Chapter 4. Regional-DR solution for OpenShift Data Foundation [Technology Preview]
Configuring OpenShift Data Foundation for Regional-DR with Advanced Cluster Management is a Technology Preview feature and is subject to Technology Preview support limitations. Technology Preview features are not supported with Red Hat production service level agreements (SLAs) and might not be functionally complete. Red Hat does not recommend using them in production. These features provide early access to upcoming product features, enabling customers to test functionality and provide feedback during the development process.
For more information, see Technology Preview Features Support Scope.
4.1. Components of Regional-DR solution
Regional-DR is composed of Red Hat Advanced Cluster Management for Kubernetes and OpenShift Data Foundation components to provide application and data mobility across Red Hat OpenShift Container Platform clusters.
Red Hat Advanced Cluster Management for Kubernetes
Red Hat Advanced Cluster Management (RHACM))provides the ability to manage multiple clusters and application lifecycles. Hence, it serves as a control plane in a multi-cluster environment.
RHACM is split into two parts:
- RHACM Hub: includes components that run on the multi-cluster control plane.
- Managed clusters: includes components that run on the clusters that are managed.
For more information about this product, see RHACM documentation and the RHACM “Manage Applications” documentation.
OpenShift Data Foundation
OpenShift Data Foundation provides the ability to provision and manage storage for stateful applications in an OpenShift Container Platform cluster.
OpenShift Data Foundation is backed by Ceph as the storage provider, whose lifecycle is managed by Rook in the OpenShift Data Foundation component stack. Ceph-CSI provides the provisioning and management of Persistent Volumes for stateful applications.
OpenShift Data Foundation stack is now enhanced with the following abilities for disaster recovery:
- Enable RBD block pools for mirroring across OpenShift Data Foundation instances (clusters)
- Ability to mirror specific images within an RBD block pool
- Provides csi-addons to manage per Persistent Volume Claim (PVC) mirroring
OpenShift DR
OpenShift DR is a set of orchestrators to configure and manage stateful applications across a set of peer OpenShift clusters which are managed using RHACM and provides cloud-native interfaces to orchestrate the life-cycle of an application’s state on Persistent Volumes. These include:
- Protecting an application and its state relationship across OpenShift clusters
- Failing over an application and its state to a peer cluster
- Relocate an application and its state to the previously deployed cluster
OpenShift DR is split into three components:
- ODF Multicluster Orchestrator: Installed on the multi-cluster control plane (RHACM Hub), it orchestrates configuration and peering of OpenShift Data Foundation clusters for Metro and Regional DR relationships
- OpenShift DR Hub Operator: Automatically installed as part of ODF Multicluster Orchestrator installation on the hub cluster to orchestrate failover or relocation of DR enabled applications.
- OpenShift DR Cluster Operator: Automatically installed on each managed cluster that is part of a Metro and Regional DR relationship to manage the lifecycle of all PVCs of an application.
4.2. Regional-DR deployment workflow
This section provides an overview of the steps required to configure and deploy Regional-DR capabilities using latest version of Red Hat OpenShift Data Foundation across two distinct OpenShift Container Platform clusters. In addition to two managed clusters, a third OpenShift Container Platform cluster will be required to deploy the Red Hat Advanced Cluster Management (RHACM).
To configure your infrastructure, perform the below steps in the order given:
- Ensure requirements across the three: Hub, Primary and Secondary Openshift Container Platform clusters that are part of the DR solution are met. See Requirements for enabling Regional-DR.
- Install OpenShift Data Foundation operator and create a storage system on Primary and Secondary managed clusters. See Creating OpenShift Data Foundation cluster on managed clusters.
- Install the ODF Multicluster Orchestrator on the Hub cluster. See Installing ODF Multicluster Orchestrator on Hub cluster.
- Configure SSL access between the Hub, Primary and Secondary clusters. See Configuring SSL access across clusters.
Create a DRPolicy resource for use with applications requiring DR protection across the Primary and Secondary clusters. See Creating Disaster Recovery Policy on Hub cluster.
NoteThere can be more than a single policy.
For testing your disaster recovery solution:
- Create a sample application using RHACM console. See Creating sample application.
- Test failover and relocate operations using the sample application between managed clusters. See application failover and relocating an application.
4.3. Requirements for enabling Regional-DR
Disaster Recovery features supported by Red Hat OpenShift Data Foundation require all of the following prerequisites in order to successfully implement a Disaster Recovery solution:
You must have three OpenShift clusters that have network reachability between them:
- Hub cluster where Red Hat Advanced Cluster Management for Kubernetes (RHACM operator) is installed.
- Primary managed cluster where OpenShift Data Foundation is installed.
- Secondary managed cluster where OpenShift Data Foundation is installed.
Ensure that RHACM operator and MultiClusterHub is installed on the Hub cluster. See RHACM installation guide for instructions.
After the operator is successfully installed, a popover with a message that the Web console update is available appears on the user interface. Click Refresh web console from this popover for the console changes to reflect.
ImportantIt is the user’s responsibility to ensure that application traffic routing and redirection are configured appropriately. Configuration and updates to the application traffic routes are currently not supported.
-
On the Hub cluster, navigate to All Clusters
Infrastructure Clusters. Ensure that you have either imported or created the Primary managed cluster and the Secondary managed cluster using the RHACM console. For instructions, see Creating a cluster and Importing a target managed cluster to the hub cluster. The managed clusters must have non-overlapping networks.
To connect the managed OpenShift cluster and service networks using the Submariner add-ons, you need to validate that the two clusters have non-overlapping networks by running the following commands for each of the managed clusters.
$ oc get networks.config.openshift.io cluster -o json | jq .specExample output for Primary cluster:
{ "clusterNetwork": [ { "cidr": "10.5.0.0/16", "hostPrefix": 23 } ], "externalIP": { "policy": {} }, "networkType": "OpenShiftSDN", "serviceNetwork": [ "10.15.0.0/16" ] }Example output for Secondary cluster:
{ "clusterNetwork": [ { "cidr": "10.6.0.0/16", "hostPrefix": 23 } ], "externalIP": { "policy": {} }, "networkType": "OpenShiftSDN", "serviceNetwork": [ "10.16.0.0/16" ] }For more information, see Submariner add-ons documentation.
Ensure that the Managed clusters can connect using
Submariner add-ons. After identifying and ensuring that the cluster and service networks have non-overlapping ranges, install theSubmariner add-onsfor each managed cluster using the RHACM console andCluster sets. For instructions, see Submariner documentation.ImportantDo not select Enable Globalnet because of overlapping cluster and service networks for the managed clusters. Using
Globalnetis not supported with Regional Disaster Recovery currently. Ensure that cluster and service networks are non-overlapping before proceeding.
4.4. Creating an OpenShift Data Foundation cluster on managed clusters
In order to configure storage replication between the two OpenShift Container Platform clusters, create an OpenShift Data Foundation storage system after you install the OpenShift Data Foundation operator.
Refer to OpenShift Data Foundation deployment guides and instructions that are specific to your infrastructure (AWS, VMware, BM, Azure, etc.).
Procedure
Install and configure the latest OpenShift Data Foundation cluster on each of the managed clusters.
For information about the OpenShift Data Foundation deployment, refer to your infrastructure specific deployment guides (for example, AWS, VMware, Bare metal, Azure).
Validate the successful deployment of OpenShift Data Foundation on each managed cluster with the following command:
$ oc get storagecluster -n openshift-storage ocs-storagecluster -o jsonpath='{.status.phase}{"\n"}'For the Multicloud Gateway (MCG):
$ oc get noobaa -n openshift-storage noobaa -o jsonpath='{.status.phase}{"\n"}'If the status result is
Readyfor both queries on the Primary managed cluster and the Secondary managed cluster, then continue with the next step.
In the OpenShift Web Console, navigate to Installed Operators ocs-storagecluster-storagesystem StorageCluster is Ready and has a green tick mark next to it.
4.5. Installing OpenShift Data Foundation Multicluster Orchestrator operator
OpenShift Data Foundation Multicluster Orchestrator is a controller that is installed from OpenShift Container Platform’s OperatorHub on the Hub cluster.
Procedure
- On the Hub cluster, navigate to OperatorHub and use the keyword filter to search for ODF Multicluster Orchestrator.
- Click ODF Multicluster Orchestrator tile.
Keep all default settings and click Install.
Ensure that the operator resources are installed in
openshift-operatorsproject and available to all namespaces.NoteThe
ODF Multicluster Orchestratoralso installs the Openshift DR Hub Operator on the RHACM hub cluster as a dependency.Verify that the operator Pods are in a
Runningstate. TheOpenShift DR Hub operatoris also installed at the same time inopenshift-operatorsnamespace.$ oc get pods -n openshift-operatorsExample output:
NAME READY UP-TO-DATE AVAILABLE AGE odf-multicluster-console-6845b795b9-blxrn 1/1 Running 0 4d20h odfmo-controller-manager-f9d9dfb59-jbrsd 1/1 Running 0 4d20h ramen-hub-operator-6fb887f885-fss4w 2/2 Running 0 4d20h
4.6. Configuring SSL access across clusters
Configure network (SSL) access between the primary and secondary clusters so that metadata can be stored on the alternate cluster in a Multicloud Gateway (MCG) object bucket using a secure transport protocol and in the Hub cluster for verifying access to the object buckets.
If all of your OpenShift clusters are deployed using a signed and valid set of certificates for your environment then this section can be skipped.
Procedure
Extract the ingress certificate for the Primary managed cluster and save the output to
primary.crt.$ oc get cm default-ingress-cert -n openshift-config-managed -o jsonpath="{['data']['ca-bundle\.crt']}" > primary.crtExtract the ingress certificate for the Secondary managed cluster and save the output to
secondary.crt.$ oc get cm default-ingress-cert -n openshift-config-managed -o jsonpath="{['data']['ca-bundle\.crt']}" > secondary.crtCreate a new ConfigMap file to hold the remote cluster’s certificate bundle with filename
cm-clusters-crt.yaml.NoteThere could be more or less than three certificates for each cluster as shown in this example file. Also, ensure that the certificate contents are correctly indented after you copy and paste from the
primary.crtandsecondary.crtfiles that were created before.apiVersion: v1 data: ca-bundle.crt: | -----BEGIN CERTIFICATE----- <copy contents of cert1 from primary.crt here> -----END CERTIFICATE----- -----BEGIN CERTIFICATE----- <copy contents of cert2 from primary.crt here> -----END CERTIFICATE----- -----BEGIN CERTIFICATE----- <copy contents of cert3 primary.crt here> -----END CERTIFICATE---- -----BEGIN CERTIFICATE----- <copy contents of cert1 from secondary.crt here> -----END CERTIFICATE----- -----BEGIN CERTIFICATE----- <copy contents of cert2 from secondary.crt here> -----END CERTIFICATE----- -----BEGIN CERTIFICATE----- <copy contents of cert3 from secondary.crt here> -----END CERTIFICATE----- kind: ConfigMap metadata: name: user-ca-bundle namespace: openshift-configCreate the ConfigMap on the Primary managed cluster, Secondary managed cluster, and the Hub cluster.
$ oc create -f cm-clusters-crt.yamlExample output:
configmap/user-ca-bundle createdPatch default proxy resource on the Primary managed cluster, Secondary managed cluster, and the Hub cluster.
$ oc patch proxy cluster --type=merge --patch='{"spec":{"trustedCA":{"name":"user-ca-bundle"}}}'Example output:
proxy.config.openshift.io/cluster patched
4.7. Creating Disaster Recovery Policy on Hub cluster
Openshift Disaster Recovery Policy (DRPolicy) resource specifies OpenShift Container Platform clusters participating in the disaster recovery solution and the desired replication interval. DRPolicy is a cluster scoped resource that users can apply to applications that require Disaster Recovery solution.
The ODF MultiCluster Orchestrator Operator facilitates the creation of each DRPolicy and the corresponding DRClusters through the Multicluster Web console.
On the initial run, VolSync operator is installed automatically. VolSync is used to setup volume replication between two clusters to protect CephFs-based PVCs. The replication feature is enabled by default.
Prerequisites
- Ensure that there is a minimum set of two managed clusters.
Procedure
On the OpenShift console, navigate to All Clusters.
- Navigate to Data Services and click Data policies.
- Click Create DRPolicy.
-
Enter Policy name. Ensure that each DRPolicy has a unique name (for example:
ocp4bos1-ocp4bos2-5m). - Select two clusters from the list of managed clusters to which this new policy will be associated with.
-
Replication policy is automaticaly set to
Asynchronous(async) based on the OpenShift clusters selected and a Sync schedule option will become available. Set Sync schedule.
ImportantFor every desired replication interval a new DRPolicy must be created with a unique name (such as:
ocp4bos1-ocp4bos2-10m). The same clusters can be selected but the Sync schedule can be configured with a different replication interval in minutes/hours/days. The minimum is one minute.- Click Create.
Verify that the DRPolicy is created successfully. Run this command on the Hub cluster for each of the DRPolicy resources created.
NoteReplace <drpolicy_name> with your unique name.
$ oc get drpolicy <drpolicy_name> -o jsonpath='{.status.conditions[].reason}{"\n"}'Example output:
SucceededNoteWhen a DRPolicy is created, along with it, two DRCluster resources are also created. It could take up to 10 minutes for all three resources to be validated and for the status to show as
Succeeded.Verify the object bucket access from the Hub cluster to both the Primary managed cluster and the Secondary managed cluster.
Get the names of the DRClusters on the Hub cluster.
$ oc get drclustersExample output:
NAME AGE ocp4bos1 4m42s ocp4bos2 4m42sCheck S3 access to each bucket created on each managed cluster using this DRCluster validation command.
NoteReplace <drcluster_name> with your unique name.
$ oc get drcluster <drcluster_name> -o jsonpath='{.status.conditions[2].reason}{"\n"}'Example output:
SucceededNoteMake sure to run command for both DRClusters on the Hub cluster.
Verify that the OpenShift DR Cluster operator installation was successful on the Primary managed cluster and the Secondary managed cluster.
$ oc get csv,pod -n openshift-dr-systemExample output:
NAME DISPLAY VERSION REPLACES PHASE clusterserviceversion.operators.coreos.com/odr-cluster-operator.v4.11.0 Openshift DR Cluster Operator 4.11.0 Succeeded NAME READY STATUS RESTARTS AGE pod/ramen-dr-cluster-operator-5564f9d669-f6lbc 2/2 Running 0 5m32sYou can also verify that
OpenShift DR Cluster Operatoris installed successfully on the OperatorHub of each managed clusters.Verify that the status of the ODF mirroring
daemonhealth on the Primary managed cluster and the Secondary managed cluster.$ oc get cephblockpool ocs-storagecluster-cephblockpool -n openshift-storage -o jsonpath='{.status.mirroringStatus.summary}{"\n"}'Example output:
{"daemon_health":"OK","health":"OK","image_health":"OK","states":{}}ImportantIt could take up to 10 minutes for the
daemon_healthandhealthto go from Warning to OK. If the status does not become OK eventually then use the RHACM console to verify that the Submariner connection between managed clusters is still in a healthy state. Do not proceed until all values are OK.When using
VolSyncto protect CephFs-based PVCs, then configure theVolSynccopy method. The default copy method is to use snapshot. A snapshot is taken at the source and synced to the temporary destination PVC. Once the syncronization is complete, another snapshot is taken from this temporary PVC and saved on the destination cluster. On failover, the application PVC is restored from the latest snapshot found on the cluster.Using a snapshot as a copy method may not be desirable when using PVCs that contain thousands of files as CephFS will take a long time to create a writable PVC from snapshot. Furthermore, when using the copy method as snapshot, after a failover or replication, the entire PVC must be syncronized to the other side. This is a very expensive operation on high latency network and big PVC size.
To avoid these issues, a “direct” copy method can be used instead. This method is preferred as synchronization is done directly to the application PVC, and a snapshot is also saved in case manual restoration is required.
You can configure the copy method “direct” as follows:
$ oc edit cm -n openshift-operators ramen-hub-operator-configAdd the following to
spec.data.ramen_manager_config.yamlsection:volsync: destinationCopyMethod: Direct
4.8. Create sample application for testing disaster recovery solution
OpenShift Data Foundation disaster recovery (DR) solution supports disaster recovery for applications that are managed by RHACM. See Managing Applications for more details.
OpenShift Data Foundation DR solution does not support ApplicationSet, which is required for applications that are deployed via ArgoCD.
ODF DR orchestrates RHACM application placement, using the PlacementRule, when an application is moved between clusters in a DRPolicy for failover or relocation requirements. The following sections detail how to apply a DRPolicy to an application and how to manage the applications placement life-cycle during and after cluster unavailability.
OpenShift users that do not have cluster-admin permissions, see the Knowledge Article on how to assign necessary permissions to an application user for executing disaster recovery actions.
4.8.1. Creating a sample application
In order to test failover from the Primary managed cluster to the Secondary managed cluster and relocate, we need a sample application.
Prerequisites
- When creating an application for general consumption, ensure that the application is deployed to ONLY one cluster.
-
Use the sample application called
busyboxas an example. - Ensure all external routes of the application are configured using either Global Traffic Manager (GTM) or Global Server Load Balancing (GLSB) service for traffic redirection when the application fails over or is relocated.
As a best practice, group Red Hat Advanced Cluster Management (RHACM) subscriptions, that belong together, to refer to a single Placement Rule to DR protect them as a group. Further create them as a single application for a logical grouping of the subscriptions for future DR actions like failover and relocate.
NoteIf unrelated subscriptions refer to the same Placement Rule for placement actions, they will also be DR protected as the DR workflow controls all subscriptions that references the Placement Rule.
Procedure
- On the Hub cluster, navigate to Applications and click Create application.
- Select type as Subscription.
-
Enter your application Name (for example,
busybox) and Namespace (for example,busybox-sample). -
In the Repository location for resources section, select Repository type
Git. Enter the Git repository URL for the sample application, the github Branch and Path where the resources
busyboxPod and PVC will be created.-
Use the sample application repository as
https://github.com/red-hat-storage/ocm-ramen-samples -
Select Branch as
release-4.12. Choose one of the following Path
-
busybox-odrto use RBD Regional-DR. -
busybox-odr-cephfsto use CephFS Regional-DR.
-
-
Use the sample application repository as
Scroll down in the form until you see Deploy application resources only on clusters matching specified labels and then add a label with its value set to the Primary managed cluster name in RHACM cluster list view.
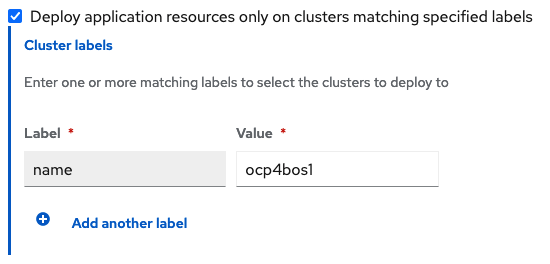
Click Create which is at the top right hand corner.
On the follow-on screen go to the
Topologytab. You should see that there are all Green checkmarks on the application topology.NoteTo get more information, click on any of the topology elements and a window will appear on the right of the topology view.
Validating the sample application deployment.
Now that the
busyboxapplication has been deployed to your preferred Cluster, the deployment can be validated.Login to your managed cluster where
busyboxwas deployed by RHACM.$ oc get pods,pvc -n busybox-sampleExample output:
NAME READY STATUS RESTARTS AGE pod/busybox-67bf494b9-zl5tr 1/1 Running 0 77s NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE persistentvolumeclaim/busybox-pvc Bound pvc-c732e5fe-daaf-4c4d-99dd-462e04c18412 5Gi RWO ocs-storagecluster-ceph-rbd 77s
4.8.2. Apply DRPolicy to sample application
Prerequisites
- Ensure that both managed clusters referenced in the DRPolicy are reachable. If not, the application will not be DR protected till both clusters are online.
Procedure
- On the Hub cluster go back to the Multicluster Web console, navigate to All Clusters.
- Login to all the clusters listed under All Clusters.
- Navigate to Data Services and then click Data policies.
- Click the Actions menu at the end of DRPolicy to view the list of available actions.
- Click Apply DRPolicy.
When the Apply DRPolicy modal is displayed, select
busyboxapplication and enter PVC label asappname=busybox.NoteWhen multiple placements rules under the same application or more than one application are selected, all PVCs within the application’s namespace will be protected by default.
- Click Apply.
Verify that a
DRPlacementControlorDRPCwas created in thebusybox-samplenamespace on the Hub cluster and that it’s CURRENTSTATE shows asDeployed. This resource is used for both failover and relocate actions for this application.$ oc get drpc -n busybox-sampleExample output:
NAME AGE PREFERREDCLUSTER FAILOVERCLUSTER DESIREDSTATE CURRENTSTATE busybox-placement-1-drpc 6m59s ocp4bos1 Deployed[Optional] Verify Rados block device (RBD)
volumereplicationandvolumereplicationgroupon the primary cluster.$ oc get volumereplications.replication.storage.openshift.ioExample output:
NAME AGE VOLUMEREPLICATIONCLASS PVCNAME DESIREDSTATE CURRENTSTATE busybox-pvc 2d16h rbd-volumereplicationclass-1625360775 busybox-pvc primary Primary$ oc get volumereplicationgroups.ramendr.openshift.ioExample output:
NAME DESIREDSTATE CURRENTSTATE busybox-drpc primary Primary[Optional] Verify CephFS volsync replication source has been setup successfully in the primary cluster and VolSync ReplicationDestination has been setup in the failover cluster.
$ oc get replicationsource -n busybox-sampleExample output:
NAME SOURCE LAST SYNC DURATION NEXT SYNC busybox-pvc busybox-pvc 2022-12-20T08:46:07Z 1m7.794661104s 2022-12-20T08:50:00Z$ oc get replicationdestination -n busybox-sampleExample output:
NAME LAST SYNC DURATION NEXT SYNC busybox-pvc 2022-12-20T08:46:32Z 4m39.52261108s
4.8.3. Deleting sample application
You can delete the sample application busybox using the RHACM console.
The instructions to delete the sample application should not be executed until the failover and relocate testing is completed and the application is ready to be removed from RHACM and the managed clusters.
Procedure
- On the RHACM console, navigate to Applications.
-
Search for the sample application to be deleted (for example,
busybox). - Click the Action Menu (⋮) next to the application you want to delete.
Click Delete application.
When the Delete application is selected a new screen will appear asking if the application related resources should also be deleted.
- Select Remove application related resources checkbox to delete the Subscription and PlacementRule.
- Click Delete. This will delete the busybox application on the Primary managed cluster (or whatever cluster the application was running on).
In addition to the resources deleted using the RHACM console, the
DRPlacementControlmust also be deleted after deleting thebusyboxapplication.-
Login to the OpenShift Web console for the Hub cluster and navigate to Installed Operators for the project
busybox-sample. - Click OpenShift DR Hub Operator and then click DRPlacementControl tab.
-
Click the Action Menu (⋮) next to the
busyboxapplication DRPlacementControl that you want to delete. - Click Delete DRPlacementControl.
- Click Delete.
-
Login to the OpenShift Web console for the Hub cluster and navigate to Installed Operators for the project
This process can be used to delete any application with a DRPlacementControl resource.
4.9. Application failover between managed clusters
Perform a failover when a managed cluster becomes unavailable, due to any reason. This failover method is application based.
Prerequisites
When the primary cluster is in a state other than
Ready, check the actual status of the cluster as it might take some time to update.-
Navigate to the RHACM console
Infrastructure Clusters Cluster list tab. Check the status of both the managed clusters individually before performing failover operation.
However, failover operation can still be performed when the cluster you are failing over to is in a Ready state.
-
Navigate to the RHACM console
Procedure
- On the Hub cluster, navigate to Applications.
- Click the Actions menu at the end of application row to view the list of available actions.
- Click Failover application.
- When the Failover application popup is shown, select policy and target cluster to which the associated application will failover in case of a disaster.
- By default, the subscription group that will replicate the application resources is selected. Click the Select subscription group dropdown to verify the default selection or modify this setting.
Check the status of the Failover readiness.
-
If the status is
Readywith a green tick, it indicates that the target cluster is ready for failover to start. Proceed to step 7. -
If the status is
UnknownorNot ready, then wait until the status changes toReady.
-
If the status is
- Click Initiate. The busybox resources are now created on the target cluster.
- Close the modal window and track the status using the Data policy column on the Applications page.
Verify that the activity status shows as FailedOver for the application.
-
Navigate to the Applications
Overview tab. - In the Data policy column, click the policy link for the application you applied the policy to.
- On the Data Policies modal page, click the View more details link.
- Verify that you can see one or more policy names and the ongoing activities (Last sync time and Activity status) associated with the policy in use with the application.
-
Navigate to the Applications
4.10. Relocating an application between managed clusters
Relocate an application to its preferred location when all managed clusters are available.
Prerequisite
When primary cluster is in a state other than Ready, check the actual status of the cluster as it might take some time to update. Relocate can only be performed when both primary and preferred clusters are up and running.
-
Navigate to RHACM console
Infrastructure Clusters Cluster list tab. - Check the status of both the managed clusters individually before performing relocate operation.
-
Navigate to RHACM console
- Relocate performed when last sync time is closer to current time would be preferred as the time taken to relocate would be lower, considering amount of data changed between last sync time and now is proportionally smaller.
- Verify that applications were cleaned up from the cluster before unfencing it.
Procedure
- On the Hub cluster, navigate to Applications.
- Click the Actions menu at the end of application row to view the list of available actions.
- Click Relocate application.
- When the Relocate application popup is shown, select policy and target cluster to which the associated application will relocate to in case of a disaster.
- By default, the subscription group that will deploy the application resources is selected. Click the Select subscription group dropdown to verify the default selection or modify this setting.
Check the status of the Relocation readiness.
-
If the status is
Readywith a green tick, it indicates that the target cluster is ready for relocation to start. Proceed to step 7. -
If the status is
UnknownorNot ready, then wait until the status changes toReady.
-
If the status is
- Click Initiate. The busybox resources are now created on the target cluster.
- Close the modal window and track the status using the Data policy column on the Applications page.
Verify that the activity status shows as Relocated for the application.
-
Navigate to the Applications
Overview tab. - In the Data policy column, click the policy link for the application you applied the policy to.
- On the Data Policies modal page, click the View more details link.
- Verify that you can see one or more policy names and the ongoing activities (Last sync time and Activity status) associated with the policy in use with the application.
-
Navigate to the Applications
4.11. Viewing Recovery Point Objective values for disaster recovery enabled applications
Recovery Point Objective (RPO) value is the most recent sync time of persistent data from the cluster where the application is currently active to its peer. This sync time helps determine duration of data lost during failover.
This RPO value is applicable only for Regional-DR during failover. Relocation ensures there is no data loss during the operation, as all peer clusters are available.
You can view the Recovery Point Objective (RPO) value of all the protected volumes for their workload on the Hub cluster.
Procedure
-
On the Hub cluster, navigate to Applications
Overview tab. In the Data policy column, click the policy link for the application you applied the policy to.
A Data Policies modal page appears with the number of disaster recovery policies applied to each application along with failover and relocation status.
On the Data Policies modal page, click the View more details link.
A detailed Data Policies modal page is displayed that shows the policy names and the ongoing activities (Last sync, Activity status) associated with the policy that is applied to the application.
The Last sync time reported in the modal page, represents the most recent sync time of all volumes that are DR protected for the application.