Chapter 11. Messaging Endpoints
Abstract
The messaging endpoint patterns describe various features and qualities of service that can be configured on an endpoint.
11.1. Messaging Mapper
Overview
The messaging mapper pattern describes how to map domain objects to and from a canonical message format, where the message format is chosen to be as platform neutral as possible. The chosen message format should be suitable for transmission through a Section 6.5, “Message Bus”, where the message bus is the backbone for integrating a variety of different systems, some of which might not be object-oriented.
Many different approaches are possible, but not all of them fulfill the requirements of a messaging mapper. For example, an obvious way to transmit an object is to use object serialization, which enables you to write an object to a data stream using an unambiguous encoding (supported natively in Java). However, this is not a suitable approach to use for the messaging mapper pattern because the serialization format is understood only by Java applications. Java object serialization creates an impedance mismatch between the original application and the other applications in the messaging system.
The requirements for a messaging mapper can be summarized as follows:
- The canonical message format used to transmit domain objects should be suitable for consumption by non-object oriented applications.
- The mapper code should be implemented separately from both the domain object code and the messaging infrastructure. Apache Camel helps fulfill this requirement by providing hooks that can be used to insert mapper code into a route.
- The mapper might need to find an effective way of dealing with certain object-oriented concepts such as inheritance, object references, and object trees. The complexity of these issues varies from application to application, but the aim of the mapper implementation must always be to create messages that can be processed effectively by non-object-oriented applications.
Finding objects to map
You can use one of the following mechanisms to find the objects to map:
-
Find a registered bean. — For singleton objects and small numbers of objects, you could use the
CamelContextregistry to store references to beans. For example, if a bean instance is instantiated using Spring XML, it is automatically entered into the registry, where the bean is identified by the value of itsidattribute. Select objects using the JoSQL language. — If all of the objects you want to access are already instantiated at runtime, you could use the JoSQL language to locate a specific object (or objects). For example, if you have a class,
org.apache.camel.builder.sql.Person, with anamebean property and the incoming message has aUserNameheader, you could select the object whosenameproperty equals the value of theUserNameheader using the following code:import static org.apache.camel.builder.sql.SqlBuilder.sql; import org.apache.camel.Expression; ... Expression expression = sql("SELECT * FROM org.apache.camel.builder.sql.Person where name = :UserName"); Object value = expression.evaluate(exchange);Where the syntax,
:HeaderName, is used to substitute the value of a header in a JoSQL expression.- Dynamic — For a more scalable solution, it might be necessary to read object data from a database. In some cases, the existing object-oriented application might already provide a finder object that can load objects from the database. In other cases, you might have to write some custom code to extract objects from a database, and in these cases the JDBC component and the SQL component might be useful.
11.2. Event Driven Consumer
Overview
The event-driven consumer pattern, shown in Figure 11.1, “Event Driven Consumer Pattern”, is a pattern for implementing the consumer endpoint in a Apache Camel component, and is only relevant to programmers who need to develop a custom component in Apache Camel. Existing components already have a consumer implementation pattern hard-wired into them.
Figure 11.1. Event Driven Consumer Pattern
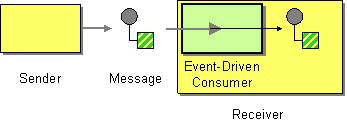
Consumers that conform to this pattern provide an event method that is automatically called by the messaging channel or transport layer whenever an incoming message is received. One of the characteristics of the event-driven consumer pattern is that the consumer endpoint itself does not provide any threads to process the incoming messages. Instead, the underlying transport or messaging channel implicitly provides a processor thread when it invokes the exposed event method (which blocks for the duration of the message processing).
For more details about this implementation pattern, see Section 38.1.3, “Consumer Patterns and Threading” and Chapter 41, Consumer Interface.
11.3. Polling Consumer
Overview
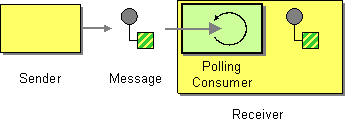
The polling consumer pattern, shown in Figure 11.2, “Polling Consumer Pattern”, is a pattern for implementing the consumer endpoint in a Apache Camel component, so it is only relevant to programmers who need to develop a custom component in Apache Camel. Existing components already have a consumer implementation pattern hard-wired into them.
Consumers that conform to this pattern expose polling methods, receive(), receive(long timeout), and receiveNoWait() that return a new exchange object, if one is available from the monitored resource. A polling consumer implementation must provide its own thread pool to perform the polling.
For more details about this implementation pattern, see Section 38.1.3, “Consumer Patterns and Threading”, Chapter 41, Consumer Interface, and Section 37.3, “Using the Consumer Template”.
Figure 11.2. Polling Consumer Pattern
Scheduled poll consumer
Many of the Apache Camel consumer endpoints employ a scheduled poll pattern to receive messages at the start of a route. That is, the endpoint appears to implement an event-driven consumer interface, but internally a scheduled poll is used to monitor a resource that provides the incoming messages for the endpoint.
See Section 41.2, “Implementing the Consumer Interface” for details of how to implement this pattern.
Quartz component
You can use the quartz component to provide scheduled delivery of messages using the Quartz enterprise scheduler. See Quartz in the Apache Camel Component Reference Guide and Quartz Component for details.
11.4. Competing Consumers
Overview
The competing consumers pattern, shown in Figure 11.3, “Competing Consumers Pattern”, enables multiple consumers to pull messages from the same queue, with the guarantee that each message is consumed once only. This pattern can be used to replace serial message processing with concurrent message processing (bringing a corresponding reduction in response latency).
Figure 11.3. Competing Consumers Pattern
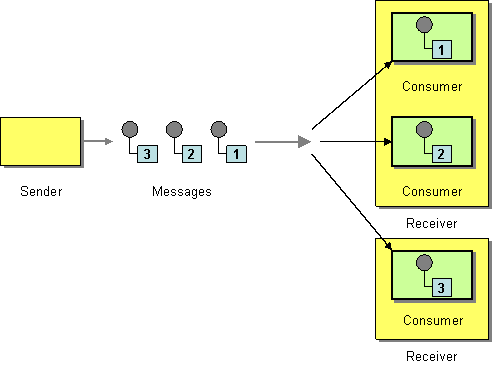
The following components demonstrate the competing consumers pattern:
JMS based competing consumers
A regular JMS queue implicitly guarantees that each message can only be consumed at once. Hence, a JMS queue automatically supports the competing consumers pattern. For example, you could define three competing consumers that pull messages from the JMS queue, HighVolumeQ, as follows:
from("jms:HighVolumeQ").to("cxf:bean:replica01");
from("jms:HighVolumeQ").to("cxf:bean:replica02");
from("jms:HighVolumeQ").to("cxf:bean:replica03");
Where the CXF (Web services) endpoints, replica01, replica02, and replica03, process messages from the HighVolumeQ queue in parallel.
Alternatively, you can set the JMS query option, concurrentConsumers, to create a thread pool of competing consumers. For example, the following route creates a pool of three competing threads that pick messages from the specified queue:
from("jms:HighVolumeQ?concurrentConsumers=3").to("cxf:bean:replica01");
And the concurrentConsumers option can also be specified in XML DSL, as follows:
<route>
<from uri="jms:HighVolumeQ?concurrentConsumers=3"/>
<to uri="cxf:bean:replica01"/>
</route>JMS topics cannot support the competing consumers pattern. By definition, a JMS topic is intended to send multiple copies of the same message to different consumers. Therefore, it is not compatible with the competing consumers pattern.
SEDA based competing consumers
The purpose of the SEDA component is to simplify concurrent processing by breaking the computation into stages. A SEDA endpoint essentially encapsulates an in-memory blocking queue (implemented by java.util.concurrent.BlockingQueue). Therefore, you can use a SEDA endpoint to break a route into stages, where each stage might use multiple threads. For example, you can define a SEDA route consisting of two stages, as follows:
// Stage 1: Read messages from file system.
from("file://var/messages").to("seda:fanout");
// Stage 2: Perform concurrent processing (3 threads).
from("seda:fanout").to("cxf:bean:replica01");
from("seda:fanout").to("cxf:bean:replica02");
from("seda:fanout").to("cxf:bean:replica03");
Where the first stage contains a single thread that consumes message from a file endpoint, file://var/messages, and routes them to a SEDA endpoint, seda:fanout. The second stage contains three threads: a thread that routes exchanges to cxf:bean:replica01, a thread that routes exchanges to cxf:bean:replica02, and a thread that routes exchanges to cxf:bean:replica03. These three threads compete to take exchange instances from the SEDA endpoint, which is implemented using a blocking queue. Because the blocking queue uses locking to prevent more than one thread from accessing the queue at a time, you are guaranteed that each exchange instance can only be consumed once.
For a discussion of the differences between a SEDA endpoint and a thread pool created by thread(), see SEDA component in the Apache Camel Component Reference Guide.
11.5. Message Dispatcher
Overview
The message dispatcher pattern, shown in Figure 11.4, “Message Dispatcher Pattern”, is used to consume messages from a channel and then distribute them locally to performers, which are responsible for processing the messages. In a Apache Camel application, performers are usually represented by in-process endpoints, which are used to transfer messages to another section of the route.
Figure 11.4. Message Dispatcher Pattern
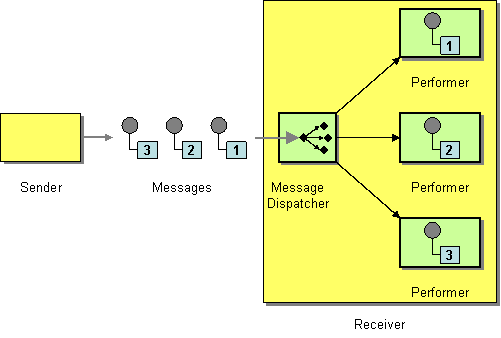
You can implement the message dispatcher pattern in Apache Camel using one of the following approaches:
JMS selectors
If your application consumes messages from a JMS queue, you can implement the message dispatcher pattern using JMS selectors. A JMS selector is a predicate expression involving JMS headers and JMS properties. If the selector evaluates to true, the JMS message is allowed to reach the consumer, and if the selector evaluates to false, the JMS message is blocked. In many respects, a JMS selector is like a Section 8.2, “Message Filter”, but it has the additional advantage that the filtering is implemented inside the JMS provider. This means that a JMS selector can block messages before they are transmitted to the Apache Camel application. This provides a significant efficiency advantage.
In Apache Camel, you can define a JMS selector on a consumer endpoint by setting the selector query option on a JMS endpoint URI. For example:
from("jms:dispatcher?selector=CountryCode='US'").to("cxf:bean:replica01");
from("jms:dispatcher?selector=CountryCode='IE'").to("cxf:bean:replica02");
from("jms:dispatcher?selector=CountryCode='DE'").to("cxf:bean:replica03");
Where the predicates that appear in a selector string are based on a subset of the SQL92 conditional expression syntax (for full details, see the JMS specification). The identifiers appearing in a selector string can refer either to JMS headers or to JMS properties. For example, in the preceding routes, the sender sets a JMS property called CountryCode.
If you want to add a JMS property to a message from within your Apache Camel application, you can do so by setting a message header (either on In message or on Out messages). When reading or writing to JMS endpoints, Apache Camel maps JMS headers and JMS properties to, and from, its native message headers.
Technically, the selector strings must be URL encoded according to the application/x-www-form-urlencoded MIME format (see the HTML specification). In practice, the &(ampersand) character might cause difficulties because it is used to delimit each query option in the URI. For more complex selector strings that might need to embed the & character, you can encode the strings using the java.net.URLEncoder utility class. For example:
from("jms:dispatcher?selector=" + java.net.URLEncoder.encode("CountryCode='US'","UTF-8")).
to("cxf:bean:replica01");Where the UTF-8 encoding must be used.
JMS selectors in ActiveMQ
You can also define JMS selectors on ActiveMQ endpoints. For example:
from("activemq:dispatcher?selector=CountryCode='US'").to("cxf:bean:replica01");
from("activemq:dispatcher?selector=CountryCode='IE'").to("cxf:bean:replica02");
from("activemq:dispatcher?selector=CountryCode='DE'").to("cxf:bean:replica03");For more details, see ActiveMQ: JMS Selectors and ActiveMQ Message Properties.
Content-based router
The essential difference between the content-based router pattern and the message dispatcher pattern is that a content-based router dispatches messages to physically separate destinations (remote endpoints), and a message dispatcher dispatches messages locally, within the same process space. In Apache Camel, the distinction between these two patterns is determined by the target endpoint. The same router logic is used to implement both a content-based router and a message dispatcher. When the target endpoint is remote, the route defines a content-based router. When the target endpoint is in-process, the route defines a message dispatcher.
For details and examples of how to use the content-based router pattern see Section 8.1, “Content-Based Router”.
11.6. Selective Consumer
Overview
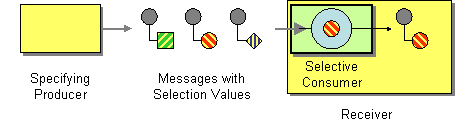
The selective consumer pattern, shown in Figure 11.5, “Selective Consumer Pattern”, describes a consumer that applies a filter to incoming messages, so that only messages meeting specific selection criteria are processed.
Figure 11.5. Selective Consumer Pattern
You can implement the selective consumer pattern in Apache Camel using one of the following approaches:
JMS selector
A JMS selector is a predicate expression involving JMS headers and JMS properties. If the selector evaluates to true, the JMS message is allowed to reach the consumer, and if the selector evaluates to false, the JMS message is blocked. For example, to consume messages from the queue, selective, and select only those messages whose country code property is equal to US, you can use the following Java DSL route:
from("jms:selective?selector=" + java.net.URLEncoder.encode("CountryCode='US'","UTF-8")).
to("cxf:bean:replica01");
Where the selector string, CountryCode='US', must be URL encoded (using UTF-8 characters) to avoid trouble with parsing the query options. This example presumes that the JMS property, CountryCode, is set by the sender. For more details about JMS selectors, see the section called “JMS selectors”.
If a selector is applied to a JMS queue, messages that are not selected remain on the queue and are potentially available to other consumers attached to the same queue.
JMS selector in ActiveMQ
You can also define JMS selectors on ActiveMQ endpoints. For example:
from("acivemq:selective?selector=" + java.net.URLEncoder.encode("CountryCode='US'","UTF-8")).
to("cxf:bean:replica01");For more details, see ActiveMQ: JMS Selectors and ActiveMQ Message Properties.
Message filter
If it is not possible to set a selector on the consumer endpoint, you can insert a filter processor into your route instead. For example, you can define a selective consumer that processes only messages with a US country code using Java DSL, as follows:
from("seda:a").filter(header("CountryCode").isEqualTo("US")).process(myProcessor);The same route can be defined using XML configuration, as follows:
<camelContext id="buildCustomProcessorWithFilter" xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="seda:a"/>
<filter>
<xpath>$CountryCode = 'US'</xpath>
<process ref="#myProcessor"/>
</filter>
</route>
</camelContext>For more information about the Apache Camel filter processor, see Section 8.2, “Message Filter”.
Be careful about using a message filter to select messages from a JMS queue. When using a filter processor, blocked messages are simply discarded. Hence, if the messages are consumed from a queue (which allows each message to be consumed only once — see Section 11.4, “Competing Consumers”), then blocked messages are not processed at all. This might not be the behavior you want.
11.7. Durable Subscriber
Overview
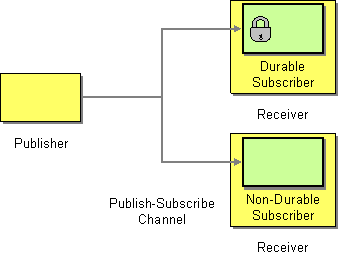
A durable subscriber, as shown in Figure 11.6, “Durable Subscriber Pattern”, is a consumer that wants to receive all of the messages sent over a particular Section 6.2, “Publish-Subscribe Channel” channel, including messages sent while the consumer is disconnected from the messaging system. This requires the messaging system to store messages for later replay to the disconnected consumer. There also has to be a mechanism for a consumer to indicate that it wants to establish a durable subscription. Generally, a publish-subscribe channel (or topic) can have both durable and non-durable subscribers, which behave as follows:
- non-durable subscriber — Can have two states: connected and disconnected. While a non-durable subscriber is connected to a topic, it receives all of the topic’s messages in real time. However, a non-durable subscriber never receives messages sent to the topic while the subscriber is disconnected.
- durable subscriber — Can have two states: connected and inactive. The inactive state means that the durable subscriber is disconnected from the topic, but wants to receive the messages that arrive in the interim. When the durable subscriber reconnects to the topic, it receives a replay of all the messages sent while it was inactive.
Figure 11.6. Durable Subscriber Pattern
JMS durable subscriber
The JMS component implements the durable subscriber pattern. In order to set up a durable subscription on a JMS endpoint, you must specify a client ID, which identifies this particular connection, and a durable subscription name, which identifies the durable subscriber. For example, the following route sets up a durable subscription to the JMS topic, news, with a client ID of conn01 and a durable subscription name of John.Doe:
from("jms:topic:news?clientId=conn01&durableSubscriptionName=John.Doe").
to("cxf:bean:newsprocessor");You can also set up a durable subscription using the ActiveMQ endpoint:
from("activemq:topic:news?clientId=conn01&durableSubscriptionName=John.Doe").
to("cxf:bean:newsprocessor");If you want to process the incoming messages concurrently, you can use a SEDA endpoint to fan out the route into multiple, parallel segments, as follows:
from("jms:topic:news?clientId=conn01&durableSubscriptionName=John.Doe").
to("seda:fanout");
from("seda:fanout").to("cxf:bean:newsproc01");
from("seda:fanout").to("cxf:bean:newsproc02");
from("seda:fanout").to("cxf:bean:newsproc03");Where each message is processed only once, because the SEDA component supports the competing consumers pattern.
Alternative example
Another alternative is to combine the Section 11.5, “Message Dispatcher” or Section 8.1, “Content-Based Router” with File or JPA components for durable subscribers then something like SEDA for non-durable.
Here is a simple example of creating durable subscribers to a JMS topic
Using the Fluent Builders
from("direct:start").to("activemq:topic:foo");
from("activemq:topic:foo?clientId=1&durableSubscriptionName=bar1").to("mock:result1");
from("activemq:topic:foo?clientId=2&durableSubscriptionName=bar2").to("mock:result2");Using the Spring XML Extensions
<route>
<from uri="direct:start"/>
<to uri="activemq:topic:foo"/>
</route>
<route>
<from uri="activemq:topic:foo?clientId=1&durableSubscriptionName=bar1"/>
<to uri="mock:result1"/>
</route>
<route>
<from uri="activemq:topic:foo?clientId=2&durableSubscriptionName=bar2"/>
<to uri="mock:result2"/>
</route>Here is another example of JMS durable subscribers, but this time using virtual topics (recommended by AMQ over durable subscriptions)
Using the Fluent Builders
from("direct:start").to("activemq:topic:VirtualTopic.foo");
from("activemq:queue:Consumer.1.VirtualTopic.foo").to("mock:result1");
from("activemq:queue:Consumer.2.VirtualTopic.foo").to("mock:result2");Using the Spring XML Extensions
<route>
<from uri="direct:start"/>
<to uri="activemq:topic:VirtualTopic.foo"/>
</route>
<route>
<from uri="activemq:queue:Consumer.1.VirtualTopic.foo"/>
<to uri="mock:result1"/>
</route>
<route>
<from uri="activemq:queue:Consumer.2.VirtualTopic.foo"/>
<to uri="mock:result2"/>
</route>11.8. Idempotent Consumer
Overview
The idempotent consumer pattern is used to filter out duplicate messages. For example, consider a scenario where the connection between a messaging system and a consumer endpoint is abruptly lost due to some fault in the system. If the messaging system was in the middle of transmitting a message, it might be unclear whether or not the consumer received the last message. To improve delivery reliability, the messaging system might decide to redeliver such messages as soon as the connection is re-established. Unfortunately, this entails the risk that the consumer might receive duplicate messages and, in some cases, the effect of duplicating a message may have undesirable consequences (such as debiting a sum of money twice from your account). In this scenario, an idempotent consumer could be used to weed out undesired duplicates from the message stream.
Camel provides the following Idempotent Consumer implementations:
-
MemoryIdempotentRepository - KafkaIdempotentRepository
- File
- Hazelcast
- SQL
- JPA
Idempotent consumer with in-memory cache
In Apache Camel, the idempotent consumer pattern is implemented by the idempotentConsumer() processor, which takes two arguments:
-
messageIdExpression— An expression that returns a message ID string for the current message. -
messageIdRepository— A reference to a message ID repository, which stores the IDs of all the messages received.
As each message comes in, the idempotent consumer processor looks up the current message ID in the repository to see if this message has been seen before. If yes, the message is discarded; if no, the message is allowed to pass and its ID is added to the repository.
The code shown in Example 11.1, “Filtering Duplicate Messages with an In-memory Cache” uses the TransactionID header to filter out duplicates.
Example 11.1. Filtering Duplicate Messages with an In-memory Cache
import static org.apache.camel.processor.idempotent.MemoryMessageIdRepository.memoryMessageIdRepository;
...
RouteBuilder builder = new RouteBuilder() {
public void configure() {
from("seda:a")
.idempotentConsumer(
header("TransactionID"),
memoryMessageIdRepository(200)
).to("seda:b");
}
};
Where the call to memoryMessageIdRepository(200) creates an in-memory cache that can hold up to 200 message IDs.
You can also define an idempotent consumer using XML configuration. For example, you can define the preceding route in XML, as follows:
<camelContext id="buildIdempotentConsumer" xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="seda:a"/>
<idempotentConsumer messageIdRepositoryRef="MsgIDRepos">
<simple>header.TransactionID</simple>
<to uri="seda:b"/>
</idempotentConsumer>
</route>
</camelContext>
<bean id="MsgIDRepos" class="org.apache.camel.processor.idempotent.MemoryMessageIdRepository">
<!-- Specify the in-memory cache size. -->
<constructor-arg type="int" value="200"/>
</bean>From Camel 2.17, Idempotent Repository supports optional serialized headers.
Idempotent consumer with JPA repository
The in-memory cache suffers from the disadvantages of easily running out of memory and not working in a clustered environment. To overcome these disadvantages, you can use a Java Persistent API (JPA) based repository instead. The JPA message ID repository uses an object-oriented database to store the message IDs. For example, you can define a route that uses a JPA repository for the idempotent consumer, as follows:
import org.springframework.orm.jpa.JpaTemplate;
import org.apache.camel.spring.SpringRouteBuilder;
import static org.apache.camel.processor.idempotent.jpa.JpaMessageIdRepository.jpaMessageIdRepository;
...
RouteBuilder builder = new SpringRouteBuilder() {
public void configure() {
from("seda:a").idempotentConsumer(
header("TransactionID"),
jpaMessageIdRepository(bean(JpaTemplate.class), "myProcessorName")
).to("seda:b");
}
};The JPA message ID repository is initialized with two arguments:
-
JpaTemplateinstance — Provides the handle for the JPA database. - processor name — Identifies the current idempotent consumer processor.
The SpringRouteBuilder.bean() method is a shortcut that references a bean defined in the Spring XML file. The JpaTemplate bean provides a handle to the underlying JPA database. See the JPA documentation for details of how to configure this bean.
For more details about setting up a JPA repository, see JPA Component documentation, the Spring JPA documentation, and the sample code in the Camel JPA unit test.
Spring XML example
The following example uses the myMessageId header to filter out duplicates:
<!-- repository for the idempotent consumer -->
<bean id="myRepo" class="org.apache.camel.processor.idempotent.MemoryIdempotentRepository"/>
<camelContext xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:start"/>
<idempotentConsumer messageIdRepositoryRef="myRepo">
<!-- use the messageId header as key for identifying duplicate messages -->
<header>messageId</header>
<!-- if not a duplicate send it to this mock endpoint -->
<to uri="mock:result"/>
</idempotentConsumer>
</route>
</camelContext>Idempotent consumer with JDBC repository
A JDBC repository is also supported for storing message IDs in the idempotent consumer pattern. The implementation of the JDBC repository is provided by the SQL component, so if you are using the Maven build system, add a dependency on the camel-sql artifact.
You can use the SingleConnectionDataSource JDBC wrapper class from the Spring persistence API in order to instantiate the connection to a SQL database. For example, to instantiate a JDBC connection to a HyperSQL database instance, you could define the following JDBC data source:
<bean id="dataSource" class="org.springframework.jdbc.datasource.SingleConnectionDataSource">
<property name="driverClassName" value="org.hsqldb.jdbcDriver"/>
<property name="url" value="jdbc:hsqldb:mem:camel_jdbc"/>
<property name="username" value="sa"/>
<property name="password" value=""/>
</bean>
The preceding JDBC data source uses the HyperSQL mem protocol, which creates a memory-only database instance. This is a toy implementation of the HyperSQL database which is not actually persistent.
Using the preceding data source, you can define an idempotent consumer pattern that uses the JDBC message ID repository, as follows:
<bean id="messageIdRepository" class="org.apache.camel.processor.idempotent.jdbc.JdbcMessageIdRepository">
<constructor-arg ref="dataSource" />
<constructor-arg value="myProcessorName" />
</bean>
<camel:camelContext>
<camel:errorHandler id="deadLetterChannel" type="DeadLetterChannel" deadLetterUri="mock:error">
<camel:redeliveryPolicy maximumRedeliveries="0" maximumRedeliveryDelay="0" logStackTrace="false" />
</camel:errorHandler>
<camel:route id="JdbcMessageIdRepositoryTest" errorHandlerRef="deadLetterChannel">
<camel:from uri="direct:start" />
<camel:idempotentConsumer messageIdRepositoryRef="messageIdRepository">
<camel:header>messageId</camel:header>
<camel:to uri="mock:result" />
</camel:idempotentConsumer>
</camel:route>
</camel:camelContext>How to handle duplicate messages in the route
Available as of Camel 2.8
You can now set the skipDuplicate option to false which instructs the idempotent consumer to route duplicate messages as well. However the duplicate message has been marked as duplicate by having a property on the the section called “Exchanges” set to true. We can leverage this fact by using a Section 8.1, “Content-Based Router” or Section 8.2, “Message Filter” to detect this and handle duplicate messages.
For example in the following example we use the Section 8.2, “Message Filter” to send the message to a duplicate endpoint, and then stop continue routing that message.
from("direct:start")
// instruct idempotent consumer to not skip duplicates as we will filter then our self
.idempotentConsumer(header("messageId")).messageIdRepository(repo).skipDuplicate(false)
.filter(property(Exchange.DUPLICATE_MESSAGE).isEqualTo(true))
// filter out duplicate messages by sending them to someplace else and then stop
.to("mock:duplicate")
.stop()
.end()
// and here we process only new messages (no duplicates)
.to("mock:result");The sample example in XML DSL would be:
<!-- idempotent repository, just use a memory based for testing -->
<bean id="myRepo" class="org.apache.camel.processor.idempotent.MemoryIdempotentRepository"/>
<camelContext xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:start"/>
<!-- we do not want to skip any duplicate messages -->
<idempotentConsumer messageIdRepositoryRef="myRepo" skipDuplicate="false">
<!-- use the messageId header as key for identifying duplicate messages -->
<header>messageId</header>
<!-- we will to handle duplicate messages using a filter -->
<filter>
<!-- the filter will only react on duplicate messages, if this property is set on the Exchange -->
<property>CamelDuplicateMessage</property>
<!-- and send the message to this mock, due its part of an unit test -->
<!-- but you can of course do anything as its part of the route -->
<to uri="mock:duplicate"/>
<!-- and then stop -->
<stop/>
</filter>
<!-- here we route only new messages -->
<to uri="mock:result"/>
</idempotentConsumer>
</route>
</camelContext>How to handle duplicate message in a clustered environment with a data grid
If you have running Camel in a clustered environment, a in memory idempotent repository doesn’t work (see above). You can setup either a central database or use the idempotent consumer implementation based on the Hazelcast data grid. Hazelcast finds the nodes over multicast (which is default - configure Hazelcast for tcp-ip) and creates automatically a map based repository:
HazelcastIdempotentRepository idempotentRepo = new HazelcastIdempotentRepository("myrepo");
from("direct:in").idempotentConsumer(header("messageId"), idempotentRepo).to("mock:out");You have to define how long the repository should hold each message id (default is to delete it never). To avoid that you run out of memory you should create an eviction strategy based on the Hazelcast configuration. For additional information see Hazelcast.
See this link:http://camel.apache.org/hazelcast-idempotent-repository-tutorial.html[Idempotent Repository
tutorial] to learn more about how to setup such an idempotent repository on two cluster nodes using Apache Karaf.
Options
The Idempotent Consumer has the following options:
| Option | Default | Description |
|
|
| Camel 2.0: Eager controls whether Camel adds the message to the repository before or after the exchange has been processed. If enabled before then Camel will be able to detect duplicate messages even when messages are currently in progress. By disabling Camel will only detect duplicates when a message has successfully been processed. |
|
|
|
A reference to a |
|
|
|
Camel 2.8: Sets whether to skip duplicate messages. If set to |
|
|
| Camel 2.16: Sets whether to complete the Idempotent consumer eager, when the exchange is done.
If you set the
If you set the |
11.9. Transactional Client
Overview
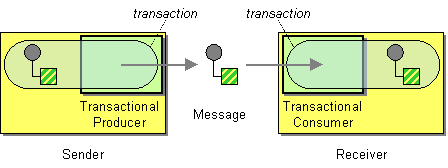
The transactional client pattern, shown in Figure 11.7, “Transactional Client Pattern”, refers to messaging endpoints that can participate in a transaction. Apache Camel supports transactions using Spring transaction management.
Figure 11.7. Transactional Client Pattern
Transaction oriented endpoints
Not all Apache Camel endpoints support transactions. Those that do are called transaction oriented endpoints (or TOEs). For example, both the JMS component and the ActiveMQ component support transactions.
To enable transactions on a component, you must perform the appropriate initialization before adding the component to the CamelContext. This entails writing code to initialize your transactional components explicitly.
References
The details of configuring transactions in Apache Camel are beyond the scope of this guide. For full details of how to use transactions, see the Apache Camel Transaction Guide.
11.10. Messaging Gateway
Overview
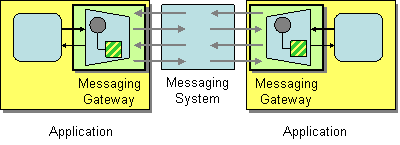
The messaging gateway pattern, shown in Figure 11.8, “Messaging Gateway Pattern”, describes an approach to integrating with a messaging system, where the messaging system’s API remains hidden from the programmer at the application level. One of the more common example is when you want to translate synchronous method calls into request/reply message exchanges, without the programmer being aware of this.
Figure 11.8. Messaging Gateway Pattern
The following Apache Camel components provide this kind of integration with the messaging system:
- CXF
- Bean component
11.11. Service Activator
Overview
The service activator pattern, shown in Figure 11.9, “Service Activator Pattern”, describes the scenario where a service’s operations are invoked in response to an incoming request message. The service activator identifies which operation to call and extracts the data to use as the operation’s parameters. Finally, the service activator invokes an operation using the data extracted from the message. The operation invocation can be either oneway (request only) or two-way (request/reply).
Figure 11.9. Service Activator Pattern
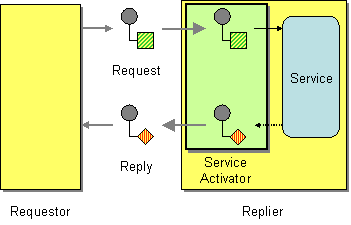
In many respects, a service activator resembles a conventional remote procedure call (RPC), where operation invocations are encoded as messages. The main difference is that a service activator needs to be more flexible. An RPC framework standardizes the request and reply message encodings (for example, Web service operations are encoded as SOAP messages), whereas a service activator typically needs to improvise the mapping between the messaging system and the service’s operations.
Bean integration
The main mechanism that Apache Camel provides to support the service activator pattern is bean integration. Bean integration provides a general framework for mapping incoming messages to method invocations on Java objects. For example, the Java fluent DSL provides the processors bean() and beanRef() that you can insert into a route to invoke methods on a registered Java bean. The detailed mapping of message data to Java method parameters is determined by the bean binding, which can be implemented by adding annotations to the bean class.
For example, consider the following route which calls the Java method, BankBean.getUserAccBalance(), to service requests incoming on a JMS/ActiveMQ queue:
from("activemq:BalanceQueries")
.setProperty("userid", xpath("/Account/BalanceQuery/UserID").stringResult())
.beanRef("bankBean", "getUserAccBalance")
.to("velocity:file:src/scripts/acc_balance.vm")
.to("activemq:BalanceResults");
The messages pulled from the ActiveMQ endpoint, activemq:BalanceQueries, have a simple XML format that provides the user ID of a bank account. For example:
<?xml version='1.0' encoding='UTF-8'?>
<Account>
<BalanceQuery>
<UserID>James.Strachan</UserID>
</BalanceQuery>
</Account>
The first processor in the route, setProperty(), extracts the user ID from the In message and stores it in the userid exchange property. This is preferable to storing it in a header, because the In headers are not available after invoking the bean.
The service activation step is performed by the beanRef() processor, which binds the incoming message to the getUserAccBalance() method on the Java object identified by the bankBean bean ID. The following code shows a sample implementation of the BankBean class:
package tutorial;
import org.apache.camel.language.XPath;
public class BankBean {
public int getUserAccBalance(@XPath("/Account/BalanceQuery/UserID") String user) {
if (user.equals("James.Strachan")) {
return 1200;
}
else {
return 0;
}
}
}
Where the binding of message data to method parameter is enabled by the @XPath annotation, which injects the content of the UserID XML element into the user method parameter. On completion of the call, the return value is inserted into the body of the Out message which is then copied into the In message for the next step in the route. In order for the bean to be accessible to the beanRef() processor, you must instantiate an instance in Spring XML. For example, you can add the following lines to the META-INF/spring/camel-context.xml configuration file to instantiate the bean:
<?xml version="1.0" encoding="UTF-8"?>
<beans ... >
...
<bean id="bankBean" class="tutorial.BankBean"/>
</beans>
Where the bean ID, bankBean, identifes this bean instance in the registry.
The output of the bean invocation is injected into a Velocity template, to produce a properly formatted result message. The Velocity endpoint, velocity:file:src/scripts/acc_balance.vm, specifies the location of a velocity script with the following contents:
<?xml version='1.0' encoding='UTF-8'?>
<Account>
<BalanceResult>
<UserID>${exchange.getProperty("userid")}</UserID>
<Balance>${body}</Balance>
</BalanceResult>
</Account>
The exchange instance is available as the Velocity variable, exchange, which enables you to retrieve the userid exchange property, using ${exchange.getProperty("userid")}. The body of the current In message, ${body}, contains the result of the getUserAccBalance() method invocation.