtual layer-2 domain.
Just as normal layer-2 traffic, data in a VXLAN is not encrypted. For security reasons, use a VXLAN over a VPN or other types of encrypted connections.
9.1. Benefits of VXLANs
A virtual extensible LAN (VXLAN) provides the following major benefits:
- VXLANs use a 24-bit ID. Therefore, you can create up to 16,777,216 isolated networks. For example, a virtual LAN (VLAN), supports only 4,096 isolated networks.
- VXLANs use the IP protocol. This enables you to route the traffic and virtually run systems in different networks and locations within the same layer-2 domain.
- Unlike most tunnel protocols, a VXLAN is not only a point-to-point network. A VXLAN can learn the IP addresses of the other endpoints either dynamically or use statically-configured forwarding entries.
- Certain network cards support UDP tunnel-related offload features.
For further details, see the /usr/share/doc/kernel-doc-<kernel_version>/Documentation/networking/vxlan.rst file provided by the kernel-doc package.
9.2. Configuring the Ethernet interface on the hosts
To connect a RHEL VM host to the Ethernet, create a network connection profile, configure the IP settings, and activate the profile.
Run this procedure on both RHEL hosts, and adjust the IP address configuration accordingly.
Prerequisites
- The host is connected to the Ethernet.
Procedure
Add a new Ethernet connection profile to NetworkManager:
# nmcli connection add con-name Example ifname enp1s0 type ethernetConfigure the IPv4 settings:
# nmcli connection modify Example ipv4.addresses 198.51.100.2/24 ipv4.method manual ipv4.gateway 198.51.100.254 ipv4.dns 198.51.100.200 ipv4.dns-search example.comSkip this step if the network uses DHCP.
Activate the
Exampleconnection:# nmcli connection up Example
Verification
Display the status of the devices and connections:
# nmcli device status DEVICE TYPE STATE CONNECTION enp1s0 ethernet connected ExamplePing a host in a remote network to verify the IP settings:
# ping RHEL-host-B.example.comNote that you cannot ping the other VM host before you have configured the network on that host as well.
9.3. Creating a network bridge with a VXLAN attached
To make a virtual extensible LAN (VXLAN) invisible to virtual machines (VMs), create a bridge on a host, and attach the VXLAN to the bridge. Use NetworkManager to create both the bridge and the VXLAN. You do not add any traffic access point (TAP) devices of the VMs, typically named vnet* on the host, to the bridge. The libvirtd service adds them dynamically when the VMs start.
Run this procedure on both RHEL hosts, and adjust the IP addresses accordingly.
Procedure
Create the bridge
bridge0:# nmcli connection add type bridge con-name bridge0 ifname bridge0 ipv4.method disabled ipv6.method disabledThis command sets no IPv4 and IPv6 addresses on the bridge device, because this bridge works on layer 2.
Create the VXLAN interface and attach it to
bridge0:# nmcli connection add type vxlan slave-type bridge con-name bridge0-vxlan10 ifname vxlan10 id 10 local 198.51.100.2 remote 203.0.113.1 master bridge0This command uses the following settings:
-
id 10: Sets the VXLAN identifier. -
local 198.51.100.2: Sets the source IP address of outgoing packets. -
remote 203.0.113.1: Sets the unicast or multicast IP address to use in outgoing packets when the destination link layer address is not known in the VXLAN device forwarding database. -
master bridge0: Sets this VXLAN connection to be created as a port in thebridge0connection. -
ipv4.method disabledandipv6.method disabled: Disables IPv4 and IPv6 on the bridge.
By default, NetworkManager uses
8472as the destination port. If the destination port is different, additionally, pass thedestination-port <port_number>option to the command.-
Activate the
bridge0connection profile:# nmcli connection up bridge0Open port
8472for incoming UDP connections in the local firewall:# firewall-cmd --permanent --add-port=8472/udp # firewall-cmd --reload
Verification
Display the forwarding table:
# bridge fdb show dev vxlan10 2a:53:bd:d5:b3:0a master bridge0 permanent 00:00:00:00:00:00 dst 203.0.113.1 self permanent ...
9.4. Creating a virtual network in libvirt with an existing VXLAN bridge
To enable virtual machines (VM) to use the bridge0 bridge with the attached virtual extensible LAN (VXLAN), first add a virtual network to the libvirtd service that uses this bridge.
Prerequisites
-
You installed the
libvirtpackage. -
You started and enabled the
libvirtdservice. -
You configured the
bridge0device with the VXLAN on RHEL.
Procedure
Create the
~/vxlan10-bridge.xmlfile with the following content:<network> <name>vxlan10-bridge</name> <forward mode="bridge" /> <bridge name="bridge0" /> </network>Use the
~/vxlan10-bridge.xmlfile to create a new virtual network inlibvirt:# virsh net-define ~/vxlan10-bridge.xmlRemove the
~/vxlan10-bridge.xmlfile:# rm ~/vxlan10-bridge.xmlStart the
vxlan10-bridgevirtual network:# virsh net-start vxlan10-bridgeConfigure the
vxlan10-bridgevirtual network to start automatically when thelibvirtdservice starts:# virsh net-autostart vxlan10-bridge
Verification
Display the list of virtual networks:
# virsh net-list Name State Autostart Persistent ---------------------------------------------------- vxlan10-bridge active yes yes ...
9.5. Configuring virtual machines to use VXLAN
To configure a VM to use a bridge device with an attached virtual extensible LAN (VXLAN) on the host, create a new VM that uses the vxlan10-bridge virtual network or update the settings of existing VMs to use this network.
Perform this procedure on the RHEL hosts.
Prerequisites
-
You configured the
vxlan10-bridgevirtual network inlibvirtd.
Procedure
To create a new VM and configure it to use the
vxlan10-bridgenetwork, pass the--network network:vxlan10-bridgeoption to thevirt-installcommand when you create the VM:# virt-install ... --network network:vxlan10-bridgeTo change the network settings of an existing VM:
Connect the VM’s network interface to the
vxlan10-bridgevirtual network:# virt-xml VM_name --edit --network network=vxlan10-bridgeShut down the VM, and start it again:
# virsh shutdown VM_name # virsh start VM_name
Verification
Display the virtual network interfaces of the VM on the host:
# virsh domiflist VM_name Interface Type Source Model MAC ------------------------------------------------------------------- vnet1 bridge vxlan10-bridge virtio 52:54:00:c5:98:1cDisplay the interfaces attached to the
vxlan10-bridgebridge:# ip link show master vxlan10-bridge 18: vxlan10: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master bridge0 state UNKNOWN mode DEFAULT group default qlen 1000 link/ether 2a:53:bd:d5:b3:0a brd ff:ff:ff:ff:ff:ff 19: vnet1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master bridge0 state UNKNOWN mode DEFAULT group default qlen 1000 link/ether 52:54:00:c5:98:1c brd ff:ff:ff:ff:ff:ffNote that the
libvirtdservice dynamically updates the bridge’s configuration. When you start a VM which uses thevxlan10-bridgenetwork, the correspondingvnet*device on the host appears as a port of the bridge.Use address resolution protocol (ARP) requests to verify whether VMs are in the same VXLAN:
- Start two or more VMs in the same VXLAN.
Send an ARP request from one VM to the other one:
# arping -c 1 192.0.2.2 ARPING 192.0.2.2 from 192.0.2.1 enp1s0 Unicast reply from 192.0.2.2 [52:54:00:c5:98:1c] 1.450ms Sent 1 probe(s) (0 broadcast(s)) Received 1 response(s) (0 request(s), 0 broadcast(s))If the command shows a reply, the VM is in the same layer-2 domain and, in this case in the same VXLAN.
Install the
iputilspackage to use thearpingutility.
Chapter 10. Managing wifi connections
If your host contains a wifi adapter, you can connect it to a wifi network.
-
Use the
nmcliutility to configure connections by using the command line. -
Use the
nmtuiapplication to configure connections in a text-based user interface. - Use the GNOME system menu to quickly connect to wifi networks that do not require any configuration.
-
Use the
GNOME Settingsapplication to configure connections by using the GNOME application. -
Use the
nm-connection-editorapplication to configure connections in a graphical user interface. -
Use the
networkRHEL system role to automate the configuration of connections on one or multiple hosts.
10.1. Supported wifi security types
Depending on the security type a wifi network supports, you can transmit data more or less securely.
Do not connect to wifi networks that do not use encryption or which support only the insecure WEP or WPA standards.
RHEL 8 supports the following wifi security types:
-
None: Encryption is disabled, and data is transferred in plain text over the network. -
Enhanced Open: With opportunistic wireless encryption (OWE), devices negotiate unique pairwise master keys (PMK) to encrypt connections in wireless networks without authentication. -
WEP 40/128-bit Key (Hex or ASCII): The Wired Equivalent Privacy (WEP) protocol in this mode uses pre-shared keys only in hex or ASCII format. WEP is deprecated and will be removed in RHEL 9.1. -
WEP 128-bit Passphrase. The WEP protocol in this mode uses an MD5 hash of the passphrase to derive a WEP key. WEP is deprecated and will be removed in RHEL 9.1. -
Dynamic WEP (802.1x): A combination of 802.1X and EAP that uses the WEP protocol with dynamic keys. WEP is deprecated and will be removed in RHEL 9.1. -
LEAP: The Lightweight Extensible Authentication Protocol, which was developed by Cisco, is a proprietary version of the extensible authentication protocol (EAP). -
WPA & WPA2 Personal: In personal mode, the Wi-Fi Protected Access (WPA) and Wi-Fi Protected Access 2 (WPA2) authentication methods use a pre-shared key. -
WPA & WPA2 Enterprise: In enterprise mode, WPA and WPA2 use the EAP framework and authenticate users to a remote authentication dial-in user service (RADIUS) server. -
WPA3 Personal: Wi-Fi Protected Access 3 (WPA3) Personal uses simultaneous authentication of equals (SAE) instead of pre-shared keys (PSK) to prevent dictionary attacks. WPA3 uses perfect forward secrecy (PFS).
10.2. Connecting to a wifi network by using nmcli
When you first use the nmcli utility to connect to a wifi network, it automatically creates a NetworkManager connection profile. You can then modify this profile to add specific settings, such as a static IP address.
Prerequisites
- A wifi device is installed on the host.
-
The wifi device is enabled. To verify, use the
nmcli radiocommand.
Procedure
If the wifi radio has been disabled in NetworkManager, enable this feature:
# nmcli radio wifi onOptional: Display the available wifi networks:
# nmcli device wifi list IN-USE BSSID SSID MODE CHAN RATE SIGNAL BARS SECURITY 00:53:00:2F:3B:08 Office Infra 44 270 Mbit/s 57 ▂▄▆_ WPA2 WPA3 00:53:00:15:03:BF -- Infra 1 130 Mbit/s 48 ▂▄__ WPA2 WPA3The service set identifier (
SSID) column contains the names of the networks. If the column shows--, the access point of this network does not broadcast an SSID.Connect to the wifi network:
# nmcli device wifi connect Office --ask Password: wifi-passwordIf you prefer to set the password in the command instead of entering it interactively, use the
password <wifi_password>option in the command instead of--ask:# nmcli device wifi connect Office password <wifi_password>Note that, if the network requires static IP addresses, NetworkManager fails to activate the connection at this point. You can configure the IP addresses in later steps.
If the network requires static IP addresses:
Configure the IPv4 address settings, for example:
# nmcli connection modify Office ipv4.method manual ipv4.addresses 192.0.2.1/24 ipv4.gateway 192.0.2.254 ipv4.dns 192.0.2.200 ipv4.dns-search example.comConfigure the IPv6 address settings, for example:
# nmcli connection modify Office ipv6.method manual ipv6.addresses 2001:db8:1::1/64 ipv6.gateway 2001:db8:1::fffe ipv6.dns 2001:db8:1::ffbb ipv6.dns-search example.com
Re-activate the connection:
# nmcli connection up Office
Verification
Display the active connections:
# nmcli connection show --active NAME ID TYPE DEVICE Office 2501eb7e-7b16-4dc6-97ef-7cc460139a58 wifi wlp0s20f3If the output lists the wifi connection you have created, the connection is active.
Ping a hostname or IP address:
# ping -c 3 example.com
10.3. Connecting to a wifi network by using the GNOME system menu
You can use the GNOME system menu to connect to a wifi network. When you connect to a network for the first time, GNOME creates a NetworkManager connection profile for it. If you configure the connection profile to not automatically connect, you can also use the GNOME system menu to manually connect to a wifi network with an existing NetworkManager connection profile.
Using the GNOME system menu to establish a connection to a wifi network for the first time has certain limitations. For example, you cannot configure IP address settings. In this case first configure the connections:
Prerequisites
- A wifi device is installed on the host.
-
The wifi device is enabled. To verify, use the
nmcli radiocommand.
Procedure
- Open the system menu on the right side of the top bar.
-
Expand the
Wi-Fi Not Connectedentry. Click
Select Network:
- Select the wifi network you want to connect to.
-
Click
Connect. -
If this is the first time you connect to this network, enter the password for the network, and click
Connect.
Verification
Open the system menu on the right side of the top bar, and verify that the wifi network is connected:
If the network is listed, it is connected.
Ping a hostname or IP address:
# ping -c 3 example.com
10.4. Connecting to a wifi network by using GNOME Settings
You can use the GNOME Settings application, also named gnome-control-center, to connect to a wifi network and configure the connection. When you connect to the network for the first time, GNOME creates a NetworkManager connection profile for it.
In GNOME Settings, you can configure wifi connections for all wifi network security types that RHEL supports.
Prerequisites
- A wifi device is installed on the host.
-
The wifi device is enabled. To verify, use the
nmcli radiocommand.
Procedure
-
Press the Super key, type
Wi-Fi, and press Enter. - Click the name of the wifi network you want to connect to.
-
Enter the password for the network, and click
Connect. If the network requires additional settings, such as static IP addresses or a security type other than WPA2 Personal:
- Click the gear icon next to the network’s name.
Optional: Configure the network profile on the
Detailstab to not automatically connect.If you deactivate this feature, you must always manually connect to the network, for example, by using GNOME Settings or the GNOME system menu.
-
Configure IPv4 settings on the
IPv4tab, and IPv6 settings on theIPv6tab. On the
Securitytab, select the authentication of the network, such asWPA3 Personal, and enter the password.Depending on the selected security, the application shows additional fields. Fill them accordingly. For details, ask the administrator of the wifi network.
-
Click
Apply.
Verification
Open the system menu on the right side of the top bar, and verify that the wifi network is connected:
If the network is listed, it is connected.
Ping a hostname or IP address:
# ping -c 3 example.com
10.5. Configuring a wifi connection by using nmtui
The nmtui application provides a text-based user interface for NetworkManager. You can use nmtui to connect to a wifi network.
In nmtui:
- Navigate by using the cursor keys.
- Press a button by selecting it and hitting Enter.
- Select and clear checkboxes by using Space.
- To return to the previous screen, use ESC.
Procedure
Start
nmtui:# nmtui-
Select
Edit a connection, and press Enter. -
Press the
Addbutton. -
Select
Wi-Fifrom the list of network types, and press Enter. Optional: Enter a name for the NetworkManager profile to be created.
On hosts with multiple profiles, a meaningful name makes it easier to identify the purpose of a profile.
-
Enter the name of the Wi-Fi network, the Service Set Identifier (SSID), into the
SSIDfield. -
Leave the
Modefield set to its default,Client. Select the
Securityfield, press Enter, and set the authentication type of the network from the list.Depending on the authentication type you have selected,
nmtuidisplays different fields.- Fill the authentication type-related fields.
If the Wi-Fi network requires static IP addresses:
-
Press the
Automaticbutton next to the protocol, and selectManualfrom the displayed list. -
Press the
Showbutton next to the protocol you want to configure to display additional fields, and fill them.
-
Press the
-
Press the
OKbutton to create and automatically activate the new connection. -
Press the
Backbutton to return to the main menu. -
Select
Quit, and press Enter to close thenmtuiapplication.
Verification
Display the active connections:
# nmcli connection show --active NAME ID TYPE DEVICE Office 2501eb7e-7b16-4dc6-97ef-7cc460139a58 wifi wlp0s20f3If the output lists the wifi connection you have created, the connection is active.
Ping a hostname or IP address:
# ping -c 3 example.com
10.6. Configuring a wifi connection by using nm-connection-editor
You can use the nm-connection-editor application to create a connection profile for a wireless network. In this application you can configure all wifi network authentication types that RHEL supports.
By default, NetworkManager enables the auto-connect feature for connection profiles and automatically connects to a saved network if it is available.
Prerequisites
- A wifi device is installed on the host.
-
The wifi device is enabled. To verify, use the
nmcli radiocommand.
Procedure
Open a console and enter:
# nm-connection-editor- Click the button to add a new connection.
-
Select the
Wi-Ficonnection type, and click . - Optional: Set a name for the connection profile.
Optional: Configure the network profile on the
Generaltab to not automatically connect.If you deactivate this feature, you must always manually connect to the network, for example, by using GNOME Settings or the GNOME system menu.
-
On the
Wi-Fitab, enter the service set identifier (SSID) in theSSIDfield. On the
Wi-Fi Securitytab, select the authentication type for the network, such asWPA3 Personal, and enter the password.Depending on the selected security, the application shows additional fields. Fill them accordingly. For details, ask the administrator of the wifi network.
-
Configure IPv4 settings on the
IPv4tab, and IPv6 settings on theIPv6tab. -
Click
Save. -
Close the
Network Connectionswindow.
Verification
Open the system menu on the right side of the top bar, and verify that the wifi network is connected:
If the network is listed, it is connected.
Ping a hostname or IP address:
# ping -c 3 example.com
10.7. Configuring a wifi connection with 802.1X network authentication in an existing profile by using nmcli
You can use the nmcli utility to configure a client to authenticate itself to a network.
For example, you can configure Protected Extensible Authentication Protocol (PEAP) authentication with Microsoft Challenge-Handshake Authentication Protocol version 2 (MSCHAPv2) in an existing NetworkManager wifi profile.
Prerequisites
- The network must have 802.1X network authentication.
- The wifi connection profile exists in NetworkManager and has a valid IP configuration.
-
If the client is required to verify the certificate of the authenticator, the Certificate Authority (CA) certificate must be stored in the
/etc/pki/ca-trust/source/anchors/directory. -
The
wpa_supplicantpackage is installed.
Procedure
Set the wifi security mode to
wpa-eap, the Extensible Authentication Protocol (EAP) topeap, the inner authentication protocol tomschapv2, and the user name:# nmcli connection modify wlp1s0 wireless-security.key-mgmt wpa-eap 802-1x.eap peap 802-1x.phase2-auth mschapv2 802-1x.identity user_nameNote that you must set the
wireless-security.key-mgmt,802-1x.eap,802-1x.phase2-auth, and802-1x.identityparameters in a single command.Optional: Store the password in the configuration:
# nmcli connection modify wlp1s0 802-1x.password passwordImportantBy default, NetworkManager stores the password in plain text in the
/etc/sysconfig/network-scripts/keys-connection_namefile, which is readable only by therootuser. However, plain text passwords in a configuration file can be a security risk.To increase the security, set the
802-1x.password-flagsparameter toagent-owned. With this setting, on servers with the GNOME desktop environment or thenm-appletrunning, NetworkManager retrieves the password from these services, after you unlock the keyring first. In other cases, NetworkManager prompts for the password.If the client needs to verify the certificate of the authenticator, set the
802-1x.ca-certparameter in the connection profile to the path of the CA certificate:# nmcli connection modify wlp1s0 802-1x.ca-cert /etc/pki/ca-trust/source/anchors/ca.crtNoteValidating the certificate of the authenticator improves the security.
Activate the connection profile:
# nmcli connection up wlp1s0
Verification
- Access resources on the network that require network authentication.
10.8. Configuring a wifi connection with 802.1X network authentication by using the network RHEL system role
By using the network RHEL system role, you can automate setting up Network Access Control (NAC) on remote hosts. You can define authentication details for clients in a playbook to ensure only authorized clients can access the network.
You can use an Ansible playbook to copy a private key, a certificate, and the CA certificate to the client, and then use the network RHEL system role to configure a connection profile with 802.1X network authentication.
Prerequisites
- You have prepared the control node and the managed nodes.
-
The account you use to connect to the managed nodes has
sudopermissions for these nodes. - The network supports 802.1X network authentication.
-
You installed the
wpa_supplicantpackage on the managed node. - DHCP is available in the network of the managed node.
The following files required for TLS authentication exist on the control node:
-
The client key is stored in the
/srv/data/client.keyfile. -
The client certificate is stored in the
/srv/data/client.crtfile. -
The CA certificate is stored in the
/srv/data/ca.crtfile.
-
The client key is stored in the
Procedure
Store your sensitive variables in an encrypted file:
Create the vault:
$ ansible-vault create ~/vault.yml New Vault password: <vault_password> Confirm New Vault password: <vault_password>After the
ansible-vault createcommand opens an editor, enter the sensitive data in the<key>: <value>format:pwd: <password>- Save the changes, and close the editor. Ansible encrypts the data in the vault.
Create a playbook file, for example,
~/playbook.yml, with the following content:--- - name: Configure a wifi connection with 802.1X authentication hosts: managed-node-01.example.com tasks: - name: Copy client key for 802.1X authentication ansible.builtin.copy: src: "/srv/data/client.key" dest: "/etc/pki/tls/private/client.key" mode: 0400 - name: Copy client certificate for 802.1X authentication ansible.builtin.copy: src: "/srv/data/client.crt" dest: "/etc/pki/tls/certs/client.crt" - name: Copy CA certificate for 802.1X authentication ansible.builtin.copy: src: "/srv/data/ca.crt" dest: "/etc/pki/ca-trust/source/anchors/ca.crt" - name: Wifi connection profile with dynamic IP address settings and 802.1X ansible.builtin.import_role: name: redhat.rhel_system_roles.network vars: network_connections: - name: Wifi connection profile with dynamic IP address settings and 802.1X interface_name: wlp1s0 state: up type: wireless autoconnect: yes ip: dhcp4: true auto6: true wireless: ssid: "Example-wifi" key_mgmt: "wpa-eap" ieee802_1x: identity: <user_name> eap: tls private_key: "/etc/pki/tls/client.key" private_key_password: "{{ pwd }}" private_key_password_flags: none client_cert: "/etc/pki/tls/client.pem" ca_cert: "/etc/pki/tls/cacert.pem" domain_suffix_match: "example.com"The settings specified in the example playbook include the following:
ieee802_1x- This variable contains the 802.1X-related settings.
eap: tls-
Configures the profile to use the certificate-based
TLSauthentication method for the Extensible Authentication Protocol (EAP).
For details about all variables used in the playbook, see the
/usr/share/ansible/roles/rhel-system-roles.network/README.mdfile on the control node.Validate the playbook syntax:
$ ansible-playbook --ask-vault-pass --syntax-check ~/playbook.ymlNote that this command only validates the syntax and does not protect against a wrong but valid configuration.
Run the playbook:
$ ansible-playbook --ask-vault-pass ~/playbook.yml
Chapter 11. Configuring a persistent qeth device on IBM Z
Channel-based network interfaces on the IBM Z platform are virtualized and not automatically visible to RHEL when attached to your logical partition (LPAR) or z/VM guest. Before you can use the device in a network configuration, you must manually group subchannels into a single logical qeth device and activate it.
Prerequisites
- You defined the I/O subchannels and attached them to your LPAR or z/VM guest.
-
You installed the
s390utils-basepackage.
Procedure
Unmask the device IDs of the
qethdevice:If you know the device IDs, unmask these IDs. For example:
# cio_ignore --remove 0.0.0600,0.0.0601,0.0.0602Specify the device IDs comma-separated as shown or as a range, for example
0.0.0600-0.0.0602.If you do not know the device IDs, you can unmask all IDs:
# cio_ignore --remove-all
Display the available
qethdevices:# lszdev qethTYPE ID ON PERS NAMES qeth 0.0.0600:0.0.0601:0.0.0602 no noThe output contains the following columns:
-
TYPE: Displays the device type. If you ranlszdev qeth, the command returns onlyqethdevices. -
ID: Displays the subchannel addresses of the hardware. This is a triplet of three hexadecimal addresses used for read, write, and data transfers. -
ON: Indicates the current operational state of the device wherenomeans that the driver has not yet grouped the channels and created a functional network device. -
PERS: Indicates the persistence status of the configuration wherenoconfirms that noudevdevice manager rule exists and, therefore, the device is not automatically be enabled after a reboot. -
NAMES: Displays the network interface name you can use in NetworkManager. If the field is empty, the channels have not been grouped or set online yet.
-
Create a
udevrule and activate theqethdevice:# chzdev qeth 0.0.0600 -eYou can specify only the first address of a triplet, and the
chzdevutility automatically detects the associated write and data channels.
Verification
Verify the hardware state, and display the assigned interface name:
# lszdev qeth TYPE ID ON PERS NAMES qeth 0.0.0600:0.0.0601:0.0.0602 yes yes enc600Ensure that both the
ONandPERScolumn returnyesfor your device. Note the interface name displayed in theNAMEScolumn. You require the name when you create a network configuration that uses this device.
Next steps
-
Use the
qethdevice in a network configuration, such as an Ethernet connection.
Chapter 12. Configuring RHEL as a WPA2 or WPA3 Personal access point
On a host with a wifi device, you can use NetworkManager to configure this host as an access point. Wireless clients can use a pre-shared key (PSK) to connect to the access point and use services on the RHEL host and in the network.
When you configure an access point, NetworkManager automatically:
-
Configures the
dnsmasqservice to provide DHCP and DNS services for clients - Enables IP forwarding
-
Adds
nftablesfirewall rules to masquerade traffic from the wifi device and configures IP forwarding
Prerequisites
- The wifi device supports running in access point mode.
- The wifi device is not in use.
- The host has internet access.
Procedure
List the wifi devices to identify the one that should provide the access point:
# nmcli device status | grep wifi wlp0s20f3 wifi disconnected --Verify that the device supports the access point mode:
# nmcli -f WIFI-PROPERTIES.AP device show wlp0s20f3 WIFI-PROPERTIES.AP: yesTo use a wifi device as an access point, the device must support this feature.
Install the
dnsmasqandNetworkManager-wifipackages:# yum install dnsmasq NetworkManager-wifiNetworkManager uses the
dnsmasqservice to provide DHCP and DNS services to clients of the access point.Create the initial access point configuration:
# nmcli device wifi hotspot ifname wlp0s20f3 con-name Example-Hotspot ssid Example-Hotspot password "password"This command creates a connection profile for an access point on the
wlp0s20f3device that provides WPA2 and WPA3 Personal authentication. The name of the wireless network, the Service Set Identifier (SSID), isExample-Hotspotand uses the pre-shared keypassword.Optional: Configure the access point to support only WPA3:
# nmcli connection modify Example-Hotspot 802-11-wireless-security.key-mgmt saeBy default, NetworkManager uses the IP address
10.42.0.1for the wifi device and assigns IP addresses from the remaining10.42.0.0/24subnet to clients. To configure a different subnet and IP address, enter:# nmcli connection modify Example-Hotspot ipv4.addresses 192.0.2.254/24The IP address you set, in this case
192.0.2.254, is the one that NetworkManager assigns to the wifi device. Clients will use this IP address as default gateway and DNS server.Activate the connection profile:
# nmcli connection up Example-Hotspot
Verification
On the server:
Verify that NetworkManager started the
dnsmasqservice and that the service listens on port 67 (DHCP) and 53 (DNS):# ss -tulpn | grep -E ":53|:67" udp UNCONN 0 0 10.42.0.1:53 0.0.0.0:* users:(("dnsmasq",pid=55905,fd=6)) udp UNCONN 0 0 0.0.0.0:67 0.0.0.0:* users:(("dnsmasq",pid=55905,fd=4)) tcp LISTEN 0 32 10.42.0.1:53 0.0.0.0:* users:(("dnsmasq",pid=55905,fd=7))Display the
nftablesrule set to ensure that NetworkManager enabled forwarding and masquerading for traffic from the10.42.0.0/24subnet:# nft list ruleset table ip nm-shared-wlp0s20f3 { chain nat_postrouting { type nat hook postrouting priority srcnat; policy accept; ip saddr 10.42.0.0/24 ip daddr != 10.42.0.0/24 masquerade } chain filter_forward { type filter hook forward priority filter; policy accept; ip daddr 10.42.0.0/24 oifname "wlp0s20f3" ct state { established, related } accept ip saddr 10.42.0.0/24 iifname "wlp0s20f3" accept iifname "wlp0s20f3" oifname "wlp0s20f3" accept iifname "wlp0s20f3" reject oifname "wlp0s20f3" reject } }
On a client with a wifi adapter:
Display the list of available networks:
# nmcli device wifi IN-USE BSSID SSID MODE CHAN RATE SIGNAL BARS SECURITY 00:53:00:88:29:04 Example-Hotspot Infra 11 130 Mbit/s 62 ▂▄▆_ WPA3 ...-
Connect to the
Example-Hotspotwireless network. See Managing Wi-Fi connections. Ping a host on the remote network or the internet to verify that the connection works:
# ping -c 3 www.redhat.com
Chapter 13. Using MACsec to encrypt layer-2 traffic in the same physical network
MACsec secures point-to-point communication between devices. For example, you can configure MACsec on the two hosts connecting your branch and central offices over a Metro-Ethernet connection to increase security.
13.1. How MACsec increases security
Media Access Control security (MACsec) is a layer-2 protocol that encrypts and authenticates all LAN traffic. It uses a pre-shared key to establish connections. To change this key, you must update the NetworkManager configuration on all hosts that use MACsec.
MACsec secures different traffic types over the Ethernet links, including:
- Dynamic host configuration protocol (DHCP)
- address resolution protocol (ARP)
- IPv4 and IPv6 traffic
- Any traffic over IP such as TCP or UDP
A MACsec connection uses an Ethernet device, such as an Ethernet network card, Virtual Local Area Network (VLAN), or tunnel device, as a parent. You can either set an IP configuration only on the MACsec device to communicate with other hosts only by using the encrypted connection, or you can also set an IP configuration on the parent device. In the latter case, you can use the parent device to communicate with other hosts using an unencrypted connection and the MACsec device for encrypted connections.
MACsec does not require any special hardware. For example, you can use any switch, except if you want to encrypt traffic only between a host and a switch. In this scenario, the switch must also support MACsec.
In other words, you can configure MACsec for two common scenarios:
- Host-to-host
- Host-to-switch and switch-to-other-hosts
You can use MACsec only between hosts being in the same physical or virtual LAN.
Using the MACsec security standard for securing communication at the link layer, also known as layer 2 of the Open Systems Interconnection (OSI) model provides the following notable benefits:
- Encryption at layer 2 eliminates the need for encrypting individual services at layer 7. This reduces the overhead associated with managing a large number of certificates for each endpoint on each host.
- Point-to-point security between directly connected network devices such as routers and switches.
- No changes needed for applications and higher-layer protocols.
13.2. Configuring a MACsec connection by using nmcli
You can use the nmcli utility to configure Ethernet interfaces to use MACsec. For example, you can create a MACsec connection between two hosts that are connected over Ethernet.
Procedure
On the first host on which you configure MACsec:
Create the connectivity association key (CAK) and connectivity-association key name (CKN) for the pre-shared key:
Create a 16-byte hexadecimal CAK:
# dd if=/dev/urandom count=16 bs=1 2> /dev/null | hexdump -e '1/2 "%04x"' 50b71a8ef0bd5751ea76de6d6c98c03aCreate a 32-byte hexadecimal CKN:
# dd if=/dev/urandom count=32 bs=1 2> /dev/null | hexdump -e '1/2 "%04x"' f2b4297d39da7330910a74abc0449feb45b5c0b9fc23df1430e1898fcf1c4550
- On both hosts you want to connect over a MACsec connection:
Create the MACsec connection:
# nmcli connection add type macsec con-name macsec0 ifname macsec0 connection.autoconnect yes macsec.parent enp1s0 macsec.mode psk macsec.mka-cak 50b71a8ef0bd5751ea76de6d6c98c03a macsec.mka-ckn f2b4297d39da7330910a74abc0449feb45b5c0b9fc23df1430e1898fcf1c4550Use the CAK and CKN generated in the previous step in the
macsec.mka-cakandmacsec.mka-cknparameters. The values must be the same on every host in the MACsec-protected network.Configure the IP settings on the MACsec connection.
Configure the
IPv4settings. For example, to set a staticIPv4address, network mask, default gateway, and DNS server to themacsec0connection, enter:# nmcli connection modify macsec0 ipv4.method manual ipv4.addresses '192.0.2.1/24' ipv4.gateway '192.0.2.254' ipv4.dns '192.0.2.253'Configure the
IPv6settings. For example, to set a staticIPv6address, network mask, default gateway, and DNS server to themacsec0connection, enter:# nmcli connection modify macsec0 ipv6.method manual ipv6.addresses '2001:db8:1::1/32' ipv6.gateway '2001:db8:1::fffe' ipv6.dns '2001:db8:1::fffd'
Activate the connection:
# nmcli connection up macsec0
Verification
Verify that the traffic is encrypted:
# tcpdump -nn -i enp1s0Optional: Display the unencrypted traffic:
# tcpdump -nn -i macsec0Display MACsec statistics:
# ip macsec showDisplay individual counters for each type of protection: integrity-only (encrypt off) and encryption (encrypt on)
# ip -s macsec show
Chapter 14. Getting started with IPVLAN
IPVLAN is a driver for a virtual network device that can be used in container environment to access the host network.
IPVLAN exposes a single MAC address to the external network regardless of the number of IPVLAN devices created inside the host network. This means that a user can have multiple IPVLAN devices in multiple containers and the corresponding switch reads a single MAC address. The IPVLAN driver is useful when the local switch imposes constraints on the total number of MAC addresses that it can manage.
14.1. IPVLAN modes
The following modes are available for IPVLAN:
L2 mode
In IPVLAN L2 mode, virtual devices receive and respond to address resolution protocol (ARP) requests. The
netfilterframework runs only inside the container that owns the virtual device. Nonetfilterchains are executed in the default namespace on the containerized traffic. Using L2 mode provides good performance, but less control on the network traffic.L3 mode
In L3 mode, virtual devices process only L3 traffic and above. Virtual devices do not respond to ARP requests and users must configure the neighbour entries for the IPVLAN IP addresses on the relevant peers manually. The egress traffic of a relevant container is landed on the
netfilterPOSTROUTING and OUTPUT chains in the default namespace while the ingress traffic is threaded in the same way as L2 mode. Using L3 mode provides good control but decreases the network traffic performance.L3S mode
In L3S mode, virtual devices process the same way as in L3 mode, except that both egress and ingress traffics of a relevant container are landed on the
netfilterchain in the default namespace. L3S mode behaves in a similar way to L3 mode but provides greater control of the network.
The IPVLAN virtual device does not receive broadcast and multicast traffic in case of L3 and L3S modes.
14.2. Comparison of IPVLAN and MACVLAN
The following table shows the major differences between MACVLAN and IPVLAN:
| MACVLAN | IPVLAN |
|---|---|
| Uses MAC address for each MACVLAN device. Note that, if a switch reaches the maximum number of MAC addresses it can store in its MAC table, connectivity can be lost. | Uses a single MAC address which does not limit the number of IPVLAN devices. |
| Netfilter rules for a global namespace cannot affect traffic to or from a MACVLAN device in a child namespace. | It is possible to control traffic to or from an IPVLAN device in L3 mode and L3S mode. |
Both IPVLAN and MACVLAN do not require any level of encapsulation.
14.3. Creating and configuring the IPVLAN device using iproute2
This procedure shows how to set up the IPVLAN device using iproute2.
Procedure
To create an IPVLAN device, enter the following command:
# ip link add link <real_nic_device> name <ipvlan_device> type ipvlan mode l2Note that network interface controller (NIC) is a hardware component which connects a computer to a network.
To assign an
IPv4orIPv6address to the interface, enter the following command:# ip addr add dev <ipvlan_device> <ip_address/subnet_mask_prefix>In case of configuring an IPVLAN device in L3 mode or L3S mode, make the following setups:
Configure the neighbor setup for the remote peer on the remote host:
# ip neigh add dev <peer_device> <ipvlan_device_IP_address> lladdr <mac_address>where MAC_address is the MAC address of the real NIC on which an IPVLAN device is based on.
Configure an IPVLAN device for L3 mode with the following command:
# ip route add dev <real_nic_device> <peer_ip_address/32>For L3S mode:
# ip route add dev <real_nic_device> <peer_ip_address>/32where IP-address represents the address of the remote peer.
To set an IPVLAN device active, enter the following command:
# ip link set dev <ipvlan_device> upTo check if the IPVLAN device is active, execute the following command on the remote host:
# ping <IP_address>where the IP_address uses the IP address of the IPVLAN device.
Chapter 15. Configuring NetworkManager to ignore certain devices
By default, NetworkManager manages all devices except the ones described in the /usr/lib/udev/rules.d/85-nm-unmanaged.rules file. To ignore certain other devices, you can configure them in NetworkManager as unmanaged.
15.1. Permanently configuring a device as unmanaged in NetworkManager
You can configure devices as unmanaged based on several criteria, such as the interface name or MAC address. If you use a device section in the configuration to set a device as unmanaged, NetworkManager does not manage the device until you start using it in a connection profile.
Procedure
Optional: Display the list of devices to identify the device or MAC address you want to set as
unmanaged:# ip link show ... 2: enp1s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP mode DEFAULT group default qlen 1000 link/ether 52:54:00:74:79:56 brd ff:ff:ff:ff:ff:ff ...-
Create a
*.conffile in the/etc/NetworkManager/conf.d/directory, for example,/etc/NetworkManager/conf.d/99-unmanaged-devices.conf. For each device you want to configure as unmanaged, add a section with a unique name to the file.
ImportantThe section name must begin with
device-.To configure a specific interface as unmanaged, add:
[device-enp1s0-unmanaged] match-device=interface-name:enp1s0 managed=0To configure a device with a specific MAC address as unmanaged, add:
[device-mac525400747956-unmanaged] match-device=mac:52:54:00:74:79:56 managed=0To configure all devices of a specific type as unmanaged, add:
[device-ethernet-unmanaged] match-device=type:ethernet managed=0To set multiple devices as unmanaged, separate the entries in the
unmanaged-devicesparameter with a semicolon, for example:[device-multiple-devices-unmanaged] match-device=interface-name:enp1s0;interface-name:enp7s0 managed=0Alternatively, you can add separate sections for each device in this file or create additional
*.conffiles in the/etc/NetworkManager/conf.d/directory.
Restart the host system:
# rebootThe reboot clears the state in the
/run/NetworkManager/devices/directory. This prevents that NetworkManager uses an existing connection from this directory for the device you set as unmanaged.
Verification
Display the list of devices:
# nmcli device status DEVICE TYPE STATE CONNECTION enp1s0 ethernet unmanaged -- ...The
unmanagedstate next to theenp1s0device indicates that NetworkManager does not manage this device.
Troubleshooting
If the output of the
nmcli device statuscommand does not list the device asunmanaged, display the NetworkManager configuration:# NetworkManager --print-config ... [device-enp1s0-unmanaged] match-device=interface-name:enp1s0 managed=0 ...If the output does not match the settings that you configured, ensure that no configuration file with a higher priority overrides your settings. For details on how NetworkManager merges multiple configuration files, see the
NetworkManager.conf(5)man page on your system.
15.2. Temporarily configuring a device as unmanaged in NetworkManager
You can temporarily configure devices as unmanaged, for example, for testing purposes. This change persists a reload and restart of the NetworkManager systemd service, but not a system reboot.
Procedure
Optional: Display the list of devices to identify the device you want to set as
unmanaged:# nmcli device status DEVICE TYPE STATE CONNECTION enp1s0 ethernet disconnected -- ...Set the
enp1s0device to theunmanagedstate:# nmcli device set enp1s0 managed no
Verification
Display the list of devices:
# nmcli device status DEVICE TYPE STATE CONNECTION enp1s0 ethernet unmanaged -- ...The
unmanagedstate next to theenp1s0device indicates that NetworkManager does not manage this device.
Chapter 16. Creating a dummy interface
As a Red Hat Enterprise Linux user, you can create and use dummy network interfaces for debugging and testing purposes. A dummy interface provides a device to route packets without actually transmitting them. It enables you to create additional loopback-like devices managed by NetworkManager and makes an inactive SLIP (Serial Line Internet Protocol) address look like a real address for local programs.
16.1. Creating a dummy interface with both an IPv4 and IPv6 address by using nmcli
You can create a dummy interface with various settings, such as IPv4 and IPv6 addresses. After creating the interface, NetworkManager automatically assigns it to the default public firewalld zone.
Procedure
Create a dummy interface named
dummy0with static IPv4 and IPv6 addresses:# nmcli connection add type dummy ifname dummy0 ipv4.method manual ipv4.addresses 192.0.2.1/24 ipv6.method manual ipv6.addresses 2001:db8:2::1/64NoteTo configure a dummy interface without IPv4 and IPv6 addresses, set both the
ipv4.methodandipv6.methodparameters todisabled. Otherwise, IP auto-configuration fails, and NetworkManager deactivates the connection and removes the device.
Verification
List the connection profiles:
# nmcli connection show NAME UUID TYPE DEVICE dummy-dummy0 aaf6eb56-73e5-4746-9037-eed42caa8a65 dummy dummy0
Chapter 17. Using NetworkManager to disable IPv6 for a specific connection
On a system that uses NetworkManager to manage network interfaces, you can disable the IPv6 protocol if the network only uses IPv4. If you disable IPv6, NetworkManager automatically sets the corresponding sysctl values in the Kernel.
If disabling IPv6 using kernel tunables or kernel boot parameters, additional consideration must be given to system configuration.
17.1. Disabling IPv6 on a connection using nmcli
You can use the nmcli utility to disable the IPv6 protocol on the command line.
Prerequisites
- The system uses NetworkManager to manage network interfaces.
Procedure
Optional: Display the list of network connections:
# nmcli connection show NAME UUID TYPE DEVICE Example 7a7e0151-9c18-4e6f-89ee-65bb2d64d365 ethernet enp1s0 ...Set the
ipv6.methodparameter of the connection todisabled:# nmcli connection modify Example ipv6.method "disabled"Restart the network connection:
# nmcli connection up Example
Verification
Display the IP settings of the device:
# ip address show enp1s0 2: enp1s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000 link/ether 52:54:00:6b:74:be brd ff:ff:ff:ff:ff:ff inet 192.0.2.1/24 brd 192.10.2.255 scope global noprefixroute enp1s0 valid_lft forever preferred_lft foreverIf no
inet6entry is displayed,IPv6is disabled on the device.Verify that the
/proc/sys/net/ipv6/conf/enp1s0/disable_ipv6file now contains the value1:# cat /proc/sys/net/ipv6/conf/enp1s0/disable_ipv6 1The value
1means thatIPv6is disabled for the device.
Chapter 18. Changing a hostname
The hostname of a system is the name on the system itself. You can set the name when you install RHEL, and you can change it afterwards.
18.1. Changing a hostname by using nmcli
You can use the nmcli utility to update the system hostname. Note that other utilities might use a different term, such as static or persistent hostname.
Procedure
Optional: Display the current hostname setting:
# nmcli general hostname old-hostname.example.comSet the new hostname:
# nmcli general hostname new-hostname.example.comNetworkManager automatically restarts the
systemd-hostnamedto activate the new name. For the changes to take effect, reboot the host:# rebootAlternatively, if you know which services use the hostname:
Restart all services that only read the hostname when the service starts:
# systemctl restart <service_name>- Active shell users must re-login for the changes to take effect.
Verification
Display the hostname:
# nmcli general hostname new-hostname.example.com
18.2. Changing a hostname by using hostnamectl
You can use the hostnamectl utility to update the hostname.
By default, hostnamectl sets the following hostname types:
-
Static hostname: Stored in the
/etc/hostnamefile. Typically, services use this name as the hostname. -
Pretty hostname: A descriptive name, such as
Proxy server in data center A. - Transient hostname: A fall-back value that is typically received from the network configuration.
Procedure
Optional: Display the current hostname setting:
# hostnamectl status --static old-hostname.example.comSet the new hostname:
# hostnamectl set-hostname new-hostname.example.comThis command sets the static and transient hostname to the new value. To set only a specific type, pass the
--static,--pretty, or--transientoption to the command.The
hostnamectlutility automatically restarts thesystemd-hostnamedto activate the new name. For the changes to take effect, reboot the host:# rebootAlternatively, if you know which services use the hostname:
Restart all services that only read the hostname when the service starts:
# systemctl restart <service_name>- Active shell users must re-login for the changes to take effect.
Verification
Display the hostname:
# hostnamectl status --static new-hostname.example.com
Chapter 19. Configuring NetworkManager DHCP settings
NetworkManager provides different configuration options related to DHCP. For example, you can configure NetworkManager to use the built-in DHCP client (default) or an external client, and you can influence DHCP settings of individual profiles.
19.1. Changing the DHCP client of NetworkManager
By default, NetworkManager uses its internal DHCP client. However, if you require a DHCP client with features that the built-in client does not provide, you can alternatively configure NetworkManager to use dhclient.
Note that RHEL does not provide dhcpcd and, therefore, NetworkManager cannot use this client.
Procedure
Create the
/etc/NetworkManager/conf.d/dhcp-client.conffile with the following content:[main] dhcp=dhclientYou can set the
dhcpparameter tointernal(default) ordhclient.If you set the
dhcpparameter todhclient, install thedhcp-clientpackage:# yum install dhcp-clientRestart NetworkManager:
# systemctl restart NetworkManagerNote that the restart temporarily interrupts all network connections.
Verification
Search in the
/var/log/messageslog file for an entry similar to the following:Apr 26 09:54:19 server NetworkManager[27748]: <info> [1650959659.8483] dhcp-init: Using DHCP client 'dhclient'This log entry confirms that NetworkManager uses
dhclientas DHCP client.
19.2. Configuring the DHCP timeout behavior of a NetworkManager connection
In a connection profile that uses DHCP, NetworkManager waits, by default, 45 seconds for the DHCP request to complete. You can customize timeout-related settings, to adjust the connection profile to your environment.
Prerequisites
- A connection that uses DHCP is configured on the host.
Procedure
Optional: Set the
ipv4.dhcp-timeoutandipv6.dhcp-timeoutproperties. For example, to set both options to30seconds, enter:# nmcli connection modify <connection_name> ipv4.dhcp-timeout 30 ipv6.dhcp-timeout 30Alternatively, set the parameters to
infinityto configure that NetworkManager does not stop trying to request and renew an IP address until it is successful.Optional: Configure the behavior if NetworkManager does not receive an IPv4 address before the timeout:
# nmcli connection modify <connection_name> ipv4.may-fail <value>If you set the
ipv4.may-failoption to:yes, the status of the connection depends on the IPv6 configuration:- If the IPv6 configuration is enabled and successful, NetworkManager activates the IPv6 connection and no longer tries to activate the IPv4 connection.
- If the IPv6 configuration is disabled or not configured, the connection fails.
no, the connection is deactivated. In this case:-
If the
autoconnectproperty of the connection is enabled, NetworkManager retries to activate the connection as many times as set in theautoconnect-retriesproperty. The default is4. - If the connection still cannot acquire a DHCP address, auto-activation fails. Note that after 5 minutes, the auto-connection process starts again to acquire an IP address from the DHCP server.
-
If the
Optional: Configure the behavior if NetworkManager does not receive an IPv6 address before the timeout:
# nmcli connection modify <connection_name> ipv6.may-fail <value>
Chapter 20. Running dhclient exit hooks using NetworkManager a dispatcher script
You can use a NetworkManager dispatcher script to execute dhclient exit hooks.
20.1. The concept of NetworkManager dispatcher scripts
The NetworkManager-dispatcher service executes user-provided scripts in alphabetical order when network events happen. These scripts are typically shell scripts, but can be any executable script or application. You can use dispatcher scripts, for example, to adjust network-related settings that you cannot manage with NetworkManager.
You can store dispatcher scripts in the following directories:
-
/etc/NetworkManager/dispatcher.d/: The general location for dispatcher scripts therootuser can edit. -
/usr/lib/NetworkManager/dispatcher.d/: For pre-deployed immutable dispatcher scripts.
For security reasons, the NetworkManager-dispatcher service executes scripts only if the following conditions met:
-
The script is owned by the
rootuser. -
The script is only readable and writable by
root. -
The
setuidbit is not set on the script.
The NetworkManager-dispatcher service runs each script with two arguments:
- The interface name of the device the operation happened on.
-
The action, such as
up, when the interface has been activated.
The Dispatcher scripts section in the NetworkManager(8) man page provides an overview of actions and environment variables you can use in scripts.
The NetworkManager-dispatcher service runs one script at a time, but asynchronously from the main NetworkManager process. Note that, if a script is queued, the service will always run it, even if a later event makes it obsolete. However, the NetworkManager-dispatcher service runs scripts that are symbolic links referring to files in /etc/NetworkManager/dispatcher.d/no-wait.d/ immediately, without waiting for the termination of previous scripts, and in parallel.
20.2. Creating a NetworkManager dispatcher script that runs dhclient exit hooks
When a DHCP server assigns or updates an IPv4 address, NetworkManager can run a dispatcher script stored in the /etc/dhcp/dhclient-exit-hooks.d/ directory. This dispatcher script can then, for example, run dhclient exit hooks.
Prerequisites
-
The
dhclientexit hooks are stored in the/etc/dhcp/dhclient-exit-hooks.d/directory.
Procedure
Create the
/etc/NetworkManager/dispatcher.d/12-dhclient-downfile with the following content:#!/bin/bash # Run dhclient.exit-hooks.d scripts if [ -n "$DHCP4_DHCP_LEASE_TIME" ] ; then if [ "$2" = "dhcp4-change" ] || [ "$2" = "up" ] ; then if [ -d /etc/dhcp/dhclient-exit-hooks.d ] ; then for f in /etc/dhcp/dhclient-exit-hooks.d/*.sh ; do if [ -x "${f}" ]; then . "${f}" fi done fi fi fiSet the
rootuser as owner of the file:# chown root:root /etc/NetworkManager/dispatcher.d/12-dhclient-downSet the permissions so that only the root user can execute it:
# chmod 0700 /etc/NetworkManager/dispatcher.d/12-dhclient-downRestore the SELinux context:
# restorecon /etc/NetworkManager/dispatcher.d/12-dhclient-down
Chapter 21. Manually configuring the /etc/resolv.conf file
By default, NetworkManager dynamically updates the /etc/resolv.conf file with the DNS settings from active NetworkManager connection profiles. However, you can disable this behavior and manually configure DNS settings in /etc/resolv.conf.
21.1. Disabling DNS processing in the NetworkManager configuration
By default, NetworkManager manages DNS settings in the /etc/resolv.conf file, and you can configure the order of DNS servers. Alternatively, you can disable DNS processing in NetworkManager if you prefer to manually configure DNS settings in /etc/resolv.conf.
Procedure
As the root user, create the
/etc/NetworkManager/conf.d/90-dns-none.conffile with the following content by using a text editor:[main] dns=noneReload the
NetworkManagerservice:# systemctl reload NetworkManagerNoteAfter you reload the service, NetworkManager no longer updates the
/etc/resolv.conffile. However, the last contents of the file are preserved.-
Optional: Remove the
Generated by NetworkManagercomment from/etc/resolv.confto avoid confusion.
Verification
-
Edit the
/etc/resolv.conffile and manually update the configuration. Reload the
NetworkManagerservice:# systemctl reload NetworkManagerDisplay the
/etc/resolv.conffile:# cat /etc/resolv.confIf you successfully disabled DNS processing, NetworkManager did not override the manually configured settings.
Troubleshooting
Display the NetworkManager configuration to ensure that no other configuration file with a higher priority overrode the setting:
# NetworkManager --print-config ... dns=none ...
21.2. Replacing /etc/resolv.conf with a symbolic link to manually configure DNS settings
By default, NetworkManager manages DNS settings in the /etc/resolv.conf file, and you can configure the order of DNS servers. Alternatively, you can disable DNS processing in NetworkManager if you prefer to manually configure DNS settings in /etc/resolv.conf. For example, NetworkManager does not automatically update the DNS configuration if /etc/resolv.conf is a symbolic link.
Prerequisites
-
The NetworkManager
rc-managerconfiguration option is not set tofile. To verify, use theNetworkManager --print-configcommand.
Procedure
-
Create a file, such as
/etc/resolv.conf.manually-configured, and add the DNS configuration for your environment to it. Use the same parameters and syntax as in the original/etc/resolv.conf. Remove the
/etc/resolv.conffile:# rm /etc/resolv.confCreate a symbolic link named
/etc/resolv.confthat refers to/etc/resolv.conf.manually-configured:# ln -s /etc/resolv.conf.manually-configured /etc/resolv.conf
Chapter 22. Configuring the order of DNS servers
The getaddrinfo() function of the glibc library sends all DNS requests to the first DNS server specified in the /etc/resolv.conf file. If this server does not reply, RHEL tries all other name servers. You can configure NetworkManager to influence the DNS server order in /etc/resolv.conf.
22.1. How NetworkManager orders DNS servers in /etc/resolv.conf
NetworkManager orders DNS servers in the /etc/resolv.conf file by applying a specific set of rules.
The ordering depends on the following conditions:
- If only one connection profile exists, NetworkManager uses the order of IPv4 and IPv6 DNS server specified in that connection.
If multiple connection profiles are activated, NetworkManager orders DNS servers based on a DNS priority value. If you set DNS priorities, the behavior of NetworkManager depends on the value set in the
dnsparameter. You can set this parameter in the[main]section in the/etc/NetworkManager/NetworkManager.conffile:dns=defaultor if thednsparameter is not set:NetworkManager orders the DNS servers from different connections based on the
ipv4.dns-priorityandipv6.dns-priorityparameters in each connection.If you set no value or you set
ipv4.dns-priorityandipv6.dns-priorityto0, NetworkManager uses the global default value.dns=dnsmasqordns=systemd-resolved:When you use one of these settings, NetworkManager sets either
127.0.0.1fordnsmasqor127.0.0.53asnameserverentry in the/etc/resolv.conffile.Both the
dnsmasqandsystemd-resolvedservices forward queries for the search domain set in a NetworkManager connection to the DNS server specified in that connection, and forwards queries to other domains to the connection with the default route. When multiple connections have the same search domain set,dnsmasqandsystemd-resolvedforward queries for this domain to the DNS server set in the connection with the lowest priority value.
NetworkManager uses the following default values for connections:
-
50for VPN connections -
100for other connections
You can set both the global default and connection-specific ipv4.dns-priority and ipv6.dns-priority parameters to a value between -2147483647 and 2147483647.
- A lower value has a higher priority.
- Negative values have the special effect of excluding other configurations with a greater value. For example, if at least one connection with a negative priority value exists, NetworkManager uses only the DNS servers specified in the connection profile with the lowest priority.
If multiple connections have the same DNS priority, NetworkManager prioritizes the DNS in the following order:
- VPN connections
- Connection with an active default route. The active default route is the default route with the lowest metric.
22.2. Setting a NetworkManager-wide default DNS server priority value
You can override NetworkManager’s system-wide DNS server priority default values to set custom defaults for IPv4 and IPv6 DNS servers.
The default values are as follows:
-
50for VPN connections -
100for other connections
Procedure
Edit the
/etc/NetworkManager/NetworkManager.conffile:Add the
[connection]section, if it does not exist:[connection]Add the custom default values to the
[connection]section. For example, to set the new default for both IPv4 and IPv6 to200, add:ipv4.dns-priority=200 ipv6.dns-priority=200You can set the parameters to a value between
-2147483647and2147483647. Note that setting the parameters to0enables the built-in defaults (50for VPN connections and100for other connections).
Reload the
NetworkManagerservice:# systemctl reload NetworkManager
22.3. Setting the DNS priority of a NetworkManager connection
If you require a specific order of DNS servers you can set priority values in connection profiles. NetworkManager uses these values to order the servers when the service creates or updates the /etc/resolv.conf file.
Note that setting DNS priorities makes only sense if you have multiple connections with different DNS servers configured. If you have only one connection with multiple DNS servers configured, manually set the DNS servers in the preferred order in the connection profile.
Prerequisites
- The system has multiple NetworkManager connections configured.
-
The system either has no
dnsparameter set in the/etc/NetworkManager/NetworkManager.conffile or the parameter is set todefault.
Procedure
Optional: Display the available connections:
# nmcli connection show NAME UUID TYPE DEVICE Example_con_1 d17ee488-4665-4de2-b28a-48befab0cd43 ethernet enp1s0 Example_con_2 916e4f67-7145-3ffa-9f7b-e7cada8f6bf7 ethernet enp7s0 ...Set the
ipv4.dns-priorityandipv6.dns-priorityparameters. For example, to set both parameters to10, enter:# nmcli connection modify <connection_name> ipv4.dns-priority 10 ipv6.dns-priority 10- Optional: Repeat the previous step for other connections.
Re-activate the connection you updated:
# nmcli connection up <connection_name>
Verification
Display the contents of the
/etc/resolv.conffile to verify that the DNS server order is correct:# cat /etc/resolv.conf
Chapter 23. Using different DNS servers for different domains
In environments where one DNS server cannot resolve all domains, you can configure Red Hat Enterprise Linux (RHEL) to send DNS requests for a specific domain to a selected DNS server.
By default, RHEL sends all DNS requests to the first DNS server specified in the /etc/resolv.conf file. If this server does not reply, RHEL tries the next server in this file until it finds a working one.
For example, you connect a server to a Virtual Private Network (VPN), and hosts in the VPN use the example.com domain. In this case, you can configure RHEL to process DNS queries in the following way:
-
Send only DNS requests for
example.comto the DNS server in the VPN network. - Send all other requests to the DNS server that is configured in the connection profile with the default gateway.
23.1. Using dnsmasq in NetworkManager to send DNS requests for a specific domain to a selected DNS server
On hosts with multiple network interfaces and where one DNS server cannot resolve all domains, you can configure RHEL to send DNS requests for a specific domain to a selected DNS server.
You can configure NetworkManager to start an instance of dnsmasq. This DNS caching server then listens on port 53 on the loopback device. Consequently, this service is only reachable from the local system and not from the network.
With this configuration, NetworkManager adds the nameserver 127.0.0.1 entry to the /etc/resolv.conf file, and dnsmasq dynamically routes DNS requests to the corresponding DNS servers specified in the NetworkManager connection profiles.
Prerequisites
- The system has multiple NetworkManager connections configured.
A DNS server and search domain are configured for the connection that is responsible for resolving a specific domain.
For example, to ensure that the DNS server specified in a VPN connection resolves queries for the
example.comdomain, the following settings must be available:-
A DNS server that can resolve
example.com. A DHCP server can provide this information dynamically or you set theipv4.dnsandipv6.dnsparameters in the VPN connection profile. -
A search domain set to
example.com. A DHCP server can provide this information dynamically or you set theipv4.dns-searchandipv6.dns-searchparameters in the VPN connection profile.
-
A DNS server that can resolve
-
The
dnsmasqservice is not running or configured to listen on a different interface thanlocalhost.
Procedure
Install the
dnsmasqpackage:# yum install dnsmasqEdit the
/etc/NetworkManager/NetworkManager.conffile, and set the following entry in the[main]section:dns=dnsmasqReload the
NetworkManagerservice:# systemctl reload NetworkManager
Verification
Search in the
systemdjournal of theNetworkManagerunit for which domains the service uses a different DNS server:# journalctl -xeu NetworkManager ... Jun 02 13:30:17 <client_hostname>_ dnsmasq[5298]: using nameserver 198.51.100.7#53 for domain example.com ...Use the
tcpdumppacket sniffer to verify the correct route of DNS requests:Install the
tcpdumppackage:# yum install tcpdumpOn one console, start
tcpdumpto capture DNS traffic on all interfaces:# tcpdump -i any port 53On a different console, resolve host names for a domain for which an exception exists and another domain, for example:
# host -t A www.example.com # host -t A www.redhat.comVerify in the
tcpdumpoutput that Red Hat Enterprise Linux sends only DNS queries for theexample.comdomain to the designated DNS server and through the corresponding interface:... 13:52:42.234533 IP server.43534 > 198.51.100.7.domain: 50121+ [1au] A? www.example.com. (33) ... 13:52:57.753235 IP server.40864 > 192.0.2.1.domain: 6906+ A? www.redhat.com. (33) ...Red Hat Enterprise Linux sends the DNS query for
www.example.comto the DNS server on198.51.100.7and the query forwww.redhat.comto192.0.2.1.
Troubleshooting
Verify that the
nameserverentry in the/etc/resolv.conffile refers to127.0.0.1:# cat /etc/resolv.conf nameserver 127.0.0.1If the entry is missing, check the
dnsparameter in the/etc/NetworkManager/NetworkManager.conffile.Verify that the
dnsmasqservice listens on port53on theloopbackdevice:# ss -tulpn | grep "127.0.0.1:53" udp UNCONN 0 0 127.0.0.1:53 0.0.0.0:* users:(("dnsmasq",pid=7340,fd=18)) tcp LISTEN 0 32 127.0.0.1:53 0.0.0.0:* users:(("dnsmasq",pid=7340,fd=19))If the service does not listen on
127.0.0.1:53, check the journal entries of theNetworkManagerunit:# journalctl -u NetworkManager
23.2. Using systemd-resolved in NetworkManager to send DNS requests for a specific domain to a selected DNS server
On hosts with multiple network interfaces and where one DNS server cannot resolve all domains, you can configure RHEL to send DNS requests for a specific domain to a selected DNS server.
You can configure NetworkManager to start an instance of systemd-resolved. This DNS stub resolver then listens on port 53 on IP address 127.0.0.53. Consequently, this stub resolver is only reachable from the local system and not from the network.
With this configuration, NetworkManager adds the nameserver 127.0.0.53 entry to the /etc/resolv.conf file, and systemd-resolved dynamically routes DNS requests to the corresponding DNS servers specified in the NetworkManager connection profiles.
The systemd-resolved service is provided as a Technology Preview only. Technology Preview features are not supported with Red Hat production Service Level Agreements (SLAs), might not be functionally complete, and Red Hat does not recommend using them for production. These previews provide early access to upcoming product features, enabling customers to test functionality and provide feedback during the development process.
See Technology Preview Features Support Scope on the Red Hat Customer Portal for information about the support scope for Technology Preview features.
For a supported solution, see Using dnsmasq in NetworkManager to send DNS requests for a specific domain to a selected DNS server.
Prerequisites
- The system has multiple NetworkManager connections configured.
A DNS server and search domain are configured for the connection that is responsible for resolving a specific domain.
For example, to ensure that the DNS server specified in a VPN connection resolves queries for the
example.comdomain, the following settings must be available:-
A DNS server that can resolve
example.com. A DHCP server can provide this information dynamically or you set theipv4.dnsandipv6.dnsparameters in the VPN connection profile. -
A search domain set to
example.com. A DHCP server can provide this information dynamically or you set theipv4.dns-searchandipv6.dns-searchparameters in the VPN connection profile.
-
A DNS server that can resolve
Procedure
Install the
systemd-resolvedpackage:# dnf install systemd-resolvedEnable and start the
systemd-resolvedservice:# systemctl --now enable systemd-resolvedEdit the
/etc/NetworkManager/NetworkManager.conffile, and set the following entry in the[main]section:dns=systemd-resolvedOverride the regular
/etc/resolv.conffile with a symbolic link to/run/systemd/resolve/stub-resolv.conf:# ln -sf /run/systemd/resolve/stub-resolv.conf /etc/resolv.confReload the
NetworkManagerservice:# systemctl reload NetworkManager
Verification
Display the DNS servers
systemd-resolveduses and for which domains the service uses a different DNS server:# resolvectl ... Link 2 (enp1s0) Current Scopes: DNS Protocols: +DefaultRoute ... Current DNS Server: 192.0.2.1 DNS Servers: 192.0.2.1 Link 3 (tun0) Current Scopes: DNS Protocols: -DefaultRoute ... Current DNS Server: 198.51.100.7 DNS Servers: 198.51.100.7 203.0.113.19 DNS Domain: example.comThe output confirms that
systemd-resolveduses different DNS servers for theexample.comdomain.Use the
tcpdumppacket sniffer to verify the correct route of DNS requests:Install the
tcpdumppackage:# yum install tcpdumpOn one console, start
tcpdumpto capture DNS traffic on all interfaces:# tcpdump -i any port 53On a different console, resolve host names for a domain for which an exception exists and another domain, for example:
# host -t A www.example.com # host -t A www.redhat.comVerify in the
tcpdumpoutput that Red Hat Enterprise Linux sends only DNS queries for theexample.comdomain to the designated DNS server and through the corresponding interface:... 13:52:42.234533 IP server.43534 > 198.51.100.7.domain: 50121+ [1au] A? www.example.com. (33) ... 13:52:57.753235 IP server.40864 > 192.0.2.1.domain: 6906+ A? www.redhat.com. (33) ...Red Hat Enterprise Linux sends the DNS query for
www.example.comto the DNS server on198.51.100.7and the query forwww.redhat.comto192.0.2.1.
Troubleshooting
Verify that the
nameserverentry in/etc/resolv.confrefers to127.0.0.53:# cat /etc/resolv.conf nameserver 127.0.0.53If the entry is missing, check the
dnsparameter in the/etc/NetworkManager/NetworkManager.conffile.Verify that the
systemd-resolvedservice listens on port53on the local IP address127.0.0.53:# ss -tulpn | grep "127.0.0.53" udp UNCONN 0 0 127.0.0.53%lo:53 0.0.0.0:* users:(("systemd-resolve",pid=1050,fd=12)) tcp LISTEN 0 4096 127.0.0.53%lo:53 0.0.0.0:* users:(("systemd-resolve",pid=1050,fd=13))If the service does not listen on
127.0.0.53:53, check if thesystemd-resolvedservice is running.
Chapter 24. Managing the default gateway setting
The default gateway is a router that forwards network packets when no other route matches the destination of a packet. In a local network, the default gateway is typically the host that is one hop closer to the internet.
24.1. Setting the default gateway on an existing connection by using nmcli
In most situations, administrators set the default gateway when they create a connection. However, you can also set or update the default gateway setting on a previously created connection by using the nmcli utility.
Prerequisites
- At least one static IP address must be configured on the connection on which the default gateway will be set.
-
If the user is logged in on a physical console, user permissions are sufficient. Otherwise, the user must have
rootpermissions.
Procedure
Set the IP addresses of the default gateway:
To set the IPv4 default gateway, enter:
# nmcli connection modify <connection_name> ipv4.gateway "<IPv4_gateway_address>"To set the IPv6 default gateway, enter:
# nmcli connection modify <connection_name> ipv6.gateway "<IPv6_gateway_address>"Restart the network connection for changes to take effect:
# nmcli connection up <connection_name>WarningAll connections currently using this network connection are temporarily interrupted during the restart.
Verification
Verify that the route is active:
To display the IPv4 default gateway, enter:
# ip -4 route default via 192.0.2.1 dev example proto static metric 100To display the IPv6 default gateway, enter:
# ip -6 route default via 2001:db8:1::1 dev example proto static metric 100 pref medium
24.2. Setting the default gateway on an existing connection by using the nmcli interactive mode
In most situations, administrators set the default gateway when they create a connection. However, you can also set or update the default gateway setting on a previously created connection by using the interactive mode of the nmcli utility.
Prerequisites
- At least one static IP address must be configured on the connection on which the default gateway will be set.
-
If the user is logged in on a physical console, user permissions are sufficient. Otherwise, the user must have
rootpermissions.
Procedure
Open the
nmcliinteractive mode for the required connection:# nmcli connection edit <connection_name>Set the default gateway
To set the IPv4 default gateway, enter:
nmcli> set ipv4.gateway "<IPv4_gateway_address>"To set the IPv6 default gateway, enter:
nmcli> set ipv6.gateway "<IPv6_gateway_address>"Optional: Verify that the default gateway was set correctly:
nmcli> print ... ipv4.gateway: <IPv4_gateway_address> ... ipv6.gateway: <IPv6_gateway_address> ...Save the configuration:
nmcli> save persistentRestart the network connection for changes to take effect:
nmcli> activate <connection_name>WarningAll connections currently using this network connection are temporarily interrupted during the restart.
Leave the
nmcliinteractive mode:nmcli> quit
Verification
Verify that the route is active:
To display the IPv4 default gateway, enter:
# ip -4 route default via 192.0.2.1 dev example proto static metric 100To display the IPv6 default gateway, enter:
# ip -6 route default via 2001:db8:1::1 dev example proto static metric 100 pref medium
24.3. Setting the default gateway on an existing connection by using nm-connection-editor
In most situations, administrators set the default gateway when they create a connection. However, you can also set or update the default gateway setting on a previously created connection using the nm-connection-editor application.
Prerequisites
- At least one static IP address must be configured on the connection on which the default gateway will be set.
Procedure
Open a console, and enter
nm-connection-editor:# nm-connection-editor- Select the connection to modify, and click the gear wheel icon to edit the existing connection.
Set the IPv4 default gateway. For example, to set the IPv4 address of the default gateway on the connection to
192.0.2.1:-
Open the
IPv4 Settingstab. Enter the address in the
gatewayfield next to the IP range the gateway’s address is within:
-
Open the
Set the IPv6 default gateway. For example, to set the IPv6 address of the default gateway on the connection to
2001:db8:1::1:-
Open the
IPv6tab. Enter the address in the
gatewayfield next to the IP range the gateway’s address is within:
-
Open the
- Click .
- Click .
Restart the network connection for changes to take effect. For example, to restart the
exampleconnection using the command line:# nmcli connection up exampleWarningAll connections currently using this network connection are temporarily interrupted during the restart.
Verification
Verify that the route is active.
To display the IPv4 default gateway:
# ip -4 route default via 192.0.2.1 dev example proto static metric 100To display the IPv6 default gateway:
# ip -6 route default via 2001:db8:1::1 dev example proto static metric 100 pref medium
24.4. Setting the default gateway on an existing connection by using control-center
In most situations, administrators set the default gateway when they create a connection. However, you can also set or update the default gateway setting on a previously created connection using the control-center application.
Prerequisites
- At least one static IP address must be configured on the connection on which the default gateway will be set.
-
The network configuration of the connection is open in the
control-centerapplication.
Procedure
Set the IPv4 default gateway. For example, to set the IPv4 address of the default gateway on the connection to
192.0.2.1:-
Open the
IPv4tab. Enter the address in the
gatewayfield next to the IP range the gateway’s address is within:
-
Open the
Set the IPv6 default gateway. For example, to set the IPv6 address of the default gateway on the connection to
2001:db8:1::1:-
Open the
IPv6tab. Enter the address in the
gatewayfield next to the IP range the gateway’s address is within:
-
Open the
- Click .
Back in the
Networkwindow, disable and re-enable the connection by switching the button for the connection to and back to for changes to take effect.WarningAll connections currently using this network connection are temporarily interrupted during the restart.
Verification
Verify that the route is active.
To display the IPv4 default gateway:
$ ip -4 route default via 192.0.2.1 dev example proto static metric 100To display the IPv6 default gateway:
$ ip -6 route default via 2001:db8:1::1 dev example proto static metric 100 pref medium
24.5. Setting the default gateway on an existing connection by using nmstatectl
You can use the declarative Nmstate API to set or update the default gateway in a connection. Nmstate ensures that the result matches the configuration file or rolls back the changes.
Prerequisites
- At least one static IP address must be configured on the connection on which the default gateway will be set.
-
The
enp1s0interface is configured, and the IP address of the default gateway is within the subnet of the IP configuration of this interface. -
The
nmstatepackage is installed.
Procedure
Create a YAML file, for example
~/set-default-gateway.yml, with the following content:--- routes: config: - destination: 0.0.0.0/0 next-hop-address: 192.0.2.1 next-hop-interface: enp1s0These settings define
192.0.2.1as the default gateway, and the default gateway is reachable through theenp1s0interface.Apply the settings to the system:
# nmstatectl apply ~/set-default-gateway.yml
24.6. Setting the default gateway on an existing connection by using the network RHEL system role
By using the network RHEL system role, you can automate setting the default gateway in a NetworkManager connection profile. With this method, you can remotely configure the default gateway on hosts defined in a playbook.
In most situations, administrators set the default gateway when they create a connection. However, you can also set or update the default gateway setting on a previously-created connection.
You cannot use the network RHEL system role to update only specific values in an existing connection profile. The role ensures that a connection profile exactly matches the settings in a playbook. If a connection profile with the same name already exists, the role applies the settings from the playbook and resets all other settings in the profile to their defaults. To prevent resetting values, always specify the whole configuration of the network connection profile in the playbook, including the settings that you do not want to change.
Prerequisites
- You have prepared the control node and the managed nodes.
-
The account you use to connect to the managed nodes has
sudopermissions for these nodes.
Procedure
Create a playbook file, for example,
~/playbook.yml, with the following content:--- - name: Configure the network hosts: managed-node-01.example.com tasks: - name: Ethernet connection profile with static IP address settings ansible.builtin.include_role: name: redhat.rhel_system_roles.network vars: network_connections: - name: enp1s0 type: ethernet autoconnect: yes ip: address: - 198.51.100.20/24 - 2001:db8:1::1/64 gateway4: 198.51.100.254 gateway6: 2001:db8:1::fffe dns: - 198.51.100.200 - 2001:db8:1::ffbb dns_search: - example.com state: upFor details about all variables used in the playbook, see the
/usr/share/ansible/roles/rhel-system-roles.network/README.mdfile on the control node.Validate the playbook syntax:
$ ansible-playbook --syntax-check ~/playbook.ymlNote that this command only validates the syntax and does not protect against a wrong but valid configuration.
Run the playbook:
$ ansible-playbook ~/playbook.yml
Verification
Query the Ansible facts of the managed node and verify the active network settings:
# ansible managed-node-01.example.com -m ansible.builtin.setup ... "ansible_default_ipv4": { ... "gateway": "198.51.100.254", "interface": "enp1s0", ... }, "ansible_default_ipv6": { ... "gateway": "2001:db8:1::fffe", "interface": "enp1s0", ... } ...
24.7. Setting the default gateway on an existing connection when using the legacy network scripts
In most situations, administrators set the default gateway when they create a connection. However, you can also set or update the default gateway setting on a previously created connection when you use the legacy network scripts.
Prerequisites
-
The
NetworkManagerpackage is not installed, or theNetworkManagerservice is disabled. -
The
network-scriptspackage is installed.
Procedure
Set the
GATEWAYparameter in the/etc/sysconfig/network-scripts/ifcfg-enp1s0file to192.0.2.1:GATEWAY=192.0.2.1Add the
defaultentry in the/etc/sysconfig/network-scripts/route-enp0s1file:default via 192.0.2.1Restart the network:
# systemctl restart network
24.8. How NetworkManager manages multiple default gateways
In certain situations, for example for fallback reasons, you set multiple default gateways on a host. However, to avoid asynchronous routing issues, each default gateway of the same protocol requires a separate metric value.
Note that RHEL only uses the connection to the default gateway that has the lowest metric set.
You can set the metric for both the IPv4 and IPv6 gateway of a connection using the following command:
# nmcli connection modify <connection_name> ipv4.route-metric <value> ipv6.route-metric <value>Do not set the same metric value for the same protocol in multiple connection profiles to avoid routing issues.
If you set a default gateway without a metric value, NetworkManager automatically sets the metric value based on the interface type. For that, NetworkManager assigns the default value of this network type to the first connection that is activated, and sets an incremented value to each other connection of the same type in the order they are activated. For example, if two Ethernet connections with a default gateway exist, NetworkManager sets a metric of 100 on the route to the default gateway of the connection that you activate first. For the second connection, NetworkManager sets 101.
The following is an overview of frequently-used network types and their default metrics:
| Connection type | Default metric value |
|---|---|
| VPN | 50 |
| Ethernet | 100 |
| MACsec | 125 |
| InfiniBand | 150 |
| Bond | 300 |
| Team | 350 |
| VLAN | 400 |
| Bridge | 425 |
| TUN | 450 |
| Wi-Fi | 600 |
| IP tunnel | 675 |
24.9. Configuring NetworkManager to avoid using a specific profile to provide a default gateway
In connection profiles that are not connected to the default gateway, you can configure that NetworkManager never uses this profile to provide the default gateway.
Prerequisites
- The NetworkManager connection profile for the connection that is not connected to the default gateway exists.
Procedure
If the connection uses a dynamic IP configuration, configure that NetworkManager does not use this connection as the default connection for the corresponding IP type, meaning that NetworkManager never assigns the default route to it:
# nmcli connection modify <connection_name> ipv4.never-default yes ipv6.never-default yesNote that setting
ipv4.never-defaultandipv6.never-defaulttoyes, automatically removes the default gateway’s IP address for the corresponding protocol from the connection profile.Activate the connection:
# nmcli connection up <connection_name>
Verification
-
Use the
ip -4 routeandip -6 routecommands to verify that RHEL does not use the network interface for the default route for the IPv4 and IPv6 protocol.
24.10. Fixing unexpected routing behavior due to multiple default gateways
For most hosts, you require only a single default gateway to prevent unexpected routing behavior and asynchronous routing issues. Multiple default gateways are typically needed only for specific scenarios, such as when using Multipath TCP.
To route traffic to different internet providers, use policy-based routing instead of multiple default gateways.
Prerequisites
- The host uses NetworkManager to manage network connections, which is the default.
- The host has multiple network interfaces.
- The host has multiple default gateways configured.
Procedure
Display the routing table:
For IPv4, enter:
# ip -4 route default via 192.0.2.1 dev enp1s0 proto dhcp metric 101 default via 198.51.100.1 dev enp7s0 proto dhcp metric 102 ...For IPv6, enter:
# ip -6 route default via 2001:db8:1::1 dev enp1s0 proto static ra 101 pref medium default via 2001:db8:2::1 dev enp7s0 proto static ra 102 pref medium ...
Entries starting with
defaultindicate a default route. Note the interface names of these entries displayed next todev.Use the following commands to display the NetworkManager connections that use the interfaces you identified in the previous step:
# nmcli -f GENERAL.CONNECTION,IP4.GATEWAY,IP6.GATEWAY device show enp1s0 GENERAL.CONNECTION: Corporate-LAN IP4.GATEWAY: 192.0.2.1 IP6.GATEWAY: 2001:db8:1::1 # nmcli -f GENERAL.CONNECTION,IP4.GATEWAY,IP6.GATEWAY device show enp7s0 GENERAL.CONNECTION: Internet-Provider IP4.GATEWAY: 198.51.100.1 IP6.GATEWAY: 2001:db8:2::1In these examples, the profiles named
Corporate-LANandInternet-Providerhave the default gateways set. Because, in a local network, the default gateway is typically the host that is one hop closer to the internet, the rest of this procedure assumes that the default gateways in theCorporate-LANare incorrect.Configure that NetworkManager does not use the
Corporate-LANconnection as the default route for IPv4 and IPv6 connections:# nmcli connection modify Corporate-LAN ipv4.never-default yes ipv6.never-default yesNote that setting
ipv4.never-defaultandipv6.never-defaulttoyes, automatically removes the default gateway’s IP address for the corresponding protocol from the connection profile.Activate the
Corporate-LANconnection:# nmcli connection up Corporate-LAN
Verification
Display the IPv4 and IPv6 routing tables and verify that only one default gateway is available for each protocol:
For IPv4, enter:
# ip -4 route default via 198.51.100.1 dev enp7s0 proto dhcp metric 102 ...For IPv6, enter:
# ip -6 route default via 2001:db8:2::1 dev enp7s0 proto ra metric 102 pref medium ...
Chapter 25. Configuring a static route
Routing directs traffic between mutually-connected networks. In larger environments, administrators configure services so that routers dynamically learn about each other. In smaller ones, administrators often configure static routes to ensure traffic can reach its destination.
You need static routes to achieve a functioning communication among multiple networks if all of these conditions apply:
- The traffic has to pass multiple networks.
- The exclusive traffic flow through the default gateways is not sufficient.
25.1. Example of a network that requires static routes
You require static routes in this example because not all IP networks are directly connected through one router. Without the static routes, some networks cannot communicate with each other. Additionally, traffic from some networks flows only in one direction.
The network topology in this example is artificial and only used to explain the concept of static routing. It is not a recommended topology in production environments.
For a functioning communication among all networks in this example, configure a static route to Raleigh (198.51.100.0/24) with next the hop Router 2 (203.0.113.10). The IP address of the next hop is the one of Router 2 in the data center network (203.0.113.0/24).
You can configure the static route as follows:
-
For a simplified configuration, set this static route only on Router 1. However, this increases the traffic on Router 1 because hosts from the data center (
203.0.113.0/24) send traffic to Raleigh (198.51.100.0/24) always through Router 1 to Router 2. -
For a more complex configuration, configure this static route on all hosts in the data center (
203.0.113.0/24). All hosts in this subnet then send traffic directly to Router 2 (203.0.113.10) that is closer to Raleigh (198.51.100.0/24).
For more details between which networks traffic flows or not, see the explanations following the diagram.
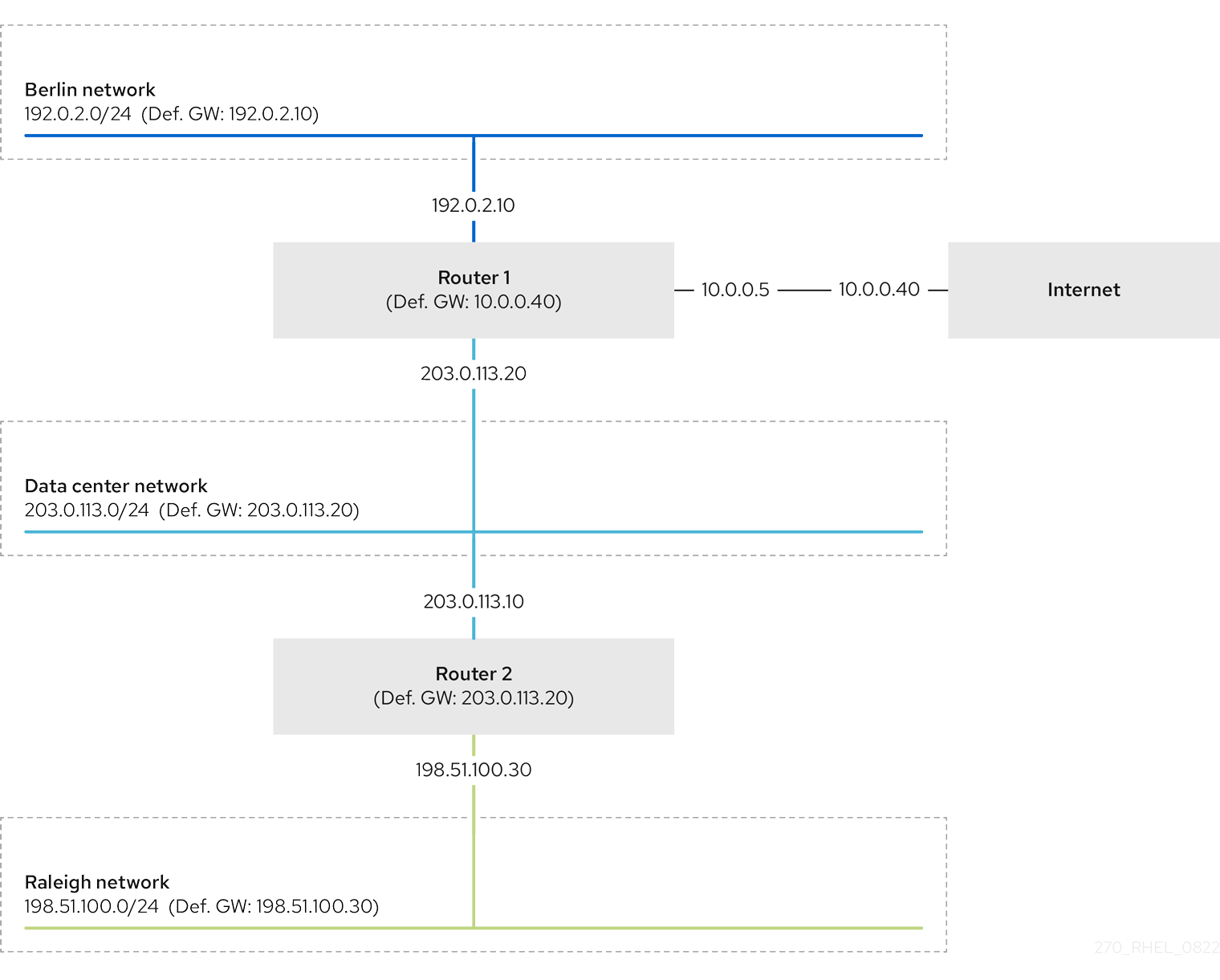
In case that the required static routes are not configured, the following are the situations in which the communication works and when it does not:
Hosts in the Berlin network (
192.0.2.0/24):- Can communicate with other hosts in the same subnet because they are directly connected.
-
Can communicate with the internet because Router 1 is in the Berlin network (
192.0.2.0/24) and has a default gateway, which leads to the internet. -
Can communicate with the data center network (
203.0.113.0/24) because Router 1 has interfaces in both the Berlin (192.0.2.0/24) and the data center (203.0.113.0/24) networks. -
Cannot communicate with the Raleigh network (
198.51.100.0/24) because Router 1 has no interface in this network. Therefore, Router 1 sends the traffic to its own default gateway (internet).
Hosts in the data center network (
203.0.113.0/24):- Can communicate with other hosts in the same subnet because they are directly connected.
-
Can communicate with the internet because they have their default gateway set to Router 1, and Router 1 has interfaces in both networks, the data center (
203.0.113.0/24) and to the internet. -
Can communicate with the Berlin network (
192.0.2.0/24) because they have their default gateway set to Router 1, and Router 1 has interfaces in both the data center (203.0.113.0/24) and the Berlin (192.0.2.0/24) networks. -
Cannot communicate with the Raleigh network (
198.51.100.0/24) because the data center network has no interface in this network. Therefore, hosts in the data center (203.0.113.0/24) send traffic to their default gateway (Router 1). Router 1 also has no interface in the Raleigh network (198.51.100.0/24) and, as a result, Router 1 sends this traffic to its own default gateway (internet).
Hosts in the Raleigh network (
198.51.100.0/24):- Can communicate with other hosts in the same subnet because they are directly connected.
-
Cannot communicate with hosts on the internet. Router 2 sends the traffic to Router 1 because of the default gateway settings. The actual behavior of Router 1 depends on the reverse path filter (
rp_filter) system control (sysctl) setting. By default on RHEL, Router 1 drops the outgoing traffic instead of routing it to the internet. However, regardless of the configured behavior, communication is not possible without the static route. -
Cannot communicate with the data center network (
203.0.113.0/24). The outgoing traffic reaches the destination through Router 2 because of the default gateway setting. However, replies to packets do not reach the sender because hosts in the data center network (203.0.113.0/24) send replies to their default gateway (Router 1). Router 1 then sends the traffic to the internet. -
Cannot communicate with the Berlin network (
192.0.2.0/24). Router 2 sends the traffic to Router 1 because of the default gateway settings. The actual behavior of Router 1 depends on thesysctlsettingrp_filter. By default on RHEL, Router 1 drops the outgoing traffic instead of sending it to the Berlin network (192.0.2.0/24). However, regardless of the configured behavior, communication is not possible without the static route.
In addition to configuring the static routes, you must enable IP forwarding on both routers.
25.2. How to use the nmcli utility to configure a static route
You can use the nmcli utility to configure a static route on the command line.
Use following syntax:
$ nmcli connection modify connection_name ipv4.routes "ip[/prefix] [next_hop] [metric] [attribute=value] [attribute=value] ..."The command supports the following route attributes:
-
cwnd=n: Sets the congestion window (CWND) size, defined in the number of packets. -
lock-cwnd=true|false: Defines whether or not the kernel can update the CWND value. -
lock-mtu=true|false: Defines whether or not the kernel can update the MTU to path MTU discovery. -
lock-window=true|false: Defines whether or not the kernel can update the maximum window size for TCP packets. -
mtu=<mtu_value>: Sets the maximum transfer unit (MTU) to use along the path to the destination. -
onlink=true|false: Defines whether the next hop is directly attached to this link even if it does not match any interface prefix. -
scope=<scope>: For an IPv4 route, this attribute sets the scope of the destinations covered by the route prefix. Set the value as an integer (0-255). -
src=<source_address>: Sets the source address to prefer when sending traffic to the destinations covered by the route prefix. -
table=<table_id>: Sets the ID of the table the route should be added to. If you omit this parameter, NetworkManager uses themaintable. -
tos=<type_of_service_key>: Sets the type of service (TOS) key. Set the value as an integer (0-255). -
type=<route_type>: Sets the route type. NetworkManager supports theunicast,local,blackhole,unreachable,prohibit, andthrowroute types. The default isunicast. -
window=<window_size>: Sets the maximal window size for TCP to advertise to these destinations, measured in bytes.
If you use the ipv4.routes option without a preceding + sign, nmcli overrides all current settings of this parameter.
To create an additional route, enter:
$ nmcli connection modify connection_name +ipv4.routes "<route>"To remove a specific route, enter:
$ nmcli connection modify connection_name -ipv4.routes "<route>"
25.3. Configuring a static route by using nmcli
You can add a static route to an existing NetworkManager connection profile using the nmcli connection modify command.
The procedure below configures the following routes:
-
An IPv4 route to the remote
198.51.100.0/24network. The corresponding gateway with the IP address192.0.2.10is reachable through theLANconnection profile. -
An IPv6 route to the remote
2001:db8:2::/64network. The corresponding gateway with the IP address2001:db8:1::10is reachable through theLANconnection profile.
Prerequisites
-
The
LANconnection profile exists and it configures this host to be in the same IP subnet as the gateways.
Procedure
Add the static IPv4 route to the
LANconnection profile:# nmcli connection modify LAN +ipv4.routes "198.51.100.0/24 192.0.2.10"To set multiple routes in one step, pass the individual routes comma-separated to the command:
# nmcli connection modify <connection_profile> +ipv4.routes "<remote_network_1>/<subnet_mask_1> <gateway_1>, <remote_network_n>/<subnet_mask_n> <gateway_n>, ..."Add the static IPv6 route to the
LANconnection profile:# nmcli connection modify LAN +ipv6.routes "2001:db8:2::/64 2001:db8:1::10"Re-activate the connection:
# nmcli connection up LAN
Verification
Display the IPv4 routes:
# ip -4 route ... 198.51.100.0/24 via 192.0.2.10 dev enp1s0Display the IPv6 routes:
# ip -6 route ... 2001:db8:2::/64 via 2001:db8:1::10 dev enp1s0 metric 1024 pref medium
25.4. Configuring a static route by using nmtui
The nmtui application provides a text-based user interface for NetworkManager. You can use nmtui to configure static routes on a host without a graphical interface.
For example, the procedure below adds a route to the 192.0.2.0/24 network that uses the gateway running on 198.51.100.1, which is reachable through an existing connection profile.
In nmtui:
- Navigate by using the cursor keys.
- Press a button by selecting it and hitting Enter.
- Select and clear checkboxes by using Space.
- To return to the previous screen, use ESC.
Prerequisites
- The network is configured.
- The gateway for the static route must be directly reachable on the interface.
- If the user is logged in on a physical console, user permissions are sufficient. Otherwise, the command requires root permissions.
Procedure
Start
nmtui:# nmtui- Select Edit a connection, and press Enter.
- Select the connection profile through which you can reach the next hop to the destination network, and press Enter.
- Depending on whether it is an IPv4 or IPv6 route, press the Show button next to the protocol’s configuration area.
Press the Edit button next to Routing. This opens a new window where you configure static routes:
Press the Add button and fill in:
- The destination network, including the prefix in Classless Inter-Domain Routing (CIDR) format
- The IP address of the next hop
- A metric value, if you add multiple routes to the same network and want to prioritize the routes by efficiency
- Repeat the previous step for every route you want to add and that is reachable through this connection profile.
Press the OK button to return to the window with the connection settings.
Figure 25.1. Example of a static route without metric

-
Press the OK button to return to the
nmtuimain menu. - Select Activate a connection and press Enter.
Select the connection profile that you edited, and press Enter twice to deactivate and activate it again.
ImportantSkip this step if you run
nmtuiover a remote connection, such as SSH, that uses the connection profile you want to reactivate. In this case, if you deactivate it innmtui, the connection is terminated and, consequently, you cannot activate it again. To avoid this problem, use thenmcli connection <connection_profile> upcommand to reactivate the connection in the mentioned scenario.- Press the Back button to return to the main menu.
-
Select Quit, and press Enter to close the
nmtuiapplication.
Verification
Verify that the route is active:
$ ip route ... 192.0.2.0/24 via 198.51.100.1 dev example proto static metric 100
25.5. Configuring a static route by using control-center
You can use control-center in GNOME to add a static route to the configuration of a network connection.
The procedure below configures the following routes:
-
An IPv4 route to the remote
198.51.100.0/24network. The corresponding gateway has the IP address192.0.2.10. -
An IPv6 route to the remote
2001:db8:2::/64network. The corresponding gateway has the IP address2001:db8:1::10.
Prerequisites
- The network is configured.
- This host is in the same IP subnet as the gateways.
-
The network configuration of the connection is opened in the
control-centerapplication. See Configuring an Ethernet connection by using nm-connection-editor.
Procedure
On the
IPv4tab:-
Optional: Disable automatic routes by clicking the button in the
Routessection of theIPv4tab to use only static routes. If automatic routes are enabled, Red Hat Enterprise Linux uses static routes and routes received from a DHCP server. Enter the address, netmask, gateway, and optionally a metric value of the IPv4 route:

-
Optional: Disable automatic routes by clicking the button in the
On the
IPv6tab:-
Optional: Disable automatic routes by clicking the button in the
Routessection of theIPv4tab to use only static routes. Enter the address, netmask, gateway, and optionally a metric value of the IPv6 route:

-
Optional: Disable automatic routes by clicking the button in the
- Click .
Back in the
Networkwindow, disable and re-enable the connection by switching the button for the connection to and back to for changes to take effect.WarningRestarting the connection briefly disrupts connectivity on that interface.
Verification
Display the IPv4 routes:
# ip -4 route ... 198.51.100.0/24 via 192.0.2.10 dev enp1s0Display the IPv6 routes:
# ip -6 route ... 2001:db8:2::/64 via 2001:db8:1::10 dev enp1s0 metric 1024 pref medium
25.6. Configuring a static route by using nm-connection-editor
You can use the nm-connection-editor application to add a static route to the configuration of a network connection.
The procedure below configures the following routes:
-
An IPv4 route to the remote
198.51.100.0/24network. The corresponding gateway with the IP address192.0.2.10is reachable through theexampleconnection. -
An IPv6 route to the remote
2001:db8:2::/64network. The corresponding gateway with the IP address2001:db8:1::10is reachable through theexampleconnection.
Prerequisites
- The network is configured.
- This host is in the same IP subnet as the gateways.
Procedure
Open a console, and enter
nm-connection-editor:$ nm-connection-editor-
Select the
exampleconnection profile, and click the gear wheel icon to edit the existing connection. On the
IPv4 Settingstab:- Click the button.
Click the button and enter the address, netmask, gateway, and optionally a metric value.

- Click .
On the
IPv6 Settingstab:- Click the button.
Click the button and enter the address, netmask, gateway, and optionally a metric value.
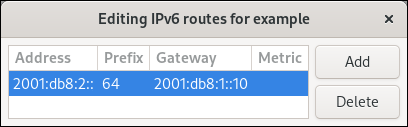
- Click .
- Click .
Restart the network connection for changes to take effect. For example, to restart the
exampleconnection using the command line:# nmcli connection up example
Verification
Display the IPv4 routes:
# ip -4 route ... 198.51.100.0/24 via 192.0.2.10 dev enp1s0Display the IPv6 routes:
# ip -6 route ... 2001:db8:2::/64 via 2001:db8:1::10 dev enp1s0 metric 1024 pref medium
25.7. Configuring a static route by using the nmcli interactive mode
You can use the interactive mode of the nmcli utility to add a static route to the configuration of a network connection.
The procedure below configures the following routes:
-
An IPv4 route to the remote
198.51.100.0/24network. The corresponding gateway with the IP address192.0.2.10is reachable through theexampleconnection. -
An IPv6 route to the remote
2001:db8:2::/64network. The corresponding gateway with the IP address2001:db8:1::10is reachable through theexampleconnection.
Prerequisites
-
The
exampleconnection profile exists and it configures this host to be in the same IP subnet as the gateways.
Procedure
Open the
nmcliinteractive mode for theexampleconnection:# nmcli connection edit exampleAdd the static IPv4 route:
nmcli> set ipv4.routes 198.51.100.0/24 192.0.2.10Add the static IPv6 route:
nmcli> set ipv6.routes 2001:db8:2::/64 2001:db8:1::10Optional: Verify that the routes were added correctly to the configuration:
nmcli> print ... ipv4.routes: { ip = 198.51.100.0/24, nh = 192.0.2.10 } ... ipv6.routes: { ip = 2001:db8:2::/64, nh = 2001:db8:1::10 } ...The
ipattribute displays the network to route and thenhattribute the gateway (next hop).Save the configuration:
nmcli> save persistentRestart the network connection:
nmcli> activate exampleLeave the
nmcliinteractive mode:nmcli> quit
Verification
Display the IPv4 routes:
# ip -4 route ... 198.51.100.0/24 via 192.0.2.10 dev enp1s0Display the IPv6 routes:
# ip -6 route ... 2001:db8:2::/64 via 2001:db8:1::10 dev enp1s0 metric 1024 pref medium
25.8. Configuring a static route by using nmstatectl
You can use the declarative Nmstate API to configure a static route. Nmstate ensures that the result matches the configuration file or rolls back the changes.
Prerequisites
-
The
enp1s0network interface is configured and is in the same IP subnet as the gateways. -
The
nmstatepackage is installed.
Procedure
Create a YAML file, for example
~/add-static-route-to-enp1s0.yml, with the following content:--- routes: config: - destination: 198.51.100.0/24 next-hop-address: 192.0.2.10 next-hop-interface: enp1s0 - destination: 2001:db8:2::/64 next-hop-address: 2001:db8:1::10 next-hop-interface: enp1s0These settings define the following static routes:
-
An IPv4 route to the remote
198.51.100.0/24network. The corresponding gateway with the IP address192.0.2.10is reachable through theenp1s0interface. -
An IPv6 route to the remote
2001:db8:2::/64network. The corresponding gateway with the IP address2001:db8:1::10is reachable through theenp1s0interface.
-
An IPv4 route to the remote
Apply the settings to the system:
# nmstatectl apply ~/add-static-route-to-enp1s0.yml
Verification
Display the IPv4 routes:
# ip -4 route ... 198.51.100.0/24 via 192.0.2.10 dev enp1s0Display the IPv6 routes:
# ip -6 route ... 2001:db8:2::/64 via 2001:db8:1::10 dev enp1s0 metric 1024 pref medium
25.9. Configuring a static route by using the network RHEL system role
You can use the network RHEL system role to configure static routes.
When you run a play that uses the network RHEL system role and if the setting values do not match the values specified in the play, the role overrides the existing connection profile with the same name. To prevent resetting these values to their defaults, always specify the whole configuration of the network connection profile in the play, even if the configuration, for example the IP configuration, already exists.
Prerequisites
- You have prepared the control node and the managed nodes.
-
The account you use to connect to the managed nodes has
sudopermissions for these nodes.
Procedure
Create a playbook file, for example,
~/playbook.yml, with the following content:--- - name: Configure the network hosts: managed-node-01.example.com tasks: - name: Ethernet connection profile with static IP address settings ansible.builtin.include_role: name: redhat.rhel_system_roles.network vars: network_connections: - name: enp7s0 type: ethernet autoconnect: yes ip: address: - 192.0.2.1/24 - 2001:db8:1::1/64 gateway4: 192.0.2.254 gateway6: 2001:db8:1::fffe dns: - 192.0.2.200 - 2001:db8:1::ffbb dns_search: - example.com route: - network: 198.51.100.0 prefix: 24 gateway: 192.0.2.10 - network: '2001:db8:2::' prefix: 64 gateway: 2001:db8:1::10 state: upFor details about all variables used in the playbook, see the
/usr/share/ansible/roles/rhel-system-roles.network/README.mdfile on the control node.Validate the playbook syntax:
$ ansible-playbook --syntax-check ~/playbook.ymlNote that this command only validates the syntax and does not protect against a wrong but valid configuration.
Run the playbook:
$ ansible-playbook ~/playbook.yml
Verification
Display the IPv4 routes:
# ansible managed-node-01.example.com -m command -a 'ip -4 route' managed-node-01.example.com | CHANGED | rc=0 >> ... 198.51.100.0/24 via 192.0.2.10 dev enp7s0Display the IPv6 routes:
# ansible managed-node-01.example.com -m command -a 'ip -6 route' managed-node-01.example.com | CHANGED | rc=0 >> ... 2001:db8:2::/64 via 2001:db8:1::10 dev enp7s0 metric 1024 pref medium
25.10. Creating static routes configuration files in key-value format when using the legacy network scripts
The legacy network scripts support setting statics routes in key-value format.
The procedure below configures an IPv4 route to the remote 198.51.100.0/24 network. The corresponding gateway with the IP address 192.0.2.10 is reachable through the enp1s0 interface.
The legacy network scripts support the key-value format only for static IPv4 routes. For IPv6 routes, use the ip-command format. See Creating static routes configuration files in ip-command format when using the legacy network scripts.
Prerequisites
- The gateways for the static route must be directly reachable on the interface.
-
The
NetworkManagerpackage is not installed, or theNetworkManagerservice is disabled. -
The
network-scriptspackage is installed. -
The
networkservice is enabled.
Procedure
Add the static IPv4 route to the
/etc/sysconfig/network-scripts/route-enp0s1file:ADDRESS0=198.51.100.0 NETMASK0=255.255.255.0 GATEWAY0=192.0.2.10-
The
ADDRESS0variable defines the network of the first routing entry. -
The
NETMASK0variable defines the netmask of the first routing entry. The
GATEWAY0variable defines the IP address of the gateway to the remote network or host for the first routing entry.If you add multiple static routes, increase the number in the variable names. Note that the variables for each route must be numbered sequentially. For example,
ADDRESS0,ADDRESS1,ADDRESS3, and so on.
-
The
Restart the network:
# systemctl restart network
Verification
Display the IPv4 routes:
# ip -4 route ... 198.51.100.0/24 via 192.0.2.10 dev enp1s0
Troubleshooting
Display the journal entries of the
networkunit:# journalctl -u networkThe following are possible error messages and their causes:
-
Error: Nexthop has invalid gateway: You specified an IPv4 gateway address in theroute-enp1s0file that is not in the same subnet as this router. -
RTNETLINK answers: No route to host: You specified an IPv6 gateway address in theroute6-enp1s0file that is not in the same subnet as this router. -
Error: Invalid prefix for given prefix length: You specified the remote network in theroute-enp1s0file by using an IP address within the remote network rather than the network address.
-
25.11. Creating static routes configuration files in ip-command format when using the legacy network scripts
The legacy network scripts support setting statics routes.
The procedure below configures the following routes:
-
An IPv4 route to the remote
198.51.100.0/24network. The corresponding gateway with the IP address192.0.2.10is reachable through theenp1s0interface. -
An IPv6 route to the remote
2001:db8:2::/64network. The corresponding gateway with the IP address2001:db8:1::10is reachable through theenp1s0interface.
IP addresses of the gateways (next hop) must be in the same IP subnet as the host on which you configure the static routes.
The examples in this procedure use configuration entries in ip-command format.
Prerequisites
- The gateways for the static route must be directly reachable on the interface.
-
The
NetworkManagerpackage is not installed, or theNetworkManagerservice is disabled. -
The
network-scriptspackage is installed. -
The
networkservice is enabled.
Procedure
Add the static IPv4 route to the
/etc/sysconfig/network-scripts/route-enp1s0file:198.51.100.0/24 via 192.0.2.10 dev enp1s0Always specify the network address of the remote network, such as
198.51.100.0. Setting an IP address within the remote network, such as198.51.100.1causes that the network scripts fail to add this route.Add the static IPv6 route to the
/etc/sysconfig/network-scripts/route6-enp1s0file:2001:db8:2::/64 via 2001:db8:1::10 dev enp1s0Restart the
networkservice:# systemctl restart network
Verification
Display the IPv4 routes:
# ip -4 route ... 198.51.100.0/24 via 192.0.2.10 dev enp1s0Display the IPv6 routes:
# ip -6 route ... 2001:db8:2::/64 via 2001:db8:1::10 dev enp1s0 metric 1024 pref medium
Troubleshooting
Display the journal entries of the
networkunit:# journalctl -u networkThe following are possible error messages and their causes:
-
Error: Nexthop has invalid gateway: You specified an IPv4 gateway address in theroute-enp1s0file that is not in the same subnet as this router. -
RTNETLINK answers: No route to host: You specified an IPv6 gateway address in theroute6-enp1s0file that is not in the same subnet as this router. -
Error: Invalid prefix for given prefix length: You specified the remote network in theroute-enp1s0file by using an IP address within the remote network rather than the network address.
-
Chapter 26. Configuring policy-based routing to define alternative routes
By default, the RHEL kernel forwards network packets based on the destination address by using a routing table. With policy-based routing, you can configure complex scenarios to route packets based on various criteria, such as the source address.
26.1. Routing traffic from a specific subnet to a different default gateway by using nmcli
You can use policy-based routing to configure a different default gateway for traffic from certain subnets.
For example, you can configure RHEL as a router that, by default, routes all traffic to internet provider A using the default route. However, traffic received from the internal workstations subnet is routed to provider B.
The procedure assumes the following network topology:

Prerequisites
-
The system uses
NetworkManagerto configure the network, which is the default. The RHEL router you want to set up in the procedure has four network interfaces:
-
The
enp7s0interface is connected to the network of provider A. The gateway IP in the provider’s network is198.51.100.2, and the network uses a/30network mask. -
The
enp1s0interface is connected to the network of provider B. The gateway IP in the provider’s network is192.0.2.2, and the network uses a/30network mask. -
The
enp8s0interface is connected to the10.0.0.0/24subnet with internal workstations. -
The
enp9s0interface is connected to the203.0.113.0/24subnet with the company’s servers.
-
The
-
Hosts in the internal workstations subnet use
10.0.0.1as the default gateway. In the procedure, you assign this IP address to theenp8s0network interface of the router. -
Hosts in the server subnet use
203.0.113.1as the default gateway. In the procedure, you assign this IP address to theenp9s0network interface of the router. -
The
firewalldservice is enabled and active.
Procedure
Configure the network interface to provider A:
# nmcli connection add type ethernet con-name Provider-A ifname enp7s0 ipv4.method manual ipv4.addresses 198.51.100.1/30 ipv4.gateway 198.51.100.2 ipv4.dns 198.51.100.200 connection.zone externalThe
nmcli connection addcommand creates a NetworkManager connection profile. The command uses the following options:-
type ethernet: Defines that the connection type is Ethernet. -
con-name <connection_name>: Sets the name of the profile. Use a meaningful name to avoid confusion. -
ifname <network_device>: Sets the network interface. -
ipv4.method manual: Enables to configure a static IP address. -
ipv4.addresses <IP_address>/<subnet_mask>: Sets the IPv4 addresses and subnet mask. -
ipv4.gateway <IP_address>: Sets the default gateway address. -
ipv4.dns <IP_of_DNS_server>: Sets the IPv4 address of the DNS server. -
connection.zone <firewalld_zone>: Assigns the network interface to the definedfirewalldzone. Note thatfirewalldautomatically enables masquerading for interfaces assigned to theexternalzone.
-
Configure the network interface to provider B:
# nmcli connection add type ethernet con-name Provider-B ifname enp1s0 ipv4.method manual ipv4.addresses 192.0.2.1/30 ipv4.routes "0.0.0.0/0 192.0.2.2 table=5000" connection.zone externalThis command uses the
ipv4.routesparameter instead ofipv4.gatewayto set the default gateway. This is required to assign the default gateway for this connection to a different routing table (5000) than the default. NetworkManager automatically creates this new routing table when the connection is activated.Configure the network interface to the internal workstations subnet:
# nmcli connection add type ethernet con-name Internal-Workstations ifname enp8s0 ipv4.method manual ipv4.addresses 10.0.0.1/24 ipv4.routes "10.0.0.0/24 table=5000" ipv4.routing-rules "priority 5 from 10.0.0.0/24 table 5000" connection.zone trustedThis command uses the
ipv4.routesparameter to add a static route to the routing table with ID5000. This static route for the10.0.0.0/24subnet uses the IP of the local network interface to provider B (192.0.2.1) as the next hop.Additionally, the command uses the
ipv4.routing-rulesparameter to add a routing rule with priority5that routes traffic from the10.0.0.0/24subnet to table5000. Low values have a high priority.Note that the syntax in the
ipv4.routing-rulesparameter is the same as in anip rule addcommand, except thatipv4.routing-rulesalways requires specifying a priority.Configure the network interface to the server subnet:
# nmcli connection add type ethernet con-name Servers ifname enp9s0 ipv4.method manual ipv4.addresses 203.0.113.1/24 connection.zone trusted
Verification
On a RHEL host in the internal workstation subnet:
Install the
traceroutepackage:# yum install tracerouteUse the
tracerouteutility to display the route to a host on the internet:# traceroute redhat.com traceroute to redhat.com (209.132.183.105), 30 hops max, 60 byte packets 1 10.0.0.1 (10.0.0.1) 0.337 ms 0.260 ms 0.223 ms 2 192.0.2.2 (192.0.2.2) 0.884 ms 1.066 ms 1.248 ms ...The output of the command displays that the router sends packets over
192.0.2.1, which is the network of provider B.
On a RHEL host in the server subnet:
Install the
traceroutepackage:# yum install tracerouteUse the
tracerouteutility to display the route to a host on the internet:# traceroute redhat.com traceroute to redhat.com (209.132.183.105), 30 hops max, 60 byte packets 1 203.0.113.1 (203.0.113.1) 2.179 ms 2.073 ms 1.944 ms 2 198.51.100.2 (198.51.100.2) 1.868 ms 1.798 ms 1.549 ms ...The output of the command displays that the router sends packets over
198.51.100.2, which is the network of provider A.
Troubleshooting steps
On the RHEL router:
Display the rule list:
# ip rule list 0: from all lookup local 5: from 10.0.0.0/24 lookup 5000 32766: from all lookup main 32767: from all lookup defaultBy default, RHEL contains rules for the tables
local,main, anddefault.Display the routes in table
5000:# ip route list table 5000 0.0.0.0/0 via 192.0.2.2 dev enp1s0 proto static metric 100 10.0.0.0/24 dev enp8s0 proto static scope link src 192.0.2.1 metric 102Display the interfaces and firewall zones:
# firewall-cmd --get-active-zones external interfaces: enp1s0 enp7s0 trusted interfaces: enp8s0 enp9s0Verify that the
externalzone has masquerading enabled:# firewall-cmd --info-zone=external external (active) target: default icmp-block-inversion: no interfaces: enp1s0 enp7s0 sources: services: ssh ports: protocols: masquerade: yes ...
26.2. Routing traffic from a specific subnet to a different default gateway by using the network RHEL system role
You can use policy-based routing to configure a different default gateway for traffic from certain subnets. By using the network RHEL system role, you can automate the creation of the connection profiles, including routing tables and rules.
For example, you can configure RHEL as a router that, by default, routes all traffic to internet provider A using the default route. However, traffic received from the internal workstations subnet is routed to provider B. By using Ansible and the network RHEL system role, you can automate this process and remotely configure connection profiles on the hosts defined in a playbook.
This procedure assumes the following network topology:
Prerequisites
- You have prepared the control node and the managed nodes.
-
The account you use to connect to the managed nodes has
sudopermissions for these nodes. -
The managed nodes use NetworkManager and the
firewalldservice. The managed nodes you want to configure has four network interfaces:
-
The
enp7s0interface is connected to the network of provider A. The gateway IP in the provider’s network is198.51.100.2, and the network uses a/30network mask. -
The
enp1s0interface is connected to the network of provider B. The gateway IP in the provider’s network is192.0.2.2, and the network uses a/30network mask. -
The
enp8s0interface is connected to the10.0.0.0/24subnet with internal workstations. -
The
enp9s0interface is connected to the203.0.113.0/24subnet with the company’s servers.
-
The
-
Hosts in the internal workstations subnet use
10.0.0.1as the default gateway. In the procedure, you assign this IP address to theenp8s0network interface of the router. -
Hosts in the server subnet use
203.0.113.1as the default gateway. In the procedure, you assign this IP address to theenp9s0network interface of the router.
Procedure
Create a playbook file, for example,
~/playbook.yml, with the following content:--- - name: Configuring policy-based routing hosts: managed-node-01.example.com tasks: - name: Routing traffic from a specific subnet to a different default gateway ansible.builtin.include_role: name: redhat.rhel_system_roles.network vars: network_connections: - name: Provider-A interface_name: enp7s0 type: ethernet autoconnect: True ip: address: - 198.51.100.1/30 gateway4: 198.51.100.2 dns: - 198.51.100.200 state: up zone: external - name: Provider-B interface_name: enp1s0 type: ethernet autoconnect: True ip: address: - 192.0.2.1/30 route: - network: 0.0.0.0 prefix: 0 gateway: 192.0.2.2 table: 5000 state: up zone: external - name: Internal-Workstations interface_name: enp8s0 type: ethernet autoconnect: True ip: address: - 10.0.0.1/24 route: - network: 10.0.0.0 prefix: 24 table: 5000 routing_rule: - priority: 5 from: 10.0.0.0/24 table: 5000 state: up zone: trusted - name: Servers interface_name: enp9s0 type: ethernet autoconnect: True ip: address: - 203.0.113.1/24 state: up zone: trustedThe settings specified in the example playbook include the following:
table: <value>-
Assigns the route from the same list entry as the
tablevariable to the specified routing table. routing_rule: <list>- Defines the priority of the specified routing rule and from a connection profile to which routing table the rule is assigned.
zone: <zone_name>-
Assigns the network interface from a connection profile to the specified
firewalldzone.
For details about all variables used in the playbook, see the
/usr/share/ansible/roles/rhel-system-roles.network/README.mdfile on the control node.Validate the playbook syntax:
$ ansible-playbook --syntax-check ~/playbook.ymlNote that this command only validates the syntax and does not protect against a wrong but valid configuration.
Run the playbook:
$ ansible-playbook ~/playbook.yml
Verification
On a RHEL host in the internal workstation subnet:
Install the
traceroutepackage:# yum install tracerouteUse the
tracerouteutility to display the route to a host on the internet:# traceroute redhat.com traceroute to redhat.com (209.132.183.105), 30 hops max, 60 byte packets 1 10.0.0.1 (10.0.0.1) 0.337 ms 0.260 ms 0.223 ms 2 192.0.2.2 (192.0.2.2) 0.884 ms 1.066 ms 1.248 ms ...The output of the command displays that the router sends packets over
192.0.2.1, which is the network of provider B.
On a RHEL host in the server subnet:
Install the
traceroutepackage:# yum install tracerouteUse the
tracerouteutility to display the route to a host on the internet:# traceroute redhat.com traceroute to redhat.com (209.132.183.105), 30 hops max, 60 byte packets 1 203.0.113.1 (203.0.113.1) 2.179 ms 2.073 ms 1.944 ms 2 198.51.100.2 (198.51.100.2) 1.868 ms 1.798 ms 1.549 ms ...The output of the command displays that the router sends packets over
198.51.100.2, which is the network of provider A.
On the RHEL router that you configured using the RHEL system role:
Display the rule list:
# ip rule list 0: from all lookup local 5: from 10.0.0.0/24 lookup 5000 32766: from all lookup main 32767: from all lookup defaultBy default, RHEL contains rules for the tables
local,main, anddefault.Display the routes in table
5000:# ip route list table 5000 0.0.0.0/0 via 192.0.2.2 dev enp1s0 proto static metric 100 10.0.0.0/24 dev enp8s0 proto static scope link src 192.0.2.1 metric 102Display the interfaces and firewall zones:
# firewall-cmd --get-active-zones external interfaces: enp1s0 enp7s0 trusted interfaces: enp8s0 enp9s0Verify that the
externalzone has masquerading enabled:# firewall-cmd --info-zone=external external (active) target: default icmp-block-inversion: no interfaces: enp1s0 enp7s0 sources: services: ssh ports: protocols: masquerade: yes ...
26.3. Overview of configuration files involved in policy-based routing when using the legacy network scripts
If you use the legacy network scripts instead of NetworkManager to configure your network, you can also configure policy-based routing.
Configuring the network using the legacy network scripts provided by the network-scripts package is deprecated in RHEL 8. Use NetworkManager to configure policy-based routing.
The following configuration files are involved in policy-based routing when you use the legacy network scripts:
/etc/sysconfig/network-scripts/route-interface: This file defines the IPv4 routes. Use thetableoption to specify the routing table. For example:192.0.2.0/24 via 198.51.100.1 table 1 203.0.113.0/24 via 198.51.100.2 table 2-
/etc/sysconfig/network-scripts/route6-interface: This file defines the IPv6 routes. /etc/sysconfig/network-scripts/rule-interface: This file defines the rules for IPv4 source networks for which the kernel routes traffic to specific routing tables. For example:from 192.0.2.0/24 lookup 1 from 203.0.113.0/24 lookup 2-
/etc/sysconfig/network-scripts/rule6-interface: This file defines the rules for IPv6 source networks for which the kernel routes traffic to specific routing tables. /etc/iproute2/rt_tables: This file defines the mappings if you want to use names instead of numbers to refer to specific routing tables. For example:1 Provider_A 2 Provider_B
26.4. Routing traffic from a specific subnet to a different default gateway by using the legacy network scripts
You can use policy-based routing to configure a different default gateway for traffic from certain subnets.
For example, you can configure RHEL as a router that, by default, routes all traffic to internet provider A using the default route. However, traffic received from the internal workstations subnet is routed to provider B.
Configuring the network using the legacy network scripts provided by the network-scripts package is deprecated in RHEL 8. Follow the procedure only if you use the legacy network scripts instead of NetworkManager on your host. If you use NetworkManager to manage your network settings, see Routing traffic from a specific subnet to a different default gateway by using nmcli.
The procedure assumes the following network topology:
The legacy network scripts process configuration files in alphabetical order. Therefore, configuration files must be named so that any interface used in the rules and routes of other interfaces is active when a dependent interface requires it. To accomplish the correct order, this procedure uses numbers in the ifcfg-*, route-*, and rules-* files.
Prerequisites
-
The
NetworkManagerpackage is not installed, or theNetworkManagerservice is disabled. -
The
network-scriptspackage is installed. The RHEL router you want to set up in the procedure has four network interfaces:
-
The
enp7s0interface is connected to the network of provider A. The gateway IP in the provider’s network is198.51.100.2, and the network uses a/30network mask. -
The
enp1s0interface is connected to the network of provider B. The gateway IP in the provider’s network is192.0.2.2, and the network uses a/30network mask. -
The
enp8s0interface is connected to the10.0.0.0/24subnet with internal workstations. -
The
enp9s0interface is connected to the203.0.113.0/24subnet with the company’s servers.
-
The
-
Hosts in the internal workstations subnet use
10.0.0.1as the default gateway. In the procedure, you assign this IP address to theenp8s0network interface of the router. -
Hosts in the server subnet use
203.0.113.1as the default gateway. In the procedure, you assign this IP address to theenp9s0network interface of the router. -
The
firewalldservice is enabled and active.
Procedure
Add the configuration for the network interface to provider A by creating the
/etc/sysconfig/network-scripts/ifcfg-1_Provider-Afile with the following content:TYPE=Ethernet IPADDR=198.51.100.1 PREFIX=30 GATEWAY=198.51.100.2 DNS1=198.51.100.200 DEFROUTE=yes NAME=1_Provider-A DEVICE=enp7s0 ONBOOT=yes ZONE=externalThe configuration file uses the following parameters:
-
TYPE=Ethernet: Defines that the connection type is Ethernet. -
IPADDR=IP_address: Sets the IPv4 address. -
PREFIX=subnet_mask: Sets the subnet mask. -
GATEWAY=IP_address: Sets the default gateway address. -
DNS1=IP_of_DNS_server: Sets the IPv4 address of the DNS server. -
DEFROUTE=yes|no: Defines whether the connection is a default route or not. -
NAME=connection_name: Sets the name of the connection profile. Use a meaningful name to avoid confusion. -
DEVICE=network_device: Sets the network interface. -
ONBOOT=yes: Defines that RHEL starts this connection when the system boots. -
ZONE=firewalld_zone: Assigns the network interface to the definedfirewalldzone. Note thatfirewalldautomatically enables masquerading for interfaces assigned to theexternalzone.
-
Add the configuration for the network interface to provider B:
Create the
/etc/sysconfig/network-scripts/ifcfg-2_Provider-Bfile with the following content:TYPE=Ethernet IPADDR=192.0.2.1 PREFIX=30 DEFROUTE=no NAME=2_Provider-B DEVICE=enp1s0 ONBOOT=yes ZONE=externalNote that the configuration file for this interface does not contain a default gateway setting.
Assign the gateway for the
2_Provider-Bconnection to a separate routing table. Therefore, create the/etc/sysconfig/network-scripts/route-2_Provider-Bfile with the following content:0.0.0.0/0 via 192.0.2.2 table 5000This entry assigns the gateway and traffic from all subnets routed through this gateway to table
5000.
Create the configuration for the network interface to the internal workstations subnet:
Create the
/etc/sysconfig/network-scripts/ifcfg-3_Internal-Workstationsfile with the following content:TYPE=Ethernet IPADDR=10.0.0.1 PREFIX=24 DEFROUTE=no NAME=3_Internal-Workstations DEVICE=enp8s0 ONBOOT=yes ZONE=internalAdd the routing rule configuration for the internal workstation subnet. Therefore, create the
/etc/sysconfig/network-scripts/rule-3_Internal-Workstationsfile with the following content:pri 5 from 10.0.0.0/24 table 5000This configuration defines a routing rule with priority
5that routes all traffic from the10.0.0.0/24subnet to table5000. Low values have a high priority.Create the
/etc/sysconfig/network-scripts/route-3_Internal-Workstationsfile with the following content to add a static route to the routing table with ID5000:10.0.0.0/24 via 192.0.2.1 table 5000This static route defines that RHEL sends traffic from the
10.0.0.0/24subnet to the IP of the local network interface to provider B (192.0.2.1). This interface is to routing table5000and used as the next hop.
Add the configuration for the network interface to the server subnet by creating the
/etc/sysconfig/network-scripts/ifcfg-4_Serversfile with the following content:TYPE=Ethernet IPADDR=203.0.113.1 PREFIX=24 DEFROUTE=no NAME=4_Servers DEVICE=enp9s0 ONBOOT=yes ZONE=internalRestart the network:
# systemctl restart network
Verification
On a RHEL host in the internal workstation subnet:
Install the
traceroutepackage:# yum install tracerouteUse the
tracerouteutility to display the route to a host on the internet:# traceroute redhat.com traceroute to redhat.com (209.132.183.105), 30 hops max, 60 byte packets 1 10.0.0.1 (10.0.0.1) 0.337 ms 0.260 ms 0.223 ms 2 192.0.2.2 (192.0.2.2) 0.884 ms 1.066 ms 1.248 ms ...The output of the command displays that the router sends packets over
192.0.2.1, which is the network of provider B.
On a RHEL host in the server subnet:
Install the
traceroutepackage:# yum install tracerouteUse the
tracerouteutility to display the route to a host on the internet:# traceroute redhat.com traceroute to redhat.com (209.132.183.105), 30 hops max, 60 byte packets 1 203.0.113.1 (203.0.113.1) 2.179 ms 2.073 ms 1.944 ms 2 198.51.100.2 (198.51.100.2) 1.868 ms 1.798 ms 1.549 ms ...The output of the command displays that the router sends packets over
198.51.100.2, which is the network of provider A.
Troubleshooting steps
On the RHEL router:
Display the rule list:
# ip rule list 0: from all lookup local 5: from 10.0.0.0/24 lookup 5000 32766: from all lookup main 32767: from all lookup defaultBy default, RHEL contains rules for the tables
local,main, anddefault.Display the routes in table
5000:# ip route list table 5000 default via 192.0.2.2 dev enp1s0 10.0.0.0/24 via 192.0.2.1 dev enp1s0Display the interfaces and firewall zones:
# firewall-cmd --get-active-zones external interfaces: enp1s0 enp7s0 internal interfaces: enp8s0 enp9s0Verify that the
externalzone has masquerading enabled:# firewall-cmd --info-zone=external external (active) target: default icmp-block-inversion: no interfaces: enp1s0 enp7s0 sources: services: ssh ports: protocols: masquerade: yes ...
Chapter 27. Reusing the same IP address on different interfaces
With Virtual routing and forwarding (VRF), administrators can use multiple routing tables simultaneously on the same host. For that, VRF partitions a network at layer 3. This enables the administrator to isolate traffic using separate and independent route tables per VRF domain. This technique is similar to virtual LANs (VLAN), which partitions a network at layer 2, where the operating system uses different VLAN tags to isolate traffic sharing the same physical medium.
One benefit of VRF over partitioning on layer 2 is that routing scales better considering the number of peers involved.
Red Hat Enterprise Linux uses a virtual vrt device for each VRF domain and adds routes to a VRF domain by adding existing network devices to a VRF device. Addresses and routes previously attached to the original device will be moved inside the VRF domain.
Note that each VRF domain is isolated from each other.
27.1. Permanently reusing the same IP address on different interfaces
You can use the virtual routing and forwarding (VRF) feature to permanently use the same IP address on different interfaces in one server.
To enable remote peers to contact both VRF interfaces while reusing the same IP address, the network interfaces must belong to different broadcasting domains. A broadcast domain in a network is a set of nodes, which receive broadcast traffic sent by any of them. In most configurations, all nodes connected to the same switch belong to the same broadcasting domain.
Prerequisites
-
You are logged in as the
rootuser. - The network interfaces are not configured.
Procedure
Create and configure the first VRF device:
Create a connection for the VRF device and assign it to a routing table. For example, to create a VRF device named
vrf0that is assigned to the1001routing table:# nmcli connection add type vrf ifname vrf0 con-name vrf0 table 1001 ipv4.method disabled ipv6.method disabledEnable the
vrf0device:# nmcli connection up vrf0Assign a network device to the VRF just created. For example, to add the
enp1s0Ethernet device to thevrf0VRF device and assign an IP address and the subnet mask toenp1s0, enter:# nmcli connection add type ethernet con-name vrf.enp1s0 ifname enp1s0 master vrf0 ipv4.method manual ipv4.address 192.0.2.1/24Activate the
vrf.enp1s0connection:# nmcli connection up vrf.enp1s0
Create and configure the next VRF device:
Create the VRF device and assign it to a routing table. For example, to create a VRF device named
vrf1that is assigned to the1002routing table, enter:# nmcli connection add type vrf ifname vrf1 con-name vrf1 table 1002 ipv4.method disabled ipv6.method disabledActivate the
vrf1device:# nmcli connection up vrf1Assign a network device to the VRF just created. For example, to add the
enp7s0Ethernet device to thevrf1VRF device and assign an IP address and the subnet mask toenp7s0, enter:# nmcli connection add type ethernet con-name vrf.enp7s0 ifname enp7s0 master vrf1 ipv4.method manual ipv4.address 192.0.2.1/24Activate the
vrf.enp7s0device:# nmcli connection up vrf.enp7s0
27.2. Temporarily reusing the same IP address on different interfaces
You can use the virtual routing and forwarding (VRF) feature to temporarily use the same IP address on different interfaces in one server. Use this procedure only for testing purposes, because the configuration is temporary and lost after you reboot the system.
To enable remote peers to contact both VRF interfaces while reusing the same IP address, the network interfaces must belong to different broadcasting domains. A broadcast domain in a network is a set of nodes which receive broadcast traffic sent by any of them. In most configurations, all nodes connected to the same switch belong to the same broadcasting domain.
Prerequisites
-
You are logged in as the
rootuser. - The network interfaces are not configured.
Procedure
Create and configure the first VRF device:
Create the VRF device and assign it to a routing table. For example, to create a VRF device named
bluethat is assigned to the1001routing table:# ip link add dev blue type vrf table 1001Enable the
bluedevice:# ip link set dev blue upAssign a network device to the VRF device. For example, to add the
enp1s0Ethernet device to theblueVRF device:# ip link set dev enp1s0 master blueEnable the
enp1s0device:# ip link set dev enp1s0 upAssign an IP address and subnet mask to the
enp1s0device. For example, to set it to192.0.2.1/24:# ip addr add dev enp1s0 192.0.2.1/24
Create and configure the next VRF device:
Create the VRF device and assign it to a routing table. For example, to create a VRF device named
redthat is assigned to the1002routing table:# ip link add dev red type vrf table 1002Enable the
reddevice:# ip link set dev red upAssign a network device to the VRF device. For example, to add the
enp7s0Ethernet device to theredVRF device:# ip link set dev enp7s0 master redEnable the
enp7s0device:# ip link set dev enp7s0 upAssign the same IP address and subnet mask to the
enp7s0device as you used forenp1s0in theblueVRF domain:# ip addr add dev enp7s0 192.0.2.1/24
- Optional: Create further VRF devices as described above.
Chapter 28. Starting a service within an isolated VRF network
With virtual routing and forwarding (VRF), you can create isolated networks with a routing table that is different to the main routing table of the operating system. You can then start services and applications so that they have only access to the network defined in that routing table.
28.1. Configuring a VRF device
To use virtual routing and forwarding (VRF), you create a VRF device and attach a physical or virtual network interface and routing information to it.
To prevent that you lock yourself out yourself out remotely, perform this procedure on the local console or remotely over a network interface that you do not want to assign to the VRF device.
Prerequisites
- You are logged in locally or using a network interface that is different to the one you want to assign to the VRF device.
Procedure
Create the
vrf0connection with a same-named virtual device, and attach it to routing table1000:# nmcli connection add type vrf ifname vrf0 con-name vrf0 table 1000 ipv4.method disabled ipv6.method disabledAdd the
enp1s0device to thevrf0connection, and configure the IP settings:# nmcli connection add type ethernet con-name enp1s0 ifname enp1s0 master vrf0 ipv4.method manual ipv4.address 192.0.2.1/24 ipv4.gateway 192.0.2.254This command creates the
enp1s0connection as a port of thevrf0connection. Due to this configuration, the routing information are automatically assigned to the routing table1000that is associated with thevrf0device.If you require static routes in the isolated network:
Add the static routes:
# nmcli connection modify enp1s0 +ipv4.routes "198.51.100.0/24 192.0.2.2"This adds a route to the
198.51.100.0/24network that uses192.0.2.2as the router.Activate the connection:
# nmcli connection up enp1s0
Verification
Display the IP settings of the device that is associated with
vrf0:# ip -br addr show vrf vrf0 enp1s0 UP 192.0.2.1/24Display the VRF devices and their associated routing table:
# ip vrf show Name Table ----------------------- vrf0 1000Display the main routing table:
# ip route show default via 203.0.113.0/24 dev enp7s0 proto static metric 100The main routing table does not mention any routes associated with the device
enp1s0device or the192.0.2.1/24subnet.Display the routing table
1000:# ip route show table 1000 default via 192.0.2.254 dev enp1s0 proto static metric 101 broadcast 192.0.2.0 dev enp1s0 proto kernel scope link src 192.0.2.1 192.0.2.0/24 dev enp1s0 proto kernel scope link src 192.0.2.1 metric 101 local 192.0.2.1 dev enp1s0 proto kernel scope host src 192.0.2.1 broadcast 192.0.2.255 dev enp1s0 proto kernel scope link src 192.0.2.1 198.51.100.0/24 via 192.0.2.2 dev enp1s0 proto static metric 101The
defaultentry indicates that services that use this routing table, use192.0.2.254as their default gateway and not the default gateway in the main routing table.Execute the
tracerouteutility in the network associated withvrf0to verify that the utility uses the route from table1000:# ip vrf exec vrf0 traceroute 203.0.113.1 traceroute to 203.0.113.1 (203.0.113.1), 30 hops max, 60 byte packets 1 192.0.2.254 (192.0.2.254) 0.516 ms 0.459 ms 0.430 ms ...The first hop is the default gateway that is assigned to the routing table
1000and not the default gateway from the system’s main routing table.
28.2. Starting a service within an isolated VRF network
You can configure a service, such as the Apache HTTP Server, to start within an isolated virtual routing and forwarding (VRF) network.
Services can only bind to local IP addresses that are in the same VRF network.
Prerequisites
-
You configured the
vrf0device. -
You configured Apache HTTP Server to listen only on the IP address that is assigned to the interface associated with the
vrf0device.
Procedure
Display the content of the
httpdsystemd service:# systemctl cat httpd ... [Service] ExecStart=/usr/sbin/httpd $OPTIONS -DFOREGROUND ...You require the content of the
ExecStartparameter in a later step to run the same command within the isolated VRF network.Create the
/etc/systemd/system/httpd.service.d/directory:# mkdir /etc/systemd/system/httpd.service.d/Create the
/etc/systemd/system/httpd.service.d/override.conffile with the following content:[Service] ExecStart= ExecStart=/usr/sbin/ip vrf exec vrf0 /usr/sbin/httpd $OPTIONS -DFOREGROUND ProtectControlGroups=noTo override an existing parameter, such as
ExecStartin the example, you first need to unset this parameter and then set it to the new value as shown.NoteThe
ProtectControlGroups=nosetting ensures that theiputility has access to the/sys/fs/cgroup/directory to set up VRF.Reload systemd.
# systemctl daemon-reloadRestart the
httpdservice.# systemctl restart httpd
Verification
Display the process IDs (PID) of
httpdprocesses:# pidof -c httpd 1904 ...Display the VRF association for the PIDs, for example:
# ip vrf identify 1904 vrf0Display all PIDs associated with the
vrf0device:# ip vrf pids vrf0 1904 httpd ...
Chapter 29. Configuring ethtool settings in NetworkManager connection profiles
NetworkManager can configure certain network driver and hardware settings persistently. Compared to using the ethtool utility to manage these settings, this has the benefit of not losing the settings after a reboot.
You can set the following ethtool settings in NetworkManager connection profiles:
- Offload features
- Network interface controllers can use the TCP offload engine (TOE) to offload processing certain operations to the network controller. This improves the network throughput.
- Interrupt coalesce settings
- By using interrupt coalescing, the system collects network packets and generates a single interrupt for multiple packets. This increases the amount of data sent to the kernel with one hardware interrupt, which reduces the interrupt load, and maximizes the throughput.
- Ring buffers
- These buffers store incoming and outgoing network packets. You can increase the ring buffer sizes to reduce a high packet drop rate.
29.1. Configuring an ethtool offload feature by using nmcli
You can use NetworkManager to enable and disable ethtool offload features in a connection profile.
Procedure
For example, to enable the RX offload feature and disable TX offload in the
enp1s0connection profile, enter:# nmcli con modify enp1s0 ethtool.feature-rx on ethtool.feature-tx offThis command explicitly enables RX offload and disables TX offload.
To remove the setting of an offload feature that you previously enabled or disabled, set the feature’s parameter to a null value. For example, to remove the configuration for TX offload, enter:
# nmcli con modify enp1s0 ethtool.feature-tx ""Reactivate the network profile:
# nmcli connection up enp1s0
Verification
Use the
ethtool -kcommand to display the current offload features of a network device:# ethtool -k network_device
29.2. Configuring an ethtool offload feature by using the network RHEL system role
You can use the network RHEL system role to automate configuring TCP offload engine (TOE) to offload processing certain operations to the network controller. TOE improves the network throughput.
You cannot use the network RHEL system role to update only specific values in an existing connection profile. The role ensures that a connection profile exactly matches the settings in a playbook. If a connection profile with the same name already exists, the role applies the settings from the playbook and resets all other settings in the profile to their defaults. To prevent resetting values, always specify the whole configuration of the network connection profile in the playbook, including the settings that you do not want to change.
Prerequisites
- You have prepared the control node and the managed nodes.
-
The account you use to connect to the managed nodes has
sudopermissions for these nodes.
Procedure
Create a playbook file, for example,
~/playbook.yml, with the following content:--- - name: Configure the network hosts: managed-node-01.example.com tasks: - name: Ethernet connection profile with dynamic IP address settings and offload features ansible.builtin.include_role: name: redhat.rhel_system_roles.network vars: network_connections: - name: enp1s0 type: ethernet autoconnect: yes ip: dhcp4: yes auto6: yes ethtool: features: gro: no gso: yes tx_sctp_segmentation: no state: upThe settings specified in the example playbook include the following:
gro: no- Disables Generic receive offload (GRO).
gso: yes- Enables Generic segmentation offload (GSO).
tx_sctp_segmentation: no- Disables TX stream control transmission protocol (SCTP) segmentation.
For details about all variables used in the playbook, see the
/usr/share/ansible/roles/rhel-system-roles.network/README.mdfile on the control node.Validate the playbook syntax:
$ ansible-playbook --syntax-check ~/playbook.ymlNote that this command only validates the syntax and does not protect against a wrong but valid configuration.
Run the playbook:
$ ansible-playbook ~/playbook.yml
Verification
Query the Ansible facts of the managed node and verify the offload settings:
# ansible managed-node-01.example.com -m ansible.builtin.setup ... "ansible_enp1s0": { "active": true, "device": "enp1s0", "features": { ... "rx_gro_hw": "off, ... "tx_gso_list": "on, ... "tx_sctp_segmentation": "off", ... } ...
29.3. Configuring an ethtool coalesce settings by using nmcli
You can use NetworkManager to set ethtool coalesce settings in connection profiles.
Procedure
For example, to set the maximum number of received packets to delay to
128in theenp1s0connection profile, enter:# nmcli connection modify enp1s0 ethtool.coalesce-rx-frames 128To remove a coalesce setting, set it to a null value. For example, to remove the
ethtool.coalesce-rx-framessetting, enter:# nmcli connection modify enp1s0 ethtool.coalesce-rx-frames ""To reactivate the network profile:
# nmcli connection up enp1s0
Verification
Use the
ethtool -ccommand to display the current offload features of a network device:# ethtool -c network_device
29.4. Configuring an ethtool coalesce settings by using the network RHEL system role
Interrupt coalescing collects network packets and generates a single interrupt for multiple packets. This reduces interrupt load and maximizes throughput. You can automate the configuration of these settings in the NetworkManager connection profile by using the network RHEL system role.
You cannot use the network RHEL system role to update only specific values in an existing connection profile. The role ensures that a connection profile exactly matches the settings in a playbook. If a connection profile with the same name already exists, the role applies the settings from the playbook and resets all other settings in the profile to their defaults. To prevent resetting values, always specify the whole configuration of the network connection profile in the playbook, including the settings that you do not want to change.
Prerequisites
- You have prepared the control node and the managed nodes.
-
The account you use to connect to the managed nodes has
sudopermissions for these nodes.
Procedure
Create a playbook file, for example,
~/playbook.yml, with the following content:--- - name: Configure the network hosts: managed-node-01.example.com tasks: - name: Ethernet connection profile with dynamic IP address settings and coalesce settings ansible.builtin.include_role: name: redhat.rhel_system_roles.network vars: network_connections: - name: enp1s0 type: ethernet autoconnect: yes ip: dhcp4: yes auto6: yes ethtool: coalesce: rx_frames: 128 tx_frames: 128 state: upThe settings specified in the example playbook include the following:
rx_frames: <value>- Sets the number of RX frames.
tx_frames: <value>- Sets the number of TX frames.
For details about all variables used in the playbook, see the
/usr/share/ansible/roles/rhel-system-roles.network/README.mdfile on the control node.Validate the playbook syntax:
$ ansible-playbook --syntax-check ~/playbook.ymlNote that this command only validates the syntax and does not protect against a wrong but valid configuration.
Run the playbook:
$ ansible-playbook ~/playbook.yml
Verification
Display the current offload features of the network device:
# ansible managed-node-01.example.com -m command -a 'ethtool -c enp1s0' managed-node-01.example.com | CHANGED | rc=0 >> ... rx-frames: 128 ... tx-frames: 128 ...
29.5. Increasing the ring buffer size to reduce a high packet drop rate by using nmcli
Increase the size of an Ethernet device’s ring buffers if the packet drop rate causes applications to report a loss of data, timeouts, or other issues.
Receive ring buffers are shared between the device driver and network interface controller (NIC). The card assigns a transmit (TX) and receive (RX) ring buffer. As the name implies, the ring buffer is a circular buffer where an overflow overwrites existing data. There are two ways to move data from the NIC to the kernel, hardware interrupts and software interrupts, also called SoftIRQs.
The kernel uses the RX ring buffer to store incoming packets until the device driver can process them. The device driver drains the RX ring, typically by using SoftIRQs, which puts the incoming packets into a kernel data structure called an sk_buff or skb to begin its journey through the kernel and up to the application that owns the relevant socket.
The kernel uses the TX ring buffer to hold outgoing packets which are sent to the network. These ring buffers reside at the bottom of the stack and are a crucial point at which packet drop can occur, which in turn adversely affects network performance.
Procedure
Display the packet drop statistics of the interface:
# ethtool -S enp1s0 ... rx_queue_0_drops: 97326 rx_queue_1_drops: 63783 ...Note that the output of the command depends on the network card and the driver.
High values in
discardordropcounters indicate that the available buffer fills up faster than the kernel can process the packets. Increasing the ring buffers can help to avoid such loss.Display the maximum ring buffer sizes:
# ethtool -g enp1s0 Ring parameters for enp1s0: Pre-set maximums: RX: 4096 RX Mini: 0 RX Jumbo: 16320 TX: 4096 Current hardware settings: RX: 255 RX Mini: 0 RX Jumbo: 0 TX: 255If the values in the
Pre-set maximumssection are higher than in theCurrent hardware settingssection, you can change the settings in the next steps.Identify the NetworkManager connection profile that uses the interface:
# nmcli connection show NAME UUID TYPE DEVICE Example-Connection a5eb6490-cc20-3668-81f8-0314a27f3f75 ethernet enp1s0Update the connection profile, and increase the ring buffers:
To increase the RX ring buffer, enter:
# nmcli connection modify Example-Connection ethtool.ring-rx 4096To increase the TX ring buffer, enter:
# nmcli connection modify Example-Connection ethtool.ring-tx 4096
Reload the NetworkManager connection:
# nmcli connection up Example-ConnectionImportantDepending on the driver your NIC uses, changing in the ring buffer can shortly interrupt the network connection.
29.6. Increasing the ring buffer size to reduce a high packet drop rate by using the network RHEL system role
Increase the size of an Ethernet device’s ring buffers if the packet drop rate causes applications to report a loss of data, timeouts, or other issues.
Ring buffers are circular buffers where an overflow overwrites existing data. The network card assigns a transmit (TX) and receive (RX) ring buffer. Receive ring buffers are shared between the device driver and the network interface controller (NIC). Data can move from NIC to the kernel through either hardware interrupts or software interrupts, also called SoftIRQs.
The kernel uses the RX ring buffer to store incoming packets until the device driver can process them. The device driver drains the RX ring, typically by using SoftIRQs, which puts the incoming packets into a kernel data structure called an sk_buff or skb to begin its journey through the kernel and up to the application that owns the relevant socket.
The kernel uses the TX ring buffer to hold outgoing packets destined for the network. These ring buffers reside at the bottom of the stack and are a crucial point at which packet drop can occur, which in turn adversely affects network performance.
You configure ring buffer settings in the NetworkManager connection profiles. By using Ansible and the network RHEL system role, you can automate this process and remotely configure connection profiles on the hosts defined in a playbook.
You cannot use the network RHEL system role to update only specific values in an existing connection profile. The role ensures that a connection profile exactly matches the settings in a playbook. If a connection profile with the same name already exists, the role applies the settings from the playbook and resets all other settings in the profile to their defaults. To prevent resetting values, always specify the whole configuration of the network connection profile in the playbook, including the settings that you do not want to change.
Prerequisites
- You have prepared the control node and the managed nodes.
-
The account you use to connect to the managed nodes has
sudopermissions for these nodes. - You know the maximum ring buffer sizes that the device supports.
Procedure
Create a playbook file, for example,
~/playbook.yml, with the following content:--- - name: Configure the network hosts: managed-node-01.example.com tasks: - name: Ethernet connection profile with dynamic IP address setting and increased ring buffer sizes ansible.builtin.include_role: name: redhat.rhel_system_roles.network vars: network_connections: - name: enp1s0 type: ethernet autoconnect: yes ip: dhcp4: yes auto6: yes ethtool: ring: rx: 4096 tx: 4096 state: upThe settings specified in the example playbook include the following:
rx: <value>- Sets the maximum number of received ring buffer entries.
tx: <value>- Sets the maximum number of transmitted ring buffer entries.
For details about all variables used in the playbook, see the
/usr/share/ansible/roles/rhel-system-roles.network/README.mdfile on the control node.Validate the playbook syntax:
$ ansible-playbook --syntax-check ~/playbook.ymlNote that this command only validates the syntax and does not protect against a wrong but valid configuration.
Run the playbook:
$ ansible-playbook ~/playbook.yml
Verification
Display the maximum ring buffer sizes:
# ansible managed-node-01.example.com -m command -a 'ethtool -g enp1s0' managed-node-01.example.com | CHANGED | rc=0 >> ... Current hardware settings: RX: 4096 RX Mini: 0 RX Jumbo: 0 TX: 4096
Chapter 30. Introduction to NetworkManager Debugging
Increasing the log levels for all or certain domains helps to log more details of the operations that NetworkManager performs. You can use this information to troubleshoot problems.
NetworkManager provides different levels and domains to produce logging information. The /etc/NetworkManager/NetworkManager.conf file is the main configuration file for NetworkManager. The logs are stored in the journal.
30.1. Introduction to NetworkManager reapply() method
NetworkManager uses profiles to manage device connection settings, which can be created, modified, or deleted through the D-Bus API. When a profile is changed, D-Bus clones the settings. To apply these changes, you must reactivate the connection’s settings or use the reapply() method.
The reapply() method has the following features:
- Updating modified connection settings without deactivation or restart of a network interface.
-
Removing pending changes from the modified connection settings. As
NetworkManagerdoes not revert the manual changes, you can reconfigure the device and revert external or manual parameters. - Creating different modified connection settings than that of the existing connection settings.
Also, reapply() method supports the following attributes:
-
bridge.ageing-time -
bridge.forward-delay -
bridge.group-address -
bridge.group-forward-mask -
bridge.hello-time -
bridge.max-age -
bridge.multicast-hash-max -
bridge.multicast-last-member-count -
bridge.multicast-last-member-interval -
bridge.multicast-membership-interval -
bridge.multicast-querier -
bridge.multicast-querier-interval -
bridge.multicast-query-interval -
bridge.multicast-query-response-interval -
bridge.multicast-query-use-ifaddr -
bridge.multicast-router -
bridge.multicast-snooping -
bridge.multicast-startup-query-count -
bridge.multicast-startup-query-interval -
bridge.priority -
bridge.stp -
bridge.VLAN-filtering -
bridge.VLAN-protocol -
bridge.VLANs -
802-3-ethernet.accept-all-mac-addresses -
802-3-ethernet.cloned-mac-address -
IPv4.addresses -
IPv4.dhcp-client-id -
IPv4.dhcp-iaid -
IPv4.dhcp-timeout -
IPv4.DNS -
IPv4.DNS-priority -
IPv4.DNS-search -
IPv4.gateway -
IPv4.ignore-auto-DNS -
IPv4.ignore-auto-routes -
IPv4.may-fail -
IPv4.method -
IPv4.never-default -
IPv4.route-table -
IPv4.routes -
IPv4.routing-rules -
IPv6.addr-gen-mode -
IPv6.addresses -
IPv6.dhcp-duid -
IPv6.dhcp-iaid -
IPv6.dhcp-timeout -
IPv6.DNS -
IPv6.DNS-priority -
IPv6.DNS-search -
IPv6.gateway -
IPv6.ignore-auto-DNS -
IPv6.may-fail -
IPv6.method -
IPv6.never-default -
IPv6.ra-timeout -
IPv6.route-metric -
IPv6.route-table -
IPv6.routes -
IPv6.routing-rules
30.2. Setting the NetworkManager log level
By default, all the log domains are set to record the INFO log level. Disable rate-limiting before collecting debug logs. With rate-limiting, systemd-journald drops messages if there are too many of them in a short time. This can occur when the log level is TRACE.
This procedure disables rate-limiting and enables recording debug logs for the all (ALL) domains.
Procedure
To disable rate-limiting, edit the
/etc/systemd/journald.conffile, uncomment theRateLimitBurstparameter in the[Journal]section, and set its value as0:RateLimitBurst=0Restart the
systemd-journaldservice.# systemctl restart systemd-journaldCreate the
/etc/NetworkManager/conf.d/95-nm-debug.conffile with the following content:[logging] domains=ALL:TRACEThe
domainsparameter can contain multiple comma-separateddomain:levelpairs.Restart the NetworkManager service.
# systemctl restart NetworkManager
Verification
Query the
systemdjournal to display the journal entries of theNetworkManagerunit:# journalctl -u NetworkManager ... Jun 30 15:24:32 server NetworkManager[164187]: <debug> [1656595472.4939] active-connection[0x5565143c80a0]: update activation type from assume to managed Jun 30 15:24:32 server NetworkManager[164187]: <trace> [1656595472.4939] device[55b33c3bdb72840c] (enp1s0): sys-iface-state: assume -> managed Jun 30 15:24:32 server NetworkManager[164187]: <trace> [1656595472.4939] l3cfg[4281fdf43e356454,ifindex=3]: commit type register (type "update", source "device", existing a369f23014b9ede3) -> a369f23014b9ede3 Jun 30 15:24:32 server NetworkManager[164187]: <info> [1656595472.4940] manager: NetworkManager state is now CONNECTED_SITE ...
30.3. Temporarily setting log levels at run time using nmcli
You can change the log level at run time using nmcli.
Procedure
Optional: Display the current logging settings:
# nmcli general logging LEVEL DOMAINS INFO PLATFORM,RFKILL,ETHER,WIFI,BT,MB,DHCP4,DHCP6,PPP,WIFI_SCAN,IP4,IP6,A UTOIP4,DNS,VPN,SHARING,SUPPLICANT,AGENTS,SETTINGS,SUSPEND,CORE,DEVICE,OLPC, WIMAX,INFINIBAND,FIREWALL,ADSL,BOND,VLAN,BRIDGE,DBUS_PROPS,TEAM,CONCHECK,DC B,DISPATCHTo modify the logging level and domains, use the following options:
To set the log level for all domains to the same
LEVEL, enter:# nmcli general logging level LEVEL domains ALLTo change the level for specific domains, enter:
# nmcli general logging level LEVEL domains DOMAINSNote that updating the logging level using this command disables logging for all the other domains.
To change the level of specific domains and preserve the level of all other domains, enter:
# nmcli general logging level KEEP domains DOMAIN:LEVEL,DOMAIN:LEVEL
30.4. Viewing NetworkManager logs
You can view the NetworkManager logs for troubleshooting.
Procedure
To view the logs, enter:
# journalctl -u NetworkManager -b
30.5. Debugging levels and domains
You can use the levels and domains parameters to manage the debugging for NetworkManager. The level defines the verbosity level, whereas the domains define the category of the messages to record the logs with given severity (level).
| Log levels | Description |
|---|---|
|
| Does not log any messages about NetworkManager |
|
| Logs only critical errors |
|
| Logs warnings that can reflect the operation |
|
| Logs various informational messages that are useful for tracking state and operations |
|
| Enables verbose logging for debugging purposes |
|
|
Enables more verbose logging than the |
Note that subsequent levels log all messages from earlier levels. For example, setting the log level to INFO also logs messages contained in the ERR and WARN log level.
Chapter 31. Using LLDP to debug network configuration problems
You can use the Link Layer Discovery Protocol (LLDP) to debug network configuration problems in the topology. This means that, LLDP can report configuration inconsistencies with other hosts or routers and switches.
31.1. Debugging an incorrect VLAN configuration using LLDP information
If you configured a switch port to use a certain VLAN and a host does not receive these VLAN packets, you can use the Link Layer Discovery Protocol (LLDP) to debug the problem.
Prerequisites
-
The
nmstatepackage is installed. - The switch supports LLDP.
- LLDP is enabled on neighbor devices.
Procedure
Create the
~/enable-LLDP-enp1s0.ymlfile with the following content:interfaces: - name: enp1s0 type: ethernet lldp: enabled: trueUse the
~/enable-LLDP-enp1s0.ymlfile to enable LLDP on interfaceenp1s0:# nmstatectl apply ~/enable-LLDP-enp1s0.ymlDisplay the LLDP information:
# nmstatectl show enp1s0 - name: enp1s0 type: ethernet state: up ipv4: enabled: false dhcp: false ipv6: enabled: false autoconf: false dhcp: false lldp: enabled: true neighbors: - - type: 5 system-name: Summit300-48 - type: 6 system-description: Summit300-48 - Version 7.4e.1 (Build 5) 05/27/05 04:53:11 - type: 7 system-capabilities: - MAC Bridge component - Router - type: 1 _description: MAC address chassis-id: 00:01:30:F9:AD:A0 chassis-id-type: 4 - type: 2 _description: Interface name port-id: 1/1 port-id-type: 5 - type: 127 ieee-802-1-vlans: - name: v2-0488-03-0505 vid: 488 oui: 00:80:c2 subtype: 3 - type: 127 ieee-802-3-mac-phy-conf: autoneg: true operational-mau-type: 16 pmd-autoneg-cap: 27648 oui: 00:12:0f subtype: 1 - type: 127 ieee-802-1-ppvids: - 0 oui: 00:80:c2 subtype: 2 - type: 8 management-addresses: - address: 00:01:30:F9:AD:A0 address-subtype: MAC interface-number: 1001 interface-number-subtype: 2 - type: 127 ieee-802-3-max-frame-size: 1522 oui: 00:12:0f subtype: 4 mac-address: 82:75:BE:6F:8C:7A mtu: 1500Verify the output to ensure that the settings match your expected configuration. For example, the LLDP information of the interface connected to the switch shows that the switch port this host is connected to uses VLAN ID
448:- type: 127 ieee-802-1-vlans: - name: v2-0488-03-0505 vid: 488If the network configuration of the
enp1s0interface uses a different VLAN ID, change it accordingly.
Chapter 32. Linux traffic control
Linux Traffic Control (TC) helps in policing, classifying, shaping, and scheduling network traffic. It uses queuing disciplines (qdisc) and filters to manage and manipulate packet transmission, including mangling packet content.
The scheduling mechanism arranges or rearranges the packets before they enter or exit different queues. The most common scheduler is the First-In-First-Out (FIFO) scheduler. You can do the qdiscs operations temporarily using the tc utility or permanently using NetworkManager.
In Red Hat Enterprise Linux, you can configure default queueing disciplines in various ways to manage the traffic on a network interface.
32.1. Overview of queuing disciplines
Queuing disciplines (qdiscs) help with queuing up and, later, scheduling of traffic transmission by a network interface.
A qdisc has two operations;
- enqueue requests so that a packet can be queued up for later transmission and
- dequeue requests so that one of the queued-up packets can be chosen for immediate transmission.
Every qdisc has a 16-bit hexadecimal identification number called a handle, with an attached colon, such as 1: or abcd:. This number is called the qdisc major number. If a qdisc has classes, then the identifiers are formed as a pair of two numbers with the major number before the minor, <major>:<minor>, for example abcd:1. The numbering scheme for the minor numbers depends on the qdisc type. Sometimes the numbering is systematic, where the first-class has the ID <major>:1, the second one <major>:2, and so on. Some qdiscs allow the user to set class minor numbers arbitrarily when creating the class.
- Classful
qdiscs Different types of
qdiscsexist and help in the transfer of packets to and from a networking interface. You can configureqdiscswith root, parent, or child classes. The point where children can be attached are called classes. Classes inqdiscare flexible and can always contain either multiple children classes or a single child,qdisc. There is no prohibition against a class containing a classfulqdiscitself, this facilitates complex traffic control scenarios.Classful
qdiscsdo not store any packets themselves. Instead, they enqueue and dequeue requests down to one of their children according to criteria specific to theqdisc. Eventually, this recursive packet passing ends up where the packets are stored (or picked up from in the case of dequeuing).- Classless
qdiscs -
Some
qdiscscontain no child classes and they are called classlessqdiscs. Classlessqdiscsrequire less customization compared to classfulqdiscs. It is usually enough to attach them to an interface.
32.2. Inspecting qdiscs of a network interface using the tc utility
By default, Red Hat Enterprise Linux systems use fq_codel qdisc. You can inspect the qdisc counters using the tc utility.
Procedure
Optional: View your current
qdisc:# tc qdisc show dev enp0s1Inspect the current
qdisccounters:# tc -s qdisc show dev enp0s1 qdisc fq_codel 0: root refcnt 2 limit 10240p flows 1024 quantum 1514 target 5.0ms interval 100.0ms memory_limit 32Mb ecn Sent 1008193 bytes 5559 pkt (dropped 233, overlimits 55 requeues 77) backlog 0b 0p requeues 0-
dropped- the number of times a packet is dropped because all queues are full -
overlimits- the number of times the configured link capacity is filled -
sent- the number of dequeues
-
32.3. Updating the default qdisc
If you observe networking packet losses with the current qdisc, you can change the qdisc based on your network-requirements.
Procedure
View the current default
qdisc:# sysctl -a | grep qdisc net.core.default_qdisc = fq_codelView the
qdiscof current Ethernet connection:# tc -s qdisc show dev enp0s1 qdisc fq_codel 0: root refcnt 2 limit 10240p flows 1024 quantum 1514 target 5.0ms interval 100.0ms memory_limit 32Mb ecn Sent 0 bytes 0 pkt (dropped 0, overlimits 0 requeues 0) backlog 0b 0p requeues 0 maxpacket 0 drop_overlimit 0 new_flow_count 0 ecn_mark 0 new_flows_len 0 old_flows_len 0Update the existing
qdisc:# sysctl -w net.core.default_qdisc=pfifo_fastTo apply the changes, reload the network driver:
# modprobe -r NETWORKDRIVERNAME # modprobe NETWORKDRIVERNAMEStart the network interface:
# ip link set enp0s1 up
Verification
View the
qdiscof the Ethernet connection:# tc -s qdisc show dev enp0s1 qdisc pfifo_fast 0: root refcnt 2 bands 3 priomap 1 2 2 2 1 2 0 0 1 1 1 1 1 1 1 1 Sent 373186 bytes 5333 pkt (dropped 0, overlimits 0 requeues 0) backlog 0b 0p requeues 0 ....
32.4. Temporarily setting the current qdisc of a network interface using the tc utility
Changing the current qdisc can optimize how the kernel handles packets as they pass through a network interface. For testing and benchmarking purposes, you can change the qdisc temporarily.
Procedure
Optional: View the current
qdisc:# tc -s qdisc show dev enp0s1Update the current
qdisc:# tc qdisc replace dev enp0s1 root htb
Verification
View the updated current
qdisc:# tc -s qdisc show dev enp0s1 qdisc htb 8001: root refcnt 2 r2q 10 default 0 direct_packets_stat 0 direct_qlen 1000 Sent 0 bytes 0 pkt (dropped 0, overlimits 0 requeues 0) backlog 0b 0p requeues 0
32.5. Permanently setting the current qdisc of a network interface using NetworkManager
Changing the current qdisc can optimize how the kernel handles packets as they pass through a network interface. If you identified the optimal qdisc for your scenario, set it permanently in the NetworkManager connection profile.
Procedure
Optional: View the current
qdisc:# tc qdisc show dev enp0s1 qdisc fq_codel 0: root refcnt 2Update the current
qdisc:# nmcli connection modify enp0s1 tc.qdiscs 'root pfifo_fast'Optional: To add another
qdiscover the existingqdisc, use the+tc.qdiscoption:# nmcli connection modify enp0s1 +tc.qdisc 'ingress handle ffff:'Activate the changes:
# nmcli connection up enp0s1
Verification
View current
qdiscthe network interface:# tc qdisc show dev enp0s1 qdisc pfifo_fast 8001: root refcnt 2 bands 3 priomap 1 2 2 2 1 2 0 0 1 1 1 1 1 1 1 1 qdisc ingress ffff: parent ffff:fff1 ----------------
32.6. Available qdiscs in RHEL
Each qdisc addresses unique networking-related issues. You can use any of them to shape network traffic based on your networking requirements.
These qdiscs are available in RHEL:
qdisc name | Included in | Offload support |
|---|---|---|
| Asynchronous Transfer Mode (ATM) |
| |
| Credit-Based Shaper |
| Yes |
| CHOose and Keep for responsive flows, CHOose and Kill for unresponsive flows (CHOKE) |
| |
| Controlled Delay (CoDel) |
| |
| Enhanced Transmission Selection (ETS) |
| Yes |
| Fair Queue (FQ) |
| |
| Fair Queuing Controlled Delay (FQ_CODel) |
| |
| Generalized Random Early Detection (GRED) |
| |
| Hierarchical Fair Service Curve (HSFC) |
| |
| Heavy-Hitter Filter (HHF) |
| |
| Hierarchy Token Bucket (HTB) |
| Yes |
| INGRESS |
| Yes |
| Multi Queue Priority (MQPRIO) |
| Yes |
| Multiqueue (MULTIQ) |
| Yes |
| Network Emulator (NETEM) |
| |
| Proportional Integral-controller Enhanced (PIE) |
| |
| PLUG |
| |
| Quick Fair Queueing (QFQ) |
| |
| Random Early Detection (RED) |
| Yes |
| Stochastic Fair Blue (SFB) |
| |
| Stochastic Fairness Queueing (SFQ) |
| |
| Token Bucket Filter (TBF) |
| Yes |
| Trivial Link Equalizer (TEQL) |
|
The qdisc offload requires hardware and driver support on NIC.
Chapter 33. Authenticating a RHEL client to the network by using the 802.1X standard with a certificate stored on the file system
Port-based Network Access Control (NAC), based on the IEEE 802.1X standard, protects a network from unauthorized clients. If the network uses Extensible Authentication Protocol Transport Layer Security (EAP-TLS), you require a certificate to authenticate the client.
33.1. Configuring 802.1X network authentication on an existing Ethernet connection by using nmcli
You can use the nmcli utility to configure an Ethernet connection with 802.1X network authentication on the command line.
Prerequisites
- The network supports 802.1X network authentication.
- The Ethernet connection profile exists in NetworkManager and has a valid IP configuration.
The following files required for TLS authentication exist on the client:
-
The client key stored is in the
/etc/pki/tls/private/client.keyfile, and the file is owned and only readable by therootuser. -
The client certificate is stored in the
/etc/pki/tls/certs/client.crtfile. -
The Certificate Authority (CA) certificate is stored in the
/etc/pki/tls/certs/ca.crtfile.
-
The client key stored is in the
-
The
wpa_supplicantpackage is installed.
Procedure
Set the Extensible Authentication Protocol (EAP) to
tlsand the paths to the client certificate and key file:# nmcli connection modify enp1s0 802-1x.eap tls 802-1x.client-cert /etc/pki/tls/certs/client.crt 802-1x.private-key /etc/pki/tls/private/client.keyNote that you must set the
802-1x.eap,802-1x.client-cert, and802-1x.private-keyparameters in a single command.Set the path to the CA certificate:
# nmcli connection modify enp1s0 802-1x.ca-cert /etc/pki/tls/certs/ca.crtSet the identity of the user used in the certificate:
# nmcli connection modify enp1s0 802-1x.identity user@example.comOptional: Store the password in the configuration:
# nmcli connection modify enp1s0 802-1x.private-key-password passwordImportantBy default, NetworkManager stores the password in clear text in the connection profile on the disk, but the file is readable only by the
rootuser. However, clear text passwords in a configuration file can be a security risk.To increase the security, set the
802-1x.password-flagsparameter toagent-owned. With this setting, on servers with the GNOME desktop environment or thenm-appletrunning, NetworkManager retrieves the password from these services, after you unlock the keyring. In other cases, NetworkManager prompts for the password.Activate the connection profile:
# nmcli connection up enp1s0
Verification
- Access resources on the network that require network authentication.
33.2. Configuring a static Ethernet connection with 802.1X network authentication by using nmstatectl
You can use the declarative Nmstate API to configure an Ethernet connection with 802.1X network authentication. Nmstate ensures that the result matches the configuration file or rolls back the changes.
The nmstate library only supports the TLS Extensible Authentication Protocol (EAP) method.
Prerequisites
- The network supports 802.1X network authentication.
- The managed node uses NetworkManager.
The following files required for TLS authentication exist on the client:
-
The client key stored is in the
/etc/pki/tls/private/client.keyfile, and the file is owned and only readable by therootuser. -
The client certificate is stored in the
/etc/pki/tls/certs/client.crtfile. -
The Certificate Authority (CA) certificate is stored in the
/etc/pki/tls/certs/ca.crtfile.
-
The client key stored is in the
Procedure
Create a YAML file, for example
~/create-ethernet-profile.yml, with the following content:--- interfaces: - name: enp1s0 type: ethernet state: up ipv4: enabled: true address: - ip: 192.0.2.1 prefix-length: 24 dhcp: false ipv6: enabled: true address: - ip: 2001:db8:1::1 prefix-length: 64 autoconf: false dhcp: false 802.1x: ca-cert: /etc/pki/tls/certs/ca.crt client-cert: /etc/pki/tls/certs/client.crt eap-methods: - tls identity: client.example.org private-key: /etc/pki/tls/private/client.key private-key-password: password routes: config: - destination: 0.0.0.0/0 next-hop-address: 192.0.2.254 next-hop-interface: enp1s0 - destination: ::/0 next-hop-address: 2001:db8:1::fffe next-hop-interface: enp1s0 dns-resolver: config: search: - example.com server: - 192.0.2.200 - 2001:db8:1::ffbbThese settings define an Ethernet connection profile for the
enp1s0device with the following settings:-
A static IPv4 address -
192.0.2.1with a/24subnet mask -
A static IPv6 address -
2001:db8:1::1with a/64subnet mask -
An IPv4 default gateway -
192.0.2.254 -
An IPv6 default gateway -
2001:db8:1::fffe -
An IPv4 DNS server -
192.0.2.200 -
An IPv6 DNS server -
2001:db8:1::ffbb -
A DNS search domain -
example.com -
802.1X network authentication using the
TLSEAP protocol
-
A static IPv4 address -
Apply the settings to the system:
# nmstatectl apply ~/create-ethernet-profile.yml
Verification
- Access resources on the network that require network authentication.
33.3. Configuring a static Ethernet connection with 802.1X network authentication by using the network RHEL system role
By using the network RHEL system role, you can automate setting up Network Access Control (NAC) on remote hosts. You can define authentication details for clients in a playbook to ensure only authorized clients can access the network.
You can use an Ansible playbook to copy a private key, a certificate, and the CA certificate to the client, and then use the network RHEL system role to configure a connection profile with 802.1X network authentication.
Prerequisites
- You have prepared the control node and the managed nodes.
-
The account you use to connect to the managed nodes has
sudopermissions for these nodes. - The network supports 802.1X network authentication.
- The managed nodes use NetworkManager.
The following files required for the TLS authentication exist on the control node:
-
The client key is stored in the
/srv/data/client.keyfile. -
The client certificate is stored in the
/srv/data/client.crtfile. -
The Certificate Authority (CA) certificate is stored in the
/srv/data/ca.crtfile.
-
The client key is stored in the
Procedure
Store your sensitive variables in an encrypted file:
Create the vault:
$ ansible-vault create ~/vault.yml New Vault password: <vault_password> Confirm New Vault password: <vault_password>After the
ansible-vault createcommand opens an editor, enter the sensitive data in the<key>: <value>format:pwd: <password>- Save the changes, and close the editor. Ansible encrypts the data in the vault.
Create a playbook file, for example,
~/playbook.yml, with the following content:--- - name: Configure an Ethernet connection with 802.1X authentication hosts: managed-node-01.example.com vars_files: - ~/vault.yml tasks: - name: Copy client key for 802.1X authentication ansible.builtin.copy: src: "/srv/data/client.key" dest: "/etc/pki/tls/private/client.key" mode: 0600 - name: Copy client certificate for 802.1X authentication ansible.builtin.copy: src: "/srv/data/client.crt" dest: "/etc/pki/tls/certs/client.crt" - name: Copy CA certificate for 802.1X authentication ansible.builtin.copy: src: "/srv/data/ca.crt" dest: "/etc/pki/ca-trust/source/anchors/ca.crt" - name: Ethernet connection profile with static IP address settings and 802.1X ansible.builtin.include_role: name: redhat.rhel_system_roles.network vars: network_connections: - name: enp1s0 type: ethernet autoconnect: yes ip: address: - 192.0.2.1/24 - 2001:db8:1::1/64 gateway4: 192.0.2.254 gateway6: 2001:db8:1::fffe dns: - 192.0.2.200 - 2001:db8:1::ffbb dns_search: - example.com ieee802_1x: identity: <user_name> eap: tls private_key: "/etc/pki/tls/private/client.key" private_key_password: "{{ pwd }}" client_cert: "/etc/pki/tls/certs/client.crt" ca_cert: "/etc/pki/ca-trust/source/anchors/ca.crt" domain_suffix_match: example.com state: upThe settings specified in the example playbook include the following:
ieee802_1x- This variable contains the 802.1X-related settings.
eap: tls-
Configures the profile to use the certificate-based
TLSauthentication method for the Extensible Authentication Protocol (EAP).
For details about all variables used in the playbook, see the
/usr/share/ansible/roles/rhel-system-roles.network/README.mdfile on the control node.Validate the playbook syntax:
$ ansible-playbook --ask-vault-pass --syntax-check ~/playbook.ymlNote that this command only validates the syntax and does not protect against a wrong but valid configuration.
Run the playbook:
$ ansible-playbook --ask-vault-pass ~/playbook.yml
Verification
- Access resources on the network that require network authentication.
Chapter 34. Setting up an 802.1x network authentication service for LAN clients by using hostapd with FreeRADIUS integration
The IEEE 802.1X standard defines secure authentication and authorization methods to protect networks from unauthorized clients. By using the hostapd service and FreeRADIUS, you can provide network access control (NAC) in your network.
Red Hat supports only FreeRADIUS with Red Hat Identity Management (IdM) as the source of authentication.
In this documentation, the RHEL host acts as a bridge to connect different clients with an existing network. However, the RHEL host grants only authenticated clients access to the network.

34.1. Prerequisites
A clean installation of the
freeradiusandfreeradius-ldappackages.If the packages are already installed, remove the
/etc/raddb/directory, uninstall and then install the packages again. Do not reinstall the packages by using theyum reinstallcommand, because the permissions and symbolic links in the/etc/raddb/directory are then different.- The host on which you want to configure FreeRADIUS is a client in an IdM domain.
34.2. Setting up the bridge on the authenticator
A network bridge is a link-layer device that forwards traffic between hosts and networks based on a table of MAC addresses. If you set up RHEL as an 802.1X authenticator, add both the interfaces on which to perform authentication and the LAN interface to the bridge.
Prerequisites
- The server has multiple Ethernet interfaces.
Procedure
If the bridge interface does not exist, create it:
# nmcli connection add type bridge con-name br0 ifname br0Assign the Ethernet interfaces to the bridge:
# nmcli connection add type ethernet slave-type bridge con-name br0-port1 ifname enp1s0 master br0 # nmcli connection add type ethernet slave-type bridge con-name br0-port2 ifname enp7s0 master br0 # nmcli connection add type ethernet slave-type bridge con-name br0-port3 ifname enp8s0 master br0 # nmcli connection add type ethernet slave-type bridge con-name br0-port4 ifname enp9s0 master br0Enable the bridge to forward extensible authentication protocol over LAN (EAPOL) packets:
# nmcli connection modify br0 group-forward-mask 8Disable the Spanning Tree Protocol (STP) on the bridge device:
# *nmcli connection modify br0 stp off"Configure the connection to automatically activate the ports:
# nmcli connection modify br0 connection.autoconnect-slaves 1Activate the connection:
# nmcli connection up br0
Verification
Display the link status of Ethernet devices that are ports of a specific bridge:
# ip link show master br0 3: enp1s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel master br0 state UP mode DEFAULT group default qlen 1000 link/ether 52:54:00:62:61:0e brd ff:ff:ff:ff:ff:ff ...Verify if forwarding of EAPOL packets is enabled on the
br0device:# cat /sys/class/net/br0/bridge/group_fwd_mask 0x8If the command returns
0x8, forwarding is enabled.
34.3. Configuring FreeRADIUS to authenticate network clients securely by using EAP
FreeRADIUS supports different methods of the Extensible authentication protocol (EAP). However, for a supported and secure scenario, use EAP-TTLS (tunneled transport layer security).
With EAP-TTLS, the clients use a secure TLS connection as the outer authentication protocol to set up the tunnel. The inner authentication then uses LDAP to authenticate to Identity Management. To use EAP-TTLS, you need a TLS server certificate.
The default FreeRADIUS configuration files serve as documentation and describe all parameters and directives. If you want to disable certain features, comment them out instead of removing the corresponding parts in the configuration files. This enables you to preserve the structure of the configuration files and the included documentation.
Prerequisites
-
You installed the
freeradiusandfreeradius-ldappackages. -
The configuration files in the
/etc/raddb/directory are unchanged and as provided by thefreeradiuspackages. - The host is enrolled in a Red Hat Enterprise Linux Identity Management (IdM) domain.
Procedure
Create a private key and request a certificate from IdM:
# ipa-getcert request -w -k /etc/pki/tls/private/radius.key -f /etc/pki/tls/certs/radius.pem -G EC -g prime256v1 -o "root:radiusd" -m 640 -O "root:radiusd" -M 640 -T caIPAserviceCert -C 'systemctl restart radiusd.service' -N freeradius.idm.example.com -D freeradius.idm.example.com -K radius/freeradius.idm.example.comThe
certmongerservice stores the private key in the/etc/pki/tls/private/radius.keyfile and the certificate in the/etc/pki/tls/certs/radius.pemfile, and it sets secure permissions. Additionally,certmongermonitors the certificate, renew it before it expires, and restart theradiusdservice after the certificate was renewed.Elliptic Curve key pairs provide the same level of security as RSA but with significantly smaller key sizes. This results in faster handshakes and reduced overhead for the FreeRADIUS server. Use elliptic curve cryptography if your host runs in Federal Information Processing Standard (FIPS) mode.
Verify that the CA successfully issued the certificate:
# ipa-getcert list -f /etc/pki/tls/certs/radius.pem ... Number of certificates and requests being tracked: 1. Request ID '20240918142211': status: MONITORING stuck: no key pair storage: type=FILE,location='/etc/pki/tls/private/radius.key' certificate: type=FILE,location='/etc/pki/tls/certs/radius.crt' ...Edit the
/etc/raddb/mods-available/eapfile:Configure the TLS-related settings in the
tls-config tls-commondirective:eap { ... tls-config tls-common { ... private_key_file = /etc/pki/tls/private/radius.key certificate_file = /etc/pki/tls/certs/radius.pem ca_file = /etc/ipa/ca.crt ecdh_curve = "prime256v1" ... } }Set the
default_eap_typeparameter in theeapdirective tottls:eap { ... default_eap_type = ttls ... }Comment out the
md5directives to disable the insecure EAP-MD5 authentication method:eap { ... # md5 { # } ... }Note that, in the default configuration file, other insecure EAP authentication methods are commented out by default.
Edit the
/etc/raddb/sites-available/defaultfile, and comment out all authentication methods other thaneap:authenticate { ... # Auth-Type PAP { # pap # } # Auth-Type CHAP { # chap # } # Auth-Type MS-CHAP { # mschap # } # mschap # digest ... }This leaves only EAP enabled for the outer authentication and disables plain-text authentication methods.
Edit the
/etc/raddb/sites-available/inner-tunnelfile, and make the following changes:Comment out the
-ldapentry and add theldapmodule configuration to theauthorizedirective:authorize { ... #-ldap ldap if ((ok || updated) && User-Password) { update { control:Auth-Type := ldap } } ... }Uncomment the LDAP authentication type in the
authenticatedirective:authenticate { Auth-Type LDAP { ldap } }
Enable the
ldapmodule:# ln -s /etc/raddb/mods-available/ldap /etc/raddb/mods-enabled/ldapEdit the
/etc/raddb/mods-available/ldapfile, and make the following changes:In the
ldapdirective, set the IdM LDAP server URL and the base distinguished name (DN):ldap { ... server = 'ldaps://idm_server.idm.example.com' base_dn = 'cn=users,cn=accounts,dc=idm,dc=example,dc=com' ... }Specify the
ldapsprotocol in the server URL to use TLS-encrypted connections between the FreeRADIUS host and the IdM server.In the
ldapdirective, enable TLS certificate validation of the IdM LDAP server:tls { ... require_cert = 'demand' ... }
Edit the
/etc/raddb/clients.conffile:Set a secure password in the
localhostandlocalhost_ipv6client directives:client localhost { ipaddr = 127.0.0.1 ... secret = localhost_client_password ... } client localhost_ipv6 { ipv6addr = ::1 secret = localhost_client_password }Add a client directive for the network authenticator:
client hostapd.example.org { ipaddr = 192.0.2.2/32 secret = hostapd_client_password }Optional: If other hosts should also be able to access the FreeRADIUS service, add client directives for them as well, for example:
client <hostname_or_description> { ipaddr = <IP_address_or_range> secret = <client_password> }The
ipaddrparameter accepts IPv4 and IPv6 addresses, and you can use the optional classless inter-domain routing (CIDR) notation to specify ranges. However, you can set only one value in this parameter. For example, to grant access to both an IPv4 and IPv6 address, you must add two client directives.Use a descriptive name for the client directive, such as a hostname or a word that describes where the IP range is used.
If the system is in FIPS mode, use the
systemctl edit radiusdcommand to edit theradiusdsystemd service unit and enter:[Service] Environment=RADIUS_MD5_FIPS_OVERRIDE=1Verify the configuration files:
# radiusd -XC ... Configuration appears to be OKOpen the RADIUS ports in the
firewalldservice:# firewall-cmd --permanent --add-service=radius # firewall-cmd --reloadEnable and start the
radiusdservice:# systemctl enable --now radiusd
Troubleshooting
If the
radiusdservice fails to start, verify that you can resolve the IdM server host name:# host -v idm_server.idm.example.comFor other problems, run
radiusdin debug mode:Stop the
radiusdservice:# systemctl stop radiusdStart the service in debug mode:
# radiusd -X ... Ready to process requests-
Perform authentication tests on the FreeRADIUS host, as referenced in the
Verificationsection.
Next steps
- Disable no longer required authentication methods and other features you do not use.
34.4. Configuring hostapd as an authenticator in a wired network
The host access point daemon (hostapd) service can act as an authenticator in a wired network to provide 802.1X authentication. For this, the hostapd service requires a RADIUS server that authenticates the clients.
The hostapd service provides an integrated RADIUS server. However, use the integrated RADIUS server only for testing purposes. For production environments, use FreeRADIUS server, which supports additional features, such as different authentication methods and access control.
The hostapd service does not interact with the traffic plane. The service acts only as an authenticator. For example, use a script or service that uses the hostapd control interface to allow or deny traffic based on the result of authentication events.
Prerequisites
-
You installed the
hostapdpackage. - The FreeRADIUS server has been configured, and it is ready to authenticate clients.
Procedure
Create the
/etc/hostapd/hostapd.conffile with the following content:# General settings of hostapd # =========================== # Control interface settings ctrl_interface=/var/run/hostapd ctrl_interface_group=wheel # Enable logging for all modules logger_syslog=-1 logger_stdout=-1 # Log level logger_syslog_level=2 logger_stdout_level=2 # Wired 802.1X authentication # =========================== # Driver interface type driver=wired # Enable IEEE 802.1X authorization ieee8021x=1 # Use port access entry (PAE) group address # (01:80:c2:00:00:03) when sending EAPOL frames use_pae_group_addr=1 # Network interface for authentication requests interface=br0 # RADIUS client configuration # =========================== # Local IP address used as NAS-IP-Address own_ip_addr=192.0.2.2 # Unique NAS-Identifier within scope of RADIUS server nas_identifier=hostapd.example.org # RADIUS authentication server auth_server_addr=192.0.2.1 auth_server_port=1812 auth_server_shared_secret=hostapd_client_password # RADIUS accounting server acct_server_addr=192.0.2.1 acct_server_port=1813 acct_server_shared_secret=hostapd_client_passwordFor further details about the parameters used in this configuration, see their descriptions in the
/usr/share/doc/hostapd/hostapd.confexample configuration file.Enable and start the
hostapdservice:# systemctl enable --now hostapd
Troubleshooting
If the
hostapdservice fails to start, verify that the bridge interface you use in the/etc/hostapd/hostapd.conffile is present on the system:# ip link show br0For other problems, run
hostapdin debug mode:Stop the
hostapdservice:# systemctl stop hostapdStart the service in debug mode:
# hostapd -d /etc/hostapd/hostapd.conf-
Perform authentication tests on the FreeRADIUS host, as referenced in the
Verificationsection.
34.5. Testing EAP-TTLS authentication against a FreeRADIUS server or authenticator
After you set up the FreeRADIUS server and the hostapd service, test if authentication by using extensible authentication protocol (EAP) over tunneled transport layer security (EAP-TTLS) works as expected.
- After you set up the FreeRADIUS server
-
After you set up the
hostapdservice as an authenticator for 802.1X network authentication.
The output of the test utilities used in this procedure provide additional information about the EAP communication and help you to debug problems.
Prerequisites
- You set up the FreeRADIUS server.
-
You set up the
hostapdservice as an authenticator for 802.1X network authentication. When you want to authenticate to:
A FreeRADIUS server:
-
The
eapol_testutility, provided by thehostapdpackage, is installed. - The client, on which you run this procedure, has been authorized in the FreeRADIUS server’s client databases.
-
The
-
An authenticator, the
wpa_supplicantutility, provided by the same-named package, is installed.
-
You stored the certificate authority (CA) certificate in the
/etc/ipa/ca.certfile.
Procedure
Optional: Create a user in Identity Management (IdM):
# ipa user-add --first "Test" --last "User" idm_user --passwordCreate the
/etc/wpa_supplicant/wpa_supplicant-TTLS.conffile with the following content:ap_scan=0 network={ eap=TTLS eapol_flags=0 key_mgmt=IEEE8021X # Anonymous identity (sent in unencrypted phase 1) # Can be any string anonymous_identity="anonymous" # Inner authentication (sent in TLS-encrypted phase 2) phase2="auth=PAP" identity="idm_user" password="idm_user_password" # CA certificate to validate the RADIUS server's identity ca_cert="/etc/ipa/ca.crt" }To authenticate to:
A FreeRADIUS server, enter:
# eapol_test -c /etc/wpa_supplicant/wpa_supplicant-TTLS.conf -a 192.0.2.1 -s <client_password> ... EAP: Status notification: remote certificate verification (param=success) ... CTRL-EVENT-EAP-SUCCESS EAP authentication completed successfully ... SUCCESSThe
-aoption defines the IP address of the FreeRADIUS server, and the-soption specifies the password for the host on which you run the command in the FreeRADIUS server’s client configuration.An authenticator, enter:
# wpa_supplicant -c /etc/wpa_supplicant/wpa_supplicant-TTLS.conf -D wired -i enp0s31f6 ... enp0s31f6: CTRL-EVENT-EAP-SUCCESS EAP authentication completed successfully ...The
-ioption specifies the network interface name on whichwpa_supplicantsends out extended authentication protocol over LAN (EAPOL) packets.For more debugging information, pass the
-doption to the command.
34.6. Blocking and allowing traffic based on hostapd authentication events
The hostapd service does not interact with the traffic plane. The service acts only as an authenticator. However, you can write a script to allow and deny traffic based on the result of authentication events.
This procedure is not supported and is no enterprise-ready solution. It only demonstrates how to block or allow traffic by evaluating events retrieved by hostapd_cli.
When the 802-1x-tr-mgmt systemd service starts, RHEL blocks all traffic on the listen port of hostapd except extensible authentication protocol over LAN (EAPOL) packets and uses the hostapd_cli utility to connect to the hostapd control interface. The /usr/local/bin/802-1x-tr-mgmt script then evaluates events. Depending on the different events received by hostapd_cli, the script allows or blocks traffic for MAC addresses. Note that, when the 802-1x-tr-mgmt service stops, all traffic is automatically allowed again.
Perform this procedure on the hostapd server.
Prerequisites
-
The
hostapdservice has been configured, and the service is ready to authenticate clients.
Procedure
Create the
/usr/local/bin/802-1x-tr-mgmtfile with the following content:#!/bin/sh TABLE="tr-mgmt-${1}" read -r -d '' TABLE_DEF << EOF table bridge ${TABLE} { set allowed_macs { type ether_addr } chain accesscontrol { ether saddr @allowed_macs accept ether daddr @allowed_macs accept drop } chain forward { type filter hook forward priority 0; policy accept; meta ibrname "$1" jump accesscontrol } } EOF case ${2:-NOTANEVENT} in block_all) nft destroy table bridge "$TABLE" printf "$TABLE_DEF" | nft -f - echo "$1: All the bridge traffic blocked. Traffic for a client with a given MAC will be allowed after 802.1x authentication" ;; AP-STA-CONNECTED | CTRL-EVENT-EAP-SUCCESS | CTRL-EVENT-EAP-SUCCESS2) nft add element bridge tr-mgmt-br0 allowed_macs { $3 } echo "$1: Allowed traffic from $3" ;; AP-STA-DISCONNECTED | CTRL-EVENT-EAP-FAILURE) nft delete element bridge tr-mgmt-br0 allowed_macs { $3 } echo "$1: Denied traffic from $3" ;; allow_all) nft destroy table bridge "$TABLE" echo "$1: Allowed all bridge traffic again" ;; NOTANEVENT) echo "$0 was called incorrectly, usage: $0 interface event [mac_address]" ;; esacCreate the
/etc/systemd/system/802-1x-tr-mgmt@.servicesystemd service file with the following content:[Unit] Description=Example 802.1x traffic management for hostapd After=hostapd.service After=sys-devices-virtual-net-%i.device [Service] Type=simple ExecStartPre=bash -c '/usr/sbin/hostapd_cli ping | grep PONG' ExecStartPre=/usr/local/bin/802-1x-tr-mgmt %i block_all ExecStart=/usr/sbin/hostapd_cli -i %i -a /usr/local/bin/802-1x-tr-mgmt ExecStopPost=/usr/local/bin/802-1x-tr-mgmt %i allow_all [Install] WantedBy=multi-user.targetReload systemd:
# systemctl daemon-reloadEnable and start the
802-1x-tr-mgmtservice with the interface namehostapdis listening on:# systemctl enable --now 802-1x-tr-mgmt@br0.service
Verification
- Authenticate with a client to the network. See Testing EAP-TTLS authentication against a FreeRADIUS server or authenticator.
Chapter 35. Getting started with Multipath TCP
Multipath TCP (MPTCP) is an extension to the original TCP protocol (single-path). MPTCP enables a transport connection to operate across multiple paths simultaneously, and brings network connection redundancy to user endpoint devices.
35.1. Understanding MPTCP
The Multipath TCP (MPTCP) protocol provides simultaneous usage of multiple paths between connection endpoints. The protocol design improves connection stability and also brings other benefits compared to the single-path TCP.
In MPTCP terminology, links are considered as paths.
The following are some of the advantages of using MPTCP:
- It allows a connection to simultaneously use multiple network interfaces.
- In case a connection is bound to a link speed, the usage of multiple links can increase the connection throughput. Note, that in case of the connection is bound to a CPU, the usage of multiple links causes the connection slowdown.
- It increases the resilience to link failures.
35.2. Preparing RHEL to enable MPTCP support
By default the MPTCP support is disabled in RHEL. Enable MPTCP so that applications that support this feature can use it. Additionally, you have to configure user space applications to force use MPTCP sockets if those applications have TCP sockets by default.
You can use the sysctl utility to enable MPTCP support and prepare RHEL for enabling MPTCP for applications system-wide using a SystemTap script.
Prerequisites
The following packages are installed:
-
systemtap -
iperf3
Procedure
Enable MPTCP sockets in the kernel:
# echo "net.mptcp.enabled=1" > /etc/sysctl.d/90-enable-MPTCP.conf # sysctl -p /etc/sysctl.d/90-enable-MPTCP.confVerify that MPTCP is enabled in the kernel:
# sysctl -a | grep mptcp.enabled net.mptcp.enabled = 1Create a
mptcp-app.stapfile with the following content:#!/usr/bin/env stap %{ #include <linux/in.h> #include <linux/ip.h> %} /* RSI contains 'type' and RDX contains 'protocol'. */ function mptcpify () %{ if (CONTEXT->kregs->si == SOCK_STREAM && (CONTEXT->kregs->dx == IPPROTO_TCP || CONTEXT->kregs->dx == 0)) { CONTEXT->kregs->dx = IPPROTO_MPTCP; STAP_RETVALUE = 1; } else { STAP_RETVALUE = 0; } %} probe kernel.function("__sys_socket") { if (mptcpify() == 1) { printf("command %16s mptcpified\n", execname()); } }Force user space applications to create MPTCP sockets instead of TCP ones:
# stap -vg mptcp-app.stapNote: This operation affects all TCP sockets which are started after the command. The applications will continue using TCP sockets after you interrupt the command above with Ctrl+C.
Alternatively, to allow MPTCP usage to only specific application, you can modify the
mptcp-app.stapfile with the following content:#!/usr/bin/env stap %{ #include <linux/in.h> #include <linux/ip.h> %} /* according to [1], RSI contains 'type' and RDX * contains 'protocol'. * [1] https://github.com/torvalds/linux/blob/master/arch/x86/entry/entry_64.S#L79 */ function mptcpify () %{ if (CONTEXT->kregs->si == SOCK_STREAM && (CONTEXT->kregs->dx == IPPROTO_TCP || CONTEXT->kregs->dx == 0)) { CONTEXT->kregs->dx = IPPROTO_MPTCP; STAP_RETVALUE = 1; } else { STAP_RETVALUE = 0; } %} probe kernel.function("__sys_socket") { cur_proc = execname() if ((cur_proc == @1) && (mptcpify() == 1)) { printf("command %16s mptcpified\n", cur_proc); } }In case of alternative choice, assuming, you want to force the
iperf3tool to use MPTCP instead of TCP. To do so, enter the following command:# stap -vg mptcp-app.stap iperf3After the
mptcp-app.stapscript installs the kernel probe, the following warnings appear in the kerneldmesgoutput# dmesg ... [ 1752.694072] Kprobes globally unoptimized [ 1752.730147] stap_1ade3b3356f3e68765322e26dec00c3d_1476: module_layout: kernel tainted. [ 1752.732162] Disabling lock debugging due to kernel taint [ 1752.733468] stap_1ade3b3356f3e68765322e26dec00c3d_1476: loading out-of-tree module taints kernel. [ 1752.737219] stap_1ade3b3356f3e68765322e26dec00c3d_1476: module verification failed: signature and/or required key missing - tainting kernel [ 1752.737219] stap_1ade3b3356f3e68765322e26dec00c3d_1476 (mptcp-app.stap): systemtap: 4.5/0.185, base: ffffffffc0550000, memory: 224data/32text/57ctx/65638net/367alloc kb, probes: 1Start the
iperf3server:# iperf3 -s Server listening on 5201Connect the client to the server:
# iperf3 -c 127.0.0.1 -t 3After the connection is established, verify the
ssoutput to see the subflow-specific status:# ss -nti '( dport :5201 )' State Recv-Q Send-Q Local Address:Port Peer Address:Port Process ESTAB 0 0 127.0.0.1:41842 127.0.0.1:5201 cubic wscale:7,7 rto:205 rtt:4.455/8.878 ato:40 mss:21888 pmtu:65535 rcvmss:536 advmss:65483 cwnd:10 bytes_sent:141 bytes_acked:142 bytes_received:4 segs_out:8 segs_in:7 data_segs_out:3 data_segs_in:3 send 393050505bps lastsnd:2813 lastrcv:2772 lastack:2772 pacing_rate 785946640bps delivery_rate 10944000000bps delivered:4 busy:41ms rcv_space:43690 rcv_ssthresh:43690 minrtt:0.008 tcp-ulp-mptcp flags:Mmec token:0000(id:0)/2ff053ec(id:0) seq:3e2cbea12d7673d4 sfseq:3 ssnoff:ad3d00f4 maplen:2Verify MPTCP counters:
# nstat MPTcp* #kernel MPTcpExtMPCapableSYNRX 2 0.0 MPTcpExtMPCapableSYNTX 2 0.0 MPTcpExtMPCapableSYNACKRX 2 0.0 MPTcpExtMPCapableACKRX 2 0.0
35.3. Using iproute2 to temporarily configure and enable multiple paths for MPTCP applications
Each MPTCP connection uses a single subflow similar to plain TCP. To get the MPTCP benefits, specify a higher limit for maximum number of subflows for each MPTCP connection. Then configure additional endpoints to create those subflows.
The configuration in this procedure will not persist after rebooting your machine.
Note that MPTCP does not yet support mixed IPv6 and IPv4 endpoints for the same socket. Use endpoints belonging to the same address family.
Prerequisites
-
The
iperf3package is installed Server network interface settings:
-
enp4s0:
192.0.2.1/24 -
enp1s0:
198.51.100.1/24
-
enp4s0:
Client network interface settings:
-
enp4s0f0:
192.0.2.2/24 -
enp4s0f1:
198.51.100.2/24
-
enp4s0f0:
Procedure
Configure the client to accept up to 1 additional remote address, as provided by the server:
# ip mptcp limits set add_addr_accepted 1Add IP address
198.51.100.1as a new MPTCP endpoint on the server:# ip mptcp endpoint add 198.51.100.1 dev enp1s0 signalThe
signaloption ensures that theADD_ADDRpacket is sent after the three-way-handshake.Start the
iperf3server:# iperf3 -s Server listening on 5201Connect the client to the server:
# iperf3 -c 192.0.2.1 -t 3
Verification
Verify the connection is established:
# ss -nti '( sport :5201 )'Verify the connection and IP address limit:
# ip mptcp limit showVerify the newly added endpoint:
# ip mptcp endpoint showVerify MPTCP counters by using the
nstat MPTcp*command on a server:# nstat MPTcp* #kernel MPTcpExtMPCapableSYNRX 2 0.0 MPTcpExtMPCapableACKRX 2 0.0 MPTcpExtMPJoinSynRx 2 0.0 MPTcpExtMPJoinAckRx 2 0.0 MPTcpExtEchoAdd 2 0.0
35.4. Permanently configuring multiple paths for MPTCP applications
You can configure MultiPath TCP (MPTCP) by using the nmcli command to permanently establish multiple subflows between a source and destination system.
The subflows can use different resources, different routes to the destination, and even different networks. Such as Ethernet, cellular, wifi, and so on. As a result, you achieve combined connections, which increase network resilience and throughput.
The server uses the following network interfaces in our example:
-
enp4s0:
192.0.2.1/24 -
enp1s0:
198.51.100.1/24 -
enp7s0:
192.0.2.3/24
The client uses the following network interfaces in our example:
-
enp4s0f0:
192.0.2.2/24 -
enp4s0f1:
198.51.100.2/24 -
enp6s0:
192.0.2.5/24
Prerequisites
- You configured the default gateway on the relevant interfaces.
Procedure
Enable MPTCP sockets in the kernel:
# echo "net.mptcp.enabled=1" > /etc/sysctl.d/90-enable-MPTCP.conf # sysctl -p /etc/sysctl.d/90-enable-MPTCP.confOptional: The RHEL kernel default for subflow limit is 2. If you require more:
Create the
/etc/systemd/system/set_mptcp_limit.servicefile with the following content:[Unit] Description=Set MPTCP subflow limit to 3 After=network.target [Service] ExecStart=ip mptcp limits set subflows 3 Type=oneshot [Install] WantedBy=multi-user.targetThe oneshot unit executes the
ip mptcp limits set subflows 3command after your network (network.target) is operational during every boot process.The
ip mptcp limits set subflows 3command sets the maximum number of additional subflows for each connection, so 4 in total. It is possible to add maximally 3 additional subflows.Enable the
set_mptcp_limitservice:# systemctl enable --now set_mptcp_limit
Enable MPTCP on all connection profiles that you want to use for connection aggregation:
# nmcli connection modify <profile_name> connection.mptcp-flags signal,subflow,also-without-default-routeThe
connection.mptcp-flagsparameter configures MPTCP endpoints and the IP address flags. If MPTCP is enabled in a NetworkManager connection profile, the setting configures the IP addresses of the relevant network interface as MPTCP endpoints.By default, NetworkManager does not add MPTCP flags to IP addresses if there is no default gateway. If you want to bypass that check, you need to use the
also-without-default-routeflag.
Verification
Verify that you enabled the MPTCP kernel parameter:
# sysctl net.mptcp.enabled net.mptcp.enabled = 1Verify that you set the subflow limit correctly, in case the default was not enough:
# ip mptcp limit show add_addr_accepted 2 subflows 3Verify that you configured the per-address MPTCP setting correctly:
# ip mptcp endpoint show 192.0.2.1 id 1 subflow dev enp4s0 198.51.100.1 id 2 subflow dev enp1s0 192.0.2.3 id 3 subflow dev enp7s0 192.0.2.4 id 4 subflow dev enp3s0 ...
35.5. Monitoring MPTCP sub-flows
Monitoring MPTCP (Multipath TCP) subflows is crucial for optimizing performance, ensuring reliability, and maintaining control over multi-path network communication.
The life cycle of a multipath TCP (MPTCP) socket can be complex: The main MPTCP socket is created, the MPTCP path is validated, one or more sub-flows are created and eventually removed. Finally, the MPTCP socket is terminated.
The MPTCP protocol allows monitoring MPTCP-specific events related to socket and sub-flow creation and deletion, using the ip utility provided by the iproute package. This utility uses the netlink interface to monitor MPTCP events.
This procedure demonstrates how to monitor MPTCP events. For that, it simulates a MPTCP server application, and a client connects to this service. The involved clients in this example use the following interfaces and IP addresses:
-
Server:
192.0.2.1 -
Client (Ethernet connection):
192.0.2.2 -
Client (WiFi connection):
192.0.2.3
To simplify this example, all interfaces are within the same subnet. This is not a requirement. However, it is important that routing has been configured correctly, and the client can reach the server via both interfaces.
Prerequisites
- A RHEL client with two network interfaces, such as a laptop with Ethernet and WiFi
- The client can connect to the server via both interfaces
- A RHEL server
- Both the client and the server run RHEL 8.6 or later
Procedure
Set the per connection additional subflow limits to
1on both client and server:# ip mptcp limits set add_addr_accepted 0 subflows 1On the server, to simulate a MPTCP server application, start
netcat(nc) in listen mode with enforced MPTCP sockets instead of TCP sockets:# nc -l -k -p 12345The
-koption causes thatncdoes not close the listener after the first accepted connection. This is required to demonstrate the monitoring of sub-flows.On the client:
Identify the interface with the lowest metric:
# ip -4 route 192.0.2.0/24 dev enp1s0 proto kernel scope link src 192.0.2.2 metric 100 192.0.2.0/24 dev wlp1s0 proto kernel scope link src 192.0.2.3 metric 600The
enp1s0interface has a lower metric thanwlp1s0. Therefore, RHEL usesenp1s0by default.On the first console, start the monitoring:
# ip mptcp monitorOn the second console, start a MPTCP connection to the server:
# nc 192.0.2.1 12345RHEL uses the
enp1s0interface and its associated IP address as a source for this connection.On the monitoring console, the
ip mptcp monitorcommand now logs:[ CREATED] token=63c070d2 remid=0 locid=0 saddr4=192.0.2.2 daddr4=192.0.2.1 sport=36444 dport=12345The token identifies the MPTCP socket as an unique ID, and later it enables you to correlate MPTCP events on the same socket.
On the console with the running
ncconnection to the server, press Enter. This first data packet fully establishes the connection. Note that, as long as no data has been sent, the connection is not established.On the monitoring console,
ip mptcp monitornow logs:[ ESTABLISHED] token=63c070d2 remid=0 locid=0 saddr4=192.0.2.2 daddr4=192.0.2.1 sport=36444 dport=12345Optional: Display the connections to port
12345on the server:# ss -taunp | grep ":12345" tcp ESTAB 0 0 192.0.2.2:36444 192.0.2.1:12345At this point, only one connection to the server has been established.
On a third console, create another endpoint:
# ip mptcp endpoint add dev wlp1s0 192.0.2.3 subflowThis command sets the name and IP address of the WiFi interface of the client in this command.
On the monitoring console,
ip mptcp monitornow logs:[SF_ESTABLISHED] token=63c070d2 remid=0 locid=2 saddr4=192.0.2.3 daddr4=192.0.2.1 sport=53345 dport=12345 backup=0 ifindex=3The
locidfield displays the local address ID of the new sub-flow and identifies this sub-flow even if the connection uses network address translation (NAT). Thesaddr4field matches the endpoint’s IP address from theip mptcp endpoint addcommand.Optional: Display the connections to port
12345on the server:# ss -taunp | grep ":12345" tcp ESTAB 0 0 192.0.2.2:36444 192.0.2.1:12345 tcp ESTAB 0 0 192.0.2.3%wlp1s0:53345 192.0.2.1:12345The command now displays two connections:
-
The connection with source address
192.0.2.2corresponds to the first MPTCP sub-flow that you established previously. -
The connection from the sub-flow over the
wlp1s0interface with source address192.0.2.3.
-
The connection with source address
On the third console, delete the endpoint:
# ip mptcp endpoint delete id 2Use the ID from the
locidfield from theip mptcp monitoroutput, or retrieve the endpoint ID using theip mptcp endpoint showcommand.On the monitoring console,
ip mptcp monitornow logs:[ SF_CLOSED] token=63c070d2 remid=0 locid=2 saddr4=192.0.2.3 daddr4=192.0.2.1 sport=53345 dport=12345 backup=0 ifindex=3On the first console with the
ncclient, press Ctrl+C to terminate the session.On the monitoring console,
ip mptcp monitornow logs:[ CLOSED] token=63c070d2
35.6. Disabling Multipath TCP in the kernel
If you do not require MPTCP, you can explicitly disable the MPTCP option in the kernel.
Procedure
Disable the
mptcp.enabledoption.# echo "net.mptcp.enabled=0" > /etc/sysctl.d/90-enable-MPTCP.conf # sysctl -p /etc/sysctl.d/90-enable-MPTCP.conf
Verification
Verify whether the
mptcp.enabledis disabled in the kernel.# sysctl -a | grep mptcp.enabled net.mptcp.enabled = 0
Chapter 36. Legacy network scripts support in RHEL
By default, RHEL uses NetworkManager to configure and manage network connections, and the /usr/sbin/ifup and /usr/sbin/ifdown scripts use NetworkManager to process ifcfg files in the /etc/sysconfig/network-scripts/ directory.
The legacy scripts are deprecated in RHEL 8 and will be removed in a future major version of RHEL. If you still use the legacy network scripts, for example, because you upgraded from an earlier version to RHEL 8, Red Hat recommends that you migrate your configuration to NetworkManager.
36.1. Installing the legacy network scripts
If you require the deprecated network scripts that processes the network configuration without using NetworkManager, you can install them. In this case, the /usr/sbin/ifup and /usr/sbin/ifdown scripts link to the deprecated shell scripts that manage the network configuration.
Procedure
Install the
network-scriptspackage:# yum install network-scripts
Chapter 37. Configuring ip networking with ifcfg files
Interface configuration (ifcfg) files control the software interfaces for individual network devices. As the system boots, it uses these files to determine what interfaces to bring up and how to configure them. These files are named ifcfg-name_pass, where the suffix name refers to the name of the device that the configuration file controls. By convention, the ifcfg file’s suffix is the same as the string given by the DEVICE directive in the configuration file itself.
NetworkManager supports profiles stored in the keyfile format. However, by default, NetworkManager uses the ifcfg format when you use the NetworkManager API to create or update profiles.
In a future major RHEL release, the keyfile format will be default. Consider using the keyfile format if you want to manually create and manage configuration files.
37.1. Configuring an interface with static network settings using ifcfg files
If you do not use the NetworkManager utilities and applications, you can manually configure a network interface by creating ifcfg files.
Procedure
To configure an interface with static network settings using
ifcfgfiles, for an interface with the nameenp1s0, create a file with the nameifcfg-enp1s0in the/etc/sysconfig/network-scripts/directory that contains:For
IPv4configuration:DEVICE=enp1s0 BOOTPROTO=none ONBOOT=yes PREFIX=24 IPADDR=192.0.2.1 GATEWAY=192.0.2.254For
IPv6configuration:DEVICE=enp1s0 BOOTPROTO=none ONBOOT=yes IPV6INIT=yes IPV6ADDR=2001:db8:1::2/64
For further details, see the
nm-settings-ifcfg-rh(5)man page on your system.
37.2. Configuring an interface with dynamic network settings using ifcfg files
If you do not use the NetworkManager utilities and applications, you can manually configure a network interface by creating ifcfg files.
Procedure
To configure an interface named em1 with dynamic network settings using
ifcfgfiles, create a file with the nameifcfg-em1in the/etc/sysconfig/network-scripts/directory that contains:DEVICE=em1 BOOTPROTO=dhcp ONBOOT=yesTo configure an interface to send:
A different host name to the
DHCPserver, add the following line to theifcfgfile:DHCP_HOSTNAME=hostnameA different fully qualified domain name (FQDN) to the
DHCPserver, add the following line to theifcfgfile:DHCP_FQDN=fully.qualified.domain.name
NoteYou can use only one of these settings. If you specify both
DHCP_HOSTNAMEandDHCP_FQDN, onlyDHCP_FQDNis used.To configure an interface to use particular
DNSservers, add the following lines to theifcfgfile:PEERDNS=no DNS1=ip-address DNS2=ip-addresswhere ip-address is the address of a
DNSserver. This will cause the network service to update/etc/resolv.confwith the specifiedDNSservers specified. Only oneDNSserver address is necessary, the other is optional.
37.3. Managing system-wide and private connection profiles with ifcfg files
By default, all users on a host can use the connections defined in ifcfg files. You can limit this behavior to specific users by adding the USERS parameter to the ifcfg file.
Prerequisites
-
The
ifcfgfile already exists.
Procedure
Edit the
ifcfgfile in the/etc/sysconfig/network-scripts/directory that you want to limit to certain users, and add:USERS="username1 username2 ..."Reactive the connection:
# nmcli connection up connection_name
Chapter 38. NetworkManager connection profiles in keyfile format
By default, NetworkManager stores connection profiles in ifcfg format, but you can also use profiles in keyfile format. Unlike the deprecated ifcfg format, the keyfile format supports all connection settings that NetworkManager provides.
In the Red Hat Enterprise Linux 9, the keyfile format will be the default.
38.1. The keyfile format of NetworkManager profiles
The keyfile format is an INI-like configuration for network connections.
For example, the following is an Ethernet connection profile in keyfile format:
[connection]
id=example_connection
uuid=82c6272d-1ff7-4d56-9c7c-0eb27c300029
type=ethernet
autoconnect=true
[ipv4]
method=auto
[ipv6]
method=auto
[ethernet]
mac-address=00:53:00:8f:fa:66Typos or incorrect placements of parameters can lead to unexpected behavior. Therefore, do not manually edit or create NetworkManager profiles.
Use the nmcli utility, the network RHEL system role, or the nmstate API to manage NetworkManager connections. For example, you can use the nmcli utility in offline mode to create connection profiles.
Each section corresponds to a NetworkManager setting name as described in the nm-settings(5) man page. Each key-value-pair in a section is one of the properties listed in the settings specification of the man page.
Most variables in NetworkManager keyfiles have a one-to-one mapping. This means that a NetworkManager property is stored in the keyfile as a variable of the same name and in the same format. However, there are exceptions, mainly to make the keyfile syntax easier to read. For a list of these exceptions, see the nm-settings-keyfile(5) man page on your system.
For security reasons, because connection profiles can contain sensitive information, such as private keys and passphrases, NetworkManager uses only configuration files owned by the root user and that are only readable and writable by root.
Save the connection profile with a .nmconnection suffix in the /etc/NetworkManager/system-connections/ directory. This directory contains persistent profiles. If you modify a persistent profile by using the NetworkManager API, NetworkManager writes and overwrites files in this directory.
NetworkManager does not automatically reload profiles from disk. When you create or update a connection profile in keyfile format, use the nmcli connection reload command to inform NetworkManager about the changes.
38.2. Using nmcli to create keyfile connection profiles in offline mode
You can use the nmcli utility in offline mode to create and manage NetworkManager connection profiles. In this mode, nmcli operates without the NetworkManager service to produce keyfile connection profiles through standard output.
This feature can be useful in the following scenarios:
- You want to create your connection profiles that need to be pre-deployed somewhere. For example in a container image, or as an RPM package.
-
You want to create your connection profiles in an environment where the
NetworkManagerservice is not available, for example, when you want to use thechrootutility. Alternatively, when you want to create or modify the network configuration of the RHEL system to be installed through the Kickstart%postscript.
Procedure
Create a new connection profile in the keyfile format. For example, for a connection profile of an Ethernet device that does not use DHCP, run a similar
nmclicommand:# nmcli --offline connection add type ethernet con-name Example-Connection ipv4.addresses 192.0.2.1/24 ipv4.dns 192.0.2.200 ipv4.method manual > /etc/NetworkManager/system-connections/example.nmconnectionNoteThe connection name you specified with the
con-namekey is saved into theidvariable of the generated profile. When you use thenmclicommand to manage this connection later, specify the connection as follows:-
When the
idvariable is not omitted, use the connection name, for exampleExample-Connection. -
When the
idvariable is omitted, use the file name without the.nmconnectionsuffix, for exampleoutput.
-
When the
Set permissions to the configuration file so that only the
rootuser can read and update it:# chmod 600 /etc/NetworkManager/system-connections/example.nmconnection # chown root:root /etc/NetworkManager/system-connections/example.nmconnectionStart the
NetworkManagerservice:# systemctl start NetworkManager.serviceIf you set the
autoconnectvariable in the profile tofalse, activate the connection:# nmcli connection up Example-Connection
Verification
Verify that the
NetworkManagerservice is running:# systemctl status NetworkManager.service ● NetworkManager.service - Network Manager Loaded: loaded (/usr/lib/systemd/system/NetworkManager.service; enabled; vendor preset: enabled) Active: active (running) since Wed 2022-08-03 13:08:32 CEST; 1min 40s ago ...Verify that NetworkManager can read the profile from the configuration file:
# nmcli -f TYPE,FILENAME,NAME connection TYPE FILENAME NAME ethernet /etc/NetworkManager/system-connections/examaple.nmconnection Example-Connection ethernet /etc/sysconfig/network-scripts/ifcfg-enp1s0 enp1s0 ...If the output does not show the newly created connection, verify that the keyfile permissions and the syntax you used are correct.
Display the connection profile:
# nmcli connection show Example-Connection connection.id: Example-Connection connection.uuid: 232290ce-5225-422a-9228-cb83b22056b4 connection.stable-id: -- connection.type: 802-3-ethernet connection.interface-name: -- connection.autoconnect: yes ...
38.3. Manually creating a NetworkManager profile in keyfile format
You can manually create a NetworkManager connection profile in keyfile format. For example, this can be required if an external application generates the profiles.
Manually creating or updating the configuration files can result in an unexpected or non-functional network configuration. As an alternative, you can use nmcli in offline mode. See Using nmcli to create keyfile connection profiles in offline mode
Procedure
Create a connection profile. For example, for a connection profile for the
enp1s0Ethernet device that uses DHCP, create the/etc/NetworkManager/system-connections/example.nmconnectionfile with the following content:[connection] id=Example-Connection type=ethernet autoconnect=true interface-name=enp1s0 [ipv4] method=auto [ipv6] method=autoNoteYou can use any file name with a
.nmconnectionsuffix. However, when you later usenmclicommands to manage the connection, you must use the connection name set in theidvariable when you refer to this connection. When you omit theidvariable, use the file name without the.nmconnectionto refer to this connection.Set permissions on the configuration file so that only the
rootuser can read and update it:# chown root:root /etc/NetworkManager/system-connections/example.nmconnection # chmod 600 /etc/NetworkManager/system-connections/example.nmconnectionReload the connection profiles:
# nmcli connection reloadVerify that NetworkManager read the profile from the configuration file:
# nmcli -f NAME,UUID,FILENAME connection NAME UUID FILENAME Example-Connection 86da2486-068d-4d05-9ac7-957ec118afba /etc/NetworkManager/system-connections/example.nmconnection ...If the command does not show the newly added connection, verify that the file permissions and the syntax you used in the file are correct.
If you set the
autoconnectvariable in the profile tofalse, activate the connection:# nmcli connection up example_connection
Verification
Display the connection profile:
# nmcli connection show example_connection
38.4. The differences in interface renaming with profiles in ifcfg and keyfile format
You can define custom network interface names, such as lan to make interface names more descriptive. In this case, the udev service renames the interfaces. The renaming process works differently depending on whether you use connection profiles in ifcfg or keyfile format.
- The interface renaming process when using a profile in
ifcfgformat -
The
udevrule file/usr/lib/udev/rules.d/60-net.rulescalls the/lib/udev/rename_devicehelper utility. -
The helper utility searches for the
HWADDRparameter in/etc/sysconfig/network-scripts/ifcfg-*files. -
If the value set in the variable matches the MAC address of an interface, the helper utility renames the interface to the name set in the
DEVICEparameter of the file.
-
The
- The interface renaming process when using a profile in keyfile format
- Create a systemd link file or a udev rule to rename an interface.
-
Use the custom interface name in the
interface-nameproperty of a NetworkManager connection profile.
38.5. Migrating NetworkManager profiles from ifcfg to keyfile format
If you use connection profiles in ifcfg format, you can convert them to the keyfile format to have all profiles in the preferred format and in one location.
If an ifcfg file contains the NM_CONTROLLED=no setting, NetworkManager does not control this profile and, consequently, the migration process ignores it.
Prerequisites
-
You have connection profiles in
ifcfgformat in the/etc/sysconfig/network-scripts/directory. -
If the connection profiles contain a
DEVICEvariable that is set to a custom device name, such asproviderorlan, you created a systemd link file or a udev rule for each of the custom device names.
Procedure
Migrate the connection profiles:
# nmcli connection migrate Connection 'enp1s0' (43ed18ab-f0c4-4934-af3d-2b3333948e45) successfully migrated. Connection 'enp2s0' (883333e8-1b87-4947-8ceb-1f8812a80a9b) successfully migrated. ...
Verification
Optional: You can verify that you successfully migrated all your connection profiles:
# nmcli -f TYPE,FILENAME,NAME connection TYPE FILENAME NAME ethernet /etc/NetworkManager/system-connections/enp1s0.nmconnection enp1s0 ethernet /etc/NetworkManager/system-connections/enp2s0.nmconnection enp2s0 ...
Chapter 39. Systemd network targets and services
RHEL uses the network and network-online targets and the NetworkManager-wait-online service while applying network settings. Configure systemd services to start after the network is fully available if those services cannot react dynamically to a change in the network state.
39.1. Differences between the network and network-online systemd target
The network target indicates that the network management stack has been started, and the network-online target is to actively wait until the network is up and a usable network connection is available.
Systemd maintains the network and network-online target units. The special units such as NetworkManager-wait-online.service, have WantedBy=network-online.target and Before=network-online.target parameters. If enabled, these units get started with network-online.target and delay the target to be reached until some form of network connectivity is established. They delay the network-online target until the network is connected.
The network-online target starts a service, which adds substantial delays to further execution. Systemd automatically adds dependencies with Wants and After parameters for this target unit to all the System V (SysV) init script service units with a Linux Standard Base (LSB) header referring to the $network facility. The LSB header is metadata for init scripts. You can use it to specify dependencies. This is similar to the systemd target.
The network target does not significantly delay the execution of the boot process. Reaching the network target means that the service that is responsible for setting up the network has started. However, it does not mean that a network device was configured. This target is important during the shutdown of the system. For example, if you have a service that was ordered after the network target during bootup, then this dependency is reversed during the shutdown. The network does not get disconnected until your service has been stopped. All mount units for remote network file systems automatically start the network-online target unit and order themselves after it.
The network-online target unit is only useful during the system startup. After the system has completed booting up, this target does not track the online state of the network. Therefore, you cannot use network-online to monitor the network connection. This target provides a one-time system startup concept.
39.2. Overview of NetworkManager-wait-online
The NetworkManager-wait-online service delays reaching the network-online target until NetworkManager reports that the startup is complete.
During boot, NetworkManager activates all profiles with the connection.autoconnect parameter set to yes. However, the activation of profiles is not complete as long as NetworkManager profiles are in an activating state. If activation fails, NetworkManager retries the activation depending on the value of the connection.autoconnect-retries.
When a device reaches the activated state depends on its configuration. For example, if a profile contains both IPv4 and IPv6 configuration, by default, NetworkManager considers the device as fully activated when only one of the Address families is ready. The ipv4.may-fail and ipv6.may-fail parameters in a connection profile control this behavior.
For Ethernet devices, NetworkManager waits for the carrier with a timeout. Consequently, if the Ethernet cable is not connected, this can further delay NetworkManager-wait-online.service.
When the startup completes, either all profiles are in a disconnected state or are successfully activated. You can configure profiles to auto-connect. The following are a few examples of parameters that set timeouts or define when the connection is considered active:
-
connection.wait-device-timeout: Sets the timeout for the driver to detect the device. -
ipv4.may-failandipv6.may-fail: Sets activation with one IP address family ready, or whether a particular address family must have completed configuration. -
ipv4.gateway-ping-timeout: Delays network activation until NetworkManager receives a ping response from the IPv4 gateway. The system waits up to the specified number of seconds before proceeding.
For further details, see the nm-settings(5), systemd.special(7), NetworkManager-wait-online.service(8) man pages on your system.
39.3. Configuring a systemd service to start after the network has been started
RHEL installs systemd service files in the /usr/lib/systemd/system/ directory. You can create a drop-in snippet in /etc/systemd/system/<service_name>.service.d/ to start a service after the network is online.
This snippet’s settings override any conflicting settings in the original service file.
Procedure
Open a service file in the editor:
# systemctl edit <service_name>Enter the following, and save the changes:
[Unit] After=network-online.targetReload the
systemdservice.# systemctl daemon-reload
Chapter 40. Introduction to Nmstate
Nmstate is a declarative network manager API. When you use Nmstate, you describe the expected networking state by using YAML or JSON-formatted instructions.
Nmstate has many benefits. For example, it:
- Provides a stable and extensible interface to manage RHEL network capabilities
- Supports atomic and transactional operations at the host and cluster level
- Supports partial editing of most properties and preserves existing settings that are not specified in the instructions
- Provides plug-in support to enable administrators to use their own plug-ins
Nmstate consists of the following packages:
| Packages | Contents |
|---|---|
|
|
The |
|
|
The |
|
| The Nmstate C library |
|
| The Nmstate C library headers |
40.1. Using the libnmstate library in a Python application
The libnmstate Python library enables developers to use Nmstate in their own application.
To use the library, import it in your source code:
import libnmstate
Note that you must install the nmstate and python3-libnmstate packages to use this library.
Example 40.1. Querying the network state by using the libnmstate library
The following Python code imports the libnmstate library and displays the available network interfaces and their state:
import libnmstate
from libnmstate.schema import Interface
net_state = libnmstate.show()
for iface_state in net_state[Interface.KEY]:
print(iface_state[Interface.NAME] + ": "
+ iface_state[Interface.STATE])40.2. Updating the current network configuration by using nmstatectl
You can use the nmstatectl utility to store the current network configuration of one or all interfaces in a file.
You can then use this file to:
- Modify the configuration and apply it to the same system.
- Copy the file to a different host and configure the host with the same or modified settings.
For example, you can export the settings of the enp1s0 interface to a file, modify the configuration, and apply the settings to the host.
Prerequisites
-
The
nmstatepackage is installed.
Procedure
Export the settings of the
enp1s0interface to the~/network-config.ymlfile:# nmstatectl show enp1s0 > ~/network-config.ymlThis command stores the configuration of
enp1s0in YAML format. To store the output in JSON format, pass the--jsonoption to the command.If you do not specify an interface name,
nmstatectlexports the configuration of all interfaces.-
Modify the
~/network-config.ymlfile using a text editor to update the configuration. Apply the settings from the
~/network-config.ymlfile:# nmstatectl apply ~/network-config.ymlIf you exported the settings in JSON format, pass the
--jsonoption to the command.
40.3. Network states for the network RHEL system role
The network RHEL system role supports state configurations in playbooks to configure the devices. For this, use the network_state variable followed by the state configurations.
Benefits of using the network_state variable in a playbook:
- Using the declarative method with the state configurations, you can configure interfaces, and the NetworkManager creates a profile for these interfaces in the background.
-
With the
network_statevariable, you can specify the options that you require to change, and all the other options remain the same as they are. However, with thenetwork_connectionsvariable, you must specify all settings to change the network connection profile.
You can set only Nmstate YAML instructions in network_state. These instructions differ from the variables you can set in network_connections.
For example, to create an Ethernet connection with dynamic IP address settings, use the following vars block in your playbook:
| Playbook with state configurations | Regular playbook |
|
|
For example, to only change the connection status of dynamic IP address settings that you created as above, use the following vars block in your playbook:
| Playbook with state configurations | Regular playbook |
|
|
Chapter 41. Using and configuring firewalld
A firewall is a way to protect machines from any unwanted traffic from outside. Administrators use a firewall to control incoming network traffic on host machines by defining a set of firewall rules. These rules are used to sort the incoming traffic and either block it or allow it through.
firewalld is a firewall service daemon that provides a dynamic, customizable firewall with a D-Bus interface. This dynamic architecture allows administrators to create, change, and delete rules without restarting the service after every modification.
You can use firewalld to configure packet filtering required by the majority of typical cases. If firewalld does not cover your scenario, or you want to have complete control of rules, use the nftables framework.
firewalld uses the concepts of zones, policies, and services to simplify traffic management. Zones logically separate a network. Network interfaces and sources can be assigned to a zone. Policies are used to deny or allow traffic flowing between zones. Firewall services are predefined rules that cover all necessary settings to allow incoming traffic for a specific service, and they apply within a zone.
Services use one or more ports or addresses for network communication. Firewalls filter communication based on ports. To allow network traffic for a service, its ports must be open. firewalld blocks all traffic on ports that are not explicitly set as open. Some zones, such as trusted, allow all traffic by default.
firewalld maintains separate runtime and permanent configurations. This allows runtime-only changes. The runtime configuration does not persist after firewalld reload or restart. At startup, it is populated from the permanent configuration.
Note that firewalld with nftables back end does not support passing custom nftables rules to firewalld, using the --direct option.
41.1. When to use firewalld, nftables, or iptables
On RHEL 8, you can use the following packet-filtering utilities depending on your scenario:
-
firewalld: Thefirewalldutility simplifies firewall configuration for common use cases. -
nftables: Use thenftablesutility to set up complex and performance-critical firewalls, such as for a whole network. -
iptables: Theiptablesutility on Red Hat Enterprise Linux uses thenf_tableskernel API instead of thelegacyback end. Thenf_tablesAPI provides backward compatibility so that scripts that useiptablescommands still work on Red Hat Enterprise Linux. For new firewall scripts, usenftables.
To prevent the different firewall-related services (firewalld, nftables, or iptables) from influencing each other, run only one of them on a RHEL host, and disable the other services.
41.2. Firewall zones
You can use the firewalld utility to separate networks into different zones according to the level of trust that you have with the interfaces and traffic within that network. A connection can only be part of one zone, but you can use that zone for many network connections.
firewalld follows strict principles in regards to zones:
- Traffic ingresses only one zone.
- Traffic egresses only one zone.
- A zone defines a level of trust.
- Intrazone traffic (within the same zone) is allowed by default.
- Interzone traffic (from zone to zone) is denied by default.
Principles 4 and 5 are a consequence of principle 3.
Principle 4 is configurable through the zone option --remove-forward. Principle 5 is configurable by adding new policies.
NetworkManager notifies firewalld of the zone of an interface. You can assign zones to interfaces with the following utilities:
-
NetworkManager -
firewall-configutility -
firewall-cmdutility - The RHEL web console
The RHEL web console, firewall-config, and firewall-cmd can only edit the appropriate NetworkManager configuration files. If you change the zone of the interface using the web console, firewall-cmd, or firewall-config, the request is forwarded to NetworkManager and is not handled by firewalld.
The /usr/lib/firewalld/zones/ directory stores the predefined zones, and you can instantly apply them to any available network interface. These files are copied to the /etc/firewalld/zones/ directory only after they are modified. The default settings of the predefined zones are as follows:
block-
Suitable for: Any incoming network connections are rejected with an icmp-host-prohibited message for
IPv4and icmp6-adm-prohibited forIPv6. - Accepts: Only network connections initiated from within the system.
-
Suitable for: Any incoming network connections are rejected with an icmp-host-prohibited message for
dmz- Suitable for: Computers in your DMZ that are publicly-accessible with limited access to your internal network.
- Accepts: Only selected incoming connections.
dropSuitable for: Any incoming network packets are dropped without any notification.
- Accepts: Only outgoing network connections.
external- Suitable for: External networks with masquerading enabled, especially for routers. Situations when you do not trust the other computers on the network.
- Accepts: Only selected incoming connections.
home- Suitable for: Home environment where you mostly trust the other computers on the network.
- Accepts: Only selected incoming connections.
internal- Suitable for: Internal networks where you mostly trust the other computers on the network.
- Accepts: Only selected incoming connections.
public- Suitable for: Public areas where you do not trust other computers on the network.
- Accepts: Only selected incoming connections.
trusted- Accepts: All network connections.
workSuitable for: Work environment where you mostly trust the other computers on the network.
- Accepts: Only selected incoming connections.
One of these zones is set as the default zone. When interface connections are added to NetworkManager, they are assigned to the default zone. On installation, the default zone in firewalld is the public zone. You can change the default zone.
Make network zone names self-explanatory to help users understand them quickly.
To avoid any security problems, review the default zone configuration and disable any unnecessary services according to your needs and risk assessments.
41.3. Firewall policies
The firewall policies specify the required security state of your network. They outline rules and actions to take for different types of traffic.
Typically, the policies contain rules for the following types of traffic:
- Incoming traffic
- Outgoing traffic
- Forward traffic
- Specific services and applications
- Network address translations (NAT)
Firewall policies use the concept of firewall zones. Each zone is associated with a specific set of firewall rules that determine the traffic allowed. Policies apply firewall rules in a stateful, unidirectional manner. This means you only consider one direction of the traffic. The traffic return path is implicitly allowed due to stateful filtering of firewalld.
Policies are associated with an ingress zone and an egress zone. The ingress zone is where the traffic originated (received). The egress zone is where the traffic leaves (sent).
The firewall rules defined in a policy can reference the firewall zones to apply consistent configurations across multiple network interfaces.
41.4. Firewall rules
You can use the firewall rules to implement specific configurations for allowing or blocking network traffic. As a result, you can control the flow of network traffic to protect your system from security threats.
Firewall rules typically define certain criteria based on various attributes. The attributes can be as:
- Source IP addresses
- Destination IP addresses
- Transfer Protocols (TCP, UDP, …)
- Ports
- Network interfaces
The firewalld utility organizes the firewall rules into zones (such as public, internal, and others) and policies. Each zone has its own set of rules that determine the level of traffic freedom for network interfaces associated with a particular zone.
41.5. Firewall direct rules
The firewalld service provides multiple ways with which to configure rules, including regular rules and direct rules.
One difference between these is how each method interacts with the underlying backend (iptables or nftables).
The direct rules are advanced, low-level rules that allow direct interaction with iptables. They bypass the structured zone-based management of firewalld to give you more control. You manually define the direct rules with the firewall-cmd command by using the raw iptables syntax. For example, firewall-cmd --direct --add-rule ipv4 filter INPUT 0 -s 198.51.100.1 -j DROP. This command adds an iptables rule to drop traffic from the 198.51.100.1 source IP address.
However, using the direct rules also has its drawbacks. Especially when nftables is your primary firewall backend. For example:
-
The direct rules are harder to maintain and can conflict with
nftablesbasedfirewalldconfigurations. -
The direct rules do not support advanced features that you can find in
nftablessuch as raw expressions and stateful objects. -
Direct rules are not future-proof. The
iptablescomponent is deprecated and will be removed in a future major RHEL version.
For the previous reasons, replace firewalld direct rules with nftables.
41.6. Predefined firewalld services
Predefined firewalld services offer an abstraction layer for low-level firewall rules. They map common network services, such as SSH or HTTP, to their specific ports and protocols, simplifying firewall management and reducing errors by using a named service instead of manual configuration.
To see available predefined services:
# firewall-cmd --get-services RH-Satellite-6 RH-Satellite-6-capsule afp amanda-client amanda-k5-client amqp amqps apcupsd audit ausweisapp2 bacula bacula-client bareos-director bareos-filedaemon bareos-storage bb bgp bitcoin bitcoin-rpc bitcoin-testnet bitcoin-testnet-rpc bittorrent-lsd ceph ceph-exporter ceph-mon cfengine checkmk-agent cockpit collectd condor-collector cratedb ctdb dds...To further inspect a particular predefined service:
# sudo firewall-cmd --info-service=RH-Satellite-6 RH-Satellite-6 ports: 5000/tcp 5646-5647/tcp 5671/tcp 8000/tcp 8080/tcp 9090/tcp protocols: source-ports: modules: destination: includes: foreman helpers:The example output shows that the
RH-Satellite-6predefined service listens on ports 5000/tcp 5646-5647/tcp 5671/tcp 8000/tcp 8080/tcp 9090/tcp. Additionally,RH-Satellite-6inherits rules from another predefined service. In this caseforeman.
Each predefined service is stored as an XML file with the same name in the /usr/lib/firewalld/services/ directory.
41.7. Working with firewalld zones
Zones represent a concept to manage incoming traffic more transparently. Network interfaces and source addresses are assigned to zones. You manage firewall rules for each zone independently, which lets you define complex firewall settings and apply them to the traffic.
41.7.1. Customizing firewall settings for a specific zone to enhance security
To strengthen network security, modify the firewalld settings by associating a specific network interface or connection with a particular firewall zone. By defining granular rules for a zone, you can control inbound and outbound traffic according to your security needs.
For example, you can achieve the following benefits:
- Protection of sensitive data
- Prevention of unauthorized access
- Mitigation of potential network threats
Prerequisites
-
The
firewalldservice is running.
Procedure
List the available firewall zones:
# firewall-cmd --get-zonesThe
firewall-cmd --get-zonescommand displays all zones that are available on the system, but it does not show any details for particular zones. To see more detailed information for all zones, use thefirewall-cmd --list-all-zonescommand.- Choose the zone you want to use for this configuration.
Modify firewall settings for the chosen zone. For example, to allow the
SSHservice and remove theftpservice:# firewall-cmd --add-service=ssh --zone=<your_chosen_zone> # firewall-cmd --remove-service=ftp --zone=<same_chosen_zone>Assign a network interface to the firewall zone:
List the available network interfaces:
# firewall-cmd --get-active-zonesActivity of a zone is determined by the presence of network interfaces or source address ranges that match its configuration. The default zone is active for unclassified traffic but is not always active if no traffic matches its rules.
Assign a network interface to the chosen zone:
# firewall-cmd --zone=<your_chosen_zone> --change-interface=<interface_name> --permanentAssigning a network interface to a zone is more suitable for applying consistent firewall settings to all traffic on a particular interface (physical or virtual).
The
firewall-cmdcommand, when used with the--permanentoption, often involves updating NetworkManager connection profiles to make changes to the firewall configuration permanent. This integration betweenfirewalldand NetworkManager ensures consistent network and firewall settings.
Verification
Display the updated settings for your chosen zone:
# firewall-cmd --zone=<your_chosen_zone> --list-allThe command output displays all zone settings including the assigned services, network interface, and network connections (sources).
41.7.2. Changing the default zone
If an interface is not assigned to a specific zone, it is assigned to the default zone. After each restart of the firewalld service, firewalld loads the settings for the default zone and makes it active. Settings for all other zones are preserved and ready to be used.
Typically, zones are assigned to interfaces by NetworkManager according to the connection.zone setting in NetworkManager connection profiles. Also, after a reboot NetworkManager manages assignments for "activating" those zones.
Prerequisites
-
The
firewalldservice is running.
Procedure
Display the current default zone:
# firewall-cmd --get-default-zoneSet the new default zone:
# firewall-cmd --set-default-zone <zone_name>NoteFollowing this procedure, the setting is a permanent setting, even without the
--permanentoption.
41.7.3. Assigning a network interface to a zone
It is possible to define different sets of rules for different zones and then change the settings quickly by changing the zone for the interface that is being used. With multiple interfaces, a specific zone can be set for each of them to distinguish traffic that is coming through them.
Procedure
List the active zones and the interfaces assigned to them:
# firewall-cmd --get-active-zonesAssign the interface to a different zone:
# firewall-cmd --zone=zone_name --change-interface=interface_name --permanent
41.7.4. Adding a source
To route incoming traffic into a specific zone, add the source to that zone. The source can be an IP address or an IP mask in the classless inter-domain routing (CIDR) notation.
In case you add multiple zones with an overlapping network range, they are ordered alphanumerically by zone name and only the first one is considered.
To set the source in the current zone:
# firewall-cmd --add-source=<source>To set the source IP address for a specific zone:
# firewall-cmd --zone=zone-name --add-source=<source>
The following procedure allows all incoming traffic from 192.168.2.15 in the trusted zone:
Procedure
List all available zones:
# firewall-cmd --get-zonesAdd the source IP to the trusted zone in the permanent mode:
# firewall-cmd --zone=trusted --add-source=192.168.2.15Make the new settings persistent:
# firewall-cmd --runtime-to-permanent
41.7.5. Removing a source
When you remove a source from a firewalld zone, its traffic is no longer directed by that source’s rules. Instead, it falls back to the rules of the interface’s zone or the default zone.
Procedure
List allowed sources for the required zone:
# firewall-cmd --zone=zone-name --list-sourcesRemove the source from the zone permanently:
# firewall-cmd --zone=zone-name --remove-source=<source>Make the new settings persistent:
# firewall-cmd --runtime-to-permanent
41.7.6. Assigning a zone to a connection by using nmcli
You can add a firewalld zone to a NetworkManager connection using the nmcli utility.
Procedure
Assign the zone to the
NetworkManagerconnection profile:# nmcli connection modify profile connection.zone zone_nameActivate the connection:
# nmcli connection up profile
41.7.7. Manually assigning a zone to a network connection in an ifcfg file
When the connection is managed by NetworkManager, it must be aware of a zone that it uses. For every network connection profile, a zone can be specified, which provides the flexibility of various firewall settings according to the location of the computer with portable devices. Thus, zones and settings can be specified for different locations, such as company or home.
Procedure
To set a zone for a connection, edit the
/etc/sysconfig/network-scripts/ifcfg-connection_namefile and add a line that assigns a zone to this connection:ZONE=zone_name
41.7.8. Creating a new zone
To use custom zones, create a new zone and use it just like a predefined zone. New zones require the --permanent option, otherwise the command does not work.
Prerequisites
-
The
firewalldservice is running.
Procedure
Create a new zone:
# firewall-cmd --permanent --new-zone=zone-nameMake the new zone usable:
# firewall-cmd --reloadThe command applies recent changes to the firewall configuration without interrupting network services that are already running.
Verification
Check if the new zone is added to your permanent settings:
# firewall-cmd --get-zones --permanent
41.7.9. Enabling zones by using the web console
You can apply predefined and existing firewall zones on a particular interface or a range of IP addresses through the RHEL web console.
Prerequisites
- You have installed the RHEL 8 web console.
- You have enabled the cockpit service.
Your user account is allowed to log in to the web console.
For instructions, see Installing and enabling the web console.
- You enabled administrative access in the web console.
-
The
firewalldservice is running.
Procedure
Log in to the RHEL 8 web console.
For details, see Logging in to the web console.
- Click Networking.
Click the button.

If you do not see the button, log in to the web console with the administrator privileges.
- In the Firewall section, click Add new zone.
In the Add zone dialog box, select a zone from the Trust level options.
The web console displays all zones predefined in the
firewalldservice.- In the Interfaces part, select an interface or interfaces to which you want to apply the selected zone.
In the Allowed Addresses part, you can select whether the zone is applied to:
- the whole subnet
a range of IP addresses in the following format:
- 192.168.1.0
- 192.168.1.0/24
- 192.168.1.0/24, 192.168.1.0
Click the button.
Verification
Check the configuration in the Firewall section:
41.7.10. Disabling zones by using the web console
You can remove a firewall zone from your firewall configuration by using the web console.
Prerequisites
- You have installed the RHEL 8 web console.
- You have enabled the cockpit service.
Your user account is allowed to log in to the web console.
For instructions, see Installing and enabling the web console.
- You enabled administrative access in the web console.
-
The
firewalldservice is running.
Procedure
Log in to the RHEL 8 web console.
For details, see Logging in to the web console.
- Click Networking.
Click the button.
If you do not see the button, log in to the web console with the administrator privileges.
Click the Options icon at the zone you want to remove.

- Click Delete.
41.7.11. Using zone targets to set default behavior for incoming traffic
For every zone, you can set a default behavior that handles incoming traffic that is not further specified. Such behavior is defined by setting the target of the zone.
-
ACCEPT: Accepts all incoming packets except those disallowed by specific rules. -
REJECT: Rejects all incoming packets except those allowed by specific rules. Whenfirewalldrejects packets, the source machine is informed about the rejection. -
DROP: Drops all incoming packets except those allowed by specific rules. Whenfirewallddrops packets, the source machine is not informed about the packet drop. -
default: Similar behavior as forREJECT, but with special meanings in certain scenarios.
Prerequisites
-
The
firewalldservice is running.
Procedure
List the information for the specific zone to see the default target:
# firewall-cmd --zone=zone-name --list-allSet a new target in the zone:
# firewall-cmd --permanent --zone=zone-name --set-target=<default|ACCEPT|REJECT|DROP>
41.7.12. Configuring dynamic updates for allowlisting with IP sets
You can make near real-time updates to flexibly allow specific IP addresses or ranges in the IP sets even in unpredictable conditions.
These updates can be triggered by various events, such as detection of security threats or changes in the network behavior. Typically, such a solution leverages automation to reduce manual effort and improve security by responding quickly to the situation.
Prerequisites
-
The
firewalldservice is running.
Procedure
Create an IP set with a meaningful name:
# firewall-cmd --permanent --new-ipset=allowlist --type=hash:ipThe new IP set called
allowlistcontains IP addresses that you want your firewall to allow.Add a dynamic update to the IP set:
# firewall-cmd --permanent --ipset=allowlist --add-entry=198.51.100.10This configuration updates the
allowlistIP set with a newly added IP address that is allowed to pass network traffic by your firewall.Create a firewall rule that references the previously created IP set:
# firewall-cmd --permanent --zone=public --add-source=ipset:allowlistWithout this rule, the IP set does not have any impact on network traffic, and the default firewall policy takes precedence.
Reload the firewall configuration to apply the changes:
# firewall-cmd --reload
Verification
List all IP sets:
# firewall-cmd --get-ipsets allowlistList the active rules:
# firewall-cmd --list-all public (active) target: default icmp-block-inversion: no interfaces: enp0s1 sources: ipset:allowlist services: cockpit dhcpv6-client ssh ports: protocols: ...The
sourcessection of the command-line output provides insights to what origins of traffic (hostnames, interfaces, IP sets, subnets, and others) are permitted or denied access to a particular firewall zone. In this case, the IP addresses contained in theallowlistIP set are allowed to pass traffic through the firewall for thepubliczone.Explore the contents of your IP set:
# cat /etc/firewalld/ipsets/allowlist.xml <?xml version="1.0" encoding="utf-8"?> <ipset type="hash:ip"> <entry>198.51.100.10</entry> </ipset>
Next steps
-
Use a script or a security utility to fetch your threat intelligence feeds and update
allowlistaccordingly in an automated fashion.
41.8. Controlling network traffic using firewalld
The firewalld package installs a large number of predefined service files and you can add more or customize them. You can then use these service definitions to open or close ports for services without knowing the protocol and port numbers they use.
41.8.1. Controlling traffic with predefined services using the CLI
The most straightforward method to control traffic is to add a predefined service to firewalld. This opens all necessary ports and modifies other settings according to the service definition file.
Prerequisites
-
The
firewalldservice is running.
Procedure
Check that the service in
firewalldis not already allowed:# firewall-cmd --list-services ssh dhcpv6-clientThe command lists the services that are enabled in the default zone.
List all predefined services in
firewalld:# firewall-cmd --get-services RH-Satellite-6 amanda-client amanda-k5-client bacula bacula-client bitcoin bitcoin-rpc bitcoin-testnet bitcoin-testnet-rpc ceph ceph-mon cfengine condor-collector ctdb dhcp dhcpv6 dhcpv6-client dns docker-registry ...The command displays a list of available services for the default zone.
Add the service to the list of services that
firewalldallows:# firewall-cmd --add-service=<service_name>The command adds the specified service to the default zone.
Make the new settings persistent:
# firewall-cmd --runtime-to-permanentThe command applies these runtime changes to the permanent configuration of the firewall. By default, it applies these changes to the configuration of the default zone.
Verification
List all permanent firewall rules:
# firewall-cmd --list-all --permanent public target: default icmp-block-inversion: no interfaces: sources: services: cockpit dhcpv6-client ssh ports: protocols: forward: no masquerade: no forward-ports: source-ports: icmp-blocks: rich rules:The command displays complete configuration with the permanent firewall rules of the default firewall zone (
public).Check the validity of the permanent configuration of the
firewalldservice.# firewall-cmd --check-config successIf the permanent configuration is invalid, the command returns an error with further details:
# firewall-cmd --check-config Error: INVALID_PROTOCOL: 'public.xml': 'tcpx' not from {'tcp'|'udp'|'sctp'|'dccp'}You can also manually inspect the permanent configuration files to verify the settings. The main configuration file is
/etc/firewalld/firewalld.conf. The zone-specific configuration files are in the/etc/firewalld/zones/directory and the policies are in the/etc/firewalld/policies/directory.
41.8.2. Enabling services on the firewall by using the web console
By default, services are added to the default firewall zone. If you use more firewall zones on more network interfaces, you must select a zone first and then add the service with port.
The RHEL web console displays predefined firewalld services and you can add them to active firewall zones.
The RHEL 8 web console configures the firewalld service.
The web console does not allow generic firewalld rules that are not listed in the web console.
Prerequisites
- You have installed the RHEL 8 web console.
- You have enabled the cockpit service.
Your user account is allowed to log in to the web console.
For instructions, see Installing and enabling the web console.
- You enabled administrative access in the web console.
-
The
firewalldservice is running.
Procedure
Log in to the RHEL 8 web console.
For details, see Logging in to the web console.
- Click Networking.
Click the button.
If you do not see the button, log in to the web console with the administrator privileges.
In the Firewall section, select a zone for which you want to add the service and click Add Services.

- In the Add Services dialog box, find the service you want to enable in the firewall.
Enable services according to your scenario:
- Click Add Services.
41.8.3. Configuring custom ports by using the web console
You can add custom ports for services through the RHEL web console.
Prerequisites
- You have installed the RHEL 8 web console.
- You have enabled the cockpit service.
Your user account is allowed to log in to the web console.
For instructions, see Installing and enabling the web console.
-
The
firewalldservice is running.
Procedure
Log in to the RHEL 8 web console.
For details, see Logging in to the web console.
- Click Networking.
Click the button.
If you do not see the button, log in to the web console with the administrative privileges.
In the Firewall section, select a zone for which you want to configure a custom port and click Add Services.
- In the Add services dialog box, click the radio button.
In the TCP and UDP fields, add ports according to examples. You can add ports in the following formats:
- Port numbers such as 22
- Range of port numbers such as 5900-5910
- Aliases such as nfs, rsync
NoteYou can add multiple values into each field. You must separate values with a comma and without a space, for example: 8080,8081,http
After adding the port number in the TCP field, the UDP field, or both, verify the service name in the Name field.
The Name field displays the name of the service for which this port is reserved. You can rewrite the name if you are sure that this port is free to use and no server requires it to communicate on this port.
- In the Name field, add a name for the service including defined ports.
Click the button.

Verification
To verify the settings, go to the Firewall page and find the service in the list of zone’s Services.
41.9. Filtering forwarded traffic between zones
You can control the flow of network data between different firewalld zones. By defining rules and policies, you can manage how traffic is allowed or blocked when it moves between these zones.
The policy objects feature provides forward and output filtering in firewalld. You can use firewalld to filter traffic between different zones to allow access to locally hosted VMs to connect the host.
41.9.1. The relationship between policy objects and zones
By using policy objects, you can attach firewalld’s primitives such as services, ports, and rich rules to the policy. You can apply the policy objects to traffic that passes between zones in a stateful and unidirectional manner.
# firewall-cmd --permanent --new-policy myOutputPolicy
# firewall-cmd --permanent --policy myOutputPolicy --add-ingress-zone HOST
# firewall-cmd --permanent --policy myOutputPolicy --add-egress-zone ANY
HOST and ANY are the symbolic zones used in the ingress and egress zone lists.
-
The
HOSTsymbolic zone allows policies for the traffic originating from or has a destination to the host running firewalld. -
The
ANYsymbolic zone applies policy to all the current and future zones.ANYsymbolic zone acts as a wildcard for all zones.
41.9.2. Using priorities to sort policies
Multiple policies can apply to the same set of traffic. Therefore, use priorities to create an order of precedence for the policies that might be applied.
Procedure
Set a priority to sort the policies:
# firewall-cmd --permanent --policy mypolicy --set-priority -500Lower numerical priority values have higher precedence and are applied first.
41.9.3. Using policy objects to filter traffic between locally hosted containers and a network physically connected to the host
The policy objects feature enables users to filter traffic between Podman and firewalld zones.
Red Hat recommends blocking all traffic by default and opening the selective services needed for the Podman utility.
Procedure
Create a new firewall policy:
# firewall-cmd --permanent --new-policy podmanToAnyBlock all traffic from Podman to other zones and allow only necessary services on Podman:
# firewall-cmd --permanent --policy podmanToAny --set-target REJECT # firewall-cmd --permanent --policy podmanToAny --add-service dhcp # firewall-cmd --permanent --policy podmanToAny --add-service dns # firewall-cmd --permanent --policy podmanToAny --add-service httpsCreate a new Podman zone:
# firewall-cmd --permanent --new-zone=podmanDefine the ingress zone for the policy:
# firewall-cmd --permanent --policy podmanToHost --add-ingress-zone podmanDefine the egress zone for all other zones:
# firewall-cmd --permanent --policy podmanToHost --add-egress-zone ANYSetting the egress zone to ANY means that you filter from Podman to other zones. If you want to filter to the host, then set the egress zone to HOST.
Restart the firewalld service:
# systemctl restart firewalld
Verification
Verify the Podman firewall policy to other zones:
# firewall-cmd --info-policy podmanToAny podmanToAny (active) ... target: REJECT ingress-zones: podman egress-zones: ANY services: dhcp dns https ...
41.9.4. Setting the default target of policy objects
You can specify --set-target options for policies.
The following targets are available:
-
ACCEPT- accepts the packet -
DROP- drops the unwanted packets -
REJECT- rejects unwanted packets with an ICMP reply -
CONTINUE(default) - packets are subject to rules in following policies and zones.
Procedure
Set the default target:
# firewall-cmd --permanent --policy mypolicy --set-target CONTINUE
Verification
Verify information about the policy
# firewall-cmd --info-policy mypolicy
41.10. Configuring NAT by using firewalld
With firewalld, you can configure the masquerading, destination NAT (DNAT), and redirect NAT types. With NAT, you can modify the source or destination IP address.
41.10.1. Network address translation types
If you require network address translation (NAT) in your network, it is important to understand the NAT types.
These are the different NAT types:
- Masquerading
Use this NAT type to change the source IP address of packets. For example, Internet Service Providers (ISPs) do not route private IP ranges, such as
10.0.0.0/8. If you use private IP ranges in your network and hosts in this network require internet access, map the source IP address of packets from these ranges to a public IP address.Masquerading automatically uses the IP address of the outgoing interface. Therefore, use masquerading if the outgoing interface uses a dynamic IP address.
- Destination NAT (DNAT)
- Use this NAT type to rewrite the destination address and port of incoming packets. For example, if your web server uses an IP address from a private IP range and is, therefore, not directly accessible from the internet, you can set a DNAT rule on the router to redirect incoming traffic to this server.
- Redirect
- This type is a special case of DNAT that redirects packets to a different port on the local machine. For example, if a service runs on a different port than its standard port, you can redirect incoming traffic from the standard port to this specific port.
41.10.2. Configuring IP address masquerading
You can enable IP masquerading on your system. IP masquerading hides individual machines behind a gateway when accessing the internet.
Procedure
To check if IP masquerading is enabled (for example, for the
externalzone), enter the following command asroot:# firewall-cmd --zone=external --query-masqueradeThe command prints
yeswith exit status0if enabled. It printsnowith exit status1otherwise. Ifzoneis omitted, firewalld uses the default zone.To enable IP masquerading, enter the following command as
root:# firewall-cmd --zone=external --add-masquerade-
To make this setting persistent, pass the
--permanentoption to the command. To disable IP masquerading, enter the following command as
root:# firewall-cmd --zone=external --remove-masqueradeTo make this setting permanent, pass the
--permanentoption to the command.
41.10.3. Using DNAT to forward incoming HTTP traffic
You can use destination network address translation (DNAT) to direct incoming traffic from one destination address and port to another. Typically, this is useful for redirecting incoming requests from an external network interface to specific internal servers or services.
Prerequisites
-
The
firewalldservice is running.
Procedure
Forward incoming HTTP traffic:
# firewall-cmd --zone=public --add-forward-port=port=80:proto=tcp:toaddr=198.51.100.10:toport=8080 --permanentThe previous command defines a DNAT rule with the following settings:
-
--zone=public- The firewall zone for which you configure the DNAT rule. You can adjust this to whatever zone you need. -
--add-forward-port- The option that indicates you are adding a port-forwarding rule. -
port=80- The external destination port. -
proto=tcp- The protocol indicating that you forward TCP traffic. -
toaddr=198.51.100.10- The destination IP address. -
toport=8080- The destination port of the internal server. -
--permanent- The option that makes the DNAT rule persistent across reboots.
-
Reload the firewall configuration to apply the changes:
# firewall-cmd --reload
Verification
Verify the DNAT rule for the firewall zone that you used:
# firewall-cmd --list-forward-ports --zone=public port=80:proto=tcp:toport=8080:toaddr=198.51.100.10Alternatively, view the corresponding XML configuration file:
# cat /etc/firewalld/zones/public.xml <?xml version="1.0" encoding="utf-8"?> <zone> <short>Public</short> <description>For use in public areas. You do not trust the other computers on networks to not harm your computer. Only selected incoming connections are accepted.</description> <service name="ssh"/> <service name="dhcpv6-client"/> <service name="cockpit"/> <forward-port port="80" protocol="tcp" to-port="8080" to-addr="198.51.100.10"/> <forward/> </zone>
41.10.4. Redirecting traffic from a non-standard port to make the web service accessible on a standard port
You can use the redirect mechanism to make the web service that internally runs on a non-standard port accessible without requiring users to specify the port in the URL.
If you use redirect, the URLs are simpler and provide better browsing experience, whereas a non-standard port is still used internally or for specific requirements.
Prerequisites
-
The
firewalldservice is running.
Procedure
Create the NAT redirect rule:
# firewall-cmd --zone=public --add-forward-port=port=<standard_port>:proto=tcp:toport=<non_standard_port> --permanentThe previous command defines the NAT redirect rule with the following settings:
-
--zone=public- The firewall zone, for which you configure the rule. You can adjust this to whatever zone you need. -
--add-forward-port=port=<non_standard_port>- The option that indicates you are adding a port-forwarding (redirecting) rule with source port on which you initially receive the incoming traffic. -
proto=tcp- The protocol indicating that you redirect TCP traffic. -
toport=<standard_port>- The destination port, to which the incoming traffic should be redirected after being received on the source port. -
--permanent- The option that makes the rule persist across reboots.
-
Reload the firewall configuration to apply the changes:
# firewall-cmd --reload
Verification
Verify the redirect rule for the firewall zone that you used:
# firewall-cmd --list-forward-ports port=8080:proto=tcp:toport=80:toaddr=Alternatively, view the corresponding XML configuration file:
# cat /etc/firewalld/zones/public.xml <?xml version="1.0" encoding="utf-8"?> <zone> <short>Public</short> <description>For use in public areas. You do not trust the other computers on networks to not harm your computer. Only selected incoming connections are accepted.</description> <service name="ssh"/> <service name="dhcpv6-client"/> <service name="cockpit"/> <forward-port port="8080" protocol="tcp" to-port="80"/> <forward/> </zone>
41.11. Prioritizing rich rules
Rich rules provide a more advanced and flexible way to define firewall rules. Rich rules are particularly useful where services, ports, and so on are not enough to express complex firewall rules.
Concepts behind rich rules:
- granularity and flexibility
- You can define detailed conditions for network traffic based on more specific criteria.
- rule structure
A rich rule consists of a family (IPv4 or IPv6), followed by conditions and actions.
rule family="ipv4|ipv6" [conditions] [actions]- conditions
- They allow rich rules to apply only when certain criteria are met.
- actions
- You can define what happens to network traffic that matches the conditions.
- combining multiple conditions
- You can create more specific and complex filtering.
- hierarchical control and reusability
- You can combine rich rules with other firewall mechanisms such as zones or services.
By default, rich rules are organized based on their rule action. For example, deny rules have precedence over allow rules. The priority parameter in rich rules provides administrators fine-grained control over rich rules and their execution order. When using the priority parameter, rules are sorted first by their priority values in ascending order. When more rules have the same priority, their order is determined by the rule action, and if the action is also the same, the order might be undefined.
41.11.1. How the priority parameter organizes rules into different chains
You can set the priority parameter in a rich rule to any number between -32768 and 32767, and lower numerical values have higher precedence.
The firewalld service organizes rules based on their priority value into different chains:
-
Priority lower than 0: the rule is redirected into a chain with the
_presuffix. -
Priority higher than 0: the rule is redirected into a chain with the
_postsuffix. -
Priority equals 0: based on the action, the rule is redirected into a chain with the
_log,_deny, or_allowthe action.
Inside these sub-chains, firewalld sorts the rules based on their priority value.
41.11.2. Setting the priority of a rich rule
You can use the priority parameter to log all traffic that is not allowed or denied by other rules. For example, you can use this feature to flag unexpected traffic.
Procedure
Add a rich rule with a very low precedence to log all traffic that has not been matched by other rules:
# firewall-cmd --add-rich-rule='rule priority=32767 log prefix="UNEXPECTED: " limit value="5/m"'The command additionally limits the number of log entries to
5per minute.
Verification
Display the
nftablesrule that the command in the previous step created:# nft list chain inet firewalld filter_IN_public_post table inet firewalld { chain filter_IN_public_post { log prefix "UNEXPECTED: " limit rate 5/minute } }
41.12. Enabling traffic forwarding between different interfaces or sources within a firewalld zone
Intra-zone forwarding is a firewalld feature that enables traffic forwarding between interfaces or sources within a firewalld zone.
41.12.1. The difference between intra-zone forwarding and zones with the default target set to ACCEPT
With intra-zone forwarding enabled, the traffic within a single firewalld zone can flow from one interface or source to another interface or source. The zone specifies the trust level of interfaces and sources. If the trust level is the same, the traffic stays inside the same zone.
Enabling intra-zone forwarding in the default zone of firewalld, applies only to the interfaces and sources added to the current default zone.
firewalld uses different zones to manage incoming and outgoing traffic. Each zone has its own set of rules and behaviors. For example, the trusted zone allows all forwarded traffic by default.
Other zones can have different default behaviors. In standard zones, forwarded traffic is typically dropped by default when the target of the zone is set to default.
To control how the traffic is forwarded between different interfaces or sources within a zone, make sure you understand and configure the target of the zone accordingly.
41.12.2. Using intra-zone forwarding to forward traffic between an Ethernet and Wi-Fi network
You can use intra-zone forwarding to forward traffic between interfaces and sources within the same firewalld zone.
This feature brings the following benefits:
-
Seamless connectivity between wired and wireless devices (you can forward traffic between an Ethernet network connected to
enp1s0and a Wi-Fi network connected towlp0s20) - Support for flexible work environments
- Shared resources that are accessible and used by multiple devices or users within a network (such as printers, databases, network-attached storage, and others)
- Efficient internal networking (such as smooth communication, reduced latency, resource accessibility, and others)
You can enable this functionality for individual firewalld zones.
Procedure
Enable packet forwarding in the kernel:
# echo "net.ipv4.ip_forward=1" > /etc/sysctl.d/95-IPv4-forwarding.conf # sysctl -p /etc/sysctl.d/95-IPv4-forwarding.confEnsure that interfaces between which you want to enable intra-zone forwarding are assigned only to the
internalzone:# firewall-cmd --get-active-zonesIf the interface is currently assigned to a zone other than
internal, reassign it:# firewall-cmd --zone=internal --change-interface=interface_name --permanentAdd the
enp1s0andwlp0s20interfaces to theinternalzone:# firewall-cmd --zone=internal --add-interface=enp1s0 --add-interface=wlp0s20Enable intra-zone forwarding:
# firewall-cmd --zone=internal --add-forward
Verification
-
Log in to a host that is on the same network as the
enp1s0interface of the host on which you enabled zone forwarding. Start an echo service with
ncatto test connectivity:# ncat -e /usr/bin/cat -l 12345-
Log in to a host that is in the same network as the
wlp0s20interface. Connect to the echo server running on the host that is in the same network as the
enp1s0:# ncat <other_host> 12345- Type something and press . Verify the text is sent back.
41.13. Configuring firewalld by using RHEL system roles
RHEL system roles is a set of contents for the Ansible automation utility. This content together with the Ansible automation utility provides a consistent configuration interface to remotely manage multiple systems at once.
The rhel-system-roles package contains the rhel-system-roles.firewall RHEL system role. This role was introduced for automated configurations of the firewalld service.
With the firewall RHEL system role you can configure many different firewalld parameters, for example:
- Zones
- The specific services permitted to receive packets
- Granting, rejection, or dropping of traffic access to ports
- Forwarding of ports or port ranges for a zone
41.13.1. Resetting the firewalld settings by using the firewall RHEL system role
The firewall RHEL system role supports automating a reset of firewalld settings to their defaults. This efficiently removes insecure or unintentional firewall rules and simplifies management.
Prerequisites
- You have prepared the control node and the managed nodes.
-
The account you use to connect to the managed nodes has
sudopermissions for these nodes.
Procedure
Create a playbook file, for example,
~/playbook.yml, with the following content:--- - name: Reset firewalld example hosts: managed-node-01.example.com tasks: - name: Reset firewalld ansible.builtin.include_role: name: redhat.rhel_system_roles.firewall vars: firewall: - previous: replacedThe settings specified in the example playbook include the following:
previous: replacedRemoves all existing user-defined settings and resets the
firewalldsettings to defaults. If you combine theprevious:replacedparameter with other settings, thefirewallrole removes all existing settings before applying new ones.For details about all variables used in the playbook, see the
/usr/share/ansible/roles/rhel-system-roles.firewall/README.mdfile on the control node.
Validate the playbook syntax:
$ ansible-playbook --syntax-check ~/playbook.ymlNote that this command only validates the syntax and does not protect against a wrong but valid configuration.
Run the playbook:
$ ansible-playbook ~/playbook.yml
Verification
Run this command on the control node to remotely check that all firewall configuration on your managed node was reset to its default values:
# ansible managed-node-01.example.com -m ansible.builtin.command -a 'firewall-cmd --list-all-zones'
41.13.2. Forwarding incoming traffic in firewalld from one local port to a different local port by using the firewall RHEL system role
You can use the firewall RHEL system role to remotely configure forwarding of incoming traffic from one local port to a different local port.
For example, if you have an environment where multiple services co-exist on the same machine and need the same default port, there are likely to become port conflicts. These conflicts can disrupt services and cause downtime. With the firewall RHEL system role, you can efficiently forward traffic to alternative ports to ensure that your services can run simultaneously without modification to their configuration.
Prerequisites
- You have prepared the control node and the managed nodes.
-
The account you use to connect to the managed nodes has
sudopermissions for these nodes.
Procedure
Create a playbook file, for example,
~/playbook.yml, with the following content:--- - name: Configure firewalld hosts: managed-node-01.example.com tasks: - name: Forward incoming traffic on port 8080 to 443 ansible.builtin.include_role: name: redhat.rhel_system_roles.firewall vars: firewall: - forward_port: 8080/tcp;443; state: enabled runtime: true permanent: trueThe settings specified in the example playbook include the following:
forward_port: 8080/tcp;443- Traffic coming to the local port 8080 using the TCP protocol is forwarded to port 443.
runtime: trueEnables changes in the runtime configuration. The default is set to
true.For details about all variables used in the playbook, see the
/usr/share/ansible/roles/rhel-system-roles.firewall/README.mdfile on the control node.
Validate the playbook syntax:
$ ansible-playbook --syntax-check ~/playbook.ymlNote that this command only validates the syntax and does not protect against a wrong but valid configuration.
Run the playbook:
$ ansible-playbook ~/playbook.yml
Verification
On the control node, run the following command to remotely check the forwarded-ports on your managed node:
# ansible managed-node-01.example.com -m ansible.builtin.command -a 'firewall-cmd --list-forward-ports' managed-node-01.example.com | CHANGED | rc=0 >> port=8080:proto=tcp:toport=443:toaddr=
41.13.3. Configuring a firewalld DMZ zone by using the firewall RHEL system role
You can use the firewall RHEL system role to configure a zone to allow certain traffic. For example, you can configure that the dmz zone with the enp1s0 interface allows HTTPS traffic to enable external users to access your web servers.
Prerequisites
- You have prepared the control node and the managed nodes.
-
The account you use to connect to the managed nodes has
sudopermissions for these nodes.
Procedure
Create a playbook file, for example,
~/playbook.yml, with the following content:--- - name: Configure firewalld hosts: managed-node-01.example.com tasks: - name: Creating a DMZ with access to HTTPS port and masquerading for hosts in DMZ ansible.builtin.include_role: name: redhat.rhel_system_roles.firewall vars: firewall: - zone: dmz interface: enp1s0 service: https state: enabled runtime: true permanent: trueFor details about all variables used in the playbook, see the
/usr/share/ansible/roles/rhel-system-roles.firewall/README.mdfile on the control node.Validate the playbook syntax:
$ ansible-playbook --syntax-check ~/playbook.ymlNote that this command only validates the syntax and does not protect against a wrong but valid configuration.
Run the playbook:
$ ansible-playbook ~/playbook.yml
Verification
On the control node, run the following command to remotely check the information about the
dmzzone on your managed node:# ansible managed-node-01.example.com -m ansible.builtin.command -a 'firewall-cmd --zone=dmz --list-all' managed-node-01.example.com | CHANGED | rc=0 >> dmz (active) target: default icmp-block-inversion: no interfaces: enp1s0 sources: services: https ssh ports: protocols: forward: no masquerade: no forward-ports: source-ports: icmp-blocks:
Chapter 42. Getting started with nftables
If your scenario does not fall under typical packet-filtering cases covered by firewalld, or you want to have complete control of rules, you can use the nftables framework.
The nftables framework classifies packets, and it is the successor to the iptables, ip6tables, arptables, ebtables, and ipset utilities. It offers numerous improvements in convenience, features, and performance over previous packet-filtering tools, most notably:
- Built-in lookup tables instead of linear processing
-
A single framework for both the
IPv4andIPv6protocols - Updating the kernel rule set in place through transactions instead of fetching, updating, and storing the entire rule set
-
Support for debugging and tracing in the rule set (
nftrace) and monitoring trace events (in thenfttool) - More consistent and compact syntax, no protocol-specific extensions
- A Netlink API for third-party applications
The nftables framework uses tables to store chains. The chains contain individual rules for performing actions. The nft utility replaces all tools from the previous packet-filtering frameworks. You can use the libnftables library for low-level interaction with nftables Netlink API through the libnftnl library.
To display the effect of rule set changes, use the nft list ruleset command. To clear the kernel rule set, use the nft flush ruleset command. Note that this may also affect the rule set installed by the iptables-nft command, as it uses the same kernel infrastructure.
42.1. Creating and managing nftables tables, chains, and rules
You can display nftables rule sets and manage them.
42.1.1. Basics of nftables tables
A table in nftables is a namespace that contains a collection of chains, rules, sets, and other objects.
Each table must have an address family assigned. The address family defines the packet types that this table processes. You can set one of the following address families when you create a table:
-
ip: Matches only IPv4 packets. This is the default if you do not specify an address family. -
ip6: Matches only IPv6 packets. -
inet: Matches both IPv4 and IPv6 packets. -
arp: Matches IPv4 address resolution protocol (ARP) packets. -
bridge: Matches packets that pass through a bridge device. -
netdev: Matches packets from ingress.
If you want to add a table, the format to use depends on your firewall script:
In scripts in native syntax, use:
table <table_address_family> <table_name> { }In shell scripts, use:
nft add table <table_address_family> <table_name>
42.1.2. Basics of nftables chains
Tables consist of chains which in turn are containers for rules. The following two rule types exists:
- Base chain: You can use base chains as an entry point for packets from the networking stack.
-
Regular chain: You can use regular chains as a
jumptarget to better organize rules.
If you want to add a base chain to a table, the format to use depends on your firewall script:
In scripts in native syntax, use:
table <table_address_family> <table_name> { chain <chain_name> { type <type> hook <hook> priority <priority> policy <policy> ; } }In shell scripts, use:
nft add chain <table_address_family> <table_name> <chain_name> { type <type> hook <hook> priority <priority> \; policy <policy> \; }To avoid that the shell interprets the semicolons as the end of the command, place the
\escape character in front of the semicolons.
Both examples create base chains. To create a regular chain, do not set any parameters in the curly brackets.
Chain types:
The following are the chain types and an overview with which address families and hooks you can use them:
| Type | Address families | Hooks | Description |
|---|---|---|---|
|
| all | all | Standard chain type |
|
|
|
| Chains of this type perform native address translation based on connection tracking entries. Only the first packet traverses this chain type. |
|
|
|
| Accepted packets that traverse this chain type cause a new route lookup if relevant parts of the IP header have changed. |
Chain priorities:
The priority parameter specifies the order in which packets traverse chains with the same hook value. You can set this parameter to an integer value or use a standard priority name.
The following matrix is an overview of the standard priority names and their numeric values, and with which address families and hooks you can use them:
| Textual value | Numeric value | Address families | Hooks |
|---|---|---|---|
|
|
|
| all |
|
|
|
| all |
|
|
|
|
|
|
|
|
| |
|
|
|
| all |
|
|
| all | |
|
|
|
| all |
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
Chain policies:
The chain policy defines whether nftables accepts or drops packets if rules in this chain do not specify any action. You can set one of the following policies in a chain:
-
accept(default) -
drop
42.1.3. Basics of nftables rules
Rules define actions to perform on packets that pass a chain that contains this rule. If the rule also contains matching expressions, nftables performs the actions only if all previous expressions apply.
If you want to add a rule to a chain, the format to use depends on your firewall script:
In scripts in native syntax, use:
table <table_address_family> <table_name> { chain <chain_name> { type <type> hook <hook> priority <priority> ; policy <policy> ; <rule> } }In shell scripts, use:
nft add rule <table_address_family> <table_name> <chain_name> <rule>This shell command appends the new rule at the end of the chain. If you prefer to add a rule at the beginning of the chain, use the
nft insertcommand instead ofnft add.
42.1.4. Managing tables, chains, and rules by using nft commands
To manage an nftables firewall on the command line or in shell scripts, use the nft utility.
The commands in this procedure do not represent a typical workflow and are not optimized. This procedure only demonstrates how to use nft commands to manage tables, chains, and rules in general.
Procedure
Create a table named
nftables_svcwith theinetaddress family so that the table can process both IPv4 and IPv6 packets:# nft add table inet nftables_svcAdd a base chain named
INPUT, that processes incoming network traffic, to theinet nftables_svctable:# nft add chain inet nftables_svc INPUT { type filter hook input priority filter \; policy accept \; }To avoid that the shell interprets the semicolons as the end of the command, escape the semicolons using the
\character.Add rules to the
INPUTchain. For example, allow incoming TCP traffic on port 22 and 443, and, as the last rule of theINPUTchain, reject other incoming traffic with an Internet Control Message Protocol (ICMP) port unreachable message:# nft add rule inet nftables_svc INPUT tcp dport 22 accept # nft add rule inet nftables_svc INPUT tcp dport 443 accept # nft add rule inet nftables_svc INPUT reject with icmpx type port-unreachableIf you enter the
nft add rulecommands as shown,nftadds the rules in the same order to the chain as you run the commands.Display the current rule set including handles:
# nft -a list table inet nftables_svc table inet nftables_svc { # handle 13 chain INPUT { # handle 1 type filter hook input priority filter; policy accept; tcp dport 22 accept # handle 2 tcp dport 443 accept # handle 3 reject # handle 4 } }Insert a rule before the existing rule with handle 3. For example, to insert a rule that allows TCP traffic on port 636, enter:
# nft insert rule inet nftables_svc INPUT position 3 tcp dport 636 acceptAppend a rule after the existing rule with handle 3. For example, to insert a rule that allows TCP traffic on port 80, enter:
# nft add rule inet nftables_svc INPUT position 3 tcp dport 80 acceptDisplay the rule set again with handles. Verify that the later added rules have been added to the specified positions:
# nft -a list table inet nftables_svc table inet nftables_svc { # handle 13 chain INPUT { # handle 1 type filter hook input priority filter; policy accept; tcp dport 22 accept # handle 2 tcp dport 636 accept # handle 5 tcp dport 443 accept # handle 3 tcp dport 80 accept # handle 6 reject # handle 4 } }Remove the rule with handle 6:
# nft delete rule inet nftables_svc INPUT handle 6To remove a rule, you must specify the handle.
Display the rule set, and verify that the removed rule is no longer present:
# nft -a list table inet nftables_svc table inet nftables_svc { # handle 13 chain INPUT { # handle 1 type filter hook input priority filter; policy accept; tcp dport 22 accept # handle 2 tcp dport 636 accept # handle 5 tcp dport 443 accept # handle 3 reject # handle 4 } }Remove all remaining rules from the
INPUTchain:# nft flush chain inet nftables_svc INPUTDisplay the rule set, and verify that the
INPUTchain is empty:# nft list table inet nftables_svc table inet nftables_svc { chain INPUT { type filter hook input priority filter; policy accept } }Delete the
INPUTchain:# nft delete chain inet nftables_svc INPUTYou can also use this command to delete chains that still contain rules.
Display the rule set, and verify that the
INPUTchain has been deleted:# nft list table inet nftables_svc table inet nftables_svc { }Delete the
nftables_svctable:# nft delete table inet nftables_svcYou can also use this command to delete tables that still contain chains.
NoteTo delete the entire rule set, use the
nft flush rulesetcommand instead of manually deleting all rules, chains, and tables in separate commands.
42.2. Migrating from iptables to nftables
If your firewall configuration still uses iptables rules, you can migrate your iptables rules to nftables.
42.2.1. When to use firewalld, nftables, or iptables
On RHEL 8, you can use the following packet-filtering utilities depending on your scenario:
-
firewalld: Thefirewalldutility simplifies firewall configuration for common use cases. -
nftables: Use thenftablesutility to set up complex and performance-critical firewalls, such as for a whole network. -
iptables: Theiptablesutility on Red Hat Enterprise Linux uses thenf_tableskernel API instead of thelegacyback end. Thenf_tablesAPI provides backward compatibility so that scripts that useiptablescommands still work on Red Hat Enterprise Linux. For new firewall scripts, usenftables.
To prevent the different firewall-related services (firewalld, nftables, or iptables) from influencing each other, run only one of them on a RHEL host, and disable the other services.
42.2.2. Concepts in the nftables framework
The nftables framework is a modern, efficient, and flexible alternative to iptables. It simplifies rule management and enhances performance, making it a better choice for complex, high-performance network environments.
- Tables and namespaces
-
In
nftables, tables represent organizational units or namespaces that group together related firewall chains, sets, flowtables, and other objects. Innftables, tables provide a more flexible way to structure firewall rules and related components. While iniptables, the tables were more rigidly defined with specific purposes. - Table families
-
Each table in
nftablesis associated with a specific family (ip,ip6,inet,arp,bridge, ornetdev). This association determines which packets the table can process. For example, a table in theipfamily handles only IPv4 packets. On the other hand,inetis a special case of table family. It offers a unified approach across protocols, because it can process both IPv4 and IPv6 packets. Another case of a special table family isnetdev, because it is used for rules that apply directly to network devices, enabling filtering at the device level. - Base chains
Base chains in
nftablesare highly configurable entry-points in the packet processing pipeline that enable users to specify the following:- Type of chain, for example, "filter"
- The hook point in the packet processing path, for example, "input", "output", "forward"
- Priority of the chain
This flexibility enables precise control over when and how the rules are applied to packets as they pass through the network stack. A special case of a chain is the
routechain, which is used to influence the routing decisions made by the kernel, based on packet headers.- Virtual machine for rule processing
The
nftablesframework uses an internal virtual machine to process rules. This virtual machine executes instructions that are similar to assembly language operations (loading data into registers, performing comparisons, and so on). Such a mechanism allows for highly flexible and efficient rule processing.Enhancements in
nftablescan be introduced as new instructions for that virtual machine. This typically requires a new kernel module and updates to thelibnftnllibrary and thenftcommand-line utility.Alternatively, you can introduce new features by combining existing instructions in innovative ways without a need for kernel modifications. The syntax of
nftablesrules reflects the flexibility of the underlying virtual machine. For example, the rulemeta mark set tcp dport map { 22: 1, 80: 2 }sets a packet’s firewall mark to 1 if the TCP destination port is 22, and to 2 if the port is 80. This demonstrates how complex logic can be expressed concisely.- Complex filtering and verdict maps
The
nftablesframework integrates and extends the functionality of theipsetutility, which is used iniptablesfor bulk matching on IP addresses, ports, other data types and, most importantly, combinations thereof. This integration makes it easier to manage large and dynamic sets of data directly withinnftables. Next,nftablesnatively supports matching packets based on multiple values or ranges for any data type, which enhances its capability to handle complex filtering requirements. Withnftablesyou can manipulate any field within a packet.In
nftables, sets can be either named or anonymous. The named sets can be referenced by multiple rules and modified dynamically. The anonymous sets are defined inline within a rule and are immutable. Sets can contain elements that are combinations of different types, for example IP address and port number pairs. This feature provides greater flexibility in matching complex criteria. To manage sets, the kernel can select the most appropriate backend based on the specific requirements (performance, memory efficiency, and others). Sets can also function as maps with key-value pairs. The value part can be used as data points (values to write into packet headers), or as verdicts or chains to jump to. This enables complex and dynamic rule behaviors, known as "verdict maps".- Flexible rule format
The structure of
nftablesrules is straightforward. The conditions and actions are applied sequentially from left to right. This intuitive format simplifies rule creating and troubleshooting.Conditions in a rule are logically connected (with the AND operator) together, which means that all conditions must be evaluated as "true" for the rule to match. If any condition fails, the evaluation moves to the next rule.
Actions in
nftablescan be final, such asdroporaccept, which stop further rule processing for the packet. Non-terminal actions, such ascounter log meta mark set 0x3, perform specific tasks (counting packets, logging, setting a mark, and others), but allow subsequent rules to be evaluated.
42.2.3. Concepts in the deprecated iptables framework
Similar to the actively-maintained nftables framework, you can perform a variety of packet filtering tasks, logging and auditing, NAT-related configuration tasks with the deprecated iptables framework.
The iptables framework is structured into multiple tables, where each table is designed for a specific purpose:
filter- The default table, ensures general packet filtering
nat- For Network Address Translation (NAT), includes altering the source and destination addresses of packets
mangle- For specific packet alteration, supports you to do modification of packet headers for advanced routing decisions
raw- For configurations that need to happen before connection tracking
These tables are implemented as separate kernel modules, where each table offers a fixed set of builtin chains such as INPUT, OUTPUT, and FORWARD. A chain is a sequence of rules that packets are evaluated against. These chains hook into specific points in the packet processing flow in the kernel. The chains have the same names across different tables, however their order of execution is determined by their respective hook priorities. The priorities are managed internally by the kernel to make sure that the rules are applied in the correct sequence.
Originally, designed for IPv4 traffic, the iptables framework was later supplemented by the ip6tables utility to support firewall rule management for IPv6 packets. Similarly, arptables was developed for Address Resolution Protocol (ARP) traffic, and ebtables was created for Ethernet bridging frames. These utilities extend the packet filtering capabilities of iptables across multiple protocols, ensuring comprehensive network coverage.
To enhance the functionality of iptables, the extensions started to be developed. The functionality extensions are typically implemented as kernel modules that are paired with user-space dynamic shared objects (DSOs). The extensions introduce "matches" and "targets" that you can use in firewall rules to perform more sophisticated operations. Extensions can implement complex matches and targets. For instance you can match on, or manipulate specific layer 4 protocol header values, perform rate-limiting, enforce quotas, and so on. Some extensions are designed to address limitations in the default iptables syntax, for example the "multiport" match extension. This extension allows a single rule to match multiple, non-consecutive ports to simplify rule definitions, and thereby reducing the number of individual rules required.
An ipset is a special kind of functionality extension to iptables. It is a kernel-level data structure that is used together with iptables to create collections of IP addresses, port numbers, and other network-related elements that you can match against packets. These sets significantly streamline, optimize, and accelerate the process of writing and managing firewall rules.
42.2.4. Converting iptables and ip6tables rule sets to nftables
Use the iptables-restore-translate and ip6tables-restore-translate utilities to translate iptables and ip6tables rule sets to nftables.
Prerequisites
-
The
nftablesandiptablespackages are installed. -
The system has
iptablesandip6tablesrules configured.
Procedure
Write the
iptablesandip6tablesrules to a file:# iptables-save >/root/iptables.dump # ip6tables-save >/root/ip6tables.dumpConvert the dump files to
nftablesinstructions:# iptables-restore-translate -f /root/iptables.dump > /etc/nftables/ruleset-migrated-from-iptables.nft # ip6tables-restore-translate -f /root/ip6tables.dump > /etc/nftables/ruleset-migrated-from-ip6tables.nft-
Review and, if needed, manually update the generated
nftablesrules. To enable the
nftablesservice to load the generated files, add the following to the/etc/sysconfig/nftables.conffile:include "/etc/nftables/ruleset-migrated-from-iptables.nft" include "/etc/nftables/ruleset-migrated-from-ip6tables.nft"Stop and disable the
iptablesservice:# systemctl disable --now iptablesIf you used a custom script to load the
iptablesrules, ensure that the script no longer starts automatically and reboot to flush all tables.Enable and start the
nftablesservice:# systemctl enable --now nftables
Verification
Display the
nftablesrule set:# nft list ruleset
42.2.5. Converting single iptables and ip6tables rules to nftables
Red Hat Enterprise Linux provides the iptables-translate and ip6tables-translate utilities to convert an iptables or ip6tables rule into the equivalent one for nftables.
Prerequisites
-
The
nftablespackage is installed.
Procedure
Use the
iptables-translateorip6tables-translateutility instead ofiptablesorip6tablesto display the correspondingnftablesrule, for example:# iptables-translate -A INPUT -s 192.0.2.0/24 -j ACCEPT nft add rule ip filter INPUT ip saddr 192.0.2.0/24 counter acceptNote that some extensions lack translation support. In these cases, the utility prints the untranslated rule prefixed with the
#sign, for example:# iptables-translate -A INPUT -j CHECKSUM --checksum-fill nft # -A INPUT -j CHECKSUM --checksum-fill
42.2.6. Comparison of common iptables and nftables commands
The following is a comparison of common iptables and nftables commands.
Listing all rules:
Expand iptables nftables iptables-savenft list rulesetListing a certain table and chain:
Expand iptables nftables iptables -Lnft list table ip filteriptables -L INPUTnft list chain ip filter INPUTiptables -t nat -L PREROUTINGnft list chain ip nat PREROUTINGThe
nftcommand does not pre-create tables and chains. They exist only if a user created them manually.Listing rules generated by firewalld:
# nft list table inet firewalld # nft list table ip firewalld # nft list table ip6 firewalld
42.3. Configuring NAT using nftables
With nftables, you can configure the masquerading, source (SNAT), destination NAT (DNAT), and redirect types. With NAT, you can modify the source or destination IP address.
You can only use real interface names in iifname and oifname parameters, and alternative names (altname) are not supported.
42.3.1. NAT types
The nftables framework supports different network address translation (NAT) types.
- Masquerading and source NAT (SNAT)
Use one of these NAT types to change the source IP address of packets. For example, Internet Service Providers (ISPs) do not route private IP ranges, such as
10.0.0.0/8. If you use private IP ranges in your network and users should be able to reach servers on the internet, map the source IP address of packets from these ranges to a public IP address.Masquerading and SNAT are very similar to one another. The differences are:
- Masquerading automatically uses the IP address of the outgoing interface. Therefore, use masquerading if the outgoing interface uses a dynamic IP address.
- SNAT sets the source IP address of packets to a specified IP and does not dynamically look up the IP of the outgoing interface. Therefore, SNAT is faster than masquerading. Use SNAT if the outgoing interface uses a fixed IP address.
- Destination NAT (DNAT)
- Use this NAT type to rewrite the destination address and port of incoming packets. For example, if your web server uses an IP address from a private IP range and is, therefore, not directly accessible from the internet, you can set a DNAT rule on the router to redirect incoming traffic to this server.
- Redirect
- This type is a special case of DNAT that redirects packets to the local machine depending on the chain hook. For example, if a service runs on a different port than its standard port, you can redirect incoming traffic from the standard port to this specific port.
42.3.2. Configuring masquerading using nftables
Masquerading enables a router to dynamically change the source IP of packets sent through an interface to the IP address of the interface. This means that if the interface gets a new IP assigned, nftables automatically uses the new IP when replacing the source IP.
Replace the source IP of packets leaving the host through the ens3 interface to the IP set on ens3.
Procedure
Create a table:
# nft add table natAdd the
preroutingandpostroutingchains to the table:# nft add chain nat postrouting { type nat hook postrouting priority 100 \; }ImportantEven if you do not add a rule to the
preroutingchain, thenftablesframework requires this chain to match incoming packet replies.Note that you must pass the
--option to thenftcommand to prevent the shell from interpreting the negative priority value as an option of thenftcommand.Add a rule to the
postroutingchain that matches outgoing packets on theens3interface:# nft add rule nat postrouting oifname "ens3" masquerade
42.3.3. Configuring source NAT using nftables
On a router, you can use Source NAT (SNAT) to change the IP of packets sent through an interface to a specific IP address. The router then replaces the source IP of outgoing packets.
Procedure
Create a table:
# nft add table natAdd the
preroutingandpostroutingchains to the table:# nft add chain nat postrouting { type nat hook postrouting priority 100 \; }ImportantEven if you do not add a rule to the
postroutingchain, thenftablesframework requires this chain to match outgoing packet replies.Note that you must pass the
--option to thenftcommand to prevent the shell from interpreting the negative priority value as an option of thenftcommand.Add a rule to the
postroutingchain that replaces the source IP of outgoing packets throughens3with192.0.2.1:# nft add rule nat postrouting oifname "ens3" snat to 192.0.2.1
42.3.4. Configuring destination NAT using nftables
Use Destination NAT (DNAT) to redirect traffic on a router to a host that is not directly accessible from the internet.
For example, with DNAT the router redirects incoming traffic sent to port 80 and 443 to a web server with the IP address 192.0.2.1.
Procedure
Create a table:
# nft add table natAdd the
preroutingandpostroutingchains to the table:# nft -- add chain nat prerouting { type nat hook prerouting priority -100 \; } # nft add chain nat postrouting { type nat hook postrouting priority 100 \; }ImportantEven if you do not add a rule to the
postroutingchain, thenftablesframework requires this chain to match outgoing packet replies.Note that you must pass the
--option to thenftcommand to prevent the shell from interpreting the negative priority value as an option of thenftcommand.Add a rule to the
preroutingchain that redirects incoming traffic to port80and443on theens3interface of the router to the web server with the IP address192.0.2.1:# nft add rule nat prerouting iifname ens3 tcp dport { 80, 443 } dnat to 192.0.2.1Depending on your environment, add either a SNAT or masquerading rule to change the source address for packets returning from the web server to the sender:
If the
ens3interface uses a dynamic IP addresses, add a masquerading rule:# nft add rule nat postrouting oifname "ens3" masqueradeIf the
ens3interface uses a static IP address, add a SNAT rule. For example, if theens3uses the198.51.100.1IP address:# nft add rule nat postrouting oifname "ens3" snat to 198.51.100.1
Enable packet forwarding:
# echo "net.ipv4.ip_forward=1" > /etc/sysctl.d/95-IPv4-forwarding.conf # sysctl -p /etc/sysctl.d/95-IPv4-forwarding.conf
42.3.5. Configuring a redirect using nftables
The redirect feature is a special case of destination network address translation (DNAT) that redirects packets to the local machine depending on the chain hook.
For example, you can redirect incoming and forwarded traffic sent to port 22 of the local host to port 2222.
Procedure
Create a table:
# nft add table natAdd the
preroutingchain to the table:# nft -- add chain nat prerouting { type nat hook prerouting priority -100 \; }Note that you must pass the
--option to thenftcommand to prevent the shell from interpreting the negative priority value as an option of thenftcommand.Add a rule to the
preroutingchain that redirects incoming traffic on port22to port2222:# nft add rule nat prerouting tcp dport 22 redirect to 2222
42.4. Writing and running nftables scripts
The major benefit of using the nftables framework is that the execution of scripts is atomic. This means that the system either applies the whole script or prevents the execution if an error occurs. This guarantees that the firewall is always in a consistent state.
Additionally, with the nftables script environment, you can:
- Add comments
- Define variables
- Include other rule-set files
When you install the nftables package, Red Hat Enterprise Linux automatically creates *.nft scripts in the /etc/nftables/ directory. These scripts contain commands that create tables and empty chains for different purposes.
42.4.1. Supported nftables script formats
The nftables framework supports scripts in different formats.
You can use the following formats:
The same format as the
nft list rulesetcommand displays the rule set:#!/usr/sbin/nft -f # Flush the rule set flush ruleset table inet example_table { chain example_chain { # Chain for incoming packets that drops all packets that # are not explicitly allowed by any rule in this chain type filter hook input priority 0; policy drop; # Accept connections to port 22 (ssh) tcp dport ssh accept } }The same syntax as for
nftcommands:#!/usr/sbin/nft -f # Flush the rule set flush ruleset # Create a table add table inet example_table # Create a chain for incoming packets that drops all packets # that are not explicitly allowed by any rule in this chain add chain inet example_table example_chain { type filter hook input priority 0 ; policy drop ; } # Add a rule that accepts connections to port 22 (ssh) add rule inet example_table example_chain tcp dport ssh accept
42.4.2. Running nftables scripts
You can run an nftables script either by passing it to the nft utility or by executing the script directly.
Procedure
To run an
nftablesscript by passing it to thenftutility, enter:# nft -f /etc/nftables/<example_firewall_script>.nftTo run an
nftablesscript directly:For the single time that you perform this:
Ensure that the script starts with the following shebang sequence:
#!/usr/sbin/nft -fImportantIf you omit the
-fparameter, thenftutility does not read the script and displays:Error: syntax error, unexpected newline, expecting string.Optional: Set the owner of the script to
root:# chown root /etc/nftables/<example_firewall_script>.nftMake the script executable for the owner:
# chmod u+x /etc/nftables/<example_firewall_script>.nft
Run the script:
# /etc/nftables/<example_firewall_script>.nftIf no output is displayed, the system runs the script successfully.
ImportantEven if
nftruns the script successfully, incorrectly placed rules, missing parameters, or other problems in the script can cause that the firewall behaves not as expected.
42.4.3. Using comments in nftables scripts
The nftables scripting environment interprets everything to the right of a # character to the end of a line as a comment.
Comments can start at the beginning of a line, or next to a command:
...
# Flush the rule set
flush ruleset
add table inet example_table # Create a table
...42.4.4. Using variables in nftables script
To define a variable in an nftables script, use the define keyword. You can store single values and anonymous sets in a variable. For more complex scenarios, use sets or verdict maps.
- Variables with a single value
The following example defines a variable named
INET_DEVwith the valueenp1s0:define INET_DEV = enp1s0You can use the variable in the script by entering the
$sign followed by the variable name:... add rule inet example_table example_chain iifname $INET_DEV tcp dport ssh accept ...- Variables that contain an anonymous set
The following example defines a variable that contains an anonymous set:
define DNS_SERVERS = { 192.0.2.1, 192.0.2.2 }You can use the variable in the script by writing the
$sign followed by the variable name:add rule inet example_table example_chain ip daddr $DNS_SERVERS acceptNoteCurly braces have special semantics when you use them in a rule because they indicate that the variable represents a set.
42.4.5. Including files in nftables scripts
In the nftables scripting environment, you can include other scripts by using the include statement.
If you specify only a file name without an absolute or relative path, nftables includes files from the default search path, which is set to /etc on Red Hat Enterprise Linux.
Example 42.1. Including files from the default search directory
To include a file from the default search directory:
include "example.nft"Example 42.2. Including all *.nft files from a directory
To include all files ending with *.nft that are stored in the /etc/nftables/rulesets/ directory:
include "/etc/nftables/rulesets/*.nft"
Note that the include statement does not match files beginning with a dot.
42.4.6. Automatically loading nftables rules when the system boots
The nftables systemd service loads firewall scripts that are included in the /etc/sysconfig/nftables.conf file.
Prerequisites
-
The
nftablesscripts are stored in the/etc/nftables/directory.
Procedure
Edit the
/etc/sysconfig/nftables.conffile.-
If you modified the
*.nftscripts that were created in/etc/nftables/with the installation of thenftablespackage, uncomment theincludestatement for these scripts. If you wrote new scripts, add
includestatements to include these scripts. For example, to load the/etc/nftables/example.nftscript when thenftablesservice starts, add:include "/etc/nftables/_example_.nft"
-
If you modified the
Optional: Start the
nftablesservice to load the firewall rules without rebooting the system:# systemctl start nftablesEnable the
nftablesservice.# systemctl enable nftables
42.5. Using sets in nftables commands
The nftables framework natively supports sets. For example, you can use sets to match multiple IP addresses, port numbers, interfaces, or any other match criteria.
42.5.1. Using anonymous sets in nftables
An anonymous set contains comma-separated values enclosed in curly brackets, such as { 22, 80, 443 }, that you use directly in a rule. You can use anonymous sets also for IP addresses and any other match criteria.
The drawback of anonymous sets is that if you want to change the set, you must replace the rule. For a dynamic solution, use named sets as described in Using named sets in nftables.
Prerequisites
-
The
example_chainchain and theexample_tabletable in theinetfamily exist.
Procedure
For example, to add a rule to
example_chaininexample_tablethat allows incoming traffic to port22,80, and443:# nft add rule inet example_table example_chain tcp dport { 22, 80, 443 } acceptOptional: Display all chains and their rules in
example_table:# nft list table inet example_table table inet example_table { chain example_chain { type filter hook input priority filter; policy accept; tcp dport { ssh, http, https } accept } }
42.5.2. Using named sets in nftables
The nftables framework supports mutable named sets. A named set is a list of ranges that you can use in multiple rules within a table. Another benefit over anonymous sets is that you can update a named set without replacing the rules that use the set.
When you create a named set, you must specify the type of elements the set contains. You can set the following types:
-
ipv4_addrfor a set that contains IPv4 addresses or ranges, such as192.0.2.1or192.0.2.0/24. -
ipv6_addrfor a set that contains IPv6 addresses or ranges, such as2001:db8:1::1or2001:db8:1::1/64. -
ether_addrfor a set that contains a list of media access control (MAC) addresses, such as52:54:00:6b:66:42. -
inet_protofor a set that contains a list of internet protocol types, such astcp. -
inet_servicefor a set that contains a list of internet services, such asssh. -
markfor a set that contains a list of packet marks. Packet marks can be any positive 32-bit integer value (0to2147483647).
Prerequisites
-
The
example_chainchain and theexample_tabletable exists.
Procedure
Create an empty set. The following examples create a set for IPv4 addresses:
To create a set that can store multiple individual IPv4 addresses:
# nft add set inet example_table example_set { type ipv4_addr \; }To create a set that can store IPv4 address ranges:
# nft add set inet example_table example_set { type ipv4_addr \; flags interval \; }
ImportantTo prevent the shell from interpreting the semicolons as the end of the command, you must escape the semicolons with a backslash.
Optional: Create rules that use the set. For example, the following command adds a rule to the
example_chainin theexample_tablethat drops all packets from IPv4 addresses inexample_set.# nft add rule inet example_table example_chain ip saddr @example_set dropBecause
example_setis still empty, the rule has currently no effect.Add IPv4 addresses to
example_set:If you create a set that stores individual IPv4 addresses, enter:
# nft add element inet example_table example_set { 192.0.2.1, 192.0.2.2 }If you create a set that stores IPv4 ranges, enter:
# nft add element inet example_table example_set { 192.0.2.0-192.0.2.255 }When you specify an IP address range, you can alternatively use the Classless Inter-Domain Routing (CIDR) notation, such as
192.0.2.0/24in the example.
42.5.3. Using dynamic sets to add entries from the packet path
Dynamic sets in nftables automatically add elements, such as IP addresses, ports, and MAC addresses from packet data. This enables real-time collection of data to create dynamic deny or ban lists, instantly reacting to security threats.
Prerequisites
-
The
example_chainchain and theexample_tabletable in theinetfamily exist.
Procedure
Create an empty set. The following examples create a set for IPv4 addresses:
To create a set that can store multiple individual IPv4 addresses:
# nft add set inet example_table example_set { type ipv4_addr \; }To create a set that can store IPv4 address ranges:
# nft add set inet example_table example_set { type ipv4_addr \; flags interval \; }ImportantTo prevent the shell from interpreting the semicolons as the end of the command, you must escape the semicolons with a backslash.
Create a rule for dynamically adding the source IPv4 addresses of incoming packets to the
example_setset:# nft add rule inet example_table example_chain set add ip saddr @example_setThe command creates a new rule within the
example_chainrule chain and theexample_tableto dynamically add the source IPv4 address of the packet to theexample_set.
Verification
Ensure the rule was added:
# nft list ruleset ... table ip example_table { set example_set { type ipv4_addr elements = { 192.0.2.250, 192.0.2.251 } } chain example_chain { type filter hook input priority 0 add @example_set { ip saddr } } }The command displays the entire ruleset currently loaded in
nftables. It shows that IPs are actively triggering the rule, andexample_setis being updated with the relevant addresses.
Next steps
After you have a dynamic set of IPs, you can use it for various security, filtering, and traffic control purposes. For example:
- block, limit, or log network traffic
- combine with allow-listing to avoid banning trusted users
- use automatic timeouts to prevent over-blocking
42.6. Using verdict maps in nftables commands
Verdict maps, which are also known as dictionaries, enable nft to perform an action based on packet information by mapping match criteria to an action.
42.6.1. Using anonymous maps in nftables
An anonymous map is a { match_criteria : action } statement that you use directly in a rule. The statement can contain multiple comma-separated mappings.
The drawback of an anonymous map is that if you want to change the map, you must replace the rule. For a dynamic solution, use named maps as described in Using named maps in nftables.
For example, you can use an anonymous map to route both TCP and UDP packets of the IPv4 and IPv6 protocol to different chains to count incoming TCP and UDP packets separately.
Procedure
Create a new table:
# nft add table inet example_tableCreate the
tcp_packetschain inexample_table:# nft add chain inet example_table tcp_packetsAdd a rule to
tcp_packetsthat counts the traffic in this chain:# nft add rule inet example_table tcp_packets counterCreate the
udp_packetschain inexample_table# nft add chain inet example_table udp_packetsAdd a rule to
udp_packetsthat counts the traffic in this chain:# nft add rule inet example_table udp_packets counterCreate a chain for incoming traffic. For example, to create a chain named
incoming_trafficinexample_tablethat filters incoming traffic:# nft add chain inet example_table incoming_traffic { type filter hook input priority 0 \; }Add a rule with an anonymous map to
incoming_traffic:# nft add rule inet example_table incoming_traffic ip protocol vmap { tcp : jump tcp_packets, udp : jump udp_packets }The anonymous map distinguishes the packets and sends them to the different counter chains based on their protocol.
To list the traffic counters, display
example_table:# nft list table inet example_table table inet example_table { chain tcp_packets { counter packets 36379 bytes 2103816 } chain udp_packets { counter packets 10 bytes 1559 } chain incoming_traffic { type filter hook input priority filter; policy accept; ip protocol vmap { tcp : jump tcp_packets, udp : jump udp_packets } } }The counters in the
tcp_packetsandudp_packetschain display both the number of received packets and bytes.
42.6.2. Using named maps in nftables
The nftables framework supports named maps. You can use these maps in multiple rules within a table. Another benefit over anonymous maps is that you can update a named map without replacing the rules that use it.
When you create a named map, you must specify the type of elements:
-
ipv4_addrfor a map whose match part contains an IPv4 address, such as192.0.2.1. -
ipv6_addrfor a map whose match part contains an IPv6 address, such as2001:db8:1::1. -
ether_addrfor a map whose match part contains a media access control (MAC) address, such as52:54:00:6b:66:42. -
inet_protofor a map whose match part contains an internet protocol type, such astcp. -
inet_servicefor a map whose match part contains an internet services name port number, such assshor22. -
markfor a map whose match part contains a packet mark. A packet mark can be any positive 32-bit integer value (0to2147483647). -
counterfor a map whose match part contains a counter value. The counter value can be any positive 64-bit integer value. -
quotafor a map whose match part contains a quota value. The quota value can be any positive 64-bit integer value.
For example, you can allow or drop incoming packets based on their source IP address. Using a named map, you require only a single rule to configure this scenario while the IP addresses and actions are dynamically stored in the map.
Procedure
Create a table. For example, to create a table named
example_tablethat processes IPv4 packets:# nft add table ip example_tableCreate a chain. For example, to create a chain named
example_chaininexample_table:# nft add chain ip example_table example_chain { type filter hook input priority 0 \; }ImportantTo prevent the shell from interpreting the semicolons as the end of the command, you must escape the semicolons with a backslash.
Create an empty map. For example, to create a map for IPv4 addresses:
# nft add map ip example_table example_map { type ipv4_addr : verdict \; }Create rules that use the map. For example, the following command adds a rule to
example_chaininexample_tablethat applies actions to IPv4 addresses which are both defined inexample_map:# nft add rule example_table example_chain ip saddr vmap @example_mapAdd IPv4 addresses and corresponding actions to
example_map:# nft add element ip example_table example_map { 192.0.2.1 : accept, 192.0.2.2 : drop }This example defines the mappings of IPv4 addresses to actions. In combination with the rule created above, the firewall accepts packets from
192.0.2.1and drops packets from192.0.2.2.Optional: Enhance the map by adding another IP address and action statement:
# nft add element ip example_table example_map { 192.0.2.3 : accept }Optional: Remove an entry from the map:
# nft delete element ip example_table example_map { 192.0.2.1 }Optional: Display the rule set:
# nft list ruleset table ip example_table { map example_map { type ipv4_addr : verdict elements = { 192.0.2.2 : drop, 192.0.2.3 : accept } } chain example_chain { type filter hook input priority filter; policy accept; ip saddr vmap @example_map } }
42.7. Example: Protecting a LAN and DMZ using an nftables script
Use the nftables framework on a RHEL router to write and install a firewall script that protects the network clients in an internal LAN and a web server in a DMZ from unauthorized access from the internet and from other networks.
This example is only for demonstration purposes and describes a scenario with specific requirements.
Firewall scripts highly depend on the network infrastructure and security requirements. Use this example to learn the concepts of nftables firewalls when you write scripts for your own environment.
42.7.1. Network conditions
The network in this example has the following conditions.
The router is connected to the following networks:
-
The internet through interface
enp1s0 -
The internal LAN through interface
enp7s0 -
The DMZ through
enp8s0
-
The internet through interface
-
The internet interface of the router has both a static IPv4 address (
203.0.113.1) and IPv6 address (2001:db8:a::1) assigned. -
The clients in the internal LAN use only private IPv4 addresses from the range
10.0.0.0/24. Consequently, traffic from the LAN to the internet requires source network address translation (SNAT). -
The administrator PCs in the internal LAN use the IP addresses
10.0.0.100and10.0.0.200. -
The DMZ uses public IP addresses from the ranges
198.51.100.0/24and2001:db8:b::/56. -
The web server in the DMZ uses the IP addresses
198.51.100.5and2001:db8:b::5. - The router acts as a caching DNS server for hosts in the LAN and DMZ.
42.7.2. Security requirements to the firewall script
The following are the requirements to the nftables firewall in the example network.
The router must be able to:
- Recursively resolve DNS queries.
- Perform all connections on the loopback interface.
Clients in the internal LAN must be able to:
- Query the caching DNS server running on the router.
- Access the HTTPS server in the DMZ.
- Access any HTTPS server on the internet.
- The PCs of the administrators must be able to access the router and every server in the DMZ using SSH.
The web server in the DMZ must be able to:
- Query the caching DNS server running on the router.
- Access HTTPS servers on the internet to download updates.
Hosts on the internet must be able to:
- Access the HTTPS servers in the DMZ.
Additionally, the following security requirements exists:
- Drop connection attempts that are not explicitly allowed.
- Log dropped packets.
42.7.3. Configuring logging of dropped packets to a file
By default, systemd logs kernel messages, such as for dropped packets, to the journal. Additionally, you can configure the rsyslog service to log such entries to a separate file. To ensure that the log file does not grow infinitely, configure a rotation policy.
Prerequisites
-
The
rsyslogpackage is installed. -
The
rsyslogservice is running.
Procedure
Create the
/etc/rsyslog.d/nftables.conffile with the following content::msg, startswith, "nft drop" -/var/log/nftables.log & stopUsing this configuration, the
rsyslogservice logs dropped packets to the/var/log/nftables.logfile instead of/var/log/messages.Restart the
rsyslogservice:# systemctl restart rsyslogCreate the
/etc/logrotate.d/nftablesfile with the following content to rotate/var/log/nftables.logif the size exceeds 10 MB:/var/log/nftables.log { size +10M maxage 30 sharedscripts postrotate /usr/bin/systemctl kill -s HUP rsyslog.service >/dev/null 2>&1 || true endscript }The
maxage 30setting defines thatlogrotateremoves rotated logs older than 30 days during the next rotation operation.
42.7.4. Writing and activating the nftables script
This example is an nftables firewall script that runs on a RHEL router and protects the clients in an internal LAN and a web server in a DMZ.
For details about the network and the requirements for the firewall used in the example, see Network conditions and Security requirements to the firewall script.
This nftables firewall script is only for demonstration purposes. Do not use it without adapting it to your environments and security requirements.
Prerequisites
- The network is configured as described in Network conditions.
Procedure
Create the
/etc/nftables/firewall.nftscript with the following content:# Remove all rules flush ruleset # Table for both IPv4 and IPv6 rules table inet nftables_svc { # Define variables for the interface name define INET_DEV = enp1s0 define LAN_DEV = enp7s0 define DMZ_DEV = enp8s0 # Set with the IPv4 addresses of admin PCs set admin_pc_ipv4 { type ipv4_addr elements = { 10.0.0.100, 10.0.0.200 } } # Chain for incoming traffic. Default policy: drop chain INPUT { type filter hook input priority filter policy drop # Accept packets in established and related state, drop invalid packets ct state vmap { established:accept, related:accept, invalid:drop } # Accept incoming traffic on loopback interface iifname lo accept # Allow request from LAN and DMZ to local DNS server iifname { $LAN_DEV, $DMZ_DEV } meta l4proto { tcp, udp } th dport 53 accept # Allow admins PCs to access the router using SSH iifname $LAN_DEV ip saddr @admin_pc_ipv4 tcp dport 22 accept # Last action: Log blocked packets # (packets that were not accepted in previous rules in this chain) log prefix "nft drop IN : " } # Chain for outgoing traffic. Default policy: drop chain OUTPUT { type filter hook output priority filter policy drop # Accept packets in established and related state, drop invalid packets ct state vmap { established:accept, related:accept, invalid:drop } # Accept outgoing traffic on loopback interface oifname lo accept # Allow local DNS server to recursively resolve queries oifname $INET_DEV meta l4proto { tcp, udp } th dport 53 accept # Last action: Log blocked packets log prefix "nft drop OUT: " } # Chain for forwarding traffic. Default policy: drop chain FORWARD { type filter hook forward priority filter policy drop # Accept packets in established and related state, drop invalid packets ct state vmap { established:accept, related:accept, invalid:drop } # IPv4 access from LAN and internet to the HTTPS server in the DMZ iifname { $LAN_DEV, $INET_DEV } oifname $DMZ_DEV ip daddr 198.51.100.5 tcp dport 443 accept # IPv6 access from internet to the HTTPS server in the DMZ iifname $INET_DEV oifname $DMZ_DEV ip6 daddr 2001:db8:b::5 tcp dport 443 accept # Access from LAN and DMZ to HTTPS servers on the internet iifname { $LAN_DEV, $DMZ_DEV } oifname $INET_DEV tcp dport 443 accept # Last action: Log blocked packets log prefix "nft drop FWD: " } # Postrouting chain to handle SNAT chain postrouting { type nat hook postrouting priority srcnat; policy accept; # SNAT for IPv4 traffic from LAN to internet iifname $LAN_DEV oifname $INET_DEV snat ip to 203.0.113.1 } }Include the
/etc/nftables/firewall.nftscript in the/etc/sysconfig/nftables.conffile:include "/etc/nftables/firewall.nft"Enable IPv4 forwarding:
# echo "net.ipv4.ip_forward=1" > /etc/sysctl.d/95-IPv4-forwarding.conf # sysctl -p /etc/sysctl.d/95-IPv4-forwarding.confEnable and start the
nftablesservice:# systemctl enable --now nftables
Verification
Optional: Verify the
nftablesrule set:# nft list ruleset ...Try to perform an access that the firewall prevents. For example, try to access the router using SSH from the DMZ:
# ssh router.example.com ssh: connect to host router.example.com port 22: Network is unreachableDepending on your logging settings, search:
The
systemdjournal for the blocked packets:# journalctl -k -g "nft drop" Oct 14 17:27:18 router kernel: nft drop IN : IN=enp8s0 OUT= MAC=... SRC=198.51.100.5 DST=198.51.100.1 ... PROTO=TCP SPT=40464 DPT=22 ... SYN ...The
/var/log/nftables.logfile for the blocked packets:Oct 14 17:27:18 router kernel: nft drop IN : IN=enp8s0 OUT= MAC=... SRC=198.51.100.5 DST=198.51.100.1 ... PROTO=TCP SPT=40464 DPT=22 ... SYN ...
42.8. Using nftables to limit the amount of connections
You can use nftables to limit the number of connections or to block IP addresses that attempt to establish a given amount of connections to prevent them from using too many system resources.
42.8.1. Limiting the number of connections by using nftables
By using the ct count parameter of the nft utility, you can limit the number of simultaneous connections per IP address. For example, you can use this feature to configure that each source IP address can only establish two parallel SSH connections to a host.
Procedure
Create the
filtertable with theinetaddress family:# nft add table inet filterAdd the
inputchain to theinet filtertable:# nft add chain inet filter input { type filter hook input priority 0 \; }Create a dynamic set for IPv4 addresses:
# nft add set inet filter limit-ssh { type ipv4_addr\; flags dynamic \;}Add a rule to the
inputchain that allows only two simultaneous incoming connections to the SSH port (22) from an IPv4 address and rejects all further connections from the same IP:# nft add rule inet filter input tcp dport ssh ct state new add @limit-ssh { ip saddr ct count over 2 } counter reject
Verification
- Establish more than two new simultaneous SSH connections from the same IP address to the host. Nftables refuses connections to the SSH port if two connections are already established.
Display the
limit-sshdynamic set:# nft list set inet filter limit-ssh table inet filter { set limit-ssh { type ipv4_addr size 65535 flags dynamic elements = { 192.0.2.1 ct count over 2 , 192.0.2.2 ct count over 2 } } }The
elementsentry displays addresses that currently match the rule. In this example,elementslists IP addresses that have active connections to the SSH port. Note that the output does not display the number of active connections or if connections were rejected.
42.8.2. Blocking IP addresses that attempt more than ten new incoming TCP connections within one minute
You can temporarily block hosts that are establishing more than ten IPv4 TCP connections within one minute.
Procedure
Create the
filtertable with theipaddress family:# nft add table ip filterAdd the
inputchain to thefiltertable:# nft add chain ip filter input { type filter hook input priority 0 \; }Add a rule that drops all packets from source addresses that attempt to establish more than ten TCP connections within one minute:
# nft add rule ip filter input ip protocol tcp ct state new, untracked meter ratemeter { ip saddr timeout 5m limit rate over 10/minute } dropThe
timeout 5mparameter defines thatnftablesautomatically removes entries after five minutes to prevent that the meter fills up with stale entries.
Verification
To display the meter’s content, enter:
# nft list meter ip filter ratemeter table ip filter { meter ratemeter { type ipv4_addr size 65535 flags dynamic,timeout elements = { 192.0.2.1 limit rate over 10/minute timeout 5m expires 4m58s224ms } } }
42.9. Debugging nftables rules
The nftables framework provides different options for administrators to debug rules and if packets match them.
42.9.1. Creating a rule with a counter
To identify if a rule is matched, you can use a counter.
Prerequisites
- The chain to which you want to add the rule exists.
Procedure
Add a new rule with the
counterparameter to the chain. The following example adds a rule with a counter that allows TCP traffic on port 22 and counts the packets and traffic that match this rule:# nft add rule inet example_table example_chain tcp dport 22 counter acceptTo display the counter values:
# nft list ruleset table inet example_table { chain example_chain { type filter hook input priority filter; policy accept; tcp dport ssh counter packets 6872 bytes 105448565 accept } }
42.9.2. Adding a counter to an existing rule
To identify if a rule is matched, you can use a counter.
Prerequisites
- The rule to which you want to add the counter exists.
Procedure
Display the rules in the chain including their handles:
# nft --handle list chain inet example_table example_chain table inet example_table { chain example_chain { # handle 1 type filter hook input priority filter; policy accept; tcp dport ssh accept # handle 4 } }Add the counter by replacing the rule but with the
counterparameter. The following example replaces the rule displayed in the previous step and adds a counter:# nft replace rule inet example_table example_chain handle 4 tcp dport 22 counter acceptTo display the counter values:
# nft list ruleset table inet example_table { chain example_chain { type filter hook input priority filter; policy accept; tcp dport ssh counter packets 6872 bytes 105448565 accept } }
42.9.3. Monitoring packets that match an existing rule
To display packets that match a rule, you can use the tracing feature in nftables in combination with the nft monitor command. You can enable tracing for a rule and use it to monitor packets that match this rule.
Prerequisites
- The rule to which you want to add the counter exists.
Procedure
Display the rules in the chain including their handles:
# nft --handle list chain inet example_table example_chain table inet example_table { chain example_chain { # handle 1 type filter hook input priority filter; policy accept; tcp dport ssh accept # handle 4 } }Add the tracing feature by replacing the rule but with the
meta nftrace set 1parameters. The following example replaces the rule displayed in the previous step and enables tracing:# nft replace rule inet example_table example_chain handle 4 tcp dport 22 meta nftrace set 1 acceptUse the
nft monitorcommand to display the tracing. The following example filters the output of the command to display only entries that containinet example_table example_chain:# nft monitor | grep "inet example_table example_chain" trace id 3c5eb15e inet example_table example_chain packet: iif "enp1s0" ether saddr 52:54:00:17:ff:e4 ether daddr 52:54:00:72:2f:6e ip saddr 192.0.2.1 ip daddr 192.0.2.2 ip dscp cs0 ip ecn not-ect ip ttl 64 ip id 49710 ip protocol tcp ip length 60 tcp sport 56728 tcp dport ssh tcp flags == syn tcp window 64240 trace id 3c5eb15e inet example_table example_chain rule tcp dport ssh nftrace set 1 accept (verdict accept) ...WarningDepending on the number of rules with tracing enabled and the amount of matching traffic, the
nft monitorcommand can display a lot of output. Usegrepor other utilities to filter the output.
42.10. Backing up and restoring the nftables rule set
You can backup nftables rules to a file and later restoring them. Also, administrators can use a file with the rules to, for example, transfer the rules to a different server.
42.10.1. Backing up the nftables rule set to a file
You can use the nft utility to back up the nftables rule set to a file.
Procedure
To backup
nftablesrules:In a format produced by
nft list rulesetformat:# nft list ruleset > file.nftIn JSON format:
# nft -j list ruleset > file.json
42.10.2. Restoring the nftables rule set from a file
You can restore the nftables rule set from a file.
Procedure
To restore
nftablesrules:If the file to restore is in the format produced by
nft list rulesetor containsnftcommands directly:# nft -f file.nftIf the file to restore is in JSON format:
# nft -j -f file.json
Chapter 43. Using xdp-filter for high-performance traffic filtering to prevent DDoS attacks
The xdp-filter utility uses XDP to drop packets directly at the network interface, making it faster than filters, such as nftables. It helps block traffic quickly during DDoS attacks and you can filter by IP, MAC address, or port.
For example, during testing, Red Hat dropped 26 million network packets per second on a single core, which is significantly higher than the drop rate of nftables on the same hardware.
The xdp-filter utility allows or drops incoming network packets using XDP. You can create rules to filter traffic to or from specific:
- IP addresses
- MAC addresses
- Ports
Note that, even if xdp-filter has a significantly higher packet-processing rate, it does not have the same capabilities as, for example, nftables. Consider xdp-filter a conceptual utility to demonstrate packet filtering using XDP. Additionally, you can use the code of the utility for a better understanding of how to write your own XDP applications.
On other architectures than AMD and Intel 64-bit, the xdp-filter utility is provided as a Technology Preview only. Technology Preview features are not supported with Red Hat production Service Level Agreements (SLAs), might not be functionally complete, and Red Hat does not recommend using them for production. These previews provide early access to upcoming product features, enabling customers to test functionality and provide feedback during the development process.
43.1. Dropping network packets that match an xdp-filter rule
The xdp-filter utility can use an allow policy that allows all traffic except packets that match specific rules, such as those from a particular source IP address, source MAC address, or to a specific destination port.
If you are a developer and interested in the code of xdp-filter, download and install the corresponding source RPM (SRPM) from the Red Hat Customer Portal.
Prerequisites
-
The
xdp-toolspackage is installed. - A network driver that supports XDP programs.
Procedure
Load
xdp-filterto process incoming packets on a certain interface, such asenp1s0:# xdp-filter load enp1s0By default,
xdp-filteruses theallowpolicy, and the utility drops only traffic that matches any rule.Optional: Use the
-f featureoption to enable only particular features, such astcp,ipv4, orethernet. Loading only the required features instead of all of them increases the speed of packet processing. To enable multiple features, separate them with a comma.If the command fails with an error, the network driver does not support XDP programs.
Add rules to drop packets that match them. For example:
To drop incoming packets to port
22, enter:# xdp-filter port 22This command adds a rule that matches TCP and UDP traffic. To match only a particular protocol, use the
-p protocoloption.To drop incoming packets from
192.0.2.1, enter:# xdp-filter ip 192.0.2.1 -m srcNote that
xdp-filterdoes not support IP ranges.To drop incoming packets from MAC address
00:53:00:AA:07:BE, enter:# xdp-filter ether 00:53:00:AA:07:BE -m src
Verification
Use the following command to display statistics about dropped and allowed packets:
# xdp-filter status
43.2. Dropping all network packets except the ones that match an xdp-filter rule
The xdp-filter utility can use a deny policy that drops all traffic except packets that match specific rules, such as those from a particular source IP address, source MAC address, or to a specific destination port.
If you set the default policy to deny when you load xdp-filter on an interface, the kernel immediately drops all packets from this interface until you create rules that allow certain traffic. To avoid being locked out from the system, enter the commands locally or connect through a different network interface to the host.
If you are a developer and you are interested in the code of xdp-filter, download and install the corresponding source RPM (SRPM) from the Red Hat Customer Portal.
Prerequisites
-
The
xdp-toolspackage is installed. - You are logged in to the host either locally or using a network interface for which you do not plan to filter the traffic.
- A network driver that supports XDP programs.
Procedure
Load
xdp-filterto process packets on a certain interface, such asenp1s0:# xdp-filter load enp1s0 -p denyOptional: Use the
-f featureoption to enable only particular features, such astcp,ipv4, orethernet. Loading only the required features instead of all of them increases the speed of packet processing. To enable multiple features, separate them with a comma.If the command fails with an error, the network driver does not support XDP programs.
Add rules to allow packets that match them. For example:
To allow packets to port
22, enter:# xdp-filter port 22This command adds a rule that matches TCP and UDP traffic. To match only a particular protocol, pass the
-p protocoloption to the command.To allow packets to
192.0.2.1, enter:# xdp-filter ip 192.0.2.1Note that
xdp-filterdoes not support IP ranges.To allow packets to MAC address
00:53:00:AA:07:BE, enter:# xdp-filter ether 00:53:00:AA:07:BE
ImportantThe
xdp-filterutility does not support stateful packet inspection. This requires that you either do not set a mode using the-m modeoption or you add explicit rules to allow incoming traffic that the machine receives in reply to outgoing traffic.
Verification
Use the following command to display statistics about dropped and allowed packets:
# xdp-filter status
Chapter 44. Capturing network packets
To debug network issues and communications, you can capture network packets. The following sections provide instructions and additional information about capturing network packets.
44.1. Using xdpdump to capture network packets including packets dropped by XDP programs
The xdpdump utility captures network packets, including those dropped or modified by XDP programs. Unlike tcpdump, xdpdump uses an eBPF program, allowing it to capture packets that traditional user-space utilities cannot.
You can use xdpdump to debug XDP programs that are already attached to an interface. Therefore, the utility can capture packets before an XDP program is started and after it has finished. In the latter case, xdpdump also captures the XDP action. By default, xdpdump captures incoming packets at the entry of the XDP program.
On other architectures than AMD and Intel 64-bit, the xdpdump utility is provided as a Technology Preview only. Technology Preview features are not supported with Red Hat production Service Level Agreements (SLAs), might not be functionally complete, and Red Hat does not recommend using them for production. These previews provide early access to upcoming product features, enabling customers to test functionality and provide feedback during the development process.
See Technology Preview Features Support Scope on the Red Hat Customer Portal for information about the support scope for Technology Preview features.
Note that xdpdump has no packet filter or decode capabilities. However, you can use it in combination with tcpdump for packet decoding.
If you are a developer and you are interested in the source code of xdpdump, download and install the corresponding source RPM (SRPM) from the Red Hat Customer Portal.
Prerequisites
- A network driver that supports XDP programs.
-
An XDP program is loaded to the
enp1s0interface. If no program is loaded,xdpdumpcaptures packets in a similar waytcpdumpdoes, for backward compatibility.
Procedure
To capture packets on the
enp1s0interface and write them to the/root/capture.pcapfile, enter:# xdpdump -i enp1s0 -w /root/capture.pcap- To stop capturing packets, press Ctrl+C.
Chapter 45. Understanding the eBPF networking features in RHEL 8
The extended Berkeley Packet Filter (eBPF) is an in-kernel virtual machine that allows code execution in the kernel space. This code runs in a restricted sandbox environment with access only to a limited set of functions.
In networking, you can use eBPF to complement or replace kernel packet processing. Depending on the hook you use, eBPF programs have, for example:
- Read and write access to packet data and metadata
- Can look up sockets and routes
- Can set socket options
- Can redirect packets
45.1. Overview of networking eBPF features in RHEL 8
Developers can run sandboxed programs in the Linux kernel by using the Extended Berkeley Packet Filter (eBPF). To manage network traffic, you configure eBPF programs at specific hooks to inspect, modify, and filter data.
You can attach extended Berkeley Packet Filter (eBPF) networking programs to the following hooks in RHEL:
- eXpress Data Path (XDP): Provides early access to received packets before the kernel networking stack processes them.
-
tceBPF classifier with direct-action flag: Provides powerful packet processing on ingress and egress. - Control Groups version 2 (cgroup v2): Enables filtering and overriding socket-based operations performed by programs in a control group.
- Socket filtering: Enables filtering of packets received from sockets. This feature was also available in the classic Berkeley Packet Filter (cBPF), but has been extended to support eBPF programs.
- Stream parser: Enables splitting up streams to individual messages, filtering, and redirecting them to sockets.
-
SO_REUSEPORTsocket selection: Provides a programmable selection of a receiving socket from areuseportsocket group. - Flow dissector: Enables overriding the way the kernel parses packet headers in certain situations.
- TCP congestion control callbacks: Enables implementing a custom TCP congestion control algorithm.
- Routes with encapsulation: Enables creating custom tunnel encapsulation.
Note that Red Hat does not support all of the eBPF functionality that is available in RHEL and described here. For further details and the support status of the individual hooks, see the RHEL 8 Release Notes and the following overview.
- XDP
You can attach programs of the
BPF_PROG_TYPE_XDPtype to a network interface. The kernel then runs the program on received packets before the kernel network stack starts processing them. This allows fast packet forwarding in certain situations, such as fast packet dropping to prevent distributed denial of service (DDoS) attacks and fast packet redirects for load balancing scenarios.You can also use XDP for different forms of packet monitoring and sampling. The kernel allows XDP programs to modify packets and to pass them for further processing to the kernel network stack.
The following XDP modes are available:
- Native (driver) XDP: The kernel runs the program from the earliest possible point during packet reception. At this moment, the kernel did not parse the packet and, therefore, no metadata provided by the kernel is available. This mode requires that the network interface driver supports XDP but not all drivers support this native mode.
- Generic XDP: The kernel network stack runs the XDP program early in the processing. At that time, kernel data structures have been allocated, and the packet has been pre-processed. If a packet should be dropped or redirected, it requires a significant overhead compared to the native mode. However, the generic mode does not require network interface driver support and works with all network interfaces.
Offloaded XDP: The kernel runs the XDP program on the network interface instead of on the host CPU. Note that this requires specific hardware, and only certain eBPF features are available in this mode.
On RHEL, load all XDP programs using the
libxdplibrary. This library enables system-controlled usage of XDP.NoteCurrently, there are some system configuration limitations for XDP programs. For example, you must disable certain hardware offload features on the receiving interface. Additionally, not all features are available with all drivers that support the native mode.
In RHEL 8.7, Red Hat supports the XDP feature only if all of the following conditions apply:
- You load the XDP program on an AMD or Intel 64-bit architecture.
-
You use the
libxdplibrary to load the program into the kernel. - The XDP program does not use the XDP hardware offloading.
Additionally, Red Hat provides the following usage of XDP features as unsupported Technology Preview:
-
Loading XDP programs on architectures other than AMD and Intel 64-bit. Note that the
libxdplibrary is not available for architectures other than AMD and Intel 64-bit. - The XDP hardware offloading.
- AF_XDP
Using an XDP program that filters and redirects packets to a given
AF_XDPsocket, you can use one or more sockets from theAF_XDPprotocol family to quickly copy packets from the kernel to the user space.In RHEL 8.7, Red Hat provides this feature as an unsupported Technology Preview.
- Traffic Control
The Traffic Control (
tc) subsystem offers the following types of eBPF programs:-
BPF_PROG_TYPE_SCHED_CLS -
BPF_PROG_TYPE_SCHED_ACT
These types enable you to write custom
tcclassifiers andtcactions in eBPF. Together with the parts of thetcecosystem, this provides the ability for powerful packet processing and is the core part of several container networking orchestration solutions.In most cases, only the classifier is used, as with the direct-action flag, the eBPF classifier can execute actions directly from the same eBPF program. The
clsactQueueing Discipline (qdisc) has been designed to enable this on the ingress side.Note that using a flow dissector eBPF program can influence operation of some other
qdiscsandtcclassifiers, such asflower.The eBPF for
tcfeature is fully supported in RHEL 8.2 and later.-
- Socket filter
Several utilities use or have used the classic Berkeley Packet Filter (cBPF) for filtering packets received on a socket. For example, with the
tcpdumputility, you can specify expressions, whichtcpdumpthen translates into cBPF code.As an alternative to cBPF, the kernel allows eBPF programs of the
BPF_PROG_TYPE_SOCKET_FILTERtype for the same purpose.In RHEL 8.7, Red Hat provides this feature as an unsupported Technology Preview.
- Control Groups
In RHEL, you can use multiple types of eBPF programs that you can attach to a cgroup. The kernel runs these programs when a program in the given cgroup performs an operation. Note that you can use only cgroups version 2.
The following networking-related cgroup eBPF programs are available in RHEL:
-
BPF_PROG_TYPE_SOCK_OPS: The kernel calls this program on various TCP events. The program can adjust the behavior of the kernel TCP stack, including custom TCP header options, and so on. -
BPF_PROG_TYPE_CGROUP_SOCK_ADDR: The kernel calls this program duringconnect,bind,sendto,recvmsg,getpeername, andgetsocknameoperations. This program allows changing IP addresses and ports. This is useful when you implement socket-based network address translation (NAT) in eBPF. -
BPF_PROG_TYPE_CGROUP_SOCKOPT: The kernel calls this program duringsetsockoptandgetsockoptoperations and allows changing the options. -
BPF_PROG_TYPE_CGROUP_SOCK: The kernel calls this program during socket creation, socket releasing, and binding to addresses. You can use these programs to allow or deny the operation, or only to inspect socket creation for statistics. -
BPF_PROG_TYPE_CGROUP_SKB: This program filters individual packets on ingress and egress, and can accept or reject packets. -
BPF_CGROUP_INET4_GETPEERNAME,BPF_CGROUP_INET6_GETPEERNAME,BPF_CGROUP_INET4_GETSOCKNAME, andBPF_CGROUP_INET6_GETSOCKNAME: Using these programs, you can override the result ofgetsocknameandgetpeernamesystem calls. This is useful when you implement socket-based network address translation (NAT) in eBPF.
In RHEL 8.7, Red Hat provides this feature as an unsupported Technology Preview.
-
- Stream Parser
A stream parser operates on a group of sockets that are added to a special eBPF map. The eBPF program then processes packets that the kernel receives or sends on those sockets.
The following stream parser eBPF programs are available in RHEL:
-
BPF_PROG_TYPE_SK_SKB: An eBPF program parses packets received from the socket into individual messages, and instructs the kernel to drop those messages or send them to another socket in the group. -
BPF_PROG_TYPE_SK_MSG: This program filters egress messages. An eBPF program parses the packets into individual messages and either approves or rejects them.
In RHEL 8.7, Red Hat provides this feature as an unsupported Technology Preview.
-
- SO_REUSEPORT socket selection
Using this socket option, you can bind multiple sockets to the same IP address and port. Without eBPF, the kernel selects the receiving socket based on a connection hash. With the
BPF_PROG_TYPE_SK_REUSEPORTprogram, the selection of the receiving socket is fully programmable.In RHEL 8.7, Red Hat provides this feature as an unsupported Technology Preview.
- Flow dissector
When the kernel needs to process packet headers without going through the full protocol decode, they are
dissected. For example, this happens in thetcsubsystem, in multipath routing, in bonding, or when calculating a packet hash. In this situation the kernel parses the packet headers and fills internal structures with the information from the packet headers. You can replace this internal parsing using theBPF_PROG_TYPE_FLOW_DISSECTORprogram. Note that you can only dissect TCP and UDP over IPv4 and IPv6 in eBPF in RHEL.In RHEL 8.7, Red Hat provides this feature as an unsupported Technology Preview.
- TCP Congestion Control
You can write a custom TCP congestion control algorithm using a group of
BPF_PROG_TYPE_STRUCT_OPSprograms that implementstruct tcp_congestion_oopscallbacks. An algorithm that is implemented this way is available to the system alongside the built-in kernel algorithms.In RHEL 8.7, Red Hat provides this feature as an unsupported Technology Preview.
- Routes with encapsulation
You can attach one of the following eBPF program types to routes in the routing table as a tunnel encapsulation attribute:
-
BPF_PROG_TYPE_LWT_IN -
BPF_PROG_TYPE_LWT_OUT -
BPF_PROG_TYPE_LWT_XMIT
The functionality of such an eBPF program is limited to specific tunnel configurations and does not allow creating a generic encapsulation or decapsulation solution.
In RHEL 8.7, Red Hat provides this feature as an unsupported Technology Preview.
-
- Socket lookup
To bypass limitations of the
bindsystem call, use an eBPF program of theBPF_PROG_TYPE_SK_LOOKUPtype. Such programs can select a listening socket for new incoming TCP connections or an unconnected socket for UDP packets.In RHEL 8.7, Red Hat provides this feature as an unsupported Technology Preview.
45.2. Overview of XDP features in RHEL 8 by network cards
The XDP features available in RHEL depend on the network card and their drivers.
The following is an overview of XDP-enabled network cards and the XDP features you can use with them:
| Network card | Driver | Red Hat Support Status | Basic | Redirect | Target | Zero-copy |
|---|---|---|---|---|---|---|
| Amazon Elastic Network Adapter |
| Technology Preview | yes | yes | yes [a] | no |
| Broadcom NetXtreme-C/E 10/25/40/50 gigabit Ethernet |
| Technology Preview | yes | yes | yes [a] | no |
| Cavium Thunder Virtual function |
| Technology Preview | yes | no | no | no |
| Google Virtual NIC (gVNIC) support |
| Technology Preview | yes | yes | yes | yes |
| Intel® 10GbE PCI Express Virtual Function Ethernet |
| Technology Preview | yes | no | no | no |
| Intel® 10GbE PCI Express adapters |
| Technology Preview | yes | yes | yes [a] | yes |
| Intel® Ethernet Connection E800 Series |
| Technology Preview | yes | yes | yes [a] | yes |
| Intel® Ethernet Controller I225-LM/I225-V family |
| Technology Preview | yes | yes | yes | yes |
| Intel® Ethernet Controller XL710 Family |
| Technology Preview | yes | yes | yes | |
| Intel® PCI Express Gigabit adapters |
| Technology Preview | yes | yes | yes [a] | no |
| Mellanox 5th generation network adapters (ConnectX series) |
| Technology Preview | yes | yes | yes [b] | yes |
| Mellanox Technologies 1/10/40Gbit Ethernet |
| Technology Preview | yes | yes | no | no |
| Microsoft Azure Network Adapter |
| Technology Preview | yes | yes | yes | no |
| Microsoft Hyper-V virtual network |
| Technology Preview | yes | yes | yes | no |
| Netronome® NFP4000/NFP6000 NIC |
| Technology Preview | yes | no | no | no |
| QEMU Virtio network |
| Technology Preview | yes | yes | yes [a] | no |
| QLogic QED 25/40/100Gb Ethernet NIC |
| Technology Preview | yes | yes | yes | no |
| Solarflare SFC9000/SFC9100/EF100-family |
| Technology Preview | yes | yes | yes [b] | no |
| Universal TUN/TAP device |
| Technology Preview | yes | yes | yes | no |
| Virtual Ethernet pair device |
| Technology Preview | yes | yes | yes | no |
[a]
Only if an XDP program is loaded on the interface.
[b]
Requires several XDP TX queues allocated that are larger or equal to the largest CPU index.
| ||||||
Legend:
-
Basic: Supports basic return codes:
DROP,PASS,ABORTED, andTX. -
Redirect: Supports the
REDIRECTreturn code. -
Target: Can be a target of a
REDIRECTreturn code. - HW offload: Supports XDP hardware offload.
-
Zero-copy: Supports the zero-copy mode for the
AF_XDPprotocol family.
Chapter 46. Network tracing using the BPF compiler collection
BPF Compiler Collection (BCC) is a library, which facilitates the creation of the extended Berkeley Packet Filter (eBPF) programs. The main utility of eBPF programs is analyzing the operating system performance and network performance without experiencing overhead or security issues.
BCC removes the need for users to know deep technical details of eBPF, and provides many out-of-the-box starting points, such as the bcc-tools package with pre-created eBPF programs.
The eBPF programs are triggered on events, such as disk I/O, TCP connections, and process creations. It is unlikely that the programs cause the kernel to crash, loop or become unresponsive because they run in a safe virtual machine in the kernel.
46.1. Installing the bcc-tools package
Install the bcc-tools package, which also installs the BPF Compiler Collection (BCC) library as a dependency.
Procedure
Install
bcc-tools.# yum install bcc-toolsThe BCC tools are installed in the
/usr/share/bcc/tools/directory.
Verification
Inspect the installed tools:
# ls -l /usr/share/bcc/tools/ ... -rwxr-xr-x. 1 root root 4198 Dec 14 17:53 dcsnoop -rwxr-xr-x. 1 root root 3931 Dec 14 17:53 dcstat -rwxr-xr-x. 1 root root 20040 Dec 14 17:53 deadlock_detector -rw-r--r--. 1 root root 7105 Dec 14 17:53 deadlock_detector.c drwxr-xr-x. 3 root root 8192 Mar 11 10:28 doc -rwxr-xr-x. 1 root root 7588 Dec 14 17:53 execsnoop -rwxr-xr-x. 1 root root 6373 Dec 14 17:53 ext4dist -rwxr-xr-x. 1 root root 10401 Dec 14 17:53 ext4slower ...The
docdirectory in the listing provides documentation for each tool.
46.2. Displaying TCP connections added to the Kernel’s accept queue
By using the tcpaccept utility, you can monitor newly accepted connections by tracing the kernel’s accept() function.
After the kernel receives the ACK packet in a TCP 3-way handshake, the kernel moves the connection from the SYN queue to the accept queue after the connection’s state changes to ESTABLISHED. Therefore, only successful TCP connections are visible in this queue.
The tcpaccept utility uses eBPF features to display all connections the kernel adds to the accept queue. The utility is lightweight because it traces the accept() function of the kernel instead of capturing packets and filtering them. For example, use tcpaccept for general troubleshooting to display new connections the server has accepted.
Procedure
Enter the following command to start the tracing the kernel
acceptqueue:# /usr/share/bcc/tools/tcpaccept PID COMM IP RADDR RPORT LADDR LPORT 843 sshd 4 192.0.2.17 50598 192.0.2.1 22 1107 ns-slapd 4 198.51.100.6 38772 192.0.2.1 389 1107 ns-slapd 4 203.0.113.85 38774 192.0.2.1 389 ...Each time the kernel accepts a connection,
tcpacceptdisplays the details of the connections.- Press Ctrl+C to stop the tracing process.
46.3. Tracing outgoing TCP connection attempts
The tcpconnect utility uses eBPF features to trace outgoing TCP connection attempts. The output of the utility also includes connections that failed.
The tcpconnect utility is lightweight because it traces, for example, the connect() function of the kernel instead of capturing packets and filtering them.
Procedure
Enter the following command to start the tracing process that displays all outgoing connections:
# /usr/share/bcc/tools/tcpconnect PID COMM IP SADDR DADDR DPORT 31346 curl 4 192.0.2.1 198.51.100.16 80 31348 telnet 4 192.0.2.1 203.0.113.231 23 31361 isc-worker00 4 192.0.2.1 192.0.2.254 53 ...Each time the kernel processes an outgoing connection,
tcpconnectdisplays the details of the connections.- Press Ctrl+C to stop the tracing process.
46.4. Measuring the latency of outgoing TCP connections
The tcpconnlat utility uses eBPF features to measure the time between a sent SYN packet and the received response packet.
The TCP connection latency is the time taken to establish a connection. This typically involves the kernel TCP/IP processing and network round trip time, and not the application runtime.
Procedure
Start measuring the latency of outgoing connections:
# /usr/share/bcc/tools/tcpconnlat PID COMM IP SADDR DADDR DPORT LAT(ms) 32151 isc-worker00 4 192.0.2.1 192.0.2.254 53 0.60 32155 ssh 4 192.0.2.1 203.0.113.190 22 26.34 32319 curl 4 192.0.2.1 198.51.100.59 443 188.96 ...Each time the kernel processes an outgoing connection,
tcpconnlatdisplays the details of the connection after the kernel receives the response packet.- Press Ctrl+C to stop the tracing process.
46.5. Displaying details about TCP packets and segments that were dropped by the kernel
You can use the tcpdrop utility to display details about TCP packets and segments that were dropped by the kernel. Use this utility to debug high rates of dropped packets that can cause the remote system to send timer-based retransmits.
High rates of dropped packets and segments can impact the performance of a server. Instead of capturing and filtering packets, which is resource-intensive, the tcpdrop utility uses eBPF features to retrieve the information directly from the kernel.
Procedure
Enter the following command to start displaying details about dropped TCP packets and segments:
# /usr/share/bcc/tools/tcpdrop TIME PID IP SADDR:SPORT > DADDR:DPORT STATE (FLAGS) 13:28:39 32253 4 192.0.2.85:51616 > 192.0.2.1:22 CLOSE_WAIT (FIN|ACK) b'tcp_drop+0x1' b'tcp_data_queue+0x2b9' ... 13:28:39 1 4 192.0.2.85:51616 > 192.0.2.1:22 CLOSE (ACK) b'tcp_drop+0x1' b'tcp_rcv_state_process+0xe2' ...Each time the kernel drops TCP packets and segments,
tcpdropdisplays the details of the connection, including the kernel stack trace that led to the dropped package.- Press Ctrl+C to stop the tracing process.
46.6. Tracing TCP sessions
The tcplife utility uses eBPF to trace TCP sessions that open and close, and prints a line of output to summarize each one. Administrators can use tcplife to identify connections and the amount of transferred traffic.
For example, you can display connections to port 22 (SSH) to retrieve the following information:
- The local process ID (PID)
- The local process name
- The local IP address and port number
- The remote IP address and port number
- The amount of received and transmitted traffic in KB.
- The time in milliseconds the connection was active
Procedure
Enter the following command to start the tracing of connections to the local port
22:# /usr/share/bcc/tools/tcplife -L 22 PID COMM LADDR LPORT RADDR RPORT TX_KB RX_KB MS 19392 sshd 192.0.2.1 22 192.0.2.17 43892 53 52 6681.95 19431 sshd 192.0.2.1 22 192.0.2.245 43902 81 249381 7585.09 19487 sshd 192.0.2.1 22 192.0.2.121 43970 6998 7 16740.35 ...Each time a connection is closed,
tcplifedisplays the details of the connections.- Press Ctrl+C to stop the tracing process.
46.7. Tracing TCP retransmissions
The tcpretrans utility displays details about TCP retransmissions, such as the local and remote IP address and port number, as well as the TCP state at the time of the retransmissions.
The utility uses eBPF features and, therefore, has a very low overhead.
Procedure
Use the following command to start displaying TCP retransmission details:
# /usr/share/bcc/tools/tcpretrans TIME PID IP LADDR:LPORT T> RADDR:RPORT STATE 00:23:02 0 4 192.0.2.1:22 R> 198.51.100.0:26788 ESTABLISHED 00:23:02 0 4 192.0.2.1:22 R> 198.51.100.0:26788 ESTABLISHED 00:45:43 0 4 192.0.2.1:22 R> 198.51.100.0:17634 ESTABLISHED ...Each time the kernel calls the TCP retransmit function,
tcpretransdisplays the details of the connection.- Press Ctrl+C to stop the tracing process.
46.8. Displaying TCP state change information
During a TCP session, the TCP state changes. The tcpstates utility uses eBPF functions to trace these state changes, and prints details including the duration in each state. For example, use tcpstates to identify if connections spend too much time in the initialization state.
Procedure
Use the following command to start tracing TCP state changes:
# /usr/share/bcc/tools/tcpstates SKADDR C-PID C-COMM LADDR LPORT RADDR RPORT OLDSTATE -> NEWSTATE MS ffff9cd377b3af80 0 swapper/1 0.0.0.0 22 0.0.0.0 0 LISTEN -> SYN_RECV 0.000 ffff9cd377b3af80 0 swapper/1 192.0.2.1 22 192.0.2.45 53152 SYN_RECV -> ESTABLISHED 0.067 ffff9cd377b3af80 818 sssd_nss 192.0.2.1 22 192.0.2.45 53152 ESTABLISHED -> CLOSE_WAIT 65636.773 ffff9cd377b3af80 1432 sshd 192.0.2.1 22 192.0.2.45 53152 CLOSE_WAIT -> LAST_ACK 24.409 ffff9cd377b3af80 1267 pulseaudio 192.0.2.1 22 192.0.2.45 53152 LAST_ACK -> CLOSE 0.376 ...Each time a connection changes its state,
tcpstatesdisplays a new line with updated connection details.If multiple connections change their state at the same time, use the socket address in the first column (
SKADDR) to determine which entries belong to the same connection.- Press Ctrl+C to stop the tracing process.
46.9. Summarizing and aggregating TCP traffic sent to specific subnets
The tcpsubnet utility summarizes and aggregates IPv4 TCP traffic that the local host sends to subnets and displays the output on a fixed interval. The utility uses eBPF features to collect and summarize the data to reduce the overhead.
By default, tcpsubnet summarizes traffic for the following subnets:
-
127.0.0.1/32 -
10.0.0.0/8 -
172.16.0.0/12 -
192.0.2.0/24/16 -
0.0.0.0/0
Note that the last subnet (0.0.0.0/0) is a catch-all option. The tcpsubnet utility counts all traffic for subnets different from the first four in this catch-all entry.
Follow the procedure to count the traffic for the 192.0.2.0/24 and 198.51.100.0/24 subnets. Traffic to other subnets is then tracked in the 0.0.0.0/0 catch-all subnet entry.
Procedure
Start monitoring the amount of traffic sent to the
192.0.2.0/24,198.51.100.0/24, and other subnets:# /usr/share/bcc/tools/tcpsubnet 192.0.2.0/24,198.51.100.0/24,0.0.0.0/0 Tracing... Output every 1 secs. Hit Ctrl-C to end [02/21/20 10:04:50] 192.0.2.0/24 856 198.51.100.0/24 7467 [02/21/20 10:04:51] 192.0.2.0/24 1200 198.51.100.0/24 8763 0.0.0.0/0 673 ...This command displays the traffic in bytes for the specified subnets once per second.
- Press Ctrl+C to stop the tracing process.
46.10. Displaying the network throughput by IP address and port
The tcptop utility displays TCP traffic the host sends and receives in kilobytes. The report automatically refreshes and contains only active TCP connections. The utility uses eBPF features and, therefore, has only a very low overhead.
Procedure
To monitor the sent and received traffic, enter:
# /usr/share/bcc/tools/tcptop 13:46:29 loadavg: 0.10 0.03 0.01 1/215 3875 PID COMM LADDR RADDR RX_KB TX_KB 3853 3853 192.0.2.1:22 192.0.2.165:41838 32 102626 1285 sshd 192.0.2.1:22 192.0.2.45:39240 0 0 ...The output of the command includes only active TCP connections. If the local or remote system closes a connection, the connection is no longer visible in the output.
- Press Ctrl+C to stop the tracing process.
46.11. Tracing established TCP connections
The tcptracer utility traces the kernel functions that connect, accept, and close TCP connections. The utility uses eBPF features and, therefore, has a very low overhead.
Procedure
Use the following command to start the tracing process:
# /usr/share/bcc/tools/tcptracer Tracing TCP established connections. Ctrl-C to end. T PID COMM IP SADDR DADDR SPORT DPORT A 1088 ns-slapd 4 192.0.2.153 192.0.2.1 0 65535 A 845 sshd 4 192.0.2.1 192.0.2.67 22 42302 X 4502 sshd 4 192.0.2.1 192.0.2.67 22 42302 ...Each time the kernel connects, accepts, or closes a connection,
tcptracerdisplays the details of the connections.- Press Ctrl+C to stop the tracing process.
46.12. Tracing IPv4 and IPv6 listen attempts
The solisten utility traces all IPv4 and IPv6 listen attempts. It traces the attempts including which ultimately fail or the listening program that does not accept the connection. The utility traces functions that the kernel calls when a program wants to listen for TCP connections.
Procedure
Enter the following command to start the tracing process that displays all listen TCP attempts:
# /usr/share/bcc/tools/solisten PID COMM PROTO BACKLOG PORT ADDR 3643 nc TCPv4 1 4242 0.0.0.0 3659 nc TCPv6 1 4242 2001:db8:1::1 4221 redis-server TCPv6 128 6379 :: 4221 redis-server TCPv4 128 6379 0.0.0.0 ....- Press Ctrl+C to stop the tracing process.
46.13. Summarizing the service time of soft interrupts
The softirqs utility summarizes the time spent servicing soft interrupts (soft IRQs) and shows this time as either totals or histogram distributions. This utility uses the irq:softirq_enter and irq:softirq_exit kernel tracepoints, which is a stable tracing mechanism.
Procedure
Enter the following command to start the tracing
soft irqevent time:# /usr/share/bcc/tools/softirqs Tracing soft irq event time... Hit Ctrl-C to end. ^C SOFTIRQ TOTAL_usecs tasklet 166 block 9152 net_rx 12829 rcu 53140 sched 182360 timer 306256- Press Ctrl+C to stop the tracing process.
46.14. Summarizing packets size and count on a network interface
The netqtop utility displays statistics about the attributes of received (RX) and transmitted (TX) packets on each network queue of a particular network interface.
The statistics include:
- Bytes per second (BPS)
- Packets per second (PPS)
- The average packet size
- Total number of packets
To generate these statistics, netqtop traces the kernel functions that perform events of transmitted packets net_dev_start_xmit and received packets netif_receive_skb.
Procedure
Display the number of packets within the range of bytes size of the time interval of
2seconds:# /usr/share/bcc/tools/netqtop -n enp1s0 -i 2 Fri Jan 31 18:08:55 2023 TX QueueID avg_size [0, 64) [64, 512) [512, 2K) [2K, 16K) [16K, 64K) 0 0 0 0 0 0 0 Total 0 0 0 0 0 0 RX QueueID avg_size [0, 64) [64, 512) [512, 2K) [2K, 16K) [16K, 64K) 0 38.0 1 0 0 0 0 Total 38.0 1 0 0 0 0 ----------------------------------------------------------------------------- Fri Jan 31 18:08:57 2023 TX QueueID avg_size [0, 64) [64, 512) [512, 2K) [2K, 16K) [16K, 64K) 0 0 0 0 0 0 0 Total 0 0 0 0 0 0 RX QueueID avg_size [0, 64) [64, 512) [512, 2K) [2K, 16K) [16K, 64K) 0 38.0 1 0 0 0 0 Total 38.0 1 0 0 0 0 ------------------------------------------------------------------------------
Press Ctrl+C to stop
netqtop.
Chapter 47. Configuring network devices to accept traffic from all MAC addresses
Network devices usually intercept and read packets that their controller is programmed to receive. You can configure the network devices to accept traffic from all MAC addresses in a virtual switch or at the port group level.
You can use this network mode to:
- Diagnose network connectivity issues
- Monitor network activity for security reasons
- Intercept private data-in-transit or intrusion in the network
You can enable this mode for any kind of network device, except InfiniBand.
47.1. Temporarily configuring a device to accept all traffic
You can use the ip utility to temporarily configure a network device to accept all traffic regardless of the MAC addresses.
Procedure
Optional: Display the network interfaces to identify the one for which you want to receive all traffic:
# ip address show 1: enp1s0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc fq_codel state DOWN group default qlen 1000 link/ether 98:fa:9b:a4:34:09 brd ff:ff:ff:ff:ff:ff ...Modify the device to enable or disable this property:
To enable the
accept-all-mac-addressesmode forenp1s0:# ip link set enp1s0 promisc onTo disable the
accept-all-mac-addressesmode forenp1s0:# ip link set enp1s0 promisc off
Verification
Verify that the
accept-all-mac-addressesmode is enabled:# ip link show enp1s0 1: enp1s0: <NO-CARRIER,BROADCAST,MULTICAST,PROMISC,UP> mtu 1500 qdisc fq_codel state DOWN mode DEFAULT group default qlen 1000 link/ether 98:fa:9b:a4:34:09 brd ff:ff:ff:ff:ff:ffThe
PROMISCflag in the device description indicates that the mode is enabled.
47.2. Permanently configuring a network device to accept all traffic using nmcli
You can use the nmcli utility to permanently configure a network device to accept all traffic regardless of the MAC addresses.
Procedure
Optional: Display the network interfaces to identify the one for which you want to receive all traffic:
# ip address show 1: enp1s0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc fq_codel state DOWN group default qlen 1000 link/ether 98:fa:9b:a4:34:09 brd ff:ff:ff:ff:ff:ff ...You can create a new connection, if you do not have any.
Modify the network device to enable or disable this property.
To enable the
ethernet.accept-all-mac-addressesmode forenp1s0:# nmcli connection modify enp1s0 ethernet.accept-all-mac-addresses yesTo disable the
accept-all-mac-addressesmode forenp1s0:# nmcli connection modify enp1s0 ethernet.accept-all-mac-addresses no
Apply the changes, reactivate the connection:
# nmcli connection up enp1s0
Verification
Verify that the
ethernet.accept-all-mac-addressesmode is enabled:# nmcli connection show enp1s0 ... 802-3-ethernet.accept-all-mac-addresses:1 (true)The
802-3-ethernet.accept-all-mac-addresses: trueindicates that the mode is enabled.
47.3. Permanently configuring a network device to accept all traffic using nmstatectl
Use the nmstatectl utility to configure a device to accept all traffic regardless of the MAC addresses through the Nmstate API. The Nmstate API ensures that, after setting the configuration, the result matches the configuration file. If anything fails, nmstatectl automatically rolls back the changes to avoid leaving the system in an incorrect state.
Prerequisites
-
The
nmstatepackage is installed. -
The
enp1s0.ymlfile that you used to configure the device is available.
Procedure
Edit the existing
enp1s0.ymlfile for theenp1s0connection and add the following content to it:--- interfaces: - name: enp1s0 type: ethernet state: up accept -all-mac-address: trueThese settings configure the
enp1s0device to accept all traffic.Apply the network settings:
# nmstatectl apply ~/enp1s0.yml
Verification
Verify that the
802-3-ethernet.accept-all-mac-addressesmode is enabled:# nmstatectl show enp1s0 interfaces: - name: enp1s0 type: ethernet state: up accept-all-mac-addresses: true ...The
802-3-ethernet.accept-all-mac-addresses: trueindicates that the mode is enabled.
Chapter 48. Mirroring a network interface by using nmcli
Network administrators can use port mirroring to replicate inbound and outbound network traffic being communicated from one network device to another. Mirroring traffic of an interface can be helpful in the following situations:
- To debug networking issues and tune the network flow
- To inspect and analyze the network traffic
- To detect an intrusion
Prerequisites
- A network interface to mirror the network traffic to.
Procedure
Add a network connection profile that you want to mirror the network traffic from:
# nmcli connection add type ethernet ifname enp1s0 con-name enp1s0 autoconnect noAttach a
qdiscof typepriotoenp1s0for the egress (outgoing) traffic with the10:handle:# nmcli connection modify enp1s0 +tc.qdisc "root prio handle 10:"The
qdiscset toprioattached without children allows attaching filters.Add a
qdiscfor the ingress traffic, with theffff:handle:# nmcli connection modify enp1s0 +tc.qdisc "ingress handle ffff:"Add the following filters to match packets on the ingress and egress
qdiscs, and to mirror them toenp7s0:# nmcli connection modify enp1s0 +tc.tfilter "parent ffff: matchall action mirred egress mirror dev enp7s0" # nmcli connection modify enp1s0 +tc.tfilter "parent 10: matchall action mirred egress mirror dev enp7s0"The
matchallfilter matches all packets, and themirredaction redirects packets to destination.Activate the connection:
# nmcli connection up enp1s0
Verification
Install the
tcpdumputility:# yum install tcpdumpDisplay the traffic mirrored on the target device (
enp7s0):# tcpdump -i enp7s0
Chapter 49. Using nmstate-autoconf to automatically configure the network state using LLDP
Network devices can use the Link Layer Discovery Protocol (LLDP) to advertise their identity, capabilities, and neighbors in a LAN. The nmstate-autoconf utility can use this information to automatically configure local network interfaces.
The nmstate-autoconf utility is provided as a Technology Preview only. Technology Preview features are not supported with Red Hat production Service Level Agreements (SLAs), might not be functionally complete, and Red Hat does not recommend using them for production. These previews provide early access to upcoming product features, enabling customers to test functionality and provide feedback during the development process.
49.1. Using nmstate-autoconf to automatically configure network interfaces
The nmstate-autoconf utility uses LLDP to identify the Virtual Local Area Network (VLAN) settings of interfaces connected to a switch to configure local devices.
This procedure assumes the following scenario and that the switch broadcasts the VLAN settings using LLDP:
-
The
enp1s0andenp2s0interfaces of the RHEL server are connected to switch ports that are configured with VLAN ID100and VLAN nameprod-net. -
The
enp3s0interface of the RHEL server is connected to a switch port that is configured with VLAN ID200and VLAN namemgmt-net.
The nmstate-autoconf utility then uses this information to create the following interfaces on the server:
-
bond100- A bond interface withenp1s0andenp2s0as ports. -
prod-net- A VLAN interface on top ofbond100with VLAN ID100. -
mgmt-net- A VLAN interface on top ofenp3s0with VLAN ID200
If you connect multiple network interfaces to different switch ports for which LLDP broadcasts the same VLAN ID, nmstate-autoconf creates a bond with these interfaces and, additionally, configures the common VLAN ID on top of it.
Prerequisites
-
The
nmstatepackage is installed. - LLDP is enabled on the network switch.
- The Ethernet interfaces are up.
Procedure
Enable LLDP on the Ethernet interfaces:
Create a YAML file, for example
~/enable-lldp.yml, with the following content:interfaces: - name: enp1s0 type: ethernet lldp: enabled: true - name: enp2s0 type: ethernet lldp: enabled: true - name: enp3s0 type: ethernet lldp: enabled: trueApply the settings to the system:
# nmstatectl apply ~/enable-lldp.yml
Configure the network interfaces using LLDP:
Optional, start a dry-run to display and verify the YAML configuration that
nmstate-autoconfgenerates:# nmstate-autoconf -d enp1s0,enp2s0,enp3s0 --- interfaces: - name: prod-net type: vlan state: up vlan: base-iface: bond100 id: 100 - name: mgmt-net type: vlan state: up vlan: base-iface: enp3s0 id: 200 - name: bond100 type: bond state: up link-aggregation: mode: balance-rr port: - enp1s0 - enp2s0Use
nmstate-autoconfto generate the configuration based on information received from LLDP, and apply the settings to the system:# nmstate-autoconf enp1s0,enp2s0,enp3s0
Verification
Display the settings of the individual interfaces:
# nmstatectl show <interface_name>
Next steps
If there is no DHCP server in your network that provides the IP settings to the interfaces, configure them manually. For details, see:
Chapter 50. Configuring 802.3 link settings
By using the auto-negotiation protocol, you have optimal performance of data transfer over the Ethernet.
Auto-negotiation is a feature of the IEEE 802.3u Fast Ethernet protocol. It targets the device ports to provide an optimal performance of speed, duplex mode, and flow control for information exchange over a link.
To utilize maximum performance of auto-negotiation, use the same configuration on both sides of a link.
50.1. Configuring 802.3 link settings using the nmcli utility
To configure the 802.3 link settings of an Ethernet connection, modify the following configuration parameters:
-
802-3-ethernet.auto-negotiate -
802-3-ethernet.speed -
802-3-ethernet.duplex
Procedure
Display the current settings of the connection:
# nmcli connection show Example-connection ... 802-3-ethernet.speed: 0 802-3-ethernet.duplex: -- 802-3-ethernet.auto-negotiate: no ...You can use these values if you need to reset the parameters in case of any problems.
Set the speed and duplex link settings:
# nmcli connection modify Example-connection 802-3-ethernet.auto-negotiate yes 802-3-ethernet.speed 10000 802-3-ethernet.duplex fullThis command enables auto-negotiation and sets the speed of the connection to
10000Mbit full duplex.Reactivate the connection:
# nmcli connection up Example-connection
Verification
Use the
ethtoolutility to verify the values of Ethernet interfaceenp1s0:# ethtool enp1s0 Settings for enp1s0: ... Speed: 10000 Mb/s Duplex: Full Auto-negotiation: on ... Link detected: yes
Chapter 51. Getting started with DPDK
The data plane development kit (DPDK) provides libraries and network drivers to accelerate packet processing in user space.
Administrators use DPDK, for example, in virtual machines to use Single Root I/O Virtualization (SR-IOV) to reduce latencies and increase I/O throughput.
Red Hat does not support experimental DPDK APIs.
51.1. Installing the dpdk package
To use DPDK, install the dpdk package.
Procedure
Use the
yumutility to install thedpdkpackage:# yum install dpdk
Chapter 52. Getting started with TIPC
Transparent Inter-process Communication (TIPC), which is also known as Cluster Domain Sockets, is an Inter-process Communication (IPC) service for cluster-wide operation.
Applications that are running in a high-available and dynamic cluster environment have special needs. The number of nodes in a cluster can vary, routers can fail, and, due to load balancing considerations, functionality can be moved to different nodes in the cluster. TIPC minimizes the effort by application developers to deal with such situations, and maximizes the chance that they are handled in a correct and optimal way. Additionally, TIPC provides a more efficient and fault-tolerant communication than general protocols, such as TCP.
Use other bearer level protocols to encrypt the communication between nodes based on the transport media.
52.1. The architecture of TIPC
TIPC is a layer between applications using TIPC and a packet transport service (bearer), and spans the level of transport, network, and signaling link layers. However, TIPC can use a different transport protocol as bearer, so that, for example, a TCP connection can serve as a bearer for a TIPC signaling link.
TIPC supports the following bearers:
- Ethernet
- InfiniBand
- UDP protocol
TIPC provides a reliable transfer of messages between TIPC ports, that are the endpoints of all TIPC communication.
The following is a diagram of the TIPC architecture:
52.2. Loading the tipc module when the system boots
Before you can use the TIPC protocol, you must load the tipc kernel module. You can configure Red Hat Enterprise Linux to automatically load this kernel module automatically when the system boots.
Procedure
Create the
/etc/modules-load.d/tipc.conffile with the following content:tipcRestart the
systemd-modules-loadservice to load the module without rebooting the system:# systemctl start systemd-modules-load
Verification
Use the following command to verify that RHEL loaded the
tipcmodule:# lsmod | grep tipc tipc 311296 0If the command shows no entry for the
tipcmodule, RHEL failed to load it.
52.3. Creating a TIPC network
To create a TIPC network, perform this procedure on each host that should join the TIPC network.
The commands configure the TIPC network only temporarily. To permanently configure TIPC on a node, use the commands of this procedure in a script, and configure RHEL to execute that script when the system boots.
Prerequisites
-
The
tipcmodule has been loaded. For details, see Loading the tipc module when the system boots
Procedure
Optional: Set a unique node identity, such as a UUID or the node’s host name:
# tipc node set identity host_nameThe identity can be any unique string consisting of a maximum 16 letters and numbers.
You cannot set or change an identity after this step.
Add a bearer. For example, to use Ethernet as media and
enp0s1device as physical bearer device, enter:# tipc bearer enable media eth device enp1s0- Optional: For redundancy and better performance, attach further bearers using the command from the previous step. You can configure up to three bearers, but not more than two on the same media.
- Repeat all previous steps on each node that should join the TIPC network.
Verification
Display the link status for cluster members:
# tipc link list broadcast-link: up 5254006b74be:enp1s0-525400df55d1:enp1s0: upThis output indicates that the link between bearer
enp1s0on node5254006b74beand bearerenp1s0on node525400df55d1isup.Display the TIPC publishing table:
# tipc nametable show Type Lower Upper Scope Port Node 0 1795222054 1795222054 cluster 0 5254006b74be 0 3741353223 3741353223 cluster 0 525400df55d1 1 1 1 node 2399405586 5254006b74be 2 3741353223 3741353223 node 0 5254006b74be-
The two entries with service type
0indicate that two nodes are members of this cluster. -
The entry with service type
1represents the built-in topology service tracking service. -
The entry with service type
2displays the link as seen from the issuing node. The range limit3741353223represents the peer endpoint’s address (a unique 32-bit hash value based on the node identity) in decimal format.
-
The two entries with service type
Chapter 53. Automatically configuring network interfaces in public clouds using nm-cloud-setup
Usually, a virtual machine (VM) has only one interface that is configurable by DHCP. However, DHCP cannot configure VMs with multiple network entities, such as interfaces, IP subnets, and IP addresses. Additionally, you cannot apply settings when the VM instance is running. To solve this runtime configuration issue, the nm-cloud-setup utility automatically retrieves configuration information from the metadata server of the cloud service provider and updates the network configuration of the host. The utility automatically picks up multiple network interfaces, multiple IP addresses, or IP subnets on one interface and helps to reconfigure the network of the running VM instance.
53.1. Configuring and pre-deploying nm-cloud-setup
To enable and configure network interfaces in public clouds, run nm-cloud-setup as a timer and service.
On Red Hat Enterprise Linux On Demand and AWS golden images, nm-cloud-setup is already enabled and no action is required.
Prerequisites
- A network connection exists.
The connection uses DHCP.
By default, NetworkManager creates a connection profile which uses DHCP. If no profile was created because you set the
no-auto-defaultparameter in/etc/NetworkManager/NetworkManager.conf, create this initial connection manually.
Procedure
Install the
nm-cloud-setuppackage:# yum install NetworkManager-cloud-setupCreate and run the snap-in file for the
nm-cloud-setupservice:Use the following command to start editing the snap-in file:
# systemctl edit nm-cloud-setup.serviceIt is important to either start the service explicitly or reboot the system to make configuration settings effective.
Use the
systemdsnap-in file to configure the cloud provider innm-cloud-setup. For example, to use Amazon EC2, enter:[Service] Environment=NM_CLOUD_SETUP_EC2=yesYou can set the following environment variables to enable the cloud provide you use:
-
NM_CLOUD_SETUP_ALIYUNfor Alibaba Cloud (Aliyun) -
NM_CLOUD_SETUP_AZUREfor Microsoft Azure -
NM_CLOUD_SETUP_EC2for Amazon EC2 (AWS) -
NM_CLOUD_SETUP_GCPfor Google Cloud
-
- Save the file and quit the editor.
Reload the
systemdconfiguration:# systemctl daemon-reloadEnable and start the
nm-cloud-setupservice:# systemctl enable --now nm-cloud-setup.serviceEnable and start the
nm-cloud-setuptimer:# systemctl enable --now nm-cloud-setup.timer
53.2. Understanding the role of IMDSv2 and nm-cloud-setup in the RHEL EC2 instance
The instance metadata service (IMDS) in Amazon EC2 allows you to manage permissions to access instance metadata of a running Red Hat Enterprise Linux (RHEL) EC2 instance. The RHEL EC2 instance uses IMDS version 2 (IMDSv2), a session-oriented method. By using the nm-cloud-setup utility, administrators can reconfigure the network and automatically update the configuration of running RHEL EC2 instances. The nm-cloud-setup utility handles IMDSv2 API calls by using IMDSv2 tokens without any user intervention.
-
IMDS runs on a link-local address
169.254.169.254for providing access to native applications on a RHEL EC2 instance. - After you have specified and configured IMDSv2 for each RHEL EC2 instance for applications and users, you can no longer access IMDSv1.
- By using IMDSv2, the RHEL EC2 instance maintains metadata without using the IAM role while remaining accessible through the IAM role.
-
When the RHEL EC2 instance boots, the
nm-cloud-setuputility automatically runs to fetch the EC2 instance API access token for using the RHEL EC2 instance API.
Use the IMDSv2 token as an HTTP header to check the details of the EC2 environment.