Chapter 2. Connecting to Kafka with Kamelets
Apache Kafka is an open-source, distributed, publish-subscribe messaging system for creating fault-tolerant, real-time data feeds. Kafka quickly stores and replicates data for a large number of consumers (external connections).
Kafka can help you build solutions that process streaming events. A distributed, event-driven architecture requires a "backbone" that captures, communicates and helps process events. Kafka can serve as the communication backbone that connects your data sources and events to applications.
You can use Kamelets to configure communication between Kafka and external resources. Kamelets allow you to configure how data moves from one endpoint to another in a Kafka stream-processing framework without writing code. Kamelets are route templates that you configure by specifying parameter values.
For example, Kafka stores data in a binary form. You can use Kamelets to serialize and deserialize the data for sending to, and receiving from, external connections. With Kamelets, you can validate the schema and make changes to the data, such as adding to it, filtering it, or masking it. Kamelets can also handle and process errors.
2.1. Overview of connecting to Kafka with Kamelets
If you use an Apache Kafka stream-processing framework, you can use Kamelets to connect services and applications to a Kafka topic. The Kamelet Catalog provides the following Kamelets specifically for making connections to a Kafka topic:
-
kafka-sink- Moves events from a data producer to a Kafka topic. In a Kamelet Binding, specify thekafka-sinkKamelet as the sink. -
kafka-source- Moves events from a Kafka topic to a data consumer. In a Kamelet Binding, specify thekafka-sourceKamelet as the source.
Figure 2.1 illustrates the flow of connecting source and sink Kamelets to a Kafka topic.
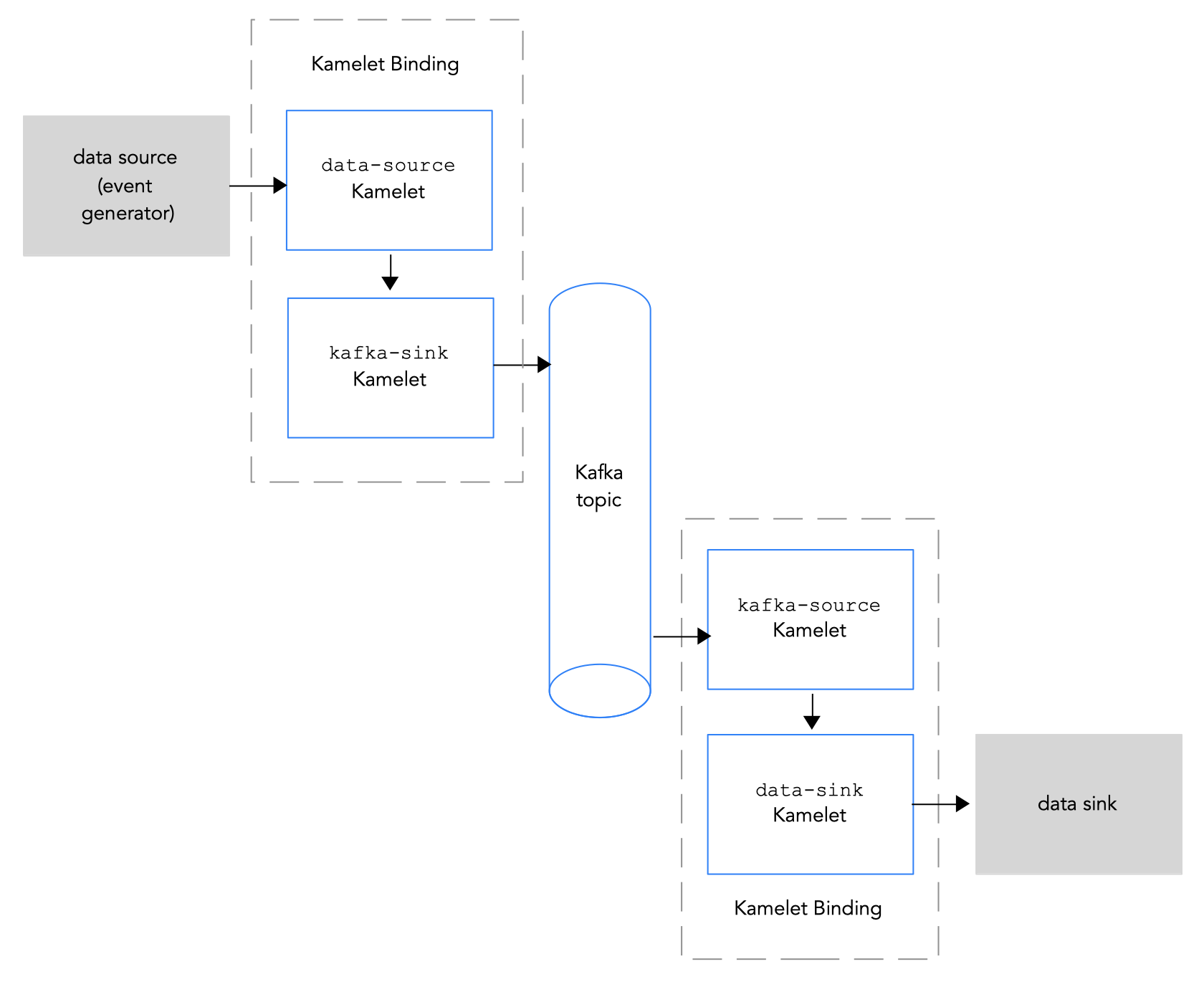
Figure 2.1: Data flow with Kamelets and a Kafka topic
Here is an overview of the basic steps for using Kamelets and Kamelet Bindings to connect applications and services to a Kafka topic:
Set up Kafka:
Install the needed OpenShift operators.
- For OpenShift Streams for Apache Kafka, install the Camel K operator, the Camel K CLI, and the Red Hat OpenShift Application Services (RHOAS) CLI.
- For AMQ streams, install the Camel K and AMQ streams operators and the Camel K CLI.
- Create a Kafka instance. A Kafka instance operates as a message broker. A broker contains topics and orchestrates the storage and passing of messages.
- Create a Kafka topic. A topic provides a destination for the storage of data.
- Obtain Kafka authentication credentials.
- Determine which services or applications you want to connect to your Kafka topic.
- View the Kamelet Catalog to find the Kamelets for the source and sink components that you want to add to your integration. Also, determine the required configuration parameters for each Kamelet that you want to use.
Create Kamelet Bindings:
-
Create a Kamelet Binding that connects a data source (a component that produces data) to the Kafka topic (by using the
kafka-sinkKamelet). -
Create a Kamelet Binding that connects the kafka topic (by using
kafka-sourceKamelet) to a data sink (a component that consumes data).
-
Create a Kamelet Binding that connects a data source (a component that produces data) to the Kafka topic (by using the
- Optionally, manipulate the data that passes between the Kafka topic and the data source or sink by adding one or more action Kamelets as intermediary steps within a Kamelet Binding.
- Optionally, define how to handle errors within a Kamelet Binding.
Apply the Kamelet Bindings as resources to the project.
The Camel K operator generates a separate Camel K integration for each Kamelet Binding.
2.2. Setting up Kafka
To set up Kafka, you must:
- Install the required OpenShift operators
- Create a Kafka instance
- Create a Kafka topic
Use the Red Hat product mentioned below to set up Kafka:
- Red Hat Advanced Message Queuing (AMQ) streams - A self-managed Apache Kafka offering. AMQ Streams is based on open source Strimzi and is included as part of Red Hat Integration. AMQ Streams is a distributed and scalable streaming platform based on Apache Kafka that includes a publish/subscribe messaging broker. Kafka Connect provides a framework to integrate Kafka-based systems with external systems. Using Kafka Connect, you can configure source and sink connectors to stream data from external systems into and out of a Kafka broker.
2.2.1. Setting up Kafka by using AMQ streams
AMQ Streams simplifies the process of running Apache Kafka in an OpenShift cluster.
2.2.1.1. Preparing your OpenShift cluster for AMQ Streams
To use Camel K or Kamelets and Red Hat AMQ Streams, you must install the following operators and tools:
- Red Hat Integration - AMQ Streams operator - Manages the communication between your Openshift Cluster and AMQ Streams for Apache Kafka instances.
- Red Hat Integration - Camel K operator - Installs and manages Camel K - a lightweight integration framework that runs natively in the cloud on OpenShift.
- Camel K CLI tool - Allows you to access all Camel K features.
Prerequisites
- You are familiar with Apache Kafka concepts.
- You can access an OpenShift 4.6 (or later) cluster with the correct access level, the ability to create projects and install operators, and the ability to install the OpenShift and the Camel K CLI on your local system.
-
You installed the OpenShift CLI tool (
oc) so that you can interact with the OpenShift cluster at the command line.
Procedure
To set up Kafka by using AMQ Streams:
- Log in to your OpenShift cluster’s web console.
- Create or open a project in which you plan to create your integration, for example my-camel-k-kafka.
- Install the Camel K operator and Camel K CLI as described in Installing Camel K.
Install the AMQ streams operator:
- From any project, select Operators > OperatorHub.
- In the Filter by Keyword field, type AMQ Streams.
Click the Red Hat Integration - AMQ Streams card and then click Install.
The Install Operator page opens.
- Accept the defaults and then click Install.
- Select Operators > Installed Operators to verify that the Camel K and AMQ Streams operators are installed.
Next steps
2.2.1.2. Setting up a Kafka topic with AMQ Streams
A Kafka topic provides a destination for the storage of data in a Kafka instance. You must set up a Kafka topic before you can send data to it.
Prerequisites
- You can access an OpenShift cluster.
- You installed the Red Hat Integration - Camel K and Red Hat Integration - AMQ Streams operators as described in Preparing your OpenShift cluster.
-
You installed the OpenShift CLI (
oc) and the Camel K CLI (kamel).
Procedure
To set up a Kafka topic by using AMQ Streams:
- Log in to your OpenShift cluster’s web console.
- Select Projects and then click the project in which you installed the Red Hat Integration - AMQ Streams operator. For example, click the my-camel-k-kafka project.
- Select Operators > Installed Operators and then click Red Hat Integration - AMQ Streams.
Create a Kafka cluster:
- Under Kafka, click Create instance.
- Type a name for the cluster, for example kafka-test.
Accept the other defaults and then click Create.
The process to create the Kafka instance might take a few minutes to complete.
When the status is ready, continue to the next step.
Create a Kafka topic:
- Select Operators > Installed Operators and then click Red Hat Integration - AMQ Streams.
- Under Kafka Topic, click Create Kafka Topic.
- Type a name for the topic, for example test-topic.
- Accept the other defaults and then click Create.
2.2.2. Setting up Kafka by using OpenShift streams
To use OpenShift Streams for Apache Kafka, you must be logged into your Red Hat account.
2.2.2.1. Preparing your OpenShift cluster for OpenShift Streams
To use managed cloud service, you must install the following operators and tools:
- OpenShift Application Services (RHOAS) CLI - Allows you to manage your application services from a terminal.
- Red Hat Integration - Camel K operator Installs and manages Camel K - a lightweight integration framework that runs natively in the cloud on OpenShift.
- Camel K CLI tool - Allows you to access all Camel K features.
Prerequisites
- You are familiar with Apache Kafka concepts.
- You can access an OpenShift 4.6 (or later) cluster with the correct access level, the ability to create projects and install operators, and the ability to install the OpenShift and Apache Camel K CLI on your local system.
-
You installed the OpenShift CLI tool (
oc) so that you can interact with the OpenShift cluster at the command line.
Procedure
- Log in to your OpenShift web console with a cluster admin account.
Create the OpenShift project for your Camel K or Kamelets application.
- Select Home > Projects.
- Click Create Project.
-
Type the name of the project, for example
my-camel-k-kafka, then click Create.
- Download and install the RHOAS CLI as described in Getting started with the rhoas CLI.
- Install the Camel K operator and Camel K CLI as described in Installing Camel K.
- To verify that the Red Hat Integration - Camel K operator is installed, click Operators > Installed Operators.
Next step
2.2.2.2. Setting up a Kafka topic with RHOAS
Kafka organizes messages around topics. Each topic has a name. Applications send messages to topics and retrieve messages from topics. A Kafka topic provides a destination for the storage of data in a Kafka instance. You must set up a Kafka topic before you can send data to it.
Prerequisites
- You can access an OpenShift cluster with the correct access level, the ability to create projects and install operators, and the ability to install the OpenShift and the Camel K CLI on your local system.
-
You installed the OpenShift CLI (
oc) , the Camel K CLI (kamel) , and RHOAS CLI (rhoas) tools as described in Preparing your OpenShift cluster. - You installed the Red Hat Integration - Camel K operator as described in Preparing your OpenShift cluster.
- You are logged in to the Red Hat Cloud site.
Procedure
To set up a Kafka topic:
- From the command line, log in to your OpenShift cluster.
Open your project, for example:
oc project my-camel-k-kafkaVerify that the Camel K operator is installed in your project:
oc get csvThe result lists the Red Hat Camel K operator and indicates that it is in the
Succeededphase.Prepare and connect a Kafka instance to RHOAS:
Login to the RHOAS CLI by using this command:
rhoas loginCreate a kafka instance, for example kafka-test:
rhoas kafka create kafka-testThe process to create the Kafka instance might take a few minutes to complete.
To check the status of your Kafka instance:
rhoas statusYou can also view the status in the web console:
https://cloud.redhat.com/application-services/streams/kafkas/
When the status is ready, continue to the next step.
Create a new Kafka topic:
rhoas kafka topic create --name test-topicConnect your Kafka instance (cluster) with the Openshift Application Services instance:
rhoas cluster connectFollow the script instructions for obtaining a credential token.
You should see output similar to the following:
Token Secret "rh-cloud-services-accesstoken-cli" created successfully Service Account Secret "rh-cloud-services-service-account" created successfully KafkaConnection resource "kafka-test" has been created KafkaConnection successfully installed on your cluster.
Token Secret "rh-cloud-services-accesstoken-cli" created successfully Service Account Secret "rh-cloud-services-service-account" created successfully KafkaConnection resource "kafka-test" has been created KafkaConnection successfully installed on your cluster.Copy to Clipboard Copied! Toggle word wrap Toggle overflow
Next step
2.2.2.3. Obtaining Kafka credentials
To connect your applications or services to a Kafka instance, you must first obtain the following Kafka credentials:
- Obtain the bootstrap URL.
- Create a service account with credentials (username and password).
For OpenShift Streams, the authentication protocol is SASL_SSL.
Prerequisite
- You have created a Kafka instance, and it has a ready status.
- You have created a Kafka topic.
Procedure
Obtain the Kafka Broker URL (Bootstrap URL):
rhoas statusThis command returns output similar to the following:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow To obtain a username and password, create a service account by using the following syntax:
rhoas service-account create --name "<account-name>" --file-format jsonNoteWhen creating a service account, you can choose the file format and location to save the credentials. For more information, type
rhoas service-account create --helpFor example:
rhoas service-account create --name "my-service-acct" --file-format jsonThe service account is created and saved to a JSON file.
To verify your service account credentials, view the
credentials.jsonfile:cat credentials.jsonThis command returns output similar to the following:
{"clientID":"srvc-acct-eb575691-b94a-41f1-ab97-50ade0cd1094", "password":"facf3df1-3c8d-4253-aa87-8c95ca5e1225"}{"clientID":"srvc-acct-eb575691-b94a-41f1-ab97-50ade0cd1094", "password":"facf3df1-3c8d-4253-aa87-8c95ca5e1225"}Copy to Clipboard Copied! Toggle word wrap Toggle overflow Grant permission for sending and receiving messages to or from the Kakfa topic. Use the following command, where
clientIDis the value provided in thecredentials.jsonfile (from Step 3).rhoas kafka acl grant-access --producer --consumer --service-account $CLIENT_ID --topic test-topic --group all
rhoas kafka acl grant-access --producer --consumer --service-account $CLIENT_ID --topic test-topic --group allCopy to Clipboard Copied! Toggle word wrap Toggle overflow For example:
rhoas kafka acl grant-access --producer --consumer --service-account srvc-acct-eb575691-b94a-41f1-ab97-50ade0cd1094 --topic test-topic --group all
rhoas kafka acl grant-access --producer --consumer --service-account srvc-acct-eb575691-b94a-41f1-ab97-50ade0cd1094 --topic test-topic --group allCopy to Clipboard Copied! Toggle word wrap Toggle overflow
2.3. Connecting a data source to a Kafka topic in a Kamelet Binding
To connect a data source to a Kafka topic, you create a Kamelet Binding as illustrated in Figure 2.2.
 Figure 2.2 Connecting a data source to a Kafka topic
Figure 2.2 Connecting a data source to a Kafka topic
Prerequisites
You know the name of the Kafka topic to which you want to send events.
The example in this procedure uses
test-topicfor receiving events.You know the values of the following parameters for your Kafka instance:
- bootstrapServers - A comma separated list of Kafka Broker URLs.
-
password - The password to authenticate to Kafka. For OpenShift Streams, this is the
passwordin thecredentials.jsonfile. For an unauthenticated kafka instance on AMQ Streams, you can specify any non-empty string. user - The user name to authenticate to Kafka. For OpenShift Streams, this is the
clientIDin thecredentials.jsonfile. For an unauthenticated kafka instance on AMQ Streams, you can specify any non-empty string.For information on how to obtain these values when you use OpenShift Streams, see Obtaining Kafka credentials.
-
securityProtocol - You know the security protocol for communicating with the Kafka brokers. For a Kafka cluster on OpenShift Streams, it is
SASL_SSL(the default). For a Kafka cluster on AMQ streams, it isPLAINTEXT.
You know which Kamelets you want to add to your Camel K integration and the required instance parameters.
The example Kamelets for this procedure are:
The
coffee-sourceKamelet - It has an optional parameter,period, that specifies how often to send each event. You can copy the code from Example source Kamelet to a file namedcoffee-source.kamelet.yamlfile and then run the following command to add it as a resource to your namespace:oc apply -f coffee-source.kamelet.yaml-
The
kafka-sinkKamelet provided in the Kamelet Catalog. You use thekafka-sinkKamelet because the Kafka topic is receiving data (it is the data consumer) in this binding.
Procedure
To connect a data source to a Kafka topic, create a Kamelet Binding:
In an editor of your choice, create a YAML file with the following basic structure:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow Add a name for the Kamelet Binding. For this example, the name is
coffees-to-kafkabecause the binding connects thecoffee-sourceKamelet to thekafka-sinkKamelet.Copy to Clipboard Copied! Toggle word wrap Toggle overflow For the Kamelet Binding’s source, specify a data source Kamelet (for example, the
coffee-sourceKamelet produces events that contain data about coffee) and configure any parameters for the Kamelet.Copy to Clipboard Copied! Toggle word wrap Toggle overflow For the Kamelet Binding’s sink, specify the
kafka-sinkKamelet and its required properties.For example, when the Kafka cluster is on OpenShift Streams:
-
For the
userproperty, specify theclientID, for example:srvc-acct-eb575691-b94a-41f1-ab97-50ade0cd1094 -
For the
passwordproperty, specify thepassword, for example:facf3df1-3c8d-4253-aa87-8c95ca5e1225 You do not need to set the
securityProtocolproperty.Copy to Clipboard Copied! Toggle word wrap Toggle overflow For another example, when the Kafka cluster is on AMQ Streams, set the
securityProtocolproperty to“PLAINTEXT”:Copy to Clipboard Copied! Toggle word wrap Toggle overflow
-
For the
-
Save the YAML file (for example,
coffees-to-kafka.yaml). - Log into your OpenShift project.
Add the Kamelet Binding as a resource to your OpenShift namespace:
oc apply -f <kamelet binding filename>For example:
oc apply -f coffees-to-kafka.yamlThe Camel K operator generates and runs a Camel K integration by using the
KameletBindingresource. It might take a few minutes to build.To see the status of the
KameletBindingresource:oc get kameletbindingsTo see the status of their integrations:
oc get integrationsTo view the integration’s log:
kamel logs <integration> -n <project>For example:
kamel logs coffees-to-kafka -n my-camel-k-kafka
2.4. Connecting a Kafka topic to a data sink in a Kamelet Binding
To connect a Kafka topic to a data sink, you create a Kamelet Binding as illustrated in Figure 2.3.
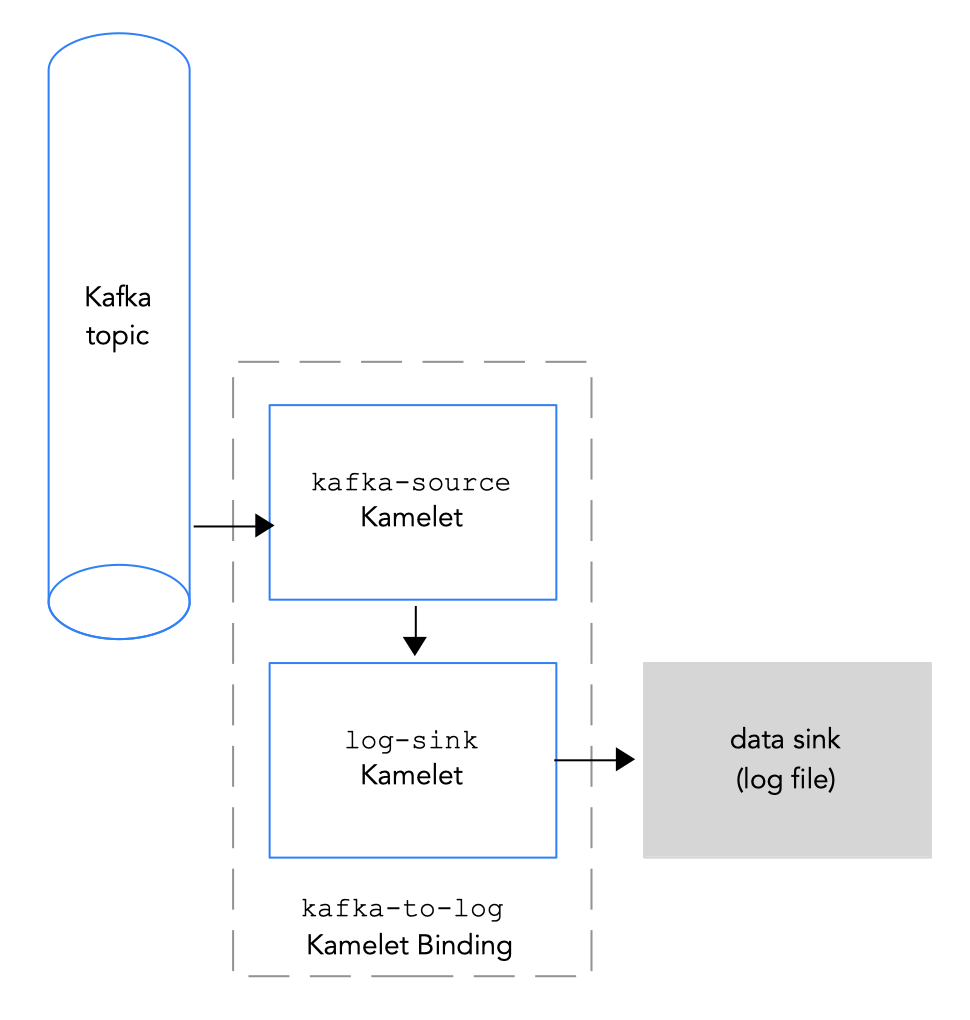 Figure 2.3 Connecting a Kafka topic to a data sink
Figure 2.3 Connecting a Kafka topic to a data sink
Prerequisites
-
You know the name of the Kafka topic from which you want to send events. The example in this procedure uses
test-topicfor sending events. It is the same topic that you used to receive events from the coffee source in Connecting a data source to a Kafka topic in a Kamelet Binding. You know the values of the following parameters for your Kafka instance:
- bootstrapServers - A comma separated list of Kafka Broker URLs.
- password - The password to authenticate to Kafka.
user - The user name to authenticate to Kafka.
For information on how to obtain these values when you use OpenShift Streams, see Obtaining Kafka credentials.
-
You know the security protocol for communicating with the Kafka brokers. For a Kafka cluster on OpenShift Streams, it is
SASL_SSL(the default). For a Kafka cluster on AMQ streams, it isPLAINTEXT. You know which Kamelets you want to add to your Camel K integration and the required instance parameters. The example Kamelets for this procedure are provided in the Kamelet Catalog:
The
kafka-sourceKamelet - Use thekafka-sourceKamelet because the Kafka topic is sending data (it is the data producer) in this binding. The example values for the required parameters are:-
bootstrapServers -
"broker.url:9092" -
password -
"testpassword" -
user -
"testuser" -
topic -
"test-topic" -
securityProtocol - For a Kafka cluster on OpenShift Streams, you do not need to set this parameter because
SASL_SSLis the default value. For a Kafka cluster on AMQ streams, this parameter value is“PLAINTEXT”.
-
bootstrapServers -
-
The
log-sinkKamelet - Use thelog-sinkto log the data that it receives from thekafka-sourceKamelet. Optionally, specify theshowStreamsparameter to show the message body of the data. Thelog-sinkKamelet is useful for debugging purposes.
Procedure
To connect a Kafka topic to a data sink, create a Kamelet Binding:
In an editor of your choice, create a YAML file with the following basic structure:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow Add a name for the Kamelet Binding. For this example, the name is
kafka-to-logbecause the binding connects thekafka-sourceKamelet to thelog-sinkKamelet.Copy to Clipboard Copied! Toggle word wrap Toggle overflow For the Kamelet Binding’s source, specify the
kafka-sourceKamelet and configure its parameters.For example, when the Kafka cluster is on OpenShift Streams (you do not need to set the
securityProtocolparameter):Copy to Clipboard Copied! Toggle word wrap Toggle overflow For example, when the Kafka cluster is on AMQ Streams you must set the
securityProtocolparameter to“PLAINTEXT”:Copy to Clipboard Copied! Toggle word wrap Toggle overflow For the Kamelet Binding’s sink, specify the data consumer Kamelet (for example, the
log-sinkKamelet) and configure any parameters for the Kamelet, for example:Copy to Clipboard Copied! Toggle word wrap Toggle overflow -
Save the YAML file (for example,
kafka-to-log.yaml). - Log into your OpenShift project.
Add the Kamelet Binding as a resource to your OpenShift namespace:
oc apply -f <kamelet binding filename>For example:
oc apply -f kafka-to-log.yamlThe Camel K operator generates and runs a Camel K integration by using the
KameletBindingresource. It might take a few minutes to build.To see the status of the
KameletBindingresource:oc get kameletbindingsTo see the status of their integrations:
oc get integrationsTo view the integration’s log:
kamel logs <integration> -n <project>For example:
kamel logs kafka-to-log -n my-camel-k-kafkaIn the output, you should see coffee events, for example:
INFO [log-sink-E80C5C904418150-0000000000000001] (Camel (camel-1) thread #0 - timer://tick) {"id":7259,"uid":"a4ecb7c2-05b8-4a49-b0d2-d1e8db5bc5e2","blend_name":"Postmodern Symphony","origin":"Huila, Colombia","variety":"Kona","notes":"delicate, chewy, black currant, red apple, star fruit","intensifier":"balanced"}INFO [log-sink-E80C5C904418150-0000000000000001] (Camel (camel-1) thread #0 - timer://tick) {"id":7259,"uid":"a4ecb7c2-05b8-4a49-b0d2-d1e8db5bc5e2","blend_name":"Postmodern Symphony","origin":"Huila, Colombia","variety":"Kona","notes":"delicate, chewy, black currant, red apple, star fruit","intensifier":"balanced"}Copy to Clipboard Copied! Toggle word wrap Toggle overflow To stop a running integration, delete the associated Kamelet Binding resource:
oc delete kameletbindings/<kameletbinding-name>For example:
oc delete kameletbindings/kafka-to-log
2.5. Applying operations to data within a Kafka connection
If you want to perform an operation on the data that passes between a Kamelet and a Kafka topic, use action Kamelets as intermediary steps within a Kamelet Binding.
2.5.1. Routing event data to different destination topics
When you configure a connection to a Kafka instance, you can optionally transform the topic information from the event data so that the event is routed to a different Kafka topic. Use one of the following transformation action Kamelets:
-
Regex Router - Modify the topic of a message by using a regular expression and a replacement string. For example, if you want to remove a topic prefix, add a prefix, or remove part of a topic name. Configure the Regex Router Action Kamelet (
regex-router-action). -
TimeStamp - Modify the topic of a message based on the original topic and the message’s timestamp. For example, when using a sink that needs to write to different tables or indexes based on timestamps. For example, when you want to write events from Kafka to Elasticsearch, but each event needs to go to a different index based on information in the event itself. Configure the Timestamp Router Action Kamelet (
timestamp-router-action). -
Message TimeStamp - Modify the topic of a message based on the original topic value and the timestamp field coming from a message value field. Configure the Message Timestamp Router Action Kamelet (
message-timestamp-router-action). -
Predicate - Filter events based on the given JSON path expression by configuring the Predicate Filter Action Kamelet (
predicate-filter-action).
Prerequisites
-
You have created a Kamelet Binding in which the sink is a
kafka-sinkKamelet, as described in Connecting a data source to a Kafka topic in a Kamelet Binding. - You know which type of transformation you want to add to the Kamelet Binding.
Procedure
To transform the destination topic, use one of the transformation action Kamelets as an intermediary step within the Kamelet Binding.
For details on how to add an action Kamelet to a Kamelet Binding, see Adding an operation to a Kamelet Binding.
2.5.2. Filtering event data for a specific Kafka topic
If you use a source Kamelet that produces records to many different Kafka topics and you want to filter out the records to one Kafka topic, add the topic-name-matches-filter-action Kamelet as an intermediary step in the Kamelet Binding.
Prerequisites
- You have created a Kamelet Binding in a YAML file.
- You know the name of the Kafka topic from which you want to filter out event data.
Procedure
Edit the Kamelet Binding to include the
topic-name-matches-filter-actionKamelet as an intermediary step between the source and sink Kamelets.Typically, you use the
kafka-sourceKamelet, as the source Kamelet and you supply a topic as the value of the requiredtopicparameter.In the following Kamelet Binding example, the
kafka-sourceKamelet specifies thetest-topic, test-topic-2, and test-topic-3Kafka topics and thetopic-name-matches-filter-actionKamelet specifies to filter out the event data from thetopic-testtopic:Copy to Clipboard Copied! Toggle word wrap Toggle overflow If you want to filter topics coming from a source Kamelet other than the
kafka-sourceKamelet, you must supply the Kafka topic information. You can use theinsert-header-actionKamelet to add a Kafka topic field as an intermediary step, before thetopic-name-matches-filter-actionstep in the Kamelet Binding as shown in the following example:Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Save the Kamelet Binding YAML file.