Apache Camel Development Guide
Develop applications with Apache Camel
Abstract
Part I. Implementing Enterprise Integration Patterns
This part describes how to build routes using Apache Camel. It covers the basic building blocks and EIP components.
Chapter 1. Building Blocks for Route Definitions
Abstract
Apache Camel supports two alternative Domain Specific Languages (DSL) for defining routes: a Java DSL and a Spring XML DSL. The basic building blocks for defining routes are endpoints and processors, where the behavior of a processor is typically modified by expressions or logical predicates. Apache Camel enables you to define expressions and predicates using a variety of different languages.
1.1. Implementing a RouteBuilder Class
Overview
To use the Domain Specific Language (DSL), you extend the RouteBuilder class and override its configure() method (where you define your routing rules).
You can define as many RouteBuilder classes as necessary. Each class is instantiated once and is registered with the CamelContext object. Normally, the lifecycle of each RouteBuilder object is managed automatically by the container in which you deploy the router.
RouteBuilder classes
As a router developer, your core task is to implement one or more RouteBuilder classes. There are two alternative RouteBuilder classes that you can inherit from:
-
org.apache.camel.builder.RouteBuilder— this is the genericRouteBuilderbase class that is suitable for deploying into any container type. It is provided in thecamel-coreartifact. -
org.apache.camel.spring.SpringRouteBuilder— this base class is specially adapted to the Spring container. In particular, it provides extra support for the following Spring specific features: looking up beans in the Spring registry (using thebeanRef()Java DSL command) and transactions (see the Transactions Guide for details). It is provided in thecamel-springartifact.
The RouteBuilder class defines methods used to initiate your routing rules (for example, from(), intercept(), and exception()).
Implementing a RouteBuilder
Example 1.1, “Implementation of a RouteBuilder Class” shows a minimal RouteBuilder implementation. The configure() method body contains a routing rule; each rule is a single Java statement.
Example 1.1. Implementation of a RouteBuilder Class
import org.apache.camel.builder.RouteBuilder; public class MyRouteBuilder extends RouteBuilder { public void configure() { // Define routing rules here: from("file:src/data?noop=true").to("file:target/messages"); // More rules can be included, in you like. // ... } }
The form of the rule from(URL1).to(URL2) instructs the router to read files from the directory src/data and send them to the directory target/messages. The option ?noop=true instructs the router to retain (not delete) the source files in the src/data directory.
When you use the contextScan with Spring or Blueprint to filter RouteBuilder classes, by default Apache Camel will look for singleton beans. However, you can turn on the old behavior to include prototype scoped with the new option includeNonSingletons.
1.2. Basic Java DSL Syntax
What is a DSL?
A Domain Specific Language (DSL) is a mini-language designed for a special purpose. A DSL does not have to be logically complete but needs enough expressive power to describe problems adequately in the chosen domain. Typically, a DSL does not require a dedicated parser, interpreter, or compiler. A DSL can piggyback on top of an existing object-oriented host language, provided DSL constructs map cleanly to constructs in the host language API.
Consider the following sequence of commands in a hypothetical DSL:
command01; command02; command03;
You can map these commands to Java method invocations, as follows:
command01().command02().command03()
You can even map blocks to Java method invocations. For example:
command01().startBlock().command02().command03().endBlock()
The DSL syntax is implicitly defined by the data types of the host language API. For example, the return type of a Java method determines which methods you can legally invoke next (equivalent to the next command in the DSL).
Router rule syntax
Apache Camel defines a router DSL for defining routing rules. You can use this DSL to define rules in the body of a RouteBuilder.configure() implementation. Figure 1.1, “Local Routing Rules” shows an overview of the basic syntax for defining local routing rules.
Figure 1.1. Local Routing Rules
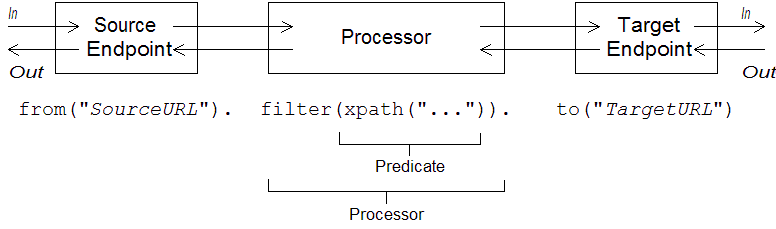
A local rule always starts with a from("EndpointURL") method, which specifies the source of messages (consumer endpoint) for the routing rule. You can then add an arbitrarily long chain of processors to the rule (for example, filter()). You typically finish off the rule with a to("EndpointURL") method, which specifies the target (producer endpoint) for the messages that pass through the rule. However, it is not always necessary to end a rule with to(). There are alternative ways of specifying the message target in a rule.
You can also define a global routing rule, by starting the rule with a special processor type (such as intercept(), exception(), or errorHandler()). Global rules are outside the scope of this guide.
Consumers and producers
A local rule always starts by defining a consumer endpoint, using from("EndpointURL"), and typically (but not always) ends by defining a producer endpoint, using to("EndpointURL"). The endpoint URLs, EndpointURL, can use any of the components configured at deploy time. For example, you could use a file endpoint, file:MyMessageDirectory, an Apache CXF endpoint, cxf:MyServiceName, or an Apache ActiveMQ endpoint, activemq:queue:MyQName. For a complete list of component types, see Apache Camel Component Reference.
Exchanges
An exchange object consists of a message, augmented by metadata. Exchanges are of central importance in Apache Camel, because the exchange is the standard form in which messages are propagated through routing rules. The main constituents of an exchange are, as follows:
In message — is the current message encapsulated by the exchange. As the exchange progresses through a route, this message may be modified. So the In message at the start of a route is typically not the same as the In message at the end of the route. The
org.apache.camel.Messagetype provides a generic model of a message, with the following parts:- Body.
- Headers.
- Attachments.
It is important to realize that this is a generic model of a message. Apache Camel supports a large variety of protocols and endpoint types. Hence, it is not possible to standardize the format of the message body or the message headers. For example, the body of a JMS message would have a completely different format to the body of a HTTP message or a Web services message. For this reason, the body and the headers are declared to be of
Objecttype. The original content of the body and the headers is then determined by the endpoint that created the exchange instance (that is, the endpoint appearing in thefrom()command).Out message — is a temporary holding area for a reply message or for a transformed message. Certain processing nodes (in particular, the
to()command) can modify the current message by treating the In message as a request, sending it to a producer endpoint, and then receiving a reply from that endpoint. The reply message is then inserted into the Out message slot in the exchange.Normally, if an Out message has been set by the current node, Apache Camel modifies the exchange as follows before passing it to the next node in the route: the old In message is discarded and the Out message is moved to the In message slot. Thus, the reply becomes the new current message. For a more detailed discussion of how Apache Camel connects nodes together in a route, see Section 2.1, “Pipeline Processing”.
There is one special case where an Out message is treated differently, however. If the consumer endpoint at the start of a route is expecting a reply message, the Out message at the very end of the route is taken to be the consumer endpoint’s reply message (and, what is more, in this case the final node must create an Out message or the consumer endpoint would hang) .
Message exchange pattern (MEP) — affects the interaction between the exchange and endpoints in the route, as follows:
- Consumer endpoint — the consumer endpoint that creates the original exchange sets the initial value of the MEP. The initial value indicates whether the consumer endpoint expects to receive a reply (for example, the InOut MEP) or not (for example, the InOnly MEP).
-
Producer endpoints — the MEP affects the producer endpoints that the exchange encounters along the route (for example, when an exchange passes through a
to()node). For example, if the current MEP is InOnly, ato()node would not expect to receive a reply from the endpoint. Sometimes you need to change the current MEP in order to customize the exchange’s interaction with a producer endpoint. For more details, see Section 1.4, “Endpoints”.
- Exchange properties — a list of named properties containing metadata for the current message.
Message exchange patterns
Using an Exchange object makes it easy to generalize message processing to different message exchange patterns. For example, an asynchronous protocol might define an MEP that consists of a single message that flows from the consumer endpoint to the producer endpoint (an InOnly MEP). An RPC protocol, on the other hand, might define an MEP that consists of a request message and a reply message (an InOut MEP). Currently, Apache Camel supports the following MEPs:
-
InOnly -
RobustInOnly -
InOut -
InOptionalOut -
OutOnly -
RobustOutOnly -
OutIn -
OutOptionalIn
Where these message exchange patterns are represented by constants in the enumeration type, org.apache.camel.ExchangePattern.
Grouped exchanges
Sometimes it is useful to have a single exchange that encapsulates multiple exchange instances. For this purpose, you can use a grouped exchange. A grouped exchange is essentially an exchange instance that contains a java.util.List of Exchange objects stored in the Exchange.GROUPED_EXCHANGE exchange property. For an example of how to use grouped exchanges, see Section 8.5, “Aggregator”.
Processors
A processor is a node in a route that can access and modify the stream of exchanges passing through the route. Processors can take expression or predicate arguments, that modify their behavior. For example, the rule shown in Figure 1.1, “Local Routing Rules” includes a filter() processor that takes an xpath() predicate as its argument.
Expressions and predicates
Expressions (evaluating to strings or other data types) and predicates (evaluating to true or false) occur frequently as arguments to the built-in processor types. For example, the following filter rule propagates In messages, only if the foo header is equal to the value bar:
from("seda:a").filter(header("foo").isEqualTo("bar")).to("seda:b");
Where the filter is qualified by the predicate, header("foo").isEqualTo("bar"). To construct more sophisticated predicates and expressions, based on the message content, you can use one of the expression and predicate languages (see Part II, “Routing Expression and Predicate Languages”).
1.3. Router Schema in a Spring XML File
Namespace
The router schema — which defines the XML DSL — belongs to the following XML schema namespace:
http://camel.apache.org/schema/spring
Specifying the schema location
The location of the router schema is normally specified to be http://camel.apache.org/schema/spring/camel-spring.xsd, which references the latest version of the schema on the Apache Web site. For example, the root beans element of an Apache Camel Spring file is normally configured as shown in Example 1.2, “Specifying the Router Schema Location”.
Example 1.2. Specifying the Router Schema Location
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:camel="http://camel.apache.org/schema/spring"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="
http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-2.0.xsd
http://camel.apache.org/schema/spring http://camel.apache.org/schema/spring/camel-spring.xsd">
<camelContext id="camel" xmlns="http://camel.apache.org/schema/spring">
<!-- Define your routing rules here -->
</camelContext>
</beans>Runtime schema location
At run time, Apache Camel does not download the router schema from schema location specified in the Spring file. Instead, Apache Camel automatically picks up a copy of the schema from the root directory of the camel-spring JAR file. This ensures that the version of the schema used to parse the Spring file always matches the current runtime version. This is important, because the latest version of the schema posted up on the Apache Web site might not match the version of the runtime you are currently using.
Using an XML editor
Generally, it is recommended that you edit your Spring files using a full-feature XML editor. An XML editor’s auto-completion features make it much easier to author XML that complies with the router schema and the editor can warn you instantly, if the XML is badly-formed.
XML editors generally do rely on downloading the schema from the location that you specify in the xsi:schemaLocation attribute. In order to be sure you are using the correct schema version whilst editing, it is usually a good idea to select a specific version of the camel-spring.xsd file. For example, to edit a Spring file for the 2.3 version of Apache Camel, you could modify the beans element as follows:
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:camel="http://camel.apache.org/schema/spring"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="
http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-2.0.xsd
http://camel.apache.org/schema/spring http://camel.apache.org/schema/spring/camel-spring-2.3.0.xsd">
...
Change back to the default, camel-spring.xsd, when you are finished editing. To see which schema versions are currently available for download, navigate to the Web page, http://camel.apache.org/schema/spring.
1.4. Endpoints
Overview
Apache Camel endpoints are the sources and sinks of messages in a route. An endpoint is a very general sort of building block: the only requirement it must satisfy is that it acts either as a source of messages (a producer endpoint) or as a sink of messages (a consumer endpoint). Hence, there are a great variety of different endpoint types supported in Apache Camel, ranging from protocol supporting endpoints, such as HTTP, to simple timer endpoints, such as Quartz, that generate dummy messages at regular time intervals. One of the major strengths of Apache Camel is that it is relatively easy to add a custom component that implements a new endpoint type.
Endpoint URIs
Endpoints are identified by endpoint URIs, which have the following general form:
scheme:contextPath[?queryOptions]
The URI scheme identifies a protocol, such as http, and the contextPath provides URI details that are interpreted by the protocol. In addition, most schemes allow you to define query options, queryOptions, which are specified in the following format:
?option01=value01&option02=value02&...
For example, the following HTTP URI can be used to connect to the Google search engine page:
http://www.google.com
The following File URI can be used to read all of the files appearing under the C:\temp\src\data directory:
file://C:/temp/src/data
Not every scheme represents a protocol. Sometimes a scheme just provides access to a useful utility, such as a timer. For example, the following Timer endpoint URI generates an exchange every second (=1000 milliseconds). You could use this to schedule activity in a route.
timer://tickTock?period=1000
Working with Long Endpoint URIs
Sometimes endpoint URIs can become quite long due to all the accompanying configuration information supplied. In JBoss Fuse 6.2 onwards, there are two approaches you can take to make your working with lengthy URIs more manageable.
- Configure Endpoints Separately
You can configure the endpoint separately, and from the routes refer to the endpoints using their shorthand IDs.
<camelContext ...> <endpoint id="foo" uri="ftp://foo@myserver"> <property name="password" value="secret"/> <property name="recursive" value="true"/> <property name="ftpClient.dataTimeout" value="30000"/> <property name="ftpClient.serverLanguageCode" value="fr"/> </endpoint> <route> <from uri="ref:foo"/> ... </route> </camelContext>You can also configure some options in the URI and then use the
propertyattribute to specify additional options (or to override options from the URI).<endpoint id="foo" uri="ftp://foo@myserver?recursive=true"> <property name="password" value="secret"/> <property name="ftpClient.dataTimeout" value="30000"/> <property name="ftpClient.serverLanguageCode" value="fr"/> </endpoint>
- Split Endpoint Configuration Across New Lines
You can split URI attributes using new lines.
<route> <from uri="ftp://foo@myserver?password=secret& recursive=true&ftpClient.dataTimeout=30000& ftpClientConfig.serverLanguageCode=fr"/> <to uri="bean:doSomething"/> </route>NoteYou can specify one or more options on each line, each separated by
&.
Specifying time periods in a URI
Many of the Apache Camel components have options whose value is a time period (for example, for specifying timeout values and so on). By default, such time period options are normally specified as a pure number, which is interpreted as a millisecond time period. But Apache Camel also supports a more readable syntax for time periods, which enables you to express the period in hours, minutes, and seconds. Formally, the human-readable time period is a string that conforms to the following syntax:
[NHour(h|hour)][NMin(m|minute)][NSec(s|second)]
Where each term in square brackets, [], is optional and the notation, (A|B), indicates that A and B are alternatives.
For example, you can configure timer endpoint with a 45 minute period as follows:
from("timer:foo?period=45m")
.to("log:foo");You can also use arbitrary combinations of the hour, minute, and second units, as follows:
from("timer:foo?period=1h15m")
.to("log:foo");
from("timer:bar?period=2h30s")
.to("log:bar");
from("timer:bar?period=3h45m58s")
.to("log:bar");Specifying raw values in URI options
By default, the option values that you specify in a URI are automatically URI-encoded. In some cases this is undesirable behavior. For example, when setting a password option, it is preferable to transmit the raw character string without URI encoding.
It is possible to switch off URI encoding by specifying an option value with the syntax, RAW(RawValue). For example,
from("SourceURI")
.to("ftp:joe@myftpserver.com?password=RAW(se+re?t&23)&binary=true")
In this example, the password value is transmitted as the literal value, se+re?t&23.
Case-insensitive enum options
Some endpoint URI options get mapped to Java enum constants. For example, the level option of the Log component, which can take the enum values, INFO, WARN, ERROR, and so on. This type conversion is case-insensitive, so any of the following alternatives could be used to set the logging level of a Log producer endpoint:
<to uri="log:foo?level=info"/> <to uri="log:foo?level=INfo"/> <to uri="log:foo?level=InFo"/>
Specifying URI Resources
From Camel 2.17, the resource based components such as XSLT, Velocity can load the resource file from the Registry by using ref: as prefix.
For example, ifmyvelocityscriptbean and mysimplescriptbean are the IDs of two beans in the registry, you can use the contents of these beans as follows:
Velocity endpoint:
------------------
from("velocity:ref:myvelocityscriptbean").<rest_of_route>.
Language endpoint (for invoking a scripting language):
-----------------------------------------------------
from("direct:start")
.to("language:simple:ref:mysimplescriptbean")
Where Camel implicitly converts the bean to a String.Apache Camel components
Each URI scheme maps to an Apache Camel component, where an Apache Camel component is essentially an endpoint factory. In other words, to use a particular type of endpoint, you must deploy the corresponding Apache Camel component in your runtime container. For example, to use JMS endpoints, you would deploy the JMS component in your container.
Apache Camel provides a large variety of different components that enable you to integrate your application with various transport protocols and third-party products. For example, some of the more commonly used components are: File, JMS, CXF (Web services), HTTP, Jetty, Direct, and Mock. For the full list of supported components, see the Apache Camel component documentation.
Most of the Apache Camel components are packaged separately to the Camel core. If you use Maven to build your application, you can easily add a component (and its third-party dependencies) to your application simply by adding a dependency on the relevant component artifact. For example, to include the HTTP component, you would add the following Maven dependency to your project POM file:
<!-- Maven POM File -->
<properties>
<camel-version>{camelFullVersion}</camel-version>
...
</properties>
<dependencies>
...
<dependency>
<groupId>org.apache.camel</groupId>
<artifactId>camel-http</artifactId>
<version>${camel-version}</version>
</dependency>
...
</dependencies>
The following components are built-in to the Camel core (in the camel-core artifact), so they are always available:
- Bean
- Browse
- Dataset
- Direct
- File
- Log
- Mock
- Properties
- Ref
- SEDA
- Timer
- VM
Consumer endpoints
A consumer endpoint is an endpoint that appears at the start of a route (that is, in a from() DSL command). In other words, the consumer endpoint is responsible for initiating processing in a route: it creates a new exchange instance (typically, based on some message that it has received or obtained), and provides a thread to process the exchange in the rest of the route.
For example, the following JMS consumer endpoint pulls messages off the payments queue and processes them in the route:
from("jms:queue:payments")
.process(SomeProcessor)
.to("TargetURI");Or equivalently, in Spring XML:
<camelContext id="CamelContextID"
xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="jms:queue:payments"/>
<process ref="someProcessorId"/>
<to uri="TargetURI"/>
</route>
</camelContext>Some components are consumer only — that is, they can only be used to define consumer endpoints. For example, the Quartz component is used exclusively to define consumer endpoints. The following Quartz endpoint generates an event every second (1000 milliseconds):
from("quartz://secondTimer?trigger.repeatInterval=1000")
.process(SomeProcessor)
.to("TargetURI");
If you like, you can specify the endpoint URI as a formatted string, using the fromF() Java DSL command. For example, to substitute the username and password into the URI for an FTP endpoint, you could write the route in Java, as follows:
fromF("ftp:%s@fusesource.com?password=%s", username, password)
.process(SomeProcessor)
.to("TargetURI");
Where the first occurrence of %s is replaced by the value of the username string and the second occurrence of %s is replaced by the password string. This string formatting mechanism is implemented by String.format() and is similar to the formatting provided by the C printf() function. For details, see java.util.Formatter.
Producer endpoints
A producer endpoint is an endpoint that appears in the middle or at the end of a route (for example, in a to() DSL command). In other words, the producer endpoint receives an existing exchange object and sends the contents of the exchange to the specified endpoint.
For example, the following JMS producer endpoint pushes the contents of the current exchange onto the specified JMS queue:
from("SourceURI")
.process(SomeProcessor)
.to("jms:queue:orderForms");Or equivalently in Spring XML:
<camelContext id="CamelContextID" xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="SourceURI"/>
<process ref="someProcessorId"/>
<to uri="jms:queue:orderForms"/>
</route>
</camelContext>Some components are producer only — that is, they can only be used to define producer endpoints. For example, the HTTP endpoint is used exclusively to define producer endpoints.
from("SourceURI")
.process(SomeProcessor)
.to("http://www.google.com/search?hl=en&q=camel+router");
If you like, you can specify the endpoint URI as a formatted string, using the toF() Java DSL command. For example, to substitute a custom Google query into the HTTP URI, you could write the route in Java, as follows:
from("SourceURI")
.process(SomeProcessor)
.toF("http://www.google.com/search?hl=en&q=%s", myGoogleQuery);
Where the occurrence of %s is replaced by your custom query string, myGoogleQuery. For details, see java.util.Formatter.
1.5. Processors
Overview
To enable the router to do something more interesting than simply connecting a consumer endpoint to a producer endpoint, you can add processors to your route. A processor is a command you can insert into a routing rule to perform arbitrary processing of messages that flow through the rule. Apache Camel provides a wide variety of different processors, as shown in Table 1.1, “Apache Camel Processors”.
| Java DSL | XML DSL | Description |
|---|---|---|
|
|
| Section 8.5, “Aggregator”: Creates an aggregator, which combines multiple incoming exchanges into a single exchange. |
|
|
| Use Aspect Oriented Programming (AOP) to do work before and after a specified sub-route. |
|
|
| Process the current exchange by invoking a method on a Java object (or bean). See Section 2.4, “Bean Integration”. |
|
|
|
Section 8.1, “Content-Based Router”: Selects a particular sub-route based on the exchange content, using |
|
|
| Converts the In message body to the specified type. |
|
|
| Section 8.9, “Delayer”: Delays the propagation of the exchange to the latter part of the route. |
|
|
|
Creates a try/catch block for handling exceptions, using |
|
| N/A | Ends the current command block. |
|
|
| Section 10.1, “Content Enricher”: Combines the current exchange with data requested from a specified producer endpoint URI. |
|
|
| Section 8.2, “Message Filter”: Uses a predicate expression to filter incoming exchanges. |
|
|
| Section 11.8, “Idempotent Consumer”: Implements a strategy to suppress duplicate messages. |
|
|
| Boolean option that can be used to disable the inherited error handler on a particular route node (defined as a sub-clause in the Java DSL and as an attribute in the XML DSL). |
|
|
| Either sets the current exchange’s MEP to InOnly (if no arguments) or sends the exchange as an InOnly to the specified endpoint(s). |
|
|
| Either sets the current exchange’s MEP to InOut (if no arguments) or sends the exchange as an InOut to the specified endpoint(s). |
|
|
| Section 8.10, “Load Balancer”: Implements load balancing over a collection of endpoints. |
|
|
| Logs a message to the console. |
|
|
| Section 8.16, “Loop”: Repeatedly resends each exchange to the latter part of the route. |
|
|
|
(Transactions) Marks the current transaction for rollback only (no exception is raised). In the XML DSL, this option is set as a boolean attribute on the |
|
|
|
(Transactions) If one or more transactions have previously been associated with this thread and then suspended, this command marks the latest transaction for rollback only (no exception is raised). In the XML DSL, this option is set as a boolean attribute on the |
|
|
| Transforms into a low-level or binary format using the specified data format, in preparation for sending over a particular transport protocol. |
|
|
| Section 8.13, “Multicast”: Multicasts the current exchange to multiple destinations, where each destination gets its own copy of the exchange. |
|
|
|
Defines a sub-route (terminated by |
|
|
|
Defines a sub-route (terminated by |
|
|
| Section 5.4, “Pipes and Filters”: Sends the exchange to a series of endpoints, where the output of one endpoint becomes the input of the next endpoint. See also Section 2.1, “Pipeline Processing”. |
|
|
| Apply a policy to the current route (currently only used for transactional policies — see Apache Karaf Transaction Guide. |
|
|
| Section 10.1, “Content Enricher”: Combines the current exchange with data polled from a specified consumer endpoint URI. |
|
|
| Execute a custom processor on the current exchange. See the section called “Custom processor” and Part III, “Advanced Camel Programming”. |
|
|
| Section 8.3, “Recipient List”: Sends the exchange to a list of recipients that is calculated at runtime (for example, based on the contents of a header). |
|
|
| Removes the specified header from the exchange’s In message. |
|
|
|
Removes the headers matching the specified pattern from the exchange’s In message. The pattern can have the form, |
|
|
| Removes the specified exchange property from the exchange. |
|
|
|
Removes the properties matching the specified pattern from the exchange. Takes a comma separated list of 1 or more strings as arguments. The first string is the pattern (see |
|
|
| Section 8.6, “Resequencer”: Re-orders incoming exchanges on the basis of a specified comparotor operation. Supports a batch mode and a stream mode. |
|
|
| (Transactions) Marks the current transaction for rollback only (also raising an exception, by default). See Apache Karaf Transaction Guide. |
|
|
| Section 8.7, “Routing Slip”: Routes the exchange through a pipeline that is constructed dynamically, based on the list of endpoint URIs extracted from a slip header. |
|
|
| Creates a sampling throttler, allowing you to extract a sample of exchanges from the traffic on a route. |
|
|
| Sets the message body of the exchange’s In message. |
|
|
| Sets the current exchange’s MEP to the specified value. See the section called “Message exchange patterns”. |
|
|
| Sets the specified header in the exchange’s In message. |
|
|
| Sets the specified header in the exchange’s Out message. |
|
|
| Sets the specified exchange property. |
|
|
| Sorts the contents of the In message body (where a custom comparator can optionally be specified). |
|
|
| Section 8.4, “Splitter”: Splits the current exchange into a sequence of exchanges, where each split exchange contains a fragment of the original message body. |
|
|
| Stops routing the current exchange and marks it as completed. |
|
|
| Creates a thread pool for concurrent processing of the latter part of the route. |
|
|
| Section 8.8, “Throttler”: Limit the flow rate to the specified level (exchanges per second). |
|
|
| Throw the specified Java exception. |
|
|
| Send the exchange to one or more endpoints. See Section 2.1, “Pipeline Processing”. |
|
| N/A |
Send the exchange to an endpoint, using string formatting. That is, the endpoint URI string can embed substitutions in the style of the C |
|
|
| Create a Spring transaction scope that encloses the latter part of the route. See Apache Karaf Transaction Guide. |
|
|
| Section 5.6, “Message Translator”: Copy the In message headers to the Out message headers and set the Out message body to the specified value. |
|
|
| Transforms the In message body from a low-level or binary format to a high-level format, using the specified data format. |
|
|
|
Takes a predicate expression to test whether the current message is valid. If the predicate returns |
|
|
|
Section 12.3, “Wire Tap”: Sends a copy of the current exchange to the specified wire tap URI, using the |
Some sample processors
To get some idea of how to use processors in a route, see the following examples:
Choice
The choice() processor is a conditional statement that is used to route incoming messages to alternative producer endpoints. Each alternative producer endpoint is preceded by a when() method, which takes a predicate argument. If the predicate is true, the following target is selected, otherwise processing proceeds to the next when() method in the rule. For example, the following choice() processor directs incoming messages to either Target1, Target2, or Target3, depending on the values of Predicate1 and Predicate2:
from("SourceURL")
.choice()
.when(Predicate1).to("Target1")
.when(Predicate2).to("Target2")
.otherwise().to("Target3");Or equivalently in Spring XML:
<camelContext id="buildSimpleRouteWithChoice" xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="SourceURL"/>
<choice>
<when>
<!-- First predicate -->
<simple>header.foo = 'bar'</simple>
<to uri="Target1"/>
</when>
<when>
<!-- Second predicate -->
<simple>header.foo = 'manchu'</simple>
<to uri="Target2"/>
</when>
<otherwise>
<to uri="Target3"/>
</otherwise>
</choice>
</route>
</camelContext>
In the Java DSL, there is a special case where you might need to use the endChoice() command. Some of the standard Apache Camel processors enable you to specify extra parameters using special sub-clauses, effectively opening an extra level of nesting which is usually terminated by the end() command. For example, you could specify a load balancer clause as loadBalance().roundRobin().to("mock:foo").to("mock:bar").end(), which load balances messages between the mock:foo and mock:bar endpoints. If the load balancer clause is embedded in a choice condition, however, it is necessary to terminate the clause using the endChoice() command, as follows:
from("direct:start")
.choice()
.when(bodyAs(String.class).contains("Camel"))
.loadBalance().roundRobin().to("mock:foo").to("mock:bar").endChoice()
.otherwise()
.to("mock:result");Filter
The filter() processor can be used to prevent uninteresting messages from reaching the producer endpoint. It takes a single predicate argument: if the predicate is true, the message exchange is allowed through to the producer; if the predicate is false, the message exchange is blocked. For example, the following filter blocks a message exchange, unless the incoming message contains a header, foo, with value equal to bar:
from("SourceURL").filter(header("foo").isEqualTo("bar")).to("TargetURL");Or equivalently in Spring XML:
<camelContext id="filterRoute" xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="SourceURL"/>
<filter>
<simple>header.foo = 'bar'</simple>
<to uri="TargetURL"/>
</filter>
</route>
</camelContext>Throttler
The throttle() processor ensures that a producer endpoint does not get overloaded. The throttler works by limiting the number of messages that can pass through per second. If the incoming messages exceed the specified rate, the throttler accumulates excess messages in a buffer and transmits them more slowly to the producer endpoint. For example, to limit the rate of throughput to 100 messages per second, you can define the following rule:
from("SourceURL").throttle(100).to("TargetURL");Or equivalently in Spring XML:
<camelContext id="throttleRoute" xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="SourceURL"/>
<throttle maximumRequestsPerPeriod="100" timePeriodMillis="1000">
<to uri="TargetURL"/>
</throttle>
</route>
</camelContext>Custom processor
If none of the standard processors described here provide the functionality you need, you can always define your own custom processor. To create a custom processor, define a class that implements the org.apache.camel.Processor interface and overrides the process() method. The following custom processor, MyProcessor, removes the header named foo from incoming messages:
Example 1.3. Implementing a Custom Processor Class
public class MyProcessor implements org.apache.camel.Processor { public void process(org.apache.camel.Exchange exchange) { inMessage = exchange.getIn(); if (inMessage != null) { inMessage.removeHeader("foo"); } } };
To insert the custom processor into a router rule, invoke the process() method, which provides a generic mechanism for inserting processors into rules. For example, the following rule invokes the processor defined in Example 1.3, “Implementing a Custom Processor Class”:
org.apache.camel.Processor myProc = new MyProcessor();
from("SourceURL").process(myProc).to("TargetURL");Chapter 2. Basic Principles of Route Building
Abstract
Apache Camel provides several processors and components that you can link together in a route. This chapter provides a basic orientation by explaining the principles of building a route using the provided building blocks.
2.1. Pipeline Processing
Overview
In Apache Camel, pipelining is the dominant paradigm for connecting nodes in a route definition. The pipeline concept is probably most familiar to users of the UNIX operating system, where it is used to join operating system commands. For example, ls | more is an example of a command that pipes a directory listing, ls, to the page-scrolling utility, more. The basic idea of a pipeline is that the output of one command is fed into the input of the next. The natural analogy in the case of a route is for the Out message from one processor to be copied to the In message of the next processor.
Processor nodes
Every node in a route, except for the initial endpoint, is a processor, in the sense that they inherit from the org.apache.camel.Processor interface. In other words, processors make up the basic building blocks of a DSL route. For example, DSL commands such as filter(), delayer(), setBody(), setHeader(), and to() all represent processors. When considering how processors connect together to build up a route, it is important to distinguish two different processing approaches.
The first approach is where the processor simply modifies the exchange’s In message, as shown in Figure 2.1, “Processor Modifying an In Message”. The exchange’s Out message remains null in this case.
Figure 2.1. Processor Modifying an In Message
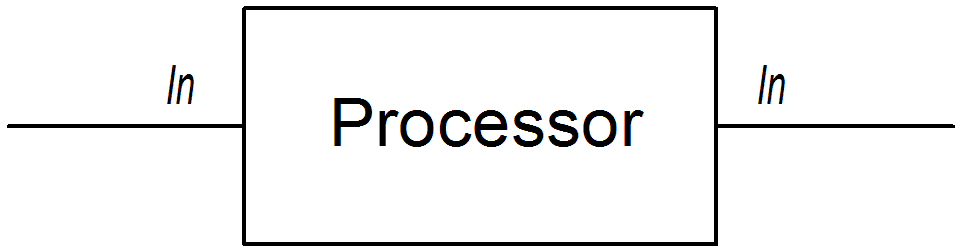
The following route shows a setHeader() command that modifies the current In message by adding (or modifying) the BillingSystem heading:
from("activemq:orderQueue")
.setHeader("BillingSystem", xpath("/order/billingSystem"))
.to("activemq:billingQueue");The second approach is where the processor creates an Out message to represent the result of the processing, as shown in Figure 2.2, “Processor Creating an Out Message”.
Figure 2.2. Processor Creating an Out Message
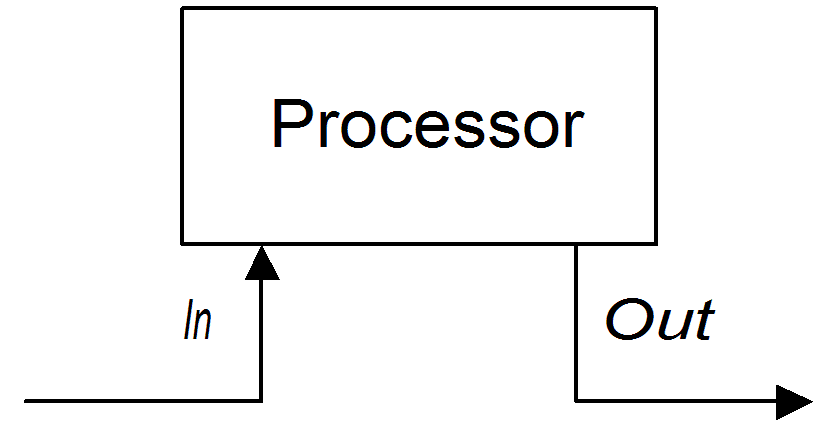
The following route shows a transform() command that creates an Out message with a message body containing the string, DummyBody:
from("activemq:orderQueue")
.transform(constant("DummyBody"))
.to("activemq:billingQueue");
where constant("DummyBody") represents a constant expression. You cannot pass the string, DummyBody, directly, because the argument to transform() must be an expression type.
Pipeline for InOnly exchanges
Figure 2.3, “Sample Pipeline for InOnly Exchanges” shows an example of a processor pipeline for InOnly exchanges. Processor A acts by modifying the In message, while processors B and C create an Out message. The route builder links the processors together as shown. In particular, processors B and C are linked together in the form of a pipeline: that is, processor B’s Out message is moved to the In message before feeding the exchange into processor C, and processor C’s Out message is moved to the In message before feeding the exchange into the producer endpoint. Thus the processors' outputs and inputs are joined into a continuous pipeline, as shown in Figure 2.3, “Sample Pipeline for InOnly Exchanges”.
Figure 2.3. Sample Pipeline for InOnly Exchanges

Apache Camel employs the pipeline pattern by default, so you do not need to use any special syntax to create a pipeline in your routes. For example, the following route pulls messages from a userdataQueue queue, pipes the message through a Velocity template (to produce a customer address in text format), and then sends the resulting text address to the queue, envelopeAddresses:
from("activemq:userdataQueue")
.to(ExchangePattern.InOut, "velocity:file:AdressTemplate.vm")
.to("activemq:envelopeAddresses");
Where the Velocity endpoint, velocity:file:AddressTemplate.vm, specifies the location of a Velocity template file, file:AddressTemplate.vm, in the file system. The to() command changes the exchange pattern to InOut before sending the exchange to the Velocity endpoint and then changes it back to InOnly afterwards. For more details of the Velocity endpoint, see Velocity in the Apache Camel Component Reference Guide.
Pipeline for InOut exchanges
Figure 2.4, “Sample Pipeline for InOut Exchanges” shows an example of a processor pipeline for InOut exchanges, which you typically use to support remote procedure call (RPC) semantics. Processors A, B, and C are linked together in the form of a pipeline, with the output of each processor being fed into the input of the next. The final Out message produced by the producer endpoint is sent all the way back to the consumer endpoint, where it provides the reply to the original request.
Figure 2.4. Sample Pipeline for InOut Exchanges

Note that in order to support the InOut exchange pattern, it is essential that the last node in the route (whether it is a producer endpoint or some other kind of processor) creates an Out message. Otherwise, any client that connects to the consumer endpoint would hang and wait indefinitely for a reply message. You should be aware that not all producer endpoints create Out messages.
Consider the following route that processes payment requests, by processing incoming HTTP requests:
from("jetty:http://localhost:8080/foo")
.to("cxf:bean:addAccountDetails")
.to("cxf:bean:getCreditRating")
.to("cxf:bean:processTransaction");
Where the incoming payment request is processed by passing it through a pipeline of Web services, cxf:bean:addAccountDetails, cxf:bean:getCreditRating, and cxf:bean:processTransaction. The final Web service, processTransaction, generates a response (Out message) that is sent back through the JETTY endpoint.
When the pipeline consists of just a sequence of endpoints, it is also possible to use the following alternative syntax:
from("jetty:http://localhost:8080/foo")
.pipeline("cxf:bean:addAccountDetails", "cxf:bean:getCreditRating", "cxf:bean:processTransaction");Pipeline for InOptionalOut exchanges
The pipeline for InOptionalOut exchanges is essentially the same as the pipeline in Figure 2.4, “Sample Pipeline for InOut Exchanges”. The difference between InOut and InOptionalOut is that an exchange with the InOptionalOut exchange pattern is allowed to have a null Out message as a reply. That is, in the case of an InOptionalOut exchange, a nullOut message is copied to the In message of the next node in the pipeline. By contrast, in the case of an InOut exchange, a nullOut message is discarded and the original In message from the current node would be copied to the In message of the next node instead.
2.2. Multiple Inputs
Overview
A standard route takes its input from just a single endpoint, using the from(EndpointURL) syntax in the Java DSL. But what if you need to define multiple inputs for your route? Apache Camel provides several alternatives for specifying multiple inputs to a route. The approach to take depends on whether you want the exchanges to be processed independently of each other or whether you want the exchanges from different inputs to be combined in some way (in which case, you should use the the section called “Content enricher pattern”).
Multiple independent inputs
The simplest way to specify multiple inputs is using the multi-argument form of the from() DSL command, for example:
from("URI1", "URI2", "URI3").to("DestinationUri");Or you can use the following equivalent syntax:
from("URI1").from("URI2").from("URI3").to("DestinationUri");In both of these examples, exchanges from each of the input endpoints, URI1, URI2, and URI3, are processed independently of each other and in separate threads. In fact, you can think of the preceding route as being equivalent to the following three separate routes:
from("URI1").to("DestinationUri");
from("URI2").to("DestinationUri");
from("URI3").to("DestinationUri");Segmented routes
For example, you might want to merge incoming messages from two different messaging systems and process them using the same route. In most cases, you can deal with multiple inputs by dividing your route into segments, as shown in Figure 2.5, “Processing Multiple Inputs with Segmented Routes”.
Figure 2.5. Processing Multiple Inputs with Segmented Routes

The initial segments of the route take their inputs from some external queues — for example, activemq:Nyse and activemq:Nasdaq — and send the incoming exchanges to an internal endpoint, InternalUrl. The second route segment merges the incoming exchanges, taking them from the internal endpoint and sending them to the destination queue, activemq:USTxn. The InternalUrl is the URL for an endpoint that is intended only for use within a router application. The following types of endpoints are suitable for internal use:
The main purpose of these endpoints is to enable you to glue together different segments of a route. They all provide an effective way of merging multiple inputs into a single route.
Direct endpoints
The direct component provides the simplest mechanism for linking together routes. The event model for the direct component is synchronous, so that subsequent segments of the route run in the same thread as the first segment. The general format of a direct URL is direct:EndpointID, where the endpoint ID, EndpointID, is simply a unique alphanumeric string that identifies the endpoint instance.
For example, if you want to take the input from two message queues, activemq:Nyse and activemq:Nasdaq, and merge them into a single message queue, activemq:USTxn, you can do this by defining the following set of routes:
from("activemq:Nyse").to("direct:mergeTxns");
from("activemq:Nasdaq").to("direct:mergeTxns");
from("direct:mergeTxns").to("activemq:USTxn");
Where the first two routes take the input from the message queues, Nyse and Nasdaq, and send them to the endpoint, direct:mergeTxns. The last queue combines the inputs from the previous two queues and sends the combined message stream to the activemq:USTxn queue.
The implementation of the direct endpoint behaves as follows: whenever an exchange arrives at a producer endpoint (for example, to("direct:mergeTxns")), the direct endpoint passes the exchange directly to all of the consumers endpoints that have the same endpoint ID (for example, from("direct:mergeTxns")). Direct endpoints can only be used to communicate between routes that belong to the same CamelContext in the same Java virtual machine (JVM) instance.
SEDA endpoints
The SEDA component provides an alternative mechanism for linking together routes. You can use it in a similar way to the direct component, but it has a different underlying event and threading model, as follows:
- Processing of a SEDA endpoint is not synchronous. That is, when you send an exchange to a SEDA producer endpoint, control immediately returns to the preceding processor in the route.
-
SEDA endpoints contain a queue buffer (of
java.util.concurrent.BlockingQueuetype), which stores all of the incoming exchanges prior to processing by the next route segment. - Each SEDA consumer endpoint creates a thread pool (the default size is 5) to process exchange objects from the blocking queue.
- The SEDA component supports the competing consumers pattern, which guarantees that each incoming exchange is processed only once, even if there are multiple consumers attached to a specific endpoint.
One of the main advantages of using a SEDA endpoint is that the routes can be more responsive, owing to the built-in consumer thread pool. The stock transactions example can be re-written to use SEDA endpoints instead of direct endpoints, as follows:
from("activemq:Nyse").to("seda:mergeTxns");
from("activemq:Nasdaq").to("seda:mergeTxns");
from("seda:mergeTxns").to("activemq:USTxn");
The main difference between this example and the direct example is that when using SEDA, the second route segment (from seda:mergeTxns to activemq:USTxn) is processed by a pool of five threads.
There is more to SEDA than simply pasting together route segments. The staged event-driven architecture (SEDA) encompasses a design philosophy for building more manageable multi-threaded applications. The purpose of the SEDA component in Apache Camel is simply to enable you to apply this design philosophy to your applications. For more details about SEDA, see http://www.eecs.harvard.edu/~mdw/proj/seda/.
VM endpoints
The VM component is very similar to the SEDA endpoint. The only difference is that, whereas the SEDA component is limited to linking together route segments from within the same CamelContext, the VM component enables you to link together routes from distinct Apache Camel applications, as long as they are running within the same Java virtual machine.
The stock transactions example can be re-written to use VM endpoints instead of SEDA endpoints, as follows:
from("activemq:Nyse").to("vm:mergeTxns");
from("activemq:Nasdaq").to("vm:mergeTxns");And in a separate router application (running in the same Java VM), you can define the second segment of the route as follows:
from("vm:mergeTxns").to("activemq:USTxn");Content enricher pattern
The content enricher pattern defines a fundamentally different way of dealing with multiple inputs to a route. When an exchange enters the enricher processor, the enricher contacts an external resource to retrieve information, which is then added to the original message. In this pattern, the external resource effectively represents a second input to the message.
For example, suppose you are writing an application that processes credit requests. Before processing a credit request, you need to augment it with the data that assigns a credit rating to the customer, where the ratings data is stored in a file in the directory, src/data/ratings. You can combine the incoming credit request with data from the ratings file using the pollEnrich() pattern and a GroupedExchangeAggregationStrategy aggregation strategy, as follows:
from("jms:queue:creditRequests")
.pollEnrich("file:src/data/ratings?noop=true", new GroupedExchangeAggregationStrategy())
.bean(new MergeCreditRequestAndRatings(), "merge")
.to("jms:queue:reformattedRequests");
Where the GroupedExchangeAggregationStrategy class is a standard aggregation strategy from the org.apache.camel.processor.aggregate package that adds each new exchange to a java.util.List instance and stores the resulting list in the Exchange.GROUPED_EXCHANGE exchange property. In this case, the list contains two elements: the original exchange (from the creditRequests JMS queue); and the enricher exchange (from the file endpoint).
To access the grouped exchange, you can use code like the following:
public class MergeCreditRequestAndRatings {
public void merge(Exchange ex) {
// Obtain the grouped exchange
List<Exchange> list = ex.getProperty(Exchange.GROUPED_EXCHANGE, List.class);
// Get the exchanges from the grouped exchange
Exchange originalEx = list.get(0);
Exchange ratingsEx = list.get(1);
// Merge the exchanges
...
}
}An alternative approach to this application would be to put the merge code directly into the implementation of the custom aggregation strategy class.
For more details about the content enricher pattern, see Section 10.1, “Content Enricher”.
2.3. Exception Handling
Abstract
Apache Camel provides several different mechanisms, which let you handle exceptions at different levels of granularity: you can handle exceptions within a route using doTry, doCatch, and doFinally; or you can specify what action to take for each exception type and apply this rule to all routes in a RouteBuilder using onException; or you can specify what action to take for all exception types and apply this rule to all routes in a RouteBuilder using errorHandler.
For more details about exception handling, see Section 6.3, “Dead Letter Channel”.
2.3.1. onException Clause
Overview
The onException clause is a powerful mechanism for trapping exceptions that occur in one or more routes: it is type-specific, enabling you to define distinct actions to handle different exception types; it allows you to define actions using essentially the same (actually, slightly extended) syntax as a route, giving you considerable flexibility in the way you handle exceptions; and it is based on a trapping model, which enables a single onException clause to deal with exceptions occurring at any node in any route.
Trapping exceptions using onException
The onException clause is a mechanism for trapping, rather than catching exceptions. That is, once you define an onException clause, it traps exceptions that occur at any point in a route. This contrasts with the Java try/catch mechanism, where an exception is caught, only if a particular code fragment is explicitly enclosed in a try block.
What really happens when you define an onException clause is that the Apache Camel runtime implicitly encloses each route node in a try block. This is why the onException clause is able to trap exceptions at any point in the route. But this wrapping is done for you automatically; it is not visible in the route definitions.
Java DSL example
In the following Java DSL example, the onException clause applies to all of the routes defined in the RouteBuilder class. If a ValidationException exception occurs while processing either of the routes (from("seda:inputA") or from("seda:inputB")), the onException clause traps the exception and redirects the current exchange to the validationFailed JMS queue (which serves as a deadletter queue).
// Java
public class MyRouteBuilder extends RouteBuilder {
public void configure() {
onException(ValidationException.class)
.to("activemq:validationFailed");
from("seda:inputA")
.to("validation:foo/bar.xsd", "activemq:someQueue");
from("seda:inputB").to("direct:foo")
.to("rnc:mySchema.rnc", "activemq:anotherQueue");
}
}XML DSL example
The preceding example can also be expressed in the XML DSL, using the onException element to define the exception clause, as follows:
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:camel="http://camel.apache.org/schema/spring"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="
http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-2.0.xsd
http://camel.apache.org/schema/spring http://camel.apache.org/schema/spring/camel-spring.xsd">
<camelContext xmlns="http://camel.apache.org/schema/spring">
<onException>
<exception>com.mycompany.ValidationException</exception>
<to uri="activemq:validationFailed"/>
</onException>
<route>
<from uri="seda:inputA"/>
<to uri="validation:foo/bar.xsd"/>
<to uri="activemq:someQueue"/>
</route>
<route>
<from uri="seda:inputB"/>
<to uri="rnc:mySchema.rnc"/>
<to uri="activemq:anotherQueue"/>
</route>
</camelContext>
</beans>Trapping multiple exceptions
You can define multiple onException clauses to trap exceptions in a RouteBuilder scope. This enables you to take different actions in response to different exceptions. For example, the following series of onException clauses defined in the Java DSL define different deadletter destinations for ValidationException, IOException, and Exception:
onException(ValidationException.class).to("activemq:validationFailed");
onException(java.io.IOException.class).to("activemq:ioExceptions");
onException(Exception.class).to("activemq:exceptions");
You can define the same series of onException clauses in the XML DSL as follows:
<onException>
<exception>com.mycompany.ValidationException</exception>
<to uri="activemq:validationFailed"/>
</onException>
<onException>
<exception>java.io.IOException</exception>
<to uri="activemq:ioExceptions"/>
</onException>
<onException>
<exception>java.lang.Exception</exception>
<to uri="activemq:exceptions"/>
</onException>
You can also group multiple exceptions together to be trapped by the same onException clause. In the Java DSL, you can group multiple exceptions as follows:
onException(ValidationException.class, BuesinessException.class)
.to("activemq:validationFailed");
In the XML DSL, you can group multiple exceptions together by defining more than one exception element inside the onException element, as follows:
<onException>
<exception>com.mycompany.ValidationException</exception>
<exception>com.mycompany.BuesinessException</exception>
<to uri="activemq:validationFailed"/>
</onException>
When trapping multiple exceptions, the order of the onException clauses is significant. Apache Camel initially attempts to match the thrown exception against the first clause. If the first clause fails to match, the next onException clause is tried, and so on until a match is found. Each matching attempt is governed by the following algorithm:
If the thrown exception is a chained exception (that is, where an exception has been caught and rethrown as a different exception), the most nested exception type serves initially as the basis for matching. This exception is tested as follows:
-
If the exception-to-test has exactly the type specified in the
onExceptionclause (tested usinginstanceof), a match is triggered. -
If the exception-to-test is a sub-type of the type specified in the
onExceptionclause, a match is triggered.
-
If the exception-to-test has exactly the type specified in the
- If the most nested exception fails to yield a match, the next exception in the chain (the wrapping exception) is tested instead. The testing continues up the chain until either a match is triggered or the chain is exhausted.
The throwException EIP enables you to create a new exception instance from a simple language expression. You can make it dynamic, based on the available information from the current exchange. for example,
<throwException exceptionType="java.lang.IllegalArgumentException" message="${body}"/>Deadletter channel
The basic examples of onException usage have so far all exploited the deadletter channel pattern. That is, when an onException clause traps an exception, the current exchange is routed to a special destination (the deadletter channel). The deadletter channel serves as a holding area for failed messages that have not been processed. An administrator can inspect the messages at a later time and decide what action needs to be taken.
For more details about the deadletter channel pattern, see Section 6.3, “Dead Letter Channel”.
Use original message
By the time an exception is raised in the middle of a route, the message in the exchange could have been modified considerably (and might not even by readable by a human). Often, it is easier for an administrator to decide what corrective actions to take, if the messages visible in the deadletter queue are the original messages, as received at the start of the route. The useOriginalMessage option is false by default, but will be auto-enabled if it is configured on an error handler.
In the Java DSL, you can replace the message in the exchange by the original message. Set the setAllowUseOriginalMessage() to true, then use the useOriginalMessage() DSL command, as follows:
onException(ValidationException.class)
.useOriginalMessage()
.to("activemq:validationFailed");
In the XML DSL, you can retrieve the original message by setting the useOriginalMessage attribute on the onException element, as follows:
<onException useOriginalMessage="true">
<exception>com.mycompany.ValidationException</exception>
<to uri="activemq:validationFailed"/>
</onException>
If the setAllowUseOriginalMessage() option is set to true, Camel makes a copy of the original message at the start of the route, which ensures that the original message is available when you call useOriginalMessage(). However, if the setAllowUseOriginalMessage() option is set to false (this is the default) on the Camel context, the original message will not be accessible and you cannot call useOriginalMessage().
A reasons to exploit the default behaviour is to optimize performance when processing large messages.
In Camel versions prior to 2.18, the default setting of allowUseOriginalMessage is true.
Redelivery policy
Instead of interrupting the processing of a message and giving up as soon as an exception is raised, Apache Camel gives you the option of attempting to redeliver the message at the point where the exception occurred. In networked systems, where timeouts can occur and temporary faults arise, it is often possible for failed messages to be processed successfully, if they are redelivered shortly after the original exception was raised.
The Apache Camel redelivery supports various strategies for redelivering messages after an exception occurs. Some of the most important options for configuring redelivery are as follows:
maximumRedeliveries()-
Specifies the maximum number of times redelivery can be attempted (default is
0). A negative value means redelivery is always attempted (equivalent to an infinite value). retryWhile()Specifies a predicate (of
Predicatetype), which determines whether Apache Camel ought to continue redelivering. If the predicate evaluates totrueon the current exchange, redelivery is attempted; otherwise, redelivery is stopped and no further redelivery attempts are made.This option takes precedence over the
maximumRedeliveries()option.
In the Java DSL, redelivery policy options are specified using DSL commands in the onException clause. For example, you can specify a maximum of six redeliveries, after which the exchange is sent to the validationFailed deadletter queue, as follows:
onException(ValidationException.class)
.maximumRedeliveries(6)
.retryAttemptedLogLevel(org.apache.camel.LogginLevel.WARN)
.to("activemq:validationFailed");
In the XML DSL, redelivery policy options are specified by setting attributes on the redeliveryPolicy element. For example, the preceding route can be expressed in XML DSL as follows:
<onException useOriginalMessage="true">
<exception>com.mycompany.ValidationException</exception>
<redeliveryPolicy maximumRedeliveries="6"/>
<to uri="activemq:validationFailed"/>
</onException>The latter part of the route — after the redelivery options are set — is not processed until after the last redelivery attempt has failed. For detailed descriptions of all the redelivery options, see Section 6.3, “Dead Letter Channel”.
Alternatively, you can specify redelivery policy options in a redeliveryPolicyProfile instance. You can then reference the redeliveryPolicyProfile instance using the onException element’s redeliverPolicyRef attribute. For example, the preceding route can be expressed as follows:
<redeliveryPolicyProfile id="redelivPolicy" maximumRedeliveries="6" retryAttemptedLogLevel="WARN"/>
<onException useOriginalMessage="true" redeliveryPolicyRef="redelivPolicy">
<exception>com.mycompany.ValidationException</exception>
<to uri="activemq:validationFailed"/>
</onException>
The approach using redeliveryPolicyProfile is useful, if you want to re-use the same redelivery policy in multiple onException clauses.
Conditional trapping
Exception trapping with onException can be made conditional by specifying the onWhen option. If you specify the onWhen option in an onException clause, a match is triggered only when the thrown exception matches the clause and the onWhen predicate evaluates to true on the current exchange.
For example, in the following Java DSL fragment,the first onException clause triggers, only if the thrown exception matches MyUserException and the user header is non-null in the current exchange:
// Java
// Here we define onException() to catch MyUserException when
// there is a header[user] on the exchange that is not null
onException(MyUserException.class)
.onWhen(header("user").isNotNull())
.maximumRedeliveries(2)
.to(ERROR_USER_QUEUE);
// Here we define onException to catch MyUserException as a kind
// of fallback when the above did not match.
// Noitce: The order how we have defined these onException is
// important as Camel will resolve in the same order as they
// have been defined
onException(MyUserException.class)
.maximumRedeliveries(2)
.to(ERROR_QUEUE);
The preceding onException clauses can be expressed in the XML DSL as follows:
<redeliveryPolicyProfile id="twoRedeliveries" maximumRedeliveries="2"/>
<onException redeliveryPolicyRef="twoRedeliveries">
<exception>com.mycompany.MyUserException</exception>
<onWhen>
<simple>${header.user} != null</simple>
</onWhen>
<to uri="activemq:error_user_queue"/>
</onException>
<onException redeliveryPolicyRef="twoRedeliveries">
<exception>com.mycompany.MyUserException</exception>
<to uri="activemq:error_queue"/>
</onException>Handling exceptions
By default, when an exception is raised in the middle of a route, processing of the current exchange is interrupted and the thrown exception is propagated back to the consumer endpoint at the start of the route. When an onException clause is triggered, the behavior is essentially the same, except that the onException clause performs some processing before the thrown exception is propagated back.
But this default behavior is not the only way to handle an exception. The onException provides various options to modify the exception handling behavior, as follows:
-
Suppressing exception rethrow — you have the option of suppressing the rethrown exception after the
onExceptionclause has completed. In other words, in this case the exception does not propagate back to the consumer endpoint at the start of the route. - Continuing processing — you have the option of resuming normal processing of the exchange from the point where the exception originally occurred. Implicitly, this approach also suppresses the rethrown exception.
- Sending a response — in the special case where the consumer endpoint at the start of the route expects a reply (that is, having an InOut MEP), you might prefer to construct a custom fault reply message, rather than propagating the exception back to the consumer endpoint.
Using a custom processor, the Camel Exception Clause and Error Handler get invoked, soon after it throws an exception using the new onExceptionOccurred option.
Suppressing exception rethrow
To prevent the current exception from being rethrown and propagated back to the consumer endpoint, you can set the handled() option to true in the Java DSL, as follows:
onException(ValidationException.class)
.handled(true)
.to("activemq:validationFailed");
In the Java DSL, the argument to the handled() option can be of boolean type, of Predicate type, or of Expression type (where any non-boolean expression is interpreted as true, if it evaluates to a non-null value).
The same route can be configured to suppress the rethrown exception in the XML DSL, using the handled element, as follows:
<onException>
<exception>com.mycompany.ValidationException</exception>
<handled>
<constant>true</constant>
</handled>
<to uri="activemq:validationFailed"/>
</onException>Continuing processing
To continue processing the current message from the point in the route where the exception was originally thrown, you can set the continued option to true in the Java DSL, as follows:
onException(ValidationException.class) .continued(true);
In the Java DSL, the argument to the continued() option can be of boolean type, of Predicate type, or of Expression type (where any non-boolean expression is interpreted as true, if it evaluates to a non-null value).
The same route can be configured in the XML DSL, using the continued element, as follows:
<onException>
<exception>com.mycompany.ValidationException</exception>
<continued>
<constant>true</constant>
</continued>
</onException>Sending a response
When the consumer endpoint that starts a route expects a reply, you might prefer to construct a custom fault reply message, instead of simply letting the thrown exception propagate back to the consumer. There are two essential steps you need to follow in this case: suppress the rethrown exception using the handled option; and populate the exchange’s Out message slot with a custom fault message.
For example, the following Java DSL fragment shows how to send a reply message containing the text string, Sorry, whenever the MyFunctionalException exception occurs:
// we catch MyFunctionalException and want to mark it as handled (= no failure returned to client)
// but we want to return a fixed text response, so we transform OUT body as Sorry.
onException(MyFunctionalException.class)
.handled(true)
.transform().constant("Sorry");
If you are sending a fault response to the client, you will often want to incorporate the text of the exception message in the response. You can access the text of the current exception message using the exceptionMessage() builder method. For example, you can send a reply containing just the text of the exception message whenever the MyFunctionalException exception occurs, as follows:
// we catch MyFunctionalException and want to mark it as handled (= no failure returned to client)
// but we want to return a fixed text response, so we transform OUT body and return the exception message
onException(MyFunctionalException.class)
.handled(true)
.transform(exceptionMessage());
The exception message text is also accessible from the Simple language, through the exception.message variable. For example, you could embed the current exception text in a reply message, as follows:
// we catch MyFunctionalException and want to mark it as handled (= no failure returned to client)
// but we want to return a fixed text response, so we transform OUT body and return a nice message
// using the simple language where we want insert the exception message
onException(MyFunctionalException.class)
.handled(true)
.transform().simple("Error reported: ${exception.message} - cannot process this message.");
The preceding onException clause can be expressed in XML DSL as follows:
<onException>
<exception>com.mycompany.MyFunctionalException</exception>
<handled>
<constant>true</constant>
</handled>
<transform>
<simple>Error reported: ${exception.message} - cannot process this message.</simple>
</transform>
</onException>Exception thrown while handling an exception
An exception that gets thrown while handling an existing exception (in other words, one that gets thrown in the middle of processing an onException clause) is handled in a special way. Such an exception is handled by the special fallback exception handler, which handles the exception as follows:
- All existing exception handlers are ignored and processing fails immediately.
- The new exception is logged.
- The new exception is set on the exchange object.
The simple strategy avoids complex failure scenarios which could otherwise end up with an onException clause getting locked into an infinite loop.
Scopes
The onException clauses can be effective in either of the following scopes:
RouteBuilder scope —
onExceptionclauses defined as standalone statements inside aRouteBuilder.configure()method affect all of the routes defined in thatRouteBuilderinstance. On the other hand, theseonExceptionclauses have no effect whatsoever on routes defined inside any otherRouteBuilderinstance. TheonExceptionclauses must appear before the route definitions.All of the examples up to this point are defined using the
RouteBuilderscope.-
Route scope —
onExceptionclauses can also be embedded directly within a route. These onException clauses affect only the route in which they are defined.
Route scope
You can embed an onException clause anywhere inside a route definition, but you must terminate the embedded onException clause using the end() DSL command.
For example, you can define an embedded onException clause in the Java DSL, as follows:
// Java
from("direct:start")
.onException(OrderFailedException.class)
.maximumRedeliveries(1)
.handled(true)
.beanRef("orderService", "orderFailed")
.to("mock:error")
.end()
.beanRef("orderService", "handleOrder")
.to("mock:result");
You can define an embedded onException clause in the XML DSL, as follows:
<route errorHandlerRef="deadLetter">
<from uri="direct:start"/>
<onException>
<exception>com.mycompany.OrderFailedException</exception>
<redeliveryPolicy maximumRedeliveries="1"/>
<handled>
<constant>true</constant>
</handled>
<bean ref="orderService" method="orderFailed"/>
<to uri="mock:error"/>
</onException>
<bean ref="orderService" method="handleOrder"/>
<to uri="mock:result"/>
</route>2.3.2. Error Handler
Overview
The errorHandler() clause provides similar features to the onException clause, except that this mechanism is not able to discriminate between different exception types. The errorHandler() clause is the original exception handling mechanism provided by Apache Camel and was available before the onException clause was implemented.
Java DSL example
The errorHandler() clause is defined in a RouteBuilder class and applies to all of the routes in that RouteBuilder class. It is triggered whenever an exception of any kind occurs in one of the applicable routes. For example, to define an error handler that routes all failed exchanges to the ActiveMQ deadLetter queue, you can define a RouteBuilder as follows:
public class MyRouteBuilder extends RouteBuilder {
public void configure() {
errorHandler(deadLetterChannel("activemq:deadLetter"));
// The preceding error handler applies
// to all of the following routes:
from("activemq:orderQueue")
.to("pop3://fulfillment@acme.com");
from("file:src/data?noop=true")
.to("file:target/messages");
// ...
}
}Redirection to the dead letter channel will not occur, however, until all attempts at redelivery have been exhausted.
XML DSL example
In the XML DSL, you define an error handler within a camelContext scope using the errorHandler element. For example, to define an error handler that routes all failed exchanges to the ActiveMQ deadLetter queue, you can define an errorHandler element as follows:
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:camel="http://camel.apache.org/schema/spring"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="
http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-2.0.xsd
http://camel.apache.org/schema/spring http://camel.apache.org/schema/spring/camel-spring.xsd">
<camelContext xmlns="http://camel.apache.org/schema/spring">
<errorHandler type="DeadLetterChannel"
deadLetterUri="activemq:deadLetter"/>
<route>
<from uri="activemq:orderQueue"/>
<to uri="pop3://fulfillment@acme.com"/>
</route>
<route>
<from uri="file:src/data?noop=true"/>
<to uri="file:target/messages"/>
</route>
</camelContext>
</beans>Types of error handler
Table 2.1, “Error Handler Types” provides an overview of the different types of error handler you can define.
| Java DSL Builder | XML DSL Type Attribute | Description |
|---|---|---|
|
|
| Propagates exceptions back to the caller and supports the redelivery policy, but it does not support a dead letter queue. |
|
|
| Supports the same features as the default error handler and, in addition, supports a dead letter queue. |
|
|
| Logs the exception text whenever an exception occurs. |
|
|
| Dummy handler implementation that can be used to disable the error handler. |
|
| An error handler for transacted routes. A default transaction error handler instance is automatically used for a route that is marked as transacted. |
2.3.3. doTry, doCatch, and doFinally
Overview
To handle exceptions within a route, you can use a combination of the doTry, doCatch, and doFinally clauses, which handle exceptions in a similar way to Java’s try, catch, and finally blocks.
Similarities between doCatch and Java catch
In general, the doCatch() clause in a route definition behaves in an analogous way to the catch() statement in Java code. In particular, the following features are supported by the doCatch() clause:
Multiple doCatch clauses — you can have multiple
doCatchclauses within a singledoTryblock. ThedoCatchclauses are tested in the order they appear, just like Javacatch()statements. Apache Camel executes the firstdoCatchclause that matches the thrown exception.NoteThis algorithm is different from the exception matching algorithm used by the
onExceptionclause — see Section 2.3.1, “onException Clause” for details.-
Rethrowing exceptions — you can rethrow the current exception from within a
doCatchclause using thehandledsub-clause (see the section called “Rethrowing exceptions in doCatch”).
Special features of doCatch
There are some special features of the doCatch() clause, however, that have no analogue in the Java catch() statement. The following features are specific to doCatch():
-
Catching multiple exceptions — the
doCatchclause allows you to specify a list of exceptions to catch, in contrast to the Javacatch()statement, which catches only one exception (see the section called “Example”). -
Conditional catching — you can catch an exception conditionally, by appending an
onWhensub-clause to thedoCatchclause (see the section called “Conditional exception catching using onWhen”).
Example
The following example shows how to write a doTry block in the Java DSL, where the doCatch() clause will be executed, if either the IOException exception or the IllegalStateException exception are raised, and the doFinally() clause is always executed, irrespective of whether an exception is raised or not.
from("direct:start")
.doTry()
.process(new ProcessorFail())
.to("mock:result")
.doCatch(IOException.class, IllegalStateException.class)
.to("mock:catch")
.doFinally()
.to("mock:finally")
.end();Or equivalently, in Spring XML:
<route>
<from uri="direct:start"/>
<!-- here the try starts. its a try .. catch .. finally just as regular java code -->
<doTry>
<process ref="processorFail"/>
<to uri="mock:result"/>
<doCatch>
<!-- catch multiple exceptions -->
<exception>java.io.IOException</exception>
<exception>java.lang.IllegalStateException</exception>
<to uri="mock:catch"/>
</doCatch>
<doFinally>
<to uri="mock:finally"/>
</doFinally>
</doTry>
</route>Rethrowing exceptions in doCatch
It is possible to rethrow an exception in a doCatch() clause by calling the handled() sub-clause with its argument set to false, as follows:
from("direct:start")
.doTry()
.process(new ProcessorFail())
.to("mock:result")
.doCatch(IOException.class)
// mark this as NOT handled, eg the caller will also get the exception
.handled(false)
.to("mock:io")
.doCatch(Exception.class)
// and catch all other exceptions
.to("mock:error")
.end();
In the preceding example, if the IOException is caught by doCatch(), the current exchange is sent to the mock:io endpoint, and then the IOException is rethrown. This gives the consumer endpoint at the start of the route (in the from() command) an opportunity to handle the exception as well.
The following example shows how to define the same route in Spring XML:
<route>
<from uri="direct:start"/>
<doTry>
<process ref="processorFail"/>
<to uri="mock:result"/>
<doCatch>
<exception>java.io.IOException</exception>
<!-- mark this as NOT handled, eg the caller will also get the exception -->
<handled>
<constant>false</constant>
</handled>
<to uri="mock:io"/>
</doCatch>
<doCatch>
<!-- and catch all other exceptions they are handled by default (ie handled = true) -->
<exception>java.lang.Exception</exception>
<to uri="mock:error"/>
</doCatch>
</doTry>
</route>Conditional exception catching using onWhen
A special feature of the Apache Camel doCatch() clause is that you can conditionalize the catching of exceptions based on an expression that is evaluated at run time. In other words, if you catch an exception using a clause of the form, doCatch(ExceptionList).doWhen(Expression), an exception will only be caught, if the predicate expression, Expression, evaluates to true at run time.
For example, the following doTry block will catch the exceptions, IOException and IllegalStateException, only if the exception message contains the word, Severe:
from("direct:start")
.doTry()
.process(new ProcessorFail())
.to("mock:result")
.doCatch(IOException.class, IllegalStateException.class)
.onWhen(exceptionMessage().contains("Severe"))
.to("mock:catch")
.doCatch(CamelExchangeException.class)
.to("mock:catchCamel")
.doFinally()
.to("mock:finally")
.end();Or equivalently, in Spring XML:
<route>
<from uri="direct:start"/>
<doTry>
<process ref="processorFail"/>
<to uri="mock:result"/>
<doCatch>
<exception>java.io.IOException</exception>
<exception>java.lang.IllegalStateException</exception>
<onWhen>
<simple>${exception.message} contains 'Severe'</simple>
</onWhen>
<to uri="mock:catch"/>
</doCatch>
<doCatch>
<exception>org.apache.camel.CamelExchangeException</exception>
<to uri="mock:catchCamel"/>
</doCatch>
<doFinally>
<to uri="mock:finally"/>
</doFinally>
</doTry>
</route>Nested Conditions in doTry
There are various options available to add Camel exception handling to a JavaDSL route. dotry() creates a try or catch block for handling exceptions and is useful for route specific error handling.
If you want to catch the exception inside of ChoiceDefinition, you can use the following doTry blocks:
from("direct:wayne-get-token").setExchangePattern(ExchangePattern.InOut)
.doTry()
.to("https4://wayne-token-service")
.choice()
.when().simple("${header.CamelHttpResponseCode} == '200'")
.convertBodyTo(String.class)
.setHeader("wayne-token").groovy("body.replaceAll('\"','')")
.log(">> Wayne Token : ${header.wayne-token}")
.endChoice()
doCatch(java.lang.Class (java.lang.Exception>)
.log(">> Exception")
.endDoTry();
from("direct:wayne-get-token").setExchangePattern(ExchangePattern.InOut)
.doTry()
.to("https4://wayne-token-service")
.doCatch(Exception.class)
.log(">> Exception")
.endDoTry();2.3.4. Propagating SOAP Exceptions
Overview
The Camel CXF component provides an integration with Apache CXF, enabling you to send and receive SOAP messages from Apache Camel endpoints. You can easily define Apache Camel endpoints in XML, which can then be referenced in a route using the endpoint’s bean ID. For more details, see CXF in the Apache Camel Component Reference Guide.
How to propagate stack trace information
It is possible to configure a CXF endpoint so that, when a Java exception is thrown on the server side, the stack trace for the exception is marshalled into a fault message and returned to the client. To enable this feaure, set the dataFormat to PAYLOAD and set the faultStackTraceEnabled property to true in the cxfEndpoint element, as follows:
<cxf:cxfEndpoint id="router" address="http://localhost:9002/TestMessage"
wsdlURL="ship.wsdl"
endpointName="s:TestSoapEndpoint"
serviceName="s:TestService"
xmlns:s="http://test">
<cxf:properties>
<!-- enable sending the stack trace back to client; the default value is false-->
<entry key="faultStackTraceEnabled" value="true" />
<entry key="dataFormat" value="PAYLOAD" />
</cxf:properties>
</cxf:cxfEndpoint>
For security reasons, the stack trace does not include the causing exception (that is, the part of a stack trace that follows Caused by). If you want to include the causing exception in the stack trace, set the exceptionMessageCauseEnabled property to true in the cxfEndpoint element, as follows:
<cxf:cxfEndpoint id="router" address="http://localhost:9002/TestMessage"
wsdlURL="ship.wsdl"
endpointName="s:TestSoapEndpoint"
serviceName="s:TestService"
xmlns:s="http://test">
<cxf:properties>
<!-- enable to show the cause exception message and the default value is false -->
<entry key="exceptionMessageCauseEnabled" value="true" />
<!-- enable to send the stack trace back to client, the default value is false-->
<entry key="faultStackTraceEnabled" value="true" />
<entry key="dataFormat" value="PAYLOAD" />
</cxf:properties>
</cxf:cxfEndpoint>
You should only enable the exceptionMessageCauseEnabled flag for testing and diagnostic purposes. It is normal practice for servers to conceal the original cause of an exception to make it harder for hostile users to probe the server.
2.4. Bean Integration
Overview
Bean integration provides a general purpose mechanism for processing messages using arbitrary Java objects. By inserting a bean reference into a route, you can call an arbitrary method on a Java object, which can then access and modify the incoming exchange. The mechanism that maps an exchange’s contents to the parameters and return values of a bean method is known as parameter binding. Parameter binding can use any combination of the following approaches in order to initialize a method’s parameters:
- Conventional method signatures — If the method signature conforms to certain conventions, the parameter binding can use Java reflection to determine what parameters to pass.
- Annotations and dependency injection — For a more flexible binding mechanism, employ Java annotations to specify what to inject into the method’s arguments. This dependency injection mechanism relies on Spring 2.5 component scanning. Normally, if you are deploying your Apache Camel application into a Spring container, the dependency injection mechanism will work automatically.
- Explicitly specified parameters — You can specify parameters explicitly (either as constants or using the Simple language), at the point where the bean is invoked.
Bean registry
Beans are made accessible through a bean registry, which is a service that enables you to look up beans using either the class name or the bean ID as a key. The way that you create an entry in the bean registry depends on the underlying framework — for example, plain Java, Spring, Guice, or Blueprint. Registry entries are usually created implicitly (for example, when you instantiate a Spring bean in a Spring XML file).
Registry plug-in strategy
Apache Camel implements a plug-in strategy for the bean registry, defining an integration layer for accessing beans which makes the underlying registry implementation transparent. Hence, it is possible to integrate Apache Camel applications with a variety of different bean registries, as shown in Table 2.2, “Registry Plug-Ins”.
| Registry Implementation | Camel Component with Registry Plug-In |
|---|---|
| Spring bean registry |
|
| Guice bean registry |
|
| Blueprint bean registry |
|
| OSGi service registry | deployed in OSGi container |
| JNDI registry |
Normally, you do not have to worry about configuring bean registries, because the relevant bean registry is automatically installed for you. For example, if you are using the Spring framework to define your routes, the Spring ApplicationContextRegistry plug-in is automatically installed in the current CamelContext instance.
Deployment in an OSGi container is a special case. When an Apache Camel route is deployed into the OSGi container, the CamelContext automatically sets up a registry chain for resolving bean instances: the registry chain consists of the OSGi registry, followed by the Blueprint (or Spring) registry.
Accessing a bean created in Java
To process exchange objects using a Java bean (which is a plain old Java object or POJO), use the bean() processor, which binds the inbound exchange to a method on the Java object. For example, to process inbound exchanges using the class, MyBeanProcessor, define a route like the following:
from("file:data/inbound")
.bean(MyBeanProcessor.class, "processBody")
.to("file:data/outbound");
Where the bean() processor creates an instance of MyBeanProcessor type and invokes the processBody() method to process inbound exchanges. This approach is adequate if you only want to access the MyBeanProcessor instance from a single route. However, if you want to access the same MyBeanProcessor instance from multiple routes, use the variant of bean() that takes the Object type as its first argument. For example:
MyBeanProcessor myBean = new MyBeanProcessor();
from("file:data/inbound")
.bean(myBean, "processBody")
.to("file:data/outbound");
from("activemq:inboundData")
.bean(myBean, "processBody")
.to("activemq:outboundData");Accessing overloaded bean methods
If a bean defines overloaded methods, you can choose which of the overloaded methods to invoke by specifying the method name along with its parameter types. For example, if the MyBeanBrocessor class has two overloaded methods, processBody(String) and processBody(String,String), you can invoke the latter overloaded method as follows:
from("file:data/inbound")
.bean(MyBeanProcessor.class, "processBody(String,String)")
.to("file:data/outbound");
Alternatively, if you want to identify a method by the number of parameters it takes, rather than specifying the type of each parameter explicitly, you can use the wildcard character, \*. For example, to invoke a method named processBody that takes two parameters, irrespective of the exact type of the parameters, invoke the bean() processor as follows:
from("file:data/inbound")
.bean(MyBeanProcessor.class, "processBody(*,*)")
.to("file:data/outbound");
When specifying the method, you can use either a simple unqualified type name—for example, processBody(Exchange)—or a fully qualified type name—for example, processBody(org.apache.camel.Exchange).
In the current implementation, the specified type name must be an exact match of the parameter type. Type inheritance is not taken into account.
Specify parameters explicitly
You can specify parameter values explicitly, when you call the bean method. The following simple type values can be passed:
-
Boolean:
trueorfalse. -
Numeric:
123,7, and so on. -
String:
'In single quotes'or"In double quotes". -
Null object:
null.
The following example shows how you can mix explicit parameter values with type specifiers in the same method invocation:
from("file:data/inbound")
.bean(MyBeanProcessor.class, "processBody(String, 'Sample string value', true, 7)")
.to("file:data/outbound");In the preceding example, the value of the first parameter would presumably be determined by a parameter binding annotation (see the section called “Basic annotations”).
In addition to the simple type values, you can also specify parameter values using the Simple language (Chapter 30, The Simple Language). This means that the full power of the Simple language is available when specifying parameter values. For example, to pass the message body and the value of the title header to a bean method:
from("file:data/inbound")
.bean(MyBeanProcessor.class, "processBodyAndHeader(${body},${header.title})")
.to("file:data/outbound");
You can also pass the entire header hash map as a parameter. For example, in the following example, the second method parameter must be declared to be of type java.util.Map:
from("file:data/inbound")
.bean(MyBeanProcessor.class, "processBodyAndAllHeaders(${body},${header})")
.to("file:data/outbound");From Apache Camel 2.19 release, returning null from a bean method call now always ensures the message body has been set as a null value.
Basic method signatures
To bind exchanges to a bean method, you can define a method signature that conforms to certain conventions. In particular, there are two basic conventions for method signatures:
Method signature for processing message bodies
If you want to implement a bean method that accesses or modifies the incoming message body, you must define a method signature that takes a single String argument and returns a String value. For example:
// Java
package com.acme;
public class MyBeanProcessor {
public String processBody(String body) {
// Do whatever you like to 'body'...
return newBody;
}
}Method signature for processing exchanges
For greater flexibility, you can implement a bean method that accesses the incoming exchange. This enables you to access or modify all headers, bodies, and exchange properties. For processing exchanges, the method signature takes a single org.apache.camel.Exchange parameter and returns void. For example:
// Java
package com.acme;
public class MyBeanProcessor {
public void processExchange(Exchange exchange) {
// Do whatever you like to 'exchange'...
exchange.getIn().setBody("Here is a new message body!");
}
}Accessing a Spring bean from Spring XML
Instead of creating a bean instance in Java, you can create an instance using Spring XML. In fact, this is the only feasible approach if you are defining your routes in XML. To define a bean in XML, use the standard Spring bean element. The following example shows how to create an instance of MyBeanProcessor:
<beans ...>
...
<bean id="myBeanId" class="com.acme.MyBeanProcessor"/>
</beans>
It is also possible to pass data to the bean’s constructor arguments using Spring syntax. For full details of how to use the Spring bean element, see The IoC Container from the Spring reference guide.
Where the beanRef() processor invokes the MyBeanProcessor.processBody() method on the specified bean instance. You can also invoke the bean from within a Spring XML route, using the Camel schema’s bean element. For example:
<camelContext id="CamelContextID" xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="file:data/inbound"/>
<bean ref="myBeanId" method="processBody"/>
<to uri="file:data/outbound"/>
</route>
</camelContext>
For a slight efficiency gain, you can set the cache option to true, which avoids looking up the registry every time a bean is used. For example, to enable caching, you can set the cache attribute on the bean element as follows:
<bean ref="myBeanId" method="processBody" cache="true"/>
Accessing a Spring bean from Java
When you create an object instance using the Spring bean element, you can reference it from Java using the bean’s ID (the value of the bean element’s id attribute). For example, given the bean element with ID equal to myBeanId, you can reference the bean in a Java DSL route using the beanRef() processor, as follows:
from("file:data/inbound").beanRef("myBeanId", "processBody").to("file:data/outbound");
Alternatively, you can reference the Spring bean by injection, using the @BeanInject annotation as follows:
// Java
import org.apache.camel.@BeanInject;
...
public class MyRouteBuilder extends RouteBuilder {
@BeanInject("myBeanId")
com.acme.MyBeanProcessor bean;
public void configure() throws Exception {
..
}
}
If you omit the bean ID from the @BeanInject annotation, Camel looks up the registry by type, but this only works if there is just a single bean of the given type. For example, to look up and inject the bean of com.acme.MyBeanProcessor type:
@BeanInject com.acme.MyBeanProcessor bean;
Bean shutdown order in Spring XML
For the beans used by a Camel context, the correct shutdown order is usually:
-
Shut down the
camelContextinstance, followed by; - Shut down the used beans.
If this shutdown order is reversed, then it could happen that the Camel context tries to access a bean that is already destroyed (either leading directly to an error; or the Camel context tries to create the missing bean while it is being destroyed, which also causes an error). The default shutdown order in Spring XML depends on the order in which the beans and the camelContext appear in the Spring XML file. In order to avoid random errors due to incorrect shutdown order, therefore, the camelContext is configured to shut down before any of the other beans in the Spring XML file. This is the default behaviour since Apache Camel 2.13.0.
If you need to change this behaviour (so that the Camel context is not forced to shut down before the other beans), you can set the shutdownEager attribute on the camelContext element to false. In this case, you could potentially exercise more fine-grained control over shutdown order using the Spring depends-on attribute.
Parameter binding annotations
The basic parameter bindings described in the section called “Basic method signatures” might not always be convenient to use. For example, if you have a legacy Java class that performs some data manipulation, you might want to extract data from an inbound exchange and map it to the arguments of an existing method signature. For this kind of parameter binding, Apache Camel provides the following kinds of Java annotation:
Basic annotations
Table 2.3, “Basic Bean Annotations” shows the annotations from the org.apache.camel Java package that you can use to inject message data into the arguments of a bean method.
| Annotation | Meaning | Parameter? |
|---|---|---|
|
| Binds to a list of attachments. | |
|
| Binds to an inbound message body. | |
|
| Binds to an inbound message header. | String name of the header. |
|
|
Binds to a | |
|
|
Binds to a | |
|
| Binds to a named exchange property. | String name of the property. |
|
|
Binds to a |
For example, the following class shows you how to use basic annotations to inject message data into the processExchange() method arguments.
// Java
import org.apache.camel.*;
public class MyBeanProcessor {
public void processExchange(
@Header(name="user") String user,
@Body String body,
Exchange exchange
) {
// Do whatever you like to 'exchange'...
exchange.getIn().setBody(body + "UserName = " + user);
}
}
Notice how you are able to mix the annotations with the default conventions. As well as injecting the annotated arguments, the parameter binding also automatically injects the exchange object into the org.apache.camel.Exchange argument.
Expression language annotations
The expression language annotations provide a powerful mechanism for injecting message data into a bean method’s arguments. Using these annotations, you can invoke an arbitrary script, written in the scripting language of your choice, to extract data from an inbound exchange and inject the data into a method argument. Table 2.4, “Expression Language Annotations” shows the annotations from the org.apache.camel.language package (and sub-packages, for the non-core annotations) that you can use to inject message data into the arguments of a bean method.
| Annotation | Description |
|---|---|
|
| Injects a Bean expression. |
|
| Injects a Constant expression |
|
| Injects an EL expression. |
|
| Injects a Groovy expression. |
|
| Injects a Header expression. |
|
| Injects a JavaScript expression. |
|
| Injects an OGNL expression. |
|
| Injects a PHP expression. |
|
| Injects a Python expression. |
|
| Injects a Ruby expression. |
|
| Injects a Simple expression. |
|
| Injects an XPath expression. |
|
| Injects an XQuery expression. |
For example, the following class shows you how to use the @XPath annotation to extract a username and a password from the body of an incoming message in XML format:
// Java
import org.apache.camel.language.*;
public class MyBeanProcessor {
public void checkCredentials(
@XPath("/credentials/username/text()") String user,
@XPath("/credentials/password/text()") String pass
) {
// Check the user/pass credentials...
...
}
}
The @Bean annotation is a special case, because it enables you to inject the result of invoking a registered bean. For example, to inject a correlation ID into a method argument, you can use the @Bean annotation to invoke an ID generator class, as follows:
// Java
import org.apache.camel.language.*;
public class MyBeanProcessor {
public void processCorrelatedMsg(
@Bean("myCorrIdGenerator") String corrId,
@Body String body
) {
// Check the user/pass credentials...
...
}
}
Where the string, myCorrIdGenerator, is the bean ID of the ID generator instance. The ID generator class can be instantiated using the spring bean element, as follows:
<beans ...>
...
<bean id="myCorrIdGenerator" class="com.acme.MyIdGenerator"/>
</beans>
Where the MyIdGenerator class could be defined as follows:
// Java
package com.acme;
public class MyIdGenerator {
private UserManager userManager;
public String generate(
@Header(name = "user") String user,
@Body String payload
) throws Exception {
User user = userManager.lookupUser(user);
String userId = user.getPrimaryId();
String id = userId + generateHashCodeForPayload(payload);
return id;
}
}
Notice that you can also use annotations in the referenced bean class, MyIdGenerator. The only restriction on the generate() method signature is that it must return the correct type to inject into the argument annotated by @Bean. Because the @Bean annotation does not let you specify a method name, the injection mechanism simply invokes the first method in the referenced bean that has the matching return type.
Some of the language annotations are available in the core component (@Bean, @Constant, @Simple, and @XPath). For non-core components, however, you will have to make sure that you load the relevant component. For example, to use the OGNL script, you must load the camel-ognl component.
Inherited annotations
Parameter binding annotations can be inherited from an interface or from a superclass. For example, if you define a Java interface with a Header annotation and a Body annotation, as follows:
// Java
import org.apache.camel.*;
public interface MyBeanProcessorIntf {
void processExchange(
@Header(name="user") String user,
@Body String body,
Exchange exchange
);
}
The overloaded methods defined in the implementation class, MyBeanProcessor, now inherit the annotations defined in the base interface, as follows:
// Java
import org.apache.camel.*;
public class MyBeanProcessor implements MyBeanProcessorIntf {
public void processExchange(
String user, // Inherits Header annotation
String body, // Inherits Body annotation
Exchange exchange
) {
...
}
}Interface implementations
The class that implements a Java interface is often protected, private or in package-only scope. If you try to invoke a method on an implementation class that is restricted in this way, the bean binding falls back to invoking the corresponding interface method, which is publicly accessible.
For example, consider the following public BeanIntf interface:
// Java
public interface BeanIntf {
void processBodyAndHeader(String body, String title);
}
Where the BeanIntf interface is implemented by the following protected BeanIntfImpl class:
// Java
protected class BeanIntfImpl implements BeanIntf {
void processBodyAndHeader(String body, String title) {
...
}
}
The following bean invocation would fall back to invoking the public BeanIntf.processBodyAndHeader method:
from("file:data/inbound")
.bean(BeanIntfImpl.class, "processBodyAndHeader(${body}, ${header.title})")
.to("file:data/outbound");Invoking static methods
Bean integration has the capability to invoke static methods without creating an instance of the associated class. For example, consider the following Java class that defines the static method, changeSomething():
// Java
...
public final class MyStaticClass {
private MyStaticClass() {
}
public static String changeSomething(String s) {
if ("Hello World".equals(s)) {
return "Bye World";
}
return null;
}
public void doSomething() {
// noop
}
}
You can use bean integration to invoke the static changeSomething method, as follows:
from("direct:a")
*.bean(MyStaticClass.class, "changeSomething")*
.to("mock:a");
Note that, although this syntax looks identical to the invocation of an ordinary function, bean integration exploits Java reflection to identify the method as static and proceeds to invoke the method without instantiating MyStaticClass.
Invoking an OSGi service
In the special case where a route is deployed into a Red Hat JBoss Fuse container, it is possible to invoke an OSGi service directly using bean integration. For example, assuming that one of the bundles in the OSGi container has exported the service, org.fusesource.example.HelloWorldOsgiService, you could invoke the sayHello method using the following bean integration code:
from("file:data/inbound")
.bean(org.fusesource.example.HelloWorldOsgiService.class, "sayHello")
.to("file:data/outbound");You could also invoke the OSGi service from within a Spring or blueprint XML file, using the bean component, as follows:
<to uri="bean:org.fusesource.example.HelloWorldOsgiService?method=sayHello"/>
The way this works is that Apache Camel sets up a chain of registries when it is deployed in the OSGi container. First of all, it looks up the specified class name in the OSGi service registry; if this lookup fails, it then falls back to the local Spring DM or blueprint registry.
2.5. Creating Exchange Instances
Overview
When processing messages with Java code (for example, in a bean class or in a processor class), it is often necessary to create a fresh exchange instance. If you need to create an Exchange object, the easiest approach is to invoke the methods of the ExchangeBuilder class, as described here.
ExchangeBuilder class
The fully qualified name of the ExchangeBuilder class is as follows:
org.apache.camel.builder.ExchangeBuilder
The ExchangeBuilder exposes the static method, anExchange, which you can use to start building an exchange object.
Example
For example, the following code creates a new exchange object containing the message body string, Hello World!, and with headers containing username and password credentials:
// Java
import org.apache.camel.Exchange;
import org.apache.camel.builder.ExchangeBuilder;
...
Exchange exch = ExchangeBuilder.anExchange(camelCtx)
.withBody("Hello World!")
.withHeader("username", "jdoe")
.withHeader("password", "pass")
.build();ExchangeBuilder methods
The ExchangeBuilder class supports the following methods:
ExchangeBuilder anExchange(CamelContext context)- (static method) Initiate building an exchange object.
Exchange build()- Build the exchange.
ExchangeBuilder withBody(Object body)- Set the message body on the exchange (that is, sets the exchange’s In message body).
ExchangeBuilder withHeader(String key, Object value)- Set a header on the exchange (that is, sets a header on the exchange’s In message).
ExchangeBuilder withPattern(ExchangePattern pattern)- Sets the exchange pattern on the exchange.
ExchangeBuilder withProperty(String key, Object value)- Sets a property on the exchange.
2.6. Transforming Message Content
Abstract
Apache Camel supports a variety of approaches to transforming message content. In addition to a simple native API for modifying message content, Apache Camel supports integration with several different third-party libraries and transformation standards.
2.6.1. Simple Message Transformations
Overview
The Java DSL has a built-in API that enables you to perform simple transformations on incoming and outgoing messages. For example, the rule shown in Example 2.1, “Simple Transformation of Incoming Messages” appends the text, World!, to the end of the incoming message body.
Example 2.1. Simple Transformation of Incoming Messages
from("SourceURL").setBody(body().append(" World!")).to("TargetURL");
Where the setBody() command replaces the content of the incoming message’s body.
API for simple transformations
You can use the following API classes to perform simple transformations of the message content in a router rule:
-
org.apache.camel.model.ProcessorDefinition -
org.apache.camel.builder.Builder -
org.apache.camel.builder.ValueBuilder
ProcessorDefinition class
The org.apache.camel.model.ProcessorDefinition class defines the DSL commands you can insert directly into a router rule — for example, the setBody() command in Example 2.1, “Simple Transformation of Incoming Messages”. Table 2.5, “Transformation Methods from the ProcessorDefinition Class” shows the ProcessorDefinition methods that are relevant to transforming message content:
| Method | Description |
|---|---|
|
| Converts the IN message body to the specified type. |
|
| Adds a processor which removes the header on the FAULT message. |
|
| Adds a processor which removes the header on the IN message. |
|
| Adds a processor which removes the exchange property. |
|
| Adds a processor which sets the body on the IN message. |
|
| Adds a processor which sets the body on the FAULT message. |
|
| Adds a processor which sets the header on the FAULT message. |
|
| Adds a processor which sets the header on the IN message. |
|
| Adds a processor which sets the header on the IN message. |
|
| Adds a processor which sets the header on the OUT message. |
|
| Adds a processor which sets the header on the OUT message. |
|
| Adds a processor which sets the exchange property. |
|
| Adds a processor which sets the exchange property. |
|
| Adds a processor which sets the body on the OUT message. |
|
| Adds a processor which sets the body on the OUT message. |
Builder class
The org.apache.camel.builder.Builder class provides access to message content in contexts where expressions or predicates are expected. In other words, Builder methods are typically invoked in the arguments of DSL commands — for example, the body() command in Example 2.1, “Simple Transformation of Incoming Messages”. Table 2.6, “Methods from the Builder Class” summarizes the static methods available in the Builder class.
| Method | Description |
|---|---|
|
| Returns a predicate and value builder for the inbound body on an exchange. |
|
| Returns a predicate and value builder for the inbound message body as a specific type. |
|
| Returns a constant expression. |
|
| Returns a predicate and value builder for the fault body on an exchange. |
|
| Returns a predicate and value builder for the fault message body as a specific type. |
|
| Returns a predicate and value builder for headers on an exchange. |
|
| Returns a predicate and value builder for the outbound body on an exchange. |
|
| Returns a predicate and value builder for the outbound message body as a specific type. |
|
| Returns a predicate and value builder for properties on an exchange. |
|
| Returns an expression that replaces all occurrences of the regular expression with the given replacement. |
|
| Returns an expression that replaces all occurrences of the regular expression with the given replacement. |
|
| Returns an expression processing the exchange to the given endpoint uri. |
|
| Returns an expression for the given system property. |
|
| Returns an expression for the given system property. |
ValueBuilder class
The org.apache.camel.builder.ValueBuilder class enables you to modify values returned by the Builder methods. In other words, the methods in ValueBuilder provide a simple way of modifying message content. Table 2.7, “Modifier Methods from the ValueBuilder Class” summarizes the methods available in the ValueBuilder class. That is, the table shows only the methods that are used to modify the value they are invoked on (for full details, see the API Reference documentation).
| Method | Description |
|---|---|
|
| Appends the string evaluation of this expression with the given value. |
|
| Create a predicate that the left hand expression contains the value of the right hand expression. |
|
| Converts the current value to the given type using the registered type converters. |
|
| Converts the current value a String using the registered type converters. |
|
| |
|
| |
|
| |
|
| |
|
|
Returns true, if the current value is equal to the given |
|
|
Returns true, if the current value is greater than the given |
|
|
Returns true, if the current value is greater than or equal to the given |
|
| Returns true, if the current value is an instance of the given type. |
|
|
Returns true, if the current value is less than the given |
|
|
Returns true, if the current value is less than or equal to the given |
|
|
Returns true, if the current value is not equal to the given |
|
|
Returns true, if the current value is not |
|
|
Returns true, if the current value is |
|
| |
|
| Negates the predicate argument. |
|
| Prepends the string evaluation of this expression to the given value. |
|
| |
|
| Replaces all occurrencies of the regular expression with the given replacement. |
|
| Replaces all occurrencies of the regular expression with the given replacement. |
|
| Tokenizes the string conversion of this expression using the given regular expression. |
|
| Sorts the current value using the given comparator. |
|
|
Returns true, if the current value matches the string value of the |
|
| Tokenizes the string conversion of this expression using the comma token separator. |
|
| Tokenizes the string conversion of this expression using the given token separator. |
2.6.2. Marshalling and Unmarshalling
Java DSL commands
You can convert between low-level and high-level message formats using the following commands:
-
marshal()— Converts a high-level data format to a low-level data format. -
unmarshal() — Converts a low-level data format to a high-level data format.
Data formats
Apache Camel supports marshalling and unmarshalling of the following data formats:
- Java serialization
- JAXB
- XMLBeans
- XStream
Java serialization
Enables you to convert a Java object to a blob of binary data. For this data format, unmarshalling converts a binary blob to a Java object, and marshalling converts a Java object to a binary blob. For example, to read a serialized Java object from an endpoint, SourceURL, and convert it to a Java object, you use a rule like the following:
from("SourceURL").unmarshal().serialization()
.<FurtherProcessing>.to("TargetURL");Or alternatively, in Spring XML:
<camelContext id="serialization" xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="SourceURL"/>
<unmarshal>
<serialization/>
</unmarshal>
<to uri="TargetURL"/>
</route>
</camelContext>JAXB
Provides a mapping between XML schema types and Java types (see https://jaxb.dev.java.net/). For JAXB, unmarshalling converts an XML data type to a Java object, and marshalling converts a Java object to an XML data type. Before you can use JAXB data formats, you must compile your XML schema using a JAXB compiler to generate the Java classes that represent the XML data types in the schema. This is called binding the schema. After the schema is bound, you define a rule to unmarshal XML data to a Java object, using code like the following:
org.apache.camel.spi.DataFormat jaxb = new org.apache.camel.model.dataformat.JaxbDataFormat("GeneratedPackageName");
from("SourceURL").unmarshal(jaxb)
.<FurtherProcessing>.to("TargetURL");where GeneratedPackagename is the name of the Java package generated by the JAXB compiler, which contains the Java classes representing your XML schema.
Or alternatively, in Spring XML:
<camelContext id="jaxb" xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="SourceURL"/>
<unmarshal>
<jaxb prettyPrint="true" contextPath="GeneratedPackageName"/>
</unmarshal>
<to uri="TargetURL"/>
</route>
</camelContext>XMLBeans
Provides an alternative mapping between XML schema types and Java types (see http://xmlbeans.apache.org/). For XMLBeans, unmarshalling converts an XML data type to a Java object and marshalling converts a Java object to an XML data type. For example, to unmarshal XML data to a Java object using XMLBeans, you use code like the following:
from("SourceURL").unmarshal().xmlBeans()
.<FurtherProcessing>.to("TargetURL");Or alternatively, in Spring XML:
<camelContext id="xmlBeans" xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="SourceURL"/>
<unmarshal>
<xmlBeans prettyPrint="true"/>
</unmarshal>
<to uri="TargetURL"/>
</route>
</camelContext>XStream
Provides another mapping between XML types and Java types (see http://www.xml.com/pub/a/2004/08/18/xstream.html). XStream is a serialization library (like Java serialization), enabling you to convert any Java object to XML. For XStream, unmarshalling converts an XML data type to a Java object, and marshalling converts a Java object to an XML data type.
from("SourceURL").unmarshal().xstream()
.<FurtherProcessing>.to("TargetURL");The XStream data format is currently not supported in Spring XML.
2.6.3. Endpoint Bindings
What is a binding?
In Apache Camel, a binding is a way of wrapping an endpoint in a contract — for example, by applying a Data Format, a Content Enricher or a validation step. A condition or transformation is applied to the messages coming in, and a complementary condition or transformation is applied to the messages going out.
DataFormatBinding
The DataFormatBinding class is useful for the specific case where you want to define a binding that marshals and unmarshals a particular data format (see Section 2.6.2, “Marshalling and Unmarshalling”). In this case, all that you need to do to create a binding is to create a DataFormatBinding instance, passing a reference to the relevant data format in the constructor.
For example, the XML DSL snippet in Example 2.2, “JAXB Binding” shows a binding (with ID, jaxb) that is capable of marshalling and unmarshalling the JAXB data format when it is associated with an Apache Camel endpoint:
Example 2.2. JAXB Binding
<beans ... >
...
<bean id="jaxb" class="org.apache.camel.processor.binding.DataFormatBinding">
<constructor-arg ref="jaxbformat"/>
</bean>
<bean id="jaxbformat" class="org.apache.camel.model.dataformat.JaxbDataFormat">
<property name="prettyPrint" value="true"/>
<property name="contextPath" value="org.apache.camel.example"/>
</bean>
</beans>Associating a binding with an endpoint
The following alternatives are available for associating a binding with an endpoint:
Binding URI
To associate a binding with an endpoint, you can prefix the endpoint URI with binding:NameOfBinding, where NameOfBinding is the bean ID of the binding (for example, the ID of a binding bean created in Spring XML).
For example, the following example shows how to associate ActiveMQ endpoints with the JAXB binding defined in Example 2.2, “JAXB Binding”.
<beans ...>
...
<camelContext xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="binding:jaxb:activemq:orderQueue"/>
<to uri="binding:jaxb:activemq:otherQueue"/>
</route>
</camelContext>
...
</beans>BindingComponent
Instead of using a prefix to associate a binding with an endpoint, you can make the association implicit, so that the binding does not need to appear in the URI. For existing endpoints that do not have an implicit binding, the easiest way to achieve this is to wrap the endpoint using the BindingComponent class.
For example, to associate the jaxb binding with activemq endpoints, you could define a new BindingComponent instance as follows:
<beans ... >
...
<bean id="jaxbmq" class="org.apache.camel.component.binding.BindingComponent">
<constructor-arg ref="jaxb"/>
<constructor-arg value="activemq:foo."/>
</bean>
<bean id="jaxb" class="org.apache.camel.processor.binding.DataFormatBinding">
<constructor-arg ref="jaxbformat"/>
</bean>
<bean id="jaxbformat" class="org.apache.camel.model.dataformat.JaxbDataFormat">
<property name="prettyPrint" value="true"/>
<property name="contextPath" value="org.apache.camel.example"/>
</bean>
</beans>
Where the (optional) second constructor argument to jaxbmq defines a URI prefix. You can now use the jaxbmq ID as the scheme for an endpoint URI. For example, you can define the following route using this binding component:
<beans ...>
...
<camelContext xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="jaxbmq:firstQueue"/>
<to uri="jaxbmq:otherQueue"/>
</route>
</camelContext>
...
</beans>The preceding route is equivalent to the following route, which uses the binding URI approach:
<beans ...>
...
<camelContext xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="binding:jaxb:activemq:foo.firstQueue"/>
<to uri="binding:jaxb:activemq:foo.otherQueue"/>
</route>
</camelContext>
...
</beans>
For developers that implement a custom Apache Camel component, it is possible to achieve this by implementing an endpoint class that inherits from the org.apache.camel.spi.HasBinding interface.
BindingComponent constructors
The BindingComponent class supports the following constructors:
public BindingComponent()- No arguments form. Use property injection to configure the binding component instance.
public BindingComponent(Binding binding)-
Associate this binding component with the specified
Bindingobject,binding. public BindingComponent(Binding binding, String uriPrefix)-
Associate this binding component with the specified
Bindingobject,binding, and URI prefix,uriPrefix. This is the most commonly used constructor. public BindingComponent(Binding binding, String uriPrefix, String uriPostfix)-
This constructor supports the additional URI post-fix,
uriPostfix, argument, which is automatically appended to any URIs defined using this binding component.
Implementing a custom binding
In addition to the DataFormatBinding, which is used for marshalling and unmarshalling data formats, you can implement your own custom bindings. Define a custom binding as follows:
-
Implement an
org.apache.camel.Processorclass to perform a transformation on messages incoming to a consumer endpoint (appearing in afromelement). -
Implement a complementary
org.apache.camel.Processorclass to perform the reverse transformation on messages outgoing from a producer endpoint (appearing in atoelement). -
Implement the
org.apache.camel.spi.Bindinginterface, which acts as a factory for the processor instances.
Binding interface
Example 2.3, “The org.apache.camel.spi.Binding Interface” shows the definition of the org.apache.camel.spi.Binding interface, which you must implement to define a custom binding.
Example 2.3. The org.apache.camel.spi.Binding Interface
// Java
package org.apache.camel.spi;
import org.apache.camel.Processor;
/**
* Represents a <a href="http://camel.apache.org/binding.html">Binding</a> or contract
* which can be applied to an Endpoint; such as ensuring that a particular
* <a href="http://camel.apache.org/data-format.html">Data Format</a> is used on messages in and out of an endpoint.
*/
public interface Binding {
/**
* Returns a new {@link Processor} which is used by a producer on an endpoint to implement
* the producer side binding before the message is sent to the underlying endpoint.
*/
Processor createProduceProcessor();
/**
* Returns a new {@link Processor} which is used by a consumer on an endpoint to process the
* message with the binding before its passed to the endpoint consumer producer.
*/
Processor createConsumeProcessor();
}When to use bindings
Bindings are useful when you need to apply the same kind of transformation to many different kinds of endpoint.
2.7. Property Placeholders
Overview
The property placeholders feature can be used to substitute strings into various contexts (such as endpoint URIs and attributes in XML DSL elements), where the placeholder settings are stored in Java properties files. This feature can be useful, if you want to share settings between different Apache Camel applications or if you want to centralize certain configuration settings.
For example, the following route sends requests to a Web server, whose host and port are substituted by the placeholders, {{remote.host}} and {{remote.port}}:
from("direct:start").to("http://{{remote.host}}:{{remote.port}}");The placeholder values are defined in a Java properties file, as follows:
# Java properties file remote.host=myserver.com remote.port=8080
Property Placeholders support an encoding option that enables you to read the .properties file, using a specific character set such as UTF-8. However, by default, it implements the ISO-8859-1 character set.
Apache Camel using the PropertyPlaceholders support the following:
- Specify the default value together with the key to lookup.
-
No need to define the
PropertiesComponent, if all the placeholder keys consist of default values, which are to be used. Use third-party functions to lookup the property values. It enables you to implement your own logic.
NoteProvide three out of the box functions to lookup values from OS environmental variable, JVM system properties, or the service name idiom.
Property files
Property settings are stored in one or more Java properties files and must conform to the standard Java properties file format. Each property setting appears on its own line, in the format Key=Value. Lines with # or ! as the first non-blank character are treated as comments.
For example, a property file could have content as shown in Example 2.4, “Sample Property File”.
Example 2.4. Sample Property File
# Property placeholder settings
# (in Java properties file format)
cool.end=mock:result
cool.result=result
cool.concat=mock:{{cool.result}}
cool.start=direct:cool
cool.showid=true
cheese.end=mock:cheese
cheese.quote=Camel rocks
cheese.type=Gouda
bean.foo=foo
bean.bar=barResolving properties
The properties component must be configured with the locations of one or more property files before you can start using it in route definitions. You must provide the property values using one of the following resolvers:
classpath:PathName,PathName,…- (Default) Specifies locations on the classpath, where PathName is a file pathname delimited using forward slashes.
file:PathName,PathName,…- Specifies locations on the file system, where PathName is a file pathname delimited using forward slashes.
ref:BeanID-
Specifies the ID of a
java.util.Propertiesobject in the registry. blueprint:BeanID-
Specifies the ID of a
cm:property-placeholderbean, which is used in the context of an OSGi blueprint file to access properties defined in the OSGi Configuration Admin service. For details, see the section called “Integration with OSGi blueprint property placeholders”.
For example, to specify the com/fusesource/cheese.properties property file and the com/fusesource/bar.properties property file, both located on the classpath, you would use the following location string:
com/fusesource/cheese.properties,com/fusesource/bar.properties
You can omit the classpath: prefix in this example, because the classpath resolver is used by default.
Specifying locations using system properties and environment variables
You can embed Java system properties and O/S environment variables in a location PathName.
Java system properties can be embedded in a location resolver using the syntax, ${PropertyName}. For example, if the root directory of Red Hat JBoss Fuse is stored in the Java system property, karaf.home, you could embed that directory value in a file location, as follows:
file:${karaf.home}/etc/foo.properties
O/S environment variables can be embedded in a location resolver using the syntax, ${env:VarName}. For example, if the root directory of JBoss Fuse is stored in the environment variable, SMX_HOME, you could embed that directory value in a file location, as follows:
file:${env:SMX_HOME}/etc/foo.propertiesConfiguring the properties component
Before you can start using property placeholders, you must configure the properties component, specifying the locations of one or more property files.
In the Java DSL, you can configure the properties component with the property file locations, as follows:
// Java
import org.apache.camel.component.properties.PropertiesComponent;
...
PropertiesComponent pc = new PropertiesComponent();
pc.setLocation("com/fusesource/cheese.properties,com/fusesource/bar.properties");
context.addComponent("properties", pc);
As shown in the addComponent() call, the name of the properties component must be set to properties.
In the XML DSL, you can configure the properties component using the dedicated propertyPlacholder element, as follows:
<camelContext ...>
<propertyPlaceholder
id="properties"
location="com/fusesource/cheese.properties,com/fusesource/bar.properties"
/>
</camelContext>
If you want the properties component to ignore any missing .properties files when it is being initialized, you can set the ignoreMissingLocation option to true (normally, a missing .properties file would result in an error being raised).
Additionally, if you want the properties component to ignore any missing locations that are specified using Java system properties or O/S environment variables, you can set the ignoreMissingLocation option to true.
Placeholder syntax
After it is configured, the property component automatically substitutes placeholders (in the appropriate contexts). The syntax of a placeholder depends on the context, as follows:
-
In endpoint URIs and in Spring XML files — the placeholder is specified as
{{Key}}. When setting XML DSL attributes —
xs:stringattributes are set using the following syntax:AttributeName="{{Key}}"
Other attribute types (for example,
xs:intorxs:boolean) must be set using the following syntax:prop:AttributeName="Key"
Where
propis associated with thehttp://camel.apache.org/schema/placeholdernamespace.When setting Java DSL EIP options — to set an option on an Enterprise Integration Pattern (EIP) command in the Java DSL, add a
placeholder()clause like the following to the fluent DSL:.placeholder("OptionName", "Key")-
In Simple language expressions — the placeholder is specified as
${properties:Key}.
Substitution in endpoint URIs
Wherever an endpoint URI string appears in a route, the first step in parsing the endpoint URI is to apply the property placeholder parser. The placeholder parser automatically substitutes any property names appearing between double braces, {{Key}}. For example, given the property settings shown in Example 2.4, “Sample Property File”, you could define a route as follows:
from("{{cool.start}}")
.to("log:{{cool.start}}?showBodyType=false&showExchangeId={{cool.showid}}")
.to("mock:{{cool.result}}");
By default, the placeholder parser looks up the properties bean ID in the registry to find the property component. If you prefer, you can explicitly specify the scheme in the endpoint URIs. For example, by prefixing properties: to each of the endpoint URIs, you can define the following equivalent route:
from("properties:{{cool.start}}")
.to("properties:log:{{cool.start}}?showBodyType=false&showExchangeId={{cool.showid}}")
.to("properties:mock:{{cool.result}}");
When specifying the scheme explicitly, you also have the option of specifying options to the properties component. For example, to override the property file location, you could set the location option as follows:
from("direct:start").to("properties:{{bar.end}}?location=com/mycompany/bar.properties");Substitution in Spring XML files
You can also use property placeholders in the XML DSL, for setting various attributes of the DSL elements. In this context, the placholder syntax also uses double braces, {{Key}}. For example, you could define a jmxAgent element using property placeholders, as follows:
<camelContext id="camel" xmlns="http://camel.apache.org/schema/spring">
<propertyPlaceholder id="properties" location="org/apache/camel/spring/jmx.properties"/>
<!-- we can use property placeholders when we define the JMX agent -->
<jmxAgent id="agent" registryPort="{{myjmx.port}}"
usePlatformMBeanServer="{{myjmx.usePlatform}}"
createConnector="true"
statisticsLevel="RoutesOnly"
/>
<route>
<from uri="seda:start"/>
<to uri="mock:result"/>
</route>
</camelContext>Substitution of XML DSL attribute values
You can use the regular placeholder syntax for specifying attribute values of xs:string type — for example, <jmxAgent registryPort="{{myjmx.port}}" …>. But for attributes of any other type (for example, xs:int or xs:boolean), you must use the special syntax, prop:AttributeName="Key".
For example, given that a property file defines the stop.flag property to have the value, true, you can use this property to set the stopOnException boolean attribute, as follows:
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:prop="http://camel.apache.org/schema/placeholder"
... >
<bean id="illegal" class="java.lang.IllegalArgumentException">
<constructor-arg index="0" value="Good grief!"/>
</bean>
<camelContext xmlns="http://camel.apache.org/schema/spring">
<propertyPlaceholder id="properties"
location="classpath:org/apache/camel/component/properties/myprop.properties"
xmlns="http://camel.apache.org/schema/spring"/>
<route>
<from uri="direct:start"/>
<multicast prop:stopOnException="stop.flag">
<to uri="mock:a"/>
<throwException ref="damn"/>
<to uri="mock:b"/>
</multicast>
</route>
</camelContext>
</beans>
The prop prefix must be explicitly assigned to the http://camel.apache.org/schema/placeholder namespace in your Spring file, as shown in the beans element of the preceding example.
Substitution of Java DSL EIP options
When invoking an EIP command in the Java DSL, you can set any EIP option using the value of a property placeholder, by adding a sub-clause of the form, placeholder("OptionName", "Key").
For example, given that a property file defines the stop.flag property to have the value, true, you can use this property to set the stopOnException option of the multicast EIP, as follows:
from("direct:start")
.multicast().placeholder("stopOnException", "stop.flag")
.to("mock:a").throwException(new IllegalAccessException("Damn")).to("mock:b");Substitution in Simple language expressions
You can also substitute property placeholders in Simple language expressions, but in this case the syntax of the placeholder is ${properties:Key}. For example, you can substitute the cheese.quote placeholder inside a Simple expression, as follows:
from("direct:start")
.transform().simple("Hi ${body} do you think ${properties:cheese.quote}?");
You can specify a default value for the property, using the syntax, ${properties:Key:DefaultVal}. For example:
from("direct:start")
.transform().simple("Hi ${body} do you think ${properties:cheese.quote:cheese is good}?");
It is also possible to override the location of the property file using the syntax, ${properties-location:Location:Key}. For example, to substitute the bar.quote placeholder using the settings from the com/mycompany/bar.properties property file, you can define a Simple expression as follows:
from("direct:start")
.transform().simple("Hi ${body}. ${properties-location:com/mycompany/bar.properties:bar.quote}.");Using Property Placeholders in the XML DSL
In older releases, the xs:string type attributes were used to support placeholders in the XML DSL. For example, the timeout attribute would be a xs:int type. Therefore, you cannot set a string value as the placeholder key.
From Apache Camel 2.7 onwards, this is now possible by using a special placeholder namespace. The following example illustrates the prop prefix for the namespace. It enables you to use the prop prefix in the attributes in the XML DSLs.
In the Multicast, set the option stopOnException as the value of the placeholder with the key stop. Also, in the properties file, define the value as
stop=true
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:prop="http://camel.apache.org/schema/placeholder"
xsi:schemaLocation="
http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
http://camel.apache.org/schema/spring http://camel.apache.org/schema/spring/camel-spring.xsd
">
<!-- Notice in the declaration above, we have defined the prop prefix as the Camel placeholder namespace -->
<bean id="damn" class="java.lang.IllegalArgumentException">
<constructor-arg index="0" value="Damn"/>
</bean>
<camelContext xmlns="http://camel.apache.org/schema/spring">
<propertyPlaceholder id="properties"
location="classpath:org/apache/camel/component/properties/myprop.properties"
xmlns="http://camel.apache.org/schema/spring"/>
<route>
<from uri="direct:start"/>
<!-- use prop namespace, to define a property placeholder, which maps to
option stopOnException={{stop}} -->
<multicast prop:stopOnException="stop">
<to uri="mock:a"/>
<throwException ref="damn"/>
<to uri="mock:b"/>
</multicast>
</route>
</camelContext>
</beans>Integration with OSGi blueprint property placeholders
If you deploy your route into the Red Hat JBoss Fuse OSGi container, you can integrate the Apache Camel property placeholder mechanism with JBoss Fuse’s blueprint property placeholder mechanism (in fact, the integration is enabled by default). There are two basic approaches to setting up the integration, as follows:
Implicit blueprint integration
If you define a camelContext element inside an OSGi blueprint file, the Apache Camel property placeholder mechanism automatically integrates with the blueprint property placeholder mechanism. That is, placeholders obeying the Apache Camel syntax (for example, {{cool.end}}) that appear within the scope of camelContext are implicitly resolved by looking up the blueprint property placeholder mechanism.
For example, consider the following route defined in an OSGi blueprint file, where the last endpoint in the route is defined by the property placeholder, {{result}}:
<blueprint xmlns="http://www.osgi.org/xmlns/blueprint/v1.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:cm="http://aries.apache.org/blueprint/xmlns/blueprint-cm/v1.0.0"
xsi:schemaLocation="
http://www.osgi.org/xmlns/blueprint/v1.0.0 https://www.osgi.org/xmlns/blueprint/v1.0.0/blueprint.xsd">
<!-- OSGI blueprint property placeholder -->
<cm:property-placeholder id="myblueprint.placeholder" persistent-id="camel.blueprint">
<!-- list some properties for this test -->
<cm:default-properties>
<cm:property name="result" value="mock:result"/>
</cm:default-properties>
</cm:property-placeholder>
<camelContext xmlns="http://camel.apache.org/schema/blueprint">
<!-- in the route we can use {{ }} placeholders which will look up in blueprint,
as Camel will auto detect the OSGi blueprint property placeholder and use it -->
<route>
<from uri="direct:start"/>
<to uri="mock:foo"/>
<to uri="{{result}}"/>
</route>
</camelContext>
</blueprint>
The blueprint property placeholder mechanism is initialized by creating a cm:property-placeholder bean. In the preceding example, the cm:property-placeholder bean is associated with the camel.blueprint persistent ID, where a persistent ID is the standard way of referencing a group of related properties from the OSGi Configuration Admin service. In other words, the cm:property-placeholder bean provides access to all of the properties defined under the camel.blueprint persistent ID. It is also possible to specify default values for some of the properties (using the nested cm:property elements).
In the context of blueprint, the Apache Camel placeholder mechanism searches for an instance of cm:property-placeholder in the bean registry. If it finds such an instance, it automatically integrates the Apache Camel placeholder mechanism, so that placeholders like, {{result}}, are resolved by looking up the key in the blueprint property placeholder mechanism (in this example, through the myblueprint.placeholder bean).
The default blueprint placeholder syntax (accessing the blueprint properties directly) is ${Key}. Hence, outside the scope of a camelContext element, the placeholder syntax you must use is ${Key}. Whereas, inside the scope of a camelContext element, the placeholder syntax you must use is {{Key}}.
Explicit blueprint integration
If you want to have more control over where the Apache Camel property placeholder mechanism finds its properties, you can define a propertyPlaceholder element and specify the resolver locations explicitly.
For example, consider the following blueprint configuration, which differs from the previous example in that it creates an explicit propertyPlaceholder instance:
<blueprint xmlns="http://www.osgi.org/xmlns/blueprint/v1.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:cm="http://aries.apache.org/blueprint/xmlns/blueprint-cm/v1.0.0"
xsi:schemaLocation="
http://www.osgi.org/xmlns/blueprint/v1.0.0 ">https://www.osgi.org/xmlns/blueprint/v1.0.0/blueprint.xsd">
<!-- OSGI blueprint property placeholder -->
<cm:property-placeholder id="myblueprint.placeholder" persistent-id="camel.blueprint">
<!-- list some properties for this test -->
<cm:default-properties>
<cm:property name="result" value="mock:result"/>
</cm:default-properties>
</cm:property-placeholder>
<camelContext xmlns="http://camel.apache.org/schema/blueprint">
<!-- using Camel properties component and refer to the blueprint property placeholder by its id -->
<propertyPlaceholder id="properties" location="blueprint:myblueprint.placeholder"/>
<!-- in the route we can use {{ }} placeholders which will lookup in blueprint -->
<route>
<from uri="direct:start"/>
<to uri="mock:foo"/>
<to uri="{{result}}"/>
</route>
</camelContext>
</blueprint>
In the preceding example, the propertyPlaceholder element specifies explicitly which cm:property-placeholder bean to use by setting the location to blueprint:myblueprint.placeholder. That is, the blueprint: resolver explicitly references the ID, myblueprint.placeholder, of the cm:property-placeholder bean.
This style of configuration is useful, if there is more than one cm:property-placeholder bean defined in the blueprint file and you need to specify which one to use. It also makes it possible to source properties from multiple locations, by specifying a comma-separated list of locations. For example, if you wanted to look up properties both from the cm:property-placeholder bean and from the properties file, myproperties.properties, on the classpath, you could define the propertyPlaceholder element as follows:
<propertyPlaceholder id="properties" location="blueprint:myblueprint.placeholder,classpath:myproperties.properties"/>
Integration with Spring property placeholders
If you define your Apache Camel application using XML DSL in a Spring XML file, you can integrate the Apache Camel property placeholder mechanism with Spring property placeholder mechanism by declaring a Spring bean of type, org.apache.camel.spring.spi.BridgePropertyPlaceholderConfigurer.
Define a BridgePropertyPlaceholderConfigurer, which replaces both Apache Camel’s propertyPlaceholder element and Spring’s ctx:property-placeholder element in the Spring XML file. You can then refer to the configured properties using either the Spring ${PropName} syntax or the Apache Camel {{PropName}} syntax.
For example, defining a bridge property placeholder that reads its property settings from the cheese.properties file:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:ctx="http://www.springframework.org/schema/context"
xsi:schemaLocation="
http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd">
<!-- Bridge Spring property placeholder with Camel -->
<!-- Do not use <ctx:property-placeholder ... > at the same time -->
<bean id="bridgePropertyPlaceholder"
class="org.apache.camel.spring.spi.BridgePropertyPlaceholderConfigurer">
<property name="location"
value="classpath:org/apache/camel/component/properties/cheese.properties"/>
</bean>
<!-- A bean that uses Spring property placeholder -->
<!-- The ${hi} is a spring property placeholder -->
<bean id="hello" class="org.apache.camel.component.properties.HelloBean">
<property name="greeting" value="${hi}"/>
</bean>
<camelContext xmlns="http://camel.apache.org/schema/spring">
<!-- Use Camel's property placeholder {{ }} style -->
<route>
<from uri="direct:{{cool.bar}}"/>
<bean ref="hello"/>
<to uri="{{cool.end}}"/>
</route>
</camelContext>
</beans>
Alternatively, you can set the location attribute of the BridgePropertyPlaceholderConfigurer to point at a Spring properties file. The Spring properties file syntax is fully supported.
2.8. Threading Model
Java thread pool API
The Apache Camel threading model is based on the powerful Java concurrency API, Package java.util.concurrent, that first became available in Sun’s JDK 1.5. The key interface in this API is the ExecutorService interface, which represents a thread pool. Using the concurrency API, you can create many different kinds of thread pool, covering a wide range of scenarios.
Apache Camel thread pool API
The Apache Camel thread pool API builds on the Java concurrency API by providing a central factory (of org.apache.camel.spi.ExecutorServiceManager type) for all of the thread pools in your Apache Camel application. Centralising the creation of thread pools in this way provides several advantages, including:
- Simplified creation of thread pools, using utility classes.
- Integrating thread pools with graceful shutdown.
- Threads automatically given informative names, which is beneficial for logging and management.
Component threading model
Some Apache Camel components — such as SEDA, JMS, and Jetty — are inherently multi-threaded. These components have all been implemented using the Apache Camel threading model and thread pool API.
If you are planning to implement your own Apache Camel component, it is recommended that you integrate your threading code with the Apache Camel threading model. For example, if your component needs a thread pool, it is recommended that you create it using the CamelContext’s ExecutorServiceManager object.
Processor threading model
Some of the standard processors in Apache Camel create their own thread pool by default. These threading-aware processors are also integrated with the Apache Camel threading model and they provide various options that enable you to customize the thread pools that they use.
Table 2.8, “Processor Threading Options” shows the various options for controlling and setting thread pools on the threading-aware processors built-in to Apache Camel.
| Processor | Java DSL | XML DSL |
|---|---|---|
|
|
parallelProcessing() executorService() executorServiceRef() |
@parallelProcessing @executorServiceRef |
|
|
parallelProcessing() executorService() executorServiceRef() |
@parallelProcessing @executorServiceRef |
|
|
parallelProcessing() executorService() executorServiceRef() |
@parallelProcessing @executorServiceRef |
|
|
parallelProcessing() executorService() executorServiceRef() |
@parallelProcessing @executorServiceRef |
|
|
executorService() executorServiceRef() poolSize() maxPoolSize() keepAliveTime() timeUnit() maxQueueSize() rejectedPolicy() |
@executorServiceRef @poolSize @maxPoolSize @keepAliveTime @timeUnit @maxQueueSize @rejectedPolicy |
|
|
wireTap(String uri, ExecutorService executorService) wireTap(String uri, String executorServiceRef) |
@executorServiceRef |
threads DSL options
The threads processor is a general-purpose DSL command, which you can use to introduce a thread pool into a route. It supports the following options to customize the thread pool:
poolSize()- Minimum number of threads in the pool (and initial pool size).
maxPoolSize()- Maximum number of threads in the pool.
keepAliveTime()- If any threads are idle for longer than this period of time (specified in seconds), they are terminated.
timeUnit()-
Time unit for keep alive, specified using the
java.util.concurrent.TimeUnittype. maxQueueSize()- Maximum number of pending tasks that this thread pool can store in its incoming task queue.
rejectedPolicy()- Specifies what course of action to take, if the incoming task queue is full. See Table 2.10, “Thread Pool Builder Options”
The preceding thread pool options are not compatible with the executorServiceRef option (for example, you cannot use these options to override the settings in the thread pool referenced by an executorServiceRef option). Apache Camel validates the DSL to enforce this.
Creating a default thread pool
To create a default thread pool for one of the threading-aware processors, enable the parallelProcessing option, using the parallelProcessing() sub-clause, in the Java DSL, or the parallelProcessing attribute, in the XML DSL.
For example, in the Java DSL, you can invoke the multicast processor with a default thread pool (where the thread pool is used to process the multicast destinations concurrently) as follows:
from("direct:start")
.multicast().parallelProcessing()
.to("mock:first")
.to("mock:second")
.to("mock:third");You can define the same route in XML DSL as follows
<camelContext id="camel" xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:start"/>
<multicast parallelProcessing="true">
<to uri="mock:first"/>
<to uri="mock:second"/>
<to uri="mock:third"/>
</multicast>
</route>
</camelContext>Default thread pool profile settings
The default thread pools are automatically created by a thread factory that takes its settings from the default thread pool profile. The default thread pool profile has the settings shown in Table 2.9, “Default Thread Pool Profile Settings” (assuming that these settings have not been modified by the application code).
| Thread Option | Default Value |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Changing the default thread pool profile
It is possible to change the default thread pool profile settings, so that all subsequent default thread pools will be created with the custom settings. You can change the profile either in Java or in Spring XML.
For example, in the Java DSL, you can customize the poolSize option and the maxQueueSize option in the default thread pool profile, as follows:
// Java import org.apache.camel.spi.ExecutorServiceManager; import org.apache.camel.spi.ThreadPoolProfile; ... ExecutorServiceManager manager = context.getExecutorServiceManager(); ThreadPoolProfile defaultProfile = manager.getDefaultThreadPoolProfile(); // Now, customize the profile settings. defaultProfile.setPoolSize(3); defaultProfile.setMaxQueueSize(100); ...
In the XML DSL, you can customize the default thread pool profile, as follows:
<camelContext id="camel" xmlns="http://camel.apache.org/schema/spring">
<threadPoolProfile
id="changedProfile"
defaultProfile="true"
poolSize="3"
maxQueueSize="100"/>
...
</camelContext>
Note that it is essential to set the defaultProfile attribute to true in the preceding XML DSL example, otherwise the thread pool profile would be treated like a custom thread pool profile (see the section called “Creating a custom thread pool profile”), instead of replacing the default thread pool profile.
Customizing a processor’s thread pool
It is also possible to specify the thread pool for a threading-aware processor more directly, using either the executorService or executorServiceRef options (where these options are used instead of the parallelProcessing option). There are two approaches you can use to customize a processor’s thread pool, as follows:
-
Specify a custom thread pool — explicitly create an
ExecutorService(thread pool) instance and pass it to theexecutorServiceoption. -
Specify a custom thread pool profile — create and register a custom thread pool factory. When you reference this factory using the
executorServiceRefoption, the processor automatically uses the factory to create a custom thread pool instance.
When you pass a bean ID to the executorServiceRef option, the threading-aware processor first tries to find a custom thread pool with that ID in the registry. If no thread pool is registered with that ID, the processor then attempts to look up a custom thread pool profile in the registry and uses the custom thread pool profile to instantiate a custom thread pool.
Creating a custom thread pool
A custom thread pool can be any thread pool of java.util.concurrent.ExecutorService type. The following approaches to creating a thread pool instance are recommended in Apache Camel:
-
Use the
org.apache.camel.builder.ThreadPoolBuilderutility to build the thread pool class. -
Use the
org.apache.camel.spi.ExecutorServiceManagerinstance from the currentCamelContextto create the thread pool class.
Ultimately, there is not much difference between the two approaches, because the ThreadPoolBuilder is actually defined using the ExecutorServiceManager instance. Normally, the ThreadPoolBuilder is preferred, because it offers a simpler approach. But there is at least one kind of thread (the ScheduledExecutorService) that can only be created by accessing the ExecutorServiceManager instance directory.
Table 2.10, “Thread Pool Builder Options” shows the options supported by the ThreadPoolBuilder class, which you can set when defining a new custom thread pool.
| Builder Option | Description |
|---|---|
|
|
Sets the maximum number of pending tasks that this thread pool can store in its incoming task queue. A value of |
|
| Sets the minimum number of threads in the pool (this is also the initial pool size). Default value is taken from default thread pool profile. |
|
| Sets the maximum number of threads that can be in the pool. Default value is taken from default thread pool profile. |
|
| If any threads are idle for longer than this period of time (specified in seconds), they are terminated. This allows the thread pool to shrink when the load is light. Default value is taken from default thread pool profile. |
|
| Specifies what course of action to take, if the incoming task queue is full. You can specify four possible values:
|
|
|
Finishes building the custom thread pool and registers the new thread pool under the ID specified as the argument to |
In Java DSL, you can define a custom thread pool using the ThreadPoolBuilder, as follows:
// Java
import org.apache.camel.builder.ThreadPoolBuilder;
import java.util.concurrent.ExecutorService;
...
ThreadPoolBuilder poolBuilder = new ThreadPoolBuilder(context);
ExecutorService customPool = poolBuilder.poolSize(5).maxPoolSize(5).maxQueueSize(100).build("customPool");
...
from("direct:start")
.multicast().executorService(customPool)
.to("mock:first")
.to("mock:second")
.to("mock:third");
Instead of passing the object reference, customPool, directly to the executorService() option, you can look up the thread pool in the registry, by passing its bean ID to the executorServiceRef() option, as follows:
// Java
from("direct:start")
.multicast().executorServiceRef("customPool")
.to("mock:first")
.to("mock:second")
.to("mock:third");
In XML DSL, you access the ThreadPoolBuilder using the threadPool element. You can then reference the custom thread pool using the executorServiceRef attribute to look up the thread pool by ID in the Spring registry, as follows:
<camelContext id="camel" xmlns="http://camel.apache.org/schema/spring">
<threadPool id="customPool"
poolSize="5"
maxPoolSize="5"
maxQueueSize="100" />
<route>
<from uri="direct:start"/>
<multicast executorServiceRef="customPool">
<to uri="mock:first"/>
<to uri="mock:second"/>
<to uri="mock:third"/>
</multicast>
</route>
</camelContext>Creating a custom thread pool profile
If you have many custom thread pool instances to create, you might find it more convenient to define a custom thread pool profile, which acts as a factory for thread pools. Whenever you reference a thread pool profile from a threading-aware processor, the processor automatically uses the profile to create a new thread pool instance. You can define a custom thread pool profile either in Java DSL or in XML DSL.
For example, in Java DSL you can create a custom thread pool profile with the bean ID, customProfile, and reference it from within a route, as follows:
// Java
import org.apache.camel.spi.ThreadPoolProfile;
import org.apache.camel.impl.ThreadPoolProfileSupport;
...
// Create the custom thread pool profile
ThreadPoolProfile customProfile = new ThreadPoolProfileSupport("customProfile");
customProfile.setPoolSize(5);
customProfile.setMaxPoolSize(5);
customProfile.setMaxQueueSize(100);
context.getExecutorServiceManager().registerThreadPoolProfile(customProfile);
...
// Reference the custom thread pool profile in a route
from("direct:start")
.multicast().executorServiceRef("customProfile")
.to("mock:first")
.to("mock:second")
.to("mock:third");
In XML DSL, use the threadPoolProfile element to create a custom pool profile (where you let the defaultProfile option default to false, because this is not a default thread pool profile). You can create a custom thread pool profile with the bean ID, customProfile, and reference it from within a route, as follows:
<camelContext id="camel" xmlns="http://camel.apache.org/schema/spring">
<threadPoolProfile
id="customProfile"
poolSize="5"
maxPoolSize="5"
maxQueueSize="100" />
<route>
<from uri="direct:start"/>
<multicast executorServiceRef="customProfile">
<to uri="mock:first"/>
<to uri="mock:second"/>
<to uri="mock:third"/>
</multicast>
</route>
</camelContext>Sharing a thread pool between components
Some of the standard poll-based components — such as File and FTP — allow you to specify the thread pool to use. This makes it possible for different components to share the same thread pool, reducing the overall number of threads in the JVM.
For example, the see File2 in the Apache Camel Component Reference Guide. and the Ftp2 in the Apache Camel Component Reference Guide both expose the scheduledExecutorService property, which you can use to specify the component’s ExecutorService object.
Customizing thread names
To make the application logs more readable, it is often a good idea to customize the thread names (which are used to identify threads in the log). To customize thread names, you can configure the thread name pattern by calling the setThreadNamePattern method on the ExecutorServiceStrategy class or the ExecutorServiceManager class. Alternatively, an easier way to set the thread name pattern is to set the threadNamePattern property on the CamelContext object.
The following placeholders can be used in a thread name pattern:
#camelId#-
The name of the current
CamelContext. #counter#- A unique thread identifier, implemented as an incrementing counter.
#name#- The regular Camel thread name.
#longName#- The long thread name — which can include endpoint parameters and so on.
The following is a typical example of a thread name pattern:
Camel (#camelId#) thread #counter# - #name#
The following example shows how to set the threadNamePattern attribute on a Camel context using XML DSL:
<camelContext xmlns="http://camel.apache.org/schema/spring"
threadNamePattern="Riding the thread #counter#" >
<route>
<from uri="seda:start"/>
<to uri="log:result"/>
<to uri="mock:result"/>
</route>
</camelContext>2.9. Controlling Start-Up and Shutdown of Routes
Overview
By default, routes are automatically started when your Apache Camel application (as represented by the CamelContext instance) starts up and routes are automatically shut down when your Apache Camel application shuts down. For non-critical deployments, the details of the shutdown sequence are usually not very important. But in a production environment, it is often crucial that existing tasks should run to completion during shutdown, in order to avoid data loss. You typically also want to control the order in which routes shut down, so that dependencies are not violated (which would prevent existing tasks from running to completion).
For this reason, Apache Camel provides a set of features to support graceful shutdown of applications. Graceful shutdown gives you full control over the stopping and starting of routes, enabling you to control the shutdown order of routes and enabling current tasks to run to completion.
Setting the route ID
It is good practice to assign a route ID to each of your routes. As well as making logging messages and management features more informative, the use of route IDs enables you to apply greater control over the stopping and starting of routes.
For example, in the Java DSL, you can assign the route ID, myCustomerRouteId, to a route by invoking the routeId() command as follows:
from("SourceURI").routeId("myCustomRouteId").process(...).to(TargetURI);
In the XML DSL, set the route element’s id attribute, as follows:
<camelContext id="CamelContextID" xmlns="http://camel.apache.org/schema/spring"> <route id="myCustomRouteId" > <from uri="SourceURI"/> <process ref="someProcessorId"/> <to uri="TargetURI"/> </route> </camelContext>
Disabling automatic start-up of routes
By default, all of the routes that the CamelContext knows about at start time will be started automatically. If you want to control the start-up of a particular route manually, however, you might prefer to disable automatic start-up for that route.
To control whether a Java DSL route starts up automatically, invoke the autoStartup command, either with a boolean argument (true or false) or a String argument (true or false). For example, you can disable automatic start-up of a route in the Java DSL, as follows:
from("SourceURI")
.routeId("nonAuto")
.autoStartup(false)
.to(TargetURI);
You can disable automatic start-up of a route in the XML DSL by setting the autoStartup attribute to false on the route element, as follows:
<camelContext id="CamelContextID" xmlns="http://camel.apache.org/schema/spring"> <route id="nonAuto" autoStartup="false"> <from uri="SourceURI"/> <to uri="TargetURI"/> </route> </camelContext>
Manually starting and stopping routes
You can manually start or stop a route at any time in Java by invoking the startRoute() and stopRoute() methods on the CamelContext instance. For example, to start the route having the route ID, nonAuto, invoke the startRoute() method on the CamelContext instance, context, as follows:
// Java
context.startRoute("nonAuto");
To stop the route having the route ID, nonAuto, invoke the stopRoute() method on the CamelContext instance, context, as follows:
// Java
context.stopRoute("nonAuto");Startup order of routes
By default, Apache Camel starts up routes in a non-deterministic order. In some applications, however, it can be important to control the startup order. To control the startup order in the Java DSL, use the startupOrder() command, which takes a positive integer value as its argument. The route with the lowest integer value starts first, followed by the routes with successively higher startup order values.
For example, the first two routes in the following example are linked together through the seda:buffer endpoint. You can ensure that the first route segment starts after the second route segment by assigning startup orders (2 and 1 respectively), as follows:
Example 2.5. Startup Order in Java DSL
from("jetty:http://fooserver:8080")
.routeId("first")
.startupOrder(2)
.to("seda:buffer");
from("seda:buffer")
.routeId("second")
.startupOrder(1)
.to("mock:result");
// This route's startup order is unspecified
from("jms:queue:foo").to("jms:queue:bar");
Or in Spring XML, you can achieve the same effect by setting the route element’s startupOrder attribute, as follows:
Example 2.6. Startup Order in XML DSL
<route id="first" startupOrder="2">
<from uri="jetty:http://fooserver:8080"/>
<to uri="seda:buffer"/>
</route>
<route id="second" startupOrder="1">
<from uri="seda:buffer"/>
<to uri="mock:result"/>
</route>
<!-- This route's startup order is unspecified -->
<route>
<from uri="jms:queue:foo"/>
<to uri="jms:queue:bar"/>
</route>Each route must be assigned a unique startup order value. You can choose any positive integer value that is less than 1000. Values of 1000 and over are reserved for Apache Camel, which automatically assigns these values to routes without an explicit startup value. For example, the last route in the preceding example would automatically be assigned the startup value, 1000 (so it starts up after the first two routes).
Shutdown sequence
When a CamelContext instance is shutting down, Apache Camel controls the shutdown sequence using a pluggable shutdown strategy. The default shutdown strategy implements the following shutdown sequence:
- Routes are shut down in the reverse of the start-up order.
- Normally, the shutdown strategy waits until the currently active exchanges have finshed processing. The treatment of running tasks is configurable, however.
- Overall, the shutdown sequence is bound by a timeout (default, 300 seconds). If the shutdown sequence exceeds this timeout, the shutdown strategy will force shutdown to occur, even if some tasks are still running.
Shutdown order of routes
Routes are shut down in the reverse of the start-up order. That is, when a start-up order is defined using the startupOrder() command (in Java DSL) or startupOrder attribute (in XML DSL), the first route to shut down is the route with the highest integer value assigned by the start-up order and the last route to shut down is the route with the lowest integer value assigned by the start-up order.
For example, in Example 2.5, “Startup Order in Java DSL”, the first route segment to be shut down is the route with the ID, first, and the second route segment to be shut down is the route with the ID, second. This example illustrates a general rule, which you should observe when shutting down routes: the routes that expose externally-accessible consumer endpoints should be shut down first, because this helps to throttle the flow of messages through the rest of the route graph.
Apache Camel also provides the option shutdownRoute(Defer), which enables you to specify that a route must be amongst the last routes to shut down (overriding the start-up order value). But you should rarely ever need this option. This option was mainly needed as a workaround for earlier versions of Apache Camel (prior to 2.3), for which routes would shut down in the same order as the start-up order.
Shutting down running tasks in a route
If a route is still processing messages when the shutdown starts, the shutdown strategy normally waits until the currently active exchange has finished processing before shutting down the route. This behavior can be configured on each route using the shutdownRunningTask option, which can take either of the following values:
ShutdownRunningTask.CompleteCurrentTaskOnly- (Default) Usually, a route operates on just a single message at a time, so you can safely shut down the route after the current task has completed.
ShutdownRunningTask.CompleteAllTasks- Specify this option in order to shut down batch consumers gracefully. Some consumer endpoints (for example, File, FTP, Mail, iBATIS, and JPA) operate on a batch of messages at a time. For these endpoints, it is more appropriate to wait until all of the messages in the current batch have completed.
For example, to shut down a File consumer endpoint gracefully, you should specify the CompleteAllTasks option, as shown in the following Java DSL fragment:
// Java
public void configure() throws Exception {
from("file:target/pending")
.routeId("first").startupOrder(2)
.shutdownRunningTask(ShutdownRunningTask.CompleteAllTasks)
.delay(1000).to("seda:foo");
from("seda:foo")
.routeId("second").startupOrder(1)
.to("mock:bar");
}The same route can be defined in the XML DSL as follows:
<camelContext id="camel" xmlns="http://camel.apache.org/schema/spring">
<!-- let this route complete all its pending messages when asked to shut down -->
<route id="first"
startupOrder="2"
shutdownRunningTask="CompleteAllTasks">
<from uri="file:target/pending"/>
<delay><constant>1000</constant></delay>
<to uri="seda:foo"/>
</route>
<route id="second" startupOrder="1">
<from uri="seda:foo"/>
<to uri="mock:bar"/>
</route>
</camelContext>Shutdown timeout
The shutdown timeout has a default value of 300 seconds. You can change the value of the timeout by invoking the setTimeout() method on the shutdown strategy. For example, you can change the timeout value to 600 seconds, as follows:
// Java // context = CamelContext instance context.getShutdownStrategy().setTimeout(600);
Integration with custom components
If you are implementing a custom Apache Camel component (which also inherits from the org.apache.camel.Service interface), you can ensure that your custom code receives a shutdown notification by implementing the org.apache.camel.spi.ShutdownPrepared interface. This gives the component an opportunity execute custom code in preparation for shutdown.
2.9.1. RouteIdFactory
Based on the consumer endpoints, you can add RouteIdFactory that can assign route ids with the logical names.
For example, when using the routes with seda or direct components as route inputs, then you may want to use their names as the route id, such as,
- direct:foo- foo
- seda:bar- bar
- jms:orders- orders
Instead of using auto-assigned names, you can use the NodeIdFactory that can assign logical names for routes. Also, you can use the context-path of route URL as the name. For example, execute the following to use the RouteIDFactory:
context.setNodeIdFactory(new RouteIdFactory());
It is possible to get the custom route id from rest endpoints.
2.10. Scheduled Route Policy
2.10.1. Overview of Scheduled Route Policies
Overview
A scheduled route policy can be used to trigger events that affect a route at runtime. In particular, the implementations that are currently available enable you to start, stop, suspend, or resume a route at any time (or times) specified by the policy.
Scheduling tasks
The scheduled route policies are capable of triggering the following kinds of event:
- Start a route — start the route at the time (or times) specified. This event only has an effect, if the route is currently in a stopped state, awaiting activation.
- Stop a route — stop the route at the time (or times) specified. This event only has an effect, if the route is currently active.
-
Suspend a route — temporarily de-activate the consumer endpoint at the start of the route (as specified in
from()). The rest of the route is still active, but clients will not be able to send new messages into the route. - Resume a route — re-activate the consumer endpoint at the start of the route, returning the route to a fully active state.
Quartz component
The Quartz component is a timer component based on Terracotta’s Quartz, which is an open source implementation of a job scheduler. The Quartz component provides the underlying implementation for both the simple scheduled route policy and the cron scheduled route policy.
2.10.2. Simple Scheduled Route Policy
Overview
The simple scheduled route policy is a route policy that enables you to start, stop, suspend, and resume routes, where the timing of these events is defined by providing the time and date of an initial event and (optionally) by specifying a certain number of subsequent repititions. To define a simple scheduled route policy, create an instance of the following class:
org.apache.camel.routepolicy.quartz.SimpleScheduledRoutePolicy
Dependency
The simple scheduled route policy depends on the Quartz component, camel-quartz. For example, if you are using Maven as your build system, you would need to add a dependency on the camel-quartz artifact.
Java DSL example
Example 2.7, “Java DSL Example of Simple Scheduled Route” shows how to schedule a route to start up using the Java DSL. The initial start time, startTime, is defined to be 3 seconds after the current time. The policy is also configured to start the route a second time, 3 seconds after the initial start time, which is configured by setting routeStartRepeatCount to 1 and routeStartRepeatInterval to 3000 milliseconds.
In Java DSL, you attach the route policy to the route by calling the routePolicy() DSL command in the route.
Example 2.7. Java DSL Example of Simple Scheduled Route
// Java
SimpleScheduledRoutePolicy policy = new SimpleScheduledRoutePolicy();
long startTime = System.currentTimeMillis() + 3000L;
policy.setRouteStartDate(new Date(startTime));
policy.setRouteStartRepeatCount(1);
policy.setRouteStartRepeatInterval(3000);
from("direct:start")
.routeId("test")
.routePolicy(policy)
.to("mock:success");
You can specify multiple policies on the route by calling routePolicy() with multiple arguments.
XML DSL example
Example 2.8, “XML DSL Example of Simple Scheduled Route” shows how to schedule a route to start up using the XML DSL.
In XML DSL, you attach the route policy to the route by setting the routePolicyRef attribute on the route element.
Example 2.8. XML DSL Example of Simple Scheduled Route
<bean id="date" class="java.util.Data"/>
<bean id="startPolicy" class="org.apache.camel.routepolicy.quartz.SimpleScheduledRoutePolicy">
<property name="routeStartDate" ref="date"/>
<property name="routeStartRepeatCount" value="1"/>
<property name="routeStartRepeatInterval" value="3000"/>
</bean>
<camelContext xmlns="http://camel.apache.org/schema/spring">
<route id="myroute" routePolicyRef="startPolicy">
<from uri="direct:start"/>
<to uri="mock:success"/>
</route>
</camelContext>
You can specify multiple policies on the route by setting the value of routePolicyRef as a comma-separated list of bean IDs.
Defining dates and times
The initial times of the triggers used in the simple scheduled route policy are specified using the java.util.Date type.The most flexible way to define a Date instance is through the java.util.GregorianCalendar class. Use the convenient constructors and methods of the GregorianCalendar class to define a date and then obtain a Date instance by calling GregorianCalendar.getTime().
For example, to define the time and date for January 1, 2011 at noon, call a GregorianCalendar constructor as follows:
// Java
import java.util.GregorianCalendar;
import java.util.Calendar;
...
GregorianCalendar gc = new GregorianCalendar(
2011,
Calendar.JANUARY,
1,
12, // hourOfDay
0, // minutes
0 // seconds
);
java.util.Date triggerDate = gc.getTime();
The GregorianCalendar class also supports the definition of times in different time zones. By default, it uses the local time zone on your computer.
Graceful shutdown
When you configure a simple scheduled route policy to stop a route, the route stopping algorithm is automatically integrated with the graceful shutdown procedure (see Section 2.9, “Controlling Start-Up and Shutdown of Routes”). This means that the task waits until the current exchange has finished processing before shutting down the route. You can set a timeout, however, that forces the route to stop after the specified time, irrespective of whether or not the route has finished processing the exchange.
Logging Inflight Exchanges on Timeout
If a graceful shutdown fails to shutdown cleanly within the given timeout period, then Apache Camel performs more aggressive shut down. It forces routes, threadpools etc to shutdown.
After the timeout, Apache Camel logs information about the current inflight exchanges. It logs the origin of the exchange and current route of exchange.
For example, the log below shows that there is one inflight exchange, that origins from route1 and is currently on the same route1 at the delay1 node.
During graceful shutdown, If you enable the DEBUG logging level on org.apache.camel.impl.DefaultShutdownStrategy, then it logs the same inflight exchange information.
2015-01-12 13:23:23,656 [- ShutdownTask] INFO DefaultShutdownStrategy - There are 1 inflight exchanges: InflightExchange: [exchangeId=ID-davsclaus-air-62213-1421065401253-0-3, fromRouteId=route1, routeId=route1, nodeId=delay1, elapsed=2007, duration=2017]
If you do not want to see these logs, you can turn this off by setting the option logInflightExchangesOnTimeout to false.
context.getShutdownStrategegy().setLogInflightExchangesOnTimeout(false);
Scheduling tasks
You can use a simple scheduled route policy to define one or more of the following scheduling tasks:
Starting a route
The following table lists the parameters for scheduling one or more route starts.
| Parameter | Type | Default | Description |
|---|---|---|---|
|
|
| None | Specifies the date and time when the route is started for the first time. |
|
|
|
| When set to a non-zero value, specifies how many times the route should be started. |
|
|
|
| Specifies the time interval between starts, in units of milliseconds. |
Stopping a route
The following table lists the parameters for scheduling one or more route stops.
| Parameter | Type | Default | Description |
|---|---|---|---|
|
|
| None | Specifies the date and time when the route is stopped for the first time. |
|
|
|
| When set to a non-zero value, specifies how many times the route should be stopped. |
|
|
|
| Specifies the time interval between stops, in units of milliseconds. |
|
|
|
| Specifies how long to wait for the current exchange to finish processing (grace period) before forcibly stopping the route. Set to 0 for an infinite grace period. |
|
|
|
| Specifies the time unit of the grace period. |
Suspending a route
The following table lists the parameters for scheduling the suspension of a route one or more times.
| Parameter | Type | Default | Description |
|---|---|---|---|
|
|
| None | Specifies the date and time when the route is suspended for the first time. |
|
|
| 0 | When set to a non-zero value, specifies how many times the route should be suspended. |
|
|
| 0 | Specifies the time interval between suspends, in units of milliseconds. |
Resuming a route
The following table lists the parameters for scheduling the resumption of a route one or more times.
| Parameter | Type | Default | Description |
|---|---|---|---|
|
|
| None | Specifies the date and time when the route is resumed for the first time. |
|
|
| 0 | When set to a non-zero value, specifies how many times the route should be resumed. |
|
|
| 0 | Specifies the time interval between resumes, in units of milliseconds. |
2.10.3. Cron Scheduled Route Policy
Overview
The cron scheduled route policy is a route policy that enables you to start, stop, suspend, and resume routes, where the timing of these events is specified using cron expressions. To define a cron scheduled route policy, create an instance of the following class:
org.apache.camel.routepolicy.quartz.CronScheduledRoutePolicy
Dependency
The simple scheduled route policy depends on the Quartz component, camel-quartz. For example, if you are using Maven as your build system, you would need to add a dependency on the camel-quartz artifact.
Java DSL example
Example 2.9, “Java DSL Example of a Cron Scheduled Route” shows how to schedule a route to start up using the Java DSL. The policy is configured with the cron expression, \*/3 * * * * ?, which triggers a start event every 3 seconds.
In Java DSL, you attach the route policy to the route by calling the routePolicy() DSL command in the route.
Example 2.9. Java DSL Example of a Cron Scheduled Route
// Java
CronScheduledRoutePolicy policy = new CronScheduledRoutePolicy();
policy.setRouteStartTime("*/3 * * * * ?");
from("direct:start")
.routeId("test")
.routePolicy(policy)
.to("mock:success");;
You can specify multiple policies on the route by calling routePolicy() with multiple arguments.
XML DSL example
Example 2.10, “XML DSL Example of a Cron Scheduled Route”shows how to schedule a route to start up using the XML DSL.
In XML DSL, you attach the route policy to the route by setting the routePolicyRef attribute on the route element.
Example 2.10. XML DSL Example of a Cron Scheduled Route
<bean id="date" class="org.apache.camel.routepolicy.quartz.SimpleDate"/>
<bean id="startPolicy" class="org.apache.camel.routepolicy.quartz.CronScheduledRoutePolicy">
<property name="routeStartTime" value="*/3 * * * * ?"/>
</bean>
<camelContext xmlns="http://camel.apache.org/schema/spring">
<route id="testRoute" routePolicyRef="startPolicy">
<from uri="direct:start"/>
<to uri="mock:success"/>
</route>
</camelContext>
You can specify multiple policies on the route by setting the value of routePolicyRef as a comma-separated list of bean IDs.
Defining cron expressions
The cron expression syntax has its origins in the UNIX cron utility, which schedules jobs to run in the background on a UNIX system. A cron expression is effectively a syntax for wildcarding dates and times that enables you to specify either a single event or multiple events that recur periodically.
A cron expression consists of 6 or 7 fields in the following order:
Seconds Minutes Hours DayOfMonth Month DayOfWeek [Year]
The Year field is optional and usually omitted, unless you want to define an event that occurs once and once only. Each field consists of a mixture of literals and special characters. For example, the following cron expression specifies an event that fires once every day at midnight:
0 0 24 * * ?
The * character is a wildcard that matches every value of a field. Hence, the preceding expression matches every day of every month. The ? character is a dummy placeholder that means *ignore this field*. It always appears either in the DayOfMonth field or in the DayOfWeek field, because it is not logically consistent to specify both of these fields at the same time. For example, if you want to schedule an event that fires once a day, but only from Monday to Friday, use the following cron expression:
0 0 24 ? * MON-FRI
Where the hyphen character specifies a range, MON-FRI. You can also use the forward slash character, /, to specify increments. For example, to specify that an event fires every 5 minutes, use the following cron expression:
0 0/5 * * * ?
For a full explanation of the cron expression syntax, see the Wikipedia article on CRON expressions.
Scheduling tasks
You can use a cron scheduled route policy to define one or more of the following scheduling tasks:
Starting a route
The following table lists the parameters for scheduling one or more route starts.
| Parameter | Type | Default | Description |
|---|---|---|---|
|
|
| None | Specifies a cron expression that triggers one or more route start events. |
Stopping a route
The following table lists the parameters for scheduling one or more route stops.
| Parameter | Type | Default | Description |
|---|---|---|---|
|
|
| None | Specifies a cron expression that triggers one or more route stop events. |
|
|
|
| Specifies how long to wait for the current exchange to finish processing (grace period) before forcibly stopping the route. Set to 0 for an infinite grace period. |
|
|
|
| Specifies the time unit of the grace period. |
Suspending a route
The following table lists the parameters for scheduling the suspension of a route one or more times.
| Parameter | Type | Default | Description |
|---|---|---|---|
|
|
| None | Specifies a cron expression that triggers one or more route suspend events. |
Resuming a route
The following table lists the parameters for scheduling the resumption of a route one or more times.
| Parameter | Type | Default | Description |
|---|---|---|---|
|
|
| None | Specifies a cron expression that triggers one or more route resume events. |
2.10.4. Route Policy Factory
Using Route Policy Factory
Available as of Camel 2.14
If you want to use a route policy for every route, you can use a org.apache.camel.spi.RoutePolicyFactory as a factory for creating a RoutePolicy instance for each route. This can be used when you want to use the same kind of route policy for every route. Then you need to only configure the factory once, and every route created will have the policy assigned.
There is API on CamelContext to add a factory, as shown below:
context.addRoutePolicyFactory(new MyRoutePolicyFactory());
From XML DSL you only define a <bean> with the factory
<bean id="myRoutePolicyFactory" class="com.foo.MyRoutePolicyFactory"/>
The factory contains the createRoutePolicy method for creating route policies.
/**
* Creates a new {@link org.apache.camel.spi.RoutePolicy} which will be assigned to the given route.
*
* @param camelContext the camel context
* @param routeId the route id
* @param route the route definition
* @return the created {@link org.apache.camel.spi.RoutePolicy}, or <tt>null</tt> to not use a policy for this route
*/
RoutePolicy createRoutePolicy(CamelContext camelContext, String routeId, RouteDefinition route);
Note you can have as many route policy factories as you want. Just call the addRoutePolicyFactory again, or declare the other factories as <bean> in XML.
2.11. Reloading Camel Routes
In Apache Camel 2.19 release, you can enable the live reload of your camel XML routes, which will trigger a reload, when you save the XML file from your editor. You can use this feature when using:
- Camel standalone with Camel Main class
- Camel Spring Boot
- From the camel:run maven plugin
However, you can also enable this manually, by setting a ReloadStrategy on the CamelContext and by providing your own custom strategies.
2.12. Camel Maven Plugin
The Camel Maven Plugin supports the following goals:
- camel:run - To run your Camel application
- camel:validate - To validate your source code for invalid Camel endpoint URIs
- camel:route-coverage - To report the coverage of your Camel routes after unit testing
2.12.1. camel:run
The camel:run goal of the Camel Maven Plugin is used to run your Camel Spring configurations in a forked JVM from Maven. A good example application to get you started is the Spring Example.
cd examples/camel-example-spring mvn camel:run
This makes it very easy to spin up and test your routing rules without having to write a main(…) method; it also lets you create multiple jars to host different sets of routing rules and easily test them independently. The Camel Maven plugin compiles the source code in the maven project, then boots up a Spring ApplicationContext using the XML configuration files on the classpath at META-INF/spring/*.xml. If you want to boot up your Camel routes a little faster, you can try the camel:embedded instead.
2.12.1.1. Options
The Camel Maven plugin run goal supports the following options which can be configured from the command line (use -D syntax), or defined in the pom.xml file in the <configuration> tag.
| Parameter | Default Value | Description |
| duration | -1 | Sets the time duration (seconds) that the application runs for before terminating. A value ⇐ 0 will run forever. |
| durationIdle | -1 | Sets the idle time duration (seconds) duration that the application can be idle for before terminating. A value ⇐ 0 will run forever. |
| durationMaxMessages | -1 | Sets the duration of maximum number of messages that the application processes before terminating. |
| logClasspath | false | Whether to log the classpath when starting |
2.12.1.2. Running OSGi Blueprint
The camel:run plugin also supports running a Blueprint application, and by default it scans for OSGi blueprint files in OSGI-INF/blueprint/*.xml. You would need to configure the camel:run plugin to use blueprint, by setting useBlueprint to true as shown below:
<plugin>
<groupId>org.jboss.redhat-fuse</groupId>
<artifactId>camel-maven-plugin</artifactId>
<configuration>
<useBlueprint>true</useBlueprint>
</configuration>
</plugin>
This allows you to boot up any Blueprint services you wish, regardless of whether they are Camel-related, or any other Blueprint. The camel:run goal can auto detect if camel-blueprint is on the classpath or there are blueprint XML files in the project, and therefore you no longer have to configure the useBlueprint option.
2.12.1.3. Using limited Blueprint container
We use the Felix Connector project as the blueprint container. This project is not a full fledged blueprint container. For that you can use Apache Karaf or Apache ServiceMix. You can use the applicationContextUri configuration to specify an explicit blueprint XML file, such as:
<plugin>
<groupId>org.jboss.redhat-fuse</groupId>
<artifactId>camel-maven-plugin</artifactId>
<configuration>
<useBlueprint>true</useBlueprint>
<applicationContextUri>myBlueprint.xml</applicationContextUri>
<!-- ConfigAdmin options which have been added since Camel 2.12.0 -->
<configAdminPid>test</configAdminPid>
<configAdminFileName>/user/test/etc/test.cfg</configAdminFileName>
</configuration>
</plugin>
The applicationContextUri loads the file from the classpath, so in the example above the myBlueprint.xml file must be in the root of the classpath. The configAdminPid is the pid name which will be used as the pid name for configuration admin service when loading the persistence properties file. The configAdminFileName is the file name which will be used to load the configuration admin service properties file.
2.12.1.4. Running CDI
The camel:run plugin also supports running a CDI application. This allows you to boot up any CDI services you wish, whether they are Camel-related, or any other CDI enabled services. You should add the CDI container of your choice (e.g. Weld or OpenWebBeans) to the dependencies of the camel-maven-plugin such as in this example. From the source of Camel you can run a CDI example as follows:
cd examples/camel-example-cdi mvn compile camel:run
2.12.1.5. Logging the classpath
You can configure whether the classpath should be logged when camel:run executes. You can enable this in the configuration using:
<plugin>
<groupId>org.jboss.redhat-fuse</groupId>
<artifactId>camel-maven-plugin</artifactId>
<configuration>
<logClasspath>true</logClasspath>
</configuration>
</plugin>2.12.1.6. Using live reload of XML files
You can configure the plugin to scan for XML file changes and trigger a reload of the Camel routes which are contained in those XML files.
<plugin>
<groupId>org.jboss.redhat-fuse</groupId>
<artifactId>camel-maven-plugin</artifactId>
<configuration>
<fileWatcherDirectory>src/main/resources/META-INF/spring</fileWatcherDirectory>
</configuration>
</plugin>
Then the plugin watches this directory. This allows you to edit the source code from your editor and save the file, and have the running Camel application utilize those changes. Note that only the changes of Camel routes, for example, <routes>, or <route> which are supported. You cannot change Spring or OSGi Blueprint <bean> elements.
2.12.2. camel:validate
For validating the source code for misconfigured Camel: * endpoint URIs * simple expressions or predicates * duplicate route ids
Then you can run the camel:validate goal from the command line or from within your Java editor such as IDEA or Eclipse.
mvn camel:validate
You can also enable the plugin to automatic run as part of the build to catch these errors.
<plugin>
<groupId>org.jboss.redhat-fuse</groupId>
<artifactId>camel-maven-plugin</artifactId>
<executions>
<execution>
<phase>process-classes</phase>
<goals>
<goal>validate</goal>
</goals>
</execution>
</executions>
</plugin>
The phase determines when the plugin runs. In the sample above the phase is process-classes which runs after the compilation of the main source code. The maven plugin can also be configured to validate the test source code, which means that the phase should be changed accordingly to process-test-classes as shown below:
<plugin>
<groupId>org.jboss.redhat-fuse</groupId>
<artifactId>camel-maven-plugin</artifactId>
<executions>
<execution>
<configuration>
<includeTest>true</includeTest>
</configuration>
<phase>process-test-classes</phase>
<goals>
<goal>validate</goal>
</goals>
</execution>
</executions>
</plugin>2.12.2.1. Running the goal on any Maven project
You can also run the validate goal on any Maven project without having to add the plugin to the pom.xml file. Doing so requires to specify the plugin using its fully qualified name. For example to run the goal on the camel-example-cdi from Apache Camel, you can run
$cd camel-example-cdi $mvn org.apache.camel:camel-maven-plugin:2.20.0:validate
which then runs and outputs the following:
[INFO] ------------------------------------------------------------------------ [INFO] Building Camel :: Example :: CDI 2.20.0 [INFO] ------------------------------------------------------------------------ [INFO] [INFO] --- camel-maven-plugin:2.20.0:validate (default-cli) @ camel-example-cdi --- [INFO] Endpoint validation success: (4 = passed, 0 = invalid, 0 = incapable, 0 = unknown components) [INFO] Simple validation success: (0 = passed, 0 = invalid) [INFO] ------------------------------------------------------------------------ [INFO] BUILD SUCCESS [INFO] ------------------------------------------------------------------------
The validation passed, and 4 endpoints was validated. Now suppose we made a typo in one of the Camel endpoint URIs in the source code, such as:
@Uri("timer:foo?period=5000")
is changed to include a typo error in the period option
@Uri("timer:foo?perid=5000")And when running the validate goal again reports the following:
[INFO] ------------------------------------------------------------------------ [INFO] Building Camel :: Example :: CDI 2.20.0 [INFO] ------------------------------------------------------------------------ [INFO] [INFO] --- camel-maven-plugin:2.20.0:validate (default-cli) @ camel-example-cdi --- [WARNING] Endpoint validation error at: org.apache.camel.example.cdi.MyRoutes(MyRoutes.java:32) timer:foo?perid=5000 perid Unknown option. Did you mean: [period] [WARNING] Endpoint validation error: (3 = passed, 1 = invalid, 0 = incapable, 0 = unknown components) [INFO] Simple validation success: (0 = passed, 0 = invalid) [INFO] ------------------------------------------------------------------------ [INFO] BUILD SUCCESS [INFO] ------------------------------------------------------------------------
2.12.2.2. Options
The Camel Maven plugin validate goal supports the following options which can be configured from the command line (use -D syntax), or defined in the pom.xml file in the <configuration> tag.
| Parameter | Default Value | Description |
| downloadVersion | true | Whether to allow downloading Camel catalog version from the internet. This is needed if the project uses a different Camel version than this plugin is using by default. |
| failOnError | false | Whether to fail if invalid Camel endpoints were found. By default the plugin logs the errors at WARN level. |
| logUnparseable | false | Whether to log endpoint URI which was un-parsable and therefore not possible to validate. |
| includeJava | true | Whether to include Java files to be validated for invalid Camel endpoints. |
| includeXml | true | Whether to include XML files to be validated for invalid Camel endpoints. |
| includeTest | false | Whether to include test source code. |
| includes | To filter the names of java and xml files to only include files matching any of the given list of patterns (wildcard and regular expression). Multiple values can be separated by comma. | |
| excludes | To filter the names of java and xml files to exclude files matching any of the given list of patterns (wildcard and regular expression). Multiple values can be separated by comma. | |
| ignoreUnknownComponent | true | Whether to ignore unknown components. |
| ignoreIncapable | true | Whether to ignore incapable of parsing the endpoint URI or simple expression. |
| ignoreLenientProperties | true | Whether to ignore components that uses lenient properties. When this is true, then the URI validation is stricter but would fail on properties that are not part of the component but in the URI because of using lenient properties. For example using the HTTP components to provide query parameters in the endpoint URI. |
| ignoreDeprecated | true | Camel 2.23 Whether to ignore deprecated options being used in the endpoint URI. |
| duplicateRouteId | true | Camel 2.20 Whether to validate for duplicate route ids. Route ids should be unique and if there are duplicates then Camel will fail to startup. |
| directOrSedaPairCheck | true | Camel 2.23 Whether to validate direct/seda endpoints sending to non existing consumers. |
| showAll | false | Whether to show all endpoints and simple expressions (both invalid and valid). |
For example to turn off ignoring usage of deprecated options from the command line, you can run:
$mvn camel:validate -Dcamel.ignoreDeprecated=true
Note that you must prefix the -D command argument with camel., eg camel.ignoreDeprecated as the option name.
2.12.2.3. Validating Endpoints using include test
If you have a Maven project then you can run the plugin to validate the endpoints in the unit test source code as well. You can pass in the options using -D style as shown:
$cd myproject $mvn org.apache.camel:camel-maven-plugin:2.20.0:validate -DincludeTest=true
2.12.3. camel:route-coverage
For generating a report of the coverage of your Camel routes from unit testing. You can use this to know which parts of your Camel routes has been used or not.
2.12.3.1. Enabling route coverage
You can enable route coverage while running unit tests either by:
- setting global JVM system property enabling for all test classes
-
using
@EnableRouteCoverageannotation per test class if usingcamel-test-springmodule -
overriding
isDumpRouteCoveragemethod per test class if usingcamel-testmodule
2.12.3.2. Enabling Route Coverage by using JVM system property
You can turn on the JVM system property CamelTestRouteCoverage to enable route coverage for all tests cases. This can be done either in the configuration of the maven-surefire-plugin:
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<configuration>
<systemPropertyVariables>
<CamelTestRouteCoverage>true</CamelTestRouteCoverage>
</systemPropertyVariables>
</configuration>
</plugin>Or from the command line when running tests:
mvn clean test -DCamelTestRouteCoverage=true
2.12.3.3. Enabling via @EnableRouteCoverage annotation
You can enable route coverage in the unit tests classes by adding the @EnableRouteCoverage annotation to the test class if you are testing using camel-test-spring:
@RunWith(CamelSpringBootRunner.class)
@SpringBootTest(classes = SampleCamelApplication.class)
@EnableRouteCoverage
public class FooApplicationTest {2.12.3.4. Enabling via isDumpRouteCoverage method
However if you are using camel-test and your unit tests are extending CamelTestSupport then you can turn on route coverage as shown:
@Override
public boolean isDumpRouteCoverage() {
return true;
}
Routes that can be coveraged under RouteCoverage method must have an unique id assigned, in other words you cannot use anonymous routes. You do this using routeId in Java DSL:
from("jms:queue:cheese").routeId("cheesy")
.to("log:foo")
...And in XML DSL you just assign the route id via the id attribute
<route id="cheesy"> <from uri="jms:queue:cheese"/> <to uri="log:foo"/> ... </route>
2.12.3.5. Generating route coverage report
TO generate the route coverage report, run the unit test with:
mvn test
You can then run the goal to report the route coverage as follows:
mvn camel:route-coverage
This reports which routes has missing route coverage with precise source code line reporting:
[INFO] --- camel-maven-plugin:2.21.0:route-coverage (default-cli) @ camel-example-spring-boot-xml ---
[INFO] Discovered 1 routes
[INFO] Route coverage summary:
File: src/main/resources/my-camel.xml
RouteId: hello
Line # Count Route
------ ----- -----
28 1 from
29 1 transform
32 1 filter
34 0 to
36 1 to
Coverage: 4 out of 5 (80.0%)
Here we can see that the 2nd last line with to has 0 in the count column, and therefore is not covered. We can also see that this is one line 34 in the source code file, which is in the my-camel.xml XML file.
2.12.3.6. Options
The Camel Maven plugin coverage goal supports the following options which can be configured from the command line (use -D syntax), or defined in the pom.xml file in the <configuration> tag.
| Parameter | Default Value | Description |
| failOnError | false | Whether to fail if any of the routes does not have 100% coverage. |
| includeTest | false | Whether to include test source code. |
| includes | To filter the names of java and xml files to only include files matching any of the given list of patterns (wildcard and regular expression). Multiple values can be separated by comma. | |
| excludes | To filter the names of java and xml files to exclude files matching any of the given list of patterns (wildcard and regular expression). Multiple values can be separated by comma. | |
| anonymousRoutes | false | Whether to allow anonymous routes (routes without any route id assigned). By using route id’s then its safer to match the route cover data with the route source code. Anonymous routes are less safe to use for route coverage as its harder to know exactly which route that was tested corresponds to which of the routes from the source code. |
2.13. Running Apache Camel Standalone
When you run camel as a standalone application, it provides the Main class that you can use to run the application and keep it running until the JVM terminates. You can find the MainListener class within the org.apache.camel.main Java package.
Following are the components of the Main class:
-
camel-coreJAR in theorg.apache.camel.Mainclass -
camel-springJAR in theorg.apache.camel.spring.Mainclass
The following example shows how you can create and use the Main class from Camel:
public class MainExample {
private Main main;
public static void main(String[] args) throws Exception {
MainExample example = new MainExample();
example.boot();
}
public void boot() throws Exception {
// create a Main instance
main = new Main();
// bind MyBean into the registry
main.bind("foo", new MyBean());
// add routes
main.addRouteBuilder(new MyRouteBuilder());
// add event listener
main.addMainListener(new Events());
// set the properties from a file
main.setPropertyPlaceholderLocations("example.properties");
// run until you terminate the JVM
System.out.println("Starting Camel. Use ctrl + c to terminate the JVM.\n");
main.run();
}
private static class MyRouteBuilder extends RouteBuilder {
@Override
public void configure() throws Exception {
from("timer:foo?delay={{millisecs}}")
.process(new Processor() {
public void process(Exchange exchange) throws Exception {
System.out.println("Invoked timer at " + new Date());
}
})
.bean("foo");
}
}
public static class MyBean {
public void callMe() {
System.out.println("MyBean.callMe method has been called");
}
}
public static class Events extends MainListenerSupport {
@Override
public void afterStart(MainSupport main) {
System.out.println("MainExample with Camel is now started!");
}
@Override
public void beforeStop(MainSupport main) {
System.out.println("MainExample with Camel is now being stopped!");
}
}
}2.14. OnCompletion
Overview
The OnCompletion DSL name is used to define an action that is to take place when a Unit of Work is completed. A Unit of Work is a Camel concept that encompasses an entire exchange. See Section 34.1, “Exchanges”. The onCompletion command has the following features:
-
The scope of the
OnCompletioncommand can be global or per route. A route scope overrides global scope. -
OnCompletioncan be configured to be triggered on success for failure. -
The
onWhenpredicate can be used to only trigger theonCompletionin certain situations. - You can define whether or not to use a thread pool, though the default is no thread pool.
Route Only Scope for onCompletion
When an onCompletion DSL is specified on an exchange, Camel spins off a new thread. This allows the original thread to continue without interference from the onCompletion task. A route will only support one onCompletion. In the following example, the onCompletion is triggered whether the exchange completes with success or failure. This is the default action.
from("direct:start")
.onCompletion()
// This route is invoked when the original route is complete.
// This is similar to a completion callback.
.to("log:sync")
.to("mock:sync")
// Must use end to denote the end of the onCompletion route.
.end()
// here the original route contiues
.process(new MyProcessor())
.to("mock:result");For XML the format is as follows:
<route>
<from uri="direct:start"/>
<!-- This onCompletion block is executed when the exchange is done being routed. -->
<!-- This callback is always triggered even if the exchange fails. -->
<onCompletion>
<!-- This is similar to an after completion callback. -->
<to uri="log:sync"/>
<to uri="mock:sync"/>
</onCompletion>
<process ref="myProcessor"/>
<to uri="mock:result"/>
</route>
To trigger the onCompletion on failure, the onFailureOnly parameter can be used. Similarly, to trigger the onCompletion on success, use the onCompleteOnly parameter.
from("direct:start")
// Here onCompletion is qualified to invoke only when the exchange fails (exception or FAULT body).
.onCompletion().onFailureOnly()
.to("log:sync")
.to("mock:sync")
// Must use end to denote the end of the onCompletion route.
.end()
// here the original route continues
.process(new MyProcessor())
.to("mock:result");
For XML, onFailureOnly and onCompleteOnly are expressed as booleans on the onCompletion tag:
<route>
<from uri="direct:start"/>
<!-- this onCompletion block will only be executed when the exchange is done being routed -->
<!-- this callback is only triggered when the exchange failed, as we have onFailure=true -->
<onCompletion onFailureOnly="true">
<to uri="log:sync"/>
<to uri="mock:sync"/>
</onCompletion>
<process ref="myProcessor"/>
<to uri="mock:result"/>
</route>Global Scope for onCompletion
To define onCompletion for more than just one route:
// define a global on completion that is invoked when the exchange is complete
onCompletion().to("log:global").to("mock:sync");
from("direct:start")
.process(new MyProcessor())
.to("mock:result");Using onWhen
To trigger the onCompletion under certain circumstances, use the onWhen predicate. The following example will trigger the onCompletion when the body of the message contains the word Hello:
/from("direct:start")
.onCompletion().onWhen(body().contains("Hello"))
// this route is only invoked when the original route is complete as a kind
// of completion callback. And also only if the onWhen predicate is true
.to("log:sync")
.to("mock:sync")
// must use end to denote the end of the onCompletion route
.end()
// here the original route contiues
.to("log:original")
.to("mock:result");Using onCompletion with or without a thread pool
As of Camel 2.14, onCompletion will not use a thread pool by default. To force the use of a thread pool, either set an executorService or set parallelProcessing to true. For example, in Java DSL, use the following format:
onCompletion().parallelProcessing()
.to("mock:before")
.delay(1000)
.setBody(simple("OnComplete:${body}"));For XML the format is:
<onCompletion parallelProcessing="true">
<to uri="before"/>
<delay><constant>1000</constant></delay>
<setBody><simple>OnComplete:${body}<simple></setBody>
</onCompletion>
Use the executorServiceRef option to refer to a specific thread pool:
<onCompletion executorServiceRef="myThreadPool"
<to uri="before"/>
<delay><constant>1000</constant></delay>
<setBody><simple>OnComplete:${body}</simple></setBody>
</onCompletion>>Run onCompletion before Consumer Sends Response
onCompletion can be run in two modes:
- AfterConsumer - The default mode which runs after the consumer is finished
-
BeforeConsumer - Runs before the consumer writes a response back to the callee. This allows
onCompletionto modify the Exchange, such as adding special headers, or to log the Exchange as a response logger.
For example, to add a created by header to the response, use modeBeforeConsumer() as shown below:
.onCompletion().modeBeforeConsumer()
.setHeader("createdBy", constant("Someone"))
.end()
For XML, set the mode attribute to BeforeConsumer:
<onCompletion mode="BeforeConsumer">
<setHeader headerName="createdBy">
<constant>Someone</constant>
</setHeader>
</onCompletion>2.15. Metrics
Overview
Available as of Camel 2.14
While Camel provides a lot of existing metrics integration with Codahale metrics has been added for Camel routes. This allows end users to seamless feed Camel routing information together with existing data they are gathering using Codahale metrics.
To use the Codahale metrics you will need to:
- Add camel-metrics component
- Enable route metrics in XML or Java code
Note that performance metrics are only usable if you have a way of displaying them; any kind of monitoring tooling which can integrate with JMX can be used, as the metrics are available over JMX. In addition, the actual data is 100% Codehale JSON.
Metrics Route Policy
Obtaining Codahale metrics for a single route can be accomplished by defining a MetricsRoutePolicy on a per route basis.
From Java create an instance of MetricsRoutePolicy to be assigned as the route’s policy. This is shown below:
from("file:src/data?noop=true").routePolicy(new MetricsRoutePolicy()).to("jms:incomingOrders");
From XML DSL you define a <bean> which is specified as the route’s policy; for example:
<bean id="policy" class="org.apache.camel.component.metrics.routepolicy.MetricsRoutePolicy"/>
<camelContext xmlns="http://camel.apache.org/schema/spring">
<route routePolicyRef="policy">
<from uri="file:src/data?noop=true"/>
[...]Metrics Route Policy Factory
This factory allows one to add a RoutePolicy for each route which exposes route utilization statistics using Codahale metrics. This factory can be used in Java and XML as the examples below demonstrate.
From Java you just add the factory to the CamelContext as shown below:
context.addRoutePolicyFactory(new MetricsRoutePolicyFactory());
And from XML DSL you define a <bean> as follows:
<!-- use camel-metrics route policy to gather metrics for all routes --> <bean id="metricsRoutePolicyFactory" class="org.apache.camel.component.metrics.routepolicy.MetricsRoutePolicyFactory"/>
From Java code you can get hold of the com.codahale.metrics.MetricRegistry from the org.apache.camel.component.metrics.routepolicy.MetricsRegistryService as shown below:
MetricRegistryService registryService = context.hasService(MetricsRegistryService.class);
if (registryService != null) {
MetricsRegistry registry = registryService.getMetricsRegistry();
...
}Options
The MetricsRoutePolicyFactory and MetricsRoutePolicy supports the following options:
| Name | Default | Description |
|
|
| The unit to use for duration in the metrics reporter or when dumping the statistics as json. |
|
|
| The JXM domain name. |
|
|
Allow to use a shared | |
|
|
| Whether to use pretty print when outputting statistics in json format. |
|
|
| The unit to use for rate in the metrics reporter or when dumping the statistics as json. |
|
|
|
Whether to report fine grained statistics to JMX by using the
Notice that if JMX is enabled on CamelContext then a |
2.16. JMX Naming
Overview
Apache Camel allows you to customize the name of a CamelContext bean as it appears in JMX, by defining a management name pattern for it. For example, you can customize the name pattern of an XML CamelContext instance, as follows:
<camelContext id="myCamel" managementNamePattern="#name#">
...
</camelContext>
If you do not explicitly set a name pattern for the CamelContext bean, Apache Camel reverts to a default naming strategy.
Default naming strategy
By default, the JMX name of a CamelContext bean deployed in an OSGi bundle is equal to the OSGi symbolic name of the bundle. For example, if the OSGi symbolic name is MyCamelBundle, the JMX name would be MyCamelBundle. In cases where there is more than one CamelContext in the bundle, the JMX name is disambiguated by adding a counter value as a suffix. For example, if there are multiple Camel contexts in the MyCamelBundle bundle, the corresponding JMX MBeans are named as follows:
MyCamelBundle-1 MyCamelBundle-2 MyCamelBundle-3 ...
Customizing the JMX naming strategy
One drawback of the default naming strategy is that you cannot guarantee that a given CamelContext bean will have the same JMX name between runs. If you want to have greater consistency between runs, you can control the JMX name more precisely by defining a JMX name pattern for the CamelContext instances.
Specifying a name pattern in Java
To specify a name pattern on a CamelContext in Java, call the setNamePattern method, as follows:
// Java
context.getManagementNameStrategy().setNamePattern("#name#");Specifying a name pattern in XML
To specify a name pattern on a CamelContext in XML, set the managementNamePattern attribute on the camelContext element, as follows:
<camelContext id="myCamel" managementNamePattern="#name#">
Name pattern tokens
You can construct a JMX name pattern by mixing literal text with any of the following tokens:
| Token | Description |
|---|---|
|
|
Value of the |
|
|
Same as |
|
|
An incrementing counter (starting at |
|
| The OSGi bundle ID of the deployed bundle (OSGi only). |
|
| The OSGi symbolic name (OSGi only). |
|
| The OSGi bundle version (OSGi only). |
Examples
Here are some examples of JMX name patterns you could define using the supported tokens:
<camelContext id="fooContext" managementNamePattern="FooApplication-#name#">
...
</camelContext>
<camelContext id="myCamel" managementNamePattern="#bundleID#-#symbolicName#-#name#">
...
</camelContext>Ambiguous names
Because the customised naming pattern overrides the default naming strategy, it is possible to define ambiguous JMX MBean names using this approach. For example:
<camelContext id="foo" managementNamePattern="SameOldSameOld"> ... </camelContext> ... <camelContext id="bar" managementNamePattern="SameOldSameOld"> ... </camelContext>
In this case, Apache Camel would fail on start-up and report an MBean already exists exception. You should, therefore, take extra care to ensure that you do not define ambiguous name patterns.
2.17. Performance and Optimization
Message copying
The allowUseOriginalMessage option default setting is false, to cut down on copies being made of the original message when they are not needed. To enable the allowUseOriginalMessage option use the following commands:
-
Set
useOriginalMessage=trueon any of the error handlers or on theonExceptionelement. -
In Java application code, set
AllowUseOriginalMessage=true, then use thegetOriginalMessagemethod.
In Camel versions prior to 2.18, the default setting of allowUseOriginalMessage is true.
Chapter 3. Introducing Enterprise Integration Patterns
Abstract
The Apache Camel’s Enterprise Integration Patterns are inspired by a book of the same name written by Gregor Hohpe and Bobby Woolf. The patterns described by these authors provide an excellent toolbox for developing enterprise integration projects. In addition to providing a common language for discussing integration architectures, many of the patterns can be implemented directly using Apache Camel’s programming interfaces and XML configuration.
3.1. Overview of the Patterns
Enterprise Integration Patterns book
Apache Camel supports most of the patterns from the book, Enterprise Integration Patterns by Gregor Hohpe and Bobby Woolf.
Messaging systems
The messaging systems patterns, shown in Table 3.1, “Messaging Systems”, introduce the fundamental concepts and components that make up a messaging system.
| Icon | Name | Use Case |
|---|---|---|
|
| How can two applications connected by a message channel exchange a piece of information? | |
|
| How does one application communicate with another application using messaging? | |
|
| How does an application connect to a messaging channel to send and receive messages? | |
|
| How can we perform complex processing on a message while still maintaining independence and flexibility? | |
|
| How can you decouple individual processing steps so that messages can be passed to different filters depending on a set of defined conditions? | |
|
| How do systems using different data formats communicate with each other using messaging? |
Messaging channels
A messaging channel is the basic component used for connecting the participants in a messaging system. The patterns in Table 3.2, “Messaging Channels” describe the different kinds of messaging channels available.
| Icon | Name | Use Case |
|---|---|---|
|
| How can the caller be sure that exactly one receiver will receive the document or will perform the call? | |
|
| How can the sender broadcast an event to all interested receivers? | |
|
| What will the messaging system do with a message it cannot deliver? | |
|
| How does the sender make sure that a message will be delivered, even if the messaging system fails? | |
|
| What is an architecture that enables separate, decoupled applications to work together, such that one or more of the applications can be added or removed without affecting the others? |
Message construction
The message construction patterns, shown in Table 3.3, “Message Construction”, describe the various forms and functions of the messages that pass through the system.
| Icon | Name | Use Case |
|---|---|---|
|
| How does a requestor identify the request that generated the received reply? | |
|
| How does a replier know where to send the reply? |
Message routing
The message routing patterns, shown in Table 3.4, “Message Routing”, describe various ways of linking message channels together, including various algorithms that can be applied to the message stream (without modifying the body of the message).
| Icon | Name | Use Case |
|---|---|---|
|
| How do we handle a situation where the implementation of a single logical function (for example, inventory check) is spread across multiple physical systems? | |
|
| How does a component avoid receiving uninteresting messages? | |
|
| How do we route a message to a list of dynamically specified recipients? | |
|
| How can we process a message if it contains multiple elements, each of which might have to be processed in a different way? | |
|
| How do we combine the results of individual, but related messages so that they can be processed as a whole? | |
|
| How can we get a stream of related, but out-of-sequence, messages back into the correct order? | |
|
| How can you maintain the overall message flow when processing a message consisting of multiple elements, each of which may require different processing? | |
| How do you maintain the overall message flow when a message needs to be sent to multiple recipients, each of which may send a reply? | ||
|
| How do we route a message consecutively through a series of processing steps when the sequence of steps is not known at design-time, and might vary for each message? | |
| How can I throttle messages to ensure that a specific endpoint does not get overloaded, or that we don’t exceed an agreed SLA with some external service? | ||
| How can I delay the sending of a message? | ||
| How can I balance load across a number of endpoints? | ||
| How can I use a Hystrix circuit breaker when calling an external service? New in Camel 2.18. | ||
| How can I call a remote service in a distributed system by looking up the service in a registry? New in Camel 2.18. | ||
| How can I route a message to a number of endpoints at the same time? | ||
| How can I repeat processing a message in a loop? | ||
| How can I sample one message out of many in a given period to avoid overloading a ownstream route? |
Message transformation
The message transformation patterns, shown in Table 3.5, “Message Transformation”, describe how to modify the contents of messages for various purposes.
| Icon | Name | Use Case |
|---|---|---|
|
| How do I communicate with another system if the message originator does not have all required data items? | |
|
| How do you simplify dealing with a large message, when you are interested in only a few data items? | |
|
| How can we reduce the data volume of messages sent across the system without sacrificing information content? | |
|
| How do you process messages that are semantically equivalent, but arrive in a different format? | |
| How can I sort the body of a message? |
Messaging endpoints
A messaging endpoint denotes the point of contact between a messaging channel and an application. The messaging endpoint patterns, shown in Table 3.6, “Messaging Endpoints”, describe various features and qualities of service that can be configured on an endpoint.
| Icon | Name | Use Case |
|---|---|---|
| How do you move data between domain objects and the messaging infrastructure while keeping the two independent of each other? | ||
|
| How can an application automatically consume messages as they become available? | |
|
| How can an application consume a message when the application is ready? | |
|
| How can a messaging client process multiple messages concurrently? | |
|
| How can multiple consumers on a single channel coordinate their message processing? | |
|
| How can a message consumer select which messages it wants to receive? | |
|
| How can a subscriber avoid missing messages when it’s not listening for them? | |
| How can a message receiver deal with duplicate messages? | ||
|
| How can a client control its transactions with the messaging system? | |
|
| How do you encapsulate access to the messaging system from the rest of the application? | |
|
| How can an application design a service to be invoked by various messaging technologies as well as by non-messaging techniques? |
System management
The system management patterns, shown in Table 3.7, “System Management”, describe how to monitor, test, and administer a messaging system.
| Icon | Name | Use Case |
|---|---|---|
|
| How do you inspect messages that travel on a point-to-point channel? |
Chapter 4. Defining REST Services
Abstract
Apache Camel supports multiple approaches to defining REST services. In particular, Apache Camel provides the REST DSL (Domain Specific Language), which is a simple but powerful fluent API that can be layered over any REST component and provides integration with Swagger.
4.1. Overview of REST in Camel
Overview
Apache Camel provides many different approaches and components for defining REST services in your Camel applications. This section provides a quick overview of these different approaches and components, so that you can decide which implementation and API best suits your requirements.
What is REST?
Representational State Transfer (REST) is an architecture for distributed applications that centers around the transmission of data over HTTP, using only the four basic HTTP verbs: GET, POST, PUT, and DELETE.
In contrast to a protocol such as SOAP, which treats HTTP as a mere transport protocol for SOAP messages, the REST architecture exploits HTTP directly. The key insight is that the HTTP protocol itself, augmented by a few simple conventions, is eminently suitable to serve as the framework for distributed applications.
A sample REST invocation
Because the REST architecture is built around the standard HTTP verbs, in many cases you can use a regular browser as a REST client. For example, to invoke a simple Hello World REST service running on the host and port, localhost:9091, you could navigate to a URL like the following in your browser:
http://localhost:9091/say/hello/Garp
The Hello World REST service might then return a response string, such as:
Hello Garp
Which gets displayed in your browser window. The ease with which you can invoke REST services, using nothing more than a standard browser (or the curl command-line utility), is one of the many reasons why the REST protocol has rapidly gained popularity.
REST wrapper layers
The following REST wrapper layers offer a simplified syntax for defining REST services and can be layered on top of different REST implementations:
- REST DSL
The REST DSL (in
camel-core) is a facade or wrapper layer that provides a simplified builder API for defining REST services. The REST DSL does not itself provide a REST implementation: it must be combined with an underlying REST implementation. For example, the following Java code shows how to define a simple Hello World service using the REST DSL:rest("/say") .get("/hello/{name}").route().transform().simple("Hello ${header.name}");For more details, see Section 4.2, “Defining Services with REST DSL”.
- Rest component
The Rest component (in
camel-core) is a wrapper layer that enables you to define REST services using a URI syntax. Like the REST DSL, the Rest component does not itself provide a REST implementation. It must be combined with an underlying REST implementation.If you do not explicitly configure an HTTP transport component then the REST DSL automatically discovers which HTTP component to use by checking for available components on the classpath. The REST DSL looks for the default names of any HTTP components and uses the first one it finds. If there are no HTTP components on the classpath and you did not explicitly configure an HTTP transport then the default HTTP component is
camel-http.NoteThe ability to automatically discover which HTTP component to use is new in Camel 2.18. It is not available in Camel 2.17.
The following Java code shows how to define a simple Hello World service using the camel-rest component:
from("rest:get:say:/hello/{name}").transform().simple("Hello ${header.name}");
REST implementations
Apache Camel provides several different REST implementations, through the following components:
- Spark-Rest component
The Spark-Rest component (in
camel-spark-rest) is a REST implementation that enables you to define REST services using a URI syntax. The Spark framework itself is a Java API, which is loosely based on the Sinatra framework (a Python API). For example, the following Java code shows how to define a simple Hello World service using the Spark-Rest component:from("spark-rest:get:/say/hello/:name").transform().simple("Hello ${header.name}");Notice that, in contrast to the Rest component, the syntax for a variable in the URI is
:nameinstead of{name}.NoteThe Spark-Rest component requires Java 8.
- Restlet component
The Restlet component (in
camel-restlet) is a REST implementation that can, in principle, be layered above different transport protocols (although this component is only tested against the HTTP protocol). This component also provides an integration with the Restlet Framework, which is a commercial framework for developing REST services in Java. For example, the following Java code shows how to define a simple Hello World service using the Restlet component:from("restlet:http://0.0.0.0:9091/say/hello/{name}?restletMethod=get") .transform().simple("Hello ${header.name}");For more details, see Restlet in the Apache Camel Component Reference Guide.
- Servlet component
The Servlet component (in
camel-servlet) is a component that binds a Java servlet to a Camel route. In other words, the Servlet component enables you to package and deploy a Camel route as if it was a standard Java servlet. The Servlet component is therefore particularly useful, if you need to deploy a Camel route inside a servlet container (for example, into an Apache Tomcat HTTP server or into a JBoss Enterprise Application Platform container).The Servlet component on its own, however, does not provide any convenient REST API for defining REST services. The easiest way to use the Servlet component, therefore, is to combine it with the REST DSL, so that you can define REST services with a user-friendly API.
For more details, see Servlet in the Apache Camel Component Reference Guide.
JAX-RS REST implementation
JAX-RS (Java API for RESTful Web Services) is a framework for binding REST requests to Java objects, where the Java classes must be decorated with JAX-RS annotations in order to define the binding. The JAX-RS framework is relatively mature and provides a sophisticated framework for developing REST services, but it is also somewhat complex to program.
The JAX-RS integration with Apache Camel is implemented by the CXFRS component, which is layered over Apache CXF. In outline, JAX-RS binds a REST request to a Java class using the following annotations (where this is only an incomplete sample of the many available annotations):
- @Path
- Annotation that can map a context path to a Java class or map a sub-path to a particular Java method.
- @GET, @POST, @PUT, @DELETE
- Annotations that map a HTTP method to a Java method.
- @PathParam
- Annotation that either maps a URI parameter to a Java method argument, or injects a URI parameter into a field.
- @QueryParam
- Annotation that either maps a query parameter to a Java method argument, or injects a query parameter into a field.
The body of a REST request or REST response is normally expected to be in JAXB (XML) data format. But Apache CXF also supports conversion of JSON format to JAXB format, so that JSON messages can also be parsed.
For more details, see CXFRS in the Apache Camel Component Reference Guide and Apache CXF Development Guide.
The CXFRS component is not integrated with the REST DSL.
4.2. Defining Services with REST DSL
REST DSL is a facade
The REST DSL is effectively a facade that provides a simplified syntax for defining REST services in a Java DSL or an XML DSL (Domain Specific Language). REST DSL does not actually provide the REST implementation, it is just a wrapper around an existing REST implementation (of which there are several in Apache Camel).
Advantages of the REST DSL
The REST DSL wrapper layer offers the following advantages:
- A modern easy-to-use syntax for defining REST services.
- Compatible with multiple different Apache Camel components.
-
Swagger integration (through the
camel-swaggercomponent).
Components that integrate with REST DSL
Because the REST DSL is not an actual REST implementation, one of the first things you need to do is to choose a Camel component to provide the underlying implementation. The following Camel components are currently integrated with the REST DSL:
-
Servlet component (
camel-servlet). -
Spark REST component (
camel-spark-rest). -
Netty4 HTTP component (
camel-netty4-http). -
Jetty component (
camel-jetty). -
https://access.redhat.com/documentation/en-us/red_hat_fuse/7.3/html-single/apache_camel_component_reference/index#restlet-component component (
camel-restlet).
The Rest component (part of camel-core) is not a REST implementation. Like the REST DSL, the Rest component is a facade, providing a simplified syntax to define REST services using a URI syntax. The Rest component also requires an underlying REST implementation.
Configuring REST DSL to use a REST implementation
To specify the REST implementation, you use either the restConfiguration() builder (in Java DSL) or the restConfiguration element (in XML DSL). For example, to configure REST DSL to use the Spark-Rest component, you would use a builder expression like the following in the Java DSL:
restConfiguration().component("spark-rest").port(9091);
And you would use an element like the following (as a child of camelContext) in the XML DSL:
<restConfiguration component="spark-rest" port="9091"/>
Syntax
The Java DSL syntax for defining a REST service is as follows:
rest("BasePath").Option().
.Verb("Path").Option().[to() | route().CamelRoute.endRest()]
.Verb("Path").Option().[to() | route().CamelRoute.endRest()]
...
.Verb("Path").Option().[to() | route().CamelRoute];
Where CamelRoute is an optional embedded Camel route (defined using the standard Java DSL syntax for routes).
The REST service definition starts with the rest() keyword, followed by one or more verb clauses that handle specific URL path segments. The HTTP verb can be one of get(), head(), put(), post(), delete(), patch() or verb(). Each verb clause can use either of the following syntaxes:
Verb clause ending in
to()keyword. For example:get("...").Option()+.to("...")Verb clause ending in
route()keyword (for embedding a Camel route). For example:get("...").Option()+.route("...").CamelRoute.endRest()
REST DSL with Java
In Java, to define a service with the REST DSL, put the REST definition into the body of a RouteBuilder.configure() method, just like you do for regular Apache Camel routes. For example, to define a simple Hello World service using the REST DSL with the Spark-Rest component, define the following Java code:
restConfiguration().component("spark-rest").port(9091);
rest("/say")
.get("/hello").to("direct:hello")
.get("/bye").to("direct:bye");
from("direct:hello")
.transform().constant("Hello World");
from("direct:bye")
.transform().constant("Bye World");The preceding example features three different kinds of builder:
restConfiguration()- Configures the REST DSL to use a specific REST implementation (Spark-Rest).
rest()-
Defines a service using the REST DSL. Each of the verb clauses are terminated by a
to()keyword, which forwards the incoming message to adirectendpoint (thedirectcomponent splices routes together within the same application). from()- Defines a regular Camel route.
REST DSL with XML
In XML, to define a service with the XML DSL, define a rest element as a child of the camelContext element. For example, to define a simple Hello World service using the REST DSL with the Spark-Rest component, define the following XML code (in Blueprint):
<camelContext xmlns="http://camel.apache.org/schema/blueprint">
<restConfiguration component="spark-rest" port="9091"/>
<rest path="/say">
<get uri="/hello">
<to uri="direct:hello"/>
</get>
<get uri="/bye">
<to uri="direct:bye"/>
</get>
</rest>
<route>
<from uri="direct:hello"/>
<transform>
<constant>Hello World</constant>
</transform>
</route>
<route>
<from uri="direct:bye"/>
<transform>
<constant>Bye World</constant>
</transform>
</route>
</camelContext>Specifying a base path
The rest() keyword (Java DSL) or the path attribute of the rest element (XML DSL) allows you to define a base path, which is then prefixed to the paths in all of the verb clauses. For example, given the following snippet of Java DSL:
rest("/say")
.get("/hello").to("direct:hello")
.get("/bye").to("direct:bye");Or given the following snippet of XML DSL:
<rest path="/say">
<get uri="/hello">
<to uri="direct:hello"/>
</get>
<get uri="/bye" consumes="application/json">
<to uri="direct:bye"/>
</get>
</rest>The REST DSL builder gives you the following URL mappings:
/say/hello /say/bye
The base path is optional. If you prefer, you could (less elegantly) specify the full path in each of the verb clauses:
rest()
.get("/say/hello").to("direct:hello")
.get("/say/bye").to("direct:bye");Using Dynamic To
The REST DSL supports the toD dynamic to parameter. Use this parameter to specify URIs.
For example, in JMS a dynamic endpoint URI could be defined in the following way:
public void configure() throws Exception {
rest("/say")
.get("/hello/{language}").toD("jms:queue:hello-${header.language}");
}In XML DSL, the same details would look like this:
<rest uri="/say">
<get uri="/hello//{language}">
<toD uri="jms:queue:hello-${header.language}"/>
</get>
<rest>
For more information about the toD dynamic to parameter, see the section called “Dynamic To”.
URI templates
In a verb argument, you can specify a URI template, which enables you to capture specific path segments in named properties (which are then mapped to Camel message headers). For example, if you would like to personalize the Hello World application so that it greets the caller by name, you could define a REST service like the following:
rest("/say")
.get("/hello/{name}").to("direct:hello")
.get("/bye/{name}").to("direct:bye");
from("direct:hello")
.transform().simple("Hello ${header.name}");
from("direct:bye")
.transform().simple("Bye ${header.name}");
The URI template captures the text of the {name} path segment and copies this captured text into the name message header. If you invoke the service by sending a GET HTTP Request with the URL ending in /say/hello/Joe, the HTTP Response is Hello Joe.
Embedded route syntax
Instead of terminating a verb clause with the to() keyword (Java DSL) or the to element (XML DSL), you have the option of embedding an Apache Camel route directly into the REST DSL, using the route() keyword (Java DSL) or the route element (XML DSL). The route() keyword enables you to embed a route into a verb clause, with the following syntax:
RESTVerbClause.route("...").CamelRoute.endRest()
Where the endRest() keyword (Java DSL only) is a necessary punctuation mark that enables you to separate the verb clauses (when there is more than one verb clause in the rest() builder).
For example, you could refactor the Hello World example to use embedded Camel routes, as follows in Java DSL:
rest("/say")
.get("/hello").route().transform().constant("Hello World").endRest()
.get("/bye").route().transform().constant("Bye World");And as follows in XML DSL:
<camelContext xmlns="http://camel.apache.org/schema/blueprint">
...
<rest path="/say">
<get uri="/hello">
<route>
<transform>
<constant>Hello World</constant>
</transform>
</route>
</get>
<get uri="/bye">
<route>
<transform>
<constant>Bye World</constant>
</transform>
</route>
</get>
</rest>
</camelContext>
If you define any exception clauses (using onException()) or interceptors (using intercept()) in the current CamelContext, these exception clauses and interceptors are also active in the embedded routes.
REST DSL and HTTP transport component
If you do not explicitly configure an HTTP transport component then the REST DSL automatically discovers which HTTP component to use by checking for available components on the classpath. The REST DSL looks for the default names of any HTTP components and uses the first one it finds. If there are no HTTP components on the classpath and you did not explicitly configure an HTTP transport then the default HTTP component is camel-http.
Specifying the content type of requests and responses
You can filter the content type of HTTP requests and responses using the consumes() and produces() options in Java, or the consumes and produces attributes in XML. For example, some common content types (officially known as Internet media types) are the following:
-
text/plain -
text/html -
text/xml -
application/json -
application/xml
The content type is specified as an option on a verb clause in the REST DSL. For example, to restrict a verb clause to accept only text/plain HTTP requests, and to send only text/html HTTP responses, you would use Java code like the following:
rest("/email")
.post("/to/{recipient}").consumes("text/plain").produces("text/html").to("direct:foo");
And in XML, you can set the consumes and produces attributes, as follows:
<camelContext xmlns="http://camel.apache.org/schema/blueprint">
...
<rest path="/email">
<post uri="/to/{recipient}" consumes="text/plain" produces="text/html">
<to "direct:foo"/>
</get>
</rest>
</camelContext>
You can also specify the argument to consumes() or produces() as a comma-separated list. For example, consumes("text/plain, application/json").
Additional HTTP methods
Some HTTP server implementations support additional HTTP methods, which are not provided by the standard set of verbs in the REST DSL, get(), head(), put(), post(), delete(), patch(). To access additional HTTP methods, you can use the generic keyword, verb(), in Java DSL and the generic element, verb, in XML DSL.
For example, to implement the TRACE HTTP method in Java:
rest("/say")
.verb("TRACE", "/hello").route().transform();
Where transform() copies the body of the IN message to the body of the OUT message, thus echoing the HTTP request.
To implement the TRACE HTTP method in XML:
<camelContext xmlns="http://camel.apache.org/schema/blueprint">
...
<rest path="/say">
<verb uri="/hello" method="TRACE">
<route>
<transform/>
</route>
</get>
</camelContext>Defining custom HTTP error messages
If your REST service needs to send an error message as its response, you can define a custom HTTP error message as follows:
-
Specify the HTTP error code by setting the
Exchange.HTTP_RESPONSE_CODEheader key to the error code value (for example,400,404, and so on). This setting indicates to the REST DSL that you want to send an error message reply, instead of a regular response. - Populate the message body with your custom error message.
-
Set the
Content-Typeheader, if required. If your REST service is configured to marshal to and from Java objects (that is,
bindingModeis enabled), you should ensure that theskipBindingOnErrorCodeoption is enabled (which it is, by default). This is to ensure that the REST DSL does not attempt to unmarshal the message body when sending the response.For more details about object binding, see Section 4.3, “Marshalling to and from Java Objects”.
The following Java example shows how to define a custom error message:
// Java
// Configure the REST DSL, with JSON binding mode
restConfiguration().component("restlet").host("localhost").port(portNum).bindingMode(RestBindingMode.json);
// Define the service with REST DSL
rest("/users/")
.post("lives").type(UserPojo.class).outType(CountryPojo.class)
.route()
.choice()
.when().simple("${body.id} < 100")
.bean(new UserErrorService(), "idTooLowError")
.otherwise()
.bean(new UserService(), "livesWhere");
In this example, if the input ID is a number less than 100, we return a custom error message, using the UserErrorService bean, which is implemented as follows:
// Java
public class UserErrorService {
public void idTooLowError(Exchange exchange) {
exchange.getIn().setBody("id value is too low");
exchange.getIn().setHeader(Exchange.CONTENT_TYPE, "text/plain");
exchange.getIn().setHeader(Exchange.HTTP_RESPONSE_CODE, 400);
}
}
In the UserErrorService bean we define the custom error message and set the HTTP error code to 400.
Parameter Default Values
Default values can be specified for the headers of an incoming Camel message.
You can specify a default value by using a key word such as verbose on the query parameter. For example, in the code below, the default value is false. This means that if no other value is provided for a header with the verbose key, false will be inserted as a default.
rest("/customers/")
.get("/{id}").to("direct:customerDetail")
.get("/{id}/orders")
.param()
.name("verbose")
.type(RestParamType.query)
.defaultValue("false")
.description("Verbose order details")
.endParam()
.to("direct:customerOrders")
.post("/neworder").to("direct:customerNewOrder");Wrapping a JsonParserException in a custom HTTP error message
A common case where you might want to return a custom error message is in order to wrap a JsonParserException exception. For example, you can conveniently exploit the Camel exception handling mechanism to create a custom HTTP error message, with HTTP error code 400, as follows:
// Java
onException(JsonParseException.class)
.handled(true)
.setHeader(Exchange.HTTP_RESPONSE_CODE, constant(400))
.setHeader(Exchange.CONTENT_TYPE, constant("text/plain"))
.setBody().constant("Invalid json data");REST DSL options
In general, REST DSL options can be applied either directly to the base part of the service definition (that is, immediately following rest()), as follows:
rest("/email").consumes("text/plain").produces("text/html")
.post("/to/{recipient}").to("direct:foo")
.get("/for/{username}").to("direct:bar");In which case the specified options apply to all of the subordinate verb clauses. Or the options can be applied to each individual verb clause, as follows:
rest("/email")
.post("/to/{recipient}").consumes("text/plain").produces("text/html").to("direct:foo")
.get("/for/{username}").consumes("text/plain").produces("text/html").to("direct:bar");In which case the specified options apply only to the relevant verb clause, overriding any settings from the base part.
Table 4.1, “REST DSL Options” summarizes the options supported by the REST DSL.
| Java DSL | XML DSL | Description |
|---|---|---|
|
|
|
Specifies the binding mode, which can be used to marshal incoming messages to Java objects (and, optionally, unmarshal Java objects to outgoing messages). Can have the following values: |
|
|
|
Restricts the verb clause to accept only the specified Internet media type (MIME type) in a HTTP Request. Typical values are: |
|
|
| Defines a custom ID for JMX management. |
|
|
| Document the REST service or verb clause. Useful for JMX management and tooling. |
|
|
|
If |
|
|
| Defines a unique ID for the REST service, which is useful to define for JMX management and other tooling. |
|
|
|
Specifies the HTTP method processed by this verb clause. Usually used in conjunction with the generic |
|
|
|
When object binding is enabled (that is, when |
|
|
|
Restricts the verb clause to produce only the specified Internet media type (MIME type) in a HTTP Response. Typical values are: |
|
|
|
When object binding is enabled (that is, when |
|
|
|
Specifies a path segment or URI template as an argument to a verb. For example, |
|
|
|
Specifies the base path in the |
4.3. Marshalling to and from Java Objects
Marshalling Java objects for transmission over HTTP
One of the most common ways to use the REST protocol is to transmit the contents of a Java bean in the message body. In order for this to work, you need to have a mechanism for marshalling the Java object to and from a suitable data format. The following data formats, which are suitable for encoding Java objects, are supported by the REST DSL:
- JSON
JSON (JavaScript object notation) is a lightweight data format that can easily be mapped to and from Java objects. The JSON syntax is compact, lightly typed, and easy for humans to read and write. For all of these reasons, JSON has become popular as a message format for REST services.
For example, the following JSON code could represent a
Userbean with two property fields,idandname:{ "id" : 1234, "name" : "Jane Doe" }- JAXB
JAXB (Java Architecture for XML Binding) is an XML-based data format that can easily be mapped to and from Java objects. In order to marshal the XML to a Java object, you must also annotate the Java class that you want to use.
For example, the following JAXB code could represent a
Userbean with two property fields,idandname:<?xml version="1.0" encoding="UTF-8" standalone="yes"?> <User> <Id>1234</Id> <Name>Jane Doe</Name> </User>
NoteFrom Camel 2.17.0, JAXB data format and type converter supports the conversion from XML to POJO for classes, that use
ObjectFactoryinstead ofXmlRootElement. Also, the camel context should include theCamelJaxbObjectFactoryproperty with value true. However, due to optimization the default value is false.
Integration of JSON and JAXB with the REST DSL
You could, of course, write the required code to convert the message body to and from a Java object yourself. But the REST DSL offers the convenience of performing this conversion automatically. In particular, the integration of JSON and JAXB with the REST DSL offers the following advantages:
- Marshalling to and from Java objects is performed automatically (given the appropriate configuration).
- The REST DSL can automatically detect the data format (either JSON or JAXB) and perform the appropriate conversion.
- The REST DSL provides an abstraction layer, so that the code you write is not specific to a particular JSON or JAXB implementation. So you can switch the implementation later on, with minimum impact to your application code.
Supported data format components
Apache Camel provides a number of different implementations of the JSON and JAXB data formats. The following data formats are currently supported by the REST DSL:
JSON
-
Jackson data format (
camel-jackson) (default) -
GSon data format (
camel-gson) -
XStream data format (
camel-xstream)
-
Jackson data format (
JAXB
-
JAXB data format (
camel-jaxb)
-
JAXB data format (
How to enable object marshalling
To enable object marshalling in the REST DSL, observe the following points:
-
Enable binding mode, by setting the
bindingModeoption (there are several levels at which you can set the binding mode — for details, see the section called “Configuring the binding mode”). -
Specify the Java type to convert to (or from), on the incoming message with the
typeoption (required), and on the outgoing message with theoutTypeoption (optional). - If you want to convert your Java object to and from the JAXB data format, you must remember to annotate the Java class with the appropriate JAXB annotations.
-
Specify the underlying data format implementation (or implementations), using the
jsonDataFormatoption and/or thexmlDataFormatoption (which can be specified on therestConfigurationbuilder). If your route provides a return value in JAXB format, you are normally expected to set the Out message of the exchange body to be an instance of a class with JAXB annotations (a JAXB element). If you prefer to provide the JAXB return value directly in XML format, however, set the
dataFormatPropertywith the key,xml.out.mustBeJAXBElement, tofalse(which can be specified on therestConfigurationbuilder). For example, in the XML DSL syntax:<restConfiguration ...> <dataFormatProperty key="xml.out.mustBeJAXBElement" value="false"/> ... </restConfiguration>Add the required dependencies to your project build file. For example, if you are using the Maven build system and you are using the Jackson data format, you would add the following dependency to your Maven POM file:
<?xml version="1.0" encoding="UTF-8"?> <project ...> ... <dependencies> ... <!-- use for json binding --> <dependency> <groupId>org.apache.camel</groupId> <artifactId>camel-jackson</artifactId> </dependency> ... </dependencies> </project>When deploying your application to the OSGi container, remember to install the requisite feature for your chosen data format. For example, if you are using the Jackson data format (the default), you would install the
camel-jacksonfeature, by entering the following Karaf console command:JBossFuse:karaf@root> features:install camel-jackson
Alternatively, if you are deploying into a Fabric environment, you would add the feature to a Fabric profile. For example, if you are using the profile,
MyRestProfile, you could add the feature by entering the following console command:JBossFuse:karaf@root> fabric:profile-edit --features camel-jackson MyRestProfile
Configuring the binding mode
The bindingMode option is off by default, so you must configure it explicitly, in order to enable marshalling of Java objects. TABLE shows the list of supported binding modes.
From Camel 2.16.3 onwards the binding from POJO to JSon/JAXB will only happen if the content-type header includes json or xml. This allows you to specify a custom content-type if the message body should not attempt to be marshalled using the binding. This is useful if, for example, the message body is a custom binary payload.
| Binding Mode | Description |
|---|---|
|
| Binding is turned off (default). |
|
| Binding is enabled for JSON and/or XML. In this mode, Camel auto-selects either JSON or XML (JAXB), based on the format of the incoming message. You are not required to enable both kinds of data format, however: either a JSON implementation, an XML implementation, or both can be provided on the classpath. |
|
|
Binding is enabled for JSON only. A JSON implementation must be provided on the classpath (by default, Camel tries to enable the |
|
|
Binding is enabled for XML only. An XML implementation must be provided on the classpath (by default, Camel tries to enable the |
|
| Binding is enabled for both JSON and XML. In this mode, Camel auto-selects either JSON or XML (JAXB), based on the format of the incoming message. You are required to provide both kinds of data format on the classpath. |
In Java, these binding mode values are represented as instances of the following enum type:
org.apache.camel.model.rest.RestBindingMode
There are several different levels at which you can set the bindingMode, as follows:
- REST DSL configuration
You can set the
bindingModeoption from therestConfigurationbuilder, as follows:restConfiguration().component("servlet").port(8181).bindingMode(RestBindingMode.json);- Service definition base part
You can set the
bindingModeoption immediately following therest()keyword (before the verb clauses), as follows:rest("/user").bindingMode(RestBindingMode.json).get("/{id}").VerbClause- Verb clause
You can set the
bindingModeoption in a verb clause, as follows:rest("/user") .get("/{id}").bindingMode(RestBindingMode.json).to("...");
Example
For a complete code example, showing how to use the REST DSL, using the Servlet component as the REST implementation, take a look at the Apache Camel camel-example-servlet-rest-blueprint example. You can find this example by installing the standalone Apache Camel distribution, apache-camel-2.21.0.fuse-730078-redhat-00001.zip, which is provided in the extras/ subdirectory of your Fuse installation.
After installing the standalone Apache Camel distribution, you can find the example code under the following directory:
ApacheCamelInstallDir/examples/camel-example-servlet-rest-blueprintConfigure the Servlet component as the REST implementation
In the camel-example-servlet-rest-blueprint example, the underlying implementation of the REST DSL is provided by the Servlet component. The Servlet component is configured in the Blueprint XML file, as shown in Example 4.1, “Configure Servlet Component for REST DSL”.
Example 4.1. Configure Servlet Component for REST DSL
<?xml version="1.0" encoding="UTF-8"?>
<blueprint ...>
<!-- to setup camel servlet with OSGi HttpService -->
<reference id="httpService" interface="org.osgi.service.http.HttpService"/>
<bean class="org.apache.camel.component.servlet.osgi.OsgiServletRegisterer"
init-method="register"
destroy-method="unregister">
<property name="alias" value="/camel-example-servlet-rest-blueprint/rest"/>
<property name="httpService" ref="httpService"/>
<property name="servlet" ref="camelServlet"/>
</bean>
<bean id="camelServlet" class="org.apache.camel.component.servlet.CamelHttpTransportServlet"/>
...
<camelContext xmlns="http://camel.apache.org/schema/blueprint">
<restConfiguration component="servlet"
bindingMode="json"
contextPath="/camel-example-servlet-rest-blueprint/rest"
port="8181">
<dataFormatProperty key="prettyPrint" value="true"/>
</restConfiguration>
...
</camelContext>
</blueprint>To configure the Servlet component with REST DSL, you need to configure a stack consisting of the following three layers:
- REST DSL layer
-
The REST DSL layer is configured by the
restConfigurationelement, which integrates with the Servlet component by setting thecomponentattribute to the value,servlet. - Servlet component layer
-
The Servlet component layer is implemented as an instance of the class,
CamelHttpTransportServlet, where the example instance has the bean ID,camelServlet. - HTTP container layer
The Servlet component must be deployed into a HTTP container. The Karaf container is normally configured with a default HTTP container (a Jetty HTTP container), which listens for HTTP requests on the port, 8181. To deploy the Servlet component to the default Jetty container, you need to do the following:
-
Get an OSGi reference to the
org.osgi.service.http.HttpServiceOSGi service, where this service is a standardised OSGi interface that provides access to the default HTTP server in OSGi. -
Create an instance of the utility class,
OsgiServletRegisterer, to register the Servlet component in the HTTP container. TheOsgiServletRegistererclass is a utility that simplifies managing the lifecycle of the Servlet component. When an instance of this class is created, it automatically calls theregisterServletmethod on theHttpServiceOSGi service; and when the instance is destroyed, it automatically calls theunregistermethod.
-
Get an OSGi reference to the
Required dependencies
This example has two dependencies which are of key importance to the REST DSL, as follows:
- Servlet component
Provides the underlying implementation of the REST DSL. This is specified in the Maven POM file, as follows:
<dependency> <groupId>org.apache.camel</groupId> <artifactId>camel-servlet</artifactId> <version>${camel-version}</version> </dependency>And before you deploy the application bundle to the OSGi container, you must install the Servlet component feature, as follows:
JBossFuse:karaf@root> features:install camel-servlet
- Jackson data format
Provides the JSON data format implementation. This is specified in the Maven POM file, as follows:
<dependency> <groupId>org.apache.camel</groupId> <artifactId>camel-jackson</artifactId> <version>${camel-version}</version> </dependency>And before you deploy the application bundle to the OSGi container, you must install the Jackson data format feature, as follows:
JBossFuse:karaf@root> features:install camel-jackson
Java type for responses
The example application passes User type objects back and forth in HTTP Request and Response messages. The User Java class is defined as shown in Example 4.2, “User Class for JSON Response”.
Example 4.2. User Class for JSON Response
// Java
package org.apache.camel.example.rest;
public class User {
private int id;
private String name;
public User() {
}
public User(int id, String name) {
this.id = id;
this.name = name;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
The User class has a relatively simple representation in the JSON data format. For example, a typical instance of this class expressed in JSON format is:
{
"id" : 1234,
"name" : "Jane Doe"
}Sample REST DSL route with JSON binding
The REST DSL configuration and the REST service definition for this example are shown in Example 4.3, “REST DSL Route with JSON Binding”.
Example 4.3. REST DSL Route with JSON Binding
<?xml version="1.0" encoding="UTF-8"?>
<blueprint xmlns="http://www.osgi.org/xmlns/blueprint/v1.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
...>
...
<!-- a bean for user services -->
<bean id="userService" class="org.apache.camel.example.rest.UserService"/>
<camelContext xmlns="http://camel.apache.org/schema/blueprint">
<restConfiguration component="servlet"
bindingMode="json"
contextPath="/camel-example-servlet-rest-blueprint/rest"
port="8181">
<dataFormatProperty key="prettyPrint" value="true"/>
</restConfiguration>
<!-- defines the REST services using the base path, /user -->
<rest path="/user" consumes="application/json" produces="application/json">
<description>User rest service</description>
<!-- this is a rest GET to view a user with the given id -->
<get uri="/{id}" outType="org.apache.camel.example.rest.User">
<description>Find user by id</description>
<to uri="bean:userService?method=getUser(${header.id})"/>
</get>
<!-- this is a rest PUT to create/update a user -->
<put type="org.apache.camel.example.rest.User">
<description>Updates or create a user</description>
<to uri="bean:userService?method=updateUser"/>
</put>
<!-- this is a rest GET to find all users -->
<get uri="/findAll" outType="org.apache.camel.example.rest.User[]">
<description>Find all users</description>
<to uri="bean:userService?method=listUsers"/>
</get>
</rest>
</camelContext>
</blueprint>REST operations
The REST service from Example 4.3, “REST DSL Route with JSON Binding” defines the following REST operations:
GET /camel-example-servlet-rest-blueprint/rest/user/{id}-
Get the details for the user identified by
{id}, where the HTTP response is returned in JSON format. PUT /camel-example-servlet-rest-blueprint/rest/user-
Create a new user, where the user details are contained in the body of the PUT message, encoded in JSON format (to match the
Userobject type). GET /camel-example-servlet-rest-blueprint/rest/user/findAll- Get the details for all users, where the HTTP response is returned as an array of users, in JSON format.
URLs to invoke the REST service
By inspecting the REST DSL definitions from Example 4.3, “REST DSL Route with JSON Binding”, you can piece together the URLs required to invoke each of the REST operations. For example, to invoke the first REST operation, which returns details of a user with a given ID, the URL is built up as follows:
http://localhost:8181-
In
restConfiguration, the protocol defaults tohttpand the port is set explicitly to8181. /camel-example-servlet-rest-blueprint/rest-
Specified by the
contextPathattribute of therestConfigurationelement. /user-
Specified by the
pathattribute of therestelement. /{id}-
Specified by the
uriattribute of thegetverb element.
Hence, it is possible to invoke this REST operation with the curl utility, by entering the following command at the command line:
curl -X GET -H "Accept: application/json" http://localhost:8181/camel-example-servlet-rest-blueprint/rest/user/123
Similarly, the remaining REST operations could be invoked with curl, by entering the following sample commands:
curl -X GET -H "Accept: application/json" http://localhost:8181/camel-example-servlet-rest-blueprint/rest/user/findAll
curl -X PUT -d "{ \"id\": 666, \"name\": \"The devil\"}" -H "Accept: application/json" http://localhost:8181/camel-example-servlet-rest-blueprint/rest/user4.4. Configuring the REST DSL
Configuring with Java
In Java, you can configure the REST DSL using the restConfiguration() builder API. For example, to configure the REST DSL to use the Servlet component as the underlying implementation:
restConfiguration().component("servlet").bindingMode("json").port("8181")
.contextPath("/camel-example-servlet-rest-blueprint/rest");Configuring with XML
In XML, you can configure the REST DSL using the restConfiguration element. For example, to configure the REST DSL to use the Servlet component as the underlying implementation:
<?xml version="1.0" encoding="UTF-8"?>
<blueprint ...>
...
<camelContext xmlns="http://camel.apache.org/schema/blueprint">
...
<restConfiguration component="servlet"
bindingMode="json"
contextPath="/camel-example-servlet-rest-blueprint/rest"
port="8181">
<dataFormatProperty key="prettyPrint" value="true"/>
</restConfiguration>
...
</camelContext>
</blueprint>Configuration options
Table 4.3, “Options for Configuring REST DSL” shows options for configuring the REST DSL using the restConfiguration() builder (Java DSL) or the restConfiguration element (XML DSL).
| Java DSL | XML DSL | Description |
|---|---|---|
|
|
|
Specifies the Camel component to use as the REST transport (for example, |
|
|
|
The protocol to use for exposing the REST service. Depends on the underlying REST implementation, but |
|
|
| The hostname to use for exposing the REST service. |
|
|
| The port number to use for exposing the REST service. Note: This setting is ignored by the Servlet component, which uses the container’s standard HTTP port instead. In the case of the Apache Karaf OSGi container, the standard HTTP port is normally 8181. It is good practice to set the port value nonetheless, for the sake of JMX and tooling. |
|
|
|
Sets a leading context path for the REST services. This can be used with components such as Servlet, where the deployed Web application is deployed using a |
|
|
|
If a hostname is not set explicitly, this resolver determines the host for the REST service. Possible values are
The default is |
|
|
|
Enables binding mode for JSON or XML format messages. Possible values are: |
|
|
|
Specifies whether to skip binding on output, if there is a custom HTTP error code header. This allows you to build custom error messages that do not bind to JSON or XML, as successful messages would otherwise do. Default is |
|
|
|
If |
|
|
|
Specifies the component that Camel uses to implement the JSON data format. Possible values are: |
|
|
|
Specifies the component that Camel uses to implement the XML data format. Possible value is: |
|
|
| Enables you to set arbitrary component level properties on the underlying REST implementation. |
|
|
| Enables you to set arbitrary endpoint level properties on the underlying REST implementation. |
|
|
| Enables you to set arbitrary consumer endpoint properties on the underlying REST implementation. |
|
|
| Enables you to set arbitrary properties on the underlying data format component (for example, Jackson or JAXB). From Camel 2.14.1 onwards, you can attach the following prefixes to the property keys:
To restrict the property setting to a specific format type (JSON or XML) and a particular message direction (IN or OUT). |
|
|
| Enables you to specify custom CORS headers, as key/value pairs. |
Default CORS headers
If CORS (cross-origin resource sharing) is enabled, the following headers are set by default. You can optionally override the default settings, by invoking the corsHeaderProperty DSL command.
| Header Key | Header Value |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
Enabling or disabling Jackson JSON features
You can enable or disable specific Jackson JSON features by configuring the following keys in the dataFormatProperty option:
-
json.in.disableFeatures -
json.in.enableFeatures
For example, to disable Jackson’s FAIL_ON_UNKNOWN_PROPERTIES feature (which causes Jackson to fail if a JSON input has a property that cannot be mapped to a Java object):
restConfiguration().component("jetty")
.host("localhost").port(getPort())
.bindingMode(RestBindingMode.json)
.dataFormatProperty("json.in.disableFeatures", "FAIL_ON_UNKNOWN_PROPERTIES");You can disable multiple features by specifying a comma-separated list. For example:
.dataFormatProperty("json.in.disableFeatures", "FAIL_ON_UNKNOWN_PROPERTIES,ADJUST_DATES_TO_CONTEXT_TIME_ZONE");Here is an example that shows how to disable and enable Jackson JSON features in the Java DSL:
restConfiguration().component("jetty")
.host("localhost").port(getPort())
.bindingMode(RestBindingMode.json)
.dataFormatProperty("json.in.disableFeatures", "FAIL_ON_UNKNOWN_PROPERTIES,ADJUST_DATES_TO_CONTEXT_TIME_ZONE")
.dataFormatProperty("json.in.enableFeatures", "FAIL_ON_NUMBERS_FOR_ENUMS,USE_BIG_DECIMAL_FOR_FLOATS");Here is an example that shows how to disable and enable Jackson JSON features in the XML DSL:
<restConfiguration component="jetty" host="localhost" port="9090" bindingMode="json"> <dataFormatProperty key="json.in.disableFeatures" value="FAIL_ON_UNKNOWN_PROPERTIES,ADJUST_DATES_TO_CONTEXT_TIME_ZONE"/> <dataFormatProperty key="json.in.enableFeatures" value="FAIL_ON_NUMBERS_FOR_ENUMS,USE_BIG_DECIMAL_FOR_FLOATS"/> </restConfiguration>
The Jackson features that can be disabled or enabled correspond to the enum IDs from the following Jackson classes
4.5. Swagger Integration
Overview
You can use a Swagger service to create API documentation for any REST-defined routes and endpoints in a CamelContext file. To do this, use the Camel REST DSL with the camel-swagger-java module, which is purely Java-based. The camel-swagger-java module creates a servlet that is integrated with the CamelContext and that pulls the information from each REST endpoint to generate the API documentation in JSON or YAML format.
If you use Maven then edit your pom.xml file to add a dependency on the camel-swagger-java component:
<dependency> <groupId>org.apache.camel</groupId> <artifactId>camel-swagger-java</artifactId> <version>x.x.x</version> <!-- Specify the version of your camel-core module. --> </dependency>
Configuring a CamelContext to enable Swagger
To enable the use of the Swagger API in the Camel REST DSL, invoke apiContextPath() to set the context path for the Swagger-generated API documentation. For example:
public class UserRouteBuilder extends RouteBuilder {
@Override
public void configure() throws Exception {
// Configure the Camel REST DSL to use the netty4-http component:
restConfiguration().component("netty4-http").bindingMode(RestBindingMode.json)
// Generate pretty print output:
.dataFormatProperty("prettyPrint", "true")
// Set the context path and port number that netty will use:
.contextPath("/").port(8080)
// Add the context path for the Swagger-generated API documentation:
.apiContextPath("/api-doc")
.apiProperty("api.title", "User API").apiProperty("api.version", "1.2.3")
// Enable CORS:
.apiProperty("cors", "true");
// This user REST service handles only JSON files:
rest("/user").description("User rest service")
.consumes("application/json").produces("application/json")
.get("/{id}").description("Find user by id").outType(User.class)
.param().name("id").type(path).description("The id of the user to get").dataType("int").endParam()
.to("bean:userService?method=getUser(${header.id})")
.put().description("Updates or create a user").type(User.class)
.param().name("body").type(body).description("The user to update or create").endParam()
.to("bean:userService?method=updateUser")
.get("/findAll").description("Find all users").outTypeList(User.class)
.to("bean:userService?method=listUsers");
}
}Swagger module configuration options
The options described in the table below let you configure the Swagger module. Set an option as follows:
-
If you are using the
camel-swagger-javamodule as a servlet, set an option by updating theweb.xmlfile and specifying aninit-paramelement for each configuration option you want to set. -
If you are using the
camel-swagger-javamodule from Camel REST components, set an option by invoking the appropriateRestConfigurationDefinitionmethod, such asenableCORS(),host(), orcontextPath(). Set theapi.xxxoptions with theRestConfigurationDefinition.apiProperty()method.
| Option | Type | Description |
|---|---|---|
|
| String | Email address to be used for API-related correspondence. |
|
| String | Name of person or organization to contact. |
|
| String | URL to a website for more contact information. |
|
| Boolean |
If your application uses more than one |
|
| String | Pattern that filters which CamelContext IDs appear in the context listing. You can specify regular expressions and use * as a wildcard. This is the same pattern matching facility as used by the Camel Intercept feature. |
|
| String | License name used for the API. |
|
| String | URL to the license used for the API. |
|
| String |
Sets the path where the REST API to generate documentation for is available, for example, |
|
| String | URL to the terms of service of the API. |
|
| String | Title of the application. |
|
| String | Version of the API. The default is 0.0.0. |
|
| String |
Required. Sets the path where the REST services are available. Specify a relative path. That is, do not specify, for example, |
|
| Boolean |
Whether to enable HTTP Access Control (CORS). This enable CORS only for viewing the REST API documentation, and not for access to the REST service. The default is false. The recommendation is to use the |
|
| String |
Set the name of the host that the Swagger service is running on. The default is to calculate the host name based on |
|
| String |
Protocol schemes to use. Separate multiple values with a comma, for example, |
|
| String | Swagger specification version. The default is 2.0. |
Using the CORS filter to enable CORS support
If you use the Swagger user interface to view your REST API documentation then you probably need to enable support for HTTP Access Control (CORS). This support is required when the Swagger user interface is hosted and running on a hostname/port that is different from the hostname/port on which your REST APIs are running.
To enable support for CORS, add the RestSwaggerCorsFilter to your web.xml file. The CORS filter adds the HTTP headers that enable CORS. For example:
<!-- Enable CORS filter to allow use of Swagger UI for browsing and testing APIs. -->
<filter>
<filter-name>RestSwaggerCorsFilter</filter-name>
<filter-class>org.apache.camel.swagger.rest.RestSwaggerCorsFilter</filter-class>
</filter>
<filter-mapping>
<filter-name>RestSwaggerCorsFilter</filter-name>
<url-pattern>/api-docs/*</url-pattern>
<url-pattern>/rest/*</url-pattern>
</filter-mapping>
The RestSwaggerCorsFilter sets the following headers for all requests:
- Access-Control-Allow-Origin= *
- Access-Control-Allow-Methods = GET, HEAD, POST, PUT, DELETE, TRACE, OPTIONS, CONNECT, PATCH
- Access-Control-Max-Age = 3600'
- Access-Control-Allow-Headers = Origin, Accept, X-Requested-With, Content-Type, Access-Control-Request-Method, Access-Control-Request-Headers
RestSwaggerCorsFilter is a simple filter. You might need a more sophisticated filter if you need to block certain clients or set the header values differently for a given client.
Obtaining JSON or YAML output
Starting with Camel 2.17, the camel-swagger-java module supports both JSON and YAML formatted output. To specify the output you want, add /swagger.json or /swagger.yaml to the request URL. If a request URL does not specify a format then the camel-swagger-java module inspects the HTTP Accept header to detect whether JSON or YAML can be accepted. If both are accepted or if none was set as accepted then JSON is the default return format.
Examples
In the Apache Camel distribution, camel-example-swagger-cdi and camel-example-swagger-java demonstrate the use of the camel-swagger-java module.
Enhancing documentation generated by Swagger
Starting with Camel 2.16, you can enhance the documentation generated by Swagger by defining parameter details such as name, description, data type, parameter type and so on. If you are using XML, specify the param element to add this information. The following example shows how to provide information about the ID path parameter:
<!-- This is a REST GET request to view information for the user with the given ID: -->
<get uri="/{id}" outType="org.apache.camel.example.rest.User">
<description>Find user by ID.</description>
<param name="id" type="path" description="The ID of the user to get information about." dataType="int"/>
<to uri="bean:userService?method=getUser(${header.id})"/>
</get>Following is the same example in Java DSL:
.get("/{id}").description("Find user by ID.").outType(User.class)
.param().name("id").type(path).description("The ID of the user to get information about.").dataType("int").endParam()
.to("bean:userService?method=getUser(${header.id})")
If you define a parameter whose name is body then you must also specify body as the type of that parameter. For example:
<!-- This is a REST PUT request to create/update information about a user. -->
<put type="org.apache.camel.example.rest.User">
<description>Updates or creates a user.</description>
<param name="body" type="body" description="The user to update or create."/>
<to uri="bean:userService?method=updateUser"/>
</put>Following is the same example in Java DSL:
.put().description("Updates or create a user").type(User.class)
.param().name("body").type(body).description("The user to update or create.").endParam()
.to("bean:userService?method=updateUser")
See also: examples/camel-example-servlet-rest-tomcat in the Apache Camel distribution.
Chapter 5. Messaging Systems
Abstract
This chapter introduces the fundamental building blocks of a messaging system, such as endpoints, messaging channels, and message routers.
5.1. Message
Overview
A message is the smallest unit for transmitting data in a messaging system (represented by the grey dot in the figure below). The message itself might have some internal structure — for example, a message containing multiple parts — which is represented by geometrical figures attached to the grey dot in Figure 5.1, “Message Pattern”.
Figure 5.1. Message Pattern
Types of message
Apache Camel defines the following distinct message types:
- In message — A message that travels through a route from a consumer endpoint to a producer endpoint (typically, initiating a message exchange).
- Out message — A message that travels through a route from a producer endpoint back to a consumer endpoint (usually, in response to an In message).
All of these message types are represented internally by the org.apache.camel.Message interface.
Message structure
By default, Apache Camel applies the following structure to all message types:
- Headers — Contains metadata or header data extracted from the message.
- Body — Usually contains the entire message in its original form.
- Attachments — Message attachments (required for integrating with certain messaging systems, such as JBI).
It is important to remember that this division into headers, body, and attachments is an abstract model of the message. Apache Camel supports many different components, that generate a wide variety of message formats. Ultimately, it is the underlying component implementation that decides what gets placed into the headers and body of a message.
Correlating messages
Internally, Apache Camel remembers the message IDs, which are used to correlate individual messages. In practice, however, the most important way that Apache Camel correlates messages is through exchange objects.
Exchange objects
An exchange object is an entity that encapsulates related messages, where the collection of related messages is referred to as a message exchange and the rules governing the sequence of messages are referred to as an exchange pattern. For example, two common exchange patterns are: one-way event messages (consisting of an In message), and request-reply exchanges (consisting of an In message, followed by an Out message).
Accessing messages
When defining a routing rule in the Java DSL, you can access the headers and body of a message using the following DSL builder methods:
-
header(String name),body()— Returns the named header and the body of the current In message. -
outBody()— Returns the body of the current Out message.
For example, to populate the In message’s username header, you can use the following Java DSL route:
from(SourceURL).setHeader("username", "John.Doe").to(TargetURL);
5.2. Message Channel
Overview
A message channel is a logical channel in a messaging system. That is, sending messages to different message channels provides an elementary way of sorting messages into different message types. Message queues and message topics are examples of message channels. You should remember that a logical channel is not the same as a physical channel. There can be several different ways of physically realizing a logical channel.
In Apache Camel, a message channel is represented by an endpoint URI of a message-oriented component as shown in Figure 5.2, “Message Channel Pattern”.
Figure 5.2. Message Channel Pattern
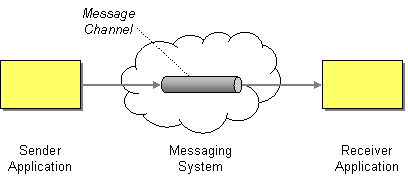
Message-oriented components
The following message-oriented components in Apache Camel support the notion of a message channel:
ActiveMQ
In ActiveMQ, message channels are represented by queues or topics. The endpoint URI for a specific queue, QueueName, has the following format:
activemq:QueueNameThe endpoint URI for a specific topic, TopicName, has the following format:
activemq:topic:TopicName
For example, to send messages to the queue, Foo.Bar, use the following endpoint URI:
activemq:Foo.Bar
See ActiveMQ in the Apache Camel Component Reference Guide for more details and instructions on setting up the ActiveMQ component.
JMS
The Java Messaging Service (JMS) is a generic wrapper layer that is used to access many different kinds of message systems (for example, you can use it to wrap ActiveMQ, MQSeries, Tibco, BEA, Sonic, and others). In JMS, message channels are represented by queues, or topics. The endpoint URI for a specific queue, QueueName, has the following format:
jms:QueueNameThe endpoint URI for a specific topic, TopicName, has the following format:
jms:topic:TopicNameSee Jms in the Apache Camel Component Reference Guide for more details and instructions on setting up the JMS component.
AMQP
In AMQP, message channels are represented by queues, or topics. The endpoint URI for a specific queue, QueueName, has the following format:
amqp:QueueNameThe endpoint URI for a specific topic, TopicName, has the following format:
amqp:topic:TopicNameSee Amqp in the Apache Camel Component Reference Guide. for more details and instructions on setting up the AMQP component.
5.3. Message Endpoint
Overview
A message endpoint is the interface between an application and a messaging system. As shown in Figure 5.3, “Message Endpoint Pattern”, you can have a sender endpoint, sometimes called a proxy or a service consumer, which is responsible for sending In messages, and a receiver endpoint, sometimes called an endpoint or a service, which is responsible for receiving In messages.
Figure 5.3. Message Endpoint Pattern

Types of endpoint
Apache Camel defines two basic types of endpoint:
- Consumer endpoint — Appears at the start of a Apache Camel route and reads In messages from an incoming channel (equivalent to a receiver endpoint).
- Producer endpoint — Appears at the end of a Apache Camel route and writes In messages to an outgoing channel (equivalent to a sender endpoint). It is possible to define a route with multiple producer endpoints.
Endpoint URIs
In Apache Camel, an endpoint is represented by an endpoint URI, which typically encapsulates the following kinds of data:
- Endpoint URI for a consumer endpoint — Advertises a specific location (for example, to expose a service to which senders can connect). Alternatively, the URI can specify a message source, such as a message queue. The endpoint URI can include settings to configure the endpoint.
- Endpoint URI for a producer endpoint — Contains details of where to send messages and includes the settings to configure the endpoint. In some cases, the URI specifies the location of a remote receiver endpoint; in other cases, the destination can have an abstract form, such as a queue name.
An endpoint URI in Apache Camel has the following general form:
ComponentPrefix:ComponentSpecificURI
Where ComponentPrefix is a URI prefix that identifies a particular Apache Camel component (see Apache Camel Component Reference for details of all the supported components). The remaining part of the URI, ComponentSpecificURI, has a syntax defined by the particular component. For example, to connect to the JMS queue, Foo.Bar, you can define an endpoint URI like the following:
jms:Foo.Bar
To define a route that connects the consumer endpoint, file://local/router/messages/foo, directly to the producer endpoint, jms:Foo.Bar, you can use the following Java DSL fragment:
from("file://local/router/messages/foo").to("jms:Foo.Bar");Alternatively, you can define the same route in XML, as follows:
<camelContext id="CamelContextID" xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="file://local/router/messages/foo"/>
<to uri="jms:Foo.Bar"/>
</route>
</camelContext>Dynamic To
The <toD> parameter allows you to send a message to a dynamically computed endpoint using one or more expressions that are concatenated together.
By default, the Simple language is used to compute the endpoint. The following example sends a message to an endpoint defined by a header:
<route>
<from uri="direct:start"/>
<toD uri="${header.foo}"/>
</route>In Java DSL the format for the same command is:
from("direct:start")
.toD("${header.foo}");The URI can also be prefixed with a literal, as shown in the following example:
<route>
<from uri="direct:start"/>
<toD uri="mock:${header.foo}"/>
</route>In Java DSL the format for the same command is:
from("direct:start")
.toD("mock:${header.foo}");
In the example above, if the value of header.foo is orange, the URI will resolve as mock:orange.
To use a language other than Simple, you need to define the language: parameter. See Part II, “Routing Expression and Predicate Languages”.
The format for using a different language is to use language:languagename: in the URI. For example, to use Xpath use the following format:
<route> <from uri="direct:start"/> <toD uri="language:xpath:/order/@uri/"> </route>
Here is the same example in Java DSL:
from("direct:start")
.toD("language:xpath:/order/@uri");
If you do not specify language: then the endpoint is a component name. In some cases a component and a language have the same name, such as xquery.
You can concatenate multiple languages using a + sign. In the example below, the URI is a combination of Simple and Xpath languages. Simple is the default so the language does not have to be defined. After the + sign is the Xpath instruction, indicated by language:xpath.
<route>
<from uri="direct:start"/>
<toD uri="jms:${header.base}+language:xpath:/order/@id"/>
</route>In Java DSL the format is as follows:
from("direct:start")
.toD("jms:${header.base}+language:xpath:/order/@id");
Many languages can be concatenated at one time, just separate each with a + and specify each language with language:languagename.
The following options are available with toD:
| Name | Default Value | Description |
|
| Mandatory: The URI to use. | |
|
| Set a specific Exchange Pattern to use when sending to the endpoint. The original MEP is restored afterwards. | |
|
|
Configure the cache size of the | |
|
|
| Specifies whether to ignore an endpoint URI that could not be resolved. If disabled, Camel will throw an exception identifying the invalid endpoint URI. |
5.4. Pipes and Filters
Overview
The pipes and filters pattern, shown in Figure 5.4, “Pipes and Filters Pattern”, describes a way of constructing a route by creating a chain of filters, where the output of one filter is fed into the input of the next filter in the pipeline (analogous to the UNIX pipe command). The advantage of the pipeline approach is that it enables you to compose services (some of which can be external to the Apache Camel application) to create more complex forms of message processing.
Figure 5.4. Pipes and Filters Pattern

Pipeline for the InOut exchange pattern
Normally, all of the endpoints in a pipeline have an input (In message) and an output (Out message), which implies that they are compatible with the InOut message exchange pattern. A typical message flow through an InOut pipeline is shown in Figure 5.5, “Pipeline for InOut Exchanges”.
Figure 5.5. Pipeline for InOut Exchanges
The pipeline connects the output of each endpoint to the input of the next endpoint. The Out message from the final endpoint is sent back to the original caller. You can define a route for this pipeline, as follows:
from("jms:RawOrders").pipeline("cxf:bean:decrypt", "cxf:bean:authenticate", "cxf:bean:dedup", "jms:CleanOrders");The same route can be configured in XML, as follows:
<camelContext id="buildPipeline" xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="jms:RawOrders"/>
<to uri="cxf:bean:decrypt"/>
<to uri="cxf:bean:authenticate"/>
<to uri="cxf:bean:dedup"/>
<to uri="jms:CleanOrders"/>
</route>
</camelContext>
There is no dedicated pipeline element in XML. The preceding combination of from and to elements is semantically equivalent to a pipeline. See the section called “Comparison of pipeline() and to() DSL commands”.
Pipeline for the InOnly and RobustInOnly exchange patterns
When there are no Out messages available from the endpoints in the pipeline (as is the case for the InOnly and RobustInOnly exchange patterns), a pipeline cannot be connected in the normal way. In this special case, the pipeline is constructed by passing a copy of the original In message to each of the endpoints in the pipeline, as shown in Figure 5.6, “Pipeline for InOnly Exchanges”. This type of pipeline is equivalent to a recipient list with fixed destinations (see Section 8.3, “Recipient List”).
Figure 5.6. Pipeline for InOnly Exchanges

The route for this pipeline is defined using the same syntax as an InOut pipeline (either in Java DSL or in XML).
Comparison of pipeline() and to() DSL commands
In the Java DSL, you can define a pipeline route using either of the following syntaxes:
Using the pipeline() processor command — Use the pipeline processor to construct a pipeline route as follows:
from(SourceURI).pipeline(FilterA, FilterB, TargetURI);
Using the to() command — Use the
to()command to construct a pipeline route as follows:from(SourceURI).to(FilterA, FilterB, TargetURI);
Alternatively, you can use the equivalent syntax:
from(SourceURI).to(FilterA).to(FilterB).to(TargetURI);
Exercise caution when using the to() command syntax, because it is not always equivalent to a pipeline processor. In Java DSL, the meaning of to() can be modified by the preceding command in the route. For example, when the multicast() command precedes the to() command, it binds the listed endpoints into a multicast pattern, instead of a pipeline pattern (see Section 8.13, “Multicast”).
5.5. Message Router
Overview
A message router, shown in Figure 5.7, “Message Router Pattern”, is a type of filter that consumes messages from a single consumer endpoint and redirects them to the appropriate target endpoint, based on a particular decision criterion. A message router is concerned only with redirecting messages; it does not modify the message content.
However, by default, whenever Camel routes a message exchange to a recipient endpoint, it sends is a shallow copy of the original exchange object. In a shallow copy, elements of the original exchange, such as the message body, headers, and attachments, are copied by reference only. By sending shallow copies that reuse resources, Camel optimizes for performance. But because these shallow copies are all linked, in cases where Camel routes a message to multiple endpoints, the tradeoff is that you lose the ability to apply custom logic to copies that are routed to different recipients. For information about how to enable Camel to route unique versions of a message to different endpoints, see "Apply custom processing to the outgoing messages".
Figure 5.7. Message Router Pattern
A message router can easily be implemented in Apache Camel using the choice() processor, where each of the alternative target endpoints can be selected using a when() subclause (for details of the choice processor, see Section 1.5, “Processors”).
Java DSL example
The following Java DSL example shows how to route messages to three alternative destinations (either seda:a, seda:b, or seda:c) depending on the contents of the foo header:
from("seda:a").choice()
.when(header("foo").isEqualTo("bar")).to("seda:b")
.when(header("foo").isEqualTo("cheese")).to("seda:c")
.otherwise().to("seda:d");XML configuration example
The following example shows how to configure the same route in XML:
<camelContext id="buildSimpleRouteWithChoice" xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="seda:a"/>
<choice>
<when>
<xpath>$foo = 'bar'</xpath>
<to uri="seda:b"/>
</when>
<when>
<xpath>$foo = 'cheese'</xpath>
<to uri="seda:c"/>
</when>
<otherwise>
<to uri="seda:d"/>
</otherwise>
</choice>
</route>
</camelContext>Choice without otherwise
If you use choice() without an otherwise() clause, any unmatched exchanges are dropped by default.
5.6. Message Translator
Overview
The message translator pattern, shown in Figure 5.8, “Message Translator Pattern” describes a component that modifies the contents of a message, translating it to a different format. You can use Apache Camel’s bean integration feature to perform the message translation.
Figure 5.8. Message Translator Pattern
Bean integration
You can transform a message using bean integration, which enables you to call a method on any registered bean. For example, to call the method, myMethodName(), on the bean with ID, myTransformerBean:
from("activemq:SomeQueue")
.beanRef("myTransformerBean", "myMethodName")
.to("mqseries:AnotherQueue");
Where the myTransformerBean bean is defined in either a Spring XML file or in JNDI. If, you omit the method name parameter from beanRef(), the bean integration will try to deduce the method name to invoke by examining the message exchange.
You can also add your own explicit Processor instance to perform the transformation, as follows:
from("direct:start").process(new Processor() {
public void process(Exchange exchange) {
Message in = exchange.getIn();
in.setBody(in.getBody(String.class) + " World!");
}
}).to("mock:result");Or, you can use the DSL to explicitly configure the transformation, as follows:
from("direct:start").setBody(body().append(" World!")).to("mock:result");You can also use templating to consume a message from one destination, transform it with something like Velocity or XQuery and then send it on to another destination. For example, using the InOnly exchange pattern (one-way messaging) :
from("activemq:My.Queue").
to("velocity:com/acme/MyResponse.vm").
to("activemq:Another.Queue");
If you want to use InOut (request-reply) semantics to process requests on the My.Queue queue on ActiveMQ with a template generated response, then you could use a route like the following to send responses back to the JMSReplyTo destination:
from("activemq:My.Queue").
to("velocity:com/acme/MyResponse.vm");5.7. Message History
Overview
The Message History pattern enables you to analyze and debug the flow of messages in a loosely coupled system. If you attach a message history to the message, it displays a list of all applications that the message passed through since its origination.
In Apache Camel, using the getTracedRouteNodes method, you can trace a message flow using the Tracer or access information using the Java API from UnitOfWork.
Limiting Character Length in Logs
When you run Apache Camel with logging mechanism, it enables you to log the messages and its content from time to time.
Some messages may contain very big payloads. By default, Apache Camel will clip the log message and show only the first 1000 characters. For example, it displays the following log as:
[DEBUG ProducerCache - >>>> Endpoint[direct:start] Exchange[Message: 01234567890123456789... [Body clipped after 20 characters, total length is 1000]
You can customize the limit when Apache Camel clips the body in the log. You can also set zero or a negative value, such as -1, means the message body is not logged.
- Customizing the Limit using Java DSL
You can set the limit in Camel properties using Java DSL. For example,
context.getProperties().put(Exchange.LOG_DEBUG_BODY_MAX_CHARS, "500");
- Customizing the Limit using Spring DSL
You can set the limit in Camel properties using Spring DSL. For example,
<camelContext> <properties> <property key="CamelLogDebugBodyMaxChars" value="500"/> </properties> </camelContext>
Chapter 6. Messaging Channels
Abstract
Messaging channels provide the plumbing for a messaging application. This chapter describes the different kinds of messaging channels available in a messaging system, and the roles that they play.
6.1. Point-to-Point Channel
Overview
A point-to-point channel, shown in Figure 6.1, “Point to Point Channel Pattern” is a message channel that guarantees that only one receiver consumes any given message. This is in contrast to a publish-subscribe channel, which allows multiple receivers to consume the same message. In particular, with a publish-subscribe channel, it is possible for multiple receivers to subscribe to the same channel. If more than one receiver competes to consume a message, it is up to the message channel to ensure that only one receiver actually consumes the message.
Figure 6.1. Point to Point Channel Pattern

Components that support point-to-point channel
The following Apache Camel components support the point-to-point channel pattern:
JMS
In JMS, a point-to-point channel is represented by a queue. For example, you can specify the endpoint URI for a JMS queue called Foo.Bar as follows:
jms:queue:Foo.Bar
The qualifier, queue:, is optional, because the JMS component creates a queue endpoint by default. Therefore, you can also specify the following equivalent endpoint URI:
jms:Foo.Bar
See Jms in the Apache Camel Component Reference Guide for more details.
ActiveMQ
In ActiveMQ, a point-to-point channel is represented by a queue. For example, you can specify the endpoint URI for an ActiveMQ queue called Foo.Bar as follows:
activemq:queue:Foo.Bar
See ActiveMQ in the Apache Camel Component Reference Guide for more details.
SEDA
The Apache Camel Staged Event-Driven Architecture (SEDA) component is implemented using a blocking queue. Use the SEDA component if you want to create a lightweight point-to-point channel that is internal to the Apache Camel application. For example, you can specify an endpoint URI for a SEDA queue called SedaQueue as follows:
seda:SedaQueue
JPA
The Java Persistence API (JPA) component is an EJB 3 persistence standard that is used to write entity beans out to a database. See JPA in the Apache Camel Component Reference Guide for more details.
XMPP
The XMPP (Jabber) component supports the point-to-point channel pattern when it is used in the person-to-person mode of communication. See XMPP in the Apache Camel Component Reference Guide for more details.
6.2. Publish-Subscribe Channel
Overview
A publish-subscribe channel, shown in Figure 6.2, “Publish Subscribe Channel Pattern”, is a Section 5.2, “Message Channel” that enables multiple subscribers to consume any given message. This is in contrast with a Section 6.1, “Point-to-Point Channel”. Publish-subscribe channels are frequently used as a means of broadcasting events or notifications to multiple subscribers.
Figure 6.2. Publish Subscribe Channel Pattern
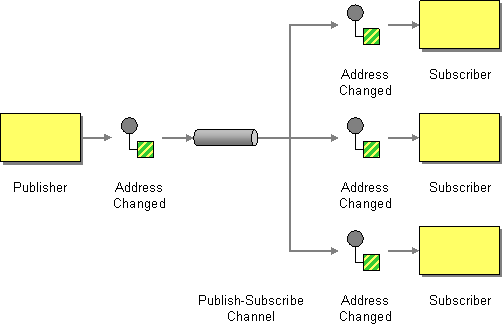
Components that support publish-subscribe channel
The following Apache Camel components support the publish-subscribe channel pattern:
JMS
In JMS, a publish-subscribe channel is represented by a topic. For example, you can specify the endpoint URI for a JMS topic called StockQuotes as follows:
jms:topic:StockQuotes
See Jms in the Apache Camel Component Reference Guide for more details.
ActiveMQ
In ActiveMQ, a publish-subscribe channel is represented by a topic. For example, you can specify the endpoint URI for an ActiveMQ topic called StockQuotes, as follows:
activemq:topic:StockQuotes
See ActiveMQ in the Apache Camel Component Reference Guide for more details.
XMPP
The XMPP (Jabber) component supports the publish-subscribe channel pattern when it is used in the group communication mode. See Xmpp in the Apache Camel Component Reference Guide for more details.
Static subscription lists
If you prefer, you can also implement publish-subscribe logic within the Apache Camel application itself. A simple approach is to define a static subscription list, where the target endpoints are all explicitly listed at the end of the route. However, this approach is not as flexible as a JMS or ActiveMQ topic.
Java DSL example
The following Java DSL example shows how to simulate a publish-subscribe channel with a single publisher, seda:a, and three subscribers, seda:b, seda:c, and seda:d:
from("seda:a").to("seda:b", "seda:c", "seda:d");This only works for the InOnly message exchange pattern.
XML configuration example
The following example shows how to configure the same route in XML:
<camelContext id="buildStaticRecipientList" xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="seda:a"/>
<to uri="seda:b"/>
<to uri="seda:c"/>
<to uri="seda:d"/>
</route>
</camelContext>6.3. Dead Letter Channel
Overview
The dead letter channel pattern, shown in Figure 6.3, “Dead Letter Channel Pattern”, describes the actions to take when the messaging system fails to deliver a message to the intended recipient. This includes such features as retrying delivery and, if delivery ultimately fails, sending the message to a dead letter channel, which archives the undelivered messages.
Figure 6.3. Dead Letter Channel Pattern
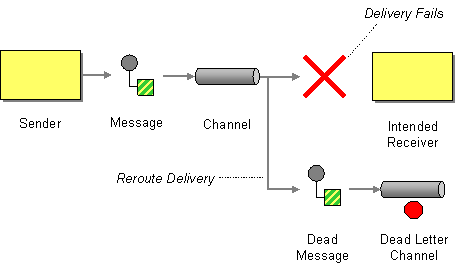
Creating a dead letter channel in Java DSL
The following example shows how to create a dead letter channel using Java DSL:
errorHandler(deadLetterChannel("seda:errors"));
from("seda:a").to("seda:b");
Where the errorHandler() method is a Java DSL interceptor, which implies that all of the routes defined in the current route builder are affected by this setting. The deadLetterChannel() method is a Java DSL command that creates a new dead letter channel with the specified destination endpoint, seda:errors.
The errorHandler() interceptor provides a catch-all mechanism for handling all error types. If you want to apply a more fine-grained approach to exception handling, you can use the onException clauses instead(see the section called “onException clause”).
XML DSL example
You can define a dead letter channel in the XML DSL, as follows:
<route errorHandlerRef="myDeadLetterErrorHandler">
...
</route>
<bean id="myDeadLetterErrorHandler" class="org.apache.camel.builder.DeadLetterChannelBuilder">
<property name="deadLetterUri" value="jms:queue:dead"/>
<property name="redeliveryPolicy" ref="myRedeliveryPolicyConfig"/>
</bean>
<bean id="myRedeliveryPolicyConfig" class="org.apache.camel.processor.RedeliveryPolicy">
<property name="maximumRedeliveries" value="3"/>
<property name="redeliveryDelay" value="5000"/>
</bean>Redelivery policy
Normally, you do not send a message straight to the dead letter channel, if a delivery attempt fails. Instead, you re-attempt delivery up to some maximum limit, and after all redelivery attempts fail you would send the message to the dead letter channel. To customize message redelivery, you can configure the dead letter channel to have a redelivery policy. For example, to specify a maximum of two redelivery attempts, and to apply an exponential backoff algorithm to the time delay between delivery attempts, you can configure the dead letter channel as follows:
errorHandler(deadLetterChannel("seda:errors").maximumRedeliveries(2).useExponentialBackOff());
from("seda:a").to("seda:b");
Where you set the redelivery options on the dead letter channel by invoking the relevant methods in a chain (each method in the chain returns a reference to the current RedeliveryPolicy object). Table 6.1, “Redelivery Policy Settings” summarizes the methods that you can use to set redelivery policies.
| Method Signature | Default | Description |
|---|---|---|
|
|
| Controls whether redelivery is attempted during graceful shutdown or while a route is stopping. A delivery that is already in progress when stopping is initiated will not be interrupted. |
|
|
|
If exponential backoff is enabled, let d, m*d, m*m*d, m*m*m*d, ... |
|
|
|
If collision avoidance is enabled, let |
|
|
|
Camel 2.15: Specifies whether or not to handle an exception that occurs while processing a message in the dead letter channel. If |
|
| None | Apache Camel 2.0: See the section called “Redeliver delay pattern”. |
|
|
|
Apache Camel 2.0: Disables the redelivery feature. To enable redelivery, set |
|
|
|
Apache Camel 2.0: If |
|
|
| Specifies the delay (in milliseconds) before attempting the first redelivery. |
|
|
| Specifies whether to log at WARN level, when an exception is raised in the dead letter channel. |
|
|
|
Apache Camel 2.0: If |
|
|
| Apache Camel 2.0: Maximum number of delivery attempts. |
|
|
|
Apache Camel 2.0: When using an exponential backoff strategy (see |
|
| None | Apache Camel 2.0: Configures a processor that gets called before every redelivery attempt. |
|
|
| Apache Camel 2.0: Specifies the delay (in milliseconds) between redelivery attempts. Apache Camel 2.16.0 : The default redelivery delay is one second. |
|
|
|
Apache Camel 2.0: Specifies the logging level at which to log delivery failure (specified as an |
|
|
|
Apache Camel 2.0: Specifies the logging level at which to redelivery attempts (specified as an |
|
|
| Enables collision avoidence, which adds some randomization to the backoff timings to reduce contention probability. |
|
|
|
Apache Camel 2.0: If this feature is enabled, the message sent to the dead letter channel is a copy of the original message exchange, as it existed at the beginning of the route (in the |
|
|
| Enables exponential backoff. |
Redelivery headers
If Apache Camel attempts to redeliver a message, it automatically sets the headers described in Table 6.2, “Dead Letter Redelivery Headers” on the In message.
| Header Name | Type | Description |
|---|---|---|
|
|
|
Apache Camel 2.0: Counts the number of unsuccessful delivery attempts. This value is also set in |
|
|
|
Apache Camel 2.0: True, if one or more redelivery attempts have been made. This value is also set in |
|
|
|
Apache Camel 2.6: Holds the maximum redelivery setting (also set in the |
Redelivery exchange properties
If Apache Camel attempts to redeliver a message, it automatically sets the exchange properties described in Table 6.3, “Redelivery Exchange Properties”.
| Exchange Property Name | Type | Description |
|---|---|---|
|
|
|
Provides the route ID of the route that failed. The literal name of this property is |
Using the original message
Available as of Apache Camel 2.0 Because an exchange object is subject to modification as it passes through the route, the exchange that is current when an exception is raised is not necessarily the copy that you would want to store in the dead letter channel. In many cases, it is preferable to log the message that arrived at the start of the route, before it was subject to any kind of transformation by the route. For example, consider the following route:
from("jms:queue:order:input")
.to("bean:validateOrder");
.to("bean:transformOrder")
.to("bean:handleOrder");
The preceding route listen for incoming JMS messages and then processes the messages using the sequence of beans: validateOrder, transformOrder, and handleOrder. But when an error occurs, we do not know in which state the message is in. Did the error happen before the transformOrder bean or after? We can ensure that the original message from jms:queue:order:input is logged to the dead letter channel by enabling the useOriginalMessage option as follows:
// will use original body
errorHandler(deadLetterChannel("jms:queue:dead")
.useOriginalMessage().maximumRedeliveries(5).redeliveryDelay(5000);Redeliver delay pattern
Available as of Apache Camel 2.0 The delayPattern option is used to specify delays for particular ranges of the redelivery count. The delay pattern has the following syntax: limit1:delay1;limit2:delay2;limit3:delay3;…, where each delayN is applied to redeliveries in the range limitN ⇐ redeliveryCount < limitN+1
For example, consider the pattern, 5:1000;10:5000;20:20000, which defines three groups and results in the following redelivery delays:
- Attempt number 1..4 = 0 milliseconds (as the first group starts with 5).
- Attempt number 5..9 = 1000 milliseconds (the first group).
- Attempt number 10..19 = 5000 milliseconds (the second group).
- Attempt number 20.. = 20000 milliseconds (the last group).
You can start a group with limit 1 to define a starting delay. For example, 1:1000;5:5000 results in the following redelivery delays:
- Attempt number 1..4 = 1000 millis (the first group)
- Attempt number 5.. = 5000 millis (the last group)
There is no requirement that the next delay should be higher than the previous and you can use any delay value you like. For example, the delay pattern, 1:5000;3:1000, starts with a 5 second delay and then reduces the delay to 1 second.
Which endpoint failed?
When Apache Camel routes messages, it updates an Exchange property that contains the last endpoint the Exchange was sent to. Hence, you can obtain the URI for the current exchange’s most recent destination using the following code:
// Java String lastEndpointUri = exchange.getProperty(Exchange.TO_ENDPOINT, String.class);
Where Exchange.TO_ENDPOINT is a string constant equal to CamelToEndpoint. This property is updated whenever Camel sends a message to any endpoint.
If an error occurs during routing and the exchange is moved into the dead letter queue, Apache Camel will additionally set a property named CamelFailureEndpoint, which identifies the last destination the exchange was sent to before the error occured. Hence, you can access the failure endpoint from within a dead letter queue using the following code:
// Java String failedEndpointUri = exchange.getProperty(Exchange.FAILURE_ENDPOINT, String.class);
Where Exchange.FAILURE_ENDPOINT is a string constant equal to CamelFailureEndpoint.
These properties remain set in the current exchange, even if the failure occurs after the given destination endpoint has finished processing. For example, consider the following route:
from("activemq:queue:foo")
.to("http://someserver/somepath")
.beanRef("foo");
Now suppose that a failure happens in the foo bean. In this case the Exchange.TO_ENDPOINT property and the Exchange.FAILURE_ENDPOINT property still contain the value.
onRedelivery processor
When a dead letter channel is performing redeliveries, it is possible to configure a Processor that is executed just before every redelivery attempt. This can be used for situations where you need to alter the message before it is redelivered.
For example, the following dead letter channel is configured to call the MyRedeliverProcessor before redelivering exchanges:
// we configure our Dead Letter Channel to invoke
// MyRedeliveryProcessor before a redelivery is
// attempted. This allows us to alter the message before
errorHandler(deadLetterChannel("mock:error").maximumRedeliveries(5)
.onRedelivery(new MyRedeliverProcessor())
// setting delay to zero is just to make unit teting faster
.redeliveryDelay(0L));
Where the MyRedeliveryProcessor process is implemented as follows:
// This is our processor that is executed before every redelivery attempt
// here we can do what we want in the java code, such as altering the message
public class MyRedeliverProcessor implements Processor {
public void process(Exchange exchange) throws Exception {
// the message is being redelivered so we can alter it
// we just append the redelivery counter to the body
// you can of course do all kind of stuff instead
String body = exchange.getIn().getBody(String.class);
int count = exchange.getIn().getHeader(Exchange.REDELIVERY_COUNTER, Integer.class);
exchange.getIn().setBody(body + count);
// the maximum redelivery was set to 5
int max = exchange.getIn().getHeader(Exchange.REDELIVERY_MAX_COUNTER, Integer.class);
assertEquals(5, max);
}
}Control redelivery during shutdown or stopping
If you stop a route or initiate graceful shutdown, the default behavior of the error handler is to continue attempting redelivery. Because this is typically not the desired behavior, you have the option of disabling redelivery during shutdown or stopping, by setting the allowRedeliveryWhileStopping option to false, as shown in the following example:
errorHandler(deadLetterChannel("jms:queue:dead")
.allowRedeliveryWhileStopping(false)
.maximumRedeliveries(20)
.redeliveryDelay(1000)
.retryAttemptedLogLevel(LoggingLevel.INFO));
The allowRedeliveryWhileStopping option is true by default, for backwards compatibility reasons. During aggressive shutdown, however, redelivery is always suppressed, irrespective of this option setting (for example, after graceful shutdown has timed out).
Using onExceptionOccurred Processor
Dead Letter channel supports the onExceptionOccurred processor to allow the custom processing of a message, after an exception occurs. You can use it for custom logging too. Any new exceptions thrown from the onExceptionOccurred processor is logged as WARN and ignored, not to override the existing exception.
The difference between the onRedelivery processor and onExceptionOccurred processor is you can process the former exactly before the redelivery attempt. However, it does not happen immediately after an exception occurs. For example, If you configure the error handler to do five seconds delay between the redelivery attempts, then the redelivery processor is invoked five seconds later, after an exception occurs.
The following example explains how to do the custom logging when an exception occurs. You need to configure the onExceptionOccurred to use the custom processor.
errorHandler(defaultErrorHandler().maximumRedeliveries(3).redeliveryDelay(5000).onExceptionOccurred(myProcessor));
onException clause
Instead of using the errorHandler() interceptor in your route builder, you can define a series of onException() clauses that define different redelivery policies and different dead letter channels for various exception types. For example, to define distinct behavior for each of the NullPointerException, IOException, and Exception types, you can define the following rules in your route builder using Java DSL:
onException(NullPointerException.class)
.maximumRedeliveries(1)
.setHeader("messageInfo", "Oh dear! An NPE.")
.to("mock:npe_error");
onException(IOException.class)
.initialRedeliveryDelay(5000L)
.maximumRedeliveries(3)
.backOffMultiplier(1.0)
.useExponentialBackOff()
.setHeader("messageInfo", "Oh dear! Some kind of I/O exception.")
.to("mock:io_error");
onException(Exception.class)
.initialRedeliveryDelay(1000L)
.maximumRedeliveries(2)
.setHeader("messageInfo", "Oh dear! An exception.")
.to("mock:error");
from("seda:a").to("seda:b");
Where the redelivery options are specified by chaining the redelivery policy methods (as listed in Table 6.1, “Redelivery Policy Settings”), and you specify the dead letter channel’s endpoint using the to() DSL command. You can also call other Java DSL commands in the onException() clauses. For example, the preceding example calls setHeader() to record some error details in a message header named, messageInfo.
In this example, the NullPointerException and the IOException exception types are configured specially. All other exception types are handled by the generic Exception exception interceptor. By default, Apache Camel applies the exception interceptor that most closely matches the thrown exception. If it fails to find an exact match, it tries to match the closest base type, and so on. Finally, if no other interceptor matches, the interceptor for the Exception type matches all remaining exceptions.
OnPrepareFailure
Before you pass the exchange to the dead letter queue, you can use the onPrepare option to allow a custom processor to prepare the exchange. It enables you to add information about the exchange, such as the cause of exchange failure. For example, the following processor adds a header with the exception message.
public class MyPrepareProcessor implements Processor {
@Override
public void process(Exchange exchange) throws Exception {
Exception cause = exchange.getProperty(Exchange.EXCEPTION_CAUGHT, Exception.class);
exchange.getIn().setHeader("FailedBecause", cause.getMessage());
}
}You can configue the error handler to use the processor as follows.
errorHandler(deadLetterChannel("jms:dead").onPrepareFailure(new MyPrepareProcessor()));
However, the onPrepare option is also available using the default error handler.
<bean id="myPrepare" class="org.apache.camel.processor.DeadLetterChannelOnPrepareTest.MyPrepareProcessor"/> <errorHandler id="dlc" type="DeadLetterChannel" deadLetterUri="jms:dead" onPrepareFailureRef="myPrepare"/>
6.4. Guaranteed Delivery
Overview
Guaranteed delivery means that once a message is placed into a message channel, the messaging system guarantees that the message will reach its destination, even if parts of the application should fail. In general, messaging systems implement the guaranteed delivery pattern, shown in Figure 6.4, “Guaranteed Delivery Pattern”, by writing messages to persistent storage before attempting to deliver them to their destination.
Figure 6.4. Guaranteed Delivery Pattern
Components that support guaranteed delivery
The following Apache Camel components support the guaranteed delivery pattern:
- JMS
- ActiveMQ
- ActiveMQ Journal
- File Component in the Apache Camel Component Reference Guide
JMS
In JMS, the deliveryPersistent query option indicates whether or not persistent storage of messages is enabled. Usually it is unnecessary to set this option, because the default behavior is to enable persistent delivery. To configure all the details of guaranteed delivery, it is necessary to set configuration options on the JMS provider. These details vary, depending on what JMS provider you are using. For example, MQSeries, TibCo, BEA, Sonic, and others, all provide various qualities of service to support guaranteed delivery.
See Jms in the Apache Camel Component Reference Guide> for more details.
ActiveMQ
In ActiveMQ, message persistence is enabled by default. From version 5 onwards, ActiveMQ uses the AMQ message store as the default persistence mechanism. There are several different approaches you can use to enabe message persistence in ActiveMQ.
The simplest option (different from Figure 6.4, “Guaranteed Delivery Pattern”) is to enable persistence in a central broker and then connect to that broker using a reliable protocol. After a message is been sent to the central broker, delivery to consumers is guaranteed. For example, in the Apache Camel configuration file, META-INF/spring/camel-context.xml, you can configure the ActiveMQ component to connect to the central broker using the OpenWire/TCP protocol as follows:
<beans ... >
...
<bean id="activemq" class="org.apache.activemq.camel.component.ActiveMQComponent">
<property name="brokerURL" value="tcp://somehost:61616"/>
</bean>
...
</beans>
If you prefer to implement an architecture where messages are stored locally before being sent to a remote endpoint (similar to Figure 6.4, “Guaranteed Delivery Pattern”), you do this by instantiating an embedded broker in your Apache Camel application. A simple way to achieve this is to use the ActiveMQ Peer-to-Peer protocol, which implicitly creates an embedded broker to communicate with other peer endpoints. For example, in the camel-context.xml configuration file, you can configure the ActiveMQ component to connect to all of the peers in group, GroupA, as follows:
<beans ... >
...
<bean id="activemq" class="org.apache.activemq.camel.component.ActiveMQComponent">
<property name="brokerURL" value="peer://GroupA/broker1"/>
</bean>
...
</beans>
Where broker1 is the broker name of the embedded broker (other peers in the group should use different broker names). One limiting feature of the Peer-to-Peer protocol is that it relies on IP multicast to locate the other peers in its group. This makes it unsuitable for use in wide area networks (and in some local area networks that do not have IP multicast enabled).
A more flexible way to create an embedded broker in the ActiveMQ component is to exploit ActiveMQ’s VM protocol, which connects to an embedded broker instance. If a broker of the required name does not already exist, the VM protocol automatically creates one. You can use this mechanism to create an embedded broker with custom configuration. For example:
<beans ... >
...
<bean id="activemq" class="org.apache.activemq.camel.component.ActiveMQComponent">
<property name="brokerURL" value="vm://broker1?brokerConfig=xbean:activemq.xml"/>
</bean>
...
</beans>
Where activemq.xml is an ActiveMQ file which configures the embedded broker instance. Within the ActiveMQ configuration file, you can choose to enable one of the following persistence mechanisms:
- AMQ persistence(the default) — A fast and reliable message store that is native to ActiveMQ. For details, see amqPersistenceAdapter and AMQ Message Store.
- JDBC persistence — Uses JDBC to store messages in any JDBC-compatible database. For details, see jdbcPersistenceAdapter and ActiveMQ Persistence.
- Journal persistence — A fast persistence mechanism that stores messages in a rolling log file. For details, see journalPersistenceAdapter and ActiveMQ Persistence.
- Kaha persistence — A persistence mechanism developed specifically for ActiveMQ. For details, see kahaPersistenceAdapter and ActiveMQ Persistence.
See ActiveMQ in the Apache Camel Component Reference Guide for more details.
ActiveMQ Journal
The ActiveMQ Journal component is optimized for a special use case where multiple, concurrent producers write messages to queues, but there is only one active consumer. Messages are stored in rolling log files and concurrent writes are aggregated to boost efficiency.
6.5. Message Bus
Overview
Message bus refers to a messaging architecture, shown in Figure 6.5, “Message Bus Pattern”, that enables you to connect diverse applications running on diverse computing platforms. In effect, the Apache Camel and its components constitute a message bus.
Figure 6.5. Message Bus Pattern
The following features of the message bus pattern are reflected in Apache Camel:
- Common communication infrastructure — The router itself provides the core of the common communication infrastructure in Apache Camel. However, in contrast to some message bus architectures, Apache Camel provides a heterogeneous infrastructure: messages can be sent into the bus using a wide variety of different transports and using a wide variety of different message formats.
Adapters — Where necessary, Apache Camel can translate message formats and propagate messages using different transports. In effect, Apache Camel is capable of behaving like an adapter, so that external applications can hook into the message bus without refactoring their messaging protocols.
In some cases, it is also possible to integrate an adapter directly into an external application. For example, if you develop an application using Apache CXF, where the service is implemented using JAX-WS and JAXB mappings, it is possible to bind a variety of different transports to the service. These transport bindings function as adapters.
Chapter 7. Message Construction
Abstract
The message construction patterns describe the various forms and functions of the messages that pass through the system.
7.1. Correlation Identifier
Overview
The correlation identifier pattern, shown in Figure 7.1, “Correlation Identifier Pattern”, describes how to match reply messages with request messages, given that an asynchronous messaging system is used to implement a request-reply protocol. The essence of this idea is that request messages should be generated with a unique token, the request ID, that identifies the request message and reply messages should include a token, the correlation ID, that contains the matching request ID.
Apache Camel supports the Correlation Identifier from the EIP patterns by getting or setting a header on a Message.
When working with the ActiveMQ or JMS components, the correlation identifier header is called JMSCorrelationID. You can add your own correlation identifier to any message exchange to help correlate messages together in a single conversation (or business process). A correlation identifier is usually stored in a Apache Camel message header.
Some EIP patterns spin off a sub message and, in those cases, Apache Camel adds a correlation ID to the Exchanges as a property with they key, Exchange.CORRELATION_ID, which links back to the source Exchanges. For example, the splitter, multicast, recipient list, and wire tap EIPs do this.
Figure 7.1. Correlation Identifier Pattern

7.2. Event Message
Event Message
Camel supports the Event Message from the Enterprise Integration Patterns by supporting the Exchange Pattern on a message which can be set to InOnly to indicate a oneway event message. Camel Apache Camel Component Reference then implement this pattern using the underlying transport or protocols.
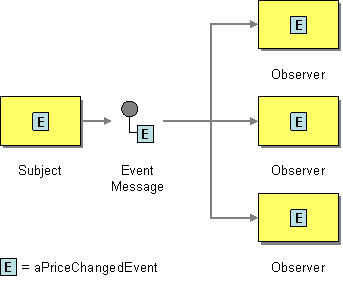
The default behavior of many Apache Camel Component Reference is InOnly such as for JMS, File or SEDA
Explicitly specifying InOnly
If you are using a component which defaults to InOut you can override the message exchange patterns for an endpoint using the pattern property.
foo:bar?exchangePattern=InOnly
From 2.0 onwards on Camel you can specify the message exchange patterns using the DSL.
Using the Fluent Builders
from("mq:someQueue").
inOnly().
bean(Foo.class);or you can invoke an endpoint with an explicit pattern
from("mq:someQueue").
inOnly("mq:anotherQueue");Using the Spring XML Extensions
<route>
<from uri="mq:someQueue"/>
<inOnly uri="bean:foo"/>
</route><route>
<from uri="mq:someQueue"/>
<inOnly uri="mq:anotherQueue"/>
</route>7.3. Return Address
Return Address
Apache Camel supports the Return Address from the Enterprise Integration Patterns using the JMSReplyTo header.
For example when using JMS with InOut, the component will by default be returned to the address given in JMSReplyTo.
Example
Requestor Code
getMockEndpoint("mock:bar").expectedBodiesReceived("Bye World");
template.sendBodyAndHeader("direct:start", "World", "JMSReplyTo", "queue:bar");Route Using the Fluent Builders
from("direct:start").to("activemq:queue:foo?preserveMessageQos=true");
from("activemq:queue:foo").transform(body().prepend("Bye "));
from("activemq:queue:bar?disableReplyTo=true").to("mock:bar");Route Using the Spring XML Extensions
<route>
<from uri="direct:start"/>
<to uri="activemq:queue:foo?preserveMessageQos=true"/>
</route>
<route>
<from uri="activemq:queue:foo"/>
<transform>
<simple>Bye ${in.body}</simple>
</transform>
</route>
<route>
<from uri="activemq:queue:bar?disableReplyTo=true"/>
<to uri="mock:bar"/>
</route>For a complete example of this pattern, see this JUnit test case
Chapter 8. Message Routing
Abstract
The message routing patterns describe various ways of linking message channels together. This includes various algorithms that can be applied to the message stream (without modifying the body of the message).
8.1. Content-Based Router
Overview
A content-based router, shown in Figure 8.1, “Content-Based Router Pattern”, enables you to route messages to the appropriate destination based on the message contents.
Figure 8.1. Content-Based Router Pattern
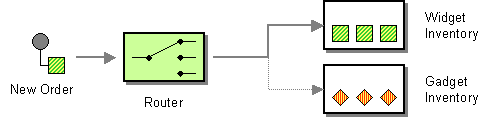
Java DSL example
The following example shows how to route a request from an input, seda:a, endpoint to either seda:b, queue:c, or seda:d depending on the evaluation of various predicate expressions:
RouteBuilder builder = new RouteBuilder() {
public void configure() {
from("seda:a").choice()
.when(header("foo").isEqualTo("bar")).to("seda:b")
.when(header("foo").isEqualTo("cheese")).to("seda:c")
.otherwise().to("seda:d");
}
};XML configuration example
The following example shows how to configure the same route in XML:
<camelContext id="buildSimpleRouteWithChoice" xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="seda:a"/>
<choice>
<when>
<xpath>$foo = 'bar'</xpath>
<to uri="seda:b"/>
</when>
<when>
<xpath>$foo = 'cheese'</xpath>
<to uri="seda:c"/>
</when>
<otherwise>
<to uri="seda:d"/>
</otherwise>
</choice>
</route>
</camelContext>8.2. Message Filter
Overview
A message filter is a processor that eliminates undesired messages based on specific criteria. In Apache Camel, the message filter pattern, shown in Figure 8.2, “Message Filter Pattern”, is implemented by the filter() Java DSL command. The filter() command takes a single predicate argument, which controls the filter. When the predicate is true, the incoming message is allowed to proceed, and when the predicate is false, the incoming message is blocked.
Figure 8.2. Message Filter Pattern

Java DSL example
The following example shows how to create a route from endpoint, seda:a, to endpoint, seda:b, that blocks all messages except for those messages whose foo header have the value, bar:
RouteBuilder builder = new RouteBuilder() {
public void configure() {
from("seda:a").filter(header("foo").isEqualTo("bar")).to("seda:b");
}
};
To evaluate more complex filter predicates, you can invoke one of the supported scripting languages, such as XPath, XQuery, or SQL (see Part II, “Routing Expression and Predicate Languages”). The following example defines a route that blocks all messages except for those containing a person element whose name attribute is equal to James:
from("direct:start").
filter().xpath("/person[@name='James']").
to("mock:result");XML configuration example
The following example shows how to configure the route with an XPath predicate in XML (see Part II, “Routing Expression and Predicate Languages”):
<camelContext id="simpleFilterRoute" xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="seda:a"/>
<filter>
<xpath>$foo = 'bar'</xpath>
<to uri="seda:b"/>
</filter>
</route>
</camelContext>
Make sure you put the endpoint you want to filter (for example, <to uri="seda:b"/>) before the closing </filter> tag or the filter will not be applied (in 2.8+, omitting this will result in an error).
Filtering with beans
Here is an example of using a bean to define the filter behavior:
from("direct:start")
.filter().method(MyBean.class, "isGoldCustomer").to("mock:result").end()
.to("mock:end");
public static class MyBean {
public boolean isGoldCustomer(@Header("level") String level) {
return level.equals("gold");
}
}Using stop()
Available as of Camel 2.0
Stop is a special type of filter that filters out all messages. Stop is convenient to use in a content-based router when you need to stop further processing in one of the predicates.
In the following example, we do not want messages with the word Bye in the message body to propagate any further in the route. We prevent this in the when() predicate using .stop().
from("direct:start")
.choice()
.when(bodyAs(String.class).contains("Hello")).to("mock:hello")
.when(bodyAs(String.class).contains("Bye")).to("mock:bye").stop()
.otherwise().to("mock:other")
.end()
.to("mock:result");Knowing if Exchange was filtered or not
Available as of Camel 2.5
The message filter EIP will add a property on the Exchange which states if it was filtered or not.
The property has the key Exchange.FILTER_MATCHED which has the String value of CamelFilterMatched. Its value is a boolean indicating true or false. If the value is true then the Exchange was routed in the filter block.
8.3. Recipient List
Overview
A recipient list, shown in Figure 8.3, “Recipient List Pattern”, is a type of router that sends each incoming message to multiple different destinations. In addition, a recipient list typically requires that the list of recipients be calculated at run time.
Figure 8.3. Recipient List Pattern
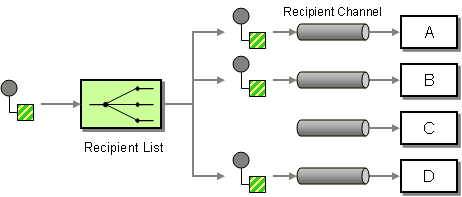
Recipient list with fixed destinations
The simplest kind of recipient list is where the list of destinations is fixed and known in advance, and the exchange pattern is InOnly. In this case, you can hardwire the list of destinations into the to() Java DSL command.
The examples given here, for the recipient list with fixed destinations, work only with the InOnly exchange pattern (similar to a pipes and filters pattern). If you want to create a recipient list for exchange patterns with Out messages, use the multicast pattern instead.
Java DSL example
The following example shows how to route an InOnly exchange from a consumer endpoint, queue:a, to a fixed list of destinations:
from("seda:a").to("seda:b", "seda:c", "seda:d");XML configuration example
The following example shows how to configure the same route in XML:
<camelContext id="buildStaticRecipientList" xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="seda:a"/>
<to uri="seda:b"/>
<to uri="seda:c"/>
<to uri="seda:d"/>
</route>
</camelContext>Recipient list calculated at run time
In most cases, when you use the recipient list pattern, the list of recipients should be calculated at runtime. To do this use the recipientList() processor, which takes a list of destinations as its sole argument. Because Apache Camel applies a type converter to the list argument, it should be possible to use most standard Java list types (for example, a collection, a list, or an array). For more details about type converters, see Section 34.3, “Built-In Type Converters”.
The recipients receive a copy of the same exchange instance and Apache Camel executes them sequentially.
Java DSL example
The following example shows how to extract the list of destinations from a message header called recipientListHeader, where the header value is a comma-separated list of endpoint URIs:
from("direct:a").recipientList(header("recipientListHeader").tokenize(","));
In some cases, if the header value is a list type, you might be able to use it directly as the argument to recipientList(). For example:
from("seda:a").recipientList(header("recipientListHeader"));However, this example is entirely dependent on how the underlying component parses this particular header. If the component parses the header as a simple string, this example will not work. The header must be parsed into some type of Java list.
XML configuration example
The following example shows how to configure the preceding route in XML, where the header value is a comma-separated list of endpoint URIs:
<camelContext id="buildDynamicRecipientList" xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="seda:a"/>
<recipientList delimiter=",">
<header>recipientListHeader</header>
</recipientList>
</route>
</camelContext>Sending to multiple recipients in parallel
Available as of Camel 2.2
The recipient list pattern supports parallelProcessing, which is similar to the corresponding feature in the splitter pattern. Use the parallel processing feature to send the exchange to multiple recipients concurrently — for example:
from("direct:a").recipientList(header("myHeader")).parallelProcessing();
In Spring XML, the parallel processing feature is implemented as an attribute on the recipientList tag — for example:
<route>
<from uri="direct:a"/>
<recipientList parallelProcessing="true">
<header>myHeader</header>
</recipientList>
</route>Stop on exception
Available as of Camel 2.2
The recipient list supports the stopOnException feature, which you can use to stop sending to any further recipients, if any recipient fails.
from("direct:a").recipientList(header("myHeader")).stopOnException();And in Spring XML its an attribute on the recipient list tag.
In Spring XML, the stop on exception feature is implemented as an attribute on the recipientList tag — for example:
<route>
<from uri="direct:a"/>
<recipientList stopOnException="true">
<header>myHeader</header>
</recipientList>
</route>
You can combine parallelProcessing and stopOnException in the same route.
Ignore invalid endpoints
Available as of Camel 2.3
The recipient list pattern supports the ignoreInvalidEndpoints option, which enables the recipient list to skip invalid endpoints (the routing slips pattern also supports this option). For example:
from("direct:a").recipientList(header("myHeader")).ignoreInvalidEndpoints();
And in Spring XML, you can enable this option by setting the ignoreInvalidEndpoints attribute on the recipientList tag, as follows
<route>
<from uri="direct:a"/>
<recipientList ignoreInvalidEndpoints="true">
<header>myHeader</header>
</recipientList>
</route>
Consider the case where myHeader contains the two endpoints, direct:foo,xxx:bar. The first endpoint is valid and works. The second is invalid and, therefore, ignored. Apache Camel logs at INFO level whenever an invalid endpoint is encountered.
Using custom AggregationStrategy
Available as of Camel 2.2
You can use a custom AggregationStrategy with the recipient list pattern, which is useful for aggregating replies from the recipients in the list. By default, Apache Camel uses the UseLatestAggregationStrategy aggregation strategy, which keeps just the last received reply. For a more sophisticated aggregation strategy, you can define your own implementation of the AggregationStrategy interface — see Section 8.5, “Aggregator” for details. For example, to apply the custom aggregation strategy, MyOwnAggregationStrategy, to the reply messages, you can define a Java DSL route as follows:
from("direct:a")
.recipientList(header("myHeader")).aggregationStrategy(new MyOwnAggregationStrategy())
.to("direct:b");
In Spring XML, you can specify the custom aggregation strategy as an attribute on the recipientList tag, as follows:
<route>
<from uri="direct:a"/>
<recipientList strategyRef="myStrategy">
<header>myHeader</header>
</recipientList>
<to uri="direct:b"/>
</route>
<bean id="myStrategy" class="com.mycompany.MyOwnAggregationStrategy"/>Using custom thread pool
Available as of Camel 2.2
This is only needed when you use parallelProcessing. By default Camel uses a thread pool with 10 threads. Notice this is subject to change when we overhaul thread pool management and configuration later (hopefully in Camel 2.2).
You configure this just as you would with the custom aggregation strategy.
Using method call as recipient list
You can use a bean integration to provide the recipients, for example:
from("activemq:queue:test").recipientList().method(MessageRouter.class, "routeTo");
Where the MessageRouter bean is defined as follows:
public class MessageRouter {
public String routeTo() {
String queueName = "activemq:queue:test2";
return queueName;
}
}Bean as recipient list
You can make a bean behave as a recipient list by adding the @RecipientList annotation to a methods that returns a list of recipients. For example:
public class MessageRouter {
@RecipientList
public String routeTo() {
String queueList = "activemq:queue:test1,activemq:queue:test2";
return queueList;
}
}
In this case, do not include the recipientList DSL command in the route. Define the route as follows:
from("activemq:queue:test").bean(MessageRouter.class, "routeTo");Using timeout
Available as of Camel 2.5
If you use parallelProcessing, you can configure a total timeout value in milliseconds. Camel will then process the messages in parallel until the timeout is hit. This allows you to continue processing if one message is slow.
In the example below, the recipientlist header has the value, direct:a,direct:b,direct:c, so that the message is sent to three recipients. We have a timeout of 250 milliseconds, which means only the last two messages can be completed within the timeframe. The aggregation therefore yields the string result, BC.
from("direct:start")
.recipientList(header("recipients"), ",")
.aggregationStrategy(new AggregationStrategy() {
public Exchange aggregate(Exchange oldExchange, Exchange newExchange) {
if (oldExchange == null) {
return newExchange;
}
String body = oldExchange.getIn().getBody(String.class);
oldExchange.getIn().setBody(body + newExchange.getIn().getBody(String.class));
return oldExchange;
}
})
.parallelProcessing().timeout(250)
// use end to indicate end of recipientList clause
.end()
.to("mock:result");
from("direct:a").delay(500).to("mock:A").setBody(constant("A"));
from("direct:b").to("mock:B").setBody(constant("B"));
from("direct:c").to("mock:C").setBody(constant("C"));
This timeout feature is also supported by splitter and both multicast and recipientList.
By default if a timeout occurs the AggregationStrategy is not invoked. However you can implement a specialized version
// Java
public interface TimeoutAwareAggregationStrategy extends AggregationStrategy {
/**
* A timeout occurred
*
* @param oldExchange the oldest exchange (is <tt>null</tt> on first aggregation as we only have the new exchange)
* @param index the index
* @param total the total
* @param timeout the timeout value in millis
*/
void timeout(Exchange oldExchange, int index, int total, long timeout);
This allows you to deal with the timeout in the AggregationStrategy if you really need to.
The timeout is total, which means that after X time, Camel will aggregate the messages which has completed within the timeframe. The remainders will be cancelled. Camel will also only invoke the timeout method in the TimeoutAwareAggregationStrategy once, for the first index which caused the timeout.
Apply custom processing to the outgoing messages
Before recipientList sends a message to one of the recipient endpoints, it creates a message replica, which is a shallow copy of the original message. In a shallow copy, the headers and payload of the original message are copied by reference only. Each new copy does not contain its own instance of those elements. As a result, shallow copies of a message are linked and you cannot apply custom processing when routing them to different endpoints.
If you want to perform some custom processing on each message replica before the replica is sent to its endpoint, you can invoke the onPrepare DSL command in the recipientList clause. The onPrepare command inserts a custom processor just after the message has been shallow-copied and just before the message is dispatched to its endpoint. For example, in the following route, the CustomProc processor is invoked on the message replica for each recipient endpoint:
from("direct:start")
.recipientList().onPrepare(new CustomProc());
A common use case for the onPrepare DSL command is to perform a deep copy of some or all elements of a message. This allows each message replica to be modified independently of the others. For example, the following CustomProc processor class performs a deep copy of the message body, where the message body is presumed to be of type, BodyType, and the deep copy is performed by the method, BodyType.deepCopy().
// Java
import org.apache.camel.*;
...
public class CustomProc implements Processor {
public void process(Exchange exchange) throws Exception {
BodyType body = exchange.getIn().getBody(BodyType.class);
// Make a _deep_ copy of of the body object
BodyType clone = BodyType.deepCopy();
exchange.getIn().setBody(clone);
// Headers and attachments have already been
// shallow-copied. If you need deep copies,
// add some more code here.
}
}Options
The recipientList DSL command supports the following options:
| Name | Default Value | Description |
|
|
| Delimiter used if the Expression returned multiple endpoints. |
|
| Refers to an AggregationStrategy to be used to assemble the replies from the recipients, into a single outgoing message from the Section 8.3, “Recipient List”. By default Camel will use the last reply as the outgoing message. | |
|
|
This option can be used to explicitly specify the method name to use, when using POJOs as the | |
|
|
|
This option can be used, when using POJOs as the |
|
|
| Camel 2.2: If enables then sending messages to the recipients occurs concurrently. Note the caller thread will still wait until all messages has been fully processed, before it continues. Its only the sending and processing the replies from the recipients which happens concurrently. |
|
|
|
If enabled, the |
|
| Camel 2.2: Refers to a custom Thread Pool to be used for parallel processing. Notice if you set this option, then parallel processing is automatic implied, and you do not have to enable that option as well. | |
|
|
| Camel 2.2: Whether or not to stop continue processing immediately when an exception occurred. If disable, then Camel will send the message to all recipients regardless if one of them failed. You can deal with exceptions in the AggregationStrategy class where you have full control how to handle that. |
|
|
| Camel 2.3: If an endpoint uri could not be resolved, should it be ignored. Otherwise Camel will thrown an exception stating the endpoint uri is not valid. |
|
|
| Camel 2.5: If enabled then Camel will process replies out-of-order, eg in the order they come back. If disabled, Camel will process replies in the same order as the Expression specified. |
|
|
Camel 2.5: Sets a total timeout specified in millis. If the Section 8.3, “Recipient List” hasn’t been able to send and process all replies within the given timeframe, then the timeout triggers and the Section 8.3, “Recipient List” breaks out and continues. Notice if you provide a TimeoutAwareAggregationStrategy then the | |
|
| Camel 2.8: Refers to a custom Processor to prepare the copy of the Exchange each recipient will receive. This allows you to do any custom logic, such as deep-cloning the message payload if that’s needed etc. | |
|
|
| Camel 2.8: Whether the unit of work should be shared. See the same option on Section 8.4, “Splitter” for more details. |
|
|
| Camel 2.13.1/2.12.4: Allows to configure the cache size for the ProducerCache which caches producers for reuse in the routing slip. Will by default use the default cache size which is 0. Setting the value to -1 allows to turn off the cache all together. |
Using Exchange Pattern in Recipient List
By default, the Recipient List uses the current exchange pattern. However, there may be few cases where you can send a message to a recipient using a different exchange pattern.
For example, you may have a route that initiates as a InOnly route. Now, If you want to use InOut exchange pattern with a recipient list, you need to configure the exchange pattern directly in the recipient endpoints.
The following example illustrates the route where the new files will start as InOnly and then route to a recipient list. If you want to use InOut with the ActiveMQ (JMS) endpoint, you need to specify this using the exchangePattern equals to InOut option. However, the response form the JMS request or reply will then be continued routed, and thus the response is stored in as a file in the outbox directory.
from("file:inbox")
// the exchange pattern is InOnly initially when using a file route
.recipientList().constant("activemq:queue:inbox?exchangePattern=InOut")
.to("file:outbox");
The InOut exchange pattern must get a response during the timeout. However, it fails if the response is not recieved.
8.4. Splitter
Overview
A splitter is a type of router that splits an incoming message into a series of outgoing messages. Each of the outgoing messages contains a piece of the original message. In Apache Camel, the splitter pattern, shown in Figure 8.4, “Splitter Pattern”, is implemented by the split() Java DSL command.
Figure 8.4. Splitter Pattern
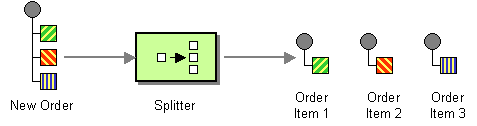
The Apache Camel splitter actually supports two patterns, as follows:
- Simple splitter — implements the splitter pattern on its own.
- Splitter/aggregator — combines the splitter pattern with the aggregator pattern, such that the pieces of the message are recombined after they have been processed.
Before the splitter separates the original message into parts, it makes a shallow copy of the original message. In a shallow copy, the headers and payload of the original message are copied as references only. Although the splitter does not itself route the resulting message parts to different endpoints, parts of the split message might undergo secondary routing.
Because the message parts are shallow copies, they remain linked to the original message. As a result, they cannot be modified independently. If you want to apply custom logic to different copies of a message part before routing it to a set of endpoints, you must use the onPrepareRef DSL option in the splitter clause to make a deep copy of the original message. For information about using options, see the section called “Options”.
Java DSL example
The following example defines a route from seda:a to seda:b that splits messages by converting each line of an incoming message into a separate outgoing message:
RouteBuilder builder = new RouteBuilder() {
public void configure() {
from("seda:a")
.split(bodyAs(String.class).tokenize("\n"))
.to("seda:b");
}
};
The splitter can use any expression language, so you can split messages using any of the supported scripting languages, such as XPath, XQuery, or SQL (see Part II, “Routing Expression and Predicate Languages”). The following example extracts bar elements from an incoming message and insert them into separate outgoing messages:
from("activemq:my.queue")
.split(xpath("//foo/bar"))
.to("file://some/directory")XML configuration example
The following example shows how to configure a splitter route in XML, using the XPath scripting language:
<camelContext id="buildSplitter" xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="seda:a"/>
<split>
<xpath>//foo/bar</xpath>
<to uri="seda:b"/>
</split>
</route>
</camelContext>
You can use the tokenize expression in the XML DSL to split bodies or headers using a token, where the tokenize expression is defined using the tokenize element. In the following example, the message body is tokenized using the \n separator character. To use a regular expression pattern, set regex=true in the tokenize element.
<camelContext xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:start"/>
<split>
<tokenize token="\n"/>
<to uri="mock:result"/>
</split>
</route>
</camelContext>Splitting into groups of lines
To split a big file into chunks of 1000 lines, you can define a splitter route as follows in the Java DSL:
from("file:inbox")
.split().tokenize("\n", 1000).streaming()
.to("activemq:queue:order");
The second argument to tokenize specifies the number of lines that should be grouped into a single chunk. The streaming() clause directs the splitter not to read the whole file at once (resulting in much better performance if the file is large).
The same route can be defined in XML DSL as follows:
<route>
<from uri="file:inbox"/>
<split streaming="true">
<tokenize token="\n" group="1000"/>
<to uri="activemq:queue:order"/>
</split>
</route>
The output when using the group option is always of java.lang.String type.
Skip first item
To skip the first item in the message you can use the skipFirst option.
In Java DSL, make the third option in the tokenize parameter true:
from("direct:start")
// split by new line and group by 3, and skip the very first element
.split().tokenize("\n", 3, true).streaming()
.to("mock:group");The same route can be defined in XML DSL as follows:
<route>
<from uri="file:inbox"/>
<split streaming="true">
<tokenize token="\n" group="1000" skipFirst="true" />
<to uri="activemq:queue:order"/>
</split>
</route>Splitter reply
If the exchange that enters the splitter has the InOut message-exchange pattern (that is, a reply is expected), the splitter returns a copy of the original input message as the reply message in the Out message slot. You can override this default behavior by implementing your own aggregation strategy.
Parallel execution
If you want to execute the resulting pieces of the message in parallel, you can enable the parallel processing option, which instantiates a thread pool to process the message pieces. For example:
XPathBuilder xPathBuilder = new XPathBuilder("//foo/bar");
from("activemq:my.queue").split(xPathBuilder).parallelProcessing().to("activemq:my.parts");
You can customize the underlying ThreadPoolExecutor used in the parallel splitter. For example, you can specify a custom executor in the Java DSL as follows:
XPathBuilder xPathBuilder = new XPathBuilder("//foo/bar");
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(8, 16, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue());
from("activemq:my.queue")
.split(xPathBuilder)
.parallelProcessing()
.executorService(threadPoolExecutor)
.to("activemq:my.parts");You can specify a custom executor in the XML DSL as follows:
<camelContext xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:parallel-custom-pool"/>
<split executorServiceRef="threadPoolExecutor">
<xpath>/invoice/lineItems</xpath>
<to uri="mock:result"/>
</split>
</route>
</camelContext>
<bean id="threadPoolExecutor" class="java.util.concurrent.ThreadPoolExecutor">
<constructor-arg index="0" value="8"/>
<constructor-arg index="1" value="16"/>
<constructor-arg index="2" value="0"/>
<constructor-arg index="3" value="MILLISECONDS"/>
<constructor-arg index="4"><bean class="java.util.concurrent.LinkedBlockingQueue"/></constructor-arg>
</bean>Using a bean to perform splitting
As the splitter can use any expression to do the splitting, you can use a bean to perform splitting, by invoking the method() expression. The bean should return an iterable value such as: java.util.Collection, java.util.Iterator, or an array.
The following route defines a method() expression that calls a method on the mySplitterBean bean instance:
from("direct:body")
// here we use a POJO bean mySplitterBean to do the split of the payload
.split()
.method("mySplitterBean", "splitBody")
.to("mock:result");
from("direct:message")
// here we use a POJO bean mySplitterBean to do the split of the message
// with a certain header value
.split()
.method("mySplitterBean", "splitMessage")
.to("mock:result");
Where mySplitterBean is an instance of the MySplitterBean class, which is defined as follows:
public class MySplitterBean {
/**
* The split body method returns something that is iteratable such as a java.util.List.
*
* @param body the payload of the incoming message
* @return a list containing each part split
*/
public List<String> splitBody(String body) {
// since this is based on an unit test you can of couse
// use different logic for splitting as {router} have out
// of the box support for splitting a String based on comma
// but this is for show and tell, since this is java code
// you have the full power how you like to split your messages
List<String> answer = new ArrayList<String>();
String[] parts = body.split(",");
for (String part : parts) {
answer.add(part);
}
return answer;
}
/**
* The split message method returns something that is iteratable such as a java.util.List.
*
* @param header the header of the incoming message with the name user
* @param body the payload of the incoming message
* @return a list containing each part split
*/
public List<Message> splitMessage(@Header(value = "user") String header, @Body String body) {
// we can leverage the Parameter Binding Annotations
// http://camel.apache.org/parameter-binding-annotations.html
// to access the message header and body at same time,
// then create the message that we want, splitter will
// take care rest of them.
// *NOTE* this feature requires {router} version >= 1.6.1
List<Message> answer = new ArrayList<Message>();
String[] parts = header.split(",");
for (String part : parts) {
DefaultMessage message = new DefaultMessage();
message.setHeader("user", part);
message.setBody(body);
answer.add(message);
}
return answer;
}
}
You can use aBeanIOSplitter object with the Splitter EIP to split big payloads by using a stream mode to avoid reading the entire content into memory. The following example shows how to set up a BeanIOSplitter object by using the mapping file, which is loaded from the classpath:
The BeanIOSplitter class is new in Camel 2.18. It is not available in Camel 2.17.
BeanIOSplitter splitter = new BeanIOSplitter();
splitter.setMapping("org/apache/camel/dataformat/beanio/mappings.xml");
splitter.setStreamName("employeeFile");
// Following is a route that uses the beanio data format to format CSV data
// in Java objects:
from("direct:unmarshal")
// Here the message body is split to obtain a message for each row:
.split(splitter).streaming()
.to("log:line")
.to("mock:beanio-unmarshal");The following example adds an error handler:
BeanIOSplitter splitter = new BeanIOSplitter();
splitter.setMapping("org/apache/camel/dataformat/beanio/mappings.xml");
splitter.setStreamName("employeeFile");
splitter.setBeanReaderErrorHandlerType(MyErrorHandler.class);
from("direct:unmarshal")
.split(splitter).streaming()
.to("log:line")
.to("mock:beanio-unmarshal");Exchange properties
The following properties are set on each split exchange:
| header | type | description |
|---|---|---|
|
|
| Apache Camel 2.0: A split counter that increases for each Exchange being split. The counter starts from 0. |
|
|
| Apache Camel 2.0: The total number of Exchanges that was split. This header is not applied for stream based splitting. |
|
|
| Apache Camel 2.4: Whether or not this Exchange is the last. |
Splitter/aggregator pattern
It is a common pattern for the message pieces to be aggregated back into a single exchange, after processing of the individual pieces has completed. To support this pattern, the split() DSL command lets you provide an AggregationStrategy object as the second argument.
Java DSL example
The following example shows how to use a custom aggregation strategy to recombine a split message after all of the message pieces have been processed:
from("direct:start")
.split(body().tokenize("@"), new MyOrderStrategy())
// each split message is then send to this bean where we can process it
.to("bean:MyOrderService?method=handleOrder")
// this is important to end the splitter route as we do not want to do more routing
// on each split message
.end()
// after we have split and handled each message we want to send a single combined
// response back to the original caller, so we let this bean build it for us
// this bean will receive the result of the aggregate strategy: MyOrderStrategy
.to("bean:MyOrderService?method=buildCombinedResponse")AggregationStrategy implementation
The custom aggregation strategy, MyOrderStrategy, used in the preceding route is implemented as follows:
/**
* This is our own order aggregation strategy where we can control
* how each split message should be combined. As we do not want to
* lose any message, we copy from the new to the old to preserve the
* order lines as long we process them
*/
public static class MyOrderStrategy implements AggregationStrategy {
public Exchange aggregate(Exchange oldExchange, Exchange newExchange) {
// put order together in old exchange by adding the order from new exchange
if (oldExchange == null) {
// the first time we aggregate we only have the new exchange,
// so we just return it
return newExchange;
}
String orders = oldExchange.getIn().getBody(String.class);
String newLine = newExchange.getIn().getBody(String.class);
LOG.debug("Aggregate old orders: " + orders);
LOG.debug("Aggregate new order: " + newLine);
// put orders together separating by semi colon
orders = orders + ";" + newLine;
// put combined order back on old to preserve it
oldExchange.getIn().setBody(orders);
// return old as this is the one that has all the orders gathered until now
return oldExchange;
}
}Stream based processing
When parallel processing is enabled, it is theoretically possible for a later message piece to be ready for aggregation before an earlier piece. In other words, the message pieces might arrive at the aggregator out of order. By default, this does not happen, because the splitter implementation rearranges the message pieces back into their original order before passing them into the aggregator.
If you would prefer to aggregate the message pieces as soon as they are ready (and possibly out of order), you can enable the streaming option, as follows:
from("direct:streaming")
.split(body().tokenize(","), new MyOrderStrategy())
.parallelProcessing()
.streaming()
.to("activemq:my.parts")
.end()
.to("activemq:all.parts");You can also supply a custom iterator to use with streaming, as follows:
// Java
import static org.apache.camel.builder.ExpressionBuilder.beanExpression;
...
from("direct:streaming")
.split(beanExpression(new MyCustomIteratorFactory(), "iterator"))
.streaming().to("activemq:my.parts")You cannot use streaming mode in conjunction with XPath. XPath requires the complete DOM XML document in memory.
Stream based processing with XML
If an incoming messages is a very large XML file, you can process the message most efficiently using the tokenizeXML sub-command in streaming mode.
For example, given a large XML file that contains a sequence of order elements, you can split the file into order elements using a route like the following:
from("file:inbox")
.split().tokenizeXML("order").streaming()
.to("activemq:queue:order");You can do the same thing in XML, by defining a route like the following:
<route>
<from uri="file:inbox"/>
<split streaming="true">
<tokenize token="order" xml="true"/>
<to uri="activemq:queue:order"/>
</split>
</route>It is often the case that you need access to namespaces that are defined in one of the enclosing (ancestor) elements of the token elements. You can copy namespace definitions from one of the ancestor elements into the token element, by specifing which element you want to inherit namespace definitions from.
In the Java DSL, you specify the ancestor element as the second argument of tokenizeXML. For example, to inherit namespace definitions from the enclosing orders element:
from("file:inbox")
.split().tokenizeXML("order", "orders").streaming()
.to("activemq:queue:order");
In the XML DSL, you specify the ancestor element using the inheritNamespaceTagName attribute. For example:
<route>
<from uri="file:inbox"/>
<split streaming="true">
<tokenize token="order"
xml="true"
inheritNamespaceTagName="orders"/>
<to uri="activemq:queue:order"/>
</split>
</route>Options
The split DSL command supports the following options:
| Name | Default Value | Description |
|
| Refers to an AggregationStrategy to be used to assemble the replies from the sub-messages, into a single outgoing message from the Section 8.4, “Splitter”. See the section titled What does the splitter return below for whats used by default. | |
|
|
This option can be used to explicitly specify the method name to use, when using POJOs as the | |
|
|
|
This option can be used, when using POJOs as the |
|
|
| If enables then processing the sub-messages occurs concurrently. Note the caller thread will still wait until all sub-messages has been fully processed, before it continues. |
|
|
|
If enabled, the |
|
| Refers to a custom Thread Pool to be used for parallel processing. Notice if you set this option, then parallel processing is automatic implied, and you do not have to enable that option as well. | |
|
|
| Camel 2.2: Whether or not to stop continue processing immediately when an exception occurred. If disable, then Camel continue splitting and process the sub-messages regardless if one of them failed. You can deal with exceptions in the AggregationStrategy class where you have full control how to handle that. |
|
|
| If enabled then Camel will split in a streaming fashion, which means it will split the input message in chunks. This reduces the memory overhead. For example if you split big messages its recommended to enable streaming. If streaming is enabled then the sub-message replies will be aggregated out-of-order, eg in the order they come back. If disabled, Camel will process sub-message replies in the same order as they where splitted. |
|
|
Camel 2.5: Sets a total timeout specified in millis. If the Section 8.3, “Recipient List” hasn’t been able to split and process all replies within the given timeframe, then the timeout triggers and the Section 8.4, “Splitter” breaks out and continues. Notice if you provide a TimeoutAwareAggregationStrategy then the | |
|
| Camel 2.8: Refers to a custom Processor to prepare the sub-message of the Exchange, before its processed. This allows you to do any custom logic, such as deep-cloning the message payload if that’s needed etc. | |
|
|
| Camel 2.8: Whether the unit of work should be shared. See further below for more details. |
8.5. Aggregator
Overview
The aggregator pattern, shown in Figure 8.5, “Aggregator Pattern”, enables you to combine a batch of related messages into a single message.
Figure 8.5. Aggregator Pattern
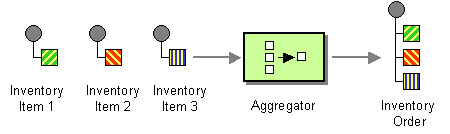
To control the aggregator’s behavior, Apache Camel allows you to specify the properties described in Enterprise Integration Patterns, as follows:
- Correlation expression — Determines which messages should be aggregated together. The correlation expression is evaluated on each incoming message to produce a correlation key. Incoming messages with the same correlation key are then grouped into the same batch. For example, if you want to aggregate all incoming messages into a single message, you can use a constant expression.
- Completeness condition — Determines when a batch of messages is complete. You can specify this either as a simple size limit or, more generally, you can specify a predicate condition that flags when the batch is complete.
- Aggregation algorithm — Combines the message exchanges for a single correlation key into a single message exchange.
For example, consider a stock market data system that receives 30,000 messages per second. You might want to throttle down the message flow if your GUI tool cannot cope with such a massive update rate. The incoming stock quotes can be aggregated together simply by choosing the latest quote and discarding the older prices. (You can apply a delta processing algorithm, if you prefer to capture some of the history.)
The Aggregator now enlists in JMX using a ManagedAggregateProcessorMBean that includes more information. It enables you to use the aggregate controller to control it.
How the aggregator works
Figure 8.6, “Aggregator Implementation” shows an overview of how the aggregator works, assuming it is fed with a stream of exchanges that have correlation keys such as A, B, C, or D.
Figure 8.6. Aggregator Implementation
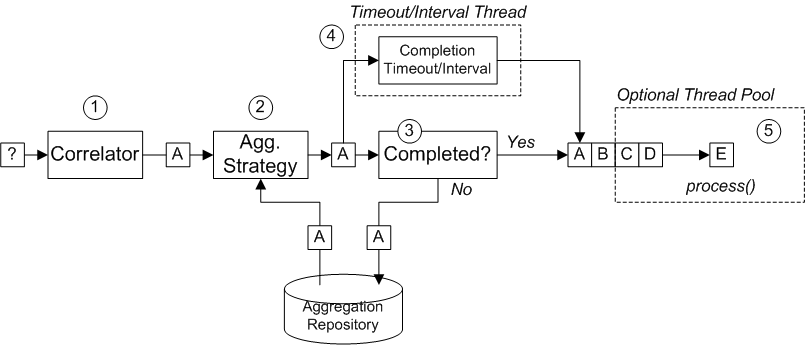
The incoming stream of exchanges shown in Figure 8.6, “Aggregator Implementation” is processed as follows:
- The correlator is responsible for sorting exchanges based on the correlation key. For each incoming exchange, the correlation expression is evaluated, yielding the correlation key. For example, for the exchange shown in Figure 8.6, “Aggregator Implementation”, the correlation key evaluates to A.
The aggregation strategy is responsible for merging exchanges with the same correlation key. When a new exchange, A, comes in, the aggregator looks up the corresponding aggregate exchange, A', in the aggregation repository and combines it with the new exchange.
Until a particular aggregation cycle is completed, incoming exchanges are continuously aggregated with the corresponding aggregate exchange. An aggregation cycle lasts until terminated by one of the completion mechanisms.
NoteFrom Camel 2.16, the new XSLT Aggregation Strategy allows you to merge two messages with an XSLT file. You can access the
AggregationStrategies.xslt()file from the toolbox.If a completion predicate is specified on the aggregator, the aggregate exchange is tested to determine whether it is ready to be sent to the next processor in the route. Processing continues as follows:
- If complete, the aggregate exchange is processed by the latter part of the route. There are two alternative models for this: synchronous (the default), which causes the calling thread to block, or asynchronous (if parallel processing is enabled), where the aggregate exchange is submitted to an executor thread pool (as shown in Figure 8.6, “Aggregator Implementation”).
- If not complete, the aggregate exchange is saved back to the aggregation repository.
-
In parallel with the synchronous completion tests, it is possible to enable an asynchronous completion test by enabling either the
completionTimeoutoption or thecompletionIntervaloption. These completion tests run in a separate thread and, whenever the completion test is satisfied, the corresponding exchange is marked as complete and starts to be processed by the latter part of the route (either synchronously or asynchronously, depending on whether parallel processing is enabled or not). - If parallel processing is enabled, a thread pool is responsible for processing exchanges in the latter part of the route. By default, this thread pool contains ten threads, but you have the option of customizing the pool (the section called “Threading options”).
Java DSL example
The following example aggregates exchanges with the same StockSymbol header value, using the UseLatestAggregationStrategy aggregation strategy. For a given StockSymbol value, if more than three seconds elapse since the last exchange with that correlation key was received, the aggregated exchange is deemed to be complete and is sent to the mock endpoint.
from("direct:start")
.aggregate(header("id"), new UseLatestAggregationStrategy())
.completionTimeout(3000)
.to("mock:aggregated");XML DSL example
The following example shows how to configure the same route in XML:
<camelContext xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:start"/>
<aggregate strategyRef="aggregatorStrategy"
completionTimeout="3000">
<correlationExpression>
<simple>header.StockSymbol</simple>
</correlationExpression>
<to uri="mock:aggregated"/>
</aggregate>
</route>
</camelContext>
<bean id="aggregatorStrategy"
class="org.apache.camel.processor.aggregate.UseLatestAggregationStrategy"/>Specifying the correlation expression
In the Java DSL, the correlation expression is always passed as the first argument to the aggregate() DSL command. You are not limited to using the Simple expression language here. You can specify a correlation expression using any of the expression languages or scripting languages, such as XPath, XQuery, SQL, and so on.
For exampe, to correlate exchanges using an XPath expression, you could use the following Java DSL route:
from("direct:start")
.aggregate(xpath("/stockQuote/@symbol"), new UseLatestAggregationStrategy())
.completionTimeout(3000)
.to("mock:aggregated");
If the correlation expression cannot be evaluated on a particular incoming exchange, the aggregator throws a CamelExchangeException by default. You can suppress this exception by setting the ignoreInvalidCorrelationKeys option. For example, in the Java DSL:
from(...).aggregate(...).ignoreInvalidCorrelationKeys()
In the XML DSL, you can set the ignoreInvalidCorrelationKeys option is set as an attribute, as follows:
<aggregate strategyRef="aggregatorStrategy"
ignoreInvalidCorrelationKeys="true"
...>
...
</aggregate>Specifying the aggregation strategy
In Java DSL, you can either pass the aggregation strategy as the second argument to the aggregate() DSL command or specify it using the aggregationStrategy() clause. For example, you can use the aggregationStrategy() clause as follows:
from("direct:start")
.aggregate(header("id"))
.aggregationStrategy(new UseLatestAggregationStrategy())
.completionTimeout(3000)
.to("mock:aggregated");
Apache Camel provides the following basic aggregation strategies (where the classes belong to the org.apache.camel.processor.aggregate Java package):
UseLatestAggregationStrategy- Return the last exchange for a given correlation key, discarding all earlier exchanges with this key. For example, this strategy could be useful for throttling the feed from a stock exchange, where you just want to know the latest price of a particular stock symbol.
UseOriginalAggregationStrategy-
Return the first exchange for a given correlation key, discarding all later exchanges with this key. You must set the first exchange by calling
UseOriginalAggregationStrategy.setOriginal()before you can use this strategy. GroupedExchangeAggregationStrategy-
Concatenates all of the exchanges for a given correlation key into a list, which is stored in the
Exchange.GROUPED_EXCHANGEexchange property. See the section called “Grouped exchanges”.
Implementing a custom aggregation strategy
If you want to apply a different aggregation strategy, you can implement one of the following aggregation strategy base interfaces:
org.apache.camel.processor.aggregate.AggregationStrategy- The basic aggregation strategy interface.
org.apache.camel.processor.aggregate.TimeoutAwareAggregationStrategyImplement this interface, if you want your implementation to receive a notification when an aggregation cycle times out. The
timeoutnotification method has the following signature:void timeout(Exchange oldExchange, int index, int total, long timeout)
org.apache.camel.processor.aggregate.CompletionAwareAggregationStrategyImplement this interface, if you want your implementation to receive a notification when an aggregation cycle completes normally. The notification method has the following signature:
void onCompletion(Exchange exchange)
For example, the following code shows two different custom aggregation strategies, StringAggregationStrategy and ArrayListAggregationStrategy::
//simply combines Exchange String body values using '' as a delimiter class StringAggregationStrategy implements AggregationStrategy { public Exchange aggregate(Exchange oldExchange, Exchange newExchange) { if (oldExchange == null) { return newExchange; } String oldBody = oldExchange.getIn().getBody(String.class); String newBody = newExchange.getIn().getBody(String.class); oldExchange.getIn().setBody(oldBody + "" + newBody); return oldExchange; } } //simply combines Exchange body values into an ArrayList<Object> class ArrayListAggregationStrategy implements AggregationStrategy { public Exchange aggregate(Exchange oldExchange, Exchange newExchange) { Object newBody = newExchange.getIn().getBody(); ArrayList<Object> list = null; if (oldExchange == null) { list = new ArrayList<Object>(); list.add(newBody); newExchange.getIn().setBody(list); return newExchange; } else { list = oldExchange.getIn().getBody(ArrayList.class); list.add(newBody); return oldExchange; } } }
Since Apache Camel 2.0, the AggregationStrategy.aggregate() callback method is also invoked for the very first exchange. On the first invocation of the aggregate method, the oldExchange parameter is null and the newExchange parameter contains the first incoming exchange.
To aggregate messages using the custom strategy class, ArrayListAggregationStrategy, define a route like the following:
from("direct:start")
.aggregate(header("StockSymbol"), new ArrayListAggregationStrategy())
.completionTimeout(3000)
.to("mock:result");You can also configure a route with a custom aggregation strategy in XML, as follows:
<camelContext xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:start"/>
<aggregate strategyRef="aggregatorStrategy"
completionTimeout="3000">
<correlationExpression>
<simple>header.StockSymbol</simple>
</correlationExpression>
<to uri="mock:aggregated"/>
</aggregate>
</route>
</camelContext>
<bean id="aggregatorStrategy" class="com.my_package_name.ArrayListAggregationStrategy"/>Controlling the lifecycle of a custom aggregation strategy
You can implement a custom aggregation strategy so that its lifecycle is aligned with the lifecycle of the enterprise integration pattern that is controlling it. This can be useful for ensuring that the aggregation strategy can shut down gracefully.
To implement an aggregation strategy with lifecycle support, you must implement the org.apache.camel.Service interface (in addition to the AggregationStrategy interface) and provide implementations of the start() and stop() lifecycle methods. For example, the following code example shows an outline of an aggregation strategy with lifecycle support:
// Java
import org.apache.camel.processor.aggregate.AggregationStrategy;
import org.apache.camel.Service;
import java.lang.Exception;
...
class MyAggStrategyWithLifecycleControl
implements AggregationStrategy, Service {
public Exchange aggregate(Exchange oldExchange, Exchange newExchange) {
// Implementation not shown...
...
}
public void start() throws Exception {
// Actions to perform when the enclosing EIP starts up
...
}
public void stop() throws Exception {
// Actions to perform when the enclosing EIP is stopping
...
}
}Exchange properties
The following properties are set on each aggregated exchange:
| Header | Type | Description Aggregated Exchange Properties |
|---|---|---|
|
|
| The total number of exchanges aggregated into this exchange. |
|
|
|
Indicates the mechanism responsible for completing the aggregate exchange. Possible values are: |
The following properties are set on exchanges redelivered by the SQL Component aggregation repository (see the section called “Persistent aggregation repository”):
| Header | Type | Description Redelivered Exchange Properties |
|---|---|---|
|
|
|
Sequence number of the current redelivery attempt (starting at |
Specifying a completion condition
It is mandatory to specify at least one completion condition, which determines when an aggregate exchange leaves the aggregator and proceeds to the next node on the route. The following completion conditions can be specified:
completionPredicate-
Evaluates a predicate after each exchange is aggregated in order to determine completeness. A value of
trueindicates that the aggregate exchange is complete. Alternatively, instead of setting this option, you can define a customAggregationStrategythat implements thePredicateinterface, in which case theAggregationStrategywill be used as the completion predicate. completionSize- Completes the aggregate exchange after the specified number of incoming exchanges are aggregated.
completionTimeout(Incompatible with
completionInterval) Completes the aggregate exchange, if no incoming exchanges are aggregated within the specified timeout.In other words, the timeout mechanism keeps track of a timeout for each correlation key value. The clock starts ticking after the latest exchange with a particular key value is received. If another exchange with the same key value is not received within the specified timeout, the corresponding aggregate exchange is marked complete and sent to the next node on the route.
completionInterval(Incompatible with
completionTimeout) Completes all outstanding aggregate exchanges, after each time interval (of specified length) has elapsed.The time interval is not tailored to each aggregate exchange. This mechanism forces simultaneous completion of all outstanding aggregate exchanges. Hence, in some cases, this mechanism could complete an aggregate exchange immediately after it started aggregating.
completionFromBatchConsumer- When used in combination with a consumer endpoint that supports the batch consumer mechanism, this completion option automatically figures out when the current batch of exchanges is complete, based on information it receives from the consumer endpoint. See the section called “Batch consumer”.
forceCompletionOnStop- When this option is enabled, it forces completion of all outstanding aggregate exchanges when the current route context is stopped.
The preceding completion conditions can be combined arbitrarily, except for the completionTimeout and completionInterval conditions, which cannot be simultaneously enabled. When conditions are used in combination, the general rule is that the first completion condition to trigger is the effective completion condition.
Specifying the completion predicate
You can specify an arbitrary predicate expression that determines when an aggregated exchange is complete. There are two possible ways of evaluating the predicate expression:
- On the latest aggregate exchange — this is the default behavior.
-
On the latest incoming exchange — this behavior is selected when you enable the
eagerCheckCompletionoption.
For example, if you want to terminate a stream of stock quotes every time you receive an ALERT message (as indicated by the value of a MsgType header in the latest incoming exchange), you can define a route like the following:
from("direct:start")
.aggregate(
header("id"),
new UseLatestAggregationStrategy()
)
.completionPredicate(
header("MsgType").isEqualTo("ALERT")
)
.eagerCheckCompletion()
.to("mock:result");The following example shows how to configure the same route using XML:
<camelContext xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:start"/>
<aggregate strategyRef="aggregatorStrategy"
eagerCheckCompletion="true">
<correlationExpression>
<simple>header.StockSymbol</simple>
</correlationExpression>
<completionPredicate>
<simple>$MsgType = 'ALERT'</simple>
</completionPredicate>
<to uri="mock:result"/>
</aggregate>
</route>
</camelContext>
<bean id="aggregatorStrategy"
class="org.apache.camel.processor.aggregate.UseLatestAggregationStrategy"/>Specifying a dynamic completion timeout
It is possible to specify a dynamic completion timeout, where the timeout value is recalculated for every incoming exchange. For example, to set the timeout value from the timeout header in each incoming exchange, you could define a route as follows:
from("direct:start")
.aggregate(header("StockSymbol"), new UseLatestAggregationStrategy())
.completionTimeout(header("timeout"))
.to("mock:aggregated");You can configure the same route in the XML DSL, as follows:
<camelContext xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:start"/>
<aggregate strategyRef="aggregatorStrategy">
<correlationExpression>
<simple>header.StockSymbol</simple>
</correlationExpression>
<completionTimeout>
<header>timeout</header>
</completionTimeout>
<to uri="mock:aggregated"/>
</aggregate>
</route>
</camelContext>
<bean id="aggregatorStrategy"
class="org.apache.camel.processor.UseLatestAggregationStrategy"/>
You can also add a fixed timeout value and Apache Camel will fall back to use this value, if the dynamic value is null or 0.
Specifying a dynamic completion size
It is possible to specify a dynamic completion size, where the completion size is recalculated for every incoming exchange. For example, to set the completion size from the mySize header in each incoming exchange, you could define a route as follows:
from("direct:start")
.aggregate(header("StockSymbol"), new UseLatestAggregationStrategy())
.completionSize(header("mySize"))
.to("mock:aggregated");And the same example using Spring XML:
<camelContext xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:start"/>
<aggregate strategyRef="aggregatorStrategy">
<correlationExpression>
<simple>header.StockSymbol</simple>
</correlationExpression>
<completionSize>
<header>mySize</header>
</completionSize>
<to uri="mock:aggregated"/>
</aggregate>
</route>
</camelContext>
<bean id="aggregatorStrategy"
class="org.apache.camel.processor.UseLatestAggregationStrategy"/>
You can also add a fixed size value and Apache Camel will fall back to use this value, if the dynamic value is null or 0.
Forcing completion of a single group from within an AggregationStrategy
If you implement a custom AggregationStrategy class, there is a mechanism available to force the completion of the current message group, by setting the Exchange.AGGREGATION_COMPLETE_CURRENT_GROUP exchange property to true on the exchange returned from the AggregationStrategy.aggregate() method. This mechanism only affects the current group: other message groups (with different correlation IDs) are not forced to complete. This mechanism overrides any other completion mechanisms, such as predicate, size, timeout, and so on.
For example, the following sample AggregationStrategy class completes the current group, if the message body size is larger than 5:
// Java
public final class MyCompletionStrategy implements AggregationStrategy {
@Override
public Exchange aggregate(Exchange oldExchange, Exchange newExchange) {
if (oldExchange == null) {
return newExchange;
}
String body = oldExchange.getIn().getBody(String.class) + "+"
+ newExchange.getIn().getBody(String.class);
oldExchange.getIn().setBody(body);
if (body.length() >= 5) {
oldExchange.setProperty(Exchange.AGGREGATION_COMPLETE_CURRENT_GROUP, true);
}
return oldExchange;
}
}Forcing completion of all groups with a special message
It is possible to force completion of all outstanding aggregate messages, by sending a message with a special header to the route. There are two alternative header settings you can use to force completion:
Exchange.AGGREGATION_COMPLETE_ALL_GROUPS-
Set to
true, to force completion of the current aggregation cycle. This message acts purely as a signal and is not included in any aggregation cycle. After processing this signal message, the content of the message is discarded. Exchange.AGGREGATION_COMPLETE_ALL_GROUPS_INCLUSIVE-
Set to
true, to force completion of the current aggregation cycle. This message is included in the current aggregation cycle.
Using AggregateController
The org.apache.camel.processor.aggregate.AggregateController enables you to control the aggregate at runtime using Java or JMX API. This can be used to force completing groups of exchanges, or query the current runtime statistics.
If no custom have been configured, the aggregator provides a default implementation which you can access using the getAggregateController() method. However, it is easy to configure a controller in the route using aggregateController.
private AggregateController controller = new DefaultAggregateController();
from("direct:start")
.aggregate(header("id"), new MyAggregationStrategy()).completionSize(10).id("myAggregator")
.aggregateController(controller)
.to("mock:aggregated");
Also, you can use the API on AggregateControllerto force completion. For example, to complete a group with key foo
int groups = controller.forceCompletionOfGroup("foo");The number return would be the number of groups completed. Following is an API to complete all groups:
int groups = controller.forceCompletionOfAllGroups();
Enforcing unique correlation keys
In some aggregation scenarios, you might want to enforce the condition that the correlation key is unique for each batch of exchanges. In other words, when the aggregate exchange for a particular correlation key completes, you want to make sure that no further aggregate exchanges with that correlation key are allowed to proceed. For example, you might want to enforce this condition, if the latter part of the route expects to process exchanges with unique correlation key values.
Depending on how the completion conditions are configured, there might be a risk of more than one aggregate exchange being generated with a particular correlation key. For example, although you might define a completion predicate that is designed to wait until all the exchanges with a particular correlation key are received, you might also define a completion timeout, which could fire before all of the exchanges with that key have arrived. In this case, the late-arriving exchanges could give rise to a second aggregate exchange with the same correlation key value.
For such scenarios, you can configure the aggregator to suppress aggregate exchanges that duplicate previous correlation key values, by setting the closeCorrelationKeyOnCompletion option. In order to suppress duplicate correlation key values, it is necessary for the aggregator to record previous correlation key values in a cache. The size of this cache (the number of cached correlation keys) is specified as an argument to the closeCorrelationKeyOnCompletion() DSL command. To specify a cache of unlimited size, you can pass a value of zero or a negative integer. For example, to specify a cache size of 10000 key values:
from("direct:start")
.aggregate(header("UniqueBatchID"), new MyConcatenateStrategy())
.completionSize(header("mySize"))
.closeCorrelationKeyOnCompletion(10000)
.to("mock:aggregated");
If an aggregate exchange completes with a duplicate correlation key value, the aggregator throws a ClosedCorrelationKeyException exception.
Stream based processing using Simple expressions
You can use Simple language expressions as the token with the tokenizeXML sub-command in streaming mode. Using Simple language expressions will enable support for dynamic tokens.
For example, to use Java to split a sequence of names delineated up by the tag person, you can split the file into name elements using the tokenizeXML bean and a Simple language token.
public void testTokenizeXMLPairSimple() throws Exception {
Expression exp = TokenizeLanguage.tokenizeXML("${header.foo}", null);
Get the input string of names delineated by <person> and set <person> as the token.
exchange.getIn().setHeader("foo", "<person>");
exchange.getIn().setBody("<persons><person>James</person><person>Claus</person><person>Jonathan</person><person>Hadrian</person></persons>");List the names split from the input.
List<?> names = exp.evaluate(exchange, List.class);
assertEquals(4, names.size());
assertEquals("<person>James</person>", names.get(0));
assertEquals("<person>Claus</person>", names.get(1));
assertEquals("<person>Jonathan</person>", names.get(2));
assertEquals("<person>Hadrian</person>", names.get(3));
}Grouped exchanges
You can combine all of the aggregated exchanges in an outgoing batch into a single org.apache.camel.impl.GroupedExchange holder class. To enable grouped exchanges, specify the groupExchanges() option, as shown in the following Java DSL route:
from("direct:start")
.aggregate(header("StockSymbol"))
.completionTimeout(3000)
.groupExchanges()
.to("mock:result");
The grouped exchange sent to mock:result contains the list of aggregated exchanges in the message body. The following line of code shows how a subsequent processor can access the contents of the grouped exchange in the form of a list:
// Java List<Exchange> grouped = ex.getIn().getBody(List.class);
When you enable the grouped exchanges feature, you must not configure an aggregation strategy (the grouped exchanges feature is itself an aggregation strategy).
The old approach of accessing the grouped exchanges from a property on the outgoing exchange is now deprecated and will be removed in a future release.
Batch consumer
The aggregator can work together with the batch consumer pattern to aggregate the total number of messages reported by the batch consumer (a batch consumer endpoint sets the CamelBatchSize, CamelBatchIndex , and CamelBatchComplete properties on the incoming exchange). For example, to aggregate all of the files found by a File consumer endpoint, you could use a route like the following:
from("file://inbox")
.aggregate(xpath("//order/@customerId"), new AggregateCustomerOrderStrategy())
.completionFromBatchConsumer()
.to("bean:processOrder");Currently, the following endpoints support the batch consumer mechanism: File, FTP, Mail, iBatis, and JPA.
Persistent aggregation repository
The default aggregator uses an in-memory only AggregationRepository. If you want to store pending aggregated exchanges persistently, you can use the SQL Component as a persistent aggregation repository. The SQL Component includes a JdbcAggregationRepository that persists aggregated messages on-the-fly, and ensures that you do not lose any messages.
When an exchange has been successfully processed, it is marked as complete when the confirm method is invoked on the repository. This means that if the same exchange fails again, it will be retried until it is successful.
Add a dependency on camel-sql
To use the SQL Component, you must include a dependency on camel-sql in your project. For example, if you are using a Maven pom.xml file:
<dependency>
<groupId>org.apache.camel</groupId>
<artifactId>camel-sql</artifactId>
<version>x.x.x</version>
<!-- use the same version as your Camel core version -->
</dependency>Create the aggregation database tables
You must create separate aggregation and completed database tables for persistence. For example, the following query creates the tables for a database named my_aggregation_repo:
CREATE TABLE my_aggregation_repo ( id varchar(255) NOT NULL, exchange blob NOT NULL, constraint aggregation_pk PRIMARY KEY (id) ); CREATE TABLE my_aggregation_repo_completed ( id varchar(255) NOT NULL, exchange blob NOT NULL, constraint aggregation_completed_pk PRIMARY KEY (id) ); }
Configure the aggregation repository
You must also configure the aggregation repository in your framework XML file (for example, Spring or Blueprint):
<bean id="my_repo"
class="org.apache.camel.processor.aggregate.jdbc.JdbcAggregationRepository">
<property name="repositoryName" value="my_aggregation_repo"/>
<property name="transactionManager" ref="my_tx_manager"/>
<property name="dataSource" ref="my_data_source"/>
...
</bean>
The repositoryName, transactionManager, and dataSource properties are required. For details on more configuration options for the persistent aggregation repository, see SQL Component in the Apache Camel Component Reference Guide.
Threading options
As shown in Figure 8.6, “Aggregator Implementation”, the aggregator is decoupled from the latter part of the route, where the exchanges sent to the latter part of the route are processed by a dedicated thread pool. By default, this pool contains just a single thread. If you want to specify a pool with multiple threads, enable the parallelProcessing option, as follows:
from("direct:start")
.aggregate(header("id"), new UseLatestAggregationStrategy())
.completionTimeout(3000)
.parallelProcessing()
.to("mock:aggregated");By default, this creates a pool with 10 worker threads.
If you want to exercise more control over the created thread pool, specify a custom java.util.concurrent.ExecutorService instance using the executorService option (in which case it is unnecessary to enable the parallelProcessing option).
Aggregating into a List
A common aggregation scenario involves aggregating a series of incoming message bodies into a List object. To facilitate this scenario, Apache Camel provides the AbstractListAggregationStrategy abstract class, which you can quickly extend to create an aggregation strategy for this case. Incoming message bodies of type, T, are aggregated into a completed exchange, with a message body of type List<T>.
For example, to aggregate a series of Integer message bodies into a List<Integer> object, you could use an aggregation strategy defined as follows:
import org.apache.camel.processor.aggregate.AbstractListAggregationStrategy;
...
/**
* Strategy to aggregate integers into a List<Integer>.
*/
public final class MyListOfNumbersStrategy extends AbstractListAggregationStrategy<Integer> {
@Override
public Integer getValue(Exchange exchange) {
// the message body contains a number, so just return that as-is
return exchange.getIn().getBody(Integer.class);
}
}Aggregator options
The aggregator supports the following options:
| Option | Default | Description |
|---|---|---|
|
|
Mandatory Expression which evaluates the correlation key to use for aggregation. The Exchange which has the same correlation key is aggregated together. If the correlation key could not be evaluated an Exception is thrown. You can disable this by using the | |
|
|
Mandatory | |
|
|
A reference to lookup the | |
|
|
Number of messages aggregated before the aggregation is complete. This option can be set as either a fixed value or using an Expression which allows you to evaluate a size dynamically - will use | |
|
|
Time in millis that an aggregated exchange should be inactive before its complete. This option can be set as either a fixed value or using an Expression which allows you to evaluate a timeout dynamically - will use | |
|
| A repeating period in millis by which the aggregator will complete all current aggregated exchanges. Camel has a background task which is triggered every period. You cannot use this option together with completionTimeout, only one of them can be used. | |
|
|
Specifies a predicate (of | |
|
|
|
This option is if the exchanges are coming from a Batch Consumer. Then when enabled the Section 8.5, “Aggregator” will use the batch size determined by the Batch Consumer in the message header |
|
|
|
Whether or not to eager check for completion when a new incoming Exchange has been received. This option influences the behavior of the |
|
|
|
If |
|
|
|
If enabled then Camel will group all aggregated Exchanges into a single combined |
|
|
| Whether or not to ignore correlation keys which could not be evaluated to a value. By default Camel will throw an Exception, but you can enable this option and ignore the situation instead. |
|
|
Whether or not late Exchanges should be accepted or not. You can enable this to indicate that if a correlation key has already been completed, then any new exchanges with the same correlation key be denied. Camel will then throw a | |
|
|
| Camel 2.5: Whether or not exchanges which complete due to a timeout should be discarded. If enabled, then when a timeout occurs the aggregated message will not be sent out but dropped (discarded). |
|
|
Allows you to plug in you own implementation of | |
|
|
Reference to lookup a | |
|
|
| When aggregated are completed they are being send out of the aggregator. This option indicates whether or not Camel should use a thread pool with multiple threads for concurrency. If no custom thread pool has been specified then Camel creates a default pool with 10 concurrent threads. |
|
|
If using | |
|
|
Reference to lookup a | |
|
|
If using one of the | |
|
|
Reference to look up a | |
|
| When you stop the Aggregator, this option allows it to complete all pending exchanges from the aggregation repository. | |
|
|
| Turns on optimistic locking, which can be used in combination with an aggregation repository. |
|
| Configures the retry policy for optimistic locking. |
8.6. Resequencer
Overview
The resequencer pattern, shown in Figure 8.7, “Resequencer Pattern”, enables you to resequence messages according to a sequencing expression. Messages that generate a low value for the sequencing expression are moved to the front of the batch and messages that generate a high value are moved to the back.
Figure 8.7. Resequencer Pattern
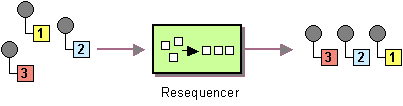
Apache Camel supports two resequencing algorithms:
- Batch resequencing — Collects messages into a batch, sorts the messages and sends them to their output.
- Stream resequencing — Re-orders (continuous) message streams based on the detection of gaps between messages.
By default the resequencer does not support duplicate messages and will only keep the last message, in cases where a message arrives with the same message expression. However, in batch mode you can enable the resequencer to allow duplicates.
Batch resequencing
The batch resequencing algorithm is enabled by default. For example, to resequence a batch of incoming messages based on the value of a timestamp contained in the TimeStamp header, you can define the following route in Java DSL:
from("direct:start").resequence(header("TimeStamp")).to("mock:result");
By default, the batch is obtained by collecting all of the incoming messages that arrive in a time interval of 1000 milliseconds (default batch timeout), up to a maximum of 100 messages (default batch size). You can customize the values of the batch timeout and the batch size by appending a batch() DSL command, which takes a BatchResequencerConfig instance as its sole argument. For example, to modify the preceding route so that the batch consists of messages collected in a 4000 millisecond time window, up to a maximum of 300 messages, you can define the Java DSL route as follows:
import org.apache.camel.model.config.BatchResequencerConfig;
RouteBuilder builder = new RouteBuilder() {
public void configure() {
from("direct:start").resequence(header("TimeStamp")).batch(new BatchResequencerConfig(300,4000L)).to("mock:result");
}
};You can also specify a batch resequencer pattern using XML configuration. The following example defines a batch resequencer with a batch size of 300 and a batch timeout of 4000 milliseconds:
<camelContext id="resequencerBatch" xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:start" />
<resequence>
<!--
batch-config can be omitted for default (batch) resequencer settings
-->
<batch-config batchSize="300" batchTimeout="4000" />
<simple>header.TimeStamp</simple>
<to uri="mock:result" />
</resequence>
</route>
</camelContext>Batch options
Table 8.2, “Batch Resequencer Options” shows the options that are available in batch mode only.
| Java DSL | XML DSL | Default | Description |
|---|---|---|---|
|
|
|
|
If |
|
|
|
|
If |
For example, if you want to resequence messages from JMS queues based on JMSPriority, you would need to combine the options, allowDuplicates and reverse, as follows:
from("jms:queue:foo")
// sort by JMSPriority by allowing duplicates (message can have same JMSPriority)
// and use reverse ordering so 9 is first output (most important), and 0 is last
// use batch mode and fire every 3th second
.resequence(header("JMSPriority")).batch().timeout(3000).allowDuplicates().reverse()
.to("mock:result");Stream resequencing
To enable the stream resequencing algorithm, you must append stream() to the resequence() DSL command. For example, to resequence incoming messages based on the value of a sequence number in the seqnum header, you define a DSL route as follows:
from("direct:start").resequence(header("seqnum")).stream().to("mock:result");
The stream-processing resequencer algorithm is based on the detection of gaps in a message stream, rather than on a fixed batch size. Gap detection, in combination with timeouts, removes the constraint of needing to know the number of messages of a sequence (that is, the batch size) in advance. Messages must contain a unique sequence number for which a predecessor and a successor is known. For example a message with the sequence number 3 has a predecessor message with the sequence number 2 and a successor message with the sequence number 4. The message sequence 2,3,5 has a gap because the successor of 3 is missing. The resequencer therefore must retain message 5 until message 4 arrives (or a timeout occurs).
By default, the stream resequencer is configured with a timeout of 1000 milliseconds, and a maximum message capacity of 100. To customize the stream’s timeout and message capacity, you can pass a StreamResequencerConfig object as an argument to stream(). For example, to configure a stream resequencer with a message capacity of 5000 and a timeout of 4000 milliseconds, you define a route as follows:
// Java
import org.apache.camel.model.config.StreamResequencerConfig;
RouteBuilder builder = new RouteBuilder() {
public void configure() {
from("direct:start").resequence(header("seqnum")).
stream(new StreamResequencerConfig(5000, 4000L)).
to("mock:result");
}
};If the maximum time delay between successive messages (that is, messages with adjacent sequence numbers) in a message stream is known, the resequencer’s timeout parameter should be set to this value. In this case, you can guarantee that all messages in the stream are delivered in the correct order to the next processor. The lower the timeout value that is compared to the out-of-sequence time difference, the more likely it is that the resequencer will deliver messages out of sequence. Large timeout values should be supported by sufficiently high capacity values, where the capacity parameter is used to prevent the resequencer from running out of memory.
If you want to use sequence numbers of some type other than long, you would must define a custom comparator, as follows:
// Java
ExpressionResultComparator<Exchange> comparator = new MyComparator();
StreamResequencerConfig config = new StreamResequencerConfig(5000, 4000L, comparator);
from("direct:start").resequence(header("seqnum")).stream(config).to("mock:result");You can also specify a stream resequencer pattern using XML configuration. The following example defines a stream resequencer with a message capacity of 5000 and a timeout of 4000 milliseconds:
<camelContext id="resequencerStream" xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:start"/>
<resequence>
<stream-config capacity="5000" timeout="4000"/>
<simple>header.seqnum</simple>
<to uri="mock:result" />
</resequence>
</route>
</camelContext>Ignore invalid exchanges
The resequencer EIP throws a CamelExchangeException exception, if the incoming exchange is not valid — that is, if the sequencing expression cannot be evaluated for some reason (for example, due to a missing header). You can use the ignoreInvalidExchanges option to ignore these exceptions, which means the resequencer will skip any invalid exchanges.
from("direct:start")
.resequence(header("seqno")).batch().timeout(1000)
// ignore invalid exchanges (they are discarded)
.ignoreInvalidExchanges()
.to("mock:result");Reject old messages
The rejectOld option can be used to prevent messages being sent out of order, regardless of the mechanism used to resequence messages. When the rejectOld option is enabled, the resequencer rejects an incoming message (by throwing a MessageRejectedException exception), if the incoming messages is older (as defined by the current comparator) than the last delivered message.
from("direct:start")
.onException(MessageRejectedException.class).handled(true).to("mock:error").end()
.resequence(header("seqno")).stream().timeout(1000).rejectOld()
.to("mock:result");8.7. Routing Slip
Overview
The routing slip pattern, shown in Figure 8.8, “Routing Slip Pattern”, enables you to route a message consecutively through a series of processing steps, where the sequence of steps is not known at design time and can vary for each message. The list of endpoints through which the message should pass is stored in a header field (the slip), which Apache Camel reads at run time to construct a pipeline on the fly.
Figure 8.8. Routing Slip Pattern
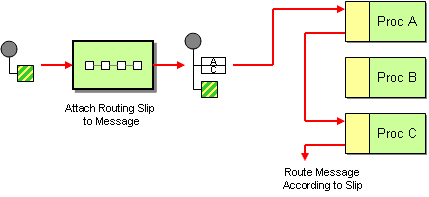
The slip header
The routing slip appears in a user-defined header, where the header value is a comma-separated list of endpoint URIs. For example, a routing slip that specifies a sequence of security tasks — decrypting, authenticating, and de-duplicating a message — might look like the following:
cxf:bean:decrypt,cxf:bean:authenticate,cxf:bean:dedup
The current endpoint property
From Camel 2.5 the Routing Slip will set a property (Exchange.SLIP_ENDPOINT) on the exchange which contains the current endpoint as it advanced though the slip. This enables you to find out how far the exchange has progressed through the slip.
The Section 8.7, “Routing Slip” will compute the slip beforehand which means, the slip is only computed once. If you need to compute the slip on-the-fly then use the Section 8.18, “Dynamic Router” pattern instead.
Java DSL example
The following route takes messages from the direct:a endpoint and reads a routing slip from the aRoutingSlipHeader header:
from("direct:b").routingSlip("aRoutingSlipHeader");You can specify the header name either as a string literal or as an expression.
You can also customize the URI delimiter using the two-argument form of routingSlip(). The following example defines a route that uses the aRoutingSlipHeader header key for the routing slip and uses the # character as the URI delimiter:
from("direct:c").routingSlip("aRoutingSlipHeader", "#");XML configuration example
The following example shows how to configure the same route in XML:
<camelContext id="buildRoutingSlip" xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:c"/>
<routingSlip uriDelimiter="#">
<headerName>aRoutingSlipHeader</headerName>
</routingSlip>
</route>
</camelContext>Ignore invalid endpoints
The Section 8.7, “Routing Slip” now supports ignoreInvalidEndpoints, which the Section 8.3, “Recipient List” pattern also supports. You can use it to skip endpoints that are invalid. For example:
from("direct:a").routingSlip("myHeader").ignoreInvalidEndpoints();
In Spring XML, this feature is enabled by setting the ignoreInvalidEndpoints attribute on the <routingSlip> tag:
<route>
<from uri="direct:a"/>
<routingSlip ignoreInvalidEndpoints="true">
<headerName>myHeader</headerName>
</routingSlip>
</route>
Consider the case where myHeader contains the two endpoints, direct:foo,xxx:bar. The first endpoint is valid and works. The second is invalid and, therefore, ignored. Apache Camel logs at INFO level whenever an invalid endpoint is encountered.
Options
The routingSlip DSL command supports the following options:
| Name | Default Value | Description |
|
|
| Delimiter used if the Expression returned multiple endpoints. |
|
|
| If an endpoint uri could not be resolved, should it be ignored. Otherwise Camel will thrown an exception stating the endpoint uri is not valid. |
|
|
| Camel 2.13.1/2.12.4: Allows to configure the cache size for the ProducerCache which caches producers for reuse in the routing slip. Will by default use the default cache size which is 0. Setting the value to -1 allows to turn off the cache all together. |
8.8. Throttler
Overview
A throttler is a processor that limits the flow rate of incoming messages. You can use this pattern to protect a target endpoint from getting overloaded. In Apache Camel, you can implement the throttler pattern using the throttle() Java DSL command.
Java DSL example
To limit the flow rate to 100 messages per second, define a route as follows:
from("seda:a").throttle(100).to("seda:b");
If necessary, you can customize the time period that governs the flow rate using the timePeriodMillis() DSL command. For example, to limit the flow rate to 3 messages per 30000 milliseconds, define a route as follows:
from("seda:a").throttle(3).timePeriodMillis(30000).to("mock:result");XML configuration example
The following example shows how to configure the preceding route in XML:
<camelContext id="throttleRoute" xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="seda:a"/>
<!-- throttle 3 messages per 30 sec -->
<throttle timePeriodMillis="30000">
<constant>3</constant>
<to uri="mock:result"/>
</throttle>
</route>
</camelContext>Dynamically changing maximum requests per period
Available os of Camel 2.8 Since we use an Expression, you can adjust this value at runtime, for example you can provide a header with the value. At runtime Camel evaluates the expression and converts the result to a java.lang.Long type. In the example below we use a header from the message to determine the maximum requests per period. If the header is absent, then the Section 8.8, “Throttler” uses the old value. So that allows you to only provide a header if the value is to be changed:
<camelContext id="throttleRoute" xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:expressionHeader"/>
<throttle timePeriodMillis="500">
<!-- use a header to determine how many messages to throttle per 0.5 sec -->
<header>throttleValue</header>
<to uri="mock:result"/>
</throttle>
</route>
</camelContext>Asynchronous delaying
The throttler can enable non-blocking asynchronous delaying, which means that Apache Camel schedules a task to be executed in the future. The task is responsible for processing the latter part of the route (after the throttler). This allows the caller thread to unblock and service further incoming messages. For example:
from("seda:a").throttle(100).asyncDelayed().to("seda:b");From Camel 2.17, the Throttler will use the rolling window for time periods that give a better flow of messages. However, It will enhance the performance of a throttler.
Options
The throttle DSL command supports the following options:
| Name | Default Value | Description |
|
| Maximum number of requests per period to throttle. This option must be provided and a positive number. Notice, in the XML DSL, from Camel 2.8 onwards this option is configured using an Expression instead of an attribute. | |
|
|
|
The time period in millis, in which the throttler will allow at most |
|
|
| Camel 2.4: If enabled then any messages which is delayed happens asynchronously using a scheduled thread pool. |
|
|
Camel 2.4: Refers to a custom Thread Pool to be used if | |
|
|
|
Camel 2.4: Is used if |
8.9. Delayer
Overview
A delayer is a processor that enables you to apply a relative time delay to incoming messages.
Java DSL example
You can use the delay() command to add a relative time delay, in units of milliseconds, to incoming messages. For example, the following route delays all incoming messages by 2 seconds:
from("seda:a").delay(2000).to("mock:result");Alternatively, you can specify the time delay using an expression:
from("seda:a").delay(header("MyDelay")).to("mock:result");
The DSL commands that follow delay() are interpreted as sub-clauses of delay(). Hence, in some contexts it is necessary to terminate the sub-clauses of delay() by inserting the end() command. For example, when delay() appears inside an onException() clause, you would terminate it as follows:
from("direct:start")
.onException(Exception.class)
.maximumRedeliveries(2)
.backOffMultiplier(1.5)
.handled(true)
.delay(1000)
.log("Halting for some time")
.to("mock:halt")
.end()
.end()
.to("mock:result");XML configuration example
The following example demonstrates the delay in XML DSL:
<camelContext xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="seda:a"/>
<delay>
<header>MyDelay</header>
</delay>
<to uri="mock:result"/>
</route>
<route>
<from uri="seda:b"/>
<delay>
<constant>1000</constant>
</delay>
<to uri="mock:result"/>
</route>
</camelContext>Creating a custom delay
You can use an expression combined with a bean to determine the delay as follows:
from("activemq:foo").
delay().expression().method("someBean", "computeDelay").
to("activemq:bar");Where the bean class could be defined as follows:
public class SomeBean {
public long computeDelay() {
long delay = 0;
// use java code to compute a delay value in millis
return delay;
}
}Asynchronous delaying
You can let the delayer use non-blocking asynchronous delaying, which means that Apache Camel schedules a task to be executed in the future. The task is responsible for processing the latter part of the route (after the delayer). This allows the caller thread to unblock and service further incoming messages. For example:
from("activemq:queue:foo")
.delay(1000)
.asyncDelayed()
.to("activemq:aDelayedQueue");The same route can be written in the XML DSL, as follows:
<route>
<from uri="activemq:queue:foo"/>
<delay asyncDelayed="true">
<constant>1000</constant>
</delay>
<to uri="activemq:aDealyedQueue"/>
</route>Options
The delayer pattern supports the following options:
| Name | Default Value | Description |
|
|
| Camel 2.4: If enabled then delayed messages happens asynchronously using a scheduled thread pool. |
|
|
Camel 2.4: Refers to a custom Thread Pool to be used if | |
|
|
|
Camel 2.4: Is used if |
8.10. Load Balancer
Overview
The load balancer pattern allows you to delegate message processing to one of several endpoints, using a variety of different load-balancing policies.
Java DSL example
The following route distributes incoming messages between the target endpoints, mock:x, mock:y, mock:z, using a round robin load-balancing policy:
from("direct:start").loadBalance().roundRobin().to("mock:x", "mock:y", "mock:z");XML configuration example
The following example shows how to configure the same route in XML:
<camelContext xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:start"/>
<loadBalance>
<roundRobin/>
<to uri="mock:x"/>
<to uri="mock:y"/>
<to uri="mock:z"/>
</loadBalance>
</route>
</camelContext>Load-balancing policies
The Apache Camel load balancer supports the following load-balancing policies:
Round robin
The round robin load-balancing policy cycles through all of the target endpoints, sending each incoming message to the next endpoint in the cycle. For example, if the list of target endpoints is, mock:x, mock:y, mock:z, then the incoming messages are sent to the following sequence of endpoints: mock:x, mock:y, mock:z, mock:x, mock:y, mock:z, and so on.
You can specify the round robin load-balancing policy in Java DSL, as follows:
from("direct:start").loadBalance().roundRobin().to("mock:x", "mock:y", "mock:z");Alternatively, you can configure the same route in XML, as follows:
<camelContext xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:start"/>
<loadBalance>
<roundRobin/>
<to uri="mock:x"/>
<to uri="mock:y"/>
<to uri="mock:z"/>
</loadBalance>
</route>
</camelContext>Random
The random load-balancing policy chooses the target endpoint randomly from the specified list.
You can specify the random load-balancing policy in Java DSL, as follows:
from("direct:start").loadBalance().random().to("mock:x", "mock:y", "mock:z");Alternatively, you can configure the same route in XML, as follows:
<camelContext xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:start"/>
<loadBalance>
<random/>
<to uri="mock:x"/>
<to uri="mock:y"/>
<to uri="mock:z"/>
</loadBalance>
</route>
</camelContext>Sticky
The sticky load-balancing policy directs the In message to an endpoint that is chosen by calculating a hash value from a specified expression. The advantage of this load-balancing policy is that expressions of the same value are always sent to the same server. For example, by calculating the hash value from a header that contains a username, you ensure that messages from a particular user are always sent to the same target endpoint. Another useful approach is to specify an expression that extracts the session ID from an incoming message. This ensures that all messages belonging to the same session are sent to the same target endpoint.
You can specify the sticky load-balancing policy in Java DSL, as follows:
from("direct:start").loadBalance().sticky(header("username")).to("mock:x", "mock:y", "mock:z");Alternatively, you can configure the same route in XML, as follows:
<camelContext xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:start"/>
<loadBalance>
<sticky>
<correlationExpression>
<simple>header.username</simple>
</correlationExpression>
</sticky>
<to uri="mock:x"/>
<to uri="mock:y"/>
<to uri="mock:z"/>
</loadBalance>
</route>
</camelContext>When you add the sticky option to the failover load balancer, the load balancer starts from the last known good endpoint.
Topic
The topic load-balancing policy sends a copy of each In message to all of the listed destination endpoints (effectively broadcasting the message to all of the destinations, like a JMS topic).
You can use the Java DSL to specify the topic load-balancing policy, as follows:
from("direct:start").loadBalance().topic().to("mock:x", "mock:y", "mock:z");Alternatively, you can configure the same route in XML, as follows:
<camelContext xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:start"/>
<loadBalance>
<topic/>
<to uri="mock:x"/>
<to uri="mock:y"/>
<to uri="mock:z"/>
</loadBalance>
</route>
</camelContext>Failover
Available as of Apache Camel 2.0 The failover load balancer is capable of trying the next processor in case an Exchange failed with an exception during processing. You can configure the failover with a list of specific exceptions that trigger failover. If you do not specify any exceptions, failover is triggered by any exception. The failover load balancer uses the same strategy for matching exceptions as the onException exception clause.
If you use streaming, you should enable Stream Caching when using the failover load balancer. This is needed so the stream can be re-read when failing over.
The failover load balancer supports the following options:
| Option | Type | Default | Description |
|
|
|
|
Camel 2.3: Specifies whether to use the
For example, the |
|
|
|
|
Camel 2.3: Specifies the maximum number of attempts to fail over to a new endpoint. The value, |
|
|
|
|
Camel 2.3: Specifies whether the |
The following example is configured to fail over, only if an IOException exception is thrown:
from("direct:start")
// here we will load balance if IOException was thrown
// any other kind of exception will result in the Exchange as failed
// to failover over any kind of exception we can just omit the exception
// in the failOver DSL
.loadBalance().failover(IOException.class)
.to("direct:x", "direct:y", "direct:z");You can optionally specify multiple exceptions to fail over, as follows:
// enable redelivery so failover can react
errorHandler(defaultErrorHandler().maximumRedeliveries(5));
from("direct:foo")
.loadBalance()
.failover(IOException.class, MyOtherException.class)
.to("direct:a", "direct:b");You can configure the same route in XML, as follows:
<route errorHandlerRef="myErrorHandler">
<from uri="direct:foo"/>
<loadBalance>
<failover>
<exception>java.io.IOException</exception>
<exception>com.mycompany.MyOtherException</exception>
</failover>
<to uri="direct:a"/>
<to uri="direct:b"/>
</loadBalance>
</route>The following example shows how to fail over in round robin mode:
from("direct:start")
// Use failover load balancer in stateful round robin mode,
// which means it will fail over immediately in case of an exception
// as it does NOT inherit error handler. It will also keep retrying, as
// it is configured to retry indefinitely.
.loadBalance().failover(-1, false, true)
.to("direct:bad", "direct:bad2", "direct:good", "direct:good2");You can configure the same route in XML, as follows:
<route>
<from uri="direct:start"/>
<loadBalance>
<!-- failover using stateful round robin,
which will keep retrying the 4 endpoints indefinitely.
You can set the maximumFailoverAttempt to break out after X attempts -->
<failover roundRobin="true"/>
<to uri="direct:bad"/>
<to uri="direct:bad2"/>
<to uri="direct:good"/>
<to uri="direct:good2"/>
</loadBalance>
</route>
If you want to failover to the next endpoint as soon as possible, you can disable the inheritErrorHandler by configuring inheritErrorHandler=false. By disabling the Error Handler you can ensure that it does not intervene. This allows the failover load balancer to handle failover as soon as possible. If you also enable the roundRobin mode, then it keeps retrying until it successes. You can then configure the maximumFailoverAttempts option to a high value to let it eventually exhaust and fail.
Weighted round robin and weighted random
In many enterprise environments, where server nodes of unequal processing power are hosting services, it is usually preferable to distribute the load in accordance with the individual server processing capacities. A weighted round robin algorithm or a weighted random algorithm can be used to address this problem.
The weighted load balancing policy allows you to specify a processing load distribution ratio for each server with respect to the others. You can specify this value as a positive processing weight for each server. A larger number indicates that the server can handle a larger load. The processing weight is used to determine the payload distribution ratio of each processing endpoint with respect to the others.
The parameters that can be used are described in the following table:
| Option | Type | Default | Description |
|---|---|---|---|
|
|
|
|
The default value for round-robin is |
|
|
|
|
The |
The following Java DSL examples show how to define a weighted round-robin route and a weighted random route:
// Java
// round-robin
from("direct:start")
.loadBalance().weighted(true, "4:2:1" distributionRatioDelimiter=":")
.to("mock:x", "mock:y", "mock:z");
//random
from("direct:start")
.loadBalance().weighted(false, "4,2,1")
.to("mock:x", "mock:y", "mock:z");You can configure the round-robin route in XML, as follows:
<!-- round-robin -->
<route>
<from uri="direct:start"/>
<loadBalance>
<weighted roundRobin="true" distributionRatio="4:2:1" distributionRatioDelimiter=":" />
<to uri="mock:x"/>
<to uri="mock:y"/>
<to uri="mock:z"/>
</loadBalance>
</route>Custom Load Balancer
You can use a custom load balancer (eg your own implementation) also.
An example using Java DSL:
from("direct:start")
// using our custom load balancer
.loadBalance(new MyLoadBalancer())
.to("mock:x", "mock:y", "mock:z");And the same example using XML DSL:
<!-- this is the implementation of our custom load balancer -->
<bean id="myBalancer" class="org.apache.camel.processor.CustomLoadBalanceTest$MyLoadBalancer"/>
<camelContext xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:start"/>
<loadBalance>
<!-- refer to my custom load balancer -->
<custom ref="myBalancer"/>
<!-- these are the endpoints to balancer -->
<to uri="mock:x"/>
<to uri="mock:y"/>
<to uri="mock:z"/>
</loadBalance>
</route>
</camelContext>Notice in the XML DSL above we use <custom> which is only available in Camel 2.8 onwards. In older releases you would have to do as follows instead:
<loadBalance ref="myBalancer">
<!-- these are the endpoints to balancer -->
<to uri="mock:x"/>
<to uri="mock:y"/>
<to uri="mock:z"/>
</loadBalance>
To implement a custom load balancer you can extend some support classes such as LoadBalancerSupport and SimpleLoadBalancerSupport. The former supports the asynchronous routing engine, and the latter does not. Here is an example:
public static class MyLoadBalancer extends LoadBalancerSupport {
public boolean process(Exchange exchange, AsyncCallback callback) {
String body = exchange.getIn().getBody(String.class);
try {
if ("x".equals(body)) {
getProcessors().get(0).process(exchange);
} else if ("y".equals(body)) {
getProcessors().get(1).process(exchange);
} else {
getProcessors().get(2).process(exchange);
}
} catch (Throwable e) {
exchange.setException(e);
}
callback.done(true);
return true;
}
}Circuit Breaker
The Circuit Breaker load balancer is a stateful pattern that is used to monitor all calls for certain exceptions. Initially, the Circuit Breaker is in closed state and passes all messages. If there are failures and the threshold is reached, it moves to open state and rejects all calls until halfOpenAfter timeout is reached. After the timeout, if there is a new call, the Circuit Breaker passes all the messages. If the result is success, the Circuit Breaker moves to a closed state, if not, it moves back to open state.
Java DSL example:
from("direct:start").loadBalance()
.circuitBreaker(2, 1000L, MyCustomException.class)
.to("mock:result");Spring XML example:
<camelContext id="camel" xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:start"/>
<loadBalance>
<circuitBreaker threshold="2" halfOpenAfter="1000">
<exception>MyCustomException</exception>
</circuitBreaker>
<to uri="mock:result"/>
</loadBalance>
</route>
</camelContext>8.11. Hystrix
Overview
Available as of Camel 2.18.
The Hystrix pattern lets an application integrate with Netflix Hystrix, which can provide a circuit breaker in Camel routes. Hystrix is a latency and fault tolerance library designed to
- Isolate points of access to remote systems, services and third-party libraries
- Stop cascading failure
- Enable resilience in complex distributed systems where failure is inevitable
If you use maven then add the following dependency to your pom.xml file to use Hystrix:
<dependency>
<groupId>org.apache.camel</groupId>
<artifactId>camel-hystrix</artifactId>
<version>x.x.x</version>
<!-- Specify the same version as your Camel core version. -->
</dependency>Java DSL example
Below is an example route that shows a Hystrix endpoint that protects against slow operation by falling back to the in-lined fallback route. By default, the timeout request is just 1000ms so the HTTP endpoint has to be fairly quick to succeed.
from("direct:start")
.hystrix()
.to("http://fooservice.com/slow")
.onFallback()
.transform().constant("Fallback message")
.end()
.to("mock:result");XML configuration example
Following is the same example but in XML:
<camelContext xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:start"/>
<hystrix>
<to uri="http://fooservice.com/slow"/>
<onFallback>
<transform>
<constant>Fallback message</constant>
</transform>
</onFallback>
</hystrix>
<to uri="mock:result"/>
</route>
</camelContext>Using the Hystrix fallback feature
The onFallback() method is for local processing where you can transform a message or call a bean or something else as the fallback. If you need to call an external service over the network then you should use the onFallbackViaNetwork() method, which runs in an independent HystrixCommand object that uses its own thread pool so it does not exhaust the first command object.
Hystrix configuration examples
Hystrix has many options as listed in the next section. The example below shows the Java DSL for setting the execution timeout to 5 seconds rather than the default 1 second and for letting the circuit breaker wait 10 seconds rather than 5 seconds (the default) before attempting a request again when the state was tripped to be open.
from("direct:start")
.hystrix()
.hystrixConfiguration()
.executionTimeoutInMilliseconds(5000).circuitBreakerSleepWindowInMilliseconds(10000)
.end()
.to("http://fooservice.com/slow")
.onFallback()
.transform().constant("Fallback message")
.end()
.to("mock:result");Following is the same example but in XML:
<camelContext xmlns="http://camel.apache.org/schema/spring">
<camelContext xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:start"/>
<hystrix>
<hystrixConfiguration executionTimeoutInMilliseconds="5000" circuitBreakerSleepWindowInMilliseconds="10000"/>
<to uri="http://fooservice.com/slow"/>
<onFallback>
<transform>
<constant>Fallback message</constant>
</transform>
</onFallback>
</hystrix>
<to uri="mock:result"/>
</route>
</camelContext>You can also configure Hystrix globally and then refer to that configuration. For example:
<camelContext xmlns="http://camel.apache.org/schema/spring">
<!-- This is a shared config that you can refer to from all Hystrix patterns. -->
<hystrixConfiguration id="sharedConfig" executionTimeoutInMilliseconds="5000" circuitBreakerSleepWindowInMilliseconds="10000"/>
<route>
<from uri="direct:start"/>
<hystrix hystrixConfigurationRef="sharedConfig">
<to uri="http://fooservice.com/slow"/>
<onFallback>
<transform>
<constant>Fallback message</constant>
</transform>
</onFallback>
</hystrix>
<to uri="mock:result"/>
</route>
</camelContext>Options
Ths Hystrix component supports the following options. Hystrix provides the default values.
| Name | Default Value | Type | Description |
|---|---|---|---|
|
|
| Boolean | Determines whether a circuit breaker will be used to track health and to short-circuit requests if it trips. |
|
|
| Integer | Sets the error percentage at or above which the circuit should trip open and start short-circuiting requests to fallback logic. |
|
|
| Boolean | A value of true forces the circuit breaker into a closed state in which it allows requests regardless of the error percentage. |
|
|
| Boolean | A value of true forces the circuit breaker into an open (tripped) state in which it rejects all requests. |
|
|
| Integer | Sets the minimum number of requests in a rolling window that will trip the circuit. |
|
|
| Integer | Sets the amount of time, after tripping the circuit, to reject requests. After this time elapses, request attempts are allowed to determine if the circuit should again be closed. |
|
| Node ID | String | Identifies the Hystrix command. You cannot configure this option. it is always the node ID to make the command unique. |
|
|
| Integer |
Sets the core thread-pool size. This is the maximum number of |
|
|
| Integer |
Sets the maximum number of requests that a |
|
|
| String |
Indicates which of these isolation strategies |
|
|
| Boolean |
Indicates whether the |
|
|
| Integer | Sets the timeout in milliseconds for execution completion. |
|
|
| Boolean |
Indicates whether the execution of |
|
|
| Boolean |
Determines whether a call to |
|
|
| Integer |
Sets the maximum number of requests that a |
|
|
| String | Identifies the Hystrix group being used to correlate statistics and circuit breaker properties. |
|
|
| Integer | Sets the keep-alive time, in minutes. |
|
|
| Integer |
Sets the maximum queue size of the |
|
|
| Integer | Sets the time to wait, in milliseconds, between allowing health snapshots to be taken. Health snapshots calculate success and error percentages and affect circuit breaker status. |
|
|
| Integer | Sets the maximum number of execution times that are kept per bucket. If more executions occur during the time they will wrap around and start over-writing at the beginning of the bucket. |
|
|
| Boolean | Indicates whether execution latency should be tracked. The latency is calculated as a percentile. A value of false causes summary statistics (mean, percentiles) to be returned as -1. |
|
|
| Integer |
Sets the number of buckets the |
|
|
| Integer | Sets the duration of the rolling window in which execution times are kept to allow for percentile calculations, in milliseconds. |
|
|
| Integer | Sets the number of buckets the rolling statistical window is divided into. |
|
|
| Integer |
This option and the following options apply to capturing metrics from |
|
|
| Integer |
Sets the queue size rejection threshold — an artificial maximum queue size at which rejections occur even ifý |
|
|
| Boolean |
Indicates whether |
|
|
| String | Defines which thread-pool this command should run in. By default this is using the same key as the group key. |
|
|
| Integer | Sets the number of buckets the rolling statistical window is divided into. |
|
|
| Integer | Sets the duration of the statistical rolling window, in milliseconds. This is how long metrics are kept for the thread pool. |
8.12. Service Call
Overview
Available as of Camel 2.18.
The service call pattern lets you call remote services in a distributed system. The service to call is looked up in a service registry such as Kubernetes, Consul, etcd or Zookeeper. The pattern separates the configuration of the service registry from the calling of the service.
Maven users must add a dependency for the service registry to be used. Possibilities include:
-
camel-consul -
camel-etcd -
camel-kubenetes -
camel-ribbon
Syntax for calling a service
To call a service, refer to the name of the service as shown below:
from("direct:start")
.serviceCall("foo")
.to("mock:result");The following example shows the XML DSL for calling a service:
<camelContext xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:start"/>
<serviceCall name="foo"/>
<to uri="mock:result"/>
</route>
</camelContext>
In these examples, Camel uses the component that integrates with the service registry to look up a service with the name foo. The lookup returns a set of IP:PORT pairs that refer to a list of active servers that host the remote service. Camel then randomly selects from that list the server to use and builds a Camel URI with the chosen IP and PORT number.
By default, Camel uses the HTTP component. In the example above, the call resolves to a Camel URI that is called by a dynamic toD endpoint as shown below:
toD("http://IP:PORT")<toD uri="http:IP:port"/>
You can use URI parameters to call the service, for example, beer=yes:
serviceCall("foo?beer=yes")<serviceCall name="foo?beer=yes"/>
You can also provide a context path, for example:
serviceCall("foo/beverage?beer=yes")<serviceCall name="foo/beverage?beer=yes"/>
Translating service names to URIs
As you can see, the service name resolves to a Camel endpoint URI. Following are a few more examples. The → shows the resolution of the Camel URI):
serviceCall("myService") -> http://hostname:port
serviceCall("myService/foo") -> http://hostname:port/foo
serviceCall("http:myService/foo") -> http:hostname:port/foo<serviceCall name="myService"/> -> http://hostname:port <serviceCall name="myService/foo"/> -> http://hostname:port/foo <serviceCall name="http:myService/foo"/> -> http:hostname:port/foo
To fully control the resolved URI, provide an additional URI parameter that specifies the desired Camel URI. In the specified URI, you can use the service name, which resolves to IP:PORT. Here are some examples:
serviceCall("myService", "http:myService.host:myService.port/foo") -> http:hostname:port/foo
serviceCall("myService", "netty4:tcp:myService?connectTimeout=1000") -> netty:tcp:hostname:port?connectTimeout=1000<serviceCall name="myService" uri="http:myService.host:myService.port/foo"/> -> http:hostname:port/foo <serviceCall name="myService" uri="netty4:tcp:myService?connectTimeout=1000"/> -> netty:tcp:hostname:port?connectTimeout=1000
The examples above call a service named myService. The second parameter controls the value of the resolved URI. Notice that the first example uses serviceName.host and serviceName.port to refer to either the IP or the PORT. If you specify just serviceName then it resolves to IP:PORT.
Configuring the component that calls the service
By default, Camel uses the HTTP component to call the service. You can configure the use of a different component, such as HTTP4 or Netty4 HTTP, as in the following example:
KubernetesConfigurationDefinition config = new KubernetesConfigurationDefinition();
config.setComponent("netty4-http");
// Register the service call configuration:
context.setServiceCallConfiguration(config);
from("direct:start")
.serviceCall("foo")
.to("mock:result");Following is an example in XML DSL:
<camelContext xmlns="http://camel.apache.org/schema/spring">
<kubernetesConfiguration id="kubernetes" component="netty4-http"/>
<route>
<from uri="direct:start"/>
<serviceCall name="foo"/>
<to uri="mock:result"/>
</route>
</camelContext>Service call options when using Kubernetes
A Kubernetes implementation supports the following options:
| Option | Default Value | Description |
|
| Kubernetes API version when using client lookup. | |
|
| Sets the Certificate Authority data when using client lookup. | |
|
| Sets the Certificate Authority data that are loaded from the file when using client lookup. | |
|
| Sets the Client Certificate data when using client lookup. | |
|
| Sets the Client Certificate data that are loaded from the file when using client lookup. | |
|
| Sets the Client Keystore algorithm, such as RSA, when using client lookup. | |
|
| Sets the Client Keystore data when using client lookup. | |
|
| Sets the Client Keystore data that are loaded from the file when using client lookup. | |
|
| Sets the Client Keystore passphrase when using client lookup. | |
|
|
Sets the DNS domain to use for | |
|
|
| The choice of strategy used to look up the service. The lookup strategies include:
|
|
| The URL for the Kubernetes master when using client lookup. | |
|
|
The Kubernetes namespace to use. By default the namespace’s name is taken from the environment variable | |
|
| Sets the OAUTH token for authentication (instead of username/password) when using client lookup. | |
|
| Sets the password for authentication when using client lookup. | |
|
| false | Sets whether to turn on trust certificate check when using client lookup. |
|
| Sets the username for authentication when using client lookup. |
8.13. Multicast
Overview
The multicast pattern, shown in Figure 8.9, “Multicast Pattern”, is a variation of the recipient list with a fixed destination pattern, which is compatible with the InOut message exchange pattern. This is in contrast to recipient list, which is only compatible with the InOnly exchange pattern.
Figure 8.9. Multicast Pattern
Multicast with a custom aggregation strategy
Whereas the multicast processor receives multiple Out messages in response to the original request (one from each of the recipients), the original caller is only expecting to receive a single reply. Thus, there is an inherent mismatch on the reply leg of the message exchange, and to overcome this mismatch, you must provide a custom aggregation strategy to the multicast processor. The aggregation strategy class is responsible for aggregating all of the Out messages into a single reply message.
Consider the example of an electronic auction service, where a seller offers an item for sale to a list of buyers. The buyers each put in a bid for the item, and the seller automatically selects the bid with the highest price. You can implement the logic for distributing an offer to a fixed list of buyers using the multicast() DSL command, as follows:
from("cxf:bean:offer").multicast(new HighestBidAggregationStrategy()).
to("cxf:bean:Buyer1", "cxf:bean:Buyer2", "cxf:bean:Buyer3");
Where the seller is represented by the endpoint, cxf:bean:offer, and the buyers are represented by the endpoints, cxf:bean:Buyer1, cxf:bean:Buyer2, cxf:bean:Buyer3. To consolidate the bids received from the various buyers, the multicast processor uses the aggregation strategy, HighestBidAggregationStrategy. You can implement the HighestBidAggregationStrategy in Java, as follows:
// Java
import org.apache.camel.processor.aggregate.AggregationStrategy;
import org.apache.camel.Exchange;
public class HighestBidAggregationStrategy implements AggregationStrategy {
public Exchange aggregate(Exchange oldExchange, Exchange newExchange) {
float oldBid = oldExchange.getOut().getHeader("Bid", Float.class);
float newBid = newExchange.getOut().getHeader("Bid", Float.class);
return (newBid > oldBid) ? newExchange : oldExchange;
}
}
Where it is assumed that the buyers insert the bid price into a header named, Bid. For more details about custom aggregation strategies, see Section 8.5, “Aggregator”.
Parallel processing
By default, the multicast processor invokes each of the recipient endpoints one after another (in the order listed in the to() command). In some cases, this might cause unacceptably long latency. To avoid these long latency times, you have the option of enabling parallel processing by adding the parallelProcessing() clause. For example, to enable parallel processing in the electronic auction example, define the route as follows:
from("cxf:bean:offer")
.multicast(new HighestBidAggregationStrategy())
.parallelProcessing()
.to("cxf:bean:Buyer1", "cxf:bean:Buyer2", "cxf:bean:Buyer3");Where the multicast processor now invokes the buyer endpoints, using a thread pool that has one thread for each of the endpoints.
If you want to customize the size of the thread pool that invokes the buyer endpoints, you can invoke the executorService() method to specify your own custom executor service. For example:
from("cxf:bean:offer")
.multicast(new HighestBidAggregationStrategy())
.executorService(MyExecutor)
.to("cxf:bean:Buyer1", "cxf:bean:Buyer2", "cxf:bean:Buyer3");Where MyExecutor is an instance of java.util.concurrent.ExecutorService type.
When the exchange has an InOut pattern, an aggregation strategy is used to aggregate reply messages. The default aggregation strategy takes the latest reply message and discards earlier replies. For example, in the following route, the custom strategy, MyAggregationStrategy, is used to aggregate the replies from the endpoints, direct:a, direct:b, and direct:c:
from("direct:start")
.multicast(new MyAggregationStrategy())
.parallelProcessing()
.timeout(500)
.to("direct:a", "direct:b", "direct:c")
.end()
.to("mock:result");XML configuration example
The following example shows how to configure a similar route in XML, where the route uses a custom aggregation strategy and a custom thread executor:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="
http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-3.0.xsd
http://camel.apache.org/schema/spring http://camel.apache.org/schema/spring/camel-spring.xsd
">
<camelContext xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="cxf:bean:offer"/>
<multicast strategyRef="highestBidAggregationStrategy"
parallelProcessing="true"
threadPoolRef="myThreadExcutor">
<to uri="cxf:bean:Buyer1"/>
<to uri="cxf:bean:Buyer2"/>
<to uri="cxf:bean:Buyer3"/>
</multicast>
</route>
</camelContext>
<bean id="highestBidAggregationStrategy" class="com.acme.example.HighestBidAggregationStrategy"/>
<bean id="myThreadExcutor" class="com.acme.example.MyThreadExcutor"/>
</beans>
Where both the parallelProcessing attribute and the threadPoolRef attribute are optional. It is only necessary to set them if you want to customize the threading behavior of the multicast processor.
Apply custom processing to the outgoing messages
The multicast pattern copies the source Exchange and multicasts the copy. By default, the router makes a shallow copy of the source message. In a shallow copy, the headers and payload of the original message are copied by reference only, so that resulting copies of the original message are linked. Because shallow copies of a multicast message are linked, you’re unable to apply custom processing if the message body is mutable. Custom processing that you apply to a copy sent to one endpoint are also applied to copies sent to every other endpoint.
Although the multicast syntax allows you to invoke the process DSL command in the multicast clause, this does not make sense semantically and it does not have the same effect as onPrepare (in fact, in this context, the process DSL command has no effect).
Using onPrepare to execute custom logic when preparing messages
If you want to apply custom processing to each message replica before it is sent to its endpoint, you can invoke the onPrepare DSL command in the multicast clause. The onPrepare command inserts a custom processor just after the message has been shallow-copied and just before the message is dispatched to its endpoint. For example, in the following route, the CustomProc processor is invoked on the message sent to direct:a and the CustomProc processor is also invoked on the message sent to direct:b.
from("direct:start")
.multicast().onPrepare(new CustomProc())
.to("direct:a").to("direct:b");
A common use case for the onPrepare DSL command is to perform a deep copy of some or all elements of a message. For example, the following CustomProc processor class performs a deep copy of the message body, where the message body is presumed to be of type, BodyType, and the deep copy is performed by the method, BodyType.deepCopy().
// Java
import org.apache.camel.*;
...
public class CustomProc implements Processor {
public void process(Exchange exchange) throws Exception {
BodyType body = exchange.getIn().getBody(BodyType.class);
// Make a _deep_ copy of of the body object
BodyType clone = BodyType.deepCopy();
exchange.getIn().setBody(clone);
// Headers and attachments have already been
// shallow-copied. If you need deep copies,
// add some more code here.
}
}
You can use onPrepare to implement any kind of custom logic that you want to execute before the Exchange is multicast.
It is recommended practice to design for immutable objects.
For example if you have a mutable message body as this Animal class:
public class Animal implements Serializable {
private int id;
private String name;
public Animal() {
}
public Animal(int id, String name) {
this.id = id;
this.name = name;
}
public Animal deepClone() {
Animal clone = new Animal();
clone.setId(getId());
clone.setName(getName());
return clone;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public String toString() {
return id + " " + name;
}
}Then we can create a deep clone processor which clones the message body:
public class AnimalDeepClonePrepare implements Processor {
public void process(Exchange exchange) throws Exception {
Animal body = exchange.getIn().getBody(Animal.class);
// do a deep clone of the body which wont affect when doing multicasting
Animal clone = body.deepClone();
exchange.getIn().setBody(clone);
}
}
Then we can use the AnimalDeepClonePrepare class in the multicast route using the onPrepare option as shown:
from("direct:start")
.multicast().onPrepare(new AnimalDeepClonePrepare()).to("direct:a").to("direct:b");And the same example in XML DSL
<camelContext xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:start"/>
<!-- use on prepare with multicast -->
<multicast onPrepareRef="animalDeepClonePrepare">
<to uri="direct:a"/>
<to uri="direct:b"/>
</multicast>
</route>
<route>
<from uri="direct:a"/>
<process ref="processorA"/>
<to uri="mock:a"/>
</route>
<route>
<from uri="direct:b"/>
<process ref="processorB"/>
<to uri="mock:b"/>
</route>
</camelContext>
<!-- the on prepare Processor which performs the deep cloning -->
<bean id="animalDeepClonePrepare" class="org.apache.camel.processor.AnimalDeepClonePrepare"/>
<!-- processors used for the last two routes, as part of unit test -->
<bean id="processorA" class="org.apache.camel.processor.MulticastOnPrepareTest$ProcessorA"/>
<bean id="processorB" class="org.apache.camel.processor.MulticastOnPrepareTest$ProcessorB"/>Options
The multicast DSL command supports the following options:
| Name | Default Value | Description |
|
| Refers to an AggregationStrategy to be used to assemble the replies from the multicasts, into a single outgoing message from the multicast. By default Camel will use the last reply as the outgoing message. | |
|
|
This option can be used to explicitly specify the method name to use, when using POJOs as the | |
|
|
|
This option can be used, when using POJOs as the |
|
|
| If enabled, sending messages to the multicasts occurs concurrently. Note the caller thread will still wait until all messages has been fully processed, before it continues. Its only the sending and processing the replies from the multicasts which happens concurrently. |
|
|
|
If enabled, the |
|
| Refers to a custom Thread Pool to be used for parallel processing. Notice if you set this option, then parallel processing is automatic implied, and you do not have to enable that option as well. | |
|
|
| Camel 2.2: Whether or not to stop continue processing immediately when an exception occurred. If disable, then Camel will send the message to all multicasts regardless if one of them failed. You can deal with exceptions in the AggregationStrategy class where you have full control how to handle that. |
|
|
| If enabled then Camel will process replies out-of-order, eg in the order they come back. If disabled, Camel will process replies in the same order as multicasted. |
|
|
Camel 2.5: Sets a total timeout specified in milliseconds. If the multicast hasn’t been able to send and process all replies within the given timeframe, then the timeout triggers and the multicast breaks out and continues. Notice if you provide a TimeoutAwareAggregationStrategy then the | |
|
| Camel 2.8: Refers to a custom Processor to prepare the copy of the Exchange each multicast will receive. This allows you to do any custom logic, such as deep-cloning the message payload if that’s needed etc. | |
|
|
| Camel 2.8: Whether the unit of work should be shared. See the same option on Section 8.4, “Splitter” for more details. |
8.14. Composed Message Processor
Composed Message Processor
The composed message processor pattern, as shown in Figure 8.10, “Composed Message Processor Pattern”, allows you to process a composite message by splitting it up, routing the sub-messages to appropriate destinations, and then re-aggregating the responses back into a single message.
Figure 8.10. Composed Message Processor Pattern
Java DSL example
The following example checks that a multipart order can be filled, where each part of the order requires a check to be made at a different inventory:
// split up the order so individual OrderItems can be validated by the appropriate bean
from("direct:start")
.split().body()
.choice()
.when().method("orderItemHelper", "isWidget")
.to("bean:widgetInventory")
.otherwise()
.to("bean:gadgetInventory")
.end()
.to("seda:aggregate");
// collect and re-assemble the validated OrderItems into an order again
from("seda:aggregate")
.aggregate(new MyOrderAggregationStrategy())
.header("orderId")
.completionTimeout(1000L)
.to("mock:result");XML DSL example
The preceding route can also be written in XML DSL, as follows:
<route>
<from uri="direct:start"/>
<split>
<simple>body</simple>
<choice>
<when>
<method bean="orderItemHelper" method="isWidget"/>
<to uri="bean:widgetInventory"/>
</when>
<otherwise>
<to uri="bean:gadgetInventory"/>
</otherwise>
</choice>
<to uri="seda:aggregate"/>
</split>
</route>
<route>
<from uri="seda:aggregate"/>
<aggregate strategyRef="myOrderAggregatorStrategy" completionTimeout="1000">
<correlationExpression>
<simple>header.orderId</simple>
</correlationExpression>
<to uri="mock:result"/>
</aggregate>
</route>Processing steps
Processing starts by splitting the order, using a Section 8.4, “Splitter”. The Section 8.4, “Splitter” then sends individual OrderItems to a Section 8.1, “Content-Based Router”, which routes messages based on the item type. Widget items get sent for checking in the widgetInventory bean and gadget items get sent to the gadgetInventory bean. Once these OrderItems have been validated by the appropriate bean, they are sent on to the Section 8.5, “Aggregator” which collects and re-assembles the validated OrderItems into an order again.
Each received order has a header containing an order ID. We make use of the order ID during the aggregation step: the .header("orderId") qualifier on the aggregate() DSL command instructs the aggregator to use the header with the key, orderId, as the correlation expression.
For full details, check the ComposedMessageProcessorTest.java example source at camel-core/src/test/java/org/apache/camel/processor.
8.15. Scatter-Gather
Scatter-Gather
The scatter-gather pattern, as shown in Figure 8.11, “Scatter-Gather Pattern”, enables you to route messages to a number of dynamically specified recipients and re-aggregate the responses back into a single message.
Figure 8.11. Scatter-Gather Pattern
Dynamic scatter-gather example
The following example outlines an application that gets the best quote for beer from several different vendors. The examples uses a dynamic Section 8.3, “Recipient List” to request a quote from all vendors and an Section 8.5, “Aggregator” to pick the best quote out of all the responses. The routes for this application are defined as follows:
<camelContext id="camel" xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:start"/>
<recipientList>
<header>listOfVendors</header>
</recipientList>
</route>
<route>
<from uri="seda:quoteAggregator"/>
<aggregate strategyRef="aggregatorStrategy" completionTimeout="1000">
<correlationExpression>
<header>quoteRequestId</header>
</correlationExpression>
<to uri="mock:result"/>
</aggregate>
</route>
</camelContext>
In the first route, the Section 8.3, “Recipient List” looks at the listOfVendors header to obtain the list of recipients. Hence, the client that sends messages to this application needs to add a listOfVendors header to the message. Example 8.1, “Messaging Client Sample” shows some sample code from a messaging client that adds the relevant header data to outgoing messages.
Example 8.1. Messaging Client Sample
Map<String, Object> headers = new HashMap<String, Object>();
headers.put("listOfVendors", "bean:vendor1, bean:vendor2, bean:vendor3");
headers.put("quoteRequestId", "quoteRequest-1");
template.sendBodyAndHeaders("direct:start", "<quote_request item=\"beer\"/>", headers);
The message would be distributed to the following endpoints: bean:vendor1, bean:vendor2, and bean:vendor3. These beans are all implemented by the following class:
public class MyVendor {
private int beerPrice;
@Produce(uri = "seda:quoteAggregator")
private ProducerTemplate quoteAggregator;
public MyVendor(int beerPrice) {
this.beerPrice = beerPrice;
}
public void getQuote(@XPath("/quote_request/@item") String item, Exchange exchange) throws Exception {
if ("beer".equals(item)) {
exchange.getIn().setBody(beerPrice);
quoteAggregator.send(exchange);
} else {
throw new Exception("No quote available for " + item);
}
}
}
The bean instances, vendor1, vendor2, and vendor3, are instantiated using Spring XML syntax, as follows:
<bean id="aggregatorStrategy" class="org.apache.camel.spring.processor.scattergather.LowestQuoteAggregationStrategy"/>
<bean id="vendor1" class="org.apache.camel.spring.processor.scattergather.MyVendor">
<constructor-arg>
<value>1</value>
</constructor-arg>
</bean>
<bean id="vendor2" class="org.apache.camel.spring.processor.scattergather.MyVendor">
<constructor-arg>
<value>2</value>
</constructor-arg>
</bean>
<bean id="vendor3" class="org.apache.camel.spring.processor.scattergather.MyVendor">
<constructor-arg>
<value>3</value>
</constructor-arg>
</bean>
Each bean is initialized with a different price for beer (passed to the constructor argument). When a message is sent to each bean endpoint, it arrives at the MyVendor.getQuote method. This method does a simple check to see whether this quote request is for beer and then sets the price of beer on the exchange for retrieval at a later step. The message is forwarded to the next step using POJO Producing (see the @Produce annotation).
At the next step, we want to take the beer quotes from all vendors and find out which one was the best (that is, the lowest). For this, we use an Section 8.5, “Aggregator” with a custom aggregation strategy. The Section 8.5, “Aggregator” needs to identify which messages are relevant to the current quote, which is done by correlating messages based on the value of the quoteRequestId header (passed to the correlationExpression). As shown in Example 8.1, “Messaging Client Sample”, the correlation ID is set to quoteRequest-1 (the correlation ID should be unique). To pick the lowest quote out of the set, you can use a custom aggregation strategy like the following:
public class LowestQuoteAggregationStrategy implements AggregationStrategy {
public Exchange aggregate(Exchange oldExchange, Exchange newExchange) {
// the first time we only have the new exchange
if (oldExchange == null) {
return newExchange;
}
if (oldExchange.getIn().getBody(int.class) < newExchange.getIn().getBody(int.class)) {
return oldExchange;
} else {
return newExchange;
}
}
}Static scatter-gather example
You can specify the recipients explicitly in the scatter-gather application by employing a static Section 8.3, “Recipient List”. The following example shows the routes you would use to implement a static scatter-gather scenario:
from("direct:start").multicast().to("seda:vendor1", "seda:vendor2", "seda:vendor3");
from("seda:vendor1").to("bean:vendor1").to("seda:quoteAggregator");
from("seda:vendor2").to("bean:vendor2").to("seda:quoteAggregator");
from("seda:vendor3").to("bean:vendor3").to("seda:quoteAggregator");
from("seda:quoteAggregator")
.aggregate(header("quoteRequestId"), new LowestQuoteAggregationStrategy()).to("mock:result")8.16. Loop
Loop
The loop pattern enables you to process a message multiple times. It is used mainly for testing.
By default, the loop uses the same exchange throughout the looping. The result from the previous iteration is used for the next (see Section 5.4, “Pipes and Filters”). From Camel 2.8 on you can enable copy mode instead. See the options table for details.
Exchange properties
On each loop iteration, two exchange properties are set, which can optionally be read by any processors included in the loop.
| Property | Description |
|---|---|
|
| Apache Camel 2.0: Total number of loops |
|
| Apache Camel 2.0: Index of the current iteration (0 based) |
Java DSL examples
The following examples show how to take a request from the direct:x endpoint and then send the message repeatedly to mock:result. The number of loop iterations is specified either as an argument to loop() or by evaluating an expression at run time, where the expression must evaluate to an int (or else a RuntimeCamelException is thrown).
The following example passes the loop count as a constant:
from("direct:a").loop(8).to("mock:result");The following example evaluates a simple expression to determine the loop count:
from("direct:b").loop(header("loop")).to("mock:result");The following example evaluates an XPath expression to determine the loop count:
from("direct:c").loop().xpath("/hello/@times").to("mock:result");XML configuration example
You can configure the same routes in Spring XML.
The following example passes the loop count as a constant:
<route>
<from uri="direct:a"/>
<loop>
<constant>8</constant>
<to uri="mock:result"/>
</loop>
</route>The following example evaluates a simple expression to determine the loop count:
<route>
<from uri="direct:b"/>
<loop>
<header>loop</header>
<to uri="mock:result"/>
</loop>
</route>Using copy mode
Now suppose we send a message to direct:start endpoint containing the letter A. The output of processing this route will be that, each mock:loop endpoint will receive AB as message.
from("direct:start")
// instruct loop to use copy mode, which mean it will use a copy of the input exchange
// for each loop iteration, instead of keep using the same exchange all over
.loop(3).copy()
.transform(body().append("B"))
.to("mock:loop")
.end()
.to("mock:result");
However if we do not enable copy mode then mock:loop will receive AB, ABB, ABBB messages.
from("direct:start")
// by default loop will keep using the same exchange so on the 2nd and 3rd iteration its
// the same exchange that was previous used that are being looped all over
.loop(3)
.transform(body().append("B"))
.to("mock:loop")
.end()
.to("mock:result");The equivalent example in XML DSL in copy mode is as follows:
<route>
<from uri="direct:start"/>
<!-- enable copy mode for loop eip -->
<loop copy="true">
<constant>3</constant>
<transform>
<simple>${body}B</simple>
</transform>
<to uri="mock:loop"/>
</loop>
<to uri="mock:result"/>
</route>Options
The loop DSL command supports the following options:
| Name | Default Value | Description |
|
|
|
Camel 2.8: Whether or not copy mode is used. If |
Do While Loop
You can perform the loop until a condition is met using a do while loop. The condition will either be true or false.
In DSL, the command is LoopDoWhile. The following example will perform the loop until the message body length is 5 characters or less:
from("direct:start")
.loopDoWhile(simple("${body.length} <= 5"))
.to("mock:loop")
.transform(body().append("A"))
.end()
.to("mock:result");
In XML, the command is loop doWhile. The following example also performs the loop until the message body length is 5 characters or less:
<route>
<from uri="direct:start"/>
<loop doWhile="true">
<simple>${body.length} <= 5</simple>
<to uri="mock:loop"/>
<transform>
<simple>A${body}</simple>
</transform>
</loop>
<to uri="mock:result"/>
</route>8.17. Sampling
Sampling Throttler
A sampling throttler allows you to extract a sample of exchanges from the traffic through a route. It is configured with a sampling period during which only a single exchange is allowed to pass through. All other exchanges will be stopped.
By default, the sample period is 1 second.
Java DSL example
Use the sample() DSL command to invoke the sampler as follows:
// Sample with default sampling period (1 second)
from("direct:sample")
.sample()
.to("mock:result");
// Sample with explicitly specified sample period
from("direct:sample-configured")
.sample(1, TimeUnit.SECONDS)
.to("mock:result");
// Alternative syntax for specifying sampling period
from("direct:sample-configured-via-dsl")
.sample().samplePeriod(1).timeUnits(TimeUnit.SECONDS)
.to("mock:result");
from("direct:sample-messageFrequency")
.sample(10)
.to("mock:result");
from("direct:sample-messageFrequency-via-dsl")
.sample().sampleMessageFrequency(5)
.to("mock:result");Spring XML example
In Spring XML, use the sample element to invoke the sampler, where you have the option of specifying the sampling period using the samplePeriod and units attributes:
<route>
<from uri="direct:sample"/>
<sample samplePeriod="1" units="seconds">
<to uri="mock:result"/>
</sample>
</route>
<route>
<from uri="direct:sample-messageFrequency"/>
<sample messageFrequency="10">
<to uri="mock:result"/>
</sample>
</route>
<route>
<from uri="direct:sample-messageFrequency-via-dsl"/>
<sample messageFrequency="5">
<to uri="mock:result"/>
</sample>
</route>Options
The sample DSL command supports the following options:
| Name | Default Value | Description |
|
| Samples the message every N’th message. You can only use either frequency or period. | |
|
|
| Samples the message every N’th period. You can only use either frequency or period. |
|
|
|
Time unit as an enum of |
8.18. Dynamic Router
Dynamic Router
The Dynamic Router pattern, as shown in Figure 8.12, “Dynamic Router Pattern”, enables you to route a message consecutively through a series of processing steps, where the sequence of steps is not known at design time. The list of endpoints through which the message should pass is calculated dynamically at run time. Each time the message returns from an endpoint, the dynamic router calls back on a bean to discover the next endpoint in the route.
Figure 8.12. Dynamic Router Pattern
In Camel 2.5 we introduced a dynamicRouter in the DSL, which is like a dynamic Section 8.7, “Routing Slip” that evaluates the slip on-the-fly.
You must ensure that the expression used for the dynamicRouter (such as a bean), returns null to indicate the end. Otherwise, the dynamicRouter continues in an endless loop.
Dynamic Router in Camel 2.5 onwards
From Camel 2.5, the Section 8.18, “Dynamic Router” updates the exchange property, Exchange.SLIP_ENDPOINT, with the current endpoint as it advances through the slip. This enables you to find out how far the exchange has progressed through the slip. (It’s a slip because the Section 8.18, “Dynamic Router” implementation is based on Section 8.7, “Routing Slip”).
Java DSL
In Java DSL you can use the dynamicRouter as follows:
from("direct:start")
// use a bean as the dynamic router
.dynamicRouter(bean(DynamicRouterTest.class, "slip"));Which will leverage a bean integration to compute the slip on-the-fly, which could be implemented as follows:
// Java
/**
* Use this method to compute dynamic where we should route next.
*
* @param body the message body
* @return endpoints to go, or <tt>null</tt> to indicate the end
*/
public String slip(String body) {
bodies.add(body);
invoked++;
if (invoked == 1) {
return "mock:a";
} else if (invoked == 2) {
return "mock:b,mock:c";
} else if (invoked == 3) {
return "direct:foo";
} else if (invoked == 4) {
return "mock:result";
}
// no more so return null
return null;
}
The preceding example is not thread safe. You would have to store the state on the Exchange to ensure thread safety.
Spring XML
The same example in Spring XML would be:
<bean id="mySlip" class="org.apache.camel.processor.DynamicRouterTest"/>
<camelContext xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:start"/>
<dynamicRouter>
<!-- use a method call on a bean as dynamic router -->
<method ref="mySlip" method="slip"/>
</dynamicRouter>
</route>
<route>
<from uri="direct:foo"/>
<transform><constant>Bye World</constant></transform>
<to uri="mock:foo"/>
</route>
</camelContext>Options
The dynamicRouter DSL command supports the following options:
| Name | Default Value | Description |
|
|
| Delimiter used if the Part II, “Routing Expression and Predicate Languages” returned multiple endpoints. |
|
|
| If an endpoint uri could not be resolved, should it be ignored. Otherwise Camel will thrown an exception stating the endpoint uri is not valid. |
@DynamicRouter annotation
You can also use the @DynamicRouter annotation. For example:
// Java
public class MyDynamicRouter {
@Consume(uri = "activemq:foo")
@DynamicRouter
public String route(@XPath("/customer/id") String customerId, @Header("Location") String location, Document body) {
// query a database to find the best match of the endpoint based on the input parameteres
// return the next endpoint uri, where to go. Return null to indicate the end.
}
}
The route method is invoked repeatedly as the message progresses through the slip. The idea is to return the endpoint URI of the next destination. Return null to indicate the end. You can return multiple endpoints if you like, just as the Section 8.7, “Routing Slip”, where each endpoint is separated by a delimiter.
Chapter 9. Saga EIP
9.1. Overview
The Saga EIP provides a way to define a series of related actions in a Camel route that can be either completed successfully or not executed or compensated. Saga implementations coordinate distributed services communicating using any transport towards a globally consistent outcome. Saga EIPs are different from classical ACID distributed (XA) transactions because the status of the different participating services is guaranteed to be consistent only at the end of the Saga and not in any intermediate step.
Saga EIPs are suitable for the use cases where usage of distributed transactions is discouraged. For example, services participating in a Saga are allowed to use any kind of datastore, such as classical databases or even NoSQL non-transactional datastores. They are also suitable for being used in stateless cloud services as they do not require a transaction log to be stored alongside the service. Saga EIPs are also not required to be completed in a small amount of time, because they don’t use database level locks, which is different from transactions. Hence they can live for a longer time span, from few seconds to several days.
Saga EIPs do not use locks on data. Instead they define the concept of Compensating Action, which is an action that should be executed when the standard flow encounters an error, with the purpose of restoring the status that was present before the flow execution. Compensating actions can be declared in Camel routes using the Java or XML DSL and are invoked by Camel only when needed (if the saga is canceled due to an error).
9.2. Saga EIP Options
The Saga EIP supports 6 options which are listed below:
| Name | Description | Default | Type |
|---|---|---|---|
| propagation | Set the Saga propagation mode (REQUIRED, REQUIRES_NEW, MANDATORY, SUPPORTS, NOT_SUPPORTED, NEVER). | REQUIRED | SagaPropagation |
| completionMode |
Determine how the Saga should be considered complete. When set to | AUTO | SagaCompletionMode |
| timeoutInMilliseconds | Set the maximum amount of time for the Saga. After the timeout is expired, the saga is compensated automatically (unless a different decision has been taken in the meantime). | Long | |
| compensation | The compensation endpoint URI that must be called to compensate all changes done in the route. The route corresponding to the compensation URI must perform compensation and complete without error. If error occurs during compensation, the Saga service calls the compensation URI again to retry. | SagaActionUri Definition | |
| completion | The completion endpoint URI that is called when the Saga is completed successfully. The route corresponding to the completion URI must perform completion tasks and terminate without error. If error occurs during completion, the Saga service calls the completion URI again to retry. | SagaActionUri Definition | |
| option | Allows to save properties of the current exchange in order to reuse them in a compensation or completion callback route. Options are usually helpful, for example, to store and retrieve identifiers of objects that are deleted in compensating actions. Option values are transformed into input headers of the compensation/completion exchange. | List |
9.3. Saga Service Configuration
The Saga EIP requires that a service implementing the interface org.apache.camel.saga.CamelSagaService is added to the Camel context. Camel currently supports the following Saga Service:
- InMemorySagaService: This is a basic implementation of the Saga EIP that does not support advanced features (no remote context propagation, no consistency guarantee in case of application failure).
9.3.1. Using the In-Memory Saga Service
The In-memory Saga service is not recommended for production environments as it does not support persistence of the Saga status (it is kept only in-memory), so it cannot guarantee consistency of the Saga EIPs in case of application failure (for example, JVM crash). Also, when using a in-memory Saga service, Saga contexts cannot be propagated to remote services using transport-level headers (it can be done with other implementations). You can add the following code to customize the Camel context when you want to use the in-memory saga service. The service belongs to the camel-core module.
context.addService(new org.apache.camel.impl.saga.InMemorySagaService());
9.4. Examples
For example, you want to place a new order and you have two distinct services in your system: one managing the orders and one managing the credit. Logically you can place a order if you have enough credit for it. With the Saga EIP you can model the direct:buy route as a Saga composed of two distinct actions, one to create the order and one to take the credit. Both actions must be executed, or none of them as an order placed without credit can be considered a inconsistent outcome (as well as a payment without an order).
from("direct:buy")
.saga()
.to("direct:newOrder")
.to("direct:reserveCredit");The buy action does not change for the rest of the examples. Different options that are used to model the New Order and Reserve Credit action are as follows:
from("direct:newOrder")
.saga()
.propagation(SagaPropagation.MANDATORY)
.compensation("direct:cancelOrder")
.transform().header(Exchange.SAGA_LONG_RUNNING_ACTION)
.bean(orderManagerService, "newOrder")
.log("Order ${body} created");Here the propagation mode is set to MANDATORY meaning that any exchange flowing in this route must be already part of a Saga (and it is the case in this example, since the Saga is created in the direct:buy route). The direct:newOrder route declares a compensating action that is called direct:cancelOrder, responsible for undoing the order in case the Saga is canceled.
Each exchange always contains a Exchange.SAGA_LONG_RUNNING_ACTION header that is used here as the id of the order. This identifies the order to delete in the corresponding compensating action, but it is not a requirement (options can be used as alternative solution). The compensating action of direct:newOrder is direct:cancelOrder and it is shown below:
from("direct:cancelOrder")
.transform().header(Exchange.SAGA_LONG_RUNNING_ACTION)
.bean(orderManagerService, "cancelOrder")
.log("Order ${body} cancelled");It is called automatically by the Saga EIP implementation when the order should be cancelled. It does not terminate with an error. In case an error is thrown in the direct:cancelOrder route, the EIP implementation should periodically retry to execute the compensating action up to a certain limit. This means that any compensating action must be idempotent, so it should take into account that it may be triggered multiple times and should not fail in any case. If compensation cannot be done after all retries, a manual intervention process should be triggered by the Saga implementation.
It may happen that due to a delay in the execution of the direct:newOrder route the Saga is cancelled by another party in the meantime (due to an error in a parallel route or a timeout at Saga level). So, when the compensating action direct:cancelOrder is called, it may not find the Order record that is cancelled. It is important, in order to guarantee full global consistency, that any main action and its corresponding compensating action are commutative, for example, if compensation occurs before the main action it should have the same effect.
Another possible approach, when using a commutative behavior is not possible, is to consistently fail in the compensating action until data produced by the main action is found (or the maximum number of retries is exhausted). This approach may work in many contexts, but it’s heuristic.
The credit service is implemented almost in the same way as the order service.
from("direct:reserveCredit")
.saga()
.propagation(SagaPropagation.MANDATORY)
.compensation("direct:refundCredit")
.transform().header(Exchange.SAGA_LONG_RUNNING_ACTION)
.bean(creditService, "reserveCredit")
.log("Credit ${header.amount} reserved in action ${body}");Call on compensation action:
from("direct:refundCredit")
.transform().header(Exchange.SAGA_LONG_RUNNING_ACTION)
.bean(creditService, "refundCredit")
.log("Credit for action ${body} refunded");Here the compensating action for a credit reservation is a refund. This example can be run with both implementations of the Saga EIP, as it does not involve remote endpoints.
9.4.1. Handling Completion Events
Some type of processing is required when the Saga is completed. Compensation endpoints are invoked when something wrong happens and the Saga is cancelled. The completion endpoints can be invoked to do further processing when the Saga is completed successfully. For example, in the order service above, we may need to know when the order is completed (and the credit reserved) to actually start preparing the order. We do not want to start to prepare the order if the payment is not done (unlike most modern CPUs that give you access to reserved memory before ensuring that you have rights to read it). This can be done easily with a modified version of the direct:newOrder endpoint:
- Invoke completeion endpoint:
from("direct:newOrder")
.saga()
.propagation(SagaPropagation.MANDATORY)
.compensation("direct:cancelOrder")
.completion("direct:completeOrder")
.transform().header(Exchange.SAGA_LONG_RUNNING_ACTION)
.bean(orderManagerService, "newOrder")
.log("Order ${body} created");- The direct:cancelOrder is the same as in the previous example. Call on the successful completion as follows:
from("direct:completeOrder")
.transform().header(Exchange.SAGA_LONG_RUNNING_ACTION)
.bean(orderManagerService, "findExternalId")
.to("jms:prepareOrder")
.log("Order ${body} sent for preparation");When the Saga is completed, the order is sent to a JMS queue for preparation. Like compensating actions, also completion actions may be called multiple times by the Saga coordinator (especially in case of errors, like network errors). In this example, the service listening to the prepareOrder JMS queue is prepared to hold possible duplicates (see the Idempotent Consumer EIP for examples on how to handle duplicates).
9.4.2. Using Custom Identifiers and Options
You can use Saga options to register custom identifiers. For example, the credit service is refactored as follows:
- Generate a custom ID and set it in the body as follows:
from("direct:reserveCredit")
.bean(idService, "generateCustomId")
.to("direct:creditReservation")- Delegate action and mark the current body as needed in the compensating action.
from("direct:creditReservation")
.saga()
.propagation(SagaPropagation.SUPPORTS)
.option("CreditId", body())
.compensation("direct:creditRefund")
.bean(creditService, "reserveCredit")
.log("Credit ${header.amount} reserved. Custom Id used is ${body}");- Retrieve the CreditId option from the headers only if the saga is cancelled.
from("direct:creditRefund")
.transform(header("CreditId")) // retrieve the CreditId option from headers
.bean(creditService, "refundCredit")
.log("Credit for Custom Id ${body} refunded");The direct:creditReservation endpoint can be called outside of the Saga, by setting the propagation mode to SUPPORTS. This way multiple options can be declared in a Saga route.
9.4.3. Setting Timeouts
Setting timeouts on Saga EIPs guarantees that a Saga does not remain stuck forever in the case of machine failure. The Saga EIP implementation has a default timeout set on all Saga EIPs that do not specify it explicitly. When the timeout expires, the Saga EIP will decide to cancel the Saga (and compensate all participants), unless a different decision has been taken before.
Timeouts can be set on Saga participants as follows:
from("direct:newOrder")
.saga()
.timeout(1, TimeUnit.MINUTES) // newOrder requires that the saga is completed within 1 minute
.propagation(SagaPropagation.MANDATORY)
.compensation("direct:cancelOrder")
.completion("direct:completeOrder")
// ...
.log("Order ${body} created");All participants (for example, credit service, order service) can set their own timeout. The minimum value of those timeouts is taken as timeout for the saga when they are composed together. A timeout can also be specified at the Saga level as follows:
from("direct:buy")
.saga()
.timeout(5, TimeUnit.MINUTES) // timeout at saga level
.to("direct:newOrder")
.to("direct:reserveCredit");9.4.4. Choosing Propagation
The examples above uses the MANDATORY , SUPPORTS, and REQUIRED propagation modes, which is the default propagation used when nothing else is specified. These propagation modes map 1:1 the equivalent modes used in transactional contexts.
| Propagation | Description |
|---|---|
|
| Join the existing Saga or create a new one if it does not exist. |
|
| Always create a new Saga. Suspend the old Saga and resume it when the new one terminates. |
|
| A Saga must be already present. The existing Saga is joined. |
|
| If a Saga already exists, then join it. |
|
| If a Saga already exists, it is suspended and resumed when the current block completes. |
|
| The current block must never be invoked within a Saga. |
9.4.5. Using Manual Completion (Advanced)
When a Saga cannot be all executed in a synchronous way, but it requires, for example, communication with external services using asynchronous communication channels, then the completion mode cannot be set to AUTO (default), because the Saga is not completed when the exchange that creates it is done. This is often the case for the Saga EIPs that have long execution times (hours, days). In these cases, the MANUAL completion mode should be used.
from("direct:mysaga")
.saga()
.completionMode(SagaCompletionMode.MANUAL)
.completion("direct:finalize")
.timeout(2, TimeUnit.HOURS)
.to("seda:newOrder")
.to("seda:reserveCredit");Add the asynchronous processing for seda:newOrder and seda:reserveCredit. These send the asynchronous callbacks to seda:operationCompleted.
from("seda:operationCompleted") // an asynchronous callback
.saga()
.propagation(SagaPropagation.MANDATORY)
.bean(controlService, "actionExecuted")
.choice()
.when(body().isEqualTo("ok"))
.to("saga:complete") // complete the current saga manually (saga component)
.end()You can add the direct:finalize endpoint to execute final actions.
Setting the completion mode to MANUAL means that the Saga is not completed when the exchange is processed in the route direct:mysaga but it will last longer (max duration is set to 2 hours). When both asynchronous actions are completed the Saga is completed. The call to complete is done using the Camel Saga Component’s saga:complete endpoint. There is a similar endpoint for manually compensating the Saga (saga:compensate).
9.5. XML Configuration
Saga features are available for users that want to use the XML configuration. The following snippet shows an example:
<route>
<from uri="direct:start"/>
<saga>
<compensation uri="direct:compensation" />
<completion uri="direct:completion" />
<option optionName="myOptionKey">
<constant>myOptionValue</constant>
</option>
<option optionName="myOptionKey2">
<constant>myOptionValue2</constant>
</option>
</saga>
<to uri="direct:action1" />
<to uri="direct:action2" />
</route>Chapter 10. Message Transformation
Abstract
The message transformation patterns describe how to modify the contents of messages for various purposes.
10.1. Content Enricher
Overview
The content enricher pattern describes a scenario where the message destination requires more data than is present in the original message. In this case, you would use a message translator, an arbitrary processor in the routing logic, or a content enricher method to pull in the extra data from an external resource.
Figure 10.1. Content Enricher Pattern
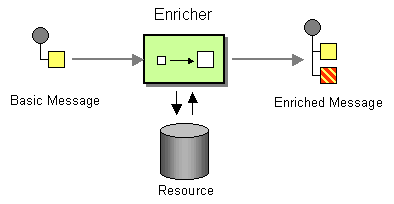
Alternatives for enriching content
Apache Camel supports several ways to enrich content:
- Message translator with arbitrary processor in the routing logic
-
The
enrich()method obtains additional data from the resource by sending a copy of the current exchange to a producer endpoint and then using the data in the resulting reply. The exchange created by the enricher is always an InOut exchange. -
The
pollEnrich()method obtains additional data by polling a consumer endpoint for data. Effectively, the consumer endpoint from the main route and the consumer endpoint inpollEnrich()operation are coupled. That is, an incoming message on the initial consumer in the route triggers thepollEnrich()method on the consumer to be polled.
The enrich() and pollEnrich() methods support dynamic endpoint URIs. You can compute URIs by specifying an expression that enables you to obtain values from the current exchange. For example, you can poll a file with a name that is computed from the data exchange. This behavior was introduced in Camel 2.16. This change breaks the XML DSL and enables you to migrate easily. The Java DSL stays backwards compatible.
Using message translators and processors to enrich content
Camel provides fluent builders for creating routing and mediation rules using a type-safe IDE-friendly way that provides smart completion and is refactoring safe. When you are testing distributed systems it is a very common requirement to have to stub out certain external systems so that you can test other parts of the system until a specific system is available or written. One way to do this is to use some kind of template system to generate responses to requests by generating a dynamic message that has a mostly-static body. Another way to use templates is to consume a message from one destination, transform it with something like Velocity or XQuery, and then send it to another destination. The following example shows this for an InOnly (one way) message:
from("activemq:My.Queue").
to("velocity:com/acme/MyResponse.vm").
to("activemq:Another.Queue");
Suppose you want to use InOut (request-reply) messaging to process requests on the My.Queue queue on ActiveMQ. You want a template-generated response that goes to a JMSReplyTo destination. The following example shows how to do this:
from("activemq:My.Queue").
to("velocity:com/acme/MyResponse.vm");The following simple example shows how to use DSL to transform the message body:
from("direct:start").setBody(body().append(" World!")).to("mock:result");The following example uses explicit Java code to add a processor:
from("direct:start").process(new Processor() {
public void process(Exchange exchange) {
Message in = exchange.getIn();
in.setBody(in.getBody(String.class) + " World!");
}
}).to("mock:result");The next example uses bean integration to enable the use of any bean to act as the transformer:
from("activemq:My.Queue").
beanRef("myBeanName", "myMethodName").
to("activemq:Another.Queue");The following example shows a Spring XML implementation:
<route> <from uri="activemq:Input"/> <bean ref="myBeanName" method="doTransform"/> <to uri="activemq:Output"/> </route>/>
Using the enrich() method to enrich content
AggregationStrategy aggregationStrategy = ...
from("direct:start")
.enrich("direct:resource", aggregationStrategy)
.to("direct:result");
from("direct:resource")
...
The content enricher (enrich) retrieves additional data from a resource endpoint in order to enrich an incoming message (contained in the orginal exchange). An aggregation strategy combines the original exchange and the resource exchange. The first parameter of the AggregationStrategy.aggregate(Exchange, Exchange) method corresponds to the the original exchange, and the second parameter corresponds to the resource exchange. The results from the resource endpoint are stored in the resource exchange’s Out message. Here is a sample template for implementing your own aggregation strategy class:
public class ExampleAggregationStrategy implements AggregationStrategy {
public Exchange aggregate(Exchange original, Exchange resource) {
Object originalBody = original.getIn().getBody();
Object resourceResponse = resource.getOut().getBody();
Object mergeResult = ... // combine original body and resource response
if (original.getPattern().isOutCapable()) {
original.getOut().setBody(mergeResult);
} else {
original.getIn().setBody(mergeResult);
}
return original;
}
}Using this template, the original exchange can have any exchange pattern. The resource exchange created by the enricher is always an InOut exchange.
Spring XML enrich example
The preceding example can also be implemented in Spring XML:
<camelContext id="camel" xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:start"/>
<enrich strategyRef="aggregationStrategy">
<constant>direct:resource</constant>
<to uri="direct:result"/>
</route>
<route>
<from uri="direct:resource"/>
...
</route>
</camelContext>
<bean id="aggregationStrategy" class="..." />Default aggregation strategy when enriching content
The aggregation strategy is optional. If you do not provide it, Apache Camel will use the body obtained from the resource by default. For example:
from("direct:start")
.enrich("direct:resource")
.to("direct:result");
In the preceding route, the message sent to the direct:result endpoint contains the output from the direct:resource, because this example does not use any custom aggregation.
In XML DSL, just omit the strategyRef attribute, as follows:
<route>
<from uri="direct:start"/>
<enrich uri="direct:resource"/>
<to uri="direct:result"/>
</route>Options supported by the enrich() method
The enrich DSL command supports the following options:
| Name | Default Value | Description |
|
| None | Starting with Camel 2.16, this option is required. Specify an expression for configuring the URI of the external service to enrich from. You can use the Simple expression language, the Constant expression language, or any other language that can dynamically compute the URI from values in the current exchange. |
|
|
These options have been removed. Specify the | |
|
|
Refers to the endpoint for the external service to enrich from. You must use either | |
|
|
Refers to an AggregationStrategy to be used to merge the reply from the external service into a single outgoing message. By default, Camel uses the reply from the external service as the outgoing message. You can use a POJO as the | |
|
|
When using POJOs as the | |
|
| false |
The default behavior is that the aggregate method is not used if there is no data to enrich. If this option is true then null values are used as the |
|
| false |
The default behavior is that the aggregate method is not used if there was an exception thrown while trying to retrieve the data to enrich from the resource. Setting this option to |
|
| false | Starting with Camel 2.16, the default behavior is that the enrich operation does not share the unit of work between the parent exchange and the resource exchange. This means that the resource exchange has its own individual unit of work. For more information, see the documentation for the Splitter pattern. |
|
|
|
Starting with Camel 2.16, specify this option to configure the cache size for the |
|
| false | Starting with Camel 2.16, this option indicates whether or not to ignore an endpoint URI that cannot be resolved. The default behavior is that Camel throws an exception that identifies the invalid endpoint URI. |
Specifying an aggregation strategy when using the enrich() method
The enrich() method retrieves additional data from a resource endpoint to enrich an incoming message, which is contained in the original exchange. You can use an aggregation strategy to combine the original exchange and the resource exchange. The first parameter of the AggregationStrategy.aggregate(Exchange, Exchange) method corresponds to the original exchange. The second parameter corresponds to the resource exchange. The results from the resource endpoint are stored in the resource exchange’s Out message. For example:
AggregationStrategy aggregationStrategy = ...
from("direct:start")
.enrich("direct:resource", aggregationStrategy)
.to("direct:result");
from("direct:resource")
...The following code is a template for implementing an aggregation strategy. In an implementation that uses this template, the original exchange can be any message exchange pattern. The resource exchange created by the enricher is always an InOut message exchange pattern.
public class ExampleAggregationStrategy implements AggregationStrategy {
public Exchange aggregate(Exchange original, Exchange resource) {
Object originalBody = original.getIn().getBody();
Object resourceResponse = resource.getIn().getBody();
Object mergeResult = ... // combine original body and resource response
if (original.getPattern().isOutCapable()) {
original.getOut().setBody(mergeResult);
} else {
original.getIn().setBody(mergeResult);
}
return original;
}
}The following example shows the use of the Spring XML DSL to implement an aggregation strategy:
<camelContext id="camel" xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:start"/>
<enrich strategyRef="aggregationStrategy">
<constant>direct:resource</constant>
</enrich>
<to uri="direct:result"/>
</route>
<route>
<from uri="direct:resource"/>
...
</route>
</camelContext>
<bean id="aggregationStrategy" class="..." />Using dynamic URIs with enrich()
Starting with Camel 2.16, the enrich() and pollEnrich() methods support the use of dynamic URIs that are computed based on information from the current exchange. For example, to enrich from an HTTP endpoint where the header with the orderId key is used as part of the content path of the HTTP URL, you can do something like this:
from("direct:start")
.enrich().simple("http:myserver/${header.orderId}/order")
.to("direct:result");Following is the same example in XML DSL:
<camelContext id="camel" xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:start"/>
<enrich>
<simple>http:myserver/${header.orderId}/order</simple>
</enrich>
<to uri="direct:result"/>
</route>Using the pollEnrich() method to enrich content
The pollEnrich command treats the resource endpoint as a consumer. Instead of sending an exchange to the resource endpoint, it polls the endpoint. By default, the poll returns immediately, if there is no exchange available from the resource endpoint. For example, the following route reads a file whose name is extracted from the header of an incoming JMS message:
from("activemq:queue:order")
.pollEnrich("file://order/data/additional?fileName=orderId")
.to("bean:processOrder");You can limit the time to wait for the file to be ready. The following example shows a maximum wait of 20 seconds:
from("activemq:queue:order")
.pollEnrich("file://order/data/additional?fileName=orderId", 20000) // timeout is in milliseconds
.to("bean:processOrder");
You can also specify an aggregation strategy for pollEnrich(), for example:
.pollEnrich("file://order/data/additional?fileName=orderId", 20000, aggregationStrategy)
The pollEnrich() method supports consumers that are configured with consumer.bridgeErrorHandler=true. This lets any exceptions from the poll propagate to the route error handler, which could, for example, retry the poll.
Support for consumer.bridgeErrorHandler=true is new in Camel 2.18. This behavior is not supported in Camel 2.17.
The resource exchange passed to the aggregation strategy’s aggregate() method might be null if the poll times out before an exchange is received.
Polling methods used by pollEnrich()
The pollEnrich() method polls the consumer endpoint by calling one of the following polling methods:
-
receiveNoWait()(This is the default.) -
receive() -
receive(long timeout)
The pollEnrich() command’s timeout argument (specified in milliseconds) determines which method to call, as follows:
-
When the timeout is
0or not specified,pollEnrich()callsreceiveNoWait. -
When the timeout is negative,
pollEnrich()callsreceive. -
Otherwise,
pollEnrich()callsreceive(timeout).
If there is no data then the newExchange in the aggregation strategy is null.
Examples of using the pollEnrich() method
The following example shows enrichment of the message by loading the content from the inbox/data.txt file:
from("direct:start")
.pollEnrich("file:inbox?fileName=data.txt")
.to("direct:result");Following is the same example in XML DSL:
<route>
<from uri="direct:start"/>
<pollEnrich>
<constant>file:inbox?fileName=data.txt"</constant>
</pollEnrich>
<to uri="direct:result"/>
</route>If the specified file does not exist then the message is empty. You can specify a timeout to wait (potentially forever) until a file exists or to wait up to a particular length of time. In the following example, the command waits no more than 5 seconds:
<route>
<from uri="direct:start"/>
<pollEnrich timeout="5000">
<constant>file:inbox?fileName=data.txt"</constant>
</pollEnrich>
<to uri="direct:result"/>
</route>Using dynamic URIs with pollEnrich()
Starting with Camel 2.16, the enrich() and pollEnrich() methods support the use of dynamic URIs that are computed based on information from the current exchange. For example, to poll enrich from an endpoint that uses a header to indicate a SEDA queue name, you can do something like this:
from("direct:start")
.pollEnrich().simple("seda:${header.name}")
.to("direct:result");Following is the same example in XML DSL:
<route>
<from uri="direct:start"/>
<pollEnrich>
<simple>seda${header.name}</simple>
</pollEnrich>
<to uri="direct:result"/>
</route>Options supported by the pollEnrich() method
The pollEnrich DSL command supports the following options:
| Name | Default Value | Description |
|
| None | Starting with Camel 2.16, this option is required. Specify an expression for configuring the URI of the external service to enrich from. You can use the Simple expression language, the Constant expression language, or any other language that can dynamically compute the URI from values in the current exchange. |
|
|
These options have been removed. Specify the | |
|
|
Refers to the endpoint for the external service to enrich from. You must use either | |
|
|
Refers to an AggregationStrategy to be used to merge the reply from the external service into a single outgoing message. By default, Camel uses the reply from the external service as the outgoing message. You can use a POJO as the | |
|
|
When using POJOs as the | |
|
| false |
The default behavior is that the aggregate method is not used if there is no data to enrich. If this option is true then null values are used as the |
|
|
|
The maximum length of time, in milliseconds, to wait for a response when polling from the external service. The default behavior is that the |
|
| false |
The default behavior is that the aggregate method is not used if there was an exception thrown while trying to retrieve the data to enrich from the resource. Setting this option to |
|
|
|
Specify this option to configure the cache size for the |
|
| false | Indicates whether or not to ignore an endpoint URI that cannot be resolved. The default behavior is that Camel throws an exception that identifies the invalid endpoint URI. |
10.2. Content Filter
Overview
The content filter pattern describes a scenario where you need to filter out extraneous content from a message before delivering it to its intended recipient. For example, you might employ a content filter to strip out confidential information from a message.
Figure 10.2. Content Filter Pattern
A common way to filter messages is to use an expression in the DSL, written in one of the supported scripting languages (for example, XSLT, XQuery or JoSQL).
Implementing a content filter
A content filter is essentially an application of a message processing technique for a particular purpose. To implement a content filter, you can employ any of the following message processing techniques:
- Message translator — see Section 5.6, “Message Translator”.
- Processors — see Chapter 35, Implementing a Processor.
- Bean integration.
XML configuration example
The following example shows how to configure the same route in XML:
<camelContext xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="activemq:My.Queue"/>
<to uri="xslt:classpath:com/acme/content_filter.xsl"/>
<to uri="activemq:Another.Queue"/>
</route>
</camelContext>Using an XPath filter
You can also use XPath to filter out part of the message you are interested in:
<route> <from uri="activemq:Input"/> <setBody><xpath resultType="org.w3c.dom.Document">//foo:bar</xpath></setBody> <to uri="activemq:Output"/> </route>
10.3. Normalizer
Overview
The normalizer pattern is used to process messages that are semantically equivalent, but arrive in different formats. The normalizer transforms the incoming messages into a common format.
In Apache Camel, you can implement the normalizer pattern by combining a Section 8.1, “Content-Based Router”, which detects the incoming message’s format, with a collection of different Section 5.6, “Message Translator”, which transform the different incoming formats into a common format.
Figure 10.3. Normalizer Pattern
Java DSL example
This example shows a Message Normalizer that converts two types of XML messages into a common format. Messages in this common format are then filtered.
Using the Fluent Builders
// we need to normalize two types of incoming messages
from("direct:start")
.choice()
.when().xpath("/employee").to("bean:normalizer?method=employeeToPerson")
.when().xpath("/customer").to("bean:normalizer?method=customerToPerson")
.end()
.to("mock:result");In this case we’re using a Java bean as the normalizer. The class looks like this
// Java
public class MyNormalizer {
public void employeeToPerson(Exchange exchange, @XPath("/employee/name/text()") String name) {
exchange.getOut().setBody(createPerson(name));
}
public void customerToPerson(Exchange exchange, @XPath("/customer/@name") String name) {
exchange.getOut().setBody(createPerson(name));
}
private String createPerson(String name) {
return "<person name=\"" + name + "\"/>";
}
}XML configuration example
The same example in the XML DSL
<camelContext xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:start"/>
<choice>
<when>
<xpath>/employee</xpath>
<to uri="bean:normalizer?method=employeeToPerson"/>
</when>
<when>
<xpath>/customer</xpath>
<to uri="bean:normalizer?method=customerToPerson"/>
</when>
</choice>
<to uri="mock:result"/>
</route>
</camelContext>
<bean id="normalizer" class="org.apache.camel.processor.MyNormalizer"/>10.4. Claim Check EIP
Claim Check EIP
The claim check EIP pattern, shown in Figure 10.4, “Claim Check Pattern”, allows you to replace the message content with a claim check (a unique key). Use the claim check EIP pattern to retrieve the message content at a later time. You can store the message content temporarily in a persistent store like a database or file system. This pattern is useful when the message content is very large (and, expensive to send around) and not all components require all the information.
It can also be useful when you cannot trust the information with an outside party. In this case, use the Claim Check to hide the sensitive portions of data.
The Camel implementation of the EIP pattern stores the message content temporarily in an internal memory store.
Figure 10.4. Claim Check Pattern
10.4.1. Claim Check EIP Options
The Claim Check EIP supports the options listed in the following table:
| Name | Description | Default | Type |
| operation | Need to use the claim check operation. It supports the following operations:
*
*
*
*
*
When using the | ClaimCheckOperation | |
| key | To use a specific key for claim check-id. | String | |
| filter | Specify a filter to control the data that you want to merge back from the claim check repository. | String | |
| strategyRef |
To use a custom | String |
Filter Option
Use the Filter option to define the data to merge back when using the Get or the Pop operations. Merge the data back by using an AggregationStrategy. The default strategy uses the filter option to easily specify the data to be merged back.
The filter option takes a String value with the following syntax:
-
body: To aggregate the message body -
attachments: To aggregate all the message attachments -
headers: To aggregate all the message headers -
header:pattern: To aggregate all the message headers that match the pattern
The pattern rule supports wildcard and regular expression.
-
Wildcard match (pattern ends with a
*and the name starts with the pattern) - Regular expression match
To specify multiple rules, separate them by commas (,).
Following are the basic filter examples to include the message body and all headers starting with foo:
body, header:foo*
-
To merge the message body only:
body -
To merge the message attachments only:
attachments -
To merge headers only:
headers -
To merge a header name
fooonly:header:foo
If you specify the filter rule as empty or as wildcard, you can merge everything. For more information, see Filter what data to merge back.
When you merge the data back, the system overwrites any existing data. Also, it stores the existing data.
10.4.2. Filter Option with Include and Exclude Pattern
Following is the syntax that supports the prefixes that you can use to specify include,exclude, or remove options.
- + : to include (which is the default mode)
- - : to exclude (exclude takes precedence over include)
- -- : to remove (remove takes precedence)
For example:
-
To skip the message body and mergemeverything else, use-
-body -
To skip the message header
fooand merge everything else, use--header:foo
You can also instruct the system to remove headers when merging the data. For example, to remove all headers starting with bar, use- --headers:bar*.
Do not use both the include (+) and exclude (-) header:pattern at the same time.
10.4.3. Java Examples
The following example shows the Push and Pop operations in action:
from("direct:start")
.to("mock:a")
.claimCheck(ClaimCheckOperation.Push)
.transform().constant("Bye World")
.to("mock:b")
.claimCheck(ClaimCheckOperation.Pop)
.to("mock:c");
Following is an example of using the Get and Set operations. The example, uses the foo key.
from("direct:start")
.to("mock:a")
.claimCheck(ClaimCheckOperation.Set, "foo")
.transform().constant("Bye World")
.to("mock:b")
.claimCheck(ClaimCheckOperation.Get, "foo")
.to("mock:c")
.transform().constant("Hi World")
.to("mock:d")
.claimCheck(ClaimCheckOperation.Get, "foo")
.to("mock:e");
You can get the same data twice using the Get operation because it does not remove the data. However, if you want to get the data only once, use GetAndRemove operation.
The following example shows how to use the filter option where you only want to get back header as foo or bar.
from("direct:start")
.to("mock:a")
.claimCheck(ClaimCheckOperation.Push)
.transform().constant("Bye World")
.setHeader("foo", constant(456))
.removeHeader("bar")
.to("mock:b")
// only merge in the message headers foo or bar
.claimCheck(ClaimCheckOperation.Pop, null, "header:(foo|bar)")
.to("mock:c");10.4.4. XML Examples
The following example shows the Push and Pop operations in action.
<route>
<from uri="direct:start"/>
<to uri="mock:a"/>
<claimCheck operation="Push"/>
<transform>
<constant>Bye World</constant>
</transform>
<to uri="mock:b"/>
<claimCheck operation="Pop"/>
<to uri="mock:c"/>
</route>
Following is an example of using the Get and Set operations. The example, uses the foo key.
<route>
<from uri="direct:start"/>
<to uri="mock:a"/>
<claimCheck operation="Set" key="foo"/>
<transform>
<constant>Bye World</constant>
</transform>
<to uri="mock:b"/>
<claimCheck operation="Get" key="foo"/>
<to uri="mock:c"/>
<transform>
<constant>Hi World</constant>
</transform>
<to uri="mock:d"/>
<claimCheck operation="Get" key="foo"/>
<to uri="mock:e"/>
</route>
You can get the same data twice by using the Get operation because it does not remove the data. However, if you want to get the data once, you can use GetAndRemove operation.
The following example shows how to use the filter option to get back the header as foo or bar.
<route>
<from uri="direct:start"/>
<to uri="mock:a"/>
<claimCheck operation="Push"/>
<transform>
<constant>Bye World</constant>
</transform>
<setHeader headerName="foo">
<constant>456</constant>
</setHeader>
<removeHeader headerName="bar"/>
<to uri="mock:b"/>
<!-- only merge in the message headers foo or bar -->
<claimCheck operation="Pop" filter="header:(foo|bar)"/>
<to uri="mock:c"/>
</route>10.5. Sort
Sort
The sort pattern is used to sort the contents of a message body, assuming that the message body contains a list of items that can be sorted.
By default, the contents of the message are sorted using a default comparator that handles numeric values or strings. You can provide your own comparator and you can specify an expression that returns the list to be sorted (the expression must be convertible to java.util.List).
Java DSL example
The following example generates the list of items to sort by tokenizing on the line break character:
from("file://inbox").sort(body().tokenize("\n")).to("bean:MyServiceBean.processLine");
You can pass in your own comparator as the second argument to sort():
from("file://inbox").sort(body().tokenize("\n"), new MyReverseComparator()).to("bean:MyServiceBean.processLine");XML configuration example
You can configure the same routes in Spring XML.
The following example generates the list of items to sort by tokenizing on the line break character:
<route>
<from uri="file://inbox"/>
<sort>
<simple>body</simple>
</sort>
<beanRef ref="myServiceBean" method="processLine"/>
</route>And to use a custom comparator, you can reference it as a Spring bean:
<route>
<from uri="file://inbox"/>
<sort comparatorRef="myReverseComparator">
<simple>body</simple>
</sort>
<beanRef ref="MyServiceBean" method="processLine"/>
</route>
<bean id="myReverseComparator" class="com.mycompany.MyReverseComparator"/>
Besides <simple>, you can supply an expression using any language you like, so long as it returns a list.
Options
The sort DSL command supports the following options:
| Name | Default Value | Description |
|
|
Refers to a custom |
10.6. Transformer
Transformer performs declarative transformation of the message according to the declared Input Type and/or Output Type on a route definition. The default camel message implements DataTypeAware, which holds the message type represented by DataType.
10.6.1. How the Transformer works?
The route definition declares the Input Type and/or Output Type. If the Input Type and/or Output Type are different from the message type at runtime, the camel internal processor looks for a Transformer. The Transformer transforms the current message type to the expected message type. Once the message is transformed successfully or if the message is already in expected type, then the message data type is updated.
10.6.1.1. Data type format
The format for the data type is scheme:name, where scheme is the type of data model such as java, xml or json and name is the data type name.
If you only specify scheme then it matches all the data types with that scheme.
10.6.1.2. Supported Transformers
| Transformer | Description |
|---|---|
| Data Format Transformer | Transforms by using Data Format |
| Endpoint Transformer | Transforms by using Endpoint |
| Custom Transformer | Transforms by using custom transformer class. |
10.6.1.3. Common Options
All transformers have the following common options to specify the supported data type by the transformer.
Either scheme or both fromType and toType must be specified.
| Name | Description |
|---|---|
| scheme |
Type of data model such as |
| fromType | Data type to transform from. |
| toType | Data type to transform to. |
10.6.1.4. DataFormat Transformer Options
| Name | Description |
|---|---|
| type | Data Format type |
| ref | Reference to the Data Format ID |
An example to specify bindy DataFormat type:
Java DSL:
BindyDataFormat bindy = new BindyDataFormat();
bindy.setType(BindyType.Csv);
bindy.setClassType(com.example.Order.class);
transformer()
.fromType(com.example.Order.class)
.toType("csv:CSVOrder")
.withDataFormat(bindy);XML DSL:
<dataFormatTransformer fromType="java:com.example.Order" toType="csv:CSVOrder">
<bindy id="csvdf" type="Csv" classType="com.example.Order"/>
</dataFormatTransformer>10.6.2. Endpoint Transformer Options
| Name | Description |
|---|---|
| ref | Reference to the Endpoint ID |
| uri | Endpoint URI |
An example to specify endpoint URI in Java DSL:
transformer()
.fromType("xml")
.toType("json")
.withUri("dozer:myDozer?mappingFile=myMapping.xml...");An example to specify endpoint ref in XML DSL:
<transformers> <endpointTransformer ref="myDozerEndpoint" fromType="xml" toType="json"/> </transformers>
10.6.3. Custom Transformer Options
Transformer must be a subclass of org.apache.camel.spi.Transformer
| Name | Description |
|---|---|
| ref | Reference to the custom Transformer bean ID |
| className | Fully qualified class name of the custom Transformer class |
An example to specify custom Transformer class:
Java DSL:
transformer()
.fromType("xml")
.toType("json")
.withJava(com.example.MyCustomTransformer.class);XML DSL:
<transformers> <customTransformer className="com.example.MyCustomTransformer" fromType="xml" toType="json"/> </transformers>
10.6.4. Transformer Example
This example is in two parts, the first part declares the Endpoint Transformer which transforms the message. The second part shows how the transformer is applied to a route.
10.6.4.1. Part I
Declares the Endpoint Transformer which uses xslt component to transform from xml:ABCOrder to xml:XYZOrder.
Java DSL:
transformer()
.fromType("xml:ABCOrder")
.toType("xml:XYZOrder")
.withUri("xslt:transform.xsl");XML DSL:
<camelContext id="camel" xmlns="http://camel.apache.org/schema/spring">
<transformers>
<endpointTransformer uri="xslt:transform.xsl" fromType="xml:ABCOrder" toType="xml:XYZOrder"/>
</transformers>
....
</camelContext>10.6.4.2. Part II
The above transformer is applied to the following route definition when direct:abc endpoint sends the message to direct:xyz:
Java DSL:
from("direct:abc")
.inputType("xml:ABCOrder")
.to("direct:xyz");
from("direct:xyz")
.inputType("xml:XYZOrder")
.to("somewhere:else");XML DSL:
<camelContext id="camel" xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:abc"/>
<inputType urn="xml:ABCOrder"/>
<to uri="direct:xyz"/>
</route>
<route>
<from uri="direct:xyz"/>
<inputType urn="xml:XYZOrder"/>
<to uri="somewhere:else"/>
</route>
</camelContext>10.7. Validator
Validator performs declarative validation of the message according to the declared Input Type and/or Output Type on a route definition which declares the expected message type.
The validation is performed only if the validate attribute on the type declaration is true.
If the validate attribute is true on an Input Type and/or Output Type declaration, camel internal processor looks for a corresponding Validator from the registry.
10.7.1. Data type format
The format for the data type is scheme:name, where scheme is the type of data model such as java, xml, or json and name is the data type name.
10.7.2. Supported Validators
| Validator | Description |
|---|---|
| Predicate Validator | Validate by using Expression or Predicate |
| Endpoint Validator | Validate by forwarding to the Endpoint to be used with the validation component such as Validation Component or Bean Validation Component. |
| Custom Validator |
Validate using custom validator class. Validator must be a subclass of |
10.7.3. Common Option
All validators must include the type option that specifies the Data type to validate.
10.7.4. Predicate Validator Option
| Name | Description |
|---|---|
| expression | Expression or Predicate to use for validation. |
An example that specifies a validation predicate:
Java DSL:
validator()
.type("csv:CSVOrder")
.withExpression(bodyAs(String.class).contains("{name:XOrder}"));XML DSL:
<predicateValidator Type="csv:CSVOrder">
<simple>${body} contains 'name:XOrder'</simple>
</predicateValidator>10.7.5. Endpoint Validator Options
| Name | Description |
|---|---|
| ref | Reference to the Endpoint ID. |
| uri | Endpoint URI. |
An example that specifies endpoint URI in Java DSL:
validator()
.type("xml")
.withUri("validator:xsd/schema.xsd");An example that specifies endpoint ref in XML DSL:
<validators> <endpointValidator uri="validator:xsd/schema.xsd" type="xml"/> </validators>
The Endpoint Validator forwards the message to the specified endpoint. In above example, camel forwards the message to the validator: endpoint, which is a Validation Component. You can also use a different validation component, such as Bean Validation Component.
10.7.6. Custom Validator Options
The Validator must be a subclass of org.apache.camel.spi.Validator
| Name | Description |
|---|---|
| ref | Reference to the custom Validator bean ID. |
| className | Fully qualified class name of the custom Validator class. |
An example that specifies custom Validator class:
Java DSL:
validator()
.type("json")
.withJava(com.example.MyCustomValidator.class);XML DSL:
<validators> <customValidator className="com.example.MyCustomValidator" type="json"/> </validators>
10.7.7. Validator Examples
This example is in two parts, the first part declares the Endpoint Validator which validates the message. The second part shows how the validator is applied to a route.
10.7.7.1. Part I
Declares the Endpoint Validator which uses validator component to validate from xml:ABCOrder.
Java DSL:
validator()
.type("xml:ABCOrder")
.withUri("validator:xsd/schema.xsd");XML DSL:
<camelContext id="camel" xmlns="http://camel.apache.org/schema/spring">
<validators>
<endpointValidator uri="validator:xsd/schema.xsd" type="xml:ABCOrder"/>
</validators>
</camelContext>10.7.7.2. Part II
The above validator is applied to the following route definition when direct:abc endpoint receives the message.
The inputTypeWithValidate is used instead of inputType in Java DSL, and the validate attribute on the inputType declaration is set to true in XML DSL:
Java DSL:
from("direct:abc")
.inputTypeWithValidate("xml:ABCOrder")
.log("${body}");XML DSL:
<camelContext id="camel" xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:abc"/>
<inputType urn="xml:ABCOrder" validate="true"/>
<log message="${body}"/>
</route>
</camelContext>10.8. Validate
Overview
The validate pattern provides a convenient syntax to check whether the content of a message is valid. The validate DSL command takes a predicate expression as its sole argument: if the predicate evaluates to true, the route continues processing normally; if the predicate evaluates to false, a PredicateValidationException is thrown.
Java DSL example
The following route validates the body of the current message using a regular expression:
from("jms:queue:incoming")
.validate(body(String.class).regex("^\\w{10}\\,\\d{2}\\,\\w{24}$"))
.to("bean:MyServiceBean.processLine");You can also validate a message header — for example:
from("jms:queue:incoming")
.validate(header("bar").isGreaterThan(100))
.to("bean:MyServiceBean.processLine");And you can use validate with the simple expression language:
from("jms:queue:incoming")
.validate(simple("${in.header.bar} == 100"))
.to("bean:MyServiceBean.processLine");XML DSL example
To use validate in the XML DSL, the recommended approach is to use the simple expression language:
<route>
<from uri="jms:queue:incoming"/>
<validate>
<simple>${body} regex ^\\w{10}\\,\\d{2}\\,\\w{24}$</simple>
</validate>
<beanRef ref="myServiceBean" method="processLine"/>
</route>
<bean id="myServiceBean" class="com.mycompany.MyServiceBean"/>You can also validate a message header — for example:
<route>
<from uri="jms:queue:incoming"/>
<validate>
<simple>${in.header.bar} == 100</simple>
</validate>
<beanRef ref="myServiceBean" method="processLine"/>
</route>
<bean id="myServiceBean" class="com.mycompany.MyServiceBean"/>Chapter 11. Messaging Endpoints
Abstract
The messaging endpoint patterns describe various features and qualities of service that can be configured on an endpoint.
11.1. Messaging Mapper
Overview
The messaging mapper pattern describes how to map domain objects to and from a canonical message format, where the message format is chosen to be as platform neutral as possible. The chosen message format should be suitable for transmission through a Section 6.5, “Message Bus”, where the message bus is the backbone for integrating a variety of different systems, some of which might not be object-oriented.
Many different approaches are possible, but not all of them fulfill the requirements of a messaging mapper. For example, an obvious way to transmit an object is to use object serialization, which enables you to write an object to a data stream using an unambiguous encoding (supported natively in Java). However, this is not a suitable approach to use for the messaging mapper pattern, however, because the serialization format is understood only by Java applications. Java object serialization creates an impedance mismatch between the original application and the other applications in the messaging system.
The requirements for a messaging mapper can be summarized as follows:
- The canonical message format used to transmit domain objects should be suitable for consumption by non-object oriented applications.
- The mapper code should be implemented separately from both the domain object code and the messaging infrastructure. Apache Camel helps fulfill this requirement by providing hooks that can be used to insert mapper code into a route.
- The mapper might need to find an effective way of dealing with certain object-oriented concepts such as inheritance, object references, and object trees. The complexity of these issues varies from application to application, but the aim of the mapper implementation must always be to create messages that can be processed effectively by non-object-oriented applications.
Finding objects to map
You can use one of the following mechanisms to find the objects to map:
-
Find a registered bean. — For singleton objects and small numbers of objects, you could use the
CamelContextregistry to store references to beans. For example, if a bean instance is instantiated using Spring XML, it is automatically entered into the registry, where the bean is identified by the value of itsidattribute. Select objects using the JoSQL language. — If all of the objects you want to access are already instantiated at runtime, you could use the JoSQL language to locate a specific object (or objects). For example, if you have a class,
org.apache.camel.builder.sql.Person, with anamebean property and the incoming message has aUserNameheader, you could select the object whosenameproperty equals the value of theUserNameheader using the following code:import static org.apache.camel.builder.sql.SqlBuilder.sql; import org.apache.camel.Expression; ... Expression expression = sql("SELECT * FROM org.apache.camel.builder.sql.Person where name = :UserName"); Object value = expression.evaluate(exchange);Where the syntax,
:HeaderName, is used to substitute the value of a header in a JoSQL expression.- Dynamic — For a more scalable solution, it might be necessary to read object data from a database. In some cases, the existing object-oriented application might already provide a finder object that can load objects from the database. In other cases, you might have to write some custom code to extract objects from a database, and in these cases the JDBC component and the SQL component might be useful.
11.2. Event Driven Consumer
Overview
The event-driven consumer pattern, shown in Figure 11.1, “Event Driven Consumer Pattern”, is a pattern for implementing the consumer endpoint in a Apache Camel component, and is only relevant to programmers who need to develop a custom component in Apache Camel. Existing components already have a consumer implementation pattern hard-wired into them.
Figure 11.1. Event Driven Consumer Pattern
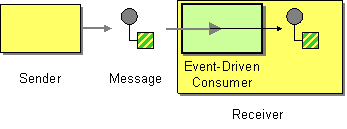
Consumers that conform to this pattern provide an event method that is automatically called by the messaging channel or transport layer whenever an incoming message is received. One of the characteristics of the event-driven consumer pattern is that the consumer endpoint itself does not provide any threads to process the incoming messages. Instead, the underlying transport or messaging channel implicitly provides a processor thread when it invokes the exposed event method (which blocks for the duration of the message processing).
For more details about this implementation pattern, see Section 38.1.3, “Consumer Patterns and Threading” and Chapter 41, Consumer Interface.
11.3. Polling Consumer
Overview
The polling consumer pattern, shown in Figure 11.2, “Polling Consumer Pattern”, is a pattern for implementing the consumer endpoint in a Apache Camel component, so it is only relevant to programmers who need to develop a custom component in Apache Camel. Existing components already have a consumer implementation pattern hard-wired into them.
Consumers that conform to this pattern expose polling methods, receive(), receive(long timeout), and receiveNoWait() that return a new exchange object, if one is available from the monitored resource. A polling consumer implementation must provide its own thread pool to perform the polling.
For more details about this implementation pattern, see Section 38.1.3, “Consumer Patterns and Threading”, Chapter 41, Consumer Interface, and Section 37.3, “Using the Consumer Template”.
Figure 11.2. Polling Consumer Pattern
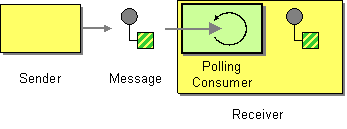
Scheduled poll consumer
Many of the Apache Camel consumer endpoints employ a scheduled poll pattern to receive messages at the start of a route. That is, the endpoint appears to implement an event-driven consumer interface, but internally a scheduled poll is used to monitor a resource that provides the incoming messages for the endpoint.
See Section 41.2, “Implementing the Consumer Interface” for details of how to implement this pattern.
Quartz component
You can use the quartz component to provide scheduled delivery of messages using the Quartz enterprise scheduler. See Quartz in the Apache Camel Component Reference Guide and Quartz Component for details.
11.4. Competing Consumers
Overview
The competing consumers pattern, shown in Figure 11.3, “Competing Consumers Pattern”, enables multiple consumers to pull messages from the same queue, with the guarantee that each message is consumed once only. This pattern can be used to replace serial message processing with concurrent message processing (bringing a corresponding reduction in response latency).
Figure 11.3. Competing Consumers Pattern
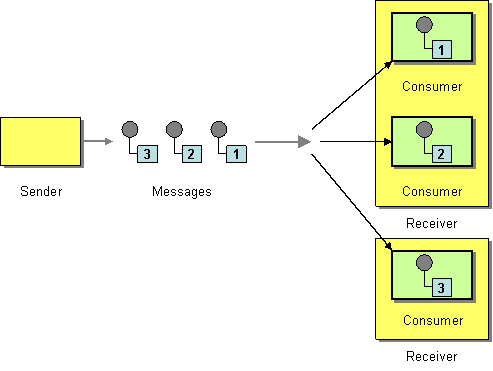
The following components demonstrate the competing consumers pattern:
JMS based competing consumers
A regular JMS queue implicitly guarantees that each message can only be consumed at once. Hence, a JMS queue automatically supports the competing consumers pattern. For example, you could define three competing consumers that pull messages from the JMS queue, HighVolumeQ, as follows:
from("jms:HighVolumeQ").to("cxf:bean:replica01");
from("jms:HighVolumeQ").to("cxf:bean:replica02");
from("jms:HighVolumeQ").to("cxf:bean:replica03");
Where the CXF (Web services) endpoints, replica01, replica02, and replica03, process messages from the HighVolumeQ queue in parallel.
Alternatively, you can set the JMS query option, concurrentConsumers, to create a thread pool of competing consumers. For example, the following route creates a pool of three competing threads that pick messages from the specified queue:
from("jms:HighVolumeQ?concurrentConsumers=3").to("cxf:bean:replica01");
And the concurrentConsumers option can also be specified in XML DSL, as follows:
<route> <from uri="jms:HighVolumeQ?concurrentConsumers=3"/> <to uri="cxf:bean:replica01"/> </route>
JMS topics cannot support the competing consumers pattern. By definition, a JMS topic is intended to send multiple copies of the same message to different consumers. Therefore, it is not compatible with the competing consumers pattern.
SEDA based competing consumers
The purpose of the SEDA component is to simplify concurrent processing by breaking the computation into stages. A SEDA endpoint essentially encapsulates an in-memory blocking queue (implemented by java.util.concurrent.BlockingQueue). Therefore, you can use a SEDA endpoint to break a route into stages, where each stage might use multiple threads. For example, you can define a SEDA route consisting of two stages, as follows:
// Stage 1: Read messages from file system.
from("file://var/messages").to("seda:fanout");
// Stage 2: Perform concurrent processing (3 threads).
from("seda:fanout").to("cxf:bean:replica01");
from("seda:fanout").to("cxf:bean:replica02");
from("seda:fanout").to("cxf:bean:replica03");
Where the first stage contains a single thread that consumes message from a file endpoint, file://var/messages, and routes them to a SEDA endpoint, seda:fanout. The second stage contains three threads: a thread that routes exchanges to cxf:bean:replica01, a thread that routes exchanges to cxf:bean:replica02, and a thread that routes exchanges to cxf:bean:replica03. These three threads compete to take exchange instances from the SEDA endpoint, which is implemented using a blocking queue. Because the blocking queue uses locking to prevent more than one thread from accessing the queue at a time, you are guaranteed that each exchange instance can only be consumed once.
For a discussion of the differences between a SEDA endpoint and a thread pool created by thread(), see SEDA component in NameOfCamelCompRef.
11.5. Message Dispatcher
Overview
The message dispatcher pattern, shown in Figure 11.4, “Message Dispatcher Pattern”, is used to consume messages from a channel and then distribute them locally to performers, which are responsible for processing the messages. In a Apache Camel application, performers are usually represented by in-process endpoints, which are used to transfer messages to another section of the route.
Figure 11.4. Message Dispatcher Pattern
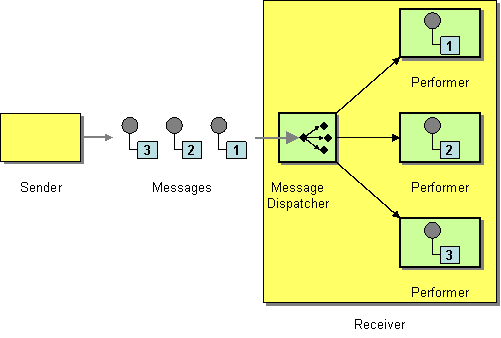
You can implement the message dispatcher pattern in Apache Camel using one of the following approaches:
JMS selectors
If your application consumes messages from a JMS queue, you can implement the message dispatcher pattern using JMS selectors. A JMS selector is a predicate expression involving JMS headers and JMS properties. If the selector evaluates to true, the JMS message is allowed to reach the consumer, and if the selector evaluates to false, the JMS message is blocked. In many respects, a JMS selector is like a Section 8.2, “Message Filter”, but it has the additional advantage that the filtering is implemented inside the JMS provider. This means that a JMS selector can block messages before they are transmitted to the Apache Camel application. This provides a significant efficiency advantage.
In Apache Camel, you can define a JMS selector on a consumer endpoint by setting the selector query option on a JMS endpoint URI. For example:
from("jms:dispatcher?selector=CountryCode='US'").to("cxf:bean:replica01");
from("jms:dispatcher?selector=CountryCode='IE'").to("cxf:bean:replica02");
from("jms:dispatcher?selector=CountryCode='DE'").to("cxf:bean:replica03");
Where the predicates that appear in a selector string are based on a subset of the SQL92 conditional expression syntax (for full details, see the JMS specification). The identifiers appearing in a selector string can refer either to JMS headers or to JMS properties. For example, in the preceding routes, the sender sets a JMS property called CountryCode.
If you want to add a JMS property to a message from within your Apache Camel application, you can do so by setting a message header (either on In message or on Out messages). When reading or writing to JMS endpoints, Apache Camel maps JMS headers and JMS properties to, and from, its native message headers.
Technically, the selector strings must be URL encoded according to the application/x-www-form-urlencoded MIME format (see the HTML specification). In practice, the &(ampersand) character might cause difficulties because it is used to delimit each query option in the URI. For more complex selector strings that might need to embed the & character, you can encode the strings using the java.net.URLEncoder utility class. For example:
from("jms:dispatcher?selector=" + java.net.URLEncoder.encode("CountryCode='US'","UTF-8")).
to("cxf:bean:replica01");Where the UTF-8 encoding must be used.
JMS selectors in ActiveMQ
You can also define JMS selectors on ActiveMQ endpoints. For example:
from("activemq:dispatcher?selector=CountryCode='US'").to("cxf:bean:replica01");
from("activemq:dispatcher?selector=CountryCode='IE'").to("cxf:bean:replica02");
from("activemq:dispatcher?selector=CountryCode='DE'").to("cxf:bean:replica03");For more details, see ActiveMQ: JMS Selectors and ActiveMQ Message Properties.
Content-based router
The essential difference between the content-based router pattern and the message dispatcher pattern is that a content-based router dispatches messages to physically separate destinations (remote endpoints), and a message dispatcher dispatches messages locally, within the same process space. In Apache Camel, the distinction between these two patterns is determined by the target endpoint. The same router logic is used to implement both a content-based router and a message dispatcher. When the target endpoint is remote, the route defines a content-based router. When the target endpoint is in-process, the route defines a message dispatcher.
For details and examples of how to use the content-based router pattern see Section 8.1, “Content-Based Router”.
11.6. Selective Consumer
Overview
The selective consumer pattern, shown in Figure 11.5, “Selective Consumer Pattern”, describes a consumer that applies a filter to incoming messages, so that only messages meeting specific selection criteria are processed.
Figure 11.5. Selective Consumer Pattern
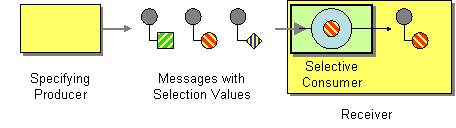
You can implement the selective consumer pattern in Apache Camel using one of the following approaches:
JMS selector
A JMS selector is a predicate expression involving JMS headers and JMS properties. If the selector evaluates to true, the JMS message is allowed to reach the consumer, and if the selector evaluates to false, the JMS message is blocked. For example, to consume messages from the queue, selective, and select only those messages whose country code property is equal to US, you can use the following Java DSL route:
from("jms:selective?selector=" + java.net.URLEncoder.encode("CountryCode='US'","UTF-8")).
to("cxf:bean:replica01");
Where the selector string, CountryCode='US', must be URL encoded (using UTF-8 characters) to avoid trouble with parsing the query options. This example presumes that the JMS property, CountryCode, is set by the sender. For more details about JMS selectors, see the section called “JMS selectors”.
If a selector is applied to a JMS queue, messages that are not selected remain on the queue and are potentially available to other consumers attached to the same queue.
JMS selector in ActiveMQ
You can also define JMS selectors on ActiveMQ endpoints. For example:
from("acivemq:selective?selector=" + java.net.URLEncoder.encode("CountryCode='US'","UTF-8")).
to("cxf:bean:replica01");For more details, see ActiveMQ: JMS Selectors and ActiveMQ Message Properties.
Message filter
If it is not possible to set a selector on the consumer endpoint, you can insert a filter processor into your route instead. For example, you can define a selective consumer that processes only messages with a US country code using Java DSL, as follows:
from("seda:a").filter(header("CountryCode").isEqualTo("US")).process(myProcessor);The same route can be defined using XML configuration, as follows:
<camelContext id="buildCustomProcessorWithFilter" xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="seda:a"/>
<filter>
<xpath>$CountryCode = 'US'</xpath>
<process ref="#myProcessor"/>
</filter>
</route>
</camelContext>For more information about the Apache Camel filter processor, see Section 8.2, “Message Filter”.
Be careful about using a message filter to select messages from a JMS queue. When using a filter processor, blocked messages are simply discarded. Hence, if the messages are consumed from a queue (which allows each message to be consumed only once — see Section 11.4, “Competing Consumers”), then blocked messages are not processed at all. This might not be the behavior you want.
11.7. Durable Subscriber
Overview
A durable subscriber, as shown in Figure 11.6, “Durable Subscriber Pattern”, is a consumer that wants to receive all of the messages sent over a particular Section 6.2, “Publish-Subscribe Channel” channel, including messages sent while the consumer is disconnected from the messaging system. This requires the messaging system to store messages for later replay to the disconnected consumer. There also has to be a mechanism for a consumer to indicate that it wants to establish a durable subscription. Generally, a publish-subscribe channel (or topic) can have both durable and non-durable subscribers, which behave as follows:
- non-durable subscriber — Can have two states: connected and disconnected. While a non-durable subscriber is connected to a topic, it receives all of the topic’s messages in real time. However, a non-durable subscriber never receives messages sent to the topic while the subscriber is disconnected.
- durable subscriber — Can have two states: connected and inactive. The inactive state means that the durable subscriber is disconnected from the topic, but wants to receive the messages that arrive in the interim. When the durable subscriber reconnects to the topic, it receives a replay of all the messages sent while it was inactive.
Figure 11.6. Durable Subscriber Pattern
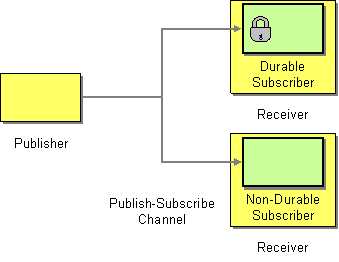
JMS durable subscriber
The JMS component implements the durable subscriber pattern. In order to set up a durable subscription on a JMS endpoint, you must specify a client ID, which identifies this particular connection, and a durable subscription name, which identifies the durable subscriber. For example, the following route sets up a durable subscription to the JMS topic, news, with a client ID of conn01 and a durable subscription name of John.Doe:
from("jms:topic:news?clientId=conn01&durableSubscriptionName=John.Doe").
to("cxf:bean:newsprocessor");You can also set up a durable subscription using the ActiveMQ endpoint:
from("activemq:topic:news?clientId=conn01&durableSubscriptionName=John.Doe").
to("cxf:bean:newsprocessor");If you want to process the incoming messages concurrently, you can use a SEDA endpoint to fan out the route into multiple, parallel segments, as follows:
from("jms:topic:news?clientId=conn01&durableSubscriptionName=John.Doe").
to("seda:fanout");
from("seda:fanout").to("cxf:bean:newsproc01");
from("seda:fanout").to("cxf:bean:newsproc02");
from("seda:fanout").to("cxf:bean:newsproc03");Where each message is processed only once, because the SEDA component supports the competing consumers pattern.
Alternative example
Another alternative is to combine the Section 11.5, “Message Dispatcher” or Section 8.1, “Content-Based Router” with File or JPA components for durable subscribers then something like SEDA for non-durable.
Here is a simple example of creating durable subscribers to a JMS topic
Using the Fluent Builders
from("direct:start").to("activemq:topic:foo");
from("activemq:topic:foo?clientId=1&durableSubscriptionName=bar1").to("mock:result1");
from("activemq:topic:foo?clientId=2&durableSubscriptionName=bar2").to("mock:result2");Using the Spring XML Extensions
<route>
<from uri="direct:start"/>
<to uri="activemq:topic:foo"/>
</route>
<route>
<from uri="activemq:topic:foo?clientId=1&durableSubscriptionName=bar1"/>
<to uri="mock:result1"/>
</route>
<route>
<from uri="activemq:topic:foo?clientId=2&durableSubscriptionName=bar2"/>
<to uri="mock:result2"/>
</route>Here is another example of JMS durable subscribers, but this time using virtual topics (recommended by AMQ over durable subscriptions)
Using the Fluent Builders
from("direct:start").to("activemq:topic:VirtualTopic.foo");
from("activemq:queue:Consumer.1.VirtualTopic.foo").to("mock:result1");
from("activemq:queue:Consumer.2.VirtualTopic.foo").to("mock:result2");Using the Spring XML Extensions
<route>
<from uri="direct:start"/>
<to uri="activemq:topic:VirtualTopic.foo"/>
</route>
<route>
<from uri="activemq:queue:Consumer.1.VirtualTopic.foo"/>
<to uri="mock:result1"/>
</route>
<route>
<from uri="activemq:queue:Consumer.2.VirtualTopic.foo"/>
<to uri="mock:result2"/>
</route>11.8. Idempotent Consumer
Overview
The idempotent consumer pattern is used to filter out duplicate messages. For example, consider a scenario where the connection between a messaging system and a consumer endpoint is abruptly lost due to some fault in the system. If the messaging system was in the middle of transmitting a message, it might be unclear whether or not the consumer received the last message. To improve delivery reliability, the messaging system might decide to redeliver such messages as soon as the connection is re-established. Unfortunately, this entails the risk that the consumer might receive duplicate messages and, in some cases, the effect of duplicating a message may have undesirable consequences (such as debiting a sum of money twice from your account). In this scenario, an idempotent consumer could be used to weed out undesired duplicates from the message stream.
Camel provides the following Idempotent Consumer implementations:
Idempotent consumer with in-memory cache
In Apache Camel, the idempotent consumer pattern is implemented by the idempotentConsumer() processor, which takes two arguments:
-
messageIdExpression— An expression that returns a message ID string for the current message. -
messageIdRepository— A reference to a message ID repository, which stores the IDs of all the messages received.
As each message comes in, the idempotent consumer processor looks up the current message ID in the repository to see if this message has been seen before. If yes, the message is discarded; if no, the message is allowed to pass and its ID is added to the repository.
The code shown in Example 11.1, “Filtering Duplicate Messages with an In-memory Cache” uses the TransactionID header to filter out duplicates.
Example 11.1. Filtering Duplicate Messages with an In-memory Cache
import static org.apache.camel.processor.idempotent.MemoryMessageIdRepository.memoryMessageIdRepository;
...
RouteBuilder builder = new RouteBuilder() {
public void configure() {
from("seda:a")
.idempotentConsumer(
header("TransactionID"),
memoryMessageIdRepository(200)
).to("seda:b");
}
};
Where the call to memoryMessageIdRepository(200) creates an in-memory cache that can hold up to 200 message IDs.
You can also define an idempotent consumer using XML configuration. For example, you can define the preceding route in XML, as follows:
<camelContext id="buildIdempotentConsumer" xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="seda:a"/>
<idempotentConsumer messageIdRepositoryRef="MsgIDRepos">
<simple>header.TransactionID</simple>
<to uri="seda:b"/>
</idempotentConsumer>
</route>
</camelContext>
<bean id="MsgIDRepos" class="org.apache.camel.processor.idempotent.MemoryMessageIdRepository">
<!-- Specify the in-memory cache size. -->
<constructor-arg type="int" value="200"/>
</bean>From Camel 2.17, Idempotent Repository supports optional serialized headers.
Idempotent consumer with JPA repository
The in-memory cache suffers from the disadvantages of easily running out of memory and not working in a clustered environment. To overcome these disadvantages, you can use a Java Persistent API (JPA) based repository instead. The JPA message ID repository uses an object-oriented database to store the message IDs. For example, you can define a route that uses a JPA repository for the idempotent consumer, as follows:
import org.springframework.orm.jpa.JpaTemplate;
import org.apache.camel.spring.SpringRouteBuilder;
import static org.apache.camel.processor.idempotent.jpa.JpaMessageIdRepository.jpaMessageIdRepository;
...
RouteBuilder builder = new SpringRouteBuilder() {
public void configure() {
from("seda:a").idempotentConsumer(
header("TransactionID"),
jpaMessageIdRepository(bean(JpaTemplate.class), "myProcessorName")
).to("seda:b");
}
};The JPA message ID repository is initialized with two arguments:
-
JpaTemplateinstance — Provides the handle for the JPA database. - processor name — Identifies the current idempotent consumer processor.
The SpringRouteBuilder.bean() method is a shortcut that references a bean defined in the Spring XML file. The JpaTemplate bean provides a handle to the underlying JPA database. See the JPA documentation for details of how to configure this bean.
For more details about setting up a JPA repository, see JPA Component documentation, the Spring JPA documentation, and the sample code in the Camel JPA unit test.
Spring XML example
The following example uses the myMessageId header to filter out duplicates:
<!-- repository for the idempotent consumer -->
<bean id="myRepo" class="org.apache.camel.processor.idempotent.MemoryIdempotentRepository"/>
<camelContext xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:start"/>
<idempotentConsumer messageIdRepositoryRef="myRepo">
<!-- use the messageId header as key for identifying duplicate messages -->
<header>messageId</header>
<!-- if not a duplicate send it to this mock endpoint -->
<to uri="mock:result"/>
</idempotentConsumer>
</route>
</camelContext>Idempotent consumer with JDBC repository
A JDBC repository is also supported for storing message IDs in the idempotent consumer pattern. The implementation of the JDBC repository is provided by the SQL component, so if you are using the Maven build system, add a dependency on the camel-sql artifact.
You can use the SingleConnectionDataSource JDBC wrapper class from the Spring persistence API in order to instantiate the connection to a SQL database. For example, to instantiate a JDBC connection to a HyperSQL database instance, you could define the following JDBC data source:
<bean id="dataSource" class="org.springframework.jdbc.datasource.SingleConnectionDataSource">
<property name="driverClassName" value="org.hsqldb.jdbcDriver"/>
<property name="url" value="jdbc:hsqldb:mem:camel_jdbc"/>
<property name="username" value="sa"/>
<property name="password" value=""/>
</bean>
The preceding JDBC data source uses the HyperSQL mem protocol, which creates a memory-only database instance. This is a toy implementation of the HyperSQL database which is not actually persistent.
Using the preceding data source, you can define an idempotent consumer pattern that uses the JDBC message ID repository, as follows:
<bean id="messageIdRepository" class="org.apache.camel.processor.idempotent.jdbc.JdbcMessageIdRepository"> <constructor-arg ref="dataSource" /> <constructor-arg value="myProcessorName" /> </bean> <camel:camelContext> <camel:errorHandler id="deadLetterChannel" type="DeadLetterChannel" deadLetterUri="mock:error"> <camel:redeliveryPolicy maximumRedeliveries="0" maximumRedeliveryDelay="0" logStackTrace="false" /> </camel:errorHandler> <camel:route id="JdbcMessageIdRepositoryTest" errorHandlerRef="deadLetterChannel"> <camel:from uri="direct:start" /> <camel:idempotentConsumer messageIdRepositoryRef="messageIdRepository"> <camel:header>messageId</camel:header> <camel:to uri="mock:result" /> </camel:idempotentConsumer> </camel:route> </camel:camelContext>
How to handle duplicate messages in the route
Available as of Camel 2.8
You can now set the skipDuplicate option to false which instructs the idempotent consumer to route duplicate messages as well. However the duplicate message has been marked as duplicate by having a property on the the section called “Exchanges” set to true. We can leverage this fact by using a Section 8.1, “Content-Based Router” or Section 8.2, “Message Filter” to detect this and handle duplicate messages.
For example in the following example we use the Section 8.2, “Message Filter” to send the message to a duplicate endpoint, and then stop continue routing that message.
from("direct:start")
// instruct idempotent consumer to not skip duplicates as we will filter then our self
.idempotentConsumer(header("messageId")).messageIdRepository(repo).skipDuplicate(false)
.filter(property(Exchange.DUPLICATE_MESSAGE).isEqualTo(true))
// filter out duplicate messages by sending them to someplace else and then stop
.to("mock:duplicate")
.stop()
.end()
// and here we process only new messages (no duplicates)
.to("mock:result");The sample example in XML DSL would be:
<!-- idempotent repository, just use a memory based for testing -->
<bean id="myRepo" class="org.apache.camel.processor.idempotent.MemoryIdempotentRepository"/>
<camelContext xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:start"/>
<!-- we do not want to skip any duplicate messages -->
<idempotentConsumer messageIdRepositoryRef="myRepo" skipDuplicate="false">
<!-- use the messageId header as key for identifying duplicate messages -->
<header>messageId</header>
<!-- we will to handle duplicate messages using a filter -->
<filter>
<!-- the filter will only react on duplicate messages, if this property is set on the Exchange -->
<property>CamelDuplicateMessage</property>
<!-- and send the message to this mock, due its part of an unit test -->
<!-- but you can of course do anything as its part of the route -->
<to uri="mock:duplicate"/>
<!-- and then stop -->
<stop/>
</filter>
<!-- here we route only new messages -->
<to uri="mock:result"/>
</idempotentConsumer>
</route>
</camelContext>How to handle duplicate message in a clustered environment with a data grid
If you have running Camel in a clustered environment, a in memory idempotent repository doesn’t work (see above). You can setup either a central database or use the idempotent consumer implementation based on the Hazelcast data grid. Hazelcast finds the nodes over multicast (which is default - configure Hazelcast for tcp-ip) and creates automatically a map based repository:
HazelcastIdempotentRepository idempotentRepo = new HazelcastIdempotentRepository("myrepo");
from("direct:in").idempotentConsumer(header("messageId"), idempotentRepo).to("mock:out");You have to define how long the repository should hold each message id (default is to delete it never). To avoid that you run out of memory you should create an eviction strategy based on the Hazelcast configuration. For additional information see Hazelcast.
See this link:http://camel.apache.org/hazelcast-idempotent-repository-tutorial.html[Idempotent Repository
tutorial] to learn more about how to setup such an idempotent repository on two cluster nodes using Apache Karaf.
Options
The Idempotent Consumer has the following options:
| Option | Default | Description |
|
|
| Camel 2.0: Eager controls whether Camel adds the message to the repository before or after the exchange has been processed. If enabled before then Camel will be able to detect duplicate messages even when messages are currently in progress. By disabling Camel will only detect duplicates when a message has successfully been processed. |
|
|
|
A reference to a |
|
|
|
Camel 2.8: Sets whether to skip duplicate messages. If set to |
|
|
| Camel 2.16: Sets whether to complete the Idempotent consumer eager, when the exchange is done.
If you set the
If you set the |
11.9. Transactional Client
Overview
The transactional client pattern, shown in Figure 11.7, “Transactional Client Pattern”, refers to messaging endpoints that can participate in a transaction. Apache Camel supports transactions using Spring transaction management.
Figure 11.7. Transactional Client Pattern
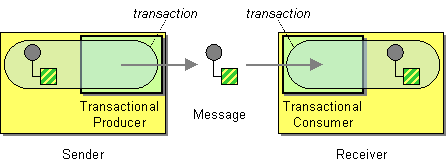
Transaction oriented endpoints
Not all Apache Camel endpoints support transactions. Those that do are called transaction oriented endpoints (or TOEs). For example, both the JMS component and the ActiveMQ component support transactions.
To enable transactions on a component, you must perform the appropriate initialization before adding the component to the CamelContext. This entails writing code to initialize your transactional components explicitly.
References
The details of configuring transactions in Apache Camel are beyond the scope of this guide. For full details of how to use transactions, see the Apache Camel Transaction Guide.
11.10. Messaging Gateway
Overview
The messaging gateway pattern, shown in Figure 11.8, “Messaging Gateway Pattern”, describes an approach to integrating with a messaging system, where the messaging system’s API remains hidden from the programmer at the application level. One of the more common example is when you want to translate synchronous method calls into request/reply message exchanges, without the programmer being aware of this.
Figure 11.8. Messaging Gateway Pattern
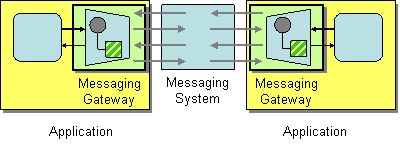
The following Apache Camel components provide this kind of integration with the messaging system:
- CXF
- Bean component
11.11. Service Activator
Overview
The service activator pattern, shown in Figure 11.9, “Service Activator Pattern”, describes the scenario where a service’s operations are invoked in response to an incoming request message. The service activator identifies which operation to call and extracts the data to use as the operation’s parameters. Finally, the service activator invokes an operation using the data extracted from the message. The operation invocation can be either oneway (request only) or two-way (request/reply).
Figure 11.9. Service Activator Pattern
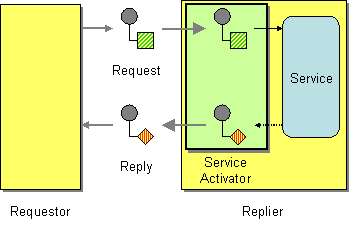
In many respects, a service activator resembles a conventional remote procedure call (RPC), where operation invocations are encoded as messages. The main difference is that a service activator needs to be more flexible. An RPC framework standardizes the request and reply message encodings (for example, Web service operations are encoded as SOAP messages), whereas a service activator typically needs to improvise the mapping between the messaging system and the service’s operations.
Bean integration
The main mechanism that Apache Camel provides to support the service activator pattern is bean integration. Bean integration provides a general framework for mapping incoming messages to method invocations on Java objects. For example, the Java fluent DSL provides the processors bean() and beanRef() that you can insert into a route to invoke methods on a registered Java bean. The detailed mapping of message data to Java method parameters is determined by the bean binding, which can be implemented by adding annotations to the bean class.
For example, consider the following route which calls the Java method, BankBean.getUserAccBalance(), to service requests incoming on a JMS/ActiveMQ queue:
from("activemq:BalanceQueries")
.setProperty("userid", xpath("/Account/BalanceQuery/UserID").stringResult())
.beanRef("bankBean", "getUserAccBalance")
.to("velocity:file:src/scripts/acc_balance.vm")
.to("activemq:BalanceResults");
The messages pulled from the ActiveMQ endpoint, activemq:BalanceQueries, have a simple XML format that provides the user ID of a bank account. For example:
<?xml version='1.0' encoding='UTF-8'?>
<Account>
<BalanceQuery>
<UserID>James.Strachan</UserID>
</BalanceQuery>
</Account>
The first processor in the route, setProperty(), extracts the user ID from the In message and stores it in the userid exchange property. This is preferable to storing it in a header, because the In headers are not available after invoking the bean.
The service activation step is performed by the beanRef() processor, which binds the incoming message to the getUserAccBalance() method on the Java object identified by the bankBean bean ID. The following code shows a sample implementation of the BankBean class:
package tutorial; import org.apache.camel.language.XPath; public class BankBean { public int getUserAccBalance(@XPath("/Account/BalanceQuery/UserID") String user) { if (user.equals("James.Strachan")) { return 1200; } else { return 0; } } }
Where the binding of message data to method parameter is enabled by the @XPath annotation, which injects the content of the UserID XML element into the user method parameter. On completion of the call, the return value is inserted into the body of the Out message which is then copied into the In message for the next step in the route. In order for the bean to be accessible to the beanRef() processor, you must instantiate an instance in Spring XML. For example, you can add the following lines to the META-INF/spring/camel-context.xml configuration file to instantiate the bean:
<?xml version="1.0" encoding="UTF-8"?> <beans ... > ... <bean id="bankBean" class="tutorial.BankBean"/> </beans>
Where the bean ID, bankBean, identifes this bean instance in the registry.
The output of the bean invocation is injected into a Velocity template, to produce a properly formatted result message. The Velocity endpoint, velocity:file:src/scripts/acc_balance.vm, specifies the location of a velocity script with the following contents:
<?xml version='1.0' encoding='UTF-8'?>
<Account>
<BalanceResult>
<UserID>${exchange.getProperty("userid")}</UserID>
<Balance>${body}</Balance>
</BalanceResult>
</Account>
The exchange instance is available as the Velocity variable, exchange, which enables you to retrieve the userid exchange property, using ${exchange.getProperty("userid")}. The body of the current In message, ${body}, contains the result of the getUserAccBalance() method invocation.
Chapter 12. System Management
Abstract
The system management patterns describe how to monitor, test, and administer a messaging system.
12.1. Detour
Detour
The Detour from the Chapter 3, Introducing Enterprise Integration Patterns allows you to send messages through additional steps if a control condition is met. It can be useful for turning on extra validation, testing, debugging code when needed.
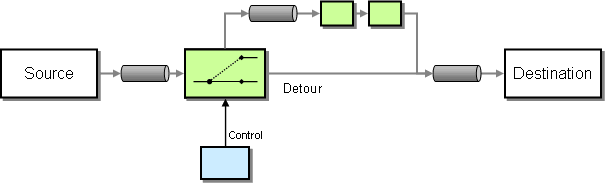
Example
In this example we essentially have a route like from("direct:start").to("mock:result") with a conditional detour to the mock:detour endpoint in the middle of the route..
from("direct:start").choice()
.when().method("controlBean", "isDetour").to("mock:detour").end()
.to("mock:result");Using the Spring XML Extensions
<route>
<from uri="direct:start"/>
<choice>
<when>
<method bean="controlBean" method="isDetour"/>
<to uri="mock:detour"/>
</when>
</choice>
<to uri="mock:result"/>
</split>
</route>
whether the detour is turned on or off is decided by the ControlBean. So, when the detour is on the message is routed to mock:detour and then mock:result. When the detour is off, the message is routed to mock:result.
For full details, check the example source here:
camel-core/src/test/java/org/apache/camel/processor/DetourTest.java
12.2. LogEIP
Overview
Apache Camel provides several ways to perform logging in a route:
-
Using the
logDSL command. - Using the Log component, which can log the message content.
- Using the Tracer, which traces message flow.
-
Using a
Processoror a Bean endpoint to perform logging in Java.
The log DSL is much lighter and meant for logging human logs such as Starting to do …. It can only log a message based on the Simple language. In contrast, the Log component is a fully featured logging component. The Log component is capable of logging the message itself and you have many URI options to control the logging.
Java DSL example
Since Apache Camel 2.2, you can use the log DSL command to construct a log message at run time using the Simple expression language. For example, you can create a log message within a route, as follows:
from("direct:start").log("Processing ${id}").to("bean:foo");
This route constructs a String format message at run time. The log message will by logged at INFO level, using the route ID as the log name. By default, routes are named consecutively, route-1, route-2 and so on. But you can use the DSL command, routeId("myCoolRoute"), to specify a custom route ID.
The log DSL also provides variants that enable you to set the logging level and the log name explicitly. For example, to set the logging level explicitly to LoggingLevel.DEBUG, you can invoke the log DSL as follows:
has overloaded methods to set the logging level and/or name as well.
from("direct:start").log(LoggingLevel.DEBUG, "Processing ${id}").to("bean:foo");
To set the log name to fileRoute, you can invoke the log DSL as follows:
from("file://target/files").log(LoggingLevel.DEBUG, "fileRoute", "Processing file ${file:name}").to("bean:foo");XML DSL example
In XML DSL, the log DSL is represented by the log element and the log message is specified by setting the message attribute to a Simple expression, as follows:
<route id="foo">
<from uri="direct:foo"/>
<log message="Got ${body}"/>
<to uri="mock:foo"/>
</route>
The log element supports the message, loggingLevel and logName attributes. For example:
<route id="baz">
<from uri="direct:baz"/>
<log message="Me Got ${body}" loggingLevel="FATAL" logName="cool"/>
<to uri="mock:baz"/>
</route>Global Log Name
The route ID is used as the the default log name. Since Apache Camel 2.17 the log name can be changed by configuring a logname parameter.
Java DSL, configure the log name based on the following example:
CamelContext context = ... context.getProperties().put(Exchange.LOG_EIP_NAME, "com.foo.myapp");
In XML, configure the log name in the following way:
<camelContext ...>
<properties>
<property key="CamelLogEipName" value="com.foo.myapp"/>
</properties>If you have more than one log and you want to have the same log name on all of them, you must add the configuration to each log.
12.3. Wire Tap
Wire Tap
The wire tap pattern, as shown in Figure 12.1, “Wire Tap Pattern”, enables you to route a copy of the message to a separate tap location, while the original message is forwarded to the ultimate destination.
Figure 12.1. Wire Tap Pattern
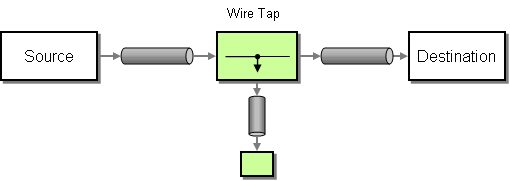
If you WireTap a stream message body, you should consider enabling Stream Caching to ensure the message body can be re-read. See more details at Stream Caching
WireTap node
Apache Camel 2.0 introduces the wireTap node for doing wire taps. The wireTap node copies the original exchange to a tapped exchange, whose exchange pattern is set to InOnly, because the tapped exchange should be propagated in a oneway style. The tapped exchange is processed in a separate thread, so that it can run concurrently with the main route.
The wireTap supports two different approaches to tapping an exchange:
- Tap a copy of the original exchange.
- Tap a new exchange instance, enabling you to customize the tapped exchange.
From Camel 2.16, the Wire Tap EIP emits event notifications when you send the exchange to the wire tap destination.
As of Camel 2.20, the Wire Tap EIP will complete any inflight wire tapped exchanges while shutting down.
Tap a copy of the original exchange
Using the Java DSL:
from("direct:start")
.to("log:foo")
.wireTap("direct:tap")
.to("mock:result");Using Spring XML extensions:
<route>
<from uri="direct:start"/>
<to uri="log:foo"/>
<wireTap uri="direct:tap"/>
<to uri="mock:result"/>
</route>Tap and modify a copy of the original exchange
Using the Java DSL, Apache Camel supports using either a processor or an expression to modify a copy of the original exchange. Using a processor gives you full power over how the exchange is populated, because you can set properties, headers and so on. The expression approach can only be used to modify the In message body.
For example, to modify a copy of the original exchange using the processor approach:
from("direct:start")
.wireTap("direct:foo", new Processor() {
public void process(Exchange exchange) throws Exception {
exchange.getIn().setHeader("foo", "bar");
}
}).to("mock:result");
from("direct:foo").to("mock:foo");And to modify a copy of the original exchange using the expression approach:
from("direct:start")
.wireTap("direct:foo", constant("Bye World"))
.to("mock:result");
from("direct:foo").to("mock:foo");
Using the Spring XML extensions, you can modify a copy of the original exchange using the processor approach, where the processorRef attribute references a spring bean with the myProcessor ID:
<route>
<from uri="direct:start2"/>
<wireTap uri="direct:foo" processorRef="myProcessor"/>
<to uri="mock:result"/>
</route>And to modify a copy of the original exchange using the expression approach:
<route>
<from uri="direct:start"/>
<wireTap uri="direct:foo">
<body><constant>Bye World</constant></body>
</wireTap>
<to uri="mock:result"/>
</route>Tap a new exchange instance
You can define a wiretap with a new exchange instance by setting the copy flag to false (the default is true). In this case, an initially empty exchange is created for the wiretap.
For example, to create a new exchange instance using the processor approach:
from("direct:start")
.wireTap("direct:foo", false, new Processor() {
public void process(Exchange exchange) throws Exception {
exchange.getIn().setBody("Bye World");
exchange.getIn().setHeader("foo", "bar");
}
}).to("mock:result");
from("direct:foo").to("mock:foo");
Where the second wireTap argument sets the copy flag to false, indicating that the original exchange is not copied and an empty exchange is created instead.
To create a new exchange instance using the expression approach:
from("direct:start")
.wireTap("direct:foo", false, constant("Bye World"))
.to("mock:result");
from("direct:foo").to("mock:foo");
Using the Spring XML extensions, you can indicate that a new exchange is to be created by setting the wireTap element’s copy attribute to false.
To create a new exchange instance using the processor approach, where the processorRef attribute references a spring bean with the myProcessor ID, as follows:
<route>
<from uri="direct:start2"/>
<wireTap uri="direct:foo" processorRef="myProcessor" copy="false"/>
<to uri="mock:result"/>
</route>And to create a new exchange instance using the expression approach:
<route>
<from uri="direct:start"/>
<wireTap uri="direct:foo" copy="false">
<body><constant>Bye World</constant></body>
</wireTap>
<to uri="mock:result"/>
</route>Sending a new Exchange and set headers in DSL
Available as of Camel 2.8
If you send a new messages using the Section 12.3, “Wire Tap” then you could only set the message body using an Part II, “Routing Expression and Predicate Languages” from the DSL. If you also need to set new headers you would have to use a Section 1.5, “Processors” for that. So in Camel 2.8 onwards we have improved this situation so you can now set headers as well in the DSL.
The following example sends a new message which has
- "Bye World" as message body
- a header with key "id" with the value 123
- a header with key "date" which has current date as value
Java DSL
from("direct:start")
// tap a new message and send it to direct:tap
// the new message should be Bye World with 2 headers
.wireTap("direct:tap")
// create the new tap message body and headers
.newExchangeBody(constant("Bye World"))
.newExchangeHeader("id", constant(123))
.newExchangeHeader("date", simple("${date:now:yyyyMMdd}"))
.end()
// here we continue routing the original messages
.to("mock:result");
// this is the tapped route
from("direct:tap")
.to("mock:tap");XML DSL
The XML DSL is slightly different than Java DSL as how you configure the message body and headers. In XML you use <body> and <setHeader> as shown:
<route>
<from uri="direct:start"/>
<!-- tap a new message and send it to direct:tap -->
<!-- the new message should be Bye World with 2 headers -->
<wireTap uri="direct:tap">
<!-- create the new tap message body and headers -->
<body><constant>Bye World</constant></body>
<setHeader headerName="id"><constant>123</constant></setHeader>
<setHeader headerName="date"><simple>${date:now:yyyyMMdd}</simple></setHeader>
</wireTap>
<!-- here we continue routing the original message -->
<to uri="mock:result"/>
</route>Using URIs
Wire Tap supports static and dynamic endpoint URIs. Static endpoint URIs are available as of Camel 2.20.
The following example displays how to wire tap to a JMS queue where the header ID is a part of the queue name.
from("direct:start")
.wireTap("jms:queue:backup-${header.id}")
.to("bean:doSomething");For more information about dynamic endpoint URIs, see the section called “Dynamic To”.
Using onPrepare to execute custom logic when preparing messages
Available as of Camel 2.8
For details, see Section 8.13, “Multicast”.
Options
The wireTap DSL command supports the following options:
| Name | Default Value | Description |
|
|
The endpoint uri where to send the wire tapped message. You should use either | |
|
|
Refers to the endpoint where to send the wire tapped message. You should use either | |
|
| Refers to a custom Section 2.8, “Threading Model” to be used when processing the wire tapped messages. If not set then Camel uses a default thread pool. | |
|
| Refers to a custom Section 1.5, “Processors”to be used for creating a new message (eg the send a new message mode). See below. | |
|
|
| Camel 2.3: Should a copy of the the section called “Exchanges” to used when wire tapping the message. |
|
| Camel 2.8: Refers to a custom Section 1.5, “Processors” to prepare the copy of the the section called “Exchanges” to be wire tapped. This allows you to do any custom logic, such as deep-cloning the message payload if that’s needed etc. |
Part II. Routing Expression and Predicate Languages
This guide describes the basic syntax used by the evaluative languages supported by Apache Camel.
Chapter 13. Introduction
Abstract
This chapter provides an overview of all the expression languages supported by Apache Camel.
13.1. Overview of the Languages
Table of expression and predicate languages
Table 13.1, “Expression and Predicate Languages” gives an overview of the different syntaxes for invoking expression and predicate languages.
| Language | Static Method | Fluent DSL Method | XML Element | Annotation | Artifact |
|---|---|---|---|---|---|
| See Bean Integration in the Apache Camel Development Guide on the customer portal. |
|
|
|
| Camel core |
|
|
|
|
| Camel core | |
|
|
|
|
|
| |
|
|
|
|
|
| |
|
|
|
|
| Camel core | |
|
|
|
|
|
| |
|
|
|
|
|
| |
| None |
|
|
|
| |
| None |
|
|
|
| |
|
|
|
|
|
| |
|
|
|
|
|
| |
|
|
|
|
|
| |
|
|
|
|
| Camel core | |
|
|
|
|
|
| |
|
|
|
| N/A | Camel core | |
|
|
|
|
|
| |
| Chapter 30, The Simple Language/Chapter 16, The File Language |
|
|
|
| Camel core |
|
|
|
|
|
| |
|
|
|
|
| Camel core | |
|
|
|
|
|
|
13.2. How to Invoke an Expression Language
Prerequisites
Before you can use a particular expression language, you must ensure that the required JAR files are available on the classpath. If the language you want to use is not included in the Apache Camel core, you must add the relevant JARs to your classpath.
If you are using the Maven build system, you can modify the build-time classpath simply by adding the relevant dependency to your POM file. For example, if you want to use the Ruby language, add the following dependency to your POM file:
<dependency>
<groupId>org.apache.camel</groupId>
<artifactId>camel-groovy</artifactId>
<!-- Use the same version as your Camel core version -->
<version>${camel.version}</version>
</dependency>
If you are going to deploy your application in a Red Hat JBoss Fuse OSGi container, you also need to ensure that the relevant language features are installed (features are named after the corresponding Maven artifact). For example, to use the Groovy language in the OSGi container, you must first install the camel-groovy feature by entering the following OSGi console command:
karaf@root> features:install camel-groovy
If you are using an expression or predicate in the routes, refer the value as an external resource by using resource:classpath:path or resource:file:path. For example, resource:classpath:com/foo/myscript.groovy.
Camel on EAP deployment
The camel-groovy component is supported by the Camel on EAP (Wildfly Camel) framework, which offers a simplified deployment model on the Red Hat JBoss Enterprise Application Platform (JBoss EAP) container.
Approaches to invoking
As shown in Table 13.1, “Expression and Predicate Languages”, there are several different syntaxes for invoking an expression language, depending on the context in which it is used. You can invoke an expression language:
As a static method
Most of the languages define a static method that can be used in any context where an org.apache.camel.Expression type or an org.apache.camel.Predicate type is expected. The static method takes a string expression (or predicate) as its argument and returns an Expression object (which is usually also a Predicate object).
For example, to implement a content-based router that processes messages in XML format, you could route messages based on the value of the /order/address/countryCode element, as follows:
from("SourceURL")
.choice
.when(xpath("/order/address/countryCode = 'us'"))
.to("file://countries/us/")
.when(xpath("/order/address/countryCode = 'uk'"))
.to("file://countries/uk/")
.otherwise()
.to("file://countries/other/")
.to("TargetURL");As a fluent DSL method
The Java fluent DSL supports another style of invoking expression languages. Instead of providing the expression as an argument to an Enterprise Integration Pattern (EIP), you can provide the expression as a sub-clause of the DSL command. For example, instead of invoking an XPath expression as filter(xpath("Expression")), you can invoke the expression as, filter().xpath("Expression").
For example, the preceding content-based router can be re-implemented in this style of invocation, as follows:
from("SourceURL")
.choice
.when().xpath("/order/address/countryCode = 'us'")
.to("file://countries/us/")
.when().xpath("/order/address/countryCode = 'uk'")
.to("file://countries/uk/")
.otherwise()
.to("file://countries/other/")
.to("TargetURL");As an XML element
You can also invoke an expression language in XML, by putting the expression string inside the relevant XML element.
For example, the XML element for invoking XPath in XML is xpath (which belongs to the standard Apache Camel namespace). You can use XPath expressions in a XML DSL content-based router, as follows:
<from uri="file://input/orders"/>
<choice>
<when>
<xpath>/order/address/countryCode = 'us'</xpath>
<to uri="file://countries/us/"/>
</when>
<when>
<xpath>/order/address/countryCode = 'uk'</xpath>
<to uri="file://countries/uk/"/>
</when>
<otherwise>
<to uri="file://countries/other/"/>
</otherwise>
</choice>
Alternatively, you can specify a language expression using the language element, where you specify the name of the language in the language attribute. For example, you can define an XPath expression using the language element as follows:
<language language="xpath">/order/address/countryCode = 'us'</language>
As an annotation
Language annotations are used in the context of bean integration . The annotations provide a convenient way of extracting information from a message or header and then injecting the extracted data into a bean’s method parmeters.
For example, consider the bean, myBeanProc, which is invoked as a predicate of the filter() EIP. If the bean’s checkCredentials method returns true, the message is allowed to proceed; but if the method returns false, the message is blocked by the filter. The filter pattern is implemented as follows:
// Java
MyBeanProcessor myBeanProc = new MyBeanProcessor();
from("SourceURL")
.filter().method(myBeanProc, "checkCredentials")
.to("TargetURL");
The implementation of the MyBeanProcessor class exploits the @XPath annotation to extract the username and password from the underlying XML message, as follows:
// Java
import org.apache.camel.language.XPath;
public class MyBeanProcessor {
boolean void checkCredentials(
@XPath("/credentials/username/text()") String user,
@XPath("/credentials/password/text()") String pass
) {
// Check the user/pass credentials...
...
}
}
The @XPath annotation is placed just before the parameter into which it gets injected. Notice how the XPath expression explicitly selects the text node, by appending /text() to the path, which ensures that just the content of the element is selected, not the enclosing tags.
As a Camel endpoint URI
Using the Camel Language component, you can invoke a supported language in an endpoint URI. There are two alternative syntaxes.
To invoke a language script stored in a file (or other resource type defined by Scheme), use the following URI syntax:
language://LanguageName:resource:Scheme:Location[?Options]
Where the scheme can be file:, classpath:, or http:.
For example, the following route executes the mysimplescript.txt from the classpath:
from("direct:start")
.to("language:simple:classpath:org/apache/camel/component/language/mysimplescript.txt")
.to("mock:result");To invoke an embedded language script, use the following URI syntax:
language://LanguageName[:Script][?Options]
For example, to run the Simple language script stored in the script string:
String script = URLEncoder.encode("Hello ${body}", "UTF-8");
from("direct:start")
.to("language:simple:" + script)
.to("mock:result");For more details about the Language component, see Language in the Apache Camel Component Reference Guide.
Chapter 14. Constant
Overview
The constant language is a trivial built-in language that is used to specify a plain text string. This makes it possible to provide a plain text string in any context where an expression type is expected.
XML example
In XML, you can set the username header to the value, Jane Doe as follows:
<camelContext>
<route>
<from uri="SourceURL"/>
<setHeader headerName="username">
<constant>Jane Doe</constant>
</setHeader>
<to uri="TargetURL"/>
</route>
</camelContext>Java example
In Java, you can set the username header to the value, Jane Doe as follows:
from("SourceURL")
.setHeader("username", constant("Jane Doe"))
.to("TargetURL");Chapter 15. EL
Overview
The Unified Expression Language (EL) was originally specified as part of the JSP 2.1 standard (JSR-245), but it is now available as a standalone language. Apache Camel integrates with JUEL (http://juel.sourceforge.net/), which is an open source implementation of the EL language.
Adding JUEL package
To use EL in your routes you need to add a dependency on camel-juel to your project as shown in Example 15.1, “Adding the camel-juel dependency”.
Example 15.1. Adding the camel-juel dependency
<!-- Maven POM File -->
<properties>
<camel-version>2.21.0.fuse-730078-redhat-00001</camel-version>
...
</properties>
<dependencies>
...
<dependency>
<groupId>org.apache.camel</groupId>
<artifactId>camel-juel</artifactId>
<version>${camel-version}</version>
</dependency>
...
</dependencies>Static import
To use the el() static method in your application code, include the following import statement in your Java source files:
import static org.apache.camel.language.juel.JuelExpression.el;
Variables
Table 15.1, “EL variables” lists the variables that are accessible when using EL.
| Variable | Type | Value |
|---|---|---|
|
|
| The current Exchange |
|
|
| The IN message |
|
|
| The OUT message |
Example
Example 15.2, “Routes using EL” shows two routes that use EL.
Example 15.2. Routes using EL
<camelContext>
<route>
<from uri="seda:foo"/>
<filter>
<language language="el">${in.headers.foo == 'bar'}</language>
<to uri="seda:bar"/>
</filter>
</route>
<route>
<from uri="seda:foo2"/>
<filter>
<language language="el">${in.headers['My Header'] == 'bar'}</language>
<to uri="seda:bar"/>
</filter>
</route>
</camelContext>Chapter 16. The File Language
Abstract
The file language is an extension to the simple language, not an independent language in its own right. But the file language extension can only be used in conjunction with File or FTP endpoints.
16.1. When to Use the File Language
Overview
The file language is an extension to the simple language which is not always available. You can use it under the following circumstances:
The escape character, \, is not available in the file language.
In a File or FTP consumer endpoint
There are several URI options that you can set on a File or FTP consumer endpoint, which take a file language expression as their value. For example, in a File consumer endpoint URI you can set the fileName, move, preMove, moveFailed, and sortBy options using a file expression.
In a File consumer endpoint, the fileName option acts as a filter, determining which file will actually be read from the starting directory. If a plain text string is specified (for example, fileName=report.txt), the File consumer reads the same file each time it is updated. You can make this option more dynamic, however, by specifying a simple expression. For example, you could use a counter bean to select a different file each time the File consumer polls the starting directory, as follows:
file://target/filelanguage/bean/?fileName=${bean:counter.next}.txt&delete=true
Where the ${bean:counter.next} expression invokes the next() method on the bean registered under the ID, counter.
The move option is used to move files to a backup location after then have been read by a File consumer endpoint. For example, the following endpoint moves files to a backup directory, after they have been processed:
file://target/filelanguage/?move=backup/${date:now:yyyyMMdd}/${file:name.noext}.bak&recursive=false
Where the ${file:name.noext}.bak expression modifies the original file name, replacing the file extension with .bak.
You can use the sortBy option to specify the order in which file should be processed. For example, to process files according to the alphabetical order of their file name, you could use the following File consumer endpoint:
file://target/filelanguage/?sortBy=file:name
To process file according to the order in which they were last modified, you could use the following File consumer endpoint:
file://target/filelanguage/?sortBy=file:modified
You can reverse the order by adding the reverse: prefix — for example:
file://target/filelanguage/?sortBy=reverse:file:modified
On exchanges created by a File or FTP consumer
When an exchange originates from a File or FTP consumer endpoint, it is possible to apply file language expressions to the exchange throughout the route (as long as the original message headers are not erased). For example, you could define a content-based router, which routes messages according to their file extension, as follows:
<from uri="file://input/orders"/>
<choice>
<when>
<simple>${file:ext} == 'txt'</simple>
<to uri="bean:orderService?method=handleTextFiles"/>
</when>
<when>
<simple>${file:ext} == 'xml'</simple>
<to uri="bean:orderService?method=handleXmlFiles"/>
</when>
<otherwise>
<to uri="bean:orderService?method=handleOtherFiles"/>
</otherwise>
</choice>16.2. File Variables
Overview
File variables can be used whenever a route starts with a File or FTP consumer endpoint, which implies that the underlying message body is of java.io.File type. The file variables enable you to access various parts of the file pathname, almost as if you were invoking the methods of the java.io.File class (in fact, the file language extracts the information it needs from message headers that have been set by the File or FTP endpoint).
Starting directory
Some of file variables return paths that are defined relative to a starting directory, which is just the directory that is specified in the File or FTP endpoint. For example, the following File consumer endpoint has the starting directory, ./filetransfer (a relative path):
file:filetransfer
The following FTP consumer endpoint has the starting directory, ./ftptransfer (a relative path):
ftp://myhost:2100/ftptransfer
Naming convention of file variables
In general, the file variables are named after corresponding methods on the java.io.File class. For example, the file:absolute variable gives the value that would be returned by the java.io.File.getAbsolute() method.
This naming convention is not strictly followed, however. For example, there is no such method as java.io.File.getSize().
Table of variables
Table 16.1, “Variables for the File Language” shows all of the variable supported by the file language.
| Variable | Type | Description |
|---|---|---|
|
|
| The pathname relative to the starting directory. |
|
|
|
The file extension (characters following the last |
|
|
|
The file extension (characters following the last |
|
|
| The pathname relative to the starting directory, omitting the file extension. |
|
|
| The pathname relative to the starting directory, omitting the file extension. If the file extension has multiple dots, then this expression strips only the last part, and keep the others. |
|
|
| The final segment of the pathname. That is, the file name without the parent directory path. |
|
|
| The final segment of the pathname, omitting the file extension. |
|
|
| The final segment of the pathname, omitting the file extension. If the file extension has multiple dots, then this expression strips only the last part, and keep the others. |
|
|
|
The file extension (same as |
|
|
| The pathname of the parent directory, including the starting directory in the path. |
|
|
| The file pathname, including the starting directory in the path. |
|
|
|
|
|
|
| The absolute pathname of the file. |
|
|
| The size of the referenced file. |
|
|
|
Same as |
|
|
| Date last modified. |
16.3. Examples
Relative pathname
Consider a File consumer endpoint, where the starting directory is specified as a relative pathname. For example, the following File endpoint has the starting directory, ./filelanguage:
file://filelanguage
Now, while scanning the filelanguage directory, suppose that the endpoint has just consumed the following file:
./filelanguage/test/hello.txt
And, finally, assume that the filelanguage directory itself has the following absolute location:
/workspace/camel/camel-core/target/filelanguage
Given the preceding scenario, the file language variables return the following values, when applied to the current exchange:
| Expression | Result |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Absolute pathname
Consider a File consumer endpoint, where the starting directory is specified as an absolute pathname. For example, the following File endpoint has the starting directory, /workspace/camel/camel-core/target/filelanguage:
file:///workspace/camel/camel-core/target/filelanguage
Now, while scanning the filelanguage directory, suppose that the endpoint has just consumed the following file:
./filelanguage/test/hello.txt
Given the preceding scenario, the file language variables return the following values, when applied to the current exchange:
| Expression | Result |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Chapter 17. Groovy
Overview
Groovy is a Java-based scripting language that allows quick parsing of object. The Groovy support is part of the camel-groovy module.
Adding the script module
To use Groovy in your routes you need to add a dependencies on camel-groovy to your project as shown in Example 17.1, “Adding the camel-groovy dependency”.
Example 17.1. Adding the camel-groovy dependency
<!-- Maven POM File -->
<properties>
<camel-version>2.21.0.fuse-730078-redhat-00001</camel-version>
...
</properties>
<dependencies>
...
<dependency>
<groupId>org.apache.camel</groupId>
<artifactId>camel-groovy</artifactId>
<version>${camel-version}</version>
</dependency>
</dependencies>Static import
To use the groovy() static method in your application code, include the following import statement in your Java source files:
import static org.apache.camel.builder.script.ScriptBuilder.*;
Built-in attributes
Table 17.1, “Groovy attributes” lists the built-in attributes that are accessible when using Groovy.
| Attribute | Type | Value |
|---|---|---|
|
|
| The Camel Context |
|
|
| The current Exchange |
|
|
| The IN message |
|
|
| The OUT message |
|
|
|
Function with a |
The attributes all set at ENGINE_SCOPE.
Example
Example 17.2, “Routes using Groovy” shows two routes that use Groovy scripts.
Example 17.2. Routes using Groovy
<camelContext>
<route>
<from uri="direct:items" />
<filter>
<language language="groovy">request.lineItems.any { i -> i.value > 100 }</language>
<to uri="mock:mock1" />
</filter>
</route>
<route>
<from uri="direct:in"/>
<setHeader headerName="firstName">
<language language="groovy">$user.firstName $user.lastName</language>
</setHeader>
<to uri="seda:users"/>
</route>
</camelContext>Using the properties component
To access a property value from the properties component, invoke the resolve method on the built-in properties attribute, as follows:
.setHeader("myHeader").groovy("properties.resolve(PropKey)")
Where PropKey is the key of the property you want to resolve, where the key value is of String type.
For more details about the properties component, see Properties in the Apache Camel Component Reference Guide.
Customizing Groovy Shell
Sometimes, you might need to use the custom GroovyShell instance, in your Groovy expressions. To provide custom GroovyShell, add an implementation of the org.apache.camel.language.groovy.GroovyShellFactory SPI interface to your Camel registry.
For example, when you add the following bean to your Spring context, Apache Camel will use the custom GroovyShell instance that includes the custom static imports, instead of the default one.
public class CustomGroovyShellFactory implements GroovyShellFactory {
public GroovyShell createGroovyShell(Exchange exchange) {
ImportCustomizer importCustomizer = new ImportCustomizer();
importCustomizer.addStaticStars("com.example.Utils");
CompilerConfiguration configuration = new CompilerConfiguration();
configuration.addCompilationCustomizers(importCustomizer);
return new GroovyShell(configuration);
}
}Chapter 18. Header
Overview
The header language provides a convenient way of accessing header values in the current message. When you supply a header name, the header language performs a case-insensitive lookup and returns the corresponding header value.
The header language is part of camel-core.
XML example
For example, to resequence incoming exchanges according to the value of a SequenceNumber header (where the sequence number must be a positive integer), you can define a route as follows:
<camelContext xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="SourceURL"/>
<resequence>
<language language="header">SequenceNumber</language>
</resequence>
<to uri="TargetURL"/>
</route>
</camelContext>Java example
The same route can be defined in Java, as follows:
from("SourceURL")
.resequence(header("SequenceNumber"))
.to("TargetURL");Chapter 19. JavaScript
Overview
JavaScript, also known as ECMAScript is a Java-based scripting language that allows quick parsing of object. The JavaScript support is part of the camel-script module.
Adding the script module
To use JavaScript in your routes you need to add a dependency on camel-script to your project as shown in Example 19.1, “Adding the camel-script dependency”.
Example 19.1. Adding the camel-script dependency
<!-- Maven POM File -->
<properties>
<camel-version>2.21.0.fuse-730078-redhat-00001</camel-version>
...
</properties>
<dependencies>
...
<dependency>
<groupId>org.apache.camel</groupId>
<artifactId>camel-script</artifactId>
<version>${camel-version}</version>
</dependency>
...
</dependencies>Static import
To use the javaScript() static method in your application code, include the following import statement in your Java source files:
import static org.apache.camel.builder.script.ScriptBuilder.*;
Built-in attributes
Table 19.1, “JavaScript attributes” lists the built-in attributes that are accessible when using JavaScript.
| Attribute | Type | Value |
|---|---|---|
|
|
| The Camel Context |
|
|
| The current Exchange |
|
|
| The IN message |
|
|
| The OUT message |
|
|
|
Function with a |
The attributes all set at ENGINE_SCOPE.
Example
Example 19.2, “Route using JavaScript” shows a route that uses JavaScript.
Example 19.2. Route using JavaScript
<camelContext>
<route>
<from uri="direct:start"/>
<choice>
<when>
<langauge langauge="javaScript">request.headers.get('user') == 'admin'</langauge>
<to uri="seda:adminQueue"/>
</when>
<otherwise>
<to uri="seda:regularQueue"/>
</otherwise>
</choice>
</route>
</camelContext>Using the properties component
To access a property value from the properties component, invoke the resolve method on the built-in properties attribute, as follows:
.setHeader("myHeader").javaScript("properties.resolve(PropKey)")
Where PropKey is the key of the property you want to resolve, where the key value is of String type.
For more details about the properties component, see Properties in the Apache Camel Component Reference Guide.
Chapter 20. JoSQL
Overview
The JoSQL (SQL for Java objects) language enables you to evaluate predicates and expressions in Apache Camel. JoSQL employs a SQL-like query syntax to perform selection and ordering operations on data from in-memory Java objects — however, JoSQL is not a database. In the JoSQL syntax, each Java object instance is treated like a table row and each object method is treated like a column name. Using this syntax, it is possible to construct powerful statements for extracting and compiling data from collections of Java objects. For details, see http://josql.sourceforge.net/.
Adding the JoSQL module
To use JoSQL in your routes you need to add a dependency on camel-josql to your project as shown in Example 20.1, “Adding the camel-josql dependency”.
Example 20.1. Adding the camel-josql dependency
<!-- Maven POM File -->
...
<dependencies>
...
<dependency>
<groupId>org.apache.camel</groupId>
<artifactId>camel-josql</artifactId>
<version>${camel-version}</version>
</dependency>
...
</dependencies>Static import
To use the sql() static method in your application code, include the following import statement in your Java source files:
import static org.apache.camel.builder.sql.SqlBuilder.sql;
Variables
Table 20.1, “SQL variables” lists the variables that are accessible when using JoSQL.
| Name | Type | Description |
|---|---|---|
|
|
| The current Exchange |
|
|
| The IN message |
|
|
| The OUT message |
| property |
| the Exchange property whose key is property |
| header |
| the IN message header whose key is header |
| variable |
| the variable whose key is variable |
Example
Example 20.2, “Route using JoSQL” shows a route that uses JoSQL.
Example 20.2. Route using JoSQL
<camelContext>
<route>
<from uri="direct:start"/>
<setBody>
<language language="sql">select * from MyType</language>
</setBody>
<to uri="seda:regularQueue"/>
</route>
</camelContext>Chapter 21. JsonPath
Overview
The JsonPath language provides a convenient syntax for extracting portions of a JSON message. The syntax of JSON is similar to XPath, but it is used to extract JSON objects from a JSON message, instead of acting on XML. The jsonpath DSL command can be used either as an expression or as a predicate (where an empty result gets interpreted as boolean false).
Adding the JsonPath package
To use JsonPath in your Camel routes, you need to add a dependency on camel-jsonpath to your project, as follows:
<dependency>
<groupId>org.apache.camel</groupId>
<artifactId>camel-jsonpath</artifactId>
<version>${camel-version}</version>
</dependency>Java example
The following Java example shows how to use the jsonpath() DSL command to select items in a certain price range:
from("queue:books.new")
.choice()
.when().jsonpath("$.store.book[?(@.price < 10)]")
.to("jms:queue:book.cheap")
.when().jsonpath("$.store.book[?(@.price < 30)]")
.to("jms:queue:book.average")
.otherwise()
.to("jms:queue:book.expensive")
If the JsonPath query returns an empty set, the result is interpreted as false. In this way, you can use a JsonPath query as a predicate.
XML example
The following XML example shows how to use the jsonpath DSL element to define predicates in a route:
<camelContext id="camel" xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:start"/>
<choice>
<when>
<jsonpath>$.store.book[?(@.price < 10)]</jsonpath>
<to uri="mock:cheap"/>
</when>
<when>
<jsonpath>$.store.book[?(@.price < 30)]</jsonpath>
<to uri="mock:average"/>
</when>
<otherwise>
<to uri="mock:expensive"/>
</otherwise>
</choice>
</route>
</camelContext>Easy Syntax
When you wish to define a basic predicate using jsonpath syntax it can be a bit hard to remember the syntax. For example, to find out all the cheap books, you have to write the syntax as follows:
$.store.book[?(@.price < 20)]
However, what if you could just write it as:
store.book.price < 20
You can also omit the path if you just want to look at nodes with a price key:
price < 20
To support this, there is a EasyPredicateParser which you use to define the predicate using a basic style. That means the predicate must not start with the $ sign, and must include only one operator. The easy syntax is as follows:
left OP right
You can use Camel simple language in the right operator, for example,
store.book.price < ${header.limit}Supported Message Body Types
Camel JSonPath supports message body using the following types:
| Type | Description |
|---|---|
| File | Reading from files |
| String | Plain strings |
| Map |
essage body as |
| List | Message body as java.util.List type |
|
|
Optional If Jackson is on the classpath, then |
|
|
If none of the above types matches, then Camel will attempt to read the message body as an |
If a message body is of unsupported type then an exception is thrown by default, however you can configure JSonPath to suppress exceptions.
Suppress Exceptions
JsonPath will throw an exception if the path configured by the jsonpath expression is not found. The exception can be ignored by setting the SuppressExceptions option to true. For example, in the code below, adding the true option as part of the jsonpath parameters:
from("direct:start")
.choice()
// use true to suppress exceptions
.when().jsonpath("person.middlename", true)
.to("mock:middle")
.otherwise()
.to("mock:other");In XML DSL use the following syntax:
<route>
<from uri="direct:start"/>
<choice>
<when>
<jsonpath suppressExceptions="true">person.middlename</jsonpath>
<to uri="mock:middle"/>
</when>
<otherwise>
<to uri="mock:other"/>
</otherwise>
</choice>
</route>JsonPath injection
When using bean integration to invoke a bean method, you can use JsonPath to extract a value from the message and bind it to a method parameter. For example:
// Java
public class Foo {
@Consume(uri = "activemq:queue:books.new")
public void doSomething(@JsonPath("$.store.book[*].author") String author, @Body String json) {
// process the inbound message here
}
}Inline Simple Expressions
New in Camel 2.18.
Camel supports inline Simple expressions in the JsonPath expressions. The Simple language insertions must be expressed in Simple syntax as shown below:
from("direct:start")
.choice()
.when().jsonpath("$.store.book[?(@.price < `${header.cheap}`)]")
.to("mock:cheap")
.when().jsonpath("$.store.book[?(@.price < `${header.average}`)]")
.to("mock:average")
.otherwise()
.to("mock:expensive");
Turn off support for Simple expressions by setting the option allowSimple=false as shown below.
Java:
// Java DSL
.when().jsonpath("$.store.book[?(@.price < 10)]", `false, false`)XML DSL:
// XML DSL <jsonpath allowSimple="false">$.store.book[?(@.price < 10)]</jsonpath>
Reference
For more details about JsonPath, see the JSonPath project page.
Chapter 22. JXPath
Overview
The JXPath language enables you to invoke Java beans using the Apache Commons JXPath language. The JXPath language has a similar syntax to XPath, but instead of selecting element or attribute nodes from an XML document, it invokes methods on an object graph of Java beans. If one of the bean attributes returns an XML document (a DOM/JDOM instance), however, the remaining portion of the path is interpreted as an XPath expression and is used to extract an XML node from the document. In other words, the JXPath language provides a hybrid of object graph navigation and XML node selection.
Adding JXPath package
To use JXPath in your routes you need to add a dependency on camel-jxpath to your project as shown in Example 22.1, “Adding the camel-jxpath dependency”.
Example 22.1. Adding the camel-jxpath dependency
<!-- Maven POM File -->
<properties>
<camel-version>2.21.0.fuse-730078-redhat-00001</camel-version>
...
</properties>
<dependencies>
...
<dependency>
<groupId>org.apache.camel</groupId>
<artifactId>camel-jxpath</artifactId>
<version>${camel-version}</version>
</dependency>
...
</dependencies>Variables
Table 22.1, “JXPath variables” lists the variables that are accessible when using JXPath.
| Variable | Type | Value |
|---|---|---|
|
|
| The current Exchange |
|
|
| The IN message |
|
|
| The OUT message |
Options
Table 22.2, “JXPath option” describes the option for JXPath.
| Option | Type | Description |
|---|---|---|
|
|
| Camel 2.11/2.10.5: Allows to turn lenient on the JXPathContext. When turned on this option allows the JXPath expression to evaluate against expressions and message bodies which might be invalid or missing data. See more details at the JXPath Documentation. This option is false, by default. |
Examples
The following example route uses JXPath:
<camelContext>
<route>
<from uri="activemq:MyQueue"/>
<filter>
<jxpath>in/body/name = 'James'</xpath>
<to uri="mqseries:SomeOtherQueue"/>
</filter>
</route>
</camelContext>The following simple example uses a JXPath expression as a predicate in a Message Filter:
{snippet:id=example|lang=java|url=camel/trunk/components/camel-jxpath/src/test/java/org/apache/camel/language/jxpath/JXPathFilterTest.java}JXPath injection
You can use Bean Integration to invoke a method on a bean and use various languages, such as JXPath, to extract a value from the message and bind it to a method parameter.
For example:
public class Foo {
@MessageDriven(uri = "activemq:my.queue")
public void doSomething(@JXPath("in/body/foo") String correlationID, @Body String body)
{ // process the inbound message here }
}Loading the script from an external resource
Available as of Camel 2.11
You can externalize the script and have Camel load it from a resource such as "classpath:", "file:", or "http:". Use the following syntax:
"resource:scheme:location"
For example, to reference a file on the classpath:
.setHeader("myHeader").jxpath("resource:classpath:myjxpath.txt")Chapter 23. MVEL
Overview
MVEL is a Java-based dynamic language that is similar to OGNL, but is reported to be much faster. The MVEL support is in the camel-mvel module.
Syntax
You use the MVEL dot syntax to invoke Java methods, for example:
getRequest().getBody().getFamilyName()
Because MVEL is dynamically typed, it is unnecessary to cast the message body instance (of Object type) before invoking the getFamilyName() method. You can also use an abbreviated syntax for invoking bean attributes, for example:
request.body.familyName
Adding the MVEL module
To use MVEL in your routes you need to add a dependency on camel-mvel to your project as shown in Example 23.1, “Adding the camel-mvel dependency”.
Example 23.1. Adding the camel-mvel dependency
<!-- Maven POM File -->
<properties>
<camel-version>2.21.0.fuse-730078-redhat-00001</camel-version>
...
</properties>
<dependencies>
...
<dependency>
<groupId>org.apache.camel</groupId>
<artifactId>camel-mvel</artifactId>
<version>${camel-version}</version>
</dependency>
...
</dependencies>Built-in variables
Table 23.1, “MVEL variables” lists the built-in variables that are accessible when using MVEL.
| Name | Type | Description |
|---|---|---|
|
|
| The current Exchange |
|
|
| The current Exchange |
|
|
| the Exchange exception (if any) |
|
|
| the Exchange ID |
|
|
| The Fault message(if any) |
|
|
| The IN message |
|
|
| The OUT message |
|
|
| The Exchange properties |
|
|
| The value of the named Exchange property |
|
|
| The typed value of the named Exchange property |
Example
Example 23.2, “Route using MVEL” shows a route that uses MVEL.
Example 23.2. Route using MVEL
<camelContext>
<route>
<from uri="seda:foo"/>
<filter>
<language langauge="mvel">request.headers.foo == 'bar'</language>
<to uri="seda:bar"/>
</filter>
</route>
</camelContext>Chapter 24. The Object-Graph Navigation Language(OGNL)
Overview
OGNL is an expression language for getting and setting properties of Java objects. You use the same expression for both getting and setting the value of a property. The OGNL support is in the camel-ognl module.
Camel on EAP deployment
This component is supported by the Camel on EAP (Wildfly Camel) framework, which offers a simplified deployment model on the Red Hat JBoss Enterprise Application Platform (JBoss EAP) container.
Adding the OGNL module
To use OGNL in your routes you need to add a dependency on camel-ognl to your project as shown in Example 24.1, “Adding the camel-ognl dependency”.
Example 24.1. Adding the camel-ognl dependency
<!-- Maven POM File -->
...
<dependencies>
...
<dependency>
<groupId>org.apache.camel</groupId>
<artifactId>camel-ognl</artifactId>
<version>${camel-version}</version>
</dependency>
...
</dependencies>Static import
To use the ognl() static method in your application code, include the following import statement in your Java source files:
import static org.apache.camel.language.ognl.OgnlExpression.ognl;
Built-in variables
Table 24.1, “OGNL variables” lists the built-in variables that are accessible when using OGNL.
| Name | Type | Description |
|---|---|---|
|
|
| The current Exchange |
|
|
| The current Exchange |
|
|
| the Exchange exception (if any) |
|
|
| the Exchange ID |
|
|
| The Fault message(if any) |
|
|
| The IN message |
|
|
| The OUT message |
|
|
| The Exchange properties |
|
|
| The value of the named Exchange property |
|
|
| The typed value of the named Exchange property |
Example
Example 24.2, “Route using OGNL” shows a route that uses OGNL.
Example 24.2. Route using OGNL
<camelContext>
<route>
<from uri="seda:foo"/>
<filter>
<language langauge="ognl">request.headers.foo == 'bar'</language>
<to uri="seda:bar"/>
</filter>
</route>
</camelContext>Chapter 25. PHP
Overview
PHP is a widely-used general-purpose scripting language that is especially suited for Web development. The PHP support is part of the camel-script module.
Adding the script module
To use PHP in your routes you need to add a dependency on camel-script to your project as shown in Example 25.1, “Adding the camel-script dependency”.
Example 25.1. Adding the camel-script dependency
<!-- Maven POM File -->
...
<dependencies>
...
<dependency>
<groupId>org.apache.camel</groupId>
<artifactId>camel-script</artifactId>
<version>${camel-version}</version>
</dependency>
...
</dependencies>Static import
To use the php() static method in your application code, include the following import statement in your Java source files:
import static org.apache.camel.builder.script.ScriptBuilder.*;
Built-in attributes
Table 25.1, “PHP attributes” lists the built-in attributes that are accessible when using PHP.
| Attribute | Type | Value |
|---|---|---|
|
|
| The Camel Context |
|
|
| The current Exchange |
|
|
| The IN message |
|
|
| The OUT message |
|
|
|
Function with a |
The attributes all set at ENGINE_SCOPE.
Example
Example 25.2, “Route using PHP” shows a route that uses PHP.
Example 25.2. Route using PHP
<camelContext>
<route>
<from uri="direct:start"/>
<choice>
<when>
<language language="php">strpos(request.headers.get('user'), 'admin')!== FALSE</language>
<to uri="seda:adminQueue"/>
</when>
<otherwise>
<to uri="seda:regularQueue"/>
</otherwise>
</choice>
</route>
</camelContext>Using the properties component
To access a property value from the properties component, invoke the resolve method on the built-in properties attribute, as follows:
.setHeader("myHeader").php("properties.resolve(PropKey)")
Where PropKey is the key of the property you want to resolve, where the key value is of String type.
For more details about the properties component, see Properties in the Apache Camel Component Reference Guide.
Chapter 26. Exchange Property
Overview
The exchange property language provides a convenient way of accessing exchange properties. When you supply a key that matches one of the exchange property names, the exchange property language returns the corresponding value.
The exchange property language is part of camel-core.
XML example
For example, to implement the recipient list pattern when the listOfEndpoints exchange property contains the recipient list, you could define a route as follows:
<camelContext>
<route>
<from uri="direct:a"/>
<recipientList>
<exchangeProperty>listOfEndpoints</exchangeProperty>
</recipientList>
</route>
</camelContext>Java example
The same recipient list example can be implemented in Java as follows:
from("direct:a").recipientList(exchangeProperty("listOfEndpoints"));Chapter 27. Python
Overview
Python is a remarkably powerful dynamic programming language that is used in a wide variety of application domains. Python is often compared to Tcl, Perl, Ruby, Scheme or Java. The Python support is part of the camel-script module.
Adding the script module
To use Python in your routes you need to add a dependency on camel-script to your project as shown in Example 27.1, “Adding the camel-script dependency”.
Example 27.1. Adding the camel-script dependency
<!-- Maven POM File -->
...
<dependencies>
...
<dependency>
<groupId>org.apache.camel</groupId>
<artifactId>camel-script</artifactId>
<version>${camel-version}</version>
</dependency>
...
</dependencies>Static import
To use the python() static method in your application code, include the following import statement in your Java source files:
import static org.apache.camel.builder.script.ScriptBuilder.*;
Built-in attributes
Table 27.1, “Python attributes” lists the built-in attributes that are accessible when using Python.
| Attribute | Type | Value |
|---|---|---|
|
|
| The Camel Context |
|
|
| The current Exchange |
|
|
| The IN message |
|
|
| The OUT message |
|
|
|
Function with a |
The attributes all set at ENGINE_SCOPE.
Example
Example 27.2, “Route using Python” shows a route that uses Python.
Example 27.2. Route using Python
<camelContext>
<route>
<from uri="direct:start"/>
<choice>
<when>
<langauge langauge="python">if request.headers.get('user') = 'admin'</langauge>
<to uri="seda:adminQueue"/>
</when>
<otherwise>
<to uri="seda:regularQueue"/>
</otherwise>
</choice>
</route>
</camelContext>Using the properties component
To access a property value from the properties component, invoke the resolve method on the built-in properties attribute, as follows:
.setHeader("myHeader").python("properties.resolve(PropKey)")
Where PropKey is the key of the property you want to resolve, where the key value is of String type.
For more details about the properties component, see Properties in the Apache Camel Component Reference Guide.
Chapter 28. Ref
Overview
The Ref expression language is really just a way to look up a custom Expression from the Registry. This is particular convenient to use in the XML DSL.
The Ref language is part of camel-core.
Static import
To use the Ref language in your Java application code, include the following import statement in your Java source files:
import static org.apache.camel.language.ref.RefLanguage.ref;
XML example
For example, the splitter pattern can reference a custom expression using the Ref language, as follows:
<beans ...> <bean id="myExpression" class="com.mycompany.MyCustomExpression"/> ... <camelContext> <route> <from uri="seda:a"/> <split> <ref>myExpression</ref> <to uri="mock:b"/> </split> </route> </camelContext> </beans>
Java example
The preceding route can also be implemented in the Java DSL, as follows:
from("seda:a")
.split().ref("myExpression")
.to("seda:b");Chapter 29. Ruby
Overview
Ruby is a dynamic, open source programming language with a focus on simplicity and productivity. It has an elegant syntax that is natural to read and easy to write. The Ruby support is part of the camel-script module.
Adding the script module
To use Ruby in your routes you need to add a dependency on camel-script to your project as shown in Example 29.1, “Adding the camel-script dependency”.
Example 29.1. Adding the camel-script dependency
<!-- Maven POM File -->
...
<dependencies>
...
<dependency>
<groupId>org.apache.camel</groupId>
<artifactId>camel-script</artifactId>
<version>${camel-version}</version>
</dependency>
...
</dependencies>Static import
To use the ruby() static method in your application code, include the following import statement in your Java source files:
import static org.apache.camel.builder.script.ScriptBuilder.*;
Built-in attributes
Table 29.1, “Ruby attributes” lists the built-in attributes that are accessible when using Ruby.
| Attribute | Type | Value |
|---|---|---|
|
|
| The Camel Context |
|
|
| The current Exchange |
|
|
| The IN message |
|
|
| The OUT message |
|
|
|
Function with a |
The attributes all set at ENGINE_SCOPE.
Example
Example 29.2, “Route using Ruby” shows a route that uses Ruby.
Example 29.2. Route using Ruby
<camelContext>
<route>
<from uri="direct:start"/>
<choice>
<when>
<langauge langauge="ruby">$request.headers['user'] == 'admin'</langauge>
<to uri="seda:adminQueue"/>
</when>
<otherwise>
<to uri="seda:regularQueue"/>
</otherwise>
</choice>
</route>
</camelContext>Using the properties component
To access a property value from the properties component, invoke the resolve method on the built-in properties attribute, as follows:
.setHeader("myHeader").ruby("properties.resolve(PropKey)")
Where PropKey is the key of the property you want to resolve, where the key value is of String type.
For more details about the properties component, see Properties in the Apache Camel Component Reference Guide.
Chapter 30. The Simple Language
Abstract
The simple language is a language that was developed in Apache Camel specifically for the purpose of accessing and manipulating the various parts of an exchange object. The language is not quite as simple as when it was originally created and it now features a comprehensive set of logical operators and conjunctions.
30.1. Java DSL
Simple expressions in Java DSL
In the Java DSL, there are two styles for using the simple() command in a route. You can either pass the simple() command as an argument to a processor, as follows:
from("seda:order")
.filter(simple("${in.header.foo}"))
.to("mock:fooOrders");
Or you can call the simple() command as a sub-clause on the processor, for example:
from("seda:order")
.filter()
.simple("${in.header.foo}")
.to("mock:fooOrders");Embedding in a string
If you are embedding a simple expression inside a plain text string, you must use the placeholder syntax, ${Expression}. For example, to embed the in.header.name expression in a string:
simple("Hello ${in.header.name}, how are you?")Customizing the start and end tokens
From Java, you can customize the start and end tokens ({ and }, by default) by calling the changeFunctionStartToken static method and the changeFunctionEndToken static method on the SimpleLanguage object.
For example, you can change the start and end tokens to [ and ] in Java, as follows:
// Java
import org.apache.camel.language.simple.SimpleLanguage;
...
SimpleLanguage.changeFunctionStartToken("[");
SimpleLanguage.changeFunctionEndToken("]");
Customizing the start and end tokens affects all Apache Camel applications that share the same camel-core library on their classpath. For example, in an OSGi server this might affect many applications; whereas in a Web application (WAR file) it would affect only the Web application itself.
30.2. XML DSL
Simple expressions in XML DSL
In the XML DSL, you can use a simple expression by putting the expression inside a simple element. For example, to define a route that performs filtering based on the contents of the foo header:
<route id="simpleExample">
<from uri="seda:orders"/>
<filter>
<simple>${in.header.foo}</simple>
<to uri="mock:fooOrders"/>
</filter>
</route>Alternative placeholder syntax
Sometimes — for example, if you have enabled Spring property placeholders or OSGi blueprint property placeholders — you might find that the ${Expression} syntax clashes with another property placeholder syntax. In this case, you can disambiguate the placeholder using the alternative syntax, $simple{Expression}, for the simple expression. For example:
<simple>Hello $simple{in.header.name}, how are you?</simple>Customizing the start and end tokens
From XML configuration, you can customize the start and end tokens ({ and }, by default) by overriding the SimpleLanguage instance. For example, to change the start and end tokens to [ and ], define a new SimpleLanguage bean in your XML configuration file, as follows:
<bean id="simple" class="org.apache.camel.language.simple.SimpleLanguage"> <constructor-arg name="functionStartToken" value="["/> <constructor-arg name="functionEndToken" value="]"/> </bean>
Customizing the start and end tokens affects all Apache Camel applications that share the same camel-core library on their classpath. For example, in an OSGi server this might affect many applications; whereas in a Web application (WAR file) it would affect only the Web application itself.
Whitespace and auto-trim in XML DSL
By default, whitespace preceding and following a simple expression is automatically trimmed in XML DSL. So this expression with surrounding whitespace:
<transform>
<simple>
data=${body}
</simple>
</transform>is automatically trimmed, so that it is equivalent to this expression (no surrounding whitespace):
<transform>
<simple>data=${body}</simple>
</transform>If you want to include newlines before or after the expression, you can either explicitly add a newline character, as follows:
<transform>
<simple>data=${body}\n</simple>
</transform>
or you can switch off auto-trimming, by setting the trim attribute to false, as follows:
<transform trim="false">
<simple>data=${body}
</simple>
</transform>30.3. Invoking an External Script
Overview
It is possible to execute Simple scripts that are stored in an external resource, as described here.
Syntax for script resource
Use the following syntax to access a Simple script that is stored as an external resource:
resource:Scheme:Location
Where the Scheme: can be either classpath:, file:, or http:.
For example, to read the mysimple.txt script from the classpath,
simple("resource:classpath:mysimple.txt")30.4. Expressions
Overview
The simple language provides various elementary expressions that return different parts of a message exchange. For example, the expression, simple("${header.timeOfDay}"), would return the contents of a header called timeOfDay from the incoming message.
Since Apache Camel 2.9, you must always use the placeholder syntax, ${Expression}, to return a variable value. It is never permissible to omit the enclosing tokens (${ and }).
Contents of a single variable
You can use the simple language to define string expressions, based on the variables provided. For example, you can use a variable of the form, in.header.HeaderName, to obtain the value of the HeaderName header, as follows:
simple("${in.header.foo}")Variables embedded in a string
You can embed simple variables in a string expression — for example:
simple("Received a message from ${in.header.user} on ${date:in.header.date:yyyyMMdd}.")date and bean variables
As well as providing variables that access all of the different parts of an exchange (see Table 30.1, “Variables for the Simple Language”), the simple language also provides special variables for formatting dates, date:command:pattern, and for calling bean methods, bean:beanRef. For example, you can use the date and the bean variables as follows:
simple("Todays date is ${date:now:yyyyMMdd}")
simple("The order type is ${bean:orderService?method=getOrderType}")Specifying the result type
You can specify the result type of an expression explicitly. This is mainly useful for converting the result type to a boolean or numerical type.
In the Java DSL, specify the result type as an extra argument to simple(). For example, to return an integer result, you could evaluate a simple expression as follows:
...
.setHeader("five", simple("5", Integer.class))
In the XML DSL, specify the result type using the resultType attribute. For example:
<setHeader headerName="five">
<!-- use resultType to indicate that the type should be a java.lang.Integer -->
<simple resultType="java.lang.Integer">5</simple>
</setHeader>Dynamic Header Key
From Camel 2.17, the setHeaderand setExchange properties allows to use a dynamic header key using the Simple language, if the name of the key is a Simple language expression.
<camelContext xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:start"/>
<setHeader headerName="$simple{type:org.apache.camel.spring.processor.SpringSetPropertyNameDynamicTest$TestConstans.EXCHANGE_PROP_TX_FAILED}">
<simple>${type:java.lang.Boolean.TRUE}</simple>
</setHeader>
<to uri="mock:end"/>
</route>
</camelContext>Nested expressions
Simple expressions can be nested — for example:
simple("${header.${bean:headerChooser?method=whichHeader}}")Accessing constants or enums
You can access a bean’s constant or enum fields using the following syntax:
type:ClassName.Field
For example, consider the following Java enum type:
package org.apache.camel.processor;
...
public enum Customer {
GOLD, SILVER, BRONZE
}
You can access the Customer enum fields, as follows:
from("direct:start")
.choice()
.when().simple("${header.customer} ==
${type:org.apache.camel.processor.Customer.GOLD}")
.to("mock:gold")
.when().simple("${header.customer} ==
${type:org.apache.camel.processor.Customer.SILVER}")
.to("mock:silver")
.otherwise()
.to("mock:other");OGNL expressions
The Object Graph Navigation Language (OGNL) is a notation for invoking bean methods in a chain-like fashion. If a message body contains a Java bean, you can easily access its bean properties using OGNL notation. For example, if the message body is a Java object with a getAddress() accessor, you can access the Address object and the Address object’s properties as follows:
simple("${body.address}")
simple("${body.address.street}")
simple("${body.address.zip}")
simple("${body.address.city}")
Where the notation, ${body.address.street}, is shorthand for ${body.getAddress.getStreet}.
OGNL null-safe operator
You can use the null-safe operator, ?., to avoid encountering null-pointer exceptions, in case the body does not have an address. For example:
simple("${body?.address?.street}")
If the body is a java.util.Map type, you can look up a value in the map with the key, foo, using the following notation:
simple("${body[foo]?.name}")OGNL list element access
You can also use square brackets notation, [k], to access the elements of a list. For example:
simple("${body.address.lines[0]}")
simple("${body.address.lines[1]}")
simple("${body.address.lines[2]}")
The last keyword returns the index of the last element of a list. For example, you can access the second last element of a list, as follows:
simple("${body.address.lines[last-1]}")
You can use the size method to query the size of a list, as follows:
simple("${body.address.lines.size}")OGNL array length access
You can access the length of a Java array through the length method, as follows:
String[] lines = new String[]{"foo", "bar", "cat"};
exchange.getIn().setBody(lines);
simple("There are ${body.length} lines")30.5. Predicates
Overview
You can construct predicates by testing expressions for equality. For example, the predicate, simple("${header.timeOfDay} == '14:30'"), tests whether the timeOfDay header in the incoming message is equal to 14:30.
In addition, whenever the resultType is specified as a Boolean the expression is evaluated as a predicate instead of an expression. This allows the predicate syntax to be used for these expressions.
Syntax
You can also test various parts of an exchange (headers, message body, and so on) using simple predicates. Simple predicates have the following general syntax:
${LHSVariable} Op RHSValueWhere the variable on the left hand side, LHSVariable, is one of the variables shown in Table 30.1, “Variables for the Simple Language” and the value on the right hand side, RHSValue, is one of the following:
-
Another variable,
${RHSVariable}. -
A string literal, enclosed in single quotes,
' '. -
A numeric constant, enclosed in single quotes,
' '. -
The null object,
null.
The simple language always attempts to convert the RHS value to the type of the LHS value.
While the simple language will attempt to convert the RHS, depending on the operator the LHS may need to be cast into the appropriate Type before the comparison is made.
Examples
For example, you can perform simple string comparisons and numerical comparisons as follows:
simple("${in.header.user} == 'john'")
simple("${in.header.number} > '100'") // String literal can be converted to integerYou can test whether the left hand side is a member of a comma-separated list, as follows:
simple("${in.header.type} in 'gold,silver'")You can test whether the left hand side matches a regular expression, as follows:
simple("${in.header.number} regex '\d{4}'")
You can test the type of the left hand side using the is operator, as follows:
simple("${in.header.type} is 'java.lang.String'")
simple("${in.header.type} is 'String'") // You can abbreviate java.lang. typesYou can test whether the left hand side lies in a specified numerical range (where the range is inclusive), as follows:
simple("${in.header.number} range '100..199'")Conjunctions
You can also combine predicates using the logical conjunctions, && and ||.
For example, here is an expression using the && conjunction (logical and):
simple("${in.header.title} contains 'Camel' && ${in.header.type} == 'gold'")
And here is an expression using the || conjunction (logical inclusive or):
simple("${in.header.title} contains 'Camel' || ${in.header.type} == 'gold'")30.6. Variable Reference
Table of variables
Table 30.1, “Variables for the Simple Language” shows all of the variables supported by the simple language.
| Variable | Type | Description |
|---|---|---|
|
|
| The Camel context. Supports OGNL expressions. |
|
|
| The Camel context’s ID value. |
|
|
| The exchange’s ID value. |
|
|
| The In message ID value. |
|
|
| The In message body. Supports OGNL expressions. |
|
|
| The In message body. Supports OGNL expressions. |
|
|
| The Out message body. |
|
| Type |
The In message body, converted to the specified type. All types, Type, must be specified using their fully-qualified Java name, except for the types: |
|
| Type |
The In message body, converted to the specified type. All types, Type, must be specified using their fully-qualified Java name, except for the types: |
|
|
| The In message’s HeaderName header. Supports OGNL expressions. |
|
|
| The In message’s HeaderName header (alternative syntax). |
|
|
| The In message’s HeaderName header. |
|
|
| The In message’s HeaderName header (alternative syntax). |
|
|
| The In message’s HeaderName header. Supports OGNL expressions. |
|
|
| The In message’s HeaderName header (alternative syntax). |
|
|
| The In message’s HeaderName header. Supports OGNL expressions. |
|
|
| The In message’s HeaderName header (alternative syntax). |
|
|
| The Out message’s HeaderName header. |
|
|
| The Out message’s HeaderName header (alternative syntax). |
|
|
| The Out message’s HeaderName header. |
|
|
| The Out message’s HeaderName header (alternative syntax). |
|
| Type |
The Key header, converted to the specified type. All types, Type, must be specified using their fully-qualified Java name, except for the types: |
|
|
|
All of the In headers (as a |
|
|
|
All of the In headers (as a |
|
|
| The PropertyName property on the exchange. |
|
|
| The PropertyName property on the exchange (alternative syntax). |
|
|
| The SysPropertyName Java system property. |
|
|
| The SysEnvVar system environment variable. |
|
|
|
Either the exception object from |
|
|
|
If an exception is set on the exchange, returns the value of |
|
|
|
If an exception is set on the exchange, returns the value of |
|
|
|
A date formatted using a java.text.SimpleDateFormat pattern. The following commands are supported: |
|
|
|
Invokes a method on the referenced bean and returns the result of the method invocation. To specify a method name, you can either use the |
|
|
| Looks up the bean with the ID, beanID, in the registry and returns a reference to the bean itself. For example, if you are using the splitter EIP, you could use this variable to reference the bean that implements the splitting algorithm. |
|
|
| The value of the Key property placeholder . |
|
|
| The value of the Key property placeholder, where the location of the properties file is given by Location . |
|
|
| The name of the current thread. |
|
|
|
Returns the ID of the current route through which the |
|
|
|
References a type or field by its Fully-Qualified-Name (FQN). To refer to a field, append |
|
|
| From Camel 2.17, the collate function iterates the message body and groups the data into the sub lists of specific size. You can use with the Splitter EIP to split a message body and group or batch the submessages into a group of N sublists. |
|
|
| The skip function iterates the message body and skips the first number of items. This can be used with the Splitter EIP to split a message body and skip the first N number of items. |
30.7. Operator Reference
Binary operators
The binary operators for simple language predicates are shown in Table 30.2, “Binary Operators for the Simple Language”.
| Operator | Description |
|---|---|
|
| Equals. |
|
| Equals ignore case. Ignore the case when comparing string values. |
|
| Greater than. |
|
| Greater than or equals. |
|
| Less than. |
|
| Less than or equals. |
|
| Not equal to. |
|
| Test if LHS string contains RHS string. |
|
| Test if LHS string does not contain RHS string. |
|
| Test if LHS string matches RHS regular expression. |
|
| Test if LHS string does not match RHS regular expression. |
|
| Test if LHS string appears in the RHS comma-separated list. |
|
| Test if LHS string does not appear in the RHS comma-separated list. |
|
|
Test if LHS is an instance of RHS Java type (using Java |
|
|
Test if LHS is not an instance of RHS Java type (using Java |
|
|
Test if LHS number lies in the RHS range (where range has the format, |
|
|
Test if LHS number does not lie in the RHS range (where range has the format, |
|
| New in Camel 2.18. Test if the LHS string starts with the RHS string. |
|
| New in Camel 2.18. Test if the LHS string ends with the RHS string. |
Unary operators and character escapes
The binary operators for simple language predicates are shown in Table 30.3, “Unary Operators for the Simple Language”.
| Operator | Description |
|---|---|
|
| Increment a number by 1. |
|
| Decrement a number by 1. |
|
| The newline character. |
|
| The carriage return character. |
|
| The tab character. |
|
| (Obsolete) Since Camel version 2.11, the backslash escape character is not supported. |
Combining predicates
The conjunctions shown in Table 30.4, “Conjunctions for Simple Language Predicates” can be used to combine two or more simple language predicates.
| Operator | Description |
|---|---|
|
| Combine two predicates with logical and. |
|
| Combine two predicates with logical inclusive or. |
|
|
Deprecated. Use |
|
|
Deprecated. Use |
Chapter 31. SpEL
Overview
The Spring Expression Language (SpEL) is an object graph navigation language provided with Spring 3, which can be used to construct predicates and expressions in a route. A notable feature of SpEL is the ease with which you can access beans from the registry.
Syntax
The SpEL expressions must use the placeholder syntax, #{SpelExpression}, so that they can be embedded in a plain text string (in other words, SpEL has expression templating enabled).
SpEL can also look up beans in the registry (typically, the Spring registry), using the @BeanID syntax. For example, given a bean with the ID, headerUtils, and the method, count() (which counts the number of headers on the current message), you could use the headerUtils bean in an SpEL predicate, as follows:
#{@headerUtils.count > 4}Adding SpEL package
To use SpEL in your routes you need to add a dependency on camel-spring to your project as shown in Example 31.1, “Adding the camel-spring dependency”.
Example 31.1. Adding the camel-spring dependency
<!-- Maven POM File -->
<properties>
<camel-version>2.21.0.fuse-730078-redhat-00001</camel-version>
...
</properties>
<dependencies>
...
<dependency>
<groupId>org.apache.camel</groupId>
<artifactId>camel-spring</artifactId>
<version>${camel-version}</version>
</dependency>
...
</dependencies>Variables
Table 31.1, “SpEL variables” lists the variables that are accessible when using SpEL.
| Variable | Type | Description |
|---|---|---|
|
|
| The current exchange is the root object. |
|
|
| The current exchange. |
|
|
| The current exchange’s ID. |
|
|
| The exchange exception (if any). |
|
|
| The fault message (if any). |
|
|
| The exchange’s In message. |
|
|
| The exchange’s Out message (if any). |
|
|
| The exchange properties. |
|
|
| The exchange property keyed by Name. |
|
|
| The exchange property keyed by Name, converted to the type, Type. |
XML example
For example, to select only those messages whose Country header has the value USA, you can use the following SpEL expression:
<route>
<from uri="SourceURL"/>
<filter>
<spel>#{request.headers['Country'] == 'USA'}}</spel>
<to uri="TargetURL"/>
</filter>
</route>Java example
You can define the same route in the Java DSL, as follows:
from("SourceURL")
.filter().spel("#{request.headers['Country'] == 'USA'}")
.to("TargetURL");The following example shows how to embed SpEL expressions within a plain text string:
from("SourceURL")
.setBody(spel("Hello #{request.body}! What a beautiful #{request.headers['dayOrNight']}"))
.to("TargetURL");Chapter 32. The XPath Language
Abstract
When processing XML messages, the XPath language enables you to select part of a message, by specifying an XPath expression that acts on the message’s Document Object Model (DOM). You can also define XPath predicates to test the contents of an element or an attribute.
32.1. Java DSL
Basic expressions
You can use xpath("Expression") to evaluate an XPath expression on the current exchange (where the XPath expression is applied to the body of the current In message). The result of the xpath() expression is an XML node (or node set, if more than one node matches).
For example, to extract the contents of the /person/name element from the current In message body and use it to set a header named user, you could define a route like the following:
from("queue:foo")
.setHeader("user", xpath("/person/name/text()"))
.to("direct:tie");
Instead of specifying xpath() as an argument to setHeader(), you can use the fluent builder xpath() command — for example:
from("queue:foo")
.setHeader("user").xpath("/person/name/text()")
.to("direct:tie");
If you want to convert the result to a specific type, specify the result type as the second argument of xpath(). For example, to specify explicitly that the result type is String:
xpath("/person/name/text()", String.class)Namespaces
Typically, XML elements belong to a schema, which is identified by a namespace URI. When processing documents like this, it is necessary to associate namespace URIs with prefixes, so that you can identify element names unambiguously in your XPath expressions. Apache Camel provides the helper class, org.apache.camel.builder.xml.Namespaces, which enables you to define associations between namespaces and prefixes.
For example, to associate the prefix, cust, with the namespace, http://acme.com/customer/record, and then extract the contents of the element, /cust:person/cust:name, you could define a route like the following:
import org.apache.camel.builder.xml.Namespaces;
...
Namespaces ns = new Namespaces("cust", "http://acme.com/customer/record");
from("queue:foo")
.setHeader("user", xpath("/cust:person/cust:name/text()", ns))
.to("direct:tie");
Where you make the namespace definitions available to the xpath() expression builder by passing the Namespaces object, ns, as an additional argument. If you need to define multiple namespaces, use the Namespace.add() method, as follows:
import org.apache.camel.builder.xml.Namespaces;
...
Namespaces ns = new Namespaces("cust", "http://acme.com/customer/record");
ns.add("inv", "http://acme.com/invoice");
ns.add("xsi", "http://www.w3.org/2001/XMLSchema-instance");
If you need to specify the result type and define namespaces, you can use the three-argument form of xpath(), as follows:
xpath("/person/name/text()", String.class, ns)Auditing namespaces
One of the most frequent problems that can occur when using XPath expressions is that there is a mismatch between the namespaces appearing in the incoming messages and the namespaces used in the XPath expression. To help you troubleshoot this kind of problem, the XPath language supports an option to dump all of the namespaces from all of the incoming messages into the system log.
To enable namespace logging at the INFO log level, enable the logNamespaces option in the Java DSL, as follows:
xpath("/foo:person/@id", String.class).logNamespaces()
Alternatively, you could configure your logging system to enable TRACE level logging on the org.apache.camel.builder.xml.XPathBuilder logger.
When namespace logging is enabled, you will see log messages like the following for each processed message:
2012-01-16 13:23:45,878 [stSaxonWithFlag] INFO XPathBuilder -
Namespaces discovered in message: {xmlns:a=[http://apache.org/camel],
DEFAULT=[http://apache.org/default],
xmlns:b=[http://apache.org/camelA, http://apache.org/camelB]}32.2. XML DSL
Basic expressions
To evaluate an XPath expression in the XML DSL, put the XPath expression inside an xpath element. The XPath expression is applied to the body of the current In message and returns an XML node (or node set). Typically, the returned XML node is automatically converted to a string.
For example, to extract the contents of the /person/name element from the current In message body and use it to set a header named user, you could define a route like the following:
<beans ...>
<camelContext xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="queue:foo"/>
<setHeader headerName="user">
<xpath>/person/name/text()</xpath>
</setHeader>
<to uri="direct:tie"/>
</route>
</camelContext>
</beans>
If you want to convert the result to a specific type, specify the result type by setting the resultType attribute to a Java type name (where you must specify the fully-qualified type name). For example, to specify explicitly that the result type is java.lang.String (you can omit the java.lang. prefix here):
<xpath resultType="String">/person/name/text()</xpath>
Namespaces
When processing documents whose elements belong to one or more XML schemas, it is typically necessary to associate namespace URIs with prefixes, so that you can identify element names unambiguously in your XPath expressions. It is possible to use the standard XML mechanism for associating prefixes with namespace URIs. That is, you can set an attribute like this: xmlns:Prefix="NamespaceURI".
For example, to associate the prefix, cust, with the namespace, http://acme.com/customer/record, and then extract the contents of the element, /cust:person/cust:name, you could define a route like the following:
<beans ...>
<camelContext xmlns="http://camel.apache.org/schema/spring"
xmlns:cust="http://acme.com/customer/record" >
<route>
<from uri="queue:foo"/>
<setHeader headerName="user">
<xpath>/cust:person/cust:name/text()</xpath>
</setHeader>
<to uri="direct:tie"/>
</route>
</camelContext>
</beans>Auditing namespaces
One of the most frequent problems that can occur when using XPath expressions is that there is a mismatch between the namespaces appearing in the incoming messages and the namespaces used in the XPath expression. To help you troubleshoot this kind of problem, the XPath language supports an option to dump all of the namespaces from all of the incoming messages into the system log.
To enable namespace logging at the INFO log level, enable the logNamespaces option in the XML DSL, as follows:
<xpath logNamespaces="true" resultType="String">/foo:person/@id</xpath>
Alternatively, you could configure your logging system to enable TRACE level logging on the org.apache.camel.builder.xml.XPathBuilder logger.
When namespace logging is enabled, you will see log messages like the following for each processed message:
2012-01-16 13:23:45,878 [stSaxonWithFlag] INFO XPathBuilder -
Namespaces discovered in message: {xmlns:a=[http://apache.org/camel],
DEFAULT=[http://apache.org/default],
xmlns:b=[http://apache.org/camelA, http://apache.org/camelB]}32.3. XPath Injection
Parameter binding annotation
When using Apache Camel bean integration to invoke a method on a Java bean, you can use the @XPath annotation to extract a value from the exchange and bind it to a method parameter.
For example, consider the following route fragment, which invokes the credit method on an AccountService object:
from("queue:payments")
.beanRef("accountService","credit")
...
The credit method uses parameter binding annotations to extract relevant data from the message body and inject it into its parameters, as follows:
public class AccountService {
...
public void credit(
@XPath("/transaction/transfer/receiver/text()") String name,
@XPath("/transaction/transfer/amount/text()") String amount
)
{
...
}
...
}For more information, see Bean Integration in the Apache Camel Development Guide on the customer portal.
Namespaces
Table 32.1, “Predefined Namespaces for @XPath” shows the namespaces that are predefined for XPath. You can use these namespace prefixes in the XPath expression that appears in the @XPath annotation.
| Namespace URI | Prefix |
|---|---|
|
| |
|
|
Custom namespaces
You can use the @NamespacePrefix annotation to define custom XML namespaces. Invoke the @NamespacePrefix annotation to initialize the namespaces argument of the @XPath annotation. The namespaces defined by @NamespacePrefix can then be used in the @XPath annotation’s expression value.
For example, to associate the prefix, ex, with the custom namespace, http://fusesource.com/examples, invoke the @XPath annotation as follows:
public class AccountService {
...
public void credit(
@XPath(
value = "/ex:transaction/ex:transfer/ex:receiver/text()",
namespaces = @NamespacePrefix( prefix = "ex", uri = "http://fusesource.com/examples"
)
) String name,
@XPath(
value = "/ex:transaction/ex:transfer/ex:amount/text()",
namespaces = @NamespacePrefix( prefix = "ex", uri = "http://fusesource.com/examples"
)
) String amount,
)
{
...
}
...
}32.4. XPath Builder
Overview
The org.apache.camel.builder.xml.XPathBuilder class enables you to evaluate XPath expressions independently of an exchange. That is, if you have an XML fragment from any source, you can use XPathBuilder to evaluate an XPath expression on the XML fragment.
Matching expressions
Use the matches() method to check whether one or more XML nodes can be found that match the given XPath expression. The basic syntax for matching an XPath expression using XPathBuilder is as follows:
boolean matches = XPathBuilder
.xpath("Expression")
.matches(CamelContext, "XMLString");
Where the given expression, Expression, is evaluated against the XML fragment, XMLString, and the result is true, if at least one node is found that matches the expression. For example, the following example returns true, because the XPath expression finds a match in the xyz attribute.
boolean matches = XPathBuilder
.xpath("/foo/bar/@xyz")
.matches(getContext(), "<foo><bar xyz='cheese'/></foo>"));Evaluating expressions
Use the evaluate() method to return the contents of the first node that matches the given XPath expression. The basic syntax for evaluating an XPath expression using XPathBuilder is as follows:
String nodeValue = XPathBuilder
.xpath("Expression")
.evaluate(CamelContext, "XMLString");
You can also specify the result type by passing the required type as the second argument to evaluate() — for example:
String name = XPathBuilder
.xpath("foo/bar")
.evaluate(context, "<foo><bar>cheese</bar></foo>", String.class);
Integer number = XPathBuilder
.xpath("foo/bar")
.evaluate(context, "<foo><bar>123</bar></foo>", Integer.class);
Boolean bool = XPathBuilder
.xpath("foo/bar")
.evaluate(context, "<foo><bar>true</bar></foo>", Boolean.class);32.5. Enabling Saxon
Prerequisites
A prerequisite for using the Saxon parser is that you add a dependency on the camel-saxon artifact (either adding this dependency to your Maven POM, if you use Maven, or adding the camel-saxon-7.3.0.fuse-730079-redhat-00001.jar file to your classpath, otherwise).
Using the Saxon parser in Java DSL
In Java DSL, the simplest way to enable the Saxon parser is to call the saxon() fluent builder method. For example, you could invoke the Saxon parser as shown in the following example:
// Java
// create a builder to evaluate the xpath using saxon
XPathBuilder builder = XPathBuilder.xpath("tokenize(/foo/bar, '_')[2]").saxon();
// evaluate as a String result
String result = builder.evaluate(context, "<foo><bar>abc_def_ghi</bar></foo>");Using the Saxon parser in XML DSL
In XML DSL, the simplest way to enable the Saxon parser is to set the saxon attribute to true in the xpath element. For example, you could invoke the Saxon parser as shown in the following example:
<xpath saxon="true" resultType="java.lang.String">current-dateTime()</xpath>
Programming with Saxon
If you want to use the Saxon XML parser in your application code, you can create an instance of the Saxon transformer factory explicitly using the following code:
// Java import javax.xml.transform.TransformerFactory; import net.sf.saxon.TransformerFactoryImpl; ... TransformerFactory saxonFactory = new net.sf.saxon.TransformerFactoryImpl();
On the other hand, if you prefer to use the generic JAXP API to create a transformer factory instance, you must first set the javax.xml.transform.TransformerFactory property in the ESBInstall/etc/system.properties file, as follows:
javax.xml.transform.TransformerFactory=net.sf.saxon.TransformerFactoryImpl
You can then instantiate the Saxon factory using the generic JAXP API, as follows:
// Java import javax.xml.transform.TransformerFactory; ... TransformerFactory factory = TransformerFactory.newInstance();
If your application depends on any third-party libraries that use Saxon, it might be necessary to use the second, generic approach.
The Saxon library must be installed in the container as the OSGi bundle, net.sf.saxon/saxon9he (normally installed by default). In versions of Fuse ESB prior to 7.1, it is not possible to load Saxon using the generic JAXP API.
32.6. Expressions
Result type
By default, an XPath expression returns a list of one or more XML nodes, of org.w3c.dom.NodeList type. You can use the type converter mechanism to convert the result to a different type, however. In the Java DSL, you can specify the result type in the second argument of the xpath() command. For example, to return the result of an XPath expression as a String:
xpath("/person/name/text()", String.class)
In the XML DSL, you can specify the result type in the resultType attribute, as follows:
<xpath resultType="java.lang.String">/person/name/text()</xpath>
Patterns in location paths
You can use the following patterns in XPath location paths:
/people/personThe basic location path specifies the nested location of a particular element. That is, the preceding location path would match the person element in the following XML fragment:
<people> <person>...</person> </people>
Note that this basic pattern can match multiple nodes — for example, if there is more than one
personelement inside thepeopleelement./name/text()-
If you just want to access the text inside by the element, append
/text()to the location path, otherwise the node includes the element’s start and end tags (and these tags would be included when you convert the node to a string). /person/telephone/@isDayTimeTo select the value of an attribute, AttributeName, use the syntax
@AttributeName. For example, the preceding location path returnstruewhen applied to the following XML fragment:<person> <telephone isDayTime="true">1234567890</telephone> </person>
*-
A wildcard that matches all elements in the specified scope. For example,
/people/person/\*matches all the child elements ofperson. @*-
A wildcard that matches all attributes of the matched elements. For example,
/person/name/@\*matches all attributes of every matchednameelement. //Match the location path at every nesting level. For example, the
//namepattern matches everynameelement highlighted in the following XML fragment:<invoice> <person> <name .../> </person> </invoice> <person> <name .../> </person> <name .../>..- Selects the parent of the current context node. Not normally useful in the Apache Camel XPath language, because the current context node is the document root, which has no parent.
node()- Match any kind of node.
text()- Match a text node.
comment()- Match a comment node.
processing-instruction()- Match a processing-instruction node.
Predicate filters
You can filter the set of nodes matching a location path by appending a predicate in square brackets, [Predicate]. For example, you can select the Nth node from the list of matches by appending [N] to a location path. The following expression selects the first matching person element:
/people/person[1]
The following expression selects the second-last person element:
/people/person[last()-1]
You can test the value of attributes in order to select elements with particular attribute values. The following expression selects the name elements, whose surname attribute is either Strachan or Davies:
/person/name[@surname="Strachan" or @surname="Davies"]
You can combine predicate expressions using any of the conjunctions and, or, not(), and you can compare expressions using the comparators, =, !=, >, >=, <, ⇐ (in practice, the less-than symbol must be replaced by the < entity). You can also use XPath functions in the predicate filter.
Axes
When you consider the structure of an XML document, the root element contains a sequence of children, and some of those child elements contain further children, and so on. Looked at in this way, where nested elements are linked together by the child-of relationship, the whole XML document has the structure of a tree. Now, if you choose a particular node in this element tree (call it the context node), you might want to refer to different parts of the tree relative to the chosen node. For example, you might want to refer to the children of the context node, to the parent of the context node, or to all of the nodes that share the same parent as the context node (sibling nodes).
An XPath axis is used to specify the scope of a node match, restricting the search to a particular part of the node tree, relative to the current context node. The axis is attached as a prefix to the node name that you want to match, using the syntax, AxisType::MatchingNode. For example, you can use the child:: axis to search the children of the current context node, as follows:
/invoice/items/child::item
The context node of child::item is the items element that is selected by the path, /invoice/items. The child:: axis restricts the search to the children of the context node, items, so that child::item matches the children of items that are named item. As a matter of fact, the child:: axis is the default axis, so the preceding example can be written equivalently as:
/invoice/items/item
But there several other axes (13 in all), some of which you have already seen in abbreviated form: @ is an abbreviation of attribute::, and // is an abbreviation of descendant-or-self::. The full list of axes is as follows (for details consult the reference below):
-
ancestor -
ancestor-or-self -
attribute -
child -
descendant -
descendant-or-self -
following -
following-sibling -
namespace -
parent -
preceding -
preceding-sibling -
self
Functions
XPath provides a small set of standard functions, which can be useful when evaluating predicates. For example, to select the last matching node from a node set, you can use the last() function, which returns the index of the last node in a node set, as follows:
/people/person[last()]
Where the preceding example selects the last person element in a sequence (in document order).
For full details of all the functions that XPath provides, consult the reference below.
Reference
For full details of the XPath grammar, see the XML Path Language, Version 1.0 specification.
32.7. Predicates
Basic predicates
You can use xpath in the Java DSL or the XML DSL in a context where a predicate is expected — for example, as the argument to a filter() processor or as the argument to a when() clause.
For example, the following route filters incoming messages, allowing a message to pass, only if the /person/city element contains the value, London:
from("direct:tie")
.filter().xpath("/person/city = 'London'").to("file:target/messages/uk");
The following route evaluates the XPath predicate in a when() clause:
from("direct:tie")
.choice()
.when(xpath("/person/city = 'London'")).to("file:target/messages/uk")
.otherwise().to("file:target/messages/others");XPath predicate operators
The XPath language supports the standard XPath predicate operators, as shown in Table 32.2, “Operators for the XPath Language”.
| Operator | Description |
|---|---|
|
| Equals. |
|
| Not equal to. |
|
| Greater than. |
|
| Greater than or equals. |
|
| Less than. |
|
| Less than or equals. |
|
| Combine two predicates with logical and. |
|
| Combine two predicates with logical inclusive or. |
|
| Negate predicate argument. |
32.8. Using Variables and Functions
Evaluating variables in a route
When evaluating XPath expressions inside a route, you can use XPath variables to access the contents of the current exchange, as well as O/S environment variables and Java system properties. The syntax to access a variable value is $VarName or $Prefix:VarName, if the variable is accessed through an XML namespace.
For example, you can access the In message’s body as $in:body and the In message’s header value as $in:HeaderName. O/S environment variables can be accessed as $env:EnvVar and Java system properties can be accessed as $system:SysVar.
In the following example, the first route extracts the value of the /person/city element and inserts it into the city header. The second route filters exchanges using the XPath expression, $in:city = 'London', where the $in:city variable is replaced by the value of the city header.
from("file:src/data?noop=true")
.setHeader("city").xpath("/person/city/text()")
.to("direct:tie");
from("direct:tie")
.filter().xpath("$in:city = 'London'").to("file:target/messages/uk");Evaluating functions in a route
In addition to the standard XPath functions, the XPath language defines additional functions. These additional functions (which are listed in Table 32.4, “XPath Custom Functions”) can be used to access the underlying exchange, to evaluate a simple expression or to look up a property in the Apache Camel property placeholder component.
For example, the following example uses the in:header() function and the in:body() function to access a head and the body from the underlying exchange:
from("direct:start").choice()
.when().xpath("in:header('foo') = 'bar'").to("mock:x")
.when().xpath("in:body() = '<two/>'").to("mock:y")
.otherwise().to("mock:z");
Notice the similarity between theses functions and the corresponding in:HeaderName or in:body variables. The functions have a slightly different syntax however: in:header('HeaderName') instead of in:HeaderName; and in:body() instead of in:body.
Evaluating variables in XPathBuilder
You can also use variables in expressions that are evaluated using the XPathBuilder class. In this case, you cannot use variables such as $in:body or $in:HeaderName, because there is no exchange object to evaluate against. But you can use variables that are defined inline using the variable(Name, Value) fluent builder method.
For example, the following XPathBuilder construction evaluates the $test variable, which is defined to have the value, London:
String var = XPathBuilder.xpath("$test")
.variable("test", "London")
.evaluate(getContext(), "<name>foo</name>");
Note that variables defined in this way are automatically entered into the global namespace (for example, the variable, $test, uses no prefix).
32.9. Variable Namespaces
Table of namespaces
Table 32.3, “XPath Variable Namespaces” shows the namespace URIs that are associated with the various namespace prefixes.
| Namespace URI | Prefix | Description |
|---|---|---|
| None | Default namespace (associated with variables that have no namespace prefix). | |
|
| Used to reference header or body of the current exchange’s In message. | |
|
| Used to reference header or body of the current exchange’s Out message. | |
|
| Used to reference some custom functions. | |
|
| Used to reference O/S environment variables. | |
|
| Used to reference Java system properties. | |
| Undefined | Used to reference exchange properties. You must define your own prefix for this namespace. |
32.10. Function Reference
Table of custom functions
Table 32.4, “XPath Custom Functions” shows the custom functions that you can use in Apache Camel XPath expressions. These functions can be used in addition to the standard XPath functions.
| Function | Description |
|---|---|
|
| Returns the In message body. |
|
| Returns the In message header with name, HeaderName. |
|
| Returns the Out message body. |
|
| Returns the Out message header with name, HeaderName. |
|
| Looks up a property with the key, PropKey . |
|
| Evaluates the specified simple expression, SimpleExp. |
Chapter 33. XQuery
Overview
XQuery was originally devised as a query language for data stored in XML form in a database. The XQuery language enables you to select parts of the current message, when the message is in XML format. XQuery is a superset of the XPath language; hence, any valid XPath expression is also a valid XQuery expression.
Java syntax
You can pass an XQuery expression to xquery() in several ways. For simple expressions, you can pass the XQuery expressions as a string (java.lang.String). For longer XQuery expressions, you might prefer to store the expression in a file, which you can then reference by passing a java.io.File argument or a java.net.URL argument to the overloaded xquery() method. The XQuery expression implicitly acts on the message content and returns a node set as the result. Depending on the context, the return value is interpreted either as a predicate (where an empty node set is interpreted as false) or as an expression.
Adding the Saxon module
To use XQuery in your routes you need to add a dependency on camel-saxon to your project as shown in Example 33.1, “Adding the camel-saxon dependency”.
Example 33.1. Adding the camel-saxon dependency
<!-- Maven POM File -->
...
<dependencies>
...
<dependency>
<groupId>org.apache.camel</groupId>
<artifactId>camel-saxon</artifactId>
<version>${camel-version}</version>
</dependency>
...
</dependencies>Camel on EAP deployment
The camel-saxon component is supported by the Camel on EAP (Wildfly Camel) framework, which offers a simplified deployment model on the Red Hat JBoss Enterprise Application Platform (JBoss EAP) container.
Static import
To use the xquery() static method in your application code, include the following import statement in your Java source files:
import static org.apache.camel.component.xquery.XQueryBuilder.xquery;
Variables
Table 33.1, “XQuery variables” lists the variables that are accessible when using XQuery.
| Variable | Type | Description |
|---|---|---|
|
|
| The current Exchange |
|
|
| The body of the IN message |
|
|
| The body of the OUT message |
|
|
| The IN message header whose key is key |
|
|
| The OUT message header whose key is key |
| key |
| The Exchange property whose key is key |
Example
Example 33.2, “Route using XQuery” shows a route that uses XQuery.
Example 33.2. Route using XQuery
<camelContext>
<route>
<from uri="activemq:MyQueue"/>
<filter>
<language langauge="xquery">/foo:person[@name='James']</language>
<to uri="mqseries:SomeOtherQueue"/>
</filter>
</route>
</camelContext>Part III. Advanced Camel Programming
This guide describes how to use the Apache Camel API.
Chapter 34. Understanding Message Formats
Abstract
Before you can begin programming with Apache Camel, you should have a clear understanding of how messages and message exchanges are modelled. Because Apache Camel can process many message formats, the basic message type is designed to have an abstract format. Apache Camel provides the APIs needed to access and transform the data formats that underly message bodies and message headers.
34.1. Exchanges
Overview
An exchange object is a wrapper that encapsulates a received message and stores its associated metadata (including the exchange properties). In addition, if the current message is dispatched to a producer endpoint, the exchange provides a temporary slot to hold the reply (the Out message).
An important feature of exchanges in Apache Camel is that they support lazy creation of messages. This can provide a significant optimization in the case of routes that do not require explicit access to messages.
Figure 34.1. Exchange Object Passing through a Route
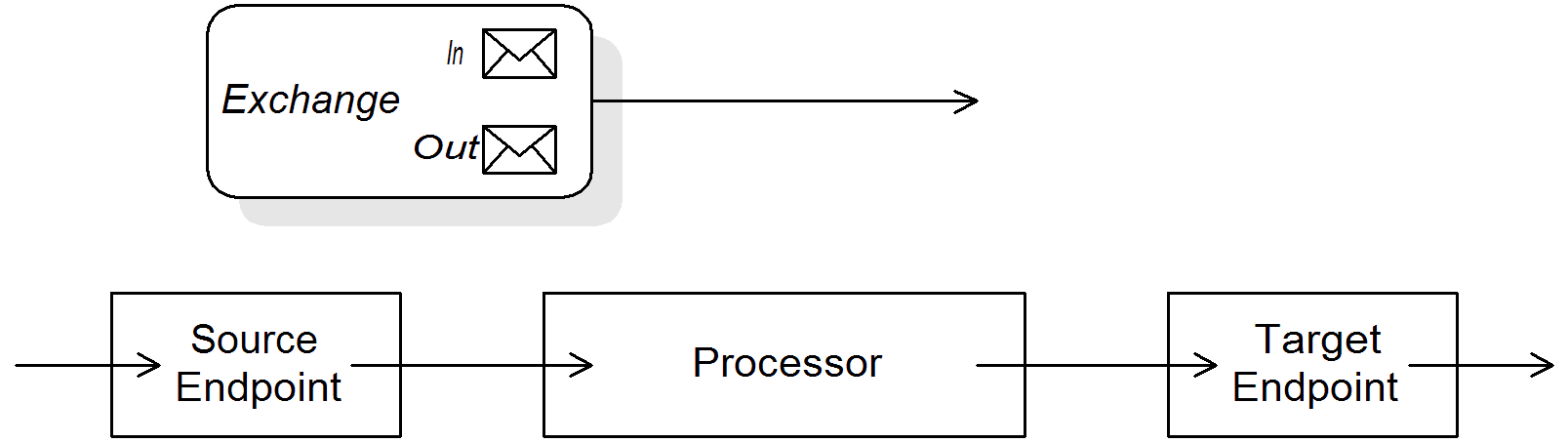
Figure 34.1, “Exchange Object Passing through a Route” shows an exchange object passing through a route. In the context of a route, an exchange object gets passed as the argument of the Processor.process() method. This means that the exchange object is directly accessible to the source endpoint, the target endpoint, and all of the processors in between.
The Exchange interface
The org.apache.camel.Exchange interface defines methods to access In and Out messages, as shown in Example 34.1, “Exchange Methods”.
Example 34.1. Exchange Methods
// Access the In message Message getIn(); void setIn(Message in); // Access the Out message (if any) Message getOut(); void setOut(Message out); boolean hasOut(); // Access the exchange ID String getExchangeId(); void setExchangeId(String id);
For a complete description of the methods in the Exchange interface, see Section 43.1, “The Exchange Interface”.
Lazy creation of messages
Apache Camel supports lazy creation of In, Out, and Fault messages. This means that message instances are not created until you try to access them (for example, by calling getIn() or getOut()). The lazy message creation semantics are implemented by the org.apache.camel.impl.DefaultExchange class.
If you call one of the no-argument accessors (getIn() or getOut()), or if you call an accessor with the boolean argument equal to true (that is, getIn(true) or getOut(true)), the default method implementation creates a new message instance, if one does not already exist.
If you call an accessor with the boolean argument equal to false (that is, getIn(false) or getOut(false)), the default method implementation returns the current message value.[1]
Lazy creation of exchange IDs
Apache Camel supports lazy creation of exchange IDs. You can call getExchangeId() on any exchange to obtain a unique ID for that exchange instance, but the ID is generated only when you actually call the method. The DefaultExchange.getExchangeId() implementation of this method delegates ID generation to the UUID generator that is registered with the CamelContext.
For details of how to register UUID generators with the CamelContext, see Section 34.4, “Built-In UUID Generators”.
34.2. Messages
Overview
Message objects represent messages using the following abstract model:
- Message body
- Message headers
- Message attachments
The message body and the message headers can be of arbitrary type (they are declared as type Object) and the message attachments are declared to be of type javax.activation.DataHandler , which can contain arbitrary MIME types. If you need to obtain a concrete representation of the message contents, you can convert the body and headers to another type using the type converter mechanism and, possibly, using the marshalling and unmarshalling mechanism.
One important feature of Apache Camel messages is that they support lazy creation of message bodies and headers. In some cases, this means that a message can pass through a route without needing to be parsed at all.
The Message interface
The org.apache.camel.Message interface defines methods to access the message body, message headers and message attachments, as shown in Example 34.2, “Message Interface”.
Example 34.2. Message Interface
// Access the message body Object getBody(); <T> T getBody(Class<T> type); void setBody(Object body); <T> void setBody(Object body, Class<T> type); // Access message headers Object getHeader(String name); <T> T getHeader(String name, Class<T> type); void setHeader(String name, Object value); Object removeHeader(String name); Map<String, Object> getHeaders(); void setHeaders(Map<String, Object> headers); // Access message attachments javax.activation.DataHandler getAttachment(String id); java.util.Map<String, javax.activation.DataHandler> getAttachments(); java.util.Set<String> getAttachmentNames(); void addAttachment(String id, javax.activation.DataHandler content) // Access the message ID String getMessageId(); void setMessageId(String messageId);
For a complete description of the methods in the Message interface, see Section 44.1, “The Message Interface”.
Lazy creation of bodies, headers, and attachments
Apache Camel supports lazy creation of bodies, headers, and attachments. This means that the objects that represent a message body, a message header, or a message attachment are not created until they are needed.
For example, consider the following route that accesses the foo message header from the In message:
from("SourceURL")
.filter(header("foo")
.isEqualTo("bar"))
.to("TargetURL");
In this route, if we assume that the component referenced by SourceURL supports lazy creation, the In message headers are not actually parsed until the header("foo") call is executed. At that point, the underlying message implementation parses the headers and populates the header map. The message body is not parsed until you reach the end of the route, at the to("TargetURL") call. At that point, the body is converted into the format required for writing it to the target endpoint, TargetURL.
By waiting until the last possible moment before populating the bodies, headers, and attachments, you can ensure that unnecessary type conversions are avoided. In some cases, you can completely avoid parsing. For example, if a route contains no explicit references to message headers, a message could traverse the route without ever parsing the headers.
Whether or not lazy creation is implemented in practice depends on the underlying component implementation. In general, lazy creation is valuable for those cases where creating a message body, a message header, or a message attachment is expensive. For details about implementing a message type that supports lazy creation, see Section 44.2, “Implementing the Message Interface”.
Lazy creation of message IDs
Apache Camel supports lazy creation of message IDs. That is, a message ID is generated only when you actually call the getMessageId() method. The DefaultExchange.getExchangeId() implementation of this method delegates ID generation to the UUID generator that is registered with the CamelContext.
Some endpoint implementations would call the getMessageId() method implicitly, if the endpoint implements a protocol that requires a unique message ID. In particular, JMS messages normally include a header containing unique message ID, so the JMS component automatically calls getMessageId() to obtain the message ID (this is controlled by the messageIdEnabled option on the JMS endpoint).
For details of how to register UUID generators with the CamelContext, see Section 34.4, “Built-In UUID Generators”.
Initial message format
The initial format of an In message is determined by the source endpoint, and the initial format of an Out message is determined by the target endpoint. If lazy creation is supported by the underlying component, the message remains unparsed until it is accessed explicitly by the application. Most Apache Camel components create the message body in a relatively raw form — for example, representing it using types such as byte[], ByteBuffer, InputStream, or OutputStream. This ensures that the overhead required for creating the initial message is minimal. Where more elaborate message formats are required components usually rely on type converters or marshalling processors.
Type converters
It does not matter what the initial format of the message is, because you can easily convert a message from one format to another using the built-in type converters (see Section 34.3, “Built-In Type Converters”). There are various methods in the Apache Camel API that expose type conversion functionality. For example, the convertBodyTo(Class type) method can be inserted into a route to convert the body of an In message, as follows:
from("SourceURL").convertBodyTo(String.class).to("TargetURL");
Where the body of the In message is converted to a java.lang.String. The following example shows how to append a string to the end of the In message body:
from("SourceURL").setBody(bodyAs(String.class).append("My Special Signature")).to("TargetURL");Where the message body is converted to a string format before appending a string to the end. It is not necessary to convert the message body explicitly in this example. You can also use:
from("SourceURL").setBody(body().append("My Special Signature")).to("TargetURL");
Where the append() method automatically converts the message body to a string before appending its argument.
Type conversion methods in Message
The org.apache.camel.Message interface exposes some methods that perform type conversion explicitly:
-
getBody(Class<T> type)— Returns the message body as type,T. -
getHeader(String name, Class<T> type)— Returns the named header value as type,T.
For the complete list of supported conversion types, see Section 34.3, “Built-In Type Converters”.
Converting to XML
In addition to supporting conversion between simple types (such as byte[], ByteBuffer, String, and so on), the built-in type converter also supports conversion to XML formats. For example, you can convert a message body to the org.w3c.dom.Document type. This conversion is more expensive than the simple conversions, because it involves parsing the entire message and then creating a tree of nodes to represent the XML document structure. You can convert to the following XML document types:
-
org.w3c.dom.Document -
javax.xml.transform.sax.SAXSource
XML type conversions have narrower applicability than the simpler conversions. Because not every message body conforms to an XML structure, you have to remember that this type conversion might fail. On the other hand, there are many scenarios where a router deals exclusively with XML message types.
Marshalling and unmarshalling
Marshalling involves converting a high-level format to a low-level format, and unmarshalling involves converting a low-level format to a high-level format. The following two processors are used to perform marshalling or unmarshalling in a route:
-
marshal() -
unmarshal()
For example, to read a serialized Java object from a file and unmarshal it into a Java object, you could use the route definition shown in Example 34.3, “Unmarshalling a Java Object”.
Example 34.3. Unmarshalling a Java Object
from("file://tmp/appfiles/serialized")
.unmarshal()
.serialization()
.<FurtherProcessing>
.to("TargetURL");Final message format
When an In message reaches the end of a route, the target endpoint must be able to convert the message body into a format that can be written to the physical endpoint. The same rule applies to Out messages that arrive back at the source endpoint. This conversion is usually performed implicitly, using the Apache Camel type converter. Typically, this involves converting from a low-level format to another low-level format, such as converting from a byte[] array to an InputStream type.
34.3. Built-In Type Converters
Overview
This section describes the conversions supported by the master type converter. These conversions are built into the Apache Camel core.
Usually, the type converter is called through convenience functions, such as Message.getBody(Class<T> type) or Message.getHeader(String name, Class<T> type). It is also possible to invoke the master type converter directly. For example, if you have an exchange object, exchange, you could convert a given value to a String as shown in Example 34.4, “Converting a Value to a String”.
Example 34.4. Converting a Value to a String
org.apache.camel.TypeConverter tc = exchange.getContext().getTypeConverter(); String str_value = tc.convertTo(String.class, value);
Basic type converters
Apache Camel provides built-in type converters that perform conversions to and from the following basic types:
-
java.io.File -
String -
byte[]andjava.nio.ByteBuffer -
java.io.InputStreamandjava.io.OutputStream -
java.io.Readerandjava.io.Writer -
java.io.BufferedReaderandjava.io.BufferedWriter -
java.io.StringReader
However, not all of these types are inter-convertible. The built-in converter is mainly focused on providing conversions from the File and String types. The File type can be converted to any of the preceding types, except Reader, Writer, and StringReader. The String type can be converted to File, byte[], ByteBuffer, InputStream, or StringReader. The conversion from String to File works by interpreting the string as a file name. The trio of String, byte[], and ByteBuffer are completely inter-convertible.
You can explicitly specify which character encoding to use for conversion from byte[] to String and from String to byte[] by setting the Exchange.CHARSET_NAME exchange property in the current exchange. For example, to perform conversions using the UTF-8 character encoding, call exchange.setProperty("Exchange.CHARSET_NAME", "UTF-8"). The supported character sets are described in the java.nio.charset.Charset class.
Collection type converters
Apache Camel provides built-in type converters that perform conversions to and from the following collection types:
-
Object[] -
java.util.Set -
java.util.List
All permutations of conversions between the preceding collection types are supported.
Map type converters
Apache Camel provides built-in type converters that perform conversions to and from the following map types:
-
java.util.Map -
java.util.HashMap -
java.util.Hashtable -
java.util.Properties
The preceding map types can also be converted into a set, of java.util.Set type, where the set elements are of the MapEntry<K,V> type.
DOM type converters
You can perform type conversions to the following Document Object Model (DOM) types:
-
org.w3c.dom.Document— convertible frombyte[],String,java.io.File, andjava.io.InputStream. -
org.w3c.dom.Node -
javax.xml.transform.dom.DOMSource— convertible fromString. -
javax.xml.transform.Source— convertible frombyte[]andString.
All permutations of conversions between the preceding DOM types are supported.
SAX type converters
You can also perform conversions to the javax.xml.transform.sax.SAXSource type, which supports the SAX event-driven XML parser (see the SAX Web site for details). You can convert to SAXSource from the following types:
-
String -
InputStream -
Source -
StreamSource -
DOMSource
enum type converter
Camel provides a type converter for performing String to enum type conversions, where the string value is converted to the matching enum constant from the specified enumeration class (the matching is case-insensitive). This type converter is rarely needed for converting message bodies, but it is frequently used internally by Apache Camel to select particular options.
For example, when setting the logging level option, the following value, INFO, is converted into an enum constant:
<to uri="log:foo?level=INFO"/>
Because the enum type converter is case-insensitive, any of the following alternatives would also work:
<to uri="log:foo?level=info"/> <to uri="log:foo?level=INfo"/> <to uri="log:foo?level=InFo"/>
Custom type converters
Apache Camel also enables you to implement your own custom type converters. For details on how to implement a custom type converter, see Chapter 36, Type Converters.
34.4. Built-In UUID Generators
Overview
Apache Camel enables you to register a UUID generator in the CamelContext. This UUID generator is then used whenever Apache Camel needs to generate a unique ID — in particular, the registered UUID generator is called to generate the IDs returned by the Exchange.getExchangeId() and the Message.getMessageId() methods.
For example, you might prefer to replace the default UUID generator, if part of your application does not support IDs with a length of 36 characters (like Websphere MQ). Also, it can be convenient to generate IDs using a simple counter (see the SimpleUuidGenerator) for testing purposes.
Provided UUID generators
You can configure Apache Camel to use one of the following UUID generators, which are provided in the core:
-
org.apache.camel.impl.ActiveMQUuidGenerator— (Default) generates the same style of ID as is used by Apache ActiveMQ. This implementation might not be suitable for all applications, because it uses some JDK APIs that are forbidden in the context of cloud computing (such as the Google App Engine). -
org.apache.camel.impl.SimpleUuidGenerator— implements a simple counter ID, starting at1. The underlying implementation uses thejava.util.concurrent.atomic.AtomicLongtype, so that it is thread-safe. -
org.apache.camel.impl.JavaUuidGenerator— implements an ID based on thejava.util.UUIDtype. Becausejava.util.UUIDis synchronized, this might affect performance on some highly concurrent systems.
Custom UUID generator
To implement a custom UUID generator, implement the org.apache.camel.spi.UuidGenerator interface, which is shown in Example 34.5, “UuidGenerator Interface”. The generateUuid() must be implemented to return a unique ID string.
Example 34.5. UuidGenerator Interface
// Java
package org.apache.camel.spi;
/**
* Generator to generate UUID strings.
*/
public interface UuidGenerator {
String generateUuid();
}Specifying the UUID generator using Java
To replace the default UUID generator using Java, call the setUuidGenerator() method on the current CamelContext object. For example, you can register a SimpleUuidGenerator instance with the current CamelContext, as follows:
// Java getContext().setUuidGenerator(new org.apache.camel.impl.SimpleUuidGenerator());
The setUuidGenerator() method should be called during startup, before any routes are activated.
Specifying the UUID generator using Spring
To replace the default UUID generator using Spring, all you need to do is to create an instance of a UUID generator using the Spring bean element. When a camelContext instance is created, it automatically looks up the Spring registry, searching for a bean that implements org.apache.camel.spi.UuidGenerator. For example, you can register a SimpleUuidGenerator instance with the CamelContext as follows:
<beans ...>
<bean id="simpleUuidGenerator"
class="org.apache.camel.impl.SimpleUuidGenerator" />
<camelContext id="camel" xmlns="http://camel.apache.org/schema/spring">
...
</camelContext>
...
</beans>Chapter 35. Implementing a Processor
Abstract
Apache Camel allows you to implement a custom processor. You can then insert the custom processor into a route to perform operations on exchange objects as they pass through the route.
35.1. Processing Model
Pipelining model
The pipelining model describes the way in which processors are arranged in Section 5.4, “Pipes and Filters”. Pipelining is the most common way to process a sequence of endpoints (a producer endpoint is just a special type of processor). When the processors are arranged in this way, the exchange’s In and Out messages are processed as shown in Figure 35.1, “Pipelining Model”.
Figure 35.1. Pipelining Model
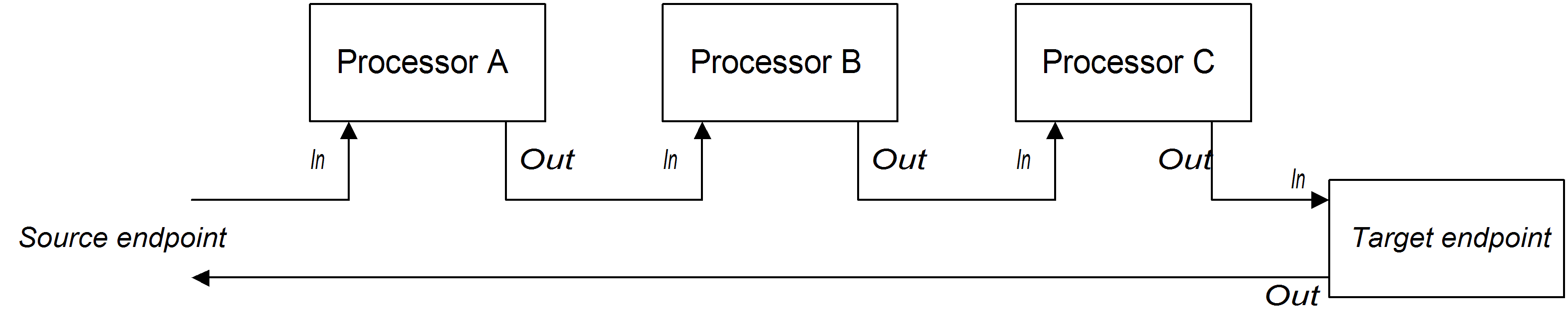
The processors in the pipeline look like services, where the In message is analogous to a request, and the Out message is analogous to a reply. In fact, in a realistic pipeline, the nodes in the pipeline are often implemented by Web service endpoints, such as the CXF component.
For example, Example 35.1, “Java DSL Pipeline” shows a Java DSL pipeline constructed from a sequence of two processors, ProcessorA, ProcessorB, and a producer endpoint, TargetURI.
Example 35.1. Java DSL Pipeline
from(SourceURI).pipeline(ProcessorA, ProcessorB, TargetURI);
35.2. Implementing a Simple Processor
Overview
This section describes how to implement a simple processor that executes message processing logic before delegating the exchange to the next processor in the route.
Processor interface
Simple processors are created by implementing the org.apache.camel.Processor interface. As shown in Example 35.2, “Processor Interface”, the interface defines a single method, process(), which processes an exchange object.
Example 35.2. Processor Interface
package org.apache.camel;
public interface Processor {
void process(Exchange exchange) throws Exception;
}Implementing the Processor interface
To create a simple processor you must implement the Processor interface and provide the logic for the process() method. Example 35.3, “Simple Processor Implementation” shows the outline of a simple processor implementation.
Example 35.3. Simple Processor Implementation
import org.apache.camel.Processor;
public class MyProcessor implements Processor {
public MyProcessor() { }
public void process(Exchange exchange) throws Exception
{
// Insert code that gets executed *before* delegating
// to the next processor in the chain.
...
}
}
All of the code in the process() method gets executed before the exchange object is delegated to the next processor in the chain.
For examples of how to access the message body and header values inside a simple processor, see Section 35.3, “Accessing Message Content”.
Inserting the simple processor into a route
Use the process() DSL command to insert a simple processor into a route. Create an instance of your custom processor and then pass this instance as an argument to the process() method, as follows:
org.apache.camel.Processor myProc = new MyProcessor();
from("SourceURL").process(myProc).to("TargetURL");35.3. Accessing Message Content
Accessing message headers
Message headers typically contain the most useful message content from the perspective of a router, because headers are often intended to be processed in a router service. To access header data, you must first get the message from the exchange object (for example, using Exchange.getIn()), and then use the Message interface to retrieve the individual headers (for example, using Message.getHeader()).
Example 35.4, “Accessing an Authorization Header” shows an example of a custom processor that accesses the value of a header named Authorization. This example uses the ExchangeHelper.getMandatoryHeader() method, which eliminates the need to test for a null header value.
Example 35.4. Accessing an Authorization Header
import org.apache.camel.*;
import org.apache.camel.util.ExchangeHelper;
public class MyProcessor implements Processor {
public void process(Exchange exchange) {
String auth = ExchangeHelper.getMandatoryHeader(
exchange,
"Authorization",
String.class
);
// process the authorization string...
// ...
}
}For full details of the Message interface, see Section 34.2, “Messages”.
Accessing the message body
You can also access the message body. For example, to append a string to the end of the In message, you can use the processor shown in Example 35.5, “Accessing the Message Body”.
Example 35.5. Accessing the Message Body
import org.apache.camel.*;
import org.apache.camel.util.ExchangeHelper;
public class MyProcessor implements Processor {
public void process(Exchange exchange) {
Message in = exchange.getIn();
in.setBody(in.getBody(String.class) + " World!");
}
}Accessing message attachments
You can access a message’s attachments using either the Message.getAttachment() method or the Message.getAttachments() method. See Example 34.2, “Message Interface” for more details.
35.4. The ExchangeHelper Class
Overview
The org.apache.camel.util.ExchangeHelper class is a Apache Camel utility class that provides methods that are useful when implementing a processor.
Resolve an endpoint
The static resolveEndpoint() method is one of the most useful methods in the ExchangeHelper class. You use it inside a processor to create new Endpoint instances on the fly.
Example 35.6. The resolveEndpoint() Method
public final class ExchangeHelper {
...
@SuppressWarnings({"unchecked" })
public static Endpoint
resolveEndpoint(Exchange exchange, Object value)
throws NoSuchEndpointException { ... }
...
}
The first argument to resolveEndpoint() is an exchange instance, and the second argument is usually an endpoint URI string. Example 35.7, “Creating a File Endpoint” shows how to create a new file endpoint from an exchange instance exchange
Example 35.7. Creating a File Endpoint
Endpoint file_endp = ExchangeHelper.resolveEndpoint(exchange, "file://tmp/messages/in.xml");
Wrapping the exchange accessors
The ExchangeHelper class provides several static methods of the form getMandatoryBeanProperty(), which wrap the corresponding getBeanProperty() methods on the Exchange class. The difference between them is that the original getBeanProperty() accessors return null, if the corresponding property is unavailable, and the getMandatoryBeanProperty() wrapper methods throw a Java exception. The following wrapper methods are implemented in the ExchangeHelper class:
public final class ExchangeHelper {
...
public static <T> T getMandatoryProperty(Exchange exchange, String propertyName, Class<T> type)
throws NoSuchPropertyException { ... }
public static <T> T getMandatoryHeader(Exchange exchange, String propertyName, Class<T> type)
throws NoSuchHeaderException { ... }
public static Object getMandatoryInBody(Exchange exchange)
throws InvalidPayloadException { ... }
public static <T> T getMandatoryInBody(Exchange exchange, Class<T> type)
throws InvalidPayloadException { ... }
public static Object getMandatoryOutBody(Exchange exchange)
throws InvalidPayloadException { ... }
public static <T> T getMandatoryOutBody(Exchange exchange, Class<T> type)
throws InvalidPayloadException { ... }
...
}Testing the exchange pattern
Several different exchange patterns are compatible with holding an In message. Several different exchange patterns are also compatible with holding an Out message. To provide a quick way of checking whether or not an exchange object is capable of holding an In message or an Out message, the ExchangeHelper class provides the following methods:
public final class ExchangeHelper {
...
public static boolean isInCapable(Exchange exchange) { ... }
public static boolean isOutCapable(Exchange exchange) { ... }
...
}Get the In message’s MIME content type
If you want to find out the MIME content type of the exchange’s In message, you can access it by calling the ExchangeHelper.getContentType(exchange) method. To implement this, the ExchangeHelper object looks up the value of the In message’s Content-Type header — this method relies on the underlying component to populate the header value).
Chapter 36. Type Converters
Abstract
Apache Camel has a built-in type conversion mechanism, which is used to convert message bodies and message headers to different types. This chapter explains how to extend the type conversion mechanism by adding your own custom converter methods.
36.1. Type Converter Architecture
Overview
This section describes the overall architecture of the type converter mechanism, which you must understand, if you want to write custom type converters. If you only need to use the built-in type converters, see Chapter 34, Understanding Message Formats.
Type converter interface
Example 36.1, “TypeConverter Interface” shows the definition of the org.apache.camel.TypeConverter interface, which all type converters must implement.
Example 36.1. TypeConverter Interface
package org.apache.camel;
public interface TypeConverter {
<T> T convertTo(Class<T> type, Object value);
}Master type converter
The Apache Camel type converter mechanism follows a master/slave pattern. There are many slave type converters, which are each capable of performing a limited number of type conversions, and a single master type converter, which aggregates the type conversions performed by the slaves. The master type converter acts as a front-end for the slave type converters. When you request the master to perform a type conversion, it selects the appropriate slave and delegates the conversion task to that slave.
For users of the type conversion mechanism, the master type converter is the most important because it provides the entry point for accessing the conversion mechanism. During start up, Apache Camel automatically associates a master type converter instance with the CamelContext object. To obtain a reference to the master type converter, you call the CamelContext.getTypeConverter() method. For example, if you have an exchange object, exchange, you can obtain a reference to the master type converter as shown in Example 36.2, “Getting a Master Type Converter”.
Example 36.2. Getting a Master Type Converter
org.apache.camel.TypeConverter tc = exchange.getContext().getTypeConverter();
Type converter loader
The master type converter uses a type converter loader to populate the registry of slave type converters. A type converter loader is any class that implements the TypeConverterLoader interface. Apache Camel currently uses only one kind of type converter loader — the annotation type converter loader (of AnnotationTypeConverterLoader type).
Type conversion process
Figure 36.1, “Type Conversion Process” gives an overview of the type conversion process, showing the steps involved in converting a given data value, value, to a specified type, toType.
Figure 36.1. Type Conversion Process

The type conversion mechanism proceeds as follows:
-
The
CamelContextobject holds a reference to the master TypeConverter instance. The first step in the conversion process is to retrieve the master type converter by callingCamelContext.getTypeConverter(). -
Type conversion is initiated by calling the
convertTo()method on the master type converter. This method instructs the type converter to convert the data object,value, from its original type to the type specified by thetoTypeargument. -
Because the master type converter is a front end for many different slave type converters, it looks up the appropriate slave type converter by checking a registry of type mappings The registry of type converters is keyed by a type mapping pair
(toType, fromType). If a suitable type converter is found in the registry, the master type converter calls the slave’sconvertTo()method and returns the result. - If a suitable type converter cannot be found in the registry, the master type converter loads a new type converter, using the type converter loader.
-
The type converter loader searches the available JAR libraries on the classpath to find a suitable type converter. Currently, the loader strategy that is used is implemented by the annotation type converter loader, which attempts to load a class annotated by the
org.apache.camel.Converterannotation. See the section called “Create a TypeConverter file”. -
If the type converter loader is successful, a new slave type converter is loaded and entered into the type converter registry. This type converter is then used to convert the
valueargument to thetoTypetype. -
If the data is successfully converted, the converted data value is returned. If the conversion does not succeed,
nullis returned.
36.2. Handling Duplicate Type Converters
You can configure what must happen if a duplicate type converter is added.
In the TypeConverterRegistry (See Section 36.3, “Implementing Type Converter Using Annotations”) you can set the action to Override, Ignore or Fail using the following code:
typeconverterregistry = camelContext.getTypeConverter() // Define the behaviour if the TypeConverter already exists typeconverterregistry.setTypeConverterExists(TypeConverterExists.Override);
Override in this code can be replaced by Ignore or Fail, depending on your requirements.
TypeConverterExists Class
The TypeConverterExists class consists of the following commands:
package org.apache.camel;
import javax.xml.bind.annotation.XmlEnum;
/**
* What to do if attempting to add a duplicate type converter
*
* @version
*/
@XmlEnum
public enum TypeConverterExists {
Override, Ignore, Fail
}36.3. Implementing Type Converter Using Annotations
Overview
The type conversion mechanism can easily be customized by adding a new slave type converter. This section describes how to implement a slave type converter and how to integrate it with Apache Camel, so that it is automatically loaded by the annotation type converter loader.
How to implement a type converter
To implement a custom type converter, perform the following steps:
Implement an annotated converter class
You can implement a custom type converter class using the @Converter annotation. You must annotate the class itself and each of the static methods intended to perform type conversion. Each converter method takes an argument that defines the from type, optionally takes a second Exchange argument, and has a non-void return value that defines the to type. The type converter loader uses Java reflection to find the annotated methods and integrate them into the type converter mechanism. Example 36.3, “Example of an Annotated Converter Class” shows an example of an annotated converter class that defines a converter method for converting from java.io.File to java.io.InputStream and another converter method (with an Exchange argument) for converting from byte[] to String.
Example 36.3. Example of an Annotated Converter Class
package com.YourDomain.YourPackageName; import org.apache.camel.Converter; import java.io.*; @Converter public class IOConverter { private IOConverter() { } @Converter public static InputStream toInputStream(File file) throws FileNotFoundException { return new BufferedInputStream(new FileInputStream(file)); } @Converter public static String toString(byte[] data, Exchange exchange) { if (exchange != null) { String charsetName = exchange.getProperty(Exchange.CHARSET_NAME, String.class); if (charsetName != null) { try { return new String(data, charsetName); } catch (UnsupportedEncodingException e) { LOG.warn("Can't convert the byte to String with the charset " + charsetName, e); } } } return new String(data); } }
The toInputStream() method is responsible for performing the conversion from the File type to the InputStream type and the toString() method is responsible for performing the conversion from the byte[] type to the String type.
The method name is unimportant, and can be anything you choose. What is important are the argument type, the return type, and the presence of the @Converter annotation.
Create a TypeConverter file
To enable the discovery mechanism (which is implemented by the annotation type converter loader) for your custom converter, create a TypeConverter file at the following location:
META-INF/services/org/apache/camel/TypeConverter
The TypeConverter file must contain a comma-separated list of Fully Qualified Names (FQN) of type converter classes. For example, if you want the type converter loader to search the YourPackageName.YourClassName package for annotated converter classes, the TypeConverter file would have the following contents:
com.PackageName.FooClass
An alternative method of enabling the discovery mechanism is to add just package names to the TypeConverter file. For example, the TypeConverter file would have the following contents:
com.PackageName
This would cause the package scanner to scan through the packages for the @Converter tag. Using the FQN method is faster and is the preferred method.
Package the type converter
The type converter is packaged as a JAR file containing the compiled classes of your custom type converters and the META-INF directory. Put this JAR file on your classpath to make it available to your Apache Camel application.
Fallback converter method
In addition to defining regular converter methods using the @Converter annotation, you can optionally define a fallback converter method using the @FallbackConverter annotation. The fallback converter method will only be tried, if the master type converter fails to find a regular converter method in the type registry.
The essential difference between a regular converter method and a fallback converter method is that whereas a regular converter is defined to perform conversion between a specific pair of types (for example, from byte[] to String), a fallback converter can potentially perform conversion between any pair of types. It is up to the code in the body of the fallback converter method to figure out which conversions it is able to perform. At run time, if a conversion cannot be performed by a regular converter, the master type converter iterates through every available fallback converter until it finds one that can perform the conversion.
The method signature of a fallback converter can have either of the following forms:
// 1. Non-generic form of signature @FallbackConverter public static Object MethodName( Class type, Exchange exchange, Object value, TypeConverterRegistry registry ) // 2. Templating form of signature @FallbackConverter public static <T> T MethodName( Class<T> type, Exchange exchange, Object value, TypeConverterRegistry registry )
Where MethodName is an arbitrary method name for the fallback converter.
For example, the following code extract (taken from the implementation of the File component) shows a fallback converter that can convert the body of a GenericFile object, exploiting the type converters already available in the type converter registry:
package org.apache.camel.component.file; import org.apache.camel.Converter; import org.apache.camel.FallbackConverter; import org.apache.camel.Exchange; import org.apache.camel.TypeConverter; import org.apache.camel.spi.TypeConverterRegistry; @Converter public final class GenericFileConverter { private GenericFileConverter() { // Helper Class } @FallbackConverter public static <T> T convertTo(Class<T> type, Exchange exchange, Object value, TypeConverterRegistry registry) { // use a fallback type converter so we can convert the embedded body if the value is GenericFile if (GenericFile.class.isAssignableFrom(value.getClass())) { GenericFile file = (GenericFile) value; Class from = file.getBody().getClass(); TypeConverter tc = registry.lookup(type, from); if (tc != null) { Object body = file.getBody(); return tc.convertTo(type, exchange, body); } } return null; } ... }
36.4. Implementing a Type Converter Directly
Overview
Generally, the recommended way to implement a type converter is to use an annotated class, as described in the previous section, Section 36.3, “Implementing Type Converter Using Annotations”. But if you want to have complete control over the registration of your type converter, you can implement a custom slave type converter and add it directly to the type converter registry, as described here.
Implement the TypeConverter interface
To implement your own type converter class, define a class that implements the TypeConverter interface. For example, the following MyOrderTypeConverter class converts an integer value to a MyOrder object, where the integer value is used to initialize the order ID in the MyOrder object.
import org.apache.camel.TypeConverter
private class MyOrderTypeConverter implements TypeConverter {
public <T> T convertTo(Class<T> type, Object value) {
// converter from value to the MyOrder bean
MyOrder order = new MyOrder();
order.setId(Integer.parseInt(value.toString()));
return (T) order;
}
public <T> T convertTo(Class<T> type, Exchange exchange, Object value) {
// this method with the Exchange parameter will be preferd by Camel to invoke
// this allows you to fetch information from the exchange during convertions
// such as an encoding parameter or the likes
return convertTo(type, value);
}
public <T> T mandatoryConvertTo(Class<T> type, Object value) {
return convertTo(type, value);
}
public <T> T mandatoryConvertTo(Class<T> type, Exchange exchange, Object value) {
return convertTo(type, value);
}
}Add the type converter to the registry
You can add the custom type converter directly to the type converter registry using code like the following:
// Add the custom type converter to the type converter registry context.getTypeConverterRegistry().addTypeConverter(MyOrder.class, String.class, new MyOrderTypeConverter());
Where context is the current org.apache.camel.CamelContext instance. The addTypeConverter() method registers the MyOrderTypeConverter class against the specific type conversion, from String.class to MyOrder.class.
You can add custom type converters to your Camel applications without having to use the META-INF file. If you are using Spring or Blueprint, then you can just declare a <bean>. CamelContext discovers the bean automatically and adds the converters.
<bean id="myOrderTypeConverters" class="..."/> <camelContext> ... </camelContext>
You can declare multiple <bean>s if you have more classes.
Chapter 37. Producer and Consumer Templates
Abstract
The producer and consumer templates in Apache Camel are modelled after a feature of the Spring container API, whereby access to a resource is provided through a simplified, easy-to-use API known as a template. In the case of Apache Camel, the producer template and consumer template provide simplified interfaces for sending messages to and receiving messages from producer endpoints and consumer endpoints.
37.1. Using the Producer Template
37.1.1. Introduction to the Producer Template
Overview
The producer template supports a variety of different approaches to invoking producer endpoints. There are methods that support different formats for the request message (as an Exchange object, as a message body, as a message body with a single header setting, and so on) and there are methods to support both the synchronous and the asynchronous style of invocation. Overall, producer template methods can be grouped into the following categories:
Alternatively, see Section 37.2, “Using Fluent Producer Templates”.
Synchronous invocation
The methods for invoking endpoints synchronously have names of the form sendSuffix() and requestSuffix(). For example, the methods for invoking an endpoint using either the default message exchange pattern (MEP) or an explicitly specified MEP are named send(), sendBody(), and sendBodyAndHeader() (where these methods respectively send an Exchange object, a message body, or a message body and header value). If you want to force the MEP to be InOut (request/reply semantics), you can call the request(), requestBody(), and requestBodyAndHeader() methods instead.
The following example shows how to create a ProducerTemplate instance and use it to send a message body to the activemq:MyQueue endpoint. The example also shows how to send a message body and header value using sendBodyAndHeader().
import org.apache.camel.ProducerTemplate
import org.apache.camel.impl.DefaultProducerTemplate
...
ProducerTemplate template = context.createProducerTemplate();
// Send to a specific queue
template.sendBody("activemq:MyQueue", "<hello>world!</hello>");
// Send with a body and header
template.sendBodyAndHeader(
"activemq:MyQueue",
"<hello>world!</hello>",
"CustomerRating", "Gold" );Synchronous invocation with a processor
A special case of synchronous invocation is where you provide the send() method with a Processor argument instead of an Exchange argument. In this case, the producer template implicitly asks the specified endpoint to create an Exchange instance (typically, but not always having the InOnly MEP by default). This default exchange is then passed to the processor, which initializes the contents of the exchange object.
The following example shows how to send an exchange initialized by the MyProcessor processor to the activemq:MyQueue endpoint.
import org.apache.camel.ProducerTemplate
import org.apache.camel.impl.DefaultProducerTemplate
...
ProducerTemplate template = context.createProducerTemplate();
// Send to a specific queue, using a processor to initialize
template.send("activemq:MyQueue", new MyProcessor());
The MyProcessor class is implemented as shown in the following example. In addition to setting the In message body (as shown here), you could also initialize message heades and exchange properties.
import org.apache.camel.Processor;
import org.apache.camel.Exchange;
...
public class MyProcessor implements Processor {
public MyProcessor() { }
public void process(Exchange ex) {
ex.getIn().setBody("<hello>world!</hello>");
}
}Asynchronous invocation
The methods for invoking endpoints asynchronously have names of the form asyncSendSuffix() and asyncRequestSuffix(). For example, the methods for invoking an endpoint using either the default message exchange pattern (MEP) or an explicitly specified MEP are named asyncSend() and asyncSendBody() (where these methods respectively send an Exchange object or a message body). If you want to force the MEP to be InOut (request/reply semantics), you can call the asyncRequestBody(), asyncRequestBodyAndHeader(), and asyncRequestBodyAndHeaders() methods instead.
The following example shows how to send an exchange asynchronously to the direct:start endpoint. The asyncSend() method returns a java.util.concurrent.Future object, which is used to retrieve the invocation result at a later time.
import java.util.concurrent.Future;
import org.apache.camel.Exchange;
import org.apache.camel.impl.DefaultExchange;
...
Exchange exchange = new DefaultExchange(context);
exchange.getIn().setBody("Hello");
Future<Exchange> future = template.asyncSend("direct:start", exchange);
// You can do other things, whilst waiting for the invocation to complete
...
// Now, retrieve the resulting exchange from the Future
Exchange result = future.get();
The producer template also provides methods to send a message body asynchronously (for example, using asyncSendBody() or asyncRequestBody()). In this case, you can use one of the following helper methods to extract the returned message body from the Future object:
<T> T extractFutureBody(Future future, Class<T> type); <T> T extractFutureBody(Future future, long timeout, TimeUnit unit, Class<T> type) throws TimeoutException;
The first version of the extractFutureBody() method blocks until the invocation completes and the reply message is available. The second version of the extractFutureBody() method allows you to specify a timeout. Both methods have a type argument, type, which casts the returned message body to the specified type using a built-in type converter.
The following example shows how to use the asyncRequestBody() method to send a message body to the direct:start endpoint. The blocking extractFutureBody() method is then used to retrieve the reply message body from the Future object.
Future<Object> future = template.asyncRequestBody("direct:start", "Hello");
// You can do other things, whilst waiting for the invocation to complete
...
// Now, retrieve the reply message body as a String type
String result = template.extractFutureBody(future, String.class);Asynchronous invocation with a callback
In the preceding asynchronous examples, the request message is dispatched in a sub-thread, while the reply is retrieved and processed by the main thread. The producer template also gives you the option, however, of processing replies in the sub-thread, using one of the asyncCallback(), asyncCallbackSendBody(), or asyncCallbackRequestBody() methods. In this case, you supply a callback object (of org.apache.camel.impl.SynchronizationAdapter type), which automatically gets invoked in the sub-thread as soon as a reply message arrives.
The Synchronization callback interface is defined as follows:
package org.apache.camel.spi;
import org.apache.camel.Exchange;
public interface Synchronization {
void onComplete(Exchange exchange);
void onFailure(Exchange exchange);
}
Where the onComplete() method is called on receipt of a normal reply and the onFailure() method is called on receipt of a fault message reply. Only one of these methods gets called back, so you must override both of them to ensure that all types of reply are processed.
The following example shows how to send an exchange to the direct:start endpoint, where the reply message is processed in the sub-thread by the SynchronizationAdapter callback object.
import java.util.concurrent.Future;
import java.util.concurrent.TimeUnit;
import org.apache.camel.Exchange;
import org.apache.camel.impl.DefaultExchange;
import org.apache.camel.impl.SynchronizationAdapter;
...
Exchange exchange = context.getEndpoint("direct:start").createExchange();
exchange.getIn().setBody("Hello");
Future<Exchange> future = template.asyncCallback("direct:start", exchange, new SynchronizationAdapter() {
@Override
public void onComplete(Exchange exchange) {
assertEquals("Hello World", exchange.getIn().getBody());
}
});
Where the SynchronizationAdapter class is a default implementation of the Synchronization interface, which you can override to provide your own definitions of the onComplete() and onFailure() callback methods.
You still have the option of accessing the reply from the main thread, because the asyncCallback() method also returns a Future object — for example:
// Retrieve the reply from the main thread, specifying a timeout Exchange reply = future.get(10, TimeUnit.SECONDS);
37.1.2. Synchronous Send
Overview
The synchronous send methods are a collection of methods that you can use to invoke a producer endpoint, where the current thread blocks until the method invocation is complete and the reply (if any) has been received. These methods are compatible with any kind of message exchange protocol.
Send an exchange
The basic send() method is a general-purpose method that sends the contents of an Exchange object to an endpoint, using the message exchange pattern (MEP) of the exchange. The return value is the exchange that you get after it has been processed by the producer endpoint (possibly containing an Out message, depending on the MEP).
There are three varieties of send() method for sending an exchange that let you specify the target endpoint in one of the following ways: as the default endpoint, as an endpoint URI, or as an Endpoint object.
Exchange send(Exchange exchange); Exchange send(String endpointUri, Exchange exchange); Exchange send(Endpoint endpoint, Exchange exchange);
Send an exchange populated by a processor
A simple variation of the general send() method is to use a processor to populate a default exchange, instead of supplying the exchange object explicitly (see the section called “Synchronous invocation with a processor” for details).
The send() methods for sending an exchange populated by a processor let you specify the target endpoint in one of the following ways: as the default endpoint, as an endpoint URI, or as an Endpoint object. In addition, you can optionally specify the exchange’s MEP by supplying the pattern argument, instead of accepting the default.
Exchange send(Processor processor);
Exchange send(String endpointUri, Processor processor);
Exchange send(Endpoint endpoint, Processor processor);
Exchange send(
String endpointUri,
ExchangePattern pattern,
Processor processor
);
Exchange send(
Endpoint endpoint,
ExchangePattern pattern,
Processor processor
);Send a message body
If you are only concerned with the contents of the message body that you want to send, you can use the sendBody() methods to provide the message body as an argument and let the producer template take care of inserting the body into a default exchange object.
The sendBody() methods let you specify the target endpoint in one of the following ways: as the default endpoint, as an endpoint URI, or as an Endpoint object. In addition, you can optionally specify the exchange’s MEP by supplying the pattern argument, instead of accepting the default. The methods without a pattern argument return void (even though the invocation might give rise to a reply in some cases); and the methods with a pattern argument return either the body of the Out message (if there is one) or the body of the In message (otherwise).
void sendBody(Object body);
void sendBody(String endpointUri, Object body);
void sendBody(Endpoint endpoint, Object body);
Object sendBody(
String endpointUri,
ExchangePattern pattern,
Object body
);
Object sendBody(
Endpoint endpoint,
ExchangePattern pattern,
Object body
);Send a message body and header(s)
For testing purposes, it is often interesting to try out the effect of a single header setting and the sendBodyAndHeader() methods are useful for this kind of header testing. You supply the message body and header setting as arguments to sendBodyAndHeader() and let the producer template take care of inserting the body and header setting into a default exchange object.
The sendBodyAndHeader() methods let you specify the target endpoint in one of the following ways: as the default endpoint, as an endpoint URI, or as an Endpoint object. In addition, you can optionally specify the exchange’s MEP by supplying the pattern argument, instead of accepting the default. The methods without a pattern argument return void (even though the invocation might give rise to a reply in some cases); and the methods with a pattern argument return either the body of the Out message (if there is one) or the body of the In message (otherwise).
void sendBodyAndHeader(
Object body,
String header,
Object headerValue
);
void sendBodyAndHeader(
String endpointUri,
Object body,
String header,
Object headerValue
);
void sendBodyAndHeader(
Endpoint endpoint,
Object body,
String header,
Object headerValue
);
Object sendBodyAndHeader(
String endpointUri,
ExchangePattern pattern,
Object body,
String header,
Object headerValue
);
Object sendBodyAndHeader(
Endpoint endpoint,
ExchangePattern pattern,
Object body,
String header,
Object headerValue
);
The sendBodyAndHeaders() methods are similar to the sendBodyAndHeader() methods, except that instead of supplying just a single header setting, these methods allow you to specify a complete hash map of header settings.
void sendBodyAndHeaders(
Object body,
Map<String, Object> headers
);
void sendBodyAndHeaders(
String endpointUri,
Object body,
Map<String, Object> headers
);
void sendBodyAndHeaders(
Endpoint endpoint,
Object body,
Map<String, Object> headers
);
Object sendBodyAndHeaders(
String endpointUri,
ExchangePattern pattern,
Object body,
Map<String, Object> headers
);
Object sendBodyAndHeaders(
Endpoint endpoint,
ExchangePattern pattern,
Object body,
Map<String, Object> headers
);Send a message body and exchange property
You can try out the effect of setting a single exchange property using the sendBodyAndProperty() methods. You supply the message body and property setting as arguments to sendBodyAndProperty() and let the producer template take care of inserting the body and exchange property into a default exchange object.
The sendBodyAndProperty() methods let you specify the target endpoint in one of the following ways: as the default endpoint, as an endpoint URI, or as an Endpoint object. In addition, you can optionally specify the exchange’s MEP by supplying the pattern argument, instead of accepting the default. The methods without a pattern argument return void (even though the invocation might give rise to a reply in some cases); and the methods with a pattern argument return either the body of the Out message (if there is one) or the body of the In message (otherwise).
void sendBodyAndProperty(
Object body,
String property,
Object propertyValue
);
void sendBodyAndProperty(
String endpointUri,
Object body,
String property,
Object propertyValue
);
void sendBodyAndProperty(
Endpoint endpoint,
Object body,
String property,
Object propertyValue
);
Object sendBodyAndProperty(
String endpoint,
ExchangePattern pattern,
Object body,
String property,
Object propertyValue
);
Object sendBodyAndProperty(
Endpoint endpoint,
ExchangePattern pattern,
Object body,
String property,
Object propertyValue
);37.1.3. Synchronous Request with InOut Pattern
Overview
The synchronous request methods are similar to the synchronous send methods, except that the request methods force the message exchange pattern to be InOut (conforming to request/reply semantics). Hence, it is generally convenient to use a synchronous request method, if you expect to receive a reply from the producer endpoint.
Request an exchange populated by a processor
The basic request() method is a general-purpose method that uses a processor to populate a default exchange and forces the message exchange pattern to be InOut (so that the invocation obeys request/reply semantics). The return value is the exchange that you get after it has been processed by the producer endpoint, where the Out message contains the reply message.
The request() methods for sending an exchange populated by a processor let you specify the target endpoint in one of the following ways: as an endpoint URI, or as an Endpoint object.
Exchange request(String endpointUri, Processor processor); Exchange request(Endpoint endpoint, Processor processor);
Request a message body
If you are only concerned with the contents of the message body in the request and in the reply, you can use the requestBody() methods to provide the request message body as an argument and let the producer template take care of inserting the body into a default exchange object.
The requestBody() methods let you specify the target endpoint in one of the following ways: as the default endpoint, as an endpoint URI, or as an Endpoint object. The return value is the body of the reply message (Out message body), which can either be returned as plain Object or converted to a specific type, T, using the built-in type converters (see Section 34.3, “Built-In Type Converters”).
Object requestBody(Object body);
<T> T requestBody(Object body, Class<T> type);
Object requestBody(
String endpointUri,
Object body
);
<T> T requestBody(
String endpointUri,
Object body,
Class<T> type
);
Object requestBody(
Endpoint endpoint,
Object body
);
<T> T requestBody(
Endpoint endpoint,
Object body,
Class<T> type
);Request a message body and header(s)
You can try out the effect of setting a single header value using the requestBodyAndHeader() methods. You supply the message body and header setting as arguments to requestBodyAndHeader() and let the producer template take care of inserting the body and exchange property into a default exchange object.
The requestBodyAndHeader() methods let you specify the target endpoint in one of the following ways: as an endpoint URI, or as an Endpoint object. The return value is the body of the reply message (Out message body), which can either be returned as plain Object or converted to a specific type, T, using the built-in type converters (see Section 34.3, “Built-In Type Converters”).
Object requestBodyAndHeader(
String endpointUri,
Object body,
String header,
Object headerValue
);
<T> T requestBodyAndHeader(
String endpointUri,
Object body,
String header,
Object headerValue,
Class<T> type
);
Object requestBodyAndHeader(
Endpoint endpoint,
Object body,
String header,
Object headerValue
);
<T> T requestBodyAndHeader(
Endpoint endpoint,
Object body,
String header,
Object headerValue,
Class<T> type
);
The requestBodyAndHeaders() methods are similar to the requestBodyAndHeader() methods, except that instead of supplying just a single header setting, these methods allow you to specify a complete hash map of header settings.
Object requestBodyAndHeaders(
String endpointUri,
Object body,
Map<String, Object> headers
);
<T> T requestBodyAndHeaders(
String endpointUri,
Object body,
Map<String, Object> headers,
Class<T> type
);
Object requestBodyAndHeaders(
Endpoint endpoint,
Object body,
Map<String, Object> headers
);
<T> T requestBodyAndHeaders(
Endpoint endpoint,
Object body,
Map<String, Object> headers,
Class<T> type
);37.1.4. Asynchronous Send
Overview
The producer template provides a variety of methods for invoking a producer endpoint asynchronously, so that the main thread does not block while waiting for the invocation to complete and the reply message can be retrieved at a later time. The asynchronous send methods described in this section are compatible with any kind of message exchange protocol.
Send an exchange
The basic asyncSend() method takes an Exchange argument and invokes an endpoint asynchronously, using the message exchange pattern (MEP) of the specified exchange. The return value is a java.util.concurrent.Future object, which is a ticket you can use to collect the reply message at a later time — for details of how to obtain the return value from the Future object, see the section called “Asynchronous invocation”.
The following asyncSend() methods let you specify the target endpoint in one of the following ways: as an endpoint URI, or as an Endpoint object.
Future<Exchange> asyncSend(String endpointUri, Exchange exchange); Future<Exchange> asyncSend(Endpoint endpoint, Exchange exchange);
Send an exchange populated by a processor
A simple variation of the general asyncSend() method is to use a processor to populate a default exchange, instead of supplying the exchange object explicitly.
The following asyncSend() methods let you specify the target endpoint in one of the following ways: as an endpoint URI, or as an Endpoint object.
Future<Exchange> asyncSend(String endpointUri, Processor processor); Future<Exchange> asyncSend(Endpoint endpoint, Processor processor);
Send a message body
If you are only concerned with the contents of the message body that you want to send, you can use the asyncSendBody() methods to send a message body asynchronously and let the producer template take care of inserting the body into a default exchange object.
The asyncSendBody() methods let you specify the target endpoint in one of the following ways: as an endpoint URI, or as an Endpoint object.
Future<Object> asyncSendBody(String endpointUri, Object body); Future<Object> asyncSendBody(Endpoint endpoint, Object body);
37.1.5. Asynchronous Request with InOut Pattern
Overview
The asynchronous request methods are similar to the asynchronous send methods, except that the request methods force the message exchange pattern to be InOut (conforming to request/reply semantics). Hence, it is generally convenient to use an asynchronous request method, if you expect to receive a reply from the producer endpoint.
Request a message body
If you are only concerned with the contents of the message body in the request and in the reply, you can use the requestBody() methods to provide the request message body as an argument and let the producer template take care of inserting the body into a default exchange object.
The asyncRequestBody() methods let you specify the target endpoint in one of the following ways: as an endpoint URI, or as an Endpoint object. The return value that is retrievable from the Future object is the body of the reply message (Out message body), which can be returned either as a plain Object or converted to a specific type, T, using a built-in type converter (see the section called “Asynchronous invocation”).
Future<Object> asyncRequestBody(
String endpointUri,
Object body
);
<T> Future<T> asyncRequestBody(
String endpointUri,
Object body,
Class<T> type
);
Future<Object> asyncRequestBody(
Endpoint endpoint,
Object body
);
<T> Future<T> asyncRequestBody(
Endpoint endpoint,
Object body,
Class<T> type
);Request a message body and header(s)
You can try out the effect of setting a single header value using the asyncRequestBodyAndHeader() methods. You supply the message body and header setting as arguments to asyncRequestBodyAndHeader() and let the producer template take care of inserting the body and exchange property into a default exchange object.
The asyncRequestBodyAndHeader() methods let you specify the target endpoint in one of the following ways: as an endpoint URI, or as an Endpoint object. The return value that is retrievable from the Future object is the body of the reply message (Out message body), which can be returned either as a plain Object or converted to a specific type, T, using a built-in type converter (see the section called “Asynchronous invocation”).
Future<Object> asyncRequestBodyAndHeader(
String endpointUri,
Object body,
String header,
Object headerValue
);
<T> Future<T> asyncRequestBodyAndHeader(
String endpointUri,
Object body,
String header,
Object headerValue,
Class<T> type
);
Future<Object> asyncRequestBodyAndHeader(
Endpoint endpoint,
Object body,
String header,
Object headerValue
);
<T> Future<T> asyncRequestBodyAndHeader(
Endpoint endpoint,
Object body,
String header,
Object headerValue,
Class<T> type
);
The asyncRequestBodyAndHeaders() methods are similar to the asyncRequestBodyAndHeader() methods, except that instead of supplying just a single header setting, these methods allow you to specify a complete hash map of header settings.
Future<Object> asyncRequestBodyAndHeaders(
String endpointUri,
Object body,
Map<String, Object> headers
);
<T> Future<T> asyncRequestBodyAndHeaders(
String endpointUri,
Object body,
Map<String, Object> headers,
Class<T> type
);
Future<Object> asyncRequestBodyAndHeaders(
Endpoint endpoint,
Object body,
Map<String, Object> headers
);
<T> Future<T> asyncRequestBodyAndHeaders(
Endpoint endpoint,
Object body,
Map<String, Object> headers,
Class<T> type
);37.1.6. Asynchronous Send with Callback
Overview
The producer template also provides the option of processing the reply message in the same sub-thread that is used to invoke the producer endpoint. In this case, you provide a callback object, which automatically gets invoked in the sub-thread as soon as the reply message is received. In other words, the asynchronous send with callback methods enable you to initiate an invocation in your main thread and then have all of the associated processing — invocation of the producer endpoint, waiting for a reply and processing the reply — occur asynchronously in a sub-thread.
Send an exchange
The basic asyncCallback() method takes an Exchange argument and invokes an endpoint asynchronously, using the message exchange pattern (MEP) of the specified exchange. This method is similar to the asyncSend() method for exchanges, except that it takes an additional org.apache.camel.spi.Synchronization argument, which is a callback interface with two methods: onComplete() and onFailure(). For details of how to use the Synchronization callback, see the section called “Asynchronous invocation with a callback”.
The following asyncCallback() methods let you specify the target endpoint in one of the following ways: as an endpoint URI, or as an Endpoint object.
Future<Exchange> asyncCallback(
String endpointUri,
Exchange exchange,
Synchronization onCompletion
);
Future<Exchange> asyncCallback(
Endpoint endpoint,
Exchange exchange,
Synchronization onCompletion
);Send an exchange populated by a processor
The asyncCallback() method for processors calls a processor to populate a default exchange and forces the message exchange pattern to be InOut (so that the invocation obeys request/reply semantics).
The following asyncCallback() methods let you specify the target endpoint in one of the following ways: as an endpoint URI, or as an Endpoint object.
Future<Exchange> asyncCallback(
String endpointUri,
Processor processor,
Synchronization onCompletion
);
Future<Exchange> asyncCallback(
Endpoint endpoint,
Processor processor,
Synchronization onCompletion
);Send a message body
If you are only concerned with the contents of the message body that you want to send, you can use the asyncCallbackSendBody() methods to send a message body asynchronously and let the producer template take care of inserting the body into a default exchange object.
The asyncCallbackSendBody() methods let you specify the target endpoint in one of the following ways: as an endpoint URI, or as an Endpoint object.
Future<Object> asyncCallbackSendBody(
String endpointUri,
Object body,
Synchronization onCompletion
);
Future<Object> asyncCallbackSendBody(
Endpoint endpoint,
Object body,
Synchronization onCompletion
);Request a message body
If you are only concerned with the contents of the message body in the request and in the reply, you can use the asyncCallbackRequestBody() methods to provide the request message body as an argument and let the producer template take care of inserting the body into a default exchange object.
The asyncCallbackRequestBody() methods let you specify the target endpoint in one of the following ways: as an endpoint URI, or as an Endpoint object.
Future<Object> asyncCallbackRequestBody(
String endpointUri,
Object body,
Synchronization onCompletion
);
Future<Object> asyncCallbackRequestBody(
Endpoint endpoint,
Object body,
Synchronization onCompletion
);37.2. Using Fluent Producer Templates
Available as of Camel 2.18
The FluentProducerTemplate interface provides a fluent syntax for building a producer. The DefaultFluentProducerTemplate class implements FluentProducerTemplate.
The following example uses a DefaultFluentProducerTemplate object to set headers and a body:
Integer result = DefaultFluentProducerTemplate.on(context)
.withHeader("key-1", "value-1")
.withHeader("key-2", "value-2")
.withBody("Hello")
.to("direct:inout")
.request(Integer.class);
The following example shows how to specify a processor in a DefaultFluentProducerTemplate object:
Integer result = DefaultFluentProducerTemplate.on(context)
.withProcessor(exchange -> exchange.getIn().setBody("Hello World"))
.to("direct:exception")
.request(Integer.class);The next example shows how to customize the default fluent producer template:
Object result = DefaultFluentProducerTemplate.on(context)
.withTemplateCustomizer(
template -> {
template.setExecutorService(myExecutor);
template.setMaximumCacheSize(10);
}
)
.withBody("the body")
.to("direct:start")
.request();
To create a FluentProducerTemplate instance, call the createFluentProducerTemplate() method on the Camel context. For example:
FluentProducerTemplate fluentProducerTemplate = context.createFluentProducerTemplate();
37.3. Using the Consumer Template
Overview
The consumer template provides methods for polling a consumer endpoint in order to receive incoming messages. You can choose to receive the incoming message either in the form of an exchange object or in the form of a message body (where the message body can be cast to a particular type using a built-in type converter).
Example of polling exchanges
You can use a consumer template to poll a consumer endpoint for exchanges using one of the following polling methods: blocking receive(); receive() with a timeout; or receiveNoWait(), which returns immediately. Because a consumer endpoint represents a service, it is also essential to start the service thread by calling start() before you attempt to poll for exchanges.
The following example shows how to poll an exchange from the seda:foo consumer endpoint using the blocking receive() method:
import org.apache.camel.ProducerTemplate; import org.apache.camel.ConsumerTemplate; import org.apache.camel.Exchange; ... ProducerTemplate template = context.createProducerTemplate(); ConsumerTemplate consumer = context.createConsumerTemplate(); // Start the consumer service consumer.start(); ... template.sendBody("seda:foo", "Hello"); Exchange out = consumer.receive("seda:foo"); ... // Stop the consumer service consumer.stop();
Where the consumer template instance, consumer, is instantiated using the CamelContext.createConsumerTemplate() method and the consumer service thread is started by calling ConsumerTemplate.start().
Example of polling message bodies
You can also poll a consumer endpoint for incoming message bodies using one of the following methods: blocking receiveBody(); receiveBody() with a timeout; or receiveBodyNoWait(), which returns immediately. As in the previous example, it is also essential to start the service thread by calling start() before you attempt to poll for exchanges.
The following example shows how to poll an incoming message body from the seda:foo consumer endpoint using the blocking receiveBody() method:
import org.apache.camel.ProducerTemplate; import org.apache.camel.ConsumerTemplate; ... ProducerTemplate template = context.createProducerTemplate(); ConsumerTemplate consumer = context.createConsumerTemplate(); // Start the consumer service consumer.start(); ... template.sendBody("seda:foo", "Hello"); Object body = consumer.receiveBody("seda:foo"); ... // Stop the consumer service consumer.stop();
Methods for polling exchanges
There are three basic methods for polling exchanges from a consumer endpoint: receive() without a timeout blocks indefinitely; receive() with a timeout blocks for the specified period of milliseconds; and receiveNoWait() is non-blocking. You can specify the consumer endpoint either as an endpoint URI or as an Endpoint instance.
Exchange receive(String endpointUri); Exchange receive(String endpointUri, long timeout); Exchange receiveNoWait(String endpointUri); Exchange receive(Endpoint endpoint); Exchange receive(Endpoint endpoint, long timeout); Exchange receiveNoWait(Endpoint endpoint);
Methods for polling message bodies
There are three basic methods for polling message bodies from a consumer endpoint: receiveBody() without a timeout blocks indefinitely; receiveBody() with a timeout blocks for the specified period of milliseconds; and receiveBodyNoWait() is non-blocking. You can specify the consumer endpoint either as an endpoint URI or as an Endpoint instance. Moreover, by calling the templating forms of these methods, you can convert the returned body to a particular type, T, using a built-in type converter.
Object receiveBody(String endpointUri); Object receiveBody(String endpointUri, long timeout); Object receiveBodyNoWait(String endpointUri); Object receiveBody(Endpoint endpoint); Object receiveBody(Endpoint endpoint, long timeout); Object receiveBodyNoWait(Endpoint endpoint); <T> T receiveBody(String endpointUri, Class<T> type); <T> T receiveBody(String endpointUri, long timeout, Class<T> type); <T> T receiveBodyNoWait(String endpointUri, Class<T> type); <T> T receiveBody(Endpoint endpoint, Class<T> type); <T> T receiveBody(Endpoint endpoint, long timeout, Class<T> type); <T> T receiveBodyNoWait(Endpoint endpoint, Class<T> type);
M
Chapter 38. Implementing a Component
Abstract
This chapter provides a general overview of the approaches can be used to implement a Apache Camel component.
38.1. Component Architecture
38.1.1. Factory Patterns for a Component
Overview
An Apache Camel component consists of a set of classes that are related to each other through a factory pattern. The primary entry point to a component is the Component object itself (an instance of org.apache.camel.Component type). You can use the Component object as a factory to create Endpoint objects, which in turn act as factories for creating Consumer, Producer, and Exchange objects. These relationships are summarized in Figure 38.1, “Component Factory Patterns”
Figure 38.1. Component Factory Patterns
Component
A component implementation is an endpoint factory. The main task of a component implementor is to implement the Component.createEndpoint() method, which is responsible for creating new endpoints on demand.
Each kind of component must be associated with a component prefix that appears in an endpoint URI. For example, the file component is usually associated with the file prefix, which can be used in an endpoint URI like file://tmp/messages/input. When you install a new component in Apache Camel, you must define the association between a particular component prefix and the name of the class that implements the component.
Endpoint
Each endpoint instance encapsulates a particular endpoint URI. Every time Apache Camel encounters a new endpoint URI, it creates a new endpoint instance. An endpoint object is also a factory for creating consumer endpoints and producer endpoints.
Endpoints must implement the org.apache.camel.Endpoint interface. The Endpoint interface defines the following factory methods:
-
createConsumer()andcreatePollingConsumer()— Creates a consumer endpoint, which represents the source endpoint at the beginning of a route. -
createProducer()— Creates a producer endpoint, which represents the target endpoint at the end of a route. -
createExchange()— Creates an exchange object, which encapsulates the messages passed up and down the route.
Consumer
Consumer endpoints consume requests. They always appear at the start of a route and they encapsulate the code responsible for receiving incoming requests and dispatching outgoing replies. From a service-oriented prospective a consumer represents a service.
Consumers must implement the org.apache.camel.Consumer interface. There are a number of different patterns you can follow when implementing a consumer. These patterns are described in Section 38.1.3, “Consumer Patterns and Threading”.
Producer
Producer endpoints produce requests. They always appears at the end of a route and they encapsulate the code responsible for dispatching outgoing requests and receiving incoming replies. From a service-oriented prospective a producer represents a service consumer.
Producers must implement the org.apache.camel.Producer interface. You can optionally implement the producer to support an asynchronous style of processing. See Section 38.1.4, “Asynchronous Processing” for details.
Exchange
Exchange objects encapsulate a related set of messages. For example, one kind of message exchange is a synchronous invocation, which consists of a request message and its related reply.
Exchanges must implement the org.apache.camel.Exchange interface. The default implementation, DefaultExchange, is sufficient for many component implementations. However, if you want to associated extra data with the exchanges or have the exchanges preform additional processing, it can be useful to customize the exchange implementation.
Message
There are two different message slots in an Exchange object:
- In message — holds the current message.
- Out message — temporarily holds a reply message.
All of the message types are represented by the same Java object, org.apache.camel.Message. It is not always necessary to customize the message implementation — the default implementation, DefaultMessage, is usually adequate.
38.1.2. Using a Component in a Route
Overview
A Apache Camel route is essentially a pipeline of processors, of org.apache.camel.Processor type. Messages are encapsulated in an exchange object, E, which gets passed from node to node by invoking the process() method. The architecture of the processor pipeline is illustrated in Figure 38.2, “Consumer and Producer Instances in a Route”.
Figure 38.2. Consumer and Producer Instances in a Route
Source endpoint
At the start of the route, you have the source endpoint, which is represented by an org.apache.camel.Consumer object. The source endpoint is responsible for accepting incoming request messages and dispatching replies. When constructing the route, Apache Camel creates the appropriate Consumer type based on the component prefix from the endpoint URI, as described in Section 38.1.1, “Factory Patterns for a Component”.
Processors
Each intermediate node in the pipeline is represented by a processor object (implementing the org.apache.camel.Processor interface). You can insert either standard processors (for example, filter, throttler, or delayer) or insert your own custom processor implementations.
Target endpoint
At the end of the route is the target endpoint, which is represented by an org.apache.camel.Producer object. Because it comes at the end of a processor pipeline, the producer is also a processor object (implementing the org.apache.camel.Processor interface). The target endpoint is responsible for sending outgoing request messages and receiving incoming replies. When constructing the route, Apache Camel creates the appropriate Producer type based on the component prefix from the endpoint URI.
38.1.3. Consumer Patterns and Threading
Overview
The pattern used to implement the consumer determines the threading model used in processing the incoming exchanges. Consumers can be implemented using one of the following patterns:
- Event-driven pattern — The consumer is driven by an external thread.
- Scheduled poll pattern — The consumer is driven by a dedicated thread pool.
- Polling pattern — The threading model is left undefined.
Event-driven pattern
In the event-driven pattern, the processing of an incoming request is initiated when another part of the application (typically a third-party library) calls a method implemented by the consumer. A good example of an event-driven consumer is the Apache Camel JMX component, where events are initiated by the JMX library. The JMX library calls the handleNotification() method to initiate request processing — see Example 41.4, “JMXConsumer Implementation” for details.
Figure 38.3, “Event-Driven Consumer” shows an outline of the event-driven consumer pattern. In this example, it is assumed that processing is triggered by a call to the notify() method.
Figure 38.3. Event-Driven Consumer

The event-driven consumer processes incoming requests as follows:
The consumer must implement a method to receive the incoming event (in Figure 38.3, “Event-Driven Consumer” this is represented by the
notify()method). The thread that callsnotify()is normally a separate part of the application, so the consumer’s threading policy is externally driven.For example, in the case of the JMX consumer implementation, the consumer implements the
NotificationListener.handleNotification()method to receive notifications from JMX. The threads that drive the consumer processing are created within the JMX layer.-
In the body of the
notify()method, the consumer first converts the incoming event into an exchange object,E, and then callsprocess()on the next processor in the route, passing the exchange object as its argument.
Scheduled poll pattern
In the scheduled poll pattern, the consumer retrieves incoming requests by checking at regular time intervals whether or not a request has arrived. Checking for requests is scheduled automatically by a built-in timer class, the scheduled executor service, which is a standard pattern provided by the java.util.concurrent library. The scheduled executor service executes a particular task at timed intervals and it also manages a pool of threads, which are used to run the task instances.
Figure 38.4, “Scheduled Poll Consumer” shows an outline of the scheduled poll consumer pattern.
Figure 38.4. Scheduled Poll Consumer
The scheduled poll consumer processes incoming requests as follows:
-
The scheduled executor service has a pool of threads at its disposal, that can be used to initiate consumer processing. After each scheduled time interval has elapsed, the scheduled executor service attempts to grab a free thread from its pool (there are five threads in the pool by default). If a free thread is available, it uses that thread to call the
poll()method on the consumer. -
The consumer’s
poll()method is intended to trigger processing of an incoming request. In the body of thepoll()method, the consumer attempts to retrieve an incoming message. If no request is available, thepoll()method returns immediately. -
If a request message is available, the consumer inserts it into an exchange object and then calls
process()on the next processor in the route, passing the exchange object as its argument.
Polling pattern
In the polling pattern, processing of an incoming request is initiated when a third-party calls one of the consumer’s polling methods:
-
receive() -
receiveNoWait() -
receive(long timeout)
It is up to the component implementation to define the precise mechanism for initiating calls on the polling methods. This mechanism is not specified by the polling pattern.
Figure 38.5, “Polling Consumer” shows an outline of the polling consumer pattern.
Figure 38.5. Polling Consumer
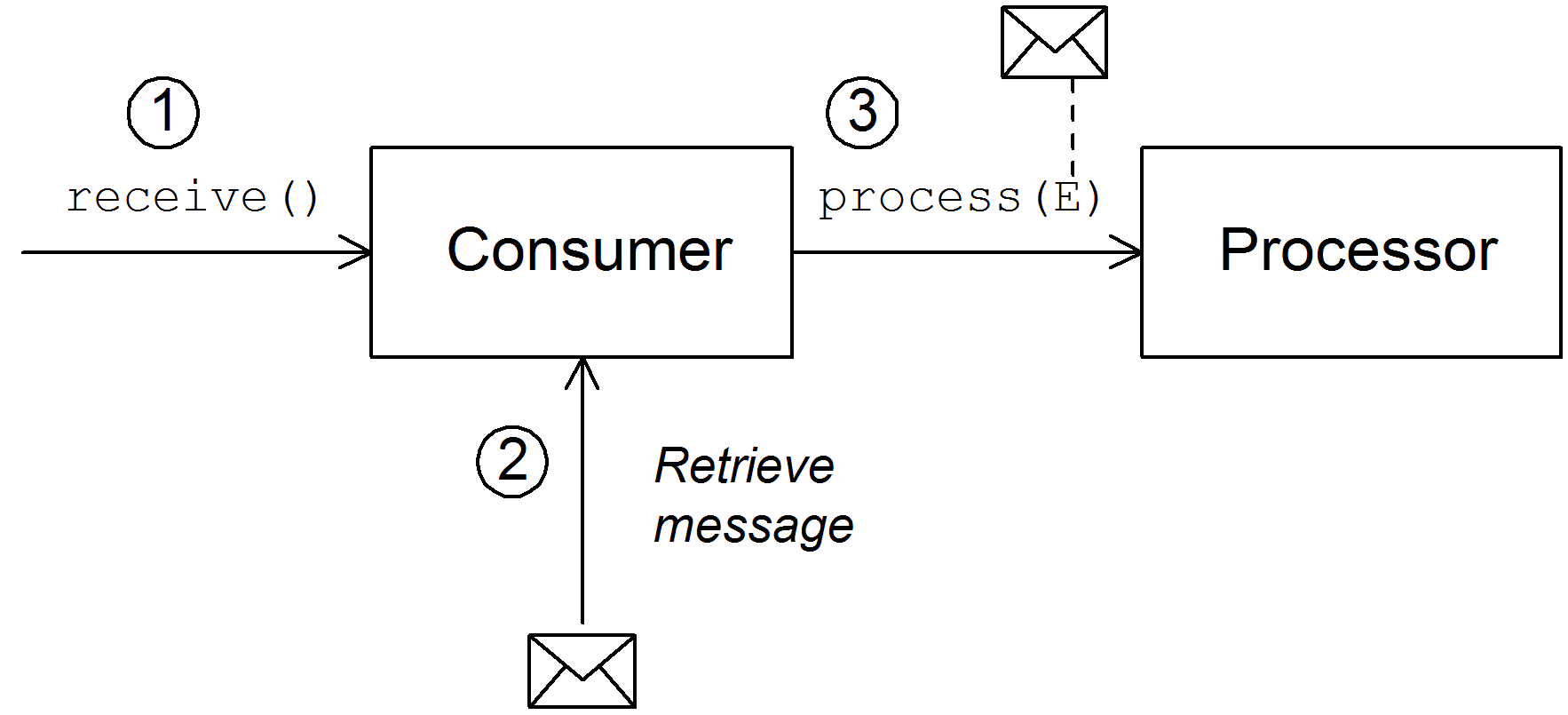
The polling consumer processes incoming requests as follows:
- Processing of an incoming request is initiated whenever one of the consumer’s polling methods is called. The mechanism for calling these polling methods is implementation defined.
In the body of the
receive()method, the consumer attempts to retrieve an incoming request message. If no message is currently available, the behavior depends on which receive method was called.-
receiveNoWait()returns immediately -
receive(long timeout)waits for the specified timeout interval[2] before returning -
receive()waits until a message is received
-
-
If a request message is available, the consumer inserts it into an exchange object and then calls
process()on the next processor in the route, passing the exchange object as its argument.
38.1.4. Asynchronous Processing
Overview
Producer endpoints normally follow a synchronous pattern when processing an exchange. When the preceding processor in a pipeline calls process() on a producer, the process() method blocks until a reply is received. In this case, the processor’s thread remains blocked until the producer has completed the cycle of sending the request and receiving the reply.
Sometimes, however, you might prefer to decouple the preceding processor from the producer, so that the processor’s thread is released immediately and the process() call does not block. In this case, you should implement the producer using an asynchronous pattern, which gives the preceding processor the option of invoking a non-blocking version of the process() method.
To give you an overview of the different implementation options, this section describes both the synchronous and the asynchronous patterns for implementing a producer endpoint.
Synchronous producer
Figure 38.6, “Synchronous Producer” shows an outline of a synchronous producer, where the preceding processor blocks until the producer has finished processing the exchange.
Figure 38.6. Synchronous Producer
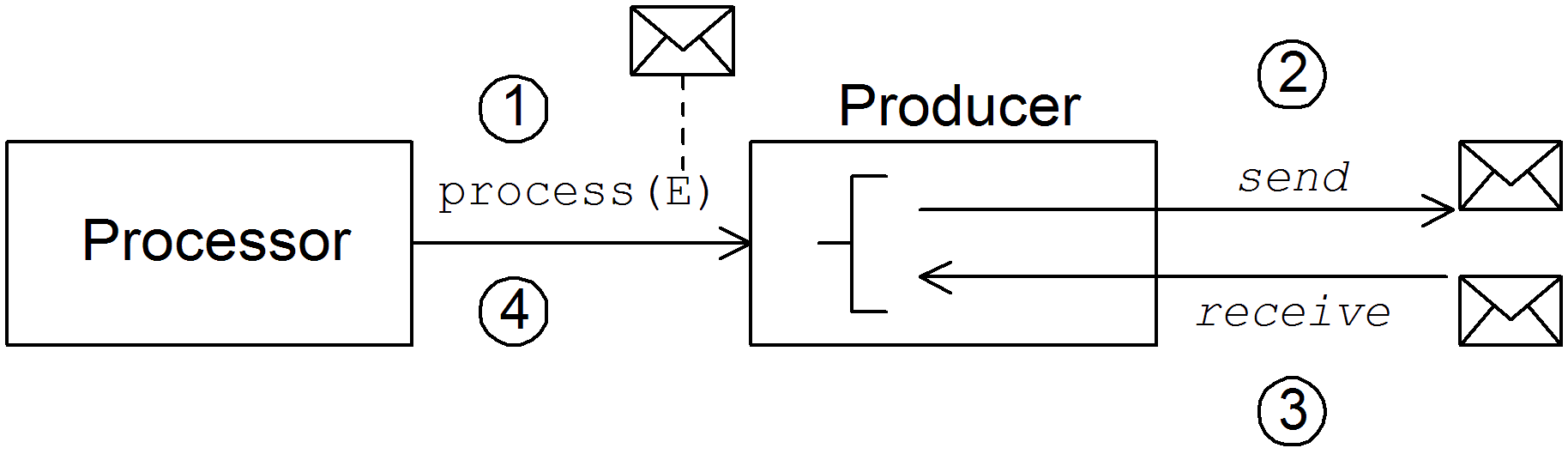
The synchronous producer processes an exchange as follows:
-
The preceding processor in the pipeline calls the synchronous
process()method on the producer to initiate synchronous processing. The synchronousprocess()method takes a single exchange argument. -
In the body of the
process()method, the producer sends the request (In message) to the endpoint. -
If required by the exchange pattern, the producer waits for the reply (Out message) to arrive from the endpoint. This step can cause the
process()method to block indefinitely. However, if the exchange pattern does not mandate a reply, theprocess()method can return immediately after sending the request. -
When the
process()method returns, the exchange object contains the reply from the synchronous call (an Out message message).
Asynchronous producer
Figure 38.7, “Asynchronous Producer” shows an outline of an asynchronous producer, where the producer processes the exchange in a sub-thread, and the preceding processor is not blocked for any significant length of time.
Figure 38.7. Asynchronous Producer
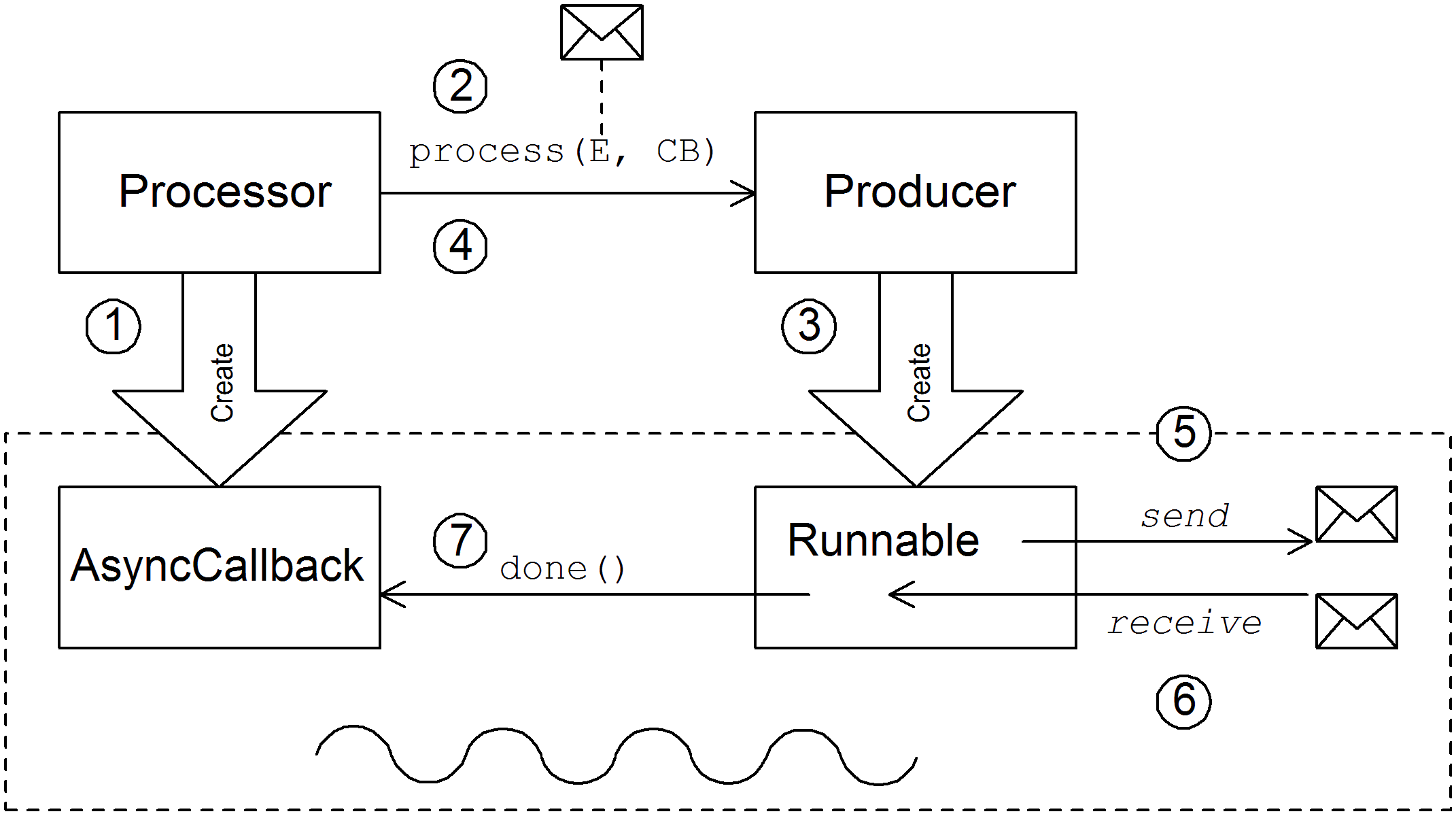
The asynchronous producer processes an exchange as follows:
-
Before the processor can call the asynchronous
process()method, it must create an asynchronous callback object, which is responsible for processing the exchange on the return portion of the route. For the asynchronous callback, the processor must implement a class that inherits from the AsyncCallback interface. The processor calls the asynchronous
process()method on the producer to initiate asynchronous processing. The asynchronousprocess()method takes two arguments:- an exchange object
- a synchronous callback object
-
In the body of the
process()method, the producer creates aRunnableobject that encapsulates the processing code. The producer then delegates the execution of thisRunnableobject to a sub-thread. -
The asynchronous
process()method returns, thereby freeing up the processor’s thread. The exchange processing continues in a separate sub-thread. -
The
Runnableobject sends the In message to the endpoint. -
If required by the exchange pattern, the
Runnableobject waits for the reply (Out or Fault message) to arrive from the endpoint. TheRunnableobject remains blocked until the reply is received. -
After the reply arrives, the
Runnableobject inserts the reply (Out message) into the exchange object and then callsdone()on the asynchronous callback object. The asynchronous callback is then responsible for processing the reply message (executed in the sub-thread).
38.2. How to Implement a Component
Overview
This section gives a brief overview of the steps required to implement a custom Apache Camel component.
Which interfaces do you need to implement?
When implementing a component, it is usually necessary to implement the following Java interfaces:
- org.apache.camel.Component
- org.apache.camel.Endpoint
- org.apache.camel.Consumer
- org.apache.camel.Producer
In addition, it can also be necessary to implement the following Java interfaces:
- org.apache.camel.Exchange
- org.apache.camel.Message
Implementation steps
You typically implement a custom component as follows:
Implement the Component interface — A component object acts as an endpoint factory. You extend the
DefaultComponentclass and implement thecreateEndpoint()method.Implement the Endpoint interface — An endpoint represents a resource identified by a specific URI. The approach taken when implementing an endpoint depends on whether the consumers follow an event-driven pattern, a scheduled poll pattern, or a polling pattern. For an event-driven pattern, implement the endpoint by extending the
DefaultEndpointclass and implementing the following methods:-
createProducer() createConsumer()For a scheduled poll pattern, implement the endpoint by extending the
ScheduledPollEndpointclass and implementing the following methods:-
createProducer() createConsumer()For a polling pattern, implement the endpoint by extending the
DefaultPollingEndpointclass and implementing the following methods:-
createProducer() createPollConsumer()
-
Implement the Consumer interface — There are several different approaches you can take to implementing a consumer, depending on which pattern you need to implement (event-driven, scheduled poll, or polling). The consumer implementation is also crucially important for determining the threading model used for processing a message exchange.
Implement the Producer interface — To implement a producer, you extend the
DefaultProducerclass and implement theprocess()method.Optionally implement the Exchange or the Message interface — The default implementations of Exchange and Message can be used directly, but occasionally, you might find it necessary to customize these types.
See Chapter 43, Exchange Interface and Chapter 44, Message Interface.
Installing and configuring the component
You can install a custom component in one of the following ways:
-
Add the component directly to the CamelContext — The
CamelContext.addComponent()method adds a component programatically. -
Add the component using Spring configuration — The standard Spring
beanelement creates a component instance. The bean’sidattribute implicitly defines the component prefix. For details, see Section 38.3.2, “Configuring a Component”. - Configure Apache Camel to auto-discover the component — Auto-discovery, ensures that Apache Camel automatically loads the component on demand. For details, see Section 38.3.1, “Setting Up Auto-Discovery”.
38.3. Auto-Discovery and Configuration
38.3.1. Setting Up Auto-Discovery
Overview
Auto-discovery is a mechanism that enables you to dynamically add components to your Apache Camel application. The component URI prefix is used as a key to load components on demand. For example, if Apache Camel encounters the endpoint URI, activemq://MyQName, and the ActiveMQ endpoint is not yet loaded, Apache Camel searches for the component identified by the activemq prefix and dynamically loads the component.
Availability of component classes
Before configuring auto-discovery, you must ensure that your custom component classes are accessible from your current classpath. Typically, you bundle the custom component classes into a JAR file, and add the JAR file to your classpath.
Configuring auto-discovery
To enable auto-discovery of your component, create a Java properties file named after the component prefix, component-prefix, and store that file in the following location:
/META-INF/services/org/apache/camel/component/component-prefixThe component-prefix properties file must contain the following property setting:
class=component-class-nameWhere component-class-name is the fully-qualified name of your custom component class. You can also define additional system property settings in this file.
Example
For example, you can enable auto-discovery for the Apache Camel FTP component by creating the following Java properties file:
/META-INF/services/org/apache/camel/component/ftp
Which contains the following Java property setting:
class=org.apache.camel.component.file.remote.RemoteFileComponent
The Java properties file for the FTP component is already defined in the JAR file, camel-ftp-Version.jar.
38.3.2. Configuring a Component
Overview
You can add a component by configuring it in the Apache Camel Spring configuration file, META-INF/spring/camel-context.xml. To find the component, the component’s URI prefix is matched against the ID attribute of a bean element in the Spring configuration. If the component prefix matches a bean element ID, Apache Camel instantiates the referenced class and injects the properties specified in the Spring configuration.
This mechanism has priority over auto-discovery. If the CamelContext finds a Spring bean with the requisite ID, it will not attempt to find the component using auto-discovery.
Define bean properties on your component class
If there are any properties that you want to inject into your component class, define them as bean properties. For example:
public class CustomComponent extends DefaultComponent<CustomExchange> { ... PropType getProperty() { ... } void setProperty(PropType v) { ... } }
The getProperty() method and the setProperty() method access the value of property.
Configure the component in Spring
To configure a component in Spring, edit the configuration file, META-INF/spring/camel-context.xml, as shown in Example 38.1, “Configuring a Component in Spring”.
Example 38.1. Configuring a Component in Spring
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="
http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-2.0.xsd
http://camel.apache.org/schema/spring http://camel.apache.org/schema/spring/camel-spring.xsd">
<camelContext id="camel" xmlns="http://camel.apache.org/schema/spring">
<package>RouteBuilderPackage</package>
</camelContext>
<bean id="component-prefix" class="component-class-name">
<property name="property" value="propertyValue"/>
</bean>
</beans>
The bean element with ID component-prefix configures the component-class-name component. You can inject properties into the component instance using property elements. For example, the property element in the preceding example would inject the value, propertyValue, into the property property by calling setProperty() on the component.
Examples
Example 38.2, “JMS Component Spring Configuration” shows an example of how to configure the Apache Camel’s JMS component by defining a bean element with ID equal to jms. These settings are added to the Spring configuration file, camel-context.xml.
Example 38.2. JMS Component Spring Configuration
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="
http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-2.0.xsd
http://camel.apache.org/schema/spring http://camel.apache.org/schema/spring/camel-spring.xsd">
<camelContext id="camel" xmlns="http://camel.apache.org/schema/spring">
<package>org.apache.camel.example.spring</package> 1
</camelContext>
<bean id="jms" class="org.apache.camel.component.jms.JmsComponent"> 2
<property name="connectionFactory"3
<bean class="org.apache.activemq.ActiveMQConnectionFactory">
<property name="brokerURL"
value="vm://localhost?broker.persistent=false&broker.useJmx=false"/> 4
</bean>
</property>
</bean>
</beans>- 1
- The
CamelContextautomatically instantiates anyRouteBuilderclasses that it finds in the specified Java package, org.apache.camel.example.spring. - 2
- The bean element with ID,
jms, configures the JMS component. The bean ID corresponds to the component’s URI prefix. For example, if a route specifies an endpoint with the URI, jms://MyQName, Apache Camel automatically loads the JMS component using the settings from thejmsbean element. - 3
- JMS is just a wrapper for a messaging service. You must specify the concrete implementation of the messaging system by setting the
connectionFactoryproperty on theJmsComponentclass. - 4
- In this example, the concrete implementation of the JMS messaging service is Apache ActiveMQ. The
brokerURLproperty initializes a connection to an ActiveMQ broker instance, where the message broker is embedded in the local Java virtual machine (JVM). If a broker is not already present in the JVM, ActiveMQ will instantiate it with the optionsbroker.persistent=false(the broker does not persist messages) andbroker.useJmx=false(the broker does not open a JMX port).
Chapter 39. Component Interface
Abstract
This chapter describes how to implement the Component interface.
39.1. The Component Interface
Overview
To implement a Apache Camel component, you must implement the org.apache.camel.Component interface. An instance of Component type provides the entry point into a custom component. That is, all of the other objects in a component are ultimately accessible through the Component instance. Figure 39.1, “Component Inheritance Hierarchy” shows the relevant Java interfaces and classes that make up the Component inheritance hierarchy.
Figure 39.1. Component Inheritance Hierarchy
The Component interface
Example 39.1, “Component Interface” shows the definition of the org.apache.camel.Component interface.
Example 39.1. Component Interface
package org.apache.camel;
public interface Component {
CamelContext getCamelContext();
void setCamelContext(CamelContext context);
Endpoint createEndpoint(String uri) throws Exception;
}Component methods
The Component interface defines the following methods:
-
getCamelContext()andsetCamelContext()— References theCamelContextto which this Component belongs. ThesetCamelContext()method is automatically called when you add the component to aCamelContext. -
createEndpoint()— The factory method that gets called to createEndpointinstances for this component. Theuriparameter is the endpoint URI, which contains the details required to create the endpoint.
39.2. Implementing the Component Interface
The DefaultComponent class
You implement a new component by extending the org.apache.camel.impl.DefaultComponent class, which provides some standard functionality and default implementations for some of the methods. In particular, the DefaultComponent class provides support for URI parsing and for creating a scheduled executor (which is used for the scheduled poll pattern).
URI parsing
The createEndpoint(String uri) method defined in the base Component interface takes a complete, unparsed endpoint URI as its sole argument. The DefaultComponent class, on the other hand, defines a three-argument version of the createEndpoint() method with the following signature:
protected abstract Endpoint createEndpoint(
String uri,
String remaining,
Map parameters
)
throws Exception;
uri is the original, unparsed URI; remaining is the part of the URI that remains after stripping off the component prefix at the start and cutting off the query options at the end; and parameters contains the parsed query options. It is this version of the createEndpoint() method that you must override when inheriting from DefaultComponent. This has the advantage that the endpoint URI is already parsed for you.
The following sample endpoint URI for the file component shows how URI parsing works in practice:
file:///tmp/messages/foo?delete=true&moveNamePostfix=.old
For this URI, the following arguments are passed to the three-argument version of createEndpoint():
| Argument | Sample Value |
|---|---|
|
| |
|
|
|
|
|
Two entries are set in
|
Parameter injection
By default, the parameters extracted from the URI query options are injected on the endpoint’s bean properties. The DefaultComponent class automatically injects the parameters for you.
For example, if you want to define a custom endpoint that supports two URI query options: delete and moveNamePostfix. All you must do is define the corresponding bean methods (getters and setters) in the endpoint class:
public class FileEndpoint extends ScheduledPollEndpoint {
...
public boolean isDelete() {
return delete;
}
public void setDelete(boolean delete) {
this.delete = delete;
}
...
public String getMoveNamePostfix() {
return moveNamePostfix;
}
public void setMoveNamePostfix(String moveNamePostfix) {
this.moveNamePostfix = moveNamePostfix;
}
}It is also possible to inject URI query options into consumer parameters. For details, see the section called “Consumer parameter injection”.
Disabling endpoint parameter injection
If there are no parameters defined on your Endpoint class, you can optimize the process of endpoint creation by disabling endpoint parameter injection. To disable parameter injection on endpoints, override the useIntrospectionOnEndpoint() method and implement it to return false, as follows:
protected boolean useIntrospectionOnEndpoint() {
return false;
}
The useIntrospectionOnEndpoint() method does not affect the parameter injection that might be performed on a Consumer class. Parameter injection at that level is controlled by the Endpoint.configureProperties() method (see Section 40.2, “Implementing the Endpoint Interface”).
Scheduled executor service
The scheduled executor is used in the scheduled poll pattern, where it is responsible for driving the periodic polling of a consumer endpoint (a scheduled executor is effectively a thread pool implementation).
To instantiate a scheduled executor service, use the ExecutorServiceStrategy object that is returned by the CamelContext.getExecutorServiceStrategy() method. For details of the Apache Camel threading model, see Section 2.8, “Threading Model”.
Prior to Apache Camel 2.3, the DefaultComponent class provided a getExecutorService() method for creating thread pool instances. Since 2.3, however, the creation of thread pools is now managed centrally by the ExecutorServiceStrategy object.
Validating the URI
If you want to validate the URI before creating an endpoint instance, you can override the validateURI() method from the DefaultComponent class, which has the following signature:
protected void validateURI(String uri,
String path,
Map parameters)
throws ResolveEndpointFailedException;
If the supplied URI does not have the required format, the implementation of validateURI() should throw the org.apache.camel.ResolveEndpointFailedException exception.
Creating an endpoint
Example 39.2, “Implementation of createEndpoint()” outlines how to implement the DefaultComponent.createEndpoint() method, which is responsible for creating endpoint instances on demand.
Example 39.2. Implementation of createEndpoint()
public class CustomComponent extends DefaultComponent { 1
...
protected Endpoint createEndpoint(String uri, String remaining, Map parameters) throws Exception { 2
CustomEndpoint result = new CustomEndpoint(uri, this); 3
// ...
return result;
}
}- 1
- The CustomComponent is the name of your custom component class, which is defined by extending the
DefaultComponentclass. - 2
- When extending
DefaultComponent, you must implement thecreateEndpoint()method with three arguments (see the section called “URI parsing”). - 3
- Create an instance of your custom endpoint type, CustomEndpoint, by calling its constructor. At a minimum, this constructor takes a copy of the original URI string,
uri, and a reference to this component instance,this.
Example
Example 39.3, “FileComponent Implementation” shows a sample implementation of a FileComponent class.
Example 39.3. FileComponent Implementation
package org.apache.camel.component.file;
import org.apache.camel.CamelContext;
import org.apache.camel.Endpoint;
import org.apache.camel.impl.DefaultComponent;
import java.io.File;
import java.util.Map;
public class FileComponent extends DefaultComponent {
public static final String HEADER_FILE_NAME = "org.apache.camel.file.name";
public FileComponent() { 1
}
public FileComponent(CamelContext context) { 2
super(context);
}
protected Endpoint createEndpoint(String uri, String remaining, Map parameters) throws Exception { 3
File file = new File(remaining);
FileEndpoint result = new FileEndpoint(file, uri, this);
return result;
}
}- 1
- Always define a no-argument constructor for the component class in order to facilitate automatic instantiation of the class.
- 2
- A constructor that takes the parent
CamelContextinstance as an argument is convenient when creating a component instance by programming. - 3
- The implementation of the
FileComponent.createEndpoint()method follows the pattern described in Example 39.2, “Implementation ofcreateEndpoint()”. The implementation creates aFileEndpointobject.
SynchronizationRouteAware Interface
SynchronizationRouteAware interface allows you to have callbacks before and after the exchange has been routed.
-
onBeforeRoute: Invoked before the exchange has been routed by the given route. However, this callback may not get invoked, if you add theSynchronizationRouteAwareimplementation to theUnitOfWork, after starting the route. onAfterRoute: Invoked after the exchange has been routed by the given route. However, if the exchange is being routed through multiple routes, it would generate call backs for each route.This invocation occurs before these callbacks:
-
The consumer of the route writes any response back to the caller (if in
InOutmode) -
The
UnitOfWorkis done by calling eitherSynchronization.onComplete(org.apache.camel.Exchange)orSynchronization.onFailure(org.apache.camel.Exchange)
-
The consumer of the route writes any response back to the caller (if in
Chapter 40. Endpoint Interface
Abstract
This chapter describes how to implement the Endpoint interface, which is an essential step in the implementation of a Apache Camel component.
40.1. The Endpoint Interface
Overview
An instance of org.apache.camel.Endpoint type encapsulates an endpoint URI, and it also serves as a factory for Consumer, Producer, and Exchange objects. There are three different approaches to implementing an endpoint:
- Event-driven
- scheduled poll
- polling
These endpoint implementation patterns complement the corresponding patterns for implementing a consumer — see Section 41.2, “Implementing the Consumer Interface”.
Figure 40.1, “Endpoint Inheritance Hierarchy” shows the relevant Java interfaces and classes that make up the Endpoint inheritance hierarchy.
Figure 40.1. Endpoint Inheritance Hierarchy
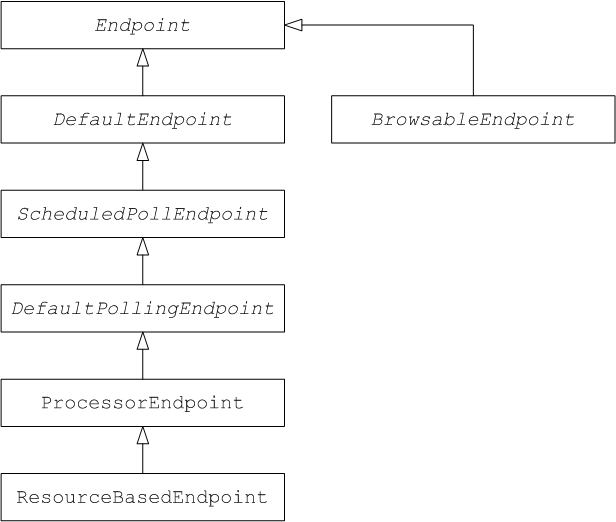
The Endpoint interface
Example 40.1, “Endpoint Interface” shows the definition of the org.apache.camel.Endpoint interface.
Example 40.1. Endpoint Interface
package org.apache.camel;
public interface Endpoint {
boolean isSingleton();
String getEndpointUri();
String getEndpointKey();
CamelContext getCamelContext();
void setCamelContext(CamelContext context);
void configureProperties(Map options);
boolean isLenientProperties();
Exchange createExchange();
Exchange createExchange(ExchangePattern pattern);
Exchange createExchange(Exchange exchange);
Producer createProducer() throws Exception;
Consumer createConsumer(Processor processor) throws Exception;
PollingConsumer createPollingConsumer() throws Exception;
}Endpoint methods
The Endpoint interface defines the following methods:
-
isSingleton()— Returnstrue, if you want to ensure that each URI maps to a single endpoint within a CamelContext. When this property istrue, multiple references to the identical URI within your routes always refer to a single endpoint instance. When this property isfalse, on the other hand, multiple references to the same URI within your routes refer to distinct endpoint instances. Each time you refer to the URI in a route, a new endpoint instance is created. -
getEndpointUri()— Returns the endpoint URI of this endpoint. -
getEndpointKey()— Used byorg.apache.camel.spi.LifecycleStrategywhen registering the endpoint. -
getCamelContext()— return a reference to theCamelContextinstance to which this endpoint belongs. -
setCamelContext()— Sets theCamelContextinstance to which this endpoint belongs. -
configureProperties()— Stores a copy of the parameter map that is used to inject parameters when creating a newConsumerinstance. -
isLenientProperties()— Returnstrueto indicate that the URI is allowed to contain unknown parameters (that is, parameters that cannot be injected on the Endpoint or theConsumerclass). Normally, this method should be implemented to returnfalse. createExchange()— An overloaded method with the following variants:-
Exchange createExchange()— Creates a new exchange instance with a default exchange pattern setting. -
Exchange createExchange(ExchangePattern pattern)— Creates a new exchange instance with the specified exchange pattern. -
Exchange createExchange(Exchange exchange)— Converts the givenexchangeargument to the type of exchange needed for this endpoint. If the given exchange is not already of the correct type, this method copies it into a new instance of the correct type. A default implementation of this method is provided in theDefaultEndpointclass.
-
-
createProducer()— Factory method used to create newProducerinstances. -
createConsumer()— Factory method to create new event-driven consumer instances. Theprocessorargument is a reference to the first processor in the route. -
createPollingConsumer()— Factory method to create new polling consumer instances.
Endpoint singletons
In order to avoid unnecessary overhead, it is a good idea to create a single endpoint instance for all endpoints that have the same URI (within a CamelContext). You can enforce this condition by implementing isSingleton() to return true.
In this context, same URI means that two URIs are the same when compared using string equality. In principle, it is possible to have two URIs that are equivalent, though represented by different strings. In that case, the URIs would not be treated as the same.
40.2. Implementing the Endpoint Interface
Alternative ways of implementing an endpoint
The following alternative endpoint implementation patterns are supported:
Event-driven endpoint implementation
If your custom endpoint conforms to the event-driven pattern (see Section 38.1.3, “Consumer Patterns and Threading”), it is implemented by extending the abstract class, org.apache.camel.impl.DefaultEndpoint, as shown in Example 40.2, “Implementing DefaultEndpoint”.
Example 40.2. Implementing DefaultEndpoint
import java.util.Map; import java.util.concurrent.BlockingQueue; import org.apache.camel.Component; import org.apache.camel.Consumer; import org.apache.camel.Exchange; import org.apache.camel.Processor; import org.apache.camel.Producer; import org.apache.camel.impl.DefaultEndpoint; import org.apache.camel.impl.DefaultExchange; public class CustomEndpoint extends DefaultEndpoint { 1 public CustomEndpoint(String endpointUri, Component component) { 2 super(endpointUri, component); // Do any other initialization... } public Producer createProducer() throws Exception { 3 return new CustomProducer(this); } public Consumer createConsumer(Processor processor) throws Exception { 4 return new CustomConsumer(this, processor); } public boolean isSingleton() { return true; } // Implement the following methods, only if you need to set exchange properties. // public Exchange createExchange() { 5 return this.createExchange(getExchangePattern()); } public Exchange createExchange(ExchangePattern pattern) { Exchange result = new DefaultExchange(getCamelContext(), pattern); // Set exchange properties ... return result; } }
- 1
- Implement an event-driven custom endpoint, CustomEndpoint, by extending the
DefaultEndpointclass. - 2
- You must have at least one constructor that takes the endpoint URI,
endpointUri, and the parent component reference,component, as arguments. - 3
- Implement the
createProducer()factory method to create producer endpoints. - 4
- Implement the
createConsumer()factory method to create event-driven consumer instances. - 5
- In general, it is not necessary to override the
createExchange()methods. The implementations inherited fromDefaultEndpointcreate aDefaultExchangeobject by default, which can be used in any Apache Camel component. If you need to initialize some exchange properties in theDefaultExchangeobject, however, it is appropriate to override thecreateExchange()methods here in order to add the exchange property settings.
Do not override the createPollingConsumer() method.
The DefaultEndpoint class provides default implementations of the following methods, which you might find useful when writing your custom endpoint code:
-
getEndpointUri()— Returns the endpoint URI. -
getCamelContext()— Returns a reference to theCamelContext. -
getComponent()— Returns a reference to the parent component. -
createPollingConsumer()— Creates a polling consumer. The created polling consumer’s functionality is based on the event-driven consumer. If you override the event-driven consumer method,createConsumer(), you get a polling consumer implementation for free. -
createExchange(Exchange e)— Converts the given exchange object,e, to the type required for this endpoint. This method creates a new endpoint using the overriddencreateExchange()endpoints. This ensures that the method also works for custom exchange types.
Scheduled poll endpoint implementation
If your custom endpoint conforms to the scheduled poll pattern (see Section 38.1.3, “Consumer Patterns and Threading”) it is implemented by inheriting from the abstract class, org.apache.camel.impl.ScheduledPollEndpoint, as shown in Example 40.3, “ScheduledPollEndpoint Implementation”.
Example 40.3. ScheduledPollEndpoint Implementation
import org.apache.camel.Consumer; import org.apache.camel.Processor; import org.apache.camel.Producer; import org.apache.camel.ExchangePattern; import org.apache.camel.Message; import org.apache.camel.impl.ScheduledPollEndpoint; public class CustomEndpoint extends ScheduledPollEndpoint { 1 protected CustomEndpoint(String endpointUri, CustomComponent component) { 2 super(endpointUri, component); // Do any other initialization... } public Producer createProducer() throws Exception { 3 Producer result = new CustomProducer(this); return result; } public Consumer createConsumer(Processor processor) throws Exception { 4 Consumer result = new CustomConsumer(this, processor); configureConsumer(result); 5 return result; } public boolean isSingleton() { return true; } // Implement the following methods, only if you need to set exchange properties. // public Exchange createExchange() { 6 return this.createExchange(getExchangePattern()); } public Exchange createExchange(ExchangePattern pattern) { Exchange result = new DefaultExchange(getCamelContext(), pattern); // Set exchange properties ... return result; } }
- 1
- Implement a scheduled poll custom endpoint, CustomEndpoint, by extending the
ScheduledPollEndpointclass. - 2
- You must to have at least one constructor that takes the endpoint URI,
endpointUri, and the parent component reference,component, as arguments. - 3
- Implement the
createProducer()factory method to create a producer endpoint. - 4
- Implement the
createConsumer()factory method to create a scheduled poll consumer instance. - 5
- The
configureConsumer()method, defined in theScheduledPollEndpointbase class, is responsible for injecting consumer query options into the consumer. See the section called “Consumer parameter injection”. - 6
- In general, it is not necessary to override the
createExchange()methods. The implementations inherited fromDefaultEndpointcreate aDefaultExchangeobject by default, which can be used in any Apache Camel component. If you need to initialize some exchange properties in theDefaultExchangeobject, however, it is appropriate to override thecreateExchange()methods here in order to add the exchange property settings.
Do not override the createPollingConsumer() method.
Polling endpoint implementation
If your custom endpoint conforms to the polling consumer pattern (see Section 38.1.3, “Consumer Patterns and Threading”), it is implemented by inheriting from the abstract class, org.apache.camel.impl.DefaultPollingEndpoint, as shown in Example 40.4, “DefaultPollingEndpoint Implementation”.
Example 40.4. DefaultPollingEndpoint Implementation
import org.apache.camel.Consumer; import org.apache.camel.Processor; import org.apache.camel.Producer; import org.apache.camel.ExchangePattern; import org.apache.camel.Message; import org.apache.camel.impl.DefaultPollingEndpoint; public class CustomEndpoint extends DefaultPollingEndpoint { ... public PollingConsumer createPollingConsumer() throws Exception { PollingConsumer result = new CustomConsumer(this); configureConsumer(result); return result; } // Do NOT implement createConsumer(). It is already implemented in DefaultPollingEndpoint. ... }
Because this CustomEndpoint class is a polling endpoint, you must implement the createPollingConsumer() method instead of the createConsumer() method. The consumer instance returned from createPollingConsumer() must inherit from the PollingConsumer interface. For details of how to implement a polling consumer, see the section called “Polling consumer implementation”.
Apart from the implementation of the createPollingConsumer() method, the steps for implementing a DefaultPollingEndpoint are similar to the steps for implementing a ScheduledPollEndpoint. See Example 40.3, “ScheduledPollEndpoint Implementation” for details.
Implementing the BrowsableEndpoint interface
If you want to expose the list of exchange instances that are pending in the current endpoint, you can implement the org.apache.camel.spi.BrowsableEndpoint interface, as shown in Example 40.5, “BrowsableEndpoint Interface”. It makes sense to implement this interface if the endpoint performs some sort of buffering of incoming events. For example, the Apache Camel SEDA endpoint implements the BrowsableEndpoint interface — see Example 40.6, “SedaEndpoint Implementation”.
Example 40.5. BrowsableEndpoint Interface
package org.apache.camel.spi;
import java.util.List;
import org.apache.camel.Endpoint;
import org.apache.camel.Exchange;
public interface BrowsableEndpoint extends Endpoint {
List<Exchange> getExchanges();
}Example
Example 40.6, “SedaEndpoint Implementation” shows a sample implementation of SedaEndpoint. The SEDA endpoint is an example of an event-driven endpoint. Incoming events are stored in a FIFO queue (an instance of java.util.concurrent.BlockingQueue) and a SEDA consumer starts up a thread to read and process the events. The events themselves are represented by org.apache.camel.Exchange objects.
Example 40.6. SedaEndpoint Implementation
package org.apache.camel.component.seda;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
import java.util.concurrent.BlockingQueue;
import org.apache.camel.Component;
import org.apache.camel.Consumer;
import org.apache.camel.Exchange;
import org.apache.camel.Processor;
import org.apache.camel.Producer;
import org.apache.camel.impl.DefaultEndpoint;
import org.apache.camel.spi.BrowsableEndpoint;
public class SedaEndpoint extends DefaultEndpoint implements BrowsableEndpoint { 1
private BlockingQueue<Exchange> queue;
public SedaEndpoint(String endpointUri, Component component, BlockingQueue<Exchange> queue) { 2
super(endpointUri, component);
this.queue = queue;
}
public SedaEndpoint(String uri, SedaComponent component, Map parameters) { 3
this(uri, component, component.createQueue(uri, parameters));
}
public Producer createProducer() throws Exception { 4
return new CollectionProducer(this, getQueue());
}
public Consumer createConsumer(Processor processor) throws Exception { 5
return new SedaConsumer(this, processor);
}
public BlockingQueue<Exchange> getQueue() { 6
return queue;
}
public boolean isSingleton() { 7
return true;
}
public List<Exchange> getExchanges() { 8
return new ArrayList<Exchange> getQueue());
}
}- 1
- The
SedaEndpointclass follows the pattern for implementing an event-driven endpoint by extending theDefaultEndpointclass. TheSedaEndpointclass also implements the BrowsableEndpoint interface, which provides access to the list of exchange objects in the queue. - 2
- Following the usual pattern for an event-driven consumer,
SedaEndpointdefines a constructor that takes an endpoint argument,endpointUri, and a component reference argument,component. - 3
- Another constructor is provided, which delegates queue creation to the parent component instance.
- 4
- The
createProducer()factory method creates an instance ofCollectionProducer, which is a producer implementation that adds events to the queue. - 5
- The
createConsumer()factory method creates an instance ofSedaConsumer, which is responsible for pulling events off the queue and processing them. - 6
- The
getQueue()method returns a reference to the queue. - 7
- The
isSingleton()method returnstrue, indicating that a single endpoint instance should be created for each unique URI string. - 8
- The
getExchanges()method implements the corresponding abstract method from BrowsableEndpoint.
Chapter 41. Consumer Interface
Abstract
This chapter describes how to implement the Consumer interface, which is an essential step in the implementation of a Apache Camel component.
41.1. The Consumer Interface
Overview
An instance of org.apache.camel.Consumer type represents a source endpoint in a route. There are several different ways of implementing a consumer (see Section 38.1.3, “Consumer Patterns and Threading”), and this degree of flexibility is reflected in the inheritance hierarchy ( see Figure 41.1, “Consumer Inheritance Hierarchy”), which includes several different base classes for implementing a consumer.
Figure 41.1. Consumer Inheritance Hierarchy
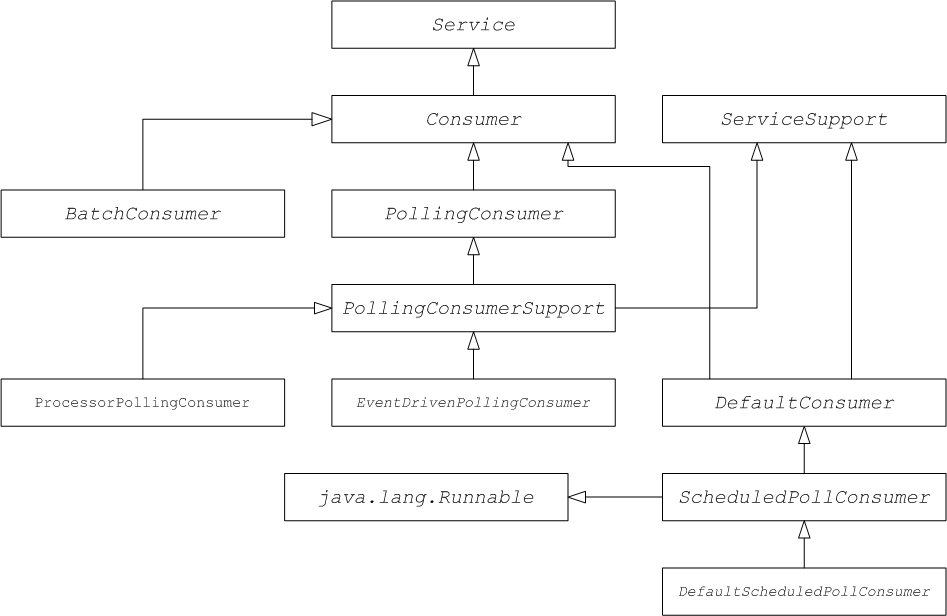
Consumer parameter injection
For consumers that follow the scheduled poll pattern (see the section called “Scheduled poll pattern”), Apache Camel provides support for injecting parameters into consumer instances. For example, consider the following endpoint URI for a component identified by the custom prefix:
custom:destination?consumer.myConsumerParam
Apache Camel provides support for automatically injecting query options of the form consumer.\*. For the consumer.myConsumerParam parameter, you need to define corresponding setter and getter methods on the Consumer implementation class as follows:
public class CustomConsumer extends ScheduledPollConsumer {
...
String getMyConsumerParam() { ... }
void setMyConsumerParam(String s) { ... }
...
}Where the getter and setter methods follow the usual Java bean conventions (including capitalizing the first letter of the property name).
In addition to defining the bean methods in your Consumer implementation, you must also remember to call the configureConsumer() method in the implementation of Endpoint.createConsumer(). See the section called “Scheduled poll endpoint implementation”). Example 41.1, “FileEndpoint createConsumer() Implementation” shows an example of a createConsumer() method implementation, taken from the FileEndpoint class in the file component:
Example 41.1. FileEndpoint createConsumer() Implementation
...
public class FileEndpoint extends ScheduledPollEndpoint {
...
public Consumer createConsumer(Processor processor) throws Exception {
Consumer result = new FileConsumer(this, processor);
configureConsumer(result);
return result;
}
...
}At run time, consumer parameter injection works as follows:
-
When the endpoint is created, the default implementation of
DefaultComponent.createEndpoint(String uri)parses the URI to extract the consumer parameters, and stores them in the endpoint instance by callingScheduledPollEndpoint.configureProperties(). -
When
createConsumer()is called, the method implementation callsconfigureConsumer()to inject the consumer parameters (see Example 41.1, “FileEndpoint createConsumer() Implementation”). -
The
configureConsumer()method uses Java reflection to call the setter methods whose names match the relevant options after theconsumer.prefix has been stripped off.
Scheduled poll parameters
A consumer that follows the scheduled poll pattern automatically supports the consumer parameters shown in Table 41.1, “Scheduled Poll Parameters” (which can appear as query options in the endpoint URI).
| Name | Default | Description |
|---|---|---|
|
|
| Delay, in milliseconds, before the first poll. |
|
|
|
Depends on the value of the |
|
|
|
If
If |
Converting between event-driven and polling consumers
Apache Camel provides two special consumer implementations which can be used to convert back and forth between an event-driven consumer and a polling consumer. The following conversion classes are provided:
-
org.apache.camel.impl.EventDrivenPollingConsumer— Converts an event-driven consumer into a polling consumer instance. -
org.apache.camel.impl.DefaultScheduledPollConsumer— Converts a polling consumer into an event-driven consumer instance.
In practice, these classes are used to simplify the task of implementing an Endpoint type. The Endpoint interface defines the following two methods for creating a consumer instance:
package org.apache.camel;
public interface Endpoint {
...
Consumer createConsumer(Processor processor) throws Exception;
PollingConsumer createPollingConsumer() throws Exception;
}
createConsumer() returns an event-driven consumer and createPollingConsumer() returns a polling consumer. You would only implement one these methods. For example, if you are following the event-driven pattern for your consumer, you would implement the createConsumer() method provide a method implementation for createPollingConsumer() that simply raises an exception. With the help of the conversion classes, however, Apache Camel is able to provide a more useful default implementation.
For example, if you want to implement your consumer according to the event-driven pattern, you implement the endpoint by extending DefaultEndpoint and implementing the createConsumer() method. The implementation of createPollingConsumer() is inherited from DefaultEndpoint, where it is defined as follows:
public PollingConsumer<E> createPollingConsumer() throws Exception {
return new EventDrivenPollingConsumer<E>(this);
}
The EventDrivenPollingConsumer constructor takes a reference to the event-driven consumer, this, effectively wrapping it and converting it into a polling consumer. To implement the conversion, the EventDrivenPollingConsumer instance buffers incoming events and makes them available on demand through the receive(), the receive(long timeout), and the receiveNoWait() methods.
Analogously, if you are implementing your consumer according to the polling pattern, you implement the endpoint by extending DefaultPollingEndpoint and implementing the createPollingConsumer() method. In this case, the implementation of the createConsumer() method is inherited from DefaultPollingEndpoint, and the default implementation returns a DefaultScheduledPollConsumer instance (which converts the polling consumer into an event-driven consumer).
ShutdownPrepared interface
Consumer classes can optionally implement the org.apache.camel.spi.ShutdownPrepared interface, which enables your custom consumer endpoint to receive shutdown notifications.
Example 41.2, “ShutdownPrepared Interface” shows the definition of the ShutdownPrepared interface.
Example 41.2. ShutdownPrepared Interface
package org.apache.camel.spi;
public interface ShutdownPrepared {
void prepareShutdown(boolean forced);
}
The ShutdownPrepared interface defines the following methods:
prepareShutdownReceives notifications to shut down the consumer endpoint in one or two phases, as follows:
-
Graceful shutdown — where the
forcedargument has the valuefalse. Attempt to clean up resources gracefully. For example, by stopping threads gracefully. -
Forced shutdown — where the
forcedargument has the valuetrue. This means that the shutdown has timed out, so you must clean up resources more aggressively. This is the last chance to clean up resources before the process exits.
-
Graceful shutdown — where the
ShutdownAware interface
Consumer classes can optionally implement the org.apache.camel.spi.ShutdownAware interface, which interacts with the graceful shutdown mechanism, enabling a consumer to ask for extra time to shut down. This is typically needed for components such as SEDA, which can have pending exchanges stored in an internal queue. Normally, you would want to process all of the exchanges in the queue before shutting down the SEDA consumer.
Example 41.3, “ShutdownAware Interface” shows the definition of the ShutdownAware interface.
Example 41.3. ShutdownAware Interface
// Java
package org.apache.camel.spi;
import org.apache.camel.ShutdownRunningTask;
public interface ShutdownAware extends ShutdownPrepared {
boolean deferShutdown(ShutdownRunningTask shutdownRunningTask);
int getPendingExchangesSize();
}
The ShutdownAware interface defines the following methods:
deferShutdownReturn
truefrom this method, if you want to delay shutdown of the consumer. TheshutdownRunningTaskargument is anenumwhich can take either of the following values:-
ShutdownRunningTask.CompleteCurrentTaskOnly— finish processing the exchanges that are currently being processed by the consumer’s thread pool, but do not attempt to process any more exchanges than that. -
ShutdownRunningTask.CompleteAllTasks— process all of the pending exchanges. For example, in the case of the SEDA component, the consumer would process all of the exchanges from its incoming queue.
-
getPendingExchangesSize- Indicates how many exchanges remain to be processed by the consumer. A zero value indicates that processing is finished and the consumer can be shut down.
For an example of how to define the ShutdownAware methods, see Example 41.7, “Custom Threading Implementation”.
41.2. Implementing the Consumer Interface
Alternative ways of implementing a consumer
You can implement a consumer in one of the following ways:
Event-driven consumer implementation
In an event-driven consumer, processing is driven explicitly by external events. The events are received through an event-listener interface, where the listener interface is specific to the particular event source.
Example 41.4, “JMXConsumer Implementation” shows the implementation of the JMXConsumer class, which is taken from the Apache Camel JMX component implementation. The JMXConsumer class is an example of an event-driven consumer, which is implemented by inheriting from the org.apache.camel.impl.DefaultConsumer class. In the case of the JMXConsumer example, events are represented by calls on the NotificationListener.handleNotification() method, which is a standard way of receiving JMX events. In order to receive these JMX events, it is necessary to implement the NotificationListener interface and override the handleNotification() method, as shown in Example 41.4, “JMXConsumer Implementation”.
Example 41.4. JMXConsumer Implementation
package org.apache.camel.component.jmx;
import javax.management.Notification;
import javax.management.NotificationListener;
import org.apache.camel.Processor;
import org.apache.camel.impl.DefaultConsumer;
public class JMXConsumer extends DefaultConsumer implements NotificationListener { 1
JMXEndpoint jmxEndpoint;
public JMXConsumer(JMXEndpoint endpoint, Processor processor) { 2
super(endpoint, processor);
this.jmxEndpoint = endpoint;
}
public void handleNotification(Notification notification, Object handback) { 3
try {
getProcessor().process(jmxEndpoint.createExchange(notification)); 4
} catch (Throwable e) {
handleException(e); 5
}
}
}- 1
- The
JMXConsumerpattern follows the usual pattern for event-driven consumers by extending theDefaultConsumerclass. Additionally, because this consumer is designed to receive events from JMX (which are represented by JMX notifications), it is necessary to implement theNotificationListenerinterface. - 2
- You must implement at least one constructor that takes a reference to the parent endpoint,
endpoint, and a reference to the next processor in the chain,processor, as arguments. - 3
- The
handleNotification()method (which is defined inNotificationListener) is automatically invoked by JMX whenever a JMX notification arrives. The body of this method should contain the code that performs the consumer’s event processing. Because thehandleNotification()call originates from the JMX layer, the consumer’s threading model is implicitly controlled by the JMX layer, not by theJMXConsumerclass. - 4
- This line of code combines two steps. First, the JMX notification object is converted into an exchange object, which is the generic representation of an event in Apache Camel. Then the newly created exchange object is passed to the next processor in the route (invoked synchronously).
- 5
- The
handleException()method is implemented by theDefaultConsumerbase class. By default, it handles exceptions using theorg.apache.camel.impl.LoggingExceptionHandlerclass.
The handleNotification() method is specific to the JMX example. When implementing your own event-driven consumer, you must identify an analogous event listener method to implement in your custom consumer.
Scheduled poll consumer implementation
In a scheduled poll consumer, polling events are automatically generated by a timer class, java.util.concurrent.ScheduledExecutorService. To receive the generated polling events, you must implement the ScheduledPollConsumer.poll() method (see Section 38.1.3, “Consumer Patterns and Threading”).
Example 41.5, “ScheduledPollConsumer Implementation” shows how to implement a consumer that follows the scheduled poll pattern, which is implemented by extending the ScheduledPollConsumer class.
Example 41.5. ScheduledPollConsumer Implementation
import java.util.concurrent.ScheduledExecutorService; import org.apache.camel.Consumer; import org.apache.camel.Endpoint; import org.apache.camel.Exchange; import org.apache.camel.Message; import org.apache.camel.PollingConsumer; import org.apache.camel.Processor; import org.apache.camel.impl.ScheduledPollConsumer; public class pass:quotes[CustomConsumer] extends ScheduledPollConsumer { 1 private final pass:quotes[CustomEndpoint] endpoint; public pass:quotes[CustomConsumer](pass:quotes[CustomEndpoint] endpoint, Processor processor) { 2 super(endpoint, processor); this.endpoint = endpoint; } protected void poll() throws Exception { 3 Exchange exchange = /* Receive exchange object ... */; // Example of a synchronous processor. getProcessor().process(exchange); 4 } @Override protected void doStart() throws Exception { 5 // Pre-Start: // Place code here to execute just before start of processing. super.doStart(); // Post-Start: // Place code here to execute just after start of processing. } @Override protected void doStop() throws Exception { 6 // Pre-Stop: // Place code here to execute just before processing stops. super.doStop(); // Post-Stop: // Place code here to execute just after processing stops. } }
- 1
- Implement a scheduled poll consumer class, CustomConsumer, by extending the
org.apache.camel.impl.ScheduledPollConsumerclass. - 2
- You must implement at least one constructor that takes a reference to the parent endpoint,
endpoint, and a reference to the next processor in the chain,processor, as arguments. - 3
- Override the
poll()method to receive the scheduled polling events. This is where you should put the code that retrieves and processes incoming events (represented by exchange objects). - 4
- In this example, the event is processed synchronously. If you want to process events asynchronously, you should use a reference to an asynchronous processor instead, by calling
getAsyncProcessor(). For details of how to process events asynchronously, see Section 38.1.4, “Asynchronous Processing”. - 5
- (Optional) If you want some lines of code to execute as the consumer is starting up, override the
doStart()method as shown. - 6
- (Optional) If you want some lines of code to execute as the consumer is stopping, override the
doStop()method as shown.
Polling consumer implementation
Example 41.6, “PollingConsumerSupport Implementation” outlines how to implement a consumer that follows the polling pattern, which is implemented by extending the PollingConsumerSupport class.
Example 41.6. PollingConsumerSupport Implementation
import org.apache.camel.Exchange; import org.apache.camel.RuntimeCamelException; import org.apache.camel.impl.PollingConsumerSupport; public class pass:quotes[CustomConsumer] extends PollingConsumerSupport { 1 private final pass:quotes[CustomEndpoint] endpoint; public pass:quotes[CustomConsumer](pass:quotes[CustomEndpoint] endpoint) { 2 super(endpoint); this.endpoint = endpoint; } public Exchange receiveNoWait() { 3 Exchange exchange = /* Obtain an exchange object. */; // Further processing ... return exchange; } public Exchange receive() { 4 // Blocking poll ... } public Exchange receive(long timeout) { 5 // Poll with timeout ... } protected void doStart() throws Exception { 6 // Code to execute whilst starting up. } protected void doStop() throws Exception { // Code to execute whilst shutting down. } }
- 1
- Implement your polling consumer class, CustomConsumer, by extending the
org.apache.camel.impl.PollingConsumerSupportclass. - 2
- You must implement at least one constructor that takes a reference to the parent endpoint,
endpoint, as an argument. A polling consumer does not need a reference to a processor instance. - 3
- The
receiveNoWait()method should implement a non-blocking algorithm for retrieving an event (exchange object). If no event is available, it should returnnull. - 4
- The
receive()method should implement a blocking algorithm for retrieving an event. This method can block indefinitely, if events remain unavailable. - 5
- The
receive(long timeout)method implements an algorithm that can block for as long as the specified timeout (typically specified in units of milliseconds). - 6
- If you want to insert code that executes while a consumer is starting up or shutting down, implement the
doStart()method and thedoStop()method, respectively.
Custom threading implementation
If the standard consumer patterns are not suitable for your consumer implementation, you can implement the Consumer interface directly and write the threading code yourself. When writing the threading code, however, it is important that you comply with the standard Apache Camel threading model, as described in Section 2.8, “Threading Model”.
For example, the SEDA component from camel-core implements its own consumer threading, which is consistent with the Apache Camel threading model. Example 41.7, “Custom Threading Implementation” shows an outline of how the SedaConsumer class implements its threading.
Example 41.7. Custom Threading Implementation
package org.apache.camel.component.seda;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.TimeUnit;
import org.apache.camel.Consumer;
import org.apache.camel.Endpoint;
import org.apache.camel.Exchange;
import org.apache.camel.Processor;
import org.apache.camel.ShutdownRunningTask;
import org.apache.camel.impl.LoggingExceptionHandler;
import org.apache.camel.impl.ServiceSupport;
import org.apache.camel.util.ServiceHelper;
...
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
/**
* A Consumer for the SEDA component.
*
* @version $Revision: 922485 $
*/
public class SedaConsumer extends ServiceSupport implements Consumer, Runnable, ShutdownAware { 1
private static final transient Log LOG = LogFactory.getLog(SedaConsumer.class);
private SedaEndpoint endpoint;
private Processor processor;
private ExecutorService executor;
...
public SedaConsumer(SedaEndpoint endpoint, Processor processor) {
this.endpoint = endpoint;
this.processor = processor;
}
...
public void run() { 2
BlockingQueue<Exchange> queue = endpoint.getQueue();
// Poll the queue and process exchanges
...
}
...
protected void doStart() throws Exception { 3
int poolSize = endpoint.getConcurrentConsumers();
executor = endpoint.getCamelContext().getExecutorServiceStrategy()
.newFixedThreadPool(this, endpoint.getEndpointUri(), poolSize); 4
for (int i = 0; i < poolSize; i++) { 5
executor.execute(this);
}
endpoint.onStarted(this);
}
protected void doStop() throws Exception { 6
endpoint.onStopped(this);
// must shutdown executor on stop to avoid overhead of having them running
endpoint.getCamelContext().getExecutorServiceStrategy().shutdownNow(executor); 7
if (multicast != null) {
ServiceHelper.stopServices(multicast);
}
}
...
//----------
// Implementation of ShutdownAware interface
public boolean deferShutdown(ShutdownRunningTask shutdownRunningTask) {
// deny stopping on shutdown as we want seda consumers to run in case some other queues
// depend on this consumer to run, so it can complete its exchanges
return true;
}
public int getPendingExchangesSize() {
// number of pending messages on the queue
return endpoint.getQueue().size();
}
}- 1
- The
SedaConsumerclass is implemented by extending theorg.apache.camel.impl.ServiceSupportclass and implementing theConsumer,Runnable, andShutdownAwareinterfaces. - 2
- Implement the
Runnable.run()method to define what the consumer does while it is running in a thread. In this case, the consumer runs in a loop, polling the queue for new exchanges and then processing the exchanges in the latter part of the queue. - 3
- The
doStart()method is inherited fromServiceSupport. You override this method in order to define what the consumer does when it starts up. - 4
- Instead of creating threads directly, you should create a thread pool using the
ExecutorServiceStrategyobject that is registered with theCamelContext. This is important, because it enables Apache Camel to implement centralized management of threads and support such features as graceful shutdown. For details, see Section 2.8, “Threading Model”. - 5
- Kick off the threads by calling the
ExecutorService.execute()methodpoolSizetimes. - 6
- The
doStop()method is inherited fromServiceSupport. You override this method in order to define what the consumer does when it shuts down. - 7
- Shut down the thread pool, which is represented by the
executorinstance.
Chapter 42. Producer Interface
Abstract
This chapter describes how to implement the Producer interface, which is an essential step in the implementation of a Apache Camel component.
42.1. The Producer Interface
Overview
An instance of org.apache.camel.Producer type represents a target endpoint in a route. The role of the producer is to send requests (In messages) to a specific physical endpoint and to receive the corresponding response (Out or Fault message). A Producer object is essentially a special kind of Processor that appears at the end of a processor chain (equivalent to a route). Figure 42.1, “Producer Inheritance Hierarchy” shows the inheritance hierarchy for producers.
Figure 42.1. Producer Inheritance Hierarchy
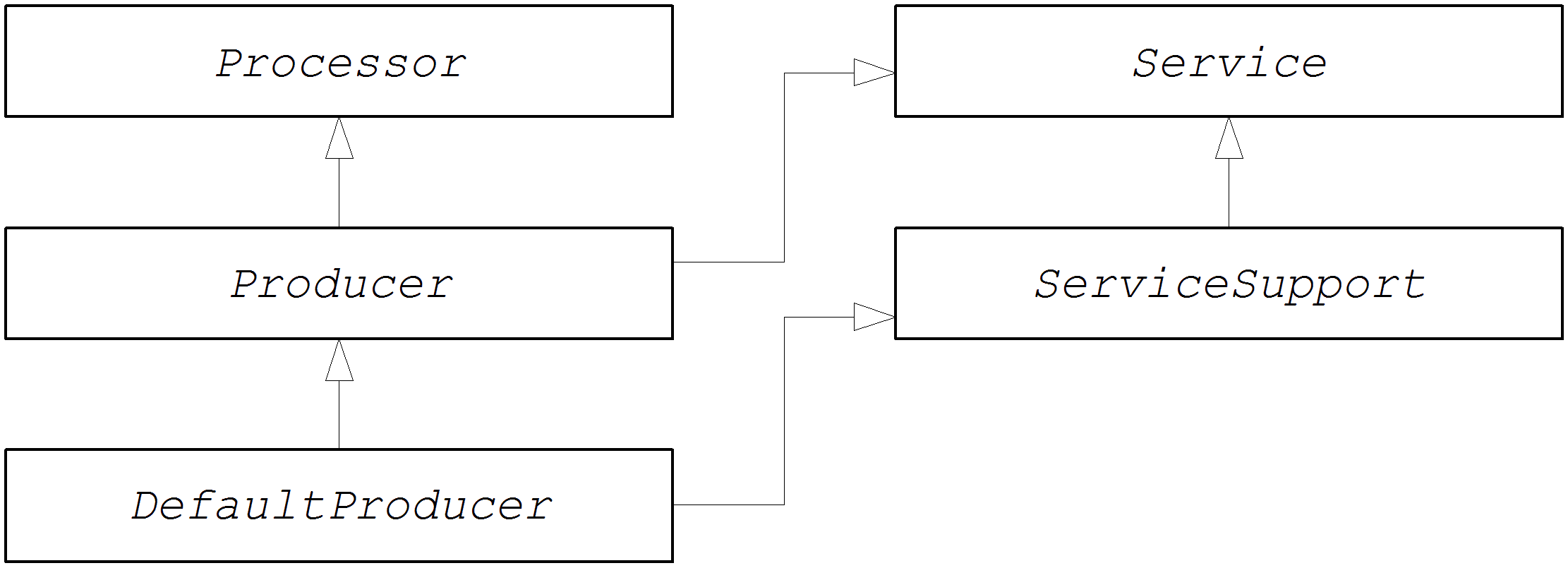
The Producer interface
Example 42.1, “Producer Interface” shows the definition of the org.apache.camel.Producer interface.
Example 42.1. Producer Interface
package org.apache.camel;
public interface Producer extends Processor, Service, IsSingleton {
Endpoint<E> getEndpoint();
Exchange createExchange();
Exchange createExchange(ExchangePattern pattern);
Exchange createExchange(E exchange);
}Producer methods
The Producer interface defines the following methods:
-
process()(inherited from Processor) — The most important method. A producer is essentially a special type of processor that sends a request to an endpoint, instead of forwarding the exchange object to another processor. By overriding theprocess()method, you define how the producer sends and receives messages to and from the relevant endpoint. -
getEndpoint()— Returns a reference to the parent endpoint instance. -
createExchange()— These overloaded methods are analogous to the corresponding methods defined in the Endpoint interface. Normally, these methods delegate to the corresponding methods defined on the parent Endpoint instance (this is what theDefaultEndpointclass does by default). Occasionally, you might need to override these methods.
Asynchronous processing
Processing an exchange object in a producer — which usually involves sending a message to a remote destination and waiting for a reply — can potentially block for a significant length of time. If you want to avoid blocking the current thread, you can opt to implement the producer as an asynchronous processor. The asynchronous processing pattern decouples the preceding processor from the producer, so that the process() method returns without delay. See Section 38.1.4, “Asynchronous Processing”.
When implementing a producer, you can support the asynchronous processing model by implementing the org.apache.camel.AsyncProcessor interface. On its own, this is not enough to ensure that the asynchronous processing model will be used: it is also necessary for the preceding processor in the chain to call the asynchronous version of the process() method. The definition of the AsyncProcessor interface is shown in Example 42.2, “AsyncProcessor Interface”.
Example 42.2. AsyncProcessor Interface
package org.apache.camel;
public interface AsyncProcessor extends Processor {
boolean process(Exchange exchange, AsyncCallback callback);
}
The asynchronous version of the process() method takes an extra argument, callback, of org.apache.camel.AsyncCallback type. The corresponding AsyncCallback interface is defined as shown in Example 42.3, “AsyncCallback Interface”.
Example 42.3. AsyncCallback Interface
package org.apache.camel;
public interface AsyncCallback {
void done(boolean doneSynchronously);
}
The caller of AsyncProcessor.process() must provide an implementation of AsyncCallback to receive the notification that processing has finished. The AsyncCallback.done() method takes a boolean argument that indicates whether the processing was performed synchronously or not. Normally, the flag would be false, to indicate asynchronous processing. In some cases, however, it can make sense for the producer not to process asynchronously (in spite of being asked to do so). For example, if the producer knows that the processing of the exchange will complete rapidly, it could optimise the processing by doing it synchronously. In this case, the doneSynchronously flag should be set to true.
ExchangeHelper class
When implementing a producer, you might find it helpful to call some of the methods in the org.apache.camel.util.ExchangeHelper utility class. For full details of the ExchangeHelper class, see Section 35.4, “The ExchangeHelper Class”.
42.2. Implementing the Producer Interface
Alternative ways of implementing a producer
You can implement a producer in one of the following ways:
How to implement a synchronous producer
Example 42.4, “DefaultProducer Implementation” outlines how to implement a synchronous producer. In this case, call to Producer.process() blocks until a reply is received.
Example 42.4. DefaultProducer Implementation
import org.apache.camel.Endpoint; import org.apache.camel.Exchange; import org.apache.camel.Producer; import org.apache.camel.impl.DefaultProducer; public class CustomProducer extends DefaultProducer { 1 public CustomProducer(Endpoint endpoint) { 2 super(endpoint); // Perform other initialization tasks... } public void process(Exchange exchange) throws Exception { 3 // Process exchange synchronously. // ... } }
- 1
- Implement a custom synchronous producer class, CustomProducer, by extending the
org.apache.camel.impl.DefaultProducerclass. - 2
- Implement a constructor that takes a reference to the parent endpoint.
- 3
- The
process()method implementation represents the core of the producer code. The implementation of theprocess()method is entirely dependent on the type of component that you are implementing.
In outline, the process() method is normally implemented as follows:
- If the exchange contains an In message, and if this is consistent with the specified exchange pattern, then send the In message to the designated endpoint.
-
If the exchange pattern anticipates the receipt of an Out message, then wait until the Out message has been received. This typically causes the
process()method to block for a significant length of time. -
When a reply is received, call
exchange.setOut()to attach the reply to the exchange object. If the reply contains a fault message, set the fault flag on the Out message usingMessage.setFault(true).
How to implement an asynchronous producer
Example 42.5, “CollectionProducer Implementation” outlines how to implement an asynchronous producer. In this case, you must implement both a synchronous process() method and an asynchronous process() method (which takes an additional AsyncCallback argument).
Example 42.5. CollectionProducer Implementation
import org.apache.camel.AsyncCallback;
import org.apache.camel.AsyncProcessor;
import org.apache.camel.Endpoint;
import org.apache.camel.Exchange;
import org.apache.camel.Producer;
import org.apache.camel.impl.DefaultProducer;
public class _CustomProducer_ extends DefaultProducer implements AsyncProcessor { 1
public _CustomProducer_(Endpoint endpoint) { 2
super(endpoint);
// ...
}
public void process(Exchange exchange) throws Exception { 3
// Process exchange synchronously.
// ...
}
public boolean process(Exchange exchange, AsyncCallback callback) { 4
// Process exchange asynchronously.
CustomProducerTask task = new CustomProducerTask(exchange, callback);
// Process 'task' in a separate thread...
// ...
return false; 5
}
}
public class CustomProducerTask implements Runnable { 6
private Exchange exchange;
private AsyncCallback callback;
public CustomProducerTask(Exchange exchange, AsyncCallback callback) {
this.exchange = exchange;
this.callback = callback;
}
public void run() { 7
// Process exchange.
// ...
callback.done(false);
}
}- 1
- Implement a custom asynchronous producer class, CustomProducer, by extending the
org.apache.camel.impl.DefaultProducerclass, and implementing the AsyncProcessor interface. - 2
- Implement a constructor that takes a reference to the parent endpoint.
- 3
- Implement the synchronous
process()method. - 4
- Implement the asynchronous
process()method. You can implement the asynchronous method in several ways. The approach shown here is to create ajava.lang.Runnableinstance,task, that represents the code that runs in a sub-thread. You then use the Java threading API to run the task in a sub-thread (for example, by creating a new thread or by allocating the task to an existing thread pool). - 5
- Normally, you return
falsefrom the asynchronousprocess()method, to indicate that the exchange was processed asynchronously. - 6
- The
CustomProducerTaskclass encapsulates the processing code that runs in a sub-thread. This class must store a copy of theExchangeobject,exchange, and theAsyncCallbackobject,callback, as private member variables. - 7
- The
run()method contains the code that sends the In message to the producer endpoint and waits to receive the reply, if any. After receiving the reply (Out message or Fault message) and inserting it into the exchange object, you must callcallback.done()to notify the caller that processing is complete.
Chapter 43. Exchange Interface
Abstract
This chapter describes the Exchange interface. Since the refactoring of the camel-core module performed in Apache Camel 2.0, there is no longer any necessity to define custom exchange types. The DefaultExchange implementation can now be used in all cases.
43.1. The Exchange Interface
Overview
An instance of org.apache.camel.Exchange type encapsulates the current message passing through a route, with additional metadata encoded as exchange properties.
Figure 43.1, “Exchange Inheritance Hierarchy” shows the inheritance hierarchy for the exchange type. The default implementation, DefaultExchange, is always used.
Figure 43.1. Exchange Inheritance Hierarchy
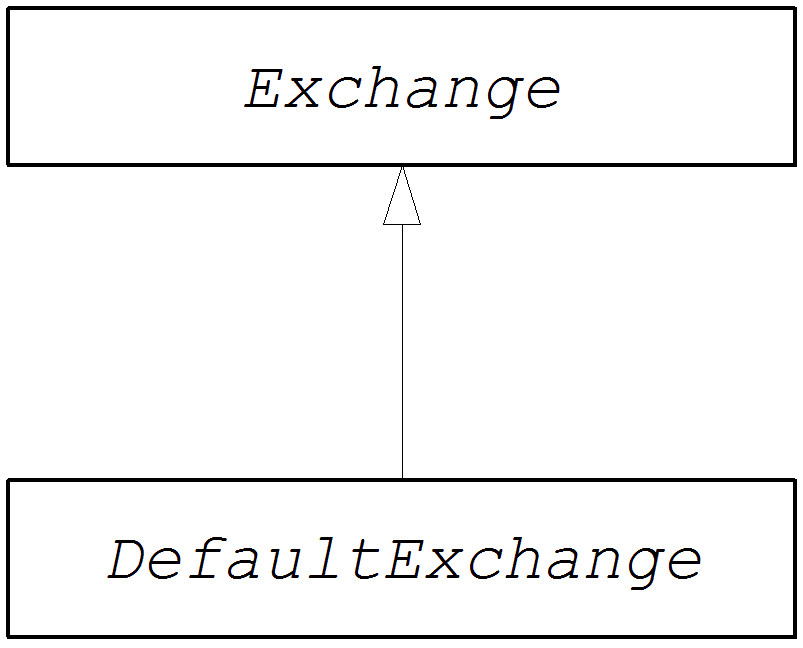
The Exchange interface
Example 43.1, “Exchange Interface” shows the definition of the org.apache.camel.Exchange interface.
Example 43.1. Exchange Interface
package org.apache.camel;
import java.util.Map;
import org.apache.camel.spi.Synchronization;
import org.apache.camel.spi.UnitOfWork;
public interface Exchange {
// Exchange property names (string constants)
// (Not shown here)
...
ExchangePattern getPattern();
void setPattern(ExchangePattern pattern);
Object getProperty(String name);
Object getProperty(String name, Object defaultValue);
<T> T getProperty(String name, Class<T> type);
<T> T getProperty(String name, Object defaultValue, Class<T> type);
void setProperty(String name, Object value);
Object removeProperty(String name);
Map<String, Object> getProperties();
boolean hasProperties();
Message getIn();
<T> T getIn(Class<T> type);
void setIn(Message in);
Message getOut();
<T> T getOut(Class<T> type);
void setOut(Message out);
boolean hasOut();
Throwable getException();
<T> T getException(Class<T> type);
void setException(Throwable e);
boolean isFailed();
boolean isTransacted();
boolean isRollbackOnly();
CamelContext getContext();
Exchange copy();
Endpoint getFromEndpoint();
void setFromEndpoint(Endpoint fromEndpoint);
String getFromRouteId();
void setFromRouteId(String fromRouteId);
UnitOfWork getUnitOfWork();
void setUnitOfWork(UnitOfWork unitOfWork);
String getExchangeId();
void setExchangeId(String id);
void addOnCompletion(Synchronization onCompletion);
void handoverCompletions(Exchange target);
}Exchange methods
The Exchange interface defines the following methods:
getPattern(),setPattern()— The exchange pattern can be one of the values enumerated inorg.apache.camel.ExchangePattern. The following exchange pattern values are supported:-
InOnly -
RobustInOnly -
InOut -
InOptionalOut -
OutOnly -
RobustOutOnly -
OutIn -
OutOptionalIn
-
-
setProperty(),getProperty(),getProperties(),removeProperty(),hasProperties()— Use the property setter and getter methods to associate named properties with the exchange instance. The properties consist of miscellaneous metadata that you might need for your component implementation. setIn(),getIn()— Setter and getter methods for the In message.The
getIn()implementation provided by theDefaultExchangeclass implements lazy creation semantics: if the In message is null whengetIn()is called, theDefaultExchangeclass creates a default In message.setOut(),getOut(),hasOut()— Setter and getter methods for the Out message.The
getOut()method implicitly supports lazy creation of an Out message. That is, if the current Out message isnull, a new message instance is automatically created.-
setException(),getException()— Getter and setter methods for an exception object (ofThrowabletype). -
isFailed()— Returnstrue, if the exchange failed either due to an exception or due to a fault. -
isTransacted()— Returnstrue, if the exchange is transacted. -
isRollback()— Returnstrue, if the exchange is marked for rollback. -
getContext()— Returns a reference to the associatedCamelContextinstance. -
copy()— Creates a new, identical (apart from the exchange ID) copy of the current custom exchange object. The body and headers of the In message, the Out message (if any), and the Fault message (if any) are also copied by this operation. -
setFromEndpoint(),getFromEndpoint()— Getter and setter methods for the consumer endpoint that orginated this message (which is typically the endpoint appearing in thefrom()DSL command at the start of a route). -
setFromRouteId(),getFromRouteId()— Getters and setters for the route ID that originated this exchange. ThegetFromRouteId()method should only be called internally. -
setUnitOfWork(),getUnitOfWork()— Getter and setter methods for theorg.apache.camel.spi.UnitOfWorkbean property. This property is only required for exchanges that can participate in a transaction. -
setExchangeId(),getExchangeId()— Getter and setter methods for the exchange ID. Whether or not a custom component uses and exchange ID is an implementation detail. -
addOnCompletion()— Adds anorg.apache.camel.spi.Synchronizationcallback object, which gets called when processing of the exchange has completed. -
handoverCompletions()— Hands over all of the OnCompletion callback objects to the specified exchange object.
Chapter 44. Message Interface
Abstract
This chapter describes how to implement the Message interface, which is an optional step in the implementation of a Apache Camel component.
44.1. The Message Interface
Overview
An instance of org.apache.camel.Message type can represent any kind of message (In or Out). Figure 44.1, “Message Inheritance Hierarchy” shows the inheritance hierarchy for the message type. You do not always need to implement a custom message type for a component. In many cases, the default implementation, DefaultMessage, is adequate.
Figure 44.1. Message Inheritance Hierarchy
The Message interface
Example 44.1, “Message Interface” shows the definition of the org.apache.camel.Message interface.
Example 44.1. Message Interface
package org.apache.camel;
import java.util.Map;
import java.util.Set;
import javax.activation.DataHandler;
public interface Message {
String getMessageId();
void setMessageId(String messageId);
Exchange getExchange();
boolean isFault();
void setFault(boolean fault);
Object getHeader(String name);
Object getHeader(String name, Object defaultValue);
<T> T getHeader(String name, Class<T> type);
<T> T getHeader(String name, Object defaultValue, Class<T> type);
Map<String, Object> getHeaders();
void setHeader(String name, Object value);
void setHeaders(Map<String, Object> headers);
Object removeHeader(String name);
boolean removeHeaders(String pattern);
boolean hasHeaders();
Object getBody();
Object getMandatoryBody() throws InvalidPayloadException;
<T> T getBody(Class<T> type);
<T> T getMandatoryBody(Class<T> type) throws InvalidPayloadException;
void setBody(Object body);
<T> void setBody(Object body, Class<T> type);
DataHandler getAttachment(String id);
Map<String, DataHandler> getAttachments();
Set<String> getAttachmentNames();
void removeAttachment(String id);
void addAttachment(String id, DataHandler content);
void setAttachments(Map<String, DataHandler> attachments);
boolean hasAttachments();
Message copy();
void copyFrom(Message message);
String createExchangeId();
}Message methods
The Message interface defines the following methods:
-
setMessageId(),getMessageId()— Getter and setter methods for the message ID. Whether or not you need to use a message ID in your custom component is an implementation detail. -
getExchange()— Returns a reference to the parent exchange object. -
isFault(),setFault()— Getter and setter methods for the fault flag, which indicates whether or not this message is a fault message. -
getHeader(),getHeaders(),setHeader(),setHeaders(),removeHeader(),hasHeaders()— Getter and setter methods for the message headers. In general, these message headers can be used either to store actual header data, or to store miscellaneous metadata. -
getBody(),getMandatoryBody(),setBody()— Getter and setter methods for the message body. The getMandatoryBody() accessor guarantees that the returned body is non-null, otherwise theInvalidPayloadExceptionexception is thrown. -
getAttachment(),getAttachments(),getAttachmentNames(),removeAttachment(),addAttachment(),setAttachments(),hasAttachments()— Methods to get, set, add, and remove attachments. -
copy()— Creates a new, identical (including the message ID) copy of the current custom message object. -
copyFrom()— Copies the complete contents (including the message ID) of the specified generic message object,message, into the current message instance. Because this method must be able to copy from any message type, it copies the generic message properties, but not the custom properties. -
createExchangeId()— Returns the unique ID for this exchange, if the message implementation is capable of providing an ID; otherwise, returnnull.
44.2. Implementing the Message Interface
How to implement a custom message
Example 44.2, “Custom Message Implementation” outlines how to implement a message by extending the DefaultMessage class.
Example 44.2. Custom Message Implementation
import org.apache.camel.Exchange; import org.apache.camel.impl.DefaultMessage; public class CustomMessage extends DefaultMessage { 1 public CustomMessage() { 2 // Create message with default properties... } @Override public String toString() { 3 // Return a stringified message... } @Override public CustomMessage newInstance() { 4 return new CustomMessage( ... ); } @Override protected Object createBody() { 5 // Return message body (lazy creation). } @Override protected void populateInitialHeaders(Map<String, Object> map) { 6 // Initialize headers from underlying message (lazy creation). } @Override protected void populateInitialAttachments(Map<String, DataHandler> map) { 7 // Initialize attachments from underlying message (lazy creation). } }
- 1
- Implements a custom message class, CustomMessage, by extending the
org.apache.camel.impl.DefaultMessageclass. - 2
- Typically, you need a default constructor that creates a message with default properties.
- 3
- Override the
toString()method to customize message stringification. - 4
- The
newInstance()method is called from inside theMessageSupport.copy()method. Customization of thenewInstance()method should focus on copying all of the custom properties of the current message instance into the new message instance. TheMessageSupport.copy()method copies the generic message properties by callingcopyFrom(). - 5
- The
createBody()method works in conjunction with theMessageSupport.getBody()method to implement lazy access to the message body. By default, the message body isnull. It is only when the application code tries to access the body (by callinggetBody()), that the body should be created. TheMessageSupport.getBody()automatically callscreateBody(), when the message body is accessed for the first time. - 6
- The
populateInitialHeaders()method works in conjunction with the header getter and setter methods to implement lazy access to the message headers. This method parses the message to extract any message headers and inserts them into the hash map,map. ThepopulateInitialHeaders()method is automatically called when a user attempts to access a header (or headers) for the first time (by callinggetHeader(),getHeaders(),setHeader(), orsetHeaders()). - 7
- The
populateInitialAttachments()method works in conjunction with the attachment getter and setter methods to implement lazy access to the attachments. This method extracts the message attachments and inserts them into the hash map,map. ThepopulateInitialAttachments()method is automatically called when a user attempts to access an attachment (or attachments) for the first time by callinggetAttachment(),getAttachments(),getAttachmentNames(), oraddAttachment().
Part IV. The API Component Framework
How to create a Camel component that wraps any Java API, using the API Component Framework.
Chapter 45. Introduction to the API Component Framework
Abstract
The API component framework helps you with the challenge of implementing complex Camel components based on a large Java API.
45.1. What is the API Component Framework?
Motivation
For components with a small number of options, the standard approach to implementing components (Chapter 38, Implementing a Component) is quite effective. Where it starts to become problematic, however, is when you need to implement a component with a large number of options. This problem becomes dramatic when it comes to enterprise-level components, which can require you to wrap an API consisting of hundreds of operations. Such components require a large effort to create and maintain.
The API component framework was developed precisely to deal with the challenge of implementing such components.
Turning APIs into components
Experience of implementing Camel components based on Java APIs has shown that a lot of the work is routine and mechanical. It consists of taking a particular Java method, mapping it to a particular URI syntax, and enabling the user to set the method parameters through URI options. This type of work is an obvious candidate for automation and code generation.
Generic URI format
The first step in automating the implementation of a Java API is to design a standard way of mapping an API method to a URI. For this we need to define a generic URI format, which can be used to wrap any Java API. Hence, the API component framework defines the following syntax for endpoint URIs:
scheme://endpoint-prefix/endpoint?Option1=Value1&...&OptionN=ValueN
Where scheme is the default URI scheme defined by the component; endpoint-prefix is a short API name, which maps to one of the classes or interfaces from the wrapped Java API; endpoint maps to a method name; and the URI options map to method argument names.
URI format for a single API class
In the case where an API consists of just a single Java class, the endpoint-prefix part of the URI becomes redundant, and you can specify the URI in the following, shorter format:
scheme://endpoint?Option1=Value1&...&OptionN=ValueN
To enable this URI format, it is also necessary for the component implementor to leave the apiName element blank in the configuration of the API component Maven plug-in. For more information, see the the section called “Configuring the API mapping” section.
Reflection and metadata
In order to map Java method invocations to a URI syntax, it is obvious that some form of reflection mechanism is needed. But the standard Java reflection API suffers from a notable limitation: it does not preserve method argument names. This is a problem, because we need the method argument names in order to generate meaningful URI option names. The solution is to provide metadata in alternative format: either as Javadoc or in method signature files.
Javadoc
Javadoc is an ideal form of metadata for the API component framework, because it preserves the complete method signature, including method argument names. It is also easy to generate (particularly, using maven-javadoc-plugin) and, in many cases, is already provided in a third-party library.
Method signature files
If Javadoc is unavailable or unsuitable for some reason, the API component framework also supports an alternative source of metadata: the method signature files. A signature file is a simple text file which consists of a list of Java method signatures. It is relatively easy to create these files manually by copying and pasting from Java code (and lightly editing the resulting files).
What does the framework consist of?
From the perspective of a component developer, the API component framework consists of a number of different elements, as follows:
- A Maven archetype
-
The
camel-archetype-api-componentMaven archetype is used to generate skeleton code for the component implementation. - A Maven plug-in
-
The
camel-api-component-maven-pluginMaven plug-in is responsible for generating the code that implements the mapping between the Java API and the endpoint URI syntax. - Specialized base classes
-
To support the programming model of the API component framework, the Apache Camel core provides a specialized API in the
org.apache.camel.util.componentpackage. Amongst other things, this API provides specialized base classes for the component, endpoint, consumer, and producer classes.
45.2. How to use the Framework
Overview
The procedure for implementing a component using the API framework involve a mixture of automated code generation, implementing Java code, and customizing the build, by editing Maven POM files. The following figure gives an overview of this development process.
Figure 45.1. Using the API Component Framework
Java API
The starting point for your API component is always a Java API. Generally speaking, in the context of Camel, this usually means a Java client API, which connects to a remote server endpoint. The first question is, where does the Java API come from? Here are a few possibilities:
- Implement the Java API yourself (though this typically would involve a lot of work and is generally not the preferred approach).
- Use a third-party Java API. For example, the Apache Camel Box component is based on the third-party Box Java SDK library.
-
Generate the Java API from a language-neutral interface. For example, the Apache Camel LinkedIn component obtains its Java API by converting a WADL description of its REST services to Java (using the Apache CXF
wadl2javatool).
Javadoc metadata
You have the option of providing metadata for the Java API in the form of Javadoc (which is needed for generating code in the API component framework). If you use a third-party Java API from a Maven repository, you will usually find that the Javadoc is already provided in the Maven artifact. But even in the cases where Javadoc is not provided, you can easily generate it, using the maven-javadoc-plugin Maven plug-in.
Currently, there is a limitation in the processing of Javadoc metadata, such that generic nesting is not supported. For example, java.util.List<String> is supported, but java.util.List<java.util.List<String>> is not. The workaround is to specify the nested generic type as java.util.List<java.util.List> in a signature file.
Signature file metadata
If for some reason it is not convenient to provide Java API metadata in the form of Javadoc, you have the option of providing metadata in the form of signature files. The signature files consist of a list of method signatures (one method signature per line). These files can be created manually and are needed only at build time.
Note the following points about signature files:
- You must create one signature file for each proxy class (Java API class).
-
The method signatures should not throw an exception. All exceptions raised at runtime are wrapped in a
RuntimeCamelExceptionand returned from the endpoint. -
Class names that specify the type of an argument must be fully-qualified class names (except for the
java.lang.\*types). There is no mechanism for importing package names. -
Currently, there is a limitation in the signature parser, such that generic nesting is not supported. For example,
java.util.List<String>is supported, whereasjava.util.List<java.util.List<String>>is not. The workaround is to specify the nested generic type asjava.util.List<java.util.List>.
The following shows a simple example of the contents of a signature file:
public String sayHi(); public String greetMe(String name); public String greetUs(String name1, String name2);
Generate starting code with the Maven archetype
The easiest way to get started developing an API component is to generate an initial Maven project using the camel-archetype-api-component Maven archetype. For details of how to run the archetype, see Section 46.1, “Generate Code with the Maven Archetype”.
After you run the Maven archetype, you will find two sub-projects under the generated ProjectName directory:
ProjectName-api- This project contains the Java API, which forms the basis of the API component. When you build this project, it packages up the Java API in a Maven bundle and generates the requisite Javadoc as well. If the Java API and Javadoc are already provided by a third-party, however, you do not need this sub-project.
ProjectName-component- This project contains the skeleton code for the API component.
Edit component classes
You can edit the skeleton code in ProjectName-component to develop your own component implementation. The following generated classes make up the core of the skeleton implementation:
ComponentNameComponent ComponentNameEndpoint ComponentNameConsumer ComponentNameProducer ComponentNameConfiguration
Customize POM files
You also need to edit the Maven POM files to customize the build, and to configure the camel-api-component-maven-plugin Maven plug-in.
Configure the camel-api-component-maven-plugin
The most important aspect of configuring the POM files is the configuration of the camel-api-component-maven-plugin Maven plug-in. This plug-in is responsible for generating the mapping between API methods and endpoint URIs, and by editing the plug-in configuration, you can customize the mapping.
For example, in the ProjectName-component/pom.xml file, the following camel-api-component-maven-plugin plug-in configuration shows a minimal configuration for an API class called ExampleJavadocHello.
<configuration>
<apis>
<api>
<apiName>hello-javadoc</apiName>
<proxyClass>org.jboss.fuse.example.api.ExampleJavadocHello</proxyClass>
<fromJavadoc/>
</api>
</apis>
</configuration>
In this example, the hello-javadoc API name is mapped to the ExampleJavadocHello class, which means you can invoke methods from this class using URIs of the form, scheme://hello-javadoc/endpoint. The presence of the fromJavadoc element indicates that the ExampleJavadocHello class gets its metadata from Javadoc.
OSGi bundle configuration
The sample POM for the component sub-project, ProjectName-component/pom.xml, is configured to package the component as an OSGi bundle. The component POM includes a sample configuration of the maven-bundle-plugin. You should customize the configuration of the maven-bundle-plugin plug-in, to ensure that Maven generates a properly configured OSGi bundle for your component.
Build the component
When you build the component with Maven (for example, by using mvn clean package), the camel-api-component-maven-plugin plug-in automatically generates the API mapping classes (which define the mapping between the Java API and the endpoint URI syntax), placing them into the target/classes project subdirectory. When you are dealing with a large and complex Java API, this generated code actually constitutes the bulk of the component source code.
When the Maven build completes, the compiled code and resources are packaged up as an OSGi bundle and stored in your local Maven repository as a Maven artifact.
Chapter 46. Getting Started with the Framework
Abstract
This chapter explains the basic principles of implementing a Camel component using the API component framework, based on code generated using the camel-archetype-api-component Maven archetype.
46.1. Generate Code with the Maven Archetype
Maven archetypes
A Maven archetype is analogous to a code wizard: given a few simple parameters, it generates a complete, working Maven project, populated with sample code. You can then use this project as a template, customizing the implementation to create your own application.
The API component Maven archetype
The API component framework provides a Maven archetype, camel-archetype-api-component, that can generate starting point code for your own API component implementation. This is the recommended approach to start creating your own API component.
Prerequisites
The only prerequisites for running the camel-archetype-api-component archetype are that Apache Maven is installed and the Maven settings.xml file is configured to use the standard Fuse repositories.
Invoke the Maven archetype
To create an Example component, which uses the example URI scheme, invoke the camel-archetype-api-component archetype to generate a new Maven project, as follows:
mvn archetype:generate \ -DarchetypeGroupId=org.apache.camel.archetypes \ -DarchetypeArtifactId=camel-archetype-api-component \ -DarchetypeVersion=2.21.0.fuse-730078-redhat-00001 \ -DgroupId=org.jboss.fuse.example \ -DartifactId=camel-api-example \ -Dname=Example \ -Dscheme=example \ -Dversion=1.0-SNAPSHOT \ -DinteractiveMode=false
The backslash character, \, at the end of each line represents line continuation, which works only on Linux and UNIX platforms. On Windows platforms, remove the backslash and put the arguments all on a single line.
Options
Options are provided to the archetype generation command using the syntax, -DName=Value. Most of the options should be set as shown in the preceding mvn archetype:generate command, but a few of the options can be modified, to customize the generated project. The following table shows the options that you can use to customize the generated API component project:
| Name | Description |
|---|---|
|
| (Generic Maven option) Specifies the group ID of the generated Maven project. By default, this value also defines the Java package name for the generated classes. Hence, it is a good idea to choose this value to match the Java package name that you want. |
|
| (Generic Maven option) Specifies the artifact ID of the generated Maven project. |
|
| The name of the API component. This value is used for generating class names in the generated code (hence, it is recommended that the name should start with a capital letter). |
|
| The default scheme to use in URIs for this component. You should make sure that this scheme does not conflict with the scheme of any existing Camel components. |
|
| (Generic Maven option) Ideally, this should be the Apache Camel version used by the container where you plan to deploy the component. If necessary, however, you can also modify the versions of Maven dependencies after you have generated the project. |
Structure of the generated project
Assuming that the code generation step completes successfully, you should see a new directory, camel-api-example, which contains the new Maven project. If you look inside the camel-api-example directory, you will see that it has the following general structure:
camel-api-example/
pom.xml
camel-api-example-api/
camel-api-example-component/
At the top level of the project is an aggregate POM, pom.xml, which is configured to build two sub-projects, as follows:
- camel-api-example-api
The API sub-project (named as
ArtifactId-api) holds the Java API which you are about to turn into a component. If you are basing the API component on a Java API that you wrote yourself, you can put the Java API code directly into this project.The API sub-project can be used for one or more of the following purposes:
- To package up the Java API code (if it is not already available as a Maven package).
- To generate Javadoc for the Java API (providing the needed metadata for the API component framework).
- To generate the Java API code from an API description (for example, from a WADL description of a REST API).
In some cases, however, you might not need to perform any of these tasks. For example, if the API component is based on a third-party API, which already provides the Java API and Javadoc in a Maven package. In such cases, you can delete the API sub-project.
- camel-api-example-component
-
The component sub-project (named as
ArtifactId-component) holds the implementation of the new API component. This includes the component implementation classes and the configuration of thecamel-api-component-mavenplug-in (which generates the API mapping classes from the Java API).
46.2. Generated API Sub-Project
Overview
Assuming that you generated a new Maven project as described in Section 46.1, “Generate Code with the Maven Archetype”, you can now find a Maven sub-project for packaging the Java API under the camel-api-example/camel-api-example-api project directory. In this section, we take a closer look at the generated example code and describe how it works.
Sample Java API
The generated example code includes a sample Java API, on which the example API component is based. The sample Java API is relatively simple, consisting of just two Hello World classes: ExampleJavadocHello and ExampleFileHello.
ExampleJavadocHello class
Example 46.1, “ExampleJavadocHello class” shows the ExampleJavadocHello class from the sample Java API. As the name of the class suggests, this particular class is used to show how you can supply mapping metadata from Javadoc.
Example 46.1. ExampleJavadocHello class
// Java
package org.jboss.fuse.example.api;
/**
* Sample API used by Example Component whose method signatures are read from Javadoc.
*/
public class ExampleJavadocHello {
public String sayHi() {
return "Hello!";
}
public String greetMe(String name) {
return "Hello " + name;
}
public String greetUs(String name1, String name2) {
return "Hello " + name1 + ", " + name2;
}
}ExampleFileHello class
Example 46.2, “ExampleFileHello class” shows the ExampleFileHello class from the sample Java API. As the name of the class suggests, this particular class is used to show how you can supply mapping metadata from a signature file.
Example 46.2. ExampleFileHello class
// Java
package org.jboss.fuse.example.api;
/**
* Sample API used by Example Component whose method signatures are read from File.
*/
public class ExampleFileHello {
public String sayHi() {
return "Hello!";
}
public String greetMe(String name) {
return "Hello " + name;
}
public String greetUs(String name1, String name2) {
return "Hello " + name1 + ", " + name2;
}
}Generating the Javadoc metadata for ExampleJavadocHello
Because the metadata for ExampleJavadocHello is provided as Javadoc, it is necessary to generate Javadoc for the sample Java API and install it into the camel-api-example-api Maven artifact. The API POM file, camel-api-example-api/pom.xml, configures the maven-javadoc-plugin to perform this step automatically during the Maven build.
46.3. Generated Component Sub-Project
Overview
The Maven sub-project for building the new component is located under the camel-api-example/camel-api-example-component project directory. In this section, we take a closer look at the generated example code and describe how it works.
Providing the Java API in the component POM
The Java API must be provided as a dependency in the component POM. For example, the sample Java API is defined as a dependency in the component POM file, camel-api-example-component/pom.xml, as follows:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
...
<dependencies>
...
<dependency>
<groupId>org.jboss.fuse.example</groupId>
<artifactId>camel-api-example-api</artifactId>
<version>1.0-SNAPSHOT</version>
</dependency>
...
</dependencies>
...
</project>Providing the Javadoc metadata in the component POM
If you are using Javadoc metadata for all or part of the Java API, you must provide the Javadoc as a dependency in the component POM. There are two things to note about this dependency:
The Maven coordinates for the Javadoc are almost the same as for the Java API, except that you must also specify a
classifierelement, as follows:<classifier>javadoc</classifier>
You must declare the Javadoc to have
providedscope, as follows:<scope>provided</scope>
For example, in the component POM, the Javadoc dependency is defined as follows:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
...
<dependencies>
...
<!-- Component API javadoc in provided scope to read API signatures -->
<dependency>
<groupId>org.jboss.fuse.example</groupId>
<artifactId>camel-api-example-api</artifactId>
<version>1.0-SNAPSHOT</version>
<classifier>javadoc</classifier>
<scope>provided</scope>
</dependency>
...
</dependencies>
...
</project>Defining the file metadata for Example File Hello
The metadata for ExampleFileHello is provided in a signature file. In general, this file must be created manually, but it has quite a simple format, which consists of a list of method signatures (one on each line). The example code provides the signature file, file-sig-api.txt, in the directory, camel-api-example-component/signatures, which has the following contents:
public String sayHi(); public String greetMe(String name); public String greetUs(String name1, String name2);
For more details about the signature file format, see the section called “Signature file metadata”.
Configuring the API mapping
One of the key features of the API component framework is that it automatically generates the code to perform API mapping. That is, generating stub code that maps endpoint URIs to method invocations on the Java API. The basic inputs to the API mapping are: the Java API, the Javadoc metadata, and/or the signature file metadata.
The component that performs the API mapping is the camel-api-component-maven-plugin Maven plug-in, which is configured in the component POM. The following extract from the component POM shows how the camel-api-component-maven-plugin plug-in is configured:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
...
<build>
<defaultGoal>install</defaultGoal>
<plugins>
...
<!-- generate Component source and test source -->
<plugin>
<groupId>org.apache.camel</groupId>
<artifactId>camel-api-component-maven-plugin</artifactId>
<executions>
<execution>
<id>generate-test-component-classes</id>
<goals>
<goal>fromApis</goal>
</goals>
<configuration>
<apis>
<api>
<apiName>hello-file</apiName>
<proxyClass>org.jboss.fuse.example.api.ExampleFileHello</proxyClass>
<fromSignatureFile>signatures/file-sig-api.txt</fromSignatureFile>
</api>
<api>
<apiName>hello-javadoc</apiName>
<proxyClass>org.jboss.fuse.example.api.ExampleJavadocHello</proxyClass>
<fromJavadoc/>
</api>
</apis>
</configuration>
</execution>
</executions>
</plugin>
...
</plugins>
...
</build>
...
</project>
The plug-in is configured by the configuration element, which contains a single apis child element to configure the classes of the Java API. Each API class is configured by an api element, as follows:
apiNameThe API name is a short name for the API class and is used as the
endpoint-prefixpart of an endpoint URI.NoteIf the API consists of just a single Java class, you can leave the
apiNameelement empty, so that theendpoint-prefixbecomes redundant, and you can then specify the endpoint URI using the format shown in the section called “URI format for a single API class”.proxyClass- The proxy class element specifies the fully-qualified name of the API class.
fromJavadoc-
If the API class is accompanied by Javadoc metadata, you must indicate this by including the
fromJavadocelement and the Javadoc itself must also be specified in the Maven file, as aprovideddependency (see the section called “Providing the Javadoc metadata in the component POM”). fromSignatureFileIf the API class is accompanied by signature file metadata, you must indicate this by including the
fromSignatureFileelement, where the content of this element specifies the location of the signature file.NoteThe signature files do not get included in the final package built by Maven, because these files are needed only at build time, not at run time.
Generated component implementation
The API component consists of the following core classes (which must be implemented for every Camel component), under the camel-api-example-component/src/main/java directory:
ExampleComponent-
Represents the component itself. This class acts as a factory for endpoint instances (for example, instances of
ExampleEndpoint). ExampleEndpoint-
Represents an endpoint URI. This class acts as a factory for consumer endpoints (for example,
ExampleConsumer) and as a factory for producer endpoints (for example,ExampleProducer). ExampleConsumer- Represents a concrete instance of a consumer endpoint, which is capable of consuming messages from the location specified in the endpoint URI.
ExampleProducer- Represents a concrete instance of a producer endpoint, which is capable of sending messages to the location specified in the endpoint URI.
ExampleConfigurationCan be used to define endpoint URI options. The URI options defined by this configuration class are not tied to any specific API class. That is, you can combine these URI options with any of the API classes or methods. This can be useful, for example, if you need to declare username and password credentials in order to connect to the remote service. The primary purpose of the
ExampleConfigurationclass is to provide values for parameters required to instantiate API classes, or classes that implement API interfaces. For example, these could be constructor parameters, or parameter values for a factory method or class.To implement a URI option,
option, in this class, all that you need to do is implement the pair of accessor methods,getOptionandsetOption. The component framework automatically parses the endpoint URI and injects the option values at run time.
ExampleComponent class
The generated ExampleComponent class is defined as follows:
// Java
package org.jboss.fuse.example;
import org.apache.camel.CamelContext;
import org.apache.camel.Endpoint;
import org.apache.camel.spi.UriEndpoint;
import org.apache.camel.util.component.AbstractApiComponent;
import org.jboss.fuse.example.internal.ExampleApiCollection;
import org.jboss.fuse.example.internal.ExampleApiName;
/**
* Represents the component that manages {@link ExampleEndpoint}.
*/
@UriEndpoint(scheme = "example", consumerClass = ExampleConsumer.class, consumerPrefix = "consumer")
public class ExampleComponent extends AbstractApiComponent<ExampleApiName, ExampleConfiguration, ExampleApiCollection> {
public ExampleComponent() {
super(ExampleEndpoint.class, ExampleApiName.class, ExampleApiCollection.getCollection());
}
public ExampleComponent(CamelContext context) {
super(context, ExampleEndpoint.class, ExampleApiName.class, ExampleApiCollection.getCollection());
}
@Override
protected ExampleApiName getApiName(String apiNameStr) throws IllegalArgumentException {
return ExampleApiName.fromValue(apiNameStr);
}
@Override
protected Endpoint createEndpoint(String uri, String methodName, ExampleApiName apiName,
ExampleConfiguration endpointConfiguration) {
return new ExampleEndpoint(uri, this, apiName, methodName, endpointConfiguration);
}
}
The important method in this class is createEndpoint, which creates new endpoint instances. Typically, you do not need to change any of the default code in the component class. If there are any other objects with the same life cycle as this component, however, you might want to make those objects available from the component class (for example, by adding a methods to create those objects or by injecting those objects into the component).
ExampleEndpoint class
The generated ExampleEndpoint class is defined as follows:
// Java
package org.jboss.fuse.example;
import java.util.Map;
import org.apache.camel.Consumer;
import org.apache.camel.Processor;
import org.apache.camel.Producer;
import org.apache.camel.spi.UriEndpoint;
import org.apache.camel.util.component.AbstractApiEndpoint;
import org.apache.camel.util.component.ApiMethod;
import org.apache.camel.util.component.ApiMethodPropertiesHelper;
import org.jboss.fuse.example.api.ExampleFileHello;
import org.jboss.fuse.example.api.ExampleJavadocHello;
import org.jboss.fuse.example.internal.ExampleApiCollection;
import org.jboss.fuse.example.internal.ExampleApiName;
import org.jboss.fuse.example.internal.ExampleConstants;
import org.jboss.fuse.example.internal.ExamplePropertiesHelper;
/**
* Represents a Example endpoint.
*/
@UriEndpoint(scheme = "example", consumerClass = ExampleConsumer.class, consumerPrefix = "consumer")
public class ExampleEndpoint extends AbstractApiEndpoint<ExampleApiName, ExampleConfiguration> {
// TODO create and manage API proxy
private Object apiProxy;
public ExampleEndpoint(String uri, ExampleComponent component,
ExampleApiName apiName, String methodName, ExampleConfiguration endpointConfiguration) {
super(uri, component, apiName, methodName, ExampleApiCollection.getCollection().getHelper(apiName), endpointConfiguration);
}
public Producer createProducer() throws Exception {
return new ExampleProducer(this);
}
public Consumer createConsumer(Processor processor) throws Exception {
// make sure inBody is not set for consumers
if (inBody != null) {
throw new IllegalArgumentException("Option inBody is not supported for consumer endpoint");
}
final ExampleConsumer consumer = new ExampleConsumer(this, processor);
// also set consumer.* properties
configureConsumer(consumer);
return consumer;
}
@Override
protected ApiMethodPropertiesHelper<ExampleConfiguration> getPropertiesHelper() {
return ExamplePropertiesHelper.getHelper();
}
protected String getThreadProfileName() {
return ExampleConstants.THREAD_PROFILE_NAME;
}
@Override
protected void afterConfigureProperties() {
// TODO create API proxy, set connection properties, etc.
switch (apiName) {
case HELLO_FILE:
apiProxy = new ExampleFileHello();
break;
case HELLO_JAVADOC:
apiProxy = new ExampleJavadocHello();
break;
default:
throw new IllegalArgumentException("Invalid API name " + apiName);
}
}
@Override
public Object getApiProxy(ApiMethod method, Map<String, Object> args) {
return apiProxy;
}
}
In the context of the API component framework, one of the key steps performed by the endpoint class is to create an API proxy. The API proxy is an instance from the target Java API, whose methods are invoked by the endpoint. Because a Java API typically consists of many classes, it is necessary to pick the appropriate API class, based on the endpoint-prefix appearing in the URI (recall that a URI has the general form, scheme://endpoint-prefix/endpoint).
ExampleConsumer class
The generated ExampleConsumer class is defined as follows:
// Java
package org.jboss.fuse.example;
import org.apache.camel.Processor;
import org.apache.camel.util.component.AbstractApiConsumer;
import org.jboss.fuse.example.internal.ExampleApiName;
/**
* The Example consumer.
*/
public class ExampleConsumer extends AbstractApiConsumer<ExampleApiName, ExampleConfiguration> {
public ExampleConsumer(ExampleEndpoint endpoint, Processor processor) {
super(endpoint, processor);
}
}ExampleProducer class
The generated ExampleProducer class is defined as follows:
// Java
package org.jboss.fuse.example;
import org.apache.camel.util.component.AbstractApiProducer;
import org.jboss.fuse.example.internal.ExampleApiName;
import org.jboss.fuse.example.internal.ExamplePropertiesHelper;
/**
* The Example producer.
*/
public class ExampleProducer extends AbstractApiProducer<ExampleApiName, ExampleConfiguration> {
public ExampleProducer(ExampleEndpoint endpoint) {
super(endpoint, ExamplePropertiesHelper.getHelper());
}
}ExampleConfiguration class
The generated ExampleConfiguration class is defined as follows:
// Java
package org.jboss.fuse.example;
import org.apache.camel.spi.UriParams;
/**
* Component configuration for Example component.
*/
@UriParams
public class ExampleConfiguration {
// TODO add component configuration properties
}
To add a URI option, option, to this class, define a field of the appropriate type, and implement a corresponding pair of accessor methods, getOption and setOption. The component framework automatically parses the endpoint URI and injects the option values at run time.
This class is used to define general URI options, which can be combined with any API method. To define URI options tied to a specific API method, configure extra options in the API component Maven plug-in. See Section 47.7, “Extra Options” for details.
URI format
Recall the general format of an API component URI:
scheme://endpoint-prefix/endpoint?Option1=Value1&...&OptionN=ValueN
In general, a URI maps to a specific method invocation on the Java API. For example, suppose you want to invoke the API method, ExampleJavadocHello.greetMe("Jane Doe"), the URI would be constructed, as follows:
- scheme
-
The API component scheme, as specified when you generated the code with the Maven archetype. In this case, the scheme is
example. - endpoint-prefix
The API name, which maps to the API class defined by the
camel-api-component-maven-pluginMaven plug-in configuration. For theExampleJavadocHelloclass, the relevant configuration is:<configuration> <apis> <api> <apiName>hello-javadoc</apiName> <proxyClass>org.jboss.fuse.example.api.ExampleJavadocHello</proxyClass> <fromJavadoc/> </api> ... </apis> </configuration>Which shows that the required
endpoint-prefixishello-javadoc.- endpoint
-
The
endpointmaps to the method name, which isgreetMe. - Option1=Value1
-
The URI options specify method parameters. The
greetMe(String name)method takes the single parameter,name, which can be specified asname=Jane%20Doe. If you want to define default values for options, you can do this by overriding theinterceptPropertiesmethod (see Section 46.4, “Programming Model”).
Putting together the pieces of the URI, we see that we can invoke ExampleJavadocHello.greetMe("Jane Doe") with the following URI:
example://hello-javadoc/greetMe?name=Jane%20Doe
Default component instance
In order to map the example URI scheme to the default component instance, the Maven archetype creates the following file under the camel-api-example-component sub-project:
src/main/resources/META-INF/services/org/apache/camel/component/example
This resource file is what enables the Camel core to identify the component associated with the example URI scheme. Whenever you use an example:// URI in a route, Camel searches the classpath to look for the corresponding example resource file. The example file has the following contents:
class=org.jboss.fuse.example.ExampleComponent
This enables the Camel core to create a default instance of the ExampleComponent component. The only time you would need to edit this file is if you refactor the name of the component class.
46.4. Programming Model
Overview
In the context of the API component framework, the main component implementation classes are derived from base classes in the org.apache.camel.util.component package. These base classes define some methods which you can (optionally) override when you are implementing your component. In this section, we provide a brief description of those methods and how you might use them in your own component implementation.
Component methods to implement
In addition to the generated method implementations (which you usually do not need to modify), you can optionally override some of the following methods in the Component class:
doStart()-
(Optional) A callback to create resources for the component during a cold start. An alternative approach is to adopt the strategy of lazy initialization (creating resources only when they are needed). In fact, lazy initialization is often the best strategy, so the
doStartmethod is often not needed. doStop()(Optional) A callback to invoke code while the component is stopping. Stopping a component means that all of its resources are shut down, internal state is deleted, caches are cleared, and so on.
NoteCamel guarantees that
doStopis always called when the currentCamelContextshuts down, even if the correspondingdoStartwas never called.doShutdown-
(Optional) A callback to invoke code while the
CamelContextis shutting down. Whereas a stopped component can be restarted (with the semantics of a cold start), a component that gets shut down is completely finished. Hence, this callback represents the last chance to free up any resources belonging to the component.
What else to implement in the Component class?
The Component class is the natural place to hold references to objects that have the same (or similar) life cycle to the component object itself. For example, if a component uses OAuth security, it would be natural to hold references to the required OAuth objects in the Component class and to define methods in the Component class for creating the OAuth objects.
Endpoint methods to implement
You can modify some of the generated methods and, optionally, override some inherited methods in the Endpoint class, as follows:
afterConfigureProperties()The main thing you need to do in this method is to create the appropriate type of proxy class (API class), to match the API name. The API name (which has already been extracted from the endpoint URI) is available either through the inherited
apiNamefield or through thegetApiNameaccessor. Typically, you would do a switch on theapiNamefield to create the corresponding proxy class. For example:// Java private Object apiProxy; ... @Override protected void afterConfigureProperties() { // TODO create API proxy, set connection properties, etc. switch (apiName) { case HELLO_FILE: apiProxy = new ExampleFileHello(); break; case HELLO_JAVADOC: apiProxy = new ExampleJavadocHello(); break; default: throw new IllegalArgumentException("Invalid API name " + apiName); } }getApiProxy(ApiMethod method, Map<String, Object> args)Override this method to return the proxy instance that you created in
afterConfigureProperties. For example:@Override public Object getApiProxy(ApiMethod method, Map<String, Object> args) { return apiProxy; }In special cases, you might want to make the choice of proxy dependent on the API method and arguments. The
getApiProxygives you the flexibility to take this approach, if required.doStart()-
(Optional) A callback to create resources during a cold start. Has the same semantics as
Component.doStart(). doStop()-
(Optional) A callback to invoke code while the component is stopping. Has the same semantics as
Component.doStop(). doShutdown-
(Optional) A callback to invoke code while the component is shutting down. Has the same semantics as
Component.doShutdown(). interceptPropertyNames(Set<String> propertyNames)(Optional) The API component framework uses the endpoint URI and supplied option values to determine which method to invoke (ambiguity could be due to overloading and aliases). If the component internally adds options or method parameters, however, the framework might need help in order to determine the right method to invoke. In this case, you must override the
interceptPropertyNamesmethod and add the extra (hidden or implicit) options to thepropertyNamesset. When the complete list of method parameters are provided in thepropertyNamesset, the framework will be able to identify the right method to invoke.NoteYou can override this method at the level of the
Endpoint,ProducerorConsumerclass. The basic rule is, if an option affects both producer endpoints and consumer endpoints, override the method in theEndpointclass.interceptProperties(Map<String,Object> properties)(Optional) By overriding this method, you can modify or set the actual values of the options, before the API method is invoked. For example, you could use this method to set default values for some options, if necessary. In practice, it is often necessary to override both the
interceptPropertyNamesmethod and theinterceptPropertymethod.NoteYou can override this method at the level of the
Endpoint,ProducerorConsumerclass. The basic rule is, if an option affects both producer endpoints and consumer endpoints, override the method in theEndpointclass.
Consumer methods to implement
You can optionally override some inherited methods in the Consumer class, as follows:
interceptPropertyNames(Set<String> propertyNames)-
(Optional) The semantics of this method are similar to
Endpoint.interceptPropertyNames interceptProperties(Map<String,Object> properties)-
(Optional) The semantics of this method are similar to
Endpoint.interceptProperties doInvokeMethod(Map<String, Object> args)(Optional) Overriding this method enables you to intercept the invocation of the Java API method. The most common reason for overriding this method is to customize the error handling around the method invocation. For example, a typical approach to overriding
doInvokeMethodis shown in the following code fragment:// Java @Override protected Object doInvokeMethod(Map<String, Object> args) { try { return super.doInvokeMethod(args); } catch (RuntimeCamelException e) { // TODO - Insert custom error handling here! ... } }You should invoke
doInvokeMethodon the super-class, at some point in this implementation, to ensure that the Java API method gets invoked.interceptResult(Object methodResult, Exchange resultExchange)-
(Optional) Do some additional processing on the result of the API method invocation. For example, you could add custom headers to the Camel exchange object,
resultExchange, at this point. Object splitResult(Object result)(Optional) By default, if the result of the method API invocation is a
java.util.Collectionobject or a Java array, the API component framework splits the result into multiple exchange objects (so that a single invocation result is converted into multiple messages).If you want to change the default behaviour, you can override the
splitResultmethod in the consumer endpoint. Theresultargument contains the result of the API message invocation. If you want to split the result, you should return an array type.NoteYou can also switch off the default splitting behaviour by setting
consumer.splitResult=falseon the endpoint URI.
Producer methods to implement
You can optionally override some inherited methods in the Producer class, as follows:
interceptPropertyNames(Set<String> propertyNames)-
(Optional) The semantics of this method are similar to
Endpoint.interceptPropertyNames interceptProperties(Map<String,Object> properties)-
(Optional) The semantics of this method are similar to
Endpoint.interceptProperties doInvokeMethod(Map<String, Object> args)-
(Optional) The semantics of this method are similar to
Consumer.doInvokeMethod. interceptResult(Object methodResult, Exchange resultExchange)-
(Optional) The semantics of this method are similar to
Consumer.interceptResult.
The Producer.splitResult() method is never called, so it is not possible to split an API method result in the same way as you can for a consumer endpoint. To get a similar effect for a producer endpoint, you can use Camel’s split() DSL command (one of the standard enterprise integration patterns) to split Collection or array results.
Consumer polling and threading model
The default threading model for consumer endpoints in the API component framework is scheduled poll consumer. This implies that the API method in a consumer endpoint is invoked at regular, scheduled time intervals. For more details, see the section called “Scheduled poll consumer implementation”.
46.5. Sample Component Implementations
Overview
Several of the components distributed with Apache Camel have been implemented with the aid of the API component framework. If you want to learn more about the techniques for implementing Camel components using the framework, it is a good idea to study the source code of these component implementations.
Box.com
The Camel Box component shows how to model and invoke the third party Box.com Java SDK using the API component framework. It also demonstrates how the framework can be adapted to customize consumer polling, in order to support Box.com’s long polling API.
The Camel LinkedIn component demonstrates how to wrap a REST API provided in the form of WADL and XML schemas. The implementation of this component exploits the Apache CXF wadl2java Maven plug-in to generate a Java API, which can then be wrapped using the API component framework.
This approach can be easily replicated to create a Camel component for any SaaS product or platform.
GoogleDrive
The Camel GoogleDrive component demonstrates how the API component framework can handle even Method Object style Google APIs. In this case, URI options are mapped to a method object, which is then invoked by overriding the doInvoke method in the consumer and the producer.
Olingo2
The Camel Olingo2 component demonstrates how a callback-based Asynchronous API can be wrapped using the API component framework. This example shows how asynchronous processing can be pushed into underlying resources, like HTTP NIO connections, to make Camel endpoints more resource efficient.
Chapter 47. Configuring the API Component Maven Plug-In
Abstract
This chapter provides a reference for all of the configuration options available on the API component Maven plug-in.
47.1. Overview of the Plug-In Configuration
Overview
The main purpose of the API component Maven plug-in, camel-api-component-maven-plugin, is to generate the API mapping classes, which implement the mapping between endpoint URIs and API method invocations. By editing the configuration of the API component Maven plug-in, you can customize various aspects of the API mapping.
Location of the generated code
The API mapping classes generated by the API component Maven plug-in are placed in the following location, by default:
ProjectName-component/target/generated-sources/camel-componentPrerequisites
The main inputs to the API component Maven plug-in are the Java API classes and the Javadoc metadata. These are made available to the plug-in by declaring them as regular Maven dependencies (where the Javadoc Maven dependencies should be declared with provided scope).
Setting up the plug-in
The recommended way to set up the API component Maven plug-in is to generate starting point code using the API component archetype. This generates the default plug-in configuration in the ProjectName-component/pom.xml file, which you can then customize for your project. The main aspects of the plug-in set-up are, as follows:
- Maven dependencies must be declared for the requisite Java API and for the Javadoc metadata.
-
The plug-in’s base configuration is declared in the
pluginManagementscope (which also defines the version of the plug-in to use). - The plug-in instance itself is declared and configured.
-
The
build-helper-mavenplug-in is configured to pick up the generated sources from thetarget/generated-sources/camel-componentdirectory and include them in the Maven build.
Example base configuration
The following POM file extract shows the base configuration of the API component Maven plug-in, as defined in the Maven pluginManagement scope when the code has been generated using the API component archetype:
<?xml version="1.0" encoding="UTF-8"?>
<project ...>
...
<build>
...
<pluginManagement>
<plugins>
<plugin>
<groupId>org.apache.camel</groupId>
<artifactId>camel-api-component-maven-plugin</artifactId>
<version>2.21.0.fuse-730078-redhat-00001</version>
<configuration>
<scheme>${schemeName}</scheme>
<componentName>${componentName}</componentName>
<componentPackage>${componentPackage}</componentPackage>
<outPackage>${outPackage}</outPackage>
</configuration>
</plugin>
</plugins>
</pluginManagement>
...
</build>
...
</project
The configuration specified in the pluginManagement scope provides default settings for the plug-in. It does not actually create an instance of a plug-in, but its default settings will be used by any API component plug-in instance.
Base configuration
In addition to specifying the plug-in version (in the version element), the preceding base configuration specifies the following configuration properties:
scheme- The URI scheme for this API component.
componentName- The name of this API component (which is also used as a prefix for generated class names).
componentPackage-
Specifies the Java package containing the classes generated by the API component Maven archetype. This package is also exported by the default
maven-bundle-pluginconfiguration. Hence, if you want a class to be publicly visible, you should place it in this Java package. outPackage-
Specifies the Java package where the generated API mapping classes are placed (when they are generated by the API component Maven plug-in). By default, this has the value of the
componentNameproperty, with the addition of the.internalsuffix. This package is declared as private by the defaultmaven-bundle-pluginconfiguration. Hence, if you want a class to be private, you should place it in this Java package.
Example instance configuration
The following POM file extract shows a sample instance of the API component Maven plug-in, which is configured to generate an API mapping during the Maven build:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
...
<build>
<defaultGoal>install</defaultGoal>
<plugins>
...
<!-- generate Component source and test source -->
<plugin>
<groupId>org.apache.camel</groupId>
<artifactId>camel-api-component-maven-plugin</artifactId>
<executions>
<execution>
<id>generate-test-component-classes</id>
<goals>
<goal>fromApis</goal>
</goals>
<configuration>
<apis>
<api>
<apiName>hello-file</apiName>
<proxyClass>org.jboss.fuse.example.api.ExampleFileHello</proxyClass>
<fromSignatureFile>signatures/file-sig-api.txt</fromSignatureFile>
</api>
<api>
<apiName>hello-javadoc</apiName>
<proxyClass>org.jboss.fuse.example.api.ExampleJavadocHello</proxyClass>
<fromJavadoc/>
</api>
</apis>
</configuration>
</execution>
</executions>
</plugin>
...
</plugins>
...
</build>
...
</project>Basic mapping configuration
The plug-in is configured by the configuration element, which contains a single apis child element to configure the classes of the Java API. Each API class is configured by an api element, as follows:
apiNameThe API name is a short name for the API class and is used as the
endpoint-prefixpart of an endpoint URI.NoteIf the API consists of just a single Java class, you can leave the
apiNameelement empty, so that theendpoint-prefixbecomes redundant, and you can then specify the endpoint URI using the format shown in the section called “URI format for a single API class”.proxyClass- This element specifies the fully-qualified name of the API class.
fromJavadoc-
If the API class is accompanied by Javadoc metadata, you must indicate this by including the
fromJavadocelement and the Javadoc itself must also be specified in the Maven file, as aprovideddependency. fromSignatureFileIf the API class is accompanied by signature file metadata, you must indicate this by including the
fromSignatureFileelement, where the content of this element specifies the location of the signature file.NoteThe signature files do not get included in the final package built by Maven, because these files are needed only at build time, not at run time.
Customizing the API mapping
The following aspects of the API mapping can be customized by configuring the plug-in:
-
Method aliases — you can define additional names (aliases) for an API method using the
aliasesconfiguration element. For details, see Section 47.3, “Method Aliases”. -
Nullable options — you can use the
nullableOptionsconfiguration element to declare method arguments that default tonull. For details, see Section 47.4, “Nullable Options”. -
Argument name substitution — due to the way the API mapping is implemented, the arguments from all of the methods in a particular API class belong to the same namespace. If two arguments with the same name are declared to be of different type, this leads to a clash. To avoid such name clashes, you can use the
substitutionsconfiguration element to rename method arguments (as they would appear in a URI). For details, see Section 47.5, “Argument Name Substitution”. -
Excluding arguments — when it comes to mapping Java arguments to URI options, you might sometimes want to exclude certain arguments from the mapping. You can filter out unwanted arguments by specifying either the
excludeConfigNameselement or theexcludeConfigTypeselement. For details, see Section 47.6, “Excluded Arguments”. -
Extra options — sometimes you might want to define extra options, which are not part of the Java API. You can do this using the
extraOptionsconfiguration element.
Configuring Javadoc metadata
It is possible to filter the Javadoc metadata to ignore or explicitly include certain content. For details of how to do this, see Section 47.2, “Javadoc Options”.
Configuring signature file metadata
In cases where no Javadoc is available, you can resort to signature files to supply the needed mapping metadata. The fromSignatureFile is used to specify the location of the corresponding signature file. It has no special options.
47.2. Javadoc Options
Overview
If the metadata for your Java API is provided by Javadoc, it is generally sufficient to specify the fromJavadoc element with no options. But in cases where you do not want to include the entire Java API in your API mapping, you can filter the Javadoc metadata to customize the content. In other words, because the API component Maven plug-in generates the API mapping by iterating over the Javadoc metadata, it is possible to customize the scope of the generated API mapping by filtering out unwanted parts of the Javadoc metadata.
Syntax
The fromJavadoc element can be configured with optional child elements, as follows:
<fromJavadoc> <excludePackages>PackageNamePattern</excludePackages> <excludeClasses>ClassNamePattern</excludeClasses> <excludeMethods>MethodNamePattern</excludeMethods> <includeMethods>MethodNamePattern</includeMethods> <includeStaticMethods>[true|false]<includeStaticMethods> </fromJavadoc>
Scope
As shown in the following extract, the fromJavadoc element can optionally appear as a child of the apis element and/or as a child of api elements:
<configuration>
<apis>
<api>
<apiName>...</apiName>
...
<fromJavadoc>...</fromJavadoc>
</api>
<fromJavadoc>...</fromJavadoc>
...
</apis>
</configuration>
You can define the fromJavadoc element at the following scopes:
-
As a child of an
apielement — thefromJavadocoptions apply only to the API class specified by theapielement. -
As a child of the
apiselement — thefromJavadocoptions apply to all API classes by default, but can be overridden at theapilevel.
Options
The following options can be defined as child elements of fromJavadoc:
excludePackages-
Specifies a regular expression (
java.util.regexsyntax) for excluding Java packages from the API mapping model. All package names that match the regular expression are excluded; and all classes derived from the excluded classes are also ignored. Default value isjavax?\.lang.\*. excludeClasses-
Specifies a regular expression (
java.util.regexsyntax) for excluding API base classes from the API mapping. All class names that match the regular expression are excluded; and all classes derived from the excluded classes are also ignored. excludeMethods-
Specifies a regular expression (
java.util.regexsyntax) for excluding methods from the API mapping model. includeMethods-
Specifies a regular expression (
java.util.regexsyntax) for including methods from the API mapping model. includeStaticMethods-
If
true, static methods will also be included in the API mapping model. Default isfalse.
47.3. Method Aliases
Overview
Often it can be useful to define additional names (aliases) for a given method, in addition to the standard method name that appears in the Java API. A particularly common case is where you allow a property name (such as widget) to be used as an alias for an accessor method (such as getWidget or setWidget).
Syntax
The aliases element can be defined with one or more alias child elements, as follows:
<aliases>
<alias>
<methodPattern>MethodPattern</methodPattern>
<methodAlias>Alias</methodAlias>
</alias>
...
</aliases>
Where MethodPattern is a regular expression (java.util.regex syntax) for matching method names from the Java API, and the pattern typically includes capturing groups. The Alias is the replacement expression (for use in a URI), which can use the text from the preceding capturing groups (for example, specified as $1, $2, or $3 for the text from the first, second, or third capturing group).
Scope
As shown in the following extract, the aliases element can optionally appear as a child of the apis element and/or as a child of api elements:
<configuration>
<apis>
<api>
<apiName>...</apiName>
...
<aliases>...</aliases>
</api>
<aliases>...</aliases>
...
</apis>
</configuration>
You can define the aliases element at the following scopes:
-
As a child of an
apielement — thealiasesmappings apply only to the API class specified by theapielement. -
As a child of the
apiselement — thealiasesmappings apply to all API classes by default, but can be overridden at theapilevel.
Example
The following example shows how to generate aliases for the common get/set bean method pattern:
<aliases>
<alias>
<methodPattern>[gs]et(.+)</methodPattern>
<methodAlias>$1</methodAlias>
</alias>
</aliases>
With the preceding alias definition, you could use widget as an alias for either of the methods getWidget or setWidget. Note the use of a capturing group, (.+), to capture the latter part of the method name (for example, Widget).
47.4. Nullable Options
Overview
In some cases, it can make sense to let method arguments default to null. But this is not allowed by default. If you want to allow some of your method arguments from the Java API to take null values, you must declare this explicitly using the nullableOptions element.
Syntax
The nullableOptions element can be defined with one or more nullableOption child elements, as follows:
<nullableOptions>
<nullableOption>ArgumentName</nullableOption>
...
</nullableOptions>
Where ArgumentName is the name of a method argument from the Java API.
Scope
As shown in the following extract, the nullableOptions element can optionally appear as a child of the apis element and/or as a child of api elements:
<configuration>
<apis>
<api>
<apiName>...</apiName>
...
<nullableOptions>...</nullableOptions>
</api>
...
<nullableOptions>...</nullableOptions>
</apis>
</configuration>
You can define the nullableOptions element at the following scopes:
-
As a child of an
apielement — thenullableOptionsmappings apply only to the API class specified by theapielement. -
As a child of the
apiselement — thenullableOptionsmappings apply to all API classes by default, but can be overridden at theapilevel.
Example
The following example shows the nullable options declared for the CompaniesResource proxy class from the Apache Camel LinkedIn component:
<nullableOptions> <nullableOption>companySizes</nullableOption> <nullableOption>count</nullableOption> <nullableOption>email_domain</nullableOption> <nullableOption>end_timestamp</nullableOption> <nullableOption>event_type</nullableOption> <nullableOption>geos</nullableOption> <nullableOption>industries</nullableOption> <nullableOption>is_company_admin</nullableOption> <nullableOption>jobFunc</nullableOption> <nullableOption>secure_urls</nullableOption> <nullableOption>seniorities</nullableOption> <nullableOption>start</nullableOption> <nullableOption>start_timestamp</nullableOption> <nullableOption>statistics_update_key</nullableOption> <nullableOption>time_granularity</nullableOption> </nullableOptions>
47.5. Argument Name Substitution
Overview
The API component framework requires that URI option names are unique within each proxy class (Java API class). This is not always the case for method argument names, however. For example, consider the following Java methods in an API class:
public void doSomething(int id, String name); public void doSomethingElse(int id, String name);
When you build your Maven project, the camel-api-component-maven-plugin generates the configuration class, ProxyClassEndpointConfiguration, which contains getter and setter methods for all of the arguments in the ProxyClass class. For example, given the preceding methods, the plug-in would generate the following getter and setter methods in the configuration class:
public int getId(); public void setId(int id); public String getName(); public void setName(String name);
But what happens, if the id argument appears multiple times as different types, as in the following example:
public void doSomething(int id, String name); public void doSomethingElse(int id, String name); public String lookupByID(String id);
In this case, the code generation would fail, because you cannot define a getId method that returns int and a getId method that returns String in the same scope. The solution to this problem is to use argument name substitution to customize the mapping of argument names to URI option names.
Syntax
The substitutions element can be defined with one or more substitution child elements, as follows:
<substitutions>
<substitution>
<method>MethodPattern</method>
<argName>ArgumentNamePattern</argName>
<argType>TypeNamePattern</argType>
<replacement>SubstituteArgName</replacement>
<replaceWithType>[true|false]</replaceWithType>
</substitution>
...
</substitutions>
Where the argType element and the replaceWithType element are optional and can be omitted.
Scope
As shown in the following extract, the substitutions element can optionally appear as a child of the apis element and/or as a child of api elements:
<configuration>
<apis>
<api>
<apiName>...</apiName>
...
<substitutions>...</substitutions>
</api>
<substitutions>...</substitutions>
...
</apis>
</configuration>
You can define the substitutions element at the following scopes:
-
As a child of an
apielement — thesubstitutionsapply only to the API class specified by theapielement. -
As a child of the
apiselement — thesubstitutionsapply to all API classes by default, but can be overridden at theapilevel.
Child elements
Each substitution element can be defined with the following child elements:
method-
Specifies a regular expression (
java.util.regexsyntax) to match a method name from the Java API. argName-
Specifies a regular expression (
java.util.regexsyntax) to match an argument name from the matched method, where the pattern typically includes capturing groups. argType-
(Optional) Specifies a regular expression (
java.util.regexsyntax) to match the type of the argument. If you set thereplaceWithTypeoption totrue, you would typically use capturing groups in this regular expression. replacement-
Given a particular match of the
methodpattern,argNamepattern, and (optionally)argTypepattern, thereplacementelement defines the substitute argument name (for use in a URI). The replacement text can be constructed using strings captured from theargNameregular expression pattern (using the syntax,$1,$2,$3to insert the first, second, or third capturing group, respectively). Alternatively, the replacement text can be constructed using strings captured from theargTyperegular expression pattern, if you set thereplaceWithTypeoption totrue. replaceWithType-
When
true, specifies that the replacement text is constructed using strings captured from theargTyperegular expression. Defaults tofalse.
Example
The following substitution example modifies every argument of java.lang.String type, by adding the suffix, Param to the argument name:
<substitutions>
<substitution>
<method>^.+$</method>
<argName>^.+$</argName>
<argType>java.lang.String</argType>
<replacement>$1Param</replacement>
<replaceWithType>false</replaceWithType>
</substitution>
</substitutions>For example, given the following method signature:
public String greetUs(String name1, String name2);
The arguments of this method would be specified through the options, name1Param and name2Param, in the endpoint URI.
47.6. Excluded Arguments
Overview
Sometimes, you might need to exclude certain arguments, when it comes to mapping Java arguments to URI options. You can filter out unwanted arguments by specifying either the excludeConfigNames element or the excludeConfigTypes element in the camel-api-component-maven-plugin plug-in configuration.
Syntax
The excludeConfigNames element and the excludeConfigTypes element are specified as follows:
<excludeConfigNames>ArgumentNamePattern</excludeConfigNames> <excludeConfigTypes>TypeNamePattern</excludeConfigTypes>
Where ArgumentNamePattern and TypeNamePattern are regular expressions that match the argument name and the argument type, respectively.
Scope
As shown in the following extract, the excludeConfigNames element and the excludeConfigTypes element can optionally appear as children of the apis element and/or as children of api elements:
<configuration>
<apis>
<api>
<apiName>...</apiName>
...
<excludeConfigNames>...</excludeConfigNames>
<excludeConfigTypes>...</excludeConfigTypes>
</api>
<excludeConfigNames>...</excludeConfigNames>
<excludeConfigTypes>...</excludeConfigTypes>
...
</apis>
</configuration>
You can define the excludeConfigNames element and the excludeConfigTypes element at the following scopes:
-
As a child of an
apielement — the exclusions apply only to the API class specified by theapielement. -
As a child of the
apiselement — the exclusions apply to all API classes by default, but can be overridden at theapilevel.
Elements
The following elements can be used to exclude arguments from the API mapping (so that they are unavailable as URI options):
excludeConfigNames-
Specifies a regular expression (
java.util.regexsyntax) for excluding arguments, based on matching the argument name. excludeConfigTypes-
Specifies a regular expression (
java.util.regexsyntax) for excluding arguments, based on matching the argument type.
47.7. Extra Options
Overview
The extraOptions options are usually used to either compute or hide complex API parameters by providing simpler options instead. For example, the API method might take a POJO option, that could be provided more easily as parts of the POJO in the URI. The component could do this by adding the parts as extra options, and creating the POJO parameter internally. To complete the implementation of these extra options, you also need to override the interceptProperties method in the EndpointConsumer and/or EndpointProducer classes (see Section 46.4, “Programming Model”).
Syntax
The extraOptions element can be defined with one or more extraOption child elements, as follows:
<extraOptions>
<extraOption>
<type>TypeName</type>
<name>OptionName</name>
</extraOption>
</extraOptions>
Where TypeName is the fully-qualified type name of the extra option and OptionName is the name of the extra URI option.
Scope
As shown in the following extract, the extraOptions element can optionally appear as a child of the apis element and/or as a child of api elements:
<configuration>
<apis>
<api>
<apiName>...</apiName>
...
<extraOptions>...</extraOptions>
</api>
<extraOptions>...</extraOptions>
...
</apis>
</configuration>
You can define the extraOptions element at the following scopes:
-
As a child of an
apielement — theextraOptionsapply only to the API class specified by theapielement. -
As a child of the
apiselement — theextraOptionsapply to all API classes by default, but can be overridden at theapilevel.
Child elements
Each extraOptions element can be defined with the following child elements:
type- Specifies the fully-qualified type name of the extra option.
name- Specifies the option name, as it would appear in an endpoint URI.
Example
The following example defines an extra URI option, customOption, which is of java.util.list<String> type:
<extraOptions>
<extraOption>
<type>java.util.List<String></type>
<name>customOption</name>
</extraOption>
</extraOptions>Index
Symbols
- @Converter, Implement an annotated converter class
A
- accessing, Accessing message headers, Wrapping the exchange accessors
- annotating the implementation, Implement an annotated converter class
- AsyncCallback, Asynchronous processing
- asynchronous, Asynchronous producer
- asynchronous producer
- implementing, How to implement an asynchronous producer
- AsyncProcessor, Asynchronous processing
- auto-discovery
- configuration, Configuring auto-discovery
B
- bean properties, Define bean properties on your component class
C
- Component
- createEndpoint(), URI parsing
- definition, The Component interface
- methods, Component methods
- component prefix, Component
- components, Component
- bean properties, Define bean properties on your component class
- configuring, Installing and configuring the component
- implementation steps, Implementation steps
- installing, Installing and configuring the component
- interfaces to implement, Which interfaces do you need to implement?
- parameter injection, Parameter injection
- Spring configuration, Configure the component in Spring
- configuration, Configuring auto-discovery
- configuring, Installing and configuring the component
- Consumer, Consumer
- consumers, Consumer
- event-driven, Event-driven pattern, Implementation steps
- polling, Polling pattern, Implementation steps
- scheduled, Scheduled poll pattern, Implementation steps
- threading, Overview
- copy(), Exchange methods
- createConsumer(), Endpoint methods
- createEndpoint(), URI parsing
- createExchange(), Endpoint methods, Event-driven endpoint implementation, Producer methods
- createPollingConsumer(), Endpoint methods, Event-driven endpoint implementation
- createProducer(), Endpoint methods
D
- DefaultComponent
- createEndpoint(), URI parsing
- DefaultEndpoint, Event-driven endpoint implementation
- createExchange(), Event-driven endpoint implementation
- createPollingConsumer(), Event-driven endpoint implementation
- getCamelConext(), Event-driven endpoint implementation
- getComponent(), Event-driven endpoint implementation
- getEndpointUri(), Event-driven endpoint implementation
- definition, The Component interface
- discovery file, Create a TypeConverter file
E
- Endpoint, Endpoint
- createConsumer(), Endpoint methods
- createExchange(), Endpoint methods
- createPollingConsumer(), Endpoint methods
- createProducer(), Endpoint methods
- getCamelContext(), Endpoint methods
- getEndpointURI(), Endpoint methods
- interface definition, The Endpoint interface
- isLenientProperties(), Endpoint methods
- isSingleton(), Endpoint methods
- setCamelContext(), Endpoint methods
- endpoint
- event-driven, Event-driven endpoint implementation
- scheduled, Scheduled poll endpoint implementation
- endpoints, Endpoint
- event-driven, Event-driven pattern, Implementation steps, Event-driven endpoint implementation
- Exchange, Exchange, The Exchange interface
- copy(), Exchange methods
- getExchangeId(), Exchange methods
- getIn(), Accessing message headers, Exchange methods
- getOut(), Exchange methods
- getPattern(), Exchange methods
- getProperties(), Exchange methods
- getProperty(), Exchange methods
- getUnitOfWork(), Exchange methods
- removeProperty(), Exchange methods
- setExchangeId(), Exchange methods
- setIn(), Exchange methods
- setOut(), Exchange methods
- setProperty(), Exchange methods
- setUnitOfWork(), Exchange methods
- exchange
- in capable, Testing the exchange pattern
- out capable, Testing the exchange pattern
- exchange properties
- accessing, Wrapping the exchange accessors
- ExchangeHelper, The ExchangeHelper Class
- getContentType(), Get the In message’s MIME content type
- getMandatoryHeader(), Accessing message headers, Wrapping the exchange accessors
- getMandatoryInBody(), Wrapping the exchange accessors
- getMandatoryOutBody(), Wrapping the exchange accessors
- getMandatoryProperty(), Wrapping the exchange accessors
- isInCapable(), Testing the exchange pattern
- isOutCapable(), Testing the exchange pattern
- resolveEndpoint(), Resolve an endpoint
- exchanges, Exchange
G
- getCamelConext(), Event-driven endpoint implementation
- getCamelContext(), Endpoint methods
- getComponent(), Event-driven endpoint implementation
- getContentType(), Get the In message’s MIME content type
- getEndpoint(), Producer methods
- getEndpointURI(), Endpoint methods
- getEndpointUri(), Event-driven endpoint implementation
- getExchangeId(), Exchange methods
- getHeader(), Accessing message headers
- getIn(), Accessing message headers, Exchange methods
- getMandatoryHeader(), Accessing message headers, Wrapping the exchange accessors
- getMandatoryInBody(), Wrapping the exchange accessors
- getMandatoryOutBody(), Wrapping the exchange accessors
- getMandatoryProperty(), Wrapping the exchange accessors
- getOut(), Exchange methods
- getPattern(), Exchange methods
- getProperties(), Exchange methods
- getProperty(), Exchange methods
- getUnitOfWork(), Exchange methods
I
- implementation steps, How to implement a type converter, Implementation steps
- implementing, Implementing the Processor interface, How to implement a synchronous producer, How to implement an asynchronous producer
- in capable, Testing the exchange pattern
- in message
- MIME type, Get the In message’s MIME content type
- installing, Installing and configuring the component
- interface definition, The Endpoint interface
- interfaces to implement, Which interfaces do you need to implement?
- isInCapable(), Testing the exchange pattern
- isLenientProperties(), Endpoint methods
- isOutCapable(), Testing the exchange pattern
- isSingleton(), Endpoint methods
M
- mater, Master type converter
- Message, Message
- getHeader(), Accessing message headers
- message headers
- accessing, Accessing message headers
- messages, Message
- methods, Component methods
- MIME type, Get the In message’s MIME content type
O
- out capable, Testing the exchange pattern
P
- packaging, Package the type converter
- parameter injection, Parameter injection
- performer, Overview
- pipeline, Pipelining model
- polling, Polling pattern, Implementation steps
- process(), Producer methods
- Processor, Processor interface
- implementing, Implementing the Processor interface
- producer, Producer
- Producer, Producer
- createExchange(), Producer methods
- getEndpoint(), Producer methods
- process(), Producer methods
- producers
- asynchronous, Asynchronous producer
- synchronous, Synchronous producer
R
- removeProperty(), Exchange methods
- resolveEndpoint(), Resolve an endpoint
- runtime process, Type conversion process
S
- scheduled, Scheduled poll pattern, Implementation steps, Scheduled poll endpoint implementation
- ScheduledPollEndpoint, Scheduled poll endpoint implementation
- setCamelContext(), Endpoint methods
- setExchangeId(), Exchange methods
- setIn(), Exchange methods
- setOut(), Exchange methods
- setProperty(), Exchange methods
- setUnitOfWork(), Exchange methods
- simple processor
- implementing, Implementing the Processor interface
- slave, Master type converter
- Spring configuration, Configure the component in Spring
- synchronous, Synchronous producer
- synchronous producer
- implementing, How to implement a synchronous producer
T
- threading, Overview
- type conversion
- runtime process, Type conversion process
- type converter
- annotating the implementation, Implement an annotated converter class
- discovery file, Create a TypeConverter file
- implementation steps, How to implement a type converter
- mater, Master type converter
- packaging, Package the type converter
- slave, Master type converter
- TypeConverter, Type converter interface
- TypeConverterLoader, Type converter loader
U
- useIntrospectionOnEndpoint(), Disabling endpoint parameter injection
W
- wire tap pattern, System Management