Chapter 4. Testing VDO performance
You can perform a series of tests to measure VDO performance, obtain a performance profile of your system with VDO, and determine which applications perform well with VDO.
Prerequisites
- One or more Linux physical block devices are available.
-
The target block device (for example,
/dev/sdb) is larger than 512 GiB. -
Flexible I/O Tester (
fio) is installed. - VDO is installed.
4.1. Preparing an environment for VDO performance testing
Before testing VDO performance, you must consider the host system configuration, VDO configuration, and the workloads that will be used during testing. These choices affect the benchmarking of space efficiency, bandwidth, and latency.
To prevent one test from affecting the results of another, you must create a new VDO volume for each iteration of each test.
4.1.1. Considerations before testing VDO performance
The following conditions and configurations affect the VDO test results:
System configuration
-
Number and type of CPU cores available. You can list this information using the
tasksetutility. - Available memory and total installed memory
- Configuration of storage devices
- Active disk scheduler
- Linux kernel version
- Packages installed
VDO configuration
- Partitioning scheme
- File systems used on VDO volumes
- Size of the physical storage assigned to a VDO volume
- Size of the logical VDO volume created
- Sparse or dense UDS indexing
- UDS Index in memory size
- VDO thread configuration
Workloads
- Types of tools used to generate test data
- Number of concurrent clients
- The quantity of duplicate 4 KiB blocks in the written data
- Read and write patterns
- The working set size
4.1.2. Special considerations for testing VDO read performance
You must consider these additional factors before testing VDO read performance:
- If a 4 KiB block has never been written, VDO does not read from the storage and immediately responds with a zero block.
- If a 4 KiB block has been written but contains all zeros, VDO does not read from the storage and immediately responds with a zero block.
This behavior results in very fast read performance when there is no data to read. This is why read tests must prefill the volume with actual data.
4.1.3. Preparing the system for testing VDO performance
This procedure configures system settings to achieve optimal VDO performance during testing.
Testing beyond the bounds listed in any particular test might result in the loss of testing time due to abnormal results.
For example, the VDO tests describe a test that conducts random reads over a 100 GiB address range. To test a working set of 500 GiB, you must increase the amount of RAM allocated for the VDO block map cache accordingly.
Procedure
- Ensure that your CPU is running at its highest performance setting.
-
If possible, disable CPU frequency scaling using the BIOS configuration or the Linux
cpupowerutility. - If possible, enable dynamic processor frequency adjustment (Turbo Boost or Turbo Core) for the CPU. This feature introduces some variability in the test results, but improves overall performance.
File systems might have unique impacts on performance. They often skew performance measurements, making it harder to isolate the impact of VDO on the results.
If reasonable, measure performance on the raw block device. If this is not possible, format the device using the file system that VDO will use in the target implementation.
4.2. Creating a VDO volume for performance testing
This procedure creates a VDO volume with a logical size of 1 TiB on a 512 GiB physical volume for testing VDO performance.
Procedure
Create a VDO volume:
# vdo create --name=vdo-test \ --device=/dev/sdb \ --vdoLogicalSize=1T \ --writePolicy=policy \ --verbose-
Replace
/dev/sdbwith the path to a block device. -
To test the VDO
asyncmode on top of asynchronous storage, create an asynchronous volume using the--writePolicy=asyncoption. -
To test the VDO
syncmode on top of synchronous storage, create a synchronous volume using the--writePolicy=syncoption.
-
Replace
4.3. Cleaning up the VDO performance testing volume
This procedure removes the VDO volume used for testing VDO performance from the system.
Prerequisites
- A VDO test volume exists on the system.
Procedure
Remove the VDO test volume from the system:
# vdo remove --name=vdo-test
Verification
Verify that the volume has been removed:
# vdo list --all | grep vdo-testThe command should not list the VDO test partition.
4.4. Testing the effects of I/O depth on VDO performance
These tests determine the I/O depth that produces the optimal throughput and the lowest latency for your VDO configuration. I/O depth represents the number of I/O requests that the fio tool submits at a time.
Because VDO uses a 4 KiB sector size, the tests perform four-corner testing at 4 KiB I/O operations, and I/O depth of 1, 8, 16, 32, 64, 128, 256, 512, and 1024.
4.4.1. Testing the effect of I/O depth on sequential 100% reads in VDO
This test determines how sequential 100% read operations perform on a VDO volume at different I/O depth values.
Procedure
Create a new VDO volume.
For details, see Section 4.2, “Creating a VDO volume for performance testing”.
Prefill any areas that the test might access by performing a write
fiojob on the test volume:# fio --rw=write \ --bs=8M \ --name=vdo \ --filename=/dev/mapper/vdo-test \ --ioengine=libaio \ --thread \ --direct=1 \ --scramble_buffers=1Record the reported throughput and latency for sequential 100% reads:
# for depth in 1 2 4 8 16 32 64 128 256 512 1024 2048; do fio --rw=read \ --bs=4096 \ --name=vdo \ --filename=/dev/mapper/vdo-test \ --ioengine=libaio \ --numjobs=1 \ --thread \ --norandommap \ --runtime=300 \ --direct=1 \ --iodepth=$depth \ --scramble_buffers=1 \ --offset=0 \ --size=100g doneRemove the VDO test volume.
For details, see Section 4.3, “Cleaning up the VDO performance testing volume”.
4.4.2. Testing the effect of I/O depth on sequential 100% writes in VDO
This test determines how sequential 100% write operations perform on a VDO volume at different I/O depth values.
Procedure
Create a new VDO test volume.
For details, see Section 4.2, “Creating a VDO volume for performance testing”.
Prefill any areas that the test might access by performing a write
fiojob:# fio --rw=write \ --bs=8M \ --name=vdo \ --filename=/dev/mapper/vdo-test \ --ioengine=libaio \ --thread \ --direct=1 \ --scramble_buffers=1Record the reported throughput and latency for sequential 100% writes:
# for depth in 1 2 4 8 16 32 64 128 256 512 1024 2048; do fio --rw=write \ --bs=4096 \ --name=vdo \ --filename=/dev/mapper/vdo-test \ --ioengine=libaio \ --numjobs=1 \ --thread \ --norandommap \ --runtime=300 \ --direct=1 \ --iodepth=$depth \ --scramble_buffers=1 \ --offset=0 \ --size=100g doneRemove the VDO test volume.
For details, see Section 4.3, “Cleaning up the VDO performance testing volume”.
4.4.3. Testing the effect of I/O depth on random 100% reads in VDO
This test determines how random 100% read operations perform on a VDO volume at different I/O depth values.
Procedure
Create a new VDO test volume.
For details, see Section 4.2, “Creating a VDO volume for performance testing”.
Prefill any areas that the test might access by performing a write
fiojob:# fio --rw=write \ --bs=8M \ --name=vdo \ --filename=/dev/mapper/vdo-test \ --ioengine=libaio \ --thread \ --direct=1 \ --scramble_buffers=1Record the reported throughput and latency for random 100% reads:
# for depth in 1 2 4 8 16 32 64 128 256 512 1024 2048; do fio --rw=randread \ --bs=4096 \ --name=vdo \ --filename=/dev/mapper/vdo-test \ --ioengine=libaio \ --numjobs=1 \ --thread \ --norandommap \ --runtime=300 \ --direct=1 \ --iodepth=$depth \ --scramble_buffers=1 \ --offset=0 \ --size=100g doneRemove the VDO test volume.
For details, see Section 4.3, “Cleaning up the VDO performance testing volume”.
4.4.4. Testing the effect of I/O depth on random 100% writes in VDO
This test determines how random 100% write operations perform on a VDO volume at different I/O depth values.
You must recreate the VDO volume between each I/O depth test run.
Procedure
Perform the following series of steps separately for the I/O depth values of 1, 2, 4, 8, 16, 32, 64, 128, 256, 512, 1024, and 2048:
Create a new VDO test volume.
For details, see Section 4.2, “Creating a VDO volume for performance testing”.
Prefill any areas that the test might access by performing a write
fiojob:# fio --rw=write \ --bs=8M \ --name=vdo \ --filename=/dev/mapper/vdo-test \ --ioengine=libaio \ --thread \ --direct=1 \ --scramble_buffers=1Record the reported throughput and latency for random 100% writes:
# fio --rw=randwrite \ --bs=4096 \ --name=vdo \ --filename=/dev/mapper/vdo-test \ --ioengine=libaio \ --numjobs=1 \ --thread \ --norandommap \ --runtime=300 \ --direct=1 \ --iodepth=depth-value --scramble_buffers=1 \ --offset=0 \ --size=100g doneRemove the VDO test volume.
For details, see Section 4.3, “Cleaning up the VDO performance testing volume”.
4.4.5. Analysis of VDO performance at different I/O depths
The following example analyses VDO throughput and latency recorded at different I/O depth values.
Watch the behavior across the range and the points of inflection where increased I/O depth provides diminishing throughput gains. Sequential access and random access probably peak at different values, but the peaks might be different for all types of storage configurations.
Example 4.1. I/O depth analysis
Figure 4.1. VDO throughput analysis

Notice the "knee" in each performance curve:
- Marker 1 identifies the peak sequential throughput at point X. This particular configuration does not benefit from sequential 4 KiB I/O depth larger than X.
- Marker 2 identifies peak random 4 KiB throughput at point Z. This particular configuration does not benefit from random 4 KiB I/O depth larger than Z.
Beyond the I/O depth at points X and Z, there are diminishing bandwidth gains, and average request latency increases 1:1 for each additional I/O request.
The following image shows an example of the random write latency after the "knee" of the curve in the previous graph. You should test at these points for maximum throughput that incurs the least response time penalty.
Figure 4.2. VDO latency analysis

Optimal I/O depth
Point Z marks the optimal I/O depth. The test plan collects additional data with I/O depth equal to Z.
4.5. Testing the effects of I/O request size on VDO performance
Using these tests, you can identify the block size that produces the best performance of VDO at the optimal I/O depth.
The tests perform four-corner testing at a fixed I/O depth, with varied block sizes over the range of 8 KiB to 1 MiB.
Prerequisites
You have determined the optimal I/O depth value. For details, see Section 4.4, “Testing the effects of I/O depth on VDO performance”.
In the following tests, replace optimal-depth with the optimal I/O depth value.
4.5.1. Testing the effect of I/O request size on sequential writes in VDO
This test determines how sequential write operations perform on a VDO volume at different I/O request sizes.
Procedure
Create a new VDO volume.
For details, see Section 4.2, “Creating a VDO volume for performance testing”.
Prefill any areas that the test might access by performing a write
fiojob on the test volume:# fio --rw=write \ --bs=8M \ --name=vdo \ --filename=/dev/mapper/vdo-test \ --ioengine=libaio \ --thread \ --direct=1 \ --scramble_buffers=1Record the reported throughput and latency for the sequential write test:
# for iosize in 4 8 16 32 64 128 256 512 1024; do fio --rw=write \ --bs=${iosize}k \ --name=vdo \ --filename=/dev/mapper/vdo-test \ --ioengine=libaio \ --numjobs=1 \ --thread \ --norandommap \ --runtime=300 \ --direct=1 \ --iodepth=optimal-depth \ --scramble_buffers=1 \ --offset=0 \ --size=100g doneRemove the VDO test volume.
For details, see Section 4.3, “Cleaning up the VDO performance testing volume”.
4.5.2. Testing the effect of I/O request size on random writes in VDO
This test determines how random write operations perform on a VDO volume at different I/O request sizes.
You must recreate the VDO volume between each I/O request size test run.
Procedure
Perform the following series steps separately for the I/O request sizes of 4k, 8k, 16k, 32k, 64k, 128k, 256k, 512k, and 1024k:
Create a new VDO volume.
For details, see Section 4.2, “Creating a VDO volume for performance testing”.
Prefill any areas that the test might access by performing a write
fiojob on the test volume:# fio --rw=write \ --bs=8M \ --name=vdo \ --filename=/dev/mapper/vdo-test \ --ioengine=libaio \ --thread \ --direct=1 \ --scramble_buffers=1Record the reported throughput and latency for the random write test:
# fio --rw=randwrite \ --bs=request-size \ --name=vdo \ --filename=/dev/mapper/vdo-test \ --ioengine=libaio \ --numjobs=1 \ --thread \ --norandommap \ --runtime=300 \ --direct=1 \ --iodepth=optimal-depth \ --scramble_buffers=1 \ --offset=0 \ --size=100g doneRemove the VDO test volume.
For details, see Section 4.3, “Cleaning up the VDO performance testing volume”.
4.5.3. Testing the effect of I/O request size on sequential read in VDO
This test determines how sequential read operations perform on a VDO volume at different I/O request sizes.
Procedure
Create a new VDO volume.
For details, see Section 4.2, “Creating a VDO volume for performance testing”.
Prefill any areas that the test might access by performing a write
fiojob on the test volume:# fio --rw=write \ --bs=8M \ --name=vdo \ --filename=/dev/mapper/vdo-test \ --ioengine=libaio \ --thread \ --direct=1 \ --scramble_buffers=1Record the reported throughput and latency for the sequential read test:
# for iosize in 4 8 16 32 64 128 256 512 1024; do fio --rw=read \ --bs=${iosize}k \ --name=vdo \ --filename=/dev/mapper/vdo-test \ --ioengine=libaio \ --numjobs=1 \ --thread \ --norandommap \ --runtime=300 \ --direct=1 \ --iodepth=optimal-depth \ --scramble_buffers=1 \ --offset=0 \ --size=100g doneRemove the VDO test volume.
For details, see Section 4.3, “Cleaning up the VDO performance testing volume”.
4.5.4. Testing the effect of I/O request size on random read in VDO
This test determines how random read operations perform on a VDO volume at different I/O request sizes.
Procedure
Create a new VDO volume.
For details, see Section 4.2, “Creating a VDO volume for performance testing”.
Prefill any areas that the test might access by performing a write
fiojob on the test volume:# fio --rw=write \ --bs=8M \ --name=vdo \ --filename=/dev/mapper/vdo-test \ --ioengine=libaio \ --thread \ --direct=1 \ --scramble_buffers=1Record the reported throughput and latency for the random read test:
# for iosize in 4 8 16 32 64 128 256 512 1024; do fio --rw=read \ --bs=${iosize}k \ --name=vdo \ --filename=/dev/mapper/vdo-test \ --ioengine=libaio \ --numjobs=1 \ --thread \ --norandommap \ --runtime=300 \ --direct=1 \ --iodepth=optimal-depth \ --scramble_buffers=1 \ --offset=0 \ --size=100g doneRemove the VDO test volume.
For details, see Section 4.3, “Cleaning up the VDO performance testing volume”.
4.5.5. Analysis of VDO performance at different I/O request sizes
The following example analyses VDO throughput and latency recorded at different I/O request sizes.
Example 4.2. I/O request size analysis
Figure 4.3. Request size versus throughput analysis and key inflection points

Analyzing the example results:
Sequential writes reach a peak throughput at request size Y.
This curve demonstrates how applications that are configurable or naturally dominated by certain request sizes might perceive performance. Larger request sizes often provide more throughput because 4 KiB I/O operations might benefit from merging.
Sequential reads reach a similar peak throughput at point Z.
After these peaks, the overall latency before the I/O operation completes increases with no additional throughput. You should tune the device to not accept I/O operations larger than this size.
Random reads achieve peak throughput at point X.
Certain devices might achieve near-sequential throughput rates at large request size random accesses, but others suffer more penalty when varying from purely sequential access.
Random writes achieve peak throughput at point Y.
Random writes involve the most interaction of a deduplication device, and VDO achieves high performance especially when request sizes or I/O depths are large.
4.6. Testing the effects of mixed I/O loads on VDO performance
This test determines how your VDO configuration behaves with mixed read and write I/O loads, and analyzes the effects of mixed reads and writes at the optimal random queue depth and request sizes from 4 KB to 1 MB.
This procedure performs four-corner testing at fixed I/O depth, varied block size over the 8 KB to 256 KB range, and set read percentage at 10% increments, beginning with 0%.
Prerequisites
You have determined the optimal I/O depth value. For details, see Section 4.4, “Testing the effects of I/O depth on VDO performance”.
In the following procedure, replace optimal-depth with the optimal I/O depth value.
Procedure
Create a new VDO volume.
For details, see Section 4.2, “Creating a VDO volume for performance testing”.
Prefill any areas that the test might access by performing a write
fiojob on the test volume:# fio --rw=write \ --bs=8M \ --name=vdo \ --filename=/dev/mapper/vdo-test \ --ioengine=libaio \ --thread \ --direct=1 \ --scramble_buffers=1Record the reported throughput and latency for the read and write input stimulus:
# for readmix in 0 10 20 30 40 50 60 70 80 90 100; do for iosize in 4 8 16 32 64 128 256 512 1024; do fio --rw=rw \ --rwmixread=$readmix \ --bs=${iosize}k \ --name=vdo \ --filename=/dev/mapper/vdo-test \ --ioengine=libaio \ --numjobs=1 \ --thread \ --norandommap \ --runtime=300 \ --direct=0 \ --iodepth=optimal-depth \ --scramble_buffers=1 \ --offset=0 \ --size=100g done doneRemove the VDO test volume.
For details, see Section 4.3, “Cleaning up the VDO performance testing volume”.
Graph the test results.
Example 4.3. Mixed I/O loads analysis
The following image shows an example of how VDO might respond to mixed I/O loads:
Figure 4.4. Performance is consistent across varying read and write mixes

Aggregate performance and aggregate latency are relatively consistent across the range of mixing reads and writes, trending from the lower maximum write throughput to the higher maximum read throughput.
This behavior might vary with different storage, but the important observation is that the performance is consistent under varying loads or that you can understand performance expectation for applications that demonstrate specific read and write mixes.
NoteIf your system does not show a similar response consistency, it might be a sign of a sub-optimal configuration. Contact your Red Hat Sales Engineer if this occurs.
4.7. Testing the effects of application environments on VDO performance
These tests determine how your VDO configuration behaves when deployed in a mixed, real application environment. If you know more details about the expected environment, test them as well.
Prerequisites
- Consider limiting the permissible queue depth on your configuration.
- If possible, tune the application to issue requests with the block sizes that are the most beneficial to VDO performance.
Procedure
Create a new VDO volume.
For details, see Section 4.2, “Creating a VDO volume for performance testing”.
Prefill any areas that the test might access by performing a write
fiojob on the test volume:# fio --rw=write \ --bs=8M \ --name=vdo \ --filename=/dev/mapper/vdo-test \ --ioengine=libaio \ --thread \ --direct=1 \ --scramble_buffers=1Record the reported throughput and latency for the read and write input stimulus:
# for readmix in 20 50 80; do for iosize in 4 8 16 32 64 128 256 512 1024; do fio --rw=rw \ --rwmixread=$readmix \ --bsrange=4k-256k \ --name=vdo \ --filename=/dev/mapper/vdo-name \ --ioengine=libaio \ --numjobs=1 \ --thread \ --norandommap \ --runtime=300 \ --direct=0 \ --iodepth=$iosize \ --scramble_buffers=1 \ --offset=0 \ --size=100g done doneRemove the VDO test volume.
For details, see Section 4.3, “Cleaning up the VDO performance testing volume”.
Graph the test results.
Example 4.4. Application environment analysis
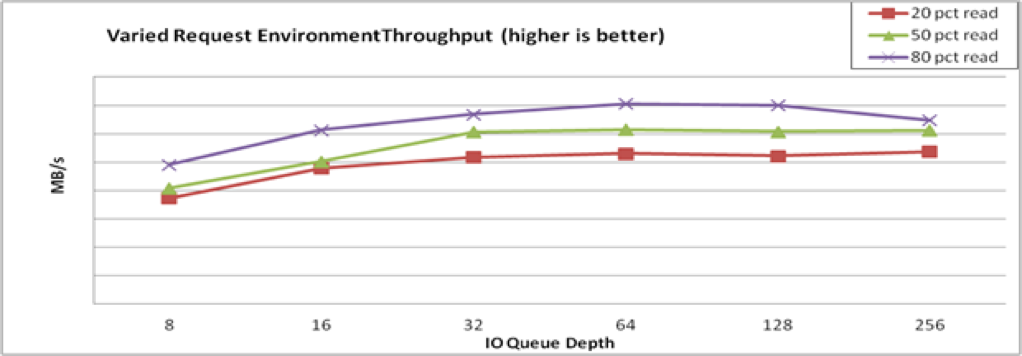
The following image shows an example of how VDO might respond to mixed I/O loads:
Figure 4.5. Mixed environment performance
4.8. Options used for testing VDO performance with fio
The VDO tests use the fio utility to synthetically generate data with repeatable characteristics. The following fio options are necessary to simulate real world workloads in the tests:
| Argument | Description | Value used in the tests |
|---|---|---|
|
|
The quantity of data that
See also the | 100 GiB |
|
|
The block size of each read-and-write request produced by Red Hat recommends a 4 KiB block size to match 4 KiB default of VDO. | 4k |
|
|
The number of jobs that
Each job sends the amount of data specified by the To achieve peak performance on flash disks (SSD), Red Hat recommends at least two jobs. One job is typically enough to saturate rotational disk (HDD) throughput. | 1 for HDD, 2 for SSD |
|
|
Instructs | none |
|
|
The I/O engine that
Red Hat testing uses the asynchronous unbuffered engine called |
|
|
| The option enables requests submitted to the device to bypass the kernel page cache.
You must use the |
1 ( |
|
| The number of I/O buffers in flight at any time. A high value usually increases performance, particularly for random reads or writes. High values ensure that the controller always has requests to batch. However, setting the value too high, (typically greater than 1K, might cause undesirable latency. Red Hat recommends a value between 128 and 512. The final value is a trade-off and depends on how your application tolerates latency. | 128 at minimum |
|
| The number of I/O requests to create when the I/O depth buffer pool begins to empty. This option limits task switching from I/O operations to buffer creation during the test. | 16 |
|
| The number of I/O operations to complete before submitting a batch. This option limits task switching from I/O operations to buffer creation during the test. | 16 |
|
| Disables time-of-day calls to calculate latency. This setting lowers throughput if enabled. Enable the option unless you require latency measurement. | 1 |